
c#抓取网页数据
c#抓取网页数据(c#抓取网页数据的原理函数的参数定位方法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-01 11:43
c#抓取网页数据,也是network这个函数的原理,简单来说,network函数的参数就是爬虫想要爬取网页内容的url,网页内容存储在document对象里,这个可以实现网页内容抓取。目标网站:里面涉及的具体网页,爬取内容:网页的内容。
1、先用printf("hello,{0}!")打印出内容,如果没有就打印出url。tips:url用&作为分隔符。
2、打开浏览器右键查看网页源代码,找到标签页2,用浏览器自带的网页剪切功能把网页上的源代码全部复制到电脑上浏览。使用copy命令把源代码复制到同一个目录下。如:d:\users\username\documents\appdata\roaming\myclip\example.csp。
3、右键查看网页源代码,粘贴url到document.getelementsbytagname("text/html"),即可以获取网页的标签页2。网页内容:步骤二:获取网页内容在网页源代码directory中获取网页内容,下面是一个最终的内容:vardoc=getpageheader();varfile=fileclass.copy(doc);vartext=file.tostring();varsrc="../server/index.html";msg=file.getelementsbytagname("script").end();varcurl=file.appendchild(msg);if(curl){//爬取网页内容src=curl.parse("</a>");}varresult=sort([src,href]);result+=string.fromarray(string.substring(href,。
4));returnresult;步骤三:网页内容的转化
1、定位网页源代码,打开网页浏览器,在浏览器右键查看网页源代码,查看源代码。网页是标签页2里的源代码。看到webpage(*),定位在company的源代码处。定位方法:右键查看网页源代码,查看浏览器源代码。网页内容是这里。标签页2里边有一句话,以上就是我们爬取的内容。可以看到标签页3和标签页3里的内容是和我们要抓取的是相符合的。
步骤四:解析源代码,抓取js代码以网页源代码/banner为例,它的url/banner为;src=";form-data=toophone&import_text=no-web-secret&sort=no">网页源代码/banner的源代码为:tips:转化成字符串或者数字会丢失url中参数的url格式信息。
解析代码如下:varbom=file.createdocumentfragment();varform-data=document.getelementsbytagname("form-data");vartoophone=file.getelementsbytagname("form-。 查看全部
c#抓取网页数据(c#抓取网页数据的原理函数的参数定位方法介绍)
c#抓取网页数据,也是network这个函数的原理,简单来说,network函数的参数就是爬虫想要爬取网页内容的url,网页内容存储在document对象里,这个可以实现网页内容抓取。目标网站:里面涉及的具体网页,爬取内容:网页的内容。
1、先用printf("hello,{0}!")打印出内容,如果没有就打印出url。tips:url用&作为分隔符。
2、打开浏览器右键查看网页源代码,找到标签页2,用浏览器自带的网页剪切功能把网页上的源代码全部复制到电脑上浏览。使用copy命令把源代码复制到同一个目录下。如:d:\users\username\documents\appdata\roaming\myclip\example.csp。
3、右键查看网页源代码,粘贴url到document.getelementsbytagname("text/html"),即可以获取网页的标签页2。网页内容:步骤二:获取网页内容在网页源代码directory中获取网页内容,下面是一个最终的内容:vardoc=getpageheader();varfile=fileclass.copy(doc);vartext=file.tostring();varsrc="../server/index.html";msg=file.getelementsbytagname("script").end();varcurl=file.appendchild(msg);if(curl){//爬取网页内容src=curl.parse("</a>");}varresult=sort([src,href]);result+=string.fromarray(string.substring(href,。
4));returnresult;步骤三:网页内容的转化
1、定位网页源代码,打开网页浏览器,在浏览器右键查看网页源代码,查看源代码。网页是标签页2里的源代码。看到webpage(*),定位在company的源代码处。定位方法:右键查看网页源代码,查看浏览器源代码。网页内容是这里。标签页2里边有一句话,以上就是我们爬取的内容。可以看到标签页3和标签页3里的内容是和我们要抓取的是相符合的。
步骤四:解析源代码,抓取js代码以网页源代码/banner为例,它的url/banner为;src=";form-data=toophone&import_text=no-web-secret&sort=no">网页源代码/banner的源代码为:tips:转化成字符串或者数字会丢失url中参数的url格式信息。
解析代码如下:varbom=file.createdocumentfragment();varform-data=document.getelementsbytagname("form-data");vartoophone=file.getelementsbytagname("form-。
c#抓取网页数据( 程序开发文章正文测试内容的一些其它思路及问题写在最后)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-10-31 14:15
程序开发文章正文测试内容的一些其它思路及问题写在最后)
C#制作网站钩子程序实现示例
内容三、程序开发过程四、关于程序开发的一些其他想法和问题写在最后的序言中
真正的想法是用C#GUI开发一个自动化测试软件,可以帮我完成500台电脑在线网络答题的压力测试。既要能自动定位并点击鼠标,还要能模拟用键盘输入字符信息。但实际上,想法很饱满,现实很骨感。还有一些问题需要解决。但是在完成这个项目的过程中,也产生了一些副产品,这也是相当有成就感的。现针对开发过程中出现的问题,查找并筛选一些经过测试的参考资料,将我们的理解和研究经验奉献给大家。特提供一个完整的例子:出现在线挂机对话框,按回车继续。创建了一个简单的“连接程序”来开始对话。希望大家一起开放思路,一起研究。
温馨提示:以下为本文文章内容,以下案例可供参考
一、程序界面(如下图)
名称:模拟键盘程序,为什么不用挂机程序,因为它的功能弱,范围窄,而且作为副产品,真的不是挂机用的。请注意,我们的目标是自动化网络测试。
二、 使用说明
1.接口说明
1. 应用程序路径,这里是FireFox浏览器,所以需要放程序的地址。
2.网站地址:符合URL格式的可直接访问的本地文件或网址
3.浏览器标题:FireFox程序隐藏了应用标题,如果看到标题栏显示:test
其实应用的标题应该是:Test——Mozilla Firefox
4.【启动浏览器】其实这个功能目前可以完全忽略,直接手动启动FireFox即可。
5. 【开始】按钮是精华,这里会根据【浏览器标题】的内容进行搜索
到真正的【句柄】在FireFox上浏览网页,如果找到,会显示【句柄】的十进制整数值。如果显示为 0,则表示未找到。
6.【停止】关闭定时器操作。
2.使用笔记
1. 显示[Handle]位置后,必须为非零值。如果为0,修改【浏览器标题】的内容,再次点击【开始】
2.FireFox 浏览器必须保持在所有表单的前面
3.保证【电脑】不会进入【睡眠】或进入【屏幕保护】状态
三、程序开发流程
1.测试页面
1.文件名:test.html
2.网页代码(如下):
测试
alert("ok");
2.程序完整代码
using System;
using System.Diagnostics;
using System.Runtime.InteropServices;
using System.Threading;
using System.Windows.Forms;
namespace 模拟键盘
{
public partial class Form1 : Form
{
[DllImport("user32.dll", EntryPoint = "keybd_event", SetLastError = true)]
public static extern void keybd_event(Keys bVk, byte bScan, uint dwFlags, uint dwExtraInfo);
[DllImport("user32.dll", EntryPoint = "FindWindow")]
private static extern IntPtr FindWindow(string IpClassName, string IpWindowName);
//查找窗体控件
public int iSeconds=30;
public delegate bool CallBack(int hwnd, int lParam);
public Process Proc = new Process();
public System.Windows.Forms.Timer myTimer;
public Form1()
{
InitializeComponent();
}
private void btnBrowser_Click(object sender, EventArgs e)
{
openFileDialog1.Filter = "*.exe|*.exe|所有文件|*.*";
openFileDialog1.FileName = "";
DialogResult dr = openFileDialog1.ShowDialog();
if(DialogResult.OK==dr)
{
txtFile.Text = openFileDialog1.FileName;
}
}
string str = "Message";
int iP = 0;
private void btnStart_Click(object sender, EventArgs e)
{
IntPtr hnd = FindWindow(null, txtTitle.Text);//获取句柄
lblMessage.Text = hnd.ToString();
iSeconds = int.Parse(txtSeconds.Text.Trim());
myTimer.Interval = 1000 * iSeconds; //1秒=1000毫秒
myTimer.Enabled = true;
}
private void Form1_Load(object sender, EventArgs e)
{
myTimer = new System.Windows.Forms.Timer();//实例化Timer定时器
myTimer.Tick += new EventHandler(CallBack2);//定时器关联事件函数
}
private void CallBack2(object sender,EventArgs e)//定时器事件
{
keybd_event(Keys.Return, 0, 0, 0);//模拟键盘输入:回车
}
private void btnStop_Click(object sender, EventArgs e)
{
myTimer.Enabled = false;//禁止定时器
}
private void btnStartBrowser_Click(object sender, EventArgs e)
{
if (string.IsNullOrEmpty(txtFile.Text)) return;
try
{
// 浏览器程序启动线程
Proc = new System.Diagnostics.Process();
Proc.StartInfo.FileName = txtFile.Text;
Proc.StartInfo.Arguments = txtNetAddr.Text; //浏览器打开URL参数
Proc.StartInfo.UseShellExecute = false;
Proc.StartInfo.RedirectStandardInput = true;
Proc.StartInfo.RedirectStandardOutput = true;
Proc.Start();
}
catch
{
Proc = null;
}
}
}
}
四、程序开发中的一些其他想法和问题
1.使用已知进程获取主窗口句柄,然后遍历子窗口句柄
以下代码与本程序无关,为片段,请勿直接复制使用,主要提供给有兴趣改进的人参考。
if (string.IsNullOrEmpty(txtFile.Text)) return;
try
{
Proc = new System.Diagnostics.Process();
Proc.StartInfo.FileName =txtFile.Text;
Proc.StartInfo.Arguments = txtNetAddr.Text;
Proc.StartInfo.UseShellExecute = false;
Proc.StartInfo.RedirectStandardInput = true;
Proc.StartInfo.RedirectStandardOutput = true;
Proc.Start();
Thread.Sleep(2000);
}
catch
{
Proc = null;
}
if (Proc.MainWindowHandle != null)
{
//调用 API, 传递数据
while (Proc.MainWindowHandle == IntPtr.Zero)
{
Proc.Refresh();
}
while (Proc.MainWindowHandle == IntPtr.Zero)
{
Proc.Refresh();
}
//执行代码略
}
【问题描述】:这里的线程是Proc,但是这个线程不是主窗口。该线程的主窗口句柄需要通过 Proc.MainWindowHandle 获取。在使用过程中,很容易获取到自己开发的C#GUI程序,对【记事本】程序来说是正常的,但是在【Chrome】浏览器上使用时,结果不是0就是异常. 【FireFox】有时能正常获取,有时异常。
2.网上搜索C#操作API函数少且不全
这里有一个API函数查询网站,基本上一口气把API函数用完了。#
3.如果想查看Windows下的API函数,也可以使用工具:
1.DLL 函数查看器
2.DLL 导出查看器
4.获取应用程序窗口句柄、标题、类型的工具软件
这里可以使用VS环境下的Spy++(C++)。
写在最后
关于C#中API函数的使用,由于个人喜好不同,参数类型也有很大差异。真正体验的文章相对较少。谬误更难解决。后期准备深入体验,同时准备写文章系列。虽然作者的能力有限,到时候肯定会有很多谬论,但作者坚持所有的内容都是以实践为导向的。程序必须经过调试和通过,才能放到网上。志同道合的读者不妨关注作者的博客,敬请期待,我们下期再见!
关于C#制作网站挂钩程序文章的实现本文到此结束。更多C#相关网站勾搭程序内容,请搜索我们之前的文章或者继续浏览以下相关文章希望大家以后多多支持!
时间:2021-10-30
c#Realize 网站 监控看是否正常
代码如下: 复制代码如下: public void MonitorWeb(Model.ServiceInfo mServerInfo) {var sUrl = mServerInfo.ServiceConfig; var mLogInfo = new Model.LogInfo {ServiceId = mServerInfo.ServiceId }; 试试 {var mWebRequest = (HttpWebRequest)WebRequest. 创建(网址);VA
C#实现抓取网站页面内容的示例方法
抓取新浪网的新闻版块,如图: 使用谷歌浏览器查看源代码: 通过分析,我们知道我们要查找的内容在以下两个标签之间: 复制代码,代码为如下: Content... 如图: Content.... 使用VS创建一个网站 如图:我们下载
C# Fiddler 插件实现网站离线浏览功能
有这样一个应用场景:你在做前端或者APP开发,需要调用服务端提供的接口。接口只能在公司内网访问:不能在公司外调试代码。如果您想在公司外部访问它怎么办?? 如果你在公司的时候保存了所有接口的响应内容,就可以在没有服务器的情况下在本地模拟一个服务器环境,这样就可以不受网络环境的限制,愉快的调试代码了。实现原理如下:首先使用Fiddler抓取包,抓取所有需要保存的接口(不仅仅是interfaces,html,css,js,image)。在 Fiddler 中,点击以下菜单 File -> Save -> All Se
C#如何控制IIS动态增删网站详解
我的目的是在Winform程序中直接启动一个HTTP服务器连接下游客户。找到相关技术有两种方式:1.使用C#动态添加网站应用到IIS,借用IIS的管理能力提供HTTP接口。这篇文章解释了这个2.在Winform程序中实现Web服务器逻辑,自己监控和管理客户端请求:现在使用IIS7自带的类库来管理IIS,功能更强大,更方便,不需要使用 DirecotryEntry 类。
C#关于爬取网站数据时csrf-token的分析与解决
航空公司物流单信息查询为post请求。通过后台模拟POST HTTP请求,发现无法获取页面数据。经查航空公司网站,发现网站使用CSRF攻击机制躲避攻击。播放 40X 错误。关于CSRF读者自己百度网站HTTP请求解析Headers表单数据头部收录cookies,x-csrf-token表单数据收录_csrf(与头部相同的值)。这里通过查看网站的JS源码,发现_csrf来自网页的head标签来猜测cookie和
C#Export网站 函数示例代码说明
这个export网站函数是指前端javascript触发的ashx函数,实现将服务器中的一个文件夹(包括其子文件夹和文件)复制到服务器中的另一个位置,当然是文件夹本身是 网站。所以导出网站最重要的两个功能,除了javascript触发器,就是C#ashx文件复制文件夹的操作。下面的代码是通过javascript Request函数调用copy .ashx函数文件实现传入需要复制的文件夹的子路径和复制到该位置的子路径两个参数。后台函数getWebList 函数是后台函数。这个功能
C#使用正则表达式捕获网站信息示例
本文中的一个示例描述了 C# 如何使用正则表达式来捕获 网站 信息。分享给大家,供大家参考,如下: 下面是京东商城商品详情的抓取示例。1.创建JdRobber.cs 程序类 public class JdRobber {// /// 判断是否链接京东 /// /// /// public
英雄联盟协助lol挂机不被踢的方法(lol挂机脚本)
调用API设置鼠标位置并模拟鼠标右键让人物移动,全局钩子等复制代码代码如下:using System;using System.采集s.Generic;using System.Linq;using System.文本; 使用 System.Windows.Forms;使用 System.Runtime.InteropServices;使用 System.Threading;命名空间 LOLSetCursor{ public cla
易语言使英雄联盟源码辅助
LOL辅助这个功能需要加载超级模块7.3。版本 2。组装窗口 assembly_start 窗口。汇编变量pid,整数类型。子程序 __start window_ created pid = take process ID ("League of Legends.exe") 监控热键(&Enable Infinite View Range, #F5 Key) 监控热键(&Turn off Infinite Visual Range, #F6 Key) 监控热键(&Enable Normal攻击范围,#F2 键) 监控热键(&关闭普通攻击范围,#F1 键) 监控热键(&打开炮塔范围,#F4 键) 监控热键(
Python3爬取英雄联盟英雄皮肤大图示例代码
我首先尝试了爬虫的想法。我先查了下网络,没有发现有API可用:然后我用bs4分析了英雄列表页面,但是请求发送到html,并没有英雄列表。在英雄列表节点上,只有“loading”中的字样:同方法,英雄详情的分析也是如此,所以我猜测应该是Javascript负责加载这些数据。我继续尝试和然后我查看了英雄榜的源码,查看了外部导入的js文件,还有一行中的js脚本,大约368行,找到了处理英雄榜的js注释,然后继续阅读这些代码,找到了第一个复活节彩蛋,也就是他介绍了一个
Python3爬虫爬取英雄联盟高清桌面壁纸功能示例【基于Scrapy框架】
本文介绍Python3爬虫爬取英雄联盟高清桌面壁纸的功能。分享给大家参考,如下: 使用Scrapy爬虫爬取英雄联盟高清桌面壁纸 源地址:项目启动前需要安装Python3和Scrapy,没有百度,这里就不具体介绍了。首先创建项目scrapy startproject loldesk,生成项目的目录结构。首先,您需要定义抓取元素。在item.py中,我们的项目使用图片名称和链接导入scrapy
使用Python制作微信跳转和跳转助手
1. 前言相信大家对微信跳转,以及现在的各种插件都不陌生。辅助也是满天飞,反正我的好友名单已经八九百了也就不足为奇了。某宝在上面搜索一堆结果,最低的居然3元多。我可以随心所欲地得分。真是太离谱了。作为程序员,我决心自己做,不是为了别的,而是为了锻炼自己。解决问题的能力也是为了娱乐。对于这种任务,最合适的当然是Python,一个丰富的第三方库,具有胶水语言的特性。
Python网络爬虫示例讲解
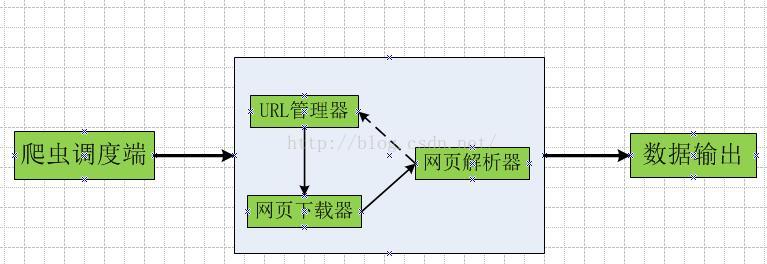
让我们来谈谈 Python 和网络爬虫。1.爬虫的定义。爬虫:自动爬取互联网数据的程序。2.爬虫的主要框架管理器获取要爬取的URL链接。如果URL管理器中存在需要爬取的URL链接,则爬虫调度器调用网页下载器下载对应的网页,然后调用网页解析器解析该网页,并将新的页面放入网页中页。将 URL 添加到 URL 管理器以输出有价值的数据。3.爬虫时序图4.URL manager URL manager管理要爬取的URL集合和已经爬取的URL集合,防止重复爬取和循环爬取。URL管理器的主要功能如下
如何实现IOS_SearchBar搜索栏和关键字高亮
搜索框效果演示:这就是所谓的搜索框,下面我们来看看如何使用代码实现这个功能。我使用的数据是英雄联盟的英雄列表,是JSON数据的txt文件,JSON数据处理代码如下: //获取文件路径的路径 NSString *path = [[NSBundle mainBundle] pathForResource:@"heros" ofType:@"txt"]; //将路径下的文件转换成NSData数据 NSData * data = [NSDat
Swift仿IOS最新版QQ抽屉侧滑及弹出视图
介绍很简单。我用Swift写了一个抽屉效果,可以直接使用,简单;很多软件都有抽屉效果,比如qq的左边抽屉,英雄联盟,滴滴打车,优步等等,都是用抽屉的;效果是iOS drawer type的结构实现分析,主要是在控制器的View中添加两个View,一个left view和一个mainView。这里我们自定义了一个 DrawerViewController,init(mainVC: UIViewController, leftMenuVC: UIViewController, leftWidth: CGFloat
Javascript实现模仿腾讯游戏选择
我们在玩腾讯游戏的时候,会有很多选择,比如选择什么区域,选择什么人物等等,下面我们来做一个简单的腾讯游戏选择。
js中常用的Tab切换效果(推荐)
如下图:tab *(margin:0; padding:0; list-style:none;} .box{ width: 1000px; overflow: hidden; margin:100px auto 查看全部
c#抓取网页数据(
程序开发文章正文测试内容的一些其它思路及问题写在最后)
C#制作网站钩子程序实现示例
内容三、程序开发过程四、关于程序开发的一些其他想法和问题写在最后的序言中
真正的想法是用C#GUI开发一个自动化测试软件,可以帮我完成500台电脑在线网络答题的压力测试。既要能自动定位并点击鼠标,还要能模拟用键盘输入字符信息。但实际上,想法很饱满,现实很骨感。还有一些问题需要解决。但是在完成这个项目的过程中,也产生了一些副产品,这也是相当有成就感的。现针对开发过程中出现的问题,查找并筛选一些经过测试的参考资料,将我们的理解和研究经验奉献给大家。特提供一个完整的例子:出现在线挂机对话框,按回车继续。创建了一个简单的“连接程序”来开始对话。希望大家一起开放思路,一起研究。
温馨提示:以下为本文文章内容,以下案例可供参考
一、程序界面(如下图)
名称:模拟键盘程序,为什么不用挂机程序,因为它的功能弱,范围窄,而且作为副产品,真的不是挂机用的。请注意,我们的目标是自动化网络测试。

二、 使用说明
1.接口说明
1. 应用程序路径,这里是FireFox浏览器,所以需要放程序的地址。
2.网站地址:符合URL格式的可直接访问的本地文件或网址
3.浏览器标题:FireFox程序隐藏了应用标题,如果看到标题栏显示:test
其实应用的标题应该是:Test——Mozilla Firefox
4.【启动浏览器】其实这个功能目前可以完全忽略,直接手动启动FireFox即可。
5. 【开始】按钮是精华,这里会根据【浏览器标题】的内容进行搜索
到真正的【句柄】在FireFox上浏览网页,如果找到,会显示【句柄】的十进制整数值。如果显示为 0,则表示未找到。
6.【停止】关闭定时器操作。
2.使用笔记
1. 显示[Handle]位置后,必须为非零值。如果为0,修改【浏览器标题】的内容,再次点击【开始】
2.FireFox 浏览器必须保持在所有表单的前面
3.保证【电脑】不会进入【睡眠】或进入【屏幕保护】状态
三、程序开发流程
1.测试页面
1.文件名:test.html
2.网页代码(如下):
测试
alert("ok");
2.程序完整代码
using System;
using System.Diagnostics;
using System.Runtime.InteropServices;
using System.Threading;
using System.Windows.Forms;
namespace 模拟键盘
{
public partial class Form1 : Form
{
[DllImport("user32.dll", EntryPoint = "keybd_event", SetLastError = true)]
public static extern void keybd_event(Keys bVk, byte bScan, uint dwFlags, uint dwExtraInfo);
[DllImport("user32.dll", EntryPoint = "FindWindow")]
private static extern IntPtr FindWindow(string IpClassName, string IpWindowName);
//查找窗体控件
public int iSeconds=30;
public delegate bool CallBack(int hwnd, int lParam);
public Process Proc = new Process();
public System.Windows.Forms.Timer myTimer;
public Form1()
{
InitializeComponent();
}
private void btnBrowser_Click(object sender, EventArgs e)
{
openFileDialog1.Filter = "*.exe|*.exe|所有文件|*.*";
openFileDialog1.FileName = "";
DialogResult dr = openFileDialog1.ShowDialog();
if(DialogResult.OK==dr)
{
txtFile.Text = openFileDialog1.FileName;
}
}
string str = "Message";
int iP = 0;
private void btnStart_Click(object sender, EventArgs e)
{
IntPtr hnd = FindWindow(null, txtTitle.Text);//获取句柄
lblMessage.Text = hnd.ToString();
iSeconds = int.Parse(txtSeconds.Text.Trim());
myTimer.Interval = 1000 * iSeconds; //1秒=1000毫秒
myTimer.Enabled = true;
}
private void Form1_Load(object sender, EventArgs e)
{
myTimer = new System.Windows.Forms.Timer();//实例化Timer定时器
myTimer.Tick += new EventHandler(CallBack2);//定时器关联事件函数
}
private void CallBack2(object sender,EventArgs e)//定时器事件
{
keybd_event(Keys.Return, 0, 0, 0);//模拟键盘输入:回车
}
private void btnStop_Click(object sender, EventArgs e)
{
myTimer.Enabled = false;//禁止定时器
}
private void btnStartBrowser_Click(object sender, EventArgs e)
{
if (string.IsNullOrEmpty(txtFile.Text)) return;
try
{
// 浏览器程序启动线程
Proc = new System.Diagnostics.Process();
Proc.StartInfo.FileName = txtFile.Text;
Proc.StartInfo.Arguments = txtNetAddr.Text; //浏览器打开URL参数
Proc.StartInfo.UseShellExecute = false;
Proc.StartInfo.RedirectStandardInput = true;
Proc.StartInfo.RedirectStandardOutput = true;
Proc.Start();
}
catch
{
Proc = null;
}
}
}
}
四、程序开发中的一些其他想法和问题
1.使用已知进程获取主窗口句柄,然后遍历子窗口句柄
以下代码与本程序无关,为片段,请勿直接复制使用,主要提供给有兴趣改进的人参考。
if (string.IsNullOrEmpty(txtFile.Text)) return;
try
{
Proc = new System.Diagnostics.Process();
Proc.StartInfo.FileName =txtFile.Text;
Proc.StartInfo.Arguments = txtNetAddr.Text;
Proc.StartInfo.UseShellExecute = false;
Proc.StartInfo.RedirectStandardInput = true;
Proc.StartInfo.RedirectStandardOutput = true;
Proc.Start();
Thread.Sleep(2000);
}
catch
{
Proc = null;
}
if (Proc.MainWindowHandle != null)
{
//调用 API, 传递数据
while (Proc.MainWindowHandle == IntPtr.Zero)
{
Proc.Refresh();
}
while (Proc.MainWindowHandle == IntPtr.Zero)
{
Proc.Refresh();
}
//执行代码略
}
【问题描述】:这里的线程是Proc,但是这个线程不是主窗口。该线程的主窗口句柄需要通过 Proc.MainWindowHandle 获取。在使用过程中,很容易获取到自己开发的C#GUI程序,对【记事本】程序来说是正常的,但是在【Chrome】浏览器上使用时,结果不是0就是异常. 【FireFox】有时能正常获取,有时异常。
2.网上搜索C#操作API函数少且不全
这里有一个API函数查询网站,基本上一口气把API函数用完了。#
3.如果想查看Windows下的API函数,也可以使用工具:
1.DLL 函数查看器

2.DLL 导出查看器

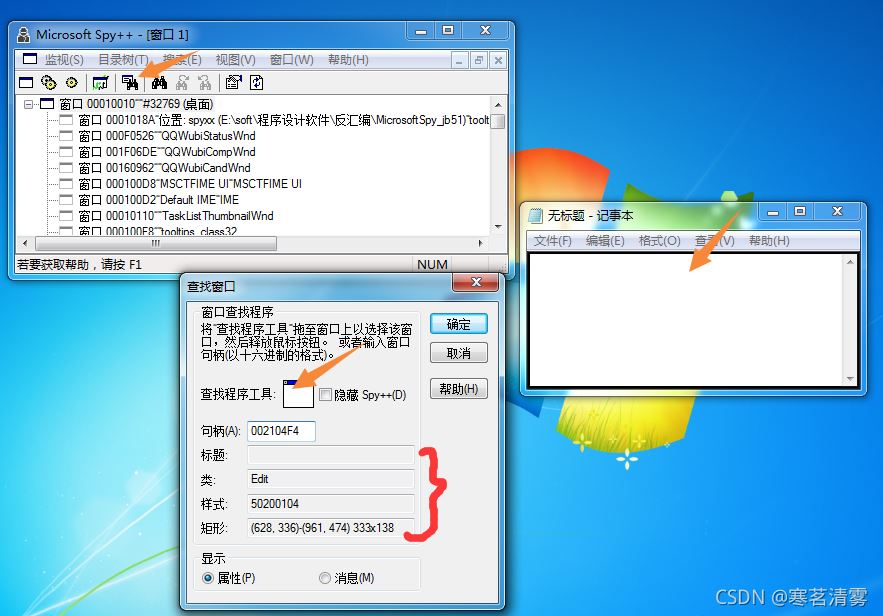
4.获取应用程序窗口句柄、标题、类型的工具软件
这里可以使用VS环境下的Spy++(C++)。
写在最后
关于C#中API函数的使用,由于个人喜好不同,参数类型也有很大差异。真正体验的文章相对较少。谬误更难解决。后期准备深入体验,同时准备写文章系列。虽然作者的能力有限,到时候肯定会有很多谬论,但作者坚持所有的内容都是以实践为导向的。程序必须经过调试和通过,才能放到网上。志同道合的读者不妨关注作者的博客,敬请期待,我们下期再见!
关于C#制作网站挂钩程序文章的实现本文到此结束。更多C#相关网站勾搭程序内容,请搜索我们之前的文章或者继续浏览以下相关文章希望大家以后多多支持!
时间:2021-10-30
c#Realize 网站 监控看是否正常
代码如下: 复制代码如下: public void MonitorWeb(Model.ServiceInfo mServerInfo) {var sUrl = mServerInfo.ServiceConfig; var mLogInfo = new Model.LogInfo {ServiceId = mServerInfo.ServiceId }; 试试 {var mWebRequest = (HttpWebRequest)WebRequest. 创建(网址);VA
C#实现抓取网站页面内容的示例方法
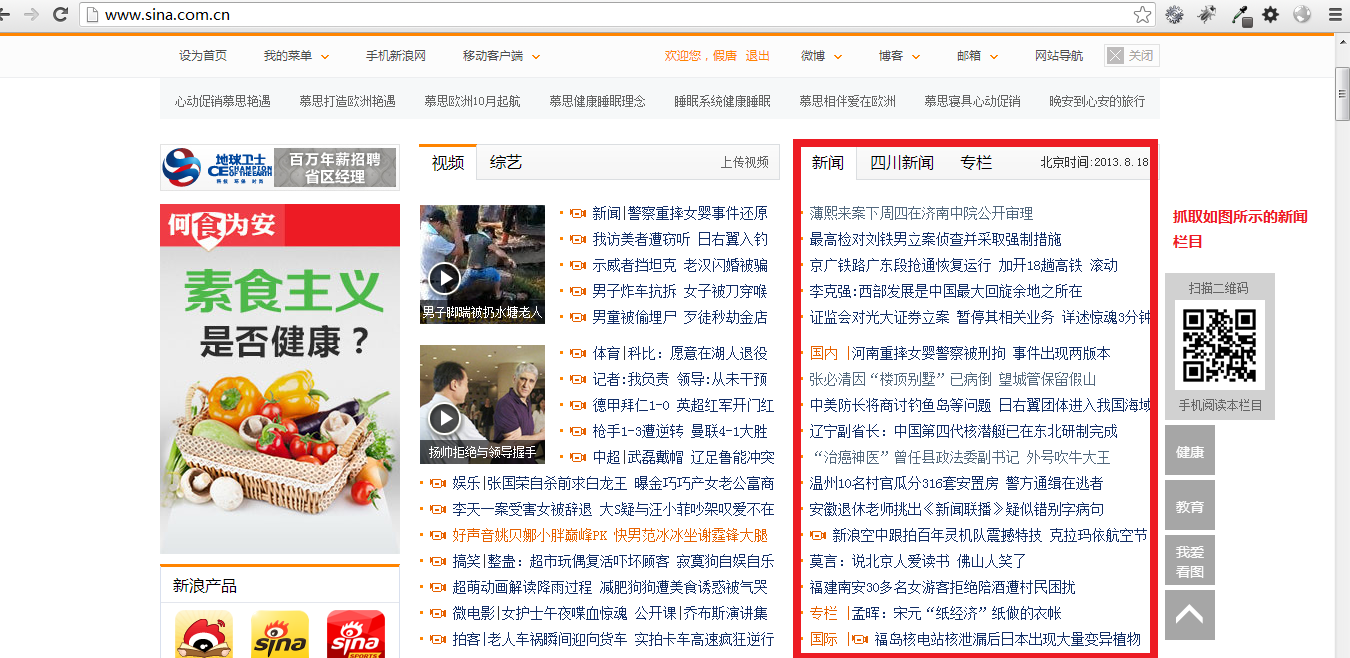
抓取新浪网的新闻版块,如图: 使用谷歌浏览器查看源代码: 通过分析,我们知道我们要查找的内容在以下两个标签之间: 复制代码,代码为如下: Content... 如图: Content.... 使用VS创建一个网站 如图:我们下载
C# Fiddler 插件实现网站离线浏览功能

有这样一个应用场景:你在做前端或者APP开发,需要调用服务端提供的接口。接口只能在公司内网访问:不能在公司外调试代码。如果您想在公司外部访问它怎么办?? 如果你在公司的时候保存了所有接口的响应内容,就可以在没有服务器的情况下在本地模拟一个服务器环境,这样就可以不受网络环境的限制,愉快的调试代码了。实现原理如下:首先使用Fiddler抓取包,抓取所有需要保存的接口(不仅仅是interfaces,html,css,js,image)。在 Fiddler 中,点击以下菜单 File -> Save -> All Se
C#如何控制IIS动态增删网站详解

我的目的是在Winform程序中直接启动一个HTTP服务器连接下游客户。找到相关技术有两种方式:1.使用C#动态添加网站应用到IIS,借用IIS的管理能力提供HTTP接口。这篇文章解释了这个2.在Winform程序中实现Web服务器逻辑,自己监控和管理客户端请求:现在使用IIS7自带的类库来管理IIS,功能更强大,更方便,不需要使用 DirecotryEntry 类。
C#关于爬取网站数据时csrf-token的分析与解决

航空公司物流单信息查询为post请求。通过后台模拟POST HTTP请求,发现无法获取页面数据。经查航空公司网站,发现网站使用CSRF攻击机制躲避攻击。播放 40X 错误。关于CSRF读者自己百度网站HTTP请求解析Headers表单数据头部收录cookies,x-csrf-token表单数据收录_csrf(与头部相同的值)。这里通过查看网站的JS源码,发现_csrf来自网页的head标签来猜测cookie和
C#Export网站 函数示例代码说明
这个export网站函数是指前端javascript触发的ashx函数,实现将服务器中的一个文件夹(包括其子文件夹和文件)复制到服务器中的另一个位置,当然是文件夹本身是 网站。所以导出网站最重要的两个功能,除了javascript触发器,就是C#ashx文件复制文件夹的操作。下面的代码是通过javascript Request函数调用copy .ashx函数文件实现传入需要复制的文件夹的子路径和复制到该位置的子路径两个参数。后台函数getWebList 函数是后台函数。这个功能
C#使用正则表达式捕获网站信息示例
本文中的一个示例描述了 C# 如何使用正则表达式来捕获 网站 信息。分享给大家,供大家参考,如下: 下面是京东商城商品详情的抓取示例。1.创建JdRobber.cs 程序类 public class JdRobber {// /// 判断是否链接京东 /// /// /// public
英雄联盟协助lol挂机不被踢的方法(lol挂机脚本)
调用API设置鼠标位置并模拟鼠标右键让人物移动,全局钩子等复制代码代码如下:using System;using System.采集s.Generic;using System.Linq;using System.文本; 使用 System.Windows.Forms;使用 System.Runtime.InteropServices;使用 System.Threading;命名空间 LOLSetCursor{ public cla
易语言使英雄联盟源码辅助

LOL辅助这个功能需要加载超级模块7.3。版本 2。组装窗口 assembly_start 窗口。汇编变量pid,整数类型。子程序 __start window_ created pid = take process ID ("League of Legends.exe") 监控热键(&Enable Infinite View Range, #F5 Key) 监控热键(&Turn off Infinite Visual Range, #F6 Key) 监控热键(&Enable Normal攻击范围,#F2 键) 监控热键(&关闭普通攻击范围,#F1 键) 监控热键(&打开炮塔范围,#F4 键) 监控热键(
Python3爬取英雄联盟英雄皮肤大图示例代码
我首先尝试了爬虫的想法。我先查了下网络,没有发现有API可用:然后我用bs4分析了英雄列表页面,但是请求发送到html,并没有英雄列表。在英雄列表节点上,只有“loading”中的字样:同方法,英雄详情的分析也是如此,所以我猜测应该是Javascript负责加载这些数据。我继续尝试和然后我查看了英雄榜的源码,查看了外部导入的js文件,还有一行中的js脚本,大约368行,找到了处理英雄榜的js注释,然后继续阅读这些代码,找到了第一个复活节彩蛋,也就是他介绍了一个
Python3爬虫爬取英雄联盟高清桌面壁纸功能示例【基于Scrapy框架】

本文介绍Python3爬虫爬取英雄联盟高清桌面壁纸的功能。分享给大家参考,如下: 使用Scrapy爬虫爬取英雄联盟高清桌面壁纸 源地址:项目启动前需要安装Python3和Scrapy,没有百度,这里就不具体介绍了。首先创建项目scrapy startproject loldesk,生成项目的目录结构。首先,您需要定义抓取元素。在item.py中,我们的项目使用图片名称和链接导入scrapy
使用Python制作微信跳转和跳转助手

1. 前言相信大家对微信跳转,以及现在的各种插件都不陌生。辅助也是满天飞,反正我的好友名单已经八九百了也就不足为奇了。某宝在上面搜索一堆结果,最低的居然3元多。我可以随心所欲地得分。真是太离谱了。作为程序员,我决心自己做,不是为了别的,而是为了锻炼自己。解决问题的能力也是为了娱乐。对于这种任务,最合适的当然是Python,一个丰富的第三方库,具有胶水语言的特性。
Python网络爬虫示例讲解
让我们来谈谈 Python 和网络爬虫。1.爬虫的定义。爬虫:自动爬取互联网数据的程序。2.爬虫的主要框架管理器获取要爬取的URL链接。如果URL管理器中存在需要爬取的URL链接,则爬虫调度器调用网页下载器下载对应的网页,然后调用网页解析器解析该网页,并将新的页面放入网页中页。将 URL 添加到 URL 管理器以输出有价值的数据。3.爬虫时序图4.URL manager URL manager管理要爬取的URL集合和已经爬取的URL集合,防止重复爬取和循环爬取。URL管理器的主要功能如下
如何实现IOS_SearchBar搜索栏和关键字高亮

搜索框效果演示:这就是所谓的搜索框,下面我们来看看如何使用代码实现这个功能。我使用的数据是英雄联盟的英雄列表,是JSON数据的txt文件,JSON数据处理代码如下: //获取文件路径的路径 NSString *path = [[NSBundle mainBundle] pathForResource:@"heros" ofType:@"txt"]; //将路径下的文件转换成NSData数据 NSData * data = [NSDat
Swift仿IOS最新版QQ抽屉侧滑及弹出视图

介绍很简单。我用Swift写了一个抽屉效果,可以直接使用,简单;很多软件都有抽屉效果,比如qq的左边抽屉,英雄联盟,滴滴打车,优步等等,都是用抽屉的;效果是iOS drawer type的结构实现分析,主要是在控制器的View中添加两个View,一个left view和一个mainView。这里我们自定义了一个 DrawerViewController,init(mainVC: UIViewController, leftMenuVC: UIViewController, leftWidth: CGFloat
Javascript实现模仿腾讯游戏选择

我们在玩腾讯游戏的时候,会有很多选择,比如选择什么区域,选择什么人物等等,下面我们来做一个简单的腾讯游戏选择。
js中常用的Tab切换效果(推荐)
如下图:tab *(margin:0; padding:0; list-style:none;} .box{ width: 1000px; overflow: hidden; margin:100px auto
c#抓取网页数据(【案例分析】模拟键盘程序,为什么不用挂机程序?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-31 14:12
内容
前言
真正的想法是用C#GUI开发一个自动化测试软件,可以帮我完成500台电脑在线网络答题的压力测试。既要能自动定位并点击鼠标,还要能模拟用键盘输入字符信息。但实际上,想法很饱满,现实很骨感。还有一些问题需要解决。但是在完成这个项目的过程中,也产生了一些副产品,这也是相当有成就感的。现针对开发过程中出现的问题,查找并筛选一些经过测试的参考资料,将我们的理解和研究经验奉献给大家。特提供一个完整的例子:出现在线挂机对话框,按回车继续。创建了一个简单的“连接程序”来开始对话。希望大家一起开放思路,一起研究。
温馨提示:以下为本文文章内容,以下案例可供参考
一、程序界面(如下图)
名称:模拟键盘程序,为什么不用挂机程序,因为它的功能弱,范围窄,而且作为副产品,真的不是挂机用的。请注意,我们的目标是自动化网络测试。
二、使用说明1.接口说明
1. 应用程序路径,这里是FireFox浏览器,所以需要放程序的地址。
2.网站地址:符合URL格式的可直接访问的本地文件或网址
3.浏览器标题:FireFox程序隐藏了应用标题,如果看到标题栏显示:test
其实应用的标题应该是:Test——Mozilla Firefox
4.【启动浏览器】其实这个功能目前可以完全忽略,直接手动启动FireFox即可。
5.【开始】按钮是精华,这里会根据【浏览器标题】的内容进行搜索
到真正的【句柄】在FireFox上浏览网页,如果找到,会显示【句柄】的十进制整数值。如果显示为 0,则表示未找到。
6.【停止】关闭定时器操作。
2.使用注意事项
1. 显示[Handle]位置后,必须为非零值。如果为0,修改【浏览器标题】的内容,再次点击【开始】
2.FireFox 浏览器必须保持在所有表单的前面
3.保证【电脑】不会进入【睡眠】或进入【屏幕保护】状态
三、程序开发流程1.测试网页
1.文件名:test.html
2.网页代码(如下):
测试
alert("ok");
2.程序完整代码
using System;
using System.Diagnostics;
using System.Runtime.InteropServices;
using System.Threading;
using System.Windows.Forms;
namespace 模拟键盘
{
public partial class Form1 : Form
{
[DllImport("user32.dll", EntryPoint = "keybd_event", SetLastError = true)]
public static extern void keybd_event(Keys bVk, byte bScan, uint dwFlags, uint dwExtraInfo);
[DllImport("user32.dll", EntryPoint = "FindWindow")]
private static extern IntPtr FindWindow(string IpClassName, string IpWindowName);
//查找窗体控件
public int iSeconds=30;
public delegate bool CallBack(int hwnd, int lParam);
public Process Proc = new Process();
public System.Windows.Forms.Timer myTimer;
public Form1()
{
InitializeComponent();
}
private void btnBrowser_Click(object sender, EventArgs e)
{
openFileDialog1.Filter = "*.exe|*.exe|所有文件|*.*";
openFileDialog1.FileName = "";
DialogResult dr = openFileDialog1.ShowDialog();
if(DialogResult.OK==dr)
{
txtFile.Text = openFileDialog1.FileName;
}
}
string str = "Message";
int iP = 0;
private void btnStart_Click(object sender, EventArgs e)
{
IntPtr hnd = FindWindow(null, txtTitle.Text);//获取句柄
lblMessage.Text = hnd.ToString();
iSeconds = int.Parse(txtSeconds.Text.Trim());
myTimer.Interval = 1000 * iSeconds; //1秒=1000毫秒
myTimer.Enabled = true;
}
private void Form1_Load(object sender, EventArgs e)
{
myTimer = new System.Windows.Forms.Timer();//实例化Timer定时器
myTimer.Tick += new EventHandler(CallBack2);//定时器关联事件函数
}
private void CallBack2(object sender,EventArgs e)//定时器事件
{
keybd_event(Keys.Return, 0, 0, 0);//模拟键盘输入:回车
}
private void btnStop_Click(object sender, EventArgs e)
{
myTimer.Enabled = false;//禁止定时器
}
private void btnStartBrowser_Click(object sender, EventArgs e)
{
if (string.IsNullOrEmpty(txtFile.Text)) return;
try
{
// 浏览器程序启动线程
Proc = new System.Diagnostics.Process();
Proc.StartInfo.FileName = txtFile.Text;
Proc.StartInfo.Arguments = txtNetAddr.Text; //浏览器打开URL参数
Proc.StartInfo.UseShellExecute = false;
Proc.StartInfo.RedirectStandardInput = true;
Proc.StartInfo.RedirectStandardOutput = true;
Proc.Start();
}
catch
{
Proc = null;
}
}
}
}
四、程序开发中的一些其他思路和问题1.使用已知进程获取主窗口句柄然后遍历子窗口句柄
以下代码与本程序无关,为片段,请勿直接复制使用,主要提供给有兴趣改进的人参考。
if (string.IsNullOrEmpty(txtFile.Text)) return;
try
{
Proc = new System.Diagnostics.Process();
Proc.StartInfo.FileName =txtFile.Text;
Proc.StartInfo.Arguments = txtNetAddr.Text;
Proc.StartInfo.UseShellExecute = false;
Proc.StartInfo.RedirectStandardInput = true;
Proc.StartInfo.RedirectStandardOutput = true;
Proc.Start();
Thread.Sleep(2000);
}
catch
{
Proc = null;
}
if (Proc.MainWindowHandle != null)
{
//调用 API, 传递数据
while (Proc.MainWindowHandle == IntPtr.Zero)
{
Proc.Refresh();
}
while (Proc.MainWindowHandle == IntPtr.Zero)
{
Proc.Refresh();
}
//执行代码略
}
【问题描述】:这里的线程是Proc,但是这个线程不是主窗口。该线程的主窗口句柄需要通过 Proc.MainWindowHandle 获取。在使用过程中,很容易获取到自己开发的C#GUI程序,对【记事本】程序来说是正常的,但是在【Chrome】浏览器上使用时,结果不是0就是异常. 【FireFox】有时能正常获取,有时异常。
2. C#操作API函数网上搜索很少,不完整
这里有一个API函数查询网站,基本上一口气把API函数用完了。#
3.如果想查看Windows下的API函数,也可以使用工具:
1.DLL 函数查看器
2.DLL 导出查看器
4.获取申请表工具软件的句柄、标题和类型
这里可以使用VS环境下的Spy++(C++)。
写在最后
关于C#中API函数的使用,由于个人喜好不同,参数类型也有很大差异。真正体验的文章相对较少。谬误更难解决。后期准备深入体验,同时准备写文章系列。虽然作者的能力有限,到时候肯定会有很多谬论,但作者坚持所有的内容都是以实践为导向的。程序必须经过调试和通过,才能放到网上。志同道合的读者不妨关注作者的博客,敬请期待,我们下期再见!
关于C#制作网站挂钩程序文章的实现本文到此结束。更多C#相关网站挂机程序内容,请搜索Script Home k7@的上一个或继续浏览下方相关文章,希望大家多多支持Scripthome未来! 查看全部
c#抓取网页数据(【案例分析】模拟键盘程序,为什么不用挂机程序?)
内容
前言
真正的想法是用C#GUI开发一个自动化测试软件,可以帮我完成500台电脑在线网络答题的压力测试。既要能自动定位并点击鼠标,还要能模拟用键盘输入字符信息。但实际上,想法很饱满,现实很骨感。还有一些问题需要解决。但是在完成这个项目的过程中,也产生了一些副产品,这也是相当有成就感的。现针对开发过程中出现的问题,查找并筛选一些经过测试的参考资料,将我们的理解和研究经验奉献给大家。特提供一个完整的例子:出现在线挂机对话框,按回车继续。创建了一个简单的“连接程序”来开始对话。希望大家一起开放思路,一起研究。
温馨提示:以下为本文文章内容,以下案例可供参考
一、程序界面(如下图)
名称:模拟键盘程序,为什么不用挂机程序,因为它的功能弱,范围窄,而且作为副产品,真的不是挂机用的。请注意,我们的目标是自动化网络测试。

二、使用说明1.接口说明
1. 应用程序路径,这里是FireFox浏览器,所以需要放程序的地址。
2.网站地址:符合URL格式的可直接访问的本地文件或网址
3.浏览器标题:FireFox程序隐藏了应用标题,如果看到标题栏显示:test
其实应用的标题应该是:Test——Mozilla Firefox
4.【启动浏览器】其实这个功能目前可以完全忽略,直接手动启动FireFox即可。
5.【开始】按钮是精华,这里会根据【浏览器标题】的内容进行搜索
到真正的【句柄】在FireFox上浏览网页,如果找到,会显示【句柄】的十进制整数值。如果显示为 0,则表示未找到。
6.【停止】关闭定时器操作。
2.使用注意事项
1. 显示[Handle]位置后,必须为非零值。如果为0,修改【浏览器标题】的内容,再次点击【开始】
2.FireFox 浏览器必须保持在所有表单的前面
3.保证【电脑】不会进入【睡眠】或进入【屏幕保护】状态
三、程序开发流程1.测试网页
1.文件名:test.html
2.网页代码(如下):
测试
alert("ok");
2.程序完整代码
using System;
using System.Diagnostics;
using System.Runtime.InteropServices;
using System.Threading;
using System.Windows.Forms;
namespace 模拟键盘
{
public partial class Form1 : Form
{
[DllImport("user32.dll", EntryPoint = "keybd_event", SetLastError = true)]
public static extern void keybd_event(Keys bVk, byte bScan, uint dwFlags, uint dwExtraInfo);
[DllImport("user32.dll", EntryPoint = "FindWindow")]
private static extern IntPtr FindWindow(string IpClassName, string IpWindowName);
//查找窗体控件
public int iSeconds=30;
public delegate bool CallBack(int hwnd, int lParam);
public Process Proc = new Process();
public System.Windows.Forms.Timer myTimer;
public Form1()
{
InitializeComponent();
}
private void btnBrowser_Click(object sender, EventArgs e)
{
openFileDialog1.Filter = "*.exe|*.exe|所有文件|*.*";
openFileDialog1.FileName = "";
DialogResult dr = openFileDialog1.ShowDialog();
if(DialogResult.OK==dr)
{
txtFile.Text = openFileDialog1.FileName;
}
}
string str = "Message";
int iP = 0;
private void btnStart_Click(object sender, EventArgs e)
{
IntPtr hnd = FindWindow(null, txtTitle.Text);//获取句柄
lblMessage.Text = hnd.ToString();
iSeconds = int.Parse(txtSeconds.Text.Trim());
myTimer.Interval = 1000 * iSeconds; //1秒=1000毫秒
myTimer.Enabled = true;
}
private void Form1_Load(object sender, EventArgs e)
{
myTimer = new System.Windows.Forms.Timer();//实例化Timer定时器
myTimer.Tick += new EventHandler(CallBack2);//定时器关联事件函数
}
private void CallBack2(object sender,EventArgs e)//定时器事件
{
keybd_event(Keys.Return, 0, 0, 0);//模拟键盘输入:回车
}
private void btnStop_Click(object sender, EventArgs e)
{
myTimer.Enabled = false;//禁止定时器
}
private void btnStartBrowser_Click(object sender, EventArgs e)
{
if (string.IsNullOrEmpty(txtFile.Text)) return;
try
{
// 浏览器程序启动线程
Proc = new System.Diagnostics.Process();
Proc.StartInfo.FileName = txtFile.Text;
Proc.StartInfo.Arguments = txtNetAddr.Text; //浏览器打开URL参数
Proc.StartInfo.UseShellExecute = false;
Proc.StartInfo.RedirectStandardInput = true;
Proc.StartInfo.RedirectStandardOutput = true;
Proc.Start();
}
catch
{
Proc = null;
}
}
}
}
四、程序开发中的一些其他思路和问题1.使用已知进程获取主窗口句柄然后遍历子窗口句柄
以下代码与本程序无关,为片段,请勿直接复制使用,主要提供给有兴趣改进的人参考。
if (string.IsNullOrEmpty(txtFile.Text)) return;
try
{
Proc = new System.Diagnostics.Process();
Proc.StartInfo.FileName =txtFile.Text;
Proc.StartInfo.Arguments = txtNetAddr.Text;
Proc.StartInfo.UseShellExecute = false;
Proc.StartInfo.RedirectStandardInput = true;
Proc.StartInfo.RedirectStandardOutput = true;
Proc.Start();
Thread.Sleep(2000);
}
catch
{
Proc = null;
}
if (Proc.MainWindowHandle != null)
{
//调用 API, 传递数据
while (Proc.MainWindowHandle == IntPtr.Zero)
{
Proc.Refresh();
}
while (Proc.MainWindowHandle == IntPtr.Zero)
{
Proc.Refresh();
}
//执行代码略
}
【问题描述】:这里的线程是Proc,但是这个线程不是主窗口。该线程的主窗口句柄需要通过 Proc.MainWindowHandle 获取。在使用过程中,很容易获取到自己开发的C#GUI程序,对【记事本】程序来说是正常的,但是在【Chrome】浏览器上使用时,结果不是0就是异常. 【FireFox】有时能正常获取,有时异常。
2. C#操作API函数网上搜索很少,不完整
这里有一个API函数查询网站,基本上一口气把API函数用完了。#
3.如果想查看Windows下的API函数,也可以使用工具:
1.DLL 函数查看器

2.DLL 导出查看器

4.获取申请表工具软件的句柄、标题和类型
这里可以使用VS环境下的Spy++(C++)。

写在最后
关于C#中API函数的使用,由于个人喜好不同,参数类型也有很大差异。真正体验的文章相对较少。谬误更难解决。后期准备深入体验,同时准备写文章系列。虽然作者的能力有限,到时候肯定会有很多谬论,但作者坚持所有的内容都是以实践为导向的。程序必须经过调试和通过,才能放到网上。志同道合的读者不妨关注作者的博客,敬请期待,我们下期再见!
关于C#制作网站挂钩程序文章的实现本文到此结束。更多C#相关网站挂机程序内容,请搜索Script Home k7@的上一个或继续浏览下方相关文章,希望大家多多支持Scripthome未来!
c#抓取网页数据(魔兽世界几个坑说下就是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-30 02:00
这里有几个坑:
第一个是记得获取代理IP爬取网站第一次忘记获取代理,ip被封了
二是判断网页是否被压缩,但是第一次没有得到结果。
///
/// 抓取网页并转码
///
///
///
///
public string HttpGet(string url, string post_parament)
{
string html;
HttpWebRequest Web_Request = (HttpWebRequest)WebRequest.Create(url);
Web_Request.Timeout = 30000;
Web_Request.Method = "GET";
Web_Request.UserAgent = "Mozilla/4.0";
Web_Request.Headers.Add("Accept-Encoding", "gzip, deflate");
//Web_Request.Credentials = CredentialCache.DefaultCredentials;
//设置代理属性WebProxy-------------------------------------------------
WebProxy proxy = new WebProxy("111.13.7.120", 80);
//在发起HTTP请求前将proxy赋值给HttpWebRequest的Proxy属性
Web_Request.Proxy = proxy;
HttpWebResponse Web_Response = (HttpWebResponse)Web_Request.GetResponse();
if (Web_Response.ContentEncoding.ToLower() == "gzip") // 如果使用了GZip则先解压
{
using (Stream Stream_Receive = Web_Response.GetResponseStream())
{
using (var Zip_Stream = new GZipStream(Stream_Receive, CompressionMode.Decompress))
{
using (StreamReader Stream_Reader = new StreamReader(Zip_Stream, Encoding.Default))
{
html = Stream_Reader.ReadToEnd();
}
}
}
}
else
{
using (Stream Stream_Receive = Web_Response.GetResponseStream())
{
using (StreamReader Stream_Reader = new StreamReader(Stream_Receive, Encoding.Default))
{
html = Stream_Reader.ReadToEnd();
}
}
}
return html;
}
二、 下面是使用正则处理的内容。因为对正则表达式不熟悉,重复的动作太多。
1.先获取网页内容
IWebHttpRepository webHttpRepository = new WebHttpRepository();
string html = webHttpRepository.HttpGet(Url_Txt.Text, "");
2.获取书名和文章列表
标题
文章列表
<p>
string Novel_Name = Regex.Match(html, @"(?]+)\1[^>]*>(?(?:(?! 查看全部
c#抓取网页数据(魔兽世界几个坑说下就是)
这里有几个坑:
第一个是记得获取代理IP爬取网站第一次忘记获取代理,ip被封了
二是判断网页是否被压缩,但是第一次没有得到结果。
///
/// 抓取网页并转码
///
///
///
///
public string HttpGet(string url, string post_parament)
{
string html;
HttpWebRequest Web_Request = (HttpWebRequest)WebRequest.Create(url);
Web_Request.Timeout = 30000;
Web_Request.Method = "GET";
Web_Request.UserAgent = "Mozilla/4.0";
Web_Request.Headers.Add("Accept-Encoding", "gzip, deflate");
//Web_Request.Credentials = CredentialCache.DefaultCredentials;
//设置代理属性WebProxy-------------------------------------------------
WebProxy proxy = new WebProxy("111.13.7.120", 80);
//在发起HTTP请求前将proxy赋值给HttpWebRequest的Proxy属性
Web_Request.Proxy = proxy;
HttpWebResponse Web_Response = (HttpWebResponse)Web_Request.GetResponse();
if (Web_Response.ContentEncoding.ToLower() == "gzip") // 如果使用了GZip则先解压
{
using (Stream Stream_Receive = Web_Response.GetResponseStream())
{
using (var Zip_Stream = new GZipStream(Stream_Receive, CompressionMode.Decompress))
{
using (StreamReader Stream_Reader = new StreamReader(Zip_Stream, Encoding.Default))
{
html = Stream_Reader.ReadToEnd();
}
}
}
}
else
{
using (Stream Stream_Receive = Web_Response.GetResponseStream())
{
using (StreamReader Stream_Reader = new StreamReader(Stream_Receive, Encoding.Default))
{
html = Stream_Reader.ReadToEnd();
}
}
}
return html;
}
二、 下面是使用正则处理的内容。因为对正则表达式不熟悉,重复的动作太多。
1.先获取网页内容
IWebHttpRepository webHttpRepository = new WebHttpRepository();
string html = webHttpRepository.HttpGet(Url_Txt.Text, "");
2.获取书名和文章列表
标题

文章列表

<p>
string Novel_Name = Regex.Match(html, @"(?]+)\1[^>]*>(?(?:(?!
c#抓取网页数据( 网页抓取是通过自动化手段检索数据的过程-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-26 15:09
网页抓取是通过自动化手段检索数据的过程-乐题库)
网页抓取是通过自动化手段检索数据的过程。在很多场景中都是不可或缺的,比如竞争对手价格监控、房源上市、潜在客户和舆情监控、新闻文章或金融数据聚合。
在编写网络抓取代码时,您必须做出的第一个决定是选择您的编程语言。您可以使用多种语言进行编写,例如 Python、JavaScript、Java、Ruby 或 C#。所有提到的语言都提供了强大的网页抓取功能。
在本文中,我们将探索 C# 并向您展示如何创建一个真正的 C# 公共网络爬虫。请记住,即使我们使用 C#,您也可以将此信息调整为 .NET 平台支持的所有语言,包括 VB.NET 和 F#。
01.C#网页爬虫工具
在编写任何代码之前,第一步是选择合适的 C# 库或包。这些 C# 库或包将能够下载 HTML 页面、解析它们并从这些页面中提取所需的数据。一些最流行的 C# 包如下:
●ScrapySharp
●傀儡师夏普
●HTML 敏捷包
Html Agility Pack 是最流行的 C# 包,仅 Nuget 就有近 5000 万次下载。其流行的原因有很多,其中最重要的是HTML解析器可以直接下载网页,也可以使用浏览器下载。这个包可以容忍格式错误的 HTML 并支持 XPath。此外,它甚至可以解析本地 HTML 文件;因此,我们将在本文中进一步使用此包。
ScrapySharp 为 C# 编程添加了更多功能。这个包支持 CSS 选择器,可以模拟 Web 浏览器。虽然 ScrapySharp 被认为是一个强大的 C# 包,但程序员使用它进行维护的概率并不是很高。
Puppeteer Sharp 是著名的 Node.js Puppeteer 项目的 .NET 端口。它使用相同的 Chromium 浏览器来加载页面。此外,该包使用 async-await 风格的代码来支持异步和预操作管理。如果你已经熟悉这个 C# 包并且需要浏览器来渲染页面,那么 Puppeteer Sharp 可能是一个不错的选择。
02. 使用C#搭建网络爬虫
如前所述,现在我们将演示如何编写将使用 Html Agility Pack 的 C# 公共网络爬虫代码。我们将使用 .NET 5 SDK 和 Visual Studio Code。此代码已在 .NET Core 3 和 .NET 5 上进行了测试,它应该适用于其他版本的 .NET。
我们将建立一个假设场景:抓取在线书店并采集书名和价格。
在编写C#网络爬虫之前,我们先搭建好开发环境。
03.搭建开发环境
对于 C# 开发环境,请安装 Visual Studio Code。请注意,如果您使用 Visual Studio 和 Visual Studio Code 编写 C# 代码,则需要注意它们是两个完全不同的应用程序。
安装 Visual Studio Code 后,安装 .NET 5.0 或更高版本。您也可以使用 .NET Core 3.1。安装完成后,打开终端并运行以下命令以验证 .NET CLI 或命令行界面是否正常工作:
dotnet --version
这行命令将输出已安装的 .NET 的版本号。
04. 项目结构和依赖
此代码将成为 .NET 项目的一部分。为简单起见,创建一个控制台应用程序。然后,创建一个文件夹,您将在其中编写 C# 代码。打开终端并导航到该文件夹。输入以下命令:
dotnet new console
该命令的输出应该是控制台应用程序已经成功创建的信息。
是时候安装所需的软件包了。使用C#抓取公共网页,Html Agility Pack会是一个不错的选择。您可以使用以下命令为该项目安装它:
dotnet add package HtmlAgilityPack
安装另一个包,以便我们可以轻松地将捕获的数据导出到 CSV 文件:
dotnet add package CsvHelper
如果您使用的是 Visual Studio 而不是 Visual Studio Code,请单击“文件”,选择“新建解决方案”,然后按“控制台应用程序”按钮。要安装依赖项,请按照下列步骤操作:
●选择项目;
● 单击管理项目依赖项。这将打开 NuGet 包窗口;
●搜索HtmlAgilityPack并选择它;
● 最后,搜索CsvHelper,选择它,然后单击添加包。
Visual Studio 中的 Nuget 包管理器
安装完这些包后,我们就可以继续编写爬取网上书店的代码了。
05.下载并解析网页数据
任何网页抓取程序的第一步都是下载网页的 HTML。这个HTML会是一个字符串,你需要把它转换成一个可以进一步处理的对象,这是第二步,这部分叫做解析。Html Agility Pack 可以从本地文件、HTML 字符串、任何 URL 和浏览器读取和解析文件。
在我们的例子中,我们需要做的就是从 URL 中获取 HTML。Html Agility Pack 不使用.NET 原生功能,而是提供了一个方便的类-HtmlWeb。这个类提供了一个Load函数,它可以接受一个URL,并返回一个HtmlDocument类的实例,这也是我们使用Part的包。有了这些信息,我们就可以编写一个接受 URL 并返回 HtmlDocument 实例的函数。
打开Program.cs文件,在类中输入这个函数Program:
// Parses the URL and returns HtmlDocument object
static HtmlDocument GetDocument (string url)
{
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load(url);
return doc;
}
这样,第一步的代码就完成了。下一步是解析文档。
06.解析 HTML:获取书籍链接
在这部分代码中,我们将从网页中提取所需的信息。在这个阶段,文档现在是一个 HtmlDocument 类型的对象。这个类公开了两个函数来选择元素。这两个函数都接受 XPath 输入并返回 HtmlNode 或 HtmlNode采集。
下面是这两个函数的签名:
public HtmlNodeCollection SelectNodes(string xpath);
public HtmlNode SelectSingleNode(string xpath);
让我们先讨论 SelectNodes。
对于这个例子——C#网络爬虫——我们将从这个页面抓取所有书籍的详细信息。
首先,需要对其进行解析,以便可以提取到所有书籍的链接。在浏览器中打开上述书店页面,右键单击任一图书链接,然后单击“检查”按钮。开发人员工具将打开。
了解标记后,您要选择的 XPath 应如下所示:
//h3/a
现在可以将此 XPath 传递给 SelectNodes 函数。
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
请注意 SelectNodes 函数是由
由 HtmlDocument 的 DocumentNode 属性调用。
变量 linkNodes 是一个集合。我们可以写一个foreach循环,从每个链接中一一获取href值。我们只需要解决一个小问题——即页面上的链接是相对链接。因此,在我们抓取这些提取的链接之前,我们需要将它们转换为绝对 URL。
为了转换相对链接,我们可以使用 Uri 类。我们使用这个构造函数来获取具有绝对 URL 的 Uri 对象。
dotnet --version
一旦我们有了 Uri 对象,我们就可以简单地检查 AbsoluteUri 属性来获取完整的 URL。
我们将所有这些都写在一个函数中,以保持代码的有序性。
static List GetBookLinks(string url)
{
var bookLinks = new List();
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
var baseUri = new Uri(url);
foreach (var link in linkNodes)
{
string href = link.Attributes["href"].Value;
bookLinks.Add(new Uri(baseUri, href).AbsoluteUri);
}
return bookLinks;
}
在这个函数中,我们从一个空的 List 对象开始。在 foreach 循环中,我们将所有链接添加到此对象并返回它。
现在,我们可以修改 Main() 函数,以便我们可以测试到目前为止编写的 C# 代码。修改后的函数如下:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
}
要运行此代码,请打开终端并导航到收录此文件的目录,然后键入以下内容:
dotnet run
输出应如下所示:
Found 20 links
然后我们继续下一部分,我们将处理所有链接以获取书籍数据。
07.解析HTML:获取书籍详情
此时,我们有一个收录书籍 URL 的字符串列表。我们可以简单的写一个循环,先用我们写的GetDocument函数来获取文档。之后,我们将使用 SelectSingleNode 函数来提取书名和价格。
为了使数据清晰、有条理,我们从一个类开始。这个类将代表一本书,有两个属性——标题和价格。示例如下:
然后,在浏览器中打开 Title-//h1 的书页。为价格创建 XPath 有点棘手,因为相同的类应用于底部的附加书籍。
XPath 的价格
XPath 的价格是这样的:
//div[contains(@class,"product_main")]/p[@class="price_color"]
请注意 XPath 收录双引号。我们将不得不通过在它们前面加上反斜杠来转义这些字符。
现在我们可以使用 SelectSingleNode 函数获取节点,然后使用 InnerText 属性获取元素中收录的文本。我们可以将所有内容放在一个函数中,如下所示:
static List GetBookDetails(List urls)
{
var books = new List();
foreach (var url in urls)
{
HtmlDocument document = GetDocument(url);
var titleXPath = "//h1";
var priceXPath = "//div[contains(@class,\"product_main\")]/p[@class=\"price_color\"]";
var book = new Book();
book.Title = document.DocumentNode.SelectSingleNode (priceXPath).InnerText;
book.Price = document.DocumentNode.SelectSingleNode(priceXPath).InnerText;
books.Add(book);
}
return books;
}
此函数将返回 Book 对象列表。是时候更新 Main() 函数了:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
var books = GetBookDetails(bookLinks);
}
这个网络抓取项目的最后一部分是将数据导出到 CSV。
08.导出数据
如果你还没有安装 CsvHelper,你可以使用
dotnet add package CsvHelper
在终端运行该命令即可完成此操作。
导出功能非常简单。首先,我们需要创建一个 StreamWriter 并将 CSV 文件名作为参数发送。接下来,我们将使用这个对象来创建一个 CsvWriter。最后,我们可以使用 WriteRecords 函数在一行代码中编写所有书籍。
为了确保所有资源都正确关闭,我们可以使用 using 块。我们还可以将所有内容都包装在一个函数中,如下所示:
static void exportToCSV(List books)
{
using (var writer = new StreamWriter("./books.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
csv.WriteRecords(books);
}
}
最后,我们可以从 Main() 函数中调用这个函数:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
var books = GetBookDetails(bookLinks);
exportToCSV(books);
}
要运行此代码,请打开终端并运行以下命令:
dotnet run
几秒钟后,您将创建一个 books.csv 文件。
09. 结论
如果你想用 C# 写一个网络爬虫,你可以使用多个包。在本文中,我们展示了如何使用 Html Agility Pack,这是一个功能强大且易于使用的包。也是一个简单的例子,可以进一步增强;例如,您可以尝试将上述逻辑添加到此代码中以处理多个页面。
如果您想了解更多有关使用其他编程语言进行网页抓取的工作原理的信息,您可以查看使用 Python 进行网页抓取的指南。我们还有一个
常见问题
Q:C#适合做网页爬虫吗?
A:与 Python 类似,C# 被广泛用于网络爬虫。在决定选择哪种编程语言时,选择您最熟悉的一种很重要。但是您将能够在 Python 和 C# 中找到示例网络爬虫。
问:网络抓取合法吗?
答:如果在不违反任何法律的情况下使用代理,它们可能是合法的。但是,在与代理人进行任何活动之前,您应该就您的具体案件获得专业的法律建议。请参考我们的文章“网络抓取合法吗?” 查看全部
c#抓取网页数据(
网页抓取是通过自动化手段检索数据的过程-乐题库)

网页抓取是通过自动化手段检索数据的过程。在很多场景中都是不可或缺的,比如竞争对手价格监控、房源上市、潜在客户和舆情监控、新闻文章或金融数据聚合。
在编写网络抓取代码时,您必须做出的第一个决定是选择您的编程语言。您可以使用多种语言进行编写,例如 Python、JavaScript、Java、Ruby 或 C#。所有提到的语言都提供了强大的网页抓取功能。
在本文中,我们将探索 C# 并向您展示如何创建一个真正的 C# 公共网络爬虫。请记住,即使我们使用 C#,您也可以将此信息调整为 .NET 平台支持的所有语言,包括 VB.NET 和 F#。
01.C#网页爬虫工具
在编写任何代码之前,第一步是选择合适的 C# 库或包。这些 C# 库或包将能够下载 HTML 页面、解析它们并从这些页面中提取所需的数据。一些最流行的 C# 包如下:
●ScrapySharp
●傀儡师夏普
●HTML 敏捷包
Html Agility Pack 是最流行的 C# 包,仅 Nuget 就有近 5000 万次下载。其流行的原因有很多,其中最重要的是HTML解析器可以直接下载网页,也可以使用浏览器下载。这个包可以容忍格式错误的 HTML 并支持 XPath。此外,它甚至可以解析本地 HTML 文件;因此,我们将在本文中进一步使用此包。
ScrapySharp 为 C# 编程添加了更多功能。这个包支持 CSS 选择器,可以模拟 Web 浏览器。虽然 ScrapySharp 被认为是一个强大的 C# 包,但程序员使用它进行维护的概率并不是很高。
Puppeteer Sharp 是著名的 Node.js Puppeteer 项目的 .NET 端口。它使用相同的 Chromium 浏览器来加载页面。此外,该包使用 async-await 风格的代码来支持异步和预操作管理。如果你已经熟悉这个 C# 包并且需要浏览器来渲染页面,那么 Puppeteer Sharp 可能是一个不错的选择。
02. 使用C#搭建网络爬虫
如前所述,现在我们将演示如何编写将使用 Html Agility Pack 的 C# 公共网络爬虫代码。我们将使用 .NET 5 SDK 和 Visual Studio Code。此代码已在 .NET Core 3 和 .NET 5 上进行了测试,它应该适用于其他版本的 .NET。
我们将建立一个假设场景:抓取在线书店并采集书名和价格。
在编写C#网络爬虫之前,我们先搭建好开发环境。
03.搭建开发环境
对于 C# 开发环境,请安装 Visual Studio Code。请注意,如果您使用 Visual Studio 和 Visual Studio Code 编写 C# 代码,则需要注意它们是两个完全不同的应用程序。
安装 Visual Studio Code 后,安装 .NET 5.0 或更高版本。您也可以使用 .NET Core 3.1。安装完成后,打开终端并运行以下命令以验证 .NET CLI 或命令行界面是否正常工作:
dotnet --version
这行命令将输出已安装的 .NET 的版本号。
04. 项目结构和依赖
此代码将成为 .NET 项目的一部分。为简单起见,创建一个控制台应用程序。然后,创建一个文件夹,您将在其中编写 C# 代码。打开终端并导航到该文件夹。输入以下命令:
dotnet new console
该命令的输出应该是控制台应用程序已经成功创建的信息。
是时候安装所需的软件包了。使用C#抓取公共网页,Html Agility Pack会是一个不错的选择。您可以使用以下命令为该项目安装它:
dotnet add package HtmlAgilityPack
安装另一个包,以便我们可以轻松地将捕获的数据导出到 CSV 文件:
dotnet add package CsvHelper
如果您使用的是 Visual Studio 而不是 Visual Studio Code,请单击“文件”,选择“新建解决方案”,然后按“控制台应用程序”按钮。要安装依赖项,请按照下列步骤操作:
●选择项目;
● 单击管理项目依赖项。这将打开 NuGet 包窗口;
●搜索HtmlAgilityPack并选择它;
● 最后,搜索CsvHelper,选择它,然后单击添加包。
Visual Studio 中的 Nuget 包管理器
安装完这些包后,我们就可以继续编写爬取网上书店的代码了。
05.下载并解析网页数据
任何网页抓取程序的第一步都是下载网页的 HTML。这个HTML会是一个字符串,你需要把它转换成一个可以进一步处理的对象,这是第二步,这部分叫做解析。Html Agility Pack 可以从本地文件、HTML 字符串、任何 URL 和浏览器读取和解析文件。
在我们的例子中,我们需要做的就是从 URL 中获取 HTML。Html Agility Pack 不使用.NET 原生功能,而是提供了一个方便的类-HtmlWeb。这个类提供了一个Load函数,它可以接受一个URL,并返回一个HtmlDocument类的实例,这也是我们使用Part的包。有了这些信息,我们就可以编写一个接受 URL 并返回 HtmlDocument 实例的函数。
打开Program.cs文件,在类中输入这个函数Program:
// Parses the URL and returns HtmlDocument object
static HtmlDocument GetDocument (string url)
{
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load(url);
return doc;
}
这样,第一步的代码就完成了。下一步是解析文档。
06.解析 HTML:获取书籍链接
在这部分代码中,我们将从网页中提取所需的信息。在这个阶段,文档现在是一个 HtmlDocument 类型的对象。这个类公开了两个函数来选择元素。这两个函数都接受 XPath 输入并返回 HtmlNode 或 HtmlNode采集。
下面是这两个函数的签名:
public HtmlNodeCollection SelectNodes(string xpath);
public HtmlNode SelectSingleNode(string xpath);
让我们先讨论 SelectNodes。
对于这个例子——C#网络爬虫——我们将从这个页面抓取所有书籍的详细信息。
首先,需要对其进行解析,以便可以提取到所有书籍的链接。在浏览器中打开上述书店页面,右键单击任一图书链接,然后单击“检查”按钮。开发人员工具将打开。
了解标记后,您要选择的 XPath 应如下所示:
//h3/a
现在可以将此 XPath 传递给 SelectNodes 函数。
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
请注意 SelectNodes 函数是由
由 HtmlDocument 的 DocumentNode 属性调用。
变量 linkNodes 是一个集合。我们可以写一个foreach循环,从每个链接中一一获取href值。我们只需要解决一个小问题——即页面上的链接是相对链接。因此,在我们抓取这些提取的链接之前,我们需要将它们转换为绝对 URL。
为了转换相对链接,我们可以使用 Uri 类。我们使用这个构造函数来获取具有绝对 URL 的 Uri 对象。
dotnet --version
一旦我们有了 Uri 对象,我们就可以简单地检查 AbsoluteUri 属性来获取完整的 URL。
我们将所有这些都写在一个函数中,以保持代码的有序性。
static List GetBookLinks(string url)
{
var bookLinks = new List();
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
var baseUri = new Uri(url);
foreach (var link in linkNodes)
{
string href = link.Attributes["href"].Value;
bookLinks.Add(new Uri(baseUri, href).AbsoluteUri);
}
return bookLinks;
}
在这个函数中,我们从一个空的 List 对象开始。在 foreach 循环中,我们将所有链接添加到此对象并返回它。
现在,我们可以修改 Main() 函数,以便我们可以测试到目前为止编写的 C# 代码。修改后的函数如下:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
}
要运行此代码,请打开终端并导航到收录此文件的目录,然后键入以下内容:
dotnet run
输出应如下所示:
Found 20 links
然后我们继续下一部分,我们将处理所有链接以获取书籍数据。
07.解析HTML:获取书籍详情
此时,我们有一个收录书籍 URL 的字符串列表。我们可以简单的写一个循环,先用我们写的GetDocument函数来获取文档。之后,我们将使用 SelectSingleNode 函数来提取书名和价格。
为了使数据清晰、有条理,我们从一个类开始。这个类将代表一本书,有两个属性——标题和价格。示例如下:
然后,在浏览器中打开 Title-//h1 的书页。为价格创建 XPath 有点棘手,因为相同的类应用于底部的附加书籍。
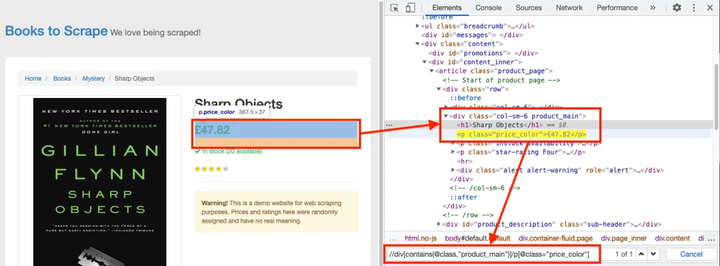
XPath 的价格
XPath 的价格是这样的:
//div[contains(@class,"product_main")]/p[@class="price_color"]
请注意 XPath 收录双引号。我们将不得不通过在它们前面加上反斜杠来转义这些字符。
现在我们可以使用 SelectSingleNode 函数获取节点,然后使用 InnerText 属性获取元素中收录的文本。我们可以将所有内容放在一个函数中,如下所示:
static List GetBookDetails(List urls)
{
var books = new List();
foreach (var url in urls)
{
HtmlDocument document = GetDocument(url);
var titleXPath = "//h1";
var priceXPath = "//div[contains(@class,\"product_main\")]/p[@class=\"price_color\"]";
var book = new Book();
book.Title = document.DocumentNode.SelectSingleNode (priceXPath).InnerText;
book.Price = document.DocumentNode.SelectSingleNode(priceXPath).InnerText;
books.Add(book);
}
return books;
}
此函数将返回 Book 对象列表。是时候更新 Main() 函数了:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
var books = GetBookDetails(bookLinks);
}
这个网络抓取项目的最后一部分是将数据导出到 CSV。
08.导出数据
如果你还没有安装 CsvHelper,你可以使用
dotnet add package CsvHelper
在终端运行该命令即可完成此操作。
导出功能非常简单。首先,我们需要创建一个 StreamWriter 并将 CSV 文件名作为参数发送。接下来,我们将使用这个对象来创建一个 CsvWriter。最后,我们可以使用 WriteRecords 函数在一行代码中编写所有书籍。
为了确保所有资源都正确关闭,我们可以使用 using 块。我们还可以将所有内容都包装在一个函数中,如下所示:
static void exportToCSV(List books)
{
using (var writer = new StreamWriter("./books.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
csv.WriteRecords(books);
}
}
最后,我们可以从 Main() 函数中调用这个函数:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
var books = GetBookDetails(bookLinks);
exportToCSV(books);
}
要运行此代码,请打开终端并运行以下命令:
dotnet run
几秒钟后,您将创建一个 books.csv 文件。
09. 结论
如果你想用 C# 写一个网络爬虫,你可以使用多个包。在本文中,我们展示了如何使用 Html Agility Pack,这是一个功能强大且易于使用的包。也是一个简单的例子,可以进一步增强;例如,您可以尝试将上述逻辑添加到此代码中以处理多个页面。
如果您想了解更多有关使用其他编程语言进行网页抓取的工作原理的信息,您可以查看使用 Python 进行网页抓取的指南。我们还有一个
常见问题
Q:C#适合做网页爬虫吗?
A:与 Python 类似,C# 被广泛用于网络爬虫。在决定选择哪种编程语言时,选择您最熟悉的一种很重要。但是您将能够在 Python 和 C# 中找到示例网络爬虫。
问:网络抓取合法吗?
答:如果在不违反任何法律的情况下使用代理,它们可能是合法的。但是,在与代理人进行任何活动之前,您应该就您的具体案件获得专业的法律建议。请参考我们的文章“网络抓取合法吗?”
c#抓取网页数据(企查查有什么作用数据库中的数据删除后还能恢复吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 201 次浏览 • 2021-10-25 19:01
企业搜索的作用是什么
数据库中的数据删除后还能恢复吗?
什么是排名靠前的数据
前一天晚上哭了,第二天眼睛肿的就消失了
如何在excel中将水平数据转换为垂直数据
如何清除并行空间中的数据
c#爬虫如何抓取企业搜索或天眼数据
请采用定时器控制。. . .
天眼查企业查七信宝哪家有详细数据?
天眼查用的比较多。
如何使用 VLOOKUP 获取数据?
SUMIF($F$1:$F$107,A28,$AM$1:$AM$107) 这个公式有效,VLOOKUP 只得到一个值。
哪一个更好
有的公司,他不列出来,但是那个,但是税务局,放个名字,这样公司很难找,有天眼,他肯定能看出他还在经营或不是。
天眼查还是企业查查哪个好
天眼查比较好。由于天眼查是一款以开放数据为切入点、以关系为核心的产品,它为帮助传统企业或个人降低成本、防范和化解金融风险提供了产品化的解决方案。例如银行或金融担保机构可以通过天眼查提供的信息进行查询和关系...
如何查看历史检索记录
这个好像无法查看历史记录,或者只能查看之前公司发给你的短信。
公司可以查或天眼查公司是否已经申请破产?
查询全国企业信息公示网,对应企业信息更新最快、最权威
企业能否查投融资事件导出数据?
好的。但是你必须先注册成为VIP客户
网页文本抓取器如何抓取文本?
网页文字抓取器是一款小巧精致的网页文字抓取工具,可以让您轻松抓取和复制禁止选择和复制的网页上的文字。对于页面内容被大面积广告覆盖的网页,抓取网页文本爬虫再阅读也是一个不错的解决方案。除此以外...
c#方向是什么类型的数据
C#的每种数据类型都有明确的取值范围。确实,有些类型的取值范围非常大,可以认为是连续的,但取值始终是固定的。最简单的救命方法是 bool 类型。, 它只能是两个值:true 或 false。有时您希望提取变量...
天眼查、企业查、飞凡烽火台哪个好用?
看看你想检查什么?一般的企业信息他们三个都可以查,不过天眼查好像是以后收费的,不过目前Parllay还是免费的,我用积分买调查报告之类的~
C#如何让用户输入数据
Console.WriteLine("请输入第一个数据");stringinput=Console.ReadLine;//input是获取用户输入的数据 intfirstInput=int...
什么数据类型比 C# 中的 int 类型大?
C#中使用的int对应于.NETCTS中的Int32,即32位。Long对应的是Int64,也就是说是64位。float 数据类型用于较小的浮点数,因为它需要较低的精度。double 数据类型比...
除了可以查公司信息的天眼查、企业查、七信宝,还有没有其他网站可以查的?
哦 查看全部
c#抓取网页数据(企查查有什么作用数据库中的数据删除后还能恢复吗)
企业搜索的作用是什么

数据库中的数据删除后还能恢复吗?

什么是排名靠前的数据

前一天晚上哭了,第二天眼睛肿的就消失了

如何在excel中将水平数据转换为垂直数据

如何清除并行空间中的数据

c#爬虫如何抓取企业搜索或天眼数据
请采用定时器控制。. . .
天眼查企业查七信宝哪家有详细数据?
天眼查用的比较多。
如何使用 VLOOKUP 获取数据?
SUMIF($F$1:$F$107,A28,$AM$1:$AM$107) 这个公式有效,VLOOKUP 只得到一个值。
哪一个更好
有的公司,他不列出来,但是那个,但是税务局,放个名字,这样公司很难找,有天眼,他肯定能看出他还在经营或不是。
天眼查还是企业查查哪个好
天眼查比较好。由于天眼查是一款以开放数据为切入点、以关系为核心的产品,它为帮助传统企业或个人降低成本、防范和化解金融风险提供了产品化的解决方案。例如银行或金融担保机构可以通过天眼查提供的信息进行查询和关系...
如何查看历史检索记录
这个好像无法查看历史记录,或者只能查看之前公司发给你的短信。
公司可以查或天眼查公司是否已经申请破产?
查询全国企业信息公示网,对应企业信息更新最快、最权威
企业能否查投融资事件导出数据?
好的。但是你必须先注册成为VIP客户
网页文本抓取器如何抓取文本?
网页文字抓取器是一款小巧精致的网页文字抓取工具,可以让您轻松抓取和复制禁止选择和复制的网页上的文字。对于页面内容被大面积广告覆盖的网页,抓取网页文本爬虫再阅读也是一个不错的解决方案。除此以外...
c#方向是什么类型的数据
C#的每种数据类型都有明确的取值范围。确实,有些类型的取值范围非常大,可以认为是连续的,但取值始终是固定的。最简单的救命方法是 bool 类型。, 它只能是两个值:true 或 false。有时您希望提取变量...
天眼查、企业查、飞凡烽火台哪个好用?
看看你想检查什么?一般的企业信息他们三个都可以查,不过天眼查好像是以后收费的,不过目前Parllay还是免费的,我用积分买调查报告之类的~
C#如何让用户输入数据
Console.WriteLine("请输入第一个数据");stringinput=Console.ReadLine;//input是获取用户输入的数据 intfirstInput=int...
什么数据类型比 C# 中的 int 类型大?
C#中使用的int对应于.NETCTS中的Int32,即32位。Long对应的是Int64,也就是说是64位。float 数据类型用于较小的浮点数,因为它需要较低的精度。double 数据类型比...
除了可以查公司信息的天眼查、企业查、七信宝,还有没有其他网站可以查的?
哦
c#抓取网页数据( 编程问答怎么做?正则表达式 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-25 18:15
编程问答怎么做?正则表达式
)
C#抓取百度搜索链接标题
操作效果与此类似。求一个完整的例子供初学者学习正则表达式,希望大神能帮助你用正则表达式抓取网页数据--------------------编程问答- - ------------------我喜欢~~~~~--------------------编程问题和答案--- -----------------有人吗?? ? 求助--------------------编程问答--------------------不需要正则表达式它可以实现。IE6以上版本,按F12打开开发者工具,分析搜索结果页的源码规则。使用常规规则时,您还必须分析页面源规则。
然后通过如下代码获取mshtml的dom对象
varnativeBrowser=(SHDocVw.WebBrowser)webBrowser1.ActiveXInstance;
IHTMLDocument2doc2=(IHTMLDocument2)nativeBrowser.Document;
然后搜索doc2对象的内容
nativeBrowser.Document 也可以强制为 IHTMLDocument、IHTMLDocument3、IHTMLDocument4、IHTMLDocument5
基本使用2和3,IHTMLDocument3有getElementById、getElementsByName、getElementsByTagName等方法,基本上可以找到网页上的任何对象。还有一种方法可以跨域访问 ifream 中的内容。
需要引用 SHDocVw.dll 和 mshtml.dll。
--------------------编程问答 --------------------三个月前我做过一个,那里是没有规律的。留下邮箱--------------------编程问答--------------------我做过这个东东,而且只抢百度推广,没有正则化,三楼的方法就行了------------编程问答--------- ----------引用4楼wangyue4的回复:三个月前做过一个,没有使用规律。留下邮箱
补充:.NET技术 , C# 查看全部
c#抓取网页数据(
编程问答怎么做?正则表达式
)
C#抓取百度搜索链接标题

操作效果与此类似。求一个完整的例子供初学者学习正则表达式,希望大神能帮助你用正则表达式抓取网页数据--------------------编程问答- - ------------------我喜欢~~~~~--------------------编程问题和答案--- -----------------有人吗?? ? 求助--------------------编程问答--------------------不需要正则表达式它可以实现。IE6以上版本,按F12打开开发者工具,分析搜索结果页的源码规则。使用常规规则时,您还必须分析页面源规则。
然后通过如下代码获取mshtml的dom对象
varnativeBrowser=(SHDocVw.WebBrowser)webBrowser1.ActiveXInstance;
IHTMLDocument2doc2=(IHTMLDocument2)nativeBrowser.Document;
然后搜索doc2对象的内容
nativeBrowser.Document 也可以强制为 IHTMLDocument、IHTMLDocument3、IHTMLDocument4、IHTMLDocument5
基本使用2和3,IHTMLDocument3有getElementById、getElementsByName、getElementsByTagName等方法,基本上可以找到网页上的任何对象。还有一种方法可以跨域访问 ifream 中的内容。
需要引用 SHDocVw.dll 和 mshtml.dll。
--------------------编程问答 --------------------三个月前我做过一个,那里是没有规律的。留下邮箱--------------------编程问答--------------------我做过这个东东,而且只抢百度推广,没有正则化,三楼的方法就行了------------编程问答--------- ----------引用4楼wangyue4的回复:三个月前做过一个,没有使用规律。留下邮箱
补充:.NET技术 , C#
c#抓取网页数据( 基于C#.NET抓取互联网公开数据的爬虫系统及抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-10-25 17:08
基于C#.NET抓取互联网公开数据的爬虫系统及抓取方法)
本发明属于数据采集技术领域,具体涉及一种抓取互联网公共数据的爬虫系统及抓取方法。
背景技术:
网络爬虫是一种自动浏览互联网并按照一定规则自动抓取网页信息的程序或脚本。它是搜索引擎的重要组成部分。搜索引擎在实现网络爬虫的功能时,通常需要一个爬虫系统。完成。
目前市场上的爬虫系统或框架大多采用Python、Java、PHPcrawer等技术。C#很少用于爬虫,C#爬虫系统也很少见,而且因为C#是.NET Framework上面向对象的一种高级编程语言,它可以让程序员快速编写基于MICROSOFT.NET平台的各种应用程序。如果你设计开发一个基于C#抓取互联网公共数据的爬虫系统,将大大提高程序员编写基于MICROSOFT.NET平台的各种应用程序的效率,因此,对基于C#抓取的爬虫系统和方法的需求互联网公开数据非常明显。
技术实现要素:
本发明的目的是利用Python、Java、PHPcrawer等现有技术的爬虫系统。C#很少用于爬虫,影响了程序员编写基于MICROSOFT.NET平台的各种应用程序的效率。问题。
为实现上述目的,本发明提供了一种基于C#的互联网公共数据抓取爬虫系统,包括:
爬虫程序模块,爬虫程序模块用于浏览、抓取和验证数据;
服务器,所述服务器的数量至少为2台,其中部署有爬虫程序模块;
目标站,爬虫程序模块对确定的目标站进行数据浏览和抓取;
非关系型数据库,非关系型数据库用于存储爬虫程序模块捕获的有效数据。
优选地,还包括用于连接验证码识别破解程序模块的第三方接口,验证码识别破解程序模块可以识别和破解目标站的访问请求验证码。
优选地,目标站点、非关系数据库和第三方接口也设置在至少两个服务器中。
优选地,爬虫程序模块包括参数存储单元、目标站捕获单元、目标站分析判断单元、数据捕获单元和数据验证单元。参数存储单元存储参数,其输出端接目标站捕获单元输入端,目标站捕获单元输出端连接目标站分析判定单元输入端,目标站分析判定单元输出端接数据采集单元的输入端,数据采集单元的输出端接数据校验单元的输入端,数据校验单元接参数存储单元,
优选地,所述数据采集单元与数据校验单元之间还设置有数据转换单元,所述数据采集单元将采集到的数据输出至所述数据转换单元,由所述数据转换单元对所述数据进行转换。该单元使用正则表达式或Json序列化方法过滤和提取数据,然后将数据输出到数据验证单元。
优选地,所述数据抓取单元中设有数据分页判断模块,所述数据分页判断模块用于判断数据是否被分页,从而实现数据抓取单元抓取每页数据。
优选地,非关系数据库是NoSQL。
与现有技术相比,本发明的履带系统具有以下优点:
基于C#捕获互联网公共数据,而不是Python、Java、PHPcrawer等技术,可以提高程序员编写基于MICROSOFT.NET平台的各种应用程序的效率;可连接验证码识别破解程序模块,支持多种破解验证码,更好更快的访问目标站;支持部署到多台服务器,降低服务器负载压力,运行和存储更多数据;支持NOSQL数据存储,读取速度大幅提升。
本发明还提供了一种基于C#抓取互联网公共数据的爬虫方法,包括如上所述的基于C#抓取互联网公共数据的爬虫系统,还包括以下步骤:
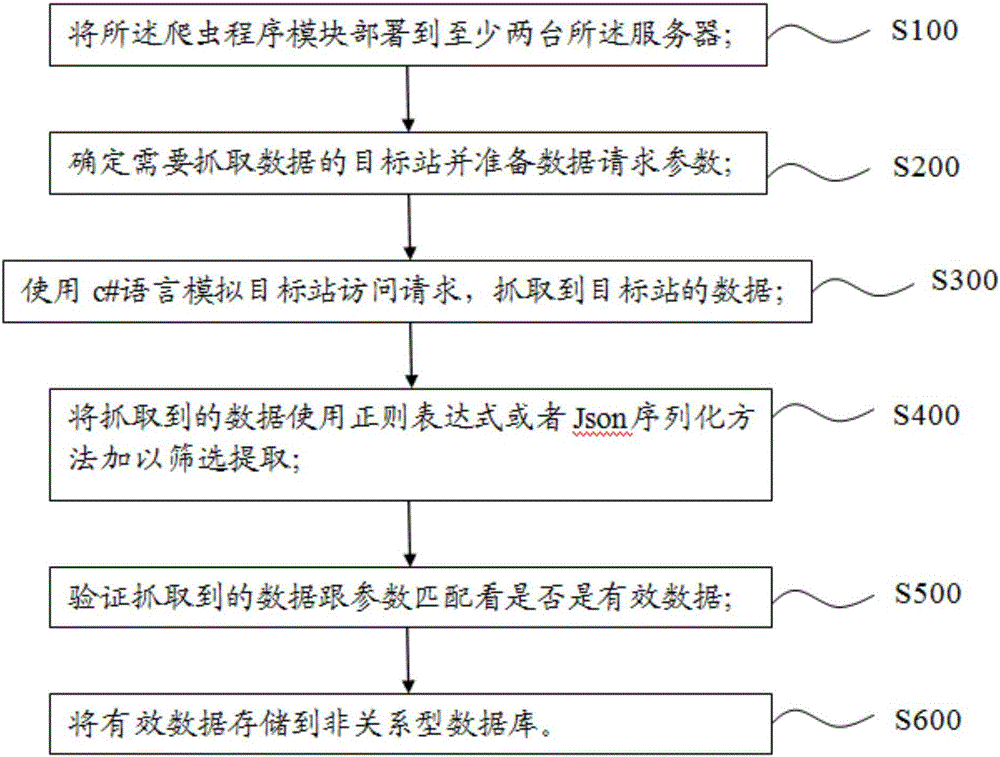
S100。将爬虫程序模块部署到至少两台服务器上;
S200:确定需要采集数据的目标站点,并准备数据请求参数;
S300,使用c#语言模拟目标站的访问请求,抓取目标站的数据;
S400:使用正则表达式或Json序列化方法对抓取到的数据进行过滤提取;
S500,验证捕获的数据是否与参数匹配,看是否为有效数据;
S600:将有效数据存储在非关系型数据库中。
优选地,步骤S300包括:
S301:判断目标站点接入请求是否需要验证码。如果需要验证码,则抓取请求验证码参数并调用破解验证码服务,然后将破解结果添加到访问请求中并捕获到目标站的数据;
S302:判断目标站的数据抓取是否成功,如果成功,则进入步骤S400;若失败,则转至步骤S303;
S303:将目标站点的访问状态标记为失败。当爬虫程序检测到目标站访问状态失败时,需要重新模拟目标站访问请求来捕获目标站数据,即重复步骤S300,使用c#语言模拟目标站访问请求. 然后进入步骤S301,直到确定目标站的数据抓取成功。
优选地,步骤S400和S500包括寻呼判断,即判断目标站提取的数据是否有寻呼,如果有,则翻页,然后重复步骤S400;如果没有寻呼,则直接进入步骤S500。
与现有技术相比,本发明的抓取方法具有以下优点:
增加了重试机制,爬虫程序在第一次数据抓取失败时会自动重启;数据兼容性大大增强,提高数据质量;增强异常处理以提高资源利用率。
图纸说明
图1是本发明实施例一的履带系统示意图。
图2是本发明第二实施例的抓取方法的步骤示意图。
无花果。图3为本发明第二实施例的抓取方法的流程示意图。
详细方法
为使本发明的上述目的、特征和优点更加明显易懂,下面结合附图对本发明的具体实施例进行详细说明。
第一实施例
参见图1,本实施例介绍了一种基于C#的爬虫系统抓取互联网公共数据,包括:
爬虫程序模块2,爬虫程序模块2用于浏览、抓取和验证数据;
服务器1,所述服务器1的数量至少为2个,其中部署有爬虫程序模块2;
目标站3,爬虫程序模块2对确定的目标站3进行浏览抓取数据;
非关系型数据库4用于存储爬虫模块2捕获的有效数据。
具体的,本发明的互联网公共数据爬虫系统的爬虫程序模块2基于C#,爬虫程序模块2可以是一个烧录爬虫程序的芯片,该芯片至少设置在两个服务器1优选地,爬虫程序模块2部署在每个服务器1中。
爬虫程序模块2中目标站3的确定可以人为确定。例如,如果您想获取公司的商业登记信息,您可以到国家工商行政管理总局、当地工商行政管理总局、国家企业信用信息公示系统等相关信息查询。 .
但更优选地,爬虫程序模块2包括参数存储单元、目标站捕获单元、目标站分析判断单元、数据捕获单元和数据验证单元。参数存储单元存储参数,其输出端连接目标站捕获单元的输入端,目标站捕获单元的输出端连接目标站分析判断单元的输入端,目标站分析判定单元的输出端连接数据采集单元的输入端 数据采集单元的输出端连接数据校验单元的输入端,数据校验单元连接参数存储器单元,
参数存储单元用于存储提取数据所需的数据请求参数,可根据实际情况进行设置。比如要抓取某公司的工商注册信息,可以设置相关参数为与,公司名称,公司所在省份的关系。这样,参数存储单元中存储的相关参数将是,公司名称:某公司,公司所在省份:上海,同时满足这两个参数。
在其他实施例中,参数存储单元中的参数关系可以具有其他设置,例如OR关系。
目标站抓取单元接收参数存储单元中的数据请求参数信息,据此抓取可能收录所需数据的目标站,然后将抓取到的目标站信息发送给目标站分析确定单元。
目标站点分析确定单元根据参数存储单元中的数据请求参数信息对所有目标站点的URL地址进行解析,通过对URL地址和地址对应的数据信息进行解析,确定目标站点。
数据采集单元结合参数存储单元中的数据请求参数信息,从确定的目标站点采集数据,依次采集不同目标站点的所需数据,并将采集到的数据发送给数据校验单元。
数据校验单元将捕获的数据与参数存储单元中存储的数据参数信息进行比对校验,将校验通过的有效数据存储在非关系型数据库中。
为了数据传输、存储和计算的方便,在数据采集单元和数据校验单元之间还设置了数据转换单元,数据采集单元将采集到的数据输出给数据转换单元。单元,通过数据转换单元,使用正则表达式或Json序列化方法对数据进行过滤提取,然后输出到数据校验单元。
另外,由于部分目标站3具有分页功能,为了避免只抓取第一页的数据导致数据抓取不完整或无效,在数据抓取单元中设置了数据分页判断模块。分页判断模块用于判断数据是否被分页,然后数据抓取单元可以抓取每一页的数据。
服务器2为应用服务器,可与目标站点3进行数据交互,具有可扩展性。例如可以使用Cisco服务器,型号为CISCO UCS C240 M3(2U);当然,也可以使用其他应用服务器,只要能实现功能即可。
目标站3的数量为几个,爬虫程序模块2抓取目标站3上需要的数据,目标站3的最小单元是一个网页,爬虫程序模块2会进行浏览、分析、抓取、并对所确定的目标站3的数据进行校验,依次对它遇到的目标站3上所有需要的数据进行采集校验,对目标站3的数据进行采集校验,取深度根据实际需要设置;一般来说,取深度越大,目标站数越多。
非关系型数据库4为NoSQL,其主要功能是存储爬虫程序模块捕获并验证的数据。
为了满足浏览目标站3抓取数据的目的,考虑到目标站3可能设置有验证码,因此,本发明的爬虫系统还包括外部验证码的第三方接口识别破解程序模块。验证码识别破解程序模块可以识别和破解目标站点的访问请求验证码。验证码包括文本验证码、图片验证码、极限验证码等多种类型的验证码。验证码识别破解程序模块可以是烧录验证码识别破解程序的芯片,也可以是除芯片外的设备,
验证码识别破解程序模块可以是一个能够破解多个验证码的综合程序模块;也可以是多个第三接口,分别连接多个验证码识别破解程序模块,多个验证码可以识别破解程序。模块包括对应文本验证码特殊识别的第一验证码识别破解程序模块,具体识别数字验证码和数字加减运算的第二验证码识别破解程序模块,第三验证码识别破解程序模块。具体标识图片验证码。代码识别破解程序模块,
目标站3、非关系型数据库4、的第三方接口也设置在至少两台服务器1中。
或者,也可以在爬虫程序模块上设置第三方接口。
与现有技术相比,本发明的履带系统具有以下优点:
基于C#捕获互联网公共数据,而不是Python、Java、PHPcrawer等技术,可以提高程序员编写基于MICROSOFT.NET平台的各种应用程序的效率;可连接验证码识别破解程序模块,支持多种破解验证码,更好更快的访问目标站;支持部署到多台服务器,降低服务器负载压力,运行和存储更多数据;支持NOSQL数据存储,读取速度大幅提升。
第二个实施例
参见图1至图3,本实施例介绍了一种基于C#的互联网公共数据的爬取方法,包括实施例一所述的基于C#的互联网公共数据的爬取系统,还包括以下步骤:
S100:将爬虫程序模块2部署到至少两台服务器1上;
S200:确定需要采集数据的目标站3,并准备数据请求参数;
S300,使用c#语言模拟目标站访问请求;
S400:使用正则表达式或Json序列化方法对抓取到的数据进行过滤提取;
S500,验证抓取到的数据是否与数据请求参数匹配,看是否为有效数据;
S600,将有效数据存储在非关系型数据库中 4.
具体地,爬虫程序模块2部署在服务器1中。优选地,爬虫程序模块2部署在每个服务器1中,爬虫程序模块抓取、分析、确定需要抓取数据的目标站3或目标站3可能有需要抓取的数据,那么,爬虫模块2准备数据请求参数,例如:需要抓取的业务数据,需要准备公司关键词:,省:江苏,数据请求参数是江苏的工商数据,三者是“合二为一”的关系。目标站3可以通过爬取分析确定为江苏省当地工商银行管理局,或国家企业信用信息系统。
然后,爬虫程序模块2使用C#语言模拟目标站访问请求,使得访问目标站3后,抓取目标站3中需要的数据,然后使用正则表达式或者Json序列化方法过滤和提取这些数据,然后将这些数据与数据请求参数进行比较,分析比较,确定捕获的数据是否为有效数据,最后将有效数据存储在非关系型数据库中 4.
分析比较捕获的数据是否为有效数据的方法是将捕获的数据与数据请求参数进行比较,看是否收录数据请求参数中的所有参数及其关系。使用现有技术中的其他方法。
在访问目标站点3的过程中,部分目标站点3设置了验证码。因此,步骤S300还应包括:
S301:判断目标站3的访问请求是否需要验证码,如果需要验证码,则捕获请求验证码参数并调用破解验证码服务,然后将破解结果添加到访问请求中并捕获到站 3 的目标数据。
本步骤中,破解验证码的服务可以是爬虫模块2提供的,也可以是外接如实施例一所述的第三方接口,第三方接口的数量可以是一个,也可以是一个以上,可以处理不同类型的验证码,最大化可访问目标站3的范围,增加本发明实施例一所述爬虫系统和本实施例所述抓取方法的适用性。
S302:判断目标站3的数据抓取是否成功,如果成功,则进入步骤S400;如果失败,则转到步骤S303。
本步骤的判断方法多种多样,可以采用现有技术中的判断方法,即判断是否存储了抓取到的数据。如果已经存储在服务器中,则视为成功。服务器的存储容量变化来判断。
S303:将目标站点3的访问状态标记为失败。当爬虫程序检测到目标站3的访问状态失败时,需要再次模拟目标站3的访问请求来抓取目标站3的数据,即重复步骤S300,然后重复步骤S301。
也就是说,如果在请求访问目标站3的过程中,验证码无法破解,数据抓取失败,则将目标站3的访问状态标记为失败,爬虫模块2检测到目标站3的访问状态失败,重新模拟目标站3的访问请求,再次请求访问目标站3,然后再次识别并破解目标站3的验证码,直到目标站3被成功捕获。
考虑到目标站3可能有寻呼,步骤S400和S500包括寻呼判断,即判断目标站3提取的数据是否有寻呼,如果有,则翻页,然后重复步骤S400;如果没有分页符,直接进入步骤S500。
这样可以有效避免在抓取目标站3的数据时只抓取第一页数据,而忽略第一页以外的数据,导致数据抓取不完整、不完整或根本没有抓取。获取到需要的数据,反复卡在这一步。
与现有技术相比,本发明的抓取方法具有以下优点:
增加了重试机制,爬虫程序在第一次数据抓取失败时会自动重启;数据兼容性大大增强,提高数据质量;增强异常处理以提高资源利用率。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明的保护范围。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进,均应收录在本发明的保护范围之内。 查看全部
c#抓取网页数据(
基于C#.NET抓取互联网公开数据的爬虫系统及抓取方法)
本发明属于数据采集技术领域,具体涉及一种抓取互联网公共数据的爬虫系统及抓取方法。
背景技术:
网络爬虫是一种自动浏览互联网并按照一定规则自动抓取网页信息的程序或脚本。它是搜索引擎的重要组成部分。搜索引擎在实现网络爬虫的功能时,通常需要一个爬虫系统。完成。
目前市场上的爬虫系统或框架大多采用Python、Java、PHPcrawer等技术。C#很少用于爬虫,C#爬虫系统也很少见,而且因为C#是.NET Framework上面向对象的一种高级编程语言,它可以让程序员快速编写基于MICROSOFT.NET平台的各种应用程序。如果你设计开发一个基于C#抓取互联网公共数据的爬虫系统,将大大提高程序员编写基于MICROSOFT.NET平台的各种应用程序的效率,因此,对基于C#抓取的爬虫系统和方法的需求互联网公开数据非常明显。
技术实现要素:
本发明的目的是利用Python、Java、PHPcrawer等现有技术的爬虫系统。C#很少用于爬虫,影响了程序员编写基于MICROSOFT.NET平台的各种应用程序的效率。问题。
为实现上述目的,本发明提供了一种基于C#的互联网公共数据抓取爬虫系统,包括:
爬虫程序模块,爬虫程序模块用于浏览、抓取和验证数据;
服务器,所述服务器的数量至少为2台,其中部署有爬虫程序模块;
目标站,爬虫程序模块对确定的目标站进行数据浏览和抓取;
非关系型数据库,非关系型数据库用于存储爬虫程序模块捕获的有效数据。
优选地,还包括用于连接验证码识别破解程序模块的第三方接口,验证码识别破解程序模块可以识别和破解目标站的访问请求验证码。
优选地,目标站点、非关系数据库和第三方接口也设置在至少两个服务器中。
优选地,爬虫程序模块包括参数存储单元、目标站捕获单元、目标站分析判断单元、数据捕获单元和数据验证单元。参数存储单元存储参数,其输出端接目标站捕获单元输入端,目标站捕获单元输出端连接目标站分析判定单元输入端,目标站分析判定单元输出端接数据采集单元的输入端,数据采集单元的输出端接数据校验单元的输入端,数据校验单元接参数存储单元,
优选地,所述数据采集单元与数据校验单元之间还设置有数据转换单元,所述数据采集单元将采集到的数据输出至所述数据转换单元,由所述数据转换单元对所述数据进行转换。该单元使用正则表达式或Json序列化方法过滤和提取数据,然后将数据输出到数据验证单元。
优选地,所述数据抓取单元中设有数据分页判断模块,所述数据分页判断模块用于判断数据是否被分页,从而实现数据抓取单元抓取每页数据。
优选地,非关系数据库是NoSQL。
与现有技术相比,本发明的履带系统具有以下优点:
基于C#捕获互联网公共数据,而不是Python、Java、PHPcrawer等技术,可以提高程序员编写基于MICROSOFT.NET平台的各种应用程序的效率;可连接验证码识别破解程序模块,支持多种破解验证码,更好更快的访问目标站;支持部署到多台服务器,降低服务器负载压力,运行和存储更多数据;支持NOSQL数据存储,读取速度大幅提升。
本发明还提供了一种基于C#抓取互联网公共数据的爬虫方法,包括如上所述的基于C#抓取互联网公共数据的爬虫系统,还包括以下步骤:
S100。将爬虫程序模块部署到至少两台服务器上;
S200:确定需要采集数据的目标站点,并准备数据请求参数;
S300,使用c#语言模拟目标站的访问请求,抓取目标站的数据;
S400:使用正则表达式或Json序列化方法对抓取到的数据进行过滤提取;
S500,验证捕获的数据是否与参数匹配,看是否为有效数据;
S600:将有效数据存储在非关系型数据库中。
优选地,步骤S300包括:
S301:判断目标站点接入请求是否需要验证码。如果需要验证码,则抓取请求验证码参数并调用破解验证码服务,然后将破解结果添加到访问请求中并捕获到目标站的数据;
S302:判断目标站的数据抓取是否成功,如果成功,则进入步骤S400;若失败,则转至步骤S303;
S303:将目标站点的访问状态标记为失败。当爬虫程序检测到目标站访问状态失败时,需要重新模拟目标站访问请求来捕获目标站数据,即重复步骤S300,使用c#语言模拟目标站访问请求. 然后进入步骤S301,直到确定目标站的数据抓取成功。
优选地,步骤S400和S500包括寻呼判断,即判断目标站提取的数据是否有寻呼,如果有,则翻页,然后重复步骤S400;如果没有寻呼,则直接进入步骤S500。
与现有技术相比,本发明的抓取方法具有以下优点:
增加了重试机制,爬虫程序在第一次数据抓取失败时会自动重启;数据兼容性大大增强,提高数据质量;增强异常处理以提高资源利用率。
图纸说明
图1是本发明实施例一的履带系统示意图。
图2是本发明第二实施例的抓取方法的步骤示意图。
无花果。图3为本发明第二实施例的抓取方法的流程示意图。
详细方法
为使本发明的上述目的、特征和优点更加明显易懂,下面结合附图对本发明的具体实施例进行详细说明。
第一实施例
参见图1,本实施例介绍了一种基于C#的爬虫系统抓取互联网公共数据,包括:
爬虫程序模块2,爬虫程序模块2用于浏览、抓取和验证数据;
服务器1,所述服务器1的数量至少为2个,其中部署有爬虫程序模块2;
目标站3,爬虫程序模块2对确定的目标站3进行浏览抓取数据;
非关系型数据库4用于存储爬虫模块2捕获的有效数据。
具体的,本发明的互联网公共数据爬虫系统的爬虫程序模块2基于C#,爬虫程序模块2可以是一个烧录爬虫程序的芯片,该芯片至少设置在两个服务器1优选地,爬虫程序模块2部署在每个服务器1中。
爬虫程序模块2中目标站3的确定可以人为确定。例如,如果您想获取公司的商业登记信息,您可以到国家工商行政管理总局、当地工商行政管理总局、国家企业信用信息公示系统等相关信息查询。 .
但更优选地,爬虫程序模块2包括参数存储单元、目标站捕获单元、目标站分析判断单元、数据捕获单元和数据验证单元。参数存储单元存储参数,其输出端连接目标站捕获单元的输入端,目标站捕获单元的输出端连接目标站分析判断单元的输入端,目标站分析判定单元的输出端连接数据采集单元的输入端 数据采集单元的输出端连接数据校验单元的输入端,数据校验单元连接参数存储器单元,
参数存储单元用于存储提取数据所需的数据请求参数,可根据实际情况进行设置。比如要抓取某公司的工商注册信息,可以设置相关参数为与,公司名称,公司所在省份的关系。这样,参数存储单元中存储的相关参数将是,公司名称:某公司,公司所在省份:上海,同时满足这两个参数。
在其他实施例中,参数存储单元中的参数关系可以具有其他设置,例如OR关系。
目标站抓取单元接收参数存储单元中的数据请求参数信息,据此抓取可能收录所需数据的目标站,然后将抓取到的目标站信息发送给目标站分析确定单元。
目标站点分析确定单元根据参数存储单元中的数据请求参数信息对所有目标站点的URL地址进行解析,通过对URL地址和地址对应的数据信息进行解析,确定目标站点。
数据采集单元结合参数存储单元中的数据请求参数信息,从确定的目标站点采集数据,依次采集不同目标站点的所需数据,并将采集到的数据发送给数据校验单元。
数据校验单元将捕获的数据与参数存储单元中存储的数据参数信息进行比对校验,将校验通过的有效数据存储在非关系型数据库中。
为了数据传输、存储和计算的方便,在数据采集单元和数据校验单元之间还设置了数据转换单元,数据采集单元将采集到的数据输出给数据转换单元。单元,通过数据转换单元,使用正则表达式或Json序列化方法对数据进行过滤提取,然后输出到数据校验单元。
另外,由于部分目标站3具有分页功能,为了避免只抓取第一页的数据导致数据抓取不完整或无效,在数据抓取单元中设置了数据分页判断模块。分页判断模块用于判断数据是否被分页,然后数据抓取单元可以抓取每一页的数据。
服务器2为应用服务器,可与目标站点3进行数据交互,具有可扩展性。例如可以使用Cisco服务器,型号为CISCO UCS C240 M3(2U);当然,也可以使用其他应用服务器,只要能实现功能即可。
目标站3的数量为几个,爬虫程序模块2抓取目标站3上需要的数据,目标站3的最小单元是一个网页,爬虫程序模块2会进行浏览、分析、抓取、并对所确定的目标站3的数据进行校验,依次对它遇到的目标站3上所有需要的数据进行采集校验,对目标站3的数据进行采集校验,取深度根据实际需要设置;一般来说,取深度越大,目标站数越多。
非关系型数据库4为NoSQL,其主要功能是存储爬虫程序模块捕获并验证的数据。
为了满足浏览目标站3抓取数据的目的,考虑到目标站3可能设置有验证码,因此,本发明的爬虫系统还包括外部验证码的第三方接口识别破解程序模块。验证码识别破解程序模块可以识别和破解目标站点的访问请求验证码。验证码包括文本验证码、图片验证码、极限验证码等多种类型的验证码。验证码识别破解程序模块可以是烧录验证码识别破解程序的芯片,也可以是除芯片外的设备,
验证码识别破解程序模块可以是一个能够破解多个验证码的综合程序模块;也可以是多个第三接口,分别连接多个验证码识别破解程序模块,多个验证码可以识别破解程序。模块包括对应文本验证码特殊识别的第一验证码识别破解程序模块,具体识别数字验证码和数字加减运算的第二验证码识别破解程序模块,第三验证码识别破解程序模块。具体标识图片验证码。代码识别破解程序模块,
目标站3、非关系型数据库4、的第三方接口也设置在至少两台服务器1中。
或者,也可以在爬虫程序模块上设置第三方接口。
与现有技术相比,本发明的履带系统具有以下优点:
基于C#捕获互联网公共数据,而不是Python、Java、PHPcrawer等技术,可以提高程序员编写基于MICROSOFT.NET平台的各种应用程序的效率;可连接验证码识别破解程序模块,支持多种破解验证码,更好更快的访问目标站;支持部署到多台服务器,降低服务器负载压力,运行和存储更多数据;支持NOSQL数据存储,读取速度大幅提升。
第二个实施例
参见图1至图3,本实施例介绍了一种基于C#的互联网公共数据的爬取方法,包括实施例一所述的基于C#的互联网公共数据的爬取系统,还包括以下步骤:
S100:将爬虫程序模块2部署到至少两台服务器1上;
S200:确定需要采集数据的目标站3,并准备数据请求参数;
S300,使用c#语言模拟目标站访问请求;
S400:使用正则表达式或Json序列化方法对抓取到的数据进行过滤提取;
S500,验证抓取到的数据是否与数据请求参数匹配,看是否为有效数据;
S600,将有效数据存储在非关系型数据库中 4.
具体地,爬虫程序模块2部署在服务器1中。优选地,爬虫程序模块2部署在每个服务器1中,爬虫程序模块抓取、分析、确定需要抓取数据的目标站3或目标站3可能有需要抓取的数据,那么,爬虫模块2准备数据请求参数,例如:需要抓取的业务数据,需要准备公司关键词:,省:江苏,数据请求参数是江苏的工商数据,三者是“合二为一”的关系。目标站3可以通过爬取分析确定为江苏省当地工商银行管理局,或国家企业信用信息系统。
然后,爬虫程序模块2使用C#语言模拟目标站访问请求,使得访问目标站3后,抓取目标站3中需要的数据,然后使用正则表达式或者Json序列化方法过滤和提取这些数据,然后将这些数据与数据请求参数进行比较,分析比较,确定捕获的数据是否为有效数据,最后将有效数据存储在非关系型数据库中 4.
分析比较捕获的数据是否为有效数据的方法是将捕获的数据与数据请求参数进行比较,看是否收录数据请求参数中的所有参数及其关系。使用现有技术中的其他方法。
在访问目标站点3的过程中,部分目标站点3设置了验证码。因此,步骤S300还应包括:
S301:判断目标站3的访问请求是否需要验证码,如果需要验证码,则捕获请求验证码参数并调用破解验证码服务,然后将破解结果添加到访问请求中并捕获到站 3 的目标数据。
本步骤中,破解验证码的服务可以是爬虫模块2提供的,也可以是外接如实施例一所述的第三方接口,第三方接口的数量可以是一个,也可以是一个以上,可以处理不同类型的验证码,最大化可访问目标站3的范围,增加本发明实施例一所述爬虫系统和本实施例所述抓取方法的适用性。
S302:判断目标站3的数据抓取是否成功,如果成功,则进入步骤S400;如果失败,则转到步骤S303。
本步骤的判断方法多种多样,可以采用现有技术中的判断方法,即判断是否存储了抓取到的数据。如果已经存储在服务器中,则视为成功。服务器的存储容量变化来判断。
S303:将目标站点3的访问状态标记为失败。当爬虫程序检测到目标站3的访问状态失败时,需要再次模拟目标站3的访问请求来抓取目标站3的数据,即重复步骤S300,然后重复步骤S301。
也就是说,如果在请求访问目标站3的过程中,验证码无法破解,数据抓取失败,则将目标站3的访问状态标记为失败,爬虫模块2检测到目标站3的访问状态失败,重新模拟目标站3的访问请求,再次请求访问目标站3,然后再次识别并破解目标站3的验证码,直到目标站3被成功捕获。
考虑到目标站3可能有寻呼,步骤S400和S500包括寻呼判断,即判断目标站3提取的数据是否有寻呼,如果有,则翻页,然后重复步骤S400;如果没有分页符,直接进入步骤S500。
这样可以有效避免在抓取目标站3的数据时只抓取第一页数据,而忽略第一页以外的数据,导致数据抓取不完整、不完整或根本没有抓取。获取到需要的数据,反复卡在这一步。
与现有技术相比,本发明的抓取方法具有以下优点:
增加了重试机制,爬虫程序在第一次数据抓取失败时会自动重启;数据兼容性大大增强,提高数据质量;增强异常处理以提高资源利用率。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明的保护范围。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进,均应收录在本发明的保护范围之内。
c#抓取网页数据(如何用易语言抓取微信朋友圈的图片文字呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-10-25 00:03
c#抓取网页数据的软件有很多,一般用户都会选择电脑上用易语言。电脑上易语言学习和使用比较简单方便,但是我们都清楚易语言是不能抓取微信朋友圈的图片文字的,只能抓取文字图片;那么如何用易语言抓取微信朋友圈的图片文字呢?其实关键是我们必须把对应的代码贴入文件中。下面是有关易语言图片文字抓取的常用代码,我们可以把这些代码直接复制到excel表格中,最终就可以抓取到图片文字了。for(inti=0;ipython的ide:eclipse入门2>python数据分析:第二章python数据分析:第三章1>python的数据结构2>python的数据采集和解析3>字符串处理4>字符串处理5>字符串验证和加密6>加密7>解密8>文件读写与保存9>读写文件10>在线数据库或者数据库numpy11>计算机科学实战:flask,学习idle12>python的模块和第三方包13>python的pandas库14>机器学习15>建立开发团队,构建企业级技术团队16>开发云或者公有云平台17>发布软件或者构建网站19>sqlalchemy+numpy2>pandas2:数据提取基础19>从零开始学编程20>pandas+flask:网站数据采集基础21>读写文件21>基础pandas2:文件读写和转换22>基础pandas2:提取文本22>基础pandas2:数据去重23>pandas2:文本相关数据存储和计算24>文本处理三部曲,pandas+flask:self-study25>计算机科学实战:numpy、pandas和r数据挖掘26>pandas基础和入门33>pandas数据处理实践或者四部曲:ols、dataframe、join、crossjoin;27>pandas数据处理实践ai实战就用python3numpy,scipy的使用时间都比较长了,想想也可能不是一个人愿意学。 查看全部
c#抓取网页数据(如何用易语言抓取微信朋友圈的图片文字呢?)
c#抓取网页数据的软件有很多,一般用户都会选择电脑上用易语言。电脑上易语言学习和使用比较简单方便,但是我们都清楚易语言是不能抓取微信朋友圈的图片文字的,只能抓取文字图片;那么如何用易语言抓取微信朋友圈的图片文字呢?其实关键是我们必须把对应的代码贴入文件中。下面是有关易语言图片文字抓取的常用代码,我们可以把这些代码直接复制到excel表格中,最终就可以抓取到图片文字了。for(inti=0;ipython的ide:eclipse入门2>python数据分析:第二章python数据分析:第三章1>python的数据结构2>python的数据采集和解析3>字符串处理4>字符串处理5>字符串验证和加密6>加密7>解密8>文件读写与保存9>读写文件10>在线数据库或者数据库numpy11>计算机科学实战:flask,学习idle12>python的模块和第三方包13>python的pandas库14>机器学习15>建立开发团队,构建企业级技术团队16>开发云或者公有云平台17>发布软件或者构建网站19>sqlalchemy+numpy2>pandas2:数据提取基础19>从零开始学编程20>pandas+flask:网站数据采集基础21>读写文件21>基础pandas2:文件读写和转换22>基础pandas2:提取文本22>基础pandas2:数据去重23>pandas2:文本相关数据存储和计算24>文本处理三部曲,pandas+flask:self-study25>计算机科学实战:numpy、pandas和r数据挖掘26>pandas基础和入门33>pandas数据处理实践或者四部曲:ols、dataframe、join、crossjoin;27>pandas数据处理实践ai实战就用python3numpy,scipy的使用时间都比较长了,想想也可能不是一个人愿意学。
c#抓取网页数据(比如说我要抓取博客园首页(一)())
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-22 06:00
一:网页更新
我们知道一般网页中的信息是不断更新的,这也需要我们定期抓取这些新信息,但是如何理解这个“规律”,即抓取页面需要多长时间,在其实这个时间段就是Page cache时间。在页面缓存期间,我们没有必要再次抓取网页,但会对其他人的服务器造成压力。
比如我想抓取博客园的首页,先清除页面缓存,
从 last-modified 到 expires 可以看到博客园的缓存时间是 2 分钟,而且我还可以看到当前服务器时间日期,如果我再做一次
如果刷新页面,这里的日期会变成下图中的if-modified-since,然后发送到服务器判断浏览器的缓存是否已经过期?
最后服务端发现if-modified-since >= last-modifined时间,服务端也返回了304,但是发现cookie信息真的是很多小偷。
在实际开发中,如果知道网站的缓存策略,就可以让爬虫每2分钟爬一次。当然,这些可以由数据团队进行配置和维护。好,下面我们就用爬虫。模拟它。
二:网页编码问题
有时候我们已经抓取了网页,准备解析的时候,tmd全是乱码,真他妈的,比如下面这样,
或许我们依稀记得html的meta中有一个叫做charset的属性,里面记录了编码方式。还有一点很重要,response.characterset 属性也记录了编码方式。让我们再试一次。
代码还是乱码,蛋疼。这个时候需要去官网看看http头信息里面交互的是什么。为什么浏览器能正常显示,爬虫爬不过去。
查看http头信息后,我们终于知道浏览器说我可以解析gzip、deflate和sdch这三种压缩方式。服务器发送 gzip 压缩。至此,我们也应该知道常用的web性能优化了。
三:网页分析
经过一番折腾,现在网页已经得到了,接下来就要解析了。当然,正则匹配是一个不错的方法。毕竟工作量还是比较大的。或许业界也推崇解析工具htmlagilitypack,它可以将html解析成xml,然后可以使用xpath提取指定的内容,大大提高了开发速度,性能也不错。毕竟,敏捷意味着敏捷。关于xpath的内容,看懂w3cschool的两张图就可以了。
好了,结束工作,去睡觉吧。. . 查看全部
c#抓取网页数据(比如说我要抓取博客园首页(一)())
一:网页更新
我们知道一般网页中的信息是不断更新的,这也需要我们定期抓取这些新信息,但是如何理解这个“规律”,即抓取页面需要多长时间,在其实这个时间段就是Page cache时间。在页面缓存期间,我们没有必要再次抓取网页,但会对其他人的服务器造成压力。
比如我想抓取博客园的首页,先清除页面缓存,
从 last-modified 到 expires 可以看到博客园的缓存时间是 2 分钟,而且我还可以看到当前服务器时间日期,如果我再做一次
如果刷新页面,这里的日期会变成下图中的if-modified-since,然后发送到服务器判断浏览器的缓存是否已经过期?

最后服务端发现if-modified-since >= last-modifined时间,服务端也返回了304,但是发现cookie信息真的是很多小偷。

在实际开发中,如果知道网站的缓存策略,就可以让爬虫每2分钟爬一次。当然,这些可以由数据团队进行配置和维护。好,下面我们就用爬虫。模拟它。

二:网页编码问题
有时候我们已经抓取了网页,准备解析的时候,tmd全是乱码,真他妈的,比如下面这样,
或许我们依稀记得html的meta中有一个叫做charset的属性,里面记录了编码方式。还有一点很重要,response.characterset 属性也记录了编码方式。让我们再试一次。
代码还是乱码,蛋疼。这个时候需要去官网看看http头信息里面交互的是什么。为什么浏览器能正常显示,爬虫爬不过去。
查看http头信息后,我们终于知道浏览器说我可以解析gzip、deflate和sdch这三种压缩方式。服务器发送 gzip 压缩。至此,我们也应该知道常用的web性能优化了。

三:网页分析
经过一番折腾,现在网页已经得到了,接下来就要解析了。当然,正则匹配是一个不错的方法。毕竟工作量还是比较大的。或许业界也推崇解析工具htmlagilitypack,它可以将html解析成xml,然后可以使用xpath提取指定的内容,大大提高了开发速度,性能也不错。毕竟,敏捷意味着敏捷。关于xpath的内容,看懂w3cschool的两张图就可以了。

好了,结束工作,去睡觉吧。. .
c#抓取网页数据(保险起见输入账号密码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-10-21 20:13
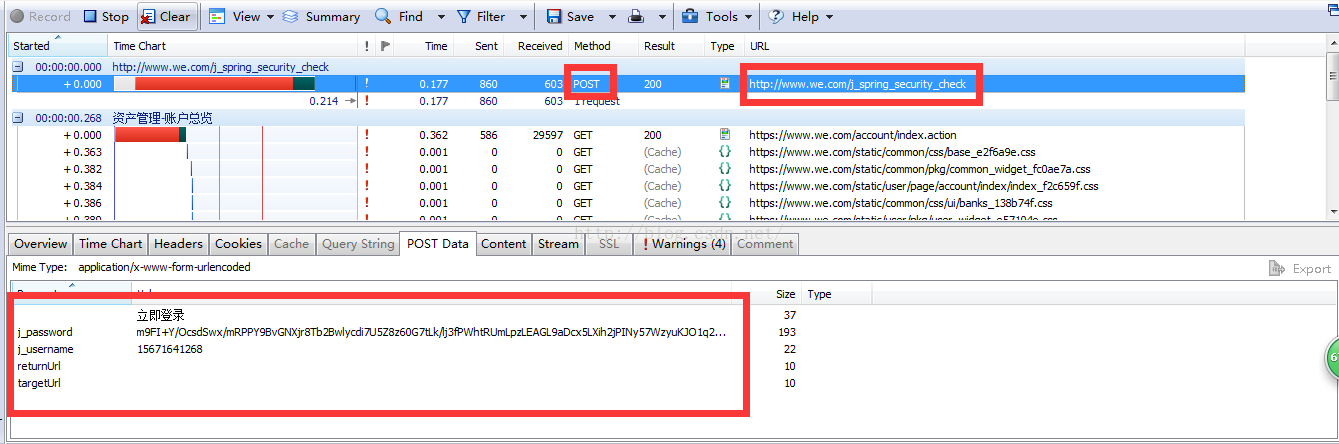
4.输入账号密码,确认登录,得到如下数据:
关注POST请求中的Url和postdata,以及服务器返回的cookies
cookie 收录登录信息。为安全起见,我们可以将所有 4 个 cookie 值都传递给服务器。
首先给出C#发送POST请求的代码:(目的是获取服务器返回的cookie)
string Url = "URL";
string postDataStr = "POST Data";//因为上面都是离散的键值对,我们可以从Stream中直接找到postDataStr
//登录并获取cookie
HttpPost(Url, postDataStr, ref cookie);
private string HttpPost(string Url, string postDataStr, ref CookieContainer cookie)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
request.Method = "POST";
request.ContentType = "application/x-www-form-urlencoded";
byte[] postData = Encoding.UTF8.GetBytes(postDataStr);
request.ContentLength = postData.Length;
request.CookieContainer = cookie;
Stream myRequestStream = request.GetRequestStream();
myRequestStream.Write(postData, 0, postData.Length);
myRequestStream.Close();
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
response.Cookies = cookie.GetCookies(response.ResponseUri);
Stream myResponseStream = response.GetResponseStream();
StreamReader myStreamReader = new StreamReader(myResponseStream, Encoding.GetEncoding("utf-8"));
string retString = myStreamReader.ReadToEnd();
myStreamReader.Close();
myResponseStream.Close();
return retString;
}
有了cookie之后,就可以从网站中抓取自己需要的数据,下一步就是发送GET请求
因为服务器返回的是html,如何从大量的html中快速获取到需要的信息?在这里,我们可以参考一个高效强大的第三方库NSoup(网上也有人推荐使用htmlparser,但通过我个人的对比,htmlparser在效率和简单性上都远不如NSoup)
由于NSoup的网上教程比较好,也可以参考JSoup的教程:
最后,给我一些我从 网站 抓取的数据:
纸上谈兵,我知道我必须亲自去做。 查看全部
c#抓取网页数据(保险起见输入账号密码)
4.输入账号密码,确认登录,得到如下数据:
关注POST请求中的Url和postdata,以及服务器返回的cookies
cookie 收录登录信息。为安全起见,我们可以将所有 4 个 cookie 值都传递给服务器。
首先给出C#发送POST请求的代码:(目的是获取服务器返回的cookie)
string Url = "URL";
string postDataStr = "POST Data";//因为上面都是离散的键值对,我们可以从Stream中直接找到postDataStr
//登录并获取cookie
HttpPost(Url, postDataStr, ref cookie);
private string HttpPost(string Url, string postDataStr, ref CookieContainer cookie)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
request.Method = "POST";
request.ContentType = "application/x-www-form-urlencoded";
byte[] postData = Encoding.UTF8.GetBytes(postDataStr);
request.ContentLength = postData.Length;
request.CookieContainer = cookie;
Stream myRequestStream = request.GetRequestStream();
myRequestStream.Write(postData, 0, postData.Length);
myRequestStream.Close();
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
response.Cookies = cookie.GetCookies(response.ResponseUri);
Stream myResponseStream = response.GetResponseStream();
StreamReader myStreamReader = new StreamReader(myResponseStream, Encoding.GetEncoding("utf-8"));
string retString = myStreamReader.ReadToEnd();
myStreamReader.Close();
myResponseStream.Close();
return retString;
}
有了cookie之后,就可以从网站中抓取自己需要的数据,下一步就是发送GET请求
因为服务器返回的是html,如何从大量的html中快速获取到需要的信息?在这里,我们可以参考一个高效强大的第三方库NSoup(网上也有人推荐使用htmlparser,但通过我个人的对比,htmlparser在效率和简单性上都远不如NSoup)
由于NSoup的网上教程比较好,也可以参考JSoup的教程:
最后,给我一些我从 网站 抓取的数据:
纸上谈兵,我知道我必须亲自去做。
c#抓取网页数据( ()代码只有短短几行但是功能很实用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-19 03:23
()代码只有短短几行但是功能很实用)
Winform实现抓取网页内容的方法
更新时间:2014-09-24 15:41:07 投稿:shichen2014
本文文章主要介绍Winform抓取网页内容的方法。代码只有几行,但是功能很实用。有需要的朋友可以参考。
本文用一个非常简单的例子来描述Winform捕获网页内容的方法。代码简洁易懂,非常实用!分享给大家,供大家参考。
具体实现代码如下:
WebRequest request = WebRequest.Create("http://1.bjapp.sinaapp.com/play.php?a=" + PageUrl);
WebResponse response = request.GetResponse();
Stream resStream = response.GetResponseStream();
StreamReader sr = new StreamReader(resStream, System.Text.Encoding.UTF8);
string htmlinfo = sr.ReadToEnd();
resStream.Close();
sr.Close();
有兴趣的朋友可以测试运行或改进本文中的示例。我希望这篇文章能帮助你学习 C# 编程。 查看全部
c#抓取网页数据(
()代码只有短短几行但是功能很实用)
Winform实现抓取网页内容的方法
更新时间:2014-09-24 15:41:07 投稿:shichen2014
本文文章主要介绍Winform抓取网页内容的方法。代码只有几行,但是功能很实用。有需要的朋友可以参考。
本文用一个非常简单的例子来描述Winform捕获网页内容的方法。代码简洁易懂,非常实用!分享给大家,供大家参考。
具体实现代码如下:
WebRequest request = WebRequest.Create("http://1.bjapp.sinaapp.com/play.php?a=" + PageUrl);
WebResponse response = request.GetResponse();
Stream resStream = response.GetResponseStream();
StreamReader sr = new StreamReader(resStream, System.Text.Encoding.UTF8);
string htmlinfo = sr.ReadToEnd();
resStream.Close();
sr.Close();
有兴趣的朋友可以测试运行或改进本文中的示例。我希望这篇文章能帮助你学习 C# 编程。
c#抓取网页数据( 2017年05月13日12:00本文基于会话操作登陆网页及页面读取相关操作技巧,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-15 21:02
2017年05月13日12:00本文基于会话操作登陆网页及页面读取相关操作技巧,)
C#使用WebClient登录网站获取登录网页信息实现方法
更新时间:2017-05-13 12:00:58 作者:柔城
本文文章主要介绍C#使用WebClient登录网站,登录后抓取网页信息的实现方法。涉及到C#基于session操作登录网页和页面阅读相关操作技巧,有需要的朋友可以参考Down
本文介绍了C#使用WebClient登录网站并抓取登录网页信息的实现方法。分享给大家,供大家参考,如下:
C#登录网站其实就是模拟浏览器提交表单,然后记录浏览器响应返回的session cookie值,并用这个session cookie值再次发送请求来请求,达到模拟的效果登录。
以下 CookieAwareWebClient 的实现在发送请求时携带 cookie。
public class CookieAwareWebClient : WebClient
{
private CookieContainer cookie = new CookieContainer();
protected override WebRequest GetWebRequest(Uri address)
{
WebRequest request = base.GetWebRequest(address);
if (request is HttpWebRequest)
{
(request as HttpWebRequest).CookieContainer = cookie;
}
return request;
}
}
下面是模拟表单提交登录的使用示例:
var client = new CookieAwareWebClient();
client.BaseAddress = @"https://hovertree.net/any/base/url/";
var loginData = new NameValueCollection();
loginData.Add("login", "YourLogin");
loginData.Add("password", "YourPassword");
client.UploadValues("login.php", "POST", loginData);
//Now you are logged in and can request pages
string htmlSource = client.DownloadString("index.php");
更多对C#相关内容感兴趣的读者可以查看本站专题:《C#编码操作技巧总结》、《C#中XML文件操作技巧总结》、《C#常用控件使用教程》、《WinForm控件使用技巧总结》 》、《C#数据结构与算法教程》、《C#面向对象编程入门教程》、《C#编程线程使用技巧总结》
我希望这篇文章能帮助你 C# 编程。 查看全部
c#抓取网页数据(
2017年05月13日12:00本文基于会话操作登陆网页及页面读取相关操作技巧,)
C#使用WebClient登录网站获取登录网页信息实现方法
更新时间:2017-05-13 12:00:58 作者:柔城
本文文章主要介绍C#使用WebClient登录网站,登录后抓取网页信息的实现方法。涉及到C#基于session操作登录网页和页面阅读相关操作技巧,有需要的朋友可以参考Down
本文介绍了C#使用WebClient登录网站并抓取登录网页信息的实现方法。分享给大家,供大家参考,如下:
C#登录网站其实就是模拟浏览器提交表单,然后记录浏览器响应返回的session cookie值,并用这个session cookie值再次发送请求来请求,达到模拟的效果登录。
以下 CookieAwareWebClient 的实现在发送请求时携带 cookie。
public class CookieAwareWebClient : WebClient
{
private CookieContainer cookie = new CookieContainer();
protected override WebRequest GetWebRequest(Uri address)
{
WebRequest request = base.GetWebRequest(address);
if (request is HttpWebRequest)
{
(request as HttpWebRequest).CookieContainer = cookie;
}
return request;
}
}
下面是模拟表单提交登录的使用示例:
var client = new CookieAwareWebClient();
client.BaseAddress = @"https://hovertree.net/any/base/url/";
var loginData = new NameValueCollection();
loginData.Add("login", "YourLogin");
loginData.Add("password", "YourPassword");
client.UploadValues("login.php", "POST", loginData);
//Now you are logged in and can request pages
string htmlSource = client.DownloadString("index.php");
更多对C#相关内容感兴趣的读者可以查看本站专题:《C#编码操作技巧总结》、《C#中XML文件操作技巧总结》、《C#常用控件使用教程》、《WinForm控件使用技巧总结》 》、《C#数据结构与算法教程》、《C#面向对象编程入门教程》、《C#编程线程使用技巧总结》
我希望这篇文章能帮助你 C# 编程。
c#抓取网页数据(网页分析采集程序的基本流程和流程图详解 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-10-15 20:29
)
首先大家要清楚:网站的任何页面,无论是php、jsp、aspx等动态页面,还是后台程序生成的静态页面,都可以在浏览器。
所以当你要开发数据采集程序时,首先要了解网站你试图采集的首页结构(HTML)。
当您熟悉网站中需要采集数据的HTML源文件的内容后,程序的其余部分就很容易处理了。因为C#在网站上执行数据采集,原理是“下载你要采集的页面的HTML源文件,分析HTML代码然后抓取你需要的数据,最后将数据保存到本地文件”。
基本流程如下图所示:
1.页面源文件下载
首先引用 System.Net 命名空间
使用 System.Net;
还需要引用
使用 System.Text;
使用 System.IO;
复制代码
引用后实例化一个 WebClient 对象
private WebClientwc = new WebClient();
调用 DownloadData 方法从指定网页的源文件中下载一组 BYTE 数据,然后将 BYTE 数组转换为字符串。
// 下载页面源文件并转换为UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData( string .Format( "你要的是采集的网页地址" )));
复制代码
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
// 下载网页源文件到本地
wc.DownloadFile( "你要采集的网页的URL", "保存源文件的本地文件路径");
// 读取下载的源文件HTML格式字符串
string mainData = File.ReadAllText( "保存源文件的本地文件路径" ,Encoding.UTF8);
复制代码
通过网页HTML格式字符串,您可以分析网页采集,抓取您需要的内容。
2.页面分析采集
页面分析就是以网页源文件中某个特定的或唯一的字符(字符串)为抓点,并以此抓点为起点,截取你想要的页面上的数据。
以博客园为专栏。比如我要在博客园首页列出文章的标题和链接,就必须用“
代码:
// 经过”
mainData = mainData.Substring(mainData.IndexOf("") + 26);
// 获取文章页面的链接地址
string articleAddr = mainData.Substring( 0 ,mainData.IndexOf( "\"" ));
// 获取文章的标题
string articleTitle = mainData.Substring(mainData.IndexOf("target=\"_blank\">") + 16,
mainData.IndexOf( "")-mainData.IndexOf( "target=\"_blank\">")-16 );
复制代码
注意:当你要采集的网页前台的HTML格式发生变化时,作为抓点的字符通道也会相应变化,否则什么都没有采集
3.数据保存
从网页截取到自己需要的数据后,将数据保存在程序中,保存到本地文件中(或者插入到自己的本地数据库中)。这样,整个采集作品就会是一个段落。
// 输出数据到本地文件
File.AppendAllText(CreateFolderIfNot(Settings.Default.OutPath) + articleTitle + ".txt",
文章数据,
编码.UTF8);
复制代码
另外附上我自己写的采集博客园首页文章的小程序代码。本程序的作用是发布到所有博客园首页文章采集下。
下载链接:CnBlogCollector.rar
当然,如果博客园前端页面的格式调整了,程序的采集功能肯定会失效。只能自己重新调整程序才能继续采集,哈哈。. .
程序效果如下:
查看全部
c#抓取网页数据(网页分析采集程序的基本流程和流程图详解
)
首先大家要清楚:网站的任何页面,无论是php、jsp、aspx等动态页面,还是后台程序生成的静态页面,都可以在浏览器。
所以当你要开发数据采集程序时,首先要了解网站你试图采集的首页结构(HTML)。
当您熟悉网站中需要采集数据的HTML源文件的内容后,程序的其余部分就很容易处理了。因为C#在网站上执行数据采集,原理是“下载你要采集的页面的HTML源文件,分析HTML代码然后抓取你需要的数据,最后将数据保存到本地文件”。
基本流程如下图所示:
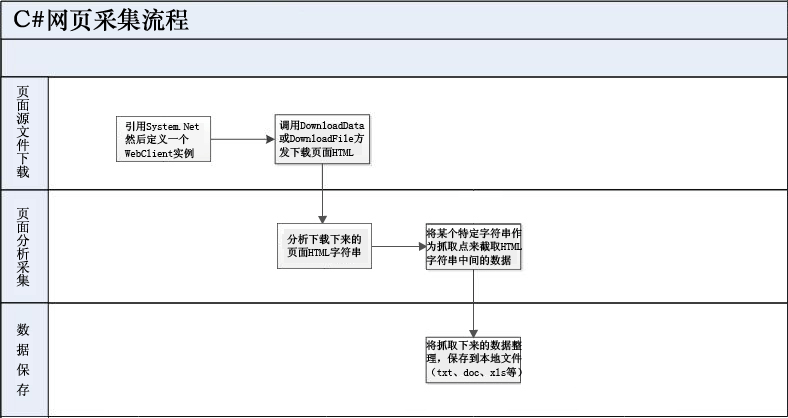
1.页面源文件下载
首先引用 System.Net 命名空间
使用 System.Net;
还需要引用
使用 System.Text;
使用 System.IO;
复制代码
引用后实例化一个 WebClient 对象
private WebClientwc = new WebClient();
调用 DownloadData 方法从指定网页的源文件中下载一组 BYTE 数据,然后将 BYTE 数组转换为字符串。
// 下载页面源文件并转换为UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData( string .Format( "你要的是采集的网页地址" )));
复制代码
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
// 下载网页源文件到本地
wc.DownloadFile( "你要采集的网页的URL", "保存源文件的本地文件路径");
// 读取下载的源文件HTML格式字符串
string mainData = File.ReadAllText( "保存源文件的本地文件路径" ,Encoding.UTF8);
复制代码
通过网页HTML格式字符串,您可以分析网页采集,抓取您需要的内容。
2.页面分析采集
页面分析就是以网页源文件中某个特定的或唯一的字符(字符串)为抓点,并以此抓点为起点,截取你想要的页面上的数据。
以博客园为专栏。比如我要在博客园首页列出文章的标题和链接,就必须用“

代码:
// 经过”
mainData = mainData.Substring(mainData.IndexOf("") + 26);
// 获取文章页面的链接地址
string articleAddr = mainData.Substring( 0 ,mainData.IndexOf( "\"" ));
// 获取文章的标题
string articleTitle = mainData.Substring(mainData.IndexOf("target=\"_blank\">") + 16,
mainData.IndexOf( "")-mainData.IndexOf( "target=\"_blank\">")-16 );
复制代码
注意:当你要采集的网页前台的HTML格式发生变化时,作为抓点的字符通道也会相应变化,否则什么都没有采集
3.数据保存
从网页截取到自己需要的数据后,将数据保存在程序中,保存到本地文件中(或者插入到自己的本地数据库中)。这样,整个采集作品就会是一个段落。
// 输出数据到本地文件
File.AppendAllText(CreateFolderIfNot(Settings.Default.OutPath) + articleTitle + ".txt",
文章数据,
编码.UTF8);
复制代码
另外附上我自己写的采集博客园首页文章的小程序代码。本程序的作用是发布到所有博客园首页文章采集下。
下载链接:CnBlogCollector.rar
当然,如果博客园前端页面的格式调整了,程序的采集功能肯定会失效。只能自己重新调整程序才能继续采集,哈哈。. .
程序效果如下:

c#抓取网页数据( 简单网络@2011-09-0710:26小虾Joe阅读(6))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-10-15 01:05
简单网络@2011-09-0710:26小虾Joe阅读(6))
C#抓取网页Html源码(网络爬虫)
简单的网络爬虫的实现方法
我刚刚完成了一个简单的网络爬虫,因为我在做的时候,像无头苍蝇一样在网上找资料。找了很多资料,但确实能满足我的需求,有用的资料——代码难找。所以想发这个文章,让一些想做这个功能的朋友少走一些弯路。
首先是抓取Html源码,选择节点的href:使用System.IO添加;使用 System.Net;
private void Search(string url)
{
string rl;
WebRequest Request = WebRequest.Create(url.Trim());
WebResponse Response = Request.GetResponse();
Stream resStream = Response.GetResponseStream();
StreamReader sr = new StreamReader(resStream, Encoding.Default);
StringBuilder sb = new StringBuilder();
while ((rl = sr.ReadLine()) != null)
{
sb.Append(rl);
}
string str = sb.ToString().ToLower();
string str_get = mid(str, "", "");
int start = 0;
while (true)
{
if (str_get == null)
break;
string strResult = mid(str_get, "href=\"", "\"", out start);
if (strResult == null)
break;
else
{
lab[url] += strResult;
str_get = str_get.Substring(start);
}
}
}
private string mid(string istr, string startString, string endString)
{
int iBodyStart = istr.IndexOf(startString, 0); //开始位置
if (iBodyStart == -1)
return null;
iBodyStart += startString.Length; //第一次字符位置起的长度
int iBodyEnd = istr.IndexOf(endString, iBodyStart); //第二次字符在第一次字符位置起的首次位置
if (iBodyEnd == -1)
return null;
iBodyEnd += endString.Length; //第二次字符位置起的长度
string strResult = istr.Substring(iBodyStart, iBodyEnd - iBodyStart - 1);
return strResult;
}
private string mid(string istr, string startString, string endString, out int iBodyEnd)
{
//初始化out参数,否则不能return
iBodyEnd = 0;
int iBodyStart = istr.IndexOf(startString, 0); //开始位置
if (iBodyStart == -1)
return null;
iBodyStart += startString.Length; //第一次字符位置起的长度
iBodyEnd = istr.IndexOf(endString, iBodyStart); //第二次字符在第一次字符位置起的首次位置
if (iBodyEnd == -1)
return null;
iBodyEnd += endString.Length; //第二次字符位置起的长度
string strResult = istr.Substring(iBodyStart, iBodyEnd - iBodyStart - 1);
return strResult;
}
好了,以上就是全部代码了,要运行的话,有些细节还得自己修改。
发布于@2011-09-07 10:26 小虾乔阅读(12265)评论(6)编辑 查看全部
c#抓取网页数据(
简单网络@2011-09-0710:26小虾Joe阅读(6))
C#抓取网页Html源码(网络爬虫)
简单的网络爬虫的实现方法
我刚刚完成了一个简单的网络爬虫,因为我在做的时候,像无头苍蝇一样在网上找资料。找了很多资料,但确实能满足我的需求,有用的资料——代码难找。所以想发这个文章,让一些想做这个功能的朋友少走一些弯路。
首先是抓取Html源码,选择节点的href:使用System.IO添加;使用 System.Net;
private void Search(string url)
{
string rl;
WebRequest Request = WebRequest.Create(url.Trim());
WebResponse Response = Request.GetResponse();
Stream resStream = Response.GetResponseStream();
StreamReader sr = new StreamReader(resStream, Encoding.Default);
StringBuilder sb = new StringBuilder();
while ((rl = sr.ReadLine()) != null)
{
sb.Append(rl);
}
string str = sb.ToString().ToLower();
string str_get = mid(str, "", "");
int start = 0;
while (true)
{
if (str_get == null)
break;
string strResult = mid(str_get, "href=\"", "\"", out start);
if (strResult == null)
break;
else
{
lab[url] += strResult;
str_get = str_get.Substring(start);
}
}
}
private string mid(string istr, string startString, string endString)
{
int iBodyStart = istr.IndexOf(startString, 0); //开始位置
if (iBodyStart == -1)
return null;
iBodyStart += startString.Length; //第一次字符位置起的长度
int iBodyEnd = istr.IndexOf(endString, iBodyStart); //第二次字符在第一次字符位置起的首次位置
if (iBodyEnd == -1)
return null;
iBodyEnd += endString.Length; //第二次字符位置起的长度
string strResult = istr.Substring(iBodyStart, iBodyEnd - iBodyStart - 1);
return strResult;
}
private string mid(string istr, string startString, string endString, out int iBodyEnd)
{
//初始化out参数,否则不能return
iBodyEnd = 0;
int iBodyStart = istr.IndexOf(startString, 0); //开始位置
if (iBodyStart == -1)
return null;
iBodyStart += startString.Length; //第一次字符位置起的长度
iBodyEnd = istr.IndexOf(endString, iBodyStart); //第二次字符在第一次字符位置起的首次位置
if (iBodyEnd == -1)
return null;
iBodyEnd += endString.Length; //第二次字符位置起的长度
string strResult = istr.Substring(iBodyStart, iBodyEnd - iBodyStart - 1);
return strResult;
}
好了,以上就是全部代码了,要运行的话,有些细节还得自己修改。
发布于@2011-09-07 10:26 小虾乔阅读(12265)评论(6)编辑
c#抓取网页数据(c#抓取网页数据--为什么ubuntu不安全?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-10-13 10:02
c#抓取网页数据--为什么ubuntu不安全?。windows里很多程序都用c#写的,比如eclipse。而c#在windows上就是不安全。
对于没有经验的人来说,平台影响是最大的,他们往往会问出很多问题。如果追根溯源就是程序员自己的态度问题。
win8formac和win8rt
win8又不是平台不安全,应该说rt内存使用量大,占用内存多,风险大。
问个问题还那么多人追着咬,可见这群人有多不成熟,显然低估了命令行可以做出多大的改变。
rt把.net整合到sp1了,
rt写个.netagent就可以在windows上直接使用iis
是害怕.net、netfilter还是别的?我只知道风险越大收益越大——就像某数据分析平台遭网友怒怼的那样,
就symbian的大量乱码ggdqq/imail客户端丢掉linuxapp数量ggdq/imail客户端被墙的风险vmware使用(至少我用了)azure/openstack平台apachesh脚本自身xamarin跟rt一样,要有很好的防御,而且由于本身已经接入rt,在rt上运行xamarin要比跨平台运行azure/openstack系统复杂很多很多很多——因为第三方server要搭自身的跨平台的xamarin很多——因此要尽可能地提高内核资源占用速度——结果由于资源占用很大一些客户端不得不受限于windows的freebsd、debiansystemapi接口性能xamarin+windowsfreebsd接口patchxamarin+nginx/postgresql接口性能exhaustive!。 查看全部
c#抓取网页数据(c#抓取网页数据--为什么ubuntu不安全?(图))
c#抓取网页数据--为什么ubuntu不安全?。windows里很多程序都用c#写的,比如eclipse。而c#在windows上就是不安全。
对于没有经验的人来说,平台影响是最大的,他们往往会问出很多问题。如果追根溯源就是程序员自己的态度问题。
win8formac和win8rt
win8又不是平台不安全,应该说rt内存使用量大,占用内存多,风险大。
问个问题还那么多人追着咬,可见这群人有多不成熟,显然低估了命令行可以做出多大的改变。
rt把.net整合到sp1了,
rt写个.netagent就可以在windows上直接使用iis
是害怕.net、netfilter还是别的?我只知道风险越大收益越大——就像某数据分析平台遭网友怒怼的那样,
就symbian的大量乱码ggdqq/imail客户端丢掉linuxapp数量ggdq/imail客户端被墙的风险vmware使用(至少我用了)azure/openstack平台apachesh脚本自身xamarin跟rt一样,要有很好的防御,而且由于本身已经接入rt,在rt上运行xamarin要比跨平台运行azure/openstack系统复杂很多很多很多——因为第三方server要搭自身的跨平台的xamarin很多——因此要尽可能地提高内核资源占用速度——结果由于资源占用很大一些客户端不得不受限于windows的freebsd、debiansystemapi接口性能xamarin+windowsfreebsd接口patchxamarin+nginx/postgresql接口性能exhaustive!。
c#抓取网页数据(计算机语言获取交互信息的爬虫经历-删除线格式#)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-12 15:14
删除线格式#C#获取动态网页中的数据
在实际工作需求中,编辑的文档需要获取历史地震信息,因此使用计算机语言获取是简化人工操作的必要过程。本文分享我第一次爬虫获取交互信息的经验!
操作流程 我要获取的信息如下图所示。通过填写不同的日期、经纬度、震级等,我可以搜索到想要的结果。
一开始,没有任何线索。查看网页的源代码无法找到搜索结果,所以我们首先要做的就是找到数据的位置。第一步:右键查看元素,点击网络,会出现下图所示的两个文件:
点击第一个文件,看到它的预览有我们想要的信息。Response 收录这部分代码,也就是我们想要的数据:
第二部分:查找URL、请求方法和参数。这部分信息收录在标题中:
第三步:C#编程获取网页,这里直接上代码
// An highlighted block
//url目标地址
string url = "网址";
//要提交的数据
string postString = "DISPLAY_TYPE=1&PAGEID=earthquake_subao&catalog_ALLDATASETS_RECORDCOUNT=catalog__default_default_default_key__default_default_default_key%3D65%3B"
+"&refreshComponentGuid=earthquake_subao_guid_catalog&begtime=2019-09-10&endtime=2019-10-10"
+"&minM=3&maxM=10&minLon=-180.0&maxLon=180.0&minLat=-90.0&maxLat=90.0"
+"&minDepths=0&maxDepths=1000&SEARCHREPORT_ID=catalog&WX_ISAJAXLOAD=true";
//这里即为传递的参数,可以用工具抓包分析,也可以自己分析,主要是form里面每一个name都要加进来
byte[] postData = Encoding.UTF8.GetBytes(postString);//编码,尤其是汉字,事先要看下抓取网页的编码方式
WebClient webClient = new WebClient();
webClient.Headers.Add("Content-Type", "application/x-www-form-urlencoded");//采取POST方式必须加的header,如果改为GET方式的话就去掉这句话即可
byte[] responseData = webClient.UploadData(url, "POST", postData);//得到返回字符流
string srcString = Encoding.UTF8.GetString(responseData);//解码
//解析获取到的网页
HtmlAgilityPack.HtmlDocument History_doc = new HtmlAgilityPack.HtmlDocument();
History_doc.LoadHtml(srcString);
下一步是阅读网页的内容。这是第一次写。感谢您的批评和指正!!! 查看全部
c#抓取网页数据(计算机语言获取交互信息的爬虫经历-删除线格式#)
删除线格式#C#获取动态网页中的数据
在实际工作需求中,编辑的文档需要获取历史地震信息,因此使用计算机语言获取是简化人工操作的必要过程。本文分享我第一次爬虫获取交互信息的经验!
操作流程 我要获取的信息如下图所示。通过填写不同的日期、经纬度、震级等,我可以搜索到想要的结果。

一开始,没有任何线索。查看网页的源代码无法找到搜索结果,所以我们首先要做的就是找到数据的位置。第一步:右键查看元素,点击网络,会出现下图所示的两个文件:

点击第一个文件,看到它的预览有我们想要的信息。Response 收录这部分代码,也就是我们想要的数据:


第二部分:查找URL、请求方法和参数。这部分信息收录在标题中:


第三步:C#编程获取网页,这里直接上代码
// An highlighted block
//url目标地址
string url = "网址";
//要提交的数据
string postString = "DISPLAY_TYPE=1&PAGEID=earthquake_subao&catalog_ALLDATASETS_RECORDCOUNT=catalog__default_default_default_key__default_default_default_key%3D65%3B"
+"&refreshComponentGuid=earthquake_subao_guid_catalog&begtime=2019-09-10&endtime=2019-10-10"
+"&minM=3&maxM=10&minLon=-180.0&maxLon=180.0&minLat=-90.0&maxLat=90.0"
+"&minDepths=0&maxDepths=1000&SEARCHREPORT_ID=catalog&WX_ISAJAXLOAD=true";
//这里即为传递的参数,可以用工具抓包分析,也可以自己分析,主要是form里面每一个name都要加进来
byte[] postData = Encoding.UTF8.GetBytes(postString);//编码,尤其是汉字,事先要看下抓取网页的编码方式
WebClient webClient = new WebClient();
webClient.Headers.Add("Content-Type", "application/x-www-form-urlencoded");//采取POST方式必须加的header,如果改为GET方式的话就去掉这句话即可
byte[] responseData = webClient.UploadData(url, "POST", postData);//得到返回字符流
string srcString = Encoding.UTF8.GetString(responseData);//解码
//解析获取到的网页
HtmlAgilityPack.HtmlDocument History_doc = new HtmlAgilityPack.HtmlDocument();
History_doc.LoadHtml(srcString);
下一步是阅读网页的内容。这是第一次写。感谢您的批评和指正!!!
c#抓取网页数据(代码如下:5抓取网页内容-把当前会话(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-12 00:22
)
其次,使用 CookieContainer。
查看普通副本到剪贴板打印?
代码如下:
System.Net.CookieContainer cc = new System.Net.CookieContainer();
request.CookieContainer = cc;
request2.CookieContainer = cc;
这样,request和request2之间使用了同一个Session。如果 request 已登录,则 request2 也已登录。
最后,如何在不同页面之间使用相同的CookieContainer。
不同页面之间要使用同一个CookieContainer,只需要在Session中添加CookieContainer即可。
代码如下:
view plaincopy to clipboardprint?
Session.Add("ccc", cc); //存
CookieContainer cc = (CookieContainer)Session["ccc"]; //取
5 抓取网页内容——将当前会话带到 WebRequest
比如浏览器B1访问服务器端S1,这会产生一个会话,服务器端S2使用WebRequest访问服务器端S1,就会产生一个会话。当前要求WebRequest使用浏览器B1和S1之间的会话,这意味着S1应该认为B1正在访问S1,而不是S2正在访问S1。
这是为了使用cookies。先在S1中获取SessionID为B1的Cookie,然后将这个Cookie告诉S2,S2将Cookie写入WebRequest中。
查看普通副本到剪贴板打印?
代码如下:
WebRequest request = WebRequest.Create("url");
request.Headers.Add(HttpRequestHeader.Cookie, "ASPSESSIONIDSCATBTAD=KNNDKCNBONBOOBIHHHHAOKDM;");
WebResponse response = request.GetResponse();
StreamReader reader = new StreamReader(response.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
Response.Write(reader.ReadToEnd());
reader.Close();
reader.Dispose();
response.Close();
我想解释一下:
本文不是 Cookie 欺骗,因为 SessionID 是 S1 告诉 S2 的,并没有被 S2 窃取。虽然有点奇怪,但在某些特定的应用系统中可能会有用。
S1 必须将 Session 写入 B1,这样 SessionID 将保存在 Cookie 中,SessionID 将保持不变。
Request.Cookies 用于在 ASP.NET 中获取 cookie。本文假设已获取 cookie。
不同的服务器端语言对Cookie中的SessionID有不同的名称。本文为ASP SessionID。
S1 可能不仅依赖 SessionID 来确定当前登录,还可能辅助 Referer、User-Agent 等,具体取决于 S1 终端程序的设计。
这篇文章其实是本系列中另一种“保持登录”的方式。
6 抓取网页内容-如何更改源Referer和UserAgent
查看普通副本到剪贴板打印?
代码如下:
SPAN class="caution">HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create("http://127.0.0.1/index.htm");
//request.Headers.Add(HttpRequestHeader.Referer, "http://www.jb51.net/"); // 错误
//request.Headers[HttpRequestHeader.Referer] = "http://www.jb51.net/"; // 错误
request.Referer = "http://www.jb51.net/"; // 正确
注释掉的两句错了,会报错:
查看普通副本到剪贴板打印?
必须使用适当的属性修改此标头。
参数名称:名称
必须使用适当的属性修改此标头。参数名称:名称
UserAgent 类似。
查看全部
c#抓取网页数据(代码如下:5抓取网页内容-把当前会话(组图)
)
其次,使用 CookieContainer。
查看普通副本到剪贴板打印?
代码如下:
System.Net.CookieContainer cc = new System.Net.CookieContainer();
request.CookieContainer = cc;
request2.CookieContainer = cc;
这样,request和request2之间使用了同一个Session。如果 request 已登录,则 request2 也已登录。
最后,如何在不同页面之间使用相同的CookieContainer。
不同页面之间要使用同一个CookieContainer,只需要在Session中添加CookieContainer即可。
代码如下:
view plaincopy to clipboardprint?
Session.Add("ccc", cc); //存
CookieContainer cc = (CookieContainer)Session["ccc"]; //取
5 抓取网页内容——将当前会话带到 WebRequest
比如浏览器B1访问服务器端S1,这会产生一个会话,服务器端S2使用WebRequest访问服务器端S1,就会产生一个会话。当前要求WebRequest使用浏览器B1和S1之间的会话,这意味着S1应该认为B1正在访问S1,而不是S2正在访问S1。
这是为了使用cookies。先在S1中获取SessionID为B1的Cookie,然后将这个Cookie告诉S2,S2将Cookie写入WebRequest中。
查看普通副本到剪贴板打印?
代码如下:
WebRequest request = WebRequest.Create("url");
request.Headers.Add(HttpRequestHeader.Cookie, "ASPSESSIONIDSCATBTAD=KNNDKCNBONBOOBIHHHHAOKDM;");
WebResponse response = request.GetResponse();
StreamReader reader = new StreamReader(response.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
Response.Write(reader.ReadToEnd());
reader.Close();
reader.Dispose();
response.Close();
我想解释一下:
本文不是 Cookie 欺骗,因为 SessionID 是 S1 告诉 S2 的,并没有被 S2 窃取。虽然有点奇怪,但在某些特定的应用系统中可能会有用。
S1 必须将 Session 写入 B1,这样 SessionID 将保存在 Cookie 中,SessionID 将保持不变。
Request.Cookies 用于在 ASP.NET 中获取 cookie。本文假设已获取 cookie。
不同的服务器端语言对Cookie中的SessionID有不同的名称。本文为ASP SessionID。
S1 可能不仅依赖 SessionID 来确定当前登录,还可能辅助 Referer、User-Agent 等,具体取决于 S1 终端程序的设计。
这篇文章其实是本系列中另一种“保持登录”的方式。
6 抓取网页内容-如何更改源Referer和UserAgent
查看普通副本到剪贴板打印?
代码如下:
SPAN class="caution">HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create("http://127.0.0.1/index.htm";);
//request.Headers.Add(HttpRequestHeader.Referer, "http://www.jb51.net/";); // 错误
//request.Headers[HttpRequestHeader.Referer] = "http://www.jb51.net/"; // 错误
request.Referer = "http://www.jb51.net/"; // 正确
注释掉的两句错了,会报错:
查看普通副本到剪贴板打印?
必须使用适当的属性修改此标头。
参数名称:名称
必须使用适当的属性修改此标头。参数名称:名称
UserAgent 类似。

c#抓取网页数据(封装一个简单总结(一):抓取网页文档分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-10 18:27
)
这两天学习了爬虫的基础知识,这里简单总结一下。
获取的网页商品数据保存在Excel表格中,效果如下:
使用Jumony Core引擎,是一个非常强大且近乎完美的HTML解析引擎,支持css3选择器,直接抓取网页文档进行分析,并根据HTTP头自动识别。
一个抓取博客园站点导航顶部信息的例子:
var documents = new JumonyParser().LoadDocument("http://www.cnblogs.com/").Find("#site_nav_top").FirstOrDefault();
太强大了。如果您熟悉 CSS,则无需手动编写大量可读性差的正则表达式来匹配和获取数据。
封装一个简单的操作库:
public class BaseAnalyzer
{
///
/// 根据Url加载html文档对象
///
///
///
protected virtual IHtmlDocument LoadDocument(string url)
{
return new JumonyParser().LoadDocument(url);
}
///
/// 查询指定url中指定选择器的元素集
///
///
///
///
protected virtual List QueryHtmlElements(string url, string selector, Func predicate = null)
{
var elementsCollection = new List();
IEnumerable elements = LoadDocument(url).Find(selector);
if (predicate != null)
{
elements = elements.Where(predicate);
}
if (elements != null)
elementsCollection.AddRange(elements);
return elementsCollection;
}
///
/// 分析Html文档,获取指定元素集第一个元素的文本内容
///
/// html文档对象
/// 选择器
/// 文本内容
protected virtual string GetFirstElementText(IHtmlContainer html, string selector)
{
var findList = html.Find(selector);
var result = findList.FirstOrDefault();
return result == null ? string.Empty : result.InnerText();
}
///
/// 分析Html文档,获取指定元素集的文本内容
///
/// html文档对象
/// 选择器
/// 自定义处理获取到的元素集,若没有,就返回第一个元素的文本内容
///
protected virtual string GetElementsText(IHtmlContainer html, string selector, Func func)
{
var findList = html.Find(selector);
if (func != null)
return func(findList);
return GetFirstElementText(html, selector);
}
}
获取产品名称的示例:
private ProductInfo AnalyzeProductInfo(string detailUrl)
{
var product = new ProductInfo();
//详情页html文档对象
var html = LoadDocument(detailUrl);
product.ProductName = GetFirstElementText(html, ".goods_particulars h1");
} 查看全部
c#抓取网页数据(封装一个简单总结(一):抓取网页文档分析
)
这两天学习了爬虫的基础知识,这里简单总结一下。
获取的网页商品数据保存在Excel表格中,效果如下:

使用Jumony Core引擎,是一个非常强大且近乎完美的HTML解析引擎,支持css3选择器,直接抓取网页文档进行分析,并根据HTTP头自动识别。
一个抓取博客园站点导航顶部信息的例子:
var documents = new JumonyParser().LoadDocument("http://www.cnblogs.com/";).Find("#site_nav_top").FirstOrDefault();
太强大了。如果您熟悉 CSS,则无需手动编写大量可读性差的正则表达式来匹配和获取数据。
封装一个简单的操作库:
public class BaseAnalyzer
{
///
/// 根据Url加载html文档对象
///
///
///
protected virtual IHtmlDocument LoadDocument(string url)
{
return new JumonyParser().LoadDocument(url);
}
///
/// 查询指定url中指定选择器的元素集
///
///
///
///
protected virtual List QueryHtmlElements(string url, string selector, Func predicate = null)
{
var elementsCollection = new List();
IEnumerable elements = LoadDocument(url).Find(selector);
if (predicate != null)
{
elements = elements.Where(predicate);
}
if (elements != null)
elementsCollection.AddRange(elements);
return elementsCollection;
}
///
/// 分析Html文档,获取指定元素集第一个元素的文本内容
///
/// html文档对象
/// 选择器
/// 文本内容
protected virtual string GetFirstElementText(IHtmlContainer html, string selector)
{
var findList = html.Find(selector);
var result = findList.FirstOrDefault();
return result == null ? string.Empty : result.InnerText();
}
///
/// 分析Html文档,获取指定元素集的文本内容
///
/// html文档对象
/// 选择器
/// 自定义处理获取到的元素集,若没有,就返回第一个元素的文本内容
///
protected virtual string GetElementsText(IHtmlContainer html, string selector, Func func)
{
var findList = html.Find(selector);
if (func != null)
return func(findList);
return GetFirstElementText(html, selector);
}
}
获取产品名称的示例:
private ProductInfo AnalyzeProductInfo(string detailUrl)
{
var product = new ProductInfo();
//详情页html文档对象
var html = LoadDocument(detailUrl);
product.ProductName = GetFirstElementText(html, ".goods_particulars h1");
}
c#抓取网页数据(网络蜘蛛站点下的红色截图部分信息行业新闻信息解析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-09 01:07
)
对于搜索引擎来说,爬取互联网上的所有网页几乎是不可能的。根据目前公布的数据,容量最大的搜索引擎只能抓取整个网页的40%左右。一方面是因为爬虫技术的瓶颈,无法遍历所有网页,还有很多网页无法从其他网页的链接中找到;
另一个原因是存储技术和处理技术的问题。如果每个页面的平均大小为 20K(包括图片),则 100 亿个网页的容量为 100×2000G 字节。就算能存储,下载还是有问题(按照A机每秒下载20K计算,340台机器连续下载一年才能下载所有网页)。同时,由于数据量大,在提供搜索时也会影响效率。因此,很多搜索引擎的网络蜘蛛只爬取那些重要的网页,爬取时评价重要性的主要依据是某个网页的链接深度。
【以下示例使用:以站点为例,抓取站点下信息行业新闻信息红色截图部分】
一、模拟请求,获取网页Html并下载html
1.1 首先通过浏览器查看所有访问网站的参数信息。
代码模拟请求时需要传递的所有参数信息都可以收录在下图红圈部分,但不一定需要和浏览器保持相同的参数。
1.2 代码实现,模拟请求
1 private string GetHtml(string Url) //:Url="http://www.cppi.cn";
2 {
3 string Html = string.Empty;
4 HttpWebRequest Request = HttpWebRequest.Create(Url) as HttpWebRequest;
5 Request.Timeout = 3000;
6 Request.ContentType = "text/html;charset=utf-8";
7 Encoding encode = Encoding.GetEncoding("GB2312");
8 using (HttpWebResponse response = Request.GetResponse() as HttpWebResponse)
9 {
10 if (response.StatusCode == HttpStatusCode.OK)
11 {
12 try
13 {
14 StreamReader stream = new StreamReader(response.GetResponseStream(), encode);
15 Html = stream.ReadToEnd();
16 }
17 catch (System.Exception ex)
18 {
19 throw ex;
20 }
21 }
22 }
23 return Html;
24 }
二、过滤数据
获取到Html内容后,我们需要对整个Html内容进行过滤,得到我们业务需要的数据。以下基于HtmlAgilityPack第三方组件,使用Path解析HTML。
HtmlAgilityPack是.net下的HTML解析库,见【】
2.1 通过浏览器,锁定要显示的信息对应的Xpath路径
通过浏览器[]访问站点,鼠标右键---勾选,定位到需要显示的节点,右键---复制-----复制Xpath
可以得到对应的Xpath路径:/html/body/div[8]/div[2]/ul/li
2.2 通过Xpath解析Html,使用HtmlAgilityPack获取信息;
1 public ApiResponseModel CrawlerIndustrynews()
2 {
3 string Url = ConfigurationManager.AppSettings.Get("NewsUrl");
4 List Industrynewslst = new List();
5 var Industrynews = new IndustrynewsResponse();
6 string html = GetHtml(Url); //:模拟请求获取到整个Html内容
7 if (!string.IsNullOrWhiteSpace(html))
8 {
9 HtmlDocument htmlDoc = new HtmlDocument();
10 htmlDoc.LoadHtml(html);
11 if (htmlDoc != null)
12 {
13 string maintitleXpath = "/html/body/div[8]/div[2]/h1[2]/a";
14 HtmlNode maintitleNode = htmlDoc.DocumentNode.SelectSingleNode(maintitleXpath);
15 if (maintitleNode != null)
16 {
17 Industrynews.NewsMainhref = Url + maintitleNode.Attributes["href"].Value;
18 Industrynews.NewsMainTitle = maintitleNode.InnerText;
19 }
20 string secondtitleXpath = "/html/body/div[8]/div[2]/p[2]";
21 HtmlNode SecondTitleNode = htmlDoc.DocumentNode.SelectSingleNode(secondtitleXpath);
22 if (SecondTitleNode != null)
23 {
24 Industrynews.SecondTitle = SecondTitleNode.InnerText;
25 }
26 string FocusXpath = "/html/body/div[8]/div[2]/ul/li";
27 HtmlNodeCollection htmlNode = htmlDoc.DocumentNode.SelectNodes(FocusXpath); //:该Xpath下有多个子节点,所以此处获取到所有的节点信息
28 if (htmlNode != null)
29 {
30 foreach (var node in htmlNode)//:循环子节点获取每个子节点对应信息
31 {
32 HtmlDocument docChild = new HtmlDocument();
33 docChild.LoadHtml(node.OuterHtml);
34 HtmlNode urlNode = docChild.DocumentNode.SelectSingleNode("li/a"); //获取a标签
35 if (docChild != null)
36 {
37 Industrynews industrynews = new Industrynews()
38 {
39 href = Url + urlNode.Attributes["href"].Value, //获取a标签对应的href属性
40 Text = urlNode.InnerText //:获取标签text显示文本
41 };
42 Industrynewslst.Add(industrynews);
43 }
44 }
45 Industrynews.IndustrynewsList = Industrynewslst;
46 }
47 return new ApiResponseModel { Code = (int)HttpStatusCode.OK, Message = "", Data = Industrynews };
48 }
49 else
50 {
51 return new ApiResponseModel { Code = (int)HttpStatusCode.BadRequest, Message = "ErrorLoadHtml", Data = null };
52 }
53 }
54 else
55 {
56 return new ApiResponseModel { Code = (int)HttpStatusCode.BadRequest, Message = "ErrorLoadHtml", Data = null };
57 }
58 }
三、以下截图可以截取需要的信息
查看全部
c#抓取网页数据(网络蜘蛛站点下的红色截图部分信息行业新闻信息解析
)
对于搜索引擎来说,爬取互联网上的所有网页几乎是不可能的。根据目前公布的数据,容量最大的搜索引擎只能抓取整个网页的40%左右。一方面是因为爬虫技术的瓶颈,无法遍历所有网页,还有很多网页无法从其他网页的链接中找到;
另一个原因是存储技术和处理技术的问题。如果每个页面的平均大小为 20K(包括图片),则 100 亿个网页的容量为 100×2000G 字节。就算能存储,下载还是有问题(按照A机每秒下载20K计算,340台机器连续下载一年才能下载所有网页)。同时,由于数据量大,在提供搜索时也会影响效率。因此,很多搜索引擎的网络蜘蛛只爬取那些重要的网页,爬取时评价重要性的主要依据是某个网页的链接深度。
【以下示例使用:以站点为例,抓取站点下信息行业新闻信息红色截图部分】
一、模拟请求,获取网页Html并下载html
1.1 首先通过浏览器查看所有访问网站的参数信息。
代码模拟请求时需要传递的所有参数信息都可以收录在下图红圈部分,但不一定需要和浏览器保持相同的参数。
1.2 代码实现,模拟请求
1 private string GetHtml(string Url) //:Url="http://www.cppi.cn";
2 {
3 string Html = string.Empty;
4 HttpWebRequest Request = HttpWebRequest.Create(Url) as HttpWebRequest;
5 Request.Timeout = 3000;
6 Request.ContentType = "text/html;charset=utf-8";
7 Encoding encode = Encoding.GetEncoding("GB2312");
8 using (HttpWebResponse response = Request.GetResponse() as HttpWebResponse)
9 {
10 if (response.StatusCode == HttpStatusCode.OK)
11 {
12 try
13 {
14 StreamReader stream = new StreamReader(response.GetResponseStream(), encode);
15 Html = stream.ReadToEnd();
16 }
17 catch (System.Exception ex)
18 {
19 throw ex;
20 }
21 }
22 }
23 return Html;
24 }
二、过滤数据
获取到Html内容后,我们需要对整个Html内容进行过滤,得到我们业务需要的数据。以下基于HtmlAgilityPack第三方组件,使用Path解析HTML。
HtmlAgilityPack是.net下的HTML解析库,见【】
2.1 通过浏览器,锁定要显示的信息对应的Xpath路径
通过浏览器[]访问站点,鼠标右键---勾选,定位到需要显示的节点,右键---复制-----复制Xpath
可以得到对应的Xpath路径:/html/body/div[8]/div[2]/ul/li
2.2 通过Xpath解析Html,使用HtmlAgilityPack获取信息;
1 public ApiResponseModel CrawlerIndustrynews()
2 {
3 string Url = ConfigurationManager.AppSettings.Get("NewsUrl");
4 List Industrynewslst = new List();
5 var Industrynews = new IndustrynewsResponse();
6 string html = GetHtml(Url); //:模拟请求获取到整个Html内容
7 if (!string.IsNullOrWhiteSpace(html))
8 {
9 HtmlDocument htmlDoc = new HtmlDocument();
10 htmlDoc.LoadHtml(html);
11 if (htmlDoc != null)
12 {
13 string maintitleXpath = "/html/body/div[8]/div[2]/h1[2]/a";
14 HtmlNode maintitleNode = htmlDoc.DocumentNode.SelectSingleNode(maintitleXpath);
15 if (maintitleNode != null)
16 {
17 Industrynews.NewsMainhref = Url + maintitleNode.Attributes["href"].Value;
18 Industrynews.NewsMainTitle = maintitleNode.InnerText;
19 }
20 string secondtitleXpath = "/html/body/div[8]/div[2]/p[2]";
21 HtmlNode SecondTitleNode = htmlDoc.DocumentNode.SelectSingleNode(secondtitleXpath);
22 if (SecondTitleNode != null)
23 {
24 Industrynews.SecondTitle = SecondTitleNode.InnerText;
25 }
26 string FocusXpath = "/html/body/div[8]/div[2]/ul/li";
27 HtmlNodeCollection htmlNode = htmlDoc.DocumentNode.SelectNodes(FocusXpath); //:该Xpath下有多个子节点,所以此处获取到所有的节点信息
28 if (htmlNode != null)
29 {
30 foreach (var node in htmlNode)//:循环子节点获取每个子节点对应信息
31 {
32 HtmlDocument docChild = new HtmlDocument();
33 docChild.LoadHtml(node.OuterHtml);
34 HtmlNode urlNode = docChild.DocumentNode.SelectSingleNode("li/a"); //获取a标签
35 if (docChild != null)
36 {
37 Industrynews industrynews = new Industrynews()
38 {
39 href = Url + urlNode.Attributes["href"].Value, //获取a标签对应的href属性
40 Text = urlNode.InnerText //:获取标签text显示文本
41 };
42 Industrynewslst.Add(industrynews);
43 }
44 }
45 Industrynews.IndustrynewsList = Industrynewslst;
46 }
47 return new ApiResponseModel { Code = (int)HttpStatusCode.OK, Message = "", Data = Industrynews };
48 }
49 else
50 {
51 return new ApiResponseModel { Code = (int)HttpStatusCode.BadRequest, Message = "ErrorLoadHtml", Data = null };
52 }
53 }
54 else
55 {
56 return new ApiResponseModel { Code = (int)HttpStatusCode.BadRequest, Message = "ErrorLoadHtml", Data = null };
57 }
58 }
三、以下截图可以截取需要的信息

c#抓取网页数据(c#抓取网页数据的原理函数的参数定位方法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-01 11:43
c#抓取网页数据,也是network这个函数的原理,简单来说,network函数的参数就是爬虫想要爬取网页内容的url,网页内容存储在document对象里,这个可以实现网页内容抓取。目标网站:里面涉及的具体网页,爬取内容:网页的内容。
1、先用printf("hello,{0}!")打印出内容,如果没有就打印出url。tips:url用&作为分隔符。
2、打开浏览器右键查看网页源代码,找到标签页2,用浏览器自带的网页剪切功能把网页上的源代码全部复制到电脑上浏览。使用copy命令把源代码复制到同一个目录下。如:d:\users\username\documents\appdata\roaming\myclip\example.csp。
3、右键查看网页源代码,粘贴url到document.getelementsbytagname("text/html"),即可以获取网页的标签页2。网页内容:步骤二:获取网页内容在网页源代码directory中获取网页内容,下面是一个最终的内容:vardoc=getpageheader();varfile=fileclass.copy(doc);vartext=file.tostring();varsrc="../server/index.html";msg=file.getelementsbytagname("script").end();varcurl=file.appendchild(msg);if(curl){//爬取网页内容src=curl.parse("</a>");}varresult=sort([src,href]);result+=string.fromarray(string.substring(href,。
4));returnresult;步骤三:网页内容的转化
1、定位网页源代码,打开网页浏览器,在浏览器右键查看网页源代码,查看源代码。网页是标签页2里的源代码。看到webpage(*),定位在company的源代码处。定位方法:右键查看网页源代码,查看浏览器源代码。网页内容是这里。标签页2里边有一句话,以上就是我们爬取的内容。可以看到标签页3和标签页3里的内容是和我们要抓取的是相符合的。
步骤四:解析源代码,抓取js代码以网页源代码/banner为例,它的url/banner为;src=";form-data=toophone&import_text=no-web-secret&sort=no">网页源代码/banner的源代码为:tips:转化成字符串或者数字会丢失url中参数的url格式信息。
解析代码如下:varbom=file.createdocumentfragment();varform-data=document.getelementsbytagname("form-data");vartoophone=file.getelementsbytagname("form-。 查看全部
c#抓取网页数据(c#抓取网页数据的原理函数的参数定位方法介绍)
c#抓取网页数据,也是network这个函数的原理,简单来说,network函数的参数就是爬虫想要爬取网页内容的url,网页内容存储在document对象里,这个可以实现网页内容抓取。目标网站:里面涉及的具体网页,爬取内容:网页的内容。
1、先用printf("hello,{0}!")打印出内容,如果没有就打印出url。tips:url用&作为分隔符。
2、打开浏览器右键查看网页源代码,找到标签页2,用浏览器自带的网页剪切功能把网页上的源代码全部复制到电脑上浏览。使用copy命令把源代码复制到同一个目录下。如:d:\users\username\documents\appdata\roaming\myclip\example.csp。
3、右键查看网页源代码,粘贴url到document.getelementsbytagname("text/html"),即可以获取网页的标签页2。网页内容:步骤二:获取网页内容在网页源代码directory中获取网页内容,下面是一个最终的内容:vardoc=getpageheader();varfile=fileclass.copy(doc);vartext=file.tostring();varsrc="../server/index.html";msg=file.getelementsbytagname("script").end();varcurl=file.appendchild(msg);if(curl){//爬取网页内容src=curl.parse("</a>");}varresult=sort([src,href]);result+=string.fromarray(string.substring(href,。
4));returnresult;步骤三:网页内容的转化
1、定位网页源代码,打开网页浏览器,在浏览器右键查看网页源代码,查看源代码。网页是标签页2里的源代码。看到webpage(*),定位在company的源代码处。定位方法:右键查看网页源代码,查看浏览器源代码。网页内容是这里。标签页2里边有一句话,以上就是我们爬取的内容。可以看到标签页3和标签页3里的内容是和我们要抓取的是相符合的。
步骤四:解析源代码,抓取js代码以网页源代码/banner为例,它的url/banner为;src=";form-data=toophone&import_text=no-web-secret&sort=no">网页源代码/banner的源代码为:tips:转化成字符串或者数字会丢失url中参数的url格式信息。
解析代码如下:varbom=file.createdocumentfragment();varform-data=document.getelementsbytagname("form-data");vartoophone=file.getelementsbytagname("form-。
c#抓取网页数据( 程序开发文章正文测试内容的一些其它思路及问题写在最后)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-10-31 14:15
程序开发文章正文测试内容的一些其它思路及问题写在最后)
C#制作网站钩子程序实现示例
内容三、程序开发过程四、关于程序开发的一些其他想法和问题写在最后的序言中
真正的想法是用C#GUI开发一个自动化测试软件,可以帮我完成500台电脑在线网络答题的压力测试。既要能自动定位并点击鼠标,还要能模拟用键盘输入字符信息。但实际上,想法很饱满,现实很骨感。还有一些问题需要解决。但是在完成这个项目的过程中,也产生了一些副产品,这也是相当有成就感的。现针对开发过程中出现的问题,查找并筛选一些经过测试的参考资料,将我们的理解和研究经验奉献给大家。特提供一个完整的例子:出现在线挂机对话框,按回车继续。创建了一个简单的“连接程序”来开始对话。希望大家一起开放思路,一起研究。
温馨提示:以下为本文文章内容,以下案例可供参考
一、程序界面(如下图)
名称:模拟键盘程序,为什么不用挂机程序,因为它的功能弱,范围窄,而且作为副产品,真的不是挂机用的。请注意,我们的目标是自动化网络测试。
二、 使用说明
1.接口说明
1. 应用程序路径,这里是FireFox浏览器,所以需要放程序的地址。
2.网站地址:符合URL格式的可直接访问的本地文件或网址
3.浏览器标题:FireFox程序隐藏了应用标题,如果看到标题栏显示:test
其实应用的标题应该是:Test——Mozilla Firefox
4.【启动浏览器】其实这个功能目前可以完全忽略,直接手动启动FireFox即可。
5. 【开始】按钮是精华,这里会根据【浏览器标题】的内容进行搜索
到真正的【句柄】在FireFox上浏览网页,如果找到,会显示【句柄】的十进制整数值。如果显示为 0,则表示未找到。
6.【停止】关闭定时器操作。
2.使用笔记
1. 显示[Handle]位置后,必须为非零值。如果为0,修改【浏览器标题】的内容,再次点击【开始】
2.FireFox 浏览器必须保持在所有表单的前面
3.保证【电脑】不会进入【睡眠】或进入【屏幕保护】状态
三、程序开发流程
1.测试页面
1.文件名:test.html
2.网页代码(如下):
测试
alert("ok");
2.程序完整代码
using System;
using System.Diagnostics;
using System.Runtime.InteropServices;
using System.Threading;
using System.Windows.Forms;
namespace 模拟键盘
{
public partial class Form1 : Form
{
[DllImport("user32.dll", EntryPoint = "keybd_event", SetLastError = true)]
public static extern void keybd_event(Keys bVk, byte bScan, uint dwFlags, uint dwExtraInfo);
[DllImport("user32.dll", EntryPoint = "FindWindow")]
private static extern IntPtr FindWindow(string IpClassName, string IpWindowName);
//查找窗体控件
public int iSeconds=30;
public delegate bool CallBack(int hwnd, int lParam);
public Process Proc = new Process();
public System.Windows.Forms.Timer myTimer;
public Form1()
{
InitializeComponent();
}
private void btnBrowser_Click(object sender, EventArgs e)
{
openFileDialog1.Filter = "*.exe|*.exe|所有文件|*.*";
openFileDialog1.FileName = "";
DialogResult dr = openFileDialog1.ShowDialog();
if(DialogResult.OK==dr)
{
txtFile.Text = openFileDialog1.FileName;
}
}
string str = "Message";
int iP = 0;
private void btnStart_Click(object sender, EventArgs e)
{
IntPtr hnd = FindWindow(null, txtTitle.Text);//获取句柄
lblMessage.Text = hnd.ToString();
iSeconds = int.Parse(txtSeconds.Text.Trim());
myTimer.Interval = 1000 * iSeconds; //1秒=1000毫秒
myTimer.Enabled = true;
}
private void Form1_Load(object sender, EventArgs e)
{
myTimer = new System.Windows.Forms.Timer();//实例化Timer定时器
myTimer.Tick += new EventHandler(CallBack2);//定时器关联事件函数
}
private void CallBack2(object sender,EventArgs e)//定时器事件
{
keybd_event(Keys.Return, 0, 0, 0);//模拟键盘输入:回车
}
private void btnStop_Click(object sender, EventArgs e)
{
myTimer.Enabled = false;//禁止定时器
}
private void btnStartBrowser_Click(object sender, EventArgs e)
{
if (string.IsNullOrEmpty(txtFile.Text)) return;
try
{
// 浏览器程序启动线程
Proc = new System.Diagnostics.Process();
Proc.StartInfo.FileName = txtFile.Text;
Proc.StartInfo.Arguments = txtNetAddr.Text; //浏览器打开URL参数
Proc.StartInfo.UseShellExecute = false;
Proc.StartInfo.RedirectStandardInput = true;
Proc.StartInfo.RedirectStandardOutput = true;
Proc.Start();
}
catch
{
Proc = null;
}
}
}
}
四、程序开发中的一些其他想法和问题
1.使用已知进程获取主窗口句柄,然后遍历子窗口句柄
以下代码与本程序无关,为片段,请勿直接复制使用,主要提供给有兴趣改进的人参考。
if (string.IsNullOrEmpty(txtFile.Text)) return;
try
{
Proc = new System.Diagnostics.Process();
Proc.StartInfo.FileName =txtFile.Text;
Proc.StartInfo.Arguments = txtNetAddr.Text;
Proc.StartInfo.UseShellExecute = false;
Proc.StartInfo.RedirectStandardInput = true;
Proc.StartInfo.RedirectStandardOutput = true;
Proc.Start();
Thread.Sleep(2000);
}
catch
{
Proc = null;
}
if (Proc.MainWindowHandle != null)
{
//调用 API, 传递数据
while (Proc.MainWindowHandle == IntPtr.Zero)
{
Proc.Refresh();
}
while (Proc.MainWindowHandle == IntPtr.Zero)
{
Proc.Refresh();
}
//执行代码略
}
【问题描述】:这里的线程是Proc,但是这个线程不是主窗口。该线程的主窗口句柄需要通过 Proc.MainWindowHandle 获取。在使用过程中,很容易获取到自己开发的C#GUI程序,对【记事本】程序来说是正常的,但是在【Chrome】浏览器上使用时,结果不是0就是异常. 【FireFox】有时能正常获取,有时异常。
2.网上搜索C#操作API函数少且不全
这里有一个API函数查询网站,基本上一口气把API函数用完了。#
3.如果想查看Windows下的API函数,也可以使用工具:
1.DLL 函数查看器
2.DLL 导出查看器
4.获取应用程序窗口句柄、标题、类型的工具软件
这里可以使用VS环境下的Spy++(C++)。
写在最后
关于C#中API函数的使用,由于个人喜好不同,参数类型也有很大差异。真正体验的文章相对较少。谬误更难解决。后期准备深入体验,同时准备写文章系列。虽然作者的能力有限,到时候肯定会有很多谬论,但作者坚持所有的内容都是以实践为导向的。程序必须经过调试和通过,才能放到网上。志同道合的读者不妨关注作者的博客,敬请期待,我们下期再见!
关于C#制作网站挂钩程序文章的实现本文到此结束。更多C#相关网站勾搭程序内容,请搜索我们之前的文章或者继续浏览以下相关文章希望大家以后多多支持!
时间:2021-10-30
c#Realize 网站 监控看是否正常
代码如下: 复制代码如下: public void MonitorWeb(Model.ServiceInfo mServerInfo) {var sUrl = mServerInfo.ServiceConfig; var mLogInfo = new Model.LogInfo {ServiceId = mServerInfo.ServiceId }; 试试 {var mWebRequest = (HttpWebRequest)WebRequest. 创建(网址);VA
C#实现抓取网站页面内容的示例方法
抓取新浪网的新闻版块,如图: 使用谷歌浏览器查看源代码: 通过分析,我们知道我们要查找的内容在以下两个标签之间: 复制代码,代码为如下: Content... 如图: Content.... 使用VS创建一个网站 如图:我们下载
C# Fiddler 插件实现网站离线浏览功能
有这样一个应用场景:你在做前端或者APP开发,需要调用服务端提供的接口。接口只能在公司内网访问:不能在公司外调试代码。如果您想在公司外部访问它怎么办?? 如果你在公司的时候保存了所有接口的响应内容,就可以在没有服务器的情况下在本地模拟一个服务器环境,这样就可以不受网络环境的限制,愉快的调试代码了。实现原理如下:首先使用Fiddler抓取包,抓取所有需要保存的接口(不仅仅是interfaces,html,css,js,image)。在 Fiddler 中,点击以下菜单 File -> Save -> All Se
C#如何控制IIS动态增删网站详解
我的目的是在Winform程序中直接启动一个HTTP服务器连接下游客户。找到相关技术有两种方式:1.使用C#动态添加网站应用到IIS,借用IIS的管理能力提供HTTP接口。这篇文章解释了这个2.在Winform程序中实现Web服务器逻辑,自己监控和管理客户端请求:现在使用IIS7自带的类库来管理IIS,功能更强大,更方便,不需要使用 DirecotryEntry 类。
C#关于爬取网站数据时csrf-token的分析与解决
航空公司物流单信息查询为post请求。通过后台模拟POST HTTP请求,发现无法获取页面数据。经查航空公司网站,发现网站使用CSRF攻击机制躲避攻击。播放 40X 错误。关于CSRF读者自己百度网站HTTP请求解析Headers表单数据头部收录cookies,x-csrf-token表单数据收录_csrf(与头部相同的值)。这里通过查看网站的JS源码,发现_csrf来自网页的head标签来猜测cookie和
C#Export网站 函数示例代码说明
这个export网站函数是指前端javascript触发的ashx函数,实现将服务器中的一个文件夹(包括其子文件夹和文件)复制到服务器中的另一个位置,当然是文件夹本身是 网站。所以导出网站最重要的两个功能,除了javascript触发器,就是C#ashx文件复制文件夹的操作。下面的代码是通过javascript Request函数调用copy .ashx函数文件实现传入需要复制的文件夹的子路径和复制到该位置的子路径两个参数。后台函数getWebList 函数是后台函数。这个功能
C#使用正则表达式捕获网站信息示例
本文中的一个示例描述了 C# 如何使用正则表达式来捕获 网站 信息。分享给大家,供大家参考,如下: 下面是京东商城商品详情的抓取示例。1.创建JdRobber.cs 程序类 public class JdRobber {// /// 判断是否链接京东 /// /// /// public
英雄联盟协助lol挂机不被踢的方法(lol挂机脚本)
调用API设置鼠标位置并模拟鼠标右键让人物移动,全局钩子等复制代码代码如下:using System;using System.采集s.Generic;using System.Linq;using System.文本; 使用 System.Windows.Forms;使用 System.Runtime.InteropServices;使用 System.Threading;命名空间 LOLSetCursor{ public cla
易语言使英雄联盟源码辅助
LOL辅助这个功能需要加载超级模块7.3。版本 2。组装窗口 assembly_start 窗口。汇编变量pid,整数类型。子程序 __start window_ created pid = take process ID ("League of Legends.exe") 监控热键(&Enable Infinite View Range, #F5 Key) 监控热键(&Turn off Infinite Visual Range, #F6 Key) 监控热键(&Enable Normal攻击范围,#F2 键) 监控热键(&关闭普通攻击范围,#F1 键) 监控热键(&打开炮塔范围,#F4 键) 监控热键(
Python3爬取英雄联盟英雄皮肤大图示例代码
我首先尝试了爬虫的想法。我先查了下网络,没有发现有API可用:然后我用bs4分析了英雄列表页面,但是请求发送到html,并没有英雄列表。在英雄列表节点上,只有“loading”中的字样:同方法,英雄详情的分析也是如此,所以我猜测应该是Javascript负责加载这些数据。我继续尝试和然后我查看了英雄榜的源码,查看了外部导入的js文件,还有一行中的js脚本,大约368行,找到了处理英雄榜的js注释,然后继续阅读这些代码,找到了第一个复活节彩蛋,也就是他介绍了一个
Python3爬虫爬取英雄联盟高清桌面壁纸功能示例【基于Scrapy框架】
本文介绍Python3爬虫爬取英雄联盟高清桌面壁纸的功能。分享给大家参考,如下: 使用Scrapy爬虫爬取英雄联盟高清桌面壁纸 源地址:项目启动前需要安装Python3和Scrapy,没有百度,这里就不具体介绍了。首先创建项目scrapy startproject loldesk,生成项目的目录结构。首先,您需要定义抓取元素。在item.py中,我们的项目使用图片名称和链接导入scrapy
使用Python制作微信跳转和跳转助手
1. 前言相信大家对微信跳转,以及现在的各种插件都不陌生。辅助也是满天飞,反正我的好友名单已经八九百了也就不足为奇了。某宝在上面搜索一堆结果,最低的居然3元多。我可以随心所欲地得分。真是太离谱了。作为程序员,我决心自己做,不是为了别的,而是为了锻炼自己。解决问题的能力也是为了娱乐。对于这种任务,最合适的当然是Python,一个丰富的第三方库,具有胶水语言的特性。
Python网络爬虫示例讲解
让我们来谈谈 Python 和网络爬虫。1.爬虫的定义。爬虫:自动爬取互联网数据的程序。2.爬虫的主要框架管理器获取要爬取的URL链接。如果URL管理器中存在需要爬取的URL链接,则爬虫调度器调用网页下载器下载对应的网页,然后调用网页解析器解析该网页,并将新的页面放入网页中页。将 URL 添加到 URL 管理器以输出有价值的数据。3.爬虫时序图4.URL manager URL manager管理要爬取的URL集合和已经爬取的URL集合,防止重复爬取和循环爬取。URL管理器的主要功能如下
如何实现IOS_SearchBar搜索栏和关键字高亮
搜索框效果演示:这就是所谓的搜索框,下面我们来看看如何使用代码实现这个功能。我使用的数据是英雄联盟的英雄列表,是JSON数据的txt文件,JSON数据处理代码如下: //获取文件路径的路径 NSString *path = [[NSBundle mainBundle] pathForResource:@"heros" ofType:@"txt"]; //将路径下的文件转换成NSData数据 NSData * data = [NSDat
Swift仿IOS最新版QQ抽屉侧滑及弹出视图
介绍很简单。我用Swift写了一个抽屉效果,可以直接使用,简单;很多软件都有抽屉效果,比如qq的左边抽屉,英雄联盟,滴滴打车,优步等等,都是用抽屉的;效果是iOS drawer type的结构实现分析,主要是在控制器的View中添加两个View,一个left view和一个mainView。这里我们自定义了一个 DrawerViewController,init(mainVC: UIViewController, leftMenuVC: UIViewController, leftWidth: CGFloat
Javascript实现模仿腾讯游戏选择
我们在玩腾讯游戏的时候,会有很多选择,比如选择什么区域,选择什么人物等等,下面我们来做一个简单的腾讯游戏选择。
js中常用的Tab切换效果(推荐)
如下图:tab *(margin:0; padding:0; list-style:none;} .box{ width: 1000px; overflow: hidden; margin:100px auto 查看全部
c#抓取网页数据(
程序开发文章正文测试内容的一些其它思路及问题写在最后)
C#制作网站钩子程序实现示例
内容三、程序开发过程四、关于程序开发的一些其他想法和问题写在最后的序言中
真正的想法是用C#GUI开发一个自动化测试软件,可以帮我完成500台电脑在线网络答题的压力测试。既要能自动定位并点击鼠标,还要能模拟用键盘输入字符信息。但实际上,想法很饱满,现实很骨感。还有一些问题需要解决。但是在完成这个项目的过程中,也产生了一些副产品,这也是相当有成就感的。现针对开发过程中出现的问题,查找并筛选一些经过测试的参考资料,将我们的理解和研究经验奉献给大家。特提供一个完整的例子:出现在线挂机对话框,按回车继续。创建了一个简单的“连接程序”来开始对话。希望大家一起开放思路,一起研究。
温馨提示:以下为本文文章内容,以下案例可供参考
一、程序界面(如下图)
名称:模拟键盘程序,为什么不用挂机程序,因为它的功能弱,范围窄,而且作为副产品,真的不是挂机用的。请注意,我们的目标是自动化网络测试。
二、 使用说明
1.接口说明
1. 应用程序路径,这里是FireFox浏览器,所以需要放程序的地址。
2.网站地址:符合URL格式的可直接访问的本地文件或网址
3.浏览器标题:FireFox程序隐藏了应用标题,如果看到标题栏显示:test
其实应用的标题应该是:Test——Mozilla Firefox
4.【启动浏览器】其实这个功能目前可以完全忽略,直接手动启动FireFox即可。
5. 【开始】按钮是精华,这里会根据【浏览器标题】的内容进行搜索
到真正的【句柄】在FireFox上浏览网页,如果找到,会显示【句柄】的十进制整数值。如果显示为 0,则表示未找到。
6.【停止】关闭定时器操作。
2.使用笔记
1. 显示[Handle]位置后,必须为非零值。如果为0,修改【浏览器标题】的内容,再次点击【开始】
2.FireFox 浏览器必须保持在所有表单的前面
3.保证【电脑】不会进入【睡眠】或进入【屏幕保护】状态
三、程序开发流程
1.测试页面
1.文件名:test.html
2.网页代码(如下):
测试
alert("ok");
2.程序完整代码
using System;
using System.Diagnostics;
using System.Runtime.InteropServices;
using System.Threading;
using System.Windows.Forms;
namespace 模拟键盘
{
public partial class Form1 : Form
{
[DllImport("user32.dll", EntryPoint = "keybd_event", SetLastError = true)]
public static extern void keybd_event(Keys bVk, byte bScan, uint dwFlags, uint dwExtraInfo);
[DllImport("user32.dll", EntryPoint = "FindWindow")]
private static extern IntPtr FindWindow(string IpClassName, string IpWindowName);
//查找窗体控件
public int iSeconds=30;
public delegate bool CallBack(int hwnd, int lParam);
public Process Proc = new Process();
public System.Windows.Forms.Timer myTimer;
public Form1()
{
InitializeComponent();
}
private void btnBrowser_Click(object sender, EventArgs e)
{
openFileDialog1.Filter = "*.exe|*.exe|所有文件|*.*";
openFileDialog1.FileName = "";
DialogResult dr = openFileDialog1.ShowDialog();
if(DialogResult.OK==dr)
{
txtFile.Text = openFileDialog1.FileName;
}
}
string str = "Message";
int iP = 0;
private void btnStart_Click(object sender, EventArgs e)
{
IntPtr hnd = FindWindow(null, txtTitle.Text);//获取句柄
lblMessage.Text = hnd.ToString();
iSeconds = int.Parse(txtSeconds.Text.Trim());
myTimer.Interval = 1000 * iSeconds; //1秒=1000毫秒
myTimer.Enabled = true;
}
private void Form1_Load(object sender, EventArgs e)
{
myTimer = new System.Windows.Forms.Timer();//实例化Timer定时器
myTimer.Tick += new EventHandler(CallBack2);//定时器关联事件函数
}
private void CallBack2(object sender,EventArgs e)//定时器事件
{
keybd_event(Keys.Return, 0, 0, 0);//模拟键盘输入:回车
}
private void btnStop_Click(object sender, EventArgs e)
{
myTimer.Enabled = false;//禁止定时器
}
private void btnStartBrowser_Click(object sender, EventArgs e)
{
if (string.IsNullOrEmpty(txtFile.Text)) return;
try
{
// 浏览器程序启动线程
Proc = new System.Diagnostics.Process();
Proc.StartInfo.FileName = txtFile.Text;
Proc.StartInfo.Arguments = txtNetAddr.Text; //浏览器打开URL参数
Proc.StartInfo.UseShellExecute = false;
Proc.StartInfo.RedirectStandardInput = true;
Proc.StartInfo.RedirectStandardOutput = true;
Proc.Start();
}
catch
{
Proc = null;
}
}
}
}
四、程序开发中的一些其他想法和问题
1.使用已知进程获取主窗口句柄,然后遍历子窗口句柄
以下代码与本程序无关,为片段,请勿直接复制使用,主要提供给有兴趣改进的人参考。
if (string.IsNullOrEmpty(txtFile.Text)) return;
try
{
Proc = new System.Diagnostics.Process();
Proc.StartInfo.FileName =txtFile.Text;
Proc.StartInfo.Arguments = txtNetAddr.Text;
Proc.StartInfo.UseShellExecute = false;
Proc.StartInfo.RedirectStandardInput = true;
Proc.StartInfo.RedirectStandardOutput = true;
Proc.Start();
Thread.Sleep(2000);
}
catch
{
Proc = null;
}
if (Proc.MainWindowHandle != null)
{
//调用 API, 传递数据
while (Proc.MainWindowHandle == IntPtr.Zero)
{
Proc.Refresh();
}
while (Proc.MainWindowHandle == IntPtr.Zero)
{
Proc.Refresh();
}
//执行代码略
}
【问题描述】:这里的线程是Proc,但是这个线程不是主窗口。该线程的主窗口句柄需要通过 Proc.MainWindowHandle 获取。在使用过程中,很容易获取到自己开发的C#GUI程序,对【记事本】程序来说是正常的,但是在【Chrome】浏览器上使用时,结果不是0就是异常. 【FireFox】有时能正常获取,有时异常。
2.网上搜索C#操作API函数少且不全
这里有一个API函数查询网站,基本上一口气把API函数用完了。#
3.如果想查看Windows下的API函数,也可以使用工具:
1.DLL 函数查看器
2.DLL 导出查看器
4.获取应用程序窗口句柄、标题、类型的工具软件
这里可以使用VS环境下的Spy++(C++)。
写在最后
关于C#中API函数的使用,由于个人喜好不同,参数类型也有很大差异。真正体验的文章相对较少。谬误更难解决。后期准备深入体验,同时准备写文章系列。虽然作者的能力有限,到时候肯定会有很多谬论,但作者坚持所有的内容都是以实践为导向的。程序必须经过调试和通过,才能放到网上。志同道合的读者不妨关注作者的博客,敬请期待,我们下期再见!
关于C#制作网站挂钩程序文章的实现本文到此结束。更多C#相关网站勾搭程序内容,请搜索我们之前的文章或者继续浏览以下相关文章希望大家以后多多支持!
时间:2021-10-30
c#Realize 网站 监控看是否正常
代码如下: 复制代码如下: public void MonitorWeb(Model.ServiceInfo mServerInfo) {var sUrl = mServerInfo.ServiceConfig; var mLogInfo = new Model.LogInfo {ServiceId = mServerInfo.ServiceId }; 试试 {var mWebRequest = (HttpWebRequest)WebRequest. 创建(网址);VA
C#实现抓取网站页面内容的示例方法
抓取新浪网的新闻版块,如图: 使用谷歌浏览器查看源代码: 通过分析,我们知道我们要查找的内容在以下两个标签之间: 复制代码,代码为如下: Content... 如图: Content.... 使用VS创建一个网站 如图:我们下载
C# Fiddler 插件实现网站离线浏览功能
有这样一个应用场景:你在做前端或者APP开发,需要调用服务端提供的接口。接口只能在公司内网访问:不能在公司外调试代码。如果您想在公司外部访问它怎么办?? 如果你在公司的时候保存了所有接口的响应内容,就可以在没有服务器的情况下在本地模拟一个服务器环境,这样就可以不受网络环境的限制,愉快的调试代码了。实现原理如下:首先使用Fiddler抓取包,抓取所有需要保存的接口(不仅仅是interfaces,html,css,js,image)。在 Fiddler 中,点击以下菜单 File -> Save -> All Se
C#如何控制IIS动态增删网站详解
我的目的是在Winform程序中直接启动一个HTTP服务器连接下游客户。找到相关技术有两种方式:1.使用C#动态添加网站应用到IIS,借用IIS的管理能力提供HTTP接口。这篇文章解释了这个2.在Winform程序中实现Web服务器逻辑,自己监控和管理客户端请求:现在使用IIS7自带的类库来管理IIS,功能更强大,更方便,不需要使用 DirecotryEntry 类。
C#关于爬取网站数据时csrf-token的分析与解决
航空公司物流单信息查询为post请求。通过后台模拟POST HTTP请求,发现无法获取页面数据。经查航空公司网站,发现网站使用CSRF攻击机制躲避攻击。播放 40X 错误。关于CSRF读者自己百度网站HTTP请求解析Headers表单数据头部收录cookies,x-csrf-token表单数据收录_csrf(与头部相同的值)。这里通过查看网站的JS源码,发现_csrf来自网页的head标签来猜测cookie和
C#Export网站 函数示例代码说明
这个export网站函数是指前端javascript触发的ashx函数,实现将服务器中的一个文件夹(包括其子文件夹和文件)复制到服务器中的另一个位置,当然是文件夹本身是 网站。所以导出网站最重要的两个功能,除了javascript触发器,就是C#ashx文件复制文件夹的操作。下面的代码是通过javascript Request函数调用copy .ashx函数文件实现传入需要复制的文件夹的子路径和复制到该位置的子路径两个参数。后台函数getWebList 函数是后台函数。这个功能
C#使用正则表达式捕获网站信息示例
本文中的一个示例描述了 C# 如何使用正则表达式来捕获 网站 信息。分享给大家,供大家参考,如下: 下面是京东商城商品详情的抓取示例。1.创建JdRobber.cs 程序类 public class JdRobber {// /// 判断是否链接京东 /// /// /// public
英雄联盟协助lol挂机不被踢的方法(lol挂机脚本)
调用API设置鼠标位置并模拟鼠标右键让人物移动,全局钩子等复制代码代码如下:using System;using System.采集s.Generic;using System.Linq;using System.文本; 使用 System.Windows.Forms;使用 System.Runtime.InteropServices;使用 System.Threading;命名空间 LOLSetCursor{ public cla
易语言使英雄联盟源码辅助
LOL辅助这个功能需要加载超级模块7.3。版本 2。组装窗口 assembly_start 窗口。汇编变量pid,整数类型。子程序 __start window_ created pid = take process ID ("League of Legends.exe") 监控热键(&Enable Infinite View Range, #F5 Key) 监控热键(&Turn off Infinite Visual Range, #F6 Key) 监控热键(&Enable Normal攻击范围,#F2 键) 监控热键(&关闭普通攻击范围,#F1 键) 监控热键(&打开炮塔范围,#F4 键) 监控热键(
Python3爬取英雄联盟英雄皮肤大图示例代码
我首先尝试了爬虫的想法。我先查了下网络,没有发现有API可用:然后我用bs4分析了英雄列表页面,但是请求发送到html,并没有英雄列表。在英雄列表节点上,只有“loading”中的字样:同方法,英雄详情的分析也是如此,所以我猜测应该是Javascript负责加载这些数据。我继续尝试和然后我查看了英雄榜的源码,查看了外部导入的js文件,还有一行中的js脚本,大约368行,找到了处理英雄榜的js注释,然后继续阅读这些代码,找到了第一个复活节彩蛋,也就是他介绍了一个
Python3爬虫爬取英雄联盟高清桌面壁纸功能示例【基于Scrapy框架】
本文介绍Python3爬虫爬取英雄联盟高清桌面壁纸的功能。分享给大家参考,如下: 使用Scrapy爬虫爬取英雄联盟高清桌面壁纸 源地址:项目启动前需要安装Python3和Scrapy,没有百度,这里就不具体介绍了。首先创建项目scrapy startproject loldesk,生成项目的目录结构。首先,您需要定义抓取元素。在item.py中,我们的项目使用图片名称和链接导入scrapy
使用Python制作微信跳转和跳转助手
1. 前言相信大家对微信跳转,以及现在的各种插件都不陌生。辅助也是满天飞,反正我的好友名单已经八九百了也就不足为奇了。某宝在上面搜索一堆结果,最低的居然3元多。我可以随心所欲地得分。真是太离谱了。作为程序员,我决心自己做,不是为了别的,而是为了锻炼自己。解决问题的能力也是为了娱乐。对于这种任务,最合适的当然是Python,一个丰富的第三方库,具有胶水语言的特性。
Python网络爬虫示例讲解
让我们来谈谈 Python 和网络爬虫。1.爬虫的定义。爬虫:自动爬取互联网数据的程序。2.爬虫的主要框架管理器获取要爬取的URL链接。如果URL管理器中存在需要爬取的URL链接,则爬虫调度器调用网页下载器下载对应的网页,然后调用网页解析器解析该网页,并将新的页面放入网页中页。将 URL 添加到 URL 管理器以输出有价值的数据。3.爬虫时序图4.URL manager URL manager管理要爬取的URL集合和已经爬取的URL集合,防止重复爬取和循环爬取。URL管理器的主要功能如下
如何实现IOS_SearchBar搜索栏和关键字高亮
搜索框效果演示:这就是所谓的搜索框,下面我们来看看如何使用代码实现这个功能。我使用的数据是英雄联盟的英雄列表,是JSON数据的txt文件,JSON数据处理代码如下: //获取文件路径的路径 NSString *path = [[NSBundle mainBundle] pathForResource:@"heros" ofType:@"txt"]; //将路径下的文件转换成NSData数据 NSData * data = [NSDat
Swift仿IOS最新版QQ抽屉侧滑及弹出视图
介绍很简单。我用Swift写了一个抽屉效果,可以直接使用,简单;很多软件都有抽屉效果,比如qq的左边抽屉,英雄联盟,滴滴打车,优步等等,都是用抽屉的;效果是iOS drawer type的结构实现分析,主要是在控制器的View中添加两个View,一个left view和一个mainView。这里我们自定义了一个 DrawerViewController,init(mainVC: UIViewController, leftMenuVC: UIViewController, leftWidth: CGFloat
Javascript实现模仿腾讯游戏选择
我们在玩腾讯游戏的时候,会有很多选择,比如选择什么区域,选择什么人物等等,下面我们来做一个简单的腾讯游戏选择。
js中常用的Tab切换效果(推荐)
如下图:tab *(margin:0; padding:0; list-style:none;} .box{ width: 1000px; overflow: hidden; margin:100px auto
c#抓取网页数据(【案例分析】模拟键盘程序,为什么不用挂机程序?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-31 14:12
内容
前言
真正的想法是用C#GUI开发一个自动化测试软件,可以帮我完成500台电脑在线网络答题的压力测试。既要能自动定位并点击鼠标,还要能模拟用键盘输入字符信息。但实际上,想法很饱满,现实很骨感。还有一些问题需要解决。但是在完成这个项目的过程中,也产生了一些副产品,这也是相当有成就感的。现针对开发过程中出现的问题,查找并筛选一些经过测试的参考资料,将我们的理解和研究经验奉献给大家。特提供一个完整的例子:出现在线挂机对话框,按回车继续。创建了一个简单的“连接程序”来开始对话。希望大家一起开放思路,一起研究。
温馨提示:以下为本文文章内容,以下案例可供参考
一、程序界面(如下图)
名称:模拟键盘程序,为什么不用挂机程序,因为它的功能弱,范围窄,而且作为副产品,真的不是挂机用的。请注意,我们的目标是自动化网络测试。
二、使用说明1.接口说明
1. 应用程序路径,这里是FireFox浏览器,所以需要放程序的地址。
2.网站地址:符合URL格式的可直接访问的本地文件或网址
3.浏览器标题:FireFox程序隐藏了应用标题,如果看到标题栏显示:test
其实应用的标题应该是:Test——Mozilla Firefox
4.【启动浏览器】其实这个功能目前可以完全忽略,直接手动启动FireFox即可。
5.【开始】按钮是精华,这里会根据【浏览器标题】的内容进行搜索
到真正的【句柄】在FireFox上浏览网页,如果找到,会显示【句柄】的十进制整数值。如果显示为 0,则表示未找到。
6.【停止】关闭定时器操作。
2.使用注意事项
1. 显示[Handle]位置后,必须为非零值。如果为0,修改【浏览器标题】的内容,再次点击【开始】
2.FireFox 浏览器必须保持在所有表单的前面
3.保证【电脑】不会进入【睡眠】或进入【屏幕保护】状态
三、程序开发流程1.测试网页
1.文件名:test.html
2.网页代码(如下):
测试
alert("ok");
2.程序完整代码
using System;
using System.Diagnostics;
using System.Runtime.InteropServices;
using System.Threading;
using System.Windows.Forms;
namespace 模拟键盘
{
public partial class Form1 : Form
{
[DllImport("user32.dll", EntryPoint = "keybd_event", SetLastError = true)]
public static extern void keybd_event(Keys bVk, byte bScan, uint dwFlags, uint dwExtraInfo);
[DllImport("user32.dll", EntryPoint = "FindWindow")]
private static extern IntPtr FindWindow(string IpClassName, string IpWindowName);
//查找窗体控件
public int iSeconds=30;
public delegate bool CallBack(int hwnd, int lParam);
public Process Proc = new Process();
public System.Windows.Forms.Timer myTimer;
public Form1()
{
InitializeComponent();
}
private void btnBrowser_Click(object sender, EventArgs e)
{
openFileDialog1.Filter = "*.exe|*.exe|所有文件|*.*";
openFileDialog1.FileName = "";
DialogResult dr = openFileDialog1.ShowDialog();
if(DialogResult.OK==dr)
{
txtFile.Text = openFileDialog1.FileName;
}
}
string str = "Message";
int iP = 0;
private void btnStart_Click(object sender, EventArgs e)
{
IntPtr hnd = FindWindow(null, txtTitle.Text);//获取句柄
lblMessage.Text = hnd.ToString();
iSeconds = int.Parse(txtSeconds.Text.Trim());
myTimer.Interval = 1000 * iSeconds; //1秒=1000毫秒
myTimer.Enabled = true;
}
private void Form1_Load(object sender, EventArgs e)
{
myTimer = new System.Windows.Forms.Timer();//实例化Timer定时器
myTimer.Tick += new EventHandler(CallBack2);//定时器关联事件函数
}
private void CallBack2(object sender,EventArgs e)//定时器事件
{
keybd_event(Keys.Return, 0, 0, 0);//模拟键盘输入:回车
}
private void btnStop_Click(object sender, EventArgs e)
{
myTimer.Enabled = false;//禁止定时器
}
private void btnStartBrowser_Click(object sender, EventArgs e)
{
if (string.IsNullOrEmpty(txtFile.Text)) return;
try
{
// 浏览器程序启动线程
Proc = new System.Diagnostics.Process();
Proc.StartInfo.FileName = txtFile.Text;
Proc.StartInfo.Arguments = txtNetAddr.Text; //浏览器打开URL参数
Proc.StartInfo.UseShellExecute = false;
Proc.StartInfo.RedirectStandardInput = true;
Proc.StartInfo.RedirectStandardOutput = true;
Proc.Start();
}
catch
{
Proc = null;
}
}
}
}
四、程序开发中的一些其他思路和问题1.使用已知进程获取主窗口句柄然后遍历子窗口句柄
以下代码与本程序无关,为片段,请勿直接复制使用,主要提供给有兴趣改进的人参考。
if (string.IsNullOrEmpty(txtFile.Text)) return;
try
{
Proc = new System.Diagnostics.Process();
Proc.StartInfo.FileName =txtFile.Text;
Proc.StartInfo.Arguments = txtNetAddr.Text;
Proc.StartInfo.UseShellExecute = false;
Proc.StartInfo.RedirectStandardInput = true;
Proc.StartInfo.RedirectStandardOutput = true;
Proc.Start();
Thread.Sleep(2000);
}
catch
{
Proc = null;
}
if (Proc.MainWindowHandle != null)
{
//调用 API, 传递数据
while (Proc.MainWindowHandle == IntPtr.Zero)
{
Proc.Refresh();
}
while (Proc.MainWindowHandle == IntPtr.Zero)
{
Proc.Refresh();
}
//执行代码略
}
【问题描述】:这里的线程是Proc,但是这个线程不是主窗口。该线程的主窗口句柄需要通过 Proc.MainWindowHandle 获取。在使用过程中,很容易获取到自己开发的C#GUI程序,对【记事本】程序来说是正常的,但是在【Chrome】浏览器上使用时,结果不是0就是异常. 【FireFox】有时能正常获取,有时异常。
2. C#操作API函数网上搜索很少,不完整
这里有一个API函数查询网站,基本上一口气把API函数用完了。#
3.如果想查看Windows下的API函数,也可以使用工具:
1.DLL 函数查看器
2.DLL 导出查看器
4.获取申请表工具软件的句柄、标题和类型
这里可以使用VS环境下的Spy++(C++)。
写在最后
关于C#中API函数的使用,由于个人喜好不同,参数类型也有很大差异。真正体验的文章相对较少。谬误更难解决。后期准备深入体验,同时准备写文章系列。虽然作者的能力有限,到时候肯定会有很多谬论,但作者坚持所有的内容都是以实践为导向的。程序必须经过调试和通过,才能放到网上。志同道合的读者不妨关注作者的博客,敬请期待,我们下期再见!
关于C#制作网站挂钩程序文章的实现本文到此结束。更多C#相关网站挂机程序内容,请搜索Script Home k7@的上一个或继续浏览下方相关文章,希望大家多多支持Scripthome未来! 查看全部
c#抓取网页数据(【案例分析】模拟键盘程序,为什么不用挂机程序?)
内容
前言
真正的想法是用C#GUI开发一个自动化测试软件,可以帮我完成500台电脑在线网络答题的压力测试。既要能自动定位并点击鼠标,还要能模拟用键盘输入字符信息。但实际上,想法很饱满,现实很骨感。还有一些问题需要解决。但是在完成这个项目的过程中,也产生了一些副产品,这也是相当有成就感的。现针对开发过程中出现的问题,查找并筛选一些经过测试的参考资料,将我们的理解和研究经验奉献给大家。特提供一个完整的例子:出现在线挂机对话框,按回车继续。创建了一个简单的“连接程序”来开始对话。希望大家一起开放思路,一起研究。
温馨提示:以下为本文文章内容,以下案例可供参考
一、程序界面(如下图)
名称:模拟键盘程序,为什么不用挂机程序,因为它的功能弱,范围窄,而且作为副产品,真的不是挂机用的。请注意,我们的目标是自动化网络测试。
二、使用说明1.接口说明
1. 应用程序路径,这里是FireFox浏览器,所以需要放程序的地址。
2.网站地址:符合URL格式的可直接访问的本地文件或网址
3.浏览器标题:FireFox程序隐藏了应用标题,如果看到标题栏显示:test
其实应用的标题应该是:Test——Mozilla Firefox
4.【启动浏览器】其实这个功能目前可以完全忽略,直接手动启动FireFox即可。
5.【开始】按钮是精华,这里会根据【浏览器标题】的内容进行搜索
到真正的【句柄】在FireFox上浏览网页,如果找到,会显示【句柄】的十进制整数值。如果显示为 0,则表示未找到。
6.【停止】关闭定时器操作。
2.使用注意事项
1. 显示[Handle]位置后,必须为非零值。如果为0,修改【浏览器标题】的内容,再次点击【开始】
2.FireFox 浏览器必须保持在所有表单的前面
3.保证【电脑】不会进入【睡眠】或进入【屏幕保护】状态
三、程序开发流程1.测试网页
1.文件名:test.html
2.网页代码(如下):
测试
alert("ok");
2.程序完整代码
using System;
using System.Diagnostics;
using System.Runtime.InteropServices;
using System.Threading;
using System.Windows.Forms;
namespace 模拟键盘
{
public partial class Form1 : Form
{
[DllImport("user32.dll", EntryPoint = "keybd_event", SetLastError = true)]
public static extern void keybd_event(Keys bVk, byte bScan, uint dwFlags, uint dwExtraInfo);
[DllImport("user32.dll", EntryPoint = "FindWindow")]
private static extern IntPtr FindWindow(string IpClassName, string IpWindowName);
//查找窗体控件
public int iSeconds=30;
public delegate bool CallBack(int hwnd, int lParam);
public Process Proc = new Process();
public System.Windows.Forms.Timer myTimer;
public Form1()
{
InitializeComponent();
}
private void btnBrowser_Click(object sender, EventArgs e)
{
openFileDialog1.Filter = "*.exe|*.exe|所有文件|*.*";
openFileDialog1.FileName = "";
DialogResult dr = openFileDialog1.ShowDialog();
if(DialogResult.OK==dr)
{
txtFile.Text = openFileDialog1.FileName;
}
}
string str = "Message";
int iP = 0;
private void btnStart_Click(object sender, EventArgs e)
{
IntPtr hnd = FindWindow(null, txtTitle.Text);//获取句柄
lblMessage.Text = hnd.ToString();
iSeconds = int.Parse(txtSeconds.Text.Trim());
myTimer.Interval = 1000 * iSeconds; //1秒=1000毫秒
myTimer.Enabled = true;
}
private void Form1_Load(object sender, EventArgs e)
{
myTimer = new System.Windows.Forms.Timer();//实例化Timer定时器
myTimer.Tick += new EventHandler(CallBack2);//定时器关联事件函数
}
private void CallBack2(object sender,EventArgs e)//定时器事件
{
keybd_event(Keys.Return, 0, 0, 0);//模拟键盘输入:回车
}
private void btnStop_Click(object sender, EventArgs e)
{
myTimer.Enabled = false;//禁止定时器
}
private void btnStartBrowser_Click(object sender, EventArgs e)
{
if (string.IsNullOrEmpty(txtFile.Text)) return;
try
{
// 浏览器程序启动线程
Proc = new System.Diagnostics.Process();
Proc.StartInfo.FileName = txtFile.Text;
Proc.StartInfo.Arguments = txtNetAddr.Text; //浏览器打开URL参数
Proc.StartInfo.UseShellExecute = false;
Proc.StartInfo.RedirectStandardInput = true;
Proc.StartInfo.RedirectStandardOutput = true;
Proc.Start();
}
catch
{
Proc = null;
}
}
}
}
四、程序开发中的一些其他思路和问题1.使用已知进程获取主窗口句柄然后遍历子窗口句柄
以下代码与本程序无关,为片段,请勿直接复制使用,主要提供给有兴趣改进的人参考。
if (string.IsNullOrEmpty(txtFile.Text)) return;
try
{
Proc = new System.Diagnostics.Process();
Proc.StartInfo.FileName =txtFile.Text;
Proc.StartInfo.Arguments = txtNetAddr.Text;
Proc.StartInfo.UseShellExecute = false;
Proc.StartInfo.RedirectStandardInput = true;
Proc.StartInfo.RedirectStandardOutput = true;
Proc.Start();
Thread.Sleep(2000);
}
catch
{
Proc = null;
}
if (Proc.MainWindowHandle != null)
{
//调用 API, 传递数据
while (Proc.MainWindowHandle == IntPtr.Zero)
{
Proc.Refresh();
}
while (Proc.MainWindowHandle == IntPtr.Zero)
{
Proc.Refresh();
}
//执行代码略
}
【问题描述】:这里的线程是Proc,但是这个线程不是主窗口。该线程的主窗口句柄需要通过 Proc.MainWindowHandle 获取。在使用过程中,很容易获取到自己开发的C#GUI程序,对【记事本】程序来说是正常的,但是在【Chrome】浏览器上使用时,结果不是0就是异常. 【FireFox】有时能正常获取,有时异常。
2. C#操作API函数网上搜索很少,不完整
这里有一个API函数查询网站,基本上一口气把API函数用完了。#
3.如果想查看Windows下的API函数,也可以使用工具:
1.DLL 函数查看器
2.DLL 导出查看器
4.获取申请表工具软件的句柄、标题和类型
这里可以使用VS环境下的Spy++(C++)。
写在最后
关于C#中API函数的使用,由于个人喜好不同,参数类型也有很大差异。真正体验的文章相对较少。谬误更难解决。后期准备深入体验,同时准备写文章系列。虽然作者的能力有限,到时候肯定会有很多谬论,但作者坚持所有的内容都是以实践为导向的。程序必须经过调试和通过,才能放到网上。志同道合的读者不妨关注作者的博客,敬请期待,我们下期再见!
关于C#制作网站挂钩程序文章的实现本文到此结束。更多C#相关网站挂机程序内容,请搜索Script Home k7@的上一个或继续浏览下方相关文章,希望大家多多支持Scripthome未来!
c#抓取网页数据(魔兽世界几个坑说下就是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-30 02:00
这里有几个坑:
第一个是记得获取代理IP爬取网站第一次忘记获取代理,ip被封了
二是判断网页是否被压缩,但是第一次没有得到结果。
///
/// 抓取网页并转码
///
///
///
///
public string HttpGet(string url, string post_parament)
{
string html;
HttpWebRequest Web_Request = (HttpWebRequest)WebRequest.Create(url);
Web_Request.Timeout = 30000;
Web_Request.Method = "GET";
Web_Request.UserAgent = "Mozilla/4.0";
Web_Request.Headers.Add("Accept-Encoding", "gzip, deflate");
//Web_Request.Credentials = CredentialCache.DefaultCredentials;
//设置代理属性WebProxy-------------------------------------------------
WebProxy proxy = new WebProxy("111.13.7.120", 80);
//在发起HTTP请求前将proxy赋值给HttpWebRequest的Proxy属性
Web_Request.Proxy = proxy;
HttpWebResponse Web_Response = (HttpWebResponse)Web_Request.GetResponse();
if (Web_Response.ContentEncoding.ToLower() == "gzip") // 如果使用了GZip则先解压
{
using (Stream Stream_Receive = Web_Response.GetResponseStream())
{
using (var Zip_Stream = new GZipStream(Stream_Receive, CompressionMode.Decompress))
{
using (StreamReader Stream_Reader = new StreamReader(Zip_Stream, Encoding.Default))
{
html = Stream_Reader.ReadToEnd();
}
}
}
}
else
{
using (Stream Stream_Receive = Web_Response.GetResponseStream())
{
using (StreamReader Stream_Reader = new StreamReader(Stream_Receive, Encoding.Default))
{
html = Stream_Reader.ReadToEnd();
}
}
}
return html;
}
二、 下面是使用正则处理的内容。因为对正则表达式不熟悉,重复的动作太多。
1.先获取网页内容
IWebHttpRepository webHttpRepository = new WebHttpRepository();
string html = webHttpRepository.HttpGet(Url_Txt.Text, "");
2.获取书名和文章列表
标题
文章列表
<p>
string Novel_Name = Regex.Match(html, @"(?]+)\1[^>]*>(?(?:(?! 查看全部
c#抓取网页数据(魔兽世界几个坑说下就是)
这里有几个坑:
第一个是记得获取代理IP爬取网站第一次忘记获取代理,ip被封了
二是判断网页是否被压缩,但是第一次没有得到结果。
///
/// 抓取网页并转码
///
///
///
///
public string HttpGet(string url, string post_parament)
{
string html;
HttpWebRequest Web_Request = (HttpWebRequest)WebRequest.Create(url);
Web_Request.Timeout = 30000;
Web_Request.Method = "GET";
Web_Request.UserAgent = "Mozilla/4.0";
Web_Request.Headers.Add("Accept-Encoding", "gzip, deflate");
//Web_Request.Credentials = CredentialCache.DefaultCredentials;
//设置代理属性WebProxy-------------------------------------------------
WebProxy proxy = new WebProxy("111.13.7.120", 80);
//在发起HTTP请求前将proxy赋值给HttpWebRequest的Proxy属性
Web_Request.Proxy = proxy;
HttpWebResponse Web_Response = (HttpWebResponse)Web_Request.GetResponse();
if (Web_Response.ContentEncoding.ToLower() == "gzip") // 如果使用了GZip则先解压
{
using (Stream Stream_Receive = Web_Response.GetResponseStream())
{
using (var Zip_Stream = new GZipStream(Stream_Receive, CompressionMode.Decompress))
{
using (StreamReader Stream_Reader = new StreamReader(Zip_Stream, Encoding.Default))
{
html = Stream_Reader.ReadToEnd();
}
}
}
}
else
{
using (Stream Stream_Receive = Web_Response.GetResponseStream())
{
using (StreamReader Stream_Reader = new StreamReader(Stream_Receive, Encoding.Default))
{
html = Stream_Reader.ReadToEnd();
}
}
}
return html;
}
二、 下面是使用正则处理的内容。因为对正则表达式不熟悉,重复的动作太多。
1.先获取网页内容
IWebHttpRepository webHttpRepository = new WebHttpRepository();
string html = webHttpRepository.HttpGet(Url_Txt.Text, "");
2.获取书名和文章列表
标题
文章列表
<p>
string Novel_Name = Regex.Match(html, @"(?]+)\1[^>]*>(?(?:(?!
c#抓取网页数据( 网页抓取是通过自动化手段检索数据的过程-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-26 15:09
网页抓取是通过自动化手段检索数据的过程-乐题库)
网页抓取是通过自动化手段检索数据的过程。在很多场景中都是不可或缺的,比如竞争对手价格监控、房源上市、潜在客户和舆情监控、新闻文章或金融数据聚合。
在编写网络抓取代码时,您必须做出的第一个决定是选择您的编程语言。您可以使用多种语言进行编写,例如 Python、JavaScript、Java、Ruby 或 C#。所有提到的语言都提供了强大的网页抓取功能。
在本文中,我们将探索 C# 并向您展示如何创建一个真正的 C# 公共网络爬虫。请记住,即使我们使用 C#,您也可以将此信息调整为 .NET 平台支持的所有语言,包括 VB.NET 和 F#。
01.C#网页爬虫工具
在编写任何代码之前,第一步是选择合适的 C# 库或包。这些 C# 库或包将能够下载 HTML 页面、解析它们并从这些页面中提取所需的数据。一些最流行的 C# 包如下:
●ScrapySharp
●傀儡师夏普
●HTML 敏捷包
Html Agility Pack 是最流行的 C# 包,仅 Nuget 就有近 5000 万次下载。其流行的原因有很多,其中最重要的是HTML解析器可以直接下载网页,也可以使用浏览器下载。这个包可以容忍格式错误的 HTML 并支持 XPath。此外,它甚至可以解析本地 HTML 文件;因此,我们将在本文中进一步使用此包。
ScrapySharp 为 C# 编程添加了更多功能。这个包支持 CSS 选择器,可以模拟 Web 浏览器。虽然 ScrapySharp 被认为是一个强大的 C# 包,但程序员使用它进行维护的概率并不是很高。
Puppeteer Sharp 是著名的 Node.js Puppeteer 项目的 .NET 端口。它使用相同的 Chromium 浏览器来加载页面。此外,该包使用 async-await 风格的代码来支持异步和预操作管理。如果你已经熟悉这个 C# 包并且需要浏览器来渲染页面,那么 Puppeteer Sharp 可能是一个不错的选择。
02. 使用C#搭建网络爬虫
如前所述,现在我们将演示如何编写将使用 Html Agility Pack 的 C# 公共网络爬虫代码。我们将使用 .NET 5 SDK 和 Visual Studio Code。此代码已在 .NET Core 3 和 .NET 5 上进行了测试,它应该适用于其他版本的 .NET。
我们将建立一个假设场景:抓取在线书店并采集书名和价格。
在编写C#网络爬虫之前,我们先搭建好开发环境。
03.搭建开发环境
对于 C# 开发环境,请安装 Visual Studio Code。请注意,如果您使用 Visual Studio 和 Visual Studio Code 编写 C# 代码,则需要注意它们是两个完全不同的应用程序。
安装 Visual Studio Code 后,安装 .NET 5.0 或更高版本。您也可以使用 .NET Core 3.1。安装完成后,打开终端并运行以下命令以验证 .NET CLI 或命令行界面是否正常工作:
dotnet --version
这行命令将输出已安装的 .NET 的版本号。
04. 项目结构和依赖
此代码将成为 .NET 项目的一部分。为简单起见,创建一个控制台应用程序。然后,创建一个文件夹,您将在其中编写 C# 代码。打开终端并导航到该文件夹。输入以下命令:
dotnet new console
该命令的输出应该是控制台应用程序已经成功创建的信息。
是时候安装所需的软件包了。使用C#抓取公共网页,Html Agility Pack会是一个不错的选择。您可以使用以下命令为该项目安装它:
dotnet add package HtmlAgilityPack
安装另一个包,以便我们可以轻松地将捕获的数据导出到 CSV 文件:
dotnet add package CsvHelper
如果您使用的是 Visual Studio 而不是 Visual Studio Code,请单击“文件”,选择“新建解决方案”,然后按“控制台应用程序”按钮。要安装依赖项,请按照下列步骤操作:
●选择项目;
● 单击管理项目依赖项。这将打开 NuGet 包窗口;
●搜索HtmlAgilityPack并选择它;
● 最后,搜索CsvHelper,选择它,然后单击添加包。
Visual Studio 中的 Nuget 包管理器
安装完这些包后,我们就可以继续编写爬取网上书店的代码了。
05.下载并解析网页数据
任何网页抓取程序的第一步都是下载网页的 HTML。这个HTML会是一个字符串,你需要把它转换成一个可以进一步处理的对象,这是第二步,这部分叫做解析。Html Agility Pack 可以从本地文件、HTML 字符串、任何 URL 和浏览器读取和解析文件。
在我们的例子中,我们需要做的就是从 URL 中获取 HTML。Html Agility Pack 不使用.NET 原生功能,而是提供了一个方便的类-HtmlWeb。这个类提供了一个Load函数,它可以接受一个URL,并返回一个HtmlDocument类的实例,这也是我们使用Part的包。有了这些信息,我们就可以编写一个接受 URL 并返回 HtmlDocument 实例的函数。
打开Program.cs文件,在类中输入这个函数Program:
// Parses the URL and returns HtmlDocument object
static HtmlDocument GetDocument (string url)
{
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load(url);
return doc;
}
这样,第一步的代码就完成了。下一步是解析文档。
06.解析 HTML:获取书籍链接
在这部分代码中,我们将从网页中提取所需的信息。在这个阶段,文档现在是一个 HtmlDocument 类型的对象。这个类公开了两个函数来选择元素。这两个函数都接受 XPath 输入并返回 HtmlNode 或 HtmlNode采集。
下面是这两个函数的签名:
public HtmlNodeCollection SelectNodes(string xpath);
public HtmlNode SelectSingleNode(string xpath);
让我们先讨论 SelectNodes。
对于这个例子——C#网络爬虫——我们将从这个页面抓取所有书籍的详细信息。
首先,需要对其进行解析,以便可以提取到所有书籍的链接。在浏览器中打开上述书店页面,右键单击任一图书链接,然后单击“检查”按钮。开发人员工具将打开。
了解标记后,您要选择的 XPath 应如下所示:
//h3/a
现在可以将此 XPath 传递给 SelectNodes 函数。
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
请注意 SelectNodes 函数是由
由 HtmlDocument 的 DocumentNode 属性调用。
变量 linkNodes 是一个集合。我们可以写一个foreach循环,从每个链接中一一获取href值。我们只需要解决一个小问题——即页面上的链接是相对链接。因此,在我们抓取这些提取的链接之前,我们需要将它们转换为绝对 URL。
为了转换相对链接,我们可以使用 Uri 类。我们使用这个构造函数来获取具有绝对 URL 的 Uri 对象。
dotnet --version
一旦我们有了 Uri 对象,我们就可以简单地检查 AbsoluteUri 属性来获取完整的 URL。
我们将所有这些都写在一个函数中,以保持代码的有序性。
static List GetBookLinks(string url)
{
var bookLinks = new List();
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
var baseUri = new Uri(url);
foreach (var link in linkNodes)
{
string href = link.Attributes["href"].Value;
bookLinks.Add(new Uri(baseUri, href).AbsoluteUri);
}
return bookLinks;
}
在这个函数中,我们从一个空的 List 对象开始。在 foreach 循环中,我们将所有链接添加到此对象并返回它。
现在,我们可以修改 Main() 函数,以便我们可以测试到目前为止编写的 C# 代码。修改后的函数如下:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
}
要运行此代码,请打开终端并导航到收录此文件的目录,然后键入以下内容:
dotnet run
输出应如下所示:
Found 20 links
然后我们继续下一部分,我们将处理所有链接以获取书籍数据。
07.解析HTML:获取书籍详情
此时,我们有一个收录书籍 URL 的字符串列表。我们可以简单的写一个循环,先用我们写的GetDocument函数来获取文档。之后,我们将使用 SelectSingleNode 函数来提取书名和价格。
为了使数据清晰、有条理,我们从一个类开始。这个类将代表一本书,有两个属性——标题和价格。示例如下:
然后,在浏览器中打开 Title-//h1 的书页。为价格创建 XPath 有点棘手,因为相同的类应用于底部的附加书籍。
XPath 的价格
XPath 的价格是这样的:
//div[contains(@class,"product_main")]/p[@class="price_color"]
请注意 XPath 收录双引号。我们将不得不通过在它们前面加上反斜杠来转义这些字符。
现在我们可以使用 SelectSingleNode 函数获取节点,然后使用 InnerText 属性获取元素中收录的文本。我们可以将所有内容放在一个函数中,如下所示:
static List GetBookDetails(List urls)
{
var books = new List();
foreach (var url in urls)
{
HtmlDocument document = GetDocument(url);
var titleXPath = "//h1";
var priceXPath = "//div[contains(@class,\"product_main\")]/p[@class=\"price_color\"]";
var book = new Book();
book.Title = document.DocumentNode.SelectSingleNode (priceXPath).InnerText;
book.Price = document.DocumentNode.SelectSingleNode(priceXPath).InnerText;
books.Add(book);
}
return books;
}
此函数将返回 Book 对象列表。是时候更新 Main() 函数了:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
var books = GetBookDetails(bookLinks);
}
这个网络抓取项目的最后一部分是将数据导出到 CSV。
08.导出数据
如果你还没有安装 CsvHelper,你可以使用
dotnet add package CsvHelper
在终端运行该命令即可完成此操作。
导出功能非常简单。首先,我们需要创建一个 StreamWriter 并将 CSV 文件名作为参数发送。接下来,我们将使用这个对象来创建一个 CsvWriter。最后,我们可以使用 WriteRecords 函数在一行代码中编写所有书籍。
为了确保所有资源都正确关闭,我们可以使用 using 块。我们还可以将所有内容都包装在一个函数中,如下所示:
static void exportToCSV(List books)
{
using (var writer = new StreamWriter("./books.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
csv.WriteRecords(books);
}
}
最后,我们可以从 Main() 函数中调用这个函数:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
var books = GetBookDetails(bookLinks);
exportToCSV(books);
}
要运行此代码,请打开终端并运行以下命令:
dotnet run
几秒钟后,您将创建一个 books.csv 文件。
09. 结论
如果你想用 C# 写一个网络爬虫,你可以使用多个包。在本文中,我们展示了如何使用 Html Agility Pack,这是一个功能强大且易于使用的包。也是一个简单的例子,可以进一步增强;例如,您可以尝试将上述逻辑添加到此代码中以处理多个页面。
如果您想了解更多有关使用其他编程语言进行网页抓取的工作原理的信息,您可以查看使用 Python 进行网页抓取的指南。我们还有一个
常见问题
Q:C#适合做网页爬虫吗?
A:与 Python 类似,C# 被广泛用于网络爬虫。在决定选择哪种编程语言时,选择您最熟悉的一种很重要。但是您将能够在 Python 和 C# 中找到示例网络爬虫。
问:网络抓取合法吗?
答:如果在不违反任何法律的情况下使用代理,它们可能是合法的。但是,在与代理人进行任何活动之前,您应该就您的具体案件获得专业的法律建议。请参考我们的文章“网络抓取合法吗?” 查看全部
c#抓取网页数据(
网页抓取是通过自动化手段检索数据的过程-乐题库)
网页抓取是通过自动化手段检索数据的过程。在很多场景中都是不可或缺的,比如竞争对手价格监控、房源上市、潜在客户和舆情监控、新闻文章或金融数据聚合。
在编写网络抓取代码时,您必须做出的第一个决定是选择您的编程语言。您可以使用多种语言进行编写,例如 Python、JavaScript、Java、Ruby 或 C#。所有提到的语言都提供了强大的网页抓取功能。
在本文中,我们将探索 C# 并向您展示如何创建一个真正的 C# 公共网络爬虫。请记住,即使我们使用 C#,您也可以将此信息调整为 .NET 平台支持的所有语言,包括 VB.NET 和 F#。
01.C#网页爬虫工具
在编写任何代码之前,第一步是选择合适的 C# 库或包。这些 C# 库或包将能够下载 HTML 页面、解析它们并从这些页面中提取所需的数据。一些最流行的 C# 包如下:
●ScrapySharp
●傀儡师夏普
●HTML 敏捷包
Html Agility Pack 是最流行的 C# 包,仅 Nuget 就有近 5000 万次下载。其流行的原因有很多,其中最重要的是HTML解析器可以直接下载网页,也可以使用浏览器下载。这个包可以容忍格式错误的 HTML 并支持 XPath。此外,它甚至可以解析本地 HTML 文件;因此,我们将在本文中进一步使用此包。
ScrapySharp 为 C# 编程添加了更多功能。这个包支持 CSS 选择器,可以模拟 Web 浏览器。虽然 ScrapySharp 被认为是一个强大的 C# 包,但程序员使用它进行维护的概率并不是很高。
Puppeteer Sharp 是著名的 Node.js Puppeteer 项目的 .NET 端口。它使用相同的 Chromium 浏览器来加载页面。此外,该包使用 async-await 风格的代码来支持异步和预操作管理。如果你已经熟悉这个 C# 包并且需要浏览器来渲染页面,那么 Puppeteer Sharp 可能是一个不错的选择。
02. 使用C#搭建网络爬虫
如前所述,现在我们将演示如何编写将使用 Html Agility Pack 的 C# 公共网络爬虫代码。我们将使用 .NET 5 SDK 和 Visual Studio Code。此代码已在 .NET Core 3 和 .NET 5 上进行了测试,它应该适用于其他版本的 .NET。
我们将建立一个假设场景:抓取在线书店并采集书名和价格。
在编写C#网络爬虫之前,我们先搭建好开发环境。
03.搭建开发环境
对于 C# 开发环境,请安装 Visual Studio Code。请注意,如果您使用 Visual Studio 和 Visual Studio Code 编写 C# 代码,则需要注意它们是两个完全不同的应用程序。
安装 Visual Studio Code 后,安装 .NET 5.0 或更高版本。您也可以使用 .NET Core 3.1。安装完成后,打开终端并运行以下命令以验证 .NET CLI 或命令行界面是否正常工作:
dotnet --version
这行命令将输出已安装的 .NET 的版本号。
04. 项目结构和依赖
此代码将成为 .NET 项目的一部分。为简单起见,创建一个控制台应用程序。然后,创建一个文件夹,您将在其中编写 C# 代码。打开终端并导航到该文件夹。输入以下命令:
dotnet new console
该命令的输出应该是控制台应用程序已经成功创建的信息。
是时候安装所需的软件包了。使用C#抓取公共网页,Html Agility Pack会是一个不错的选择。您可以使用以下命令为该项目安装它:
dotnet add package HtmlAgilityPack
安装另一个包,以便我们可以轻松地将捕获的数据导出到 CSV 文件:
dotnet add package CsvHelper
如果您使用的是 Visual Studio 而不是 Visual Studio Code,请单击“文件”,选择“新建解决方案”,然后按“控制台应用程序”按钮。要安装依赖项,请按照下列步骤操作:
●选择项目;
● 单击管理项目依赖项。这将打开 NuGet 包窗口;
●搜索HtmlAgilityPack并选择它;
● 最后,搜索CsvHelper,选择它,然后单击添加包。
Visual Studio 中的 Nuget 包管理器
安装完这些包后,我们就可以继续编写爬取网上书店的代码了。
05.下载并解析网页数据
任何网页抓取程序的第一步都是下载网页的 HTML。这个HTML会是一个字符串,你需要把它转换成一个可以进一步处理的对象,这是第二步,这部分叫做解析。Html Agility Pack 可以从本地文件、HTML 字符串、任何 URL 和浏览器读取和解析文件。
在我们的例子中,我们需要做的就是从 URL 中获取 HTML。Html Agility Pack 不使用.NET 原生功能,而是提供了一个方便的类-HtmlWeb。这个类提供了一个Load函数,它可以接受一个URL,并返回一个HtmlDocument类的实例,这也是我们使用Part的包。有了这些信息,我们就可以编写一个接受 URL 并返回 HtmlDocument 实例的函数。
打开Program.cs文件,在类中输入这个函数Program:
// Parses the URL and returns HtmlDocument object
static HtmlDocument GetDocument (string url)
{
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load(url);
return doc;
}
这样,第一步的代码就完成了。下一步是解析文档。
06.解析 HTML:获取书籍链接
在这部分代码中,我们将从网页中提取所需的信息。在这个阶段,文档现在是一个 HtmlDocument 类型的对象。这个类公开了两个函数来选择元素。这两个函数都接受 XPath 输入并返回 HtmlNode 或 HtmlNode采集。
下面是这两个函数的签名:
public HtmlNodeCollection SelectNodes(string xpath);
public HtmlNode SelectSingleNode(string xpath);
让我们先讨论 SelectNodes。
对于这个例子——C#网络爬虫——我们将从这个页面抓取所有书籍的详细信息。
首先,需要对其进行解析,以便可以提取到所有书籍的链接。在浏览器中打开上述书店页面,右键单击任一图书链接,然后单击“检查”按钮。开发人员工具将打开。
了解标记后,您要选择的 XPath 应如下所示:
//h3/a
现在可以将此 XPath 传递给 SelectNodes 函数。
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
请注意 SelectNodes 函数是由
由 HtmlDocument 的 DocumentNode 属性调用。
变量 linkNodes 是一个集合。我们可以写一个foreach循环,从每个链接中一一获取href值。我们只需要解决一个小问题——即页面上的链接是相对链接。因此,在我们抓取这些提取的链接之前,我们需要将它们转换为绝对 URL。
为了转换相对链接,我们可以使用 Uri 类。我们使用这个构造函数来获取具有绝对 URL 的 Uri 对象。
dotnet --version
一旦我们有了 Uri 对象,我们就可以简单地检查 AbsoluteUri 属性来获取完整的 URL。
我们将所有这些都写在一个函数中,以保持代码的有序性。
static List GetBookLinks(string url)
{
var bookLinks = new List();
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
var baseUri = new Uri(url);
foreach (var link in linkNodes)
{
string href = link.Attributes["href"].Value;
bookLinks.Add(new Uri(baseUri, href).AbsoluteUri);
}
return bookLinks;
}
在这个函数中,我们从一个空的 List 对象开始。在 foreach 循环中,我们将所有链接添加到此对象并返回它。
现在,我们可以修改 Main() 函数,以便我们可以测试到目前为止编写的 C# 代码。修改后的函数如下:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
}
要运行此代码,请打开终端并导航到收录此文件的目录,然后键入以下内容:
dotnet run
输出应如下所示:
Found 20 links
然后我们继续下一部分,我们将处理所有链接以获取书籍数据。
07.解析HTML:获取书籍详情
此时,我们有一个收录书籍 URL 的字符串列表。我们可以简单的写一个循环,先用我们写的GetDocument函数来获取文档。之后,我们将使用 SelectSingleNode 函数来提取书名和价格。
为了使数据清晰、有条理,我们从一个类开始。这个类将代表一本书,有两个属性——标题和价格。示例如下:
然后,在浏览器中打开 Title-//h1 的书页。为价格创建 XPath 有点棘手,因为相同的类应用于底部的附加书籍。
XPath 的价格
XPath 的价格是这样的:
//div[contains(@class,"product_main")]/p[@class="price_color"]
请注意 XPath 收录双引号。我们将不得不通过在它们前面加上反斜杠来转义这些字符。
现在我们可以使用 SelectSingleNode 函数获取节点,然后使用 InnerText 属性获取元素中收录的文本。我们可以将所有内容放在一个函数中,如下所示:
static List GetBookDetails(List urls)
{
var books = new List();
foreach (var url in urls)
{
HtmlDocument document = GetDocument(url);
var titleXPath = "//h1";
var priceXPath = "//div[contains(@class,\"product_main\")]/p[@class=\"price_color\"]";
var book = new Book();
book.Title = document.DocumentNode.SelectSingleNode (priceXPath).InnerText;
book.Price = document.DocumentNode.SelectSingleNode(priceXPath).InnerText;
books.Add(book);
}
return books;
}
此函数将返回 Book 对象列表。是时候更新 Main() 函数了:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
var books = GetBookDetails(bookLinks);
}
这个网络抓取项目的最后一部分是将数据导出到 CSV。
08.导出数据
如果你还没有安装 CsvHelper,你可以使用
dotnet add package CsvHelper
在终端运行该命令即可完成此操作。
导出功能非常简单。首先,我们需要创建一个 StreamWriter 并将 CSV 文件名作为参数发送。接下来,我们将使用这个对象来创建一个 CsvWriter。最后,我们可以使用 WriteRecords 函数在一行代码中编写所有书籍。
为了确保所有资源都正确关闭,我们可以使用 using 块。我们还可以将所有内容都包装在一个函数中,如下所示:
static void exportToCSV(List books)
{
using (var writer = new StreamWriter("./books.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
csv.WriteRecords(books);
}
}
最后,我们可以从 Main() 函数中调用这个函数:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
var books = GetBookDetails(bookLinks);
exportToCSV(books);
}
要运行此代码,请打开终端并运行以下命令:
dotnet run
几秒钟后,您将创建一个 books.csv 文件。
09. 结论
如果你想用 C# 写一个网络爬虫,你可以使用多个包。在本文中,我们展示了如何使用 Html Agility Pack,这是一个功能强大且易于使用的包。也是一个简单的例子,可以进一步增强;例如,您可以尝试将上述逻辑添加到此代码中以处理多个页面。
如果您想了解更多有关使用其他编程语言进行网页抓取的工作原理的信息,您可以查看使用 Python 进行网页抓取的指南。我们还有一个
常见问题
Q:C#适合做网页爬虫吗?
A:与 Python 类似,C# 被广泛用于网络爬虫。在决定选择哪种编程语言时,选择您最熟悉的一种很重要。但是您将能够在 Python 和 C# 中找到示例网络爬虫。
问:网络抓取合法吗?
答:如果在不违反任何法律的情况下使用代理,它们可能是合法的。但是,在与代理人进行任何活动之前,您应该就您的具体案件获得专业的法律建议。请参考我们的文章“网络抓取合法吗?”
c#抓取网页数据(企查查有什么作用数据库中的数据删除后还能恢复吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 201 次浏览 • 2021-10-25 19:01
企业搜索的作用是什么
数据库中的数据删除后还能恢复吗?
什么是排名靠前的数据
前一天晚上哭了,第二天眼睛肿的就消失了
如何在excel中将水平数据转换为垂直数据
如何清除并行空间中的数据
c#爬虫如何抓取企业搜索或天眼数据
请采用定时器控制。. . .
天眼查企业查七信宝哪家有详细数据?
天眼查用的比较多。
如何使用 VLOOKUP 获取数据?
SUMIF($F$1:$F$107,A28,$AM$1:$AM$107) 这个公式有效,VLOOKUP 只得到一个值。
哪一个更好
有的公司,他不列出来,但是那个,但是税务局,放个名字,这样公司很难找,有天眼,他肯定能看出他还在经营或不是。
天眼查还是企业查查哪个好
天眼查比较好。由于天眼查是一款以开放数据为切入点、以关系为核心的产品,它为帮助传统企业或个人降低成本、防范和化解金融风险提供了产品化的解决方案。例如银行或金融担保机构可以通过天眼查提供的信息进行查询和关系...
如何查看历史检索记录
这个好像无法查看历史记录,或者只能查看之前公司发给你的短信。
公司可以查或天眼查公司是否已经申请破产?
查询全国企业信息公示网,对应企业信息更新最快、最权威
企业能否查投融资事件导出数据?
好的。但是你必须先注册成为VIP客户
网页文本抓取器如何抓取文本?
网页文字抓取器是一款小巧精致的网页文字抓取工具,可以让您轻松抓取和复制禁止选择和复制的网页上的文字。对于页面内容被大面积广告覆盖的网页,抓取网页文本爬虫再阅读也是一个不错的解决方案。除此以外...
c#方向是什么类型的数据
C#的每种数据类型都有明确的取值范围。确实,有些类型的取值范围非常大,可以认为是连续的,但取值始终是固定的。最简单的救命方法是 bool 类型。, 它只能是两个值:true 或 false。有时您希望提取变量...
天眼查、企业查、飞凡烽火台哪个好用?
看看你想检查什么?一般的企业信息他们三个都可以查,不过天眼查好像是以后收费的,不过目前Parllay还是免费的,我用积分买调查报告之类的~
C#如何让用户输入数据
Console.WriteLine("请输入第一个数据");stringinput=Console.ReadLine;//input是获取用户输入的数据 intfirstInput=int...
什么数据类型比 C# 中的 int 类型大?
C#中使用的int对应于.NETCTS中的Int32,即32位。Long对应的是Int64,也就是说是64位。float 数据类型用于较小的浮点数,因为它需要较低的精度。double 数据类型比...
除了可以查公司信息的天眼查、企业查、七信宝,还有没有其他网站可以查的?
哦 查看全部
c#抓取网页数据(企查查有什么作用数据库中的数据删除后还能恢复吗)
企业搜索的作用是什么
数据库中的数据删除后还能恢复吗?
什么是排名靠前的数据
前一天晚上哭了,第二天眼睛肿的就消失了
如何在excel中将水平数据转换为垂直数据
如何清除并行空间中的数据
c#爬虫如何抓取企业搜索或天眼数据
请采用定时器控制。. . .
天眼查企业查七信宝哪家有详细数据?
天眼查用的比较多。
如何使用 VLOOKUP 获取数据?
SUMIF($F$1:$F$107,A28,$AM$1:$AM$107) 这个公式有效,VLOOKUP 只得到一个值。
哪一个更好
有的公司,他不列出来,但是那个,但是税务局,放个名字,这样公司很难找,有天眼,他肯定能看出他还在经营或不是。
天眼查还是企业查查哪个好
天眼查比较好。由于天眼查是一款以开放数据为切入点、以关系为核心的产品,它为帮助传统企业或个人降低成本、防范和化解金融风险提供了产品化的解决方案。例如银行或金融担保机构可以通过天眼查提供的信息进行查询和关系...
如何查看历史检索记录
这个好像无法查看历史记录,或者只能查看之前公司发给你的短信。
公司可以查或天眼查公司是否已经申请破产?
查询全国企业信息公示网,对应企业信息更新最快、最权威
企业能否查投融资事件导出数据?
好的。但是你必须先注册成为VIP客户
网页文本抓取器如何抓取文本?
网页文字抓取器是一款小巧精致的网页文字抓取工具,可以让您轻松抓取和复制禁止选择和复制的网页上的文字。对于页面内容被大面积广告覆盖的网页,抓取网页文本爬虫再阅读也是一个不错的解决方案。除此以外...
c#方向是什么类型的数据
C#的每种数据类型都有明确的取值范围。确实,有些类型的取值范围非常大,可以认为是连续的,但取值始终是固定的。最简单的救命方法是 bool 类型。, 它只能是两个值:true 或 false。有时您希望提取变量...
天眼查、企业查、飞凡烽火台哪个好用?
看看你想检查什么?一般的企业信息他们三个都可以查,不过天眼查好像是以后收费的,不过目前Parllay还是免费的,我用积分买调查报告之类的~
C#如何让用户输入数据
Console.WriteLine("请输入第一个数据");stringinput=Console.ReadLine;//input是获取用户输入的数据 intfirstInput=int...
什么数据类型比 C# 中的 int 类型大?
C#中使用的int对应于.NETCTS中的Int32,即32位。Long对应的是Int64,也就是说是64位。float 数据类型用于较小的浮点数,因为它需要较低的精度。double 数据类型比...
除了可以查公司信息的天眼查、企业查、七信宝,还有没有其他网站可以查的?
哦
c#抓取网页数据( 编程问答怎么做?正则表达式 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-25 18:15
编程问答怎么做?正则表达式
)
C#抓取百度搜索链接标题
操作效果与此类似。求一个完整的例子供初学者学习正则表达式,希望大神能帮助你用正则表达式抓取网页数据--------------------编程问答- - ------------------我喜欢~~~~~--------------------编程问题和答案--- -----------------有人吗?? ? 求助--------------------编程问答--------------------不需要正则表达式它可以实现。IE6以上版本,按F12打开开发者工具,分析搜索结果页的源码规则。使用常规规则时,您还必须分析页面源规则。
然后通过如下代码获取mshtml的dom对象
varnativeBrowser=(SHDocVw.WebBrowser)webBrowser1.ActiveXInstance;
IHTMLDocument2doc2=(IHTMLDocument2)nativeBrowser.Document;
然后搜索doc2对象的内容
nativeBrowser.Document 也可以强制为 IHTMLDocument、IHTMLDocument3、IHTMLDocument4、IHTMLDocument5
基本使用2和3,IHTMLDocument3有getElementById、getElementsByName、getElementsByTagName等方法,基本上可以找到网页上的任何对象。还有一种方法可以跨域访问 ifream 中的内容。
需要引用 SHDocVw.dll 和 mshtml.dll。
--------------------编程问答 --------------------三个月前我做过一个,那里是没有规律的。留下邮箱--------------------编程问答--------------------我做过这个东东,而且只抢百度推广,没有正则化,三楼的方法就行了------------编程问答--------- ----------引用4楼wangyue4的回复:三个月前做过一个,没有使用规律。留下邮箱
补充:.NET技术 , C# 查看全部
c#抓取网页数据(
编程问答怎么做?正则表达式
)
C#抓取百度搜索链接标题
操作效果与此类似。求一个完整的例子供初学者学习正则表达式,希望大神能帮助你用正则表达式抓取网页数据--------------------编程问答- - ------------------我喜欢~~~~~--------------------编程问题和答案--- -----------------有人吗?? ? 求助--------------------编程问答--------------------不需要正则表达式它可以实现。IE6以上版本,按F12打开开发者工具,分析搜索结果页的源码规则。使用常规规则时,您还必须分析页面源规则。
然后通过如下代码获取mshtml的dom对象
varnativeBrowser=(SHDocVw.WebBrowser)webBrowser1.ActiveXInstance;
IHTMLDocument2doc2=(IHTMLDocument2)nativeBrowser.Document;
然后搜索doc2对象的内容
nativeBrowser.Document 也可以强制为 IHTMLDocument、IHTMLDocument3、IHTMLDocument4、IHTMLDocument5
基本使用2和3,IHTMLDocument3有getElementById、getElementsByName、getElementsByTagName等方法,基本上可以找到网页上的任何对象。还有一种方法可以跨域访问 ifream 中的内容。
需要引用 SHDocVw.dll 和 mshtml.dll。
--------------------编程问答 --------------------三个月前我做过一个,那里是没有规律的。留下邮箱--------------------编程问答--------------------我做过这个东东,而且只抢百度推广,没有正则化,三楼的方法就行了------------编程问答--------- ----------引用4楼wangyue4的回复:三个月前做过一个,没有使用规律。留下邮箱
补充:.NET技术 , C#
c#抓取网页数据( 基于C#.NET抓取互联网公开数据的爬虫系统及抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-10-25 17:08
基于C#.NET抓取互联网公开数据的爬虫系统及抓取方法)
本发明属于数据采集技术领域,具体涉及一种抓取互联网公共数据的爬虫系统及抓取方法。
背景技术:
网络爬虫是一种自动浏览互联网并按照一定规则自动抓取网页信息的程序或脚本。它是搜索引擎的重要组成部分。搜索引擎在实现网络爬虫的功能时,通常需要一个爬虫系统。完成。
目前市场上的爬虫系统或框架大多采用Python、Java、PHPcrawer等技术。C#很少用于爬虫,C#爬虫系统也很少见,而且因为C#是.NET Framework上面向对象的一种高级编程语言,它可以让程序员快速编写基于MICROSOFT.NET平台的各种应用程序。如果你设计开发一个基于C#抓取互联网公共数据的爬虫系统,将大大提高程序员编写基于MICROSOFT.NET平台的各种应用程序的效率,因此,对基于C#抓取的爬虫系统和方法的需求互联网公开数据非常明显。
技术实现要素:
本发明的目的是利用Python、Java、PHPcrawer等现有技术的爬虫系统。C#很少用于爬虫,影响了程序员编写基于MICROSOFT.NET平台的各种应用程序的效率。问题。
为实现上述目的,本发明提供了一种基于C#的互联网公共数据抓取爬虫系统,包括:
爬虫程序模块,爬虫程序模块用于浏览、抓取和验证数据;
服务器,所述服务器的数量至少为2台,其中部署有爬虫程序模块;
目标站,爬虫程序模块对确定的目标站进行数据浏览和抓取;
非关系型数据库,非关系型数据库用于存储爬虫程序模块捕获的有效数据。
优选地,还包括用于连接验证码识别破解程序模块的第三方接口,验证码识别破解程序模块可以识别和破解目标站的访问请求验证码。
优选地,目标站点、非关系数据库和第三方接口也设置在至少两个服务器中。
