
网页源代码抓取工具
网页源代码抓取工具(爬虫网页源代码的查看工具-爬虫的开发环境)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-07 22:04
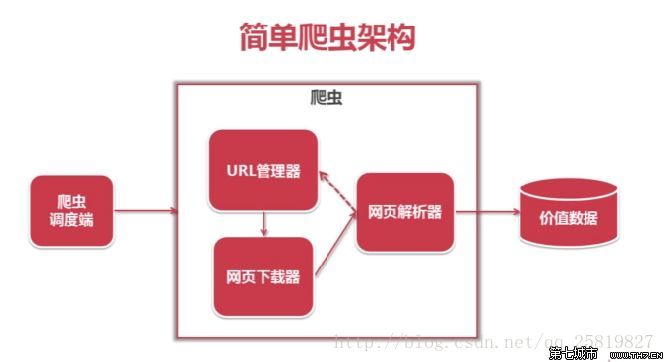
爬虫主要是过滤掉网页中无用的信息。从网页抓取有用的信息
一般的爬虫架构是:
在python爬虫之前,你必须对网页的结构知识有一定的了解。网页标签、网页语言等知识,推荐去W3School:
W3school 链接查找
爬取前还有一些工具:
1.首先是Python的开发环境:这里我选择了python2.7。开发的IDE为了安装调试方便,选择在VS2013上使用python插件在VS上开发(python程序的调试和c的调试差不多,比较熟悉)。
2.网页源代码查看工具:虽然每个浏览器都可以查看网页源代码。但是这里我还是推荐火狐浏览器和FirBug插件(同时这两个也是web开发者必备的工具之一);
FirBug插件的安装可以在右侧添加的组件中安装;
接下来,让我们尝试查看网页的源代码。这里我以我们要爬取的篮球数据为例:
比如我要爬取网页中Team Comparison表的内容:
<p> 查看全部
网页源代码抓取工具(爬虫网页源代码的查看工具-爬虫的开发环境)
爬虫主要是过滤掉网页中无用的信息。从网页抓取有用的信息
一般的爬虫架构是:
在python爬虫之前,你必须对网页的结构知识有一定的了解。网页标签、网页语言等知识,推荐去W3School:
W3school 链接查找
爬取前还有一些工具:
1.首先是Python的开发环境:这里我选择了python2.7。开发的IDE为了安装调试方便,选择在VS2013上使用python插件在VS上开发(python程序的调试和c的调试差不多,比较熟悉)。
2.网页源代码查看工具:虽然每个浏览器都可以查看网页源代码。但是这里我还是推荐火狐浏览器和FirBug插件(同时这两个也是web开发者必备的工具之一);
FirBug插件的安装可以在右侧添加的组件中安装;
接下来,让我们尝试查看网页的源代码。这里我以我们要爬取的篮球数据为例:
比如我要爬取网页中Team Comparison表的内容:
<p>
网页源代码抓取工具(调色板formac您所需要的--ColorWellfor )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-07 06:24
)
ColorWell for mac 是一款可以非常轻松地生成无限调色板的软件,您可以从任何颜色源快速获取 Hex/HSL/HSB/RGB 和代码片段。如果您从未从源(或多源)图像中快速生成调色板,那么您需要调色板生成器。您还可以将您生成的任何调色板保存在 ColorWell 调色板数据库中!
软件功能
主要特征
调色板与 macOS 系统调色板同步
导入/导出 Adobe .ase 和 Apple .clr 调色板文件
无限的历史/快照
完全可定制的界面
Swift/Objective-C 颜色代码生成
支持按名称、十六进制、RGB、HSL、HSB、Lab 和 CMYK 更改颜色
从图像生成调色板
配色方案生成器
可配置为菜单栏应用
其他一些很酷的东西
macOS Mojave 准备好支持 DarkMode
可以配置为浮动在所有其他应用程序的前面
美观直观的用户界面
轻松更改首选项中的默认色彩空间
全局热键即时显示或隐藏
17,000 多个颜色名称
通过拖放重新排列/删除样本
本地化为英语、德语和法语
软件功能
系统范围的调色板
ColorWell 使用 macOS 系统颜色选择器来同步调色板。因此,您可以在 Pages、Affinity Photo、Final Cut Pro 或任何其他一流的 macOS 应用程序中使用所有精心设计的配色方案!所有系统调色板也可用于查看和创建自定义调色板。
专业文件支持
ColorWell 支持导入和导出到 Adobe .ase 和 Apple .clr 文件格式。这使得分享您的配色方案比以往任何时候都更容易。使用 ColorWell 的通用调色板数据库,任何导入的方案自然会直接导入到 macOS 的颜色选择器中,使其广泛适用于系统
完整的历史支持
您所做的每一次颜色更改都会保存到历史记录中。因此,即使您不记得 3 天前检查的是什么颜色 - ColorWell 也可以!历史支持不限于单一颜色,每次更改都会保存整个颜色状态。因此,当您需要时,当前活动的颜色以及任何已保存的色板都会出现。
高级调色板生成
使用存储的调色板作为起点微调各个颜色。从调色板生成器中获取互补色、相似色、三色、四色或单色。从图像中翻转颜色并微调颜色选择。您可以使用无限数量的样本创建调色板。
推荐理由
ColorWell for mac 通过配置热键提供对 macOS 色轮的快速访问!通过快速访问所有颜色信息和代码生成来生成无限的调色板以进行应用程序开发。通过拖放从任何源图像轻松创建调色板。
查看全部
网页源代码抓取工具(调色板formac您所需要的--ColorWellfor
)
ColorWell for mac 是一款可以非常轻松地生成无限调色板的软件,您可以从任何颜色源快速获取 Hex/HSL/HSB/RGB 和代码片段。如果您从未从源(或多源)图像中快速生成调色板,那么您需要调色板生成器。您还可以将您生成的任何调色板保存在 ColorWell 调色板数据库中!

软件功能
主要特征
调色板与 macOS 系统调色板同步
导入/导出 Adobe .ase 和 Apple .clr 调色板文件
无限的历史/快照
完全可定制的界面
Swift/Objective-C 颜色代码生成
支持按名称、十六进制、RGB、HSL、HSB、Lab 和 CMYK 更改颜色
从图像生成调色板
配色方案生成器
可配置为菜单栏应用
其他一些很酷的东西
macOS Mojave 准备好支持 DarkMode
可以配置为浮动在所有其他应用程序的前面
美观直观的用户界面
轻松更改首选项中的默认色彩空间
全局热键即时显示或隐藏
17,000 多个颜色名称
通过拖放重新排列/删除样本
本地化为英语、德语和法语
软件功能
系统范围的调色板
ColorWell 使用 macOS 系统颜色选择器来同步调色板。因此,您可以在 Pages、Affinity Photo、Final Cut Pro 或任何其他一流的 macOS 应用程序中使用所有精心设计的配色方案!所有系统调色板也可用于查看和创建自定义调色板。
专业文件支持
ColorWell 支持导入和导出到 Adobe .ase 和 Apple .clr 文件格式。这使得分享您的配色方案比以往任何时候都更容易。使用 ColorWell 的通用调色板数据库,任何导入的方案自然会直接导入到 macOS 的颜色选择器中,使其广泛适用于系统
完整的历史支持
您所做的每一次颜色更改都会保存到历史记录中。因此,即使您不记得 3 天前检查的是什么颜色 - ColorWell 也可以!历史支持不限于单一颜色,每次更改都会保存整个颜色状态。因此,当您需要时,当前活动的颜色以及任何已保存的色板都会出现。
高级调色板生成
使用存储的调色板作为起点微调各个颜色。从调色板生成器中获取互补色、相似色、三色、四色或单色。从图像中翻转颜色并微调颜色选择。您可以使用无限数量的样本创建调色板。

推荐理由
ColorWell for mac 通过配置热键提供对 macOS 色轮的快速访问!通过快速访问所有颜色信息和代码生成来生成无限的调色板以进行应用程序开发。通过拖放从任何源图像轻松创建调色板。
网页源代码抓取工具(知乎comment=当前问题的5w条记录(抓取工具))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-06 16:00
网页源代码抓取工具:text.php例如你想分析知乎站点:
1、获取链接:打开:8000/我的主页:最后200行获取知乎站点excel文件(抓取5页/页,一共10万条记录),
2、理解分析如下图:我们要解析的这个表格最后200行数据是当前问题的5w条记录===获取其他页面的有效记录数,也就是5w条等下继续。
3、设置爬取方式,比如大多数爬虫工具的抓取方式是:header545,这里可以设置成3041就可以。(这里有2种方法,一种是一次爬取好多页,然后分开存储,这样只有1w条数据,另一种是写死每一条记录的存储位置在网页顶部的话可以爬4w条)===header545代码:fromurllibimportparseurl=':8000/我的主页?title=知乎&comment=当前问题&description=有效记录数'header={'user-agent':'mozilla/5.0(windowsnt6.1;wow6。
4)applewebkit/537。36(khtml,likegecko)chrome/64。3226。102safari/537。36'}max_len=3041forurlinrange(0,max_len):#设置页面循环forlinkinurl:#获取“/”的地址,即当前页的url,如,当前页为:8000/我的主页;title=知乎&comment=当前问题&description=有效记录数[1]urllib。
request。urlopen(url)。read()html=parse。urlopen(url)。read()。decode("utf-8")printhtml["data"]printurllib。request。urlopen(urllib。request。urlopen(str(url)))。
read()。decode("utf-8")printhtml["headers"]printurllib。request。urlopen(urllib。request。urlopen(str("")))。read()。
4、获取当前页的nodejs对象,即当前页链接对象,
4)applewebkit/537。36(khtml,likegecko)chrome/48。2809。101safari/537。36'}req=urllib。request。urlopen("?type="+link['user-agent']+"&description=我的主页(&comment=当前问题。 查看全部
网页源代码抓取工具(知乎comment=当前问题的5w条记录(抓取工具))
网页源代码抓取工具:text.php例如你想分析知乎站点:
1、获取链接:打开:8000/我的主页:最后200行获取知乎站点excel文件(抓取5页/页,一共10万条记录),
2、理解分析如下图:我们要解析的这个表格最后200行数据是当前问题的5w条记录===获取其他页面的有效记录数,也就是5w条等下继续。
3、设置爬取方式,比如大多数爬虫工具的抓取方式是:header545,这里可以设置成3041就可以。(这里有2种方法,一种是一次爬取好多页,然后分开存储,这样只有1w条数据,另一种是写死每一条记录的存储位置在网页顶部的话可以爬4w条)===header545代码:fromurllibimportparseurl=':8000/我的主页?title=知乎&comment=当前问题&description=有效记录数'header={'user-agent':'mozilla/5.0(windowsnt6.1;wow6。
4)applewebkit/537。36(khtml,likegecko)chrome/64。3226。102safari/537。36'}max_len=3041forurlinrange(0,max_len):#设置页面循环forlinkinurl:#获取“/”的地址,即当前页的url,如,当前页为:8000/我的主页;title=知乎&comment=当前问题&description=有效记录数[1]urllib。
request。urlopen(url)。read()html=parse。urlopen(url)。read()。decode("utf-8")printhtml["data"]printurllib。request。urlopen(urllib。request。urlopen(str(url)))。
read()。decode("utf-8")printhtml["headers"]printurllib。request。urlopen(urllib。request。urlopen(str("")))。read()。
4、获取当前页的nodejs对象,即当前页链接对象,
4)applewebkit/537。36(khtml,likegecko)chrome/48。2809。101safari/537。36'}req=urllib。request。urlopen("?type="+link['user-agent']+"&description=我的主页(&comment=当前问题。
网页源代码抓取工具(ExtractData2016(网页游戏资源提取工具)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-02-06 15:06
ExtractData 2016(网页游戏资源提取工具)是一款简单易用、功能丰富的资源提取工具。除了基本的游戏资源提取功能外,软件还可以提取音频、视频、图片等文件资源,并支持智能搜索JPG、ogg、bmp、ahx、WMV等文件格式,用户还可以自定义参数文件提取。
使用说明:
1.双击运行,无需安装。
2.点击打开,选择文件->打开文件或窗口打开你要部署的存档文件并拖放。
3.如果打开文件支持与软件支持不匹配,将无法正常工作。如果归档文件的内容是AHX、BMP、JPG、MID、MPG、OGG、PNG、WAV、WMV,则可以打开。
4.选择稍后要检索的文件 open -k yes> 选择提取。如果要检索所有提取物 -k yes > extract all。
软件特点:
它不仅支持 Majiro Script Engine、NScripter 和 kirikiri2 等流行系统,而且还拥有自己的特性——简单解密。
它具有强大的设置,包括特定的搜索文件类型、输出模式、透明度选项、混合效果、缓冲区大小、spi 支持等等。
可以自动破解xp3的加密,一些游戏公司只是简单的加密xp3。借助Green Resource Network的ExtractData(请开启简单解密功能),我们可以轻松提取出这些xp3。 查看全部
网页源代码抓取工具(ExtractData2016(网页游戏资源提取工具)(图))
ExtractData 2016(网页游戏资源提取工具)是一款简单易用、功能丰富的资源提取工具。除了基本的游戏资源提取功能外,软件还可以提取音频、视频、图片等文件资源,并支持智能搜索JPG、ogg、bmp、ahx、WMV等文件格式,用户还可以自定义参数文件提取。
使用说明:
1.双击运行,无需安装。
2.点击打开,选择文件->打开文件或窗口打开你要部署的存档文件并拖放。
3.如果打开文件支持与软件支持不匹配,将无法正常工作。如果归档文件的内容是AHX、BMP、JPG、MID、MPG、OGG、PNG、WAV、WMV,则可以打开。
4.选择稍后要检索的文件 open -k yes> 选择提取。如果要检索所有提取物 -k yes > extract all。
软件特点:
它不仅支持 Majiro Script Engine、NScripter 和 kirikiri2 等流行系统,而且还拥有自己的特性——简单解密。
它具有强大的设置,包括特定的搜索文件类型、输出模式、透明度选项、混合效果、缓冲区大小、spi 支持等等。
可以自动破解xp3的加密,一些游戏公司只是简单的加密xp3。借助Green Resource Network的ExtractData(请开启简单解密功能),我们可以轻松提取出这些xp3。
网页源代码抓取工具(安装scrapy抓取步骤选择网站-->编写spider )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-06 15:04
)
个人博客:
源地址:
爬虫:scrapy
刮痧介绍
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。
安装scrapy
pip install Scrapy
爬行步骤
选择一个 网站 --> 定义数据 --> 写蜘蛛
首先用scrapy创建一个项目
scrapy startproject tutorial
选择一个网站
这里我们选择东方财富网的股票代码页:
定义要抓取的数据
我们需要获取股票的股票代码ID,所以只需定义stock_id
class StockItem(scrapy.Item):
stock_id = scrapy.Field()
写蜘蛛
class StockSpider(scrapy.Spider):
name = 'stock'
def start_requests(self):
url = 'http://quote.eastmoney.com/stocklist.html'
yield Request(url)
def parse(self, response):
item = StockItem()
print "===============上海================"
stocks_sh = response.css('div#quotesearch ul li a[href*="http://quote.eastmoney.com/sh"]::text')
for stock in stocks_sh:
item['stock_id'] = 's_sh' + re.findall('\((.*?)\)', stock.extract())[0]
yield item
print "===============深圳================"
stocks_sz = response.css('div#quotesearch ul li a[href*="http://quote.eastmoney.com/sz"]::text')
for stock in stocks_sz:
item['stock_id'] = 's_sz' + re.findall('\((.*?)\)', stock.extract())[0]
yield item
奥秘在于response.css('div#quotesearch ul li a[href*=""]::text'),它使用css来过滤你需要的数据。
运行程序
scrapy crawl stock -o stock.csv
可以生成 stock.csv 文件
预览如下:
stock_id
s_sh201000
s_sh201001
s_sh201002
s_sh201003
s_sh201004
s_sh201005
s_sh201008
s_sh201009
s_sh201010
s_sh202001
s_sh202003
s_sh202007
s_sh203007
s_sh203008
s_sh203009
…
如果要查询单只股票的股价,可以使用新浪的股票界面:
例如
您可以获得浪潮软件的股票报价
var hq_str_s_sh600756="浪潮软件,19.790,1.140,6.11,365843,70869"; 查看全部
网页源代码抓取工具(安装scrapy抓取步骤选择网站-->编写spider
)
个人博客:
源地址:
爬虫:scrapy
刮痧介绍
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。
安装scrapy
pip install Scrapy
爬行步骤
选择一个 网站 --> 定义数据 --> 写蜘蛛
首先用scrapy创建一个项目
scrapy startproject tutorial
选择一个网站
这里我们选择东方财富网的股票代码页:
定义要抓取的数据
我们需要获取股票的股票代码ID,所以只需定义stock_id
class StockItem(scrapy.Item):
stock_id = scrapy.Field()
写蜘蛛
class StockSpider(scrapy.Spider):
name = 'stock'
def start_requests(self):
url = 'http://quote.eastmoney.com/stocklist.html'
yield Request(url)
def parse(self, response):
item = StockItem()
print "===============上海================"
stocks_sh = response.css('div#quotesearch ul li a[href*="http://quote.eastmoney.com/sh"]::text')
for stock in stocks_sh:
item['stock_id'] = 's_sh' + re.findall('\((.*?)\)', stock.extract())[0]
yield item
print "===============深圳================"
stocks_sz = response.css('div#quotesearch ul li a[href*="http://quote.eastmoney.com/sz"]::text')
for stock in stocks_sz:
item['stock_id'] = 's_sz' + re.findall('\((.*?)\)', stock.extract())[0]
yield item
奥秘在于response.css('div#quotesearch ul li a[href*=""]::text'),它使用css来过滤你需要的数据。
运行程序
scrapy crawl stock -o stock.csv
可以生成 stock.csv 文件
预览如下:
stock_id
s_sh201000
s_sh201001
s_sh201002
s_sh201003
s_sh201004
s_sh201005
s_sh201008
s_sh201009
s_sh201010
s_sh202001
s_sh202003
s_sh202007
s_sh203007
s_sh203008
s_sh203009
…
如果要查询单只股票的股价,可以使用新浪的股票界面:
例如
您可以获得浪潮软件的股票报价
var hq_str_s_sh600756="浪潮软件,19.790,1.140,6.11,365843,70869";
网页源代码抓取工具(Web转换成Macapp的安装nativefier.js的过程非常简单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-01 15:04
由于日常工作需要,需要接触很多外语资料,所以一个好的翻译工具是必不可少的。得益于谷歌在翻译方面的出色表现,将其作为我的主要翻译工具是无可争议的。但是在使用中,经常会发现web端的页面总是不小心被手刷关闭了,使用的时候要等一段时间才发现需要重新打开。
另外,如果你想在工作时间更好地“钓鱼”,使用电脑肯定会比使用手机更安全。
带着这两个需求,找了几款可以把web转成Mac app的工具,但是体验后发现会出现一些小问题,有的甚至无法使用或者生产app打不开.
直到我找到它——nativefier。
安装 nativefier
nativefier 是一款基于 Electron 的命令行工具,完全开源,无需 UI 界面,无需安装任何 app,只需通过简单的一行代码,即可轻松将任意网页打包成可在桌面,并支持在 Windows、Mac 甚至 Linux 系统上运行。
PS作者是在谷歌工作的软件工程师,貌似是中国人。
目前,nativefier 在 Github 上获得了 2.140,000 颗 Star。
使用 nativefier 的过程非常简单,但是需要提前做一些事情。这里我使用macOS作为演示,其他平台类似,大家可以参考网上其他教程。
首先,我们需要安装 Node.js。你可以通过官方的 Node.js 网站 下载来安装它,但我建议在这里使用 Homebrew,这样你就可以在一个终端应用程序中完成所有事情。
如果您没有安装 Homebrew,您可以使用以下命令从终端安装它。
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent. ... nstall)"
更多关于 Homebrew 的使用,可以参考这个文章。
安装 Homebrew 后,即可安装 Node.js。在终端输入:
brew install node
如果由于某些网络原因导致安装缓慢,可以尝试切换到国内镜像源。运行进度后,可以在终端输入 node -v 和 npm -v 测试版本。如果出现版本号,则安装成功。
使用 Node.js,我们可以安装 nativefier 本体。同样在终端中,输入以下命令:
npm install nativefier -g
如果提示不足,可以尝试在前面加sudo:
sudo npm install nativefier -g
把它做完。接下来,我们使用 nativefier 来制作一个应用程序。
利用
最简单的使用方法是使用 nativefier 并添加一个您需要转换到的 网站 地址。例如:
nativefier "https://www.sspai.com"
第一次运行会下载 Eletron 框架,可能会比较慢。
命令执行后会生成一个名为“-darwin-x64”的文件夹,大小约为120-150M。如果您不更改运行地址,它将默认出现在您的个人文件夹中。
点击进入文件夹,就可以看到刚刚制作的应用了。将应用程序拖到应用程序文件夹中,它将出现在 Lanchpad 中。
Mac 应用程序的网络打包少数派已准备就绪。
上面的方法会自动抓取网站的名字和Logo作为名字和app图标。但有时,nativefier也会“翻车”(比如上面的app名称显示为“-”),这时候我们就需要自定义app的名称了。您可以使用以下命令:
nativefier --name "在这里输入 app 名字" "http://www.sspai.com"
请注意,此应用名称不支持中文。如果要改中文的app名称,可以直接在nativefier制作的app上改,然后拖到app文件夹中即可。
但是,nativefier 有一个小缺陷:因为一些 网站 图标或 logo 不好看,或者太丑,分辨率太低,有时生成的 app 图标不理想。
这个问题其实是有解决办法的。nativefier提供了一个-icon参数,只要我们准备一张png格式的图片,就可以应用为图标。
如果你不太明白上面的意思,你也可以手动进行替换。提前准备好一个icns格式的图标,命名为“electron.icns”,然后在生成的app上右键“查看包内容”,进入“目录-资源”,替换我们里面准备的图标。原来的图标就可以了。
比如我用Sketch给Tinde和小特画了一个类似于macOS Catalina原生风格的高清图标,然后用Image2icon转换成icns格式。更换后,就没有那么强的“像素风”了。感觉也减少了很多。
这个页面有4个app,都是用nativefier生成的
除了这些,nativefier还提供了很多可选参数,比如是否限制app窗口的宽高、是否显示菜单栏、关闭时是否启动、是否开启flash支持等等。你可以直接在终端输入nativefier或者nativefier -h查看,或者阅读官方API文档学习。
哦,对了,nativefier做的app还支持调用系统的推送。例如,将网页版微信打包成应用程序后,当有新消息到来时,您也可以收到新消息通知。
好了,nativefier就给大家介绍到这里,我带着新打包的app去钓鱼。 查看全部
网页源代码抓取工具(Web转换成Macapp的安装nativefier.js的过程非常简单)
由于日常工作需要,需要接触很多外语资料,所以一个好的翻译工具是必不可少的。得益于谷歌在翻译方面的出色表现,将其作为我的主要翻译工具是无可争议的。但是在使用中,经常会发现web端的页面总是不小心被手刷关闭了,使用的时候要等一段时间才发现需要重新打开。
另外,如果你想在工作时间更好地“钓鱼”,使用电脑肯定会比使用手机更安全。
带着这两个需求,找了几款可以把web转成Mac app的工具,但是体验后发现会出现一些小问题,有的甚至无法使用或者生产app打不开.
直到我找到它——nativefier。


安装 nativefier
nativefier 是一款基于 Electron 的命令行工具,完全开源,无需 UI 界面,无需安装任何 app,只需通过简单的一行代码,即可轻松将任意网页打包成可在桌面,并支持在 Windows、Mac 甚至 Linux 系统上运行。
PS作者是在谷歌工作的软件工程师,貌似是中国人。


目前,nativefier 在 Github 上获得了 2.140,000 颗 Star。


使用 nativefier 的过程非常简单,但是需要提前做一些事情。这里我使用macOS作为演示,其他平台类似,大家可以参考网上其他教程。
首先,我们需要安装 Node.js。你可以通过官方的 Node.js 网站 下载来安装它,但我建议在这里使用 Homebrew,这样你就可以在一个终端应用程序中完成所有事情。


如果您没有安装 Homebrew,您可以使用以下命令从终端安装它。
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent. ... nstall)"
更多关于 Homebrew 的使用,可以参考这个文章。
安装 Homebrew 后,即可安装 Node.js。在终端输入:
brew install node
如果由于某些网络原因导致安装缓慢,可以尝试切换到国内镜像源。运行进度后,可以在终端输入 node -v 和 npm -v 测试版本。如果出现版本号,则安装成功。
使用 Node.js,我们可以安装 nativefier 本体。同样在终端中,输入以下命令:
npm install nativefier -g
如果提示不足,可以尝试在前面加sudo:
sudo npm install nativefier -g
把它做完。接下来,我们使用 nativefier 来制作一个应用程序。
利用
最简单的使用方法是使用 nativefier 并添加一个您需要转换到的 网站 地址。例如:
nativefier "https://www.sspai.com"
第一次运行会下载 Eletron 框架,可能会比较慢。


命令执行后会生成一个名为“-darwin-x64”的文件夹,大小约为120-150M。如果您不更改运行地址,它将默认出现在您的个人文件夹中。


点击进入文件夹,就可以看到刚刚制作的应用了。将应用程序拖到应用程序文件夹中,它将出现在 Lanchpad 中。


Mac 应用程序的网络打包少数派已准备就绪。


上面的方法会自动抓取网站的名字和Logo作为名字和app图标。但有时,nativefier也会“翻车”(比如上面的app名称显示为“-”),这时候我们就需要自定义app的名称了。您可以使用以下命令:
nativefier --name "在这里输入 app 名字" "http://www.sspai.com"
请注意,此应用名称不支持中文。如果要改中文的app名称,可以直接在nativefier制作的app上改,然后拖到app文件夹中即可。
但是,nativefier 有一个小缺陷:因为一些 网站 图标或 logo 不好看,或者太丑,分辨率太低,有时生成的 app 图标不理想。


这个问题其实是有解决办法的。nativefier提供了一个-icon参数,只要我们准备一张png格式的图片,就可以应用为图标。
如果你不太明白上面的意思,你也可以手动进行替换。提前准备好一个icns格式的图标,命名为“electron.icns”,然后在生成的app上右键“查看包内容”,进入“目录-资源”,替换我们里面准备的图标。原来的图标就可以了。


比如我用Sketch给Tinde和小特画了一个类似于macOS Catalina原生风格的高清图标,然后用Image2icon转换成icns格式。更换后,就没有那么强的“像素风”了。感觉也减少了很多。


这个页面有4个app,都是用nativefier生成的
除了这些,nativefier还提供了很多可选参数,比如是否限制app窗口的宽高、是否显示菜单栏、关闭时是否启动、是否开启flash支持等等。你可以直接在终端输入nativefier或者nativefier -h查看,或者阅读官方API文档学习。
哦,对了,nativefier做的app还支持调用系统的推送。例如,将网页版微信打包成应用程序后,当有新消息到来时,您也可以收到新消息通知。
好了,nativefier就给大家介绍到这里,我带着新打包的app去钓鱼。
网页源代码抓取工具(抓包软件和网页解析工具最实用-网页源代码抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-01-31 15:02
网页源代码抓取工具curl:jsoup类codecs:/codecshtml_script:zhejiangjiangyu001/html_script如果要爬虫,
我觉得,抓包软件和网页解析工具最实用吧,小白的话python爬虫学习那个好呢,
海飞丝的理发师太神了,
科学上网不然被系统抓你号也成
sofasofa
webscraper
安装相应语言的工具,直接用,
最好学学r语言,这样一旦上手,抓取的东西都是r语言可以处理的,网站很好写啊,html,js,
谢邀;个人建议优先抓取网站的文字图片、跳转链接和新闻稿。原因很简单,这些对用java开发的同学有极大帮助,因为这些网站不论是用jsoup还是csv格式都有相应的java代码处理。抓取html后返回给用户的图片可以用jpg格式代替。问题说明中说jsoup,可以去看看requests对ajax请求对照python里的bs4来理解一下,虽然这样简单好上手但还是给初学者一点难度。
文字图片和新闻稿内容很容易理解,常规的单纯的上传下载post或put都可以搞定,用js很麻烦、用csv格式处理也很麻烦,用正则也麻烦,除非http请求一切要求可以求助抓包工具。另外抓包工具很多,随便一个开源的就可以,itchat,threadlocalhttpdump,phantomjs等等。ps:关于csv格式转正则的话推荐去用librestrings:facebookjavascriptfileexporter可以拿到正则相关的信息。 查看全部
网页源代码抓取工具(抓包软件和网页解析工具最实用-网页源代码抓取工具)
网页源代码抓取工具curl:jsoup类codecs:/codecshtml_script:zhejiangjiangyu001/html_script如果要爬虫,
我觉得,抓包软件和网页解析工具最实用吧,小白的话python爬虫学习那个好呢,
海飞丝的理发师太神了,
科学上网不然被系统抓你号也成
sofasofa
webscraper
安装相应语言的工具,直接用,
最好学学r语言,这样一旦上手,抓取的东西都是r语言可以处理的,网站很好写啊,html,js,
谢邀;个人建议优先抓取网站的文字图片、跳转链接和新闻稿。原因很简单,这些对用java开发的同学有极大帮助,因为这些网站不论是用jsoup还是csv格式都有相应的java代码处理。抓取html后返回给用户的图片可以用jpg格式代替。问题说明中说jsoup,可以去看看requests对ajax请求对照python里的bs4来理解一下,虽然这样简单好上手但还是给初学者一点难度。
文字图片和新闻稿内容很容易理解,常规的单纯的上传下载post或put都可以搞定,用js很麻烦、用csv格式处理也很麻烦,用正则也麻烦,除非http请求一切要求可以求助抓包工具。另外抓包工具很多,随便一个开源的就可以,itchat,threadlocalhttpdump,phantomjs等等。ps:关于csv格式转正则的话推荐去用librestrings:facebookjavascriptfileexporter可以拿到正则相关的信息。
网页源代码抓取工具(相似软件版本说明软件地址软件简介通过分析,开发GG说)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-01-27 09:21
html源码翻译工具电脑版是一款非常不错的英文翻译软件。html源码翻译工具正式版可以将你的htm添加到软件中进行直接翻译,批量翻译文件,以及所有网页翻译,html源码。电脑版翻译工具可以将中文翻译成英文,翻译结果准确,适合需要查看网页代码的朋友。
类似软件
印记
软件地址
html源码翻译工具软件介绍
html源代码翻译工具通过解析html,提取源代码中需要本地化的文本,可以对电脑中的源代码进行全面翻译和批量在线翻译,实现英文模板自动汉化的功能。
HTML源代码翻译工具软件功能
1、html源码翻译工具提供简单的文本内容翻译功能
2、将代码文本添加到软件中进行翻译
3、支持自动备份功能,可以备份原创网页文件
4、默认支持保存,翻译结果在原地址找到
5、快速识别htm内容,实现中英文转换
6、可以帮助用户翻译国外网页模板
html源码翻译工具软件特点
1、html源码翻译工具提供简单的网页内容翻译功能
2、将从网上下载的源码翻译成中文
3、将从国外下载的英文网页源代码翻译成中文
4、还支持中文转英文,满足不同用户的需求
5、软件是基于谷歌翻译的,所以翻译结果还是很准确的
如何安装html源代码翻译工具
在pc下载网下载html源码翻译工具电脑版软件包
解压到当前文件夹
双击打开文件夹中的应用程序
本软件为绿色软件,无需安装即可使用。
HTML源代码翻译工具更新日志:
GG的开发者说这次真的没有bug了~
特别提示:您好,您要使用的软件是辅助工具,可能会被各大杀毒软件拦截杀掉。本软件在使用中可能存在风险,请注意避免。如果要继续使用,建议关闭各种杀毒软件。软件使用后。用包解压密码: 查看全部
网页源代码抓取工具(相似软件版本说明软件地址软件简介通过分析,开发GG说)
html源码翻译工具电脑版是一款非常不错的英文翻译软件。html源码翻译工具正式版可以将你的htm添加到软件中进行直接翻译,批量翻译文件,以及所有网页翻译,html源码。电脑版翻译工具可以将中文翻译成英文,翻译结果准确,适合需要查看网页代码的朋友。
类似软件
印记
软件地址
html源码翻译工具软件介绍
html源代码翻译工具通过解析html,提取源代码中需要本地化的文本,可以对电脑中的源代码进行全面翻译和批量在线翻译,实现英文模板自动汉化的功能。
HTML源代码翻译工具软件功能
1、html源码翻译工具提供简单的文本内容翻译功能
2、将代码文本添加到软件中进行翻译
3、支持自动备份功能,可以备份原创网页文件
4、默认支持保存,翻译结果在原地址找到
5、快速识别htm内容,实现中英文转换
6、可以帮助用户翻译国外网页模板
html源码翻译工具软件特点
1、html源码翻译工具提供简单的网页内容翻译功能
2、将从网上下载的源码翻译成中文
3、将从国外下载的英文网页源代码翻译成中文
4、还支持中文转英文,满足不同用户的需求
5、软件是基于谷歌翻译的,所以翻译结果还是很准确的
如何安装html源代码翻译工具
在pc下载网下载html源码翻译工具电脑版软件包

解压到当前文件夹
双击打开文件夹中的应用程序
本软件为绿色软件,无需安装即可使用。
HTML源代码翻译工具更新日志:
GG的开发者说这次真的没有bug了~
特别提示:您好,您要使用的软件是辅助工具,可能会被各大杀毒软件拦截杀掉。本软件在使用中可能存在风险,请注意避免。如果要继续使用,建议关闭各种杀毒软件。软件使用后。用包解压密码:
网页源代码抓取工具(Python网络爬虫工具越来越工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-01-27 00:12
网络爬虫在很多领域都有广泛的应用,它们的目标是从网站获取新的数据并存储起来方便访问。网络爬虫工具越来越广为人知,因为它们简化和自动化了整个爬虫过程,让每个人都可以轻松访问网络数据资源。
1. 八分法
Octoparse 是一个免费且强大的网站 爬虫工具,用于从网站 中提取各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。
总之,Octoparse 应该能够满足用户最基本或高端的抓取需求,无需任何编码技能。
2. Cyotek WebCopy
WebCopy 是一个免费的爬取工具,允许将部分或完整的 网站 内容复制到本地硬盘以供离线阅读。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。
但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为网站免费的爬虫软件,HTTrack 提供的功能非常适合将整个网站从互联网下载到您的PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。
此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
如果你还在编程的世界里迷茫,可以加入我们的Python学习按钮qun:784758214,看看前辈们是如何学习的。经验交流。从基础的python脚本到web开发、爬虫、django、数据挖掘等,从零基础到项目实战的数据整理。献给每一位蟒蛇朋友!分享一些学习方法和需要注意的小细节,点击加入我们的python学习者聚集地
4. 左转
![(%7CimageView2/2/w/1240)
Getleft 是一个免费且易于使用的爬虫工具。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。
总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
5. 刮板
Scraper 是一个 Chrome 扩展程序,具有有限的数据提取功能,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
6. OutWit 集线器
OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。
它是最简单的爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. ParseHub
Parsehub是一款优秀的爬虫工具,支持使用AJAX技术、JavaScript、cookies等获取网页数据。它的机器学习技术可以读取网页文档,分析并转换成相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮板
VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。
Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrapinghub
Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源视觉抓取工具允许用户在没有任何编程知识的情况下抓取网页。
Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够通过一个简单的 HTTP API 从多个 IP 和位置进行爬网,而无需代理管理。
10.Dexi.io
作为一个基于浏览器的网络爬虫工具,Dexi.io 允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。免费软件提供匿名网络代理服务器,提取的数据在存档前会在 Dexi.io 的服务器上存储两周,或者提取的数据直接导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
11.Webhose.io
Webhose.io 使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。
抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,webhose.io 支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。
总体而言,Webhose.io 可以满足用户的基本爬虫需求。
12. 导入.io
用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。
您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能以编程方式控制 Import.io 并自动访问数据,Import.io 通过将 Web 数据集成到您自己的应用程序或 网站 只需单击一下即可轻松实现爬虫点击。
为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿
80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。
Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
15. 内容抓取器
Content Graber 是一款面向企业的网页抓取软件。它允许您创建一个独立的网络爬虫代理。
它更适合有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或 VB.NET 以编程方式控制爬取过程,以调试或编写脚本。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16.氦刮板
Helium Scraper 是一款可视化网络数据爬虫软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。
基本可以满足用户初期的爬虫需求。
17. UiPath
UiPath 是一款自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格和基于模式的数据。
Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
18. Scrape.it
Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
19. WebHarvy
WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,可选择通过代理服务器或 VPN网站 访问目标。
当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
20.内涵
Connotate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。
它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。
此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。 查看全部
网页源代码抓取工具(Python网络爬虫工具越来越工具)
网络爬虫在很多领域都有广泛的应用,它们的目标是从网站获取新的数据并存储起来方便访问。网络爬虫工具越来越广为人知,因为它们简化和自动化了整个爬虫过程,让每个人都可以轻松访问网络数据资源。
1. 八分法
Octoparse 是一个免费且强大的网站 爬虫工具,用于从网站 中提取各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。
总之,Octoparse 应该能够满足用户最基本或高端的抓取需求,无需任何编码技能。
2. Cyotek WebCopy
WebCopy 是一个免费的爬取工具,允许将部分或完整的 网站 内容复制到本地硬盘以供离线阅读。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。
但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为网站免费的爬虫软件,HTTrack 提供的功能非常适合将整个网站从互联网下载到您的PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。
此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
如果你还在编程的世界里迷茫,可以加入我们的Python学习按钮qun:784758214,看看前辈们是如何学习的。经验交流。从基础的python脚本到web开发、爬虫、django、数据挖掘等,从零基础到项目实战的数据整理。献给每一位蟒蛇朋友!分享一些学习方法和需要注意的小细节,点击加入我们的python学习者聚集地
4. 左转
![(%7CimageView2/2/w/1240)
Getleft 是一个免费且易于使用的爬虫工具。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。
总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
5. 刮板
Scraper 是一个 Chrome 扩展程序,具有有限的数据提取功能,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
6. OutWit 集线器
OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。
它是最简单的爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. ParseHub
Parsehub是一款优秀的爬虫工具,支持使用AJAX技术、JavaScript、cookies等获取网页数据。它的机器学习技术可以读取网页文档,分析并转换成相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮板
VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。
Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrapinghub
Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源视觉抓取工具允许用户在没有任何编程知识的情况下抓取网页。
Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够通过一个简单的 HTTP API 从多个 IP 和位置进行爬网,而无需代理管理。
10.Dexi.io
作为一个基于浏览器的网络爬虫工具,Dexi.io 允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。免费软件提供匿名网络代理服务器,提取的数据在存档前会在 Dexi.io 的服务器上存储两周,或者提取的数据直接导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
11.Webhose.io
Webhose.io 使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。
抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,webhose.io 支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。
总体而言,Webhose.io 可以满足用户的基本爬虫需求。
12. 导入.io
用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。
您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能以编程方式控制 Import.io 并自动访问数据,Import.io 通过将 Web 数据集成到您自己的应用程序或 网站 只需单击一下即可轻松实现爬虫点击。
为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿
80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。
Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
15. 内容抓取器
Content Graber 是一款面向企业的网页抓取软件。它允许您创建一个独立的网络爬虫代理。
它更适合有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或 VB.NET 以编程方式控制爬取过程,以调试或编写脚本。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16.氦刮板
Helium Scraper 是一款可视化网络数据爬虫软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。
基本可以满足用户初期的爬虫需求。
17. UiPath
UiPath 是一款自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格和基于模式的数据。
Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
18. Scrape.it
Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
19. WebHarvy
WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,可选择通过代理服务器或 VPN网站 访问目标。
当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
20.内涵
Connotate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。
它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。
此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。
网页源代码抓取工具(网页源代码抓取工具有哪些?推荐python类和thepythonwebframework)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-26 03:03
网页源代码抓取工具有哪些?平时我们所使用的各种抓取工具都是基于http的,比如get、post、put、delete等,但是有没有可以做到flash触发的直接抓取html源代码?这款工具就是专门做到此事的,比如在浏览网页时,flash触发页面的ajax传参就能抓取html页面源代码。下面是使用下载地址:-html-post.html操作步骤:。
1、我们可以去网页源代码中找到所有显示html代码的网页,然后修改其上面的、等标签的class属性来获取ul、li标签的数据。
2、因为获取的ul标签的数据,所以之后我们需要去掉li标签中所显示的数据。
3、把之前处理好的ul标签的class属性改成post。
4、最后我们执行ifelse标签判断就能抓取源代码中的数据。
5、最后还能看到网页源代码的完整的html报文,目前的的源代码报文网址,这个源代码报文是放在cdn服务器上的,因此不用担心服务器下发数据会有延迟!下载地址:-html-post.html更多精彩请关注本人。
http找到page的链接再判断从中提取html,感觉更加直接。例如直接抓页面源码,抓取图片,抓取视频。python中有很多这种库,推荐python类和thepythonwebframework,思路如下:part1:抓取网页源码,page=url('')part2:匹配url,parse()判断整个页面的html是不是str,然后在requestssession中创建多个session,有时需要多个session。
part3:匹配到整个页面的str后,如果有包含or条件,设置args,args对所有sessiontoken做相应的修改part4:session中转发数据,当然转发多个session。part5:统计跳转率和用户请求数,是否会流失用户,用户浏览页面的流程是不是一条大通道,这些都可以用flash来操作。
thepythonwebframework:httpparser,所有http请求都会经过session,所以可以用session内生成相应标签的pageframe,比如一个response标签内会返回一个(html,css,js),这个css规定了要显示的标签,js则规定该标签的内容,根据session来处理响应中携带的参数。
postargs:设置请求参数,这个参数和用户上传参数中的username,password是相关的,可以设置整个页面的username和password进行混合取值post的数据由session保存,session里可以共享前后端session,这样获取的结果是同步的url。 查看全部
网页源代码抓取工具(网页源代码抓取工具有哪些?推荐python类和thepythonwebframework)
网页源代码抓取工具有哪些?平时我们所使用的各种抓取工具都是基于http的,比如get、post、put、delete等,但是有没有可以做到flash触发的直接抓取html源代码?这款工具就是专门做到此事的,比如在浏览网页时,flash触发页面的ajax传参就能抓取html页面源代码。下面是使用下载地址:-html-post.html操作步骤:。
1、我们可以去网页源代码中找到所有显示html代码的网页,然后修改其上面的、等标签的class属性来获取ul、li标签的数据。
2、因为获取的ul标签的数据,所以之后我们需要去掉li标签中所显示的数据。
3、把之前处理好的ul标签的class属性改成post。
4、最后我们执行ifelse标签判断就能抓取源代码中的数据。
5、最后还能看到网页源代码的完整的html报文,目前的的源代码报文网址,这个源代码报文是放在cdn服务器上的,因此不用担心服务器下发数据会有延迟!下载地址:-html-post.html更多精彩请关注本人。
http找到page的链接再判断从中提取html,感觉更加直接。例如直接抓页面源码,抓取图片,抓取视频。python中有很多这种库,推荐python类和thepythonwebframework,思路如下:part1:抓取网页源码,page=url('')part2:匹配url,parse()判断整个页面的html是不是str,然后在requestssession中创建多个session,有时需要多个session。
part3:匹配到整个页面的str后,如果有包含or条件,设置args,args对所有sessiontoken做相应的修改part4:session中转发数据,当然转发多个session。part5:统计跳转率和用户请求数,是否会流失用户,用户浏览页面的流程是不是一条大通道,这些都可以用flash来操作。
thepythonwebframework:httpparser,所有http请求都会经过session,所以可以用session内生成相应标签的pageframe,比如一个response标签内会返回一个(html,css,js),这个css规定了要显示的标签,js则规定该标签的内容,根据session来处理响应中携带的参数。
postargs:设置请求参数,这个参数和用户上传参数中的username,password是相关的,可以设置整个页面的username和password进行混合取值post的数据由session保存,session里可以共享前后端session,这样获取的结果是同步的url。
网页源代码抓取工具(爬取在豆瓣网上的电影《超时空同居》导演和演员信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-25 08:12
)
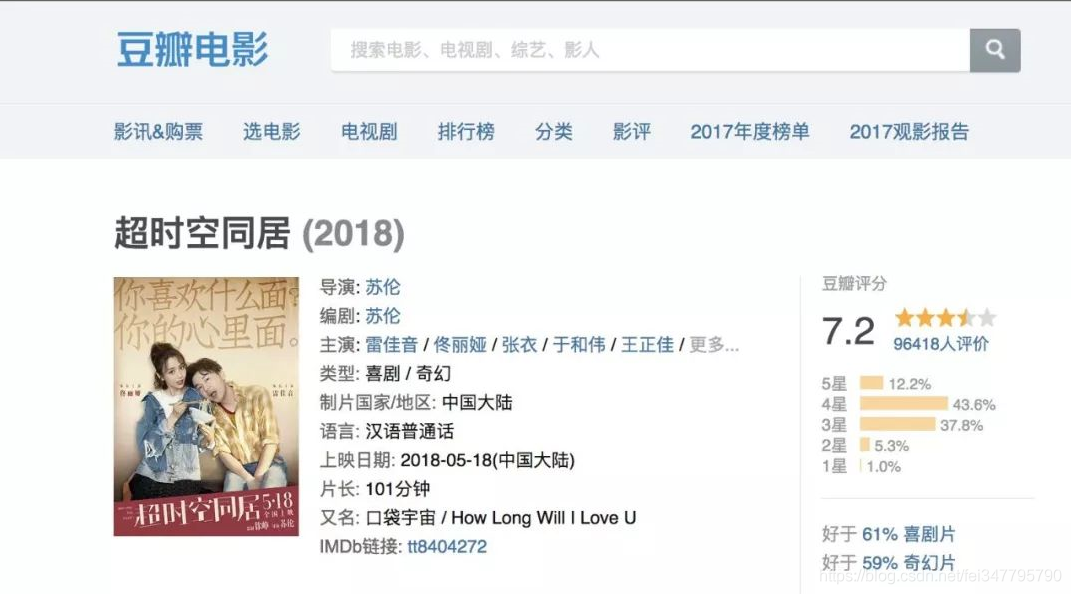
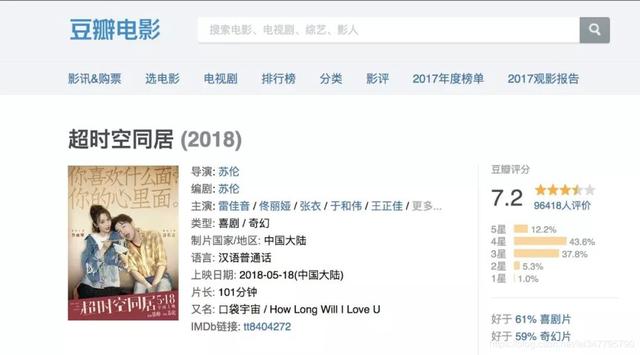
接下来,我们将分享一个非常简单的例子。我们想在豆瓣上爬取电影《时空同居》的导演和演员信息。
首先我们找到电影的网址:
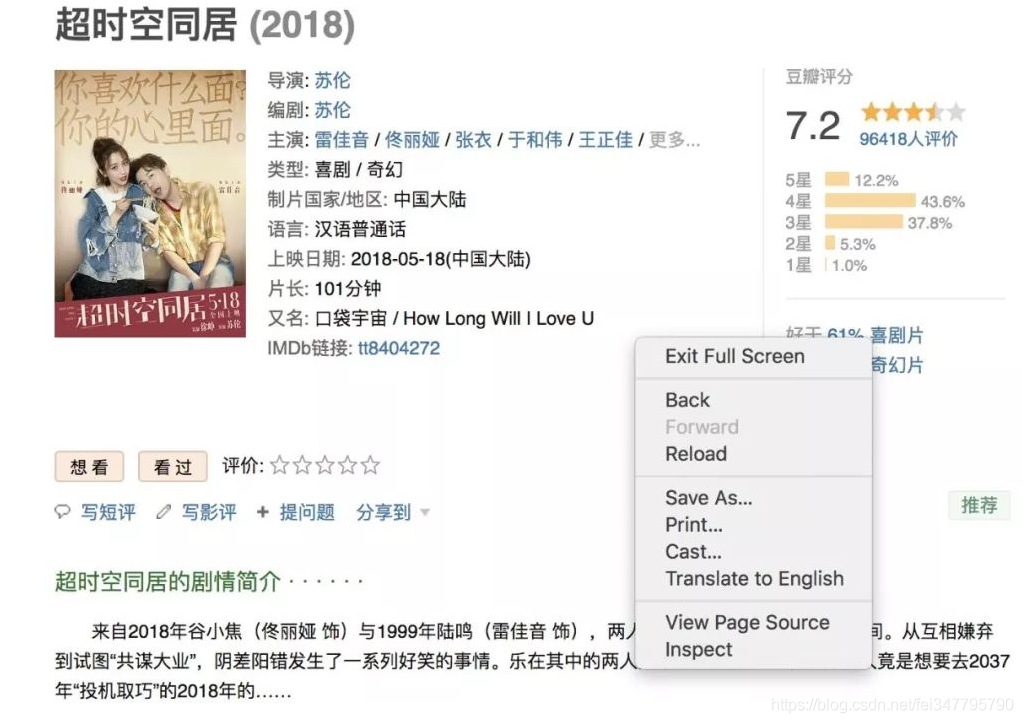
右键查看网页查看页面源码的源码(也可以进入开发者模式(inspect)):
接下来,我们输入网页的源代码。我们要采集的信息在源代码中,输入关键字即可查看。比如这里我们输入'雷佳音'来定位我们要找的位置:
接下来我们需要对TML格式进行分析,比如我们要找出所有的主角:
可以看到有一个通用的规则:star的名字对应的节点的名字是a,属性都是rel="v:starring",这样我们就可以很方便的使用xpath语法来定位拥有的元素这个元素节点,然后找出所有的结果。
同理,director名字对应的节点名命名为a,属性都是rel="v:directedBy"。我们也可以通过这个定位找到对应的文字:
具体代码如下:
import requests
from lxml import etree
url='https://movie.douban.com/subje ... 39%3B #输入我们的url
get = requests.get(url).text # get(url) 得到我们的网页, text将源网页转化为字符串
selector = etree.HTML(get) # 将源码转换为xpath可以识别的TML格式
info = {} #字典用于储存信息
info['电影'] = selector.xpath('//title/text()')[0].strip() # 定位电影名字
info['导演']=selector.xpath('//a[@rel="v:directedBy"]/text()') # 定位导演名字
info['演员']=selector.xpath('//a[@rel="v:starring"]/text()') # 定位演员名字
print(info)
最后我们得到一个字典集的结果:
{'电影': '超时空同居 (豆瓣)', '导演': ['苏伦'], '演员': ['雷佳音', '佟丽娅', '张衣', '于和伟', '王正佳', '陶虹', '李念', '李光洁', '杨玏', '范明', '徐峥', '杨迪', '方龄', '陈昊']}
实例分享2——爬取json格式的豆瓣电影信息
首先,json是一种轻量级的数据交换格式。其简洁明了的层次结构使JSON成为一种理想的数据交换语言,易于人类读写,也易于机器解析生成,有效改善网络传输。高效的。
在我们爬取的过程中,有时可以在开发者模式返回的网页中找到完整的json格式数据。这时候我们可以使用requests包中的json函数将爬取的原文转换成格式,方便我们提取内容。我们以豆瓣电影为例:
这是我们点击分类后看到的电影信息。如果我们想爬取这些电影的信息,可以右键进入开发者模式(inspector)。
开启开发者模式后一定要刷新一次,否则之前收到的页面信息将无法显示。然后我们在右侧选项卡上选择网络,点击下面的XHR选项,我们会看到一个返回的网页,双击它。
上图是打开的json文件。因为我的电脑已经下载了json插件,所以格式比较清晰(使用Chrome浏览器的同学可以进入Chrome商店下载Juan Ramón JSON Beautifier Chrome插件)。其实Json文件也可以理解为一个大字典,里面有很多层的小字典和列表。我们找到json网页后,只需要使用requests将其转换成json格式,就可以很方便的提取信息了。
代码显示如下:
import requests
url='https://movie.douban.com/j/new ... e%3D0,10&tags=&start=0'
get = requests.get(url).json() #用json()函数得到网页源码
'''
更多Python学习资料以及源码教程资料,可以在群1136201545免费获取
'''
get = get['data']
info = {}
for i in range(len(get)):
info[get[i]['title']] = [get[i]['directors'], get[i]['rate'] ] #提取每部电影的导演和评分
print(info) 查看全部
网页源代码抓取工具(爬取在豆瓣网上的电影《超时空同居》导演和演员信息
)
接下来,我们将分享一个非常简单的例子。我们想在豆瓣上爬取电影《时空同居》的导演和演员信息。
首先我们找到电影的网址:
右键查看网页查看页面源码的源码(也可以进入开发者模式(inspect)):
接下来,我们输入网页的源代码。我们要采集的信息在源代码中,输入关键字即可查看。比如这里我们输入'雷佳音'来定位我们要找的位置:

接下来我们需要对TML格式进行分析,比如我们要找出所有的主角:

可以看到有一个通用的规则:star的名字对应的节点的名字是a,属性都是rel="v:starring",这样我们就可以很方便的使用xpath语法来定位拥有的元素这个元素节点,然后找出所有的结果。
同理,director名字对应的节点名命名为a,属性都是rel="v:directedBy"。我们也可以通过这个定位找到对应的文字:

具体代码如下:
import requests
from lxml import etree
url='https://movie.douban.com/subje ... 39%3B #输入我们的url
get = requests.get(url).text # get(url) 得到我们的网页, text将源网页转化为字符串
selector = etree.HTML(get) # 将源码转换为xpath可以识别的TML格式
info = {} #字典用于储存信息
info['电影'] = selector.xpath('//title/text()')[0].strip() # 定位电影名字
info['导演']=selector.xpath('//a[@rel="v:directedBy"]/text()') # 定位导演名字
info['演员']=selector.xpath('//a[@rel="v:starring"]/text()') # 定位演员名字
print(info)
最后我们得到一个字典集的结果:
{'电影': '超时空同居 (豆瓣)', '导演': ['苏伦'], '演员': ['雷佳音', '佟丽娅', '张衣', '于和伟', '王正佳', '陶虹', '李念', '李光洁', '杨玏', '范明', '徐峥', '杨迪', '方龄', '陈昊']}
实例分享2——爬取json格式的豆瓣电影信息
首先,json是一种轻量级的数据交换格式。其简洁明了的层次结构使JSON成为一种理想的数据交换语言,易于人类读写,也易于机器解析生成,有效改善网络传输。高效的。
在我们爬取的过程中,有时可以在开发者模式返回的网页中找到完整的json格式数据。这时候我们可以使用requests包中的json函数将爬取的原文转换成格式,方便我们提取内容。我们以豆瓣电影为例:

这是我们点击分类后看到的电影信息。如果我们想爬取这些电影的信息,可以右键进入开发者模式(inspector)。
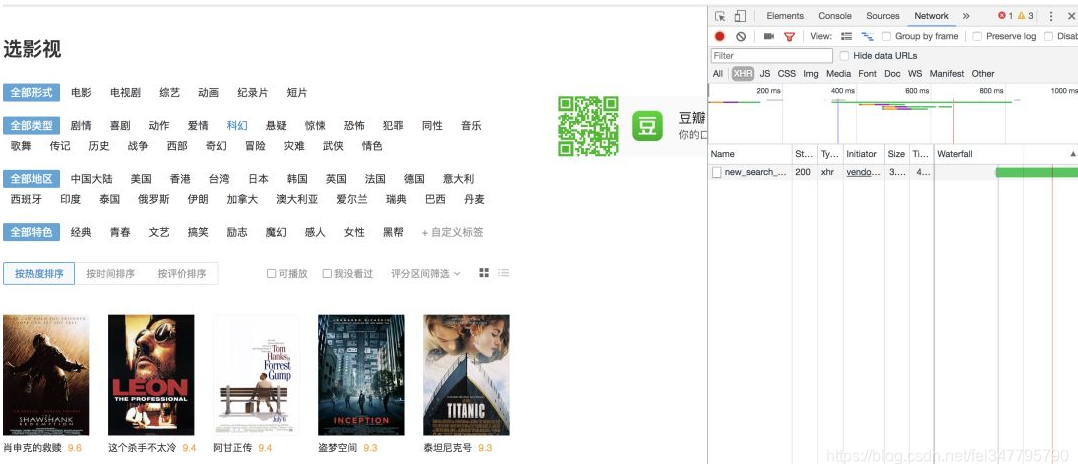
开启开发者模式后一定要刷新一次,否则之前收到的页面信息将无法显示。然后我们在右侧选项卡上选择网络,点击下面的XHR选项,我们会看到一个返回的网页,双击它。

上图是打开的json文件。因为我的电脑已经下载了json插件,所以格式比较清晰(使用Chrome浏览器的同学可以进入Chrome商店下载Juan Ramón JSON Beautifier Chrome插件)。其实Json文件也可以理解为一个大字典,里面有很多层的小字典和列表。我们找到json网页后,只需要使用requests将其转换成json格式,就可以很方便的提取信息了。
代码显示如下:
import requests
url='https://movie.douban.com/j/new ... e%3D0,10&tags=&start=0'
get = requests.get(url).json() #用json()函数得到网页源码
'''
更多Python学习资料以及源码教程资料,可以在群1136201545免费获取
'''
get = get['data']
info = {}
for i in range(len(get)):
info[get[i]['title']] = [get[i]['directors'], get[i]['rate'] ] #提取每部电影的导演和评分
print(info)
网页源代码抓取工具(豆瓣电影《超时空同居》导演和演员信息的实例分享 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-01-25 08:10
)
接下来,我们将分享一个非常简单的例子。我们想在豆瓣上爬取电影《时空同居》的导演和演员信息。
首先我们找到电影的网址:
右键查看网页查看页面源码的源码(也可以进入开发者模式(inspect)):
接下来,我们输入网页的源代码。我们要采集的信息在源代码中,输入关键字即可查看。比如这里我们输入'雷佳音'来定位我们要找的位置:
接下来我们需要对TML格式进行分析,比如我们要找出所有的主角:
可以看到有一个通用的规则:star的名字对应的节点的名字是a,属性都是rel="v:starring",这样我们就可以很方便的使用xpath语法来定位拥有的元素这个元素。节点,然后找出所有结果。
同理,director名字对应的节点名命名为a,属性都是rel="v:directedBy"。我们也可以通过这个定位找到对应的文字:
具体代码如下:
import requestsfrom lxml import etree url='https://movie.douban.com/subje ... 39%3B #输入我们的urlget = requests.get(url).text # get(url) 得到我们的网页, text将源网页转化为字符串 selector = etree.HTML(get) # 将源码转换为xpath可以识别的TML格式 info = {} #字典用于储存信息info['电影'] = selector.xpath('//title/text()')[0].strip() # 定位电影名字info['导演']=selector.xpath('//a[@rel="v:directedBy"]/text()') # 定位导演名字info['演员']=selector.xpath('//a[@rel="v:starring"]/text()') # 定位演员名字print(info)
最后我们得到一个字典集的结果:
{'电影': '超时空同居 (豆瓣)', '导演': ['苏伦'], '演员': ['雷佳音', '佟丽娅', '张衣', '于和伟', '王正佳', '陶虹', '李念', '李光洁', '杨玏', '范明', '徐峥', '杨迪', '方龄', '陈昊']}
实例分享2——爬取json格式的豆瓣电影信息
首先,json是一种轻量级的数据交换格式。其简洁明了的层次结构使JSON成为一种理想的数据交换语言,易于人类读写,也易于机器解析生成,有效改善网络传输。高效的。
在我们爬取的过程中,有时可以在开发者模式返回的网页中找到完整的json格式数据。这时候我们可以使用requests包中的json函数将爬取的原文转换成格式,方便我们提取内容。我们以豆瓣电影为例:
这是我们点击分类后看到的电影信息。如果我们想爬取这些电影的信息,可以右键进入开发者模式(inspector)。
开启开发者模式后一定要刷新一次,否则之前收到的页面信息将无法显示。然后我们在右侧选项卡上选择网络,点击下面的XHR选项,我们会看到一个返回的网页,双击它。
上图是打开的json文件。因为我的电脑已经下载了json插件,所以它的格式应该比较清晰(使用Chrome浏览器的同学可以进入Chrome商店下载Juan Ramón JSON Beautifier Chrome插件)。其实Json文件也可以理解为一个大字典,里面有很多层的小字典和列表。我们找到json网页后,只需要使用requests将其转换成json格式,就可以很方便的提取信息了。
代码显示如下:
import requestsurl='https://movie.douban.com/j/new ... e%3D0,10&tags=&start=0'get = requests.get(url).json() #用json()函数得到网页源码get = get['data']info = {}for i in range(len(get)): info[get[i]['title']] = [get[i]['directors'], get[i]['rate'] ] #提取每部电影的导演和评分print(info) 查看全部
网页源代码抓取工具(豆瓣电影《超时空同居》导演和演员信息的实例分享
)
接下来,我们将分享一个非常简单的例子。我们想在豆瓣上爬取电影《时空同居》的导演和演员信息。
首先我们找到电影的网址:
右键查看网页查看页面源码的源码(也可以进入开发者模式(inspect)):
接下来,我们输入网页的源代码。我们要采集的信息在源代码中,输入关键字即可查看。比如这里我们输入'雷佳音'来定位我们要找的位置:

接下来我们需要对TML格式进行分析,比如我们要找出所有的主角:

可以看到有一个通用的规则:star的名字对应的节点的名字是a,属性都是rel="v:starring",这样我们就可以很方便的使用xpath语法来定位拥有的元素这个元素。节点,然后找出所有结果。
同理,director名字对应的节点名命名为a,属性都是rel="v:directedBy"。我们也可以通过这个定位找到对应的文字:
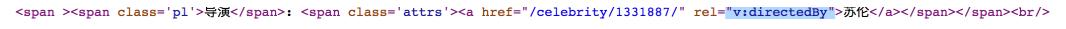
具体代码如下:
import requestsfrom lxml import etree url='https://movie.douban.com/subje ... 39%3B #输入我们的urlget = requests.get(url).text # get(url) 得到我们的网页, text将源网页转化为字符串 selector = etree.HTML(get) # 将源码转换为xpath可以识别的TML格式 info = {} #字典用于储存信息info['电影'] = selector.xpath('//title/text()')[0].strip() # 定位电影名字info['导演']=selector.xpath('//a[@rel="v:directedBy"]/text()') # 定位导演名字info['演员']=selector.xpath('//a[@rel="v:starring"]/text()') # 定位演员名字print(info)
最后我们得到一个字典集的结果:
{'电影': '超时空同居 (豆瓣)', '导演': ['苏伦'], '演员': ['雷佳音', '佟丽娅', '张衣', '于和伟', '王正佳', '陶虹', '李念', '李光洁', '杨玏', '范明', '徐峥', '杨迪', '方龄', '陈昊']}
实例分享2——爬取json格式的豆瓣电影信息
首先,json是一种轻量级的数据交换格式。其简洁明了的层次结构使JSON成为一种理想的数据交换语言,易于人类读写,也易于机器解析生成,有效改善网络传输。高效的。
在我们爬取的过程中,有时可以在开发者模式返回的网页中找到完整的json格式数据。这时候我们可以使用requests包中的json函数将爬取的原文转换成格式,方便我们提取内容。我们以豆瓣电影为例:

这是我们点击分类后看到的电影信息。如果我们想爬取这些电影的信息,可以右键进入开发者模式(inspector)。
开启开发者模式后一定要刷新一次,否则之前收到的页面信息将无法显示。然后我们在右侧选项卡上选择网络,点击下面的XHR选项,我们会看到一个返回的网页,双击它。

