
网页源代码抓取工具
网页源代码抓取工具(使用直观的网页分析工具(Chrome开发者工具)对网页进行抓包分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-13 15:08
在本期文章中,我们将尝试使用直观的网页分析工具(Chrome Developer Tools)对网页进行抓取和分析,对网页爬虫的本质和内涵有更深入的了解
1、测试环境
浏览器:Chrome浏览器
浏览器版本:67.0.3396.99(正式版)(32位)
网络分析工具:开发者工具
2、网页分析
(1)网页源码解析
我们知道网页分为静态网页和动态网页。很多人误以为静态网页就是没有动态效果的网页。事实上,这种说法是错误的。静态网页是指没有后台数据库的非交互式网页。, .html, .xml 是后缀
动态网页是指可以与后台数据库传输数据的交互式网页,通常以.aspx、.asp、.jsp、.php为后缀
另外,目前很多动态网站都采用异步加载技术(Ajax),这也是为什么抓到的源码和网站显示的源码不一致的原因,至于怎么爬取动态网页,这里提供了两种方法:一种是通过抓包来分析Ajax请求,下面会讲到。
二是使用Selenium等工具进行动态渲染,可以参考我的另一篇文章文章——
下面以京东产品为例,分析如何通过Chrome抓包。我们先打开一个产品的首页
进入网页空白处,右键,选择查看网页源代码(或使用快捷键Ctrl+U直接打开)
请注意查看网页源代码获取的是网站最原创的源代码,通常是我们抓取的源代码
再次进入网页空白处,右键选择Inspect(或使用快捷键Ctrl+Shift+I/F12直接打开)
请注意,检查结果是通过Ajax加载并通过JavaScript渲染的源代码,也就是网站当前显示的内容的源代码
经过对比我们可以发现两者的内容是不一样的,这是异步加载技术(Ajax)的典型例子
目前,至少京东产品的价格是异步加载生成的。这里提供三种判断网页中的某个内容是否是动态生成的方法:一种是分析查看网页源代码生成的源代码,其中可以找到动态请求。也可以与检查生成的源代码进行比较
二是通过网页抓取的分析来判断,下面会解释。这种方法是最常用的,应该好好掌握。
第三种是比较刁钻的方法,就是禁用Chrome浏览器的JavaScript加载
您可以在 Chrome 的地址栏中输入
(2)网页抓取分析
下面以京东产品为例进行讲解,打开某款产品的首页,尝试抓取动态加载的产品价格数据
使用快捷键Ctrl+Shift+I或F12打开开发者工具,然后选择Network选项卡进行抓包分析
此时按快捷键F5刷新页面。可以看到开发者工具中出现了各种包。我们使用过滤器来过滤包。
首先,我们选择Doc,我们可以看到列表中只出现了一个包
一般来说,这是浏览器接收到的第一个获取请求原创源代码的数据包网站
点击Header查看其header参数设置
单击响应以查看返回的源代码。不难发现,其实和查看网页源码返回的信息是一样的。
让我们回到主题。对于抓包的动态加载分析,我们主要看XHR和JS选项卡。
选择JS进行过滤,发现列表中有很多包。经过分析,我们过滤掉下图中标记的包。
这个包返回了关于价格的信息,但是仔细分析后发现这些价格不属于当前产品,而是属于相关产品。
但是怎么说这个包还是跟价格有关,我们先来看看这个包的请求URL。
%2CJ_26395831446%2CJ_20823451030%2CJ_%2CJ_%2CJ_26498549638&ext=11100000&source=item-pc
过滤包括回调在内的不必要参数以获得简单有效的URL
%2CJ_26395831446%2CJ_20823451030%2CJ_%2CJ_%2CJ_26498549638
直接用浏览器打开网址,可以看到返回的JSON数据中收录价格信息(可惜是其他商品的价格)
通过分析URL的参数,可以推断出skuId应该是每个产品的唯一标识,那么在哪里可以找到我们需要的产品的skuId呢?实际上,SKU是物流、运输等行业常用的缩写。它的全称是Stock Keeping Unit,是库存进出计量的基本单位。现已扩展为统一产品编号的缩写。每个产品都有一个独特的 SKU
这不是隐藏了当前产品的唯一编号标识符()吗?试一试!
通过直接访问这个网址,我们可以得到当前产品的价格信息
其实我们也可以适当的泛化URL来适应京东所有产品的价格爬取
通过泛化的URL,理论上只要能获取到产品的skuId,我们就可以访问到对应产品的价格 查看全部
网页源代码抓取工具(使用直观的网页分析工具(Chrome开发者工具)对网页进行抓包分析)
在本期文章中,我们将尝试使用直观的网页分析工具(Chrome Developer Tools)对网页进行抓取和分析,对网页爬虫的本质和内涵有更深入的了解
1、测试环境
浏览器:Chrome浏览器
浏览器版本:67.0.3396.99(正式版)(32位)
网络分析工具:开发者工具
2、网页分析
(1)网页源码解析
我们知道网页分为静态网页和动态网页。很多人误以为静态网页就是没有动态效果的网页。事实上,这种说法是错误的。静态网页是指没有后台数据库的非交互式网页。, .html, .xml 是后缀
动态网页是指可以与后台数据库传输数据的交互式网页,通常以.aspx、.asp、.jsp、.php为后缀
另外,目前很多动态网站都采用异步加载技术(Ajax),这也是为什么抓到的源码和网站显示的源码不一致的原因,至于怎么爬取动态网页,这里提供了两种方法:一种是通过抓包来分析Ajax请求,下面会讲到。
二是使用Selenium等工具进行动态渲染,可以参考我的另一篇文章文章——
下面以京东产品为例,分析如何通过Chrome抓包。我们先打开一个产品的首页
进入网页空白处,右键,选择查看网页源代码(或使用快捷键Ctrl+U直接打开)
请注意查看网页源代码获取的是网站最原创的源代码,通常是我们抓取的源代码
再次进入网页空白处,右键选择Inspect(或使用快捷键Ctrl+Shift+I/F12直接打开)
请注意,检查结果是通过Ajax加载并通过JavaScript渲染的源代码,也就是网站当前显示的内容的源代码
经过对比我们可以发现两者的内容是不一样的,这是异步加载技术(Ajax)的典型例子
目前,至少京东产品的价格是异步加载生成的。这里提供三种判断网页中的某个内容是否是动态生成的方法:一种是分析查看网页源代码生成的源代码,其中可以找到动态请求。也可以与检查生成的源代码进行比较
二是通过网页抓取的分析来判断,下面会解释。这种方法是最常用的,应该好好掌握。
第三种是比较刁钻的方法,就是禁用Chrome浏览器的JavaScript加载
您可以在 Chrome 的地址栏中输入
(2)网页抓取分析
下面以京东产品为例进行讲解,打开某款产品的首页,尝试抓取动态加载的产品价格数据
使用快捷键Ctrl+Shift+I或F12打开开发者工具,然后选择Network选项卡进行抓包分析
此时按快捷键F5刷新页面。可以看到开发者工具中出现了各种包。我们使用过滤器来过滤包。
首先,我们选择Doc,我们可以看到列表中只出现了一个包
一般来说,这是浏览器接收到的第一个获取请求原创源代码的数据包网站
点击Header查看其header参数设置
单击响应以查看返回的源代码。不难发现,其实和查看网页源码返回的信息是一样的。
让我们回到主题。对于抓包的动态加载分析,我们主要看XHR和JS选项卡。
选择JS进行过滤,发现列表中有很多包。经过分析,我们过滤掉下图中标记的包。
这个包返回了关于价格的信息,但是仔细分析后发现这些价格不属于当前产品,而是属于相关产品。
但是怎么说这个包还是跟价格有关,我们先来看看这个包的请求URL。
%2CJ_26395831446%2CJ_20823451030%2CJ_%2CJ_%2CJ_26498549638&ext=11100000&source=item-pc
过滤包括回调在内的不必要参数以获得简单有效的URL
%2CJ_26395831446%2CJ_20823451030%2CJ_%2CJ_%2CJ_26498549638
直接用浏览器打开网址,可以看到返回的JSON数据中收录价格信息(可惜是其他商品的价格)
通过分析URL的参数,可以推断出skuId应该是每个产品的唯一标识,那么在哪里可以找到我们需要的产品的skuId呢?实际上,SKU是物流、运输等行业常用的缩写。它的全称是Stock Keeping Unit,是库存进出计量的基本单位。现已扩展为统一产品编号的缩写。每个产品都有一个独特的 SKU
这不是隐藏了当前产品的唯一编号标识符()吗?试一试!
通过直接访问这个网址,我们可以得到当前产品的价格信息
其实我们也可以适当的泛化URL来适应京东所有产品的价格爬取
通过泛化的URL,理论上只要能获取到产品的skuId,我们就可以访问到对应产品的价格
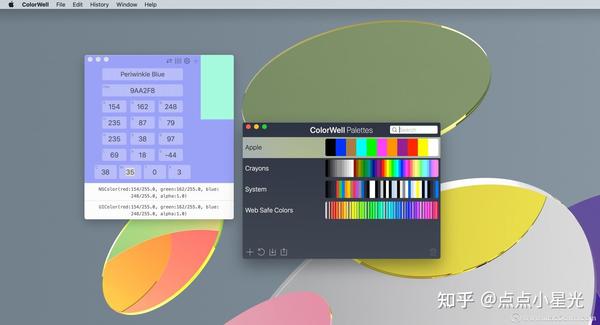
网页源代码抓取工具(ColorWell分享ColorWellmac破解版破解版破解版破解版破解版下载 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-13 15:06
)
ColorWell for mac 是一款可以非常轻松地生成无限调色板的软件,您可以从任何颜色源快速获取 Hex/HSL/HSB/RGB 和代码片段。如果您从未从源(或多源)图像快速生成调色板,那么调色板生成器就是您所需要的。您还可以将您生成的任何调色板保存在 ColorWell 调色板数据库中!本站分享ColorWell mac破解版下载。本软件测试环境为10.15.7系统!
Colorwell mac破解版软件功能
主要特征
调色板与 macOS 系统调色板同步
导入/导出 Adobe .ase 和 Apple .clr 调色板文件
无限的历史/快照
完全可定制的界面
Swift/Objective-C 颜色代码生成
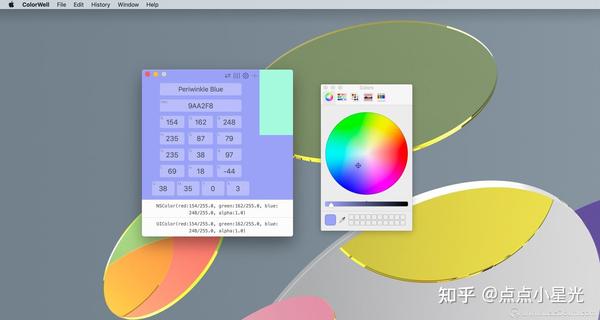
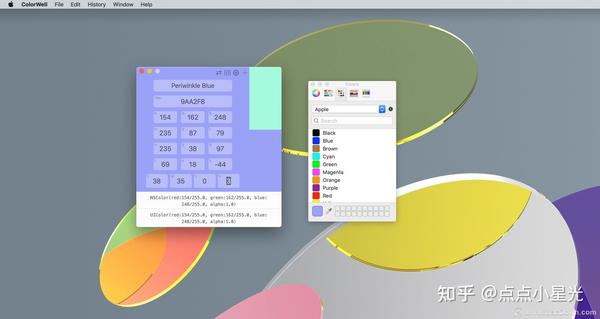
支持按名称、十六进制、RGB、HSL、HSB、Lab 和 CMYK 更改颜色
从图像生成调色板
配色方案生成器
可配置为菜单栏应用
其他一些很酷的东西
macOS Mojave 准备好支持 DarkMode
可以配置为浮动在所有其他应用程序的前面
美观直观的用户界面
轻松更改首选项中的默认色彩空间
全局热键即时显示或隐藏
17,000 多个颜色名称
通过拖放重新排列/删除样本
本地化为英语、德语和法语
Colorwell mac破解版软件功能
系统范围的调色板
ColorWell 使用 macOS 系统颜色选择器来同步调色板。因此,您可以在 Pages、Affinity Photo、Final Cut Pro 或任何其他一流的 macOS 应用程序中使用所有精心设计的配色方案!所有系统调色板也可用于查看和创建自定义调色板。
专业文件支持
ColorWell 支持导入和导出到 Adobe .ase 和 Apple .clr 文件格式。这使得分享您的配色方案比以往任何时候都更容易。使用 ColorWell 的通用调色板数据库,任何导入的方案自然会直接导入到 macOS 的颜色选择器中,使其广泛适用于系统
完整的历史支持
您所做的每一次颜色更改都会保存到历史记录中。因此,即使您不记得 3 天前检查的是什么颜色 - ColorWell 也可以!历史支持不限于单一颜色,每次更改都会保存整个颜色状态。因此,当您需要时,当前活动的颜色以及任何已保存的色板都会出现。
高级调色板生成
使用存储的调色板作为起点微调各个颜色。从调色板生成器中获取互补色、类似色、三色、四色或单色。从图像中翻转颜色并微调颜色选择。您可以使用无限数量的样本创建调色板。
ColorWell for mac 更改日志
荷兰本地化
查看全部
网页源代码抓取工具(ColorWell分享ColorWellmac破解版破解版破解版破解版破解版下载
)
ColorWell for mac 是一款可以非常轻松地生成无限调色板的软件,您可以从任何颜色源快速获取 Hex/HSL/HSB/RGB 和代码片段。如果您从未从源(或多源)图像快速生成调色板,那么调色板生成器就是您所需要的。您还可以将您生成的任何调色板保存在 ColorWell 调色板数据库中!本站分享ColorWell mac破解版下载。本软件测试环境为10.15.7系统!

Colorwell mac破解版软件功能
主要特征
调色板与 macOS 系统调色板同步
导入/导出 Adobe .ase 和 Apple .clr 调色板文件
无限的历史/快照
完全可定制的界面
Swift/Objective-C 颜色代码生成
支持按名称、十六进制、RGB、HSL、HSB、Lab 和 CMYK 更改颜色
从图像生成调色板
配色方案生成器
可配置为菜单栏应用

其他一些很酷的东西
macOS Mojave 准备好支持 DarkMode
可以配置为浮动在所有其他应用程序的前面
美观直观的用户界面
轻松更改首选项中的默认色彩空间
全局热键即时显示或隐藏
17,000 多个颜色名称
通过拖放重新排列/删除样本
本地化为英语、德语和法语
Colorwell mac破解版软件功能
系统范围的调色板
ColorWell 使用 macOS 系统颜色选择器来同步调色板。因此,您可以在 Pages、Affinity Photo、Final Cut Pro 或任何其他一流的 macOS 应用程序中使用所有精心设计的配色方案!所有系统调色板也可用于查看和创建自定义调色板。
专业文件支持
ColorWell 支持导入和导出到 Adobe .ase 和 Apple .clr 文件格式。这使得分享您的配色方案比以往任何时候都更容易。使用 ColorWell 的通用调色板数据库,任何导入的方案自然会直接导入到 macOS 的颜色选择器中,使其广泛适用于系统
完整的历史支持
您所做的每一次颜色更改都会保存到历史记录中。因此,即使您不记得 3 天前检查的是什么颜色 - ColorWell 也可以!历史支持不限于单一颜色,每次更改都会保存整个颜色状态。因此,当您需要时,当前活动的颜色以及任何已保存的色板都会出现。
高级调色板生成
使用存储的调色板作为起点微调各个颜色。从调色板生成器中获取互补色、类似色、三色、四色或单色。从图像中翻转颜色并微调颜色选择。您可以使用无限数量的样本创建调色板。
ColorWell for mac 更改日志
荷兰本地化


网页源代码抓取工具(如何应对数据匮乏?最简单的方法在这里!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-13 15:04
介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!想要获得更多数据来训练我们的机器学习模型是一个持续存在的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吧?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络抓取。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 中采集数据。今天,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这就是网络抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将了解网页抓取的不同组件,然后直接深入 Python 以了解如何使用流行且高效的 BeautifulSoup 库执行网页抓取。
请注意,网络抓取受许多准则和规则的约束。并非每个 网站 都允许用户抓取内容,因此存在法律限制。在尝试执行此操作之前,请确保您已阅读 网站 的网站 条款和条件。
3 个流行的 Python 网络爬虫工具和库 用于网络爬虫的组件 爬网解析和转换 网页抓取 URL 和电子邮件 ID 抓取图像 在页面加载时抓取数据 3 个流行的 Python 网络爬虫工具和库
您将在 Python 中遇到几个用于 Web 抓取的库和框架。以下是三种用于高效完成工作的流行工具:
美丽汤
刮擦
硒
网络爬虫的组成部分
这是构成网络抓取的三个主要组件的绝佳说明:
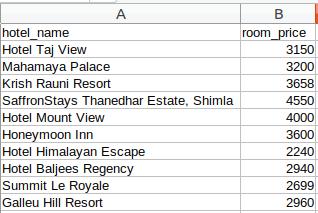
让我们详细了解这些组件。我们将通过 goibibo网站 获取酒店详细信息,例如酒店名称和每间客房的价格以执行此操作:
注意:始终遵循目标 网站 的 robots.txt 文件,也称为机器人排除协议。这告诉网络机器人不要抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴为我们的网络机器人编写脚本。开始吧!
第 1 步:抓取(抓取)
网页抓取的第一步是导航到目标 网站 并下载网页的源代码。我们将使用 requests 库来执行此操作。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页的源代码后,我们需要过滤我们想要的内容:
"""Web Scraping - Beautiful Soup"""# importing required librariesimport requestsfrom bs4 import BeautifulSoupimport pandas as pd# target URL to scrapurl = "https://www.goibibo.com/hotels ... 3B%23 headersheaders = { 'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36" }# send request to download the dataresponse = requests.request("GET", url, headers=headers)# parse the downloaded datadata = BeautifulSoup(response.text, 'html.parser')print(data)
第 2 步:解析和转换
网页抓取的下一步是将这些数据解析为 HTML 解析器,为此我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,与大多数页面一样,特定酒店的详细信息在不同的卡片上。
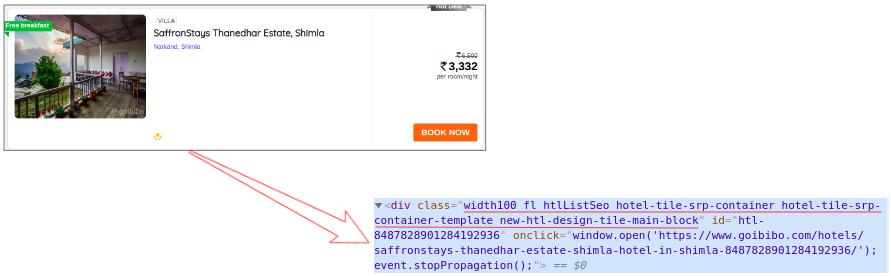
所以下一步是从完整的源代码中过滤卡片数据。接下来,我们将选择该卡并单击“检查元素”选项以获取该特定卡的源代码。你会得到这样的东西:
所有卡片都有相同的类名,我们可以通过传递标签名称和具有如下名称的属性(如标签)来获取这些卡片的列表:
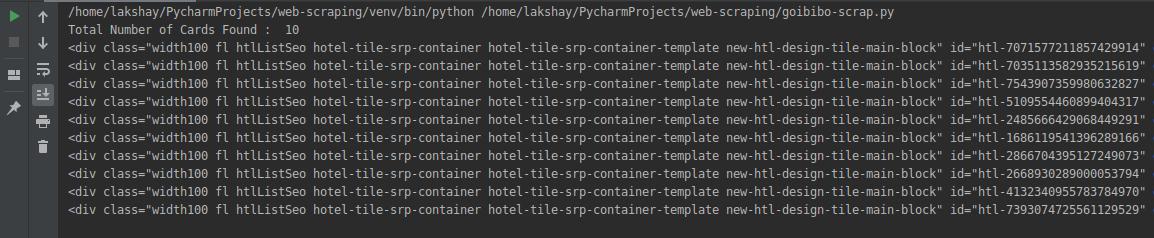
# find all the sections with specifiedd class namecards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})# total number of cardsprint('Total Number of Cards Found : ', len(cards_data))# source code of hotel cardsfor card in cards_data: print(card)
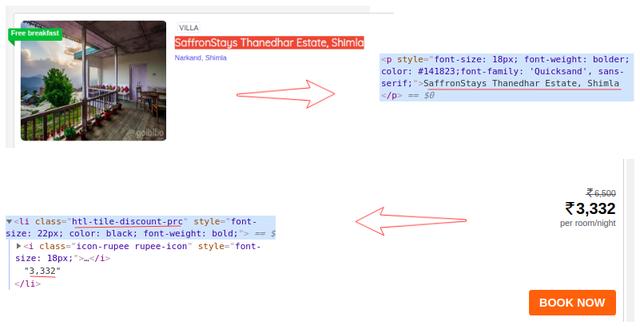
我们从网页的完整源代码中过滤掉了卡片数据,其中每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在对于每张卡,我们必须找到上面的酒店名称,只能从
从标签中提取。这是因为每张卡和费率只有一个标签和标签和类别名称:
# extract the hotel name and price per roomfor card in cards_data: # get the hotel name hotel_name = card.find('p') # get the room price room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'}) print(hotel_name.text, room_price.text)
第三步:存储(存储数据)
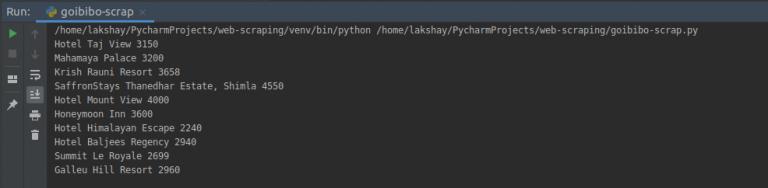
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后我们最终将它添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the datascraped_data = []for card in cards_data: # initialize the dictionary card_details = {} # get the hotel name hotel_name = card.find('p') # get the room price room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'}) # add data to the dictionary card_details['hotel_name'] = hotel_name.text card_details['room_price'] = room_price.text # append the scraped data to the list scraped_data.append(card_details)# create a data frame from the list of dictionariesdataFrame = pd.DataFrame.from_dict(scraped_data)# save the scraped data as CSV filedataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络抓取工具。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的评级和地址。现在,让我们看看如何执行一些常见任务,例如在页面加载时抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试通过网络抓取来抓取的两个最常见的功能是 网站URL 和电子邮件 ID。我确定您参与过需要大量提取电子邮件 ID 的项目或挑战。那么让我们看看如何在 Python 中抓取这些内容。
使用 Web 浏览器的控制台 查看全部
网页源代码抓取工具(如何应对数据匮乏?最简单的方法在这里!!)
介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!想要获得更多数据来训练我们的机器学习模型是一个持续存在的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吧?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络抓取。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 中采集数据。今天,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。

但有时您可能需要从不提供特定 API 的 网站 采集数据。这就是网络抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将了解网页抓取的不同组件,然后直接深入 Python 以了解如何使用流行且高效的 BeautifulSoup 库执行网页抓取。
请注意,网络抓取受许多准则和规则的约束。并非每个 网站 都允许用户抓取内容,因此存在法律限制。在尝试执行此操作之前,请确保您已阅读 网站 的网站 条款和条件。
3 个流行的 Python 网络爬虫工具和库 用于网络爬虫的组件 爬网解析和转换 网页抓取 URL 和电子邮件 ID 抓取图像 在页面加载时抓取数据 3 个流行的 Python 网络爬虫工具和库
您将在 Python 中遇到几个用于 Web 抓取的库和框架。以下是三种用于高效完成工作的流行工具:
美丽汤
刮擦
硒
网络爬虫的组成部分
这是构成网络抓取的三个主要组件的绝佳说明:
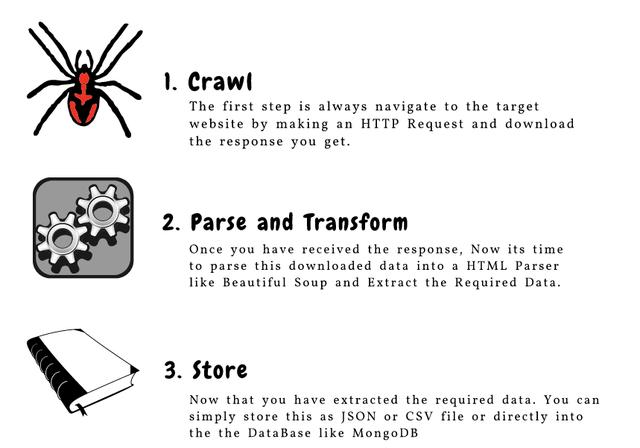
让我们详细了解这些组件。我们将通过 goibibo网站 获取酒店详细信息,例如酒店名称和每间客房的价格以执行此操作:
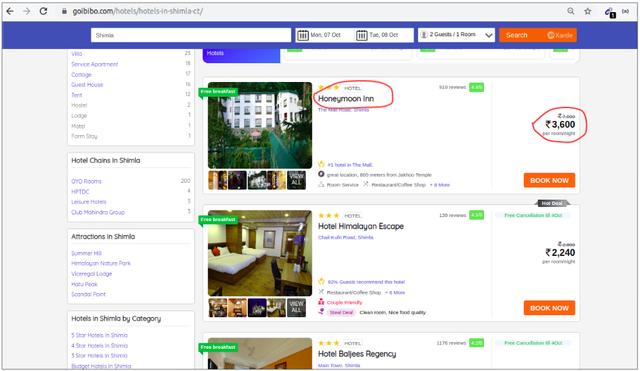
注意:始终遵循目标 网站 的 robots.txt 文件,也称为机器人排除协议。这告诉网络机器人不要抓取哪些页面。
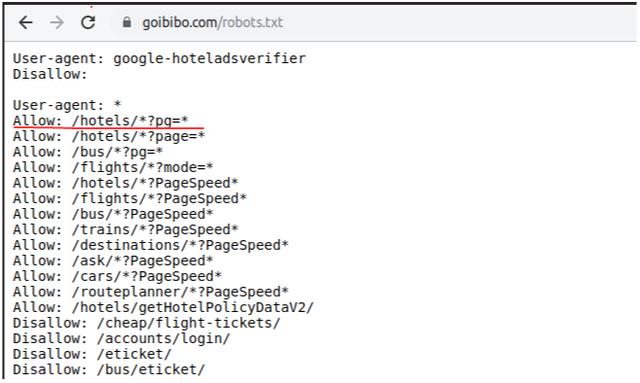
因此,我们可以从目标 URL 中抓取数据。我们很高兴为我们的网络机器人编写脚本。开始吧!
第 1 步:抓取(抓取)
网页抓取的第一步是导航到目标 网站 并下载网页的源代码。我们将使用 requests 库来执行此操作。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页的源代码后,我们需要过滤我们想要的内容:
"""Web Scraping - Beautiful Soup"""# importing required librariesimport requestsfrom bs4 import BeautifulSoupimport pandas as pd# target URL to scrapurl = "https://www.goibibo.com/hotels ... 3B%23 headersheaders = { 'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36" }# send request to download the dataresponse = requests.request("GET", url, headers=headers)# parse the downloaded datadata = BeautifulSoup(response.text, 'html.parser')print(data)
第 2 步:解析和转换
网页抓取的下一步是将这些数据解析为 HTML 解析器,为此我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,与大多数页面一样,特定酒店的详细信息在不同的卡片上。
所以下一步是从完整的源代码中过滤卡片数据。接下来,我们将选择该卡并单击“检查元素”选项以获取该特定卡的源代码。你会得到这样的东西:
所有卡片都有相同的类名,我们可以通过传递标签名称和具有如下名称的属性(如标签)来获取这些卡片的列表:
# find all the sections with specifiedd class namecards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})# total number of cardsprint('Total Number of Cards Found : ', len(cards_data))# source code of hotel cardsfor card in cards_data: print(card)
我们从网页的完整源代码中过滤掉了卡片数据,其中每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在对于每张卡,我们必须找到上面的酒店名称,只能从
从标签中提取。这是因为每张卡和费率只有一个标签和标签和类别名称:
# extract the hotel name and price per roomfor card in cards_data: # get the hotel name hotel_name = card.find('p') # get the room price room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'}) print(hotel_name.text, room_price.text)
第三步:存储(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后我们最终将它添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the datascraped_data = []for card in cards_data: # initialize the dictionary card_details = {} # get the hotel name hotel_name = card.find('p') # get the room price room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'}) # add data to the dictionary card_details['hotel_name'] = hotel_name.text card_details['room_price'] = room_price.text # append the scraped data to the list scraped_data.append(card_details)# create a data frame from the list of dictionariesdataFrame = pd.DataFrame.from_dict(scraped_data)# save the scraped data as CSV filedataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络抓取工具。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的评级和地址。现在,让我们看看如何执行一些常见任务,例如在页面加载时抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试通过网络抓取来抓取的两个最常见的功能是 网站URL 和电子邮件 ID。我确定您参与过需要大量提取电子邮件 ID 的项目或挑战。那么让我们看看如何在 Python 中抓取这些内容。
使用 Web 浏览器的控制台
网页源代码抓取工具(百度首页没有模块的作用及解决办法(二):导入requests模块)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-12 20:09
请求模块:
在做这件事之前,你需要先了解一下,requests 模块是什么?
requests的底层实现是urllib,通过爬虫运行!
在python中,我们需要使用第三方库requests来发送网络请求
所以requests模块的作用就是发送网络请求并返回响应数据
接下来就是下载了:使用:pip install requests -i 命令下载(注:这里下载有问题的可以私聊我,教你如何下载成功!)
具体步骤:
0:导入请求模块
导入请求
1:确定网址
在爬取网页之前,必须要做的是确定要爬取的网页;
我们要的百度web域名是/
保存在变量中
网址='/'
2:发送请求
这一步主要是获取上一步的URL中的数据
我们开始使用 requests 模块中的 get 方法来获取 URL 网页数据并保存在 response 变量中
接下来需要将类型转换为使用文本和内容转换为字符串和字节类型
response=request.get(url) #注意:这里的响应不是数据
print(response) #可以试试用print看看是什么数据
str_data=response.text #转换为字符串类型
bytes_data=response.content #转换为字节类型
#Crawler 爱好者可以尝试打印他们的类型以及变量中的内容是什么?
3:提取数据(略)
有很多方法可以做到这一点,但在这里列出是因为它是重要的一步。
抓取百度主页的时候不需要过滤百度主页的数据,所以就省略了~
想跟我学习的朋友,关注我,一起学习吧!每天加油~
4:保存数据
很明显,保存数据就是把你从网页上抓取的数据保存到你的电脑上。
用 open("baidu_01.html",'w',encoding="UTF-8") as f:
f.write(str_data)
with open("baidu_02.html",'wb') as f:
f.write(bytes_data)
使用 open("filename","identifier"",encoding="UTF-8")) 作为 f:
f.write(需要存入文件的变量名)
可以理解为一种简单的语法格式,放上去就行了。
在标识符中:分为w和wb,分别是string和byte类型。不同的是wb下载保存的网页没有乱码。因为网页是字节类型的。
笔记:
文件操作:使用 open 进行文件操作,建议使用 with 创建运行时环境。您可以在不使用 close() 方法的情况下关闭文件。无论您在文件使用过程中遇到什么问题,都可以安全退出。即使发生错误,您也可以退出运行时环境。可以安全地退出文件并给出错误信息。
with创建临时运行环境的作用:with用于创建临时运行环境,运行环境中的代码执行完毕后自动安全退出环境。
最后给大家一个源码:
导入请求
网址='/'
响应=requests.get(url)
str_data=response.text
bytes_data=response.content
with open("baidu_01.html",'w',encoding="utf-8")as f:
f.write(str_data)
with open("baidu_02.html",'wb') as f:
f.write(bytes_data)
———————————————
版权声明:本文为CSDN博主“Systemer~Fred”的原创文章,遵循CC4.0 BY-SA版权协议。转载请附上原文出处链接和本声明。
原文链接:简单爬虫案例:抓取百度首页(通俗易懂,附源码)-Systemer~Fred的博客-CSDN博客 查看全部
网页源代码抓取工具(百度首页没有模块的作用及解决办法(二):导入requests模块)
请求模块:
在做这件事之前,你需要先了解一下,requests 模块是什么?
requests的底层实现是urllib,通过爬虫运行!
在python中,我们需要使用第三方库requests来发送网络请求
所以requests模块的作用就是发送网络请求并返回响应数据
接下来就是下载了:使用:pip install requests -i 命令下载(注:这里下载有问题的可以私聊我,教你如何下载成功!)
具体步骤:
0:导入请求模块
导入请求
1:确定网址
在爬取网页之前,必须要做的是确定要爬取的网页;
我们要的百度web域名是/
保存在变量中
网址='/'
2:发送请求
这一步主要是获取上一步的URL中的数据
我们开始使用 requests 模块中的 get 方法来获取 URL 网页数据并保存在 response 变量中
接下来需要将类型转换为使用文本和内容转换为字符串和字节类型
response=request.get(url) #注意:这里的响应不是数据
print(response) #可以试试用print看看是什么数据
str_data=response.text #转换为字符串类型
bytes_data=response.content #转换为字节类型
#Crawler 爱好者可以尝试打印他们的类型以及变量中的内容是什么?
3:提取数据(略)
有很多方法可以做到这一点,但在这里列出是因为它是重要的一步。
抓取百度主页的时候不需要过滤百度主页的数据,所以就省略了~
想跟我学习的朋友,关注我,一起学习吧!每天加油~
4:保存数据
很明显,保存数据就是把你从网页上抓取的数据保存到你的电脑上。
用 open("baidu_01.html",'w',encoding="UTF-8") as f:
f.write(str_data)
with open("baidu_02.html",'wb') as f:
f.write(bytes_data)
使用 open("filename","identifier"",encoding="UTF-8")) 作为 f:
f.write(需要存入文件的变量名)
可以理解为一种简单的语法格式,放上去就行了。
在标识符中:分为w和wb,分别是string和byte类型。不同的是wb下载保存的网页没有乱码。因为网页是字节类型的。
笔记:
文件操作:使用 open 进行文件操作,建议使用 with 创建运行时环境。您可以在不使用 close() 方法的情况下关闭文件。无论您在文件使用过程中遇到什么问题,都可以安全退出。即使发生错误,您也可以退出运行时环境。可以安全地退出文件并给出错误信息。
with创建临时运行环境的作用:with用于创建临时运行环境,运行环境中的代码执行完毕后自动安全退出环境。
最后给大家一个源码:
导入请求
网址='/'
响应=requests.get(url)
str_data=response.text
bytes_data=response.content
with open("baidu_01.html",'w',encoding="utf-8")as f:
f.write(str_data)
with open("baidu_02.html",'wb') as f:
f.write(bytes_data)
———————————————
版权声明:本文为CSDN博主“Systemer~Fred”的原创文章,遵循CC4.0 BY-SA版权协议。转载请附上原文出处链接和本声明。
原文链接:简单爬虫案例:抓取百度首页(通俗易懂,附源码)-Systemer~Fred的博客-CSDN博客
网页源代码抓取工具(强大易用!新一代爬虫利器Playwright的介绍目录(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 733 次浏览 • 2022-01-12 11:03
)
官方文档:入门 | 剧作家蟒蛇
参考链接:功能强大,好用!新一代爬虫工具Playwright介绍
内容
安装
Playwrigth 会安装 Chromium、Firefox 和 WebKit 浏览器并配置一些驱动程序,我们不需要关心中间的配置过程,Playwright 会为我们配置。
pip install playwright
# 安装完后初始化
playwright install
基本用途
打开浏览器,跳转到百度网页,打印标题;设置headless参数为False,表示显示浏览器界面。
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
rowser = browser_type.launch(headless=False)
page = browser.new_page()
page.goto('https://www.baidu.com')
print(page.title())
browser.close()
代码生成
我们可以在浏览器中记录我们的操作并自动生成代码,可以在爬虫中进行点击、跳转、鼠标移动等自动化操作。
当有些步骤不知道怎么写时,自动生成代码引用很方便。
在指定路径输入命令,会弹出对应的窗口,可以开始手动操作,会生成代码,但是操作有点复杂,好像自动生成不成功。
playwright codegen -o script.py
启动一个谷歌浏览器,然后将运行结果输出到script.py文件,生成代码如下图。
以下代码,打开茶语网,点击【茶语评论】,会打开一个新窗口跳转过去。
from playwright.sync_api import Playwright, sync_playwright
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
# Open new page
page = context.new_page()
# Go to https://www.chayu.com/
page.goto("https://www.chayu.com/")
# Click #sub-nav >> text=茶评
# 由于弹出新窗口,需要等待,这里就是自动等待页面加载
# 点击茶评,等待页面加载
with page.expect_popup() as popup_info:
# 就页面的操作都可以在这里面继续加
page.click("#sub-nav >> text=茶评")
page1 = popup_info.value # 赋值新窗口对象
# Close page
page.close()
# Close page
page1.close()
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)
AJAX动态加载数据获取
获取动态加载的数据,需要注意浏览器需要在上面显示动态加载的页面才能提取出来,例如:获取评论数据,ajax加载,打开页面:
如果打开页面直接提取评论数据,是无法提取的。您需要将数据滑动到页面上然后提取它(它已经死了)
事件监听器
Page对象提供了一个on方法,可以用来监控页面中发生的各种事件,如关闭、控制台、加载、请求、响应等。
您可以收听响应事件。每次响应网络请求时都可以触发响应事件。我们可以设置相应的回调方法。
可以和ajax结合使用,获取数据,拦截Ajax请求,输出对应的JSON结果。
from playwright.sync_api import sync_playwright
def on_response(response):
if '/api/movie/' in response.url and response.status == 200:
print(response.json())
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.on('response', on_response)
page.goto('https://spa6.scrape.center/')
page.wait_for_load_state('networkidle')
browser.close()
不加载图像
调用route方法,第一个参数通过正则表达式传入匹配的URL路径。这表示任何收录 .png 或 .jpg 的链接。当遇到这样的请求时,会回调cancel_request方法进行处理。cancel_request 方法可以接收两个参数,一个是 route,代表 CallableRoute 对象,另一个是 request,代表 Request 对象。这里我们直接调用路由的abort方法取消请求,所以最终的结果就是图片的加载完全取消了
from playwright.sync_api import sync_playwright
import re
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
# 不加载图片
def cancel_request(route, request):
route.abort()
page.route(re.compile(r"(\.png)|(\.jpg)"), cancel_request)
page.goto("https://spa6.scrape.center/")
page.wait_for_load_state('networkidle')
page.screenshot(path='no_picture.png')
browser.close()
CSS 选择器、文本选择器、click()
click 方法中有一个选择器表达式。解压点击后,可以设置超时时间。默认值为 30 秒,设置以毫秒为单位。如果等待5秒后点击不成功,报错timeout=5000
# 选择文本是 Log in 的节点,并点击
page.click("text=Log in",timeout=5000)
# 选择 id 为 nav-bar 子孙节点 class 属性值为 contact-us-item,并点击
page.click("#nav-bar .contact-us-item")
# 选择文本中包含 Playwright 的 article 节点
page.click("article:has-text('Playwright')")
# 选择 id 为 nav-bar 节点中文本值等于 Contact us 的节点
page.click("#nav-bar :text('Contact us')")
# 选择 class 为 item-description 的节点,且该节点还要包含 class 为 item-promo-banner 的子节点
page.click(".item-description:has(.item-promo-banner)")
# 择的就是一个 input 节点,并且该 input 节点要位于文本值为 Username 的节点的右侧
page.click("input:right-of(:text('Username'))")
xpath 选择器
您需要在开头指定 xpath= 字符串,这意味着它后面是一个 XPath 表达式
page.click("xpath=//button")
获取网页源代码
此处获取的网页源代码,不管网页是否通过ajax加载,都是为了获取最终的html。
任何需要对 html 中的元素进行操作的 page.wait_for_load_state('networkidle') 都必须写入等待 html 加载。
page.wait_for_load_state('networkidle')
html = page.content()
文本输入
在输入标签名称属性是 wd 输入 nba
page.fill("input[name=\"wd\"]", "nba")
选择提取选项卡
提取所有class属性为list的div标签
elements = page.query_selector_all('div.list')
提取span标签的class属性作为score,如果有多个匹配,取第一个
score = element.query_selector('span.score')
提取文本
提取带有文本[Brand:]的标签,并提取标签下的所有文本
brand = element.query_selector('text=品牌:').text_content()
从标签中提取属性
提取h5标签下的a标签,得到a标签中href属性的值
link = element.query_selector('h5 a').get_attribute('href')
鼠标滚动
向右滚动0,向下滚动7000,可用于下拉滚动条功能
page1.mouse.wheel(0,7000)
下拉滚动条
执行js代码,下拉滚动条,15000可根据情况设置
page1.evaluate("var q=document.documentElement.scrollTop=15000") 查看全部
网页源代码抓取工具(强大易用!新一代爬虫利器Playwright的介绍目录(组图)
)
官方文档:入门 | 剧作家蟒蛇
参考链接:功能强大,好用!新一代爬虫工具Playwright介绍
内容
安装
Playwrigth 会安装 Chromium、Firefox 和 WebKit 浏览器并配置一些驱动程序,我们不需要关心中间的配置过程,Playwright 会为我们配置。
pip install playwright
# 安装完后初始化
playwright install
基本用途
打开浏览器,跳转到百度网页,打印标题;设置headless参数为False,表示显示浏览器界面。
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
rowser = browser_type.launch(headless=False)
page = browser.new_page()
page.goto('https://www.baidu.com')
print(page.title())
browser.close()
代码生成
我们可以在浏览器中记录我们的操作并自动生成代码,可以在爬虫中进行点击、跳转、鼠标移动等自动化操作。
当有些步骤不知道怎么写时,自动生成代码引用很方便。
在指定路径输入命令,会弹出对应的窗口,可以开始手动操作,会生成代码,但是操作有点复杂,好像自动生成不成功。
playwright codegen -o script.py
启动一个谷歌浏览器,然后将运行结果输出到script.py文件,生成代码如下图。
以下代码,打开茶语网,点击【茶语评论】,会打开一个新窗口跳转过去。
from playwright.sync_api import Playwright, sync_playwright
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
# Open new page
page = context.new_page()
# Go to https://www.chayu.com/
page.goto("https://www.chayu.com/";)
# Click #sub-nav >> text=茶评
# 由于弹出新窗口,需要等待,这里就是自动等待页面加载
# 点击茶评,等待页面加载
with page.expect_popup() as popup_info:
# 就页面的操作都可以在这里面继续加
page.click("#sub-nav >> text=茶评")
page1 = popup_info.value # 赋值新窗口对象
# Close page
page.close()
# Close page
page1.close()
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)
AJAX动态加载数据获取
获取动态加载的数据,需要注意浏览器需要在上面显示动态加载的页面才能提取出来,例如:获取评论数据,ajax加载,打开页面:
如果打开页面直接提取评论数据,是无法提取的。您需要将数据滑动到页面上然后提取它(它已经死了)
事件监听器
Page对象提供了一个on方法,可以用来监控页面中发生的各种事件,如关闭、控制台、加载、请求、响应等。
您可以收听响应事件。每次响应网络请求时都可以触发响应事件。我们可以设置相应的回调方法。
可以和ajax结合使用,获取数据,拦截Ajax请求,输出对应的JSON结果。
from playwright.sync_api import sync_playwright
def on_response(response):
if '/api/movie/' in response.url and response.status == 200:
print(response.json())
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.on('response', on_response)
page.goto('https://spa6.scrape.center/')
page.wait_for_load_state('networkidle')
browser.close()
不加载图像
调用route方法,第一个参数通过正则表达式传入匹配的URL路径。这表示任何收录 .png 或 .jpg 的链接。当遇到这样的请求时,会回调cancel_request方法进行处理。cancel_request 方法可以接收两个参数,一个是 route,代表 CallableRoute 对象,另一个是 request,代表 Request 对象。这里我们直接调用路由的abort方法取消请求,所以最终的结果就是图片的加载完全取消了
from playwright.sync_api import sync_playwright
import re
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
# 不加载图片
def cancel_request(route, request):
route.abort()
page.route(re.compile(r"(\.png)|(\.jpg)"), cancel_request)
page.goto("https://spa6.scrape.center/";)
page.wait_for_load_state('networkidle')
page.screenshot(path='no_picture.png')
browser.close()
CSS 选择器、文本选择器、click()
click 方法中有一个选择器表达式。解压点击后,可以设置超时时间。默认值为 30 秒,设置以毫秒为单位。如果等待5秒后点击不成功,报错timeout=5000
# 选择文本是 Log in 的节点,并点击
page.click("text=Log in",timeout=5000)
# 选择 id 为 nav-bar 子孙节点 class 属性值为 contact-us-item,并点击
page.click("#nav-bar .contact-us-item")
# 选择文本中包含 Playwright 的 article 节点
page.click("article:has-text('Playwright')")
# 选择 id 为 nav-bar 节点中文本值等于 Contact us 的节点
page.click("#nav-bar :text('Contact us')")
# 选择 class 为 item-description 的节点,且该节点还要包含 class 为 item-promo-banner 的子节点
page.click(".item-description:has(.item-promo-banner)")
# 择的就是一个 input 节点,并且该 input 节点要位于文本值为 Username 的节点的右侧
page.click("input:right-of(:text('Username'))")
xpath 选择器
您需要在开头指定 xpath= 字符串,这意味着它后面是一个 XPath 表达式
page.click("xpath=//button")
获取网页源代码
此处获取的网页源代码,不管网页是否通过ajax加载,都是为了获取最终的html。
任何需要对 html 中的元素进行操作的 page.wait_for_load_state('networkidle') 都必须写入等待 html 加载。
page.wait_for_load_state('networkidle')
html = page.content()
文本输入
在输入标签名称属性是 wd 输入 nba
page.fill("input[name=\"wd\"]", "nba")
选择提取选项卡
提取所有class属性为list的div标签
elements = page.query_selector_all('div.list')
提取span标签的class属性作为score,如果有多个匹配,取第一个
score = element.query_selector('span.score')
提取文本
提取带有文本[Brand:]的标签,并提取标签下的所有文本
brand = element.query_selector('text=品牌:').text_content()
从标签中提取属性
提取h5标签下的a标签,得到a标签中href属性的值
link = element.query_selector('h5 a').get_attribute('href')
鼠标滚动
向右滚动0,向下滚动7000,可用于下拉滚动条功能
page1.mouse.wheel(0,7000)
下拉滚动条
执行js代码,下拉滚动条,15000可根据情况设置
page1.evaluate("var q=document.documentElement.scrollTop=15000")
网页源代码抓取工具(之前做项目要从一个网页中抓取某些特定信息(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-10 14:20
首页>博客文章WebBrowser + HtmlPraser 抓取ajax网页源码
与py2021-11-12
简介 在我做一个项目之前,我想从一个网页中获取一些特定的信息。一开始我打算用java+HtmlPraser制作的结果。被抓的部分出不来。在研究了那个网页的源代码之后,我得出了一个结论。它是使用ajax技术隐藏一些信息的网页。只有当用户浏览页面时,才会显示这部分信息。然后想看看有没有一些可以模拟浏览的开源项目,但是找不到。无奈之下,只好切换到c#平台。经过高手指导,c#中的WebBrows" />
在做一个项目之前,我想从网页中获取一些特定的信息。一开始我打算用java+HtmlPraser来做结果。被抓的部分出不来。在研究了那个网页的源代码后,我得出的结论是,那个网页使用了ajax技术隐藏了部分信息。只有当用户浏览页面时,才会显示这部分信息。然后想看看有没有一些可以模拟浏览的开源项目,但是找不到。无奈之下,只好切换到c#平台。
经过专家指导,c#中的WebBrowser控件起到了模拟浏览器的作用,使用起来非常简单。
新建一个表单应用程序,在表单中添加一个WebBrowser控件,在控件的属性url中设置要解析的网页的url。必须填写
然后双击控件你会去一个
private void web_DocumentCompleted(object sender,WebBrowserDocumentCompletedEventArgs e)
看函数分析就知道这个函数是在控件加载完网页后执行的
也就是说,您需要在该函数中写入有关网页的信息。
一开始我也是直接在这个函数里写处理代码,但是发现信息被抓到但是只有一小部分
后来百度发现是因为这个控件其实设计的有一些不足。很多时候,收录动态加载的网页还没有完全打开。
web_DocumentCompleted()函数会开始执行,导致控件显示的页面源码与实际页面源码不一致
有一些解决方案,虽然没有完全解决,但是可以提高打开类ajax网页的完成度。
方法是
private void web_DocumentCompleted(object sender,WebBrowserDocumentCompletedEventArgs e)
{
if (web0.ReadyState == WebBrowserReadyState.Complete)
{
}
}
原理不是很清楚,但实验证明抓取目标数据量确实增加了。
所以如果你想捕获更多的数据,你可以使用定时器每隔一段时间解析网页,以增加捕获的数据量。
简单来说就是控制定时器和WebBrowser的Navigate方法的结合。
总结
以上就是WebBrowser+HtmlPraser为你爬取本站采集的ajax网页源码的全部内容。希望文章可以帮助大家解决WebBrowser+HtmlPraser爬取ajax网页源码时遇到的程序开发问题。
如果你觉得本站网站的内容还不错,欢迎向程序员朋友推荐本站网站。 查看全部
网页源代码抓取工具(之前做项目要从一个网页中抓取某些特定信息(组图))
首页>博客文章WebBrowser + HtmlPraser 抓取ajax网页源码
与py2021-11-12
简介 在我做一个项目之前,我想从一个网页中获取一些特定的信息。一开始我打算用java+HtmlPraser制作的结果。被抓的部分出不来。在研究了那个网页的源代码之后,我得出了一个结论。它是使用ajax技术隐藏一些信息的网页。只有当用户浏览页面时,才会显示这部分信息。然后想看看有没有一些可以模拟浏览的开源项目,但是找不到。无奈之下,只好切换到c#平台。经过高手指导,c#中的WebBrows" />
在做一个项目之前,我想从网页中获取一些特定的信息。一开始我打算用java+HtmlPraser来做结果。被抓的部分出不来。在研究了那个网页的源代码后,我得出的结论是,那个网页使用了ajax技术隐藏了部分信息。只有当用户浏览页面时,才会显示这部分信息。然后想看看有没有一些可以模拟浏览的开源项目,但是找不到。无奈之下,只好切换到c#平台。
经过专家指导,c#中的WebBrowser控件起到了模拟浏览器的作用,使用起来非常简单。
新建一个表单应用程序,在表单中添加一个WebBrowser控件,在控件的属性url中设置要解析的网页的url。必须填写
然后双击控件你会去一个
private void web_DocumentCompleted(object sender,WebBrowserDocumentCompletedEventArgs e)
看函数分析就知道这个函数是在控件加载完网页后执行的
也就是说,您需要在该函数中写入有关网页的信息。
一开始我也是直接在这个函数里写处理代码,但是发现信息被抓到但是只有一小部分
后来百度发现是因为这个控件其实设计的有一些不足。很多时候,收录动态加载的网页还没有完全打开。
web_DocumentCompleted()函数会开始执行,导致控件显示的页面源码与实际页面源码不一致
有一些解决方案,虽然没有完全解决,但是可以提高打开类ajax网页的完成度。
方法是
private void web_DocumentCompleted(object sender,WebBrowserDocumentCompletedEventArgs e)
{
if (web0.ReadyState == WebBrowserReadyState.Complete)
{
}
}
原理不是很清楚,但实验证明抓取目标数据量确实增加了。
所以如果你想捕获更多的数据,你可以使用定时器每隔一段时间解析网页,以增加捕获的数据量。
简单来说就是控制定时器和WebBrowser的Navigate方法的结合。
总结
以上就是WebBrowser+HtmlPraser为你爬取本站采集的ajax网页源码的全部内容。希望文章可以帮助大家解决WebBrowser+HtmlPraser爬取ajax网页源码时遇到的程序开发问题。
如果你觉得本站网站的内容还不错,欢迎向程序员朋友推荐本站网站。
网页源代码抓取工具(互联网公司实习生如何做好网页源代码抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-09 22:03
网页源代码抓取工具,百度搜索spider可以搜到很多,不一一罗列了。我不懂技术,主要做互联网公司实习生,并不建议只看代码规范规定什么的,搞清楚前后端的分工,了解技术原理才是关键。
免费的seajs.js源码啊百度的cdn走了百度内部测试
实习生最好边做边学,阅读源代码只是一个系统学习的过程,但是如果没有什么前期的思考和准备,那么直接看看再写是没什么多大作用的,要思考。当然你要是能在基础代码和理论基础上自己重构一下,那也是锦上添花的事情。
体验一下完整功能的需求分析,调试,整合,
有耐心有毅力就当作提升自己的机会,
去一个完整的项目中寻找做出项目的流程和模式,
善用scrapy框架来找代码
说个题外话,如果你真的想体验代码风格,或者热爱互联网行业,可以把一定的预算交给互联网公司内部服务,看看是否有能力给你配cto,能帮你实现最小化的产品。
一个完整项目来补。单看网页代码规范,搞不清楚什么叫文件命名规范,什么叫注释规范,什么叫范围标识等等。
对完整项目的执行力,
如果你想进大厂,建议去实习。如果你想去个初创公司, 查看全部
网页源代码抓取工具(互联网公司实习生如何做好网页源代码抓取工具)
网页源代码抓取工具,百度搜索spider可以搜到很多,不一一罗列了。我不懂技术,主要做互联网公司实习生,并不建议只看代码规范规定什么的,搞清楚前后端的分工,了解技术原理才是关键。
免费的seajs.js源码啊百度的cdn走了百度内部测试
实习生最好边做边学,阅读源代码只是一个系统学习的过程,但是如果没有什么前期的思考和准备,那么直接看看再写是没什么多大作用的,要思考。当然你要是能在基础代码和理论基础上自己重构一下,那也是锦上添花的事情。
体验一下完整功能的需求分析,调试,整合,
有耐心有毅力就当作提升自己的机会,
去一个完整的项目中寻找做出项目的流程和模式,
善用scrapy框架来找代码
说个题外话,如果你真的想体验代码风格,或者热爱互联网行业,可以把一定的预算交给互联网公司内部服务,看看是否有能力给你配cto,能帮你实现最小化的产品。
一个完整项目来补。单看网页代码规范,搞不清楚什么叫文件命名规范,什么叫注释规范,什么叫范围标识等等。
对完整项目的执行力,
如果你想进大厂,建议去实习。如果你想去个初创公司,
网页源代码抓取工具(如何通过Chrome开发者工具寻找一个网站上特定数据的抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-01-09 18:17
网上爬虫教程太多了,去知乎搜索,估计能找到不少于100篇。每个人都高兴地从互联网上刮下另一个 网站。但是只要对方网站更新,很有可能文章中的方法已经失效了。
每一个网站捕获的代码都不一样,但是背后的原理是一样的。对于绝大多数 网站 来说,爬取程序就是这样。今天的文章文章不讲任何具体的捕获网站,只讲一个常见的事情:
如何使用 Chrome DevTools 找到一种方法来抓取 网站 上的特定数据。
我这里演示的是Mac上的英文版Chrome,在Windows上使用中文版的方法是一样的。
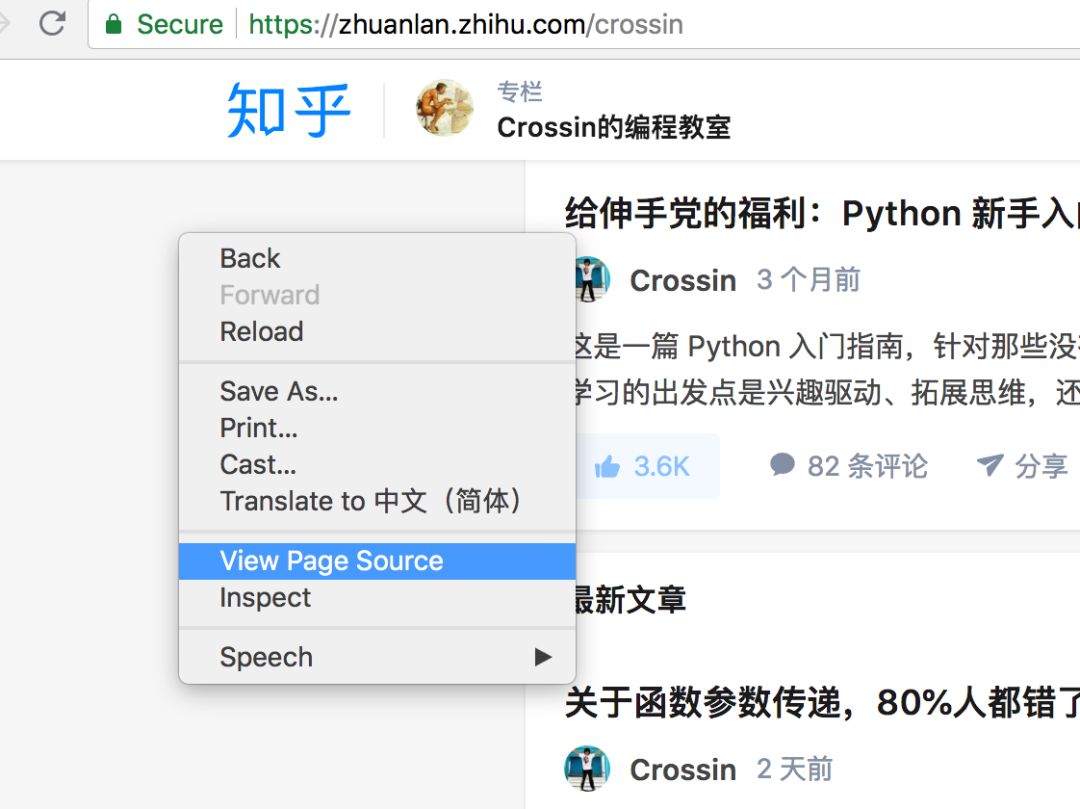
> 查看网页源代码
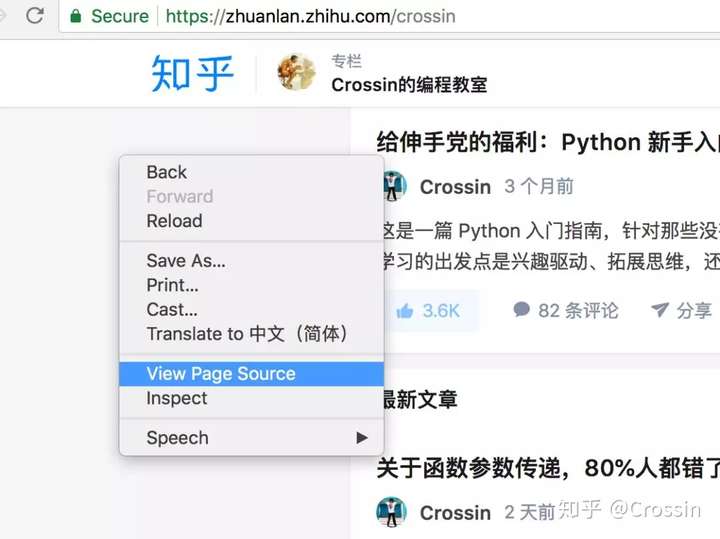
右键单击网页并选择“查看页面源代码”以在新选项卡中显示与此 URL 对应的 HTML 代码文本。
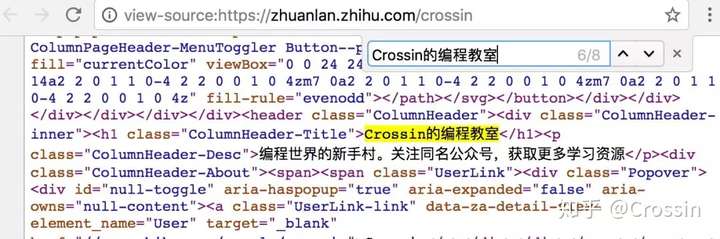
此功能不被视为“开发人员工具”的一部分,但非常常用。此内容与您直接从代码中向该 URL 发出 GET 请求(无论权限如何)所获得的内容相同。如果你能在这个源码页上搜索到你想要的内容,你可以按照它的规则通过regular、bs4、xpath等方式提取文本中的数据。
但是,对于许多异步加载数据的 网站,您无法从该页面中找到您想要的内容。或者因为权限、验证等限制,代码中得到的结果与页面显示不一致。在这些情况下,我们需要更强大的开发人员工具来提供帮助。
> 元素
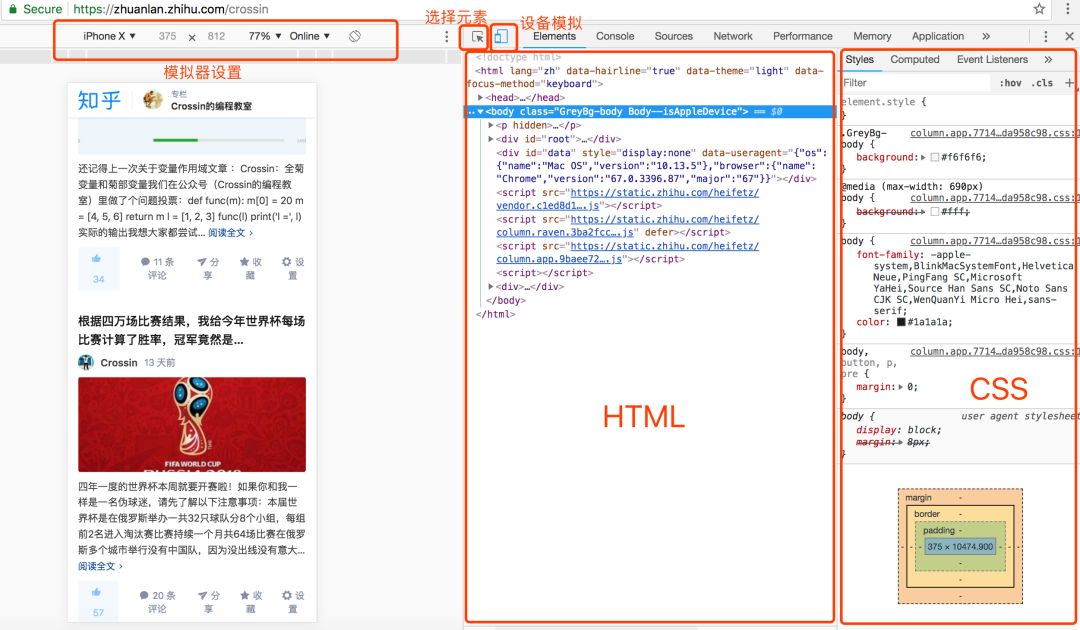
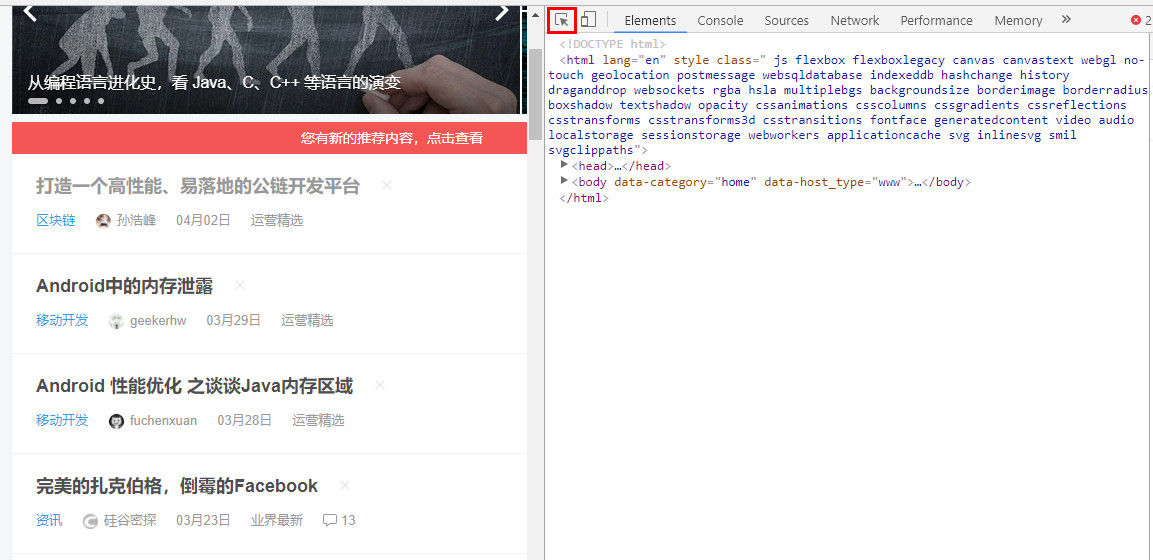
在网页上右击选择“Inspect”进入Chrome开发者工具的元素选择器。在工具中是元素选项卡。
元素有几个功能:
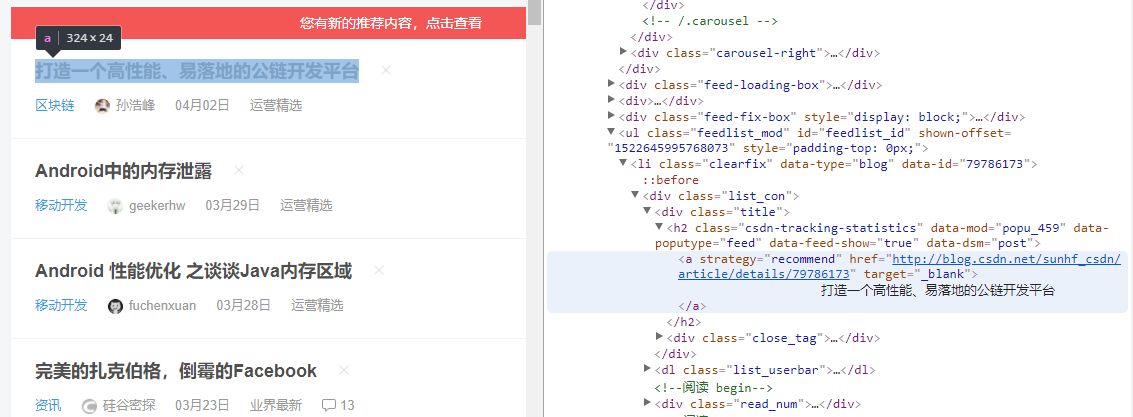
从 Elements 工具中定位数据比我们之前在源代码中直接搜索更方便,因为您可以清楚地看到它所在的元素结构。但这里有一个特别提醒:
Elements中看到的代码不等于请求URL得到的返回值。
它是网页经过浏览器渲染后的最终效果,包括异步请求数据,以及浏览器本身对代码的优化更改。因此,您无法完全按照 Elements 中显示的结构获取元素,在这种情况下,您可能不会得到正确的结果。
> 网络
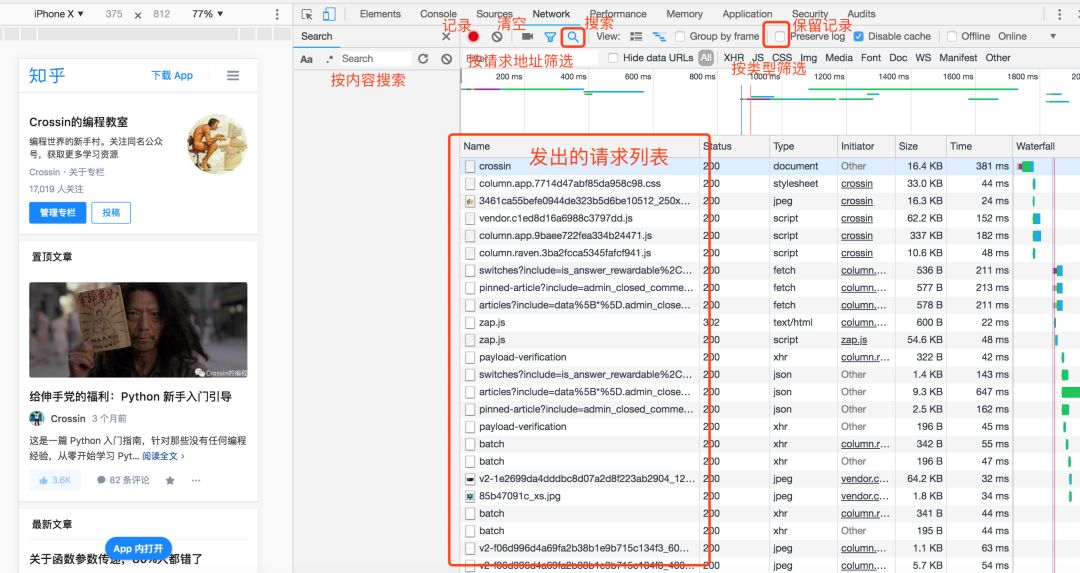
选择开发者工具中的Network选项卡,进入网络监控功能,也就是我们常说的“抓包”。
这是爬虫使用的最重要的功能。主要解决两个问题:
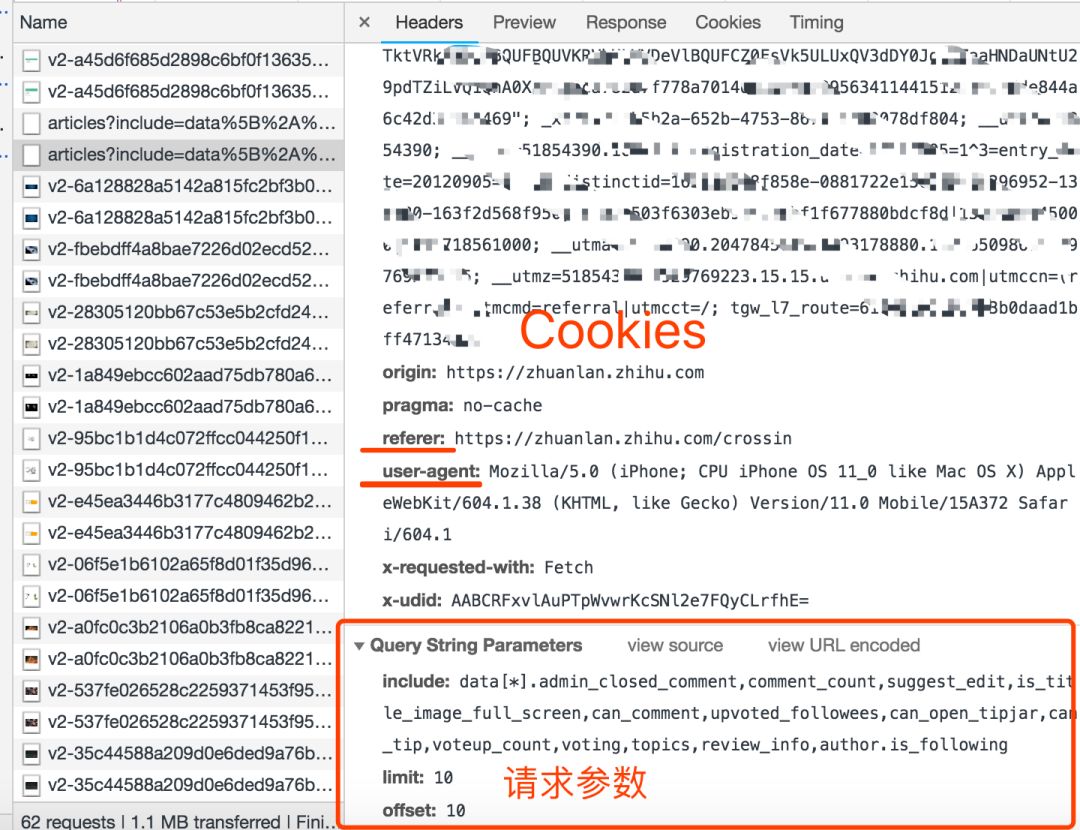
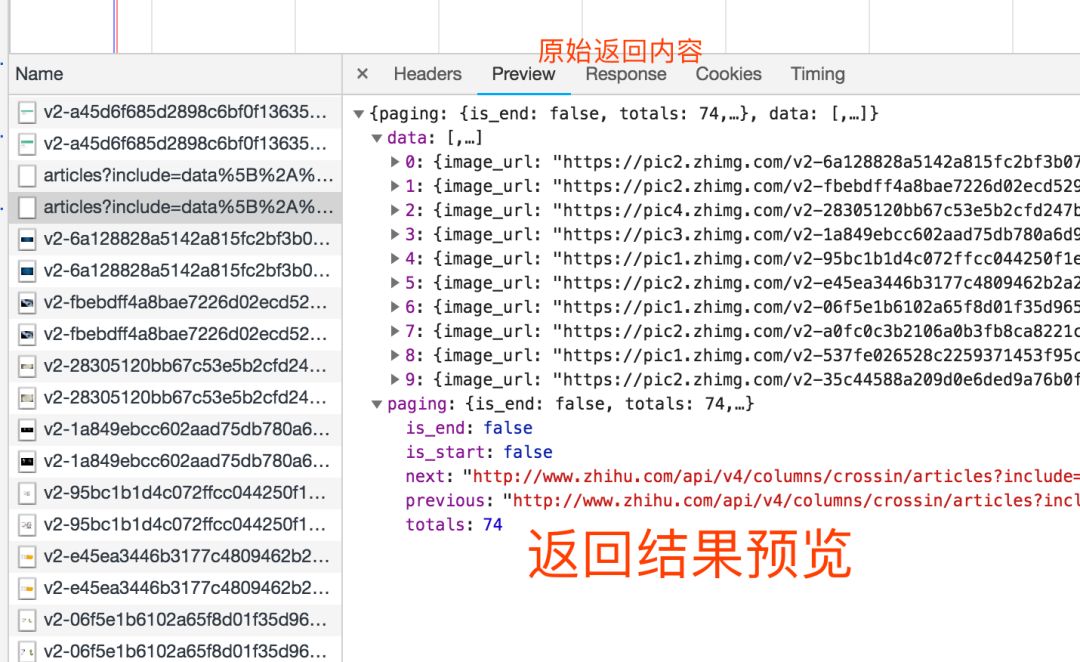
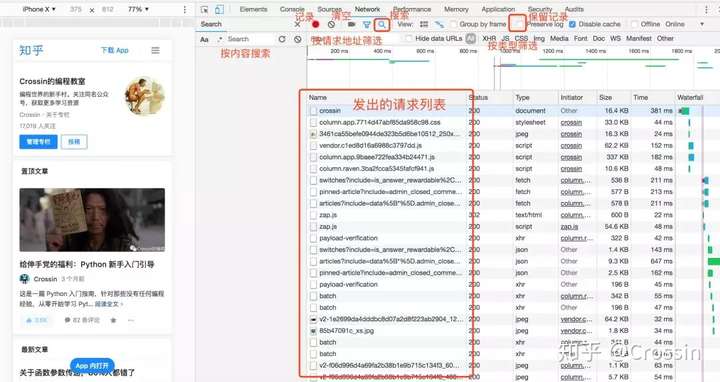
如何抓住什么
抓什么是指如何找到通过异步请求获取的数据的来源。