优选地,爬虫程序模块包括参数存储单元、目标站捕获单元、目标站分析判断单元、数据捕获单元和数据验证单元。参数存储单元存储参数,其输出端接目标站捕获单元输入端,目标站捕获单元输出端连接目标站分析判定单元输入端,目标站分析判定单元输出端接数据采集单元的输入端,数据采集单元的输出端接数据校验单元的输入端,数据校验单元接参数存储单元,
优选地,所述数据采集单元与数据校验单元之间还设置有数据转换单元,所述数据采集单元将采集到的数据输出至所述数据转换单元,由所述数据转换单元对所述数据进行转换。该单元使用正则表达式或Json序列化方法过滤和提取数据,然后将数据输出到数据验证单元。
优选地,所述数据抓取单元中设有数据分页判断模块,所述数据分页判断模块用于判断数据是否被分页,从而实现数据抓取单元抓取每页数据。
优选地,非关系数据库是NoSQL。
与现有技术相比,本发明的履带系统具有以下优点:
基于C#捕获互联网公共数据,而不是Python、Java、PHPcrawer等技术,可以提高程序员编写基于MICROSOFT.NET平台的各种应用程序的效率;可连接验证码识别破解程序模块,支持多种破解验证码,更好更快的访问目标站;支持部署到多台服务器,降低服务器负载压力,运行和存储更多数据;支持NOSQL数据存储,读取速度大幅提升。
本发明还提供了一种基于C#抓取互联网公共数据的爬虫方法,包括如上所述的基于C#抓取互联网公共数据的爬虫系统,还包括以下步骤:
S100。将爬虫程序模块部署到至少两台服务器上;
S200:确定需要采集数据的目标站点,并准备数据请求参数;
S300,使用c#语言模拟目标站的访问请求,抓取目标站的数据;
S400:使用正则表达式或Json序列化方法对抓取到的数据进行过滤提取;
S500,验证捕获的数据是否与参数匹配,看是否为有效数据;
S600:将有效数据存储在非关系型数据库中。
优选地,步骤S300包括:
S301:判断目标站点接入请求是否需要验证码。如果需要验证码,则抓取请求验证码参数并调用破解验证码服务,然后将破解结果添加到访问请求中并捕获到目标站的数据;
S302:判断目标站的数据抓取是否成功,如果成功,则进入步骤S400;若失败,则转至步骤S303;
S303:将目标站点的访问状态标记为失败。当爬虫程序检测到目标站访问状态失败时,需要重新模拟目标站访问请求来捕获目标站数据,即重复步骤S300,使用c#语言模拟目标站访问请求. 然后进入步骤S301,直到确定目标站的数据抓取成功。
优选地,步骤S400和S500包括寻呼判断,即判断目标站提取的数据是否有寻呼,如果有,则翻页,然后重复步骤S400;如果没有寻呼,则直接进入步骤S500。
与现有技术相比,本发明的抓取方法具有以下优点:
增加了重试机制,爬虫程序在第一次数据抓取失败时会自动重启;数据兼容性大大增强,提高数据质量;增强异常处理以提高资源利用率。
图纸说明
图1是本发明实施例一的履带系统示意图。
图2是本发明第二实施例的抓取方法的步骤示意图。
无花果。图3为本发明第二实施例的抓取方法的流程示意图。
详细方法
为使本发明的上述目的、特征和优点更加明显易懂,下面结合附图对本发明的具体实施例进行详细说明。
第一实施例
参见图1,本实施例介绍了一种基于C#的爬虫系统抓取互联网公共数据,包括:
爬虫程序模块2,爬虫程序模块2用于浏览、抓取和验证数据;
服务器1,所述服务器1的数量至少为2个,其中部署有爬虫程序模块2;
目标站3,爬虫程序模块2对确定的目标站3进行浏览抓取数据;
非关系型数据库4用于存储爬虫模块2捕获的有效数据。
具体的,本发明的互联网公共数据爬虫系统的爬虫程序模块2基于C#,爬虫程序模块2可以是一个烧录爬虫程序的芯片,该芯片至少设置在两个服务器1优选地,爬虫程序模块2部署在每个服务器1中。
爬虫程序模块2中目标站3的确定可以人为确定。例如,如果您想获取公司的商业登记信息,您可以到国家工商行政管理总局、当地工商行政管理总局、国家企业信用信息公示系统等相关信息查询。 .
但更优选地,爬虫程序模块2包括参数存储单元、目标站捕获单元、目标站分析判断单元、数据捕获单元和数据验证单元。参数存储单元存储参数,其输出端连接目标站捕获单元的输入端,目标站捕获单元的输出端连接目标站分析判断单元的输入端,目标站分析判定单元的输出端连接数据采集单元的输入端 数据采集单元的输出端连接数据校验单元的输入端,数据校验单元连接参数存储器单元,
参数存储单元用于存储提取数据所需的数据请求参数,可根据实际情况进行设置。比如要抓取某公司的工商注册信息,可以设置相关参数为与,公司名称,公司所在省份的关系。这样,参数存储单元中存储的相关参数将是,公司名称:某公司,公司所在省份:上海,同时满足这两个参数。
在其他实施例中,参数存储单元中的参数关系可以具有其他设置,例如OR关系。
目标站抓取单元接收参数存储单元中的数据请求参数信息,据此抓取可能收录所需数据的目标站,然后将抓取到的目标站信息发送给目标站分析确定单元。
目标站点分析确定单元根据参数存储单元中的数据请求参数信息对所有目标站点的URL地址进行解析,通过对URL地址和地址对应的数据信息进行解析,确定目标站点。
数据采集单元结合参数存储单元中的数据请求参数信息,从确定的目标站点采集数据,依次采集不同目标站点的所需数据,并将采集到的数据发送给数据校验单元。
数据校验单元将捕获的数据与参数存储单元中存储的数据参数信息进行比对校验,将校验通过的有效数据存储在非关系型数据库中。
为了数据传输、存储和计算的方便,在数据采集单元和数据校验单元之间还设置了数据转换单元,数据采集单元将采集到的数据输出给数据转换单元。单元,通过数据转换单元,使用正则表达式或Json序列化方法对数据进行过滤提取,然后输出到数据校验单元。
另外,由于部分目标站3具有分页功能,为了避免只抓取第一页的数据导致数据抓取不完整或无效,在数据抓取单元中设置了数据分页判断模块。分页判断模块用于判断数据是否被分页,然后数据抓取单元可以抓取每一页的数据。
服务器2为应用服务器,可与目标站点3进行数据交互,具有可扩展性。例如可以使用Cisco服务器,型号为CISCO UCS C240 M3(2U);当然,也可以使用其他应用服务器,只要能实现功能即可。
目标站3的数量为几个,爬虫程序模块2抓取目标站3上需要的数据,目标站3的最小单元是一个网页,爬虫程序模块2会进行浏览、分析、抓取、并对所确定的目标站3的数据进行校验,依次对它遇到的目标站3上所有需要的数据进行采集校验,对目标站3的数据进行采集校验,取深度根据实际需要设置;一般来说,取深度越大,目标站数越多。
非关系型数据库4为NoSQL,其主要功能是存储爬虫程序模块捕获并验证的数据。
为了满足浏览目标站3抓取数据的目的,考虑到目标站3可能设置有验证码,因此,本发明的爬虫系统还包括外部验证码的第三方接口识别破解程序模块。验证码识别破解程序模块可以识别和破解目标站点的访问请求验证码。验证码包括文本验证码、图片验证码、极限验证码等多种类型的验证码。验证码识别破解程序模块可以是烧录验证码识别破解程序的芯片,也可以是除芯片外的设备,
验证码识别破解程序模块可以是一个能够破解多个验证码的综合程序模块;也可以是多个第三接口,分别连接多个验证码识别破解程序模块,多个验证码可以识别破解程序。模块包括对应文本验证码特殊识别的第一验证码识别破解程序模块,具体识别数字验证码和数字加减运算的第二验证码识别破解程序模块,第三验证码识别破解程序模块。具体标识图片验证码。代码识别破解程序模块,
目标站3、非关系型数据库4、的第三方接口也设置在至少两台服务器1中。
或者,也可以在爬虫程序模块上设置第三方接口。
与现有技术相比,本发明的履带系统具有以下优点:
基于C#捕获互联网公共数据,而不是Python、Java、PHPcrawer等技术,可以提高程序员编写基于MICROSOFT.NET平台的各种应用程序的效率;可连接验证码识别破解程序模块,支持多种破解验证码,更好更快的访问目标站;支持部署到多台服务器,降低服务器负载压力,运行和存储更多数据;支持NOSQL数据存储,读取速度大幅提升。
第二个实施例
参见图1至图3,本实施例介绍了一种基于C#的互联网公共数据的爬取方法,包括实施例一所述的基于C#的互联网公共数据的爬取系统,还包括以下步骤:
S100:将爬虫程序模块2部署到至少两台服务器1上;
S200:确定需要采集数据的目标站3,并准备数据请求参数;
S300,使用c#语言模拟目标站访问请求;
S400:使用正则表达式或Json序列化方法对抓取到的数据进行过滤提取;
S500,验证抓取到的数据是否与数据请求参数匹配,看是否为有效数据;
S600,将有效数据存储在非关系型数据库中 4.
具体地,爬虫程序模块2部署在服务器1中。优选地,爬虫程序模块2部署在每个服务器1中,爬虫程序模块抓取、分析、确定需要抓取数据的目标站3或目标站3可能有需要抓取的数据,那么,爬虫模块2准备数据请求参数,例如:需要抓取的业务数据,需要准备公司关键词:,省:江苏,数据请求参数是江苏的工商数据,三者是“合二为一”的关系。目标站3可以通过爬取分析确定为江苏省当地工商银行管理局,或国家企业信用信息系统。
然后,爬虫程序模块2使用C#语言模拟目标站访问请求,使得访问目标站3后,抓取目标站3中需要的数据,然后使用正则表达式或者Json序列化方法过滤和提取这些数据,然后将这些数据与数据请求参数进行比较,分析比较,确定捕获的数据是否为有效数据,最后将有效数据存储在非关系型数据库中 4.
分析比较捕获的数据是否为有效数据的方法是将捕获的数据与数据请求参数进行比较,看是否收录数据请求参数中的所有参数及其关系。使用现有技术中的其他方法。
在访问目标站点3的过程中,部分目标站点3设置了验证码。因此,步骤S300还应包括:
S301:判断目标站3的访问请求是否需要验证码,如果需要验证码,则捕获请求验证码参数并调用破解验证码服务,然后将破解结果添加到访问请求中并捕获到站 3 的目标数据。
本步骤中,破解验证码的服务可以是爬虫模块2提供的,也可以是外接如实施例一所述的第三方接口,第三方接口的数量可以是一个,也可以是一个以上,可以处理不同类型的验证码,最大化可访问目标站3的范围,增加本发明实施例一所述爬虫系统和本实施例所述抓取方法的适用性。
S302:判断目标站3的数据抓取是否成功,如果成功,则进入步骤S400;如果失败,则转到步骤S303。
本步骤的判断方法多种多样,可以采用现有技术中的判断方法,即判断是否存储了抓取到的数据。如果已经存储在服务器中,则视为成功。服务器的存储容量变化来判断。
S303:将目标站点3的访问状态标记为失败。当爬虫程序检测到目标站3的访问状态失败时,需要再次模拟目标站3的访问请求来抓取目标站3的数据,即重复步骤S300,然后重复步骤S301。
也就是说,如果在请求访问目标站3的过程中,验证码无法破解,数据抓取失败,则将目标站3的访问状态标记为失败,爬虫模块2检测到目标站3的访问状态失败,重新模拟目标站3的访问请求,再次请求访问目标站3,然后再次识别并破解目标站3的验证码,直到目标站3被成功捕获。
考虑到目标站3可能有寻呼,步骤S400和S500包括寻呼判断,即判断目标站3提取的数据是否有寻呼,如果有,则翻页,然后重复步骤S400;如果没有分页符,直接进入步骤S500。
这样可以有效避免在抓取目标站3的数据时只抓取第一页数据,而忽略第一页以外的数据,导致数据抓取不完整、不完整或根本没有抓取。获取到需要的数据,反复卡在这一步。
与现有技术相比,本发明的抓取方法具有以下优点:
增加了重试机制,爬虫程序在第一次数据抓取失败时会自动重启;数据兼容性大大增强,提高数据质量;增强异常处理以提高资源利用率。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明的保护范围。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进,均应收录在本发明的保护范围之内。 查看全部
c#抓取网页数据(
基于C#.NET抓取互联网公开数据的爬虫系统及抓取方法)
本发明属于数据采集技术领域,具体涉及一种抓取互联网公共数据的爬虫系统及抓取方法。
背景技术:
网络爬虫是一种自动浏览互联网并按照一定规则自动抓取网页信息的程序或脚本。它是搜索引擎的重要组成部分。搜索引擎在实现网络爬虫的功能时,通常需要一个爬虫系统。完成。
目前市场上的爬虫系统或框架大多采用Python、Java、PHPcrawer等技术。C#很少用于爬虫,C#爬虫系统也很少见,而且因为C#是.NET Framework上面向对象的一种高级编程语言,它可以让程序员快速编写基于MICROSOFT.NET平台的各种应用程序。如果你设计开发一个基于C#抓取互联网公共数据的爬虫系统,将大大提高程序员编写基于MICROSOFT.NET平台的各种应用程序的效率,因此,对基于C#抓取的爬虫系统和方法的需求互联网公开数据非常明显。
技术实现要素:
本发明的目的是利用Python、Java、PHPcrawer等现有技术的爬虫系统。C#很少用于爬虫,影响了程序员编写基于MICROSOFT.NET平台的各种应用程序的效率。问题。
为实现上述目的,本发明提供了一种基于C#的互联网公共数据抓取爬虫系统,包括:
爬虫程序模块,爬虫程序模块用于浏览、抓取和验证数据;
服务器,所述服务器的数量至少为2台,其中部署有爬虫程序模块;
目标站,爬虫程序模块对确定的目标站进行数据浏览和抓取;
非关系型数据库,非关系型数据库用于存储爬虫程序模块捕获的有效数据。
优选地,还包括用于连接验证码识别破解程序模块的第三方接口,验证码识别破解程序模块可以识别和破解目标站的访问请求验证码。
优选地,目标站点、非关系数据库和第三方接口也设置在至少两个服务器中。
优选地,爬虫程序模块包括参数存储单元、目标站捕获单元、目标站分析判断单元、数据捕获单元和数据验证单元。参数存储单元存储参数,其输出端接目标站捕获单元输入端,目标站捕获单元输出端连接目标站分析判定单元输入端,目标站分析判定单元输出端接数据采集单元的输入端,数据采集单元的输出端接数据校验单元的输入端,数据校验单元接参数存储单元,
优选地,所述数据采集单元与数据校验单元之间还设置有数据转换单元,所述数据采集单元将采集到的数据输出至所述数据转换单元,由所述数据转换单元对所述数据进行转换。该单元使用正则表达式或Json序列化方法过滤和提取数据,然后将数据输出到数据验证单元。
优选地,所述数据抓取单元中设有数据分页判断模块,所述数据分页判断模块用于判断数据是否被分页,从而实现数据抓取单元抓取每页数据。
优选地,非关系数据库是NoSQL。
与现有技术相比,本发明的履带系统具有以下优点:
基于C#捕获互联网公共数据,而不是Python、Java、PHPcrawer等技术,可以提高程序员编写基于MICROSOFT.NET平台的各种应用程序的效率;可连接验证码识别破解程序模块,支持多种破解验证码,更好更快的访问目标站;支持部署到多台服务器,降低服务器负载压力,运行和存储更多数据;支持NOSQL数据存储,读取速度大幅提升。
本发明还提供了一种基于C#抓取互联网公共数据的爬虫方法,包括如上所述的基于C#抓取互联网公共数据的爬虫系统,还包括以下步骤:
S100。将爬虫程序模块部署到至少两台服务器上;
S200:确定需要采集数据的目标站点,并准备数据请求参数;
S300,使用c#语言模拟目标站的访问请求,抓取目标站的数据;
S400:使用正则表达式或Json序列化方法对抓取到的数据进行过滤提取;
S500,验证捕获的数据是否与参数匹配,看是否为有效数据;
S600:将有效数据存储在非关系型数据库中。
优选地,步骤S300包括:
S301:判断目标站点接入请求是否需要验证码。如果需要验证码,则抓取请求验证码参数并调用破解验证码服务,然后将破解结果添加到访问请求中并捕获到目标站的数据;
S302:判断目标站的数据抓取是否成功,如果成功,则进入步骤S400;若失败,则转至步骤S303;
S303:将目标站点的访问状态标记为失败。当爬虫程序检测到目标站访问状态失败时,需要重新模拟目标站访问请求来捕获目标站数据,即重复步骤S300,使用c#语言模拟目标站访问请求. 然后进入步骤S301,直到确定目标站的数据抓取成功。
优选地,步骤S400和S500包括寻呼判断,即判断目标站提取的数据是否有寻呼,如果有,则翻页,然后重复步骤S400;如果没有寻呼,则直接进入步骤S500。
与现有技术相比,本发明的抓取方法具有以下优点:
增加了重试机制,爬虫程序在第一次数据抓取失败时会自动重启;数据兼容性大大增强,提高数据质量;增强异常处理以提高资源利用率。
图纸说明
图1是本发明实施例一的履带系统示意图。
图2是本发明第二实施例的抓取方法的步骤示意图。
无花果。图3为本发明第二实施例的抓取方法的流程示意图。
详细方法
为使本发明的上述目的、特征和优点更加明显易懂,下面结合附图对本发明的具体实施例进行详细说明。
第一实施例
参见图1,本实施例介绍了一种基于C#的爬虫系统抓取互联网公共数据,包括:
爬虫程序模块2,爬虫程序模块2用于浏览、抓取和验证数据;
服务器1,所述服务器1的数量至少为2个,其中部署有爬虫程序模块2;
目标站3,爬虫程序模块2对确定的目标站3进行浏览抓取数据;
非关系型数据库4用于存储爬虫模块2捕获的有效数据。
具体的,本发明的互联网公共数据爬虫系统的爬虫程序模块2基于C#,爬虫程序模块2可以是一个烧录爬虫程序的芯片,该芯片至少设置在两个服务器1优选地,爬虫程序模块2部署在每个服务器1中。
爬虫程序模块2中目标站3的确定可以人为确定。例如,如果您想获取公司的商业登记信息,您可以到国家工商行政管理总局、当地工商行政管理总局、国家企业信用信息公示系统等相关信息查询。 .
但更优选地,爬虫程序模块2包括参数存储单元、目标站捕获单元、目标站分析判断单元、数据捕获单元和数据验证单元。参数存储单元存储参数,其输出端连接目标站捕获单元的输入端,目标站捕获单元的输出端连接目标站分析判断单元的输入端,目标站分析判定单元的输出端连接数据采集单元的输入端 数据采集单元的输出端连接数据校验单元的输入端,数据校验单元连接参数存储器单元,
参数存储单元用于存储提取数据所需的数据请求参数,可根据实际情况进行设置。比如要抓取某公司的工商注册信息,可以设置相关参数为与,公司名称,公司所在省份的关系。这样,参数存储单元中存储的相关参数将是,公司名称:某公司,公司所在省份:上海,同时满足这两个参数。
在其他实施例中,参数存储单元中的参数关系可以具有其他设置,例如OR关系。
目标站抓取单元接收参数存储单元中的数据请求参数信息,据此抓取可能收录所需数据的目标站,然后将抓取到的目标站信息发送给目标站分析确定单元。
目标站点分析确定单元根据参数存储单元中的数据请求参数信息对所有目标站点的URL地址进行解析,通过对URL地址和地址对应的数据信息进行解析,确定目标站点。
数据采集单元结合参数存储单元中的数据请求参数信息,从确定的目标站点采集数据,依次采集不同目标站点的所需数据,并将采集到的数据发送给数据校验单元。
数据校验单元将捕获的数据与参数存储单元中存储的数据参数信息进行比对校验,将校验通过的有效数据存储在非关系型数据库中。
为了数据传输、存储和计算的方便,在数据采集单元和数据校验单元之间还设置了数据转换单元,数据采集单元将采集到的数据输出给数据转换单元。单元,通过数据转换单元,使用正则表达式或Json序列化方法对数据进行过滤提取,然后输出到数据校验单元。
另外,由于部分目标站3具有分页功能,为了避免只抓取第一页的数据导致数据抓取不完整或无效,在数据抓取单元中设置了数据分页判断模块。分页判断模块用于判断数据是否被分页,然后数据抓取单元可以抓取每一页的数据。
服务器2为应用服务器,可与目标站点3进行数据交互,具有可扩展性。例如可以使用Cisco服务器,型号为CISCO UCS C240 M3(2U);当然,也可以使用其他应用服务器,只要能实现功能即可。
目标站3的数量为几个,爬虫程序模块2抓取目标站3上需要的数据,目标站3的最小单元是一个网页,爬虫程序模块2会进行浏览、分析、抓取、并对所确定的目标站3的数据进行校验,依次对它遇到的目标站3上所有需要的数据进行采集校验,对目标站3的数据进行采集校验,取深度根据实际需要设置;一般来说,取深度越大,目标站数越多。
非关系型数据库4为NoSQL,其主要功能是存储爬虫程序模块捕获并验证的数据。
为了满足浏览目标站3抓取数据的目的,考虑到目标站3可能设置有验证码,因此,本发明的爬虫系统还包括外部验证码的第三方接口识别破解程序模块。验证码识别破解程序模块可以识别和破解目标站点的访问请求验证码。验证码包括文本验证码、图片验证码、极限验证码等多种类型的验证码。验证码识别破解程序模块可以是烧录验证码识别破解程序的芯片,也可以是除芯片外的设备,
验证码识别破解程序模块可以是一个能够破解多个验证码的综合程序模块;也可以是多个第三接口,分别连接多个验证码识别破解程序模块,多个验证码可以识别破解程序。模块包括对应文本验证码特殊识别的第一验证码识别破解程序模块,具体识别数字验证码和数字加减运算的第二验证码识别破解程序模块,第三验证码识别破解程序模块。具体标识图片验证码。代码识别破解程序模块,
目标站3、非关系型数据库4、的第三方接口也设置在至少两台服务器1中。
或者,也可以在爬虫程序模块上设置第三方接口。
与现有技术相比,本发明的履带系统具有以下优点:
基于C#捕获互联网公共数据,而不是Python、Java、PHPcrawer等技术,可以提高程序员编写基于MICROSOFT.NET平台的各种应用程序的效率;可连接验证码识别破解程序模块,支持多种破解验证码,更好更快的访问目标站;支持部署到多台服务器,降低服务器负载压力,运行和存储更多数据;支持NOSQL数据存储,读取速度大幅提升。
第二个实施例
参见图1至图3,本实施例介绍了一种基于C#的互联网公共数据的爬取方法,包括实施例一所述的基于C#的互联网公共数据的爬取系统,还包括以下步骤:
S100:将爬虫程序模块2部署到至少两台服务器1上;
S200:确定需要采集数据的目标站3,并准备数据请求参数;
S300,使用c#语言模拟目标站访问请求;
S400:使用正则表达式或Json序列化方法对抓取到的数据进行过滤提取;
S500,验证抓取到的数据是否与数据请求参数匹配,看是否为有效数据;
S600,将有效数据存储在非关系型数据库中 4.
具体地,爬虫程序模块2部署在服务器1中。优选地,爬虫程序模块2部署在每个服务器1中,爬虫程序模块抓取、分析、确定需要抓取数据的目标站3或目标站3可能有需要抓取的数据,那么,爬虫模块2准备数据请求参数,例如:需要抓取的业务数据,需要准备公司关键词:,省:江苏,数据请求参数是江苏的工商数据,三者是“合二为一”的关系。目标站3可以通过爬取分析确定为江苏省当地工商银行管理局,或国家企业信用信息系统。
然后,爬虫程序模块2使用C#语言模拟目标站访问请求,使得访问目标站3后,抓取目标站3中需要的数据,然后使用正则表达式或者Json序列化方法过滤和提取这些数据,然后将这些数据与数据请求参数进行比较,分析比较,确定捕获的数据是否为有效数据,最后将有效数据存储在非关系型数据库中 4.
分析比较捕获的数据是否为有效数据的方法是将捕获的数据与数据请求参数进行比较,看是否收录数据请求参数中的所有参数及其关系。使用现有技术中的其他方法。
在访问目标站点3的过程中,部分目标站点3设置了验证码。因此,步骤S300还应包括:
S301:判断目标站3的访问请求是否需要验证码,如果需要验证码,则捕获请求验证码参数并调用破解验证码服务,然后将破解结果添加到访问请求中并捕获到站 3 的目标数据。
本步骤中,破解验证码的服务可以是爬虫模块2提供的,也可以是外接如实施例一所述的第三方接口,第三方接口的数量可以是一个,也可以是一个以上,可以处理不同类型的验证码,最大化可访问目标站3的范围,增加本发明实施例一所述爬虫系统和本实施例所述抓取方法的适用性。
S302:判断目标站3的数据抓取是否成功,如果成功,则进入步骤S400;如果失败,则转到步骤S303。
本步骤的判断方法多种多样,可以采用现有技术中的判断方法,即判断是否存储了抓取到的数据。如果已经存储在服务器中,则视为成功。服务器的存储容量变化来判断。
S303:将目标站点3的访问状态标记为失败。当爬虫程序检测到目标站3的访问状态失败时,需要再次模拟目标站3的访问请求来抓取目标站3的数据,即重复步骤S300,然后重复步骤S301。
也就是说,如果在请求访问目标站3的过程中,验证码无法破解,数据抓取失败,则将目标站3的访问状态标记为失败,爬虫模块2检测到目标站3的访问状态失败,重新模拟目标站3的访问请求,再次请求访问目标站3,然后再次识别并破解目标站3的验证码,直到目标站3被成功捕获。
考虑到目标站3可能有寻呼,步骤S400和S500包括寻呼判断,即判断目标站3提取的数据是否有寻呼,如果有,则翻页,然后重复步骤S400;如果没有分页符,直接进入步骤S500。
这样可以有效避免在抓取目标站3的数据时只抓取第一页数据,而忽略第一页以外的数据,导致数据抓取不完整、不完整或根本没有抓取。获取到需要的数据,反复卡在这一步。
与现有技术相比,本发明的抓取方法具有以下优点:
增加了重试机制,爬虫程序在第一次数据抓取失败时会自动重启;数据兼容性大大增强,提高数据质量;增强异常处理以提高资源利用率。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明的保护范围。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进,均应收录在本发明的保护范围之内。
c#抓取网页数据(如何用易语言抓取微信朋友圈的图片文字呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-10-25 00:03
c#抓取网页数据的软件有很多,一般用户都会选择电脑上用易语言。电脑上易语言学习和使用比较简单方便,但是我们都清楚易语言是不能抓取微信朋友圈的图片文字的,只能抓取文字图片;那么如何用易语言抓取微信朋友圈的图片文字呢?其实关键是我们必须把对应的代码贴入文件中。下面是有关易语言图片文字抓取的常用代码,我们可以把这些代码直接复制到excel表格中,最终就可以抓取到图片文字了。for(inti=0;ipython的ide:eclipse入门2>python数据分析:第二章python数据分析:第三章1>python的数据结构2>python的数据采集和解析3>字符串处理4>字符串处理5>字符串验证和加密6>加密7>解密8>文件读写与保存9>读写文件10>在线数据库或者数据库numpy11>计算机科学实战:flask,学习idle12>python的模块和第三方包13>python的pandas库14>机器学习15>建立开发团队,构建企业级技术团队16>开发云或者公有云平台17>发布软件或者构建网站19>sqlalchemy+numpy2>pandas2:数据提取基础19>从零开始学编程20>pandas+flask:网站数据采集基础21>读写文件21>基础pandas2:文件读写和转换22>基础pandas2:提取文本22>基础pandas2:数据去重23>pandas2:文本相关数据存储和计算24>文本处理三部曲,pandas+flask:self-study25>计算机科学实战:numpy、pandas和r数据挖掘26>pandas基础和入门33>pandas数据处理实践或者四部曲:ols、dataframe、join、crossjoin;27>pandas数据处理实践ai实战就用python3numpy,scipy的使用时间都比较长了,想想也可能不是一个人愿意学。 查看全部
c#抓取网页数据(如何用易语言抓取微信朋友圈的图片文字呢?)
c#抓取网页数据的软件有很多,一般用户都会选择电脑上用易语言。电脑上易语言学习和使用比较简单方便,但是我们都清楚易语言是不能抓取微信朋友圈的图片文字的,只能抓取文字图片;那么如何用易语言抓取微信朋友圈的图片文字呢?其实关键是我们必须把对应的代码贴入文件中。下面是有关易语言图片文字抓取的常用代码,我们可以把这些代码直接复制到excel表格中,最终就可以抓取到图片文字了。for(inti=0;ipython的ide:eclipse入门2>python数据分析:第二章python数据分析:第三章1>python的数据结构2>python的数据采集和解析3>字符串处理4>字符串处理5>字符串验证和加密6>加密7>解密8>文件读写与保存9>读写文件10>在线数据库或者数据库numpy11>计算机科学实战:flask,学习idle12>python的模块和第三方包13>python的pandas库14>机器学习15>建立开发团队,构建企业级技术团队16>开发云或者公有云平台17>发布软件或者构建网站19>sqlalchemy+numpy2>pandas2:数据提取基础19>从零开始学编程20>pandas+flask:网站数据采集基础21>读写文件21>基础pandas2:文件读写和转换22>基础pandas2:提取文本22>基础pandas2:数据去重23>pandas2:文本相关数据存储和计算24>文本处理三部曲,pandas+flask:self-study25>计算机科学实战:numpy、pandas和r数据挖掘26>pandas基础和入门33>pandas数据处理实践或者四部曲:ols、dataframe、join、crossjoin;27>pandas数据处理实践ai实战就用python3numpy,scipy的使用时间都比较长了,想想也可能不是一个人愿意学。
c#抓取网页数据(比如说我要抓取博客园首页(一)())
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-22 06:00
一:网页更新
我们知道一般网页中的信息是不断更新的,这也需要我们定期抓取这些新信息,但是如何理解这个“规律”,即抓取页面需要多长时间,在其实这个时间段就是Page cache时间。在页面缓存期间,我们没有必要再次抓取网页,但会对其他人的服务器造成压力。
比如我想抓取博客园的首页,先清除页面缓存,
从 last-modified 到 expires 可以看到博客园的缓存时间是 2 分钟,而且我还可以看到当前服务器时间日期,如果我再做一次
如果刷新页面,这里的日期会变成下图中的if-modified-since,然后发送到服务器判断浏览器的缓存是否已经过期?
最后服务端发现if-modified-since >= last-modifined时间,服务端也返回了304,但是发现cookie信息真的是很多小偷。
在实际开发中,如果知道网站的缓存策略,就可以让爬虫每2分钟爬一次。当然,这些可以由数据团队进行配置和维护。好,下面我们就用爬虫。模拟它。
二:网页编码问题
有时候我们已经抓取了网页,准备解析的时候,tmd全是乱码,真他妈的,比如下面这样,
或许我们依稀记得html的meta中有一个叫做charset的属性,里面记录了编码方式。还有一点很重要,response.characterset 属性也记录了编码方式。让我们再试一次。
代码还是乱码,蛋疼。这个时候需要去官网看看http头信息里面交互的是什么。为什么浏览器能正常显示,爬虫爬不过去。
查看http头信息后,我们终于知道浏览器说我可以解析gzip、deflate和sdch这三种压缩方式。服务器发送 gzip 压缩。至此,我们也应该知道常用的web性能优化了。
三:网页分析
经过一番折腾,现在网页已经得到了,接下来就要解析了。当然,正则匹配是一个不错的方法。毕竟工作量还是比较大的。或许业界也推崇解析工具htmlagilitypack,它可以将html解析成xml,然后可以使用xpath提取指定的内容,大大提高了开发速度,性能也不错。毕竟,敏捷意味着敏捷。关于xpath的内容,看懂w3cschool的两张图就可以了。
好了,结束工作,去睡觉吧。. . 查看全部
c#抓取网页数据(比如说我要抓取博客园首页(一)())
一:网页更新
我们知道一般网页中的信息是不断更新的,这也需要我们定期抓取这些新信息,但是如何理解这个“规律”,即抓取页面需要多长时间,在其实这个时间段就是Page cache时间。在页面缓存期间,我们没有必要再次抓取网页,但会对其他人的服务器造成压力。
比如我想抓取博客园的首页,先清除页面缓存,
从 last-modified 到 expires 可以看到博客园的缓存时间是 2 分钟,而且我还可以看到当前服务器时间日期,如果我再做一次
如果刷新页面,这里的日期会变成下图中的if-modified-since,然后发送到服务器判断浏览器的缓存是否已经过期?
最后服务端发现if-modified-since >= last-modifined时间,服务端也返回了304,但是发现cookie信息真的是很多小偷。
在实际开发中,如果知道网站的缓存策略,就可以让爬虫每2分钟爬一次。当然,这些可以由数据团队进行配置和维护。好,下面我们就用爬虫。模拟它。
二:网页编码问题
有时候我们已经抓取了网页,准备解析的时候,tmd全是乱码,真他妈的,比如下面这样,
或许我们依稀记得html的meta中有一个叫做charset的属性,里面记录了编码方式。还有一点很重要,response.characterset 属性也记录了编码方式。让我们再试一次。
代码还是乱码,蛋疼。这个时候需要去官网看看http头信息里面交互的是什么。为什么浏览器能正常显示,爬虫爬不过去。
查看http头信息后,我们终于知道浏览器说我可以解析gzip、deflate和sdch这三种压缩方式。服务器发送 gzip 压缩。至此,我们也应该知道常用的web性能优化了。
三:网页分析
经过一番折腾,现在网页已经得到了,接下来就要解析了。当然,正则匹配是一个不错的方法。毕竟工作量还是比较大的。或许业界也推崇解析工具htmlagilitypack,它可以将html解析成xml,然后可以使用xpath提取指定的内容,大大提高了开发速度,性能也不错。毕竟,敏捷意味着敏捷。关于xpath的内容,看懂w3cschool的两张图就可以了。
好了,结束工作,去睡觉吧。. .
c#抓取网页数据(保险起见输入账号密码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-10-21 20:13
4.输入账号密码,确认登录,得到如下数据:
关注POST请求中的Url和postdata,以及服务器返回的cookies
cookie 收录登录信息。为安全起见,我们可以将所有 4 个 cookie 值都传递给服务器。
首先给出C#发送POST请求的代码:(目的是获取服务器返回的cookie)
string Url = "URL";
string postDataStr = "POST Data";//因为上面都是离散的键值对,我们可以从Stream中直接找到postDataStr
//登录并获取cookie
HttpPost(Url, postDataStr, ref cookie);
private string HttpPost(string Url, string postDataStr, ref CookieContainer cookie)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
request.Method = "POST";
request.ContentType = "application/x-www-form-urlencoded";
byte[] postData = Encoding.UTF8.GetBytes(postDataStr);
request.ContentLength = postData.Length;
request.CookieContainer = cookie;
Stream myRequestStream = request.GetRequestStream();
myRequestStream.Write(postData, 0, postData.Length);
myRequestStream.Close();
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
response.Cookies = cookie.GetCookies(response.ResponseUri);
Stream myResponseStream = response.GetResponseStream();
StreamReader myStreamReader = new StreamReader(myResponseStream, Encoding.GetEncoding("utf-8"));
string retString = myStreamReader.ReadToEnd();
myStreamReader.Close();
myResponseStream.Close();
return retString;
}
有了cookie之后,就可以从网站中抓取自己需要的数据,下一步就是发送GET请求
因为服务器返回的是html,如何从大量的html中快速获取到需要的信息?在这里,我们可以参考一个高效强大的第三方库NSoup(网上也有人推荐使用htmlparser,但通过我个人的对比,htmlparser在效率和简单性上都远不如NSoup)
由于NSoup的网上教程比较好,也可以参考JSoup的教程:
最后,给我一些我从 网站 抓取的数据:
纸上谈兵,我知道我必须亲自去做。 查看全部
c#抓取网页数据(保险起见输入账号密码)
4.输入账号密码,确认登录,得到如下数据:
关注POST请求中的Url和postdata,以及服务器返回的cookies
cookie 收录登录信息。为安全起见,我们可以将所有 4 个 cookie 值都传递给服务器。
首先给出C#发送POST请求的代码:(目的是获取服务器返回的cookie)
string Url = "URL";
string postDataStr = "POST Data";//因为上面都是离散的键值对,我们可以从Stream中直接找到postDataStr
//登录并获取cookie
HttpPost(Url, postDataStr, ref cookie);
private string HttpPost(string Url, string postDataStr, ref CookieContainer cookie)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
request.Method = "POST";
request.ContentType = "application/x-www-form-urlencoded";
byte[] postData = Encoding.UTF8.GetBytes(postDataStr);
request.ContentLength = postData.Length;
request.CookieContainer = cookie;
Stream myRequestStream = request.GetRequestStream();
myRequestStream.Write(postData, 0, postData.Length);
myRequestStream.Close();
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
response.Cookies = cookie.GetCookies(response.ResponseUri);
Stream myResponseStream = response.GetResponseStream();
StreamReader myStreamReader = new StreamReader(myResponseStream, Encoding.GetEncoding("utf-8"));
string retString = myStreamReader.ReadToEnd();
myStreamReader.Close();
myResponseStream.Close();
return retString;
}
有了cookie之后,就可以从网站中抓取自己需要的数据,下一步就是发送GET请求
因为服务器返回的是html,如何从大量的html中快速获取到需要的信息?在这里,我们可以参考一个高效强大的第三方库NSoup(网上也有人推荐使用htmlparser,但通过我个人的对比,htmlparser在效率和简单性上都远不如NSoup)
由于NSoup的网上教程比较好,也可以参考JSoup的教程:
最后,给我一些我从 网站 抓取的数据:
纸上谈兵,我知道我必须亲自去做。
c#抓取网页数据( ()代码只有短短几行但是功能很实用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-19 03:23
()代码只有短短几行但是功能很实用)
Winform实现抓取网页内容的方法
更新时间:2014-09-24 15:41:07 投稿:shichen2014
本文文章主要介绍Winform抓取网页内容的方法。代码只有几行,但是功能很实用。有需要的朋友可以参考。
本文用一个非常简单的例子来描述Winform捕获网页内容的方法。代码简洁易懂,非常实用!分享给大家,供大家参考。
具体实现代码如下:
WebRequest request = WebRequest.Create("http://1.bjapp.sinaapp.com/play.php?a=" + PageUrl);
WebResponse response = request.GetResponse();
Stream resStream = response.GetResponseStream();
StreamReader sr = new StreamReader(resStream, System.Text.Encoding.UTF8);
string htmlinfo = sr.ReadToEnd();
resStream.Close();
sr.Close();
有兴趣的朋友可以测试运行或改进本文中的示例。我希望这篇文章能帮助你学习 C# 编程。 查看全部
c#抓取网页数据(
()代码只有短短几行但是功能很实用)
Winform实现抓取网页内容的方法
更新时间:2014-09-24 15:41:07 投稿:shichen2014
本文文章主要介绍Winform抓取网页内容的方法。代码只有几行,但是功能很实用。有需要的朋友可以参考。
本文用一个非常简单的例子来描述Winform捕获网页内容的方法。代码简洁易懂,非常实用!分享给大家,供大家参考。
具体实现代码如下:
WebRequest request = WebRequest.Create("http://1.bjapp.sinaapp.com/play.php?a=" + PageUrl);
WebResponse response = request.GetResponse();
Stream resStream = response.GetResponseStream();
StreamReader sr = new StreamReader(resStream, System.Text.Encoding.UTF8);
string htmlinfo = sr.ReadToEnd();
resStream.Close();
sr.Close();
有兴趣的朋友可以测试运行或改进本文中的示例。我希望这篇文章能帮助你学习 C# 编程。
c#抓取网页数据( 2017年05月13日12:00本文基于会话操作登陆网页及页面读取相关操作技巧,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-15 21:02
2017年05月13日12:00本文基于会话操作登陆网页及页面读取相关操作技巧,)
C#使用WebClient登录网站获取登录网页信息实现方法
更新时间:2017-05-13 12:00:58 作者:柔城
本文文章主要介绍C#使用WebClient登录网站,登录后抓取网页信息的实现方法。涉及到C#基于session操作登录网页和页面阅读相关操作技巧,有需要的朋友可以参考Down
本文介绍了C#使用WebClient登录网站并抓取登录网页信息的实现方法。分享给大家,供大家参考,如下:
C#登录网站其实就是模拟浏览器提交表单,然后记录浏览器响应返回的session cookie值,并用这个session cookie值再次发送请求来请求,达到模拟的效果登录。
以下 CookieAwareWebClient 的实现在发送请求时携带 cookie。
public class CookieAwareWebClient : WebClient
{
private CookieContainer cookie = new CookieContainer();
protected override WebRequest GetWebRequest(Uri address)
{
WebRequest request = base.GetWebRequest(address);
if (request is HttpWebRequest)
{
(request as HttpWebRequest).CookieContainer = cookie;
}
return request;
}
}
下面是模拟表单提交登录的使用示例:
var client = new CookieAwareWebClient();
client.BaseAddress = @"https://hovertree.net/any/base/url/";
var loginData = new NameValueCollection();
loginData.Add("login", "YourLogin");
loginData.Add("password", "YourPassword");
client.UploadValues("login.php", "POST", loginData);
//Now you are logged in and can request pages
string htmlSource = client.DownloadString("index.php");
更多对C#相关内容感兴趣的读者可以查看本站专题:《C#编码操作技巧总结》、《C#中XML文件操作技巧总结》、《C#常用控件使用教程》、《WinForm控件使用技巧总结》 》、《C#数据结构与算法教程》、《C#面向对象编程入门教程》、《C#编程线程使用技巧总结》
我希望这篇文章能帮助你 C# 编程。 查看全部
c#抓取网页数据(
2017年05月13日12:00本文基于会话操作登陆网页及页面读取相关操作技巧,)
C#使用WebClient登录网站获取登录网页信息实现方法
更新时间:2017-05-13 12:00:58 作者:柔城
本文文章主要介绍C#使用WebClient登录网站,登录后抓取网页信息的实现方法。涉及到C#基于session操作登录网页和页面阅读相关操作技巧,有需要的朋友可以参考Down
本文介绍了C#使用WebClient登录网站并抓取登录网页信息的实现方法。分享给大家,供大家参考,如下:
C#登录网站其实就是模拟浏览器提交表单,然后记录浏览器响应返回的session cookie值,并用这个session cookie值再次发送请求来请求,达到模拟的效果登录。
以下 CookieAwareWebClient 的实现在发送请求时携带 cookie。
public class CookieAwareWebClient : WebClient
{
private CookieContainer cookie = new CookieContainer();
protected override WebRequest GetWebRequest(Uri address)
{
WebRequest request = base.GetWebRequest(address);
if (request is HttpWebRequest)
{
(request as HttpWebRequest).CookieContainer = cookie;
}
return request;
}
}
下面是模拟表单提交登录的使用示例:
var client = new CookieAwareWebClient();
client.BaseAddress = @"https://hovertree.net/any/base/url/";
var loginData = new NameValueCollection();
loginData.Add("login", "YourLogin");
loginData.Add("password", "YourPassword");
client.UploadValues("login.php", "POST", loginData);
//Now you are logged in and can request pages
string htmlSource = client.DownloadString("index.php");
更多对C#相关内容感兴趣的读者可以查看本站专题:《C#编码操作技巧总结》、《C#中XML文件操作技巧总结》、《C#常用控件使用教程》、《WinForm控件使用技巧总结》 》、《C#数据结构与算法教程》、《C#面向对象编程入门教程》、《C#编程线程使用技巧总结》
我希望这篇文章能帮助你 C# 编程。
c#抓取网页数据(网页分析采集程序的基本流程和流程图详解 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-10-15 20:29
)
首先大家要清楚:网站的任何页面,无论是php、jsp、aspx等动态页面,还是后台程序生成的静态页面,都可以在浏览器。
所以当你要开发数据采集程序时,首先要了解网站你试图采集的首页结构(HTML)。
当您熟悉网站中需要采集数据的HTML源文件的内容后,程序的其余部分就很容易处理了。因为C#在网站上执行数据采集,原理是“下载你要采集的页面的HTML源文件,分析HTML代码然后抓取你需要的数据,最后将数据保存到本地文件”。
基本流程如下图所示:
1.页面源文件下载
首先引用 System.Net 命名空间
使用 System.Net;
还需要引用
使用 System.Text;
使用 System.IO;
复制代码
引用后实例化一个 WebClient 对象
private WebClientwc = new WebClient();
调用 DownloadData 方法从指定网页的源文件中下载一组 BYTE 数据,然后将 BYTE 数组转换为字符串。
// 下载页面源文件并转换为UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData( string .Format( "你要的是采集的网页地址" )));
复制代码
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
// 下载网页源文件到本地
wc.DownloadFile( "你要采集的网页的URL", "保存源文件的本地文件路径");
// 读取下载的源文件HTML格式字符串
string mainData = File.ReadAllText( "保存源文件的本地文件路径" ,Encoding.UTF8);
复制代码
通过网页HTML格式字符串,您可以分析网页采集,抓取您需要的内容。
2.页面分析采集
页面分析就是以网页源文件中某个特定的或唯一的字符(字符串)为抓点,并以此抓点为起点,截取你想要的页面上的数据。
以博客园为专栏。比如我要在博客园首页列出文章的标题和链接,就必须用“
代码:
// 经过”
mainData = mainData.Substring(mainData.IndexOf("") + 26);
// 获取文章页面的链接地址
string articleAddr = mainData.Substring( 0 ,mainData.IndexOf( "\"" ));
// 获取文章的标题
string articleTitle = mainData.Substring(mainData.IndexOf("target=\"_blank\">") + 16,
mainData.IndexOf( "")-mainData.IndexOf( "target=\"_blank\">")-16 );
复制代码
注意:当你要采集的网页前台的HTML格式发生变化时,作为抓点的字符通道也会相应变化,否则什么都没有采集
3.数据保存
从网页截取到自己需要的数据后,将数据保存在程序中,保存到本地文件中(或者插入到自己的本地数据库中)。这样,整个采集作品就会是一个段落。
// 输出数据到本地文件
File.AppendAllText(CreateFolderIfNot(Settings.Default.OutPath) + articleTitle + ".txt",
文章数据,
编码.UTF8);
复制代码
另外附上我自己写的采集博客园首页文章的小程序代码。本程序的作用是发布到所有博客园首页文章采集下。
下载链接:CnBlogCollector.rar
当然,如果博客园前端页面的格式调整了,程序的采集功能肯定会失效。只能自己重新调整程序才能继续采集,哈哈。. .
程序效果如下:
查看全部
c#抓取网页数据(网页分析采集程序的基本流程和流程图详解
)
首先大家要清楚:网站的任何页面,无论是php、jsp、aspx等动态页面,还是后台程序生成的静态页面,都可以在浏览器。
所以当你要开发数据采集程序时,首先要了解网站你试图采集的首页结构(HTML)。
当您熟悉网站中需要采集数据的HTML源文件的内容后,程序的其余部分就很容易处理了。因为C#在网站上执行数据采集,原理是“下载你要采集的页面的HTML源文件,分析HTML代码然后抓取你需要的数据,最后将数据保存到本地文件”。
基本流程如下图所示:
1.页面源文件下载
首先引用 System.Net 命名空间
使用 System.Net;
还需要引用
使用 System.Text;
使用 System.IO;
复制代码
引用后实例化一个 WebClient 对象
private WebClientwc = new WebClient();
调用 DownloadData 方法从指定网页的源文件中下载一组 BYTE 数据,然后将 BYTE 数组转换为字符串。
// 下载页面源文件并转换为UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData( string .Format( "你要的是采集的网页地址" )));
复制代码
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
// 下载网页源文件到本地
wc.DownloadFile( "你要采集的网页的URL", "保存源文件的本地文件路径");
// 读取下载的源文件HTML格式字符串
string mainData = File.ReadAllText( "保存源文件的本地文件路径" ,Encoding.UTF8);
复制代码
通过网页HTML格式字符串,您可以分析网页采集,抓取您需要的内容。
2.页面分析采集
页面分析就是以网页源文件中某个特定的或唯一的字符(字符串)为抓点,并以此抓点为起点,截取你想要的页面上的数据。
以博客园为专栏。比如我要在博客园首页列出文章的标题和链接,就必须用“
代码:
// 经过”
mainData = mainData.Substring(mainData.IndexOf("") + 26);
// 获取文章页面的链接地址
string articleAddr = mainData.Substring( 0 ,mainData.IndexOf( "\"" ));
// 获取文章的标题
string articleTitle = mainData.Substring(mainData.IndexOf("target=\"_blank\">") + 16,
mainData.IndexOf( "")-mainData.IndexOf( "target=\"_blank\">")-16 );
复制代码
注意:当你要采集的网页前台的HTML格式发生变化时,作为抓点的字符通道也会相应变化,否则什么都没有采集
3.数据保存
从网页截取到自己需要的数据后,将数据保存在程序中,保存到本地文件中(或者插入到自己的本地数据库中)。这样,整个采集作品就会是一个段落。
// 输出数据到本地文件
File.AppendAllText(CreateFolderIfNot(Settings.Default.OutPath) + articleTitle + ".txt",
文章数据,
编码.UTF8);
复制代码
另外附上我自己写的采集博客园首页文章的小程序代码。本程序的作用是发布到所有博客园首页文章采集下。
下载链接:CnBlogCollector.rar
当然,如果博客园前端页面的格式调整了,程序的采集功能肯定会失效。只能自己重新调整程序才能继续采集,哈哈。. .
程序效果如下:
c#抓取网页数据( 简单网络@2011-09-0710:26小虾Joe阅读(6))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-10-15 01:05
简单网络@2011-09-0710:26小虾Joe阅读(6))
C#抓取网页Html源码(网络爬虫)
简单的网络爬虫的实现方法
我刚刚完成了一个简单的网络爬虫,因为我在做的时候,像无头苍蝇一样在网上找资料。找了很多资料,但确实能满足我的需求,有用的资料——代码难找。所以想发这个文章,让一些想做这个功能的朋友少走一些弯路。
首先是抓取Html源码,选择节点的href:使用System.IO添加;使用 System.Net;
private void Search(string url)
{
string rl;
WebRequest Request = WebRequest.Create(url.Trim());
WebResponse Response = Request.GetResponse();
Stream resStream = Response.GetResponseStream();
StreamReader sr = new StreamReader(resStream, Encoding.Default);
StringBuilder sb = new StringBuilder();
while ((rl = sr.ReadLine()) != null)
{
sb.Append(rl);
}
string str = sb.ToString().ToLower();
string str_get = mid(str, "", "");
int start = 0;
while (true)
{
if (str_get == null)
break;
string strResult = mid(str_get, "href=\"", "\"", out start);
if (strResult == null)
break;
else
{
lab[url] += strResult;
str_get = str_get.Substring(start);
}
}
}
private string mid(string istr, string startString, string endString)
{
int iBodyStart = istr.IndexOf(startString, 0); //开始位置
if (iBodyStart == -1)
return null;
iBodyStart += startString.Length; //第一次字符位置起的长度
int iBodyEnd = istr.IndexOf(endString, iBodyStart); //第二次字符在第一次字符位置起的首次位置
if (iBodyEnd == -1)
return null;
iBodyEnd += endString.Length; //第二次字符位置起的长度
string strResult = istr.Substring(iBodyStart, iBodyEnd - iBodyStart - 1);
return strResult;
}
private string mid(string istr, string startString, string endString, out int iBodyEnd)
{
//初始化out参数,否则不能return
iBodyEnd = 0;
int iBodyStart = istr.IndexOf(startString, 0); //开始位置
if (iBodyStart == -1)
return null;
iBodyStart += startString.Length; //第一次字符位置起的长度
iBodyEnd = istr.IndexOf(endString, iBodyStart); //第二次字符在第一次字符位置起的首次位置
if (iBodyEnd == -1)
return null;
iBodyEnd += endString.Length; //第二次字符位置起的长度
string strResult = istr.Substring(iBodyStart, iBodyEnd - iBodyStart - 1);
return strResult;
}
好了,以上就是全部代码了,要运行的话,有些细节还得自己修改。
发布于@2011-09-07 10:26 小虾乔阅读(12265)评论(6)编辑 查看全部
c#抓取网页数据(
简单网络@2011-09-0710:26小虾Joe阅读(6))
C#抓取网页Html源码(网络爬虫)
简单的网络爬虫的实现方法
我刚刚完成了一个简单的网络爬虫,因为我在做的时候,像无头苍蝇一样在网上找资料。找了很多资料,但确实能满足我的需求,有用的资料——代码难找。所以想发这个文章,让一些想做这个功能的朋友少走一些弯路。
首先是抓取Html源码,选择节点的href:使用System.IO添加;使用 System.Net;
private void Search(string url)
{
string rl;
WebRequest Request = WebRequest.Create(url.Trim());
WebResponse Response = Request.GetResponse();
Stream resStream = Response.GetResponseStream();
StreamReader sr = new StreamReader(resStream, Encoding.Default);
StringBuilder sb = new StringBuilder();
while ((rl = sr.ReadLine()) != null)
{
sb.Append(rl);
}
string str = sb.ToString().ToLower();
string str_get = mid(str, "", "");
int start = 0;
while (true)
{
if (str_get == null)
break;
string strResult = mid(str_get, "href=\"", "\"", out start);
if (strResult == null)
break;
else
{
lab[url] += strResult;
str_get = str_get.Substring(start);
}
}
}
private string mid(string istr, string startString, string endString)
{
int iBodyStart = istr.IndexOf(startString, 0); //开始位置
if (iBodyStart == -1)
return null;
iBodyStart += startString.Length; //第一次字符位置起的长度
int iBodyEnd = istr.IndexOf(endString, iBodyStart); //第二次字符在第一次字符位置起的首次位置
if (iBodyEnd == -1)
return null;
iBodyEnd += endString.Length; //第二次字符位置起的长度
string strResult = istr.Substring(iBodyStart, iBodyEnd - iBodyStart - 1);
return strResult;
}
private string mid(string istr, string startString, string endString, out int iBodyEnd)
{
//初始化out参数,否则不能return
iBodyEnd = 0;
int iBodyStart = istr.IndexOf(startString, 0); //开始位置
if (iBodyStart == -1)
return null;
iBodyStart += startString.Length; //第一次字符位置起的长度
iBodyEnd = istr.IndexOf(endString, iBodyStart); //第二次字符在第一次字符位置起的首次位置
if (iBodyEnd == -1)
return null;
iBodyEnd += endString.Length; //第二次字符位置起的长度
string strResult = istr.Substring(iBodyStart, iBodyEnd - iBodyStart - 1);
return strResult;
}
好了,以上就是全部代码了,要运行的话,有些细节还得自己修改。
发布于@2011-09-07 10:26 小虾乔阅读(12265)评论(6)编辑
c#抓取网页数据(c#抓取网页数据--为什么ubuntu不安全?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-10-13 10:02
c#抓取网页数据--为什么ubuntu不安全?。windows里很多程序都用c#写的,比如eclipse。而c#在windows上就是不安全。
对于没有经验的人来说,平台影响是最大的,他们往往会问出很多问题。如果追根溯源就是程序员自己的态度问题。
win8formac和win8rt
win8又不是平台不安全,应该说rt内存使用量大,占用内存多,风险大。
问个问题还那么多人追着咬,可见这群人有多不成熟,显然低估了命令行可以做出多大的改变。
rt把.net整合到sp1了,
rt写个.netagent就可以在windows上直接使用iis
是害怕.net、netfilter还是别的?我只知道风险越大收益越大——就像某数据分析平台遭网友怒怼的那样,
就symbian的大量乱码ggdqq/imail客户端丢掉linuxapp数量ggdq/imail客户端被墙的风险vmware使用(至少我用了)azure/openstack平台apachesh脚本自身xamarin跟rt一样,要有很好的防御,而且由于本身已经接入rt,在rt上运行xamarin要比跨平台运行azure/openstack系统复杂很多很多很多——因为第三方server要搭自身的跨平台的xamarin很多——因此要尽可能地提高内核资源占用速度——结果由于资源占用很大一些客户端不得不受限于windows的freebsd、debiansystemapi接口性能xamarin+windowsfreebsd接口patchxamarin+nginx/postgresql接口性能exhaustive!。 查看全部
c#抓取网页数据(c#抓取网页数据--为什么ubuntu不安全?(图))
c#抓取网页数据--为什么ubuntu不安全?。windows里很多程序都用c#写的,比如eclipse。而c#在windows上就是不安全。
对于没有经验的人来说,平台影响是最大的,他们往往会问出很多问题。如果追根溯源就是程序员自己的态度问题。
win8formac和win8rt
win8又不是平台不安全,应该说rt内存使用量大,占用内存多,风险大。
问个问题还那么多人追着咬,可见这群人有多不成熟,显然低估了命令行可以做出多大的改变。
rt把.net整合到sp1了,
rt写个.netagent就可以在windows上直接使用iis
是害怕.net、netfilter还是别的?我只知道风险越大收益越大——就像某数据分析平台遭网友怒怼的那样,
就symbian的大量乱码ggdqq/imail客户端丢掉linuxapp数量ggdq/imail客户端被墙的风险vmware使用(至少我用了)azure/openstack平台apachesh脚本自身xamarin跟rt一样,要有很好的防御,而且由于本身已经接入rt,在rt上运行xamarin要比跨平台运行azure/openstack系统复杂很多很多很多——因为第三方server要搭自身的跨平台的xamarin很多——因此要尽可能地提高内核资源占用速度——结果由于资源占用很大一些客户端不得不受限于windows的freebsd、debiansystemapi接口性能xamarin+windowsfreebsd接口patchxamarin+nginx/postgresql接口性能exhaustive!。
c#抓取网页数据(计算机语言获取交互信息的爬虫经历-删除线格式#)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-12 15:14
删除线格式#C#获取动态网页中的数据
在实际工作需求中,编辑的文档需要获取历史地震信息,因此使用计算机语言获取是简化人工操作的必要过程。本文分享我第一次爬虫获取交互信息的经验!
操作流程 我要获取的信息如下图所示。通过填写不同的日期、经纬度、震级等,我可以搜索到想要的结果。
一开始,没有任何线索。查看网页的源代码无法找到搜索结果,所以我们首先要做的就是找到数据的位置。第一步:右键查看元素,点击网络,会出现下图所示的两个文件:
点击第一个文件,看到它的预览有我们想要的信息。Response 收录这部分代码,也就是我们想要的数据:
第二部分:查找URL、请求方法和参数。这部分信息收录在标题中:
第三步:C#编程获取网页,这里直接上代码
// An highlighted block
//url目标地址
string url = "网址";
//要提交的数据
string postString = "DISPLAY_TYPE=1&PAGEID=earthquake_subao&catalog_ALLDATASETS_RECORDCOUNT=catalog__default_default_default_key__default_default_default_key%3D65%3B"
+"&refreshComponentGuid=earthquake_subao_guid_catalog&begtime=2019-09-10&endtime=2019-10-10"
+"&minM=3&maxM=10&minLon=-180.0&maxLon=180.0&minLat=-90.0&maxLat=90.0"
+"&minDepths=0&maxDepths=1000&SEARCHREPORT_ID=catalog&WX_ISAJAXLOAD=true";
//这里即为传递的参数,可以用工具抓包分析,也可以自己分析,主要是form里面每一个name都要加进来
byte[] postData = Encoding.UTF8.GetBytes(postString);//编码,尤其是汉字,事先要看下抓取网页的编码方式
WebClient webClient = new WebClient();
webClient.Headers.Add("Content-Type", "application/x-www-form-urlencoded");//采取POST方式必须加的header,如果改为GET方式的话就去掉这句话即可
byte[] responseData = webClient.UploadData(url, "POST", postData);//得到返回字符流
string srcString = Encoding.UTF8.GetString(responseData);//解码
//解析获取到的网页
HtmlAgilityPack.HtmlDocument History_doc = new HtmlAgilityPack.HtmlDocument();
History_doc.LoadHtml(srcString);
下一步是阅读网页的内容。这是第一次写。感谢您的批评和指正!!! 查看全部
c#抓取网页数据(计算机语言获取交互信息的爬虫经历-删除线格式#)
删除线格式#C#获取动态网页中的数据
在实际工作需求中,编辑的文档需要获取历史地震信息,因此使用计算机语言获取是简化人工操作的必要过程。本文分享我第一次爬虫获取交互信息的经验!
操作流程 我要获取的信息如下图所示。通过填写不同的日期、经纬度、震级等,我可以搜索到想要的结果。
一开始,没有任何线索。查看网页的源代码无法找到搜索结果,所以我们首先要做的就是找到数据的位置。第一步:右键查看元素,点击网络,会出现下图所示的两个文件:
点击第一个文件,看到它的预览有我们想要的信息。Response 收录这部分代码,也就是我们想要的数据:
第二部分:查找URL、请求方法和参数。这部分信息收录在标题中:
第三步:C#编程获取网页,这里直接上代码
// An highlighted block
//url目标地址
string url = "网址";
//要提交的数据
string postString = "DISPLAY_TYPE=1&PAGEID=earthquake_subao&catalog_ALLDATASETS_RECORDCOUNT=catalog__default_default_default_key__default_default_default_key%3D65%3B"
+"&refreshComponentGuid=earthquake_subao_guid_catalog&begtime=2019-09-10&endtime=2019-10-10"
+"&minM=3&maxM=10&minLon=-180.0&maxLon=180.0&minLat=-90.0&maxLat=90.0"
+"&minDepths=0&maxDepths=1000&SEARCHREPORT_ID=catalog&WX_ISAJAXLOAD=true";
//这里即为传递的参数,可以用工具抓包分析,也可以自己分析,主要是form里面每一个name都要加进来
byte[] postData = Encoding.UTF8.GetBytes(postString);//编码,尤其是汉字,事先要看下抓取网页的编码方式
WebClient webClient = new WebClient();
webClient.Headers.Add("Content-Type", "application/x-www-form-urlencoded");//采取POST方式必须加的header,如果改为GET方式的话就去掉这句话即可
byte[] responseData = webClient.UploadData(url, "POST", postData);//得到返回字符流
string srcString = Encoding.UTF8.GetString(responseData);//解码
//解析获取到的网页
HtmlAgilityPack.HtmlDocument History_doc = new HtmlAgilityPack.HtmlDocument();
History_doc.LoadHtml(srcString);
下一步是阅读网页的内容。这是第一次写。感谢您的批评和指正!!!
c#抓取网页数据(代码如下:5抓取网页内容-把当前会话(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-12 00:22
)
其次,使用 CookieContainer。
查看普通副本到剪贴板打印?
代码如下:
System.Net.CookieContainer cc = new System.Net.CookieContainer();
request.CookieContainer = cc;
request2.CookieContainer = cc;
这样,request和request2之间使用了同一个Session。如果 request 已登录,则 request2 也已登录。
最后,如何在不同页面之间使用相同的CookieContainer。
不同页面之间要使用同一个CookieContainer,只需要在Session中添加CookieContainer即可。
代码如下:
view plaincopy to clipboardprint?
Session.Add("ccc", cc); //存
CookieContainer cc = (CookieContainer)Session["ccc"]; //取
5 抓取网页内容——将当前会话带到 WebRequest
比如浏览器B1访问服务器端S1,这会产生一个会话,服务器端S2使用WebRequest访问服务器端S1,就会产生一个会话。当前要求WebRequest使用浏览器B1和S1之间的会话,这意味着S1应该认为B1正在访问S1,而不是S2正在访问S1。
这是为了使用cookies。先在S1中获取SessionID为B1的Cookie,然后将这个Cookie告诉S2,S2将Cookie写入WebRequest中。
查看普通副本到剪贴板打印?
代码如下:
WebRequest request = WebRequest.Create("url");
request.Headers.Add(HttpRequestHeader.Cookie, "ASPSESSIONIDSCATBTAD=KNNDKCNBONBOOBIHHHHAOKDM;");
WebResponse response = request.GetResponse();
StreamReader reader = new StreamReader(response.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
Response.Write(reader.ReadToEnd());
reader.Close();
reader.Dispose();
response.Close();
我想解释一下:
本文不是 Cookie 欺骗,因为 SessionID 是 S1 告诉 S2 的,并没有被 S2 窃取。虽然有点奇怪,但在某些特定的应用系统中可能会有用。
S1 必须将 Session 写入 B1,这样 SessionID 将保存在 Cookie 中,SessionID 将保持不变。
Request.Cookies 用于在 ASP.NET 中获取 cookie。本文假设已获取 cookie。
不同的服务器端语言对Cookie中的SessionID有不同的名称。本文为ASP SessionID。
S1 可能不仅依赖 SessionID 来确定当前登录,还可能辅助 Referer、User-Agent 等,具体取决于 S1 终端程序的设计。
这篇文章其实是本系列中另一种“保持登录”的方式。
6 抓取网页内容-如何更改源Referer和UserAgent
查看普通副本到剪贴板打印?
代码如下:
SPAN class="caution">HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create("http://127.0.0.1/index.htm");
//request.Headers.Add(HttpRequestHeader.Referer, "http://www.jb51.net/"); // 错误
//request.Headers[HttpRequestHeader.Referer] = "http://www.jb51.net/"; // 错误
request.Referer = "http://www.jb51.net/"; // 正确
注释掉的两句错了,会报错:
查看普通副本到剪贴板打印?
必须使用适当的属性修改此标头。
参数名称:名称
必须使用适当的属性修改此标头。参数名称:名称
UserAgent 类似。
查看全部
c#抓取网页数据(代码如下:5抓取网页内容-把当前会话(组图)
)
其次,使用 CookieContainer。
查看普通副本到剪贴板打印?
代码如下:
System.Net.CookieContainer cc = new System.Net.CookieContainer();
request.CookieContainer = cc;
request2.CookieContainer = cc;
这样,request和request2之间使用了同一个Session。如果 request 已登录,则 request2 也已登录。
最后,如何在不同页面之间使用相同的CookieContainer。
不同页面之间要使用同一个CookieContainer,只需要在Session中添加CookieContainer即可。
代码如下:
view plaincopy to clipboardprint?
Session.Add("ccc", cc); //存
CookieContainer cc = (CookieContainer)Session["ccc"]; //取
5 抓取网页内容——将当前会话带到 WebRequest
比如浏览器B1访问服务器端S1,这会产生一个会话,服务器端S2使用WebRequest访问服务器端S1,就会产生一个会话。当前要求WebRequest使用浏览器B1和S1之间的会话,这意味着S1应该认为B1正在访问S1,而不是S2正在访问S1。
这是为了使用cookies。先在S1中获取SessionID为B1的Cookie,然后将这个Cookie告诉S2,S2将Cookie写入WebRequest中。
查看普通副本到剪贴板打印?
代码如下:
WebRequest request = WebRequest.Create("url");
request.Headers.Add(HttpRequestHeader.Cookie, "ASPSESSIONIDSCATBTAD=KNNDKCNBONBOOBIHHHHAOKDM;");
WebResponse response = request.GetResponse();
StreamReader reader = new StreamReader(response.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
Response.Write(reader.ReadToEnd());
reader.Close();
reader.Dispose();
response.Close();
我想解释一下:
本文不是 Cookie 欺骗,因为 SessionID 是 S1 告诉 S2 的,并没有被 S2 窃取。虽然有点奇怪,但在某些特定的应用系统中可能会有用。
S1 必须将 Session 写入 B1,这样 SessionID 将保存在 Cookie 中,SessionID 将保持不变。
Request.Cookies 用于在 ASP.NET 中获取 cookie。本文假设已获取 cookie。
不同的服务器端语言对Cookie中的SessionID有不同的名称。本文为ASP SessionID。
S1 可能不仅依赖 SessionID 来确定当前登录,还可能辅助 Referer、User-Agent 等,具体取决于 S1 终端程序的设计。
这篇文章其实是本系列中另一种“保持登录”的方式。
6 抓取网页内容-如何更改源Referer和UserAgent
查看普通副本到剪贴板打印?
代码如下:
SPAN class="caution">HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create("http://127.0.0.1/index.htm";);
//request.Headers.Add(HttpRequestHeader.Referer, "http://www.jb51.net/";); // 错误
//request.Headers[HttpRequestHeader.Referer] = "http://www.jb51.net/"; // 错误
request.Referer = "http://www.jb51.net/"; // 正确
注释掉的两句错了,会报错:
查看普通副本到剪贴板打印?
必须使用适当的属性修改此标头。
参数名称:名称
必须使用适当的属性修改此标头。参数名称:名称
UserAgent 类似。
c#抓取网页数据(封装一个简单总结(一):抓取网页文档分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-10 18:27
)
这两天学习了爬虫的基础知识,这里简单总结一下。
获取的网页商品数据保存在Excel表格中,效果如下:
使用Jumony Core引擎,是一个非常强大且近乎完美的HTML解析引擎,支持css3选择器,直接抓取网页文档进行分析,并根据HTTP头自动识别。
一个抓取博客园站点导航顶部信息的例子:
var documents = new JumonyParser().LoadDocument("http://www.cnblogs.com/").Find("#site_nav_top").FirstOrDefault();
太强大了。如果您熟悉 CSS,则无需手动编写大量可读性差的正则表达式来匹配和获取数据。
封装一个简单的操作库:
public class BaseAnalyzer
{
///
/// 根据Url加载html文档对象
///
///
///
protected virtual IHtmlDocument LoadDocument(string url)
{
return new JumonyParser().LoadDocument(url);
}
///
/// 查询指定url中指定选择器的元素集
///
///
///
///
protected virtual List QueryHtmlElements(string url, string selector, Func predicate = null)
{
var elementsCollection = new List();
IEnumerable elements = LoadDocument(url).Find(selector);
if (predicate != null)
{
elements = elements.Where(predicate);
}
if (elements != null)
elementsCollection.AddRange(elements);
return elementsCollection;
}
///
/// 分析Html文档,获取指定元素集第一个元素的文本内容
///
/// html文档对象
/// 选择器
/// 文本内容
protected virtual string GetFirstElementText(IHtmlContainer html, string selector)
{
var findList = html.Find(selector);
var result = findList.FirstOrDefault();
return result == null ? string.Empty : result.InnerText();
}
///
/// 分析Html文档,获取指定元素集的文本内容
///
/// html文档对象
/// 选择器
/// 自定义处理获取到的元素集,若没有,就返回第一个元素的文本内容
///
protected virtual string GetElementsText(IHtmlContainer html, string selector, Func func)
{
var findList = html.Find(selector);
if (func != null)
return func(findList);
return GetFirstElementText(html, selector);
}
}
获取产品名称的示例:
private ProductInfo AnalyzeProductInfo(string detailUrl)
{
var product = new ProductInfo();
//详情页html文档对象
var html = LoadDocument(detailUrl);
product.ProductName = GetFirstElementText(html, ".goods_particulars h1");
} 查看全部
c#抓取网页数据(封装一个简单总结(一):抓取网页文档分析
)
这两天学习了爬虫的基础知识,这里简单总结一下。
获取的网页商品数据保存在Excel表格中,效果如下:
使用Jumony Core引擎,是一个非常强大且近乎完美的HTML解析引擎,支持css3选择器,直接抓取网页文档进行分析,并根据HTTP头自动识别。
一个抓取博客园站点导航顶部信息的例子:
var documents = new JumonyParser().LoadDocument("http://www.cnblogs.com/";).Find("#site_nav_top").FirstOrDefault();
太强大了。如果您熟悉 CSS,则无需手动编写大量可读性差的正则表达式来匹配和获取数据。
封装一个简单的操作库:
public class BaseAnalyzer
{
///
/// 根据Url加载html文档对象
///
///
///
protected virtual IHtmlDocument LoadDocument(string url)
{
return new JumonyParser().LoadDocument(url);
}
///
/// 查询指定url中指定选择器的元素集
///
///
///
///
protected virtual List QueryHtmlElements(string url, string selector, Func predicate = null)
{
var elementsCollection = new List();
IEnumerable elements = LoadDocument(url).Find(selector);
if (predicate != null)
{
elements = elements.Where(predicate);
}
if (elements != null)
elementsCollection.AddRange(elements);
return elementsCollection;
}
///
/// 分析Html文档,获取指定元素集第一个元素的文本内容
///
/// html文档对象
/// 选择器
/// 文本内容
protected virtual string GetFirstElementText(IHtmlContainer html, string selector)
{
var findList = html.Find(selector);
var result = findList.FirstOrDefault();
return result == null ? string.Empty : result.InnerText();
}
///
/// 分析Html文档,获取指定元素集的文本内容
///
/// html文档对象
/// 选择器
/// 自定义处理获取到的元素集,若没有,就返回第一个元素的文本内容
///
protected virtual string GetElementsText(IHtmlContainer html, string selector, Func func)
{
var findList = html.Find(selector);
if (func != null)
return func(findList);
return GetFirstElementText(html, selector);
}
}
获取产品名称的示例:
private ProductInfo AnalyzeProductInfo(string detailUrl)
{
var product = new ProductInfo();
//详情页html文档对象
var html = LoadDocument(detailUrl);
product.ProductName = GetFirstElementText(html, ".goods_particulars h1");
}
c#抓取网页数据(网络蜘蛛站点下的红色截图部分信息行业新闻信息解析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-09 01:07
)
对于搜索引擎来说,爬取互联网上的所有网页几乎是不可能的。根据目前公布的数据,容量最大的搜索引擎只能抓取整个网页的40%左右。一方面是因为爬虫技术的瓶颈,无法遍历所有网页,还有很多网页无法从其他网页的链接中找到;
另一个原因是存储技术和处理技术的问题。如果每个页面的平均大小为 20K(包括图片),则 100 亿个网页的容量为 100×2000G 字节。就算能存储,下载还是有问题(按照A机每秒下载20K计算,340台机器连续下载一年才能下载所有网页)。同时,由于数据量大,在提供搜索时也会影响效率。因此,很多搜索引擎的网络蜘蛛只爬取那些重要的网页,爬取时评价重要性的主要依据是某个网页的链接深度。
【以下示例使用:以站点为例,抓取站点下信息行业新闻信息红色截图部分】
一、模拟请求,获取网页Html并下载html
1.1 首先通过浏览器查看所有访问网站的参数信息。
代码模拟请求时需要传递的所有参数信息都可以收录在下图红圈部分,但不一定需要和浏览器保持相同的参数。
1.2 代码实现,模拟请求
1 private string GetHtml(string Url) //:Url="http://www.cppi.cn";
2 {
3 string Html = string.Empty;
4 HttpWebRequest Request = HttpWebRequest.Create(Url) as HttpWebRequest;
5 Request.Timeout = 3000;
6 Request.ContentType = "text/html;charset=utf-8";
7 Encoding encode = Encoding.GetEncoding("GB2312");
8 using (HttpWebResponse response = Request.GetResponse() as HttpWebResponse)
9 {
10 if (response.StatusCode == HttpStatusCode.OK)
11 {
12 try
13 {
14 StreamReader stream = new StreamReader(response.GetResponseStream(), encode);
15 Html = stream.ReadToEnd();
16 }
17 catch (System.Exception ex)
18 {
19 throw ex;
20 }
21 }
22 }
23 return Html;
24 }
二、过滤数据
获取到Html内容后,我们需要对整个Html内容进行过滤,得到我们业务需要的数据。以下基于HtmlAgilityPack第三方组件,使用Path解析HTML。
HtmlAgilityPack是.net下的HTML解析库,见【】
2.1 通过浏览器,锁定要显示的信息对应的Xpath路径
通过浏览器[]访问站点,鼠标右键---勾选,定位到需要显示的节点,右键---复制-----复制Xpath
可以得到对应的Xpath路径:/html/body/div[8]/div[2]/ul/li
2.2 通过Xpath解析Html,使用HtmlAgilityPack获取信息;
1 public ApiResponseModel CrawlerIndustrynews()
2 {
3 string Url = ConfigurationManager.AppSettings.Get("NewsUrl");
4 List Industrynewslst = new List();
5 var Industrynews = new IndustrynewsResponse();
6 string html = GetHtml(Url); //:模拟请求获取到整个Html内容
7 if (!string.IsNullOrWhiteSpace(html))
8 {
9 HtmlDocument htmlDoc = new HtmlDocument();
10 htmlDoc.LoadHtml(html);
11 if (htmlDoc != null)
12 {
13 string maintitleXpath = "/html/body/div[8]/div[2]/h1[2]/a";
14 HtmlNode maintitleNode = htmlDoc.DocumentNode.SelectSingleNode(maintitleXpath);
15 if (maintitleNode != null)
16 {
17 Industrynews.NewsMainhref = Url + maintitleNode.Attributes["href"].Value;
18 Industrynews.NewsMainTitle = maintitleNode.InnerText;
19 }
20 string secondtitleXpath = "/html/body/div[8]/div[2]/p[2]";
21 HtmlNode SecondTitleNode = htmlDoc.DocumentNode.SelectSingleNode(secondtitleXpath);
22 if (SecondTitleNode != null)
23 {
24 Industrynews.SecondTitle = SecondTitleNode.InnerText;
25 }
26 string FocusXpath = "/html/body/div[8]/div[2]/ul/li";
27 HtmlNodeCollection htmlNode = htmlDoc.DocumentNode.SelectNodes(FocusXpath); //:该Xpath下有多个子节点,所以此处获取到所有的节点信息
28 if (htmlNode != null)
29 {
30 foreach (var node in htmlNode)//:循环子节点获取每个子节点对应信息
31 {
32 HtmlDocument docChild = new HtmlDocument();
33 docChild.LoadHtml(node.OuterHtml);
34 HtmlNode urlNode = docChild.DocumentNode.SelectSingleNode("li/a"); //获取a标签
35 if (docChild != null)
36 {
37 Industrynews industrynews = new Industrynews()
38 {
39 href = Url + urlNode.Attributes["href"].Value, //获取a标签对应的href属性
40 Text = urlNode.InnerText //:获取标签text显示文本
41 };
42 Industrynewslst.Add(industrynews);
43 }
44 }
45 Industrynews.IndustrynewsList = Industrynewslst;
46 }
47 return new ApiResponseModel { Code = (int)HttpStatusCode.OK, Message = "", Data = Industrynews };
48 }
49 else
50 {
51 return new ApiResponseModel { Code = (int)HttpStatusCode.BadRequest, Message = "ErrorLoadHtml", Data = null };
52 }
53 }
54 else
55 {
56 return new ApiResponseModel { Code = (int)HttpStatusCode.BadRequest, Message = "ErrorLoadHtml", Data = null };
57 }
58 }
三、以下截图可以截取需要的信息
查看全部
c#抓取网页数据(网络蜘蛛站点下的红色截图部分信息行业新闻信息解析
)
对于搜索引擎来说,爬取互联网上的所有网页几乎是不可能的。根据目前公布的数据,容量最大的搜索引擎只能抓取整个网页的40%左右。一方面是因为爬虫技术的瓶颈,无法遍历所有网页,还有很多网页无法从其他网页的链接中找到;
另一个原因是存储技术和处理技术的问题。如果每个页面的平均大小为 20K(包括图片),则 100 亿个网页的容量为 100×2000G 字节。就算能存储,下载还是有问题(按照A机每秒下载20K计算,340台机器连续下载一年才能下载所有网页)。同时,由于数据量大,在提供搜索时也会影响效率。因此,很多搜索引擎的网络蜘蛛只爬取那些重要的网页,爬取时评价重要性的主要依据是某个网页的链接深度。
【以下示例使用:以站点为例,抓取站点下信息行业新闻信息红色截图部分】
一、模拟请求,获取网页Html并下载html
1.1 首先通过浏览器查看所有访问网站的参数信息。
代码模拟请求时需要传递的所有参数信息都可以收录在下图红圈部分,但不一定需要和浏览器保持相同的参数。
1.2 代码实现,模拟请求
1 private string GetHtml(string Url) //:Url="http://www.cppi.cn";
2 {
3 string Html = string.Empty;
4 HttpWebRequest Request = HttpWebRequest.Create(Url) as HttpWebRequest;
5 Request.Timeout = 3000;
6 Request.ContentType = "text/html;charset=utf-8";
7 Encoding encode = Encoding.GetEncoding("GB2312");
8 using (HttpWebResponse response = Request.GetResponse() as HttpWebResponse)
9 {
10 if (response.StatusCode == HttpStatusCode.OK)
11 {
12 try
13 {
14 StreamReader stream = new StreamReader(response.GetResponseStream(), encode);
15 Html = stream.ReadToEnd();
16 }
17 catch (System.Exception ex)
18 {
19 throw ex;
20 }
21 }
22 }
23 return Html;
24 }
二、过滤数据
获取到Html内容后,我们需要对整个Html内容进行过滤,得到我们业务需要的数据。以下基于HtmlAgilityPack第三方组件,使用Path解析HTML。
HtmlAgilityPack是.net下的HTML解析库,见【】
2.1 通过浏览器,锁定要显示的信息对应的Xpath路径
通过浏览器[]访问站点,鼠标右键---勾选,定位到需要显示的节点,右键---复制-----复制Xpath
可以得到对应的Xpath路径:/html/body/div[8]/div[2]/ul/li
2.2 通过Xpath解析Html,使用HtmlAgilityPack获取信息;
1 public ApiResponseModel CrawlerIndustrynews()
2 {
3 string Url = ConfigurationManager.AppSettings.Get("NewsUrl");
4 List Industrynewslst = new List();
5 var Industrynews = new IndustrynewsResponse();
6 string html = GetHtml(Url); //:模拟请求获取到整个Html内容
7 if (!string.IsNullOrWhiteSpace(html))
8 {
9 HtmlDocument htmlDoc = new HtmlDocument();
10 htmlDoc.LoadHtml(html);
11 if (htmlDoc != null)
12 {
13 string maintitleXpath = "/html/body/div[8]/div[2]/h1[2]/a";
14 HtmlNode maintitleNode = htmlDoc.DocumentNode.SelectSingleNode(maintitleXpath);
15 if (maintitleNode != null)
16 {
17 Industrynews.NewsMainhref = Url + maintitleNode.Attributes["href"].Value;
18 Industrynews.NewsMainTitle = maintitleNode.InnerText;
19 }
20 string secondtitleXpath = "/html/body/div[8]/div[2]/p[2]";
21 HtmlNode SecondTitleNode = htmlDoc.DocumentNode.SelectSingleNode(secondtitleXpath);
22 if (SecondTitleNode != null)
23 {
24 Industrynews.SecondTitle = SecondTitleNode.InnerText;
25 }
26 string FocusXpath = "/html/body/div[8]/div[2]/ul/li";
27 HtmlNodeCollection htmlNode = htmlDoc.DocumentNode.SelectNodes(FocusXpath); //:该Xpath下有多个子节点,所以此处获取到所有的节点信息
28 if (htmlNode != null)
29 {
30 foreach (var node in htmlNode)//:循环子节点获取每个子节点对应信息
31 {
32 HtmlDocument docChild = new HtmlDocument();
33 docChild.LoadHtml(node.OuterHtml);
34 HtmlNode urlNode = docChild.DocumentNode.SelectSingleNode("li/a"); //获取a标签
35 if (docChild != null)
36 {
37 Industrynews industrynews = new Industrynews()
38 {
39 href = Url + urlNode.Attributes["href"].Value, //获取a标签对应的href属性
40 Text = urlNode.InnerText //:获取标签text显示文本
41 };
42 Industrynewslst.Add(industrynews);
43 }
44 }
45 Industrynews.IndustrynewsList = Industrynewslst;
46 }
47 return new ApiResponseModel { Code = (int)HttpStatusCode.OK, Message = "", Data = Industrynews };
48 }
49 else
50 {
51 return new ApiResponseModel { Code = (int)HttpStatusCode.BadRequest, Message = "ErrorLoadHtml", Data = null };
52 }
53 }
54 else
55 {
56 return new ApiResponseModel { Code = (int)HttpStatusCode.BadRequest, Message = "ErrorLoadHtml", Data = null };
57 }
58 }
三、以下截图可以截取需要的信息

