c#抓取网页数据(什么是抓取、收录网页抓取工具robots.txt文件介绍)
优采云 发布时间: 2021-09-17 09:14c#抓取网页数据(什么是抓取、收录网页抓取工具robots.txt文件介绍)
网站建成后,我们如何才能使搜索引擎收录网站?如果搜索引擎收录无法搜索该页面,则意味着没有显示,并且不可能竞争排名和获得SEO流量。本文将重点关注捕获和收录亮点,并从三个维度讨论搜索引擎优化:基本原理、常见问题和解决方案。什么是爬行,收录web爬行工具robots.txt文件介绍
如何查看网站的收录@
设置不被搜索引擎索引的网页
搜索引擎原理:搜索引擎将互联网上的网页内容存储在自己的服务器上。当用户搜索一个单词时,搜索引擎将在其自己的服务器上查找相关内容,即只搜索保存在搜索引擎服务器上的网页
哪些网页可以保存到搜索引擎服务器
只有搜索引擎捕获程序捕获的网页才会保存到搜索引擎的服务器。这个网页捕获程序是搜索引擎的蜘蛛。整个过程分为爬行和爬行
一、什么是抓取,收录
爬行:
这是搜索引擎爬虫在网站上爬行的过程。谷歌的官方解释是,“爬行”指的是找到新的或更新的网页并将其添加到谷歌的过程;(点击此处查看谷歌官方网站上的文档)
收录(索引):
这是搜索引擎将页面存储在其数据库中的结果,该数据库也称为索引。谷歌的官方解释是,谷歌爬虫(“谷歌机器人”)已经访问了该网页,分析了其内容和含义,并将其存储在谷歌索引中。索引网页可以显示在谷歌搜索结果;(点击此处查看谷歌官方网站上的文档)
预算:
是搜索引擎爬行器在网站页面上爬行的最长总时间。一般来说,小的网站(数百或数千页)不需要担心搜索引擎分配的爬网配额是否足够;大网站(数百万或数以百万计的页面)将考虑更多。如果搜索引擎每天抓取数万页,那么整个网站页面抓取可能需要几个月或一年的时间。一般来说,这些数据可以通过谷歌搜索控制台的后台学习。如下面的屏幕截图所示,红色框中的平均值是网站分配的抓取配额
让我们通过一个示例更好地了解爬网、收录和配额爬网:
将搜索引擎比作一个巨大的图书馆,网站比作一家书店,书店里的书比作网站页面,蜘蛛比作图书馆购买者
为了丰富图书馆的藏书,购买者会定期检查书店是否有新书。浏览书籍的过程可以理解为抓取
当买主认为这本书有价值时,他会买下来带回图书馆采集。这本书就是我们所说的收录
每个买家都有一个有限的购书预算。他将优先购买高价值的书籍。这个预算案就是我们所理解的“抢占配额”
二、web爬虫
“爬虫”是一个通用术语,通常指通过跟踪从一个网页到另一个网页的链接,在网站自动发现和扫描的任何程序(如漫游设备或“蜘蛛”程序)。谷歌的主要爬虫程序叫做谷歌机器人
三、robots.txt文件介绍
robots.txt文件指定爬行工具的爬行规则
robots.txt文件必须位于主机的顶级目录中
通常,robots.txt文件中有三种不同的爬行结果:
robots.txt的使用示例:网站目录中的所有文件都可以被所有搜索引擎爬行器访问。用户代理:*
Disallow:
禁止所有搜索引擎蜘蛛访问网站的任何部分
User-agent: *
Disallow: /
禁止所有的搜索引擎蜘蛛访问网站的几个目录
User-agent: *
Disallow: /a/
Disallow: /b/
只允许某个搜索引擎蜘蛛访问
User-agent: Googlebot
Disallow:
屏蔽所有带参数的 URL
User-agent: *
Disallow: /*?
您应该限制爬行器捕获网站某些文件:
一般来说,网站爬行器不需要捕获的文件包括后台管理文件、程序脚本、附件、数据库文件、编码文件、样式表文件、模板文件、导航图片和背景图片
robots.txt文件引起的风险和解决方案:
Robots.txt也带来了一些风险:它还向攻击者指示网站的目录结构和私有数据的位置。设置访问权限和密码以保护您的私人内容,使攻击者无法进入
四、如何查看收录或网站
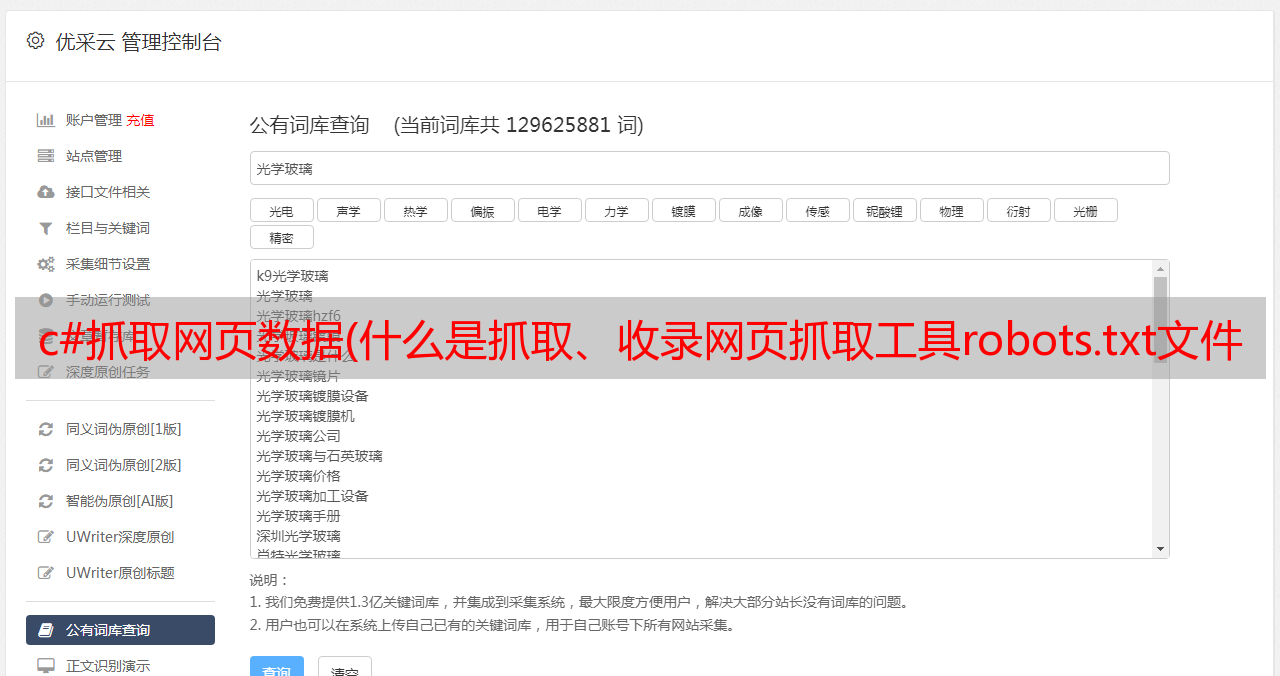
① 通过site命令
谷歌、百度和必应等主流搜索引擎支持站点命令。通过site命令,您可以查看在宏级别网站已经收录了多少页。该值不准确,有一定波动,但有一定参考价值。如下图所示,网站约为165页,由谷歌收录发布@
② 如果网站已经验证了谷歌搜索控制台,您可以获得网站验证Google收录的准确值显示在下面的红色框中,Google收录216页共网站页@
③ 如果要查询特定页面是否为收录,可以使用info命令。谷歌支持info命令,但百度和必应不支持。在谷歌中输入Info:URL。如果返回结果,则页面已被收录,如下图所示:
五、set不被搜索引擎索引的网页
建议使用robots meta标记,并将以下代码添加到head标记中:
可以选择多条指令,它们不区分大小写
全部
对索引或内容显示没有任何限制。此命令是默认命令,因此显式列出时无效
诺因迪斯
在搜索结果中不显示此页面。Nofollow不跟踪此页面上的链接
没有
相当于Noindex,nofollow。Noarchive不在搜索结果中显示缓存链接
nosnippet
不要在搜索结果中显示此页面的文本摘要或视频预览。如果静态图片缩略图(如果有)可以实现更好的用户体验,则仍然可以显示它们。这适用于所有形式的搜索结果(例如谷歌网页搜索、谷歌图片、谷歌探索)
最大代码段:[数字]
此搜索结果的文本摘要最多只能使用[number]个字符。(请注意,网址可能在搜索结果页面中显示为多个搜索结果。)这不会影响图片或视频预览。这适用于所有形式的搜索结果(例如谷歌网页搜索、谷歌图片、谷歌发现、谷歌助手)。但是,如果发布者已单独授予内容权限,则此限制不适用。例如,如果发布者以页面结构化数据的形式提供内容,或者与谷歌签订了许可协议,则此设置不会阻止这些更具体的允许使用。如果未指定可解析的[number],则忽略此指令
特殊值:
例如:
最大图像预览:[设置]
设置搜索结果中此页面图片预览的最大大小
可接受的设定值:
这适用于所有形式的搜索结果(例如谷歌网页搜索、谷歌图片、谷歌发现、谷歌助手)。但是,如果发布者已单独授予内容权限,则此限制不适用。例如,如果发布者以页内结构化数据的形式提供内容(如amp网页和文章的规范版本),或者与Google签订了许可协议,则此设置不会阻止这些更具体的允许使用
如果出版商不希望Google在搜索结果页面或“浏览”功能中文章显示其amp网页和规范版本时使用大缩略图,则应将Max image preview的值指定为“标准”或“无”
例如:
最大视频预览:[数字]
此页面上的视频在搜索结果中的摘要时间不能超过[number]秒
其他支持的值:
这适用于所有形式的搜索结果(例如谷歌网页搜索、谷歌图片、谷歌视频、谷歌发现、谷歌助手)。如果未指定可解析的[number],则忽略此指令
例如:
不翻译
不要在搜索结果中提供此页面的翻译
noimageindex
不要为此页上的图片编制索引
[日期/时间]之后不可用
在指定的日期/时间之后,不要在搜索结果中显示此页面。必须以广泛使用的格式指定日期/时间,包括但不限于RFC822、RFC 850和ISO 8601。如果未指定有效的[日期/时间],则忽略此指令。默认情况下,内容没有过期日期
例如:
参考资料:

