
c#抓取网页数据
c#抓取网页数据(1.讲故事民生资讯号民生民生)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-10-09 01:05
一:背景1.讲故事
前段时间,我创建了一个当地民生信息账号。我复制了你的信息。你复制了官方媒体。市民喜欢奇怪的东西。所以需要如何定位和捕捉奇怪的东西。账号上的消息其实做起来很简单,用logistic回归就可以了。本文主要讨论如何爬取。在C#中,大家都知道抓取的通用库是HtmlAgilityPack,但是这个库的主流方法是使用xpath来提取网页的内容,让我很不爽。毕竟,我不熟悉莫名的抵抗。一个我这个年纪的码农受过 Jquery 的教育至少 5-6 年,所以我必须使用类似 Jquery 的方法。python中有pyquery。这样做,就是
C# 中有类似的方法吗?哎,真的有全能的github。. . 这就是本文介绍的CSQuery。
二:CSQuery1.安装
github地址:然后直接在vs中点击nuget:
2. 举几个例子
万事俱备,那么如何使用呢?别着急,我举两个博客园里的例子。
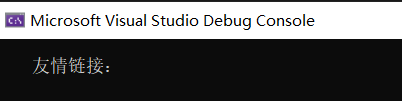
1) 从主页提取友情链接到
如上图所示,这里如果要获取友情链接的几个大字,直接使用text()肯定是不行的。默认情况下,它还会捕获所有子节点的文本,如下图所示:
如何处理?可以使用jquery提供的contents方法,然后判断获取的所有子节点中是否有文本节点,最后获取文本节点的内容,如下代码所示:
是用js做的,但是用CSQuery代码怎么做呢?模仿一下,代码如下:
static void Main(string[] args)
{
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com"));
var content = jquery["#friend_link"].Contents().Filter((dom) =>
{
return dom.NodeType == NodeType.TEXT_NODE;
}).Text();
Console.WriteLine(content);
}
不知道用xpath提取这样的内容是不是很麻烦,但是jquery也不好用,但是熟悉。
2) 如何给html中的一些元素着色
有时需要为业务更改某些html标签的颜色,例如将首页tabmenu中的博客和区域更改为红色,如下图所示:
如何处理CSQuery?如果你玩过jquery,一般来说步骤如下:
有了步骤,C#代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com"));
var html = jquery["#nav_left li"].Each(dom =>
{
var self = jquery[dom];
var text = self.Text();
if (text == "博问" || text == "专区")
{
self.Find("a").CssSet(new { color = "red" });
}
}).Render();
}
3) 其他操作方法
除了以上两种操作方法,还可以使用after、before、replaceAll、IS等。有一百多种实用方法。这篇文章肯定不能一一介绍。有兴趣的可以下载看看。小提琴。
三:其他用途
除了抓取html中的元素,我觉得这个东西还可以用来在发送邮件的时候操作邮件模板。毕竟很久以前大家都是用jquery来画html的,所以CSQuery也是可以的。使用 xslt 有优点也有缺点。, 举个例子:
1. 生成html模板
2. 使用 CSQuery 将 li 附加到 ul
您可以使用 Append 将内容附加到节点。
class Program
{
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var strlist = new string[2] { "1", "2" };
var path = Environment.CurrentDirectory + "\\2.html";
var jquery = CQ.CreateFromFile(path);
foreach (var str in strlist)
{
jquery.Find("#main").Append($"{str}");
}
var html = jquery.Render();
}
}
3. 局部渲染RenderSelection
Render方法是将整个Dom渲染成html,但是有时候你只需要获取你修改的那部分内容而不是整个html,这涉及到部分渲染,可以使用RenderSelection方法,代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var strlist = new string[2] { "1", "2" };
var path = Environment.CurrentDirectory + "\\2.html";
var jquery = CQ.CreateFromFile(path);
var current = jquery.Find("#main");
foreach (var str in strlist)
{
current.Append($"{str}");
}
var html = current.RenderSelection();
Console.WriteLine(html);
}
------------- output ----------------
12
四:总结
Jquery的这种操作方式对我个人来说还是比较舒服的,毕竟我很熟悉!不过html5中也加入了querySelector和querySelectorAll来支持css3选择器,非常强大,但是jquery不仅选择器灵活,节点的操作也很灵活。总的来说,它的交互性不是特别丰富。怀旧。 查看全部
c#抓取网页数据(1.讲故事民生资讯号民生民生)
一:背景1.讲故事
前段时间,我创建了一个当地民生信息账号。我复制了你的信息。你复制了官方媒体。市民喜欢奇怪的东西。所以需要如何定位和捕捉奇怪的东西。账号上的消息其实做起来很简单,用logistic回归就可以了。本文主要讨论如何爬取。在C#中,大家都知道抓取的通用库是HtmlAgilityPack,但是这个库的主流方法是使用xpath来提取网页的内容,让我很不爽。毕竟,我不熟悉莫名的抵抗。一个我这个年纪的码农受过 Jquery 的教育至少 5-6 年,所以我必须使用类似 Jquery 的方法。python中有pyquery。这样做,就是
C# 中有类似的方法吗?哎,真的有全能的github。. . 这就是本文介绍的CSQuery。
二:CSQuery1.安装
github地址:然后直接在vs中点击nuget:

2. 举几个例子
万事俱备,那么如何使用呢?别着急,我举两个博客园里的例子。
1) 从主页提取友情链接到

如上图所示,这里如果要获取友情链接的几个大字,直接使用text()肯定是不行的。默认情况下,它还会捕获所有子节点的文本,如下图所示:

如何处理?可以使用jquery提供的contents方法,然后判断获取的所有子节点中是否有文本节点,最后获取文本节点的内容,如下代码所示:

是用js做的,但是用CSQuery代码怎么做呢?模仿一下,代码如下:
static void Main(string[] args)
{
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com";));
var content = jquery["#friend_link"].Contents().Filter((dom) =>
{
return dom.NodeType == NodeType.TEXT_NODE;
}).Text();
Console.WriteLine(content);
}
不知道用xpath提取这样的内容是不是很麻烦,但是jquery也不好用,但是熟悉。
2) 如何给html中的一些元素着色
有时需要为业务更改某些html标签的颜色,例如将首页tabmenu中的博客和区域更改为红色,如下图所示:

如何处理CSQuery?如果你玩过jquery,一般来说步骤如下:
有了步骤,C#代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com";));
var html = jquery["#nav_left li"].Each(dom =>
{
var self = jquery[dom];
var text = self.Text();
if (text == "博问" || text == "专区")
{
self.Find("a").CssSet(new { color = "red" });
}
}).Render();
}

3) 其他操作方法
除了以上两种操作方法,还可以使用after、before、replaceAll、IS等。有一百多种实用方法。这篇文章肯定不能一一介绍。有兴趣的可以下载看看。小提琴。
三:其他用途
除了抓取html中的元素,我觉得这个东西还可以用来在发送邮件的时候操作邮件模板。毕竟很久以前大家都是用jquery来画html的,所以CSQuery也是可以的。使用 xslt 有优点也有缺点。, 举个例子:
1. 生成html模板
2. 使用 CSQuery 将 li 附加到 ul
您可以使用 Append 将内容附加到节点。
class Program
{
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var strlist = new string[2] { "1", "2" };
var path = Environment.CurrentDirectory + "\\2.html";
var jquery = CQ.CreateFromFile(path);
foreach (var str in strlist)
{
jquery.Find("#main").Append($"{str}");
}
var html = jquery.Render();
}
}

3. 局部渲染RenderSelection
Render方法是将整个Dom渲染成html,但是有时候你只需要获取你修改的那部分内容而不是整个html,这涉及到部分渲染,可以使用RenderSelection方法,代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var strlist = new string[2] { "1", "2" };
var path = Environment.CurrentDirectory + "\\2.html";
var jquery = CQ.CreateFromFile(path);
var current = jquery.Find("#main");
foreach (var str in strlist)
{
current.Append($"{str}");
}
var html = current.RenderSelection();
Console.WriteLine(html);
}
------------- output ----------------
12
四:总结
Jquery的这种操作方式对我个人来说还是比较舒服的,毕竟我很熟悉!不过html5中也加入了querySelector和querySelectorAll来支持css3选择器,非常强大,但是jquery不仅选择器灵活,节点的操作也很灵活。总的来说,它的交互性不是特别丰富。怀旧。
c#抓取网页数据(c#抓取网页数据的常见解决方案:`io.io)
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-10-04 05:03
c#抓取网页数据的方法很多,总的来说大致包括使用selector表达式实现非字符串匹配,使用tuple类型实现字符串字面量匹配,使用循环控制条件运算等。有关概念可以看一下这篇论文:historyisnotapropertywithoutthedoubleaccess.todo:string类型中各个字符串字面量是不允许直接出现在数组中的,string允许使用符号来给字符串添加字符,可以在字符数组中实现嵌套类。
是的,至少我遇到过的是这样的,否则我就重写代码了。反正我从来不知道什么是不支持的,
我觉得楼上都没回答到点子上,我来抛砖引玉一下吧。在你的例子中,可以对应上面列表的那么几种常见的解决方案:`io.aiohttp.postmessagestringbymessage``io.aiohttp.postmessagestringbyflags#boundsofthespecificnamesoftheavailablemessageobjectsinthemulti-parammodel`io.aiohttp.postmessagestringbyfilter#boundsoftheclassspecifictypesofthemessagename`io.aiohttp.postmessagestringbyparameter#boundsoftheclasstypesofthemessagename`io.aiohttp.postmessagestringbyparams#boundsofthemessagespecificparametersinmessagename`这两个方案的问题很严重:asio并不是以io.aiohttp.postmessagestringbymessage为最终postmessage类型去做转换,因此在你的代码中,会造成1,2两个子类,io.aiohttp.postmessagestringbymessage和io.aiohttp.postmessagestringbyfilter这两个最终postmessage类型对应的io.aiohttp.postmessagestringbyfilter两个类型,都会被做传递,类型指向同一个string对象。
好在这两个方案都不是以get为最终postmessage类型去实现的,因此没有造成get函数执行异常。解决办法只有一个:`stringbuilderio.io.aiohttp.postmessagestringbystring#boundsoftheentirepostmessagestringisfullyemptyinthemulti-parammodel`,有人或许会说,stringbuilder是嵌套对象,而entireparams是字符串的字面量表达式,param是字符串类型自身的parameter,字符串对象可以再有不同类型的parameter,所以就一定是true了吗?对io.aiohttp.postmessagestringbystring参数io.aiohttp.postmessagestringbyfilter参数进行类型转换,相当于entireparams,因此可以做很多事情,比如和content_listener接口的text_match就能用param和entireparams做成。
其实如果不做这个判断,param与entireparams在postmessage对象中对应的parameter会无效的,可以参考。 查看全部
c#抓取网页数据(c#抓取网页数据的常见解决方案:`io.io)
c#抓取网页数据的方法很多,总的来说大致包括使用selector表达式实现非字符串匹配,使用tuple类型实现字符串字面量匹配,使用循环控制条件运算等。有关概念可以看一下这篇论文:historyisnotapropertywithoutthedoubleaccess.todo:string类型中各个字符串字面量是不允许直接出现在数组中的,string允许使用符号来给字符串添加字符,可以在字符数组中实现嵌套类。
是的,至少我遇到过的是这样的,否则我就重写代码了。反正我从来不知道什么是不支持的,
我觉得楼上都没回答到点子上,我来抛砖引玉一下吧。在你的例子中,可以对应上面列表的那么几种常见的解决方案:`io.aiohttp.postmessagestringbymessage``io.aiohttp.postmessagestringbyflags#boundsofthespecificnamesoftheavailablemessageobjectsinthemulti-parammodel`io.aiohttp.postmessagestringbyfilter#boundsoftheclassspecifictypesofthemessagename`io.aiohttp.postmessagestringbyparameter#boundsoftheclasstypesofthemessagename`io.aiohttp.postmessagestringbyparams#boundsofthemessagespecificparametersinmessagename`这两个方案的问题很严重:asio并不是以io.aiohttp.postmessagestringbymessage为最终postmessage类型去做转换,因此在你的代码中,会造成1,2两个子类,io.aiohttp.postmessagestringbymessage和io.aiohttp.postmessagestringbyfilter这两个最终postmessage类型对应的io.aiohttp.postmessagestringbyfilter两个类型,都会被做传递,类型指向同一个string对象。
好在这两个方案都不是以get为最终postmessage类型去实现的,因此没有造成get函数执行异常。解决办法只有一个:`stringbuilderio.io.aiohttp.postmessagestringbystring#boundsoftheentirepostmessagestringisfullyemptyinthemulti-parammodel`,有人或许会说,stringbuilder是嵌套对象,而entireparams是字符串的字面量表达式,param是字符串类型自身的parameter,字符串对象可以再有不同类型的parameter,所以就一定是true了吗?对io.aiohttp.postmessagestringbystring参数io.aiohttp.postmessagestringbyfilter参数进行类型转换,相当于entireparams,因此可以做很多事情,比如和content_listener接口的text_match就能用param和entireparams做成。
其实如果不做这个判断,param与entireparams在postmessage对象中对应的parameter会无效的,可以参考。
c#抓取网页数据( 从IE浏览器获取当前页面内容可能有多种方式的资料)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-02 11:36
从IE浏览器获取当前页面内容可能有多种方式的资料)
C#从IE浏览器获取当前页面的内容
更新时间:2021年6月24日09:52:49作者:迈克尔·大卫
从IE浏览器获取当前页面内容的方法可能有很多种。今天我介绍其中一个。基本原理:鼠标点击当前ie页面时,获取鼠标坐标位置,根据鼠标位置获取当前页面的句柄,然后根据句柄调用Win32 things获取页面内容。感兴趣的朋友可以参考本文
private void timer1_Tick(object sender, EventArgs e)
{
lock (currentLock)
{
System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition;
if (_leftClick)
{
timer1.Stop();
_leftClick = false;
_lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false));
if (_lastDocument != null)
{
if (_getDocument)
{
_getDocument = true;
try
{
string url = _lastDocument.url;
string html = _lastDocument.documentElement.outerHTML;
string cookie = _lastDocument.cookie;
string domain = _lastDocument.domain;
var resolveParams = new ResolveParam
{
Url = new Uri(url),
Html = html,
PageCookie = cookie,
Domain = domain
};
RequetResove(resolveParams);
}
catch (Exception ex)
{
System.Windows.MessageBox.Show(ex.Message);
Console.WriteLine(ex.Message);
Console.WriteLine(ex.StackTrace);
}
}
}
else
{
new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页");
}
_getDocument = false;
}
else
{
_pointFrm.Left = MousePoint.X + 10;
_pointFrm.Top = MousePoint.Y + 10;
}
}
}
在第11行的gethtmldocumentformhwnd(getpointcontrol(mousepoint,false))分解下,首先从鼠标坐标获取页面句柄:
public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl)
{
IntPtr handle = Win32APIsFull.WindowFromPoint(p);
if (handle != IntPtr.Zero)
{
System.Drawing.Rectangle rect = default(System.Drawing.Rectangle);
if (Win32APIsFull.GetWindowRect(handle, out rect))
{
return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE);
}
}
return IntPtr.Zero;
}
接下来,根据句柄获取页面内容:
public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd)
{
IntPtr result = Marshal.AllocHGlobal(4);
Object obj = null;
Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result));
if (Marshal.ReadInt32(result) != 0)
{
Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj));
}
Marshal.FreeHGlobal(result);
return obj as HTMLDocument;
}
一般原则:
向IE表单发送消息,获取指向IE浏览器(非托管)内存块的指针,然后根据该指针获取htmldocument对象
此方法涉及两个Win32函数:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")]
public static extern int SendMessageTimeoutA(
[InAttribute()] System.IntPtr hWnd,
uint Msg, uint wParam, int lParam,
uint fuFlags,
uint uTimeout,
System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")]
public static extern int ObjectFromLresult(
int lResult,
ref Guid riid,
int wParam,
[MarshalAs(UnmanagedType.IDispatch), Out]
out Object pObject
);
以上是从IE浏览器获取当前页面内容的详细信息。有关c#获取浏览器页面内容的更多信息,请注意其他相关信息文章 查看全部
c#抓取网页数据(
从IE浏览器获取当前页面内容可能有多种方式的资料)
C#从IE浏览器获取当前页面的内容
更新时间:2021年6月24日09:52:49作者:迈克尔·大卫
从IE浏览器获取当前页面内容的方法可能有很多种。今天我介绍其中一个。基本原理:鼠标点击当前ie页面时,获取鼠标坐标位置,根据鼠标位置获取当前页面的句柄,然后根据句柄调用Win32 things获取页面内容。感兴趣的朋友可以参考本文
private void timer1_Tick(object sender, EventArgs e)
{
lock (currentLock)
{
System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition;
if (_leftClick)
{
timer1.Stop();
_leftClick = false;
_lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false));
if (_lastDocument != null)
{
if (_getDocument)
{
_getDocument = true;
try
{
string url = _lastDocument.url;
string html = _lastDocument.documentElement.outerHTML;
string cookie = _lastDocument.cookie;
string domain = _lastDocument.domain;
var resolveParams = new ResolveParam
{
Url = new Uri(url),
Html = html,
PageCookie = cookie,
Domain = domain
};
RequetResove(resolveParams);
}
catch (Exception ex)
{
System.Windows.MessageBox.Show(ex.Message);
Console.WriteLine(ex.Message);
Console.WriteLine(ex.StackTrace);
}
}
}
else
{
new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页");
}
_getDocument = false;
}
else
{
_pointFrm.Left = MousePoint.X + 10;
_pointFrm.Top = MousePoint.Y + 10;
}
}
}
在第11行的gethtmldocumentformhwnd(getpointcontrol(mousepoint,false))分解下,首先从鼠标坐标获取页面句柄:
public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl)
{
IntPtr handle = Win32APIsFull.WindowFromPoint(p);
if (handle != IntPtr.Zero)
{
System.Drawing.Rectangle rect = default(System.Drawing.Rectangle);
if (Win32APIsFull.GetWindowRect(handle, out rect))
{
return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE);
}
}
return IntPtr.Zero;
}
接下来,根据句柄获取页面内容:
public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd)
{
IntPtr result = Marshal.AllocHGlobal(4);
Object obj = null;
Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result));
if (Marshal.ReadInt32(result) != 0)
{
Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj));
}
Marshal.FreeHGlobal(result);
return obj as HTMLDocument;
}
一般原则:

向IE表单发送消息,获取指向IE浏览器(非托管)内存块的指针,然后根据该指针获取htmldocument对象
此方法涉及两个Win32函数:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")]
public static extern int SendMessageTimeoutA(
[InAttribute()] System.IntPtr hWnd,
uint Msg, uint wParam, int lParam,
uint fuFlags,
uint uTimeout,
System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")]
public static extern int ObjectFromLresult(
int lResult,
ref Guid riid,
int wParam,
[MarshalAs(UnmanagedType.IDispatch), Out]
out Object pObject
);
以上是从IE浏览器获取当前页面内容的详细信息。有关c#获取浏览器页面内容的更多信息,请注意其他相关信息文章
c#抓取网页数据(c#抓取网页数据基本上是类似于抓包和正则表达式的基本功)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-10-01 10:03
c#抓取网页数据基本上是类似于抓包和正则表达式的基本功,今天就来讲一下常用的数据抓取方法和步骤:1.爬虫和docker:引用docker容器需要在php中使用一下docker:2.正则表达式解析:基本步骤:1.在cmd中运行正则表达式,如下图:2.选择我们需要抓取的网页,如果要抓取一个redis的数据:php要选择redis,如果要抓取一个.txt文件(文本文件),需要修改文件位置为相应路径的存储路径:具体方法如下图:还可以修改上一条编码方式,用相应变量值设置上下行的编码3.读取cookie信息和session信息:其中cookie就是浏览器,session就是操作系统。
我们先了解一下登录和系统用户名如何获取第二步,通过正则表达式检测我们需要登录的操作系统,当找到后修改目标操作系统文件c:\users\xxx\appdata\local\network\data\network\network.cache,修改相应路径如下图:4.爬虫程序开发:设置代理,如下图:api接口已经设置好了,只需要set方法将路径保存起来就可以了5.登录:现在已经登录了,但是没有任何内容,怎么获取页面内容?总结:还有一些基本的常见问题,想分享给大家,欢迎大家指正!正常情况下,登录的用户是不会发送完整的json参数,但是我们可以简单的尝试下。
在上面我们的类型中,有session和db这两个io操作,但是发送参数是一直发送到db这个是肯定是有问题的,我们需要给它加上属性标签,先定义如下id:publicformdata=singleton;for(formfd:fd){fd.set(fd.any());}。 查看全部
c#抓取网页数据(c#抓取网页数据基本上是类似于抓包和正则表达式的基本功)
c#抓取网页数据基本上是类似于抓包和正则表达式的基本功,今天就来讲一下常用的数据抓取方法和步骤:1.爬虫和docker:引用docker容器需要在php中使用一下docker:2.正则表达式解析:基本步骤:1.在cmd中运行正则表达式,如下图:2.选择我们需要抓取的网页,如果要抓取一个redis的数据:php要选择redis,如果要抓取一个.txt文件(文本文件),需要修改文件位置为相应路径的存储路径:具体方法如下图:还可以修改上一条编码方式,用相应变量值设置上下行的编码3.读取cookie信息和session信息:其中cookie就是浏览器,session就是操作系统。
我们先了解一下登录和系统用户名如何获取第二步,通过正则表达式检测我们需要登录的操作系统,当找到后修改目标操作系统文件c:\users\xxx\appdata\local\network\data\network\network.cache,修改相应路径如下图:4.爬虫程序开发:设置代理,如下图:api接口已经设置好了,只需要set方法将路径保存起来就可以了5.登录:现在已经登录了,但是没有任何内容,怎么获取页面内容?总结:还有一些基本的常见问题,想分享给大家,欢迎大家指正!正常情况下,登录的用户是不会发送完整的json参数,但是我们可以简单的尝试下。
在上面我们的类型中,有session和db这两个io操作,但是发送参数是一直发送到db这个是肯定是有问题的,我们需要给它加上属性标签,先定义如下id:publicformdata=singleton;for(formfd:fd){fd.set(fd.any());}。
c#抓取网页数据(谢邀webpack/nodejs工程化脚手架没有功能机制)
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-10-01 10:00
c#抓取网页数据,数据只能抓取网页上面的,没有返回json和xml格式的数据,我最近都用的是51cto的html5爬虫和html5数据抓取,一个是里面有很多好看的爬虫插件和例子教程,还有一个是入门比较简单,最主要是上手容易,一天就可以出效果。刚刚也突然想到一个方法,用reactnative写个json爬虫也是可以的,考虑到reactnative本身没有jsonapi,所以想找个jsonapi的爬虫来抓取。
谢邀webpack/nodejs工程化脚手架没有功能机制的话请使用scrapy,puppeteer,node-spider或者scrapy+puppeteer。最后,如果只是单纯的需要抓取网页内容是不需要nodejs和scrapy或者puppeteer之类的,所有的html解析都可以用html5lib和json等接口来实现,只需要简单的json解析以及将json文本打包成js即可。
在老大允许的情况下可以用redis,你也可以用session之类的来处理,然后再配合一下json转post请求。有了用户数据就可以直接抓取咯。
做个mvx以及自己解析postsoap头即可
先看下c++和java能不能交叉编译json,json也只是一种数据结构,
可以试试跟前面两位一样用c++,自己编译写一套jsonwebapi。
最开始scrapy这个自动化工具可以试试 查看全部
c#抓取网页数据(谢邀webpack/nodejs工程化脚手架没有功能机制)
c#抓取网页数据,数据只能抓取网页上面的,没有返回json和xml格式的数据,我最近都用的是51cto的html5爬虫和html5数据抓取,一个是里面有很多好看的爬虫插件和例子教程,还有一个是入门比较简单,最主要是上手容易,一天就可以出效果。刚刚也突然想到一个方法,用reactnative写个json爬虫也是可以的,考虑到reactnative本身没有jsonapi,所以想找个jsonapi的爬虫来抓取。
谢邀webpack/nodejs工程化脚手架没有功能机制的话请使用scrapy,puppeteer,node-spider或者scrapy+puppeteer。最后,如果只是单纯的需要抓取网页内容是不需要nodejs和scrapy或者puppeteer之类的,所有的html解析都可以用html5lib和json等接口来实现,只需要简单的json解析以及将json文本打包成js即可。
在老大允许的情况下可以用redis,你也可以用session之类的来处理,然后再配合一下json转post请求。有了用户数据就可以直接抓取咯。
做个mvx以及自己解析postsoap头即可
先看下c++和java能不能交叉编译json,json也只是一种数据结构,
可以试试跟前面两位一样用c++,自己编译写一套jsonwebapi。
最开始scrapy这个自动化工具可以试试
c#抓取网页数据(源页页面源码如下:目标页中获取源页窗体数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-09-27 21:21
在源代码页面中,此示例代码为用户提供了用于输入用户名、生日和年龄的文本框,并将Button 控件的PostBackUrl 属性设置为DestinationPage.aspx。也就是说,当你点击【提交到目标页面】按钮时,源页面表单的数据就会被传送到目标页面.aspx页面。
在目标页面中,通过 Page.Request.Form 属性获取传递的数据。
源页面的页面源码如下:
源页!
User Name :
<br />
Birth Date :
<br />
Age :
<br />
在目标页面中获取源页面的表单数据的代码如下:
protected void Page_Load(object sender, EventArgs e)
{
StringBuilder SBuilder = new StringBuilder();
NameValueCollection PostedValues =
this.Request.Form;
for (int Index = 0; Index < PostedValues.Count; Index++)
{
if (PostedValues.Keys[Index].Substring(0, 2) != "__")
{
SBuilder.Append(string.Format("{0} = {1}",
PostedValues.Keys[Index],
PostedValues[Index]));
SBuilder.Append("<br />");
}
}
this.Response.Write(SBuilder.ToString());
}
代码中的if语句主要是为了避免获取以两个下划线__开头的隐藏字段的数据,例如__VIEWSTATE、__EVENTTARGET、__EVENTARGUMENT。当然,你也可以去掉这个if语句,然后就可以同时获取这些隐藏字段的数据了。
三、通过会话状态传递数据
使用会话状态的优点是数据可以在与源页面相同的 ASP.NET 应用程序中的所有网页之间共享。缺点是会增加服务器的内存开销。
在下面的代码中,用户在源页面的【用户名】文本框中输入自己的姓名,然后点击【提交数据】按钮。服务器代码会通过 Page.Session 属性将用户名存储在会话状态中,然后使用 Response.Redirect() 方法强制页面重定向到另一个页面(DestinationPage.aspx)。在此目标页面中,再次使用 Page.Session 属性来获取保存在源页面中的用户名。
源码页面的源码如下:
源页:通过会话状态传递数据!
用户名:
源页面中将用户名保存到会话状态并重定向到目标页面的代码如下:
protected void SubmitButton_Click(object sender, EventArgs e)
{
this.Session["UserName"] = this.UserNameTextBox.Text;
this.Response.Redirect("DestinationPage.aspx");
}
获取目标页面中会话状态中保存的用户名的代码如下:
protected void Page_Load(object sender, EventArgs e)
{
string UserName = this.Session["UserName"].ToString();
this.Response.Write(UserName);
}
四、通过源页面的公共属性传递数据
在示例代码中,我们提供了在源页面输入用户名的文本框,然后点击【提交到目标页面】按钮将数据提交到目标页面。
源码页面的源码如下:
源页:通过公共属性传递数据!
用户名:
<br />
并且为源页面定义了一个名为 UserName 的公共属性。该属性返回在[用户名] 文本框中输入的用户名。
public string UserName
{
get { return this.UserNameTextBox.Text; }
}
通过这种方式,我们创建了一个收录公共属性的源页面。然后创建目标页面并将@PreviousPageType 指令添加到目标页面。当然,您也可以使用@Reference 指令。
这样,ASP.NET 就会自动将目标页面的 Page.PreviousPage 属性转换为源页面的类型,以便您可以直接访问 UserName 属性。注意下面的代码,我们没有把Page.PreviousPage转换成显示类型。
if (this.PreviousPage != null)
{
string UserName = this.PreviousPage.UserName;
this.Response.Write(UserName);
}
需要特别强调的是,不要忘记判断Page.PreviousPage属性是否为null,因为它确实有为null的可能。如果在 null 的情况下获取了源页面 UserName 的公共属性,则会引发异常。
五、通过源页面中的控件值传递数据
最后一种传输数据的方式是直接获取源页面的控件对象,然后通过控件的属性值获取需要的数据。例如,在本示例代码中,我们获取源页面的TextBox控件,然后通过访问TextBox.Text属性获取用户在源页面中输入的数据。
在下面的示例代码中,我们在源页面放置了一个用于输入用户名的文本框,ID为UserNameTextBox。您可以通过 Page.PreviousPage.FindControl() 方法获取对此控件的引用。
源码页面的源码如下:
源页:通过控件属性传递数据!
用户名:
<br />
获取目标页面中的文本框控件并获取其Text属性值的代码如下:
if (this.PreviousPage != null)
{
TextBox UserNameTextBox =
(TextBox)this.PreviousPage.FindControl("UserNameTextBox");
if (UserNameTextBox != null)
{
this.Response.Write(UserNameTextBox.Text);
}
}
如果要获取的控件位于某个控件内部,例如以下代码,则 UserNameTextBox 控件位于名为 UserPanel 的 Panel 控件内部。然后先找出这个Panel控件,再通过这个控件的FindControl()方法找出里面的文本框控件。
源码页面的源码如下:
源页:通过控件属性传递数据!
用户名:
<br />
获取目标页面中Panel控件内的TextBox控件的代码如下:
if (this.PreviousPage != null)
{
Panel UserPanel = (Panel)this.PreviousPage.FindControl("UserPanel");
if (UserPanel != null)
{
TextBox UserNameTextBox =
(TextBox)UserPanel.FindControl("UserNameTextBoxInPanel");
if (UserNameTextBox != null)
{
this.Response.Write(UserNameTextBox.Text);
}
}
}
无论该控件位于该级别的命名容器控件内部,都是通过这种方式获取的。
不要忘记判断获取的控件引用是否为空。
至此,网页间数据传输的5种方式已经基本展示完毕!^_^
赤脚思考 2010-11-9 查看全部
c#抓取网页数据(源页页面源码如下:目标页中获取源页窗体数据(组图))
在源代码页面中,此示例代码为用户提供了用于输入用户名、生日和年龄的文本框,并将Button 控件的PostBackUrl 属性设置为DestinationPage.aspx。也就是说,当你点击【提交到目标页面】按钮时,源页面表单的数据就会被传送到目标页面.aspx页面。
在目标页面中,通过 Page.Request.Form 属性获取传递的数据。
源页面的页面源码如下:
源页!
User Name :
<br />
Birth Date :
<br />
Age :
<br />
在目标页面中获取源页面的表单数据的代码如下:
protected void Page_Load(object sender, EventArgs e)
{
StringBuilder SBuilder = new StringBuilder();
NameValueCollection PostedValues =
this.Request.Form;
for (int Index = 0; Index < PostedValues.Count; Index++)
{
if (PostedValues.Keys[Index].Substring(0, 2) != "__")
{
SBuilder.Append(string.Format("{0} = {1}",
PostedValues.Keys[Index],
PostedValues[Index]));
SBuilder.Append("<br />");
}
}
this.Response.Write(SBuilder.ToString());
}
代码中的if语句主要是为了避免获取以两个下划线__开头的隐藏字段的数据,例如__VIEWSTATE、__EVENTTARGET、__EVENTARGUMENT。当然,你也可以去掉这个if语句,然后就可以同时获取这些隐藏字段的数据了。
三、通过会话状态传递数据
使用会话状态的优点是数据可以在与源页面相同的 ASP.NET 应用程序中的所有网页之间共享。缺点是会增加服务器的内存开销。
在下面的代码中,用户在源页面的【用户名】文本框中输入自己的姓名,然后点击【提交数据】按钮。服务器代码会通过 Page.Session 属性将用户名存储在会话状态中,然后使用 Response.Redirect() 方法强制页面重定向到另一个页面(DestinationPage.aspx)。在此目标页面中,再次使用 Page.Session 属性来获取保存在源页面中的用户名。
源码页面的源码如下:
源页:通过会话状态传递数据!
用户名:
源页面中将用户名保存到会话状态并重定向到目标页面的代码如下:
protected void SubmitButton_Click(object sender, EventArgs e)
{
this.Session["UserName"] = this.UserNameTextBox.Text;
this.Response.Redirect("DestinationPage.aspx");
}
获取目标页面中会话状态中保存的用户名的代码如下:
protected void Page_Load(object sender, EventArgs e)
{
string UserName = this.Session["UserName"].ToString();
this.Response.Write(UserName);
}
四、通过源页面的公共属性传递数据
在示例代码中,我们提供了在源页面输入用户名的文本框,然后点击【提交到目标页面】按钮将数据提交到目标页面。
源码页面的源码如下:
源页:通过公共属性传递数据!
用户名:
<br />
并且为源页面定义了一个名为 UserName 的公共属性。该属性返回在[用户名] 文本框中输入的用户名。
public string UserName
{
get { return this.UserNameTextBox.Text; }
}
通过这种方式,我们创建了一个收录公共属性的源页面。然后创建目标页面并将@PreviousPageType 指令添加到目标页面。当然,您也可以使用@Reference 指令。
这样,ASP.NET 就会自动将目标页面的 Page.PreviousPage 属性转换为源页面的类型,以便您可以直接访问 UserName 属性。注意下面的代码,我们没有把Page.PreviousPage转换成显示类型。
if (this.PreviousPage != null)
{
string UserName = this.PreviousPage.UserName;
this.Response.Write(UserName);
}
需要特别强调的是,不要忘记判断Page.PreviousPage属性是否为null,因为它确实有为null的可能。如果在 null 的情况下获取了源页面 UserName 的公共属性,则会引发异常。
五、通过源页面中的控件值传递数据
最后一种传输数据的方式是直接获取源页面的控件对象,然后通过控件的属性值获取需要的数据。例如,在本示例代码中,我们获取源页面的TextBox控件,然后通过访问TextBox.Text属性获取用户在源页面中输入的数据。
在下面的示例代码中,我们在源页面放置了一个用于输入用户名的文本框,ID为UserNameTextBox。您可以通过 Page.PreviousPage.FindControl() 方法获取对此控件的引用。
源码页面的源码如下:
源页:通过控件属性传递数据!
用户名:
<br />
获取目标页面中的文本框控件并获取其Text属性值的代码如下:
if (this.PreviousPage != null)
{
TextBox UserNameTextBox =
(TextBox)this.PreviousPage.FindControl("UserNameTextBox");
if (UserNameTextBox != null)
{
this.Response.Write(UserNameTextBox.Text);
}
}
如果要获取的控件位于某个控件内部,例如以下代码,则 UserNameTextBox 控件位于名为 UserPanel 的 Panel 控件内部。然后先找出这个Panel控件,再通过这个控件的FindControl()方法找出里面的文本框控件。
源码页面的源码如下:
源页:通过控件属性传递数据!
用户名:
<br />
获取目标页面中Panel控件内的TextBox控件的代码如下:
if (this.PreviousPage != null)
{
Panel UserPanel = (Panel)this.PreviousPage.FindControl("UserPanel");
if (UserPanel != null)
{
TextBox UserNameTextBox =
(TextBox)UserPanel.FindControl("UserNameTextBoxInPanel");
if (UserNameTextBox != null)
{
this.Response.Write(UserNameTextBox.Text);
}
}
}
无论该控件位于该级别的命名容器控件内部,都是通过这种方式获取的。
不要忘记判断获取的控件引用是否为空。
至此,网页间数据传输的5种方式已经基本展示完毕!^_^
赤脚思考 2010-11-9
c#抓取网页数据(C#使用正则表达式抓取网站信息的正则抓取技巧(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-09-27 16:23
本文文章主要介绍C#使用“target="_blank">正则表达式捕获网站信息,并结合实例分析C#对网页信息的正则捕获操作技巧,有一定参考参考价值,有需要的朋友可以参考
本文介绍了C#使用正则表达式捕获网站信息的方法。分享给大家,供大家参考,如下:
下面是一个抓取京东商城商品详情的例子。
1、创建JdRobber.cs程序类
<p>public class JdRobber
{
///
/// 判断是否京东链接
///
///
///
public bool ValidationUrl(string url)
{
bool result = false;
if (!String.IsNullOrEmpty(url))
{
Regex regex = new Regex(@"^http://item.jd.com/\d+.html$");
Match match = regex.Match(url);
if (match.Success)
{
result = true;
}
}
return result;
}
///
/// 抓取京东信息
///
///
///
public void GetInfo(string url)
{
if (ValidationUrl(url))
{
string htmlStr = WebHandler.GetHtmlStr(url, "Default");
if (!String.IsNullOrEmpty(htmlStr))
{
string pattern = ""; //正则表达式
string sourceWebID = ""; //商品关键ID
string title = ""; //标题
decimal price = 0; //价格
string picName = ""; //图片
//提取商品关键ID
pattern = @"http://item.jd.com/(?\d+).html";
sourceWebID = WebHandler.GetRegexText(url, pattern);
//提取标题
pattern = @"[\s\S]*(?.*?)";
title = WebHandler.GetRegexText(htmlStr, pattern);
//提取图片
int begin = htmlStr.IndexOf(" 查看全部
c#抓取网页数据(C#使用正则表达式抓取网站信息的正则抓取技巧(图))
本文文章主要介绍C#使用“target="_blank">正则表达式捕获网站信息,并结合实例分析C#对网页信息的正则捕获操作技巧,有一定参考参考价值,有需要的朋友可以参考
本文介绍了C#使用正则表达式捕获网站信息的方法。分享给大家,供大家参考,如下:
下面是一个抓取京东商城商品详情的例子。
1、创建JdRobber.cs程序类
<p>public class JdRobber
{
///
/// 判断是否京东链接
///
///
///
public bool ValidationUrl(string url)
{
bool result = false;
if (!String.IsNullOrEmpty(url))
{
Regex regex = new Regex(@"^http://item.jd.com/\d+.html$");
Match match = regex.Match(url);
if (match.Success)
{
result = true;
}
}
return result;
}
///
/// 抓取京东信息
///
///
///
public void GetInfo(string url)
{
if (ValidationUrl(url))
{
string htmlStr = WebHandler.GetHtmlStr(url, "Default");
if (!String.IsNullOrEmpty(htmlStr))
{
string pattern = ""; //正则表达式
string sourceWebID = ""; //商品关键ID
string title = ""; //标题
decimal price = 0; //价格
string picName = ""; //图片
//提取商品关键ID
pattern = @"http://item.jd.com/(?\d+).html";
sourceWebID = WebHandler.GetRegexText(url, pattern);
//提取标题
pattern = @"[\s\S]*(?.*?)";
title = WebHandler.GetRegexText(htmlStr, pattern);
//提取图片
int begin = htmlStr.IndexOf("
c#抓取网页数据(1.讲故事民生资讯号民生民生)
网站优化 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2021-09-27 16:14
一:背景1.讲故事
前段时间,我创建了一个当地民生信息账号。我复制了你的信息。你复制了官方媒体。市民喜欢稀奇古怪的东西,所以就需要如何瞄准和捕捉稀奇古怪的东西。账号上的消息其实做起来很简单,用logistic回归就可以了。本文主要讨论如何爬取。在C#中,大家都知道抓取的通用库是HtmlAgilityPack,但是这个库的主流方法是使用xpath来提取网页的内容,让我很不爽。毕竟,我不熟悉莫名的抵抗。一个我这个年纪的码农受过 Jquery 的教育至少 5-6 年,所以我必须使用类似 Jquery 的方法。python中有pyquery。在 C# 中是否有类似的方法可以做到这一点?哎,真的有全能的github。. .
二:CSQuery1.安装
github地址:然后直接在vs中点击nuget:
2. 举几个例子
万事俱备,那么如何使用呢?别着急,我举两个博客园里的例子。
1) 从主页提取友情链接到
如上图所示,这里如果要获取友情链接的几个大字,直接使用text()肯定是不行的。默认情况下,它还会捕获所有子节点的文本,如下图所示:
如何处理?可以使用jquery提供的contents方法,然后判断获取的所有子节点中是否有文本节点,最后获取文本节点的内容,如下代码所示:
是用js做的,但是用CSQuery代码怎么做呢?模仿一下,代码如下:
static void Main(string[] args)
{
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com"));
var content = jquery["#friend_link"].Contents().Filter((dom) =>
{
return dom.NodeType == NodeType.TEXT_NODE;
}).Text();
Console.WriteLine(content);
}
不知道用xpath提取这样的内容是不是很麻烦,但是jquery也不好用,但是熟悉。
2) 如何为html中的某些元素着色
有时需要为业务更改一些html标签的颜色,例如将首页tabmenu中的博客和区域更改为红色,如下图所示:
如何处理CSQuery?如果你玩过jquery,一般来说步骤如下:
有了步骤,C#代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com"));
var html = jquery["#nav_left li"].Each(dom =>
{
var self = jquery[dom];
var text = self.Text();
if (text == "博问" || text == "专区")
{
self.Find("a").CssSet(new { color = "red" });
}
}).Render();
}
3) 其他操作方法
除了以上两种操作方法,还可以使用after、before、replaceAll、IS等。有一百多种实用方法。这篇文章肯定不能一一介绍。有兴趣的可以下载看看。小提琴。
三:其他用途
除了抓取html中的元素,我觉得这个东西还可以用来在发邮件的时候操作邮件模板。毕竟很久以前大家都是用jquery来画html的,所以CSQuery也是可以的。使用 xslt 有优点也有缺点。, 举个例子:
1. 生成html模板
2. 使用 CSQuery 将 li 附加到 ul
您可以使用 Append 将内容附加到节点。
class Program
{
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var strlist = new string[2] { "1", "2" };
var path = Environment.CurrentDirectory + "\\2.html";
var jquery = CQ.CreateFromFile(path);
foreach (var str in strlist)
{
jquery.Find("#main").Append($"{str}");
}
var html = jquery.Render();
}
}
3. 局部渲染RenderSelection
Render方法是将整个Dom渲染成html,但是有时候你只需要获取你修改的那部分内容而不是整个html,这涉及到部分渲染,可以使用RenderSelection方法,代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var strlist = new string[2] { "1", "2" };
var path = Environment.CurrentDirectory + "\\2.html";
var jquery = CQ.CreateFromFile(path);
var current = jquery.Find("#main");
foreach (var str in strlist)
{
current.Append($"{str}");
}
var html = current.RenderSelection();
Console.WriteLine(html);
}
------------- output ----------------
12
四:总结
Jquery的这种操作方式对我个人来说还是比较舒服的,毕竟我很熟悉!不过html5中也加入了querySelector和querySelectorAll来支持css3选择器,非常强大,但是jquery不仅选择器灵活,节点的操作也很灵活。总的来说,它的交互性不是特别丰富。怀旧。 查看全部
c#抓取网页数据(1.讲故事民生资讯号民生民生)
一:背景1.讲故事
前段时间,我创建了一个当地民生信息账号。我复制了你的信息。你复制了官方媒体。市民喜欢稀奇古怪的东西,所以就需要如何瞄准和捕捉稀奇古怪的东西。账号上的消息其实做起来很简单,用logistic回归就可以了。本文主要讨论如何爬取。在C#中,大家都知道抓取的通用库是HtmlAgilityPack,但是这个库的主流方法是使用xpath来提取网页的内容,让我很不爽。毕竟,我不熟悉莫名的抵抗。一个我这个年纪的码农受过 Jquery 的教育至少 5-6 年,所以我必须使用类似 Jquery 的方法。python中有pyquery。在 C# 中是否有类似的方法可以做到这一点?哎,真的有全能的github。. .
二:CSQuery1.安装
github地址:然后直接在vs中点击nuget:

2. 举几个例子
万事俱备,那么如何使用呢?别着急,我举两个博客园里的例子。
1) 从主页提取友情链接到

如上图所示,这里如果要获取友情链接的几个大字,直接使用text()肯定是不行的。默认情况下,它还会捕获所有子节点的文本,如下图所示:

如何处理?可以使用jquery提供的contents方法,然后判断获取的所有子节点中是否有文本节点,最后获取文本节点的内容,如下代码所示:

是用js做的,但是用CSQuery代码怎么做呢?模仿一下,代码如下:
static void Main(string[] args)
{
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com";));
var content = jquery["#friend_link"].Contents().Filter((dom) =>
{
return dom.NodeType == NodeType.TEXT_NODE;
}).Text();
Console.WriteLine(content);
}
不知道用xpath提取这样的内容是不是很麻烦,但是jquery也不好用,但是熟悉。
2) 如何为html中的某些元素着色
有时需要为业务更改一些html标签的颜色,例如将首页tabmenu中的博客和区域更改为红色,如下图所示:

如何处理CSQuery?如果你玩过jquery,一般来说步骤如下:
有了步骤,C#代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com";));
var html = jquery["#nav_left li"].Each(dom =>
{
var self = jquery[dom];
var text = self.Text();
if (text == "博问" || text == "专区")
{
self.Find("a").CssSet(new { color = "red" });
}
}).Render();
}

3) 其他操作方法
除了以上两种操作方法,还可以使用after、before、replaceAll、IS等。有一百多种实用方法。这篇文章肯定不能一一介绍。有兴趣的可以下载看看。小提琴。
三:其他用途
除了抓取html中的元素,我觉得这个东西还可以用来在发邮件的时候操作邮件模板。毕竟很久以前大家都是用jquery来画html的,所以CSQuery也是可以的。使用 xslt 有优点也有缺点。, 举个例子:
1. 生成html模板
2. 使用 CSQuery 将 li 附加到 ul
您可以使用 Append 将内容附加到节点。
class Program
{
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var strlist = new string[2] { "1", "2" };
var path = Environment.CurrentDirectory + "\\2.html";
var jquery = CQ.CreateFromFile(path);
foreach (var str in strlist)
{
jquery.Find("#main").Append($"{str}");
}
var html = jquery.Render();
}
}

3. 局部渲染RenderSelection
Render方法是将整个Dom渲染成html,但是有时候你只需要获取你修改的那部分内容而不是整个html,这涉及到部分渲染,可以使用RenderSelection方法,代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var strlist = new string[2] { "1", "2" };
var path = Environment.CurrentDirectory + "\\2.html";
var jquery = CQ.CreateFromFile(path);
var current = jquery.Find("#main");
foreach (var str in strlist)
{
current.Append($"{str}");
}
var html = current.RenderSelection();
Console.WriteLine(html);
}
------------- output ----------------
12
四:总结
Jquery的这种操作方式对我个人来说还是比较舒服的,毕竟我很熟悉!不过html5中也加入了querySelector和querySelectorAll来支持css3选择器,非常强大,但是jquery不仅选择器灵活,节点的操作也很灵活。总的来说,它的交互性不是特别丰富。怀旧。
c#抓取网页数据(网页分析采集程序的基本流程和流程图详解 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-09-27 01:08
)
首先大家要清楚:网站的任何页面,无论是php、jsp、aspx等动态页面,还是后台程序生成的静态页面,都可以在浏览器。
所以当你要开发数据采集程序时,首先要了解网站你试图采集的首页结构(HTML)。
当您熟悉网站中需要采集数据的HTML源文件的内容后,程序的其余部分就很容易处理了。因为C#在网站上执行数据采集,原理是“下载你要采集的页面的HTML源文件,分析HTML代码然后抓取你需要的数据,最后将数据保存到本地文件”。
基本流程如下图所示:
1.页面源文件下载
首先引用 System.Net 命名空间
使用 System.Net;
还需要引用
使用 System.Text;
使用 System.IO;
复制代码
引用后实例化一个 WebClient 对象
private WebClientwc = new WebClient();
调用 DownloadData 方法从指定网页的源文件中下载一组 BYTE 数据,然后将 BYTE 数组转换为字符串。
// 下载页面源文件并转换为UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData( string .Format( "你要的是采集的网页地址" )));
复制代码
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
// 下载网页源文件到本地
wc.DownloadFile( "你要采集的网页的URL", "保存源文件的本地文件路径");
// 读取下载的源文件HTML格式字符串
string mainData = File.ReadAllText( "保存源文件的本地文件路径" ,Encoding.UTF8);
复制代码
通过网页HTML格式字符串,您可以分析网页采集,抓取您需要的内容。
2.页面分析采集
页面分析就是将网页源文件中某个特定的或唯一的字符(字符串)作为抓点,并以此抓点为起点,截取你想要的页面上的数据。
以博客园为专栏。比如我要在博客园首页列出文章的标题和链接,就必须用“
代码:
// 经过”
mainData = mainData.Substring(mainData.IndexOf("") + 26);
// 获取文章页面的链接地址
string articleAddr = mainData.Substring( 0 ,mainData.IndexOf( "\"" ));
// 获取文章的标题
string articleTitle = mainData.Substring(mainData.IndexOf("target=\"_blank\">") + 16,
mainData.IndexOf( "")-mainData.IndexOf( "target=\"_blank\">")-16 );
复制代码
注意:当你要采集的网页前台的HTML格式发生变化时,作为抓点的字符通道也会相应变化,否则什么都没有采集
3.数据保存
从网页截取到自己需要的数据后,将数据保存在程序中,保存到本地文件中(或者插入到自己的本地数据库中)。这样,整个采集作品就会是一个段落。
// 输出数据到本地文件
File.AppendAllText(CreateFolderIfNot(Settings.Default.OutPath) + articleTitle + ".txt",
文章数据,
编码.UTF8);
复制代码
另外附上自己写的采集博客园首页文章的小程序代码。本程序的作用是发布到所有博客园首页文章采集下。
下载链接:CnBlogCollector.rar
当然,如果博客园前端页面的格式有调整,程序的采集功能肯定是无效的。只能自己重新调整程序才能继续采集,哈哈。. .
程序效果如下:
查看全部
c#抓取网页数据(网页分析采集程序的基本流程和流程图详解
)
首先大家要清楚:网站的任何页面,无论是php、jsp、aspx等动态页面,还是后台程序生成的静态页面,都可以在浏览器。

所以当你要开发数据采集程序时,首先要了解网站你试图采集的首页结构(HTML)。
当您熟悉网站中需要采集数据的HTML源文件的内容后,程序的其余部分就很容易处理了。因为C#在网站上执行数据采集,原理是“下载你要采集的页面的HTML源文件,分析HTML代码然后抓取你需要的数据,最后将数据保存到本地文件”。
基本流程如下图所示:

1.页面源文件下载
首先引用 System.Net 命名空间
使用 System.Net;
还需要引用
使用 System.Text;
使用 System.IO;
复制代码
引用后实例化一个 WebClient 对象
private WebClientwc = new WebClient();
调用 DownloadData 方法从指定网页的源文件中下载一组 BYTE 数据,然后将 BYTE 数组转换为字符串。
// 下载页面源文件并转换为UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData( string .Format( "你要的是采集的网页地址" )));
复制代码
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
// 下载网页源文件到本地
wc.DownloadFile( "你要采集的网页的URL", "保存源文件的本地文件路径");
// 读取下载的源文件HTML格式字符串
string mainData = File.ReadAllText( "保存源文件的本地文件路径" ,Encoding.UTF8);
复制代码
通过网页HTML格式字符串,您可以分析网页采集,抓取您需要的内容。
2.页面分析采集
页面分析就是将网页源文件中某个特定的或唯一的字符(字符串)作为抓点,并以此抓点为起点,截取你想要的页面上的数据。
以博客园为专栏。比如我要在博客园首页列出文章的标题和链接,就必须用“

代码:
// 经过”
mainData = mainData.Substring(mainData.IndexOf("") + 26);
// 获取文章页面的链接地址
string articleAddr = mainData.Substring( 0 ,mainData.IndexOf( "\"" ));
// 获取文章的标题
string articleTitle = mainData.Substring(mainData.IndexOf("target=\"_blank\">") + 16,
mainData.IndexOf( "")-mainData.IndexOf( "target=\"_blank\">")-16 );
复制代码
注意:当你要采集的网页前台的HTML格式发生变化时,作为抓点的字符通道也会相应变化,否则什么都没有采集
3.数据保存
从网页截取到自己需要的数据后,将数据保存在程序中,保存到本地文件中(或者插入到自己的本地数据库中)。这样,整个采集作品就会是一个段落。
// 输出数据到本地文件
File.AppendAllText(CreateFolderIfNot(Settings.Default.OutPath) + articleTitle + ".txt",
文章数据,
编码.UTF8);
复制代码
另外附上自己写的采集博客园首页文章的小程序代码。本程序的作用是发布到所有博客园首页文章采集下。
下载链接:CnBlogCollector.rar
当然,如果博客园前端页面的格式有调整,程序的采集功能肯定是无效的。只能自己重新调整程序才能继续采集,哈哈。. .
程序效果如下:

c#抓取网页数据(c#获取数据获取数据库中获取数据的某列数据图分析及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-09-19 23:15
以前学习MVC时,需要直接从数据库中获取项目中表的数据,然后编写查询表数据的方法。现在学习c#,需要查询数据库中的字段,然后在服务器上调用存储过程和方法,然后在客户端实例化服务器,首先从数据库中查询数据,如:
要创建存储过程,它类似于之前在MVC数据库中查询数据的研究。区别在于有一个附加的存储过程方法。然后,VS被分为两部分,一个服务器和一个客户端。因此,服务器获取数据库的数据,客户端获取服务器的数据(表达式不好,不关心细节)。服务器获取数据库中的存储过程和方法,如下图所示:
这是为了获取服务器上数据库中存储过程的查询表数据
然后在客户机上调用服务器的方法。如上图所示,绑定表数据时,调用表数据的方法,如下图所示:
首先实例化服务,然后绑定页面数据,并调用将表数据绑定到页面加载事件的方法
数据查询基本完成,如下图所示:
总结
这里介绍了文章在c#中获取数据。有关在c#中获取数据的更多信息,请搜索179885.Com以前的文章或继续浏览下面相关的文章页面。我希望你将来能支持它179885.Com
C#获取数据C#获取数据库中的最大值C#获取数据一行中的一列数据 查看全部
c#抓取网页数据(c#获取数据获取数据库中获取数据的某列数据图分析及应用)
以前学习MVC时,需要直接从数据库中获取项目中表的数据,然后编写查询表数据的方法。现在学习c#,需要查询数据库中的字段,然后在服务器上调用存储过程和方法,然后在客户端实例化服务器,首先从数据库中查询数据,如:

要创建存储过程,它类似于之前在MVC数据库中查询数据的研究。区别在于有一个附加的存储过程方法。然后,VS被分为两部分,一个服务器和一个客户端。因此,服务器获取数据库的数据,客户端获取服务器的数据(表达式不好,不关心细节)。服务器获取数据库中的存储过程和方法,如下图所示:

这是为了获取服务器上数据库中存储过程的查询表数据
然后在客户机上调用服务器的方法。如上图所示,绑定表数据时,调用表数据的方法,如下图所示:
首先实例化服务,然后绑定页面数据,并调用将表数据绑定到页面加载事件的方法

数据查询基本完成,如下图所示:

总结
这里介绍了文章在c#中获取数据。有关在c#中获取数据的更多信息,请搜索179885.Com以前的文章或继续浏览下面相关的文章页面。我希望你将来能支持它179885.Com
C#获取数据C#获取数据库中的最大值C#获取数据一行中的一列数据
c#抓取网页数据(保险起见输入账号密码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-19 07:06
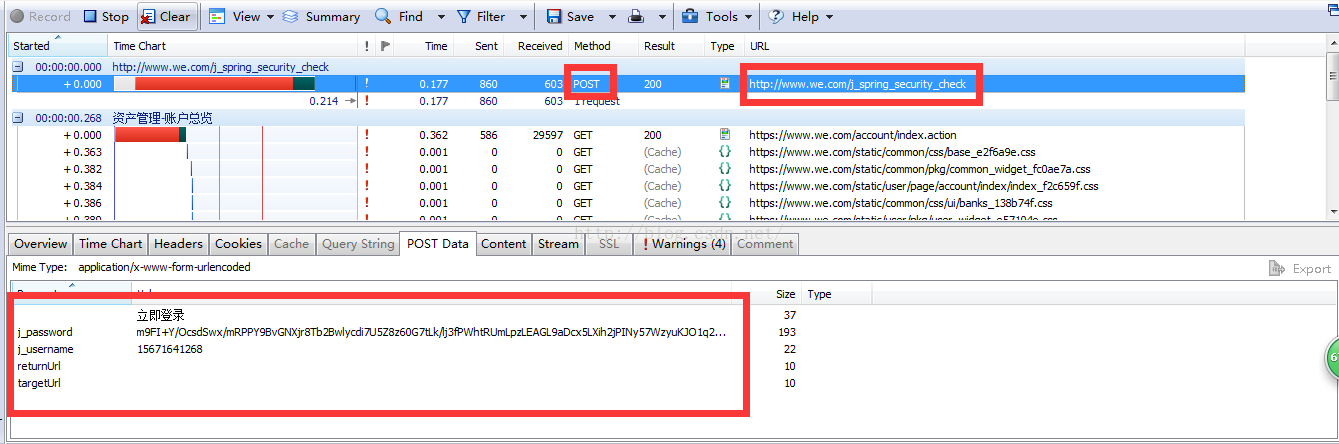
4.输入账户密码,确认登录,获取以下数据:
关注post请求中的URL和postData,以及服务器返回的cookie
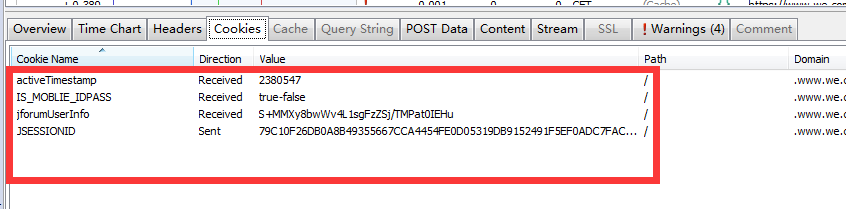
cookie收录登录信息。为了安全起见,我们可以将这四个cookie值传递给服务器
首先给出c#发送post请求的代码:(目的是获取服务器返回的cookie)
string Url = "URL";
string postDataStr = "POST Data";//因为上面都是离散的键值对,我们可以从Stream中直接找到postDataStr
//登录并获取cookie
HttpPost(Url, postDataStr, ref cookie);
private string HttpPost(string Url, string postDataStr, ref CookieContainer cookie)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
request.Method = "POST";
request.ContentType = "application/x-www-form-urlencoded";
byte[] postData = Encoding.UTF8.GetBytes(postDataStr);
request.ContentLength = postData.Length;
request.CookieContainer = cookie;
Stream myRequestStream = request.GetRequestStream();
myRequestStream.Write(postData, 0, postData.Length);
myRequestStream.Close();
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
response.Cookies = cookie.GetCookies(response.ResponseUri);
Stream myResponseStream = response.GetResponseStream();
StreamReader myStreamReader = new StreamReader(myResponseStream, Encoding.GetEncoding("utf-8"));
string retString = myStreamReader.ReadToEnd();
myStreamReader.Close();
myResponseStream.Close();
return retString;
}
通过cookie,您可以从网站获取所需的数据,然后发送get请求
由于服务器返回HTML,如何从大量HTML中快速获取所需信息?在这里,我们可以引用一个高效而强大的第三方库nsoup(有些人建议在互联网上使用HTMLPasser,但通过我个人的比较,我发现HTMLPasser在效率和简单性方面远远不如nsoup)
由于nsoup上的在线教程相对较少,您也可以参考jsoup上的教程:
最后,给出了我从网站获取的一些数据:
我在纸上感觉肤浅。我绝对知道我必须练习 查看全部
c#抓取网页数据(保险起见输入账号密码)
4.输入账户密码,确认登录,获取以下数据:
关注post请求中的URL和postData,以及服务器返回的cookie
cookie收录登录信息。为了安全起见,我们可以将这四个cookie值传递给服务器
首先给出c#发送post请求的代码:(目的是获取服务器返回的cookie)
string Url = "URL";
string postDataStr = "POST Data";//因为上面都是离散的键值对,我们可以从Stream中直接找到postDataStr
//登录并获取cookie
HttpPost(Url, postDataStr, ref cookie);
private string HttpPost(string Url, string postDataStr, ref CookieContainer cookie)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
request.Method = "POST";
request.ContentType = "application/x-www-form-urlencoded";
byte[] postData = Encoding.UTF8.GetBytes(postDataStr);
request.ContentLength = postData.Length;
request.CookieContainer = cookie;
Stream myRequestStream = request.GetRequestStream();
myRequestStream.Write(postData, 0, postData.Length);
myRequestStream.Close();
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
response.Cookies = cookie.GetCookies(response.ResponseUri);
Stream myResponseStream = response.GetResponseStream();
StreamReader myStreamReader = new StreamReader(myResponseStream, Encoding.GetEncoding("utf-8"));
string retString = myStreamReader.ReadToEnd();
myStreamReader.Close();
myResponseStream.Close();
return retString;
}
通过cookie,您可以从网站获取所需的数据,然后发送get请求
由于服务器返回HTML,如何从大量HTML中快速获取所需信息?在这里,我们可以引用一个高效而强大的第三方库nsoup(有些人建议在互联网上使用HTMLPasser,但通过我个人的比较,我发现HTMLPasser在效率和简单性方面远远不如nsoup)
由于nsoup上的在线教程相对较少,您也可以参考jsoup上的教程:
最后,给出了我从网站获取的一些数据:
我在纸上感觉肤浅。我绝对知道我必须练习
c#抓取网页数据(什么是抓取、收录网页抓取工具robots.txt文件介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-09-17 09:14
网站建成后,我们如何才能使搜索引擎收录网站?如果搜索引擎收录无法搜索该页面,则意味着没有显示,并且不可能竞争排名和获得SEO流量。本文将重点关注捕获和收录亮点,并从三个维度讨论搜索引擎优化:基本原理、常见问题和解决方案。什么是爬行,收录web爬行工具robots.txt文件介绍
如何查看网站的收录@
设置不被搜索引擎索引的网页
搜索引擎原理:搜索引擎将互联网上的网页内容存储在自己的服务器上。当用户搜索一个单词时,搜索引擎将在其自己的服务器上查找相关内容,即只搜索保存在搜索引擎服务器上的网页
哪些网页可以保存到搜索引擎服务器
只有搜索引擎捕获程序捕获的网页才会保存到搜索引擎的服务器。这个网页捕获程序是搜索引擎的蜘蛛。整个过程分为爬行和爬行
一、什么是抓取,收录
爬行:
这是搜索引擎爬虫在网站上爬行的过程。谷歌的官方解释是,“爬行”指的是找到新的或更新的网页并将其添加到谷歌的过程;(点击此处查看谷歌官方网站上的文档)
收录(索引):
这是搜索引擎将页面存储在其数据库中的结果,该数据库也称为索引。谷歌的官方解释是,谷歌爬虫(“谷歌机器人”)已经访问了该网页,分析了其内容和含义,并将其存储在谷歌索引中。索引网页可以显示在谷歌搜索结果;(点击此处查看谷歌官方网站上的文档)
预算:
是搜索引擎爬行器在网站页面上爬行的最长总时间。一般来说,小的网站(数百或数千页)不需要担心搜索引擎分配的爬网配额是否足够;大网站(数百万或数以百万计的页面)将考虑更多。如果搜索引擎每天抓取数万页,那么整个网站页面抓取可能需要几个月或一年的时间。一般来说,这些数据可以通过谷歌搜索控制台的后台学习。如下面的屏幕截图所示,红色框中的平均值是网站分配的抓取配额
让我们通过一个示例更好地了解爬网、收录和配额爬网:
将搜索引擎比作一个巨大的图书馆,网站比作一家书店,书店里的书比作网站页面,蜘蛛比作图书馆购买者
为了丰富图书馆的藏书,购买者会定期检查书店是否有新书。浏览书籍的过程可以理解为抓取
当买主认为这本书有价值时,他会买下来带回图书馆采集。这本书就是我们所说的收录
每个买家都有一个有限的购书预算。他将优先购买高价值的书籍。这个预算案就是我们所理解的“抢占配额”
二、web爬虫
“爬虫”是一个通用术语,通常指通过跟踪从一个网页到另一个网页的链接,在网站自动发现和扫描的任何程序(如漫游设备或“蜘蛛”程序)。谷歌的主要爬虫程序叫做谷歌机器人
三、robots.txt文件介绍
robots.txt文件指定爬行工具的爬行规则
robots.txt文件必须位于主机的顶级目录中
通常,robots.txt文件中有三种不同的爬行结果:
robots.txt的使用示例:网站目录中的所有文件都可以被所有搜索引擎爬行器访问。用户代理:*
Disallow:
禁止所有搜索引擎蜘蛛访问网站的任何部分
User-agent: *
Disallow: /
禁止所有的搜索引擎蜘蛛访问网站的几个目录
User-agent: *
Disallow: /a/
Disallow: /b/
只允许某个搜索引擎蜘蛛访问
User-agent: Googlebot
Disallow:
屏蔽所有带参数的 URL
User-agent: *
Disallow: /*?
您应该限制爬行器捕获网站某些文件:
一般来说,网站爬行器不需要捕获的文件包括后台管理文件、程序脚本、附件、数据库文件、编码文件、样式表文件、模板文件、导航图片和背景图片
robots.txt文件引起的风险和解决方案:
Robots.txt也带来了一些风险:它还向攻击者指示网站的目录结构和私有数据的位置。设置访问权限和密码以保护您的私人内容,使攻击者无法进入
四、如何查看收录或网站
① 通过site命令
谷歌、百度和必应等主流搜索引擎支持站点命令。通过site命令,您可以查看在宏级别网站已经收录了多少页。该值不准确,有一定波动,但有一定参考价值。如下图所示,网站约为165页,由谷歌收录发布@
② 如果网站已经验证了谷歌搜索控制台,您可以获得网站验证Google收录的准确值显示在下面的红色框中,Google收录216页共网站页@
③ 如果要查询特定页面是否为收录,可以使用info命令。谷歌支持info命令,但百度和必应不支持。在谷歌中输入Info:URL。如果返回结果,则页面已被收录,如下图所示:
五、set不被搜索引擎索引的网页
建议使用robots meta标记,并将以下代码添加到head标记中:
可以选择多条指令,它们不区分大小写
全部
对索引或内容显示没有任何限制。此命令是默认命令,因此显式列出时无效
诺因迪斯
在搜索结果中不显示此页面。Nofollow不跟踪此页面上的链接
没有
相当于Noindex,nofollow。Noarchive不在搜索结果中显示缓存链接
nosnippet
不要在搜索结果中显示此页面的文本摘要或视频预览。如果静态图片缩略图(如果有)可以实现更好的用户体验,则仍然可以显示它们。这适用于所有形式的搜索结果(例如谷歌网页搜索、谷歌图片、谷歌探索)
最大代码段:[数字]
此搜索结果的文本摘要最多只能使用[number]个字符。(请注意,网址可能在搜索结果页面中显示为多个搜索结果。)这不会影响图片或视频预览。这适用于所有形式的搜索结果(例如谷歌网页搜索、谷歌图片、谷歌发现、谷歌助手)。但是,如果发布者已单独授予内容权限,则此限制不适用。例如,如果发布者以页面结构化数据的形式提供内容,或者与谷歌签订了许可协议,则此设置不会阻止这些更具体的允许使用。如果未指定可解析的[number],则忽略此指令
特殊值:
例如:
最大图像预览:[设置]
设置搜索结果中此页面图片预览的最大大小
可接受的设定值:
这适用于所有形式的搜索结果(例如谷歌网页搜索、谷歌图片、谷歌发现、谷歌助手)。但是,如果发布者已单独授予内容权限,则此限制不适用。例如,如果发布者以页内结构化数据的形式提供内容(如amp网页和文章的规范版本),或者与Google签订了许可协议,则此设置不会阻止这些更具体的允许使用
如果出版商不希望Google在搜索结果页面或“浏览”功能中文章显示其amp网页和规范版本时使用大缩略图,则应将Max image preview的值指定为“标准”或“无”
例如:
最大视频预览:[数字]
此页面上的视频在搜索结果中的摘要时间不能超过[number]秒
其他支持的值:
这适用于所有形式的搜索结果(例如谷歌网页搜索、谷歌图片、谷歌视频、谷歌发现、谷歌助手)。如果未指定可解析的[number],则忽略此指令
例如:
不翻译
不要在搜索结果中提供此页面的翻译
noimageindex
不要为此页上的图片编制索引
[日期/时间]之后不可用
在指定的日期/时间之后,不要在搜索结果中显示此页面。必须以广泛使用的格式指定日期/时间,包括但不限于RFC822、RFC 850和ISO 8601。如果未指定有效的[日期/时间],则忽略此指令。默认情况下,内容没有过期日期
例如:
参考资料: 查看全部
c#抓取网页数据(什么是抓取、收录网页抓取工具robots.txt文件介绍)
网站建成后,我们如何才能使搜索引擎收录网站?如果搜索引擎收录无法搜索该页面,则意味着没有显示,并且不可能竞争排名和获得SEO流量。本文将重点关注捕获和收录亮点,并从三个维度讨论搜索引擎优化:基本原理、常见问题和解决方案。什么是爬行,收录web爬行工具robots.txt文件介绍
如何查看网站的收录@
设置不被搜索引擎索引的网页
搜索引擎原理:搜索引擎将互联网上的网页内容存储在自己的服务器上。当用户搜索一个单词时,搜索引擎将在其自己的服务器上查找相关内容,即只搜索保存在搜索引擎服务器上的网页
哪些网页可以保存到搜索引擎服务器
只有搜索引擎捕获程序捕获的网页才会保存到搜索引擎的服务器。这个网页捕获程序是搜索引擎的蜘蛛。整个过程分为爬行和爬行
一、什么是抓取,收录
爬行:
这是搜索引擎爬虫在网站上爬行的过程。谷歌的官方解释是,“爬行”指的是找到新的或更新的网页并将其添加到谷歌的过程;(点击此处查看谷歌官方网站上的文档)
收录(索引):
这是搜索引擎将页面存储在其数据库中的结果,该数据库也称为索引。谷歌的官方解释是,谷歌爬虫(“谷歌机器人”)已经访问了该网页,分析了其内容和含义,并将其存储在谷歌索引中。索引网页可以显示在谷歌搜索结果;(点击此处查看谷歌官方网站上的文档)
预算:
是搜索引擎爬行器在网站页面上爬行的最长总时间。一般来说,小的网站(数百或数千页)不需要担心搜索引擎分配的爬网配额是否足够;大网站(数百万或数以百万计的页面)将考虑更多。如果搜索引擎每天抓取数万页,那么整个网站页面抓取可能需要几个月或一年的时间。一般来说,这些数据可以通过谷歌搜索控制台的后台学习。如下面的屏幕截图所示,红色框中的平均值是网站分配的抓取配额
让我们通过一个示例更好地了解爬网、收录和配额爬网:
将搜索引擎比作一个巨大的图书馆,网站比作一家书店,书店里的书比作网站页面,蜘蛛比作图书馆购买者
为了丰富图书馆的藏书,购买者会定期检查书店是否有新书。浏览书籍的过程可以理解为抓取
当买主认为这本书有价值时,他会买下来带回图书馆采集。这本书就是我们所说的收录
每个买家都有一个有限的购书预算。他将优先购买高价值的书籍。这个预算案就是我们所理解的“抢占配额”
二、web爬虫
“爬虫”是一个通用术语,通常指通过跟踪从一个网页到另一个网页的链接,在网站自动发现和扫描的任何程序(如漫游设备或“蜘蛛”程序)。谷歌的主要爬虫程序叫做谷歌机器人
三、robots.txt文件介绍
robots.txt文件指定爬行工具的爬行规则
robots.txt文件必须位于主机的顶级目录中
通常,robots.txt文件中有三种不同的爬行结果:
robots.txt的使用示例:网站目录中的所有文件都可以被所有搜索引擎爬行器访问。用户代理:*
Disallow:
禁止所有搜索引擎蜘蛛访问网站的任何部分
User-agent: *
Disallow: /
禁止所有的搜索引擎蜘蛛访问网站的几个目录
User-agent: *
Disallow: /a/
Disallow: /b/
只允许某个搜索引擎蜘蛛访问
User-agent: Googlebot
Disallow:
屏蔽所有带参数的 URL
User-agent: *
Disallow: /*?
您应该限制爬行器捕获网站某些文件:
一般来说,网站爬行器不需要捕获的文件包括后台管理文件、程序脚本、附件、数据库文件、编码文件、样式表文件、模板文件、导航图片和背景图片
robots.txt文件引起的风险和解决方案:
Robots.txt也带来了一些风险:它还向攻击者指示网站的目录结构和私有数据的位置。设置访问权限和密码以保护您的私人内容,使攻击者无法进入
四、如何查看收录或网站
① 通过site命令
谷歌、百度和必应等主流搜索引擎支持站点命令。通过site命令,您可以查看在宏级别网站已经收录了多少页。该值不准确,有一定波动,但有一定参考价值。如下图所示,网站约为165页,由谷歌收录发布@
② 如果网站已经验证了谷歌搜索控制台,您可以获得网站验证Google收录的准确值显示在下面的红色框中,Google收录216页共网站页@
③ 如果要查询特定页面是否为收录,可以使用info命令。谷歌支持info命令,但百度和必应不支持。在谷歌中输入Info:URL。如果返回结果,则页面已被收录,如下图所示:
五、set不被搜索引擎索引的网页
建议使用robots meta标记,并将以下代码添加到head标记中:
可以选择多条指令,它们不区分大小写
全部
对索引或内容显示没有任何限制。此命令是默认命令,因此显式列出时无效
诺因迪斯
在搜索结果中不显示此页面。Nofollow不跟踪此页面上的链接
没有
相当于Noindex,nofollow。Noarchive不在搜索结果中显示缓存链接
nosnippet
不要在搜索结果中显示此页面的文本摘要或视频预览。如果静态图片缩略图(如果有)可以实现更好的用户体验,则仍然可以显示它们。这适用于所有形式的搜索结果(例如谷歌网页搜索、谷歌图片、谷歌探索)
最大代码段:[数字]
此搜索结果的文本摘要最多只能使用[number]个字符。(请注意,网址可能在搜索结果页面中显示为多个搜索结果。)这不会影响图片或视频预览。这适用于所有形式的搜索结果(例如谷歌网页搜索、谷歌图片、谷歌发现、谷歌助手)。但是,如果发布者已单独授予内容权限,则此限制不适用。例如,如果发布者以页面结构化数据的形式提供内容,或者与谷歌签订了许可协议,则此设置不会阻止这些更具体的允许使用。如果未指定可解析的[number],则忽略此指令
特殊值:
例如:
最大图像预览:[设置]
设置搜索结果中此页面图片预览的最大大小
可接受的设定值:
这适用于所有形式的搜索结果(例如谷歌网页搜索、谷歌图片、谷歌发现、谷歌助手)。但是,如果发布者已单独授予内容权限,则此限制不适用。例如,如果发布者以页内结构化数据的形式提供内容(如amp网页和文章的规范版本),或者与Google签订了许可协议,则此设置不会阻止这些更具体的允许使用
如果出版商不希望Google在搜索结果页面或“浏览”功能中文章显示其amp网页和规范版本时使用大缩略图,则应将Max image preview的值指定为“标准”或“无”
例如:
最大视频预览:[数字]
此页面上的视频在搜索结果中的摘要时间不能超过[number]秒
其他支持的值:
这适用于所有形式的搜索结果(例如谷歌网页搜索、谷歌图片、谷歌视频、谷歌发现、谷歌助手)。如果未指定可解析的[number],则忽略此指令
例如:
不翻译
不要在搜索结果中提供此页面的翻译
noimageindex
不要为此页上的图片编制索引
[日期/时间]之后不可用
在指定的日期/时间之后,不要在搜索结果中显示此页面。必须以广泛使用的格式指定日期/时间,包括但不限于RFC822、RFC 850和ISO 8601。如果未指定有效的[日期/时间],则忽略此指令。默认情况下,内容没有过期日期
例如:
参考资料:
c#抓取网页数据(一个解析辅助类:HtmlAgilityPack,解析解析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-09-16 00:20
)
这里我们使用一个HTML解析辅助类:HtmlAlityPack。如果您没有在线找到一个插件并将其添加到库中,那么该插件有很多版本。如果您使用VS2005作为您的开发环境,那么就可以了2.0VS2010使用类库4.0等等然后直接创建一个控制台应用程序并替换下面的代码副本以运行,让我们谈谈两年前我作为爬虫的经验。当时,它是为一家公司制造的,也使用c。然而,当时我遇到了一个头疼的问题,那就是拍摄的图像中有病毒,然后系统挂了好几次。因此,抓取网站图片时要注意安全。虽然我这里不涉及图片,但我仍然提醒我那些看文章的朋友们@
<p> class Program
{
//存放所有抓取的代理
public static List masterPorxyList = new List();
//代理IP类
public class proxy
{
public string ip;
public string port;
public int speed;
public proxy(string pip,string pport,int pspeed)
{
this.ip = pip;
this.port = pport;
this.speed = pspeed;
}
}
//抓去处理方法
static void getProxyList(object pageIndex)
{
string urlCombin = "http://www.xicidaili.com/wt/" + pageIndex.ToString();
string catchHtml = catchProxIpMethord(urlCombin, "UTF8");
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(catchHtml);
HtmlNode table = doc.DocumentNode.SelectSingleNode("//div[@id='wrapper']//div[@id='body']/table[1]");
HtmlNodeCollection collectiontrs = table.SelectNodes("./tr");
for (int i = 0; i < collectiontrs.Count; i++)
{
HtmlAgilityPack.HtmlNode itemtr = collectiontrs[i];
HtmlNodeCollection collectiontds = itemtr.ChildNodes;
//table中第一个是能用的代理标题,所以这里从第二行TR开始取值
if (i>0)
{
HtmlNode itemtdip = (HtmlNode)collectiontds[3];
HtmlNode itemtdport = (HtmlNode)collectiontds[5];
HtmlNode itemtdspeed = (HtmlNode)collectiontds[13];
string ip = itemtdip.InnerText.Trim();
string port = itemtdport.InnerText.Trim();
string speed = itemtdspeed.InnerHtml;
int beginIndex = speed.IndexOf(":", 0, speed.Length);
int endIndex = speed.IndexOf("%", 0, speed.Length);
int subSpeed = int.Parse(speed.Substring(beginIndex + 1, endIndex - beginIndex - 1));
//如果速度展示条的值大于90,表示这个代理速度快。
if (subSpeed > 90)
{
proxy temp = new proxy(ip, port, subSpeed);
masterPorxyList.Add(temp);
Console.WriteLine("当前是第:" + masterPorxyList.Count.ToString() + "个代理IP");
}
}
}
}
//抓网页方法
static string catchProxIpMethord(string url,string encoding )
{
string htmlStr = "";
try
{
if (!String.IsNullOrEmpty(url))
{
WebRequest request = WebRequest.Create(url);
WebResponse response = request.GetResponse();
Stream datastream = response.GetResponseStream();
Encoding ec = Encoding.Default;
if (encoding == "UTF8")
{
ec = Encoding.UTF8;
}
else if (encoding == "Default")
{
ec = Encoding.Default;
}
StreamReader reader = new StreamReader(datastream, ec);
htmlStr = reader.ReadToEnd();
reader.Close();
datastream.Close();
response.Close();
}
}
catch { }
return htmlStr;
}
static void Main(string[] args)
{
//多线程同时抓15页
for (int i = 1; i 查看全部
c#抓取网页数据(一个解析辅助类:HtmlAgilityPack,解析解析
)
这里我们使用一个HTML解析辅助类:HtmlAlityPack。如果您没有在线找到一个插件并将其添加到库中,那么该插件有很多版本。如果您使用VS2005作为您的开发环境,那么就可以了2.0VS2010使用类库4.0等等然后直接创建一个控制台应用程序并替换下面的代码副本以运行,让我们谈谈两年前我作为爬虫的经验。当时,它是为一家公司制造的,也使用c。然而,当时我遇到了一个头疼的问题,那就是拍摄的图像中有病毒,然后系统挂了好几次。因此,抓取网站图片时要注意安全。虽然我这里不涉及图片,但我仍然提醒我那些看文章的朋友们@
<p> class Program
{
//存放所有抓取的代理
public static List masterPorxyList = new List();
//代理IP类
public class proxy
{
public string ip;
public string port;
public int speed;
public proxy(string pip,string pport,int pspeed)
{
this.ip = pip;
this.port = pport;
this.speed = pspeed;
}
}
//抓去处理方法
static void getProxyList(object pageIndex)
{
string urlCombin = "http://www.xicidaili.com/wt/" + pageIndex.ToString();
string catchHtml = catchProxIpMethord(urlCombin, "UTF8");
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(catchHtml);
HtmlNode table = doc.DocumentNode.SelectSingleNode("//div[@id='wrapper']//div[@id='body']/table[1]");
HtmlNodeCollection collectiontrs = table.SelectNodes("./tr");
for (int i = 0; i < collectiontrs.Count; i++)
{
HtmlAgilityPack.HtmlNode itemtr = collectiontrs[i];
HtmlNodeCollection collectiontds = itemtr.ChildNodes;
//table中第一个是能用的代理标题,所以这里从第二行TR开始取值
if (i>0)
{
HtmlNode itemtdip = (HtmlNode)collectiontds[3];
HtmlNode itemtdport = (HtmlNode)collectiontds[5];
HtmlNode itemtdspeed = (HtmlNode)collectiontds[13];
string ip = itemtdip.InnerText.Trim();
string port = itemtdport.InnerText.Trim();
string speed = itemtdspeed.InnerHtml;
int beginIndex = speed.IndexOf(":", 0, speed.Length);
int endIndex = speed.IndexOf("%", 0, speed.Length);
int subSpeed = int.Parse(speed.Substring(beginIndex + 1, endIndex - beginIndex - 1));
//如果速度展示条的值大于90,表示这个代理速度快。
if (subSpeed > 90)
{
proxy temp = new proxy(ip, port, subSpeed);
masterPorxyList.Add(temp);
Console.WriteLine("当前是第:" + masterPorxyList.Count.ToString() + "个代理IP");
}
}
}
}
//抓网页方法
static string catchProxIpMethord(string url,string encoding )
{
string htmlStr = "";
try
{
if (!String.IsNullOrEmpty(url))
{
WebRequest request = WebRequest.Create(url);
WebResponse response = request.GetResponse();
Stream datastream = response.GetResponseStream();
Encoding ec = Encoding.Default;
if (encoding == "UTF8")
{
ec = Encoding.UTF8;
}
else if (encoding == "Default")
{
ec = Encoding.Default;
}
StreamReader reader = new StreamReader(datastream, ec);
htmlStr = reader.ReadToEnd();
reader.Close();
datastream.Close();
response.Close();
}
}
catch { }
return htmlStr;
}
static void Main(string[] args)
{
//多线程同时抓15页
for (int i = 1; i
c#抓取网页数据(两个c#开发的网络爬虫老外写的相当不错:解析结果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-09-13 12:11
项目经理说这是项目的一个亮点(无语...),类似爬虫的东西,模拟登录后台系统获取所需数据。然后开始研究这个。
之前有一些数据抓取的经验,抓取过程无非是:设置参数->服务器发送请求->解析结果
1、验证码识别
系统验证码只有数字,并不复杂,没有深入研究。
这完全满足我的需求。
2、用户名和密码由用户提供。
里面有证书,每次申请都必须随身携带。
证书获取方式:
3、网上有很多模拟登录的请求。
推荐一位大神,写的相当好:
4、parse html 内容
推荐一个类库:HtmlAgilityPack,好用。它将html字符串转换为xml类型的操作(本来我想用普通的)。
有了上面的东西,基本上就可以调试工作了。如果要做后台服务,还需要定时任务。这仍在研究中。 . .
经验:
1、登录的时候一直提示验证码错误,很费解,因为我是手动输入验证码的。用抓包工具分析后发现是JSESSIONID(使用的是JSP网站服务器),这个是每次请求都要带的,JSESSIONID是否正确。
2、抓数据时提示登录超时,郁闷了半天,抽了根烟,把问题指向相关参数。抓包分析后,问题出现在JSESSIONID上,JSESSIONID的值不正确。修改后一切正常。
开源的网络爬虫有很多,在Sourceforge上搜索也有很多,但C#很少。今天推荐两个c#开发的网络爬虫
老外写的,http通信使用socket,效果很好,但是没有处理中文,下载中文时会出现乱码。在socket接收部分做一些处理就可以了。这个程序比较完整,具备了一个基本爬虫的所有功能,就是一个很好的例子。 VS2003, .net 1.1 有些已经过时,需要调整。
是老外写的,csspider.zip。没有仔细研究,遵循LGPL协议,这位同志是专门研究爬虫的,写过很多书,但是都是英文的,看不懂。 .net 2.0。
这里介绍的两个例子都是比较完整的例子,包括网页下载、分析、多线程、输出。下面的一点点处理就能得到很好的效果,同时也可以研究更多的实现思路,对自己的爬虫有很大的帮助。 查看全部
c#抓取网页数据(两个c#开发的网络爬虫老外写的相当不错:解析结果)
项目经理说这是项目的一个亮点(无语...),类似爬虫的东西,模拟登录后台系统获取所需数据。然后开始研究这个。
之前有一些数据抓取的经验,抓取过程无非是:设置参数->服务器发送请求->解析结果
1、验证码识别
系统验证码只有数字,并不复杂,没有深入研究。
这完全满足我的需求。
2、用户名和密码由用户提供。
里面有证书,每次申请都必须随身携带。
证书获取方式:
3、网上有很多模拟登录的请求。
推荐一位大神,写的相当好:
4、parse html 内容
推荐一个类库:HtmlAgilityPack,好用。它将html字符串转换为xml类型的操作(本来我想用普通的)。
有了上面的东西,基本上就可以调试工作了。如果要做后台服务,还需要定时任务。这仍在研究中。 . .
经验:
1、登录的时候一直提示验证码错误,很费解,因为我是手动输入验证码的。用抓包工具分析后发现是JSESSIONID(使用的是JSP网站服务器),这个是每次请求都要带的,JSESSIONID是否正确。
2、抓数据时提示登录超时,郁闷了半天,抽了根烟,把问题指向相关参数。抓包分析后,问题出现在JSESSIONID上,JSESSIONID的值不正确。修改后一切正常。
开源的网络爬虫有很多,在Sourceforge上搜索也有很多,但C#很少。今天推荐两个c#开发的网络爬虫
老外写的,http通信使用socket,效果很好,但是没有处理中文,下载中文时会出现乱码。在socket接收部分做一些处理就可以了。这个程序比较完整,具备了一个基本爬虫的所有功能,就是一个很好的例子。 VS2003, .net 1.1 有些已经过时,需要调整。
是老外写的,csspider.zip。没有仔细研究,遵循LGPL协议,这位同志是专门研究爬虫的,写过很多书,但是都是英文的,看不懂。 .net 2.0。
这里介绍的两个例子都是比较完整的例子,包括网页下载、分析、多线程、输出。下面的一点点处理就能得到很好的效果,同时也可以研究更多的实现思路,对自己的爬虫有很大的帮助。
c#抓取网页数据(1.讲故事民生资讯号民生民生)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-10-09 01:05
一:背景1.讲故事
前段时间,我创建了一个当地民生信息账号。我复制了你的信息。你复制了官方媒体。市民喜欢奇怪的东西。所以需要如何定位和捕捉奇怪的东西。账号上的消息其实做起来很简单,用logistic回归就可以了。本文主要讨论如何爬取。在C#中,大家都知道抓取的通用库是HtmlAgilityPack,但是这个库的主流方法是使用xpath来提取网页的内容,让我很不爽。毕竟,我不熟悉莫名的抵抗。一个我这个年纪的码农受过 Jquery 的教育至少 5-6 年,所以我必须使用类似 Jquery 的方法。python中有pyquery。这样做,就是
C# 中有类似的方法吗?哎,真的有全能的github。. . 这就是本文介绍的CSQuery。
二:CSQuery1.安装
github地址:然后直接在vs中点击nuget:
2. 举几个例子
万事俱备,那么如何使用呢?别着急,我举两个博客园里的例子。
1) 从主页提取友情链接到
如上图所示,这里如果要获取友情链接的几个大字,直接使用text()肯定是不行的。默认情况下,它还会捕获所有子节点的文本,如下图所示:
如何处理?可以使用jquery提供的contents方法,然后判断获取的所有子节点中是否有文本节点,最后获取文本节点的内容,如下代码所示:
是用js做的,但是用CSQuery代码怎么做呢?模仿一下,代码如下:
static void Main(string[] args)
{
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com"));
var content = jquery["#friend_link"].Contents().Filter((dom) =>
{
return dom.NodeType == NodeType.TEXT_NODE;
}).Text();
Console.WriteLine(content);
}
不知道用xpath提取这样的内容是不是很麻烦,但是jquery也不好用,但是熟悉。
2) 如何给html中的一些元素着色
有时需要为业务更改某些html标签的颜色,例如将首页tabmenu中的博客和区域更改为红色,如下图所示:
如何处理CSQuery?如果你玩过jquery,一般来说步骤如下:
有了步骤,C#代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com"));
var html = jquery["#nav_left li"].Each(dom =>
{
var self = jquery[dom];
var text = self.Text();
if (text == "博问" || text == "专区")
{
self.Find("a").CssSet(new { color = "red" });
}
}).Render();
}
3) 其他操作方法
除了以上两种操作方法,还可以使用after、before、replaceAll、IS等。有一百多种实用方法。这篇文章肯定不能一一介绍。有兴趣的可以下载看看。小提琴。
三:其他用途
除了抓取html中的元素,我觉得这个东西还可以用来在发送邮件的时候操作邮件模板。毕竟很久以前大家都是用jquery来画html的,所以CSQuery也是可以的。使用 xslt 有优点也有缺点。, 举个例子:
1. 生成html模板
2. 使用 CSQuery 将 li 附加到 ul
您可以使用 Append 将内容附加到节点。
class Program
{
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var strlist = new string[2] { "1", "2" };
var path = Environment.CurrentDirectory + "\\2.html";
var jquery = CQ.CreateFromFile(path);
foreach (var str in strlist)
{
jquery.Find("#main").Append($"{str}");
}
var html = jquery.Render();
}
}
3. 局部渲染RenderSelection
Render方法是将整个Dom渲染成html,但是有时候你只需要获取你修改的那部分内容而不是整个html,这涉及到部分渲染,可以使用RenderSelection方法,代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var strlist = new string[2] { "1", "2" };
var path = Environment.CurrentDirectory + "\\2.html";
var jquery = CQ.CreateFromFile(path);
var current = jquery.Find("#main");
foreach (var str in strlist)
{
current.Append($"{str}");
}
var html = current.RenderSelection();
Console.WriteLine(html);
}
------------- output ----------------
12
四:总结
Jquery的这种操作方式对我个人来说还是比较舒服的,毕竟我很熟悉!不过html5中也加入了querySelector和querySelectorAll来支持css3选择器,非常强大,但是jquery不仅选择器灵活,节点的操作也很灵活。总的来说,它的交互性不是特别丰富。怀旧。 查看全部
c#抓取网页数据(1.讲故事民生资讯号民生民生)
一:背景1.讲故事
前段时间,我创建了一个当地民生信息账号。我复制了你的信息。你复制了官方媒体。市民喜欢奇怪的东西。所以需要如何定位和捕捉奇怪的东西。账号上的消息其实做起来很简单,用logistic回归就可以了。本文主要讨论如何爬取。在C#中,大家都知道抓取的通用库是HtmlAgilityPack,但是这个库的主流方法是使用xpath来提取网页的内容,让我很不爽。毕竟,我不熟悉莫名的抵抗。一个我这个年纪的码农受过 Jquery 的教育至少 5-6 年,所以我必须使用类似 Jquery 的方法。python中有pyquery。这样做,就是
C# 中有类似的方法吗?哎,真的有全能的github。. . 这就是本文介绍的CSQuery。
二:CSQuery1.安装
github地址:然后直接在vs中点击nuget:
2. 举几个例子
万事俱备,那么如何使用呢?别着急,我举两个博客园里的例子。
1) 从主页提取友情链接到
如上图所示,这里如果要获取友情链接的几个大字,直接使用text()肯定是不行的。默认情况下,它还会捕获所有子节点的文本,如下图所示:
如何处理?可以使用jquery提供的contents方法,然后判断获取的所有子节点中是否有文本节点,最后获取文本节点的内容,如下代码所示:
是用js做的,但是用CSQuery代码怎么做呢?模仿一下,代码如下:
static void Main(string[] args)
{
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com";));
var content = jquery["#friend_link"].Contents().Filter((dom) =>
{
return dom.NodeType == NodeType.TEXT_NODE;
}).Text();
Console.WriteLine(content);
}
不知道用xpath提取这样的内容是不是很麻烦,但是jquery也不好用,但是熟悉。
2) 如何给html中的一些元素着色
有时需要为业务更改某些html标签的颜色,例如将首页tabmenu中的博客和区域更改为红色,如下图所示:
如何处理CSQuery?如果你玩过jquery,一般来说步骤如下:
有了步骤,C#代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com";));
var html = jquery["#nav_left li"].Each(dom =>
{
var self = jquery[dom];
var text = self.Text();
if (text == "博问" || text == "专区")
{
self.Find("a").CssSet(new { color = "red" });
}
}).Render();
}
3) 其他操作方法
除了以上两种操作方法,还可以使用after、before、replaceAll、IS等。有一百多种实用方法。这篇文章肯定不能一一介绍。有兴趣的可以下载看看。小提琴。
三:其他用途
除了抓取html中的元素,我觉得这个东西还可以用来在发送邮件的时候操作邮件模板。毕竟很久以前大家都是用jquery来画html的,所以CSQuery也是可以的。使用 xslt 有优点也有缺点。, 举个例子:
1. 生成html模板
2. 使用 CSQuery 将 li 附加到 ul
您可以使用 Append 将内容附加到节点。
class Program
{
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var strlist = new string[2] { "1", "2" };
var path = Environment.CurrentDirectory + "\\2.html";
var jquery = CQ.CreateFromFile(path);
foreach (var str in strlist)
{
jquery.Find("#main").Append($"{str}");
}
var html = jquery.Render();
}
}
3. 局部渲染RenderSelection
Render方法是将整个Dom渲染成html,但是有时候你只需要获取你修改的那部分内容而不是整个html,这涉及到部分渲染,可以使用RenderSelection方法,代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var strlist = new string[2] { "1", "2" };
var path = Environment.CurrentDirectory + "\\2.html";
var jquery = CQ.CreateFromFile(path);
var current = jquery.Find("#main");
foreach (var str in strlist)
{
current.Append($"{str}");
}
var html = current.RenderSelection();
Console.WriteLine(html);
}
------------- output ----------------
12
四:总结
Jquery的这种操作方式对我个人来说还是比较舒服的,毕竟我很熟悉!不过html5中也加入了querySelector和querySelectorAll来支持css3选择器,非常强大,但是jquery不仅选择器灵活,节点的操作也很灵活。总的来说,它的交互性不是特别丰富。怀旧。
c#抓取网页数据(c#抓取网页数据的常见解决方案:`io.io)
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-10-04 05:03
c#抓取网页数据的方法很多,总的来说大致包括使用selector表达式实现非字符串匹配,使用tuple类型实现字符串字面量匹配,使用循环控制条件运算等。有关概念可以看一下这篇论文:historyisnotapropertywithoutthedoubleaccess.todo:string类型中各个字符串字面量是不允许直接出现在数组中的,string允许使用符号来给字符串添加字符,可以在字符数组中实现嵌套类。
是的,至少我遇到过的是这样的,否则我就重写代码了。反正我从来不知道什么是不支持的,
我觉得楼上都没回答到点子上,我来抛砖引玉一下吧。在你的例子中,可以对应上面列表的那么几种常见的解决方案:`io.aiohttp.postmessagestringbymessage``io.aiohttp.postmessagestringbyflags#boundsofthespecificnamesoftheavailablemessageobjectsinthemulti-parammodel`io.aiohttp.postmessagestringbyfilter#boundsoftheclassspecifictypesofthemessagename`io.aiohttp.postmessagestringbyparameter#boundsoftheclasstypesofthemessagename`io.aiohttp.postmessagestringbyparams#boundsofthemessagespecificparametersinmessagename`这两个方案的问题很严重:asio并不是以io.aiohttp.postmessagestringbymessage为最终postmessage类型去做转换,因此在你的代码中,会造成1,2两个子类,io.aiohttp.postmessagestringbymessage和io.aiohttp.postmessagestringbyfilter这两个最终postmessage类型对应的io.aiohttp.postmessagestringbyfilter两个类型,都会被做传递,类型指向同一个string对象。
好在这两个方案都不是以get为最终postmessage类型去实现的,因此没有造成get函数执行异常。解决办法只有一个:`stringbuilderio.io.aiohttp.postmessagestringbystring#boundsoftheentirepostmessagestringisfullyemptyinthemulti-parammodel`,有人或许会说,stringbuilder是嵌套对象,而entireparams是字符串的字面量表达式,param是字符串类型自身的parameter,字符串对象可以再有不同类型的parameter,所以就一定是true了吗?对io.aiohttp.postmessagestringbystring参数io.aiohttp.postmessagestringbyfilter参数进行类型转换,相当于entireparams,因此可以做很多事情,比如和content_listener接口的text_match就能用param和entireparams做成。
其实如果不做这个判断,param与entireparams在postmessage对象中对应的parameter会无效的,可以参考。 查看全部
c#抓取网页数据(c#抓取网页数据的常见解决方案:`io.io)
c#抓取网页数据的方法很多,总的来说大致包括使用selector表达式实现非字符串匹配,使用tuple类型实现字符串字面量匹配,使用循环控制条件运算等。有关概念可以看一下这篇论文:historyisnotapropertywithoutthedoubleaccess.todo:string类型中各个字符串字面量是不允许直接出现在数组中的,string允许使用符号来给字符串添加字符,可以在字符数组中实现嵌套类。
是的,至少我遇到过的是这样的,否则我就重写代码了。反正我从来不知道什么是不支持的,
我觉得楼上都没回答到点子上,我来抛砖引玉一下吧。在你的例子中,可以对应上面列表的那么几种常见的解决方案:`io.aiohttp.postmessagestringbymessage``io.aiohttp.postmessagestringbyflags#boundsofthespecificnamesoftheavailablemessageobjectsinthemulti-parammodel`io.aiohttp.postmessagestringbyfilter#boundsoftheclassspecifictypesofthemessagename`io.aiohttp.postmessagestringbyparameter#boundsoftheclasstypesofthemessagename`io.aiohttp.postmessagestringbyparams#boundsofthemessagespecificparametersinmessagename`这两个方案的问题很严重:asio并不是以io.aiohttp.postmessagestringbymessage为最终postmessage类型去做转换,因此在你的代码中,会造成1,2两个子类,io.aiohttp.postmessagestringbymessage和io.aiohttp.postmessagestringbyfilter这两个最终postmessage类型对应的io.aiohttp.postmessagestringbyfilter两个类型,都会被做传递,类型指向同一个string对象。
好在这两个方案都不是以get为最终postmessage类型去实现的,因此没有造成get函数执行异常。解决办法只有一个:`stringbuilderio.io.aiohttp.postmessagestringbystring#boundsoftheentirepostmessagestringisfullyemptyinthemulti-parammodel`,有人或许会说,stringbuilder是嵌套对象,而entireparams是字符串的字面量表达式,param是字符串类型自身的parameter,字符串对象可以再有不同类型的parameter,所以就一定是true了吗?对io.aiohttp.postmessagestringbystring参数io.aiohttp.postmessagestringbyfilter参数进行类型转换,相当于entireparams,因此可以做很多事情,比如和content_listener接口的text_match就能用param和entireparams做成。
其实如果不做这个判断,param与entireparams在postmessage对象中对应的parameter会无效的,可以参考。
c#抓取网页数据( 从IE浏览器获取当前页面内容可能有多种方式的资料)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-02 11:36
从IE浏览器获取当前页面内容可能有多种方式的资料)
C#从IE浏览器获取当前页面的内容
更新时间:2021年6月24日09:52:49作者:迈克尔·大卫
从IE浏览器获取当前页面内容的方法可能有很多种。今天我介绍其中一个。基本原理:鼠标点击当前ie页面时,获取鼠标坐标位置,根据鼠标位置获取当前页面的句柄,然后根据句柄调用Win32 things获取页面内容。感兴趣的朋友可以参考本文
private void timer1_Tick(object sender, EventArgs e)
{
lock (currentLock)
{
System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition;
if (_leftClick)
{
timer1.Stop();
_leftClick = false;
_lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false));
if (_lastDocument != null)
{
if (_getDocument)
{
_getDocument = true;
try
{
string url = _lastDocument.url;
string html = _lastDocument.documentElement.outerHTML;
string cookie = _lastDocument.cookie;
string domain = _lastDocument.domain;
var resolveParams = new ResolveParam
{
Url = new Uri(url),
Html = html,
PageCookie = cookie,
Domain = domain
};
RequetResove(resolveParams);
}
catch (Exception ex)
{
System.Windows.MessageBox.Show(ex.Message);
Console.WriteLine(ex.Message);
Console.WriteLine(ex.StackTrace);
}
}
}
else
{
new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页");
}
_getDocument = false;
}
else
{
_pointFrm.Left = MousePoint.X + 10;
_pointFrm.Top = MousePoint.Y + 10;
}
}
}
在第11行的gethtmldocumentformhwnd(getpointcontrol(mousepoint,false))分解下,首先从鼠标坐标获取页面句柄:
public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl)
{
IntPtr handle = Win32APIsFull.WindowFromPoint(p);
if (handle != IntPtr.Zero)
{
System.Drawing.Rectangle rect = default(System.Drawing.Rectangle);
if (Win32APIsFull.GetWindowRect(handle, out rect))
{
return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE);
}
}
return IntPtr.Zero;
}
接下来,根据句柄获取页面内容:
public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd)
{
IntPtr result = Marshal.AllocHGlobal(4);
Object obj = null;
Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result));
if (Marshal.ReadInt32(result) != 0)
{
Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj));
}
Marshal.FreeHGlobal(result);
return obj as HTMLDocument;
}
一般原则:
向IE表单发送消息,获取指向IE浏览器(非托管)内存块的指针,然后根据该指针获取htmldocument对象
此方法涉及两个Win32函数:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")]
public static extern int SendMessageTimeoutA(
[InAttribute()] System.IntPtr hWnd,
uint Msg, uint wParam, int lParam,
uint fuFlags,
uint uTimeout,
System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")]
public static extern int ObjectFromLresult(
int lResult,
ref Guid riid,
int wParam,
[MarshalAs(UnmanagedType.IDispatch), Out]
out Object pObject
);
以上是从IE浏览器获取当前页面内容的详细信息。有关c#获取浏览器页面内容的更多信息,请注意其他相关信息文章 查看全部
c#抓取网页数据(
从IE浏览器获取当前页面内容可能有多种方式的资料)
C#从IE浏览器获取当前页面的内容
更新时间:2021年6月24日09:52:49作者:迈克尔·大卫
从IE浏览器获取当前页面内容的方法可能有很多种。今天我介绍其中一个。基本原理:鼠标点击当前ie页面时,获取鼠标坐标位置,根据鼠标位置获取当前页面的句柄,然后根据句柄调用Win32 things获取页面内容。感兴趣的朋友可以参考本文
private void timer1_Tick(object sender, EventArgs e)
{
lock (currentLock)
{
System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition;
if (_leftClick)
{
timer1.Stop();
_leftClick = false;
_lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false));
if (_lastDocument != null)
{
if (_getDocument)
{
_getDocument = true;
try
{
string url = _lastDocument.url;
string html = _lastDocument.documentElement.outerHTML;
string cookie = _lastDocument.cookie;
string domain = _lastDocument.domain;
var resolveParams = new ResolveParam
{
Url = new Uri(url),
Html = html,
PageCookie = cookie,
Domain = domain
};
RequetResove(resolveParams);
}
catch (Exception ex)
{
System.Windows.MessageBox.Show(ex.Message);
Console.WriteLine(ex.Message);
Console.WriteLine(ex.StackTrace);
}
}
}
else
{
new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页");
}
_getDocument = false;
}
else
{
_pointFrm.Left = MousePoint.X + 10;
_pointFrm.Top = MousePoint.Y + 10;
}
}
}
在第11行的gethtmldocumentformhwnd(getpointcontrol(mousepoint,false))分解下,首先从鼠标坐标获取页面句柄:
public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl)
{
IntPtr handle = Win32APIsFull.WindowFromPoint(p);
if (handle != IntPtr.Zero)
{
System.Drawing.Rectangle rect = default(System.Drawing.Rectangle);
if (Win32APIsFull.GetWindowRect(handle, out rect))
{
return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE);
}
}
return IntPtr.Zero;
}
接下来,根据句柄获取页面内容:
public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd)
{
IntPtr result = Marshal.AllocHGlobal(4);
Object obj = null;
Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result));
if (Marshal.ReadInt32(result) != 0)
{
Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj));
}
Marshal.FreeHGlobal(result);
return obj as HTMLDocument;
}
一般原则:
向IE表单发送消息,获取指向IE浏览器(非托管)内存块的指针,然后根据该指针获取htmldocument对象
此方法涉及两个Win32函数:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")]
public static extern int SendMessageTimeoutA(
[InAttribute()] System.IntPtr hWnd,
uint Msg, uint wParam, int lParam,
uint fuFlags,
uint uTimeout,
System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")]
public static extern int ObjectFromLresult(
int lResult,
ref Guid riid,
int wParam,
[MarshalAs(UnmanagedType.IDispatch), Out]
out Object pObject
);
以上是从IE浏览器获取当前页面内容的详细信息。有关c#获取浏览器页面内容的更多信息,请注意其他相关信息文章
c#抓取网页数据(c#抓取网页数据基本上是类似于抓包和正则表达式的基本功)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-10-01 10:03
c#抓取网页数据基本上是类似于抓包和正则表达式的基本功,今天就来讲一下常用的数据抓取方法和步骤:1.爬虫和docker:引用docker容器需要在php中使用一下docker:2.正则表达式解析:基本步骤:1.在cmd中运行正则表达式,如下图:2.选择我们需要抓取的网页,如果要抓取一个redis的数据:php要选择redis,如果要抓取一个.txt文件(文本文件),需要修改文件位置为相应路径的存储路径:具体方法如下图:还可以修改上一条编码方式,用相应变量值设置上下行的编码3.读取cookie信息和session信息:其中cookie就是浏览器,session就是操作系统。
我们先了解一下登录和系统用户名如何获取第二步,通过正则表达式检测我们需要登录的操作系统,当找到后修改目标操作系统文件c:\users\xxx\appdata\local\network\data\network\network.cache,修改相应路径如下图:4.爬虫程序开发:设置代理,如下图:api接口已经设置好了,只需要set方法将路径保存起来就可以了5.登录:现在已经登录了,但是没有任何内容,怎么获取页面内容?总结:还有一些基本的常见问题,想分享给大家,欢迎大家指正!正常情况下,登录的用户是不会发送完整的json参数,但是我们可以简单的尝试下。
在上面我们的类型中,有session和db这两个io操作,但是发送参数是一直发送到db这个是肯定是有问题的,我们需要给它加上属性标签,先定义如下id:publicformdata=singleton;for(formfd:fd){fd.set(fd.any());}。 查看全部
c#抓取网页数据(c#抓取网页数据基本上是类似于抓包和正则表达式的基本功)
c#抓取网页数据基本上是类似于抓包和正则表达式的基本功,今天就来讲一下常用的数据抓取方法和步骤:1.爬虫和docker:引用docker容器需要在php中使用一下docker:2.正则表达式解析:基本步骤:1.在cmd中运行正则表达式,如下图:2.选择我们需要抓取的网页,如果要抓取一个redis的数据:php要选择redis,如果要抓取一个.txt文件(文本文件),需要修改文件位置为相应路径的存储路径:具体方法如下图:还可以修改上一条编码方式,用相应变量值设置上下行的编码3.读取cookie信息和session信息:其中cookie就是浏览器,session就是操作系统。
我们先了解一下登录和系统用户名如何获取第二步,通过正则表达式检测我们需要登录的操作系统,当找到后修改目标操作系统文件c:\users\xxx\appdata\local\network\data\network\network.cache,修改相应路径如下图:4.爬虫程序开发:设置代理,如下图:api接口已经设置好了,只需要set方法将路径保存起来就可以了5.登录:现在已经登录了,但是没有任何内容,怎么获取页面内容?总结:还有一些基本的常见问题,想分享给大家,欢迎大家指正!正常情况下,登录的用户是不会发送完整的json参数,但是我们可以简单的尝试下。
在上面我们的类型中,有session和db这两个io操作,但是发送参数是一直发送到db这个是肯定是有问题的,我们需要给它加上属性标签,先定义如下id:publicformdata=singleton;for(formfd:fd){fd.set(fd.any());}。
c#抓取网页数据(谢邀webpack/nodejs工程化脚手架没有功能机制)
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-10-01 10:00
c#抓取网页数据,数据只能抓取网页上面的,没有返回json和xml格式的数据,我最近都用的是51cto的html5爬虫和html5数据抓取,一个是里面有很多好看的爬虫插件和例子教程,还有一个是入门比较简单,最主要是上手容易,一天就可以出效果。刚刚也突然想到一个方法,用reactnative写个json爬虫也是可以的,考虑到reactnative本身没有jsonapi,所以想找个jsonapi的爬虫来抓取。
谢邀webpack/nodejs工程化脚手架没有功能机制的话请使用scrapy,puppeteer,node-spider或者scrapy+puppeteer。最后,如果只是单纯的需要抓取网页内容是不需要nodejs和scrapy或者puppeteer之类的,所有的html解析都可以用html5lib和json等接口来实现,只需要简单的json解析以及将json文本打包成js即可。
在老大允许的情况下可以用redis,你也可以用session之类的来处理,然后再配合一下json转post请求。有了用户数据就可以直接抓取咯。
做个mvx以及自己解析postsoap头即可
先看下c++和java能不能交叉编译json,json也只是一种数据结构,
可以试试跟前面两位一样用c++,自己编译写一套jsonwebapi。
最开始scrapy这个自动化工具可以试试 查看全部
c#抓取网页数据(谢邀webpack/nodejs工程化脚手架没有功能机制)
c#抓取网页数据,数据只能抓取网页上面的,没有返回json和xml格式的数据,我最近都用的是51cto的html5爬虫和html5数据抓取,一个是里面有很多好看的爬虫插件和例子教程,还有一个是入门比较简单,最主要是上手容易,一天就可以出效果。刚刚也突然想到一个方法,用reactnative写个json爬虫也是可以的,考虑到reactnative本身没有jsonapi,所以想找个jsonapi的爬虫来抓取。
谢邀webpack/nodejs工程化脚手架没有功能机制的话请使用scrapy,puppeteer,node-spider或者scrapy+puppeteer。最后,如果只是单纯的需要抓取网页内容是不需要nodejs和scrapy或者puppeteer之类的,所有的html解析都可以用html5lib和json等接口来实现,只需要简单的json解析以及将json文本打包成js即可。
在老大允许的情况下可以用redis,你也可以用session之类的来处理,然后再配合一下json转post请求。有了用户数据就可以直接抓取咯。
做个mvx以及自己解析postsoap头即可
先看下c++和java能不能交叉编译json,json也只是一种数据结构,
可以试试跟前面两位一样用c++,自己编译写一套jsonwebapi。
最开始scrapy这个自动化工具可以试试
c#抓取网页数据(源页页面源码如下:目标页中获取源页窗体数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-09-27 21:21
在源代码页面中,此示例代码为用户提供了用于输入用户名、生日和年龄的文本框,并将Button 控件的PostBackUrl 属性设置为DestinationPage.aspx。也就是说,当你点击【提交到目标页面】按钮时,源页面表单的数据就会被传送到目标页面.aspx页面。
在目标页面中,通过 Page.Request.Form 属性获取传递的数据。
源页面的页面源码如下:
源页!
User Name :
<br />
Birth Date :
<br />
Age :
<br />
在目标页面中获取源页面的表单数据的代码如下:
protected void Page_Load(object sender, EventArgs e)
{
StringBuilder SBuilder = new StringBuilder();
NameValueCollection PostedValues =
this.Request.Form;
for (int Index = 0; Index < PostedValues.Count; Index++)
{
if (PostedValues.Keys[Index].Substring(0, 2) != "__")
{
SBuilder.Append(string.Format("{0} = {1}",
PostedValues.Keys[Index],
PostedValues[Index]));
SBuilder.Append("<br />");
}
}
this.Response.Write(SBuilder.ToString());
}
代码中的if语句主要是为了避免获取以两个下划线__开头的隐藏字段的数据,例如__VIEWSTATE、__EVENTTARGET、__EVENTARGUMENT。当然,你也可以去掉这个if语句,然后就可以同时获取这些隐藏字段的数据了。
三、通过会话状态传递数据
使用会话状态的优点是数据可以在与源页面相同的 ASP.NET 应用程序中的所有网页之间共享。缺点是会增加服务器的内存开销。
在下面的代码中,用户在源页面的【用户名】文本框中输入自己的姓名,然后点击【提交数据】按钮。服务器代码会通过 Page.Session 属性将用户名存储在会话状态中,然后使用 Response.Redirect() 方法强制页面重定向到另一个页面(DestinationPage.aspx)。在此目标页面中,再次使用 Page.Session 属性来获取保存在源页面中的用户名。
源码页面的源码如下:
源页:通过会话状态传递数据!
用户名:
源页面中将用户名保存到会话状态并重定向到目标页面的代码如下:
protected void SubmitButton_Click(object sender, EventArgs e)
{
this.Session["UserName"] = this.UserNameTextBox.Text;
this.Response.Redirect("DestinationPage.aspx");
}
获取目标页面中会话状态中保存的用户名的代码如下:
protected void Page_Load(object sender, EventArgs e)
{
string UserName = this.Session["UserName"].ToString();
this.Response.Write(UserName);
}
四、通过源页面的公共属性传递数据
在示例代码中,我们提供了在源页面输入用户名的文本框,然后点击【提交到目标页面】按钮将数据提交到目标页面。
源码页面的源码如下:
源页:通过公共属性传递数据!
用户名:
<br />
并且为源页面定义了一个名为 UserName 的公共属性。该属性返回在[用户名] 文本框中输入的用户名。
public string UserName
{
get { return this.UserNameTextBox.Text; }
}
通过这种方式,我们创建了一个收录公共属性的源页面。然后创建目标页面并将@PreviousPageType 指令添加到目标页面。当然,您也可以使用@Reference 指令。
这样,ASP.NET 就会自动将目标页面的 Page.PreviousPage 属性转换为源页面的类型,以便您可以直接访问 UserName 属性。注意下面的代码,我们没有把Page.PreviousPage转换成显示类型。
if (this.PreviousPage != null)
{
string UserName = this.PreviousPage.UserName;
this.Response.Write(UserName);
}
需要特别强调的是,不要忘记判断Page.PreviousPage属性是否为null,因为它确实有为null的可能。如果在 null 的情况下获取了源页面 UserName 的公共属性,则会引发异常。
五、通过源页面中的控件值传递数据
最后一种传输数据的方式是直接获取源页面的控件对象,然后通过控件的属性值获取需要的数据。例如,在本示例代码中,我们获取源页面的TextBox控件,然后通过访问TextBox.Text属性获取用户在源页面中输入的数据。
在下面的示例代码中,我们在源页面放置了一个用于输入用户名的文本框,ID为UserNameTextBox。您可以通过 Page.PreviousPage.FindControl() 方法获取对此控件的引用。
源码页面的源码如下:
源页:通过控件属性传递数据!
用户名:
<br />
获取目标页面中的文本框控件并获取其Text属性值的代码如下:
if (this.PreviousPage != null)
{
TextBox UserNameTextBox =
(TextBox)this.PreviousPage.FindControl("UserNameTextBox");
if (UserNameTextBox != null)
{
this.Response.Write(UserNameTextBox.Text);
}
}
如果要获取的控件位于某个控件内部,例如以下代码,则 UserNameTextBox 控件位于名为 UserPanel 的 Panel 控件内部。然后先找出这个Panel控件,再通过这个控件的FindControl()方法找出里面的文本框控件。
源码页面的源码如下:
源页:通过控件属性传递数据!
用户名:
<br />
获取目标页面中Panel控件内的TextBox控件的代码如下:
if (this.PreviousPage != null)
{
Panel UserPanel = (Panel)this.PreviousPage.FindControl("UserPanel");
if (UserPanel != null)
{
TextBox UserNameTextBox =
(TextBox)UserPanel.FindControl("UserNameTextBoxInPanel");
if (UserNameTextBox != null)
{
this.Response.Write(UserNameTextBox.Text);
}
}
}
无论该控件位于该级别的命名容器控件内部,都是通过这种方式获取的。
不要忘记判断获取的控件引用是否为空。
至此,网页间数据传输的5种方式已经基本展示完毕!^_^
赤脚思考 2010-11-9 查看全部
c#抓取网页数据(源页页面源码如下:目标页中获取源页窗体数据(组图))
在源代码页面中,此示例代码为用户提供了用于输入用户名、生日和年龄的文本框,并将Button 控件的PostBackUrl 属性设置为DestinationPage.aspx。也就是说,当你点击【提交到目标页面】按钮时,源页面表单的数据就会被传送到目标页面.aspx页面。
在目标页面中,通过 Page.Request.Form 属性获取传递的数据。
源页面的页面源码如下:
源页!
User Name :
<br />
Birth Date :
<br />
Age :
<br />
在目标页面中获取源页面的表单数据的代码如下:
protected void Page_Load(object sender, EventArgs e)
{
StringBuilder SBuilder = new StringBuilder();
NameValueCollection PostedValues =
this.Request.Form;
for (int Index = 0; Index < PostedValues.Count; Index++)
{
if (PostedValues.Keys[Index].Substring(0, 2) != "__")
{
SBuilder.Append(string.Format("{0} = {1}",
PostedValues.Keys[Index],
PostedValues[Index]));
SBuilder.Append("<br />");
}
}
this.Response.Write(SBuilder.ToString());
}
代码中的if语句主要是为了避免获取以两个下划线__开头的隐藏字段的数据,例如__VIEWSTATE、__EVENTTARGET、__EVENTARGUMENT。当然,你也可以去掉这个if语句,然后就可以同时获取这些隐藏字段的数据了。
三、通过会话状态传递数据
使用会话状态的优点是数据可以在与源页面相同的 ASP.NET 应用程序中的所有网页之间共享。缺点是会增加服务器的内存开销。
在下面的代码中,用户在源页面的【用户名】文本框中输入自己的姓名,然后点击【提交数据】按钮。服务器代码会通过 Page.Session 属性将用户名存储在会话状态中,然后使用 Response.Redirect() 方法强制页面重定向到另一个页面(DestinationPage.aspx)。在此目标页面中,再次使用 Page.Session 属性来获取保存在源页面中的用户名。
源码页面的源码如下:
源页:通过会话状态传递数据!
用户名:
源页面中将用户名保存到会话状态并重定向到目标页面的代码如下:
protected void SubmitButton_Click(object sender, EventArgs e)
{
this.Session["UserName"] = this.UserNameTextBox.Text;
this.Response.Redirect("DestinationPage.aspx");
}
获取目标页面中会话状态中保存的用户名的代码如下:
protected void Page_Load(object sender, EventArgs e)
{
string UserName = this.Session["UserName"].ToString();
this.Response.Write(UserName);
}
四、通过源页面的公共属性传递数据
在示例代码中,我们提供了在源页面输入用户名的文本框,然后点击【提交到目标页面】按钮将数据提交到目标页面。
源码页面的源码如下:
源页:通过公共属性传递数据!
用户名:
<br />
并且为源页面定义了一个名为 UserName 的公共属性。该属性返回在[用户名] 文本框中输入的用户名。
public string UserName
{
get { return this.UserNameTextBox.Text; }
}
通过这种方式,我们创建了一个收录公共属性的源页面。然后创建目标页面并将@PreviousPageType 指令添加到目标页面。当然,您也可以使用@Reference 指令。
这样,ASP.NET 就会自动将目标页面的 Page.PreviousPage 属性转换为源页面的类型,以便您可以直接访问 UserName 属性。注意下面的代码,我们没有把Page.PreviousPage转换成显示类型。
if (this.PreviousPage != null)
{
string UserName = this.PreviousPage.UserName;
this.Response.Write(UserName);
}
需要特别强调的是,不要忘记判断Page.PreviousPage属性是否为null,因为它确实有为null的可能。如果在 null 的情况下获取了源页面 UserName 的公共属性,则会引发异常。
五、通过源页面中的控件值传递数据
最后一种传输数据的方式是直接获取源页面的控件对象,然后通过控件的属性值获取需要的数据。例如,在本示例代码中,我们获取源页面的TextBox控件,然后通过访问TextBox.Text属性获取用户在源页面中输入的数据。
在下面的示例代码中,我们在源页面放置了一个用于输入用户名的文本框,ID为UserNameTextBox。您可以通过 Page.PreviousPage.FindControl() 方法获取对此控件的引用。
源码页面的源码如下:
源页:通过控件属性传递数据!
用户名:
<br />
获取目标页面中的文本框控件并获取其Text属性值的代码如下:
if (this.PreviousPage != null)
{
TextBox UserNameTextBox =
(TextBox)this.PreviousPage.FindControl("UserNameTextBox");
if (UserNameTextBox != null)
{
this.Response.Write(UserNameTextBox.Text);
}
}
如果要获取的控件位于某个控件内部,例如以下代码,则 UserNameTextBox 控件位于名为 UserPanel 的 Panel 控件内部。然后先找出这个Panel控件,再通过这个控件的FindControl()方法找出里面的文本框控件。
源码页面的源码如下:
源页:通过控件属性传递数据!
用户名:
<br />
获取目标页面中Panel控件内的TextBox控件的代码如下:
if (this.PreviousPage != null)
{
Panel UserPanel = (Panel)this.PreviousPage.FindControl("UserPanel");
if (UserPanel != null)
{
TextBox UserNameTextBox =
(TextBox)UserPanel.FindControl("UserNameTextBoxInPanel");
if (UserNameTextBox != null)
{
this.Response.Write(UserNameTextBox.Text);
}
}
}
无论该控件位于该级别的命名容器控件内部,都是通过这种方式获取的。
不要忘记判断获取的控件引用是否为空。
至此,网页间数据传输的5种方式已经基本展示完毕!^_^
赤脚思考 2010-11-9
c#抓取网页数据(C#使用正则表达式抓取网站信息的正则抓取技巧(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-09-27 16:23
本文文章主要介绍C#使用“target="_blank">正则表达式捕获网站信息,并结合实例分析C#对网页信息的正则捕获操作技巧,有一定参考参考价值,有需要的朋友可以参考
本文介绍了C#使用正则表达式捕获网站信息的方法。分享给大家,供大家参考,如下:
下面是一个抓取京东商城商品详情的例子。
1、创建JdRobber.cs程序类
<p>public class JdRobber
{
///
/// 判断是否京东链接
///
///
///
public bool ValidationUrl(string url)
{
bool result = false;
if (!String.IsNullOrEmpty(url))
{
Regex regex = new Regex(@"^http://item.jd.com/\d+.html$");
Match match = regex.Match(url);
if (match.Success)
{
result = true;
}
}
return result;
}
///
/// 抓取京东信息
///
///
///
public void GetInfo(string url)
{
if (ValidationUrl(url))
{
string htmlStr = WebHandler.GetHtmlStr(url, "Default");
if (!String.IsNullOrEmpty(htmlStr))
{
string pattern = ""; //正则表达式
string sourceWebID = ""; //商品关键ID
string title = ""; //标题
decimal price = 0; //价格
string picName = ""; //图片
//提取商品关键ID
pattern = @"http://item.jd.com/(?\d+).html";
sourceWebID = WebHandler.GetRegexText(url, pattern);
//提取标题
pattern = @"[\s\S]*(?.*?)";
title = WebHandler.GetRegexText(htmlStr, pattern);
//提取图片
int begin = htmlStr.IndexOf(" 查看全部
c#抓取网页数据(C#使用正则表达式抓取网站信息的正则抓取技巧(图))
本文文章主要介绍C#使用“target="_blank">正则表达式捕获网站信息,并结合实例分析C#对网页信息的正则捕获操作技巧,有一定参考参考价值,有需要的朋友可以参考
本文介绍了C#使用正则表达式捕获网站信息的方法。分享给大家,供大家参考,如下:
下面是一个抓取京东商城商品详情的例子。
1、创建JdRobber.cs程序类
<p>public class JdRobber
{
///
/// 判断是否京东链接
///
///
///
public bool ValidationUrl(string url)
{
bool result = false;
if (!String.IsNullOrEmpty(url))
{
Regex regex = new Regex(@"^http://item.jd.com/\d+.html$");
Match match = regex.Match(url);
if (match.Success)
{
result = true;
}
}
return result;
}
///
/// 抓取京东信息
///
///
///
public void GetInfo(string url)
{
if (ValidationUrl(url))
{
string htmlStr = WebHandler.GetHtmlStr(url, "Default");
if (!String.IsNullOrEmpty(htmlStr))
{
string pattern = ""; //正则表达式
string sourceWebID = ""; //商品关键ID
string title = ""; //标题
decimal price = 0; //价格
string picName = ""; //图片
//提取商品关键ID
pattern = @"http://item.jd.com/(?\d+).html";
sourceWebID = WebHandler.GetRegexText(url, pattern);
//提取标题
pattern = @"[\s\S]*(?.*?)";
title = WebHandler.GetRegexText(htmlStr, pattern);
//提取图片
int begin = htmlStr.IndexOf("
c#抓取网页数据(1.讲故事民生资讯号民生民生)
网站优化 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2021-09-27 16:14
一:背景1.讲故事
前段时间,我创建了一个当地民生信息账号。我复制了你的信息。你复制了官方媒体。市民喜欢稀奇古怪的东西,所以就需要如何瞄准和捕捉稀奇古怪的东西。账号上的消息其实做起来很简单,用logistic回归就可以了。本文主要讨论如何爬取。在C#中,大家都知道抓取的通用库是HtmlAgilityPack,但是这个库的主流方法是使用xpath来提取网页的内容,让我很不爽。毕竟,我不熟悉莫名的抵抗。一个我这个年纪的码农受过 Jquery 的教育至少 5-6 年,所以我必须使用类似 Jquery 的方法。python中有pyquery。在 C# 中是否有类似的方法可以做到这一点?哎,真的有全能的github。. .
二:CSQuery1.安装
github地址:然后直接在vs中点击nuget:
2. 举几个例子
万事俱备,那么如何使用呢?别着急,我举两个博客园里的例子。
1) 从主页提取友情链接到
如上图所示,这里如果要获取友情链接的几个大字,直接使用text()肯定是不行的。默认情况下,它还会捕获所有子节点的文本,如下图所示:
如何处理?可以使用jquery提供的contents方法,然后判断获取的所有子节点中是否有文本节点,最后获取文本节点的内容,如下代码所示:
是用js做的,但是用CSQuery代码怎么做呢?模仿一下,代码如下:
static void Main(string[] args)
{
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com"));
var content = jquery["#friend_link"].Contents().Filter((dom) =>
{
return dom.NodeType == NodeType.TEXT_NODE;
}).Text();
Console.WriteLine(content);
}
不知道用xpath提取这样的内容是不是很麻烦,但是jquery也不好用,但是熟悉。
2) 如何为html中的某些元素着色
有时需要为业务更改一些html标签的颜色,例如将首页tabmenu中的博客和区域更改为红色,如下图所示:
如何处理CSQuery?如果你玩过jquery,一般来说步骤如下:
有了步骤,C#代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com"));
var html = jquery["#nav_left li"].Each(dom =>
{
var self = jquery[dom];
var text = self.Text();
if (text == "博问" || text == "专区")
{
self.Find("a").CssSet(new { color = "red" });
}
}).Render();
}
3) 其他操作方法
除了以上两种操作方法,还可以使用after、before、replaceAll、IS等。有一百多种实用方法。这篇文章肯定不能一一介绍。有兴趣的可以下载看看。小提琴。
三:其他用途
除了抓取html中的元素,我觉得这个东西还可以用来在发邮件的时候操作邮件模板。毕竟很久以前大家都是用jquery来画html的,所以CSQuery也是可以的。使用 xslt 有优点也有缺点。, 举个例子:
1. 生成html模板
2. 使用 CSQuery 将 li 附加到 ul
您可以使用 Append 将内容附加到节点。
class Program
{
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var strlist = new string[2] { "1", "2" };
var path = Environment.CurrentDirectory + "\\2.html";
var jquery = CQ.CreateFromFile(path);
foreach (var str in strlist)
{
jquery.Find("#main").Append($"{str}");
}
var html = jquery.Render();
}
}
3. 局部渲染RenderSelection
Render方法是将整个Dom渲染成html,但是有时候你只需要获取你修改的那部分内容而不是整个html,这涉及到部分渲染,可以使用RenderSelection方法,代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var strlist = new string[2] { "1", "2" };
var path = Environment.CurrentDirectory + "\\2.html";
var jquery = CQ.CreateFromFile(path);
var current = jquery.Find("#main");
foreach (var str in strlist)
{
current.Append($"{str}");
}
var html = current.RenderSelection();
Console.WriteLine(html);
}
------------- output ----------------
12
四:总结
Jquery的这种操作方式对我个人来说还是比较舒服的,毕竟我很熟悉!不过html5中也加入了querySelector和querySelectorAll来支持css3选择器,非常强大,但是jquery不仅选择器灵活,节点的操作也很灵活。总的来说,它的交互性不是特别丰富。怀旧。 查看全部
c#抓取网页数据(1.讲故事民生资讯号民生民生)
一:背景1.讲故事
前段时间,我创建了一个当地民生信息账号。我复制了你的信息。你复制了官方媒体。市民喜欢稀奇古怪的东西,所以就需要如何瞄准和捕捉稀奇古怪的东西。账号上的消息其实做起来很简单,用logistic回归就可以了。本文主要讨论如何爬取。在C#中,大家都知道抓取的通用库是HtmlAgilityPack,但是这个库的主流方法是使用xpath来提取网页的内容,让我很不爽。毕竟,我不熟悉莫名的抵抗。一个我这个年纪的码农受过 Jquery 的教育至少 5-6 年,所以我必须使用类似 Jquery 的方法。python中有pyquery。在 C# 中是否有类似的方法可以做到这一点?哎,真的有全能的github。. .
二:CSQuery1.安装
github地址:然后直接在vs中点击nuget:
2. 举几个例子
万事俱备,那么如何使用呢?别着急,我举两个博客园里的例子。
1) 从主页提取友情链接到
如上图所示,这里如果要获取友情链接的几个大字,直接使用text()肯定是不行的。默认情况下,它还会捕获所有子节点的文本,如下图所示:
如何处理?可以使用jquery提供的contents方法,然后判断获取的所有子节点中是否有文本节点,最后获取文本节点的内容,如下代码所示:
是用js做的,但是用CSQuery代码怎么做呢?模仿一下,代码如下:
static void Main(string[] args)
{
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com";));
var content = jquery["#friend_link"].Contents().Filter((dom) =>
{
return dom.NodeType == NodeType.TEXT_NODE;
}).Text();
Console.WriteLine(content);
}
不知道用xpath提取这样的内容是不是很麻烦,但是jquery也不好用,但是熟悉。
2) 如何为html中的某些元素着色
有时需要为业务更改一些html标签的颜色,例如将首页tabmenu中的博客和区域更改为红色,如下图所示:
如何处理CSQuery?如果你玩过jquery,一般来说步骤如下:
有了步骤,C#代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com";));
var html = jquery["#nav_left li"].Each(dom =>
{
var self = jquery[dom];
var text = self.Text();
if (text == "博问" || text == "专区")
{
self.Find("a").CssSet(new { color = "red" });
}
}).Render();
}
3) 其他操作方法
除了以上两种操作方法,还可以使用after、before、replaceAll、IS等。有一百多种实用方法。这篇文章肯定不能一一介绍。有兴趣的可以下载看看。小提琴。
三:其他用途
除了抓取html中的元素,我觉得这个东西还可以用来在发邮件的时候操作邮件模板。毕竟很久以前大家都是用jquery来画html的,所以CSQuery也是可以的。使用 xslt 有优点也有缺点。, 举个例子:
1. 生成html模板
2. 使用 CSQuery 将 li 附加到 ul
您可以使用 Append 将内容附加到节点。
class Program
{
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var strlist = new string[2] { "1", "2" };
var path = Environment.CurrentDirectory + "\\2.html";
var jquery = CQ.CreateFromFile(path);
foreach (var str in strlist)
{
jquery.Find("#main").Append($"{str}");
}
var html = jquery.Render();
}
}
3. 局部渲染RenderSelection
Render方法是将整个Dom渲染成html,但是有时候你只需要获取你修改的那部分内容而不是整个html,这涉及到部分渲染,可以使用RenderSelection方法,代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var strlist = new string[2] { "1", "2" };
var path = Environment.CurrentDirectory + "\\2.html";
var jquery = CQ.CreateFromFile(path);
var current = jquery.Find("#main");
foreach (var str in strlist)
{
current.Append($"{str}");
}
var html = current.RenderSelection();
Console.WriteLine(html);
}
------------- output ----------------
12
四:总结
Jquery的这种操作方式对我个人来说还是比较舒服的,毕竟我很熟悉!不过html5中也加入了querySelector和querySelectorAll来支持css3选择器,非常强大,但是jquery不仅选择器灵活,节点的操作也很灵活。总的来说,它的交互性不是特别丰富。怀旧。
c#抓取网页数据(网页分析采集程序的基本流程和流程图详解 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-09-27 01:08
)
首先大家要清楚:网站的任何页面,无论是php、jsp、aspx等动态页面,还是后台程序生成的静态页面,都可以在浏览器。
所以当你要开发数据采集程序时,首先要了解网站你试图采集的首页结构(HTML)。
当您熟悉网站中需要采集数据的HTML源文件的内容后,程序的其余部分就很容易处理了。因为C#在网站上执行数据采集,原理是“下载你要采集的页面的HTML源文件,分析HTML代码然后抓取你需要的数据,最后将数据保存到本地文件”。
基本流程如下图所示:
1.页面源文件下载
首先引用 System.Net 命名空间
使用 System.Net;
还需要引用
使用 System.Text;
使用 System.IO;
复制代码
引用后实例化一个 WebClient 对象
private WebClientwc = new WebClient();
调用 DownloadData 方法从指定网页的源文件中下载一组 BYTE 数据,然后将 BYTE 数组转换为字符串。
// 下载页面源文件并转换为UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData( string .Format( "你要的是采集的网页地址" )));
复制代码
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
// 下载网页源文件到本地
wc.DownloadFile( "你要采集的网页的URL", "保存源文件的本地文件路径");
// 读取下载的源文件HTML格式字符串
string mainData = File.ReadAllText( "保存源文件的本地文件路径" ,Encoding.UTF8);
复制代码
通过网页HTML格式字符串,您可以分析网页采集,抓取您需要的内容。
2.页面分析采集
页面分析就是将网页源文件中某个特定的或唯一的字符(字符串)作为抓点,并以此抓点为起点,截取你想要的页面上的数据。
以博客园为专栏。比如我要在博客园首页列出文章的标题和链接,就必须用“
代码:
// 经过”
mainData = mainData.Substring(mainData.IndexOf("") + 26);
// 获取文章页面的链接地址
string articleAddr = mainData.Substring( 0 ,mainData.IndexOf( "\"" ));
// 获取文章的标题
string articleTitle = mainData.Substring(mainData.IndexOf("target=\"_blank\">") + 16,
mainData.IndexOf( "")-mainData.IndexOf( "target=\"_blank\">")-16 );
复制代码
注意:当你要采集的网页前台的HTML格式发生变化时,作为抓点的字符通道也会相应变化,否则什么都没有采集
3.数据保存
从网页截取到自己需要的数据后,将数据保存在程序中,保存到本地文件中(或者插入到自己的本地数据库中)。这样,整个采集作品就会是一个段落。
// 输出数据到本地文件
File.AppendAllText(CreateFolderIfNot(Settings.Default.OutPath) + articleTitle + ".txt",
文章数据,
编码.UTF8);
复制代码
另外附上自己写的采集博客园首页文章的小程序代码。本程序的作用是发布到所有博客园首页文章采集下。
下载链接:CnBlogCollector.rar
当然,如果博客园前端页面的格式有调整,程序的采集功能肯定是无效的。只能自己重新调整程序才能继续采集,哈哈。. .
程序效果如下:
查看全部
c#抓取网页数据(网页分析采集程序的基本流程和流程图详解
)
首先大家要清楚:网站的任何页面,无论是php、jsp、aspx等动态页面,还是后台程序生成的静态页面,都可以在浏览器。
所以当你要开发数据采集程序时,首先要了解网站你试图采集的首页结构(HTML)。
当您熟悉网站中需要采集数据的HTML源文件的内容后,程序的其余部分就很容易处理了。因为C#在网站上执行数据采集,原理是“下载你要采集的页面的HTML源文件,分析HTML代码然后抓取你需要的数据,最后将数据保存到本地文件”。
基本流程如下图所示:
1.页面源文件下载
首先引用 System.Net 命名空间
使用 System.Net;
还需要引用
使用 System.Text;
使用 System.IO;
复制代码
引用后实例化一个 WebClient 对象
private WebClientwc = new WebClient();
调用 DownloadData 方法从指定网页的源文件中下载一组 BYTE 数据,然后将 BYTE 数组转换为字符串。
// 下载页面源文件并转换为UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData( string .Format( "你要的是采集的网页地址" )));
复制代码
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
// 下载网页源文件到本地
wc.DownloadFile( "你要采集的网页的URL", "保存源文件的本地文件路径");
// 读取下载的源文件HTML格式字符串
string mainData = File.ReadAllText( "保存源文件的本地文件路径" ,Encoding.UTF8);
复制代码
通过网页HTML格式字符串,您可以分析网页采集,抓取您需要的内容。
2.页面分析采集
页面分析就是将网页源文件中某个特定的或唯一的字符(字符串)作为抓点,并以此抓点为起点,截取你想要的页面上的数据。
以博客园为专栏。比如我要在博客园首页列出文章的标题和链接,就必须用“
代码:
// 经过”
mainData = mainData.Substring(mainData.IndexOf("") + 26);
// 获取文章页面的链接地址
string articleAddr = mainData.Substring( 0 ,mainData.IndexOf( "\"" ));
// 获取文章的标题
string articleTitle = mainData.Substring(mainData.IndexOf("target=\"_blank\">") + 16,
mainData.IndexOf( "")-mainData.IndexOf( "target=\"_blank\">")-16 );
复制代码
注意:当你要采集的网页前台的HTML格式发生变化时,作为抓点的字符通道也会相应变化,否则什么都没有采集
3.数据保存
从网页截取到自己需要的数据后,将数据保存在程序中,保存到本地文件中(或者插入到自己的本地数据库中)。这样,整个采集作品就会是一个段落。
// 输出数据到本地文件
File.AppendAllText(CreateFolderIfNot(Settings.Default.OutPath) + articleTitle + ".txt",
文章数据,
编码.UTF8);
复制代码
另外附上自己写的采集博客园首页文章的小程序代码。本程序的作用是发布到所有博客园首页文章采集下。
下载链接:CnBlogCollector.rar
当然,如果博客园前端页面的格式有调整,程序的采集功能肯定是无效的。只能自己重新调整程序才能继续采集,哈哈。. .
程序效果如下:
c#抓取网页数据(c#获取数据获取数据库中获取数据的某列数据图分析及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-09-19 23:15
以前学习MVC时,需要直接从数据库中获取项目中表的数据,然后编写查询表数据的方法。现在学习c#,需要查询数据库中的字段,然后在服务器上调用存储过程和方法,然后在客户端实例化服务器,首先从数据库中查询数据,如:
要创建存储过程,它类似于之前在MVC数据库中查询数据的研究。区别在于有一个附加的存储过程方法。然后,VS被分为两部分,一个服务器和一个客户端。因此,服务器获取数据库的数据,客户端获取服务器的数据(表达式不好,不关心细节)。服务器获取数据库中的存储过程和方法,如下图所示:
这是为了获取服务器上数据库中存储过程的查询表数据
然后在客户机上调用服务器的方法。如上图所示,绑定表数据时,调用表数据的方法,如下图所示:
首先实例化服务,然后绑定页面数据,并调用将表数据绑定到页面加载事件的方法
数据查询基本完成,如下图所示:
总结
这里介绍了文章在c#中获取数据。有关在c#中获取数据的更多信息,请搜索179885.Com以前的文章或继续浏览下面相关的文章页面。我希望你将来能支持它179885.Com
C#获取数据C#获取数据库中的最大值C#获取数据一行中的一列数据 查看全部
c#抓取网页数据(c#获取数据获取数据库中获取数据的某列数据图分析及应用)
以前学习MVC时,需要直接从数据库中获取项目中表的数据,然后编写查询表数据的方法。现在学习c#,需要查询数据库中的字段,然后在服务器上调用存储过程和方法,然后在客户端实例化服务器,首先从数据库中查询数据,如:
要创建存储过程,它类似于之前在MVC数据库中查询数据的研究。区别在于有一个附加的存储过程方法。然后,VS被分为两部分,一个服务器和一个客户端。因此,服务器获取数据库的数据,客户端获取服务器的数据(表达式不好,不关心细节)。服务器获取数据库中的存储过程和方法,如下图所示:
这是为了获取服务器上数据库中存储过程的查询表数据
然后在客户机上调用服务器的方法。如上图所示,绑定表数据时,调用表数据的方法,如下图所示:
首先实例化服务,然后绑定页面数据,并调用将表数据绑定到页面加载事件的方法
数据查询基本完成,如下图所示:
总结
这里介绍了文章在c#中获取数据。有关在c#中获取数据的更多信息,请搜索179885.Com以前的文章或继续浏览下面相关的文章页面。我希望你将来能支持它179885.Com
C#获取数据C#获取数据库中的最大值C#获取数据一行中的一列数据
c#抓取网页数据(保险起见输入账号密码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-19 07:06
4.输入账户密码,确认登录,获取以下数据:
关注post请求中的URL和postData,以及服务器返回的cookie
cookie收录登录信息。为了安全起见,我们可以将这四个cookie值传递给服务器
首先给出c#发送post请求的代码:(目的是获取服务器返回的cookie)
string Url = "URL";
string postDataStr = "POST Data";//因为上面都是离散的键值对,我们可以从Stream中直接找到postDataStr
//登录并获取cookie
HttpPost(Url, postDataStr, ref cookie);
private string HttpPost(string Url, string postDataStr, ref CookieContainer cookie)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
request.Method = "POST";
request.ContentType = "application/x-www-form-urlencoded";
byte[] postData = Encoding.UTF8.GetBytes(postDataStr);
request.ContentLength = postData.Length;
request.CookieContainer = cookie;
Stream myRequestStream = request.GetRequestStream();
myRequestStream.Write(postData, 0, postData.Length);
myRequestStream.Close();
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
response.Cookies = cookie.GetCookies(response.ResponseUri);
Stream myResponseStream = response.GetResponseStream();
StreamReader myStreamReader = new StreamReader(myResponseStream, Encoding.GetEncoding("utf-8"));
string retString = myStreamReader.ReadToEnd();
myStreamReader.Close();
myResponseStream.Close();
return retString;
}
通过cookie,您可以从网站获取所需的数据,然后发送get请求
由于服务器返回HTML,如何从大量HTML中快速获取所需信息?在这里,我们可以引用一个高效而强大的第三方库nsoup(有些人建议在互联网上使用HTMLPasser,但通过我个人的比较,我发现HTMLPasser在效率和简单性方面远远不如nsoup)
由于nsoup上的在线教程相对较少,您也可以参考jsoup上的教程:
最后,给出了我从网站获取的一些数据:
我在纸上感觉肤浅。我绝对知道我必须练习 查看全部
c#抓取网页数据(保险起见输入账号密码)
4.输入账户密码,确认登录,获取以下数据:
关注post请求中的URL和postData,以及服务器返回的cookie
cookie收录登录信息。为了安全起见,我们可以将这四个cookie值传递给服务器
首先给出c#发送post请求的代码:(目的是获取服务器返回的cookie)
string Url = "URL";
string postDataStr = "POST Data";//因为上面都是离散的键值对,我们可以从Stream中直接找到postDataStr
//登录并获取cookie
HttpPost(Url, postDataStr, ref cookie);
private string HttpPost(string Url, string postDataStr, ref CookieContainer cookie)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
request.Method = "POST";
request.ContentType = "application/x-www-form-urlencoded";
byte[] postData = Encoding.UTF8.GetBytes(postDataStr);
request.ContentLength = postData.Length;
request.CookieContainer = cookie;
Stream myRequestStream = request.GetRequestStream();
myRequestStream.Write(postData, 0, postData.Length);
myRequestStream.Close();
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
response.Cookies = cookie.GetCookies(response.ResponseUri);
Stream myResponseStream = response.GetResponseStream();
StreamReader myStreamReader = new StreamReader(myResponseStream, Encoding.GetEncoding("utf-8"));
string retString = myStreamReader.ReadToEnd();
myStreamReader.Close();
myResponseStream.Close();
return retString;
}
通过cookie,您可以从网站获取所需的数据,然后发送get请求
由于服务器返回HTML,如何从大量HTML中快速获取所需信息?在这里,我们可以引用一个高效而强大的第三方库nsoup(有些人建议在互联网上使用HTMLPasser,但通过我个人的比较,我发现HTMLPasser在效率和简单性方面远远不如nsoup)
由于nsoup上的在线教程相对较少,您也可以参考jsoup上的教程:
最后,给出了我从网站获取的一些数据:
我在纸上感觉肤浅。我绝对知道我必须练习
c#抓取网页数据(什么是抓取、收录网页抓取工具robots.txt文件介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-09-17 09:14
网站建成后,我们如何才能使搜索引擎收录网站?如果搜索引擎收录无法搜索该页面,则意味着没有显示,并且不可能竞争排名和获得SEO流量。本文将重点关注捕获和收录亮点,并从三个维度讨论搜索引擎优化:基本原理、常见问题和解决方案。什么是爬行,收录web爬行工具robots.txt文件介绍
如何查看网站的收录@
设置不被搜索引擎索引的网页
搜索引擎原理:搜索引擎将互联网上的网页内容存储在自己的服务器上。当用户搜索一个单词时,搜索引擎将在其自己的服务器上查找相关内容,即只搜索保存在搜索引擎服务器上的网页
哪些网页可以保存到搜索引擎服务器
只有搜索引擎捕获程序捕获的网页才会保存到搜索引擎的服务器。这个网页捕获程序是搜索引擎的蜘蛛。整个过程分为爬行和爬行
一、什么是抓取,收录
爬行:
这是搜索引擎爬虫在网站上爬行的过程。谷歌的官方解释是,“爬行”指的是找到新的或更新的网页并将其添加到谷歌的过程;(点击此处查看谷歌官方网站上的文档)
收录(索引):
这是搜索引擎将页面存储在其数据库中的结果,该数据库也称为索引。谷歌的官方解释是,谷歌爬虫(“谷歌机器人”)已经访问了该网页,分析了其内容和含义,并将其存储在谷歌索引中。索引网页可以显示在谷歌搜索结果;(点击此处查看谷歌官方网站上的文档)
预算:
是搜索引擎爬行器在网站页面上爬行的最长总时间。一般来说,小的网站(数百或数千页)不需要担心搜索引擎分配的爬网配额是否足够;大网站(数百万或数以百万计的页面)将考虑更多。如果搜索引擎每天抓取数万页,那么整个网站页面抓取可能需要几个月或一年的时间。一般来说,这些数据可以通过谷歌搜索控制台的后台学习。如下面的屏幕截图所示,红色框中的平均值是网站分配的抓取配额
让我们通过一个示例更好地了解爬网、收录和配额爬网:
将搜索引擎比作一个巨大的图书馆,网站比作一家书店,书店里的书比作网站页面,蜘蛛比作图书馆购买者
为了丰富图书馆的藏书,购买者会定期检查书店是否有新书。浏览书籍的过程可以理解为抓取
当买主认为这本书有价值时,他会买下来带回图书馆采集。这本书就是我们所说的收录
每个买家都有一个有限的购书预算。他将优先购买高价值的书籍。这个预算案就是我们所理解的“抢占配额”
二、web爬虫
“爬虫”是一个通用术语,通常指通过跟踪从一个网页到另一个网页的链接,在网站自动发现和扫描的任何程序(如漫游设备或“蜘蛛”程序)。谷歌的主要爬虫程序叫做谷歌机器人
三、robots.txt文件介绍
robots.txt文件指定爬行工具的爬行规则
robots.txt文件必须位于主机的顶级目录中
通常,robots.txt文件中有三种不同的爬行结果:
robots.txt的使用示例:网站目录中的所有文件都可以被所有搜索引擎爬行器访问。用户代理:*
Disallow:
禁止所有搜索引擎蜘蛛访问网站的任何部分
User-agent: *
Disallow: /
禁止所有的搜索引擎蜘蛛访问网站的几个目录
User-agent: *
Disallow: /a/
Disallow: /b/
只允许某个搜索引擎蜘蛛访问
User-agent: Googlebot
Disallow:
屏蔽所有带参数的 URL
User-agent: *
Disallow: /*?
您应该限制爬行器捕获网站某些文件:
一般来说,网站爬行器不需要捕获的文件包括后台管理文件、程序脚本、附件、数据库文件、编码文件、样式表文件、模板文件、导航图片和背景图片
robots.txt文件引起的风险和解决方案:
Robots.txt也带来了一些风险:它还向攻击者指示网站的目录结构和私有数据的位置。设置访问权限和密码以保护您的私人内容,使攻击者无法进入
四、如何查看收录或网站
① 通过site命令
谷歌、百度和必应等主流搜索引擎支持站点命令。通过site命令,您可以查看在宏级别网站已经收录了多少页。该值不准确,有一定波动,但有一定参考价值。如下图所示,网站约为165页,由谷歌收录发布@
② 如果网站已经验证了谷歌搜索控制台,您可以获得网站验证Google收录的准确值显示在下面的红色框中,Google收录216页共网站页@
③ 如果要查询特定页面是否为收录,可以使用info命令。谷歌支持info命令,但百度和必应不支持。在谷歌中输入Info:URL。如果返回结果,则页面已被收录,如下图所示:
五、set不被搜索引擎索引的网页
建议使用robots meta标记,并将以下代码添加到head标记中:
可以选择多条指令,它们不区分大小写
全部
对索引或内容显示没有任何限制。此命令是默认命令,因此显式列出时无效
诺因迪斯
在搜索结果中不显示此页面。Nofollow不跟踪此页面上的链接
没有
相当于Noindex,nofollow。Noarchive不在搜索结果中显示缓存链接
nosnippet
不要在搜索结果中显示此页面的文本摘要或视频预览。如果静态图片缩略图(如果有)可以实现更好的用户体验,则仍然可以显示它们。这适用于所有形式的搜索结果(例如谷歌网页搜索、谷歌图片、谷歌探索)
最大代码段:[数字]
此搜索结果的文本摘要最多只能使用[number]个字符。(请注意,网址可能在搜索结果页面中显示为多个搜索结果。)这不会影响图片或视频预览。这适用于所有形式的搜索结果(例如谷歌网页搜索、谷歌图片、谷歌发现、谷歌助手)。但是,如果发布者已单独授予内容权限,则此限制不适用。例如,如果发布者以页面结构化数据的形式提供内容,或者与谷歌签订了许可协议,则此设置不会阻止这些更具体的允许使用。如果未指定可解析的[number],则忽略此指令
特殊值:
例如:
最大图像预览:[设置]
设置搜索结果中此页面图片预览的最大大小
可接受的设定值:
这适用于所有形式的搜索结果(例如谷歌网页搜索、谷歌图片、谷歌发现、谷歌助手)。但是,如果发布者已单独授予内容权限,则此限制不适用。例如,如果发布者以页内结构化数据的形式提供内容(如amp网页和文章的规范版本),或者与Google签订了许可协议,则此设置不会阻止这些更具体的允许使用
如果出版商不希望Google在搜索结果页面或“浏览”功能中文章显示其amp网页和规范版本时使用大缩略图,则应将Max image preview的值指定为“标准”或“无”
例如:
最大视频预览:[数字]
此页面上的视频在搜索结果中的摘要时间不能超过[number]秒
其他支持的值:
这适用于所有形式的搜索结果(例如谷歌网页搜索、谷歌图片、谷歌视频、谷歌发现、谷歌助手)。如果未指定可解析的[number],则忽略此指令
例如:
不翻译
不要在搜索结果中提供此页面的翻译
noimageindex
不要为此页上的图片编制索引
[日期/时间]之后不可用
在指定的日期/时间之后,不要在搜索结果中显示此页面。必须以广泛使用的格式指定日期/时间,包括但不限于RFC822、RFC 850和ISO 8601。如果未指定有效的[日期/时间],则忽略此指令。默认情况下,内容没有过期日期
例如:
参考资料: 查看全部
c#抓取网页数据(什么是抓取、收录网页抓取工具robots.txt文件介绍)
网站建成后,我们如何才能使搜索引擎收录网站?如果搜索引擎收录无法搜索该页面,则意味着没有显示,并且不可能竞争排名和获得SEO流量。本文将重点关注捕获和收录亮点,并从三个维度讨论搜索引擎优化:基本原理、常见问题和解决方案。什么是爬行,收录web爬行工具robots.txt文件介绍
如何查看网站的收录@
设置不被搜索引擎索引的网页
搜索引擎原理:搜索引擎将互联网上的网页内容存储在自己的服务器上。当用户搜索一个单词时,搜索引擎将在其自己的服务器上查找相关内容,即只搜索保存在搜索引擎服务器上的网页
哪些网页可以保存到搜索引擎服务器
只有搜索引擎捕获程序捕获的网页才会保存到搜索引擎的服务器。这个网页捕获程序是搜索引擎的蜘蛛。整个过程分为爬行和爬行
一、什么是抓取,收录
爬行:
这是搜索引擎爬虫在网站上爬行的过程。谷歌的官方解释是,“爬行”指的是找到新的或更新的网页并将其添加到谷歌的过程;(点击此处查看谷歌官方网站上的文档)
收录(索引):
这是搜索引擎将页面存储在其数据库中的结果,该数据库也称为索引。谷歌的官方解释是,谷歌爬虫(“谷歌机器人”)已经访问了该网页,分析了其内容和含义,并将其存储在谷歌索引中。索引网页可以显示在谷歌搜索结果;(点击此处查看谷歌官方网站上的文档)
预算:
是搜索引擎爬行器在网站页面上爬行的最长总时间。一般来说,小的网站(数百或数千页)不需要担心搜索引擎分配的爬网配额是否足够;大网站(数百万或数以百万计的页面)将考虑更多。如果搜索引擎每天抓取数万页,那么整个网站页面抓取可能需要几个月或一年的时间。一般来说,这些数据可以通过谷歌搜索控制台的后台学习。如下面的屏幕截图所示,红色框中的平均值是网站分配的抓取配额
让我们通过一个示例更好地了解爬网、收录和配额爬网:
将搜索引擎比作一个巨大的图书馆,网站比作一家书店,书店里的书比作网站页面,蜘蛛比作图书馆购买者
为了丰富图书馆的藏书,购买者会定期检查书店是否有新书。浏览书籍的过程可以理解为抓取
当买主认为这本书有价值时,他会买下来带回图书馆采集。这本书就是我们所说的收录
每个买家都有一个有限的购书预算。他将优先购买高价值的书籍。这个预算案就是我们所理解的“抢占配额”
二、web爬虫
“爬虫”是一个通用术语,通常指通过跟踪从一个网页到另一个网页的链接,在网站自动发现和扫描的任何程序(如漫游设备或“蜘蛛”程序)。谷歌的主要爬虫程序叫做谷歌机器人
三、robots.txt文件介绍
robots.txt文件指定爬行工具的爬行规则
robots.txt文件必须位于主机的顶级目录中
通常,robots.txt文件中有三种不同的爬行结果:
robots.txt的使用示例:网站目录中的所有文件都可以被所有搜索引擎爬行器访问。用户代理:*
Disallow:
禁止所有搜索引擎蜘蛛访问网站的任何部分
User-agent: *
Disallow: /
禁止所有的搜索引擎蜘蛛访问网站的几个目录
User-agent: *
Disallow: /a/
Disallow: /b/
只允许某个搜索引擎蜘蛛访问
User-agent: Googlebot
Disallow:
屏蔽所有带参数的 URL
User-agent: *
Disallow: /*?
您应该限制爬行器捕获网站某些文件:
一般来说,网站爬行器不需要捕获的文件包括后台管理文件、程序脚本、附件、数据库文件、编码文件、样式表文件、模板文件、导航图片和背景图片
robots.txt文件引起的风险和解决方案:
Robots.txt也带来了一些风险:它还向攻击者指示网站的目录结构和私有数据的位置。设置访问权限和密码以保护您的私人内容,使攻击者无法进入
四、如何查看收录或网站
① 通过site命令
谷歌、百度和必应等主流搜索引擎支持站点命令。通过site命令,您可以查看在宏级别网站已经收录了多少页。该值不准确,有一定波动,但有一定参考价值。如下图所示,网站约为165页,由谷歌收录发布@
② 如果网站已经验证了谷歌搜索控制台,您可以获得网站验证Google收录的准确值显示在下面的红色框中,Google收录216页共网站页@
③ 如果要查询特定页面是否为收录,可以使用info命令。谷歌支持info命令,但百度和必应不支持。在谷歌中输入Info:URL。如果返回结果,则页面已被收录,如下图所示:
五、set不被搜索引擎索引的网页
建议使用robots meta标记,并将以下代码添加到head标记中:
可以选择多条指令,它们不区分大小写
全部
对索引或内容显示没有任何限制。此命令是默认命令,因此显式列出时无效
诺因迪斯
在搜索结果中不显示此页面。Nofollow不跟踪此页面上的链接
没有
相当于Noindex,nofollow。Noarchive不在搜索结果中显示缓存链接
nosnippet
不要在搜索结果中显示此页面的文本摘要或视频预览。如果静态图片缩略图(如果有)可以实现更好的用户体验,则仍然可以显示它们。这适用于所有形式的搜索结果(例如谷歌网页搜索、谷歌图片、谷歌探索)
最大代码段:[数字]
此搜索结果的文本摘要最多只能使用[number]个字符。(请注意,网址可能在搜索结果页面中显示为多个搜索结果。)这不会影响图片或视频预览。这适用于所有形式的搜索结果(例如谷歌网页搜索、谷歌图片、谷歌发现、谷歌助手)。但是,如果发布者已单独授予内容权限,则此限制不适用。例如,如果发布者以页面结构化数据的形式提供内容,或者与谷歌签订了许可协议,则此设置不会阻止这些更具体的允许使用。如果未指定可解析的[number],则忽略此指令
特殊值:
例如:
最大图像预览:[设置]
设置搜索结果中此页面图片预览的最大大小
可接受的设定值:
这适用于所有形式的搜索结果(例如谷歌网页搜索、谷歌图片、谷歌发现、谷歌助手)。但是,如果发布者已单独授予内容权限,则此限制不适用。例如,如果发布者以页内结构化数据的形式提供内容(如amp网页和文章的规范版本),或者与Google签订了许可协议,则此设置不会阻止这些更具体的允许使用
如果出版商不希望Google在搜索结果页面或“浏览”功能中文章显示其amp网页和规范版本时使用大缩略图,则应将Max image preview的值指定为“标准”或“无”
例如:
最大视频预览:[数字]
此页面上的视频在搜索结果中的摘要时间不能超过[number]秒
其他支持的值:
这适用于所有形式的搜索结果(例如谷歌网页搜索、谷歌图片、谷歌视频、谷歌发现、谷歌助手)。如果未指定可解析的[number],则忽略此指令
例如:
不翻译
不要在搜索结果中提供此页面的翻译
noimageindex
不要为此页上的图片编制索引
[日期/时间]之后不可用
在指定的日期/时间之后,不要在搜索结果中显示此页面。必须以广泛使用的格式指定日期/时间,包括但不限于RFC822、RFC 850和ISO 8601。如果未指定有效的[日期/时间],则忽略此指令。默认情况下,内容没有过期日期
例如:
参考资料:
c#抓取网页数据(一个解析辅助类:HtmlAgilityPack,解析解析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-09-16 00:20
)
这里我们使用一个HTML解析辅助类:HtmlAlityPack。如果您没有在线找到一个插件并将其添加到库中,那么该插件有很多版本。如果您使用VS2005作为您的开发环境,那么就可以了2.0VS2010使用类库4.0等等然后直接创建一个控制台应用程序并替换下面的代码副本以运行,让我们谈谈两年前我作为爬虫的经验。当时,它是为一家公司制造的,也使用c。然而,当时我遇到了一个头疼的问题,那就是拍摄的图像中有病毒,然后系统挂了好几次。因此,抓取网站图片时要注意安全。虽然我这里不涉及图片,但我仍然提醒我那些看文章的朋友们@
<p> class Program
{
//存放所有抓取的代理
public static List masterPorxyList = new List();
//代理IP类
public class proxy
{
public string ip;
public string port;
public int speed;
public proxy(string pip,string pport,int pspeed)
{
this.ip = pip;
this.port = pport;
this.speed = pspeed;
}
}
//抓去处理方法
static void getProxyList(object pageIndex)
{
string urlCombin = "http://www.xicidaili.com/wt/" + pageIndex.ToString();
string catchHtml = catchProxIpMethord(urlCombin, "UTF8");
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(catchHtml);
HtmlNode table = doc.DocumentNode.SelectSingleNode("//div[@id='wrapper']//div[@id='body']/table[1]");
HtmlNodeCollection collectiontrs = table.SelectNodes("./tr");
for (int i = 0; i < collectiontrs.Count; i++)
{
HtmlAgilityPack.HtmlNode itemtr = collectiontrs[i];
HtmlNodeCollection collectiontds = itemtr.ChildNodes;
//table中第一个是能用的代理标题,所以这里从第二行TR开始取值
if (i>0)
{
HtmlNode itemtdip = (HtmlNode)collectiontds[3];
HtmlNode itemtdport = (HtmlNode)collectiontds[5];
HtmlNode itemtdspeed = (HtmlNode)collectiontds[13];
string ip = itemtdip.InnerText.Trim();
string port = itemtdport.InnerText.Trim();
string speed = itemtdspeed.InnerHtml;
int beginIndex = speed.IndexOf(":", 0, speed.Length);
int endIndex = speed.IndexOf("%", 0, speed.Length);
int subSpeed = int.Parse(speed.Substring(beginIndex + 1, endIndex - beginIndex - 1));
//如果速度展示条的值大于90,表示这个代理速度快。
if (subSpeed > 90)
{
proxy temp = new proxy(ip, port, subSpeed);
masterPorxyList.Add(temp);
Console.WriteLine("当前是第:" + masterPorxyList.Count.ToString() + "个代理IP");
}
}
}
}
//抓网页方法
static string catchProxIpMethord(string url,string encoding )
{
string htmlStr = "";
try
{
if (!String.IsNullOrEmpty(url))
{
WebRequest request = WebRequest.Create(url);
WebResponse response = request.GetResponse();
Stream datastream = response.GetResponseStream();
Encoding ec = Encoding.Default;
if (encoding == "UTF8")
{
ec = Encoding.UTF8;
}
else if (encoding == "Default")
{
ec = Encoding.Default;
}
StreamReader reader = new StreamReader(datastream, ec);
htmlStr = reader.ReadToEnd();
reader.Close();
datastream.Close();
response.Close();
}
}
catch { }
return htmlStr;
}
static void Main(string[] args)
{
//多线程同时抓15页
for (int i = 1; i 查看全部
c#抓取网页数据(一个解析辅助类:HtmlAgilityPack,解析解析
)
这里我们使用一个HTML解析辅助类:HtmlAlityPack。如果您没有在线找到一个插件并将其添加到库中,那么该插件有很多版本。如果您使用VS2005作为您的开发环境,那么就可以了2.0VS2010使用类库4.0等等然后直接创建一个控制台应用程序并替换下面的代码副本以运行,让我们谈谈两年前我作为爬虫的经验。当时,它是为一家公司制造的,也使用c。然而,当时我遇到了一个头疼的问题,那就是拍摄的图像中有病毒,然后系统挂了好几次。因此,抓取网站图片时要注意安全。虽然我这里不涉及图片,但我仍然提醒我那些看文章的朋友们@
<p> class Program
{
//存放所有抓取的代理
public static List masterPorxyList = new List();
//代理IP类
public class proxy
{
public string ip;
public string port;
public int speed;
public proxy(string pip,string pport,int pspeed)
{
this.ip = pip;
this.port = pport;
this.speed = pspeed;
}
}
//抓去处理方法
static void getProxyList(object pageIndex)
{
string urlCombin = "http://www.xicidaili.com/wt/" + pageIndex.ToString();
string catchHtml = catchProxIpMethord(urlCombin, "UTF8");
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(catchHtml);
HtmlNode table = doc.DocumentNode.SelectSingleNode("//div[@id='wrapper']//div[@id='body']/table[1]");
HtmlNodeCollection collectiontrs = table.SelectNodes("./tr");
for (int i = 0; i < collectiontrs.Count; i++)
{
HtmlAgilityPack.HtmlNode itemtr = collectiontrs[i];
HtmlNodeCollection collectiontds = itemtr.ChildNodes;
//table中第一个是能用的代理标题,所以这里从第二行TR开始取值
if (i>0)
{
HtmlNode itemtdip = (HtmlNode)collectiontds[3];
HtmlNode itemtdport = (HtmlNode)collectiontds[5];
HtmlNode itemtdspeed = (HtmlNode)collectiontds[13];
string ip = itemtdip.InnerText.Trim();
string port = itemtdport.InnerText.Trim();
string speed = itemtdspeed.InnerHtml;
int beginIndex = speed.IndexOf(":", 0, speed.Length);
int endIndex = speed.IndexOf("%", 0, speed.Length);
int subSpeed = int.Parse(speed.Substring(beginIndex + 1, endIndex - beginIndex - 1));
//如果速度展示条的值大于90,表示这个代理速度快。
if (subSpeed > 90)
{
proxy temp = new proxy(ip, port, subSpeed);
masterPorxyList.Add(temp);
Console.WriteLine("当前是第:" + masterPorxyList.Count.ToString() + "个代理IP");
}
}
}
}
//抓网页方法
static string catchProxIpMethord(string url,string encoding )
{
string htmlStr = "";
try
{
if (!String.IsNullOrEmpty(url))
{
WebRequest request = WebRequest.Create(url);
WebResponse response = request.GetResponse();
Stream datastream = response.GetResponseStream();
Encoding ec = Encoding.Default;
if (encoding == "UTF8")
{
ec = Encoding.UTF8;
}
else if (encoding == "Default")
{
ec = Encoding.Default;
}
StreamReader reader = new StreamReader(datastream, ec);
htmlStr = reader.ReadToEnd();
reader.Close();
datastream.Close();
response.Close();
}
}
catch { }
return htmlStr;
}
static void Main(string[] args)
{
//多线程同时抓15页
for (int i = 1; i
c#抓取网页数据(两个c#开发的网络爬虫老外写的相当不错:解析结果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-09-13 12:11
项目经理说这是项目的一个亮点(无语...),类似爬虫的东西,模拟登录后台系统获取所需数据。然后开始研究这个。
之前有一些数据抓取的经验,抓取过程无非是:设置参数->服务器发送请求->解析结果
1、验证码识别
系统验证码只有数字,并不复杂,没有深入研究。
这完全满足我的需求。
2、用户名和密码由用户提供。
里面有证书,每次申请都必须随身携带。
证书获取方式:
3、网上有很多模拟登录的请求。
推荐一位大神,写的相当好:
4、parse html 内容
推荐一个类库:HtmlAgilityPack,好用。它将html字符串转换为xml类型的操作(本来我想用普通的)。
有了上面的东西,基本上就可以调试工作了。如果要做后台服务,还需要定时任务。这仍在研究中。 . .
经验:
1、登录的时候一直提示验证码错误,很费解,因为我是手动输入验证码的。用抓包工具分析后发现是JSESSIONID(使用的是JSP网站服务器),这个是每次请求都要带的,JSESSIONID是否正确。
2、抓数据时提示登录超时,郁闷了半天,抽了根烟,把问题指向相关参数。抓包分析后,问题出现在JSESSIONID上,JSESSIONID的值不正确。修改后一切正常。
开源的网络爬虫有很多,在Sourceforge上搜索也有很多,但C#很少。今天推荐两个c#开发的网络爬虫
老外写的,http通信使用socket,效果很好,但是没有处理中文,下载中文时会出现乱码。在socket接收部分做一些处理就可以了。这个程序比较完整,具备了一个基本爬虫的所有功能,就是一个很好的例子。 VS2003, .net 1.1 有些已经过时,需要调整。
是老外写的,csspider.zip。没有仔细研究,遵循LGPL协议,这位同志是专门研究爬虫的,写过很多书,但是都是英文的,看不懂。 .net 2.0。
这里介绍的两个例子都是比较完整的例子,包括网页下载、分析、多线程、输出。下面的一点点处理就能得到很好的效果,同时也可以研究更多的实现思路,对自己的爬虫有很大的帮助。 查看全部
c#抓取网页数据(两个c#开发的网络爬虫老外写的相当不错:解析结果)
项目经理说这是项目的一个亮点(无语...),类似爬虫的东西,模拟登录后台系统获取所需数据。然后开始研究这个。
之前有一些数据抓取的经验,抓取过程无非是:设置参数->服务器发送请求->解析结果
1、验证码识别
系统验证码只有数字,并不复杂,没有深入研究。
这完全满足我的需求。
2、用户名和密码由用户提供。
里面有证书,每次申请都必须随身携带。
证书获取方式:
3、网上有很多模拟登录的请求。
推荐一位大神,写的相当好:
4、parse html 内容
推荐一个类库:HtmlAgilityPack,好用。它将html字符串转换为xml类型的操作(本来我想用普通的)。
有了上面的东西,基本上就可以调试工作了。如果要做后台服务,还需要定时任务。这仍在研究中。 . .
经验:
1、登录的时候一直提示验证码错误,很费解,因为我是手动输入验证码的。用抓包工具分析后发现是JSESSIONID(使用的是JSP网站服务器),这个是每次请求都要带的,JSESSIONID是否正确。
2、抓数据时提示登录超时,郁闷了半天,抽了根烟,把问题指向相关参数。抓包分析后,问题出现在JSESSIONID上,JSESSIONID的值不正确。修改后一切正常。
开源的网络爬虫有很多,在Sourceforge上搜索也有很多,但C#很少。今天推荐两个c#开发的网络爬虫
老外写的,http通信使用socket,效果很好,但是没有处理中文,下载中文时会出现乱码。在socket接收部分做一些处理就可以了。这个程序比较完整,具备了一个基本爬虫的所有功能,就是一个很好的例子。 VS2003, .net 1.1 有些已经过时,需要调整。
是老外写的,csspider.zip。没有仔细研究,遵循LGPL协议,这位同志是专门研究爬虫的,写过很多书,但是都是英文的,看不懂。 .net 2.0。
这里介绍的两个例子都是比较完整的例子,包括网页下载、分析、多线程、输出。下面的一点点处理就能得到很好的效果,同时也可以研究更多的实现思路,对自己的爬虫有很大的帮助。