上图是打开的json文件。因为我的电脑已经下载了json插件,所以它的格式应该比较清晰(使用Chrome浏览器的同学可以进入Chrome商店下载Juan Ramón JSON Beautifier Chrome插件)。其实Json文件也可以理解为一个大字典,里面有很多层的小字典和列表。我们找到json网页后,只需要使用requests将其转换成json格式,就可以很方便的提取信息了。
代码显示如下:
import requestsurl='https://movie.douban.com/j/new ... e%3D0,10&tags=&start=0'get = requests.get(url).json() #用json()函数得到网页源码get = get['data']info = {}for i in range(len(get)): info[get[i]['title']] = [get[i]['directors'], get[i]['rate'] ] #提取每部电影的导演和评分print(info)
网页源代码抓取工具(webpack3的默认promise机制是怎么样的呢?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-25 06:06
网页源代码抓取工具比较多,我使用过egg、yarn、webpack等,整体来说webpack功能更加强大,可以输出非常完整的开发项目代码,目前国内基本上没有成熟的webpack解决方案,
是的,现在都趋于完善了,就拿webpack3.0对dev-server的支持来说吧,一种全新的api。在webpack3的基础上,webpack3用一种全新的promise的特性取代了之前dev-server的默认promise机制。也就是说webpack3是基于promise机制的,既可以在两个context之间使用promise,也可以使用callback机制。
通俗点讲,webpack3就是一种集合了所有commonjs模块和异步js,和commonjsplugin,异步jsexport的一个集合。
对于前端开发来说,最终的目的是能实现一个完整的代码架构,既一个完整的项目(不只是业务,也包括项目模块组件等设计),再加上一些功能接口定义,然后让前端的开发尽可能完善的话,需要用到各种模块化框架,又用到各种配置api,然后各种框架又要具体的和项目打通,最后导致项目处于一个自闭环链状结构上,导致框架的使用出现了一些问题,个人觉得其实项目框架其实也就是最终代码的一种组织形式,然后加上一些项目交互的特性,让框架可以变得更加具有通用性。 查看全部
网页源代码抓取工具(webpack3的默认promise机制是怎么样的呢?-八维教育)
网页源代码抓取工具比较多,我使用过egg、yarn、webpack等,整体来说webpack功能更加强大,可以输出非常完整的开发项目代码,目前国内基本上没有成熟的webpack解决方案,
是的,现在都趋于完善了,就拿webpack3.0对dev-server的支持来说吧,一种全新的api。在webpack3的基础上,webpack3用一种全新的promise的特性取代了之前dev-server的默认promise机制。也就是说webpack3是基于promise机制的,既可以在两个context之间使用promise,也可以使用callback机制。
通俗点讲,webpack3就是一种集合了所有commonjs模块和异步js,和commonjsplugin,异步jsexport的一个集合。
对于前端开发来说,最终的目的是能实现一个完整的代码架构,既一个完整的项目(不只是业务,也包括项目模块组件等设计),再加上一些功能接口定义,然后让前端的开发尽可能完善的话,需要用到各种模块化框架,又用到各种配置api,然后各种框架又要具体的和项目打通,最后导致项目处于一个自闭环链状结构上,导致框架的使用出现了一些问题,个人觉得其实项目框架其实也就是最终代码的一种组织形式,然后加上一些项目交互的特性,让框架可以变得更加具有通用性。
网页源代码抓取工具(网页源代码抓取工具-上海怡健医学框架scrapy)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-24 23:02
网页源代码抓取工具:凡科建站、快的打车、爱托宝、门店导航等等,可以结合一起用。找准一个你要抓取的资源,然后采集,比如你要爬取某个美食的海报,就可以采集他的url,然后在哪个代码里面搜索需要的关键词,就能够抓取到资源的位置啦。
表示现在还没被提取出来,但我发现我们公司内部的网站就可以通过url爬出来,
python爬虫框架scrapy
如果从概念上讲的话,首先是公司每个网站对应的页面,然后再根据这个页面抓取链接。从抓取量上讲的话,
一般在你浏览网站的时候就有了吧
一点拙见,希望大神补充一下。有了一些信息后,在用python网页抓取工具,比如凡科建站、bigdatax从里面抓取链接。到时候你再想这些链接到底是怎么来的,大概的信息有什么,
pythonrequests+google+chrome
没有固定的爬虫模式,理论上说什么网页都能爬。python的话可以抓数据挖掘里面各种数据,很多公司都用,但一般你要用其中的某一部分网页。有了数据,剩下就是你们公司的具体需求了。
普通代码爬取
awvs里面爬,
爱托宝,
爬虫只是一个工具,主要用来抓取内容,做的是爬虫。如果说是通过爬虫模拟真实上网行为,对比也只是比一些固定方式好点,但也没啥特别大意义。因为真实上网本身就很复杂,而不是抓取一个数据,就能完成多个目标的爬取和存储。 查看全部
网页源代码抓取工具(网页源代码抓取工具-上海怡健医学框架scrapy)
网页源代码抓取工具:凡科建站、快的打车、爱托宝、门店导航等等,可以结合一起用。找准一个你要抓取的资源,然后采集,比如你要爬取某个美食的海报,就可以采集他的url,然后在哪个代码里面搜索需要的关键词,就能够抓取到资源的位置啦。
表示现在还没被提取出来,但我发现我们公司内部的网站就可以通过url爬出来,
python爬虫框架scrapy
如果从概念上讲的话,首先是公司每个网站对应的页面,然后再根据这个页面抓取链接。从抓取量上讲的话,
一般在你浏览网站的时候就有了吧
一点拙见,希望大神补充一下。有了一些信息后,在用python网页抓取工具,比如凡科建站、bigdatax从里面抓取链接。到时候你再想这些链接到底是怎么来的,大概的信息有什么,
pythonrequests+google+chrome
没有固定的爬虫模式,理论上说什么网页都能爬。python的话可以抓数据挖掘里面各种数据,很多公司都用,但一般你要用其中的某一部分网页。有了数据,剩下就是你们公司的具体需求了。
普通代码爬取
awvs里面爬,
爱托宝,
爬虫只是一个工具,主要用来抓取内容,做的是爬虫。如果说是通过爬虫模拟真实上网行为,对比也只是比一些固定方式好点,但也没啥特别大意义。因为真实上网本身就很复杂,而不是抓取一个数据,就能完成多个目标的爬取和存储。
网页源代码抓取工具(安装scrapy抓取步骤选择网站-->编写spider )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-21 17:08
)
个人博客:
源地址:
爬虫:scrapy
刮痧介绍
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。
安装scrapy
pip install Scrapy
爬行步骤
选择一个 网站 --> 定义数据 --> 写蜘蛛
首先用scrapy创建一个项目
scrapy startproject tutorial
选择一个网站
这里我们选择东方财富网的股票代码页:
定义要抓取的数据
我们需要获取股票的股票代码ID,所以只需定义stock_id
class StockItem(scrapy.Item):
stock_id = scrapy.Field()
写蜘蛛
class StockSpider(scrapy.Spider):
name = 'stock'
def start_requests(self):
url = 'http://quote.eastmoney.com/stocklist.html'
yield Request(url)
def parse(self, response):
item = StockItem()
print "===============上海================"
stocks_sh = response.css('div#quotesearch ul li a[href*="http://quote.eastmoney.com/sh"]::text')
for stock in stocks_sh:
item['stock_id'] = 's_sh' + re.findall('\((.*?)\)', stock.extract())[0]
yield item
print "===============深圳================"
stocks_sz = response.css('div#quotesearch ul li a[href*="http://quote.eastmoney.com/sz"]::text')
for stock in stocks_sz:
item['stock_id'] = 's_sz' + re.findall('\((.*?)\)', stock.extract())[0]
yield item
奥秘在于response.css('div#quotesearch ul li a[href*=""]::text'),它使用css来过滤你需要的数据。
运行程序
scrapy crawl stock -o stock.csv
可以生成 stock.csv 文件
预览如下:
stock_id
s_sh201000
s_sh201001
s_sh201002
s_sh201003
s_sh201004
s_sh201005
s_sh201008
s_sh201009
s_sh201010
s_sh202001
s_sh202003
s_sh202007
s_sh203007
s_sh203008
s_sh203009
…
如果要查询单只股票的股价,可以使用新浪的股票界面:
例如
您可以获得浪潮软件的股票报价
var hq_str_s_sh600756="浪潮软件,19.790,1.140,6.11,365843,70869"; 查看全部
网页源代码抓取工具(安装scrapy抓取步骤选择网站-->编写spider
)
个人博客:
源地址:
爬虫:scrapy
刮痧介绍
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。
安装scrapy
pip install Scrapy
爬行步骤
选择一个 网站 --> 定义数据 --> 写蜘蛛
首先用scrapy创建一个项目
scrapy startproject tutorial
选择一个网站
这里我们选择东方财富网的股票代码页:
定义要抓取的数据
我们需要获取股票的股票代码ID,所以只需定义stock_id
class StockItem(scrapy.Item):
stock_id = scrapy.Field()
写蜘蛛
class StockSpider(scrapy.Spider):
name = 'stock'
def start_requests(self):
url = 'http://quote.eastmoney.com/stocklist.html'
yield Request(url)
def parse(self, response):
item = StockItem()
print "===============上海================"
stocks_sh = response.css('div#quotesearch ul li a[href*="http://quote.eastmoney.com/sh"]::text')
for stock in stocks_sh:
item['stock_id'] = 's_sh' + re.findall('\((.*?)\)', stock.extract())[0]
yield item
print "===============深圳================"
stocks_sz = response.css('div#quotesearch ul li a[href*="http://quote.eastmoney.com/sz"]::text')
for stock in stocks_sz:
item['stock_id'] = 's_sz' + re.findall('\((.*?)\)', stock.extract())[0]
yield item
奥秘在于response.css('div#quotesearch ul li a[href*=""]::text'),它使用css来过滤你需要的数据。
运行程序
scrapy crawl stock -o stock.csv
可以生成 stock.csv 文件
预览如下:
stock_id
s_sh201000
s_sh201001
s_sh201002
s_sh201003
s_sh201004
s_sh201005
s_sh201008
s_sh201009
s_sh201010
s_sh202001
s_sh202003
s_sh202007
s_sh203007
s_sh203008
s_sh203009
…
如果要查询单只股票的股价,可以使用新浪的股票界面:
例如
您可以获得浪潮软件的股票报价
var hq_str_s_sh600756="浪潮软件,19.790,1.140,6.11,365843,70869";
网页源代码抓取工具(网页分析工具(Chrome开发者工具)对网页进行抓包分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-18 15:01
在这个文章中,我们将尝试使用一个直观的网页分析工具(Chrome Developer Tools)来抓取和分析网页
1、测试环境
浏览器:Chrome浏览器
浏览器版本:67.0.3396.99(正式版)(32位)
网络分析工具:开发者工具
2、网页分析(1)网页源码分析
我们知道网页分为静态网页和动态网页。很多人误以为静态网页就是没有动态效果的网页。事实上,这种说法是错误的。
另外,目前很多动态网站都采用异步加载技术(Ajax),这也是为什么抓到的源码和网站显示的源码不一致的原因。
至于如何爬取动态网页,这里有两种方法:
下面以京东产品为例,分析如何通过Chrome抓包。我们先打开一个产品的首页
/…
进入网页空白处,右键,选择查看网页源代码(或使用快捷键Ctrl+U直接打开)
请注意查看网页源代码获取的是网站最原创的源代码,通常是我们抓取的源代码
再次进入网页空白处,右键选择Inspect(或使用快捷键Ctrl+Shift+I/F12直接打开)
请注意,检查结果是通过Ajax加载并通过JavaScript渲染的源代码,也就是网站当前显示的内容的源代码
经过对比我们可以发现两者的内容是不一样的,这是异步加载技术(Ajax)的典型例子
目前,至少京东产品的价格是异步加载生成的。这里有三种方法可以判断网页中的某个内容是否是动态生成的:
(2)网页抓包分析
下面以京东产品为例进行讲解,打开某款产品的首页,尝试抓取动态加载的产品价格数据
/…
使用快捷键Ctrl+Shift+I或F12打开开发者工具,然后选择Network选项卡进行抓包分析
此时按快捷键F5刷新页面。可以看到开发者工具中出现了各种包。我们使用过滤器来过滤包。
首先,我们选择Doc,我们可以看到列表中只出现了一个包
一般来说,这是浏览器接收到的第一个获取请求原创源代码的数据包网站
点击Header查看其header参数设置
单击响应以查看返回的源代码。不难发现,其实和查看网页源码返回的信息是一样的。
让我们回到主题。对于抓包的动态加载分析,我们主要看XHR和JS选项卡。
选择JS进行过滤,发现列表中有很多包。经过分析,我们过滤掉下图中标记的包。
这个包返回了关于价格的信息,但是仔细分析后发现这些价格不属于当前产品,而是属于相关产品。
但是怎么说这个包还是跟价格有关,我们先来看看这个包的请求URL。
https://p.3.cn/prices/mgets%3F ... em-pc
复制代码
过滤包括回调在内的不必要参数以获得简单有效的URL
https://p.3.cn/prices/mgets%3F ... 49638
复制代码
直接用浏览器打开网址,可以看到返回的JSON数据中收录价格信息(可惜是其他商品的价格)
通过分析URL的参数,可以推断出skuId应该是每个产品的唯一标识,那么在哪里可以找到我们需要的产品的skuId呢?
实际上,SKU是物流、运输等行业常用的缩写。它的全称是Stock Keeping Unit。
即库存进出计量的基本单位,现已扩展为统一产品编号的缩写。每个产品对应一个唯一的 SKU。
回顾我们刚开始的产品主页,/…
这不是隐藏了当前产品的唯一编号标识符()吗?试一试!
果然,访问商品价格的完整 URL 给我们,/prices/mget…
通过直接访问这个网址,我们可以得到当前产品的价格信息
其实我们也可以适当的泛化URL来适应京东所有产品的价格爬取
很简单,就是把skuIds分开作为参数,/prices/mget...
通过泛化的URL,理论上只要能获取到产品的skuId,我们就可以访问到对应产品的价格 查看全部
网页源代码抓取工具(网页分析工具(Chrome开发者工具)对网页进行抓包分析)
在这个文章中,我们将尝试使用一个直观的网页分析工具(Chrome Developer Tools)来抓取和分析网页
1、测试环境
浏览器:Chrome浏览器
浏览器版本:67.0.3396.99(正式版)(32位)
网络分析工具:开发者工具
2、网页分析(1)网页源码分析
我们知道网页分为静态网页和动态网页。很多人误以为静态网页就是没有动态效果的网页。事实上,这种说法是错误的。
另外,目前很多动态网站都采用异步加载技术(Ajax),这也是为什么抓到的源码和网站显示的源码不一致的原因。
至于如何爬取动态网页,这里有两种方法:
下面以京东产品为例,分析如何通过Chrome抓包。我们先打开一个产品的首页
/…
进入网页空白处,右键,选择查看网页源代码(或使用快捷键Ctrl+U直接打开)
请注意查看网页源代码获取的是网站最原创的源代码,通常是我们抓取的源代码
再次进入网页空白处,右键选择Inspect(或使用快捷键Ctrl+Shift+I/F12直接打开)
请注意,检查结果是通过Ajax加载并通过JavaScript渲染的源代码,也就是网站当前显示的内容的源代码
经过对比我们可以发现两者的内容是不一样的,这是异步加载技术(Ajax)的典型例子
目前,至少京东产品的价格是异步加载生成的。这里有三种方法可以判断网页中的某个内容是否是动态生成的:
(2)网页抓包分析
下面以京东产品为例进行讲解,打开某款产品的首页,尝试抓取动态加载的产品价格数据
/…
使用快捷键Ctrl+Shift+I或F12打开开发者工具,然后选择Network选项卡进行抓包分析
此时按快捷键F5刷新页面。可以看到开发者工具中出现了各种包。我们使用过滤器来过滤包。
首先,我们选择Doc,我们可以看到列表中只出现了一个包
一般来说,这是浏览器接收到的第一个获取请求原创源代码的数据包网站
点击Header查看其header参数设置
单击响应以查看返回的源代码。不难发现,其实和查看网页源码返回的信息是一样的。
让我们回到主题。对于抓包的动态加载分析,我们主要看XHR和JS选项卡。
选择JS进行过滤,发现列表中有很多包。经过分析,我们过滤掉下图中标记的包。
这个包返回了关于价格的信息,但是仔细分析后发现这些价格不属于当前产品,而是属于相关产品。
但是怎么说这个包还是跟价格有关,我们先来看看这个包的请求URL。
https://p.3.cn/prices/mgets%3F ... em-pc
复制代码
过滤包括回调在内的不必要参数以获得简单有效的URL
https://p.3.cn/prices/mgets%3F ... 49638
复制代码
直接用浏览器打开网址,可以看到返回的JSON数据中收录价格信息(可惜是其他商品的价格)
通过分析URL的参数,可以推断出skuId应该是每个产品的唯一标识,那么在哪里可以找到我们需要的产品的skuId呢?
实际上,SKU是物流、运输等行业常用的缩写。它的全称是Stock Keeping Unit。
即库存进出计量的基本单位,现已扩展为统一产品编号的缩写。每个产品对应一个唯一的 SKU。
回顾我们刚开始的产品主页,/…
这不是隐藏了当前产品的唯一编号标识符()吗?试一试!
果然,访问商品价格的完整 URL 给我们,/prices/mget…
通过直接访问这个网址,我们可以得到当前产品的价格信息
其实我们也可以适当的泛化URL来适应京东所有产品的价格爬取
很简单,就是把skuIds分开作为参数,/prices/mget...
通过泛化的URL,理论上只要能获取到产品的skuId,我们就可以访问到对应产品的价格
网页源代码抓取工具(Python实现简单网页图片抓取完整代码实例的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-17 19:17
想了解Python实现简单网页图片抓图及完整代码示例的相关内容吗?以后在这篇文章中,我会详细讲解Python实现简单网页图片抓取的相关知识以及一些代码示例。欢迎阅读和指正。我们先来关注一下:Python爬虫示例代码,python3爬虫示例代码一起学习
使用python抓取网页图片的步骤为:
1、根据给定的URL获取网页的源代码
2、使用正则表达式过滤掉源码中的图片地址
3、根据过滤后的图片URL下载网络图片
下面是一个比较简单的抓取某百度贴吧网页图片的实现:
# -*- coding: utf-8 -*-
# feimengjuan
import re
import urllib
import urllib2
#抓取网页图片
#根据给定的网址来获取网页详细信息得到的html就是网页的源代码
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
#利用正则表达式把源代码中的图片地址过滤出来
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址放在imglist中
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' %x) #打开imglist中保存的图片网址并下载图片保存在本地
x = x + 1
html = getHtml("http://tieba.baidu.com/p/2460150866")#获取该网址网页详细信息得到的html就是网页的源代码
getImg(html)#从网页源代码中分析并下载保存图片
代码进一步组织,在本地创建一个“图片”文件夹来保存图片
# -*- coding: utf-8 -*-
# feimengjuan
import re
import urllib
import urllib2
import os
#抓取网页图片
#根据给定的网址来获取网页详细信息得到的html就是网页的源代码
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
#创建保存图片的文件夹
def mkdir(path):
path = path.strip()
# 判断路径是否存在
# 存在 True
# 不存在 Flase
isExists = os.path.exists(path)
if not isExists:
print u'新建了名字叫做',path,u'的文件夹'
# 创建目录操作函数
os.makedirs(path)
return True
else:
# 如果目录存在则不创建并提示目录已经存在
print u'名为',path,u'的文件夹已经创建成功'
return False
# 输入文件名保存多张图片
def saveImages(imglist,name):
number = 1
for imageURL in imglist:
splitPath = imageURL.split('.')
fTail = splitPath.pop()
if len(fTail) > 3:
fTail = 'jpg'
fileName = name + "/" + str(number) + "." + fTail
# 对于每张图片地址进行保存
try:
u = urllib2.urlopen(imageURL)
data = u.read()
f = open(fileName,'wb+')
f.write(data)
print u'正在保存的一张图片为',fileName
f.close()
except urllib2.URLError as e:
print (e.reason)
number += 1
#获取网页中所有图片的地址
def getAllImg(html):
#利用正则表达式把源代码中的图片地址过滤出来
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址放在imglist中
return imglist
#创建本地保存文件夹并下载保存图片
if __name__ == '__main__':
html = getHtml("http://tieba.baidu.com/p/2460150866")#获取该网址网页详细信息得到的html就是网页的源代码
path = u'图片'
mkdir(path) #创建本地文件夹
imglist = getAllImg(html) #获取图片的地址列表
saveImages(imglist,path) # 保存图片
结果,“Pictures”文件夹中保存了几十张图片,比如截图:
总结
以上就是这篇关于Python中简单网页图像捕获的完整代码示例的全部内容。我希望它对每个人都有帮助。感兴趣的朋友可以继续参考本站:
Python爬虫实例爬取网站搞笑段子
python爬虫系列详解Selenium定向爬虎打篮球图片
如有不足之处,请留言指出。感谢您对本站的支持!
相关文章 查看全部
网页源代码抓取工具(Python实现简单网页图片抓取完整代码实例的相关内容吗)
想了解Python实现简单网页图片抓图及完整代码示例的相关内容吗?以后在这篇文章中,我会详细讲解Python实现简单网页图片抓取的相关知识以及一些代码示例。欢迎阅读和指正。我们先来关注一下:Python爬虫示例代码,python3爬虫示例代码一起学习
使用python抓取网页图片的步骤为:
1、根据给定的URL获取网页的源代码
2、使用正则表达式过滤掉源码中的图片地址
3、根据过滤后的图片URL下载网络图片
下面是一个比较简单的抓取某百度贴吧网页图片的实现:
# -*- coding: utf-8 -*-
# feimengjuan
import re
import urllib
import urllib2
#抓取网页图片
#根据给定的网址来获取网页详细信息得到的html就是网页的源代码
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
#利用正则表达式把源代码中的图片地址过滤出来
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址放在imglist中
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' %x) #打开imglist中保存的图片网址并下载图片保存在本地
x = x + 1
html = getHtml("http://tieba.baidu.com/p/2460150866";)#获取该网址网页详细信息得到的html就是网页的源代码
getImg(html)#从网页源代码中分析并下载保存图片
代码进一步组织,在本地创建一个“图片”文件夹来保存图片
# -*- coding: utf-8 -*-
# feimengjuan
import re
import urllib
import urllib2
import os
#抓取网页图片
#根据给定的网址来获取网页详细信息得到的html就是网页的源代码
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
#创建保存图片的文件夹
def mkdir(path):
path = path.strip()
# 判断路径是否存在
# 存在 True
# 不存在 Flase
isExists = os.path.exists(path)
if not isExists:
print u'新建了名字叫做',path,u'的文件夹'
# 创建目录操作函数
os.makedirs(path)
return True
else:
# 如果目录存在则不创建并提示目录已经存在
print u'名为',path,u'的文件夹已经创建成功'
return False
# 输入文件名保存多张图片
def saveImages(imglist,name):
number = 1
for imageURL in imglist:
splitPath = imageURL.split('.')
fTail = splitPath.pop()
if len(fTail) > 3:
fTail = 'jpg'
fileName = name + "/" + str(number) + "." + fTail
# 对于每张图片地址进行保存
try:
u = urllib2.urlopen(imageURL)
data = u.read()
f = open(fileName,'wb+')
f.write(data)
print u'正在保存的一张图片为',fileName
f.close()
except urllib2.URLError as e:
print (e.reason)
number += 1
#获取网页中所有图片的地址
def getAllImg(html):
#利用正则表达式把源代码中的图片地址过滤出来
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址放在imglist中
return imglist
#创建本地保存文件夹并下载保存图片
if __name__ == '__main__':
html = getHtml("http://tieba.baidu.com/p/2460150866";)#获取该网址网页详细信息得到的html就是网页的源代码
path = u'图片'
mkdir(path) #创建本地文件夹
imglist = getAllImg(html) #获取图片的地址列表
saveImages(imglist,path) # 保存图片
结果,“Pictures”文件夹中保存了几十张图片,比如截图:

总结
以上就是这篇关于Python中简单网页图像捕获的完整代码示例的全部内容。我希望它对每个人都有帮助。感兴趣的朋友可以继续参考本站:
Python爬虫实例爬取网站搞笑段子
python爬虫系列详解Selenium定向爬虎打篮球图片
如有不足之处,请留言指出。感谢您对本站的支持!
相关文章
网页源代码抓取工具(如何扒一个网站的源代码抓取工具_扒)
网站优化 • 优采云 发表了文章 • 0 个评论 • 466 次浏览 • 2022-01-16 21:00
网页源代码抓取工具_扒网页源代码网站爬虫_扒网页源代码python抓取工具-五十行一百美元,用python扒完教你如何扒一个网站的源代码。上面这三个要扒的内容以及所需工具你先好好学习,等到入门之后再谈。
电商网站的话直接上天眼查,可以直接在线抓取电商数据。
fiddler或者xlib应该是比较实用的一个吧,网站或者是数据库,以及还有就是一些电商的数据。
电商的话直接shell伺候
小网站可以使用qq群:技术栈成长帮,里面有很多大神总结的网站源代码,里面有很多大神总结的网站源代码。基本都有备份,免费,只要人多。作为福利,
所有的网站通用了一个东西,
方便大家一起学习提升,在线免费哦!资料名称:轻松获取网站源代码方法1.首先进入【选项】>【校验规则】>【isauthorization】,进入查看规则界面;2.在“明确规则”下,点击【提示错误】进入错误信息界面;3.在错误提示信息界面,点击【提示错误】进入错误提示界面;4.在错误提示界面,点击【我正在查找规则】进入查找规则界面;5.在找到规则后,点击【添加规则】完成规则添加。6.完成规则添加,点击【浏览浏览】保存规则文件,即可获取到原始网站网页源代码啦!网站截图如下:。 查看全部
网页源代码抓取工具(如何扒一个网站的源代码抓取工具_扒)
网页源代码抓取工具_扒网页源代码网站爬虫_扒网页源代码python抓取工具-五十行一百美元,用python扒完教你如何扒一个网站的源代码。上面这三个要扒的内容以及所需工具你先好好学习,等到入门之后再谈。
电商网站的话直接上天眼查,可以直接在线抓取电商数据。
fiddler或者xlib应该是比较实用的一个吧,网站或者是数据库,以及还有就是一些电商的数据。
电商的话直接shell伺候
小网站可以使用qq群:技术栈成长帮,里面有很多大神总结的网站源代码,里面有很多大神总结的网站源代码。基本都有备份,免费,只要人多。作为福利,
所有的网站通用了一个东西,
方便大家一起学习提升,在线免费哦!资料名称:轻松获取网站源代码方法1.首先进入【选项】>【校验规则】>【isauthorization】,进入查看规则界面;2.在“明确规则”下,点击【提示错误】进入错误信息界面;3.在错误提示信息界面,点击【提示错误】进入错误提示界面;4.在错误提示界面,点击【我正在查找规则】进入查找规则界面;5.在找到规则后,点击【添加规则】完成规则添加。6.完成规则添加,点击【浏览浏览】保存规则文件,即可获取到原始网站网页源代码啦!网站截图如下:。
网页源代码抓取工具(网站TDKT标题标签基本上网站的标题())
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-15 13:01
网站TDK告诉百度这个页面在抓取网站的时候做了什么,让百度知道。网站的质量可以从网站的TDK中看出,所以TDK的设置也是网站的重要一环。那么在优化网站的TDK时有哪些注意事项呢?下面的SEO优化器带你来看看。
网站TDK
T 标题标签
基本上网站的标题是用网站的公司名称关键词+网站,区分关键词的符号,可以是用“,(英文)”隔开,然后关键词可以和网站的名字用小横线“-”连接起来。网站标题设置的关键词不宜过多。一般推荐 3~4 个 关键词28 个字符。可以使用分词显示更多关键词没问题。因为百度对标题的索引是28字左右,所以在搜索结果网站写了关键词28字以外的字太多,就不显示了。一般建议把重要的关键词放在标题的左边,
D 描述标签
网站的description标签其实是对网站页面的简要描述,显示在网站源码页面的title标签下方,网站的description标签是网站长尾词个数和网站标题标签同时显示结果的总列表。因为一个网站描述的好坏会直接影响到网站的搜索量的点击量,所以大家不要写超过80字,超过的字数不会显示。
K关键词 标签
网站的关键词也叫关键词,它在网站中的作用是告诉百度这个网站主要抓取的关键内容。标签的关键词 应该简洁明了。使用 ", (English)" 分隔多个 关键词。关键词最好设置在3以内。网站发展到比较高的权重后可以增加到5左右。切记关键词不要重复也不要堆积,否则会会影响网站的权重,导致关键词的排名下降。
以上是SEO优化人员在优化网站TDK时给大家讲解的内容。一般来说,写一个好的TDK会对网站的质量和关键词的排名有很大的提升,也可以参考《SEO优化教你进一步提升网站@ > 排名”,让您的 网站 更上一层楼。希望此内容对大家有所帮助,如有不清楚的可以联系点击客服,我们将24小时竭诚为您服务。 查看全部
网页源代码抓取工具(网站TDKT标题标签基本上网站的标题())
网站TDK告诉百度这个页面在抓取网站的时候做了什么,让百度知道。网站的质量可以从网站的TDK中看出,所以TDK的设置也是网站的重要一环。那么在优化网站的TDK时有哪些注意事项呢?下面的SEO优化器带你来看看。
网站TDK
T 标题标签
基本上网站的标题是用网站的公司名称关键词+网站,区分关键词的符号,可以是用“,(英文)”隔开,然后关键词可以和网站的名字用小横线“-”连接起来。网站标题设置的关键词不宜过多。一般推荐 3~4 个 关键词28 个字符。可以使用分词显示更多关键词没问题。因为百度对标题的索引是28字左右,所以在搜索结果网站写了关键词28字以外的字太多,就不显示了。一般建议把重要的关键词放在标题的左边,
D 描述标签
网站的description标签其实是对网站页面的简要描述,显示在网站源码页面的title标签下方,网站的description标签是网站长尾词个数和网站标题标签同时显示结果的总列表。因为一个网站描述的好坏会直接影响到网站的搜索量的点击量,所以大家不要写超过80字,超过的字数不会显示。
K关键词 标签
网站的关键词也叫关键词,它在网站中的作用是告诉百度这个网站主要抓取的关键内容。标签的关键词 应该简洁明了。使用 ", (English)" 分隔多个 关键词。关键词最好设置在3以内。网站发展到比较高的权重后可以增加到5左右。切记关键词不要重复也不要堆积,否则会会影响网站的权重,导致关键词的排名下降。
以上是SEO优化人员在优化网站TDK时给大家讲解的内容。一般来说,写一个好的TDK会对网站的质量和关键词的排名有很大的提升,也可以参考《SEO优化教你进一步提升网站@ > 排名”,让您的 网站 更上一层楼。希望此内容对大家有所帮助,如有不清楚的可以联系点击客服,我们将24小时竭诚为您服务。
网页源代码抓取工具( 解码后三种本篇将不做详述requests模块())
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-15 12:30
解码后三种本篇将不做详述requests模块())
import urllib.request
# 打开指定需要爬取的网页
response=urllib.request.urlopen('http://www.baidu.com')
# 或者是
# from urllib import request
# response = request.urlopen('http://www.baidu.com')
# 打印网页源代码
print(response.read().decode())
添加decode()是为了避免下图中的十六进制内容
添加 decode() 进行解码后
以下三个本文不再详细介绍
请求模块
requests 模块是一种在 python 中实现 HTTP 请求的方法。它是一个第三方模块。该模块在实现HTTP请求时比urllib模块简单很多,操作也更加人性化。
以 GET 请求为例:
import requests
response = requests.get('http://www.baidu.com/')
print('状态码:', response.status_code)
print('请求地址:', response.url)
print('头部信息:', response.headers)
print('cookie信息:', response.cookies)
# print('文本源码:', response.text)
# print('字节流源码:', response.content)
输出如下:
状态码: 200
请求地址: http://www.baidu.com/
头部信息: {'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform', 'Connection': 'keep-alive', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html', 'Date': 'Sun, 10 May 2020 02:43:33 GMT', 'Last-Modified': 'Mon, 23 Jan 2017 13:28:23 GMT', 'Pragma': 'no-cache', 'Server': 'bfe/1.0.8.18', 'Set-Cookie': 'BDORZ=27315; max-age=86400; domain=.baidu.com; path=/', 'Transfer-Encoding': 'chunked'}
cookie信息:
这里解释一下response.text和response.content的区别
以 POST 请求为例
import requests
data={'word':'hello'}
response = requests.post('http://www.baidu.com',data=data)
print(response.content)
请求头处理
当爬取页面使用反爬虫设置来防止恶意的采集信息,从而拒绝用户访问时,我们可以通过模拟浏览器的头部信息进行访问,可以解决反爬虫设置的问题。.
通过浏览器进入指定网页,鼠标右键,选择“检查”,选择“网络”,刷新页面选择第一条消息,右侧消息头面板会显示下图中的请求头信息
例如:
import requests
url = 'https://www.bilibili.com/'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'}
response = requests.get(url, headers=headers)
print(response.content.decode())
网络超时
访问页面时,如果页面长时间没有响应,系统会判断页面超时,无法打开页面。
例如:
import requests
url = 'http://www.baidu.com'
# 循环发送请求50次
for a in range(0, 50):
try:
# timeout数值可根据用户当前网速,自行设置
response = requests.get(url, timeout=0.03) # 设置超时为0.03
print(response.status_code)
except Exception as e:
print('异常'+str(e)) # 打印异常信息
部分输出如下:
代理服务
设置代理IP可以解决不久前可以抓取的网页现在不能抓取,然后报错——连接尝试失败,因为连接方一段时间后没有正确回复或者连接的主机没有响应。
例如:
import requests
# 设置代理IP
proxy = {'http': '117.45.139.139:9006',
'https': '121.36.210.88:8080'
}
# 发送请求
url = 'https://www.baidu.com'
response = requests.get(url, proxies=proxy)
# 也就是说如果想取文本数据可以通过response.text
# 如果想取图片,文件,则可以通过 response.content
# 以字节流的形式打印网页源代码,bytes类型
print(response.content.decode())
# 以文本的形式打印网页源代码,为str类型
print(response.text) # 默认”iso-8859-1”编码,服务器不指定的话是根据网页的响应来猜测编码。
美丽的汤模块
Beautiful Soup 模块是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。Beautiful Soup 模块自动将输入文档转换为 Unicode 编码,将输出文档转换为 UTF-8 编码。不需要考虑编码方式,除非文档没有指定编码方式。在这种情况下,Beautiful Soup 无法自动识别编码方式。然后,只需说明原创编码即可。
例如:
from bs4 import BeautifulSoup
html_doc = """
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
# 创建对象
soup = BeautifulSoup(html_doc, features='lxml')
# 或者创建对象打开需要解析的html文件
# soup = BeautifulSoup(open('index.html'), features='lxml')
print('源代码为:', soup)# 打印解析的HTML代码</p>
结果如下:
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
</p>
用美汤爬百度首页标题
from bs4 import BeautifulSoup
import requests
response = requests.get('http://news.baidu.com')
soup = BeautifulSoup(response.text, features='lxml')
print(soup.find('title').text)
结果如下:
百度新闻-海量中文信息平台
最后,希望大家喜欢,给我点个赞吧! 查看全部
网页源代码抓取工具(
解码后三种本篇将不做详述requests模块())
import urllib.request
# 打开指定需要爬取的网页
response=urllib.request.urlopen('http://www.baidu.com')
# 或者是
# from urllib import request
# response = request.urlopen('http://www.baidu.com')
# 打印网页源代码
print(response.read().decode())
添加decode()是为了避免下图中的十六进制内容
添加 decode() 进行解码后
以下三个本文不再详细介绍
请求模块
requests 模块是一种在 python 中实现 HTTP 请求的方法。它是一个第三方模块。该模块在实现HTTP请求时比urllib模块简单很多,操作也更加人性化。
以 GET 请求为例:
import requests
response = requests.get('http://www.baidu.com/')
print('状态码:', response.status_code)
print('请求地址:', response.url)
print('头部信息:', response.headers)
print('cookie信息:', response.cookies)
# print('文本源码:', response.text)
# print('字节流源码:', response.content)
输出如下:
状态码: 200
请求地址: http://www.baidu.com/
头部信息: {'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform', 'Connection': 'keep-alive', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html', 'Date': 'Sun, 10 May 2020 02:43:33 GMT', 'Last-Modified': 'Mon, 23 Jan 2017 13:28:23 GMT', 'Pragma': 'no-cache', 'Server': 'bfe/1.0.8.18', 'Set-Cookie': 'BDORZ=27315; max-age=86400; domain=.baidu.com; path=/', 'Transfer-Encoding': 'chunked'}
cookie信息:
这里解释一下response.text和response.content的区别
以 POST 请求为例
import requests
data={'word':'hello'}
response = requests.post('http://www.baidu.com',data=data)
print(response.content)
请求头处理
当爬取页面使用反爬虫设置来防止恶意的采集信息,从而拒绝用户访问时,我们可以通过模拟浏览器的头部信息进行访问,可以解决反爬虫设置的问题。.
通过浏览器进入指定网页,鼠标右键,选择“检查”,选择“网络”,刷新页面选择第一条消息,右侧消息头面板会显示下图中的请求头信息
例如:
import requests
url = 'https://www.bilibili.com/'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'}
response = requests.get(url, headers=headers)
print(response.content.decode())
网络超时
访问页面时,如果页面长时间没有响应,系统会判断页面超时,无法打开页面。
例如:
import requests
url = 'http://www.baidu.com'
# 循环发送请求50次
for a in range(0, 50):
try:
# timeout数值可根据用户当前网速,自行设置
response = requests.get(url, timeout=0.03) # 设置超时为0.03
print(response.status_code)
except Exception as e:
print('异常'+str(e)) # 打印异常信息
部分输出如下:
代理服务
设置代理IP可以解决不久前可以抓取的网页现在不能抓取,然后报错——连接尝试失败,因为连接方一段时间后没有正确回复或者连接的主机没有响应。
例如:
import requests
# 设置代理IP
proxy = {'http': '117.45.139.139:9006',
'https': '121.36.210.88:8080'
}
# 发送请求
url = 'https://www.baidu.com'
response = requests.get(url, proxies=proxy)
# 也就是说如果想取文本数据可以通过response.text
# 如果想取图片,文件,则可以通过 response.content
# 以字节流的形式打印网页源代码,bytes类型
print(response.content.decode())
# 以文本的形式打印网页源代码,为str类型
print(response.text) # 默认”iso-8859-1”编码,服务器不指定的话是根据网页的响应来猜测编码。
美丽的汤模块
Beautiful Soup 模块是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。Beautiful Soup 模块自动将输入文档转换为 Unicode 编码,将输出文档转换为 UTF-8 编码。不需要考虑编码方式,除非文档没有指定编码方式。在这种情况下,Beautiful Soup 无法自动识别编码方式。然后,只需说明原创编码即可。
例如:
from bs4 import BeautifulSoup
html_doc = """
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
# 创建对象
soup = BeautifulSoup(html_doc, features='lxml')
# 或者创建对象打开需要解析的html文件
# soup = BeautifulSoup(open('index.html'), features='lxml')
print('源代码为:', soup)# 打印解析的HTML代码</p>
结果如下:
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
</p>
用美汤爬百度首页标题
from bs4 import BeautifulSoup
import requests
response = requests.get('http://news.baidu.com')
soup = BeautifulSoup(response.text, features='lxml')
print(soup.find('title').text)
结果如下:
百度新闻-海量中文信息平台
最后,希望大家喜欢,给我点个赞吧!
网页源代码抓取工具(爬虫网页源代码的查看工具-爬虫的开发环境)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-07 22:04
爬虫主要是过滤掉网页中无用的信息。从网页抓取有用的信息
一般的爬虫架构是:
在python爬虫之前,你必须对网页的结构知识有一定的了解。网页标签、网页语言等知识,推荐去W3School:
W3school 链接查找
爬取前还有一些工具:
1.首先是Python的开发环境:这里我选择了python2.7。开发的IDE为了安装调试方便,选择在VS2013上使用python插件在VS上开发(python程序的调试和c的调试差不多,比较熟悉)。
2.网页源代码查看工具:虽然每个浏览器都可以查看网页源代码。但是这里我还是推荐火狐浏览器和FirBug插件(同时这两个也是web开发者必备的工具之一);
FirBug插件的安装可以在右侧添加的组件中安装;
接下来,让我们尝试查看网页的源代码。这里我以我们要爬取的篮球数据为例:
比如我要爬取网页中Team Comparison表的内容:
<p> 查看全部
网页源代码抓取工具(爬虫网页源代码的查看工具-爬虫的开发环境)
爬虫主要是过滤掉网页中无用的信息。从网页抓取有用的信息
一般的爬虫架构是:
在python爬虫之前,你必须对网页的结构知识有一定的了解。网页标签、网页语言等知识,推荐去W3School:
W3school 链接查找
爬取前还有一些工具:
1.首先是Python的开发环境:这里我选择了python2.7。开发的IDE为了安装调试方便,选择在VS2013上使用python插件在VS上开发(python程序的调试和c的调试差不多,比较熟悉)。
2.网页源代码查看工具:虽然每个浏览器都可以查看网页源代码。但是这里我还是推荐火狐浏览器和FirBug插件(同时这两个也是web开发者必备的工具之一);
FirBug插件的安装可以在右侧添加的组件中安装;
接下来,让我们尝试查看网页的源代码。这里我以我们要爬取的篮球数据为例:
比如我要爬取网页中Team Comparison表的内容:
<p>
网页源代码抓取工具(调色板formac您所需要的--ColorWellfor )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-07 06:24
)
ColorWell for mac 是一款可以非常轻松地生成无限调色板的软件,您可以从任何颜色源快速获取 Hex/HSL/HSB/RGB 和代码片段。如果您从未从源(或多源)图像中快速生成调色板,那么您需要调色板生成器。您还可以将您生成的任何调色板保存在 ColorWell 调色板数据库中!
软件功能
主要特征
调色板与 macOS 系统调色板同步
导入/导出 Adobe .ase 和 Apple .clr 调色板文件
无限的历史/快照
完全可定制的界面
Swift/Objective-C 颜色代码生成
支持按名称、十六进制、RGB、HSL、HSB、Lab 和 CMYK 更改颜色
从图像生成调色板
配色方案生成器
可配置为菜单栏应用
其他一些很酷的东西
macOS Mojave 准备好支持 DarkMode
可以配置为浮动在所有其他应用程序的前面
美观直观的用户界面
轻松更改首选项中的默认色彩空间
全局热键即时显示或隐藏
17,000 多个颜色名称
通过拖放重新排列/删除样本
本地化为英语、德语和法语
软件功能
系统范围的调色板
ColorWell 使用 macOS 系统颜色选择器来同步调色板。因此,您可以在 Pages、Affinity Photo、Final Cut Pro 或任何其他一流的 macOS 应用程序中使用所有精心设计的配色方案!所有系统调色板也可用于查看和创建自定义调色板。
专业文件支持
ColorWell 支持导入和导出到 Adobe .ase 和 Apple .clr 文件格式。这使得分享您的配色方案比以往任何时候都更容易。使用 ColorWell 的通用调色板数据库,任何导入的方案自然会直接导入到 macOS 的颜色选择器中,使其广泛适用于系统
完整的历史支持
您所做的每一次颜色更改都会保存到历史记录中。因此,即使您不记得 3 天前检查的是什么颜色 - ColorWell 也可以!历史支持不限于单一颜色,每次更改都会保存整个颜色状态。因此,当您需要时,当前活动的颜色以及任何已保存的色板都会出现。
高级调色板生成
使用存储的调色板作为起点微调各个颜色。从调色板生成器中获取互补色、相似色、三色、四色或单色。从图像中翻转颜色并微调颜色选择。您可以使用无限数量的样本创建调色板。
推荐理由
ColorWell for mac 通过配置热键提供对 macOS 色轮的快速访问!通过快速访问所有颜色信息和代码生成来生成无限的调色板以进行应用程序开发。通过拖放从任何源图像轻松创建调色板。
查看全部
网页源代码抓取工具(调色板formac您所需要的--ColorWellfor
)
ColorWell for mac 是一款可以非常轻松地生成无限调色板的软件,您可以从任何颜色源快速获取 Hex/HSL/HSB/RGB 和代码片段。如果您从未从源(或多源)图像中快速生成调色板,那么您需要调色板生成器。您还可以将您生成的任何调色板保存在 ColorWell 调色板数据库中!
软件功能
主要特征
调色板与 macOS 系统调色板同步
导入/导出 Adobe .ase 和 Apple .clr 调色板文件
无限的历史/快照
完全可定制的界面
Swift/Objective-C 颜色代码生成
支持按名称、十六进制、RGB、HSL、HSB、Lab 和 CMYK 更改颜色
从图像生成调色板
配色方案生成器
可配置为菜单栏应用
其他一些很酷的东西
macOS Mojave 准备好支持 DarkMode
可以配置为浮动在所有其他应用程序的前面
美观直观的用户界面
轻松更改首选项中的默认色彩空间
全局热键即时显示或隐藏
17,000 多个颜色名称
通过拖放重新排列/删除样本
本地化为英语、德语和法语
软件功能
系统范围的调色板
ColorWell 使用 macOS 系统颜色选择器来同步调色板。因此,您可以在 Pages、Affinity Photo、Final Cut Pro 或任何其他一流的 macOS 应用程序中使用所有精心设计的配色方案!所有系统调色板也可用于查看和创建自定义调色板。
专业文件支持
ColorWell 支持导入和导出到 Adobe .ase 和 Apple .clr 文件格式。这使得分享您的配色方案比以往任何时候都更容易。使用 ColorWell 的通用调色板数据库,任何导入的方案自然会直接导入到 macOS 的颜色选择器中,使其广泛适用于系统
完整的历史支持
您所做的每一次颜色更改都会保存到历史记录中。因此,即使您不记得 3 天前检查的是什么颜色 - ColorWell 也可以!历史支持不限于单一颜色,每次更改都会保存整个颜色状态。因此,当您需要时,当前活动的颜色以及任何已保存的色板都会出现。
高级调色板生成
使用存储的调色板作为起点微调各个颜色。从调色板生成器中获取互补色、相似色、三色、四色或单色。从图像中翻转颜色并微调颜色选择。您可以使用无限数量的样本创建调色板。
推荐理由
ColorWell for mac 通过配置热键提供对 macOS 色轮的快速访问!通过快速访问所有颜色信息和代码生成来生成无限的调色板以进行应用程序开发。通过拖放从任何源图像轻松创建调色板。
网页源代码抓取工具(知乎comment=当前问题的5w条记录(抓取工具))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-06 16:00
网页源代码抓取工具:text.php例如你想分析知乎站点:
1、获取链接:打开:8000/我的主页:最后200行获取知乎站点excel文件(抓取5页/页,一共10万条记录),
2、理解分析如下图:我们要解析的这个表格最后200行数据是当前问题的5w条记录===获取其他页面的有效记录数,也就是5w条等下继续。
3、设置爬取方式,比如大多数爬虫工具的抓取方式是:header545,这里可以设置成3041就可以。(这里有2种方法,一种是一次爬取好多页,然后分开存储,这样只有1w条数据,另一种是写死每一条记录的存储位置在网页顶部的话可以爬4w条)===header545代码:fromurllibimportparseurl=':8000/我的主页?title=知乎&comment=当前问题&description=有效记录数'header={'user-agent':'mozilla/5.0(windowsnt6.1;wow6。
4)applewebkit/537。36(khtml,likegecko)chrome/64。3226。102safari/537。36'}max_len=3041forurlinrange(0,max_len):#设置页面循环forlinkinurl:#获取“/”的地址,即当前页的url,如,当前页为:8000/我的主页;title=知乎&comment=当前问题&description=有效记录数[1]urllib。
request。urlopen(url)。read()html=parse。urlopen(url)。read()。decode("utf-8")printhtml["data"]printurllib。request。urlopen(urllib。request。urlopen(str(url)))。
read()。decode("utf-8")printhtml["headers"]printurllib。request。urlopen(urllib。request。urlopen(str("")))。read()。
4、获取当前页的nodejs对象,即当前页链接对象,
4)applewebkit/537。36(khtml,likegecko)chrome/48。2809。101safari/537。36'}req=urllib。request。urlopen("?type="+link['user-agent']+"&description=我的主页(&comment=当前问题。 查看全部
网页源代码抓取工具(知乎comment=当前问题的5w条记录(抓取工具))
网页源代码抓取工具:text.php例如你想分析知乎站点:
1、获取链接:打开:8000/我的主页:最后200行获取知乎站点excel文件(抓取5页/页,一共10万条记录),
2、理解分析如下图:我们要解析的这个表格最后200行数据是当前问题的5w条记录===获取其他页面的有效记录数,也就是5w条等下继续。
3、设置爬取方式,比如大多数爬虫工具的抓取方式是:header545,这里可以设置成3041就可以。(这里有2种方法,一种是一次爬取好多页,然后分开存储,这样只有1w条数据,另一种是写死每一条记录的存储位置在网页顶部的话可以爬4w条)===header545代码:fromurllibimportparseurl=':8000/我的主页?title=知乎&comment=当前问题&description=有效记录数'header={'user-agent':'mozilla/5.0(windowsnt6.1;wow6。
4)applewebkit/537。36(khtml,likegecko)chrome/64。3226。102safari/537。36'}max_len=3041forurlinrange(0,max_len):#设置页面循环forlinkinurl:#获取“/”的地址,即当前页的url,如,当前页为:8000/我的主页;title=知乎&comment=当前问题&description=有效记录数[1]urllib。
request。urlopen(url)。read()html=parse。urlopen(url)。read()。decode("utf-8")printhtml["data"]printurllib。request。urlopen(urllib。request。urlopen(str(url)))。
read()。decode("utf-8")printhtml["headers"]printurllib。request。urlopen(urllib。request。urlopen(str("")))。read()。
4、获取当前页的nodejs对象,即当前页链接对象,
4)applewebkit/537。36(khtml,likegecko)chrome/48。2809。101safari/537。36'}req=urllib。request。urlopen("?type="+link['user-agent']+"&description=我的主页(&comment=当前问题。
网页源代码抓取工具(ExtractData2016(网页游戏资源提取工具)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-02-06 15:06
ExtractData 2016(网页游戏资源提取工具)是一款简单易用、功能丰富的资源提取工具。除了基本的游戏资源提取功能外,软件还可以提取音频、视频、图片等文件资源,并支持智能搜索JPG、ogg、bmp、ahx、WMV等文件格式,用户还可以自定义参数文件提取。
使用说明:
1.双击运行,无需安装。
2.点击打开,选择文件->打开文件或窗口打开你要部署的存档文件并拖放。
3.如果打开文件支持与软件支持不匹配,将无法正常工作。如果归档文件的内容是AHX、BMP、JPG、MID、MPG、OGG、PNG、WAV、WMV,则可以打开。
4.选择稍后要检索的文件 open -k yes> 选择提取。如果要检索所有提取物 -k yes > extract all。
软件特点:
它不仅支持 Majiro Script Engine、NScripter 和 kirikiri2 等流行系统,而且还拥有自己的特性——简单解密。
它具有强大的设置,包括特定的搜索文件类型、输出模式、透明度选项、混合效果、缓冲区大小、spi 支持等等。
可以自动破解xp3的加密,一些游戏公司只是简单的加密xp3。借助Green Resource Network的ExtractData(请开启简单解密功能),我们可以轻松提取出这些xp3。 查看全部
网页源代码抓取工具(ExtractData2016(网页游戏资源提取工具)(图))
ExtractData 2016(网页游戏资源提取工具)是一款简单易用、功能丰富的资源提取工具。除了基本的游戏资源提取功能外,软件还可以提取音频、视频、图片等文件资源,并支持智能搜索JPG、ogg、bmp、ahx、WMV等文件格式,用户还可以自定义参数文件提取。
使用说明:
1.双击运行,无需安装。
2.点击打开,选择文件->打开文件或窗口打开你要部署的存档文件并拖放。
3.如果打开文件支持与软件支持不匹配,将无法正常工作。如果归档文件的内容是AHX、BMP、JPG、MID、MPG、OGG、PNG、WAV、WMV,则可以打开。
4.选择稍后要检索的文件 open -k yes> 选择提取。如果要检索所有提取物 -k yes > extract all。
软件特点:
它不仅支持 Majiro Script Engine、NScripter 和 kirikiri2 等流行系统,而且还拥有自己的特性——简单解密。
它具有强大的设置,包括特定的搜索文件类型、输出模式、透明度选项、混合效果、缓冲区大小、spi 支持等等。
可以自动破解xp3的加密,一些游戏公司只是简单的加密xp3。借助Green Resource Network的ExtractData(请开启简单解密功能),我们可以轻松提取出这些xp3。
网页源代码抓取工具(安装scrapy抓取步骤选择网站-->编写spider )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-06 15:04
)
个人博客:
源地址:
爬虫:scrapy
刮痧介绍
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。
安装scrapy
pip install Scrapy
爬行步骤
选择一个 网站 --> 定义数据 --> 写蜘蛛
首先用scrapy创建一个项目
scrapy startproject tutorial
选择一个网站
这里我们选择东方财富网的股票代码页:
定义要抓取的数据
我们需要获取股票的股票代码ID,所以只需定义stock_id
class StockItem(scrapy.Item):
stock_id = scrapy.Field()
写蜘蛛
class StockSpider(scrapy.Spider):
name = 'stock'
def start_requests(self):
url = 'http://quote.eastmoney.com/stocklist.html'
yield Request(url)
def parse(self, response):
item = StockItem()
print "===============上海================"
stocks_sh = response.css('div#quotesearch ul li a[href*="http://quote.eastmoney.com/sh"]::text')
for stock in stocks_sh:
item['stock_id'] = 's_sh' + re.findall('\((.*?)\)', stock.extract())[0]
yield item
print "===============深圳================"
stocks_sz = response.css('div#quotesearch ul li a[href*="http://quote.eastmoney.com/sz"]::text')
for stock in stocks_sz:
item['stock_id'] = 's_sz' + re.findall('\((.*?)\)', stock.extract())[0]
yield item
奥秘在于response.css('div#quotesearch ul li a[href*=""]::text'),它使用css来过滤你需要的数据。
运行程序
scrapy crawl stock -o stock.csv
可以生成 stock.csv 文件
预览如下:
stock_id
s_sh201000
s_sh201001
s_sh201002
s_sh201003
s_sh201004
s_sh201005
s_sh201008
s_sh201009
s_sh201010
s_sh202001
s_sh202003
s_sh202007
s_sh203007
s_sh203008
s_sh203009
…
如果要查询单只股票的股价,可以使用新浪的股票界面:
例如
您可以获得浪潮软件的股票报价
var hq_str_s_sh600756="浪潮软件,19.790,1.140,6.11,365843,70869"; 查看全部
网页源代码抓取工具(安装scrapy抓取步骤选择网站-->编写spider
)
个人博客:
源地址:
爬虫:scrapy
刮痧介绍
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。
安装scrapy
pip install Scrapy
爬行步骤
选择一个 网站 --> 定义数据 --> 写蜘蛛
首先用scrapy创建一个项目
scrapy startproject tutorial
选择一个网站
这里我们选择东方财富网的股票代码页:
定义要抓取的数据
我们需要获取股票的股票代码ID,所以只需定义stock_id
class StockItem(scrapy.Item):
stock_id = scrapy.Field()
写蜘蛛
class StockSpider(scrapy.Spider):
name = 'stock'
def start_requests(self):
url = 'http://quote.eastmoney.com/stocklist.html'
yield Request(url)
def parse(self, response):
item = StockItem()
print "===============上海================"
stocks_sh = response.css('div#quotesearch ul li a[href*="http://quote.eastmoney.com/sh"]::text')
for stock in stocks_sh:
item['stock_id'] = 's_sh' + re.findall('\((.*?)\)', stock.extract())[0]
yield item
print "===============深圳================"
stocks_sz = response.css('div#quotesearch ul li a[href*="http://quote.eastmoney.com/sz"]::text')
for stock in stocks_sz:
item['stock_id'] = 's_sz' + re.findall('\((.*?)\)', stock.extract())[0]
yield item
奥秘在于response.css('div#quotesearch ul li a[href*=""]::text'),它使用css来过滤你需要的数据。
运行程序
scrapy crawl stock -o stock.csv
可以生成 stock.csv 文件
预览如下:
stock_id
s_sh201000
s_sh201001
s_sh201002
s_sh201003
s_sh201004
s_sh201005
s_sh201008
s_sh201009
s_sh201010
s_sh202001
s_sh202003
s_sh202007
s_sh203007
s_sh203008
s_sh203009
…
如果要查询单只股票的股价,可以使用新浪的股票界面:
例如
您可以获得浪潮软件的股票报价
var hq_str_s_sh600756="浪潮软件,19.790,1.140,6.11,365843,70869";
网页源代码抓取工具(Web转换成Macapp的安装nativefier.js的过程非常简单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-01 15:04
由于日常工作需要,需要接触很多外语资料,所以一个好的翻译工具是必不可少的。得益于谷歌在翻译方面的出色表现,将其作为我的主要翻译工具是无可争议的。但是在使用中,经常会发现web端的页面总是不小心被手刷关闭了,使用的时候要等一段时间才发现需要重新打开。
另外,如果你想在工作时间更好地“钓鱼”,使用电脑肯定会比使用手机更安全。
带着这两个需求,找了几款可以把web转成Mac app的工具,但是体验后发现会出现一些小问题,有的甚至无法使用或者生产app打不开.
直到我找到它——nativefier。
安装 nativefier
nativefier 是一款基于 Electron 的命令行工具,完全开源,无需 UI 界面,无需安装任何 app,只需通过简单的一行代码,即可轻松将任意网页打包成可在桌面,并支持在 Windows、Mac 甚至 Linux 系统上运行。
PS作者是在谷歌工作的软件工程师,貌似是中国人。
目前,nativefier 在 Github 上获得了 2.140,000 颗 Star。
使用 nativefier 的过程非常简单,但是需要提前做一些事情。这里我使用macOS作为演示,其他平台类似,大家可以参考网上其他教程。
首先,我们需要安装 Node.js。你可以通过官方的 Node.js 网站 下载来安装它,但我建议在这里使用 Homebrew,这样你就可以在一个终端应用程序中完成所有事情。
如果您没有安装 Homebrew,您可以使用以下命令从终端安装它。
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent. ... nstall)"
更多关于 Homebrew 的使用,可以参考这个文章。
安装 Homebrew 后,即可安装 Node.js。在终端输入:
brew install node
如果由于某些网络原因导致安装缓慢,可以尝试切换到国内镜像源。运行进度后,可以在终端输入 node -v 和 npm -v 测试版本。如果出现版本号,则安装成功。
使用 Node.js,我们可以安装 nativefier 本体。同样在终端中,输入以下命令:
npm install nativefier -g
如果提示不足,可以尝试在前面加sudo:
sudo npm install nativefier -g
把它做完。接下来,我们使用 nativefier 来制作一个应用程序。
利用
最简单的使用方法是使用 nativefier 并添加一个您需要转换到的 网站 地址。例如:
nativefier "https://www.sspai.com"
第一次运行会下载 Eletron 框架,可能会比较慢。
命令执行后会生成一个名为“-darwin-x64”的文件夹,大小约为120-150M。如果您不更改运行地址,它将默认出现在您的个人文件夹中。
点击进入文件夹,就可以看到刚刚制作的应用了。将应用程序拖到应用程序文件夹中,它将出现在 Lanchpad 中。
Mac 应用程序的网络打包少数派已准备就绪。
上面的方法会自动抓取网站的名字和Logo作为名字和app图标。但有时,nativefier也会“翻车”(比如上面的app名称显示为“-”),这时候我们就需要自定义app的名称了。您可以使用以下命令:
nativefier --name "在这里输入 app 名字" "http://www.sspai.com"
请注意,此应用名称不支持中文。如果要改中文的app名称,可以直接在nativefier制作的app上改,然后拖到app文件夹中即可。
但是,nativefier 有一个小缺陷:因为一些 网站 图标或 logo 不好看,或者太丑,分辨率太低,有时生成的 app 图标不理想。
这个问题其实是有解决办法的。nativefier提供了一个-icon参数,只要我们准备一张png格式的图片,就可以应用为图标。
如果你不太明白上面的意思,你也可以手动进行替换。提前准备好一个icns格式的图标,命名为“electron.icns”,然后在生成的app上右键“查看包内容”,进入“目录-资源”,替换我们里面准备的图标。原来的图标就可以了。
比如我用Sketch给Tinde和小特画了一个类似于macOS Catalina原生风格的高清图标,然后用Image2icon转换成icns格式。更换后,就没有那么强的“像素风”了。感觉也减少了很多。
这个页面有4个app,都是用nativefier生成的
除了这些,nativefier还提供了很多可选参数,比如是否限制app窗口的宽高、是否显示菜单栏、关闭时是否启动、是否开启flash支持等等。你可以直接在终端输入nativefier或者nativefier -h查看,或者阅读官方API文档学习。
哦,对了,nativefier做的app还支持调用系统的推送。例如,将网页版微信打包成应用程序后,当有新消息到来时,您也可以收到新消息通知。
好了,nativefier就给大家介绍到这里,我带着新打包的app去钓鱼。 查看全部
网页源代码抓取工具(Web转换成Macapp的安装nativefier.js的过程非常简单)
由于日常工作需要,需要接触很多外语资料,所以一个好的翻译工具是必不可少的。得益于谷歌在翻译方面的出色表现,将其作为我的主要翻译工具是无可争议的。但是在使用中,经常会发现web端的页面总是不小心被手刷关闭了,使用的时候要等一段时间才发现需要重新打开。
另外,如果你想在工作时间更好地“钓鱼”,使用电脑肯定会比使用手机更安全。
带着这两个需求,找了几款可以把web转成Mac app的工具,但是体验后发现会出现一些小问题,有的甚至无法使用或者生产app打不开.
直到我找到它——nativefier。
安装 nativefier
nativefier 是一款基于 Electron 的命令行工具,完全开源,无需 UI 界面,无需安装任何 app,只需通过简单的一行代码,即可轻松将任意网页打包成可在桌面,并支持在 Windows、Mac 甚至 Linux 系统上运行。
PS作者是在谷歌工作的软件工程师,貌似是中国人。
目前,nativefier 在 Github 上获得了 2.140,000 颗 Star。
使用 nativefier 的过程非常简单,但是需要提前做一些事情。这里我使用macOS作为演示,其他平台类似,大家可以参考网上其他教程。
首先,我们需要安装 Node.js。你可以通过官方的 Node.js 网站 下载来安装它,但我建议在这里使用 Homebrew,这样你就可以在一个终端应用程序中完成所有事情。
如果您没有安装 Homebrew,您可以使用以下命令从终端安装它。
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent. ... nstall)"
更多关于 Homebrew 的使用,可以参考这个文章。
安装 Homebrew 后,即可安装 Node.js。在终端输入:
brew install node
如果由于某些网络原因导致安装缓慢,可以尝试切换到国内镜像源。运行进度后,可以在终端输入 node -v 和 npm -v 测试版本。如果出现版本号,则安装成功。
使用 Node.js,我们可以安装 nativefier 本体。同样在终端中,输入以下命令:
npm install nativefier -g
如果提示不足,可以尝试在前面加sudo:
sudo npm install nativefier -g
把它做完。接下来,我们使用 nativefier 来制作一个应用程序。
利用
最简单的使用方法是使用 nativefier 并添加一个您需要转换到的 网站 地址。例如:
nativefier "https://www.sspai.com"
第一次运行会下载 Eletron 框架,可能会比较慢。
命令执行后会生成一个名为“-darwin-x64”的文件夹,大小约为120-150M。如果您不更改运行地址,它将默认出现在您的个人文件夹中。
点击进入文件夹,就可以看到刚刚制作的应用了。将应用程序拖到应用程序文件夹中,它将出现在 Lanchpad 中。
Mac 应用程序的网络打包少数派已准备就绪。
上面的方法会自动抓取网站的名字和Logo作为名字和app图标。但有时,nativefier也会“翻车”(比如上面的app名称显示为“-”),这时候我们就需要自定义app的名称了。您可以使用以下命令:
nativefier --name "在这里输入 app 名字" "http://www.sspai.com"
请注意,此应用名称不支持中文。如果要改中文的app名称,可以直接在nativefier制作的app上改,然后拖到app文件夹中即可。
但是,nativefier 有一个小缺陷:因为一些 网站 图标或 logo 不好看,或者太丑,分辨率太低,有时生成的 app 图标不理想。
这个问题其实是有解决办法的。nativefier提供了一个-icon参数,只要我们准备一张png格式的图片,就可以应用为图标。
如果你不太明白上面的意思,你也可以手动进行替换。提前准备好一个icns格式的图标,命名为“electron.icns”,然后在生成的app上右键“查看包内容”,进入“目录-资源”,替换我们里面准备的图标。原来的图标就可以了。
比如我用Sketch给Tinde和小特画了一个类似于macOS Catalina原生风格的高清图标,然后用Image2icon转换成icns格式。更换后,就没有那么强的“像素风”了。感觉也减少了很多。
这个页面有4个app,都是用nativefier生成的
除了这些,nativefier还提供了很多可选参数,比如是否限制app窗口的宽高、是否显示菜单栏、关闭时是否启动、是否开启flash支持等等。你可以直接在终端输入nativefier或者nativefier -h查看,或者阅读官方API文档学习。
哦,对了,nativefier做的app还支持调用系统的推送。例如,将网页版微信打包成应用程序后,当有新消息到来时,您也可以收到新消息通知。
好了,nativefier就给大家介绍到这里,我带着新打包的app去钓鱼。
网页源代码抓取工具(抓包软件和网页解析工具最实用-网页源代码抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-01-31 15:02
网页源代码抓取工具curl:jsoup类codecs:/codecshtml_script:zhejiangjiangyu001/html_script如果要爬虫,
我觉得,抓包软件和网页解析工具最实用吧,小白的话python爬虫学习那个好呢,
海飞丝的理发师太神了,
科学上网不然被系统抓你号也成
sofasofa
webscraper
安装相应语言的工具,直接用,
最好学学r语言,这样一旦上手,抓取的东西都是r语言可以处理的,网站很好写啊,html,js,
谢邀;个人建议优先抓取网站的文字图片、跳转链接和新闻稿。原因很简单,这些对用java开发的同学有极大帮助,因为这些网站不论是用jsoup还是csv格式都有相应的java代码处理。抓取html后返回给用户的图片可以用jpg格式代替。问题说明中说jsoup,可以去看看requests对ajax请求对照python里的bs4来理解一下,虽然这样简单好上手但还是给初学者一点难度。
文字图片和新闻稿内容很容易理解,常规的单纯的上传下载post或put都可以搞定,用js很麻烦、用csv格式处理也很麻烦,用正则也麻烦,除非http请求一切要求可以求助抓包工具。另外抓包工具很多,随便一个开源的就可以,itchat,threadlocalhttpdump,phantomjs等等。ps:关于csv格式转正则的话推荐去用librestrings:facebookjavascriptfileexporter可以拿到正则相关的信息。 查看全部
网页源代码抓取工具(抓包软件和网页解析工具最实用-网页源代码抓取工具)
网页源代码抓取工具curl:jsoup类codecs:/codecshtml_script:zhejiangjiangyu001/html_script如果要爬虫,
我觉得,抓包软件和网页解析工具最实用吧,小白的话python爬虫学习那个好呢,
海飞丝的理发师太神了,
科学上网不然被系统抓你号也成
sofasofa
webscraper
安装相应语言的工具,直接用,
最好学学r语言,这样一旦上手,抓取的东西都是r语言可以处理的,网站很好写啊,html,js,
谢邀;个人建议优先抓取网站的文字图片、跳转链接和新闻稿。原因很简单,这些对用java开发的同学有极大帮助,因为这些网站不论是用jsoup还是csv格式都有相应的java代码处理。抓取html后返回给用户的图片可以用jpg格式代替。问题说明中说jsoup,可以去看看requests对ajax请求对照python里的bs4来理解一下,虽然这样简单好上手但还是给初学者一点难度。
文字图片和新闻稿内容很容易理解,常规的单纯的上传下载post或put都可以搞定,用js很麻烦、用csv格式处理也很麻烦,用正则也麻烦,除非http请求一切要求可以求助抓包工具。另外抓包工具很多,随便一个开源的就可以,itchat,threadlocalhttpdump,phantomjs等等。ps:关于csv格式转正则的话推荐去用librestrings:facebookjavascriptfileexporter可以拿到正则相关的信息。
网页源代码抓取工具(相似软件版本说明软件地址软件简介通过分析,开发GG说)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-01-27 09:21
html源码翻译工具电脑版是一款非常不错的英文翻译软件。html源码翻译工具正式版可以将你的htm添加到软件中进行直接翻译,批量翻译文件,以及所有网页翻译,html源码。电脑版翻译工具可以将中文翻译成英文,翻译结果准确,适合需要查看网页代码的朋友。
类似软件
印记
软件地址
html源码翻译工具软件介绍
html源代码翻译工具通过解析html,提取源代码中需要本地化的文本,可以对电脑中的源代码进行全面翻译和批量在线翻译,实现英文模板自动汉化的功能。
HTML源代码翻译工具软件功能
1、html源码翻译工具提供简单的文本内容翻译功能
2、将代码文本添加到软件中进行翻译
3、支持自动备份功能,可以备份原创网页文件
4、默认支持保存,翻译结果在原地址找到
5、快速识别htm内容,实现中英文转换
6、可以帮助用户翻译国外网页模板
html源码翻译工具软件特点
1、html源码翻译工具提供简单的网页内容翻译功能
2、将从网上下载的源码翻译成中文
3、将从国外下载的英文网页源代码翻译成中文
4、还支持中文转英文,满足不同用户的需求
5、软件是基于谷歌翻译的,所以翻译结果还是很准确的
如何安装html源代码翻译工具
在pc下载网下载html源码翻译工具电脑版软件包
解压到当前文件夹
双击打开文件夹中的应用程序
本软件为绿色软件,无需安装即可使用。
HTML源代码翻译工具更新日志:
GG的开发者说这次真的没有bug了~
特别提示:您好,您要使用的软件是辅助工具,可能会被各大杀毒软件拦截杀掉。本软件在使用中可能存在风险,请注意避免。如果要继续使用,建议关闭各种杀毒软件。软件使用后。用包解压密码: 查看全部
网页源代码抓取工具(相似软件版本说明软件地址软件简介通过分析,开发GG说)
html源码翻译工具电脑版是一款非常不错的英文翻译软件。html源码翻译工具正式版可以将你的htm添加到软件中进行直接翻译,批量翻译文件,以及所有网页翻译,html源码。电脑版翻译工具可以将中文翻译成英文,翻译结果准确,适合需要查看网页代码的朋友。
类似软件
印记
软件地址
html源码翻译工具软件介绍
html源代码翻译工具通过解析html,提取源代码中需要本地化的文本,可以对电脑中的源代码进行全面翻译和批量在线翻译,实现英文模板自动汉化的功能。
HTML源代码翻译工具软件功能
1、html源码翻译工具提供简单的文本内容翻译功能
2、将代码文本添加到软件中进行翻译
3、支持自动备份功能,可以备份原创网页文件
4、默认支持保存,翻译结果在原地址找到
5、快速识别htm内容,实现中英文转换
6、可以帮助用户翻译国外网页模板
html源码翻译工具软件特点
1、html源码翻译工具提供简单的网页内容翻译功能
2、将从网上下载的源码翻译成中文
3、将从国外下载的英文网页源代码翻译成中文
4、还支持中文转英文,满足不同用户的需求
5、软件是基于谷歌翻译的,所以翻译结果还是很准确的
如何安装html源代码翻译工具
在pc下载网下载html源码翻译工具电脑版软件包
解压到当前文件夹
双击打开文件夹中的应用程序
本软件为绿色软件,无需安装即可使用。
HTML源代码翻译工具更新日志:
GG的开发者说这次真的没有bug了~
特别提示:您好,您要使用的软件是辅助工具,可能会被各大杀毒软件拦截杀掉。本软件在使用中可能存在风险,请注意避免。如果要继续使用,建议关闭各种杀毒软件。软件使用后。用包解压密码:
网页源代码抓取工具(Python网络爬虫工具越来越工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-01-27 00:12
网络爬虫在很多领域都有广泛的应用,它们的目标是从网站获取新的数据并存储起来方便访问。网络爬虫工具越来越广为人知,因为它们简化和自动化了整个爬虫过程,让每个人都可以轻松访问网络数据资源。
1. 八分法
Octoparse 是一个免费且强大的网站 爬虫工具,用于从网站 中提取各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。
总之,Octoparse 应该能够满足用户最基本或高端的抓取需求,无需任何编码技能。
2. Cyotek WebCopy
WebCopy 是一个免费的爬取工具,允许将部分或完整的 网站 内容复制到本地硬盘以供离线阅读。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。
但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为网站免费的爬虫软件,HTTrack 提供的功能非常适合将整个网站从互联网下载到您的PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。
此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
如果你还在编程的世界里迷茫,可以加入我们的Python学习按钮qun:784758214,看看前辈们是如何学习的。经验交流。从基础的python脚本到web开发、爬虫、django、数据挖掘等,从零基础到项目实战的数据整理。献给每一位蟒蛇朋友!分享一些学习方法和需要注意的小细节,点击加入我们的python学习者聚集地
4. 左转
![(%7CimageView2/2/w/1240)
Getleft 是一个免费且易于使用的爬虫工具。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。
总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
5. 刮板
Scraper 是一个 Chrome 扩展程序,具有有限的数据提取功能,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
6. OutWit 集线器
OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。
它是最简单的爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. ParseHub
Parsehub是一款优秀的爬虫工具,支持使用AJAX技术、JavaScript、cookies等获取网页数据。它的机器学习技术可以读取网页文档,分析并转换成相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮板
VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。
Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrapinghub
Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源视觉抓取工具允许用户在没有任何编程知识的情况下抓取网页。
Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够通过一个简单的 HTTP API 从多个 IP 和位置进行爬网,而无需代理管理。
10.Dexi.io
作为一个基于浏览器的网络爬虫工具,Dexi.io 允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。免费软件提供匿名网络代理服务器,提取的数据在存档前会在 Dexi.io 的服务器上存储两周,或者提取的数据直接导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
11.Webhose.io
Webhose.io 使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。
抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,webhose.io 支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。
总体而言,Webhose.io 可以满足用户的基本爬虫需求。
12. 导入.io
用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。
您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能以编程方式控制 Import.io 并自动访问数据,Import.io 通过将 Web 数据集成到您自己的应用程序或 网站 只需单击一下即可轻松实现爬虫点击。
为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿
80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。
Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
15. 内容抓取器
Content Graber 是一款面向企业的网页抓取软件。它允许您创建一个独立的网络爬虫代理。
它更适合有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或 VB.NET 以编程方式控制爬取过程,以调试或编写脚本。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16.氦刮板
Helium Scraper 是一款可视化网络数据爬虫软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。
基本可以满足用户初期的爬虫需求。
17. UiPath
UiPath 是一款自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格和基于模式的数据。
Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
18. Scrape.it
Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
19. WebHarvy
WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,可选择通过代理服务器或 VPN网站 访问目标。
当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
20.内涵
Connotate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。
它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。
此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。 查看全部
网页源代码抓取工具(Python网络爬虫工具越来越工具)
网络爬虫在很多领域都有广泛的应用,它们的目标是从网站获取新的数据并存储起来方便访问。网络爬虫工具越来越广为人知,因为它们简化和自动化了整个爬虫过程,让每个人都可以轻松访问网络数据资源。
1. 八分法
Octoparse 是一个免费且强大的网站 爬虫工具,用于从网站 中提取各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。
总之,Octoparse 应该能够满足用户最基本或高端的抓取需求,无需任何编码技能。
2. Cyotek WebCopy
WebCopy 是一个免费的爬取工具,允许将部分或完整的 网站 内容复制到本地硬盘以供离线阅读。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。
但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为网站免费的爬虫软件,HTTrack 提供的功能非常适合将整个网站从互联网下载到您的PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。
此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
如果你还在编程的世界里迷茫,可以加入我们的Python学习按钮qun:784758214,看看前辈们是如何学习的。经验交流。从基础的python脚本到web开发、爬虫、django、数据挖掘等,从零基础到项目实战的数据整理。献给每一位蟒蛇朋友!分享一些学习方法和需要注意的小细节,点击加入我们的python学习者聚集地
4. 左转
![(%7CimageView2/2/w/1240)
Getleft 是一个免费且易于使用的爬虫工具。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。
总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
5. 刮板
Scraper 是一个 Chrome 扩展程序,具有有限的数据提取功能,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
6. OutWit 集线器
OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。
它是最简单的爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. ParseHub
Parsehub是一款优秀的爬虫工具,支持使用AJAX技术、JavaScript、cookies等获取网页数据。它的机器学习技术可以读取网页文档,分析并转换成相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮板
VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。
Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrapinghub
Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源视觉抓取工具允许用户在没有任何编程知识的情况下抓取网页。
Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够通过一个简单的 HTTP API 从多个 IP 和位置进行爬网,而无需代理管理。
10.Dexi.io
作为一个基于浏览器的网络爬虫工具,Dexi.io 允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。免费软件提供匿名网络代理服务器,提取的数据在存档前会在 Dexi.io 的服务器上存储两周,或者提取的数据直接导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
11.Webhose.io
Webhose.io 使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。
抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,webhose.io 支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。
总体而言,Webhose.io 可以满足用户的基本爬虫需求。
12. 导入.io
用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。
您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能以编程方式控制 Import.io 并自动访问数据,Import.io 通过将 Web 数据集成到您自己的应用程序或 网站 只需单击一下即可轻松实现爬虫点击。
为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿
80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。
Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
15. 内容抓取器
Content Graber 是一款面向企业的网页抓取软件。它允许您创建一个独立的网络爬虫代理。
它更适合有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或 VB.NET 以编程方式控制爬取过程,以调试或编写脚本。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16.氦刮板
Helium Scraper 是一款可视化网络数据爬虫软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。
基本可以满足用户初期的爬虫需求。
17. UiPath
UiPath 是一款自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格和基于模式的数据。
Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
18. Scrape.it
Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
19. WebHarvy
WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,可选择通过代理服务器或 VPN网站 访问目标。
当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
20.内涵
Connotate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。
它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。
此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。
网页源代码抓取工具(网页源代码抓取工具有哪些?推荐python类和thepythonwebframework)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-26 03:03
网页源代码抓取工具有哪些?平时我们所使用的各种抓取工具都是基于http的,比如get、post、put、delete等,但是有没有可以做到flash触发的直接抓取html源代码?这款工具就是专门做到此事的,比如在浏览网页时,flash触发页面的ajax传参就能抓取html页面源代码。下面是使用下载地址:-html-post.html操作步骤:。
1、我们可以去网页源代码中找到所有显示html代码的网页,然后修改其上面的、等标签的class属性来获取ul、li标签的数据。
2、因为获取的ul标签的数据,所以之后我们需要去掉li标签中所显示的数据。
3、把之前处理好的ul标签的class属性改成post。
4、最后我们执行ifelse标签判断就能抓取源代码中的数据。
5、最后还能看到网页源代码的完整的html报文,目前的的源代码报文网址,这个源代码报文是放在cdn服务器上的,因此不用担心服务器下发数据会有延迟!下载地址:-html-post.html更多精彩请关注本人。
http找到page的链接再判断从中提取html,感觉更加直接。例如直接抓页面源码,抓取图片,抓取视频。python中有很多这种库,推荐python类和thepythonwebframework,思路如下:part1:抓取网页源码,page=url('')part2:匹配url,parse()判断整个页面的html是不是str,然后在requestssession中创建多个session,有时需要多个session。
part3:匹配到整个页面的str后,如果有包含or条件,设置args,args对所有sessiontoken做相应的修改part4:session中转发数据,当然转发多个session。part5:统计跳转率和用户请求数,是否会流失用户,用户浏览页面的流程是不是一条大通道,这些都可以用flash来操作。
thepythonwebframework:httpparser,所有http请求都会经过session,所以可以用session内生成相应标签的pageframe,比如一个response标签内会返回一个(html,css,js),这个css规定了要显示的标签,js则规定该标签的内容,根据session来处理响应中携带的参数。
postargs:设置请求参数,这个参数和用户上传参数中的username,password是相关的,可以设置整个页面的username和password进行混合取值post的数据由session保存,session里可以共享前后端session,这样获取的结果是同步的url。 查看全部
网页源代码抓取工具(网页源代码抓取工具有哪些?推荐python类和thepythonwebframework)
网页源代码抓取工具有哪些?平时我们所使用的各种抓取工具都是基于http的,比如get、post、put、delete等,但是有没有可以做到flash触发的直接抓取html源代码?这款工具就是专门做到此事的,比如在浏览网页时,flash触发页面的ajax传参就能抓取html页面源代码。下面是使用下载地址:-html-post.html操作步骤:。
1、我们可以去网页源代码中找到所有显示html代码的网页,然后修改其上面的、等标签的class属性来获取ul、li标签的数据。
2、因为获取的ul标签的数据,所以之后我们需要去掉li标签中所显示的数据。
3、把之前处理好的ul标签的class属性改成post。
4、最后我们执行ifelse标签判断就能抓取源代码中的数据。
5、最后还能看到网页源代码的完整的html报文,目前的的源代码报文网址,这个源代码报文是放在cdn服务器上的,因此不用担心服务器下发数据会有延迟!下载地址:-html-post.html更多精彩请关注本人。
http找到page的链接再判断从中提取html,感觉更加直接。例如直接抓页面源码,抓取图片,抓取视频。python中有很多这种库,推荐python类和thepythonwebframework,思路如下:part1:抓取网页源码,page=url('')part2:匹配url,parse()判断整个页面的html是不是str,然后在requestssession中创建多个session,有时需要多个session。
part3:匹配到整个页面的str后,如果有包含or条件,设置args,args对所有sessiontoken做相应的修改part4:session中转发数据,当然转发多个session。part5:统计跳转率和用户请求数,是否会流失用户,用户浏览页面的流程是不是一条大通道,这些都可以用flash来操作。
thepythonwebframework:httpparser,所有http请求都会经过session,所以可以用session内生成相应标签的pageframe,比如一个response标签内会返回一个(html,css,js),这个css规定了要显示的标签,js则规定该标签的内容,根据session来处理响应中携带的参数。
postargs:设置请求参数,这个参数和用户上传参数中的username,password是相关的,可以设置整个页面的username和password进行混合取值post的数据由session保存,session里可以共享前后端session,这样获取的结果是同步的url。
网页源代码抓取工具(爬取在豆瓣网上的电影《超时空同居》导演和演员信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-25 08:12
)
接下来,我们将分享一个非常简单的例子。我们想在豆瓣上爬取电影《时空同居》的导演和演员信息。
首先我们找到电影的网址:
右键查看网页查看页面源码的源码(也可以进入开发者模式(inspect)):
接下来,我们输入网页的源代码。我们要采集的信息在源代码中,输入关键字即可查看。比如这里我们输入'雷佳音'来定位我们要找的位置:
接下来我们需要对TML格式进行分析,比如我们要找出所有的主角:
可以看到有一个通用的规则:star的名字对应的节点的名字是a,属性都是rel="v:starring",这样我们就可以很方便的使用xpath语法来定位拥有的元素这个元素节点,然后找出所有的结果。
同理,director名字对应的节点名命名为a,属性都是rel="v:directedBy"。我们也可以通过这个定位找到对应的文字:
具体代码如下:
import requests
from lxml import etree
url='https://movie.douban.com/subje ... 39%3B #输入我们的url
get = requests.get(url).text # get(url) 得到我们的网页, text将源网页转化为字符串
selector = etree.HTML(get) # 将源码转换为xpath可以识别的TML格式
info = {} #字典用于储存信息
info['电影'] = selector.xpath('//title/text()')[0].strip() # 定位电影名字
info['导演']=selector.xpath('//a[@rel="v:directedBy"]/text()') # 定位导演名字
info['演员']=selector.xpath('//a[@rel="v:starring"]/text()') # 定位演员名字
print(info)
最后我们得到一个字典集的结果:
{'电影': '超时空同居 (豆瓣)', '导演': ['苏伦'], '演员': ['雷佳音', '佟丽娅', '张衣', '于和伟', '王正佳', '陶虹', '李念', '李光洁', '杨玏', '范明', '徐峥', '杨迪', '方龄', '陈昊']}
实例分享2——爬取json格式的豆瓣电影信息
首先,json是一种轻量级的数据交换格式。其简洁明了的层次结构使JSON成为一种理想的数据交换语言,易于人类读写,也易于机器解析生成,有效改善网络传输。高效的。
在我们爬取的过程中,有时可以在开发者模式返回的网页中找到完整的json格式数据。这时候我们可以使用requests包中的json函数将爬取的原文转换成格式,方便我们提取内容。我们以豆瓣电影为例:
这是我们点击分类后看到的电影信息。如果我们想爬取这些电影的信息,可以右键进入开发者模式(inspector)。
开启开发者模式后一定要刷新一次,否则之前收到的页面信息将无法显示。然后我们在右侧选项卡上选择网络,点击下面的XHR选项,我们会看到一个返回的网页,双击它。
上图是打开的json文件。因为我的电脑已经下载了json插件,所以格式比较清晰(使用Chrome浏览器的同学可以进入Chrome商店下载Juan Ramón JSON Beautifier Chrome插件)。其实Json文件也可以理解为一个大字典,里面有很多层的小字典和列表。我们找到json网页后,只需要使用requests将其转换成json格式,就可以很方便的提取信息了。
代码显示如下:
import requests
url='https://movie.douban.com/j/new ... e%3D0,10&tags=&start=0'
get = requests.get(url).json() #用json()函数得到网页源码
'''
更多Python学习资料以及源码教程资料,可以在群1136201545免费获取
'''
get = get['data']
info = {}
for i in range(len(get)):
info[get[i]['title']] = [get[i]['directors'], get[i]['rate'] ] #提取每部电影的导演和评分
print(info) 查看全部
网页源代码抓取工具(爬取在豆瓣网上的电影《超时空同居》导演和演员信息
)
接下来,我们将分享一个非常简单的例子。我们想在豆瓣上爬取电影《时空同居》的导演和演员信息。
首先我们找到电影的网址:
右键查看网页查看页面源码的源码(也可以进入开发者模式(inspect)):
接下来,我们输入网页的源代码。我们要采集的信息在源代码中,输入关键字即可查看。比如这里我们输入'雷佳音'来定位我们要找的位置:
接下来我们需要对TML格式进行分析,比如我们要找出所有的主角:
可以看到有一个通用的规则:star的名字对应的节点的名字是a,属性都是rel="v:starring",这样我们就可以很方便的使用xpath语法来定位拥有的元素这个元素节点,然后找出所有的结果。
同理,director名字对应的节点名命名为a,属性都是rel="v:directedBy"。我们也可以通过这个定位找到对应的文字:
具体代码如下:
import requests
from lxml import etree
url='https://movie.douban.com/subje ... 39%3B #输入我们的url
get = requests.get(url).text # get(url) 得到我们的网页, text将源网页转化为字符串
selector = etree.HTML(get) # 将源码转换为xpath可以识别的TML格式
info = {} #字典用于储存信息
info['电影'] = selector.xpath('//title/text()')[0].strip() # 定位电影名字
info['导演']=selector.xpath('//a[@rel="v:directedBy"]/text()') # 定位导演名字
info['演员']=selector.xpath('//a[@rel="v:starring"]/text()') # 定位演员名字
print(info)
最后我们得到一个字典集的结果:
{'电影': '超时空同居 (豆瓣)', '导演': ['苏伦'], '演员': ['雷佳音', '佟丽娅', '张衣', '于和伟', '王正佳', '陶虹', '李念', '李光洁', '杨玏', '范明', '徐峥', '杨迪', '方龄', '陈昊']}
实例分享2——爬取json格式的豆瓣电影信息
首先,json是一种轻量级的数据交换格式。其简洁明了的层次结构使JSON成为一种理想的数据交换语言,易于人类读写,也易于机器解析生成,有效改善网络传输。高效的。
在我们爬取的过程中,有时可以在开发者模式返回的网页中找到完整的json格式数据。这时候我们可以使用requests包中的json函数将爬取的原文转换成格式,方便我们提取内容。我们以豆瓣电影为例:
这是我们点击分类后看到的电影信息。如果我们想爬取这些电影的信息,可以右键进入开发者模式(inspector)。
开启开发者模式后一定要刷新一次,否则之前收到的页面信息将无法显示。然后我们在右侧选项卡上选择网络,点击下面的XHR选项,我们会看到一个返回的网页,双击它。
上图是打开的json文件。因为我的电脑已经下载了json插件,所以格式比较清晰(使用Chrome浏览器的同学可以进入Chrome商店下载Juan Ramón JSON Beautifier Chrome插件)。其实Json文件也可以理解为一个大字典,里面有很多层的小字典和列表。我们找到json网页后,只需要使用requests将其转换成json格式,就可以很方便的提取信息了。
代码显示如下:
import requests
url='https://movie.douban.com/j/new ... e%3D0,10&tags=&start=0'
get = requests.get(url).json() #用json()函数得到网页源码
'''
更多Python学习资料以及源码教程资料,可以在群1136201545免费获取
'''
get = get['data']
info = {}
for i in range(len(get)):
info[get[i]['title']] = [get[i]['directors'], get[i]['rate'] ] #提取每部电影的导演和评分
print(info)
网页源代码抓取工具(豆瓣电影《超时空同居》导演和演员信息的实例分享 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-01-25 08:10
)
接下来,我们将分享一个非常简单的例子。我们想在豆瓣上爬取电影《时空同居》的导演和演员信息。
首先我们找到电影的网址:
右键查看网页查看页面源码的源码(也可以进入开发者模式(inspect)):
接下来,我们输入网页的源代码。我们要采集的信息在源代码中,输入关键字即可查看。比如这里我们输入'雷佳音'来定位我们要找的位置:
接下来我们需要对TML格式进行分析,比如我们要找出所有的主角:
可以看到有一个通用的规则:star的名字对应的节点的名字是a,属性都是rel="v:starring",这样我们就可以很方便的使用xpath语法来定位拥有的元素这个元素。节点,然后找出所有结果。
同理,director名字对应的节点名命名为a,属性都是rel="v:directedBy"。我们也可以通过这个定位找到对应的文字:
具体代码如下:
import requestsfrom lxml import etree url='https://movie.douban.com/subje ... 39%3B #输入我们的urlget = requests.get(url).text # get(url) 得到我们的网页, text将源网页转化为字符串 selector = etree.HTML(get) # 将源码转换为xpath可以识别的TML格式 info = {} #字典用于储存信息info['电影'] = selector.xpath('//title/text()')[0].strip() # 定位电影名字info['导演']=selector.xpath('//a[@rel="v:directedBy"]/text()') # 定位导演名字info['演员']=selector.xpath('//a[@rel="v:starring"]/text()') # 定位演员名字print(info)
最后我们得到一个字典集的结果:
{'电影': '超时空同居 (豆瓣)', '导演': ['苏伦'], '演员': ['雷佳音', '佟丽娅', '张衣', '于和伟', '王正佳', '陶虹', '李念', '李光洁', '杨玏', '范明', '徐峥', '杨迪', '方龄', '陈昊']}
实例分享2——爬取json格式的豆瓣电影信息
首先,json是一种轻量级的数据交换格式。其简洁明了的层次结构使JSON成为一种理想的数据交换语言,易于人类读写,也易于机器解析生成,有效改善网络传输。高效的。
在我们爬取的过程中,有时可以在开发者模式返回的网页中找到完整的json格式数据。这时候我们可以使用requests包中的json函数将爬取的原文转换成格式,方便我们提取内容。我们以豆瓣电影为例:
这是我们点击分类后看到的电影信息。如果我们想爬取这些电影的信息,可以右键进入开发者模式(inspector)。
开启开发者模式后一定要刷新一次,否则之前收到的页面信息将无法显示。然后我们在右侧选项卡上选择网络,点击下面的XHR选项,我们会看到一个返回的网页,双击它。
上图是打开的json文件。因为我的电脑已经下载了json插件,所以它的格式应该比较清晰(使用Chrome浏览器的同学可以进入Chrome商店下载Juan Ramón JSON Beautifier Chrome插件)。其实Json文件也可以理解为一个大字典,里面有很多层的小字典和列表。我们找到json网页后,只需要使用requests将其转换成json格式,就可以很方便的提取信息了。
代码显示如下:
import requestsurl='https://movie.douban.com/j/new ... e%3D0,10&tags=&start=0'get = requests.get(url).json() #用json()函数得到网页源码get = get['data']info = {}for i in range(len(get)): info[get[i]['title']] = [get[i]['directors'], get[i]['rate'] ] #提取每部电影的导演和评分print(info) 查看全部
网页源代码抓取工具(豆瓣电影《超时空同居》导演和演员信息的实例分享
)
接下来,我们将分享一个非常简单的例子。我们想在豆瓣上爬取电影《时空同居》的导演和演员信息。
首先我们找到电影的网址:
右键查看网页查看页面源码的源码(也可以进入开发者模式(inspect)):
接下来,我们输入网页的源代码。我们要采集的信息在源代码中,输入关键字即可查看。比如这里我们输入'雷佳音'来定位我们要找的位置:
接下来我们需要对TML格式进行分析,比如我们要找出所有的主角:
可以看到有一个通用的规则:star的名字对应的节点的名字是a,属性都是rel="v:starring",这样我们就可以很方便的使用xpath语法来定位拥有的元素这个元素。节点,然后找出所有结果。
同理,director名字对应的节点名命名为a,属性都是rel="v:directedBy"。我们也可以通过这个定位找到对应的文字:
具体代码如下:
import requestsfrom lxml import etree url='https://movie.douban.com/subje ... 39%3B #输入我们的urlget = requests.get(url).text # get(url) 得到我们的网页, text将源网页转化为字符串 selector = etree.HTML(get) # 将源码转换为xpath可以识别的TML格式 info = {} #字典用于储存信息info['电影'] = selector.xpath('//title/text()')[0].strip() # 定位电影名字info['导演']=selector.xpath('//a[@rel="v:directedBy"]/text()') # 定位导演名字info['演员']=selector.xpath('//a[@rel="v:starring"]/text()') # 定位演员名字print(info)
最后我们得到一个字典集的结果:
{'电影': '超时空同居 (豆瓣)', '导演': ['苏伦'], '演员': ['雷佳音', '佟丽娅', '张衣', '于和伟', '王正佳', '陶虹', '李念', '李光洁', '杨玏', '范明', '徐峥', '杨迪', '方龄', '陈昊']}
实例分享2——爬取json格式的豆瓣电影信息
首先,json是一种轻量级的数据交换格式。其简洁明了的层次结构使JSON成为一种理想的数据交换语言,易于人类读写,也易于机器解析生成,有效改善网络传输。高效的。
在我们爬取的过程中,有时可以在开发者模式返回的网页中找到完整的json格式数据。这时候我们可以使用requests包中的json函数将爬取的原文转换成格式,方便我们提取内容。我们以豆瓣电影为例:
这是我们点击分类后看到的电影信息。如果我们想爬取这些电影的信息,可以右键进入开发者模式(inspector)。
开启开发者模式后一定要刷新一次,否则之前收到的页面信息将无法显示。然后我们在右侧选项卡上选择网络,点击下面的XHR选项,我们会看到一个返回的网页,双击它。
上图是打开的json文件。因为我的电脑已经下载了json插件,所以它的格式应该比较清晰(使用Chrome浏览器的同学可以进入Chrome商店下载Juan Ramón JSON Beautifier Chrome插件)。其实Json文件也可以理解为一个大字典,里面有很多层的小字典和列表。我们找到json网页后,只需要使用requests将其转换成json格式,就可以很方便的提取信息了。
代码显示如下:
import requestsurl='https://movie.douban.com/j/new ... e%3D0,10&tags=&start=0'get = requests.get(url).json() #用json()函数得到网页源码get = get['data']info = {}for i in range(len(get)): info[get[i]['title']] = [get[i]['directors'], get[i]['rate'] ] #提取每部电影的导演和评分print(info)
网页源代码抓取工具(webpack3的默认promise机制是怎么样的呢?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-25 06:06
网页源代码抓取工具比较多,我使用过egg、yarn、webpack等,整体来说webpack功能更加强大,可以输出非常完整的开发项目代码,目前国内基本上没有成熟的webpack解决方案,
是的,现在都趋于完善了,就拿webpack3.0对dev-server的支持来说吧,一种全新的api。在webpack3的基础上,webpack3用一种全新的promise的特性取代了之前dev-server的默认promise机制。也就是说webpack3是基于promise机制的,既可以在两个context之间使用promise,也可以使用callback机制。
通俗点讲,webpack3就是一种集合了所有commonjs模块和异步js,和commonjsplugin,异步jsexport的一个集合。
对于前端开发来说,最终的目的是能实现一个完整的代码架构,既一个完整的项目(不只是业务,也包括项目模块组件等设计),再加上一些功能接口定义,然后让前端的开发尽可能完善的话,需要用到各种模块化框架,又用到各种配置api,然后各种框架又要具体的和项目打通,最后导致项目处于一个自闭环链状结构上,导致框架的使用出现了一些问题,个人觉得其实项目框架其实也就是最终代码的一种组织形式,然后加上一些项目交互的特性,让框架可以变得更加具有通用性。 查看全部
网页源代码抓取工具(webpack3的默认promise机制是怎么样的呢?-八维教育)
网页源代码抓取工具比较多,我使用过egg、yarn、webpack等,整体来说webpack功能更加强大,可以输出非常完整的开发项目代码,目前国内基本上没有成熟的webpack解决方案,
是的,现在都趋于完善了,就拿webpack3.0对dev-server的支持来说吧,一种全新的api。在webpack3的基础上,webpack3用一种全新的promise的特性取代了之前dev-server的默认promise机制。也就是说webpack3是基于promise机制的,既可以在两个context之间使用promise,也可以使用callback机制。
通俗点讲,webpack3就是一种集合了所有commonjs模块和异步js,和commonjsplugin,异步jsexport的一个集合。
对于前端开发来说,最终的目的是能实现一个完整的代码架构,既一个完整的项目(不只是业务,也包括项目模块组件等设计),再加上一些功能接口定义,然后让前端的开发尽可能完善的话,需要用到各种模块化框架,又用到各种配置api,然后各种框架又要具体的和项目打通,最后导致项目处于一个自闭环链状结构上,导致框架的使用出现了一些问题,个人觉得其实项目框架其实也就是最终代码的一种组织形式,然后加上一些项目交互的特性,让框架可以变得更加具有通用性。
网页源代码抓取工具(网页源代码抓取工具-上海怡健医学框架scrapy)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-24 23:02
网页源代码抓取工具:凡科建站、快的打车、爱托宝、门店导航等等,可以结合一起用。找准一个你要抓取的资源,然后采集,比如你要爬取某个美食的海报,就可以采集他的url,然后在哪个代码里面搜索需要的关键词,就能够抓取到资源的位置啦。
表示现在还没被提取出来,但我发现我们公司内部的网站就可以通过url爬出来,
python爬虫框架scrapy
如果从概念上讲的话,首先是公司每个网站对应的页面,然后再根据这个页面抓取链接。从抓取量上讲的话,
一般在你浏览网站的时候就有了吧
一点拙见,希望大神补充一下。有了一些信息后,在用python网页抓取工具,比如凡科建站、bigdatax从里面抓取链接。到时候你再想这些链接到底是怎么来的,大概的信息有什么,
pythonrequests+google+chrome
没有固定的爬虫模式,理论上说什么网页都能爬。python的话可以抓数据挖掘里面各种数据,很多公司都用,但一般你要用其中的某一部分网页。有了数据,剩下就是你们公司的具体需求了。
普通代码爬取
awvs里面爬,
爱托宝,
爬虫只是一个工具,主要用来抓取内容,做的是爬虫。如果说是通过爬虫模拟真实上网行为,对比也只是比一些固定方式好点,但也没啥特别大意义。因为真实上网本身就很复杂,而不是抓取一个数据,就能完成多个目标的爬取和存储。 查看全部
网页源代码抓取工具(网页源代码抓取工具-上海怡健医学框架scrapy)
网页源代码抓取工具:凡科建站、快的打车、爱托宝、门店导航等等,可以结合一起用。找准一个你要抓取的资源,然后采集,比如你要爬取某个美食的海报,就可以采集他的url,然后在哪个代码里面搜索需要的关键词,就能够抓取到资源的位置啦。
表示现在还没被提取出来,但我发现我们公司内部的网站就可以通过url爬出来,
python爬虫框架scrapy
如果从概念上讲的话,首先是公司每个网站对应的页面,然后再根据这个页面抓取链接。从抓取量上讲的话,
一般在你浏览网站的时候就有了吧
一点拙见,希望大神补充一下。有了一些信息后,在用python网页抓取工具,比如凡科建站、bigdatax从里面抓取链接。到时候你再想这些链接到底是怎么来的,大概的信息有什么,
pythonrequests+google+chrome
没有固定的爬虫模式,理论上说什么网页都能爬。python的话可以抓数据挖掘里面各种数据,很多公司都用,但一般你要用其中的某一部分网页。有了数据,剩下就是你们公司的具体需求了。
普通代码爬取
awvs里面爬,
爱托宝,
爬虫只是一个工具,主要用来抓取内容,做的是爬虫。如果说是通过爬虫模拟真实上网行为,对比也只是比一些固定方式好点,但也没啥特别大意义。因为真实上网本身就很复杂,而不是抓取一个数据,就能完成多个目标的爬取和存储。
网页源代码抓取工具(安装scrapy抓取步骤选择网站-->编写spider )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-21 17:08
)
个人博客:
源地址:
爬虫:scrapy
刮痧介绍
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。
安装scrapy
pip install Scrapy
爬行步骤
选择一个 网站 --> 定义数据 --> 写蜘蛛
首先用scrapy创建一个项目
scrapy startproject tutorial
选择一个网站
这里我们选择东方财富网的股票代码页:
定义要抓取的数据
我们需要获取股票的股票代码ID,所以只需定义stock_id
class StockItem(scrapy.Item):
stock_id = scrapy.Field()
写蜘蛛
class StockSpider(scrapy.Spider):
name = 'stock'
def start_requests(self):
url = 'http://quote.eastmoney.com/stocklist.html'
yield Request(url)
def parse(self, response):
item = StockItem()
print "===============上海================"
stocks_sh = response.css('div#quotesearch ul li a[href*="http://quote.eastmoney.com/sh"]::text')
for stock in stocks_sh:
item['stock_id'] = 's_sh' + re.findall('\((.*?)\)', stock.extract())[0]
yield item
print "===============深圳================"
stocks_sz = response.css('div#quotesearch ul li a[href*="http://quote.eastmoney.com/sz"]::text')
for stock in stocks_sz:
item['stock_id'] = 's_sz' + re.findall('\((.*?)\)', stock.extract())[0]
yield item
奥秘在于response.css('div#quotesearch ul li a[href*=""]::text'),它使用css来过滤你需要的数据。
运行程序
scrapy crawl stock -o stock.csv
可以生成 stock.csv 文件
预览如下:
stock_id
s_sh201000
s_sh201001
s_sh201002
s_sh201003
s_sh201004
s_sh201005
s_sh201008
s_sh201009
s_sh201010
s_sh202001
s_sh202003
s_sh202007
s_sh203007
s_sh203008
s_sh203009
…
如果要查询单只股票的股价,可以使用新浪的股票界面:
例如
您可以获得浪潮软件的股票报价
var hq_str_s_sh600756="浪潮软件,19.790,1.140,6.11,365843,70869"; 查看全部
网页源代码抓取工具(安装scrapy抓取步骤选择网站-->编写spider
)
个人博客:
源地址:
爬虫:scrapy
刮痧介绍
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。
安装scrapy
pip install Scrapy
爬行步骤
选择一个 网站 --> 定义数据 --> 写蜘蛛
首先用scrapy创建一个项目
scrapy startproject tutorial
选择一个网站
这里我们选择东方财富网的股票代码页:
定义要抓取的数据
我们需要获取股票的股票代码ID,所以只需定义stock_id
class StockItem(scrapy.Item):
stock_id = scrapy.Field()
写蜘蛛
class StockSpider(scrapy.Spider):
name = 'stock'
def start_requests(self):
url = 'http://quote.eastmoney.com/stocklist.html'
yield Request(url)
def parse(self, response):
item = StockItem()
print "===============上海================"
stocks_sh = response.css('div#quotesearch ul li a[href*="http://quote.eastmoney.com/sh"]::text')
for stock in stocks_sh:
item['stock_id'] = 's_sh' + re.findall('\((.*?)\)', stock.extract())[0]
yield item
print "===============深圳================"
stocks_sz = response.css('div#quotesearch ul li a[href*="http://quote.eastmoney.com/sz"]::text')
for stock in stocks_sz:
item['stock_id'] = 's_sz' + re.findall('\((.*?)\)', stock.extract())[0]
yield item
奥秘在于response.css('div#quotesearch ul li a[href*=""]::text'),它使用css来过滤你需要的数据。
运行程序
scrapy crawl stock -o stock.csv
可以生成 stock.csv 文件
预览如下:
stock_id
s_sh201000
s_sh201001
s_sh201002
s_sh201003
s_sh201004
s_sh201005
s_sh201008
s_sh201009
s_sh201010
s_sh202001
s_sh202003
s_sh202007
s_sh203007
s_sh203008
s_sh203009
…
如果要查询单只股票的股价,可以使用新浪的股票界面:
例如
您可以获得浪潮软件的股票报价
var hq_str_s_sh600756="浪潮软件,19.790,1.140,6.11,365843,70869";
网页源代码抓取工具(网页分析工具(Chrome开发者工具)对网页进行抓包分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-18 15:01
在这个文章中,我们将尝试使用一个直观的网页分析工具(Chrome Developer Tools)来抓取和分析网页
1、测试环境
浏览器:Chrome浏览器
浏览器版本:67.0.3396.99(正式版)(32位)
网络分析工具:开发者工具
2、网页分析(1)网页源码分析
我们知道网页分为静态网页和动态网页。很多人误以为静态网页就是没有动态效果的网页。事实上,这种说法是错误的。
另外,目前很多动态网站都采用异步加载技术(Ajax),这也是为什么抓到的源码和网站显示的源码不一致的原因。
至于如何爬取动态网页,这里有两种方法:
下面以京东产品为例,分析如何通过Chrome抓包。我们先打开一个产品的首页
/…
进入网页空白处,右键,选择查看网页源代码(或使用快捷键Ctrl+U直接打开)
请注意查看网页源代码获取的是网站最原创的源代码,通常是我们抓取的源代码
再次进入网页空白处,右键选择Inspect(或使用快捷键Ctrl+Shift+I/F12直接打开)
请注意,检查结果是通过Ajax加载并通过JavaScript渲染的源代码,也就是网站当前显示的内容的源代码
经过对比我们可以发现两者的内容是不一样的,这是异步加载技术(Ajax)的典型例子
目前,至少京东产品的价格是异步加载生成的。这里有三种方法可以判断网页中的某个内容是否是动态生成的:
(2)网页抓包分析
下面以京东产品为例进行讲解,打开某款产品的首页,尝试抓取动态加载的产品价格数据
/…
使用快捷键Ctrl+Shift+I或F12打开开发者工具,然后选择Network选项卡进行抓包分析
此时按快捷键F5刷新页面。可以看到开发者工具中出现了各种包。我们使用过滤器来过滤包。
首先,我们选择Doc,我们可以看到列表中只出现了一个包
一般来说,这是浏览器接收到的第一个获取请求原创源代码的数据包网站
点击Header查看其header参数设置
单击响应以查看返回的源代码。不难发现,其实和查看网页源码返回的信息是一样的。
让我们回到主题。对于抓包的动态加载分析,我们主要看XHR和JS选项卡。
选择JS进行过滤,发现列表中有很多包。经过分析,我们过滤掉下图中标记的包。
这个包返回了关于价格的信息,但是仔细分析后发现这些价格不属于当前产品,而是属于相关产品。
但是怎么说这个包还是跟价格有关,我们先来看看这个包的请求URL。
https://p.3.cn/prices/mgets%3F ... em-pc
复制代码
过滤包括回调在内的不必要参数以获得简单有效的URL
https://p.3.cn/prices/mgets%3F ... 49638
复制代码
直接用浏览器打开网址,可以看到返回的JSON数据中收录价格信息(可惜是其他商品的价格)
通过分析URL的参数,可以推断出skuId应该是每个产品的唯一标识,那么在哪里可以找到我们需要的产品的skuId呢?
实际上,SKU是物流、运输等行业常用的缩写。它的全称是Stock Keeping Unit。
即库存进出计量的基本单位,现已扩展为统一产品编号的缩写。每个产品对应一个唯一的 SKU。
回顾我们刚开始的产品主页,/…
这不是隐藏了当前产品的唯一编号标识符()吗?试一试!
果然,访问商品价格的完整 URL 给我们,/prices/mget…
通过直接访问这个网址,我们可以得到当前产品的价格信息
其实我们也可以适当的泛化URL来适应京东所有产品的价格爬取
很简单,就是把skuIds分开作为参数,/prices/mget...
通过泛化的URL,理论上只要能获取到产品的skuId,我们就可以访问到对应产品的价格 查看全部
网页源代码抓取工具(网页分析工具(Chrome开发者工具)对网页进行抓包分析)
在这个文章中,我们将尝试使用一个直观的网页分析工具(Chrome Developer Tools)来抓取和分析网页
1、测试环境
浏览器:Chrome浏览器
浏览器版本:67.0.3396.99(正式版)(32位)
网络分析工具:开发者工具
2、网页分析(1)网页源码分析
我们知道网页分为静态网页和动态网页。很多人误以为静态网页就是没有动态效果的网页。事实上,这种说法是错误的。
另外,目前很多动态网站都采用异步加载技术(Ajax),这也是为什么抓到的源码和网站显示的源码不一致的原因。
至于如何爬取动态网页,这里有两种方法:
下面以京东产品为例,分析如何通过Chrome抓包。我们先打开一个产品的首页
/…
进入网页空白处,右键,选择查看网页源代码(或使用快捷键Ctrl+U直接打开)
请注意查看网页源代码获取的是网站最原创的源代码,通常是我们抓取的源代码
再次进入网页空白处,右键选择Inspect(或使用快捷键Ctrl+Shift+I/F12直接打开)
请注意,检查结果是通过Ajax加载并通过JavaScript渲染的源代码,也就是网站当前显示的内容的源代码
经过对比我们可以发现两者的内容是不一样的,这是异步加载技术(Ajax)的典型例子
目前,至少京东产品的价格是异步加载生成的。这里有三种方法可以判断网页中的某个内容是否是动态生成的:
(2)网页抓包分析
下面以京东产品为例进行讲解,打开某款产品的首页,尝试抓取动态加载的产品价格数据
/…
使用快捷键Ctrl+Shift+I或F12打开开发者工具,然后选择Network选项卡进行抓包分析
此时按快捷键F5刷新页面。可以看到开发者工具中出现了各种包。我们使用过滤器来过滤包。
首先,我们选择Doc,我们可以看到列表中只出现了一个包
一般来说,这是浏览器接收到的第一个获取请求原创源代码的数据包网站
点击Header查看其header参数设置
单击响应以查看返回的源代码。不难发现,其实和查看网页源码返回的信息是一样的。
让我们回到主题。对于抓包的动态加载分析,我们主要看XHR和JS选项卡。
选择JS进行过滤,发现列表中有很多包。经过分析,我们过滤掉下图中标记的包。
这个包返回了关于价格的信息,但是仔细分析后发现这些价格不属于当前产品,而是属于相关产品。
但是怎么说这个包还是跟价格有关,我们先来看看这个包的请求URL。
https://p.3.cn/prices/mgets%3F ... em-pc
复制代码
过滤包括回调在内的不必要参数以获得简单有效的URL
https://p.3.cn/prices/mgets%3F ... 49638
复制代码
直接用浏览器打开网址,可以看到返回的JSON数据中收录价格信息(可惜是其他商品的价格)
通过分析URL的参数,可以推断出skuId应该是每个产品的唯一标识,那么在哪里可以找到我们需要的产品的skuId呢?
实际上,SKU是物流、运输等行业常用的缩写。它的全称是Stock Keeping Unit。
即库存进出计量的基本单位,现已扩展为统一产品编号的缩写。每个产品对应一个唯一的 SKU。
回顾我们刚开始的产品主页,/…
这不是隐藏了当前产品的唯一编号标识符()吗?试一试!
果然,访问商品价格的完整 URL 给我们,/prices/mget…
通过直接访问这个网址,我们可以得到当前产品的价格信息
其实我们也可以适当的泛化URL来适应京东所有产品的价格爬取
很简单,就是把skuIds分开作为参数,/prices/mget...
通过泛化的URL,理论上只要能获取到产品的skuId,我们就可以访问到对应产品的价格
网页源代码抓取工具(Python实现简单网页图片抓取完整代码实例的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-17 19:17
想了解Python实现简单网页图片抓图及完整代码示例的相关内容吗?以后在这篇文章中,我会详细讲解Python实现简单网页图片抓取的相关知识以及一些代码示例。欢迎阅读和指正。我们先来关注一下:Python爬虫示例代码,python3爬虫示例代码一起学习
使用python抓取网页图片的步骤为:
1、根据给定的URL获取网页的源代码
2、使用正则表达式过滤掉源码中的图片地址
3、根据过滤后的图片URL下载网络图片
下面是一个比较简单的抓取某百度贴吧网页图片的实现:
# -*- coding: utf-8 -*-
# feimengjuan
import re
import urllib
import urllib2
#抓取网页图片
#根据给定的网址来获取网页详细信息得到的html就是网页的源代码
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
#利用正则表达式把源代码中的图片地址过滤出来
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址放在imglist中
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' %x) #打开imglist中保存的图片网址并下载图片保存在本地
x = x + 1
html = getHtml("http://tieba.baidu.com/p/2460150866")#获取该网址网页详细信息得到的html就是网页的源代码
getImg(html)#从网页源代码中分析并下载保存图片
代码进一步组织,在本地创建一个“图片”文件夹来保存图片
# -*- coding: utf-8 -*-
# feimengjuan
import re
import urllib
import urllib2
import os
#抓取网页图片
#根据给定的网址来获取网页详细信息得到的html就是网页的源代码
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
#创建保存图片的文件夹
def mkdir(path):
path = path.strip()
# 判断路径是否存在
# 存在 True
# 不存在 Flase
isExists = os.path.exists(path)
if not isExists:
print u'新建了名字叫做',path,u'的文件夹'
# 创建目录操作函数
os.makedirs(path)
return True
else:
# 如果目录存在则不创建并提示目录已经存在
print u'名为',path,u'的文件夹已经创建成功'
return False
# 输入文件名保存多张图片
def saveImages(imglist,name):
number = 1
for imageURL in imglist:
splitPath = imageURL.split('.')
fTail = splitPath.pop()
if len(fTail) > 3:
fTail = 'jpg'
fileName = name + "/" + str(number) + "." + fTail
# 对于每张图片地址进行保存
try:
u = urllib2.urlopen(imageURL)
data = u.read()
f = open(fileName,'wb+')
f.write(data)
print u'正在保存的一张图片为',fileName
f.close()
except urllib2.URLError as e:
print (e.reason)
number += 1
#获取网页中所有图片的地址
def getAllImg(html):
#利用正则表达式把源代码中的图片地址过滤出来
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址放在imglist中
return imglist
#创建本地保存文件夹并下载保存图片
if __name__ == '__main__':
html = getHtml("http://tieba.baidu.com/p/2460150866")#获取该网址网页详细信息得到的html就是网页的源代码
path = u'图片'
mkdir(path) #创建本地文件夹
imglist = getAllImg(html) #获取图片的地址列表
saveImages(imglist,path) # 保存图片
结果,“Pictures”文件夹中保存了几十张图片,比如截图:
总结
以上就是这篇关于Python中简单网页图像捕获的完整代码示例的全部内容。我希望它对每个人都有帮助。感兴趣的朋友可以继续参考本站:
Python爬虫实例爬取网站搞笑段子
python爬虫系列详解Selenium定向爬虎打篮球图片
如有不足之处,请留言指出。感谢您对本站的支持!
相关文章 查看全部
网页源代码抓取工具(Python实现简单网页图片抓取完整代码实例的相关内容吗)
想了解Python实现简单网页图片抓图及完整代码示例的相关内容吗?以后在这篇文章中,我会详细讲解Python实现简单网页图片抓取的相关知识以及一些代码示例。欢迎阅读和指正。我们先来关注一下:Python爬虫示例代码,python3爬虫示例代码一起学习
使用python抓取网页图片的步骤为:
1、根据给定的URL获取网页的源代码
2、使用正则表达式过滤掉源码中的图片地址
3、根据过滤后的图片URL下载网络图片
下面是一个比较简单的抓取某百度贴吧网页图片的实现:
# -*- coding: utf-8 -*-
# feimengjuan
import re
import urllib
import urllib2
#抓取网页图片
#根据给定的网址来获取网页详细信息得到的html就是网页的源代码
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
#利用正则表达式把源代码中的图片地址过滤出来
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址放在imglist中
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' %x) #打开imglist中保存的图片网址并下载图片保存在本地
x = x + 1
html = getHtml("http://tieba.baidu.com/p/2460150866";)#获取该网址网页详细信息得到的html就是网页的源代码
getImg(html)#从网页源代码中分析并下载保存图片
代码进一步组织,在本地创建一个“图片”文件夹来保存图片
# -*- coding: utf-8 -*-
# feimengjuan
import re
import urllib
import urllib2
import os
#抓取网页图片
#根据给定的网址来获取网页详细信息得到的html就是网页的源代码
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
#创建保存图片的文件夹
def mkdir(path):
path = path.strip()
# 判断路径是否存在
# 存在 True
# 不存在 Flase
isExists = os.path.exists(path)
if not isExists:
print u'新建了名字叫做',path,u'的文件夹'
# 创建目录操作函数
os.makedirs(path)
return True
else:
# 如果目录存在则不创建并提示目录已经存在
print u'名为',path,u'的文件夹已经创建成功'
return False
# 输入文件名保存多张图片
def saveImages(imglist,name):
number = 1
for imageURL in imglist:
splitPath = imageURL.split('.')
fTail = splitPath.pop()
if len(fTail) > 3:
fTail = 'jpg'
fileName = name + "/" + str(number) + "." + fTail
# 对于每张图片地址进行保存
try:
u = urllib2.urlopen(imageURL)
data = u.read()
f = open(fileName,'wb+')
f.write(data)
print u'正在保存的一张图片为',fileName
f.close()
except urllib2.URLError as e:
print (e.reason)
number += 1
#获取网页中所有图片的地址
def getAllImg(html):
#利用正则表达式把源代码中的图片地址过滤出来
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址放在imglist中
return imglist
#创建本地保存文件夹并下载保存图片
if __name__ == '__main__':
html = getHtml("http://tieba.baidu.com/p/2460150866";)#获取该网址网页详细信息得到的html就是网页的源代码
path = u'图片'
mkdir(path) #创建本地文件夹
imglist = getAllImg(html) #获取图片的地址列表
saveImages(imglist,path) # 保存图片
结果,“Pictures”文件夹中保存了几十张图片,比如截图:
总结
以上就是这篇关于Python中简单网页图像捕获的完整代码示例的全部内容。我希望它对每个人都有帮助。感兴趣的朋友可以继续参考本站:
Python爬虫实例爬取网站搞笑段子
python爬虫系列详解Selenium定向爬虎打篮球图片
如有不足之处,请留言指出。感谢您对本站的支持!
相关文章
网页源代码抓取工具(如何扒一个网站的源代码抓取工具_扒)
网站优化 • 优采云 发表了文章 • 0 个评论 • 466 次浏览 • 2022-01-16 21:00
网页源代码抓取工具_扒网页源代码网站爬虫_扒网页源代码python抓取工具-五十行一百美元,用python扒完教你如何扒一个网站的源代码。上面这三个要扒的内容以及所需工具你先好好学习,等到入门之后再谈。
电商网站的话直接上天眼查,可以直接在线抓取电商数据。
fiddler或者xlib应该是比较实用的一个吧,网站或者是数据库,以及还有就是一些电商的数据。
电商的话直接shell伺候
小网站可以使用qq群:技术栈成长帮,里面有很多大神总结的网站源代码,里面有很多大神总结的网站源代码。基本都有备份,免费,只要人多。作为福利,
所有的网站通用了一个东西,
方便大家一起学习提升,在线免费哦!资料名称:轻松获取网站源代码方法1.首先进入【选项】>【校验规则】>【isauthorization】,进入查看规则界面;2.在“明确规则”下,点击【提示错误】进入错误信息界面;3.在错误提示信息界面,点击【提示错误】进入错误提示界面;4.在错误提示界面,点击【我正在查找规则】进入查找规则界面;5.在找到规则后,点击【添加规则】完成规则添加。6.完成规则添加,点击【浏览浏览】保存规则文件,即可获取到原始网站网页源代码啦!网站截图如下:。 查看全部
网页源代码抓取工具(如何扒一个网站的源代码抓取工具_扒)
网页源代码抓取工具_扒网页源代码网站爬虫_扒网页源代码python抓取工具-五十行一百美元,用python扒完教你如何扒一个网站的源代码。上面这三个要扒的内容以及所需工具你先好好学习,等到入门之后再谈。
电商网站的话直接上天眼查,可以直接在线抓取电商数据。
fiddler或者xlib应该是比较实用的一个吧,网站或者是数据库,以及还有就是一些电商的数据。
电商的话直接shell伺候
小网站可以使用qq群:技术栈成长帮,里面有很多大神总结的网站源代码,里面有很多大神总结的网站源代码。基本都有备份,免费,只要人多。作为福利,
所有的网站通用了一个东西,
方便大家一起学习提升,在线免费哦!资料名称:轻松获取网站源代码方法1.首先进入【选项】>【校验规则】>【isauthorization】,进入查看规则界面;2.在“明确规则”下,点击【提示错误】进入错误信息界面;3.在错误提示信息界面,点击【提示错误】进入错误提示界面;4.在错误提示界面,点击【我正在查找规则】进入查找规则界面;5.在找到规则后,点击【添加规则】完成规则添加。6.完成规则添加,点击【浏览浏览】保存规则文件,即可获取到原始网站网页源代码啦!网站截图如下:。
网页源代码抓取工具(网站TDKT标题标签基本上网站的标题())
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-15 13:01
网站TDK告诉百度这个页面在抓取网站的时候做了什么,让百度知道。网站的质量可以从网站的TDK中看出,所以TDK的设置也是网站的重要一环。那么在优化网站的TDK时有哪些注意事项呢?下面的SEO优化器带你来看看。
网站TDK
T 标题标签
基本上网站的标题是用网站的公司名称关键词+网站,区分关键词的符号,可以是用“,(英文)”隔开,然后关键词可以和网站的名字用小横线“-”连接起来。网站标题设置的关键词不宜过多。一般推荐 3~4 个 关键词28 个字符。可以使用分词显示更多关键词没问题。因为百度对标题的索引是28字左右,所以在搜索结果网站写了关键词28字以外的字太多,就不显示了。一般建议把重要的关键词放在标题的左边,
D 描述标签
网站的description标签其实是对网站页面的简要描述,显示在网站源码页面的title标签下方,网站的description标签是网站长尾词个数和网站标题标签同时显示结果的总列表。因为一个网站描述的好坏会直接影响到网站的搜索量的点击量,所以大家不要写超过80字,超过的字数不会显示。
K关键词 标签
网站的关键词也叫关键词,它在网站中的作用是告诉百度这个网站主要抓取的关键内容。标签的关键词 应该简洁明了。使用 ", (English)" 分隔多个 关键词。关键词最好设置在3以内。网站发展到比较高的权重后可以增加到5左右。切记关键词不要重复也不要堆积,否则会会影响网站的权重,导致关键词的排名下降。
以上是SEO优化人员在优化网站TDK时给大家讲解的内容。一般来说,写一个好的TDK会对网站的质量和关键词的排名有很大的提升,也可以参考《SEO优化教你进一步提升网站@ > 排名”,让您的 网站 更上一层楼。希望此内容对大家有所帮助,如有不清楚的可以联系点击客服,我们将24小时竭诚为您服务。 查看全部
网页源代码抓取工具(网站TDKT标题标签基本上网站的标题())
网站TDK告诉百度这个页面在抓取网站的时候做了什么,让百度知道。网站的质量可以从网站的TDK中看出,所以TDK的设置也是网站的重要一环。那么在优化网站的TDK时有哪些注意事项呢?下面的SEO优化器带你来看看。
网站TDK
T 标题标签
基本上网站的标题是用网站的公司名称关键词+网站,区分关键词的符号,可以是用“,(英文)”隔开,然后关键词可以和网站的名字用小横线“-”连接起来。网站标题设置的关键词不宜过多。一般推荐 3~4 个 关键词28 个字符。可以使用分词显示更多关键词没问题。因为百度对标题的索引是28字左右,所以在搜索结果网站写了关键词28字以外的字太多,就不显示了。一般建议把重要的关键词放在标题的左边,
D 描述标签
网站的description标签其实是对网站页面的简要描述,显示在网站源码页面的title标签下方,网站的description标签是网站长尾词个数和网站标题标签同时显示结果的总列表。因为一个网站描述的好坏会直接影响到网站的搜索量的点击量,所以大家不要写超过80字,超过的字数不会显示。
K关键词 标签
网站的关键词也叫关键词,它在网站中的作用是告诉百度这个网站主要抓取的关键内容。标签的关键词 应该简洁明了。使用 ", (English)" 分隔多个 关键词。关键词最好设置在3以内。网站发展到比较高的权重后可以增加到5左右。切记关键词不要重复也不要堆积,否则会会影响网站的权重,导致关键词的排名下降。
以上是SEO优化人员在优化网站TDK时给大家讲解的内容。一般来说,写一个好的TDK会对网站的质量和关键词的排名有很大的提升,也可以参考《SEO优化教你进一步提升网站@ > 排名”,让您的 网站 更上一层楼。希望此内容对大家有所帮助,如有不清楚的可以联系点击客服,我们将24小时竭诚为您服务。
网页源代码抓取工具( 解码后三种本篇将不做详述requests模块())
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-15 12:30
解码后三种本篇将不做详述requests模块())
import urllib.request
# 打开指定需要爬取的网页
response=urllib.request.urlopen('http://www.baidu.com')
# 或者是
# from urllib import request
# response = request.urlopen('http://www.baidu.com')
# 打印网页源代码
print(response.read().decode())
添加decode()是为了避免下图中的十六进制内容
添加 decode() 进行解码后
以下三个本文不再详细介绍
请求模块
requests 模块是一种在 python 中实现 HTTP 请求的方法。它是一个第三方模块。该模块在实现HTTP请求时比urllib模块简单很多,操作也更加人性化。
以 GET 请求为例:
import requests
response = requests.get('http://www.baidu.com/')
print('状态码:', response.status_code)
print('请求地址:', response.url)
print('头部信息:', response.headers)
print('cookie信息:', response.cookies)
# print('文本源码:', response.text)
# print('字节流源码:', response.content)
输出如下:
状态码: 200
请求地址: http://www.baidu.com/
头部信息: {'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform', 'Connection': 'keep-alive', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html', 'Date': 'Sun, 10 May 2020 02:43:33 GMT', 'Last-Modified': 'Mon, 23 Jan 2017 13:28:23 GMT', 'Pragma': 'no-cache', 'Server': 'bfe/1.0.8.18', 'Set-Cookie': 'BDORZ=27315; max-age=86400; domain=.baidu.com; path=/', 'Transfer-Encoding': 'chunked'}
cookie信息:
这里解释一下response.text和response.content的区别
以 POST 请求为例
import requests
data={'word':'hello'}
response = requests.post('http://www.baidu.com',data=data)
print(response.content)
请求头处理
当爬取页面使用反爬虫设置来防止恶意的采集信息,从而拒绝用户访问时,我们可以通过模拟浏览器的头部信息进行访问,可以解决反爬虫设置的问题。.
通过浏览器进入指定网页,鼠标右键,选择“检查”,选择“网络”,刷新页面选择第一条消息,右侧消息头面板会显示下图中的请求头信息
例如:
import requests
url = 'https://www.bilibili.com/'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'}
response = requests.get(url, headers=headers)
print(response.content.decode())
网络超时
访问页面时,如果页面长时间没有响应,系统会判断页面超时,无法打开页面。
例如:
import requests
url = 'http://www.baidu.com'
# 循环发送请求50次
for a in range(0, 50):
try:
# timeout数值可根据用户当前网速,自行设置
response = requests.get(url, timeout=0.03) # 设置超时为0.03
print(response.status_code)
except Exception as e:
print('异常'+str(e)) # 打印异常信息
部分输出如下:
代理服务
设置代理IP可以解决不久前可以抓取的网页现在不能抓取,然后报错——连接尝试失败,因为连接方一段时间后没有正确回复或者连接的主机没有响应。
例如:
import requests
# 设置代理IP
proxy = {'http': '117.45.139.139:9006',
'https': '121.36.210.88:8080'
}
# 发送请求
url = 'https://www.baidu.com'
response = requests.get(url, proxies=proxy)
# 也就是说如果想取文本数据可以通过response.text
# 如果想取图片,文件,则可以通过 response.content
# 以字节流的形式打印网页源代码,bytes类型
print(response.content.decode())
# 以文本的形式打印网页源代码,为str类型
print(response.text) # 默认”iso-8859-1”编码,服务器不指定的话是根据网页的响应来猜测编码。
美丽的汤模块
Beautiful Soup 模块是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。Beautiful Soup 模块自动将输入文档转换为 Unicode 编码,将输出文档转换为 UTF-8 编码。不需要考虑编码方式,除非文档没有指定编码方式。在这种情况下,Beautiful Soup 无法自动识别编码方式。然后,只需说明原创编码即可。
例如:
from bs4 import BeautifulSoup
html_doc = """
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
# 创建对象
soup = BeautifulSoup(html_doc, features='lxml')
# 或者创建对象打开需要解析的html文件
# soup = BeautifulSoup(open('index.html'), features='lxml')
print('源代码为:', soup)# 打印解析的HTML代码</p>
结果如下:
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
</p>
用美汤爬百度首页标题
from bs4 import BeautifulSoup
import requests
response = requests.get('http://news.baidu.com')
soup = BeautifulSoup(response.text, features='lxml')
print(soup.find('title').text)
结果如下:
百度新闻-海量中文信息平台
最后,希望大家喜欢,给我点个赞吧! 查看全部
网页源代码抓取工具(
解码后三种本篇将不做详述requests模块())
import urllib.request
# 打开指定需要爬取的网页
response=urllib.request.urlopen('http://www.baidu.com')
# 或者是
# from urllib import request
# response = request.urlopen('http://www.baidu.com')
# 打印网页源代码
print(response.read().decode())
添加decode()是为了避免下图中的十六进制内容
添加 decode() 进行解码后
以下三个本文不再详细介绍
请求模块
requests 模块是一种在 python 中实现 HTTP 请求的方法。它是一个第三方模块。该模块在实现HTTP请求时比urllib模块简单很多,操作也更加人性化。
以 GET 请求为例:
import requests
response = requests.get('http://www.baidu.com/')
print('状态码:', response.status_code)
print('请求地址:', response.url)
print('头部信息:', response.headers)
print('cookie信息:', response.cookies)
# print('文本源码:', response.text)
# print('字节流源码:', response.content)
输出如下:
状态码: 200
请求地址: http://www.baidu.com/
头部信息: {'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform', 'Connection': 'keep-alive', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html', 'Date': 'Sun, 10 May 2020 02:43:33 GMT', 'Last-Modified': 'Mon, 23 Jan 2017 13:28:23 GMT', 'Pragma': 'no-cache', 'Server': 'bfe/1.0.8.18', 'Set-Cookie': 'BDORZ=27315; max-age=86400; domain=.baidu.com; path=/', 'Transfer-Encoding': 'chunked'}
cookie信息:
这里解释一下response.text和response.content的区别
以 POST 请求为例
import requests
data={'word':'hello'}
response = requests.post('http://www.baidu.com',data=data)
print(response.content)
请求头处理
当爬取页面使用反爬虫设置来防止恶意的采集信息,从而拒绝用户访问时,我们可以通过模拟浏览器的头部信息进行访问,可以解决反爬虫设置的问题。.
通过浏览器进入指定网页,鼠标右键,选择“检查”,选择“网络”,刷新页面选择第一条消息,右侧消息头面板会显示下图中的请求头信息
例如:
import requests
url = 'https://www.bilibili.com/'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'}
response = requests.get(url, headers=headers)
print(response.content.decode())
网络超时
访问页面时,如果页面长时间没有响应,系统会判断页面超时,无法打开页面。
例如:
import requests
url = 'http://www.baidu.com'
# 循环发送请求50次
for a in range(0, 50):
try:
# timeout数值可根据用户当前网速,自行设置
response = requests.get(url, timeout=0.03) # 设置超时为0.03
print(response.status_code)
except Exception as e:
print('异常'+str(e)) # 打印异常信息
部分输出如下:
代理服务
设置代理IP可以解决不久前可以抓取的网页现在不能抓取,然后报错——连接尝试失败,因为连接方一段时间后没有正确回复或者连接的主机没有响应。
例如:
import requests
# 设置代理IP
proxy = {'http': '117.45.139.139:9006',
'https': '121.36.210.88:8080'
}
# 发送请求
url = 'https://www.baidu.com'
response = requests.get(url, proxies=proxy)
# 也就是说如果想取文本数据可以通过response.text
# 如果想取图片,文件,则可以通过 response.content
# 以字节流的形式打印网页源代码,bytes类型
print(response.content.decode())
# 以文本的形式打印网页源代码,为str类型
print(response.text) # 默认”iso-8859-1”编码,服务器不指定的话是根据网页的响应来猜测编码。
美丽的汤模块
Beautiful Soup 模块是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。Beautiful Soup 模块自动将输入文档转换为 Unicode 编码,将输出文档转换为 UTF-8 编码。不需要考虑编码方式,除非文档没有指定编码方式。在这种情况下,Beautiful Soup 无法自动识别编码方式。然后,只需说明原创编码即可。
例如:
from bs4 import BeautifulSoup
html_doc = """
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
# 创建对象
soup = BeautifulSoup(html_doc, features='lxml')
# 或者创建对象打开需要解析的html文件
# soup = BeautifulSoup(open('index.html'), features='lxml')
print('源代码为:', soup)# 打印解析的HTML代码</p>
结果如下:
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
</p>
用美汤爬百度首页标题
from bs4 import BeautifulSoup
import requests
response = requests.get('http://news.baidu.com')
soup = BeautifulSoup(response.text, features='lxml')
print(soup.find('title').text)
结果如下:
百度新闻-海量中文信息平台
最后,希望大家喜欢,给我点个赞吧!

