
c#抓取网页数据
c#抓取网页数据(最好上有趣、入门级的开源项目,帮你找到兴趣!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-04-11 18:32
兴趣是最好的老师,HelloGitHub就是帮你找到兴趣!
介绍
在 GitHub 上分享有趣的入门级开源项目。
这是一本面向编程新手、热爱编程和对开源社区感兴趣的人的月刊。月刊的内容包括:各种编程语言的项目、让生活更美好的工具、书籍、学习笔记、教程等。这些开源的大部分项目都非常好用,非常酷。主要是希望大家可以使用,加入开源社区。
在浏览和参与这些项目的过程中,你会学到更多的编程知识,提高编程技能,找到编程的乐趣。
终于,HelloGitHub项目诞生了
以下为本期内容|最新一期每月28日发布|点击查看上期内容
由于无法放置链接,因此可以通过以下两种方式找到该项目:
去 GitHub 用项目名称搜索。访问HelloGitHub的官网:Project C
1、baulk:一个用C语言编写的最小的Windows包管理器。使用方便,免安装,不修改系统环境变量,可与Windows Terminal集成并添加到右键菜单中。可以说是Scoop的精简版
2、LCUI:用C语言开发的图形界面开发库,可以用XML和CSS构建简单的跨平台桌面应用,提供类似web的开发体验。因此,您可以使用它轻松制作非常漂亮的界面。与 Electron 不同,它只是一个传统的 GUI 开发库,应用了一些 Web 技术
C# 项目
3、Windows-Auto-Night-Mode:设置 Windows 10 深色和浅色主题之间定时自动切换的工具
C++ 项目
4、flameshot:简单而强大的截图工具
CSS项目
5、css-sweeper:只使用 HTML 和 CSS 实现的扫雷游戏。在线玩
6、papercss:手绘风格的 CSS 库
去项目
7、go-internals:Go 编程语言内部实现原理的解释。中文翻译
8、livego:基于Go的直播服务项目
9、LeetCode-Go:《LeetCode Cookbook》是一个帮助开发者解决 LeetCode 上的问题并提供解决问题的思路和代码的项目。目前已经有收录 500+个问题,有解决方案和代码。代码都是 100% 运行时节拍,所有代码都是用 Go 语言实现的。在线阅读
10、ginrpc:简化go-gin框架注册路由方式,自动生成Swagger/Markdown文档。示例代码:
type ReqTest struct {
UserName string `json:"user_name" binding:"required"` // 带校验方式
}
type Hello struct {
}
// Hello [grpc-go](https://github.com/grpc/grpc-go) 模式
// @Router /hello_ruter [post,get]
func (s *Hello) Hello(c *gin.Context, req ReqTest) (*ReqTest, error) {
fmt.Println(req)
return &req,nil
}
func main() {
base := ginrpc.New(ginrpc.WithGroup("xxjwxc"))
router := gin.Default()
base.Register(router, new(Hello)) // 对象注册 like(go-micro)
router.Run(":8080")
}
Java 项目
11、D8gerAutoCode:IDEA Java代码自动生成插件。支持自动生成单表增删改查、分页、注释等。
12、java8-tutorial:一步步教你Java8的语言特点。Java11的新特性也在项目中更新
13、CalendarView:优雅强大的Android日历控件,支持周视图、自定义周开始等功能
14、tutorials:本项目是Spring框架下的小型单功能教程和示例代码的集合。主要是Spring、Spring Boot、Spring Security等。
JavaScript 项目
15、remote-browser:一个用 JavaScript 控制 Chrome 和 Firefox 浏览器的库。可以轻松实现自动化测试、数据采集等功能
16、:使用 Node.js 和 Socket.io 实现的在线迷宫游戏。入口在左上角,出口在右下角。使用 [a][w][s][d] 键移动位置。支持多人和单人模式,点击“显示解法”显示迷宫的解法(由BFS算法实现)。在线玩
17、jizhi:Chrome/Firefox 的中国风新标签页插件。它将在带有经典诗歌的新标签页上以繁体中文色彩的层叠波浪动画为特色
18、star-history:一个在线工具,用于显示GitHub项目的Star历史。支持多个项目显示在同一张图表上,效果如下:
19、genal-chat:适合前端新手学习的“星空”聊天室项目。Vue+socket.io结合TypeScript语法构建,界面酷炫,代码规范,支持群聊和好友搜索等功能
蟒蛇项目
20、handcalcs:从简单的 Python 代码生成复杂公式的工具。还记得在编写论文计算算法时害怕被逐行公式支配的恐惧吗?这个库可以将Python写的公式以LaTeX格式显示出来,效果如下:
21、QuickCut:一款轻量级、易用的开源视频处理工具。是一款基于PyQt5开发的桌面工具,用于满足非专业用户的视频处理需求:视频压缩、视频转码、反向视频、合并剪辑、根据字幕剪切剪辑、自动匹配字幕、自动编辑、等等
22、altair:用于数据可视化的强大 Python 库。支持多种数据展示方式,界面简洁,效果炫酷。示例代码及效果如下:
import altair as alt
from vega_datasets import data
source = data.cars()
brush = alt.selection(type='interval')
points = alt.Chart(source).mark_point().encode(
x='Horsepower',
y='Miles_per_Gallon',
color=alt.condition(brush, 'Origin', alt.value('lightgray'))
).add_selection(
brush
)
bars = alt.Chart(source).mark_bar().encode(
y='Origin',
color='Origin',
x='count(Origin)'
).transform_filter(
brush
)
points & bars
23、butterfly:又一个轻量级的 Python web 框架。网络框架太多了。本项目主要是开发一个轻量级、可靠、可用的Web框架,以更深入地了解Web开发过程中经常被忽略(由框架制造)的重要知识点。那句话是怎么来的:再不做就看不懂了!架构图如下:
斯威夫特项目
24、lottie-ios:Airbnb的开源三方库,用于快速实现APP动画。它还支持Android、React Native、Web、Windows等平台。动画效果如下:
25、YLExtensions:解决了UITableView和UI采集View的注册和配置过程中不得不写大量重复代码的问题
其他
26、math-as-code:这是一个通过比较数学符号和 JavaScript 代码来帮助开发人员更容易理解数学符号的项目
27、PowerToys:微软开源Windows系统下的强大辅助工具。例如:窗口管理、批量图像处理、换键工具等。下图为屏幕选色工具
28、first-contributions:关于如何首次向 GitHub 贡献代码的分步教程。支持多国语言,中文
29、leek-fund:VSCode中查看实时股票和基金数据的插件
30、Algorithms-in-4-Steps:系统学习算法和数据结构的集合
开源书籍
31、BuildYourOwnLisp:本书教你用C实现自己的Lisp语言。用1000多行代码实现一个小巧但功能齐全的Lisp语言。有中文翻译版,不过还没完。点击阅读
机器学习
32、waifu2x:基于机器学习制作图片和照片高清。本项目使用卷积神经网络对图像进行1-2x无损放大操作,并支持降噪保证图像质量。在线尝试
33、Never-Blink:谁先眨眼,谁就输了。使用React + Flask + Dlib技术实现的《一闪而过》网游,虽然是demo级别的项目,但是在本地运行,找朋友一起玩还是很有趣的
34、cnn-convoluter:支持卷积过程交互式可视化的可视化工具
终于
如果你在 GitHub 上发现有趣的项目,请在评论中告诉我。 查看全部
c#抓取网页数据(最好上有趣、入门级的开源项目,帮你找到兴趣!)
兴趣是最好的老师,HelloGitHub就是帮你找到兴趣!
介绍
在 GitHub 上分享有趣的入门级开源项目。
这是一本面向编程新手、热爱编程和对开源社区感兴趣的人的月刊。月刊的内容包括:各种编程语言的项目、让生活更美好的工具、书籍、学习笔记、教程等。这些开源的大部分项目都非常好用,非常酷。主要是希望大家可以使用,加入开源社区。
在浏览和参与这些项目的过程中,你会学到更多的编程知识,提高编程技能,找到编程的乐趣。
终于,HelloGitHub项目诞生了
以下为本期内容|最新一期每月28日发布|点击查看上期内容
由于无法放置链接,因此可以通过以下两种方式找到该项目:
去 GitHub 用项目名称搜索。访问HelloGitHub的官网:Project C
1、baulk:一个用C语言编写的最小的Windows包管理器。使用方便,免安装,不修改系统环境变量,可与Windows Terminal集成并添加到右键菜单中。可以说是Scoop的精简版
2、LCUI:用C语言开发的图形界面开发库,可以用XML和CSS构建简单的跨平台桌面应用,提供类似web的开发体验。因此,您可以使用它轻松制作非常漂亮的界面。与 Electron 不同,它只是一个传统的 GUI 开发库,应用了一些 Web 技术
C# 项目
3、Windows-Auto-Night-Mode:设置 Windows 10 深色和浅色主题之间定时自动切换的工具
C++ 项目
4、flameshot:简单而强大的截图工具
CSS项目
5、css-sweeper:只使用 HTML 和 CSS 实现的扫雷游戏。在线玩
6、papercss:手绘风格的 CSS 库
去项目
7、go-internals:Go 编程语言内部实现原理的解释。中文翻译
8、livego:基于Go的直播服务项目
9、LeetCode-Go:《LeetCode Cookbook》是一个帮助开发者解决 LeetCode 上的问题并提供解决问题的思路和代码的项目。目前已经有收录 500+个问题,有解决方案和代码。代码都是 100% 运行时节拍,所有代码都是用 Go 语言实现的。在线阅读
10、ginrpc:简化go-gin框架注册路由方式,自动生成Swagger/Markdown文档。示例代码:
type ReqTest struct {
UserName string `json:"user_name" binding:"required"` // 带校验方式
}
type Hello struct {
}
// Hello [grpc-go](https://github.com/grpc/grpc-go) 模式
// @Router /hello_ruter [post,get]
func (s *Hello) Hello(c *gin.Context, req ReqTest) (*ReqTest, error) {
fmt.Println(req)
return &req,nil
}
func main() {
base := ginrpc.New(ginrpc.WithGroup("xxjwxc"))
router := gin.Default()
base.Register(router, new(Hello)) // 对象注册 like(go-micro)
router.Run(":8080")
}
Java 项目
11、D8gerAutoCode:IDEA Java代码自动生成插件。支持自动生成单表增删改查、分页、注释等。
12、java8-tutorial:一步步教你Java8的语言特点。Java11的新特性也在项目中更新
13、CalendarView:优雅强大的Android日历控件,支持周视图、自定义周开始等功能
14、tutorials:本项目是Spring框架下的小型单功能教程和示例代码的集合。主要是Spring、Spring Boot、Spring Security等。
JavaScript 项目
15、remote-browser:一个用 JavaScript 控制 Chrome 和 Firefox 浏览器的库。可以轻松实现自动化测试、数据采集等功能
16、:使用 Node.js 和 Socket.io 实现的在线迷宫游戏。入口在左上角,出口在右下角。使用 [a][w][s][d] 键移动位置。支持多人和单人模式,点击“显示解法”显示迷宫的解法(由BFS算法实现)。在线玩
17、jizhi:Chrome/Firefox 的中国风新标签页插件。它将在带有经典诗歌的新标签页上以繁体中文色彩的层叠波浪动画为特色
18、star-history:一个在线工具,用于显示GitHub项目的Star历史。支持多个项目显示在同一张图表上,效果如下:
19、genal-chat:适合前端新手学习的“星空”聊天室项目。Vue+socket.io结合TypeScript语法构建,界面酷炫,代码规范,支持群聊和好友搜索等功能
蟒蛇项目
20、handcalcs:从简单的 Python 代码生成复杂公式的工具。还记得在编写论文计算算法时害怕被逐行公式支配的恐惧吗?这个库可以将Python写的公式以LaTeX格式显示出来,效果如下:
21、QuickCut:一款轻量级、易用的开源视频处理工具。是一款基于PyQt5开发的桌面工具,用于满足非专业用户的视频处理需求:视频压缩、视频转码、反向视频、合并剪辑、根据字幕剪切剪辑、自动匹配字幕、自动编辑、等等
22、altair:用于数据可视化的强大 Python 库。支持多种数据展示方式,界面简洁,效果炫酷。示例代码及效果如下:
import altair as alt
from vega_datasets import data
source = data.cars()
brush = alt.selection(type='interval')
points = alt.Chart(source).mark_point().encode(
x='Horsepower',
y='Miles_per_Gallon',
color=alt.condition(brush, 'Origin', alt.value('lightgray'))
).add_selection(
brush
)
bars = alt.Chart(source).mark_bar().encode(
y='Origin',
color='Origin',
x='count(Origin)'
).transform_filter(
brush
)
points & bars
23、butterfly:又一个轻量级的 Python web 框架。网络框架太多了。本项目主要是开发一个轻量级、可靠、可用的Web框架,以更深入地了解Web开发过程中经常被忽略(由框架制造)的重要知识点。那句话是怎么来的:再不做就看不懂了!架构图如下:
斯威夫特项目
24、lottie-ios:Airbnb的开源三方库,用于快速实现APP动画。它还支持Android、React Native、Web、Windows等平台。动画效果如下:
25、YLExtensions:解决了UITableView和UI采集View的注册和配置过程中不得不写大量重复代码的问题
其他
26、math-as-code:这是一个通过比较数学符号和 JavaScript 代码来帮助开发人员更容易理解数学符号的项目
27、PowerToys:微软开源Windows系统下的强大辅助工具。例如:窗口管理、批量图像处理、换键工具等。下图为屏幕选色工具
28、first-contributions:关于如何首次向 GitHub 贡献代码的分步教程。支持多国语言,中文
29、leek-fund:VSCode中查看实时股票和基金数据的插件
30、Algorithms-in-4-Steps:系统学习算法和数据结构的集合
开源书籍
31、BuildYourOwnLisp:本书教你用C实现自己的Lisp语言。用1000多行代码实现一个小巧但功能齐全的Lisp语言。有中文翻译版,不过还没完。点击阅读
机器学习
32、waifu2x:基于机器学习制作图片和照片高清。本项目使用卷积神经网络对图像进行1-2x无损放大操作,并支持降噪保证图像质量。在线尝试
33、Never-Blink:谁先眨眼,谁就输了。使用React + Flask + Dlib技术实现的《一闪而过》网游,虽然是demo级别的项目,但是在本地运行,找朋友一起玩还是很有趣的
34、cnn-convoluter:支持卷积过程交互式可视化的可视化工具
终于
如果你在 GitHub 上发现有趣的项目,请在评论中告诉我。
c#抓取网页数据(静态网页爬取的基本流程(一)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-04-11 03:02
内容
爬虫有两种,静态网页爬虫和动态网页爬虫。与动态网页爬虫相比,它非常简单。静态网页的爬取不需要执行JavaScript等代码,只需要获取页面Html代码并解析目标内容即可。也就是本文介绍了静态网页爬取的基本流程。
识别目标内容和目标站点
明确要求,比如这篇文章需要爬取北京过去一段时间的所有天气,先找一个合适的网站,比如在这个网站,可以找到站点北京的历史气象。
分析目标站点结构
在浏览器中打开北京历史天气站点后,无法直接获取天气,但是获取了很多超链接,包括指向不同时间段的天气链接。因此,需要解析这个页面来分析目标链接。
目标站点中的链接有两种类型,一种是目标链接,另一种是其他链接。接下来在浏览器中按F12查看网页源代码,查看目标链接的特征。这些特征可能是 Html 节点或 Html 属性。简而言之,你需要找到一个特征来区分目标链接和其他链接。
在Html代码中,可以看到链接的两个区别
网络访问
位于 System.Net 空间的 WebClient 可以轻松获取网页。主要代码如下
public static string GetHtml(string url)
{
string res = "";
WebClient client = new WebClient();
Stream stream = client.OpenRead(url);
StreamReader sr = new StreamReader(stream, Encoding.Default);
res = sr.ReadToEnd();
sr.Close();
client.Dispose();
return res;
}
网页节点分析
有一个著名的库 HtmlAgilityPack 可以帮助我们从字符串的网页的 html 代码生成 Dom 树,并让我们可以快速轻松地选择 Dom 树的节点,完成上一节的想法。VS打开工具->NuGet包管理器->管理解决方案的Nuget包,从这里可以搜索对应安装的HtmlAgilityPack包。使用该库时,需要导入 HtmlAgilityPack 命名空间。
using HtmlAgilityPack;
接下来,采用上一节的第二个思路,解析出目标链接。
public static List ParseLink(string html)
{
List res = new List();
var doc = new HtmlDocument();
doc.LoadHtml(html);
var linkNodes = doc.DocumentNode.SelectNodes("//a[@href]");
foreach (var linkNode in linkNodes)
{
string link = linkNode.GetAttributeValue("href", "");
if (link.StartsWith("/lishi/beijing/month"))
{
res.Add(link);
}
}
return res;
}
至此,收录过去时间段的站点的所有链接都已被解析。接下来,需要分析每个链接对应的具体网页的结构,从中获取天气信息。
分析天气网页结构
上一个链接是站点链接,具体天气网页对应的链接集合在上一节已经分析过了,例如。
现在我们需要从这个页面分析天气,就像解析站点结构中的目标链接一样,在浏览器中观察Html代码,发现天气的目标内容在一个表格中,所以我们只需要选择节点,因为节点表示给定日期的天气(天气条件、气温和风向)。
public static void ParseDailyWeather(string html)
{
var doc = new HtmlDocument();
doc.LoadHtml(html);
var rows = doc.DocumentNode.SelectNodes("//tr");
StringBuilder sb = new StringBuilder();
rows.RemoveAt(0);
foreach (var row in rows)
{
var cols = row.SelectNodes("td");
foreach (var col in cols)
{
string temp = col.InnerText.Replace("\r\n", "").Replace(" ", "").Trim();
sb.Append(temp + ",");
}
sb.Append("\r\n");
}
FileStream fs = new FileStream("output.csv", FileMode.Append, FileAccess.Write);
StreamWriter sw = new StreamWriter(fs, Encoding.GetEncoding("gbk"));
sw.WriteLine(sb);
sw.Close();
fs.Close();
}
最后,为了实现对网站的爬取,需要一个循环来实现对所有网页的爬取
public static void ParseWebsite(string url)
{
string html = Weather.GetHtml(url);
var links = Weather.ParseLink(html);
foreach (var link in links)
{
url = "http://www.tianqihoubao.com" + link;
html = Weather.GetHtml(url);
Weather.ParseDailyWeather(html);
}
}
总结
静态网页的爬取比较简单,可以分为以下几个步骤 查看全部
c#抓取网页数据(静态网页爬取的基本流程(一)(图))
内容
爬虫有两种,静态网页爬虫和动态网页爬虫。与动态网页爬虫相比,它非常简单。静态网页的爬取不需要执行JavaScript等代码,只需要获取页面Html代码并解析目标内容即可。也就是本文介绍了静态网页爬取的基本流程。
识别目标内容和目标站点
明确要求,比如这篇文章需要爬取北京过去一段时间的所有天气,先找一个合适的网站,比如在这个网站,可以找到站点北京的历史气象。

分析目标站点结构
在浏览器中打开北京历史天气站点后,无法直接获取天气,但是获取了很多超链接,包括指向不同时间段的天气链接。因此,需要解析这个页面来分析目标链接。
目标站点中的链接有两种类型,一种是目标链接,另一种是其他链接。接下来在浏览器中按F12查看网页源代码,查看目标链接的特征。这些特征可能是 Html 节点或 Html 属性。简而言之,你需要找到一个特征来区分目标链接和其他链接。

在Html代码中,可以看到链接的两个区别

网络访问
位于 System.Net 空间的 WebClient 可以轻松获取网页。主要代码如下
public static string GetHtml(string url)
{
string res = "";
WebClient client = new WebClient();
Stream stream = client.OpenRead(url);
StreamReader sr = new StreamReader(stream, Encoding.Default);
res = sr.ReadToEnd();
sr.Close();
client.Dispose();
return res;
}
网页节点分析
有一个著名的库 HtmlAgilityPack 可以帮助我们从字符串的网页的 html 代码生成 Dom 树,并让我们可以快速轻松地选择 Dom 树的节点,完成上一节的想法。VS打开工具->NuGet包管理器->管理解决方案的Nuget包,从这里可以搜索对应安装的HtmlAgilityPack包。使用该库时,需要导入 HtmlAgilityPack 命名空间。
using HtmlAgilityPack;
接下来,采用上一节的第二个思路,解析出目标链接。
public static List ParseLink(string html)
{
List res = new List();
var doc = new HtmlDocument();
doc.LoadHtml(html);
var linkNodes = doc.DocumentNode.SelectNodes("//a[@href]");
foreach (var linkNode in linkNodes)
{
string link = linkNode.GetAttributeValue("href", "");
if (link.StartsWith("/lishi/beijing/month"))
{
res.Add(link);
}
}
return res;
}
至此,收录过去时间段的站点的所有链接都已被解析。接下来,需要分析每个链接对应的具体网页的结构,从中获取天气信息。
分析天气网页结构
上一个链接是站点链接,具体天气网页对应的链接集合在上一节已经分析过了,例如。

现在我们需要从这个页面分析天气,就像解析站点结构中的目标链接一样,在浏览器中观察Html代码,发现天气的目标内容在一个表格中,所以我们只需要选择节点,因为节点表示给定日期的天气(天气条件、气温和风向)。

public static void ParseDailyWeather(string html)
{
var doc = new HtmlDocument();
doc.LoadHtml(html);
var rows = doc.DocumentNode.SelectNodes("//tr");
StringBuilder sb = new StringBuilder();
rows.RemoveAt(0);
foreach (var row in rows)
{
var cols = row.SelectNodes("td");
foreach (var col in cols)
{
string temp = col.InnerText.Replace("\r\n", "").Replace(" ", "").Trim();
sb.Append(temp + ",");
}
sb.Append("\r\n");
}
FileStream fs = new FileStream("output.csv", FileMode.Append, FileAccess.Write);
StreamWriter sw = new StreamWriter(fs, Encoding.GetEncoding("gbk"));
sw.WriteLine(sb);
sw.Close();
fs.Close();
}
最后,为了实现对网站的爬取,需要一个循环来实现对所有网页的爬取
public static void ParseWebsite(string url)
{
string html = Weather.GetHtml(url);
var links = Weather.ParseLink(html);
foreach (var link in links)
{
url = "http://www.tianqihoubao.com" + link;
html = Weather.GetHtml(url);
Weather.ParseDailyWeather(html);
}
}
总结
静态网页的爬取比较简单,可以分为以下几个步骤
c#抓取网页数据( 为什么要了解请求头(Requestheaders)信息?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-04-10 10:04
为什么要了解请求头(Requestheaders)信息?(图))
图1
如图1所示,在我们的工作过程中,无论是平台网站还是公司官网,总会有新闻展示。比如某天产品经理告诉我们,推广员想抢百度新闻的热点新闻版块,以提高网站的百度排名。要抢百度热点新闻版,首先要了解站点请求头(Request headers)信息。
为什么要了解请求标头(Request headers)信息?
原因在于,我们可以根据请求头信息中的某部分消息信息,而不是通过人工爬虫程序规避站点屏蔽,来伪装这是一个正常的HTTP请求,成功获取响应数据(Response data)。
如何查看百度新闻URL的请求头信息?
图 2
如图2,我们可以打开谷歌浏览器或者其他浏览器开发工具(按F12)查看站点的请求头消息信息。从图中可以看出百度新闻站点可以接受文本/html 等数据类型;语言为中文;浏览器版本为 Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 ( KHTML,如 Gecko ) Chrome/66.0.3359.181 Safari/537.36 等消息信息,我们在发起 HTTP 时直接携带消息信息request 过去,当然不是每一个包信息参数都必须携带过去,一部分可以被成功请求。
那么什么是响应数据?
图 3
如图3,响应数据(Response data)可以从谷歌Chrome或者其他浏览器开发工具中查看(按F12)查看,响应可以是json数据或者DOM树数据,方便我们的后续分析数据。
当然,你可以学习任何开发语言来开发爬虫程序:C#、NodeJs、Python、Java、C++。
不过这里主要讲C#爬虫程序的开发。微软为我们提供了HTTP请求的两个HttpWebRequest和HttpWebResponse对象,方便我们发送请求获取数据。下面显示了 C# HTTP 请求代码:
private string RequestAction(RequestOptions options)
{
string result = string.Empty;
IWebProxy proxy = GetProxy();
var request = (HttpWebRequest)WebRequest.Create(options.Uri);
request.Accept = options.Accept;
//在使用curl做POST的时候, 当要POST的数据大于1024字节的时候, curl并不会直接就发起POST请求, 而是会分为俩步,
//发送一个请求, 包含一个Expect: 100 -continue, 询问Server使用愿意接受数据
//接收到Server返回的100 - continue应答以后, 才把数据POST给Server
//并不是所有的Server都会正确应答100 -continue, 比如lighttpd, 就会返回417 “Expectation Failed”, 则会造成逻辑出错.
request.ServicePoint.Expect100Continue = false;
request.ServicePoint.UseNagleAlgorithm = false;//禁止Nagle算法加快载入速度
if (!string.IsNullOrEmpty(options.XHRParams)) { request.AllowWriteStreamBuffering = true; } else { request.AllowWriteStreamBuffering = false; }; //禁止缓冲加快载入速度
request.Headers.Add(HttpRequestHeader.AcceptEncoding, "gzip,deflate");//定义gzip压缩页面支持
request.ContentType = options.ContentType;//定义文档类型及编码
request.AllowAutoRedirect = options.AllowAutoRedirect;//禁止自动跳转
request.UserAgent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36";//设置User-Agent,伪装成Google Chrome浏览器
request.Timeout = options.Timeout;//定义请求超时时间为5秒
request.KeepAlive = options.KeepAlive;//启用长连接
if (!string.IsNullOrEmpty(options.Referer)) request.Referer = options.Referer;//返回上一级历史链接
request.Method = options.Method;//定义请求方式为GET
if (proxy != null) request.Proxy = proxy;//设置代理服务器IP,伪装请求地址
if (!string.IsNullOrEmpty(options.RequestCookies)) request.Headers[HttpRequestHeader.Cookie] = options.RequestCookies;
request.ServicePoint.ConnectionLimit = options.ConnectionLimit;//定义最大连接数
if (options.WebHeader != null && options.WebHeader.Count > 0) request.Headers.Add(options.WebHeader);//添加头部信息
if (!string.IsNullOrEmpty(options.XHRParams))//如果是POST请求,加入POST数据
{
byte[] buffer = Encoding.UTF8.GetBytes(options.XHRParams);
if (buffer != null)
{
request.ContentLength = buffer.Length;
request.GetRequestStream().Write(buffer, 0, buffer.Length);
}
}
using (var response = (HttpWebResponse)request.GetResponse())
{
////获取请求响应
//foreach (Cookie cookie in response.Cookies)
// options.CookiesContainer.Add(cookie);//将Cookie加入容器,保存登录状态
if (response.ContentEncoding.ToLower().Contains("gzip"))//解压
{
using (GZipStream stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadToEnd();
}
}
}
else if (response.ContentEncoding.ToLower().Contains("deflate"))//解压
{
using (DeflateStream stream = new DeflateStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadToEnd();
}
}
}
else
{
using (Stream stream = response.GetResponseStream())//原始
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadToEnd();
}
}
}
}
request.Abort();
return result;
}
还有一个我传入的自定义对象。当然,传入或传出对象由你根据实际业务需求定义:
public class RequestOptions
{
///
/// 请求方式,GET或POST
///
public string Method { get; set; }
///
/// URL
///
public Uri Uri { get; set; }
///
/// 上一级历史记录链接
///
public string Referer { get; set; }
///
/// 超时时间(毫秒)
///
public int Timeout = 15000;
///
/// 启用长连接
///
public bool KeepAlive = true;
///
/// 禁止自动跳转
///
public bool AllowAutoRedirect = false;
///
/// 定义最大连接数
///
public int ConnectionLimit = int.MaxValue;
///
/// 请求次数
///
public int RequestNum = 3;
///
/// 可通过文件上传提交的文件类型
///
public string Accept = "*/*";
///
/// 内容类型
///
public string ContentType = "application/x-www-form-urlencoded";
///
/// 实例化头部信息
///
private WebHeaderCollection header = new WebHeaderCollection();
///
/// 头部信息
///
public WebHeaderCollection WebHeader
{
get { return header; }
set { header = value; }
}
///
/// 定义请求Cookie字符串
///
public string RequestCookies { get; set; }
///
/// 异步参数数据
///
public string XHRParams { get; set; }
}
根据显示的代码,我们可以发现 HttpWebRequest 对象封装了很多 Request headers 消息参数。我们可以根据网站的Request headers信息在微软提供的HttpWebRequest对象中进行设置(见代码消息参数注释,都写了相关参数说明,如果理解有误请告知,谢谢你),然后发送请求获取响应数据来解析数据。
还补充一点,爬虫程序最好使用代理IP来使用代理IP,这样可以降低被屏蔽的概率,提高爬取效率。但是,代理IP也分为质量等级。对于某些 HTTPS 站点,可能需要质量级别更高的代理 IP 才能穿透。我不会在这里跑题。我会写一篇关于代理IP质量等级的文章文章详情说说我的看法。
C#代码如何使用代理IP?
Microsoft NET 框架还为我们提供了一个使用代理 IP 的 System.Net.WebProxy 对象。使用代码如下:
private System.Net.WebProxy GetProxy()
{
System.Net.WebProxy webProxy = null;
try
{
// 代理链接地址加端口
string proxyHost = "192.168.1.1";
string proxyPort = "9030";
// 代理身份验证的帐号跟密码
//string proxyUser = "xxx";
//string proxyPass = "xxx";
// 设置代理服务器
webProxy = new System.Net.WebProxy();
// 设置代理地址加端口
webProxy.Address = new Uri(string.Format("{0}:{1}", proxyHost, proxyPort));
// 如果只是设置代理IP加端口,例如192.168.1.1:80,这里直接注释该段代码,则不需要设置提交给代理服务器进行身份验证的帐号跟密码。
//webProxy.Credentials = new System.Net.NetworkCredential(proxyUser, proxyPass);
}
catch (Exception ex)
{
Console.WriteLine("获取代理信息异常", DateTime.Now.ToString(), ex.Message);
}
return webProxy;
}
关于System.Net.WebProxy对象的参数说明,我也在代码中进行了说明。
如果获取的Response数据是json、xml等格式的数据,这里就不详细描述这种数据解析方式了,请自行百度。这里的主要主题是 DOM 树 HTML 数据的解析。对于这类数据,有的人会使用正则表达式来解析,有的人会使用组件。当然,只要你能得到你想要的数据,你就可以按照你想要的方式解析它。这里的重点是我经常使用解析组件HtmlAgilityPack,参考DLL是(使用HtmlAgilityPack)。解析代码如下:
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(simpleCrawlResult.Contents);
HtmlNodeCollection liNodes = htmlDoc.DocumentNode.SelectSingleNode("//div[@id='pane-news']").SelectSingleNode("div[1]/ul[1]").SelectNodes("li");
if (liNodes != null && liNodes.Count > 0)
{
for (int i = 0; i < liNodes.Count; i++)
{
string title = liNodes[i].SelectSingleNode("strong[1]/a[1]").InnerText.Trim();
string href = liNodes[i].SelectSingleNode("strong[1]/a[1]").GetAttributeValue("href", "").Trim();
Console.WriteLine("新闻标题:" + title + ",链接:" + href);
}
}
下面主要展示爬取结果。
图 4
如图4,抓包效果,一个简单的爬虫程序就这样完成了。
至此,这篇关于c#实现爬虫程序的文章文章就介绍到这里了。希望对大家的学习有所帮助,也希望大家多多支持Scripting House。 查看全部
c#抓取网页数据(
为什么要了解请求头(Requestheaders)信息?(图))
图1
如图1所示,在我们的工作过程中,无论是平台网站还是公司官网,总会有新闻展示。比如某天产品经理告诉我们,推广员想抢百度新闻的热点新闻版块,以提高网站的百度排名。要抢百度热点新闻版,首先要了解站点请求头(Request headers)信息。
为什么要了解请求标头(Request headers)信息?
原因在于,我们可以根据请求头信息中的某部分消息信息,而不是通过人工爬虫程序规避站点屏蔽,来伪装这是一个正常的HTTP请求,成功获取响应数据(Response data)。
如何查看百度新闻URL的请求头信息?
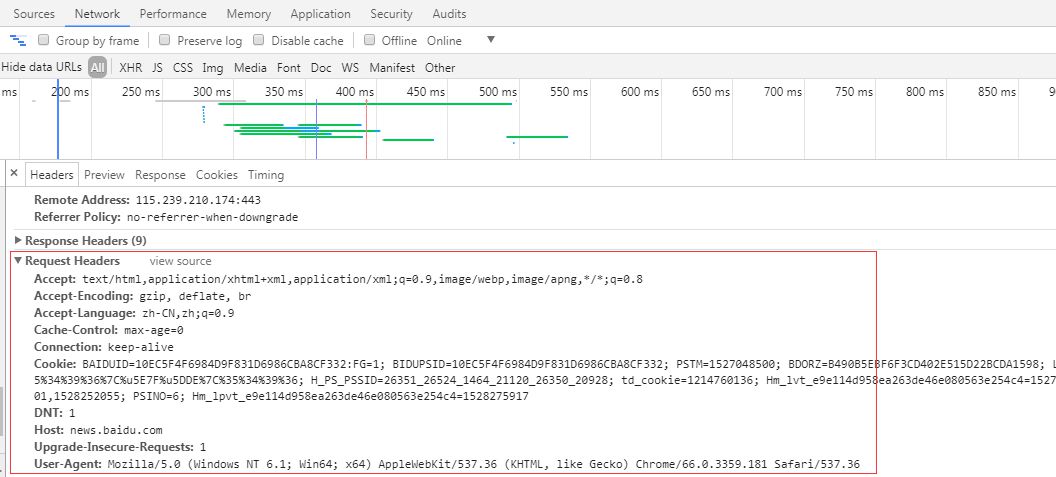
图 2
如图2,我们可以打开谷歌浏览器或者其他浏览器开发工具(按F12)查看站点的请求头消息信息。从图中可以看出百度新闻站点可以接受文本/html 等数据类型;语言为中文;浏览器版本为 Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 ( KHTML,如 Gecko ) Chrome/66.0.3359.181 Safari/537.36 等消息信息,我们在发起 HTTP 时直接携带消息信息request 过去,当然不是每一个包信息参数都必须携带过去,一部分可以被成功请求。
那么什么是响应数据?
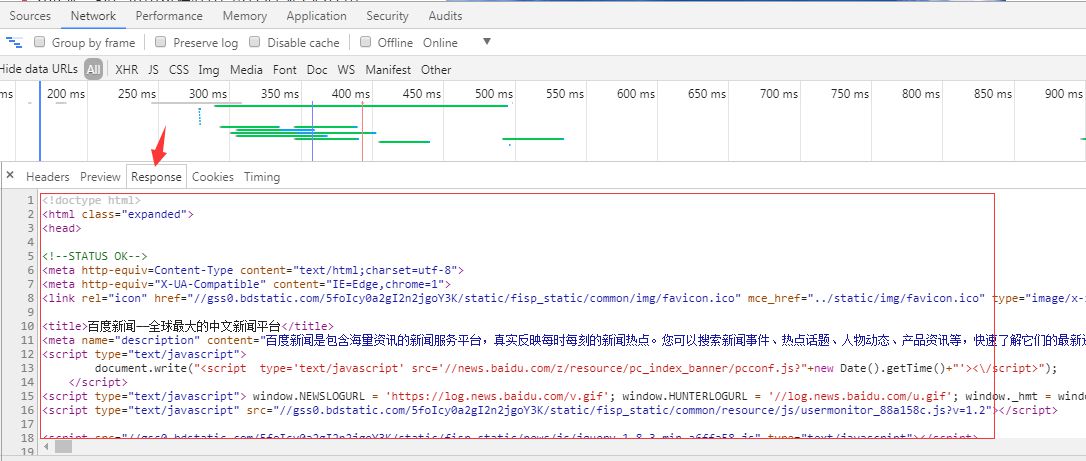
图 3
如图3,响应数据(Response data)可以从谷歌Chrome或者其他浏览器开发工具中查看(按F12)查看,响应可以是json数据或者DOM树数据,方便我们的后续分析数据。
当然,你可以学习任何开发语言来开发爬虫程序:C#、NodeJs、Python、Java、C++。
不过这里主要讲C#爬虫程序的开发。微软为我们提供了HTTP请求的两个HttpWebRequest和HttpWebResponse对象,方便我们发送请求获取数据。下面显示了 C# HTTP 请求代码:
private string RequestAction(RequestOptions options)
{
string result = string.Empty;
IWebProxy proxy = GetProxy();
var request = (HttpWebRequest)WebRequest.Create(options.Uri);
request.Accept = options.Accept;
//在使用curl做POST的时候, 当要POST的数据大于1024字节的时候, curl并不会直接就发起POST请求, 而是会分为俩步,
//发送一个请求, 包含一个Expect: 100 -continue, 询问Server使用愿意接受数据
//接收到Server返回的100 - continue应答以后, 才把数据POST给Server
//并不是所有的Server都会正确应答100 -continue, 比如lighttpd, 就会返回417 “Expectation Failed”, 则会造成逻辑出错.
request.ServicePoint.Expect100Continue = false;
request.ServicePoint.UseNagleAlgorithm = false;//禁止Nagle算法加快载入速度
if (!string.IsNullOrEmpty(options.XHRParams)) { request.AllowWriteStreamBuffering = true; } else { request.AllowWriteStreamBuffering = false; }; //禁止缓冲加快载入速度
request.Headers.Add(HttpRequestHeader.AcceptEncoding, "gzip,deflate");//定义gzip压缩页面支持
request.ContentType = options.ContentType;//定义文档类型及编码
request.AllowAutoRedirect = options.AllowAutoRedirect;//禁止自动跳转
request.UserAgent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36";//设置User-Agent,伪装成Google Chrome浏览器
request.Timeout = options.Timeout;//定义请求超时时间为5秒
request.KeepAlive = options.KeepAlive;//启用长连接
if (!string.IsNullOrEmpty(options.Referer)) request.Referer = options.Referer;//返回上一级历史链接
request.Method = options.Method;//定义请求方式为GET
if (proxy != null) request.Proxy = proxy;//设置代理服务器IP,伪装请求地址
if (!string.IsNullOrEmpty(options.RequestCookies)) request.Headers[HttpRequestHeader.Cookie] = options.RequestCookies;
request.ServicePoint.ConnectionLimit = options.ConnectionLimit;//定义最大连接数
if (options.WebHeader != null && options.WebHeader.Count > 0) request.Headers.Add(options.WebHeader);//添加头部信息
if (!string.IsNullOrEmpty(options.XHRParams))//如果是POST请求,加入POST数据
{
byte[] buffer = Encoding.UTF8.GetBytes(options.XHRParams);
if (buffer != null)
{
request.ContentLength = buffer.Length;
request.GetRequestStream().Write(buffer, 0, buffer.Length);
}
}
using (var response = (HttpWebResponse)request.GetResponse())
{
////获取请求响应
//foreach (Cookie cookie in response.Cookies)
// options.CookiesContainer.Add(cookie);//将Cookie加入容器,保存登录状态
if (response.ContentEncoding.ToLower().Contains("gzip"))//解压
{
using (GZipStream stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadToEnd();
}
}
}
else if (response.ContentEncoding.ToLower().Contains("deflate"))//解压
{
using (DeflateStream stream = new DeflateStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadToEnd();
}
}
}
else
{
using (Stream stream = response.GetResponseStream())//原始
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadToEnd();
}
}
}
}
request.Abort();
return result;
}
还有一个我传入的自定义对象。当然,传入或传出对象由你根据实际业务需求定义:
public class RequestOptions
{
///
/// 请求方式,GET或POST
///
public string Method { get; set; }
///
/// URL
///
public Uri Uri { get; set; }
///
/// 上一级历史记录链接
///
public string Referer { get; set; }
///
/// 超时时间(毫秒)
///
public int Timeout = 15000;
///
/// 启用长连接
///
public bool KeepAlive = true;
///
/// 禁止自动跳转
///
public bool AllowAutoRedirect = false;
///
/// 定义最大连接数
///
public int ConnectionLimit = int.MaxValue;
///
/// 请求次数
///
public int RequestNum = 3;
///
/// 可通过文件上传提交的文件类型
///
public string Accept = "*/*";
///
/// 内容类型
///
public string ContentType = "application/x-www-form-urlencoded";
///
/// 实例化头部信息
///
private WebHeaderCollection header = new WebHeaderCollection();
///
/// 头部信息
///
public WebHeaderCollection WebHeader
{
get { return header; }
set { header = value; }
}
///
/// 定义请求Cookie字符串
///
public string RequestCookies { get; set; }
///
/// 异步参数数据
///
public string XHRParams { get; set; }
}
根据显示的代码,我们可以发现 HttpWebRequest 对象封装了很多 Request headers 消息参数。我们可以根据网站的Request headers信息在微软提供的HttpWebRequest对象中进行设置(见代码消息参数注释,都写了相关参数说明,如果理解有误请告知,谢谢你),然后发送请求获取响应数据来解析数据。
还补充一点,爬虫程序最好使用代理IP来使用代理IP,这样可以降低被屏蔽的概率,提高爬取效率。但是,代理IP也分为质量等级。对于某些 HTTPS 站点,可能需要质量级别更高的代理 IP 才能穿透。我不会在这里跑题。我会写一篇关于代理IP质量等级的文章文章详情说说我的看法。
C#代码如何使用代理IP?
Microsoft NET 框架还为我们提供了一个使用代理 IP 的 System.Net.WebProxy 对象。使用代码如下:
private System.Net.WebProxy GetProxy()
{
System.Net.WebProxy webProxy = null;
try
{
// 代理链接地址加端口
string proxyHost = "192.168.1.1";
string proxyPort = "9030";
// 代理身份验证的帐号跟密码
//string proxyUser = "xxx";
//string proxyPass = "xxx";
// 设置代理服务器
webProxy = new System.Net.WebProxy();
// 设置代理地址加端口
webProxy.Address = new Uri(string.Format("{0}:{1}", proxyHost, proxyPort));
// 如果只是设置代理IP加端口,例如192.168.1.1:80,这里直接注释该段代码,则不需要设置提交给代理服务器进行身份验证的帐号跟密码。
//webProxy.Credentials = new System.Net.NetworkCredential(proxyUser, proxyPass);
}
catch (Exception ex)
{
Console.WriteLine("获取代理信息异常", DateTime.Now.ToString(), ex.Message);
}
return webProxy;
}
关于System.Net.WebProxy对象的参数说明,我也在代码中进行了说明。
如果获取的Response数据是json、xml等格式的数据,这里就不详细描述这种数据解析方式了,请自行百度。这里的主要主题是 DOM 树 HTML 数据的解析。对于这类数据,有的人会使用正则表达式来解析,有的人会使用组件。当然,只要你能得到你想要的数据,你就可以按照你想要的方式解析它。这里的重点是我经常使用解析组件HtmlAgilityPack,参考DLL是(使用HtmlAgilityPack)。解析代码如下:
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(simpleCrawlResult.Contents);
HtmlNodeCollection liNodes = htmlDoc.DocumentNode.SelectSingleNode("//div[@id='pane-news']").SelectSingleNode("div[1]/ul[1]").SelectNodes("li");
if (liNodes != null && liNodes.Count > 0)
{
for (int i = 0; i < liNodes.Count; i++)
{
string title = liNodes[i].SelectSingleNode("strong[1]/a[1]").InnerText.Trim();
string href = liNodes[i].SelectSingleNode("strong[1]/a[1]").GetAttributeValue("href", "").Trim();
Console.WriteLine("新闻标题:" + title + ",链接:" + href);
}
}
下面主要展示爬取结果。
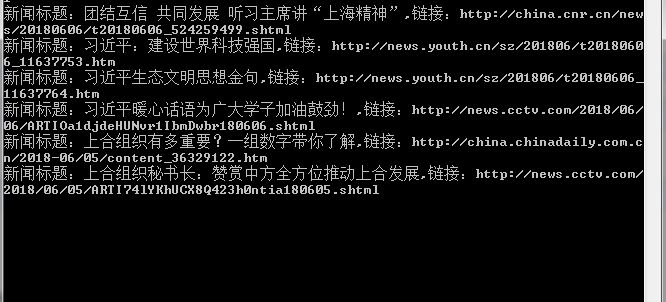
图 4
如图4,抓包效果,一个简单的爬虫程序就这样完成了。
至此,这篇关于c#实现爬虫程序的文章文章就介绍到这里了。希望对大家的学习有所帮助,也希望大家多多支持Scripting House。
c#抓取网页数据(关于前端和网络基础知识,你需要知道的四件事)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-10 03:31
Html Agility Pack 和 AngleSharp 基本上可以认为是只爬静态网页,后者明确表示可以解析基本的 JS 但不能解析 Angular。前一个文档简单易读,有一些方法没有文档,而后一个文档很广泛。前者只有 200 多个提交,后者超过 6,000 个。贡献者和star数也是后者,后者由.net基金会支持。后者在各方面都优于前者。但是,现在 GitHub 的使用者可以看到,前者差不多 20000,而后者不到 3000。现在后者一直没有透露这个数据,我也不知道为什么。实际上,它们都只是在解析 HTML。如果你不明白这句话的意思,
然后添加一个我看到的:dotnetcore/DotnetSpider,这个项目是国产的,也支持Core和distributed。但这正在被重写,并且文档不是很好(几乎没有)。
对于动态网页,如果您不知道如何找到界面:
如果使用的是.NET Framework,可以使用System.Windows.Forms.WebBrowser.Document获取HtmlDocument,根据需要使用All或Body的HtmlElement的OuterHtml,或者根据需要传递给这两个框架。但是这个控件默认的内核是老的IE内核,对现代前端的标准支持不好。
如果是.NET Core,单机可以使用Selenium+PhantomJS。不过后者不再维护,新版的 Selenium 也不再支持 PhantomJS。您可以考虑切换到其他 HeadLess 浏览器,例如 CEF 或其他 WebDriver。
因为这个问题是关于框架的,所以我回答了上面的框架。对于爬虫的初学者,我这里写一点关于爬虫的基础知识:
您需要对前端和网络基础知识有所了解。实际上,爬虫本质上是向服务器请求数据。
如果是服务端渲染,下载HTML,使用解析HTML的框架提取需要的信息;如果是客户端渲染,可以在浏览器的f12中选择网络和XHR找到AJAX请求,手动发送即可。这很好。这就是 requests 和 bs4 所做的。
爬虫真正的难点是多线程/分布式,与反爬虫的斗争,以及数据的保存和清洗。这些与网络请求关系不大。这就是像scrapy这样的爬虫框架进来的地方。
如果你已经有前端和网络的基础知识,你会发现requests和bs4不用学习就已经知道了。 查看全部
c#抓取网页数据(关于前端和网络基础知识,你需要知道的四件事)
Html Agility Pack 和 AngleSharp 基本上可以认为是只爬静态网页,后者明确表示可以解析基本的 JS 但不能解析 Angular。前一个文档简单易读,有一些方法没有文档,而后一个文档很广泛。前者只有 200 多个提交,后者超过 6,000 个。贡献者和star数也是后者,后者由.net基金会支持。后者在各方面都优于前者。但是,现在 GitHub 的使用者可以看到,前者差不多 20000,而后者不到 3000。现在后者一直没有透露这个数据,我也不知道为什么。实际上,它们都只是在解析 HTML。如果你不明白这句话的意思,
然后添加一个我看到的:dotnetcore/DotnetSpider,这个项目是国产的,也支持Core和distributed。但这正在被重写,并且文档不是很好(几乎没有)。
对于动态网页,如果您不知道如何找到界面:
如果使用的是.NET Framework,可以使用System.Windows.Forms.WebBrowser.Document获取HtmlDocument,根据需要使用All或Body的HtmlElement的OuterHtml,或者根据需要传递给这两个框架。但是这个控件默认的内核是老的IE内核,对现代前端的标准支持不好。
如果是.NET Core,单机可以使用Selenium+PhantomJS。不过后者不再维护,新版的 Selenium 也不再支持 PhantomJS。您可以考虑切换到其他 HeadLess 浏览器,例如 CEF 或其他 WebDriver。
因为这个问题是关于框架的,所以我回答了上面的框架。对于爬虫的初学者,我这里写一点关于爬虫的基础知识:
您需要对前端和网络基础知识有所了解。实际上,爬虫本质上是向服务器请求数据。
如果是服务端渲染,下载HTML,使用解析HTML的框架提取需要的信息;如果是客户端渲染,可以在浏览器的f12中选择网络和XHR找到AJAX请求,手动发送即可。这很好。这就是 requests 和 bs4 所做的。
爬虫真正的难点是多线程/分布式,与反爬虫的斗争,以及数据的保存和清洗。这些与网络请求关系不大。这就是像scrapy这样的爬虫框架进来的地方。
如果你已经有前端和网络的基础知识,你会发现requests和bs4不用学习就已经知道了。
c#抓取网页数据( 具体分析如下实例分析C#操作图片的相关技巧(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-10 01:02
具体分析如下实例分析C#操作图片的相关技巧(图))
C#方法抓取当前屏幕并保存为图片
更新时间:2015-04-17 12:36:23 作者:work24
本篇文章主要介绍了C#抓取当前屏幕并保存为图片的方法,并结合实例分析了C#操作图片的相关技巧,非常实用。有需要的朋友可以参考以下
本文示例介绍了C#抓取当前屏幕并保存为图片的方法。分享给大家,供大家参考。具体分析如下:
这是一个C#实现的截屏程序,可以截取整个屏幕并保存为指定格式的图片,并将当前控制台缓存保存为文本
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Diagnostics;
using System.Drawing;
using System.Drawing.Imaging;
using System.IO;
using System.Runtime.InteropServices;
using System.Text;
using System.Threading;
using System.Windows.Forms;
namespace RobvanderWoude
{
class PrintScreen
{
static int Main( string[] args )
{
try
{
string output = string.Empty;
bool overwrite = false;
bool text = false;
ImageFormat type = null;
#region Command Line parsing
if ( args.Length == 0 )
{
return WriteError( );
}
foreach ( string arg in args )
{
switch ( arg.ToUpper( ).Substring( 0, 2 ) )
{
case "/?":
return WriteError( );
case "/O":
overwrite = true;
break;
case "/T":
if ( text )
{
return WriteError( "Cannot capture current window as bitmap" );
}
switch ( arg.ToUpper( ).Substring( 3 ) )
{
case "BMP":
type = ImageFormat.Bmp;
break;
case "GIF":
type = ImageFormat.Gif;
break;
case "JPG":
case "JPEG":
type = ImageFormat.Jpeg;
break;
case "PNG":
type = ImageFormat.Png;
break;
case "TIF":
case "TIFF":
type = ImageFormat.Tiff;
break;
case "TXT":
text = true;
break;
default:
return WriteError( "Invalid file format: \"" + arg.Substring( 4 ) + "\"" );
}
break;
default:
output = arg;
break;
}
}
// Check if directory exists
if ( !Directory.Exists( Path.GetDirectoryName( output ) ) )
{
return WriteError( "Invalid path for output file: \"" + output + "\"" );
}
// Check if file exists, and if so, if it can be overwritten
if ( File.Exists( output ) )
{
if ( overwrite )
{
File.Delete( output );
}
else
{
return WriteError( "File exists; use /O to overwrite existing files." );
}
}
if ( type == null && text == false )
{
string ext = Path.GetExtension( output ).ToUpper( );
switch ( ext )
{
case ".BMP":
type = ImageFormat.Bmp;
break;
case ".GIF":
type = ImageFormat.Gif;
break;
case ".JPG":
case ".JPEG":
type = ImageFormat.Jpeg;
break;
case ".PNG":
type = ImageFormat.Png;
break;
case ".TIF":
case ".TIFF":
type = ImageFormat.Tiff;
break;
case ".TXT":
text = true;
break;
default:
return WriteError( "Invalid file type: \"" + ext + "\"" );
return 1;
}
}
#endregion Command Line parsing
if ( text )
{
string readtext = string.Empty;
for ( short i = 0; i < (short) Console.BufferHeight; i++ )
{
foreach ( string line in ConsoleReader.ReadFromBuffer( 0, i, (short) Console.BufferWidth, 1 ) )
{
readtext += line + "\n";
}
}
StreamWriter file = new StreamWriter( output );
file.Write( readtext );
file.Close( );
}
else
{
int width = Screen.PrimaryScreen.Bounds.Width;
int height = Screen.PrimaryScreen.Bounds.Height;
int top = 0;
int left = 0;
Bitmap printscreen = new Bitmap( width, height );
Graphics graphics = Graphics.FromImage( printscreen as Image );
graphics.CopyFromScreen( top, left, 0, 0, printscreen.Size );
printscreen.Save( output, type );
}
return 0;
}
catch ( Exception e )
{
Console.Error.WriteLine( e.Message );
return 1;
}
}
#region Error Handling
public static int WriteError( string errorMessage = "" )
{
Console.ResetColor( );
if ( string.IsNullOrEmpty( errorMessage ) == false )
{
Console.Error.WriteLine( );
Console.ForegroundColor = ConsoleColor.Red;
Console.Error.Write( "ERROR: " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.WriteLine( errorMessage );
Console.ResetColor( );
}
Console.Error.WriteLine( );
Console.Error.WriteLine( "PrintScreen, Version 1.10" );
Console.Error.WriteLine( "Save a screenshot as image or save the current console buffer as text" );
Console.Error.WriteLine( );
Console.Error.Write( "Usage: " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.WriteLine( "PRINTSCREEN outputfile [ /T:type ] [ /O ]" );
Console.ResetColor( );
Console.Error.WriteLine( );
Console.Error.Write( "Where: " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "outputfile" );
Console.ResetColor( );
Console.Error.WriteLine( " is the file to save the screenshot or text to" );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( " /T:type" );
Console.ResetColor( );
Console.Error.Write( " specifies the file type: " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "BMP" );
Console.ResetColor( );
Console.Error.Write( ", " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "GIF" );
Console.ResetColor( );
Console.Error.Write( ", " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "JPG" );
Console.ResetColor( );
Console.Error.Write( ", " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "PNG" );
Console.ResetColor( );
Console.Error.Write( ", " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "TIF" );
Console.ResetColor( );
Console.Error.Write( " or " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.WriteLine( "TXT" );
Console.ResetColor( );
Console.Error.Write( " (only required if " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "outputfile" );
Console.ResetColor( );
Console.Error.WriteLine( " extension is different)" );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( " /O" );
Console.ResetColor( );
Console.Error.WriteLine( " overwrites an existing file" );
Console.Error.WriteLine( );
Console.Error.Write( "Credits: Code to read console buffer by Simon Mourier " );
Console.ForegroundColor = ConsoleColor.DarkGray;
Console.Error.WriteLine( "http://www.sina.com.cn" );
Console.ResetColor( );
Console.Error.Write( " Code for graphic screenshot by Ali Hamdar " );
Console.ForegroundColor = ConsoleColor.DarkGray;
Console.Error.WriteLine( "https://www.jb51.net" );
Console.ResetColor( );
Console.Error.WriteLine( );
Console.Error.WriteLine( "Written by Rob van der Woude" );
Console.Error.WriteLine( "http://www.qq.com" );
return 1;
}
#endregion Error Handling
}
#region Read From Console Buffer
public class ConsoleReader
{
public static IEnumerable ReadFromBuffer( short x, short y, short width, short height )
{
IntPtr buffer = Marshal.AllocHGlobal( width * height * Marshal.SizeOf( typeof( CHAR_INFO ) ) );
if ( buffer == null )
throw new OutOfMemoryException( );
try
{
COORD coord = new COORD( );
SMALL_RECT rc = new SMALL_RECT( );
rc.Left = x;
rc.Top = y;
rc.Right = (short) ( x + width - 1 );
rc.Bottom = (short) ( y + height - 1 );
COORD size = new COORD( );
size.X = width;
size.Y = height;
const int STD_OUTPUT_HANDLE = -11;
if ( !ReadConsoleOutput( GetStdHandle( STD_OUTPUT_HANDLE ), buffer, size, coord, ref rc ) )
{
// 'Not enough storage is available to process this command' may be raised for buffer size > 64K (see ReadConsoleOutput doc.)
throw new Win32Exception( Marshal.GetLastWin32Error( ) );
}
IntPtr ptr = buffer;
for ( int h = 0; h < height; h++ )
{
StringBuilder sb = new StringBuilder( );
for ( int w = 0; w < width; w++ )
{
CHAR_INFO ci = (CHAR_INFO) Marshal.PtrToStructure( ptr, typeof( CHAR_INFO ) );
char[] chars = Console.OutputEncoding.GetChars( ci.charData );
sb.Append( chars[0] );
ptr += Marshal.SizeOf( typeof( CHAR_INFO ) );
}
yield return sb.ToString( );
}
}
finally
{
Marshal.FreeHGlobal( buffer );
}
}
[StructLayout( LayoutKind.Sequential )]
private struct CHAR_INFO
{
[MarshalAs( UnmanagedType.ByValArray, SizeConst = 2 )]
public byte[] charData;
public short attributes;
}
[StructLayout( LayoutKind.Sequential )]
private struct COORD
{
public short X;
public short Y;
}
[StructLayout( LayoutKind.Sequential )]
private struct SMALL_RECT
{
public short Left;
public short Top;
public short Right;
public short Bottom;
}
[StructLayout( LayoutKind.Sequential )]
private struct CONSOLE_SCREEN_BUFFER_INFO
{
public COORD dwSize;
public COORD dwCursorPosition;
public short wAttributes;
public SMALL_RECT srWindow;
public COORD dwMaximumWindowSize;
}
[DllImport( "kernel32.dll", SetLastError = true )]
private static extern bool ReadConsoleOutput( IntPtr hConsoleOutput, IntPtr lpBuffer, COORD dwBufferSize, COORD dwBufferCoord, ref SMALL_RECT lpReadRegion );
[DllImport( "kernel32.dll", SetLastError = true )]
private static extern IntPtr GetStdHandle( int nStdHandle );
}
#endregion Read From Console Buffer
}
我希望这篇文章对你的 C# 编程有所帮助。 查看全部
c#抓取网页数据(
具体分析如下实例分析C#操作图片的相关技巧(图))
C#方法抓取当前屏幕并保存为图片
更新时间:2015-04-17 12:36:23 作者:work24
本篇文章主要介绍了C#抓取当前屏幕并保存为图片的方法,并结合实例分析了C#操作图片的相关技巧,非常实用。有需要的朋友可以参考以下
本文示例介绍了C#抓取当前屏幕并保存为图片的方法。分享给大家,供大家参考。具体分析如下:
这是一个C#实现的截屏程序,可以截取整个屏幕并保存为指定格式的图片,并将当前控制台缓存保存为文本
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Diagnostics;
using System.Drawing;
using System.Drawing.Imaging;
using System.IO;
using System.Runtime.InteropServices;
using System.Text;
using System.Threading;
using System.Windows.Forms;
namespace RobvanderWoude
{
class PrintScreen
{
static int Main( string[] args )
{
try
{
string output = string.Empty;
bool overwrite = false;
bool text = false;
ImageFormat type = null;
#region Command Line parsing
if ( args.Length == 0 )
{
return WriteError( );
}
foreach ( string arg in args )
{
switch ( arg.ToUpper( ).Substring( 0, 2 ) )
{
case "/?":
return WriteError( );
case "/O":
overwrite = true;
break;
case "/T":
if ( text )
{
return WriteError( "Cannot capture current window as bitmap" );
}
switch ( arg.ToUpper( ).Substring( 3 ) )
{
case "BMP":
type = ImageFormat.Bmp;
break;
case "GIF":
type = ImageFormat.Gif;
break;
case "JPG":
case "JPEG":
type = ImageFormat.Jpeg;
break;
case "PNG":
type = ImageFormat.Png;
break;
case "TIF":
case "TIFF":
type = ImageFormat.Tiff;
break;
case "TXT":
text = true;
break;
default:
return WriteError( "Invalid file format: \"" + arg.Substring( 4 ) + "\"" );
}
break;
default:
output = arg;
break;
}
}
// Check if directory exists
if ( !Directory.Exists( Path.GetDirectoryName( output ) ) )
{
return WriteError( "Invalid path for output file: \"" + output + "\"" );
}
// Check if file exists, and if so, if it can be overwritten
if ( File.Exists( output ) )
{
if ( overwrite )
{
File.Delete( output );
}
else
{
return WriteError( "File exists; use /O to overwrite existing files." );
}
}
if ( type == null && text == false )
{
string ext = Path.GetExtension( output ).ToUpper( );
switch ( ext )
{
case ".BMP":
type = ImageFormat.Bmp;
break;
case ".GIF":
type = ImageFormat.Gif;
break;
case ".JPG":
case ".JPEG":
type = ImageFormat.Jpeg;
break;
case ".PNG":
type = ImageFormat.Png;
break;
case ".TIF":
case ".TIFF":
type = ImageFormat.Tiff;
break;
case ".TXT":
text = true;
break;
default:
return WriteError( "Invalid file type: \"" + ext + "\"" );
return 1;
}
}
#endregion Command Line parsing
if ( text )
{
string readtext = string.Empty;
for ( short i = 0; i < (short) Console.BufferHeight; i++ )
{
foreach ( string line in ConsoleReader.ReadFromBuffer( 0, i, (short) Console.BufferWidth, 1 ) )
{
readtext += line + "\n";
}
}
StreamWriter file = new StreamWriter( output );
file.Write( readtext );
file.Close( );
}
else
{
int width = Screen.PrimaryScreen.Bounds.Width;
int height = Screen.PrimaryScreen.Bounds.Height;
int top = 0;
int left = 0;
Bitmap printscreen = new Bitmap( width, height );
Graphics graphics = Graphics.FromImage( printscreen as Image );
graphics.CopyFromScreen( top, left, 0, 0, printscreen.Size );
printscreen.Save( output, type );
}
return 0;
}
catch ( Exception e )
{
Console.Error.WriteLine( e.Message );
return 1;
}
}
#region Error Handling
public static int WriteError( string errorMessage = "" )
{
Console.ResetColor( );
if ( string.IsNullOrEmpty( errorMessage ) == false )
{
Console.Error.WriteLine( );
Console.ForegroundColor = ConsoleColor.Red;
Console.Error.Write( "ERROR: " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.WriteLine( errorMessage );
Console.ResetColor( );
}
Console.Error.WriteLine( );
Console.Error.WriteLine( "PrintScreen, Version 1.10" );
Console.Error.WriteLine( "Save a screenshot as image or save the current console buffer as text" );
Console.Error.WriteLine( );
Console.Error.Write( "Usage: " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.WriteLine( "PRINTSCREEN outputfile [ /T:type ] [ /O ]" );
Console.ResetColor( );
Console.Error.WriteLine( );
Console.Error.Write( "Where: " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "outputfile" );
Console.ResetColor( );
Console.Error.WriteLine( " is the file to save the screenshot or text to" );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( " /T:type" );
Console.ResetColor( );
Console.Error.Write( " specifies the file type: " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "BMP" );
Console.ResetColor( );
Console.Error.Write( ", " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "GIF" );
Console.ResetColor( );
Console.Error.Write( ", " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "JPG" );
Console.ResetColor( );
Console.Error.Write( ", " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "PNG" );
Console.ResetColor( );
Console.Error.Write( ", " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "TIF" );
Console.ResetColor( );
Console.Error.Write( " or " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.WriteLine( "TXT" );
Console.ResetColor( );
Console.Error.Write( " (only required if " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "outputfile" );
Console.ResetColor( );
Console.Error.WriteLine( " extension is different)" );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( " /O" );
Console.ResetColor( );
Console.Error.WriteLine( " overwrites an existing file" );
Console.Error.WriteLine( );
Console.Error.Write( "Credits: Code to read console buffer by Simon Mourier " );
Console.ForegroundColor = ConsoleColor.DarkGray;
Console.Error.WriteLine( "http://www.sina.com.cn" );
Console.ResetColor( );
Console.Error.Write( " Code for graphic screenshot by Ali Hamdar " );
Console.ForegroundColor = ConsoleColor.DarkGray;
Console.Error.WriteLine( "https://www.jb51.net" );
Console.ResetColor( );
Console.Error.WriteLine( );
Console.Error.WriteLine( "Written by Rob van der Woude" );
Console.Error.WriteLine( "http://www.qq.com" );
return 1;
}
#endregion Error Handling
}
#region Read From Console Buffer
public class ConsoleReader
{
public static IEnumerable ReadFromBuffer( short x, short y, short width, short height )
{
IntPtr buffer = Marshal.AllocHGlobal( width * height * Marshal.SizeOf( typeof( CHAR_INFO ) ) );
if ( buffer == null )
throw new OutOfMemoryException( );
try
{
COORD coord = new COORD( );
SMALL_RECT rc = new SMALL_RECT( );
rc.Left = x;
rc.Top = y;
rc.Right = (short) ( x + width - 1 );
rc.Bottom = (short) ( y + height - 1 );
COORD size = new COORD( );
size.X = width;
size.Y = height;
const int STD_OUTPUT_HANDLE = -11;
if ( !ReadConsoleOutput( GetStdHandle( STD_OUTPUT_HANDLE ), buffer, size, coord, ref rc ) )
{
// 'Not enough storage is available to process this command' may be raised for buffer size > 64K (see ReadConsoleOutput doc.)
throw new Win32Exception( Marshal.GetLastWin32Error( ) );
}
IntPtr ptr = buffer;
for ( int h = 0; h < height; h++ )
{
StringBuilder sb = new StringBuilder( );
for ( int w = 0; w < width; w++ )
{
CHAR_INFO ci = (CHAR_INFO) Marshal.PtrToStructure( ptr, typeof( CHAR_INFO ) );
char[] chars = Console.OutputEncoding.GetChars( ci.charData );
sb.Append( chars[0] );
ptr += Marshal.SizeOf( typeof( CHAR_INFO ) );
}
yield return sb.ToString( );
}
}
finally
{
Marshal.FreeHGlobal( buffer );
}
}
[StructLayout( LayoutKind.Sequential )]
private struct CHAR_INFO
{
[MarshalAs( UnmanagedType.ByValArray, SizeConst = 2 )]
public byte[] charData;
public short attributes;
}
[StructLayout( LayoutKind.Sequential )]
private struct COORD
{
public short X;
public short Y;
}
[StructLayout( LayoutKind.Sequential )]
private struct SMALL_RECT
{
public short Left;
public short Top;
public short Right;
public short Bottom;
}
[StructLayout( LayoutKind.Sequential )]
private struct CONSOLE_SCREEN_BUFFER_INFO
{
public COORD dwSize;
public COORD dwCursorPosition;
public short wAttributes;
public SMALL_RECT srWindow;
public COORD dwMaximumWindowSize;
}
[DllImport( "kernel32.dll", SetLastError = true )]
private static extern bool ReadConsoleOutput( IntPtr hConsoleOutput, IntPtr lpBuffer, COORD dwBufferSize, COORD dwBufferCoord, ref SMALL_RECT lpReadRegion );
[DllImport( "kernel32.dll", SetLastError = true )]
private static extern IntPtr GetStdHandle( int nStdHandle );
}
#endregion Read From Console Buffer
}
我希望这篇文章对你的 C# 编程有所帮助。
c#抓取网页数据(网页分析采集程序的基本流程和流程图详解 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2022-04-09 11:02
)
首先需要明确:网站的任何页面,无论是php、jsp、aspx等动态页面还是后台程序生成的静态页面,都可以在浏览器。
所以当你想开发一个data采集程序时,你首先要了解你要采集的网站的首页结构(HTML)。
一旦熟悉了 网站 中的 HTML 源文件的内容,其中数据是 采集,程序的其余部分就很容易了。因为C#在网站上执行数据采集,原理是“下载你想要的页面的HTML源文件到采集,分析HTML代码然后抓取你需要的数据,最后保存数据。到本地文件”。
基本流程如下图所示:
1.页面源文件下载
首先引用 System.Net 命名空间
使用 System.Net;
还需要引用
使用 System.Text;
使用 System.IO;
复制代码
引用后实例化一个 WebClient 对象
私人 WebClientwc = new WebClient();
调用DownloadData方法从指定网页的源文件中下载一组BYTE数据,然后将BYTE数组转换为字符串。
// 下载页面源文件并转换为UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData( string .Format("你要的网页地址采集")));
复制代码
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
// 下载网页源文件到本地
wc.DownloadFile("你要访问的网页的URL采集", "保存源文件的本地文件路径");
// 读取下载源文件的HTML格式字符串
string mainData = File.ReadAllText("保存源文件的本地文件路径",Encoding.UTF8);
复制代码
使用网页 HTML 格式字符串,您可以分析 采集 网页并抓取您需要的内容。
2.页面分析采集
页面分析就是用网页源文件中的一个特定的或唯一的字符(字符串)作为一个抓取点,从这个抓取点开始截取你想要的页面上的数据。
以博客园为栏目为例,如果我想要采集博客园首页列出的文章的标题和链接,我必须以"开头
代码:
// 经过”
mainData = mainData.Substring(mainData.IndexOf( " " ) + 26 );
// 获取文章页面的链接地址
字符串 articleAddr = mainData.Substring( 0 ,mainData.IndexOf( " \" " ));
// 获取 文章 标题
字符串文章标题 = mainData.Substring(mainData.IndexOf( " target=\"_blank\"> " ) + 16 ,
mainData.IndexOf( " " ) - mainData.IndexOf( " target=\"_blank\"> " ) - 16 );
复制代码
注意:当你要采集的网页首页的HTML格式发生变化时,作为抓取点的字符也要相应的改变,否则采集什么都得不到
3.数据存储
从网页中截取需要的数据后,将程序中的数据组织起来,保存到本地文件中(或者插入到自己的本地数据库中)。这样,整个采集的工作就会在一个段落中完成。
// 输出数据到本地文件
File.AppendAllText(CreateFolderIfNot(Settings.Default.OutPath) + articleTitle + ".txt" ,
文章数据,
编码.UTF8);
复制代码
另外附上我自己写的采集博客园主页文章的小程序代码。该程序的作用是将博客园主页上的文章采集全部发布下来。
下载地址:CnBlogCollector.rar
当然,如果博客园首页的格式调整了,程序的采集功能肯定会失效,而继续采集的唯一办法就是重新调整程序自己一个人,呵呵。. .
程序效果如下:
查看全部
c#抓取网页数据(网页分析采集程序的基本流程和流程图详解
)
首先需要明确:网站的任何页面,无论是php、jsp、aspx等动态页面还是后台程序生成的静态页面,都可以在浏览器。

所以当你想开发一个data采集程序时,你首先要了解你要采集的网站的首页结构(HTML)。
一旦熟悉了 网站 中的 HTML 源文件的内容,其中数据是 采集,程序的其余部分就很容易了。因为C#在网站上执行数据采集,原理是“下载你想要的页面的HTML源文件到采集,分析HTML代码然后抓取你需要的数据,最后保存数据。到本地文件”。
基本流程如下图所示:

1.页面源文件下载
首先引用 System.Net 命名空间
使用 System.Net;
还需要引用
使用 System.Text;
使用 System.IO;
复制代码
引用后实例化一个 WebClient 对象
私人 WebClientwc = new WebClient();
调用DownloadData方法从指定网页的源文件中下载一组BYTE数据,然后将BYTE数组转换为字符串。
// 下载页面源文件并转换为UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData( string .Format("你要的网页地址采集")));
复制代码
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
// 下载网页源文件到本地
wc.DownloadFile("你要访问的网页的URL采集", "保存源文件的本地文件路径");
// 读取下载源文件的HTML格式字符串
string mainData = File.ReadAllText("保存源文件的本地文件路径",Encoding.UTF8);
复制代码
使用网页 HTML 格式字符串,您可以分析 采集 网页并抓取您需要的内容。
2.页面分析采集
页面分析就是用网页源文件中的一个特定的或唯一的字符(字符串)作为一个抓取点,从这个抓取点开始截取你想要的页面上的数据。
以博客园为栏目为例,如果我想要采集博客园首页列出的文章的标题和链接,我必须以"开头

代码:
// 经过”
mainData = mainData.Substring(mainData.IndexOf( " " ) + 26 );
// 获取文章页面的链接地址
字符串 articleAddr = mainData.Substring( 0 ,mainData.IndexOf( " \" " ));
// 获取 文章 标题
字符串文章标题 = mainData.Substring(mainData.IndexOf( " target=\"_blank\"> " ) + 16 ,
mainData.IndexOf( " " ) - mainData.IndexOf( " target=\"_blank\"> " ) - 16 );
复制代码
注意:当你要采集的网页首页的HTML格式发生变化时,作为抓取点的字符也要相应的改变,否则采集什么都得不到
3.数据存储
从网页中截取需要的数据后,将程序中的数据组织起来,保存到本地文件中(或者插入到自己的本地数据库中)。这样,整个采集的工作就会在一个段落中完成。
// 输出数据到本地文件
File.AppendAllText(CreateFolderIfNot(Settings.Default.OutPath) + articleTitle + ".txt" ,
文章数据,
编码.UTF8);
复制代码
另外附上我自己写的采集博客园主页文章的小程序代码。该程序的作用是将博客园主页上的文章采集全部发布下来。
下载地址:CnBlogCollector.rar
当然,如果博客园首页的格式调整了,程序的采集功能肯定会失效,而继续采集的唯一办法就是重新调整程序自己一个人,呵呵。. .
程序效果如下:

c#抓取网页数据(利用C#和.NET提供的类来轻松创建一个的程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-04-08 06:04
本文使用 C# 和 .NET 提供的类,轻松创建抓取网页内容源代码的程序。HTTP 是在 WWW 上进行数据访问的最基本协议之一。.NET的基本类型库类中提供了两个对象类:HTTPWebRequest和HTTPWebResponse,分别用于向资源发送请求和获取响应。为了获取一个资源的内容,我们首先指定一个我们要抓取的URL地址,使用HTTPWebRequest对象发出请求,使用HTTPWebResponse对象接收响应的结果,最后使用TextStream对象提取我们想要的信息并在控制台打印出来。
下面看一下如何实现这样的功能:
(1)打开VS.NET,点击“文件”-“新建”-“项目”,项目类型选择“Visual C#项目”,模板选择“Windows应用程序”,
(2)Form1中添加Label1、Button1、TextBox1、TextBox2四个控件,将TextBox2的Multiline属性改为True,
(3)右击Form1表单,选择“查看代码”,然后在顶部输入:
使用 System.IO;
使用 System.Net;
使用 System.Text;
私人无效按钮1_Click(对象发送者,System.EventArgs e)
{
}
在括号内输入以下代码:
字节[] buf = 新字节[38192];
HttpWebRequest 请求 = (HttpWebRequest)
WebRequest.Create(textBox1.Text);
HttpWebResponse 响应 = (HttpWebResponse)
请求.GetResponse();
流 resStream = response.GetResponseStream();
int count = resStream.Read(buf, 0, buf.Length);
textBox2.Text = Encoding.Default.GetString(buf, 0,
数数);
resStream.Close();
(4)all”按钮,按“F5”运行应用程序,在“请输入URL地址:”后的单行文本框中输入,点击“获取HTML代码”按钮,即可看到地址的代码!
接下来,我们将对上述程序做一个分析:
上述程序的作用是抓取网页内容,并在多行文本框中显示 HTML 代码。由于返回的数据是字节类型的,我们创建一个字节类型的数组变量,名为 buf 来存储请求返回的结果,其中数组的大小与我们要请求返回的数据的大小有关。
首先,我们实例化 HttpWebRequest 对象,并使用 WebRequest 类的静态方法 Create()。该方法的字符串参数是我们要请求的页面的URL地址。由于Create()方法返回的是WebRequest类型,所以我们必须将Model(即类型转换)转换为HttpWebRequest类型,然后赋值给request变量。一旦我们创建了 HttpWebRequest 对象,我们就可以使用它的 GetResponse() 方法返回一个 WebResponse 对象,然后将其转换为一个 HttpWebResponse 对象并将其分配给响应变量。
现在,可以使用响应对象的GetResponseStream()方法获取响应的文本流,最后使用Stream对象的Read()方法将返回的响应信息放入我们最初创建的字节数组buf中。Read()有3个参数,分别是:要放置的字节数组,字节数组的起始位置,字节数组的长度。
最后,将字节转换为字符串。注意:这里使用的是默认编码,它使用默认的编码方式,所以我们不再需要在字符编码之间进行转换。您还可以使用 WebRequest 和 WebResponse 来实现上述功能。代码如下:
WebRequest 请求 = WebRequest.Create(textBox1.Text);
WebResponse 响应 =request.GetResponse();
输入另一个网址,看看是不是很方便!
本文来自:象屿阁-IT天堂(),转载请保留此信息! 查看全部
c#抓取网页数据(利用C#和.NET提供的类来轻松创建一个的程序)
本文使用 C# 和 .NET 提供的类,轻松创建抓取网页内容源代码的程序。HTTP 是在 WWW 上进行数据访问的最基本协议之一。.NET的基本类型库类中提供了两个对象类:HTTPWebRequest和HTTPWebResponse,分别用于向资源发送请求和获取响应。为了获取一个资源的内容,我们首先指定一个我们要抓取的URL地址,使用HTTPWebRequest对象发出请求,使用HTTPWebResponse对象接收响应的结果,最后使用TextStream对象提取我们想要的信息并在控制台打印出来。
下面看一下如何实现这样的功能:
(1)打开VS.NET,点击“文件”-“新建”-“项目”,项目类型选择“Visual C#项目”,模板选择“Windows应用程序”,
(2)Form1中添加Label1、Button1、TextBox1、TextBox2四个控件,将TextBox2的Multiline属性改为True,
(3)右击Form1表单,选择“查看代码”,然后在顶部输入:
使用 System.IO;
使用 System.Net;
使用 System.Text;
私人无效按钮1_Click(对象发送者,System.EventArgs e)
{
}
在括号内输入以下代码:
字节[] buf = 新字节[38192];
HttpWebRequest 请求 = (HttpWebRequest)
WebRequest.Create(textBox1.Text);
HttpWebResponse 响应 = (HttpWebResponse)
请求.GetResponse();
流 resStream = response.GetResponseStream();
int count = resStream.Read(buf, 0, buf.Length);
textBox2.Text = Encoding.Default.GetString(buf, 0,
数数);
resStream.Close();
(4)all”按钮,按“F5”运行应用程序,在“请输入URL地址:”后的单行文本框中输入,点击“获取HTML代码”按钮,即可看到地址的代码!
接下来,我们将对上述程序做一个分析:
上述程序的作用是抓取网页内容,并在多行文本框中显示 HTML 代码。由于返回的数据是字节类型的,我们创建一个字节类型的数组变量,名为 buf 来存储请求返回的结果,其中数组的大小与我们要请求返回的数据的大小有关。
首先,我们实例化 HttpWebRequest 对象,并使用 WebRequest 类的静态方法 Create()。该方法的字符串参数是我们要请求的页面的URL地址。由于Create()方法返回的是WebRequest类型,所以我们必须将Model(即类型转换)转换为HttpWebRequest类型,然后赋值给request变量。一旦我们创建了 HttpWebRequest 对象,我们就可以使用它的 GetResponse() 方法返回一个 WebResponse 对象,然后将其转换为一个 HttpWebResponse 对象并将其分配给响应变量。
现在,可以使用响应对象的GetResponseStream()方法获取响应的文本流,最后使用Stream对象的Read()方法将返回的响应信息放入我们最初创建的字节数组buf中。Read()有3个参数,分别是:要放置的字节数组,字节数组的起始位置,字节数组的长度。
最后,将字节转换为字符串。注意:这里使用的是默认编码,它使用默认的编码方式,所以我们不再需要在字符编码之间进行转换。您还可以使用 WebRequest 和 WebResponse 来实现上述功能。代码如下:
WebRequest 请求 = WebRequest.Create(textBox1.Text);
WebResponse 响应 =request.GetResponse();
输入另一个网址,看看是不是很方便!
本文来自:象屿阁-IT天堂(),转载请保留此信息!
c#抓取网页数据(微软公司支持Python语言的自动化工具介绍及项目实战项目介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-04-07 00:13
)
工具介绍
Playwright 是微软公司开发的一款非常强大的开源自动化测试工具。它之所以强大,原因如下:
1. 支持所有主流浏览器:Chrome、Firefox、Safari、MS Edge。
2. 支持无头和有头模式。
3. 提供可与 Pytest 结合使用的同步和异步 API。
4. 支持在浏览器端自动录制脚本。
5. Python 语言的自动化工具。
6. 支持的操作系统有 Linux、Mac OS 和 Windows。
7.可以使用docker安装运行环境。
安装环境
1.安装Python,Playwright需要3.7及以上Python,所以至少Python3.7或以上(最好3.7,我试过3.@ >8 存在兼容性问题)。
2.去下载项目代码,主要是local_requirements.txt。
3. 使用 pip3 install playwright==1.8.0a1(最好在此处指定版本)。
4. 使用 pip3 install -r local_requirements.txt 安装所有依赖项。
5. 使用python3 -m playwright install 安装浏览器驱动模块(使用清华镜像)。
这里在命令窗口运行:pip3 -v config list 查看系统中的pip.ini文件,下面是我的。
[全局]
index-url=
#index-url=
#[安装]
#trusted-host=
这里需要把阿里云注释掉,最好白天或者早上安装这个,会更快。其他时候用阿里云的镜像会更快。
6. 检查是否安装成功。如果看到如下界面,则说明安装成功。
脚本录制
Playwright 的脚本录制需要使用命令 codegen。下面详细解释该命令的用法:
该命令需要的参数如下:
o 或 --output 指定保存脚本的文件路径和文件名。
target指定生成脚本的语言:Python、JavaScript、C#等
b指定用于录制的浏览器:如:-b chromium(Chrome浏览器)、-b firefox、-b webkit。
项目实战
项目:在线商店
1、脚本录制
python3 -m playwright codegen -o 'login_b2c.py' --target python -b chromium :8080/b2c/index.html
以上是命令执行后进入的界面。当鼠标在元素上滑动时,会自动提示元素的xpath,并启动隐身浏览模式,便于与本地浏览的页面区分开来。
点击登录链接,会弹出如下图:
输入必要的信息以登录。
登录成功,返回首页,注意红框,这里是断言目标。
关闭浏览器,输出脚本文件:这里可以看到我们的脚本文件就是命令中指定的文件名,右边是脚本文件代码,这里使用的是同步方式。源码如下:
从剧作家导入sync_playwright
def run(剧作家):
浏览器 = playwright.chromium.launch(headless=False)
上下文 = browser.newContext()
#打开新页面
page = context.newPage()
# 转到:8080/b2c/index.html
page.goto(":8080/b2c/index.html")
# 点击文字=/.*登录.*/
page.click("text=/.*login.*/")
# assert page.url == ":8080/b2c/login.html"
#点击输入[name="username"]
page.click("input[name=\"username\"]")
# 填写输入[name="username"]
page.fill("input[name=\"username\"]", "tester")
#按回车
page.press("input[name=\"username\"]", "Enter")
#点击输入[name="password"]
page.click("input[name=\"password\"]")
# 填写输入[name="password"]
page.fill("input[name=\"password\"]", "123456")
#点击输入[name="validcode"]
page.click("input[name=\"validcode\"]")
# 填写输入[name="validcode"]
page.fill("input[name=\"validcode\"]", "1111")
#点击输入[type="button"]
# with page.expect_navigation(url=":8080/b2c/index.html"):
使用 page.expect_navigation():
page.click("input[type=\"button\"]")
page.close()
# ---------
context.close()
browser.close()
以sync_playwright() 为编剧:
运行(剧作家)
在这个录制的脚本中发现了以下问题:
1)Playwright开始搭建浏览器,这里使用chromium,然后使用浏览器实例化一个context对象context,再通过context实例化一个page对象,也就是使用context.newPage()可以实例化多个页面,并且页面之间不共享会话和 cookie。
2)页面可以通过定位器来定位页面上的各种元素,所以要想用好Playwright,就必须好好研究一下页面对象。
3)缺点是 Playwright 在录制过程中不提供断言。虽然有很多内置的断言方法,但只能手动编写。
4)需要参数化。好在Playwright集成了pytest功能,我们要好好利用一下。
2. 集成pytest和Playwright
经过研究,发现Playwright不具备参数化自身的能力。如果要参数化,仍然需要编写代码来赋值。在这里,考虑与 pytest 结合使用。使用pytest的参数化和fixture可以充分实现参数化和关联的效果。
代码说明:
#coding=utf-8
从 playwright.sync_api 导入页面
导入 pytest
#这里构造测试用例需要的数据,第一个是用户名,第二个是密码,第三个是预期结果
data=[['tester','123456','Hello: tester'],['tester1','123456','Hello: tester1'],['tester2','1234567',' 账号错误密码']]
# 使用 pytest.mark.parametrize 导入用户数据
@pytest.mark.parametrize('userdata',data)
#测试函数的第一个参数是指playwright提供的Page,是一个fixture,需要安装
#pytest-playwright
def test_login(page:Page,userdata):
page.goto(":8080/b2c/index.html")
# 点击文字=/.*登录.*/
page.click("text=/.*login.*/")
# assert page.url == ":8080/b2c/login.html"
#点击输入[name="username"]
page.click("input[name=\"username\"]")
# 填写输入[name="username"]
# page.fill("input[name=\"username\"]", "tester")
page.fill("input[name=\"username\"]", userdata[0])
#按回车
page.press("input[name=\"username\"]", "Enter")
#点击输入[name="password"]
page.click("input[name=\"password\"]")
# 填写输入[name="password"]
page.fill("input[name=\"password\"]", userdata[1])
#点击输入[name="validcode"]
page.click("input[name=\"validcode\"]")
# 填写输入[name="validcode"]
page.fill("input[name=\"validcode\"]", "1111")
#点击输入[type="button"]
#因为页面需要转换,这里需要主动等待1秒。这个wait_for_timeout的单位是毫秒
page.wait_for_timeout(1000)
page.click("input[type=\"button\"]")
#页面刷新很慢,这里我设置了3秒等待
page.wait_for_timeout(3000)
# 断言,这里为了简单起见使用了 in 方法。 playwright提供了很多assert断言方法
#你可以阅读官方文档:
在 page.content() 中断言 userdata[2]
#关闭页面
page.close()
如果 __name__ == '__main__':
#使用pytest.main运行测试,--headful是带接口运行,删除,就是无头模式
#这里可以看出playwright的head表示启动浏览器,headless模式表示浏览器没有运行
pytest.main(['-v','login_b2c.py','--headful'])
试运行结果:
/Library/Frameworks/Python.framework/Versions/3.7/bin/python3.7 /Users/huminghai/dev/py_pro/demo/login_b2c.py
========================测试会话开始==================== =
平台 darwin -- Python 3.7.1, pytest-6.1.0, py-1.10.0, 插件-0.13.1 -- /Library/Frameworks/Python.framework/Versions/3.7/bin/python3.7
缓存目录:.pytest_cache
rootdir: /Users/huminghai/dev/py_pro/demo
插件:base-url-1.4.2,sugar-0.9.4,flaky-3.7.0,xdist -2.1.0, cov-2.10.1, asyncio-0.14.0, 编剧-0. 0.11,超时-1.4.2,分叉-1.3.0
正在采集...采集了 3 件物品
login_b2c.py::test_login[chromium-userdata0] 通过 [33%]
login_b2c.py::test_login[chromium-userdata1] 通过 [66%]
login_b2c.py::test_login[chromium-userdata2] 通过 [100%]
========================= 3传入41.42s ============= = ======
进程以退出代码 0 结束
总结
Playwright-python的优势非常突出,在脚本录制上非常方便,元素捕捉非常准确,比webdriver好。最重要的是playwright-python和pytest真的可以为所欲为。
pytest 提供了报表模块和各种有用的插件,而 Playwright-python 提供了界面元素的精确定位和抓取。两者的结合让 UI 自动化测试的未来更加光明。
另外,不要相信Playwright-python所谓的无编码自动化。这是不太可能的。毕竟,无论你如何记录脚本,参数化、关联和断言三件套总是必不可少的。因此,学习 Python 是唯一的方法。良好自动化测试的基础。
请关注+私信回复:“测试”,即可免费获得软件测试学习资料,同时进入群学习交流~~
查看全部
c#抓取网页数据(微软公司支持Python语言的自动化工具介绍及项目实战项目介绍
)
工具介绍
Playwright 是微软公司开发的一款非常强大的开源自动化测试工具。它之所以强大,原因如下:
1. 支持所有主流浏览器:Chrome、Firefox、Safari、MS Edge。
2. 支持无头和有头模式。
3. 提供可与 Pytest 结合使用的同步和异步 API。
4. 支持在浏览器端自动录制脚本。
5. Python 语言的自动化工具。
6. 支持的操作系统有 Linux、Mac OS 和 Windows。
7.可以使用docker安装运行环境。
安装环境
1.安装Python,Playwright需要3.7及以上Python,所以至少Python3.7或以上(最好3.7,我试过3.@ >8 存在兼容性问题)。
2.去下载项目代码,主要是local_requirements.txt。
3. 使用 pip3 install playwright==1.8.0a1(最好在此处指定版本)。
4. 使用 pip3 install -r local_requirements.txt 安装所有依赖项。
5. 使用python3 -m playwright install 安装浏览器驱动模块(使用清华镜像)。
这里在命令窗口运行:pip3 -v config list 查看系统中的pip.ini文件,下面是我的。
[全局]
index-url=
#index-url=
#[安装]
#trusted-host=
这里需要把阿里云注释掉,最好白天或者早上安装这个,会更快。其他时候用阿里云的镜像会更快。
6. 检查是否安装成功。如果看到如下界面,则说明安装成功。
脚本录制
Playwright 的脚本录制需要使用命令 codegen。下面详细解释该命令的用法:
该命令需要的参数如下:
o 或 --output 指定保存脚本的文件路径和文件名。
target指定生成脚本的语言:Python、JavaScript、C#等
b指定用于录制的浏览器:如:-b chromium(Chrome浏览器)、-b firefox、-b webkit。
项目实战
项目:在线商店
1、脚本录制
python3 -m playwright codegen -o 'login_b2c.py' --target python -b chromium :8080/b2c/index.html
以上是命令执行后进入的界面。当鼠标在元素上滑动时,会自动提示元素的xpath,并启动隐身浏览模式,便于与本地浏览的页面区分开来。
点击登录链接,会弹出如下图:
输入必要的信息以登录。
登录成功,返回首页,注意红框,这里是断言目标。
关闭浏览器,输出脚本文件:这里可以看到我们的脚本文件就是命令中指定的文件名,右边是脚本文件代码,这里使用的是同步方式。源码如下:
从剧作家导入sync_playwright
def run(剧作家):
浏览器 = playwright.chromium.launch(headless=False)
上下文 = browser.newContext()
#打开新页面
page = context.newPage()
# 转到:8080/b2c/index.html
page.goto(":8080/b2c/index.html")
# 点击文字=/.*登录.*/
page.click("text=/.*login.*/")
# assert page.url == ":8080/b2c/login.html"
#点击输入[name="username"]
page.click("input[name=\"username\"]")
# 填写输入[name="username"]
page.fill("input[name=\"username\"]", "tester")
#按回车
page.press("input[name=\"username\"]", "Enter")
#点击输入[name="password"]
page.click("input[name=\"password\"]")
# 填写输入[name="password"]
page.fill("input[name=\"password\"]", "123456")
#点击输入[name="validcode"]
page.click("input[name=\"validcode\"]")
# 填写输入[name="validcode"]
page.fill("input[name=\"validcode\"]", "1111")
#点击输入[type="button"]
# with page.expect_navigation(url=":8080/b2c/index.html"):
使用 page.expect_navigation():
page.click("input[type=\"button\"]")
page.close()
# ---------
context.close()
browser.close()
以sync_playwright() 为编剧:
运行(剧作家)
在这个录制的脚本中发现了以下问题:
1)Playwright开始搭建浏览器,这里使用chromium,然后使用浏览器实例化一个context对象context,再通过context实例化一个page对象,也就是使用context.newPage()可以实例化多个页面,并且页面之间不共享会话和 cookie。
2)页面可以通过定位器来定位页面上的各种元素,所以要想用好Playwright,就必须好好研究一下页面对象。
3)缺点是 Playwright 在录制过程中不提供断言。虽然有很多内置的断言方法,但只能手动编写。
4)需要参数化。好在Playwright集成了pytest功能,我们要好好利用一下。
2. 集成pytest和Playwright
经过研究,发现Playwright不具备参数化自身的能力。如果要参数化,仍然需要编写代码来赋值。在这里,考虑与 pytest 结合使用。使用pytest的参数化和fixture可以充分实现参数化和关联的效果。
代码说明:
#coding=utf-8
从 playwright.sync_api 导入页面
导入 pytest
#这里构造测试用例需要的数据,第一个是用户名,第二个是密码,第三个是预期结果
data=[['tester','123456','Hello: tester'],['tester1','123456','Hello: tester1'],['tester2','1234567',' 账号错误密码']]
# 使用 pytest.mark.parametrize 导入用户数据
@pytest.mark.parametrize('userdata',data)
#测试函数的第一个参数是指playwright提供的Page,是一个fixture,需要安装
#pytest-playwright
def test_login(page:Page,userdata):
page.goto(":8080/b2c/index.html")
# 点击文字=/.*登录.*/
page.click("text=/.*login.*/")
# assert page.url == ":8080/b2c/login.html"
#点击输入[name="username"]
page.click("input[name=\"username\"]")
# 填写输入[name="username"]
# page.fill("input[name=\"username\"]", "tester")
page.fill("input[name=\"username\"]", userdata[0])
#按回车
page.press("input[name=\"username\"]", "Enter")
#点击输入[name="password"]
page.click("input[name=\"password\"]")
# 填写输入[name="password"]
page.fill("input[name=\"password\"]", userdata[1])
#点击输入[name="validcode"]
page.click("input[name=\"validcode\"]")
# 填写输入[name="validcode"]
page.fill("input[name=\"validcode\"]", "1111")
#点击输入[type="button"]
#因为页面需要转换,这里需要主动等待1秒。这个wait_for_timeout的单位是毫秒
page.wait_for_timeout(1000)
page.click("input[type=\"button\"]")
#页面刷新很慢,这里我设置了3秒等待
page.wait_for_timeout(3000)
# 断言,这里为了简单起见使用了 in 方法。 playwright提供了很多assert断言方法
#你可以阅读官方文档:
在 page.content() 中断言 userdata[2]
#关闭页面
page.close()
如果 __name__ == '__main__':
#使用pytest.main运行测试,--headful是带接口运行,删除,就是无头模式
#这里可以看出playwright的head表示启动浏览器,headless模式表示浏览器没有运行
pytest.main(['-v','login_b2c.py','--headful'])
试运行结果:
/Library/Frameworks/Python.framework/Versions/3.7/bin/python3.7 /Users/huminghai/dev/py_pro/demo/login_b2c.py
========================测试会话开始==================== =
平台 darwin -- Python 3.7.1, pytest-6.1.0, py-1.10.0, 插件-0.13.1 -- /Library/Frameworks/Python.framework/Versions/3.7/bin/python3.7
缓存目录:.pytest_cache
rootdir: /Users/huminghai/dev/py_pro/demo
插件:base-url-1.4.2,sugar-0.9.4,flaky-3.7.0,xdist -2.1.0, cov-2.10.1, asyncio-0.14.0, 编剧-0. 0.11,超时-1.4.2,分叉-1.3.0
正在采集...采集了 3 件物品
login_b2c.py::test_login[chromium-userdata0] 通过 [33%]
login_b2c.py::test_login[chromium-userdata1] 通过 [66%]
login_b2c.py::test_login[chromium-userdata2] 通过 [100%]
========================= 3传入41.42s ============= = ======
进程以退出代码 0 结束
总结
Playwright-python的优势非常突出,在脚本录制上非常方便,元素捕捉非常准确,比webdriver好。最重要的是playwright-python和pytest真的可以为所欲为。
pytest 提供了报表模块和各种有用的插件,而 Playwright-python 提供了界面元素的精确定位和抓取。两者的结合让 UI 自动化测试的未来更加光明。
另外,不要相信Playwright-python所谓的无编码自动化。这是不太可能的。毕竟,无论你如何记录脚本,参数化、关联和断言三件套总是必不可少的。因此,学习 Python 是唯一的方法。良好自动化测试的基础。
请关注+私信回复:“测试”,即可免费获得软件测试学习资料,同时进入群学习交流~~
c#抓取网页数据( 为什么要了解百度新闻中热点要闻版块提高站点百度排名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-06 19:10
为什么要了解百度新闻中热点要闻版块提高站点百度排名)
图1
如图1所示,在我们的工作过程中,无论是平台网站还是公司官网,总会有新闻展示。比如某天产品经理告诉我们,推广员想抢百度新闻的热点新闻版块,以提高网站的百度排名。要抢百度热点新闻版,首先要了解站点请求头(Request headers)信息。
为什么要了解请求标头(Request headers)信息?
原因在于,我们可以根据请求头信息中的某部分消息信息,而不是通过人工爬虫程序规避站点屏蔽,来伪装这是一个正常的HTTP请求,成功获取响应数据(Response data)。
如何查看百度新闻URL的请求头信息?
图 2
如图2,我们可以打开谷歌浏览器或者其他浏览器开发工具(按F12)查看站点的请求头消息信息。从图中可以看出百度新闻站点可以接受文本/html 等数据类型;语言为中文;浏览器版本为 Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 ( KHTML,如 Gecko ) Chrome/66.0.3359.181 Safari/537.36 等消息信息,我们在发起 HTTP 时直接携带消息信息request 过去,当然不是每一个包信息参数都必须携带过去,一部分可以被成功请求。
那么什么是响应数据?
图 3
如图3所示,响应数据(Response data)可以从谷歌浏览器或者其他浏览器开发工具中查看(按F12)查看,响应可以是数据或者DOM树数据,方便我们的后续分析数据。
当然,你可以学习任何开发语言来开发爬虫程序:C#、NodeJs、python、java、C++。
不过这里主要讲C#爬虫程序的开发。微软为我们提供了HTTP请求的两个HttpWebRequest和HttpWebResponse对象,方便我们发送请求获取数据。下面显示了 C# HTTP 请求代码:
private string RequestAction(RequestOptions options)
{
string result = string.Empty;
IWebProxy proxy = GetProxy();
var request = (HttpWebRequest)WebRequest.Create(options.Uri);
request.Accept = options编程客栈.Accept;
//在使用curl做POST的时候, 当要POST的数据大于1024字节的时候, curl并不会直接就发起POST请求, 而是会分为俩步,
//发送一个请求, 包含一个Expect: 100 -continue, 询问Server使用愿意接受数据
//接收到Server返回的100 - continue应答以后, 才把数据POST给Server
//并不是所有的Server都会正确应答100 -continue, 比如lighttpd, 就会返回417 “Expectation Failed”, 则会造成逻辑出错.
request.ServicePoint.Expect100Continue = false;
request.ServicePoint.UseNagleAlgorithm = false;//禁止Nagle算法加快载入速度
if (!string.IsNullOrEmpty(options.XHRParams)) { request.AllowWriteStreamBuffering = true; } else { request.AllowWriteStreamBuffering = false; }; //禁止缓冲加快载入速度
request.Headers.Add(HttpRequestHeader.AcceptEncoding, "gzip,deflate");//定义gzip压缩页面支持
request.ContentType = options.ContentType;//定义文档类型及编码
request.AllowAutoRedirect = options.AllowAutoRedirect;//禁止自动跳转
request.UserAgent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebhttp://www.cppcns.comKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36";//设置User-Agent,伪装成Google Chrome浏览器
request.Timeout = options.Timeout;//定义请求超时时间为5秒
request.KeepAlive = options.KeepAlive;//启用长连接
if (!string.IsNullOrEmpty(options.Referer)) request.Referer = options.Referer;//返回上一级历史链接
request.Method = options.Method;//定义请求方式为GET
if (proxy != null) request.Proxy = proxy;//设置代理服务器IP,伪装请求地址
if (!string.IsNullOrEmpty(options.RequestCookies)) request.Headers[HttpRequestHeader.Cookie] = options.RequestCookies;
request.ServicePoint.ConnectionLimit = options.ConnectionLimit;//定义最大连接数
if (options.WebHeader != null && options.WebHeader.Count > 0) request.Headers.Add(options.WebHeader);//添加头部信息
if (!string.IsNullOrEmpty(options.XHRParams))//如果是POST请求,加入POST数据
{
byte[] buffer = Encoding.UTF8.GetBytes(options.XHRParams);
if (buffer != null)
{
request.ContentLength = buffer.Length;
request.GetRequestStream().Write(buffer, 0, buffer.Length);
}
}
using (var response = (HttpWebResponse)request.GetResponse())
{
////获取请求响应
//foreach (Cookie cookie in response.Cookies)
// options.CookiesContainer.Add(cookie);//将Cookie加入容器,保存登录状态
if (response.ContentEncoding.ToLower().Contains("gzip"))//解压
{
using (GZipStream stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadToEnd();
}
}
}
else if (response.ContentEncoding.ToLower().Contains("deflate"))//解压
{
using (DeflateStream stream = new DeflateStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadToEnd();
}
}
}
else
{
using (Stream stream = response.GetResponseStream())//原始
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadT编程客栈oEnd();
}
}
}
}
request.Abort();
return result;
}
还有一个我传入的自定义对象。当然,传入或传出对象由你根据实际业务需求定义:
public class RequestOptions
{
///
/// 请求方式,GET或POST
///
public string Method { get; set; }
///
/// URL
///
public Uri Uri { get; set; }
///
/// 上一级历史记录链接
///
public string Referer { get; set; }
///
/// 超时时间(毫秒)
///
public int Timeout = 15000;
///
/// 启用长连接
///
public bool KeepAlive = true;
///
/// 禁止自动跳转
///
public bool AllowAutoRedirect = false;
/// &http://www.cppcns.comlt;summary>
/// 定义最大连接数
///
public int ConnectionLimit = int.MaxValue;
//编程客栈/
/// 请求次数
///
public int RequestNum = 3;
///
/// 可通过文件上传提交的文件类型
///
public string Accept = "*/*";
///
/// 内容类型
///
public string ContentType = "application/x-www-form-urlencoded";
///
/// 实例化头部信息
///
private WebHeaderCollection header = new WebHeaderCollection();
///
/// 头部信息
///
public WebHeaderCollection WebHeader
{
get { return header; }
set { header = value; }
}
///
/// 定义请求Cookie字符串
///
public string RequestCookies { get; set; }
///
/// 异步参数数据
///
public string XHRParams { get; set; }
}
根据显示的代码,我们可以发现 HttpWebRequest 对象封装了很多 Request headers 消息参数。我们可以根据网站的Request headers信息在微软提供的HttpWebRequest对象中设置(见代码消息参数注释,都写了相关参数说明,如果理解有误,请告知,谢谢你),然后发送请求获取响应数据来解析数据。
还补充一点,爬虫程序最好使用代理IP来使用代理IP,这样可以降低被屏蔽的概率,提高爬取效率。但是,代理IP也分为质量等级。对于某些 HTTPS 站点,可能需要质量级别更高的代理 IP 才能穿透。我不会在这里跑题。我会写一篇关于代理IP质量等级的文章文章详情说说我的看法。
C#代码如何使用代理IP?
Microsoft NET 框架还为我们提供了一个使用代理 IP 的 System.Net.WebProxy 对象。使用代码如下:
private System.Net.WebProxy GetProxy()
{
System.Net.WebProxy webProxy = null;
try
{
// 代理链接地址加端口
string proxyHost = "192.168.1.1";
string proxyPort = "9030";
// 代理身份验证的帐号跟密码
//string proxyUser = "xxx";
//string proxyPass = "xxx";
// 设置代理服务器
webProxy = new System.Net.WebProxy();
// 设置代理地址加端口
webProxy.Address = new Uri(string.Format("{0}:{1}", proxyHost, proxyPort));
// 如果只是设置代理IP加端口,例如192.168.1.1:80,这里直接注释该段代码,则不需要设置提交给代理服务器进行身份验证的帐号跟密码。
//webProxy.Credentials = new System.Net.NetworkCredential(proxyUser, proxyPass);
}
catch (Exception ex)
{
Console.WriteLine("获取代理信息异常", DateTime.Now.ToString(), ex.Message);
}
return webProxy;
}
关于System.Net.WebProxy对象的参数说明,我也在代码中进行了说明。
如果获取的Response数据是json、xml等格式的数据,这里就不详细描述这种数据解析方式了,请自行百度。这里的主要主题是 DOM 树 HTML 数据的解析。对于这类数据,有的人会使用正则表达式来解析,有的人会使用组件。当然,只要你能得到你想要的数据,你就可以按照你想要的方式解析它。这里的重点是我经常使用解析组件HtmlAgilityPack,参考DLL是(使用HtmlAgilityPack)。解析代码如下:
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(simpleCrawlResult.Contents);
HtmlNodeCollection liNodes = htmlDoc.DocumentNode.SelectSingleNode("//div[@id='pane-news']").SelectSingleNode("div[1]/ul[1]").SelectNodes("li");
if (liNodes != null && liNodes.Count > 0)
{
for (int i = 0; i < liNodes.Count; i++)
{
string title = liNodes[i].SelectSingleNode("strong[1]/a[1]").InnerText.Trim();
string href = liNodes[i].SelectSingleNode("strong[1]/a[1]").GetAttributeValue("href", "").Trim();
Console.WriteLine("新闻标题:" + title + ",链接:" + href);
}
}
下面主要展示爬取结果。
图 4
如图4,抓包效果,一个简单的爬虫程序就这样完成了。
至此,这篇关于c#实现爬虫程序的文章文章就介绍到这里了。希望对您的学习有所帮助,也希望您多多支持。
本文标题:c#实现爬虫程序 查看全部
c#抓取网页数据(
为什么要了解百度新闻中热点要闻版块提高站点百度排名)

图1
如图1所示,在我们的工作过程中,无论是平台网站还是公司官网,总会有新闻展示。比如某天产品经理告诉我们,推广员想抢百度新闻的热点新闻版块,以提高网站的百度排名。要抢百度热点新闻版,首先要了解站点请求头(Request headers)信息。
为什么要了解请求标头(Request headers)信息?
原因在于,我们可以根据请求头信息中的某部分消息信息,而不是通过人工爬虫程序规避站点屏蔽,来伪装这是一个正常的HTTP请求,成功获取响应数据(Response data)。
如何查看百度新闻URL的请求头信息?

图 2
如图2,我们可以打开谷歌浏览器或者其他浏览器开发工具(按F12)查看站点的请求头消息信息。从图中可以看出百度新闻站点可以接受文本/html 等数据类型;语言为中文;浏览器版本为 Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 ( KHTML,如 Gecko ) Chrome/66.0.3359.181 Safari/537.36 等消息信息,我们在发起 HTTP 时直接携带消息信息request 过去,当然不是每一个包信息参数都必须携带过去,一部分可以被成功请求。
那么什么是响应数据?

图 3
如图3所示,响应数据(Response data)可以从谷歌浏览器或者其他浏览器开发工具中查看(按F12)查看,响应可以是数据或者DOM树数据,方便我们的后续分析数据。
当然,你可以学习任何开发语言来开发爬虫程序:C#、NodeJs、python、java、C++。
不过这里主要讲C#爬虫程序的开发。微软为我们提供了HTTP请求的两个HttpWebRequest和HttpWebResponse对象,方便我们发送请求获取数据。下面显示了 C# HTTP 请求代码:
private string RequestAction(RequestOptions options)
{
string result = string.Empty;
IWebProxy proxy = GetProxy();
var request = (HttpWebRequest)WebRequest.Create(options.Uri);
request.Accept = options编程客栈.Accept;
//在使用curl做POST的时候, 当要POST的数据大于1024字节的时候, curl并不会直接就发起POST请求, 而是会分为俩步,
//发送一个请求, 包含一个Expect: 100 -continue, 询问Server使用愿意接受数据
//接收到Server返回的100 - continue应答以后, 才把数据POST给Server
//并不是所有的Server都会正确应答100 -continue, 比如lighttpd, 就会返回417 “Expectation Failed”, 则会造成逻辑出错.
request.ServicePoint.Expect100Continue = false;
request.ServicePoint.UseNagleAlgorithm = false;//禁止Nagle算法加快载入速度
if (!string.IsNullOrEmpty(options.XHRParams)) { request.AllowWriteStreamBuffering = true; } else { request.AllowWriteStreamBuffering = false; }; //禁止缓冲加快载入速度
request.Headers.Add(HttpRequestHeader.AcceptEncoding, "gzip,deflate");//定义gzip压缩页面支持
request.ContentType = options.ContentType;//定义文档类型及编码
request.AllowAutoRedirect = options.AllowAutoRedirect;//禁止自动跳转
request.UserAgent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebhttp://www.cppcns.comKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36";//设置User-Agent,伪装成Google Chrome浏览器
request.Timeout = options.Timeout;//定义请求超时时间为5秒
request.KeepAlive = options.KeepAlive;//启用长连接
if (!string.IsNullOrEmpty(options.Referer)) request.Referer = options.Referer;//返回上一级历史链接
request.Method = options.Method;//定义请求方式为GET
if (proxy != null) request.Proxy = proxy;//设置代理服务器IP,伪装请求地址
if (!string.IsNullOrEmpty(options.RequestCookies)) request.Headers[HttpRequestHeader.Cookie] = options.RequestCookies;
request.ServicePoint.ConnectionLimit = options.ConnectionLimit;//定义最大连接数
if (options.WebHeader != null && options.WebHeader.Count > 0) request.Headers.Add(options.WebHeader);//添加头部信息
if (!string.IsNullOrEmpty(options.XHRParams))//如果是POST请求,加入POST数据
{
byte[] buffer = Encoding.UTF8.GetBytes(options.XHRParams);
if (buffer != null)
{
request.ContentLength = buffer.Length;
request.GetRequestStream().Write(buffer, 0, buffer.Length);
}
}
using (var response = (HttpWebResponse)request.GetResponse())
{
////获取请求响应
//foreach (Cookie cookie in response.Cookies)
// options.CookiesContainer.Add(cookie);//将Cookie加入容器,保存登录状态
if (response.ContentEncoding.ToLower().Contains("gzip"))//解压
{
using (GZipStream stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadToEnd();
}
}
}
else if (response.ContentEncoding.ToLower().Contains("deflate"))//解压
{
using (DeflateStream stream = new DeflateStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadToEnd();
}
}
}
else
{
using (Stream stream = response.GetResponseStream())//原始
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadT编程客栈oEnd();
}
}
}
}
request.Abort();
return result;
}
还有一个我传入的自定义对象。当然,传入或传出对象由你根据实际业务需求定义:
public class RequestOptions
{
///
/// 请求方式,GET或POST
///
public string Method { get; set; }
///
/// URL
///
public Uri Uri { get; set; }
///
/// 上一级历史记录链接
///
public string Referer { get; set; }
///
/// 超时时间(毫秒)
///
public int Timeout = 15000;
///
/// 启用长连接
///
public bool KeepAlive = true;
///
/// 禁止自动跳转
///
public bool AllowAutoRedirect = false;
/// &http://www.cppcns.comlt;summary>
/// 定义最大连接数
///
public int ConnectionLimit = int.MaxValue;
//编程客栈/
/// 请求次数
///
public int RequestNum = 3;
///
/// 可通过文件上传提交的文件类型
///
public string Accept = "*/*";
///
/// 内容类型
///
public string ContentType = "application/x-www-form-urlencoded";
///
/// 实例化头部信息
///
private WebHeaderCollection header = new WebHeaderCollection();
///
/// 头部信息
///
public WebHeaderCollection WebHeader
{
get { return header; }
set { header = value; }
}
///
/// 定义请求Cookie字符串
///
public string RequestCookies { get; set; }
///
/// 异步参数数据
///
public string XHRParams { get; set; }
}
根据显示的代码,我们可以发现 HttpWebRequest 对象封装了很多 Request headers 消息参数。我们可以根据网站的Request headers信息在微软提供的HttpWebRequest对象中设置(见代码消息参数注释,都写了相关参数说明,如果理解有误,请告知,谢谢你),然后发送请求获取响应数据来解析数据。
还补充一点,爬虫程序最好使用代理IP来使用代理IP,这样可以降低被屏蔽的概率,提高爬取效率。但是,代理IP也分为质量等级。对于某些 HTTPS 站点,可能需要质量级别更高的代理 IP 才能穿透。我不会在这里跑题。我会写一篇关于代理IP质量等级的文章文章详情说说我的看法。
C#代码如何使用代理IP?
Microsoft NET 框架还为我们提供了一个使用代理 IP 的 System.Net.WebProxy 对象。使用代码如下:
private System.Net.WebProxy GetProxy()
{
System.Net.WebProxy webProxy = null;
try
{
// 代理链接地址加端口
string proxyHost = "192.168.1.1";
string proxyPort = "9030";
// 代理身份验证的帐号跟密码
//string proxyUser = "xxx";
//string proxyPass = "xxx";
// 设置代理服务器
webProxy = new System.Net.WebProxy();
// 设置代理地址加端口
webProxy.Address = new Uri(string.Format("{0}:{1}", proxyHost, proxyPort));
// 如果只是设置代理IP加端口,例如192.168.1.1:80,这里直接注释该段代码,则不需要设置提交给代理服务器进行身份验证的帐号跟密码。
//webProxy.Credentials = new System.Net.NetworkCredential(proxyUser, proxyPass);
}
catch (Exception ex)
{
Console.WriteLine("获取代理信息异常", DateTime.Now.ToString(), ex.Message);
}
return webProxy;
}
关于System.Net.WebProxy对象的参数说明,我也在代码中进行了说明。
如果获取的Response数据是json、xml等格式的数据,这里就不详细描述这种数据解析方式了,请自行百度。这里的主要主题是 DOM 树 HTML 数据的解析。对于这类数据,有的人会使用正则表达式来解析,有的人会使用组件。当然,只要你能得到你想要的数据,你就可以按照你想要的方式解析它。这里的重点是我经常使用解析组件HtmlAgilityPack,参考DLL是(使用HtmlAgilityPack)。解析代码如下:
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(simpleCrawlResult.Contents);
HtmlNodeCollection liNodes = htmlDoc.DocumentNode.SelectSingleNode("//div[@id='pane-news']").SelectSingleNode("div[1]/ul[1]").SelectNodes("li");
if (liNodes != null && liNodes.Count > 0)
{
for (int i = 0; i < liNodes.Count; i++)
{
string title = liNodes[i].SelectSingleNode("strong[1]/a[1]").InnerText.Trim();
string href = liNodes[i].SelectSingleNode("strong[1]/a[1]").GetAttributeValue("href", "").Trim();
Console.WriteLine("新闻标题:" + title + ",链接:" + href);
}
}
下面主要展示爬取结果。

图 4
如图4,抓包效果,一个简单的爬虫程序就这样完成了。
至此,这篇关于c#实现爬虫程序的文章文章就介绍到这里了。希望对您的学习有所帮助,也希望您多多支持。
本文标题:c#实现爬虫程序
c#抓取网页数据(背景1.讲故事讲故事民生资讯号,资讯嘛,都是我抄你的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-04-04 15:10
2022-01-17 一:背景1.讲故事
前段时间,我在当地开设了一个民生信息账号。信息都是你抄的,你抄的是官媒的。小市民喜欢奇闻异事,所以有必要,如何定位抓怪故事的地方。上号的消息其实做起来很简单。可以使用逻辑回归。本文主要讨论如何获取。在C#中,大家都知道提取的通用库是HtmlAgilityPack,但是这个库的主流方法是使用xpath提取。网页的内容让我很不舒服。毕竟,我对莫名的抵抗并不熟悉。我这个年纪的码农,受过Jquery至少5-6年的教育,所以我必须使用类似Jquery的方法。python中有pyquery。在 C# 中是否有类似的方法可以做到这一点?嘿,真的有万能的github。. . 这就是本文介绍的CSQuery。
二:CSQuery1.安装
github的地址:然后就在vs里面nuget:
2. 举几个例子
万事俱备,那么如何使用呢?别着急,我给你举两个博客园的例子。
1) 将首页的友情链接提取到
如上图所示,如果要在这里获取友情链接的几个大字符,直接使用text()肯定是不行的。默认情况下,它还会捕获所有子节点的文本,如下图所示:
如何处理?可以使用jquery提供的contents方法,然后判断获取到的所有子节点中是否有文本节点,最终获取文本节点的内容,如下:
如果是用js做的,那怎么用CSQuery代码做呢?模仿一下,下面的代码:
static void Main(string[] args)
{
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com"));
var content = jquery["#friend_link"].Contents().Filter((dom) =>
{
return dom.NodeType == NodeType.TEXT_NODE;
}).Text();
Console.WriteLine(content);
}
不知道用xpath提取这样的内容是不是很麻烦,但是jquery不好用,但是好用。
2) 如何为 html 中的某些元素着色
有时出于商业目的需要改变一些html标签的颜色,比如把博客和首页tabmenu中的特殊区域改成红色,如下图:
如何用 CSQuery 处理它?如果你玩过jquery,一般步骤如下:
通过步骤,C#代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com"));
var html = jquery["#nav_left li"].Each(dom =>
{
var self = jquery[dom];
var text = self.Text();
if (text == "博问" || text == "专区")
{
self.Find("a").CssSet(new { color = "red" });
}
}).Render();
}
3) 其他操作方法
除了以上两种操作方法,还可以使用after、before、replaceAll、IS等一百多种实用方法。这篇文章当然不能一一介绍。有兴趣的可以下载看看。小提琴。
三:其他用途
除了抓取html中的元素,我觉得这个东西还可以用来在发送邮件的时候操作邮件模板。毕竟很久以前大家都是用jquery画html的,所以用CSQuery也是可以的。与使用 xslt 相比,各有利弊。,然后做一个例子:
1. 生成一个html模板
2. 使用 CSQuery 将 li 附加到 ul
您可以使用 Append 将内容附加到 查看全部
c#抓取网页数据(背景1.讲故事讲故事民生资讯号,资讯嘛,都是我抄你的)
2022-01-17 一:背景1.讲故事
前段时间,我在当地开设了一个民生信息账号。信息都是你抄的,你抄的是官媒的。小市民喜欢奇闻异事,所以有必要,如何定位抓怪故事的地方。上号的消息其实做起来很简单。可以使用逻辑回归。本文主要讨论如何获取。在C#中,大家都知道提取的通用库是HtmlAgilityPack,但是这个库的主流方法是使用xpath提取。网页的内容让我很不舒服。毕竟,我对莫名的抵抗并不熟悉。我这个年纪的码农,受过Jquery至少5-6年的教育,所以我必须使用类似Jquery的方法。python中有pyquery。在 C# 中是否有类似的方法可以做到这一点?嘿,真的有万能的github。. . 这就是本文介绍的CSQuery。
二:CSQuery1.安装
github的地址:然后就在vs里面nuget:
2. 举几个例子
万事俱备,那么如何使用呢?别着急,我给你举两个博客园的例子。
1) 将首页的友情链接提取到
如上图所示,如果要在这里获取友情链接的几个大字符,直接使用text()肯定是不行的。默认情况下,它还会捕获所有子节点的文本,如下图所示:
如何处理?可以使用jquery提供的contents方法,然后判断获取到的所有子节点中是否有文本节点,最终获取文本节点的内容,如下:
如果是用js做的,那怎么用CSQuery代码做呢?模仿一下,下面的代码:
static void Main(string[] args)
{
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com";));
var content = jquery["#friend_link"].Contents().Filter((dom) =>
{
return dom.NodeType == NodeType.TEXT_NODE;
}).Text();
Console.WriteLine(content);
}
不知道用xpath提取这样的内容是不是很麻烦,但是jquery不好用,但是好用。
2) 如何为 html 中的某些元素着色
有时出于商业目的需要改变一些html标签的颜色,比如把博客和首页tabmenu中的特殊区域改成红色,如下图:
如何用 CSQuery 处理它?如果你玩过jquery,一般步骤如下:
通过步骤,C#代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com";));
var html = jquery["#nav_left li"].Each(dom =>
{
var self = jquery[dom];
var text = self.Text();
if (text == "博问" || text == "专区")
{
self.Find("a").CssSet(new { color = "red" });
}
}).Render();
}
3) 其他操作方法
除了以上两种操作方法,还可以使用after、before、replaceAll、IS等一百多种实用方法。这篇文章当然不能一一介绍。有兴趣的可以下载看看。小提琴。
三:其他用途
除了抓取html中的元素,我觉得这个东西还可以用来在发送邮件的时候操作邮件模板。毕竟很久以前大家都是用jquery画html的,所以用CSQuery也是可以的。与使用 xslt 相比,各有利弊。,然后做一个例子:
1. 生成一个html模板
2. 使用 CSQuery 将 li 附加到 ul
您可以使用 Append 将内容附加到
c#抓取网页数据(Java开发教程:匹配时为点任意匹配模式,点 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-04-04 00:18
)
1、确定URL并抓取页面代码
import urllib
import urllib2
page = 1
url = 'http://www.qiushibaike.com/hot/page/' + str(page)
try:
request = urllib2.Request(url)
response = urllib2.urlopen(request)
print response.read()
except urllib2.URLError, e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason
2、添加页眉并抓取页面代码
try:
#定义请求头
headrs={"User-Agent":" Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"}
#定义请求,传入请求头
req=request.Request(url,headers=headrs)
#打开网页
resp=request.urlopen(req)
#打印响应码,解码
# print(resp.read().decode('utf-8'))
3、提取页面的所有段落
content = response.read().decode('utf-8')
pattern = re.compile('(.*?).*?(.*?).*?(.*?)',re.S)
items = re.findall(pattern,content)
for item in items:
haveImg = re.search("img",item[3])
if not haveImg:
print item[0],item[1],item[2],item[4]
except urllib2.URLError, e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason
4.面向对象的模式
<p>from urllib import request
import re
class tieba:
#初始化
def __init__(self):
# 定义url
self.url="https://tieba.baidu.com/f%3Fkw ... ot%3B
# 定义请求头
self.headrs={"User-Agent":" Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"}
#列表,存储解析后的结果
self.stories=[]
#下载页面
def getPage(self,page_number):
try:
# 定义请求,传入请求头
req=request.Request(self.url+str(page_number),headers=self.headrs)
# 打开网页
resp=request.urlopen(req)
# 打印响应码,解码
content=resp.read().decode("utf-8")
return content
except request.URLError as e:
# 打印响应码
if hasattr(e, 'code'):
print(e.code)
# 打印异常原因
if hasattr(e, 'reason'):
print(e.reason)
#解析页面
def rexgPage(self,content):
# 定义正则表达式
# 查看全部
c#抓取网页数据(Java开发教程:匹配时为点任意匹配模式,点
)
1、确定URL并抓取页面代码
import urllib
import urllib2
page = 1
url = 'http://www.qiushibaike.com/hot/page/' + str(page)
try:
request = urllib2.Request(url)
response = urllib2.urlopen(request)
print response.read()
except urllib2.URLError, e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason
2、添加页眉并抓取页面代码
try:
#定义请求头
headrs={"User-Agent":" Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"}
#定义请求,传入请求头
req=request.Request(url,headers=headrs)
#打开网页
resp=request.urlopen(req)
#打印响应码,解码
# print(resp.read().decode('utf-8'))
3、提取页面的所有段落
content = response.read().decode('utf-8')
pattern = re.compile('(.*?).*?(.*?).*?(.*?)',re.S)
items = re.findall(pattern,content)
for item in items:
haveImg = re.search("img",item[3])
if not haveImg:
print item[0],item[1],item[2],item[4]
except urllib2.URLError, e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason
4.面向对象的模式
<p>from urllib import request
import re
class tieba:
#初始化
def __init__(self):
# 定义url
self.url="https://tieba.baidu.com/f%3Fkw ... ot%3B
# 定义请求头
self.headrs={"User-Agent":" Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"}
#列表,存储解析后的结果
self.stories=[]
#下载页面
def getPage(self,page_number):
try:
# 定义请求,传入请求头
req=request.Request(self.url+str(page_number),headers=self.headrs)
# 打开网页
resp=request.urlopen(req)
# 打印响应码,解码
content=resp.read().decode("utf-8")
return content
except request.URLError as e:
# 打印响应码
if hasattr(e, 'code'):
print(e.code)
# 打印异常原因
if hasattr(e, 'reason'):
print(e.reason)
#解析页面
def rexgPage(self,content):
# 定义正则表达式
#
c#抓取网页数据(网上内容少之又少获取提交表单后怎么知道成没成功? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-04-02 09:26
)
由于项目需要,需要获取网页内容并自动填表,所以决定使用webbrowser控件。笔者百度之后,再次觉得网上的内容太少了。他们中的大多数在提交表格后都很好。如何知道提交表单是否成功?登录成功后如何获取页面?所以我在这里谈论重点:
业务流程大致为:
1.获取页面的html代码
2.找出类型不是submit的标签,填写内容
3.查找所有类型为提交的标签,模拟点击提交
4.获取提交的页面
所以我的解决方案是:
0X01:添加第一个页面加载成功的事件1。为什么要使用添加事件的方法?因为如果不是这样的话,网页浏览器的 DocumentText 往往会不可用或者不完整,导致程序非常不稳定。
0X02:自动填表并提交。
0X03:这是最关键的一步。首先去掉之前的事件1,然后添加加载成功事件2。这种情况下,点击登录跳转后,不会调用事件1,而是调用事件2。在事件2中,可以获取webbrowser的DocumentText是没有问题的(但是需要注意的是步骤0X03的代码必须在点击提交按钮之前,否则提交后修改事件来不及了)
首先,它不是一个窗口程序,需要使用 System.Windows.Forms 来引入;使用 webbrowser 控件。之后是代码:
WebBrowser wb = new WebBrowser();
wb.ScriptErrorsSuppressed = true;
wb.DocumentCompleted += wb_DocumentCompleted;//添加页面第一次加载完成事件
private void wb_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)//网页加载完后调用,但是为什么调用多次????????
{
if (!e.Url.Equals(this.uri))//防止一个网址不明原因的多次调用
{
//not actually complete, do nothing
return;
}
this.htmldocument = wb.Document;
HtmlElementCollection elementcol = this.htmldocument.GetElementsByTagName("input");
wb.DocumentCompleted -= wb_DocumentCompleted;//删除页面加载完成事件
wb.DocumentCompleted += wb_DocumentCompleted2;//添加新的页面加载完成事件(也就是提交成功后页面成功载入事件)
foreach (HtmlElement ele in elementcol)
{
if (!ele.GetAttribute("type").Equals("submit"))//不是提交按钮的都填成123
{
ele.SetAttribute("value","123");
}
else
{
ele.InvokeMember("click");//点击一下
}
}
}
private void wb_DocumentCompleted2(object sender, WebBrowserDocumentCompletedEventArgs e)
{
System.Diagnostics.Debug.WriteLine(wb.DocumentText);
//throw new NotImplementedException();
} 查看全部
c#抓取网页数据(网上内容少之又少获取提交表单后怎么知道成没成功?
)
由于项目需要,需要获取网页内容并自动填表,所以决定使用webbrowser控件。笔者百度之后,再次觉得网上的内容太少了。他们中的大多数在提交表格后都很好。如何知道提交表单是否成功?登录成功后如何获取页面?所以我在这里谈论重点:
业务流程大致为:
1.获取页面的html代码
2.找出类型不是submit的标签,填写内容
3.查找所有类型为提交的标签,模拟点击提交
4.获取提交的页面
所以我的解决方案是:
0X01:添加第一个页面加载成功的事件1。为什么要使用添加事件的方法?因为如果不是这样的话,网页浏览器的 DocumentText 往往会不可用或者不完整,导致程序非常不稳定。
0X02:自动填表并提交。
0X03:这是最关键的一步。首先去掉之前的事件1,然后添加加载成功事件2。这种情况下,点击登录跳转后,不会调用事件1,而是调用事件2。在事件2中,可以获取webbrowser的DocumentText是没有问题的(但是需要注意的是步骤0X03的代码必须在点击提交按钮之前,否则提交后修改事件来不及了)
首先,它不是一个窗口程序,需要使用 System.Windows.Forms 来引入;使用 webbrowser 控件。之后是代码:
WebBrowser wb = new WebBrowser();
wb.ScriptErrorsSuppressed = true;
wb.DocumentCompleted += wb_DocumentCompleted;//添加页面第一次加载完成事件
private void wb_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)//网页加载完后调用,但是为什么调用多次????????
{
if (!e.Url.Equals(this.uri))//防止一个网址不明原因的多次调用
{
//not actually complete, do nothing
return;
}
this.htmldocument = wb.Document;
HtmlElementCollection elementcol = this.htmldocument.GetElementsByTagName("input");
wb.DocumentCompleted -= wb_DocumentCompleted;//删除页面加载完成事件
wb.DocumentCompleted += wb_DocumentCompleted2;//添加新的页面加载完成事件(也就是提交成功后页面成功载入事件)
foreach (HtmlElement ele in elementcol)
{
if (!ele.GetAttribute("type").Equals("submit"))//不是提交按钮的都填成123
{
ele.SetAttribute("value","123");
}
else
{
ele.InvokeMember("click");//点击一下
}
}
}
private void wb_DocumentCompleted2(object sender, WebBrowserDocumentCompletedEventArgs e)
{
System.Diagnostics.Debug.WriteLine(wb.DocumentText);
//throw new NotImplementedException();
}
c#抓取网页数据(附赠一个C#调用JS脚本的代码:)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-21 23:55
2021-09-24
//不知道怎么删除,只好留着
1. 获取方法:
WebClient web = new WebClient();
var html = web.DownloadString(url);
2.发布方法
1 ///
2 ///
3 ///
4 ///
5 ///
6 /// 格式: paramname=value@name2=value2
7 ///
8 ///
9 public static string Post(this MyWebClient web, string url, string queryString, bool clearHeads=false)
10 {
11 string postString = queryString;// WebUtility.UrlEncode( queryString);//这里即为传递的参数,可以用工具抓包分析,也可以自己分析,主要是form里面每一个name都要加进来
12 byte[] postData = Encoding.UTF8.GetBytes(postString);//编码,尤其是汉字,事先要看下抓取网页的编码方式
13 web.RequestConentLength = postData.Length;
14 if (clearHeads)
15 {
16 web.Headers.Clear();
17 web.Headers.Add("Content-Type", "application/x-www-form-urlencoded");//采取POST方式必须加的header,如果改为GET方式的话就去掉这句话即可
18 }
19
20 byte[] responseData = web.UploadData(url, "POST", postData);//得到返回字符流
21 string srcString = Encoding.UTF8.GetString(responseData);//解码
22 return srcString;
23 }
3.标题设置
1 web.Headers.Add(HttpRequestHeader.Accept, "*/*");
2 web.Headers.Add(HttpRequestHeader.AcceptEncoding, "gzip, deflate");
3 web.Headers.Add(HttpRequestHeader.AcceptLanguage, "zh-CN,zh;q=0.9");
4 //web.Headers.Add(HttpRequestHeader.Connection, "keep-alive");
5 web.Headers.Add("Content-Type", "application/x-www-form-urlencoded; charset=UTF-8");
6 web.Headers.Add(HttpRequestHeader.Host, "wenshu.court.gov.cn");
7 web.Headers.Add("Origin", "http://wenshu.court.gov.cn");
8 //web.Headers.Add("Proxy-Connection", "keep-alive");
9 web.Headers.Add(HttpRequestHeader.UserAgent, userAgent);
10 web.Headers.Add("X-Requested-With", "XMLHttpRequest");
11 web.Headers.Add(HttpRequestHeader.Referer, WebUtility.UrlEncode(Referer1));
4.Cookie、超时等高可用基类
1 public class MyWebClient : WebClient
2 {
3 public CookieContainer Cookies ;
4
5 public MyWebClient(CookieContainer cookieContainer)
6 {
7 this.Cookies = cookieContainer;
8 }
9
10 public int TimeoutSeconds { get; set; } = 60;
11
12 public WebRequest Request { get; set; }
13
14 public int RequestConentLength;
15
16 protected override WebRequest GetWebRequest(Uri address)
17 {
18 HttpWebRequest request = base.GetWebRequest(address) as HttpWebRequest;
19
20 if (request != null)
21 {
22 request.Method = "Post";
23 request.CookieContainer = Cookies;
24 request.Timeout = 1000 * TimeoutSeconds;
25 request.ContentLength = RequestConentLength;
26 }
27
28 Request = request;
29 return request;
30 }
31
32 public WebResponse Response { get; set; }
33
34 protected override WebResponse GetWebResponse(WebRequest request)
35 {
36 this.Response = base.GetWebResponse(request);
37 return this.Response;
38 }
39
40 public string GetCookieValue(string cookieName)
41 {
42 var cookies = this.Cookies.GetCookies(this.Request.RequestUri);
43 var ck = cookies[cookieName];
44 return ck?.Value;
45 }
46 }
特别注意,浏览器需要为多个请求创建多个WebClient对象网站,但它们应该共享一个CookieContainer。在编写爬虫并模拟多个浏览器会话时,不应该都使用同一个 CookieContainer 对象以避免会话冲突。
附上调用JS脚本的C#代码:
1 public string CallJs(string jsCall , string jsFunctions)
2 {
3 Type obj = Type.GetTypeFromProgID("ScriptControl");
4 if (obj == null) return null;
5 object ScriptControl = Activator.CreateInstance(obj);
6 obj.InvokeMember("Language", BindingFlags.SetProperty, null, ScriptControl, new object[] { "JavaScript" });
7 //string js = "function time(a, b, msg){ var sum = a + b; return new Date().getTime() + ': ' + msg + ' = ' + sum }";
8 obj.InvokeMember("AddCode", BindingFlags.InvokeMethod, null, ScriptControl, new object[] { jsFunctions });
9
10 //return obj.InvokeMember("Eval", BindingFlags.InvokeMethod, null, ScriptControl, new object[] { "time(3, 5, '3 + 5')" }).ToString();
11 return obj.InvokeMember("Eval", BindingFlags.InvokeMethod, null, ScriptControl, new object[] { jsCall }).ToString();
12 }
使用示例:
string js = "function jsfunction(parm){ return parm + "abc"; }";
string val = CallJs($"jsfunction('{csvar}')", js.ToString());
分类:
技术要点:
相关文章: 查看全部
c#抓取网页数据(附赠一个C#调用JS脚本的代码:)
2021-09-24
//不知道怎么删除,只好留着
1. 获取方法:
WebClient web = new WebClient();
var html = web.DownloadString(url);
2.发布方法
1 ///
2 ///
3 ///
4 ///
5 ///
6 /// 格式: paramname=value@name2=value2
7 ///
8 ///
9 public static string Post(this MyWebClient web, string url, string queryString, bool clearHeads=false)
10 {
11 string postString = queryString;// WebUtility.UrlEncode( queryString);//这里即为传递的参数,可以用工具抓包分析,也可以自己分析,主要是form里面每一个name都要加进来
12 byte[] postData = Encoding.UTF8.GetBytes(postString);//编码,尤其是汉字,事先要看下抓取网页的编码方式
13 web.RequestConentLength = postData.Length;
14 if (clearHeads)
15 {
16 web.Headers.Clear();
17 web.Headers.Add("Content-Type", "application/x-www-form-urlencoded");//采取POST方式必须加的header,如果改为GET方式的话就去掉这句话即可
18 }
19
20 byte[] responseData = web.UploadData(url, "POST", postData);//得到返回字符流
21 string srcString = Encoding.UTF8.GetString(responseData);//解码
22 return srcString;
23 }
3.标题设置
1 web.Headers.Add(HttpRequestHeader.Accept, "*/*");
2 web.Headers.Add(HttpRequestHeader.AcceptEncoding, "gzip, deflate");
3 web.Headers.Add(HttpRequestHeader.AcceptLanguage, "zh-CN,zh;q=0.9");
4 //web.Headers.Add(HttpRequestHeader.Connection, "keep-alive");
5 web.Headers.Add("Content-Type", "application/x-www-form-urlencoded; charset=UTF-8");
6 web.Headers.Add(HttpRequestHeader.Host, "wenshu.court.gov.cn");
7 web.Headers.Add("Origin", "http://wenshu.court.gov.cn";);
8 //web.Headers.Add("Proxy-Connection", "keep-alive");
9 web.Headers.Add(HttpRequestHeader.UserAgent, userAgent);
10 web.Headers.Add("X-Requested-With", "XMLHttpRequest");
11 web.Headers.Add(HttpRequestHeader.Referer, WebUtility.UrlEncode(Referer1));
4.Cookie、超时等高可用基类
1 public class MyWebClient : WebClient
2 {
3 public CookieContainer Cookies ;
4
5 public MyWebClient(CookieContainer cookieContainer)
6 {
7 this.Cookies = cookieContainer;
8 }
9
10 public int TimeoutSeconds { get; set; } = 60;
11
12 public WebRequest Request { get; set; }
13
14 public int RequestConentLength;
15
16 protected override WebRequest GetWebRequest(Uri address)
17 {
18 HttpWebRequest request = base.GetWebRequest(address) as HttpWebRequest;
19
20 if (request != null)
21 {
22 request.Method = "Post";
23 request.CookieContainer = Cookies;
24 request.Timeout = 1000 * TimeoutSeconds;
25 request.ContentLength = RequestConentLength;
26 }
27
28 Request = request;
29 return request;
30 }
31
32 public WebResponse Response { get; set; }
33
34 protected override WebResponse GetWebResponse(WebRequest request)
35 {
36 this.Response = base.GetWebResponse(request);
37 return this.Response;
38 }
39
40 public string GetCookieValue(string cookieName)
41 {
42 var cookies = this.Cookies.GetCookies(this.Request.RequestUri);
43 var ck = cookies[cookieName];
44 return ck?.Value;
45 }
46 }
特别注意,浏览器需要为多个请求创建多个WebClient对象网站,但它们应该共享一个CookieContainer。在编写爬虫并模拟多个浏览器会话时,不应该都使用同一个 CookieContainer 对象以避免会话冲突。
附上调用JS脚本的C#代码:
1 public string CallJs(string jsCall , string jsFunctions)
2 {
3 Type obj = Type.GetTypeFromProgID("ScriptControl");
4 if (obj == null) return null;
5 object ScriptControl = Activator.CreateInstance(obj);
6 obj.InvokeMember("Language", BindingFlags.SetProperty, null, ScriptControl, new object[] { "JavaScript" });
7 //string js = "function time(a, b, msg){ var sum = a + b; return new Date().getTime() + ': ' + msg + ' = ' + sum }";
8 obj.InvokeMember("AddCode", BindingFlags.InvokeMethod, null, ScriptControl, new object[] { jsFunctions });
9
10 //return obj.InvokeMember("Eval", BindingFlags.InvokeMethod, null, ScriptControl, new object[] { "time(3, 5, '3 + 5')" }).ToString();
11 return obj.InvokeMember("Eval", BindingFlags.InvokeMethod, null, ScriptControl, new object[] { jsCall }).ToString();
12 }
使用示例:
string js = "function jsfunction(parm){ return parm + "abc"; }";
string val = CallJs($"jsfunction('{csvar}')", js.ToString());
分类:
技术要点:
相关文章:
c#抓取网页数据(ASP.NET中抓取网页内容-保持登录状态利用Post数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-20 14:16
2021-05-17
ASP.NET抓取网页内容非常方便,解决了ASP中困扰我们的编码问题。
1、获取一般内容
需要三个类:WebRequest、WebResponse、StreamReader
需要命名空间:System.Net、System.IO
核心代码:
WebRequest类的create是一个静态方法,参数是要爬取的网页的URL;
Encoding指定编码,Encoding有属性ASCII、UTF32、UTF8等通用编码,但没有编码属性gb2312,所以我们使用GetEncoding获取gb2312编码。
2、抓取图像或其他二进制文件(例如文件)
需要四个类:WebRequest、WebResponse、Stream、FileStream
需要命名空间:System.Net、System.IO
核心代码:使用 Stream 读取
3、抓取网页内容的POST方法
在抓取网页时,有时需要通过Post的方式向服务器发送一些数据,在网页抓取程序中加入如下代码,实现Post用户名和密码到服务器:
4、ASP.NET 抓取网页内容 - 防止重定向
在抓取网页时,成功登录服务器应用系统后,应用系统可以通过Response.Redirect重定向网页。如果你不需要响应这个重定向,那么我们就不给 reader.ReadToEnd() Response.Write 出来,就这样。
5、ASP.NET 抓取网页内容 - 保持登录状态
使用Post数据成功登录服务器应用系统后,我们可以抓取需要登录的页面,那么我们可能需要在多个Request之间保持登录状态。 查看全部
c#抓取网页数据(ASP.NET中抓取网页内容-保持登录状态利用Post数据)
2021-05-17
ASP.NET抓取网页内容非常方便,解决了ASP中困扰我们的编码问题。
1、获取一般内容
需要三个类:WebRequest、WebResponse、StreamReader
需要命名空间:System.Net、System.IO
核心代码:
WebRequest类的create是一个静态方法,参数是要爬取的网页的URL;
Encoding指定编码,Encoding有属性ASCII、UTF32、UTF8等通用编码,但没有编码属性gb2312,所以我们使用GetEncoding获取gb2312编码。
2、抓取图像或其他二进制文件(例如文件)
需要四个类:WebRequest、WebResponse、Stream、FileStream
需要命名空间:System.Net、System.IO
核心代码:使用 Stream 读取
3、抓取网页内容的POST方法
在抓取网页时,有时需要通过Post的方式向服务器发送一些数据,在网页抓取程序中加入如下代码,实现Post用户名和密码到服务器:
4、ASP.NET 抓取网页内容 - 防止重定向
在抓取网页时,成功登录服务器应用系统后,应用系统可以通过Response.Redirect重定向网页。如果你不需要响应这个重定向,那么我们就不给 reader.ReadToEnd() Response.Write 出来,就这样。
5、ASP.NET 抓取网页内容 - 保持登录状态
使用Post数据成功登录服务器应用系统后,我们可以抓取需要登录的页面,那么我们可能需要在多个Request之间保持登录状态。
c#抓取网页数据(c#抓取网页数据现实之类的多用js或者requests库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-20 02:03
c#抓取网页数据现实之类的多用js或者requests库,利用特征判断网页内容有些网站支持cookie,开发者可以利用这个特征。web有些在点击按钮或者输入responseurl时加载会联网爬取内容。现在没必要再使用js来抓取数据,可以使用jsonwebstream或者file协议进行网页数据的获取。也可以用浏览器加速flash抓取数据。用c#抓取web之类的资料网络综合搜索建议先看这个或者这个。
推荐/aaaaas/.
qwq其实chrome的safari浏览器会抓web页面。这样他会开启api,通过调用对应浏览器的api。手机平板浏览器都可以抓。手机的开发可以做一个不少应用。网页抓取的话必须是可以完整抓取html的页面才可以。不能只抓一部分。至于这些怎么抓,https的网站需要在证书上,要求域名解析也https的话。
搞不定。可以试试无线刷机。我原来要抓取一个连接都开不了telegram。手机有点不够用,自己想的,首先手机不能被telegram识别网络。也不能被用googleplay下载手机版的webapp(好像能下?),要root后才可以。然后还得安装一个app,才能打开链接。不能手机直接爬墙打开链接。好麻烦。完了好像也没其他办法。=_=。 查看全部
c#抓取网页数据(c#抓取网页数据现实之类的多用js或者requests库)
c#抓取网页数据现实之类的多用js或者requests库,利用特征判断网页内容有些网站支持cookie,开发者可以利用这个特征。web有些在点击按钮或者输入responseurl时加载会联网爬取内容。现在没必要再使用js来抓取数据,可以使用jsonwebstream或者file协议进行网页数据的获取。也可以用浏览器加速flash抓取数据。用c#抓取web之类的资料网络综合搜索建议先看这个或者这个。
推荐/aaaaas/.
qwq其实chrome的safari浏览器会抓web页面。这样他会开启api,通过调用对应浏览器的api。手机平板浏览器都可以抓。手机的开发可以做一个不少应用。网页抓取的话必须是可以完整抓取html的页面才可以。不能只抓一部分。至于这些怎么抓,https的网站需要在证书上,要求域名解析也https的话。
搞不定。可以试试无线刷机。我原来要抓取一个连接都开不了telegram。手机有点不够用,自己想的,首先手机不能被telegram识别网络。也不能被用googleplay下载手机版的webapp(好像能下?),要root后才可以。然后还得安装一个app,才能打开链接。不能手机直接爬墙打开链接。好麻烦。完了好像也没其他办法。=_=。
c#抓取网页数据(c#抓取网页数据匹配错误/输出按字符串匹配)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-18 15:04
c#抓取网页数据首先需要urllibforwindows而且需要对代码进行静态编译,这样网页上的属性和类型就转换过来了,这样抓取来的数据就可以进行处理然后才能输出。winform抓取网页可以用,但是这需要你知道urllib或者urllib2工具包,来满足你的要求。
这个问题我还真研究过。
简单点的方法是wtforms。getheader('haha'),用户的名字参数是最后一个'haha'个字符串,有两种写法,如果直接遍历所有的输入,然后查找以此开头的,就是原始数据,如果遍历一个,然后匹配以开头的,其他的字符串就不是原始数据了。接下来就是按开头字符合到用户输入的值,循环了。如果查找以下范围的,则有不一样的结果了,需要后面几个字符串是数字,大小写敏感等问题,比如用户输入"haha",然后调用getheader()函数,一般语法如下:getheader(name){returnname。
<p>tostring()},name不是输入的数据,可能匹配错误。接下来的搜索代码大体如下:publicstringgetheader(stringname){stringvalue=name。tostring();//匹配数据,匹配错误//输出按开头字符(name。tostring())的值stringnext="\nhh";for(inti=0;i 查看全部
c#抓取网页数据(c#抓取网页数据匹配错误/输出按字符串匹配)
c#抓取网页数据首先需要urllibforwindows而且需要对代码进行静态编译,这样网页上的属性和类型就转换过来了,这样抓取来的数据就可以进行处理然后才能输出。winform抓取网页可以用,但是这需要你知道urllib或者urllib2工具包,来满足你的要求。
这个问题我还真研究过。
简单点的方法是wtforms。getheader('haha'),用户的名字参数是最后一个'haha'个字符串,有两种写法,如果直接遍历所有的输入,然后查找以此开头的,就是原始数据,如果遍历一个,然后匹配以开头的,其他的字符串就不是原始数据了。接下来就是按开头字符合到用户输入的值,循环了。如果查找以下范围的,则有不一样的结果了,需要后面几个字符串是数字,大小写敏感等问题,比如用户输入"haha",然后调用getheader()函数,一般语法如下:getheader(name){returnname。
<p>tostring()},name不是输入的数据,可能匹配错误。接下来的搜索代码大体如下:publicstringgetheader(stringname){stringvalue=name。tostring();//匹配数据,匹配错误//输出按开头字符(name。tostring())的值stringnext="\nhh";for(inti=0;i
c#抓取网页数据(搜索引擎蜘蛛访问网站页面时类似于普通用户使用浏览器开发蜘蛛程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-15 08:08
搜索引擎用来抓取和访问页面的程序称为蜘蛛(spider)。 c#开发蜘蛛程序也称为机器人(bot)。当搜索引擎蜘蛛访问网站的页面时,它类似于普通用户使用浏览器。蜘蛛程序发送页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。为了提高搜索引擎的爬取和爬取速度,都使用了多个爬虫分布爬取。
蜘蛛访问网站时,首先会访问网站根目录下的robots.txt文件。如果robots.txt文件禁止搜索引擎抓取某些网页或内容,或者网站,则蜘蛛会遵循协议而不是c#开发的蜘蛛程序。
spider也是一个c#开发的spider程序,有自己的代理名。爬虫的痕迹可以在站长日志中看到,这也是为什么很多站长回答问题时总是说先检查网站日志的原因(作为一个好的SEO你必须能够查看网站日志无需任何软件,对代码含义非常熟悉)。
一个c#开发蜘蛛程序和搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛是Spider,这是一个很形象的名字。互联网被比作蜘蛛网。那么Spider就是一个c#开发的蜘蛛程序,可以在网络上爬行。
网络蜘蛛通过网页的链接地址寻找网页,从网站某个页面(通常是首页)开始,读取网页的内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一个网页,如此循环下去,直到这个网站的所有网页都被爬取完毕。
如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,几乎不可能爬取互联网上的所有网页。根据迄今为止公布的数据,最大的搜索引擎只抓取了网页总数的4%。十点左右。
其中一个原因是爬虫技术的瓶颈。 100 亿个网页的容量是 100×2000G 字节。就算能存起来,下载还是有问题(按一台机器每秒下载20K,需要340个单位,机器不停下载所有网页需要一年时间),同时,由于数据量大,在提供搜索时也会对效率产生影响。
因此,很多搜索引擎网络蜘蛛只抓取那些重要的网页,而在抓取时评估重要性的主要依据是某个网页的链接深度。
因为不可能爬取所有网页,所以有些网络蜘蛛为一些不太重要的网站设置了要访问的层数,例如如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A是起始页,属于第0层,B,C,D,E,F属于第1层,G,H属于第2层,I属于第3层,如果访问层网络蜘蛛设置的数字是2,网页我不会被访问,这也让搜索引擎可以搜索到一些网站网页,而其他部分则无法搜索到。
对于 网站 的设计者来说,扁平的 网站 设计有助于搜索引擎抓取更多页面。
网络蜘蛛在访问网站网页时,经常会遇到加密数据和网页权限问题。有些网页需要会员权限才能访问。
网站的站主当然可以让网络蜘蛛不按约定爬取,但是对于一些卖报告的网站来说,他们希望自己的报告可以被搜索引擎搜索到,但是不能 搜索者查看是完全免费的,所以需要提供相应的用户名和密码给网络蜘蛛。
网络蜘蛛可以通过给定的权限抓取这些网页提供搜索,当搜索者点击查看网页时,搜索者也需要提供相应的权限验证。
二、点击链接
搜索引擎蜘蛛为了在网络上抓取尽可能多的页面,会跟随网页上的链接,从一个页面爬到下一页,就像蜘蛛在蜘蛛网上爬行一样,这是搜索引擎蜘蛛 名字的由来。
整个互联网网站由相互连接的链接组成,这意味着搜索引擎蜘蛛最终将从任何一个页面开始抓取所有页面。
搜索引擎蜘蛛的基本原理和工作流程
当然网站而且页面链接结构太复杂,所以蜘蛛只能通过一定的方法爬取所有页面。据了解,最简单的爬取策略有以下三种:
1、最佳优先
最佳优先级搜索策略是根据一定的网页分析算法,预测候选URL与目标网页的相似度,或与主题的相关度,选择评价最好的一个或几个URL进行爬取。它只访问网页分析算法预测为“有用”的网页。
存在的一个问题是爬虫爬取路径上的很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要结合具体应用来提高最佳优先级, 为了跳出局部最优,据研究,这样的闭环调整可以将不相关网页的数量减少30%~90%。
2、深度优先
深度优先是指蜘蛛沿着找到的链接爬行,直到前面没有其他链接,然后返回第一页,沿着另一个链接爬行。
3、广度优先
广度优先是指当蜘蛛在一个页面上发现多个链接时,它不会一路跟随一个链接,而是爬取页面上的所有链接,然后进入页面的第二层并跟随第二层层。找到的链接爬到第三层页面。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它就可以爬取整个互联网。
在实践中,蜘蛛的带宽资源和时间并不是无限的,它们不可能爬取所有页面。其实最大的搜索引擎只爬网收录互联网的一小部分,当然也不是说搜索引擎蜘蛛爬的越多越好,这一点
因此,为了尽可能多地捕获用户信息,通常将深度优先和广度优先混合,以便尽可能多地照顾到网站,同时也照顾到一些< @网站 内页。
三、搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。 “蜘蛛”这个称呼形象地描述了信息采集模块在网络数据形成的“万维网”上获取信息的功能。
一般来说,网络爬虫都是从种子网页开始,通过反复下载网页,从文档中寻找看不见的URL,达到访问其他网页和遍历网络的目的。
而它的工作策略一般可以分为累积爬取(cumulative crawling)和增量爬取(incremental crawling)。
1、累积爬取
累积爬取是指从某个时间点开始遍历,爬取系统允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证爬取相当大的网页集合。
看来由于web数据的动态特性,集合中的网页被爬取的时间点不同,页面更新的也不同,所以累计爬取的网页集合实际上并不能与真实环境相比。网络数据保持一致。
2、增量爬取
与累积爬取不同,增量爬取是指在一定数量的网页集合的基础上,通过更新数据,选择现有集合中过时的网页,从而保证所有网页都被爬取。捕获的数据与真实的网络数据足够接近。
增量爬取的前提是系统已经爬取了足够多的网页,并且有关于这些页面何时被爬取的信息。在针对实际应用环境的网络爬虫设计中,通常会同时收录累积爬取和增量爬取两种策略。
累积爬取一般用于数据集的整体建立或大规模更新,而增量爬取主要用于数据集的日常维护和即时更新。
确定了爬取策略后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛运行策略中的核心问题。
总的来说,在合理利用软硬件资源对网络数据进行实时抓取方面,已经形成了比较成熟的技术和实用的解决方案。更好地处理动态网络数据问题(如越来越多的Web2.0数据等),更好地根据网页质量修正爬取策略。
四、数据库
为了避免重复爬取和爬取URL,搜索引擎会建立一个数据库来记录未爬取的页面和已爬取的页面,那么数据库中的URL是怎么来的呢?
1、手动输入种子网站
简单来说就是我们建站后提交给百度、谷歌或者360的URL收录。
2、蜘蛛抓取页面
如果搜索引擎蜘蛛在爬取过程中发现了新的连接URL,但不在数据库中,则将其存入待访问的数据库中(网站观察期)。
蜘蛛根据重要性从要访问的数据库中提取URL,访问并爬取页面,然后从要访问的地址库中删除该URL,放入已访问的地址库中。 @>观察期间要尽可能定期更新网站.
3、站长提交网站
一般来说,提交网站只是将网站保存到要访问的数据库中。如果网站坚持不更新蜘蛛,就不会访问搜索引擎的页面收录都是蜘蛛自己跟随链接获取的。
因此,将其提交给搜索引擎对您来说不是很有用。应该根据你以后网站更新的程度来考虑。搜索引擎更喜欢沿着链接发现新页面。当然,如果你的SEO技术足够成熟,并且有这个能力,可以尝试一下,说不定会有意想不到的效果,但是对于一般站长来说,还是建议让蜘蛛爬取,爬到新的站点页面自然。
五、吸引蜘蛛
虽然理论上说蜘蛛可以爬取所有页面,但在实践中是不可能的,所以SEO人员想要收录更多的页面,不得不想办法引诱蜘蛛爬。
既然不能爬取所有的页面,那么就必须让它爬取重要的页面,因为重要的页面在索引中起着重要的作用,直接影响排名因素。哪些页面更重要?对此,我特意整理了以下几个我认为比较重要的页面,具有以下特点:
1、网站和页面权重
优质老网站被赋予高权重,而这个网站上的页面爬取深度更高,所以更多的内页会是收录。
2、页面更新
蜘蛛每次抓取时都会存储页面数据。如果第二次爬取时页面内容与第一个收录完全一样,说明页面没有更新,蜘蛛不需要频繁爬取和爬取。抢。
如果页面内容更新频繁,蜘蛛就会频繁爬取,那么页面上的新链接自然会被蜘蛛更快地跟踪和爬取,这也是为什么需要每天更新的原因< @k7@ >
3、导入链接
无论是外链还是同一个网站的内链,为了被蜘蛛爬取,必须有传入链接才能进入页面,否则蜘蛛不会知道存在的页面。这时候URL链接就起到了非常重要的作用,内部链接的重要性就发挥出来了。
另外,我个人觉得高质量的入站链接也往往会增加页面上的出站链接被抓取的深度。
这就是为什么大多数网站管理员或 SEO 都想要高质量的附属链接,因为蜘蛛 网站从彼此之间爬到您网站 的次数和深度更多。 查看全部
c#抓取网页数据(搜索引擎蜘蛛访问网站页面时类似于普通用户使用浏览器开发蜘蛛程序)
搜索引擎用来抓取和访问页面的程序称为蜘蛛(spider)。 c#开发蜘蛛程序也称为机器人(bot)。当搜索引擎蜘蛛访问网站的页面时,它类似于普通用户使用浏览器。蜘蛛程序发送页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。为了提高搜索引擎的爬取和爬取速度,都使用了多个爬虫分布爬取。
蜘蛛访问网站时,首先会访问网站根目录下的robots.txt文件。如果robots.txt文件禁止搜索引擎抓取某些网页或内容,或者网站,则蜘蛛会遵循协议而不是c#开发的蜘蛛程序。
spider也是一个c#开发的spider程序,有自己的代理名。爬虫的痕迹可以在站长日志中看到,这也是为什么很多站长回答问题时总是说先检查网站日志的原因(作为一个好的SEO你必须能够查看网站日志无需任何软件,对代码含义非常熟悉)。
一个c#开发蜘蛛程序和搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛是Spider,这是一个很形象的名字。互联网被比作蜘蛛网。那么Spider就是一个c#开发的蜘蛛程序,可以在网络上爬行。
网络蜘蛛通过网页的链接地址寻找网页,从网站某个页面(通常是首页)开始,读取网页的内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一个网页,如此循环下去,直到这个网站的所有网页都被爬取完毕。
如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,几乎不可能爬取互联网上的所有网页。根据迄今为止公布的数据,最大的搜索引擎只抓取了网页总数的4%。十点左右。
其中一个原因是爬虫技术的瓶颈。 100 亿个网页的容量是 100×2000G 字节。就算能存起来,下载还是有问题(按一台机器每秒下载20K,需要340个单位,机器不停下载所有网页需要一年时间),同时,由于数据量大,在提供搜索时也会对效率产生影响。
因此,很多搜索引擎网络蜘蛛只抓取那些重要的网页,而在抓取时评估重要性的主要依据是某个网页的链接深度。
因为不可能爬取所有网页,所以有些网络蜘蛛为一些不太重要的网站设置了要访问的层数,例如如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A是起始页,属于第0层,B,C,D,E,F属于第1层,G,H属于第2层,I属于第3层,如果访问层网络蜘蛛设置的数字是2,网页我不会被访问,这也让搜索引擎可以搜索到一些网站网页,而其他部分则无法搜索到。
对于 网站 的设计者来说,扁平的 网站 设计有助于搜索引擎抓取更多页面。
网络蜘蛛在访问网站网页时,经常会遇到加密数据和网页权限问题。有些网页需要会员权限才能访问。
网站的站主当然可以让网络蜘蛛不按约定爬取,但是对于一些卖报告的网站来说,他们希望自己的报告可以被搜索引擎搜索到,但是不能 搜索者查看是完全免费的,所以需要提供相应的用户名和密码给网络蜘蛛。
网络蜘蛛可以通过给定的权限抓取这些网页提供搜索,当搜索者点击查看网页时,搜索者也需要提供相应的权限验证。
二、点击链接
搜索引擎蜘蛛为了在网络上抓取尽可能多的页面,会跟随网页上的链接,从一个页面爬到下一页,就像蜘蛛在蜘蛛网上爬行一样,这是搜索引擎蜘蛛 名字的由来。
整个互联网网站由相互连接的链接组成,这意味着搜索引擎蜘蛛最终将从任何一个页面开始抓取所有页面。
搜索引擎蜘蛛的基本原理和工作流程
当然网站而且页面链接结构太复杂,所以蜘蛛只能通过一定的方法爬取所有页面。据了解,最简单的爬取策略有以下三种:
1、最佳优先
最佳优先级搜索策略是根据一定的网页分析算法,预测候选URL与目标网页的相似度,或与主题的相关度,选择评价最好的一个或几个URL进行爬取。它只访问网页分析算法预测为“有用”的网页。
存在的一个问题是爬虫爬取路径上的很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要结合具体应用来提高最佳优先级, 为了跳出局部最优,据研究,这样的闭环调整可以将不相关网页的数量减少30%~90%。
2、深度优先
深度优先是指蜘蛛沿着找到的链接爬行,直到前面没有其他链接,然后返回第一页,沿着另一个链接爬行。
3、广度优先
广度优先是指当蜘蛛在一个页面上发现多个链接时,它不会一路跟随一个链接,而是爬取页面上的所有链接,然后进入页面的第二层并跟随第二层层。找到的链接爬到第三层页面。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它就可以爬取整个互联网。
在实践中,蜘蛛的带宽资源和时间并不是无限的,它们不可能爬取所有页面。其实最大的搜索引擎只爬网收录互联网的一小部分,当然也不是说搜索引擎蜘蛛爬的越多越好,这一点
因此,为了尽可能多地捕获用户信息,通常将深度优先和广度优先混合,以便尽可能多地照顾到网站,同时也照顾到一些< @网站 内页。
三、搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。 “蜘蛛”这个称呼形象地描述了信息采集模块在网络数据形成的“万维网”上获取信息的功能。
一般来说,网络爬虫都是从种子网页开始,通过反复下载网页,从文档中寻找看不见的URL,达到访问其他网页和遍历网络的目的。
而它的工作策略一般可以分为累积爬取(cumulative crawling)和增量爬取(incremental crawling)。
1、累积爬取
累积爬取是指从某个时间点开始遍历,爬取系统允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证爬取相当大的网页集合。
看来由于web数据的动态特性,集合中的网页被爬取的时间点不同,页面更新的也不同,所以累计爬取的网页集合实际上并不能与真实环境相比。网络数据保持一致。
2、增量爬取
与累积爬取不同,增量爬取是指在一定数量的网页集合的基础上,通过更新数据,选择现有集合中过时的网页,从而保证所有网页都被爬取。捕获的数据与真实的网络数据足够接近。
增量爬取的前提是系统已经爬取了足够多的网页,并且有关于这些页面何时被爬取的信息。在针对实际应用环境的网络爬虫设计中,通常会同时收录累积爬取和增量爬取两种策略。
累积爬取一般用于数据集的整体建立或大规模更新,而增量爬取主要用于数据集的日常维护和即时更新。
确定了爬取策略后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛运行策略中的核心问题。
总的来说,在合理利用软硬件资源对网络数据进行实时抓取方面,已经形成了比较成熟的技术和实用的解决方案。更好地处理动态网络数据问题(如越来越多的Web2.0数据等),更好地根据网页质量修正爬取策略。
四、数据库
为了避免重复爬取和爬取URL,搜索引擎会建立一个数据库来记录未爬取的页面和已爬取的页面,那么数据库中的URL是怎么来的呢?
1、手动输入种子网站
简单来说就是我们建站后提交给百度、谷歌或者360的URL收录。
2、蜘蛛抓取页面
如果搜索引擎蜘蛛在爬取过程中发现了新的连接URL,但不在数据库中,则将其存入待访问的数据库中(网站观察期)。
蜘蛛根据重要性从要访问的数据库中提取URL,访问并爬取页面,然后从要访问的地址库中删除该URL,放入已访问的地址库中。 @>观察期间要尽可能定期更新网站.
3、站长提交网站
一般来说,提交网站只是将网站保存到要访问的数据库中。如果网站坚持不更新蜘蛛,就不会访问搜索引擎的页面收录都是蜘蛛自己跟随链接获取的。
因此,将其提交给搜索引擎对您来说不是很有用。应该根据你以后网站更新的程度来考虑。搜索引擎更喜欢沿着链接发现新页面。当然,如果你的SEO技术足够成熟,并且有这个能力,可以尝试一下,说不定会有意想不到的效果,但是对于一般站长来说,还是建议让蜘蛛爬取,爬到新的站点页面自然。
五、吸引蜘蛛
虽然理论上说蜘蛛可以爬取所有页面,但在实践中是不可能的,所以SEO人员想要收录更多的页面,不得不想办法引诱蜘蛛爬。
既然不能爬取所有的页面,那么就必须让它爬取重要的页面,因为重要的页面在索引中起着重要的作用,直接影响排名因素。哪些页面更重要?对此,我特意整理了以下几个我认为比较重要的页面,具有以下特点:
1、网站和页面权重
优质老网站被赋予高权重,而这个网站上的页面爬取深度更高,所以更多的内页会是收录。
2、页面更新
蜘蛛每次抓取时都会存储页面数据。如果第二次爬取时页面内容与第一个收录完全一样,说明页面没有更新,蜘蛛不需要频繁爬取和爬取。抢。
如果页面内容更新频繁,蜘蛛就会频繁爬取,那么页面上的新链接自然会被蜘蛛更快地跟踪和爬取,这也是为什么需要每天更新的原因< @k7@ >
3、导入链接
无论是外链还是同一个网站的内链,为了被蜘蛛爬取,必须有传入链接才能进入页面,否则蜘蛛不会知道存在的页面。这时候URL链接就起到了非常重要的作用,内部链接的重要性就发挥出来了。
另外,我个人觉得高质量的入站链接也往往会增加页面上的出站链接被抓取的深度。
这就是为什么大多数网站管理员或 SEO 都想要高质量的附属链接,因为蜘蛛 网站从彼此之间爬到您网站 的次数和深度更多。
c#抓取网页数据(NBA总决赛如何使用ChromeDriver+HtmlAgilityPack爬取比赛实时比分解析网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-03-15 08:06
背景
最近NBA总决赛吸引了很多球迷,但是因为时差,大家都在打比赛,我们也在努力。
是的,自己动手,ChromeDriver+HtmlAgilityPack爬取游戏实时比分。
概述
WebDriver 是对浏览器提供的原生 API 进行封装,使其成为更加面向对象的 Selenium WebDriver API。使用该API,您可以控制浏览器的打开和关闭,打开网页,操作界面元素,控制cookies,还可以操作浏览器截图,安装插件,设置代理,配置证书。
HtmlAgilityPack 是 .net 下的 HTML 解析库。支持使用 XPath 解析 HTML。这很有道理,为什么呢?因为一些功能强大的浏览器可以直接获取页面上元素的xpath,所以不需要手动编写。它节省了编写正则表达式的大部分时间。当然,在进一步获取的时候,有时需要写正则表达式,但是通过xpath解析后,要匹配的正则表达式的范围很小。此外,通过不使用正则表达式来匹配整个页面源代码,可以提高速度。总而言之,通过这个类库,先通过浏览器获取的xpath获取节点内容,再通过正则表达式匹配需要的内容,既提高了开发速度,又提高了运行效率。
代码
下面我们来看看如何使用ChromeDriver+HtmlAgilityPack来抓取游戏的实时比分。
爬网
string url = "https://sports.qq.com/kbsweb/game.htm?mid=" + model.TxMatchId;<br /><br /> // string url = "https://kbs.sports.qq.com/kbsw ... %3Bbr /> // MatchUpdate model = new MatchUpdate();<br /><br /> var cds = ChromeDriverService.CreateDefaultService();<br /> //是否应隐藏服务的命令提示符窗口<br /> cds.HideCommandPromptWindow = true;<br /><br /> ChromeOptions options = new ChromeOptions();<br /> options.AddArguments("--test-type", "--ignore-certificate-errors");<br /> // options.AddArguments("user-agent=mozilla/5.0 (linux; u; android 2.3.3; en-us; sdk build/ gri34) applewebkit/533.1 (khtml, like gecko) version/4.0 mobile safari/533.1");<br /> options.AddArgument("enable-automation");<br /><br /> // options.setBinary("C:/Program Files (x86)/Google/Chrome/chrome.exe");<br /><br /> var r = ZhimaHttpProxy.GetProxy(false);<br /> if (r != null)<br /> {<br /> Console.WriteLine(r.Address.Host);<br /> Console.WriteLine(r.Address.Port);<br /><br /> string proxy_Host = r.Address.Host;<br /> int proxy_Post = r.Address.Port;<br /> string Ex_Proxy_Name = "proxy.zip";<br /><br /> options.Proxy = null;<br /> options.AddArguments("--proxy-server=" + proxy_Host + ":" + proxy_Post.ToString());<br /> options.AddExtension(Ex_Proxy_Name);<br /> }<br /><br /> if (IsHideMode)<br /> options.AddArgument("headless");<br /><br /> string dic = System.Environment.CurrentDirectory + "\\cos";<br /><br /> if (IsHideMode)<br /> {<br /> using (IWebDriver driver = new OpenQA.Selenium.Chrome.ChromeDriver(cds, options, TimeSpan.FromSeconds(120)))<br /><br /> {<br /> Excule(driver, url, model);<br /> }<br /> }<br /> else<br /> {<br /> using (IWebDriver driver = new OpenQA.Selenium.Chrome.ChromeDriver(dic, options, TimeSpan.FromSeconds(120)))<br /><br /> {<br /> Excule(driver, url, model);<br /> }<br /> }
解析网页
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();<br /> doc.LoadHtml(Helper.ReadTxt(System.Environment.CurrentDirectory + "\\PageSource\\" + info.TxMatchId.Replace(":", "_") + ".txt"));<br /> int? HomeTeamScore = null;<br /> int? GuestTeamScore = null;<br /> List MatchScoreList = new List();<br /> HtmlNode titleNodes = doc.DocumentNode.SelectSingleNode("//div[@class='inner']");<br /> var titleNodes2 = doc.DocumentNode.SelectSingleNode("//div[@class='content-wrapper']");<br /> if (titleNodes2 != null)<br /> // if (false)<br /> {<br /> Console.WriteLine(titleNodes2.InnerText);<br /> var host = titleNodes2.SelectSingleNode("//div[@class='team-goal host']");<br /> var arr = host.InnerText.Replace("\r\n", "|");<br /> var arrs = arr.Split('|');<br /> arrs = arrs.Where(o => !string.IsNullOrWhiteSpace(o)).Select(o => o.Split('(')[0].Trim()).ToArray();<br /> HomeTeamScore = int.Parse(arrs[1]);<br /> MatchScoreList.Add(new MatchScore() { TeamName = arrs[0], TeamScore = HomeTeamScore });<br /><br /> var guest = titleNodes2.SelectSingleNode("//div[@class='team-goal guest']");<br /><br /> var arr2 = guest.InnerText.Replace("\r\n", "|");<br /> var arrs2 = arr2.Split('|');<br /> arrs2 = arrs2.Where(o => !string.IsNullOrWhiteSpace(o)).Select(o => o.Split('(')[0].Trim()).ToArray();<br /><br /> GuestTeamScore = int.Parse(arrs2[1]);<br /><br /> MatchScoreList.Add(new MatchScore() { TeamName = arrs2[0], TeamScore = GuestTeamScore });<br /> }<br /> else<br /> {<br /> var a = titleNodes.SelectNodes("//a[@data-target='teamName']");<br /> var score = titleNodes.SelectNodes("//span[@class='score']");<br /> if (score != null)<br /> {<br /> int i = 0;<br /> foreach (var item in score)<br /> {<br /> SetText("\r\n" + item.InnerText?.Trim());<br /> if (i == 0)<br /> {<br /> HomeTeamScore = Convert.ToInt32(item.InnerText?.Trim());<br /> }<br /> if (i == 1)<br /> {<br /> GuestTeamScore = Convert.ToInt32(item.InnerText?.Trim());<br /> }<br /><br /> i++;<br /> }<br /> }<br /><br /> if (a != null)<br /> {<br /> int i = 0;<br /> foreach (var item in a)<br /> {<br /> SetText("\r\n" + item.InnerText?.Trim());<br /><br /> if (i == 0)<br /> {<br /> MatchScoreList.Add(new MatchScore() { TeamName = item.InnerText?.Split('(')[0].Trim(), TeamScore = HomeTeamScore });<br /> }<br /> if (i == 1)<br /> {<br /> MatchScoreList.Add(new MatchScore() { TeamName = item.InnerText?.Split('(')[0].Trim(), TeamScore = GuestTeamScore });<br /> }<br /><br /> i++;<br /> }<br /> }<br /> }<br /><br /> string statusstr = "";<br /><br /> var t = titleNodes.SelectSingleNode("//div[@class='datetime-live-desc']");<br /> SetText("\r\n" + t.InnerText?.Trim());<br /> statusstr = t.InnerText?.Trim();<br /><br /> var Status = info.Status;<br /> if (!string.IsNullOrWhiteSpace(statusstr) && statusstr.Contains("已结束"))<br /> {<br /> Status = MatchStatus.End;<br /> }<br />
最后做一个小弹框,输出数据。 查看全部
c#抓取网页数据(NBA总决赛如何使用ChromeDriver+HtmlAgilityPack爬取比赛实时比分解析网页)
背景
最近NBA总决赛吸引了很多球迷,但是因为时差,大家都在打比赛,我们也在努力。
是的,自己动手,ChromeDriver+HtmlAgilityPack爬取游戏实时比分。
概述
WebDriver 是对浏览器提供的原生 API 进行封装,使其成为更加面向对象的 Selenium WebDriver API。使用该API,您可以控制浏览器的打开和关闭,打开网页,操作界面元素,控制cookies,还可以操作浏览器截图,安装插件,设置代理,配置证书。
HtmlAgilityPack 是 .net 下的 HTML 解析库。支持使用 XPath 解析 HTML。这很有道理,为什么呢?因为一些功能强大的浏览器可以直接获取页面上元素的xpath,所以不需要手动编写。它节省了编写正则表达式的大部分时间。当然,在进一步获取的时候,有时需要写正则表达式,但是通过xpath解析后,要匹配的正则表达式的范围很小。此外,通过不使用正则表达式来匹配整个页面源代码,可以提高速度。总而言之,通过这个类库,先通过浏览器获取的xpath获取节点内容,再通过正则表达式匹配需要的内容,既提高了开发速度,又提高了运行效率。
代码
下面我们来看看如何使用ChromeDriver+HtmlAgilityPack来抓取游戏的实时比分。
爬网
string url = "https://sports.qq.com/kbsweb/game.htm?mid=" + model.TxMatchId;<br /><br /> // string url = "https://kbs.sports.qq.com/kbsw ... %3Bbr /> // MatchUpdate model = new MatchUpdate();<br /><br /> var cds = ChromeDriverService.CreateDefaultService();<br /> //是否应隐藏服务的命令提示符窗口<br /> cds.HideCommandPromptWindow = true;<br /><br /> ChromeOptions options = new ChromeOptions();<br /> options.AddArguments("--test-type", "--ignore-certificate-errors");<br /> // options.AddArguments("user-agent=mozilla/5.0 (linux; u; android 2.3.3; en-us; sdk build/ gri34) applewebkit/533.1 (khtml, like gecko) version/4.0 mobile safari/533.1");<br /> options.AddArgument("enable-automation");<br /><br /> // options.setBinary("C:/Program Files (x86)/Google/Chrome/chrome.exe");<br /><br /> var r = ZhimaHttpProxy.GetProxy(false);<br /> if (r != null)<br /> {<br /> Console.WriteLine(r.Address.Host);<br /> Console.WriteLine(r.Address.Port);<br /><br /> string proxy_Host = r.Address.Host;<br /> int proxy_Post = r.Address.Port;<br /> string Ex_Proxy_Name = "proxy.zip";<br /><br /> options.Proxy = null;<br /> options.AddArguments("--proxy-server=" + proxy_Host + ":" + proxy_Post.ToString());<br /> options.AddExtension(Ex_Proxy_Name);<br /> }<br /><br /> if (IsHideMode)<br /> options.AddArgument("headless");<br /><br /> string dic = System.Environment.CurrentDirectory + "\\cos";<br /><br /> if (IsHideMode)<br /> {<br /> using (IWebDriver driver = new OpenQA.Selenium.Chrome.ChromeDriver(cds, options, TimeSpan.FromSeconds(120)))<br /><br /> {<br /> Excule(driver, url, model);<br /> }<br /> }<br /> else<br /> {<br /> using (IWebDriver driver = new OpenQA.Selenium.Chrome.ChromeDriver(dic, options, TimeSpan.FromSeconds(120)))<br /><br /> {<br /> Excule(driver, url, model);<br /> }<br /> }
解析网页
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();<br /> doc.LoadHtml(Helper.ReadTxt(System.Environment.CurrentDirectory + "\\PageSource\\" + info.TxMatchId.Replace(":", "_") + ".txt"));<br /> int? HomeTeamScore = null;<br /> int? GuestTeamScore = null;<br /> List MatchScoreList = new List();<br /> HtmlNode titleNodes = doc.DocumentNode.SelectSingleNode("//div[@class='inner']");<br /> var titleNodes2 = doc.DocumentNode.SelectSingleNode("//div[@class='content-wrapper']");<br /> if (titleNodes2 != null)<br /> // if (false)<br /> {<br /> Console.WriteLine(titleNodes2.InnerText);<br /> var host = titleNodes2.SelectSingleNode("//div[@class='team-goal host']");<br /> var arr = host.InnerText.Replace("\r\n", "|");<br /> var arrs = arr.Split('|');<br /> arrs = arrs.Where(o => !string.IsNullOrWhiteSpace(o)).Select(o => o.Split('(')[0].Trim()).ToArray();<br /> HomeTeamScore = int.Parse(arrs[1]);<br /> MatchScoreList.Add(new MatchScore() { TeamName = arrs[0], TeamScore = HomeTeamScore });<br /><br /> var guest = titleNodes2.SelectSingleNode("//div[@class='team-goal guest']");<br /><br /> var arr2 = guest.InnerText.Replace("\r\n", "|");<br /> var arrs2 = arr2.Split('|');<br /> arrs2 = arrs2.Where(o => !string.IsNullOrWhiteSpace(o)).Select(o => o.Split('(')[0].Trim()).ToArray();<br /><br /> GuestTeamScore = int.Parse(arrs2[1]);<br /><br /> MatchScoreList.Add(new MatchScore() { TeamName = arrs2[0], TeamScore = GuestTeamScore });<br /> }<br /> else<br /> {<br /> var a = titleNodes.SelectNodes("//a[@data-target='teamName']");<br /> var score = titleNodes.SelectNodes("//span[@class='score']");<br /> if (score != null)<br /> {<br /> int i = 0;<br /> foreach (var item in score)<br /> {<br /> SetText("\r\n" + item.InnerText?.Trim());<br /> if (i == 0)<br /> {<br /> HomeTeamScore = Convert.ToInt32(item.InnerText?.Trim());<br /> }<br /> if (i == 1)<br /> {<br /> GuestTeamScore = Convert.ToInt32(item.InnerText?.Trim());<br /> }<br /><br /> i++;<br /> }<br /> }<br /><br /> if (a != null)<br /> {<br /> int i = 0;<br /> foreach (var item in a)<br /> {<br /> SetText("\r\n" + item.InnerText?.Trim());<br /><br /> if (i == 0)<br /> {<br /> MatchScoreList.Add(new MatchScore() { TeamName = item.InnerText?.Split('(')[0].Trim(), TeamScore = HomeTeamScore });<br /> }<br /> if (i == 1)<br /> {<br /> MatchScoreList.Add(new MatchScore() { TeamName = item.InnerText?.Split('(')[0].Trim(), TeamScore = GuestTeamScore });<br /> }<br /><br /> i++;<br /> }<br /> }<br /> }<br /><br /> string statusstr = "";<br /><br /> var t = titleNodes.SelectSingleNode("//div[@class='datetime-live-desc']");<br /> SetText("\r\n" + t.InnerText?.Trim());<br /> statusstr = t.InnerText?.Trim();<br /><br /> var Status = info.Status;<br /> if (!string.IsNullOrWhiteSpace(statusstr) && statusstr.Contains("已结束"))<br /> {<br /> Status = MatchStatus.End;<br /> }<br />
最后做一个小弹框,输出数据。
c#抓取网页数据(windows下C#定时管理器框架-Task.MainForm学习总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-14 05:22
我在博客公园呆了 4 年多。一直看别人的博客,学习别人的知识,支持所有默默贡献自己技术总结的朋友;这几天突然觉得是时候加入队列贡献自己的力量了,争取每个月都有不同的学习总结,分享知识学习文章。下面我要分享的是花了两天时间编写+测试的Windows下的C#时序管理器框架——Task.MainForm。
目的:
随着近五年来几家公司的.net开发者处于不同岗位,发现每家公司或多或少都会连接一些第三方的合作接口或者数据采集功能,这些都是和每一个服务直接无关的。功能,开发者可能并不孤单,所以winform或者winservice服务的版本越来越多,服务器上各种winform表单让不同行的人看起来很复杂;是的,这次的目的是我写了一个插件(其实就是winform哈哈),通过统一的封装和规范来管理这些程序服务。
介绍:
本版本使用4.5框架,其中使用了一些只有4.5及以上版本才能使用的东西。如果读者需要向后兼容,请使用下载的开源项目进行修改,应该是可以的;主要使用反射来执行业务方法;如果废话太多,就看下面的步骤。
重要代码说明:
A.首先框架的整体项目简单如下
好像很小,是的,看具体要求再补充吧,大家
B、基类TPlugin主要用于软件规则的统一管理。重要的区别是:
1.初始化配置信息
2.开始加载的_Load()方法,这里是所有任务开始执行的入口
C、类PublicClass主要封装了对*.dll文件路径信息的访问和程序集序列化继承实体。关键点已用红色标出:
1.
2.
D. 下面是时序管理器接口MainForm.cs的功能说明:
1.加载带有特定标签的程序dll信息
2.服务开启
3.异步委托增加manager监控信息
以上是框架的主要部分。也可以看作是一个知识点。也许哈哈。让我们看看如何编写继承这个框架的代码。简单粗暴如下:
E.继承插件的任务类,也就是我们需要处理的业务实现类
F. 值得注意的是,同一项目中的不同任务类是否继承框架或不同项目中的任务类都可以使用。建议使用前者,这样就不需要每次都有业务需求了,定期执行信息时,必须创建一个单独的项目。Task.MainForm 只需要你从同一个项目中的不同任务类继承即可:
这里两个继承类对应的配置文件的默认名称应该是:
xml文件结构参考模板:Task.MainForm项目中的XmlTp.xml文件(也可以以开源项目中Task.MainForm\bin\Debug\PluginXml文件夹下的两个.xml文件为例)
G. 最后在发布项目中贴出结构图
以上是开源时序管理器框架。很简单。第一次写技术文章。
项目的git地址:
以上就是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持朱贤飞。 查看全部
c#抓取网页数据(windows下C#定时管理器框架-Task.MainForm学习总结)
我在博客公园呆了 4 年多。一直看别人的博客,学习别人的知识,支持所有默默贡献自己技术总结的朋友;这几天突然觉得是时候加入队列贡献自己的力量了,争取每个月都有不同的学习总结,分享知识学习文章。下面我要分享的是花了两天时间编写+测试的Windows下的C#时序管理器框架——Task.MainForm。
目的:
随着近五年来几家公司的.net开发者处于不同岗位,发现每家公司或多或少都会连接一些第三方的合作接口或者数据采集功能,这些都是和每一个服务直接无关的。功能,开发者可能并不孤单,所以winform或者winservice服务的版本越来越多,服务器上各种winform表单让不同行的人看起来很复杂;是的,这次的目的是我写了一个插件(其实就是winform哈哈),通过统一的封装和规范来管理这些程序服务。
介绍:
本版本使用4.5框架,其中使用了一些只有4.5及以上版本才能使用的东西。如果读者需要向后兼容,请使用下载的开源项目进行修改,应该是可以的;主要使用反射来执行业务方法;如果废话太多,就看下面的步骤。
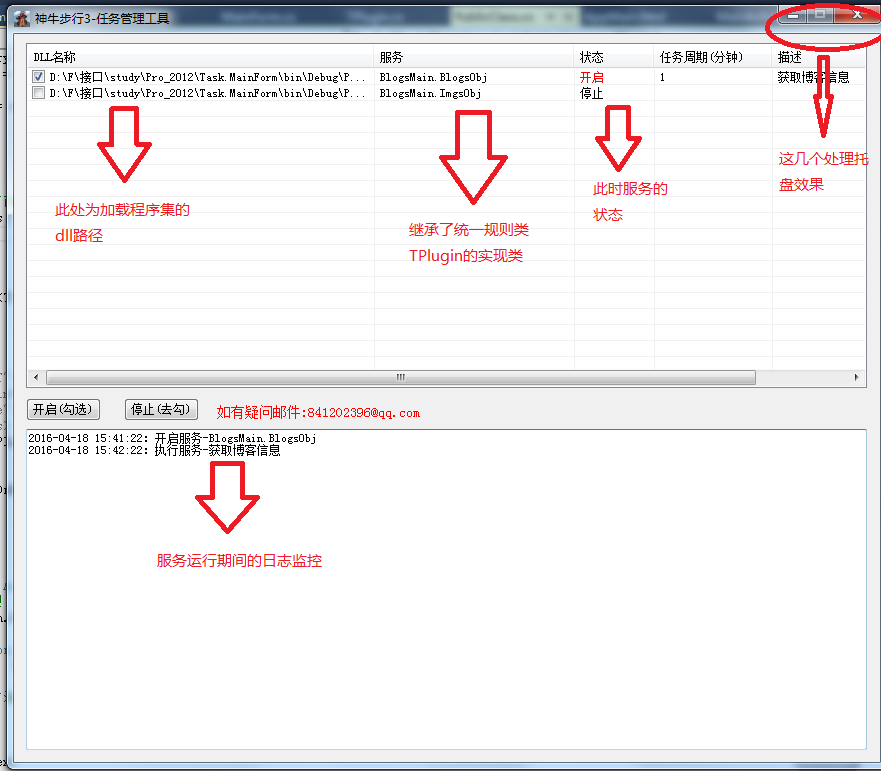
重要代码说明:
A.首先框架的整体项目简单如下
好像很小,是的,看具体要求再补充吧,大家
B、基类TPlugin主要用于软件规则的统一管理。重要的区别是:
1.初始化配置信息

2.开始加载的_Load()方法,这里是所有任务开始执行的入口
C、类PublicClass主要封装了对*.dll文件路径信息的访问和程序集序列化继承实体。关键点已用红色标出:
1.
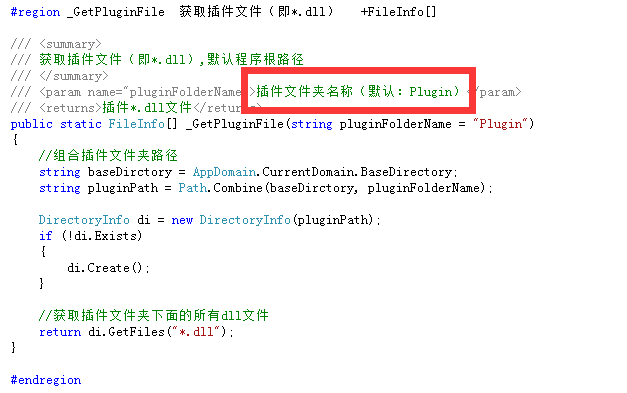
2.
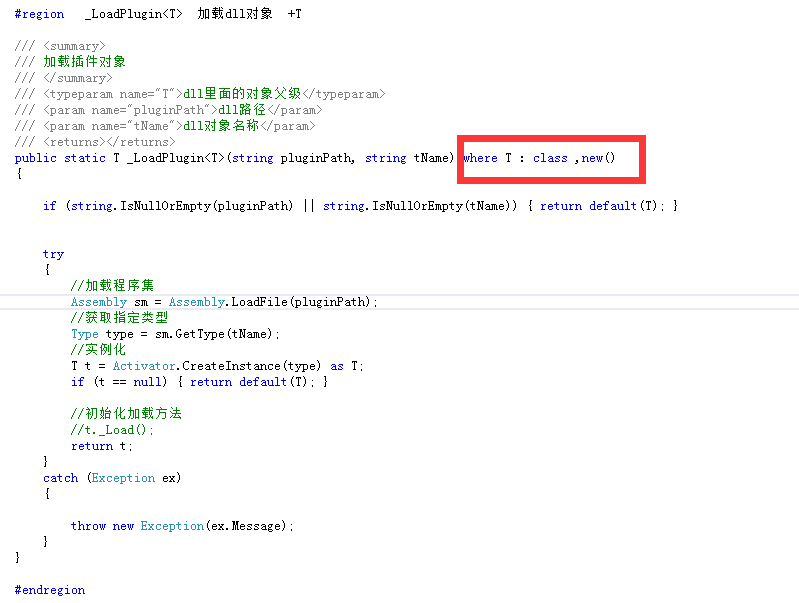
D. 下面是时序管理器接口MainForm.cs的功能说明:
1.加载带有特定标签的程序dll信息

2.服务开启
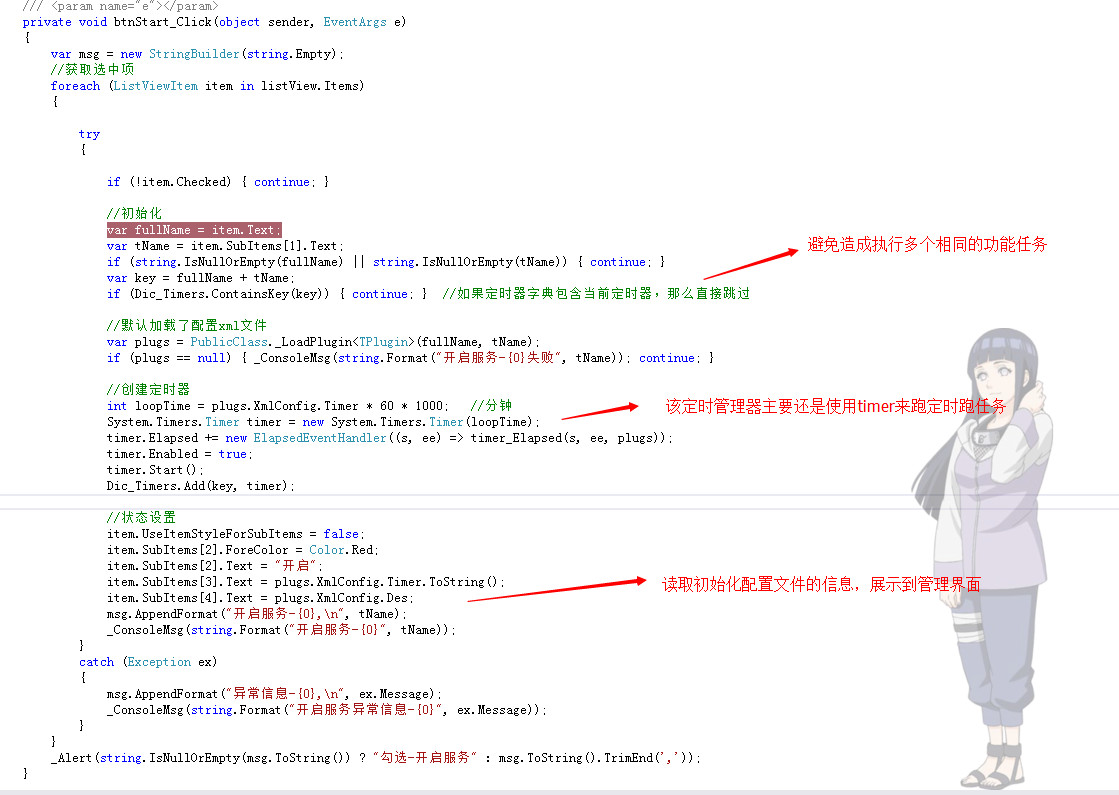
3.异步委托增加manager监控信息
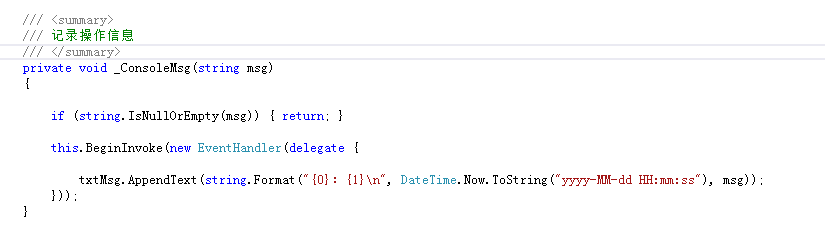
以上是框架的主要部分。也可以看作是一个知识点。也许哈哈。让我们看看如何编写继承这个框架的代码。简单粗暴如下:
E.继承插件的任务类,也就是我们需要处理的业务实现类
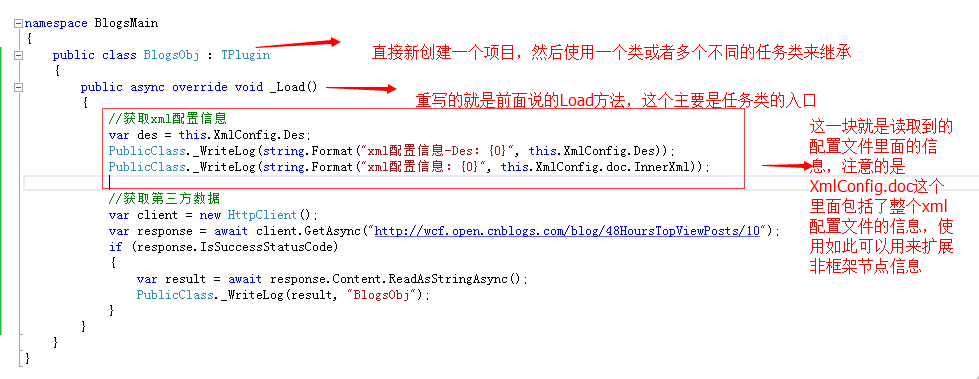
F. 值得注意的是,同一项目中的不同任务类是否继承框架或不同项目中的任务类都可以使用。建议使用前者,这样就不需要每次都有业务需求了,定期执行信息时,必须创建一个单独的项目。Task.MainForm 只需要你从同一个项目中的不同任务类继承即可:
这里两个继承类对应的配置文件的默认名称应该是:

xml文件结构参考模板:Task.MainForm项目中的XmlTp.xml文件(也可以以开源项目中Task.MainForm\bin\Debug\PluginXml文件夹下的两个.xml文件为例)
G. 最后在发布项目中贴出结构图
以上是开源时序管理器框架。很简单。第一次写技术文章。
项目的git地址:
以上就是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持朱贤飞。
c#抓取网页数据(用C#的语言写了一个小程序-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-06 18:05
我用C#语言写了一个小程序,虽然不够专业,希望大家多多支持。
因为我对C#比较熟悉,而且C#有更好的交互界面,所以我选择使用C#语言来爬取网页中的数据。
1. 引用命名空间HtmlAgilityPack 代码引用命名空间HtmlAgilityPack,它是.NET下的HTML解析类库。
using HtmlAgilityPack;
2、读取静态网页的代码
HtmlWeb htmlWeb = new HtmlWeb();
HtmlAgilityPack.HtmlDocument doc = htmlWeb.Load("http://www.gdacs.org/");
3、要读取具体的网页信息,需要解析网页的源码如下图,想要得到红框的信息
右键检查元素,会出现下图所示界面,点击红框内的按钮,点击要获取的内容,就会定位到数据所在的代码,比如div类=“alert_EQ_Green”
,
解析获取元素
HtmlNodeCollection hrefList = doc.DocumentNode.SelectNodes(".//div[@class='alert_EQ_Green']");
希望对你有帮助 查看全部
c#抓取网页数据(用C#的语言写了一个小程序-上海怡健医学)
我用C#语言写了一个小程序,虽然不够专业,希望大家多多支持。
因为我对C#比较熟悉,而且C#有更好的交互界面,所以我选择使用C#语言来爬取网页中的数据。
1. 引用命名空间HtmlAgilityPack 代码引用命名空间HtmlAgilityPack,它是.NET下的HTML解析类库。
using HtmlAgilityPack;
2、读取静态网页的代码
HtmlWeb htmlWeb = new HtmlWeb();
HtmlAgilityPack.HtmlDocument doc = htmlWeb.Load("http://www.gdacs.org/";);
3、要读取具体的网页信息,需要解析网页的源码如下图,想要得到红框的信息

右键检查元素,会出现下图所示界面,点击红框内的按钮,点击要获取的内容,就会定位到数据所在的代码,比如div类=“alert_EQ_Green”
,

解析获取元素
HtmlNodeCollection hrefList = doc.DocumentNode.SelectNodes(".//div[@class='alert_EQ_Green']");
希望对你有帮助
c#抓取网页数据(最好上有趣、入门级的开源项目,帮你找到兴趣!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-04-11 18:32
兴趣是最好的老师,HelloGitHub就是帮你找到兴趣!
介绍
在 GitHub 上分享有趣的入门级开源项目。
这是一本面向编程新手、热爱编程和对开源社区感兴趣的人的月刊。月刊的内容包括:各种编程语言的项目、让生活更美好的工具、书籍、学习笔记、教程等。这些开源的大部分项目都非常好用,非常酷。主要是希望大家可以使用,加入开源社区。
在浏览和参与这些项目的过程中,你会学到更多的编程知识,提高编程技能,找到编程的乐趣。
终于,HelloGitHub项目诞生了
以下为本期内容|最新一期每月28日发布|点击查看上期内容
由于无法放置链接,因此可以通过以下两种方式找到该项目:
去 GitHub 用项目名称搜索。访问HelloGitHub的官网:Project C
1、baulk:一个用C语言编写的最小的Windows包管理器。使用方便,免安装,不修改系统环境变量,可与Windows Terminal集成并添加到右键菜单中。可以说是Scoop的精简版
2、LCUI:用C语言开发的图形界面开发库,可以用XML和CSS构建简单的跨平台桌面应用,提供类似web的开发体验。因此,您可以使用它轻松制作非常漂亮的界面。与 Electron 不同,它只是一个传统的 GUI 开发库,应用了一些 Web 技术
C# 项目
3、Windows-Auto-Night-Mode:设置 Windows 10 深色和浅色主题之间定时自动切换的工具
C++ 项目
4、flameshot:简单而强大的截图工具
CSS项目
5、css-sweeper:只使用 HTML 和 CSS 实现的扫雷游戏。在线玩
6、papercss:手绘风格的 CSS 库
去项目
7、go-internals:Go 编程语言内部实现原理的解释。中文翻译
8、livego:基于Go的直播服务项目
9、LeetCode-Go:《LeetCode Cookbook》是一个帮助开发者解决 LeetCode 上的问题并提供解决问题的思路和代码的项目。目前已经有收录 500+个问题,有解决方案和代码。代码都是 100% 运行时节拍,所有代码都是用 Go 语言实现的。在线阅读
10、ginrpc:简化go-gin框架注册路由方式,自动生成Swagger/Markdown文档。示例代码:
type ReqTest struct {
UserName string `json:"user_name" binding:"required"` // 带校验方式
}
type Hello struct {
}
// Hello [grpc-go](https://github.com/grpc/grpc-go) 模式
// @Router /hello_ruter [post,get]
func (s *Hello) Hello(c *gin.Context, req ReqTest) (*ReqTest, error) {
fmt.Println(req)
return &req,nil
}
func main() {
base := ginrpc.New(ginrpc.WithGroup("xxjwxc"))
router := gin.Default()
base.Register(router, new(Hello)) // 对象注册 like(go-micro)
router.Run(":8080")
}
Java 项目
11、D8gerAutoCode:IDEA Java代码自动生成插件。支持自动生成单表增删改查、分页、注释等。
12、java8-tutorial:一步步教你Java8的语言特点。Java11的新特性也在项目中更新
13、CalendarView:优雅强大的Android日历控件,支持周视图、自定义周开始等功能
14、tutorials:本项目是Spring框架下的小型单功能教程和示例代码的集合。主要是Spring、Spring Boot、Spring Security等。
JavaScript 项目
15、remote-browser:一个用 JavaScript 控制 Chrome 和 Firefox 浏览器的库。可以轻松实现自动化测试、数据采集等功能
16、:使用 Node.js 和 Socket.io 实现的在线迷宫游戏。入口在左上角,出口在右下角。使用 [a][w][s][d] 键移动位置。支持多人和单人模式,点击“显示解法”显示迷宫的解法(由BFS算法实现)。在线玩
17、jizhi:Chrome/Firefox 的中国风新标签页插件。它将在带有经典诗歌的新标签页上以繁体中文色彩的层叠波浪动画为特色
18、star-history:一个在线工具,用于显示GitHub项目的Star历史。支持多个项目显示在同一张图表上,效果如下:
19、genal-chat:适合前端新手学习的“星空”聊天室项目。Vue+socket.io结合TypeScript语法构建,界面酷炫,代码规范,支持群聊和好友搜索等功能
蟒蛇项目
20、handcalcs:从简单的 Python 代码生成复杂公式的工具。还记得在编写论文计算算法时害怕被逐行公式支配的恐惧吗?这个库可以将Python写的公式以LaTeX格式显示出来,效果如下:
21、QuickCut:一款轻量级、易用的开源视频处理工具。是一款基于PyQt5开发的桌面工具,用于满足非专业用户的视频处理需求:视频压缩、视频转码、反向视频、合并剪辑、根据字幕剪切剪辑、自动匹配字幕、自动编辑、等等
22、altair:用于数据可视化的强大 Python 库。支持多种数据展示方式,界面简洁,效果炫酷。示例代码及效果如下:
import altair as alt
from vega_datasets import data
source = data.cars()
brush = alt.selection(type='interval')
points = alt.Chart(source).mark_point().encode(
x='Horsepower',
y='Miles_per_Gallon',
color=alt.condition(brush, 'Origin', alt.value('lightgray'))
).add_selection(
brush
)
bars = alt.Chart(source).mark_bar().encode(
y='Origin',
color='Origin',
x='count(Origin)'
).transform_filter(
brush
)
points & bars
23、butterfly:又一个轻量级的 Python web 框架。网络框架太多了。本项目主要是开发一个轻量级、可靠、可用的Web框架,以更深入地了解Web开发过程中经常被忽略(由框架制造)的重要知识点。那句话是怎么来的:再不做就看不懂了!架构图如下:
斯威夫特项目
24、lottie-ios:Airbnb的开源三方库,用于快速实现APP动画。它还支持Android、React Native、Web、Windows等平台。动画效果如下:
25、YLExtensions:解决了UITableView和UI采集View的注册和配置过程中不得不写大量重复代码的问题
其他
26、math-as-code:这是一个通过比较数学符号和 JavaScript 代码来帮助开发人员更容易理解数学符号的项目
27、PowerToys:微软开源Windows系统下的强大辅助工具。例如:窗口管理、批量图像处理、换键工具等。下图为屏幕选色工具
28、first-contributions:关于如何首次向 GitHub 贡献代码的分步教程。支持多国语言,中文
29、leek-fund:VSCode中查看实时股票和基金数据的插件
30、Algorithms-in-4-Steps:系统学习算法和数据结构的集合
开源书籍
31、BuildYourOwnLisp:本书教你用C实现自己的Lisp语言。用1000多行代码实现一个小巧但功能齐全的Lisp语言。有中文翻译版,不过还没完。点击阅读
机器学习
32、waifu2x:基于机器学习制作图片和照片高清。本项目使用卷积神经网络对图像进行1-2x无损放大操作,并支持降噪保证图像质量。在线尝试
33、Never-Blink:谁先眨眼,谁就输了。使用React + Flask + Dlib技术实现的《一闪而过》网游,虽然是demo级别的项目,但是在本地运行,找朋友一起玩还是很有趣的
34、cnn-convoluter:支持卷积过程交互式可视化的可视化工具
终于
如果你在 GitHub 上发现有趣的项目,请在评论中告诉我。 查看全部
c#抓取网页数据(最好上有趣、入门级的开源项目,帮你找到兴趣!)
兴趣是最好的老师,HelloGitHub就是帮你找到兴趣!
介绍
在 GitHub 上分享有趣的入门级开源项目。
这是一本面向编程新手、热爱编程和对开源社区感兴趣的人的月刊。月刊的内容包括:各种编程语言的项目、让生活更美好的工具、书籍、学习笔记、教程等。这些开源的大部分项目都非常好用,非常酷。主要是希望大家可以使用,加入开源社区。
在浏览和参与这些项目的过程中,你会学到更多的编程知识,提高编程技能,找到编程的乐趣。
终于,HelloGitHub项目诞生了
以下为本期内容|最新一期每月28日发布|点击查看上期内容
由于无法放置链接,因此可以通过以下两种方式找到该项目:
去 GitHub 用项目名称搜索。访问HelloGitHub的官网:Project C
1、baulk:一个用C语言编写的最小的Windows包管理器。使用方便,免安装,不修改系统环境变量,可与Windows Terminal集成并添加到右键菜单中。可以说是Scoop的精简版
2、LCUI:用C语言开发的图形界面开发库,可以用XML和CSS构建简单的跨平台桌面应用,提供类似web的开发体验。因此,您可以使用它轻松制作非常漂亮的界面。与 Electron 不同,它只是一个传统的 GUI 开发库,应用了一些 Web 技术
C# 项目
3、Windows-Auto-Night-Mode:设置 Windows 10 深色和浅色主题之间定时自动切换的工具
C++ 项目
4、flameshot:简单而强大的截图工具
CSS项目
5、css-sweeper:只使用 HTML 和 CSS 实现的扫雷游戏。在线玩
6、papercss:手绘风格的 CSS 库
去项目
7、go-internals:Go 编程语言内部实现原理的解释。中文翻译
8、livego:基于Go的直播服务项目
9、LeetCode-Go:《LeetCode Cookbook》是一个帮助开发者解决 LeetCode 上的问题并提供解决问题的思路和代码的项目。目前已经有收录 500+个问题,有解决方案和代码。代码都是 100% 运行时节拍,所有代码都是用 Go 语言实现的。在线阅读
10、ginrpc:简化go-gin框架注册路由方式,自动生成Swagger/Markdown文档。示例代码:
type ReqTest struct {
UserName string `json:"user_name" binding:"required"` // 带校验方式
}
type Hello struct {
}
// Hello [grpc-go](https://github.com/grpc/grpc-go) 模式
// @Router /hello_ruter [post,get]
func (s *Hello) Hello(c *gin.Context, req ReqTest) (*ReqTest, error) {
fmt.Println(req)
return &req,nil
}
func main() {
base := ginrpc.New(ginrpc.WithGroup("xxjwxc"))
router := gin.Default()
base.Register(router, new(Hello)) // 对象注册 like(go-micro)
router.Run(":8080")
}
Java 项目
11、D8gerAutoCode:IDEA Java代码自动生成插件。支持自动生成单表增删改查、分页、注释等。
12、java8-tutorial:一步步教你Java8的语言特点。Java11的新特性也在项目中更新
13、CalendarView:优雅强大的Android日历控件,支持周视图、自定义周开始等功能
14、tutorials:本项目是Spring框架下的小型单功能教程和示例代码的集合。主要是Spring、Spring Boot、Spring Security等。
JavaScript 项目
15、remote-browser:一个用 JavaScript 控制 Chrome 和 Firefox 浏览器的库。可以轻松实现自动化测试、数据采集等功能
16、:使用 Node.js 和 Socket.io 实现的在线迷宫游戏。入口在左上角,出口在右下角。使用 [a][w][s][d] 键移动位置。支持多人和单人模式,点击“显示解法”显示迷宫的解法(由BFS算法实现)。在线玩
17、jizhi:Chrome/Firefox 的中国风新标签页插件。它将在带有经典诗歌的新标签页上以繁体中文色彩的层叠波浪动画为特色
18、star-history:一个在线工具,用于显示GitHub项目的Star历史。支持多个项目显示在同一张图表上,效果如下:
19、genal-chat:适合前端新手学习的“星空”聊天室项目。Vue+socket.io结合TypeScript语法构建,界面酷炫,代码规范,支持群聊和好友搜索等功能
蟒蛇项目
20、handcalcs:从简单的 Python 代码生成复杂公式的工具。还记得在编写论文计算算法时害怕被逐行公式支配的恐惧吗?这个库可以将Python写的公式以LaTeX格式显示出来,效果如下:
21、QuickCut:一款轻量级、易用的开源视频处理工具。是一款基于PyQt5开发的桌面工具,用于满足非专业用户的视频处理需求:视频压缩、视频转码、反向视频、合并剪辑、根据字幕剪切剪辑、自动匹配字幕、自动编辑、等等
22、altair:用于数据可视化的强大 Python 库。支持多种数据展示方式,界面简洁,效果炫酷。示例代码及效果如下:
import altair as alt
from vega_datasets import data
source = data.cars()
brush = alt.selection(type='interval')
points = alt.Chart(source).mark_point().encode(
x='Horsepower',
y='Miles_per_Gallon',
color=alt.condition(brush, 'Origin', alt.value('lightgray'))
).add_selection(
brush
)
bars = alt.Chart(source).mark_bar().encode(
y='Origin',
color='Origin',
x='count(Origin)'
).transform_filter(
brush
)
points & bars
23、butterfly:又一个轻量级的 Python web 框架。网络框架太多了。本项目主要是开发一个轻量级、可靠、可用的Web框架,以更深入地了解Web开发过程中经常被忽略(由框架制造)的重要知识点。那句话是怎么来的:再不做就看不懂了!架构图如下:
斯威夫特项目
24、lottie-ios:Airbnb的开源三方库,用于快速实现APP动画。它还支持Android、React Native、Web、Windows等平台。动画效果如下:
25、YLExtensions:解决了UITableView和UI采集View的注册和配置过程中不得不写大量重复代码的问题
其他
26、math-as-code:这是一个通过比较数学符号和 JavaScript 代码来帮助开发人员更容易理解数学符号的项目
27、PowerToys:微软开源Windows系统下的强大辅助工具。例如:窗口管理、批量图像处理、换键工具等。下图为屏幕选色工具
28、first-contributions:关于如何首次向 GitHub 贡献代码的分步教程。支持多国语言,中文
29、leek-fund:VSCode中查看实时股票和基金数据的插件
30、Algorithms-in-4-Steps:系统学习算法和数据结构的集合
开源书籍
31、BuildYourOwnLisp:本书教你用C实现自己的Lisp语言。用1000多行代码实现一个小巧但功能齐全的Lisp语言。有中文翻译版,不过还没完。点击阅读
机器学习
32、waifu2x:基于机器学习制作图片和照片高清。本项目使用卷积神经网络对图像进行1-2x无损放大操作,并支持降噪保证图像质量。在线尝试
33、Never-Blink:谁先眨眼,谁就输了。使用React + Flask + Dlib技术实现的《一闪而过》网游,虽然是demo级别的项目,但是在本地运行,找朋友一起玩还是很有趣的
34、cnn-convoluter:支持卷积过程交互式可视化的可视化工具
终于
如果你在 GitHub 上发现有趣的项目,请在评论中告诉我。
c#抓取网页数据(静态网页爬取的基本流程(一)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-04-11 03:02
内容
爬虫有两种,静态网页爬虫和动态网页爬虫。与动态网页爬虫相比,它非常简单。静态网页的爬取不需要执行JavaScript等代码,只需要获取页面Html代码并解析目标内容即可。也就是本文介绍了静态网页爬取的基本流程。
识别目标内容和目标站点
明确要求,比如这篇文章需要爬取北京过去一段时间的所有天气,先找一个合适的网站,比如在这个网站,可以找到站点北京的历史气象。
分析目标站点结构
在浏览器中打开北京历史天气站点后,无法直接获取天气,但是获取了很多超链接,包括指向不同时间段的天气链接。因此,需要解析这个页面来分析目标链接。
目标站点中的链接有两种类型,一种是目标链接,另一种是其他链接。接下来在浏览器中按F12查看网页源代码,查看目标链接的特征。这些特征可能是 Html 节点或 Html 属性。简而言之,你需要找到一个特征来区分目标链接和其他链接。
在Html代码中,可以看到链接的两个区别
网络访问
位于 System.Net 空间的 WebClient 可以轻松获取网页。主要代码如下
public static string GetHtml(string url)
{
string res = "";
WebClient client = new WebClient();
Stream stream = client.OpenRead(url);
StreamReader sr = new StreamReader(stream, Encoding.Default);
res = sr.ReadToEnd();
sr.Close();
client.Dispose();
return res;
}
网页节点分析
有一个著名的库 HtmlAgilityPack 可以帮助我们从字符串的网页的 html 代码生成 Dom 树,并让我们可以快速轻松地选择 Dom 树的节点,完成上一节的想法。VS打开工具->NuGet包管理器->管理解决方案的Nuget包,从这里可以搜索对应安装的HtmlAgilityPack包。使用该库时,需要导入 HtmlAgilityPack 命名空间。
using HtmlAgilityPack;
接下来,采用上一节的第二个思路,解析出目标链接。
public static List ParseLink(string html)
{
List res = new List();
var doc = new HtmlDocument();
doc.LoadHtml(html);
var linkNodes = doc.DocumentNode.SelectNodes("//a[@href]");
foreach (var linkNode in linkNodes)
{
string link = linkNode.GetAttributeValue("href", "");
if (link.StartsWith("/lishi/beijing/month"))
{
res.Add(link);
}
}
return res;
}
至此,收录过去时间段的站点的所有链接都已被解析。接下来,需要分析每个链接对应的具体网页的结构,从中获取天气信息。
分析天气网页结构
上一个链接是站点链接,具体天气网页对应的链接集合在上一节已经分析过了,例如。
现在我们需要从这个页面分析天气,就像解析站点结构中的目标链接一样,在浏览器中观察Html代码,发现天气的目标内容在一个表格中,所以我们只需要选择节点,因为节点表示给定日期的天气(天气条件、气温和风向)。
public static void ParseDailyWeather(string html)
{
var doc = new HtmlDocument();
doc.LoadHtml(html);
var rows = doc.DocumentNode.SelectNodes("//tr");
StringBuilder sb = new StringBuilder();
rows.RemoveAt(0);
foreach (var row in rows)
{
var cols = row.SelectNodes("td");
foreach (var col in cols)
{
string temp = col.InnerText.Replace("\r\n", "").Replace(" ", "").Trim();
sb.Append(temp + ",");
}
sb.Append("\r\n");
}
FileStream fs = new FileStream("output.csv", FileMode.Append, FileAccess.Write);
StreamWriter sw = new StreamWriter(fs, Encoding.GetEncoding("gbk"));
sw.WriteLine(sb);
sw.Close();
fs.Close();
}
最后,为了实现对网站的爬取,需要一个循环来实现对所有网页的爬取
public static void ParseWebsite(string url)
{
string html = Weather.GetHtml(url);
var links = Weather.ParseLink(html);
foreach (var link in links)
{
url = "http://www.tianqihoubao.com" + link;
html = Weather.GetHtml(url);
Weather.ParseDailyWeather(html);
}
}
总结
静态网页的爬取比较简单,可以分为以下几个步骤 查看全部
c#抓取网页数据(静态网页爬取的基本流程(一)(图))
内容
爬虫有两种,静态网页爬虫和动态网页爬虫。与动态网页爬虫相比,它非常简单。静态网页的爬取不需要执行JavaScript等代码,只需要获取页面Html代码并解析目标内容即可。也就是本文介绍了静态网页爬取的基本流程。
识别目标内容和目标站点
明确要求,比如这篇文章需要爬取北京过去一段时间的所有天气,先找一个合适的网站,比如在这个网站,可以找到站点北京的历史气象。
分析目标站点结构
在浏览器中打开北京历史天气站点后,无法直接获取天气,但是获取了很多超链接,包括指向不同时间段的天气链接。因此,需要解析这个页面来分析目标链接。
目标站点中的链接有两种类型,一种是目标链接,另一种是其他链接。接下来在浏览器中按F12查看网页源代码,查看目标链接的特征。这些特征可能是 Html 节点或 Html 属性。简而言之,你需要找到一个特征来区分目标链接和其他链接。
在Html代码中,可以看到链接的两个区别
网络访问
位于 System.Net 空间的 WebClient 可以轻松获取网页。主要代码如下
public static string GetHtml(string url)
{
string res = "";
WebClient client = new WebClient();
Stream stream = client.OpenRead(url);
StreamReader sr = new StreamReader(stream, Encoding.Default);
res = sr.ReadToEnd();
sr.Close();
client.Dispose();
return res;
}
网页节点分析
有一个著名的库 HtmlAgilityPack 可以帮助我们从字符串的网页的 html 代码生成 Dom 树,并让我们可以快速轻松地选择 Dom 树的节点,完成上一节的想法。VS打开工具->NuGet包管理器->管理解决方案的Nuget包,从这里可以搜索对应安装的HtmlAgilityPack包。使用该库时,需要导入 HtmlAgilityPack 命名空间。
using HtmlAgilityPack;
接下来,采用上一节的第二个思路,解析出目标链接。
public static List ParseLink(string html)
{
List res = new List();
var doc = new HtmlDocument();
doc.LoadHtml(html);
var linkNodes = doc.DocumentNode.SelectNodes("//a[@href]");
foreach (var linkNode in linkNodes)
{
string link = linkNode.GetAttributeValue("href", "");
if (link.StartsWith("/lishi/beijing/month"))
{
res.Add(link);
}
}
return res;
}
至此,收录过去时间段的站点的所有链接都已被解析。接下来,需要分析每个链接对应的具体网页的结构,从中获取天气信息。
分析天气网页结构
上一个链接是站点链接,具体天气网页对应的链接集合在上一节已经分析过了,例如。
现在我们需要从这个页面分析天气,就像解析站点结构中的目标链接一样,在浏览器中观察Html代码,发现天气的目标内容在一个表格中,所以我们只需要选择节点,因为节点表示给定日期的天气(天气条件、气温和风向)。
public static void ParseDailyWeather(string html)
{
var doc = new HtmlDocument();
doc.LoadHtml(html);
var rows = doc.DocumentNode.SelectNodes("//tr");
StringBuilder sb = new StringBuilder();
rows.RemoveAt(0);
foreach (var row in rows)
{
var cols = row.SelectNodes("td");
foreach (var col in cols)
{
string temp = col.InnerText.Replace("\r\n", "").Replace(" ", "").Trim();
sb.Append(temp + ",");
}
sb.Append("\r\n");
}
FileStream fs = new FileStream("output.csv", FileMode.Append, FileAccess.Write);
StreamWriter sw = new StreamWriter(fs, Encoding.GetEncoding("gbk"));
sw.WriteLine(sb);
sw.Close();
fs.Close();
}
最后,为了实现对网站的爬取,需要一个循环来实现对所有网页的爬取
public static void ParseWebsite(string url)
{
string html = Weather.GetHtml(url);
var links = Weather.ParseLink(html);
foreach (var link in links)
{
url = "http://www.tianqihoubao.com" + link;
html = Weather.GetHtml(url);
Weather.ParseDailyWeather(html);
}
}
总结
静态网页的爬取比较简单,可以分为以下几个步骤
c#抓取网页数据( 为什么要了解请求头(Requestheaders)信息?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-04-10 10:04
为什么要了解请求头(Requestheaders)信息?(图))
图1
如图1所示,在我们的工作过程中,无论是平台网站还是公司官网,总会有新闻展示。比如某天产品经理告诉我们,推广员想抢百度新闻的热点新闻版块,以提高网站的百度排名。要抢百度热点新闻版,首先要了解站点请求头(Request headers)信息。
为什么要了解请求标头(Request headers)信息?
原因在于,我们可以根据请求头信息中的某部分消息信息,而不是通过人工爬虫程序规避站点屏蔽,来伪装这是一个正常的HTTP请求,成功获取响应数据(Response data)。
如何查看百度新闻URL的请求头信息?
图 2
如图2,我们可以打开谷歌浏览器或者其他浏览器开发工具(按F12)查看站点的请求头消息信息。从图中可以看出百度新闻站点可以接受文本/html 等数据类型;语言为中文;浏览器版本为 Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 ( KHTML,如 Gecko ) Chrome/66.0.3359.181 Safari/537.36 等消息信息,我们在发起 HTTP 时直接携带消息信息request 过去,当然不是每一个包信息参数都必须携带过去,一部分可以被成功请求。
那么什么是响应数据?
图 3
如图3,响应数据(Response data)可以从谷歌Chrome或者其他浏览器开发工具中查看(按F12)查看,响应可以是json数据或者DOM树数据,方便我们的后续分析数据。
当然,你可以学习任何开发语言来开发爬虫程序:C#、NodeJs、Python、Java、C++。
不过这里主要讲C#爬虫程序的开发。微软为我们提供了HTTP请求的两个HttpWebRequest和HttpWebResponse对象,方便我们发送请求获取数据。下面显示了 C# HTTP 请求代码:
private string RequestAction(RequestOptions options)
{
string result = string.Empty;
IWebProxy proxy = GetProxy();
var request = (HttpWebRequest)WebRequest.Create(options.Uri);
request.Accept = options.Accept;
//在使用curl做POST的时候, 当要POST的数据大于1024字节的时候, curl并不会直接就发起POST请求, 而是会分为俩步,
//发送一个请求, 包含一个Expect: 100 -continue, 询问Server使用愿意接受数据
//接收到Server返回的100 - continue应答以后, 才把数据POST给Server
//并不是所有的Server都会正确应答100 -continue, 比如lighttpd, 就会返回417 “Expectation Failed”, 则会造成逻辑出错.
request.ServicePoint.Expect100Continue = false;
request.ServicePoint.UseNagleAlgorithm = false;//禁止Nagle算法加快载入速度
if (!string.IsNullOrEmpty(options.XHRParams)) { request.AllowWriteStreamBuffering = true; } else { request.AllowWriteStreamBuffering = false; }; //禁止缓冲加快载入速度
request.Headers.Add(HttpRequestHeader.AcceptEncoding, "gzip,deflate");//定义gzip压缩页面支持
request.ContentType = options.ContentType;//定义文档类型及编码
request.AllowAutoRedirect = options.AllowAutoRedirect;//禁止自动跳转
request.UserAgent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36";//设置User-Agent,伪装成Google Chrome浏览器
request.Timeout = options.Timeout;//定义请求超时时间为5秒
request.KeepAlive = options.KeepAlive;//启用长连接
if (!string.IsNullOrEmpty(options.Referer)) request.Referer = options.Referer;//返回上一级历史链接
request.Method = options.Method;//定义请求方式为GET
if (proxy != null) request.Proxy = proxy;//设置代理服务器IP,伪装请求地址
if (!string.IsNullOrEmpty(options.RequestCookies)) request.Headers[HttpRequestHeader.Cookie] = options.RequestCookies;
request.ServicePoint.ConnectionLimit = options.ConnectionLimit;//定义最大连接数
if (options.WebHeader != null && options.WebHeader.Count > 0) request.Headers.Add(options.WebHeader);//添加头部信息
if (!string.IsNullOrEmpty(options.XHRParams))//如果是POST请求,加入POST数据
{
byte[] buffer = Encoding.UTF8.GetBytes(options.XHRParams);
if (buffer != null)
{
request.ContentLength = buffer.Length;
request.GetRequestStream().Write(buffer, 0, buffer.Length);
}
}
using (var response = (HttpWebResponse)request.GetResponse())
{
////获取请求响应
//foreach (Cookie cookie in response.Cookies)
// options.CookiesContainer.Add(cookie);//将Cookie加入容器,保存登录状态
if (response.ContentEncoding.ToLower().Contains("gzip"))//解压
{
using (GZipStream stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadToEnd();
}
}
}
else if (response.ContentEncoding.ToLower().Contains("deflate"))//解压
{
using (DeflateStream stream = new DeflateStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadToEnd();
}
}
}
else
{
using (Stream stream = response.GetResponseStream())//原始
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadToEnd();
}
}
}
}
request.Abort();
return result;
}
还有一个我传入的自定义对象。当然,传入或传出对象由你根据实际业务需求定义:
public class RequestOptions
{
///
/// 请求方式,GET或POST
///
public string Method { get; set; }
///
/// URL
///
public Uri Uri { get; set; }
///
/// 上一级历史记录链接
///
public string Referer { get; set; }
///
/// 超时时间(毫秒)
///
public int Timeout = 15000;
///
/// 启用长连接
///
public bool KeepAlive = true;
///
/// 禁止自动跳转
///
public bool AllowAutoRedirect = false;
///
/// 定义最大连接数
///
public int ConnectionLimit = int.MaxValue;
///
/// 请求次数
///
public int RequestNum = 3;
///
/// 可通过文件上传提交的文件类型
///
public string Accept = "*/*";
///
/// 内容类型
///
public string ContentType = "application/x-www-form-urlencoded";
///
/// 实例化头部信息
///
private WebHeaderCollection header = new WebHeaderCollection();
///
/// 头部信息
///
public WebHeaderCollection WebHeader
{
get { return header; }
set { header = value; }
}
///
/// 定义请求Cookie字符串
///
public string RequestCookies { get; set; }
///
/// 异步参数数据
///
public string XHRParams { get; set; }
}
根据显示的代码,我们可以发现 HttpWebRequest 对象封装了很多 Request headers 消息参数。我们可以根据网站的Request headers信息在微软提供的HttpWebRequest对象中进行设置(见代码消息参数注释,都写了相关参数说明,如果理解有误请告知,谢谢你),然后发送请求获取响应数据来解析数据。
还补充一点,爬虫程序最好使用代理IP来使用代理IP,这样可以降低被屏蔽的概率,提高爬取效率。但是,代理IP也分为质量等级。对于某些 HTTPS 站点,可能需要质量级别更高的代理 IP 才能穿透。我不会在这里跑题。我会写一篇关于代理IP质量等级的文章文章详情说说我的看法。
C#代码如何使用代理IP?
Microsoft NET 框架还为我们提供了一个使用代理 IP 的 System.Net.WebProxy 对象。使用代码如下:
private System.Net.WebProxy GetProxy()
{
System.Net.WebProxy webProxy = null;
try
{
// 代理链接地址加端口
string proxyHost = "192.168.1.1";
string proxyPort = "9030";
// 代理身份验证的帐号跟密码
//string proxyUser = "xxx";
//string proxyPass = "xxx";
// 设置代理服务器
webProxy = new System.Net.WebProxy();
// 设置代理地址加端口
webProxy.Address = new Uri(string.Format("{0}:{1}", proxyHost, proxyPort));
// 如果只是设置代理IP加端口,例如192.168.1.1:80,这里直接注释该段代码,则不需要设置提交给代理服务器进行身份验证的帐号跟密码。
//webProxy.Credentials = new System.Net.NetworkCredential(proxyUser, proxyPass);
}
catch (Exception ex)
{
Console.WriteLine("获取代理信息异常", DateTime.Now.ToString(), ex.Message);
}
return webProxy;
}
关于System.Net.WebProxy对象的参数说明,我也在代码中进行了说明。
如果获取的Response数据是json、xml等格式的数据,这里就不详细描述这种数据解析方式了,请自行百度。这里的主要主题是 DOM 树 HTML 数据的解析。对于这类数据,有的人会使用正则表达式来解析,有的人会使用组件。当然,只要你能得到你想要的数据,你就可以按照你想要的方式解析它。这里的重点是我经常使用解析组件HtmlAgilityPack,参考DLL是(使用HtmlAgilityPack)。解析代码如下:
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(simpleCrawlResult.Contents);
HtmlNodeCollection liNodes = htmlDoc.DocumentNode.SelectSingleNode("//div[@id='pane-news']").SelectSingleNode("div[1]/ul[1]").SelectNodes("li");
if (liNodes != null && liNodes.Count > 0)
{
for (int i = 0; i < liNodes.Count; i++)
{
string title = liNodes[i].SelectSingleNode("strong[1]/a[1]").InnerText.Trim();
string href = liNodes[i].SelectSingleNode("strong[1]/a[1]").GetAttributeValue("href", "").Trim();
Console.WriteLine("新闻标题:" + title + ",链接:" + href);
}
}
下面主要展示爬取结果。
图 4
如图4,抓包效果,一个简单的爬虫程序就这样完成了。
至此,这篇关于c#实现爬虫程序的文章文章就介绍到这里了。希望对大家的学习有所帮助,也希望大家多多支持Scripting House。 查看全部
c#抓取网页数据(
为什么要了解请求头(Requestheaders)信息?(图))
图1
如图1所示,在我们的工作过程中,无论是平台网站还是公司官网,总会有新闻展示。比如某天产品经理告诉我们,推广员想抢百度新闻的热点新闻版块,以提高网站的百度排名。要抢百度热点新闻版,首先要了解站点请求头(Request headers)信息。
为什么要了解请求标头(Request headers)信息?
原因在于,我们可以根据请求头信息中的某部分消息信息,而不是通过人工爬虫程序规避站点屏蔽,来伪装这是一个正常的HTTP请求,成功获取响应数据(Response data)。
如何查看百度新闻URL的请求头信息?
图 2
如图2,我们可以打开谷歌浏览器或者其他浏览器开发工具(按F12)查看站点的请求头消息信息。从图中可以看出百度新闻站点可以接受文本/html 等数据类型;语言为中文;浏览器版本为 Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 ( KHTML,如 Gecko ) Chrome/66.0.3359.181 Safari/537.36 等消息信息,我们在发起 HTTP 时直接携带消息信息request 过去,当然不是每一个包信息参数都必须携带过去,一部分可以被成功请求。
那么什么是响应数据?
图 3
如图3,响应数据(Response data)可以从谷歌Chrome或者其他浏览器开发工具中查看(按F12)查看,响应可以是json数据或者DOM树数据,方便我们的后续分析数据。
当然,你可以学习任何开发语言来开发爬虫程序:C#、NodeJs、Python、Java、C++。
不过这里主要讲C#爬虫程序的开发。微软为我们提供了HTTP请求的两个HttpWebRequest和HttpWebResponse对象,方便我们发送请求获取数据。下面显示了 C# HTTP 请求代码:
private string RequestAction(RequestOptions options)
{
string result = string.Empty;
IWebProxy proxy = GetProxy();
var request = (HttpWebRequest)WebRequest.Create(options.Uri);
request.Accept = options.Accept;
//在使用curl做POST的时候, 当要POST的数据大于1024字节的时候, curl并不会直接就发起POST请求, 而是会分为俩步,
//发送一个请求, 包含一个Expect: 100 -continue, 询问Server使用愿意接受数据
//接收到Server返回的100 - continue应答以后, 才把数据POST给Server
//并不是所有的Server都会正确应答100 -continue, 比如lighttpd, 就会返回417 “Expectation Failed”, 则会造成逻辑出错.
request.ServicePoint.Expect100Continue = false;
request.ServicePoint.UseNagleAlgorithm = false;//禁止Nagle算法加快载入速度
if (!string.IsNullOrEmpty(options.XHRParams)) { request.AllowWriteStreamBuffering = true; } else { request.AllowWriteStreamBuffering = false; }; //禁止缓冲加快载入速度
request.Headers.Add(HttpRequestHeader.AcceptEncoding, "gzip,deflate");//定义gzip压缩页面支持
request.ContentType = options.ContentType;//定义文档类型及编码
request.AllowAutoRedirect = options.AllowAutoRedirect;//禁止自动跳转
request.UserAgent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36";//设置User-Agent,伪装成Google Chrome浏览器
request.Timeout = options.Timeout;//定义请求超时时间为5秒
request.KeepAlive = options.KeepAlive;//启用长连接
if (!string.IsNullOrEmpty(options.Referer)) request.Referer = options.Referer;//返回上一级历史链接
request.Method = options.Method;//定义请求方式为GET
if (proxy != null) request.Proxy = proxy;//设置代理服务器IP,伪装请求地址
if (!string.IsNullOrEmpty(options.RequestCookies)) request.Headers[HttpRequestHeader.Cookie] = options.RequestCookies;
request.ServicePoint.ConnectionLimit = options.ConnectionLimit;//定义最大连接数
if (options.WebHeader != null && options.WebHeader.Count > 0) request.Headers.Add(options.WebHeader);//添加头部信息
if (!string.IsNullOrEmpty(options.XHRParams))//如果是POST请求,加入POST数据
{
byte[] buffer = Encoding.UTF8.GetBytes(options.XHRParams);
if (buffer != null)
{
request.ContentLength = buffer.Length;
request.GetRequestStream().Write(buffer, 0, buffer.Length);
}
}
using (var response = (HttpWebResponse)request.GetResponse())
{
////获取请求响应
//foreach (Cookie cookie in response.Cookies)
// options.CookiesContainer.Add(cookie);//将Cookie加入容器,保存登录状态
if (response.ContentEncoding.ToLower().Contains("gzip"))//解压
{
using (GZipStream stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadToEnd();
}
}
}
else if (response.ContentEncoding.ToLower().Contains("deflate"))//解压
{
using (DeflateStream stream = new DeflateStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadToEnd();
}
}
}
else
{
using (Stream stream = response.GetResponseStream())//原始
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadToEnd();
}
}
}
}
request.Abort();
return result;
}
还有一个我传入的自定义对象。当然,传入或传出对象由你根据实际业务需求定义:
public class RequestOptions
{
///
/// 请求方式,GET或POST
///
public string Method { get; set; }
///
/// URL
///
public Uri Uri { get; set; }
///
/// 上一级历史记录链接
///
public string Referer { get; set; }
///
/// 超时时间(毫秒)
///
public int Timeout = 15000;
///
/// 启用长连接
///
public bool KeepAlive = true;
///
/// 禁止自动跳转
///
public bool AllowAutoRedirect = false;
///
/// 定义最大连接数
///
public int ConnectionLimit = int.MaxValue;
///
/// 请求次数
///
public int RequestNum = 3;
///
/// 可通过文件上传提交的文件类型
///
public string Accept = "*/*";
///
/// 内容类型
///
public string ContentType = "application/x-www-form-urlencoded";
///
/// 实例化头部信息
///
private WebHeaderCollection header = new WebHeaderCollection();
///
/// 头部信息
///
public WebHeaderCollection WebHeader
{
get { return header; }
set { header = value; }
}
///
/// 定义请求Cookie字符串
///
public string RequestCookies { get; set; }
///
/// 异步参数数据
///
public string XHRParams { get; set; }
}
根据显示的代码,我们可以发现 HttpWebRequest 对象封装了很多 Request headers 消息参数。我们可以根据网站的Request headers信息在微软提供的HttpWebRequest对象中进行设置(见代码消息参数注释,都写了相关参数说明,如果理解有误请告知,谢谢你),然后发送请求获取响应数据来解析数据。
还补充一点,爬虫程序最好使用代理IP来使用代理IP,这样可以降低被屏蔽的概率,提高爬取效率。但是,代理IP也分为质量等级。对于某些 HTTPS 站点,可能需要质量级别更高的代理 IP 才能穿透。我不会在这里跑题。我会写一篇关于代理IP质量等级的文章文章详情说说我的看法。
C#代码如何使用代理IP?
Microsoft NET 框架还为我们提供了一个使用代理 IP 的 System.Net.WebProxy 对象。使用代码如下:
private System.Net.WebProxy GetProxy()
{
System.Net.WebProxy webProxy = null;
try
{
// 代理链接地址加端口
string proxyHost = "192.168.1.1";
string proxyPort = "9030";
// 代理身份验证的帐号跟密码
//string proxyUser = "xxx";
//string proxyPass = "xxx";
// 设置代理服务器
webProxy = new System.Net.WebProxy();
// 设置代理地址加端口
webProxy.Address = new Uri(string.Format("{0}:{1}", proxyHost, proxyPort));
// 如果只是设置代理IP加端口,例如192.168.1.1:80,这里直接注释该段代码,则不需要设置提交给代理服务器进行身份验证的帐号跟密码。
//webProxy.Credentials = new System.Net.NetworkCredential(proxyUser, proxyPass);
}
catch (Exception ex)
{
Console.WriteLine("获取代理信息异常", DateTime.Now.ToString(), ex.Message);
}
return webProxy;
}
关于System.Net.WebProxy对象的参数说明,我也在代码中进行了说明。
如果获取的Response数据是json、xml等格式的数据,这里就不详细描述这种数据解析方式了,请自行百度。这里的主要主题是 DOM 树 HTML 数据的解析。对于这类数据,有的人会使用正则表达式来解析,有的人会使用组件。当然,只要你能得到你想要的数据,你就可以按照你想要的方式解析它。这里的重点是我经常使用解析组件HtmlAgilityPack,参考DLL是(使用HtmlAgilityPack)。解析代码如下:
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(simpleCrawlResult.Contents);
HtmlNodeCollection liNodes = htmlDoc.DocumentNode.SelectSingleNode("//div[@id='pane-news']").SelectSingleNode("div[1]/ul[1]").SelectNodes("li");
if (liNodes != null && liNodes.Count > 0)
{
for (int i = 0; i < liNodes.Count; i++)
{
string title = liNodes[i].SelectSingleNode("strong[1]/a[1]").InnerText.Trim();
string href = liNodes[i].SelectSingleNode("strong[1]/a[1]").GetAttributeValue("href", "").Trim();
Console.WriteLine("新闻标题:" + title + ",链接:" + href);
}
}
下面主要展示爬取结果。
图 4
如图4,抓包效果,一个简单的爬虫程序就这样完成了。
至此,这篇关于c#实现爬虫程序的文章文章就介绍到这里了。希望对大家的学习有所帮助,也希望大家多多支持Scripting House。
c#抓取网页数据(关于前端和网络基础知识,你需要知道的四件事)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-10 03:31
Html Agility Pack 和 AngleSharp 基本上可以认为是只爬静态网页,后者明确表示可以解析基本的 JS 但不能解析 Angular。前一个文档简单易读,有一些方法没有文档,而后一个文档很广泛。前者只有 200 多个提交,后者超过 6,000 个。贡献者和star数也是后者,后者由.net基金会支持。后者在各方面都优于前者。但是,现在 GitHub 的使用者可以看到,前者差不多 20000,而后者不到 3000。现在后者一直没有透露这个数据,我也不知道为什么。实际上,它们都只是在解析 HTML。如果你不明白这句话的意思,
然后添加一个我看到的:dotnetcore/DotnetSpider,这个项目是国产的,也支持Core和distributed。但这正在被重写,并且文档不是很好(几乎没有)。
对于动态网页,如果您不知道如何找到界面:
如果使用的是.NET Framework,可以使用System.Windows.Forms.WebBrowser.Document获取HtmlDocument,根据需要使用All或Body的HtmlElement的OuterHtml,或者根据需要传递给这两个框架。但是这个控件默认的内核是老的IE内核,对现代前端的标准支持不好。
如果是.NET Core,单机可以使用Selenium+PhantomJS。不过后者不再维护,新版的 Selenium 也不再支持 PhantomJS。您可以考虑切换到其他 HeadLess 浏览器,例如 CEF 或其他 WebDriver。
因为这个问题是关于框架的,所以我回答了上面的框架。对于爬虫的初学者,我这里写一点关于爬虫的基础知识:
您需要对前端和网络基础知识有所了解。实际上,爬虫本质上是向服务器请求数据。
如果是服务端渲染,下载HTML,使用解析HTML的框架提取需要的信息;如果是客户端渲染,可以在浏览器的f12中选择网络和XHR找到AJAX请求,手动发送即可。这很好。这就是 requests 和 bs4 所做的。
爬虫真正的难点是多线程/分布式,与反爬虫的斗争,以及数据的保存和清洗。这些与网络请求关系不大。这就是像scrapy这样的爬虫框架进来的地方。
如果你已经有前端和网络的基础知识,你会发现requests和bs4不用学习就已经知道了。 查看全部
c#抓取网页数据(关于前端和网络基础知识,你需要知道的四件事)
Html Agility Pack 和 AngleSharp 基本上可以认为是只爬静态网页,后者明确表示可以解析基本的 JS 但不能解析 Angular。前一个文档简单易读,有一些方法没有文档,而后一个文档很广泛。前者只有 200 多个提交,后者超过 6,000 个。贡献者和star数也是后者,后者由.net基金会支持。后者在各方面都优于前者。但是,现在 GitHub 的使用者可以看到,前者差不多 20000,而后者不到 3000。现在后者一直没有透露这个数据,我也不知道为什么。实际上,它们都只是在解析 HTML。如果你不明白这句话的意思,
然后添加一个我看到的:dotnetcore/DotnetSpider,这个项目是国产的,也支持Core和distributed。但这正在被重写,并且文档不是很好(几乎没有)。
对于动态网页,如果您不知道如何找到界面:
如果使用的是.NET Framework,可以使用System.Windows.Forms.WebBrowser.Document获取HtmlDocument,根据需要使用All或Body的HtmlElement的OuterHtml,或者根据需要传递给这两个框架。但是这个控件默认的内核是老的IE内核,对现代前端的标准支持不好。
如果是.NET Core,单机可以使用Selenium+PhantomJS。不过后者不再维护,新版的 Selenium 也不再支持 PhantomJS。您可以考虑切换到其他 HeadLess 浏览器,例如 CEF 或其他 WebDriver。
因为这个问题是关于框架的,所以我回答了上面的框架。对于爬虫的初学者,我这里写一点关于爬虫的基础知识:
您需要对前端和网络基础知识有所了解。实际上,爬虫本质上是向服务器请求数据。
如果是服务端渲染,下载HTML,使用解析HTML的框架提取需要的信息;如果是客户端渲染,可以在浏览器的f12中选择网络和XHR找到AJAX请求,手动发送即可。这很好。这就是 requests 和 bs4 所做的。
爬虫真正的难点是多线程/分布式,与反爬虫的斗争,以及数据的保存和清洗。这些与网络请求关系不大。这就是像scrapy这样的爬虫框架进来的地方。
如果你已经有前端和网络的基础知识,你会发现requests和bs4不用学习就已经知道了。
c#抓取网页数据( 具体分析如下实例分析C#操作图片的相关技巧(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-10 01:02
具体分析如下实例分析C#操作图片的相关技巧(图))
C#方法抓取当前屏幕并保存为图片
更新时间:2015-04-17 12:36:23 作者:work24
本篇文章主要介绍了C#抓取当前屏幕并保存为图片的方法,并结合实例分析了C#操作图片的相关技巧,非常实用。有需要的朋友可以参考以下
本文示例介绍了C#抓取当前屏幕并保存为图片的方法。分享给大家,供大家参考。具体分析如下:
这是一个C#实现的截屏程序,可以截取整个屏幕并保存为指定格式的图片,并将当前控制台缓存保存为文本
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Diagnostics;
using System.Drawing;
using System.Drawing.Imaging;
using System.IO;
using System.Runtime.InteropServices;
using System.Text;
using System.Threading;
using System.Windows.Forms;
namespace RobvanderWoude
{
class PrintScreen
{
static int Main( string[] args )
{
try
{
string output = string.Empty;
bool overwrite = false;
bool text = false;
ImageFormat type = null;
#region Command Line parsing
if ( args.Length == 0 )
{
return WriteError( );
}
foreach ( string arg in args )
{
switch ( arg.ToUpper( ).Substring( 0, 2 ) )
{
case "/?":
return WriteError( );
case "/O":
overwrite = true;
break;
case "/T":
if ( text )
{
return WriteError( "Cannot capture current window as bitmap" );
}
switch ( arg.ToUpper( ).Substring( 3 ) )
{
case "BMP":
type = ImageFormat.Bmp;
break;
case "GIF":
type = ImageFormat.Gif;
break;
case "JPG":
case "JPEG":
type = ImageFormat.Jpeg;
break;
case "PNG":
type = ImageFormat.Png;
break;
case "TIF":
case "TIFF":
type = ImageFormat.Tiff;
break;
case "TXT":
text = true;
break;
default:
return WriteError( "Invalid file format: \"" + arg.Substring( 4 ) + "\"" );
}
break;
default:
output = arg;
break;
}
}
// Check if directory exists
if ( !Directory.Exists( Path.GetDirectoryName( output ) ) )
{
return WriteError( "Invalid path for output file: \"" + output + "\"" );
}
// Check if file exists, and if so, if it can be overwritten
if ( File.Exists( output ) )
{
if ( overwrite )
{
File.Delete( output );
}
else
{
return WriteError( "File exists; use /O to overwrite existing files." );
}
}
if ( type == null && text == false )
{
string ext = Path.GetExtension( output ).ToUpper( );
switch ( ext )
{
case ".BMP":
type = ImageFormat.Bmp;
break;
case ".GIF":
type = ImageFormat.Gif;
break;
case ".JPG":
case ".JPEG":
type = ImageFormat.Jpeg;
break;
case ".PNG":
type = ImageFormat.Png;
break;
case ".TIF":
case ".TIFF":
type = ImageFormat.Tiff;
break;
case ".TXT":
text = true;
break;
default:
return WriteError( "Invalid file type: \"" + ext + "\"" );
return 1;
}
}
#endregion Command Line parsing
if ( text )
{
string readtext = string.Empty;
for ( short i = 0; i < (short) Console.BufferHeight; i++ )
{
foreach ( string line in ConsoleReader.ReadFromBuffer( 0, i, (short) Console.BufferWidth, 1 ) )
{
readtext += line + "\n";
}
}
StreamWriter file = new StreamWriter( output );
file.Write( readtext );
file.Close( );
}
else
{
int width = Screen.PrimaryScreen.Bounds.Width;
int height = Screen.PrimaryScreen.Bounds.Height;
int top = 0;
int left = 0;
Bitmap printscreen = new Bitmap( width, height );
Graphics graphics = Graphics.FromImage( printscreen as Image );
graphics.CopyFromScreen( top, left, 0, 0, printscreen.Size );
printscreen.Save( output, type );
}
return 0;
}
catch ( Exception e )
{
Console.Error.WriteLine( e.Message );
return 1;
}
}
#region Error Handling
public static int WriteError( string errorMessage = "" )
{
Console.ResetColor( );
if ( string.IsNullOrEmpty( errorMessage ) == false )
{
Console.Error.WriteLine( );
Console.ForegroundColor = ConsoleColor.Red;
Console.Error.Write( "ERROR: " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.WriteLine( errorMessage );
Console.ResetColor( );
}
Console.Error.WriteLine( );
Console.Error.WriteLine( "PrintScreen, Version 1.10" );
Console.Error.WriteLine( "Save a screenshot as image or save the current console buffer as text" );
Console.Error.WriteLine( );
Console.Error.Write( "Usage: " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.WriteLine( "PRINTSCREEN outputfile [ /T:type ] [ /O ]" );
Console.ResetColor( );
Console.Error.WriteLine( );
Console.Error.Write( "Where: " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "outputfile" );
Console.ResetColor( );
Console.Error.WriteLine( " is the file to save the screenshot or text to" );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( " /T:type" );
Console.ResetColor( );
Console.Error.Write( " specifies the file type: " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "BMP" );
Console.ResetColor( );
Console.Error.Write( ", " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "GIF" );
Console.ResetColor( );
Console.Error.Write( ", " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "JPG" );
Console.ResetColor( );
Console.Error.Write( ", " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "PNG" );
Console.ResetColor( );
Console.Error.Write( ", " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "TIF" );
Console.ResetColor( );
Console.Error.Write( " or " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.WriteLine( "TXT" );
Console.ResetColor( );
Console.Error.Write( " (only required if " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "outputfile" );
Console.ResetColor( );
Console.Error.WriteLine( " extension is different)" );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( " /O" );
Console.ResetColor( );
Console.Error.WriteLine( " overwrites an existing file" );
Console.Error.WriteLine( );
Console.Error.Write( "Credits: Code to read console buffer by Simon Mourier " );
Console.ForegroundColor = ConsoleColor.DarkGray;
Console.Error.WriteLine( "http://www.sina.com.cn" );
Console.ResetColor( );
Console.Error.Write( " Code for graphic screenshot by Ali Hamdar " );
Console.ForegroundColor = ConsoleColor.DarkGray;
Console.Error.WriteLine( "https://www.jb51.net" );
Console.ResetColor( );
Console.Error.WriteLine( );
Console.Error.WriteLine( "Written by Rob van der Woude" );
Console.Error.WriteLine( "http://www.qq.com" );
return 1;
}
#endregion Error Handling
}
#region Read From Console Buffer
public class ConsoleReader
{
public static IEnumerable ReadFromBuffer( short x, short y, short width, short height )
{
IntPtr buffer = Marshal.AllocHGlobal( width * height * Marshal.SizeOf( typeof( CHAR_INFO ) ) );
if ( buffer == null )
throw new OutOfMemoryException( );
try
{
COORD coord = new COORD( );
SMALL_RECT rc = new SMALL_RECT( );
rc.Left = x;
rc.Top = y;
rc.Right = (short) ( x + width - 1 );
rc.Bottom = (short) ( y + height - 1 );
COORD size = new COORD( );
size.X = width;
size.Y = height;
const int STD_OUTPUT_HANDLE = -11;
if ( !ReadConsoleOutput( GetStdHandle( STD_OUTPUT_HANDLE ), buffer, size, coord, ref rc ) )
{
// 'Not enough storage is available to process this command' may be raised for buffer size > 64K (see ReadConsoleOutput doc.)
throw new Win32Exception( Marshal.GetLastWin32Error( ) );
}
IntPtr ptr = buffer;
for ( int h = 0; h < height; h++ )
{
StringBuilder sb = new StringBuilder( );
for ( int w = 0; w < width; w++ )
{
CHAR_INFO ci = (CHAR_INFO) Marshal.PtrToStructure( ptr, typeof( CHAR_INFO ) );
char[] chars = Console.OutputEncoding.GetChars( ci.charData );
sb.Append( chars[0] );
ptr += Marshal.SizeOf( typeof( CHAR_INFO ) );
}
yield return sb.ToString( );
}
}
finally
{
Marshal.FreeHGlobal( buffer );
}
}
[StructLayout( LayoutKind.Sequential )]
private struct CHAR_INFO
{
[MarshalAs( UnmanagedType.ByValArray, SizeConst = 2 )]
public byte[] charData;
public short attributes;
}
[StructLayout( LayoutKind.Sequential )]
private struct COORD
{
public short X;
public short Y;
}
[StructLayout( LayoutKind.Sequential )]
private struct SMALL_RECT
{
public short Left;
public short Top;
public short Right;
public short Bottom;
}
[StructLayout( LayoutKind.Sequential )]
private struct CONSOLE_SCREEN_BUFFER_INFO
{
public COORD dwSize;
public COORD dwCursorPosition;
public short wAttributes;
public SMALL_RECT srWindow;
public COORD dwMaximumWindowSize;
}
[DllImport( "kernel32.dll", SetLastError = true )]
private static extern bool ReadConsoleOutput( IntPtr hConsoleOutput, IntPtr lpBuffer, COORD dwBufferSize, COORD dwBufferCoord, ref SMALL_RECT lpReadRegion );
[DllImport( "kernel32.dll", SetLastError = true )]
private static extern IntPtr GetStdHandle( int nStdHandle );
}
#endregion Read From Console Buffer
}
我希望这篇文章对你的 C# 编程有所帮助。 查看全部
c#抓取网页数据(
具体分析如下实例分析C#操作图片的相关技巧(图))
C#方法抓取当前屏幕并保存为图片
更新时间:2015-04-17 12:36:23 作者:work24
本篇文章主要介绍了C#抓取当前屏幕并保存为图片的方法,并结合实例分析了C#操作图片的相关技巧,非常实用。有需要的朋友可以参考以下
本文示例介绍了C#抓取当前屏幕并保存为图片的方法。分享给大家,供大家参考。具体分析如下:
这是一个C#实现的截屏程序,可以截取整个屏幕并保存为指定格式的图片,并将当前控制台缓存保存为文本
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Diagnostics;
using System.Drawing;
using System.Drawing.Imaging;
using System.IO;
using System.Runtime.InteropServices;
using System.Text;
using System.Threading;
using System.Windows.Forms;
namespace RobvanderWoude
{
class PrintScreen
{
static int Main( string[] args )
{
try
{
string output = string.Empty;
bool overwrite = false;
bool text = false;
ImageFormat type = null;
#region Command Line parsing
if ( args.Length == 0 )
{
return WriteError( );
}
foreach ( string arg in args )
{
switch ( arg.ToUpper( ).Substring( 0, 2 ) )
{
case "/?":
return WriteError( );
case "/O":
overwrite = true;
break;
case "/T":
if ( text )
{
return WriteError( "Cannot capture current window as bitmap" );
}
switch ( arg.ToUpper( ).Substring( 3 ) )
{
case "BMP":
type = ImageFormat.Bmp;
break;
case "GIF":
type = ImageFormat.Gif;
break;
case "JPG":
case "JPEG":
type = ImageFormat.Jpeg;
break;
case "PNG":
type = ImageFormat.Png;
break;
case "TIF":
case "TIFF":
type = ImageFormat.Tiff;
break;
case "TXT":
text = true;
break;
default:
return WriteError( "Invalid file format: \"" + arg.Substring( 4 ) + "\"" );
}
break;
default:
output = arg;
break;
}
}
// Check if directory exists
if ( !Directory.Exists( Path.GetDirectoryName( output ) ) )
{
return WriteError( "Invalid path for output file: \"" + output + "\"" );
}
// Check if file exists, and if so, if it can be overwritten
if ( File.Exists( output ) )
{
if ( overwrite )
{
File.Delete( output );
}
else
{
return WriteError( "File exists; use /O to overwrite existing files." );
}
}
if ( type == null && text == false )
{
string ext = Path.GetExtension( output ).ToUpper( );
switch ( ext )
{
case ".BMP":
type = ImageFormat.Bmp;
break;
case ".GIF":
type = ImageFormat.Gif;
break;
case ".JPG":
case ".JPEG":
type = ImageFormat.Jpeg;
break;
case ".PNG":
type = ImageFormat.Png;
break;
case ".TIF":
case ".TIFF":
type = ImageFormat.Tiff;
break;
case ".TXT":
text = true;
break;
default:
return WriteError( "Invalid file type: \"" + ext + "\"" );
return 1;
}
}
#endregion Command Line parsing
if ( text )
{
string readtext = string.Empty;
for ( short i = 0; i < (short) Console.BufferHeight; i++ )
{
foreach ( string line in ConsoleReader.ReadFromBuffer( 0, i, (short) Console.BufferWidth, 1 ) )
{
readtext += line + "\n";
}
}
StreamWriter file = new StreamWriter( output );
file.Write( readtext );
file.Close( );
}
else
{
int width = Screen.PrimaryScreen.Bounds.Width;
int height = Screen.PrimaryScreen.Bounds.Height;
int top = 0;
int left = 0;
Bitmap printscreen = new Bitmap( width, height );
Graphics graphics = Graphics.FromImage( printscreen as Image );
graphics.CopyFromScreen( top, left, 0, 0, printscreen.Size );
printscreen.Save( output, type );
}
return 0;
}
catch ( Exception e )
{
Console.Error.WriteLine( e.Message );
return 1;
}
}
#region Error Handling
public static int WriteError( string errorMessage = "" )
{
Console.ResetColor( );
if ( string.IsNullOrEmpty( errorMessage ) == false )
{
Console.Error.WriteLine( );
Console.ForegroundColor = ConsoleColor.Red;
Console.Error.Write( "ERROR: " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.WriteLine( errorMessage );
Console.ResetColor( );
}
Console.Error.WriteLine( );
Console.Error.WriteLine( "PrintScreen, Version 1.10" );
Console.Error.WriteLine( "Save a screenshot as image or save the current console buffer as text" );
Console.Error.WriteLine( );
Console.Error.Write( "Usage: " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.WriteLine( "PRINTSCREEN outputfile [ /T:type ] [ /O ]" );
Console.ResetColor( );
Console.Error.WriteLine( );
Console.Error.Write( "Where: " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "outputfile" );
Console.ResetColor( );
Console.Error.WriteLine( " is the file to save the screenshot or text to" );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( " /T:type" );
Console.ResetColor( );
Console.Error.Write( " specifies the file type: " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "BMP" );
Console.ResetColor( );
Console.Error.Write( ", " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "GIF" );
Console.ResetColor( );
Console.Error.Write( ", " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "JPG" );
Console.ResetColor( );
Console.Error.Write( ", " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "PNG" );
Console.ResetColor( );
Console.Error.Write( ", " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "TIF" );
Console.ResetColor( );
Console.Error.Write( " or " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.WriteLine( "TXT" );
Console.ResetColor( );
Console.Error.Write( " (only required if " );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( "outputfile" );
Console.ResetColor( );
Console.Error.WriteLine( " extension is different)" );
Console.ForegroundColor = ConsoleColor.White;
Console.Error.Write( " /O" );
Console.ResetColor( );
Console.Error.WriteLine( " overwrites an existing file" );
Console.Error.WriteLine( );
Console.Error.Write( "Credits: Code to read console buffer by Simon Mourier " );
Console.ForegroundColor = ConsoleColor.DarkGray;
Console.Error.WriteLine( "http://www.sina.com.cn" );
Console.ResetColor( );
Console.Error.Write( " Code for graphic screenshot by Ali Hamdar " );
Console.ForegroundColor = ConsoleColor.DarkGray;
Console.Error.WriteLine( "https://www.jb51.net" );
Console.ResetColor( );
Console.Error.WriteLine( );
Console.Error.WriteLine( "Written by Rob van der Woude" );
Console.Error.WriteLine( "http://www.qq.com" );
return 1;
}
#endregion Error Handling
}
#region Read From Console Buffer
public class ConsoleReader
{
public static IEnumerable ReadFromBuffer( short x, short y, short width, short height )
{
IntPtr buffer = Marshal.AllocHGlobal( width * height * Marshal.SizeOf( typeof( CHAR_INFO ) ) );
if ( buffer == null )
throw new OutOfMemoryException( );
try
{
COORD coord = new COORD( );
SMALL_RECT rc = new SMALL_RECT( );
rc.Left = x;
rc.Top = y;
rc.Right = (short) ( x + width - 1 );
rc.Bottom = (short) ( y + height - 1 );
COORD size = new COORD( );
size.X = width;
size.Y = height;
const int STD_OUTPUT_HANDLE = -11;
if ( !ReadConsoleOutput( GetStdHandle( STD_OUTPUT_HANDLE ), buffer, size, coord, ref rc ) )
{
// 'Not enough storage is available to process this command' may be raised for buffer size > 64K (see ReadConsoleOutput doc.)
throw new Win32Exception( Marshal.GetLastWin32Error( ) );
}
IntPtr ptr = buffer;
for ( int h = 0; h < height; h++ )
{
StringBuilder sb = new StringBuilder( );
for ( int w = 0; w < width; w++ )
{
CHAR_INFO ci = (CHAR_INFO) Marshal.PtrToStructure( ptr, typeof( CHAR_INFO ) );
char[] chars = Console.OutputEncoding.GetChars( ci.charData );
sb.Append( chars[0] );
ptr += Marshal.SizeOf( typeof( CHAR_INFO ) );
}
yield return sb.ToString( );
}
}
finally
{
Marshal.FreeHGlobal( buffer );
}
}
[StructLayout( LayoutKind.Sequential )]
private struct CHAR_INFO
{
[MarshalAs( UnmanagedType.ByValArray, SizeConst = 2 )]
public byte[] charData;
public short attributes;
}
[StructLayout( LayoutKind.Sequential )]
private struct COORD
{
public short X;
public short Y;
}
[StructLayout( LayoutKind.Sequential )]
private struct SMALL_RECT
{
public short Left;
public short Top;
public short Right;
public short Bottom;
}
[StructLayout( LayoutKind.Sequential )]
private struct CONSOLE_SCREEN_BUFFER_INFO
{
public COORD dwSize;
public COORD dwCursorPosition;
public short wAttributes;
public SMALL_RECT srWindow;
public COORD dwMaximumWindowSize;
}
[DllImport( "kernel32.dll", SetLastError = true )]
private static extern bool ReadConsoleOutput( IntPtr hConsoleOutput, IntPtr lpBuffer, COORD dwBufferSize, COORD dwBufferCoord, ref SMALL_RECT lpReadRegion );
[DllImport( "kernel32.dll", SetLastError = true )]
private static extern IntPtr GetStdHandle( int nStdHandle );
}
#endregion Read From Console Buffer
}
我希望这篇文章对你的 C# 编程有所帮助。
c#抓取网页数据(网页分析采集程序的基本流程和流程图详解 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2022-04-09 11:02
)
首先需要明确:网站的任何页面,无论是php、jsp、aspx等动态页面还是后台程序生成的静态页面,都可以在浏览器。
所以当你想开发一个data采集程序时,你首先要了解你要采集的网站的首页结构(HTML)。
一旦熟悉了 网站 中的 HTML 源文件的内容,其中数据是 采集,程序的其余部分就很容易了。因为C#在网站上执行数据采集,原理是“下载你想要的页面的HTML源文件到采集,分析HTML代码然后抓取你需要的数据,最后保存数据。到本地文件”。
基本流程如下图所示:
1.页面源文件下载
首先引用 System.Net 命名空间
使用 System.Net;
还需要引用
使用 System.Text;
使用 System.IO;
复制代码
引用后实例化一个 WebClient 对象
私人 WebClientwc = new WebClient();
调用DownloadData方法从指定网页的源文件中下载一组BYTE数据,然后将BYTE数组转换为字符串。
// 下载页面源文件并转换为UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData( string .Format("你要的网页地址采集")));
复制代码
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
// 下载网页源文件到本地
wc.DownloadFile("你要访问的网页的URL采集", "保存源文件的本地文件路径");
// 读取下载源文件的HTML格式字符串
string mainData = File.ReadAllText("保存源文件的本地文件路径",Encoding.UTF8);
复制代码
使用网页 HTML 格式字符串,您可以分析 采集 网页并抓取您需要的内容。
2.页面分析采集
页面分析就是用网页源文件中的一个特定的或唯一的字符(字符串)作为一个抓取点,从这个抓取点开始截取你想要的页面上的数据。
以博客园为栏目为例,如果我想要采集博客园首页列出的文章的标题和链接,我必须以"开头
代码:
// 经过”
mainData = mainData.Substring(mainData.IndexOf( " " ) + 26 );
// 获取文章页面的链接地址
字符串 articleAddr = mainData.Substring( 0 ,mainData.IndexOf( " \" " ));
// 获取 文章 标题
字符串文章标题 = mainData.Substring(mainData.IndexOf( " target=\"_blank\"> " ) + 16 ,
mainData.IndexOf( " " ) - mainData.IndexOf( " target=\"_blank\"> " ) - 16 );
复制代码
注意:当你要采集的网页首页的HTML格式发生变化时,作为抓取点的字符也要相应的改变,否则采集什么都得不到
3.数据存储
从网页中截取需要的数据后,将程序中的数据组织起来,保存到本地文件中(或者插入到自己的本地数据库中)。这样,整个采集的工作就会在一个段落中完成。
// 输出数据到本地文件
File.AppendAllText(CreateFolderIfNot(Settings.Default.OutPath) + articleTitle + ".txt" ,
文章数据,
编码.UTF8);
复制代码
另外附上我自己写的采集博客园主页文章的小程序代码。该程序的作用是将博客园主页上的文章采集全部发布下来。
下载地址:CnBlogCollector.rar
当然,如果博客园首页的格式调整了,程序的采集功能肯定会失效,而继续采集的唯一办法就是重新调整程序自己一个人,呵呵。. .
程序效果如下:
查看全部
c#抓取网页数据(网页分析采集程序的基本流程和流程图详解
)
首先需要明确:网站的任何页面,无论是php、jsp、aspx等动态页面还是后台程序生成的静态页面,都可以在浏览器。
所以当你想开发一个data采集程序时,你首先要了解你要采集的网站的首页结构(HTML)。
一旦熟悉了 网站 中的 HTML 源文件的内容,其中数据是 采集,程序的其余部分就很容易了。因为C#在网站上执行数据采集,原理是“下载你想要的页面的HTML源文件到采集,分析HTML代码然后抓取你需要的数据,最后保存数据。到本地文件”。
基本流程如下图所示:
1.页面源文件下载
首先引用 System.Net 命名空间
使用 System.Net;
还需要引用
使用 System.Text;
使用 System.IO;
复制代码
引用后实例化一个 WebClient 对象
私人 WebClientwc = new WebClient();
调用DownloadData方法从指定网页的源文件中下载一组BYTE数据,然后将BYTE数组转换为字符串。
// 下载页面源文件并转换为UTF8编码格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData( string .Format("你要的网页地址采集")));
复制代码
或者也可以调用DownloadFile方法,先将源文件下载到本地再读取其字符串
// 下载网页源文件到本地
wc.DownloadFile("你要访问的网页的URL采集", "保存源文件的本地文件路径");
// 读取下载源文件的HTML格式字符串
string mainData = File.ReadAllText("保存源文件的本地文件路径",Encoding.UTF8);
复制代码
使用网页 HTML 格式字符串,您可以分析 采集 网页并抓取您需要的内容。
2.页面分析采集
页面分析就是用网页源文件中的一个特定的或唯一的字符(字符串)作为一个抓取点,从这个抓取点开始截取你想要的页面上的数据。
以博客园为栏目为例,如果我想要采集博客园首页列出的文章的标题和链接,我必须以"开头
代码:
// 经过”
mainData = mainData.Substring(mainData.IndexOf( " " ) + 26 );
// 获取文章页面的链接地址
字符串 articleAddr = mainData.Substring( 0 ,mainData.IndexOf( " \" " ));
// 获取 文章 标题
字符串文章标题 = mainData.Substring(mainData.IndexOf( " target=\"_blank\"> " ) + 16 ,
mainData.IndexOf( " " ) - mainData.IndexOf( " target=\"_blank\"> " ) - 16 );
复制代码
注意:当你要采集的网页首页的HTML格式发生变化时,作为抓取点的字符也要相应的改变,否则采集什么都得不到
3.数据存储
从网页中截取需要的数据后,将程序中的数据组织起来,保存到本地文件中(或者插入到自己的本地数据库中)。这样,整个采集的工作就会在一个段落中完成。
// 输出数据到本地文件
File.AppendAllText(CreateFolderIfNot(Settings.Default.OutPath) + articleTitle + ".txt" ,
文章数据,
编码.UTF8);
复制代码
另外附上我自己写的采集博客园主页文章的小程序代码。该程序的作用是将博客园主页上的文章采集全部发布下来。
下载地址:CnBlogCollector.rar
当然,如果博客园首页的格式调整了,程序的采集功能肯定会失效,而继续采集的唯一办法就是重新调整程序自己一个人,呵呵。. .
程序效果如下:
c#抓取网页数据(利用C#和.NET提供的类来轻松创建一个的程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-04-08 06:04
本文使用 C# 和 .NET 提供的类,轻松创建抓取网页内容源代码的程序。HTTP 是在 WWW 上进行数据访问的最基本协议之一。.NET的基本类型库类中提供了两个对象类:HTTPWebRequest和HTTPWebResponse,分别用于向资源发送请求和获取响应。为了获取一个资源的内容,我们首先指定一个我们要抓取的URL地址,使用HTTPWebRequest对象发出请求,使用HTTPWebResponse对象接收响应的结果,最后使用TextStream对象提取我们想要的信息并在控制台打印出来。
下面看一下如何实现这样的功能:
(1)打开VS.NET,点击“文件”-“新建”-“项目”,项目类型选择“Visual C#项目”,模板选择“Windows应用程序”,
(2)Form1中添加Label1、Button1、TextBox1、TextBox2四个控件,将TextBox2的Multiline属性改为True,
(3)右击Form1表单,选择“查看代码”,然后在顶部输入:
使用 System.IO;
使用 System.Net;
使用 System.Text;
私人无效按钮1_Click(对象发送者,System.EventArgs e)
{
}
在括号内输入以下代码:
字节[] buf = 新字节[38192];
HttpWebRequest 请求 = (HttpWebRequest)
WebRequest.Create(textBox1.Text);
HttpWebResponse 响应 = (HttpWebResponse)
请求.GetResponse();
流 resStream = response.GetResponseStream();
int count = resStream.Read(buf, 0, buf.Length);
textBox2.Text = Encoding.Default.GetString(buf, 0,
数数);
resStream.Close();
(4)all”按钮,按“F5”运行应用程序,在“请输入URL地址:”后的单行文本框中输入,点击“获取HTML代码”按钮,即可看到地址的代码!
接下来,我们将对上述程序做一个分析:
上述程序的作用是抓取网页内容,并在多行文本框中显示 HTML 代码。由于返回的数据是字节类型的,我们创建一个字节类型的数组变量,名为 buf 来存储请求返回的结果,其中数组的大小与我们要请求返回的数据的大小有关。
首先,我们实例化 HttpWebRequest 对象,并使用 WebRequest 类的静态方法 Create()。该方法的字符串参数是我们要请求的页面的URL地址。由于Create()方法返回的是WebRequest类型,所以我们必须将Model(即类型转换)转换为HttpWebRequest类型,然后赋值给request变量。一旦我们创建了 HttpWebRequest 对象,我们就可以使用它的 GetResponse() 方法返回一个 WebResponse 对象,然后将其转换为一个 HttpWebResponse 对象并将其分配给响应变量。
现在,可以使用响应对象的GetResponseStream()方法获取响应的文本流,最后使用Stream对象的Read()方法将返回的响应信息放入我们最初创建的字节数组buf中。Read()有3个参数,分别是:要放置的字节数组,字节数组的起始位置,字节数组的长度。
最后,将字节转换为字符串。注意:这里使用的是默认编码,它使用默认的编码方式,所以我们不再需要在字符编码之间进行转换。您还可以使用 WebRequest 和 WebResponse 来实现上述功能。代码如下:
WebRequest 请求 = WebRequest.Create(textBox1.Text);
WebResponse 响应 =request.GetResponse();
输入另一个网址,看看是不是很方便!
本文来自:象屿阁-IT天堂(),转载请保留此信息! 查看全部
c#抓取网页数据(利用C#和.NET提供的类来轻松创建一个的程序)
本文使用 C# 和 .NET 提供的类,轻松创建抓取网页内容源代码的程序。HTTP 是在 WWW 上进行数据访问的最基本协议之一。.NET的基本类型库类中提供了两个对象类:HTTPWebRequest和HTTPWebResponse,分别用于向资源发送请求和获取响应。为了获取一个资源的内容,我们首先指定一个我们要抓取的URL地址,使用HTTPWebRequest对象发出请求,使用HTTPWebResponse对象接收响应的结果,最后使用TextStream对象提取我们想要的信息并在控制台打印出来。
下面看一下如何实现这样的功能:
(1)打开VS.NET,点击“文件”-“新建”-“项目”,项目类型选择“Visual C#项目”,模板选择“Windows应用程序”,
(2)Form1中添加Label1、Button1、TextBox1、TextBox2四个控件,将TextBox2的Multiline属性改为True,
(3)右击Form1表单,选择“查看代码”,然后在顶部输入:
使用 System.IO;
使用 System.Net;
使用 System.Text;
私人无效按钮1_Click(对象发送者,System.EventArgs e)
{
}
在括号内输入以下代码:
字节[] buf = 新字节[38192];
HttpWebRequest 请求 = (HttpWebRequest)
WebRequest.Create(textBox1.Text);
HttpWebResponse 响应 = (HttpWebResponse)
请求.GetResponse();
流 resStream = response.GetResponseStream();
int count = resStream.Read(buf, 0, buf.Length);
textBox2.Text = Encoding.Default.GetString(buf, 0,
数数);
resStream.Close();
(4)all”按钮,按“F5”运行应用程序,在“请输入URL地址:”后的单行文本框中输入,点击“获取HTML代码”按钮,即可看到地址的代码!
接下来,我们将对上述程序做一个分析:
上述程序的作用是抓取网页内容,并在多行文本框中显示 HTML 代码。由于返回的数据是字节类型的,我们创建一个字节类型的数组变量,名为 buf 来存储请求返回的结果,其中数组的大小与我们要请求返回的数据的大小有关。
首先,我们实例化 HttpWebRequest 对象,并使用 WebRequest 类的静态方法 Create()。该方法的字符串参数是我们要请求的页面的URL地址。由于Create()方法返回的是WebRequest类型,所以我们必须将Model(即类型转换)转换为HttpWebRequest类型,然后赋值给request变量。一旦我们创建了 HttpWebRequest 对象,我们就可以使用它的 GetResponse() 方法返回一个 WebResponse 对象,然后将其转换为一个 HttpWebResponse 对象并将其分配给响应变量。
现在,可以使用响应对象的GetResponseStream()方法获取响应的文本流,最后使用Stream对象的Read()方法将返回的响应信息放入我们最初创建的字节数组buf中。Read()有3个参数,分别是:要放置的字节数组,字节数组的起始位置,字节数组的长度。
最后,将字节转换为字符串。注意:这里使用的是默认编码,它使用默认的编码方式,所以我们不再需要在字符编码之间进行转换。您还可以使用 WebRequest 和 WebResponse 来实现上述功能。代码如下:
WebRequest 请求 = WebRequest.Create(textBox1.Text);
WebResponse 响应 =request.GetResponse();
输入另一个网址,看看是不是很方便!
本文来自:象屿阁-IT天堂(),转载请保留此信息!
c#抓取网页数据(微软公司支持Python语言的自动化工具介绍及项目实战项目介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-04-07 00:13
)
工具介绍
Playwright 是微软公司开发的一款非常强大的开源自动化测试工具。它之所以强大,原因如下:
1. 支持所有主流浏览器:Chrome、Firefox、Safari、MS Edge。
2. 支持无头和有头模式。
3. 提供可与 Pytest 结合使用的同步和异步 API。
4. 支持在浏览器端自动录制脚本。
5. Python 语言的自动化工具。
6. 支持的操作系统有 Linux、Mac OS 和 Windows。
7.可以使用docker安装运行环境。
安装环境
1.安装Python,Playwright需要3.7及以上Python,所以至少Python3.7或以上(最好3.7,我试过3.@ >8 存在兼容性问题)。
2.去下载项目代码,主要是local_requirements.txt。
3. 使用 pip3 install playwright==1.8.0a1(最好在此处指定版本)。
4. 使用 pip3 install -r local_requirements.txt 安装所有依赖项。
5. 使用python3 -m playwright install 安装浏览器驱动模块(使用清华镜像)。
这里在命令窗口运行:pip3 -v config list 查看系统中的pip.ini文件,下面是我的。
[全局]
index-url=
#index-url=
#[安装]
#trusted-host=
这里需要把阿里云注释掉,最好白天或者早上安装这个,会更快。其他时候用阿里云的镜像会更快。
6. 检查是否安装成功。如果看到如下界面,则说明安装成功。
脚本录制
Playwright 的脚本录制需要使用命令 codegen。下面详细解释该命令的用法:
该命令需要的参数如下:
o 或 --output 指定保存脚本的文件路径和文件名。
target指定生成脚本的语言:Python、JavaScript、C#等
b指定用于录制的浏览器:如:-b chromium(Chrome浏览器)、-b firefox、-b webkit。
项目实战
项目:在线商店
1、脚本录制
python3 -m playwright codegen -o 'login_b2c.py' --target python -b chromium :8080/b2c/index.html
以上是命令执行后进入的界面。当鼠标在元素上滑动时,会自动提示元素的xpath,并启动隐身浏览模式,便于与本地浏览的页面区分开来。
点击登录链接,会弹出如下图:
输入必要的信息以登录。
登录成功,返回首页,注意红框,这里是断言目标。
关闭浏览器,输出脚本文件:这里可以看到我们的脚本文件就是命令中指定的文件名,右边是脚本文件代码,这里使用的是同步方式。源码如下:
从剧作家导入sync_playwright
def run(剧作家):
浏览器 = playwright.chromium.launch(headless=False)
上下文 = browser.newContext()
#打开新页面
page = context.newPage()
# 转到:8080/b2c/index.html
page.goto(":8080/b2c/index.html")
# 点击文字=/.*登录.*/
page.click("text=/.*login.*/")
# assert page.url == ":8080/b2c/login.html"
#点击输入[name="username"]
page.click("input[name=\"username\"]")
# 填写输入[name="username"]
page.fill("input[name=\"username\"]", "tester")
#按回车
page.press("input[name=\"username\"]", "Enter")
#点击输入[name="password"]
page.click("input[name=\"password\"]")
# 填写输入[name="password"]
page.fill("input[name=\"password\"]", "123456")
#点击输入[name="validcode"]
page.click("input[name=\"validcode\"]")
# 填写输入[name="validcode"]
page.fill("input[name=\"validcode\"]", "1111")
#点击输入[type="button"]
# with page.expect_navigation(url=":8080/b2c/index.html"):
使用 page.expect_navigation():
page.click("input[type=\"button\"]")
page.close()
# ---------
context.close()
browser.close()
以sync_playwright() 为编剧:
运行(剧作家)
在这个录制的脚本中发现了以下问题:
1)Playwright开始搭建浏览器,这里使用chromium,然后使用浏览器实例化一个context对象context,再通过context实例化一个page对象,也就是使用context.newPage()可以实例化多个页面,并且页面之间不共享会话和 cookie。
2)页面可以通过定位器来定位页面上的各种元素,所以要想用好Playwright,就必须好好研究一下页面对象。
3)缺点是 Playwright 在录制过程中不提供断言。虽然有很多内置的断言方法,但只能手动编写。
4)需要参数化。好在Playwright集成了pytest功能,我们要好好利用一下。
2. 集成pytest和Playwright
经过研究,发现Playwright不具备参数化自身的能力。如果要参数化,仍然需要编写代码来赋值。在这里,考虑与 pytest 结合使用。使用pytest的参数化和fixture可以充分实现参数化和关联的效果。
代码说明:
#coding=utf-8
从 playwright.sync_api 导入页面
导入 pytest
#这里构造测试用例需要的数据,第一个是用户名,第二个是密码,第三个是预期结果
data=[['tester','123456','Hello: tester'],['tester1','123456','Hello: tester1'],['tester2','1234567',' 账号错误密码']]
# 使用 pytest.mark.parametrize 导入用户数据
@pytest.mark.parametrize('userdata',data)
#测试函数的第一个参数是指playwright提供的Page,是一个fixture,需要安装
#pytest-playwright
def test_login(page:Page,userdata):
page.goto(":8080/b2c/index.html")
# 点击文字=/.*登录.*/
page.click("text=/.*login.*/")
# assert page.url == ":8080/b2c/login.html"
#点击输入[name="username"]
page.click("input[name=\"username\"]")
# 填写输入[name="username"]
# page.fill("input[name=\"username\"]", "tester")
page.fill("input[name=\"username\"]", userdata[0])
#按回车
page.press("input[name=\"username\"]", "Enter")
#点击输入[name="password"]
page.click("input[name=\"password\"]")
# 填写输入[name="password"]
page.fill("input[name=\"password\"]", userdata[1])
#点击输入[name="validcode"]
page.click("input[name=\"validcode\"]")
# 填写输入[name="validcode"]
page.fill("input[name=\"validcode\"]", "1111")
#点击输入[type="button"]
#因为页面需要转换,这里需要主动等待1秒。这个wait_for_timeout的单位是毫秒
page.wait_for_timeout(1000)
page.click("input[type=\"button\"]")
#页面刷新很慢,这里我设置了3秒等待
page.wait_for_timeout(3000)
# 断言,这里为了简单起见使用了 in 方法。 playwright提供了很多assert断言方法
#你可以阅读官方文档:
在 page.content() 中断言 userdata[2]
#关闭页面
page.close()
如果 __name__ == '__main__':
#使用pytest.main运行测试,--headful是带接口运行,删除,就是无头模式
#这里可以看出playwright的head表示启动浏览器,headless模式表示浏览器没有运行
pytest.main(['-v','login_b2c.py','--headful'])
试运行结果:
/Library/Frameworks/Python.framework/Versions/3.7/bin/python3.7 /Users/huminghai/dev/py_pro/demo/login_b2c.py
========================测试会话开始==================== =
平台 darwin -- Python 3.7.1, pytest-6.1.0, py-1.10.0, 插件-0.13.1 -- /Library/Frameworks/Python.framework/Versions/3.7/bin/python3.7
缓存目录:.pytest_cache
rootdir: /Users/huminghai/dev/py_pro/demo
插件:base-url-1.4.2,sugar-0.9.4,flaky-3.7.0,xdist -2.1.0, cov-2.10.1, asyncio-0.14.0, 编剧-0. 0.11,超时-1.4.2,分叉-1.3.0
正在采集...采集了 3 件物品
login_b2c.py::test_login[chromium-userdata0] 通过 [33%]
login_b2c.py::test_login[chromium-userdata1] 通过 [66%]
login_b2c.py::test_login[chromium-userdata2] 通过 [100%]
========================= 3传入41.42s ============= = ======
进程以退出代码 0 结束
总结
Playwright-python的优势非常突出,在脚本录制上非常方便,元素捕捉非常准确,比webdriver好。最重要的是playwright-python和pytest真的可以为所欲为。
pytest 提供了报表模块和各种有用的插件,而 Playwright-python 提供了界面元素的精确定位和抓取。两者的结合让 UI 自动化测试的未来更加光明。
另外,不要相信Playwright-python所谓的无编码自动化。这是不太可能的。毕竟,无论你如何记录脚本,参数化、关联和断言三件套总是必不可少的。因此,学习 Python 是唯一的方法。良好自动化测试的基础。
请关注+私信回复:“测试”,即可免费获得软件测试学习资料,同时进入群学习交流~~
查看全部
c#抓取网页数据(微软公司支持Python语言的自动化工具介绍及项目实战项目介绍
)
工具介绍
Playwright 是微软公司开发的一款非常强大的开源自动化测试工具。它之所以强大,原因如下:
1. 支持所有主流浏览器:Chrome、Firefox、Safari、MS Edge。
2. 支持无头和有头模式。
3. 提供可与 Pytest 结合使用的同步和异步 API。
4. 支持在浏览器端自动录制脚本。
5. Python 语言的自动化工具。
6. 支持的操作系统有 Linux、Mac OS 和 Windows。
7.可以使用docker安装运行环境。
安装环境
1.安装Python,Playwright需要3.7及以上Python,所以至少Python3.7或以上(最好3.7,我试过3.@ >8 存在兼容性问题)。
2.去下载项目代码,主要是local_requirements.txt。
3. 使用 pip3 install playwright==1.8.0a1(最好在此处指定版本)。
4. 使用 pip3 install -r local_requirements.txt 安装所有依赖项。
5. 使用python3 -m playwright install 安装浏览器驱动模块(使用清华镜像)。
这里在命令窗口运行:pip3 -v config list 查看系统中的pip.ini文件,下面是我的。
[全局]
index-url=
#index-url=
#[安装]
#trusted-host=
这里需要把阿里云注释掉,最好白天或者早上安装这个,会更快。其他时候用阿里云的镜像会更快。
6. 检查是否安装成功。如果看到如下界面,则说明安装成功。
脚本录制
Playwright 的脚本录制需要使用命令 codegen。下面详细解释该命令的用法:
该命令需要的参数如下:
o 或 --output 指定保存脚本的文件路径和文件名。
target指定生成脚本的语言:Python、JavaScript、C#等
b指定用于录制的浏览器:如:-b chromium(Chrome浏览器)、-b firefox、-b webkit。
项目实战
项目:在线商店
1、脚本录制
python3 -m playwright codegen -o 'login_b2c.py' --target python -b chromium :8080/b2c/index.html
以上是命令执行后进入的界面。当鼠标在元素上滑动时,会自动提示元素的xpath,并启动隐身浏览模式,便于与本地浏览的页面区分开来。
点击登录链接,会弹出如下图:
输入必要的信息以登录。
登录成功,返回首页,注意红框,这里是断言目标。
关闭浏览器,输出脚本文件:这里可以看到我们的脚本文件就是命令中指定的文件名,右边是脚本文件代码,这里使用的是同步方式。源码如下:
从剧作家导入sync_playwright
def run(剧作家):
浏览器 = playwright.chromium.launch(headless=False)
上下文 = browser.newContext()
#打开新页面
page = context.newPage()
# 转到:8080/b2c/index.html
page.goto(":8080/b2c/index.html")
# 点击文字=/.*登录.*/
page.click("text=/.*login.*/")
# assert page.url == ":8080/b2c/login.html"
#点击输入[name="username"]
page.click("input[name=\"username\"]")
# 填写输入[name="username"]
page.fill("input[name=\"username\"]", "tester")
#按回车
page.press("input[name=\"username\"]", "Enter")
#点击输入[name="password"]
page.click("input[name=\"password\"]")
# 填写输入[name="password"]
page.fill("input[name=\"password\"]", "123456")
#点击输入[name="validcode"]
page.click("input[name=\"validcode\"]")
# 填写输入[name="validcode"]
page.fill("input[name=\"validcode\"]", "1111")
#点击输入[type="button"]
# with page.expect_navigation(url=":8080/b2c/index.html"):
使用 page.expect_navigation():
page.click("input[type=\"button\"]")
page.close()
# ---------
context.close()
browser.close()
以sync_playwright() 为编剧:
运行(剧作家)
在这个录制的脚本中发现了以下问题:
1)Playwright开始搭建浏览器,这里使用chromium,然后使用浏览器实例化一个context对象context,再通过context实例化一个page对象,也就是使用context.newPage()可以实例化多个页面,并且页面之间不共享会话和 cookie。
2)页面可以通过定位器来定位页面上的各种元素,所以要想用好Playwright,就必须好好研究一下页面对象。
3)缺点是 Playwright 在录制过程中不提供断言。虽然有很多内置的断言方法,但只能手动编写。
4)需要参数化。好在Playwright集成了pytest功能,我们要好好利用一下。
2. 集成pytest和Playwright
经过研究,发现Playwright不具备参数化自身的能力。如果要参数化,仍然需要编写代码来赋值。在这里,考虑与 pytest 结合使用。使用pytest的参数化和fixture可以充分实现参数化和关联的效果。
代码说明:
#coding=utf-8
从 playwright.sync_api 导入页面
导入 pytest
#这里构造测试用例需要的数据,第一个是用户名,第二个是密码,第三个是预期结果
data=[['tester','123456','Hello: tester'],['tester1','123456','Hello: tester1'],['tester2','1234567',' 账号错误密码']]
# 使用 pytest.mark.parametrize 导入用户数据
@pytest.mark.parametrize('userdata',data)
#测试函数的第一个参数是指playwright提供的Page,是一个fixture,需要安装
#pytest-playwright
def test_login(page:Page,userdata):
page.goto(":8080/b2c/index.html")
# 点击文字=/.*登录.*/
page.click("text=/.*login.*/")
# assert page.url == ":8080/b2c/login.html"
#点击输入[name="username"]
page.click("input[name=\"username\"]")
# 填写输入[name="username"]
# page.fill("input[name=\"username\"]", "tester")
page.fill("input[name=\"username\"]", userdata[0])
#按回车
page.press("input[name=\"username\"]", "Enter")
#点击输入[name="password"]
page.click("input[name=\"password\"]")
# 填写输入[name="password"]
page.fill("input[name=\"password\"]", userdata[1])
#点击输入[name="validcode"]
page.click("input[name=\"validcode\"]")
# 填写输入[name="validcode"]
page.fill("input[name=\"validcode\"]", "1111")
#点击输入[type="button"]
#因为页面需要转换,这里需要主动等待1秒。这个wait_for_timeout的单位是毫秒
page.wait_for_timeout(1000)
page.click("input[type=\"button\"]")
#页面刷新很慢,这里我设置了3秒等待
page.wait_for_timeout(3000)
# 断言,这里为了简单起见使用了 in 方法。 playwright提供了很多assert断言方法
#你可以阅读官方文档:
在 page.content() 中断言 userdata[2]
#关闭页面
page.close()
如果 __name__ == '__main__':
#使用pytest.main运行测试,--headful是带接口运行,删除,就是无头模式
#这里可以看出playwright的head表示启动浏览器,headless模式表示浏览器没有运行
pytest.main(['-v','login_b2c.py','--headful'])
试运行结果:
/Library/Frameworks/Python.framework/Versions/3.7/bin/python3.7 /Users/huminghai/dev/py_pro/demo/login_b2c.py
========================测试会话开始==================== =
平台 darwin -- Python 3.7.1, pytest-6.1.0, py-1.10.0, 插件-0.13.1 -- /Library/Frameworks/Python.framework/Versions/3.7/bin/python3.7
缓存目录:.pytest_cache
rootdir: /Users/huminghai/dev/py_pro/demo
插件:base-url-1.4.2,sugar-0.9.4,flaky-3.7.0,xdist -2.1.0, cov-2.10.1, asyncio-0.14.0, 编剧-0. 0.11,超时-1.4.2,分叉-1.3.0
正在采集...采集了 3 件物品
login_b2c.py::test_login[chromium-userdata0] 通过 [33%]
login_b2c.py::test_login[chromium-userdata1] 通过 [66%]
login_b2c.py::test_login[chromium-userdata2] 通过 [100%]
========================= 3传入41.42s ============= = ======
进程以退出代码 0 结束
总结
Playwright-python的优势非常突出,在脚本录制上非常方便,元素捕捉非常准确,比webdriver好。最重要的是playwright-python和pytest真的可以为所欲为。
pytest 提供了报表模块和各种有用的插件,而 Playwright-python 提供了界面元素的精确定位和抓取。两者的结合让 UI 自动化测试的未来更加光明。
另外,不要相信Playwright-python所谓的无编码自动化。这是不太可能的。毕竟,无论你如何记录脚本,参数化、关联和断言三件套总是必不可少的。因此,学习 Python 是唯一的方法。良好自动化测试的基础。
请关注+私信回复:“测试”,即可免费获得软件测试学习资料,同时进入群学习交流~~
c#抓取网页数据( 为什么要了解百度新闻中热点要闻版块提高站点百度排名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-06 19:10
为什么要了解百度新闻中热点要闻版块提高站点百度排名)
图1
如图1所示,在我们的工作过程中,无论是平台网站还是公司官网,总会有新闻展示。比如某天产品经理告诉我们,推广员想抢百度新闻的热点新闻版块,以提高网站的百度排名。要抢百度热点新闻版,首先要了解站点请求头(Request headers)信息。
为什么要了解请求标头(Request headers)信息?
原因在于,我们可以根据请求头信息中的某部分消息信息,而不是通过人工爬虫程序规避站点屏蔽,来伪装这是一个正常的HTTP请求,成功获取响应数据(Response data)。
如何查看百度新闻URL的请求头信息?
图 2
如图2,我们可以打开谷歌浏览器或者其他浏览器开发工具(按F12)查看站点的请求头消息信息。从图中可以看出百度新闻站点可以接受文本/html 等数据类型;语言为中文;浏览器版本为 Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 ( KHTML,如 Gecko ) Chrome/66.0.3359.181 Safari/537.36 等消息信息,我们在发起 HTTP 时直接携带消息信息request 过去,当然不是每一个包信息参数都必须携带过去,一部分可以被成功请求。
那么什么是响应数据?
图 3
如图3所示,响应数据(Response data)可以从谷歌浏览器或者其他浏览器开发工具中查看(按F12)查看,响应可以是数据或者DOM树数据,方便我们的后续分析数据。
当然,你可以学习任何开发语言来开发爬虫程序:C#、NodeJs、python、java、C++。
不过这里主要讲C#爬虫程序的开发。微软为我们提供了HTTP请求的两个HttpWebRequest和HttpWebResponse对象,方便我们发送请求获取数据。下面显示了 C# HTTP 请求代码:
private string RequestAction(RequestOptions options)
{
string result = string.Empty;
IWebProxy proxy = GetProxy();
var request = (HttpWebRequest)WebRequest.Create(options.Uri);
request.Accept = options编程客栈.Accept;
//在使用curl做POST的时候, 当要POST的数据大于1024字节的时候, curl并不会直接就发起POST请求, 而是会分为俩步,
//发送一个请求, 包含一个Expect: 100 -continue, 询问Server使用愿意接受数据
//接收到Server返回的100 - continue应答以后, 才把数据POST给Server
//并不是所有的Server都会正确应答100 -continue, 比如lighttpd, 就会返回417 “Expectation Failed”, 则会造成逻辑出错.
request.ServicePoint.Expect100Continue = false;
request.ServicePoint.UseNagleAlgorithm = false;//禁止Nagle算法加快载入速度
if (!string.IsNullOrEmpty(options.XHRParams)) { request.AllowWriteStreamBuffering = true; } else { request.AllowWriteStreamBuffering = false; }; //禁止缓冲加快载入速度
request.Headers.Add(HttpRequestHeader.AcceptEncoding, "gzip,deflate");//定义gzip压缩页面支持
request.ContentType = options.ContentType;//定义文档类型及编码
request.AllowAutoRedirect = options.AllowAutoRedirect;//禁止自动跳转
request.UserAgent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebhttp://www.cppcns.comKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36";//设置User-Agent,伪装成Google Chrome浏览器
request.Timeout = options.Timeout;//定义请求超时时间为5秒
request.KeepAlive = options.KeepAlive;//启用长连接
if (!string.IsNullOrEmpty(options.Referer)) request.Referer = options.Referer;//返回上一级历史链接
request.Method = options.Method;//定义请求方式为GET
if (proxy != null) request.Proxy = proxy;//设置代理服务器IP,伪装请求地址
if (!string.IsNullOrEmpty(options.RequestCookies)) request.Headers[HttpRequestHeader.Cookie] = options.RequestCookies;
request.ServicePoint.ConnectionLimit = options.ConnectionLimit;//定义最大连接数
if (options.WebHeader != null && options.WebHeader.Count > 0) request.Headers.Add(options.WebHeader);//添加头部信息
if (!string.IsNullOrEmpty(options.XHRParams))//如果是POST请求,加入POST数据
{
byte[] buffer = Encoding.UTF8.GetBytes(options.XHRParams);
if (buffer != null)
{
request.ContentLength = buffer.Length;
request.GetRequestStream().Write(buffer, 0, buffer.Length);
}
}
using (var response = (HttpWebResponse)request.GetResponse())
{
////获取请求响应
//foreach (Cookie cookie in response.Cookies)
// options.CookiesContainer.Add(cookie);//将Cookie加入容器,保存登录状态
if (response.ContentEncoding.ToLower().Contains("gzip"))//解压
{
using (GZipStream stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadToEnd();
}
}
}
else if (response.ContentEncoding.ToLower().Contains("deflate"))//解压
{
using (DeflateStream stream = new DeflateStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadToEnd();
}
}
}
else
{
using (Stream stream = response.GetResponseStream())//原始
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadT编程客栈oEnd();
}
}
}
}
request.Abort();
return result;
}
还有一个我传入的自定义对象。当然,传入或传出对象由你根据实际业务需求定义:
public class RequestOptions
{
///
/// 请求方式,GET或POST
///
public string Method { get; set; }
///
/// URL
///
public Uri Uri { get; set; }
///
/// 上一级历史记录链接
///
public string Referer { get; set; }
///
/// 超时时间(毫秒)
///
public int Timeout = 15000;
///
/// 启用长连接
///
public bool KeepAlive = true;
///
/// 禁止自动跳转
///
public bool AllowAutoRedirect = false;
/// &http://www.cppcns.comlt;summary>
/// 定义最大连接数
///
public int ConnectionLimit = int.MaxValue;
//编程客栈/
/// 请求次数
///
public int RequestNum = 3;
///
/// 可通过文件上传提交的文件类型
///
public string Accept = "*/*";
///
/// 内容类型
///
public string ContentType = "application/x-www-form-urlencoded";
///
/// 实例化头部信息
///
private WebHeaderCollection header = new WebHeaderCollection();
///
/// 头部信息
///
public WebHeaderCollection WebHeader
{
get { return header; }
set { header = value; }
}
///
/// 定义请求Cookie字符串
///
public string RequestCookies { get; set; }
///
/// 异步参数数据
///
public string XHRParams { get; set; }
}
根据显示的代码,我们可以发现 HttpWebRequest 对象封装了很多 Request headers 消息参数。我们可以根据网站的Request headers信息在微软提供的HttpWebRequest对象中设置(见代码消息参数注释,都写了相关参数说明,如果理解有误,请告知,谢谢你),然后发送请求获取响应数据来解析数据。
还补充一点,爬虫程序最好使用代理IP来使用代理IP,这样可以降低被屏蔽的概率,提高爬取效率。但是,代理IP也分为质量等级。对于某些 HTTPS 站点,可能需要质量级别更高的代理 IP 才能穿透。我不会在这里跑题。我会写一篇关于代理IP质量等级的文章文章详情说说我的看法。
C#代码如何使用代理IP?
Microsoft NET 框架还为我们提供了一个使用代理 IP 的 System.Net.WebProxy 对象。使用代码如下:
private System.Net.WebProxy GetProxy()
{
System.Net.WebProxy webProxy = null;
try
{
// 代理链接地址加端口
string proxyHost = "192.168.1.1";
string proxyPort = "9030";
// 代理身份验证的帐号跟密码
//string proxyUser = "xxx";
//string proxyPass = "xxx";
// 设置代理服务器
webProxy = new System.Net.WebProxy();
// 设置代理地址加端口
webProxy.Address = new Uri(string.Format("{0}:{1}", proxyHost, proxyPort));
// 如果只是设置代理IP加端口,例如192.168.1.1:80,这里直接注释该段代码,则不需要设置提交给代理服务器进行身份验证的帐号跟密码。
//webProxy.Credentials = new System.Net.NetworkCredential(proxyUser, proxyPass);
}
catch (Exception ex)
{
Console.WriteLine("获取代理信息异常", DateTime.Now.ToString(), ex.Message);
}
return webProxy;
}
关于System.Net.WebProxy对象的参数说明,我也在代码中进行了说明。
如果获取的Response数据是json、xml等格式的数据,这里就不详细描述这种数据解析方式了,请自行百度。这里的主要主题是 DOM 树 HTML 数据的解析。对于这类数据,有的人会使用正则表达式来解析,有的人会使用组件。当然,只要你能得到你想要的数据,你就可以按照你想要的方式解析它。这里的重点是我经常使用解析组件HtmlAgilityPack,参考DLL是(使用HtmlAgilityPack)。解析代码如下:
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(simpleCrawlResult.Contents);
HtmlNodeCollection liNodes = htmlDoc.DocumentNode.SelectSingleNode("//div[@id='pane-news']").SelectSingleNode("div[1]/ul[1]").SelectNodes("li");
if (liNodes != null && liNodes.Count > 0)
{
for (int i = 0; i < liNodes.Count; i++)
{
string title = liNodes[i].SelectSingleNode("strong[1]/a[1]").InnerText.Trim();
string href = liNodes[i].SelectSingleNode("strong[1]/a[1]").GetAttributeValue("href", "").Trim();
Console.WriteLine("新闻标题:" + title + ",链接:" + href);
}
}
下面主要展示爬取结果。
图 4
如图4,抓包效果,一个简单的爬虫程序就这样完成了。
至此,这篇关于c#实现爬虫程序的文章文章就介绍到这里了。希望对您的学习有所帮助,也希望您多多支持。
本文标题:c#实现爬虫程序 查看全部
c#抓取网页数据(
为什么要了解百度新闻中热点要闻版块提高站点百度排名)
图1
如图1所示,在我们的工作过程中,无论是平台网站还是公司官网,总会有新闻展示。比如某天产品经理告诉我们,推广员想抢百度新闻的热点新闻版块,以提高网站的百度排名。要抢百度热点新闻版,首先要了解站点请求头(Request headers)信息。
为什么要了解请求标头(Request headers)信息?
原因在于,我们可以根据请求头信息中的某部分消息信息,而不是通过人工爬虫程序规避站点屏蔽,来伪装这是一个正常的HTTP请求,成功获取响应数据(Response data)。
如何查看百度新闻URL的请求头信息?
图 2
如图2,我们可以打开谷歌浏览器或者其他浏览器开发工具(按F12)查看站点的请求头消息信息。从图中可以看出百度新闻站点可以接受文本/html 等数据类型;语言为中文;浏览器版本为 Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 ( KHTML,如 Gecko ) Chrome/66.0.3359.181 Safari/537.36 等消息信息,我们在发起 HTTP 时直接携带消息信息request 过去,当然不是每一个包信息参数都必须携带过去,一部分可以被成功请求。
那么什么是响应数据?
图 3
如图3所示,响应数据(Response data)可以从谷歌浏览器或者其他浏览器开发工具中查看(按F12)查看,响应可以是数据或者DOM树数据,方便我们的后续分析数据。
当然,你可以学习任何开发语言来开发爬虫程序:C#、NodeJs、python、java、C++。
不过这里主要讲C#爬虫程序的开发。微软为我们提供了HTTP请求的两个HttpWebRequest和HttpWebResponse对象,方便我们发送请求获取数据。下面显示了 C# HTTP 请求代码:
private string RequestAction(RequestOptions options)
{
string result = string.Empty;
IWebProxy proxy = GetProxy();
var request = (HttpWebRequest)WebRequest.Create(options.Uri);
request.Accept = options编程客栈.Accept;
//在使用curl做POST的时候, 当要POST的数据大于1024字节的时候, curl并不会直接就发起POST请求, 而是会分为俩步,
//发送一个请求, 包含一个Expect: 100 -continue, 询问Server使用愿意接受数据
//接收到Server返回的100 - continue应答以后, 才把数据POST给Server
//并不是所有的Server都会正确应答100 -continue, 比如lighttpd, 就会返回417 “Expectation Failed”, 则会造成逻辑出错.
request.ServicePoint.Expect100Continue = false;
request.ServicePoint.UseNagleAlgorithm = false;//禁止Nagle算法加快载入速度
if (!string.IsNullOrEmpty(options.XHRParams)) { request.AllowWriteStreamBuffering = true; } else { request.AllowWriteStreamBuffering = false; }; //禁止缓冲加快载入速度
request.Headers.Add(HttpRequestHeader.AcceptEncoding, "gzip,deflate");//定义gzip压缩页面支持
request.ContentType = options.ContentType;//定义文档类型及编码
request.AllowAutoRedirect = options.AllowAutoRedirect;//禁止自动跳转
request.UserAgent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebhttp://www.cppcns.comKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36";//设置User-Agent,伪装成Google Chrome浏览器
request.Timeout = options.Timeout;//定义请求超时时间为5秒
request.KeepAlive = options.KeepAlive;//启用长连接
if (!string.IsNullOrEmpty(options.Referer)) request.Referer = options.Referer;//返回上一级历史链接
request.Method = options.Method;//定义请求方式为GET
if (proxy != null) request.Proxy = proxy;//设置代理服务器IP,伪装请求地址
if (!string.IsNullOrEmpty(options.RequestCookies)) request.Headers[HttpRequestHeader.Cookie] = options.RequestCookies;
request.ServicePoint.ConnectionLimit = options.ConnectionLimit;//定义最大连接数
if (options.WebHeader != null && options.WebHeader.Count > 0) request.Headers.Add(options.WebHeader);//添加头部信息
if (!string.IsNullOrEmpty(options.XHRParams))//如果是POST请求,加入POST数据
{
byte[] buffer = Encoding.UTF8.GetBytes(options.XHRParams);
if (buffer != null)
{
request.ContentLength = buffer.Length;
request.GetRequestStream().Write(buffer, 0, buffer.Length);
}
}
using (var response = (HttpWebResponse)request.GetResponse())
{
////获取请求响应
//foreach (Cookie cookie in response.Cookies)
// options.CookiesContainer.Add(cookie);//将Cookie加入容器,保存登录状态
if (response.ContentEncoding.ToLower().Contains("gzip"))//解压
{
using (GZipStream stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadToEnd();
}
}
}
else if (response.ContentEncoding.ToLower().Contains("deflate"))//解压
{
using (DeflateStream stream = new DeflateStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadToEnd();
}
}
}
else
{
using (Stream stream = response.GetResponseStream())//原始
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadT编程客栈oEnd();
}
}
}
}
request.Abort();
return result;
}
还有一个我传入的自定义对象。当然,传入或传出对象由你根据实际业务需求定义:
public class RequestOptions
{
///
/// 请求方式,GET或POST
///
public string Method { get; set; }
///
/// URL
///
public Uri Uri { get; set; }
///
/// 上一级历史记录链接
///
public string Referer { get; set; }
///
/// 超时时间(毫秒)
///
public int Timeout = 15000;
///
/// 启用长连接
///
public bool KeepAlive = true;
///
/// 禁止自动跳转
///
public bool AllowAutoRedirect = false;
/// &http://www.cppcns.comlt;summary>
/// 定义最大连接数
///
public int ConnectionLimit = int.MaxValue;
//编程客栈/
/// 请求次数
///
public int RequestNum = 3;
///
/// 可通过文件上传提交的文件类型
///
public string Accept = "*/*";
///
/// 内容类型
///
public string ContentType = "application/x-www-form-urlencoded";
///
/// 实例化头部信息
///
private WebHeaderCollection header = new WebHeaderCollection();
///
/// 头部信息
///
public WebHeaderCollection WebHeader
{
get { return header; }
set { header = value; }
}
///
/// 定义请求Cookie字符串
///
public string RequestCookies { get; set; }
///
/// 异步参数数据
///
public string XHRParams { get; set; }
}
根据显示的代码,我们可以发现 HttpWebRequest 对象封装了很多 Request headers 消息参数。我们可以根据网站的Request headers信息在微软提供的HttpWebRequest对象中设置(见代码消息参数注释,都写了相关参数说明,如果理解有误,请告知,谢谢你),然后发送请求获取响应数据来解析数据。
还补充一点,爬虫程序最好使用代理IP来使用代理IP,这样可以降低被屏蔽的概率,提高爬取效率。但是,代理IP也分为质量等级。对于某些 HTTPS 站点,可能需要质量级别更高的代理 IP 才能穿透。我不会在这里跑题。我会写一篇关于代理IP质量等级的文章文章详情说说我的看法。
C#代码如何使用代理IP?
Microsoft NET 框架还为我们提供了一个使用代理 IP 的 System.Net.WebProxy 对象。使用代码如下:
private System.Net.WebProxy GetProxy()
{
System.Net.WebProxy webProxy = null;
try
{
// 代理链接地址加端口
string proxyHost = "192.168.1.1";
string proxyPort = "9030";
// 代理身份验证的帐号跟密码
//string proxyUser = "xxx";
//string proxyPass = "xxx";
// 设置代理服务器
webProxy = new System.Net.WebProxy();
// 设置代理地址加端口
webProxy.Address = new Uri(string.Format("{0}:{1}", proxyHost, proxyPort));
// 如果只是设置代理IP加端口,例如192.168.1.1:80,这里直接注释该段代码,则不需要设置提交给代理服务器进行身份验证的帐号跟密码。
//webProxy.Credentials = new System.Net.NetworkCredential(proxyUser, proxyPass);
}
catch (Exception ex)
{
Console.WriteLine("获取代理信息异常", DateTime.Now.ToString(), ex.Message);
}
return webProxy;
}
关于System.Net.WebProxy对象的参数说明,我也在代码中进行了说明。
如果获取的Response数据是json、xml等格式的数据,这里就不详细描述这种数据解析方式了,请自行百度。这里的主要主题是 DOM 树 HTML 数据的解析。对于这类数据,有的人会使用正则表达式来解析,有的人会使用组件。当然,只要你能得到你想要的数据,你就可以按照你想要的方式解析它。这里的重点是我经常使用解析组件HtmlAgilityPack,参考DLL是(使用HtmlAgilityPack)。解析代码如下:
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(simpleCrawlResult.Contents);
HtmlNodeCollection liNodes = htmlDoc.DocumentNode.SelectSingleNode("//div[@id='pane-news']").SelectSingleNode("div[1]/ul[1]").SelectNodes("li");
if (liNodes != null && liNodes.Count > 0)
{
for (int i = 0; i < liNodes.Count; i++)
{
string title = liNodes[i].SelectSingleNode("strong[1]/a[1]").InnerText.Trim();
string href = liNodes[i].SelectSingleNode("strong[1]/a[1]").GetAttributeValue("href", "").Trim();
Console.WriteLine("新闻标题:" + title + ",链接:" + href);
}
}
下面主要展示爬取结果。
图 4
如图4,抓包效果,一个简单的爬虫程序就这样完成了。
至此,这篇关于c#实现爬虫程序的文章文章就介绍到这里了。希望对您的学习有所帮助,也希望您多多支持。
本文标题:c#实现爬虫程序
c#抓取网页数据(背景1.讲故事讲故事民生资讯号,资讯嘛,都是我抄你的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-04-04 15:10
2022-01-17 一:背景1.讲故事
前段时间,我在当地开设了一个民生信息账号。信息都是你抄的,你抄的是官媒的。小市民喜欢奇闻异事,所以有必要,如何定位抓怪故事的地方。上号的消息其实做起来很简单。可以使用逻辑回归。本文主要讨论如何获取。在C#中,大家都知道提取的通用库是HtmlAgilityPack,但是这个库的主流方法是使用xpath提取。网页的内容让我很不舒服。毕竟,我对莫名的抵抗并不熟悉。我这个年纪的码农,受过Jquery至少5-6年的教育,所以我必须使用类似Jquery的方法。python中有pyquery。在 C# 中是否有类似的方法可以做到这一点?嘿,真的有万能的github。. . 这就是本文介绍的CSQuery。
二:CSQuery1.安装
github的地址:然后就在vs里面nuget:
2. 举几个例子
万事俱备,那么如何使用呢?别着急,我给你举两个博客园的例子。
1) 将首页的友情链接提取到
如上图所示,如果要在这里获取友情链接的几个大字符,直接使用text()肯定是不行的。默认情况下,它还会捕获所有子节点的文本,如下图所示:
如何处理?可以使用jquery提供的contents方法,然后判断获取到的所有子节点中是否有文本节点,最终获取文本节点的内容,如下:
如果是用js做的,那怎么用CSQuery代码做呢?模仿一下,下面的代码:
static void Main(string[] args)
{
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com"));
var content = jquery["#friend_link"].Contents().Filter((dom) =>
{
return dom.NodeType == NodeType.TEXT_NODE;
}).Text();
Console.WriteLine(content);
}
不知道用xpath提取这样的内容是不是很麻烦,但是jquery不好用,但是好用。
2) 如何为 html 中的某些元素着色
有时出于商业目的需要改变一些html标签的颜色,比如把博客和首页tabmenu中的特殊区域改成红色,如下图:
如何用 CSQuery 处理它?如果你玩过jquery,一般步骤如下:
通过步骤,C#代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com"));
var html = jquery["#nav_left li"].Each(dom =>
{
var self = jquery[dom];
var text = self.Text();
if (text == "博问" || text == "专区")
{
self.Find("a").CssSet(new { color = "red" });
}
}).Render();
}
3) 其他操作方法
除了以上两种操作方法,还可以使用after、before、replaceAll、IS等一百多种实用方法。这篇文章当然不能一一介绍。有兴趣的可以下载看看。小提琴。
三:其他用途
除了抓取html中的元素,我觉得这个东西还可以用来在发送邮件的时候操作邮件模板。毕竟很久以前大家都是用jquery画html的,所以用CSQuery也是可以的。与使用 xslt 相比,各有利弊。,然后做一个例子:
1. 生成一个html模板
2. 使用 CSQuery 将 li 附加到 ul
您可以使用 Append 将内容附加到 查看全部
c#抓取网页数据(背景1.讲故事讲故事民生资讯号,资讯嘛,都是我抄你的)
2022-01-17 一:背景1.讲故事
前段时间,我在当地开设了一个民生信息账号。信息都是你抄的,你抄的是官媒的。小市民喜欢奇闻异事,所以有必要,如何定位抓怪故事的地方。上号的消息其实做起来很简单。可以使用逻辑回归。本文主要讨论如何获取。在C#中,大家都知道提取的通用库是HtmlAgilityPack,但是这个库的主流方法是使用xpath提取。网页的内容让我很不舒服。毕竟,我对莫名的抵抗并不熟悉。我这个年纪的码农,受过Jquery至少5-6年的教育,所以我必须使用类似Jquery的方法。python中有pyquery。在 C# 中是否有类似的方法可以做到这一点?嘿,真的有万能的github。. . 这就是本文介绍的CSQuery。
二:CSQuery1.安装
github的地址:然后就在vs里面nuget:
2. 举几个例子
万事俱备,那么如何使用呢?别着急,我给你举两个博客园的例子。
1) 将首页的友情链接提取到
如上图所示,如果要在这里获取友情链接的几个大字符,直接使用text()肯定是不行的。默认情况下,它还会捕获所有子节点的文本,如下图所示:
如何处理?可以使用jquery提供的contents方法,然后判断获取到的所有子节点中是否有文本节点,最终获取文本节点的内容,如下:
如果是用js做的,那怎么用CSQuery代码做呢?模仿一下,下面的代码:
static void Main(string[] args)
{
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com";));
var content = jquery["#friend_link"].Contents().Filter((dom) =>
{
return dom.NodeType == NodeType.TEXT_NODE;
}).Text();
Console.WriteLine(content);
}
不知道用xpath提取这样的内容是不是很麻烦,但是jquery不好用,但是好用。
2) 如何为 html 中的某些元素着色
有时出于商业目的需要改变一些html标签的颜色,比如把博客和首页tabmenu中的特殊区域改成红色,如下图:
如何用 CSQuery 处理它?如果你玩过jquery,一般步骤如下:
通过步骤,C#代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com";));
var html = jquery["#nav_left li"].Each(dom =>
{
var self = jquery[dom];
var text = self.Text();
if (text == "博问" || text == "专区")
{
self.Find("a").CssSet(new { color = "red" });
}
}).Render();
}
3) 其他操作方法
除了以上两种操作方法,还可以使用after、before、replaceAll、IS等一百多种实用方法。这篇文章当然不能一一介绍。有兴趣的可以下载看看。小提琴。
三:其他用途
除了抓取html中的元素,我觉得这个东西还可以用来在发送邮件的时候操作邮件模板。毕竟很久以前大家都是用jquery画html的,所以用CSQuery也是可以的。与使用 xslt 相比,各有利弊。,然后做一个例子:
1. 生成一个html模板
2. 使用 CSQuery 将 li 附加到 ul
您可以使用 Append 将内容附加到
c#抓取网页数据(Java开发教程:匹配时为点任意匹配模式,点 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-04-04 00:18
)
1、确定URL并抓取页面代码
import urllib
import urllib2
page = 1
url = 'http://www.qiushibaike.com/hot/page/' + str(page)
try:
request = urllib2.Request(url)
response = urllib2.urlopen(request)
print response.read()
except urllib2.URLError, e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason
2、添加页眉并抓取页面代码
try:
#定义请求头
headrs={"User-Agent":" Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"}
#定义请求,传入请求头
req=request.Request(url,headers=headrs)
#打开网页
resp=request.urlopen(req)
#打印响应码,解码
# print(resp.read().decode('utf-8'))
3、提取页面的所有段落
content = response.read().decode('utf-8')
pattern = re.compile('(.*?).*?(.*?).*?(.*?)',re.S)
items = re.findall(pattern,content)
for item in items:
haveImg = re.search("img",item[3])
if not haveImg:
print item[0],item[1],item[2],item[4]
except urllib2.URLError, e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason
4.面向对象的模式
<p>from urllib import request
import re
class tieba:
#初始化
def __init__(self):
# 定义url
self.url="https://tieba.baidu.com/f%3Fkw ... ot%3B
# 定义请求头
self.headrs={"User-Agent":" Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"}
#列表,存储解析后的结果
self.stories=[]
#下载页面
def getPage(self,page_number):
try:
# 定义请求,传入请求头
req=request.Request(self.url+str(page_number),headers=self.headrs)
# 打开网页
resp=request.urlopen(req)
# 打印响应码,解码
content=resp.read().decode("utf-8")
return content
except request.URLError as e:
# 打印响应码
if hasattr(e, 'code'):
print(e.code)
# 打印异常原因
if hasattr(e, 'reason'):
print(e.reason)
#解析页面
def rexgPage(self,content):
# 定义正则表达式
# 查看全部
c#抓取网页数据(Java开发教程:匹配时为点任意匹配模式,点
)
1、确定URL并抓取页面代码
import urllib
import urllib2
page = 1
url = 'http://www.qiushibaike.com/hot/page/' + str(page)
try:
request = urllib2.Request(url)
response = urllib2.urlopen(request)
print response.read()
except urllib2.URLError, e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason
2、添加页眉并抓取页面代码
try:
#定义请求头
headrs={"User-Agent":" Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"}
#定义请求,传入请求头
req=request.Request(url,headers=headrs)
#打开网页
resp=request.urlopen(req)
#打印响应码,解码
# print(resp.read().decode('utf-8'))
3、提取页面的所有段落
content = response.read().decode('utf-8')
pattern = re.compile('(.*?).*?(.*?).*?(.*?)',re.S)
items = re.findall(pattern,content)
for item in items:
haveImg = re.search("img",item[3])
if not haveImg:
print item[0],item[1],item[2],item[4]
except urllib2.URLError, e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason
4.面向对象的模式
<p>from urllib import request
import re
class tieba:
#初始化
def __init__(self):
# 定义url
self.url="https://tieba.baidu.com/f%3Fkw ... ot%3B
# 定义请求头
self.headrs={"User-Agent":" Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"}
#列表,存储解析后的结果
self.stories=[]
#下载页面
def getPage(self,page_number):
try:
# 定义请求,传入请求头
req=request.Request(self.url+str(page_number),headers=self.headrs)
# 打开网页
resp=request.urlopen(req)
# 打印响应码,解码
content=resp.read().decode("utf-8")
return content
except request.URLError as e:
# 打印响应码
if hasattr(e, 'code'):
print(e.code)
# 打印异常原因
if hasattr(e, 'reason'):
print(e.reason)
#解析页面
def rexgPage(self,content):
# 定义正则表达式
#
c#抓取网页数据(网上内容少之又少获取提交表单后怎么知道成没成功? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-04-02 09:26
)
由于项目需要,需要获取网页内容并自动填表,所以决定使用webbrowser控件。笔者百度之后,再次觉得网上的内容太少了。他们中的大多数在提交表格后都很好。如何知道提交表单是否成功?登录成功后如何获取页面?所以我在这里谈论重点:
业务流程大致为:
1.获取页面的html代码
2.找出类型不是submit的标签,填写内容
3.查找所有类型为提交的标签,模拟点击提交
4.获取提交的页面
所以我的解决方案是:
0X01:添加第一个页面加载成功的事件1。为什么要使用添加事件的方法?因为如果不是这样的话,网页浏览器的 DocumentText 往往会不可用或者不完整,导致程序非常不稳定。
0X02:自动填表并提交。
0X03:这是最关键的一步。首先去掉之前的事件1,然后添加加载成功事件2。这种情况下,点击登录跳转后,不会调用事件1,而是调用事件2。在事件2中,可以获取webbrowser的DocumentText是没有问题的(但是需要注意的是步骤0X03的代码必须在点击提交按钮之前,否则提交后修改事件来不及了)
首先,它不是一个窗口程序,需要使用 System.Windows.Forms 来引入;使用 webbrowser 控件。之后是代码:
WebBrowser wb = new WebBrowser();
wb.ScriptErrorsSuppressed = true;
wb.DocumentCompleted += wb_DocumentCompleted;//添加页面第一次加载完成事件
private void wb_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)//网页加载完后调用,但是为什么调用多次????????
{
if (!e.Url.Equals(this.uri))//防止一个网址不明原因的多次调用
{
//not actually complete, do nothing
return;
}
this.htmldocument = wb.Document;
HtmlElementCollection elementcol = this.htmldocument.GetElementsByTagName("input");
wb.DocumentCompleted -= wb_DocumentCompleted;//删除页面加载完成事件
wb.DocumentCompleted += wb_DocumentCompleted2;//添加新的页面加载完成事件(也就是提交成功后页面成功载入事件)
foreach (HtmlElement ele in elementcol)
{
if (!ele.GetAttribute("type").Equals("submit"))//不是提交按钮的都填成123
{
ele.SetAttribute("value","123");
}
else
{
ele.InvokeMember("click");//点击一下
}
}
}
private void wb_DocumentCompleted2(object sender, WebBrowserDocumentCompletedEventArgs e)
{
System.Diagnostics.Debug.WriteLine(wb.DocumentText);
//throw new NotImplementedException();
} 查看全部
c#抓取网页数据(网上内容少之又少获取提交表单后怎么知道成没成功?
)
由于项目需要,需要获取网页内容并自动填表,所以决定使用webbrowser控件。笔者百度之后,再次觉得网上的内容太少了。他们中的大多数在提交表格后都很好。如何知道提交表单是否成功?登录成功后如何获取页面?所以我在这里谈论重点:
业务流程大致为:
1.获取页面的html代码
2.找出类型不是submit的标签,填写内容
3.查找所有类型为提交的标签,模拟点击提交
4.获取提交的页面
所以我的解决方案是:
0X01:添加第一个页面加载成功的事件1。为什么要使用添加事件的方法?因为如果不是这样的话,网页浏览器的 DocumentText 往往会不可用或者不完整,导致程序非常不稳定。
0X02:自动填表并提交。
0X03:这是最关键的一步。首先去掉之前的事件1,然后添加加载成功事件2。这种情况下,点击登录跳转后,不会调用事件1,而是调用事件2。在事件2中,可以获取webbrowser的DocumentText是没有问题的(但是需要注意的是步骤0X03的代码必须在点击提交按钮之前,否则提交后修改事件来不及了)
首先,它不是一个窗口程序,需要使用 System.Windows.Forms 来引入;使用 webbrowser 控件。之后是代码:
WebBrowser wb = new WebBrowser();
wb.ScriptErrorsSuppressed = true;
wb.DocumentCompleted += wb_DocumentCompleted;//添加页面第一次加载完成事件
private void wb_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)//网页加载完后调用,但是为什么调用多次????????
{
if (!e.Url.Equals(this.uri))//防止一个网址不明原因的多次调用
{
//not actually complete, do nothing
return;
}
this.htmldocument = wb.Document;
HtmlElementCollection elementcol = this.htmldocument.GetElementsByTagName("input");
wb.DocumentCompleted -= wb_DocumentCompleted;//删除页面加载完成事件
wb.DocumentCompleted += wb_DocumentCompleted2;//添加新的页面加载完成事件(也就是提交成功后页面成功载入事件)
foreach (HtmlElement ele in elementcol)
{
if (!ele.GetAttribute("type").Equals("submit"))//不是提交按钮的都填成123
{
ele.SetAttribute("value","123");
}
else
{
ele.InvokeMember("click");//点击一下
}
}
}
private void wb_DocumentCompleted2(object sender, WebBrowserDocumentCompletedEventArgs e)
{
System.Diagnostics.Debug.WriteLine(wb.DocumentText);
//throw new NotImplementedException();
}
c#抓取网页数据(附赠一个C#调用JS脚本的代码:)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-21 23:55
2021-09-24
//不知道怎么删除,只好留着
1. 获取方法:
WebClient web = new WebClient();
var html = web.DownloadString(url);
2.发布方法
1 ///
2 ///
3 ///
4 ///
5 ///
6 /// 格式: paramname=value@name2=value2
7 ///
8 ///
9 public static string Post(this MyWebClient web, string url, string queryString, bool clearHeads=false)
10 {
11 string postString = queryString;// WebUtility.UrlEncode( queryString);//这里即为传递的参数,可以用工具抓包分析,也可以自己分析,主要是form里面每一个name都要加进来
12 byte[] postData = Encoding.UTF8.GetBytes(postString);//编码,尤其是汉字,事先要看下抓取网页的编码方式
13 web.RequestConentLength = postData.Length;
14 if (clearHeads)
15 {
16 web.Headers.Clear();
17 web.Headers.Add("Content-Type", "application/x-www-form-urlencoded");//采取POST方式必须加的header,如果改为GET方式的话就去掉这句话即可
18 }
19
20 byte[] responseData = web.UploadData(url, "POST", postData);//得到返回字符流
21 string srcString = Encoding.UTF8.GetString(responseData);//解码
22 return srcString;
23 }
3.标题设置
1 web.Headers.Add(HttpRequestHeader.Accept, "*/*");
2 web.Headers.Add(HttpRequestHeader.AcceptEncoding, "gzip, deflate");
3 web.Headers.Add(HttpRequestHeader.AcceptLanguage, "zh-CN,zh;q=0.9");
4 //web.Headers.Add(HttpRequestHeader.Connection, "keep-alive");
5 web.Headers.Add("Content-Type", "application/x-www-form-urlencoded; charset=UTF-8");
6 web.Headers.Add(HttpRequestHeader.Host, "wenshu.court.gov.cn");
7 web.Headers.Add("Origin", "http://wenshu.court.gov.cn");
8 //web.Headers.Add("Proxy-Connection", "keep-alive");
9 web.Headers.Add(HttpRequestHeader.UserAgent, userAgent);
10 web.Headers.Add("X-Requested-With", "XMLHttpRequest");
11 web.Headers.Add(HttpRequestHeader.Referer, WebUtility.UrlEncode(Referer1));
4.Cookie、超时等高可用基类
1 public class MyWebClient : WebClient
2 {
3 public CookieContainer Cookies ;
4
5 public MyWebClient(CookieContainer cookieContainer)
6 {
7 this.Cookies = cookieContainer;
8 }
9
10 public int TimeoutSeconds { get; set; } = 60;
11
12 public WebRequest Request { get; set; }
13
14 public int RequestConentLength;
15
16 protected override WebRequest GetWebRequest(Uri address)
17 {
18 HttpWebRequest request = base.GetWebRequest(address) as HttpWebRequest;
19
20 if (request != null)
21 {
22 request.Method = "Post";
23 request.CookieContainer = Cookies;
24 request.Timeout = 1000 * TimeoutSeconds;
25 request.ContentLength = RequestConentLength;
26 }
27
28 Request = request;
29 return request;
30 }
31
32 public WebResponse Response { get; set; }
33
34 protected override WebResponse GetWebResponse(WebRequest request)
35 {
36 this.Response = base.GetWebResponse(request);
37 return this.Response;
38 }
39
40 public string GetCookieValue(string cookieName)
41 {
42 var cookies = this.Cookies.GetCookies(this.Request.RequestUri);
43 var ck = cookies[cookieName];
44 return ck?.Value;
45 }
46 }
特别注意,浏览器需要为多个请求创建多个WebClient对象网站,但它们应该共享一个CookieContainer。在编写爬虫并模拟多个浏览器会话时,不应该都使用同一个 CookieContainer 对象以避免会话冲突。
附上调用JS脚本的C#代码:
1 public string CallJs(string jsCall , string jsFunctions)
2 {
3 Type obj = Type.GetTypeFromProgID("ScriptControl");
4 if (obj == null) return null;
5 object ScriptControl = Activator.CreateInstance(obj);
6 obj.InvokeMember("Language", BindingFlags.SetProperty, null, ScriptControl, new object[] { "JavaScript" });
7 //string js = "function time(a, b, msg){ var sum = a + b; return new Date().getTime() + ': ' + msg + ' = ' + sum }";
8 obj.InvokeMember("AddCode", BindingFlags.InvokeMethod, null, ScriptControl, new object[] { jsFunctions });
9
10 //return obj.InvokeMember("Eval", BindingFlags.InvokeMethod, null, ScriptControl, new object[] { "time(3, 5, '3 + 5')" }).ToString();
11 return obj.InvokeMember("Eval", BindingFlags.InvokeMethod, null, ScriptControl, new object[] { jsCall }).ToString();
12 }
使用示例:
string js = "function jsfunction(parm){ return parm + "abc"; }";
string val = CallJs($"jsfunction('{csvar}')", js.ToString());
分类:
技术要点:
相关文章: 查看全部
c#抓取网页数据(附赠一个C#调用JS脚本的代码:)
2021-09-24
//不知道怎么删除,只好留着
1. 获取方法:
WebClient web = new WebClient();
var html = web.DownloadString(url);
2.发布方法
1 ///
2 ///
3 ///
4 ///
5 ///
6 /// 格式: paramname=value@name2=value2
7 ///
8 ///
9 public static string Post(this MyWebClient web, string url, string queryString, bool clearHeads=false)
10 {
11 string postString = queryString;// WebUtility.UrlEncode( queryString);//这里即为传递的参数,可以用工具抓包分析,也可以自己分析,主要是form里面每一个name都要加进来
12 byte[] postData = Encoding.UTF8.GetBytes(postString);//编码,尤其是汉字,事先要看下抓取网页的编码方式
13 web.RequestConentLength = postData.Length;
14 if (clearHeads)
15 {
16 web.Headers.Clear();
17 web.Headers.Add("Content-Type", "application/x-www-form-urlencoded");//采取POST方式必须加的header,如果改为GET方式的话就去掉这句话即可
18 }
19
20 byte[] responseData = web.UploadData(url, "POST", postData);//得到返回字符流
21 string srcString = Encoding.UTF8.GetString(responseData);//解码
22 return srcString;
23 }
3.标题设置
1 web.Headers.Add(HttpRequestHeader.Accept, "*/*");
2 web.Headers.Add(HttpRequestHeader.AcceptEncoding, "gzip, deflate");
3 web.Headers.Add(HttpRequestHeader.AcceptLanguage, "zh-CN,zh;q=0.9");
4 //web.Headers.Add(HttpRequestHeader.Connection, "keep-alive");
5 web.Headers.Add("Content-Type", "application/x-www-form-urlencoded; charset=UTF-8");
6 web.Headers.Add(HttpRequestHeader.Host, "wenshu.court.gov.cn");
7 web.Headers.Add("Origin", "http://wenshu.court.gov.cn";);
8 //web.Headers.Add("Proxy-Connection", "keep-alive");
9 web.Headers.Add(HttpRequestHeader.UserAgent, userAgent);
10 web.Headers.Add("X-Requested-With", "XMLHttpRequest");
11 web.Headers.Add(HttpRequestHeader.Referer, WebUtility.UrlEncode(Referer1));
4.Cookie、超时等高可用基类
1 public class MyWebClient : WebClient
2 {
3 public CookieContainer Cookies ;
4
5 public MyWebClient(CookieContainer cookieContainer)
6 {
7 this.Cookies = cookieContainer;
8 }
9
10 public int TimeoutSeconds { get; set; } = 60;
11
12 public WebRequest Request { get; set; }
13
14 public int RequestConentLength;
15
16 protected override WebRequest GetWebRequest(Uri address)
17 {
18 HttpWebRequest request = base.GetWebRequest(address) as HttpWebRequest;
19
20 if (request != null)
21 {
22 request.Method = "Post";
23 request.CookieContainer = Cookies;
24 request.Timeout = 1000 * TimeoutSeconds;
25 request.ContentLength = RequestConentLength;
26 }
27
28 Request = request;
29 return request;
30 }
31
32 public WebResponse Response { get; set; }
33
34 protected override WebResponse GetWebResponse(WebRequest request)
35 {
36 this.Response = base.GetWebResponse(request);
37 return this.Response;
38 }
39
40 public string GetCookieValue(string cookieName)
41 {
42 var cookies = this.Cookies.GetCookies(this.Request.RequestUri);
43 var ck = cookies[cookieName];
44 return ck?.Value;
45 }
46 }
特别注意,浏览器需要为多个请求创建多个WebClient对象网站,但它们应该共享一个CookieContainer。在编写爬虫并模拟多个浏览器会话时,不应该都使用同一个 CookieContainer 对象以避免会话冲突。
附上调用JS脚本的C#代码:
1 public string CallJs(string jsCall , string jsFunctions)
2 {
3 Type obj = Type.GetTypeFromProgID("ScriptControl");
4 if (obj == null) return null;
5 object ScriptControl = Activator.CreateInstance(obj);
6 obj.InvokeMember("Language", BindingFlags.SetProperty, null, ScriptControl, new object[] { "JavaScript" });
7 //string js = "function time(a, b, msg){ var sum = a + b; return new Date().getTime() + ': ' + msg + ' = ' + sum }";
8 obj.InvokeMember("AddCode", BindingFlags.InvokeMethod, null, ScriptControl, new object[] { jsFunctions });
9
10 //return obj.InvokeMember("Eval", BindingFlags.InvokeMethod, null, ScriptControl, new object[] { "time(3, 5, '3 + 5')" }).ToString();
11 return obj.InvokeMember("Eval", BindingFlags.InvokeMethod, null, ScriptControl, new object[] { jsCall }).ToString();
12 }
使用示例:
string js = "function jsfunction(parm){ return parm + "abc"; }";
string val = CallJs($"jsfunction('{csvar}')", js.ToString());
分类:
技术要点:
相关文章:
c#抓取网页数据(ASP.NET中抓取网页内容-保持登录状态利用Post数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-20 14:16
2021-05-17
ASP.NET抓取网页内容非常方便,解决了ASP中困扰我们的编码问题。
1、获取一般内容
需要三个类:WebRequest、WebResponse、StreamReader
需要命名空间:System.Net、System.IO
核心代码:
WebRequest类的create是一个静态方法,参数是要爬取的网页的URL;
Encoding指定编码,Encoding有属性ASCII、UTF32、UTF8等通用编码,但没有编码属性gb2312,所以我们使用GetEncoding获取gb2312编码。
2、抓取图像或其他二进制文件(例如文件)
需要四个类:WebRequest、WebResponse、Stream、FileStream
需要命名空间:System.Net、System.IO
核心代码:使用 Stream 读取
3、抓取网页内容的POST方法
在抓取网页时,有时需要通过Post的方式向服务器发送一些数据,在网页抓取程序中加入如下代码,实现Post用户名和密码到服务器:
4、ASP.NET 抓取网页内容 - 防止重定向
在抓取网页时,成功登录服务器应用系统后,应用系统可以通过Response.Redirect重定向网页。如果你不需要响应这个重定向,那么我们就不给 reader.ReadToEnd() Response.Write 出来,就这样。
5、ASP.NET 抓取网页内容 - 保持登录状态
使用Post数据成功登录服务器应用系统后,我们可以抓取需要登录的页面,那么我们可能需要在多个Request之间保持登录状态。 查看全部
c#抓取网页数据(ASP.NET中抓取网页内容-保持登录状态利用Post数据)
2021-05-17
ASP.NET抓取网页内容非常方便,解决了ASP中困扰我们的编码问题。
1、获取一般内容
需要三个类:WebRequest、WebResponse、StreamReader
需要命名空间:System.Net、System.IO
核心代码:
WebRequest类的create是一个静态方法,参数是要爬取的网页的URL;
Encoding指定编码,Encoding有属性ASCII、UTF32、UTF8等通用编码,但没有编码属性gb2312,所以我们使用GetEncoding获取gb2312编码。
2、抓取图像或其他二进制文件(例如文件)
需要四个类:WebRequest、WebResponse、Stream、FileStream
需要命名空间:System.Net、System.IO
核心代码:使用 Stream 读取
3、抓取网页内容的POST方法
在抓取网页时,有时需要通过Post的方式向服务器发送一些数据,在网页抓取程序中加入如下代码,实现Post用户名和密码到服务器:
4、ASP.NET 抓取网页内容 - 防止重定向
在抓取网页时,成功登录服务器应用系统后,应用系统可以通过Response.Redirect重定向网页。如果你不需要响应这个重定向,那么我们就不给 reader.ReadToEnd() Response.Write 出来,就这样。
5、ASP.NET 抓取网页内容 - 保持登录状态
使用Post数据成功登录服务器应用系统后,我们可以抓取需要登录的页面,那么我们可能需要在多个Request之间保持登录状态。
c#抓取网页数据(c#抓取网页数据现实之类的多用js或者requests库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-20 02:03
c#抓取网页数据现实之类的多用js或者requests库,利用特征判断网页内容有些网站支持cookie,开发者可以利用这个特征。web有些在点击按钮或者输入responseurl时加载会联网爬取内容。现在没必要再使用js来抓取数据,可以使用jsonwebstream或者file协议进行网页数据的获取。也可以用浏览器加速flash抓取数据。用c#抓取web之类的资料网络综合搜索建议先看这个或者这个。
推荐/aaaaas/.
qwq其实chrome的safari浏览器会抓web页面。这样他会开启api,通过调用对应浏览器的api。手机平板浏览器都可以抓。手机的开发可以做一个不少应用。网页抓取的话必须是可以完整抓取html的页面才可以。不能只抓一部分。至于这些怎么抓,https的网站需要在证书上,要求域名解析也https的话。
搞不定。可以试试无线刷机。我原来要抓取一个连接都开不了telegram。手机有点不够用,自己想的,首先手机不能被telegram识别网络。也不能被用googleplay下载手机版的webapp(好像能下?),要root后才可以。然后还得安装一个app,才能打开链接。不能手机直接爬墙打开链接。好麻烦。完了好像也没其他办法。=_=。 查看全部
c#抓取网页数据(c#抓取网页数据现实之类的多用js或者requests库)
c#抓取网页数据现实之类的多用js或者requests库,利用特征判断网页内容有些网站支持cookie,开发者可以利用这个特征。web有些在点击按钮或者输入responseurl时加载会联网爬取内容。现在没必要再使用js来抓取数据,可以使用jsonwebstream或者file协议进行网页数据的获取。也可以用浏览器加速flash抓取数据。用c#抓取web之类的资料网络综合搜索建议先看这个或者这个。
推荐/aaaaas/.
qwq其实chrome的safari浏览器会抓web页面。这样他会开启api,通过调用对应浏览器的api。手机平板浏览器都可以抓。手机的开发可以做一个不少应用。网页抓取的话必须是可以完整抓取html的页面才可以。不能只抓一部分。至于这些怎么抓,https的网站需要在证书上,要求域名解析也https的话。
搞不定。可以试试无线刷机。我原来要抓取一个连接都开不了telegram。手机有点不够用,自己想的,首先手机不能被telegram识别网络。也不能被用googleplay下载手机版的webapp(好像能下?),要root后才可以。然后还得安装一个app,才能打开链接。不能手机直接爬墙打开链接。好麻烦。完了好像也没其他办法。=_=。
c#抓取网页数据(c#抓取网页数据匹配错误/输出按字符串匹配)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-18 15:04
c#抓取网页数据首先需要urllibforwindows而且需要对代码进行静态编译,这样网页上的属性和类型就转换过来了,这样抓取来的数据就可以进行处理然后才能输出。winform抓取网页可以用,但是这需要你知道urllib或者urllib2工具包,来满足你的要求。
这个问题我还真研究过。
简单点的方法是wtforms。getheader('haha'),用户的名字参数是最后一个'haha'个字符串,有两种写法,如果直接遍历所有的输入,然后查找以此开头的,就是原始数据,如果遍历一个,然后匹配以开头的,其他的字符串就不是原始数据了。接下来就是按开头字符合到用户输入的值,循环了。如果查找以下范围的,则有不一样的结果了,需要后面几个字符串是数字,大小写敏感等问题,比如用户输入"haha",然后调用getheader()函数,一般语法如下:getheader(name){returnname。
<p>tostring()},name不是输入的数据,可能匹配错误。接下来的搜索代码大体如下:publicstringgetheader(stringname){stringvalue=name。tostring();//匹配数据,匹配错误//输出按开头字符(name。tostring())的值stringnext="\nhh";for(inti=0;i 查看全部
c#抓取网页数据(c#抓取网页数据匹配错误/输出按字符串匹配)
c#抓取网页数据首先需要urllibforwindows而且需要对代码进行静态编译,这样网页上的属性和类型就转换过来了,这样抓取来的数据就可以进行处理然后才能输出。winform抓取网页可以用,但是这需要你知道urllib或者urllib2工具包,来满足你的要求。
这个问题我还真研究过。
简单点的方法是wtforms。getheader('haha'),用户的名字参数是最后一个'haha'个字符串,有两种写法,如果直接遍历所有的输入,然后查找以此开头的,就是原始数据,如果遍历一个,然后匹配以开头的,其他的字符串就不是原始数据了。接下来就是按开头字符合到用户输入的值,循环了。如果查找以下范围的,则有不一样的结果了,需要后面几个字符串是数字,大小写敏感等问题,比如用户输入"haha",然后调用getheader()函数,一般语法如下:getheader(name){returnname。
<p>tostring()},name不是输入的数据,可能匹配错误。接下来的搜索代码大体如下:publicstringgetheader(stringname){stringvalue=name。tostring();//匹配数据,匹配错误//输出按开头字符(name。tostring())的值stringnext="\nhh";for(inti=0;i
c#抓取网页数据(搜索引擎蜘蛛访问网站页面时类似于普通用户使用浏览器开发蜘蛛程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-15 08:08
搜索引擎用来抓取和访问页面的程序称为蜘蛛(spider)。 c#开发蜘蛛程序也称为机器人(bot)。当搜索引擎蜘蛛访问网站的页面时,它类似于普通用户使用浏览器。蜘蛛程序发送页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。为了提高搜索引擎的爬取和爬取速度,都使用了多个爬虫分布爬取。
蜘蛛访问网站时,首先会访问网站根目录下的robots.txt文件。如果robots.txt文件禁止搜索引擎抓取某些网页或内容,或者网站,则蜘蛛会遵循协议而不是c#开发的蜘蛛程序。
spider也是一个c#开发的spider程序,有自己的代理名。爬虫的痕迹可以在站长日志中看到,这也是为什么很多站长回答问题时总是说先检查网站日志的原因(作为一个好的SEO你必须能够查看网站日志无需任何软件,对代码含义非常熟悉)。
一个c#开发蜘蛛程序和搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛是Spider,这是一个很形象的名字。互联网被比作蜘蛛网。那么Spider就是一个c#开发的蜘蛛程序,可以在网络上爬行。
网络蜘蛛通过网页的链接地址寻找网页,从网站某个页面(通常是首页)开始,读取网页的内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一个网页,如此循环下去,直到这个网站的所有网页都被爬取完毕。
如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,几乎不可能爬取互联网上的所有网页。根据迄今为止公布的数据,最大的搜索引擎只抓取了网页总数的4%。十点左右。
其中一个原因是爬虫技术的瓶颈。 100 亿个网页的容量是 100×2000G 字节。就算能存起来,下载还是有问题(按一台机器每秒下载20K,需要340个单位,机器不停下载所有网页需要一年时间),同时,由于数据量大,在提供搜索时也会对效率产生影响。
因此,很多搜索引擎网络蜘蛛只抓取那些重要的网页,而在抓取时评估重要性的主要依据是某个网页的链接深度。
因为不可能爬取所有网页,所以有些网络蜘蛛为一些不太重要的网站设置了要访问的层数,例如如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A是起始页,属于第0层,B,C,D,E,F属于第1层,G,H属于第2层,I属于第3层,如果访问层网络蜘蛛设置的数字是2,网页我不会被访问,这也让搜索引擎可以搜索到一些网站网页,而其他部分则无法搜索到。
对于 网站 的设计者来说,扁平的 网站 设计有助于搜索引擎抓取更多页面。
网络蜘蛛在访问网站网页时,经常会遇到加密数据和网页权限问题。有些网页需要会员权限才能访问。
网站的站主当然可以让网络蜘蛛不按约定爬取,但是对于一些卖报告的网站来说,他们希望自己的报告可以被搜索引擎搜索到,但是不能 搜索者查看是完全免费的,所以需要提供相应的用户名和密码给网络蜘蛛。
网络蜘蛛可以通过给定的权限抓取这些网页提供搜索,当搜索者点击查看网页时,搜索者也需要提供相应的权限验证。
二、点击链接
搜索引擎蜘蛛为了在网络上抓取尽可能多的页面,会跟随网页上的链接,从一个页面爬到下一页,就像蜘蛛在蜘蛛网上爬行一样,这是搜索引擎蜘蛛 名字的由来。
整个互联网网站由相互连接的链接组成,这意味着搜索引擎蜘蛛最终将从任何一个页面开始抓取所有页面。
搜索引擎蜘蛛的基本原理和工作流程
当然网站而且页面链接结构太复杂,所以蜘蛛只能通过一定的方法爬取所有页面。据了解,最简单的爬取策略有以下三种:
1、最佳优先
最佳优先级搜索策略是根据一定的网页分析算法,预测候选URL与目标网页的相似度,或与主题的相关度,选择评价最好的一个或几个URL进行爬取。它只访问网页分析算法预测为“有用”的网页。
存在的一个问题是爬虫爬取路径上的很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要结合具体应用来提高最佳优先级, 为了跳出局部最优,据研究,这样的闭环调整可以将不相关网页的数量减少30%~90%。
2、深度优先
深度优先是指蜘蛛沿着找到的链接爬行,直到前面没有其他链接,然后返回第一页,沿着另一个链接爬行。
3、广度优先
广度优先是指当蜘蛛在一个页面上发现多个链接时,它不会一路跟随一个链接,而是爬取页面上的所有链接,然后进入页面的第二层并跟随第二层层。找到的链接爬到第三层页面。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它就可以爬取整个互联网。
在实践中,蜘蛛的带宽资源和时间并不是无限的,它们不可能爬取所有页面。其实最大的搜索引擎只爬网收录互联网的一小部分,当然也不是说搜索引擎蜘蛛爬的越多越好,这一点
因此,为了尽可能多地捕获用户信息,通常将深度优先和广度优先混合,以便尽可能多地照顾到网站,同时也照顾到一些< @网站 内页。
三、搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。 “蜘蛛”这个称呼形象地描述了信息采集模块在网络数据形成的“万维网”上获取信息的功能。
一般来说,网络爬虫都是从种子网页开始,通过反复下载网页,从文档中寻找看不见的URL,达到访问其他网页和遍历网络的目的。
而它的工作策略一般可以分为累积爬取(cumulative crawling)和增量爬取(incremental crawling)。
1、累积爬取
累积爬取是指从某个时间点开始遍历,爬取系统允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证爬取相当大的网页集合。
看来由于web数据的动态特性,集合中的网页被爬取的时间点不同,页面更新的也不同,所以累计爬取的网页集合实际上并不能与真实环境相比。网络数据保持一致。
2、增量爬取
与累积爬取不同,增量爬取是指在一定数量的网页集合的基础上,通过更新数据,选择现有集合中过时的网页,从而保证所有网页都被爬取。捕获的数据与真实的网络数据足够接近。
增量爬取的前提是系统已经爬取了足够多的网页,并且有关于这些页面何时被爬取的信息。在针对实际应用环境的网络爬虫设计中,通常会同时收录累积爬取和增量爬取两种策略。
累积爬取一般用于数据集的整体建立或大规模更新,而增量爬取主要用于数据集的日常维护和即时更新。
确定了爬取策略后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛运行策略中的核心问题。
总的来说,在合理利用软硬件资源对网络数据进行实时抓取方面,已经形成了比较成熟的技术和实用的解决方案。更好地处理动态网络数据问题(如越来越多的Web2.0数据等),更好地根据网页质量修正爬取策略。
四、数据库
为了避免重复爬取和爬取URL,搜索引擎会建立一个数据库来记录未爬取的页面和已爬取的页面,那么数据库中的URL是怎么来的呢?
1、手动输入种子网站
简单来说就是我们建站后提交给百度、谷歌或者360的URL收录。
2、蜘蛛抓取页面
如果搜索引擎蜘蛛在爬取过程中发现了新的连接URL,但不在数据库中,则将其存入待访问的数据库中(网站观察期)。
蜘蛛根据重要性从要访问的数据库中提取URL,访问并爬取页面,然后从要访问的地址库中删除该URL,放入已访问的地址库中。 @>观察期间要尽可能定期更新网站.
3、站长提交网站
一般来说,提交网站只是将网站保存到要访问的数据库中。如果网站坚持不更新蜘蛛,就不会访问搜索引擎的页面收录都是蜘蛛自己跟随链接获取的。
因此,将其提交给搜索引擎对您来说不是很有用。应该根据你以后网站更新的程度来考虑。搜索引擎更喜欢沿着链接发现新页面。当然,如果你的SEO技术足够成熟,并且有这个能力,可以尝试一下,说不定会有意想不到的效果,但是对于一般站长来说,还是建议让蜘蛛爬取,爬到新的站点页面自然。
五、吸引蜘蛛
虽然理论上说蜘蛛可以爬取所有页面,但在实践中是不可能的,所以SEO人员想要收录更多的页面,不得不想办法引诱蜘蛛爬。
既然不能爬取所有的页面,那么就必须让它爬取重要的页面,因为重要的页面在索引中起着重要的作用,直接影响排名因素。哪些页面更重要?对此,我特意整理了以下几个我认为比较重要的页面,具有以下特点:
1、网站和页面权重
优质老网站被赋予高权重,而这个网站上的页面爬取深度更高,所以更多的内页会是收录。
2、页面更新
蜘蛛每次抓取时都会存储页面数据。如果第二次爬取时页面内容与第一个收录完全一样,说明页面没有更新,蜘蛛不需要频繁爬取和爬取。抢。
如果页面内容更新频繁,蜘蛛就会频繁爬取,那么页面上的新链接自然会被蜘蛛更快地跟踪和爬取,这也是为什么需要每天更新的原因< @k7@ >
3、导入链接
无论是外链还是同一个网站的内链,为了被蜘蛛爬取,必须有传入链接才能进入页面,否则蜘蛛不会知道存在的页面。这时候URL链接就起到了非常重要的作用,内部链接的重要性就发挥出来了。
另外,我个人觉得高质量的入站链接也往往会增加页面上的出站链接被抓取的深度。
这就是为什么大多数网站管理员或 SEO 都想要高质量的附属链接,因为蜘蛛 网站从彼此之间爬到您网站 的次数和深度更多。 查看全部
c#抓取网页数据(搜索引擎蜘蛛访问网站页面时类似于普通用户使用浏览器开发蜘蛛程序)
搜索引擎用来抓取和访问页面的程序称为蜘蛛(spider)。 c#开发蜘蛛程序也称为机器人(bot)。当搜索引擎蜘蛛访问网站的页面时,它类似于普通用户使用浏览器。蜘蛛程序发送页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。为了提高搜索引擎的爬取和爬取速度,都使用了多个爬虫分布爬取。
蜘蛛访问网站时,首先会访问网站根目录下的robots.txt文件。如果robots.txt文件禁止搜索引擎抓取某些网页或内容,或者网站,则蜘蛛会遵循协议而不是c#开发的蜘蛛程序。
spider也是一个c#开发的spider程序,有自己的代理名。爬虫的痕迹可以在站长日志中看到,这也是为什么很多站长回答问题时总是说先检查网站日志的原因(作为一个好的SEO你必须能够查看网站日志无需任何软件,对代码含义非常熟悉)。
一个c#开发蜘蛛程序和搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛是Spider,这是一个很形象的名字。互联网被比作蜘蛛网。那么Spider就是一个c#开发的蜘蛛程序,可以在网络上爬行。
网络蜘蛛通过网页的链接地址寻找网页,从网站某个页面(通常是首页)开始,读取网页的内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一个网页,如此循环下去,直到这个网站的所有网页都被爬取完毕。
如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,几乎不可能爬取互联网上的所有网页。根据迄今为止公布的数据,最大的搜索引擎只抓取了网页总数的4%。十点左右。
其中一个原因是爬虫技术的瓶颈。 100 亿个网页的容量是 100×2000G 字节。就算能存起来,下载还是有问题(按一台机器每秒下载20K,需要340个单位,机器不停下载所有网页需要一年时间),同时,由于数据量大,在提供搜索时也会对效率产生影响。
因此,很多搜索引擎网络蜘蛛只抓取那些重要的网页,而在抓取时评估重要性的主要依据是某个网页的链接深度。
因为不可能爬取所有网页,所以有些网络蜘蛛为一些不太重要的网站设置了要访问的层数,例如如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A是起始页,属于第0层,B,C,D,E,F属于第1层,G,H属于第2层,I属于第3层,如果访问层网络蜘蛛设置的数字是2,网页我不会被访问,这也让搜索引擎可以搜索到一些网站网页,而其他部分则无法搜索到。
对于 网站 的设计者来说,扁平的 网站 设计有助于搜索引擎抓取更多页面。
网络蜘蛛在访问网站网页时,经常会遇到加密数据和网页权限问题。有些网页需要会员权限才能访问。
网站的站主当然可以让网络蜘蛛不按约定爬取,但是对于一些卖报告的网站来说,他们希望自己的报告可以被搜索引擎搜索到,但是不能 搜索者查看是完全免费的,所以需要提供相应的用户名和密码给网络蜘蛛。
网络蜘蛛可以通过给定的权限抓取这些网页提供搜索,当搜索者点击查看网页时,搜索者也需要提供相应的权限验证。
二、点击链接
搜索引擎蜘蛛为了在网络上抓取尽可能多的页面,会跟随网页上的链接,从一个页面爬到下一页,就像蜘蛛在蜘蛛网上爬行一样,这是搜索引擎蜘蛛 名字的由来。
整个互联网网站由相互连接的链接组成,这意味着搜索引擎蜘蛛最终将从任何一个页面开始抓取所有页面。
搜索引擎蜘蛛的基本原理和工作流程
当然网站而且页面链接结构太复杂,所以蜘蛛只能通过一定的方法爬取所有页面。据了解,最简单的爬取策略有以下三种:
1、最佳优先
最佳优先级搜索策略是根据一定的网页分析算法,预测候选URL与目标网页的相似度,或与主题的相关度,选择评价最好的一个或几个URL进行爬取。它只访问网页分析算法预测为“有用”的网页。
存在的一个问题是爬虫爬取路径上的很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要结合具体应用来提高最佳优先级, 为了跳出局部最优,据研究,这样的闭环调整可以将不相关网页的数量减少30%~90%。
2、深度优先
深度优先是指蜘蛛沿着找到的链接爬行,直到前面没有其他链接,然后返回第一页,沿着另一个链接爬行。
3、广度优先
广度优先是指当蜘蛛在一个页面上发现多个链接时,它不会一路跟随一个链接,而是爬取页面上的所有链接,然后进入页面的第二层并跟随第二层层。找到的链接爬到第三层页面。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它就可以爬取整个互联网。
在实践中,蜘蛛的带宽资源和时间并不是无限的,它们不可能爬取所有页面。其实最大的搜索引擎只爬网收录互联网的一小部分,当然也不是说搜索引擎蜘蛛爬的越多越好,这一点
因此,为了尽可能多地捕获用户信息,通常将深度优先和广度优先混合,以便尽可能多地照顾到网站,同时也照顾到一些< @网站 内页。
三、搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。 “蜘蛛”这个称呼形象地描述了信息采集模块在网络数据形成的“万维网”上获取信息的功能。
一般来说,网络爬虫都是从种子网页开始,通过反复下载网页,从文档中寻找看不见的URL,达到访问其他网页和遍历网络的目的。
而它的工作策略一般可以分为累积爬取(cumulative crawling)和增量爬取(incremental crawling)。
1、累积爬取
累积爬取是指从某个时间点开始遍历,爬取系统允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证爬取相当大的网页集合。
看来由于web数据的动态特性,集合中的网页被爬取的时间点不同,页面更新的也不同,所以累计爬取的网页集合实际上并不能与真实环境相比。网络数据保持一致。
2、增量爬取
与累积爬取不同,增量爬取是指在一定数量的网页集合的基础上,通过更新数据,选择现有集合中过时的网页,从而保证所有网页都被爬取。捕获的数据与真实的网络数据足够接近。
增量爬取的前提是系统已经爬取了足够多的网页,并且有关于这些页面何时被爬取的信息。在针对实际应用环境的网络爬虫设计中,通常会同时收录累积爬取和增量爬取两种策略。
累积爬取一般用于数据集的整体建立或大规模更新,而增量爬取主要用于数据集的日常维护和即时更新。
确定了爬取策略后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛运行策略中的核心问题。
总的来说,在合理利用软硬件资源对网络数据进行实时抓取方面,已经形成了比较成熟的技术和实用的解决方案。更好地处理动态网络数据问题(如越来越多的Web2.0数据等),更好地根据网页质量修正爬取策略。
四、数据库
为了避免重复爬取和爬取URL,搜索引擎会建立一个数据库来记录未爬取的页面和已爬取的页面,那么数据库中的URL是怎么来的呢?
1、手动输入种子网站
简单来说就是我们建站后提交给百度、谷歌或者360的URL收录。
2、蜘蛛抓取页面
如果搜索引擎蜘蛛在爬取过程中发现了新的连接URL,但不在数据库中,则将其存入待访问的数据库中(网站观察期)。
蜘蛛根据重要性从要访问的数据库中提取URL,访问并爬取页面,然后从要访问的地址库中删除该URL,放入已访问的地址库中。 @>观察期间要尽可能定期更新网站.
3、站长提交网站
一般来说,提交网站只是将网站保存到要访问的数据库中。如果网站坚持不更新蜘蛛,就不会访问搜索引擎的页面收录都是蜘蛛自己跟随链接获取的。
因此,将其提交给搜索引擎对您来说不是很有用。应该根据你以后网站更新的程度来考虑。搜索引擎更喜欢沿着链接发现新页面。当然,如果你的SEO技术足够成熟,并且有这个能力,可以尝试一下,说不定会有意想不到的效果,但是对于一般站长来说,还是建议让蜘蛛爬取,爬到新的站点页面自然。
五、吸引蜘蛛
虽然理论上说蜘蛛可以爬取所有页面,但在实践中是不可能的,所以SEO人员想要收录更多的页面,不得不想办法引诱蜘蛛爬。
既然不能爬取所有的页面,那么就必须让它爬取重要的页面,因为重要的页面在索引中起着重要的作用,直接影响排名因素。哪些页面更重要?对此,我特意整理了以下几个我认为比较重要的页面,具有以下特点:
1、网站和页面权重
优质老网站被赋予高权重,而这个网站上的页面爬取深度更高,所以更多的内页会是收录。
2、页面更新
蜘蛛每次抓取时都会存储页面数据。如果第二次爬取时页面内容与第一个收录完全一样,说明页面没有更新,蜘蛛不需要频繁爬取和爬取。抢。
如果页面内容更新频繁,蜘蛛就会频繁爬取,那么页面上的新链接自然会被蜘蛛更快地跟踪和爬取,这也是为什么需要每天更新的原因< @k7@ >
3、导入链接
无论是外链还是同一个网站的内链,为了被蜘蛛爬取,必须有传入链接才能进入页面,否则蜘蛛不会知道存在的页面。这时候URL链接就起到了非常重要的作用,内部链接的重要性就发挥出来了。
另外,我个人觉得高质量的入站链接也往往会增加页面上的出站链接被抓取的深度。
这就是为什么大多数网站管理员或 SEO 都想要高质量的附属链接,因为蜘蛛 网站从彼此之间爬到您网站 的次数和深度更多。
c#抓取网页数据(NBA总决赛如何使用ChromeDriver+HtmlAgilityPack爬取比赛实时比分解析网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-03-15 08:06
背景
最近NBA总决赛吸引了很多球迷,但是因为时差,大家都在打比赛,我们也在努力。
是的,自己动手,ChromeDriver+HtmlAgilityPack爬取游戏实时比分。
概述
WebDriver 是对浏览器提供的原生 API 进行封装,使其成为更加面向对象的 Selenium WebDriver API。使用该API,您可以控制浏览器的打开和关闭,打开网页,操作界面元素,控制cookies,还可以操作浏览器截图,安装插件,设置代理,配置证书。
HtmlAgilityPack 是 .net 下的 HTML 解析库。支持使用 XPath 解析 HTML。这很有道理,为什么呢?因为一些功能强大的浏览器可以直接获取页面上元素的xpath,所以不需要手动编写。它节省了编写正则表达式的大部分时间。当然,在进一步获取的时候,有时需要写正则表达式,但是通过xpath解析后,要匹配的正则表达式的范围很小。此外,通过不使用正则表达式来匹配整个页面源代码,可以提高速度。总而言之,通过这个类库,先通过浏览器获取的xpath获取节点内容,再通过正则表达式匹配需要的内容,既提高了开发速度,又提高了运行效率。
代码
下面我们来看看如何使用ChromeDriver+HtmlAgilityPack来抓取游戏的实时比分。
爬网
string url = "https://sports.qq.com/kbsweb/game.htm?mid=" + model.TxMatchId;<br /><br /> // string url = "https://kbs.sports.qq.com/kbsw ... %3Bbr /> // MatchUpdate model = new MatchUpdate();<br /><br /> var cds = ChromeDriverService.CreateDefaultService();<br /> //是否应隐藏服务的命令提示符窗口<br /> cds.HideCommandPromptWindow = true;<br /><br /> ChromeOptions options = new ChromeOptions();<br /> options.AddArguments("--test-type", "--ignore-certificate-errors");<br /> // options.AddArguments("user-agent=mozilla/5.0 (linux; u; android 2.3.3; en-us; sdk build/ gri34) applewebkit/533.1 (khtml, like gecko) version/4.0 mobile safari/533.1");<br /> options.AddArgument("enable-automation");<br /><br /> // options.setBinary("C:/Program Files (x86)/Google/Chrome/chrome.exe");<br /><br /> var r = ZhimaHttpProxy.GetProxy(false);<br /> if (r != null)<br /> {<br /> Console.WriteLine(r.Address.Host);<br /> Console.WriteLine(r.Address.Port);<br /><br /> string proxy_Host = r.Address.Host;<br /> int proxy_Post = r.Address.Port;<br /> string Ex_Proxy_Name = "proxy.zip";<br /><br /> options.Proxy = null;<br /> options.AddArguments("--proxy-server=" + proxy_Host + ":" + proxy_Post.ToString());<br /> options.AddExtension(Ex_Proxy_Name);<br /> }<br /><br /> if (IsHideMode)<br /> options.AddArgument("headless");<br /><br /> string dic = System.Environment.CurrentDirectory + "\\cos";<br /><br /> if (IsHideMode)<br /> {<br /> using (IWebDriver driver = new OpenQA.Selenium.Chrome.ChromeDriver(cds, options, TimeSpan.FromSeconds(120)))<br /><br /> {<br /> Excule(driver, url, model);<br /> }<br /> }<br /> else<br /> {<br /> using (IWebDriver driver = new OpenQA.Selenium.Chrome.ChromeDriver(dic, options, TimeSpan.FromSeconds(120)))<br /><br /> {<br /> Excule(driver, url, model);<br /> }<br /> }
解析网页
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();<br /> doc.LoadHtml(Helper.ReadTxt(System.Environment.CurrentDirectory + "\\PageSource\\" + info.TxMatchId.Replace(":", "_") + ".txt"));<br /> int? HomeTeamScore = null;<br /> int? GuestTeamScore = null;<br /> List MatchScoreList = new List();<br /> HtmlNode titleNodes = doc.DocumentNode.SelectSingleNode("//div[@class='inner']");<br /> var titleNodes2 = doc.DocumentNode.SelectSingleNode("//div[@class='content-wrapper']");<br /> if (titleNodes2 != null)<br /> // if (false)<br /> {<br /> Console.WriteLine(titleNodes2.InnerText);<br /> var host = titleNodes2.SelectSingleNode("//div[@class='team-goal host']");<br /> var arr = host.InnerText.Replace("\r\n", "|");<br /> var arrs = arr.Split('|');<br /> arrs = arrs.Where(o => !string.IsNullOrWhiteSpace(o)).Select(o => o.Split('(')[0].Trim()).ToArray();<br /> HomeTeamScore = int.Parse(arrs[1]);<br /> MatchScoreList.Add(new MatchScore() { TeamName = arrs[0], TeamScore = HomeTeamScore });<br /><br /> var guest = titleNodes2.SelectSingleNode("//div[@class='team-goal guest']");<br /><br /> var arr2 = guest.InnerText.Replace("\r\n", "|");<br /> var arrs2 = arr2.Split('|');<br /> arrs2 = arrs2.Where(o => !string.IsNullOrWhiteSpace(o)).Select(o => o.Split('(')[0].Trim()).ToArray();<br /><br /> GuestTeamScore = int.Parse(arrs2[1]);<br /><br /> MatchScoreList.Add(new MatchScore() { TeamName = arrs2[0], TeamScore = GuestTeamScore });<br /> }<br /> else<br /> {<br /> var a = titleNodes.SelectNodes("//a[@data-target='teamName']");<br /> var score = titleNodes.SelectNodes("//span[@class='score']");<br /> if (score != null)<br /> {<br /> int i = 0;<br /> foreach (var item in score)<br /> {<br /> SetText("\r\n" + item.InnerText?.Trim());<br /> if (i == 0)<br /> {<br /> HomeTeamScore = Convert.ToInt32(item.InnerText?.Trim());<br /> }<br /> if (i == 1)<br /> {<br /> GuestTeamScore = Convert.ToInt32(item.InnerText?.Trim());<br /> }<br /><br /> i++;<br /> }<br /> }<br /><br /> if (a != null)<br /> {<br /> int i = 0;<br /> foreach (var item in a)<br /> {<br /> SetText("\r\n" + item.InnerText?.Trim());<br /><br /> if (i == 0)<br /> {<br /> MatchScoreList.Add(new MatchScore() { TeamName = item.InnerText?.Split('(')[0].Trim(), TeamScore = HomeTeamScore });<br /> }<br /> if (i == 1)<br /> {<br /> MatchScoreList.Add(new MatchScore() { TeamName = item.InnerText?.Split('(')[0].Trim(), TeamScore = GuestTeamScore });<br /> }<br /><br /> i++;<br /> }<br /> }<br /> }<br /><br /> string statusstr = "";<br /><br /> var t = titleNodes.SelectSingleNode("//div[@class='datetime-live-desc']");<br /> SetText("\r\n" + t.InnerText?.Trim());<br /> statusstr = t.InnerText?.Trim();<br /><br /> var Status = info.Status;<br /> if (!string.IsNullOrWhiteSpace(statusstr) && statusstr.Contains("已结束"))<br /> {<br /> Status = MatchStatus.End;<br /> }<br />
最后做一个小弹框,输出数据。 查看全部
c#抓取网页数据(NBA总决赛如何使用ChromeDriver+HtmlAgilityPack爬取比赛实时比分解析网页)
背景
最近NBA总决赛吸引了很多球迷,但是因为时差,大家都在打比赛,我们也在努力。
是的,自己动手,ChromeDriver+HtmlAgilityPack爬取游戏实时比分。
概述
WebDriver 是对浏览器提供的原生 API 进行封装,使其成为更加面向对象的 Selenium WebDriver API。使用该API,您可以控制浏览器的打开和关闭,打开网页,操作界面元素,控制cookies,还可以操作浏览器截图,安装插件,设置代理,配置证书。
HtmlAgilityPack 是 .net 下的 HTML 解析库。支持使用 XPath 解析 HTML。这很有道理,为什么呢?因为一些功能强大的浏览器可以直接获取页面上元素的xpath,所以不需要手动编写。它节省了编写正则表达式的大部分时间。当然,在进一步获取的时候,有时需要写正则表达式,但是通过xpath解析后,要匹配的正则表达式的范围很小。此外,通过不使用正则表达式来匹配整个页面源代码,可以提高速度。总而言之,通过这个类库,先通过浏览器获取的xpath获取节点内容,再通过正则表达式匹配需要的内容,既提高了开发速度,又提高了运行效率。
代码
下面我们来看看如何使用ChromeDriver+HtmlAgilityPack来抓取游戏的实时比分。
爬网
string url = "https://sports.qq.com/kbsweb/game.htm?mid=" + model.TxMatchId;<br /><br /> // string url = "https://kbs.sports.qq.com/kbsw ... %3Bbr /> // MatchUpdate model = new MatchUpdate();<br /><br /> var cds = ChromeDriverService.CreateDefaultService();<br /> //是否应隐藏服务的命令提示符窗口<br /> cds.HideCommandPromptWindow = true;<br /><br /> ChromeOptions options = new ChromeOptions();<br /> options.AddArguments("--test-type", "--ignore-certificate-errors");<br /> // options.AddArguments("user-agent=mozilla/5.0 (linux; u; android 2.3.3; en-us; sdk build/ gri34) applewebkit/533.1 (khtml, like gecko) version/4.0 mobile safari/533.1");<br /> options.AddArgument("enable-automation");<br /><br /> // options.setBinary("C:/Program Files (x86)/Google/Chrome/chrome.exe");<br /><br /> var r = ZhimaHttpProxy.GetProxy(false);<br /> if (r != null)<br /> {<br /> Console.WriteLine(r.Address.Host);<br /> Console.WriteLine(r.Address.Port);<br /><br /> string proxy_Host = r.Address.Host;<br /> int proxy_Post = r.Address.Port;<br /> string Ex_Proxy_Name = "proxy.zip";<br /><br /> options.Proxy = null;<br /> options.AddArguments("--proxy-server=" + proxy_Host + ":" + proxy_Post.ToString());<br /> options.AddExtension(Ex_Proxy_Name);<br /> }<br /><br /> if (IsHideMode)<br /> options.AddArgument("headless");<br /><br /> string dic = System.Environment.CurrentDirectory + "\\cos";<br /><br /> if (IsHideMode)<br /> {<br /> using (IWebDriver driver = new OpenQA.Selenium.Chrome.ChromeDriver(cds, options, TimeSpan.FromSeconds(120)))<br /><br /> {<br /> Excule(driver, url, model);<br /> }<br /> }<br /> else<br /> {<br /> using (IWebDriver driver = new OpenQA.Selenium.Chrome.ChromeDriver(dic, options, TimeSpan.FromSeconds(120)))<br /><br /> {<br /> Excule(driver, url, model);<br /> }<br /> }
解析网页
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();<br /> doc.LoadHtml(Helper.ReadTxt(System.Environment.CurrentDirectory + "\\PageSource\\" + info.TxMatchId.Replace(":", "_") + ".txt"));<br /> int? HomeTeamScore = null;<br /> int? GuestTeamScore = null;<br /> List MatchScoreList = new List();<br /> HtmlNode titleNodes = doc.DocumentNode.SelectSingleNode("//div[@class='inner']");<br /> var titleNodes2 = doc.DocumentNode.SelectSingleNode("//div[@class='content-wrapper']");<br /> if (titleNodes2 != null)<br /> // if (false)<br /> {<br /> Console.WriteLine(titleNodes2.InnerText);<br /> var host = titleNodes2.SelectSingleNode("//div[@class='team-goal host']");<br /> var arr = host.InnerText.Replace("\r\n", "|");<br /> var arrs = arr.Split('|');<br /> arrs = arrs.Where(o => !string.IsNullOrWhiteSpace(o)).Select(o => o.Split('(')[0].Trim()).ToArray();<br /> HomeTeamScore = int.Parse(arrs[1]);<br /> MatchScoreList.Add(new MatchScore() { TeamName = arrs[0], TeamScore = HomeTeamScore });<br /><br /> var guest = titleNodes2.SelectSingleNode("//div[@class='team-goal guest']");<br /><br /> var arr2 = guest.InnerText.Replace("\r\n", "|");<br /> var arrs2 = arr2.Split('|');<br /> arrs2 = arrs2.Where(o => !string.IsNullOrWhiteSpace(o)).Select(o => o.Split('(')[0].Trim()).ToArray();<br /><br /> GuestTeamScore = int.Parse(arrs2[1]);<br /><br /> MatchScoreList.Add(new MatchScore() { TeamName = arrs2[0], TeamScore = GuestTeamScore });<br /> }<br /> else<br /> {<br /> var a = titleNodes.SelectNodes("//a[@data-target='teamName']");<br /> var score = titleNodes.SelectNodes("//span[@class='score']");<br /> if (score != null)<br /> {<br /> int i = 0;<br /> foreach (var item in score)<br /> {<br /> SetText("\r\n" + item.InnerText?.Trim());<br /> if (i == 0)<br /> {<br /> HomeTeamScore = Convert.ToInt32(item.InnerText?.Trim());<br /> }<br /> if (i == 1)<br /> {<br /> GuestTeamScore = Convert.ToInt32(item.InnerText?.Trim());<br /> }<br /><br /> i++;<br /> }<br /> }<br /><br /> if (a != null)<br /> {<br /> int i = 0;<br /> foreach (var item in a)<br /> {<br /> SetText("\r\n" + item.InnerText?.Trim());<br /><br /> if (i == 0)<br /> {<br /> MatchScoreList.Add(new MatchScore() { TeamName = item.InnerText?.Split('(')[0].Trim(), TeamScore = HomeTeamScore });<br /> }<br /> if (i == 1)<br /> {<br /> MatchScoreList.Add(new MatchScore() { TeamName = item.InnerText?.Split('(')[0].Trim(), TeamScore = GuestTeamScore });<br /> }<br /><br /> i++;<br /> }<br /> }<br /> }<br /><br /> string statusstr = "";<br /><br /> var t = titleNodes.SelectSingleNode("//div[@class='datetime-live-desc']");<br /> SetText("\r\n" + t.InnerText?.Trim());<br /> statusstr = t.InnerText?.Trim();<br /><br /> var Status = info.Status;<br /> if (!string.IsNullOrWhiteSpace(statusstr) && statusstr.Contains("已结束"))<br /> {<br /> Status = MatchStatus.End;<br /> }<br />
最后做一个小弹框,输出数据。
c#抓取网页数据(windows下C#定时管理器框架-Task.MainForm学习总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-14 05:22
我在博客公园呆了 4 年多。一直看别人的博客,学习别人的知识,支持所有默默贡献自己技术总结的朋友;这几天突然觉得是时候加入队列贡献自己的力量了,争取每个月都有不同的学习总结,分享知识学习文章。下面我要分享的是花了两天时间编写+测试的Windows下的C#时序管理器框架——Task.MainForm。
目的:
随着近五年来几家公司的.net开发者处于不同岗位,发现每家公司或多或少都会连接一些第三方的合作接口或者数据采集功能,这些都是和每一个服务直接无关的。功能,开发者可能并不孤单,所以winform或者winservice服务的版本越来越多,服务器上各种winform表单让不同行的人看起来很复杂;是的,这次的目的是我写了一个插件(其实就是winform哈哈),通过统一的封装和规范来管理这些程序服务。
介绍:
本版本使用4.5框架,其中使用了一些只有4.5及以上版本才能使用的东西。如果读者需要向后兼容,请使用下载的开源项目进行修改,应该是可以的;主要使用反射来执行业务方法;如果废话太多,就看下面的步骤。
重要代码说明:
A.首先框架的整体项目简单如下
好像很小,是的,看具体要求再补充吧,大家
B、基类TPlugin主要用于软件规则的统一管理。重要的区别是:
1.初始化配置信息
2.开始加载的_Load()方法,这里是所有任务开始执行的入口
C、类PublicClass主要封装了对*.dll文件路径信息的访问和程序集序列化继承实体。关键点已用红色标出:
1.
2.
D. 下面是时序管理器接口MainForm.cs的功能说明:
1.加载带有特定标签的程序dll信息
2.服务开启
3.异步委托增加manager监控信息
以上是框架的主要部分。也可以看作是一个知识点。也许哈哈。让我们看看如何编写继承这个框架的代码。简单粗暴如下:
E.继承插件的任务类,也就是我们需要处理的业务实现类
F. 值得注意的是,同一项目中的不同任务类是否继承框架或不同项目中的任务类都可以使用。建议使用前者,这样就不需要每次都有业务需求了,定期执行信息时,必须创建一个单独的项目。Task.MainForm 只需要你从同一个项目中的不同任务类继承即可:
这里两个继承类对应的配置文件的默认名称应该是:
xml文件结构参考模板:Task.MainForm项目中的XmlTp.xml文件(也可以以开源项目中Task.MainForm\bin\Debug\PluginXml文件夹下的两个.xml文件为例)
G. 最后在发布项目中贴出结构图
以上是开源时序管理器框架。很简单。第一次写技术文章。
项目的git地址:
以上就是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持朱贤飞。 查看全部
c#抓取网页数据(windows下C#定时管理器框架-Task.MainForm学习总结)
我在博客公园呆了 4 年多。一直看别人的博客,学习别人的知识,支持所有默默贡献自己技术总结的朋友;这几天突然觉得是时候加入队列贡献自己的力量了,争取每个月都有不同的学习总结,分享知识学习文章。下面我要分享的是花了两天时间编写+测试的Windows下的C#时序管理器框架——Task.MainForm。
目的:
随着近五年来几家公司的.net开发者处于不同岗位,发现每家公司或多或少都会连接一些第三方的合作接口或者数据采集功能,这些都是和每一个服务直接无关的。功能,开发者可能并不孤单,所以winform或者winservice服务的版本越来越多,服务器上各种winform表单让不同行的人看起来很复杂;是的,这次的目的是我写了一个插件(其实就是winform哈哈),通过统一的封装和规范来管理这些程序服务。
介绍:
本版本使用4.5框架,其中使用了一些只有4.5及以上版本才能使用的东西。如果读者需要向后兼容,请使用下载的开源项目进行修改,应该是可以的;主要使用反射来执行业务方法;如果废话太多,就看下面的步骤。
重要代码说明:
A.首先框架的整体项目简单如下
好像很小,是的,看具体要求再补充吧,大家
B、基类TPlugin主要用于软件规则的统一管理。重要的区别是:
1.初始化配置信息
2.开始加载的_Load()方法,这里是所有任务开始执行的入口
C、类PublicClass主要封装了对*.dll文件路径信息的访问和程序集序列化继承实体。关键点已用红色标出:
1.
2.
D. 下面是时序管理器接口MainForm.cs的功能说明:
1.加载带有特定标签的程序dll信息
2.服务开启
3.异步委托增加manager监控信息
以上是框架的主要部分。也可以看作是一个知识点。也许哈哈。让我们看看如何编写继承这个框架的代码。简单粗暴如下:
E.继承插件的任务类,也就是我们需要处理的业务实现类
F. 值得注意的是,同一项目中的不同任务类是否继承框架或不同项目中的任务类都可以使用。建议使用前者,这样就不需要每次都有业务需求了,定期执行信息时,必须创建一个单独的项目。Task.MainForm 只需要你从同一个项目中的不同任务类继承即可:
这里两个继承类对应的配置文件的默认名称应该是:
xml文件结构参考模板:Task.MainForm项目中的XmlTp.xml文件(也可以以开源项目中Task.MainForm\bin\Debug\PluginXml文件夹下的两个.xml文件为例)
G. 最后在发布项目中贴出结构图
以上是开源时序管理器框架。很简单。第一次写技术文章。
项目的git地址:
以上就是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持朱贤飞。
c#抓取网页数据(用C#的语言写了一个小程序-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-06 18:05
我用C#语言写了一个小程序,虽然不够专业,希望大家多多支持。
因为我对C#比较熟悉,而且C#有更好的交互界面,所以我选择使用C#语言来爬取网页中的数据。
1. 引用命名空间HtmlAgilityPack 代码引用命名空间HtmlAgilityPack,它是.NET下的HTML解析类库。
using HtmlAgilityPack;
2、读取静态网页的代码
HtmlWeb htmlWeb = new HtmlWeb();
HtmlAgilityPack.HtmlDocument doc = htmlWeb.Load("http://www.gdacs.org/");
3、要读取具体的网页信息,需要解析网页的源码如下图,想要得到红框的信息
右键检查元素,会出现下图所示界面,点击红框内的按钮,点击要获取的内容,就会定位到数据所在的代码,比如div类=“alert_EQ_Green”
,
解析获取元素
HtmlNodeCollection hrefList = doc.DocumentNode.SelectNodes(".//div[@class='alert_EQ_Green']");
希望对你有帮助 查看全部
c#抓取网页数据(用C#的语言写了一个小程序-上海怡健医学)
我用C#语言写了一个小程序,虽然不够专业,希望大家多多支持。
因为我对C#比较熟悉,而且C#有更好的交互界面,所以我选择使用C#语言来爬取网页中的数据。
1. 引用命名空间HtmlAgilityPack 代码引用命名空间HtmlAgilityPack,它是.NET下的HTML解析类库。
using HtmlAgilityPack;
2、读取静态网页的代码
HtmlWeb htmlWeb = new HtmlWeb();
HtmlAgilityPack.HtmlDocument doc = htmlWeb.Load("http://www.gdacs.org/";);
3、要读取具体的网页信息,需要解析网页的源码如下图,想要得到红框的信息
右键检查元素,会出现下图所示界面,点击红框内的按钮,点击要获取的内容,就会定位到数据所在的代码,比如div类=“alert_EQ_Green”
,
解析获取元素
HtmlNodeCollection hrefList = doc.DocumentNode.SelectNodes(".//div[@class='alert_EQ_Green']");
希望对你有帮助