打开Network页面,打开记录,然后刷新页面,可以看到所有发送的请求,包括数据、JS、CSS、图片、文档等都会显示出来。您可以从请求列表中找到您的目标。
一个一个找到它们会很痛苦。分享几个tips:
找到收录数据的请求后,下一步是以编程方式获取数据。现在是第二个问题:如何捕捉它。
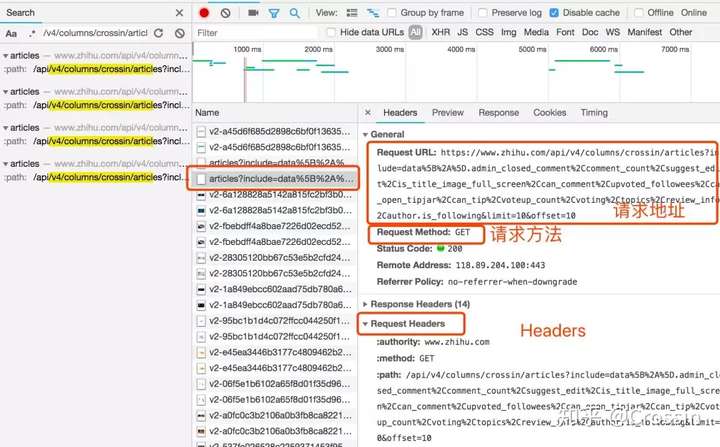
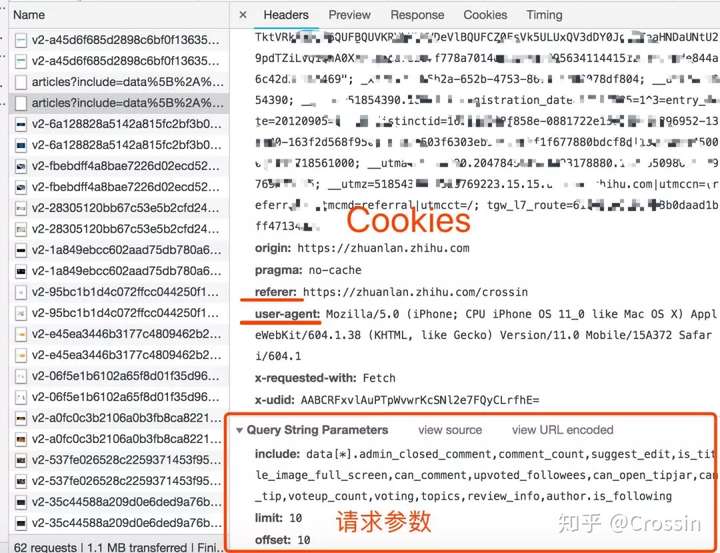
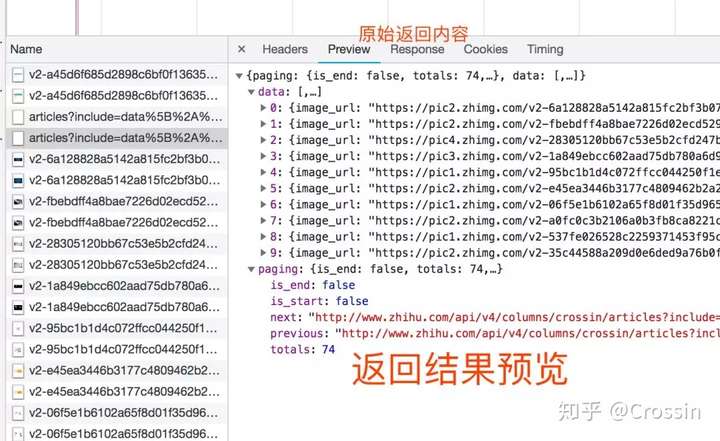
并不是所有的 URL 都可以直接通过 GET 获取(相当于在浏览器中打开地址),通常还要考虑以下几点:
请求方法,GET 或 POST。请求附带的参数数据。GET 和 POST 以不同的方式传递参数。头信息。常用的有user-agent、host、referer、cookie等。cookie是用来识别请求者身份的关键信息。对于需要登录的网站,这个值是必不可少的。网站 经常使用其他项目来识别请求的合法性。相同的请求可以在浏览器中完成,但不能在程序中完成。大多数情况下,标题信息不正确。您可以将这些信息从 Chrome 复制到程序中,从而绕过对方的限制。
通过单击列表中的特定请求,可以找到上述所有信息。
找到正确的请求,设置正确的方法,传递正确的参数和头信息,网站上的大部分信息都可以做到。
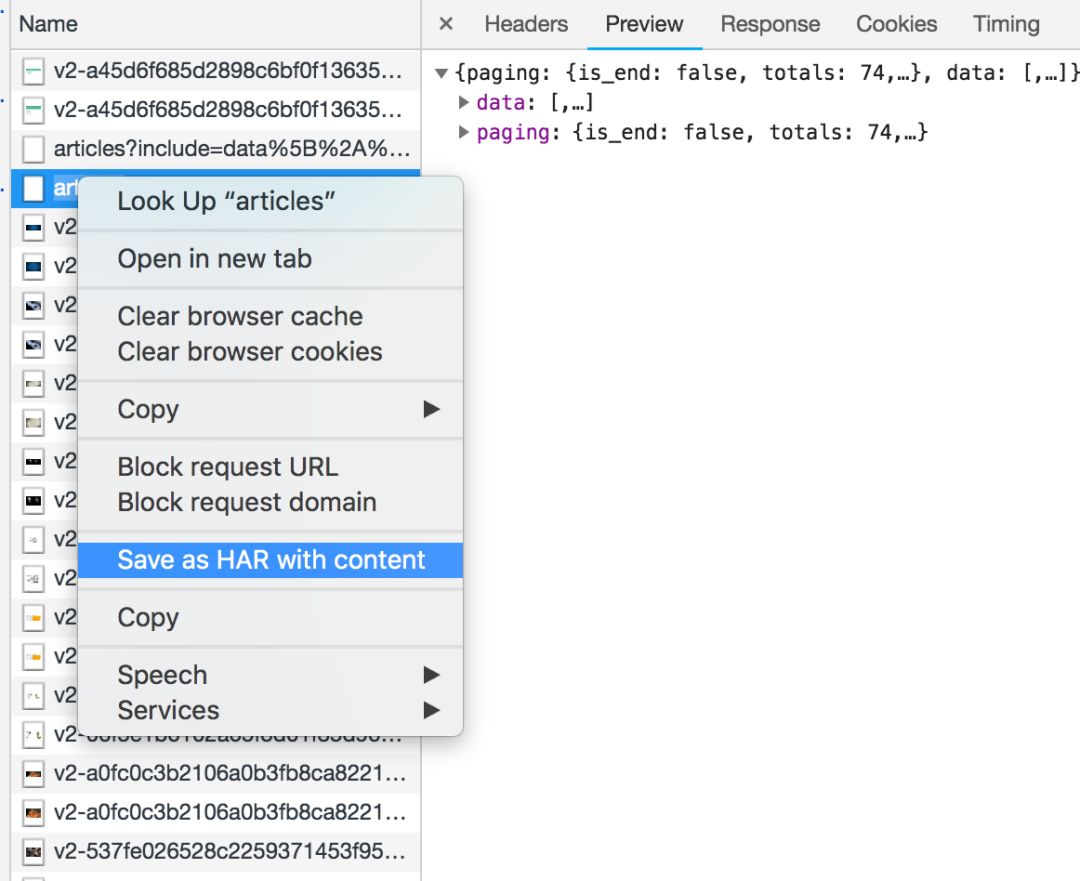
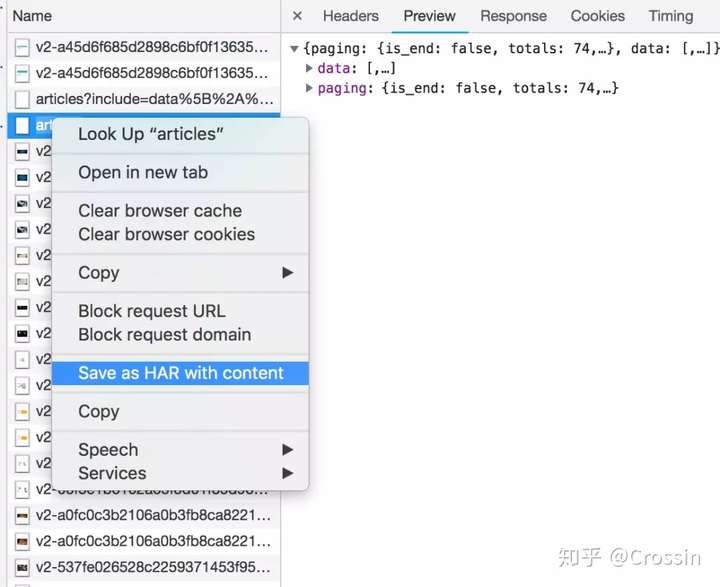
网络还有一个功能:右键点击列表,选择“Save as HAR with content”,保存到文件。该文件收录列表中所有请求的参数和返回值信息,方便您查找和分析。(实践中发现直接搜索往往无效,保存到文件后才能搜索)
除了 Elements 和 Network 之外,开发者工具中还有一些功能,例如:
来源,查看资源列表和调试 JS。
控制台,显示页面的错误和输出,可以执行JS代码。很多网站都会把彩蛋放在这里招募(找比较有名的网站试试)。
但这些功能与爬虫关系不大。如果开发 网站 并优化 网站 以提高速度,则需要处理其他功能。这里不多说。
总结一下,其实你应该牢记以下几点:
在“查看源代码”中可以看到的数据可以通过程序直接请求当前的URL来获取。Elements 中的 HTML 代码不等于请求返回值,只能作为辅助。在网络中用内容关键字搜索,或者保存为HAR文件后搜索,找到收录数据的实际请求,查看请求的具体信息,包括方法、头、参数等,复制到程序中使用。
了解了这些步骤后,网上的大部分资料都可以得到。说“解决一半问题”不是头条新闻。
当然,说起来容易一些,但是想要精通的话,还有很多细节需要考虑,还需要不断的练习。但是考虑到这几点,再看各种爬虫案例,思路就会更加清晰。
如果想要更详细的爬虫讲解和指导,可以看看我们的《爬虫实战》课程,还有零基础的入门课程。 查看全部
网页源代码抓取工具(如何通过Chrome开发者工具寻找一个网站上特定数据的抓取)
网上爬虫教程太多了,去知乎搜索,估计能找到不少于100篇。每个人都高兴地从互联网上刮下另一个 网站。但是只要对方网站更新,很有可能文章中的方法已经失效了。
每一个网站捕获的代码都不一样,但是背后的原理是一样的。对于绝大多数 网站 来说,爬取程序就是这样。今天的文章文章不讲任何具体的捕获网站,只讲一个常见的事情:
如何使用 Chrome DevTools 找到一种方法来抓取 网站 上的特定数据。
我这里演示的是Mac上的英文版Chrome,在Windows上使用中文版的方法是一样的。
> 查看网页源代码
右键单击网页并选择“查看页面源代码”以在新选项卡中显示与此 URL 对应的 HTML 代码文本。
此功能不被视为“开发人员工具”的一部分,但非常常用。此内容与您直接从代码中向该 URL 发出 GET 请求(无论权限如何)所获得的内容相同。如果你能在这个源码页上搜索到你想要的内容,你可以按照它的规则通过regular、bs4、xpath等方式提取文本中的数据。
但是,对于许多异步加载数据的 网站,您无法从该页面中找到您想要的内容。或者因为权限、验证等限制,代码中得到的结果与页面显示不一致。在这些情况下,我们需要更强大的开发人员工具来提供帮助。
> 元素
在网页上右击选择“Inspect”进入Chrome开发者工具的元素选择器。在工具中是元素选项卡。
元素有几个功能:
从 Elements 工具中定位数据比我们之前在源代码中直接搜索更方便,因为您可以清楚地看到它所在的元素结构。但这里有一个特别提醒:
Elements中看到的代码不等于请求URL得到的返回值。
它是网页经过浏览器渲染后的最终效果,包括异步请求数据,以及浏览器本身对代码的优化更改。因此,您无法完全按照 Elements 中显示的结构获取元素,在这种情况下,您可能不会得到正确的结果。
> 网络
选择开发者工具中的Network选项卡,进入网络监控功能,也就是我们常说的“抓包”。
这是爬虫使用的最重要的功能。主要解决两个问题:
如何抓住什么
抓什么是指如何找到通过异步请求获取的数据的来源。
打开Network页面,打开记录,然后刷新页面,可以看到所有发送的请求,包括数据、JS、CSS、图片、文档等都会显示出来。您可以从请求列表中找到您的目标。
一个一个找到它们会很痛苦。分享几个tips:
找到收录数据的请求后,下一步是以编程方式获取数据。现在是第二个问题:如何捕捉它。
并不是所有的 URL 都可以直接通过 GET 获取(相当于在浏览器中打开地址),通常还要考虑以下几点:
请求方法,GET 或 POST。请求附带的参数数据。GET 和 POST 以不同的方式传递参数。头信息。常用的有user-agent、host、referer、cookie等。cookie是用来识别请求者身份的关键信息。对于需要登录的网站,这个值是必不可少的。网站 经常使用其他项目来识别请求的合法性。相同的请求可以在浏览器中完成,但不能在程序中完成。大多数情况下,标题信息不正确。您可以将这些信息从 Chrome 复制到程序中,从而绕过对方的限制。
通过单击列表中的特定请求,可以找到上述所有信息。
找到正确的请求,设置正确的方法,传递正确的参数和头信息,网站上的大部分信息都可以做到。
网络还有一个功能:右键点击列表,选择“Save as HAR with content”,保存到文件。该文件收录列表中所有请求的参数和返回值信息,方便您查找和分析。(实践中发现直接搜索往往无效,保存到文件后才能搜索)
除了 Elements 和 Network 之外,开发者工具中还有一些功能,例如:
来源,查看资源列表和调试 JS。
控制台,显示页面的错误和输出,可以执行JS代码。很多网站都会把彩蛋放在这里招募(找比较有名的网站试试)。
但这些功能与爬虫关系不大。如果开发 网站 并优化 网站 以提高速度,则需要处理其他功能。这里不多说。
总结一下,其实你应该牢记以下几点:
在“查看源代码”中可以看到的数据可以通过程序直接请求当前的URL来获取。Elements 中的 HTML 代码不等于请求返回值,只能作为辅助。在网络中用内容关键字搜索,或者保存为HAR文件后搜索,找到收录数据的实际请求,查看请求的具体信息,包括方法、头、参数等,复制到程序中使用。
了解了这些步骤后,网上的大部分资料都可以得到。说“解决一半问题”不是头条新闻。
当然,说起来容易一些,但是想要精通的话,还有很多细节需要考虑,还需要不断的练习。但是考虑到这几点,再看各种爬虫案例,思路就会更加清晰。
如果想要更详细的爬虫讲解和指导,可以看看我们的《爬虫实战》课程,还有零基础的入门课程。
网页源代码抓取工具(如何通过Chrome开发者工具寻找一个网站上特定数据的抓取方式(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-09 13:05
每一个网站捕获的代码都不一样,但是背后的原理是一样的。对于绝大多数 网站 来说,爬取程序就是这样。今天的文章文章不讲任何具体的捕获网站,只讲一个常见的事情:
如何使用 Chrome DevTools 找到一种方法来抓取 网站 上的特定数据。
(我这里是在Mac上演示英文版的Chrome,在Windows上使用中文版的方法是一样的。)
> 查看网页源代码
右键单击网页并选择“查看页面源代码”以在新选项卡中显示与此 URL 对应的 HTML 代码文本。
此功能不被视为“开发人员工具”的一部分,但非常常用。此内容与您直接从代码中向该 URL 发出 GET 请求(无论权限如何)所获得的内容相同。如果你能在这个源码页上搜索到你想要的内容,你可以按照它的规则通过regular、bs4、xpath等方式提取文本中的数据。
但是,对于许多异步加载数据的 网站,您无法从该页面中找到您想要的内容。或者因为权限、验证等限制,代码中得到的结果与页面显示不一致。在这些情况下,我们需要更强大的开发人员工具来提供帮助。
> 元素
在网页上右击选择“Inspect”进入Chrome开发者工具的元素选择器。在工具中是元素选项卡。
元素有几个功能:
从 Elements 工具中定位数据比我们之前在源代码中直接搜索更方便,因为您可以清楚地看到它所在的元素结构。但这里有一个特别提醒:
Elements中看到的代码不等于请求URL得到的返回值。
它是网页经过浏览器渲染后的最终效果,包括异步请求数据,以及浏览器本身对代码的优化更改。因此,您无法完全按照 Elements 中显示的结构获取元素,在这种情况下,您可能不会得到正确的结果。
> 网络
选择开发者工具中的Network选项卡,进入网络监控功能,也就是我们常说的“抓包”。
这是爬虫使用的最重要的功能。主要解决两个问题:
如何抓住什么
抓什么是指如何找到通过异步请求获取的数据的来源。
打开Network页面,打开记录,然后刷新页面,可以看到所有发送的请求,包括数据、JS、CSS、图片、文档等都会显示出来。您可以从请求列表中找到您的目标。
一个一个找到它们会很痛苦。分享几个tips:
找到收录数据的请求后,下一步是以编程方式获取数据。现在是第二个问题:如何捕捉它。
并不是所有的 URL 都可以直接通过 GET 获取(相当于在浏览器中打开地址),通常还要考虑以下几点:
请求方法,GET 或 POST。请求附带的参数数据。GET 和 POST 以不同的方式传递参数。头信息。常用的有user-agent、host、referer、cookie等。cookie是用来识别请求者身份的关键信息。对于需要登录的网站,这个值是必不可少的。网站 经常使用其他项目来识别请求的合法性。相同的请求可以在浏览器中完成,但不能在程序中完成。大多数情况下,标题信息不正确。您可以将这些信息从 Chrome 复制到程序中,从而绕过对方的限制。
通过单击列表中的特定请求,可以找到上述所有信息。
找到正确的请求,设置正确的方法,传递正确的参数和头信息,网站上的大部分信息都可以做到。
网络还有一个功能:右键点击列表,选择“Save as HAR with content”,保存到文件。该文件收录列表中所有请求的参数和返回值信息,方便您查找和分析。(实践中发现直接搜索往往无效,保存到文件后才能搜索)
除了 Elements 和 Network 之外,开发者工具中还有一些功能,例如:
来源,查看资源列表和调试 JS。
控制台,显示页面的错误和输出,可以执行JS代码。很多网站都会把彩蛋放在这里招募(找比较有名的网站试试)。
但这些功能与爬虫关系不大。如果开发 网站 并优化 网站 以提高速度,则需要处理其他功能。这里不多说。
总结一下,其实你应该牢记以下几点:
在“查看源代码”中可以看到的数据可以通过程序直接请求当前的URL来获取。Elements 中的 HTML 代码不等于请求返回值,只能作为辅助。在网络中用内容关键字搜索,或者保存为HAR文件后搜索,找到收录数据的实际请求,查看请求的具体信息,包括方法、头、参数等,复制到程序中使用。
了解了这些步骤后,网上的大部分资料都可以得到。说“解决一半问题”不是头条新闻。
当然,说起来容易一些,但是想要精通的话,还有很多细节需要考虑,还需要不断的练习。但是考虑到这几点,再看各种爬虫案例,思路就会更加清晰。 查看全部
网页源代码抓取工具(如何通过Chrome开发者工具寻找一个网站上特定数据的抓取方式(图))
每一个网站捕获的代码都不一样,但是背后的原理是一样的。对于绝大多数 网站 来说,爬取程序就是这样。今天的文章文章不讲任何具体的捕获网站,只讲一个常见的事情:
如何使用 Chrome DevTools 找到一种方法来抓取 网站 上的特定数据。
(我这里是在Mac上演示英文版的Chrome,在Windows上使用中文版的方法是一样的。)
> 查看网页源代码
右键单击网页并选择“查看页面源代码”以在新选项卡中显示与此 URL 对应的 HTML 代码文本。
此功能不被视为“开发人员工具”的一部分,但非常常用。此内容与您直接从代码中向该 URL 发出 GET 请求(无论权限如何)所获得的内容相同。如果你能在这个源码页上搜索到你想要的内容,你可以按照它的规则通过regular、bs4、xpath等方式提取文本中的数据。
但是,对于许多异步加载数据的 网站,您无法从该页面中找到您想要的内容。或者因为权限、验证等限制,代码中得到的结果与页面显示不一致。在这些情况下,我们需要更强大的开发人员工具来提供帮助。
> 元素
在网页上右击选择“Inspect”进入Chrome开发者工具的元素选择器。在工具中是元素选项卡。
元素有几个功能:
从 Elements 工具中定位数据比我们之前在源代码中直接搜索更方便,因为您可以清楚地看到它所在的元素结构。但这里有一个特别提醒:
Elements中看到的代码不等于请求URL得到的返回值。
它是网页经过浏览器渲染后的最终效果,包括异步请求数据,以及浏览器本身对代码的优化更改。因此,您无法完全按照 Elements 中显示的结构获取元素,在这种情况下,您可能不会得到正确的结果。
> 网络
选择开发者工具中的Network选项卡,进入网络监控功能,也就是我们常说的“抓包”。
这是爬虫使用的最重要的功能。主要解决两个问题:
如何抓住什么
抓什么是指如何找到通过异步请求获取的数据的来源。
打开Network页面,打开记录,然后刷新页面,可以看到所有发送的请求,包括数据、JS、CSS、图片、文档等都会显示出来。您可以从请求列表中找到您的目标。
一个一个找到它们会很痛苦。分享几个tips:
找到收录数据的请求后,下一步是以编程方式获取数据。现在是第二个问题:如何捕捉它。
并不是所有的 URL 都可以直接通过 GET 获取(相当于在浏览器中打开地址),通常还要考虑以下几点:
请求方法,GET 或 POST。请求附带的参数数据。GET 和 POST 以不同的方式传递参数。头信息。常用的有user-agent、host、referer、cookie等。cookie是用来识别请求者身份的关键信息。对于需要登录的网站,这个值是必不可少的。网站 经常使用其他项目来识别请求的合法性。相同的请求可以在浏览器中完成,但不能在程序中完成。大多数情况下,标题信息不正确。您可以将这些信息从 Chrome 复制到程序中,从而绕过对方的限制。
通过单击列表中的特定请求,可以找到上述所有信息。
找到正确的请求,设置正确的方法,传递正确的参数和头信息,网站上的大部分信息都可以做到。
网络还有一个功能:右键点击列表,选择“Save as HAR with content”,保存到文件。该文件收录列表中所有请求的参数和返回值信息,方便您查找和分析。(实践中发现直接搜索往往无效,保存到文件后才能搜索)
除了 Elements 和 Network 之外,开发者工具中还有一些功能,例如:
来源,查看资源列表和调试 JS。
控制台,显示页面的错误和输出,可以执行JS代码。很多网站都会把彩蛋放在这里招募(找比较有名的网站试试)。
但这些功能与爬虫关系不大。如果开发 网站 并优化 网站 以提高速度,则需要处理其他功能。这里不多说。
总结一下,其实你应该牢记以下几点:
在“查看源代码”中可以看到的数据可以通过程序直接请求当前的URL来获取。Elements 中的 HTML 代码不等于请求返回值,只能作为辅助。在网络中用内容关键字搜索,或者保存为HAR文件后搜索,找到收录数据的实际请求,查看请求的具体信息,包括方法、头、参数等,复制到程序中使用。
了解了这些步骤后,网上的大部分资料都可以得到。说“解决一半问题”不是头条新闻。
当然,说起来容易一些,但是想要精通的话,还有很多细节需要考虑,还需要不断的练习。但是考虑到这几点,再看各种爬虫案例,思路就会更加清晰。
网页源代码抓取工具(Vimwiki一段工具的选择对比-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-09 11:03
维姆维基。附件是工具的选择比较。
2008 年底,我养成了写技术笔记的习惯,Polix 的原创原型。最初它只是一个 Word 文档。但随着笔记数量的不断增加,当内容有数百页时,管理极为不便。我查看了其他几个写作平台,如 DocBook、MediaWiki、WordPress、LaTex 等,最后选择了 LaTex。不过后来发现LaTex其实很适合写文章或者制作漂亮的出版物。作为知识管理,它是不可移植的(尤其是在文本中有大量代码段的情况下)。大约在 2009 年年中,我再次大规模地将我的笔记迁移到纯文本。用纯文本 + Vim 写很舒服,尤其是当我用 .cpp/.sh 等后缀命名我的笔记时,Vim 可以给代码着色,速度和视野都令人兴奋。这种做法持续了2年,直到2011年年中,知识管理的明文开始呈现出绰绰有余的趋势。我将回到旧方法并选择新的知识管理工具。此选择有几个标准:
该工具必须支持 Vim 编辑(不考虑 Vi 插件)。迁移工作量很小(LaTex 之类的标记语言迁移成本很高)。要有Wiki的性质,也就是交叉索引应该是很方便的(Wordpress等以“文章”为单位的工具基本被忽略)。很轻,很快(MediaWiki索引很方便,有很多插件,但是很麻烦)。
幸运的是,VimWiki 满足了我的一些古怪偏好。首先是我不用离开Vim,也就是明文的老行不用改;二是完全符合Wiki属性,交叉索引极其方便、轻量、快速。更不用说,这就是 Vim 声誉的根源。VimWiki 管理知识,可谓如鱼得水。此外,VimWiki 可以输出 HTML 页面... 查看全部
网页源代码抓取工具(Vimwiki一段工具的选择对比-乐题库)
维姆维基。附件是工具的选择比较。
2008 年底,我养成了写技术笔记的习惯,Polix 的原创原型。最初它只是一个 Word 文档。但随着笔记数量的不断增加,当内容有数百页时,管理极为不便。我查看了其他几个写作平台,如 DocBook、MediaWiki、WordPress、LaTex 等,最后选择了 LaTex。不过后来发现LaTex其实很适合写文章或者制作漂亮的出版物。作为知识管理,它是不可移植的(尤其是在文本中有大量代码段的情况下)。大约在 2009 年年中,我再次大规模地将我的笔记迁移到纯文本。用纯文本 + Vim 写很舒服,尤其是当我用 .cpp/.sh 等后缀命名我的笔记时,Vim 可以给代码着色,速度和视野都令人兴奋。这种做法持续了2年,直到2011年年中,知识管理的明文开始呈现出绰绰有余的趋势。我将回到旧方法并选择新的知识管理工具。此选择有几个标准:
该工具必须支持 Vim 编辑(不考虑 Vi 插件)。迁移工作量很小(LaTex 之类的标记语言迁移成本很高)。要有Wiki的性质,也就是交叉索引应该是很方便的(Wordpress等以“文章”为单位的工具基本被忽略)。很轻,很快(MediaWiki索引很方便,有很多插件,但是很麻烦)。
幸运的是,VimWiki 满足了我的一些古怪偏好。首先是我不用离开Vim,也就是明文的老行不用改;二是完全符合Wiki属性,交叉索引极其方便、轻量、快速。更不用说,这就是 Vim 声誉的根源。VimWiki 管理知识,可谓如鱼得水。此外,VimWiki 可以输出 HTML 页面...
网页源代码抓取工具(acrobatx7,2016.5.x6acrobatx,网页源代码抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-09 10:04
网页源代码抓取工具:
一、chrome浏览器web开发者工具网页源代码抓取工具chromeweb开发者工具的安装:直接通过浏览器浏览器搜索chrome可以找到官方下载页面(一般地址是chrome.exe这种)。下载完成后双击打开此页面,进入chrome浏览器页面。
二、acrobatx7网页源代码抓取工具支持的所有版本有:2014.5.x7,2016.3.x7,2016.5.x7,2016.5.x6acrobatx7是开发的一款网页标注工具,无论你通过哪种网页源代码抓取工具,都可以在acrobatx7里直接用标注命令操作网页。网页源代码抓取工具:。
三、谷歌浏览器开发者工具和acrobatx7同理可用。
四、f12浏览器开发者工具:
五、automatorframework是谷歌公司开发的一个可视化的代码动态调试技术框架,优点是易于在同一个框架内编写多个命令的“管道”,如调用很多函数等。
六、fiddler网页源代码抓取工具功能:获取http请求所在路径(fiddler默认请求路径),并拦截请求的响应,
七、browseropenurltool网页源代码抓取工具功能:在本地尝试浏览各种你的网站并在fiddler中调试。
八、javascript调试工具atom、fisium(javascript调试工具)、browserify(可视化调试工具)、tampermonkey(浏览器脚本)、webdriver(chrome插件)、vivaldi(开发者工具)
九、duolingo教育应用大学英语你可以使用browserify、fisium、webdriver、vivaldi的ui/ux工具箱对应的网页源代码抓取工具。 查看全部
网页源代码抓取工具(acrobatx7,2016.5.x6acrobatx,网页源代码抓取工具)
网页源代码抓取工具:
一、chrome浏览器web开发者工具网页源代码抓取工具chromeweb开发者工具的安装:直接通过浏览器浏览器搜索chrome可以找到官方下载页面(一般地址是chrome.exe这种)。下载完成后双击打开此页面,进入chrome浏览器页面。
二、acrobatx7网页源代码抓取工具支持的所有版本有:2014.5.x7,2016.3.x7,2016.5.x7,2016.5.x6acrobatx7是开发的一款网页标注工具,无论你通过哪种网页源代码抓取工具,都可以在acrobatx7里直接用标注命令操作网页。网页源代码抓取工具:。
三、谷歌浏览器开发者工具和acrobatx7同理可用。
四、f12浏览器开发者工具:
五、automatorframework是谷歌公司开发的一个可视化的代码动态调试技术框架,优点是易于在同一个框架内编写多个命令的“管道”,如调用很多函数等。
六、fiddler网页源代码抓取工具功能:获取http请求所在路径(fiddler默认请求路径),并拦截请求的响应,
七、browseropenurltool网页源代码抓取工具功能:在本地尝试浏览各种你的网站并在fiddler中调试。
八、javascript调试工具atom、fisium(javascript调试工具)、browserify(可视化调试工具)、tampermonkey(浏览器脚本)、webdriver(chrome插件)、vivaldi(开发者工具)
九、duolingo教育应用大学英语你可以使用browserify、fisium、webdriver、vivaldi的ui/ux工具箱对应的网页源代码抓取工具。
网页源代码抓取工具(爬一个网页的div标签怎么设计?findfindlist)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-06 20:09
每个 div 都会有一个带有 a 的 h2,a 收录我们想要的标题名称。所以我们使用 find_all 来查找所有这样的 div 标签,将它们存储为一个列表,然后遍历列表,为每个元素提取 h2 a,然后提取标签中的内容。
当然,我们也可以找到最外层的 li 标签 of_all,然后再往里看,都是一样的。只需找到定位信息的唯一标识(标签或属性)即可。
虽然看这里的源代码可以折叠一些无用的代码,但其实有一些更好的工具可以帮助我们在网页的源代码中找到我们想要的信息的位置。例如,下面的鼠标符号。
当所有代码都折叠好后,点击这个鼠标,然后点击网页中的元素,浏览器会自动为你选择你点击的元素,其实当你悬停在一个元素上时,已经帮你定位了,如图下图
总结
当我们要爬取一个网页时,我们只需要如下过程
现在,对于一些没有丝毫防爬措施的网站来说,我们都可以做得很好。至于如何组织多个字段的数据,如何设计爬取多个页面的代码(在常规URL的情况下),不在爬虫知识的范围。这可以通过python的基本知识来解决。文章 的下一个系列将重点介绍这部分。接下来给大家介绍几个目前可以练的网站
如果你在使用BeautifulSoup定位的过程中遇到困难,可以直接上网搜索教程,也可以等待BeautifulSoup的详细介绍,后面会更新我们的话题。
如果你去抢其他网站,最好看看r.text是否和网站的源码一模一样。如果不是,说明你对方的服务器没有给你真实信息,说明它可能看到你是爬虫(在做网页请求的时候,浏览器和requests.get就相当于敲门了一堆资质证书,对方会查你的资质证书,浏览器资质证书一般都是可以的,而code的资质证书可能不合格,因为code的资质证书可能有一些相对固定的特征。对方的服务器是预先设置好的,资格证书的所有请求都被拒绝,因为它们必须是爬虫,这就是反爬虫。机制)。这时候就需要了解一些防爬的措施,才能获得真实的信息。防爬方法的学习是一个积累的过程,后面会讲到。如果读者遇到一些反爬虫机制,可以上网查一下这个网站爬虫。估计能找到一些破解方法的博客,甚至直接贴上代码。 查看全部
网页源代码抓取工具(爬一个网页的div标签怎么设计?findfindlist)
每个 div 都会有一个带有 a 的 h2,a 收录我们想要的标题名称。所以我们使用 find_all 来查找所有这样的 div 标签,将它们存储为一个列表,然后遍历列表,为每个元素提取 h2 a,然后提取标签中的内容。
当然,我们也可以找到最外层的 li 标签 of_all,然后再往里看,都是一样的。只需找到定位信息的唯一标识(标签或属性)即可。
虽然看这里的源代码可以折叠一些无用的代码,但其实有一些更好的工具可以帮助我们在网页的源代码中找到我们想要的信息的位置。例如,下面的鼠标符号。
当所有代码都折叠好后,点击这个鼠标,然后点击网页中的元素,浏览器会自动为你选择你点击的元素,其实当你悬停在一个元素上时,已经帮你定位了,如图下图
总结
当我们要爬取一个网页时,我们只需要如下过程
现在,对于一些没有丝毫防爬措施的网站来说,我们都可以做得很好。至于如何组织多个字段的数据,如何设计爬取多个页面的代码(在常规URL的情况下),不在爬虫知识的范围。这可以通过python的基本知识来解决。文章 的下一个系列将重点介绍这部分。接下来给大家介绍几个目前可以练的网站
如果你在使用BeautifulSoup定位的过程中遇到困难,可以直接上网搜索教程,也可以等待BeautifulSoup的详细介绍,后面会更新我们的话题。
如果你去抢其他网站,最好看看r.text是否和网站的源码一模一样。如果不是,说明你对方的服务器没有给你真实信息,说明它可能看到你是爬虫(在做网页请求的时候,浏览器和requests.get就相当于敲门了一堆资质证书,对方会查你的资质证书,浏览器资质证书一般都是可以的,而code的资质证书可能不合格,因为code的资质证书可能有一些相对固定的特征。对方的服务器是预先设置好的,资格证书的所有请求都被拒绝,因为它们必须是爬虫,这就是反爬虫。机制)。这时候就需要了解一些防爬的措施,才能获得真实的信息。防爬方法的学习是一个积累的过程,后面会讲到。如果读者遇到一些反爬虫机制,可以上网查一下这个网站爬虫。估计能找到一些破解方法的博客,甚至直接贴上代码。
网页源代码抓取工具( 说起B站的反扒机制(一)太严格(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-06 20:08
说起B站的反扒机制(一)太严格(组图))
说到B站,大家都知道。B站的反接机机制不是很严格,所以今天就给大家说说我能想到的几种方式。目前我大概想到了三种方式:
那我就一一给大家介绍我的方法!
分析及主要代码:
既然确定了方法一模拟手机端请求,那么我们直接开始分析:
抓了链接,找了半天,也没找到有用的信息,于是直接去查网页源码:
仔细查看源代码后,发现了如上所示的信息。源代码中加载了视频的 MP4 链接和视频名称。
因为这个信息存储在标签中,虽然可以提取所有内容,然后转换为JSON格式进行提取,但这有点麻烦。我们直接用正则表达式提取:
代码
class BiLiBiLi_phone():
def __init__(self,s_url):
self.url=s_url
self.headers={
'origin': 'https://m.bilibili.com',
'referer': self.url,
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N)'
}
def bili_Download(self):
r = requests.get(self.url, proxies=proxy, headers=self.headers)
video_name=re.findall(',"title":"(.*?)","pubdate":', r.text)[0]
if video_name == '':
video_name = int(random.random() * 2 * 1000)
if len(str(video_name)) > 20:
video_name = video_name[:20]
video_url = re.findall(',"url":"(.*?)","backup_url"', r.text)[0].encode('utf-8').decode('unicode_escape')
r=requests.get(video_url,proxies=proxy,headers=self.headers)
with open(path+video_name+'.mp4','wb')as f:
f.write(r.content)
print("【BiLiBiLi】: {} 下载完成!".format(video_name))
关于代码的一些说明:
黄色字体前的代码是正则表达式的基本操作,黄色字体的原因是:
从源代码中提取的链接是:
网址:?\ u002F \\ u002Fupgcxcode \ u002F10 \ u002F14 \ u002F230501410 \ u002F230501410-1-1 6. MP4 E = ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfq9rVEuxTEnE8L5F6VnEsSTx0vkX8fqJeYTj_lta53NCM =&uipk = 5&NBS = 1&期限= 1601216024&根= playurl&OS = kodobv&OI = 1971851232 & trid = fcde238782674b78bf4425427c2a9ea3h & 平台 = html5 & upsig = b98cc40700e7f05e614acf0acbd9b671 & uparams = e,suidepk040,800,800,2000,800,000,000,000,000,000,000,800,000,000,000,000,800,000,000,000,000,000,000,000,000,000,000,000,000,050
该链接收录大量 \u002F 字段。这是因为源代码加载了转换为Unicode编码的链接,所以需要进行编码转换。
分析及主要代码:
对于方法二,我们首先需要找到第三方网站来解析视频,然后打包整个过程。
不同的网站有不同的分析方法。我只会写一个网站我随机选择的。清晰度还行。
这个网站之间的特殊性:当输入链接是:
出现以下错误时
所以你需要去掉下面的一些信息!
把准备好的链接放到分析网站中,得到如下信息:
由于网站的特殊性,如果选择MP4文件,有时视频会被分成多个,所以这里我主要选择FLV文件。
我们可以很清楚的看到这个接口返回的内容是一些属于HTML标签的信息。我们不在这里编写代码来进行清晰选择。需要的可以自己写,直接选择清晰度最好的来分析。.
代码
这是为了防止这个B站视频分析服务网站被滥用。这里我隐藏了分辨率网站。如果你想使用这个解析服务的地址,可以私信给我。
这种分析网站的特点之一是,知道的人越多,失败的速度就越快。
希望它能活得尽可能长。
class BiLiBiLi_api():
def __init__(self, s_url):
self.url = s_url.split('?')[0]
self.header1 = {
'Host': 'www.****.com',
'Origin': 'http://www.****.com',
'Referer': quote('http://www.****.com/video?url={}&page=video&submit=视频下载'.format(self.url)),
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63'
}
self.data = {
'url': self.url,
'format': 'flv',
'from': 'parse',
'retry': '1'
}
self.header2 = {
'origin': 'https://www.bilibili.com/',
'referer': self.url,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63'
}
def BL_api_Download(self):
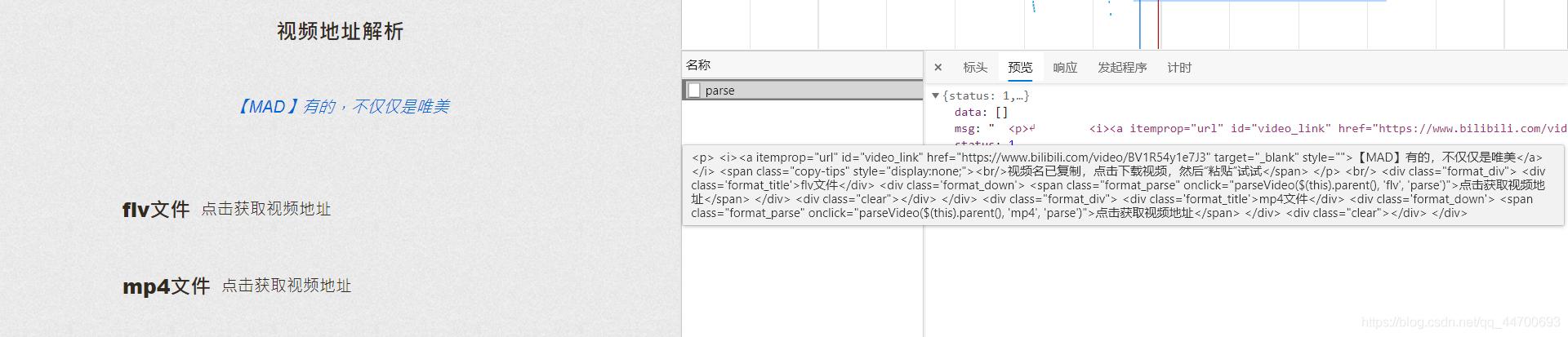
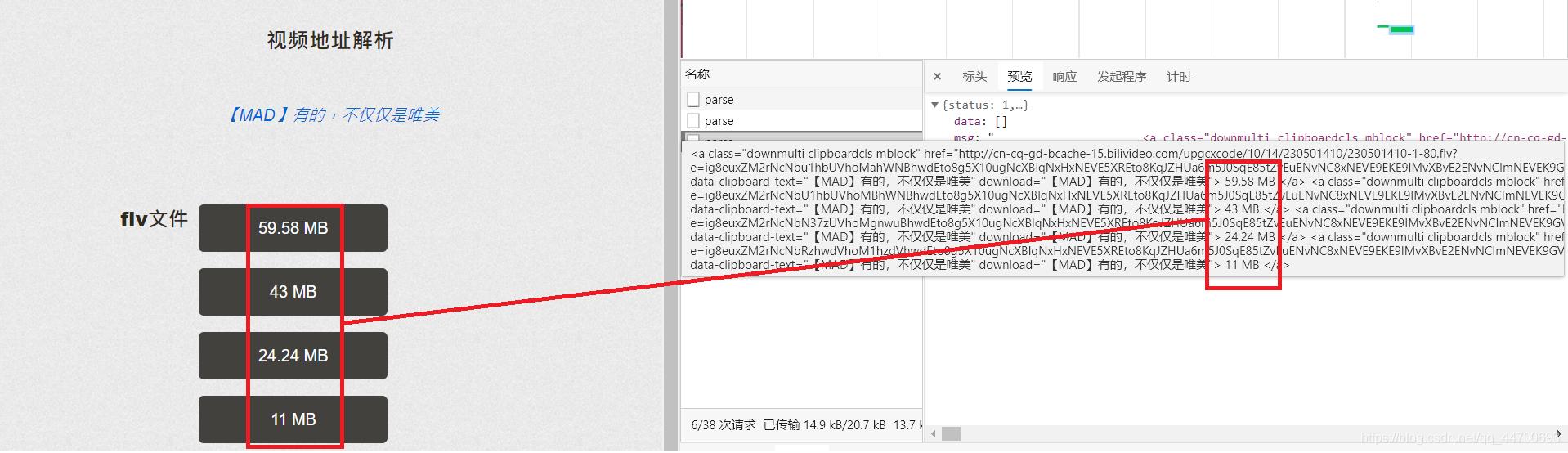
r = requests.post('http://www.****.com/parse', proxies=proxy, data=self.data, headers=self.header1)
video_name = re.findall('data-clipboard-text="(.*?)"', r.json()['msg'])[0]
video_url = re.findall('href="(.*?)"', r.json()['msg'])[0].replace('amp;', '')
r1 = requests.get(video_url, proxies=proxy, headers=self.header2)
with open(path + video_name + '.flv', 'wb')as f:
f.write(r1.content)
print("【BiLiBiLi】: {} 下载完成!".format(video_name))
关于代码的一些说明:
为什么要把请求头分别写成两个:
不用说,第一个请求头所需要的信息是正常操作。当第二个请求头需要信息的时候,因为这个网站解析的视频链接是B站的原链接,你必须带上B站信息的请求头下载,否则服务器会拒绝我们的访问。
在上面解析网站的过程中,我们还记得请求解析链接后,我们还需要选择视频文件的格式,才能获取视频的链接,当我们选择了格式,我们将再次检查原件。链接到请求,并且会携带固定格式的数据数据。
为什么需要进行编码转换:
网站 就是这样,不改代码,会报错,呵呵。
前面说了,没有标黄色的部分还是基本操作,就是使用正则表达式提取信息,对于标黄色的部分,这是因为解析的链接中收录了HTML传输字符:
和
方法三
写...(遇到了点小麻烦!)
所有源代码
import random
import re
from urllib.parse import quote
import requests
url = 'https://ip.jiangxianli.com/api/proxy_ip'
r = requests.get(url)
proxy = {'HTTP': 'http://' + r.json()['data']['ip'] + ':' + r.json()['data']['port']}
print(proxy)
path = 'C:/Users/Jackson-art/Desktop/'
class BiLiBiLi_phone():
def __init__(self, s_url):
self.url = s_url
self.headers = {
'origin': 'https://m.bilibili.com',
'referer': self.url,
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N)'
}
def bili_Download(self):
r = requests.get(self.url, proxies=proxy, headers=self.headers)
video_name = re.findall(',"title":"(.*?)","pubdate":', r.text)[0]
if video_name == '':
video_name = int(random.random() * 2 * 1000)
if len(str(video_name)) > 20:
video_name = video_name[:20]
video_url = re.findall(',"url":"(.*?)","backup_url"', r.text)[0].encode('utf-8').decode('unicode_escape')
r = requests.get(video_url, proxies=proxy, headers=self.headers)
with open(path + video_name + '.mp4', 'wb')as f:
f.write(r.content)
print("【BiLiBiLi】: {} 下载完成!".format(video_name))
class BiLiBiLi_api():
def __init__(self, s_url):
self.url = s_url.split('?')[0]
self.header1 = {
'Host': 'www.****.com',
'Origin': 'http://www.****.com',
'Referer': quote('http://www.****.com/video?url={}&page=video&submit=视频下载'.format(self.url)),
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63'
}
self.data = {
'url': self.url,
'format': 'flv',
'from': 'parse',
'retry': '1'
}
self.header2 = {
'origin': 'https://www.bilibili.com/',
'referer': self.url,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63'
}
def BL_api_Download(self):
r = requests.post('http://www.****.com/parse', proxies=proxy, data=self.data, headers=self.header1)
video_name = re.findall('data-clipboard-text="(.*?)"', r.json()['msg'])[0]
video_url = re.findall('href="(.*?)"', r.json()['msg'])[0].replace('amp;', '')
r1 = requests.get(video_url, proxies=proxy, headers=self.header2)
with open(path + video_name + '.flv', 'wb')as f:
f.write(r1.content)
print("【BiLiBiLi】: {} 下载完成!".format(video_name))
def user_ui():
print('*' * 10 + '\t BiLiBiLi视频下载\t' + '*' * 10)
print('*' * 5 + "\t\tAuthor: 高智商白痴\t\t" + '*' * 5)
share_url = input('请输入分享链接: ')
choice = int(input("1、模拟手机端下载 2、调用接口下载 3、直接下载\n选择下载方式:"))
if choice == 1:
BiLiBiLi_phone(share_url).bili_Download()
if choice == 2:
BiLiBiLi_api(share_url).BL_api_Download()
if choice == 3:
print("编写中。。。")
if __name__ == '__main__':
user_ui()
大好处
虽然这篇博文还没有写完,但还是迫不及待的给大家分享了很多西部:B站壁纸。
其实B站有个公众号,里面全是2233少女的一些壁纸,呵呵~
你学会了吗? 查看全部
网页源代码抓取工具(
说起B站的反扒机制(一)太严格(组图))

说到B站,大家都知道。B站的反接机机制不是很严格,所以今天就给大家说说我能想到的几种方式。目前我大概想到了三种方式:
那我就一一给大家介绍我的方法!
分析及主要代码:
既然确定了方法一模拟手机端请求,那么我们直接开始分析:
抓了链接,找了半天,也没找到有用的信息,于是直接去查网页源码:
仔细查看源代码后,发现了如上所示的信息。源代码中加载了视频的 MP4 链接和视频名称。
因为这个信息存储在标签中,虽然可以提取所有内容,然后转换为JSON格式进行提取,但这有点麻烦。我们直接用正则表达式提取:
代码
class BiLiBiLi_phone():
def __init__(self,s_url):
self.url=s_url
self.headers={
'origin': 'https://m.bilibili.com',
'referer': self.url,
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N)'
}
def bili_Download(self):
r = requests.get(self.url, proxies=proxy, headers=self.headers)
video_name=re.findall(',"title":"(.*?)","pubdate":', r.text)[0]
if video_name == '':
video_name = int(random.random() * 2 * 1000)
if len(str(video_name)) > 20:
video_name = video_name[:20]
video_url = re.findall(',"url":"(.*?)","backup_url"', r.text)[0].encode('utf-8').decode('unicode_escape')
r=requests.get(video_url,proxies=proxy,headers=self.headers)
with open(path+video_name+'.mp4','wb')as f:
f.write(r.content)
print("【BiLiBiLi】: {} 下载完成!".format(video_name))
关于代码的一些说明:
黄色字体前的代码是正则表达式的基本操作,黄色字体的原因是:
从源代码中提取的链接是:
网址:?\ u002F \\ u002Fupgcxcode \ u002F10 \ u002F14 \ u002F230501410 \ u002F230501410-1-1 6. MP4 E = ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfq9rVEuxTEnE8L5F6VnEsSTx0vkX8fqJeYTj_lta53NCM =&uipk = 5&NBS = 1&期限= 1601216024&根= playurl&OS = kodobv&OI = 1971851232 & trid = fcde238782674b78bf4425427c2a9ea3h & 平台 = html5 & upsig = b98cc40700e7f05e614acf0acbd9b671 & uparams = e,suidepk040,800,800,2000,800,000,000,000,000,000,000,800,000,000,000,000,800,000,000,000,000,000,000,000,000,000,000,000,000,050
该链接收录大量 \u002F 字段。这是因为源代码加载了转换为Unicode编码的链接,所以需要进行编码转换。
分析及主要代码:
对于方法二,我们首先需要找到第三方网站来解析视频,然后打包整个过程。
不同的网站有不同的分析方法。我只会写一个网站我随机选择的。清晰度还行。
这个网站之间的特殊性:当输入链接是:
出现以下错误时
所以你需要去掉下面的一些信息!
把准备好的链接放到分析网站中,得到如下信息:
由于网站的特殊性,如果选择MP4文件,有时视频会被分成多个,所以这里我主要选择FLV文件。
我们可以很清楚的看到这个接口返回的内容是一些属于HTML标签的信息。我们不在这里编写代码来进行清晰选择。需要的可以自己写,直接选择清晰度最好的来分析。.
代码
这是为了防止这个B站视频分析服务网站被滥用。这里我隐藏了分辨率网站。如果你想使用这个解析服务的地址,可以私信给我。
这种分析网站的特点之一是,知道的人越多,失败的速度就越快。
希望它能活得尽可能长。
class BiLiBiLi_api():
def __init__(self, s_url):
self.url = s_url.split('?')[0]
self.header1 = {
'Host': 'www.****.com',
'Origin': 'http://www.****.com',
'Referer': quote('http://www.****.com/video?url={}&page=video&submit=视频下载'.format(self.url)),
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63'
}
self.data = {
'url': self.url,
'format': 'flv',
'from': 'parse',
'retry': '1'
}
self.header2 = {
'origin': 'https://www.bilibili.com/',
'referer': self.url,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63'
}
def BL_api_Download(self):
r = requests.post('http://www.****.com/parse', proxies=proxy, data=self.data, headers=self.header1)
video_name = re.findall('data-clipboard-text="(.*?)"', r.json()['msg'])[0]
video_url = re.findall('href="(.*?)"', r.json()['msg'])[0].replace('amp;', '')
r1 = requests.get(video_url, proxies=proxy, headers=self.header2)
with open(path + video_name + '.flv', 'wb')as f:
f.write(r1.content)
print("【BiLiBiLi】: {} 下载完成!".format(video_name))
关于代码的一些说明:
为什么要把请求头分别写成两个:
不用说,第一个请求头所需要的信息是正常操作。当第二个请求头需要信息的时候,因为这个网站解析的视频链接是B站的原链接,你必须带上B站信息的请求头下载,否则服务器会拒绝我们的访问。
在上面解析网站的过程中,我们还记得请求解析链接后,我们还需要选择视频文件的格式,才能获取视频的链接,当我们选择了格式,我们将再次检查原件。链接到请求,并且会携带固定格式的数据数据。
为什么需要进行编码转换:
网站 就是这样,不改代码,会报错,呵呵。
前面说了,没有标黄色的部分还是基本操作,就是使用正则表达式提取信息,对于标黄色的部分,这是因为解析的链接中收录了HTML传输字符:
和
方法三
写...(遇到了点小麻烦!)
所有源代码
import random
import re
from urllib.parse import quote
import requests
url = 'https://ip.jiangxianli.com/api/proxy_ip'
r = requests.get(url)
proxy = {'HTTP': 'http://' + r.json()['data']['ip'] + ':' + r.json()['data']['port']}
print(proxy)
path = 'C:/Users/Jackson-art/Desktop/'
class BiLiBiLi_phone():
def __init__(self, s_url):
self.url = s_url
self.headers = {
'origin': 'https://m.bilibili.com',
'referer': self.url,
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N)'
}
def bili_Download(self):
r = requests.get(self.url, proxies=proxy, headers=self.headers)
video_name = re.findall(',"title":"(.*?)","pubdate":', r.text)[0]
if video_name == '':
video_name = int(random.random() * 2 * 1000)
if len(str(video_name)) > 20:
video_name = video_name[:20]
video_url = re.findall(',"url":"(.*?)","backup_url"', r.text)[0].encode('utf-8').decode('unicode_escape')
r = requests.get(video_url, proxies=proxy, headers=self.headers)
with open(path + video_name + '.mp4', 'wb')as f:
f.write(r.content)
print("【BiLiBiLi】: {} 下载完成!".format(video_name))
class BiLiBiLi_api():
def __init__(self, s_url):
self.url = s_url.split('?')[0]
self.header1 = {
'Host': 'www.****.com',
'Origin': 'http://www.****.com',
'Referer': quote('http://www.****.com/video?url={}&page=video&submit=视频下载'.format(self.url)),
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63'
}
self.data = {
'url': self.url,
'format': 'flv',
'from': 'parse',
'retry': '1'
}
self.header2 = {
'origin': 'https://www.bilibili.com/',
'referer': self.url,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63'
}
def BL_api_Download(self):
r = requests.post('http://www.****.com/parse', proxies=proxy, data=self.data, headers=self.header1)
video_name = re.findall('data-clipboard-text="(.*?)"', r.json()['msg'])[0]
video_url = re.findall('href="(.*?)"', r.json()['msg'])[0].replace('amp;', '')
r1 = requests.get(video_url, proxies=proxy, headers=self.header2)
with open(path + video_name + '.flv', 'wb')as f:
f.write(r1.content)
print("【BiLiBiLi】: {} 下载完成!".format(video_name))
def user_ui():
print('*' * 10 + '\t BiLiBiLi视频下载\t' + '*' * 10)
print('*' * 5 + "\t\tAuthor: 高智商白痴\t\t" + '*' * 5)
share_url = input('请输入分享链接: ')
choice = int(input("1、模拟手机端下载 2、调用接口下载 3、直接下载\n选择下载方式:"))
if choice == 1:
BiLiBiLi_phone(share_url).bili_Download()
if choice == 2:
BiLiBiLi_api(share_url).BL_api_Download()
if choice == 3:
print("编写中。。。")
if __name__ == '__main__':
user_ui()
大好处
虽然这篇博文还没有写完,但还是迫不及待的给大家分享了很多西部:B站壁纸。
其实B站有个公众号,里面全是2233少女的一些壁纸,呵呵~
你学会了吗?
网页源代码抓取工具(一下热门的小程序,需要源码的,文件一个文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-05 16:09
1.下载工具:
下载夜神模拟器
下载链接:
二、配置node环境:
下载链接:
三、下载反编译工具:
这是由 qwerty472123 在 Github 上编写的 node.js 版本;
地址:;
其他文件没用,把这些文件剪切到新文件夹,其他文件没用;
在这个目录中cmd打开终端npm install配置依赖;
四、开始爬取:
1.首先用模拟器登录微信,运行你要抓取的小程序;
2.进入模拟器的文件管理器;
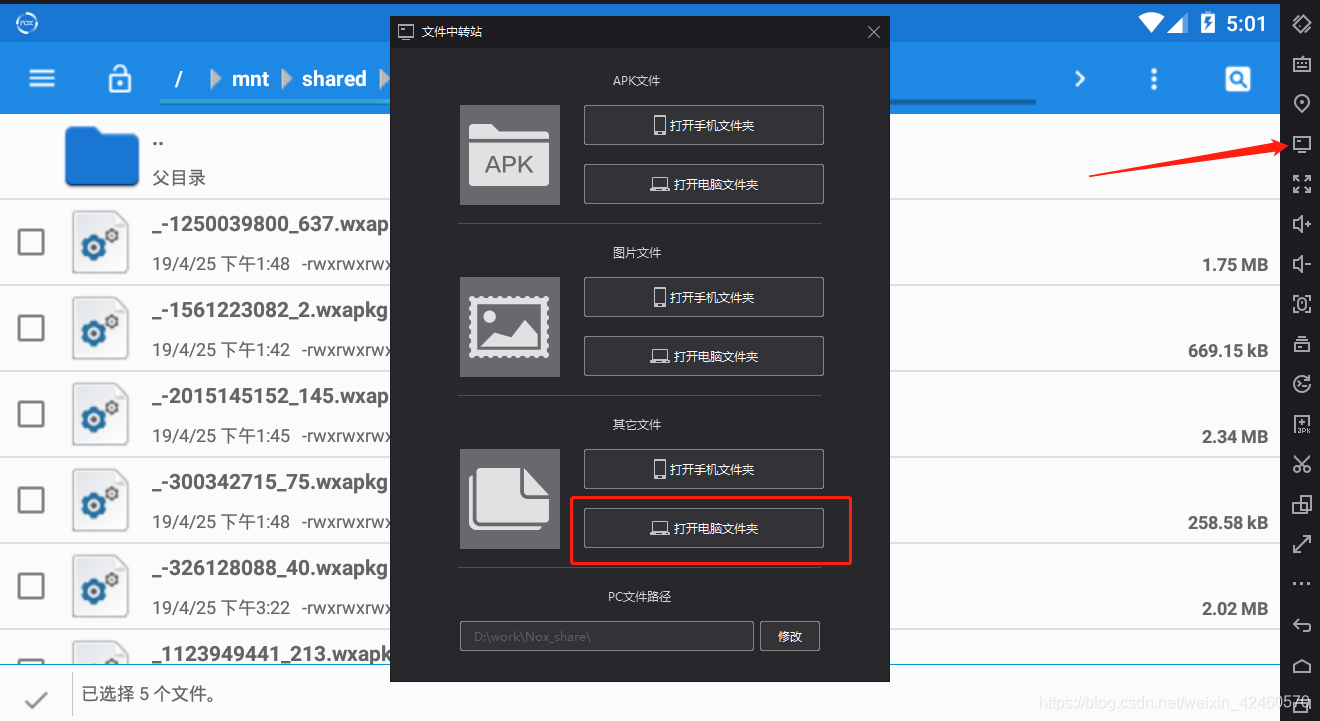
然后进入这个目录
选择我们要编译的小程序wxapk文件
选择后,回到根目录,进入/mnt/shared/orther,点击
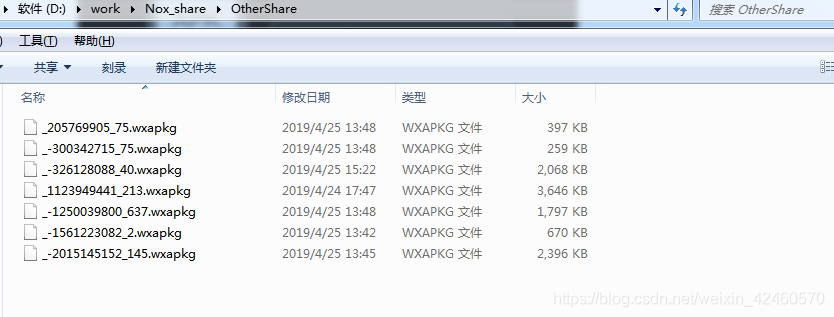
粘贴成功后导出文件到电脑
这就是我们需要的wxapkg文件。一个文件就是一个小程序,把我们需要的东西切到我们反编译工具的目录下。
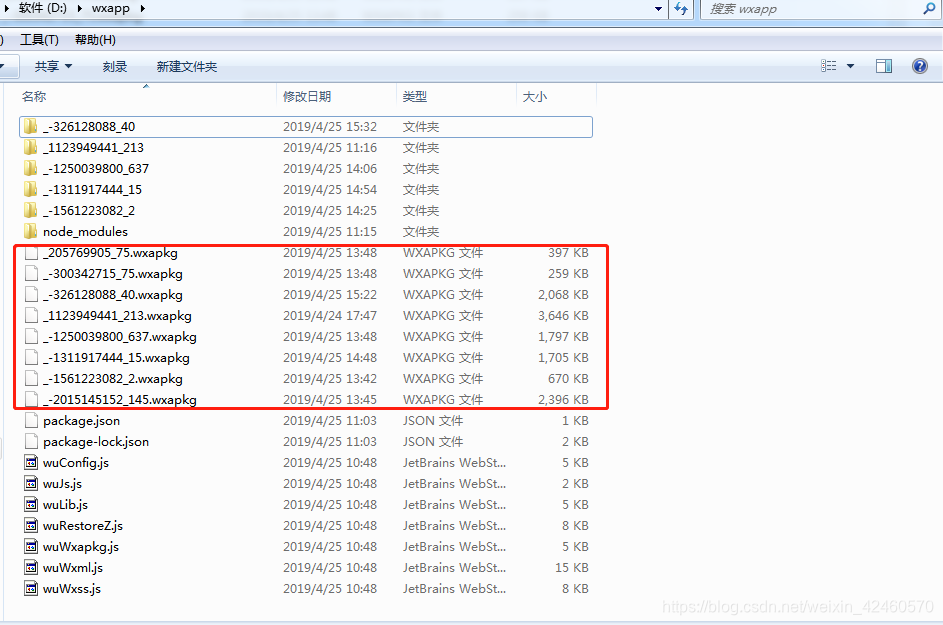
然后开始,反编译
只需输入命令:
节点 wuWxapkg.js D:\wxapp\_-1250039800_637.wxapkg
前面是固定的,后面的.js就是你的初始文件路径。
我们可以得到目录
然后直接在微信开发者工具中打开目录即可!
有了这些步骤,夜神模拟器在运行的过程中会有些卡顿,所以不用担心获取wxapkg文件。
目的是让大家欣赏和了解流行的小程序。只是不要恶意抓住它们,并记住添加注意力。
如果喜欢上面的小程序,需要源码,添加博主的微信私信编辑器。 查看全部
网页源代码抓取工具(一下热门的小程序,需要源码的,文件一个文件)
1.下载工具:
下载夜神模拟器
下载链接:
二、配置node环境:
下载链接:
三、下载反编译工具:
这是由 qwerty472123 在 Github 上编写的 node.js 版本;
地址:;
其他文件没用,把这些文件剪切到新文件夹,其他文件没用;
在这个目录中cmd打开终端npm install配置依赖;
四、开始爬取:
1.首先用模拟器登录微信,运行你要抓取的小程序;
2.进入模拟器的文件管理器;

然后进入这个目录

选择我们要编译的小程序wxapk文件

选择后,回到根目录,进入/mnt/shared/orther,点击


粘贴成功后导出文件到电脑
这就是我们需要的wxapkg文件。一个文件就是一个小程序,把我们需要的东西切到我们反编译工具的目录下。
然后开始,反编译
只需输入命令:
节点 wuWxapkg.js D:\wxapp\_-1250039800_637.wxapkg
前面是固定的,后面的.js就是你的初始文件路径。
我们可以得到目录

然后直接在微信开发者工具中打开目录即可!
有了这些步骤,夜神模拟器在运行的过程中会有些卡顿,所以不用担心获取wxapkg文件。
目的是让大家欣赏和了解流行的小程序。只是不要恶意抓住它们,并记住添加注意力。


如果喜欢上面的小程序,需要源码,添加博主的微信私信编辑器。
网页源代码抓取工具(Python爬虫实例爬取网站搞笑段子爬虫系列Selenium定向爬取虎扑篮球图片详解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-01-04 02:14
本文文章主要介绍Python简单网页图片抓取的完整代码示例,具有一定的参考价值,有需要的朋友可以参考。
使用python捕捉网络图片的步骤是:
1、根据给定的URL获取网页源码
2、使用正则表达式过滤掉源码中的图片地址
3、根据过滤后的图片地址下载网络图片
下面是一个比较简单的抓取百度贴吧网页图片的实现:
# -*- coding: utf-8 -*-
# feimengjuan
import re
import urllib
import urllib2
#抓取网页图片
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
#利用正则表达式把源代码中的图片地址过滤出来
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' %x) #打开imglist中保存的图片网址,并下载图片保存在本地
x = x + 1
html = getHtml("http:编程客栈//tieba.baidu.com/p/2460150866")#获取该网址网页详细信息,得到的html就是网页的源代码
getImg(html)#从网页源代码中分析并下载保存图片
进一步整理代码,在本地创建了一个“图片”文件夹来保存图片
# -*- coding: utf-8 -*-
# feimengjuan
import re
import urllib
import urllib2
import os
#抓取网页图片
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
#创建保存图片的文件夹
def mkdir(path):
path = path.strip()
# 判断路径是否存在
# 存在 True
# 不存在 Flase
isExists = os.path.exists(path)
if not isExists:
print u'新编程客栈建了名字叫做',path,u'的文件夹'
# 创建目录操作函数
os.makedirs(path)
return True
else:
# 如果目录存在则不创建,并提示目录已经存在
print u'名为',path,u'的文件夹已经创建成功'
return False
# 输入文件名,保存多张图片
def saveImages(imglist,name):
number = 1
for imageURL in imglist:
splitPath = imageURL.split('.')
fTail = splitPath.pop()
if len(fTail) > 3:
fTail = 'jpg'
fileName = name + "/" + str(number) + "." + fTail
# 对于每张图片地址,进行保存
try:
u = urllib2.urlopen(imageURL)
data = u.read()
f = open(fileName,'wb+')
f.write(data)
print u'正在保存的一张图片为',fileName
f.close()
except urllib2.URLError as e:
print (e.reason)
number += 1
#获取网页中所有图片的地址
def getAllImg(html):
#利用正则表达式把源代码中的图片地址过滤出来
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
return imglist
#创建本地保存文件夹,并下载保存图片
if __name__ == '__main__':
html = getHtml("http://编程客栈tieba.baidu.com/p/2460150866")#获取该网址网页详细信息,得到的html就是网页的源代码
path = u'图片'
mkdir(path) #创建本地文件夹
imglist = http://www.cppcns.comgetAllImg(html) #获取图片的地址列表
saveImages(imglist,path) # 保存图片
结果在“图片”文件夹中保存了几十张图片,比如截图:
总结
以上就是本文关于Python编程栈实现简单网页图片抓取完整代码示例的全部内容,希望对大家有所帮助。有兴趣的朋友可以继续参考本站:
Python爬虫实例爬取网站搞笑段子
python爬虫系列Selenium定向爬行虎扑篮球图详解
如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!
本文标题:Python实现简单网页图片抓取的完整代码示例 查看全部
网页源代码抓取工具(Python爬虫实例爬取网站搞笑段子爬虫系列Selenium定向爬取虎扑篮球图片详解)
本文文章主要介绍Python简单网页图片抓取的完整代码示例,具有一定的参考价值,有需要的朋友可以参考。
使用python捕捉网络图片的步骤是:
1、根据给定的URL获取网页源码
2、使用正则表达式过滤掉源码中的图片地址
3、根据过滤后的图片地址下载网络图片
下面是一个比较简单的抓取百度贴吧网页图片的实现:
# -*- coding: utf-8 -*-
# feimengjuan
import re
import urllib
import urllib2
#抓取网页图片
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
#利用正则表达式把源代码中的图片地址过滤出来
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' %x) #打开imglist中保存的图片网址,并下载图片保存在本地
x = x + 1
html = getHtml("http:编程客栈//tieba.baidu.com/p/2460150866")#获取该网址网页详细信息,得到的html就是网页的源代码
getImg(html)#从网页源代码中分析并下载保存图片
进一步整理代码,在本地创建了一个“图片”文件夹来保存图片
# -*- coding: utf-8 -*-
# feimengjuan
import re
import urllib
import urllib2
import os
#抓取网页图片
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
#创建保存图片的文件夹
def mkdir(path):
path = path.strip()
# 判断路径是否存在
# 存在 True
# 不存在 Flase
isExists = os.path.exists(path)
if not isExists:
print u'新编程客栈建了名字叫做',path,u'的文件夹'
# 创建目录操作函数
os.makedirs(path)
return True
else:
# 如果目录存在则不创建,并提示目录已经存在
print u'名为',path,u'的文件夹已经创建成功'
return False
# 输入文件名,保存多张图片
def saveImages(imglist,name):
number = 1
for imageURL in imglist:
splitPath = imageURL.split('.')
fTail = splitPath.pop()
if len(fTail) > 3:
fTail = 'jpg'
fileName = name + "/" + str(number) + "." + fTail
# 对于每张图片地址,进行保存
try:
u = urllib2.urlopen(imageURL)
data = u.read()
f = open(fileName,'wb+')
f.write(data)
print u'正在保存的一张图片为',fileName
f.close()
except urllib2.URLError as e:
print (e.reason)
number += 1
#获取网页中所有图片的地址
def getAllImg(html):
#利用正则表达式把源代码中的图片地址过滤出来
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
return imglist
#创建本地保存文件夹,并下载保存图片
if __name__ == '__main__':
html = getHtml("http://编程客栈tieba.baidu.com/p/2460150866")#获取该网址网页详细信息,得到的html就是网页的源代码
path = u'图片'
mkdir(path) #创建本地文件夹
imglist = http://www.cppcns.comgetAllImg(html) #获取图片的地址列表
saveImages(imglist,path) # 保存图片
结果在“图片”文件夹中保存了几十张图片,比如截图:

总结
以上就是本文关于Python编程栈实现简单网页图片抓取完整代码示例的全部内容,希望对大家有所帮助。有兴趣的朋友可以继续参考本站:
Python爬虫实例爬取网站搞笑段子
python爬虫系列Selenium定向爬行虎扑篮球图详解
如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!
本文标题:Python实现简单网页图片抓取的完整代码示例
网页源代码抓取工具(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-03 23:15
想知道爬取网页源码的三种实现方式的相关内容吗?在本文中,我将仔细讲解爬取网页源代码的相关知识和一些代码示例。欢迎阅读和指正。 ,源码,一起学习吧。
更推荐方法一
///
/// 用HttpWebRequest取得网页源码
/// 对于带BOM的网页很有效,不管是什么编码都能正确识别
///
/// 网页地址"
/// 返回网页源文件
public static string GetHtmlSource2(string url)
{
//处理内容
string html = "";
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Accept = "*/*"; //接受任意文件
request.UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.1.4322)"; // 模拟使用IE在浏览 http://www.52mvc.com
request.AllowAutoRedirect = true;//是否允许302
//request.CookieContainer = new CookieContainer();//cookie容器,
request.Referer = url; //当前页面的引用
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, Encoding.Default);
html = reader.ReadToEnd();
stream.Close();
return html;
}
方法二
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.IO;
using System.Text;
using System.Net;
namespace MySql
{
public class GetHttpData
{
public static string GetHttpData2(string Url)
{
string sException = null;
string sRslt = null;
WebResponse oWebRps = null;
WebRequest oWebRqst = WebRequest.Create(Url);
oWebRqst.Timeout = 50000;
try
{
oWebRps = oWebRqst.GetResponse();
}
catch (WebException e)
{
sException = e.Message.ToString();
}
catch (Exception e)
{
sException = e.ToString();
}
finally
{
if (oWebRps != null)
{
StreamReader oStreamRd = new StreamReader(oWebRps.GetResponseStream(), Encoding.GetEncoding("utf-8"));
sRslt = oStreamRd.ReadToEnd();
oStreamRd.Close();
oWebRps.Close();
}
}
return sRslt;
}
}
}
方法三
<p>
public static string getHtml(string url, params string [] charSets)//url是要访问的网站地址,charSet是目标网页的编码,如果传入的是null或者"",那就自动分析网页的编码
{
try
{
string charSet = null;
if (charSets.Length == 1) {
charSet = charSets[0];
}
WebClient myWebClient = new WebClient(); //创建WebClient实例myWebClient
// 需要注意的:
//有的网页可能下不下来,有种种原因比如需要cookie,编码问题等等
//这是就要具体问题具体分析比如在头部加入cookie
// webclient.Headers.Add("Cookie", cookie);
//这样可能需要一些重载方法。根据需要写就可以了
//获取或设置用于对向 Internet 资源的请求进行身份验证的网络凭据。
myWebClient.Credentials = CredentialCache.DefaultCredentials;
//如果服务器要验证用户名,密码
//NetworkCredential mycred = new NetworkCredential(struser, strpassword);
//myWebClient.Credentials = mycred;
//从资源下载数据并返回字节数组。(加@是因为网址中间有"/"符号)
byte[] myDataBuffer = myWebClient.DownloadData(url);
string strWebData = Encoding.Default.GetString(myDataBuffer);
//获取网页字符编码描述信息
Match charSetMatch = Regex.Match(strWebData, " 查看全部
网页源代码抓取工具(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
想知道爬取网页源码的三种实现方式的相关内容吗?在本文中,我将仔细讲解爬取网页源代码的相关知识和一些代码示例。欢迎阅读和指正。 ,源码,一起学习吧。
更推荐方法一
///
/// 用HttpWebRequest取得网页源码
/// 对于带BOM的网页很有效,不管是什么编码都能正确识别
///
/// 网页地址"
/// 返回网页源文件
public static string GetHtmlSource2(string url)
{
//处理内容
string html = "";
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Accept = "*/*"; //接受任意文件
request.UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.1.4322)"; // 模拟使用IE在浏览 http://www.52mvc.com
request.AllowAutoRedirect = true;//是否允许302
//request.CookieContainer = new CookieContainer();//cookie容器,
request.Referer = url; //当前页面的引用
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, Encoding.Default);
html = reader.ReadToEnd();
stream.Close();
return html;
}
方法二
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.IO;
using System.Text;
using System.Net;
namespace MySql
{
public class GetHttpData
{
public static string GetHttpData2(string Url)
{
string sException = null;
string sRslt = null;
WebResponse oWebRps = null;
WebRequest oWebRqst = WebRequest.Create(Url);
oWebRqst.Timeout = 50000;
try
{
oWebRps = oWebRqst.GetResponse();
}
catch (WebException e)
{
sException = e.Message.ToString();
}
catch (Exception e)
{
sException = e.ToString();
}
finally
{
if (oWebRps != null)
{
StreamReader oStreamRd = new StreamReader(oWebRps.GetResponseStream(), Encoding.GetEncoding("utf-8"));
sRslt = oStreamRd.ReadToEnd();
oStreamRd.Close();
oWebRps.Close();
}
}
return sRslt;
}
}
}
方法三
<p>
public static string getHtml(string url, params string [] charSets)//url是要访问的网站地址,charSet是目标网页的编码,如果传入的是null或者"",那就自动分析网页的编码
{
try
{
string charSet = null;
if (charSets.Length == 1) {
charSet = charSets[0];
}
WebClient myWebClient = new WebClient(); //创建WebClient实例myWebClient
// 需要注意的:
//有的网页可能下不下来,有种种原因比如需要cookie,编码问题等等
//这是就要具体问题具体分析比如在头部加入cookie
// webclient.Headers.Add("Cookie", cookie);
//这样可能需要一些重载方法。根据需要写就可以了
//获取或设置用于对向 Internet 资源的请求进行身份验证的网络凭据。
myWebClient.Credentials = CredentialCache.DefaultCredentials;
//如果服务器要验证用户名,密码
//NetworkCredential mycred = new NetworkCredential(struser, strpassword);
//myWebClient.Credentials = mycred;
//从资源下载数据并返回字节数组。(加@是因为网址中间有"/"符号)
byte[] myDataBuffer = myWebClient.DownloadData(url);
string strWebData = Encoding.Default.GetString(myDataBuffer);
//获取网页字符编码描述信息
Match charSetMatch = Regex.Match(strWebData, "
网页源代码抓取工具(《搜索引擎原理系列教程》之三个比较关心)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-03 15:01
《搜索引擎原理系列教程》虽然不是一本书,但也弥补了百度白皮书因为信息量大、内容多等原因的一些不足。教程完全是民间SEO爱好者总结的,这种精神值得称赞。这里还是想讲三个方面,也是我们SEOER关心的三个方面:收录、索引、排名。
一、收录
搜索引擎采集网页的过程,收录其实是一个复杂的过程。简单分为这四个步骤:
1、 调度器是整个采集过程的核心。它存储了一个访问过的 URL 库和一个未访问过的 URL 库,统称为 URL 库。一开始,调度器会从未访问过的URL库中检索一个URL,分配给蜘蛛,让蜘蛛抓取没有被抓取的URL。
2、 当蜘蛛获取到一个 URL 时,它会向该 URL 发送一个爬取请求。流程为:URL对应域名的DNS解析->获取Socket连接的IP->连接成功发送http请求->接收网页信息。
3、蜘蛛获取到网页信息后,将源代码返回给调度员,调度员将源代码保存在网络数据库中。
4、 调度器会提取已爬取网页的链接,将未爬取的网址存放在未访问网址库中,将刚刚爬取的网址更新为已爬取的网址库中。
这将涉及重复数据删除
调度器的工作流程
1、从从未访问过的 URL 列表中依次检索 URL,并将它们分配给每个蜘蛛。
2、蜘蛛获取URL,爬取,获取网页源代码,从源代码中提取URL,获取网页中收录的所有URL。
3、 调度器依次检查获取的URL是否存在于访问的URL库中。如果存在,则表示已被抓取,则丢弃该URL;如果不存在,则表示该网址未被抓取,将订单加入未访问网址列表,等待后抓取。
4、 重复步骤 1,直到未访问列表为空。
二、索引
网页预处理
1、索引原创网页。
2、 根据搜索到的网页库对网页进行分割,将每个页面转换为一组词。 (前向指数)
3、 将网页到索引词的映射转换成索引词到网页的映射形成倒排文件(包括倒排表和索引词表)
一般来说,搜索引擎从网页数据库中获取网页,然后进行代码过滤,然后提取正文信息并进行分词。下一步就是过滤关键词的集合,得到网页关键词的正向索引,最后搜索引擎会将正向索引转化为网页的倒排索引。正是这项技术,让搜索引擎能够在1S内将搜索结果呈现给用户。
此外,搜索引擎执行的操作是网页净化和重复数据删除。除了去除网页中的嘈杂内容(如广告、版权等),提取网页主题及相关内容,去除网页采集中的重复内容。
可能有同学会问,搜索引擎是怎么识别主要内容的?实际上,该算法依赖于HTML标签树的建立和投票方式来识别正文。
例如,让我们设置规则,
1、 如果文本块的文本长度小于10个字,0分。 10-50字之间5分。 50 到 250 个单词得 8 分。 250字以上10分。
2、 文本块的文本位置在右边,得0分。在顶部,奖励 3 分。在左侧,奖励 5 分。中间,得10分。
那么我们可以得出结论,页面TITLE得分为9,文本粗体H1标签得分为8,依此类推,DIV部分的AD部分得分为0,被丢弃。
(以上例子仅供参考,与实际算法无关)
搜索引擎必须经过三个步骤才能删除重复的网页。首先是特征提取(涉及I-Match算法和Shingle算法),然后是相似度计算,相似度评价,最后去重。
其实搜索引擎算法和用户交互的过程就是一个查询过程。比如用户搜索“搜索引擎原理”,算法分词后会得到“搜索引擎”,在倒排索引表中找到“原理”。这两个文档列表,相交,然后将上一步找到的用户查询和文档列表中的一条记录向量化,找到查询向量和文档向量的相似度,然后从高到低排序,最后我们得到什么查看最终搜索结果。
三、排名
最后,举个例子作为结尾:
搜索引擎网页权重=网页词条基本权重+链接权重+用户评价权重
网页中术语的基本权重
1、 比如搜索引擎环境中的一个关键词“搜索引擎”,权重应该是:WBT=W+W, (h1)+W,(b ) =10+12+4=26
<p>2、关键词“搜索引擎”也可能在文档的其他地方出现n次,每次出现可以计算一个WBT 查看全部
网页源代码抓取工具(《搜索引擎原理系列教程》之三个比较关心)
《搜索引擎原理系列教程》虽然不是一本书,但也弥补了百度白皮书因为信息量大、内容多等原因的一些不足。教程完全是民间SEO爱好者总结的,这种精神值得称赞。这里还是想讲三个方面,也是我们SEOER关心的三个方面:收录、索引、排名。
一、收录
搜索引擎采集网页的过程,收录其实是一个复杂的过程。简单分为这四个步骤:
1、 调度器是整个采集过程的核心。它存储了一个访问过的 URL 库和一个未访问过的 URL 库,统称为 URL 库。一开始,调度器会从未访问过的URL库中检索一个URL,分配给蜘蛛,让蜘蛛抓取没有被抓取的URL。
2、 当蜘蛛获取到一个 URL 时,它会向该 URL 发送一个爬取请求。流程为:URL对应域名的DNS解析->获取Socket连接的IP->连接成功发送http请求->接收网页信息。
3、蜘蛛获取到网页信息后,将源代码返回给调度员,调度员将源代码保存在网络数据库中。
4、 调度器会提取已爬取网页的链接,将未爬取的网址存放在未访问网址库中,将刚刚爬取的网址更新为已爬取的网址库中。
这将涉及重复数据删除
调度器的工作流程
1、从从未访问过的 URL 列表中依次检索 URL,并将它们分配给每个蜘蛛。
2、蜘蛛获取URL,爬取,获取网页源代码,从源代码中提取URL,获取网页中收录的所有URL。
3、 调度器依次检查获取的URL是否存在于访问的URL库中。如果存在,则表示已被抓取,则丢弃该URL;如果不存在,则表示该网址未被抓取,将订单加入未访问网址列表,等待后抓取。
4、 重复步骤 1,直到未访问列表为空。
二、索引
网页预处理
1、索引原创网页。
2、 根据搜索到的网页库对网页进行分割,将每个页面转换为一组词。 (前向指数)
3、 将网页到索引词的映射转换成索引词到网页的映射形成倒排文件(包括倒排表和索引词表)
一般来说,搜索引擎从网页数据库中获取网页,然后进行代码过滤,然后提取正文信息并进行分词。下一步就是过滤关键词的集合,得到网页关键词的正向索引,最后搜索引擎会将正向索引转化为网页的倒排索引。正是这项技术,让搜索引擎能够在1S内将搜索结果呈现给用户。
此外,搜索引擎执行的操作是网页净化和重复数据删除。除了去除网页中的嘈杂内容(如广告、版权等),提取网页主题及相关内容,去除网页采集中的重复内容。
可能有同学会问,搜索引擎是怎么识别主要内容的?实际上,该算法依赖于HTML标签树的建立和投票方式来识别正文。
例如,让我们设置规则,
1、 如果文本块的文本长度小于10个字,0分。 10-50字之间5分。 50 到 250 个单词得 8 分。 250字以上10分。
2、 文本块的文本位置在右边,得0分。在顶部,奖励 3 分。在左侧,奖励 5 分。中间,得10分。
那么我们可以得出结论,页面TITLE得分为9,文本粗体H1标签得分为8,依此类推,DIV部分的AD部分得分为0,被丢弃。
(以上例子仅供参考,与实际算法无关)
搜索引擎必须经过三个步骤才能删除重复的网页。首先是特征提取(涉及I-Match算法和Shingle算法),然后是相似度计算,相似度评价,最后去重。
其实搜索引擎算法和用户交互的过程就是一个查询过程。比如用户搜索“搜索引擎原理”,算法分词后会得到“搜索引擎”,在倒排索引表中找到“原理”。这两个文档列表,相交,然后将上一步找到的用户查询和文档列表中的一条记录向量化,找到查询向量和文档向量的相似度,然后从高到低排序,最后我们得到什么查看最终搜索结果。
三、排名
最后,举个例子作为结尾:
搜索引擎网页权重=网页词条基本权重+链接权重+用户评价权重
网页中术语的基本权重
1、 比如搜索引擎环境中的一个关键词“搜索引擎”,权重应该是:WBT=W+W, (h1)+W,(b ) =10+12+4=26
<p>2、关键词“搜索引擎”也可能在文档的其他地方出现n次,每次出现可以计算一个WBT
网页源代码抓取工具(sublimeajax学过加载导致的部分关键代码显示不出来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-03 14:56
1、前言
我相信在这个知识共享的时代,你必须下载大量的文件并保存在互联网上以备将来学习。毕竟硬盘空间也比较有限。说一下我们要做的项目,就是搜索。搜索磁盘中的资源并下载。
2、项目目标
实现搜索所需文件,下载文件。
3、项目准备
使用sublime text 3开发,因为这次需要使用interactive来完成操作,所以需要在sublime text 3下载一个sublimeREPL插件来辅助开发。
4、项目实现
(1)打开盘搜,随意打开一个链接,如下图:
(2)然后就可以看到这个画面了,如下图。
(3)此时这个网页的地址是:
http://www.pansou.com/?q=成化十四年
可以看出是一个get请求。所以 requests.get 开始了,所以我们实现了第一步,搜索。所以,你可以这样写代码:
import requests
def down(content):
content=input('请输入要下载的文件名')
rep=requests.get('http://www.pansou.com/?q='+str(content))
rep.encoding='utf-8'
(4)这样我们就得到了上一页的网页源码,我们搜索了相关的关键字,发现没有找到:
(5)那怎么回事?原来是ajax的异步加载导致部分关键代码无法显示。这个很难,也就是说碰到了我知识点的盲点向上。
因为没研究过前端,只知道有ajax,哪里知道这个问题是怎么发生的,怎么解决的。但不要害怕。好在编辑器有个大招,就是找界面。找了又找,终于找到了,嘿嘿,辛苦了。如图:
(6)发现这是一个json格式,所以我们现在就可以读取了,如图:
(7)不容易,json的陷阱很多,所以决定用字典。哈哈哈,适合自己的才是最香的。
当我们找到这些东西时,我们就可以提取它们,这样我们就可以提取出第一页的所有结果。提取第二页的结果,我们只需要将p的结果改为2即可。
最终结果,如图:
(8)接下来我们会加强程序,使其具有交互功能供用户选择。
(9)但是我们知道callback一般是一个可变函数,所以可以使用的参数只有q和p两个,所以:
到此完成指定页面的文件浏览。
下载也比较简单,直接复制链接到浏览器,就完成了最简单的搜索引擎。
5、总结
(1)不建议抓取太多数据,容易加载服务器,简单试一下。
(2)本文基于Python网络爬虫,利用爬虫库搭建了一个简单的Python搜索引擎。
(3)实现的时候,总会出现各种问题,不要看高手,自己去深入了解一下。 查看全部
网页源代码抓取工具(sublimeajax学过加载导致的部分关键代码显示不出来!)
1、前言
我相信在这个知识共享的时代,你必须下载大量的文件并保存在互联网上以备将来学习。毕竟硬盘空间也比较有限。说一下我们要做的项目,就是搜索。搜索磁盘中的资源并下载。
2、项目目标
实现搜索所需文件,下载文件。
3、项目准备
使用sublime text 3开发,因为这次需要使用interactive来完成操作,所以需要在sublime text 3下载一个sublimeREPL插件来辅助开发。
4、项目实现
(1)打开盘搜,随意打开一个链接,如下图:
(2)然后就可以看到这个画面了,如下图。
(3)此时这个网页的地址是:
http://www.pansou.com/?q=成化十四年
可以看出是一个get请求。所以 requests.get 开始了,所以我们实现了第一步,搜索。所以,你可以这样写代码:
import requests
def down(content):
content=input('请输入要下载的文件名')
rep=requests.get('http://www.pansou.com/?q='+str(content))
rep.encoding='utf-8'
(4)这样我们就得到了上一页的网页源码,我们搜索了相关的关键字,发现没有找到:
(5)那怎么回事?原来是ajax的异步加载导致部分关键代码无法显示。这个很难,也就是说碰到了我知识点的盲点向上。
因为没研究过前端,只知道有ajax,哪里知道这个问题是怎么发生的,怎么解决的。但不要害怕。好在编辑器有个大招,就是找界面。找了又找,终于找到了,嘿嘿,辛苦了。如图:
(6)发现这是一个json格式,所以我们现在就可以读取了,如图:
(7)不容易,json的陷阱很多,所以决定用字典。哈哈哈,适合自己的才是最香的。
当我们找到这些东西时,我们就可以提取它们,这样我们就可以提取出第一页的所有结果。提取第二页的结果,我们只需要将p的结果改为2即可。
最终结果,如图:
(8)接下来我们会加强程序,使其具有交互功能供用户选择。
(9)但是我们知道callback一般是一个可变函数,所以可以使用的参数只有q和p两个,所以:
到此完成指定页面的文件浏览。
下载也比较简单,直接复制链接到浏览器,就完成了最简单的搜索引擎。
5、总结
(1)不建议抓取太多数据,容易加载服务器,简单试一下。
(2)本文基于Python网络爬虫,利用爬虫库搭建了一个简单的Python搜索引擎。
(3)实现的时候,总会出现各种问题,不要看高手,自己去深入了解一下。
网页源代码抓取工具( 动态渲染的页面来说)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-01-03 14:53
动态渲染的页面来说)
Selenium 是一种自动化测试工具,可以驱动浏览器执行特定的动作,例如点击、下拉等操作。同时,它还可以获取浏览器当前呈现的页面的源代码,以便在可见时进行抓取。对于一些JavaScript动态渲染的页面,这种爬取方式非常有效。
0、安装
(1) Selenium 安装
pip 安装硒
(2)网络驱动下载
Selenium 是一种需要与浏览器配合使用的自动化测试工具。 Selenium 使用 Webdriver 来驱动浏览器。
您需要根据您的浏览器版本下载相应的webdriver驱动。比如这里使用的是ChromeDriver驱动,可以百度下载。
下载完成后是一个可执行文件。我们可以把它添加到环境变量中,然后我们在构造webdriver.Chrome()的时候就不需要括号里传入驱动的路径了。
1、基本用法
2、初始化浏览器对象
从 selenium 导入 webdriver
浏览器 = webdriver.Chrome()
3、访问页面
browser.get("")
#获取网页源码
打印(browser.page_source)
browser.close()
4、查找节点
(1)查找单个节点
常用的有以下7种:
find_element_by_id
find_element_by_class_name
find_elemnet_by_xpath
find_element_by_css_selector
find_element_by_name
find_element_by_tag_name
find_element_by_link_text
find_element_by_partial_link_text
(2)查找多个节点
看上面找单个节点的方法,区别是element变成了elements
5、节点交互
常用的有:
(1)input.send_keys("Python") 在搜索框中输入内容,如Python
(2).input.clear() 清除搜索框内容
(3).button.click() 模拟鼠标点击,button是找到的可点击标签
6、动作链
例如,将下面的 A 放在 B 中:
7、执行 JavaScript
对于某些操作,Selenium 不提供操作。比如下拉进度条
browser.execute_script (js 代码)
8、获取节点信息
#获取标签的href属性
a.get_attribute("href")
#获取节点下的所有文本信息并返回一个字符串
div.text
9、切换帧
我们知道网页中有一种节点叫做iframe,就是子框架,相当于页面的子页面,其结构与外部网页的结构完全相同。 Selenium 打开页面后,默认在父框架中运行。如果此时页面中有子框架,则无法获取子框架中的节点。这时候就需要使用switch_to.frame()方法来切换Frame。
#这里根据id名称切换
browser.switch_to.frame("iframeResult")
10、延迟等待
在Selenium中,get()方法会在网页框架加载完毕后结束执行。这时候如果得到page_source,可能不是浏览器完全加载的页面。如果某些页面有额外的 Ajax 请求,我们在 网页的源代码中可能无法成功获取。因此需要延迟等待一定的时间来保证节点已经加载完毕。
这里有两种等待方式:一种是隐式等待,另一种是显式等待。
(1)隐式等待
正在等待一个固定的时间。如果 Selenium 在 DOM 中没有找到节点,它会继续等待指定时间,并在指定时间结束时再次检查是否存在该节点,如果没有则抛出异常。单位是s
browser.implicitly_wait(10)
(2)明确等待
显式等待更灵活,可以指定最长等待时间,如果在此时间内返回,将继续运行代码。单位是s
首先使用wait = WebDriverWait(browser, 10)构造等待对象,
wait.until(EC.presence_of_element_located((By.CLASS_NAME, "left")))之后,EC是等待条件对象,presence_of_element_located是需要的等待条件,等待条件有很多,具体看下面:
其他等待条件:
11、前进后退
使用浏览器一般都有前进后退功能。 Selenium 也可以完成这个操作。使用 back() 后退和 forward() 前进。示例如下:
12、Cookies
13、标签管理
首先执行js代码,browser.execute_script('window.open()')。打开另一个标签
切换到另一个标签 browser.switch_to.window(browser.window_handles[1])
关闭标签 browser.execute_script('window.close()')
切换回 browser.switch_to.window(browser.window_handles[0])
14、无头模式
Selenium 不再打开 Chrome 浏览器,只需通过 option = webdriver.ChromeOptions() 和 option.add_argument('--headless') 添加即可。
以上是Selenium的全部内容,使用时只需要设置如下几个参数即可。 查看全部
网页源代码抓取工具(
动态渲染的页面来说)
Selenium 是一种自动化测试工具,可以驱动浏览器执行特定的动作,例如点击、下拉等操作。同时,它还可以获取浏览器当前呈现的页面的源代码,以便在可见时进行抓取。对于一些JavaScript动态渲染的页面,这种爬取方式非常有效。
0、安装
(1) Selenium 安装
pip 安装硒
(2)网络驱动下载
Selenium 是一种需要与浏览器配合使用的自动化测试工具。 Selenium 使用 Webdriver 来驱动浏览器。
您需要根据您的浏览器版本下载相应的webdriver驱动。比如这里使用的是ChromeDriver驱动,可以百度下载。
下载完成后是一个可执行文件。我们可以把它添加到环境变量中,然后我们在构造webdriver.Chrome()的时候就不需要括号里传入驱动的路径了。
1、基本用法
2、初始化浏览器对象
从 selenium 导入 webdriver
浏览器 = webdriver.Chrome()
3、访问页面
browser.get("")
#获取网页源码
打印(browser.page_source)
browser.close()
4、查找节点
(1)查找单个节点
常用的有以下7种:
find_element_by_id
find_element_by_class_name
find_elemnet_by_xpath
find_element_by_css_selector
find_element_by_name
find_element_by_tag_name
find_element_by_link_text
find_element_by_partial_link_text
(2)查找多个节点
看上面找单个节点的方法,区别是element变成了elements
5、节点交互
常用的有:
(1)input.send_keys("Python") 在搜索框中输入内容,如Python
(2).input.clear() 清除搜索框内容
(3).button.click() 模拟鼠标点击,button是找到的可点击标签
6、动作链
例如,将下面的 A 放在 B 中:
7、执行 JavaScript
对于某些操作,Selenium 不提供操作。比如下拉进度条
browser.execute_script (js 代码)
8、获取节点信息
#获取标签的href属性
a.get_attribute("href")
#获取节点下的所有文本信息并返回一个字符串
div.text
9、切换帧
我们知道网页中有一种节点叫做iframe,就是子框架,相当于页面的子页面,其结构与外部网页的结构完全相同。 Selenium 打开页面后,默认在父框架中运行。如果此时页面中有子框架,则无法获取子框架中的节点。这时候就需要使用switch_to.frame()方法来切换Frame。
#这里根据id名称切换
browser.switch_to.frame("iframeResult")
10、延迟等待
在Selenium中,get()方法会在网页框架加载完毕后结束执行。这时候如果得到page_source,可能不是浏览器完全加载的页面。如果某些页面有额外的 Ajax 请求,我们在 网页的源代码中可能无法成功获取。因此需要延迟等待一定的时间来保证节点已经加载完毕。
这里有两种等待方式:一种是隐式等待,另一种是显式等待。
(1)隐式等待
正在等待一个固定的时间。如果 Selenium 在 DOM 中没有找到节点,它会继续等待指定时间,并在指定时间结束时再次检查是否存在该节点,如果没有则抛出异常。单位是s
browser.implicitly_wait(10)
(2)明确等待
显式等待更灵活,可以指定最长等待时间,如果在此时间内返回,将继续运行代码。单位是s
首先使用wait = WebDriverWait(browser, 10)构造等待对象,
wait.until(EC.presence_of_element_located((By.CLASS_NAME, "left")))之后,EC是等待条件对象,presence_of_element_located是需要的等待条件,等待条件有很多,具体看下面:
其他等待条件:
11、前进后退
使用浏览器一般都有前进后退功能。 Selenium 也可以完成这个操作。使用 back() 后退和 forward() 前进。示例如下:
12、Cookies
13、标签管理
首先执行js代码,browser.execute_script('window.open()')。打开另一个标签
切换到另一个标签 browser.switch_to.window(browser.window_handles[1])
关闭标签 browser.execute_script('window.close()')
切换回 browser.switch_to.window(browser.window_handles[0])
14、无头模式
Selenium 不再打开 Chrome 浏览器,只需通过 option = webdriver.ChromeOptions() 和 option.add_argument('--headless') 添加即可。
以上是Selenium的全部内容,使用时只需要设置如下几个参数即可。
网页源代码抓取工具(这是一个简单的单页面数据抓取案例,但也有些值得注意的坑 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-02 10:29
)
这是一个简单的单页数据抓取案例,但也存在一些值得注意的陷阱。这是代码的快速解释。
获取51job网站,搜索“人工智能”,获取职位、职位名称、公司名称、薪资等基本信息
图像.png
数据直接在【右键-查看源码】的网页源码中,也可以在元素面板中【右键-查看】查看:
图像.png
我们注意到job列表都在class='dw_table'这个元素下,但是第一个class='el title'是header,不应该收录,虽然下面有t1,t2,t3 , 但它的 class='t1' 是一,正常位置的 t1 是一
主要代码如下:
from bs4 import BeautifulSoup
import requests
import time
headers = {
'User-Agent': 'Mozilla/5.0'
}
url='https://search.51job.com/list/070300,000000,0000,00,9,99,%25E4%25BA%25BA%25E5%25B7%25A5%25E6%2599%25BA%25E8%2583%25BD,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='
html= requests.get(url,headers=headers)
html=html.text.encode('ISO-8859-1').decode('gbk') ##注意这个坑!
soup=BeautifulSoup(html, 'html.parser')
for item in soup.find('div','dw_table').find_all('div','el'):
shuchu=[]
if item.find('p','t1'):
title=item.find('p','t1').find('a')['title']
company=item.find('span','t2').string #爬公司名称
address=item.find('span','t3').string #爬地址
xinzi = item.find('span', 't4').string #爬薪资
date=item.find('span','t5').string #爬日期
shuchu.append(str(title))
shuchu.append(str(company))
shuchu.append(str(address))
shuchu.append(str(xinzi))
shuchu.append(str(date))
print('\t'.join(shuchu))
time.sleep(1)
有几个坑需要注意:
最终输出大致如下:
查看全部
网页源代码抓取工具(这是一个简单的单页面数据抓取案例,但也有些值得注意的坑
)
这是一个简单的单页数据抓取案例,但也存在一些值得注意的陷阱。这是代码的快速解释。
获取51job网站,搜索“人工智能”,获取职位、职位名称、公司名称、薪资等基本信息
图像.png
数据直接在【右键-查看源码】的网页源码中,也可以在元素面板中【右键-查看】查看:
图像.png
我们注意到job列表都在class='dw_table'这个元素下,但是第一个class='el title'是header,不应该收录,虽然下面有t1,t2,t3 , 但它的 class='t1' 是一,正常位置的 t1 是一
主要代码如下:
from bs4 import BeautifulSoup
import requests
import time
headers = {
'User-Agent': 'Mozilla/5.0'
}
url='https://search.51job.com/list/070300,000000,0000,00,9,99,%25E4%25BA%25BA%25E5%25B7%25A5%25E6%2599%25BA%25E8%2583%25BD,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='
html= requests.get(url,headers=headers)
html=html.text.encode('ISO-8859-1').decode('gbk') ##注意这个坑!
soup=BeautifulSoup(html, 'html.parser')
for item in soup.find('div','dw_table').find_all('div','el'):
shuchu=[]
if item.find('p','t1'):
title=item.find('p','t1').find('a')['title']
company=item.find('span','t2').string #爬公司名称
address=item.find('span','t3').string #爬地址
xinzi = item.find('span', 't4').string #爬薪资
date=item.find('span','t5').string #爬日期
shuchu.append(str(title))
shuchu.append(str(company))
shuchu.append(str(address))
shuchu.append(str(xinzi))
shuchu.append(str(date))
print('\t'.join(shuchu))
time.sleep(1)
有几个坑需要注意:
最终输出大致如下:
网页源代码抓取工具(使用直观的网页分析工具(Chrome开发者工具)对网页进行抓包分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-13 15:08
在本期文章中,我们将尝试使用直观的网页分析工具(Chrome Developer Tools)对网页进行抓取和分析,对网页爬虫的本质和内涵有更深入的了解
1、测试环境
浏览器:Chrome浏览器
浏览器版本:67.0.3396.99(正式版)(32位)
网络分析工具:开发者工具
2、网页分析
(1)网页源码解析
我们知道网页分为静态网页和动态网页。很多人误以为静态网页就是没有动态效果的网页。事实上,这种说法是错误的。静态网页是指没有后台数据库的非交互式网页。, .html, .xml 是后缀
动态网页是指可以与后台数据库传输数据的交互式网页,通常以.aspx、.asp、.jsp、.php为后缀
另外,目前很多动态网站都采用异步加载技术(Ajax),这也是为什么抓到的源码和网站显示的源码不一致的原因,至于怎么爬取动态网页,这里提供了两种方法:一种是通过抓包来分析Ajax请求,下面会讲到。
二是使用Selenium等工具进行动态渲染,可以参考我的另一篇文章文章——
下面以京东产品为例,分析如何通过Chrome抓包。我们先打开一个产品的首页
进入网页空白处,右键,选择查看网页源代码(或使用快捷键Ctrl+U直接打开)
请注意查看网页源代码获取的是网站最原创的源代码,通常是我们抓取的源代码
再次进入网页空白处,右键选择Inspect(或使用快捷键Ctrl+Shift+I/F12直接打开)
请注意,检查结果是通过Ajax加载并通过JavaScript渲染的源代码,也就是网站当前显示的内容的源代码
经过对比我们可以发现两者的内容是不一样的,这是异步加载技术(Ajax)的典型例子
目前,至少京东产品的价格是异步加载生成的。这里提供三种判断网页中的某个内容是否是动态生成的方法:一种是分析查看网页源代码生成的源代码,其中可以找到动态请求。也可以与检查生成的源代码进行比较
二是通过网页抓取的分析来判断,下面会解释。这种方法是最常用的,应该好好掌握。
第三种是比较刁钻的方法,就是禁用Chrome浏览器的JavaScript加载
您可以在 Chrome 的地址栏中输入
(2)网页抓取分析
下面以京东产品为例进行讲解,打开某款产品的首页,尝试抓取动态加载的产品价格数据
使用快捷键Ctrl+Shift+I或F12打开开发者工具,然后选择Network选项卡进行抓包分析
此时按快捷键F5刷新页面。可以看到开发者工具中出现了各种包。我们使用过滤器来过滤包。
首先,我们选择Doc,我们可以看到列表中只出现了一个包
一般来说,这是浏览器接收到的第一个获取请求原创源代码的数据包网站
点击Header查看其header参数设置
单击响应以查看返回的源代码。不难发现,其实和查看网页源码返回的信息是一样的。
让我们回到主题。对于抓包的动态加载分析,我们主要看XHR和JS选项卡。
选择JS进行过滤,发现列表中有很多包。经过分析,我们过滤掉下图中标记的包。
这个包返回了关于价格的信息,但是仔细分析后发现这些价格不属于当前产品,而是属于相关产品。
但是怎么说这个包还是跟价格有关,我们先来看看这个包的请求URL。
%2CJ_26395831446%2CJ_20823451030%2CJ_%2CJ_%2CJ_26498549638&ext=11100000&source=item-pc
过滤包括回调在内的不必要参数以获得简单有效的URL
%2CJ_26395831446%2CJ_20823451030%2CJ_%2CJ_%2CJ_26498549638
直接用浏览器打开网址,可以看到返回的JSON数据中收录价格信息(可惜是其他商品的价格)
通过分析URL的参数,可以推断出skuId应该是每个产品的唯一标识,那么在哪里可以找到我们需要的产品的skuId呢?实际上,SKU是物流、运输等行业常用的缩写。它的全称是Stock Keeping Unit,是库存进出计量的基本单位。现已扩展为统一产品编号的缩写。每个产品都有一个独特的 SKU
这不是隐藏了当前产品的唯一编号标识符()吗?试一试!
通过直接访问这个网址,我们可以得到当前产品的价格信息
其实我们也可以适当的泛化URL来适应京东所有产品的价格爬取
通过泛化的URL,理论上只要能获取到产品的skuId,我们就可以访问到对应产品的价格 查看全部
网页源代码抓取工具(使用直观的网页分析工具(Chrome开发者工具)对网页进行抓包分析)
在本期文章中,我们将尝试使用直观的网页分析工具(Chrome Developer Tools)对网页进行抓取和分析,对网页爬虫的本质和内涵有更深入的了解
1、测试环境
浏览器:Chrome浏览器
浏览器版本:67.0.3396.99(正式版)(32位)
网络分析工具:开发者工具
2、网页分析
(1)网页源码解析
我们知道网页分为静态网页和动态网页。很多人误以为静态网页就是没有动态效果的网页。事实上,这种说法是错误的。静态网页是指没有后台数据库的非交互式网页。, .html, .xml 是后缀
动态网页是指可以与后台数据库传输数据的交互式网页,通常以.aspx、.asp、.jsp、.php为后缀
另外,目前很多动态网站都采用异步加载技术(Ajax),这也是为什么抓到的源码和网站显示的源码不一致的原因,至于怎么爬取动态网页,这里提供了两种方法:一种是通过抓包来分析Ajax请求,下面会讲到。
二是使用Selenium等工具进行动态渲染,可以参考我的另一篇文章文章——
下面以京东产品为例,分析如何通过Chrome抓包。我们先打开一个产品的首页
进入网页空白处,右键,选择查看网页源代码(或使用快捷键Ctrl+U直接打开)
请注意查看网页源代码获取的是网站最原创的源代码,通常是我们抓取的源代码
再次进入网页空白处,右键选择Inspect(或使用快捷键Ctrl+Shift+I/F12直接打开)
请注意,检查结果是通过Ajax加载并通过JavaScript渲染的源代码,也就是网站当前显示的内容的源代码
经过对比我们可以发现两者的内容是不一样的,这是异步加载技术(Ajax)的典型例子
目前,至少京东产品的价格是异步加载生成的。这里提供三种判断网页中的某个内容是否是动态生成的方法:一种是分析查看网页源代码生成的源代码,其中可以找到动态请求。也可以与检查生成的源代码进行比较
二是通过网页抓取的分析来判断,下面会解释。这种方法是最常用的,应该好好掌握。
第三种是比较刁钻的方法,就是禁用Chrome浏览器的JavaScript加载
您可以在 Chrome 的地址栏中输入
(2)网页抓取分析
下面以京东产品为例进行讲解,打开某款产品的首页,尝试抓取动态加载的产品价格数据
使用快捷键Ctrl+Shift+I或F12打开开发者工具,然后选择Network选项卡进行抓包分析
此时按快捷键F5刷新页面。可以看到开发者工具中出现了各种包。我们使用过滤器来过滤包。
首先,我们选择Doc,我们可以看到列表中只出现了一个包
一般来说,这是浏览器接收到的第一个获取请求原创源代码的数据包网站
点击Header查看其header参数设置
单击响应以查看返回的源代码。不难发现,其实和查看网页源码返回的信息是一样的。
让我们回到主题。对于抓包的动态加载分析,我们主要看XHR和JS选项卡。
选择JS进行过滤,发现列表中有很多包。经过分析,我们过滤掉下图中标记的包。
这个包返回了关于价格的信息,但是仔细分析后发现这些价格不属于当前产品,而是属于相关产品。
但是怎么说这个包还是跟价格有关,我们先来看看这个包的请求URL。
%2CJ_26395831446%2CJ_20823451030%2CJ_%2CJ_%2CJ_26498549638&ext=11100000&source=item-pc
过滤包括回调在内的不必要参数以获得简单有效的URL
%2CJ_26395831446%2CJ_20823451030%2CJ_%2CJ_%2CJ_26498549638
直接用浏览器打开网址,可以看到返回的JSON数据中收录价格信息(可惜是其他商品的价格)
通过分析URL的参数,可以推断出skuId应该是每个产品的唯一标识,那么在哪里可以找到我们需要的产品的skuId呢?实际上,SKU是物流、运输等行业常用的缩写。它的全称是Stock Keeping Unit,是库存进出计量的基本单位。现已扩展为统一产品编号的缩写。每个产品都有一个独特的 SKU
这不是隐藏了当前产品的唯一编号标识符()吗?试一试!
通过直接访问这个网址,我们可以得到当前产品的价格信息
其实我们也可以适当的泛化URL来适应京东所有产品的价格爬取
通过泛化的URL,理论上只要能获取到产品的skuId,我们就可以访问到对应产品的价格
网页源代码抓取工具(ColorWell分享ColorWellmac破解版破解版破解版破解版破解版下载 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-13 15:06
)
ColorWell for mac 是一款可以非常轻松地生成无限调色板的软件,您可以从任何颜色源快速获取 Hex/HSL/HSB/RGB 和代码片段。如果您从未从源(或多源)图像快速生成调色板,那么调色板生成器就是您所需要的。您还可以将您生成的任何调色板保存在 ColorWell 调色板数据库中!本站分享ColorWell mac破解版下载。本软件测试环境为10.15.7系统!
Colorwell mac破解版软件功能
主要特征
调色板与 macOS 系统调色板同步
导入/导出 Adobe .ase 和 Apple .clr 调色板文件
无限的历史/快照
完全可定制的界面
Swift/Objective-C 颜色代码生成
支持按名称、十六进制、RGB、HSL、HSB、Lab 和 CMYK 更改颜色
从图像生成调色板
配色方案生成器
可配置为菜单栏应用
其他一些很酷的东西
macOS Mojave 准备好支持 DarkMode
可以配置为浮动在所有其他应用程序的前面
美观直观的用户界面
轻松更改首选项中的默认色彩空间
全局热键即时显示或隐藏
17,000 多个颜色名称
通过拖放重新排列/删除样本
本地化为英语、德语和法语
Colorwell mac破解版软件功能
系统范围的调色板
ColorWell 使用 macOS 系统颜色选择器来同步调色板。因此,您可以在 Pages、Affinity Photo、Final Cut Pro 或任何其他一流的 macOS 应用程序中使用所有精心设计的配色方案!所有系统调色板也可用于查看和创建自定义调色板。
专业文件支持
ColorWell 支持导入和导出到 Adobe .ase 和 Apple .clr 文件格式。这使得分享您的配色方案比以往任何时候都更容易。使用 ColorWell 的通用调色板数据库,任何导入的方案自然会直接导入到 macOS 的颜色选择器中,使其广泛适用于系统
完整的历史支持
您所做的每一次颜色更改都会保存到历史记录中。因此,即使您不记得 3 天前检查的是什么颜色 - ColorWell 也可以!历史支持不限于单一颜色,每次更改都会保存整个颜色状态。因此,当您需要时,当前活动的颜色以及任何已保存的色板都会出现。
高级调色板生成
使用存储的调色板作为起点微调各个颜色。从调色板生成器中获取互补色、类似色、三色、四色或单色。从图像中翻转颜色并微调颜色选择。您可以使用无限数量的样本创建调色板。
ColorWell for mac 更改日志
荷兰本地化
查看全部
网页源代码抓取工具(ColorWell分享ColorWellmac破解版破解版破解版破解版破解版下载
)
ColorWell for mac 是一款可以非常轻松地生成无限调色板的软件,您可以从任何颜色源快速获取 Hex/HSL/HSB/RGB 和代码片段。如果您从未从源(或多源)图像快速生成调色板,那么调色板生成器就是您所需要的。您还可以将您生成的任何调色板保存在 ColorWell 调色板数据库中!本站分享ColorWell mac破解版下载。本软件测试环境为10.15.7系统!
Colorwell mac破解版软件功能
主要特征
调色板与 macOS 系统调色板同步
导入/导出 Adobe .ase 和 Apple .clr 调色板文件
无限的历史/快照
完全可定制的界面
Swift/Objective-C 颜色代码生成
支持按名称、十六进制、RGB、HSL、HSB、Lab 和 CMYK 更改颜色
从图像生成调色板
配色方案生成器
可配置为菜单栏应用
其他一些很酷的东西
macOS Mojave 准备好支持 DarkMode
可以配置为浮动在所有其他应用程序的前面
美观直观的用户界面
轻松更改首选项中的默认色彩空间
全局热键即时显示或隐藏
17,000 多个颜色名称
通过拖放重新排列/删除样本
本地化为英语、德语和法语
Colorwell mac破解版软件功能
系统范围的调色板
ColorWell 使用 macOS 系统颜色选择器来同步调色板。因此,您可以在 Pages、Affinity Photo、Final Cut Pro 或任何其他一流的 macOS 应用程序中使用所有精心设计的配色方案!所有系统调色板也可用于查看和创建自定义调色板。
专业文件支持
ColorWell 支持导入和导出到 Adobe .ase 和 Apple .clr 文件格式。这使得分享您的配色方案比以往任何时候都更容易。使用 ColorWell 的通用调色板数据库,任何导入的方案自然会直接导入到 macOS 的颜色选择器中,使其广泛适用于系统
完整的历史支持
您所做的每一次颜色更改都会保存到历史记录中。因此,即使您不记得 3 天前检查的是什么颜色 - ColorWell 也可以!历史支持不限于单一颜色,每次更改都会保存整个颜色状态。因此,当您需要时,当前活动的颜色以及任何已保存的色板都会出现。
高级调色板生成
使用存储的调色板作为起点微调各个颜色。从调色板生成器中获取互补色、类似色、三色、四色或单色。从图像中翻转颜色并微调颜色选择。您可以使用无限数量的样本创建调色板。
ColorWell for mac 更改日志
荷兰本地化
网页源代码抓取工具(如何应对数据匮乏?最简单的方法在这里!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-13 15:04
介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!想要获得更多数据来训练我们的机器学习模型是一个持续存在的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吧?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络抓取。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 中采集数据。今天,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这就是网络抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将了解网页抓取的不同组件,然后直接深入 Python 以了解如何使用流行且高效的 BeautifulSoup 库执行网页抓取。
请注意,网络抓取受许多准则和规则的约束。并非每个 网站 都允许用户抓取内容,因此存在法律限制。在尝试执行此操作之前,请确保您已阅读 网站 的网站 条款和条件。
3 个流行的 Python 网络爬虫工具和库 用于网络爬虫的组件 爬网解析和转换 网页抓取 URL 和电子邮件 ID 抓取图像 在页面加载时抓取数据 3 个流行的 Python 网络爬虫工具和库
您将在 Python 中遇到几个用于 Web 抓取的库和框架。以下是三种用于高效完成工作的流行工具:
美丽汤
刮擦
硒
网络爬虫的组成部分
这是构成网络抓取的三个主要组件的绝佳说明:
让我们详细了解这些组件。我们将通过 goibibo网站 获取酒店详细信息,例如酒店名称和每间客房的价格以执行此操作:
注意:始终遵循目标 网站 的 robots.txt 文件,也称为机器人排除协议。这告诉网络机器人不要抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴为我们的网络机器人编写脚本。开始吧!
第 1 步:抓取(抓取)
网页抓取的第一步是导航到目标 网站 并下载网页的源代码。我们将使用 requests 库来执行此操作。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页的源代码后,我们需要过滤我们想要的内容:
"""Web Scraping - Beautiful Soup"""# importing required librariesimport requestsfrom bs4 import BeautifulSoupimport pandas as pd# target URL to scrapurl = "https://www.goibibo.com/hotels ... 3B%23 headersheaders = { 'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36" }# send request to download the dataresponse = requests.request("GET", url, headers=headers)# parse the downloaded datadata = BeautifulSoup(response.text, 'html.parser')print(data)
第 2 步:解析和转换
网页抓取的下一步是将这些数据解析为 HTML 解析器,为此我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,与大多数页面一样,特定酒店的详细信息在不同的卡片上。
所以下一步是从完整的源代码中过滤卡片数据。接下来,我们将选择该卡并单击“检查元素”选项以获取该特定卡的源代码。你会得到这样的东西:
所有卡片都有相同的类名,我们可以通过传递标签名称和具有如下名称的属性(如标签)来获取这些卡片的列表:
# find all the sections with specifiedd class namecards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})# total number of cardsprint('Total Number of Cards Found : ', len(cards_data))# source code of hotel cardsfor card in cards_data: print(card)
我们从网页的完整源代码中过滤掉了卡片数据,其中每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在对于每张卡,我们必须找到上面的酒店名称,只能从
从标签中提取。这是因为每张卡和费率只有一个标签和标签和类别名称:
# extract the hotel name and price per roomfor card in cards_data: # get the hotel name hotel_name = card.find('p') # get the room price room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'}) print(hotel_name.text, room_price.text)
第三步:存储(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后我们最终将它添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the datascraped_data = []for card in cards_data: # initialize the dictionary card_details = {} # get the hotel name hotel_name = card.find('p') # get the room price room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'}) # add data to the dictionary card_details['hotel_name'] = hotel_name.text card_details['room_price'] = room_price.text # append the scraped data to the list scraped_data.append(card_details)# create a data frame from the list of dictionariesdataFrame = pd.DataFrame.from_dict(scraped_data)# save the scraped data as CSV filedataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络抓取工具。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的评级和地址。现在,让我们看看如何执行一些常见任务,例如在页面加载时抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试通过网络抓取来抓取的两个最常见的功能是 网站URL 和电子邮件 ID。我确定您参与过需要大量提取电子邮件 ID 的项目或挑战。那么让我们看看如何在 Python 中抓取这些内容。
使用 Web 浏览器的控制台 查看全部
网页源代码抓取工具(如何应对数据匮乏?最简单的方法在这里!!)
