c#抓取网页数据( 程序开发文章正文测试内容的一些其它思路及问题写在最后)
优采云 发布时间: 2021-10-31 14:15c#抓取网页数据(
程序开发文章正文测试内容的一些其它思路及问题写在最后)
C#制作网站钩子程序实现示例
内容三、程序开发过程四、关于程序开发的一些其他想法和问题写在最后的序言中
真正的想法是用C#GUI开发一个自动化测试软件,可以帮我完成500台电脑在线网络答题的压力测试。既要能自动定位并点击鼠标,还要能模拟用键盘输入字符信息。但实际上,想法很饱满,现实很骨感。还有一些问题需要解决。但是在完成这个项目的过程中,也产生了一些副产品,这也是相当有成就感的。现针对开发过程中出现的问题,查找并筛选一些经过测试的参考资料,将我们的理解和研究经验奉献给大家。特提供一个完整的例子:出现在线挂机对话框,按回车继续。创建了一个简单的“连接程序”来开始对话。希望大家一起开放思路,一起研究。
温馨提示:以下为本文文章内容,以下案例可供参考
一、程序界面(如下图)
名称:模拟键盘程序,为什么不用挂机程序,因为它的功能弱,范围窄,而且作为副产品,真的不是挂机用的。请注意,我们的目标是自动化网络测试。
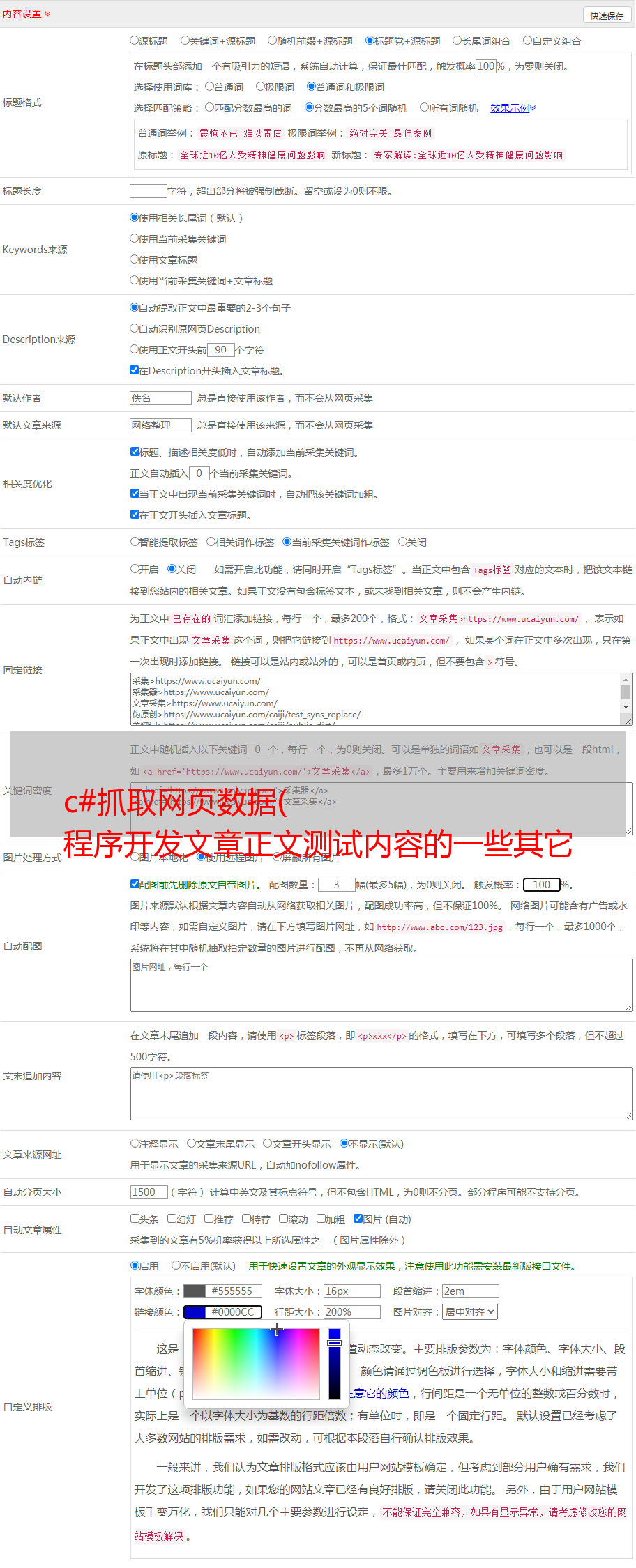
二、 使用说明
1.接口说明
1. 应用程序路径,这里是FireFox浏览器,所以需要放程序的地址。
2.网站地址:符合URL格式的可直接访问的本地文件或网址
3.浏览器标题:FireFox程序隐藏了应用标题,如果看到标题栏显示:test
其实应用的标题应该是:Test——Mozilla Firefox
4.【启动浏览器】其实这个功能目前可以完全忽略,直接手动启动FireFox即可。
5. 【开始】按钮是精华,这里会根据【浏览器标题】的内容进行搜索
到真正的【句柄】在FireFox上浏览网页,如果找到,会显示【句柄】的十进制整数值。如果显示为 0,则表示未找到。
6.【停止】关闭定时器操作。
2.使用笔记
1. 显示[Handle]位置后,必须为非零值。如果为0,修改【浏览器标题】的内容,再次点击【开始】
2.FireFox 浏览器必须保持在所有表单的前面
3.保证【电脑】不会进入【睡眠】或进入【屏幕保护】状态
三、程序开发流程
1.测试页面
1.文件名:test.html
2.网页代码(如下):
测试
alert("ok");
2.程序完整代码
using System;
using System.Diagnostics;
using System.Runtime.InteropServices;
using System.Threading;
using System.Windows.Forms;
namespace 模拟键盘
{
public partial class Form1 : Form
{
[DllImport("user32.dll", EntryPoint = "keybd_event", SetLastError = true)]
public static extern void keybd_event(Keys bVk, byte bScan, uint dwFlags, uint dwExtraInfo);
[DllImport("user32.dll", EntryPoint = "FindWindow")]
private static extern IntPtr FindWindow(string IpClassName, string IpWindowName);
//查找窗体控件
public int iSeconds=30;
public delegate bool CallBack(int hwnd, int lParam);
public Process Proc = new Process();
public System.Windows.Forms.Timer myTimer;
public Form1()
{
InitializeComponent();
}
private void btnBrowser_Click(object sender, EventArgs e)
{
openFileDialog1.Filter = "*.exe|*.exe|所有文件|*.*";
openFileDialog1.FileName = "";
DialogResult dr = openFileDialog1.ShowDialog();
if(DialogResult.OK==dr)
{
txtFile.Text = openFileDialog1.FileName;
}
}
string str = "Message";
int iP = 0;
private void btnStart_Click(object sender, EventArgs e)
{
IntPtr hnd = FindWindow(null, txtTitle.Text);//获取句柄
lblMessage.Text = hnd.ToString();
iSeconds = int.Parse(txtSeconds.Text.Trim());
myTimer.Interval = 1000 * iSeconds; //1秒=1000毫秒
myTimer.Enabled = true;
}
private void Form1_Load(object sender, EventArgs e)
{
myTimer = new System.Windows.Forms.Timer();//实例化Timer定时器
myTimer.Tick += new EventHandler(CallBack2);//定时器关联事件函数
}
private void CallBack2(object sender,EventArgs e)//定时器事件
{
keybd_event(Keys.Return, 0, 0, 0);//模拟键盘输入:回车
}
private void btnStop_Click(object sender, EventArgs e)
{
myTimer.Enabled = false;//禁止定时器
}
private void btnStartBrowser_Click(object sender, EventArgs e)
{
if (string.IsNullOrEmpty(txtFile.Text)) return;
try
{
// 浏览器程序启动线程
Proc = new System.Diagnostics.Process();
Proc.StartInfo.FileName = txtFile.Text;
Proc.StartInfo.Arguments = txtNetAddr.Text; //浏览器打开URL参数
Proc.StartInfo.UseShellExecute = false;
Proc.StartInfo.RedirectStandardInput = true;
Proc.StartInfo.RedirectStandardOutput = true;
Proc.Start();
}
catch
{
Proc = null;
}
}
}
}
四、程序开发中的一些其他想法和问题
1.使用已知进程获取主窗口句柄,然后遍历子窗口句柄
以下代码与本程序无关,为片段,请勿直接复制使用,主要提供给有兴趣改进的人参考。
if (string.IsNullOrEmpty(txtFile.Text)) return;
try
{
Proc = new System.Diagnostics.Process();
Proc.StartInfo.FileName =txtFile.Text;
Proc.StartInfo.Arguments = txtNetAddr.Text;
Proc.StartInfo.UseShellExecute = false;
Proc.StartInfo.RedirectStandardInput = true;
Proc.StartInfo.RedirectStandardOutput = true;
Proc.Start();
Thread.Sleep(2000);
}
catch
{
Proc = null;
}
if (Proc.MainWindowHandle != null)
{
//调用 API, 传递数据
while (Proc.MainWindowHandle == IntPtr.Zero)
{
Proc.Refresh();
}
while (Proc.MainWindowHandle == IntPtr.Zero)
{
Proc.Refresh();
}
//执行代码略
}
【问题描述】:这里的线程是Proc,但是这个线程不是主窗口。该线程的主窗口句柄需要通过 Proc.MainWindowHandle 获取。在使用过程中,很容易获取到自己开发的C#GUI程序,对【记事本】程序来说是正常的,但是在【Chrome】浏览器上使用时,结果不是0就是异常. 【FireFox】有时能正常获取,有时异常。
2.网上搜索C#操作API函数少且不全
这里有一个API函数查询网站,基本上一口气把API函数用完了。#
3.如果想查看Windows下的API函数,也可以使用工具:
1.DLL 函数查看器
2.DLL 导出查看器
4.获取应用程序窗口句柄、标题、类型的工具软件
这里可以使用VS环境下的Spy++(C++)。
写在最后
关于C#中API函数的使用,由于个人喜好不同,参数类型也有很大差异。真正体验的文章相对较少。谬误更难解决。后期准备深入体验,同时准备写文章系列。虽然作者的能力有限,到时候肯定会有很多谬论,但作者坚持所有的内容都是以实践为导向的。程序必须经过调试和通过,才能放到网上。志同道合的读者不妨关注作者的博客,敬请期待,我们下期再见!
关于C#制作网站挂钩程序文章的实现本文到此结束。更多C#相关网站勾搭程序内容,请搜索我们之前的文章或者继续浏览以下相关文章希望大家以后多多支持!
时间:2021-10-30
c#Realize 网站 监控看是否正常
代码如下: 复制代码如下: public void MonitorWeb(Model.ServiceInfo mServerInfo) {var sUrl = mServerInfo.ServiceConfig; var mLogInfo = new Model.LogInfo {ServiceId = mServerInfo.ServiceId }; 试试 {var mWebRequest = (HttpWebRequest)WebRequest. 创建(网址);VA
C#实现抓取网站页面内容的示例方法
抓取新浪网的新闻版块,如图: 使用谷歌浏览器查看源代码: 通过分析,我们知道我们要查找的内容在以下两个标签之间: 复制代码,代码为如下: Content... 如图: Content.... 使用VS创建一个网站 如图:我们下载
C# Fiddler 插件实现网站离线浏览功能
有这样一个应用场景:你在做前端或者APP开发,需要调用服务端提供的接口。接口只能在公司内网访问:不能在公司外调试代码。如果您想在公司外部访问它怎么办?? 如果你在公司的时候保存了所有接口的响应内容,就可以在没有服务器的情况下在本地模拟一个服务器环境,这样就可以不受网络环境的限制,愉快的调试代码了。实现原理如下:首先使用Fiddler抓取包,抓取所有需要保存的接口(不仅仅是interfaces,html,css,js,image)。在 Fiddler 中,点击以下菜单 File -> Save -> All Se
C#如何控制IIS动态增删网站详解
我的目的是在Winform程序中直接启动一个HTTP服务器连接下游客户。找到相关技术有两种方式:1.使用C#动态添加网站应用到IIS,借用IIS的管理能力提供HTTP接口。这篇文章解释了这个2.在Winform程序中实现Web服务器逻辑,自己监控和管理客户端请求:现在使用IIS7自带的类库来管理IIS,功能更强大,更方便,不需要使用 DirecotryEntry 类。
C#关于爬取网站数据时csrf-token的分析与解决
航空公司物流单信息查询为post请求。通过后台模拟POST HTTP请求,发现无法获取页面数据。经查航空公司网站,发现网站使用CSRF攻击机制躲避攻击。播放 40X 错误。关于CSRF读者自己百度网站HTTP请求解析Headers表单数据头部收录cookies,x-csrf-token表单数据收录_csrf(与头部相同的值)。这里通过查看网站的JS源码,发现_csrf来自网页的head标签来猜测cookie和
C#Export网站 函数示例代码说明
这个export网站函数是指前端javascript触发的ashx函数,实现将服务器中的一个文件夹(包括其子文件夹和文件)复制到服务器中的另一个位置,当然是文件夹本身是 网站。所以导出网站最重要的两个功能,除了javascript触发器,就是C#ashx文件复制文件夹的操作。下面的代码是通过javascript Request函数调用copy .ashx函数文件实现传入需要复制的文件夹的子路径和复制到该位置的子路径两个参数。后台函数getWebList 函数是后台函数。这个功能
C#使用正则表达式捕获网站信息示例
本文中的一个示例描述了 C# 如何使用正则表达式来捕获 网站 信息。分享给大家,供大家参考,如下: 下面是京东商城商品详情的抓取示例。1.创建JdRobber.cs 程序类 public class JdRobber {// /// 判断是否链接京东 /// /// /// public
英雄联盟协助lol挂机不被踢的方法(lol挂机脚本)
调用API设置鼠标位置并模拟鼠标右键让人物移动,全局钩子等复制代码代码如下:using System;using System.采集s.Generic;using System.Linq;using System.文本; 使用 System.Windows.Forms;使用 System.Runtime.InteropServices;使用 System.Threading;命名空间 LOLSetCursor{ public cla
易语言使英雄联盟源码辅助
LOL辅助这个功能需要加载超级模块7.3。版本 2。组装窗口 assembly_start 窗口。汇编变量pid,整数类型。子程序 __start window_ created pid = take process ID ("League of Legends.exe") 监控热键(&Enable Infinite View Range, #F5 Key) 监控热键(&Turn off Infinite Visual Range, #F6 Key) 监控热键(&Enable Normal攻击范围,#F2 键) 监控热键(&关闭普通攻击范围,#F1 键) 监控热键(&打开炮塔范围,#F4 键) 监控热键(
Python3爬取英雄联盟英雄皮肤大图示例代码
我首先尝试了爬虫的想法。我先查了下网络,没有发现有API可用:然后我用bs4分析了英雄列表页面,但是请求发送到html,并没有英雄列表。在英雄列表节点上,只有“loading”中的字样:同方法,英雄详情的分析也是如此,所以我猜测应该是Javascript负责加载这些数据。我继续尝试和然后我查看了英雄榜的源码,查看了外部导入的js文件,还有一行中的js脚本,大约368行,找到了处理英雄榜的js注释,然后继续阅读这些代码,找到了第一个复活节彩蛋,也就是他介绍了一个
Python3爬虫爬取英雄联盟高清桌面壁纸功能示例【基于Scrapy框架】
本文介绍Python3爬虫爬取英雄联盟高清桌面壁纸的功能。分享给大家参考,如下: 使用Scrapy爬虫爬取英雄联盟高清桌面壁纸 源地址:项目启动前需要安装Python3和Scrapy,没有百度,这里就不具体介绍了。首先创建项目scrapy startproject loldesk,生成项目的目录结构。首先,您需要定义抓取元素。在item.py中,我们的项目使用图片名称和链接导入scrapy
使用Python制作微信跳转和跳转助手
1. 前言相信大家对微信跳转,以及现在的各种插件都不陌生。辅助也是满天飞,反正我的好友名单已经八九百了也就不足为奇了。某宝在上面搜索一堆结果,最低的居然3元多。我可以随心所欲地得分。真是太离谱了。作为程序员,我决心自己做,不是为了别的,而是为了锻炼自己。解决问题的能力也是为了娱乐。对于这种任务,最合适的当然是Python,一个丰富的第三方库,具有胶水语言的特性。
Python网络爬虫示例讲解
让我们来谈谈 Python 和网络爬虫。1.爬虫的定义。爬虫:自动爬取互联网数据的程序。2.爬虫的主要框架管理器获取要爬取的URL链接。如果URL管理器中存在需要爬取的URL链接,则爬虫调度器调用网页下载器下载对应的网页,然后调用网页解析器解析该网页,并将新的页面放入网页中页。将 URL 添加到 URL 管理器以输出有价值的数据。3.爬虫时序图4.URL manager URL manager管理要爬取的URL集合和已经爬取的URL集合,防止重复爬取和循环爬取。URL管理器的主要功能如下
如何实现IOS_SearchBar搜索栏和关键字高亮
搜索框效果演示:这就是所谓的搜索框,下面我们来看看如何使用代码实现这个功能。我使用的数据是英雄联盟的英雄列表,是JSON数据的txt文件,JSON数据处理代码如下: //获取文件路径的路径 NSString *path = [[NSBundle mainBundle] pathForResource:@"heros" ofType:@"txt"]; //将路径下的文件转换成NSData数据 NSData * data = [NSDat
Swift仿IOS最新版QQ抽屉侧滑及弹出视图
介绍很简单。我用Swift写了一个抽屉效果,可以直接使用,简单;很多软件都有抽屉效果,比如qq的左边抽屉,英雄联盟,滴滴打车,优步等等,都是用抽屉的;效果是iOS drawer type的结构实现分析,主要是在控制器的View中添加两个View,一个left view和一个mainView。这里我们自定义了一个 DrawerViewController,init(mainVC: UIViewController, leftMenuVC: UIViewController, leftWidth: CGFloat
Javascript实现模仿腾讯游戏选择
我们在玩腾讯游戏的时候,会有很多选择,比如选择什么区域,选择什么人物等等,下面我们来做一个简单的腾讯游戏选择。
js中常用的Tab切换效果(推荐)
如下图:tab *(margin:0; padding:0; list-style:none;} .box{ width: 1000px; overflow: hidden; margin:100px auto

