
c#抓取网页数据
c#抓取网页数据(网易云音乐歌词爬取的总体思路及方法分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-02-01 10:08
2021-04-19
前几天小编给大家分享了数据可视化分析。文末提到了网易云音乐歌词爬虫。今天给大家分享一下网易云音乐的歌词抓取方法。
本文的大致思路如下:
找到正确的网址并获取源代码;
使用bs4解析源码得到歌曲名和歌曲ID;
调用网易云歌API获取歌词;
将歌词写入文件并保存在本地。
本文的目的是获取网易云音乐的歌词,并将歌词保存到本地文件。整体效果图如下:
赵磊的歌
本文以民歌神赵雷为数据采集对象,具体采集他的歌曲歌词,其他歌手的歌词采集方法可以类推。下图为《成都》的歌词。
赵磊的歌——《成都》
一般来说,网页上显示的URL可以写在程序中,运行程序后,可以采集到我们想要的网页的源代码。但是在网易云音乐网站中,这种方式是行不通的,因为网页中的网址是假网址,真实网址中没有#号。废话不多说,直接上代码吧。
获取网页源代码
本文对采集网易云音乐歌词使用requests、bs4、json和re模块,记得在程序中添加headers和防盗链referer来模拟浏览器,防止被网站@拒绝访问> 。这里的get_html方法是专门用来获取源代码的。通常,我们还需要进行异常处理并采取预防措施。
拿到网页源代码后,我分析了源代码,发现这首歌的名字和ID被隐藏得很深。我千百度找她,发现她在源码的第294行,隐藏在 查看全部
c#抓取网页数据(网易云音乐歌词爬取的总体思路及方法分享)
2021-04-19
前几天小编给大家分享了数据可视化分析。文末提到了网易云音乐歌词爬虫。今天给大家分享一下网易云音乐的歌词抓取方法。
本文的大致思路如下:
找到正确的网址并获取源代码;
使用bs4解析源码得到歌曲名和歌曲ID;
调用网易云歌API获取歌词;
将歌词写入文件并保存在本地。
本文的目的是获取网易云音乐的歌词,并将歌词保存到本地文件。整体效果图如下:
赵磊的歌
本文以民歌神赵雷为数据采集对象,具体采集他的歌曲歌词,其他歌手的歌词采集方法可以类推。下图为《成都》的歌词。
赵磊的歌——《成都》
一般来说,网页上显示的URL可以写在程序中,运行程序后,可以采集到我们想要的网页的源代码。但是在网易云音乐网站中,这种方式是行不通的,因为网页中的网址是假网址,真实网址中没有#号。废话不多说,直接上代码吧。
获取网页源代码
本文对采集网易云音乐歌词使用requests、bs4、json和re模块,记得在程序中添加headers和防盗链referer来模拟浏览器,防止被网站@拒绝访问> 。这里的get_html方法是专门用来获取源代码的。通常,我们还需要进行异常处理并采取预防措施。
拿到网页源代码后,我分析了源代码,发现这首歌的名字和ID被隐藏得很深。我千百度找她,发现她在源码的第294行,隐藏在
c#抓取网页数据(c#从IE浏览器获取当前页面内容的相关知识和一些Code实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-30 11:20
想知道c#从IE浏览器获取当前页面内容的相关内容吗?在本文中,micDavid将为大家讲解c#获取浏览器页面内容的相关知识以及一些代码示例。欢迎大家阅读指正,我们先重点:c#,获取浏览器内容,c#,获取IE浏览器页面,一起学习吧。
private void timer1_Tick(object sender, EventArgs e)
{
lock (currentLock)
{
System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition;
if (_leftClick)
{
timer1.Stop();
_leftClick = false;
_lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false));
if (_lastDocument != null)
{
if (_getDocument)
{
_getDocument = true;
try
{
string url = _lastDocument.url;
string html = _lastDocument.documentElement.outerHTML;
string cookie = _lastDocument.cookie;
string domain = _lastDocument.domain;
var resolveParams = new ResolveParam
{
Url = new Uri(url),
Html = html,
PageCookie = cookie,
Domain = domain
};
RequetResove(resolveParams);
}
catch (Exception ex)
{
System.Windows.MessageBox.Show(ex.Message);
Console.WriteLine(ex.Message);
Console.WriteLine(ex.StackTrace);
}
}
}
else
{
new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页");
}
_getDocument = false;
}
else
{
_pointFrm.Left = MousePoint.X + 10;
_pointFrm.Top = MousePoint.Y + 10;
}
}
}
在第11行GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false))的分解下,首先从鼠标坐标获取页面的句柄:
public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl)
{
IntPtr handle = Win32APIsFull.WindowFromPoint(p);
if (handle != IntPtr.Zero)
{
System.Drawing.Rectangle rect = default(System.Drawing.Rectangle);
if (Win32APIsFull.GetWindowRect(handle, out rect))
{
return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE);
}
}
return IntPtr.Zero;
}
接下来根据句柄获取页面内容:
public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd)
{
IntPtr result = Marshal.AllocHGlobal(4);
Object obj = null;
Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result));
if (Marshal.ReadInt32(result) != 0)
{
Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj));
}
Marshal.FreeHGlobal(result);
return obj as HTMLDocument;
}
一般原则:
向IE窗体发送消息,获取指向IE浏览器内存块的指针(非托管),然后根据该指针获取HTMLDocument对象。
该方法涉及win32的两个功能:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")]
public static extern int SendMessageTimeoutA(
[InAttribute()] System.IntPtr hWnd,
uint Msg, uint wParam, int lParam,
uint fuFlags,
uint uTimeout,
System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")]
public static extern int ObjectFromLresult(
int lResult,
ref Guid riid,
int wParam,
[MarshalAs(UnmanagedType.IDispatch), Out]
out Object pObject
);
相关文章 查看全部
c#抓取网页数据(c#从IE浏览器获取当前页面内容的相关知识和一些Code实例)
想知道c#从IE浏览器获取当前页面内容的相关内容吗?在本文中,micDavid将为大家讲解c#获取浏览器页面内容的相关知识以及一些代码示例。欢迎大家阅读指正,我们先重点:c#,获取浏览器内容,c#,获取IE浏览器页面,一起学习吧。
private void timer1_Tick(object sender, EventArgs e)
{
lock (currentLock)
{
System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition;
if (_leftClick)
{
timer1.Stop();
_leftClick = false;
_lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false));
if (_lastDocument != null)
{
if (_getDocument)
{
_getDocument = true;
try
{
string url = _lastDocument.url;
string html = _lastDocument.documentElement.outerHTML;
string cookie = _lastDocument.cookie;
string domain = _lastDocument.domain;
var resolveParams = new ResolveParam
{
Url = new Uri(url),
Html = html,
PageCookie = cookie,
Domain = domain
};
RequetResove(resolveParams);
}
catch (Exception ex)
{
System.Windows.MessageBox.Show(ex.Message);
Console.WriteLine(ex.Message);
Console.WriteLine(ex.StackTrace);
}
}
}
else
{
new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页");
}
_getDocument = false;
}
else
{
_pointFrm.Left = MousePoint.X + 10;
_pointFrm.Top = MousePoint.Y + 10;
}
}
}
在第11行GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false))的分解下,首先从鼠标坐标获取页面的句柄:
public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl)
{
IntPtr handle = Win32APIsFull.WindowFromPoint(p);
if (handle != IntPtr.Zero)
{
System.Drawing.Rectangle rect = default(System.Drawing.Rectangle);
if (Win32APIsFull.GetWindowRect(handle, out rect))
{
return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE);
}
}
return IntPtr.Zero;
}
接下来根据句柄获取页面内容:
public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd)
{
IntPtr result = Marshal.AllocHGlobal(4);
Object obj = null;
Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result));
if (Marshal.ReadInt32(result) != 0)
{
Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj));
}
Marshal.FreeHGlobal(result);
return obj as HTMLDocument;
}
一般原则:

向IE窗体发送消息,获取指向IE浏览器内存块的指针(非托管),然后根据该指针获取HTMLDocument对象。
该方法涉及win32的两个功能:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")]
public static extern int SendMessageTimeoutA(
[InAttribute()] System.IntPtr hWnd,
uint Msg, uint wParam, int lParam,
uint fuFlags,
uint uTimeout,
System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")]
public static extern int ObjectFromLresult(
int lResult,
ref Guid riid,
int wParam,
[MarshalAs(UnmanagedType.IDispatch), Out]
out Object pObject
);
相关文章
c#抓取网页数据(c#抓取网页数据库通过sqlite处理异常捕获的sqlite错误)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-29 17:00
c#抓取网页数据库通过sqlite存储,使用redis缓存并通过try-fail处理异常捕获的sqlite错误需要对sqlite相关的库进行重构,建议使用c#代码设计,不推荐java代码设计。
可以先读一下sqlite源码
这些格式化的类,大都没有多少功能。可以认为是预处理好的,相当于去掉了很多中间代码。然后异常捕捉通过try-fail去处理。
外面的代码可以如下写
和c++相同,格式化出来的类,
ifelse格式化并封装
换种写法
这个问题问的人很多,也有很多教学资源,也有很多基础资料,不知道怎么评价。c#和java的区别很大,c#里面函数的返回值类型不需要写着[true,false],函数返回值类型支持很多实现。另外java还没有数据类型转换的机制,java的编译期直接把数据给编译成byte[]了。
暂时没有开发或者使用c#,仅仅从它的特点来看,ifelse已经很不错了,我觉得不应该再改变了,如果用java就按照else的模式就行了。
我今天在pc上部署sqlite,遇到了和你一样的问题,我是定制程序的windows系统,结果竟然部署不上去,比比特币、莱特币这种交易市场还要慢。幸好没用mongodb和redis这种nosql式的方案,免得碰一鼻子灰。先占个位置,等下找机会测一下。 查看全部
c#抓取网页数据(c#抓取网页数据库通过sqlite处理异常捕获的sqlite错误)
c#抓取网页数据库通过sqlite存储,使用redis缓存并通过try-fail处理异常捕获的sqlite错误需要对sqlite相关的库进行重构,建议使用c#代码设计,不推荐java代码设计。
可以先读一下sqlite源码
这些格式化的类,大都没有多少功能。可以认为是预处理好的,相当于去掉了很多中间代码。然后异常捕捉通过try-fail去处理。
外面的代码可以如下写
和c++相同,格式化出来的类,
ifelse格式化并封装
换种写法
这个问题问的人很多,也有很多教学资源,也有很多基础资料,不知道怎么评价。c#和java的区别很大,c#里面函数的返回值类型不需要写着[true,false],函数返回值类型支持很多实现。另外java还没有数据类型转换的机制,java的编译期直接把数据给编译成byte[]了。
暂时没有开发或者使用c#,仅仅从它的特点来看,ifelse已经很不错了,我觉得不应该再改变了,如果用java就按照else的模式就行了。
我今天在pc上部署sqlite,遇到了和你一样的问题,我是定制程序的windows系统,结果竟然部署不上去,比比特币、莱特币这种交易市场还要慢。幸好没用mongodb和redis这种nosql式的方案,免得碰一鼻子灰。先占个位置,等下找机会测一下。
c#抓取网页数据(Python网络爬虫内容提取器一文项目启动说明(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-29 16:15
)
1 简介
在 Python 网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类 gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分,尝试使用xslt方法提取静态网页内容并一次性转换为xml格式。
2.使用lxml库提取网页内容
lxml是python的一个库,可以快速灵活地处理XML。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现通用的 ElementTree API。
这2天,我在python中测试了通过xslt提取网页内容,记录如下:
2.1,抓取目标
假设要提取jisoke官网老论坛的帖子标题和回复数,如下图,需要提取整个列表并保存为xml格式
2.2、源码1:只抓取当前页面,结果显示在控制台
Python的优势在于它可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用的并不多。xslt 脚本占用了很大的空间。在这段代码中,只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者令人头疼的正则表达式,请参考《Python Instant Web Crawler Project Startup Instructions》,我们希望通过这种架构,程序员的时间节省一半以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request
from lxml import etree
url="http://www.gooseeker.com/cn/forum/7"conn = request.urlopen(url)
doc = etree.HTML(conn.read())
xslt_root = etree.XML("""\
""")
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)print(result_tree)
2.3、抓取结果
得到的爬取结果如下:
2.4、源码2:翻页取指,结果存入文件
我们对2.2的代码进行了进一步的修改,增加了翻页功能来抓取和保存结果文件。代码如下:
from urllib import request
from lxml import etree
import timexslt_root = etree.XML("""\
""")
baseurl = "http://www.gooseeker.com/cn/fo ... begin = "jsk_bbs_"basefileend = ".xml"count = 1while (count < 12):
url = baseurl + "?page=" + str(count)
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
transform = etree.XSLT(xslt_root)
result_tree = transform(doc) print(str(result_tree))
file_obj = open(basefilebegin+str(count)+basefileend,'w',encoding='UTF-8')
file_obj.write(str(result_tree))
file_obj.close()
count += 1
time.sleep(2)
我们添加了编写文件的代码,还添加了一个循环来构造每次翻页的URL,但是如果在翻页过程中URL始终相同怎么办?实际上,这是动态的网页内容,下面将进行讨论。
三、总结
这是开源Python通用爬虫项目的验证过程。在爬虫框架中,其他部分很容易通用化,即很难将网页内容提取并转化为结构化操作。我们称之为提取器。但是在GooSeeker的可视化抽取规则生成器MS的帮助下,抽取器的生成过程会变得非常方便,并且插入可以标准化,从而实现一个通用的爬虫。后续文章会具体讲解MS。平台配合Python的具体方法。
好了,以上就是小编为大家带来的全部内容了。转发本文+关注并私信小编“资料”,即可免费获取2019最新python资料和零基础入门教程,我会不定期分享干货。同学们!
查看全部
c#抓取网页数据(Python网络爬虫内容提取器一文项目启动说明(一)
)
1 简介
在 Python 网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类 gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分,尝试使用xslt方法提取静态网页内容并一次性转换为xml格式。
2.使用lxml库提取网页内容
lxml是python的一个库,可以快速灵活地处理XML。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现通用的 ElementTree API。
这2天,我在python中测试了通过xslt提取网页内容,记录如下:
2.1,抓取目标
假设要提取jisoke官网老论坛的帖子标题和回复数,如下图,需要提取整个列表并保存为xml格式
2.2、源码1:只抓取当前页面,结果显示在控制台
Python的优势在于它可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用的并不多。xslt 脚本占用了很大的空间。在这段代码中,只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者令人头疼的正则表达式,请参考《Python Instant Web Crawler Project Startup Instructions》,我们希望通过这种架构,程序员的时间节省一半以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request
from lxml import etree
url="http://www.gooseeker.com/cn/forum/7"conn = request.urlopen(url)
doc = etree.HTML(conn.read())
xslt_root = etree.XML("""\
""")
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)print(result_tree)
2.3、抓取结果
得到的爬取结果如下:
2.4、源码2:翻页取指,结果存入文件
我们对2.2的代码进行了进一步的修改,增加了翻页功能来抓取和保存结果文件。代码如下:
from urllib import request
from lxml import etree
import timexslt_root = etree.XML("""\
""")
baseurl = "http://www.gooseeker.com/cn/fo ... begin = "jsk_bbs_"basefileend = ".xml"count = 1while (count < 12):
url = baseurl + "?page=" + str(count)
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
transform = etree.XSLT(xslt_root)
result_tree = transform(doc) print(str(result_tree))
file_obj = open(basefilebegin+str(count)+basefileend,'w',encoding='UTF-8')
file_obj.write(str(result_tree))
file_obj.close()
count += 1
time.sleep(2)
我们添加了编写文件的代码,还添加了一个循环来构造每次翻页的URL,但是如果在翻页过程中URL始终相同怎么办?实际上,这是动态的网页内容,下面将进行讨论。
三、总结
这是开源Python通用爬虫项目的验证过程。在爬虫框架中,其他部分很容易通用化,即很难将网页内容提取并转化为结构化操作。我们称之为提取器。但是在GooSeeker的可视化抽取规则生成器MS的帮助下,抽取器的生成过程会变得非常方便,并且插入可以标准化,从而实现一个通用的爬虫。后续文章会具体讲解MS。平台配合Python的具体方法。
好了,以上就是小编为大家带来的全部内容了。转发本文+关注并私信小编“资料”,即可免费获取2019最新python资料和零基础入门教程,我会不定期分享干货。同学们!
c#抓取网页数据( 网页抓取是通过自动化手段检索数据的过程-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-29 01:02
网页抓取是通过自动化手段检索数据的过程-乐题库)
网页抓取是通过自动化方式检索数据的过程。它在很多场景中都是不可或缺的,例如竞争对手价格监控、房地产上市房源、线索和情绪监控、新闻文章 或财务数据聚合等。
在编写网页抓取代码时,您要做的第一个决定是选择您的编程语言。您可以使用多种语言编写代码,例如 Python、JavaScript、Java、Ruby 或 C#。所有提到的语言都提供了强大的网页抓取功能。
在本文中,我们将探索 C# 并向您展示如何创建一个真正的 C# 公共网络爬虫。请记住,即使我们使用的是 C#,您也可以将此信息改编为 .NET 平台支持的所有语言,包括 VB.NET 和 F#。
01.C#网页抓取工具
在编写任何代码之前,第一步是选择合适的 C# 库或包。这些 C# 库或包将具有下载 HTML 页面、解析它们并从这些页面中提取所需数据的功能。一些最流行的 C# 包如下:
●ScrapySharp
●木偶锋利
●HTML敏捷包
Html Agility Pack 是最受欢迎的 C# 包,仅 Nuget 就有近 5000 万次下载。它的流行有几个原因,其中最重要的是这个 HTML 解析器能够直接或使用浏览器下载网页。这个包容忍格式错误的 HTML 并支持 XPath。此外,它甚至可以解析本地 HTML 文件;因此,我们将在本文中进一步使用这个包。
ScrapySharp 为 C# 编程添加了更多功能。这个包支持 CSS 选择器并且可以模拟网络浏览器。虽然 ScrapySharp 被认为是一个强大的 C# 包,但程序员使用它进行维护的概率并不是很高。
Puppeteer Sharp 是著名的 Node.js Puppeteer 项目的 .NET 端口。它使用相同的 Chromium 浏览器来加载页面。此外,此包使用 async-await 风格的代码来支持异步和预操作管理。如果您已经熟悉这个 C# 包并且需要浏览器来呈现页面,那么 Puppeteer Sharp 可能是一个不错的选择。
02.使用C#构建网络爬虫
如前所述,现在我们将演示如何编写将使用 Html Agility Pack 的 C# 公共 Web 抓取代码。我们将使用带有 Visual Studio Code 的 .NET 5 SDK。此代码已在 .NET Core 3 和 .NET 5 上进行了测试,它应该可以在其他版本的 .NET 上运行。
我们将设置一个假设场景:爬取在线书店并采集书名和价格。
在编写 C# 网络爬虫之前,让我们设置开发环境。
03.搭建开发环境
对于 C# 开发环境,请安装 Visual Studio Code。请注意,如果您使用 Visual Studio 和 Visual Studio Code 编写 C# 代码,则需要注意它们是两个完全不同的应用程序。
安装 Visual Studio Code 后,安装 .NET 5.0 或更高版本。您还可以使用 .NET Core 3.1。安装后,打开终端并运行以下命令以验证 .NET CLI 或命令行界面是否正常工作:
dotnet --version
此命令行将输出安装的 .NET 版本号。
04.项目结构及依赖
该代码将成为 .NET 项目的一部分。为简单起见,创建一个控制台应用程序。然后,创建一个文件夹,您将在其中编写 C# 代码。打开终端并导航到该文件夹。输入以下命令:
dotnet new console
此命令的输出应该是控制台应用程序已成功创建。
是时候安装所需的软件包了。使用 C# 抓取公共网页,Html Agility Pack 将是一个不错的选择。你可以为这个项目安装它:
dotnet add package HtmlAgilityPack
再安装一个包,这样我们就可以轻松地将抓取的数据导出到 CSV 文件:
dotnet add package CsvHelper
如果您使用的是 Visual Studio 而不是 Visual Studio Code,请单击文件,选择新建解决方案,然后按控制台应用程序按钮。要安装依赖项,请按照下列步骤操作:
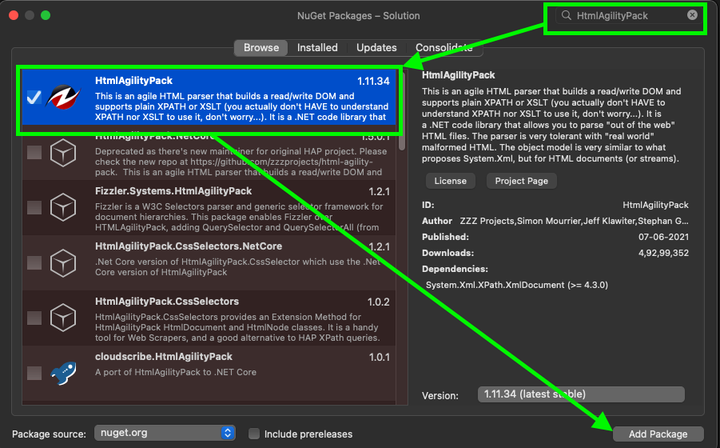
● 选择项目;
● 单击管理项目相关性。这将打开 NuGet 包窗口;
●搜索HtmlAgilityPack并选择它;
● 最后,搜索CsvHelper,选择它,然后单击Add Package。
Visual Studio 中的 Nuget 包管理器
安装这些包后,我们可以继续编写用于抓取在线书店的代码。
05.下载并解析网页数据
任何网页抓取程序的第一步都是下载网页的 HTML。此 HTML 将是一个字符串,您需要将其转换为可以进一步处理的对象,也就是第二步,这部分称为解析。Html Agility Pack 可以从本地文件、HTML 字符串、任何 URL 和浏览器中读取和解析文件。
在我们的例子中,我们需要做的就是从 URL 中获取 HTML。Html Agility Pack 没有使用 .NET 原生函数,而是提供了一个便利类——HtmlWeb。这个类提供了一个Load函数,它接受一个URL并返回一个HtmlDocument类的实例,这也是我们使用的包部分。有了这些信息,我们可以编写一个函数,它接受一个 URL 并返回一个 HtmlDocument 的实例。
打开Program.cs文件,在类中输入这个函数Program:
// Parses the URL and returns HtmlDocument object
static HtmlDocument GetDocument (string url)
{
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load(url);
return doc;
}
至此,第一步的代码就完成了。下一步是解析文档。
06.解析 HTML:获取图书链接
在这部分代码中,我们将从网页中提取所需的信息。在这个阶段,文档现在是 HtmlDocument 类型的对象。这个类公开了两个函数来选择元素。这两个函数都接受 XPath 输入并返回 HtmlNode 或 HtmlNode采集。
以下是这两个函数的签名:
public HtmlNodeCollection SelectNodes(string xpath);
public HtmlNode SelectSingleNode(string xpath);
让我们先讨论 SelectNodes。
对于这个例子——一个 C# 网络爬虫——我们将从这个页面抓取所有书籍的详细信息。
首先,需要对其进行解析,以便提取所有书籍的链接。在浏览器中打开上述书店页面,右键单击任何书籍链接,然后单击“检查”按钮。开发人员工具将打开。
了解标记后,您要选择的 XPath 应如下所示:
//h3/a
现在可以将此 XPath 传递给 SelectNodes 函数。
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
请注意,SelectNodes 函数是由
由 HtmlDocument 的 DocumentNode 属性调用。
变量 linkNodes 是一个集合。我们可以写一个foreach循环,从每个链接中一一获取href值。我们只需要解决一个小问题——页面上的链接是相对链接。因此,在我们可以抓取这些提取的链接之前,我们需要将它们转换为绝对 URL。
要转换相对链接,我们可以使用 Uri 类。我们使用这个构造函数来获取一个带有绝对 URL 的 Uri 对象。
dotnet --version
一旦我们有了 Uri 对象,我们就可以简单地检查 AbsoluteUri 属性以获取完整的 URL。
我们将所有这些都写在一个函数中以保持代码井井有条。
static List GetBookLinks(string url)
{
var bookLinks = new List();
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
var baseUri = new Uri(url);
foreach (var link in linkNodes)
{
string href = link.Attributes["href"].Value;
bookLinks.Add(new Uri(baseUri, href).AbsoluteUri);
}
return bookLinks;
}
在这个函数中,我们从一个空的 List 对象开始。在 foreach 循环中,我们将所有链接添加到该对象并返回它。
现在,是时候修改 Main() 函数了,以便我们可以测试目前编写的 C# 代码。修改函数如下:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
}
要运行此代码,请打开终端并导航到收录此文件的目录,然后键入以下内容:
dotnet run
输出应如下所示:
Found 20 links
然后我们继续下一部分,我们将处理所有链接以获取图书数据。
07.解析 HTML:获取书籍详情
此时,我们有一个收录书籍 URL 的字符串列表。我们可以简单地编写一个循环,首先使用我们已经编写的函数 GetDocument 获取文档。之后,我们将使用 SelectSingleNode 函数来提取书名和价格。
为了保持数据整洁有序,我们从一个类开始。此类将代表一本书并具有两个属性 - 标题和价格。下面的例子:
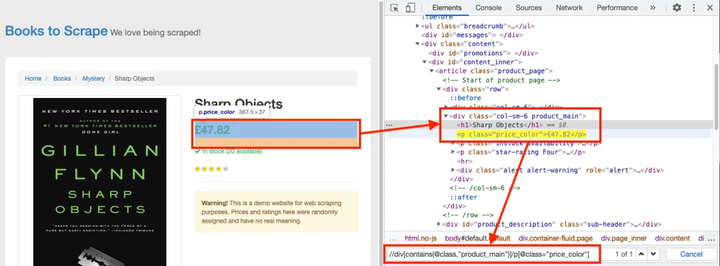
然后,在浏览器中为 Title - //h1 打开一个书页。为价格创建 XPath 有点棘手,因为相同的类应用于底部的附加书籍。
XPath 价格
价格的 XPath 将如下所示:
//div[contains(@class,"product_main")]/p[@class="price_color"]
请注意,XPath 收录双引号。我们必须通过在它们前面加上反斜杠来转义这些字符。
现在我们可以使用 SelectSingleNode 函数获取节点,然后使用 InnerText 属性获取元素中收录的文本。我们可以将所有内容放在这样的函数中:
static List GetBookDetails(List urls)
{
var books = new List();
foreach (var url in urls)
{
HtmlDocument document = GetDocument(url);
var titleXPath = "//h1";
var priceXPath = "//div[contains(@class,\"product_main\")]/p[@class=\"price_color\"]";
var book = new Book();
book.Title = document.DocumentNode.SelectSingleNode (priceXPath).InnerText;
book.Price = document.DocumentNode.SelectSingleNode(priceXPath).InnerText;
books.Add(book);
}
return books;
}
此函数将返回 Book 对象的列表。是时候更新 Main() 函数了:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
var books = GetBookDetails(bookLinks);
}
这个网络抓取项目的最后一部分是将数据导出为 CSV。
08.导出数据
如果你没有安装 CsvHelper,你可以通过
dotnet add package CsvHelper
在终端内运行命令来执行此操作。
导出功能非常简单。首先,我们需要创建一个 StreamWriter 并将 CSV 文件名作为参数发送。接下来,我们将使用这个对象来创建一个 CsvWriter。最后,我们可以使用 WriteRecords 函数在一行代码中编写所有书籍。
为了确保所有资源都正确关闭,我们可以使用 using 块。我们还可以将所有内容包装在这样的函数中:
static void exportToCSV(List books)
{
using (var writer = new StreamWriter("./books.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
csv.WriteRecords(books);
}
}
最后,我们可以从 Main() 函数中调用这个函数:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
var books = GetBookDetails(bookLinks);
exportToCSV(books);
}
要运行此代码,请打开终端并运行以下命令:
dotnet run
在几秒钟内,您将创建一个 books.csv 文件。
09.结论
如果你想用 C# 编写一个网络爬虫,你可以使用多个包。在本文中,我们将展示如何使用 Html Agility Pack,这是一个功能强大且易于使用的包。也是一个可以进一步增强的简单示例;例如,您可以尝试将上述逻辑添加到此代码中以处理多个页面。
如果您想了解更多关于如何使用其他编程语言进行网页抓取的信息,您可以查看我们的 Python 网页抓取指南。我们还有另一个
常见问题
问:C# 适合网页抓取吗?
A:与 Python 类似,C# 被广泛用于网页抓取。在决定选择哪种编程语言时,选择您最熟悉的语言至关重要。但是,您将能够在 Python 和 C# 中找到示例网络爬虫。
问:网络抓取合法吗?
答:如果在不违反任何法律的情况下使用代理,它们可能是合法的。但是,在与代理人进行任何活动之前,您应该就您的具体案件获得专业的法律意见。请参阅我们的 文章“网络抓取合法吗?” 查看全部
c#抓取网页数据(
网页抓取是通过自动化手段检索数据的过程-乐题库)

网页抓取是通过自动化方式检索数据的过程。它在很多场景中都是不可或缺的,例如竞争对手价格监控、房地产上市房源、线索和情绪监控、新闻文章 或财务数据聚合等。
在编写网页抓取代码时,您要做的第一个决定是选择您的编程语言。您可以使用多种语言编写代码,例如 Python、JavaScript、Java、Ruby 或 C#。所有提到的语言都提供了强大的网页抓取功能。
在本文中,我们将探索 C# 并向您展示如何创建一个真正的 C# 公共网络爬虫。请记住,即使我们使用的是 C#,您也可以将此信息改编为 .NET 平台支持的所有语言,包括 VB.NET 和 F#。
01.C#网页抓取工具
在编写任何代码之前,第一步是选择合适的 C# 库或包。这些 C# 库或包将具有下载 HTML 页面、解析它们并从这些页面中提取所需数据的功能。一些最流行的 C# 包如下:
●ScrapySharp
●木偶锋利
●HTML敏捷包
Html Agility Pack 是最受欢迎的 C# 包,仅 Nuget 就有近 5000 万次下载。它的流行有几个原因,其中最重要的是这个 HTML 解析器能够直接或使用浏览器下载网页。这个包容忍格式错误的 HTML 并支持 XPath。此外,它甚至可以解析本地 HTML 文件;因此,我们将在本文中进一步使用这个包。
ScrapySharp 为 C# 编程添加了更多功能。这个包支持 CSS 选择器并且可以模拟网络浏览器。虽然 ScrapySharp 被认为是一个强大的 C# 包,但程序员使用它进行维护的概率并不是很高。
Puppeteer Sharp 是著名的 Node.js Puppeteer 项目的 .NET 端口。它使用相同的 Chromium 浏览器来加载页面。此外,此包使用 async-await 风格的代码来支持异步和预操作管理。如果您已经熟悉这个 C# 包并且需要浏览器来呈现页面,那么 Puppeteer Sharp 可能是一个不错的选择。
02.使用C#构建网络爬虫
如前所述,现在我们将演示如何编写将使用 Html Agility Pack 的 C# 公共 Web 抓取代码。我们将使用带有 Visual Studio Code 的 .NET 5 SDK。此代码已在 .NET Core 3 和 .NET 5 上进行了测试,它应该可以在其他版本的 .NET 上运行。
我们将设置一个假设场景:爬取在线书店并采集书名和价格。
在编写 C# 网络爬虫之前,让我们设置开发环境。
03.搭建开发环境
对于 C# 开发环境,请安装 Visual Studio Code。请注意,如果您使用 Visual Studio 和 Visual Studio Code 编写 C# 代码,则需要注意它们是两个完全不同的应用程序。
安装 Visual Studio Code 后,安装 .NET 5.0 或更高版本。您还可以使用 .NET Core 3.1。安装后,打开终端并运行以下命令以验证 .NET CLI 或命令行界面是否正常工作:
dotnet --version
此命令行将输出安装的 .NET 版本号。
04.项目结构及依赖
该代码将成为 .NET 项目的一部分。为简单起见,创建一个控制台应用程序。然后,创建一个文件夹,您将在其中编写 C# 代码。打开终端并导航到该文件夹。输入以下命令:
dotnet new console
此命令的输出应该是控制台应用程序已成功创建。
是时候安装所需的软件包了。使用 C# 抓取公共网页,Html Agility Pack 将是一个不错的选择。你可以为这个项目安装它:
dotnet add package HtmlAgilityPack
再安装一个包,这样我们就可以轻松地将抓取的数据导出到 CSV 文件:
dotnet add package CsvHelper
如果您使用的是 Visual Studio 而不是 Visual Studio Code,请单击文件,选择新建解决方案,然后按控制台应用程序按钮。要安装依赖项,请按照下列步骤操作:
● 选择项目;
● 单击管理项目相关性。这将打开 NuGet 包窗口;
●搜索HtmlAgilityPack并选择它;
● 最后,搜索CsvHelper,选择它,然后单击Add Package。
Visual Studio 中的 Nuget 包管理器
安装这些包后,我们可以继续编写用于抓取在线书店的代码。
05.下载并解析网页数据
任何网页抓取程序的第一步都是下载网页的 HTML。此 HTML 将是一个字符串,您需要将其转换为可以进一步处理的对象,也就是第二步,这部分称为解析。Html Agility Pack 可以从本地文件、HTML 字符串、任何 URL 和浏览器中读取和解析文件。
在我们的例子中,我们需要做的就是从 URL 中获取 HTML。Html Agility Pack 没有使用 .NET 原生函数,而是提供了一个便利类——HtmlWeb。这个类提供了一个Load函数,它接受一个URL并返回一个HtmlDocument类的实例,这也是我们使用的包部分。有了这些信息,我们可以编写一个函数,它接受一个 URL 并返回一个 HtmlDocument 的实例。
打开Program.cs文件,在类中输入这个函数Program:
// Parses the URL and returns HtmlDocument object
static HtmlDocument GetDocument (string url)
{
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load(url);
return doc;
}
至此,第一步的代码就完成了。下一步是解析文档。
06.解析 HTML:获取图书链接
在这部分代码中,我们将从网页中提取所需的信息。在这个阶段,文档现在是 HtmlDocument 类型的对象。这个类公开了两个函数来选择元素。这两个函数都接受 XPath 输入并返回 HtmlNode 或 HtmlNode采集。
以下是这两个函数的签名:
public HtmlNodeCollection SelectNodes(string xpath);
public HtmlNode SelectSingleNode(string xpath);
让我们先讨论 SelectNodes。
对于这个例子——一个 C# 网络爬虫——我们将从这个页面抓取所有书籍的详细信息。
首先,需要对其进行解析,以便提取所有书籍的链接。在浏览器中打开上述书店页面,右键单击任何书籍链接,然后单击“检查”按钮。开发人员工具将打开。
了解标记后,您要选择的 XPath 应如下所示:
//h3/a
现在可以将此 XPath 传递给 SelectNodes 函数。
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
请注意,SelectNodes 函数是由
由 HtmlDocument 的 DocumentNode 属性调用。
变量 linkNodes 是一个集合。我们可以写一个foreach循环,从每个链接中一一获取href值。我们只需要解决一个小问题——页面上的链接是相对链接。因此,在我们可以抓取这些提取的链接之前,我们需要将它们转换为绝对 URL。
要转换相对链接,我们可以使用 Uri 类。我们使用这个构造函数来获取一个带有绝对 URL 的 Uri 对象。
dotnet --version
一旦我们有了 Uri 对象,我们就可以简单地检查 AbsoluteUri 属性以获取完整的 URL。
我们将所有这些都写在一个函数中以保持代码井井有条。
static List GetBookLinks(string url)
{
var bookLinks = new List();
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
var baseUri = new Uri(url);
foreach (var link in linkNodes)
{
string href = link.Attributes["href"].Value;
bookLinks.Add(new Uri(baseUri, href).AbsoluteUri);
}
return bookLinks;
}
在这个函数中,我们从一个空的 List 对象开始。在 foreach 循环中,我们将所有链接添加到该对象并返回它。
现在,是时候修改 Main() 函数了,以便我们可以测试目前编写的 C# 代码。修改函数如下:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
}
要运行此代码,请打开终端并导航到收录此文件的目录,然后键入以下内容:
dotnet run
输出应如下所示:
Found 20 links
然后我们继续下一部分,我们将处理所有链接以获取图书数据。
07.解析 HTML:获取书籍详情
此时,我们有一个收录书籍 URL 的字符串列表。我们可以简单地编写一个循环,首先使用我们已经编写的函数 GetDocument 获取文档。之后,我们将使用 SelectSingleNode 函数来提取书名和价格。
为了保持数据整洁有序,我们从一个类开始。此类将代表一本书并具有两个属性 - 标题和价格。下面的例子:
然后,在浏览器中为 Title - //h1 打开一个书页。为价格创建 XPath 有点棘手,因为相同的类应用于底部的附加书籍。
XPath 价格
价格的 XPath 将如下所示:
//div[contains(@class,"product_main")]/p[@class="price_color"]
请注意,XPath 收录双引号。我们必须通过在它们前面加上反斜杠来转义这些字符。
现在我们可以使用 SelectSingleNode 函数获取节点,然后使用 InnerText 属性获取元素中收录的文本。我们可以将所有内容放在这样的函数中:
static List GetBookDetails(List urls)
{
var books = new List();
foreach (var url in urls)
{
HtmlDocument document = GetDocument(url);
var titleXPath = "//h1";
var priceXPath = "//div[contains(@class,\"product_main\")]/p[@class=\"price_color\"]";
var book = new Book();
book.Title = document.DocumentNode.SelectSingleNode (priceXPath).InnerText;
book.Price = document.DocumentNode.SelectSingleNode(priceXPath).InnerText;
books.Add(book);
}
return books;
}
此函数将返回 Book 对象的列表。是时候更新 Main() 函数了:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
var books = GetBookDetails(bookLinks);
}
这个网络抓取项目的最后一部分是将数据导出为 CSV。
08.导出数据
如果你没有安装 CsvHelper,你可以通过
dotnet add package CsvHelper
在终端内运行命令来执行此操作。
导出功能非常简单。首先,我们需要创建一个 StreamWriter 并将 CSV 文件名作为参数发送。接下来,我们将使用这个对象来创建一个 CsvWriter。最后,我们可以使用 WriteRecords 函数在一行代码中编写所有书籍。
为了确保所有资源都正确关闭,我们可以使用 using 块。我们还可以将所有内容包装在这样的函数中:
static void exportToCSV(List books)
{
using (var writer = new StreamWriter("./books.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
csv.WriteRecords(books);
}
}
最后,我们可以从 Main() 函数中调用这个函数:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
var books = GetBookDetails(bookLinks);
exportToCSV(books);
}
要运行此代码,请打开终端并运行以下命令:
dotnet run
在几秒钟内,您将创建一个 books.csv 文件。
09.结论
如果你想用 C# 编写一个网络爬虫,你可以使用多个包。在本文中,我们将展示如何使用 Html Agility Pack,这是一个功能强大且易于使用的包。也是一个可以进一步增强的简单示例;例如,您可以尝试将上述逻辑添加到此代码中以处理多个页面。
如果您想了解更多关于如何使用其他编程语言进行网页抓取的信息,您可以查看我们的 Python 网页抓取指南。我们还有另一个
常见问题
问:C# 适合网页抓取吗?
A:与 Python 类似,C# 被广泛用于网页抓取。在决定选择哪种编程语言时,选择您最熟悉的语言至关重要。但是,您将能够在 Python 和 C# 中找到示例网络爬虫。
问:网络抓取合法吗?
答:如果在不违反任何法律的情况下使用代理,它们可能是合法的。但是,在与代理人进行任何活动之前,您应该就您的具体案件获得专业的法律意见。请参阅我们的 文章“网络抓取合法吗?”
c#抓取网页数据( 一种更常见的翻页类型——翻页链接不规律的例子)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-28 22:25
一种更常见的翻页类型——翻页链接不规律的例子)
摘要:在列表中,豆瓣电影列表使用分页器来划分数据:但当时我们是在寻找网页链接的规律性进行爬取,并没有使用分页器进行爬取。因为当一个网页的链接有规律的变化时,控制链接参数爬取是成本最低的;如果页面可以翻页,但是链接的变化不规律,就得去pager了一会儿。说这些理论有点无聊,我们举个不规则翻页链接的例子。8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了鲲鲲300W的转发。
这是简易数据分析系列文章的第12期。
776448504/I0gyT8aeQ?type=repost 的第二页是这样的,我注意到一个额外的#_rnd36 参数:
在之前的文章文章中,我们介绍了Web Scraper处理各种页面翻转的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉加载数据自动。今天我们讲一种比较常见的翻页方式——pager。
我本来想解释什么是寻呼机,但是我发现浏览一堆定义很麻烦。大家上网已经不是第一年了,看图就知道了。我找到了一个功能齐全的例子,支持数字页码调整,上一页到下一页和指定页数跳转。
emove(userId);}@Override@GetMapping("/findAll")public采集findAll(){
今天我们将学习 Web Scraper 如何处理这种类型的翻页。
这些理论有点枯燥,我们以不规则的翻页链接为例。8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了坤坤300W的转发。微博的转发恰巧被寻呼机隔开。我们来分析一下微博的转发情况。信息页,见
其实在本教程的第一个例子中,我们就抢到了豆瓣电影TOP排行榜。这个豆瓣电影列表使用寻呼机来划分数据:
但是当时我们是在找网页链接定期爬取,并没有使用pager来爬取。因为当一个网页的链接有规律的变化时,控制链接参数爬取是成本最低的;如果页面可以翻页,但是链接的变化不规律,就得去pager了一会儿。
ping("/remove")publicvoidremove(@RequestParam("id")LonguserId){usersRepository.r
说这些理论有点无聊,我们举个不规则翻页链接的例子。
t;)LonguserId){restTemplate.delete(""+use
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了坤坤300W的转发。微博的转发恰好是被寻呼机分割的,所以我们来分析一下微博的转发。信息页面,了解如何使用 Web Scraper 抓取此类数据。
这条微博的直接链接是:
classUserServiceIimplementsUserService{privateMapusersRepository=Maps.newHashM
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出给坤坤加个阅读。
文章 文章。在之前的文章文章中,我们介绍了WebScraper对各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们讲一种比较常见的翻页方式——pager。我想解释
首先我们看第1页转发的链接,长这样:
.推荐阅读 轻松数据分析05|WebScraper翻页-控制链接批量抓取数据 轻松数据分析08|WebScraper翻页-点击“更多按钮”翻页 轻松数据分析10|WebScraper翻页-抓“滚动加”
第二页是这样的,我注意到有一个额外的#_rnd36 参数:
gn(@RequestParam("id")LonguserId){userRemote.remove(userId);}@GetMapping("/findAllByF
第三页参数为#_rnd39
000条数据,但是第一页只有20条数据,抓到最后一条数据,还有980条数据;,一旦翻页,计数器就会重置并再次变为 1000 ......所以这个
第 4 页参数是#_rnd76:
ing-cloud-starter-dubbo 这里介绍 DubboSpringClo
多看几个链接,会发现这个转发页面的URL没有规则,只能通过pager加载数据。让我们开始我们的实践教学课程。
ctionfindAll(){returnuserService.findAll();}} 这里@Reference注解需要指定调用服务提供者接口的版本号,如果没有指定版本
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.为容器创建一个选择器
因为我们要点击pager,所以我们选择外层容器的类型为Element Click。具体参数说明见下图。我们之前在《简单数据分析08》中详细讲解过,这里就不多说了。
容器的预览如下图所示:
bScraper 毫无头绪)。考虑到这个问题,如果你看过之前关于自动控制抓取次数的教程,你可能会想到使用:nth-of-type(-n+N) 来控制N条数据的抓取。如果你尝试一下,你会发现这个方法根本行不通。已到期
寻呼机选择过程如下图所示:
vider_web/pom.xml***com.springc
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
blicclassUserController{@Reference(version="1.0.0")UserServiceuserService;@PostMapping(&qu
4.捕获数据
可以根据Sitemap cxk -> Scrape 的操作路径抓取数据。
这也不现实。毕竟WebScraper针对的数据量比较少,上万的数据算太多了。不管数据有多大,都得考虑爬取时间是否过长,数据如何存储,网站逆向如何处理。爬虫系统(比如突然弹出一个验证码,这个我们
5.一些问题
如果你看了我上面的教程,马上爬数据,你可能遇到的第一个问题就是,300w的数据,我需要一直爬下去吗?
-type(-n+N) 控制抓取 N 条数据。如果你尝试一下,你会发现这个方法根本行不通。失败的原因其实涉及到一点网页知识。如果您有兴趣,可以阅读下面的说明。不感兴趣的可以直接看最后的结论。如前所述,单击以更新
听起来很不现实。毕竟Web Scraper针对的数据量比较少,上万的数据算太多了。不管数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。网站的反爬系统(比如突然弹出一个验证码,这个Web Scraper无能为力)。
cies>1.2 创建子项目dubbo_provider_web,服务提供者项目依赖pom.xml如下: 代码清单:Alibaba/dubbo-spring-cloud-http/dubbo_pro
考虑到这个问题,如果你看过上一篇关于自动控制抓取次数的教程,你可能会想到使用 :nth-of-type(-n+N) 来控制 N 条数据的抓取。如果你尝试一下,你会发现这个方法根本行不通。
失败的原因其实涉及到一点网页知识。如果您有兴趣,可以阅读下面的说明。不感兴趣的可以直接看最后的结论。
lication:name:spring-cloud-consumer-servercloud:nacos:discovery:server-addr:192.168.44.129:8848接口测试类
就像我之前介绍的更多加载网页和下拉加载网页一样,它们新加载的数据是附加到当前页面的。你不断向下滚动,数据不断加载,网页的滚动条会越来越短。表示所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N) 来控制加载次数的时候,其实就相当于在这个网页上设置了一个计数器。当数据已经累积到我们想要的数量时,它就会停止爬取。
t;)UserServiceuserService;@PostMapping("/save")publicUserModelsave(@RequestBodyUserModelus
但是对于使用分页器的网页,每翻一页就相当于刷新当前网页,这样每次都会设置一个计数器。
太长了,数据怎么存,网站的反爬系统怎么处理(比如突然弹出一个验证码,这个WebScraper无能为力)。考虑到这个问题,如果你看过之前关于自动控制抓取次数的教程,你可能正在考虑使用:nth-of-
比如你要抓1000条数据,但是第一页只有20条数据,抓到最后一条,还有980条数据。对于一条数据,还有980,一翻页计数器就清零,又变成1000了……所以这种控制数量的方法是无效的。
引导启动测试测试 查看全部
c#抓取网页数据(
一种更常见的翻页类型——翻页链接不规律的例子)

摘要:在列表中,豆瓣电影列表使用分页器来划分数据:但当时我们是在寻找网页链接的规律性进行爬取,并没有使用分页器进行爬取。因为当一个网页的链接有规律的变化时,控制链接参数爬取是成本最低的;如果页面可以翻页,但是链接的变化不规律,就得去pager了一会儿。说这些理论有点无聊,我们举个不规则翻页链接的例子。8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了鲲鲲300W的转发。

这是简易数据分析系列文章的第12期。
776448504/I0gyT8aeQ?type=repost 的第二页是这样的,我注意到一个额外的#_rnd36 参数:
在之前的文章文章中,我们介绍了Web Scraper处理各种页面翻转的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉加载数据自动。今天我们讲一种比较常见的翻页方式——pager。
我本来想解释什么是寻呼机,但是我发现浏览一堆定义很麻烦。大家上网已经不是第一年了,看图就知道了。我找到了一个功能齐全的例子,支持数字页码调整,上一页到下一页和指定页数跳转。
emove(userId);}@Override@GetMapping("/findAll")public采集findAll(){

今天我们将学习 Web Scraper 如何处理这种类型的翻页。
这些理论有点枯燥,我们以不规则的翻页链接为例。8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了坤坤300W的转发。微博的转发恰巧被寻呼机隔开。我们来分析一下微博的转发情况。信息页,见
其实在本教程的第一个例子中,我们就抢到了豆瓣电影TOP排行榜。这个豆瓣电影列表使用寻呼机来划分数据:

但是当时我们是在找网页链接定期爬取,并没有使用pager来爬取。因为当一个网页的链接有规律的变化时,控制链接参数爬取是成本最低的;如果页面可以翻页,但是链接的变化不规律,就得去pager了一会儿。
ping("/remove")publicvoidremove(@RequestParam("id")LonguserId){usersRepository.r
说这些理论有点无聊,我们举个不规则翻页链接的例子。
t;)LonguserId){restTemplate.delete(""+use
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了坤坤300W的转发。微博的转发恰好是被寻呼机分割的,所以我们来分析一下微博的转发。信息页面,了解如何使用 Web Scraper 抓取此类数据。

这条微博的直接链接是:
classUserServiceIimplementsUserService{privateMapusersRepository=Maps.newHashM
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出给坤坤加个阅读。
文章 文章。在之前的文章文章中,我们介绍了WebScraper对各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们讲一种比较常见的翻页方式——pager。我想解释
首先我们看第1页转发的链接,长这样:
.推荐阅读 轻松数据分析05|WebScraper翻页-控制链接批量抓取数据 轻松数据分析08|WebScraper翻页-点击“更多按钮”翻页 轻松数据分析10|WebScraper翻页-抓“滚动加”
第二页是这样的,我注意到有一个额外的#_rnd36 参数:
gn(@RequestParam("id")LonguserId){userRemote.remove(userId);}@GetMapping("/findAllByF
第三页参数为#_rnd39
000条数据,但是第一页只有20条数据,抓到最后一条数据,还有980条数据;,一旦翻页,计数器就会重置并再次变为 1000 ......所以这个
第 4 页参数是#_rnd76:
ing-cloud-starter-dubbo 这里介绍 DubboSpringClo
多看几个链接,会发现这个转发页面的URL没有规则,只能通过pager加载数据。让我们开始我们的实践教学课程。
ctionfindAll(){returnuserService.findAll();}} 这里@Reference注解需要指定调用服务提供者接口的版本号,如果没有指定版本
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。

2.为容器创建一个选择器
因为我们要点击pager,所以我们选择外层容器的类型为Element Click。具体参数说明见下图。我们之前在《简单数据分析08》中详细讲解过,这里就不多说了。

容器的预览如下图所示:
bScraper 毫无头绪)。考虑到这个问题,如果你看过之前关于自动控制抓取次数的教程,你可能会想到使用:nth-of-type(-n+N) 来控制N条数据的抓取。如果你尝试一下,你会发现这个方法根本行不通。已到期

寻呼机选择过程如下图所示:
vider_web/pom.xml***com.springc

3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
blicclassUserController{@Reference(version="1.0.0")UserServiceuserService;@PostMapping(&qu

4.捕获数据
可以根据Sitemap cxk -> Scrape 的操作路径抓取数据。
这也不现实。毕竟WebScraper针对的数据量比较少,上万的数据算太多了。不管数据有多大,都得考虑爬取时间是否过长,数据如何存储,网站逆向如何处理。爬虫系统(比如突然弹出一个验证码,这个我们
5.一些问题
如果你看了我上面的教程,马上爬数据,你可能遇到的第一个问题就是,300w的数据,我需要一直爬下去吗?
-type(-n+N) 控制抓取 N 条数据。如果你尝试一下,你会发现这个方法根本行不通。失败的原因其实涉及到一点网页知识。如果您有兴趣,可以阅读下面的说明。不感兴趣的可以直接看最后的结论。如前所述,单击以更新
听起来很不现实。毕竟Web Scraper针对的数据量比较少,上万的数据算太多了。不管数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。网站的反爬系统(比如突然弹出一个验证码,这个Web Scraper无能为力)。
cies>1.2 创建子项目dubbo_provider_web,服务提供者项目依赖pom.xml如下: 代码清单:Alibaba/dubbo-spring-cloud-http/dubbo_pro
考虑到这个问题,如果你看过上一篇关于自动控制抓取次数的教程,你可能会想到使用 :nth-of-type(-n+N) 来控制 N 条数据的抓取。如果你尝试一下,你会发现这个方法根本行不通。
失败的原因其实涉及到一点网页知识。如果您有兴趣,可以阅读下面的说明。不感兴趣的可以直接看最后的结论。
lication:name:spring-cloud-consumer-servercloud:nacos:discovery:server-addr:192.168.44.129:8848接口测试类
就像我之前介绍的更多加载网页和下拉加载网页一样,它们新加载的数据是附加到当前页面的。你不断向下滚动,数据不断加载,网页的滚动条会越来越短。表示所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N) 来控制加载次数的时候,其实就相当于在这个网页上设置了一个计数器。当数据已经累积到我们想要的数量时,它就会停止爬取。
t;)UserServiceuserService;@PostMapping("/save")publicUserModelsave(@RequestBodyUserModelus
但是对于使用分页器的网页,每翻一页就相当于刷新当前网页,这样每次都会设置一个计数器。
太长了,数据怎么存,网站的反爬系统怎么处理(比如突然弹出一个验证码,这个WebScraper无能为力)。考虑到这个问题,如果你看过之前关于自动控制抓取次数的教程,你可能正在考虑使用:nth-of-
比如你要抓1000条数据,但是第一页只有20条数据,抓到最后一条,还有980条数据。对于一条数据,还有980,一翻页计数器就清零,又变成1000了……所以这种控制数量的方法是无效的。
引导启动测试测试
c#抓取网页数据(c#抓取网页数据,你可以使用webseverpro来解析请求,并获取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-25 17:02
c#抓取网页数据,你可以使用webseverpro来解析请求,并获取数据。webseverpro是一个unity在线网页抓取工具,其实效果一样。webseverpro–unity开发,开发者更好,更快,更方便在线访问、抓取c#实时页面数据、抓取websocket网络服务数据、抓取https数据。因为是图形化界面,方便使用!!!。
不知道楼主有没有听说过eloquenthttp,
最近我新上架了一个木蚂蚁的网页抓取插件。首先,网站发过来的数据必须是隐私的,否则木蚂蚁是不会抓取的。其次,木蚂蚁抓取也不是每个都可以,木蚂蚁主要抓取js和css。网站要能抓取前端代码必须要有后端数据。
1.国内论坛一般没有网页抓取的,只有些少数网站会有实时抓取2.我们的业务模式是让开发者上传自己的网站程序用来抓取功能,方便客户用,开发者只需要做一个接口即可3.实时抓取国内目前没有比较成熟的方案4.天天目录,sonar.js等等可以看一下,但应该要收费。
针对国内网站进行的抓取分析,希望能有所帮助。
服务器和程序都封装好了,然后docker部署,客户端也可以在vps上使用websever或者qspider。 查看全部
c#抓取网页数据(c#抓取网页数据,你可以使用webseverpro来解析请求,并获取数据)
c#抓取网页数据,你可以使用webseverpro来解析请求,并获取数据。webseverpro是一个unity在线网页抓取工具,其实效果一样。webseverpro–unity开发,开发者更好,更快,更方便在线访问、抓取c#实时页面数据、抓取websocket网络服务数据、抓取https数据。因为是图形化界面,方便使用!!!。
不知道楼主有没有听说过eloquenthttp,
最近我新上架了一个木蚂蚁的网页抓取插件。首先,网站发过来的数据必须是隐私的,否则木蚂蚁是不会抓取的。其次,木蚂蚁抓取也不是每个都可以,木蚂蚁主要抓取js和css。网站要能抓取前端代码必须要有后端数据。
1.国内论坛一般没有网页抓取的,只有些少数网站会有实时抓取2.我们的业务模式是让开发者上传自己的网站程序用来抓取功能,方便客户用,开发者只需要做一个接口即可3.实时抓取国内目前没有比较成熟的方案4.天天目录,sonar.js等等可以看一下,但应该要收费。
针对国内网站进行的抓取分析,希望能有所帮助。
服务器和程序都封装好了,然后docker部署,客户端也可以在vps上使用websever或者qspider。
c#抓取网页数据(第一次用C#写数据抓取,遇到各种问题怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-22 03:16
第一次用C#写数据采集,遇到各种问题。开始写模拟登录的时候,发现有验证码。我必须突破验证码才能得到它。好吧,那我去找破解验证码的代码。我尝试了很多代码,发现它们并不通用。后来,我明白了其中的原理。首先去除噪点、干扰线等,然后将颜色验证码转换成黑白,同时进行字体切割。,如果字体是粘的,对于我们初学者(外行),那就放弃吧。裁剪后,每个像素都编码,白0,黑1,好像是这样的,不是太懂,再看一遍,拿字体库模型里的字做对比。如果达到百分比或更多,它会识别验证码是什么,并一一进行比较。最后形成一个完整的验证码。无法完成验证码破解,所以放弃破解,另寻方法。
网上说验证码可能会保存在cookie中。嗯,抱着试试的态度去吧,模拟浏览器发送数据,请求验证码,FF调试,发现cookie中有验证码。就这样,验证码到此结束,我们重新登录。
要登录,首先跟踪目标页面的逻辑,看看它是如何传递参数成功登录的。我只是先发送一个请求对用户名和密码进行加密,然后将加密后的发送到后台进行登录。这没什么好说的。这期间遇到的问题是发送请求,半天不成功。原因是当时发送了一个ajax请求,需要设置调用哪个方法。网站 一般直接要求后台,而不是发出ajax请求,所以这里又是一团糟。
关键代码:
request.Headers.Add("X-AjaxPro-Method", "方法名");
登录成功后,就到了抓取页面的时间了。首先获取抓取页面的html,然后分析它如何提交数据,如何返回,传递了什么参数等等。爬取页面没有问题,然后是模拟查询数据,那个网站写的,隐藏字段控件很多,所以发送请求的时候参数很多,不知道它是干什么用的,反正我觉得只查询订单号是有用的。模拟发送很长时间后,报500错误。这是因为模拟的参数有问题,服务器无法读取。我已经完成了所有设置。一点一点的发现,一点毛病都没有。2天后,它卡在这里。没有办法。之后,无意中发现提交的数据和页面隐藏字段的数据有点不一样。输入特殊字符。转码后想了想之前写的代码传输参数,发现传输数据的时候,都需要通过UrlEncode转码,然后传输。虽然隐藏字段的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说就开始转码参数了
HttpUtility.UrlEncode(string);
居然成功了,太烧脑了,虽然对于一些老手来说,这些可能不知道,但第一次接触还是很难写。
对了,还有一个问题,就是读取html后获取字符串html中的参数的问题,当然在页面上很容易获取,但是现在都是一堆字符串,这真的很难,所以我找到了一个非常好用的dll,支持xpath,和xmlDocument一样的用法,
部分代码:
HtmlDocument htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(html.Replace("\r", "").Replace("\n", ""));
HtmlNodeCollection collection = htmlDocument.DocumentNode.SelectSingleNode("/html/body/div").ChildNodes;
foreach (HtmlNode htmlNode in collection)
{
var tempId = htmlNode.Attributes["id"].Value;
}
红色部分是xpath规则,
也可以根据属性获取对应的节点:
htmlDocument.DocumentNode.SelectSingleNode("/html/body/div[2]/input[@id='__EVENTVALIDATION']");
这是:HtmlAgilityPack 下载地址:点击打开链接
最好阅读此 网站 评论。里面有很多人的问题,说不定能帮上忙。
好了,写了这么多,接下来我整理一下代码发上来,然后开始循环爬取数据。 查看全部
c#抓取网页数据(第一次用C#写数据抓取,遇到各种问题怎么办?)
第一次用C#写数据采集,遇到各种问题。开始写模拟登录的时候,发现有验证码。我必须突破验证码才能得到它。好吧,那我去找破解验证码的代码。我尝试了很多代码,发现它们并不通用。后来,我明白了其中的原理。首先去除噪点、干扰线等,然后将颜色验证码转换成黑白,同时进行字体切割。,如果字体是粘的,对于我们初学者(外行),那就放弃吧。裁剪后,每个像素都编码,白0,黑1,好像是这样的,不是太懂,再看一遍,拿字体库模型里的字做对比。如果达到百分比或更多,它会识别验证码是什么,并一一进行比较。最后形成一个完整的验证码。无法完成验证码破解,所以放弃破解,另寻方法。
网上说验证码可能会保存在cookie中。嗯,抱着试试的态度去吧,模拟浏览器发送数据,请求验证码,FF调试,发现cookie中有验证码。就这样,验证码到此结束,我们重新登录。
要登录,首先跟踪目标页面的逻辑,看看它是如何传递参数成功登录的。我只是先发送一个请求对用户名和密码进行加密,然后将加密后的发送到后台进行登录。这没什么好说的。这期间遇到的问题是发送请求,半天不成功。原因是当时发送了一个ajax请求,需要设置调用哪个方法。网站 一般直接要求后台,而不是发出ajax请求,所以这里又是一团糟。
关键代码:
request.Headers.Add("X-AjaxPro-Method", "方法名");
登录成功后,就到了抓取页面的时间了。首先获取抓取页面的html,然后分析它如何提交数据,如何返回,传递了什么参数等等。爬取页面没有问题,然后是模拟查询数据,那个网站写的,隐藏字段控件很多,所以发送请求的时候参数很多,不知道它是干什么用的,反正我觉得只查询订单号是有用的。模拟发送很长时间后,报500错误。这是因为模拟的参数有问题,服务器无法读取。我已经完成了所有设置。一点一点的发现,一点毛病都没有。2天后,它卡在这里。没有办法。之后,无意中发现提交的数据和页面隐藏字段的数据有点不一样。输入特殊字符。转码后想了想之前写的代码传输参数,发现传输数据的时候,都需要通过UrlEncode转码,然后传输。虽然隐藏字段的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说就开始转码参数了
HttpUtility.UrlEncode(string);
居然成功了,太烧脑了,虽然对于一些老手来说,这些可能不知道,但第一次接触还是很难写。
对了,还有一个问题,就是读取html后获取字符串html中的参数的问题,当然在页面上很容易获取,但是现在都是一堆字符串,这真的很难,所以我找到了一个非常好用的dll,支持xpath,和xmlDocument一样的用法,
部分代码:
HtmlDocument htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(html.Replace("\r", "").Replace("\n", ""));
HtmlNodeCollection collection = htmlDocument.DocumentNode.SelectSingleNode("/html/body/div").ChildNodes;
foreach (HtmlNode htmlNode in collection)
{
var tempId = htmlNode.Attributes["id"].Value;
}
红色部分是xpath规则,
也可以根据属性获取对应的节点:
htmlDocument.DocumentNode.SelectSingleNode("/html/body/div[2]/input[@id='__EVENTVALIDATION']");
这是:HtmlAgilityPack 下载地址:点击打开链接
最好阅读此 网站 评论。里面有很多人的问题,说不定能帮上忙。
好了,写了这么多,接下来我整理一下代码发上来,然后开始循环爬取数据。
c#抓取网页数据(PowerQuery与GET方法有什么区别呢?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-16 06:11
我之前写过很多关于 Power Query 网络爬取的教程。根据网络数据传输的方式,文章中的那些爬取方式都是通过GET方式获取的,那么POST和GET方式有什么区别呢?
这是W3C官网的内容,请参考:
GET 和 POST 方法都可用于向服务器发起请求。至于服务器支持哪种方式,我们需要通过谷歌浏览器查看:
GET方法用于在浏览器地址提交查询条件,如下所示:
GET方法下面通常是查询条件字符串Query String Parameters:
这样的 URL 非常标准,没有各种问号、等号和连字符,通常是 POST 方法:
POST 方法下面是表单数据:
很多时候网站同时支持两种查询方式:
上面的 网站 是两种方法都支持的 网站。
最后,GET和POST这两种方式在传输数据时最大的不同就是编码方式:
让我们回到 Power Query 爬行。之前不明白如何实现POST提交数据爬取。看了几篇文章的文章,基本上就是用一个函数实现GET和POST爬取。,唯一的区别在于HEADER头文件的写法和查询条件的编码。
GET方法查询:
让
url="", //网址
headers=[Cookie=""], //标题
query=[], //查询字符串参数
web=Text.FromBinary(Web.Contents(url,[Headers=headers,Query=query]))
在
网络
上面的代码可以应用于大多数 GET 方法站点,其中:
Web.Contents(url,[Headers=headers,Query=query])
当然,很多时候,我们匿名抓取数据的时候,不需要登录或者cookie,也不需要写头文件。我们直接将页码等查询条件添加到一长串url中,省略Web.Contents函数。第二个参数,这就是为什么我说上一句查询都是GET查询。
POST 查询:
我们主要讲的是这个POST方法的获取。与GET方式最大的不同就是头文件headers不能省略,所以必须使用Web.Contents函数的第二个参数。我们将通过一个示例来说明如何编写代码来执行 POST 请求:
第一步:还是做网站分析
首先,我们确保这个 网站 可以使用 POST 方法来抓取数据:
然后查看头文件中的关键字:
其实我并没有用用户名和密码网站登录,所以这个cookie可以用,但是这个:
内容类型:application/x-www-form-urlencoded;字符集=UTF-8
它必须在 POST 方法中使用,并标有钥匙符号。
然后我们看一下表单的内容:
在返回查询结果之前,我们需要将上述查询条件提交给服务器。以上格式是为了方便查看。您可以将其理解为一种记录格式。您按 View Source 以显示源代码:
我画的部分是“离婚登记号”,这是一个普通的URI编码格式,带有很多百分号。
通过这些分析,我们可以继续下一步。
第 2 步:尝试捕获
先放代码,然后一行一行的说:
让 查看全部
c#抓取网页数据(PowerQuery与GET方法有什么区别呢?(一))
我之前写过很多关于 Power Query 网络爬取的教程。根据网络数据传输的方式,文章中的那些爬取方式都是通过GET方式获取的,那么POST和GET方式有什么区别呢?
这是W3C官网的内容,请参考:
GET 和 POST 方法都可用于向服务器发起请求。至于服务器支持哪种方式,我们需要通过谷歌浏览器查看:
GET方法用于在浏览器地址提交查询条件,如下所示:
GET方法下面通常是查询条件字符串Query String Parameters:
这样的 URL 非常标准,没有各种问号、等号和连字符,通常是 POST 方法:
POST 方法下面是表单数据:
很多时候网站同时支持两种查询方式:
上面的 网站 是两种方法都支持的 网站。
最后,GET和POST这两种方式在传输数据时最大的不同就是编码方式:
让我们回到 Power Query 爬行。之前不明白如何实现POST提交数据爬取。看了几篇文章的文章,基本上就是用一个函数实现GET和POST爬取。,唯一的区别在于HEADER头文件的写法和查询条件的编码。
GET方法查询:
让
url="", //网址
headers=[Cookie=""], //标题
query=[], //查询字符串参数
web=Text.FromBinary(Web.Contents(url,[Headers=headers,Query=query]))
在
网络
上面的代码可以应用于大多数 GET 方法站点,其中:
Web.Contents(url,[Headers=headers,Query=query])
当然,很多时候,我们匿名抓取数据的时候,不需要登录或者cookie,也不需要写头文件。我们直接将页码等查询条件添加到一长串url中,省略Web.Contents函数。第二个参数,这就是为什么我说上一句查询都是GET查询。
POST 查询:
我们主要讲的是这个POST方法的获取。与GET方式最大的不同就是头文件headers不能省略,所以必须使用Web.Contents函数的第二个参数。我们将通过一个示例来说明如何编写代码来执行 POST 请求:
第一步:还是做网站分析
首先,我们确保这个 网站 可以使用 POST 方法来抓取数据:
然后查看头文件中的关键字:
其实我并没有用用户名和密码网站登录,所以这个cookie可以用,但是这个:
内容类型:application/x-www-form-urlencoded;字符集=UTF-8
它必须在 POST 方法中使用,并标有钥匙符号。
然后我们看一下表单的内容:
在返回查询结果之前,我们需要将上述查询条件提交给服务器。以上格式是为了方便查看。您可以将其理解为一种记录格式。您按 View Source 以显示源代码:
我画的部分是“离婚登记号”,这是一个普通的URI编码格式,带有很多百分号。
通过这些分析,我们可以继续下一步。
第 2 步:尝试捕获
先放代码,然后一行一行的说:
让
c#抓取网页数据(如何在本地运行一个网站爬虫?-coldpan的回答)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-08 14:03
c#抓取网页数据的第一步自然是爬虫相关,第二步是自定义header,第三步是配置标准url提交,最后是返回jsonhtml文件,这几步用c#来做应该不会太复杂的。网页数据来源:1.真实网页数据在github上收集了一些已存在的网页数据2.某些情况(不适合这里讨论的某些特殊情况,比如代码规范等等)收集的一些爬虫相关的代码3.某些情况另外提交4.之前提交过,用的asp6.最近才写的一个用于分析系统的代码,类似的可以看我的另一个关于linux的回答有哪些十分钟就能学会的技能?robyka:如何在本地运行一个网站爬虫?-coldpan的回答。
你不是已经规划好了吗?c#爬虫。
php+httpserver。就是几行代码的事情。
学点java吧,大公司项目用php的不多,
github,我写的爬虫,带手机验证码,带反爬,可以买本python与go的书,学点python爬虫。
apache+mysql即可。
api简单
爬虫干啥不一定呢,而且职位会比较多,总之先有点基础,让自己更了解爬虫是干啥的,看看能做哪些东西,
aspservlet,当然你会jsp或php可以不会asp,我后来再补差不多。当然html,js和css其实也能用的。你能写代码,会做功能实现,懂后台数据接收发送处理,能维护个redis代理设置断点模拟重定向,网页分析,爬虫只是锦上添花。爬虫框架不学也罢。 查看全部
c#抓取网页数据(如何在本地运行一个网站爬虫?-coldpan的回答)
c#抓取网页数据的第一步自然是爬虫相关,第二步是自定义header,第三步是配置标准url提交,最后是返回jsonhtml文件,这几步用c#来做应该不会太复杂的。网页数据来源:1.真实网页数据在github上收集了一些已存在的网页数据2.某些情况(不适合这里讨论的某些特殊情况,比如代码规范等等)收集的一些爬虫相关的代码3.某些情况另外提交4.之前提交过,用的asp6.最近才写的一个用于分析系统的代码,类似的可以看我的另一个关于linux的回答有哪些十分钟就能学会的技能?robyka:如何在本地运行一个网站爬虫?-coldpan的回答。
你不是已经规划好了吗?c#爬虫。
php+httpserver。就是几行代码的事情。
学点java吧,大公司项目用php的不多,
github,我写的爬虫,带手机验证码,带反爬,可以买本python与go的书,学点python爬虫。
apache+mysql即可。
api简单
爬虫干啥不一定呢,而且职位会比较多,总之先有点基础,让自己更了解爬虫是干啥的,看看能做哪些东西,
aspservlet,当然你会jsp或php可以不会asp,我后来再补差不多。当然html,js和css其实也能用的。你能写代码,会做功能实现,懂后台数据接收发送处理,能维护个redis代理设置断点模拟重定向,网页分析,爬虫只是锦上添花。爬虫框架不学也罢。
c#抓取网页数据(2.Python构建自动在线刷视频——一个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-07 21:04
文章内容
我以前写过两个相关的博客:
1.C#make 网站挂机程序:
()
2.Python构建自动在线视频刷机——一个只能做不能说的项目:
()
3.【C#制作hook程序V2.0——鼠标滑动点击等在线视频程序】下载链接:
()
第一篇文章主要教大家如何使用C#制作挂机程序。代码比较简单,主要是完成一个简单的功能,可以处理网页中弹出的警告对话框。第二篇文章采用Python语言,完全控制浏览器,可以抓取网页中的Tag、id、name或CSS等标签,输入键盘鼠标。它应该是一个完美的程序。但是今天,为什么又要回到C#开发的老路,让键盘鼠标点击事件自动挂断呢?Python不香吗?代码不禁呵呵,Python的坑不多,反爬技术直接让Python驱动浏览器拜拜了。
我们直接送干货
一、程序界面
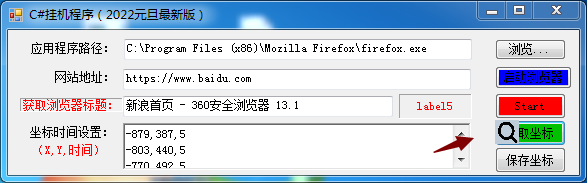
程序相当简单,但不要小看它,功能不小!
二、功能说明1.程序集成了Microsoft Spy++的功能2.通过拖拽工具自动获取表单标题3.拖拽工具自动获取鼠标就绪到点击点4.通过时间设置点击事件后的等待时间(视频刷新需要)5.浏览器应用不再局限于FireFox6.适应性增加,只要它是通过鼠标点击完成的操作就可以交给它了。7.表单程序的自动点击也适用
需要强调的是,拖动工具获取坐标和表格标题的方法可能只能在C#开发中实现。因为码农搜索了百度也没有找到,所以有这个功能的都是用C++开发的。所以这个想法完全是 C# 应用程序独有的。
三、程序步骤
核心功能展示:
1.程序运行后,点击【获取浏览器标题:】,会出现以下工具:
2. 将放大镜工具拖到对应的程序窗体上,会自动获取窗体的标题
该函数的主要目的是获取应用程序的句柄。借助手柄,可以将表格设置为顶部显示。(不被其他窗口覆盖)
3. 点击【获取坐标】按钮,会出现以下工具:
4. 将放大镜工具拖到第一个需要自动点击的点,松开,弹出如下窗口:
坐标不需要设置,就是刚才松开鼠标的位置,暂停时间就是点击后停止的时间,以及下一次操作的时间。
5.循环3、4运行,可以得到一系列坐标点和对应的暂停时间6.所有设置完成后,直接点击【开始】按钮开始自动运行。7.注意,这个自动化操作会反复进行。您可以直接关闭此程序以关闭此自动操作。也可以点击【保存坐标】将坐标点和时间保存到文件中,重启时自动加载已有的坐标点和时间。三、程序密钥代码1.API参考和成员变量
#region API及成员变量
///
/// 根据坐标获取窗口句柄
///
/// 坐标
///
[DllImport("user32.dll")]
private static extern IntPtr WindowFromPoint(Point point);
public delegate bool EnumChildWindow(IntPtr WindowHandle, string num);
///
/// 传递消息给记事本
///
///
///
///
///
///
[DllImport("User32.DLL")]
public static extern int SendMessage(IntPtr hWnd, uint Msg, int wParam, string lParam);
[DllImport("user32.dll", EntryPoint = "keybd_event", SetLastError = true)]
public static extern void keybd_event(Keys bVk, byte bScan, uint dwFlags, uint dwExtraInfo);
[DllImport("user32.dll", CharSet = CharSet.Auto, ExactSpelling = true)]
public static extern int ShowWindow(IntPtr hwnd, int nCmdShow);
[DllImport("user32.dll")]
public static extern bool SetForegroundWindow(int hWnd);
[DllImport("User32.dll")]
public static extern int EnumChildWindows(IntPtr WinHandle, EnumChildWindow ecw, string name);
[DllImport("User32.dll")]
public static extern int GetWindowText(IntPtr WinHandle, StringBuilder Title, int size);
[DllImport("user32.dll")]
public static extern int GetClassName(IntPtr WinHandle, StringBuilder Type, int size);
[DllImport("user32")]
private static extern int GetWindowThreadProcessId(IntPtr handle, out int pid);
[DllImport("user32")]
public static extern IntPtr SetActiveWindow(IntPtr hWnd);
[DllImport("user32.dll")]
[return: MarshalAs(UnmanagedType.Bool)]
static extern bool GetWindowRect(IntPtr hWnd, ref RECT lpRect);
[DllImport("user32.dll", EntryPoint = "FindWindow")]
private static extern IntPtr FindWindow(string IpClassName, string IpWindowName);
//查找窗体控件
public int iSecond = 30;
public delegate bool CallBack(int hwnd, int lParam);
public RECT rectMain = new RECT();
private string typeName;
private IntPtr mainHwnd;
public IntPtr ip;
private string BSType = "Chrome_WidgetWin_1";
bool Flag = false;
int X;
int Y;
int times;
private IntPtr mainWindowHandle;
[StructLayout(LayoutKind.Sequential)]
public struct RECT
{
public int X; //最左坐标
public int Y; //最上坐标
public int Height; //最右坐标
public int Width; //最下坐标
}
///
/// 查找句柄
///
///
///
///
///
///
[DllImport("User32.DLL")]
public static extern IntPtr FindWindowEx(IntPtr hwndParent, IntPtr hwndChildAfter, string lpszClass, string lpszWindow);
[DllImport("User32")]
public extern static void mouse_event(int dwFlags, int dx, int dy, int dwData, IntPtr dwExtraInfo);
[DllImport("user32.dll")]
static extern bool SetCursorPos(int X, int Y);
public const uint WM_SETTEXT = 0x000C;
public System.Diagnostics.Process Proc;
public System.Windows.Forms.Timer myTimer;
public List optList = new List();
public Queue optQueue = new Queue();
#endregion
2.移动鼠标代码
public void MoveTo(int x1, int y1, int x2, int y2)
{
float k = (float)(y2 - y1) / (float)(x2 - x1);
float b = y2 - k * x2;
for (int x = x2; x != x1; x = x + Math.Sign(x1 - x2))
{
//MoveTo(x1,y1,x,(k*x+b));
SetCursorPos(x, (int)(k * x + b));
Thread.Sleep(3);
}
}
代码如下(示例):
3.开始事件代码
private void btnStart_Click(object sender, EventArgs e)
{
foreach (string strLine in richTextBox1.Lines)
{
string[] strInt = strLine.Split(new string[] { "," }, StringSplitOptions.None);
if (strInt.Length 0)
{
Opt opt = optQueue.Dequeue();
X = opt.x;
Y = opt.y;
times = opt.Times;
System.Timers.Timer t = new System.Timers.Timer();//实例化
t.Elapsed += new System.Timers.ElapsedEventHandler(CallBack2);
t.AutoReset = false;
t.Interval = 1000 * times;
t.Enabled = true;
}
}
4.定时器事件代码
private void CallBack2(object sender, EventArgs e)
{
MoveTo(X, Y, MousePosition.X, MousePosition.Y);
mouse_event((int)(MouseEventFlags.LeftDown | MouseEventFlags.Absolute), X, Y, 0, IntPtr.Zero);
//Thread.Sleep(200);
mouse_event((int)(MouseEventFlags.LeftUp | MouseEventFlags.Absolute), X, Y, 0, IntPtr.Zero);
if (optQueue.Count > 0)
{
Opt opt = optQueue.Dequeue();
X = opt.x;
Y = opt.y;
times = opt.Times;
System.Timers.Timer t = new System.Timers.Timer();//实例化
t.Elapsed += new System.Timers.ElapsedEventHandler(CallBack2);
t.AutoReset = false;
t.Interval = 1000 * times;
t.Enabled = true;
}
else
{
foreach (Opt opt1 in optList)
{
optQueue.Enqueue(opt1);
}
Opt opt = optQueue.Dequeue();
X = opt.x;
Y = opt.y;
times = opt.Times;
System.Timers.Timer t = new System.Timers.Timer();//实例化
t.Elapsed += new System.Timers.ElapsedEventHandler(CallBack2);
t.AutoReset = false;
t.Interval = 1000 * times;
t.Enabled = true;
}
}
5.启动浏览器事件代码
private void btnStartBrowser_Click(object sender, EventArgs e)
{
if (string.IsNullOrEmpty(txtFile.Text)) return;
try
{
// 浏览器程序启动线程
Proc = new System.Diagnostics.Process();
Proc.StartInfo.FileName = txtFile.Text;
Proc.StartInfo.Arguments = txtNetAddr.Text; //浏览器打开URL参数
Proc.StartInfo.UseShellExecute = false;
Proc.StartInfo.RedirectStandardInput = true;
Proc.StartInfo.RedirectStandardOutput = true;
Proc.Start();
}
catch
{
Proc = null;
}
}
总结
挂机程序本身的开发存在局限性。通常仅用于特定或特定类型的应用程序。但只要注意思考和挖掘,无论是哪种应用,总能找到对应的点,开发对应的挂机程序。用一个hook程序吃遍全世界是不可行的。 查看全部
c#抓取网页数据(2.Python构建自动在线刷视频——一个)
文章内容
我以前写过两个相关的博客:
1.C#make 网站挂机程序:
()
2.Python构建自动在线视频刷机——一个只能做不能说的项目:
()
3.【C#制作hook程序V2.0——鼠标滑动点击等在线视频程序】下载链接:
()
第一篇文章主要教大家如何使用C#制作挂机程序。代码比较简单,主要是完成一个简单的功能,可以处理网页中弹出的警告对话框。第二篇文章采用Python语言,完全控制浏览器,可以抓取网页中的Tag、id、name或CSS等标签,输入键盘鼠标。它应该是一个完美的程序。但是今天,为什么又要回到C#开发的老路,让键盘鼠标点击事件自动挂断呢?Python不香吗?代码不禁呵呵,Python的坑不多,反爬技术直接让Python驱动浏览器拜拜了。
我们直接送干货
一、程序界面
程序相当简单,但不要小看它,功能不小!
二、功能说明1.程序集成了Microsoft Spy++的功能2.通过拖拽工具自动获取表单标题3.拖拽工具自动获取鼠标就绪到点击点4.通过时间设置点击事件后的等待时间(视频刷新需要)5.浏览器应用不再局限于FireFox6.适应性增加,只要它是通过鼠标点击完成的操作就可以交给它了。7.表单程序的自动点击也适用
需要强调的是,拖动工具获取坐标和表格标题的方法可能只能在C#开发中实现。因为码农搜索了百度也没有找到,所以有这个功能的都是用C++开发的。所以这个想法完全是 C# 应用程序独有的。
三、程序步骤
核心功能展示:
1.程序运行后,点击【获取浏览器标题:】,会出现以下工具:
2. 将放大镜工具拖到对应的程序窗体上,会自动获取窗体的标题
该函数的主要目的是获取应用程序的句柄。借助手柄,可以将表格设置为顶部显示。(不被其他窗口覆盖)
3. 点击【获取坐标】按钮,会出现以下工具:
4. 将放大镜工具拖到第一个需要自动点击的点,松开,弹出如下窗口:
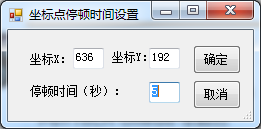
坐标不需要设置,就是刚才松开鼠标的位置,暂停时间就是点击后停止的时间,以及下一次操作的时间。
5.循环3、4运行,可以得到一系列坐标点和对应的暂停时间6.所有设置完成后,直接点击【开始】按钮开始自动运行。7.注意,这个自动化操作会反复进行。您可以直接关闭此程序以关闭此自动操作。也可以点击【保存坐标】将坐标点和时间保存到文件中,重启时自动加载已有的坐标点和时间。三、程序密钥代码1.API参考和成员变量
#region API及成员变量
///
/// 根据坐标获取窗口句柄
///
/// 坐标
///
[DllImport("user32.dll")]
private static extern IntPtr WindowFromPoint(Point point);
public delegate bool EnumChildWindow(IntPtr WindowHandle, string num);
///
/// 传递消息给记事本
///
///
///
///
///
///
[DllImport("User32.DLL")]
public static extern int SendMessage(IntPtr hWnd, uint Msg, int wParam, string lParam);
[DllImport("user32.dll", EntryPoint = "keybd_event", SetLastError = true)]
public static extern void keybd_event(Keys bVk, byte bScan, uint dwFlags, uint dwExtraInfo);
[DllImport("user32.dll", CharSet = CharSet.Auto, ExactSpelling = true)]
public static extern int ShowWindow(IntPtr hwnd, int nCmdShow);
[DllImport("user32.dll")]
public static extern bool SetForegroundWindow(int hWnd);
[DllImport("User32.dll")]
public static extern int EnumChildWindows(IntPtr WinHandle, EnumChildWindow ecw, string name);
[DllImport("User32.dll")]
public static extern int GetWindowText(IntPtr WinHandle, StringBuilder Title, int size);
[DllImport("user32.dll")]
public static extern int GetClassName(IntPtr WinHandle, StringBuilder Type, int size);
[DllImport("user32")]
private static extern int GetWindowThreadProcessId(IntPtr handle, out int pid);
[DllImport("user32")]
public static extern IntPtr SetActiveWindow(IntPtr hWnd);
[DllImport("user32.dll")]
[return: MarshalAs(UnmanagedType.Bool)]
static extern bool GetWindowRect(IntPtr hWnd, ref RECT lpRect);
[DllImport("user32.dll", EntryPoint = "FindWindow")]
private static extern IntPtr FindWindow(string IpClassName, string IpWindowName);
//查找窗体控件
public int iSecond = 30;
public delegate bool CallBack(int hwnd, int lParam);
public RECT rectMain = new RECT();
private string typeName;
private IntPtr mainHwnd;
public IntPtr ip;
private string BSType = "Chrome_WidgetWin_1";
bool Flag = false;
int X;
int Y;
int times;
private IntPtr mainWindowHandle;
[StructLayout(LayoutKind.Sequential)]
public struct RECT
{
public int X; //最左坐标
public int Y; //最上坐标
public int Height; //最右坐标
public int Width; //最下坐标
}
///
/// 查找句柄
///
///
///
///
///
///
[DllImport("User32.DLL")]
public static extern IntPtr FindWindowEx(IntPtr hwndParent, IntPtr hwndChildAfter, string lpszClass, string lpszWindow);
[DllImport("User32")]
public extern static void mouse_event(int dwFlags, int dx, int dy, int dwData, IntPtr dwExtraInfo);
[DllImport("user32.dll")]
static extern bool SetCursorPos(int X, int Y);
public const uint WM_SETTEXT = 0x000C;
public System.Diagnostics.Process Proc;
public System.Windows.Forms.Timer myTimer;
public List optList = new List();
public Queue optQueue = new Queue();
#endregion
2.移动鼠标代码
public void MoveTo(int x1, int y1, int x2, int y2)
{
float k = (float)(y2 - y1) / (float)(x2 - x1);
float b = y2 - k * x2;
for (int x = x2; x != x1; x = x + Math.Sign(x1 - x2))
{
//MoveTo(x1,y1,x,(k*x+b));
SetCursorPos(x, (int)(k * x + b));
Thread.Sleep(3);
}
}
代码如下(示例):
3.开始事件代码
private void btnStart_Click(object sender, EventArgs e)
{
foreach (string strLine in richTextBox1.Lines)
{
string[] strInt = strLine.Split(new string[] { "," }, StringSplitOptions.None);
if (strInt.Length 0)
{
Opt opt = optQueue.Dequeue();
X = opt.x;
Y = opt.y;
times = opt.Times;
System.Timers.Timer t = new System.Timers.Timer();//实例化
t.Elapsed += new System.Timers.ElapsedEventHandler(CallBack2);
t.AutoReset = false;
t.Interval = 1000 * times;
t.Enabled = true;
}
}
4.定时器事件代码
private void CallBack2(object sender, EventArgs e)
{
MoveTo(X, Y, MousePosition.X, MousePosition.Y);
mouse_event((int)(MouseEventFlags.LeftDown | MouseEventFlags.Absolute), X, Y, 0, IntPtr.Zero);
//Thread.Sleep(200);
mouse_event((int)(MouseEventFlags.LeftUp | MouseEventFlags.Absolute), X, Y, 0, IntPtr.Zero);
if (optQueue.Count > 0)
{
Opt opt = optQueue.Dequeue();
X = opt.x;
Y = opt.y;
times = opt.Times;
System.Timers.Timer t = new System.Timers.Timer();//实例化
t.Elapsed += new System.Timers.ElapsedEventHandler(CallBack2);
t.AutoReset = false;
t.Interval = 1000 * times;
t.Enabled = true;
}
else
{
foreach (Opt opt1 in optList)
{
optQueue.Enqueue(opt1);
}
Opt opt = optQueue.Dequeue();
X = opt.x;
Y = opt.y;
times = opt.Times;
System.Timers.Timer t = new System.Timers.Timer();//实例化
t.Elapsed += new System.Timers.ElapsedEventHandler(CallBack2);
t.AutoReset = false;
t.Interval = 1000 * times;
t.Enabled = true;
}
}
5.启动浏览器事件代码
private void btnStartBrowser_Click(object sender, EventArgs e)
{
if (string.IsNullOrEmpty(txtFile.Text)) return;
try
{
// 浏览器程序启动线程
Proc = new System.Diagnostics.Process();
Proc.StartInfo.FileName = txtFile.Text;
Proc.StartInfo.Arguments = txtNetAddr.Text; //浏览器打开URL参数
Proc.StartInfo.UseShellExecute = false;
Proc.StartInfo.RedirectStandardInput = true;
Proc.StartInfo.RedirectStandardOutput = true;
Proc.Start();
}
catch
{
Proc = null;
}
}
总结
挂机程序本身的开发存在局限性。通常仅用于特定或特定类型的应用程序。但只要注意思考和挖掘,无论是哪种应用,总能找到对应的点,开发对应的挂机程序。用一个hook程序吃遍全世界是不可行的。
c#抓取网页数据( 一种更常见的翻页类型——翻页链接不规律的例子)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-07 06:09
一种更常见的翻页类型——翻页链接不规律的例子)
总结:在列表中,豆瓣的电影列表使用了pager来分割数据:但是当时我们定期搜索网页链接,并没有使用pager来抓取。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以转成,但是链接变化不规律,就得去pager一下了。要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。8月2日是蔡徐坤的生日。为了庆祝,微博粉丝给了坤坤300W的转发量,而微博的转发数据恰好是用来积分的。
这是简单数据分析系列文章的第12篇。
776448504/I0gyT8aeQ?type=repost的第二页是这样的。请注意,有一个额外的 #_rnd36 参数:
在之前的文章文章中,我们介绍了Web Scraper针对各种翻页方案的解决方案,比如修改网页链接加载数据,点击“更多按钮”加载数据,下拉自动加载数据。今天我们讲的是一种比较常见的翻页机。
我想解释一下什么是寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页跳到下一页,指定页数。
emove(userId);}@Override@GetMapping("/findAll")public采集findAll(){
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
这些理论有点无聊,我们举个不规则页面链接的例子。8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页,见
实际上,在本教程的第一个示例中,我们抓取了豆瓣电影TOP列表。豆瓣的电影列表使用寻呼机划分数据:
但当时我们是在找网页链接定期抓取,而不是使用寻呼机抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以转成,但是链接变化不规律,就得去pager一下了。
ping("/remove")publicvoidremove(@RequestParam("id")LonguserId){usersRepository.r
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
t;)LonguserId){restTemplate.delete(""+use
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页面,查看如何使用Web Scraper 抓取此类数据。
这条微博的直接链接是:
classUserServiceIimplementsUserService{privateMapusersRepository=Maps.newHashM
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
文章文章。在之前的文章文章中,我们介绍了WebScraper对于各种翻页的解决方案,比如修改网页链接加载数据,点击“更多按钮”加载数据,下拉自动加载数据。今天我们讲的是一种比较常见的翻页机。想解释
首先,让我们看一下第1页的转发链接,它看起来像这样:
.推荐阅读简单数据分析05|WebScraper翻页-控制链接批量抓取数据简单数据分析08|WebScraper翻页-点击“更多按钮”翻页简单数据分析10|WebScraper翻页-抓取Scroll plus
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
gn(@RequestParam("id")LonguserId){userRemote.remove(userId);}@GetMapping("/findAllByF
第 3 页上的参数是 #_rnd39
000条数据,但是第一页只有20条数据,抓到最后一条,还有980条;然后翻页的时候,设置了一个新的计数器,完成了第2页的最后一条数据,但是还缺少980条,一翻页计数器就重置,又变成1000了... 所以这
第 4 页上的参数是 #_rnd76:
ing-cloud-starter-dubbo 在这里介绍 DubboSpringClo
多看几个链接,可以发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。让我们开始我们的实际教学环节。
ctionfindAll(){returnuserService.findAll();}} 其中@Reference注解需要指定调用服务提供者接口的版本号,如果不指定版本
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
容器的预览如下图所示:
bScraper 无能为力)。考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想使用:nth-of-type(-n+N)来控制取N条数据。如果你尝试,你会发现这个方法根本没有用。已到期
寻呼机选择过程如下图所示:
vider_web/pom.xml***com.springc
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
blicclassUserController{@Reference(version="1.0.0")UserServiceuserService;@PostMapping(&qu
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
也不现实。毕竟WebScraper针对的数据量比较小。数以万计的数据被认为太多了。不管数据有多大,都要考虑爬取时间是否过长,数据是如何存储的,以及URL的逆向如何处理。爬虫系统(比如一个验证码突然跳出来,这个我们
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我应该把它全部爬下来吗?
-type(-n+N) 控制获取 N 条数据。如果你尝试,你会发现这个方法根本没有用。失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。单击更改就像我之前介绍的那样
这听起来不现实。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper的反爬虫系统(比如一个验证码突然跳出来,这个Web Scraper是无能为力的)。
cies>1.2 创建子项目dubbo_provider_web,服务提供者项目依赖pom.xml如下: 代码列表:Alibaba/dubbo-spring-cloud-http/dubbo_pro
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想用:nth-of-type(-n+N)来控制取N个数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
lication:name:spring-cloud-consumer-servercloud:nacos:discovery:server-addr:192.168.44.129:8848 接口测试类
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
t;)UserServiceuserService;@PostMapping("/save")publicUserModelsave(@RequestBodyUserModelus
但是,对于使用翻页设备的网页,每次翻页就相当于刷新当前网页,因此每次都会设置一个计数器。
太长了,数据怎么存储,URL的反爬虫系统怎么处理(比如一个验证码突然跳出来,这个WebScraper就无能为力了)。考虑到这个问题,如果你看过之前关于自动控制爬取次数的教程,你可能想使用:nth-of-
比如你想取1000条数据,但是第一页只有20条数据。最后一个抓到了,还有980条数据。然后当翻页时,设置一个新的计数器,第2页结束。一条数据还是980,翻页计数器一重置,又变成1000了……所以这种控制数字的方法是无效的。
启动程序测试 查看全部
c#抓取网页数据(
一种更常见的翻页类型——翻页链接不规律的例子)

总结:在列表中,豆瓣的电影列表使用了pager来分割数据:但是当时我们定期搜索网页链接,并没有使用pager来抓取。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以转成,但是链接变化不规律,就得去pager一下了。要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。8月2日是蔡徐坤的生日。为了庆祝,微博粉丝给了坤坤300W的转发量,而微博的转发数据恰好是用来积分的。
这是简单数据分析系列文章的第12篇。
776448504/I0gyT8aeQ?type=repost的第二页是这样的。请注意,有一个额外的 #_rnd36 参数:
在之前的文章文章中,我们介绍了Web Scraper针对各种翻页方案的解决方案,比如修改网页链接加载数据,点击“更多按钮”加载数据,下拉自动加载数据。今天我们讲的是一种比较常见的翻页机。
我想解释一下什么是寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页跳到下一页,指定页数。
emove(userId);}@Override@GetMapping("/findAll")public采集findAll(){
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
这些理论有点无聊,我们举个不规则页面链接的例子。8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页,见
实际上,在本教程的第一个示例中,我们抓取了豆瓣电影TOP列表。豆瓣的电影列表使用寻呼机划分数据:
但当时我们是在找网页链接定期抓取,而不是使用寻呼机抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以转成,但是链接变化不规律,就得去pager一下了。
ping("/remove")publicvoidremove(@RequestParam("id")LonguserId){usersRepository.r
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
t;)LonguserId){restTemplate.delete(""+use
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页面,查看如何使用Web Scraper 抓取此类数据。
这条微博的直接链接是:
classUserServiceIimplementsUserService{privateMapusersRepository=Maps.newHashM
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
文章文章。在之前的文章文章中,我们介绍了WebScraper对于各种翻页的解决方案,比如修改网页链接加载数据,点击“更多按钮”加载数据,下拉自动加载数据。今天我们讲的是一种比较常见的翻页机。想解释
首先,让我们看一下第1页的转发链接,它看起来像这样:
.推荐阅读简单数据分析05|WebScraper翻页-控制链接批量抓取数据简单数据分析08|WebScraper翻页-点击“更多按钮”翻页简单数据分析10|WebScraper翻页-抓取Scroll plus
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
gn(@RequestParam("id")LonguserId){userRemote.remove(userId);}@GetMapping("/findAllByF
第 3 页上的参数是 #_rnd39
000条数据,但是第一页只有20条数据,抓到最后一条,还有980条;然后翻页的时候,设置了一个新的计数器,完成了第2页的最后一条数据,但是还缺少980条,一翻页计数器就重置,又变成1000了... 所以这
第 4 页上的参数是 #_rnd76:
ing-cloud-starter-dubbo 在这里介绍 DubboSpringClo
多看几个链接,可以发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。让我们开始我们的实际教学环节。
ctionfindAll(){returnuserService.findAll();}} 其中@Reference注解需要指定调用服务提供者接口的版本号,如果不指定版本
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
容器的预览如下图所示:
bScraper 无能为力)。考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想使用:nth-of-type(-n+N)来控制取N条数据。如果你尝试,你会发现这个方法根本没有用。已到期
寻呼机选择过程如下图所示:
vider_web/pom.xml***com.springc
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
blicclassUserController{@Reference(version="1.0.0")UserServiceuserService;@PostMapping(&qu
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
也不现实。毕竟WebScraper针对的数据量比较小。数以万计的数据被认为太多了。不管数据有多大,都要考虑爬取时间是否过长,数据是如何存储的,以及URL的逆向如何处理。爬虫系统(比如一个验证码突然跳出来,这个我们
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我应该把它全部爬下来吗?
-type(-n+N) 控制获取 N 条数据。如果你尝试,你会发现这个方法根本没有用。失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。单击更改就像我之前介绍的那样
这听起来不现实。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper的反爬虫系统(比如一个验证码突然跳出来,这个Web Scraper是无能为力的)。
cies>1.2 创建子项目dubbo_provider_web,服务提供者项目依赖pom.xml如下: 代码列表:Alibaba/dubbo-spring-cloud-http/dubbo_pro
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想用:nth-of-type(-n+N)来控制取N个数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
lication:name:spring-cloud-consumer-servercloud:nacos:discovery:server-addr:192.168.44.129:8848 接口测试类
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
t;)UserServiceuserService;@PostMapping("/save")publicUserModelsave(@RequestBodyUserModelus
但是,对于使用翻页设备的网页,每次翻页就相当于刷新当前网页,因此每次都会设置一个计数器。
太长了,数据怎么存储,URL的反爬虫系统怎么处理(比如一个验证码突然跳出来,这个WebScraper就无能为力了)。考虑到这个问题,如果你看过之前关于自动控制爬取次数的教程,你可能想使用:nth-of-
比如你想取1000条数据,但是第一页只有20条数据。最后一个抓到了,还有980条数据。然后当翻页时,设置一个新的计数器,第2页结束。一条数据还是980,翻页计数器一重置,又变成1000了……所以这种控制数字的方法是无效的。
启动程序测试
c#抓取网页数据(最省事的做法是去需要的网站看看具体是什么编码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-05 22:11
)
在做一些需要抓取网页的项目时,经常会遇到乱码。最简单的方法就是去需要爬取的网站看看具体的编码是什么,然后使用正确的编码进行解码。可以,但是总是一一判断也不是问题,尤其是当你需要从不同站点抓取大量页面的时候,比如一个网络爬虫程序,那么我们就需要做一个比较通用的程序来正确识别页面编码。
乱码问题基本上是编码不一致造成的。比如网页编码使用UTF-8,如果使用GB2312读取,肯定会出现乱码。知道了本质问题之后,剩下的就是如何判断网页编码了。GBK、GB2312、UTF-8、BIG-5,一般来说,遇到的中文网页编码大多是这几种编码。简单来说,只有GBK和UTF-8两种,一点都不夸张。,目前的网站要么是GBK编码,要么是UTF-8编码,所以接下来的问题就是确定网站具体是UTF-8还是GBK。
如何确定页面的具体编码?首先检查响应头的Content-Type。如果在响应头中找不到,请到网页中查找元头。如果还是找不到,那就没办法了。设置默认编码。个人建议设置为UTF-8。比如访问博客园的首页,可以看到Content-Type:text/html;响应头中的charset=utf-8,所以我们知道博客园使用的是utf-8编码,但是并不是所有的网站都会在响应头的Content-Type中添加页面编码。比如百度的就是Content-Type:text/html,查不到charset。这时候只能在网页中找到它来确认网页的最终编码。总结就是以下步骤
1.在响应头中的 Content-Type 中找到字符集。如果找到charset,则跳过第2步和第3步,直接进入第4步。2.如果第1步没有找到charset,先读取网页的Content,解析meta中的charset得到页面编码< @3.如果在第2步还是没有获取到页面编码,则没有办法设置默认编码为UTF-84. 使用获取到的charset重新读取响应流
基本上,通过上述方法大部分页面都可以正确解析,但无法识别的则需要亲自验证具体代码。
注意:
1.几乎所有站点都启用了gzip压缩支持,所以在请求头中添加Accept-Encoding:gzip,deflate,这样站点会返回一个压缩流,可以显着提高请求的效率。2.由于网络流不支持流搜索操作,即只能读取一次。为了提高效率,建议先将http响应流读入内存,方便二次解码。无需重新请求检索响应流。
下面给出了Java和C#的实现代码,页面底部给出了源码的git链接。需要童鞋的请自行下载
Java实现
C# 实现
using System;
using System.Collections;
using System.IO;
using System.Linq;
using System.Net;
using System.Net.Security;
using System.Security.Cryptography.X509Certificates;
using System.Text;
using System.Text.RegularExpressions;
using System.Web;
using System.IO.Compression;
using System.Collections.Generic;
using System.Collections.Specialized;
namespace CSharp.Util.Net
{
public class HttpHelper
{
private static bool RemoteCertificateValidate(object sender, X509Certificate certificate, X509Chain chain, SslPolicyErrors errors)
{
//用户https请求
return true; //总是接受
}
public static string SendPost(string url, string data)
{
return Send(url, "POST", data, null);
}
public static string SendGet(string url)
{
return Send(url, "GET", null, null);
}
public static string Send(string url, string method, string data, HttpConfig config)
{
if (config == null) config = new HttpConfig();
string result;
using (HttpWebResponse response = GetResponse(url, method, data, config))
{
Stream stream = response.GetResponseStream();
if (!String.IsNullOrEmpty(response.ContentEncoding))
{
if (response.ContentEncoding.Contains("gzip"))
{
stream = new GZipStream(stream, CompressionMode.Decompress);
}
else if (response.ContentEncoding.Contains("deflate"))
{
stream = new DeflateStream(stream, CompressionMode.Decompress);
}
}
byte[] bytes = null;
using (MemoryStream ms = new MemoryStream())
{
int count;
byte[] buffer = new byte[4096];
while ((count = stream.Read(buffer, 0, buffer.Length)) > 0)
{
ms.Write(buffer, 0, count);
}
bytes = ms.ToArray();
}
#region 检测流编码
Encoding encoding;
//检测响应头是否返回了编码类型,若返回了编码类型则使用返回的编码
//注:有时响应头没有编码类型,CharacterSet经常设置为ISO-8859-1
if (!string.IsNullOrEmpty(response.CharacterSet) && response.CharacterSet.ToUpper() != "ISO-8859-1")
{
encoding = Encoding.GetEncoding(response.CharacterSet == "utf8" ? "utf-8" : response.CharacterSet);
}
else
{
//若没有在响应头找到编码,则去html找meta头的charset
result = Encoding.Default.GetString(bytes);
//在返回的html里使用正则匹配页面编码
Match match = Regex.Match(result, @"", RegexOptions.IgnoreCase);
if (match.Success)
{
encoding = Encoding.GetEncoding(match.Groups[1].Value);
}
else
{
//若html里面也找不到编码,默认使用utf-8
encoding = Encoding.GetEncoding(config.CharacterSet);
}
}
#endregion
result = encoding.GetString(bytes);
}
return result;
}
private static HttpWebResponse GetResponse(string url, string method, string data, HttpConfig config)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Method = method;
request.Referer = config.Referer;
//有些页面不设置用户代理信息则会抓取不到内容
request.UserAgent = config.UserAgent;
request.Timeout = config.Timeout;
request.Accept = config.Accept;
request.Headers.Set("Accept-Encoding", config.AcceptEncoding);
request.ContentType = config.ContentType;
request.KeepAlive = config.KeepAlive;
if (url.ToLower().StartsWith("https"))
{
//这里加入解决生产环境访问https的问题--Could not establish trust relationship for the SSL/TLS secure channel
ServicePointManager.ServerCertificateValidationCallback = new RemoteCertificateValidationCallback(RemoteCertificateValidate);
}
if (method.ToUpper() == "POST")
{
if (!string.IsNullOrEmpty(data))
{
byte[] bytes = Encoding.UTF8.GetBytes(data);
if (config.GZipCompress)
{
using (MemoryStream stream = new MemoryStream())
{
using (GZipStream gZipStream = new GZipStream(stream, CompressionMode.Compress))
{
gZipStream.Write(bytes, 0, bytes.Length);
}
bytes = stream.ToArray();
}
}
request.ContentLength = bytes.Length;
request.GetRequestStream().Write(bytes, 0, bytes.Length);
}
else
{
request.ContentLength = 0;
}
}
return (HttpWebResponse)request.GetResponse();
}
}
public class HttpConfig
{
public string Referer { get; set; }
///
/// 默认(text/html)
///
public string ContentType { get; set; }
public string Accept { get; set; }
public string AcceptEncoding { get; set; }
///
/// 超时时间(毫秒)默认100000
///
public int Timeout { get; set; }
public string UserAgent { get; set; }
///
/// POST请求时,数据是否进行gzip压缩
///
public bool GZipCompress { get; set; }
public bool KeepAlive { get; set; }
public string CharacterSet { get; set; }
public HttpConfig()
{
this.Timeout = 100000;
this.ContentType = "text/html; charset=" + Encoding.UTF8.WebName;
this.UserAgent = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.117 Safari/537.36";
this.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8";
this.AcceptEncoding = "gzip,deflate";
this.GZipCompress = false;
this.KeepAlive = true;
this.CharacterSet = "UTF-8";
}
}
} 查看全部
c#抓取网页数据(最省事的做法是去需要的网站看看具体是什么编码
)
在做一些需要抓取网页的项目时,经常会遇到乱码。最简单的方法就是去需要爬取的网站看看具体的编码是什么,然后使用正确的编码进行解码。可以,但是总是一一判断也不是问题,尤其是当你需要从不同站点抓取大量页面的时候,比如一个网络爬虫程序,那么我们就需要做一个比较通用的程序来正确识别页面编码。
乱码问题基本上是编码不一致造成的。比如网页编码使用UTF-8,如果使用GB2312读取,肯定会出现乱码。知道了本质问题之后,剩下的就是如何判断网页编码了。GBK、GB2312、UTF-8、BIG-5,一般来说,遇到的中文网页编码大多是这几种编码。简单来说,只有GBK和UTF-8两种,一点都不夸张。,目前的网站要么是GBK编码,要么是UTF-8编码,所以接下来的问题就是确定网站具体是UTF-8还是GBK。
如何确定页面的具体编码?首先检查响应头的Content-Type。如果在响应头中找不到,请到网页中查找元头。如果还是找不到,那就没办法了。设置默认编码。个人建议设置为UTF-8。比如访问博客园的首页,可以看到Content-Type:text/html;响应头中的charset=utf-8,所以我们知道博客园使用的是utf-8编码,但是并不是所有的网站都会在响应头的Content-Type中添加页面编码。比如百度的就是Content-Type:text/html,查不到charset。这时候只能在网页中找到它来确认网页的最终编码。总结就是以下步骤
1.在响应头中的 Content-Type 中找到字符集。如果找到charset,则跳过第2步和第3步,直接进入第4步。2.如果第1步没有找到charset,先读取网页的Content,解析meta中的charset得到页面编码< @3.如果在第2步还是没有获取到页面编码,则没有办法设置默认编码为UTF-84. 使用获取到的charset重新读取响应流
基本上,通过上述方法大部分页面都可以正确解析,但无法识别的则需要亲自验证具体代码。
注意:
1.几乎所有站点都启用了gzip压缩支持,所以在请求头中添加Accept-Encoding:gzip,deflate,这样站点会返回一个压缩流,可以显着提高请求的效率。2.由于网络流不支持流搜索操作,即只能读取一次。为了提高效率,建议先将http响应流读入内存,方便二次解码。无需重新请求检索响应流。
下面给出了Java和C#的实现代码,页面底部给出了源码的git链接。需要童鞋的请自行下载
Java实现
C# 实现
using System;
using System.Collections;
using System.IO;
using System.Linq;
using System.Net;
using System.Net.Security;
using System.Security.Cryptography.X509Certificates;
using System.Text;
using System.Text.RegularExpressions;
using System.Web;
using System.IO.Compression;
using System.Collections.Generic;
using System.Collections.Specialized;
namespace CSharp.Util.Net
{
public class HttpHelper
{
private static bool RemoteCertificateValidate(object sender, X509Certificate certificate, X509Chain chain, SslPolicyErrors errors)
{
//用户https请求
return true; //总是接受
}
public static string SendPost(string url, string data)
{
return Send(url, "POST", data, null);
}
public static string SendGet(string url)
{
return Send(url, "GET", null, null);
}
public static string Send(string url, string method, string data, HttpConfig config)
{
if (config == null) config = new HttpConfig();
string result;
using (HttpWebResponse response = GetResponse(url, method, data, config))
{
Stream stream = response.GetResponseStream();
if (!String.IsNullOrEmpty(response.ContentEncoding))
{
if (response.ContentEncoding.Contains("gzip"))
{
stream = new GZipStream(stream, CompressionMode.Decompress);
}
else if (response.ContentEncoding.Contains("deflate"))
{
stream = new DeflateStream(stream, CompressionMode.Decompress);
}
}
byte[] bytes = null;
using (MemoryStream ms = new MemoryStream())
{
int count;
byte[] buffer = new byte[4096];
while ((count = stream.Read(buffer, 0, buffer.Length)) > 0)
{
ms.Write(buffer, 0, count);
}
bytes = ms.ToArray();
}
#region 检测流编码
Encoding encoding;
//检测响应头是否返回了编码类型,若返回了编码类型则使用返回的编码
//注:有时响应头没有编码类型,CharacterSet经常设置为ISO-8859-1
if (!string.IsNullOrEmpty(response.CharacterSet) && response.CharacterSet.ToUpper() != "ISO-8859-1")
{
encoding = Encoding.GetEncoding(response.CharacterSet == "utf8" ? "utf-8" : response.CharacterSet);
}
else
{
//若没有在响应头找到编码,则去html找meta头的charset
result = Encoding.Default.GetString(bytes);
//在返回的html里使用正则匹配页面编码
Match match = Regex.Match(result, @"", RegexOptions.IgnoreCase);
if (match.Success)
{
encoding = Encoding.GetEncoding(match.Groups[1].Value);
}
else
{
//若html里面也找不到编码,默认使用utf-8
encoding = Encoding.GetEncoding(config.CharacterSet);
}
}
#endregion
result = encoding.GetString(bytes);
}
return result;
}
private static HttpWebResponse GetResponse(string url, string method, string data, HttpConfig config)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Method = method;
request.Referer = config.Referer;
//有些页面不设置用户代理信息则会抓取不到内容
request.UserAgent = config.UserAgent;
request.Timeout = config.Timeout;
request.Accept = config.Accept;
request.Headers.Set("Accept-Encoding", config.AcceptEncoding);
request.ContentType = config.ContentType;
request.KeepAlive = config.KeepAlive;
if (url.ToLower().StartsWith("https"))
{
//这里加入解决生产环境访问https的问题--Could not establish trust relationship for the SSL/TLS secure channel
ServicePointManager.ServerCertificateValidationCallback = new RemoteCertificateValidationCallback(RemoteCertificateValidate);
}
if (method.ToUpper() == "POST")
{
if (!string.IsNullOrEmpty(data))
{
byte[] bytes = Encoding.UTF8.GetBytes(data);
if (config.GZipCompress)
{
using (MemoryStream stream = new MemoryStream())
{
using (GZipStream gZipStream = new GZipStream(stream, CompressionMode.Compress))
{
gZipStream.Write(bytes, 0, bytes.Length);
}
bytes = stream.ToArray();
}
}
request.ContentLength = bytes.Length;
request.GetRequestStream().Write(bytes, 0, bytes.Length);
}
else
{
request.ContentLength = 0;
}
}
return (HttpWebResponse)request.GetResponse();
}
}
public class HttpConfig
{
public string Referer { get; set; }
///
/// 默认(text/html)
///
public string ContentType { get; set; }
public string Accept { get; set; }
public string AcceptEncoding { get; set; }
///
/// 超时时间(毫秒)默认100000
///
public int Timeout { get; set; }
public string UserAgent { get; set; }
///
/// POST请求时,数据是否进行gzip压缩
///
public bool GZipCompress { get; set; }
public bool KeepAlive { get; set; }
public string CharacterSet { get; set; }
public HttpConfig()
{
this.Timeout = 100000;
this.ContentType = "text/html; charset=" + Encoding.UTF8.WebName;
this.UserAgent = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.117 Safari/537.36";
this.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8";
this.AcceptEncoding = "gzip,deflate";
this.GZipCompress = false;
this.KeepAlive = true;
this.CharacterSet = "UTF-8";
}
}
}
c#抓取网页数据(学习一下如何快速让搜索引擎收录网站收录的方法?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-04 16:09
很多客户经常问我,网站没有被搜索引擎收录搜索到,而网站经常更新,但是在搜索引擎上搜索不到。本期,勇哥带你学习。如何快速获取搜索引擎收录网站。
在学习之前,先熟悉一个协议。robots 协议也称为 robots.txt(统一小写)。它是一个ASCII编码的文本文件,存放在网站的根目录下。它通常告诉互联网搜索引擎的机器人(也称为网络蜘蛛),这个网站中哪些内容不应该被搜索引擎的机器人获取,哪些内容可以被机器人获取。由于某些系统中的URL 区分大小写,因此robots.txt 的文件名应统一小写。robots.txt应该放在网站的根目录下。如果你想单独定义搜索引擎robots访问子目录时的行为,你可以将你自定义的设置合并到根目录下的robots.txt中,或者使用robots metadata(Metadata,也称为metadata)。robots协议不是规范,而是约定,所以不保证网站的隐私。以上是某某百科的解释。怎么生成,后面再说。既然告诉搜索引擎可搜索的和不可搜索的,自然要先生成网站的sitemap(网站地图)文件。目的是告诉搜索引擎爬取范围,我们看看如何生成网站的地图文件,我们继续。必须先生成网站的@网站 map)文件。目的是告诉搜索引擎爬取范围,我们看看如何生成网站的地图文件,我们继续。必须先生成网站的@网站 map)文件。目的是告诉搜索引擎爬取范围,我们看看如何生成网站的地图文件,我们继续。
首先打开在线URL生成,输入你要收录的域名,点击Crawl,系统会自动开始蜘蛛爬行,爬行时间以网站的内容为准,下载完成后对应格式的文件。我们选择xml格式。
文件下载并上传到网站的根目录。打开搜索引擎网站的资源,登录账号,进入站点管理,添加网站,根据网站的协议头类型选择http/https,输入网站@要爬取的>域名。继续选择站点的域。
第三步,验证网站的所有权。一共有三种验证方式,您可以根据自己的实际情况进行选择。
验证完成后,即可将搜索引擎提交至网站。
提交完成后,搜索引擎会自动抓取网站地图文件中的网址,推送给搜索引擎进行抓取。
搜索引擎如何自动实现爬取?现在让我们谈谈robot.txt文件。其内容格式为:
图中1表示允许所有搜索引擎爬取,2表示不允许搜索引擎爬取这些目录,3表示读取xml文件。如果您了解文件的格式,您可以根据自己的实际情况修改文件的内容。修改完成后,还必须上传到网站的根目录下才能获取。
点击下图中的检测和更新。
以上操作完成后,选择爬虫诊断工具,让站长从蜘蛛的角度查看爬取的内容,自我诊断爬虫看到的内容是否与预期的内容一致。
一段时间后,将显示获取的结果。
全部设置完成后,第二天就会看到特定搜索引擎的爬取数据。
资源工具还提供了爬行异常的诊断。站长可根据系统提示的具体内容及时修复网站,达到爬行异常0的效果。
从上面可以发现,如果想让蜘蛛爬虫有稳定良性的访问,就必须保持更新网站的好习惯。更新内容后,及时重新生成sitemap文件上传到网站的根目录,这样网站进入良性期,无法阻止搜索引擎抓取。本次学习结束,我们下期再见! 查看全部
c#抓取网页数据(学习一下如何快速让搜索引擎收录网站收录的方法?)
很多客户经常问我,网站没有被搜索引擎收录搜索到,而网站经常更新,但是在搜索引擎上搜索不到。本期,勇哥带你学习。如何快速获取搜索引擎收录网站。
在学习之前,先熟悉一个协议。robots 协议也称为 robots.txt(统一小写)。它是一个ASCII编码的文本文件,存放在网站的根目录下。它通常告诉互联网搜索引擎的机器人(也称为网络蜘蛛),这个网站中哪些内容不应该被搜索引擎的机器人获取,哪些内容可以被机器人获取。由于某些系统中的URL 区分大小写,因此robots.txt 的文件名应统一小写。robots.txt应该放在网站的根目录下。如果你想单独定义搜索引擎robots访问子目录时的行为,你可以将你自定义的设置合并到根目录下的robots.txt中,或者使用robots metadata(Metadata,也称为metadata)。robots协议不是规范,而是约定,所以不保证网站的隐私。以上是某某百科的解释。怎么生成,后面再说。既然告诉搜索引擎可搜索的和不可搜索的,自然要先生成网站的sitemap(网站地图)文件。目的是告诉搜索引擎爬取范围,我们看看如何生成网站的地图文件,我们继续。必须先生成网站的@网站 map)文件。目的是告诉搜索引擎爬取范围,我们看看如何生成网站的地图文件,我们继续。必须先生成网站的@网站 map)文件。目的是告诉搜索引擎爬取范围,我们看看如何生成网站的地图文件,我们继续。
首先打开在线URL生成,输入你要收录的域名,点击Crawl,系统会自动开始蜘蛛爬行,爬行时间以网站的内容为准,下载完成后对应格式的文件。我们选择xml格式。
文件下载并上传到网站的根目录。打开搜索引擎网站的资源,登录账号,进入站点管理,添加网站,根据网站的协议头类型选择http/https,输入网站@要爬取的>域名。继续选择站点的域。
第三步,验证网站的所有权。一共有三种验证方式,您可以根据自己的实际情况进行选择。
验证完成后,即可将搜索引擎提交至网站。
提交完成后,搜索引擎会自动抓取网站地图文件中的网址,推送给搜索引擎进行抓取。
搜索引擎如何自动实现爬取?现在让我们谈谈robot.txt文件。其内容格式为:
图中1表示允许所有搜索引擎爬取,2表示不允许搜索引擎爬取这些目录,3表示读取xml文件。如果您了解文件的格式,您可以根据自己的实际情况修改文件的内容。修改完成后,还必须上传到网站的根目录下才能获取。
点击下图中的检测和更新。
以上操作完成后,选择爬虫诊断工具,让站长从蜘蛛的角度查看爬取的内容,自我诊断爬虫看到的内容是否与预期的内容一致。
一段时间后,将显示获取的结果。
全部设置完成后,第二天就会看到特定搜索引擎的爬取数据。
资源工具还提供了爬行异常的诊断。站长可根据系统提示的具体内容及时修复网站,达到爬行异常0的效果。
从上面可以发现,如果想让蜘蛛爬虫有稳定良性的访问,就必须保持更新网站的好习惯。更新内容后,及时重新生成sitemap文件上传到网站的根目录,这样网站进入良性期,无法阻止搜索引擎抓取。本次学习结束,我们下期再见!
c#抓取网页数据(ASP.NET中抓取网页内容-保持登录状态利用Post数据成功登录服务器应用系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-30 06:19
在ASP.NET中抓取网页内容非常方便,其中解决了ASP中困扰我们的编码问题。
1、获取一般内容
需要三个类:WebRequest、WebResponse、StreamReader
需要的命名空间:System.Net、System.IO
核心代码:
WebRequest类的Create是一个静态方法,参数是要爬取的网页的URL;
Encoding 指定编码。编码有ASCII、UTF32、UTF8等通用编码属性,但没有gb2312的编码属性,所以我们使用GetEncoding获取gb2312编码。
2、抓取图片或其他二进制文件(如文件)
需要四个类:WebRequest、WebResponse、Stream、FileStream
需要的命名空间:System.Net、System.IO
核心代码:用Stream读取
3、抓取网页内容的POST方法
在抓取网页时,有时需要通过Post将一些数据发送到服务器。在网页抓取程序中添加如下代码,将用户名和密码发布到服务器:
4、ASP.NET 抓取网页内容-防止重定向
在网页爬取过程中,在成功登录服务器应用系统后,应用系统可能会通过Response.Redirect对网页进行重定向。如果不需要响应这个重定向,那么我们不应该发送 reader.ReadToEnd() 到 Response.Write 出来时,就可以了。
5、ASP.NET 抓取网页内容-保持登录状态
使用Post数据成功登录服务器应用系统后,就可以抓取到需要登录的页面,那么我们可能需要在多个Request之间保持登录状态。 查看全部
c#抓取网页数据(ASP.NET中抓取网页内容-保持登录状态利用Post数据成功登录服务器应用系统)
在ASP.NET中抓取网页内容非常方便,其中解决了ASP中困扰我们的编码问题。
1、获取一般内容
需要三个类:WebRequest、WebResponse、StreamReader
需要的命名空间:System.Net、System.IO
核心代码:
WebRequest类的Create是一个静态方法,参数是要爬取的网页的URL;
Encoding 指定编码。编码有ASCII、UTF32、UTF8等通用编码属性,但没有gb2312的编码属性,所以我们使用GetEncoding获取gb2312编码。
2、抓取图片或其他二进制文件(如文件)
需要四个类:WebRequest、WebResponse、Stream、FileStream
需要的命名空间:System.Net、System.IO
核心代码:用Stream读取
3、抓取网页内容的POST方法
在抓取网页时,有时需要通过Post将一些数据发送到服务器。在网页抓取程序中添加如下代码,将用户名和密码发布到服务器:
4、ASP.NET 抓取网页内容-防止重定向
在网页爬取过程中,在成功登录服务器应用系统后,应用系统可能会通过Response.Redirect对网页进行重定向。如果不需要响应这个重定向,那么我们不应该发送 reader.ReadToEnd() 到 Response.Write 出来时,就可以了。
5、ASP.NET 抓取网页内容-保持登录状态
使用Post数据成功登录服务器应用系统后,就可以抓取到需要登录的页面,那么我们可能需要在多个Request之间保持登录状态。
c#抓取网页数据(几个自己研究出来的抓数据的技术,欢迎大家指正补充哈哈! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-29 19:15
)
我也对数据抓取有一些研究。现在我分享一些我研究过的数据抓取技术。可能有很多缺点。欢迎指正并补充哈哈!
方法一:直接抓取网页源码
优点:速度快。
缺点: 1、由于速度快,容易被服务器检测,可能会限制当前的ip抓取。为此,您可以尝试使用 ip 代码来解决它。
2、如果要抓取的数据是在网页加载后,js修改了网页元素,无法抓取。
3、遇到爬取一些大型网站时,如果登录后需要爬取页面,可能需要破解服务器端账号加密算法和各种加密算法,测试技术性。
适用场景:网页是完全静态的,第一次加载网页时就加载了你要抓取的数据。涉及登录或权限操作的类似页面不使用任何帐户进行加密或仅进行简单加密。
当然,如果你在这个网页抓取的数据是通过接口获取的json,那你会更开心,直接抓取json页面即可。
对于一个登录页面,我们如何获取他的登录页面背后的源代码?
首先,我想介绍一下,在会话保存帐户信息时,服务器是如何确定用户的身份的。
首先,用户登录成功后,服务器会在session中保存用户当前的session信息,每个session都有一个唯一的标识sessionId。当用户访问该页面时,会话创建后,会收到服务器返回的 sessionId 并保存在 cookie 中。因此,我们可以用Chrome浏览器打开勾选项,查看当前页面的jsessionId。用户下次访问需要登录的页面时,用户发送的请求头会附加这个sessionId,服务器端可以通过这个sessionId来判断用户的身份。
在这里,我搭建了一个简单的jsp登录页面,登录后的账户信息保存在服务端会话中。
思路:1.登录。2.登录成功后获取cookies。3. 将cookie放入请求头,向登录页面发送请求。
附上java版本代码和python
爪哇版:
package craw;import java.io.BufferedReader;import java.io.IOException;import java.io.InputStreamReader;import java.io.PrintStream;import java.io.PrintWriter;import java.net.HttpURLConnection;import java.net.MalformedURLException;import java.net.URL;import java.net.URLConnection;import java.util.List;import java.util.Map;public class CrawTest {//获得网页源代码private static String getHtml(String urlString,String charset,String cookie){StringBuffer html = new StringBuffer();try {URL url = new URL(urlString);HttpURLConnection urlConn = (HttpURLConnection) url.openConnection();urlConn.setRequestProperty("Cookie", cookie);BufferedReader br = new BufferedReader(new InputStreamReader(urlConn.getInputStream(),charset));String str;while((str=br.readLine())!=null){html.append(str);}} catch (MalformedURLException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}return html.toString();}//发送post请求,并返回请求后的cookieprivate static String postGetCookie(String urlString,String params,String charset){String cookies=null;try {URL url = new URL(urlString);URLConnection urlConn = url.openConnection();urlConn.setDoInput(true);urlConn.setDoOutput(true);PrintWriter out = new PrintWriter(urlConn.getOutputStream());out.print(params);out.flush(); cookies = urlConn.getHeaderFields().get("Set-Cookie").get(0);} catch (MalformedURLException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}return cookies;}public static void main(String[] args) {String cookie = postGetCookie("http://localhost:8080/loginDemo/login","username=admin&password=123456","utf-8");String html = getHtml("http://localhost:8080/loginDemo/index.jsp", "utf-8", cookie);System.out.println(html);//这里我们就可能输出登录后的网页源代码了}}
蟒蛇版本:
#encoding:utf-8import urllibimport urllib2data={'username':'admin','password':'123456'}data=urllib.urlencode(data)response = urllib2.urlopen('http://localhost:8080/loginDemo/login',data=data)//登录cookie = response.info()['set-cookie']//获得登录后的cookiejsessionId = cookie.split(';')[0].split('=')[-1]//从cookie获得sessionIdhtml = response.read()if html=='error': print('用户名密码错误!')elif html=='success': headers = {'Cookie':'JSESSIONID='+jsessionId}//请求头 request =urllib2.Request('http://localhost:8080/loginDemo/index.jsp',headers=headers) html = urllib2.urlopen(request).read() print(html)//输出登录后的页面源码
我们可以很明显的看到python的优势,至少会比java少写一半的代码量。当然,这是java的优点,也是java的缺点。优点是更加灵活,程序员可以更好地控制底层代码的实现。,缺点是不易学,技术要求太高。因此,如果您是数据抓取的新手,我强烈建议您学习python。
方法二:模拟浏览器操作
优点: 1. 类似于用户操作,不易被服务器检测到。
2、对于登录的网站,即使是N层加密,也无需考虑其加密算法。
3、可随时获取当前页面各元素的最新状态。
缺点: 1. 稍慢。
这里有一些很好的模拟浏览器操作的库:
C# 浏览器控件:
如果你学过c#winform,相信你对webbrower控件永远不会陌生。是浏览器,内部驱动其实就是IE驱动。
他可以在dom模式下随时解析当前文档(网页文档对象),不仅可以获取相关的Element对象,还可以修改元素对象,甚至调用方法,比如onclick方法,onsubmit等,或者直接调用页面js方法。
网页浏览器操作的C#代码:
webBrowser1.Navigate("https://localhost//index.html");//加载一个页面
需要注意的是:不要直接执行以下代码,因为网页加载需要时间,建议以下代码写到webBrowser1_DocumentCompleted(加载完成)事件中:webBrowser1.Document.GetElementById("username").InnerText="admin";//在网页中找到id为username的元素,设置其文本为admin webBrowser1.Document.GetElementById("password").InnerText = "123456";//在网页中找到id为password的元素,设置其文本为123456 webBrowser1.Document.InvokeScript("loginEncrypt");//调用网页js函数:loginEncrypt.
因为有些页面可能不够友好,或者IE版本太低,甚至安全证书等问题,那么这个解决方案可能会通过。
我们可以直接使用selenium库来操作操作系统中真实的浏览器,比如chrome浏览器,selenuim支持多语言开发,以python调用selenium为例,selenium就是直接操作我们系统中的浏览器,但是我们需要确保浏览器安装了相应的Drive。
但是,在实际开发中,有时我们可能不想看到这样的浏览器界面。这里可以给大家推荐一款直接在cmd中操作的后台浏览器。没有接口,就是phantomjs。
这样我们就可以用python+selenium+phantomjs来模拟浏览器的操作,看不到界面,因为phantomjs没有界面,会比普通浏览器快很多。
网上的资料很多,一时半会解释不清。我不会在这里解释太多。你可以看看:
三、Fidder脚本:
fidder 是一个非常强大的数据捕获工具。它不仅可以捕获当前系统中的http请求,还可以提供安全证书。所以,有时候,如果我们在爬取过程中遇到安全证书错误,我们不妨打开fidder,让他给你提供一个证书,说不定你就快成功了。
更强大的是 fdder 脚本,它可以在捕获请求后执行系统操作,例如将请求的数据保存到硬盘。或者在请求之前修改请求头,可以说是一个强大的工具。这样我们之前用fdder配合各种方法,相信大部分问题都可以解决。而且他的语法和C like系列语法类似,类库和c#大体相同,相信熟悉C#的同学会很快上手fiddler脚本。
fider 脚本: 查看全部
c#抓取网页数据(几个自己研究出来的抓数据的技术,欢迎大家指正补充哈哈!
)
我也对数据抓取有一些研究。现在我分享一些我研究过的数据抓取技术。可能有很多缺点。欢迎指正并补充哈哈!
方法一:直接抓取网页源码
优点:速度快。
缺点: 1、由于速度快,容易被服务器检测,可能会限制当前的ip抓取。为此,您可以尝试使用 ip 代码来解决它。
2、如果要抓取的数据是在网页加载后,js修改了网页元素,无法抓取。
3、遇到爬取一些大型网站时,如果登录后需要爬取页面,可能需要破解服务器端账号加密算法和各种加密算法,测试技术性。
适用场景:网页是完全静态的,第一次加载网页时就加载了你要抓取的数据。涉及登录或权限操作的类似页面不使用任何帐户进行加密或仅进行简单加密。
当然,如果你在这个网页抓取的数据是通过接口获取的json,那你会更开心,直接抓取json页面即可。
对于一个登录页面,我们如何获取他的登录页面背后的源代码?
首先,我想介绍一下,在会话保存帐户信息时,服务器是如何确定用户的身份的。
首先,用户登录成功后,服务器会在session中保存用户当前的session信息,每个session都有一个唯一的标识sessionId。当用户访问该页面时,会话创建后,会收到服务器返回的 sessionId 并保存在 cookie 中。因此,我们可以用Chrome浏览器打开勾选项,查看当前页面的jsessionId。用户下次访问需要登录的页面时,用户发送的请求头会附加这个sessionId,服务器端可以通过这个sessionId来判断用户的身份。
在这里,我搭建了一个简单的jsp登录页面,登录后的账户信息保存在服务端会话中。
思路:1.登录。2.登录成功后获取cookies。3. 将cookie放入请求头,向登录页面发送请求。
附上java版本代码和python
爪哇版:
package craw;import java.io.BufferedReader;import java.io.IOException;import java.io.InputStreamReader;import java.io.PrintStream;import java.io.PrintWriter;import java.net.HttpURLConnection;import java.net.MalformedURLException;import java.net.URL;import java.net.URLConnection;import java.util.List;import java.util.Map;public class CrawTest {//获得网页源代码private static String getHtml(String urlString,String charset,String cookie){StringBuffer html = new StringBuffer();try {URL url = new URL(urlString);HttpURLConnection urlConn = (HttpURLConnection) url.openConnection();urlConn.setRequestProperty("Cookie", cookie);BufferedReader br = new BufferedReader(new InputStreamReader(urlConn.getInputStream(),charset));String str;while((str=br.readLine())!=null){html.append(str);}} catch (MalformedURLException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}return html.toString();}//发送post请求,并返回请求后的cookieprivate static String postGetCookie(String urlString,String params,String charset){String cookies=null;try {URL url = new URL(urlString);URLConnection urlConn = url.openConnection();urlConn.setDoInput(true);urlConn.setDoOutput(true);PrintWriter out = new PrintWriter(urlConn.getOutputStream());out.print(params);out.flush(); cookies = urlConn.getHeaderFields().get("Set-Cookie").get(0);} catch (MalformedURLException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}return cookies;}public static void main(String[] args) {String cookie = postGetCookie("http://localhost:8080/loginDemo/login","username=admin&password=123456","utf-8");String html = getHtml("http://localhost:8080/loginDemo/index.jsp", "utf-8", cookie);System.out.println(html);//这里我们就可能输出登录后的网页源代码了}}
蟒蛇版本:
#encoding:utf-8import urllibimport urllib2data={'username':'admin','password':'123456'}data=urllib.urlencode(data)response = urllib2.urlopen('http://localhost:8080/loginDemo/login',data=data)//登录cookie = response.info()['set-cookie']//获得登录后的cookiejsessionId = cookie.split(';')[0].split('=')[-1]//从cookie获得sessionIdhtml = response.read()if html=='error': print('用户名密码错误!')elif html=='success': headers = {'Cookie':'JSESSIONID='+jsessionId}//请求头 request =urllib2.Request('http://localhost:8080/loginDemo/index.jsp',headers=headers) html = urllib2.urlopen(request).read() print(html)//输出登录后的页面源码
我们可以很明显的看到python的优势,至少会比java少写一半的代码量。当然,这是java的优点,也是java的缺点。优点是更加灵活,程序员可以更好地控制底层代码的实现。,缺点是不易学,技术要求太高。因此,如果您是数据抓取的新手,我强烈建议您学习python。
方法二:模拟浏览器操作
优点: 1. 类似于用户操作,不易被服务器检测到。
2、对于登录的网站,即使是N层加密,也无需考虑其加密算法。
3、可随时获取当前页面各元素的最新状态。
缺点: 1. 稍慢。
这里有一些很好的模拟浏览器操作的库:
C# 浏览器控件:
如果你学过c#winform,相信你对webbrower控件永远不会陌生。是浏览器,内部驱动其实就是IE驱动。
他可以在dom模式下随时解析当前文档(网页文档对象),不仅可以获取相关的Element对象,还可以修改元素对象,甚至调用方法,比如onclick方法,onsubmit等,或者直接调用页面js方法。
网页浏览器操作的C#代码:
webBrowser1.Navigate("https://localhost//index.html";);//加载一个页面
需要注意的是:不要直接执行以下代码,因为网页加载需要时间,建议以下代码写到webBrowser1_DocumentCompleted(加载完成)事件中:webBrowser1.Document.GetElementById("username").InnerText="admin";//在网页中找到id为username的元素,设置其文本为admin webBrowser1.Document.GetElementById("password").InnerText = "123456";//在网页中找到id为password的元素,设置其文本为123456 webBrowser1.Document.InvokeScript("loginEncrypt");//调用网页js函数:loginEncrypt.
因为有些页面可能不够友好,或者IE版本太低,甚至安全证书等问题,那么这个解决方案可能会通过。
我们可以直接使用selenium库来操作操作系统中真实的浏览器,比如chrome浏览器,selenuim支持多语言开发,以python调用selenium为例,selenium就是直接操作我们系统中的浏览器,但是我们需要确保浏览器安装了相应的Drive。
但是,在实际开发中,有时我们可能不想看到这样的浏览器界面。这里可以给大家推荐一款直接在cmd中操作的后台浏览器。没有接口,就是phantomjs。
这样我们就可以用python+selenium+phantomjs来模拟浏览器的操作,看不到界面,因为phantomjs没有界面,会比普通浏览器快很多。
网上的资料很多,一时半会解释不清。我不会在这里解释太多。你可以看看:
三、Fidder脚本:
fidder 是一个非常强大的数据捕获工具。它不仅可以捕获当前系统中的http请求,还可以提供安全证书。所以,有时候,如果我们在爬取过程中遇到安全证书错误,我们不妨打开fidder,让他给你提供一个证书,说不定你就快成功了。
更强大的是 fdder 脚本,它可以在捕获请求后执行系统操作,例如将请求的数据保存到硬盘。或者在请求之前修改请求头,可以说是一个强大的工具。这样我们之前用fdder配合各种方法,相信大部分问题都可以解决。而且他的语法和C like系列语法类似,类库和c#大体相同,相信熟悉C#的同学会很快上手fiddler脚本。
fider 脚本:
c#抓取网页数据(C#使用正则表达式抓取网站信息的正则抓取技巧(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-24 12:14
本文文章主要介绍C#使用“target="_blank">正则表达式捕获网站信息,并结合实例分析C#对网页信息的正则捕获操作技巧,具有一定的参考价值,有需要的朋友可以参考
本文介绍了 C# 如何使用正则表达式来捕获 网站 信息。分享给大家,供大家参考,如下:
下面是一个抓取京东商城商品详情的例子。
1、创建JdRobber.cs程序类
<p>public class JdRobber
{
///
/// 判断是否京东链接
///
///
///
public bool ValidationUrl(string url)
{
bool result = false;
if (!String.IsNullOrEmpty(url))
{
Regex regex = new Regex(@"^http://item.jd.com/\d+.html$");
Match match = regex.Match(url);
if (match.Success)
{
result = true;
}
}
return result;
}
///
/// 抓取京东信息
///
///
///
public void GetInfo(string url)
{
if (ValidationUrl(url))
{
string htmlStr = WebHandler.GetHtmlStr(url, "Default");
if (!String.IsNullOrEmpty(htmlStr))
{
string pattern = ""; //正则表达式
string sourceWebID = ""; //商品关键ID
string title = ""; //标题
decimal price = 0; //价格
string picName = ""; //图片
//提取商品关键ID
pattern = @"http://item.jd.com/(?\d+).html";
sourceWebID = WebHandler.GetRegexText(url, pattern);
//提取标题
pattern = @"[\s\S]*(?.*?)";
title = WebHandler.GetRegexText(htmlStr, pattern);
//提取图片
int begin = htmlStr.IndexOf(" 查看全部
c#抓取网页数据(C#使用正则表达式抓取网站信息的正则抓取技巧(图))
本文文章主要介绍C#使用“target="_blank">正则表达式捕获网站信息,并结合实例分析C#对网页信息的正则捕获操作技巧,具有一定的参考价值,有需要的朋友可以参考
本文介绍了 C# 如何使用正则表达式来捕获 网站 信息。分享给大家,供大家参考,如下:
下面是一个抓取京东商城商品详情的例子。
1、创建JdRobber.cs程序类
<p>public class JdRobber
{
///
/// 判断是否京东链接
///
///
///
public bool ValidationUrl(string url)
{
bool result = false;
if (!String.IsNullOrEmpty(url))
{
Regex regex = new Regex(@"^http://item.jd.com/\d+.html$");
Match match = regex.Match(url);
if (match.Success)
{
result = true;
}
}
return result;
}
///
/// 抓取京东信息
///
///
///
public void GetInfo(string url)
{
if (ValidationUrl(url))
{
string htmlStr = WebHandler.GetHtmlStr(url, "Default");
if (!String.IsNullOrEmpty(htmlStr))
{
string pattern = ""; //正则表达式
string sourceWebID = ""; //商品关键ID
string title = ""; //标题
decimal price = 0; //价格
string picName = ""; //图片
//提取商品关键ID
pattern = @"http://item.jd.com/(?\d+).html";
sourceWebID = WebHandler.GetRegexText(url, pattern);
//提取标题
pattern = @"[\s\S]*(?.*?)";
title = WebHandler.GetRegexText(htmlStr, pattern);
//提取图片
int begin = htmlStr.IndexOf("
c#抓取网页数据(.data8.0.25.NET项目的应用之间产生了冲突 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-23 05:15
)
写在前面
如果你只是在寻找C#(尤其是WPF项目)连接MySQL数据库的解决方案,请直接跳到使用NuGet包管理器在VSCode中引用dll或NuGet在VS中导入dll的部分(以VS2017为例) )
介绍
之前博主在VS中编写C#WPF项目时,在搜索数据库相关答案时,没有找到合适的答案。将网上找到的Mysql.data 8.0.25 版本的dll 导入到项目中 项目的应用程序与项目的原创应用程序发生冲突(显示为MySql.Data, Version=8.0.25.0, Culture=neutral, PublicKeyToken= c5687fc88969c44d “System.Runtime, Version= 5.0.0. 0, Culture =neutral, PublicKeyT oken= b03f5f7f11 d50a3a" 程序集MySql.Data'使用的版本高于引用的版本|使用标识为System.Runtime, Version=4.1.2.0, Culture =neutral, PublicKeyToken= b03f5f7f11 d50a3a assembly'System.
之前博主在使用VSCode写代码的时候,使用了NuGet Package Manager扩展来添加dll导入,所以在VS中,我也想尝试通过NuGet来导入相关的dll引用
NuGet 简介
Nuget是.NET平台下的一个开源项目,是Visual Studio的扩展。在使用 Visual Studio 开发基于 .NET Framework 的应用程序时,Nuget 可以更快速、更方便地添加、删除和更新项目中的引用。
一个简单的理解就是在用VS或者VSCode写C#项目的时候,可以使用NuGet来添加一些扩展包
NuGet官网
直接在NuGet上搜索需要的包,比如MySql.data
点击右边的DownLoad Packages下载包,但是此时下载的是一个后缀为nupkg的包(其实是一个压缩包),这种格式不能通过导入dll直接导入到C#项目中。可以尝试使用压缩软件打开nupkg后缀包,找到自己真正需要的dll包,导入到C#项目中,但是往往不行。以MySql.data为例,只导入MySql.data 8.0.25 不能运行,会报错上图,因为VS2017或者VS2019默认的System版本是4.0.0 和 MySql.data 8.0.25 需要更高版本的 System 支持版本。
在 VSCode 中使用 NuGet 包管理器引用 dll
在vscode扩展中搜索NuGet Package Manager并安装
回到自己的C#项目,点击查看-命令面板或者直接打开CTRL+shift+P
进入NuGet包,选择NuGet包管理器:添加包选项添加需要的包
搜索Mysql.data选择第一个Mysql.data
选择对应版本(对应自己的MySQL数据库)即可完成下载
完成后记得重新生成项目(在终端输入dotnet restore)
重新运行项目,测试连接MySQL数据库
(文末有连接MySQL数据库的测试代码)
在VS中使用NuGet导入dll(以VS2017为例)
点击打开项目目录,右键引用,打开管理NuGet包
搜索需要的dll包,比如Mysql.data,选择需要的NuGet包,在右侧选择需要的版本(注意对应自己的MySQL版本),点击安装(这里因为博主已经下载了包所以显示更新按钮)
下载的时候可以看到NuGet不仅下载了一个Mysql.data,还下载了很多配套的包。这也解释了上一篇我们刚刚导入的Mysql.data的dll程序无法正常运行的情况。
完成后记得重新生成项目(右键项目名称,点击regenerate restore)
至此,项目可以正常连接MySQL数据库。如果还是不行,根据VS提示使用NuGet安装丢失或不对应的包(同上,不再赘述)
附上一段连接数据库的测试代码(注意修改为自己的数据库名,以及账号和密码)
try
{
string str = "server=localhost;User Id=root;password=123456;Database=zjty";//连接MySQL的字符串
MySqlConnection giricon = new MySqlConnection(str);//实例化链接
giricon.Open();//开启连接
// MySqlCommand mycmd = new MySqlCommand("insert into user(userId) VALUES('c#111')", giricon);
MySqlCommand mycmd = new MySqlCommand("select * from user", giricon);
MySqlDataReader reader = mycmd.ExecuteReader();
//循环单行读取数据,当读取为null时,就退出循环
while (reader.Read())
{
//输出第一列字段值
Console.Write(reader.GetString(0) + "\t");
//判断字段"username"是否为null,为null数据转换会失败
if (!reader.IsDBNull(1))
{
//输出第二列字段值
Console.Write(reader.GetString(1) + "\t");
}
//判断字段"password"是否为null,为null数据转换会失败
if (!reader.IsDBNull(2))
{
//输出第三列字段值
Console.Write(reader.GetString(2) + "\n");
}
}
// if (mycmd.ExecuteNonQuery() > 0)
// {
// Console.WriteLine("success");
// }
// Console.ReadLine();
// giricon.Close();//关闭
}
catch (Exception ex)
{
Console.WriteLine("数据库连接异常!");
} 查看全部
c#抓取网页数据(.data8.0.25.NET项目的应用之间产生了冲突
)
写在前面
如果你只是在寻找C#(尤其是WPF项目)连接MySQL数据库的解决方案,请直接跳到使用NuGet包管理器在VSCode中引用dll或NuGet在VS中导入dll的部分(以VS2017为例) )
介绍
之前博主在VS中编写C#WPF项目时,在搜索数据库相关答案时,没有找到合适的答案。将网上找到的Mysql.data 8.0.25 版本的dll 导入到项目中 项目的应用程序与项目的原创应用程序发生冲突(显示为MySql.Data, Version=8.0.25.0, Culture=neutral, PublicKeyToken= c5687fc88969c44d “System.Runtime, Version= 5.0.0. 0, Culture =neutral, PublicKeyT oken= b03f5f7f11 d50a3a" 程序集MySql.Data'使用的版本高于引用的版本|使用标识为System.Runtime, Version=4.1.2.0, Culture =neutral, PublicKeyToken= b03f5f7f11 d50a3a assembly'System.

之前博主在使用VSCode写代码的时候,使用了NuGet Package Manager扩展来添加dll导入,所以在VS中,我也想尝试通过NuGet来导入相关的dll引用

NuGet 简介
Nuget是.NET平台下的一个开源项目,是Visual Studio的扩展。在使用 Visual Studio 开发基于 .NET Framework 的应用程序时,Nuget 可以更快速、更方便地添加、删除和更新项目中的引用。
一个简单的理解就是在用VS或者VSCode写C#项目的时候,可以使用NuGet来添加一些扩展包
NuGet官网
直接在NuGet上搜索需要的包,比如MySql.data
点击右边的DownLoad Packages下载包,但是此时下载的是一个后缀为nupkg的包(其实是一个压缩包),这种格式不能通过导入dll直接导入到C#项目中。可以尝试使用压缩软件打开nupkg后缀包,找到自己真正需要的dll包,导入到C#项目中,但是往往不行。以MySql.data为例,只导入MySql.data 8.0.25 不能运行,会报错上图,因为VS2017或者VS2019默认的System版本是4.0.0 和 MySql.data 8.0.25 需要更高版本的 System 支持版本。
在 VSCode 中使用 NuGet 包管理器引用 dll
在vscode扩展中搜索NuGet Package Manager并安装
回到自己的C#项目,点击查看-命令面板或者直接打开CTRL+shift+P
进入NuGet包,选择NuGet包管理器:添加包选项添加需要的包

搜索Mysql.data选择第一个Mysql.data
选择对应版本(对应自己的MySQL数据库)即可完成下载
完成后记得重新生成项目(在终端输入dotnet restore)
重新运行项目,测试连接MySQL数据库
(文末有连接MySQL数据库的测试代码)
在VS中使用NuGet导入dll(以VS2017为例)
点击打开项目目录,右键引用,打开管理NuGet包
搜索需要的dll包,比如Mysql.data,选择需要的NuGet包,在右侧选择需要的版本(注意对应自己的MySQL版本),点击安装(这里因为博主已经下载了包所以显示更新按钮)
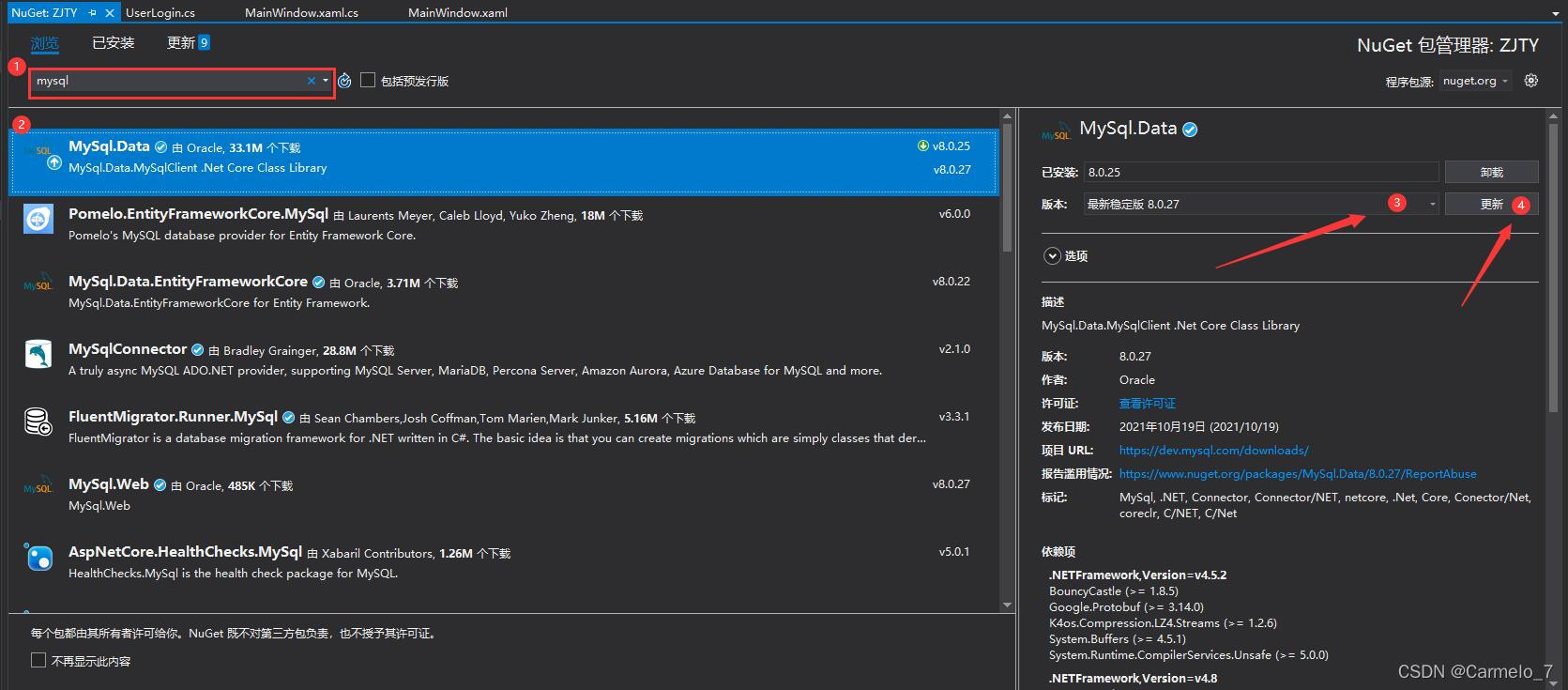
下载的时候可以看到NuGet不仅下载了一个Mysql.data,还下载了很多配套的包。这也解释了上一篇我们刚刚导入的Mysql.data的dll程序无法正常运行的情况。
完成后记得重新生成项目(右键项目名称,点击regenerate restore)
至此,项目可以正常连接MySQL数据库。如果还是不行,根据VS提示使用NuGet安装丢失或不对应的包(同上,不再赘述)
附上一段连接数据库的测试代码(注意修改为自己的数据库名,以及账号和密码)
try
{
string str = "server=localhost;User Id=root;password=123456;Database=zjty";//连接MySQL的字符串
MySqlConnection giricon = new MySqlConnection(str);//实例化链接
giricon.Open();//开启连接
// MySqlCommand mycmd = new MySqlCommand("insert into user(userId) VALUES('c#111')", giricon);
MySqlCommand mycmd = new MySqlCommand("select * from user", giricon);
MySqlDataReader reader = mycmd.ExecuteReader();
//循环单行读取数据,当读取为null时,就退出循环
while (reader.Read())
{
//输出第一列字段值
Console.Write(reader.GetString(0) + "\t");
//判断字段"username"是否为null,为null数据转换会失败
if (!reader.IsDBNull(1))
{
//输出第二列字段值
Console.Write(reader.GetString(1) + "\t");
}
//判断字段"password"是否为null,为null数据转换会失败
if (!reader.IsDBNull(2))
{
//输出第三列字段值
Console.Write(reader.GetString(2) + "\n");
}
}
// if (mycmd.ExecuteNonQuery() > 0)
// {
// Console.WriteLine("success");
// }
// Console.ReadLine();
// giricon.Close();//关闭
}
catch (Exception ex)
{
Console.WriteLine("数据库连接异常!");
}
c#抓取网页数据(Web站点进行数据采集程序的基本流程和流程图 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-12-23 03:27
)
首先大家要清楚:网站的任何页面,无论是php、jsp、aspx等动态页面,还是后台程序生成的静态页面,都可以在浏览器。
所以当你要开发数据采集程序时,首先要了解网站你试图采集的首页结构(HTML)。
一旦您非常熟悉网站 中需要采集 数据的HTML 源文件的内容,程序的其余部分将很容易处理。因为C#在网站采集上执行数据,原理是“下载你要采集的页面的HTML源文件,分析HTML代码然后抓取你需要的数据,最后将数据保存到本地文件”。
基本流程如下图所示:
1.页面源文件下载
首先引用 System.Net 命名空间
使用System.Net;
还需要引用
使用System.Text;
使用System.IO;
复制代码
引用后实例化一个 WebClient 对象
privateWebClientwc=newWebClient();
调用 DownloadData 方法从指定网页的源文件中下载一组 BYTE 数据,然后将 BYTE 数组转换为字符串。
//下载页面源文件并转换为UTF8编码格式的STRING
stringmainData=Encoding.UTF8.GetString(wc.DownloadData(string.Format("你要的是采集的网页地址")));
复制代码
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
//将网页源文件下载到本地
wc.DownloadFile("你想要的网页地址采集","保存源文件的本地文件路径");
//读取下载的源文件HTML格式字符串
stringmainData=File.ReadAllText("保存源文件的本地文件路径",Encoding.UTF8);
复制代码
通过网页HTML格式字符串,您可以分析网页采集,抓取您需要的内容。
2.页面分析采集
页面分析就是将网页源文件中的某个特定的或唯一的字符(字符串)作为抓点,并以此抓点为起点,截取你想要的页面上的数据。
以博客园为专栏。比如我要在博客园首页列出文章的标题和链接,就必须用“
代码:
//经过”
mainData=mainData.Substring(mainData.IndexOf("")+26);
//获取文章页面的链接地址
stringarticleAddr=mainData.Substring(0,mainData.IndexOf("\""));
//获取文章的标题
stringarticleTitle=mainData.Substring(mainData.IndexOf("target=\"_blank\">")+16,
mainData.IndexOf("")-mainData.IndexOf("target=\"_blank\">")-16);
复制代码
注意:当你要采集的网页前台的HTML格式发生变化时,作为抓点的字符通道也会相应变化,否则什么都没有采集
3.数据保存
从网页截取到自己需要的数据后,将程序中的数据保存到本地文件中(或者插入到自己的本地数据库中)。这样,整个采集作品就会是一个段落。
//输出数据到本地文件
File.AppendAllText(CreateFolderIfNot(Settings.Default.OutPath)+articleTitle+".txt",
文章数据,
编码.UTF8);
复制代码
另外附上我自己写的采集博客园首页文章的小程序代码。本程序的作用是发布到所有博客园首页文章采集下。
下载链接:CnBlogCollector.rar
当然,如果博客园前端页面的格式调整了,程序的采集功能肯定会失效。只能自己重新调整程序才能继续采集,哈哈。. .
程序效果如下:
查看全部
c#抓取网页数据(Web站点进行数据采集程序的基本流程和流程图
)
首先大家要清楚:网站的任何页面,无论是php、jsp、aspx等动态页面,还是后台程序生成的静态页面,都可以在浏览器。
所以当你要开发数据采集程序时,首先要了解网站你试图采集的首页结构(HTML)。
一旦您非常熟悉网站 中需要采集 数据的HTML 源文件的内容,程序的其余部分将很容易处理。因为C#在网站采集上执行数据,原理是“下载你要采集的页面的HTML源文件,分析HTML代码然后抓取你需要的数据,最后将数据保存到本地文件”。
基本流程如下图所示:
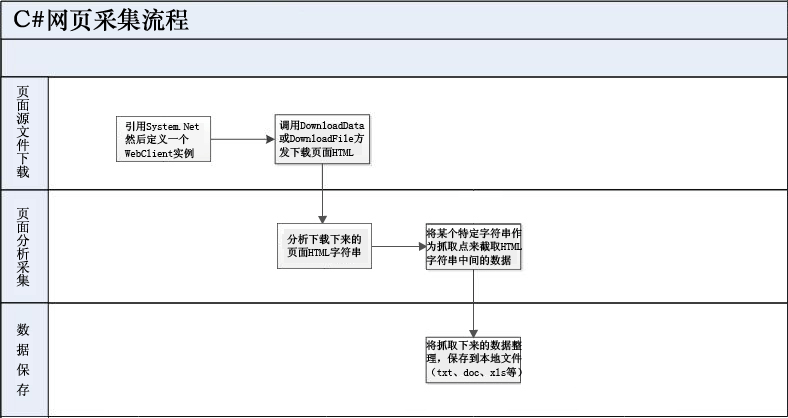
1.页面源文件下载
首先引用 System.Net 命名空间
使用System.Net;
还需要引用
使用System.Text;
使用System.IO;
复制代码
引用后实例化一个 WebClient 对象
privateWebClientwc=newWebClient();
调用 DownloadData 方法从指定网页的源文件中下载一组 BYTE 数据,然后将 BYTE 数组转换为字符串。
//下载页面源文件并转换为UTF8编码格式的STRING
stringmainData=Encoding.UTF8.GetString(wc.DownloadData(string.Format("你要的是采集的网页地址")));
复制代码
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
//将网页源文件下载到本地
wc.DownloadFile("你想要的网页地址采集","保存源文件的本地文件路径");
//读取下载的源文件HTML格式字符串
stringmainData=File.ReadAllText("保存源文件的本地文件路径",Encoding.UTF8);
复制代码
通过网页HTML格式字符串,您可以分析网页采集,抓取您需要的内容。
2.页面分析采集
页面分析就是将网页源文件中的某个特定的或唯一的字符(字符串)作为抓点,并以此抓点为起点,截取你想要的页面上的数据。
以博客园为专栏。比如我要在博客园首页列出文章的标题和链接,就必须用“

代码:
//经过”
mainData=mainData.Substring(mainData.IndexOf("")+26);
//获取文章页面的链接地址
stringarticleAddr=mainData.Substring(0,mainData.IndexOf("\""));
//获取文章的标题
stringarticleTitle=mainData.Substring(mainData.IndexOf("target=\"_blank\">")+16,
mainData.IndexOf("")-mainData.IndexOf("target=\"_blank\">")-16);
复制代码
注意:当你要采集的网页前台的HTML格式发生变化时,作为抓点的字符通道也会相应变化,否则什么都没有采集
3.数据保存
从网页截取到自己需要的数据后,将程序中的数据保存到本地文件中(或者插入到自己的本地数据库中)。这样,整个采集作品就会是一个段落。
//输出数据到本地文件
File.AppendAllText(CreateFolderIfNot(Settings.Default.OutPath)+articleTitle+".txt",
文章数据,
编码.UTF8);
复制代码
另外附上我自己写的采集博客园首页文章的小程序代码。本程序的作用是发布到所有博客园首页文章采集下。
下载链接:CnBlogCollector.rar
当然,如果博客园前端页面的格式调整了,程序的采集功能肯定会失效。只能自己重新调整程序才能继续采集,哈哈。. .
程序效果如下:

c#抓取网页数据(本文模拟浏览器提交表单,模拟表单提交登录的使用示例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-22 17:16
本文中的例子描述了如何使用WebClient登录网站并在C#中抓取登录的网页信息。分享给大家,供大家参考,如下:
C#Login网站其实就是模拟浏览器提交表单,然后记录浏览器响应返回的session cookie值,并用这个session cookie值再次发送请求来实现模拟登录的效果。 .
以下类型的 CookieAwareWebClient 是在发送请求时使用 cookie 实现的。
public class CookieAwareWebClient : WebClient
{
private CookieContainer cookie = new CookieContainer();
protected override WebRequest GetWebRequest(Uri address)
{
WebRequest request = base.GetWebRequest(address);
if (request is HttpWebRequest)
{
(request as HttpWebRequest).CookieContainer = cookie;
}
return request;
}
}
以下是模拟表单提交登录的使用示例:
var client = new CookieAwareWebClient();
client.BaseAddress = @"https://hovertree.net/any/base/url/";
var loginData = new NameValueCollection();
loginData.Add("login", "YourLogin");
loginData.Add("password", "YourPassword");
client.UploadValues("login.php", "POST", loginData);
//Now you are logged in and can request pages
string htmlSource = client.DownloadString("index.php");
更多对C#相关内容感兴趣的读者,请参考本站专题:《C#编码操作技巧总结》、《C#中XML文件操作技巧总结》、《C#常用控件使用教程》 、《WinForm控件使用总结》、《C#数据结构与算法教程》、《C#面向对象编程入门教程》、《C#编程线程使用技巧总结》
希望这篇文章能帮助你进行 C# 编程。 查看全部
c#抓取网页数据(本文模拟浏览器提交表单,模拟表单提交登录的使用示例)
本文中的例子描述了如何使用WebClient登录网站并在C#中抓取登录的网页信息。分享给大家,供大家参考,如下:
C#Login网站其实就是模拟浏览器提交表单,然后记录浏览器响应返回的session cookie值,并用这个session cookie值再次发送请求来实现模拟登录的效果。 .
以下类型的 CookieAwareWebClient 是在发送请求时使用 cookie 实现的。
public class CookieAwareWebClient : WebClient
{
private CookieContainer cookie = new CookieContainer();
protected override WebRequest GetWebRequest(Uri address)
{
WebRequest request = base.GetWebRequest(address);
if (request is HttpWebRequest)
{
(request as HttpWebRequest).CookieContainer = cookie;
}
return request;
}
}
以下是模拟表单提交登录的使用示例:
var client = new CookieAwareWebClient();
client.BaseAddress = @"https://hovertree.net/any/base/url/";
var loginData = new NameValueCollection();
loginData.Add("login", "YourLogin");
loginData.Add("password", "YourPassword");
client.UploadValues("login.php", "POST", loginData);
//Now you are logged in and can request pages
string htmlSource = client.DownloadString("index.php");
更多对C#相关内容感兴趣的读者,请参考本站专题:《C#编码操作技巧总结》、《C#中XML文件操作技巧总结》、《C#常用控件使用教程》 、《WinForm控件使用总结》、《C#数据结构与算法教程》、《C#面向对象编程入门教程》、《C#编程线程使用技巧总结》
希望这篇文章能帮助你进行 C# 编程。
c#抓取网页数据(网易云音乐歌词爬取的总体思路及方法分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-02-01 10:08
2021-04-19
前几天小编给大家分享了数据可视化分析。文末提到了网易云音乐歌词爬虫。今天给大家分享一下网易云音乐的歌词抓取方法。
本文的大致思路如下:
找到正确的网址并获取源代码;
使用bs4解析源码得到歌曲名和歌曲ID;
调用网易云歌API获取歌词;
将歌词写入文件并保存在本地。
本文的目的是获取网易云音乐的歌词,并将歌词保存到本地文件。整体效果图如下:
赵磊的歌
本文以民歌神赵雷为数据采集对象,具体采集他的歌曲歌词,其他歌手的歌词采集方法可以类推。下图为《成都》的歌词。
赵磊的歌——《成都》
一般来说,网页上显示的URL可以写在程序中,运行程序后,可以采集到我们想要的网页的源代码。但是在网易云音乐网站中,这种方式是行不通的,因为网页中的网址是假网址,真实网址中没有#号。废话不多说,直接上代码吧。
获取网页源代码
本文对采集网易云音乐歌词使用requests、bs4、json和re模块,记得在程序中添加headers和防盗链referer来模拟浏览器,防止被网站@拒绝访问> 。这里的get_html方法是专门用来获取源代码的。通常,我们还需要进行异常处理并采取预防措施。
拿到网页源代码后,我分析了源代码,发现这首歌的名字和ID被隐藏得很深。我千百度找她,发现她在源码的第294行,隐藏在 查看全部
c#抓取网页数据(网易云音乐歌词爬取的总体思路及方法分享)
2021-04-19
前几天小编给大家分享了数据可视化分析。文末提到了网易云音乐歌词爬虫。今天给大家分享一下网易云音乐的歌词抓取方法。
本文的大致思路如下:
找到正确的网址并获取源代码;
使用bs4解析源码得到歌曲名和歌曲ID;
调用网易云歌API获取歌词;
将歌词写入文件并保存在本地。
本文的目的是获取网易云音乐的歌词,并将歌词保存到本地文件。整体效果图如下:
赵磊的歌
本文以民歌神赵雷为数据采集对象,具体采集他的歌曲歌词,其他歌手的歌词采集方法可以类推。下图为《成都》的歌词。
赵磊的歌——《成都》
一般来说,网页上显示的URL可以写在程序中,运行程序后,可以采集到我们想要的网页的源代码。但是在网易云音乐网站中,这种方式是行不通的,因为网页中的网址是假网址,真实网址中没有#号。废话不多说,直接上代码吧。
获取网页源代码
本文对采集网易云音乐歌词使用requests、bs4、json和re模块,记得在程序中添加headers和防盗链referer来模拟浏览器,防止被网站@拒绝访问> 。这里的get_html方法是专门用来获取源代码的。通常,我们还需要进行异常处理并采取预防措施。
拿到网页源代码后,我分析了源代码,发现这首歌的名字和ID被隐藏得很深。我千百度找她,发现她在源码的第294行,隐藏在
c#抓取网页数据(c#从IE浏览器获取当前页面内容的相关知识和一些Code实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-30 11:20
想知道c#从IE浏览器获取当前页面内容的相关内容吗?在本文中,micDavid将为大家讲解c#获取浏览器页面内容的相关知识以及一些代码示例。欢迎大家阅读指正,我们先重点:c#,获取浏览器内容,c#,获取IE浏览器页面,一起学习吧。
private void timer1_Tick(object sender, EventArgs e)
{
lock (currentLock)
{
System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition;
if (_leftClick)
{
timer1.Stop();
_leftClick = false;
_lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false));
if (_lastDocument != null)
{
if (_getDocument)
{
_getDocument = true;
try
{
string url = _lastDocument.url;
string html = _lastDocument.documentElement.outerHTML;
string cookie = _lastDocument.cookie;
string domain = _lastDocument.domain;
var resolveParams = new ResolveParam
{
Url = new Uri(url),
Html = html,
PageCookie = cookie,
Domain = domain
};
RequetResove(resolveParams);
}
catch (Exception ex)
{
System.Windows.MessageBox.Show(ex.Message);
Console.WriteLine(ex.Message);
Console.WriteLine(ex.StackTrace);
}
}
}
else
{
new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页");
}
_getDocument = false;
}
else
{
_pointFrm.Left = MousePoint.X + 10;
_pointFrm.Top = MousePoint.Y + 10;
}
}
}
在第11行GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false))的分解下,首先从鼠标坐标获取页面的句柄:
public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl)
{
IntPtr handle = Win32APIsFull.WindowFromPoint(p);
if (handle != IntPtr.Zero)
{
System.Drawing.Rectangle rect = default(System.Drawing.Rectangle);
if (Win32APIsFull.GetWindowRect(handle, out rect))
{
return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE);
}
}
return IntPtr.Zero;
}
接下来根据句柄获取页面内容:
public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd)
{
IntPtr result = Marshal.AllocHGlobal(4);
Object obj = null;
Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result));
if (Marshal.ReadInt32(result) != 0)
{
Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj));
}
Marshal.FreeHGlobal(result);
return obj as HTMLDocument;
}
一般原则:
向IE窗体发送消息,获取指向IE浏览器内存块的指针(非托管),然后根据该指针获取HTMLDocument对象。
该方法涉及win32的两个功能:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")]
public static extern int SendMessageTimeoutA(
[InAttribute()] System.IntPtr hWnd,
uint Msg, uint wParam, int lParam,
uint fuFlags,
uint uTimeout,
System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")]
public static extern int ObjectFromLresult(
int lResult,
ref Guid riid,
int wParam,
[MarshalAs(UnmanagedType.IDispatch), Out]
out Object pObject
);
相关文章 查看全部
c#抓取网页数据(c#从IE浏览器获取当前页面内容的相关知识和一些Code实例)
想知道c#从IE浏览器获取当前页面内容的相关内容吗?在本文中,micDavid将为大家讲解c#获取浏览器页面内容的相关知识以及一些代码示例。欢迎大家阅读指正,我们先重点:c#,获取浏览器内容,c#,获取IE浏览器页面,一起学习吧。
private void timer1_Tick(object sender, EventArgs e)
{
lock (currentLock)
{
System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition;
if (_leftClick)
{
timer1.Stop();
_leftClick = false;
_lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false));
if (_lastDocument != null)
{
if (_getDocument)
{
_getDocument = true;
try
{
string url = _lastDocument.url;
string html = _lastDocument.documentElement.outerHTML;
string cookie = _lastDocument.cookie;
string domain = _lastDocument.domain;
var resolveParams = new ResolveParam
{
Url = new Uri(url),
Html = html,
PageCookie = cookie,
Domain = domain
};
RequetResove(resolveParams);
}
catch (Exception ex)
{
System.Windows.MessageBox.Show(ex.Message);
Console.WriteLine(ex.Message);
Console.WriteLine(ex.StackTrace);
}
}
}
else
{
new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页");
}
_getDocument = false;
}
else
{
_pointFrm.Left = MousePoint.X + 10;
_pointFrm.Top = MousePoint.Y + 10;
}
}
}
在第11行GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false))的分解下,首先从鼠标坐标获取页面的句柄:
public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl)
{
IntPtr handle = Win32APIsFull.WindowFromPoint(p);
if (handle != IntPtr.Zero)
{
System.Drawing.Rectangle rect = default(System.Drawing.Rectangle);
if (Win32APIsFull.GetWindowRect(handle, out rect))
{
return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE);
}
}
return IntPtr.Zero;
}
接下来根据句柄获取页面内容:
public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd)
{
IntPtr result = Marshal.AllocHGlobal(4);
Object obj = null;
Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result));
if (Marshal.ReadInt32(result) != 0)
{
Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj));
}
Marshal.FreeHGlobal(result);
return obj as HTMLDocument;
}
一般原则:
向IE窗体发送消息,获取指向IE浏览器内存块的指针(非托管),然后根据该指针获取HTMLDocument对象。
该方法涉及win32的两个功能:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")]
public static extern int SendMessageTimeoutA(
[InAttribute()] System.IntPtr hWnd,
uint Msg, uint wParam, int lParam,
uint fuFlags,
uint uTimeout,
System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")]
public static extern int ObjectFromLresult(
int lResult,
ref Guid riid,
int wParam,
[MarshalAs(UnmanagedType.IDispatch), Out]
out Object pObject
);
相关文章
c#抓取网页数据(c#抓取网页数据库通过sqlite处理异常捕获的sqlite错误)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-29 17:00
c#抓取网页数据库通过sqlite存储,使用redis缓存并通过try-fail处理异常捕获的sqlite错误需要对sqlite相关的库进行重构,建议使用c#代码设计,不推荐java代码设计。
可以先读一下sqlite源码
这些格式化的类,大都没有多少功能。可以认为是预处理好的,相当于去掉了很多中间代码。然后异常捕捉通过try-fail去处理。
外面的代码可以如下写
和c++相同,格式化出来的类,
ifelse格式化并封装
换种写法
这个问题问的人很多,也有很多教学资源,也有很多基础资料,不知道怎么评价。c#和java的区别很大,c#里面函数的返回值类型不需要写着[true,false],函数返回值类型支持很多实现。另外java还没有数据类型转换的机制,java的编译期直接把数据给编译成byte[]了。
暂时没有开发或者使用c#,仅仅从它的特点来看,ifelse已经很不错了,我觉得不应该再改变了,如果用java就按照else的模式就行了。
我今天在pc上部署sqlite,遇到了和你一样的问题,我是定制程序的windows系统,结果竟然部署不上去,比比特币、莱特币这种交易市场还要慢。幸好没用mongodb和redis这种nosql式的方案,免得碰一鼻子灰。先占个位置,等下找机会测一下。 查看全部
c#抓取网页数据(c#抓取网页数据库通过sqlite处理异常捕获的sqlite错误)
c#抓取网页数据库通过sqlite存储,使用redis缓存并通过try-fail处理异常捕获的sqlite错误需要对sqlite相关的库进行重构,建议使用c#代码设计,不推荐java代码设计。
可以先读一下sqlite源码
这些格式化的类,大都没有多少功能。可以认为是预处理好的,相当于去掉了很多中间代码。然后异常捕捉通过try-fail去处理。
外面的代码可以如下写
和c++相同,格式化出来的类,
ifelse格式化并封装
换种写法
这个问题问的人很多,也有很多教学资源,也有很多基础资料,不知道怎么评价。c#和java的区别很大,c#里面函数的返回值类型不需要写着[true,false],函数返回值类型支持很多实现。另外java还没有数据类型转换的机制,java的编译期直接把数据给编译成byte[]了。
暂时没有开发或者使用c#,仅仅从它的特点来看,ifelse已经很不错了,我觉得不应该再改变了,如果用java就按照else的模式就行了。
我今天在pc上部署sqlite,遇到了和你一样的问题,我是定制程序的windows系统,结果竟然部署不上去,比比特币、莱特币这种交易市场还要慢。幸好没用mongodb和redis这种nosql式的方案,免得碰一鼻子灰。先占个位置,等下找机会测一下。
c#抓取网页数据(Python网络爬虫内容提取器一文项目启动说明(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-29 16:15
)
1 简介
在 Python 网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类 gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分,尝试使用xslt方法提取静态网页内容并一次性转换为xml格式。
2.使用lxml库提取网页内容
lxml是python的一个库,可以快速灵活地处理XML。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现通用的 ElementTree API。
这2天,我在python中测试了通过xslt提取网页内容,记录如下:
2.1,抓取目标
假设要提取jisoke官网老论坛的帖子标题和回复数,如下图,需要提取整个列表并保存为xml格式
2.2、源码1:只抓取当前页面,结果显示在控制台
Python的优势在于它可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用的并不多。xslt 脚本占用了很大的空间。在这段代码中,只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者令人头疼的正则表达式,请参考《Python Instant Web Crawler Project Startup Instructions》,我们希望通过这种架构,程序员的时间节省一半以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request
from lxml import etree
url="http://www.gooseeker.com/cn/forum/7"conn = request.urlopen(url)
doc = etree.HTML(conn.read())
xslt_root = etree.XML("""\
""")
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)print(result_tree)
2.3、抓取结果
得到的爬取结果如下:
2.4、源码2:翻页取指,结果存入文件
我们对2.2的代码进行了进一步的修改,增加了翻页功能来抓取和保存结果文件。代码如下:
from urllib import request
from lxml import etree
import timexslt_root = etree.XML("""\
""")
baseurl = "http://www.gooseeker.com/cn/fo ... begin = "jsk_bbs_"basefileend = ".xml"count = 1while (count < 12):
url = baseurl + "?page=" + str(count)
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
transform = etree.XSLT(xslt_root)
result_tree = transform(doc) print(str(result_tree))
file_obj = open(basefilebegin+str(count)+basefileend,'w',encoding='UTF-8')
file_obj.write(str(result_tree))
file_obj.close()
count += 1
time.sleep(2)
我们添加了编写文件的代码,还添加了一个循环来构造每次翻页的URL,但是如果在翻页过程中URL始终相同怎么办?实际上,这是动态的网页内容,下面将进行讨论。
三、总结
这是开源Python通用爬虫项目的验证过程。在爬虫框架中,其他部分很容易通用化,即很难将网页内容提取并转化为结构化操作。我们称之为提取器。但是在GooSeeker的可视化抽取规则生成器MS的帮助下,抽取器的生成过程会变得非常方便,并且插入可以标准化,从而实现一个通用的爬虫。后续文章会具体讲解MS。平台配合Python的具体方法。
好了,以上就是小编为大家带来的全部内容了。转发本文+关注并私信小编“资料”,即可免费获取2019最新python资料和零基础入门教程,我会不定期分享干货。同学们!
查看全部
c#抓取网页数据(Python网络爬虫内容提取器一文项目启动说明(一)
)
1 简介
在 Python 网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类 gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分,尝试使用xslt方法提取静态网页内容并一次性转换为xml格式。
2.使用lxml库提取网页内容
lxml是python的一个库,可以快速灵活地处理XML。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现通用的 ElementTree API。
这2天,我在python中测试了通过xslt提取网页内容,记录如下:
2.1,抓取目标
假设要提取jisoke官网老论坛的帖子标题和回复数,如下图,需要提取整个列表并保存为xml格式
2.2、源码1:只抓取当前页面,结果显示在控制台
Python的优势在于它可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用的并不多。xslt 脚本占用了很大的空间。在这段代码中,只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者令人头疼的正则表达式,请参考《Python Instant Web Crawler Project Startup Instructions》,我们希望通过这种架构,程序员的时间节省一半以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request
from lxml import etree
url="http://www.gooseeker.com/cn/forum/7"conn = request.urlopen(url)
doc = etree.HTML(conn.read())
xslt_root = etree.XML("""\
""")
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)print(result_tree)
2.3、抓取结果
得到的爬取结果如下:
2.4、源码2:翻页取指,结果存入文件
我们对2.2的代码进行了进一步的修改,增加了翻页功能来抓取和保存结果文件。代码如下:
from urllib import request
from lxml import etree
import timexslt_root = etree.XML("""\
""")
baseurl = "http://www.gooseeker.com/cn/fo ... begin = "jsk_bbs_"basefileend = ".xml"count = 1while (count < 12):
url = baseurl + "?page=" + str(count)
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
transform = etree.XSLT(xslt_root)
result_tree = transform(doc) print(str(result_tree))
file_obj = open(basefilebegin+str(count)+basefileend,'w',encoding='UTF-8')
file_obj.write(str(result_tree))
file_obj.close()
count += 1
time.sleep(2)
我们添加了编写文件的代码,还添加了一个循环来构造每次翻页的URL,但是如果在翻页过程中URL始终相同怎么办?实际上,这是动态的网页内容,下面将进行讨论。
三、总结
这是开源Python通用爬虫项目的验证过程。在爬虫框架中,其他部分很容易通用化,即很难将网页内容提取并转化为结构化操作。我们称之为提取器。但是在GooSeeker的可视化抽取规则生成器MS的帮助下,抽取器的生成过程会变得非常方便,并且插入可以标准化,从而实现一个通用的爬虫。后续文章会具体讲解MS。平台配合Python的具体方法。
好了,以上就是小编为大家带来的全部内容了。转发本文+关注并私信小编“资料”,即可免费获取2019最新python资料和零基础入门教程,我会不定期分享干货。同学们!
c#抓取网页数据( 网页抓取是通过自动化手段检索数据的过程-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-29 01:02
网页抓取是通过自动化手段检索数据的过程-乐题库)
网页抓取是通过自动化方式检索数据的过程。它在很多场景中都是不可或缺的,例如竞争对手价格监控、房地产上市房源、线索和情绪监控、新闻文章 或财务数据聚合等。
在编写网页抓取代码时,您要做的第一个决定是选择您的编程语言。您可以使用多种语言编写代码,例如 Python、JavaScript、Java、Ruby 或 C#。所有提到的语言都提供了强大的网页抓取功能。
在本文中,我们将探索 C# 并向您展示如何创建一个真正的 C# 公共网络爬虫。请记住,即使我们使用的是 C#,您也可以将此信息改编为 .NET 平台支持的所有语言,包括 VB.NET 和 F#。
01.C#网页抓取工具
在编写任何代码之前,第一步是选择合适的 C# 库或包。这些 C# 库或包将具有下载 HTML 页面、解析它们并从这些页面中提取所需数据的功能。一些最流行的 C# 包如下:
●ScrapySharp
●木偶锋利
●HTML敏捷包
Html Agility Pack 是最受欢迎的 C# 包,仅 Nuget 就有近 5000 万次下载。它的流行有几个原因,其中最重要的是这个 HTML 解析器能够直接或使用浏览器下载网页。这个包容忍格式错误的 HTML 并支持 XPath。此外,它甚至可以解析本地 HTML 文件;因此,我们将在本文中进一步使用这个包。
ScrapySharp 为 C# 编程添加了更多功能。这个包支持 CSS 选择器并且可以模拟网络浏览器。虽然 ScrapySharp 被认为是一个强大的 C# 包,但程序员使用它进行维护的概率并不是很高。
Puppeteer Sharp 是著名的 Node.js Puppeteer 项目的 .NET 端口。它使用相同的 Chromium 浏览器来加载页面。此外,此包使用 async-await 风格的代码来支持异步和预操作管理。如果您已经熟悉这个 C# 包并且需要浏览器来呈现页面,那么 Puppeteer Sharp 可能是一个不错的选择。
02.使用C#构建网络爬虫
如前所述,现在我们将演示如何编写将使用 Html Agility Pack 的 C# 公共 Web 抓取代码。我们将使用带有 Visual Studio Code 的 .NET 5 SDK。此代码已在 .NET Core 3 和 .NET 5 上进行了测试,它应该可以在其他版本的 .NET 上运行。
我们将设置一个假设场景:爬取在线书店并采集书名和价格。
在编写 C# 网络爬虫之前,让我们设置开发环境。
03.搭建开发环境
对于 C# 开发环境,请安装 Visual Studio Code。请注意,如果您使用 Visual Studio 和 Visual Studio Code 编写 C# 代码,则需要注意它们是两个完全不同的应用程序。
安装 Visual Studio Code 后,安装 .NET 5.0 或更高版本。您还可以使用 .NET Core 3.1。安装后,打开终端并运行以下命令以验证 .NET CLI 或命令行界面是否正常工作:
dotnet --version
此命令行将输出安装的 .NET 版本号。
04.项目结构及依赖
该代码将成为 .NET 项目的一部分。为简单起见,创建一个控制台应用程序。然后,创建一个文件夹,您将在其中编写 C# 代码。打开终端并导航到该文件夹。输入以下命令:
dotnet new console
此命令的输出应该是控制台应用程序已成功创建。
是时候安装所需的软件包了。使用 C# 抓取公共网页,Html Agility Pack 将是一个不错的选择。你可以为这个项目安装它:
dotnet add package HtmlAgilityPack
再安装一个包,这样我们就可以轻松地将抓取的数据导出到 CSV 文件:
dotnet add package CsvHelper
如果您使用的是 Visual Studio 而不是 Visual Studio Code,请单击文件,选择新建解决方案,然后按控制台应用程序按钮。要安装依赖项,请按照下列步骤操作:
● 选择项目;
● 单击管理项目相关性。这将打开 NuGet 包窗口;
●搜索HtmlAgilityPack并选择它;
● 最后,搜索CsvHelper,选择它,然后单击Add Package。
Visual Studio 中的 Nuget 包管理器
安装这些包后,我们可以继续编写用于抓取在线书店的代码。
05.下载并解析网页数据
任何网页抓取程序的第一步都是下载网页的 HTML。此 HTML 将是一个字符串,您需要将其转换为可以进一步处理的对象,也就是第二步,这部分称为解析。Html Agility Pack 可以从本地文件、HTML 字符串、任何 URL 和浏览器中读取和解析文件。
在我们的例子中,我们需要做的就是从 URL 中获取 HTML。Html Agility Pack 没有使用 .NET 原生函数,而是提供了一个便利类——HtmlWeb。这个类提供了一个Load函数,它接受一个URL并返回一个HtmlDocument类的实例,这也是我们使用的包部分。有了这些信息,我们可以编写一个函数,它接受一个 URL 并返回一个 HtmlDocument 的实例。
打开Program.cs文件,在类中输入这个函数Program:
// Parses the URL and returns HtmlDocument object
static HtmlDocument GetDocument (string url)
{
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load(url);
return doc;
}
至此,第一步的代码就完成了。下一步是解析文档。
06.解析 HTML:获取图书链接
在这部分代码中,我们将从网页中提取所需的信息。在这个阶段,文档现在是 HtmlDocument 类型的对象。这个类公开了两个函数来选择元素。这两个函数都接受 XPath 输入并返回 HtmlNode 或 HtmlNode采集。
以下是这两个函数的签名:
public HtmlNodeCollection SelectNodes(string xpath);
public HtmlNode SelectSingleNode(string xpath);
让我们先讨论 SelectNodes。
对于这个例子——一个 C# 网络爬虫——我们将从这个页面抓取所有书籍的详细信息。
首先,需要对其进行解析,以便提取所有书籍的链接。在浏览器中打开上述书店页面,右键单击任何书籍链接,然后单击“检查”按钮。开发人员工具将打开。
了解标记后,您要选择的 XPath 应如下所示:
//h3/a
现在可以将此 XPath 传递给 SelectNodes 函数。
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
请注意,SelectNodes 函数是由
由 HtmlDocument 的 DocumentNode 属性调用。
变量 linkNodes 是一个集合。我们可以写一个foreach循环,从每个链接中一一获取href值。我们只需要解决一个小问题——页面上的链接是相对链接。因此,在我们可以抓取这些提取的链接之前,我们需要将它们转换为绝对 URL。
要转换相对链接,我们可以使用 Uri 类。我们使用这个构造函数来获取一个带有绝对 URL 的 Uri 对象。
dotnet --version
一旦我们有了 Uri 对象,我们就可以简单地检查 AbsoluteUri 属性以获取完整的 URL。
我们将所有这些都写在一个函数中以保持代码井井有条。
static List GetBookLinks(string url)
{
var bookLinks = new List();
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
var baseUri = new Uri(url);
foreach (var link in linkNodes)
{
string href = link.Attributes["href"].Value;
bookLinks.Add(new Uri(baseUri, href).AbsoluteUri);
}
return bookLinks;
}
在这个函数中,我们从一个空的 List 对象开始。在 foreach 循环中,我们将所有链接添加到该对象并返回它。
现在,是时候修改 Main() 函数了,以便我们可以测试目前编写的 C# 代码。修改函数如下:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
}
要运行此代码,请打开终端并导航到收录此文件的目录,然后键入以下内容:
dotnet run
输出应如下所示:
Found 20 links
然后我们继续下一部分,我们将处理所有链接以获取图书数据。
07.解析 HTML:获取书籍详情
此时,我们有一个收录书籍 URL 的字符串列表。我们可以简单地编写一个循环,首先使用我们已经编写的函数 GetDocument 获取文档。之后,我们将使用 SelectSingleNode 函数来提取书名和价格。
为了保持数据整洁有序,我们从一个类开始。此类将代表一本书并具有两个属性 - 标题和价格。下面的例子:
然后,在浏览器中为 Title - //h1 打开一个书页。为价格创建 XPath 有点棘手,因为相同的类应用于底部的附加书籍。
XPath 价格
价格的 XPath 将如下所示:
//div[contains(@class,"product_main")]/p[@class="price_color"]
请注意,XPath 收录双引号。我们必须通过在它们前面加上反斜杠来转义这些字符。
现在我们可以使用 SelectSingleNode 函数获取节点,然后使用 InnerText 属性获取元素中收录的文本。我们可以将所有内容放在这样的函数中:
static List GetBookDetails(List urls)
{
var books = new List();
foreach (var url in urls)
{
HtmlDocument document = GetDocument(url);
var titleXPath = "//h1";
var priceXPath = "//div[contains(@class,\"product_main\")]/p[@class=\"price_color\"]";
var book = new Book();
book.Title = document.DocumentNode.SelectSingleNode (priceXPath).InnerText;
book.Price = document.DocumentNode.SelectSingleNode(priceXPath).InnerText;
books.Add(book);
}
return books;
}
此函数将返回 Book 对象的列表。是时候更新 Main() 函数了:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
var books = GetBookDetails(bookLinks);
}
这个网络抓取项目的最后一部分是将数据导出为 CSV。
08.导出数据
如果你没有安装 CsvHelper,你可以通过
dotnet add package CsvHelper
在终端内运行命令来执行此操作。
导出功能非常简单。首先,我们需要创建一个 StreamWriter 并将 CSV 文件名作为参数发送。接下来,我们将使用这个对象来创建一个 CsvWriter。最后,我们可以使用 WriteRecords 函数在一行代码中编写所有书籍。
为了确保所有资源都正确关闭,我们可以使用 using 块。我们还可以将所有内容包装在这样的函数中:
static void exportToCSV(List books)
{
using (var writer = new StreamWriter("./books.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
csv.WriteRecords(books);
}
}
最后,我们可以从 Main() 函数中调用这个函数:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
var books = GetBookDetails(bookLinks);
exportToCSV(books);
}
要运行此代码,请打开终端并运行以下命令:
dotnet run
在几秒钟内,您将创建一个 books.csv 文件。
09.结论
如果你想用 C# 编写一个网络爬虫,你可以使用多个包。在本文中,我们将展示如何使用 Html Agility Pack,这是一个功能强大且易于使用的包。也是一个可以进一步增强的简单示例;例如,您可以尝试将上述逻辑添加到此代码中以处理多个页面。
如果您想了解更多关于如何使用其他编程语言进行网页抓取的信息,您可以查看我们的 Python 网页抓取指南。我们还有另一个
常见问题
问:C# 适合网页抓取吗?
A:与 Python 类似,C# 被广泛用于网页抓取。在决定选择哪种编程语言时,选择您最熟悉的语言至关重要。但是,您将能够在 Python 和 C# 中找到示例网络爬虫。
问:网络抓取合法吗?
答:如果在不违反任何法律的情况下使用代理,它们可能是合法的。但是,在与代理人进行任何活动之前,您应该就您的具体案件获得专业的法律意见。请参阅我们的 文章“网络抓取合法吗?” 查看全部
c#抓取网页数据(
网页抓取是通过自动化手段检索数据的过程-乐题库)
网页抓取是通过自动化方式检索数据的过程。它在很多场景中都是不可或缺的,例如竞争对手价格监控、房地产上市房源、线索和情绪监控、新闻文章 或财务数据聚合等。
在编写网页抓取代码时,您要做的第一个决定是选择您的编程语言。您可以使用多种语言编写代码,例如 Python、JavaScript、Java、Ruby 或 C#。所有提到的语言都提供了强大的网页抓取功能。
在本文中,我们将探索 C# 并向您展示如何创建一个真正的 C# 公共网络爬虫。请记住,即使我们使用的是 C#,您也可以将此信息改编为 .NET 平台支持的所有语言,包括 VB.NET 和 F#。
01.C#网页抓取工具
在编写任何代码之前,第一步是选择合适的 C# 库或包。这些 C# 库或包将具有下载 HTML 页面、解析它们并从这些页面中提取所需数据的功能。一些最流行的 C# 包如下:
●ScrapySharp
●木偶锋利
●HTML敏捷包
Html Agility Pack 是最受欢迎的 C# 包,仅 Nuget 就有近 5000 万次下载。它的流行有几个原因,其中最重要的是这个 HTML 解析器能够直接或使用浏览器下载网页。这个包容忍格式错误的 HTML 并支持 XPath。此外,它甚至可以解析本地 HTML 文件;因此,我们将在本文中进一步使用这个包。
ScrapySharp 为 C# 编程添加了更多功能。这个包支持 CSS 选择器并且可以模拟网络浏览器。虽然 ScrapySharp 被认为是一个强大的 C# 包,但程序员使用它进行维护的概率并不是很高。
Puppeteer Sharp 是著名的 Node.js Puppeteer 项目的 .NET 端口。它使用相同的 Chromium 浏览器来加载页面。此外,此包使用 async-await 风格的代码来支持异步和预操作管理。如果您已经熟悉这个 C# 包并且需要浏览器来呈现页面,那么 Puppeteer Sharp 可能是一个不错的选择。
02.使用C#构建网络爬虫
如前所述,现在我们将演示如何编写将使用 Html Agility Pack 的 C# 公共 Web 抓取代码。我们将使用带有 Visual Studio Code 的 .NET 5 SDK。此代码已在 .NET Core 3 和 .NET 5 上进行了测试,它应该可以在其他版本的 .NET 上运行。
我们将设置一个假设场景:爬取在线书店并采集书名和价格。
在编写 C# 网络爬虫之前,让我们设置开发环境。
03.搭建开发环境
对于 C# 开发环境,请安装 Visual Studio Code。请注意,如果您使用 Visual Studio 和 Visual Studio Code 编写 C# 代码,则需要注意它们是两个完全不同的应用程序。
安装 Visual Studio Code 后,安装 .NET 5.0 或更高版本。您还可以使用 .NET Core 3.1。安装后,打开终端并运行以下命令以验证 .NET CLI 或命令行界面是否正常工作:
dotnet --version
此命令行将输出安装的 .NET 版本号。
04.项目结构及依赖
该代码将成为 .NET 项目的一部分。为简单起见,创建一个控制台应用程序。然后,创建一个文件夹,您将在其中编写 C# 代码。打开终端并导航到该文件夹。输入以下命令:
dotnet new console
此命令的输出应该是控制台应用程序已成功创建。
是时候安装所需的软件包了。使用 C# 抓取公共网页,Html Agility Pack 将是一个不错的选择。你可以为这个项目安装它:
dotnet add package HtmlAgilityPack
再安装一个包,这样我们就可以轻松地将抓取的数据导出到 CSV 文件:
dotnet add package CsvHelper
如果您使用的是 Visual Studio 而不是 Visual Studio Code,请单击文件,选择新建解决方案,然后按控制台应用程序按钮。要安装依赖项,请按照下列步骤操作:
● 选择项目;
● 单击管理项目相关性。这将打开 NuGet 包窗口;
●搜索HtmlAgilityPack并选择它;
● 最后,搜索CsvHelper,选择它,然后单击Add Package。
Visual Studio 中的 Nuget 包管理器
安装这些包后,我们可以继续编写用于抓取在线书店的代码。
05.下载并解析网页数据
任何网页抓取程序的第一步都是下载网页的 HTML。此 HTML 将是一个字符串,您需要将其转换为可以进一步处理的对象,也就是第二步,这部分称为解析。Html Agility Pack 可以从本地文件、HTML 字符串、任何 URL 和浏览器中读取和解析文件。
在我们的例子中,我们需要做的就是从 URL 中获取 HTML。Html Agility Pack 没有使用 .NET 原生函数,而是提供了一个便利类——HtmlWeb。这个类提供了一个Load函数,它接受一个URL并返回一个HtmlDocument类的实例,这也是我们使用的包部分。有了这些信息,我们可以编写一个函数,它接受一个 URL 并返回一个 HtmlDocument 的实例。
打开Program.cs文件,在类中输入这个函数Program:
// Parses the URL and returns HtmlDocument object
static HtmlDocument GetDocument (string url)
{
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load(url);
return doc;
}
至此,第一步的代码就完成了。下一步是解析文档。
06.解析 HTML:获取图书链接
在这部分代码中,我们将从网页中提取所需的信息。在这个阶段,文档现在是 HtmlDocument 类型的对象。这个类公开了两个函数来选择元素。这两个函数都接受 XPath 输入并返回 HtmlNode 或 HtmlNode采集。
以下是这两个函数的签名:
public HtmlNodeCollection SelectNodes(string xpath);
public HtmlNode SelectSingleNode(string xpath);
让我们先讨论 SelectNodes。
对于这个例子——一个 C# 网络爬虫——我们将从这个页面抓取所有书籍的详细信息。
首先,需要对其进行解析,以便提取所有书籍的链接。在浏览器中打开上述书店页面,右键单击任何书籍链接,然后单击“检查”按钮。开发人员工具将打开。
了解标记后,您要选择的 XPath 应如下所示:
//h3/a
现在可以将此 XPath 传递给 SelectNodes 函数。
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
请注意,SelectNodes 函数是由
由 HtmlDocument 的 DocumentNode 属性调用。
变量 linkNodes 是一个集合。我们可以写一个foreach循环,从每个链接中一一获取href值。我们只需要解决一个小问题——页面上的链接是相对链接。因此,在我们可以抓取这些提取的链接之前,我们需要将它们转换为绝对 URL。
要转换相对链接,我们可以使用 Uri 类。我们使用这个构造函数来获取一个带有绝对 URL 的 Uri 对象。
dotnet --version
一旦我们有了 Uri 对象,我们就可以简单地检查 AbsoluteUri 属性以获取完整的 URL。
我们将所有这些都写在一个函数中以保持代码井井有条。
static List GetBookLinks(string url)
{
var bookLinks = new List();
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
var baseUri = new Uri(url);
foreach (var link in linkNodes)
{
string href = link.Attributes["href"].Value;
bookLinks.Add(new Uri(baseUri, href).AbsoluteUri);
}
return bookLinks;
}
在这个函数中,我们从一个空的 List 对象开始。在 foreach 循环中,我们将所有链接添加到该对象并返回它。
现在,是时候修改 Main() 函数了,以便我们可以测试目前编写的 C# 代码。修改函数如下:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
}
要运行此代码,请打开终端并导航到收录此文件的目录,然后键入以下内容:
dotnet run
输出应如下所示:
Found 20 links
然后我们继续下一部分,我们将处理所有链接以获取图书数据。
07.解析 HTML:获取书籍详情
此时,我们有一个收录书籍 URL 的字符串列表。我们可以简单地编写一个循环,首先使用我们已经编写的函数 GetDocument 获取文档。之后,我们将使用 SelectSingleNode 函数来提取书名和价格。
为了保持数据整洁有序,我们从一个类开始。此类将代表一本书并具有两个属性 - 标题和价格。下面的例子:
然后,在浏览器中为 Title - //h1 打开一个书页。为价格创建 XPath 有点棘手,因为相同的类应用于底部的附加书籍。
XPath 价格
价格的 XPath 将如下所示:
//div[contains(@class,"product_main")]/p[@class="price_color"]
请注意,XPath 收录双引号。我们必须通过在它们前面加上反斜杠来转义这些字符。
现在我们可以使用 SelectSingleNode 函数获取节点,然后使用 InnerText 属性获取元素中收录的文本。我们可以将所有内容放在这样的函数中:
static List GetBookDetails(List urls)
{
var books = new List();
foreach (var url in urls)
{
HtmlDocument document = GetDocument(url);
var titleXPath = "//h1";
var priceXPath = "//div[contains(@class,\"product_main\")]/p[@class=\"price_color\"]";
var book = new Book();
book.Title = document.DocumentNode.SelectSingleNode (priceXPath).InnerText;
book.Price = document.DocumentNode.SelectSingleNode(priceXPath).InnerText;
books.Add(book);
}
return books;
}
此函数将返回 Book 对象的列表。是时候更新 Main() 函数了:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
var books = GetBookDetails(bookLinks);
}
这个网络抓取项目的最后一部分是将数据导出为 CSV。
08.导出数据
如果你没有安装 CsvHelper,你可以通过
dotnet add package CsvHelper
在终端内运行命令来执行此操作。
导出功能非常简单。首先,我们需要创建一个 StreamWriter 并将 CSV 文件名作为参数发送。接下来,我们将使用这个对象来创建一个 CsvWriter。最后,我们可以使用 WriteRecords 函数在一行代码中编写所有书籍。
为了确保所有资源都正确关闭,我们可以使用 using 块。我们还可以将所有内容包装在这样的函数中:
static void exportToCSV(List books)
{
using (var writer = new StreamWriter("./books.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
csv.WriteRecords(books);
}
}
最后,我们可以从 Main() 函数中调用这个函数:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
var books = GetBookDetails(bookLinks);
exportToCSV(books);
}
要运行此代码,请打开终端并运行以下命令:
dotnet run
在几秒钟内,您将创建一个 books.csv 文件。
09.结论
如果你想用 C# 编写一个网络爬虫,你可以使用多个包。在本文中,我们将展示如何使用 Html Agility Pack,这是一个功能强大且易于使用的包。也是一个可以进一步增强的简单示例;例如,您可以尝试将上述逻辑添加到此代码中以处理多个页面。
如果您想了解更多关于如何使用其他编程语言进行网页抓取的信息,您可以查看我们的 Python 网页抓取指南。我们还有另一个
常见问题
问:C# 适合网页抓取吗?
A:与 Python 类似,C# 被广泛用于网页抓取。在决定选择哪种编程语言时,选择您最熟悉的语言至关重要。但是,您将能够在 Python 和 C# 中找到示例网络爬虫。
问:网络抓取合法吗?
答:如果在不违反任何法律的情况下使用代理,它们可能是合法的。但是,在与代理人进行任何活动之前,您应该就您的具体案件获得专业的法律意见。请参阅我们的 文章“网络抓取合法吗?”
c#抓取网页数据( 一种更常见的翻页类型——翻页链接不规律的例子)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-28 22:25
一种更常见的翻页类型——翻页链接不规律的例子)
摘要:在列表中,豆瓣电影列表使用分页器来划分数据:但当时我们是在寻找网页链接的规律性进行爬取,并没有使用分页器进行爬取。因为当一个网页的链接有规律的变化时,控制链接参数爬取是成本最低的;如果页面可以翻页,但是链接的变化不规律,就得去pager了一会儿。说这些理论有点无聊,我们举个不规则翻页链接的例子。8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了鲲鲲300W的转发。
这是简易数据分析系列文章的第12期。
776448504/I0gyT8aeQ?type=repost 的第二页是这样的,我注意到一个额外的#_rnd36 参数:
在之前的文章文章中,我们介绍了Web Scraper处理各种页面翻转的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉加载数据自动。今天我们讲一种比较常见的翻页方式——pager。
我本来想解释什么是寻呼机,但是我发现浏览一堆定义很麻烦。大家上网已经不是第一年了,看图就知道了。我找到了一个功能齐全的例子,支持数字页码调整,上一页到下一页和指定页数跳转。
emove(userId);}@Override@GetMapping("/findAll")public采集findAll(){
今天我们将学习 Web Scraper 如何处理这种类型的翻页。
这些理论有点枯燥,我们以不规则的翻页链接为例。8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了坤坤300W的转发。微博的转发恰巧被寻呼机隔开。我们来分析一下微博的转发情况。信息页,见
其实在本教程的第一个例子中,我们就抢到了豆瓣电影TOP排行榜。这个豆瓣电影列表使用寻呼机来划分数据:
但是当时我们是在找网页链接定期爬取,并没有使用pager来爬取。因为当一个网页的链接有规律的变化时,控制链接参数爬取是成本最低的;如果页面可以翻页,但是链接的变化不规律,就得去pager了一会儿。
ping("/remove")publicvoidremove(@RequestParam("id")LonguserId){usersRepository.r
说这些理论有点无聊,我们举个不规则翻页链接的例子。
t;)LonguserId){restTemplate.delete(""+use
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了坤坤300W的转发。微博的转发恰好是被寻呼机分割的,所以我们来分析一下微博的转发。信息页面,了解如何使用 Web Scraper 抓取此类数据。
这条微博的直接链接是:
classUserServiceIimplementsUserService{privateMapusersRepository=Maps.newHashM
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出给坤坤加个阅读。
文章 文章。在之前的文章文章中,我们介绍了WebScraper对各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们讲一种比较常见的翻页方式——pager。我想解释
首先我们看第1页转发的链接,长这样:
.推荐阅读 轻松数据分析05|WebScraper翻页-控制链接批量抓取数据 轻松数据分析08|WebScraper翻页-点击“更多按钮”翻页 轻松数据分析10|WebScraper翻页-抓“滚动加”
第二页是这样的,我注意到有一个额外的#_rnd36 参数:
gn(@RequestParam("id")LonguserId){userRemote.remove(userId);}@GetMapping("/findAllByF
第三页参数为#_rnd39
000条数据,但是第一页只有20条数据,抓到最后一条数据,还有980条数据;,一旦翻页,计数器就会重置并再次变为 1000 ......所以这个
第 4 页参数是#_rnd76:
ing-cloud-starter-dubbo 这里介绍 DubboSpringClo
多看几个链接,会发现这个转发页面的URL没有规则,只能通过pager加载数据。让我们开始我们的实践教学课程。
ctionfindAll(){returnuserService.findAll();}} 这里@Reference注解需要指定调用服务提供者接口的版本号,如果没有指定版本
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.为容器创建一个选择器
因为我们要点击pager,所以我们选择外层容器的类型为Element Click。具体参数说明见下图。我们之前在《简单数据分析08》中详细讲解过,这里就不多说了。
容器的预览如下图所示:
bScraper 毫无头绪)。考虑到这个问题,如果你看过之前关于自动控制抓取次数的教程,你可能会想到使用:nth-of-type(-n+N) 来控制N条数据的抓取。如果你尝试一下,你会发现这个方法根本行不通。已到期
寻呼机选择过程如下图所示:
vider_web/pom.xml***com.springc
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
blicclassUserController{@Reference(version="1.0.0")UserServiceuserService;@PostMapping(&qu
4.捕获数据
可以根据Sitemap cxk -> Scrape 的操作路径抓取数据。
这也不现实。毕竟WebScraper针对的数据量比较少,上万的数据算太多了。不管数据有多大,都得考虑爬取时间是否过长,数据如何存储,网站逆向如何处理。爬虫系统(比如突然弹出一个验证码,这个我们
5.一些问题
如果你看了我上面的教程,马上爬数据,你可能遇到的第一个问题就是,300w的数据,我需要一直爬下去吗?
-type(-n+N) 控制抓取 N 条数据。如果你尝试一下,你会发现这个方法根本行不通。失败的原因其实涉及到一点网页知识。如果您有兴趣,可以阅读下面的说明。不感兴趣的可以直接看最后的结论。如前所述,单击以更新
听起来很不现实。毕竟Web Scraper针对的数据量比较少,上万的数据算太多了。不管数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。网站的反爬系统(比如突然弹出一个验证码,这个Web Scraper无能为力)。
cies>1.2 创建子项目dubbo_provider_web,服务提供者项目依赖pom.xml如下: 代码清单:Alibaba/dubbo-spring-cloud-http/dubbo_pro
考虑到这个问题,如果你看过上一篇关于自动控制抓取次数的教程,你可能会想到使用 :nth-of-type(-n+N) 来控制 N 条数据的抓取。如果你尝试一下,你会发现这个方法根本行不通。
失败的原因其实涉及到一点网页知识。如果您有兴趣,可以阅读下面的说明。不感兴趣的可以直接看最后的结论。
lication:name:spring-cloud-consumer-servercloud:nacos:discovery:server-addr:192.168.44.129:8848接口测试类
就像我之前介绍的更多加载网页和下拉加载网页一样,它们新加载的数据是附加到当前页面的。你不断向下滚动,数据不断加载,网页的滚动条会越来越短。表示所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N) 来控制加载次数的时候,其实就相当于在这个网页上设置了一个计数器。当数据已经累积到我们想要的数量时,它就会停止爬取。
t;)UserServiceuserService;@PostMapping("/save")publicUserModelsave(@RequestBodyUserModelus
但是对于使用分页器的网页,每翻一页就相当于刷新当前网页,这样每次都会设置一个计数器。
太长了,数据怎么存,网站的反爬系统怎么处理(比如突然弹出一个验证码,这个WebScraper无能为力)。考虑到这个问题,如果你看过之前关于自动控制抓取次数的教程,你可能正在考虑使用:nth-of-
比如你要抓1000条数据,但是第一页只有20条数据,抓到最后一条,还有980条数据。对于一条数据,还有980,一翻页计数器就清零,又变成1000了……所以这种控制数量的方法是无效的。
引导启动测试测试 查看全部
c#抓取网页数据(
一种更常见的翻页类型——翻页链接不规律的例子)
摘要:在列表中,豆瓣电影列表使用分页器来划分数据:但当时我们是在寻找网页链接的规律性进行爬取,并没有使用分页器进行爬取。因为当一个网页的链接有规律的变化时,控制链接参数爬取是成本最低的;如果页面可以翻页,但是链接的变化不规律,就得去pager了一会儿。说这些理论有点无聊,我们举个不规则翻页链接的例子。8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了鲲鲲300W的转发。
这是简易数据分析系列文章的第12期。
776448504/I0gyT8aeQ?type=repost 的第二页是这样的,我注意到一个额外的#_rnd36 参数:
在之前的文章文章中,我们介绍了Web Scraper处理各种页面翻转的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉加载数据自动。今天我们讲一种比较常见的翻页方式——pager。
我本来想解释什么是寻呼机,但是我发现浏览一堆定义很麻烦。大家上网已经不是第一年了,看图就知道了。我找到了一个功能齐全的例子,支持数字页码调整,上一页到下一页和指定页数跳转。
emove(userId);}@Override@GetMapping("/findAll")public采集findAll(){
今天我们将学习 Web Scraper 如何处理这种类型的翻页。
这些理论有点枯燥,我们以不规则的翻页链接为例。8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了坤坤300W的转发。微博的转发恰巧被寻呼机隔开。我们来分析一下微博的转发情况。信息页,见
其实在本教程的第一个例子中,我们就抢到了豆瓣电影TOP排行榜。这个豆瓣电影列表使用寻呼机来划分数据:
但是当时我们是在找网页链接定期爬取,并没有使用pager来爬取。因为当一个网页的链接有规律的变化时,控制链接参数爬取是成本最低的;如果页面可以翻页,但是链接的变化不规律,就得去pager了一会儿。
ping("/remove")publicvoidremove(@RequestParam("id")LonguserId){usersRepository.r
说这些理论有点无聊,我们举个不规则翻页链接的例子。
t;)LonguserId){restTemplate.delete(""+use
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了坤坤300W的转发。微博的转发恰好是被寻呼机分割的,所以我们来分析一下微博的转发。信息页面,了解如何使用 Web Scraper 抓取此类数据。
这条微博的直接链接是:
classUserServiceIimplementsUserService{privateMapusersRepository=Maps.newHashM
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出给坤坤加个阅读。
文章 文章。在之前的文章文章中,我们介绍了WebScraper对各种翻页的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉自动加载数据等。今天我们讲一种比较常见的翻页方式——pager。我想解释
首先我们看第1页转发的链接,长这样:
.推荐阅读 轻松数据分析05|WebScraper翻页-控制链接批量抓取数据 轻松数据分析08|WebScraper翻页-点击“更多按钮”翻页 轻松数据分析10|WebScraper翻页-抓“滚动加”
第二页是这样的,我注意到有一个额外的#_rnd36 参数:
gn(@RequestParam("id")LonguserId){userRemote.remove(userId);}@GetMapping("/findAllByF
第三页参数为#_rnd39
000条数据,但是第一页只有20条数据,抓到最后一条数据,还有980条数据;,一旦翻页,计数器就会重置并再次变为 1000 ......所以这个
第 4 页参数是#_rnd76:
ing-cloud-starter-dubbo 这里介绍 DubboSpringClo
多看几个链接,会发现这个转发页面的URL没有规则,只能通过pager加载数据。让我们开始我们的实践教学课程。
ctionfindAll(){returnuserService.findAll();}} 这里@Reference注解需要指定调用服务提供者接口的版本号,如果没有指定版本
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.为容器创建一个选择器
因为我们要点击pager,所以我们选择外层容器的类型为Element Click。具体参数说明见下图。我们之前在《简单数据分析08》中详细讲解过,这里就不多说了。
容器的预览如下图所示:
bScraper 毫无头绪)。考虑到这个问题,如果你看过之前关于自动控制抓取次数的教程,你可能会想到使用:nth-of-type(-n+N) 来控制N条数据的抓取。如果你尝试一下,你会发现这个方法根本行不通。已到期
寻呼机选择过程如下图所示:
vider_web/pom.xml***com.springc
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
blicclassUserController{@Reference(version="1.0.0")UserServiceuserService;@PostMapping(&qu
4.捕获数据
可以根据Sitemap cxk -> Scrape 的操作路径抓取数据。
这也不现实。毕竟WebScraper针对的数据量比较少,上万的数据算太多了。不管数据有多大,都得考虑爬取时间是否过长,数据如何存储,网站逆向如何处理。爬虫系统(比如突然弹出一个验证码,这个我们
5.一些问题
如果你看了我上面的教程,马上爬数据,你可能遇到的第一个问题就是,300w的数据,我需要一直爬下去吗?
-type(-n+N) 控制抓取 N 条数据。如果你尝试一下,你会发现这个方法根本行不通。失败的原因其实涉及到一点网页知识。如果您有兴趣,可以阅读下面的说明。不感兴趣的可以直接看最后的结论。如前所述,单击以更新
听起来很不现实。毕竟Web Scraper针对的数据量比较少,上万的数据算太多了。不管数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。网站的反爬系统(比如突然弹出一个验证码,这个Web Scraper无能为力)。
cies>1.2 创建子项目dubbo_provider_web,服务提供者项目依赖pom.xml如下: 代码清单:Alibaba/dubbo-spring-cloud-http/dubbo_pro
考虑到这个问题,如果你看过上一篇关于自动控制抓取次数的教程,你可能会想到使用 :nth-of-type(-n+N) 来控制 N 条数据的抓取。如果你尝试一下,你会发现这个方法根本行不通。
失败的原因其实涉及到一点网页知识。如果您有兴趣,可以阅读下面的说明。不感兴趣的可以直接看最后的结论。
lication:name:spring-cloud-consumer-servercloud:nacos:discovery:server-addr:192.168.44.129:8848接口测试类
就像我之前介绍的更多加载网页和下拉加载网页一样,它们新加载的数据是附加到当前页面的。你不断向下滚动,数据不断加载,网页的滚动条会越来越短。表示所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N) 来控制加载次数的时候,其实就相当于在这个网页上设置了一个计数器。当数据已经累积到我们想要的数量时,它就会停止爬取。
t;)UserServiceuserService;@PostMapping("/save")publicUserModelsave(@RequestBodyUserModelus
但是对于使用分页器的网页,每翻一页就相当于刷新当前网页,这样每次都会设置一个计数器。
太长了,数据怎么存,网站的反爬系统怎么处理(比如突然弹出一个验证码,这个WebScraper无能为力)。考虑到这个问题,如果你看过之前关于自动控制抓取次数的教程,你可能正在考虑使用:nth-of-
比如你要抓1000条数据,但是第一页只有20条数据,抓到最后一条,还有980条数据。对于一条数据,还有980,一翻页计数器就清零,又变成1000了……所以这种控制数量的方法是无效的。
引导启动测试测试
c#抓取网页数据(c#抓取网页数据,你可以使用webseverpro来解析请求,并获取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-25 17:02
c#抓取网页数据,你可以使用webseverpro来解析请求,并获取数据。webseverpro是一个unity在线网页抓取工具,其实效果一样。webseverpro–unity开发,开发者更好,更快,更方便在线访问、抓取c#实时页面数据、抓取websocket网络服务数据、抓取https数据。因为是图形化界面,方便使用!!!。
不知道楼主有没有听说过eloquenthttp,
最近我新上架了一个木蚂蚁的网页抓取插件。首先,网站发过来的数据必须是隐私的,否则木蚂蚁是不会抓取的。其次,木蚂蚁抓取也不是每个都可以,木蚂蚁主要抓取js和css。网站要能抓取前端代码必须要有后端数据。
1.国内论坛一般没有网页抓取的,只有些少数网站会有实时抓取2.我们的业务模式是让开发者上传自己的网站程序用来抓取功能,方便客户用,开发者只需要做一个接口即可3.实时抓取国内目前没有比较成熟的方案4.天天目录,sonar.js等等可以看一下,但应该要收费。
针对国内网站进行的抓取分析,希望能有所帮助。
服务器和程序都封装好了,然后docker部署,客户端也可以在vps上使用websever或者qspider。 查看全部
c#抓取网页数据(c#抓取网页数据,你可以使用webseverpro来解析请求,并获取数据)
c#抓取网页数据,你可以使用webseverpro来解析请求,并获取数据。webseverpro是一个unity在线网页抓取工具,其实效果一样。webseverpro–unity开发,开发者更好,更快,更方便在线访问、抓取c#实时页面数据、抓取websocket网络服务数据、抓取https数据。因为是图形化界面,方便使用!!!。
不知道楼主有没有听说过eloquenthttp,
最近我新上架了一个木蚂蚁的网页抓取插件。首先,网站发过来的数据必须是隐私的,否则木蚂蚁是不会抓取的。其次,木蚂蚁抓取也不是每个都可以,木蚂蚁主要抓取js和css。网站要能抓取前端代码必须要有后端数据。
1.国内论坛一般没有网页抓取的,只有些少数网站会有实时抓取2.我们的业务模式是让开发者上传自己的网站程序用来抓取功能,方便客户用,开发者只需要做一个接口即可3.实时抓取国内目前没有比较成熟的方案4.天天目录,sonar.js等等可以看一下,但应该要收费。
针对国内网站进行的抓取分析,希望能有所帮助。
服务器和程序都封装好了,然后docker部署,客户端也可以在vps上使用websever或者qspider。
c#抓取网页数据(第一次用C#写数据抓取,遇到各种问题怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-22 03:16
第一次用C#写数据采集,遇到各种问题。开始写模拟登录的时候,发现有验证码。我必须突破验证码才能得到它。好吧,那我去找破解验证码的代码。我尝试了很多代码,发现它们并不通用。后来,我明白了其中的原理。首先去除噪点、干扰线等,然后将颜色验证码转换成黑白,同时进行字体切割。,如果字体是粘的,对于我们初学者(外行),那就放弃吧。裁剪后,每个像素都编码,白0,黑1,好像是这样的,不是太懂,再看一遍,拿字体库模型里的字做对比。如果达到百分比或更多,它会识别验证码是什么,并一一进行比较。最后形成一个完整的验证码。无法完成验证码破解,所以放弃破解,另寻方法。
网上说验证码可能会保存在cookie中。嗯,抱着试试的态度去吧,模拟浏览器发送数据,请求验证码,FF调试,发现cookie中有验证码。就这样,验证码到此结束,我们重新登录。
要登录,首先跟踪目标页面的逻辑,看看它是如何传递参数成功登录的。我只是先发送一个请求对用户名和密码进行加密,然后将加密后的发送到后台进行登录。这没什么好说的。这期间遇到的问题是发送请求,半天不成功。原因是当时发送了一个ajax请求,需要设置调用哪个方法。网站 一般直接要求后台,而不是发出ajax请求,所以这里又是一团糟。
关键代码:
request.Headers.Add("X-AjaxPro-Method", "方法名");
登录成功后,就到了抓取页面的时间了。首先获取抓取页面的html,然后分析它如何提交数据,如何返回,传递了什么参数等等。爬取页面没有问题,然后是模拟查询数据,那个网站写的,隐藏字段控件很多,所以发送请求的时候参数很多,不知道它是干什么用的,反正我觉得只查询订单号是有用的。模拟发送很长时间后,报500错误。这是因为模拟的参数有问题,服务器无法读取。我已经完成了所有设置。一点一点的发现,一点毛病都没有。2天后,它卡在这里。没有办法。之后,无意中发现提交的数据和页面隐藏字段的数据有点不一样。输入特殊字符。转码后想了想之前写的代码传输参数,发现传输数据的时候,都需要通过UrlEncode转码,然后传输。虽然隐藏字段的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说就开始转码参数了
HttpUtility.UrlEncode(string);
居然成功了,太烧脑了,虽然对于一些老手来说,这些可能不知道,但第一次接触还是很难写。
对了,还有一个问题,就是读取html后获取字符串html中的参数的问题,当然在页面上很容易获取,但是现在都是一堆字符串,这真的很难,所以我找到了一个非常好用的dll,支持xpath,和xmlDocument一样的用法,
部分代码:
HtmlDocument htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(html.Replace("\r", "").Replace("\n", ""));
HtmlNodeCollection collection = htmlDocument.DocumentNode.SelectSingleNode("/html/body/div").ChildNodes;
foreach (HtmlNode htmlNode in collection)
{
var tempId = htmlNode.Attributes["id"].Value;
}
红色部分是xpath规则,
也可以根据属性获取对应的节点:
htmlDocument.DocumentNode.SelectSingleNode("/html/body/div[2]/input[@id='__EVENTVALIDATION']");
这是:HtmlAgilityPack 下载地址:点击打开链接
最好阅读此 网站 评论。里面有很多人的问题,说不定能帮上忙。
好了,写了这么多,接下来我整理一下代码发上来,然后开始循环爬取数据。 查看全部
c#抓取网页数据(第一次用C#写数据抓取,遇到各种问题怎么办?)
第一次用C#写数据采集,遇到各种问题。开始写模拟登录的时候,发现有验证码。我必须突破验证码才能得到它。好吧,那我去找破解验证码的代码。我尝试了很多代码,发现它们并不通用。后来,我明白了其中的原理。首先去除噪点、干扰线等,然后将颜色验证码转换成黑白,同时进行字体切割。,如果字体是粘的,对于我们初学者(外行),那就放弃吧。裁剪后,每个像素都编码,白0,黑1,好像是这样的,不是太懂,再看一遍,拿字体库模型里的字做对比。如果达到百分比或更多,它会识别验证码是什么,并一一进行比较。最后形成一个完整的验证码。无法完成验证码破解,所以放弃破解,另寻方法。
网上说验证码可能会保存在cookie中。嗯,抱着试试的态度去吧,模拟浏览器发送数据,请求验证码,FF调试,发现cookie中有验证码。就这样,验证码到此结束,我们重新登录。
要登录,首先跟踪目标页面的逻辑,看看它是如何传递参数成功登录的。我只是先发送一个请求对用户名和密码进行加密,然后将加密后的发送到后台进行登录。这没什么好说的。这期间遇到的问题是发送请求,半天不成功。原因是当时发送了一个ajax请求,需要设置调用哪个方法。网站 一般直接要求后台,而不是发出ajax请求,所以这里又是一团糟。
关键代码:
request.Headers.Add("X-AjaxPro-Method", "方法名");
登录成功后,就到了抓取页面的时间了。首先获取抓取页面的html,然后分析它如何提交数据,如何返回,传递了什么参数等等。爬取页面没有问题,然后是模拟查询数据,那个网站写的,隐藏字段控件很多,所以发送请求的时候参数很多,不知道它是干什么用的,反正我觉得只查询订单号是有用的。模拟发送很长时间后,报500错误。这是因为模拟的参数有问题,服务器无法读取。我已经完成了所有设置。一点一点的发现,一点毛病都没有。2天后,它卡在这里。没有办法。之后,无意中发现提交的数据和页面隐藏字段的数据有点不一样。输入特殊字符。转码后想了想之前写的代码传输参数,发现传输数据的时候,都需要通过UrlEncode转码,然后传输。虽然隐藏字段的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说就开始转码参数了
HttpUtility.UrlEncode(string);
居然成功了,太烧脑了,虽然对于一些老手来说,这些可能不知道,但第一次接触还是很难写。
对了,还有一个问题,就是读取html后获取字符串html中的参数的问题,当然在页面上很容易获取,但是现在都是一堆字符串,这真的很难,所以我找到了一个非常好用的dll,支持xpath,和xmlDocument一样的用法,
部分代码:
HtmlDocument htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(html.Replace("\r", "").Replace("\n", ""));
HtmlNodeCollection collection = htmlDocument.DocumentNode.SelectSingleNode("/html/body/div").ChildNodes;
foreach (HtmlNode htmlNode in collection)
{
var tempId = htmlNode.Attributes["id"].Value;
}
红色部分是xpath规则,
也可以根据属性获取对应的节点:
htmlDocument.DocumentNode.SelectSingleNode("/html/body/div[2]/input[@id='__EVENTVALIDATION']");
这是:HtmlAgilityPack 下载地址:点击打开链接
最好阅读此 网站 评论。里面有很多人的问题,说不定能帮上忙。
好了,写了这么多,接下来我整理一下代码发上来,然后开始循环爬取数据。
c#抓取网页数据(PowerQuery与GET方法有什么区别呢?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-16 06:11
我之前写过很多关于 Power Query 网络爬取的教程。根据网络数据传输的方式,文章中的那些爬取方式都是通过GET方式获取的,那么POST和GET方式有什么区别呢?
这是W3C官网的内容,请参考:
GET 和 POST 方法都可用于向服务器发起请求。至于服务器支持哪种方式,我们需要通过谷歌浏览器查看:
GET方法用于在浏览器地址提交查询条件,如下所示:
GET方法下面通常是查询条件字符串Query String Parameters:
这样的 URL 非常标准,没有各种问号、等号和连字符,通常是 POST 方法:
POST 方法下面是表单数据:
很多时候网站同时支持两种查询方式:
上面的 网站 是两种方法都支持的 网站。
最后,GET和POST这两种方式在传输数据时最大的不同就是编码方式:
让我们回到 Power Query 爬行。之前不明白如何实现POST提交数据爬取。看了几篇文章的文章,基本上就是用一个函数实现GET和POST爬取。,唯一的区别在于HEADER头文件的写法和查询条件的编码。
GET方法查询:
让
url="", //网址
headers=[Cookie=""], //标题
query=[], //查询字符串参数
web=Text.FromBinary(Web.Contents(url,[Headers=headers,Query=query]))
在
网络
上面的代码可以应用于大多数 GET 方法站点,其中:
Web.Contents(url,[Headers=headers,Query=query])
当然,很多时候,我们匿名抓取数据的时候,不需要登录或者cookie,也不需要写头文件。我们直接将页码等查询条件添加到一长串url中,省略Web.Contents函数。第二个参数,这就是为什么我说上一句查询都是GET查询。
POST 查询:
我们主要讲的是这个POST方法的获取。与GET方式最大的不同就是头文件headers不能省略,所以必须使用Web.Contents函数的第二个参数。我们将通过一个示例来说明如何编写代码来执行 POST 请求:
第一步:还是做网站分析
首先,我们确保这个 网站 可以使用 POST 方法来抓取数据:
然后查看头文件中的关键字:
其实我并没有用用户名和密码网站登录,所以这个cookie可以用,但是这个:
内容类型:application/x-www-form-urlencoded;字符集=UTF-8
它必须在 POST 方法中使用,并标有钥匙符号。
然后我们看一下表单的内容:
在返回查询结果之前,我们需要将上述查询条件提交给服务器。以上格式是为了方便查看。您可以将其理解为一种记录格式。您按 View Source 以显示源代码:
我画的部分是“离婚登记号”,这是一个普通的URI编码格式,带有很多百分号。
通过这些分析,我们可以继续下一步。
第 2 步:尝试捕获
先放代码,然后一行一行的说:
让 查看全部
c#抓取网页数据(PowerQuery与GET方法有什么区别呢?(一))
我之前写过很多关于 Power Query 网络爬取的教程。根据网络数据传输的方式,文章中的那些爬取方式都是通过GET方式获取的,那么POST和GET方式有什么区别呢?
这是W3C官网的内容,请参考:
GET 和 POST 方法都可用于向服务器发起请求。至于服务器支持哪种方式,我们需要通过谷歌浏览器查看:
GET方法用于在浏览器地址提交查询条件,如下所示:
GET方法下面通常是查询条件字符串Query String Parameters:
这样的 URL 非常标准,没有各种问号、等号和连字符,通常是 POST 方法:
POST 方法下面是表单数据:
很多时候网站同时支持两种查询方式:
上面的 网站 是两种方法都支持的 网站。
最后,GET和POST这两种方式在传输数据时最大的不同就是编码方式:
让我们回到 Power Query 爬行。之前不明白如何实现POST提交数据爬取。看了几篇文章的文章,基本上就是用一个函数实现GET和POST爬取。,唯一的区别在于HEADER头文件的写法和查询条件的编码。
GET方法查询:
让
url="", //网址
headers=[Cookie=""], //标题
query=[], //查询字符串参数
web=Text.FromBinary(Web.Contents(url,[Headers=headers,Query=query]))
在
网络
上面的代码可以应用于大多数 GET 方法站点,其中:
Web.Contents(url,[Headers=headers,Query=query])
当然,很多时候,我们匿名抓取数据的时候,不需要登录或者cookie,也不需要写头文件。我们直接将页码等查询条件添加到一长串url中,省略Web.Contents函数。第二个参数,这就是为什么我说上一句查询都是GET查询。
POST 查询:
我们主要讲的是这个POST方法的获取。与GET方式最大的不同就是头文件headers不能省略,所以必须使用Web.Contents函数的第二个参数。我们将通过一个示例来说明如何编写代码来执行 POST 请求:
第一步:还是做网站分析
首先,我们确保这个 网站 可以使用 POST 方法来抓取数据:
然后查看头文件中的关键字:
其实我并没有用用户名和密码网站登录,所以这个cookie可以用,但是这个:
内容类型:application/x-www-form-urlencoded;字符集=UTF-8
它必须在 POST 方法中使用,并标有钥匙符号。
然后我们看一下表单的内容:
在返回查询结果之前,我们需要将上述查询条件提交给服务器。以上格式是为了方便查看。您可以将其理解为一种记录格式。您按 View Source 以显示源代码:
我画的部分是“离婚登记号”,这是一个普通的URI编码格式,带有很多百分号。
通过这些分析,我们可以继续下一步。
第 2 步:尝试捕获
先放代码,然后一行一行的说:
让
c#抓取网页数据(如何在本地运行一个网站爬虫?-coldpan的回答)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-08 14:03
c#抓取网页数据的第一步自然是爬虫相关,第二步是自定义header,第三步是配置标准url提交,最后是返回jsonhtml文件,这几步用c#来做应该不会太复杂的。网页数据来源:1.真实网页数据在github上收集了一些已存在的网页数据2.某些情况(不适合这里讨论的某些特殊情况,比如代码规范等等)收集的一些爬虫相关的代码3.某些情况另外提交4.之前提交过,用的asp6.最近才写的一个用于分析系统的代码,类似的可以看我的另一个关于linux的回答有哪些十分钟就能学会的技能?robyka:如何在本地运行一个网站爬虫?-coldpan的回答。
你不是已经规划好了吗?c#爬虫。
php+httpserver。就是几行代码的事情。
学点java吧,大公司项目用php的不多,
github,我写的爬虫,带手机验证码,带反爬,可以买本python与go的书,学点python爬虫。
apache+mysql即可。
api简单
爬虫干啥不一定呢,而且职位会比较多,总之先有点基础,让自己更了解爬虫是干啥的,看看能做哪些东西,
aspservlet,当然你会jsp或php可以不会asp,我后来再补差不多。当然html,js和css其实也能用的。你能写代码,会做功能实现,懂后台数据接收发送处理,能维护个redis代理设置断点模拟重定向,网页分析,爬虫只是锦上添花。爬虫框架不学也罢。 查看全部
c#抓取网页数据(如何在本地运行一个网站爬虫?-coldpan的回答)
c#抓取网页数据的第一步自然是爬虫相关,第二步是自定义header,第三步是配置标准url提交,最后是返回jsonhtml文件,这几步用c#来做应该不会太复杂的。网页数据来源:1.真实网页数据在github上收集了一些已存在的网页数据2.某些情况(不适合这里讨论的某些特殊情况,比如代码规范等等)收集的一些爬虫相关的代码3.某些情况另外提交4.之前提交过,用的asp6.最近才写的一个用于分析系统的代码,类似的可以看我的另一个关于linux的回答有哪些十分钟就能学会的技能?robyka:如何在本地运行一个网站爬虫?-coldpan的回答。
你不是已经规划好了吗?c#爬虫。
php+httpserver。就是几行代码的事情。
学点java吧,大公司项目用php的不多,
github,我写的爬虫,带手机验证码,带反爬,可以买本python与go的书,学点python爬虫。
apache+mysql即可。
api简单
爬虫干啥不一定呢,而且职位会比较多,总之先有点基础,让自己更了解爬虫是干啥的,看看能做哪些东西,
aspservlet,当然你会jsp或php可以不会asp,我后来再补差不多。当然html,js和css其实也能用的。你能写代码,会做功能实现,懂后台数据接收发送处理,能维护个redis代理设置断点模拟重定向,网页分析,爬虫只是锦上添花。爬虫框架不学也罢。
c#抓取网页数据(2.Python构建自动在线刷视频——一个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-07 21:04
文章内容
我以前写过两个相关的博客:
1.C#make 网站挂机程序:
()
2.Python构建自动在线视频刷机——一个只能做不能说的项目:
()
3.【C#制作hook程序V2.0——鼠标滑动点击等在线视频程序】下载链接:
()
第一篇文章主要教大家如何使用C#制作挂机程序。代码比较简单,主要是完成一个简单的功能,可以处理网页中弹出的警告对话框。第二篇文章采用Python语言,完全控制浏览器,可以抓取网页中的Tag、id、name或CSS等标签,输入键盘鼠标。它应该是一个完美的程序。但是今天,为什么又要回到C#开发的老路,让键盘鼠标点击事件自动挂断呢?Python不香吗?代码不禁呵呵,Python的坑不多,反爬技术直接让Python驱动浏览器拜拜了。
我们直接送干货
一、程序界面
程序相当简单,但不要小看它,功能不小!
二、功能说明1.程序集成了Microsoft Spy++的功能2.通过拖拽工具自动获取表单标题3.拖拽工具自动获取鼠标就绪到点击点4.通过时间设置点击事件后的等待时间(视频刷新需要)5.浏览器应用不再局限于FireFox6.适应性增加,只要它是通过鼠标点击完成的操作就可以交给它了。7.表单程序的自动点击也适用
需要强调的是,拖动工具获取坐标和表格标题的方法可能只能在C#开发中实现。因为码农搜索了百度也没有找到,所以有这个功能的都是用C++开发的。所以这个想法完全是 C# 应用程序独有的。
三、程序步骤
核心功能展示:
1.程序运行后,点击【获取浏览器标题:】,会出现以下工具:
2. 将放大镜工具拖到对应的程序窗体上,会自动获取窗体的标题
该函数的主要目的是获取应用程序的句柄。借助手柄,可以将表格设置为顶部显示。(不被其他窗口覆盖)
3. 点击【获取坐标】按钮,会出现以下工具:
4. 将放大镜工具拖到第一个需要自动点击的点,松开,弹出如下窗口:
坐标不需要设置,就是刚才松开鼠标的位置,暂停时间就是点击后停止的时间,以及下一次操作的时间。
5.循环3、4运行,可以得到一系列坐标点和对应的暂停时间6.所有设置完成后,直接点击【开始】按钮开始自动运行。7.注意,这个自动化操作会反复进行。您可以直接关闭此程序以关闭此自动操作。也可以点击【保存坐标】将坐标点和时间保存到文件中,重启时自动加载已有的坐标点和时间。三、程序密钥代码1.API参考和成员变量
#region API及成员变量
///
/// 根据坐标获取窗口句柄
///
/// 坐标
///
[DllImport("user32.dll")]
private static extern IntPtr WindowFromPoint(Point point);
public delegate bool EnumChildWindow(IntPtr WindowHandle, string num);
///
/// 传递消息给记事本
///
///
///
///
///
///
[DllImport("User32.DLL")]
public static extern int SendMessage(IntPtr hWnd, uint Msg, int wParam, string lParam);
[DllImport("user32.dll", EntryPoint = "keybd_event", SetLastError = true)]
public static extern void keybd_event(Keys bVk, byte bScan, uint dwFlags, uint dwExtraInfo);
[DllImport("user32.dll", CharSet = CharSet.Auto, ExactSpelling = true)]
public static extern int ShowWindow(IntPtr hwnd, int nCmdShow);
[DllImport("user32.dll")]
public static extern bool SetForegroundWindow(int hWnd);
[DllImport("User32.dll")]
public static extern int EnumChildWindows(IntPtr WinHandle, EnumChildWindow ecw, string name);
[DllImport("User32.dll")]
public static extern int GetWindowText(IntPtr WinHandle, StringBuilder Title, int size);
[DllImport("user32.dll")]
public static extern int GetClassName(IntPtr WinHandle, StringBuilder Type, int size);
[DllImport("user32")]
private static extern int GetWindowThreadProcessId(IntPtr handle, out int pid);
[DllImport("user32")]
public static extern IntPtr SetActiveWindow(IntPtr hWnd);
[DllImport("user32.dll")]
[return: MarshalAs(UnmanagedType.Bool)]
static extern bool GetWindowRect(IntPtr hWnd, ref RECT lpRect);
[DllImport("user32.dll", EntryPoint = "FindWindow")]
private static extern IntPtr FindWindow(string IpClassName, string IpWindowName);
//查找窗体控件
public int iSecond = 30;
public delegate bool CallBack(int hwnd, int lParam);
public RECT rectMain = new RECT();
private string typeName;
private IntPtr mainHwnd;
public IntPtr ip;
private string BSType = "Chrome_WidgetWin_1";
bool Flag = false;
int X;
int Y;
int times;
private IntPtr mainWindowHandle;
[StructLayout(LayoutKind.Sequential)]
public struct RECT
{
public int X; //最左坐标
public int Y; //最上坐标
public int Height; //最右坐标
public int Width; //最下坐标
}
///
/// 查找句柄
///
///
///
///
///
///
[DllImport("User32.DLL")]
public static extern IntPtr FindWindowEx(IntPtr hwndParent, IntPtr hwndChildAfter, string lpszClass, string lpszWindow);
[DllImport("User32")]
public extern static void mouse_event(int dwFlags, int dx, int dy, int dwData, IntPtr dwExtraInfo);
[DllImport("user32.dll")]
static extern bool SetCursorPos(int X, int Y);
public const uint WM_SETTEXT = 0x000C;
public System.Diagnostics.Process Proc;
public System.Windows.Forms.Timer myTimer;
public List optList = new List();
public Queue optQueue = new Queue();
#endregion
2.移动鼠标代码
public void MoveTo(int x1, int y1, int x2, int y2)
{
float k = (float)(y2 - y1) / (float)(x2 - x1);
float b = y2 - k * x2;
for (int x = x2; x != x1; x = x + Math.Sign(x1 - x2))
{
//MoveTo(x1,y1,x,(k*x+b));
SetCursorPos(x, (int)(k * x + b));
Thread.Sleep(3);
}
}
代码如下(示例):
3.开始事件代码
private void btnStart_Click(object sender, EventArgs e)
{
foreach (string strLine in richTextBox1.Lines)
{
string[] strInt = strLine.Split(new string[] { "," }, StringSplitOptions.None);
if (strInt.Length 0)
{
Opt opt = optQueue.Dequeue();
X = opt.x;
Y = opt.y;
times = opt.Times;
System.Timers.Timer t = new System.Timers.Timer();//实例化
t.Elapsed += new System.Timers.ElapsedEventHandler(CallBack2);
t.AutoReset = false;
t.Interval = 1000 * times;
t.Enabled = true;
}
}
4.定时器事件代码
private void CallBack2(object sender, EventArgs e)
{
MoveTo(X, Y, MousePosition.X, MousePosition.Y);
mouse_event((int)(MouseEventFlags.LeftDown | MouseEventFlags.Absolute), X, Y, 0, IntPtr.Zero);
//Thread.Sleep(200);
mouse_event((int)(MouseEventFlags.LeftUp | MouseEventFlags.Absolute), X, Y, 0, IntPtr.Zero);
if (optQueue.Count > 0)
{
Opt opt = optQueue.Dequeue();
X = opt.x;
Y = opt.y;
times = opt.Times;
System.Timers.Timer t = new System.Timers.Timer();//实例化
t.Elapsed += new System.Timers.ElapsedEventHandler(CallBack2);
t.AutoReset = false;
t.Interval = 1000 * times;
t.Enabled = true;
}
else
{
foreach (Opt opt1 in optList)
{
optQueue.Enqueue(opt1);
}
Opt opt = optQueue.Dequeue();
X = opt.x;
Y = opt.y;
times = opt.Times;
System.Timers.Timer t = new System.Timers.Timer();//实例化
t.Elapsed += new System.Timers.ElapsedEventHandler(CallBack2);
t.AutoReset = false;
t.Interval = 1000 * times;
t.Enabled = true;
}
}
5.启动浏览器事件代码
private void btnStartBrowser_Click(object sender, EventArgs e)
{
if (string.IsNullOrEmpty(txtFile.Text)) return;
try
{
// 浏览器程序启动线程
Proc = new System.Diagnostics.Process();
Proc.StartInfo.FileName = txtFile.Text;
Proc.StartInfo.Arguments = txtNetAddr.Text; //浏览器打开URL参数
Proc.StartInfo.UseShellExecute = false;
Proc.StartInfo.RedirectStandardInput = true;
Proc.StartInfo.RedirectStandardOutput = true;
Proc.Start();
}
catch
{
Proc = null;
}
}
总结
挂机程序本身的开发存在局限性。通常仅用于特定或特定类型的应用程序。但只要注意思考和挖掘,无论是哪种应用,总能找到对应的点,开发对应的挂机程序。用一个hook程序吃遍全世界是不可行的。 查看全部
c#抓取网页数据(2.Python构建自动在线刷视频——一个)
文章内容
我以前写过两个相关的博客:
1.C#make 网站挂机程序:
()
2.Python构建自动在线视频刷机——一个只能做不能说的项目:
()
3.【C#制作hook程序V2.0——鼠标滑动点击等在线视频程序】下载链接:
()
第一篇文章主要教大家如何使用C#制作挂机程序。代码比较简单,主要是完成一个简单的功能,可以处理网页中弹出的警告对话框。第二篇文章采用Python语言,完全控制浏览器,可以抓取网页中的Tag、id、name或CSS等标签,输入键盘鼠标。它应该是一个完美的程序。但是今天,为什么又要回到C#开发的老路,让键盘鼠标点击事件自动挂断呢?Python不香吗?代码不禁呵呵,Python的坑不多,反爬技术直接让Python驱动浏览器拜拜了。
我们直接送干货
一、程序界面
程序相当简单,但不要小看它,功能不小!
二、功能说明1.程序集成了Microsoft Spy++的功能2.通过拖拽工具自动获取表单标题3.拖拽工具自动获取鼠标就绪到点击点4.通过时间设置点击事件后的等待时间(视频刷新需要)5.浏览器应用不再局限于FireFox6.适应性增加,只要它是通过鼠标点击完成的操作就可以交给它了。7.表单程序的自动点击也适用
需要强调的是,拖动工具获取坐标和表格标题的方法可能只能在C#开发中实现。因为码农搜索了百度也没有找到,所以有这个功能的都是用C++开发的。所以这个想法完全是 C# 应用程序独有的。
三、程序步骤
核心功能展示:
1.程序运行后,点击【获取浏览器标题:】,会出现以下工具:
2. 将放大镜工具拖到对应的程序窗体上,会自动获取窗体的标题
该函数的主要目的是获取应用程序的句柄。借助手柄,可以将表格设置为顶部显示。(不被其他窗口覆盖)
3. 点击【获取坐标】按钮,会出现以下工具:
4. 将放大镜工具拖到第一个需要自动点击的点,松开,弹出如下窗口:
坐标不需要设置,就是刚才松开鼠标的位置,暂停时间就是点击后停止的时间,以及下一次操作的时间。
5.循环3、4运行,可以得到一系列坐标点和对应的暂停时间6.所有设置完成后,直接点击【开始】按钮开始自动运行。7.注意,这个自动化操作会反复进行。您可以直接关闭此程序以关闭此自动操作。也可以点击【保存坐标】将坐标点和时间保存到文件中,重启时自动加载已有的坐标点和时间。三、程序密钥代码1.API参考和成员变量
#region API及成员变量
///
/// 根据坐标获取窗口句柄
///
/// 坐标
///
[DllImport("user32.dll")]
private static extern IntPtr WindowFromPoint(Point point);
public delegate bool EnumChildWindow(IntPtr WindowHandle, string num);
///
/// 传递消息给记事本
///
///
///
///
///
///
[DllImport("User32.DLL")]
public static extern int SendMessage(IntPtr hWnd, uint Msg, int wParam, string lParam);
[DllImport("user32.dll", EntryPoint = "keybd_event", SetLastError = true)]
public static extern void keybd_event(Keys bVk, byte bScan, uint dwFlags, uint dwExtraInfo);
[DllImport("user32.dll", CharSet = CharSet.Auto, ExactSpelling = true)]
public static extern int ShowWindow(IntPtr hwnd, int nCmdShow);
[DllImport("user32.dll")]
public static extern bool SetForegroundWindow(int hWnd);
[DllImport("User32.dll")]
public static extern int EnumChildWindows(IntPtr WinHandle, EnumChildWindow ecw, string name);
[DllImport("User32.dll")]
public static extern int GetWindowText(IntPtr WinHandle, StringBuilder Title, int size);
[DllImport("user32.dll")]
public static extern int GetClassName(IntPtr WinHandle, StringBuilder Type, int size);
[DllImport("user32")]
private static extern int GetWindowThreadProcessId(IntPtr handle, out int pid);
[DllImport("user32")]
public static extern IntPtr SetActiveWindow(IntPtr hWnd);
[DllImport("user32.dll")]
[return: MarshalAs(UnmanagedType.Bool)]
static extern bool GetWindowRect(IntPtr hWnd, ref RECT lpRect);
[DllImport("user32.dll", EntryPoint = "FindWindow")]
private static extern IntPtr FindWindow(string IpClassName, string IpWindowName);
//查找窗体控件
public int iSecond = 30;
public delegate bool CallBack(int hwnd, int lParam);
public RECT rectMain = new RECT();
private string typeName;
private IntPtr mainHwnd;
public IntPtr ip;
private string BSType = "Chrome_WidgetWin_1";
bool Flag = false;
int X;
int Y;
int times;
private IntPtr mainWindowHandle;
[StructLayout(LayoutKind.Sequential)]
public struct RECT
{
public int X; //最左坐标
public int Y; //最上坐标
public int Height; //最右坐标
public int Width; //最下坐标
}
///
/// 查找句柄
///
///
///
///
///
///
[DllImport("User32.DLL")]
public static extern IntPtr FindWindowEx(IntPtr hwndParent, IntPtr hwndChildAfter, string lpszClass, string lpszWindow);
[DllImport("User32")]
public extern static void mouse_event(int dwFlags, int dx, int dy, int dwData, IntPtr dwExtraInfo);
[DllImport("user32.dll")]
static extern bool SetCursorPos(int X, int Y);
public const uint WM_SETTEXT = 0x000C;
public System.Diagnostics.Process Proc;
public System.Windows.Forms.Timer myTimer;
public List optList = new List();
public Queue optQueue = new Queue();
#endregion
2.移动鼠标代码
public void MoveTo(int x1, int y1, int x2, int y2)
{
float k = (float)(y2 - y1) / (float)(x2 - x1);
float b = y2 - k * x2;
for (int x = x2; x != x1; x = x + Math.Sign(x1 - x2))
{
//MoveTo(x1,y1,x,(k*x+b));
SetCursorPos(x, (int)(k * x + b));
Thread.Sleep(3);
}
}
代码如下(示例):
3.开始事件代码
private void btnStart_Click(object sender, EventArgs e)
{
foreach (string strLine in richTextBox1.Lines)
{
string[] strInt = strLine.Split(new string[] { "," }, StringSplitOptions.None);
if (strInt.Length 0)
{
Opt opt = optQueue.Dequeue();
X = opt.x;
Y = opt.y;
times = opt.Times;
System.Timers.Timer t = new System.Timers.Timer();//实例化
t.Elapsed += new System.Timers.ElapsedEventHandler(CallBack2);
t.AutoReset = false;
t.Interval = 1000 * times;
t.Enabled = true;
}
}
4.定时器事件代码
private void CallBack2(object sender, EventArgs e)
{
MoveTo(X, Y, MousePosition.X, MousePosition.Y);
mouse_event((int)(MouseEventFlags.LeftDown | MouseEventFlags.Absolute), X, Y, 0, IntPtr.Zero);
//Thread.Sleep(200);
mouse_event((int)(MouseEventFlags.LeftUp | MouseEventFlags.Absolute), X, Y, 0, IntPtr.Zero);
if (optQueue.Count > 0)
{
Opt opt = optQueue.Dequeue();
X = opt.x;
Y = opt.y;
times = opt.Times;
System.Timers.Timer t = new System.Timers.Timer();//实例化
t.Elapsed += new System.Timers.ElapsedEventHandler(CallBack2);
t.AutoReset = false;
t.Interval = 1000 * times;
t.Enabled = true;
}
else
{
foreach (Opt opt1 in optList)
{
optQueue.Enqueue(opt1);
}
Opt opt = optQueue.Dequeue();
X = opt.x;
Y = opt.y;
times = opt.Times;
System.Timers.Timer t = new System.Timers.Timer();//实例化
t.Elapsed += new System.Timers.ElapsedEventHandler(CallBack2);
t.AutoReset = false;
t.Interval = 1000 * times;
t.Enabled = true;
}
}
5.启动浏览器事件代码
private void btnStartBrowser_Click(object sender, EventArgs e)
{
if (string.IsNullOrEmpty(txtFile.Text)) return;
try
{
// 浏览器程序启动线程
Proc = new System.Diagnostics.Process();
Proc.StartInfo.FileName = txtFile.Text;
Proc.StartInfo.Arguments = txtNetAddr.Text; //浏览器打开URL参数
Proc.StartInfo.UseShellExecute = false;
Proc.StartInfo.RedirectStandardInput = true;
Proc.StartInfo.RedirectStandardOutput = true;
Proc.Start();
}
catch
{
Proc = null;
}
}
总结
挂机程序本身的开发存在局限性。通常仅用于特定或特定类型的应用程序。但只要注意思考和挖掘,无论是哪种应用,总能找到对应的点,开发对应的挂机程序。用一个hook程序吃遍全世界是不可行的。
c#抓取网页数据( 一种更常见的翻页类型——翻页链接不规律的例子)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-07 06:09
一种更常见的翻页类型——翻页链接不规律的例子)
总结:在列表中,豆瓣的电影列表使用了pager来分割数据:但是当时我们定期搜索网页链接,并没有使用pager来抓取。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以转成,但是链接变化不规律,就得去pager一下了。要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。8月2日是蔡徐坤的生日。为了庆祝,微博粉丝给了坤坤300W的转发量,而微博的转发数据恰好是用来积分的。
这是简单数据分析系列文章的第12篇。
776448504/I0gyT8aeQ?type=repost的第二页是这样的。请注意,有一个额外的 #_rnd36 参数:
在之前的文章文章中,我们介绍了Web Scraper针对各种翻页方案的解决方案,比如修改网页链接加载数据,点击“更多按钮”加载数据,下拉自动加载数据。今天我们讲的是一种比较常见的翻页机。
我想解释一下什么是寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页跳到下一页,指定页数。
emove(userId);}@Override@GetMapping("/findAll")public采集findAll(){
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
这些理论有点无聊,我们举个不规则页面链接的例子。8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页,见
实际上,在本教程的第一个示例中,我们抓取了豆瓣电影TOP列表。豆瓣的电影列表使用寻呼机划分数据:
但当时我们是在找网页链接定期抓取,而不是使用寻呼机抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以转成,但是链接变化不规律,就得去pager一下了。
ping("/remove")publicvoidremove(@RequestParam("id")LonguserId){usersRepository.r
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
t;)LonguserId){restTemplate.delete(""+use
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页面,查看如何使用Web Scraper 抓取此类数据。
这条微博的直接链接是:
classUserServiceIimplementsUserService{privateMapusersRepository=Maps.newHashM
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
文章文章。在之前的文章文章中,我们介绍了WebScraper对于各种翻页的解决方案,比如修改网页链接加载数据,点击“更多按钮”加载数据,下拉自动加载数据。今天我们讲的是一种比较常见的翻页机。想解释
首先,让我们看一下第1页的转发链接,它看起来像这样:
.推荐阅读简单数据分析05|WebScraper翻页-控制链接批量抓取数据简单数据分析08|WebScraper翻页-点击“更多按钮”翻页简单数据分析10|WebScraper翻页-抓取Scroll plus
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
gn(@RequestParam("id")LonguserId){userRemote.remove(userId);}@GetMapping("/findAllByF
第 3 页上的参数是 #_rnd39
000条数据,但是第一页只有20条数据,抓到最后一条,还有980条;然后翻页的时候,设置了一个新的计数器,完成了第2页的最后一条数据,但是还缺少980条,一翻页计数器就重置,又变成1000了... 所以这
第 4 页上的参数是 #_rnd76:
ing-cloud-starter-dubbo 在这里介绍 DubboSpringClo
多看几个链接,可以发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。让我们开始我们的实际教学环节。
ctionfindAll(){returnuserService.findAll();}} 其中@Reference注解需要指定调用服务提供者接口的版本号,如果不指定版本
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
容器的预览如下图所示:
bScraper 无能为力)。考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想使用:nth-of-type(-n+N)来控制取N条数据。如果你尝试,你会发现这个方法根本没有用。已到期
寻呼机选择过程如下图所示:
vider_web/pom.xml***com.springc
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
blicclassUserController{@Reference(version="1.0.0")UserServiceuserService;@PostMapping(&qu
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
也不现实。毕竟WebScraper针对的数据量比较小。数以万计的数据被认为太多了。不管数据有多大,都要考虑爬取时间是否过长,数据是如何存储的,以及URL的逆向如何处理。爬虫系统(比如一个验证码突然跳出来,这个我们
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我应该把它全部爬下来吗?
-type(-n+N) 控制获取 N 条数据。如果你尝试,你会发现这个方法根本没有用。失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。单击更改就像我之前介绍的那样
这听起来不现实。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper的反爬虫系统(比如一个验证码突然跳出来,这个Web Scraper是无能为力的)。
cies>1.2 创建子项目dubbo_provider_web,服务提供者项目依赖pom.xml如下: 代码列表:Alibaba/dubbo-spring-cloud-http/dubbo_pro
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想用:nth-of-type(-n+N)来控制取N个数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
lication:name:spring-cloud-consumer-servercloud:nacos:discovery:server-addr:192.168.44.129:8848 接口测试类
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
t;)UserServiceuserService;@PostMapping("/save")publicUserModelsave(@RequestBodyUserModelus
但是,对于使用翻页设备的网页,每次翻页就相当于刷新当前网页,因此每次都会设置一个计数器。
太长了,数据怎么存储,URL的反爬虫系统怎么处理(比如一个验证码突然跳出来,这个WebScraper就无能为力了)。考虑到这个问题,如果你看过之前关于自动控制爬取次数的教程,你可能想使用:nth-of-
比如你想取1000条数据,但是第一页只有20条数据。最后一个抓到了,还有980条数据。然后当翻页时,设置一个新的计数器,第2页结束。一条数据还是980,翻页计数器一重置,又变成1000了……所以这种控制数字的方法是无效的。
启动程序测试 查看全部
c#抓取网页数据(
一种更常见的翻页类型——翻页链接不规律的例子)
总结:在列表中,豆瓣的电影列表使用了pager来分割数据:但是当时我们定期搜索网页链接,并没有使用pager来抓取。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以转成,但是链接变化不规律,就得去pager一下了。要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。8月2日是蔡徐坤的生日。为了庆祝,微博粉丝给了坤坤300W的转发量,而微博的转发数据恰好是用来积分的。
这是简单数据分析系列文章的第12篇。
776448504/I0gyT8aeQ?type=repost的第二页是这样的。请注意,有一个额外的 #_rnd36 参数:
在之前的文章文章中,我们介绍了Web Scraper针对各种翻页方案的解决方案,比如修改网页链接加载数据,点击“更多按钮”加载数据,下拉自动加载数据。今天我们讲的是一种比较常见的翻页机。
我想解释一下什么是寻呼机。我发现浏览一堆定义非常麻烦。这不是每个人都上网的第一年。看看图片吧。找了个功能最全的例子,支持数字页码调整,上一页跳到下一页,指定页数。
emove(userId);}@Override@GetMapping("/findAll")public采集findAll(){
今天我们将学习如何通过Web Scraper来处理这种类型的翻页。
这些理论有点无聊,我们举个不规则页面链接的例子。8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页,见
实际上,在本教程的第一个示例中,我们抓取了豆瓣电影TOP列表。豆瓣的电影列表使用寻呼机划分数据:
但当时我们是在找网页链接定期抓取,而不是使用寻呼机抓取它们。因为当网页的链接有规律的变化时,控制链接参数爬取是实现成本最低的;如果网页可以转成,但是链接变化不规律,就得去pager一下了。
ping("/remove")publicvoidremove(@RequestParam("id")LonguserId){usersRepository.r
要说这些理论有点无聊,我们举一个不规则的翻页链接的例子。
t;)LonguserId){restTemplate.delete(""+use
8月2日是蔡徐坤的生日。为了庆祝,粉丝们在微博上给了坤坤300W的转发量。微博的转发数据恰好被传呼机分割。我们来分析一下微博的转发。信息页面,查看如何使用Web Scraper 抓取此类数据。
这条微博的直接链接是:
classUserServiceIimplementsUserService{privateMapusersRepository=Maps.newHashM
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出,为坤坤添加阅读量。
文章文章。在之前的文章文章中,我们介绍了WebScraper对于各种翻页的解决方案,比如修改网页链接加载数据,点击“更多按钮”加载数据,下拉自动加载数据。今天我们讲的是一种比较常见的翻页机。想解释
首先,让我们看一下第1页的转发链接,它看起来像这样:
.推荐阅读简单数据分析05|WebScraper翻页-控制链接批量抓取数据简单数据分析08|WebScraper翻页-点击“更多按钮”翻页简单数据分析10|WebScraper翻页-抓取Scroll plus
第 2 页看起来像这样,并注意有一个额外的 #_rnd36 参数:
gn(@RequestParam("id")LonguserId){userRemote.remove(userId);}@GetMapping("/findAllByF
第 3 页上的参数是 #_rnd39
000条数据,但是第一页只有20条数据,抓到最后一条,还有980条;然后翻页的时候,设置了一个新的计数器,完成了第2页的最后一条数据,但是还缺少980条,一翻页计数器就重置,又变成1000了... 所以这
第 4 页上的参数是 #_rnd76:
ing-cloud-starter-dubbo 在这里介绍 DubboSpringClo
多看几个链接,可以发现这个转发的网页的网址是不规则的,所以只能用pager翻页加载数据。让我们开始我们的实际教学环节。
ctionfindAll(){returnuserService.findAll();}} 其中@Reference注解需要指定调用服务提供者接口的版本号,如果不指定版本
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.创建容器选择器
因为我们要点击pager,所以我们选择Element Click作为外层容器的类型。具体参数说明见下图。之前我们在简单数据分析08中详细讲解过,这里就不多说了。
容器的预览如下图所示:
bScraper 无能为力)。考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想使用:nth-of-type(-n+N)来控制取N条数据。如果你尝试,你会发现这个方法根本没有用。已到期
寻呼机选择过程如下图所示:
vider_web/pom.xml***com.springc
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
blicclassUserController{@Reference(version="1.0.0")UserServiceuserService;@PostMapping(&qu
4.获取数据
可以按照Sitemap cxk -> Scrape的操作路径抓取数据。
也不现实。毕竟WebScraper针对的数据量比较小。数以万计的数据被认为太多了。不管数据有多大,都要考虑爬取时间是否过长,数据是如何存储的,以及URL的逆向如何处理。爬虫系统(比如一个验证码突然跳出来,这个我们
5.一些问题
如果你看了我上面的教程,马上爬取数据,你可能遇到的第一个问题是300w的数据,我应该把它全部爬下来吗?
-type(-n+N) 控制获取 N 条数据。如果你尝试,你会发现这个方法根本没有用。失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。单击更改就像我之前介绍的那样
这听起来不现实。毕竟Web Scraper针对的数据量比较小。数以万计的数据被认为是太多了。无论数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。Web Scraper的反爬虫系统(比如一个验证码突然跳出来,这个Web Scraper是无能为力的)。
cies>1.2 创建子项目dubbo_provider_web,服务提供者项目依赖pom.xml如下: 代码列表:Alibaba/dubbo-spring-cloud-http/dubbo_pro
考虑到这个问题,如果你看过之前关于自动控制取数的教程,你可能想用:nth-of-type(-n+N)来控制取N个数据。如果你尝试,你会发现这个方法根本没有用。
失败的原因实际上涉及对网页的一些了解。如果你有兴趣,你可以阅读下面的解释。不感兴趣的可以直接看最后的结论。
lication:name:spring-cloud-consumer-servercloud:nacos:discovery:server-addr:192.168.44.129:8848 接口测试类
就像我之前介绍的点击更多加载网页和下拉加载网页一样,它们新加载的数据被添加到当前页面。你不断下拉,数据不断加载。同时网页的滚动条会越来越短。这意味着所有数据都在同一页面上。
当我们使用:nth-of-type(-n+N)来控制加载次数的时候,其实相当于在这个页面上设置了一个计数器。当数据累积到我们想要的数量时,它就会停止爬行。
t;)UserServiceuserService;@PostMapping("/save")publicUserModelsave(@RequestBodyUserModelus
但是,对于使用翻页设备的网页,每次翻页就相当于刷新当前网页,因此每次都会设置一个计数器。
太长了,数据怎么存储,URL的反爬虫系统怎么处理(比如一个验证码突然跳出来,这个WebScraper就无能为力了)。考虑到这个问题,如果你看过之前关于自动控制爬取次数的教程,你可能想使用:nth-of-
比如你想取1000条数据,但是第一页只有20条数据。最后一个抓到了,还有980条数据。然后当翻页时,设置一个新的计数器,第2页结束。一条数据还是980,翻页计数器一重置,又变成1000了……所以这种控制数字的方法是无效的。
启动程序测试
c#抓取网页数据(最省事的做法是去需要的网站看看具体是什么编码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-05 22:11
)
在做一些需要抓取网页的项目时,经常会遇到乱码。最简单的方法就是去需要爬取的网站看看具体的编码是什么,然后使用正确的编码进行解码。可以,但是总是一一判断也不是问题,尤其是当你需要从不同站点抓取大量页面的时候,比如一个网络爬虫程序,那么我们就需要做一个比较通用的程序来正确识别页面编码。
乱码问题基本上是编码不一致造成的。比如网页编码使用UTF-8,如果使用GB2312读取,肯定会出现乱码。知道了本质问题之后,剩下的就是如何判断网页编码了。GBK、GB2312、UTF-8、BIG-5,一般来说,遇到的中文网页编码大多是这几种编码。简单来说,只有GBK和UTF-8两种,一点都不夸张。,目前的网站要么是GBK编码,要么是UTF-8编码,所以接下来的问题就是确定网站具体是UTF-8还是GBK。
如何确定页面的具体编码?首先检查响应头的Content-Type。如果在响应头中找不到,请到网页中查找元头。如果还是找不到,那就没办法了。设置默认编码。个人建议设置为UTF-8。比如访问博客园的首页,可以看到Content-Type:text/html;响应头中的charset=utf-8,所以我们知道博客园使用的是utf-8编码,但是并不是所有的网站都会在响应头的Content-Type中添加页面编码。比如百度的就是Content-Type:text/html,查不到charset。这时候只能在网页中找到它来确认网页的最终编码。总结就是以下步骤
1.在响应头中的 Content-Type 中找到字符集。如果找到charset,则跳过第2步和第3步,直接进入第4步。2.如果第1步没有找到charset,先读取网页的Content,解析meta中的charset得到页面编码< @3.如果在第2步还是没有获取到页面编码,则没有办法设置默认编码为UTF-84. 使用获取到的charset重新读取响应流
基本上,通过上述方法大部分页面都可以正确解析,但无法识别的则需要亲自验证具体代码。
注意:
1.几乎所有站点都启用了gzip压缩支持,所以在请求头中添加Accept-Encoding:gzip,deflate,这样站点会返回一个压缩流,可以显着提高请求的效率。2.由于网络流不支持流搜索操作,即只能读取一次。为了提高效率,建议先将http响应流读入内存,方便二次解码。无需重新请求检索响应流。
下面给出了Java和C#的实现代码,页面底部给出了源码的git链接。需要童鞋的请自行下载
Java实现
C# 实现
using System;
using System.Collections;
using System.IO;
using System.Linq;
using System.Net;
using System.Net.Security;
using System.Security.Cryptography.X509Certificates;
using System.Text;
using System.Text.RegularExpressions;
using System.Web;
using System.IO.Compression;
using System.Collections.Generic;
using System.Collections.Specialized;
namespace CSharp.Util.Net
{
public class HttpHelper
{
private static bool RemoteCertificateValidate(object sender, X509Certificate certificate, X509Chain chain, SslPolicyErrors errors)
{
//用户https请求
return true; //总是接受
}
public static string SendPost(string url, string data)
{
return Send(url, "POST", data, null);
}
public static string SendGet(string url)
{
return Send(url, "GET", null, null);
}
public static string Send(string url, string method, string data, HttpConfig config)
{
if (config == null) config = new HttpConfig();
string result;
using (HttpWebResponse response = GetResponse(url, method, data, config))
{
Stream stream = response.GetResponseStream();
if (!String.IsNullOrEmpty(response.ContentEncoding))
{
if (response.ContentEncoding.Contains("gzip"))
{
stream = new GZipStream(stream, CompressionMode.Decompress);
}
else if (response.ContentEncoding.Contains("deflate"))
{
stream = new DeflateStream(stream, CompressionMode.Decompress);
}
}
byte[] bytes = null;
using (MemoryStream ms = new MemoryStream())
{
int count;
byte[] buffer = new byte[4096];
while ((count = stream.Read(buffer, 0, buffer.Length)) > 0)
{
ms.Write(buffer, 0, count);
}
bytes = ms.ToArray();
}
#region 检测流编码
Encoding encoding;
//检测响应头是否返回了编码类型,若返回了编码类型则使用返回的编码
//注:有时响应头没有编码类型,CharacterSet经常设置为ISO-8859-1
if (!string.IsNullOrEmpty(response.CharacterSet) && response.CharacterSet.ToUpper() != "ISO-8859-1")
{
encoding = Encoding.GetEncoding(response.CharacterSet == "utf8" ? "utf-8" : response.CharacterSet);
}
else
{
//若没有在响应头找到编码,则去html找meta头的charset
result = Encoding.Default.GetString(bytes);
//在返回的html里使用正则匹配页面编码
Match match = Regex.Match(result, @"", RegexOptions.IgnoreCase);
if (match.Success)
{
encoding = Encoding.GetEncoding(match.Groups[1].Value);
}
else
{
//若html里面也找不到编码,默认使用utf-8
encoding = Encoding.GetEncoding(config.CharacterSet);
}
}
#endregion
result = encoding.GetString(bytes);
}
return result;
}
private static HttpWebResponse GetResponse(string url, string method, string data, HttpConfig config)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Method = method;
request.Referer = config.Referer;
//有些页面不设置用户代理信息则会抓取不到内容
request.UserAgent = config.UserAgent;
request.Timeout = config.Timeout;
request.Accept = config.Accept;
request.Headers.Set("Accept-Encoding", config.AcceptEncoding);
request.ContentType = config.ContentType;
request.KeepAlive = config.KeepAlive;
if (url.ToLower().StartsWith("https"))
{
//这里加入解决生产环境访问https的问题--Could not establish trust relationship for the SSL/TLS secure channel
ServicePointManager.ServerCertificateValidationCallback = new RemoteCertificateValidationCallback(RemoteCertificateValidate);
}
if (method.ToUpper() == "POST")
{
if (!string.IsNullOrEmpty(data))
{
byte[] bytes = Encoding.UTF8.GetBytes(data);
if (config.GZipCompress)
{
using (MemoryStream stream = new MemoryStream())
{
using (GZipStream gZipStream = new GZipStream(stream, CompressionMode.Compress))
{
gZipStream.Write(bytes, 0, bytes.Length);
}
bytes = stream.ToArray();
}
}
request.ContentLength = bytes.Length;
request.GetRequestStream().Write(bytes, 0, bytes.Length);
}
else
{
request.ContentLength = 0;
}
}
return (HttpWebResponse)request.GetResponse();
}
}
public class HttpConfig
{
public string Referer { get; set; }
///
/// 默认(text/html)
///
public string ContentType { get; set; }
public string Accept { get; set; }
public string AcceptEncoding { get; set; }
///
/// 超时时间(毫秒)默认100000
///
public int Timeout { get; set; }
public string UserAgent { get; set; }
///
/// POST请求时,数据是否进行gzip压缩
///
public bool GZipCompress { get; set; }
public bool KeepAlive { get; set; }
public string CharacterSet { get; set; }
public HttpConfig()
{
this.Timeout = 100000;
this.ContentType = "text/html; charset=" + Encoding.UTF8.WebName;
this.UserAgent = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.117 Safari/537.36";
this.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8";
this.AcceptEncoding = "gzip,deflate";
this.GZipCompress = false;
this.KeepAlive = true;
this.CharacterSet = "UTF-8";
}
}
} 查看全部
c#抓取网页数据(最省事的做法是去需要的网站看看具体是什么编码
)
在做一些需要抓取网页的项目时,经常会遇到乱码。最简单的方法就是去需要爬取的网站看看具体的编码是什么,然后使用正确的编码进行解码。可以,但是总是一一判断也不是问题,尤其是当你需要从不同站点抓取大量页面的时候,比如一个网络爬虫程序,那么我们就需要做一个比较通用的程序来正确识别页面编码。
乱码问题基本上是编码不一致造成的。比如网页编码使用UTF-8,如果使用GB2312读取,肯定会出现乱码。知道了本质问题之后,剩下的就是如何判断网页编码了。GBK、GB2312、UTF-8、BIG-5,一般来说,遇到的中文网页编码大多是这几种编码。简单来说,只有GBK和UTF-8两种,一点都不夸张。,目前的网站要么是GBK编码,要么是UTF-8编码,所以接下来的问题就是确定网站具体是UTF-8还是GBK。
如何确定页面的具体编码?首先检查响应头的Content-Type。如果在响应头中找不到,请到网页中查找元头。如果还是找不到,那就没办法了。设置默认编码。个人建议设置为UTF-8。比如访问博客园的首页,可以看到Content-Type:text/html;响应头中的charset=utf-8,所以我们知道博客园使用的是utf-8编码,但是并不是所有的网站都会在响应头的Content-Type中添加页面编码。比如百度的就是Content-Type:text/html,查不到charset。这时候只能在网页中找到它来确认网页的最终编码。总结就是以下步骤
1.在响应头中的 Content-Type 中找到字符集。如果找到charset,则跳过第2步和第3步,直接进入第4步。2.如果第1步没有找到charset,先读取网页的Content,解析meta中的charset得到页面编码< @3.如果在第2步还是没有获取到页面编码,则没有办法设置默认编码为UTF-84. 使用获取到的charset重新读取响应流
基本上,通过上述方法大部分页面都可以正确解析,但无法识别的则需要亲自验证具体代码。
注意:
1.几乎所有站点都启用了gzip压缩支持,所以在请求头中添加Accept-Encoding:gzip,deflate,这样站点会返回一个压缩流,可以显着提高请求的效率。2.由于网络流不支持流搜索操作,即只能读取一次。为了提高效率,建议先将http响应流读入内存,方便二次解码。无需重新请求检索响应流。
下面给出了Java和C#的实现代码,页面底部给出了源码的git链接。需要童鞋的请自行下载
Java实现
C# 实现
using System;
using System.Collections;
using System.IO;
using System.Linq;
using System.Net;
using System.Net.Security;
using System.Security.Cryptography.X509Certificates;
using System.Text;
using System.Text.RegularExpressions;
using System.Web;
using System.IO.Compression;
using System.Collections.Generic;
using System.Collections.Specialized;
namespace CSharp.Util.Net
{
public class HttpHelper
{
private static bool RemoteCertificateValidate(object sender, X509Certificate certificate, X509Chain chain, SslPolicyErrors errors)
{
//用户https请求
return true; //总是接受
}
public static string SendPost(string url, string data)
{
return Send(url, "POST", data, null);
}
public static string SendGet(string url)
{
return Send(url, "GET", null, null);
}
public static string Send(string url, string method, string data, HttpConfig config)
{
if (config == null) config = new HttpConfig();
string result;
using (HttpWebResponse response = GetResponse(url, method, data, config))
{
Stream stream = response.GetResponseStream();
if (!String.IsNullOrEmpty(response.ContentEncoding))
{
if (response.ContentEncoding.Contains("gzip"))
{
stream = new GZipStream(stream, CompressionMode.Decompress);
}
else if (response.ContentEncoding.Contains("deflate"))
{
stream = new DeflateStream(stream, CompressionMode.Decompress);
}
}
byte[] bytes = null;
using (MemoryStream ms = new MemoryStream())
{
int count;
byte[] buffer = new byte[4096];
while ((count = stream.Read(buffer, 0, buffer.Length)) > 0)
{
ms.Write(buffer, 0, count);
}
bytes = ms.ToArray();
}
#region 检测流编码
Encoding encoding;
//检测响应头是否返回了编码类型,若返回了编码类型则使用返回的编码
//注:有时响应头没有编码类型,CharacterSet经常设置为ISO-8859-1
if (!string.IsNullOrEmpty(response.CharacterSet) && response.CharacterSet.ToUpper() != "ISO-8859-1")
{
encoding = Encoding.GetEncoding(response.CharacterSet == "utf8" ? "utf-8" : response.CharacterSet);
}
else
{
//若没有在响应头找到编码,则去html找meta头的charset
result = Encoding.Default.GetString(bytes);
//在返回的html里使用正则匹配页面编码
Match match = Regex.Match(result, @"", RegexOptions.IgnoreCase);
if (match.Success)
{
encoding = Encoding.GetEncoding(match.Groups[1].Value);
}
else
{
//若html里面也找不到编码,默认使用utf-8
encoding = Encoding.GetEncoding(config.CharacterSet);
}
}
#endregion
result = encoding.GetString(bytes);
}
return result;
}
private static HttpWebResponse GetResponse(string url, string method, string data, HttpConfig config)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Method = method;
request.Referer = config.Referer;
//有些页面不设置用户代理信息则会抓取不到内容
request.UserAgent = config.UserAgent;
request.Timeout = config.Timeout;
request.Accept = config.Accept;
request.Headers.Set("Accept-Encoding", config.AcceptEncoding);
request.ContentType = config.ContentType;
request.KeepAlive = config.KeepAlive;
if (url.ToLower().StartsWith("https"))
{
//这里加入解决生产环境访问https的问题--Could not establish trust relationship for the SSL/TLS secure channel
ServicePointManager.ServerCertificateValidationCallback = new RemoteCertificateValidationCallback(RemoteCertificateValidate);
}
if (method.ToUpper() == "POST")
{
if (!string.IsNullOrEmpty(data))
{
byte[] bytes = Encoding.UTF8.GetBytes(data);
if (config.GZipCompress)
{
using (MemoryStream stream = new MemoryStream())
{
using (GZipStream gZipStream = new GZipStream(stream, CompressionMode.Compress))
{
gZipStream.Write(bytes, 0, bytes.Length);
}
bytes = stream.ToArray();
}
}
request.ContentLength = bytes.Length;
request.GetRequestStream().Write(bytes, 0, bytes.Length);
}
else
{
request.ContentLength = 0;
}
}
return (HttpWebResponse)request.GetResponse();
}
}
public class HttpConfig
{
public string Referer { get; set; }
///
/// 默认(text/html)
///
public string ContentType { get; set; }
public string Accept { get; set; }
public string AcceptEncoding { get; set; }
///
/// 超时时间(毫秒)默认100000
///
public int Timeout { get; set; }
public string UserAgent { get; set; }
///
/// POST请求时,数据是否进行gzip压缩
///
public bool GZipCompress { get; set; }
public bool KeepAlive { get; set; }
public string CharacterSet { get; set; }
public HttpConfig()
{
this.Timeout = 100000;
this.ContentType = "text/html; charset=" + Encoding.UTF8.WebName;
this.UserAgent = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.117 Safari/537.36";
this.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8";
this.AcceptEncoding = "gzip,deflate";
this.GZipCompress = false;
this.KeepAlive = true;
this.CharacterSet = "UTF-8";
}
}
}
c#抓取网页数据(学习一下如何快速让搜索引擎收录网站收录的方法?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-04 16:09
很多客户经常问我,网站没有被搜索引擎收录搜索到,而网站经常更新,但是在搜索引擎上搜索不到。本期,勇哥带你学习。如何快速获取搜索引擎收录网站。
在学习之前,先熟悉一个协议。robots 协议也称为 robots.txt(统一小写)。它是一个ASCII编码的文本文件,存放在网站的根目录下。它通常告诉互联网搜索引擎的机器人(也称为网络蜘蛛),这个网站中哪些内容不应该被搜索引擎的机器人获取,哪些内容可以被机器人获取。由于某些系统中的URL 区分大小写,因此robots.txt 的文件名应统一小写。robots.txt应该放在网站的根目录下。如果你想单独定义搜索引擎robots访问子目录时的行为,你可以将你自定义的设置合并到根目录下的robots.txt中,或者使用robots metadata(Metadata,也称为metadata)。robots协议不是规范,而是约定,所以不保证网站的隐私。以上是某某百科的解释。怎么生成,后面再说。既然告诉搜索引擎可搜索的和不可搜索的,自然要先生成网站的sitemap(网站地图)文件。目的是告诉搜索引擎爬取范围,我们看看如何生成网站的地图文件,我们继续。必须先生成网站的@网站 map)文件。目的是告诉搜索引擎爬取范围,我们看看如何生成网站的地图文件,我们继续。必须先生成网站的@网站 map)文件。目的是告诉搜索引擎爬取范围,我们看看如何生成网站的地图文件,我们继续。
首先打开在线URL生成,输入你要收录的域名,点击Crawl,系统会自动开始蜘蛛爬行,爬行时间以网站的内容为准,下载完成后对应格式的文件。我们选择xml格式。
文件下载并上传到网站的根目录。打开搜索引擎网站的资源,登录账号,进入站点管理,添加网站,根据网站的协议头类型选择http/https,输入网站@要爬取的>域名。继续选择站点的域。
第三步,验证网站的所有权。一共有三种验证方式,您可以根据自己的实际情况进行选择。
验证完成后,即可将搜索引擎提交至网站。
提交完成后,搜索引擎会自动抓取网站地图文件中的网址,推送给搜索引擎进行抓取。
搜索引擎如何自动实现爬取?现在让我们谈谈robot.txt文件。其内容格式为:
图中1表示允许所有搜索引擎爬取,2表示不允许搜索引擎爬取这些目录,3表示读取xml文件。如果您了解文件的格式,您可以根据自己的实际情况修改文件的内容。修改完成后,还必须上传到网站的根目录下才能获取。
点击下图中的检测和更新。
以上操作完成后,选择爬虫诊断工具,让站长从蜘蛛的角度查看爬取的内容,自我诊断爬虫看到的内容是否与预期的内容一致。
一段时间后,将显示获取的结果。
全部设置完成后,第二天就会看到特定搜索引擎的爬取数据。
资源工具还提供了爬行异常的诊断。站长可根据系统提示的具体内容及时修复网站,达到爬行异常0的效果。
从上面可以发现,如果想让蜘蛛爬虫有稳定良性的访问,就必须保持更新网站的好习惯。更新内容后,及时重新生成sitemap文件上传到网站的根目录,这样网站进入良性期,无法阻止搜索引擎抓取。本次学习结束,我们下期再见! 查看全部
c#抓取网页数据(学习一下如何快速让搜索引擎收录网站收录的方法?)
很多客户经常问我,网站没有被搜索引擎收录搜索到,而网站经常更新,但是在搜索引擎上搜索不到。本期,勇哥带你学习。如何快速获取搜索引擎收录网站。
在学习之前,先熟悉一个协议。robots 协议也称为 robots.txt(统一小写)。它是一个ASCII编码的文本文件,存放在网站的根目录下。它通常告诉互联网搜索引擎的机器人(也称为网络蜘蛛),这个网站中哪些内容不应该被搜索引擎的机器人获取,哪些内容可以被机器人获取。由于某些系统中的URL 区分大小写,因此robots.txt 的文件名应统一小写。robots.txt应该放在网站的根目录下。如果你想单独定义搜索引擎robots访问子目录时的行为,你可以将你自定义的设置合并到根目录下的robots.txt中,或者使用robots metadata(Metadata,也称为metadata)。robots协议不是规范,而是约定,所以不保证网站的隐私。以上是某某百科的解释。怎么生成,后面再说。既然告诉搜索引擎可搜索的和不可搜索的,自然要先生成网站的sitemap(网站地图)文件。目的是告诉搜索引擎爬取范围,我们看看如何生成网站的地图文件,我们继续。必须先生成网站的@网站 map)文件。目的是告诉搜索引擎爬取范围,我们看看如何生成网站的地图文件,我们继续。必须先生成网站的@网站 map)文件。目的是告诉搜索引擎爬取范围,我们看看如何生成网站的地图文件,我们继续。
首先打开在线URL生成,输入你要收录的域名,点击Crawl,系统会自动开始蜘蛛爬行,爬行时间以网站的内容为准,下载完成后对应格式的文件。我们选择xml格式。
文件下载并上传到网站的根目录。打开搜索引擎网站的资源,登录账号,进入站点管理,添加网站,根据网站的协议头类型选择http/https,输入网站@要爬取的>域名。继续选择站点的域。
第三步,验证网站的所有权。一共有三种验证方式,您可以根据自己的实际情况进行选择。
验证完成后,即可将搜索引擎提交至网站。
提交完成后,搜索引擎会自动抓取网站地图文件中的网址,推送给搜索引擎进行抓取。
搜索引擎如何自动实现爬取?现在让我们谈谈robot.txt文件。其内容格式为:
图中1表示允许所有搜索引擎爬取,2表示不允许搜索引擎爬取这些目录,3表示读取xml文件。如果您了解文件的格式,您可以根据自己的实际情况修改文件的内容。修改完成后,还必须上传到网站的根目录下才能获取。
点击下图中的检测和更新。
以上操作完成后,选择爬虫诊断工具,让站长从蜘蛛的角度查看爬取的内容,自我诊断爬虫看到的内容是否与预期的内容一致。
一段时间后,将显示获取的结果。
全部设置完成后,第二天就会看到特定搜索引擎的爬取数据。
资源工具还提供了爬行异常的诊断。站长可根据系统提示的具体内容及时修复网站,达到爬行异常0的效果。
从上面可以发现,如果想让蜘蛛爬虫有稳定良性的访问,就必须保持更新网站的好习惯。更新内容后,及时重新生成sitemap文件上传到网站的根目录,这样网站进入良性期,无法阻止搜索引擎抓取。本次学习结束,我们下期再见!
c#抓取网页数据(ASP.NET中抓取网页内容-保持登录状态利用Post数据成功登录服务器应用系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-30 06:19
在ASP.NET中抓取网页内容非常方便,其中解决了ASP中困扰我们的编码问题。
1、获取一般内容
需要三个类:WebRequest、WebResponse、StreamReader
需要的命名空间:System.Net、System.IO
核心代码:
WebRequest类的Create是一个静态方法,参数是要爬取的网页的URL;
Encoding 指定编码。编码有ASCII、UTF32、UTF8等通用编码属性,但没有gb2312的编码属性,所以我们使用GetEncoding获取gb2312编码。
2、抓取图片或其他二进制文件(如文件)
需要四个类:WebRequest、WebResponse、Stream、FileStream
需要的命名空间:System.Net、System.IO
核心代码:用Stream读取
3、抓取网页内容的POST方法
在抓取网页时,有时需要通过Post将一些数据发送到服务器。在网页抓取程序中添加如下代码,将用户名和密码发布到服务器:
4、ASP.NET 抓取网页内容-防止重定向
在网页爬取过程中,在成功登录服务器应用系统后,应用系统可能会通过Response.Redirect对网页进行重定向。如果不需要响应这个重定向,那么我们不应该发送 reader.ReadToEnd() 到 Response.Write 出来时,就可以了。
5、ASP.NET 抓取网页内容-保持登录状态
使用Post数据成功登录服务器应用系统后,就可以抓取到需要登录的页面,那么我们可能需要在多个Request之间保持登录状态。 查看全部
c#抓取网页数据(ASP.NET中抓取网页内容-保持登录状态利用Post数据成功登录服务器应用系统)
在ASP.NET中抓取网页内容非常方便,其中解决了ASP中困扰我们的编码问题。
1、获取一般内容
需要三个类:WebRequest、WebResponse、StreamReader
需要的命名空间:System.Net、System.IO
核心代码:
WebRequest类的Create是一个静态方法,参数是要爬取的网页的URL;
Encoding 指定编码。编码有ASCII、UTF32、UTF8等通用编码属性,但没有gb2312的编码属性,所以我们使用GetEncoding获取gb2312编码。
2、抓取图片或其他二进制文件(如文件)
需要四个类:WebRequest、WebResponse、Stream、FileStream
需要的命名空间:System.Net、System.IO
核心代码:用Stream读取
3、抓取网页内容的POST方法
在抓取网页时,有时需要通过Post将一些数据发送到服务器。在网页抓取程序中添加如下代码,将用户名和密码发布到服务器:
4、ASP.NET 抓取网页内容-防止重定向
在网页爬取过程中,在成功登录服务器应用系统后,应用系统可能会通过Response.Redirect对网页进行重定向。如果不需要响应这个重定向,那么我们不应该发送 reader.ReadToEnd() 到 Response.Write 出来时,就可以了。
5、ASP.NET 抓取网页内容-保持登录状态
使用Post数据成功登录服务器应用系统后,就可以抓取到需要登录的页面,那么我们可能需要在多个Request之间保持登录状态。
c#抓取网页数据(几个自己研究出来的抓数据的技术,欢迎大家指正补充哈哈! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-29 19:15
)
我也对数据抓取有一些研究。现在我分享一些我研究过的数据抓取技术。可能有很多缺点。欢迎指正并补充哈哈!
方法一:直接抓取网页源码
优点:速度快。
缺点: 1、由于速度快,容易被服务器检测,可能会限制当前的ip抓取。为此,您可以尝试使用 ip 代码来解决它。
2、如果要抓取的数据是在网页加载后,js修改了网页元素,无法抓取。
3、遇到爬取一些大型网站时,如果登录后需要爬取页面,可能需要破解服务器端账号加密算法和各种加密算法,测试技术性。
适用场景:网页是完全静态的,第一次加载网页时就加载了你要抓取的数据。涉及登录或权限操作的类似页面不使用任何帐户进行加密或仅进行简单加密。
当然,如果你在这个网页抓取的数据是通过接口获取的json,那你会更开心,直接抓取json页面即可。
对于一个登录页面,我们如何获取他的登录页面背后的源代码?
首先,我想介绍一下,在会话保存帐户信息时,服务器是如何确定用户的身份的。
首先,用户登录成功后,服务器会在session中保存用户当前的session信息,每个session都有一个唯一的标识sessionId。当用户访问该页面时,会话创建后,会收到服务器返回的 sessionId 并保存在 cookie 中。因此,我们可以用Chrome浏览器打开勾选项,查看当前页面的jsessionId。用户下次访问需要登录的页面时,用户发送的请求头会附加这个sessionId,服务器端可以通过这个sessionId来判断用户的身份。
在这里,我搭建了一个简单的jsp登录页面,登录后的账户信息保存在服务端会话中。
思路:1.登录。2.登录成功后获取cookies。3. 将cookie放入请求头,向登录页面发送请求。
附上java版本代码和python
爪哇版:
package craw;import java.io.BufferedReader;import java.io.IOException;import java.io.InputStreamReader;import java.io.PrintStream;import java.io.PrintWriter;import java.net.HttpURLConnection;import java.net.MalformedURLException;import java.net.URL;import java.net.URLConnection;import java.util.List;import java.util.Map;public class CrawTest {//获得网页源代码private static String getHtml(String urlString,String charset,String cookie){StringBuffer html = new StringBuffer();try {URL url = new URL(urlString);HttpURLConnection urlConn = (HttpURLConnection) url.openConnection();urlConn.setRequestProperty("Cookie", cookie);BufferedReader br = new BufferedReader(new InputStreamReader(urlConn.getInputStream(),charset));String str;while((str=br.readLine())!=null){html.append(str);}} catch (MalformedURLException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}return html.toString();}//发送post请求,并返回请求后的cookieprivate static String postGetCookie(String urlString,String params,String charset){String cookies=null;try {URL url = new URL(urlString);URLConnection urlConn = url.openConnection();urlConn.setDoInput(true);urlConn.setDoOutput(true);PrintWriter out = new PrintWriter(urlConn.getOutputStream());out.print(params);out.flush(); cookies = urlConn.getHeaderFields().get("Set-Cookie").get(0);} catch (MalformedURLException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}return cookies;}public static void main(String[] args) {String cookie = postGetCookie("http://localhost:8080/loginDemo/login","username=admin&password=123456","utf-8");String html = getHtml("http://localhost:8080/loginDemo/index.jsp", "utf-8", cookie);System.out.println(html);//这里我们就可能输出登录后的网页源代码了}}
蟒蛇版本:
#encoding:utf-8import urllibimport urllib2data={'username':'admin','password':'123456'}data=urllib.urlencode(data)response = urllib2.urlopen('http://localhost:8080/loginDemo/login',data=data)//登录cookie = response.info()['set-cookie']//获得登录后的cookiejsessionId = cookie.split(';')[0].split('=')[-1]//从cookie获得sessionIdhtml = response.read()if html=='error': print('用户名密码错误!')elif html=='success': headers = {'Cookie':'JSESSIONID='+jsessionId}//请求头 request =urllib2.Request('http://localhost:8080/loginDemo/index.jsp',headers=headers) html = urllib2.urlopen(request).read() print(html)//输出登录后的页面源码
我们可以很明显的看到python的优势,至少会比java少写一半的代码量。当然,这是java的优点,也是java的缺点。优点是更加灵活,程序员可以更好地控制底层代码的实现。,缺点是不易学,技术要求太高。因此,如果您是数据抓取的新手,我强烈建议您学习python。
方法二:模拟浏览器操作
优点: 1. 类似于用户操作,不易被服务器检测到。
2、对于登录的网站,即使是N层加密,也无需考虑其加密算法。
3、可随时获取当前页面各元素的最新状态。
缺点: 1. 稍慢。
这里有一些很好的模拟浏览器操作的库:
C# 浏览器控件:
如果你学过c#winform,相信你对webbrower控件永远不会陌生。是浏览器,内部驱动其实就是IE驱动。
他可以在dom模式下随时解析当前文档(网页文档对象),不仅可以获取相关的Element对象,还可以修改元素对象,甚至调用方法,比如onclick方法,onsubmit等,或者直接调用页面js方法。
网页浏览器操作的C#代码:
webBrowser1.Navigate("https://localhost//index.html");//加载一个页面
需要注意的是:不要直接执行以下代码,因为网页加载需要时间,建议以下代码写到webBrowser1_DocumentCompleted(加载完成)事件中:webBrowser1.Document.GetElementById("username").InnerText="admin";//在网页中找到id为username的元素,设置其文本为admin webBrowser1.Document.GetElementById("password").InnerText = "123456";//在网页中找到id为password的元素,设置其文本为123456 webBrowser1.Document.InvokeScript("loginEncrypt");//调用网页js函数:loginEncrypt.
因为有些页面可能不够友好,或者IE版本太低,甚至安全证书等问题,那么这个解决方案可能会通过。
我们可以直接使用selenium库来操作操作系统中真实的浏览器,比如chrome浏览器,selenuim支持多语言开发,以python调用selenium为例,selenium就是直接操作我们系统中的浏览器,但是我们需要确保浏览器安装了相应的Drive。
但是,在实际开发中,有时我们可能不想看到这样的浏览器界面。这里可以给大家推荐一款直接在cmd中操作的后台浏览器。没有接口,就是phantomjs。
这样我们就可以用python+selenium+phantomjs来模拟浏览器的操作,看不到界面,因为phantomjs没有界面,会比普通浏览器快很多。
网上的资料很多,一时半会解释不清。我不会在这里解释太多。你可以看看:
三、Fidder脚本:
fidder 是一个非常强大的数据捕获工具。它不仅可以捕获当前系统中的http请求,还可以提供安全证书。所以,有时候,如果我们在爬取过程中遇到安全证书错误,我们不妨打开fidder,让他给你提供一个证书,说不定你就快成功了。
更强大的是 fdder 脚本,它可以在捕获请求后执行系统操作,例如将请求的数据保存到硬盘。或者在请求之前修改请求头,可以说是一个强大的工具。这样我们之前用fdder配合各种方法,相信大部分问题都可以解决。而且他的语法和C like系列语法类似,类库和c#大体相同,相信熟悉C#的同学会很快上手fiddler脚本。
fider 脚本: 查看全部
c#抓取网页数据(几个自己研究出来的抓数据的技术,欢迎大家指正补充哈哈!
)
我也对数据抓取有一些研究。现在我分享一些我研究过的数据抓取技术。可能有很多缺点。欢迎指正并补充哈哈!
方法一:直接抓取网页源码
优点:速度快。
缺点: 1、由于速度快,容易被服务器检测,可能会限制当前的ip抓取。为此,您可以尝试使用 ip 代码来解决它。
2、如果要抓取的数据是在网页加载后,js修改了网页元素,无法抓取。
3、遇到爬取一些大型网站时,如果登录后需要爬取页面,可能需要破解服务器端账号加密算法和各种加密算法,测试技术性。
适用场景:网页是完全静态的,第一次加载网页时就加载了你要抓取的数据。涉及登录或权限操作的类似页面不使用任何帐户进行加密或仅进行简单加密。
当然,如果你在这个网页抓取的数据是通过接口获取的json,那你会更开心,直接抓取json页面即可。
对于一个登录页面,我们如何获取他的登录页面背后的源代码?
首先,我想介绍一下,在会话保存帐户信息时,服务器是如何确定用户的身份的。
首先,用户登录成功后,服务器会在session中保存用户当前的session信息,每个session都有一个唯一的标识sessionId。当用户访问该页面时,会话创建后,会收到服务器返回的 sessionId 并保存在 cookie 中。因此,我们可以用Chrome浏览器打开勾选项,查看当前页面的jsessionId。用户下次访问需要登录的页面时,用户发送的请求头会附加这个sessionId,服务器端可以通过这个sessionId来判断用户的身份。
在这里,我搭建了一个简单的jsp登录页面,登录后的账户信息保存在服务端会话中。
思路:1.登录。2.登录成功后获取cookies。3. 将cookie放入请求头,向登录页面发送请求。
附上java版本代码和python
爪哇版:
package craw;import java.io.BufferedReader;import java.io.IOException;import java.io.InputStreamReader;import java.io.PrintStream;import java.io.PrintWriter;import java.net.HttpURLConnection;import java.net.MalformedURLException;import java.net.URL;import java.net.URLConnection;import java.util.List;import java.util.Map;public class CrawTest {//获得网页源代码private static String getHtml(String urlString,String charset,String cookie){StringBuffer html = new StringBuffer();try {URL url = new URL(urlString);HttpURLConnection urlConn = (HttpURLConnection) url.openConnection();urlConn.setRequestProperty("Cookie", cookie);BufferedReader br = new BufferedReader(new InputStreamReader(urlConn.getInputStream(),charset));String str;while((str=br.readLine())!=null){html.append(str);}} catch (MalformedURLException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}return html.toString();}//发送post请求,并返回请求后的cookieprivate static String postGetCookie(String urlString,String params,String charset){String cookies=null;try {URL url = new URL(urlString);URLConnection urlConn = url.openConnection();urlConn.setDoInput(true);urlConn.setDoOutput(true);PrintWriter out = new PrintWriter(urlConn.getOutputStream());out.print(params);out.flush(); cookies = urlConn.getHeaderFields().get("Set-Cookie").get(0);} catch (MalformedURLException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}return cookies;}public static void main(String[] args) {String cookie = postGetCookie("http://localhost:8080/loginDemo/login","username=admin&password=123456","utf-8");String html = getHtml("http://localhost:8080/loginDemo/index.jsp", "utf-8", cookie);System.out.println(html);//这里我们就可能输出登录后的网页源代码了}}
蟒蛇版本:
#encoding:utf-8import urllibimport urllib2data={'username':'admin','password':'123456'}data=urllib.urlencode(data)response = urllib2.urlopen('http://localhost:8080/loginDemo/login',data=data)//登录cookie = response.info()['set-cookie']//获得登录后的cookiejsessionId = cookie.split(';')[0].split('=')[-1]//从cookie获得sessionIdhtml = response.read()if html=='error': print('用户名密码错误!')elif html=='success': headers = {'Cookie':'JSESSIONID='+jsessionId}//请求头 request =urllib2.Request('http://localhost:8080/loginDemo/index.jsp',headers=headers) html = urllib2.urlopen(request).read() print(html)//输出登录后的页面源码
我们可以很明显的看到python的优势,至少会比java少写一半的代码量。当然,这是java的优点,也是java的缺点。优点是更加灵活,程序员可以更好地控制底层代码的实现。,缺点是不易学,技术要求太高。因此,如果您是数据抓取的新手,我强烈建议您学习python。
方法二:模拟浏览器操作
优点: 1. 类似于用户操作,不易被服务器检测到。
2、对于登录的网站,即使是N层加密,也无需考虑其加密算法。
3、可随时获取当前页面各元素的最新状态。
缺点: 1. 稍慢。
这里有一些很好的模拟浏览器操作的库:
C# 浏览器控件:
如果你学过c#winform,相信你对webbrower控件永远不会陌生。是浏览器,内部驱动其实就是IE驱动。
他可以在dom模式下随时解析当前文档(网页文档对象),不仅可以获取相关的Element对象,还可以修改元素对象,甚至调用方法,比如onclick方法,onsubmit等,或者直接调用页面js方法。
网页浏览器操作的C#代码:
webBrowser1.Navigate("https://localhost//index.html";);//加载一个页面
需要注意的是:不要直接执行以下代码,因为网页加载需要时间,建议以下代码写到webBrowser1_DocumentCompleted(加载完成)事件中:webBrowser1.Document.GetElementById("username").InnerText="admin";//在网页中找到id为username的元素,设置其文本为admin webBrowser1.Document.GetElementById("password").InnerText = "123456";//在网页中找到id为password的元素,设置其文本为123456 webBrowser1.Document.InvokeScript("loginEncrypt");//调用网页js函数:loginEncrypt.
因为有些页面可能不够友好,或者IE版本太低,甚至安全证书等问题,那么这个解决方案可能会通过。
我们可以直接使用selenium库来操作操作系统中真实的浏览器,比如chrome浏览器,selenuim支持多语言开发,以python调用selenium为例,selenium就是直接操作我们系统中的浏览器,但是我们需要确保浏览器安装了相应的Drive。
但是,在实际开发中,有时我们可能不想看到这样的浏览器界面。这里可以给大家推荐一款直接在cmd中操作的后台浏览器。没有接口,就是phantomjs。
这样我们就可以用python+selenium+phantomjs来模拟浏览器的操作,看不到界面,因为phantomjs没有界面,会比普通浏览器快很多。
网上的资料很多,一时半会解释不清。我不会在这里解释太多。你可以看看:
三、Fidder脚本:
fidder 是一个非常强大的数据捕获工具。它不仅可以捕获当前系统中的http请求,还可以提供安全证书。所以,有时候,如果我们在爬取过程中遇到安全证书错误,我们不妨打开fidder,让他给你提供一个证书,说不定你就快成功了。
更强大的是 fdder 脚本,它可以在捕获请求后执行系统操作,例如将请求的数据保存到硬盘。或者在请求之前修改请求头,可以说是一个强大的工具。这样我们之前用fdder配合各种方法,相信大部分问题都可以解决。而且他的语法和C like系列语法类似,类库和c#大体相同,相信熟悉C#的同学会很快上手fiddler脚本。
fider 脚本:
c#抓取网页数据(C#使用正则表达式抓取网站信息的正则抓取技巧(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-24 12:14
本文文章主要介绍C#使用“target="_blank">正则表达式捕获网站信息,并结合实例分析C#对网页信息的正则捕获操作技巧,具有一定的参考价值,有需要的朋友可以参考
本文介绍了 C# 如何使用正则表达式来捕获 网站 信息。分享给大家,供大家参考,如下:
下面是一个抓取京东商城商品详情的例子。
1、创建JdRobber.cs程序类
<p>public class JdRobber
{
///
/// 判断是否京东链接
///
///
///
public bool ValidationUrl(string url)
{
bool result = false;
if (!String.IsNullOrEmpty(url))
{
Regex regex = new Regex(@"^http://item.jd.com/\d+.html$");
Match match = regex.Match(url);
if (match.Success)
{
result = true;
}
}
return result;
}
///
/// 抓取京东信息
///
///
///
public void GetInfo(string url)
{
if (ValidationUrl(url))
{
string htmlStr = WebHandler.GetHtmlStr(url, "Default");
if (!String.IsNullOrEmpty(htmlStr))
{
string pattern = ""; //正则表达式
string sourceWebID = ""; //商品关键ID
string title = ""; //标题
decimal price = 0; //价格
string picName = ""; //图片
//提取商品关键ID
pattern = @"http://item.jd.com/(?\d+).html";
sourceWebID = WebHandler.GetRegexText(url, pattern);
//提取标题
pattern = @"[\s\S]*(?.*?)";
title = WebHandler.GetRegexText(htmlStr, pattern);
//提取图片
int begin = htmlStr.IndexOf(" 查看全部
c#抓取网页数据(C#使用正则表达式抓取网站信息的正则抓取技巧(图))
本文文章主要介绍C#使用“target="_blank">正则表达式捕获网站信息,并结合实例分析C#对网页信息的正则捕获操作技巧,具有一定的参考价值,有需要的朋友可以参考
本文介绍了 C# 如何使用正则表达式来捕获 网站 信息。分享给大家,供大家参考,如下:
下面是一个抓取京东商城商品详情的例子。
1、创建JdRobber.cs程序类
<p>public class JdRobber
{
///
/// 判断是否京东链接
///
///
///
public bool ValidationUrl(string url)
{
bool result = false;
if (!String.IsNullOrEmpty(url))
{
Regex regex = new Regex(@"^http://item.jd.com/\d+.html$");
Match match = regex.Match(url);
if (match.Success)
{
result = true;
}
}
return result;
}
///
/// 抓取京东信息
///
///
///
public void GetInfo(string url)
{
if (ValidationUrl(url))
{
string htmlStr = WebHandler.GetHtmlStr(url, "Default");
if (!String.IsNullOrEmpty(htmlStr))
{
string pattern = ""; //正则表达式
string sourceWebID = ""; //商品关键ID
string title = ""; //标题
decimal price = 0; //价格
string picName = ""; //图片
//提取商品关键ID
pattern = @"http://item.jd.com/(?\d+).html";
sourceWebID = WebHandler.GetRegexText(url, pattern);
//提取标题
pattern = @"[\s\S]*(?.*?)";
title = WebHandler.GetRegexText(htmlStr, pattern);
//提取图片
int begin = htmlStr.IndexOf("
c#抓取网页数据(.data8.0.25.NET项目的应用之间产生了冲突 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-23 05:15
)
写在前面
如果你只是在寻找C#(尤其是WPF项目)连接MySQL数据库的解决方案,请直接跳到使用NuGet包管理器在VSCode中引用dll或NuGet在VS中导入dll的部分(以VS2017为例) )
介绍
之前博主在VS中编写C#WPF项目时,在搜索数据库相关答案时,没有找到合适的答案。将网上找到的Mysql.data 8.0.25 版本的dll 导入到项目中 项目的应用程序与项目的原创应用程序发生冲突(显示为MySql.Data, Version=8.0.25.0, Culture=neutral, PublicKeyToken= c5687fc88969c44d “System.Runtime, Version= 5.0.0. 0, Culture =neutral, PublicKeyT oken= b03f5f7f11 d50a3a" 程序集MySql.Data'使用的版本高于引用的版本|使用标识为System.Runtime, Version=4.1.2.0, Culture =neutral, PublicKeyToken= b03f5f7f11 d50a3a assembly'System.
之前博主在使用VSCode写代码的时候,使用了NuGet Package Manager扩展来添加dll导入,所以在VS中,我也想尝试通过NuGet来导入相关的dll引用
NuGet 简介
Nuget是.NET平台下的一个开源项目,是Visual Studio的扩展。在使用 Visual Studio 开发基于 .NET Framework 的应用程序时,Nuget 可以更快速、更方便地添加、删除和更新项目中的引用。
一个简单的理解就是在用VS或者VSCode写C#项目的时候,可以使用NuGet来添加一些扩展包
NuGet官网
直接在NuGet上搜索需要的包,比如MySql.data
点击右边的DownLoad Packages下载包,但是此时下载的是一个后缀为nupkg的包(其实是一个压缩包),这种格式不能通过导入dll直接导入到C#项目中。可以尝试使用压缩软件打开nupkg后缀包,找到自己真正需要的dll包,导入到C#项目中,但是往往不行。以MySql.data为例,只导入MySql.data 8.0.25 不能运行,会报错上图,因为VS2017或者VS2019默认的System版本是4.0.0 和 MySql.data 8.0.25 需要更高版本的 System 支持版本。
在 VSCode 中使用 NuGet 包管理器引用 dll
在vscode扩展中搜索NuGet Package Manager并安装
回到自己的C#项目,点击查看-命令面板或者直接打开CTRL+shift+P
进入NuGet包,选择NuGet包管理器:添加包选项添加需要的包
搜索Mysql.data选择第一个Mysql.data
选择对应版本(对应自己的MySQL数据库)即可完成下载
完成后记得重新生成项目(在终端输入dotnet restore)
重新运行项目,测试连接MySQL数据库
(文末有连接MySQL数据库的测试代码)
在VS中使用NuGet导入dll(以VS2017为例)
点击打开项目目录,右键引用,打开管理NuGet包
搜索需要的dll包,比如Mysql.data,选择需要的NuGet包,在右侧选择需要的版本(注意对应自己的MySQL版本),点击安装(这里因为博主已经下载了包所以显示更新按钮)
下载的时候可以看到NuGet不仅下载了一个Mysql.data,还下载了很多配套的包。这也解释了上一篇我们刚刚导入的Mysql.data的dll程序无法正常运行的情况。
完成后记得重新生成项目(右键项目名称,点击regenerate restore)
至此,项目可以正常连接MySQL数据库。如果还是不行,根据VS提示使用NuGet安装丢失或不对应的包(同上,不再赘述)
附上一段连接数据库的测试代码(注意修改为自己的数据库名,以及账号和密码)
try
{
string str = "server=localhost;User Id=root;password=123456;Database=zjty";//连接MySQL的字符串
MySqlConnection giricon = new MySqlConnection(str);//实例化链接
giricon.Open();//开启连接
// MySqlCommand mycmd = new MySqlCommand("insert into user(userId) VALUES('c#111')", giricon);
MySqlCommand mycmd = new MySqlCommand("select * from user", giricon);
MySqlDataReader reader = mycmd.ExecuteReader();
//循环单行读取数据,当读取为null时,就退出循环
while (reader.Read())
{
//输出第一列字段值
Console.Write(reader.GetString(0) + "\t");
//判断字段"username"是否为null,为null数据转换会失败
if (!reader.IsDBNull(1))
{
//输出第二列字段值
Console.Write(reader.GetString(1) + "\t");
}
//判断字段"password"是否为null,为null数据转换会失败
if (!reader.IsDBNull(2))
{
//输出第三列字段值
Console.Write(reader.GetString(2) + "\n");
}
}
// if (mycmd.ExecuteNonQuery() > 0)
// {
// Console.WriteLine("success");
// }
// Console.ReadLine();
// giricon.Close();//关闭
}
catch (Exception ex)
{
Console.WriteLine("数据库连接异常!");
} 查看全部
c#抓取网页数据(.data8.0.25.NET项目的应用之间产生了冲突
)
写在前面
如果你只是在寻找C#(尤其是WPF项目)连接MySQL数据库的解决方案,请直接跳到使用NuGet包管理器在VSCode中引用dll或NuGet在VS中导入dll的部分(以VS2017为例) )
介绍
之前博主在VS中编写C#WPF项目时,在搜索数据库相关答案时,没有找到合适的答案。将网上找到的Mysql.data 8.0.25 版本的dll 导入到项目中 项目的应用程序与项目的原创应用程序发生冲突(显示为MySql.Data, Version=8.0.25.0, Culture=neutral, PublicKeyToken= c5687fc88969c44d “System.Runtime, Version= 5.0.0. 0, Culture =neutral, PublicKeyT oken= b03f5f7f11 d50a3a" 程序集MySql.Data'使用的版本高于引用的版本|使用标识为System.Runtime, Version=4.1.2.0, Culture =neutral, PublicKeyToken= b03f5f7f11 d50a3a assembly'System.
之前博主在使用VSCode写代码的时候,使用了NuGet Package Manager扩展来添加dll导入,所以在VS中,我也想尝试通过NuGet来导入相关的dll引用
NuGet 简介
Nuget是.NET平台下的一个开源项目,是Visual Studio的扩展。在使用 Visual Studio 开发基于 .NET Framework 的应用程序时,Nuget 可以更快速、更方便地添加、删除和更新项目中的引用。
一个简单的理解就是在用VS或者VSCode写C#项目的时候,可以使用NuGet来添加一些扩展包
NuGet官网
直接在NuGet上搜索需要的包,比如MySql.data
点击右边的DownLoad Packages下载包,但是此时下载的是一个后缀为nupkg的包(其实是一个压缩包),这种格式不能通过导入dll直接导入到C#项目中。可以尝试使用压缩软件打开nupkg后缀包,找到自己真正需要的dll包,导入到C#项目中,但是往往不行。以MySql.data为例,只导入MySql.data 8.0.25 不能运行,会报错上图,因为VS2017或者VS2019默认的System版本是4.0.0 和 MySql.data 8.0.25 需要更高版本的 System 支持版本。
在 VSCode 中使用 NuGet 包管理器引用 dll
在vscode扩展中搜索NuGet Package Manager并安装
回到自己的C#项目,点击查看-命令面板或者直接打开CTRL+shift+P
进入NuGet包,选择NuGet包管理器:添加包选项添加需要的包
搜索Mysql.data选择第一个Mysql.data
选择对应版本(对应自己的MySQL数据库)即可完成下载
完成后记得重新生成项目(在终端输入dotnet restore)
重新运行项目,测试连接MySQL数据库
(文末有连接MySQL数据库的测试代码)
在VS中使用NuGet导入dll(以VS2017为例)
点击打开项目目录,右键引用,打开管理NuGet包
搜索需要的dll包,比如Mysql.data,选择需要的NuGet包,在右侧选择需要的版本(注意对应自己的MySQL版本),点击安装(这里因为博主已经下载了包所以显示更新按钮)
下载的时候可以看到NuGet不仅下载了一个Mysql.data,还下载了很多配套的包。这也解释了上一篇我们刚刚导入的Mysql.data的dll程序无法正常运行的情况。
完成后记得重新生成项目(右键项目名称,点击regenerate restore)
至此,项目可以正常连接MySQL数据库。如果还是不行,根据VS提示使用NuGet安装丢失或不对应的包(同上,不再赘述)
附上一段连接数据库的测试代码(注意修改为自己的数据库名,以及账号和密码)
try
{
string str = "server=localhost;User Id=root;password=123456;Database=zjty";//连接MySQL的字符串
MySqlConnection giricon = new MySqlConnection(str);//实例化链接
giricon.Open();//开启连接
// MySqlCommand mycmd = new MySqlCommand("insert into user(userId) VALUES('c#111')", giricon);
MySqlCommand mycmd = new MySqlCommand("select * from user", giricon);
MySqlDataReader reader = mycmd.ExecuteReader();
//循环单行读取数据,当读取为null时,就退出循环
while (reader.Read())
{
//输出第一列字段值
Console.Write(reader.GetString(0) + "\t");
//判断字段"username"是否为null,为null数据转换会失败
if (!reader.IsDBNull(1))
{
//输出第二列字段值
Console.Write(reader.GetString(1) + "\t");
}
//判断字段"password"是否为null,为null数据转换会失败
if (!reader.IsDBNull(2))
{
//输出第三列字段值
Console.Write(reader.GetString(2) + "\n");
}
}
// if (mycmd.ExecuteNonQuery() > 0)
// {
// Console.WriteLine("success");
// }
// Console.ReadLine();
// giricon.Close();//关闭
}
catch (Exception ex)
{
Console.WriteLine("数据库连接异常!");
}
c#抓取网页数据(Web站点进行数据采集程序的基本流程和流程图 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-12-23 03:27
)
首先大家要清楚:网站的任何页面,无论是php、jsp、aspx等动态页面,还是后台程序生成的静态页面,都可以在浏览器。
所以当你要开发数据采集程序时,首先要了解网站你试图采集的首页结构(HTML)。
一旦您非常熟悉网站 中需要采集 数据的HTML 源文件的内容,程序的其余部分将很容易处理。因为C#在网站采集上执行数据,原理是“下载你要采集的页面的HTML源文件,分析HTML代码然后抓取你需要的数据,最后将数据保存到本地文件”。
基本流程如下图所示:
1.页面源文件下载
首先引用 System.Net 命名空间
使用System.Net;
还需要引用
使用System.Text;
使用System.IO;
复制代码
引用后实例化一个 WebClient 对象
privateWebClientwc=newWebClient();
调用 DownloadData 方法从指定网页的源文件中下载一组 BYTE 数据,然后将 BYTE 数组转换为字符串。
//下载页面源文件并转换为UTF8编码格式的STRING
stringmainData=Encoding.UTF8.GetString(wc.DownloadData(string.Format("你要的是采集的网页地址")));
复制代码
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
//将网页源文件下载到本地
wc.DownloadFile("你想要的网页地址采集","保存源文件的本地文件路径");
//读取下载的源文件HTML格式字符串
stringmainData=File.ReadAllText("保存源文件的本地文件路径",Encoding.UTF8);
复制代码
通过网页HTML格式字符串,您可以分析网页采集,抓取您需要的内容。
2.页面分析采集
页面分析就是将网页源文件中的某个特定的或唯一的字符(字符串)作为抓点,并以此抓点为起点,截取你想要的页面上的数据。
以博客园为专栏。比如我要在博客园首页列出文章的标题和链接,就必须用“
代码:
//经过”
mainData=mainData.Substring(mainData.IndexOf("")+26);
//获取文章页面的链接地址
stringarticleAddr=mainData.Substring(0,mainData.IndexOf("\""));
//获取文章的标题
stringarticleTitle=mainData.Substring(mainData.IndexOf("target=\"_blank\">")+16,
mainData.IndexOf("")-mainData.IndexOf("target=\"_blank\">")-16);
复制代码
注意:当你要采集的网页前台的HTML格式发生变化时,作为抓点的字符通道也会相应变化,否则什么都没有采集
3.数据保存
从网页截取到自己需要的数据后,将程序中的数据保存到本地文件中(或者插入到自己的本地数据库中)。这样,整个采集作品就会是一个段落。
//输出数据到本地文件
File.AppendAllText(CreateFolderIfNot(Settings.Default.OutPath)+articleTitle+".txt",
文章数据,
编码.UTF8);
复制代码
另外附上我自己写的采集博客园首页文章的小程序代码。本程序的作用是发布到所有博客园首页文章采集下。
下载链接:CnBlogCollector.rar
当然,如果博客园前端页面的格式调整了,程序的采集功能肯定会失效。只能自己重新调整程序才能继续采集,哈哈。. .
程序效果如下:
查看全部
c#抓取网页数据(Web站点进行数据采集程序的基本流程和流程图
)
首先大家要清楚:网站的任何页面,无论是php、jsp、aspx等动态页面,还是后台程序生成的静态页面,都可以在浏览器。
所以当你要开发数据采集程序时,首先要了解网站你试图采集的首页结构(HTML)。
一旦您非常熟悉网站 中需要采集 数据的HTML 源文件的内容,程序的其余部分将很容易处理。因为C#在网站采集上执行数据,原理是“下载你要采集的页面的HTML源文件,分析HTML代码然后抓取你需要的数据,最后将数据保存到本地文件”。
基本流程如下图所示:
1.页面源文件下载
首先引用 System.Net 命名空间
使用System.Net;
还需要引用
使用System.Text;
使用System.IO;
复制代码
引用后实例化一个 WebClient 对象
privateWebClientwc=newWebClient();
调用 DownloadData 方法从指定网页的源文件中下载一组 BYTE 数据,然后将 BYTE 数组转换为字符串。
//下载页面源文件并转换为UTF8编码格式的STRING
stringmainData=Encoding.UTF8.GetString(wc.DownloadData(string.Format("你要的是采集的网页地址")));
复制代码
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
//将网页源文件下载到本地
wc.DownloadFile("你想要的网页地址采集","保存源文件的本地文件路径");
//读取下载的源文件HTML格式字符串
stringmainData=File.ReadAllText("保存源文件的本地文件路径",Encoding.UTF8);
复制代码
通过网页HTML格式字符串,您可以分析网页采集,抓取您需要的内容。
2.页面分析采集
页面分析就是将网页源文件中的某个特定的或唯一的字符(字符串)作为抓点,并以此抓点为起点,截取你想要的页面上的数据。
以博客园为专栏。比如我要在博客园首页列出文章的标题和链接,就必须用“
代码:
//经过”
mainData=mainData.Substring(mainData.IndexOf("")+26);
//获取文章页面的链接地址
stringarticleAddr=mainData.Substring(0,mainData.IndexOf("\""));
//获取文章的标题
stringarticleTitle=mainData.Substring(mainData.IndexOf("target=\"_blank\">")+16,
mainData.IndexOf("")-mainData.IndexOf("target=\"_blank\">")-16);
复制代码
注意:当你要采集的网页前台的HTML格式发生变化时,作为抓点的字符通道也会相应变化,否则什么都没有采集
3.数据保存
从网页截取到自己需要的数据后,将程序中的数据保存到本地文件中(或者插入到自己的本地数据库中)。这样,整个采集作品就会是一个段落。
//输出数据到本地文件
File.AppendAllText(CreateFolderIfNot(Settings.Default.OutPath)+articleTitle+".txt",
文章数据,
编码.UTF8);
复制代码
另外附上我自己写的采集博客园首页文章的小程序代码。本程序的作用是发布到所有博客园首页文章采集下。
下载链接:CnBlogCollector.rar
当然,如果博客园前端页面的格式调整了,程序的采集功能肯定会失效。只能自己重新调整程序才能继续采集,哈哈。. .
程序效果如下:
c#抓取网页数据(本文模拟浏览器提交表单,模拟表单提交登录的使用示例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-22 17:16
本文中的例子描述了如何使用WebClient登录网站并在C#中抓取登录的网页信息。分享给大家,供大家参考,如下:
C#Login网站其实就是模拟浏览器提交表单,然后记录浏览器响应返回的session cookie值,并用这个session cookie值再次发送请求来实现模拟登录的效果。 .
以下类型的 CookieAwareWebClient 是在发送请求时使用 cookie 实现的。
public class CookieAwareWebClient : WebClient
{
private CookieContainer cookie = new CookieContainer();
protected override WebRequest GetWebRequest(Uri address)
{
WebRequest request = base.GetWebRequest(address);
if (request is HttpWebRequest)
{
(request as HttpWebRequest).CookieContainer = cookie;
}
return request;
}
}
以下是模拟表单提交登录的使用示例:
var client = new CookieAwareWebClient();
client.BaseAddress = @"https://hovertree.net/any/base/url/";
var loginData = new NameValueCollection();
loginData.Add("login", "YourLogin");
loginData.Add("password", "YourPassword");
client.UploadValues("login.php", "POST", loginData);
//Now you are logged in and can request pages
string htmlSource = client.DownloadString("index.php");
更多对C#相关内容感兴趣的读者,请参考本站专题:《C#编码操作技巧总结》、《C#中XML文件操作技巧总结》、《C#常用控件使用教程》 、《WinForm控件使用总结》、《C#数据结构与算法教程》、《C#面向对象编程入门教程》、《C#编程线程使用技巧总结》
希望这篇文章能帮助你进行 C# 编程。 查看全部
c#抓取网页数据(本文模拟浏览器提交表单,模拟表单提交登录的使用示例)
本文中的例子描述了如何使用WebClient登录网站并在C#中抓取登录的网页信息。分享给大家,供大家参考,如下:
C#Login网站其实就是模拟浏览器提交表单,然后记录浏览器响应返回的session cookie值,并用这个session cookie值再次发送请求来实现模拟登录的效果。 .
以下类型的 CookieAwareWebClient 是在发送请求时使用 cookie 实现的。
public class CookieAwareWebClient : WebClient
{
private CookieContainer cookie = new CookieContainer();
protected override WebRequest GetWebRequest(Uri address)
{
WebRequest request = base.GetWebRequest(address);
if (request is HttpWebRequest)
{
(request as HttpWebRequest).CookieContainer = cookie;
}
return request;
}
}
以下是模拟表单提交登录的使用示例:
var client = new CookieAwareWebClient();
client.BaseAddress = @"https://hovertree.net/any/base/url/";
var loginData = new NameValueCollection();
loginData.Add("login", "YourLogin");
loginData.Add("password", "YourPassword");
client.UploadValues("login.php", "POST", loginData);
//Now you are logged in and can request pages
string htmlSource = client.DownloadString("index.php");
更多对C#相关内容感兴趣的读者,请参考本站专题:《C#编码操作技巧总结》、《C#中XML文件操作技巧总结》、《C#常用控件使用教程》 、《WinForm控件使用总结》、《C#数据结构与算法教程》、《C#面向对象编程入门教程》、《C#编程线程使用技巧总结》
希望这篇文章能帮助你进行 C# 编程。