介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!想要获得更多数据来训练我们的机器学习模型是一个持续存在的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吧?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络抓取。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 中采集数据。今天,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这就是网络抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将了解网页抓取的不同组件,然后直接深入 Python 以了解如何使用流行且高效的 BeautifulSoup 库执行网页抓取。
请注意,网络抓取受许多准则和规则的约束。并非每个 网站 都允许用户抓取内容,因此存在法律限制。在尝试执行此操作之前,请确保您已阅读 网站 的网站 条款和条件。
3 个流行的 Python 网络爬虫工具和库 用于网络爬虫的组件 爬网解析和转换 网页抓取 URL 和电子邮件 ID 抓取图像 在页面加载时抓取数据 3 个流行的 Python 网络爬虫工具和库
您将在 Python 中遇到几个用于 Web 抓取的库和框架。以下是三种用于高效完成工作的流行工具:
美丽汤
刮擦
硒
网络爬虫的组成部分
这是构成网络抓取的三个主要组件的绝佳说明:
让我们详细了解这些组件。我们将通过 goibibo网站 获取酒店详细信息,例如酒店名称和每间客房的价格以执行此操作:
注意:始终遵循目标 网站 的 robots.txt 文件,也称为机器人排除协议。这告诉网络机器人不要抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴为我们的网络机器人编写脚本。开始吧!
第 1 步:抓取(抓取)
网页抓取的第一步是导航到目标 网站 并下载网页的源代码。我们将使用 requests 库来执行此操作。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页的源代码后,我们需要过滤我们想要的内容:
"""Web Scraping - Beautiful Soup"""# importing required librariesimport requestsfrom bs4 import BeautifulSoupimport pandas as pd# target URL to scrapurl = "https://www.goibibo.com/hotels ... 3B%23 headersheaders = { 'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36" }# send request to download the dataresponse = requests.request("GET", url, headers=headers)# parse the downloaded datadata = BeautifulSoup(response.text, 'html.parser')print(data)
第 2 步:解析和转换
网页抓取的下一步是将这些数据解析为 HTML 解析器,为此我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,与大多数页面一样,特定酒店的详细信息在不同的卡片上。
所以下一步是从完整的源代码中过滤卡片数据。接下来,我们将选择该卡并单击“检查元素”选项以获取该特定卡的源代码。你会得到这样的东西:
所有卡片都有相同的类名,我们可以通过传递标签名称和具有如下名称的属性(如标签)来获取这些卡片的列表:
# find all the sections with specifiedd class namecards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})# total number of cardsprint('Total Number of Cards Found : ', len(cards_data))# source code of hotel cardsfor card in cards_data: print(card)
我们从网页的完整源代码中过滤掉了卡片数据,其中每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在对于每张卡,我们必须找到上面的酒店名称,只能从
从标签中提取。这是因为每张卡和费率只有一个标签和标签和类别名称:
# extract the hotel name and price per roomfor card in cards_data: # get the hotel name hotel_name = card.find('p') # get the room price room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'}) print(hotel_name.text, room_price.text)
第三步:存储(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后我们最终将它添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the datascraped_data = []for card in cards_data: # initialize the dictionary card_details = {} # get the hotel name hotel_name = card.find('p') # get the room price room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'}) # add data to the dictionary card_details['hotel_name'] = hotel_name.text card_details['room_price'] = room_price.text # append the scraped data to the list scraped_data.append(card_details)# create a data frame from the list of dictionariesdataFrame = pd.DataFrame.from_dict(scraped_data)# save the scraped data as CSV filedataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络抓取工具。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的评级和地址。现在,让我们看看如何执行一些常见任务,例如在页面加载时抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试通过网络抓取来抓取的两个最常见的功能是 网站URL 和电子邮件 ID。我确定您参与过需要大量提取电子邮件 ID 的项目或挑战。那么让我们看看如何在 Python 中抓取这些内容。
使用 Web 浏览器的控制台
网页源代码抓取工具(百度首页没有模块的作用及解决办法(二):导入requests模块)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-12 20:09
请求模块:
在做这件事之前,你需要先了解一下,requests 模块是什么?
requests的底层实现是urllib,通过爬虫运行!
在python中,我们需要使用第三方库requests来发送网络请求
所以requests模块的作用就是发送网络请求并返回响应数据
接下来就是下载了:使用:pip install requests -i 命令下载(注:这里下载有问题的可以私聊我,教你如何下载成功!)
具体步骤:
0:导入请求模块
导入请求
1:确定网址
在爬取网页之前,必须要做的是确定要爬取的网页;
我们要的百度web域名是/
保存在变量中
网址='/'
2:发送请求
这一步主要是获取上一步的URL中的数据
我们开始使用 requests 模块中的 get 方法来获取 URL 网页数据并保存在 response 变量中
接下来需要将类型转换为使用文本和内容转换为字符串和字节类型
response=request.get(url) #注意:这里的响应不是数据
print(response) #可以试试用print看看是什么数据
str_data=response.text #转换为字符串类型
bytes_data=response.content #转换为字节类型
#Crawler 爱好者可以尝试打印他们的类型以及变量中的内容是什么?
3:提取数据(略)
有很多方法可以做到这一点,但在这里列出是因为它是重要的一步。
抓取百度主页的时候不需要过滤百度主页的数据,所以就省略了~
想跟我学习的朋友,关注我,一起学习吧!每天加油~
4:保存数据
很明显,保存数据就是把你从网页上抓取的数据保存到你的电脑上。
用 open("baidu_01.html",'w',encoding="UTF-8") as f:
f.write(str_data)
with open("baidu_02.html",'wb') as f:
f.write(bytes_data)
使用 open("filename","identifier"",encoding="UTF-8")) 作为 f:
f.write(需要存入文件的变量名)
可以理解为一种简单的语法格式,放上去就行了。
在标识符中:分为w和wb,分别是string和byte类型。不同的是wb下载保存的网页没有乱码。因为网页是字节类型的。
笔记:
文件操作:使用 open 进行文件操作,建议使用 with 创建运行时环境。您可以在不使用 close() 方法的情况下关闭文件。无论您在文件使用过程中遇到什么问题,都可以安全退出。即使发生错误,您也可以退出运行时环境。可以安全地退出文件并给出错误信息。
with创建临时运行环境的作用:with用于创建临时运行环境,运行环境中的代码执行完毕后自动安全退出环境。
最后给大家一个源码:
导入请求
网址='/'
响应=requests.get(url)
str_data=response.text
bytes_data=response.content
with open("baidu_01.html",'w',encoding="utf-8")as f:
f.write(str_data)
with open("baidu_02.html",'wb') as f:
f.write(bytes_data)
———————————————
版权声明:本文为CSDN博主“Systemer~Fred”的原创文章,遵循CC4.0 BY-SA版权协议。转载请附上原文出处链接和本声明。
原文链接:简单爬虫案例:抓取百度首页(通俗易懂,附源码)-Systemer~Fred的博客-CSDN博客 查看全部
网页源代码抓取工具(百度首页没有模块的作用及解决办法(二):导入requests模块)
请求模块:
在做这件事之前,你需要先了解一下,requests 模块是什么?
requests的底层实现是urllib,通过爬虫运行!
在python中,我们需要使用第三方库requests来发送网络请求
所以requests模块的作用就是发送网络请求并返回响应数据
接下来就是下载了:使用:pip install requests -i 命令下载(注:这里下载有问题的可以私聊我,教你如何下载成功!)
具体步骤:
0:导入请求模块
导入请求
1:确定网址
在爬取网页之前,必须要做的是确定要爬取的网页;
我们要的百度web域名是/
保存在变量中
网址='/'
2:发送请求
这一步主要是获取上一步的URL中的数据
我们开始使用 requests 模块中的 get 方法来获取 URL 网页数据并保存在 response 变量中
接下来需要将类型转换为使用文本和内容转换为字符串和字节类型
response=request.get(url) #注意:这里的响应不是数据
print(response) #可以试试用print看看是什么数据
str_data=response.text #转换为字符串类型
bytes_data=response.content #转换为字节类型
#Crawler 爱好者可以尝试打印他们的类型以及变量中的内容是什么?
3:提取数据(略)
有很多方法可以做到这一点,但在这里列出是因为它是重要的一步。
抓取百度主页的时候不需要过滤百度主页的数据,所以就省略了~
想跟我学习的朋友,关注我,一起学习吧!每天加油~
4:保存数据
很明显,保存数据就是把你从网页上抓取的数据保存到你的电脑上。
用 open("baidu_01.html",'w',encoding="UTF-8") as f:
f.write(str_data)
with open("baidu_02.html",'wb') as f:
f.write(bytes_data)
使用 open("filename","identifier"",encoding="UTF-8")) 作为 f:
f.write(需要存入文件的变量名)
可以理解为一种简单的语法格式,放上去就行了。
在标识符中:分为w和wb,分别是string和byte类型。不同的是wb下载保存的网页没有乱码。因为网页是字节类型的。
笔记:
文件操作:使用 open 进行文件操作,建议使用 with 创建运行时环境。您可以在不使用 close() 方法的情况下关闭文件。无论您在文件使用过程中遇到什么问题,都可以安全退出。即使发生错误,您也可以退出运行时环境。可以安全地退出文件并给出错误信息。
with创建临时运行环境的作用:with用于创建临时运行环境,运行环境中的代码执行完毕后自动安全退出环境。
最后给大家一个源码:
导入请求
网址='/'
响应=requests.get(url)
str_data=response.text
bytes_data=response.content
with open("baidu_01.html",'w',encoding="utf-8")as f:
f.write(str_data)
with open("baidu_02.html",'wb') as f:
f.write(bytes_data)
———————————————
版权声明:本文为CSDN博主“Systemer~Fred”的原创文章,遵循CC4.0 BY-SA版权协议。转载请附上原文出处链接和本声明。
原文链接:简单爬虫案例:抓取百度首页(通俗易懂,附源码)-Systemer~Fred的博客-CSDN博客
网页源代码抓取工具(强大易用!新一代爬虫利器Playwright的介绍目录(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 733 次浏览 • 2022-01-12 11:03
)
官方文档:入门 | 剧作家蟒蛇
参考链接:功能强大,好用!新一代爬虫工具Playwright介绍
内容
安装
Playwrigth 会安装 Chromium、Firefox 和 WebKit 浏览器并配置一些驱动程序,我们不需要关心中间的配置过程,Playwright 会为我们配置。
pip install playwright
# 安装完后初始化
playwright install
基本用途
打开浏览器,跳转到百度网页,打印标题;设置headless参数为False,表示显示浏览器界面。
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
rowser = browser_type.launch(headless=False)
page = browser.new_page()
page.goto('https://www.baidu.com')
print(page.title())
browser.close()
代码生成
我们可以在浏览器中记录我们的操作并自动生成代码,可以在爬虫中进行点击、跳转、鼠标移动等自动化操作。
当有些步骤不知道怎么写时,自动生成代码引用很方便。
在指定路径输入命令,会弹出对应的窗口,可以开始手动操作,会生成代码,但是操作有点复杂,好像自动生成不成功。
playwright codegen -o script.py
启动一个谷歌浏览器,然后将运行结果输出到script.py文件,生成代码如下图。
以下代码,打开茶语网,点击【茶语评论】,会打开一个新窗口跳转过去。
from playwright.sync_api import Playwright, sync_playwright
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
# Open new page
page = context.new_page()
# Go to https://www.chayu.com/
page.goto("https://www.chayu.com/")
# Click #sub-nav >> text=茶评
# 由于弹出新窗口,需要等待,这里就是自动等待页面加载
# 点击茶评,等待页面加载
with page.expect_popup() as popup_info:
# 就页面的操作都可以在这里面继续加
page.click("#sub-nav >> text=茶评")
page1 = popup_info.value # 赋值新窗口对象
# Close page
page.close()
# Close page
page1.close()
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)
AJAX动态加载数据获取
获取动态加载的数据,需要注意浏览器需要在上面显示动态加载的页面才能提取出来,例如:获取评论数据,ajax加载,打开页面:
如果打开页面直接提取评论数据,是无法提取的。您需要将数据滑动到页面上然后提取它(它已经死了)
事件监听器
Page对象提供了一个on方法,可以用来监控页面中发生的各种事件,如关闭、控制台、加载、请求、响应等。
您可以收听响应事件。每次响应网络请求时都可以触发响应事件。我们可以设置相应的回调方法。
可以和ajax结合使用,获取数据,拦截Ajax请求,输出对应的JSON结果。
from playwright.sync_api import sync_playwright
def on_response(response):
if '/api/movie/' in response.url and response.status == 200:
print(response.json())
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.on('response', on_response)
page.goto('https://spa6.scrape.center/')
page.wait_for_load_state('networkidle')
browser.close()
不加载图像
调用route方法,第一个参数通过正则表达式传入匹配的URL路径。这表示任何收录 .png 或 .jpg 的链接。当遇到这样的请求时,会回调cancel_request方法进行处理。cancel_request 方法可以接收两个参数,一个是 route,代表 CallableRoute 对象,另一个是 request,代表 Request 对象。这里我们直接调用路由的abort方法取消请求,所以最终的结果就是图片的加载完全取消了
from playwright.sync_api import sync_playwright
import re
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
# 不加载图片
def cancel_request(route, request):
route.abort()
page.route(re.compile(r"(\.png)|(\.jpg)"), cancel_request)
page.goto("https://spa6.scrape.center/")
page.wait_for_load_state('networkidle')
page.screenshot(path='no_picture.png')
browser.close()
CSS 选择器、文本选择器、click()
click 方法中有一个选择器表达式。解压点击后,可以设置超时时间。默认值为 30 秒,设置以毫秒为单位。如果等待5秒后点击不成功,报错timeout=5000
# 选择文本是 Log in 的节点,并点击
page.click("text=Log in",timeout=5000)
# 选择 id 为 nav-bar 子孙节点 class 属性值为 contact-us-item,并点击
page.click("#nav-bar .contact-us-item")
# 选择文本中包含 Playwright 的 article 节点
page.click("article:has-text('Playwright')")
# 选择 id 为 nav-bar 节点中文本值等于 Contact us 的节点
page.click("#nav-bar :text('Contact us')")
# 选择 class 为 item-description 的节点,且该节点还要包含 class 为 item-promo-banner 的子节点
page.click(".item-description:has(.item-promo-banner)")
# 择的就是一个 input 节点,并且该 input 节点要位于文本值为 Username 的节点的右侧
page.click("input:right-of(:text('Username'))")
xpath 选择器
您需要在开头指定 xpath= 字符串,这意味着它后面是一个 XPath 表达式
page.click("xpath=//button")
获取网页源代码
此处获取的网页源代码,不管网页是否通过ajax加载,都是为了获取最终的html。
任何需要对 html 中的元素进行操作的 page.wait_for_load_state('networkidle') 都必须写入等待 html 加载。
page.wait_for_load_state('networkidle')
html = page.content()
文本输入
在输入标签名称属性是 wd 输入 nba
page.fill("input[name=\"wd\"]", "nba")
选择提取选项卡
提取所有class属性为list的div标签
elements = page.query_selector_all('div.list')
提取span标签的class属性作为score,如果有多个匹配,取第一个
score = element.query_selector('span.score')
提取文本
提取带有文本[Brand:]的标签,并提取标签下的所有文本
brand = element.query_selector('text=品牌:').text_content()
从标签中提取属性
提取h5标签下的a标签,得到a标签中href属性的值
link = element.query_selector('h5 a').get_attribute('href')
鼠标滚动
向右滚动0,向下滚动7000,可用于下拉滚动条功能
page1.mouse.wheel(0,7000)
下拉滚动条
执行js代码,下拉滚动条,15000可根据情况设置
page1.evaluate("var q=document.documentElement.scrollTop=15000") 查看全部
网页源代码抓取工具(强大易用!新一代爬虫利器Playwright的介绍目录(组图)
)
官方文档:入门 | 剧作家蟒蛇
参考链接:功能强大,好用!新一代爬虫工具Playwright介绍
内容
安装
Playwrigth 会安装 Chromium、Firefox 和 WebKit 浏览器并配置一些驱动程序,我们不需要关心中间的配置过程,Playwright 会为我们配置。
pip install playwright
# 安装完后初始化
playwright install
基本用途
打开浏览器,跳转到百度网页,打印标题;设置headless参数为False,表示显示浏览器界面。
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
rowser = browser_type.launch(headless=False)
page = browser.new_page()
page.goto('https://www.baidu.com')
print(page.title())
browser.close()
代码生成
我们可以在浏览器中记录我们的操作并自动生成代码,可以在爬虫中进行点击、跳转、鼠标移动等自动化操作。
当有些步骤不知道怎么写时,自动生成代码引用很方便。
在指定路径输入命令,会弹出对应的窗口,可以开始手动操作,会生成代码,但是操作有点复杂,好像自动生成不成功。
playwright codegen -o script.py
启动一个谷歌浏览器,然后将运行结果输出到script.py文件,生成代码如下图。
以下代码,打开茶语网,点击【茶语评论】,会打开一个新窗口跳转过去。
from playwright.sync_api import Playwright, sync_playwright
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
# Open new page
page = context.new_page()
# Go to https://www.chayu.com/
page.goto("https://www.chayu.com/";)
# Click #sub-nav >> text=茶评
# 由于弹出新窗口,需要等待,这里就是自动等待页面加载
# 点击茶评,等待页面加载
with page.expect_popup() as popup_info:
# 就页面的操作都可以在这里面继续加
page.click("#sub-nav >> text=茶评")
page1 = popup_info.value # 赋值新窗口对象
# Close page
page.close()
# Close page
page1.close()
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)
AJAX动态加载数据获取
获取动态加载的数据,需要注意浏览器需要在上面显示动态加载的页面才能提取出来,例如:获取评论数据,ajax加载,打开页面:
如果打开页面直接提取评论数据,是无法提取的。您需要将数据滑动到页面上然后提取它(它已经死了)
事件监听器
Page对象提供了一个on方法,可以用来监控页面中发生的各种事件,如关闭、控制台、加载、请求、响应等。
您可以收听响应事件。每次响应网络请求时都可以触发响应事件。我们可以设置相应的回调方法。
可以和ajax结合使用,获取数据,拦截Ajax请求,输出对应的JSON结果。
from playwright.sync_api import sync_playwright
def on_response(response):
if '/api/movie/' in response.url and response.status == 200:
print(response.json())
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.on('response', on_response)
page.goto('https://spa6.scrape.center/')
page.wait_for_load_state('networkidle')
browser.close()
不加载图像
调用route方法,第一个参数通过正则表达式传入匹配的URL路径。这表示任何收录 .png 或 .jpg 的链接。当遇到这样的请求时,会回调cancel_request方法进行处理。cancel_request 方法可以接收两个参数,一个是 route,代表 CallableRoute 对象,另一个是 request,代表 Request 对象。这里我们直接调用路由的abort方法取消请求,所以最终的结果就是图片的加载完全取消了
from playwright.sync_api import sync_playwright
import re
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
# 不加载图片
def cancel_request(route, request):
route.abort()
page.route(re.compile(r"(\.png)|(\.jpg)"), cancel_request)
page.goto("https://spa6.scrape.center/";)
page.wait_for_load_state('networkidle')
page.screenshot(path='no_picture.png')
browser.close()
CSS 选择器、文本选择器、click()
click 方法中有一个选择器表达式。解压点击后,可以设置超时时间。默认值为 30 秒,设置以毫秒为单位。如果等待5秒后点击不成功,报错timeout=5000
# 选择文本是 Log in 的节点,并点击
page.click("text=Log in",timeout=5000)
# 选择 id 为 nav-bar 子孙节点 class 属性值为 contact-us-item,并点击
page.click("#nav-bar .contact-us-item")
# 选择文本中包含 Playwright 的 article 节点
page.click("article:has-text('Playwright')")
# 选择 id 为 nav-bar 节点中文本值等于 Contact us 的节点
page.click("#nav-bar :text('Contact us')")
# 选择 class 为 item-description 的节点,且该节点还要包含 class 为 item-promo-banner 的子节点
page.click(".item-description:has(.item-promo-banner)")
# 择的就是一个 input 节点,并且该 input 节点要位于文本值为 Username 的节点的右侧
page.click("input:right-of(:text('Username'))")
xpath 选择器
您需要在开头指定 xpath= 字符串,这意味着它后面是一个 XPath 表达式
page.click("xpath=//button")
获取网页源代码
此处获取的网页源代码,不管网页是否通过ajax加载,都是为了获取最终的html。
任何需要对 html 中的元素进行操作的 page.wait_for_load_state('networkidle') 都必须写入等待 html 加载。
page.wait_for_load_state('networkidle')
html = page.content()
文本输入
在输入标签名称属性是 wd 输入 nba
page.fill("input[name=\"wd\"]", "nba")
选择提取选项卡
提取所有class属性为list的div标签
elements = page.query_selector_all('div.list')
提取span标签的class属性作为score,如果有多个匹配,取第一个
score = element.query_selector('span.score')
提取文本
提取带有文本[Brand:]的标签,并提取标签下的所有文本
brand = element.query_selector('text=品牌:').text_content()
从标签中提取属性
提取h5标签下的a标签,得到a标签中href属性的值
link = element.query_selector('h5 a').get_attribute('href')
鼠标滚动
向右滚动0,向下滚动7000,可用于下拉滚动条功能
page1.mouse.wheel(0,7000)
下拉滚动条
执行js代码,下拉滚动条,15000可根据情况设置
page1.evaluate("var q=document.documentElement.scrollTop=15000")
网页源代码抓取工具(之前做项目要从一个网页中抓取某些特定信息(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-10 14:20
首页>博客文章WebBrowser + HtmlPraser 抓取ajax网页源码
与py2021-11-12
简介 在我做一个项目之前,我想从一个网页中获取一些特定的信息。一开始我打算用java+HtmlPraser制作的结果。被抓的部分出不来。在研究了那个网页的源代码之后,我得出了一个结论。它是使用ajax技术隐藏一些信息的网页。只有当用户浏览页面时,才会显示这部分信息。然后想看看有没有一些可以模拟浏览的开源项目,但是找不到。无奈之下,只好切换到c#平台。经过高手指导,c#中的WebBrows" />
在做一个项目之前,我想从网页中获取一些特定的信息。一开始我打算用java+HtmlPraser来做结果。被抓的部分出不来。在研究了那个网页的源代码后,我得出的结论是,那个网页使用了ajax技术隐藏了部分信息。只有当用户浏览页面时,才会显示这部分信息。然后想看看有没有一些可以模拟浏览的开源项目,但是找不到。无奈之下,只好切换到c#平台。
经过专家指导,c#中的WebBrowser控件起到了模拟浏览器的作用,使用起来非常简单。
新建一个表单应用程序,在表单中添加一个WebBrowser控件,在控件的属性url中设置要解析的网页的url。必须填写
然后双击控件你会去一个
private void web_DocumentCompleted(object sender,WebBrowserDocumentCompletedEventArgs e)
看函数分析就知道这个函数是在控件加载完网页后执行的
也就是说,您需要在该函数中写入有关网页的信息。
一开始我也是直接在这个函数里写处理代码,但是发现信息被抓到但是只有一小部分
后来百度发现是因为这个控件其实设计的有一些不足。很多时候,收录动态加载的网页还没有完全打开。
web_DocumentCompleted()函数会开始执行,导致控件显示的页面源码与实际页面源码不一致
有一些解决方案,虽然没有完全解决,但是可以提高打开类ajax网页的完成度。
方法是
private void web_DocumentCompleted(object sender,WebBrowserDocumentCompletedEventArgs e)
{
if (web0.ReadyState == WebBrowserReadyState.Complete)
{
}
}
原理不是很清楚,但实验证明抓取目标数据量确实增加了。
所以如果你想捕获更多的数据,你可以使用定时器每隔一段时间解析网页,以增加捕获的数据量。
简单来说就是控制定时器和WebBrowser的Navigate方法的结合。
总结
以上就是WebBrowser+HtmlPraser为你爬取本站采集的ajax网页源码的全部内容。希望文章可以帮助大家解决WebBrowser+HtmlPraser爬取ajax网页源码时遇到的程序开发问题。
如果你觉得本站网站的内容还不错,欢迎向程序员朋友推荐本站网站。 查看全部
网页源代码抓取工具(之前做项目要从一个网页中抓取某些特定信息(组图))
首页>博客文章WebBrowser + HtmlPraser 抓取ajax网页源码
与py2021-11-12
简介 在我做一个项目之前,我想从一个网页中获取一些特定的信息。一开始我打算用java+HtmlPraser制作的结果。被抓的部分出不来。在研究了那个网页的源代码之后,我得出了一个结论。它是使用ajax技术隐藏一些信息的网页。只有当用户浏览页面时,才会显示这部分信息。然后想看看有没有一些可以模拟浏览的开源项目,但是找不到。无奈之下,只好切换到c#平台。经过高手指导,c#中的WebBrows" />
在做一个项目之前,我想从网页中获取一些特定的信息。一开始我打算用java+HtmlPraser来做结果。被抓的部分出不来。在研究了那个网页的源代码后,我得出的结论是,那个网页使用了ajax技术隐藏了部分信息。只有当用户浏览页面时,才会显示这部分信息。然后想看看有没有一些可以模拟浏览的开源项目,但是找不到。无奈之下,只好切换到c#平台。
经过专家指导,c#中的WebBrowser控件起到了模拟浏览器的作用,使用起来非常简单。
新建一个表单应用程序,在表单中添加一个WebBrowser控件,在控件的属性url中设置要解析的网页的url。必须填写
然后双击控件你会去一个
private void web_DocumentCompleted(object sender,WebBrowserDocumentCompletedEventArgs e)
看函数分析就知道这个函数是在控件加载完网页后执行的
也就是说,您需要在该函数中写入有关网页的信息。
一开始我也是直接在这个函数里写处理代码,但是发现信息被抓到但是只有一小部分
后来百度发现是因为这个控件其实设计的有一些不足。很多时候,收录动态加载的网页还没有完全打开。
web_DocumentCompleted()函数会开始执行,导致控件显示的页面源码与实际页面源码不一致
有一些解决方案,虽然没有完全解决,但是可以提高打开类ajax网页的完成度。
方法是
private void web_DocumentCompleted(object sender,WebBrowserDocumentCompletedEventArgs e)
{
if (web0.ReadyState == WebBrowserReadyState.Complete)
{
}
}
原理不是很清楚,但实验证明抓取目标数据量确实增加了。
所以如果你想捕获更多的数据,你可以使用定时器每隔一段时间解析网页,以增加捕获的数据量。
简单来说就是控制定时器和WebBrowser的Navigate方法的结合。
总结
以上就是WebBrowser+HtmlPraser为你爬取本站采集的ajax网页源码的全部内容。希望文章可以帮助大家解决WebBrowser+HtmlPraser爬取ajax网页源码时遇到的程序开发问题。
如果你觉得本站网站的内容还不错,欢迎向程序员朋友推荐本站网站。
网页源代码抓取工具(互联网公司实习生如何做好网页源代码抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-09 22:03
网页源代码抓取工具,百度搜索spider可以搜到很多,不一一罗列了。我不懂技术,主要做互联网公司实习生,并不建议只看代码规范规定什么的,搞清楚前后端的分工,了解技术原理才是关键。
免费的seajs.js源码啊百度的cdn走了百度内部测试
实习生最好边做边学,阅读源代码只是一个系统学习的过程,但是如果没有什么前期的思考和准备,那么直接看看再写是没什么多大作用的,要思考。当然你要是能在基础代码和理论基础上自己重构一下,那也是锦上添花的事情。
体验一下完整功能的需求分析,调试,整合,
有耐心有毅力就当作提升自己的机会,
去一个完整的项目中寻找做出项目的流程和模式,
善用scrapy框架来找代码
说个题外话,如果你真的想体验代码风格,或者热爱互联网行业,可以把一定的预算交给互联网公司内部服务,看看是否有能力给你配cto,能帮你实现最小化的产品。
一个完整项目来补。单看网页代码规范,搞不清楚什么叫文件命名规范,什么叫注释规范,什么叫范围标识等等。
对完整项目的执行力,
如果你想进大厂,建议去实习。如果你想去个初创公司, 查看全部
网页源代码抓取工具(互联网公司实习生如何做好网页源代码抓取工具)
网页源代码抓取工具,百度搜索spider可以搜到很多,不一一罗列了。我不懂技术,主要做互联网公司实习生,并不建议只看代码规范规定什么的,搞清楚前后端的分工,了解技术原理才是关键。
免费的seajs.js源码啊百度的cdn走了百度内部测试
实习生最好边做边学,阅读源代码只是一个系统学习的过程,但是如果没有什么前期的思考和准备,那么直接看看再写是没什么多大作用的,要思考。当然你要是能在基础代码和理论基础上自己重构一下,那也是锦上添花的事情。
体验一下完整功能的需求分析,调试,整合,
有耐心有毅力就当作提升自己的机会,
去一个完整的项目中寻找做出项目的流程和模式,
善用scrapy框架来找代码
说个题外话,如果你真的想体验代码风格,或者热爱互联网行业,可以把一定的预算交给互联网公司内部服务,看看是否有能力给你配cto,能帮你实现最小化的产品。
一个完整项目来补。单看网页代码规范,搞不清楚什么叫文件命名规范,什么叫注释规范,什么叫范围标识等等。
对完整项目的执行力,
如果你想进大厂,建议去实习。如果你想去个初创公司,
网页源代码抓取工具(如何通过Chrome开发者工具寻找一个网站上特定数据的抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-01-09 18:17
网上爬虫教程太多了,去知乎搜索,估计能找到不少于100篇。每个人都高兴地从互联网上刮下另一个 网站。但是只要对方网站更新,很有可能文章中的方法已经失效了。
每一个网站捕获的代码都不一样,但是背后的原理是一样的。对于绝大多数 网站 来说,爬取程序就是这样。今天的文章文章不讲任何具体的捕获网站,只讲一个常见的事情:
如何使用 Chrome DevTools 找到一种方法来抓取 网站 上的特定数据。
我这里演示的是Mac上的英文版Chrome,在Windows上使用中文版的方法是一样的。
> 查看网页源代码
右键单击网页并选择“查看页面源代码”以在新选项卡中显示与此 URL 对应的 HTML 代码文本。
此功能不被视为“开发人员工具”的一部分,但非常常用。此内容与您直接从代码中向该 URL 发出 GET 请求(无论权限如何)所获得的内容相同。如果你能在这个源码页上搜索到你想要的内容,你可以按照它的规则通过regular、bs4、xpath等方式提取文本中的数据。
但是,对于许多异步加载数据的 网站,您无法从该页面中找到您想要的内容。或者因为权限、验证等限制,代码中得到的结果与页面显示不一致。在这些情况下,我们需要更强大的开发人员工具来提供帮助。
> 元素
在网页上右击选择“Inspect”进入Chrome开发者工具的元素选择器。在工具中是元素选项卡。
元素有几个功能:
从 Elements 工具中定位数据比我们之前在源代码中直接搜索更方便,因为您可以清楚地看到它所在的元素结构。但这里有一个特别提醒:
Elements中看到的代码不等于请求URL得到的返回值。
它是网页经过浏览器渲染后的最终效果,包括异步请求数据,以及浏览器本身对代码的优化更改。因此,您无法完全按照 Elements 中显示的结构获取元素,在这种情况下,您可能不会得到正确的结果。
> 网络
选择开发者工具中的Network选项卡,进入网络监控功能,也就是我们常说的“抓包”。
这是爬虫使用的最重要的功能。主要解决两个问题:
如何抓住什么
抓什么是指如何找到通过异步请求获取的数据的来源。
打开Network页面,打开记录,然后刷新页面,可以看到所有发送的请求,包括数据、JS、CSS、图片、文档等都会显示出来。您可以从请求列表中找到您的目标。
一个一个找到它们会很痛苦。分享几个tips:
找到收录数据的请求后,下一步是以编程方式获取数据。现在是第二个问题:如何捕捉它。
并不是所有的 URL 都可以直接通过 GET 获取(相当于在浏览器中打开地址),通常还要考虑以下几点:
请求方法,GET 或 POST。请求附带的参数数据。GET 和 POST 以不同的方式传递参数。头信息。常用的有user-agent、host、referer、cookie等。cookie是用来识别请求者身份的关键信息。对于需要登录的网站,这个值是必不可少的。网站 经常使用其他项目来识别请求的合法性。相同的请求可以在浏览器中完成,但不能在程序中完成。大多数情况下,标题信息不正确。您可以将这些信息从 Chrome 复制到程序中,从而绕过对方的限制。
通过单击列表中的特定请求,可以找到上述所有信息。
找到正确的请求,设置正确的方法,传递正确的参数和头信息,网站上的大部分信息都可以做到。
网络还有一个功能:右键点击列表,选择“Save as HAR with content”,保存到文件。该文件收录列表中所有请求的参数和返回值信息,方便您查找和分析。(实践中发现直接搜索往往无效,保存到文件后才能搜索)
除了 Elements 和 Network 之外,开发者工具中还有一些功能,例如:
来源,查看资源列表和调试 JS。
控制台,显示页面的错误和输出,可以执行JS代码。很多网站都会把彩蛋放在这里招募(找比较有名的网站试试)。
但这些功能与爬虫关系不大。如果开发 网站 并优化 网站 以提高速度,则需要处理其他功能。这里不多说。
总结一下,其实你应该牢记以下几点:
在“查看源代码”中可以看到的数据可以通过程序直接请求当前的URL来获取。Elements 中的 HTML 代码不等于请求返回值,只能作为辅助。在网络中用内容关键字搜索,或者保存为HAR文件后搜索,找到收录数据的实际请求,查看请求的具体信息,包括方法、头、参数等,复制到程序中使用。
了解了这些步骤后,网上的大部分资料都可以得到。说“解决一半问题”不是头条新闻。
当然,说起来容易一些,但是想要精通的话,还有很多细节需要考虑,还需要不断的练习。但是考虑到这几点,再看各种爬虫案例,思路就会更加清晰。
如果想要更详细的爬虫讲解和指导,可以看看我们的《爬虫实战》课程,还有零基础的入门课程。 查看全部
网页源代码抓取工具(如何通过Chrome开发者工具寻找一个网站上特定数据的抓取)
网上爬虫教程太多了,去知乎搜索,估计能找到不少于100篇。每个人都高兴地从互联网上刮下另一个 网站。但是只要对方网站更新,很有可能文章中的方法已经失效了。
每一个网站捕获的代码都不一样,但是背后的原理是一样的。对于绝大多数 网站 来说,爬取程序就是这样。今天的文章文章不讲任何具体的捕获网站,只讲一个常见的事情:
如何使用 Chrome DevTools 找到一种方法来抓取 网站 上的特定数据。
我这里演示的是Mac上的英文版Chrome,在Windows上使用中文版的方法是一样的。
> 查看网页源代码
右键单击网页并选择“查看页面源代码”以在新选项卡中显示与此 URL 对应的 HTML 代码文本。
此功能不被视为“开发人员工具”的一部分,但非常常用。此内容与您直接从代码中向该 URL 发出 GET 请求(无论权限如何)所获得的内容相同。如果你能在这个源码页上搜索到你想要的内容,你可以按照它的规则通过regular、bs4、xpath等方式提取文本中的数据。
但是,对于许多异步加载数据的 网站,您无法从该页面中找到您想要的内容。或者因为权限、验证等限制,代码中得到的结果与页面显示不一致。在这些情况下,我们需要更强大的开发人员工具来提供帮助。
> 元素
在网页上右击选择“Inspect”进入Chrome开发者工具的元素选择器。在工具中是元素选项卡。
元素有几个功能:
从 Elements 工具中定位数据比我们之前在源代码中直接搜索更方便,因为您可以清楚地看到它所在的元素结构。但这里有一个特别提醒:
Elements中看到的代码不等于请求URL得到的返回值。
它是网页经过浏览器渲染后的最终效果,包括异步请求数据,以及浏览器本身对代码的优化更改。因此,您无法完全按照 Elements 中显示的结构获取元素,在这种情况下,您可能不会得到正确的结果。
> 网络
选择开发者工具中的Network选项卡,进入网络监控功能,也就是我们常说的“抓包”。
这是爬虫使用的最重要的功能。主要解决两个问题:
如何抓住什么
抓什么是指如何找到通过异步请求获取的数据的来源。
打开Network页面,打开记录,然后刷新页面,可以看到所有发送的请求,包括数据、JS、CSS、图片、文档等都会显示出来。您可以从请求列表中找到您的目标。
一个一个找到它们会很痛苦。分享几个tips:
找到收录数据的请求后,下一步是以编程方式获取数据。现在是第二个问题:如何捕捉它。
并不是所有的 URL 都可以直接通过 GET 获取(相当于在浏览器中打开地址),通常还要考虑以下几点:
请求方法,GET 或 POST。请求附带的参数数据。GET 和 POST 以不同的方式传递参数。头信息。常用的有user-agent、host、referer、cookie等。cookie是用来识别请求者身份的关键信息。对于需要登录的网站,这个值是必不可少的。网站 经常使用其他项目来识别请求的合法性。相同的请求可以在浏览器中完成,但不能在程序中完成。大多数情况下,标题信息不正确。您可以将这些信息从 Chrome 复制到程序中,从而绕过对方的限制。
通过单击列表中的特定请求,可以找到上述所有信息。
找到正确的请求,设置正确的方法,传递正确的参数和头信息,网站上的大部分信息都可以做到。
网络还有一个功能:右键点击列表,选择“Save as HAR with content”,保存到文件。该文件收录列表中所有请求的参数和返回值信息,方便您查找和分析。(实践中发现直接搜索往往无效,保存到文件后才能搜索)
除了 Elements 和 Network 之外,开发者工具中还有一些功能,例如:
来源,查看资源列表和调试 JS。
控制台,显示页面的错误和输出,可以执行JS代码。很多网站都会把彩蛋放在这里招募(找比较有名的网站试试)。
但这些功能与爬虫关系不大。如果开发 网站 并优化 网站 以提高速度,则需要处理其他功能。这里不多说。
总结一下,其实你应该牢记以下几点:
在“查看源代码”中可以看到的数据可以通过程序直接请求当前的URL来获取。Elements 中的 HTML 代码不等于请求返回值,只能作为辅助。在网络中用内容关键字搜索,或者保存为HAR文件后搜索,找到收录数据的实际请求,查看请求的具体信息,包括方法、头、参数等,复制到程序中使用。
了解了这些步骤后,网上的大部分资料都可以得到。说“解决一半问题”不是头条新闻。
当然,说起来容易一些,但是想要精通的话,还有很多细节需要考虑,还需要不断的练习。但是考虑到这几点,再看各种爬虫案例,思路就会更加清晰。
如果想要更详细的爬虫讲解和指导,可以看看我们的《爬虫实战》课程,还有零基础的入门课程。
网页源代码抓取工具(如何通过Chrome开发者工具寻找一个网站上特定数据的抓取方式(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-09 13:05
每一个网站捕获的代码都不一样,但是背后的原理是一样的。对于绝大多数 网站 来说,爬取程序就是这样。今天的文章文章不讲任何具体的捕获网站,只讲一个常见的事情:
如何使用 Chrome DevTools 找到一种方法来抓取 网站 上的特定数据。
(我这里是在Mac上演示英文版的Chrome,在Windows上使用中文版的方法是一样的。)
> 查看网页源代码
右键单击网页并选择“查看页面源代码”以在新选项卡中显示与此 URL 对应的 HTML 代码文本。
此功能不被视为“开发人员工具”的一部分,但非常常用。此内容与您直接从代码中向该 URL 发出 GET 请求(无论权限如何)所获得的内容相同。如果你能在这个源码页上搜索到你想要的内容,你可以按照它的规则通过regular、bs4、xpath等方式提取文本中的数据。
但是,对于许多异步加载数据的 网站,您无法从该页面中找到您想要的内容。或者因为权限、验证等限制,代码中得到的结果与页面显示不一致。在这些情况下,我们需要更强大的开发人员工具来提供帮助。
> 元素
在网页上右击选择“Inspect”进入Chrome开发者工具的元素选择器。在工具中是元素选项卡。
元素有几个功能:
从 Elements 工具中定位数据比我们之前在源代码中直接搜索更方便,因为您可以清楚地看到它所在的元素结构。但这里有一个特别提醒:
Elements中看到的代码不等于请求URL得到的返回值。
它是网页经过浏览器渲染后的最终效果,包括异步请求数据,以及浏览器本身对代码的优化更改。因此,您无法完全按照 Elements 中显示的结构获取元素,在这种情况下,您可能不会得到正确的结果。
> 网络
选择开发者工具中的Network选项卡,进入网络监控功能,也就是我们常说的“抓包”。
这是爬虫使用的最重要的功能。主要解决两个问题:
如何抓住什么
抓什么是指如何找到通过异步请求获取的数据的来源。
打开Network页面,打开记录,然后刷新页面,可以看到所有发送的请求,包括数据、JS、CSS、图片、文档等都会显示出来。您可以从请求列表中找到您的目标。
一个一个找到它们会很痛苦。分享几个tips:
找到收录数据的请求后,下一步是以编程方式获取数据。现在是第二个问题:如何捕捉它。
并不是所有的 URL 都可以直接通过 GET 获取(相当于在浏览器中打开地址),通常还要考虑以下几点:
请求方法,GET 或 POST。请求附带的参数数据。GET 和 POST 以不同的方式传递参数。头信息。常用的有user-agent、host、referer、cookie等。cookie是用来识别请求者身份的关键信息。对于需要登录的网站,这个值是必不可少的。网站 经常使用其他项目来识别请求的合法性。相同的请求可以在浏览器中完成,但不能在程序中完成。大多数情况下,标题信息不正确。您可以将这些信息从 Chrome 复制到程序中,从而绕过对方的限制。
通过单击列表中的特定请求,可以找到上述所有信息。
找到正确的请求,设置正确的方法,传递正确的参数和头信息,网站上的大部分信息都可以做到。
网络还有一个功能:右键点击列表,选择“Save as HAR with content”,保存到文件。该文件收录列表中所有请求的参数和返回值信息,方便您查找和分析。(实践中发现直接搜索往往无效,保存到文件后才能搜索)
除了 Elements 和 Network 之外,开发者工具中还有一些功能,例如:
来源,查看资源列表和调试 JS。
控制台,显示页面的错误和输出,可以执行JS代码。很多网站都会把彩蛋放在这里招募(找比较有名的网站试试)。
但这些功能与爬虫关系不大。如果开发 网站 并优化 网站 以提高速度,则需要处理其他功能。这里不多说。
总结一下,其实你应该牢记以下几点:
在“查看源代码”中可以看到的数据可以通过程序直接请求当前的URL来获取。Elements 中的 HTML 代码不等于请求返回值,只能作为辅助。在网络中用内容关键字搜索,或者保存为HAR文件后搜索,找到收录数据的实际请求,查看请求的具体信息,包括方法、头、参数等,复制到程序中使用。
了解了这些步骤后,网上的大部分资料都可以得到。说“解决一半问题”不是头条新闻。
当然,说起来容易一些,但是想要精通的话,还有很多细节需要考虑,还需要不断的练习。但是考虑到这几点,再看各种爬虫案例,思路就会更加清晰。 查看全部
网页源代码抓取工具(如何通过Chrome开发者工具寻找一个网站上特定数据的抓取方式(图))
每一个网站捕获的代码都不一样,但是背后的原理是一样的。对于绝大多数 网站 来说,爬取程序就是这样。今天的文章文章不讲任何具体的捕获网站,只讲一个常见的事情:
如何使用 Chrome DevTools 找到一种方法来抓取 网站 上的特定数据。
(我这里是在Mac上演示英文版的Chrome,在Windows上使用中文版的方法是一样的。)
> 查看网页源代码
右键单击网页并选择“查看页面源代码”以在新选项卡中显示与此 URL 对应的 HTML 代码文本。
此功能不被视为“开发人员工具”的一部分,但非常常用。此内容与您直接从代码中向该 URL 发出 GET 请求(无论权限如何)所获得的内容相同。如果你能在这个源码页上搜索到你想要的内容,你可以按照它的规则通过regular、bs4、xpath等方式提取文本中的数据。
但是,对于许多异步加载数据的 网站,您无法从该页面中找到您想要的内容。或者因为权限、验证等限制,代码中得到的结果与页面显示不一致。在这些情况下,我们需要更强大的开发人员工具来提供帮助。
> 元素
在网页上右击选择“Inspect”进入Chrome开发者工具的元素选择器。在工具中是元素选项卡。
元素有几个功能:
从 Elements 工具中定位数据比我们之前在源代码中直接搜索更方便,因为您可以清楚地看到它所在的元素结构。但这里有一个特别提醒:
Elements中看到的代码不等于请求URL得到的返回值。
它是网页经过浏览器渲染后的最终效果,包括异步请求数据,以及浏览器本身对代码的优化更改。因此,您无法完全按照 Elements 中显示的结构获取元素,在这种情况下,您可能不会得到正确的结果。
> 网络
选择开发者工具中的Network选项卡,进入网络监控功能,也就是我们常说的“抓包”。
这是爬虫使用的最重要的功能。主要解决两个问题:
如何抓住什么
抓什么是指如何找到通过异步请求获取的数据的来源。
打开Network页面,打开记录,然后刷新页面,可以看到所有发送的请求,包括数据、JS、CSS、图片、文档等都会显示出来。您可以从请求列表中找到您的目标。
一个一个找到它们会很痛苦。分享几个tips:
找到收录数据的请求后,下一步是以编程方式获取数据。现在是第二个问题:如何捕捉它。
并不是所有的 URL 都可以直接通过 GET 获取(相当于在浏览器中打开地址),通常还要考虑以下几点:
请求方法,GET 或 POST。请求附带的参数数据。GET 和 POST 以不同的方式传递参数。头信息。常用的有user-agent、host、referer、cookie等。cookie是用来识别请求者身份的关键信息。对于需要登录的网站,这个值是必不可少的。网站 经常使用其他项目来识别请求的合法性。相同的请求可以在浏览器中完成,但不能在程序中完成。大多数情况下,标题信息不正确。您可以将这些信息从 Chrome 复制到程序中,从而绕过对方的限制。
通过单击列表中的特定请求,可以找到上述所有信息。
找到正确的请求,设置正确的方法,传递正确的参数和头信息,网站上的大部分信息都可以做到。
网络还有一个功能:右键点击列表,选择“Save as HAR with content”,保存到文件。该文件收录列表中所有请求的参数和返回值信息,方便您查找和分析。(实践中发现直接搜索往往无效,保存到文件后才能搜索)
除了 Elements 和 Network 之外,开发者工具中还有一些功能,例如:
来源,查看资源列表和调试 JS。
控制台,显示页面的错误和输出,可以执行JS代码。很多网站都会把彩蛋放在这里招募(找比较有名的网站试试)。
但这些功能与爬虫关系不大。如果开发 网站 并优化 网站 以提高速度,则需要处理其他功能。这里不多说。
总结一下,其实你应该牢记以下几点:
在“查看源代码”中可以看到的数据可以通过程序直接请求当前的URL来获取。Elements 中的 HTML 代码不等于请求返回值,只能作为辅助。在网络中用内容关键字搜索,或者保存为HAR文件后搜索,找到收录数据的实际请求,查看请求的具体信息,包括方法、头、参数等,复制到程序中使用。
了解了这些步骤后,网上的大部分资料都可以得到。说“解决一半问题”不是头条新闻。
当然,说起来容易一些,但是想要精通的话,还有很多细节需要考虑,还需要不断的练习。但是考虑到这几点,再看各种爬虫案例,思路就会更加清晰。
网页源代码抓取工具(Vimwiki一段工具的选择对比-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-09 11:03
维姆维基。附件是工具的选择比较。
2008 年底,我养成了写技术笔记的习惯,Polix 的原创原型。最初它只是一个 Word 文档。但随着笔记数量的不断增加,当内容有数百页时,管理极为不便。我查看了其他几个写作平台,如 DocBook、MediaWiki、WordPress、LaTex 等,最后选择了 LaTex。不过后来发现LaTex其实很适合写文章或者制作漂亮的出版物。作为知识管理,它是不可移植的(尤其是在文本中有大量代码段的情况下)。大约在 2009 年年中,我再次大规模地将我的笔记迁移到纯文本。用纯文本 + Vim 写很舒服,尤其是当我用 .cpp/.sh 等后缀命名我的笔记时,Vim 可以给代码着色,速度和视野都令人兴奋。这种做法持续了2年,直到2011年年中,知识管理的明文开始呈现出绰绰有余的趋势。我将回到旧方法并选择新的知识管理工具。此选择有几个标准:
该工具必须支持 Vim 编辑(不考虑 Vi 插件)。迁移工作量很小(LaTex 之类的标记语言迁移成本很高)。要有Wiki的性质,也就是交叉索引应该是很方便的(Wordpress等以“文章”为单位的工具基本被忽略)。很轻,很快(MediaWiki索引很方便,有很多插件,但是很麻烦)。
幸运的是,VimWiki 满足了我的一些古怪偏好。首先是我不用离开Vim,也就是明文的老行不用改;二是完全符合Wiki属性,交叉索引极其方便、轻量、快速。更不用说,这就是 Vim 声誉的根源。VimWiki 管理知识,可谓如鱼得水。此外,VimWiki 可以输出 HTML 页面... 查看全部
网页源代码抓取工具(Vimwiki一段工具的选择对比-乐题库)
维姆维基。附件是工具的选择比较。
2008 年底,我养成了写技术笔记的习惯,Polix 的原创原型。最初它只是一个 Word 文档。但随着笔记数量的不断增加,当内容有数百页时,管理极为不便。我查看了其他几个写作平台,如 DocBook、MediaWiki、WordPress、LaTex 等,最后选择了 LaTex。不过后来发现LaTex其实很适合写文章或者制作漂亮的出版物。作为知识管理,它是不可移植的(尤其是在文本中有大量代码段的情况下)。大约在 2009 年年中,我再次大规模地将我的笔记迁移到纯文本。用纯文本 + Vim 写很舒服,尤其是当我用 .cpp/.sh 等后缀命名我的笔记时,Vim 可以给代码着色,速度和视野都令人兴奋。这种做法持续了2年,直到2011年年中,知识管理的明文开始呈现出绰绰有余的趋势。我将回到旧方法并选择新的知识管理工具。此选择有几个标准:
该工具必须支持 Vim 编辑(不考虑 Vi 插件)。迁移工作量很小(LaTex 之类的标记语言迁移成本很高)。要有Wiki的性质,也就是交叉索引应该是很方便的(Wordpress等以“文章”为单位的工具基本被忽略)。很轻,很快(MediaWiki索引很方便,有很多插件,但是很麻烦)。
幸运的是,VimWiki 满足了我的一些古怪偏好。首先是我不用离开Vim,也就是明文的老行不用改;二是完全符合Wiki属性,交叉索引极其方便、轻量、快速。更不用说,这就是 Vim 声誉的根源。VimWiki 管理知识,可谓如鱼得水。此外,VimWiki 可以输出 HTML 页面...
网页源代码抓取工具(acrobatx7,2016.5.x6acrobatx,网页源代码抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-09 10:04
网页源代码抓取工具:
一、chrome浏览器web开发者工具网页源代码抓取工具chromeweb开发者工具的安装:直接通过浏览器浏览器搜索chrome可以找到官方下载页面(一般地址是chrome.exe这种)。下载完成后双击打开此页面,进入chrome浏览器页面。
二、acrobatx7网页源代码抓取工具支持的所有版本有:2014.5.x7,2016.3.x7,2016.5.x7,2016.5.x6acrobatx7是开发的一款网页标注工具,无论你通过哪种网页源代码抓取工具,都可以在acrobatx7里直接用标注命令操作网页。网页源代码抓取工具:。
三、谷歌浏览器开发者工具和acrobatx7同理可用。
四、f12浏览器开发者工具:
五、automatorframework是谷歌公司开发的一个可视化的代码动态调试技术框架,优点是易于在同一个框架内编写多个命令的“管道”,如调用很多函数等。
六、fiddler网页源代码抓取工具功能:获取http请求所在路径(fiddler默认请求路径),并拦截请求的响应,
七、browseropenurltool网页源代码抓取工具功能:在本地尝试浏览各种你的网站并在fiddler中调试。
八、javascript调试工具atom、fisium(javascript调试工具)、browserify(可视化调试工具)、tampermonkey(浏览器脚本)、webdriver(chrome插件)、vivaldi(开发者工具)
九、duolingo教育应用大学英语你可以使用browserify、fisium、webdriver、vivaldi的ui/ux工具箱对应的网页源代码抓取工具。 查看全部
网页源代码抓取工具(acrobatx7,2016.5.x6acrobatx,网页源代码抓取工具)
网页源代码抓取工具:
一、chrome浏览器web开发者工具网页源代码抓取工具chromeweb开发者工具的安装:直接通过浏览器浏览器搜索chrome可以找到官方下载页面(一般地址是chrome.exe这种)。下载完成后双击打开此页面,进入chrome浏览器页面。
二、acrobatx7网页源代码抓取工具支持的所有版本有:2014.5.x7,2016.3.x7,2016.5.x7,2016.5.x6acrobatx7是开发的一款网页标注工具,无论你通过哪种网页源代码抓取工具,都可以在acrobatx7里直接用标注命令操作网页。网页源代码抓取工具:。
三、谷歌浏览器开发者工具和acrobatx7同理可用。
四、f12浏览器开发者工具:
五、automatorframework是谷歌公司开发的一个可视化的代码动态调试技术框架,优点是易于在同一个框架内编写多个命令的“管道”,如调用很多函数等。
六、fiddler网页源代码抓取工具功能:获取http请求所在路径(fiddler默认请求路径),并拦截请求的响应,
七、browseropenurltool网页源代码抓取工具功能:在本地尝试浏览各种你的网站并在fiddler中调试。
八、javascript调试工具atom、fisium(javascript调试工具)、browserify(可视化调试工具)、tampermonkey(浏览器脚本)、webdriver(chrome插件)、vivaldi(开发者工具)
九、duolingo教育应用大学英语你可以使用browserify、fisium、webdriver、vivaldi的ui/ux工具箱对应的网页源代码抓取工具。
网页源代码抓取工具(爬一个网页的div标签怎么设计?findfindlist)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-06 20:09
每个 div 都会有一个带有 a 的 h2,a 收录我们想要的标题名称。所以我们使用 find_all 来查找所有这样的 div 标签,将它们存储为一个列表,然后遍历列表,为每个元素提取 h2 a,然后提取标签中的内容。
当然,我们也可以找到最外层的 li 标签 of_all,然后再往里看,都是一样的。只需找到定位信息的唯一标识(标签或属性)即可。
虽然看这里的源代码可以折叠一些无用的代码,但其实有一些更好的工具可以帮助我们在网页的源代码中找到我们想要的信息的位置。例如,下面的鼠标符号。
当所有代码都折叠好后,点击这个鼠标,然后点击网页中的元素,浏览器会自动为你选择你点击的元素,其实当你悬停在一个元素上时,已经帮你定位了,如图下图
总结
当我们要爬取一个网页时,我们只需要如下过程
现在,对于一些没有丝毫防爬措施的网站来说,我们都可以做得很好。至于如何组织多个字段的数据,如何设计爬取多个页面的代码(在常规URL的情况下),不在爬虫知识的范围。这可以通过python的基本知识来解决。文章 的下一个系列将重点介绍这部分。接下来给大家介绍几个目前可以练的网站
如果你在使用BeautifulSoup定位的过程中遇到困难,可以直接上网搜索教程,也可以等待BeautifulSoup的详细介绍,后面会更新我们的话题。
如果你去抢其他网站,最好看看r.text是否和网站的源码一模一样。如果不是,说明你对方的服务器没有给你真实信息,说明它可能看到你是爬虫(在做网页请求的时候,浏览器和requests.get就相当于敲门了一堆资质证书,对方会查你的资质证书,浏览器资质证书一般都是可以的,而code的资质证书可能不合格,因为code的资质证书可能有一些相对固定的特征。对方的服务器是预先设置好的,资格证书的所有请求都被拒绝,因为它们必须是爬虫,这就是反爬虫。机制)。这时候就需要了解一些防爬的措施,才能获得真实的信息。防爬方法的学习是一个积累的过程,后面会讲到。如果读者遇到一些反爬虫机制,可以上网查一下这个网站爬虫。估计能找到一些破解方法的博客,甚至直接贴上代码。 查看全部
网页源代码抓取工具(爬一个网页的div标签怎么设计?findfindlist)
每个 div 都会有一个带有 a 的 h2,a 收录我们想要的标题名称。所以我们使用 find_all 来查找所有这样的 div 标签,将它们存储为一个列表,然后遍历列表,为每个元素提取 h2 a,然后提取标签中的内容。
当然,我们也可以找到最外层的 li 标签 of_all,然后再往里看,都是一样的。只需找到定位信息的唯一标识(标签或属性)即可。
虽然看这里的源代码可以折叠一些无用的代码,但其实有一些更好的工具可以帮助我们在网页的源代码中找到我们想要的信息的位置。例如,下面的鼠标符号。
当所有代码都折叠好后,点击这个鼠标,然后点击网页中的元素,浏览器会自动为你选择你点击的元素,其实当你悬停在一个元素上时,已经帮你定位了,如图下图
总结
当我们要爬取一个网页时,我们只需要如下过程
现在,对于一些没有丝毫防爬措施的网站来说,我们都可以做得很好。至于如何组织多个字段的数据,如何设计爬取多个页面的代码(在常规URL的情况下),不在爬虫知识的范围。这可以通过python的基本知识来解决。文章 的下一个系列将重点介绍这部分。接下来给大家介绍几个目前可以练的网站
如果你在使用BeautifulSoup定位的过程中遇到困难,可以直接上网搜索教程,也可以等待BeautifulSoup的详细介绍,后面会更新我们的话题。
如果你去抢其他网站,最好看看r.text是否和网站的源码一模一样。如果不是,说明你对方的服务器没有给你真实信息,说明它可能看到你是爬虫(在做网页请求的时候,浏览器和requests.get就相当于敲门了一堆资质证书,对方会查你的资质证书,浏览器资质证书一般都是可以的,而code的资质证书可能不合格,因为code的资质证书可能有一些相对固定的特征。对方的服务器是预先设置好的,资格证书的所有请求都被拒绝,因为它们必须是爬虫,这就是反爬虫。机制)。这时候就需要了解一些防爬的措施,才能获得真实的信息。防爬方法的学习是一个积累的过程,后面会讲到。如果读者遇到一些反爬虫机制,可以上网查一下这个网站爬虫。估计能找到一些破解方法的博客,甚至直接贴上代码。
网页源代码抓取工具( 说起B站的反扒机制(一)太严格(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-06 20:08
说起B站的反扒机制(一)太严格(组图))
说到B站,大家都知道。B站的反接机机制不是很严格,所以今天就给大家说说我能想到的几种方式。目前我大概想到了三种方式:
那我就一一给大家介绍我的方法!
分析及主要代码:
既然确定了方法一模拟手机端请求,那么我们直接开始分析:
抓了链接,找了半天,也没找到有用的信息,于是直接去查网页源码:
仔细查看源代码后,发现了如上所示的信息。源代码中加载了视频的 MP4 链接和视频名称。
因为这个信息存储在标签中,虽然可以提取所有内容,然后转换为JSON格式进行提取,但这有点麻烦。我们直接用正则表达式提取:
代码
class BiLiBiLi_phone():
def __init__(self,s_url):
self.url=s_url
self.headers={
'origin': 'https://m.bilibili.com',
'referer': self.url,
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N)'
}
def bili_Download(self):
r = requests.get(self.url, proxies=proxy, headers=self.headers)
video_name=re.findall(',"title":"(.*?)","pubdate":', r.text)[0]
if video_name == '':
video_name = int(random.random() * 2 * 1000)
if len(str(video_name)) > 20:
video_name = video_name[:20]
video_url = re.findall(',"url":"(.*?)","backup_url"', r.text)[0].encode('utf-8').decode('unicode_escape')
r=requests.get(video_url,proxies=proxy,headers=self.headers)
with open(path+video_name+'.mp4','wb')as f:
f.write(r.content)
print("【BiLiBiLi】: {} 下载完成!".format(video_name))
关于代码的一些说明:
黄色字体前的代码是正则表达式的基本操作,黄色字体的原因是:
从源代码中提取的链接是:
网址:?\ u002F \\ u002Fupgcxcode \ u002F10 \ u002F14 \ u002F230501410 \ u002F230501410-1-1 6. MP4 E = ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfq9rVEuxTEnE8L5F6VnEsSTx0vkX8fqJeYTj_lta53NCM =&uipk = 5&NBS = 1&期限= 1601216024&根= playurl&OS = kodobv&OI = 1971851232 & trid = fcde238782674b78bf4425427c2a9ea3h & 平台 = html5 & upsig = b98cc40700e7f05e614acf0acbd9b671 & uparams = e,suidepk040,800,800,2000,800,000,000,000,000,000,000,800,000,000,000,000,800,000,000,000,000,000,000,000,000,000,000,000,000,050
该链接收录大量 \u002F 字段。这是因为源代码加载了转换为Unicode编码的链接,所以需要进行编码转换。
分析及主要代码:
对于方法二,我们首先需要找到第三方网站来解析视频,然后打包整个过程。
不同的网站有不同的分析方法。我只会写一个网站我随机选择的。清晰度还行。
这个网站之间的特殊性:当输入链接是:
出现以下错误时
所以你需要去掉下面的一些信息!
把准备好的链接放到分析网站中,得到如下信息:
由于网站的特殊性,如果选择MP4文件,有时视频会被分成多个,所以这里我主要选择FLV文件。
我们可以很清楚的看到这个接口返回的内容是一些属于HTML标签的信息。我们不在这里编写代码来进行清晰选择。需要的可以自己写,直接选择清晰度最好的来分析。.
代码
这是为了防止这个B站视频分析服务网站被滥用。这里我隐藏了分辨率网站。如果你想使用这个解析服务的地址,可以私信给我。
这种分析网站的特点之一是,知道的人越多,失败的速度就越快。
希望它能活得尽可能长。
class BiLiBiLi_api():
def __init__(self, s_url):
self.url = s_url.split('?')[0]
self.header1 = {
'Host': 'www.****.com',
'Origin': 'http://www.****.com',
'Referer': quote('http://www.****.com/video?url={}&page=video&submit=视频下载'.format(self.url)),
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63'
}
self.data = {
'url': self.url,
'format': 'flv',
'from': 'parse',
'retry': '1'
}
self.header2 = {
'origin': 'https://www.bilibili.com/',
'referer': self.url,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63'
}
def BL_api_Download(self):
r = requests.post('http://www.****.com/parse', proxies=proxy, data=self.data, headers=self.header1)
video_name = re.findall('data-clipboard-text="(.*?)"', r.json()['msg'])[0]
video_url = re.findall('href="(.*?)"', r.json()['msg'])[0].replace('amp;', '')
r1 = requests.get(video_url, proxies=proxy, headers=self.header2)
with open(path + video_name + '.flv', 'wb')as f:
f.write(r1.content)
print("【BiLiBiLi】: {} 下载完成!".format(video_name))
关于代码的一些说明:
为什么要把请求头分别写成两个:
不用说,第一个请求头所需要的信息是正常操作。当第二个请求头需要信息的时候,因为这个网站解析的视频链接是B站的原链接,你必须带上B站信息的请求头下载,否则服务器会拒绝我们的访问。
在上面解析网站的过程中,我们还记得请求解析链接后,我们还需要选择视频文件的格式,才能获取视频的链接,当我们选择了格式,我们将再次检查原件。链接到请求,并且会携带固定格式的数据数据。
为什么需要进行编码转换:
网站 就是这样,不改代码,会报错,呵呵。
前面说了,没有标黄色的部分还是基本操作,就是使用正则表达式提取信息,对于标黄色的部分,这是因为解析的链接中收录了HTML传输字符:
和
方法三
写...(遇到了点小麻烦!)
所有源代码
import random
import re
from urllib.parse import quote
import requests
url = 'https://ip.jiangxianli.com/api/proxy_ip'
r = requests.get(url)
proxy = {'HTTP': 'http://' + r.json()['data']['ip'] + ':' + r.json()['data']['port']}
print(proxy)
path = 'C:/Users/Jackson-art/Desktop/'
class BiLiBiLi_phone():
def __init__(self, s_url):
self.url = s_url
self.headers = {
'origin': 'https://m.bilibili.com',
'referer': self.url,
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N)'
}
def bili_Download(self):
r = requests.get(self.url, proxies=proxy, headers=self.headers)
video_name = re.findall(',"title":"(.*?)","pubdate":', r.text)[0]
if video_name == '':
video_name = int(random.random() * 2 * 1000)
if len(str(video_name)) > 20:
video_name = video_name[:20]
video_url = re.findall(',"url":"(.*?)","backup_url"', r.text)[0].encode('utf-8').decode('unicode_escape')
r = requests.get(video_url, proxies=proxy, headers=self.headers)
with open(path + video_name + '.mp4', 'wb')as f:
f.write(r.content)
print("【BiLiBiLi】: {} 下载完成!".format(video_name))
class BiLiBiLi_api():
def __init__(self, s_url):
self.url = s_url.split('?')[0]
self.header1 = {
'Host': 'www.****.com',
'Origin': 'http://www.****.com',
'Referer': quote('http://www.****.com/video?url={}&page=video&submit=视频下载'.format(self.url)),
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63'
}
self.data = {
'url': self.url,
'format': 'flv',
'from': 'parse',
'retry': '1'
}
self.header2 = {
'origin': 'https://www.bilibili.com/',
'referer': self.url,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63'
}
def BL_api_Download(self):
r = requests.post('http://www.****.com/parse', proxies=proxy, data=self.data, headers=self.header1)
video_name = re.findall('data-clipboard-text="(.*?)"', r.json()['msg'])[0]
video_url = re.findall('href="(.*?)"', r.json()['msg'])[0].replace('amp;', '')
r1 = requests.get(video_url, proxies=proxy, headers=self.header2)
with open(path + video_name + '.flv', 'wb')as f:
f.write(r1.content)
print("【BiLiBiLi】: {} 下载完成!".format(video_name))
def user_ui():
print('*' * 10 + '\t BiLiBiLi视频下载\t' + '*' * 10)
print('*' * 5 + "\t\tAuthor: 高智商白痴\t\t" + '*' * 5)
share_url = input('请输入分享链接: ')
choice = int(input("1、模拟手机端下载 2、调用接口下载 3、直接下载\n选择下载方式:"))
if choice == 1:
BiLiBiLi_phone(share_url).bili_Download()
if choice == 2:
BiLiBiLi_api(share_url).BL_api_Download()
if choice == 3:
print("编写中。。。")
if __name__ == '__main__':
user_ui()
大好处
虽然这篇博文还没有写完,但还是迫不及待的给大家分享了很多西部:B站壁纸。
其实B站有个公众号,里面全是2233少女的一些壁纸,呵呵~
你学会了吗? 查看全部
网页源代码抓取工具(
说起B站的反扒机制(一)太严格(组图))
说到B站,大家都知道。B站的反接机机制不是很严格,所以今天就给大家说说我能想到的几种方式。目前我大概想到了三种方式:
那我就一一给大家介绍我的方法!
分析及主要代码:
既然确定了方法一模拟手机端请求,那么我们直接开始分析:
抓了链接,找了半天,也没找到有用的信息,于是直接去查网页源码:
仔细查看源代码后,发现了如上所示的信息。源代码中加载了视频的 MP4 链接和视频名称。
因为这个信息存储在标签中,虽然可以提取所有内容,然后转换为JSON格式进行提取,但这有点麻烦。我们直接用正则表达式提取:
代码
class BiLiBiLi_phone():
def __init__(self,s_url):
self.url=s_url
self.headers={
'origin': 'https://m.bilibili.com',
'referer': self.url,
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N)'
}
def bili_Download(self):
r = requests.get(self.url, proxies=proxy, headers=self.headers)
video_name=re.findall(',"title":"(.*?)","pubdate":', r.text)[0]
if video_name == '':
video_name = int(random.random() * 2 * 1000)
if len(str(video_name)) > 20:
video_name = video_name[:20]
video_url = re.findall(',"url":"(.*?)","backup_url"', r.text)[0].encode('utf-8').decode('unicode_escape')
r=requests.get(video_url,proxies=proxy,headers=self.headers)
with open(path+video_name+'.mp4','wb')as f:
f.write(r.content)
print("【BiLiBiLi】: {} 下载完成!".format(video_name))
关于代码的一些说明:
黄色字体前的代码是正则表达式的基本操作,黄色字体的原因是:
从源代码中提取的链接是:
网址:?\ u002F \\ u002Fupgcxcode \ u002F10 \ u002F14 \ u002F230501410 \ u002F230501410-1-1 6. MP4 E = ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfq9rVEuxTEnE8L5F6VnEsSTx0vkX8fqJeYTj_lta53NCM =&uipk = 5&NBS = 1&期限= 1601216024&根= playurl&OS = kodobv&OI = 1971851232 & trid = fcde238782674b78bf4425427c2a9ea3h & 平台 = html5 & upsig = b98cc40700e7f05e614acf0acbd9b671 & uparams = e,suidepk040,800,800,2000,800,000,000,000,000,000,000,800,000,000,000,000,800,000,000,000,000,000,000,000,000,000,000,000,000,050
该链接收录大量 \u002F 字段。这是因为源代码加载了转换为Unicode编码的链接,所以需要进行编码转换。
分析及主要代码:
对于方法二,我们首先需要找到第三方网站来解析视频,然后打包整个过程。
不同的网站有不同的分析方法。我只会写一个网站我随机选择的。清晰度还行。
这个网站之间的特殊性:当输入链接是:
出现以下错误时
所以你需要去掉下面的一些信息!
把准备好的链接放到分析网站中,得到如下信息:
由于网站的特殊性,如果选择MP4文件,有时视频会被分成多个,所以这里我主要选择FLV文件。
我们可以很清楚的看到这个接口返回的内容是一些属于HTML标签的信息。我们不在这里编写代码来进行清晰选择。需要的可以自己写,直接选择清晰度最好的来分析。.
代码
这是为了防止这个B站视频分析服务网站被滥用。这里我隐藏了分辨率网站。如果你想使用这个解析服务的地址,可以私信给我。
这种分析网站的特点之一是,知道的人越多,失败的速度就越快。
希望它能活得尽可能长。
class BiLiBiLi_api():
def __init__(self, s_url):
self.url = s_url.split('?')[0]
self.header1 = {
'Host': 'www.****.com',
'Origin': 'http://www.****.com',
'Referer': quote('http://www.****.com/video?url={}&page=video&submit=视频下载'.format(self.url)),
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63'
}
self.data = {
'url': self.url,
'format': 'flv',
'from': 'parse',
'retry': '1'
}
self.header2 = {
'origin': 'https://www.bilibili.com/',
'referer': self.url,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63'
}
def BL_api_Download(self):
r = requests.post('http://www.****.com/parse', proxies=proxy, data=self.data, headers=self.header1)
video_name = re.findall('data-clipboard-text="(.*?)"', r.json()['msg'])[0]
video_url = re.findall('href="(.*?)"', r.json()['msg'])[0].replace('amp;', '')
r1 = requests.get(video_url, proxies=proxy, headers=self.header2)
with open(path + video_name + '.flv', 'wb')as f:
f.write(r1.content)
print("【BiLiBiLi】: {} 下载完成!".format(video_name))
关于代码的一些说明:
为什么要把请求头分别写成两个:
不用说,第一个请求头所需要的信息是正常操作。当第二个请求头需要信息的时候,因为这个网站解析的视频链接是B站的原链接,你必须带上B站信息的请求头下载,否则服务器会拒绝我们的访问。
在上面解析网站的过程中,我们还记得请求解析链接后,我们还需要选择视频文件的格式,才能获取视频的链接,当我们选择了格式,我们将再次检查原件。链接到请求,并且会携带固定格式的数据数据。
为什么需要进行编码转换:
网站 就是这样,不改代码,会报错,呵呵。
前面说了,没有标黄色的部分还是基本操作,就是使用正则表达式提取信息,对于标黄色的部分,这是因为解析的链接中收录了HTML传输字符:
和
方法三
写...(遇到了点小麻烦!)
所有源代码
import random
import re
from urllib.parse import quote
import requests
url = 'https://ip.jiangxianli.com/api/proxy_ip'
r = requests.get(url)
proxy = {'HTTP': 'http://' + r.json()['data']['ip'] + ':' + r.json()['data']['port']}
print(proxy)
path = 'C:/Users/Jackson-art/Desktop/'
class BiLiBiLi_phone():
def __init__(self, s_url):
self.url = s_url
self.headers = {
'origin': 'https://m.bilibili.com',
'referer': self.url,
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N)'
}
def bili_Download(self):
r = requests.get(self.url, proxies=proxy, headers=self.headers)
video_name = re.findall(',"title":"(.*?)","pubdate":', r.text)[0]
if video_name == '':
video_name = int(random.random() * 2 * 1000)
if len(str(video_name)) > 20:
video_name = video_name[:20]
video_url = re.findall(',"url":"(.*?)","backup_url"', r.text)[0].encode('utf-8').decode('unicode_escape')
r = requests.get(video_url, proxies=proxy, headers=self.headers)
with open(path + video_name + '.mp4', 'wb')as f:
f.write(r.content)
print("【BiLiBiLi】: {} 下载完成!".format(video_name))
class BiLiBiLi_api():
def __init__(self, s_url):
self.url = s_url.split('?')[0]
self.header1 = {
'Host': 'www.****.com',
'Origin': 'http://www.****.com',
'Referer': quote('http://www.****.com/video?url={}&page=video&submit=视频下载'.format(self.url)),
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63'
}
self.data = {
'url': self.url,
'format': 'flv',
'from': 'parse',
'retry': '1'
}
self.header2 = {
'origin': 'https://www.bilibili.com/',
'referer': self.url,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63'
}
def BL_api_Download(self):
r = requests.post('http://www.****.com/parse', proxies=proxy, data=self.data, headers=self.header1)
video_name = re.findall('data-clipboard-text="(.*?)"', r.json()['msg'])[0]
video_url = re.findall('href="(.*?)"', r.json()['msg'])[0].replace('amp;', '')
r1 = requests.get(video_url, proxies=proxy, headers=self.header2)
with open(path + video_name + '.flv', 'wb')as f:
f.write(r1.content)
print("【BiLiBiLi】: {} 下载完成!".format(video_name))
def user_ui():
print('*' * 10 + '\t BiLiBiLi视频下载\t' + '*' * 10)
print('*' * 5 + "\t\tAuthor: 高智商白痴\t\t" + '*' * 5)
share_url = input('请输入分享链接: ')
choice = int(input("1、模拟手机端下载 2、调用接口下载 3、直接下载\n选择下载方式:"))
if choice == 1:
BiLiBiLi_phone(share_url).bili_Download()
if choice == 2:
BiLiBiLi_api(share_url).BL_api_Download()
if choice == 3:
print("编写中。。。")
if __name__ == '__main__':
user_ui()
大好处
虽然这篇博文还没有写完,但还是迫不及待的给大家分享了很多西部:B站壁纸。
其实B站有个公众号,里面全是2233少女的一些壁纸,呵呵~
你学会了吗?
网页源代码抓取工具(一下热门的小程序,需要源码的,文件一个文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-05 16:09
1.下载工具:
下载夜神模拟器
下载链接:
二、配置node环境:
下载链接:
三、下载反编译工具:
这是由 qwerty472123 在 Github 上编写的 node.js 版本;
地址:;
其他文件没用,把这些文件剪切到新文件夹,其他文件没用;
在这个目录中cmd打开终端npm install配置依赖;
四、开始爬取:
1.首先用模拟器登录微信,运行你要抓取的小程序;
2.进入模拟器的文件管理器;
然后进入这个目录
选择我们要编译的小程序wxapk文件
选择后,回到根目录,进入/mnt/shared/orther,点击
粘贴成功后导出文件到电脑
这就是我们需要的wxapkg文件。一个文件就是一个小程序,把我们需要的东西切到我们反编译工具的目录下。
然后开始,反编译
只需输入命令:
节点 wuWxapkg.js D:\wxapp\_-1250039800_637.wxapkg
前面是固定的,后面的.js就是你的初始文件路径。
我们可以得到目录
然后直接在微信开发者工具中打开目录即可!
有了这些步骤,夜神模拟器在运行的过程中会有些卡顿,所以不用担心获取wxapkg文件。
目的是让大家欣赏和了解流行的小程序。只是不要恶意抓住它们,并记住添加注意力。
如果喜欢上面的小程序,需要源码,添加博主的微信私信编辑器。 查看全部
网页源代码抓取工具(一下热门的小程序,需要源码的,文件一个文件)
1.下载工具:
下载夜神模拟器
下载链接:
二、配置node环境:
下载链接:
三、下载反编译工具:
这是由 qwerty472123 在 Github 上编写的 node.js 版本;
地址:;
其他文件没用,把这些文件剪切到新文件夹,其他文件没用;
在这个目录中cmd打开终端npm install配置依赖;
四、开始爬取:
1.首先用模拟器登录微信,运行你要抓取的小程序;
2.进入模拟器的文件管理器;
然后进入这个目录
选择我们要编译的小程序wxapk文件
选择后,回到根目录,进入/mnt/shared/orther,点击
粘贴成功后导出文件到电脑
这就是我们需要的wxapkg文件。一个文件就是一个小程序,把我们需要的东西切到我们反编译工具的目录下。
然后开始,反编译
只需输入命令:
节点 wuWxapkg.js D:\wxapp\_-1250039800_637.wxapkg
前面是固定的,后面的.js就是你的初始文件路径。
我们可以得到目录
然后直接在微信开发者工具中打开目录即可!
有了这些步骤,夜神模拟器在运行的过程中会有些卡顿,所以不用担心获取wxapkg文件。
目的是让大家欣赏和了解流行的小程序。只是不要恶意抓住它们,并记住添加注意力。
如果喜欢上面的小程序,需要源码,添加博主的微信私信编辑器。
网页源代码抓取工具(Python爬虫实例爬取网站搞笑段子爬虫系列Selenium定向爬取虎扑篮球图片详解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-01-04 02:14
本文文章主要介绍Python简单网页图片抓取的完整代码示例,具有一定的参考价值,有需要的朋友可以参考。
使用python捕捉网络图片的步骤是:
1、根据给定的URL获取网页源码
2、使用正则表达式过滤掉源码中的图片地址
3、根据过滤后的图片地址下载网络图片
下面是一个比较简单的抓取百度贴吧网页图片的实现:
# -*- coding: utf-8 -*-
# feimengjuan
import re
import urllib
import urllib2
#抓取网页图片
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
#利用正则表达式把源代码中的图片地址过滤出来
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' %x) #打开imglist中保存的图片网址,并下载图片保存在本地
x = x + 1
html = getHtml("http:编程客栈//tieba.baidu.com/p/2460150866")#获取该网址网页详细信息,得到的html就是网页的源代码
getImg(html)#从网页源代码中分析并下载保存图片
进一步整理代码,在本地创建了一个“图片”文件夹来保存图片
# -*- coding: utf-8 -*-
# feimengjuan
import re
import urllib
import urllib2
import os
#抓取网页图片
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
#创建保存图片的文件夹
def mkdir(path):
path = path.strip()
# 判断路径是否存在
# 存在 True
# 不存在 Flase
isExists = os.path.exists(path)
if not isExists:
print u'新编程客栈建了名字叫做',path,u'的文件夹'
# 创建目录操作函数
os.makedirs(path)
return True
else:
# 如果目录存在则不创建,并提示目录已经存在
print u'名为',path,u'的文件夹已经创建成功'
return False
# 输入文件名,保存多张图片
def saveImages(imglist,name):
number = 1
for imageURL in imglist:
splitPath = imageURL.split('.')
fTail = splitPath.pop()
if len(fTail) > 3:
fTail = 'jpg'
fileName = name + "/" + str(number) + "." + fTail
# 对于每张图片地址,进行保存
try:
u = urllib2.urlopen(imageURL)
data = u.read()
f = open(fileName,'wb+')
f.write(data)
print u'正在保存的一张图片为',fileName
f.close()
except urllib2.URLError as e:
print (e.reason)
number += 1
#获取网页中所有图片的地址
def getAllImg(html):
#利用正则表达式把源代码中的图片地址过滤出来
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
return imglist
#创建本地保存文件夹,并下载保存图片
if __name__ == '__main__':
html = getHtml("http://编程客栈tieba.baidu.com/p/2460150866")#获取该网址网页详细信息,得到的html就是网页的源代码
path = u'图片'
mkdir(path) #创建本地文件夹
imglist = http://www.cppcns.comgetAllImg(html) #获取图片的地址列表
saveImages(imglist,path) # 保存图片
结果在“图片”文件夹中保存了几十张图片,比如截图:
总结
以上就是本文关于Python编程栈实现简单网页图片抓取完整代码示例的全部内容,希望对大家有所帮助。有兴趣的朋友可以继续参考本站:
Python爬虫实例爬取网站搞笑段子
python爬虫系列Selenium定向爬行虎扑篮球图详解
如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!
本文标题:Python实现简单网页图片抓取的完整代码示例 查看全部
网页源代码抓取工具(Python爬虫实例爬取网站搞笑段子爬虫系列Selenium定向爬取虎扑篮球图片详解)
本文文章主要介绍Python简单网页图片抓取的完整代码示例,具有一定的参考价值,有需要的朋友可以参考。
使用python捕捉网络图片的步骤是:
1、根据给定的URL获取网页源码
2、使用正则表达式过滤掉源码中的图片地址
3、根据过滤后的图片地址下载网络图片
下面是一个比较简单的抓取百度贴吧网页图片的实现:
# -*- coding: utf-8 -*-
# feimengjuan
import re
import urllib
import urllib2
#抓取网页图片
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
#利用正则表达式把源代码中的图片地址过滤出来
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' %x) #打开imglist中保存的图片网址,并下载图片保存在本地
x = x + 1
html = getHtml("http:编程客栈//tieba.baidu.com/p/2460150866")#获取该网址网页详细信息,得到的html就是网页的源代码
getImg(html)#从网页源代码中分析并下载保存图片
进一步整理代码,在本地创建了一个“图片”文件夹来保存图片
# -*- coding: utf-8 -*-
# feimengjuan
import re
import urllib
import urllib2
import os
#抓取网页图片
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
#创建保存图片的文件夹
def mkdir(path):
path = path.strip()
# 判断路径是否存在
# 存在 True
# 不存在 Flase
isExists = os.path.exists(path)
if not isExists:
print u'新编程客栈建了名字叫做',path,u'的文件夹'
# 创建目录操作函数
os.makedirs(path)
return True
else:
# 如果目录存在则不创建,并提示目录已经存在
print u'名为',path,u'的文件夹已经创建成功'
return False
# 输入文件名,保存多张图片
def saveImages(imglist,name):
number = 1
for imageURL in imglist:
splitPath = imageURL.split('.')
fTail = splitPath.pop()
if len(fTail) > 3:
fTail = 'jpg'
fileName = name + "/" + str(number) + "." + fTail
# 对于每张图片地址,进行保存
try:
u = urllib2.urlopen(imageURL)
data = u.read()
f = open(fileName,'wb+')
f.write(data)
print u'正在保存的一张图片为',fileName
f.close()
except urllib2.URLError as e:
print (e.reason)
number += 1
#获取网页中所有图片的地址
def getAllImg(html):
#利用正则表达式把源代码中的图片地址过滤出来
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
return imglist
#创建本地保存文件夹,并下载保存图片
if __name__ == '__main__':
html = getHtml("http://编程客栈tieba.baidu.com/p/2460150866")#获取该网址网页详细信息,得到的html就是网页的源代码
path = u'图片'
mkdir(path) #创建本地文件夹
imglist = http://www.cppcns.comgetAllImg(html) #获取图片的地址列表
saveImages(imglist,path) # 保存图片
结果在“图片”文件夹中保存了几十张图片,比如截图:
总结
以上就是本文关于Python编程栈实现简单网页图片抓取完整代码示例的全部内容,希望对大家有所帮助。有兴趣的朋友可以继续参考本站:
Python爬虫实例爬取网站搞笑段子
python爬虫系列Selenium定向爬行虎扑篮球图详解
如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!
本文标题:Python实现简单网页图片抓取的完整代码示例
网页源代码抓取工具(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-03 23:15
想知道爬取网页源码的三种实现方式的相关内容吗?在本文中,我将仔细讲解爬取网页源代码的相关知识和一些代码示例。欢迎阅读和指正。 ,源码,一起学习吧。
更推荐方法一
///
/// 用HttpWebRequest取得网页源码
/// 对于带BOM的网页很有效,不管是什么编码都能正确识别
///
/// 网页地址"
/// 返回网页源文件
public static string GetHtmlSource2(string url)
{
//处理内容
string html = "";
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Accept = "*/*"; //接受任意文件
request.UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.1.4322)"; // 模拟使用IE在浏览 http://www.52mvc.com
request.AllowAutoRedirect = true;//是否允许302
//request.CookieContainer = new CookieContainer();//cookie容器,
request.Referer = url; //当前页面的引用
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, Encoding.Default);
html = reader.ReadToEnd();
stream.Close();
return html;
}
方法二
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.IO;
using System.Text;
using System.Net;
namespace MySql
{
public class GetHttpData
{
public static string GetHttpData2(string Url)
{
string sException = null;
string sRslt = null;
WebResponse oWebRps = null;
WebRequest oWebRqst = WebRequest.Create(Url);
oWebRqst.Timeout = 50000;
try
{
oWebRps = oWebRqst.GetResponse();
}
catch (WebException e)
{
sException = e.Message.ToString();
}
catch (Exception e)
{
sException = e.ToString();
}
finally
{
if (oWebRps != null)
{
StreamReader oStreamRd = new StreamReader(oWebRps.GetResponseStream(), Encoding.GetEncoding("utf-8"));
sRslt = oStreamRd.ReadToEnd();
oStreamRd.Close();
oWebRps.Close();
}
}
return sRslt;
}
}
}
方法三
<p>
public static string getHtml(string url, params string [] charSets)//url是要访问的网站地址,charSet是目标网页的编码,如果传入的是null或者"",那就自动分析网页的编码
{
try
{
string charSet = null;
if (charSets.Length == 1) {
charSet = charSets[0];
}
WebClient myWebClient = new WebClient(); //创建WebClient实例myWebClient
// 需要注意的:
//有的网页可能下不下来,有种种原因比如需要cookie,编码问题等等
//这是就要具体问题具体分析比如在头部加入cookie
// webclient.Headers.Add("Cookie", cookie);
//这样可能需要一些重载方法。根据需要写就可以了
//获取或设置用于对向 Internet 资源的请求进行身份验证的网络凭据。
myWebClient.Credentials = CredentialCache.DefaultCredentials;
//如果服务器要验证用户名,密码
//NetworkCredential mycred = new NetworkCredential(struser, strpassword);
//myWebClient.Credentials = mycred;
//从资源下载数据并返回字节数组。(加@是因为网址中间有"/"符号)
byte[] myDataBuffer = myWebClient.DownloadData(url);
string strWebData = Encoding.Default.GetString(myDataBuffer);
//获取网页字符编码描述信息
Match charSetMatch = Regex.Match(strWebData, " 查看全部
网页源代码抓取工具(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
想知道爬取网页源码的三种实现方式的相关内容吗?在本文中,我将仔细讲解爬取网页源代码的相关知识和一些代码示例。欢迎阅读和指正。 ,源码,一起学习吧。
更推荐方法一
///
/// 用HttpWebRequest取得网页源码
/// 对于带BOM的网页很有效,不管是什么编码都能正确识别
///
/// 网页地址"
/// 返回网页源文件
public static string GetHtmlSource2(string url)
{
//处理内容
string html = "";
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Accept = "*/*"; //接受任意文件
request.UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.1.4322)"; // 模拟使用IE在浏览 http://www.52mvc.com
request.AllowAutoRedirect = true;//是否允许302
//request.CookieContainer = new CookieContainer();//cookie容器,
request.Referer = url; //当前页面的引用
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, Encoding.Default);
html = reader.ReadToEnd();
stream.Close();
return html;
}
方法二
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.IO;
using System.Text;
using System.Net;
namespace MySql
{
public class GetHttpData
{
public static string GetHttpData2(string Url)
{
string sException = null;
string sRslt = null;
WebResponse oWebRps = null;
WebRequest oWebRqst = WebRequest.Create(Url);
oWebRqst.Timeout = 50000;
try
{
oWebRps = oWebRqst.GetResponse();
}
catch (WebException e)
{
sException = e.Message.ToString();
}
catch (Exception e)
{
sException = e.ToString();
}
finally
{
if (oWebRps != null)
{
StreamReader oStreamRd = new StreamReader(oWebRps.GetResponseStream(), Encoding.GetEncoding("utf-8"));
sRslt = oStreamRd.ReadToEnd();
oStreamRd.Close();
oWebRps.Close();
}
}
return sRslt;
}
}
}
方法三
<p>
public static string getHtml(string url, params string [] charSets)//url是要访问的网站地址,charSet是目标网页的编码,如果传入的是null或者"",那就自动分析网页的编码
{
try
{
string charSet = null;
if (charSets.Length == 1) {
charSet = charSets[0];
}
WebClient myWebClient = new WebClient(); //创建WebClient实例myWebClient
// 需要注意的:
//有的网页可能下不下来,有种种原因比如需要cookie,编码问题等等
//这是就要具体问题具体分析比如在头部加入cookie
// webclient.Headers.Add("Cookie", cookie);
//这样可能需要一些重载方法。根据需要写就可以了
//获取或设置用于对向 Internet 资源的请求进行身份验证的网络凭据。
myWebClient.Credentials = CredentialCache.DefaultCredentials;
//如果服务器要验证用户名,密码
//NetworkCredential mycred = new NetworkCredential(struser, strpassword);
//myWebClient.Credentials = mycred;
//从资源下载数据并返回字节数组。(加@是因为网址中间有"/"符号)
byte[] myDataBuffer = myWebClient.DownloadData(url);
string strWebData = Encoding.Default.GetString(myDataBuffer);
//获取网页字符编码描述信息
Match charSetMatch = Regex.Match(strWebData, "
网页源代码抓取工具(《搜索引擎原理系列教程》之三个比较关心)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-03 15:01
《搜索引擎原理系列教程》虽然不是一本书,但也弥补了百度白皮书因为信息量大、内容多等原因的一些不足。教程完全是民间SEO爱好者总结的,这种精神值得称赞。这里还是想讲三个方面,也是我们SEOER关心的三个方面:收录、索引、排名。
一、收录
搜索引擎采集网页的过程,收录其实是一个复杂的过程。简单分为这四个步骤:
1、 调度器是整个采集过程的核心。它存储了一个访问过的 URL 库和一个未访问过的 URL 库,统称为 URL 库。一开始,调度器会从未访问过的URL库中检索一个URL,分配给蜘蛛,让蜘蛛抓取没有被抓取的URL。
2、 当蜘蛛获取到一个 URL 时,它会向该 URL 发送一个爬取请求。流程为:URL对应域名的DNS解析->获取Socket连接的IP->连接成功发送http请求->接收网页信息。
3、蜘蛛获取到网页信息后,将源代码返回给调度员,调度员将源代码保存在网络数据库中。
4、 调度器会提取已爬取网页的链接,将未爬取的网址存放在未访问网址库中,将刚刚爬取的网址更新为已爬取的网址库中。
这将涉及重复数据删除
调度器的工作流程
1、从从未访问过的 URL 列表中依次检索 URL,并将它们分配给每个蜘蛛。
2、蜘蛛获取URL,爬取,获取网页源代码,从源代码中提取URL,获取网页中收录的所有URL。
3、 调度器依次检查获取的URL是否存在于访问的URL库中。如果存在,则表示已被抓取,则丢弃该URL;如果不存在,则表示该网址未被抓取,将订单加入未访问网址列表,等待后抓取。
4、 重复步骤 1,直到未访问列表为空。
二、索引
网页预处理
1、索引原创网页。
2、 根据搜索到的网页库对网页进行分割,将每个页面转换为一组词。 (前向指数)
3、 将网页到索引词的映射转换成索引词到网页的映射形成倒排文件(包括倒排表和索引词表)
一般来说,搜索引擎从网页数据库中获取网页,然后进行代码过滤,然后提取正文信息并进行分词。下一步就是过滤关键词的集合,得到网页关键词的正向索引,最后搜索引擎会将正向索引转化为网页的倒排索引。正是这项技术,让搜索引擎能够在1S内将搜索结果呈现给用户。
此外,搜索引擎执行的操作是网页净化和重复数据删除。除了去除网页中的嘈杂内容(如广告、版权等),提取网页主题及相关内容,去除网页采集中的重复内容。
可能有同学会问,搜索引擎是怎么识别主要内容的?实际上,该算法依赖于HTML标签树的建立和投票方式来识别正文。
例如,让我们设置规则,
1、 如果文本块的文本长度小于10个字,0分。 10-50字之间5分。 50 到 250 个单词得 8 分。 250字以上10分。
2、 文本块的文本位置在右边,得0分。在顶部,奖励 3 分。在左侧,奖励 5 分。中间,得10分。
那么我们可以得出结论,页面TITLE得分为9,文本粗体H1标签得分为8,依此类推,DIV部分的AD部分得分为0,被丢弃。
(以上例子仅供参考,与实际算法无关)
搜索引擎必须经过三个步骤才能删除重复的网页。首先是特征提取(涉及I-Match算法和Shingle算法),然后是相似度计算,相似度评价,最后去重。
其实搜索引擎算法和用户交互的过程就是一个查询过程。比如用户搜索“搜索引擎原理”,算法分词后会得到“搜索引擎”,在倒排索引表中找到“原理”。这两个文档列表,相交,然后将上一步找到的用户查询和文档列表中的一条记录向量化,找到查询向量和文档向量的相似度,然后从高到低排序,最后我们得到什么查看最终搜索结果。
三、排名
最后,举个例子作为结尾:
搜索引擎网页权重=网页词条基本权重+链接权重+用户评价权重
网页中术语的基本权重
1、 比如搜索引擎环境中的一个关键词“搜索引擎”,权重应该是:WBT=W+W, (h1)+W,(b ) =10+12+4=26
<p>2、关键词“搜索引擎”也可能在文档的其他地方出现n次,每次出现可以计算一个WBT 查看全部
网页源代码抓取工具(《搜索引擎原理系列教程》之三个比较关心)
《搜索引擎原理系列教程》虽然不是一本书,但也弥补了百度白皮书因为信息量大、内容多等原因的一些不足。教程完全是民间SEO爱好者总结的,这种精神值得称赞。这里还是想讲三个方面,也是我们SEOER关心的三个方面:收录、索引、排名。
一、收录
搜索引擎采集网页的过程,收录其实是一个复杂的过程。简单分为这四个步骤:
1、 调度器是整个采集过程的核心。它存储了一个访问过的 URL 库和一个未访问过的 URL 库,统称为 URL 库。一开始,调度器会从未访问过的URL库中检索一个URL,分配给蜘蛛,让蜘蛛抓取没有被抓取的URL。
2、 当蜘蛛获取到一个 URL 时,它会向该 URL 发送一个爬取请求。流程为:URL对应域名的DNS解析->获取Socket连接的IP->连接成功发送http请求->接收网页信息。
3、蜘蛛获取到网页信息后,将源代码返回给调度员,调度员将源代码保存在网络数据库中。
4、 调度器会提取已爬取网页的链接,将未爬取的网址存放在未访问网址库中,将刚刚爬取的网址更新为已爬取的网址库中。
这将涉及重复数据删除
调度器的工作流程
1、从从未访问过的 URL 列表中依次检索 URL,并将它们分配给每个蜘蛛。
2、蜘蛛获取URL,爬取,获取网页源代码,从源代码中提取URL,获取网页中收录的所有URL。
3、 调度器依次检查获取的URL是否存在于访问的URL库中。如果存在,则表示已被抓取,则丢弃该URL;如果不存在,则表示该网址未被抓取,将订单加入未访问网址列表,等待后抓取。
4、 重复步骤 1,直到未访问列表为空。
二、索引
网页预处理
1、索引原创网页。
2、 根据搜索到的网页库对网页进行分割,将每个页面转换为一组词。 (前向指数)
3、 将网页到索引词的映射转换成索引词到网页的映射形成倒排文件(包括倒排表和索引词表)
一般来说,搜索引擎从网页数据库中获取网页,然后进行代码过滤,然后提取正文信息并进行分词。下一步就是过滤关键词的集合,得到网页关键词的正向索引,最后搜索引擎会将正向索引转化为网页的倒排索引。正是这项技术,让搜索引擎能够在1S内将搜索结果呈现给用户。
此外,搜索引擎执行的操作是网页净化和重复数据删除。除了去除网页中的嘈杂内容(如广告、版权等),提取网页主题及相关内容,去除网页采集中的重复内容。
可能有同学会问,搜索引擎是怎么识别主要内容的?实际上,该算法依赖于HTML标签树的建立和投票方式来识别正文。
例如,让我们设置规则,
1、 如果文本块的文本长度小于10个字,0分。 10-50字之间5分。 50 到 250 个单词得 8 分。 250字以上10分。
2、 文本块的文本位置在右边,得0分。在顶部,奖励 3 分。在左侧,奖励 5 分。中间,得10分。
那么我们可以得出结论,页面TITLE得分为9,文本粗体H1标签得分为8,依此类推,DIV部分的AD部分得分为0,被丢弃。
(以上例子仅供参考,与实际算法无关)
搜索引擎必须经过三个步骤才能删除重复的网页。首先是特征提取(涉及I-Match算法和Shingle算法),然后是相似度计算,相似度评价,最后去重。
其实搜索引擎算法和用户交互的过程就是一个查询过程。比如用户搜索“搜索引擎原理”,算法分词后会得到“搜索引擎”,在倒排索引表中找到“原理”。这两个文档列表,相交,然后将上一步找到的用户查询和文档列表中的一条记录向量化,找到查询向量和文档向量的相似度,然后从高到低排序,最后我们得到什么查看最终搜索结果。
三、排名
最后,举个例子作为结尾:
搜索引擎网页权重=网页词条基本权重+链接权重+用户评价权重
网页中术语的基本权重
1、 比如搜索引擎环境中的一个关键词“搜索引擎”,权重应该是:WBT=W+W, (h1)+W,(b ) =10+12+4=26
<p>2、关键词“搜索引擎”也可能在文档的其他地方出现n次,每次出现可以计算一个WBT
网页源代码抓取工具(sublimeajax学过加载导致的部分关键代码显示不出来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-03 14:56
1、前言
我相信在这个知识共享的时代,你必须下载大量的文件并保存在互联网上以备将来学习。毕竟硬盘空间也比较有限。说一下我们要做的项目,就是搜索。搜索磁盘中的资源并下载。
2、项目目标
实现搜索所需文件,下载文件。
3、项目准备
使用sublime text 3开发,因为这次需要使用interactive来完成操作,所以需要在sublime text 3下载一个sublimeREPL插件来辅助开发。
4、项目实现
(1)打开盘搜,随意打开一个链接,如下图:
(2)然后就可以看到这个画面了,如下图。
(3)此时这个网页的地址是:
http://www.pansou.com/?q=成化十四年
可以看出是一个get请求。所以 requests.get 开始了,所以我们实现了第一步,搜索。所以,你可以这样写代码:
import requests
def down(content):
content=input('请输入要下载的文件名')
rep=requests.get('http://www.pansou.com/?q='+str(content))
rep.encoding='utf-8'
(4)这样我们就得到了上一页的网页源码,我们搜索了相关的关键字,发现没有找到:
(5)那怎么回事?原来是ajax的异步加载导致部分关键代码无法显示。这个很难,也就是说碰到了我知识点的盲点向上。
因为没研究过前端,只知道有ajax,哪里知道这个问题是怎么发生的,怎么解决的。但不要害怕。好在编辑器有个大招,就是找界面。找了又找,终于找到了,嘿嘿,辛苦了。如图:
(6)发现这是一个json格式,所以我们现在就可以读取了,如图:
(7)不容易,json的陷阱很多,所以决定用字典。哈哈哈,适合自己的才是最香的。
当我们找到这些东西时,我们就可以提取它们,这样我们就可以提取出第一页的所有结果。提取第二页的结果,我们只需要将p的结果改为2即可。
最终结果,如图:
(8)接下来我们会加强程序,使其具有交互功能供用户选择。
(9)但是我们知道callback一般是一个可变函数,所以可以使用的参数只有q和p两个,所以:
到此完成指定页面的文件浏览。
下载也比较简单,直接复制链接到浏览器,就完成了最简单的搜索引擎。
5、总结
(1)不建议抓取太多数据,容易加载服务器,简单试一下。
(2)本文基于Python网络爬虫,利用爬虫库搭建了一个简单的Python搜索引擎。
(3)实现的时候,总会出现各种问题,不要看高手,自己去深入了解一下。 查看全部
网页源代码抓取工具(sublimeajax学过加载导致的部分关键代码显示不出来!)
1、前言
我相信在这个知识共享的时代,你必须下载大量的文件并保存在互联网上以备将来学习。毕竟硬盘空间也比较有限。说一下我们要做的项目,就是搜索。搜索磁盘中的资源并下载。
2、项目目标
实现搜索所需文件,下载文件。
3、项目准备
使用sublime text 3开发,因为这次需要使用interactive来完成操作,所以需要在sublime text 3下载一个sublimeREPL插件来辅助开发。
4、项目实现
(1)打开盘搜,随意打开一个链接,如下图:
(2)然后就可以看到这个画面了,如下图。
(3)此时这个网页的地址是:
http://www.pansou.com/?q=成化十四年
可以看出是一个get请求。所以 requests.get 开始了,所以我们实现了第一步,搜索。所以,你可以这样写代码:
import requests
def down(content):
content=input('请输入要下载的文件名')
rep=requests.get('http://www.pansou.com/?q='+str(content))
rep.encoding='utf-8'
(4)这样我们就得到了上一页的网页源码,我们搜索了相关的关键字,发现没有找到:
(5)那怎么回事?原来是ajax的异步加载导致部分关键代码无法显示。这个很难,也就是说碰到了我知识点的盲点向上。
因为没研究过前端,只知道有ajax,哪里知道这个问题是怎么发生的,怎么解决的。但不要害怕。好在编辑器有个大招,就是找界面。找了又找,终于找到了,嘿嘿,辛苦了。如图:
(6)发现这是一个json格式,所以我们现在就可以读取了,如图:
(7)不容易,json的陷阱很多,所以决定用字典。哈哈哈,适合自己的才是最香的。
当我们找到这些东西时,我们就可以提取它们,这样我们就可以提取出第一页的所有结果。提取第二页的结果,我们只需要将p的结果改为2即可。
最终结果,如图:
(8)接下来我们会加强程序,使其具有交互功能供用户选择。
(9)但是我们知道callback一般是一个可变函数,所以可以使用的参数只有q和p两个,所以:
到此完成指定页面的文件浏览。
下载也比较简单,直接复制链接到浏览器,就完成了最简单的搜索引擎。
5、总结
(1)不建议抓取太多数据,容易加载服务器,简单试一下。
(2)本文基于Python网络爬虫,利用爬虫库搭建了一个简单的Python搜索引擎。
(3)实现的时候,总会出现各种问题,不要看高手,自己去深入了解一下。
网页源代码抓取工具( 动态渲染的页面来说)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-01-03 14:53
动态渲染的页面来说)
Selenium 是一种自动化测试工具,可以驱动浏览器执行特定的动作,例如点击、下拉等操作。同时,它还可以获取浏览器当前呈现的页面的源代码,以便在可见时进行抓取。对于一些JavaScript动态渲染的页面,这种爬取方式非常有效。
0、安装
(1) Selenium 安装
pip 安装硒
(2)网络驱动下载
Selenium 是一种需要与浏览器配合使用的自动化测试工具。 Selenium 使用 Webdriver 来驱动浏览器。
您需要根据您的浏览器版本下载相应的webdriver驱动。比如这里使用的是ChromeDriver驱动,可以百度下载。
下载完成后是一个可执行文件。我们可以把它添加到环境变量中,然后我们在构造webdriver.Chrome()的时候就不需要括号里传入驱动的路径了。
1、基本用法
2、初始化浏览器对象
从 selenium 导入 webdriver
浏览器 = webdriver.Chrome()
3、访问页面
browser.get("")
#获取网页源码
打印(browser.page_source)
browser.close()
4、查找节点
(1)查找单个节点
常用的有以下7种:
find_element_by_id
find_element_by_class_name
find_elemnet_by_xpath
find_element_by_css_selector
find_element_by_name
find_element_by_tag_name
find_element_by_link_text
find_element_by_partial_link_text
(2)查找多个节点
看上面找单个节点的方法,区别是element变成了elements
5、节点交互
常用的有:
(1)input.send_keys("Python") 在搜索框中输入内容,如Python
(2).input.clear() 清除搜索框内容
(3).button.click() 模拟鼠标点击,button是找到的可点击标签
6、动作链
例如,将下面的 A 放在 B 中:
7、执行 JavaScript
对于某些操作,Selenium 不提供操作。比如下拉进度条
browser.execute_script (js 代码)
8、获取节点信息
#获取标签的href属性
a.get_attribute("href")
#获取节点下的所有文本信息并返回一个字符串
div.text
9、切换帧
我们知道网页中有一种节点叫做iframe,就是子框架,相当于页面的子页面,其结构与外部网页的结构完全相同。 Selenium 打开页面后,默认在父框架中运行。如果此时页面中有子框架,则无法获取子框架中的节点。这时候就需要使用switch_to.frame()方法来切换Frame。
#这里根据id名称切换
browser.switch_to.frame("iframeResult")
10、延迟等待
在Selenium中,get()方法会在网页框架加载完毕后结束执行。这时候如果得到page_source,可能不是浏览器完全加载的页面。如果某些页面有额外的 Ajax 请求,我们在 网页的源代码中可能无法成功获取。因此需要延迟等待一定的时间来保证节点已经加载完毕。
这里有两种等待方式:一种是隐式等待,另一种是显式等待。
(1)隐式等待
正在等待一个固定的时间。如果 Selenium 在 DOM 中没有找到节点,它会继续等待指定时间,并在指定时间结束时再次检查是否存在该节点,如果没有则抛出异常。单位是s
browser.implicitly_wait(10)
(2)明确等待
显式等待更灵活,可以指定最长等待时间,如果在此时间内返回,将继续运行代码。单位是s
首先使用wait = WebDriverWait(browser, 10)构造等待对象,
wait.until(EC.presence_of_element_located((By.CLASS_NAME, "left")))之后,EC是等待条件对象,presence_of_element_located是需要的等待条件,等待条件有很多,具体看下面:
其他等待条件:
11、前进后退
使用浏览器一般都有前进后退功能。 Selenium 也可以完成这个操作。使用 back() 后退和 forward() 前进。示例如下:
12、Cookies
13、标签管理
首先执行js代码,browser.execute_script('window.open()')。打开另一个标签
切换到另一个标签 browser.switch_to.window(browser.window_handles[1])
关闭标签 browser.execute_script('window.close()')
切换回 browser.switch_to.window(browser.window_handles[0])
14、无头模式
Selenium 不再打开 Chrome 浏览器,只需通过 option = webdriver.ChromeOptions() 和 option.add_argument('--headless') 添加即可。
以上是Selenium的全部内容,使用时只需要设置如下几个参数即可。 查看全部
网页源代码抓取工具(
动态渲染的页面来说)
Selenium 是一种自动化测试工具,可以驱动浏览器执行特定的动作,例如点击、下拉等操作。同时,它还可以获取浏览器当前呈现的页面的源代码,以便在可见时进行抓取。对于一些JavaScript动态渲染的页面,这种爬取方式非常有效。
0、安装
(1) Selenium 安装
pip 安装硒
(2)网络驱动下载
Selenium 是一种需要与浏览器配合使用的自动化测试工具。 Selenium 使用 Webdriver 来驱动浏览器。
您需要根据您的浏览器版本下载相应的webdriver驱动。比如这里使用的是ChromeDriver驱动,可以百度下载。
下载完成后是一个可执行文件。我们可以把它添加到环境变量中,然后我们在构造webdriver.Chrome()的时候就不需要括号里传入驱动的路径了。
1、基本用法
2、初始化浏览器对象
从 selenium 导入 webdriver
浏览器 = webdriver.Chrome()
3、访问页面
browser.get("")
#获取网页源码
打印(browser.page_source)
browser.close()
4、查找节点
(1)查找单个节点
常用的有以下7种:
find_element_by_id
find_element_by_class_name
find_elemnet_by_xpath
find_element_by_css_selector
find_element_by_name
find_element_by_tag_name
find_element_by_link_text
find_element_by_partial_link_text
(2)查找多个节点
看上面找单个节点的方法,区别是element变成了elements
5、节点交互
常用的有:
(1)input.send_keys("Python") 在搜索框中输入内容,如Python
(2).input.clear() 清除搜索框内容
(3).button.click() 模拟鼠标点击,button是找到的可点击标签
6、动作链
例如,将下面的 A 放在 B 中:
7、执行 JavaScript
对于某些操作,Selenium 不提供操作。比如下拉进度条
browser.execute_script (js 代码)
8、获取节点信息
#获取标签的href属性
a.get_attribute("href")
#获取节点下的所有文本信息并返回一个字符串
div.text
9、切换帧
我们知道网页中有一种节点叫做iframe,就是子框架,相当于页面的子页面,其结构与外部网页的结构完全相同。 Selenium 打开页面后,默认在父框架中运行。如果此时页面中有子框架,则无法获取子框架中的节点。这时候就需要使用switch_to.frame()方法来切换Frame。
#这里根据id名称切换
browser.switch_to.frame("iframeResult")
10、延迟等待
在Selenium中,get()方法会在网页框架加载完毕后结束执行。这时候如果得到page_source,可能不是浏览器完全加载的页面。如果某些页面有额外的 Ajax 请求,我们在 网页的源代码中可能无法成功获取。因此需要延迟等待一定的时间来保证节点已经加载完毕。
这里有两种等待方式:一种是隐式等待,另一种是显式等待。
(1)隐式等待
正在等待一个固定的时间。如果 Selenium 在 DOM 中没有找到节点,它会继续等待指定时间,并在指定时间结束时再次检查是否存在该节点,如果没有则抛出异常。单位是s
browser.implicitly_wait(10)
(2)明确等待
显式等待更灵活,可以指定最长等待时间,如果在此时间内返回,将继续运行代码。单位是s
首先使用wait = WebDriverWait(browser, 10)构造等待对象,
wait.until(EC.presence_of_element_located((By.CLASS_NAME, "left")))之后,EC是等待条件对象,presence_of_element_located是需要的等待条件,等待条件有很多,具体看下面:
其他等待条件:
11、前进后退
使用浏览器一般都有前进后退功能。 Selenium 也可以完成这个操作。使用 back() 后退和 forward() 前进。示例如下:
12、Cookies
13、标签管理
首先执行js代码,browser.execute_script('window.open()')。打开另一个标签
切换到另一个标签 browser.switch_to.window(browser.window_handles[1])
关闭标签 browser.execute_script('window.close()')
切换回 browser.switch_to.window(browser.window_handles[0])
14、无头模式
Selenium 不再打开 Chrome 浏览器,只需通过 option = webdriver.ChromeOptions() 和 option.add_argument('--headless') 添加即可。
以上是Selenium的全部内容,使用时只需要设置如下几个参数即可。
网页源代码抓取工具(这是一个简单的单页面数据抓取案例,但也有些值得注意的坑 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-02 10:29
)
这是一个简单的单页数据抓取案例,但也存在一些值得注意的陷阱。这是代码的快速解释。
获取51job网站,搜索“人工智能”,获取职位、职位名称、公司名称、薪资等基本信息
图像.png
数据直接在【右键-查看源码】的网页源码中,也可以在元素面板中【右键-查看】查看:
图像.png
我们注意到job列表都在class='dw_table'这个元素下,但是第一个class='el title'是header,不应该收录,虽然下面有t1,t2,t3 , 但它的 class='t1' 是一,正常位置的 t1 是一
主要代码如下:
from bs4 import BeautifulSoup
import requests
import time
headers = {
'User-Agent': 'Mozilla/5.0'
}
url='https://search.51job.com/list/070300,000000,0000,00,9,99,%25E4%25BA%25BA%25E5%25B7%25A5%25E6%2599%25BA%25E8%2583%25BD,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='
html= requests.get(url,headers=headers)
html=html.text.encode('ISO-8859-1').decode('gbk') ##注意这个坑!
soup=BeautifulSoup(html, 'html.parser')
for item in soup.find('div','dw_table').find_all('div','el'):
shuchu=[]
if item.find('p','t1'):
title=item.find('p','t1').find('a')['title']
company=item.find('span','t2').string #爬公司名称
address=item.find('span','t3').string #爬地址
xinzi = item.find('span', 't4').string #爬薪资
date=item.find('span','t5').string #爬日期
shuchu.append(str(title))
shuchu.append(str(company))
shuchu.append(str(address))
shuchu.append(str(xinzi))
shuchu.append(str(date))
print('\t'.join(shuchu))
time.sleep(1)
有几个坑需要注意:
最终输出大致如下:
查看全部
网页源代码抓取工具(这是一个简单的单页面数据抓取案例,但也有些值得注意的坑
)
这是一个简单的单页数据抓取案例,但也存在一些值得注意的陷阱。这是代码的快速解释。
获取51job网站,搜索“人工智能”,获取职位、职位名称、公司名称、薪资等基本信息
图像.png
数据直接在【右键-查看源码】的网页源码中,也可以在元素面板中【右键-查看】查看:
图像.png
我们注意到job列表都在class='dw_table'这个元素下,但是第一个class='el title'是header,不应该收录,虽然下面有t1,t2,t3 , 但它的 class='t1' 是一,正常位置的 t1 是一
主要代码如下:
from bs4 import BeautifulSoup
import requests
import time
headers = {
'User-Agent': 'Mozilla/5.0'
}
url='https://search.51job.com/list/070300,000000,0000,00,9,99,%25E4%25BA%25BA%25E5%25B7%25A5%25E6%2599%25BA%25E8%2583%25BD,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='
html= requests.get(url,headers=headers)
html=html.text.encode('ISO-8859-1').decode('gbk') ##注意这个坑!
soup=BeautifulSoup(html, 'html.parser')
for item in soup.find('div','dw_table').find_all('div','el'):
shuchu=[]
if item.find('p','t1'):
title=item.find('p','t1').find('a')['title']
company=item.find('span','t2').string #爬公司名称
address=item.find('span','t3').string #爬地址
xinzi = item.find('span', 't4').string #爬薪资
date=item.find('span','t5').string #爬日期
shuchu.append(str(title))
shuchu.append(str(company))
shuchu.append(str(address))
shuchu.append(str(xinzi))
shuchu.append(str(date))
print('\t'.join(shuchu))
time.sleep(1)
有几个坑需要注意:
最终输出大致如下:

