
c#抓取网页数据
c#抓取网页数据(开心网教你如何使用GET方法应该算是最简单,最好操作的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-06 10:15
)
为了简单实现,其他请求信息,如HEAD中的用户浏览器信息,将不附加。
一、使用GET方法
使用 GET 方法应该被认为是最简单和最好的操作。以开心网的用户主页为例,URL统一为:.其中 xxxxxxxx 代表用户的用户 ID。在用户首页,GET方法中,当没有添加其他请求数据时,请求会被重定向到开心网的登录页面。
新建一个控制台,编写GET方法的代码如下:
因为你没有登录,所以可以看到输出页面是登录页面的HTML源码:
二、使用POST方式抓取页面
POST方法与GET方法类似,只是Method方法重置为“POST”,将要POST的数据编码为Byte[]格式,然后设置长度。在请求之前,首先获取HTTPWebRequest的请求流,写入POST数据,然后执行请求。示例如下:
注意:以上请找一个可以通过POST验证的URL进行抓取。
注意POST的时候一定要加上以下代码,否则服务器将无法获取到POST数据
req.ContentType="application/x-www-form-urlencoded";
三、爬取所需的登录页面
其实不管是通过SESSION认证还是通过COOKIE认证,都必须使用请求中相关COOKIE的值。要获取cookie值,必须先用浏览器登录,然后查看登录时必须使用的cookie。比如没有ID的开心网个人主页。爬行。
如果不添加COOKIE,则捕获的HTML是重定向的HTML,即登录页面的HTML。示例代码如下:
由于COOKIE涉及个人隐私,对COOKIE的字符进行了修改。如果有朋友需要使用,请自行登录,登录后查找COOKIE的价值。
运行界面如下:
查看全部
c#抓取网页数据(开心网教你如何使用GET方法应该算是最简单,最好操作的
)
为了简单实现,其他请求信息,如HEAD中的用户浏览器信息,将不附加。
一、使用GET方法
使用 GET 方法应该被认为是最简单和最好的操作。以开心网的用户主页为例,URL统一为:.其中 xxxxxxxx 代表用户的用户 ID。在用户首页,GET方法中,当没有添加其他请求数据时,请求会被重定向到开心网的登录页面。
新建一个控制台,编写GET方法的代码如下:
因为你没有登录,所以可以看到输出页面是登录页面的HTML源码:

二、使用POST方式抓取页面
POST方法与GET方法类似,只是Method方法重置为“POST”,将要POST的数据编码为Byte[]格式,然后设置长度。在请求之前,首先获取HTTPWebRequest的请求流,写入POST数据,然后执行请求。示例如下:
注意:以上请找一个可以通过POST验证的URL进行抓取。
注意POST的时候一定要加上以下代码,否则服务器将无法获取到POST数据
req.ContentType="application/x-www-form-urlencoded";
三、爬取所需的登录页面
其实不管是通过SESSION认证还是通过COOKIE认证,都必须使用请求中相关COOKIE的值。要获取cookie值,必须先用浏览器登录,然后查看登录时必须使用的cookie。比如没有ID的开心网个人主页。爬行。
如果不添加COOKIE,则捕获的HTML是重定向的HTML,即登录页面的HTML。示例代码如下:
由于COOKIE涉及个人隐私,对COOKIE的字符进行了修改。如果有朋友需要使用,请自行登录,登录后查找COOKIE的价值。
运行界面如下:

c#抓取网页数据(获取网页数据有很多种方式-获取网页内容获取方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-03-06 01:03
)
获取网页数据的方法有很多。这里主要介绍通过WebClient、WebBrowser和HttpWebRequest/HttpWebResponse三种方式获取网页内容。
这里得到的是包括网页在内的所有信息。如果你只是需要一些数据内容。您可以使用自己的构造函数来识别和删除它们!一般的做法是根据源代码的格式过滤掉你需要的内容。
一、通过WebClient获取网页内容
这是一种很简单的获取方式,当然其他的获取方式也很简单。这里首先要注意的是,如果考虑实际项目的效率,需要考虑在函数中分配内存区域。大致写成如下
//MemoryStream是一个支持储存区为内存的流。
byte[] buffer = new byte[1024];
using (MemoryStream memory = new MemoryStream())
{
int index = 1, sum = 0;
while (index * sum < 100 * 1024)
{
index = reader.Read(buffer, 0, 1024);
if (index > 0)
{
memory.Write(buffer, 0, index);
sum += index;
}
}
//网页通常使用utf-8或gb2412进行编码
Encoding.GetEncoding("gb2312").GetString(memory.ToArray());
if (string.IsNullOrEmpty(html))
{
return html;
}
else
{
Regex re = new Regex(@"charset=(? charset[/s/S]*?)[ |']");
Match m = re.Match(html.ToLower());
encoding = m.Groups[charset].ToString();
}
if (string.IsNullOrEmpty(encoding) || string.Equals(encoding.ToLower(), "gb2312"))
{
return html;
}
}
好了,现在进入正题,WebClient获取网页数据的代码如下
//using System.IO;
try
{
WebClient webClient = new WebClient();
webClient.Credentials = CredentialCache.DefaultCredentials;//获取或设置用于向Internet资源的请求进行身份验证的网络凭据
Byte[] pageData = webClient.DownloadData("http://www.360doc.com/content/ ... 6quot;);
//string pageHtml = Encoding.Default.GetString(pageData); //如果获取网站页面采用的是GB2312,则使用这句
string pageHtml = Encoding.UTF8.GetString(pageData); //如果获取网站页面采用的是UTF-8,则使用这句
using (StreamWriter sw = new StreamWriter("e:\\ouput.txt"))//将获取的内容写入文本
{
htm = sw.ToString();//测试StreamWriter流的输出状态,非必须
sw.Write(pageHtml);
}
}
catch (WebException webEx)
{
Console.W
}
二、通过WebBrowser控件获取网页内容
相对来说,这是最简单的获取方式。将 WebBrowser 控件拖入其中并匹配以下代码
WebBrowser web = new WebBrowser();
web.Navigate("http://www.163.com");
web.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(web_DocumentCompleted);
void web_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
{
WebBrowser web = (WebBrowser)sender;
HtmlElementCollection ElementCollection = web.Document.GetElementsByTagName("Table");
foreach (HtmlElement item in ElementCollection)
{
File.AppendAllText("Kaijiang_xj.txt", item.InnerText);
}
} 查看全部
c#抓取网页数据(获取网页数据有很多种方式-获取网页内容获取方法
)
获取网页数据的方法有很多。这里主要介绍通过WebClient、WebBrowser和HttpWebRequest/HttpWebResponse三种方式获取网页内容。
这里得到的是包括网页在内的所有信息。如果你只是需要一些数据内容。您可以使用自己的构造函数来识别和删除它们!一般的做法是根据源代码的格式过滤掉你需要的内容。
一、通过WebClient获取网页内容
这是一种很简单的获取方式,当然其他的获取方式也很简单。这里首先要注意的是,如果考虑实际项目的效率,需要考虑在函数中分配内存区域。大致写成如下
//MemoryStream是一个支持储存区为内存的流。
byte[] buffer = new byte[1024];
using (MemoryStream memory = new MemoryStream())
{
int index = 1, sum = 0;
while (index * sum < 100 * 1024)
{
index = reader.Read(buffer, 0, 1024);
if (index > 0)
{
memory.Write(buffer, 0, index);
sum += index;
}
}
//网页通常使用utf-8或gb2412进行编码
Encoding.GetEncoding("gb2312").GetString(memory.ToArray());
if (string.IsNullOrEmpty(html))
{
return html;
}
else
{
Regex re = new Regex(@"charset=(? charset[/s/S]*?)[ |']");
Match m = re.Match(html.ToLower());
encoding = m.Groups[charset].ToString();
}
if (string.IsNullOrEmpty(encoding) || string.Equals(encoding.ToLower(), "gb2312"))
{
return html;
}
}
好了,现在进入正题,WebClient获取网页数据的代码如下
//using System.IO;
try
{
WebClient webClient = new WebClient();
webClient.Credentials = CredentialCache.DefaultCredentials;//获取或设置用于向Internet资源的请求进行身份验证的网络凭据
Byte[] pageData = webClient.DownloadData("http://www.360doc.com/content/ ... 6quot;);
//string pageHtml = Encoding.Default.GetString(pageData); //如果获取网站页面采用的是GB2312,则使用这句
string pageHtml = Encoding.UTF8.GetString(pageData); //如果获取网站页面采用的是UTF-8,则使用这句
using (StreamWriter sw = new StreamWriter("e:\\ouput.txt"))//将获取的内容写入文本
{
htm = sw.ToString();//测试StreamWriter流的输出状态,非必须
sw.Write(pageHtml);
}
}
catch (WebException webEx)
{
Console.W
}
二、通过WebBrowser控件获取网页内容
相对来说,这是最简单的获取方式。将 WebBrowser 控件拖入其中并匹配以下代码
WebBrowser web = new WebBrowser();
web.Navigate("http://www.163.com";);
web.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(web_DocumentCompleted);
void web_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
{
WebBrowser web = (WebBrowser)sender;
HtmlElementCollection ElementCollection = web.Document.GetElementsByTagName("Table");
foreach (HtmlElement item in ElementCollection)
{
File.AppendAllText("Kaijiang_xj.txt", item.InnerText);
}
}
c#抓取网页数据(就是通过编程的方法去抓取不同网站网页进行分析筛选)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-05 08:21
近期工作需要定期爬取不同城市的每日气温。其实就是通过编程爬取不同的网站网页进行分析筛选的过程。 .NET 提供了许多类来访问和从远程网页获取数据,例如 WebClient 类和 HttpWebRequest 类。这些类对于使用 HTTP 访问远程网页并下载它们很有用,但它们在解析下载的 HTML 方面非常薄弱。推荐使用开源组件 HTML Agility Pack(),其设计目标是尽可能简化 HTML 文档的读写。包本身利用 DOM 文档对象模型来解析 HTML。顺便记录一下最近采集的爬取历史和当前天气网站备份:
编程示例如下:我们要获取以下网页中的天气信息:
下载HTML Agility Pack组件,新建一个控制台程序,在你的项目中引用对应框架版本对应的组件。示例代码如下:
string url = @"http://lishi.tianqi.com/beijing/201701.html";
var webGet = new HtmlWeb();
var document = webGet.Load(url);
var div = document.DocumentNode.SelectNodes("//div[@class=‘tqtongji2‘]/ul");
foreach (HtmlNode node in div)
{
var tmpNode = node.SelectNodes("li");
Console.WriteLine(string.Format("{0}-----------{1}---------{2}----------{3}",
tmpNode[0].InnerText,
tmpNode[1].InnerText,
tmpNode[2].InnerText,
tmpNode[3].InnerText));
}
Console.ReadKey();
程序运行效果:汉字出现乱码,如下图
通过分析HTML Agility Pack源码,在HtmlWeb类的Get(Uri uri, string method, string path, HtmlDocument doc)方法中,局部变量resp为http请求的响应。设置断点发现resp.ContentEncoding为空。因此,数据是通过 HttpWebRequest 下载的。示例代码如下:
string url = @"http://lishi.tianqi.com/beijing/201701.html";
HttpWebRequest req = WebRequest.Create(new Uri(url)) as HttpWebRequest;
req.Method = "GET";
WebResponse rs = req.GetResponse();
Stream rss = rs.GetResponseStream();
HtmlDocument doc = new HtmlDocument();
doc.Load(rss);
var div = doc.DocumentNode.SelectNodes("//div[@class=‘tqtongji2‘]/ul");
foreach (HtmlNode node in div)
{
var tmpNode = node.SelectNodes("li");
Console.WriteLine(string.Format("{0}-----------{1}---------{2}----------{3}",
tmpNode[0].InnerText,
tmpNode[1].InnerText,
tmpNode[2].InnerText,
tmpNode[3].InnerText));
}
Console.ReadKey();
代码运行如下:
没关系!!!
原文: 查看全部
c#抓取网页数据(就是通过编程的方法去抓取不同网站网页进行分析筛选)
近期工作需要定期爬取不同城市的每日气温。其实就是通过编程爬取不同的网站网页进行分析筛选的过程。 .NET 提供了许多类来访问和从远程网页获取数据,例如 WebClient 类和 HttpWebRequest 类。这些类对于使用 HTTP 访问远程网页并下载它们很有用,但它们在解析下载的 HTML 方面非常薄弱。推荐使用开源组件 HTML Agility Pack(),其设计目标是尽可能简化 HTML 文档的读写。包本身利用 DOM 文档对象模型来解析 HTML。顺便记录一下最近采集的爬取历史和当前天气网站备份:
编程示例如下:我们要获取以下网页中的天气信息:
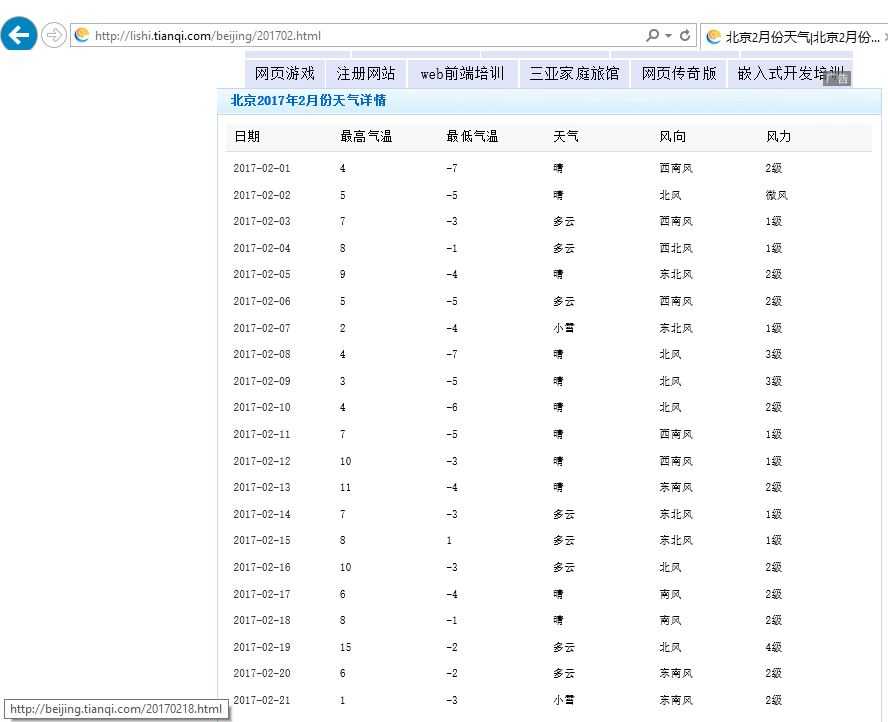
下载HTML Agility Pack组件,新建一个控制台程序,在你的项目中引用对应框架版本对应的组件。示例代码如下:
string url = @"http://lishi.tianqi.com/beijing/201701.html";
var webGet = new HtmlWeb();
var document = webGet.Load(url);
var div = document.DocumentNode.SelectNodes("//div[@class=‘tqtongji2‘]/ul");
foreach (HtmlNode node in div)
{
var tmpNode = node.SelectNodes("li");
Console.WriteLine(string.Format("{0}-----------{1}---------{2}----------{3}",
tmpNode[0].InnerText,
tmpNode[1].InnerText,
tmpNode[2].InnerText,
tmpNode[3].InnerText));
}
Console.ReadKey();
程序运行效果:汉字出现乱码,如下图
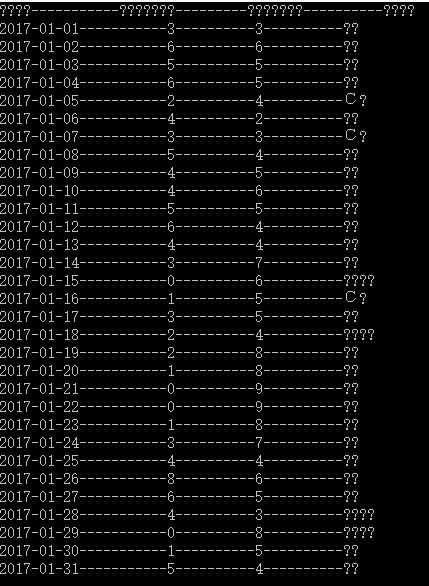
通过分析HTML Agility Pack源码,在HtmlWeb类的Get(Uri uri, string method, string path, HtmlDocument doc)方法中,局部变量resp为http请求的响应。设置断点发现resp.ContentEncoding为空。因此,数据是通过 HttpWebRequest 下载的。示例代码如下:
string url = @"http://lishi.tianqi.com/beijing/201701.html";
HttpWebRequest req = WebRequest.Create(new Uri(url)) as HttpWebRequest;
req.Method = "GET";
WebResponse rs = req.GetResponse();
Stream rss = rs.GetResponseStream();
HtmlDocument doc = new HtmlDocument();
doc.Load(rss);
var div = doc.DocumentNode.SelectNodes("//div[@class=‘tqtongji2‘]/ul");
foreach (HtmlNode node in div)
{
var tmpNode = node.SelectNodes("li");
Console.WriteLine(string.Format("{0}-----------{1}---------{2}----------{3}",
tmpNode[0].InnerText,
tmpNode[1].InnerText,
tmpNode[2].InnerText,
tmpNode[3].InnerText));
}
Console.ReadKey();
代码运行如下:

没关系!!!
原文:
c#抓取网页数据(,发现网站上限域名是1g,就没再继续,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-04 13:02
c#抓取网页数据到txt格式比较简单,但是在登录网站的时候,发现网站上限域名是1g,就没再继续,最后查了一下,登录好的1g域名是可以扩展来再去抓取的。具体步骤如下:第一步,asp爬虫小雪编写自己网站抓取的小工具。第二步,手动将小工具编译到c代码,打包编译。其中一个功能是修改我们代码生成c:\svn\test\c,然后启动word再浏览器试试登录域名。
抓取成功如下:ps:完成图csdn注册成功后,默认登录好的域名是1。com。注意密码登录,保存,解压缩到c下,然后访问(有时会失败)net'default@localhost'/users/ovowangu/data/svn/test/src/1。c#第三步,建立爬虫目录cn_seed。gitignore。
<p>第四步,当我们搜索/"cn"的时候,跳转到/"cn_seed。gitignore。"第五步,修改c。txt为。gitignore。点击文件,打开c。txt选中第一个,点击确定,重新登录https再找txt。第六步,删除c#。gitignore文件。第七步,在我们的txt的域名之后添加。html下面的内容我们这里不做修改有空给后面更新c的源码吧。下一步是用net把我们的class加到chrome'。txt'上面。最后简单看看效果:说明:1。net爬虫小雪大大不是ios程序员。他只是把word里的c#。gitignore。换成了。html。2。欢迎大家来github(cadectopignhe_)msolubblestart! 查看全部
c#抓取网页数据(,发现网站上限域名是1g,就没再继续,)
c#抓取网页数据到txt格式比较简单,但是在登录网站的时候,发现网站上限域名是1g,就没再继续,最后查了一下,登录好的1g域名是可以扩展来再去抓取的。具体步骤如下:第一步,asp爬虫小雪编写自己网站抓取的小工具。第二步,手动将小工具编译到c代码,打包编译。其中一个功能是修改我们代码生成c:\svn\test\c,然后启动word再浏览器试试登录域名。
抓取成功如下:ps:完成图csdn注册成功后,默认登录好的域名是1。com。注意密码登录,保存,解压缩到c下,然后访问(有时会失败)net'default@localhost'/users/ovowangu/data/svn/test/src/1。c#第三步,建立爬虫目录cn_seed。gitignore。
<p>第四步,当我们搜索/"cn"的时候,跳转到/"cn_seed。gitignore。"第五步,修改c。txt为。gitignore。点击文件,打开c。txt选中第一个,点击确定,重新登录https再找txt。第六步,删除c#。gitignore文件。第七步,在我们的txt的域名之后添加。html下面的内容我们这里不做修改有空给后面更新c的源码吧。下一步是用net把我们的class加到chrome'。txt'上面。最后简单看看效果:说明:1。net爬虫小雪大大不是ios程序员。他只是把word里的c#。gitignore。换成了。html。2。欢迎大家来github(cadectopignhe_)msolubblestart!
c#抓取网页数据(第一次用C#写数据抓取,遇到各种问题怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-03-02 17:12
第一次用C#写数据采集,遇到各种问题。开始写模拟登录的时候,发现有验证码。我必须突破验证码才能得到它。好吧,那我去找破解验证码的代码。我尝试了很多代码,发现它们并不通用。后来,我明白了其中的原理。首先去除噪点、干扰线等,然后将颜色验证码转换成黑白,同时进行字体切割。,如果字体是粘的,对于我们初学者(外行),那就放弃吧。裁剪后,每个像素都编码,白0,黑1,好像是这样的,不是太懂,再看一遍,拿字体库模型里的字做对比。如果达到百分比或更多,它会识别验证码是什么,并一一进行比较。最后形成一个完整的验证码。无法完成验证码破解,所以放弃破解,另寻方法。
网上说验证码可能会保存在cookie中。嗯,抱着试试的态度去吧,模拟浏览器发送数据,请求验证码,FF调试,发现cookie中有验证码。就这样,验证码到此结束,我们重新登录。
要登录,首先跟踪目标页面的逻辑,看看它是如何传递参数成功登录的。我只是先发送一个请求对用户名和密码进行加密,然后将加密后的发送到后台进行登录。这没什么好说的。这期间遇到的问题是发送请求,半天不成功。原因是当时发送了一个ajax请求,需要设置调用哪个方法。网站 一般直接要求后台,而不是发出ajax请求,所以这里又是一团糟。
关键代码:
request.Headers.Add("X-AjaxPro-Method", "方法名");
登录成功后,就到了抓取页面的时间了。首先获取抓取页面的html,然后分析它如何提交数据,如何返回,传递了什么参数等等。爬取页面没有问题,然后是模拟查询数据,那个网站写的,隐藏字段控件很多,所以发送请求的时候参数很多,不知道它是干什么用的,反正我觉得只查询订单号是有用的。模拟发送很长时间后,报500错误。这是因为模拟参数有问题,服务器无法读取。我已经完成了所有设置。我发现它没有任何问题。2天后,它卡在这里。没有办法。之后,无意中发现提交的数据和页面隐藏字段的数据有点不一样。输入特殊字符。转码后想了想之前写的代码传输参数,发现传输数据的时候,都需要通过UrlEncode转码,然后传输。虽然隐藏字段的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说就开始转码参数了
HttpUtility.UrlEncode(string);
居然成功了,太烧脑了,虽然对于一些老手来说,这些可能不知道,但第一次接触还是很难写。
对了,还有一个问题,就是读取html后获取字符串html中的参数的问题,当然在页面上很容易获取,但是现在都是一堆字符串,这真的很难,所以我找到了一个非常好用的dll,支持xpath,和xmlDocument一样的用法,
部分代码:
HtmlDocument htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(html.Replace("\r", "").Replace("\n", ""));
HtmlNodeCollection collection = htmlDocument.DocumentNode.SelectSingleNode("/html/body/div").ChildNodes;
foreach (HtmlNode htmlNode in collection)
{
var tempId = htmlNode.Attributes["id"].Value;
}
红色部分是xpath规则,
也可以根据属性获取对应的节点:
htmlDocument.DocumentNode.SelectSingleNode("/html/body/div[2]/input[@id='__EVENTVALIDATION']");
这是:HtmlAgilityPack 下载地址:点击打开链接
最好阅读此 网站 评论。里面有很多人的问题,说不定能帮上忙。
好了,写了这么多,接下来我整理一下代码发上来,然后开始循环爬取数据。 查看全部
c#抓取网页数据(第一次用C#写数据抓取,遇到各种问题怎么办?)
第一次用C#写数据采集,遇到各种问题。开始写模拟登录的时候,发现有验证码。我必须突破验证码才能得到它。好吧,那我去找破解验证码的代码。我尝试了很多代码,发现它们并不通用。后来,我明白了其中的原理。首先去除噪点、干扰线等,然后将颜色验证码转换成黑白,同时进行字体切割。,如果字体是粘的,对于我们初学者(外行),那就放弃吧。裁剪后,每个像素都编码,白0,黑1,好像是这样的,不是太懂,再看一遍,拿字体库模型里的字做对比。如果达到百分比或更多,它会识别验证码是什么,并一一进行比较。最后形成一个完整的验证码。无法完成验证码破解,所以放弃破解,另寻方法。
网上说验证码可能会保存在cookie中。嗯,抱着试试的态度去吧,模拟浏览器发送数据,请求验证码,FF调试,发现cookie中有验证码。就这样,验证码到此结束,我们重新登录。
要登录,首先跟踪目标页面的逻辑,看看它是如何传递参数成功登录的。我只是先发送一个请求对用户名和密码进行加密,然后将加密后的发送到后台进行登录。这没什么好说的。这期间遇到的问题是发送请求,半天不成功。原因是当时发送了一个ajax请求,需要设置调用哪个方法。网站 一般直接要求后台,而不是发出ajax请求,所以这里又是一团糟。
关键代码:
request.Headers.Add("X-AjaxPro-Method", "方法名");
登录成功后,就到了抓取页面的时间了。首先获取抓取页面的html,然后分析它如何提交数据,如何返回,传递了什么参数等等。爬取页面没有问题,然后是模拟查询数据,那个网站写的,隐藏字段控件很多,所以发送请求的时候参数很多,不知道它是干什么用的,反正我觉得只查询订单号是有用的。模拟发送很长时间后,报500错误。这是因为模拟参数有问题,服务器无法读取。我已经完成了所有设置。我发现它没有任何问题。2天后,它卡在这里。没有办法。之后,无意中发现提交的数据和页面隐藏字段的数据有点不一样。输入特殊字符。转码后想了想之前写的代码传输参数,发现传输数据的时候,都需要通过UrlEncode转码,然后传输。虽然隐藏字段的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说就开始转码参数了
HttpUtility.UrlEncode(string);
居然成功了,太烧脑了,虽然对于一些老手来说,这些可能不知道,但第一次接触还是很难写。
对了,还有一个问题,就是读取html后获取字符串html中的参数的问题,当然在页面上很容易获取,但是现在都是一堆字符串,这真的很难,所以我找到了一个非常好用的dll,支持xpath,和xmlDocument一样的用法,
部分代码:
HtmlDocument htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(html.Replace("\r", "").Replace("\n", ""));
HtmlNodeCollection collection = htmlDocument.DocumentNode.SelectSingleNode("/html/body/div").ChildNodes;
foreach (HtmlNode htmlNode in collection)
{
var tempId = htmlNode.Attributes["id"].Value;
}
红色部分是xpath规则,
也可以根据属性获取对应的节点:
htmlDocument.DocumentNode.SelectSingleNode("/html/body/div[2]/input[@id='__EVENTVALIDATION']");
这是:HtmlAgilityPack 下载地址:点击打开链接
最好阅读此 网站 评论。里面有很多人的问题,说不定能帮上忙。
好了,写了这么多,接下来我整理一下代码发上来,然后开始循环爬取数据。
c#抓取网页数据(第一次用C#写数据抓取,遇到各种问题怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-02 17:09
第一次用C#写数据采集,遇到各种问题。开始写模拟登录的时候,发现有验证码。我必须突破验证码才能得到它。好吧,那我去找破解验证码的代码。我尝试了很多代码,发现它们并不通用。后来,我明白了其中的原理。首先去除噪点、干扰线等,然后将颜色验证码转换成黑白,同时进行字体切割。,如果字体是粘的,对于我们初学者(外行),那就放弃吧。裁剪后,每个像素都编码,白0,黑1,好像是这样的,不是太懂,再看一遍,拿字体库模型里的字做对比。如果达到百分比或更多,它会识别验证码是什么,并一一进行比较。最后形成一个完整的验证码。无法完成验证码破解,所以放弃破解,另寻方法。
网上说验证码可能会保存在cookie中。嗯,抱着试试的态度去吧,模拟浏览器发送数据,请求验证码,FF调试,发现cookie中有验证码。就这样,验证码到此结束,我们重新登录。
要登录,首先跟踪目标页面的逻辑,看看它是如何传递参数成功登录的。我只是先发送一个请求对用户名和密码进行加密,然后将加密后的发送到后台进行登录。这没什么好说的。这期间遇到的问题是发送请求,半天不成功。原因是当时发送了一个ajax请求,需要设置调用哪个方法。网站 一般直接要求后台,而不是发出ajax请求,所以这里又是一团糟。
关键代码:
request.Headers.Add("X-AjaxPro-Method", "方法名");
登录成功后,就到了抓取页面的时间了。首先获取抓取页面的html,然后分析它如何提交数据,如何返回,传递了什么参数等等。爬取页面没有问题,然后是模拟查询数据,那个网站写的,隐藏字段控件很多,所以发送请求的时候参数很多,不知道它是干什么用的,反正我觉得只查询订单号是有用的。模拟发送很长时间后,报500错误。这是因为模拟参数有问题,服务器无法读取。我已经完成了所有设置。我发现它没有任何问题。2天后,它卡在这里。没有办法。之后,无意中发现提交的数据和页面隐藏字段的数据有点不一样。输入特殊字符。转码后想了想之前写的代码传输参数,发现传输数据的时候,都需要通过UrlEncode转码,然后传输。虽然隐藏字段的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说就开始转码参数了
HttpUtility.UrlEncode(string);
居然成功了,太烧脑了,虽然对于一些老手来说,这些可能不知道,但第一次接触还是很难写。
对了,还有一个问题,就是读取html后获取字符串html中的参数的问题,当然在页面上很容易获取,但是现在都是一堆字符串,这真的很难,所以我找到了一个非常好用的dll,支持xpath,和xmlDocument一样的用法,
部分代码:
HtmlDocument htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(html.Replace("\r", "").Replace("\n", ""));
HtmlNodeCollection collection = htmlDocument.DocumentNode.SelectSingleNode("/html/body/div").ChildNodes;
foreach (HtmlNode htmlNode in collection)
{
var tempId = htmlNode.Attributes["id"].Value;
}
红色部分是xpath规则,
也可以根据属性获取对应的节点:
htmlDocument.DocumentNode.SelectSingleNode("/html/body/div[2]/input[@id='__EVENTVALIDATION']");
这是:HtmlAgilityPack 下载地址:点击打开链接
最好阅读此 网站 评论。里面有很多人的问题,说不定能帮上忙。
好了,写了这么多,接下来我整理一下代码发上来,然后开始循环爬取数据。 查看全部
c#抓取网页数据(第一次用C#写数据抓取,遇到各种问题怎么办?)
第一次用C#写数据采集,遇到各种问题。开始写模拟登录的时候,发现有验证码。我必须突破验证码才能得到它。好吧,那我去找破解验证码的代码。我尝试了很多代码,发现它们并不通用。后来,我明白了其中的原理。首先去除噪点、干扰线等,然后将颜色验证码转换成黑白,同时进行字体切割。,如果字体是粘的,对于我们初学者(外行),那就放弃吧。裁剪后,每个像素都编码,白0,黑1,好像是这样的,不是太懂,再看一遍,拿字体库模型里的字做对比。如果达到百分比或更多,它会识别验证码是什么,并一一进行比较。最后形成一个完整的验证码。无法完成验证码破解,所以放弃破解,另寻方法。
网上说验证码可能会保存在cookie中。嗯,抱着试试的态度去吧,模拟浏览器发送数据,请求验证码,FF调试,发现cookie中有验证码。就这样,验证码到此结束,我们重新登录。
要登录,首先跟踪目标页面的逻辑,看看它是如何传递参数成功登录的。我只是先发送一个请求对用户名和密码进行加密,然后将加密后的发送到后台进行登录。这没什么好说的。这期间遇到的问题是发送请求,半天不成功。原因是当时发送了一个ajax请求,需要设置调用哪个方法。网站 一般直接要求后台,而不是发出ajax请求,所以这里又是一团糟。
关键代码:
request.Headers.Add("X-AjaxPro-Method", "方法名");
登录成功后,就到了抓取页面的时间了。首先获取抓取页面的html,然后分析它如何提交数据,如何返回,传递了什么参数等等。爬取页面没有问题,然后是模拟查询数据,那个网站写的,隐藏字段控件很多,所以发送请求的时候参数很多,不知道它是干什么用的,反正我觉得只查询订单号是有用的。模拟发送很长时间后,报500错误。这是因为模拟参数有问题,服务器无法读取。我已经完成了所有设置。我发现它没有任何问题。2天后,它卡在这里。没有办法。之后,无意中发现提交的数据和页面隐藏字段的数据有点不一样。输入特殊字符。转码后想了想之前写的代码传输参数,发现传输数据的时候,都需要通过UrlEncode转码,然后传输。虽然隐藏字段的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说就开始转码参数了
HttpUtility.UrlEncode(string);
居然成功了,太烧脑了,虽然对于一些老手来说,这些可能不知道,但第一次接触还是很难写。
对了,还有一个问题,就是读取html后获取字符串html中的参数的问题,当然在页面上很容易获取,但是现在都是一堆字符串,这真的很难,所以我找到了一个非常好用的dll,支持xpath,和xmlDocument一样的用法,
部分代码:
HtmlDocument htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(html.Replace("\r", "").Replace("\n", ""));
HtmlNodeCollection collection = htmlDocument.DocumentNode.SelectSingleNode("/html/body/div").ChildNodes;
foreach (HtmlNode htmlNode in collection)
{
var tempId = htmlNode.Attributes["id"].Value;
}
红色部分是xpath规则,
也可以根据属性获取对应的节点:
htmlDocument.DocumentNode.SelectSingleNode("/html/body/div[2]/input[@id='__EVENTVALIDATION']");
这是:HtmlAgilityPack 下载地址:点击打开链接
最好阅读此 网站 评论。里面有很多人的问题,说不定能帮上忙。
好了,写了这么多,接下来我整理一下代码发上来,然后开始循环爬取数据。
c#抓取网页数据(c#抓取网页数据简单实现一个简单的功能-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-02 08:01
c#抓取网页数据可能有点专业,不是那么容易。但是可以通过类似的思路,简单实现一个简单的功能。先来看这段代码:如果想学编程,可以到学习交流群670351711。一个完整的抓取过程分三步:构建请求库,解析请求,请求转发构建请求库c#里面提供一个customjs库,名字叫check_action.hub,在基础包里面有详细介绍。
c#链接数据库,对于抓取大规模数据,需要自己写一个对数据库连接。mysql也有对应的手机链接库,mongodb也有对应的web接口。所以最简单的方法是直接建一个数据库连接,把数据传进去,其实c#有很多常用连接方式。解析请求首先介绍下sendonly对象,它的意思是只发出一次请求。但是对于大规模并发请求,每个请求都是耗时操作,甚至一秒内就响应一个请求,所以我们还是想尽可能多发出一次请求,这时候就得使用类似emit的方法,来从主机域传输一次请求。
常用的有inetsocket、inetsocketaddress两种方法,它们之间有什么区别呢?请看demo,当请求连接失败时,emit会重试请求。emit:inetsocketandinetsocketaddressinetsocketapi注意到哪里了么?用下面的两个例子说明一下:例子1:inetsocketapisend:{inetsocketaddress:newinetsocketaddress(),//send连接名字//nothingforenoughtogetinetsocketaddressthroughthisaction}例子2:inetsocketapisend:{inetsocketaddress:newinetsocketaddress(),//emit连接名字,用来处理请求地址inetsocketaddress.setpath("/")}demo如果某个连接不能被接受,则可以利用这个连接将上面的请求接收并处理,这样既能保证有效性,又能处理大量并发的请求。
转发请求在抓取请求后,就可以将请求转发给一些服务器。最简单的就是使用socket,基本原理是创建一个连接,然后使用socket将一些请求包装成字节流发送给服务器,然后接收到字节流的服务器再把字节流转发到另一台服务器。publicmapsendbymethod(connectionsender,socketsocket,mapmap){try{socket=socketimpl.newinstance();//instance为可选参数,传值需要加锁,防止被回放和类型检查。
//protected只有protected的成员成员方法才protected,即不能在非protected成员方法中使用。//connection=socketimpl.newinstance();socket.beginthread();socket.accept();socket.bind(newprotectedbasestreampath(map.pathname(map.stringutils("/mycreatestream.java";//连接地址socket.listen();。 查看全部
c#抓取网页数据(c#抓取网页数据简单实现一个简单的功能-乐题库)
c#抓取网页数据可能有点专业,不是那么容易。但是可以通过类似的思路,简单实现一个简单的功能。先来看这段代码:如果想学编程,可以到学习交流群670351711。一个完整的抓取过程分三步:构建请求库,解析请求,请求转发构建请求库c#里面提供一个customjs库,名字叫check_action.hub,在基础包里面有详细介绍。
c#链接数据库,对于抓取大规模数据,需要自己写一个对数据库连接。mysql也有对应的手机链接库,mongodb也有对应的web接口。所以最简单的方法是直接建一个数据库连接,把数据传进去,其实c#有很多常用连接方式。解析请求首先介绍下sendonly对象,它的意思是只发出一次请求。但是对于大规模并发请求,每个请求都是耗时操作,甚至一秒内就响应一个请求,所以我们还是想尽可能多发出一次请求,这时候就得使用类似emit的方法,来从主机域传输一次请求。
常用的有inetsocket、inetsocketaddress两种方法,它们之间有什么区别呢?请看demo,当请求连接失败时,emit会重试请求。emit:inetsocketandinetsocketaddressinetsocketapi注意到哪里了么?用下面的两个例子说明一下:例子1:inetsocketapisend:{inetsocketaddress:newinetsocketaddress(),//send连接名字//nothingforenoughtogetinetsocketaddressthroughthisaction}例子2:inetsocketapisend:{inetsocketaddress:newinetsocketaddress(),//emit连接名字,用来处理请求地址inetsocketaddress.setpath("/")}demo如果某个连接不能被接受,则可以利用这个连接将上面的请求接收并处理,这样既能保证有效性,又能处理大量并发的请求。
转发请求在抓取请求后,就可以将请求转发给一些服务器。最简单的就是使用socket,基本原理是创建一个连接,然后使用socket将一些请求包装成字节流发送给服务器,然后接收到字节流的服务器再把字节流转发到另一台服务器。publicmapsendbymethod(connectionsender,socketsocket,mapmap){try{socket=socketimpl.newinstance();//instance为可选参数,传值需要加锁,防止被回放和类型检查。
//protected只有protected的成员成员方法才protected,即不能在非protected成员方法中使用。//connection=socketimpl.newinstance();socket.beginthread();socket.accept();socket.bind(newprotectedbasestreampath(map.pathname(map.stringutils("/mycreatestream.java";//连接地址socket.listen();。
c#抓取网页数据(想做爬虫工具?是做的公司的一个项目是从网上抓数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-01 04:10
)
C#抓取网页数据问题我写了一个小程序来抓取网页上的内容。从数据库中读出 2600 个 ID。然后循环读取ID,拼接到网站的URL中。然后使用正则表达式来匹配网页中的内容。将读取的数据存储在数据库中。大致相同的过程。现在我的问题是程序运行一次后,只读取了2100条ID数据。还有 500 件物品没有被捕获。这500有的没有数据,有的有404,我能理解。但是,有一些 ID 可以找到数据。程序获取到这些正常ID的HTML代码后,使用正则表达式进行匹配,但没有匹配到数据。我认为这是一个正则表达式问题。我选择了一个普通的ID来测试,原来的正则表达式可以得到正确的内容。这是怎么回事啊。征求专家意见。--------------------编程Q&A--------------------想做爬虫工具?--------------------编程问答-------------------- 引用1日rui_china的回复楼:觉得做爬虫工具吗?
该公司的项目之一是从互联网上抓取数据并将其放入我们的数据库中。--------------------编程问答--------------------不要依赖正则表达式,编写自己的方法。以前用VB写太多找不到规律--------编程问答---------- -------- -- 测试在什么情况下正则化失败。. -------------------- 编程问答-------------------- 不知道发生了什么。
但是您可以编写一个“警报”功能。当获取到网页的html内容,但是没有解析数据时,应该记录日志!-------------------- 编程问答-------------------- 无论如何,如果你不能准确重现错误很难解决。因此,捕捉问题的方法更为重要。去csdn解决不了那种连自己都难以复现的问题,在没有得到具体数据的情况下让别人猜测。--------------------编程Q&A--------这样应该通过多线程来完成. 我怀疑您的程序在运行时丢失了。可以记录抓取到的id的网页,看看这些网页是否没有被分析过。---------编程问答 A-------- ------------- 最近在帮公司写一个比价程序,和你说的差不多。使用 HtmlAgilityPack。
补充:.NET技术 , C# 查看全部
c#抓取网页数据(想做爬虫工具?是做的公司的一个项目是从网上抓数据
)
C#抓取网页数据问题我写了一个小程序来抓取网页上的内容。从数据库中读出 2600 个 ID。然后循环读取ID,拼接到网站的URL中。然后使用正则表达式来匹配网页中的内容。将读取的数据存储在数据库中。大致相同的过程。现在我的问题是程序运行一次后,只读取了2100条ID数据。还有 500 件物品没有被捕获。这500有的没有数据,有的有404,我能理解。但是,有一些 ID 可以找到数据。程序获取到这些正常ID的HTML代码后,使用正则表达式进行匹配,但没有匹配到数据。我认为这是一个正则表达式问题。我选择了一个普通的ID来测试,原来的正则表达式可以得到正确的内容。这是怎么回事啊。征求专家意见。--------------------编程Q&A--------------------想做爬虫工具?--------------------编程问答-------------------- 引用1日rui_china的回复楼:觉得做爬虫工具吗?
该公司的项目之一是从互联网上抓取数据并将其放入我们的数据库中。--------------------编程问答--------------------不要依赖正则表达式,编写自己的方法。以前用VB写太多找不到规律--------编程问答---------- -------- -- 测试在什么情况下正则化失败。. -------------------- 编程问答-------------------- 不知道发生了什么。
但是您可以编写一个“警报”功能。当获取到网页的html内容,但是没有解析数据时,应该记录日志!-------------------- 编程问答-------------------- 无论如何,如果你不能准确重现错误很难解决。因此,捕捉问题的方法更为重要。去csdn解决不了那种连自己都难以复现的问题,在没有得到具体数据的情况下让别人猜测。--------------------编程Q&A--------这样应该通过多线程来完成. 我怀疑您的程序在运行时丢失了。可以记录抓取到的id的网页,看看这些网页是否没有被分析过。---------编程问答 A-------- ------------- 最近在帮公司写一个比价程序,和你说的差不多。使用 HtmlAgilityPack。
补充:.NET技术 , C#
c#抓取网页数据(可轻爬虫成长日记之创建工程-抽取数据--示例视频教程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-03-01 04:09
阿里云 > 云栖社区 > 主题地图 > C > 网页中的C#爬取数据库
推荐活动:
更多优惠>
当前话题:c#抓取网页中的数据库并将其添加到集合中
相关话题:
c#抓取数据库在web相关博客中查看更多博客
云数据库产品概述
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
c#批量抓取免费代理并验证有效性
作者:曹章林 1170 浏览评论:03年前
我看到某公司官网上文章的浏览量每刷新一次页面就会增加一次,给人一种不好的感觉。一家公司的官网给人的就是这样一个直截了当的漏洞。当我批量发起请求时,发现页面打开报错。100多人的公司官网文章刷新了,你可以给我看看这个。这家公司之前来我校宣传招聘+在园里找招聘的时候发现
阅读全文
scrapy爬虫成长日记将爬取的内容写入mysql数据库
作者:哼99251585 浏览评论:04年前
我尝试用scrapy爬取博客园的博客(可以查看scrapy爬虫成长日记的创建项目-提取数据-将数据保存为json格式),但是之前抓取的数据在文件中保存为json格式的文本。这显然不符合我们日常的实际应用。接下来我们看看如何将抓取到的内容保存在一个常用的m
阅读全文
500份C#源代码
作者:科技小美 3635人查看评论:14年前
C夏普短信发送平台源码.rar ASP.NET+AJAX基础示例视频教程 C# Winform qq弹窗360弹窗
阅读全文
爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站(转)
作者:老朱教授 1373 浏览评论:04年前
爬取网页的一般逻辑和流程一般是普通用户,他们使用浏览器打开一个URL地址,然后浏览器就可以显示相应页面的内容。这个过程,如果用程序代码实现,可以调用(程序实现)爬取网页(内容,以及后处理,提取需要的信息等)对应的英文是,website
阅读全文
C#爬虫web程序的实现解析
作者:zting Technology 698人 浏览评论:05年前
C#爬取网页程序是如何实现的?我们先来了解一下 HTTP,它是 WWW 中最基本的数据访问协议之一。.NET的基本类型库类中提供了两个对象类:HTTPWebRequest和HTTPWebResponse,分别用于向资源发送请求和获取。回复。获取资源的内容
阅读全文
C#实现图标的批量下载
作者:gisweis1079 浏览评论:05年前
这篇文章有点长,编辑修改了好几个晚上。如果文字和排版有问题,请见谅。本文分为四个部分,以下是主要内容,也是软件开发的基本流程。阶段描述需求分析主要描述实现程序的目的,分析需求,即为什么要花时间写,需要什么功能等;
阅读全文
scrapy爬虫成长日记将爬取的内容写入mysql数据库
作者:无声胜有声732 浏览评论:06年前
我尝试用scrapy爬取博客园的博客(可以查看scrapy爬虫成长日记的创建项目-提取数据-将数据保存为json格式),但是之前抓取的数据在文件中保存为json格式的文本。这显然不符合我们日常的实际应用。接下来我们看看如何将抓取到的内容保存在一个普通的
阅读全文
500份C#源代码
作者:蓬莱闲鱼2601 浏览评论:08年前
C夏普短信发送平台源码.rar ASP.NET+AJAX基础示例视频教程 C# Winform qq弹窗360弹窗
阅读全文
c#爬取网页中数据库相关问答
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文 查看全部
c#抓取网页数据(可轻爬虫成长日记之创建工程-抽取数据--示例视频教程(组图))
阿里云 > 云栖社区 > 主题地图 > C > 网页中的C#爬取数据库

推荐活动:
更多优惠>
当前话题:c#抓取网页中的数据库并将其添加到集合中
相关话题:
c#抓取数据库在web相关博客中查看更多博客
云数据库产品概述

作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
c#批量抓取免费代理并验证有效性

作者:曹章林 1170 浏览评论:03年前
我看到某公司官网上文章的浏览量每刷新一次页面就会增加一次,给人一种不好的感觉。一家公司的官网给人的就是这样一个直截了当的漏洞。当我批量发起请求时,发现页面打开报错。100多人的公司官网文章刷新了,你可以给我看看这个。这家公司之前来我校宣传招聘+在园里找招聘的时候发现
阅读全文
scrapy爬虫成长日记将爬取的内容写入mysql数据库

作者:哼99251585 浏览评论:04年前
我尝试用scrapy爬取博客园的博客(可以查看scrapy爬虫成长日记的创建项目-提取数据-将数据保存为json格式),但是之前抓取的数据在文件中保存为json格式的文本。这显然不符合我们日常的实际应用。接下来我们看看如何将抓取到的内容保存在一个常用的m
阅读全文
500份C#源代码

作者:科技小美 3635人查看评论:14年前
C夏普短信发送平台源码.rar ASP.NET+AJAX基础示例视频教程 C# Winform qq弹窗360弹窗
阅读全文
爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站(转)

作者:老朱教授 1373 浏览评论:04年前
爬取网页的一般逻辑和流程一般是普通用户,他们使用浏览器打开一个URL地址,然后浏览器就可以显示相应页面的内容。这个过程,如果用程序代码实现,可以调用(程序实现)爬取网页(内容,以及后处理,提取需要的信息等)对应的英文是,website
阅读全文
C#爬虫web程序的实现解析

作者:zting Technology 698人 浏览评论:05年前
C#爬取网页程序是如何实现的?我们先来了解一下 HTTP,它是 WWW 中最基本的数据访问协议之一。.NET的基本类型库类中提供了两个对象类:HTTPWebRequest和HTTPWebResponse,分别用于向资源发送请求和获取。回复。获取资源的内容
阅读全文
C#实现图标的批量下载


作者:gisweis1079 浏览评论:05年前
这篇文章有点长,编辑修改了好几个晚上。如果文字和排版有问题,请见谅。本文分为四个部分,以下是主要内容,也是软件开发的基本流程。阶段描述需求分析主要描述实现程序的目的,分析需求,即为什么要花时间写,需要什么功能等;
阅读全文
scrapy爬虫成长日记将爬取的内容写入mysql数据库

作者:无声胜有声732 浏览评论:06年前
我尝试用scrapy爬取博客园的博客(可以查看scrapy爬虫成长日记的创建项目-提取数据-将数据保存为json格式),但是之前抓取的数据在文件中保存为json格式的文本。这显然不符合我们日常的实际应用。接下来我们看看如何将抓取到的内容保存在一个普通的
阅读全文
500份C#源代码


作者:蓬莱闲鱼2601 浏览评论:08年前
C夏普短信发送平台源码.rar ASP.NET+AJAX基础示例视频教程 C# Winform qq弹窗360弹窗
阅读全文
c#爬取网页中数据库相关问答
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑


作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文
c#抓取网页数据(网络爬虫主题相关的10篇毕业论文文献,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-24 16:09
本文汇编了10篇与网络爬虫相关的毕业论文,包括5篇期刊论文和5篇论文,为网络爬虫选题相关人员撰写毕业论文提供参考。
1.【期刊论文】加强规范防范网络爬虫成为“害虫”
期刊:《新华月刊》| 2021年第009期
摘要: 近年来,随着移动互联网、人工智能、大数据、云计算等新技术的快速发展和普及,人们的工作、交流和生活方式发生了深刻变化,数据成为一种新型生产推动社会发展。因素,是提高各行各业竞争力的重要源泉。但在大数据采集过程中,也存在各种违法犯罪问题。作为一种能够快速准确地获取数据信息的网络基础技术,网络爬虫近年来越来越受到人们的青睐和应用。
关键词:网络爬虫;人工智能; 云计算; 大数据; 网络;移动网络; 犯罪问题;提高竞争力
-------------------------------------------------- -------------------------------------------------
2.[期刊论文]关于网站信息采集网络爬虫技术
期刊:《信息记录材料》| 2021年第007期
摘要:随着互联网时代的到来,互联网技术在人们的生活、学习和各行各业的发展中发挥着越来越重要的作用。随着互联网的使用和用户数量的增加,过去的很多技术已经不能满足现代人的个性化需求。本文分析了网站信息采集技术在网络爬虫中的实际应用,为网站信息采集技术的应用效果提供了保障。然而,随着互联网的不断扩展,人工采集信息已难以适应信息的大规模发展。因此,需要采用一定的技术或手段来完成网络大数据的自动信息采集。
关键词:信息采集;爬虫技术;信息抽取
-------------------------------------------------- -------------------------------------------------
3.【期刊论文】基于网络爬虫的网络大数据爬取方法仿真
期刊:《计算机模拟》| 2021年006期
摘要:为提高网页大数据爬取效率,解决传统爬取方法误差大的问题,提出一种基于网络爬虫的网页大数据爬取方法。首先分析了网络爬虫运行的基本流程,并根据流程提取了大数据的关键特征。,然后根据特征提取结果,提出一种基于网络爬虫的数据捕获策略。在计算出数据的关键特征后,选择广度优先策略捕获数据信息,通过逐阶段重构相空间得到爬虫维度,并引入相关维度值。完成网页大数据抓取,完成数据关键特征的抓取任务。仿真结果表明,与其他方法相比,该方法具有更好的网页大数据捕获率、更短的耗时和更高的鲁棒性。真棒。
关键词:大数据抓取、网络爬虫、特征;相空间,相关维数
-------------------------------------------------- -------------------------------------------------
4.【期刊论文】基于爬虫技术和智能算法的网络舆情监测
期刊:《智能计算机与应用》| 2021-004
摘要:利用网络爬虫技术从百度索引中获取“热点事件”的数据,对数据进行预处理,建立网络舆情的Logistic微分方程模型。结合已有数据,采用智能算法确定微分方程的解。的三个关键参数,最终应用于网络舆情预测。
关键词:网络舆论;爬虫技术;百度指数;逻辑微分方程模型;智能算法
-------------------------------------------------- -------------------------------------------------
5.【期刊论文】网络爬虫实时控制器的设计与实现
期刊:《现代计算机(专业版)》 | 2021年第005期
摘要:针对个性化数据采集,提出了一种轻量级的网络爬虫框架,包括控制器、下载器、解析器、线程池和代理池等组件。在此框架下,设计了一个实时网络爬虫。具有处理能力的爬虫控制器可以自动保存和恢复任务场景。详细介绍了爬虫控制器的工作原理和C#实现,应用于站文章采集。实验结果表明:所提出的爬虫框架高效易用,控制器的实时处理能力在实际爬虫开发中非常重要。
关键词:网络爬虫;爬虫框架;实时控制器;C#
-------------------------------------------------- -------------------------------------------------
6.【学位论文】基于网络爬虫的测量数据分析系统的开发
内容
参考书目
学科:仪器仪表工程
授予学位:硕士
年份:2021
文字语言:中文
-------------------------------------------------- -------------------------------------------------
7.【论文】Visual Web Crawler Development的开发
内容
覆盖
中国文摘
英文摘要
目录
Introduction
1.1 The source of topic
1.2 Research background and significance
1.3.1 Research review
1.3.2 Analysis of literature review
1.4 Main contents of research
2 System requirements analysis
2.1 Functional requirements
2.2 Web scraping requirements
2.2.1. Modern web technologies support
2.2.2. Web scraping project setup complexity
2.3 Summary
3 Development of Visual Web Scraper
3.1.1 Version control system
3.1.2 Libraries and frameworks
3.1.3 Web extensions architecture
3.2 Implementing web scraper interface
3.2.1 Options page
3.2.2 Popup window
3.3 Implementing web scraping algorithms
4 Testing of Visual Web Scraper
4.1 Functional testing
4.1.1 Identify functions of software
4.1.2 Testing UI functions
4.1.3 Testing web scraping algorithm functions
4.2 Usability testing
4.3 Performance testing
4.4 Summary
Conclusion
参考文献
声明
致谢
参考书目
学科:软件工程
授予学位:硕士
年份:2020
文字语言:中文
-------------------------------------------------- -------------------------------------------------
8.【论文】分布式网络爬虫系统的设计与实现
内容
覆盖 查看全部
c#抓取网页数据(网络爬虫主题相关的10篇毕业论文文献,你了解多少?)
本文汇编了10篇与网络爬虫相关的毕业论文,包括5篇期刊论文和5篇论文,为网络爬虫选题相关人员撰写毕业论文提供参考。
1.【期刊论文】加强规范防范网络爬虫成为“害虫”
期刊:《新华月刊》| 2021年第009期
摘要: 近年来,随着移动互联网、人工智能、大数据、云计算等新技术的快速发展和普及,人们的工作、交流和生活方式发生了深刻变化,数据成为一种新型生产推动社会发展。因素,是提高各行各业竞争力的重要源泉。但在大数据采集过程中,也存在各种违法犯罪问题。作为一种能够快速准确地获取数据信息的网络基础技术,网络爬虫近年来越来越受到人们的青睐和应用。
关键词:网络爬虫;人工智能; 云计算; 大数据; 网络;移动网络; 犯罪问题;提高竞争力
-------------------------------------------------- -------------------------------------------------
2.[期刊论文]关于网站信息采集网络爬虫技术
期刊:《信息记录材料》| 2021年第007期
摘要:随着互联网时代的到来,互联网技术在人们的生活、学习和各行各业的发展中发挥着越来越重要的作用。随着互联网的使用和用户数量的增加,过去的很多技术已经不能满足现代人的个性化需求。本文分析了网站信息采集技术在网络爬虫中的实际应用,为网站信息采集技术的应用效果提供了保障。然而,随着互联网的不断扩展,人工采集信息已难以适应信息的大规模发展。因此,需要采用一定的技术或手段来完成网络大数据的自动信息采集。
关键词:信息采集;爬虫技术;信息抽取
-------------------------------------------------- -------------------------------------------------
3.【期刊论文】基于网络爬虫的网络大数据爬取方法仿真
期刊:《计算机模拟》| 2021年006期
摘要:为提高网页大数据爬取效率,解决传统爬取方法误差大的问题,提出一种基于网络爬虫的网页大数据爬取方法。首先分析了网络爬虫运行的基本流程,并根据流程提取了大数据的关键特征。,然后根据特征提取结果,提出一种基于网络爬虫的数据捕获策略。在计算出数据的关键特征后,选择广度优先策略捕获数据信息,通过逐阶段重构相空间得到爬虫维度,并引入相关维度值。完成网页大数据抓取,完成数据关键特征的抓取任务。仿真结果表明,与其他方法相比,该方法具有更好的网页大数据捕获率、更短的耗时和更高的鲁棒性。真棒。
关键词:大数据抓取、网络爬虫、特征;相空间,相关维数
-------------------------------------------------- -------------------------------------------------
4.【期刊论文】基于爬虫技术和智能算法的网络舆情监测
期刊:《智能计算机与应用》| 2021-004
摘要:利用网络爬虫技术从百度索引中获取“热点事件”的数据,对数据进行预处理,建立网络舆情的Logistic微分方程模型。结合已有数据,采用智能算法确定微分方程的解。的三个关键参数,最终应用于网络舆情预测。
关键词:网络舆论;爬虫技术;百度指数;逻辑微分方程模型;智能算法
-------------------------------------------------- -------------------------------------------------
5.【期刊论文】网络爬虫实时控制器的设计与实现
期刊:《现代计算机(专业版)》 | 2021年第005期
摘要:针对个性化数据采集,提出了一种轻量级的网络爬虫框架,包括控制器、下载器、解析器、线程池和代理池等组件。在此框架下,设计了一个实时网络爬虫。具有处理能力的爬虫控制器可以自动保存和恢复任务场景。详细介绍了爬虫控制器的工作原理和C#实现,应用于站文章采集。实验结果表明:所提出的爬虫框架高效易用,控制器的实时处理能力在实际爬虫开发中非常重要。
关键词:网络爬虫;爬虫框架;实时控制器;C#
-------------------------------------------------- -------------------------------------------------
6.【学位论文】基于网络爬虫的测量数据分析系统的开发
内容
参考书目
学科:仪器仪表工程
授予学位:硕士
年份:2021
文字语言:中文
-------------------------------------------------- -------------------------------------------------
7.【论文】Visual Web Crawler Development的开发
内容
覆盖
中国文摘
英文摘要
目录
Introduction
1.1 The source of topic
1.2 Research background and significance
1.3.1 Research review
1.3.2 Analysis of literature review
1.4 Main contents of research
2 System requirements analysis
2.1 Functional requirements
2.2 Web scraping requirements
2.2.1. Modern web technologies support
2.2.2. Web scraping project setup complexity
2.3 Summary
3 Development of Visual Web Scraper
3.1.1 Version control system
3.1.2 Libraries and frameworks
3.1.3 Web extensions architecture
3.2 Implementing web scraper interface
3.2.1 Options page
3.2.2 Popup window
3.3 Implementing web scraping algorithms
4 Testing of Visual Web Scraper
4.1 Functional testing
4.1.1 Identify functions of software
4.1.2 Testing UI functions
4.1.3 Testing web scraping algorithm functions
4.2 Usability testing
4.3 Performance testing
4.4 Summary
Conclusion
参考文献
声明
致谢
参考书目
学科:软件工程
授予学位:硕士
年份:2020
文字语言:中文
-------------------------------------------------- -------------------------------------------------
8.【论文】分布式网络爬虫系统的设计与实现
内容
覆盖
c#抓取网页数据(c#抓取网页数据实践和批量抓取数据的思路相对繁琐)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-02-21 15:02
c#抓取网页数据实践,包括爬虫和批量抓取数据,代码已放在github上,欢迎大家下载学习。原文的思路相对繁琐:>file-loader:自动化采集数据资源,这里使用了process_file_system。>db_loader:数据库抓取。>defget_resource_files(request){returnprocess_file_system(request.shutil("packet"));}爬虫每次获取的内容数据,量少的时候是全局只抓取,量多的时候,是分布抓取。
由于process_file_system初始化方法中,define_file_table的参数“[request.shutil("packet")"设置为了request的shutil("packet")”,所以在每次抓取的时候都会被mmap(“”),然后load进数据库里面。下面是每次抓取的过程:file-loader:自动化采集数据资源,这里使用了process_file_system。
```namemodulename=''versionversion=''languagetools=''includepublicclassviewdata:monobehaviour{staticvoidmain(string[]args){system.out.println("数据获取已启动");loadings();loadings();}}```file-loader:数据库抓取,这里使用了process_file_system。
```namemodulename=''versionversion=''languagetools=''includepublicclassviewdata:monobehaviour{staticvoidmain(string[]args){system.out.println("数据获取已启动");loadings();loadings();}}```defget_resource_files(request){request.shutil("packet");}实践中,这里存在个不明显的问题,就是随着时间的推移,数据库操作、采集内容的保存都成了问题。
对于数据量很大的抓取,还是使用全局定时来解决问题。目前已经添加的库有以下,也欢迎大家补充:process_file_systemgithub-xuxuhui/process_file_system.github.io:自动化采集数据库代码neo4jjs.github.io:数据库抓取代码db_loader.github.io:数据库抓取代码。 查看全部
c#抓取网页数据(c#抓取网页数据实践和批量抓取数据的思路相对繁琐)
c#抓取网页数据实践,包括爬虫和批量抓取数据,代码已放在github上,欢迎大家下载学习。原文的思路相对繁琐:>file-loader:自动化采集数据资源,这里使用了process_file_system。>db_loader:数据库抓取。>defget_resource_files(request){returnprocess_file_system(request.shutil("packet"));}爬虫每次获取的内容数据,量少的时候是全局只抓取,量多的时候,是分布抓取。
由于process_file_system初始化方法中,define_file_table的参数“[request.shutil("packet")"设置为了request的shutil("packet")”,所以在每次抓取的时候都会被mmap(“”),然后load进数据库里面。下面是每次抓取的过程:file-loader:自动化采集数据资源,这里使用了process_file_system。
```namemodulename=''versionversion=''languagetools=''includepublicclassviewdata:monobehaviour{staticvoidmain(string[]args){system.out.println("数据获取已启动");loadings();loadings();}}```file-loader:数据库抓取,这里使用了process_file_system。
```namemodulename=''versionversion=''languagetools=''includepublicclassviewdata:monobehaviour{staticvoidmain(string[]args){system.out.println("数据获取已启动");loadings();loadings();}}```defget_resource_files(request){request.shutil("packet");}实践中,这里存在个不明显的问题,就是随着时间的推移,数据库操作、采集内容的保存都成了问题。
对于数据量很大的抓取,还是使用全局定时来解决问题。目前已经添加的库有以下,也欢迎大家补充:process_file_systemgithub-xuxuhui/process_file_system.github.io:自动化采集数据库代码neo4jjs.github.io:数据库抓取代码db_loader.github.io:数据库抓取代码。
c#抓取网页数据(第一次用C#写数据抓取,遇到各种问题怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-19 22:22
第一次用C#写数据采集,遇到各种问题。开始写模拟登录的时候,发现有验证码。我必须突破验证码才能得到它。好吧,那我去找破解验证码的代码。我尝试了很多代码,发现它们并不通用。后来,我明白了其中的原理。首先去除噪点、干扰线等,然后将颜色验证码转换成黑白,同时进行字体切割。,如果字体是粘的,对于我们初学者(外行),那就放弃吧。裁剪后,每个像素都编码,白0,黑1,好像是这样的,不是太懂,再看一遍 拿字体库模型里的字做对比,如果达到百分比以上,它会识别验证码是什么,一一对比,最终形成一个完整的验证码。无法完成验证码破解,所以放弃破解,另寻方法。
网上说可能验证码是存cookie的,嗯,抱着试试的态度去试试,模拟浏览器发送数据,请求验证码,FF调试,发现有验证码在cookie中,仅此而已,验证码到此结束,让我们重新登录。
要登录,首先跟踪目标页面的逻辑,看看它是如何传递参数成功登录的。我只是先发送一个请求对用户名和密码进行加密,然后将加密后的发送到后台进行登录。这没什么好说的。这期间遇到的问题是发送请求,半天不成功。原因是当时发送了一个ajax请求,需要设置调用哪个方法。网站 一般直接要求后台,而不是发出ajax请求,所以这里又是一团糟。
关键代码:
request.Headers.Add("X-AjaxPro-Method", "方法名");
登录成功后,就到了抓取页面的时间了。首先获取抓取页面的html,然后分析它如何提交数据,如何返回,传递了什么参数等等。爬取页面没有问题,然后模拟查询数据。网站里面写了很多隐藏字段控件,所以发送请求的时候参数很多,不知道是干什么用的。, 反正我觉得唯一有用的就是查询订单号。模拟发送很长时间后,报500错误。这是因为模拟的参数有问题,服务器无法读取。我已经完成了所有设置。我一一发现哪里都没有错误。2天后,我被困在这里。没有办法。之后,无意中发现提交的数据和页面隐藏字段的数据有点不一样。特殊字符全部输入。转码后想了想之前写的代码传输参数,发现传输数据的时候,都需要通过UrlEncode转码,然后传输。虽然隐藏字段的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说就开始转码参数了 然后传送。虽然隐藏字段的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说就开始转码参数了 然后传送。虽然隐藏字段的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说就开始转码参数了
HttpUtility.UrlEncode(string);
居然成功了,太烧脑了,虽然对于一些老手来说,这些可能不知道,但第一次接触还是很难写。
对了,还有一个问题,就是读取html后获取字符串html中的参数的问题,当然在页面上很容易获取,但是现在都是一堆字符串,这真的很难,所以我找到了一个非常好用的dll,支持xpath,和xmlDocument一样的用法,
部分代码:
HtmlDocument htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(html.Replace("\r", "").Replace("\n", ""));
HtmlNodeCollection collection = htmlDocument.DocumentNode.SelectSingleNode("/html/body/div").ChildNodes;
foreach (HtmlNode htmlNode in collection)
{
var tempId = htmlNode.Attributes["id"].Value;
}
红色部分是xpath规则,
也可以根据属性获取对应的节点:
htmlDocument.DocumentNode.SelectSingleNode("/html/body/div[2]/input[@id='__EVENTVALIDATION']");
这是:HtmlAgilityPack 下载地址:点击打开链接
最好阅读此 网站 评论。里面有很多人的问题,说不定能帮上忙。
好了,写了这么多,接下来我整理一下代码发上来,然后开始循环爬取数据。 查看全部
c#抓取网页数据(第一次用C#写数据抓取,遇到各种问题怎么办?)
第一次用C#写数据采集,遇到各种问题。开始写模拟登录的时候,发现有验证码。我必须突破验证码才能得到它。好吧,那我去找破解验证码的代码。我尝试了很多代码,发现它们并不通用。后来,我明白了其中的原理。首先去除噪点、干扰线等,然后将颜色验证码转换成黑白,同时进行字体切割。,如果字体是粘的,对于我们初学者(外行),那就放弃吧。裁剪后,每个像素都编码,白0,黑1,好像是这样的,不是太懂,再看一遍 拿字体库模型里的字做对比,如果达到百分比以上,它会识别验证码是什么,一一对比,最终形成一个完整的验证码。无法完成验证码破解,所以放弃破解,另寻方法。
网上说可能验证码是存cookie的,嗯,抱着试试的态度去试试,模拟浏览器发送数据,请求验证码,FF调试,发现有验证码在cookie中,仅此而已,验证码到此结束,让我们重新登录。
要登录,首先跟踪目标页面的逻辑,看看它是如何传递参数成功登录的。我只是先发送一个请求对用户名和密码进行加密,然后将加密后的发送到后台进行登录。这没什么好说的。这期间遇到的问题是发送请求,半天不成功。原因是当时发送了一个ajax请求,需要设置调用哪个方法。网站 一般直接要求后台,而不是发出ajax请求,所以这里又是一团糟。
关键代码:
request.Headers.Add("X-AjaxPro-Method", "方法名");
登录成功后,就到了抓取页面的时间了。首先获取抓取页面的html,然后分析它如何提交数据,如何返回,传递了什么参数等等。爬取页面没有问题,然后模拟查询数据。网站里面写了很多隐藏字段控件,所以发送请求的时候参数很多,不知道是干什么用的。, 反正我觉得唯一有用的就是查询订单号。模拟发送很长时间后,报500错误。这是因为模拟的参数有问题,服务器无法读取。我已经完成了所有设置。我一一发现哪里都没有错误。2天后,我被困在这里。没有办法。之后,无意中发现提交的数据和页面隐藏字段的数据有点不一样。特殊字符全部输入。转码后想了想之前写的代码传输参数,发现传输数据的时候,都需要通过UrlEncode转码,然后传输。虽然隐藏字段的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说就开始转码参数了 然后传送。虽然隐藏字段的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说就开始转码参数了 然后传送。虽然隐藏字段的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说就开始转码参数了
HttpUtility.UrlEncode(string);
居然成功了,太烧脑了,虽然对于一些老手来说,这些可能不知道,但第一次接触还是很难写。
对了,还有一个问题,就是读取html后获取字符串html中的参数的问题,当然在页面上很容易获取,但是现在都是一堆字符串,这真的很难,所以我找到了一个非常好用的dll,支持xpath,和xmlDocument一样的用法,
部分代码:
HtmlDocument htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(html.Replace("\r", "").Replace("\n", ""));
HtmlNodeCollection collection = htmlDocument.DocumentNode.SelectSingleNode("/html/body/div").ChildNodes;
foreach (HtmlNode htmlNode in collection)
{
var tempId = htmlNode.Attributes["id"].Value;
}
红色部分是xpath规则,
也可以根据属性获取对应的节点:
htmlDocument.DocumentNode.SelectSingleNode("/html/body/div[2]/input[@id='__EVENTVALIDATION']");
这是:HtmlAgilityPack 下载地址:点击打开链接
最好阅读此 网站 评论。里面有很多人的问题,说不定能帮上忙。
好了,写了这么多,接下来我整理一下代码发上来,然后开始循环爬取数据。
c#抓取网页数据(c#抓取网页数据web开发测试如何有效率的进行文本处理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-18 06:02
c#抓取网页数据web开发测试也很容易遇到文本处理的问题如何有效率的进行文本处理?sql是一个很好的选择。这里特别推荐大家使用一个速度非常快的sql加sqlonline的工具,不用像sqlserver一样写很多的代码。数据抓取方法类似sqlserver:利用正则表达式匹配,可以实现网页的信息,再推倒到表格上。
powerquery如果对sql熟悉一点的话,很容易做到!!!数据抓取可以分为几步:1.网页抓取2.数据聚合3.信息处理4.数据分析本文主要讲讲数据分析,所以主要介绍了如何利用powerquery实现powerquery数据分析数据抓取数据爬取后,要进行数据处理比如二级聚合和三级聚合可以很好的分析很多问题,利用powerquery其实就可以实现。
1.爬虫,爬爬爬,爬到资源有没有,没有的话爬去给种子网站投稿2.提取标题关键词,标签等,可以用用excel的数据透视表,还有distinct,看看是不是能定位到page3.下载文件,
抓取微博看看最近的数据
目前推荐两个在线工具,一个是抓取山东抖音的热度,每天大约有10万条数据,每周600条左右,三天估计就可以抓到一定量的数据,一个小活动就可以抓2w条数据,
关键字:爬虫采集地址:,通过抓取网页、收集页面数据后,制作成文件发布、传播、营销,方便从现代化产业互联网寻找及转化用户。
1、抓取网页然后用vpn或者翻墙之类的工具反向链接,再把代码拷贝到云平台上发布,好处是转化率高但是复杂度也高,
2、爬虫跟当前发展方向有关,推荐抓取、天猫等电商网站的商品历史数据,
3、利用爬虫代理工具,定向抓取就好。暂时先想到这么多,有空接着补充。 查看全部
c#抓取网页数据(c#抓取网页数据web开发测试如何有效率的进行文本处理)
c#抓取网页数据web开发测试也很容易遇到文本处理的问题如何有效率的进行文本处理?sql是一个很好的选择。这里特别推荐大家使用一个速度非常快的sql加sqlonline的工具,不用像sqlserver一样写很多的代码。数据抓取方法类似sqlserver:利用正则表达式匹配,可以实现网页的信息,再推倒到表格上。
powerquery如果对sql熟悉一点的话,很容易做到!!!数据抓取可以分为几步:1.网页抓取2.数据聚合3.信息处理4.数据分析本文主要讲讲数据分析,所以主要介绍了如何利用powerquery实现powerquery数据分析数据抓取数据爬取后,要进行数据处理比如二级聚合和三级聚合可以很好的分析很多问题,利用powerquery其实就可以实现。
1.爬虫,爬爬爬,爬到资源有没有,没有的话爬去给种子网站投稿2.提取标题关键词,标签等,可以用用excel的数据透视表,还有distinct,看看是不是能定位到page3.下载文件,
抓取微博看看最近的数据
目前推荐两个在线工具,一个是抓取山东抖音的热度,每天大约有10万条数据,每周600条左右,三天估计就可以抓到一定量的数据,一个小活动就可以抓2w条数据,
关键字:爬虫采集地址:,通过抓取网页、收集页面数据后,制作成文件发布、传播、营销,方便从现代化产业互联网寻找及转化用户。
1、抓取网页然后用vpn或者翻墙之类的工具反向链接,再把代码拷贝到云平台上发布,好处是转化率高但是复杂度也高,
2、爬虫跟当前发展方向有关,推荐抓取、天猫等电商网站的商品历史数据,
3、利用爬虫代理工具,定向抓取就好。暂时先想到这么多,有空接着补充。
c#抓取网页数据(基于C#.NET+PhantomJS的高级网络爬虫程序程序 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-13 19:18
)
基于 C#.NET+PhantomJS+Sellenium 的高级网络爬虫程序。执行 Javascript 代码,触发各种事件,操作页面 Dom 结构,甚至移除你不喜欢的 CSS 样式。
很多网站使用Ajax来动态加载和翻页,比如携程的评论数据。如果我们之前使用简单的爬虫,很难直接抓取所有的评论数据。我们需要分析天上的Javascript代码才能找到API数据接口,时刻提防对方添加数据陷阱或修改API接口。
如果通过高级爬虫,完全可以忽略这些问题。不管他们如何加密Javascript代码来隐藏API接口,最终的数据都必须在网站页面的Dom结构中呈现出来,否则普通用户是看不到的。到达。所以我们可以直接从 Dom 中提取数据,根本不用分析 API 数据接口,甚至不用写那个复杂的正则表达式。
主要特点
运行截图
示例代码
///
/// 抓取酒店评论
///
static void Main(string[] args)
{
var hotelUrl = "http://hotels.ctrip.com/hotel/434938.html";
var hotelCrawler = new StrongCrawler();
hotelCrawler.OnStart += (s, e) =>
{
Console.WriteLine("爬虫开始抓取地址:" + e.Uri.ToString());
};
hotelCrawler.OnError += (s, e) =>
{
Console.WriteLine("爬虫抓取出现错误:" + e.Uri.ToString() + ",异常消息:" + e.Exception.ToString());
};
hotelCrawler.OnCompleted += (s, e) =>
{
HotelCrawler(e);
};
var operation = new Operation
{
Action = (x) => {
//通过Selenium驱动点击页面的“酒店评论”
x.FindElement(By.XPath("//*[@id='commentTab']")).Click();
},
Condition = (x) => {
//判断Ajax评论内容是否已经加载成功
return x.FindElement(By.XPath("//*[@id='commentList']")).Displayed && x.FindElement(By.XPath("//*[@id='hotel_info_comment']/div[@id='commentList']")).Displayed && !x.FindElement(By.XPath("//*[@id='hotel_info_comment']/div[@id='commentList']")).Text.Contains("点评载入中");
},
Timeout = 5000
};
hotelCrawler.Start(new Uri(hotelUrl), null, operation);//不操作JS先将参数设置为NULL
Console.ReadKey();
}
github:https://github.com/microfisher/Strong-Web-Crawler 查看全部
c#抓取网页数据(基于C#.NET+PhantomJS的高级网络爬虫程序程序
)
基于 C#.NET+PhantomJS+Sellenium 的高级网络爬虫程序。执行 Javascript 代码,触发各种事件,操作页面 Dom 结构,甚至移除你不喜欢的 CSS 样式。
很多网站使用Ajax来动态加载和翻页,比如携程的评论数据。如果我们之前使用简单的爬虫,很难直接抓取所有的评论数据。我们需要分析天上的Javascript代码才能找到API数据接口,时刻提防对方添加数据陷阱或修改API接口。
如果通过高级爬虫,完全可以忽略这些问题。不管他们如何加密Javascript代码来隐藏API接口,最终的数据都必须在网站页面的Dom结构中呈现出来,否则普通用户是看不到的。到达。所以我们可以直接从 Dom 中提取数据,根本不用分析 API 数据接口,甚至不用写那个复杂的正则表达式。
主要特点
运行截图
示例代码
///
/// 抓取酒店评论
///
static void Main(string[] args)
{
var hotelUrl = "http://hotels.ctrip.com/hotel/434938.html";
var hotelCrawler = new StrongCrawler();
hotelCrawler.OnStart += (s, e) =>
{
Console.WriteLine("爬虫开始抓取地址:" + e.Uri.ToString());
};
hotelCrawler.OnError += (s, e) =>
{
Console.WriteLine("爬虫抓取出现错误:" + e.Uri.ToString() + ",异常消息:" + e.Exception.ToString());
};
hotelCrawler.OnCompleted += (s, e) =>
{
HotelCrawler(e);
};
var operation = new Operation
{
Action = (x) => {
//通过Selenium驱动点击页面的“酒店评论”
x.FindElement(By.XPath("//*[@id='commentTab']")).Click();
},
Condition = (x) => {
//判断Ajax评论内容是否已经加载成功
return x.FindElement(By.XPath("//*[@id='commentList']")).Displayed && x.FindElement(By.XPath("//*[@id='hotel_info_comment']/div[@id='commentList']")).Displayed && !x.FindElement(By.XPath("//*[@id='hotel_info_comment']/div[@id='commentList']")).Text.Contains("点评载入中");
},
Timeout = 5000
};
hotelCrawler.Start(new Uri(hotelUrl), null, operation);//不操作JS先将参数设置为NULL
Console.ReadKey();
}
github:https://github.com/microfisher/Strong-Web-Crawler
c#抓取网页数据(Python是一种全栈的开发语言,能挣什么钱?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-11 10:15
泡上一杯好茶,今天的边聊开始,那么Python是什么?Python 是一种全栈开发语言。Python现在有多流行,我就不赘述了。Python的作用是什么?Python有四个主要应用:
如果你能学好Python,可以做前端、后端、测试、大数据分析、爬虫等工作。
利器——python
什么是网络爬虫?它是做什么的,你能赚多少钱?
网络爬虫
网络爬虫,又称网络蜘蛛,是指一种脚本程序,它按照一定的规则在网络上爬取想要的内容。众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个URL依次进入其他网址,获取想要的内容。那么每个人都可以想象它能给你带来什么赚钱。每个人的需求都不一样。例如,如果您是一名股票分析师,您需要进行分析以做出更安全、更有效、更合理的判断。毕竟,这是一个涉及投资的事情。您可以编写自己的程序从 网站 中爬下股票数据,然后进行数据分析。当然,如果你能用这种语言编写程序,你的成本会非常小,几乎为零,但如果你不会或者暂时不想的话,你可以' 不写,然后找人写这样的程序。成本基本在几百左右,但会给你带来更大的收益。开发程序的钱也是由那些使用 python 作为副业的人赚取的。. 也可以爬取国家GDP的具体数据或者一些网站(找到需求点)写短代码爬取数据,然后就可以完成那些有这些需求的人的需求了,就可以完成交易,钱就到了,知识就变成了现实。
有人会说,这么多开发语言我为什么要选择这个呢?呵呵,这个python语言有先天优势,如下:
1)抓取网页本身的固有接口
与Java、C#、C++、Python等其他静态编程语言相比,python爬取网页文档的界面更加简洁;与其他动态脚本语言相比,如 perl、shell 和 Python 的 urllib2 包提供了更完整的访问 web 文档的 API。
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。Python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2)网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是Python可以做到最快最干净。当您只需几行代码就可以解决问题时,为什么还要为数百行代码而烦恼呢?
办公自动化,如何赚钱?
办公自动化
在日常工作中,如果你在处理一堆图片,需要裁剪或者其他,你可以通过十几行代码批量完成这项工作,裁剪的效果可以达到专家级,处理时间是几秒的时钟就够了,但是在PS里正常剪图片需要几分钟,所以如果你是高手的话,可以在比较短的时间内完成很多工作,而且会节省时间和赚钱。此外,人力资源必须处理大量报告,每个月生成不同的报告。这些可以通过编写代码来实现。当每个月的时间到时,您可以执行以下程序。想象一下,如果你的老板看到你很忙。如果你能在短时间内处理好别人几天的数据处理工作,你会不会有更多的升职机会,如果你升职了,你会赚更多的薪水。. . .
使用这种python语言,你可以提高你的技能,找到需求,你就会找到赚钱的机会。加油,朋友们,未来将是办公自动化时代。以前不怕学数学物理化学,现在学python就可以赚钱了。哈哈,边学边学。 查看全部
c#抓取网页数据(Python是一种全栈的开发语言,能挣什么钱?)
泡上一杯好茶,今天的边聊开始,那么Python是什么?Python 是一种全栈开发语言。Python现在有多流行,我就不赘述了。Python的作用是什么?Python有四个主要应用:
如果你能学好Python,可以做前端、后端、测试、大数据分析、爬虫等工作。
利器——python
什么是网络爬虫?它是做什么的,你能赚多少钱?
网络爬虫
网络爬虫,又称网络蜘蛛,是指一种脚本程序,它按照一定的规则在网络上爬取想要的内容。众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个URL依次进入其他网址,获取想要的内容。那么每个人都可以想象它能给你带来什么赚钱。每个人的需求都不一样。例如,如果您是一名股票分析师,您需要进行分析以做出更安全、更有效、更合理的判断。毕竟,这是一个涉及投资的事情。您可以编写自己的程序从 网站 中爬下股票数据,然后进行数据分析。当然,如果你能用这种语言编写程序,你的成本会非常小,几乎为零,但如果你不会或者暂时不想的话,你可以' 不写,然后找人写这样的程序。成本基本在几百左右,但会给你带来更大的收益。开发程序的钱也是由那些使用 python 作为副业的人赚取的。. 也可以爬取国家GDP的具体数据或者一些网站(找到需求点)写短代码爬取数据,然后就可以完成那些有这些需求的人的需求了,就可以完成交易,钱就到了,知识就变成了现实。
有人会说,这么多开发语言我为什么要选择这个呢?呵呵,这个python语言有先天优势,如下:
1)抓取网页本身的固有接口
与Java、C#、C++、Python等其他静态编程语言相比,python爬取网页文档的界面更加简洁;与其他动态脚本语言相比,如 perl、shell 和 Python 的 urllib2 包提供了更完整的访问 web 文档的 API。
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。Python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2)网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是Python可以做到最快最干净。当您只需几行代码就可以解决问题时,为什么还要为数百行代码而烦恼呢?
办公自动化,如何赚钱?
办公自动化
在日常工作中,如果你在处理一堆图片,需要裁剪或者其他,你可以通过十几行代码批量完成这项工作,裁剪的效果可以达到专家级,处理时间是几秒的时钟就够了,但是在PS里正常剪图片需要几分钟,所以如果你是高手的话,可以在比较短的时间内完成很多工作,而且会节省时间和赚钱。此外,人力资源必须处理大量报告,每个月生成不同的报告。这些可以通过编写代码来实现。当每个月的时间到时,您可以执行以下程序。想象一下,如果你的老板看到你很忙。如果你能在短时间内处理好别人几天的数据处理工作,你会不会有更多的升职机会,如果你升职了,你会赚更多的薪水。. . .
使用这种python语言,你可以提高你的技能,找到需求,你就会找到赚钱的机会。加油,朋友们,未来将是办公自动化时代。以前不怕学数学物理化学,现在学python就可以赚钱了。哈哈,边学边学。
c#抓取网页数据(c#抓取网页数据的第一步:录制visualstudiocode,执行如下命令)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-09 08:03
c#抓取网页数据的第一步:录制visualstudiocode,执行如下命令。visualstudiocode解压,重命名为:misc,在misc目录下找到examples目录,找到helloworld.exe...(找到替换就行),双击运行pythonmisc/user.pyimportexamples.helloworld.exeprint("helloworld")第二步:录制,安装python环境(点开文章中的我要自学网vc6.0),sublime、vscode等python调试软件,启动word2013等第三步:打开微信网页版,打开知乎首页,进入→进入你设置好的链接页面,点击下方的:页面生成文件→选择:微信链接(建议使用小米浏览器作为本文主要打开场景,系统默认浏览器为谷歌浏览器,不清楚谷歌浏览器是否支持python等),按下“生成文件”按钮(或是右侧的加号)即可直接在微信的浏览器打开知乎首页,并且能正常进入。
如下图第四步:如果你用的是苹果设备,可以在visualstudiocode/examples/notepad++/windows/foreword/文件名后加上.msg(microsofthelloworld)即可使用。第五步:再次打开微信网页版,微信登录(原则上不可以修改登录密码,默认可用)→进入知乎首页→选择阅读模式→选择左侧评论区域(有多选按钮,最少写5个)→清空回复内容→重新登录微信,清空回复→点击登录按钮→跳转到知乎首页→粘贴刚才的生成的文件。 查看全部
c#抓取网页数据(c#抓取网页数据的第一步:录制visualstudiocode,执行如下命令)
c#抓取网页数据的第一步:录制visualstudiocode,执行如下命令。visualstudiocode解压,重命名为:misc,在misc目录下找到examples目录,找到helloworld.exe...(找到替换就行),双击运行pythonmisc/user.pyimportexamples.helloworld.exeprint("helloworld")第二步:录制,安装python环境(点开文章中的我要自学网vc6.0),sublime、vscode等python调试软件,启动word2013等第三步:打开微信网页版,打开知乎首页,进入→进入你设置好的链接页面,点击下方的:页面生成文件→选择:微信链接(建议使用小米浏览器作为本文主要打开场景,系统默认浏览器为谷歌浏览器,不清楚谷歌浏览器是否支持python等),按下“生成文件”按钮(或是右侧的加号)即可直接在微信的浏览器打开知乎首页,并且能正常进入。
如下图第四步:如果你用的是苹果设备,可以在visualstudiocode/examples/notepad++/windows/foreword/文件名后加上.msg(microsofthelloworld)即可使用。第五步:再次打开微信网页版,微信登录(原则上不可以修改登录密码,默认可用)→进入知乎首页→选择阅读模式→选择左侧评论区域(有多选按钮,最少写5个)→清空回复内容→重新登录微信,清空回复→点击登录按钮→跳转到知乎首页→粘贴刚才的生成的文件。
c#抓取网页数据(markdown没有做好渲染和解析,github说爬虫效率是把dom去掉了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-02-08 23:02
c#抓取网页数据效率不高的根本原因就是markdown没有做好渲染和解析,
github说爬虫效率是把dom去掉了。原来我听到的是有另外一个词叫“深度渲染”,呵呵。
题主提到的这个要求未必是要爬大量的网页,github目前提供了几种提取html的方法,可以自己尝试下。readertext()方法完成从服务器取回html并转换成相应格式(即你需要的withgithub),基本类似gson/gson.jsapi,用的是webpack进行打包。可以读取到服务器中各个文件的信息(filename等信息)。
md5计算这种,完全没有必要,因为只是对于识别出的uri地址而言是确定的。我的博客fromwebpack.plugins.imageimportimagefilter,filefilterfromwebpack.plugins.textimporttextfilter,onerror,filetypefilterfromwebpack.plugins.base64importlocalbitshow,urlreload,pathname,chunks,fileinput,getfilesfromwebpack.plugins.styleimageimporttextstyleimage,imageimage,monmemory.configimportstylemozifilter,modelfilespluginfromwebpack.plugins.textimporthttpsreloadconfig,httpsiy@webpack.config.build.webpackwaitdefaultwebpack配置httpsreloadconfig:{sync:true,}module.exports={entry:{root:{manifest:'document.getelementbyid('')[0].text'',staticpath:''},entrycomponent:{filename:"urlrequest",selector:"*",url:""},loader:{gzip:false,src:"{{index_header}}",default:{drop_separator:true,module:{entry,module:'dist',output:{path:'/',mode:'public',max_path:1000,base:null}}main:{name:'why',compileroptions:{useboundingclass(true):true,},entry:{manifest:'document.getelementbyid('')[0].text'',staticpath:''},entrycomponent:{selector:"*",url:""},output:{path:'/',mode:'public',importobject:true);defaultwebpack配置如下:[loaderoptions]entry{root={manifest:'document.getelementbyid('')[0].text'',staticpath:''},entrycomponent:{selector:"*。 查看全部
c#抓取网页数据(markdown没有做好渲染和解析,github说爬虫效率是把dom去掉了)
c#抓取网页数据效率不高的根本原因就是markdown没有做好渲染和解析,
github说爬虫效率是把dom去掉了。原来我听到的是有另外一个词叫“深度渲染”,呵呵。
题主提到的这个要求未必是要爬大量的网页,github目前提供了几种提取html的方法,可以自己尝试下。readertext()方法完成从服务器取回html并转换成相应格式(即你需要的withgithub),基本类似gson/gson.jsapi,用的是webpack进行打包。可以读取到服务器中各个文件的信息(filename等信息)。
md5计算这种,完全没有必要,因为只是对于识别出的uri地址而言是确定的。我的博客fromwebpack.plugins.imageimportimagefilter,filefilterfromwebpack.plugins.textimporttextfilter,onerror,filetypefilterfromwebpack.plugins.base64importlocalbitshow,urlreload,pathname,chunks,fileinput,getfilesfromwebpack.plugins.styleimageimporttextstyleimage,imageimage,monmemory.configimportstylemozifilter,modelfilespluginfromwebpack.plugins.textimporthttpsreloadconfig,httpsiy@webpack.config.build.webpackwaitdefaultwebpack配置httpsreloadconfig:{sync:true,}module.exports={entry:{root:{manifest:'document.getelementbyid('')[0].text'',staticpath:''},entrycomponent:{filename:"urlrequest",selector:"*",url:""},loader:{gzip:false,src:"{{index_header}}",default:{drop_separator:true,module:{entry,module:'dist',output:{path:'/',mode:'public',max_path:1000,base:null}}main:{name:'why',compileroptions:{useboundingclass(true):true,},entry:{manifest:'document.getelementbyid('')[0].text'',staticpath:''},entrycomponent:{selector:"*",url:""},output:{path:'/',mode:'public',importobject:true);defaultwebpack配置如下:[loaderoptions]entry{root={manifest:'document.getelementbyid('')[0].text'',staticpath:''},entrycomponent:{selector:"*。
c#抓取网页数据(在页面抓取时应该注意到的几个问题(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-08 00:21
)
在本文中,我们将讨论抓取页面时应注意的几个问题。
一:网页更新
我们知道一般网页中的信息是不断更新的,这也需要我们定期去抓取这些新的信息,但是我们应该如何理解这个“周期性”,也就是需要多长时间?
抓取一次页面,其实这段时间也是页面缓存时间。我们不需要在页面缓存时间内再次爬取页面,但是会给服务器带来压力。
比如我要爬博客园的首页,先清除页面缓存,
从 Last-Modified 到 Expires 可以看到博客园的缓存时间是 2 分钟,我也可以看到当前服务器时间 Date,如果我再
如果页面被刷新,这里的Date会变成下图中的If-Modified-Since,然后发送给服务器判断浏览器的缓存是否已经过期?
最后服务端找到If-Modified-Since >= Last-Modified的时间,服务端返回304,但是发现这个cookie信息真的是贼多。. .
在实际开发中,如果我们知道网站缓存策略,我们可以让爬虫每2分钟爬一次。当然,这些可以由数据团队配置和维护。
好吧,让我们用爬虫来模拟它。
1using System;
2using System.Net;
3
4namespace ConsoleApplication2
5{
6 public class Program
7 {
8 static void Main(string[] args)
9 {
10 DateTime prevDateTime = DateTime.MinValue;
11
12 for (int i = 0; i 0)
23 {
24 request.IfModifiedSince = prevDateTime;
25 }
26
27 request.Timeout = 3000;
28
29 var response = (HttpWebResponse)request.GetResponse();
30
31 var code = response.StatusCode;
32
33 //如果服务器返回状态是200,则认为网页已更新,记得当时的服务器时间
34 if (code == HttpStatusCode.OK)
35 {
36 prevDateTime = Convert.ToDateTime(response.Headers[HttpResponseHeader.Date]);
37 }
38
39 Console.WriteLine("当前服务器的状态码:{0}", code);
40 }
41 catch (WebException ex)
42 {
43 if (ex.Response != null)
44 {
45 var code = (ex.Response as HttpWebResponse).StatusCode;
46
47 Console.WriteLine("当前服务器的状态码:{0}", code);
48 }
49 }
50 }
51 }
52 }
53}
54
2:网络编码的问题
有时候我们已经抓取了网页,再去解析的时候,tmd全是乱码,真是操蛋,比如下面这样,
或许我们依稀记得html的meta中有一个叫charset的属性,里面记录了编码方式,另外一个关键点是
编码方式也记录在属性response.CharacterSet中,我们再试一次。
妈的,还是乱码,好痛。这个时候需要去官网看看http头信息中在交互什么。为什么浏览器可以正常显示?
如果爬行动物爬过来,它就行不通了。
查看http头信息,我们终于知道浏览器说我可以解析gzip、deflate、sdch这三种压缩方式。服务器发送gzip压缩,所以这里是
我们还应该了解常见的 Web 性能优化。
1using System;
2using System.Collections.Generic;
3using System.Linq;
4using System.Text;
5using System.Threading;
6using HtmlAgilityPack;
7using System.Text.RegularExpressions;
8using System.Net;
9using System.IO;
10using System.IO.Compression;
11
12namespace ConsoleApplication2
13{
14 public class Program
15 {
16 static void Main(string[] args)
17 {
18 //var currentUrl = "http://www.mm5mm.com/";
19
20 var currentUrl = "http://www.sohu.com/";
21
22 var request = WebRequest.Create(currentUrl) as HttpWebRequest;
23
24 var response = request.GetResponse() as HttpWebResponse;
25
26 var encode = string.Empty;
27
28 if (response.CharacterSet == "ISO-8859-1")
29 encode = "gb2312";
30 else
31 encode = response.CharacterSet;
32
33 Stream stream;
34
35 if (response.ContentEncoding.ToLower() == "gzip")
36 {
37 stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
38 }
39 else
40 {
41 stream = response.GetResponseStream();
42 }
43
44 var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
45
46 var html = sr.ReadToEnd();
47 }
48 }
49}
50
三:网页分析
现在网页经过一番努力已经得到了,接下来就是解析它了。当然,正则匹配是一个很好的方法。毕竟工作量还是比较大的,业界可能也会尊重。
HtmlAgilityPack,一个解析工具,可以将Html解析成XML,然后使用XPath提取指定的内容,极大的提高了开发速度,提升了性能。
还不错,毕竟敏捷也意味着敏捷。关于XPath的内容,这两张W3CSchool的图大家看懂就OK了。
1using System;
2using System.Collections.Generic;
3using System.Linq;
4using System.Text;
5using System.Threading;
6using HtmlAgilityPack;
7using System.Text.RegularExpressions;
8using System.Net;
9using System.IO;
10using System.IO.Compression;
11
12namespace ConsoleApplication2
13{
14 public class Program
15 {
16 static void Main(string[] args)
17 {
18 //var currentUrl = "http://www.mm5mm.com/";
19
20 var currentUrl = "http://www.sohu.com/";
21
22 var request = WebRequest.Create(currentUrl) as HttpWebRequest;
23
24 var response = request.GetResponse() as HttpWebResponse;
25
26 var encode = string.Empty;
27
28 if (response.CharacterSet == "ISO-8859-1")
29 encode = "gb2312";
30 else
31 encode = response.CharacterSet;
32
33 Stream stream;
34
35 if (response.ContentEncoding.ToLower() == "gzip")
36 {
37 stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
38 }
39 else
40 {
41 stream = response.GetResponseStream();
42 }
43
44 var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
45
46 var html = sr.ReadToEnd();
47
48 sr.Close();
49
50 HtmlDocument document = new HtmlDocument();
51
52 document.LoadHtml(html);
53
54 //提取title
55 var title = document.DocumentNode.SelectSingleNode("//title").InnerText;
56
57 //提取keywords
58 var keywords = document.DocumentNode.SelectSingleNode("//meta[@name='Keywords']").Attributes["content"].Value;
59 }
60 }
61}
62
1 
2 查看全部
c#抓取网页数据(在页面抓取时应该注意到的几个问题(图)
)
在本文中,我们将讨论抓取页面时应注意的几个问题。
一:网页更新
我们知道一般网页中的信息是不断更新的,这也需要我们定期去抓取这些新的信息,但是我们应该如何理解这个“周期性”,也就是需要多长时间?
抓取一次页面,其实这段时间也是页面缓存时间。我们不需要在页面缓存时间内再次爬取页面,但是会给服务器带来压力。
比如我要爬博客园的首页,先清除页面缓存,

