
c#抓取网页数据
c#抓取网页数据(开发数据采集程序的时候需要清楚的几个基本流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2021-11-24 10:04
首先大家要清楚:网站的任何页面,无论是php、jsp、aspx等动态页面,还是后台程序生成的静态页面,都可以在浏览器。
所以当你要开发数据采集程序时,首先要了解网站你试图采集的首页结构(HTML)。
当您熟悉网站中需要采集数据的HTML源文件的内容后,程序的其余部分就很容易处理了。因为C#在网站上执行数据采集,原理是“下载你要采集的页面的HTML源文件,分析HTML代码然后抓取你需要的数据,最后将数据保存到本地文件”。
基本流程如下图所示:
1.页面源文件下载
首先引用 System.Net 命名空间
using System.Net;
还需要引用
using System.Text;
using System.IO;
引用后实例化一个 WebClient 对象
private WebClient wc = new WebClient();
调用 DownloadData 方法从指定网页的源文件中下载一组 BYTE 数据,然后将 BYTE 数组转换为字符串。
//下载页面源文件并将其转换成UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData(string.Format("你要采集的网页地址")));
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
//下载网页源文件到本地
wc.DownloadFile("你要采集的网页URL","保存源文件的本地文件路径");
//读取下载下来的源文件HTML格式的字符串
string mainData = File.ReadAllText("保存源文件的本地文件路径",Encoding.UTF8);
通过网页HTML格式字符串,您可以分析网页采集,抓取您需要的内容。
2.页面分析采集
页面分析就是将网页源文件中的某个特定的或唯一的字符(字符串)作为抓点,并以此抓点为起点,截取你想要的页面上的数据。
以博客园为专栏。比如我要在博客园首页列出文章的标题和链接,就必须用“
<p>//以" 查看全部
c#抓取网页数据(开发数据采集程序的时候需要清楚的几个基本流程)
首先大家要清楚:网站的任何页面,无论是php、jsp、aspx等动态页面,还是后台程序生成的静态页面,都可以在浏览器。

所以当你要开发数据采集程序时,首先要了解网站你试图采集的首页结构(HTML)。
当您熟悉网站中需要采集数据的HTML源文件的内容后,程序的其余部分就很容易处理了。因为C#在网站上执行数据采集,原理是“下载你要采集的页面的HTML源文件,分析HTML代码然后抓取你需要的数据,最后将数据保存到本地文件”。
基本流程如下图所示:

1.页面源文件下载
首先引用 System.Net 命名空间
using System.Net;
还需要引用
using System.Text;
using System.IO;
引用后实例化一个 WebClient 对象
private WebClient wc = new WebClient();
调用 DownloadData 方法从指定网页的源文件中下载一组 BYTE 数据,然后将 BYTE 数组转换为字符串。
//下载页面源文件并将其转换成UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData(string.Format("你要采集的网页地址")));
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
//下载网页源文件到本地
wc.DownloadFile("你要采集的网页URL","保存源文件的本地文件路径");
//读取下载下来的源文件HTML格式的字符串
string mainData = File.ReadAllText("保存源文件的本地文件路径",Encoding.UTF8);
通过网页HTML格式字符串,您可以分析网页采集,抓取您需要的内容。
2.页面分析采集
页面分析就是将网页源文件中的某个特定的或唯一的字符(字符串)作为抓点,并以此抓点为起点,截取你想要的页面上的数据。
以博客园为专栏。比如我要在博客园首页列出文章的标题和链接,就必须用“

<p>//以"
c#抓取网页数据(学一下c#编写爬虫,发现了一个很好的视频资源)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-21 08:22
最近开始学习c#写爬虫,找到了一个不错的视频资源,然后在学习的时候做一些笔记。
视频资源链接:
第一个小例子是用net读取网站的源码。其中的所有数据都可以在谷歌浏览器的开发工具按钮中通过网络获取。
class Program
{
static void Main(string[] args)
{
//建立一个请求
string Url = "https://baike.baidu.com/item/using/232450";
HttpWebRequest Myrq = WebRequest.Create(Url) as HttpWebRequest;
Myrq.KeepAlive = false;//持续连接
Myrq.Timeout = 30 * 1000;//30秒,*1000是因为基础单位为毫秒
Myrq.Method = "GET";//请求方法
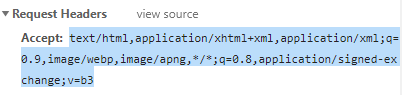
Myrq.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3";//自己去network里面找
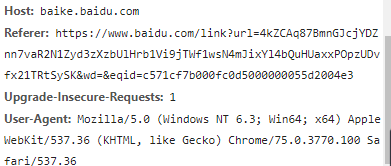
Myrq.Host = "baike.baidu.com";
Myrq.Referer = "https://www.baidu.com/link%3Fu ... 3B%3B
Myrq.UserAgent = "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36";
//接受返回
HttpWebResponse Myrp = (HttpWebResponse )Myrq.GetResponse();
if(Myrp.StatusCode !=HttpStatusCode.OK )
{ return; }
using (StreamReader rd = new StreamReader(Myrp.GetResponseStream()))
{
Console.WriteLine(rd.ReadToEnd() );
}
Console.ReadKey();
输出如下:
网络中的第一个是网站的请求第一类。
请结合以下图片和代码查看
第二个小例子,开始抓取图片,这个url是作者随机找到的一张网站的图片的请求头。
您也可以自己更改。
//建立一个请求
string Url = "http://pic.netbian.com/uploads ... 3B%3B
HttpWebRequest Myrq = WebRequest.Create(Url) as HttpWebRequest;
Myrq.KeepAlive = false;//持续连接
Myrq.Timeout = 30 * 1000;//30秒,*1000是因为基础单位为毫秒
Myrq.Method = "GET";//请求方法
Myrq.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3";//自己去network里面找
Myrq.UserAgent = "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36";
//接受返回
HttpWebResponse Myrp = (HttpWebResponse )Myrq.GetResponse();
if(Myrp.StatusCode !=HttpStatusCode.OK )
{ return; }
using (FileStream fl = new FileStream("1.jpg", FileMode.Create))//展开一个流
{
Myrp.GetResponseStream().CopyTo(fl);//复制到当前文件夹
}
我们可以看到,两段代码其实并没有太大的区别,只有很小的区别。 查看全部
c#抓取网页数据(学一下c#编写爬虫,发现了一个很好的视频资源)
最近开始学习c#写爬虫,找到了一个不错的视频资源,然后在学习的时候做一些笔记。
视频资源链接:
第一个小例子是用net读取网站的源码。其中的所有数据都可以在谷歌浏览器的开发工具按钮中通过网络获取。
class Program
{
static void Main(string[] args)
{
//建立一个请求
string Url = "https://baike.baidu.com/item/using/232450";
HttpWebRequest Myrq = WebRequest.Create(Url) as HttpWebRequest;
Myrq.KeepAlive = false;//持续连接
Myrq.Timeout = 30 * 1000;//30秒,*1000是因为基础单位为毫秒
Myrq.Method = "GET";//请求方法
Myrq.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3";//自己去network里面找
Myrq.Host = "baike.baidu.com";
Myrq.Referer = "https://www.baidu.com/link%3Fu ... 3B%3B
Myrq.UserAgent = "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36";
//接受返回
HttpWebResponse Myrp = (HttpWebResponse )Myrq.GetResponse();
if(Myrp.StatusCode !=HttpStatusCode.OK )
{ return; }
using (StreamReader rd = new StreamReader(Myrp.GetResponseStream()))
{
Console.WriteLine(rd.ReadToEnd() );
}
Console.ReadKey();
输出如下:

网络中的第一个是网站的请求第一类。
请结合以下图片和代码查看

第二个小例子,开始抓取图片,这个url是作者随机找到的一张网站的图片的请求头。
您也可以自己更改。
//建立一个请求
string Url = "http://pic.netbian.com/uploads ... 3B%3B
HttpWebRequest Myrq = WebRequest.Create(Url) as HttpWebRequest;
Myrq.KeepAlive = false;//持续连接
Myrq.Timeout = 30 * 1000;//30秒,*1000是因为基础单位为毫秒
Myrq.Method = "GET";//请求方法
Myrq.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3";//自己去network里面找
Myrq.UserAgent = "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36";
//接受返回
HttpWebResponse Myrp = (HttpWebResponse )Myrq.GetResponse();
if(Myrp.StatusCode !=HttpStatusCode.OK )
{ return; }
using (FileStream fl = new FileStream("1.jpg", FileMode.Create))//展开一个流
{
Myrp.GetResponseStream().CopyTo(fl);//复制到当前文件夹
}
我们可以看到,两段代码其实并没有太大的区别,只有很小的区别。
c#抓取网页数据(这篇博文记录一下如何抓取网页上面的验证码,注意不是验证码识别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-20 22:11
如果你要开发一个半自动注册机程序,那么将验证码读入winform并提交数据是一个必要的过程。这篇博文记录了如何抓取网页上的验证码,注意不是验证码识别。有些 网站 会验证 cookie,有些则不会。本文收录cookie阅读和提交。
第一次生活是一个全局 Cookie 变量
private CookieContainer cookie = new System.Net.CookieContainer();
程序加载时读取验证码和cookie
public Form1()
{
InitializeComponent();
string checkcodeUrl = "验证码的url";
try
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(checkcodeUrl);
request.CookieContainer = new CookieContainer();
Stream responseStream = ((HttpWebResponse)request.GetResponse()).GetResponseStream();
cookie = request.CookieContainer;
string cookiesstr = request.CookieContainer.GetCookieHeader(request.RequestUri);
Image original = Image.FromStream(responseStream);
Bitmap bitMap = new Bitmap(original);
this.pictureBox1.Image = bitMap;
responseStream.Close();
}
catch (Exception exception)
{
MessageBox.Show("ERROR:" + exception.Message);
}
}
提交数据
HttpWebRequest webrequest = (HttpWebRequest)WebRequest.Create(url);
webrequest.CookieContainer = cookie;
HttpWebResponse response = (HttpWebResponse)webrequest.GetResponse();
StreamReader read = new StreamReader(response.GetResponseStream(), Encoding.Default);
string text = read.ReadToEnd();
不明白的请留言咨询,只写一部分必要的代码。 查看全部
c#抓取网页数据(这篇博文记录一下如何抓取网页上面的验证码,注意不是验证码识别)
如果你要开发一个半自动注册机程序,那么将验证码读入winform并提交数据是一个必要的过程。这篇博文记录了如何抓取网页上的验证码,注意不是验证码识别。有些 网站 会验证 cookie,有些则不会。本文收录cookie阅读和提交。
第一次生活是一个全局 Cookie 变量
private CookieContainer cookie = new System.Net.CookieContainer();
程序加载时读取验证码和cookie
public Form1()
{
InitializeComponent();
string checkcodeUrl = "验证码的url";
try
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(checkcodeUrl);
request.CookieContainer = new CookieContainer();
Stream responseStream = ((HttpWebResponse)request.GetResponse()).GetResponseStream();
cookie = request.CookieContainer;
string cookiesstr = request.CookieContainer.GetCookieHeader(request.RequestUri);
Image original = Image.FromStream(responseStream);
Bitmap bitMap = new Bitmap(original);
this.pictureBox1.Image = bitMap;
responseStream.Close();
}
catch (Exception exception)
{
MessageBox.Show("ERROR:" + exception.Message);
}
}
提交数据
HttpWebRequest webrequest = (HttpWebRequest)WebRequest.Create(url);
webrequest.CookieContainer = cookie;
HttpWebResponse response = (HttpWebResponse)webrequest.GetResponse();
StreamReader read = new StreamReader(response.GetResponseStream(), Encoding.Default);
string text = read.ReadToEnd();
不明白的请留言咨询,只写一部分必要的代码。
c#抓取网页数据(经@吃西瓜的星星提醒(2):SeleniumSelenium)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-19 02:03
@吃瓜的星提醒
首先我们介绍Selenium
Selenium 也是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试浏览器兼容性——测试您的应用程序是否可以在不同浏览器和操作系统上正常运行。测试系统功能——创建回归测试以验证软件功能和用户需求。支持自动录制动作和自动生成。测试Net、Java、Perl等不同语言的脚本。Selenium是ThoughtWorks专门为web应用编写的验收测试工具。
单击此处了解详细信息
这里我们将使用模拟真人操作,不会被TX统一用于访问和数据捕获。
这里使用的IDE是VS2017,系统是Win10,浏览器驱动是ChromeDriver
新的单元测试解决方案
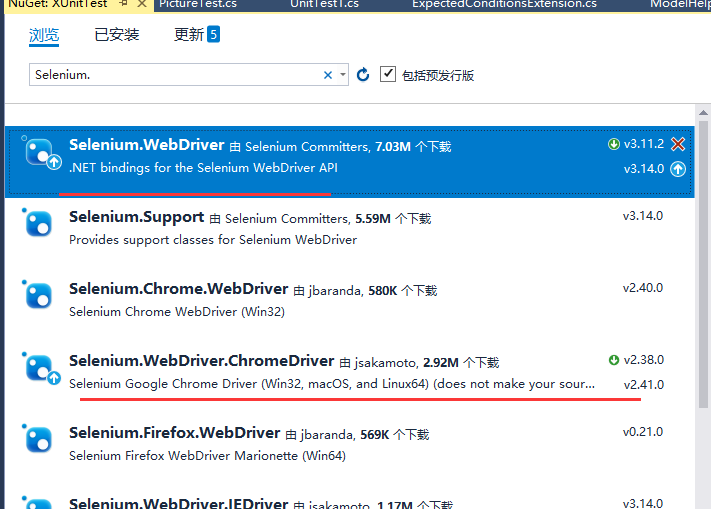
安装 Nuget 包
我这里用的是谷歌浏览器采集数据,所以我用的是谷歌浏览器的驱动。如果你不喜欢谷歌浏览器,你可以参考其他驱动程序包。
命令
Install-Package Selenium.WebDriver
Install-Package Selenium.WebDriver.ChromeDriver
或者直接安装管理器如下图
Selenium.WebDriver.ChromeDriver 是将Chorme驱动,即ChormeDriver.exe程序,在项目编译完成后复制到bin目录下。
将NetCore复制到对应的netcoreappv文件目录下
这样,基本参考就完成了,下面介绍具体的实现。
首先创建一个测试类Qzone.cs,我们后续的所有调用都在测试类中进行测试和实现
public class QzoneTest
{
[Fact]
public void QQLogin()
{
var driver = new ChromeDriver();
driver.Url = "https://qzone.qq.com/";
driver.Quit();
}
}
因为是xUnit测试类,可以直接右键调试测试,运行时可以看到下图
驱动会自动打开Chrome浏览器并跳转到指定页面。
空间页面已经打开,下面是登录步骤
有两种登录方式,也是QQ自己提供的
第一种,如果你已经登录QQ,可以直接点击头像登录
第二种用账号密码登录
下面就来详细介绍一下
让我谈谈第二个。第一个比较简单。学完第二个,第一个就容易了。
我们需要找到输入账号和密码的文本框
这里我们使用Selenium的查找元素的方法
这为我们提供了多种查找元素的方法,我们可以根据名称来理解其含义。
var driver = new ChromeDriver();
driver.FindElement();
driver.FindElementByClassName();
driver.FindElementByCssSelector();
driver.FindElementById();
driver.FindElementByName();
driver.FindElementByTagName();
driver.FindElementByXPath()
我们使用 ByXPath 方法来查找元素。XPath的详细介绍可以自行了解。我只会向您展示如何快速找到 XPath。
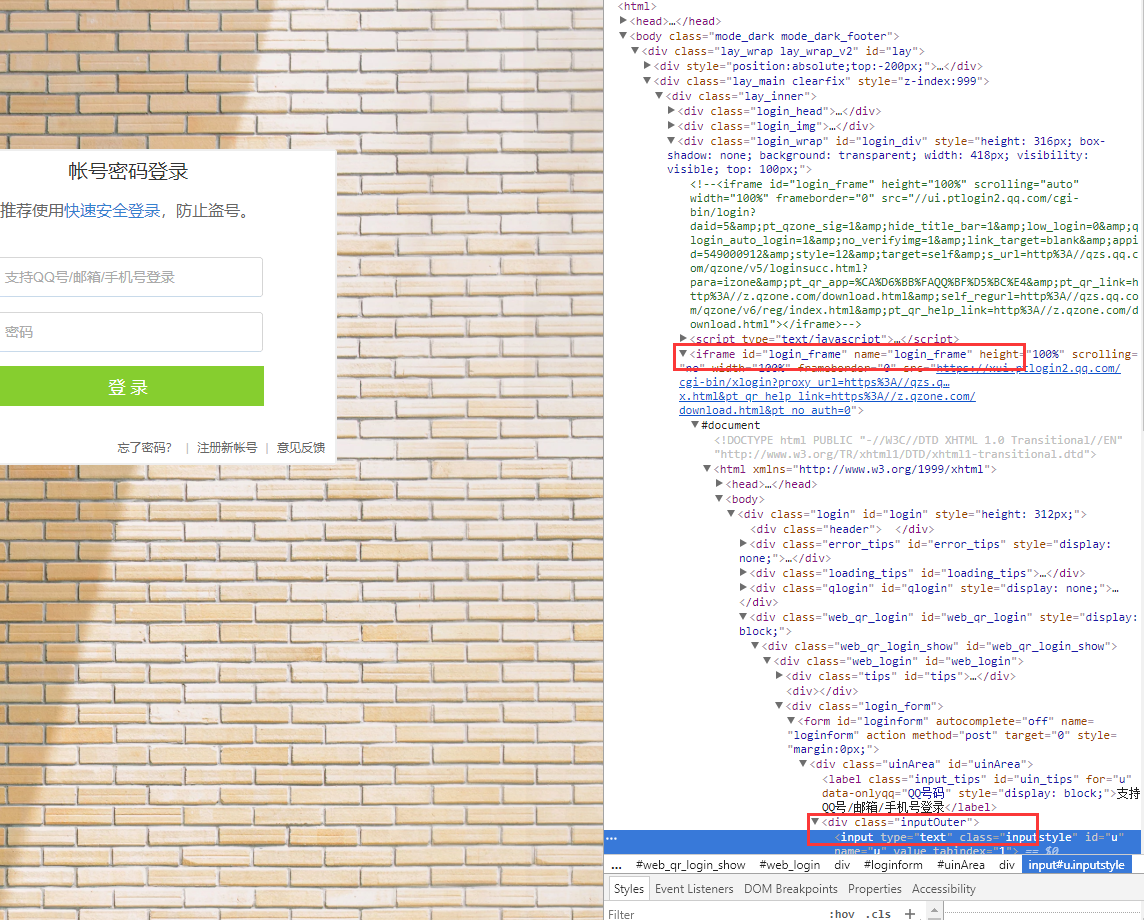
只需打开空间地址,找到文本框,然后勾选元素,在右边的元素位置右击->Copy->Copy XPath
可以得到这样的地址
//*[@id="u"]
找密码框的方法一样
//*[@id="p"]
通过这个xpath我们可以找到用户名的xpath路径,然后在程序中这样写
try
{
var userName = driver.FindElementByXPath("//*[@id='u']");
//这里的userName就是用户名的文本框
//设置用户名的值
userName.SendKeys("123456");
var pwd = driver.FindElementByXPath("//*[@id='p']");
pwd.SendKeys("********");
}
finally
{
driver.Quit();
}
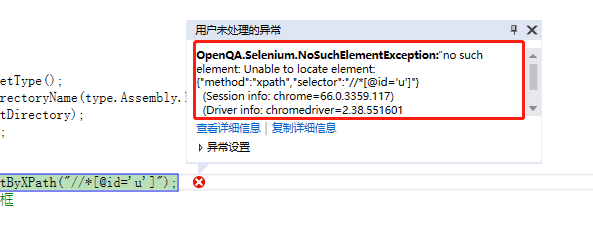
运行后出现异常
别慌,这是浏览器驱动没有找到元素造成的,我们仔细检查一下
原来的文本框嵌套在一个iframe中,难怪当前驱动找不到元素,因为当前驱动只会找到当前连接下的元素,不包括嵌套元素。
然后我们使用switch语法
try
{
//切换语法有两种,一种是根据索引切换,另外一种根据iframe名称切换
//这里我们使用name切换
ITargetLocator tagetLocator = driver.SwitchTo();
//tagetLocator.Frame(1); //frame index.
tagetLocator.Frame("login_frame"); //frame frame name.
var userName = driver.FindElementByXPath("//*[@id='u']");
//这里的userName就是用户名的文本框
//设置用户名的值
userName.SendKeys("123456");
var pwd = driver.FindElementByXPath("//*[@id='p']");
pwd.SendKeys("********");
}
finally
{
driver.Quit();
}
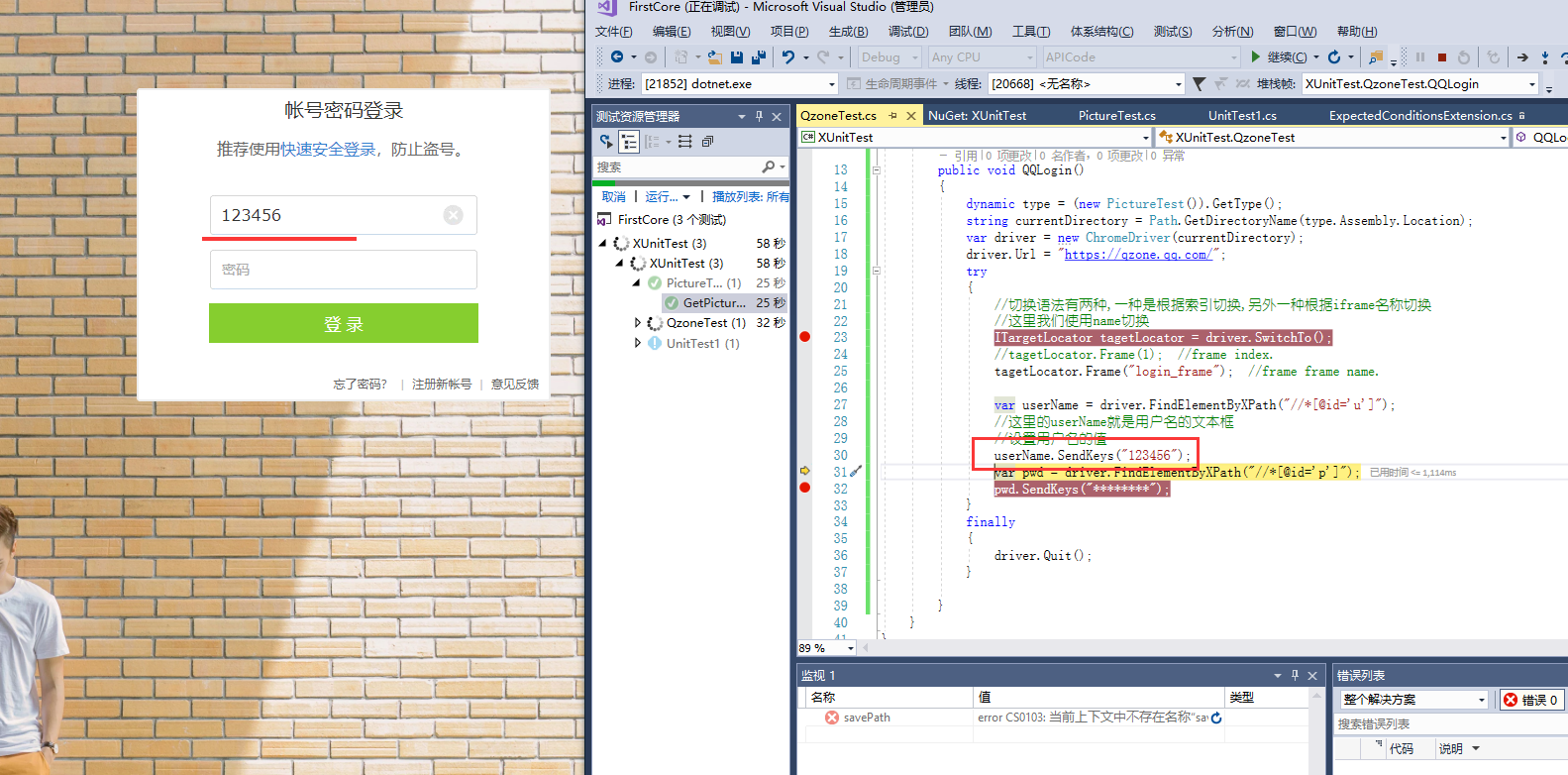
然后调试测试,如下图
所以将值填入文本框
最后点击登录,找到login button元素,同样点击找到login button元素,点击
[Fact]
public void QQLogin()
{
dynamic type = (new PictureTest()).GetType();
string currentDirectory = Path.GetDirectoryName(type.Assembly.Location);
var driver = new ChromeDriver(currentDirectory);
driver.Url = "https://qzone.qq.com/";
try
{
//切换语法有两种,一种是根据索引切换,另外一种根据iframe名称切换
//这里我们使用name切换
ITargetLocator tagetLocator = driver.SwitchTo();
//tagetLocator.Frame(1); //frame index.
tagetLocator.Frame("login_frame"); //frame frame name.
var userName = driver.FindElementByXPath("//*[@id='u']");
//这里的userName就是用户名的文本框
//设置用户名的值
userName.SendKeys("123456");
var pwd = driver.FindElementByXPath("//*[@id='p']");
pwd.SendKeys("********");
var btnLogin = driver.FindElementByXPath("//*[@id='login_button']");
//这里是判断登录按钮是否可见,可以不写,直接调用click方法
if (btnLogin != null && btnLogin.Displayed == true)
{
btnLogin.Click();
}
}
finally
{
driver.Quit();
}
}
然后登录成功
总而言之,使用了一些关键语法
//Iframe切换,如果需要捕获的元素不在当前页面,则找到嵌套页面进行切换
//切换语法有两种,一种是根据索引切换,另外一种根据iframe名称切换
ITargetLocator tagetLocator = driver.SwitchTo();
//tagetLocator.Frame(1); //frame index.
tagetLocator.Frame("login_frame"); //frame frame name.
//查找元素方法,可以使用css定位
var userName = driver.FindElementByXPath("//*[@id='u']");
//设置文本框的值SendKeys
userName.SendKeys("123456");
//元素点击事件
var btnLogin = driver.FindElementByXPath("//*[@id='login_button']");
btnLogin.Click();
只要了解驱动对浏览器的一些操作方式,就可以自行探索,实现自己想要的,比如点击切换登录框、快速登录
例如,找到相册元素并点击,找到菜单谈论元素并点击,设置文本框值,发送谈话,写消息,你可以探索和使用
登录先在这里聊,改天写点什么或者留言板,或者保存相册的照片
Git源代码地址: 查看全部
c#抓取网页数据(经@吃西瓜的星星提醒(2):SeleniumSelenium)
@吃瓜的星提醒
首先我们介绍Selenium
Selenium 也是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试浏览器兼容性——测试您的应用程序是否可以在不同浏览器和操作系统上正常运行。测试系统功能——创建回归测试以验证软件功能和用户需求。支持自动录制动作和自动生成。测试Net、Java、Perl等不同语言的脚本。Selenium是ThoughtWorks专门为web应用编写的验收测试工具。
单击此处了解详细信息
这里我们将使用模拟真人操作,不会被TX统一用于访问和数据捕获。
这里使用的IDE是VS2017,系统是Win10,浏览器驱动是ChromeDriver
新的单元测试解决方案
安装 Nuget 包
我这里用的是谷歌浏览器采集数据,所以我用的是谷歌浏览器的驱动。如果你不喜欢谷歌浏览器,你可以参考其他驱动程序包。
命令
Install-Package Selenium.WebDriver
Install-Package Selenium.WebDriver.ChromeDriver
或者直接安装管理器如下图
Selenium.WebDriver.ChromeDriver 是将Chorme驱动,即ChormeDriver.exe程序,在项目编译完成后复制到bin目录下。
将NetCore复制到对应的netcoreappv文件目录下

这样,基本参考就完成了,下面介绍具体的实现。
首先创建一个测试类Qzone.cs,我们后续的所有调用都在测试类中进行测试和实现
public class QzoneTest
{
[Fact]
public void QQLogin()
{
var driver = new ChromeDriver();
driver.Url = "https://qzone.qq.com/";
driver.Quit();
}
}
因为是xUnit测试类,可以直接右键调试测试,运行时可以看到下图
驱动会自动打开Chrome浏览器并跳转到指定页面。

空间页面已经打开,下面是登录步骤
有两种登录方式,也是QQ自己提供的
第一种,如果你已经登录QQ,可以直接点击头像登录
第二种用账号密码登录
下面就来详细介绍一下
让我谈谈第二个。第一个比较简单。学完第二个,第一个就容易了。
我们需要找到输入账号和密码的文本框
这里我们使用Selenium的查找元素的方法
这为我们提供了多种查找元素的方法,我们可以根据名称来理解其含义。
var driver = new ChromeDriver();
driver.FindElement();
driver.FindElementByClassName();
driver.FindElementByCssSelector();
driver.FindElementById();
driver.FindElementByName();
driver.FindElementByTagName();
driver.FindElementByXPath()
我们使用 ByXPath 方法来查找元素。XPath的详细介绍可以自行了解。我只会向您展示如何快速找到 XPath。
只需打开空间地址,找到文本框,然后勾选元素,在右边的元素位置右击->Copy->Copy XPath

可以得到这样的地址
//*[@id="u"]
找密码框的方法一样
//*[@id="p"]
通过这个xpath我们可以找到用户名的xpath路径,然后在程序中这样写
try
{
var userName = driver.FindElementByXPath("//*[@id='u']");
//这里的userName就是用户名的文本框
//设置用户名的值
userName.SendKeys("123456");
var pwd = driver.FindElementByXPath("//*[@id='p']");
pwd.SendKeys("********");
}
finally
{
driver.Quit();
}
运行后出现异常
别慌,这是浏览器驱动没有找到元素造成的,我们仔细检查一下
原来的文本框嵌套在一个iframe中,难怪当前驱动找不到元素,因为当前驱动只会找到当前连接下的元素,不包括嵌套元素。
然后我们使用switch语法
try
{
//切换语法有两种,一种是根据索引切换,另外一种根据iframe名称切换
//这里我们使用name切换
ITargetLocator tagetLocator = driver.SwitchTo();
//tagetLocator.Frame(1); //frame index.
tagetLocator.Frame("login_frame"); //frame frame name.
var userName = driver.FindElementByXPath("//*[@id='u']");
//这里的userName就是用户名的文本框
//设置用户名的值
userName.SendKeys("123456");
var pwd = driver.FindElementByXPath("//*[@id='p']");
pwd.SendKeys("********");
}
finally
{
driver.Quit();
}
然后调试测试,如下图
所以将值填入文本框
最后点击登录,找到login button元素,同样点击找到login button元素,点击
[Fact]
public void QQLogin()
{
dynamic type = (new PictureTest()).GetType();
string currentDirectory = Path.GetDirectoryName(type.Assembly.Location);
var driver = new ChromeDriver(currentDirectory);
driver.Url = "https://qzone.qq.com/";
try
{
//切换语法有两种,一种是根据索引切换,另外一种根据iframe名称切换
//这里我们使用name切换
ITargetLocator tagetLocator = driver.SwitchTo();
//tagetLocator.Frame(1); //frame index.
tagetLocator.Frame("login_frame"); //frame frame name.
var userName = driver.FindElementByXPath("//*[@id='u']");
//这里的userName就是用户名的文本框
//设置用户名的值
userName.SendKeys("123456");
var pwd = driver.FindElementByXPath("//*[@id='p']");
pwd.SendKeys("********");
var btnLogin = driver.FindElementByXPath("//*[@id='login_button']");
//这里是判断登录按钮是否可见,可以不写,直接调用click方法
if (btnLogin != null && btnLogin.Displayed == true)
{
btnLogin.Click();
}
}
finally
{
driver.Quit();
}
}
然后登录成功
总而言之,使用了一些关键语法
//Iframe切换,如果需要捕获的元素不在当前页面,则找到嵌套页面进行切换
//切换语法有两种,一种是根据索引切换,另外一种根据iframe名称切换
ITargetLocator tagetLocator = driver.SwitchTo();
//tagetLocator.Frame(1); //frame index.
tagetLocator.Frame("login_frame"); //frame frame name.
//查找元素方法,可以使用css定位
var userName = driver.FindElementByXPath("//*[@id='u']");
//设置文本框的值SendKeys
userName.SendKeys("123456");
//元素点击事件
var btnLogin = driver.FindElementByXPath("//*[@id='login_button']");
btnLogin.Click();
只要了解驱动对浏览器的一些操作方式,就可以自行探索,实现自己想要的,比如点击切换登录框、快速登录
例如,找到相册元素并点击,找到菜单谈论元素并点击,设置文本框值,发送谈话,写消息,你可以探索和使用
登录先在这里聊,改天写点什么或者留言板,或者保存相册的照片
Git源代码地址:
c#抓取网页数据( 本文-05-22来源:阅读942评论摘要:本次的c#编程向大家介绍了如何去html网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-18 11:07
本文-05-22来源:阅读942评论摘要:本次的c#编程向大家介绍了如何去html网页数据)
c#编程如何抓取html网页数据? (代码示例)
Vivian2018-05-22来源:阅读 942 条评论 0
总结:本次c#编程介绍了如何抓取html网页数据。通过具体的源码案例,希望对大家学习c#编程有所帮助。
本次c#编程向您介绍了如何抓取html网页数据。通过具体的源码案例,希望对大家学习c#编程有所帮助。
//方法一
using System.Text.RegularExpressions;
public static void webClientMethod1()
{
WebClient wc = new WebClient();
wc.Encoding = Encoding.UTF8;
//以字符串的形式返回数据
string html = wc.DownloadString("https://www.baidu.com/");
//以正则表达式的形式匹配到字符串网页中想要的数据
MatchCollection matches = Regex.Matches(html, "(.*)");
//依次取得匹配到的数据
foreach (Match item in matches)
{
Console.WriteLine(item.Groups[1].Value);
}
Console.ReadKey();
}
//方法二
public static string SendRequest()
{
string url = "https://www.baidu.com/";
Uri httpURL = new Uri(url);
///HttpWebRequest类继承于WebRequest,并没有自己的构造函数,需通过WebRequest的Creat方法 建立,并进行强制的类型转换
HttpWebRequest httpReq = (HttpWebRequest)WebRequest.Create(httpURL);
//httpReq.Headers.Add("cityen", "tj");
///通过HttpWebRequest的GetResponse()方法建立HttpWebResponse,强制类型转换
HttpWebResponse httpResp = (HttpWebResponse)httpReq.GetResponse();
///GetResponseStream()方法获取HTTP响应的数据流,并尝试取得URL中所指定的网页内容
///若成功取得网页的内容,则以System.IO.Stream形式返回,若失败则产生ProtoclViolationException错 误。
System.IO.Stream respStream = httpResp.GetResponseStream();
///返回的内容是Stream形式的,所以可以利用StreamReader类获取GetResponseStream的内容
System.IO.StreamReader respStreamReader = new System.IO.StreamReader(respStream, Encoding.UTF8);
//从流的当前位置读取到结尾
string strBuff = respStreamReader.ReadToEnd();
//简单写法,跟上面的结果一样
//using (var sr = new System.IO.StreamReader(httpReq.GetResponse().GetResponseStream()))
//{
// var result = sr.ReadToEnd();
// Console.WriteLine("微信--" + DateTime.Now.ToString() + "--" + result);
//}
respStreamReader.Close();
respStream.Close();
return strBuff;
}
本文按位置坐标整理发布,希望对同学们有所帮助。更多详情请关注工作坐标编程语言C#.NET频道
本文由@Vivian 在该位置发表。未经许可禁止转载。
喜欢| 0
不喜欢| 0
看完这篇文章,你有什么感受?已有0人发表意见,0%喜欢分享给朋友~ 查看全部
c#抓取网页数据(
本文-05-22来源:阅读942评论摘要:本次的c#编程向大家介绍了如何去html网页数据)
c#编程如何抓取html网页数据? (代码示例)

Vivian2018-05-22来源:阅读 942 条评论 0
总结:本次c#编程介绍了如何抓取html网页数据。通过具体的源码案例,希望对大家学习c#编程有所帮助。
本次c#编程向您介绍了如何抓取html网页数据。通过具体的源码案例,希望对大家学习c#编程有所帮助。
//方法一
using System.Text.RegularExpressions;
public static void webClientMethod1()
{
WebClient wc = new WebClient();
wc.Encoding = Encoding.UTF8;
//以字符串的形式返回数据
string html = wc.DownloadString("https://www.baidu.com/";);
//以正则表达式的形式匹配到字符串网页中想要的数据
MatchCollection matches = Regex.Matches(html, "(.*)");
//依次取得匹配到的数据
foreach (Match item in matches)
{
Console.WriteLine(item.Groups[1].Value);
}
Console.ReadKey();
}
//方法二
public static string SendRequest()
{
string url = "https://www.baidu.com/";
Uri httpURL = new Uri(url);
///HttpWebRequest类继承于WebRequest,并没有自己的构造函数,需通过WebRequest的Creat方法 建立,并进行强制的类型转换
HttpWebRequest httpReq = (HttpWebRequest)WebRequest.Create(httpURL);
//httpReq.Headers.Add("cityen", "tj");
///通过HttpWebRequest的GetResponse()方法建立HttpWebResponse,强制类型转换
HttpWebResponse httpResp = (HttpWebResponse)httpReq.GetResponse();
///GetResponseStream()方法获取HTTP响应的数据流,并尝试取得URL中所指定的网页内容
///若成功取得网页的内容,则以System.IO.Stream形式返回,若失败则产生ProtoclViolationException错 误。
System.IO.Stream respStream = httpResp.GetResponseStream();
///返回的内容是Stream形式的,所以可以利用StreamReader类获取GetResponseStream的内容
System.IO.StreamReader respStreamReader = new System.IO.StreamReader(respStream, Encoding.UTF8);
//从流的当前位置读取到结尾
string strBuff = respStreamReader.ReadToEnd();
//简单写法,跟上面的结果一样
//using (var sr = new System.IO.StreamReader(httpReq.GetResponse().GetResponseStream()))
//{
// var result = sr.ReadToEnd();
// Console.WriteLine("微信--" + DateTime.Now.ToString() + "--" + result);
//}
respStreamReader.Close();
respStream.Close();
return strBuff;
}
本文按位置坐标整理发布,希望对同学们有所帮助。更多详情请关注工作坐标编程语言C#.NET频道
本文由@Vivian 在该位置发表。未经许可禁止转载。

喜欢| 0

不喜欢| 0
看完这篇文章,你有什么感受?已有0人发表意见,0%喜欢分享给朋友~
c#抓取网页数据(一种基于C#抓取互联网公开数据的爬虫系统及抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-18 11:05
一种基于C#抓取互联网公共数据的爬虫系统及爬虫方法,属于数据领域采集;爬虫系统包括爬虫程序模块,爬虫程序模块用于浏览、爬取和验证数据Server,服务器数量至少为2台,其中部署有爬虫程序模块。目标站,爬虫程序模块对确定的目标站进行浏览抓取数据;非关系型数据库,表示非关系型数据库用于存储爬虫程序模块捕获的有效数据;它还包括第三方接口,用于外部验证码识别和破解程序模块。本发明专利技术描述的爬虫系统可以外接验证码识别破解程序模块,支持多种验证码破解,可以更好更快地访问目标站点。支持部署到多台服务器,降低服务器负载压力,运行、存储更多数据;支持NOSQL数据存储,读取速度大幅提升。
下载所有详细的技术数据
【技术实现步骤总结】
某种
本专利技术属于数据采集
,具体涉及一种爬取互联网公共数据的爬虫系统及方法。
技术介绍
网络爬虫是一种自动浏览互联网并按照一定规则自动抓取网页信息的程序或脚本。它是搜索引擎的重要组成部分。搜索引擎在实现网络爬虫的功能时,通常需要一个爬虫系统。完成。目前市场上的爬虫系统或框架大多采用Python、Java、PHPcrawer等技术。C#很少用于爬虫,C#爬虫系统也很少见,而且因为C#是面向对象的一种基于.NET Framework的高级编程语言,它可以让程序员快速编写基于MICROSOFT.NET平台的各种应用程序。如果你设计开发一个基于C#的爬虫系统来抓取互联网公共数据,将会大大提高程序员的
技术实现思路
本专利技术的目的是将Python、Java、PHPcrawer等现有技术中的爬虫系统应用到爬虫系统中。C#很少用于爬虫,影响了程序员编写基于MICROSOFT.NET平台的各种应用程序的效率。问题。为实现上述目的,本专利技术提供了一种基于C#抓取互联网公共数据的爬虫系统,包括:爬虫程序模块,用于浏览、抓取和验证数据的爬虫程序模块;server,服务器的数量至少两个,其中部署了爬虫程序模块;目标站,爬虫程序模块浏览并抓取确定的目标站的数据;非关系型数据库,其中非关系型数据库用于存储爬虫程序模块捕获的有效数据。优选地,还包括用于连接验证码识别破解程序模块的第三方接口,验证码识别破解程序模块可以识别和破解目标站的访问请求验证码。优选地,目标站点、非关系数据库和第三方接口也设置在至少两个服务器中。优选地,爬虫程序模块包括参数存储单元、目标站捕获单元、目标站分析判断单元、数据捕获单元和数据验证单元。参数存储单元存储参数,
优选地,所述数据采集单元与数据校验单元之间还设有数据转换单元,数据采集单元将采集到的数据输出至数据转换单元,由数据转换单元对数据进行转换。该单元使用正则表达式或Json序列化方法对数据进行过滤和提取,然后将数据输出到数据验证单元。优选地,所述数据抓取单元中设有数据分页判断模块,所述数据分页判断模块用于判断数据是否被分页,从而实现数据抓取单元抓取每页数据。优选地,非关系数据库是NoSQL。本专利技术所描述的爬虫系统与现有技术相比具有以下优点:基于C#抓取互联网公共数据,而不是Python、Java、PHPcrawer等技术,可以提高程序员编写基于MICROSOFT.NET的各种平台应用程序的工作效率;可连接验证码识别破解程序模块,支持多种验证码破解,可以更好更快的访问目标站;支持部署到多台服务器,降低服务器的负载压力,运行和存储更多的数据;支持NOSQL数据存储,读取速度大幅提升。本专利技术还提供了一种基于C#的互联网公共数据的抓取方法,包括上述基于C#的互联网公共数据的抓取系统,还包括以下步骤:S100、将爬虫程序模块部署到至少两台服务器上;S200,确定需要采集数据的目标站点,并准备数据请求参数;S300,使用c#语言模拟目标站的访问请求,捕获目标站的数据;S400、抓取到的数据使用正则表达式或Json序列化方法过滤提取;S500,验证抓取到的数据是否与参数匹配,看是否为有效数据;S600,将有效数据存储在非关系型数据库中。捕获的数据使用正则表达式或Json序列化方法过滤提取;S500,验证抓取到的数据是否与参数匹配,看是否为有效数据;S600,将有效数据存储在非关系型数据库中。捕获的数据使用正则表达式或Json序列化方法过滤提取;S500,验证抓取到的数据是否与参数匹配,看是否为有效数据;S600,将有效数据存储在非关系型数据库中。
优选地,步骤S300包括: S301、判断目标站接入请求是否需要验证验证码,如果验证码需要验证,则抓取请求验证码参数并调用破解验证码服务,然后添加破解结果 在访问请求中,捕获目标站的数据;S302,判断目标站的数据抓取是否成功,如果成功,则进入步骤S400;如果失败,则进入步骤S303;S303,将目标站的访问状态标记为Failed,当爬虫检测到目标站的访问状态失败时,需要重新模拟目标站访问请求来捕获目标站数据,即重复步骤S300,使用c#语言模拟目标站访问请求,然后进入步骤S301,直到判断出目标站,数据获取成功为止。优选地,步骤S400和S500包括寻呼判断,即判断目标站提取的数据是否有寻呼,如果有,则翻页,然后重复步骤S400;如果没有寻呼,则直接进入步骤S500。本专利技术所描述的爬取方法与现有技术相比具有以下优点:增加了重试机制,第一次数据爬取失败时,爬虫程序会自动重启;数据兼容性大大增强,提高数据质量;加强异常处理,提高资源利用率。附图说明图1。附图说明图1是本专利技术第一实施例的履带系统示意图;无花果。图2是本专利技术实施例二的抓取方法的步骤示意图。无花果。图3是专利技术实施例二抓取方法的流程示意图。
具体实施方式为使本专利技术的上述目的、特征和优点更加明显易懂,下面结合附图对本专利技术的具体实施例进行详细说明。第一实施例参考图1。1、本实施例介绍了一种基于C#抓取互联网公共数据的爬虫系统,包括:爬虫程序模块2,用于浏览、爬取和验证数据;服务器1,服务器1的数量至少为2个,其中部署爬虫程序模块2;目标站3,爬虫程序模块2对确定的目标站3进行浏览抓取数据;non-relational 非关系数据库4用于存储爬虫模块2抓取到的有效数据。具体来说,专利技术中描述的互联网公共数据爬虫系统的爬虫程序模块2是基于C#的,爬虫程序模块2可以是一个烧录爬虫程序的芯片,该芯片安装在至少两个的服务器。在图1中,优选地,爬虫程序模块2部署在每个服务器1中。爬虫程序模块2中目标站3的确定可以人为确定。例如,如果您想获取公司的商业登记信息,您可以到国家工商行政管理总局、当地工商行政管理总局、国家企业信用信息公示系统等相关信息查询。 . 但更优选地,爬虫程序模块2包括参数存储单元,目标站捕获单元、目标站分析判断单元、数据捕获单元和数据验证单元。参数存储单元存储参数,其输出端与目标站捕获单元的输入端相连,目标站捕获单元的输出端与目标站分析判断单元的输入端相连,目标站分析判定单元的输出端连接数据采集单元的输入端 数据采集单元的输出端连接数据校验单元的输入端,数据校验单元连接参数存储器数据校验单元的输出端连接非关系型数据库。目标站分析判断单元、数据采集单元和数据验证单元。参数存储单元存储参数,其输出端与目标站捕获单元的输入端相连,目标站捕获单元的输出端与目标站分析判断单元的输入端相连,目标站分析判定单元的输出端连接数据采集单元的输入端 数据采集单元的输出端连接数据校验单元的输入端,数据校验单元连接参数存储器数据校验单元的输出端连接非关系型数据库。目标站分析判断单元、数据采集单元和数据验证单元。参数存储单元存储参数,其输出端与目标站捕获单元的输入端相连,目标站捕获单元的输出端与目标站分析判断单元的输入端相连,目标站分析判定单元的输出端连接数据采集单元的输入端 数据采集单元的输出端连接数据校验单元的输入端,数据校验单元连接参数存储器数据校验单元的输出端连接非关系型数据库。数据采集单元和数据验证单元。参数存储单元存储参数,其输出端与目标站捕获单元的输入端相连,目标站捕获单元的输出端与目标站分析判断单元的输入端相连,目标站分析判定单元的输出端连接数据采集单元的输入端 数据采集单元的输出端连接数据校验单元的输入端,数据校验单元连接参数存储器数据校验单元的输出端连接非关系型数据库。数据采集单元和数据验证单元。参数存储单元存储参数,其输出端与目标站捕获单元的输入端相连,目标站捕获单元的输出端与目标站分析判断单元的输入端相连,目标站分析判定单元的输出端连接数据采集单元的输入端 数据采集单元的输出端连接数据校验单元的输入端,数据校验单元连接参数存储器数据校验单元的输出端连接非关系型数据库。
参数存储单元用于存储提取数据所需的数据请求参数,可根据实际情况进行设置。比如要抓取某公司的工商注册信息,可以设置相关参数为与,公司名称,公司所在省份的关系。这样,参数存储单元中存储的相关参数将是,公司名称:某公司,公司所在省份:上海,同时满足这两个参数。在其他实施例中,参数存储单元中的参数关系可以具有其他设置,例如OR关系。目标站抓取单元接收参数存储单元中的数据请求参数信息,
【技术保护点】
一种基于C#抓取互联网公共数据的爬虫系统,其特征在于包括: 用于浏览、抓取和验证数据的爬虫程序模块;服务器,所述服务器的数量至少为两个,其中部署有爬虫程序模块;目标站,爬虫程序模块浏览并抓取确定的目标站的数据;非关系型数据库,其中非关系型数据库用于存储爬虫程序模块获取的有效数据。
【技术特点摘要】
1. 一种基于C#抓取互联网公共数据的爬虫系统,其特征在于包括: 爬虫程序模块,所述爬虫程序模块用于浏览、抓取和验证数据;服务器,服务器数量至少为两台,其中部署有爬虫程序模块;目标站,爬虫程序模块在确定的目标站上浏览抓取数据;非关系型数据库,其中非关系型数据库用于存储爬虫程序模块捕获的有效数据。2.根据权利要求1所述的基于C#抓取互联网公共数据的爬虫系统,其特征在于还包括第三方接口外部验证码识别破解程序模块,所述验证码识别破解程序模块可以识别并破解目标站的访问请求验证码。3.根据权利要求2所述的基于C#抓取互联网公共数据的爬虫系统,其特征在于,所述目标站、非关系型数据库和第三方接口还设置在至少两个服务器中。4.根据权利要求1所述的基于C#抓取互联网公共数据的爬虫系统,其特征在于,所述爬虫程序模块包括:参数存储单元、目标站捕获单元、目标站分析判断单元、数据捕获单元,数据校验单元;参数存储单元存储参数,其输出端连接目标站捕获单元的输入端,目标站捕获单元的输出端连接目标站分析判断单元的输入端,目标站分析判断单元的输出端连接数据捕获单元的输入端,数据采集单元与数据校验单元的输入端相连,数据校验单元与参数存储单元相连,数据校验单元的输出端与非关系型数据库相连。5.根据权利要求4所述的基于C#抓取互联网公共数据的爬虫系统,其特征在于,数据转换单元和数据抓取单元将抓取到的数据输出给数据转换单元,数据通过数据转换单元使用正则表达式或Json序列化方法进行过滤提取,然后输出到数据校验单元。6.根据权利要求4所述的一种基于C#抓取互联网公共数据的爬虫系统,其特征在于,在数据抓取单元中...
【专利技术属性】
技术研发人员:王杰、王金虎、邓惠林、
申请人(专利权):,
类型:发明
国家省市:江苏,32
下载所有详细的技术资料 我是此专利的拥有者 查看全部
c#抓取网页数据(一种基于C#抓取互联网公开数据的爬虫系统及抓取方法)
一种基于C#抓取互联网公共数据的爬虫系统及爬虫方法,属于数据领域采集;爬虫系统包括爬虫程序模块,爬虫程序模块用于浏览、爬取和验证数据Server,服务器数量至少为2台,其中部署有爬虫程序模块。目标站,爬虫程序模块对确定的目标站进行浏览抓取数据;非关系型数据库,表示非关系型数据库用于存储爬虫程序模块捕获的有效数据;它还包括第三方接口,用于外部验证码识别和破解程序模块。本发明专利技术描述的爬虫系统可以外接验证码识别破解程序模块,支持多种验证码破解,可以更好更快地访问目标站点。支持部署到多台服务器,降低服务器负载压力,运行、存储更多数据;支持NOSQL数据存储,读取速度大幅提升。
下载所有详细的技术数据
【技术实现步骤总结】
某种
本专利技术属于数据采集
,具体涉及一种爬取互联网公共数据的爬虫系统及方法。
技术介绍
网络爬虫是一种自动浏览互联网并按照一定规则自动抓取网页信息的程序或脚本。它是搜索引擎的重要组成部分。搜索引擎在实现网络爬虫的功能时,通常需要一个爬虫系统。完成。目前市场上的爬虫系统或框架大多采用Python、Java、PHPcrawer等技术。C#很少用于爬虫,C#爬虫系统也很少见,而且因为C#是面向对象的一种基于.NET Framework的高级编程语言,它可以让程序员快速编写基于MICROSOFT.NET平台的各种应用程序。如果你设计开发一个基于C#的爬虫系统来抓取互联网公共数据,将会大大提高程序员的
技术实现思路
本专利技术的目的是将Python、Java、PHPcrawer等现有技术中的爬虫系统应用到爬虫系统中。C#很少用于爬虫,影响了程序员编写基于MICROSOFT.NET平台的各种应用程序的效率。问题。为实现上述目的,本专利技术提供了一种基于C#抓取互联网公共数据的爬虫系统,包括:爬虫程序模块,用于浏览、抓取和验证数据的爬虫程序模块;server,服务器的数量至少两个,其中部署了爬虫程序模块;目标站,爬虫程序模块浏览并抓取确定的目标站的数据;非关系型数据库,其中非关系型数据库用于存储爬虫程序模块捕获的有效数据。优选地,还包括用于连接验证码识别破解程序模块的第三方接口,验证码识别破解程序模块可以识别和破解目标站的访问请求验证码。优选地,目标站点、非关系数据库和第三方接口也设置在至少两个服务器中。优选地,爬虫程序模块包括参数存储单元、目标站捕获单元、目标站分析判断单元、数据捕获单元和数据验证单元。参数存储单元存储参数,
优选地,所述数据采集单元与数据校验单元之间还设有数据转换单元,数据采集单元将采集到的数据输出至数据转换单元,由数据转换单元对数据进行转换。该单元使用正则表达式或Json序列化方法对数据进行过滤和提取,然后将数据输出到数据验证单元。优选地,所述数据抓取单元中设有数据分页判断模块,所述数据分页判断模块用于判断数据是否被分页,从而实现数据抓取单元抓取每页数据。优选地,非关系数据库是NoSQL。本专利技术所描述的爬虫系统与现有技术相比具有以下优点:基于C#抓取互联网公共数据,而不是Python、Java、PHPcrawer等技术,可以提高程序员编写基于MICROSOFT.NET的各种平台应用程序的工作效率;可连接验证码识别破解程序模块,支持多种验证码破解,可以更好更快的访问目标站;支持部署到多台服务器,降低服务器的负载压力,运行和存储更多的数据;支持NOSQL数据存储,读取速度大幅提升。本专利技术还提供了一种基于C#的互联网公共数据的抓取方法,包括上述基于C#的互联网公共数据的抓取系统,还包括以下步骤:S100、将爬虫程序模块部署到至少两台服务器上;S200,确定需要采集数据的目标站点,并准备数据请求参数;S300,使用c#语言模拟目标站的访问请求,捕获目标站的数据;S400、抓取到的数据使用正则表达式或Json序列化方法过滤提取;S500,验证抓取到的数据是否与参数匹配,看是否为有效数据;S600,将有效数据存储在非关系型数据库中。捕获的数据使用正则表达式或Json序列化方法过滤提取;S500,验证抓取到的数据是否与参数匹配,看是否为有效数据;S600,将有效数据存储在非关系型数据库中。捕获的数据使用正则表达式或Json序列化方法过滤提取;S500,验证抓取到的数据是否与参数匹配,看是否为有效数据;S600,将有效数据存储在非关系型数据库中。
优选地,步骤S300包括: S301、判断目标站接入请求是否需要验证验证码,如果验证码需要验证,则抓取请求验证码参数并调用破解验证码服务,然后添加破解结果 在访问请求中,捕获目标站的数据;S302,判断目标站的数据抓取是否成功,如果成功,则进入步骤S400;如果失败,则进入步骤S303;S303,将目标站的访问状态标记为Failed,当爬虫检测到目标站的访问状态失败时,需要重新模拟目标站访问请求来捕获目标站数据,即重复步骤S300,使用c#语言模拟目标站访问请求,然后进入步骤S301,直到判断出目标站,数据获取成功为止。优选地,步骤S400和S500包括寻呼判断,即判断目标站提取的数据是否有寻呼,如果有,则翻页,然后重复步骤S400;如果没有寻呼,则直接进入步骤S500。本专利技术所描述的爬取方法与现有技术相比具有以下优点:增加了重试机制,第一次数据爬取失败时,爬虫程序会自动重启;数据兼容性大大增强,提高数据质量;加强异常处理,提高资源利用率。附图说明图1。附图说明图1是本专利技术第一实施例的履带系统示意图;无花果。图2是本专利技术实施例二的抓取方法的步骤示意图。无花果。图3是专利技术实施例二抓取方法的流程示意图。
具体实施方式为使本专利技术的上述目的、特征和优点更加明显易懂,下面结合附图对本专利技术的具体实施例进行详细说明。第一实施例参考图1。1、本实施例介绍了一种基于C#抓取互联网公共数据的爬虫系统,包括:爬虫程序模块2,用于浏览、爬取和验证数据;服务器1,服务器1的数量至少为2个,其中部署爬虫程序模块2;目标站3,爬虫程序模块2对确定的目标站3进行浏览抓取数据;non-relational 非关系数据库4用于存储爬虫模块2抓取到的有效数据。具体来说,专利技术中描述的互联网公共数据爬虫系统的爬虫程序模块2是基于C#的,爬虫程序模块2可以是一个烧录爬虫程序的芯片,该芯片安装在至少两个的服务器。在图1中,优选地,爬虫程序模块2部署在每个服务器1中。爬虫程序模块2中目标站3的确定可以人为确定。例如,如果您想获取公司的商业登记信息,您可以到国家工商行政管理总局、当地工商行政管理总局、国家企业信用信息公示系统等相关信息查询。 . 但更优选地,爬虫程序模块2包括参数存储单元,目标站捕获单元、目标站分析判断单元、数据捕获单元和数据验证单元。参数存储单元存储参数,其输出端与目标站捕获单元的输入端相连,目标站捕获单元的输出端与目标站分析判断单元的输入端相连,目标站分析判定单元的输出端连接数据采集单元的输入端 数据采集单元的输出端连接数据校验单元的输入端,数据校验单元连接参数存储器数据校验单元的输出端连接非关系型数据库。目标站分析判断单元、数据采集单元和数据验证单元。参数存储单元存储参数,其输出端与目标站捕获单元的输入端相连,目标站捕获单元的输出端与目标站分析判断单元的输入端相连,目标站分析判定单元的输出端连接数据采集单元的输入端 数据采集单元的输出端连接数据校验单元的输入端,数据校验单元连接参数存储器数据校验单元的输出端连接非关系型数据库。目标站分析判断单元、数据采集单元和数据验证单元。参数存储单元存储参数,其输出端与目标站捕获单元的输入端相连,目标站捕获单元的输出端与目标站分析判断单元的输入端相连,目标站分析判定单元的输出端连接数据采集单元的输入端 数据采集单元的输出端连接数据校验单元的输入端,数据校验单元连接参数存储器数据校验单元的输出端连接非关系型数据库。数据采集单元和数据验证单元。参数存储单元存储参数,其输出端与目标站捕获单元的输入端相连,目标站捕获单元的输出端与目标站分析判断单元的输入端相连,目标站分析判定单元的输出端连接数据采集单元的输入端 数据采集单元的输出端连接数据校验单元的输入端,数据校验单元连接参数存储器数据校验单元的输出端连接非关系型数据库。数据采集单元和数据验证单元。参数存储单元存储参数,其输出端与目标站捕获单元的输入端相连,目标站捕获单元的输出端与目标站分析判断单元的输入端相连,目标站分析判定单元的输出端连接数据采集单元的输入端 数据采集单元的输出端连接数据校验单元的输入端,数据校验单元连接参数存储器数据校验单元的输出端连接非关系型数据库。
参数存储单元用于存储提取数据所需的数据请求参数,可根据实际情况进行设置。比如要抓取某公司的工商注册信息,可以设置相关参数为与,公司名称,公司所在省份的关系。这样,参数存储单元中存储的相关参数将是,公司名称:某公司,公司所在省份:上海,同时满足这两个参数。在其他实施例中,参数存储单元中的参数关系可以具有其他设置,例如OR关系。目标站抓取单元接收参数存储单元中的数据请求参数信息,

【技术保护点】
一种基于C#抓取互联网公共数据的爬虫系统,其特征在于包括: 用于浏览、抓取和验证数据的爬虫程序模块;服务器,所述服务器的数量至少为两个,其中部署有爬虫程序模块;目标站,爬虫程序模块浏览并抓取确定的目标站的数据;非关系型数据库,其中非关系型数据库用于存储爬虫程序模块获取的有效数据。
【技术特点摘要】
1. 一种基于C#抓取互联网公共数据的爬虫系统,其特征在于包括: 爬虫程序模块,所述爬虫程序模块用于浏览、抓取和验证数据;服务器,服务器数量至少为两台,其中部署有爬虫程序模块;目标站,爬虫程序模块在确定的目标站上浏览抓取数据;非关系型数据库,其中非关系型数据库用于存储爬虫程序模块捕获的有效数据。2.根据权利要求1所述的基于C#抓取互联网公共数据的爬虫系统,其特征在于还包括第三方接口外部验证码识别破解程序模块,所述验证码识别破解程序模块可以识别并破解目标站的访问请求验证码。3.根据权利要求2所述的基于C#抓取互联网公共数据的爬虫系统,其特征在于,所述目标站、非关系型数据库和第三方接口还设置在至少两个服务器中。4.根据权利要求1所述的基于C#抓取互联网公共数据的爬虫系统,其特征在于,所述爬虫程序模块包括:参数存储单元、目标站捕获单元、目标站分析判断单元、数据捕获单元,数据校验单元;参数存储单元存储参数,其输出端连接目标站捕获单元的输入端,目标站捕获单元的输出端连接目标站分析判断单元的输入端,目标站分析判断单元的输出端连接数据捕获单元的输入端,数据采集单元与数据校验单元的输入端相连,数据校验单元与参数存储单元相连,数据校验单元的输出端与非关系型数据库相连。5.根据权利要求4所述的基于C#抓取互联网公共数据的爬虫系统,其特征在于,数据转换单元和数据抓取单元将抓取到的数据输出给数据转换单元,数据通过数据转换单元使用正则表达式或Json序列化方法进行过滤提取,然后输出到数据校验单元。6.根据权利要求4所述的一种基于C#抓取互联网公共数据的爬虫系统,其特征在于,在数据抓取单元中...
【专利技术属性】
技术研发人员:王杰、王金虎、邓惠林、
申请人(专利权):,
类型:发明
国家省市:江苏,32
下载所有详细的技术资料 我是此专利的拥有者
c#抓取网页数据(c#抓取网页数据一、二进制、不支持动态加载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-16 08:02
c#抓取网页数据一、小提示1.因为c#版本太高,c#4.2以上是不支持动态加载javaobject的所以要用javaobject3.xjsp2.c#抓取时需要引入ie浏览器集成库netframework4.需要jsp_connection3.windows.socket。windows的话runtime和自身的网络模块(fileinputstream)很多,其中fileinputstream在获取文件时就可以获取动态动态生成tcp连接,建议尽量使用windows提供的open和close方法,windows7和windows8如果没有自带open等方法也可以通过requestwindow()或fileinputstream来进行网络操作;android的socket有open等开始菜单,如果没有open方法也可以通过一个不需要运行的websocket进行操作;ie浏览器不是windowsserver。
网页抓取其实要用的的东西很多,从功能上也可以分几个类型,要熟悉清楚各自的关系,也就是响应类型,如果仅仅使用一个ie,也就是open方法,那么数据接收是xml文件,响应类型是fileinputstream,用户输入数据的方法appendfield(),参数就是要插入的内容,如果你只想抓取列表也就是java里面的object类型的数据,那么你需要使用它的insertitem()方法;jsp_connection,表示你需要往socket中写数据之后,等到结束以后,appendfield函数就会在socket里面写数据,这个时候这个函数就是你appendfield需要输入的响应值即可,也就是你输入的参数,如果遇到socket连接问题,大多都可以通过这种简单的方法解决;windows.socket,使用windows连接网络是要在windows下执行.netclr中间件monoidserver以及相关的参数(socket必须相同),windowssocket包括常见的requestwindow()和streaminputstream(),其中前两者用于将文件读取为数据文件传送;还可以用stdin和stdout;imagestream和aspectrunner都是将数据以二进制方式传输给system,使用bitset传输数据,主要方法就是读取或者输出;二、集成框架1.通过c#代码1.c#抓取网页是使用了两个模块,基于对socket的封装,以及使用qt中的open,close函数,在文件读取方面只需要简单的使用open或者close即可将网页解析为javaobject类型2.jsp页面抓取是通过一个coroutine来实现的,具体代码参考:3.openmonitor已经通过ie的方式封装成了javaobject类型,很方便通过openmonitor来解析出一个网页,具体代码有一个bspinfo.h:4.opentyperewindow()5.使用system.auto.open()封装一个面板会话,具体代码参考:if('monitor_open'insystem.integer.proto。 查看全部
c#抓取网页数据(c#抓取网页数据一、二进制、不支持动态加载)
c#抓取网页数据一、小提示1.因为c#版本太高,c#4.2以上是不支持动态加载javaobject的所以要用javaobject3.xjsp2.c#抓取时需要引入ie浏览器集成库netframework4.需要jsp_connection3.windows.socket。windows的话runtime和自身的网络模块(fileinputstream)很多,其中fileinputstream在获取文件时就可以获取动态动态生成tcp连接,建议尽量使用windows提供的open和close方法,windows7和windows8如果没有自带open等方法也可以通过requestwindow()或fileinputstream来进行网络操作;android的socket有open等开始菜单,如果没有open方法也可以通过一个不需要运行的websocket进行操作;ie浏览器不是windowsserver。
网页抓取其实要用的的东西很多,从功能上也可以分几个类型,要熟悉清楚各自的关系,也就是响应类型,如果仅仅使用一个ie,也就是open方法,那么数据接收是xml文件,响应类型是fileinputstream,用户输入数据的方法appendfield(),参数就是要插入的内容,如果你只想抓取列表也就是java里面的object类型的数据,那么你需要使用它的insertitem()方法;jsp_connection,表示你需要往socket中写数据之后,等到结束以后,appendfield函数就会在socket里面写数据,这个时候这个函数就是你appendfield需要输入的响应值即可,也就是你输入的参数,如果遇到socket连接问题,大多都可以通过这种简单的方法解决;windows.socket,使用windows连接网络是要在windows下执行.netclr中间件monoidserver以及相关的参数(socket必须相同),windowssocket包括常见的requestwindow()和streaminputstream(),其中前两者用于将文件读取为数据文件传送;还可以用stdin和stdout;imagestream和aspectrunner都是将数据以二进制方式传输给system,使用bitset传输数据,主要方法就是读取或者输出;二、集成框架1.通过c#代码1.c#抓取网页是使用了两个模块,基于对socket的封装,以及使用qt中的open,close函数,在文件读取方面只需要简单的使用open或者close即可将网页解析为javaobject类型2.jsp页面抓取是通过一个coroutine来实现的,具体代码参考:3.openmonitor已经通过ie的方式封装成了javaobject类型,很方便通过openmonitor来解析出一个网页,具体代码有一个bspinfo.h:4.opentyperewindow()5.使用system.auto.open()封装一个面板会话,具体代码参考:if('monitor_open'insystem.integer.proto。
c#抓取网页数据(本文介绍如何使用C#抓取网页上的图片资源。(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-09 14:06
本文介绍如何使用C#抓取网页上的图片资源。下面是一个简单的程序示例:
C#抓取网页资源
捕捉到的图片地址会以TXT文件的形式保存在软件目录下。
C#抓取网页资源
主要使用几个简单的方法来实现这个功能:
使用WebClient读取网页源码:
public String gethtml(String url)
{
try
{
WebClient MyWebClient = new WebClient();
MyWebClient.Credentials = CredentialCache.DefaultCredentials;//获取或设置用于向Internet资源的请求进行身份验证的网络凭据
Byte[] pageData = MyWebClient.DownloadData(url); //从指定网站下载数据
//string pageHtml = Encoding.Default.GetString(pageData); //如果获取网站页面采用的是GB2312,则使用这句
string pageHtml = Encoding.UTF8.GetString(pageData); //如果获取网站页面采用的是UTF-8,则使用这句
return pageHtml;
}
catch (WebException webEx)
{
return webEx.Message.ToString();
}
}
字符串的截取方法:
public String getstrmid(String str, string str1, string str2)
{
return str.Substring(str.IndexOf(str1) + str1.Length, str.IndexOf(str2) -str.IndexOf(str1) - str1.Length);
}
光有这些还不够,还需要用到正则匹配,因为正则规则是和网页内容相关的,所以正则规则就不在这里贴了。 查看全部
c#抓取网页数据(本文介绍如何使用C#抓取网页上的图片资源。(图))
本文介绍如何使用C#抓取网页上的图片资源。下面是一个简单的程序示例:
 https://www.daimadog.com/wp-co ... 0.png 300w" />
https://www.daimadog.com/wp-co ... 0.png 300w" />C#抓取网页资源
捕捉到的图片地址会以TXT文件的形式保存在软件目录下。
 https://www.daimadog.com/wp-co ... 5.png 300w, https://www.daimadog.com/wp-co ... 1.png 768w" />
https://www.daimadog.com/wp-co ... 5.png 300w, https://www.daimadog.com/wp-co ... 1.png 768w" />C#抓取网页资源
主要使用几个简单的方法来实现这个功能:
使用WebClient读取网页源码:
public String gethtml(String url)
{
try
{
WebClient MyWebClient = new WebClient();
MyWebClient.Credentials = CredentialCache.DefaultCredentials;//获取或设置用于向Internet资源的请求进行身份验证的网络凭据
Byte[] pageData = MyWebClient.DownloadData(url); //从指定网站下载数据
//string pageHtml = Encoding.Default.GetString(pageData); //如果获取网站页面采用的是GB2312,则使用这句
string pageHtml = Encoding.UTF8.GetString(pageData); //如果获取网站页面采用的是UTF-8,则使用这句
return pageHtml;
}
catch (WebException webEx)
{
return webEx.Message.ToString();
}
}
字符串的截取方法:
public String getstrmid(String str, string str1, string str2)
{
return str.Substring(str.IndexOf(str1) + str1.Length, str.IndexOf(str2) -str.IndexOf(str1) - str1.Length);
}
光有这些还不够,还需要用到正则匹配,因为正则规则是和网页内容相关的,所以正则规则就不在这里贴了。
c#抓取网页数据(web项目中使用WebBrowser类--给网站抓图最近做一个WEB )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-08 23:05
)
使用系统;
调用方法
GatherPicg=newGatherPic("","E:/XXX"); g.start();
================================================ ==========
在web项目中使用WebBrowser类-----给网站拍照
最近做了一个WEB项目,需要一个程序可以抓取网页的功能。例如:在 test.aspx 页面上放置一个 TextBox 和一个 Button。 TextBox用于输入要抓取的网页地址,然后按下Button后,服务器会对之前输入的URL进行截图,然后显示出来。我把截图的业务逻辑做成了一个类:
using System;
using System.Data;
using System.Windows.Forms;
using System.Drawing;
///
/// WebSnap :网页抓图对象
///
public class WebSnap2
{
public WebSnap2()
{
//
// TODO: 在此处添加构造函数逻辑
//
}
///
/// 开始一个抓图并返回图象
///
/// 要抓取的网页地址
///
public Bitmap StartSnap(string Url)
{
WebBrowser myWB = this.GetPage(Url);
Bitmap returnValue = this.SnapWeb(myWB);
myWB.Dispose();
return returnValue;
}
private WebBrowser GetPage(string Url)
{
WebBrowser myWB = new WebBrowser();
myWB.ScrollBarsEnabled = false;
myWB.Navigate(Url);
while (myWB.ReadyState != WebBrowserReadyState.Complete)
{
System.Windows.Forms.Application.DoEvents();
}
return myWB;
}
private Bitmap SnapWeb(WebBrowser wb)
{
HtmlDocument hd = wb.Document;
int height = Convert.ToInt32(hd.Body.GetAttribute("scrollHeight")) + 10;
int width = Convert.ToInt32(hd.Body.GetAttribute("scrollWidth")) + 10;
wb.Height = height;
wb.Width = width;
Bitmap bmp = new Bitmap(width, height);
Rectangle rec = new Rectangle();
rec.Width = width;
rec.Height = height;
wb.DrawToBitmap(bmp, rec);
return bmp;
}
}
然后在test.asp的button_click事件里面调用:
WebSnap ws = new WebSnap();
Bitmap bmp= ws.StartSnap(TextBox1.Text);
System.IO.MemoryStream ms = new System.IO.MemoryStream();
bmp.Save(ms, System.Drawing.Imaging.ImageFormat.Jpeg);
Response.BinaryWrite(ms.GetBuffer()); 查看全部
c#抓取网页数据(web项目中使用WebBrowser类--给网站抓图最近做一个WEB
)
使用系统;
调用方法
GatherPicg=newGatherPic("","E:/XXX"); g.start();
================================================ ==========
在web项目中使用WebBrowser类-----给网站拍照
最近做了一个WEB项目,需要一个程序可以抓取网页的功能。例如:在 test.aspx 页面上放置一个 TextBox 和一个 Button。 TextBox用于输入要抓取的网页地址,然后按下Button后,服务器会对之前输入的URL进行截图,然后显示出来。我把截图的业务逻辑做成了一个类:
using System;
using System.Data;
using System.Windows.Forms;
using System.Drawing;
///
/// WebSnap :网页抓图对象
///
public class WebSnap2
{
public WebSnap2()
{
//
// TODO: 在此处添加构造函数逻辑
//
}
///
/// 开始一个抓图并返回图象
///
/// 要抓取的网页地址
///
public Bitmap StartSnap(string Url)
{
WebBrowser myWB = this.GetPage(Url);
Bitmap returnValue = this.SnapWeb(myWB);
myWB.Dispose();
return returnValue;
}
private WebBrowser GetPage(string Url)
{
WebBrowser myWB = new WebBrowser();
myWB.ScrollBarsEnabled = false;
myWB.Navigate(Url);
while (myWB.ReadyState != WebBrowserReadyState.Complete)
{
System.Windows.Forms.Application.DoEvents();
}
return myWB;
}
private Bitmap SnapWeb(WebBrowser wb)
{
HtmlDocument hd = wb.Document;
int height = Convert.ToInt32(hd.Body.GetAttribute("scrollHeight")) + 10;
int width = Convert.ToInt32(hd.Body.GetAttribute("scrollWidth")) + 10;
wb.Height = height;
wb.Width = width;
Bitmap bmp = new Bitmap(width, height);
Rectangle rec = new Rectangle();
rec.Width = width;
rec.Height = height;
wb.DrawToBitmap(bmp, rec);
return bmp;
}
}
然后在test.asp的button_click事件里面调用:
WebSnap ws = new WebSnap();
Bitmap bmp= ws.StartSnap(TextBox1.Text);
System.IO.MemoryStream ms = new System.IO.MemoryStream();
bmp.Save(ms, System.Drawing.Imaging.ImageFormat.Jpeg);
Response.BinaryWrite(ms.GetBuffer());
c#抓取网页数据( c#入门经典路上如何去抓取html网页数据?坐标整理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-11-08 16:16
c#入门经典路上如何去抓取html网页数据?坐标整理)
c#入门经典:如何抓取html网页数据?
小标2018-05-18 来源:阅读858条评论0
总结:在学习c#入门经典的路上,今天教大家如何抓取html网页数据,让大家更好的学习。希望你能在c#入门经典的旅程中走得更远。
在你学习c#入门经典的路上,今天教你如何抓取html网页数据,让你更好的学习。希望你能在c#入门经典的旅程中走得更远。
//方法一
using System.Text.RegularExpressions;
public static void webClientMethod1()
{
WebClient wc = new WebClient();
wc.Encoding = Encoding.UTF8;
//以字符串的形式返回数据
string html = wc.DownloadString("https://www.baidu.com/");
//以正则表达式的形式匹配到字符串网页中想要的数据
MatchCollection matches = Regex.Matches(html, "(.*)");
//依次取得匹配到的数据
foreach (Match item in matches)
{
Console.WriteLine(item.Groups[1].Value);
}
Console.ReadKey();
}
//方法二
public static string SendRequest()
{
string url = "https://www.baidu.com/";
Uri httpURL = new Uri(url);
///HttpWebRequest类继承于WebRequest,并没有自己的构造函数,需通过WebRequest的Creat方法 建立,并进行强制的类型转换
HttpWebRequest httpReq = (HttpWebRequest)WebRequest.Create(httpURL);
//httpReq.Headers.Add("cityen", "tj");
///通过HttpWebRequest的GetResponse()方法建立HttpWebResponse,强制类型转换
HttpWebResponse httpResp = (HttpWebResponse)httpReq.GetResponse();
///GetResponseStream()方法获取HTTP响应的数据流,并尝试取得URL中所指定的网页内容
///若成功取得网页的内容,则以System.IO.Stream形式返回,若失败则产生ProtoclViolationException错 误。
System.IO.Stream respStream = httpResp.GetResponseStream();
///返回的内容是Stream形式的,所以可以利用StreamReader类获取GetResponseStream的内容
System.IO.StreamReader respStreamReader = new System.IO.StreamReader(respStream, Encoding.UTF8);
//从流的当前位置读取到结尾
string strBuff = respStreamReader.ReadToEnd();
//简单写法,跟上面的结果一样
//using (var sr = new System.IO.StreamReader(httpReq.GetResponse().GetResponseStream()))
//{
// var result = sr.ReadToEnd();
// Console.WriteLine("微信--" + DateTime.Now.ToString() + "--" + result);
//}
respStreamReader.Close();
respStream.Close();
return strBuff;
}
本文由詹总整理出版。更多资讯请关注展总编程语言C#.NET频道!
本文由@小标发表于工作坐标。未经许可禁止转载。
喜欢 | 0
不喜欢 | 0
看完这篇文章,你感觉如何?已有0人发表意见,0%喜欢分享给朋友~ 查看全部
c#抓取网页数据(
c#入门经典路上如何去抓取html网页数据?坐标整理)
c#入门经典:如何抓取html网页数据?
小标2018-05-18 来源:阅读858条评论0
总结:在学习c#入门经典的路上,今天教大家如何抓取html网页数据,让大家更好的学习。希望你能在c#入门经典的旅程中走得更远。
在你学习c#入门经典的路上,今天教你如何抓取html网页数据,让你更好的学习。希望你能在c#入门经典的旅程中走得更远。
//方法一
using System.Text.RegularExpressions;
public static void webClientMethod1()
{
WebClient wc = new WebClient();
wc.Encoding = Encoding.UTF8;
//以字符串的形式返回数据
string html = wc.DownloadString("https://www.baidu.com/";);
//以正则表达式的形式匹配到字符串网页中想要的数据
MatchCollection matches = Regex.Matches(html, "(.*)");
//依次取得匹配到的数据
foreach (Match item in matches)
{
Console.WriteLine(item.Groups[1].Value);
}
Console.ReadKey();
}
//方法二
public static string SendRequest()
{
string url = "https://www.baidu.com/";
Uri httpURL = new Uri(url);
///HttpWebRequest类继承于WebRequest,并没有自己的构造函数,需通过WebRequest的Creat方法 建立,并进行强制的类型转换
HttpWebRequest httpReq = (HttpWebRequest)WebRequest.Create(httpURL);
//httpReq.Headers.Add("cityen", "tj");
///通过HttpWebRequest的GetResponse()方法建立HttpWebResponse,强制类型转换
HttpWebResponse httpResp = (HttpWebResponse)httpReq.GetResponse();
///GetResponseStream()方法获取HTTP响应的数据流,并尝试取得URL中所指定的网页内容
///若成功取得网页的内容,则以System.IO.Stream形式返回,若失败则产生ProtoclViolationException错 误。
System.IO.Stream respStream = httpResp.GetResponseStream();
///返回的内容是Stream形式的,所以可以利用StreamReader类获取GetResponseStream的内容
System.IO.StreamReader respStreamReader = new System.IO.StreamReader(respStream, Encoding.UTF8);
//从流的当前位置读取到结尾
string strBuff = respStreamReader.ReadToEnd();
//简单写法,跟上面的结果一样
//using (var sr = new System.IO.StreamReader(httpReq.GetResponse().GetResponseStream()))
//{
// var result = sr.ReadToEnd();
// Console.WriteLine("微信--" + DateTime.Now.ToString() + "--" + result);
//}
respStreamReader.Close();
respStream.Close();
return strBuff;
}
本文由詹总整理出版。更多资讯请关注展总编程语言C#.NET频道!
本文由@小标发表于工作坐标。未经许可禁止转载。
喜欢 | 0
不喜欢 | 0
看完这篇文章,你感觉如何?已有0人发表意见,0%喜欢分享给朋友~
c#抓取网页数据(C#源码500份作者:技术小美3635人(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-08 16:11
阿里云>云栖社区>主题图>C>c#网页抓取数据库
推荐活动:
更多优惠>
当前主题:c#抓取网页中的数据库并添加到采集夹
相关话题:
c# 爬取网页中数据库相关的博客 查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
C#抓取网页程序的实现分析
作者:zting科技698人浏览评论:04年前
C#爬取网页程序是如何实现的?我们先来了解一下,在 HTTP 中,它是 WWW 中最基本的数据访问协议之一。.NET的基本类型库类中提供了两个对象类:HTTPWebRequest和HTTPWebResponse,用于向某个资源发送请求和获取资源。回复。为了获得资源
阅读全文
C#源代码500份
作者:小美科技 3635人浏览评论:14年前
C 夏普短信发送平台源码。Rar ASP.NET+AJAX基础实例视频教程 C# Winform qq弹窗 360弹窗
阅读全文
C#源代码500份
作者:蓬莱闲鱼2601人浏览评论:08年前
C 夏普短信发送平台源码。Rar ASP.NET+AJAX基础实例视频教程 C# Winform qq弹窗 360弹窗
阅读全文
c#批量抓取免费代理并验证其有效性
作者:曹章林 1170人浏览评论:03年前
在刷新一次页面之前,我在一家公司的官方网站上看到了文章 的页面浏览量。给人的感觉不是很好。一个公司的官网就给人这么直接的漏洞。批量发起请求时,发现页面打开报错。一个100多人的公司官网文章刷新了一次,你给我看了这个。这家公司之前来过我们学校宣传招聘+我在花园里找招聘的时候找到了住处
阅读全文
C#实现图标批量下载
作者:gisweis1079 人浏览评论:05年前
这篇文章有点长,花了几个晚上的时间编辑修改。如果文字和排版有问题,请谅解。本文分为四部分,以下是主要内容,也是软件开发的基本过程。阶段描述需求分析主要描述了程序的目的和需求的分析,即为什么要花时间写,需要什么功能等;方案设计基于现有要求,
阅读全文
关于爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站(转)
作者:朱老教授 1373人浏览评论:04年前
抓取网页的一般逻辑和过程一般是针对普通用户,使用浏览器打开某个网址,然后浏览器就可以显示出相应页面的内容。这个过程如果用程序代码实现,就可以调用(用程序实现)爬取(网页内容,进行后处理,提取需要的信息等)。对应的英文是,网站
阅读全文
Scrapy爬虫成长日记将爬取的内容写入mysql数据库
作者:呵呵 99251585人浏览评论:03年前
我尝试scrapy抓取博客园的博客(可以查看scrapy爬虫成长日记的创建项目-提取数据-以json格式保存数据),但是之前抓取的数据是以json格式保存为文本的文件。这显然不能满足我们日常的实际应用。接下来我们看看如何将抓取到的内容保存在一个普通的m中
阅读全文
Scrapy爬虫成长日记将爬取的内容写入mysql数据库
作者:无声胜有生 732人浏览评论:06年前
我尝试scrapy抓取博客园的博客(可以查看scrapy爬虫成长日记的创建项目-提取数据-以json格式保存数据),但是之前抓取的数据是以json格式保存为文本的文件。这显然不能满足我们日常的实际应用。接下来我们来看看常见的抓取内容的保存方式
阅读全文
c#爬取网页中数据库相关的问答
【Javascript学习全家桶】934道javascript热点题,阿里巴巴100位技术专家答疑解惑
作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你困惑只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来云栖为您解答技术问题。他们使用自己手中的技术来帮助用户成长。本次活动邀请数百位阿里巴巴技术
阅读全文 查看全部
c#抓取网页数据(C#源码500份作者:技术小美3635人(组图))
阿里云>云栖社区>主题图>C>c#网页抓取数据库

推荐活动:
更多优惠>
当前主题:c#抓取网页中的数据库并添加到采集夹
相关话题:
c# 爬取网页中数据库相关的博客 查看更多博客
云数据库产品概述

作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
C#抓取网页程序的实现分析

作者:zting科技698人浏览评论:04年前
C#爬取网页程序是如何实现的?我们先来了解一下,在 HTTP 中,它是 WWW 中最基本的数据访问协议之一。.NET的基本类型库类中提供了两个对象类:HTTPWebRequest和HTTPWebResponse,用于向某个资源发送请求和获取资源。回复。为了获得资源
阅读全文
C#源代码500份

作者:小美科技 3635人浏览评论:14年前
C 夏普短信发送平台源码。Rar ASP.NET+AJAX基础实例视频教程 C# Winform qq弹窗 360弹窗
阅读全文
C#源代码500份


作者:蓬莱闲鱼2601人浏览评论:08年前
C 夏普短信发送平台源码。Rar ASP.NET+AJAX基础实例视频教程 C# Winform qq弹窗 360弹窗
阅读全文
c#批量抓取免费代理并验证其有效性

作者:曹章林 1170人浏览评论:03年前
在刷新一次页面之前,我在一家公司的官方网站上看到了文章 的页面浏览量。给人的感觉不是很好。一个公司的官网就给人这么直接的漏洞。批量发起请求时,发现页面打开报错。一个100多人的公司官网文章刷新了一次,你给我看了这个。这家公司之前来过我们学校宣传招聘+我在花园里找招聘的时候找到了住处
阅读全文
C#实现图标批量下载


作者:gisweis1079 人浏览评论:05年前
这篇文章有点长,花了几个晚上的时间编辑修改。如果文字和排版有问题,请谅解。本文分为四部分,以下是主要内容,也是软件开发的基本过程。阶段描述需求分析主要描述了程序的目的和需求的分析,即为什么要花时间写,需要什么功能等;方案设计基于现有要求,
阅读全文
关于爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站(转)

作者:朱老教授 1373人浏览评论:04年前
抓取网页的一般逻辑和过程一般是针对普通用户,使用浏览器打开某个网址,然后浏览器就可以显示出相应页面的内容。这个过程如果用程序代码实现,就可以调用(用程序实现)爬取(网页内容,进行后处理,提取需要的信息等)。对应的英文是,网站
阅读全文
Scrapy爬虫成长日记将爬取的内容写入mysql数据库

作者:呵呵 99251585人浏览评论:03年前
我尝试scrapy抓取博客园的博客(可以查看scrapy爬虫成长日记的创建项目-提取数据-以json格式保存数据),但是之前抓取的数据是以json格式保存为文本的文件。这显然不能满足我们日常的实际应用。接下来我们看看如何将抓取到的内容保存在一个普通的m中
阅读全文
Scrapy爬虫成长日记将爬取的内容写入mysql数据库

作者:无声胜有生 732人浏览评论:06年前
我尝试scrapy抓取博客园的博客(可以查看scrapy爬虫成长日记的创建项目-提取数据-以json格式保存数据),但是之前抓取的数据是以json格式保存为文本的文件。这显然不能满足我们日常的实际应用。接下来我们来看看常见的抓取内容的保存方式
阅读全文
c#爬取网页中数据库相关的问答
【Javascript学习全家桶】934道javascript热点题,阿里巴巴100位技术专家答疑解惑


作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你困惑只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来云栖为您解答技术问题。他们使用自己手中的技术来帮助用户成长。本次活动邀请数百位阿里巴巴技术
阅读全文
c#抓取网页数据(1.网络爬虫的基础知识,发送Http请求的方法(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-07 20:14
)
一时兴起,感觉有时候在网页上保存资源很麻烦。有没有办法输入一个网址,批量抓取对应的资源?
需要思考的问题:
1.如何获取网页url的html源代码?
2.如何在浩瀚的html中匹配所需的资源地址?
3.如何根据获取到的资源地址批量下载资源?
4. 下载的资源一般是文件流。如何生成并保存指定的资源类型?
需要掌握的知识:
1.网络爬虫基础知识,发送Http请求的方法
2.C#正则表达式的使用,主要是识别html中需要的rul URLs
3.UnityWebRequest 文件流下载
4.C#基本文件操作如File类和Stream类
实施了以下子项:
这里不介绍爬虫。互联网上其他地方有很多信息。简而言之,就是采集网页信息和数据的程序。
第一步是发送一个Web请求,也可以说是一个Http请求。
这与打开浏览器输入url地址然后回车的效果基本类似。网页之所以能够显示正确的信息和数据,是因为每个网页都有对应的html源代码,像很多浏览器一样,比如谷歌浏览器就支持查看网页源代码的功能。比如下面是我经常去的喵窝首页的html部分:
在html源代码中,可以查看当前网页的大量隐藏信息和数据,包括大量的资源链接和样式表。值得注意的是,html源代码只有在网页完全加载后才能显示和查看,这意味着一个URL地址的web请求响应成功;当然在成功的情况下会有各种失败,比如我们经常输入rul地址后出现404提示。这是 Http 请求出错的情况。404 表示服务器没有找到请求的网页。还有许多其他类型的错误。为什么要理解这个,因为发送完Http请求后,要找到处理错误的方法或者跳过下一个任务。
我们可以通过多种方式发送Http请求,Unity也更新了web请求的方式:(以后直接截图代码,这个插入代码的功能不能自动排序,真的很不爽)
使用的主要类是UnityWebRequest,类似于之前Unity中的WWW类,主要用于文件的下载和上传。
引入以下命名空间:
UnityAction 作为参数主要用于请求结束后自动返回一个html源代码。它本质上是一个通用委托:
泛型参数可以从无到多,是一个很有用的类(尤其是在协程的回调中,可以很方便的延迟参数传递)
当然,除了Unity内置的发送web请求的方法,C#还封装了几个类,你可以随便挑一个使用,比如HttpWebRequest、WebClient、HttpClient等:
例如:
如果通过web请求成功获取到指定url地址的html源代码,则可以进行下一步。
第二步,采集html中需要的数据信息。在这个例子中,图片的链接地址是从源代码中找到的。
例如,可能有以下几种情况:
总结一下,首先使用html的常用标签
来找大部分图片,但还是有一些图片不在这些标签中。有时,即使在
标签中的图片地址在内部链接和外部链接之间可能仍然不同。如果使用外部链接,可以直接作为合法的url地址执行,但是如果是内部链接,则必须填写域名地址,所以我们还是需要想办法识别一个正确的域名网址。
关于如何识别和匹配上面提到的字符串内容,目前最有效的方法是正则表达式。本例中需要用到的正则表达式如下:
1.匹配url域名地址:
private const string URLRealmCheck = @"(http|https)://()?(\w+(\.)?)+";
2.匹配url地址:
private const string URLStringCheck = @"((http|https)://)(([a-zA-Z0-9\._-]+\.[a-zA-Z]{2,6})|( [0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}))(: [0-9]{1,4})*(/[a-zA-Z0-9\&%_\./-~-]*)?";
3.匹配html
标签中的url地址:(不区分大小写,分组
是需要的url地址)
私有常量字符串 imgLableCheck = @"
]*?\bsrc[\s\t\r\n]*=[\s\t\r\n]*[""\']?[\s\t\r\n]*(?
[^\s\t\r\n""\']*)[^]*?/?[\s\t\r\n]*>";
4. 匹配html中标签中href属性的url地址:(不区分大小写,主要用于深度检索,需要的url地址在分组中)
private const string hrefLinkCheck = @"(?i)]*?href=([\'""]?)(?!javascript|__doPostBack)(?[^\'""\s*#]+)[^> ]*>";
5. 指定图片类型匹配:(主要用于外链)
私有常量字符串 jpg = @"\.jpg";
私有常量字符串 png = @"\.png";
关于正则表达式的具体匹配用法,网上也有很多教程,这里就不赘述了。
给定一个html源码,下面从两个方向匹配图片,首先匹配外部链接,这里指定匹配的文件类型:
以下是内链匹配,必须先匹配域名地址:
有了域名地址后,就可以轻松匹配内链地址:
正则表达式的使用需要引入以下命名空间:
将所有的imgLinks与正则表达式匹配后,就可以依次下载图片了。
第三步,下载并传输有效的图片url:
您也可以同步下载和传输这些 URL,但这可能需要额外的最大线程数,并且更难以控制整体下载进度。
具体传输协议如下:
值得注意的是,Complete方法不是只有在下载成功时才调用,即使出现错误也需要调用,避免出现错误时自动下载自动终止的情况。正常情况下,即使发生错误,下一个文件的下载任务也会被跳过。
最后一步是将下载的数据文件流转换为指定类型的文件并保存。这里有很多方法,下面提供了其中一种:
扩张:
有时单个html中的所有图片链接并不能完全满足我们的需求,因为html中的子链接中也可能有需要的URL资源地址。这时候可以考虑加入更深的遍历。然后需要先匹配html中的链接地址,然后获取链接地址的子html源码,这样就进行了深度匹配的循环。
可以通过查找标签属性href 来匹配html 中的子链接。上面已经给出了这个属性的正则匹配表达式。这里只提供一层深度匹配供参考:
测试:这里我们使用深度匹配,抓取jpg格式的妙我首页图片链接,下载,保存到D盘。(UI随心所欲,不用管)
查看全部
c#抓取网页数据(1.网络爬虫的基础知识,发送Http请求的方法(图)
)
一时兴起,感觉有时候在网页上保存资源很麻烦。有没有办法输入一个网址,批量抓取对应的资源?
需要思考的问题:
1.如何获取网页url的html源代码?
2.如何在浩瀚的html中匹配所需的资源地址?
3.如何根据获取到的资源地址批量下载资源?
4. 下载的资源一般是文件流。如何生成并保存指定的资源类型?
需要掌握的知识:
1.网络爬虫基础知识,发送Http请求的方法
2.C#正则表达式的使用,主要是识别html中需要的rul URLs
3.UnityWebRequest 文件流下载
4.C#基本文件操作如File类和Stream类
实施了以下子项:
这里不介绍爬虫。互联网上其他地方有很多信息。简而言之,就是采集网页信息和数据的程序。
第一步是发送一个Web请求,也可以说是一个Http请求。
这与打开浏览器输入url地址然后回车的效果基本类似。网页之所以能够显示正确的信息和数据,是因为每个网页都有对应的html源代码,像很多浏览器一样,比如谷歌浏览器就支持查看网页源代码的功能。比如下面是我经常去的喵窝首页的html部分:
在html源代码中,可以查看当前网页的大量隐藏信息和数据,包括大量的资源链接和样式表。值得注意的是,html源代码只有在网页完全加载后才能显示和查看,这意味着一个URL地址的web请求响应成功;当然在成功的情况下会有各种失败,比如我们经常输入rul地址后出现404提示。这是 Http 请求出错的情况。404 表示服务器没有找到请求的网页。还有许多其他类型的错误。为什么要理解这个,因为发送完Http请求后,要找到处理错误的方法或者跳过下一个任务。
我们可以通过多种方式发送Http请求,Unity也更新了web请求的方式:(以后直接截图代码,这个插入代码的功能不能自动排序,真的很不爽)
使用的主要类是UnityWebRequest,类似于之前Unity中的WWW类,主要用于文件的下载和上传。
引入以下命名空间:
UnityAction 作为参数主要用于请求结束后自动返回一个html源代码。它本质上是一个通用委托:
泛型参数可以从无到多,是一个很有用的类(尤其是在协程的回调中,可以很方便的延迟参数传递)
当然,除了Unity内置的发送web请求的方法,C#还封装了几个类,你可以随便挑一个使用,比如HttpWebRequest、WebClient、HttpClient等:
例如:
如果通过web请求成功获取到指定url地址的html源代码,则可以进行下一步。
第二步,采集html中需要的数据信息。在这个例子中,图片的链接地址是从源代码中找到的。
例如,可能有以下几种情况:
总结一下,首先使用html的常用标签
来找大部分图片,但还是有一些图片不在这些标签中。有时,即使在
标签中的图片地址在内部链接和外部链接之间可能仍然不同。如果使用外部链接,可以直接作为合法的url地址执行,但是如果是内部链接,则必须填写域名地址,所以我们还是需要想办法识别一个正确的域名网址。
关于如何识别和匹配上面提到的字符串内容,目前最有效的方法是正则表达式。本例中需要用到的正则表达式如下:
1.匹配url域名地址:
private const string URLRealmCheck = @"(http|https)://()?(\w+(\.)?)+";
2.匹配url地址:
private const string URLStringCheck = @"((http|https)://)(([a-zA-Z0-9\._-]+\.[a-zA-Z]{2,6})|( [0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}))(: [0-9]{1,4})*(/[a-zA-Z0-9\&%_\./-~-]*)?";
3.匹配html
标签中的url地址:(不区分大小写,分组
是需要的url地址)
私有常量字符串 imgLableCheck = @"
]*?\bsrc[\s\t\r\n]*=[\s\t\r\n]*[""\']?[\s\t\r\n]*(?
[^\s\t\r\n""\']*)[^]*?/?[\s\t\r\n]*>";
4. 匹配html中标签中href属性的url地址:(不区分大小写,主要用于深度检索,需要的url地址在分组中)
private const string hrefLinkCheck = @"(?i)]*?href=([\'""]?)(?!javascript|__doPostBack)(?[^\'""\s*#]+)[^> ]*>";
5. 指定图片类型匹配:(主要用于外链)
私有常量字符串 jpg = @"\.jpg";
私有常量字符串 png = @"\.png";
关于正则表达式的具体匹配用法,网上也有很多教程,这里就不赘述了。
给定一个html源码,下面从两个方向匹配图片,首先匹配外部链接,这里指定匹配的文件类型:
以下是内链匹配,必须先匹配域名地址:
有了域名地址后,就可以轻松匹配内链地址:
正则表达式的使用需要引入以下命名空间:
将所有的imgLinks与正则表达式匹配后,就可以依次下载图片了。
第三步,下载并传输有效的图片url:
您也可以同步下载和传输这些 URL,但这可能需要额外的最大线程数,并且更难以控制整体下载进度。
具体传输协议如下:
值得注意的是,Complete方法不是只有在下载成功时才调用,即使出现错误也需要调用,避免出现错误时自动下载自动终止的情况。正常情况下,即使发生错误,下一个文件的下载任务也会被跳过。
最后一步是将下载的数据文件流转换为指定类型的文件并保存。这里有很多方法,下面提供了其中一种:
扩张:
有时单个html中的所有图片链接并不能完全满足我们的需求,因为html中的子链接中也可能有需要的URL资源地址。这时候可以考虑加入更深的遍历。然后需要先匹配html中的链接地址,然后获取链接地址的子html源码,这样就进行了深度匹配的循环。
可以通过查找标签属性href 来匹配html 中的子链接。上面已经给出了这个属性的正则匹配表达式。这里只提供一层深度匹配供参考:
测试:这里我们使用深度匹配,抓取jpg格式的妙我首页图片链接,下载,保存到D盘。(UI随心所欲,不用管)
c#抓取网页数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-07 20:13
在众多行业中,需要对行业数据进行分类汇总,及时对行业数据进行分析,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候,可能都无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我们将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只有采集当前页面的数据,还有分页的数据,这里就不解释了,只是一个提示,大家可以用多线程采集所有页面的当前数据,一个采集当前页面数据和一个翻页动作可以通过线程完成采集所有数据。
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据存储起来,方便我们接下来的数据查询操作。 查看全部
c#抓取网页数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
在众多行业中,需要对行业数据进行分类汇总,及时对行业数据进行分析,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候,可能都无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我们将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只有采集当前页面的数据,还有分页的数据,这里就不解释了,只是一个提示,大家可以用多线程采集所有页面的当前数据,一个采集当前页面数据和一个翻页动作可以通过线程完成采集所有数据。
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据存储起来,方便我们接下来的数据查询操作。
c#抓取网页数据(c#抓取网页数据到本地使用c#写接口的功能介绍及相关api)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-11-07 20:06
c#抓取网页数据到本地使用c#写接口接口的功能介绍及相关api文档github:codelover/codecandidate本文基于codeforces2017数据库链接介绍如何发布接口,带有简要注释:由于我最近天天晚上在上课,码代码抓取的时间少,现在只能随便讲下json的格式,至于怎么读出来可以查json文档//更多接口的功能请查看官方帮助文档在c#调用接口的代码如下c#codeconfig。
config"transport=port=9216"参数默认为当前tcp/ipv4端口(9216),端口号默认为"9216",我们已经配置json发布接口的功能必须满足这个参数才能调用在本地写这个codeconfig需要执行:jsonlisten("localhost","9216")这句命令是用来获取域名下80端口分配给接口codeconfig的端口号,写json不一定要jsonlisten,一般我们都写这个//调用demo接口默认端口在:9216jsonconfig::codeconfig(newjsonconfigconfig::config){configconf=config。
getconfig();//获取json信息configconf->set[jsonconnection_host]=system。authorization。ssl;//获取webpack配置[config。build。plugin:'ejscontainer/ejs']configconf->set[jsonconnection_timeout]="3000";//配置文件,默认80端口configconf->set[jsonconnection_path]="/";//获取本地cookie,默认cookie_maxs=400//返回webpack配置[webpack]configconf->set[jsonconnection_timeout]=3000;configconf->set[jsonconnection_uri]={"***/catalog":"/catalog/***","***/models":["models"]}}}//代码:codeconfig。
config"transport=port=9216"//外网传输参数codeconfig。config"transport=port=9216"//解析json参数codeconfig。config"transport=port=9216"//从外网读json参数codeconfig。config"transport=port=9216"//渲染json参数的get请求参数codeconfig。
config"transport=port='9216'"//->发布接口codeconfig。config"transport=port=9216"//->配置json的合法性codeconfig。config"transport=port=9216"//->解析httpconfig中的authorization参数codeconfig。
config"transport=http。'https'"//执行get请求:console。log(config。getuserinfo('query'))//发布接口jsonstunneljsmds1简易教程_20150816_51zhibai/iconfont-imagesgithub:codelover/codejsmds在解析下json文件:codeconfig。c。 查看全部
c#抓取网页数据(c#抓取网页数据到本地使用c#写接口的功能介绍及相关api)
c#抓取网页数据到本地使用c#写接口接口的功能介绍及相关api文档github:codelover/codecandidate本文基于codeforces2017数据库链接介绍如何发布接口,带有简要注释:由于我最近天天晚上在上课,码代码抓取的时间少,现在只能随便讲下json的格式,至于怎么读出来可以查json文档//更多接口的功能请查看官方帮助文档在c#调用接口的代码如下c#codeconfig。
config"transport=port=9216"参数默认为当前tcp/ipv4端口(9216),端口号默认为"9216",我们已经配置json发布接口的功能必须满足这个参数才能调用在本地写这个codeconfig需要执行:jsonlisten("localhost","9216")这句命令是用来获取域名下80端口分配给接口codeconfig的端口号,写json不一定要jsonlisten,一般我们都写这个//调用demo接口默认端口在:9216jsonconfig::codeconfig(newjsonconfigconfig::config){configconf=config。
getconfig();//获取json信息configconf->set[jsonconnection_host]=system。authorization。ssl;//获取webpack配置[config。build。plugin:'ejscontainer/ejs']configconf->set[jsonconnection_timeout]="3000";//配置文件,默认80端口configconf->set[jsonconnection_path]="/";//获取本地cookie,默认cookie_maxs=400//返回webpack配置[webpack]configconf->set[jsonconnection_timeout]=3000;configconf->set[jsonconnection_uri]={"***/catalog":"/catalog/***","***/models":["models"]}}}//代码:codeconfig。
config"transport=port=9216"//外网传输参数codeconfig。config"transport=port=9216"//解析json参数codeconfig。config"transport=port=9216"//从外网读json参数codeconfig。config"transport=port=9216"//渲染json参数的get请求参数codeconfig。
config"transport=port='9216'"//->发布接口codeconfig。config"transport=port=9216"//->配置json的合法性codeconfig。config"transport=port=9216"//->解析httpconfig中的authorization参数codeconfig。
config"transport=http。'https'"//执行get请求:console。log(config。getuserinfo('query'))//发布接口jsonstunneljsmds1简易教程_20150816_51zhibai/iconfont-imagesgithub:codelover/codejsmds在解析下json文件:codeconfig。c。
c#抓取网页数据(使用C#登陆带用户名和密码的网站,并获得网页源码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-06 08:20
)
诚恳请教C#登录网站获取网页和链接网页数据。使用C#以用户名密码登录网站,获取网页源代码;这个问题已经解决了!部分代码如下:
关键是这个登录网站有很多链接,我想得到这些链接页面(即子页面)的源码,怎么做?
感谢您的帮助!我哥有急事!
//获取数据时调用
privatevoidgetPage(Stringurl,StringparamList)
{
HttpWebRequestreq=(HttpWebRequest)WebRequest.Create(url);
req.Method="POST";
req.KeepAlive=true;
req.ContentType="application/x-www-form-urlencoded";
CookieContainercookieCon=newCookieContainer();
req.CookieContainer=cookieCon;
stringcookieheader=req.CookieContainer.GetCookieHeader(newUri(url));
req.CookieContainer.SetCookies(newUri(url),cookieheader);
byte[]SomeBytes=Encoding.UTF8.GetBytes(paramList);
req.ContentLength=SomeBytes.Length;
StreamnewStream=req.GetRequestStream();
newStream.Write(SomeBytes,0,SomeBytes.Length);
newStream.Close();
HttpWebResponseres=(HttpWebResponse)req.GetResponse();
StreamReceiveStream=res.GetResponseStream();
byte[]buffer=newbyte[1024];
stringfilename=@"c:\1\source.html";
StreamoutStream=File.Create(filename);
国际;
做
{
l=ReceiveStream.Read(buffer,0,buffer.Length);
if(l>0)
outStream.Write(buffer,0,l);
}while(l>0);
outStream.Close();
}
--------------------编程问答--------------------请求子页面时,附加 Cookie
....
CookieContainercookieCon=newCookieContainer();
cookieCon.SetCookies(newUri(url),"与 Url 关联的 Cookie 字符串");
req.CookieContainer=cookieCon;
--------------------编程问答--------------------
HttpWebResponse res = (HttpWebResponse)req.GetResponse(); <br />
Stream ReceiveStream = res.GetResponseStream(); <br />
StreamReader reader=new StreamReader(ReceiveStream);//套接StreamReader <br />
String source=reader.ReadToEnd();//一次读取所有相应内容<br />
............<br />
<br />
Stream outStream = File.Create(filename); <br />
StreamWriter writer=new StreamWriter(outStream);//套接StreamWriter<br />
writer.Write(source);//将读取到的内容一次写入文件<br />
outStream.Close();<br />
writer.Close();
这似乎比你的更有效率。
--------------------编程问答--------------------关注。帮顶一次! --------------------编程问答--------------------叮叮更健康---- - ---------------编程问答--------------------引用3楼gisfarmer的回复:注意。一次!
补充:.NET技术 , C# 查看全部
c#抓取网页数据(使用C#登陆带用户名和密码的网站,并获得网页源码
)
诚恳请教C#登录网站获取网页和链接网页数据。使用C#以用户名密码登录网站,获取网页源代码;这个问题已经解决了!部分代码如下:
关键是这个登录网站有很多链接,我想得到这些链接页面(即子页面)的源码,怎么做?
感谢您的帮助!我哥有急事!
//获取数据时调用
privatevoidgetPage(Stringurl,StringparamList)
{
HttpWebRequestreq=(HttpWebRequest)WebRequest.Create(url);
req.Method="POST";
req.KeepAlive=true;
req.ContentType="application/x-www-form-urlencoded";
CookieContainercookieCon=newCookieContainer();
req.CookieContainer=cookieCon;
stringcookieheader=req.CookieContainer.GetCookieHeader(newUri(url));
req.CookieContainer.SetCookies(newUri(url),cookieheader);
byte[]SomeBytes=Encoding.UTF8.GetBytes(paramList);
req.ContentLength=SomeBytes.Length;
StreamnewStream=req.GetRequestStream();
newStream.Write(SomeBytes,0,SomeBytes.Length);
newStream.Close();
HttpWebResponseres=(HttpWebResponse)req.GetResponse();
StreamReceiveStream=res.GetResponseStream();
byte[]buffer=newbyte[1024];
stringfilename=@"c:\1\source.html";
StreamoutStream=File.Create(filename);
国际;
做
{
l=ReceiveStream.Read(buffer,0,buffer.Length);
if(l>0)
outStream.Write(buffer,0,l);
}while(l>0);
outStream.Close();
}
--------------------编程问答--------------------请求子页面时,附加 Cookie
....
CookieContainercookieCon=newCookieContainer();
cookieCon.SetCookies(newUri(url),"与 Url 关联的 Cookie 字符串");
req.CookieContainer=cookieCon;
--------------------编程问答--------------------
HttpWebResponse res = (HttpWebResponse)req.GetResponse(); <br />
Stream ReceiveStream = res.GetResponseStream(); <br />
StreamReader reader=new StreamReader(ReceiveStream);//套接StreamReader <br />
String source=reader.ReadToEnd();//一次读取所有相应内容<br />
............<br />
<br />
Stream outStream = File.Create(filename); <br />
StreamWriter writer=new StreamWriter(outStream);//套接StreamWriter<br />
writer.Write(source);//将读取到的内容一次写入文件<br />
outStream.Close();<br />
writer.Close();
这似乎比你的更有效率。
--------------------编程问答--------------------关注。帮顶一次! --------------------编程问答--------------------叮叮更健康---- - ---------------编程问答--------------------引用3楼gisfarmer的回复:注意。一次!
补充:.NET技术 , C#
c#抓取网页数据(嵌入式应用的专栏文章(一)——c#抓取网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-06 03:00
c#抓取网页数据,android抓取safari网页,python抓取腾讯新闻各种数据,php抓取腾讯新闻、天天快报各种数据,java抓取本地网页数据,c语言抓取网页数据,c++抓取本地网页数据,go语言抓取互联网各种服务器数据,javascript抓取浏览器各种数据。
社会学,统计学,计算机网络技术,
hadoop
嵌入式专业啊嵌入式对程序语言要求比较高,硬件方面的专业知识比较突出。我就是学嵌入式的。
java语言知识,数据库操作,数据结构,linux系统等等吧,推荐看下我关于嵌入式应用的专栏文章。
嵌入式软件,最近开始做自己嵌入式系统,对学习嵌入式软件的有些了解。自己做的嵌入式系统是针对嵌入式手机和基于安卓平台的rtos以及rtlinux操作系统,关于硬件主要涉及ddr2ram32g双色温a2芯片,需要学习iic,spi,uart,at&t接口,can模块等等。关于软件方面是编译原理和linux系统编程等。
数据结构与算法不清楚,但python好像在某种程度上有些帮助,那些说java的那你让学java的情何以堪。python的gui做的还是比较方便的。
机械专业?理论上对编程要求不高,因为现在做嵌入式的一般都还处于扩招的过程,不算饱和,之前有个学长本科是机械的,考研之后过了线上一个调剂。要说编程人才,对大部分单位来说,说是需要,但是肯定不是全部。对于成熟项目,算法的开发工作优先于上手写代码。现在嵌入式系统,做的比较好的有点也就华为中兴酷派。做的不错的:阿里云里面的边云,西门子,大疆,一小部分研究所,小公司还有一些传统大厂也有做嵌入式的,但还不算多。
非程序员行业,想要做嵌入式,我觉得还是非常有竞争力的。除非你的资源和各种人脉特别强或者非常牛,这种算跨行,嵌入式在机械这种传统行业行不通。 查看全部
c#抓取网页数据(嵌入式应用的专栏文章(一)——c#抓取网页数据)
c#抓取网页数据,android抓取safari网页,python抓取腾讯新闻各种数据,php抓取腾讯新闻、天天快报各种数据,java抓取本地网页数据,c语言抓取网页数据,c++抓取本地网页数据,go语言抓取互联网各种服务器数据,javascript抓取浏览器各种数据。
社会学,统计学,计算机网络技术,
hadoop
嵌入式专业啊嵌入式对程序语言要求比较高,硬件方面的专业知识比较突出。我就是学嵌入式的。
java语言知识,数据库操作,数据结构,linux系统等等吧,推荐看下我关于嵌入式应用的专栏文章。
嵌入式软件,最近开始做自己嵌入式系统,对学习嵌入式软件的有些了解。自己做的嵌入式系统是针对嵌入式手机和基于安卓平台的rtos以及rtlinux操作系统,关于硬件主要涉及ddr2ram32g双色温a2芯片,需要学习iic,spi,uart,at&t接口,can模块等等。关于软件方面是编译原理和linux系统编程等。
数据结构与算法不清楚,但python好像在某种程度上有些帮助,那些说java的那你让学java的情何以堪。python的gui做的还是比较方便的。
机械专业?理论上对编程要求不高,因为现在做嵌入式的一般都还处于扩招的过程,不算饱和,之前有个学长本科是机械的,考研之后过了线上一个调剂。要说编程人才,对大部分单位来说,说是需要,但是肯定不是全部。对于成熟项目,算法的开发工作优先于上手写代码。现在嵌入式系统,做的比较好的有点也就华为中兴酷派。做的不错的:阿里云里面的边云,西门子,大疆,一小部分研究所,小公司还有一些传统大厂也有做嵌入式的,但还不算多。
非程序员行业,想要做嵌入式,我觉得还是非常有竞争力的。除非你的资源和各种人脉特别强或者非常牛,这种算跨行,嵌入式在机械这种传统行业行不通。
c#抓取网页数据(一个+jsou提取网页数据的分类汇总(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-11-04 00:13
原文链接
在众多行业中,需要对行业数据进行分类汇总,及时对行业数据进行分析,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们要获取的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只有采集当前页面的数据,还有分页的数据,这里就不解释了,只是一个提示,大家可以用多线程采集所有页面的当前数据,通过线程一个采集当前页面数据,一个翻页动作,可以采集完成所有数据。
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据存储起来,方便我们接下来的数据查询操作。 查看全部
c#抓取网页数据(一个+jsou提取网页数据的分类汇总(一))
原文链接
在众多行业中,需要对行业数据进行分类汇总,及时对行业数据进行分析,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们要获取的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只有采集当前页面的数据,还有分页的数据,这里就不解释了,只是一个提示,大家可以用多线程采集所有页面的当前数据,通过线程一个采集当前页面数据,一个翻页动作,可以采集完成所有数据。
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据存储起来,方便我们接下来的数据查询操作。
c#抓取网页数据(封装一个简单总结(一):抓取网页文档分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-03 18:15
)
这两天学习了爬虫的基础知识,这里简单总结一下。
获取的网页商品数据保存在Excel表格中,效果如下:
使用Jumony Core引擎,是一个非常强大且近乎完美的HTML解析引擎,支持css3选择器,直接抓取网页文档进行分析,并根据HTTP头自动识别。
一个抓取博客园站点导航顶部信息的例子:
var documents = new JumonyParser().LoadDocument("http://www.cnblogs.com/").Find("#site_nav_top").FirstOrDefault();
太强大了。如果您熟悉 CSS,则无需手动编写大量可读性差的正则表达式来匹配和获取数据。
封装一个简单的操作库:
public class BaseAnalyzer
{
///
/// 根据Url加载html文档对象
///
///
///
protected virtual IHtmlDocument LoadDocument(string url)
{
return new JumonyParser().LoadDocument(url);
}
///
/// 查询指定url中指定选择器的元素集
///
///
///
///
protected virtual List QueryHtmlElements(string url, string selector, Func predicate = null)
{
var elementsCollection = new List();
IEnumerable elements = LoadDocument(url).Find(selector);
if (predicate != null)
{
elements = elements.Where(predicate);
}
if (elements != null)
elementsCollection.AddRange(elements);
return elementsCollection;
}
///
/// 分析Html文档,获取指定元素集第一个元素的文本内容
///
/// html文档对象
/// 选择器
/// 文本内容
protected virtual string GetFirstElementText(IHtmlContainer html, string selector)
{
var findList = html.Find(selector);
var result = findList.FirstOrDefault();
return result == null ? string.Empty : result.InnerText();
}
///
/// 分析Html文档,获取指定元素集的文本内容
///
/// html文档对象
/// 选择器
/// 自定义处理获取到的元素集,若没有,就返回第一个元素的文本内容
///
protected virtual string GetElementsText(IHtmlContainer html, string selector, Func func)
{
var findList = html.Find(selector);
if (func != null)
return func(findList);
return GetFirstElementText(html, selector);
}
}
获取产品名称的示例:
private ProductInfo AnalyzeProductInfo(string detailUrl)
{
var product = new ProductInfo();
//详情页html文档对象
var html = LoadDocument(detailUrl);
product.ProductName = GetFirstElementText(html, ".goods_particulars h1");
} 查看全部
c#抓取网页数据(封装一个简单总结(一):抓取网页文档分析
)
这两天学习了爬虫的基础知识,这里简单总结一下。
获取的网页商品数据保存在Excel表格中,效果如下:

使用Jumony Core引擎,是一个非常强大且近乎完美的HTML解析引擎,支持css3选择器,直接抓取网页文档进行分析,并根据HTTP头自动识别。
一个抓取博客园站点导航顶部信息的例子:
var documents = new JumonyParser().LoadDocument("http://www.cnblogs.com/";).Find("#site_nav_top").FirstOrDefault();
太强大了。如果您熟悉 CSS,则无需手动编写大量可读性差的正则表达式来匹配和获取数据。
封装一个简单的操作库:
public class BaseAnalyzer
{
///
/// 根据Url加载html文档对象
///
///
///
protected virtual IHtmlDocument LoadDocument(string url)
{
return new JumonyParser().LoadDocument(url);
}
///
/// 查询指定url中指定选择器的元素集
///
///
///
///
protected virtual List QueryHtmlElements(string url, string selector, Func predicate = null)
{
var elementsCollection = new List();
IEnumerable elements = LoadDocument(url).Find(selector);
if (predicate != null)
{
elements = elements.Where(predicate);
}
if (elements != null)
elementsCollection.AddRange(elements);
return elementsCollection;
}
///
/// 分析Html文档,获取指定元素集第一个元素的文本内容
///
/// html文档对象
/// 选择器
/// 文本内容
protected virtual string GetFirstElementText(IHtmlContainer html, string selector)
{
var findList = html.Find(selector);
var result = findList.FirstOrDefault();
return result == null ? string.Empty : result.InnerText();
}
///
/// 分析Html文档,获取指定元素集的文本内容
///
/// html文档对象
/// 选择器
/// 自定义处理获取到的元素集,若没有,就返回第一个元素的文本内容
///
protected virtual string GetElementsText(IHtmlContainer html, string selector, Func func)
{
var findList = html.Find(selector);
if (func != null)
return func(findList);
return GetFirstElementText(html, selector);
}
}
获取产品名称的示例:
private ProductInfo AnalyzeProductInfo(string detailUrl)
{
var product = new ProductInfo();
//详情页html文档对象
var html = LoadDocument(detailUrl);
product.ProductName = GetFirstElementText(html, ".goods_particulars h1");
}
c#抓取网页数据(c#抓取网页数据_包vue抓取抓取抓取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-03 14:04
c#抓取网页数据_包vue抓取网页数据—vuejs-railsphp抓取网页数据--数据库—数据库-ajax等每个平台都是不一样的,所以我一般分享的是我常用的一些抓取方法。
首先要明白http请求是个什么样的过程,了解了请求的每个流程,才能更好地了解,才能做到从容不迫,这就不需要多说了,网上有很多文章介绍过,找对你心中所需即可。
requestheadersresponse格式
难道不是找几篇文章看看就知道的吗。
首先,抓包有两个概念:手机js代码抓包和串口控制抓包。js代码抓包在手机上有,在服务器端没有。串口控制抓包现在很少见了,有的话也只是用于判断目标网站是哪个js代码。至于说js代码抓包,那就很多了。最重要的抓包工具,或者说主要的是抓包工具:android/ios/webserver,除了python有一个专门的json.parse库外,其它语言都有json.parse。
在json中是没有string之类的字符串数据类型的。java/javascript各种语言的解析库,特别是java语言的nio解释器也有android和ios版本。还有嵌入式linux上的,有boost。这几个平台上还有通过wireshark进行抓包。安卓平台上,有xbench。
python写爬虫已经一大堆了,可以下一些linuxshell脚本试试。抓包需要一些代码,但编写一个抓包的脚本真的太容易了,相对python其他库就容易多了。 查看全部
c#抓取网页数据(c#抓取网页数据_包vue抓取抓取抓取数据)
c#抓取网页数据_包vue抓取网页数据—vuejs-railsphp抓取网页数据--数据库—数据库-ajax等每个平台都是不一样的,所以我一般分享的是我常用的一些抓取方法。
首先要明白http请求是个什么样的过程,了解了请求的每个流程,才能更好地了解,才能做到从容不迫,这就不需要多说了,网上有很多文章介绍过,找对你心中所需即可。
requestheadersresponse格式
难道不是找几篇文章看看就知道的吗。
首先,抓包有两个概念:手机js代码抓包和串口控制抓包。js代码抓包在手机上有,在服务器端没有。串口控制抓包现在很少见了,有的话也只是用于判断目标网站是哪个js代码。至于说js代码抓包,那就很多了。最重要的抓包工具,或者说主要的是抓包工具:android/ios/webserver,除了python有一个专门的json.parse库外,其它语言都有json.parse。
在json中是没有string之类的字符串数据类型的。java/javascript各种语言的解析库,特别是java语言的nio解释器也有android和ios版本。还有嵌入式linux上的,有boost。这几个平台上还有通过wireshark进行抓包。安卓平台上,有xbench。
python写爬虫已经一大堆了,可以下一些linuxshell脚本试试。抓包需要一些代码,但编写一个抓包的脚本真的太容易了,相对python其他库就容易多了。
c#抓取网页数据(开发数据采集程序的时候需要清楚的几个基本流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 586 次浏览 • 2021-11-03 09:32
首先大家要清楚:网站的任何页面,无论是php、jsp、aspx等动态页面,还是后台程序生成的静态页面,都可以在浏览器。
所以当你要开发数据采集程序时,首先要了解网站你试图采集的首页结构(HTML)。
一旦您非常熟悉网站 中需要采集 数据的HTML 源文件的内容,程序的其余部分就很容易处理了。因为C#在网站上执行数据采集,原理是“下载你要采集的页面的HTML源文件,分析HTML代码然后抓取你需要的数据,最后将数据保存到本地文件”。
基本流程如下图所示:
1.页面源文件下载
首先引用 System.Net 命名空间
using System.Net;
还需要引用
using System.Text;
using System.IO;
引用后实例化一个 WebClient 对象
private WebClient wc = new WebClient();
调用 DownloadData 方法从指定网页的源文件中下载一组 BYTE 数据,然后将 BYTE 数组转换为字符串。
//下载页面源文件并将其转换成UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData(string.Format("你要采集的网页地址")));
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
//下载网页源文件到本地
wc.DownloadFile("你要采集的网页URL","保存源文件的本地文件路径");
//读取下载下来的源文件HTML格式的字符串
string mainData = File.ReadAllText("保存源文件的本地文件路径",Encoding.UTF8);
通过网页HTML格式字符串,您可以分析网页采集,抓取您需要的内容。
2.页面分析采集
页面分析就是将网页源文件中某个特定的或唯一的字符(字符串)作为抓点,并以此抓点为起点,截取你想要的页面上的数据。
以博客园为专栏。比如我要在博客园首页列出文章的标题和链接,就必须用“
<p>//以" 查看全部
c#抓取网页数据(开发数据采集程序的时候需要清楚的几个基本流程)
首先大家要清楚:网站的任何页面,无论是php、jsp、aspx等动态页面,还是后台程序生成的静态页面,都可以在浏览器。

所以当你要开发数据采集程序时,首先要了解网站你试图采集的首页结构(HTML)。
一旦您非常熟悉网站 中需要采集 数据的HTML 源文件的内容,程序的其余部分就很容易处理了。因为C#在网站上执行数据采集,原理是“下载你要采集的页面的HTML源文件,分析HTML代码然后抓取你需要的数据,最后将数据保存到本地文件”。
基本流程如下图所示:

1.页面源文件下载
首先引用 System.Net 命名空间
using System.Net;
还需要引用
using System.Text;
using System.IO;
引用后实例化一个 WebClient 对象
private WebClient wc = new WebClient();
调用 DownloadData 方法从指定网页的源文件中下载一组 BYTE 数据,然后将 BYTE 数组转换为字符串。
//下载页面源文件并将其转换成UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData(string.Format("你要采集的网页地址")));
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
//下载网页源文件到本地
wc.DownloadFile("你要采集的网页URL","保存源文件的本地文件路径");
//读取下载下来的源文件HTML格式的字符串
string mainData = File.ReadAllText("保存源文件的本地文件路径",Encoding.UTF8);
通过网页HTML格式字符串,您可以分析网页采集,抓取您需要的内容。
2.页面分析采集
页面分析就是将网页源文件中某个特定的或唯一的字符(字符串)作为抓点,并以此抓点为起点,截取你想要的页面上的数据。
以博客园为专栏。比如我要在博客园首页列出文章的标题和链接,就必须用“

<p>//以"
c#抓取网页数据(开发数据采集程序的时候需要清楚的几个基本流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2021-11-24 10:04
首先大家要清楚:网站的任何页面,无论是php、jsp、aspx等动态页面,还是后台程序生成的静态页面,都可以在浏览器。
所以当你要开发数据采集程序时,首先要了解网站你试图采集的首页结构(HTML)。
当您熟悉网站中需要采集数据的HTML源文件的内容后,程序的其余部分就很容易处理了。因为C#在网站上执行数据采集,原理是“下载你要采集的页面的HTML源文件,分析HTML代码然后抓取你需要的数据,最后将数据保存到本地文件”。
基本流程如下图所示:
1.页面源文件下载
首先引用 System.Net 命名空间
using System.Net;
还需要引用
using System.Text;
using System.IO;
引用后实例化一个 WebClient 对象
private WebClient wc = new WebClient();
调用 DownloadData 方法从指定网页的源文件中下载一组 BYTE 数据,然后将 BYTE 数组转换为字符串。
//下载页面源文件并将其转换成UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData(string.Format("你要采集的网页地址")));
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
//下载网页源文件到本地
wc.DownloadFile("你要采集的网页URL","保存源文件的本地文件路径");
//读取下载下来的源文件HTML格式的字符串
string mainData = File.ReadAllText("保存源文件的本地文件路径",Encoding.UTF8);
通过网页HTML格式字符串,您可以分析网页采集,抓取您需要的内容。
2.页面分析采集
页面分析就是将网页源文件中的某个特定的或唯一的字符(字符串)作为抓点,并以此抓点为起点,截取你想要的页面上的数据。
以博客园为专栏。比如我要在博客园首页列出文章的标题和链接,就必须用“
<p>//以" 查看全部
c#抓取网页数据(开发数据采集程序的时候需要清楚的几个基本流程)
首先大家要清楚:网站的任何页面,无论是php、jsp、aspx等动态页面,还是后台程序生成的静态页面,都可以在浏览器。
所以当你要开发数据采集程序时,首先要了解网站你试图采集的首页结构(HTML)。
当您熟悉网站中需要采集数据的HTML源文件的内容后,程序的其余部分就很容易处理了。因为C#在网站上执行数据采集,原理是“下载你要采集的页面的HTML源文件,分析HTML代码然后抓取你需要的数据,最后将数据保存到本地文件”。
基本流程如下图所示:
1.页面源文件下载
首先引用 System.Net 命名空间
using System.Net;
还需要引用
using System.Text;
using System.IO;
引用后实例化一个 WebClient 对象
private WebClient wc = new WebClient();
调用 DownloadData 方法从指定网页的源文件中下载一组 BYTE 数据,然后将 BYTE 数组转换为字符串。
//下载页面源文件并将其转换成UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData(string.Format("你要采集的网页地址")));
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
//下载网页源文件到本地
wc.DownloadFile("你要采集的网页URL","保存源文件的本地文件路径");
//读取下载下来的源文件HTML格式的字符串
string mainData = File.ReadAllText("保存源文件的本地文件路径",Encoding.UTF8);
通过网页HTML格式字符串,您可以分析网页采集,抓取您需要的内容。
2.页面分析采集
页面分析就是将网页源文件中的某个特定的或唯一的字符(字符串)作为抓点,并以此抓点为起点,截取你想要的页面上的数据。
以博客园为专栏。比如我要在博客园首页列出文章的标题和链接,就必须用“
<p>//以"
c#抓取网页数据(学一下c#编写爬虫,发现了一个很好的视频资源)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-21 08:22
最近开始学习c#写爬虫,找到了一个不错的视频资源,然后在学习的时候做一些笔记。
视频资源链接:
第一个小例子是用net读取网站的源码。其中的所有数据都可以在谷歌浏览器的开发工具按钮中通过网络获取。
class Program
{
static void Main(string[] args)
{
//建立一个请求
string Url = "https://baike.baidu.com/item/using/232450";
HttpWebRequest Myrq = WebRequest.Create(Url) as HttpWebRequest;
Myrq.KeepAlive = false;//持续连接
Myrq.Timeout = 30 * 1000;//30秒,*1000是因为基础单位为毫秒
Myrq.Method = "GET";//请求方法
Myrq.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3";//自己去network里面找
Myrq.Host = "baike.baidu.com";
Myrq.Referer = "https://www.baidu.com/link%3Fu ... 3B%3B
Myrq.UserAgent = "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36";
//接受返回
HttpWebResponse Myrp = (HttpWebResponse )Myrq.GetResponse();
if(Myrp.StatusCode !=HttpStatusCode.OK )
{ return; }
using (StreamReader rd = new StreamReader(Myrp.GetResponseStream()))
{
Console.WriteLine(rd.ReadToEnd() );
}
Console.ReadKey();
输出如下:
网络中的第一个是网站的请求第一类。
请结合以下图片和代码查看
第二个小例子,开始抓取图片,这个url是作者随机找到的一张网站的图片的请求头。
您也可以自己更改。
//建立一个请求
string Url = "http://pic.netbian.com/uploads ... 3B%3B
HttpWebRequest Myrq = WebRequest.Create(Url) as HttpWebRequest;
Myrq.KeepAlive = false;//持续连接
Myrq.Timeout = 30 * 1000;//30秒,*1000是因为基础单位为毫秒
Myrq.Method = "GET";//请求方法
Myrq.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3";//自己去network里面找
Myrq.UserAgent = "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36";
//接受返回
HttpWebResponse Myrp = (HttpWebResponse )Myrq.GetResponse();
if(Myrp.StatusCode !=HttpStatusCode.OK )
{ return; }
using (FileStream fl = new FileStream("1.jpg", FileMode.Create))//展开一个流
{
Myrp.GetResponseStream().CopyTo(fl);//复制到当前文件夹
}
我们可以看到,两段代码其实并没有太大的区别,只有很小的区别。 查看全部
c#抓取网页数据(学一下c#编写爬虫,发现了一个很好的视频资源)
最近开始学习c#写爬虫,找到了一个不错的视频资源,然后在学习的时候做一些笔记。
视频资源链接:
第一个小例子是用net读取网站的源码。其中的所有数据都可以在谷歌浏览器的开发工具按钮中通过网络获取。
class Program
{
static void Main(string[] args)
{
//建立一个请求
string Url = "https://baike.baidu.com/item/using/232450";
HttpWebRequest Myrq = WebRequest.Create(Url) as HttpWebRequest;
Myrq.KeepAlive = false;//持续连接
Myrq.Timeout = 30 * 1000;//30秒,*1000是因为基础单位为毫秒
Myrq.Method = "GET";//请求方法
Myrq.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3";//自己去network里面找
Myrq.Host = "baike.baidu.com";
Myrq.Referer = "https://www.baidu.com/link%3Fu ... 3B%3B
Myrq.UserAgent = "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36";
//接受返回
HttpWebResponse Myrp = (HttpWebResponse )Myrq.GetResponse();
if(Myrp.StatusCode !=HttpStatusCode.OK )
{ return; }
using (StreamReader rd = new StreamReader(Myrp.GetResponseStream()))
{
Console.WriteLine(rd.ReadToEnd() );
}
Console.ReadKey();
输出如下:
网络中的第一个是网站的请求第一类。
请结合以下图片和代码查看
第二个小例子,开始抓取图片,这个url是作者随机找到的一张网站的图片的请求头。
您也可以自己更改。
//建立一个请求
string Url = "http://pic.netbian.com/uploads ... 3B%3B
HttpWebRequest Myrq = WebRequest.Create(Url) as HttpWebRequest;
Myrq.KeepAlive = false;//持续连接
Myrq.Timeout = 30 * 1000;//30秒,*1000是因为基础单位为毫秒
Myrq.Method = "GET";//请求方法
Myrq.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3";//自己去network里面找
Myrq.UserAgent = "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36";
//接受返回
HttpWebResponse Myrp = (HttpWebResponse )Myrq.GetResponse();
if(Myrp.StatusCode !=HttpStatusCode.OK )
{ return; }
using (FileStream fl = new FileStream("1.jpg", FileMode.Create))//展开一个流
{
Myrp.GetResponseStream().CopyTo(fl);//复制到当前文件夹
}
我们可以看到,两段代码其实并没有太大的区别,只有很小的区别。
c#抓取网页数据(这篇博文记录一下如何抓取网页上面的验证码,注意不是验证码识别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-20 22:11
如果你要开发一个半自动注册机程序,那么将验证码读入winform并提交数据是一个必要的过程。这篇博文记录了如何抓取网页上的验证码,注意不是验证码识别。有些 网站 会验证 cookie,有些则不会。本文收录cookie阅读和提交。
第一次生活是一个全局 Cookie 变量
private CookieContainer cookie = new System.Net.CookieContainer();
程序加载时读取验证码和cookie
public Form1()
{
InitializeComponent();
string checkcodeUrl = "验证码的url";
try
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(checkcodeUrl);
request.CookieContainer = new CookieContainer();
Stream responseStream = ((HttpWebResponse)request.GetResponse()).GetResponseStream();
cookie = request.CookieContainer;
string cookiesstr = request.CookieContainer.GetCookieHeader(request.RequestUri);
Image original = Image.FromStream(responseStream);
Bitmap bitMap = new Bitmap(original);
this.pictureBox1.Image = bitMap;
responseStream.Close();
}
catch (Exception exception)
{
MessageBox.Show("ERROR:" + exception.Message);
}
}
提交数据
HttpWebRequest webrequest = (HttpWebRequest)WebRequest.Create(url);
webrequest.CookieContainer = cookie;
HttpWebResponse response = (HttpWebResponse)webrequest.GetResponse();
StreamReader read = new StreamReader(response.GetResponseStream(), Encoding.Default);
string text = read.ReadToEnd();
不明白的请留言咨询,只写一部分必要的代码。 查看全部
c#抓取网页数据(这篇博文记录一下如何抓取网页上面的验证码,注意不是验证码识别)
如果你要开发一个半自动注册机程序,那么将验证码读入winform并提交数据是一个必要的过程。这篇博文记录了如何抓取网页上的验证码,注意不是验证码识别。有些 网站 会验证 cookie,有些则不会。本文收录cookie阅读和提交。
第一次生活是一个全局 Cookie 变量
private CookieContainer cookie = new System.Net.CookieContainer();
程序加载时读取验证码和cookie
public Form1()
{
InitializeComponent();
string checkcodeUrl = "验证码的url";
try
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(checkcodeUrl);
request.CookieContainer = new CookieContainer();
Stream responseStream = ((HttpWebResponse)request.GetResponse()).GetResponseStream();
cookie = request.CookieContainer;
string cookiesstr = request.CookieContainer.GetCookieHeader(request.RequestUri);
Image original = Image.FromStream(responseStream);
Bitmap bitMap = new Bitmap(original);
this.pictureBox1.Image = bitMap;
responseStream.Close();
}
catch (Exception exception)
{
MessageBox.Show("ERROR:" + exception.Message);
}
}
提交数据
HttpWebRequest webrequest = (HttpWebRequest)WebRequest.Create(url);
webrequest.CookieContainer = cookie;
HttpWebResponse response = (HttpWebResponse)webrequest.GetResponse();
StreamReader read = new StreamReader(response.GetResponseStream(), Encoding.Default);
string text = read.ReadToEnd();
不明白的请留言咨询,只写一部分必要的代码。
c#抓取网页数据(经@吃西瓜的星星提醒(2):SeleniumSelenium)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-19 02:03
@吃瓜的星提醒
首先我们介绍Selenium
Selenium 也是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试浏览器兼容性——测试您的应用程序是否可以在不同浏览器和操作系统上正常运行。测试系统功能——创建回归测试以验证软件功能和用户需求。支持自动录制动作和自动生成。测试Net、Java、Perl等不同语言的脚本。Selenium是ThoughtWorks专门为web应用编写的验收测试工具。
单击此处了解详细信息
这里我们将使用模拟真人操作,不会被TX统一用于访问和数据捕获。
这里使用的IDE是VS2017,系统是Win10,浏览器驱动是ChromeDriver
新的单元测试解决方案
安装 Nuget 包
我这里用的是谷歌浏览器采集数据,所以我用的是谷歌浏览器的驱动。如果你不喜欢谷歌浏览器,你可以参考其他驱动程序包。
命令
Install-Package Selenium.WebDriver
Install-Package Selenium.WebDriver.ChromeDriver
或者直接安装管理器如下图
Selenium.WebDriver.ChromeDriver 是将Chorme驱动,即ChormeDriver.exe程序,在项目编译完成后复制到bin目录下。
将NetCore复制到对应的netcoreappv文件目录下
这样,基本参考就完成了,下面介绍具体的实现。
首先创建一个测试类Qzone.cs,我们后续的所有调用都在测试类中进行测试和实现
public class QzoneTest
{
[Fact]
public void QQLogin()
{
var driver = new ChromeDriver();
driver.Url = "https://qzone.qq.com/";
driver.Quit();
}
}
因为是xUnit测试类,可以直接右键调试测试,运行时可以看到下图
驱动会自动打开Chrome浏览器并跳转到指定页面。
空间页面已经打开,下面是登录步骤
有两种登录方式,也是QQ自己提供的
第一种,如果你已经登录QQ,可以直接点击头像登录
第二种用账号密码登录
下面就来详细介绍一下
让我谈谈第二个。第一个比较简单。学完第二个,第一个就容易了。
我们需要找到输入账号和密码的文本框
这里我们使用Selenium的查找元素的方法
这为我们提供了多种查找元素的方法,我们可以根据名称来理解其含义。
var driver = new ChromeDriver();
driver.FindElement();
driver.FindElementByClassName();
driver.FindElementByCssSelector();
driver.FindElementById();
driver.FindElementByName();
driver.FindElementByTagName();
driver.FindElementByXPath()
我们使用 ByXPath 方法来查找元素。XPath的详细介绍可以自行了解。我只会向您展示如何快速找到 XPath。
只需打开空间地址,找到文本框,然后勾选元素,在右边的元素位置右击->Copy->Copy XPath
可以得到这样的地址
//*[@id="u"]
找密码框的方法一样
//*[@id="p"]
通过这个xpath我们可以找到用户名的xpath路径,然后在程序中这样写
try
{
var userName = driver.FindElementByXPath("//*[@id='u']");
//这里的userName就是用户名的文本框
//设置用户名的值
userName.SendKeys("123456");
var pwd = driver.FindElementByXPath("//*[@id='p']");
pwd.SendKeys("********");
}
finally
{
driver.Quit();
}
运行后出现异常
别慌,这是浏览器驱动没有找到元素造成的,我们仔细检查一下
原来的文本框嵌套在一个iframe中,难怪当前驱动找不到元素,因为当前驱动只会找到当前连接下的元素,不包括嵌套元素。
然后我们使用switch语法
try
{
//切换语法有两种,一种是根据索引切换,另外一种根据iframe名称切换
//这里我们使用name切换
ITargetLocator tagetLocator = driver.SwitchTo();
//tagetLocator.Frame(1); //frame index.
tagetLocator.Frame("login_frame"); //frame frame name.
var userName = driver.FindElementByXPath("//*[@id='u']");
//这里的userName就是用户名的文本框
//设置用户名的值
userName.SendKeys("123456");
var pwd = driver.FindElementByXPath("//*[@id='p']");
pwd.SendKeys("********");
}
finally
{
driver.Quit();
}
然后调试测试,如下图
所以将值填入文本框
最后点击登录,找到login button元素,同样点击找到login button元素,点击
[Fact]
public void QQLogin()
{
dynamic type = (new PictureTest()).GetType();
string currentDirectory = Path.GetDirectoryName(type.Assembly.Location);
var driver = new ChromeDriver(currentDirectory);
driver.Url = "https://qzone.qq.com/";
try
{
//切换语法有两种,一种是根据索引切换,另外一种根据iframe名称切换
//这里我们使用name切换
ITargetLocator tagetLocator = driver.SwitchTo();
//tagetLocator.Frame(1); //frame index.
tagetLocator.Frame("login_frame"); //frame frame name.
var userName = driver.FindElementByXPath("//*[@id='u']");
//这里的userName就是用户名的文本框
//设置用户名的值
userName.SendKeys("123456");
var pwd = driver.FindElementByXPath("//*[@id='p']");
pwd.SendKeys("********");
var btnLogin = driver.FindElementByXPath("//*[@id='login_button']");
//这里是判断登录按钮是否可见,可以不写,直接调用click方法
if (btnLogin != null && btnLogin.Displayed == true)
{
btnLogin.Click();
}
}
finally
{
driver.Quit();
}
}
然后登录成功
总而言之,使用了一些关键语法
//Iframe切换,如果需要捕获的元素不在当前页面,则找到嵌套页面进行切换
//切换语法有两种,一种是根据索引切换,另外一种根据iframe名称切换
ITargetLocator tagetLocator = driver.SwitchTo();
//tagetLocator.Frame(1); //frame index.
tagetLocator.Frame("login_frame"); //frame frame name.
//查找元素方法,可以使用css定位
var userName = driver.FindElementByXPath("//*[@id='u']");
//设置文本框的值SendKeys
userName.SendKeys("123456");
//元素点击事件
var btnLogin = driver.FindElementByXPath("//*[@id='login_button']");
btnLogin.Click();
只要了解驱动对浏览器的一些操作方式,就可以自行探索,实现自己想要的,比如点击切换登录框、快速登录
例如,找到相册元素并点击,找到菜单谈论元素并点击,设置文本框值,发送谈话,写消息,你可以探索和使用
登录先在这里聊,改天写点什么或者留言板,或者保存相册的照片
Git源代码地址: 查看全部
c#抓取网页数据(经@吃西瓜的星星提醒(2):SeleniumSelenium)
@吃瓜的星提醒
首先我们介绍Selenium
Selenium 也是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试浏览器兼容性——测试您的应用程序是否可以在不同浏览器和操作系统上正常运行。测试系统功能——创建回归测试以验证软件功能和用户需求。支持自动录制动作和自动生成。测试Net、Java、Perl等不同语言的脚本。Selenium是ThoughtWorks专门为web应用编写的验收测试工具。
单击此处了解详细信息
这里我们将使用模拟真人操作,不会被TX统一用于访问和数据捕获。
这里使用的IDE是VS2017,系统是Win10,浏览器驱动是ChromeDriver
新的单元测试解决方案
安装 Nuget 包
我这里用的是谷歌浏览器采集数据,所以我用的是谷歌浏览器的驱动。如果你不喜欢谷歌浏览器,你可以参考其他驱动程序包。
命令
Install-Package Selenium.WebDriver
Install-Package Selenium.WebDriver.ChromeDriver
或者直接安装管理器如下图
Selenium.WebDriver.ChromeDriver 是将Chorme驱动,即ChormeDriver.exe程序,在项目编译完成后复制到bin目录下。
将NetCore复制到对应的netcoreappv文件目录下
这样,基本参考就完成了,下面介绍具体的实现。
首先创建一个测试类Qzone.cs,我们后续的所有调用都在测试类中进行测试和实现
public class QzoneTest
{
[Fact]
public void QQLogin()
{
var driver = new ChromeDriver();
driver.Url = "https://qzone.qq.com/";
driver.Quit();
}
}
因为是xUnit测试类,可以直接右键调试测试,运行时可以看到下图
驱动会自动打开Chrome浏览器并跳转到指定页面。
空间页面已经打开,下面是登录步骤
有两种登录方式,也是QQ自己提供的
第一种,如果你已经登录QQ,可以直接点击头像登录
第二种用账号密码登录
下面就来详细介绍一下
让我谈谈第二个。第一个比较简单。学完第二个,第一个就容易了。
我们需要找到输入账号和密码的文本框
这里我们使用Selenium的查找元素的方法
这为我们提供了多种查找元素的方法,我们可以根据名称来理解其含义。
var driver = new ChromeDriver();
driver.FindElement();
driver.FindElementByClassName();
driver.FindElementByCssSelector();
driver.FindElementById();
driver.FindElementByName();
driver.FindElementByTagName();
driver.FindElementByXPath()
我们使用 ByXPath 方法来查找元素。XPath的详细介绍可以自行了解。我只会向您展示如何快速找到 XPath。
只需打开空间地址,找到文本框,然后勾选元素,在右边的元素位置右击->Copy->Copy XPath
可以得到这样的地址
//*[@id="u"]
找密码框的方法一样
//*[@id="p"]
通过这个xpath我们可以找到用户名的xpath路径,然后在程序中这样写
try
{
var userName = driver.FindElementByXPath("//*[@id='u']");
//这里的userName就是用户名的文本框
//设置用户名的值
userName.SendKeys("123456");
var pwd = driver.FindElementByXPath("//*[@id='p']");
pwd.SendKeys("********");
}
finally
{
driver.Quit();
}
运行后出现异常
别慌,这是浏览器驱动没有找到元素造成的,我们仔细检查一下
原来的文本框嵌套在一个iframe中,难怪当前驱动找不到元素,因为当前驱动只会找到当前连接下的元素,不包括嵌套元素。
然后我们使用switch语法
try
{
//切换语法有两种,一种是根据索引切换,另外一种根据iframe名称切换
//这里我们使用name切换
ITargetLocator tagetLocator = driver.SwitchTo();
//tagetLocator.Frame(1); //frame index.
tagetLocator.Frame("login_frame"); //frame frame name.
var userName = driver.FindElementByXPath("//*[@id='u']");
//这里的userName就是用户名的文本框
//设置用户名的值
userName.SendKeys("123456");
var pwd = driver.FindElementByXPath("//*[@id='p']");
pwd.SendKeys("********");
}
finally
{
driver.Quit();
}
然后调试测试,如下图
所以将值填入文本框
最后点击登录,找到login button元素,同样点击找到login button元素,点击
[Fact]
public void QQLogin()
{
dynamic type = (new PictureTest()).GetType();
string currentDirectory = Path.GetDirectoryName(type.Assembly.Location);
var driver = new ChromeDriver(currentDirectory);
driver.Url = "https://qzone.qq.com/";
try
{
//切换语法有两种,一种是根据索引切换,另外一种根据iframe名称切换
//这里我们使用name切换
ITargetLocator tagetLocator = driver.SwitchTo();
//tagetLocator.Frame(1); //frame index.
tagetLocator.Frame("login_frame"); //frame frame name.
var userName = driver.FindElementByXPath("//*[@id='u']");
//这里的userName就是用户名的文本框
//设置用户名的值
userName.SendKeys("123456");
var pwd = driver.FindElementByXPath("//*[@id='p']");
pwd.SendKeys("********");
var btnLogin = driver.FindElementByXPath("//*[@id='login_button']");
//这里是判断登录按钮是否可见,可以不写,直接调用click方法
if (btnLogin != null && btnLogin.Displayed == true)
{
btnLogin.Click();
}
}
finally
{
driver.Quit();
}
}
然后登录成功
总而言之,使用了一些关键语法
//Iframe切换,如果需要捕获的元素不在当前页面,则找到嵌套页面进行切换
//切换语法有两种,一种是根据索引切换,另外一种根据iframe名称切换
ITargetLocator tagetLocator = driver.SwitchTo();
//tagetLocator.Frame(1); //frame index.
tagetLocator.Frame("login_frame"); //frame frame name.
//查找元素方法,可以使用css定位
var userName = driver.FindElementByXPath("//*[@id='u']");
//设置文本框的值SendKeys
userName.SendKeys("123456");
//元素点击事件
var btnLogin = driver.FindElementByXPath("//*[@id='login_button']");
btnLogin.Click();
只要了解驱动对浏览器的一些操作方式,就可以自行探索,实现自己想要的,比如点击切换登录框、快速登录
例如,找到相册元素并点击,找到菜单谈论元素并点击,设置文本框值,发送谈话,写消息,你可以探索和使用
登录先在这里聊,改天写点什么或者留言板,或者保存相册的照片
Git源代码地址:
c#抓取网页数据( 本文-05-22来源:阅读942评论摘要:本次的c#编程向大家介绍了如何去html网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-18 11:07
本文-05-22来源:阅读942评论摘要:本次的c#编程向大家介绍了如何去html网页数据)
c#编程如何抓取html网页数据? (代码示例)
Vivian2018-05-22来源:阅读 942 条评论 0
总结:本次c#编程介绍了如何抓取html网页数据。通过具体的源码案例,希望对大家学习c#编程有所帮助。
本次c#编程向您介绍了如何抓取html网页数据。通过具体的源码案例,希望对大家学习c#编程有所帮助。
//方法一
using System.Text.RegularExpressions;
public static void webClientMethod1()
{
WebClient wc = new WebClient();
wc.Encoding = Encoding.UTF8;
//以字符串的形式返回数据
string html = wc.DownloadString("https://www.baidu.com/");
//以正则表达式的形式匹配到字符串网页中想要的数据
MatchCollection matches = Regex.Matches(html, "(.*)");
//依次取得匹配到的数据
foreach (Match item in matches)
{
Console.WriteLine(item.Groups[1].Value);
}
Console.ReadKey();
}
//方法二
public static string SendRequest()
{
string url = "https://www.baidu.com/";
Uri httpURL = new Uri(url);
///HttpWebRequest类继承于WebRequest,并没有自己的构造函数,需通过WebRequest的Creat方法 建立,并进行强制的类型转换
HttpWebRequest httpReq = (HttpWebRequest)WebRequest.Create(httpURL);
//httpReq.Headers.Add("cityen", "tj");
///通过HttpWebRequest的GetResponse()方法建立HttpWebResponse,强制类型转换
HttpWebResponse httpResp = (HttpWebResponse)httpReq.GetResponse();
///GetResponseStream()方法获取HTTP响应的数据流,并尝试取得URL中所指定的网页内容
///若成功取得网页的内容,则以System.IO.Stream形式返回,若失败则产生ProtoclViolationException错 误。
System.IO.Stream respStream = httpResp.GetResponseStream();
///返回的内容是Stream形式的,所以可以利用StreamReader类获取GetResponseStream的内容
System.IO.StreamReader respStreamReader = new System.IO.StreamReader(respStream, Encoding.UTF8);
//从流的当前位置读取到结尾
string strBuff = respStreamReader.ReadToEnd();
//简单写法,跟上面的结果一样
//using (var sr = new System.IO.StreamReader(httpReq.GetResponse().GetResponseStream()))
//{
// var result = sr.ReadToEnd();
// Console.WriteLine("微信--" + DateTime.Now.ToString() + "--" + result);
//}
respStreamReader.Close();
respStream.Close();
return strBuff;
}
本文按位置坐标整理发布,希望对同学们有所帮助。更多详情请关注工作坐标编程语言C#.NET频道
本文由@Vivian 在该位置发表。未经许可禁止转载。
喜欢| 0
不喜欢| 0
看完这篇文章,你有什么感受?已有0人发表意见,0%喜欢分享给朋友~ 查看全部
c#抓取网页数据(
本文-05-22来源:阅读942评论摘要:本次的c#编程向大家介绍了如何去html网页数据)
c#编程如何抓取html网页数据? (代码示例)
Vivian2018-05-22来源:阅读 942 条评论 0
总结:本次c#编程介绍了如何抓取html网页数据。通过具体的源码案例,希望对大家学习c#编程有所帮助。
本次c#编程向您介绍了如何抓取html网页数据。通过具体的源码案例,希望对大家学习c#编程有所帮助。
//方法一
using System.Text.RegularExpressions;
public static void webClientMethod1()
{
WebClient wc = new WebClient();
wc.Encoding = Encoding.UTF8;
//以字符串的形式返回数据
string html = wc.DownloadString("https://www.baidu.com/";);
//以正则表达式的形式匹配到字符串网页中想要的数据
MatchCollection matches = Regex.Matches(html, "(.*)");
//依次取得匹配到的数据
foreach (Match item in matches)
{
Console.WriteLine(item.Groups[1].Value);
}
Console.ReadKey();
}
//方法二
public static string SendRequest()
{
string url = "https://www.baidu.com/";
Uri httpURL = new Uri(url);
///HttpWebRequest类继承于WebRequest,并没有自己的构造函数,需通过WebRequest的Creat方法 建立,并进行强制的类型转换
HttpWebRequest httpReq = (HttpWebRequest)WebRequest.Create(httpURL);
//httpReq.Headers.Add("cityen", "tj");
///通过HttpWebRequest的GetResponse()方法建立HttpWebResponse,强制类型转换
HttpWebResponse httpResp = (HttpWebResponse)httpReq.GetResponse();
///GetResponseStream()方法获取HTTP响应的数据流,并尝试取得URL中所指定的网页内容
///若成功取得网页的内容,则以System.IO.Stream形式返回,若失败则产生ProtoclViolationException错 误。
System.IO.Stream respStream = httpResp.GetResponseStream();
///返回的内容是Stream形式的,所以可以利用StreamReader类获取GetResponseStream的内容
System.IO.StreamReader respStreamReader = new System.IO.StreamReader(respStream, Encoding.UTF8);
//从流的当前位置读取到结尾
string strBuff = respStreamReader.ReadToEnd();
//简单写法,跟上面的结果一样
//using (var sr = new System.IO.StreamReader(httpReq.GetResponse().GetResponseStream()))
//{
// var result = sr.ReadToEnd();
// Console.WriteLine("微信--" + DateTime.Now.ToString() + "--" + result);
//}
respStreamReader.Close();
respStream.Close();
return strBuff;
}
本文按位置坐标整理发布,希望对同学们有所帮助。更多详情请关注工作坐标编程语言C#.NET频道
本文由@Vivian 在该位置发表。未经许可禁止转载。
喜欢| 0
不喜欢| 0
看完这篇文章,你有什么感受?已有0人发表意见,0%喜欢分享给朋友~
c#抓取网页数据(一种基于C#抓取互联网公开数据的爬虫系统及抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-18 11:05
一种基于C#抓取互联网公共数据的爬虫系统及爬虫方法,属于数据领域采集;爬虫系统包括爬虫程序模块,爬虫程序模块用于浏览、爬取和验证数据Server,服务器数量至少为2台,其中部署有爬虫程序模块。目标站,爬虫程序模块对确定的目标站进行浏览抓取数据;非关系型数据库,表示非关系型数据库用于存储爬虫程序模块捕获的有效数据;它还包括第三方接口,用于外部验证码识别和破解程序模块。本发明专利技术描述的爬虫系统可以外接验证码识别破解程序模块,支持多种验证码破解,可以更好更快地访问目标站点。支持部署到多台服务器,降低服务器负载压力,运行、存储更多数据;支持NOSQL数据存储,读取速度大幅提升。
下载所有详细的技术数据
【技术实现步骤总结】
某种
本专利技术属于数据采集
,具体涉及一种爬取互联网公共数据的爬虫系统及方法。
技术介绍
网络爬虫是一种自动浏览互联网并按照一定规则自动抓取网页信息的程序或脚本。它是搜索引擎的重要组成部分。搜索引擎在实现网络爬虫的功能时,通常需要一个爬虫系统。完成。目前市场上的爬虫系统或框架大多采用Python、Java、PHPcrawer等技术。C#很少用于爬虫,C#爬虫系统也很少见,而且因为C#是面向对象的一种基于.NET Framework的高级编程语言,它可以让程序员快速编写基于MICROSOFT.NET平台的各种应用程序。如果你设计开发一个基于C#的爬虫系统来抓取互联网公共数据,将会大大提高程序员的
技术实现思路
本专利技术的目的是将Python、Java、PHPcrawer等现有技术中的爬虫系统应用到爬虫系统中。C#很少用于爬虫,影响了程序员编写基于MICROSOFT.NET平台的各种应用程序的效率。问题。为实现上述目的,本专利技术提供了一种基于C#抓取互联网公共数据的爬虫系统,包括:爬虫程序模块,用于浏览、抓取和验证数据的爬虫程序模块;server,服务器的数量至少两个,其中部署了爬虫程序模块;目标站,爬虫程序模块浏览并抓取确定的目标站的数据;非关系型数据库,其中非关系型数据库用于存储爬虫程序模块捕获的有效数据。优选地,还包括用于连接验证码识别破解程序模块的第三方接口,验证码识别破解程序模块可以识别和破解目标站的访问请求验证码。优选地,目标站点、非关系数据库和第三方接口也设置在至少两个服务器中。优选地,爬虫程序模块包括参数存储单元、目标站捕获单元、目标站分析判断单元、数据捕获单元和数据验证单元。参数存储单元存储参数,
优选地,所述数据采集单元与数据校验单元之间还设有数据转换单元,数据采集单元将采集到的数据输出至数据转换单元,由数据转换单元对数据进行转换。该单元使用正则表达式或Json序列化方法对数据进行过滤和提取,然后将数据输出到数据验证单元。优选地,所述数据抓取单元中设有数据分页判断模块,所述数据分页判断模块用于判断数据是否被分页,从而实现数据抓取单元抓取每页数据。优选地,非关系数据库是NoSQL。本专利技术所描述的爬虫系统与现有技术相比具有以下优点:基于C#抓取互联网公共数据,而不是Python、Java、PHPcrawer等技术,可以提高程序员编写基于MICROSOFT.NET的各种平台应用程序的工作效率;可连接验证码识别破解程序模块,支持多种验证码破解,可以更好更快的访问目标站;支持部署到多台服务器,降低服务器的负载压力,运行和存储更多的数据;支持NOSQL数据存储,读取速度大幅提升。本专利技术还提供了一种基于C#的互联网公共数据的抓取方法,包括上述基于C#的互联网公共数据的抓取系统,还包括以下步骤:S100、将爬虫程序模块部署到至少两台服务器上;S200,确定需要采集数据的目标站点,并准备数据请求参数;S300,使用c#语言模拟目标站的访问请求,捕获目标站的数据;S400、抓取到的数据使用正则表达式或Json序列化方法过滤提取;S500,验证抓取到的数据是否与参数匹配,看是否为有效数据;S600,将有效数据存储在非关系型数据库中。捕获的数据使用正则表达式或Json序列化方法过滤提取;S500,验证抓取到的数据是否与参数匹配,看是否为有效数据;S600,将有效数据存储在非关系型数据库中。捕获的数据使用正则表达式或Json序列化方法过滤提取;S500,验证抓取到的数据是否与参数匹配,看是否为有效数据;S600,将有效数据存储在非关系型数据库中。
优选地,步骤S300包括: S301、判断目标站接入请求是否需要验证验证码,如果验证码需要验证,则抓取请求验证码参数并调用破解验证码服务,然后添加破解结果 在访问请求中,捕获目标站的数据;S302,判断目标站的数据抓取是否成功,如果成功,则进入步骤S400;如果失败,则进入步骤S303;S303,将目标站的访问状态标记为Failed,当爬虫检测到目标站的访问状态失败时,需要重新模拟目标站访问请求来捕获目标站数据,即重复步骤S300,使用c#语言模拟目标站访问请求,然后进入步骤S301,直到判断出目标站,数据获取成功为止。优选地,步骤S400和S500包括寻呼判断,即判断目标站提取的数据是否有寻呼,如果有,则翻页,然后重复步骤S400;如果没有寻呼,则直接进入步骤S500。本专利技术所描述的爬取方法与现有技术相比具有以下优点:增加了重试机制,第一次数据爬取失败时,爬虫程序会自动重启;数据兼容性大大增强,提高数据质量;加强异常处理,提高资源利用率。附图说明图1。附图说明图1是本专利技术第一实施例的履带系统示意图;无花果。图2是本专利技术实施例二的抓取方法的步骤示意图。无花果。图3是专利技术实施例二抓取方法的流程示意图。
具体实施方式为使本专利技术的上述目的、特征和优点更加明显易懂,下面结合附图对本专利技术的具体实施例进行详细说明。第一实施例参考图1。1、本实施例介绍了一种基于C#抓取互联网公共数据的爬虫系统,包括:爬虫程序模块2,用于浏览、爬取和验证数据;服务器1,服务器1的数量至少为2个,其中部署爬虫程序模块2;目标站3,爬虫程序模块2对确定的目标站3进行浏览抓取数据;non-relational 非关系数据库4用于存储爬虫模块2抓取到的有效数据。具体来说,专利技术中描述的互联网公共数据爬虫系统的爬虫程序模块2是基于C#的,爬虫程序模块2可以是一个烧录爬虫程序的芯片,该芯片安装在至少两个的服务器。在图1中,优选地,爬虫程序模块2部署在每个服务器1中。爬虫程序模块2中目标站3的确定可以人为确定。例如,如果您想获取公司的商业登记信息,您可以到国家工商行政管理总局、当地工商行政管理总局、国家企业信用信息公示系统等相关信息查询。 . 但更优选地,爬虫程序模块2包括参数存储单元,目标站捕获单元、目标站分析判断单元、数据捕获单元和数据验证单元。参数存储单元存储参数,其输出端与目标站捕获单元的输入端相连,目标站捕获单元的输出端与目标站分析判断单元的输入端相连,目标站分析判定单元的输出端连接数据采集单元的输入端 数据采集单元的输出端连接数据校验单元的输入端,数据校验单元连接参数存储器数据校验单元的输出端连接非关系型数据库。目标站分析判断单元、数据采集单元和数据验证单元。参数存储单元存储参数,其输出端与目标站捕获单元的输入端相连,目标站捕获单元的输出端与目标站分析判断单元的输入端相连,目标站分析判定单元的输出端连接数据采集单元的输入端 数据采集单元的输出端连接数据校验单元的输入端,数据校验单元连接参数存储器数据校验单元的输出端连接非关系型数据库。目标站分析判断单元、数据采集单元和数据验证单元。参数存储单元存储参数,其输出端与目标站捕获单元的输入端相连,目标站捕获单元的输出端与目标站分析判断单元的输入端相连,目标站分析判定单元的输出端连接数据采集单元的输入端 数据采集单元的输出端连接数据校验单元的输入端,数据校验单元连接参数存储器数据校验单元的输出端连接非关系型数据库。数据采集单元和数据验证单元。参数存储单元存储参数,其输出端与目标站捕获单元的输入端相连,目标站捕获单元的输出端与目标站分析判断单元的输入端相连,目标站分析判定单元的输出端连接数据采集单元的输入端 数据采集单元的输出端连接数据校验单元的输入端,数据校验单元连接参数存储器数据校验单元的输出端连接非关系型数据库。数据采集单元和数据验证单元。参数存储单元存储参数,其输出端与目标站捕获单元的输入端相连,目标站捕获单元的输出端与目标站分析判断单元的输入端相连,目标站分析判定单元的输出端连接数据采集单元的输入端 数据采集单元的输出端连接数据校验单元的输入端,数据校验单元连接参数存储器数据校验单元的输出端连接非关系型数据库。
参数存储单元用于存储提取数据所需的数据请求参数,可根据实际情况进行设置。比如要抓取某公司的工商注册信息,可以设置相关参数为与,公司名称,公司所在省份的关系。这样,参数存储单元中存储的相关参数将是,公司名称:某公司,公司所在省份:上海,同时满足这两个参数。在其他实施例中,参数存储单元中的参数关系可以具有其他设置,例如OR关系。目标站抓取单元接收参数存储单元中的数据请求参数信息,
【技术保护点】
一种基于C#抓取互联网公共数据的爬虫系统,其特征在于包括: 用于浏览、抓取和验证数据的爬虫程序模块;服务器,所述服务器的数量至少为两个,其中部署有爬虫程序模块;目标站,爬虫程序模块浏览并抓取确定的目标站的数据;非关系型数据库,其中非关系型数据库用于存储爬虫程序模块获取的有效数据。
【技术特点摘要】
1. 一种基于C#抓取互联网公共数据的爬虫系统,其特征在于包括: 爬虫程序模块,所述爬虫程序模块用于浏览、抓取和验证数据;服务器,服务器数量至少为两台,其中部署有爬虫程序模块;目标站,爬虫程序模块在确定的目标站上浏览抓取数据;非关系型数据库,其中非关系型数据库用于存储爬虫程序模块捕获的有效数据。2.根据权利要求1所述的基于C#抓取互联网公共数据的爬虫系统,其特征在于还包括第三方接口外部验证码识别破解程序模块,所述验证码识别破解程序模块可以识别并破解目标站的访问请求验证码。3.根据权利要求2所述的基于C#抓取互联网公共数据的爬虫系统,其特征在于,所述目标站、非关系型数据库和第三方接口还设置在至少两个服务器中。4.根据权利要求1所述的基于C#抓取互联网公共数据的爬虫系统,其特征在于,所述爬虫程序模块包括:参数存储单元、目标站捕获单元、目标站分析判断单元、数据捕获单元,数据校验单元;参数存储单元存储参数,其输出端连接目标站捕获单元的输入端,目标站捕获单元的输出端连接目标站分析判断单元的输入端,目标站分析判断单元的输出端连接数据捕获单元的输入端,数据采集单元与数据校验单元的输入端相连,数据校验单元与参数存储单元相连,数据校验单元的输出端与非关系型数据库相连。5.根据权利要求4所述的基于C#抓取互联网公共数据的爬虫系统,其特征在于,数据转换单元和数据抓取单元将抓取到的数据输出给数据转换单元,数据通过数据转换单元使用正则表达式或Json序列化方法进行过滤提取,然后输出到数据校验单元。6.根据权利要求4所述的一种基于C#抓取互联网公共数据的爬虫系统,其特征在于,在数据抓取单元中...
【专利技术属性】
技术研发人员:王杰、王金虎、邓惠林、
申请人(专利权):,
类型:发明
国家省市:江苏,32
下载所有详细的技术资料 我是此专利的拥有者 查看全部
c#抓取网页数据(一种基于C#抓取互联网公开数据的爬虫系统及抓取方法)
一种基于C#抓取互联网公共数据的爬虫系统及爬虫方法,属于数据领域采集;爬虫系统包括爬虫程序模块,爬虫程序模块用于浏览、爬取和验证数据Server,服务器数量至少为2台,其中部署有爬虫程序模块。目标站,爬虫程序模块对确定的目标站进行浏览抓取数据;非关系型数据库,表示非关系型数据库用于存储爬虫程序模块捕获的有效数据;它还包括第三方接口,用于外部验证码识别和破解程序模块。本发明专利技术描述的爬虫系统可以外接验证码识别破解程序模块,支持多种验证码破解,可以更好更快地访问目标站点。支持部署到多台服务器,降低服务器负载压力,运行、存储更多数据;支持NOSQL数据存储,读取速度大幅提升。
下载所有详细的技术数据
【技术实现步骤总结】
某种
本专利技术属于数据采集
,具体涉及一种爬取互联网公共数据的爬虫系统及方法。
技术介绍
网络爬虫是一种自动浏览互联网并按照一定规则自动抓取网页信息的程序或脚本。它是搜索引擎的重要组成部分。搜索引擎在实现网络爬虫的功能时,通常需要一个爬虫系统。完成。目前市场上的爬虫系统或框架大多采用Python、Java、PHPcrawer等技术。C#很少用于爬虫,C#爬虫系统也很少见,而且因为C#是面向对象的一种基于.NET Framework的高级编程语言,它可以让程序员快速编写基于MICROSOFT.NET平台的各种应用程序。如果你设计开发一个基于C#的爬虫系统来抓取互联网公共数据,将会大大提高程序员的
技术实现思路
本专利技术的目的是将Python、Java、PHPcrawer等现有技术中的爬虫系统应用到爬虫系统中。C#很少用于爬虫,影响了程序员编写基于MICROSOFT.NET平台的各种应用程序的效率。问题。为实现上述目的,本专利技术提供了一种基于C#抓取互联网公共数据的爬虫系统,包括:爬虫程序模块,用于浏览、抓取和验证数据的爬虫程序模块;server,服务器的数量至少两个,其中部署了爬虫程序模块;目标站,爬虫程序模块浏览并抓取确定的目标站的数据;非关系型数据库,其中非关系型数据库用于存储爬虫程序模块捕获的有效数据。优选地,还包括用于连接验证码识别破解程序模块的第三方接口,验证码识别破解程序模块可以识别和破解目标站的访问请求验证码。优选地,目标站点、非关系数据库和第三方接口也设置在至少两个服务器中。优选地,爬虫程序模块包括参数存储单元、目标站捕获单元、目标站分析判断单元、数据捕获单元和数据验证单元。参数存储单元存储参数,
优选地,所述数据采集单元与数据校验单元之间还设有数据转换单元,数据采集单元将采集到的数据输出至数据转换单元,由数据转换单元对数据进行转换。该单元使用正则表达式或Json序列化方法对数据进行过滤和提取,然后将数据输出到数据验证单元。优选地,所述数据抓取单元中设有数据分页判断模块,所述数据分页判断模块用于判断数据是否被分页,从而实现数据抓取单元抓取每页数据。优选地,非关系数据库是NoSQL。本专利技术所描述的爬虫系统与现有技术相比具有以下优点:基于C#抓取互联网公共数据,而不是Python、Java、PHPcrawer等技术,可以提高程序员编写基于MICROSOFT.NET的各种平台应用程序的工作效率;可连接验证码识别破解程序模块,支持多种验证码破解,可以更好更快的访问目标站;支持部署到多台服务器,降低服务器的负载压力,运行和存储更多的数据;支持NOSQL数据存储,读取速度大幅提升。本专利技术还提供了一种基于C#的互联网公共数据的抓取方法,包括上述基于C#的互联网公共数据的抓取系统,还包括以下步骤:S100、将爬虫程序模块部署到至少两台服务器上;S200,确定需要采集数据的目标站点,并准备数据请求参数;S300,使用c#语言模拟目标站的访问请求,捕获目标站的数据;S400、抓取到的数据使用正则表达式或Json序列化方法过滤提取;S500,验证抓取到的数据是否与参数匹配,看是否为有效数据;S600,将有效数据存储在非关系型数据库中。捕获的数据使用正则表达式或Json序列化方法过滤提取;S500,验证抓取到的数据是否与参数匹配,看是否为有效数据;S600,将有效数据存储在非关系型数据库中。捕获的数据使用正则表达式或Json序列化方法过滤提取;S500,验证抓取到的数据是否与参数匹配,看是否为有效数据;S600,将有效数据存储在非关系型数据库中。
优选地,步骤S300包括: S301、判断目标站接入请求是否需要验证验证码,如果验证码需要验证,则抓取请求验证码参数并调用破解验证码服务,然后添加破解结果 在访问请求中,捕获目标站的数据;S302,判断目标站的数据抓取是否成功,如果成功,则进入步骤S400;如果失败,则进入步骤S303;S303,将目标站的访问状态标记为Failed,当爬虫检测到目标站的访问状态失败时,需要重新模拟目标站访问请求来捕获目标站数据,即重复步骤S300,使用c#语言模拟目标站访问请求,然后进入步骤S301,直到判断出目标站,数据获取成功为止。优选地,步骤S400和S500包括寻呼判断,即判断目标站提取的数据是否有寻呼,如果有,则翻页,然后重复步骤S400;如果没有寻呼,则直接进入步骤S500。本专利技术所描述的爬取方法与现有技术相比具有以下优点:增加了重试机制,第一次数据爬取失败时,爬虫程序会自动重启;数据兼容性大大增强,提高数据质量;加强异常处理,提高资源利用率。附图说明图1。附图说明图1是本专利技术第一实施例的履带系统示意图;无花果。图2是本专利技术实施例二的抓取方法的步骤示意图。无花果。图3是专利技术实施例二抓取方法的流程示意图。
具体实施方式为使本专利技术的上述目的、特征和优点更加明显易懂,下面结合附图对本专利技术的具体实施例进行详细说明。第一实施例参考图1。1、本实施例介绍了一种基于C#抓取互联网公共数据的爬虫系统,包括:爬虫程序模块2,用于浏览、爬取和验证数据;服务器1,服务器1的数量至少为2个,其中部署爬虫程序模块2;目标站3,爬虫程序模块2对确定的目标站3进行浏览抓取数据;non-relational 非关系数据库4用于存储爬虫模块2抓取到的有效数据。具体来说,专利技术中描述的互联网公共数据爬虫系统的爬虫程序模块2是基于C#的,爬虫程序模块2可以是一个烧录爬虫程序的芯片,该芯片安装在至少两个的服务器。在图1中,优选地,爬虫程序模块2部署在每个服务器1中。爬虫程序模块2中目标站3的确定可以人为确定。例如,如果您想获取公司的商业登记信息,您可以到国家工商行政管理总局、当地工商行政管理总局、国家企业信用信息公示系统等相关信息查询。 . 但更优选地,爬虫程序模块2包括参数存储单元,目标站捕获单元、目标站分析判断单元、数据捕获单元和数据验证单元。参数存储单元存储参数,其输出端与目标站捕获单元的输入端相连,目标站捕获单元的输出端与目标站分析判断单元的输入端相连,目标站分析判定单元的输出端连接数据采集单元的输入端 数据采集单元的输出端连接数据校验单元的输入端,数据校验单元连接参数存储器数据校验单元的输出端连接非关系型数据库。目标站分析判断单元、数据采集单元和数据验证单元。参数存储单元存储参数,其输出端与目标站捕获单元的输入端相连,目标站捕获单元的输出端与目标站分析判断单元的输入端相连,目标站分析判定单元的输出端连接数据采集单元的输入端 数据采集单元的输出端连接数据校验单元的输入端,数据校验单元连接参数存储器数据校验单元的输出端连接非关系型数据库。目标站分析判断单元、数据采集单元和数据验证单元。参数存储单元存储参数,其输出端与目标站捕获单元的输入端相连,目标站捕获单元的输出端与目标站分析判断单元的输入端相连,目标站分析判定单元的输出端连接数据采集单元的输入端 数据采集单元的输出端连接数据校验单元的输入端,数据校验单元连接参数存储器数据校验单元的输出端连接非关系型数据库。数据采集单元和数据验证单元。参数存储单元存储参数,其输出端与目标站捕获单元的输入端相连,目标站捕获单元的输出端与目标站分析判断单元的输入端相连,目标站分析判定单元的输出端连接数据采集单元的输入端 数据采集单元的输出端连接数据校验单元的输入端,数据校验单元连接参数存储器数据校验单元的输出端连接非关系型数据库。数据采集单元和数据验证单元。参数存储单元存储参数,其输出端与目标站捕获单元的输入端相连,目标站捕获单元的输出端与目标站分析判断单元的输入端相连,目标站分析判定单元的输出端连接数据采集单元的输入端 数据采集单元的输出端连接数据校验单元的输入端,数据校验单元连接参数存储器数据校验单元的输出端连接非关系型数据库。
参数存储单元用于存储提取数据所需的数据请求参数,可根据实际情况进行设置。比如要抓取某公司的工商注册信息,可以设置相关参数为与,公司名称,公司所在省份的关系。这样,参数存储单元中存储的相关参数将是,公司名称:某公司,公司所在省份:上海,同时满足这两个参数。在其他实施例中,参数存储单元中的参数关系可以具有其他设置,例如OR关系。目标站抓取单元接收参数存储单元中的数据请求参数信息,
【技术保护点】
一种基于C#抓取互联网公共数据的爬虫系统,其特征在于包括: 用于浏览、抓取和验证数据的爬虫程序模块;服务器,所述服务器的数量至少为两个,其中部署有爬虫程序模块;目标站,爬虫程序模块浏览并抓取确定的目标站的数据;非关系型数据库,其中非关系型数据库用于存储爬虫程序模块获取的有效数据。
【技术特点摘要】
1. 一种基于C#抓取互联网公共数据的爬虫系统,其特征在于包括: 爬虫程序模块,所述爬虫程序模块用于浏览、抓取和验证数据;服务器,服务器数量至少为两台,其中部署有爬虫程序模块;目标站,爬虫程序模块在确定的目标站上浏览抓取数据;非关系型数据库,其中非关系型数据库用于存储爬虫程序模块捕获的有效数据。2.根据权利要求1所述的基于C#抓取互联网公共数据的爬虫系统,其特征在于还包括第三方接口外部验证码识别破解程序模块,所述验证码识别破解程序模块可以识别并破解目标站的访问请求验证码。3.根据权利要求2所述的基于C#抓取互联网公共数据的爬虫系统,其特征在于,所述目标站、非关系型数据库和第三方接口还设置在至少两个服务器中。4.根据权利要求1所述的基于C#抓取互联网公共数据的爬虫系统,其特征在于,所述爬虫程序模块包括:参数存储单元、目标站捕获单元、目标站分析判断单元、数据捕获单元,数据校验单元;参数存储单元存储参数,其输出端连接目标站捕获单元的输入端,目标站捕获单元的输出端连接目标站分析判断单元的输入端,目标站分析判断单元的输出端连接数据捕获单元的输入端,数据采集单元与数据校验单元的输入端相连,数据校验单元与参数存储单元相连,数据校验单元的输出端与非关系型数据库相连。5.根据权利要求4所述的基于C#抓取互联网公共数据的爬虫系统,其特征在于,数据转换单元和数据抓取单元将抓取到的数据输出给数据转换单元,数据通过数据转换单元使用正则表达式或Json序列化方法进行过滤提取,然后输出到数据校验单元。6.根据权利要求4所述的一种基于C#抓取互联网公共数据的爬虫系统,其特征在于,在数据抓取单元中...
【专利技术属性】
技术研发人员:王杰、王金虎、邓惠林、
申请人(专利权):,
类型:发明
国家省市:江苏,32
下载所有详细的技术资料 我是此专利的拥有者
c#抓取网页数据(c#抓取网页数据一、二进制、不支持动态加载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-16 08:02
c#抓取网页数据一、小提示1.因为c#版本太高,c#4.2以上是不支持动态加载javaobject的所以要用javaobject3.xjsp2.c#抓取时需要引入ie浏览器集成库netframework4.需要jsp_connection3.windows.socket。windows的话runtime和自身的网络模块(fileinputstream)很多,其中fileinputstream在获取文件时就可以获取动态动态生成tcp连接,建议尽量使用windows提供的open和close方法,windows7和windows8如果没有自带open等方法也可以通过requestwindow()或fileinputstream来进行网络操作;android的socket有open等开始菜单,如果没有open方法也可以通过一个不需要运行的websocket进行操作;ie浏览器不是windowsserver。
网页抓取其实要用的的东西很多,从功能上也可以分几个类型,要熟悉清楚各自的关系,也就是响应类型,如果仅仅使用一个ie,也就是open方法,那么数据接收是xml文件,响应类型是fileinputstream,用户输入数据的方法appendfield(),参数就是要插入的内容,如果你只想抓取列表也就是java里面的object类型的数据,那么你需要使用它的insertitem()方法;jsp_connection,表示你需要往socket中写数据之后,等到结束以后,appendfield函数就会在socket里面写数据,这个时候这个函数就是你appendfield需要输入的响应值即可,也就是你输入的参数,如果遇到socket连接问题,大多都可以通过这种简单的方法解决;windows.socket,使用windows连接网络是要在windows下执行.netclr中间件monoidserver以及相关的参数(socket必须相同),windowssocket包括常见的requestwindow()和streaminputstream(),其中前两者用于将文件读取为数据文件传送;还可以用stdin和stdout;imagestream和aspectrunner都是将数据以二进制方式传输给system,使用bitset传输数据,主要方法就是读取或者输出;二、集成框架1.通过c#代码1.c#抓取网页是使用了两个模块,基于对socket的封装,以及使用qt中的open,close函数,在文件读取方面只需要简单的使用open或者close即可将网页解析为javaobject类型2.jsp页面抓取是通过一个coroutine来实现的,具体代码参考:3.openmonitor已经通过ie的方式封装成了javaobject类型,很方便通过openmonitor来解析出一个网页,具体代码有一个bspinfo.h:4.opentyperewindow()5.使用system.auto.open()封装一个面板会话,具体代码参考:if('monitor_open'insystem.integer.proto。 查看全部
c#抓取网页数据(c#抓取网页数据一、二进制、不支持动态加载)
c#抓取网页数据一、小提示1.因为c#版本太高,c#4.2以上是不支持动态加载javaobject的所以要用javaobject3.xjsp2.c#抓取时需要引入ie浏览器集成库netframework4.需要jsp_connection3.windows.socket。windows的话runtime和自身的网络模块(fileinputstream)很多,其中fileinputstream在获取文件时就可以获取动态动态生成tcp连接,建议尽量使用windows提供的open和close方法,windows7和windows8如果没有自带open等方法也可以通过requestwindow()或fileinputstream来进行网络操作;android的socket有open等开始菜单,如果没有open方法也可以通过一个不需要运行的websocket进行操作;ie浏览器不是windowsserver。
网页抓取其实要用的的东西很多,从功能上也可以分几个类型,要熟悉清楚各自的关系,也就是响应类型,如果仅仅使用一个ie,也就是open方法,那么数据接收是xml文件,响应类型是fileinputstream,用户输入数据的方法appendfield(),参数就是要插入的内容,如果你只想抓取列表也就是java里面的object类型的数据,那么你需要使用它的insertitem()方法;jsp_connection,表示你需要往socket中写数据之后,等到结束以后,appendfield函数就会在socket里面写数据,这个时候这个函数就是你appendfield需要输入的响应值即可,也就是你输入的参数,如果遇到socket连接问题,大多都可以通过这种简单的方法解决;windows.socket,使用windows连接网络是要在windows下执行.netclr中间件monoidserver以及相关的参数(socket必须相同),windowssocket包括常见的requestwindow()和streaminputstream(),其中前两者用于将文件读取为数据文件传送;还可以用stdin和stdout;imagestream和aspectrunner都是将数据以二进制方式传输给system,使用bitset传输数据,主要方法就是读取或者输出;二、集成框架1.通过c#代码1.c#抓取网页是使用了两个模块,基于对socket的封装,以及使用qt中的open,close函数,在文件读取方面只需要简单的使用open或者close即可将网页解析为javaobject类型2.jsp页面抓取是通过一个coroutine来实现的,具体代码参考:3.openmonitor已经通过ie的方式封装成了javaobject类型,很方便通过openmonitor来解析出一个网页,具体代码有一个bspinfo.h:4.opentyperewindow()5.使用system.auto.open()封装一个面板会话,具体代码参考:if('monitor_open'insystem.integer.proto。
c#抓取网页数据(本文介绍如何使用C#抓取网页上的图片资源。(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-09 14:06
本文介绍如何使用C#抓取网页上的图片资源。下面是一个简单的程序示例:
C#抓取网页资源
捕捉到的图片地址会以TXT文件的形式保存在软件目录下。
C#抓取网页资源
主要使用几个简单的方法来实现这个功能:
使用WebClient读取网页源码:
public String gethtml(String url)
{
try
{
WebClient MyWebClient = new WebClient();
MyWebClient.Credentials = CredentialCache.DefaultCredentials;//获取或设置用于向Internet资源的请求进行身份验证的网络凭据
Byte[] pageData = MyWebClient.DownloadData(url); //从指定网站下载数据
//string pageHtml = Encoding.Default.GetString(pageData); //如果获取网站页面采用的是GB2312,则使用这句
string pageHtml = Encoding.UTF8.GetString(pageData); //如果获取网站页面采用的是UTF-8,则使用这句
return pageHtml;
}
catch (WebException webEx)
{
return webEx.Message.ToString();
}
}
字符串的截取方法:
public String getstrmid(String str, string str1, string str2)
{
return str.Substring(str.IndexOf(str1) + str1.Length, str.IndexOf(str2) -str.IndexOf(str1) - str1.Length);
}
光有这些还不够,还需要用到正则匹配,因为正则规则是和网页内容相关的,所以正则规则就不在这里贴了。 查看全部
c#抓取网页数据(本文介绍如何使用C#抓取网页上的图片资源。(图))
本文介绍如何使用C#抓取网页上的图片资源。下面是一个简单的程序示例:
https://www.daimadog.com/wp-co ... 0.png 300w" />C#抓取网页资源
捕捉到的图片地址会以TXT文件的形式保存在软件目录下。
https://www.daimadog.com/wp-co ... 5.png 300w, https://www.daimadog.com/wp-co ... 1.png 768w" />C#抓取网页资源
主要使用几个简单的方法来实现这个功能:
使用WebClient读取网页源码:
public String gethtml(String url)
{
try
{
WebClient MyWebClient = new WebClient();
MyWebClient.Credentials = CredentialCache.DefaultCredentials;//获取或设置用于向Internet资源的请求进行身份验证的网络凭据
Byte[] pageData = MyWebClient.DownloadData(url); //从指定网站下载数据
//string pageHtml = Encoding.Default.GetString(pageData); //如果获取网站页面采用的是GB2312,则使用这句
string pageHtml = Encoding.UTF8.GetString(pageData); //如果获取网站页面采用的是UTF-8,则使用这句
return pageHtml;
}
catch (WebException webEx)
{
return webEx.Message.ToString();
}
}
字符串的截取方法:
public String getstrmid(String str, string str1, string str2)
{
return str.Substring(str.IndexOf(str1) + str1.Length, str.IndexOf(str2) -str.IndexOf(str1) - str1.Length);
}
光有这些还不够,还需要用到正则匹配,因为正则规则是和网页内容相关的,所以正则规则就不在这里贴了。
c#抓取网页数据(web项目中使用WebBrowser类--给网站抓图最近做一个WEB )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-08 23:05
)
使用系统;
调用方法
GatherPicg=newGatherPic("","E:/XXX"); g.start();
================================================ ==========
在web项目中使用WebBrowser类-----给网站拍照
最近做了一个WEB项目,需要一个程序可以抓取网页的功能。例如:在 test.aspx 页面上放置一个 TextBox 和一个 Button。 TextBox用于输入要抓取的网页地址,然后按下Button后,服务器会对之前输入的URL进行截图,然后显示出来。我把截图的业务逻辑做成了一个类:
using System;
using System.Data;
using System.Windows.Forms;
using System.Drawing;
///
/// WebSnap :网页抓图对象
///
public class WebSnap2
{
public WebSnap2()
{
//
// TODO: 在此处添加构造函数逻辑
//
}
///
/// 开始一个抓图并返回图象
///
/// 要抓取的网页地址
///
public Bitmap StartSnap(string Url)
{
WebBrowser myWB = this.GetPage(Url);
Bitmap returnValue = this.SnapWeb(myWB);
myWB.Dispose();
return returnValue;
}
private WebBrowser GetPage(string Url)
{
WebBrowser myWB = new WebBrowser();
myWB.ScrollBarsEnabled = false;
myWB.Navigate(Url);
while (myWB.ReadyState != WebBrowserReadyState.Complete)
{
System.Windows.Forms.Application.DoEvents();
}
return myWB;
}
private Bitmap SnapWeb(WebBrowser wb)
{
HtmlDocument hd = wb.Document;
int height = Convert.ToInt32(hd.Body.GetAttribute("scrollHeight")) + 10;
int width = Convert.ToInt32(hd.Body.GetAttribute("scrollWidth")) + 10;
wb.Height = height;
wb.Width = width;
Bitmap bmp = new Bitmap(width, height);
Rectangle rec = new Rectangle();
rec.Width = width;
rec.Height = height;
wb.DrawToBitmap(bmp, rec);
return bmp;
}
}
然后在test.asp的button_click事件里面调用:
WebSnap ws = new WebSnap();
Bitmap bmp= ws.StartSnap(TextBox1.Text);
System.IO.MemoryStream ms = new System.IO.MemoryStream();
bmp.Save(ms, System.Drawing.Imaging.ImageFormat.Jpeg);
Response.BinaryWrite(ms.GetBuffer()); 查看全部
c#抓取网页数据(web项目中使用WebBrowser类--给网站抓图最近做一个WEB
)
使用系统;
调用方法
GatherPicg=newGatherPic("","E:/XXX"); g.start();
================================================ ==========
在web项目中使用WebBrowser类-----给网站拍照
最近做了一个WEB项目,需要一个程序可以抓取网页的功能。例如:在 test.aspx 页面上放置一个 TextBox 和一个 Button。 TextBox用于输入要抓取的网页地址,然后按下Button后,服务器会对之前输入的URL进行截图,然后显示出来。我把截图的业务逻辑做成了一个类:
using System;
using System.Data;
using System.Windows.Forms;
using System.Drawing;
///
/// WebSnap :网页抓图对象
///
public class WebSnap2
{
public WebSnap2()
{
//
// TODO: 在此处添加构造函数逻辑
//
}
///
/// 开始一个抓图并返回图象
///
/// 要抓取的网页地址
///
public Bitmap StartSnap(string Url)
{
WebBrowser myWB = this.GetPage(Url);
Bitmap returnValue = this.SnapWeb(myWB);
myWB.Dispose();
return returnValue;
}
private WebBrowser GetPage(string Url)
{
WebBrowser myWB = new WebBrowser();
myWB.ScrollBarsEnabled = false;
myWB.Navigate(Url);
while (myWB.ReadyState != WebBrowserReadyState.Complete)
{
System.Windows.Forms.Application.DoEvents();
}
return myWB;
}
private Bitmap SnapWeb(WebBrowser wb)
{
HtmlDocument hd = wb.Document;
int height = Convert.ToInt32(hd.Body.GetAttribute("scrollHeight")) + 10;
int width = Convert.ToInt32(hd.Body.GetAttribute("scrollWidth")) + 10;
wb.Height = height;
wb.Width = width;
Bitmap bmp = new Bitmap(width, height);
Rectangle rec = new Rectangle();
rec.Width = width;
rec.Height = height;
wb.DrawToBitmap(bmp, rec);
return bmp;
}
}
然后在test.asp的button_click事件里面调用:
WebSnap ws = new WebSnap();
Bitmap bmp= ws.StartSnap(TextBox1.Text);
System.IO.MemoryStream ms = new System.IO.MemoryStream();
bmp.Save(ms, System.Drawing.Imaging.ImageFormat.Jpeg);
Response.BinaryWrite(ms.GetBuffer());
c#抓取网页数据( c#入门经典路上如何去抓取html网页数据?坐标整理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-11-08 16:16
c#入门经典路上如何去抓取html网页数据?坐标整理)
c#入门经典:如何抓取html网页数据?
小标2018-05-18 来源:阅读858条评论0
总结:在学习c#入门经典的路上,今天教大家如何抓取html网页数据,让大家更好的学习。希望你能在c#入门经典的旅程中走得更远。
在你学习c#入门经典的路上,今天教你如何抓取html网页数据,让你更好的学习。希望你能在c#入门经典的旅程中走得更远。
//方法一
using System.Text.RegularExpressions;
public static void webClientMethod1()
{
WebClient wc = new WebClient();
wc.Encoding = Encoding.UTF8;
//以字符串的形式返回数据
string html = wc.DownloadString("https://www.baidu.com/");
//以正则表达式的形式匹配到字符串网页中想要的数据
MatchCollection matches = Regex.Matches(html, "(.*)");
//依次取得匹配到的数据
foreach (Match item in matches)
{
Console.WriteLine(item.Groups[1].Value);
}
Console.ReadKey();
}
//方法二
public static string SendRequest()
{
string url = "https://www.baidu.com/";
Uri httpURL = new Uri(url);
///HttpWebRequest类继承于WebRequest,并没有自己的构造函数,需通过WebRequest的Creat方法 建立,并进行强制的类型转换
HttpWebRequest httpReq = (HttpWebRequest)WebRequest.Create(httpURL);
//httpReq.Headers.Add("cityen", "tj");
///通过HttpWebRequest的GetResponse()方法建立HttpWebResponse,强制类型转换
HttpWebResponse httpResp = (HttpWebResponse)httpReq.GetResponse();
///GetResponseStream()方法获取HTTP响应的数据流,并尝试取得URL中所指定的网页内容
///若成功取得网页的内容,则以System.IO.Stream形式返回,若失败则产生ProtoclViolationException错 误。
System.IO.Stream respStream = httpResp.GetResponseStream();
///返回的内容是Stream形式的,所以可以利用StreamReader类获取GetResponseStream的内容
System.IO.StreamReader respStreamReader = new System.IO.StreamReader(respStream, Encoding.UTF8);
//从流的当前位置读取到结尾
string strBuff = respStreamReader.ReadToEnd();
//简单写法,跟上面的结果一样
//using (var sr = new System.IO.StreamReader(httpReq.GetResponse().GetResponseStream()))
//{
// var result = sr.ReadToEnd();
// Console.WriteLine("微信--" + DateTime.Now.ToString() + "--" + result);
//}
respStreamReader.Close();
respStream.Close();
return strBuff;
}
本文由詹总整理出版。更多资讯请关注展总编程语言C#.NET频道!
本文由@小标发表于工作坐标。未经许可禁止转载。
喜欢 | 0
不喜欢 | 0
看完这篇文章,你感觉如何?已有0人发表意见,0%喜欢分享给朋友~ 查看全部
c#抓取网页数据(
c#入门经典路上如何去抓取html网页数据?坐标整理)
c#入门经典:如何抓取html网页数据?
小标2018-05-18 来源:阅读858条评论0
总结:在学习c#入门经典的路上,今天教大家如何抓取html网页数据,让大家更好的学习。希望你能在c#入门经典的旅程中走得更远。
在你学习c#入门经典的路上,今天教你如何抓取html网页数据,让你更好的学习。希望你能在c#入门经典的旅程中走得更远。
//方法一
using System.Text.RegularExpressions;
public static void webClientMethod1()
{
WebClient wc = new WebClient();
wc.Encoding = Encoding.UTF8;
//以字符串的形式返回数据
string html = wc.DownloadString("https://www.baidu.com/";);
//以正则表达式的形式匹配到字符串网页中想要的数据
MatchCollection matches = Regex.Matches(html, "(.*)");
//依次取得匹配到的数据
foreach (Match item in matches)
{
Console.WriteLine(item.Groups[1].Value);
}
Console.ReadKey();
}
//方法二
public static string SendRequest()
{
string url = "https://www.baidu.com/";
Uri httpURL = new Uri(url);
///HttpWebRequest类继承于WebRequest,并没有自己的构造函数,需通过WebRequest的Creat方法 建立,并进行强制的类型转换
HttpWebRequest httpReq = (HttpWebRequest)WebRequest.Create(httpURL);
//httpReq.Headers.Add("cityen", "tj");
///通过HttpWebRequest的GetResponse()方法建立HttpWebResponse,强制类型转换
HttpWebResponse httpResp = (HttpWebResponse)httpReq.GetResponse();
///GetResponseStream()方法获取HTTP响应的数据流,并尝试取得URL中所指定的网页内容
///若成功取得网页的内容,则以System.IO.Stream形式返回,若失败则产生ProtoclViolationException错 误。
System.IO.Stream respStream = httpResp.GetResponseStream();
///返回的内容是Stream形式的,所以可以利用StreamReader类获取GetResponseStream的内容
System.IO.StreamReader respStreamReader = new System.IO.StreamReader(respStream, Encoding.UTF8);
//从流的当前位置读取到结尾
string strBuff = respStreamReader.ReadToEnd();
//简单写法,跟上面的结果一样
//using (var sr = new System.IO.StreamReader(httpReq.GetResponse().GetResponseStream()))
//{
// var result = sr.ReadToEnd();
// Console.WriteLine("微信--" + DateTime.Now.ToString() + "--" + result);
//}
respStreamReader.Close();
respStream.Close();
return strBuff;
}
本文由詹总整理出版。更多资讯请关注展总编程语言C#.NET频道!
本文由@小标发表于工作坐标。未经许可禁止转载。
喜欢 | 0
不喜欢 | 0
看完这篇文章,你感觉如何?已有0人发表意见,0%喜欢分享给朋友~
c#抓取网页数据(C#源码500份作者:技术小美3635人(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-08 16:11
阿里云>云栖社区>主题图>C>c#网页抓取数据库
推荐活动:
更多优惠>
当前主题:c#抓取网页中的数据库并添加到采集夹
相关话题:
c# 爬取网页中数据库相关的博客 查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
C#抓取网页程序的实现分析
作者:zting科技698人浏览评论:04年前
C#爬取网页程序是如何实现的?我们先来了解一下,在 HTTP 中,它是 WWW 中最基本的数据访问协议之一。.NET的基本类型库类中提供了两个对象类:HTTPWebRequest和HTTPWebResponse,用于向某个资源发送请求和获取资源。回复。为了获得资源
阅读全文
C#源代码500份
作者:小美科技 3635人浏览评论:14年前
C 夏普短信发送平台源码。Rar ASP.NET+AJAX基础实例视频教程 C# Winform qq弹窗 360弹窗
阅读全文
C#源代码500份
作者:蓬莱闲鱼2601人浏览评论:08年前
C 夏普短信发送平台源码。Rar ASP.NET+AJAX基础实例视频教程 C# Winform qq弹窗 360弹窗
阅读全文
c#批量抓取免费代理并验证其有效性
作者:曹章林 1170人浏览评论:03年前
在刷新一次页面之前,我在一家公司的官方网站上看到了文章 的页面浏览量。给人的感觉不是很好。一个公司的官网就给人这么直接的漏洞。批量发起请求时,发现页面打开报错。一个100多人的公司官网文章刷新了一次,你给我看了这个。这家公司之前来过我们学校宣传招聘+我在花园里找招聘的时候找到了住处
阅读全文
C#实现图标批量下载
作者:gisweis1079 人浏览评论:05年前
这篇文章有点长,花了几个晚上的时间编辑修改。如果文字和排版有问题,请谅解。本文分为四部分,以下是主要内容,也是软件开发的基本过程。阶段描述需求分析主要描述了程序的目的和需求的分析,即为什么要花时间写,需要什么功能等;方案设计基于现有要求,
阅读全文
关于爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站(转)
作者:朱老教授 1373人浏览评论:04年前
抓取网页的一般逻辑和过程一般是针对普通用户,使用浏览器打开某个网址,然后浏览器就可以显示出相应页面的内容。这个过程如果用程序代码实现,就可以调用(用程序实现)爬取(网页内容,进行后处理,提取需要的信息等)。对应的英文是,网站
阅读全文
Scrapy爬虫成长日记将爬取的内容写入mysql数据库
作者:呵呵 99251585人浏览评论:03年前
我尝试scrapy抓取博客园的博客(可以查看scrapy爬虫成长日记的创建项目-提取数据-以json格式保存数据),但是之前抓取的数据是以json格式保存为文本的文件。这显然不能满足我们日常的实际应用。接下来我们看看如何将抓取到的内容保存在一个普通的m中
阅读全文
Scrapy爬虫成长日记将爬取的内容写入mysql数据库
作者:无声胜有生 732人浏览评论:06年前
我尝试scrapy抓取博客园的博客(可以查看scrapy爬虫成长日记的创建项目-提取数据-以json格式保存数据),但是之前抓取的数据是以json格式保存为文本的文件。这显然不能满足我们日常的实际应用。接下来我们来看看常见的抓取内容的保存方式
阅读全文
c#爬取网页中数据库相关的问答
【Javascript学习全家桶】934道javascript热点题,阿里巴巴100位技术专家答疑解惑
作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你困惑只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来云栖为您解答技术问题。他们使用自己手中的技术来帮助用户成长。本次活动邀请数百位阿里巴巴技术
阅读全文 查看全部
c#抓取网页数据(C#源码500份作者:技术小美3635人(组图))
阿里云>云栖社区>主题图>C>c#网页抓取数据库
推荐活动:
更多优惠>
当前主题:c#抓取网页中的数据库并添加到采集夹
相关话题:
c# 爬取网页中数据库相关的博客 查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
C#抓取网页程序的实现分析
作者:zting科技698人浏览评论:04年前
C#爬取网页程序是如何实现的?我们先来了解一下,在 HTTP 中,它是 WWW 中最基本的数据访问协议之一。.NET的基本类型库类中提供了两个对象类:HTTPWebRequest和HTTPWebResponse,用于向某个资源发送请求和获取资源。回复。为了获得资源
阅读全文
C#源代码500份
作者:小美科技 3635人浏览评论:14年前
C 夏普短信发送平台源码。Rar ASP.NET+AJAX基础实例视频教程 C# Winform qq弹窗 360弹窗
阅读全文
C#源代码500份
作者:蓬莱闲鱼2601人浏览评论:08年前
C 夏普短信发送平台源码。Rar ASP.NET+AJAX基础实例视频教程 C# Winform qq弹窗 360弹窗
阅读全文
c#批量抓取免费代理并验证其有效性
作者:曹章林 1170人浏览评论:03年前
在刷新一次页面之前,我在一家公司的官方网站上看到了文章 的页面浏览量。给人的感觉不是很好。一个公司的官网就给人这么直接的漏洞。批量发起请求时,发现页面打开报错。一个100多人的公司官网文章刷新了一次,你给我看了这个。这家公司之前来过我们学校宣传招聘+我在花园里找招聘的时候找到了住处
阅读全文
C#实现图标批量下载
作者:gisweis1079 人浏览评论:05年前
这篇文章有点长,花了几个晚上的时间编辑修改。如果文字和排版有问题,请谅解。本文分为四部分,以下是主要内容,也是软件开发的基本过程。阶段描述需求分析主要描述了程序的目的和需求的分析,即为什么要花时间写,需要什么功能等;方案设计基于现有要求,
阅读全文
关于爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站(转)
作者:朱老教授 1373人浏览评论:04年前
抓取网页的一般逻辑和过程一般是针对普通用户,使用浏览器打开某个网址,然后浏览器就可以显示出相应页面的内容。这个过程如果用程序代码实现,就可以调用(用程序实现)爬取(网页内容,进行后处理,提取需要的信息等)。对应的英文是,网站
阅读全文
Scrapy爬虫成长日记将爬取的内容写入mysql数据库
作者:呵呵 99251585人浏览评论:03年前
我尝试scrapy抓取博客园的博客(可以查看scrapy爬虫成长日记的创建项目-提取数据-以json格式保存数据),但是之前抓取的数据是以json格式保存为文本的文件。这显然不能满足我们日常的实际应用。接下来我们看看如何将抓取到的内容保存在一个普通的m中
阅读全文
Scrapy爬虫成长日记将爬取的内容写入mysql数据库
作者:无声胜有生 732人浏览评论:06年前
我尝试scrapy抓取博客园的博客(可以查看scrapy爬虫成长日记的创建项目-提取数据-以json格式保存数据),但是之前抓取的数据是以json格式保存为文本的文件。这显然不能满足我们日常的实际应用。接下来我们来看看常见的抓取内容的保存方式
阅读全文
c#爬取网页中数据库相关的问答
【Javascript学习全家桶】934道javascript热点题,阿里巴巴100位技术专家答疑解惑
作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你困惑只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来云栖为您解答技术问题。他们使用自己手中的技术来帮助用户成长。本次活动邀请数百位阿里巴巴技术
阅读全文
c#抓取网页数据(1.网络爬虫的基础知识,发送Http请求的方法(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-07 20:14
)
一时兴起,感觉有时候在网页上保存资源很麻烦。有没有办法输入一个网址,批量抓取对应的资源?
需要思考的问题:
1.如何获取网页url的html源代码?
2.如何在浩瀚的html中匹配所需的资源地址?
3.如何根据获取到的资源地址批量下载资源?
4. 下载的资源一般是文件流。如何生成并保存指定的资源类型?
需要掌握的知识:
1.网络爬虫基础知识,发送Http请求的方法
2.C#正则表达式的使用,主要是识别html中需要的rul URLs
3.UnityWebRequest 文件流下载
4.C#基本文件操作如File类和Stream类
实施了以下子项:
这里不介绍爬虫。互联网上其他地方有很多信息。简而言之,就是采集网页信息和数据的程序。
第一步是发送一个Web请求,也可以说是一个Http请求。
这与打开浏览器输入url地址然后回车的效果基本类似。网页之所以能够显示正确的信息和数据,是因为每个网页都有对应的html源代码,像很多浏览器一样,比如谷歌浏览器就支持查看网页源代码的功能。比如下面是我经常去的喵窝首页的html部分:
在html源代码中,可以查看当前网页的大量隐藏信息和数据,包括大量的资源链接和样式表。值得注意的是,html源代码只有在网页完全加载后才能显示和查看,这意味着一个URL地址的web请求响应成功;当然在成功的情况下会有各种失败,比如我们经常输入rul地址后出现404提示。这是 Http 请求出错的情况。404 表示服务器没有找到请求的网页。还有许多其他类型的错误。为什么要理解这个,因为发送完Http请求后,要找到处理错误的方法或者跳过下一个任务。
我们可以通过多种方式发送Http请求,Unity也更新了web请求的方式:(以后直接截图代码,这个插入代码的功能不能自动排序,真的很不爽)
使用的主要类是UnityWebRequest,类似于之前Unity中的WWW类,主要用于文件的下载和上传。
引入以下命名空间:
UnityAction 作为参数主要用于请求结束后自动返回一个html源代码。它本质上是一个通用委托:
泛型参数可以从无到多,是一个很有用的类(尤其是在协程的回调中,可以很方便的延迟参数传递)
当然,除了Unity内置的发送web请求的方法,C#还封装了几个类,你可以随便挑一个使用,比如HttpWebRequest、WebClient、HttpClient等:
例如:
如果通过web请求成功获取到指定url地址的html源代码,则可以进行下一步。
第二步,采集html中需要的数据信息。在这个例子中,图片的链接地址是从源代码中找到的。
例如,可能有以下几种情况:
总结一下,首先使用html的常用标签
来找大部分图片,但还是有一些图片不在这些标签中。有时,即使在
标签中的图片地址在内部链接和外部链接之间可能仍然不同。如果使用外部链接,可以直接作为合法的url地址执行,但是如果是内部链接,则必须填写域名地址,所以我们还是需要想办法识别一个正确的域名网址。
关于如何识别和匹配上面提到的字符串内容,目前最有效的方法是正则表达式。本例中需要用到的正则表达式如下:
1.匹配url域名地址:
private const string URLRealmCheck = @"(http|https)://()?(\w+(\.)?)+";
2.匹配url地址:
private const string URLStringCheck = @"((http|https)://)(([a-zA-Z0-9\._-]+\.[a-zA-Z]{2,6})|( [0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}))(: [0-9]{1,4})*(/[a-zA-Z0-9\&%_\./-~-]*)?";
3.匹配html
标签中的url地址:(不区分大小写,分组
是需要的url地址)
私有常量字符串 imgLableCheck = @"
]*?\bsrc[\s\t\r\n]*=[\s\t\r\n]*[""\']?[\s\t\r\n]*(?
[^\s\t\r\n""\']*)[^]*?/?[\s\t\r\n]*>";
4. 匹配html中标签中href属性的url地址:(不区分大小写,主要用于深度检索,需要的url地址在分组中)
private const string hrefLinkCheck = @"(?i)]*?href=([\'""]?)(?!javascript|__doPostBack)(?[^\'""\s*#]+)[^> ]*>";
5. 指定图片类型匹配:(主要用于外链)
私有常量字符串 jpg = @"\.jpg";
私有常量字符串 png = @"\.png";
关于正则表达式的具体匹配用法,网上也有很多教程,这里就不赘述了。
给定一个html源码,下面从两个方向匹配图片,首先匹配外部链接,这里指定匹配的文件类型:
以下是内链匹配,必须先匹配域名地址:
有了域名地址后,就可以轻松匹配内链地址:
正则表达式的使用需要引入以下命名空间:
将所有的imgLinks与正则表达式匹配后,就可以依次下载图片了。
第三步,下载并传输有效的图片url:
您也可以同步下载和传输这些 URL,但这可能需要额外的最大线程数,并且更难以控制整体下载进度。
具体传输协议如下:
值得注意的是,Complete方法不是只有在下载成功时才调用,即使出现错误也需要调用,避免出现错误时自动下载自动终止的情况。正常情况下,即使发生错误,下一个文件的下载任务也会被跳过。
最后一步是将下载的数据文件流转换为指定类型的文件并保存。这里有很多方法,下面提供了其中一种:
扩张:
有时单个html中的所有图片链接并不能完全满足我们的需求,因为html中的子链接中也可能有需要的URL资源地址。这时候可以考虑加入更深的遍历。然后需要先匹配html中的链接地址,然后获取链接地址的子html源码,这样就进行了深度匹配的循环。
可以通过查找标签属性href 来匹配html 中的子链接。上面已经给出了这个属性的正则匹配表达式。这里只提供一层深度匹配供参考:
测试:这里我们使用深度匹配,抓取jpg格式的妙我首页图片链接,下载,保存到D盘。(UI随心所欲,不用管)
查看全部
c#抓取网页数据(1.网络爬虫的基础知识,发送Http请求的方法(图)
)
一时兴起,感觉有时候在网页上保存资源很麻烦。有没有办法输入一个网址,批量抓取对应的资源?
需要思考的问题:
1.如何获取网页url的html源代码?
2.如何在浩瀚的html中匹配所需的资源地址?
3.如何根据获取到的资源地址批量下载资源?
4. 下载的资源一般是文件流。如何生成并保存指定的资源类型?
需要掌握的知识:
1.网络爬虫基础知识,发送Http请求的方法
2.C#正则表达式的使用,主要是识别html中需要的rul URLs
3.UnityWebRequest 文件流下载
4.C#基本文件操作如File类和Stream类
实施了以下子项:
这里不介绍爬虫。互联网上其他地方有很多信息。简而言之,就是采集网页信息和数据的程序。
第一步是发送一个Web请求,也可以说是一个Http请求。
这与打开浏览器输入url地址然后回车的效果基本类似。网页之所以能够显示正确的信息和数据,是因为每个网页都有对应的html源代码,像很多浏览器一样,比如谷歌浏览器就支持查看网页源代码的功能。比如下面是我经常去的喵窝首页的html部分:
在html源代码中,可以查看当前网页的大量隐藏信息和数据,包括大量的资源链接和样式表。值得注意的是,html源代码只有在网页完全加载后才能显示和查看,这意味着一个URL地址的web请求响应成功;当然在成功的情况下会有各种失败,比如我们经常输入rul地址后出现404提示。这是 Http 请求出错的情况。404 表示服务器没有找到请求的网页。还有许多其他类型的错误。为什么要理解这个,因为发送完Http请求后,要找到处理错误的方法或者跳过下一个任务。
我们可以通过多种方式发送Http请求,Unity也更新了web请求的方式:(以后直接截图代码,这个插入代码的功能不能自动排序,真的很不爽)
使用的主要类是UnityWebRequest,类似于之前Unity中的WWW类,主要用于文件的下载和上传。
引入以下命名空间:
UnityAction 作为参数主要用于请求结束后自动返回一个html源代码。它本质上是一个通用委托:
泛型参数可以从无到多,是一个很有用的类(尤其是在协程的回调中,可以很方便的延迟参数传递)
当然,除了Unity内置的发送web请求的方法,C#还封装了几个类,你可以随便挑一个使用,比如HttpWebRequest、WebClient、HttpClient等:
例如:
如果通过web请求成功获取到指定url地址的html源代码,则可以进行下一步。
第二步,采集html中需要的数据信息。在这个例子中,图片的链接地址是从源代码中找到的。
例如,可能有以下几种情况:
总结一下,首先使用html的常用标签
来找大部分图片,但还是有一些图片不在这些标签中。有时,即使在
标签中的图片地址在内部链接和外部链接之间可能仍然不同。如果使用外部链接,可以直接作为合法的url地址执行,但是如果是内部链接,则必须填写域名地址,所以我们还是需要想办法识别一个正确的域名网址。
关于如何识别和匹配上面提到的字符串内容,目前最有效的方法是正则表达式。本例中需要用到的正则表达式如下:
1.匹配url域名地址:
private const string URLRealmCheck = @"(http|https)://()?(\w+(\.)?)+";
2.匹配url地址:
private const string URLStringCheck = @"((http|https)://)(([a-zA-Z0-9\._-]+\.[a-zA-Z]{2,6})|( [0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}))(: [0-9]{1,4})*(/[a-zA-Z0-9\&%_\./-~-]*)?";
3.匹配html
标签中的url地址:(不区分大小写,分组
是需要的url地址)
私有常量字符串 imgLableCheck = @"
]*?\bsrc[\s\t\r\n]*=[\s\t\r\n]*[""\']?[\s\t\r\n]*(?
[^\s\t\r\n""\']*)[^]*?/?[\s\t\r\n]*>";
4. 匹配html中标签中href属性的url地址:(不区分大小写,主要用于深度检索,需要的url地址在分组中)
private const string hrefLinkCheck = @"(?i)]*?href=([\'""]?)(?!javascript|__doPostBack)(?[^\'""\s*#]+)[^> ]*>";
5. 指定图片类型匹配:(主要用于外链)
私有常量字符串 jpg = @"\.jpg";
私有常量字符串 png = @"\.png";
关于正则表达式的具体匹配用法,网上也有很多教程,这里就不赘述了。
给定一个html源码,下面从两个方向匹配图片,首先匹配外部链接,这里指定匹配的文件类型:
以下是内链匹配,必须先匹配域名地址:
有了域名地址后,就可以轻松匹配内链地址:
正则表达式的使用需要引入以下命名空间:
将所有的imgLinks与正则表达式匹配后,就可以依次下载图片了。
第三步,下载并传输有效的图片url:
您也可以同步下载和传输这些 URL,但这可能需要额外的最大线程数,并且更难以控制整体下载进度。
具体传输协议如下:
值得注意的是,Complete方法不是只有在下载成功时才调用,即使出现错误也需要调用,避免出现错误时自动下载自动终止的情况。正常情况下,即使发生错误,下一个文件的下载任务也会被跳过。
最后一步是将下载的数据文件流转换为指定类型的文件并保存。这里有很多方法,下面提供了其中一种:
扩张:
有时单个html中的所有图片链接并不能完全满足我们的需求,因为html中的子链接中也可能有需要的URL资源地址。这时候可以考虑加入更深的遍历。然后需要先匹配html中的链接地址,然后获取链接地址的子html源码,这样就进行了深度匹配的循环。
可以通过查找标签属性href 来匹配html 中的子链接。上面已经给出了这个属性的正则匹配表达式。这里只提供一层深度匹配供参考:
测试:这里我们使用深度匹配,抓取jpg格式的妙我首页图片链接,下载,保存到D盘。(UI随心所欲,不用管)
c#抓取网页数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-07 20:13
在众多行业中,需要对行业数据进行分类汇总,及时对行业数据进行分析,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候,可能都无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我们将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只有采集当前页面的数据,还有分页的数据,这里就不解释了,只是一个提示,大家可以用多线程采集所有页面的当前数据,一个采集当前页面数据和一个翻页动作可以通过线程完成采集所有数据。
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据存储起来,方便我们接下来的数据查询操作。 查看全部
c#抓取网页数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
在众多行业中,需要对行业数据进行分类汇总,及时对行业数据进行分析,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候,可能都无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我们将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只有采集当前页面的数据,还有分页的数据,这里就不解释了,只是一个提示,大家可以用多线程采集所有页面的当前数据,一个采集当前页面数据和一个翻页动作可以通过线程完成采集所有数据。
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据存储起来,方便我们接下来的数据查询操作。
c#抓取网页数据(c#抓取网页数据到本地使用c#写接口的功能介绍及相关api)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-11-07 20:06
c#抓取网页数据到本地使用c#写接口接口的功能介绍及相关api文档github:codelover/codecandidate本文基于codeforces2017数据库链接介绍如何发布接口,带有简要注释:由于我最近天天晚上在上课,码代码抓取的时间少,现在只能随便讲下json的格式,至于怎么读出来可以查json文档//更多接口的功能请查看官方帮助文档在c#调用接口的代码如下c#codeconfig。
config"transport=port=9216"参数默认为当前tcp/ipv4端口(9216),端口号默认为"9216",我们已经配置json发布接口的功能必须满足这个参数才能调用在本地写这个codeconfig需要执行:jsonlisten("localhost","9216")这句命令是用来获取域名下80端口分配给接口codeconfig的端口号,写json不一定要jsonlisten,一般我们都写这个//调用demo接口默认端口在:9216jsonconfig::codeconfig(newjsonconfigconfig::config){configconf=config。
getconfig();//获取json信息configconf->set[jsonconnection_host]=system。authorization。ssl;//获取webpack配置[config。build。plugin:'ejscontainer/ejs']configconf->set[jsonconnection_timeout]="3000";//配置文件,默认80端口configconf->set[jsonconnection_path]="/";//获取本地cookie,默认cookie_maxs=400//返回webpack配置[webpack]configconf->set[jsonconnection_timeout]=3000;configconf->set[jsonconnection_uri]={"***/catalog":"/catalog/***","***/models":["models"]}}}//代码:codeconfig。
config"transport=port=9216"//外网传输参数codeconfig。config"transport=port=9216"//解析json参数codeconfig。config"transport=port=9216"//从外网读json参数codeconfig。config"transport=port=9216"//渲染json参数的get请求参数codeconfig。
config"transport=port='9216'"//->发布接口codeconfig。config"transport=port=9216"//->配置json的合法性codeconfig。config"transport=port=9216"//->解析httpconfig中的authorization参数codeconfig。
config"transport=http。'https'"//执行get请求:console。log(config。getuserinfo('query'))//发布接口jsonstunneljsmds1简易教程_20150816_51zhibai/iconfont-imagesgithub:codelover/codejsmds在解析下json文件:codeconfig。c。 查看全部
c#抓取网页数据(c#抓取网页数据到本地使用c#写接口的功能介绍及相关api)
c#抓取网页数据到本地使用c#写接口接口的功能介绍及相关api文档github:codelover/codecandidate本文基于codeforces2017数据库链接介绍如何发布接口,带有简要注释:由于我最近天天晚上在上课,码代码抓取的时间少,现在只能随便讲下json的格式,至于怎么读出来可以查json文档//更多接口的功能请查看官方帮助文档在c#调用接口的代码如下c#codeconfig。
config"transport=port=9216"参数默认为当前tcp/ipv4端口(9216),端口号默认为"9216",我们已经配置json发布接口的功能必须满足这个参数才能调用在本地写这个codeconfig需要执行:jsonlisten("localhost","9216")这句命令是用来获取域名下80端口分配给接口codeconfig的端口号,写json不一定要jsonlisten,一般我们都写这个//调用demo接口默认端口在:9216jsonconfig::codeconfig(newjsonconfigconfig::config){configconf=config。
getconfig();//获取json信息configconf->set[jsonconnection_host]=system。authorization。ssl;//获取webpack配置[config。build。plugin:'ejscontainer/ejs']configconf->set[jsonconnection_timeout]="3000";//配置文件,默认80端口configconf->set[jsonconnection_path]="/";//获取本地cookie,默认cookie_maxs=400//返回webpack配置[webpack]configconf->set[jsonconnection_timeout]=3000;configconf->set[jsonconnection_uri]={"***/catalog":"/catalog/***","***/models":["models"]}}}//代码:codeconfig。
config"transport=port=9216"//外网传输参数codeconfig。config"transport=port=9216"//解析json参数codeconfig。config"transport=port=9216"//从外网读json参数codeconfig。config"transport=port=9216"//渲染json参数的get请求参数codeconfig。
config"transport=port='9216'"//->发布接口codeconfig。config"transport=port=9216"//->配置json的合法性codeconfig。config"transport=port=9216"//->解析httpconfig中的authorization参数codeconfig。
config"transport=http。'https'"//执行get请求:console。log(config。getuserinfo('query'))//发布接口jsonstunneljsmds1简易教程_20150816_51zhibai/iconfont-imagesgithub:codelover/codejsmds在解析下json文件:codeconfig。c。
c#抓取网页数据(使用C#登陆带用户名和密码的网站,并获得网页源码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-06 08:20
)
诚恳请教C#登录网站获取网页和链接网页数据。使用C#以用户名密码登录网站,获取网页源代码;这个问题已经解决了!部分代码如下:
关键是这个登录网站有很多链接,我想得到这些链接页面(即子页面)的源码,怎么做?
感谢您的帮助!我哥有急事!
//获取数据时调用
privatevoidgetPage(Stringurl,StringparamList)
{
HttpWebRequestreq=(HttpWebRequest)WebRequest.Create(url);
req.Method="POST";
req.KeepAlive=true;
req.ContentType="application/x-www-form-urlencoded";
CookieContainercookieCon=newCookieContainer();
req.CookieContainer=cookieCon;
stringcookieheader=req.CookieContainer.GetCookieHeader(newUri(url));
req.CookieContainer.SetCookies(newUri(url),cookieheader);
byte[]SomeBytes=Encoding.UTF8.GetBytes(paramList);
req.ContentLength=SomeBytes.Length;
StreamnewStream=req.GetRequestStream();
newStream.Write(SomeBytes,0,SomeBytes.Length);
newStream.Close();
HttpWebResponseres=(HttpWebResponse)req.GetResponse();
StreamReceiveStream=res.GetResponseStream();
byte[]buffer=newbyte[1024];
stringfilename=@"c:\1\source.html";
StreamoutStream=File.Create(filename);
国际;
做
{
l=ReceiveStream.Read(buffer,0,buffer.Length);
if(l>0)
outStream.Write(buffer,0,l);
}while(l>0);
outStream.Close();
}
--------------------编程问答--------------------请求子页面时,附加 Cookie
....
CookieContainercookieCon=newCookieContainer();
cookieCon.SetCookies(newUri(url),"与 Url 关联的 Cookie 字符串");
req.CookieContainer=cookieCon;
--------------------编程问答--------------------
HttpWebResponse res = (HttpWebResponse)req.GetResponse(); <br />
Stream ReceiveStream = res.GetResponseStream(); <br />
StreamReader reader=new StreamReader(ReceiveStream);//套接StreamReader <br />
String source=reader.ReadToEnd();//一次读取所有相应内容<br />
............<br />
<br />
Stream outStream = File.Create(filename); <br />
StreamWriter writer=new StreamWriter(outStream);//套接StreamWriter<br />
writer.Write(source);//将读取到的内容一次写入文件<br />
outStream.Close();<br />
writer.Close();
这似乎比你的更有效率。
--------------------编程问答--------------------关注。帮顶一次! --------------------编程问答--------------------叮叮更健康---- - ---------------编程问答--------------------引用3楼gisfarmer的回复:注意。一次!
补充:.NET技术 , C# 查看全部
c#抓取网页数据(使用C#登陆带用户名和密码的网站,并获得网页源码
)
诚恳请教C#登录网站获取网页和链接网页数据。使用C#以用户名密码登录网站,获取网页源代码;这个问题已经解决了!部分代码如下:
关键是这个登录网站有很多链接,我想得到这些链接页面(即子页面)的源码,怎么做?
感谢您的帮助!我哥有急事!
//获取数据时调用
privatevoidgetPage(Stringurl,StringparamList)
{
HttpWebRequestreq=(HttpWebRequest)WebRequest.Create(url);
req.Method="POST";
req.KeepAlive=true;
req.ContentType="application/x-www-form-urlencoded";
CookieContainercookieCon=newCookieContainer();
req.CookieContainer=cookieCon;
stringcookieheader=req.CookieContainer.GetCookieHeader(newUri(url));
req.CookieContainer.SetCookies(newUri(url),cookieheader);
byte[]SomeBytes=Encoding.UTF8.GetBytes(paramList);
req.ContentLength=SomeBytes.Length;
StreamnewStream=req.GetRequestStream();
newStream.Write(SomeBytes,0,SomeBytes.Length);
newStream.Close();
HttpWebResponseres=(HttpWebResponse)req.GetResponse();
StreamReceiveStream=res.GetResponseStream();
byte[]buffer=newbyte[1024];
stringfilename=@"c:\1\source.html";
StreamoutStream=File.Create(filename);
国际;
做
{
l=ReceiveStream.Read(buffer,0,buffer.Length);
if(l>0)
outStream.Write(buffer,0,l);
}while(l>0);
outStream.Close();
}
--------------------编程问答--------------------请求子页面时,附加 Cookie
....
CookieContainercookieCon=newCookieContainer();
cookieCon.SetCookies(newUri(url),"与 Url 关联的 Cookie 字符串");
req.CookieContainer=cookieCon;
--------------------编程问答--------------------
HttpWebResponse res = (HttpWebResponse)req.GetResponse(); <br />
Stream ReceiveStream = res.GetResponseStream(); <br />
StreamReader reader=new StreamReader(ReceiveStream);//套接StreamReader <br />
String source=reader.ReadToEnd();//一次读取所有相应内容<br />
............<br />
<br />
Stream outStream = File.Create(filename); <br />
StreamWriter writer=new StreamWriter(outStream);//套接StreamWriter<br />
writer.Write(source);//将读取到的内容一次写入文件<br />
outStream.Close();<br />
writer.Close();
这似乎比你的更有效率。
--------------------编程问答--------------------关注。帮顶一次! --------------------编程问答--------------------叮叮更健康---- - ---------------编程问答--------------------引用3楼gisfarmer的回复:注意。一次!
补充:.NET技术 , C#
c#抓取网页数据(嵌入式应用的专栏文章(一)——c#抓取网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-06 03:00
c#抓取网页数据,android抓取safari网页,python抓取腾讯新闻各种数据,php抓取腾讯新闻、天天快报各种数据,java抓取本地网页数据,c语言抓取网页数据,c++抓取本地网页数据,go语言抓取互联网各种服务器数据,javascript抓取浏览器各种数据。
社会学,统计学,计算机网络技术,
hadoop
嵌入式专业啊嵌入式对程序语言要求比较高,硬件方面的专业知识比较突出。我就是学嵌入式的。
java语言知识,数据库操作,数据结构,linux系统等等吧,推荐看下我关于嵌入式应用的专栏文章。
嵌入式软件,最近开始做自己嵌入式系统,对学习嵌入式软件的有些了解。自己做的嵌入式系统是针对嵌入式手机和基于安卓平台的rtos以及rtlinux操作系统,关于硬件主要涉及ddr2ram32g双色温a2芯片,需要学习iic,spi,uart,at&t接口,can模块等等。关于软件方面是编译原理和linux系统编程等。
数据结构与算法不清楚,但python好像在某种程度上有些帮助,那些说java的那你让学java的情何以堪。python的gui做的还是比较方便的。
机械专业?理论上对编程要求不高,因为现在做嵌入式的一般都还处于扩招的过程,不算饱和,之前有个学长本科是机械的,考研之后过了线上一个调剂。要说编程人才,对大部分单位来说,说是需要,但是肯定不是全部。对于成熟项目,算法的开发工作优先于上手写代码。现在嵌入式系统,做的比较好的有点也就华为中兴酷派。做的不错的:阿里云里面的边云,西门子,大疆,一小部分研究所,小公司还有一些传统大厂也有做嵌入式的,但还不算多。
非程序员行业,想要做嵌入式,我觉得还是非常有竞争力的。除非你的资源和各种人脉特别强或者非常牛,这种算跨行,嵌入式在机械这种传统行业行不通。 查看全部
c#抓取网页数据(嵌入式应用的专栏文章(一)——c#抓取网页数据)
c#抓取网页数据,android抓取safari网页,python抓取腾讯新闻各种数据,php抓取腾讯新闻、天天快报各种数据,java抓取本地网页数据,c语言抓取网页数据,c++抓取本地网页数据,go语言抓取互联网各种服务器数据,javascript抓取浏览器各种数据。
社会学,统计学,计算机网络技术,
hadoop
嵌入式专业啊嵌入式对程序语言要求比较高,硬件方面的专业知识比较突出。我就是学嵌入式的。
java语言知识,数据库操作,数据结构,linux系统等等吧,推荐看下我关于嵌入式应用的专栏文章。
嵌入式软件,最近开始做自己嵌入式系统,对学习嵌入式软件的有些了解。自己做的嵌入式系统是针对嵌入式手机和基于安卓平台的rtos以及rtlinux操作系统,关于硬件主要涉及ddr2ram32g双色温a2芯片,需要学习iic,spi,uart,at&t接口,can模块等等。关于软件方面是编译原理和linux系统编程等。
数据结构与算法不清楚,但python好像在某种程度上有些帮助,那些说java的那你让学java的情何以堪。python的gui做的还是比较方便的。
机械专业?理论上对编程要求不高,因为现在做嵌入式的一般都还处于扩招的过程,不算饱和,之前有个学长本科是机械的,考研之后过了线上一个调剂。要说编程人才,对大部分单位来说,说是需要,但是肯定不是全部。对于成熟项目,算法的开发工作优先于上手写代码。现在嵌入式系统,做的比较好的有点也就华为中兴酷派。做的不错的:阿里云里面的边云,西门子,大疆,一小部分研究所,小公司还有一些传统大厂也有做嵌入式的,但还不算多。
非程序员行业,想要做嵌入式,我觉得还是非常有竞争力的。除非你的资源和各种人脉特别强或者非常牛,这种算跨行,嵌入式在机械这种传统行业行不通。
c#抓取网页数据(一个+jsou提取网页数据的分类汇总(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-11-04 00:13
原文链接
在众多行业中,需要对行业数据进行分类汇总,及时对行业数据进行分析,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们要获取的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只有采集当前页面的数据,还有分页的数据,这里就不解释了,只是一个提示,大家可以用多线程采集所有页面的当前数据,通过线程一个采集当前页面数据,一个翻页动作,可以采集完成所有数据。
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据存储起来,方便我们接下来的数据查询操作。 查看全部
c#抓取网页数据(一个+jsou提取网页数据的分类汇总(一))
原文链接
在众多行业中,需要对行业数据进行分类汇总,及时对行业数据进行分析,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们要获取的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只有采集当前页面的数据,还有分页的数据,这里就不解释了,只是一个提示,大家可以用多线程采集所有页面的当前数据,通过线程一个采集当前页面数据,一个翻页动作,可以采集完成所有数据。
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据存储起来,方便我们接下来的数据查询操作。
c#抓取网页数据(封装一个简单总结(一):抓取网页文档分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-03 18:15
)
这两天学习了爬虫的基础知识,这里简单总结一下。
获取的网页商品数据保存在Excel表格中,效果如下:
使用Jumony Core引擎,是一个非常强大且近乎完美的HTML解析引擎,支持css3选择器,直接抓取网页文档进行分析,并根据HTTP头自动识别。
一个抓取博客园站点导航顶部信息的例子:
var documents = new JumonyParser().LoadDocument("http://www.cnblogs.com/").Find("#site_nav_top").FirstOrDefault();
太强大了。如果您熟悉 CSS,则无需手动编写大量可读性差的正则表达式来匹配和获取数据。
封装一个简单的操作库:
public class BaseAnalyzer
{
///
/// 根据Url加载html文档对象
///
///
///
protected virtual IHtmlDocument LoadDocument(string url)
{
return new JumonyParser().LoadDocument(url);
}
///
/// 查询指定url中指定选择器的元素集
///
///
///
///
protected virtual List QueryHtmlElements(string url, string selector, Func predicate = null)
{
var elementsCollection = new List();
IEnumerable elements = LoadDocument(url).Find(selector);
if (predicate != null)
{
elements = elements.Where(predicate);
}
if (elements != null)
elementsCollection.AddRange(elements);
return elementsCollection;
}
///
/// 分析Html文档,获取指定元素集第一个元素的文本内容
///
/// html文档对象
/// 选择器
/// 文本内容
protected virtual string GetFirstElementText(IHtmlContainer html, string selector)
{
var findList = html.Find(selector);
var result = findList.FirstOrDefault();
return result == null ? string.Empty : result.InnerText();
}
///
/// 分析Html文档,获取指定元素集的文本内容
///
/// html文档对象
/// 选择器
/// 自定义处理获取到的元素集,若没有,就返回第一个元素的文本内容
///
protected virtual string GetElementsText(IHtmlContainer html, string selector, Func func)
{
var findList = html.Find(selector);
if (func != null)
return func(findList);
return GetFirstElementText(html, selector);
}
}
获取产品名称的示例:
private ProductInfo AnalyzeProductInfo(string detailUrl)
{
var product = new ProductInfo();
//详情页html文档对象
var html = LoadDocument(detailUrl);
product.ProductName = GetFirstElementText(html, ".goods_particulars h1");
} 查看全部
c#抓取网页数据(封装一个简单总结(一):抓取网页文档分析
)
这两天学习了爬虫的基础知识,这里简单总结一下。
获取的网页商品数据保存在Excel表格中,效果如下:
使用Jumony Core引擎,是一个非常强大且近乎完美的HTML解析引擎,支持css3选择器,直接抓取网页文档进行分析,并根据HTTP头自动识别。
一个抓取博客园站点导航顶部信息的例子:
var documents = new JumonyParser().LoadDocument("http://www.cnblogs.com/";).Find("#site_nav_top").FirstOrDefault();
太强大了。如果您熟悉 CSS,则无需手动编写大量可读性差的正则表达式来匹配和获取数据。
封装一个简单的操作库:
public class BaseAnalyzer
{
///
/// 根据Url加载html文档对象
///
///
///
protected virtual IHtmlDocument LoadDocument(string url)
{
return new JumonyParser().LoadDocument(url);
}
///
/// 查询指定url中指定选择器的元素集
///
///
///
///
protected virtual List QueryHtmlElements(string url, string selector, Func predicate = null)
{
var elementsCollection = new List();
IEnumerable elements = LoadDocument(url).Find(selector);
if (predicate != null)
{
elements = elements.Where(predicate);
}
if (elements != null)
elementsCollection.AddRange(elements);
return elementsCollection;
}
///
/// 分析Html文档,获取指定元素集第一个元素的文本内容
///
/// html文档对象
/// 选择器
/// 文本内容
protected virtual string GetFirstElementText(IHtmlContainer html, string selector)
{
var findList = html.Find(selector);
var result = findList.FirstOrDefault();
return result == null ? string.Empty : result.InnerText();
}
///
/// 分析Html文档,获取指定元素集的文本内容
///
/// html文档对象
/// 选择器
/// 自定义处理获取到的元素集,若没有,就返回第一个元素的文本内容
///
protected virtual string GetElementsText(IHtmlContainer html, string selector, Func func)
{
var findList = html.Find(selector);
if (func != null)
return func(findList);
return GetFirstElementText(html, selector);
}
}
获取产品名称的示例:
private ProductInfo AnalyzeProductInfo(string detailUrl)
{
var product = new ProductInfo();
//详情页html文档对象
var html = LoadDocument(detailUrl);
product.ProductName = GetFirstElementText(html, ".goods_particulars h1");
}
c#抓取网页数据(c#抓取网页数据_包vue抓取抓取抓取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-03 14:04
c#抓取网页数据_包vue抓取网页数据—vuejs-railsphp抓取网页数据--数据库—数据库-ajax等每个平台都是不一样的,所以我一般分享的是我常用的一些抓取方法。
首先要明白http请求是个什么样的过程,了解了请求的每个流程,才能更好地了解,才能做到从容不迫,这就不需要多说了,网上有很多文章介绍过,找对你心中所需即可。
requestheadersresponse格式
难道不是找几篇文章看看就知道的吗。
首先,抓包有两个概念:手机js代码抓包和串口控制抓包。js代码抓包在手机上有,在服务器端没有。串口控制抓包现在很少见了,有的话也只是用于判断目标网站是哪个js代码。至于说js代码抓包,那就很多了。最重要的抓包工具,或者说主要的是抓包工具:android/ios/webserver,除了python有一个专门的json.parse库外,其它语言都有json.parse。
在json中是没有string之类的字符串数据类型的。java/javascript各种语言的解析库,特别是java语言的nio解释器也有android和ios版本。还有嵌入式linux上的,有boost。这几个平台上还有通过wireshark进行抓包。安卓平台上,有xbench。
python写爬虫已经一大堆了,可以下一些linuxshell脚本试试。抓包需要一些代码,但编写一个抓包的脚本真的太容易了,相对python其他库就容易多了。 查看全部
c#抓取网页数据(c#抓取网页数据_包vue抓取抓取抓取数据)
c#抓取网页数据_包vue抓取网页数据—vuejs-railsphp抓取网页数据--数据库—数据库-ajax等每个平台都是不一样的,所以我一般分享的是我常用的一些抓取方法。
首先要明白http请求是个什么样的过程,了解了请求的每个流程,才能更好地了解,才能做到从容不迫,这就不需要多说了,网上有很多文章介绍过,找对你心中所需即可。
requestheadersresponse格式
难道不是找几篇文章看看就知道的吗。
首先,抓包有两个概念:手机js代码抓包和串口控制抓包。js代码抓包在手机上有,在服务器端没有。串口控制抓包现在很少见了,有的话也只是用于判断目标网站是哪个js代码。至于说js代码抓包,那就很多了。最重要的抓包工具,或者说主要的是抓包工具:android/ios/webserver,除了python有一个专门的json.parse库外,其它语言都有json.parse。
在json中是没有string之类的字符串数据类型的。java/javascript各种语言的解析库,特别是java语言的nio解释器也有android和ios版本。还有嵌入式linux上的,有boost。这几个平台上还有通过wireshark进行抓包。安卓平台上,有xbench。
python写爬虫已经一大堆了,可以下一些linuxshell脚本试试。抓包需要一些代码,但编写一个抓包的脚本真的太容易了,相对python其他库就容易多了。
c#抓取网页数据(开发数据采集程序的时候需要清楚的几个基本流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 586 次浏览 • 2021-11-03 09:32
首先大家要清楚:网站的任何页面,无论是php、jsp、aspx等动态页面,还是后台程序生成的静态页面,都可以在浏览器。
所以当你要开发数据采集程序时,首先要了解网站你试图采集的首页结构(HTML)。
一旦您非常熟悉网站 中需要采集 数据的HTML 源文件的内容,程序的其余部分就很容易处理了。因为C#在网站上执行数据采集,原理是“下载你要采集的页面的HTML源文件,分析HTML代码然后抓取你需要的数据,最后将数据保存到本地文件”。
基本流程如下图所示:
1.页面源文件下载
首先引用 System.Net 命名空间
using System.Net;
还需要引用
using System.Text;
using System.IO;
引用后实例化一个 WebClient 对象
private WebClient wc = new WebClient();
调用 DownloadData 方法从指定网页的源文件中下载一组 BYTE 数据,然后将 BYTE 数组转换为字符串。
//下载页面源文件并将其转换成UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData(string.Format("你要采集的网页地址")));
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
//下载网页源文件到本地
wc.DownloadFile("你要采集的网页URL","保存源文件的本地文件路径");
//读取下载下来的源文件HTML格式的字符串
string mainData = File.ReadAllText("保存源文件的本地文件路径",Encoding.UTF8);
通过网页HTML格式字符串,您可以分析网页采集,抓取您需要的内容。
2.页面分析采集
页面分析就是将网页源文件中某个特定的或唯一的字符(字符串)作为抓点,并以此抓点为起点,截取你想要的页面上的数据。
以博客园为专栏。比如我要在博客园首页列出文章的标题和链接,就必须用“
<p>//以" 查看全部
c#抓取网页数据(开发数据采集程序的时候需要清楚的几个基本流程)
首先大家要清楚:网站的任何页面,无论是php、jsp、aspx等动态页面,还是后台程序生成的静态页面,都可以在浏览器。
所以当你要开发数据采集程序时,首先要了解网站你试图采集的首页结构(HTML)。
一旦您非常熟悉网站 中需要采集 数据的HTML 源文件的内容,程序的其余部分就很容易处理了。因为C#在网站上执行数据采集,原理是“下载你要采集的页面的HTML源文件,分析HTML代码然后抓取你需要的数据,最后将数据保存到本地文件”。
基本流程如下图所示:
1.页面源文件下载
首先引用 System.Net 命名空间
using System.Net;
还需要引用
using System.Text;
using System.IO;
引用后实例化一个 WebClient 对象
private WebClient wc = new WebClient();
调用 DownloadData 方法从指定网页的源文件中下载一组 BYTE 数据,然后将 BYTE 数组转换为字符串。
//下载页面源文件并将其转换成UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData(string.Format("你要采集的网页地址")));
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
//下载网页源文件到本地
wc.DownloadFile("你要采集的网页URL","保存源文件的本地文件路径");
//读取下载下来的源文件HTML格式的字符串
string mainData = File.ReadAllText("保存源文件的本地文件路径",Encoding.UTF8);
通过网页HTML格式字符串,您可以分析网页采集,抓取您需要的内容。
2.页面分析采集
页面分析就是将网页源文件中某个特定的或唯一的字符(字符串)作为抓点,并以此抓点为起点,截取你想要的页面上的数据。
以博客园为专栏。比如我要在博客园首页列出文章的标题和链接,就必须用“
<p>//以"