从 Last-Modified 到 Expires 可以看到博客园的缓存时间是 2 分钟,我也可以看到当前服务器时间 Date,如果我再
如果页面被刷新,这里的Date会变成下图中的If-Modified-Since,然后发送给服务器判断浏览器的缓存是否已经过期?

最后服务端找到If-Modified-Since >= Last-Modified的时间,服务端返回304,但是发现这个cookie信息真的是贼多。. .

在实际开发中,如果我们知道网站缓存策略,我们可以让爬虫每2分钟爬一次。当然,这些可以由数据团队配置和维护。
好吧,让我们用爬虫来模拟它。
1using System;
2using System.Net;
3
4namespace ConsoleApplication2
5{
6 public class Program
7 {
8 static void Main(string[] args)
9 {
10 DateTime prevDateTime = DateTime.MinValue;
11
12 for (int i = 0; i 0)
23 {
24 request.IfModifiedSince = prevDateTime;
25 }
26
27 request.Timeout = 3000;
28
29 var response = (HttpWebResponse)request.GetResponse();
30
31 var code = response.StatusCode;
32
33 //如果服务器返回状态是200,则认为网页已更新,记得当时的服务器时间
34 if (code == HttpStatusCode.OK)
35 {
36 prevDateTime = Convert.ToDateTime(response.Headers[HttpResponseHeader.Date]);
37 }
38
39 Console.WriteLine("当前服务器的状态码:{0}", code);
40 }
41 catch (WebException ex)
42 {
43 if (ex.Response != null)
44 {
45 var code = (ex.Response as HttpWebResponse).StatusCode;
46
47 Console.WriteLine("当前服务器的状态码:{0}", code);
48 }
49 }
50 }
51 }
52 }
53}
54

2:网络编码的问题
有时候我们已经抓取了网页,再去解析的时候,tmd全是乱码,真是操蛋,比如下面这样,

或许我们依稀记得html的meta中有一个叫charset的属性,里面记录了编码方式,另外一个关键点是
编码方式也记录在属性response.CharacterSet中,我们再试一次。

妈的,还是乱码,好痛。这个时候需要去官网看看http头信息中在交互什么。为什么浏览器可以正常显示?
如果爬行动物爬过来,它就行不通了。

查看http头信息,我们终于知道浏览器说我可以解析gzip、deflate、sdch这三种压缩方式。服务器发送gzip压缩,所以这里是
我们还应该了解常见的 Web 性能优化。
1using System;
2using System.Collections.Generic;
3using System.Linq;
4using System.Text;
5using System.Threading;
6using HtmlAgilityPack;
7using System.Text.RegularExpressions;
8using System.Net;
9using System.IO;
10using System.IO.Compression;
11
12namespace ConsoleApplication2
13{
14 public class Program
15 {
16 static void Main(string[] args)
17 {
18 //var currentUrl = "http://www.mm5mm.com/";
19
20 var currentUrl = "http://www.sohu.com/";
21
22 var request = WebRequest.Create(currentUrl) as HttpWebRequest;
23
24 var response = request.GetResponse() as HttpWebResponse;
25
26 var encode = string.Empty;
27
28 if (response.CharacterSet == "ISO-8859-1")
29 encode = "gb2312";
30 else
31 encode = response.CharacterSet;
32
33 Stream stream;
34
35 if (response.ContentEncoding.ToLower() == "gzip")
36 {
37 stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
38 }
39 else
40 {
41 stream = response.GetResponseStream();
42 }
43
44 var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
45
46 var html = sr.ReadToEnd();
47 }
48 }
49}
50

三:网页分析
现在网页经过一番努力已经得到了,接下来就是解析它了。当然,正则匹配是一个很好的方法。毕竟工作量还是比较大的,业界可能也会尊重。
HtmlAgilityPack,一个解析工具,可以将Html解析成XML,然后使用XPath提取指定的内容,极大的提高了开发速度,提升了性能。
还不错,毕竟敏捷也意味着敏捷。关于XPath的内容,这两张W3CSchool的图大家看懂就OK了。

1using System;
2using System.Collections.Generic;
3using System.Linq;
4using System.Text;
5using System.Threading;
6using HtmlAgilityPack;
7using System.Text.RegularExpressions;
8using System.Net;
9using System.IO;
10using System.IO.Compression;
11
12namespace ConsoleApplication2
13{
14 public class Program
15 {
16 static void Main(string[] args)
17 {
18 //var currentUrl = "http://www.mm5mm.com/";
19
20 var currentUrl = "http://www.sohu.com/";
21
22 var request = WebRequest.Create(currentUrl) as HttpWebRequest;
23
24 var response = request.GetResponse() as HttpWebResponse;
25
26 var encode = string.Empty;
27
28 if (response.CharacterSet == "ISO-8859-1")
29 encode = "gb2312";
30 else
31 encode = response.CharacterSet;
32
33 Stream stream;
34
35 if (response.ContentEncoding.ToLower() == "gzip")
36 {
37 stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
38 }
39 else
40 {
41 stream = response.GetResponseStream();
42 }
43
44 var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
45
46 var html = sr.ReadToEnd();
47
48 sr.Close();
49
50 HtmlDocument document = new HtmlDocument();
51
52 document.LoadHtml(html);
53
54 //提取title
55 var title = document.DocumentNode.SelectSingleNode("//title").InnerText;
56
57 //提取keywords
58 var keywords = document.DocumentNode.SelectSingleNode("//meta[@name='Keywords']").Attributes["content"].Value;
59 }
60 }
61}
62
1 
2
c#抓取网页数据(识别不能实现的原理和问题产生进行介绍(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-05 07:23
困扰了我几天的问题今天终于解决了,分享一下最近使用solr的一些心得。
最初是使用nutch来爬取页面,但是客户需要爬取RSS,通过RSS提要可以识别那些被爬取的页面。虽然 nutch 自带了解析 RSS 的插件,但是有些 RSS 无法解析,难以控制。更重要的是,爬取后和普通页面并没有太大区别。它无法识别和判断爬取的是哪个RSS源。. 由于以上原因,我用C#写了一个项目,用Solr爬取RSS。
一切落实后,客户很满意,我也觉得做工还不错,但是用了一段时间,发现solrdedup时nutch出现故障,导致nutch无法使用。下面将介绍rss的实现原理和问题的产生。Solr和nutch没有解决是因为非常难懂,主要是这样的问题在网上很难找到。由于公司没有外网和版权,一切只能凭记忆写。
RSS+Solr的实现是利用webrequest读取rss源的xml格式的内容,在post方法中直接为solr创建索引。为了满足客户的要求,我在solr的schame中添加了rss和isrss字段,其中rss是rss源的url地址,isrss固定为true。由于nutch没有这两个字段,我们只需要输入isrss:"true"查询rss就可以过滤掉不是来自rss的页面。
实施过程中应注意以下几点
1.rss源不是后缀为xml的文件,有些是普通页面的响应,有些需要登录权限
2.RSS目前主要有两种格式,常见的xml结构是rss/channel/item,另一种是我们博客园rss的结构feed/entry。
里面的label是固定的,可以通过不同的label找到solr中filed所需要的值
3.id、digest、tstamp 三个字段是必须的。
如上所述,nutch 运行到 solrdedup 时,会报错。一开始我以为是solr新增的两个字段。我尝试在nutch中添加两个字段,并且还使用了nutch的静态字段插件和额外字段插件,但是没有成功。最后发现,清除solr数据后,nutch可以正常运行了。我也在谷歌上查了很多,但它根本没有帮助。我认为这是solr缓存的原因。今天刚好有点空,于是找到nutch的报错文件solrdeleteduplicates.java,发现nutch是通过直接从solr中取出id、digest、tstamp字段来去除重复的,不判断是否是直接使用空的。
但是,我写的程序中没有添加digest和tsamp。果然,加上这两个字段后,我完成了没有这两个字段的所有数据,nutch又可以正常运行了。
4.digest是网页的32位hash值,用于nutch去重复时比较差异
5.solr可以直接通过请求url添加、修改、删除内容,修改后的格式和新的一样
主要核心是:xx.xx.xx.xx/solr/update?stream.body=xx&stream.contentType=text/xm;charset=utf-8&commit=true
如果内容有ur格式和html格式,需要转码
6. solr的时间是GMT格式的,所以不要搞错,而且rss中有些GMT格式是错误的,我遇到过很多,错误的星期会导致solr索引失效。
目前信息还是比较全的,搜索也比较方便,但是还有很多问题需要解决,主要是js生成的页面无法读取,可以过滤页面信息。文章的主要内容,过滤导航等信息仍然难以获取。目前,我发现的其他人正在根据统计规则进行过滤。比如很多导航栏用|隔开,内容中的空格用空格隔开。等待。每个站点的html布局风格不同,标签难以统一。百度和谷歌不知道如何实现,或者他们没有真正实现。
Nutch还是比较强大的,但是我总觉得维护和修改不容易。上次编译源码的时间比较长,solr查询也比较高效。可能正计划编写一个 .net 版本的爬虫和搜索,但这只是在计划中,因为涉及的问题太多...... 查看全部
c#抓取网页数据(识别不能实现的原理和问题产生进行介绍(图))
困扰了我几天的问题今天终于解决了,分享一下最近使用solr的一些心得。
最初是使用nutch来爬取页面,但是客户需要爬取RSS,通过RSS提要可以识别那些被爬取的页面。虽然 nutch 自带了解析 RSS 的插件,但是有些 RSS 无法解析,难以控制。更重要的是,爬取后和普通页面并没有太大区别。它无法识别和判断爬取的是哪个RSS源。. 由于以上原因,我用C#写了一个项目,用Solr爬取RSS。
一切落实后,客户很满意,我也觉得做工还不错,但是用了一段时间,发现solrdedup时nutch出现故障,导致nutch无法使用。下面将介绍rss的实现原理和问题的产生。Solr和nutch没有解决是因为非常难懂,主要是这样的问题在网上很难找到。由于公司没有外网和版权,一切只能凭记忆写。
RSS+Solr的实现是利用webrequest读取rss源的xml格式的内容,在post方法中直接为solr创建索引。为了满足客户的要求,我在solr的schame中添加了rss和isrss字段,其中rss是rss源的url地址,isrss固定为true。由于nutch没有这两个字段,我们只需要输入isrss:"true"查询rss就可以过滤掉不是来自rss的页面。
实施过程中应注意以下几点
1.rss源不是后缀为xml的文件,有些是普通页面的响应,有些需要登录权限
2.RSS目前主要有两种格式,常见的xml结构是rss/channel/item,另一种是我们博客园rss的结构feed/entry。
里面的label是固定的,可以通过不同的label找到solr中filed所需要的值
3.id、digest、tstamp 三个字段是必须的。
如上所述,nutch 运行到 solrdedup 时,会报错。一开始我以为是solr新增的两个字段。我尝试在nutch中添加两个字段,并且还使用了nutch的静态字段插件和额外字段插件,但是没有成功。最后发现,清除solr数据后,nutch可以正常运行了。我也在谷歌上查了很多,但它根本没有帮助。我认为这是solr缓存的原因。今天刚好有点空,于是找到nutch的报错文件solrdeleteduplicates.java,发现nutch是通过直接从solr中取出id、digest、tstamp字段来去除重复的,不判断是否是直接使用空的。
但是,我写的程序中没有添加digest和tsamp。果然,加上这两个字段后,我完成了没有这两个字段的所有数据,nutch又可以正常运行了。
4.digest是网页的32位hash值,用于nutch去重复时比较差异
5.solr可以直接通过请求url添加、修改、删除内容,修改后的格式和新的一样
主要核心是:xx.xx.xx.xx/solr/update?stream.body=xx&stream.contentType=text/xm;charset=utf-8&commit=true
如果内容有ur格式和html格式,需要转码
6. solr的时间是GMT格式的,所以不要搞错,而且rss中有些GMT格式是错误的,我遇到过很多,错误的星期会导致solr索引失效。
目前信息还是比较全的,搜索也比较方便,但是还有很多问题需要解决,主要是js生成的页面无法读取,可以过滤页面信息。文章的主要内容,过滤导航等信息仍然难以获取。目前,我发现的其他人正在根据统计规则进行过滤。比如很多导航栏用|隔开,内容中的空格用空格隔开。等待。每个站点的html布局风格不同,标签难以统一。百度和谷歌不知道如何实现,或者他们没有真正实现。
Nutch还是比较强大的,但是我总觉得维护和修改不容易。上次编译源码的时间比较长,solr查询也比较高效。可能正计划编写一个 .net 版本的爬虫和搜索,但这只是在计划中,因为涉及的问题太多......
c#抓取网页数据(网页分析采集程序的基本流程和流程图详解 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-02-04 12:05
)
首先需要明确:网站的任何页面,无论是php、jsp、aspx等动态页面还是后台程序生成的静态页面,都可以在浏览器。
所以当你想开发一个data采集程序时,你首先要了解你要采集的网站的首页结构(HTML)。
一旦熟悉了 网站 中的 HTML 源文件的内容,其中数据是 采集,程序的其余部分就很容易了。因为C#在网站上执行数据采集,原理是“下载你想要的页面的HTML源文件到采集,分析HTML代码然后抓取你需要的数据,最后保存数据。到本地文件”。
基本流程如下图所示:
1.页面源文件下载
首先引用 System.Net 命名空间
使用 System.Net;
还需要引用
使用 System.Text;
使用 System.IO;
复制代码
引用后实例化一个 WebClient 对象
私人 WebClientwc = new WebClient();
调用DownloadData方法从指定网页的源文件中下载一组BYTE数据,然后将BYTE数组转换为字符串。
// 下载页面源文件并转换为UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData( string .Format("你要的网页地址采集")));
复制代码
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
// 下载网页源文件到本地
wc.DownloadFile("你要访问的网页的URL采集", "保存源文件的本地文件路径");
// 读取下载源文件的HTML格式字符串
string mainData = File.ReadAllText("保存源文件的本地文件路径",Encoding.UTF8);
复制代码
使用网页 HTML 格式字符串,您可以分析 采集 网页并抓取您需要的内容。
2.页面分析采集
页面分析就是用网页源文件中的一个特定的或唯一的字符(字符串)作为一个抓取点,从这个抓取点开始截取你想要的页面上的数据。
以博客园为栏目为例,如果我想要采集博客园首页列出的文章的标题和链接,我必须以"开头
代码:
// 经过”
mainData = mainData.Substring(mainData.IndexOf( " " ) + 26 );
// 获取文章页面的链接地址
字符串 articleAddr = mainData.Substring( 0 ,mainData.IndexOf( " \" " ));
// 获取 文章 标题
字符串文章标题 = mainData.Substring(mainData.IndexOf( " target=\"_blank\"> " ) + 16 ,
mainData.IndexOf( " " ) - mainData.IndexOf( " target=\"_blank\"> " ) - 16 );
复制代码
注意:当你要采集的网页首页的HTML格式发生变化时,作为抓取点的字符也要相应的改变,否则采集什么都得不到
3.数据存储
从网页中截取需要的数据后,将程序中的数据组织起来,保存到本地文件中(或者插入到自己的本地数据库中)。这样,整个采集的工作就会在一个段落中完成。
// 输出数据到本地文件
File.AppendAllText(CreateFolderIfNot(Settings.Default.OutPath) + articleTitle + ".txt" ,
文章数据,
编码.UTF8);
复制代码
另外附上我自己写的采集博客园主页文章的小程序代码。该程序的作用是将博客园主页上的文章采集全部发布下来。
下载地址:CnBlogCollector.rar
当然,如果博客园首页的格式调整了,程序的采集功能肯定会失效,而继续采集的唯一办法就是重新调整程序自己一个人,呵呵。. .
程序效果如下:
查看全部
c#抓取网页数据(网页分析采集程序的基本流程和流程图详解
)
首先需要明确:网站的任何页面,无论是php、jsp、aspx等动态页面还是后台程序生成的静态页面,都可以在浏览器。
所以当你想开发一个data采集程序时,你首先要了解你要采集的网站的首页结构(HTML)。
一旦熟悉了 网站 中的 HTML 源文件的内容,其中数据是 采集,程序的其余部分就很容易了。因为C#在网站上执行数据采集,原理是“下载你想要的页面的HTML源文件到采集,分析HTML代码然后抓取你需要的数据,最后保存数据。到本地文件”。
基本流程如下图所示:
1.页面源文件下载
首先引用 System.Net 命名空间
使用 System.Net;
还需要引用
使用 System.Text;
使用 System.IO;
复制代码
引用后实例化一个 WebClient 对象
私人 WebClientwc = new WebClient();
调用DownloadData方法从指定网页的源文件中下载一组BYTE数据,然后将BYTE数组转换为字符串。
// 下载页面源文件并转换为UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData( string .Format("你要的网页地址采集")));
复制代码
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
// 下载网页源文件到本地
wc.DownloadFile("你要访问的网页的URL采集", "保存源文件的本地文件路径");
// 读取下载源文件的HTML格式字符串
string mainData = File.ReadAllText("保存源文件的本地文件路径",Encoding.UTF8);
复制代码
使用网页 HTML 格式字符串,您可以分析 采集 网页并抓取您需要的内容。
2.页面分析采集
页面分析就是用网页源文件中的一个特定的或唯一的字符(字符串)作为一个抓取点,从这个抓取点开始截取你想要的页面上的数据。
以博客园为栏目为例,如果我想要采集博客园首页列出的文章的标题和链接,我必须以"开头

代码:
// 经过”
mainData = mainData.Substring(mainData.IndexOf( " " ) + 26 );
// 获取文章页面的链接地址
字符串 articleAddr = mainData.Substring( 0 ,mainData.IndexOf( " \" " ));
// 获取 文章 标题
字符串文章标题 = mainData.Substring(mainData.IndexOf( " target=\"_blank\"> " ) + 16 ,
mainData.IndexOf( " " ) - mainData.IndexOf( " target=\"_blank\"> " ) - 16 );
复制代码
注意:当你要采集的网页首页的HTML格式发生变化时,作为抓取点的字符也要相应的改变,否则采集什么都得不到
3.数据存储
从网页中截取需要的数据后,将程序中的数据组织起来,保存到本地文件中(或者插入到自己的本地数据库中)。这样,整个采集的工作就会在一个段落中完成。
// 输出数据到本地文件
File.AppendAllText(CreateFolderIfNot(Settings.Default.OutPath) + articleTitle + ".txt" ,
文章数据,
编码.UTF8);
复制代码
另外附上我自己写的采集博客园主页文章的小程序代码。该程序的作用是将博客园主页上的文章采集全部发布下来。
下载地址:CnBlogCollector.rar
当然,如果博客园首页的格式调整了,程序的采集功能肯定会失效,而继续采集的唯一办法就是重新调整程序自己一个人,呵呵。. .
程序效果如下:

c#抓取网页数据(开心网教你如何使用GET方法应该算是最简单,最好操作的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-06 10:15
)
为了简单实现,其他请求信息,如HEAD中的用户浏览器信息,将不附加。
一、使用GET方法
使用 GET 方法应该被认为是最简单和最好的操作。以开心网的用户主页为例,URL统一为:.其中 xxxxxxxx 代表用户的用户 ID。在用户首页,GET方法中,当没有添加其他请求数据时,请求会被重定向到开心网的登录页面。
新建一个控制台,编写GET方法的代码如下:
因为你没有登录,所以可以看到输出页面是登录页面的HTML源码:
二、使用POST方式抓取页面
POST方法与GET方法类似,只是Method方法重置为“POST”,将要POST的数据编码为Byte[]格式,然后设置长度。在请求之前,首先获取HTTPWebRequest的请求流,写入POST数据,然后执行请求。示例如下:
注意:以上请找一个可以通过POST验证的URL进行抓取。
注意POST的时候一定要加上以下代码,否则服务器将无法获取到POST数据
req.ContentType="application/x-www-form-urlencoded";
三、爬取所需的登录页面
其实不管是通过SESSION认证还是通过COOKIE认证,都必须使用请求中相关COOKIE的值。要获取cookie值,必须先用浏览器登录,然后查看登录时必须使用的cookie。比如没有ID的开心网个人主页。爬行。
如果不添加COOKIE,则捕获的HTML是重定向的HTML,即登录页面的HTML。示例代码如下:
由于COOKIE涉及个人隐私,对COOKIE的字符进行了修改。如果有朋友需要使用,请自行登录,登录后查找COOKIE的价值。
运行界面如下:
查看全部
c#抓取网页数据(开心网教你如何使用GET方法应该算是最简单,最好操作的
)
为了简单实现,其他请求信息,如HEAD中的用户浏览器信息,将不附加。
一、使用GET方法
使用 GET 方法应该被认为是最简单和最好的操作。以开心网的用户主页为例,URL统一为:.其中 xxxxxxxx 代表用户的用户 ID。在用户首页,GET方法中,当没有添加其他请求数据时,请求会被重定向到开心网的登录页面。
新建一个控制台,编写GET方法的代码如下:
因为你没有登录,所以可以看到输出页面是登录页面的HTML源码:
二、使用POST方式抓取页面
POST方法与GET方法类似,只是Method方法重置为“POST”,将要POST的数据编码为Byte[]格式,然后设置长度。在请求之前,首先获取HTTPWebRequest的请求流,写入POST数据,然后执行请求。示例如下:
注意:以上请找一个可以通过POST验证的URL进行抓取。
注意POST的时候一定要加上以下代码,否则服务器将无法获取到POST数据
req.ContentType="application/x-www-form-urlencoded";
三、爬取所需的登录页面
其实不管是通过SESSION认证还是通过COOKIE认证,都必须使用请求中相关COOKIE的值。要获取cookie值,必须先用浏览器登录,然后查看登录时必须使用的cookie。比如没有ID的开心网个人主页。爬行。
如果不添加COOKIE,则捕获的HTML是重定向的HTML,即登录页面的HTML。示例代码如下:
由于COOKIE涉及个人隐私,对COOKIE的字符进行了修改。如果有朋友需要使用,请自行登录,登录后查找COOKIE的价值。
运行界面如下:
c#抓取网页数据(获取网页数据有很多种方式-获取网页内容获取方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-03-06 01:03
)
获取网页数据的方法有很多。这里主要介绍通过WebClient、WebBrowser和HttpWebRequest/HttpWebResponse三种方式获取网页内容。
这里得到的是包括网页在内的所有信息。如果你只是需要一些数据内容。您可以使用自己的构造函数来识别和删除它们!一般的做法是根据源代码的格式过滤掉你需要的内容。
一、通过WebClient获取网页内容
这是一种很简单的获取方式,当然其他的获取方式也很简单。这里首先要注意的是,如果考虑实际项目的效率,需要考虑在函数中分配内存区域。大致写成如下
//MemoryStream是一个支持储存区为内存的流。
byte[] buffer = new byte[1024];
using (MemoryStream memory = new MemoryStream())
{
int index = 1, sum = 0;
while (index * sum < 100 * 1024)
{
index = reader.Read(buffer, 0, 1024);
if (index > 0)
{
memory.Write(buffer, 0, index);
sum += index;
}
}
//网页通常使用utf-8或gb2412进行编码
Encoding.GetEncoding("gb2312").GetString(memory.ToArray());
if (string.IsNullOrEmpty(html))
{
return html;
}
else
{
Regex re = new Regex(@"charset=(? charset[/s/S]*?)[ |']");
Match m = re.Match(html.ToLower());
encoding = m.Groups[charset].ToString();
}
if (string.IsNullOrEmpty(encoding) || string.Equals(encoding.ToLower(), "gb2312"))
{
return html;
}
}
好了,现在进入正题,WebClient获取网页数据的代码如下
//using System.IO;
try
{
WebClient webClient = new WebClient();
webClient.Credentials = CredentialCache.DefaultCredentials;//获取或设置用于向Internet资源的请求进行身份验证的网络凭据
Byte[] pageData = webClient.DownloadData("http://www.360doc.com/content/ ... 6quot;);
//string pageHtml = Encoding.Default.GetString(pageData); //如果获取网站页面采用的是GB2312,则使用这句
string pageHtml = Encoding.UTF8.GetString(pageData); //如果获取网站页面采用的是UTF-8,则使用这句
using (StreamWriter sw = new StreamWriter("e:\\ouput.txt"))//将获取的内容写入文本
{
htm = sw.ToString();//测试StreamWriter流的输出状态,非必须
sw.Write(pageHtml);
}
}
catch (WebException webEx)
{
Console.W
}
二、通过WebBrowser控件获取网页内容
相对来说,这是最简单的获取方式。将 WebBrowser 控件拖入其中并匹配以下代码
WebBrowser web = new WebBrowser();
web.Navigate("http://www.163.com");
web.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(web_DocumentCompleted);
void web_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
{
WebBrowser web = (WebBrowser)sender;
HtmlElementCollection ElementCollection = web.Document.GetElementsByTagName("Table");
foreach (HtmlElement item in ElementCollection)
{
File.AppendAllText("Kaijiang_xj.txt", item.InnerText);
}
} 查看全部
c#抓取网页数据(获取网页数据有很多种方式-获取网页内容获取方法
)
获取网页数据的方法有很多。这里主要介绍通过WebClient、WebBrowser和HttpWebRequest/HttpWebResponse三种方式获取网页内容。
这里得到的是包括网页在内的所有信息。如果你只是需要一些数据内容。您可以使用自己的构造函数来识别和删除它们!一般的做法是根据源代码的格式过滤掉你需要的内容。
一、通过WebClient获取网页内容
这是一种很简单的获取方式,当然其他的获取方式也很简单。这里首先要注意的是,如果考虑实际项目的效率,需要考虑在函数中分配内存区域。大致写成如下
//MemoryStream是一个支持储存区为内存的流。
byte[] buffer = new byte[1024];
using (MemoryStream memory = new MemoryStream())
{
int index = 1, sum = 0;
while (index * sum < 100 * 1024)
{
index = reader.Read(buffer, 0, 1024);
if (index > 0)
{
memory.Write(buffer, 0, index);
sum += index;
}
}
//网页通常使用utf-8或gb2412进行编码
Encoding.GetEncoding("gb2312").GetString(memory.ToArray());
if (string.IsNullOrEmpty(html))
{
return html;
}
else
{
Regex re = new Regex(@"charset=(? charset[/s/S]*?)[ |']");
Match m = re.Match(html.ToLower());
encoding = m.Groups[charset].ToString();
}
if (string.IsNullOrEmpty(encoding) || string.Equals(encoding.ToLower(), "gb2312"))
{
return html;
}
}
好了,现在进入正题,WebClient获取网页数据的代码如下
//using System.IO;
try
{
WebClient webClient = new WebClient();
webClient.Credentials = CredentialCache.DefaultCredentials;//获取或设置用于向Internet资源的请求进行身份验证的网络凭据
Byte[] pageData = webClient.DownloadData("http://www.360doc.com/content/ ... 6quot;);
//string pageHtml = Encoding.Default.GetString(pageData); //如果获取网站页面采用的是GB2312,则使用这句
string pageHtml = Encoding.UTF8.GetString(pageData); //如果获取网站页面采用的是UTF-8,则使用这句
using (StreamWriter sw = new StreamWriter("e:\\ouput.txt"))//将获取的内容写入文本
{
htm = sw.ToString();//测试StreamWriter流的输出状态,非必须
sw.Write(pageHtml);
}
}
catch (WebException webEx)
{
Console.W
}
二、通过WebBrowser控件获取网页内容
相对来说,这是最简单的获取方式。将 WebBrowser 控件拖入其中并匹配以下代码
WebBrowser web = new WebBrowser();
web.Navigate("http://www.163.com";);
web.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(web_DocumentCompleted);
void web_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
{
WebBrowser web = (WebBrowser)sender;
HtmlElementCollection ElementCollection = web.Document.GetElementsByTagName("Table");
foreach (HtmlElement item in ElementCollection)
{
File.AppendAllText("Kaijiang_xj.txt", item.InnerText);
}
}
c#抓取网页数据(就是通过编程的方法去抓取不同网站网页进行分析筛选)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-05 08:21
近期工作需要定期爬取不同城市的每日气温。其实就是通过编程爬取不同的网站网页进行分析筛选的过程。 .NET 提供了许多类来访问和从远程网页获取数据,例如 WebClient 类和 HttpWebRequest 类。这些类对于使用 HTTP 访问远程网页并下载它们很有用,但它们在解析下载的 HTML 方面非常薄弱。推荐使用开源组件 HTML Agility Pack(),其设计目标是尽可能简化 HTML 文档的读写。包本身利用 DOM 文档对象模型来解析 HTML。顺便记录一下最近采集的爬取历史和当前天气网站备份:
编程示例如下:我们要获取以下网页中的天气信息:
下载HTML Agility Pack组件,新建一个控制台程序,在你的项目中引用对应框架版本对应的组件。示例代码如下:
string url = @"http://lishi.tianqi.com/beijing/201701.html";
var webGet = new HtmlWeb();
var document = webGet.Load(url);
var div = document.DocumentNode.SelectNodes("//div[@class=‘tqtongji2‘]/ul");
foreach (HtmlNode node in div)
{
var tmpNode = node.SelectNodes("li");
Console.WriteLine(string.Format("{0}-----------{1}---------{2}----------{3}",
tmpNode[0].InnerText,
tmpNode[1].InnerText,
tmpNode[2].InnerText,
tmpNode[3].InnerText));
}
Console.ReadKey();
程序运行效果:汉字出现乱码,如下图
通过分析HTML Agility Pack源码,在HtmlWeb类的Get(Uri uri, string method, string path, HtmlDocument doc)方法中,局部变量resp为http请求的响应。设置断点发现resp.ContentEncoding为空。因此,数据是通过 HttpWebRequest 下载的。示例代码如下:
string url = @"http://lishi.tianqi.com/beijing/201701.html";
HttpWebRequest req = WebRequest.Create(new Uri(url)) as HttpWebRequest;
req.Method = "GET";
WebResponse rs = req.GetResponse();
Stream rss = rs.GetResponseStream();
HtmlDocument doc = new HtmlDocument();
doc.Load(rss);
var div = doc.DocumentNode.SelectNodes("//div[@class=‘tqtongji2‘]/ul");
foreach (HtmlNode node in div)
{
var tmpNode = node.SelectNodes("li");
Console.WriteLine(string.Format("{0}-----------{1}---------{2}----------{3}",
tmpNode[0].InnerText,
tmpNode[1].InnerText,
tmpNode[2].InnerText,
tmpNode[3].InnerText));
}
Console.ReadKey();
代码运行如下:
没关系!!!
原文: 查看全部
c#抓取网页数据(就是通过编程的方法去抓取不同网站网页进行分析筛选)
近期工作需要定期爬取不同城市的每日气温。其实就是通过编程爬取不同的网站网页进行分析筛选的过程。 .NET 提供了许多类来访问和从远程网页获取数据,例如 WebClient 类和 HttpWebRequest 类。这些类对于使用 HTTP 访问远程网页并下载它们很有用,但它们在解析下载的 HTML 方面非常薄弱。推荐使用开源组件 HTML Agility Pack(),其设计目标是尽可能简化 HTML 文档的读写。包本身利用 DOM 文档对象模型来解析 HTML。顺便记录一下最近采集的爬取历史和当前天气网站备份:
编程示例如下:我们要获取以下网页中的天气信息:
下载HTML Agility Pack组件,新建一个控制台程序,在你的项目中引用对应框架版本对应的组件。示例代码如下:
string url = @"http://lishi.tianqi.com/beijing/201701.html";
var webGet = new HtmlWeb();
var document = webGet.Load(url);
var div = document.DocumentNode.SelectNodes("//div[@class=‘tqtongji2‘]/ul");
foreach (HtmlNode node in div)
{
var tmpNode = node.SelectNodes("li");
Console.WriteLine(string.Format("{0}-----------{1}---------{2}----------{3}",
tmpNode[0].InnerText,
tmpNode[1].InnerText,
tmpNode[2].InnerText,
tmpNode[3].InnerText));
}
Console.ReadKey();
程序运行效果:汉字出现乱码,如下图
通过分析HTML Agility Pack源码,在HtmlWeb类的Get(Uri uri, string method, string path, HtmlDocument doc)方法中,局部变量resp为http请求的响应。设置断点发现resp.ContentEncoding为空。因此,数据是通过 HttpWebRequest 下载的。示例代码如下:
string url = @"http://lishi.tianqi.com/beijing/201701.html";
HttpWebRequest req = WebRequest.Create(new Uri(url)) as HttpWebRequest;
req.Method = "GET";
WebResponse rs = req.GetResponse();
Stream rss = rs.GetResponseStream();
HtmlDocument doc = new HtmlDocument();
doc.Load(rss);
var div = doc.DocumentNode.SelectNodes("//div[@class=‘tqtongji2‘]/ul");
foreach (HtmlNode node in div)
{
var tmpNode = node.SelectNodes("li");
Console.WriteLine(string.Format("{0}-----------{1}---------{2}----------{3}",
tmpNode[0].InnerText,
tmpNode[1].InnerText,
tmpNode[2].InnerText,
tmpNode[3].InnerText));
}
Console.ReadKey();
代码运行如下:
没关系!!!
原文:
c#抓取网页数据(,发现网站上限域名是1g,就没再继续,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-04 13:02
c#抓取网页数据到txt格式比较简单,但是在登录网站的时候,发现网站上限域名是1g,就没再继续,最后查了一下,登录好的1g域名是可以扩展来再去抓取的。具体步骤如下:第一步,asp爬虫小雪编写自己网站抓取的小工具。第二步,手动将小工具编译到c代码,打包编译。其中一个功能是修改我们代码生成c:\svn\test\c,然后启动word再浏览器试试登录域名。
抓取成功如下:ps:完成图csdn注册成功后,默认登录好的域名是1。com。注意密码登录,保存,解压缩到c下,然后访问(有时会失败)net'default@localhost'/users/ovowangu/data/svn/test/src/1。c#第三步,建立爬虫目录cn_seed。gitignore。
<p>第四步,当我们搜索/"cn"的时候,跳转到/"cn_seed。gitignore。"第五步,修改c。txt为。gitignore。点击文件,打开c。txt选中第一个,点击确定,重新登录https再找txt。第六步,删除c#。gitignore文件。第七步,在我们的txt的域名之后添加。html下面的内容我们这里不做修改有空给后面更新c的源码吧。下一步是用net把我们的class加到chrome'。txt'上面。最后简单看看效果:说明:1。net爬虫小雪大大不是ios程序员。他只是把word里的c#。gitignore。换成了。html。2。欢迎大家来github(cadectopignhe_)msolubblestart! 查看全部
c#抓取网页数据(,发现网站上限域名是1g,就没再继续,)
c#抓取网页数据到txt格式比较简单,但是在登录网站的时候,发现网站上限域名是1g,就没再继续,最后查了一下,登录好的1g域名是可以扩展来再去抓取的。具体步骤如下:第一步,asp爬虫小雪编写自己网站抓取的小工具。第二步,手动将小工具编译到c代码,打包编译。其中一个功能是修改我们代码生成c:\svn\test\c,然后启动word再浏览器试试登录域名。
抓取成功如下:ps:完成图csdn注册成功后,默认登录好的域名是1。com。注意密码登录,保存,解压缩到c下,然后访问(有时会失败)net'default@localhost'/users/ovowangu/data/svn/test/src/1。c#第三步,建立爬虫目录cn_seed。gitignore。
<p>第四步,当我们搜索/"cn"的时候,跳转到/"cn_seed。gitignore。"第五步,修改c。txt为。gitignore。点击文件,打开c。txt选中第一个,点击确定,重新登录https再找txt。第六步,删除c#。gitignore文件。第七步,在我们的txt的域名之后添加。html下面的内容我们这里不做修改有空给后面更新c的源码吧。下一步是用net把我们的class加到chrome'。txt'上面。最后简单看看效果:说明:1。net爬虫小雪大大不是ios程序员。他只是把word里的c#。gitignore。换成了。html。2。欢迎大家来github(cadectopignhe_)msolubblestart!
c#抓取网页数据(第一次用C#写数据抓取,遇到各种问题怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-03-02 17:12
第一次用C#写数据采集,遇到各种问题。开始写模拟登录的时候,发现有验证码。我必须突破验证码才能得到它。好吧,那我去找破解验证码的代码。我尝试了很多代码,发现它们并不通用。后来,我明白了其中的原理。首先去除噪点、干扰线等,然后将颜色验证码转换成黑白,同时进行字体切割。,如果字体是粘的,对于我们初学者(外行),那就放弃吧。裁剪后,每个像素都编码,白0,黑1,好像是这样的,不是太懂,再看一遍,拿字体库模型里的字做对比。如果达到百分比或更多,它会识别验证码是什么,并一一进行比较。最后形成一个完整的验证码。无法完成验证码破解,所以放弃破解,另寻方法。
网上说验证码可能会保存在cookie中。嗯,抱着试试的态度去吧,模拟浏览器发送数据,请求验证码,FF调试,发现cookie中有验证码。就这样,验证码到此结束,我们重新登录。
要登录,首先跟踪目标页面的逻辑,看看它是如何传递参数成功登录的。我只是先发送一个请求对用户名和密码进行加密,然后将加密后的发送到后台进行登录。这没什么好说的。这期间遇到的问题是发送请求,半天不成功。原因是当时发送了一个ajax请求,需要设置调用哪个方法。网站 一般直接要求后台,而不是发出ajax请求,所以这里又是一团糟。
关键代码:
request.Headers.Add("X-AjaxPro-Method", "方法名");
登录成功后,就到了抓取页面的时间了。首先获取抓取页面的html,然后分析它如何提交数据,如何返回,传递了什么参数等等。爬取页面没有问题,然后是模拟查询数据,那个网站写的,隐藏字段控件很多,所以发送请求的时候参数很多,不知道它是干什么用的,反正我觉得只查询订单号是有用的。模拟发送很长时间后,报500错误。这是因为模拟参数有问题,服务器无法读取。我已经完成了所有设置。我发现它没有任何问题。2天后,它卡在这里。没有办法。之后,无意中发现提交的数据和页面隐藏字段的数据有点不一样。输入特殊字符。转码后想了想之前写的代码传输参数,发现传输数据的时候,都需要通过UrlEncode转码,然后传输。虽然隐藏字段的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说就开始转码参数了
HttpUtility.UrlEncode(string);
居然成功了,太烧脑了,虽然对于一些老手来说,这些可能不知道,但第一次接触还是很难写。
对了,还有一个问题,就是读取html后获取字符串html中的参数的问题,当然在页面上很容易获取,但是现在都是一堆字符串,这真的很难,所以我找到了一个非常好用的dll,支持xpath,和xmlDocument一样的用法,
部分代码:
HtmlDocument htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(html.Replace("\r", "").Replace("\n", ""));
HtmlNodeCollection collection = htmlDocument.DocumentNode.SelectSingleNode("/html/body/div").ChildNodes;
foreach (HtmlNode htmlNode in collection)
{
var tempId = htmlNode.Attributes["id"].Value;
}
红色部分是xpath规则,
也可以根据属性获取对应的节点:
htmlDocument.DocumentNode.SelectSingleNode("/html/body/div[2]/input[@id='__EVENTVALIDATION']");
这是:HtmlAgilityPack 下载地址:点击打开链接
最好阅读此 网站 评论。里面有很多人的问题,说不定能帮上忙。
好了,写了这么多,接下来我整理一下代码发上来,然后开始循环爬取数据。 查看全部
c#抓取网页数据(第一次用C#写数据抓取,遇到各种问题怎么办?)
第一次用C#写数据采集,遇到各种问题。开始写模拟登录的时候,发现有验证码。我必须突破验证码才能得到它。好吧,那我去找破解验证码的代码。我尝试了很多代码,发现它们并不通用。后来,我明白了其中的原理。首先去除噪点、干扰线等,然后将颜色验证码转换成黑白,同时进行字体切割。,如果字体是粘的,对于我们初学者(外行),那就放弃吧。裁剪后,每个像素都编码,白0,黑1,好像是这样的,不是太懂,再看一遍,拿字体库模型里的字做对比。如果达到百分比或更多,它会识别验证码是什么,并一一进行比较。最后形成一个完整的验证码。无法完成验证码破解,所以放弃破解,另寻方法。
网上说验证码可能会保存在cookie中。嗯,抱着试试的态度去吧,模拟浏览器发送数据,请求验证码,FF调试,发现cookie中有验证码。就这样,验证码到此结束,我们重新登录。
要登录,首先跟踪目标页面的逻辑,看看它是如何传递参数成功登录的。我只是先发送一个请求对用户名和密码进行加密,然后将加密后的发送到后台进行登录。这没什么好说的。这期间遇到的问题是发送请求,半天不成功。原因是当时发送了一个ajax请求,需要设置调用哪个方法。网站 一般直接要求后台,而不是发出ajax请求,所以这里又是一团糟。
关键代码:
request.Headers.Add("X-AjaxPro-Method", "方法名");
登录成功后,就到了抓取页面的时间了。首先获取抓取页面的html,然后分析它如何提交数据,如何返回,传递了什么参数等等。爬取页面没有问题,然后是模拟查询数据,那个网站写的,隐藏字段控件很多,所以发送请求的时候参数很多,不知道它是干什么用的,反正我觉得只查询订单号是有用的。模拟发送很长时间后,报500错误。这是因为模拟参数有问题,服务器无法读取。我已经完成了所有设置。我发现它没有任何问题。2天后,它卡在这里。没有办法。之后,无意中发现提交的数据和页面隐藏字段的数据有点不一样。输入特殊字符。转码后想了想之前写的代码传输参数,发现传输数据的时候,都需要通过UrlEncode转码,然后传输。虽然隐藏字段的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说就开始转码参数了
HttpUtility.UrlEncode(string);
居然成功了,太烧脑了,虽然对于一些老手来说,这些可能不知道,但第一次接触还是很难写。
对了,还有一个问题,就是读取html后获取字符串html中的参数的问题,当然在页面上很容易获取,但是现在都是一堆字符串,这真的很难,所以我找到了一个非常好用的dll,支持xpath,和xmlDocument一样的用法,
部分代码:
HtmlDocument htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(html.Replace("\r", "").Replace("\n", ""));
HtmlNodeCollection collection = htmlDocument.DocumentNode.SelectSingleNode("/html/body/div").ChildNodes;
foreach (HtmlNode htmlNode in collection)
{
var tempId = htmlNode.Attributes["id"].Value;
}
红色部分是xpath规则,
也可以根据属性获取对应的节点:
htmlDocument.DocumentNode.SelectSingleNode("/html/body/div[2]/input[@id='__EVENTVALIDATION']");
这是:HtmlAgilityPack 下载地址:点击打开链接
最好阅读此 网站 评论。里面有很多人的问题,说不定能帮上忙。
好了,写了这么多,接下来我整理一下代码发上来,然后开始循环爬取数据。
c#抓取网页数据(第一次用C#写数据抓取,遇到各种问题怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-02 17:09
第一次用C#写数据采集,遇到各种问题。开始写模拟登录的时候,发现有验证码。我必须突破验证码才能得到它。好吧,那我去找破解验证码的代码。我尝试了很多代码,发现它们并不通用。后来,我明白了其中的原理。首先去除噪点、干扰线等,然后将颜色验证码转换成黑白,同时进行字体切割。,如果字体是粘的,对于我们初学者(外行),那就放弃吧。裁剪后,每个像素都编码,白0,黑1,好像是这样的,不是太懂,再看一遍,拿字体库模型里的字做对比。如果达到百分比或更多,它会识别验证码是什么,并一一进行比较。最后形成一个完整的验证码。无法完成验证码破解,所以放弃破解,另寻方法。
网上说验证码可能会保存在cookie中。嗯,抱着试试的态度去吧,模拟浏览器发送数据,请求验证码,FF调试,发现cookie中有验证码。就这样,验证码到此结束,我们重新登录。
要登录,首先跟踪目标页面的逻辑,看看它是如何传递参数成功登录的。我只是先发送一个请求对用户名和密码进行加密,然后将加密后的发送到后台进行登录。这没什么好说的。这期间遇到的问题是发送请求,半天不成功。原因是当时发送了一个ajax请求,需要设置调用哪个方法。网站 一般直接要求后台,而不是发出ajax请求,所以这里又是一团糟。
关键代码:
request.Headers.Add("X-AjaxPro-Method", "方法名");
登录成功后,就到了抓取页面的时间了。首先获取抓取页面的html,然后分析它如何提交数据,如何返回,传递了什么参数等等。爬取页面没有问题,然后是模拟查询数据,那个网站写的,隐藏字段控件很多,所以发送请求的时候参数很多,不知道它是干什么用的,反正我觉得只查询订单号是有用的。模拟发送很长时间后,报500错误。这是因为模拟参数有问题,服务器无法读取。我已经完成了所有设置。我发现它没有任何问题。2天后,它卡在这里。没有办法。之后,无意中发现提交的数据和页面隐藏字段的数据有点不一样。输入特殊字符。转码后想了想之前写的代码传输参数,发现传输数据的时候,都需要通过UrlEncode转码,然后传输。虽然隐藏字段的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说就开始转码参数了
HttpUtility.UrlEncode(string);
居然成功了,太烧脑了,虽然对于一些老手来说,这些可能不知道,但第一次接触还是很难写。
对了,还有一个问题,就是读取html后获取字符串html中的参数的问题,当然在页面上很容易获取,但是现在都是一堆字符串,这真的很难,所以我找到了一个非常好用的dll,支持xpath,和xmlDocument一样的用法,
部分代码:
HtmlDocument htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(html.Replace("\r", "").Replace("\n", ""));
HtmlNodeCollection collection = htmlDocument.DocumentNode.SelectSingleNode("/html/body/div").ChildNodes;
foreach (HtmlNode htmlNode in collection)
{
var tempId = htmlNode.Attributes["id"].Value;
}
红色部分是xpath规则,
也可以根据属性获取对应的节点:
htmlDocument.DocumentNode.SelectSingleNode("/html/body/div[2]/input[@id='__EVENTVALIDATION']");
这是:HtmlAgilityPack 下载地址:点击打开链接
最好阅读此 网站 评论。里面有很多人的问题,说不定能帮上忙。
好了,写了这么多,接下来我整理一下代码发上来,然后开始循环爬取数据。 查看全部
c#抓取网页数据(第一次用C#写数据抓取,遇到各种问题怎么办?)
第一次用C#写数据采集,遇到各种问题。开始写模拟登录的时候,发现有验证码。我必须突破验证码才能得到它。好吧,那我去找破解验证码的代码。我尝试了很多代码,发现它们并不通用。后来,我明白了其中的原理。首先去除噪点、干扰线等,然后将颜色验证码转换成黑白,同时进行字体切割。,如果字体是粘的,对于我们初学者(外行),那就放弃吧。裁剪后,每个像素都编码,白0,黑1,好像是这样的,不是太懂,再看一遍,拿字体库模型里的字做对比。如果达到百分比或更多,它会识别验证码是什么,并一一进行比较。最后形成一个完整的验证码。无法完成验证码破解,所以放弃破解,另寻方法。
网上说验证码可能会保存在cookie中。嗯,抱着试试的态度去吧,模拟浏览器发送数据,请求验证码,FF调试,发现cookie中有验证码。就这样,验证码到此结束,我们重新登录。
要登录,首先跟踪目标页面的逻辑,看看它是如何传递参数成功登录的。我只是先发送一个请求对用户名和密码进行加密,然后将加密后的发送到后台进行登录。这没什么好说的。这期间遇到的问题是发送请求,半天不成功。原因是当时发送了一个ajax请求,需要设置调用哪个方法。网站 一般直接要求后台,而不是发出ajax请求,所以这里又是一团糟。
关键代码:
request.Headers.Add("X-AjaxPro-Method", "方法名");
登录成功后,就到了抓取页面的时间了。首先获取抓取页面的html,然后分析它如何提交数据,如何返回,传递了什么参数等等。爬取页面没有问题,然后是模拟查询数据,那个网站写的,隐藏字段控件很多,所以发送请求的时候参数很多,不知道它是干什么用的,反正我觉得只查询订单号是有用的。模拟发送很长时间后,报500错误。这是因为模拟参数有问题,服务器无法读取。我已经完成了所有设置。我发现它没有任何问题。2天后,它卡在这里。没有办法。之后,无意中发现提交的数据和页面隐藏字段的数据有点不一样。输入特殊字符。转码后想了想之前写的代码传输参数,发现传输数据的时候,都需要通过UrlEncode转码,然后传输。虽然隐藏字段的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说就开始转码参数了
HttpUtility.UrlEncode(string);
居然成功了,太烧脑了,虽然对于一些老手来说,这些可能不知道,但第一次接触还是很难写。
对了,还有一个问题,就是读取html后获取字符串html中的参数的问题,当然在页面上很容易获取,但是现在都是一堆字符串,这真的很难,所以我找到了一个非常好用的dll,支持xpath,和xmlDocument一样的用法,
部分代码:
HtmlDocument htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(html.Replace("\r", "").Replace("\n", ""));
HtmlNodeCollection collection = htmlDocument.DocumentNode.SelectSingleNode("/html/body/div").ChildNodes;
foreach (HtmlNode htmlNode in collection)
{
var tempId = htmlNode.Attributes["id"].Value;
}
红色部分是xpath规则,
也可以根据属性获取对应的节点:
htmlDocument.DocumentNode.SelectSingleNode("/html/body/div[2]/input[@id='__EVENTVALIDATION']");
这是:HtmlAgilityPack 下载地址:点击打开链接
最好阅读此 网站 评论。里面有很多人的问题,说不定能帮上忙。
好了,写了这么多,接下来我整理一下代码发上来,然后开始循环爬取数据。
c#抓取网页数据(c#抓取网页数据简单实现一个简单的功能-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-02 08:01
c#抓取网页数据可能有点专业,不是那么容易。但是可以通过类似的思路,简单实现一个简单的功能。先来看这段代码:如果想学编程,可以到学习交流群670351711。一个完整的抓取过程分三步:构建请求库,解析请求,请求转发构建请求库c#里面提供一个customjs库,名字叫check_action.hub,在基础包里面有详细介绍。
c#链接数据库,对于抓取大规模数据,需要自己写一个对数据库连接。mysql也有对应的手机链接库,mongodb也有对应的web接口。所以最简单的方法是直接建一个数据库连接,把数据传进去,其实c#有很多常用连接方式。解析请求首先介绍下sendonly对象,它的意思是只发出一次请求。但是对于大规模并发请求,每个请求都是耗时操作,甚至一秒内就响应一个请求,所以我们还是想尽可能多发出一次请求,这时候就得使用类似emit的方法,来从主机域传输一次请求。
常用的有inetsocket、inetsocketaddress两种方法,它们之间有什么区别呢?请看demo,当请求连接失败时,emit会重试请求。emit:inetsocketandinetsocketaddressinetsocketapi注意到哪里了么?用下面的两个例子说明一下:例子1:inetsocketapisend:{inetsocketaddress:newinetsocketaddress(),//send连接名字//nothingforenoughtogetinetsocketaddressthroughthisaction}例子2:inetsocketapisend:{inetsocketaddress:newinetsocketaddress(),//emit连接名字,用来处理请求地址inetsocketaddress.setpath("/")}demo如果某个连接不能被接受,则可以利用这个连接将上面的请求接收并处理,这样既能保证有效性,又能处理大量并发的请求。
转发请求在抓取请求后,就可以将请求转发给一些服务器。最简单的就是使用socket,基本原理是创建一个连接,然后使用socket将一些请求包装成字节流发送给服务器,然后接收到字节流的服务器再把字节流转发到另一台服务器。publicmapsendbymethod(connectionsender,socketsocket,mapmap){try{socket=socketimpl.newinstance();//instance为可选参数,传值需要加锁,防止被回放和类型检查。
//protected只有protected的成员成员方法才protected,即不能在非protected成员方法中使用。//connection=socketimpl.newinstance();socket.beginthread();socket.accept();socket.bind(newprotectedbasestreampath(map.pathname(map.stringutils("/mycreatestream.java";//连接地址socket.listen();。 查看全部
c#抓取网页数据(c#抓取网页数据简单实现一个简单的功能-乐题库)
c#抓取网页数据可能有点专业,不是那么容易。但是可以通过类似的思路,简单实现一个简单的功能。先来看这段代码:如果想学编程,可以到学习交流群670351711。一个完整的抓取过程分三步:构建请求库,解析请求,请求转发构建请求库c#里面提供一个customjs库,名字叫check_action.hub,在基础包里面有详细介绍。
c#链接数据库,对于抓取大规模数据,需要自己写一个对数据库连接。mysql也有对应的手机链接库,mongodb也有对应的web接口。所以最简单的方法是直接建一个数据库连接,把数据传进去,其实c#有很多常用连接方式。解析请求首先介绍下sendonly对象,它的意思是只发出一次请求。但是对于大规模并发请求,每个请求都是耗时操作,甚至一秒内就响应一个请求,所以我们还是想尽可能多发出一次请求,这时候就得使用类似emit的方法,来从主机域传输一次请求。
常用的有inetsocket、inetsocketaddress两种方法,它们之间有什么区别呢?请看demo,当请求连接失败时,emit会重试请求。emit:inetsocketandinetsocketaddressinetsocketapi注意到哪里了么?用下面的两个例子说明一下:例子1:inetsocketapisend:{inetsocketaddress:newinetsocketaddress(),//send连接名字//nothingforenoughtogetinetsocketaddressthroughthisaction}例子2:inetsocketapisend:{inetsocketaddress:newinetsocketaddress(),//emit连接名字,用来处理请求地址inetsocketaddress.setpath("/")}demo如果某个连接不能被接受,则可以利用这个连接将上面的请求接收并处理,这样既能保证有效性,又能处理大量并发的请求。
转发请求在抓取请求后,就可以将请求转发给一些服务器。最简单的就是使用socket,基本原理是创建一个连接,然后使用socket将一些请求包装成字节流发送给服务器,然后接收到字节流的服务器再把字节流转发到另一台服务器。publicmapsendbymethod(connectionsender,socketsocket,mapmap){try{socket=socketimpl.newinstance();//instance为可选参数,传值需要加锁,防止被回放和类型检查。
//protected只有protected的成员成员方法才protected,即不能在非protected成员方法中使用。//connection=socketimpl.newinstance();socket.beginthread();socket.accept();socket.bind(newprotectedbasestreampath(map.pathname(map.stringutils("/mycreatestream.java";//连接地址socket.listen();。
c#抓取网页数据(想做爬虫工具?是做的公司的一个项目是从网上抓数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-01 04:10
)
C#抓取网页数据问题我写了一个小程序来抓取网页上的内容。从数据库中读出 2600 个 ID。然后循环读取ID,拼接到网站的URL中。然后使用正则表达式来匹配网页中的内容。将读取的数据存储在数据库中。大致相同的过程。现在我的问题是程序运行一次后,只读取了2100条ID数据。还有 500 件物品没有被捕获。这500有的没有数据,有的有404,我能理解。但是,有一些 ID 可以找到数据。程序获取到这些正常ID的HTML代码后,使用正则表达式进行匹配,但没有匹配到数据。我认为这是一个正则表达式问题。我选择了一个普通的ID来测试,原来的正则表达式可以得到正确的内容。这是怎么回事啊。征求专家意见。--------------------编程Q&A--------------------想做爬虫工具?--------------------编程问答-------------------- 引用1日rui_china的回复楼:觉得做爬虫工具吗?
该公司的项目之一是从互联网上抓取数据并将其放入我们的数据库中。--------------------编程问答--------------------不要依赖正则表达式,编写自己的方法。以前用VB写太多找不到规律--------编程问答---------- -------- -- 测试在什么情况下正则化失败。. -------------------- 编程问答-------------------- 不知道发生了什么。
但是您可以编写一个“警报”功能。当获取到网页的html内容,但是没有解析数据时,应该记录日志!-------------------- 编程问答-------------------- 无论如何,如果你不能准确重现错误很难解决。因此,捕捉问题的方法更为重要。去csdn解决不了那种连自己都难以复现的问题,在没有得到具体数据的情况下让别人猜测。--------------------编程Q&A--------这样应该通过多线程来完成. 我怀疑您的程序在运行时丢失了。可以记录抓取到的id的网页,看看这些网页是否没有被分析过。---------编程问答 A-------- ------------- 最近在帮公司写一个比价程序,和你说的差不多。使用 HtmlAgilityPack。
补充:.NET技术 , C# 查看全部
c#抓取网页数据(想做爬虫工具?是做的公司的一个项目是从网上抓数据
)
C#抓取网页数据问题我写了一个小程序来抓取网页上的内容。从数据库中读出 2600 个 ID。然后循环读取ID,拼接到网站的URL中。然后使用正则表达式来匹配网页中的内容。将读取的数据存储在数据库中。大致相同的过程。现在我的问题是程序运行一次后,只读取了2100条ID数据。还有 500 件物品没有被捕获。这500有的没有数据,有的有404,我能理解。但是,有一些 ID 可以找到数据。程序获取到这些正常ID的HTML代码后,使用正则表达式进行匹配,但没有匹配到数据。我认为这是一个正则表达式问题。我选择了一个普通的ID来测试,原来的正则表达式可以得到正确的内容。这是怎么回事啊。征求专家意见。--------------------编程Q&A--------------------想做爬虫工具?--------------------编程问答-------------------- 引用1日rui_china的回复楼:觉得做爬虫工具吗?
该公司的项目之一是从互联网上抓取数据并将其放入我们的数据库中。--------------------编程问答--------------------不要依赖正则表达式,编写自己的方法。以前用VB写太多找不到规律--------编程问答---------- -------- -- 测试在什么情况下正则化失败。. -------------------- 编程问答-------------------- 不知道发生了什么。
但是您可以编写一个“警报”功能。当获取到网页的html内容,但是没有解析数据时,应该记录日志!-------------------- 编程问答-------------------- 无论如何,如果你不能准确重现错误很难解决。因此,捕捉问题的方法更为重要。去csdn解决不了那种连自己都难以复现的问题,在没有得到具体数据的情况下让别人猜测。--------------------编程Q&A--------这样应该通过多线程来完成. 我怀疑您的程序在运行时丢失了。可以记录抓取到的id的网页,看看这些网页是否没有被分析过。---------编程问答 A-------- ------------- 最近在帮公司写一个比价程序,和你说的差不多。使用 HtmlAgilityPack。
补充:.NET技术 , C#
c#抓取网页数据(可轻爬虫成长日记之创建工程-抽取数据--示例视频教程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-03-01 04:09
阿里云 > 云栖社区 > 主题地图 > C > 网页中的C#爬取数据库
推荐活动:
更多优惠>
当前话题:c#抓取网页中的数据库并将其添加到集合中
相关话题:
c#抓取数据库在web相关博客中查看更多博客
云数据库产品概述
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
c#批量抓取免费代理并验证有效性
作者:曹章林 1170 浏览评论:03年前
我看到某公司官网上文章的浏览量每刷新一次页面就会增加一次,给人一种不好的感觉。一家公司的官网给人的就是这样一个直截了当的漏洞。当我批量发起请求时,发现页面打开报错。100多人的公司官网文章刷新了,你可以给我看看这个。这家公司之前来我校宣传招聘+在园里找招聘的时候发现
阅读全文
scrapy爬虫成长日记将爬取的内容写入mysql数据库
作者:哼99251585 浏览评论:04年前
我尝试用scrapy爬取博客园的博客(可以查看scrapy爬虫成长日记的创建项目-提取数据-将数据保存为json格式),但是之前抓取的数据在文件中保存为json格式的文本。这显然不符合我们日常的实际应用。接下来我们看看如何将抓取到的内容保存在一个常用的m
阅读全文
500份C#源代码
作者:科技小美 3635人查看评论:14年前
C夏普短信发送平台源码.rar ASP.NET+AJAX基础示例视频教程 C# Winform qq弹窗360弹窗
阅读全文
爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站(转)
作者:老朱教授 1373 浏览评论:04年前
爬取网页的一般逻辑和流程一般是普通用户,他们使用浏览器打开一个URL地址,然后浏览器就可以显示相应页面的内容。这个过程,如果用程序代码实现,可以调用(程序实现)爬取网页(内容,以及后处理,提取需要的信息等)对应的英文是,website
阅读全文
C#爬虫web程序的实现解析
作者:zting Technology 698人 浏览评论:05年前
C#爬取网页程序是如何实现的?我们先来了解一下 HTTP,它是 WWW 中最基本的数据访问协议之一。.NET的基本类型库类中提供了两个对象类:HTTPWebRequest和HTTPWebResponse,分别用于向资源发送请求和获取。回复。获取资源的内容
阅读全文
C#实现图标的批量下载
作者:gisweis1079 浏览评论:05年前
这篇文章有点长,编辑修改了好几个晚上。如果文字和排版有问题,请见谅。本文分为四个部分,以下是主要内容,也是软件开发的基本流程。阶段描述需求分析主要描述实现程序的目的,分析需求,即为什么要花时间写,需要什么功能等;
阅读全文
scrapy爬虫成长日记将爬取的内容写入mysql数据库
作者:无声胜有声732 浏览评论:06年前
我尝试用scrapy爬取博客园的博客(可以查看scrapy爬虫成长日记的创建项目-提取数据-将数据保存为json格式),但是之前抓取的数据在文件中保存为json格式的文本。这显然不符合我们日常的实际应用。接下来我们看看如何将抓取到的内容保存在一个普通的
阅读全文
500份C#源代码
作者:蓬莱闲鱼2601 浏览评论:08年前
C夏普短信发送平台源码.rar ASP.NET+AJAX基础示例视频教程 C# Winform qq弹窗360弹窗
阅读全文
c#爬取网页中数据库相关问答
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文 查看全部
c#抓取网页数据(可轻爬虫成长日记之创建工程-抽取数据--示例视频教程(组图))
阿里云 > 云栖社区 > 主题地图 > C > 网页中的C#爬取数据库
推荐活动:
更多优惠>
当前话题:c#抓取网页中的数据库并将其添加到集合中
相关话题:
c#抓取数据库在web相关博客中查看更多博客
云数据库产品概述
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
c#批量抓取免费代理并验证有效性
作者:曹章林 1170 浏览评论:03年前
我看到某公司官网上文章的浏览量每刷新一次页面就会增加一次,给人一种不好的感觉。一家公司的官网给人的就是这样一个直截了当的漏洞。当我批量发起请求时,发现页面打开报错。100多人的公司官网文章刷新了,你可以给我看看这个。这家公司之前来我校宣传招聘+在园里找招聘的时候发现
阅读全文
scrapy爬虫成长日记将爬取的内容写入mysql数据库
作者:哼99251585 浏览评论:04年前
我尝试用scrapy爬取博客园的博客(可以查看scrapy爬虫成长日记的创建项目-提取数据-将数据保存为json格式),但是之前抓取的数据在文件中保存为json格式的文本。这显然不符合我们日常的实际应用。接下来我们看看如何将抓取到的内容保存在一个常用的m
阅读全文
500份C#源代码
作者:科技小美 3635人查看评论:14年前
C夏普短信发送平台源码.rar ASP.NET+AJAX基础示例视频教程 C# Winform qq弹窗360弹窗
阅读全文
爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站(转)
作者:老朱教授 1373 浏览评论:04年前
爬取网页的一般逻辑和流程一般是普通用户,他们使用浏览器打开一个URL地址,然后浏览器就可以显示相应页面的内容。这个过程,如果用程序代码实现,可以调用(程序实现)爬取网页(内容,以及后处理,提取需要的信息等)对应的英文是,website
阅读全文
C#爬虫web程序的实现解析
作者:zting Technology 698人 浏览评论:05年前
C#爬取网页程序是如何实现的?我们先来了解一下 HTTP,它是 WWW 中最基本的数据访问协议之一。.NET的基本类型库类中提供了两个对象类:HTTPWebRequest和HTTPWebResponse,分别用于向资源发送请求和获取。回复。获取资源的内容
阅读全文
C#实现图标的批量下载
作者:gisweis1079 浏览评论:05年前
这篇文章有点长,编辑修改了好几个晚上。如果文字和排版有问题,请见谅。本文分为四个部分,以下是主要内容,也是软件开发的基本流程。阶段描述需求分析主要描述实现程序的目的,分析需求,即为什么要花时间写,需要什么功能等;
阅读全文
scrapy爬虫成长日记将爬取的内容写入mysql数据库
作者:无声胜有声732 浏览评论:06年前
我尝试用scrapy爬取博客园的博客(可以查看scrapy爬虫成长日记的创建项目-提取数据-将数据保存为json格式),但是之前抓取的数据在文件中保存为json格式的文本。这显然不符合我们日常的实际应用。接下来我们看看如何将抓取到的内容保存在一个普通的
阅读全文
500份C#源代码
作者:蓬莱闲鱼2601 浏览评论:08年前
C夏普短信发送平台源码.rar ASP.NET+AJAX基础示例视频教程 C# Winform qq弹窗360弹窗
阅读全文
c#爬取网页中数据库相关问答
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文
c#抓取网页数据(网络爬虫主题相关的10篇毕业论文文献,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-24 16:09
本文汇编了10篇与网络爬虫相关的毕业论文,包括5篇期刊论文和5篇论文,为网络爬虫选题相关人员撰写毕业论文提供参考。
1.【期刊论文】加强规范防范网络爬虫成为“害虫”
期刊:《新华月刊》| 2021年第009期
摘要: 近年来,随着移动互联网、人工智能、大数据、云计算等新技术的快速发展和普及,人们的工作、交流和生活方式发生了深刻变化,数据成为一种新型生产推动社会发展。因素,是提高各行各业竞争力的重要源泉。但在大数据采集过程中,也存在各种违法犯罪问题。作为一种能够快速准确地获取数据信息的网络基础技术,网络爬虫近年来越来越受到人们的青睐和应用。
关键词:网络爬虫;人工智能; 云计算; 大数据; 网络;移动网络; 犯罪问题;提高竞争力
-------------------------------------------------- -------------------------------------------------
2.[期刊论文]关于网站信息采集网络爬虫技术
期刊:《信息记录材料》| 2021年第007期
摘要:随着互联网时代的到来,互联网技术在人们的生活、学习和各行各业的发展中发挥着越来越重要的作用。随着互联网的使用和用户数量的增加,过去的很多技术已经不能满足现代人的个性化需求。本文分析了网站信息采集技术在网络爬虫中的实际应用,为网站信息采集技术的应用效果提供了保障。然而,随着互联网的不断扩展,人工采集信息已难以适应信息的大规模发展。因此,需要采用一定的技术或手段来完成网络大数据的自动信息采集。
关键词:信息采集;爬虫技术;信息抽取
-------------------------------------------------- -------------------------------------------------
3.【期刊论文】基于网络爬虫的网络大数据爬取方法仿真
期刊:《计算机模拟》| 2021年006期
摘要:为提高网页大数据爬取效率,解决传统爬取方法误差大的问题,提出一种基于网络爬虫的网页大数据爬取方法。首先分析了网络爬虫运行的基本流程,并根据流程提取了大数据的关键特征。,然后根据特征提取结果,提出一种基于网络爬虫的数据捕获策略。在计算出数据的关键特征后,选择广度优先策略捕获数据信息,通过逐阶段重构相空间得到爬虫维度,并引入相关维度值。完成网页大数据抓取,完成数据关键特征的抓取任务。仿真结果表明,与其他方法相比,该方法具有更好的网页大数据捕获率、更短的耗时和更高的鲁棒性。真棒。
关键词:大数据抓取、网络爬虫、特征;相空间,相关维数
-------------------------------------------------- -------------------------------------------------
4.【期刊论文】基于爬虫技术和智能算法的网络舆情监测
期刊:《智能计算机与应用》| 2021-004
摘要:利用网络爬虫技术从百度索引中获取“热点事件”的数据,对数据进行预处理,建立网络舆情的Logistic微分方程模型。结合已有数据,采用智能算法确定微分方程的解。的三个关键参数,最终应用于网络舆情预测。
关键词:网络舆论;爬虫技术;百度指数;逻辑微分方程模型;智能算法
-------------------------------------------------- -------------------------------------------------
5.【期刊论文】网络爬虫实时控制器的设计与实现
期刊:《现代计算机(专业版)》 | 2021年第005期
摘要:针对个性化数据采集,提出了一种轻量级的网络爬虫框架,包括控制器、下载器、解析器、线程池和代理池等组件。在此框架下,设计了一个实时网络爬虫。具有处理能力的爬虫控制器可以自动保存和恢复任务场景。详细介绍了爬虫控制器的工作原理和C#实现,应用于站文章采集。实验结果表明:所提出的爬虫框架高效易用,控制器的实时处理能力在实际爬虫开发中非常重要。
关键词:网络爬虫;爬虫框架;实时控制器;C#
-------------------------------------------------- -------------------------------------------------
6.【学位论文】基于网络爬虫的测量数据分析系统的开发
内容
参考书目
学科:仪器仪表工程
授予学位:硕士
年份:2021
文字语言:中文
-------------------------------------------------- -------------------------------------------------
7.【论文】Visual Web Crawler Development的开发
内容
覆盖
中国文摘
英文摘要
目录
Introduction
1.1 The source of topic
1.2 Research background and significance
1.3.1 Research review
1.3.2 Analysis of literature review
1.4 Main contents of research
2 System requirements analysis
2.1 Functional requirements
2.2 Web scraping requirements
2.2.1. Modern web technologies support
2.2.2. Web scraping project setup complexity
2.3 Summary
3 Development of Visual Web Scraper
3.1.1 Version control system
3.1.2 Libraries and frameworks
3.1.3 Web extensions architecture
3.2 Implementing web scraper interface
3.2.1 Options page
3.2.2 Popup window
3.3 Implementing web scraping algorithms
4 Testing of Visual Web Scraper
4.1 Functional testing
4.1.1 Identify functions of software
4.1.2 Testing UI functions
4.1.3 Testing web scraping algorithm functions
4.2 Usability testing
4.3 Performance testing
4.4 Summary
Conclusion
参考文献
声明
致谢
参考书目
学科:软件工程
授予学位:硕士
年份:2020
文字语言:中文
-------------------------------------------------- -------------------------------------------------
8.【论文】分布式网络爬虫系统的设计与实现
内容
覆盖 查看全部
c#抓取网页数据(网络爬虫主题相关的10篇毕业论文文献,你了解多少?)
本文汇编了10篇与网络爬虫相关的毕业论文,包括5篇期刊论文和5篇论文,为网络爬虫选题相关人员撰写毕业论文提供参考。
1.【期刊论文】加强规范防范网络爬虫成为“害虫”
期刊:《新华月刊》| 2021年第009期
摘要: 近年来,随着移动互联网、人工智能、大数据、云计算等新技术的快速发展和普及,人们的工作、交流和生活方式发生了深刻变化,数据成为一种新型生产推动社会发展。因素,是提高各行各业竞争力的重要源泉。但在大数据采集过程中,也存在各种违法犯罪问题。作为一种能够快速准确地获取数据信息的网络基础技术,网络爬虫近年来越来越受到人们的青睐和应用。
关键词:网络爬虫;人工智能; 云计算; 大数据; 网络;移动网络; 犯罪问题;提高竞争力
-------------------------------------------------- -------------------------------------------------
2.[期刊论文]关于网站信息采集网络爬虫技术
期刊:《信息记录材料》| 2021年第007期
摘要:随着互联网时代的到来,互联网技术在人们的生活、学习和各行各业的发展中发挥着越来越重要的作用。随着互联网的使用和用户数量的增加,过去的很多技术已经不能满足现代人的个性化需求。本文分析了网站信息采集技术在网络爬虫中的实际应用,为网站信息采集技术的应用效果提供了保障。然而,随着互联网的不断扩展,人工采集信息已难以适应信息的大规模发展。因此,需要采用一定的技术或手段来完成网络大数据的自动信息采集。
关键词:信息采集;爬虫技术;信息抽取
-------------------------------------------------- -------------------------------------------------
3.【期刊论文】基于网络爬虫的网络大数据爬取方法仿真
期刊:《计算机模拟》| 2021年006期
摘要:为提高网页大数据爬取效率,解决传统爬取方法误差大的问题,提出一种基于网络爬虫的网页大数据爬取方法。首先分析了网络爬虫运行的基本流程,并根据流程提取了大数据的关键特征。,然后根据特征提取结果,提出一种基于网络爬虫的数据捕获策略。在计算出数据的关键特征后,选择广度优先策略捕获数据信息,通过逐阶段重构相空间得到爬虫维度,并引入相关维度值。完成网页大数据抓取,完成数据关键特征的抓取任务。仿真结果表明,与其他方法相比,该方法具有更好的网页大数据捕获率、更短的耗时和更高的鲁棒性。真棒。
关键词:大数据抓取、网络爬虫、特征;相空间,相关维数
-------------------------------------------------- -------------------------------------------------
4.【期刊论文】基于爬虫技术和智能算法的网络舆情监测
期刊:《智能计算机与应用》| 2021-004
摘要:利用网络爬虫技术从百度索引中获取“热点事件”的数据,对数据进行预处理,建立网络舆情的Logistic微分方程模型。结合已有数据,采用智能算法确定微分方程的解。的三个关键参数,最终应用于网络舆情预测。
关键词:网络舆论;爬虫技术;百度指数;逻辑微分方程模型;智能算法
-------------------------------------------------- -------------------------------------------------
5.【期刊论文】网络爬虫实时控制器的设计与实现
期刊:《现代计算机(专业版)》 | 2021年第005期
摘要:针对个性化数据采集,提出了一种轻量级的网络爬虫框架,包括控制器、下载器、解析器、线程池和代理池等组件。在此框架下,设计了一个实时网络爬虫。具有处理能力的爬虫控制器可以自动保存和恢复任务场景。详细介绍了爬虫控制器的工作原理和C#实现,应用于站文章采集。实验结果表明:所提出的爬虫框架高效易用,控制器的实时处理能力在实际爬虫开发中非常重要。
关键词:网络爬虫;爬虫框架;实时控制器;C#
-------------------------------------------------- -------------------------------------------------
6.【学位论文】基于网络爬虫的测量数据分析系统的开发
内容
参考书目
学科:仪器仪表工程
授予学位:硕士
年份:2021
文字语言:中文
-------------------------------------------------- -------------------------------------------------
7.【论文】Visual Web Crawler Development的开发
内容
覆盖
中国文摘
英文摘要
目录
Introduction
1.1 The source of topic
1.2 Research background and significance
1.3.1 Research review
1.3.2 Analysis of literature review
1.4 Main contents of research
2 System requirements analysis
2.1 Functional requirements
2.2 Web scraping requirements
2.2.1. Modern web technologies support
2.2.2. Web scraping project setup complexity
2.3 Summary
3 Development of Visual Web Scraper
3.1.1 Version control system
3.1.2 Libraries and frameworks
3.1.3 Web extensions architecture
3.2 Implementing web scraper interface
3.2.1 Options page
3.2.2 Popup window
3.3 Implementing web scraping algorithms
4 Testing of Visual Web Scraper
4.1 Functional testing
4.1.1 Identify functions of software
4.1.2 Testing UI functions
4.1.3 Testing web scraping algorithm functions
4.2 Usability testing
4.3 Performance testing
4.4 Summary
Conclusion
参考文献
声明
致谢
参考书目
学科:软件工程
授予学位:硕士
年份:2020
文字语言:中文
-------------------------------------------------- -------------------------------------------------
8.【论文】分布式网络爬虫系统的设计与实现
内容
覆盖
c#抓取网页数据(c#抓取网页数据实践和批量抓取数据的思路相对繁琐)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-02-21 15:02
c#抓取网页数据实践,包括爬虫和批量抓取数据,代码已放在github上,欢迎大家下载学习。原文的思路相对繁琐:>file-loader:自动化采集数据资源,这里使用了process_file_system。>db_loader:数据库抓取。>defget_resource_files(request){returnprocess_file_system(request.shutil("packet"));}爬虫每次获取的内容数据,量少的时候是全局只抓取,量多的时候,是分布抓取。
由于process_file_system初始化方法中,define_file_table的参数“[request.shutil("packet")"设置为了request的shutil("packet")”,所以在每次抓取的时候都会被mmap(“”),然后load进数据库里面。下面是每次抓取的过程:file-loader:自动化采集数据资源,这里使用了process_file_system。
```namemodulename=''versionversion=''languagetools=''includepublicclassviewdata:monobehaviour{staticvoidmain(string[]args){system.out.println("数据获取已启动");loadings();loadings();}}```file-loader:数据库抓取,这里使用了process_file_system。
```namemodulename=''versionversion=''languagetools=''includepublicclassviewdata:monobehaviour{staticvoidmain(string[]args){system.out.println("数据获取已启动");loadings();loadings();}}```defget_resource_files(request){request.shutil("packet");}实践中,这里存在个不明显的问题,就是随着时间的推移,数据库操作、采集内容的保存都成了问题。
对于数据量很大的抓取,还是使用全局定时来解决问题。目前已经添加的库有以下,也欢迎大家补充:process_file_systemgithub-xuxuhui/process_file_system.github.io:自动化采集数据库代码neo4jjs.github.io:数据库抓取代码db_loader.github.io:数据库抓取代码。 查看全部
c#抓取网页数据(c#抓取网页数据实践和批量抓取数据的思路相对繁琐)
c#抓取网页数据实践,包括爬虫和批量抓取数据,代码已放在github上,欢迎大家下载学习。原文的思路相对繁琐:>file-loader:自动化采集数据资源,这里使用了process_file_system。>db_loader:数据库抓取。>defget_resource_files(request){returnprocess_file_system(request.shutil("packet"));}爬虫每次获取的内容数据,量少的时候是全局只抓取,量多的时候,是分布抓取。
由于process_file_system初始化方法中,define_file_table的参数“[request.shutil("packet")"设置为了request的shutil("packet")”,所以在每次抓取的时候都会被mmap(“”),然后load进数据库里面。下面是每次抓取的过程:file-loader:自动化采集数据资源,这里使用了process_file_system。
```namemodulename=''versionversion=''languagetools=''includepublicclassviewdata:monobehaviour{staticvoidmain(string[]args){system.out.println("数据获取已启动");loadings();loadings();}}```file-loader:数据库抓取,这里使用了process_file_system。
```namemodulename=''versionversion=''languagetools=''includepublicclassviewdata:monobehaviour{staticvoidmain(string[]args){system.out.println("数据获取已启动");loadings();loadings();}}```defget_resource_files(request){request.shutil("packet");}实践中,这里存在个不明显的问题,就是随着时间的推移,数据库操作、采集内容的保存都成了问题。
对于数据量很大的抓取,还是使用全局定时来解决问题。目前已经添加的库有以下,也欢迎大家补充:process_file_systemgithub-xuxuhui/process_file_system.github.io:自动化采集数据库代码neo4jjs.github.io:数据库抓取代码db_loader.github.io:数据库抓取代码。
c#抓取网页数据(第一次用C#写数据抓取,遇到各种问题怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-19 22:22
第一次用C#写数据采集,遇到各种问题。开始写模拟登录的时候,发现有验证码。我必须突破验证码才能得到它。好吧,那我去找破解验证码的代码。我尝试了很多代码,发现它们并不通用。后来,我明白了其中的原理。首先去除噪点、干扰线等,然后将颜色验证码转换成黑白,同时进行字体切割。,如果字体是粘的,对于我们初学者(外行),那就放弃吧。裁剪后,每个像素都编码,白0,黑1,好像是这样的,不是太懂,再看一遍 拿字体库模型里的字做对比,如果达到百分比以上,它会识别验证码是什么,一一对比,最终形成一个完整的验证码。无法完成验证码破解,所以放弃破解,另寻方法。
网上说可能验证码是存cookie的,嗯,抱着试试的态度去试试,模拟浏览器发送数据,请求验证码,FF调试,发现有验证码在cookie中,仅此而已,验证码到此结束,让我们重新登录。
要登录,首先跟踪目标页面的逻辑,看看它是如何传递参数成功登录的。我只是先发送一个请求对用户名和密码进行加密,然后将加密后的发送到后台进行登录。这没什么好说的。这期间遇到的问题是发送请求,半天不成功。原因是当时发送了一个ajax请求,需要设置调用哪个方法。网站 一般直接要求后台,而不是发出ajax请求,所以这里又是一团糟。
关键代码:
request.Headers.Add("X-AjaxPro-Method", "方法名");
登录成功后,就到了抓取页面的时间了。首先获取抓取页面的html,然后分析它如何提交数据,如何返回,传递了什么参数等等。爬取页面没有问题,然后模拟查询数据。网站里面写了很多隐藏字段控件,所以发送请求的时候参数很多,不知道是干什么用的。, 反正我觉得唯一有用的就是查询订单号。模拟发送很长时间后,报500错误。这是因为模拟的参数有问题,服务器无法读取。我已经完成了所有设置。我一一发现哪里都没有错误。2天后,我被困在这里。没有办法。之后,无意中发现提交的数据和页面隐藏字段的数据有点不一样。特殊字符全部输入。转码后想了想之前写的代码传输参数,发现传输数据的时候,都需要通过UrlEncode转码,然后传输。虽然隐藏字段的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说就开始转码参数了 然后传送。虽然隐藏字段的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说就开始转码参数了 然后传送。虽然隐藏字段的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说就开始转码参数了
HttpUtility.UrlEncode(string);
居然成功了,太烧脑了,虽然对于一些老手来说,这些可能不知道,但第一次接触还是很难写。
对了,还有一个问题,就是读取html后获取字符串html中的参数的问题,当然在页面上很容易获取,但是现在都是一堆字符串,这真的很难,所以我找到了一个非常好用的dll,支持xpath,和xmlDocument一样的用法,
部分代码:
HtmlDocument htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(html.Replace("\r", "").Replace("\n", ""));
HtmlNodeCollection collection = htmlDocument.DocumentNode.SelectSingleNode("/html/body/div").ChildNodes;
foreach (HtmlNode htmlNode in collection)
{
var tempId = htmlNode.Attributes["id"].Value;
}
红色部分是xpath规则,
也可以根据属性获取对应的节点:
htmlDocument.DocumentNode.SelectSingleNode("/html/body/div[2]/input[@id='__EVENTVALIDATION']");
这是:HtmlAgilityPack 下载地址:点击打开链接
最好阅读此 网站 评论。里面有很多人的问题,说不定能帮上忙。
好了,写了这么多,接下来我整理一下代码发上来,然后开始循环爬取数据。 查看全部
c#抓取网页数据(第一次用C#写数据抓取,遇到各种问题怎么办?)
第一次用C#写数据采集,遇到各种问题。开始写模拟登录的时候,发现有验证码。我必须突破验证码才能得到它。好吧,那我去找破解验证码的代码。我尝试了很多代码,发现它们并不通用。后来,我明白了其中的原理。首先去除噪点、干扰线等,然后将颜色验证码转换成黑白,同时进行字体切割。,如果字体是粘的,对于我们初学者(外行),那就放弃吧。裁剪后,每个像素都编码,白0,黑1,好像是这样的,不是太懂,再看一遍 拿字体库模型里的字做对比,如果达到百分比以上,它会识别验证码是什么,一一对比,最终形成一个完整的验证码。无法完成验证码破解,所以放弃破解,另寻方法。
网上说可能验证码是存cookie的,嗯,抱着试试的态度去试试,模拟浏览器发送数据,请求验证码,FF调试,发现有验证码在cookie中,仅此而已,验证码到此结束,让我们重新登录。
要登录,首先跟踪目标页面的逻辑,看看它是如何传递参数成功登录的。我只是先发送一个请求对用户名和密码进行加密,然后将加密后的发送到后台进行登录。这没什么好说的。这期间遇到的问题是发送请求,半天不成功。原因是当时发送了一个ajax请求,需要设置调用哪个方法。网站 一般直接要求后台,而不是发出ajax请求,所以这里又是一团糟。
关键代码:
request.Headers.Add("X-AjaxPro-Method", "方法名");
登录成功后,就到了抓取页面的时间了。首先获取抓取页面的html,然后分析它如何提交数据,如何返回,传递了什么参数等等。爬取页面没有问题,然后模拟查询数据。网站里面写了很多隐藏字段控件,所以发送请求的时候参数很多,不知道是干什么用的。, 反正我觉得唯一有用的就是查询订单号。模拟发送很长时间后,报500错误。这是因为模拟的参数有问题,服务器无法读取。我已经完成了所有设置。我一一发现哪里都没有错误。2天后,我被困在这里。没有办法。之后,无意中发现提交的数据和页面隐藏字段的数据有点不一样。特殊字符全部输入。转码后想了想之前写的代码传输参数,发现传输数据的时候,都需要通过UrlEncode转码,然后传输。虽然隐藏字段的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说就开始转码参数了 然后传送。虽然隐藏字段的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说就开始转码参数了 然后传送。虽然隐藏字段的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说就开始转码参数了
HttpUtility.UrlEncode(string);
居然成功了,太烧脑了,虽然对于一些老手来说,这些可能不知道,但第一次接触还是很难写。
对了,还有一个问题,就是读取html后获取字符串html中的参数的问题,当然在页面上很容易获取,但是现在都是一堆字符串,这真的很难,所以我找到了一个非常好用的dll,支持xpath,和xmlDocument一样的用法,
部分代码:
HtmlDocument htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(html.Replace("\r", "").Replace("\n", ""));
HtmlNodeCollection collection = htmlDocument.DocumentNode.SelectSingleNode("/html/body/div").ChildNodes;
foreach (HtmlNode htmlNode in collection)
{
var tempId = htmlNode.Attributes["id"].Value;
}
红色部分是xpath规则,
也可以根据属性获取对应的节点:
htmlDocument.DocumentNode.SelectSingleNode("/html/body/div[2]/input[@id='__EVENTVALIDATION']");
这是:HtmlAgilityPack 下载地址:点击打开链接
最好阅读此 网站 评论。里面有很多人的问题,说不定能帮上忙。
好了,写了这么多,接下来我整理一下代码发上来,然后开始循环爬取数据。
c#抓取网页数据(c#抓取网页数据web开发测试如何有效率的进行文本处理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-18 06:02
c#抓取网页数据web开发测试也很容易遇到文本处理的问题如何有效率的进行文本处理?sql是一个很好的选择。这里特别推荐大家使用一个速度非常快的sql加sqlonline的工具,不用像sqlserver一样写很多的代码。数据抓取方法类似sqlserver:利用正则表达式匹配,可以实现网页的信息,再推倒到表格上。
powerquery如果对sql熟悉一点的话,很容易做到!!!数据抓取可以分为几步:1.网页抓取2.数据聚合3.信息处理4.数据分析本文主要讲讲数据分析,所以主要介绍了如何利用powerquery实现powerquery数据分析数据抓取数据爬取后,要进行数据处理比如二级聚合和三级聚合可以很好的分析很多问题,利用powerquery其实就可以实现。
1.爬虫,爬爬爬,爬到资源有没有,没有的话爬去给种子网站投稿2.提取标题关键词,标签等,可以用用excel的数据透视表,还有distinct,看看是不是能定位到page3.下载文件,
抓取微博看看最近的数据
目前推荐两个在线工具,一个是抓取山东抖音的热度,每天大约有10万条数据,每周600条左右,三天估计就可以抓到一定量的数据,一个小活动就可以抓2w条数据,
关键字:爬虫采集地址:,通过抓取网页、收集页面数据后,制作成文件发布、传播、营销,方便从现代化产业互联网寻找及转化用户。
1、抓取网页然后用vpn或者翻墙之类的工具反向链接,再把代码拷贝到云平台上发布,好处是转化率高但是复杂度也高,
2、爬虫跟当前发展方向有关,推荐抓取、天猫等电商网站的商品历史数据,
3、利用爬虫代理工具,定向抓取就好。暂时先想到这么多,有空接着补充。 查看全部
c#抓取网页数据(c#抓取网页数据web开发测试如何有效率的进行文本处理)
c#抓取网页数据web开发测试也很容易遇到文本处理的问题如何有效率的进行文本处理?sql是一个很好的选择。这里特别推荐大家使用一个速度非常快的sql加sqlonline的工具,不用像sqlserver一样写很多的代码。数据抓取方法类似sqlserver:利用正则表达式匹配,可以实现网页的信息,再推倒到表格上。
powerquery如果对sql熟悉一点的话,很容易做到!!!数据抓取可以分为几步:1.网页抓取2.数据聚合3.信息处理4.数据分析本文主要讲讲数据分析,所以主要介绍了如何利用powerquery实现powerquery数据分析数据抓取数据爬取后,要进行数据处理比如二级聚合和三级聚合可以很好的分析很多问题,利用powerquery其实就可以实现。
1.爬虫,爬爬爬,爬到资源有没有,没有的话爬去给种子网站投稿2.提取标题关键词,标签等,可以用用excel的数据透视表,还有distinct,看看是不是能定位到page3.下载文件,
抓取微博看看最近的数据
目前推荐两个在线工具,一个是抓取山东抖音的热度,每天大约有10万条数据,每周600条左右,三天估计就可以抓到一定量的数据,一个小活动就可以抓2w条数据,
关键字:爬虫采集地址:,通过抓取网页、收集页面数据后,制作成文件发布、传播、营销,方便从现代化产业互联网寻找及转化用户。
1、抓取网页然后用vpn或者翻墙之类的工具反向链接,再把代码拷贝到云平台上发布,好处是转化率高但是复杂度也高,
2、爬虫跟当前发展方向有关,推荐抓取、天猫等电商网站的商品历史数据,
3、利用爬虫代理工具,定向抓取就好。暂时先想到这么多,有空接着补充。
c#抓取网页数据(基于C#.NET+PhantomJS的高级网络爬虫程序程序 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-13 19:18
)
基于 C#.NET+PhantomJS+Sellenium 的高级网络爬虫程序。执行 Javascript 代码,触发各种事件,操作页面 Dom 结构,甚至移除你不喜欢的 CSS 样式。
很多网站使用Ajax来动态加载和翻页,比如携程的评论数据。如果我们之前使用简单的爬虫,很难直接抓取所有的评论数据。我们需要分析天上的Javascript代码才能找到API数据接口,时刻提防对方添加数据陷阱或修改API接口。
如果通过高级爬虫,完全可以忽略这些问题。不管他们如何加密Javascript代码来隐藏API接口,最终的数据都必须在网站页面的Dom结构中呈现出来,否则普通用户是看不到的。到达。所以我们可以直接从 Dom 中提取数据,根本不用分析 API 数据接口,甚至不用写那个复杂的正则表达式。
主要特点
运行截图
示例代码
///
/// 抓取酒店评论
///
static void Main(string[] args)
{
var hotelUrl = "http://hotels.ctrip.com/hotel/434938.html";
var hotelCrawler = new StrongCrawler();
hotelCrawler.OnStart += (s, e) =>
{
Console.WriteLine("爬虫开始抓取地址:" + e.Uri.ToString());
};
hotelCrawler.OnError += (s, e) =>
{
Console.WriteLine("爬虫抓取出现错误:" + e.Uri.ToString() + ",异常消息:" + e.Exception.ToString());
};
hotelCrawler.OnCompleted += (s, e) =>
{
HotelCrawler(e);
};
var operation = new Operation
{
Action = (x) => {
//通过Selenium驱动点击页面的“酒店评论”
x.FindElement(By.XPath("//*[@id='commentTab']")).Click();
},
Condition = (x) => {
//判断Ajax评论内容是否已经加载成功
return x.FindElement(By.XPath("//*[@id='commentList']")).Displayed && x.FindElement(By.XPath("//*[@id='hotel_info_comment']/div[@id='commentList']")).Displayed && !x.FindElement(By.XPath("//*[@id='hotel_info_comment']/div[@id='commentList']")).Text.Contains("点评载入中");
},
Timeout = 5000
};
hotelCrawler.Start(new Uri(hotelUrl), null, operation);//不操作JS先将参数设置为NULL
Console.ReadKey();
}
github:https://github.com/microfisher/Strong-Web-Crawler 查看全部
c#抓取网页数据(基于C#.NET+PhantomJS的高级网络爬虫程序程序
)
基于 C#.NET+PhantomJS+Sellenium 的高级网络爬虫程序。执行 Javascript 代码,触发各种事件,操作页面 Dom 结构,甚至移除你不喜欢的 CSS 样式。
很多网站使用Ajax来动态加载和翻页,比如携程的评论数据。如果我们之前使用简单的爬虫,很难直接抓取所有的评论数据。我们需要分析天上的Javascript代码才能找到API数据接口,时刻提防对方添加数据陷阱或修改API接口。
如果通过高级爬虫,完全可以忽略这些问题。不管他们如何加密Javascript代码来隐藏API接口,最终的数据都必须在网站页面的Dom结构中呈现出来,否则普通用户是看不到的。到达。所以我们可以直接从 Dom 中提取数据,根本不用分析 API 数据接口,甚至不用写那个复杂的正则表达式。
主要特点
运行截图
示例代码
///
/// 抓取酒店评论
///
static void Main(string[] args)
{
var hotelUrl = "http://hotels.ctrip.com/hotel/434938.html";
var hotelCrawler = new StrongCrawler();
hotelCrawler.OnStart += (s, e) =>
{
Console.WriteLine("爬虫开始抓取地址:" + e.Uri.ToString());
};
hotelCrawler.OnError += (s, e) =>
{
Console.WriteLine("爬虫抓取出现错误:" + e.Uri.ToString() + ",异常消息:" + e.Exception.ToString());
};
hotelCrawler.OnCompleted += (s, e) =>
{
HotelCrawler(e);
};
var operation = new Operation
{
Action = (x) => {
//通过Selenium驱动点击页面的“酒店评论”
x.FindElement(By.XPath("//*[@id='commentTab']")).Click();
},
Condition = (x) => {
//判断Ajax评论内容是否已经加载成功
return x.FindElement(By.XPath("//*[@id='commentList']")).Displayed && x.FindElement(By.XPath("//*[@id='hotel_info_comment']/div[@id='commentList']")).Displayed && !x.FindElement(By.XPath("//*[@id='hotel_info_comment']/div[@id='commentList']")).Text.Contains("点评载入中");
},
Timeout = 5000
};
hotelCrawler.Start(new Uri(hotelUrl), null, operation);//不操作JS先将参数设置为NULL
Console.ReadKey();
}
github:https://github.com/microfisher/Strong-Web-Crawler
c#抓取网页数据(Python是一种全栈的开发语言,能挣什么钱?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-11 10:15
泡上一杯好茶,今天的边聊开始,那么Python是什么?Python 是一种全栈开发语言。Python现在有多流行,我就不赘述了。Python的作用是什么?Python有四个主要应用:
如果你能学好Python,可以做前端、后端、测试、大数据分析、爬虫等工作。
利器——python
什么是网络爬虫?它是做什么的,你能赚多少钱?
网络爬虫
网络爬虫,又称网络蜘蛛,是指一种脚本程序,它按照一定的规则在网络上爬取想要的内容。众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个URL依次进入其他网址,获取想要的内容。那么每个人都可以想象它能给你带来什么赚钱。每个人的需求都不一样。例如,如果您是一名股票分析师,您需要进行分析以做出更安全、更有效、更合理的判断。毕竟,这是一个涉及投资的事情。您可以编写自己的程序从 网站 中爬下股票数据,然后进行数据分析。当然,如果你能用这种语言编写程序,你的成本会非常小,几乎为零,但如果你不会或者暂时不想的话,你可以' 不写,然后找人写这样的程序。成本基本在几百左右,但会给你带来更大的收益。开发程序的钱也是由那些使用 python 作为副业的人赚取的。. 也可以爬取国家GDP的具体数据或者一些网站(找到需求点)写短代码爬取数据,然后就可以完成那些有这些需求的人的需求了,就可以完成交易,钱就到了,知识就变成了现实。
有人会说,这么多开发语言我为什么要选择这个呢?呵呵,这个python语言有先天优势,如下:
1)抓取网页本身的固有接口
与Java、C#、C++、Python等其他静态编程语言相比,python爬取网页文档的界面更加简洁;与其他动态脚本语言相比,如 perl、shell 和 Python 的 urllib2 包提供了更完整的访问 web 文档的 API。
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。Python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2)网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是Python可以做到最快最干净。当您只需几行代码就可以解决问题时,为什么还要为数百行代码而烦恼呢?
办公自动化,如何赚钱?
办公自动化
在日常工作中,如果你在处理一堆图片,需要裁剪或者其他,你可以通过十几行代码批量完成这项工作,裁剪的效果可以达到专家级,处理时间是几秒的时钟就够了,但是在PS里正常剪图片需要几分钟,所以如果你是高手的话,可以在比较短的时间内完成很多工作,而且会节省时间和赚钱。此外,人力资源必须处理大量报告,每个月生成不同的报告。这些可以通过编写代码来实现。当每个月的时间到时,您可以执行以下程序。想象一下,如果你的老板看到你很忙。如果你能在短时间内处理好别人几天的数据处理工作,你会不会有更多的升职机会,如果你升职了,你会赚更多的薪水。. . .
使用这种python语言,你可以提高你的技能,找到需求,你就会找到赚钱的机会。加油,朋友们,未来将是办公自动化时代。以前不怕学数学物理化学,现在学python就可以赚钱了。哈哈,边学边学。 查看全部
c#抓取网页数据(Python是一种全栈的开发语言,能挣什么钱?)
泡上一杯好茶,今天的边聊开始,那么Python是什么?Python 是一种全栈开发语言。Python现在有多流行,我就不赘述了。Python的作用是什么?Python有四个主要应用:
如果你能学好Python,可以做前端、后端、测试、大数据分析、爬虫等工作。
利器——python
什么是网络爬虫?它是做什么的,你能赚多少钱?
网络爬虫
网络爬虫,又称网络蜘蛛,是指一种脚本程序,它按照一定的规则在网络上爬取想要的内容。众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个URL依次进入其他网址,获取想要的内容。那么每个人都可以想象它能给你带来什么赚钱。每个人的需求都不一样。例如,如果您是一名股票分析师,您需要进行分析以做出更安全、更有效、更合理的判断。毕竟,这是一个涉及投资的事情。您可以编写自己的程序从 网站 中爬下股票数据,然后进行数据分析。当然,如果你能用这种语言编写程序,你的成本会非常小,几乎为零,但如果你不会或者暂时不想的话,你可以' 不写,然后找人写这样的程序。成本基本在几百左右,但会给你带来更大的收益。开发程序的钱也是由那些使用 python 作为副业的人赚取的。. 也可以爬取国家GDP的具体数据或者一些网站(找到需求点)写短代码爬取数据,然后就可以完成那些有这些需求的人的需求了,就可以完成交易,钱就到了,知识就变成了现实。
有人会说,这么多开发语言我为什么要选择这个呢?呵呵,这个python语言有先天优势,如下:
1)抓取网页本身的固有接口
与Java、C#、C++、Python等其他静态编程语言相比,python爬取网页文档的界面更加简洁;与其他动态脚本语言相比,如 perl、shell 和 Python 的 urllib2 包提供了更完整的访问 web 文档的 API。
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。Python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2)网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是Python可以做到最快最干净。当您只需几行代码就可以解决问题时,为什么还要为数百行代码而烦恼呢?
办公自动化,如何赚钱?
办公自动化
在日常工作中,如果你在处理一堆图片,需要裁剪或者其他,你可以通过十几行代码批量完成这项工作,裁剪的效果可以达到专家级,处理时间是几秒的时钟就够了,但是在PS里正常剪图片需要几分钟,所以如果你是高手的话,可以在比较短的时间内完成很多工作,而且会节省时间和赚钱。此外,人力资源必须处理大量报告,每个月生成不同的报告。这些可以通过编写代码来实现。当每个月的时间到时,您可以执行以下程序。想象一下,如果你的老板看到你很忙。如果你能在短时间内处理好别人几天的数据处理工作,你会不会有更多的升职机会,如果你升职了,你会赚更多的薪水。. . .
使用这种python语言,你可以提高你的技能,找到需求,你就会找到赚钱的机会。加油,朋友们,未来将是办公自动化时代。以前不怕学数学物理化学,现在学python就可以赚钱了。哈哈,边学边学。
c#抓取网页数据(c#抓取网页数据的第一步:录制visualstudiocode,执行如下命令)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-09 08:03
c#抓取网页数据的第一步:录制visualstudiocode,执行如下命令。visualstudiocode解压,重命名为:misc,在misc目录下找到examples目录,找到helloworld.exe...(找到替换就行),双击运行pythonmisc/user.pyimportexamples.helloworld.exeprint("helloworld")第二步:录制,安装python环境(点开文章中的我要自学网vc6.0),sublime、vscode等python调试软件,启动word2013等第三步:打开微信网页版,打开知乎首页,进入→进入你设置好的链接页面,点击下方的:页面生成文件→选择:微信链接(建议使用小米浏览器作为本文主要打开场景,系统默认浏览器为谷歌浏览器,不清楚谷歌浏览器是否支持python等),按下“生成文件”按钮(或是右侧的加号)即可直接在微信的浏览器打开知乎首页,并且能正常进入。
如下图第四步:如果你用的是苹果设备,可以在visualstudiocode/examples/notepad++/windows/foreword/文件名后加上.msg(microsofthelloworld)即可使用。第五步:再次打开微信网页版,微信登录(原则上不可以修改登录密码,默认可用)→进入知乎首页→选择阅读模式→选择左侧评论区域(有多选按钮,最少写5个)→清空回复内容→重新登录微信,清空回复→点击登录按钮→跳转到知乎首页→粘贴刚才的生成的文件。 查看全部
c#抓取网页数据(c#抓取网页数据的第一步:录制visualstudiocode,执行如下命令)
c#抓取网页数据的第一步:录制visualstudiocode,执行如下命令。visualstudiocode解压,重命名为:misc,在misc目录下找到examples目录,找到helloworld.exe...(找到替换就行),双击运行pythonmisc/user.pyimportexamples.helloworld.exeprint("helloworld")第二步:录制,安装python环境(点开文章中的我要自学网vc6.0),sublime、vscode等python调试软件,启动word2013等第三步:打开微信网页版,打开知乎首页,进入→进入你设置好的链接页面,点击下方的:页面生成文件→选择:微信链接(建议使用小米浏览器作为本文主要打开场景,系统默认浏览器为谷歌浏览器,不清楚谷歌浏览器是否支持python等),按下“生成文件”按钮(或是右侧的加号)即可直接在微信的浏览器打开知乎首页,并且能正常进入。
如下图第四步:如果你用的是苹果设备,可以在visualstudiocode/examples/notepad++/windows/foreword/文件名后加上.msg(microsofthelloworld)即可使用。第五步:再次打开微信网页版,微信登录(原则上不可以修改登录密码,默认可用)→进入知乎首页→选择阅读模式→选择左侧评论区域(有多选按钮,最少写5个)→清空回复内容→重新登录微信,清空回复→点击登录按钮→跳转到知乎首页→粘贴刚才的生成的文件。
c#抓取网页数据(markdown没有做好渲染和解析,github说爬虫效率是把dom去掉了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-02-08 23:02
c#抓取网页数据效率不高的根本原因就是markdown没有做好渲染和解析,
github说爬虫效率是把dom去掉了。原来我听到的是有另外一个词叫“深度渲染”,呵呵。
题主提到的这个要求未必是要爬大量的网页,github目前提供了几种提取html的方法,可以自己尝试下。readertext()方法完成从服务器取回html并转换成相应格式(即你需要的withgithub),基本类似gson/gson.jsapi,用的是webpack进行打包。可以读取到服务器中各个文件的信息(filename等信息)。
md5计算这种,完全没有必要,因为只是对于识别出的uri地址而言是确定的。我的博客fromwebpack.plugins.imageimportimagefilter,filefilterfromwebpack.plugins.textimporttextfilter,onerror,filetypefilterfromwebpack.plugins.base64importlocalbitshow,urlreload,pathname,chunks,fileinput,getfilesfromwebpack.plugins.styleimageimporttextstyleimage,imageimage,monmemory.configimportstylemozifilter,modelfilespluginfromwebpack.plugins.textimporthttpsreloadconfig,httpsiy@webpack.config.build.webpackwaitdefaultwebpack配置httpsreloadconfig:{sync:true,}module.exports={entry:{root:{manifest:'document.getelementbyid('')[0].text'',staticpath:''},entrycomponent:{filename:"urlrequest",selector:"*",url:""},loader:{gzip:false,src:"{{index_header}}",default:{drop_separator:true,module:{entry,module:'dist',output:{path:'/',mode:'public',max_path:1000,base:null}}main:{name:'why',compileroptions:{useboundingclass(true):true,},entry:{manifest:'document.getelementbyid('')[0].text'',staticpath:''},entrycomponent:{selector:"*",url:""},output:{path:'/',mode:'public',importobject:true);defaultwebpack配置如下:[loaderoptions]entry{root={manifest:'document.getelementbyid('')[0].text'',staticpath:''},entrycomponent:{selector:"*。 查看全部
c#抓取网页数据(markdown没有做好渲染和解析,github说爬虫效率是把dom去掉了)
c#抓取网页数据效率不高的根本原因就是markdown没有做好渲染和解析,
github说爬虫效率是把dom去掉了。原来我听到的是有另外一个词叫“深度渲染”,呵呵。
题主提到的这个要求未必是要爬大量的网页,github目前提供了几种提取html的方法,可以自己尝试下。readertext()方法完成从服务器取回html并转换成相应格式(即你需要的withgithub),基本类似gson/gson.jsapi,用的是webpack进行打包。可以读取到服务器中各个文件的信息(filename等信息)。
md5计算这种,完全没有必要,因为只是对于识别出的uri地址而言是确定的。我的博客fromwebpack.plugins.imageimportimagefilter,filefilterfromwebpack.plugins.textimporttextfilter,onerror,filetypefilterfromwebpack.plugins.base64importlocalbitshow,urlreload,pathname,chunks,fileinput,getfilesfromwebpack.plugins.styleimageimporttextstyleimage,imageimage,monmemory.configimportstylemozifilter,modelfilespluginfromwebpack.plugins.textimporthttpsreloadconfig,httpsiy@webpack.config.build.webpackwaitdefaultwebpack配置httpsreloadconfig:{sync:true,}module.exports={entry:{root:{manifest:'document.getelementbyid('')[0].text'',staticpath:''},entrycomponent:{filename:"urlrequest",selector:"*",url:""},loader:{gzip:false,src:"{{index_header}}",default:{drop_separator:true,module:{entry,module:'dist',output:{path:'/',mode:'public',max_path:1000,base:null}}main:{name:'why',compileroptions:{useboundingclass(true):true,},entry:{manifest:'document.getelementbyid('')[0].text'',staticpath:''},entrycomponent:{selector:"*",url:""},output:{path:'/',mode:'public',importobject:true);defaultwebpack配置如下:[loaderoptions]entry{root={manifest:'document.getelementbyid('')[0].text'',staticpath:''},entrycomponent:{selector:"*。
c#抓取网页数据(在页面抓取时应该注意到的几个问题(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-08 00:21
)
在本文中,我们将讨论抓取页面时应注意的几个问题。
一:网页更新
我们知道一般网页中的信息是不断更新的,这也需要我们定期去抓取这些新的信息,但是我们应该如何理解这个“周期性”,也就是需要多长时间?
抓取一次页面,其实这段时间也是页面缓存时间。我们不需要在页面缓存时间内再次爬取页面,但是会给服务器带来压力。
比如我要爬博客园的首页,先清除页面缓存,
从 Last-Modified 到 Expires 可以看到博客园的缓存时间是 2 分钟,我也可以看到当前服务器时间 Date,如果我再
如果页面被刷新,这里的Date会变成下图中的If-Modified-Since,然后发送给服务器判断浏览器的缓存是否已经过期?
最后服务端找到If-Modified-Since >= Last-Modified的时间,服务端返回304,但是发现这个cookie信息真的是贼多。. .
在实际开发中,如果我们知道网站缓存策略,我们可以让爬虫每2分钟爬一次。当然,这些可以由数据团队配置和维护。
好吧,让我们用爬虫来模拟它。
1using System;
2using System.Net;
3
4namespace ConsoleApplication2
5{
6 public class Program
7 {
8 static void Main(string[] args)
9 {
10 DateTime prevDateTime = DateTime.MinValue;
11
12 for (int i = 0; i 0)
23 {
24 request.IfModifiedSince = prevDateTime;
25 }
26
27 request.Timeout = 3000;
28
29 var response = (HttpWebResponse)request.GetResponse();
30
31 var code = response.StatusCode;
32
33 //如果服务器返回状态是200,则认为网页已更新,记得当时的服务器时间
34 if (code == HttpStatusCode.OK)
35 {
36 prevDateTime = Convert.ToDateTime(response.Headers[HttpResponseHeader.Date]);
37 }
38
39 Console.WriteLine("当前服务器的状态码:{0}", code);
40 }
41 catch (WebException ex)
42 {
43 if (ex.Response != null)
44 {
45 var code = (ex.Response as HttpWebResponse).StatusCode;
46
47 Console.WriteLine("当前服务器的状态码:{0}", code);
48 }
49 }
50 }
51 }
52 }
53}
54
2:网络编码的问题
有时候我们已经抓取了网页,再去解析的时候,tmd全是乱码,真是操蛋,比如下面这样,
或许我们依稀记得html的meta中有一个叫charset的属性,里面记录了编码方式,另外一个关键点是
编码方式也记录在属性response.CharacterSet中,我们再试一次。
妈的,还是乱码,好痛。这个时候需要去官网看看http头信息中在交互什么。为什么浏览器可以正常显示?
如果爬行动物爬过来,它就行不通了。
查看http头信息,我们终于知道浏览器说我可以解析gzip、deflate、sdch这三种压缩方式。服务器发送gzip压缩,所以这里是
我们还应该了解常见的 Web 性能优化。
1using System;
2using System.Collections.Generic;
3using System.Linq;
4using System.Text;
5using System.Threading;
6using HtmlAgilityPack;
7using System.Text.RegularExpressions;
8using System.Net;
9using System.IO;
10using System.IO.Compression;
11
12namespace ConsoleApplication2
13{
14 public class Program
15 {
16 static void Main(string[] args)
17 {
18 //var currentUrl = "http://www.mm5mm.com/";
19
20 var currentUrl = "http://www.sohu.com/";
21
22 var request = WebRequest.Create(currentUrl) as HttpWebRequest;
23
24 var response = request.GetResponse() as HttpWebResponse;
25
26 var encode = string.Empty;
27
28 if (response.CharacterSet == "ISO-8859-1")
29 encode = "gb2312";
30 else
31 encode = response.CharacterSet;
32
33 Stream stream;
34
35 if (response.ContentEncoding.ToLower() == "gzip")
36 {
37 stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
38 }
39 else
40 {
41 stream = response.GetResponseStream();
42 }
43
44 var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
45
46 var html = sr.ReadToEnd();
47 }
48 }
49}
50
三:网页分析
现在网页经过一番努力已经得到了,接下来就是解析它了。当然,正则匹配是一个很好的方法。毕竟工作量还是比较大的,业界可能也会尊重。
HtmlAgilityPack,一个解析工具,可以将Html解析成XML,然后使用XPath提取指定的内容,极大的提高了开发速度,提升了性能。
还不错,毕竟敏捷也意味着敏捷。关于XPath的内容,这两张W3CSchool的图大家看懂就OK了。
1using System;
2using System.Collections.Generic;
3using System.Linq;
4using System.Text;
5using System.Threading;
6using HtmlAgilityPack;
7using System.Text.RegularExpressions;
8using System.Net;
9using System.IO;
10using System.IO.Compression;
11
12namespace ConsoleApplication2
13{
14 public class Program
15 {
16 static void Main(string[] args)
17 {
18 //var currentUrl = "http://www.mm5mm.com/";
19
20 var currentUrl = "http://www.sohu.com/";
21
22 var request = WebRequest.Create(currentUrl) as HttpWebRequest;
23
24 var response = request.GetResponse() as HttpWebResponse;
25
26 var encode = string.Empty;
27
28 if (response.CharacterSet == "ISO-8859-1")
29 encode = "gb2312";
30 else
31 encode = response.CharacterSet;
32
33 Stream stream;
34
35 if (response.ContentEncoding.ToLower() == "gzip")
36 {
37 stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
38 }
39 else
40 {
41 stream = response.GetResponseStream();
42 }
43
44 var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
45
46 var html = sr.ReadToEnd();
47
48 sr.Close();
49
50 HtmlDocument document = new HtmlDocument();
51
52 document.LoadHtml(html);
53
54 //提取title
55 var title = document.DocumentNode.SelectSingleNode("//title").InnerText;
56
57 //提取keywords
58 var keywords = document.DocumentNode.SelectSingleNode("//meta[@name='Keywords']").Attributes["content"].Value;
59 }
60 }
61}
62
1 
2 查看全部
c#抓取网页数据(在页面抓取时应该注意到的几个问题(图)
)
在本文中,我们将讨论抓取页面时应注意的几个问题。
一:网页更新
我们知道一般网页中的信息是不断更新的,这也需要我们定期去抓取这些新的信息,但是我们应该如何理解这个“周期性”,也就是需要多长时间?
抓取一次页面,其实这段时间也是页面缓存时间。我们不需要在页面缓存时间内再次爬取页面,但是会给服务器带来压力。
比如我要爬博客园的首页,先清除页面缓存,
从 Last-Modified 到 Expires 可以看到博客园的缓存时间是 2 分钟,我也可以看到当前服务器时间 Date,如果我再
如果页面被刷新,这里的Date会变成下图中的If-Modified-Since,然后发送给服务器判断浏览器的缓存是否已经过期?
最后服务端找到If-Modified-Since >= Last-Modified的时间,服务端返回304,但是发现这个cookie信息真的是贼多。. .
在实际开发中,如果我们知道网站缓存策略,我们可以让爬虫每2分钟爬一次。当然,这些可以由数据团队配置和维护。
好吧,让我们用爬虫来模拟它。
1using System;
2using System.Net;
3
4namespace ConsoleApplication2
5{
6 public class Program
7 {
8 static void Main(string[] args)
9 {
10 DateTime prevDateTime = DateTime.MinValue;
11
12 for (int i = 0; i 0)
23 {
24 request.IfModifiedSince = prevDateTime;
25 }
26
27 request.Timeout = 3000;
28
29 var response = (HttpWebResponse)request.GetResponse();
30
31 var code = response.StatusCode;
32
33 //如果服务器返回状态是200,则认为网页已更新,记得当时的服务器时间
34 if (code == HttpStatusCode.OK)
35 {
36 prevDateTime = Convert.ToDateTime(response.Headers[HttpResponseHeader.Date]);
37 }
38
39 Console.WriteLine("当前服务器的状态码:{0}", code);
40 }
41 catch (WebException ex)
42 {
43 if (ex.Response != null)
44 {
45 var code = (ex.Response as HttpWebResponse).StatusCode;
46
47 Console.WriteLine("当前服务器的状态码:{0}", code);
48 }
49 }
50 }
51 }
52 }
53}
54
2:网络编码的问题
有时候我们已经抓取了网页,再去解析的时候,tmd全是乱码,真是操蛋,比如下面这样,
或许我们依稀记得html的meta中有一个叫charset的属性,里面记录了编码方式,另外一个关键点是
编码方式也记录在属性response.CharacterSet中,我们再试一次。
妈的,还是乱码,好痛。这个时候需要去官网看看http头信息中在交互什么。为什么浏览器可以正常显示?
如果爬行动物爬过来,它就行不通了。
查看http头信息,我们终于知道浏览器说我可以解析gzip、deflate、sdch这三种压缩方式。服务器发送gzip压缩,所以这里是
我们还应该了解常见的 Web 性能优化。
1using System;
2using System.Collections.Generic;
3using System.Linq;
4using System.Text;
5using System.Threading;
6using HtmlAgilityPack;
7using System.Text.RegularExpressions;
8using System.Net;
9using System.IO;
10using System.IO.Compression;
11
12namespace ConsoleApplication2
13{
14 public class Program
15 {
16 static void Main(string[] args)
17 {
18 //var currentUrl = "http://www.mm5mm.com/";
19
20 var currentUrl = "http://www.sohu.com/";
21
22 var request = WebRequest.Create(currentUrl) as HttpWebRequest;
23
24 var response = request.GetResponse() as HttpWebResponse;
25
26 var encode = string.Empty;
27
28 if (response.CharacterSet == "ISO-8859-1")
29 encode = "gb2312";
30 else
31 encode = response.CharacterSet;
32
33 Stream stream;
34
35 if (response.ContentEncoding.ToLower() == "gzip")
36 {
37 stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
38 }
39 else
40 {
41 stream = response.GetResponseStream();
42 }
43
44 var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
45
46 var html = sr.ReadToEnd();
47 }
48 }
49}
50
三:网页分析
现在网页经过一番努力已经得到了,接下来就是解析它了。当然,正则匹配是一个很好的方法。毕竟工作量还是比较大的,业界可能也会尊重。
HtmlAgilityPack,一个解析工具,可以将Html解析成XML,然后使用XPath提取指定的内容,极大的提高了开发速度,提升了性能。
还不错,毕竟敏捷也意味着敏捷。关于XPath的内容,这两张W3CSchool的图大家看懂就OK了。
1using System;
2using System.Collections.Generic;
3using System.Linq;
4using System.Text;
5using System.Threading;
6using HtmlAgilityPack;
7using System.Text.RegularExpressions;
8using System.Net;
9using System.IO;
10using System.IO.Compression;
11
12namespace ConsoleApplication2
13{
14 public class Program
15 {
16 static void Main(string[] args)
17 {
18 //var currentUrl = "http://www.mm5mm.com/";
19
20 var currentUrl = "http://www.sohu.com/";
21
22 var request = WebRequest.Create(currentUrl) as HttpWebRequest;
23
24 var response = request.GetResponse() as HttpWebResponse;
25
26 var encode = string.Empty;
27
28 if (response.CharacterSet == "ISO-8859-1")
29 encode = "gb2312";
30 else
31 encode = response.CharacterSet;
32
33 Stream stream;
34
35 if (response.ContentEncoding.ToLower() == "gzip")
36 {
37 stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
38 }
39 else
40 {
41 stream = response.GetResponseStream();
42 }
43
44 var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
45
46 var html = sr.ReadToEnd();
47
48 sr.Close();
49
50 HtmlDocument document = new HtmlDocument();
51
52 document.LoadHtml(html);
53
54 //提取title
55 var title = document.DocumentNode.SelectSingleNode("//title").InnerText;
56
57 //提取keywords
58 var keywords = document.DocumentNode.SelectSingleNode("//meta[@name='Keywords']").Attributes["content"].Value;
59 }
60 }
61}
62
1 
2
c#抓取网页数据(识别不能实现的原理和问题产生进行介绍(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-05 07:23
困扰了我几天的问题今天终于解决了,分享一下最近使用solr的一些心得。
最初是使用nutch来爬取页面,但是客户需要爬取RSS,通过RSS提要可以识别那些被爬取的页面。虽然 nutch 自带了解析 RSS 的插件,但是有些 RSS 无法解析,难以控制。更重要的是,爬取后和普通页面并没有太大区别。它无法识别和判断爬取的是哪个RSS源。. 由于以上原因,我用C#写了一个项目,用Solr爬取RSS。
一切落实后,客户很满意,我也觉得做工还不错,但是用了一段时间,发现solrdedup时nutch出现故障,导致nutch无法使用。下面将介绍rss的实现原理和问题的产生。Solr和nutch没有解决是因为非常难懂,主要是这样的问题在网上很难找到。由于公司没有外网和版权,一切只能凭记忆写。
RSS+Solr的实现是利用webrequest读取rss源的xml格式的内容,在post方法中直接为solr创建索引。为了满足客户的要求,我在solr的schame中添加了rss和isrss字段,其中rss是rss源的url地址,isrss固定为true。由于nutch没有这两个字段,我们只需要输入isrss:"true"查询rss就可以过滤掉不是来自rss的页面。
实施过程中应注意以下几点
1.rss源不是后缀为xml的文件,有些是普通页面的响应,有些需要登录权限
2.RSS目前主要有两种格式,常见的xml结构是rss/channel/item,另一种是我们博客园rss的结构feed/entry。
里面的label是固定的,可以通过不同的label找到solr中filed所需要的值
3.id、digest、tstamp 三个字段是必须的。
如上所述,nutch 运行到 solrdedup 时,会报错。一开始我以为是solr新增的两个字段。我尝试在nutch中添加两个字段,并且还使用了nutch的静态字段插件和额外字段插件,但是没有成功。最后发现,清除solr数据后,nutch可以正常运行了。我也在谷歌上查了很多,但它根本没有帮助。我认为这是solr缓存的原因。今天刚好有点空,于是找到nutch的报错文件solrdeleteduplicates.java,发现nutch是通过直接从solr中取出id、digest、tstamp字段来去除重复的,不判断是否是直接使用空的。
但是,我写的程序中没有添加digest和tsamp。果然,加上这两个字段后,我完成了没有这两个字段的所有数据,nutch又可以正常运行了。
4.digest是网页的32位hash值,用于nutch去重复时比较差异
5.solr可以直接通过请求url添加、修改、删除内容,修改后的格式和新的一样
主要核心是:xx.xx.xx.xx/solr/update?stream.body=xx&stream.contentType=text/xm;charset=utf-8&commit=true
如果内容有ur格式和html格式,需要转码
6. solr的时间是GMT格式的,所以不要搞错,而且rss中有些GMT格式是错误的,我遇到过很多,错误的星期会导致solr索引失效。
目前信息还是比较全的,搜索也比较方便,但是还有很多问题需要解决,主要是js生成的页面无法读取,可以过滤页面信息。文章的主要内容,过滤导航等信息仍然难以获取。目前,我发现的其他人正在根据统计规则进行过滤。比如很多导航栏用|隔开,内容中的空格用空格隔开。等待。每个站点的html布局风格不同,标签难以统一。百度和谷歌不知道如何实现,或者他们没有真正实现。
Nutch还是比较强大的,但是我总觉得维护和修改不容易。上次编译源码的时间比较长,solr查询也比较高效。可能正计划编写一个 .net 版本的爬虫和搜索,但这只是在计划中,因为涉及的问题太多...... 查看全部
c#抓取网页数据(识别不能实现的原理和问题产生进行介绍(图))
困扰了我几天的问题今天终于解决了,分享一下最近使用solr的一些心得。
最初是使用nutch来爬取页面,但是客户需要爬取RSS,通过RSS提要可以识别那些被爬取的页面。虽然 nutch 自带了解析 RSS 的插件,但是有些 RSS 无法解析,难以控制。更重要的是,爬取后和普通页面并没有太大区别。它无法识别和判断爬取的是哪个RSS源。. 由于以上原因,我用C#写了一个项目,用Solr爬取RSS。
一切落实后,客户很满意,我也觉得做工还不错,但是用了一段时间,发现solrdedup时nutch出现故障,导致nutch无法使用。下面将介绍rss的实现原理和问题的产生。Solr和nutch没有解决是因为非常难懂,主要是这样的问题在网上很难找到。由于公司没有外网和版权,一切只能凭记忆写。
RSS+Solr的实现是利用webrequest读取rss源的xml格式的内容,在post方法中直接为solr创建索引。为了满足客户的要求,我在solr的schame中添加了rss和isrss字段,其中rss是rss源的url地址,isrss固定为true。由于nutch没有这两个字段,我们只需要输入isrss:"true"查询rss就可以过滤掉不是来自rss的页面。
实施过程中应注意以下几点
1.rss源不是后缀为xml的文件,有些是普通页面的响应,有些需要登录权限
2.RSS目前主要有两种格式,常见的xml结构是rss/channel/item,另一种是我们博客园rss的结构feed/entry。
里面的label是固定的,可以通过不同的label找到solr中filed所需要的值
3.id、digest、tstamp 三个字段是必须的。
如上所述,nutch 运行到 solrdedup 时,会报错。一开始我以为是solr新增的两个字段。我尝试在nutch中添加两个字段,并且还使用了nutch的静态字段插件和额外字段插件,但是没有成功。最后发现,清除solr数据后,nutch可以正常运行了。我也在谷歌上查了很多,但它根本没有帮助。我认为这是solr缓存的原因。今天刚好有点空,于是找到nutch的报错文件solrdeleteduplicates.java,发现nutch是通过直接从solr中取出id、digest、tstamp字段来去除重复的,不判断是否是直接使用空的。
但是,我写的程序中没有添加digest和tsamp。果然,加上这两个字段后,我完成了没有这两个字段的所有数据,nutch又可以正常运行了。
4.digest是网页的32位hash值,用于nutch去重复时比较差异
5.solr可以直接通过请求url添加、修改、删除内容,修改后的格式和新的一样
主要核心是:xx.xx.xx.xx/solr/update?stream.body=xx&stream.contentType=text/xm;charset=utf-8&commit=true
如果内容有ur格式和html格式,需要转码
6. solr的时间是GMT格式的,所以不要搞错,而且rss中有些GMT格式是错误的,我遇到过很多,错误的星期会导致solr索引失效。
目前信息还是比较全的,搜索也比较方便,但是还有很多问题需要解决,主要是js生成的页面无法读取,可以过滤页面信息。文章的主要内容,过滤导航等信息仍然难以获取。目前,我发现的其他人正在根据统计规则进行过滤。比如很多导航栏用|隔开,内容中的空格用空格隔开。等待。每个站点的html布局风格不同,标签难以统一。百度和谷歌不知道如何实现,或者他们没有真正实现。
Nutch还是比较强大的,但是我总觉得维护和修改不容易。上次编译源码的时间比较长,solr查询也比较高效。可能正计划编写一个 .net 版本的爬虫和搜索,但这只是在计划中,因为涉及的问题太多......
c#抓取网页数据(网页分析采集程序的基本流程和流程图详解 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-02-04 12:05
)
首先需要明确:网站的任何页面,无论是php、jsp、aspx等动态页面还是后台程序生成的静态页面,都可以在浏览器。
所以当你想开发一个data采集程序时,你首先要了解你要采集的网站的首页结构(HTML)。
一旦熟悉了 网站 中的 HTML 源文件的内容,其中数据是 采集,程序的其余部分就很容易了。因为C#在网站上执行数据采集,原理是“下载你想要的页面的HTML源文件到采集,分析HTML代码然后抓取你需要的数据,最后保存数据。到本地文件”。
基本流程如下图所示:
1.页面源文件下载
首先引用 System.Net 命名空间
使用 System.Net;
还需要引用
使用 System.Text;
使用 System.IO;
复制代码
引用后实例化一个 WebClient 对象
私人 WebClientwc = new WebClient();
调用DownloadData方法从指定网页的源文件中下载一组BYTE数据,然后将BYTE数组转换为字符串。
// 下载页面源文件并转换为UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData( string .Format("你要的网页地址采集")));
复制代码
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
// 下载网页源文件到本地
wc.DownloadFile("你要访问的网页的URL采集", "保存源文件的本地文件路径");
// 读取下载源文件的HTML格式字符串
string mainData = File.ReadAllText("保存源文件的本地文件路径",Encoding.UTF8);
复制代码
使用网页 HTML 格式字符串,您可以分析 采集 网页并抓取您需要的内容。
2.页面分析采集
页面分析就是用网页源文件中的一个特定的或唯一的字符(字符串)作为一个抓取点,从这个抓取点开始截取你想要的页面上的数据。
以博客园为栏目为例,如果我想要采集博客园首页列出的文章的标题和链接,我必须以"开头
代码:
// 经过”
mainData = mainData.Substring(mainData.IndexOf( " " ) + 26 );
// 获取文章页面的链接地址
字符串 articleAddr = mainData.Substring( 0 ,mainData.IndexOf( " \" " ));
// 获取 文章 标题
字符串文章标题 = mainData.Substring(mainData.IndexOf( " target=\"_blank\"> " ) + 16 ,
mainData.IndexOf( " " ) - mainData.IndexOf( " target=\"_blank\"> " ) - 16 );
复制代码
注意:当你要采集的网页首页的HTML格式发生变化时,作为抓取点的字符也要相应的改变,否则采集什么都得不到
3.数据存储
从网页中截取需要的数据后,将程序中的数据组织起来,保存到本地文件中(或者插入到自己的本地数据库中)。这样,整个采集的工作就会在一个段落中完成。
// 输出数据到本地文件
File.AppendAllText(CreateFolderIfNot(Settings.Default.OutPath) + articleTitle + ".txt" ,
文章数据,
编码.UTF8);
复制代码
另外附上我自己写的采集博客园主页文章的小程序代码。该程序的作用是将博客园主页上的文章采集全部发布下来。
下载地址:CnBlogCollector.rar
当然,如果博客园首页的格式调整了,程序的采集功能肯定会失效,而继续采集的唯一办法就是重新调整程序自己一个人,呵呵。. .
程序效果如下:
查看全部
c#抓取网页数据(网页分析采集程序的基本流程和流程图详解
)
首先需要明确:网站的任何页面,无论是php、jsp、aspx等动态页面还是后台程序生成的静态页面,都可以在浏览器。
所以当你想开发一个data采集程序时,你首先要了解你要采集的网站的首页结构(HTML)。
一旦熟悉了 网站 中的 HTML 源文件的内容,其中数据是 采集,程序的其余部分就很容易了。因为C#在网站上执行数据采集,原理是“下载你想要的页面的HTML源文件到采集,分析HTML代码然后抓取你需要的数据,最后保存数据。到本地文件”。
基本流程如下图所示:
1.页面源文件下载
首先引用 System.Net 命名空间
使用 System.Net;
还需要引用
使用 System.Text;
使用 System.IO;
复制代码
引用后实例化一个 WebClient 对象
私人 WebClientwc = new WebClient();
调用DownloadData方法从指定网页的源文件中下载一组BYTE数据,然后将BYTE数组转换为字符串。
// 下载页面源文件并转换为UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData( string .Format("你要的网页地址采集")));
复制代码
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
// 下载网页源文件到本地
wc.DownloadFile("你要访问的网页的URL采集", "保存源文件的本地文件路径");
// 读取下载源文件的HTML格式字符串
string mainData = File.ReadAllText("保存源文件的本地文件路径",Encoding.UTF8);
复制代码
使用网页 HTML 格式字符串,您可以分析 采集 网页并抓取您需要的内容。
2.页面分析采集
页面分析就是用网页源文件中的一个特定的或唯一的字符(字符串)作为一个抓取点,从这个抓取点开始截取你想要的页面上的数据。
以博客园为栏目为例,如果我想要采集博客园首页列出的文章的标题和链接,我必须以"开头
代码:
// 经过”
mainData = mainData.Substring(mainData.IndexOf( " " ) + 26 );
// 获取文章页面的链接地址
字符串 articleAddr = mainData.Substring( 0 ,mainData.IndexOf( " \" " ));
// 获取 文章 标题
字符串文章标题 = mainData.Substring(mainData.IndexOf( " target=\"_blank\"> " ) + 16 ,
mainData.IndexOf( " " ) - mainData.IndexOf( " target=\"_blank\"> " ) - 16 );
复制代码
注意:当你要采集的网页首页的HTML格式发生变化时,作为抓取点的字符也要相应的改变,否则采集什么都得不到
3.数据存储
从网页中截取需要的数据后,将程序中的数据组织起来,保存到本地文件中(或者插入到自己的本地数据库中)。这样,整个采集的工作就会在一个段落中完成。
// 输出数据到本地文件
File.AppendAllText(CreateFolderIfNot(Settings.Default.OutPath) + articleTitle + ".txt" ,
文章数据,
编码.UTF8);
复制代码
另外附上我自己写的采集博客园主页文章的小程序代码。该程序的作用是将博客园主页上的文章采集全部发布下来。
下载地址:CnBlogCollector.rar
当然,如果博客园首页的格式调整了,程序的采集功能肯定会失效,而继续采集的唯一办法就是重新调整程序自己一个人,呵呵。. .
程序效果如下:

