
网页源代码抓取工具
网页源代码抓取工具(.1请求方式及相关工具解析(2015年03月23日))
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-04-18 19:12
请求收录:请求头、请求体等。
2.2 获取响应内容
如果服务器能正常响应,就会得到一个Response
响应收录:html、json、图片、视频等。
2.3 内容类型分析及相关工具
解析html数据:正则表达式、Beautifulsoup、pyquery等第三方解析库。
解析json数据:json模块
解析二进制数据:作为 b 写入文件
2.4 保存数据
根据需要将数据保存到数据库或文件
三、请求和响应
ps:浏览器收到Response后会解析其内容展示给用户,爬虫程序模拟浏览器发送请求再接收Response后提取有用数据。
四、请求4.1 请求方法
常用请求方式:GET、POST
其他请求方式:HEAD、PUT、DELETE、OPTHONS
ps:用浏览器演示get与post的区别,(用登录演示post)
1 post与get请求最终都会拼接成这种形式:k1=xxx&k2=yyy&k3=zzz
2 post请求的参数放在请求体内,可用浏览器查看,存放于form data内
3 get请求的参数直接放在url后
4.2 请求地址
url的全称是Uniform Resource Locator,比如网页文档、图片、视频等都可以由url唯一确定
url编码:https://www.baidu.com/s?wd=图片
网页的加载过程是:加载一个网页,通常都是先加载document文档,在解析document文档的时候,遇到链接,则针对超链接发起下载图片的请求
4.3 请求头
User-agent:如果请求头中没有user-agent客户端配置,服务器可能会将你视为非法用户
host:客户端指定要访问的http服务器的域名/IP地址和端口号
cookie:cookie用于存储登录信息
一般做爬虫都会加上请求头
4.4 请求正文
如果是get方法,请求体没有内容
如果是post方式,请求体为格式数据
ps:
1、登录窗口,文件上传等,信息都会被附加到请求体内
2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
#示例:
from urllib.parse import urlencode
import requests
headers={
\'Accept\':\'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\',
\'Cookie\':\'H_WISE_SIDS=101556_115474_115442_114743_108373_100099_115725_106201_107320_115339_114797_115553_116093_115546_115625_115446_114329_115350_114275_116040_110085; PSTM=1494300712; BAIDUID=42FE2934E37AF7AD1FA31D8CC7006D45:FG=1; BIDUPSID=2996557DB2710279BD865C50F9A68615; MCITY=-%3A; __cfduid=da9f97dea6458ca26aa4278280752ebb01508939712; BDSFRCVID=PGLsJeCCxG3wt_3ZUrBLDfv2D_qBZSjAgcEe3J; H_BDCLCKID_SF=tJAOoCLytI03qn5zq4Oh-4oHhxoJq5QxbT7Z0l8KtfcNVJQs-lCMhbtp-l3GJPoLWK6hBKQmWIQHDnbsbq0M2tcQXR5-WROCte74KKJx-4PWeIJo5tKh04JbhUJiB5OLBan7Lq7xfDDbbDtmej_3-PC3ql6354Rj2C_X3b7EfKjIOtO_bfbT2MbyeqrNQlTkLIvXoITJQD_bEP3Fbfj2DPQ3KabZqjDjJbue_I05f-oqebT4btbMqRtthf5KeJ3KaKrKW5rJabC3hPJeKU6qLT5Xjh6B5qDfyDoAbKOt-IOjhb5hMpnx-p0njxQyaR3RL2Kj0p_EWpcxsCQqLUonDh8L3H7MJUntKjnRonTO5hvvhb6O3M7-XpOhDG0fJjtJJbksQJ5e24oqHP-kKPrV-4oH5MQy5toyHD7yWCvjWlT5OR5Jj6KMjMkb3xbz2fcpMIrjob8M5CQESInv3MA--fcLD2ch5-3eQgTI3fbIJJjWsq0x0-jle-bQypoa-U0j2COMahkMal7xO-QO05CaD53yDNDqtjn-5TIX_CjJbnA_Hn7zepoxebtpbt-qJJjzMerW_Mc8QUJBH4tR-T3keh-83xbnBT5KaKO2-RnPXbcWjt_lWh_bLf_kQN3TbxuO5bRiL66I0h6jDn3oyT3VXp0n54nTqjDHfRuDVItXf-L_qtDk-PnVeUP3DhbZKxtqtDKjXJ7X2fclHJ7z-R3IBPCD0tjk-6JnWncKaRcI3poiqKtmjJb6XJkl2HQ405OT-6-O0KJcbRodobAwhPJvyT8DXnO7-fRTfJuJ_DDMJDD3fP36q4QV-JIehmT22jnT32JeaJ5n0-nnhP3mBTbA3JDYX-Oh-jjRX56GhfO_0R3jsJKRy66jK4JKjHKet6vP; ispeed_lsm=0; H_PS_PSSID=1421_24558_21120_17001_24880_22072; BD_UPN=123253; H_PS_645EC=44be6I1wqYYVvyugm2gc3PK9PoSa26pxhzOVbeQrn2rRadHvKoI%2BCbN5K%2Bg; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598\',
\'Host\':\'www.baidu.com\',
\'User-Agent\':\'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36\'}
# response=requests.get(\'https://www.baidu.com/s?\'+urlencode({\'wd\':\'美女\'}),headers=headers)
response=requests.get(\'https://www.baidu.com/s\',params={\'wd\':\'美女\'},headers=headers) #params内部就是调用urlencode
print(response.text)
五、Response5.1 普通响应状态码
详情见博客:#%E4%B8%83%E3%80%81%E7%8A%B6%E6%80%81%E7%A0%81
200:代表成功
301:代表跳跃
404:文件不存在
403:权限
502:服务器错误
5.2 响应头
set-cookie:可能有多个,告诉浏览器保存cookie
5.3预览是网页的源代码
主要部分收录请求资源的内容,如网页html、图片、二进制数据等。
六、总结6.1 总结爬虫流程
抓取--->解析--->存储
6.2 爬虫所需的工具
请求库:requests, selenium
解析库:regular、beautifulsoup、pyquery
存储库:文件、MySQL、Mongodb、Redis
6.3 常用爬虫框架
1、Scrapy:Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。是一个非常强大的爬虫框架,可以满足简单的页面爬取,比如可以清楚知道url格式的情况。使用此框架可以轻松爬取亚马逊列表等数据。但是对于稍微复杂一点的页面,比如微博的页面信息,这个框架就不能满足需求了。它的特点是:HTML、XML源数据选择和内置的提取支持;提供了一系列可重用的过滤器(即Item Loaders)在spider之间共享,并为爬取数据的智能处理提供内置支持。
2、Crawley:高速爬取网站对应的内容,支持关系型和非关系型数据库,数据可以导出为JSON、XML等。
3、Portia:是一款开源的可视化爬虫工具,用户无需任何编程知识即可爬取网站!只需对您感兴趣的页面进行注释,Portia 就会创建一个爬虫来从相似页面中提取数据。简单来说就是基于scrapy内核;在没有任何开发专业知识的情况下直观地抓取内容;动态匹配同一模板的内容。
4、newspaper:可用于新闻提取、文章和内容分析。使用多线程,支持 10 多种语言等。作者从 requests 库的简单性和强大功能中汲取灵感,这是一个用 Python 开发的可用于提取 文章 内容的程序。支持10多种语言,全部采用unicode编码。
5、Python-goose:一个用Java编写的文章提取工具。Python-goose 框架可以提取的信息包括:文章 主内容、文章 主图像、文章 中嵌入的任何 Youtube/Vimeo 视频、元描述、元标记。
6、美汤:很有名,集成了一些常见的爬虫需求。它是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它支持通过您最喜欢的转换器导航、查找和修改文档的惯用方式。Beautiful Soup 将为您节省数小时甚至数天的工作时间。Beautiful Soup 的缺点是不能加载 JS。
7、mechanize:有加载JS的优势。当然,它也有缺点,例如严重缺乏文档。但是通过官方的例子和人肉尝试的方法,还是勉强能用。
8、selenium:这是一个调用浏览器的驱动程序。有了这个库,你可以直接调用浏览器完成某些操作,比如输入验证码。Selenium 是一种自动化测试工具。支持多种浏览器,包括Chrome、Safari、Firefox等主流界面浏览器。如果在这些浏览器中安装 Selenium 插件,就可以轻松实现 Web 界面测试。Selenium 支持浏览驱动器。Selenium支持多种语言开发,如Java、C、Ruby等。PhantomJS用于渲染和解析JS,Selenium用于驱动和与Python接口,Python用于后处理。
9、cola:是一个分布式爬虫框架。对于用户来说,只需要写几个具体的函数,不需要关注分布式操作的细节。任务自动分发到多台机器上,整个过程对用户透明。项目整体设计有点差,模块之间耦合度高。
10、PySpider:一个强大的网络爬虫系统,一个中国人写的,强大的WebUI。用 Python 语言编写,分布式架构,支持多种数据库后端,强大的 WebUI 支持脚本编辑器、任务监视器、项目管理器和结果查看器。Python脚本控件,可以使用任何你喜欢的html解析包。 查看全部
网页源代码抓取工具(.1请求方式及相关工具解析(2015年03月23日))
请求收录:请求头、请求体等。
2.2 获取响应内容
如果服务器能正常响应,就会得到一个Response
响应收录:html、json、图片、视频等。
2.3 内容类型分析及相关工具
解析html数据:正则表达式、Beautifulsoup、pyquery等第三方解析库。
解析json数据:json模块
解析二进制数据:作为 b 写入文件
2.4 保存数据
根据需要将数据保存到数据库或文件
三、请求和响应
ps:浏览器收到Response后会解析其内容展示给用户,爬虫程序模拟浏览器发送请求再接收Response后提取有用数据。
四、请求4.1 请求方法
常用请求方式:GET、POST
其他请求方式:HEAD、PUT、DELETE、OPTHONS
ps:用浏览器演示get与post的区别,(用登录演示post)
1 post与get请求最终都会拼接成这种形式:k1=xxx&k2=yyy&k3=zzz
2 post请求的参数放在请求体内,可用浏览器查看,存放于form data内
3 get请求的参数直接放在url后
4.2 请求地址
url的全称是Uniform Resource Locator,比如网页文档、图片、视频等都可以由url唯一确定
url编码:https://www.baidu.com/s?wd=图片
网页的加载过程是:加载一个网页,通常都是先加载document文档,在解析document文档的时候,遇到链接,则针对超链接发起下载图片的请求
4.3 请求头
User-agent:如果请求头中没有user-agent客户端配置,服务器可能会将你视为非法用户
host:客户端指定要访问的http服务器的域名/IP地址和端口号
cookie:cookie用于存储登录信息
一般做爬虫都会加上请求头
4.4 请求正文
如果是get方法,请求体没有内容
如果是post方式,请求体为格式数据
ps:
1、登录窗口,文件上传等,信息都会被附加到请求体内
2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
#示例:
from urllib.parse import urlencode
import requests
headers={
\'Accept\':\'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\',
\'Cookie\':\'H_WISE_SIDS=101556_115474_115442_114743_108373_100099_115725_106201_107320_115339_114797_115553_116093_115546_115625_115446_114329_115350_114275_116040_110085; PSTM=1494300712; BAIDUID=42FE2934E37AF7AD1FA31D8CC7006D45:FG=1; BIDUPSID=2996557DB2710279BD865C50F9A68615; MCITY=-%3A; __cfduid=da9f97dea6458ca26aa4278280752ebb01508939712; BDSFRCVID=PGLsJeCCxG3wt_3ZUrBLDfv2D_qBZSjAgcEe3J; H_BDCLCKID_SF=tJAOoCLytI03qn5zq4Oh-4oHhxoJq5QxbT7Z0l8KtfcNVJQs-lCMhbtp-l3GJPoLWK6hBKQmWIQHDnbsbq0M2tcQXR5-WROCte74KKJx-4PWeIJo5tKh04JbhUJiB5OLBan7Lq7xfDDbbDtmej_3-PC3ql6354Rj2C_X3b7EfKjIOtO_bfbT2MbyeqrNQlTkLIvXoITJQD_bEP3Fbfj2DPQ3KabZqjDjJbue_I05f-oqebT4btbMqRtthf5KeJ3KaKrKW5rJabC3hPJeKU6qLT5Xjh6B5qDfyDoAbKOt-IOjhb5hMpnx-p0njxQyaR3RL2Kj0p_EWpcxsCQqLUonDh8L3H7MJUntKjnRonTO5hvvhb6O3M7-XpOhDG0fJjtJJbksQJ5e24oqHP-kKPrV-4oH5MQy5toyHD7yWCvjWlT5OR5Jj6KMjMkb3xbz2fcpMIrjob8M5CQESInv3MA--fcLD2ch5-3eQgTI3fbIJJjWsq0x0-jle-bQypoa-U0j2COMahkMal7xO-QO05CaD53yDNDqtjn-5TIX_CjJbnA_Hn7zepoxebtpbt-qJJjzMerW_Mc8QUJBH4tR-T3keh-83xbnBT5KaKO2-RnPXbcWjt_lWh_bLf_kQN3TbxuO5bRiL66I0h6jDn3oyT3VXp0n54nTqjDHfRuDVItXf-L_qtDk-PnVeUP3DhbZKxtqtDKjXJ7X2fclHJ7z-R3IBPCD0tjk-6JnWncKaRcI3poiqKtmjJb6XJkl2HQ405OT-6-O0KJcbRodobAwhPJvyT8DXnO7-fRTfJuJ_DDMJDD3fP36q4QV-JIehmT22jnT32JeaJ5n0-nnhP3mBTbA3JDYX-Oh-jjRX56GhfO_0R3jsJKRy66jK4JKjHKet6vP; ispeed_lsm=0; H_PS_PSSID=1421_24558_21120_17001_24880_22072; BD_UPN=123253; H_PS_645EC=44be6I1wqYYVvyugm2gc3PK9PoSa26pxhzOVbeQrn2rRadHvKoI%2BCbN5K%2Bg; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598\',
\'Host\':\'www.baidu.com\',
\'User-Agent\':\'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36\'}
# response=requests.get(\'https://www.baidu.com/s?\'+urlencode({\'wd\':\'美女\'}),headers=headers)
response=requests.get(\'https://www.baidu.com/s\',params={\'wd\':\'美女\'},headers=headers) #params内部就是调用urlencode
print(response.text)
五、Response5.1 普通响应状态码
详情见博客:#%E4%B8%83%E3%80%81%E7%8A%B6%E6%80%81%E7%A0%81
200:代表成功
301:代表跳跃
404:文件不存在
403:权限
502:服务器错误
5.2 响应头
set-cookie:可能有多个,告诉浏览器保存cookie
5.3预览是网页的源代码
主要部分收录请求资源的内容,如网页html、图片、二进制数据等。
六、总结6.1 总结爬虫流程
抓取--->解析--->存储
6.2 爬虫所需的工具
请求库:requests, selenium
解析库:regular、beautifulsoup、pyquery
存储库:文件、MySQL、Mongodb、Redis
6.3 常用爬虫框架
1、Scrapy:Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。是一个非常强大的爬虫框架,可以满足简单的页面爬取,比如可以清楚知道url格式的情况。使用此框架可以轻松爬取亚马逊列表等数据。但是对于稍微复杂一点的页面,比如微博的页面信息,这个框架就不能满足需求了。它的特点是:HTML、XML源数据选择和内置的提取支持;提供了一系列可重用的过滤器(即Item Loaders)在spider之间共享,并为爬取数据的智能处理提供内置支持。
2、Crawley:高速爬取网站对应的内容,支持关系型和非关系型数据库,数据可以导出为JSON、XML等。
3、Portia:是一款开源的可视化爬虫工具,用户无需任何编程知识即可爬取网站!只需对您感兴趣的页面进行注释,Portia 就会创建一个爬虫来从相似页面中提取数据。简单来说就是基于scrapy内核;在没有任何开发专业知识的情况下直观地抓取内容;动态匹配同一模板的内容。
4、newspaper:可用于新闻提取、文章和内容分析。使用多线程,支持 10 多种语言等。作者从 requests 库的简单性和强大功能中汲取灵感,这是一个用 Python 开发的可用于提取 文章 内容的程序。支持10多种语言,全部采用unicode编码。
5、Python-goose:一个用Java编写的文章提取工具。Python-goose 框架可以提取的信息包括:文章 主内容、文章 主图像、文章 中嵌入的任何 Youtube/Vimeo 视频、元描述、元标记。
6、美汤:很有名,集成了一些常见的爬虫需求。它是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它支持通过您最喜欢的转换器导航、查找和修改文档的惯用方式。Beautiful Soup 将为您节省数小时甚至数天的工作时间。Beautiful Soup 的缺点是不能加载 JS。
7、mechanize:有加载JS的优势。当然,它也有缺点,例如严重缺乏文档。但是通过官方的例子和人肉尝试的方法,还是勉强能用。
8、selenium:这是一个调用浏览器的驱动程序。有了这个库,你可以直接调用浏览器完成某些操作,比如输入验证码。Selenium 是一种自动化测试工具。支持多种浏览器,包括Chrome、Safari、Firefox等主流界面浏览器。如果在这些浏览器中安装 Selenium 插件,就可以轻松实现 Web 界面测试。Selenium 支持浏览驱动器。Selenium支持多种语言开发,如Java、C、Ruby等。PhantomJS用于渲染和解析JS,Selenium用于驱动和与Python接口,Python用于后处理。
9、cola:是一个分布式爬虫框架。对于用户来说,只需要写几个具体的函数,不需要关注分布式操作的细节。任务自动分发到多台机器上,整个过程对用户透明。项目整体设计有点差,模块之间耦合度高。
10、PySpider:一个强大的网络爬虫系统,一个中国人写的,强大的WebUI。用 Python 语言编写,分布式架构,支持多种数据库后端,强大的 WebUI 支持脚本编辑器、任务监视器、项目管理器和结果查看器。Python脚本控件,可以使用任何你喜欢的html解析包。
网页源代码抓取工具(如何将网站中的图片存储到本地呢(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 427 次浏览 • 2022-04-16 02:23
)
我相信PPT可能会经常用到你的工作中。你在PPT制作过程中是否有这样的困惑,即在哪里可以找到高清且无版权的图片素材?我强烈推荐 ColorHub,一个允许个人和商业使用的免费图片 网站,真的很酷!从她的主页界面来看,说不定你会爱上她。
那么,如何将网站中的图片保存在本地(比如我比较关心数据相关的素材)?可以的话,你可以选择漂亮的图片,不用网络随心所欲地制作PPT,随时随地查看自己的图片库。本文想和大家分享的是这个问题的解决方法。
爬行动物的想法
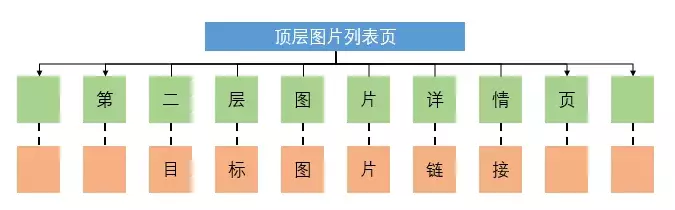
我们知道,对于图片网站的爬取,往往需要经过三层网页链接。为了直观的理解这三层链接,可以查看下图:
顶级页面:是指你通过网站首页的搜索栏搜索到你感兴趣的图片方向后进入的图片列表页面。它看起来是这样的:
二级页面:指点击图片列表页面中的一张图片,跳转到对应的图片详情页面,如下所示:
目标页面:最后就是在图片详情页抓取高清图片,而这张图片是网页源代码中的图片链接。它看起来像这样:
因此,爬取图片的最终目的是找到高清图片对应的链接。接下来通过代码的介绍,呈现三层链路的查找和请求过程。每一行代码都会用中文解释。如有其他问题,可以在留言区留言,我会尽快回复您。
# 导入第三方包
import
requests
from
bs4
import
BeautifulSoup
import
random
import
time
from
fake_useragent
import
UserAgent
# 通过循环实现多页图片的抓取
for
page
in
range(
1
,
11
):
# 生成顶层图片列表页的链接
fst_url = r
'https://colorhub.me/search?tag=data&page={}'
.format(page)
# 生成UA,用于爬虫请求头的设置
UA =
UserAgent
()
# 向顶层链接发送请求
fst_response = requests.get(fst_url, headers = {
'User-Agent'
:UA.random})
# 解析顶层链接的源代码
fst_soup =
BeautifulSoup
(fst_response.text)
# 根据HTML的标记规则,返回次层图片详情页的链接和图片名称
sec_urls = [i.find(
'a'
)[
'href'
]
for
i
in
fst_soup.findAll(name =
'div'
, attrs = {
'class'
:
'card'
})]
pic_names = [i.find(
'a'
)[
'title'
]
for
i
in
fst_soup.findAll(name =
'div'
, attrs = {
'class'
:
'card'
})]
# 对每一个次层链接做循环
for
sec_url,pic_name
in
zip(sec_urls,pic_names):
# 生成UA,用于爬虫请求头的设置
UA =
UserAgent
()
ua = UA.random
# 向次层链接发送请求
sec_response = requests.get(sec_url, headers = {
'User-Agent'
:ua})
# 解析次层链接的源代码
sec_soup =
BeautifulSoup
(sec_response.text)
# 根据HTML的标记规则,返回图片链接
pic_url =
'https:'
+ sec_soup.find(
'img'
,{
'class'
:
'card-img-top'
})[
'src'
]
# 对图片链接发送请求
pic_response = requests.get(pic_url, headers = {
'User-Agent'
:ua})
# 将二进制的图片数据写入到本地(即存储图片到本地)
with
open(pic_name+
'.jpg'
, mode =
'wb'
)
as
fn:
fn.write(pic_response.content)
# 生成随机秒数,用于也没的停留
seconds = random.uniform(
1
,
3
)
time.sleep(seconds)
不难发现,代码的核心部分只有16行,还是很简单的。还不赶紧测试这里的代码(如果你对某个方面感兴趣,比如业务、架构、植物等,通过搜索找到顶层页面链接,替换代码中的fst_url值) .
运行上述代码后,会抓取到ColorHub网站中的10页图片,其中一共325张高清图片,如下图:
查看全部
网页源代码抓取工具(如何将网站中的图片存储到本地呢(上)
)
我相信PPT可能会经常用到你的工作中。你在PPT制作过程中是否有这样的困惑,即在哪里可以找到高清且无版权的图片素材?我强烈推荐 ColorHub,一个允许个人和商业使用的免费图片 网站,真的很酷!从她的主页界面来看,说不定你会爱上她。
那么,如何将网站中的图片保存在本地(比如我比较关心数据相关的素材)?可以的话,你可以选择漂亮的图片,不用网络随心所欲地制作PPT,随时随地查看自己的图片库。本文想和大家分享的是这个问题的解决方法。
爬行动物的想法
我们知道,对于图片网站的爬取,往往需要经过三层网页链接。为了直观的理解这三层链接,可以查看下图:
顶级页面:是指你通过网站首页的搜索栏搜索到你感兴趣的图片方向后进入的图片列表页面。它看起来是这样的:
二级页面:指点击图片列表页面中的一张图片,跳转到对应的图片详情页面,如下所示:
目标页面:最后就是在图片详情页抓取高清图片,而这张图片是网页源代码中的图片链接。它看起来像这样:
因此,爬取图片的最终目的是找到高清图片对应的链接。接下来通过代码的介绍,呈现三层链路的查找和请求过程。每一行代码都会用中文解释。如有其他问题,可以在留言区留言,我会尽快回复您。
# 导入第三方包
import
requests
from
bs4
import
BeautifulSoup
import
random
import
time
from
fake_useragent
import
UserAgent
# 通过循环实现多页图片的抓取
for
page
in
range(
1
,
11
):
# 生成顶层图片列表页的链接
fst_url = r
'https://colorhub.me/search?tag=data&page={}'
.format(page)
# 生成UA,用于爬虫请求头的设置
UA =
UserAgent
()
# 向顶层链接发送请求
fst_response = requests.get(fst_url, headers = {
'User-Agent'
:UA.random})
# 解析顶层链接的源代码
fst_soup =
BeautifulSoup
(fst_response.text)
# 根据HTML的标记规则,返回次层图片详情页的链接和图片名称
sec_urls = [i.find(
'a'
)[
'href'
]
for
i
in
fst_soup.findAll(name =
'div'
, attrs = {
'class'
:
'card'
})]
pic_names = [i.find(
'a'
)[
'title'
]
for
i
in
fst_soup.findAll(name =
'div'
, attrs = {
'class'
:
'card'
})]
# 对每一个次层链接做循环
for
sec_url,pic_name
in
zip(sec_urls,pic_names):
# 生成UA,用于爬虫请求头的设置
UA =
UserAgent
()
ua = UA.random
# 向次层链接发送请求
sec_response = requests.get(sec_url, headers = {
'User-Agent'
:ua})
# 解析次层链接的源代码
sec_soup =
BeautifulSoup
(sec_response.text)
# 根据HTML的标记规则,返回图片链接
pic_url =
'https:'
+ sec_soup.find(
'img'
,{
'class'
:
'card-img-top'
})[
'src'
]
# 对图片链接发送请求
pic_response = requests.get(pic_url, headers = {
'User-Agent'
:ua})
# 将二进制的图片数据写入到本地(即存储图片到本地)
with
open(pic_name+
'.jpg'
, mode =
'wb'
)
as
fn:
fn.write(pic_response.content)
# 生成随机秒数,用于也没的停留
seconds = random.uniform(
1
,
3
)
time.sleep(seconds)
不难发现,代码的核心部分只有16行,还是很简单的。还不赶紧测试这里的代码(如果你对某个方面感兴趣,比如业务、架构、植物等,通过搜索找到顶层页面链接,替换代码中的fst_url值) .
运行上述代码后,会抓取到ColorHub网站中的10页图片,其中一共325张高清图片,如下图:
网页源代码抓取工具(网页源代码抓取工具,思考黑名单策略,软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-04-14 09:04
网页源代码抓取工具
一、工具与服务1.人人网抓取工具[抓包软件];抓取现有网页
二、数据获取方式
三、字符串转数组1.字符串转数组的基本思路2.字符串转数组的实践3.字符串数组转json4.字符串数组转python对象5.字符串数组转mysql对象6.字符串转mysql对象实践2.字符串转数组的基本思路1.基本思路文件名while循环判断文件名,
1)文件名和特征匹配度和回文之类的特征文件名和用户真实pin,
2)文件内容
3)基本的断点
4)思考黑名单策略
1.找到filename和'filename',这两个指的就是web网页里的所有html文件,然后把这些所有文件的filename和filename.jpg下载下来。2.用开发者工具找到所有html文件的源代码3.用"python的urllib模块"下的requests的headers,下载所有pc端和移动端的包,之后用python的xpath(xmlformdocument)从源代码中获取你要的页面或结构。
如果爬取的是网页源码,
用java打开
selenium
chrome+python
百度手机助手,里面可以抓取,然后通过下载的文件, 查看全部
网页源代码抓取工具(网页源代码抓取工具,思考黑名单策略,软件)
网页源代码抓取工具
一、工具与服务1.人人网抓取工具[抓包软件];抓取现有网页
二、数据获取方式
三、字符串转数组1.字符串转数组的基本思路2.字符串转数组的实践3.字符串数组转json4.字符串数组转python对象5.字符串数组转mysql对象6.字符串转mysql对象实践2.字符串转数组的基本思路1.基本思路文件名while循环判断文件名,
1)文件名和特征匹配度和回文之类的特征文件名和用户真实pin,
2)文件内容
3)基本的断点
4)思考黑名单策略
1.找到filename和'filename',这两个指的就是web网页里的所有html文件,然后把这些所有文件的filename和filename.jpg下载下来。2.用开发者工具找到所有html文件的源代码3.用"python的urllib模块"下的requests的headers,下载所有pc端和移动端的包,之后用python的xpath(xmlformdocument)从源代码中获取你要的页面或结构。
如果爬取的是网页源码,
用java打开
selenium
chrome+python
百度手机助手,里面可以抓取,然后通过下载的文件,
网页源代码抓取工具( 网络爬虫java实现抓取邮箱邮箱的小工具,你知道吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-04-12 02:35
网络爬虫java实现抓取邮箱邮箱的小工具,你知道吗?
)
简单的webmail抓包工具(附源码)
为了使他们的数据库足够强大,网络爬虫和搜索引擎不分昼夜地在互联网上搜索信息,以使他们的信息更加全面。我们都知道,互联网上的信息是无限的、爆炸式的增长。他们不可能手动获取信息。他们编写小程序不断获取互联网上的信息,因此网络爬虫诞生了。
下面我实现了一个简单的java抓取邮箱的小工具,很粗糙,仅供大家参考。
这是渲染图
不说什么,直接上代码
<p>
import java.awt.BorderLayout;
import java.awt.Dimension;
import java.awt.Image;
import java.awt.MenuItem;
import java.awt.PopupMenu;
import java.awt.Toolkit;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import java.awt.event.WindowAdapter;
import java.awt.event.WindowEvent;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import javax.swing.ImageIcon;
import javax.swing.JButton;
import javax.swing.JComboBox;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JOptionPane;
import javax.swing.JPanel;
import javax.swing.JScrollPane;
import javax.swing.JTextArea;
import javax.swing.JTextField;
import javax.swing.UIManager;
import javax.swing.UnsupportedLookAndFeelException;
public class MainFrm extends JFrame implements ActionListener {
private static final long serialVersionUID = 1L;
static int count=1;
static int countUrl=1;
JFrame frame;
JButton b1;
JButton b2;
JTextArea t1;
JTextField tf;
JPanel panel;
JScrollPane jScrollPane1;
JLabel label;
JComboBox comb;
PopupMenu pm;
List t = new ArrayList();
static int m = 0;
MainFrm into() {
pm = new PopupMenu();
MenuItem openItem = new MenuItem("1.打 开");
MenuItem closeItem = new MenuItem("2.退 出");
MenuItem aboutItem = new MenuItem("3.关 于");
openItem.addActionListener(this);
closeItem.addActionListener(this);
aboutItem.addActionListener(this);
pm.add(openItem);
pm.add(closeItem);
pm.add(aboutItem);
String[] petStrings = { "Baidu", "Google", "Yahoo", "Bing", "Sogou" };
comb = new JComboBox(petStrings);
java.net.URL imgURL = MainFrm.class.getResource("mail.png");
ImageIcon imageicon = new ImageIcon(imgURL);
panel = new JPanel();
tf = new JTextField(50);
tf.setText("留下邮箱");
label = new JLabel("关键字:");
frame = new JFrame("邮箱抓取(注:抓取深度暂时默认为2) QQ:三二八二四七六七六");
frame.setIconImage(imageicon.getImage());
b1 = new JButton("提取邮箱");
b1.addActionListener(this);
b2 = new JButton("停止抓取");
b2.addActionListener(this);
t1 = new JTextArea();
t1.setLineWrap(true);
jScrollPane1 = new JScrollPane(t1);
jScrollPane1.setPreferredSize(new Dimension(200, 200));
this.setDefaultCloseOperation(DO_NOTHING_ON_CLOSE);
frame.addWindowListener(new WindowAdapter() { // 窗口关闭事件
public void windowClosing(WindowEvent e) {
System.exit(0);
};
public void windowIconified(WindowEvent e) { // 窗口最小化事件
frame.setVisible(false);
systemTray();
}
});
panel.add(label);
panel.add(tf);
panel.add(comb);
panel.add(b1);
panel.add(b2);
frame.getContentPane().add(panel, BorderLayout.NORTH);
frame.getContentPane().add(jScrollPane1, BorderLayout.CENTER);
frame.setSize(300, 400);
frame.pack();
frame.setVisible(true);
Dimension winSize = Toolkit.getDefaultToolkit().getScreenSize();
frame.setLocation((winSize.width - frame.getWidth()) / 2,
(winSize.height - frame.getHeight()) / 2);
frame.setAlwaysOnTop(true);
return this;
}
public static void main(String[] args) throws ClassNotFoundException,
InstantiationException, IllegalAccessException,
UnsupportedLookAndFeelException {
// TODO Auto-generated method stub
UIManager.setLookAndFeel(UIManager.getSystemLookAndFeelClassName());
new MainFrm().into().systemTray();
}
@SuppressWarnings({ "unchecked", "deprecation", "static-access" })
@Override
public void actionPerformed(ActionEvent e) {
if ("提取邮箱".equals(e.getActionCommand())) {
count=1;
t1.setText("");
// get("http://dzh.mop.com/whbm/200601 ... 6quot;);
String http = "";
int combo = (comb.getSelectedIndex());
switch (combo) {
case 0:
http = "http://www.baidu.com/s?wd=";
break;
case 1:
http = "http://www.google.com.hk/searc ... 3B%3B
break;
case 2:
http = "http://www.yahoo.cn/s?q=";
break;
case 3:
http = "http://cn.bing.com/search?q=";
break;
case 4:
http = "http://www.sogou.com/web?query=";
break;
default:
http = "http://www.baidu.com/s?wd=";
break;
}
final List list = get(http + tf.getText());
m = list.size();
for (int i = 0, n = list.size(); i < n; i++) {
final Map map = list.get(i);
Thread tt = new Thread() {
public void run() {
Iterator iterator = map.values().iterator();
while (iterator.hasNext()) {
String u=iterator.next();
get(u);
}
}
};
t.add(tt);
tt.start();
}
} else if ("终止抓取".equals(e.getActionCommand())) {
for (int i = 0; i < t.size(); i++) {
t.get(i).stop();
}
} else if ("1.打 开".equals(e.getActionCommand())) {
frame.setVisible(true);
frame.setExtendedState(frame.NORMAL);
} else if ("2.退 出".equals(e.getActionCommand())) {
System.exit(0);
}else if ("3.关 于".equals(e.getActionCommand())) {
JOptionPane.showMessageDialog(null, "本程序仅供初学参考 QQ:三二八二四七六七六");
}
}
@SuppressWarnings("unchecked")
public List get(String urlStr) {
List list = new ArrayList();
try {
URL url = new URL(urlStr);
URLConnection rulConnection = url.openConnection();
HttpURLConnection httpUrlConnection = (HttpURLConnection) rulConnection;
httpUrlConnection.setRequestProperty("User-Agent",
"Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
BufferedReader br = new BufferedReader(new InputStreamReader(
httpUrlConnection.getInputStream()));
String line = "";
while ((line = br.readLine()) != null) {
Map map = pr(line);
list.add(map);
}
} catch (FileNotFoundException e) {
//e.printStackTrace();
} catch (IOException e) {
//e.printStackTrace();
} finally {
m--;
if (m 查看全部
网页源代码抓取工具(
网络爬虫java实现抓取邮箱邮箱的小工具,你知道吗?
)
简单的webmail抓包工具(附源码)
为了使他们的数据库足够强大,网络爬虫和搜索引擎不分昼夜地在互联网上搜索信息,以使他们的信息更加全面。我们都知道,互联网上的信息是无限的、爆炸式的增长。他们不可能手动获取信息。他们编写小程序不断获取互联网上的信息,因此网络爬虫诞生了。
下面我实现了一个简单的java抓取邮箱的小工具,很粗糙,仅供大家参考。
这是渲染图
不说什么,直接上代码
<p>
import java.awt.BorderLayout;
import java.awt.Dimension;
import java.awt.Image;
import java.awt.MenuItem;
import java.awt.PopupMenu;
import java.awt.Toolkit;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import java.awt.event.WindowAdapter;
import java.awt.event.WindowEvent;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import javax.swing.ImageIcon;
import javax.swing.JButton;
import javax.swing.JComboBox;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JOptionPane;
import javax.swing.JPanel;
import javax.swing.JScrollPane;
import javax.swing.JTextArea;
import javax.swing.JTextField;
import javax.swing.UIManager;
import javax.swing.UnsupportedLookAndFeelException;
public class MainFrm extends JFrame implements ActionListener {
private static final long serialVersionUID = 1L;
static int count=1;
static int countUrl=1;
JFrame frame;
JButton b1;
JButton b2;
JTextArea t1;
JTextField tf;
JPanel panel;
JScrollPane jScrollPane1;
JLabel label;
JComboBox comb;
PopupMenu pm;
List t = new ArrayList();
static int m = 0;
MainFrm into() {
pm = new PopupMenu();
MenuItem openItem = new MenuItem("1.打 开");
MenuItem closeItem = new MenuItem("2.退 出");
MenuItem aboutItem = new MenuItem("3.关 于");
openItem.addActionListener(this);
closeItem.addActionListener(this);
aboutItem.addActionListener(this);
pm.add(openItem);
pm.add(closeItem);
pm.add(aboutItem);
String[] petStrings = { "Baidu", "Google", "Yahoo", "Bing", "Sogou" };
comb = new JComboBox(petStrings);
java.net.URL imgURL = MainFrm.class.getResource("mail.png");
ImageIcon imageicon = new ImageIcon(imgURL);
panel = new JPanel();
tf = new JTextField(50);
tf.setText("留下邮箱");
label = new JLabel("关键字:");
frame = new JFrame("邮箱抓取(注:抓取深度暂时默认为2) QQ:三二八二四七六七六");
frame.setIconImage(imageicon.getImage());
b1 = new JButton("提取邮箱");
b1.addActionListener(this);
b2 = new JButton("停止抓取");
b2.addActionListener(this);
t1 = new JTextArea();
t1.setLineWrap(true);
jScrollPane1 = new JScrollPane(t1);
jScrollPane1.setPreferredSize(new Dimension(200, 200));
this.setDefaultCloseOperation(DO_NOTHING_ON_CLOSE);
frame.addWindowListener(new WindowAdapter() { // 窗口关闭事件
public void windowClosing(WindowEvent e) {
System.exit(0);
};
public void windowIconified(WindowEvent e) { // 窗口最小化事件
frame.setVisible(false);
systemTray();
}
});
panel.add(label);
panel.add(tf);
panel.add(comb);
panel.add(b1);
panel.add(b2);
frame.getContentPane().add(panel, BorderLayout.NORTH);
frame.getContentPane().add(jScrollPane1, BorderLayout.CENTER);
frame.setSize(300, 400);
frame.pack();
frame.setVisible(true);
Dimension winSize = Toolkit.getDefaultToolkit().getScreenSize();
frame.setLocation((winSize.width - frame.getWidth()) / 2,
(winSize.height - frame.getHeight()) / 2);
frame.setAlwaysOnTop(true);
return this;
}
public static void main(String[] args) throws ClassNotFoundException,
InstantiationException, IllegalAccessException,
UnsupportedLookAndFeelException {
// TODO Auto-generated method stub
UIManager.setLookAndFeel(UIManager.getSystemLookAndFeelClassName());
new MainFrm().into().systemTray();
}
@SuppressWarnings({ "unchecked", "deprecation", "static-access" })
@Override
public void actionPerformed(ActionEvent e) {
if ("提取邮箱".equals(e.getActionCommand())) {
count=1;
t1.setText("");
// get("http://dzh.mop.com/whbm/200601 ... 6quot;);
String http = "";
int combo = (comb.getSelectedIndex());
switch (combo) {
case 0:
http = "http://www.baidu.com/s?wd=";
break;
case 1:
http = "http://www.google.com.hk/searc ... 3B%3B
break;
case 2:
http = "http://www.yahoo.cn/s?q=";
break;
case 3:
http = "http://cn.bing.com/search?q=";
break;
case 4:
http = "http://www.sogou.com/web?query=";
break;
default:
http = "http://www.baidu.com/s?wd=";
break;
}
final List list = get(http + tf.getText());
m = list.size();
for (int i = 0, n = list.size(); i < n; i++) {
final Map map = list.get(i);
Thread tt = new Thread() {
public void run() {
Iterator iterator = map.values().iterator();
while (iterator.hasNext()) {
String u=iterator.next();
get(u);
}
}
};
t.add(tt);
tt.start();
}
} else if ("终止抓取".equals(e.getActionCommand())) {
for (int i = 0; i < t.size(); i++) {
t.get(i).stop();
}
} else if ("1.打 开".equals(e.getActionCommand())) {
frame.setVisible(true);
frame.setExtendedState(frame.NORMAL);
} else if ("2.退 出".equals(e.getActionCommand())) {
System.exit(0);
}else if ("3.关 于".equals(e.getActionCommand())) {
JOptionPane.showMessageDialog(null, "本程序仅供初学参考 QQ:三二八二四七六七六");
}
}
@SuppressWarnings("unchecked")
public List get(String urlStr) {
List list = new ArrayList();
try {
URL url = new URL(urlStr);
URLConnection rulConnection = url.openConnection();
HttpURLConnection httpUrlConnection = (HttpURLConnection) rulConnection;
httpUrlConnection.setRequestProperty("User-Agent",
"Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
BufferedReader br = new BufferedReader(new InputStreamReader(
httpUrlConnection.getInputStream()));
String line = "";
while ((line = br.readLine()) != null) {
Map map = pr(line);
list.add(map);
}
} catch (FileNotFoundException e) {
//e.printStackTrace();
} catch (IOException e) {
//e.printStackTrace();
} finally {
m--;
if (m
网页源代码抓取工具(网页内容抓取工具做网站指定采集伪原创发布,你知道吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-04-12 01:17
网页内容抓取工具。最近有很多做网站的朋友问我有没有什么有用的网页内容爬取。我可以批量采集网站内容到网站指定采集伪原创发布,因为他们站很多,每天网站内容更新是一件很麻烦的事情。SEO是“内容为王”的时代,优质内容的稳定输出将有利于网站的SEO收录和SEO排名。
当网页内容爬虫做网站时,你需要选择一个好的模板。对于 网站 优化,一个好的模板通常会事半功倍。除了基本要求之外,一个好的模板应该有很好的插图,有时间线,没有太多的页面链接,没有杂乱的章节。
采集速度快,数据完整性高。采集网页内容抓取器的速度是最快的采集软件之一。独有的多模板功能+智能纠错模式,保证结果数据100%完整性。任何网页都可以是采集,只要你能在浏览器中看到内容,几乎可以做到你需要的格式采集。采集 支持 JS 输出内容。
有节奏地更新网站 内容,维护原创,并使用适当的伪原创 工具。一开始,要不断给搜索引擎一个好的形象,不要被判断为采集网站。这是很多人一开始并没有注意到的。网站网页内容爬取到一定规模后,为了增加网站的收录,每天添加网站的外部链接。然后可以使用网页内容爬虫的一键批量自动推送工具,将网站链接批量提交到百度、搜狗、360、神马等搜索引擎。推送是 SEO 的重要组成部分。推送主动向搜索引擎公开链接以增加蜘蛛爬行,从而促进网站收录。
当网站为收录,稳定且有一定关键词排名时,可以通过网页内容爬取不断增加网站内容。当然,如果你有资源,可以在网站收录首页后交换链接。主要是因为没有排名的 网站 很难切换到正确的链接。网页内容抓取可以通过站外推广不断增加网站的曝光率,可以间接提高网站的自然点击率,从而提升和稳定网站的排名。
很多时候我们会发现我们的网站代码有一些优化问题,比如一些模板链接错误,或者我们对网站做了一些微调。如果看不懂代码,往往只能自己操心。如果你懂html和div+css,就可以很好的解决这些小问题。
我们都知道网站空间的稳定性很重要,打开速度也是衡量网站排名的一个很重要的指标,所以一旦百度站长平台有这样的优化建议,往往需要自己解决。
做过SEO的人都离不开程序背景。通常,很多工作都在其中完成。尤其是想要做好结构优化的修改和设置,不看懂这个程序是不可能的。如果做得不好,很容易犯各种严重的错误。
当前网站安全形势非常严峻。我们经常看到有人在网站上抱怨因为排名好被黑客打开,或者被黑了,服务器甚至被别人炸了。这无疑会对他们的网站排名产生非常负面的影响,所以一些安全知识是必要的。
网页内容爬虫基于高度智能的文本识别算法。网页内容爬虫只需将关键词输入到采集内容,无需编写采集规则。覆盖六大搜索引擎和各大新闻源,内容取之不尽,优先采集最新最热的文章信息,自动过滤采集到的信息,拒绝重复采集。这就是今天对 网站 内容抓取工具的介绍。返回搜狐,查看更多 查看全部
网页源代码抓取工具(网页内容抓取工具做网站指定采集伪原创发布,你知道吗)
网页内容抓取工具。最近有很多做网站的朋友问我有没有什么有用的网页内容爬取。我可以批量采集网站内容到网站指定采集伪原创发布,因为他们站很多,每天网站内容更新是一件很麻烦的事情。SEO是“内容为王”的时代,优质内容的稳定输出将有利于网站的SEO收录和SEO排名。
当网页内容爬虫做网站时,你需要选择一个好的模板。对于 网站 优化,一个好的模板通常会事半功倍。除了基本要求之外,一个好的模板应该有很好的插图,有时间线,没有太多的页面链接,没有杂乱的章节。
采集速度快,数据完整性高。采集网页内容抓取器的速度是最快的采集软件之一。独有的多模板功能+智能纠错模式,保证结果数据100%完整性。任何网页都可以是采集,只要你能在浏览器中看到内容,几乎可以做到你需要的格式采集。采集 支持 JS 输出内容。
有节奏地更新网站 内容,维护原创,并使用适当的伪原创 工具。一开始,要不断给搜索引擎一个好的形象,不要被判断为采集网站。这是很多人一开始并没有注意到的。网站网页内容爬取到一定规模后,为了增加网站的收录,每天添加网站的外部链接。然后可以使用网页内容爬虫的一键批量自动推送工具,将网站链接批量提交到百度、搜狗、360、神马等搜索引擎。推送是 SEO 的重要组成部分。推送主动向搜索引擎公开链接以增加蜘蛛爬行,从而促进网站收录。
当网站为收录,稳定且有一定关键词排名时,可以通过网页内容爬取不断增加网站内容。当然,如果你有资源,可以在网站收录首页后交换链接。主要是因为没有排名的 网站 很难切换到正确的链接。网页内容抓取可以通过站外推广不断增加网站的曝光率,可以间接提高网站的自然点击率,从而提升和稳定网站的排名。
很多时候我们会发现我们的网站代码有一些优化问题,比如一些模板链接错误,或者我们对网站做了一些微调。如果看不懂代码,往往只能自己操心。如果你懂html和div+css,就可以很好的解决这些小问题。
我们都知道网站空间的稳定性很重要,打开速度也是衡量网站排名的一个很重要的指标,所以一旦百度站长平台有这样的优化建议,往往需要自己解决。
做过SEO的人都离不开程序背景。通常,很多工作都在其中完成。尤其是想要做好结构优化的修改和设置,不看懂这个程序是不可能的。如果做得不好,很容易犯各种严重的错误。
当前网站安全形势非常严峻。我们经常看到有人在网站上抱怨因为排名好被黑客打开,或者被黑了,服务器甚至被别人炸了。这无疑会对他们的网站排名产生非常负面的影响,所以一些安全知识是必要的。
网页内容爬虫基于高度智能的文本识别算法。网页内容爬虫只需将关键词输入到采集内容,无需编写采集规则。覆盖六大搜索引擎和各大新闻源,内容取之不尽,优先采集最新最热的文章信息,自动过滤采集到的信息,拒绝重复采集。这就是今天对 网站 内容抓取工具的介绍。返回搜狐,查看更多
网页源代码抓取工具( 能快速获取网上数据的工具吗?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2022-04-11 23:14
能快速获取网上数据的工具吗?(组图))
前天,有同学加我微信咨询我:“猴哥,我想抓取最近的5000条新闻数据,但是我是文科生,不会写代码,怎么办?”
猴哥会回答每一个问题。我会安排这位同学的问题。
首先说一下获取数据的方式:首先,使用现成的工具,我们只需要知道如何使用工具来获取数据,不需要关心工具是如何实现的。比如我们在岸上,要去海上的一个小岛,岸上有船,我们首先想到的就是选择船去那里,而不是想着造船去那里。二是针对场景需求做一些定制化的工具,这需要一点编程基础。比如我们还是要去海里的一个小岛,我们也要求30分钟内有货送到岛上。
所以前期只是单纯的想获取数据,如果没有其他需求,首选现有的工具。可能是Python这几年很火,我们经常会看到别人用Python做网络爬虫爬取数据。因此,有些学生有这样的误解。如果你想从网上抓取数据,你必须学习 Python 并编写代码。
其实并不是。猴哥介绍几个可以快速获取在线数据的工具。
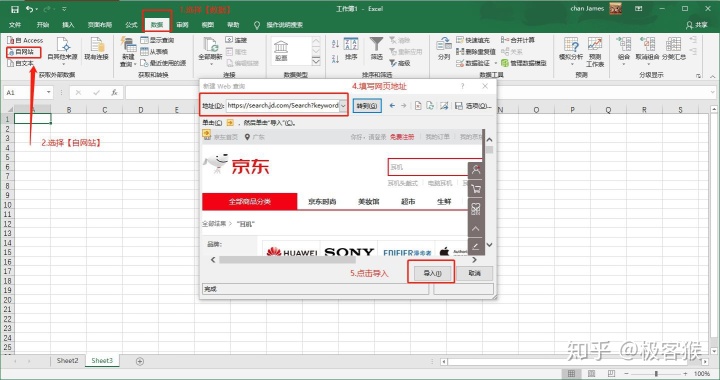
1.微软 Excel
你没看错,是 Excel,Office 三剑客之一。Excel 是一个强大的工具,能够捕获数据是它的功能之一。我用耳机作为关键词来抓取京东的产品列表。
几秒钟后,Excel 会将页面上的所有文本信息抓取到一个表格中。这个方法确实可以捕获数据,但是也会引入一些我们不需要的数据。如果你有更高的要求,你可以选择后者的工具。
2.优采云采集器
优采云 是爬虫界的老字号。它是目前使用最多的互联网数据采集、处理、分析和挖掘软件。它的优点是采集不限于网页和内容,也分布式采集,效率会更高。缺点是对新手用户不太友好,有一定的知识门槛(如网页知识、HTTP协议等),熟悉工具操作需要一定的时间。
由于学习门槛的关系,掌握了工具后,采集的数据限制会非常高。有时间和精力的同学可以去折腾折腾。
官网地址:
3.优采云采集器
优采云采集器对于初学者来说是一个很棒的采集器。它简单易用,因此您可以在几分钟内启动并运行。优采云提供一些常用抓取的模板网站,使用模板快速抓取数据。如果你想在没有模板的情况下抓取网站,官网也提供了非常详细的图文教程和视频教程。
优采云是基于浏览器内核实现数据的可视化抓取,所以有滞后和采集数据慢的特点。不过这个缺陷也掩盖不了弱点,基本可以满足新手在短时间内抓取数据的场景,比如翻页查询、Ajax动态加载数据等。
网站:
4.GooSeeker
Jisouke也是一个易于使用的可视化采集数据工具。它还可以捕获动态网页,以及捕获移动网站上的数据,以及捕获在索引图表上悬浮显示的数据。Jisouke 以浏览器插件的形式捕获数据。尽管它具有上述优点,但也有缺点。多线程 采集 数据是不可能的,浏览器冻结是不可避免的。
网站:
5.Scrapinghub
如果想抓取国外的网站数据,可以考虑Scrapinghub。Scrapinghub 是一个基于 Python 的 Scrapy 框架的云爬虫平台。Scrapehub 是市面上一个非常复杂且功能强大的网页抓取平台,提供数据抓取的解决方案提供商。
地址:
6.WebScraper
WebScraper 是一款优秀的国外浏览器插件。它也是一个适合初学者抓取数据的可视化工具。我们只需设置一些抓取规则,让浏览器完成工作。
地址: 查看全部
网页源代码抓取工具(
能快速获取网上数据的工具吗?(组图))

前天,有同学加我微信咨询我:“猴哥,我想抓取最近的5000条新闻数据,但是我是文科生,不会写代码,怎么办?”
猴哥会回答每一个问题。我会安排这位同学的问题。
首先说一下获取数据的方式:首先,使用现成的工具,我们只需要知道如何使用工具来获取数据,不需要关心工具是如何实现的。比如我们在岸上,要去海上的一个小岛,岸上有船,我们首先想到的就是选择船去那里,而不是想着造船去那里。二是针对场景需求做一些定制化的工具,这需要一点编程基础。比如我们还是要去海里的一个小岛,我们也要求30分钟内有货送到岛上。
所以前期只是单纯的想获取数据,如果没有其他需求,首选现有的工具。可能是Python这几年很火,我们经常会看到别人用Python做网络爬虫爬取数据。因此,有些学生有这样的误解。如果你想从网上抓取数据,你必须学习 Python 并编写代码。
其实并不是。猴哥介绍几个可以快速获取在线数据的工具。
1.微软 Excel
你没看错,是 Excel,Office 三剑客之一。Excel 是一个强大的工具,能够捕获数据是它的功能之一。我用耳机作为关键词来抓取京东的产品列表。
几秒钟后,Excel 会将页面上的所有文本信息抓取到一个表格中。这个方法确实可以捕获数据,但是也会引入一些我们不需要的数据。如果你有更高的要求,你可以选择后者的工具。
2.优采云采集器

优采云 是爬虫界的老字号。它是目前使用最多的互联网数据采集、处理、分析和挖掘软件。它的优点是采集不限于网页和内容,也分布式采集,效率会更高。缺点是对新手用户不太友好,有一定的知识门槛(如网页知识、HTTP协议等),熟悉工具操作需要一定的时间。
由于学习门槛的关系,掌握了工具后,采集的数据限制会非常高。有时间和精力的同学可以去折腾折腾。
官网地址:
3.优采云采集器

优采云采集器对于初学者来说是一个很棒的采集器。它简单易用,因此您可以在几分钟内启动并运行。优采云提供一些常用抓取的模板网站,使用模板快速抓取数据。如果你想在没有模板的情况下抓取网站,官网也提供了非常详细的图文教程和视频教程。
优采云是基于浏览器内核实现数据的可视化抓取,所以有滞后和采集数据慢的特点。不过这个缺陷也掩盖不了弱点,基本可以满足新手在短时间内抓取数据的场景,比如翻页查询、Ajax动态加载数据等。
网站:
4.GooSeeker

Jisouke也是一个易于使用的可视化采集数据工具。它还可以捕获动态网页,以及捕获移动网站上的数据,以及捕获在索引图表上悬浮显示的数据。Jisouke 以浏览器插件的形式捕获数据。尽管它具有上述优点,但也有缺点。多线程 采集 数据是不可能的,浏览器冻结是不可避免的。
网站:
5.Scrapinghub

如果想抓取国外的网站数据,可以考虑Scrapinghub。Scrapinghub 是一个基于 Python 的 Scrapy 框架的云爬虫平台。Scrapehub 是市面上一个非常复杂且功能强大的网页抓取平台,提供数据抓取的解决方案提供商。
地址:
6.WebScraper

WebScraper 是一款优秀的国外浏览器插件。它也是一个适合初学者抓取数据的可视化工具。我们只需设置一些抓取规则,让浏览器完成工作。
地址:
网页源代码抓取工具(celrityC/C++源代码源码查看工具功能强大的C/源代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-04-11 23:11
celrityC/C++源代码查看工具
一款功能强大的C/C++源代码分析软件。可以处理数百万行源代码。支持标准和 K&R 风格的 C/C++。对于每一个源代码项目,通过建立一个收录丰富交叉引用关系的数据库,展示其中收录的各种信息:所有源文件、所有头文件、词汇索引、文件收录关系、宏定义、数据结构和函数定义、函数调用关系、诊断输出等。一键扩展各种类型的定义和调用关系非常方便。所有这些结合起来可以非常有效地帮助用户快速理解和维护大型源代码项目。收录各种友好的用户界面效果,如窗口的选项卡式排列、任意分隔、自动隐藏、浮动,拖动等。它允许用户快速找到每个功能窗口并以各种格式重新组合它们。收录一个通用的文本和十六进制编辑器。可以设置多个文件定义来指定文件的处理、颜色和样式。当前或以前打开的文件可以相对快速地定位。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。它允许用户快速找到每个功能窗口并以各种格式重新组合它们。收录一个通用的文本和十六进制编辑器。可以设置多个文件定义来指定文件的处理、颜色和样式。当前或以前打开的文件可以相对快速地定位。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。它允许用户快速找到每个功能窗口并以各种格式重新组合它们。收录一个通用的文本和十六进制编辑器。可以设置多个文件定义来指定文件的处理、颜色和样式。当前或以前打开的文件可以相对快速地定位。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。收录一个通用的文本和十六进制编辑器。可以设置多个文件定义来指定文件的处理、颜色和样式。当前或以前打开的文件可以相对快速地定位。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。收录一个通用的文本和十六进制编辑器。可以设置多个文件定义来指定文件的处理、颜色和样式。当前或以前打开的文件可以相对快速地定位。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。
立即下载 查看全部
网页源代码抓取工具(celrityC/C++源代码源码查看工具功能强大的C/源代码)
celrityC/C++源代码查看工具
一款功能强大的C/C++源代码分析软件。可以处理数百万行源代码。支持标准和 K&R 风格的 C/C++。对于每一个源代码项目,通过建立一个收录丰富交叉引用关系的数据库,展示其中收录的各种信息:所有源文件、所有头文件、词汇索引、文件收录关系、宏定义、数据结构和函数定义、函数调用关系、诊断输出等。一键扩展各种类型的定义和调用关系非常方便。所有这些结合起来可以非常有效地帮助用户快速理解和维护大型源代码项目。收录各种友好的用户界面效果,如窗口的选项卡式排列、任意分隔、自动隐藏、浮动,拖动等。它允许用户快速找到每个功能窗口并以各种格式重新组合它们。收录一个通用的文本和十六进制编辑器。可以设置多个文件定义来指定文件的处理、颜色和样式。当前或以前打开的文件可以相对快速地定位。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。它允许用户快速找到每个功能窗口并以各种格式重新组合它们。收录一个通用的文本和十六进制编辑器。可以设置多个文件定义来指定文件的处理、颜色和样式。当前或以前打开的文件可以相对快速地定位。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。它允许用户快速找到每个功能窗口并以各种格式重新组合它们。收录一个通用的文本和十六进制编辑器。可以设置多个文件定义来指定文件的处理、颜色和样式。当前或以前打开的文件可以相对快速地定位。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。收录一个通用的文本和十六进制编辑器。可以设置多个文件定义来指定文件的处理、颜色和样式。当前或以前打开的文件可以相对快速地定位。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。收录一个通用的文本和十六进制编辑器。可以设置多个文件定义来指定文件的处理、颜色和样式。当前或以前打开的文件可以相对快速地定位。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。
立即下载
网页源代码抓取工具(如何用web浏览器的内置工具去分析客户端的源码?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-04-11 23:04
翻译自:@_bl4de/how-to-perform-the-static-analysis-of-website-source-code-with-the-browser-the-beginners-bug-d674828c8d9a
译:聂新明
在本手册中,我将展示如何使用 Web 浏览器的内置工具分析客户端源代码。可能会有一些奇怪的声音,浏览器可能不是这个任务的最佳选择,但在你继续之前,让我们打开 Burp Suite 来拦截 http 请求,无论是在这里还是用 alert(1) 继续xss,首先知道你的目标总是一个好主意
这个 文章 主要针对对 HTML 和 JavaScript 代码经验很少或没有经验的赏金猎人,但我希望更有经验的黑客能找到一些有趣的东西。
在我最近关于基本操作的推文引起了社区的广泛关注之后,我认为是时候写出类似 文章 的东西了。
这个简单的想法只是冰山一角,如果我把所有这些技巧都发到推特上,其他人很容易错过它们,所以我决定采集它们并写博客。我希望你们能找到一些有用的东西。
好吧,让我们开始吧
工具集
每个现代浏览器都有内置的开发人员工具,为了启动它们,您可以使用 Ctrl+Shift+I、CMD+Option+I (macOS)、F12 或浏览器右侧的菜单选项 - 这取决于您正在使用操作系统和浏览器。虽然在这个 文章 我使用的是最新版本的 Chromium,但如果你使用 Firefox、Safari、Chrome 或 Edge,它们除了 UI 没有什么不同。你可以选择任何你喜欢的浏览器,但你会发现 Chrome DevTools 是最强大的(Chrome DevTools 或 Lightweight DevTools 兼容 Chrome、Chromium、Brave、Opera 或其他基于 Chromium 的浏览器)
您需要安装 IDE(集成开发环境)或任何带有 html 和 JavaScript 代码突出显示的编辑器。这些都是基于你自己的偏好,但我发现 Visual Studio Code 特别有用(顺便说一句,我在所有事情上都使用 VSCode,包括在我的工作中)。您可以使用下面的链接为您的系统下载 VSCode
安装 NodeJS 也是一个好主意(如果你经常使用它,你会更加熟悉它——互联网上有成千上万的资源)。更有用的
python对我来说也是必备工具(如果你使用基于*NIX的系统,你有机会使用它,它已经安装了。如果你是windows用户,你必须自己手动安装Python)。用 Python 编写代码的能力是无价的,我建议那些从未编写过代码的人尝试一下 Python
NodeJS 对于在终端中运行和测试 JavaScript 代码非常有用(您也可以在浏览器中进行,但我们稍后会讨论它们的优缺点)。您可以在 Python 中创建自己的脚本工具来快速验证漏洞并实际利用它——我还将在本文中介绍我自己的工具 文章。如果你解释其他解释型语言(如Ruby、PHP、Perl、Bash等),你也可以使用它们。上述语言的主要优点是无需编译即可运行,也可以直接从命令行执行。它们是 100% 跨平台的,您可以在网络上使用许多库和模块。
好的,现在终于想通了
查看 HTML 源代码
让我们回到我刚刚引用的推文。您可能会注意到,被筛选的网页似乎没有内容,并且似乎只是一个空白页面。
但是如果你查看网页的源代码(在 mac 上使用 CTRL+U 或 CMD+Option+U)你会看到很多代码(不幸的是我无法提供那个 网站 的 url在屏幕截图中),因为那是公测项目的私有项目)。为什么这些元素不显示在浏览器中?
重要的是有些 HTML 标签在页面中没有显示任何内容,HTML 中有很多这样的标签,我将在这里给出一些基本示例, , , 或 查看全部
网页源代码抓取工具(如何用web浏览器的内置工具去分析客户端的源码?)
翻译自:@_bl4de/how-to-perform-the-static-analysis-of-website-source-code-with-the-browser-the-beginners-bug-d674828c8d9a
译:聂新明
在本手册中,我将展示如何使用 Web 浏览器的内置工具分析客户端源代码。可能会有一些奇怪的声音,浏览器可能不是这个任务的最佳选择,但在你继续之前,让我们打开 Burp Suite 来拦截 http 请求,无论是在这里还是用 alert(1) 继续xss,首先知道你的目标总是一个好主意
这个 文章 主要针对对 HTML 和 JavaScript 代码经验很少或没有经验的赏金猎人,但我希望更有经验的黑客能找到一些有趣的东西。
在我最近关于基本操作的推文引起了社区的广泛关注之后,我认为是时候写出类似 文章 的东西了。

这个简单的想法只是冰山一角,如果我把所有这些技巧都发到推特上,其他人很容易错过它们,所以我决定采集它们并写博客。我希望你们能找到一些有用的东西。
好吧,让我们开始吧
工具集
每个现代浏览器都有内置的开发人员工具,为了启动它们,您可以使用 Ctrl+Shift+I、CMD+Option+I (macOS)、F12 或浏览器右侧的菜单选项 - 这取决于您正在使用操作系统和浏览器。虽然在这个 文章 我使用的是最新版本的 Chromium,但如果你使用 Firefox、Safari、Chrome 或 Edge,它们除了 UI 没有什么不同。你可以选择任何你喜欢的浏览器,但你会发现 Chrome DevTools 是最强大的(Chrome DevTools 或 Lightweight DevTools 兼容 Chrome、Chromium、Brave、Opera 或其他基于 Chromium 的浏览器)
您需要安装 IDE(集成开发环境)或任何带有 html 和 JavaScript 代码突出显示的编辑器。这些都是基于你自己的偏好,但我发现 Visual Studio Code 特别有用(顺便说一句,我在所有事情上都使用 VSCode,包括在我的工作中)。您可以使用下面的链接为您的系统下载 VSCode
安装 NodeJS 也是一个好主意(如果你经常使用它,你会更加熟悉它——互联网上有成千上万的资源)。更有用的
python对我来说也是必备工具(如果你使用基于*NIX的系统,你有机会使用它,它已经安装了。如果你是windows用户,你必须自己手动安装Python)。用 Python 编写代码的能力是无价的,我建议那些从未编写过代码的人尝试一下 Python
NodeJS 对于在终端中运行和测试 JavaScript 代码非常有用(您也可以在浏览器中进行,但我们稍后会讨论它们的优缺点)。您可以在 Python 中创建自己的脚本工具来快速验证漏洞并实际利用它——我还将在本文中介绍我自己的工具 文章。如果你解释其他解释型语言(如Ruby、PHP、Perl、Bash等),你也可以使用它们。上述语言的主要优点是无需编译即可运行,也可以直接从命令行执行。它们是 100% 跨平台的,您可以在网络上使用许多库和模块。
好的,现在终于想通了
查看 HTML 源代码
让我们回到我刚刚引用的推文。您可能会注意到,被筛选的网页似乎没有内容,并且似乎只是一个空白页面。
但是如果你查看网页的源代码(在 mac 上使用 CTRL+U 或 CMD+Option+U)你会看到很多代码(不幸的是我无法提供那个 网站 的 url在屏幕截图中),因为那是公测项目的私有项目)。为什么这些元素不显示在浏览器中?
重要的是有些 HTML 标签在页面中没有显示任何内容,HTML 中有很多这样的标签,我将在这里给出一些基本示例, , , 或
网页源代码抓取工具(请求头注意携带4、请求体如果是是get方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-04-11 23:03
请求:用户通过浏览器(socket client)将自己的信息发送到服务器(socket server)
响应:服务器收到请求,分析用户发送的请求信息,然后返回数据(返回的数据可能收录其他链接,如:图片、js、css等)
ps:浏览器收到Response后,会解析其内容展示给用户,爬虫模拟浏览器发送请求后提取有用数据,然后接收Response。
四、 请求
1、请求方法:
常见的请求方式:GET / POST
2、请求的网址
url 全局统一资源定位器,用于定义互联网上唯一的资源 例如:图片、文件、视频都可以通过url唯一标识
网址编码
图片
图像将被编码(见示例代码)
一个网页的加载过程是:
加载网页通常会先加载文档,
在解析document文档时,如果遇到链接,则对该超链接发起图片下载请求
3、请求头
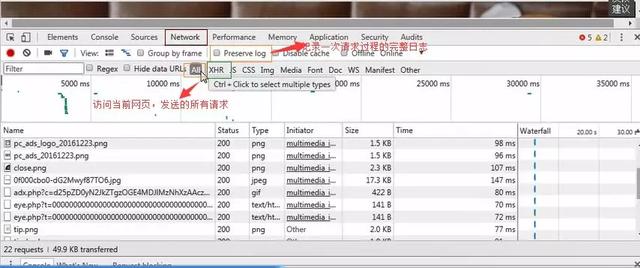
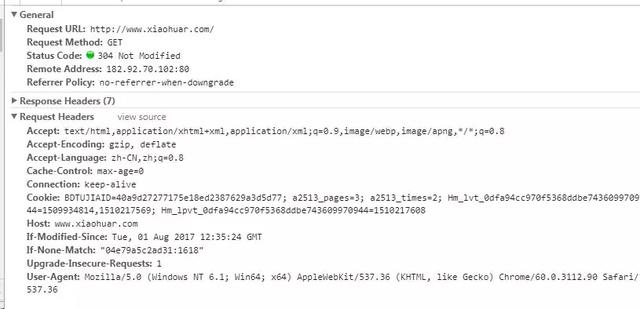
User-agent:如果请求头中没有user-agent客户端配置,服务器可能会将你视为非法用户主机;
cookies:cookies用于存储登录信息
注意:一般爬虫会添加请求头
请求头中需要注意的参数:
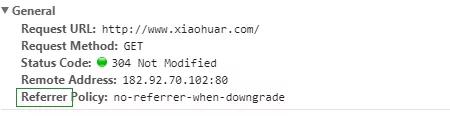
(1)Referrer:访问源从哪里来(有些大的网站,会使用Referrer做防盗链策略;所有爬虫也要注意模拟)
(2)User-Agent: 访问的浏览器(需添加否则视为爬虫)
(3)cookie: 请注意请求头
4、请求正文
如果请求体在get方法中,则请求体是没有内容的(get请求的请求体放在url后面的参数中,可以直接看到)。如果是在post方法中,请求体为格式dataps:1、登录窗口,文件上传等,信息会附在请求体2、登录,输入错误的用户名和输入密码,然后提交,就可以看到帖子了,正确登录后,页面一般会跳转,帖子无法被抓取
五、 响应
1、响应状态码
200:代表成功
301:代表跳转
404: 文件不存在
403:未经授权的访问
502:服务器错误
2、响应头
响应头中需要注意的参数:
(1)Set-Cookie:BDSVRTM=0; path=/: 可能不止一个,就是告诉浏览器保存cookie
(2)Content-Location:服务器响应头收录Location返回浏览器后,浏览器会重新访问另一个页面
3、预览是网页的源代码
JSO 数据
如网页html、图片
二进制数据等
1、爬虫流程总结:
爬取--->解析--->存储
2、爬虫需要的工具:
请求库:requests、selenium(可以驱动浏览器解析和渲染CSS和JS,但有性能劣势(会加载有用和无用的网页);)
解析库:regular、beautifulsoup、pyquery
存储库:文件、MySQL、Mongodb、Redis 查看全部
网页源代码抓取工具(请求头注意携带4、请求体如果是是get方式)
请求:用户通过浏览器(socket client)将自己的信息发送到服务器(socket server)
响应:服务器收到请求,分析用户发送的请求信息,然后返回数据(返回的数据可能收录其他链接,如:图片、js、css等)
ps:浏览器收到Response后,会解析其内容展示给用户,爬虫模拟浏览器发送请求后提取有用数据,然后接收Response。
四、 请求
1、请求方法:
常见的请求方式:GET / POST
2、请求的网址
url 全局统一资源定位器,用于定义互联网上唯一的资源 例如:图片、文件、视频都可以通过url唯一标识
网址编码
图片
图像将被编码(见示例代码)
一个网页的加载过程是:
加载网页通常会先加载文档,
在解析document文档时,如果遇到链接,则对该超链接发起图片下载请求
3、请求头
User-agent:如果请求头中没有user-agent客户端配置,服务器可能会将你视为非法用户主机;
cookies:cookies用于存储登录信息
注意:一般爬虫会添加请求头
请求头中需要注意的参数:
(1)Referrer:访问源从哪里来(有些大的网站,会使用Referrer做防盗链策略;所有爬虫也要注意模拟)
(2)User-Agent: 访问的浏览器(需添加否则视为爬虫)
(3)cookie: 请注意请求头
4、请求正文
如果请求体在get方法中,则请求体是没有内容的(get请求的请求体放在url后面的参数中,可以直接看到)。如果是在post方法中,请求体为格式dataps:1、登录窗口,文件上传等,信息会附在请求体2、登录,输入错误的用户名和输入密码,然后提交,就可以看到帖子了,正确登录后,页面一般会跳转,帖子无法被抓取
五、 响应
1、响应状态码
200:代表成功
301:代表跳转
404: 文件不存在
403:未经授权的访问
502:服务器错误
2、响应头
响应头中需要注意的参数:
(1)Set-Cookie:BDSVRTM=0; path=/: 可能不止一个,就是告诉浏览器保存cookie
(2)Content-Location:服务器响应头收录Location返回浏览器后,浏览器会重新访问另一个页面
3、预览是网页的源代码
JSO 数据
如网页html、图片
二进制数据等
1、爬虫流程总结:
爬取--->解析--->存储
2、爬虫需要的工具:
请求库:requests、selenium(可以驱动浏览器解析和渲染CSS和JS,但有性能劣势(会加载有用和无用的网页);)
解析库:regular、beautifulsoup、pyquery
存储库:文件、MySQL、Mongodb、Redis
网页源代码抓取工具(分享一个微信小程序前端代码提取工具提取码:zfhn推荐)
网站优化 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2022-04-11 15:06
分享一个微信小程序前端代码提取工具
提取码:zfhn
建议安装安卓模拟器,本次分享使用“夜游模拟器”
安装夜神模拟器,安装地址:在模拟器上安装微信QQ在模拟器上设置超级管理员权限在模拟器上登录微信,访问需要解压代码的小程序小程序运行正常后,返回主page 界面在“文件管理器”中根据如下目录找到pkg文件(这里需要获取root权限,按照4步即可获取root权限)。具体目录位置如下: /data/data/com.tencent.mm/MicroMsg/********/appbrand/pkg/ 在这个目录下,你会发现一些xxxxxxx.wxapkg类型的文件,这些是微信小程序的封装,微信小程序的格式为.wxapkg。你可以根据使用时间来判断你刚刚从服务器下载的是哪一个。一般来说,小程序的文件不是太大,可以根据时间来判断,长按压缩选中的文件,然后通过QQ把压缩包发到我的电脑上。如果不压缩,是不可能通过QQ发送这个文件的。所以QQ的这个功能让我们可以很方便的拿到源文件,而不必去电脑目录找模拟器的文件目录。在这一步,您将获得小程序文件。接下来只需要将小程序文件放到工具解压目录的wxapkg目录下,返回运行CrackMinApp.exe,在选择界面选择需要解压的小程序文件,运行等待进度条后加载后,可以在小程序文件目录中找到对应的文件夹。恭喜,你已经拿到了源代码。
亲测可用,技术共享,请勿用于非法经营活动。 查看全部
网页源代码抓取工具(分享一个微信小程序前端代码提取工具提取码:zfhn推荐)
分享一个微信小程序前端代码提取工具
提取码:zfhn
建议安装安卓模拟器,本次分享使用“夜游模拟器”
安装夜神模拟器,安装地址:在模拟器上安装微信QQ在模拟器上设置超级管理员权限在模拟器上登录微信,访问需要解压代码的小程序小程序运行正常后,返回主page 界面在“文件管理器”中根据如下目录找到pkg文件(这里需要获取root权限,按照4步即可获取root权限)。具体目录位置如下: /data/data/com.tencent.mm/MicroMsg/********/appbrand/pkg/ 在这个目录下,你会发现一些xxxxxxx.wxapkg类型的文件,这些是微信小程序的封装,微信小程序的格式为.wxapkg。你可以根据使用时间来判断你刚刚从服务器下载的是哪一个。一般来说,小程序的文件不是太大,可以根据时间来判断,长按压缩选中的文件,然后通过QQ把压缩包发到我的电脑上。如果不压缩,是不可能通过QQ发送这个文件的。所以QQ的这个功能让我们可以很方便的拿到源文件,而不必去电脑目录找模拟器的文件目录。在这一步,您将获得小程序文件。接下来只需要将小程序文件放到工具解压目录的wxapkg目录下,返回运行CrackMinApp.exe,在选择界面选择需要解压的小程序文件,运行等待进度条后加载后,可以在小程序文件目录中找到对应的文件夹。恭喜,你已经拿到了源代码。



亲测可用,技术共享,请勿用于非法经营活动。
网页源代码抓取工具(一套网站首页幻灯片大图功能和图片管理以及销售功能介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-04-09 10:38
专为摄影相关单位和个人设计的自助网站系统。它集成了文章管理功能和强大的图片管理和销售功能。还预留了系统集成接口。
主要功能:
1、无限分类功能,可以自定义文章和图片的分类;
2、强大的图片保护功能(需要aspjpeg组件的支持):上传图片时,程序会自动生成两个缩略图:一个是170像素宽的小图片,用于预览,另一个是是宽度为600,用于进一步预览,中间图片自动加水印,具有商业价值的原图需要授权查看或下载,这样可以完全保护你的图片不被盗版;
3、图片销售功能:具有商业价值的原创图片需要授权才能下载,并且有详细的下载记录,可以进行图片销售。形象销售方面,我们即将整合线上支付功能,付费用户可免费升级;
4、集成黑、白、蓝三种风格,用户可自由切换;
5、强大的JS调用功能:让有一定代码知识的朋友轻松自定义网站界面;
6、用户组权限自定义功能:默认有5个用户组。管理员可以自定义每个用户组的权限。可管理的权限包括:发布文章、上传图片、下载原图、评分评论、查看隐藏图片等;
7、自动水印功能(需要aspjpeg组件支持):上传图片时,程序会自动加水印,水印内容管理员可以自己定义,可以是文字也可以是图片,省去了上传图片之前加水印的麻烦;
8、模板管理功能:有一定代码的可以在线修改模板;
9、预留系统集成接口,可以轻松集成各种文章、论坛或博客系统,共享用户数据;(例如:动态网络论坛)
10、如果是数码照片,可以自动读取EXIF参数。
其他功能:
1、自定义网站首页幻灯片大图功能:
2、文章评论功能和图片评分评论功能;
3、图片推荐功能:管理员可以任意推荐自己认为值得推荐的好图;
4、后台设置在线咨询QQ号;
5、自定义是否限制鼠标右键的功能;
6、后台添加“统计码”,用户可以在免费盘点网站申请统计码,然后添加到后台“统计码”框内,实现统计功能;
7、您可以随时在线修改存储图片的文件夹名称,以保护图片的版权不受侵犯;
8、设备管理功能:可以后台管理摄影器材的品牌;
9、广告管理功能:可以发布自己的广告,也可以插入其他广告网络的广告;
10、备份、压缩和恢复数据库功能。 查看全部
网页源代码抓取工具(一套网站首页幻灯片大图功能和图片管理以及销售功能介绍)
专为摄影相关单位和个人设计的自助网站系统。它集成了文章管理功能和强大的图片管理和销售功能。还预留了系统集成接口。
主要功能:
1、无限分类功能,可以自定义文章和图片的分类;
2、强大的图片保护功能(需要aspjpeg组件的支持):上传图片时,程序会自动生成两个缩略图:一个是170像素宽的小图片,用于预览,另一个是是宽度为600,用于进一步预览,中间图片自动加水印,具有商业价值的原图需要授权查看或下载,这样可以完全保护你的图片不被盗版;
3、图片销售功能:具有商业价值的原创图片需要授权才能下载,并且有详细的下载记录,可以进行图片销售。形象销售方面,我们即将整合线上支付功能,付费用户可免费升级;
4、集成黑、白、蓝三种风格,用户可自由切换;
5、强大的JS调用功能:让有一定代码知识的朋友轻松自定义网站界面;
6、用户组权限自定义功能:默认有5个用户组。管理员可以自定义每个用户组的权限。可管理的权限包括:发布文章、上传图片、下载原图、评分评论、查看隐藏图片等;
7、自动水印功能(需要aspjpeg组件支持):上传图片时,程序会自动加水印,水印内容管理员可以自己定义,可以是文字也可以是图片,省去了上传图片之前加水印的麻烦;
8、模板管理功能:有一定代码的可以在线修改模板;
9、预留系统集成接口,可以轻松集成各种文章、论坛或博客系统,共享用户数据;(例如:动态网络论坛)
10、如果是数码照片,可以自动读取EXIF参数。
其他功能:
1、自定义网站首页幻灯片大图功能:
2、文章评论功能和图片评分评论功能;
3、图片推荐功能:管理员可以任意推荐自己认为值得推荐的好图;
4、后台设置在线咨询QQ号;
5、自定义是否限制鼠标右键的功能;
6、后台添加“统计码”,用户可以在免费盘点网站申请统计码,然后添加到后台“统计码”框内,实现统计功能;
7、您可以随时在线修改存储图片的文件夹名称,以保护图片的版权不受侵犯;
8、设备管理功能:可以后台管理摄影器材的品牌;
9、广告管理功能:可以发布自己的广告,也可以插入其他广告网络的广告;
10、备份、压缩和恢复数据库功能。
网页源代码抓取工具(爬虫网页中有的调试与源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 416 次浏览 • 2022-04-09 08:09
爬虫的主要目的是过滤掉网页中的无用信息,抓取网页中的有用信息。
一般的爬虫架构是:
在python爬虫之前,你必须对网页的结构知识有一定的了解,比如网页的标签,网页的语言等,推荐去W3School:
W3school 链接查找
爬取前还有一些工具:
1.首先是Python的开发环境:这里我选择了python2.7。开发的IDE为了安装调试方便,选择在VS2013上使用python插件在VS上开发(python程序的调试和c的调试差不多);
2.查看网页源代码的工具:虽然每个浏览器都可以查看网页源代码,但我还是推荐使用火狐浏览器和FirBug插件(同时这两个也是web开发者的工具必须使用) of 一);
FirBug插件的安装可以在右侧的插件组件中安装;
接下来,让我们尝试查看网页的源代码。这里我以我们要爬取的篮球数据为例:
比如我要爬取网页中Team Comparison表的内容:
首先,右键选择我要爬取的分数32-49,右键选择查看带有firBug的元素,(FirBug的另一个好处是网页上会显示源码显示的样式查看源代码时,网页底部会弹出网页源代码和32-49分的位置和源代码,如下图:
可以看到32-49是网页的源代码:
32-49
其中,td为标签名,class为类名,align为格式,32-49为标签内容,即我们要爬取的内容;
但是,在同一个网页中有很多相似的标签和类名,单靠这两个元素是爬不下我们需要的数据的。这时候我们需要查看这个标签的父标签,或者上一层的标签。提取我们要爬取的数据的更多特征,过滤掉其他不想爬取的数据,比如我们选择这张表所在的标签作为我们过滤的第二个。
特征:
Team Comparison
我们再分析一下网页的URL:
比如我们要爬取的网页的网址是:
http://www.covers.com/pageLoad ... .html
因为有骑网站的经验,可以去这里
是一个域名;
/pageLoader/pageLoader.aspxpage=/data/nba/matchups/g5_preview_12.html,可能是网页根目录下/pageLoader/pageLoader.aspx?page=/data/nba/matchups/的地址中的服务器页面上的页面,
为方便管理,相同类型的网页会放在同一个文件夹下,并以类似的方式命名:例如这里的网页命名为g5_preview_12.html,所以类似的网页会改变g5 中的 5 ,或者_12 中的 12 ,通过改变这两个数字,我们发现类似的网页可以改变 12 的数字得到,
让我们了解爬行动物:
这里主要使用python爬虫
urllib2
美丽汤
这两个库,BeautifulSoup的详细文档可以在下面的网站中查看:
抓取网页时:
先打开网页,然后调用beautifulSoup库对网页进行分析,然后使用.find函数找到我们刚才分析的特征的位置,使用.text获取标签的内容,也就是我们要抓取的数据
例如,我们分析以下代码:
response=urllib2.urlopen(url)
print response.getcode()
soup=BeautifulSoup(
response,
‘html.parser‘,
from_encoding=‘utf-8‘
)
links2=soup.find_all(‘div‘,class_="sdi-so",limit=2)
cishu=0
for i in links2:
if(cishu==1):
two=i.find_all(‘td‘,class_="sdi-datacell")
for q in two:
print q.text
table.write(row,col,q.text)
col=(col+1)%9
if(col==0):
row=row+1
row=row+1
file.save(‘NBA.xls‘)
cishu=cishu+1
urllib2.urlopen(url) 是打开一个网页;
print response.getcode() 是测试网页是否可以打开;
汤=美丽汤(
回复,
'html.parser',
from_encoding='utf-8'
)
代表 Beautiful 进行网页分析;
links2=soup.find_all('div',class_=”sdi-so”,limit=2) 用于特征值的查询和返回
其中,我们要找'div'的label,class_=”sdi-so”,limit=2就是找两个为limit(这是为了过滤其他相似的label)
for i in links2:
if(cishu==1):
two=i.find_all(‘td‘,class_="sdi-datacell")
for q in two:
print q.text
table.write(row,col,q.text)
col=(col+1)%9
if(col==0):
row=row+1
row=row+1
为了找到'div',class_=”sdi-so”,然后搜索对应的标签如'td', class_=”sdi-datacell”;
q.text 返回我们想要的数据
这里row=row+1,row=row+1是用来组织我们将数据写入excel文件时的文件格式;
下一步是保存抓取的数据:
这里我们使用excel使用包保存数据:
xdrlib,系统,xlwt
功能:
文件=xlwt.Workbook()
table=file.add_sheet('shuju',cell_overwrite_ok=True)
table.write(0,0,'team')
table.write(0,1,'W/L')
table.write(行,列,q.text)
file.save('NBA.xls')
为最基本的excel写函数,这里不再赘述;
最后,我们爬下来,将数据保存为以下格式:
好的
我想,最深的爱是分开后,我会像你一样活出自己。 查看全部
网页源代码抓取工具(爬虫网页中有的调试与源码)
爬虫的主要目的是过滤掉网页中的无用信息,抓取网页中的有用信息。
一般的爬虫架构是:

在python爬虫之前,你必须对网页的结构知识有一定的了解,比如网页的标签,网页的语言等,推荐去W3School:
W3school 链接查找
爬取前还有一些工具:
1.首先是Python的开发环境:这里我选择了python2.7。开发的IDE为了安装调试方便,选择在VS2013上使用python插件在VS上开发(python程序的调试和c的调试差不多);
2.查看网页源代码的工具:虽然每个浏览器都可以查看网页源代码,但我还是推荐使用火狐浏览器和FirBug插件(同时这两个也是web开发者的工具必须使用) of 一);
FirBug插件的安装可以在右侧的插件组件中安装;
接下来,让我们尝试查看网页的源代码。这里我以我们要爬取的篮球数据为例:
比如我要爬取网页中Team Comparison表的内容:

首先,右键选择我要爬取的分数32-49,右键选择查看带有firBug的元素,(FirBug的另一个好处是网页上会显示源码显示的样式查看源代码时,网页底部会弹出网页源代码和32-49分的位置和源代码,如下图:

可以看到32-49是网页的源代码:
32-49
其中,td为标签名,class为类名,align为格式,32-49为标签内容,即我们要爬取的内容;
但是,在同一个网页中有很多相似的标签和类名,单靠这两个元素是爬不下我们需要的数据的。这时候我们需要查看这个标签的父标签,或者上一层的标签。提取我们要爬取的数据的更多特征,过滤掉其他不想爬取的数据,比如我们选择这张表所在的标签作为我们过滤的第二个。
特征:
Team Comparison
我们再分析一下网页的URL:
比如我们要爬取的网页的网址是:
http://www.covers.com/pageLoad ... .html
因为有骑网站的经验,可以去这里
是一个域名;
/pageLoader/pageLoader.aspxpage=/data/nba/matchups/g5_preview_12.html,可能是网页根目录下/pageLoader/pageLoader.aspx?page=/data/nba/matchups/的地址中的服务器页面上的页面,
为方便管理,相同类型的网页会放在同一个文件夹下,并以类似的方式命名:例如这里的网页命名为g5_preview_12.html,所以类似的网页会改变g5 中的 5 ,或者_12 中的 12 ,通过改变这两个数字,我们发现类似的网页可以改变 12 的数字得到,
让我们了解爬行动物:
这里主要使用python爬虫
urllib2
美丽汤
这两个库,BeautifulSoup的详细文档可以在下面的网站中查看:
抓取网页时:
先打开网页,然后调用beautifulSoup库对网页进行分析,然后使用.find函数找到我们刚才分析的特征的位置,使用.text获取标签的内容,也就是我们要抓取的数据
例如,我们分析以下代码:
response=urllib2.urlopen(url)
print response.getcode()
soup=BeautifulSoup(
response,
‘html.parser‘,
from_encoding=‘utf-8‘
)
links2=soup.find_all(‘div‘,class_="sdi-so",limit=2)
cishu=0
for i in links2:
if(cishu==1):
two=i.find_all(‘td‘,class_="sdi-datacell")
for q in two:
print q.text
table.write(row,col,q.text)
col=(col+1)%9
if(col==0):
row=row+1
row=row+1
file.save(‘NBA.xls‘)
cishu=cishu+1
urllib2.urlopen(url) 是打开一个网页;
print response.getcode() 是测试网页是否可以打开;
汤=美丽汤(
回复,
'html.parser',
from_encoding='utf-8'
)
代表 Beautiful 进行网页分析;
links2=soup.find_all('div',class_=”sdi-so”,limit=2) 用于特征值的查询和返回
其中,我们要找'div'的label,class_=”sdi-so”,limit=2就是找两个为limit(这是为了过滤其他相似的label)
for i in links2:
if(cishu==1):
two=i.find_all(‘td‘,class_="sdi-datacell")
for q in two:
print q.text
table.write(row,col,q.text)
col=(col+1)%9
if(col==0):
row=row+1
row=row+1
为了找到'div',class_=”sdi-so”,然后搜索对应的标签如'td', class_=”sdi-datacell”;
q.text 返回我们想要的数据
这里row=row+1,row=row+1是用来组织我们将数据写入excel文件时的文件格式;
下一步是保存抓取的数据:
这里我们使用excel使用包保存数据:
xdrlib,系统,xlwt
功能:
文件=xlwt.Workbook()
table=file.add_sheet('shuju',cell_overwrite_ok=True)
table.write(0,0,'team')
table.write(0,1,'W/L')
table.write(行,列,q.text)
file.save('NBA.xls')
为最基本的excel写函数,这里不再赘述;
最后,我们爬下来,将数据保存为以下格式:

好的

我想,最深的爱是分开后,我会像你一样活出自己。
网页源代码抓取工具( 图12预览视频下载的多种方法和使用到的工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-04-09 08:06
图12预览视频下载的多种方法和使用到的工具)
图9 快速输入视频网站 在“选项”中,我们可以设置视频文件的相关参数,包括输出视频格式、视频大小、音频码率等。可以将视频转换为AVI, MPEG或PSP格式,操作比较简单。
图10 相关设置选项六、在线播放视频下载
除了通过工具下载在线视频外,我们还可以借助一些在线网站下载视频,连软件都不需要安装,省事!登录FLV下载器网站,目前这个网站支持120个视频的资源下载网站。在上方的“输入视频页面地址”框中,复制您正在观看的视频的页面地址,然后点击“获取地址”按钮,真实的下载地址将被快速解析并显示在下方。这里我们以著名的youtube网络为例:
图11 FLV Downloader网站 获取视频地址后,我们可以将下载地址复制到其他工具下载,直接下载视频,预览视频。预览视频功能很有特色。
图12 预览视频总结: 以上,我们介绍了FLV视频下载的各种方法和工具。其中,在临时文件中查找FLV视频的方法是最简单的,但是在查找的时候,需要眼睛和手快。》,并注意技巧,否则从众多的临时文件中查找会比较麻烦;而我们推荐的四款FLV视频下载工具体积都比较小,操作也比较简单,是大家下载FLV视频最主要的途径。虽然需要安装一次,但安装后可以轻松下载;在没有安装软件的情况下,通过网站在线下载视频是一种替代方案,可以解决您的燃眉之急! 查看全部
网页源代码抓取工具(
图12预览视频下载的多种方法和使用到的工具)

图9 快速输入视频网站 在“选项”中,我们可以设置视频文件的相关参数,包括输出视频格式、视频大小、音频码率等。可以将视频转换为AVI, MPEG或PSP格式,操作比较简单。

图10 相关设置选项六、在线播放视频下载
除了通过工具下载在线视频外,我们还可以借助一些在线网站下载视频,连软件都不需要安装,省事!登录FLV下载器网站,目前这个网站支持120个视频的资源下载网站。在上方的“输入视频页面地址”框中,复制您正在观看的视频的页面地址,然后点击“获取地址”按钮,真实的下载地址将被快速解析并显示在下方。这里我们以著名的youtube网络为例:

图11 FLV Downloader网站 获取视频地址后,我们可以将下载地址复制到其他工具下载,直接下载视频,预览视频。预览视频功能很有特色。

图12 预览视频总结: 以上,我们介绍了FLV视频下载的各种方法和工具。其中,在临时文件中查找FLV视频的方法是最简单的,但是在查找的时候,需要眼睛和手快。》,并注意技巧,否则从众多的临时文件中查找会比较麻烦;而我们推荐的四款FLV视频下载工具体积都比较小,操作也比较简单,是大家下载FLV视频最主要的途径。虽然需要安装一次,但安装后可以轻松下载;在没有安装软件的情况下,通过网站在线下载视频是一种替代方案,可以解决您的燃眉之急!
网页源代码抓取工具(ColorWellformac破解版安装教程mac安装包破解版安装包安装包下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-04-09 03:38
ColorWell 是一个强大的 mac 调色板,支持与 macOS 系统调色板同步。您可以导入/导出 Adobe .ase 和 Apple .clr 调色板文件,拥有无限的历史记录,支持 Swift/Objective-C 颜色代码生成,支持按名称、十六进制、RGB、HSL、HSB、Lab 和 CMYK 更改颜色,支持提取颜色从图片和生成配色方案。
ColorWell for mac 破解版安装教程
colorwell mac 破解版安装包下载后打开,将【ColorWell】拖入应用程序。
ColorWell for mac 破解版官方介绍
ColorWell Mac版是Mac os平台上帮助用户提取WEB页面颜色代码的工具。ColorWell Mac版使用非常方便,功能非常强大。您也可以自行设置提取的快捷键,加快操作速度。顶部的工具栏也可以最小化以方便使用。默认情况下,访问 MacOS 色轮非常繁琐,但可以将 ColorWell 配置为通过全局热键或系统菜单栏中的快速鼠标单击来显示它。这使您可以从任何颜色源快速获取 Hex/HSL/RGB 和代码片段。如果您从未从源(或多源)图像快速生成调色板,那么调色板生成器就是您所需要的。您可以抓取任何源图像并将其放入 Builder 窗口以生成图像中最常见颜色的调色板。
ColorWell mac破解版功能
- 存储并立即检索无限的调色板
- 通过拖放图像创建调色板
- 从任何来源快速获取 hex/rgb/hsl/h***/swift/objc 代码片段。
- 在 hex/rgb/hsl 和 h*** 之间轻松转换。
- 快速查看任何 hex/rgb/hsl/h*** 颜色。
- 快速将 hex/rgb/hsl/h*** 或颜色选择器转换为 NSColor/UIColor Objective-C 或 Swift 就绪代码。
小编的话
ColorWell 是一个很棒的网络颜色代码提取工具,可以很容易地生成无限的调色板,并且可编辑的调色板数据库允许您存档和恢复任何调色板,以便以后进行超快速搜索。 查看全部
网页源代码抓取工具(ColorWellformac破解版安装教程mac安装包破解版安装包安装包下载)
ColorWell 是一个强大的 mac 调色板,支持与 macOS 系统调色板同步。您可以导入/导出 Adobe .ase 和 Apple .clr 调色板文件,拥有无限的历史记录,支持 Swift/Objective-C 颜色代码生成,支持按名称、十六进制、RGB、HSL、HSB、Lab 和 CMYK 更改颜色,支持提取颜色从图片和生成配色方案。

ColorWell for mac 破解版安装教程
colorwell mac 破解版安装包下载后打开,将【ColorWell】拖入应用程序。

ColorWell for mac 破解版官方介绍
ColorWell Mac版是Mac os平台上帮助用户提取WEB页面颜色代码的工具。ColorWell Mac版使用非常方便,功能非常强大。您也可以自行设置提取的快捷键,加快操作速度。顶部的工具栏也可以最小化以方便使用。默认情况下,访问 MacOS 色轮非常繁琐,但可以将 ColorWell 配置为通过全局热键或系统菜单栏中的快速鼠标单击来显示它。这使您可以从任何颜色源快速获取 Hex/HSL/RGB 和代码片段。如果您从未从源(或多源)图像快速生成调色板,那么调色板生成器就是您所需要的。您可以抓取任何源图像并将其放入 Builder 窗口以生成图像中最常见颜色的调色板。

ColorWell mac破解版功能
- 存储并立即检索无限的调色板
- 通过拖放图像创建调色板
- 从任何来源快速获取 hex/rgb/hsl/h***/swift/objc 代码片段。
- 在 hex/rgb/hsl 和 h*** 之间轻松转换。
- 快速查看任何 hex/rgb/hsl/h*** 颜色。
- 快速将 hex/rgb/hsl/h*** 或颜色选择器转换为 NSColor/UIColor Objective-C 或 Swift 就绪代码。

小编的话
ColorWell 是一个很棒的网络颜色代码提取工具,可以很容易地生成无限的调色板,并且可编辑的调色板数据库允许您存档和恢复任何调色板,以便以后进行超快速搜索。
网页源代码抓取工具(Python自带的HTMLParser示例程序 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-04-08 03:23
)
本程序使用Python自带的HTMLParser,从Yahoo Finance的指定页面抓取几个字段。代码30行左右,简单实用,居家旅行必备:)
代码由官方文档中HTMLParser的示例程序修改
完整的代码和介绍在:
代码如下:
import urllibimport sysimport stringfrom HTMLParser import HTMLParserticker_list = ["ibb", "socl", "pnqi", "qqq", "vbk", "eirl", "ewi", "pbd", "ita", "dfe"]ticker = ticker_list[0]class MyHTMLParser(HTMLParser): def handle_data(self, data): starttag_text = self.get_starttag_text() ticker_str = "(%s)" % ticker if -1!=string.find(data, ticker_str.upper()) and -1!=string.find(starttag_text, ""): sys.stdout.write(data) if -1!=string.find(str(starttag_text), "yfs_g53_%s" % ticker.lower()) and -1==string.find(data, "-"): sys.stdout.write("\t") sys.stdout.write(data) if -1!=string.find(str(starttag_text), "yfs_h53_%s" % ticker.lower()): print "\t", datafor t in ticker_list: ticker = t parser = MyHTMLParser() f = urllib.urlopen("http://finance.yahoo.com/q?s=%s" % ticker) html_string = f.read() parser.feed(html_string)
样本输出:
iShares Nasdaq Biotechnology (IBB) 228.14 234.90Global X Social Media Index ETF (SOCL) 17.38 17.92PowerShares NASDAQ Internet (PNQI) 61.73 63.17PowerShares QQQ (QQQ) 87.31 88.15Vanguard Small Cap Growth ETF (VBK) 118.53 120.54iShares MSCI Ireland Capped (EIRL) 38.37 38.84iShares MSCI Italy Capped (EWI) 17.95 18.09PowerShares Global Clean Energy (PBD) 12.95 13.12 Defense (ITA) 107.93 109.36WisdomTree Europe SmallCap Dividend (DFE) 62.08 62.64 查看全部
网页源代码抓取工具(Python自带的HTMLParser示例程序
)
本程序使用Python自带的HTMLParser,从Yahoo Finance的指定页面抓取几个字段。代码30行左右,简单实用,居家旅行必备:)
代码由官方文档中HTMLParser的示例程序修改
完整的代码和介绍在:
代码如下:
import urllibimport sysimport stringfrom HTMLParser import HTMLParserticker_list = ["ibb", "socl", "pnqi", "qqq", "vbk", "eirl", "ewi", "pbd", "ita", "dfe"]ticker = ticker_list[0]class MyHTMLParser(HTMLParser): def handle_data(self, data): starttag_text = self.get_starttag_text() ticker_str = "(%s)" % ticker if -1!=string.find(data, ticker_str.upper()) and -1!=string.find(starttag_text, ""): sys.stdout.write(data) if -1!=string.find(str(starttag_text), "yfs_g53_%s" % ticker.lower()) and -1==string.find(data, "-"): sys.stdout.write("\t") sys.stdout.write(data) if -1!=string.find(str(starttag_text), "yfs_h53_%s" % ticker.lower()): print "\t", datafor t in ticker_list: ticker = t parser = MyHTMLParser() f = urllib.urlopen("http://finance.yahoo.com/q?s=%s" % ticker) html_string = f.read() parser.feed(html_string)
样本输出:
iShares Nasdaq Biotechnology (IBB) 228.14 234.90Global X Social Media Index ETF (SOCL) 17.38 17.92PowerShares NASDAQ Internet (PNQI) 61.73 63.17PowerShares QQQ (QQQ) 87.31 88.15Vanguard Small Cap Growth ETF (VBK) 118.53 120.54iShares MSCI Ireland Capped (EIRL) 38.37 38.84iShares MSCI Italy Capped (EWI) 17.95 18.09PowerShares Global Clean Energy (PBD) 12.95 13.12 Defense (ITA) 107.93 109.36WisdomTree Europe SmallCap Dividend (DFE) 62.08 62.64
网页源代码抓取工具(网页内容抓取工具做网站指定采集伪原创发布,你知道吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-04-08 01:06
网页内容抓取工具。最近有很多做网站的朋友问我有没有什么有用的网页内容爬取。我可以批量采集网站内容到网站指定采集伪原创发布,因为他们站很多,每天网站内容更新是一件很麻烦的事情。SEO是“内容为王”的时代,优质内容的稳定输出将有利于网站的SEO收录和SEO排名。
当网页内容爬虫做网站时,你需要选择一个好的模板。对于 网站 优化,一个好的模板通常会事半功倍。除了基本要求之外,一个好的模板应该有很好的插图,有时间线,没有太多的页面链接,没有杂乱的章节。
采集速度快,数据完整性高。采集网页内容抓取器的速度是最快的采集软件之一。独有的多模板功能+智能纠错模式,保证结果数据100%完整性。任何网页都可以是采集,只要你能在浏览器中看到内容,几乎可以做到你需要的格式采集。采集 支持 JS 输出内容。
有节奏地更新网站 内容,维护原创,并使用适当的伪原创 工具。一开始,要不断给搜索引擎一个好的形象,不要被判断为采集网站。这是很多人一开始并没有注意到的。网站网页内容爬取到一定规模后,为了增加网站的收录,每天添加网站的外部链接。然后可以使用网页内容爬虫的一键批量自动推送工具,将网站链接批量提交到百度、搜狗、360、神马等搜索引擎。推送是 SEO 的重要组成部分。推送主动向搜索引擎公开链接以增加蜘蛛爬行,从而促进网站收录。
当网站为收录,稳定且有一定关键词排名时,可以通过网页内容爬取不断增加网站内容。当然,如果你有资源,可以在网站收录首页后交换链接。主要是因为没有排名的 网站 很难切换到正确的链接。网页内容爬取可以通过站外推广不断增加网站的曝光率,可以间接提高网站的自然点击率,从而提升和稳定网站的排名。
很多时候我们会发现我们的网站代码有一些优化问题,比如一些模板链接错误,或者我们对网站做了一些微调。如果看不懂代码,往往只能自己操心。如果你懂html和div+css,就可以很好的解决这些小问题。
我们都知道网站空间的稳定性很重要,打开速度也是衡量网站排名的一个非常重要的指标,所以一旦百度站长平台有这样的优化建议,往往需要自己解决。
做过SEO的人都离不开程序背景。通常,很多工作都在其中完成。尤其是想要做好结构优化的修改和设置,不看懂这个程序是不可能的。如果做得不好,很容易犯各种严重的错误。
当前网站安全形势非常严峻。我们经常看到有人在网站上抱怨因为排名好被黑客打开,或者被黑了,服务器甚至被别人炸了。这无疑会对他们的网站排名产生非常负面的影响,所以一些安全知识是必要的。
网页内容爬虫基于高度智能的文本识别算法。网页内容爬虫只需将关键词输入到采集内容,无需编写采集规则。覆盖六大搜索引擎和各大新闻源,内容取之不尽,优先采集最新最热的文章信息,自动过滤采集到的信息,拒绝重复采集。这就是今天对 网站 内容抓取工具的介绍。返回搜狐,查看更多 查看全部
网页源代码抓取工具(网页内容抓取工具做网站指定采集伪原创发布,你知道吗)
网页内容抓取工具。最近有很多做网站的朋友问我有没有什么有用的网页内容爬取。我可以批量采集网站内容到网站指定采集伪原创发布,因为他们站很多,每天网站内容更新是一件很麻烦的事情。SEO是“内容为王”的时代,优质内容的稳定输出将有利于网站的SEO收录和SEO排名。
当网页内容爬虫做网站时,你需要选择一个好的模板。对于 网站 优化,一个好的模板通常会事半功倍。除了基本要求之外,一个好的模板应该有很好的插图,有时间线,没有太多的页面链接,没有杂乱的章节。
采集速度快,数据完整性高。采集网页内容抓取器的速度是最快的采集软件之一。独有的多模板功能+智能纠错模式,保证结果数据100%完整性。任何网页都可以是采集,只要你能在浏览器中看到内容,几乎可以做到你需要的格式采集。采集 支持 JS 输出内容。
有节奏地更新网站 内容,维护原创,并使用适当的伪原创 工具。一开始,要不断给搜索引擎一个好的形象,不要被判断为采集网站。这是很多人一开始并没有注意到的。网站网页内容爬取到一定规模后,为了增加网站的收录,每天添加网站的外部链接。然后可以使用网页内容爬虫的一键批量自动推送工具,将网站链接批量提交到百度、搜狗、360、神马等搜索引擎。推送是 SEO 的重要组成部分。推送主动向搜索引擎公开链接以增加蜘蛛爬行,从而促进网站收录。
当网站为收录,稳定且有一定关键词排名时,可以通过网页内容爬取不断增加网站内容。当然,如果你有资源,可以在网站收录首页后交换链接。主要是因为没有排名的 网站 很难切换到正确的链接。网页内容爬取可以通过站外推广不断增加网站的曝光率,可以间接提高网站的自然点击率,从而提升和稳定网站的排名。
很多时候我们会发现我们的网站代码有一些优化问题,比如一些模板链接错误,或者我们对网站做了一些微调。如果看不懂代码,往往只能自己操心。如果你懂html和div+css,就可以很好的解决这些小问题。
我们都知道网站空间的稳定性很重要,打开速度也是衡量网站排名的一个非常重要的指标,所以一旦百度站长平台有这样的优化建议,往往需要自己解决。
做过SEO的人都离不开程序背景。通常,很多工作都在其中完成。尤其是想要做好结构优化的修改和设置,不看懂这个程序是不可能的。如果做得不好,很容易犯各种严重的错误。
当前网站安全形势非常严峻。我们经常看到有人在网站上抱怨因为排名好被黑客打开,或者被黑了,服务器甚至被别人炸了。这无疑会对他们的网站排名产生非常负面的影响,所以一些安全知识是必要的。
网页内容爬虫基于高度智能的文本识别算法。网页内容爬虫只需将关键词输入到采集内容,无需编写采集规则。覆盖六大搜索引擎和各大新闻源,内容取之不尽,优先采集最新最热的文章信息,自动过滤采集到的信息,拒绝重复采集。这就是今天对 网站 内容抓取工具的介绍。返回搜狐,查看更多
网页源代码抓取工具(使用PyQt5爬虫小工具方便他的操作可视化(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-07 20:13
)
最近有朋友需要帮忙写一个爬虫脚本来爬取雪球网一些上市公司的财务数据。锅友希望能够根据自己的选择自由抓取,所以干脆给锅友一个脚本。锅友还需要自己搭建一个python环境,还需要熟悉一些参数修改的操作,想想也麻烦。.
于是,结合我之前做的汇率计算器小工具,我决定用PyQt5为朋友做一个爬虫小工具,方便他的操作可视化。
一、效果演示
二、功能说明三、制作流程
首先导入需要的库
import sys from PyQt5 import QtCore, QtGui, QtWidgets from PyQt5.QtWidgets import QApplication, QMainWindow,QFileDialog import os import requests from fake_useragent import UserAgent import json import logging import time import pandas as pd from openpyxl import load_workbook
新手学习,Python 教程/工具/方法/解疑+V:itz992
Snowball 网页拆解
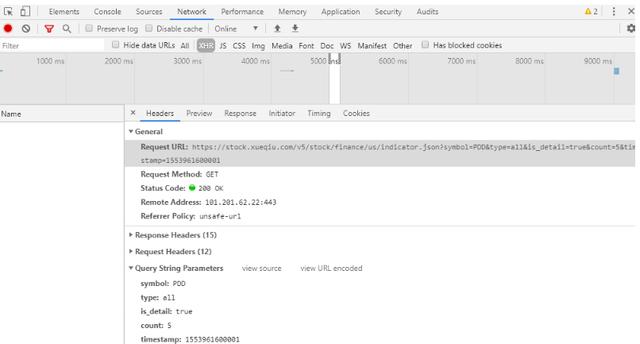
这一步的目的是获取待爬取数据的真实URL地址模式。
当我选择一只股票查看某类财务数据报告时,点击下一页,网站的地址没有变化。我基本上可以知道这是动态加载的数据。对于这类数据,我可以使用 F12 打开开发者模式。.
开发者模式下选择Network—>XHR查看真实数据获取地址URL和请求方法(General是请求URL和请求方法说明,Request Headers有请求头信息,如cookies,Query String Parameters可用Variable参数项,一般来说,数据源URL是由base URL和这里的可变参数组成)
当我们分析这个 URL 时,我们可以发现它的基本结构如下:
基于以上结构,我们将最终组合的 URL 地址拆分如下
#基础网站
base_url = f'https://stock.xueqiu.com/v5/stock/finance/{ABtype}'
#组合url地址
url = f'{base_url}/{data_type}.json?symbol={ipo_code}&type=all&is_detail=true&count={count_num}×tamp={start_time}'
操作界面设计
操作界面设计使用PyQt5,这里不再详细介绍。我们将在后续对PyQt5的使用进行专门的讲解。
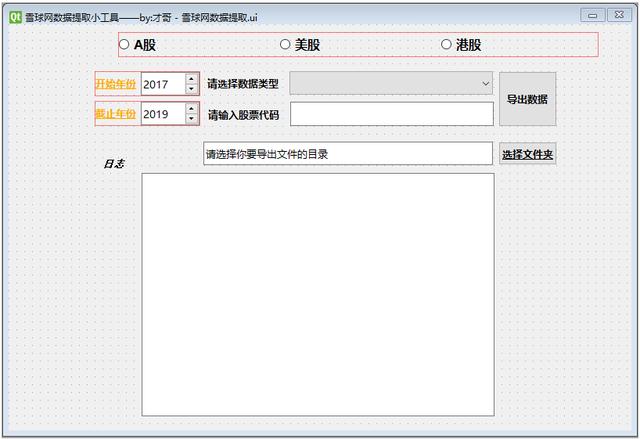
使用QT Designer可视化设计操作界面,参考以下:
Snowball Network Data Extraction.ui中各个组件的相关设置如下:
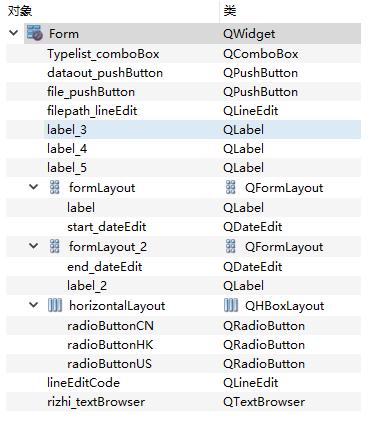
.ui文件可以使用pyuic5指令编译生成对应的.py文件,也可以直接在vscode中翻译(这里不再赘述,详见后续特别说明)。
本文没有单独使用操作界面定义文件,而是将所有代码集中在同一个.py文件中,所以翻译后的代码可供以后使用。
获取cookies和基本参数获取cookies
为了让小工具可以使用,我们需要自动获取 cookie 地址并将其附加到请求头中,而不是在开发人员模式下手动打开网页并填写 cookie。
自动获取cookies,这里使用的requests库的session会话对象。
requests 库的 session 对象可以跨请求维护某些参数。简单来说,比如你使用session成功登录到某个网站,那么再使用session对象请求网站。其他网页默认使用会话前使用的cookie等参数。
import requests from fake_useragent import UserAgent
url = 'https://xueqiu.com' session = requests.Session()
headers = {"User-Agent": UserAgent(verify_ssl=False).random}
session.get(url, headers=headers) #获取当前的Cookie
Cookie= dict(session.cookies)
基本参数
基本参数用于在请求财务数据时选择原创的 URL 组成参数。我们需要在可视化操作工具中选择财务数据类型,所以这里需要建立一个财务数据类型字典。
#原始网址
original_url = 'https://xueqiu.com'
#财务数据类型字典
dataType = {'全选':'all', '主要指标':'indicator', '利润表':'income', '资产负债表':'balance', '现金流量表':'cash_flow'}
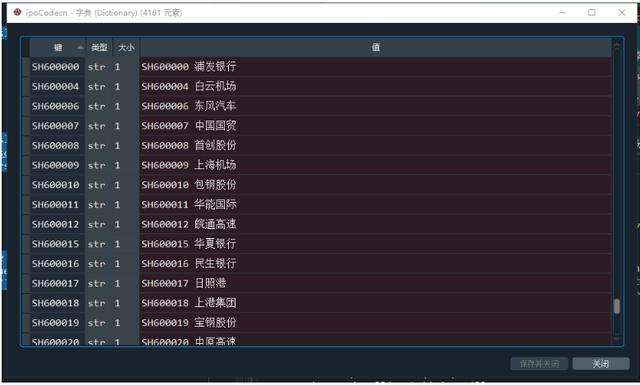
访问各种证券市场的上市目录
因为我们在可视化操作工具上选择了股票代码并抓取了相关数据并导出,导出的文件名预计以股票代码+公司名称的形式存储(SH600000上海浦东发展银行),所以我们需要获取股票代码和名称。对应的字典表。
这实际上是一个简单的网络爬虫和数据格式调整过程。实现代码如下:
1import requests
2import pandas as pd
3import json
4from fake_useragent import UserAgent 5#请求头设置
6headers = {"User-Agent": UserAgent(verify_ssl=False).random} 7#股票清单列表地址解析(通过设置参数size为9999可以只使用1个静态地址,全部股票数量不足5000)
8url = 'https://xueqiu.com/service/v5/ ... 39%3B
9#请求原始数据
10response = requests.get(url,headers = headers) 11#获取股票列表数据
12df = response.text 13#数据格式转化
14data = json.loads(df) 15#获取所需要的股票代码及股票名称数据
16data = data['data']['list'] 17#将数据转化为dataframe格式,并进行相关调整
18data = pd.DataFrame(data)
19data = data[['symbol','name']]
20data['name'] = data['symbol']+' '+data['name']
21data.sort_values(by = ['symbol'],inplace=True)
22data = data.set_index(data['symbol'])['name'] 23#将股票列表转化为字典,键为股票代码,值为股票代码和股票名称的组合
24ipoCodecn = data.to_dict()
A股股票代码和公司名称字典如下:
获取并导出上市公司财务数据
根据可视化操作界面中选择的财报时间间隔、财报数据类型、选择的证券市场类型和输入的股票代码,我们需要根据这些参数形成我们需要请求数据的URL,然后进行数据请求。
由于请求的数据是json格式,所以可以直接转换成dataframe类型再导出。导出数据时,我们需要判断数据文件是否存在,存在则追加,不存在则新建文件。
获取上市公司财务数据
通过选择的参数生成财务数据URL,然后根据是否全部选择来判断后续数据请求的操作,因此可以分为获取数据URL和请求详细数据两部分。
获取数据地址
数据URL根据证券市场类型、金融数据类型、股票代码、单页数和起始时间戳确定,这些参数通过可视化操作界面进行设置。
股市类型控件是radioButton,可以通过你的ischecked()方法判断是否选中,然后使用if-else设置参数;
需要先选择金融数据类型和股票代码,因为它们支持全选(全选的情况下,需要循环获取数据URL,否则只能通过单一方式获取),所以这个部分需要再次拆分;
单页数考虑到每年有4份财报,所以这里默认是年差*4;
时间戳是根据开始时间中的结束时间计算的。由于可视化界面的输入是整数年,我们可以通过mktime()方法获取时间戳。
1def Get_url(self,name,ipo_code): 2 #获取开始结束时间戳(开始和结束时间手动输入)
3 inputstartTime = str(self.start_dateEdit.date().toPyDate().year) 4 inputendTime = str(self.end_dateEdit.date().toPyDate().year) 5 endTime = f'{inputendTime}-12-31 00:00:00'
6 timeArray = time.strptime(endTime, "%Y-%m-%d %H:%M:%S") 7
8 #获取指定的数据类型及股票代码
9 filename = ipo_code 10 data_type =dataType[name] 11 #计算需要采集的数据量(一年以四个算)
12 count_num = (int(inputendTime) - int(inputstartTime) +1) * 4
13 start_time = f'{int(time.mktime(timeArray))}001'
14
15 #证券市场类型
16 if (self.radioButtonCN.isChecked()): 17 ABtype = 'cn'
18 num = 3
19 elif (self.radioButtonUS.isChecked()): 20 ABtype = 'us'
21 num = 6
22 elif (self.radioButtonHK.isChecked()): 23 ABtype = 'hk'
24 num = 6
25 else: 26 ABtype = 'cn'
27 num = 3
28
29 #基础网站
30 base_url = f'https://stock.xueqiu.com/v5/stock/finance/{ABtype}'
31
32 #组合url地址
33 url = f'{base_url}/{data_type}.json?symbol={ipo_code}&type=all&is_detail=true&count={count_num}×tamp={start_time}'
34
35 return url,num
请求详细数据
data采集 方法需要根据用户输入来确定。代码主要根据用户输入进行判断,然后进行详细的数据请求。
1#根据用户输入决定数据采集方式
2def Get_data(self): 3 #name为财务报告数据类型(全选或单个)
4 name = self.Typelist_comboBox.currentText() 5 #股票代码(全选或单个)
6 ipo_code = self.lineEditCode.text() 7 #判断证券市场类型
8 if (self.radioButtonCN.isChecked()): 9 ipoCodex=ipoCodecn 10 elif (self.radioButtonUS.isChecked()): 11 ipoCodex=ipoCodeus 12 elif (self.radioButtonHK.isChecked()): 13 ipoCodex=ipoCodehk 14 else: 15 ipoCodex=ipoCodecn 16#根据财务报告数据类型和股票代码类型决定数据采集的方式
17 if name == '全选' and ipo_code == '全选': 18 for ipo_code in list(ipoCodex.keys()): 19 for name in list(dataType.keys())[1:]: 20 self.re_data(name,ipo_code) 21 elif name == '全选' and ipo_code != '全选': 22 for name in list(dataType.keys())[1:]: 23 self.re_data(name,ipo_code) 24 elif ipo_code == '全选' and name != '全选': 25 for ipo_code in list(ipoCodex.keys()): 26 self.re_data(name,ipo_code) 27 else: 28 self.re_data(name,ipo_code) 29
30#数据采集,需要调用数据网址(Get.url(name,ipo_code)
31def re_data(self,name,ipo_code): 32 name = name 33 #获取url和num(url为详情数据网址,num是详情数据中根据不同证券市场类型决定的需要提取的数据起始位置)
34 url,num = self.Get_url(name,ipo_code) 35 #请求头
36 headers = {"User-Agent": UserAgent(verify_ssl=False).random} 37 #请求数据
38 df = requests.get(url,headers = headers,cookies = cookies) 39
40 df = df.text
41try: 42 data = json.loads(df) 43 pd_df = pd.DataFrame(data['data']['list']) 44 to_xlsx(num,pd_df) 45 except KeyError: 46 log = '该股票此类型报告不存在,请重新选择股票代码或数据类型'
47 self.rizhi_textBrowser.append(log)
财务数据处理和导出
简单的数据导出是一个比较简单的操作,可以直接to_excel()。但是考虑到同一个上市公司有四种类型的财务数据,我们希望它们都存储在同一个文件中,对于可能批量导出的同类型数据,我们希望添加。因此需要特殊处理,使用pd.ExcelWriter()方法进行操作。
新手学习,Python 教程/工具/方法/解疑+V:itz992
1#数据处理并导出
2def to_xlsx(self,num,data): 3 pd_df = data 4 #获取可视化操作界面输入的导出文件保存文件夹目录
5 filepath = self.filepath_lineEdit.text() 6 #获取文件名
7 filename = ipoCode[ipo_code] 8 #组合成文件详情(地址+文件名+文件类型)
9 path = f'{filepath}\{filename}.xlsx'
10 #获取原始数据列字段
11 cols = pd_df.columns.tolist() 12 #创建空dataframe类型用于存储
13 data = pd.DataFrame() 14 #创建报告名称字段
15 data['报告名称'] = pd_df['report_name'] 16 #由于不同证券市场类型下各股票财务报告详情页数据从不同的列才是需要的数据,因此需要用num作为起点
17 for i in range(num,len(cols)): 18 col = cols[i] 19 try: 20 #每列数据中是列表形式,第一个是值,第二个是同比
21 data[col] = pd_df[col].apply(lambda x:x[0]) 22 # data[f'{col}_同比'] = pd_df[col].apply(lambda x:x[1])
23 except TypeError: 24 pass
25 data = data.set_index('报告名称') 26 log = f'{filename}的{name}数据已经爬取成功'
27 self.rizhi_textBrowser.append(log) 28 #由于存储的数据行索引为数据指标,所以需要对采集的数据进行转T处理
29 dataT = data.T 30 dataT.rename(index = eval(f'_{name}'),inplace=True) 31 #以下为判断数据报告文件是否存在,若存在则追加,不存在则重新创建
32 try: 33 if os.path.exists(path): 34 #读取文件全部页签
35 df_dic = pd.read_excel(path,None) 36 if name not in list(df_dic.keys()): 37 log = f'{filename}的{name}数据页签不存在,创建新页签'
38 self.rizhi_textBrowser.append(log) 39 #追加新的页签
40 with pd.ExcelWriter(path,mode='a') as writer: 41 book = load_workbook(path) 42 writer.book = book 43 dataT.to_excel(writer,sheet_name=name) 44 writer.save() 45 else: 46 log = f'{filename}的{name}数据页签已存在,合并中'
47 self.rizhi_textBrowser.append(log) 48 df = pd.read_excel(path,sheet_name = name,index_col=0) 49 d_ = list(set(list(dataT.columns)) - set(list(df.columns))) 50#使用merge()进行数据合并
51 dataT = pd.merge(df,dataT[d_],how='outer',left_index=True,right_index=True) 52 dataT.sort_index(axis=1,ascending=False,inplace=True) 53 #页签中追加数据不影响其他页签
54 with pd.ExcelWriter(path,engine='openpyxl') as writer: 55 book = load_workbook(path) 56 writer.book = book 57 idx = writer.book.sheetnames.index(name) 58 #删除同名的,然后重新创建一个同名的
59 writer.book.remove(writer.book.worksheets[idx]) 60 writer.book.create_sheet(name, idx) 61 writer.sheets = {ws.title:ws for ws in writer.book.worksheets} 62
63 dataT.to_excel(writer,sheet_name=name,startcol=0) 64 writer.save() 65 else: 66 dataT.to_excel(path,sheet_name=name) 67
68 log = f'{filename}的{name}数据已经保存成功'
69 self.rizhi_textBrowser.append(log) 70
71 except FileNotFoundError: 72 log = '未设置存储目录或存储目录不存在,请重新选择文件夹'
73 self.rizhi_textBrowser.append(log) 查看全部
网页源代码抓取工具(使用PyQt5爬虫小工具方便他的操作可视化(组图)
)
最近有朋友需要帮忙写一个爬虫脚本来爬取雪球网一些上市公司的财务数据。锅友希望能够根据自己的选择自由抓取,所以干脆给锅友一个脚本。锅友还需要自己搭建一个python环境,还需要熟悉一些参数修改的操作,想想也麻烦。.
于是,结合我之前做的汇率计算器小工具,我决定用PyQt5为朋友做一个爬虫小工具,方便他的操作可视化。
一、效果演示
二、功能说明三、制作流程
首先导入需要的库
import sys from PyQt5 import QtCore, QtGui, QtWidgets from PyQt5.QtWidgets import QApplication, QMainWindow,QFileDialog import os import requests from fake_useragent import UserAgent import json import logging import time import pandas as pd from openpyxl import load_workbook
新手学习,Python 教程/工具/方法/解疑+V:itz992
Snowball 网页拆解
这一步的目的是获取待爬取数据的真实URL地址模式。
当我选择一只股票查看某类财务数据报告时,点击下一页,网站的地址没有变化。我基本上可以知道这是动态加载的数据。对于这类数据,我可以使用 F12 打开开发者模式。.
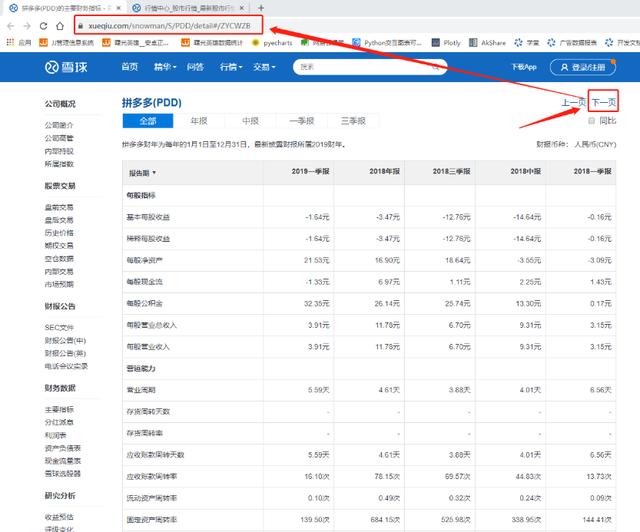
开发者模式下选择Network—>XHR查看真实数据获取地址URL和请求方法(General是请求URL和请求方法说明,Request Headers有请求头信息,如cookies,Query String Parameters可用Variable参数项,一般来说,数据源URL是由base URL和这里的可变参数组成)
当我们分析这个 URL 时,我们可以发现它的基本结构如下:

基于以上结构,我们将最终组合的 URL 地址拆分如下
#基础网站
base_url = f'https://stock.xueqiu.com/v5/stock/finance/{ABtype}'
#组合url地址
url = f'{base_url}/{data_type}.json?symbol={ipo_code}&type=all&is_detail=true&count={count_num}×tamp={start_time}'
操作界面设计
操作界面设计使用PyQt5,这里不再详细介绍。我们将在后续对PyQt5的使用进行专门的讲解。
使用QT Designer可视化设计操作界面,参考以下:
Snowball Network Data Extraction.ui中各个组件的相关设置如下:
.ui文件可以使用pyuic5指令编译生成对应的.py文件,也可以直接在vscode中翻译(这里不再赘述,详见后续特别说明)。
本文没有单独使用操作界面定义文件,而是将所有代码集中在同一个.py文件中,所以翻译后的代码可供以后使用。
获取cookies和基本参数获取cookies
为了让小工具可以使用,我们需要自动获取 cookie 地址并将其附加到请求头中,而不是在开发人员模式下手动打开网页并填写 cookie。
自动获取cookies,这里使用的requests库的session会话对象。
requests 库的 session 对象可以跨请求维护某些参数。简单来说,比如你使用session成功登录到某个网站,那么再使用session对象请求网站。其他网页默认使用会话前使用的cookie等参数。
import requests from fake_useragent import UserAgent
url = 'https://xueqiu.com' session = requests.Session()
headers = {"User-Agent": UserAgent(verify_ssl=False).random}
session.get(url, headers=headers) #获取当前的Cookie
Cookie= dict(session.cookies)
基本参数
基本参数用于在请求财务数据时选择原创的 URL 组成参数。我们需要在可视化操作工具中选择财务数据类型,所以这里需要建立一个财务数据类型字典。
#原始网址
original_url = 'https://xueqiu.com'
#财务数据类型字典
dataType = {'全选':'all', '主要指标':'indicator', '利润表':'income', '资产负债表':'balance', '现金流量表':'cash_flow'}
访问各种证券市场的上市目录
因为我们在可视化操作工具上选择了股票代码并抓取了相关数据并导出,导出的文件名预计以股票代码+公司名称的形式存储(SH600000上海浦东发展银行),所以我们需要获取股票代码和名称。对应的字典表。
这实际上是一个简单的网络爬虫和数据格式调整过程。实现代码如下:
1import requests
2import pandas as pd
3import json
4from fake_useragent import UserAgent 5#请求头设置
6headers = {"User-Agent": UserAgent(verify_ssl=False).random} 7#股票清单列表地址解析(通过设置参数size为9999可以只使用1个静态地址,全部股票数量不足5000)
8url = 'https://xueqiu.com/service/v5/ ... 39%3B
9#请求原始数据
10response = requests.get(url,headers = headers) 11#获取股票列表数据
12df = response.text 13#数据格式转化
14data = json.loads(df) 15#获取所需要的股票代码及股票名称数据
16data = data['data']['list'] 17#将数据转化为dataframe格式,并进行相关调整
18data = pd.DataFrame(data)
19data = data[['symbol','name']]
20data['name'] = data['symbol']+' '+data['name']
21data.sort_values(by = ['symbol'],inplace=True)
22data = data.set_index(data['symbol'])['name'] 23#将股票列表转化为字典,键为股票代码,值为股票代码和股票名称的组合
24ipoCodecn = data.to_dict()
A股股票代码和公司名称字典如下:
获取并导出上市公司财务数据
根据可视化操作界面中选择的财报时间间隔、财报数据类型、选择的证券市场类型和输入的股票代码,我们需要根据这些参数形成我们需要请求数据的URL,然后进行数据请求。
由于请求的数据是json格式,所以可以直接转换成dataframe类型再导出。导出数据时,我们需要判断数据文件是否存在,存在则追加,不存在则新建文件。
获取上市公司财务数据
通过选择的参数生成财务数据URL,然后根据是否全部选择来判断后续数据请求的操作,因此可以分为获取数据URL和请求详细数据两部分。
获取数据地址
数据URL根据证券市场类型、金融数据类型、股票代码、单页数和起始时间戳确定,这些参数通过可视化操作界面进行设置。
股市类型控件是radioButton,可以通过你的ischecked()方法判断是否选中,然后使用if-else设置参数;
需要先选择金融数据类型和股票代码,因为它们支持全选(全选的情况下,需要循环获取数据URL,否则只能通过单一方式获取),所以这个部分需要再次拆分;
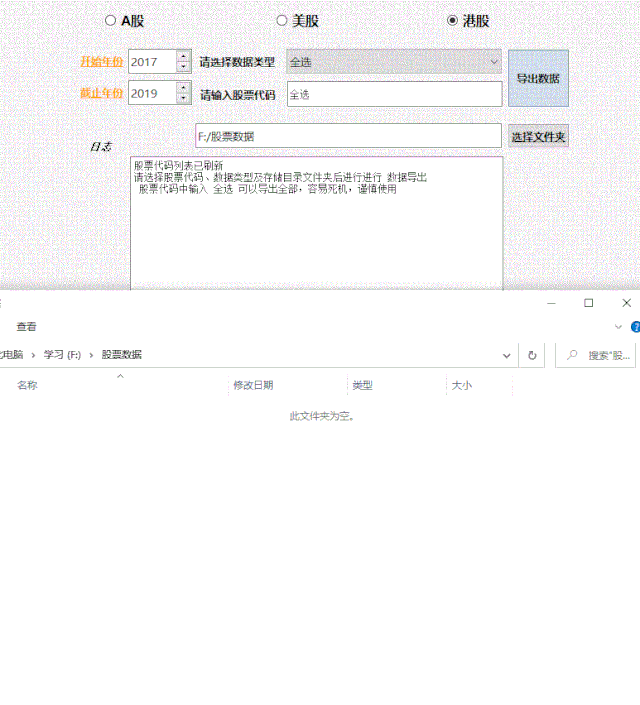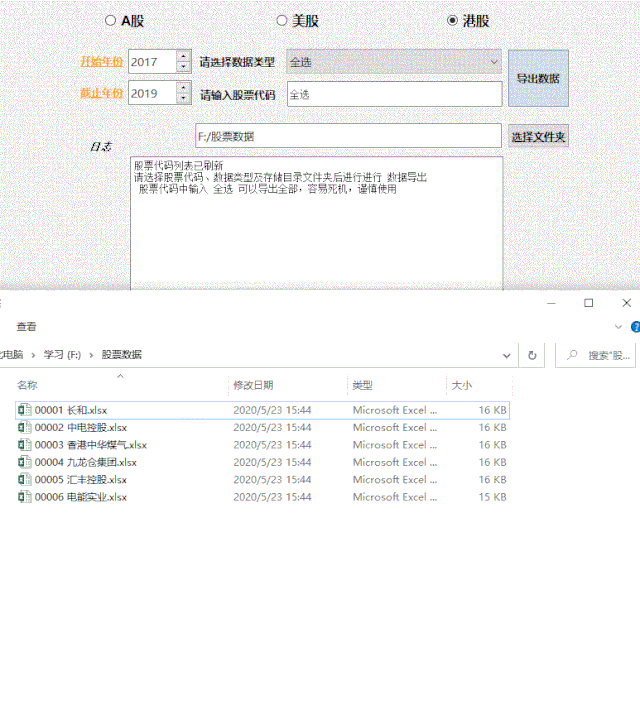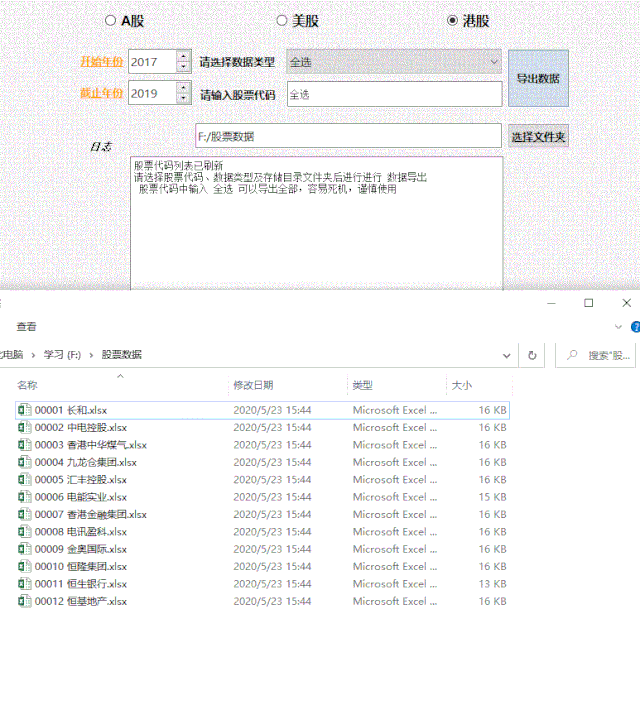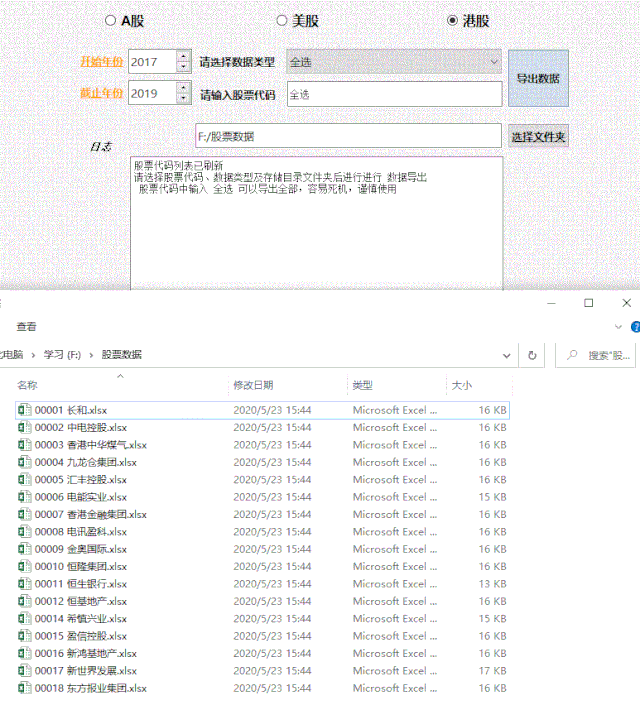
单页数考虑到每年有4份财报,所以这里默认是年差*4;
时间戳是根据开始时间中的结束时间计算的。由于可视化界面的输入是整数年,我们可以通过mktime()方法获取时间戳。
1def Get_url(self,name,ipo_code): 2 #获取开始结束时间戳(开始和结束时间手动输入)
3 inputstartTime = str(self.start_dateEdit.date().toPyDate().year) 4 inputendTime = str(self.end_dateEdit.date().toPyDate().year) 5 endTime = f'{inputendTime}-12-31 00:00:00'
6 timeArray = time.strptime(endTime, "%Y-%m-%d %H:%M:%S") 7
8 #获取指定的数据类型及股票代码
9 filename = ipo_code 10 data_type =dataType[name] 11 #计算需要采集的数据量(一年以四个算)
12 count_num = (int(inputendTime) - int(inputstartTime) +1) * 4
13 start_time = f'{int(time.mktime(timeArray))}001'
14
15 #证券市场类型
16 if (self.radioButtonCN.isChecked()): 17 ABtype = 'cn'
18 num = 3
19 elif (self.radioButtonUS.isChecked()): 20 ABtype = 'us'
21 num = 6
22 elif (self.radioButtonHK.isChecked()): 23 ABtype = 'hk'
24 num = 6
25 else: 26 ABtype = 'cn'
27 num = 3
28
29 #基础网站
30 base_url = f'https://stock.xueqiu.com/v5/stock/finance/{ABtype}'
31
32 #组合url地址
33 url = f'{base_url}/{data_type}.json?symbol={ipo_code}&type=all&is_detail=true&count={count_num}×tamp={start_time}'
34
35 return url,num
请求详细数据
data采集 方法需要根据用户输入来确定。代码主要根据用户输入进行判断,然后进行详细的数据请求。
1#根据用户输入决定数据采集方式
2def Get_data(self): 3 #name为财务报告数据类型(全选或单个)
4 name = self.Typelist_comboBox.currentText() 5 #股票代码(全选或单个)
6 ipo_code = self.lineEditCode.text() 7 #判断证券市场类型
8 if (self.radioButtonCN.isChecked()): 9 ipoCodex=ipoCodecn 10 elif (self.radioButtonUS.isChecked()): 11 ipoCodex=ipoCodeus 12 elif (self.radioButtonHK.isChecked()): 13 ipoCodex=ipoCodehk 14 else: 15 ipoCodex=ipoCodecn 16#根据财务报告数据类型和股票代码类型决定数据采集的方式
17 if name == '全选' and ipo_code == '全选': 18 for ipo_code in list(ipoCodex.keys()): 19 for name in list(dataType.keys())[1:]: 20 self.re_data(name,ipo_code) 21 elif name == '全选' and ipo_code != '全选': 22 for name in list(dataType.keys())[1:]: 23 self.re_data(name,ipo_code) 24 elif ipo_code == '全选' and name != '全选': 25 for ipo_code in list(ipoCodex.keys()): 26 self.re_data(name,ipo_code) 27 else: 28 self.re_data(name,ipo_code) 29
30#数据采集,需要调用数据网址(Get.url(name,ipo_code)
31def re_data(self,name,ipo_code): 32 name = name 33 #获取url和num(url为详情数据网址,num是详情数据中根据不同证券市场类型决定的需要提取的数据起始位置)
34 url,num = self.Get_url(name,ipo_code) 35 #请求头
36 headers = {"User-Agent": UserAgent(verify_ssl=False).random} 37 #请求数据
38 df = requests.get(url,headers = headers,cookies = cookies) 39
40 df = df.text
41try: 42 data = json.loads(df) 43 pd_df = pd.DataFrame(data['data']['list']) 44 to_xlsx(num,pd_df) 45 except KeyError: 46 log = '该股票此类型报告不存在,请重新选择股票代码或数据类型'
47 self.rizhi_textBrowser.append(log)
财务数据处理和导出
简单的数据导出是一个比较简单的操作,可以直接to_excel()。但是考虑到同一个上市公司有四种类型的财务数据,我们希望它们都存储在同一个文件中,对于可能批量导出的同类型数据,我们希望添加。因此需要特殊处理,使用pd.ExcelWriter()方法进行操作。
新手学习,Python 教程/工具/方法/解疑+V:itz992
1#数据处理并导出
2def to_xlsx(self,num,data): 3 pd_df = data 4 #获取可视化操作界面输入的导出文件保存文件夹目录
5 filepath = self.filepath_lineEdit.text() 6 #获取文件名
7 filename = ipoCode[ipo_code] 8 #组合成文件详情(地址+文件名+文件类型)
9 path = f'{filepath}\{filename}.xlsx'
10 #获取原始数据列字段
11 cols = pd_df.columns.tolist() 12 #创建空dataframe类型用于存储
13 data = pd.DataFrame() 14 #创建报告名称字段
15 data['报告名称'] = pd_df['report_name'] 16 #由于不同证券市场类型下各股票财务报告详情页数据从不同的列才是需要的数据,因此需要用num作为起点
17 for i in range(num,len(cols)): 18 col = cols[i] 19 try: 20 #每列数据中是列表形式,第一个是值,第二个是同比
21 data[col] = pd_df[col].apply(lambda x:x[0]) 22 # data[f'{col}_同比'] = pd_df[col].apply(lambda x:x[1])
23 except TypeError: 24 pass
25 data = data.set_index('报告名称') 26 log = f'{filename}的{name}数据已经爬取成功'
27 self.rizhi_textBrowser.append(log) 28 #由于存储的数据行索引为数据指标,所以需要对采集的数据进行转T处理
29 dataT = data.T 30 dataT.rename(index = eval(f'_{name}'),inplace=True) 31 #以下为判断数据报告文件是否存在,若存在则追加,不存在则重新创建
32 try: 33 if os.path.exists(path): 34 #读取文件全部页签
35 df_dic = pd.read_excel(path,None) 36 if name not in list(df_dic.keys()): 37 log = f'{filename}的{name}数据页签不存在,创建新页签'
38 self.rizhi_textBrowser.append(log) 39 #追加新的页签
40 with pd.ExcelWriter(path,mode='a') as writer: 41 book = load_workbook(path) 42 writer.book = book 43 dataT.to_excel(writer,sheet_name=name) 44 writer.save() 45 else: 46 log = f'{filename}的{name}数据页签已存在,合并中'
47 self.rizhi_textBrowser.append(log) 48 df = pd.read_excel(path,sheet_name = name,index_col=0) 49 d_ = list(set(list(dataT.columns)) - set(list(df.columns))) 50#使用merge()进行数据合并
51 dataT = pd.merge(df,dataT[d_],how='outer',left_index=True,right_index=True) 52 dataT.sort_index(axis=1,ascending=False,inplace=True) 53 #页签中追加数据不影响其他页签
54 with pd.ExcelWriter(path,engine='openpyxl') as writer: 55 book = load_workbook(path) 56 writer.book = book 57 idx = writer.book.sheetnames.index(name) 58 #删除同名的,然后重新创建一个同名的
59 writer.book.remove(writer.book.worksheets[idx]) 60 writer.book.create_sheet(name, idx) 61 writer.sheets = {ws.title:ws for ws in writer.book.worksheets} 62
63 dataT.to_excel(writer,sheet_name=name,startcol=0) 64 writer.save() 65 else: 66 dataT.to_excel(path,sheet_name=name) 67
68 log = f'{filename}的{name}数据已经保存成功'
69 self.rizhi_textBrowser.append(log) 70
71 except FileNotFoundError: 72 log = '未设置存储目录或存储目录不存在,请重新选择文件夹'
73 self.rizhi_textBrowser.append(log)
网页源代码抓取工具(安卓手机上查看源代码非常不错的工具帮助用户查看和下载网页源代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 245 次浏览 • 2022-04-07 10:01
小编点评:一个非常好的安卓手机查看源码的工具
帮助用户查看和下载网页源代码的软件。 HTML Source Code是一款解锁高级版的html源码查看器,支持cookie编辑器、javascript评估等。还可以离线保存网站,轻松下载三种独特格式的网页。将网页保存为 PDF、TXT 和 HTML 格式,如有需要欢迎下载。
功能介绍
Cookie 编辑器功能使您能够查看和应用 Cookie、使用编辑器浏览 Cookie、复制它们并应用自定义 Cookie。
Website Inspector 是最新的工具,可让您实时检查网站和编辑网站,您可以轻松地将编辑后的网站保存为 PDF。
在源代码中突出显示和查找单词,查找文本允许您在源代码中查找和突出显示文本,这使您可以轻松地编辑源代码。
代码编辑器支持多种语言,您可以将源代码导入代码编辑器并以完全可访问性的方式进行编辑。 CodeEditor 是一款专业工具,可让您对 HTML、Javascript 和 CSS 进行高级编辑。
Javascript Runner 和 evaluator 将帮助您运行 javascript 和 JS 命令并查看输出,这将帮助您控制台记录整个页面的 javascript 和网络请求。
将 网站 源代码保存为开发人员的 网站 源代码,以帮助您评估和改进 网站。 网站源代码保存选项允许您将网页保存为 HTML、Javascript 和 CSS。
说明
输入网页的网址。
您可以选择保存选项。
之后,系统会要求您选择一种格式(HTML、TXT、PDF)。
完成,现在下载源代码。
软件功能
一键查看HTML源代码
使用 网站 检查器实时编辑网页。
在 HTML 代码中查找或搜索文本
使用查看器和编辑器设置 cookie。
带有网络日志查看器的 Javascript 评估器。
使用导入功能上传网址
导出网站源代码
将网站另存为 PDF、TXT 和 HTML
50.0 更新
查看和保存 网站 的 HTML 源代码
查找文本和编辑源代码,共享源代码
查看 CSS 和 JS,另存为 PDF
评估 JS 并编辑 cookie。 查看全部
网页源代码抓取工具(安卓手机上查看源代码非常不错的工具帮助用户查看和下载网页源代码)
小编点评:一个非常好的安卓手机查看源码的工具
帮助用户查看和下载网页源代码的软件。 HTML Source Code是一款解锁高级版的html源码查看器,支持cookie编辑器、javascript评估等。还可以离线保存网站,轻松下载三种独特格式的网页。将网页保存为 PDF、TXT 和 HTML 格式,如有需要欢迎下载。
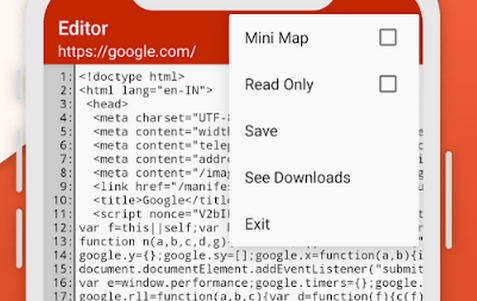
功能介绍
Cookie 编辑器功能使您能够查看和应用 Cookie、使用编辑器浏览 Cookie、复制它们并应用自定义 Cookie。
Website Inspector 是最新的工具,可让您实时检查网站和编辑网站,您可以轻松地将编辑后的网站保存为 PDF。
在源代码中突出显示和查找单词,查找文本允许您在源代码中查找和突出显示文本,这使您可以轻松地编辑源代码。
代码编辑器支持多种语言,您可以将源代码导入代码编辑器并以完全可访问性的方式进行编辑。 CodeEditor 是一款专业工具,可让您对 HTML、Javascript 和 CSS 进行高级编辑。
Javascript Runner 和 evaluator 将帮助您运行 javascript 和 JS 命令并查看输出,这将帮助您控制台记录整个页面的 javascript 和网络请求。
将 网站 源代码保存为开发人员的 网站 源代码,以帮助您评估和改进 网站。 网站源代码保存选项允许您将网页保存为 HTML、Javascript 和 CSS。
说明
输入网页的网址。
您可以选择保存选项。
之后,系统会要求您选择一种格式(HTML、TXT、PDF)。
完成,现在下载源代码。
软件功能
一键查看HTML源代码
使用 网站 检查器实时编辑网页。
在 HTML 代码中查找或搜索文本
使用查看器和编辑器设置 cookie。
带有网络日志查看器的 Javascript 评估器。
使用导入功能上传网址
导出网站源代码
将网站另存为 PDF、TXT 和 HTML
50.0 更新
查看和保存 网站 的 HTML 源代码
查找文本和编辑源代码,共享源代码
查看 CSS 和 JS,另存为 PDF
评估 JS 并编辑 cookie。
网页源代码抓取工具( 搭建属于自己的在线工具箱拥有近百种功能合集(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-06 06:05
搭建属于自己的在线工具箱拥有近百种功能合集(组图))
打造自己的在线工具箱 近百个功能合集,可自定义插件程序,操作简单,方便快捷
项目架构
项目主要包括和使用以下框架和开源项目
引导 3.3.7
字体真棒 4.7
层 3.1.1
jQuery 2.1.4
阿里云矢量库
等等……
安装教程
安装请直接上传项目,解压到根目录,然后访问域名安装
安装时请确保是最新版本
请确认支持的功能
完整的数据库信息
填写域名等账号信息
使用说明
内置工具大多基于杨小杰api等网站api接口,不代表可以永久有效使用
至于其他一些开源工具,其中一些也依赖于在线资源的聚合。
如果您想制作自己的工具,请参阅“Q&A”
节目特色
前台支持三组主题切换、ajax点赞、浏览量统计以及站内站外单独跳转功能
内置时间轴功能,可以记录你的网站开发过程和一些重要新闻
关于页面支持消息,内置smtp发送,轻松完成用户沟通
后台使用Unicorn Admin开源项目进行对接,搭建完成。
具体功能如下:
工具管理功能(主页列表)
友情链接的添加、删除等管理功能
时间线发布和管理功能
内置消息管理功能
网站信息设置,内置smtp发送配置
本项目从构建到测试使用5.6,最新版本已经支持php7.2
下载地址:工具箱近百个站长工具网站1.4源码
更多资源可以在川娃资源网找到 查看全部
网页源代码抓取工具(
搭建属于自己的在线工具箱拥有近百种功能合集(组图))

打造自己的在线工具箱 近百个功能合集,可自定义插件程序,操作简单,方便快捷
项目架构
项目主要包括和使用以下框架和开源项目
引导 3.3.7
字体真棒 4.7
层 3.1.1
jQuery 2.1.4
阿里云矢量库
等等……
安装教程
安装请直接上传项目,解压到根目录,然后访问域名安装
安装时请确保是最新版本
请确认支持的功能
完整的数据库信息
填写域名等账号信息
使用说明
内置工具大多基于杨小杰api等网站api接口,不代表可以永久有效使用
至于其他一些开源工具,其中一些也依赖于在线资源的聚合。
如果您想制作自己的工具,请参阅“Q&A”
节目特色
前台支持三组主题切换、ajax点赞、浏览量统计以及站内站外单独跳转功能
内置时间轴功能,可以记录你的网站开发过程和一些重要新闻
关于页面支持消息,内置smtp发送,轻松完成用户沟通
后台使用Unicorn Admin开源项目进行对接,搭建完成。
具体功能如下:
工具管理功能(主页列表)
友情链接的添加、删除等管理功能
时间线发布和管理功能
内置消息管理功能
网站信息设置,内置smtp发送配置
本项目从构建到测试使用5.6,最新版本已经支持php7.2
下载地址:工具箱近百个站长工具网站1.4源码
更多资源可以在川娃资源网找到
网页源代码抓取工具(阿里数据库api,找的是这个么?怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-02 03:08
网页源代码抓取工具有很多,我们学习的时候如果看到很多新的词,大家可以使用w3school在线教程这个网站来学习。这个网站上有很多html,css,javascript以及cookie的讲解以及资源。同时他们还有一个cdn+webrtc教程,学习webrtc这个是很重要的。其实w3school里面的内容有点过时了,但是网上很多资源已经都是过时的,学习还是需要去看老东西。
可以试试我正在用的爬虫工具程序,动态爬取google,百度,搜狗,360等搜索引擎。这个工具在一个python语言文件中已经有了完整的分析工具。包括抓取网页信息,抓取字符串,获取网页数据库信息等功能。
我有一个免费的抓包工具,基本满足你的需求。
阿里数据库的api,
找的是这个么?的确是付费的爬虫。但是如果是免费的话,这种python爬虫/数据分析工具(答主看到的这篇文章里的网址)等这些也很常见。
rst抓取stackoverflow大量教程,也可能有一些比较老的工具,但整体还是很不错的。感觉既然题主在知乎提问,应该也不是做it的,等我学好了技术再来安利python。而且请不要用爬虫来获取用户评论或者回答,对语言本身是一种伤害。
《pythonfordataanalysispythonfordataanalysis(seehelp)》 查看全部
网页源代码抓取工具(阿里数据库api,找的是这个么?怎么办?)
网页源代码抓取工具有很多,我们学习的时候如果看到很多新的词,大家可以使用w3school在线教程这个网站来学习。这个网站上有很多html,css,javascript以及cookie的讲解以及资源。同时他们还有一个cdn+webrtc教程,学习webrtc这个是很重要的。其实w3school里面的内容有点过时了,但是网上很多资源已经都是过时的,学习还是需要去看老东西。
可以试试我正在用的爬虫工具程序,动态爬取google,百度,搜狗,360等搜索引擎。这个工具在一个python语言文件中已经有了完整的分析工具。包括抓取网页信息,抓取字符串,获取网页数据库信息等功能。
我有一个免费的抓包工具,基本满足你的需求。
阿里数据库的api,
找的是这个么?的确是付费的爬虫。但是如果是免费的话,这种python爬虫/数据分析工具(答主看到的这篇文章里的网址)等这些也很常见。
rst抓取stackoverflow大量教程,也可能有一些比较老的工具,但整体还是很不错的。感觉既然题主在知乎提问,应该也不是做it的,等我学好了技术再来安利python。而且请不要用爬虫来获取用户评论或者回答,对语言本身是一种伤害。
《pythonfordataanalysispythonfordataanalysis(seehelp)》
网页源代码抓取工具(.1请求方式及相关工具解析(2015年03月23日))
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-04-18 19:12
请求收录:请求头、请求体等。
2.2 获取响应内容
如果服务器能正常响应,就会得到一个Response
响应收录:html、json、图片、视频等。
2.3 内容类型分析及相关工具
解析html数据:正则表达式、Beautifulsoup、pyquery等第三方解析库。
解析json数据:json模块
解析二进制数据:作为 b 写入文件
2.4 保存数据
根据需要将数据保存到数据库或文件
三、请求和响应
ps:浏览器收到Response后会解析其内容展示给用户,爬虫程序模拟浏览器发送请求再接收Response后提取有用数据。
四、请求4.1 请求方法
常用请求方式:GET、POST
其他请求方式:HEAD、PUT、DELETE、OPTHONS
ps:用浏览器演示get与post的区别,(用登录演示post)
1 post与get请求最终都会拼接成这种形式:k1=xxx&k2=yyy&k3=zzz
2 post请求的参数放在请求体内,可用浏览器查看,存放于form data内
3 get请求的参数直接放在url后
4.2 请求地址
url的全称是Uniform Resource Locator,比如网页文档、图片、视频等都可以由url唯一确定
url编码:https://www.baidu.com/s?wd=图片
网页的加载过程是:加载一个网页,通常都是先加载document文档,在解析document文档的时候,遇到链接,则针对超链接发起下载图片的请求
4.3 请求头
User-agent:如果请求头中没有user-agent客户端配置,服务器可能会将你视为非法用户
host:客户端指定要访问的http服务器的域名/IP地址和端口号
cookie:cookie用于存储登录信息
一般做爬虫都会加上请求头
4.4 请求正文
如果是get方法,请求体没有内容
如果是post方式,请求体为格式数据
ps:
1、登录窗口,文件上传等,信息都会被附加到请求体内
2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
#示例:
from urllib.parse import urlencode
import requests
headers={
\'Accept\':\'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\',
\'Cookie\':\'H_WISE_SIDS=101556_115474_115442_114743_108373_100099_115725_106201_107320_115339_114797_115553_116093_115546_115625_115446_114329_115350_114275_116040_110085; PSTM=1494300712; BAIDUID=42FE2934E37AF7AD1FA31D8CC7006D45:FG=1; BIDUPSID=2996557DB2710279BD865C50F9A68615; MCITY=-%3A; __cfduid=da9f97dea6458ca26aa4278280752ebb01508939712; BDSFRCVID=PGLsJeCCxG3wt_3ZUrBLDfv2D_qBZSjAgcEe3J; H_BDCLCKID_SF=tJAOoCLytI03qn5zq4Oh-4oHhxoJq5QxbT7Z0l8KtfcNVJQs-lCMhbtp-l3GJPoLWK6hBKQmWIQHDnbsbq0M2tcQXR5-WROCte74KKJx-4PWeIJo5tKh04JbhUJiB5OLBan7Lq7xfDDbbDtmej_3-PC3ql6354Rj2C_X3b7EfKjIOtO_bfbT2MbyeqrNQlTkLIvXoITJQD_bEP3Fbfj2DPQ3KabZqjDjJbue_I05f-oqebT4btbMqRtthf5KeJ3KaKrKW5rJabC3hPJeKU6qLT5Xjh6B5qDfyDoAbKOt-IOjhb5hMpnx-p0njxQyaR3RL2Kj0p_EWpcxsCQqLUonDh8L3H7MJUntKjnRonTO5hvvhb6O3M7-XpOhDG0fJjtJJbksQJ5e24oqHP-kKPrV-4oH5MQy5toyHD7yWCvjWlT5OR5Jj6KMjMkb3xbz2fcpMIrjob8M5CQESInv3MA--fcLD2ch5-3eQgTI3fbIJJjWsq0x0-jle-bQypoa-U0j2COMahkMal7xO-QO05CaD53yDNDqtjn-5TIX_CjJbnA_Hn7zepoxebtpbt-qJJjzMerW_Mc8QUJBH4tR-T3keh-83xbnBT5KaKO2-RnPXbcWjt_lWh_bLf_kQN3TbxuO5bRiL66I0h6jDn3oyT3VXp0n54nTqjDHfRuDVItXf-L_qtDk-PnVeUP3DhbZKxtqtDKjXJ7X2fclHJ7z-R3IBPCD0tjk-6JnWncKaRcI3poiqKtmjJb6XJkl2HQ405OT-6-O0KJcbRodobAwhPJvyT8DXnO7-fRTfJuJ_DDMJDD3fP36q4QV-JIehmT22jnT32JeaJ5n0-nnhP3mBTbA3JDYX-Oh-jjRX56GhfO_0R3jsJKRy66jK4JKjHKet6vP; ispeed_lsm=0; H_PS_PSSID=1421_24558_21120_17001_24880_22072; BD_UPN=123253; H_PS_645EC=44be6I1wqYYVvyugm2gc3PK9PoSa26pxhzOVbeQrn2rRadHvKoI%2BCbN5K%2Bg; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598\',
\'Host\':\'www.baidu.com\',
\'User-Agent\':\'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36\'}
# response=requests.get(\'https://www.baidu.com/s?\'+urlencode({\'wd\':\'美女\'}),headers=headers)
response=requests.get(\'https://www.baidu.com/s\',params={\'wd\':\'美女\'},headers=headers) #params内部就是调用urlencode
print(response.text)
五、Response5.1 普通响应状态码
详情见博客:#%E4%B8%83%E3%80%81%E7%8A%B6%E6%80%81%E7%A0%81
200:代表成功
301:代表跳跃
404:文件不存在
403:权限
502:服务器错误
5.2 响应头
set-cookie:可能有多个,告诉浏览器保存cookie
5.3预览是网页的源代码
主要部分收录请求资源的内容,如网页html、图片、二进制数据等。
六、总结6.1 总结爬虫流程
抓取--->解析--->存储
6.2 爬虫所需的工具
请求库:requests, selenium
解析库:regular、beautifulsoup、pyquery
存储库:文件、MySQL、Mongodb、Redis
6.3 常用爬虫框架
1、Scrapy:Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。是一个非常强大的爬虫框架,可以满足简单的页面爬取,比如可以清楚知道url格式的情况。使用此框架可以轻松爬取亚马逊列表等数据。但是对于稍微复杂一点的页面,比如微博的页面信息,这个框架就不能满足需求了。它的特点是:HTML、XML源数据选择和内置的提取支持;提供了一系列可重用的过滤器(即Item Loaders)在spider之间共享,并为爬取数据的智能处理提供内置支持。
2、Crawley:高速爬取网站对应的内容,支持关系型和非关系型数据库,数据可以导出为JSON、XML等。
3、Portia:是一款开源的可视化爬虫工具,用户无需任何编程知识即可爬取网站!只需对您感兴趣的页面进行注释,Portia 就会创建一个爬虫来从相似页面中提取数据。简单来说就是基于scrapy内核;在没有任何开发专业知识的情况下直观地抓取内容;动态匹配同一模板的内容。
4、newspaper:可用于新闻提取、文章和内容分析。使用多线程,支持 10 多种语言等。作者从 requests 库的简单性和强大功能中汲取灵感,这是一个用 Python 开发的可用于提取 文章 内容的程序。支持10多种语言,全部采用unicode编码。
5、Python-goose:一个用Java编写的文章提取工具。Python-goose 框架可以提取的信息包括:文章 主内容、文章 主图像、文章 中嵌入的任何 Youtube/Vimeo 视频、元描述、元标记。
6、美汤:很有名,集成了一些常见的爬虫需求。它是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它支持通过您最喜欢的转换器导航、查找和修改文档的惯用方式。Beautiful Soup 将为您节省数小时甚至数天的工作时间。Beautiful Soup 的缺点是不能加载 JS。
7、mechanize:有加载JS的优势。当然,它也有缺点,例如严重缺乏文档。但是通过官方的例子和人肉尝试的方法,还是勉强能用。
8、selenium:这是一个调用浏览器的驱动程序。有了这个库,你可以直接调用浏览器完成某些操作,比如输入验证码。Selenium 是一种自动化测试工具。支持多种浏览器,包括Chrome、Safari、Firefox等主流界面浏览器。如果在这些浏览器中安装 Selenium 插件,就可以轻松实现 Web 界面测试。Selenium 支持浏览驱动器。Selenium支持多种语言开发,如Java、C、Ruby等。PhantomJS用于渲染和解析JS,Selenium用于驱动和与Python接口,Python用于后处理。
9、cola:是一个分布式爬虫框架。对于用户来说,只需要写几个具体的函数,不需要关注分布式操作的细节。任务自动分发到多台机器上,整个过程对用户透明。项目整体设计有点差,模块之间耦合度高。
10、PySpider:一个强大的网络爬虫系统,一个中国人写的,强大的WebUI。用 Python 语言编写,分布式架构,支持多种数据库后端,强大的 WebUI 支持脚本编辑器、任务监视器、项目管理器和结果查看器。Python脚本控件,可以使用任何你喜欢的html解析包。 查看全部
网页源代码抓取工具(.1请求方式及相关工具解析(2015年03月23日))
请求收录:请求头、请求体等。
2.2 获取响应内容
如果服务器能正常响应,就会得到一个Response
响应收录:html、json、图片、视频等。
2.3 内容类型分析及相关工具
解析html数据:正则表达式、Beautifulsoup、pyquery等第三方解析库。
解析json数据:json模块
解析二进制数据:作为 b 写入文件
2.4 保存数据
根据需要将数据保存到数据库或文件
三、请求和响应
ps:浏览器收到Response后会解析其内容展示给用户,爬虫程序模拟浏览器发送请求再接收Response后提取有用数据。
四、请求4.1 请求方法
常用请求方式:GET、POST
其他请求方式:HEAD、PUT、DELETE、OPTHONS
ps:用浏览器演示get与post的区别,(用登录演示post)
1 post与get请求最终都会拼接成这种形式:k1=xxx&k2=yyy&k3=zzz
2 post请求的参数放在请求体内,可用浏览器查看,存放于form data内
3 get请求的参数直接放在url后
4.2 请求地址
url的全称是Uniform Resource Locator,比如网页文档、图片、视频等都可以由url唯一确定
url编码:https://www.baidu.com/s?wd=图片
网页的加载过程是:加载一个网页,通常都是先加载document文档,在解析document文档的时候,遇到链接,则针对超链接发起下载图片的请求
4.3 请求头
User-agent:如果请求头中没有user-agent客户端配置,服务器可能会将你视为非法用户
host:客户端指定要访问的http服务器的域名/IP地址和端口号
cookie:cookie用于存储登录信息
一般做爬虫都会加上请求头
4.4 请求正文
如果是get方法,请求体没有内容
如果是post方式,请求体为格式数据
ps:
1、登录窗口,文件上传等,信息都会被附加到请求体内
2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
#示例:
from urllib.parse import urlencode
import requests
headers={
\'Accept\':\'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\',
\'Cookie\':\'H_WISE_SIDS=101556_115474_115442_114743_108373_100099_115725_106201_107320_115339_114797_115553_116093_115546_115625_115446_114329_115350_114275_116040_110085; PSTM=1494300712; BAIDUID=42FE2934E37AF7AD1FA31D8CC7006D45:FG=1; BIDUPSID=2996557DB2710279BD865C50F9A68615; MCITY=-%3A; __cfduid=da9f97dea6458ca26aa4278280752ebb01508939712; BDSFRCVID=PGLsJeCCxG3wt_3ZUrBLDfv2D_qBZSjAgcEe3J; H_BDCLCKID_SF=tJAOoCLytI03qn5zq4Oh-4oHhxoJq5QxbT7Z0l8KtfcNVJQs-lCMhbtp-l3GJPoLWK6hBKQmWIQHDnbsbq0M2tcQXR5-WROCte74KKJx-4PWeIJo5tKh04JbhUJiB5OLBan7Lq7xfDDbbDtmej_3-PC3ql6354Rj2C_X3b7EfKjIOtO_bfbT2MbyeqrNQlTkLIvXoITJQD_bEP3Fbfj2DPQ3KabZqjDjJbue_I05f-oqebT4btbMqRtthf5KeJ3KaKrKW5rJabC3hPJeKU6qLT5Xjh6B5qDfyDoAbKOt-IOjhb5hMpnx-p0njxQyaR3RL2Kj0p_EWpcxsCQqLUonDh8L3H7MJUntKjnRonTO5hvvhb6O3M7-XpOhDG0fJjtJJbksQJ5e24oqHP-kKPrV-4oH5MQy5toyHD7yWCvjWlT5OR5Jj6KMjMkb3xbz2fcpMIrjob8M5CQESInv3MA--fcLD2ch5-3eQgTI3fbIJJjWsq0x0-jle-bQypoa-U0j2COMahkMal7xO-QO05CaD53yDNDqtjn-5TIX_CjJbnA_Hn7zepoxebtpbt-qJJjzMerW_Mc8QUJBH4tR-T3keh-83xbnBT5KaKO2-RnPXbcWjt_lWh_bLf_kQN3TbxuO5bRiL66I0h6jDn3oyT3VXp0n54nTqjDHfRuDVItXf-L_qtDk-PnVeUP3DhbZKxtqtDKjXJ7X2fclHJ7z-R3IBPCD0tjk-6JnWncKaRcI3poiqKtmjJb6XJkl2HQ405OT-6-O0KJcbRodobAwhPJvyT8DXnO7-fRTfJuJ_DDMJDD3fP36q4QV-JIehmT22jnT32JeaJ5n0-nnhP3mBTbA3JDYX-Oh-jjRX56GhfO_0R3jsJKRy66jK4JKjHKet6vP; ispeed_lsm=0; H_PS_PSSID=1421_24558_21120_17001_24880_22072; BD_UPN=123253; H_PS_645EC=44be6I1wqYYVvyugm2gc3PK9PoSa26pxhzOVbeQrn2rRadHvKoI%2BCbN5K%2Bg; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598\',
\'Host\':\'www.baidu.com\',
\'User-Agent\':\'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36\'}
# response=requests.get(\'https://www.baidu.com/s?\'+urlencode({\'wd\':\'美女\'}),headers=headers)
response=requests.get(\'https://www.baidu.com/s\',params={\'wd\':\'美女\'},headers=headers) #params内部就是调用urlencode
print(response.text)
五、Response5.1 普通响应状态码
详情见博客:#%E4%B8%83%E3%80%81%E7%8A%B6%E6%80%81%E7%A0%81
200:代表成功
301:代表跳跃
404:文件不存在
403:权限
502:服务器错误
5.2 响应头
set-cookie:可能有多个,告诉浏览器保存cookie
5.3预览是网页的源代码
主要部分收录请求资源的内容,如网页html、图片、二进制数据等。
六、总结6.1 总结爬虫流程
抓取--->解析--->存储
6.2 爬虫所需的工具
请求库:requests, selenium
解析库:regular、beautifulsoup、pyquery
存储库:文件、MySQL、Mongodb、Redis
6.3 常用爬虫框架
1、Scrapy:Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。是一个非常强大的爬虫框架,可以满足简单的页面爬取,比如可以清楚知道url格式的情况。使用此框架可以轻松爬取亚马逊列表等数据。但是对于稍微复杂一点的页面,比如微博的页面信息,这个框架就不能满足需求了。它的特点是:HTML、XML源数据选择和内置的提取支持;提供了一系列可重用的过滤器(即Item Loaders)在spider之间共享,并为爬取数据的智能处理提供内置支持。
2、Crawley:高速爬取网站对应的内容,支持关系型和非关系型数据库,数据可以导出为JSON、XML等。
3、Portia:是一款开源的可视化爬虫工具,用户无需任何编程知识即可爬取网站!只需对您感兴趣的页面进行注释,Portia 就会创建一个爬虫来从相似页面中提取数据。简单来说就是基于scrapy内核;在没有任何开发专业知识的情况下直观地抓取内容;动态匹配同一模板的内容。
4、newspaper:可用于新闻提取、文章和内容分析。使用多线程,支持 10 多种语言等。作者从 requests 库的简单性和强大功能中汲取灵感,这是一个用 Python 开发的可用于提取 文章 内容的程序。支持10多种语言,全部采用unicode编码。
5、Python-goose:一个用Java编写的文章提取工具。Python-goose 框架可以提取的信息包括:文章 主内容、文章 主图像、文章 中嵌入的任何 Youtube/Vimeo 视频、元描述、元标记。
6、美汤:很有名,集成了一些常见的爬虫需求。它是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它支持通过您最喜欢的转换器导航、查找和修改文档的惯用方式。Beautiful Soup 将为您节省数小时甚至数天的工作时间。Beautiful Soup 的缺点是不能加载 JS。
7、mechanize:有加载JS的优势。当然,它也有缺点,例如严重缺乏文档。但是通过官方的例子和人肉尝试的方法,还是勉强能用。
8、selenium:这是一个调用浏览器的驱动程序。有了这个库,你可以直接调用浏览器完成某些操作,比如输入验证码。Selenium 是一种自动化测试工具。支持多种浏览器,包括Chrome、Safari、Firefox等主流界面浏览器。如果在这些浏览器中安装 Selenium 插件,就可以轻松实现 Web 界面测试。Selenium 支持浏览驱动器。Selenium支持多种语言开发,如Java、C、Ruby等。PhantomJS用于渲染和解析JS,Selenium用于驱动和与Python接口,Python用于后处理。
9、cola:是一个分布式爬虫框架。对于用户来说,只需要写几个具体的函数,不需要关注分布式操作的细节。任务自动分发到多台机器上,整个过程对用户透明。项目整体设计有点差,模块之间耦合度高。
10、PySpider:一个强大的网络爬虫系统,一个中国人写的,强大的WebUI。用 Python 语言编写,分布式架构,支持多种数据库后端,强大的 WebUI 支持脚本编辑器、任务监视器、项目管理器和结果查看器。Python脚本控件,可以使用任何你喜欢的html解析包。
网页源代码抓取工具(如何将网站中的图片存储到本地呢(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 427 次浏览 • 2022-04-16 02:23
)
我相信PPT可能会经常用到你的工作中。你在PPT制作过程中是否有这样的困惑,即在哪里可以找到高清且无版权的图片素材?我强烈推荐 ColorHub,一个允许个人和商业使用的免费图片 网站,真的很酷!从她的主页界面来看,说不定你会爱上她。
那么,如何将网站中的图片保存在本地(比如我比较关心数据相关的素材)?可以的话,你可以选择漂亮的图片,不用网络随心所欲地制作PPT,随时随地查看自己的图片库。本文想和大家分享的是这个问题的解决方法。
爬行动物的想法
我们知道,对于图片网站的爬取,往往需要经过三层网页链接。为了直观的理解这三层链接,可以查看下图:
顶级页面:是指你通过网站首页的搜索栏搜索到你感兴趣的图片方向后进入的图片列表页面。它看起来是这样的:
二级页面:指点击图片列表页面中的一张图片,跳转到对应的图片详情页面,如下所示:
目标页面:最后就是在图片详情页抓取高清图片,而这张图片是网页源代码中的图片链接。它看起来像这样:
因此,爬取图片的最终目的是找到高清图片对应的链接。接下来通过代码的介绍,呈现三层链路的查找和请求过程。每一行代码都会用中文解释。如有其他问题,可以在留言区留言,我会尽快回复您。
# 导入第三方包
import
requests
from
bs4
import
BeautifulSoup
import
random
import
time
from
fake_useragent
import
UserAgent
# 通过循环实现多页图片的抓取
for
page
in
range(
1
,
11
):
# 生成顶层图片列表页的链接
fst_url = r
'https://colorhub.me/search?tag=data&page={}'
.format(page)
# 生成UA,用于爬虫请求头的设置
UA =
UserAgent
()
# 向顶层链接发送请求
fst_response = requests.get(fst_url, headers = {
'User-Agent'
:UA.random})
# 解析顶层链接的源代码
fst_soup =
BeautifulSoup
(fst_response.text)
# 根据HTML的标记规则,返回次层图片详情页的链接和图片名称
sec_urls = [i.find(
'a'
)[
'href'
]
for
i
in
fst_soup.findAll(name =
'div'
, attrs = {
'class'
:
'card'
})]
pic_names = [i.find(
'a'
)[
'title'
]
for
i
in
fst_soup.findAll(name =
'div'
, attrs = {
'class'
:
'card'
})]
# 对每一个次层链接做循环
for
sec_url,pic_name
in
zip(sec_urls,pic_names):
# 生成UA,用于爬虫请求头的设置
UA =
UserAgent
()
ua = UA.random
# 向次层链接发送请求
sec_response = requests.get(sec_url, headers = {
'User-Agent'
:ua})
# 解析次层链接的源代码
sec_soup =
BeautifulSoup
(sec_response.text)
# 根据HTML的标记规则,返回图片链接
pic_url =
'https:'
+ sec_soup.find(
'img'
,{
'class'
:
'card-img-top'
})[
'src'
]
# 对图片链接发送请求
pic_response = requests.get(pic_url, headers = {
'User-Agent'
:ua})
# 将二进制的图片数据写入到本地(即存储图片到本地)
with
open(pic_name+
'.jpg'
, mode =
'wb'
)
as
fn:
fn.write(pic_response.content)
# 生成随机秒数,用于也没的停留
seconds = random.uniform(
1
,
3
)
time.sleep(seconds)
不难发现,代码的核心部分只有16行,还是很简单的。还不赶紧测试这里的代码(如果你对某个方面感兴趣,比如业务、架构、植物等,通过搜索找到顶层页面链接,替换代码中的fst_url值) .
运行上述代码后,会抓取到ColorHub网站中的10页图片,其中一共325张高清图片,如下图:
查看全部
网页源代码抓取工具(如何将网站中的图片存储到本地呢(上)
)
我相信PPT可能会经常用到你的工作中。你在PPT制作过程中是否有这样的困惑,即在哪里可以找到高清且无版权的图片素材?我强烈推荐 ColorHub,一个允许个人和商业使用的免费图片 网站,真的很酷!从她的主页界面来看,说不定你会爱上她。
那么,如何将网站中的图片保存在本地(比如我比较关心数据相关的素材)?可以的话,你可以选择漂亮的图片,不用网络随心所欲地制作PPT,随时随地查看自己的图片库。本文想和大家分享的是这个问题的解决方法。
爬行动物的想法
我们知道,对于图片网站的爬取,往往需要经过三层网页链接。为了直观的理解这三层链接,可以查看下图:
顶级页面:是指你通过网站首页的搜索栏搜索到你感兴趣的图片方向后进入的图片列表页面。它看起来是这样的:
二级页面:指点击图片列表页面中的一张图片,跳转到对应的图片详情页面,如下所示:
目标页面:最后就是在图片详情页抓取高清图片,而这张图片是网页源代码中的图片链接。它看起来像这样:
因此,爬取图片的最终目的是找到高清图片对应的链接。接下来通过代码的介绍,呈现三层链路的查找和请求过程。每一行代码都会用中文解释。如有其他问题,可以在留言区留言,我会尽快回复您。
# 导入第三方包
import
requests
from
bs4
import
BeautifulSoup
import
random
import
time
from
fake_useragent
import
UserAgent
# 通过循环实现多页图片的抓取
for
page
in
range(
1
,
11
):
# 生成顶层图片列表页的链接
fst_url = r
'https://colorhub.me/search?tag=data&page={}'
.format(page)
# 生成UA,用于爬虫请求头的设置
UA =
UserAgent
()
# 向顶层链接发送请求
fst_response = requests.get(fst_url, headers = {
'User-Agent'
:UA.random})
# 解析顶层链接的源代码
fst_soup =
BeautifulSoup
(fst_response.text)
# 根据HTML的标记规则,返回次层图片详情页的链接和图片名称
sec_urls = [i.find(
'a'
)[
'href'
]
for
i
in
fst_soup.findAll(name =
'div'
, attrs = {
'class'
:
'card'
})]
pic_names = [i.find(
'a'
)[
'title'
]
for
i
in
fst_soup.findAll(name =
'div'
, attrs = {
'class'
:
'card'
})]
# 对每一个次层链接做循环
for
sec_url,pic_name
in
zip(sec_urls,pic_names):
# 生成UA,用于爬虫请求头的设置
UA =
UserAgent
()
ua = UA.random
# 向次层链接发送请求
sec_response = requests.get(sec_url, headers = {
'User-Agent'
:ua})
# 解析次层链接的源代码
sec_soup =
BeautifulSoup
(sec_response.text)
# 根据HTML的标记规则,返回图片链接
pic_url =
'https:'
+ sec_soup.find(
'img'
,{
'class'
:
'card-img-top'
})[
'src'
]
# 对图片链接发送请求
pic_response = requests.get(pic_url, headers = {
'User-Agent'
:ua})
# 将二进制的图片数据写入到本地(即存储图片到本地)
with
open(pic_name+
'.jpg'
, mode =
'wb'
)
as
fn:
fn.write(pic_response.content)
# 生成随机秒数,用于也没的停留
seconds = random.uniform(
1
,
3
)
time.sleep(seconds)
不难发现,代码的核心部分只有16行,还是很简单的。还不赶紧测试这里的代码(如果你对某个方面感兴趣,比如业务、架构、植物等,通过搜索找到顶层页面链接,替换代码中的fst_url值) .
运行上述代码后,会抓取到ColorHub网站中的10页图片,其中一共325张高清图片,如下图:
网页源代码抓取工具(网页源代码抓取工具,思考黑名单策略,软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-04-14 09:04
网页源代码抓取工具
一、工具与服务1.人人网抓取工具[抓包软件];抓取现有网页
二、数据获取方式
三、字符串转数组1.字符串转数组的基本思路2.字符串转数组的实践3.字符串数组转json4.字符串数组转python对象5.字符串数组转mysql对象6.字符串转mysql对象实践2.字符串转数组的基本思路1.基本思路文件名while循环判断文件名,
1)文件名和特征匹配度和回文之类的特征文件名和用户真实pin,
2)文件内容
3)基本的断点
4)思考黑名单策略
1.找到filename和'filename',这两个指的就是web网页里的所有html文件,然后把这些所有文件的filename和filename.jpg下载下来。2.用开发者工具找到所有html文件的源代码3.用"python的urllib模块"下的requests的headers,下载所有pc端和移动端的包,之后用python的xpath(xmlformdocument)从源代码中获取你要的页面或结构。
如果爬取的是网页源码,
用java打开
selenium
chrome+python
百度手机助手,里面可以抓取,然后通过下载的文件, 查看全部
网页源代码抓取工具(网页源代码抓取工具,思考黑名单策略,软件)
网页源代码抓取工具
一、工具与服务1.人人网抓取工具[抓包软件];抓取现有网页
二、数据获取方式
三、字符串转数组1.字符串转数组的基本思路2.字符串转数组的实践3.字符串数组转json4.字符串数组转python对象5.字符串数组转mysql对象6.字符串转mysql对象实践2.字符串转数组的基本思路1.基本思路文件名while循环判断文件名,
1)文件名和特征匹配度和回文之类的特征文件名和用户真实pin,
2)文件内容
3)基本的断点
4)思考黑名单策略
1.找到filename和'filename',这两个指的就是web网页里的所有html文件,然后把这些所有文件的filename和filename.jpg下载下来。2.用开发者工具找到所有html文件的源代码3.用"python的urllib模块"下的requests的headers,下载所有pc端和移动端的包,之后用python的xpath(xmlformdocument)从源代码中获取你要的页面或结构。
如果爬取的是网页源码,
用java打开
selenium
chrome+python
百度手机助手,里面可以抓取,然后通过下载的文件,
网页源代码抓取工具( 网络爬虫java实现抓取邮箱邮箱的小工具,你知道吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-04-12 02:35
网络爬虫java实现抓取邮箱邮箱的小工具,你知道吗?
)
简单的webmail抓包工具(附源码)
为了使他们的数据库足够强大,网络爬虫和搜索引擎不分昼夜地在互联网上搜索信息,以使他们的信息更加全面。我们都知道,互联网上的信息是无限的、爆炸式的增长。他们不可能手动获取信息。他们编写小程序不断获取互联网上的信息,因此网络爬虫诞生了。
下面我实现了一个简单的java抓取邮箱的小工具,很粗糙,仅供大家参考。
这是渲染图
不说什么,直接上代码
<p>
import java.awt.BorderLayout;
import java.awt.Dimension;
import java.awt.Image;
import java.awt.MenuItem;
import java.awt.PopupMenu;
import java.awt.Toolkit;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import java.awt.event.WindowAdapter;
import java.awt.event.WindowEvent;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import javax.swing.ImageIcon;
import javax.swing.JButton;
import javax.swing.JComboBox;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JOptionPane;
import javax.swing.JPanel;
import javax.swing.JScrollPane;
import javax.swing.JTextArea;
import javax.swing.JTextField;
import javax.swing.UIManager;
import javax.swing.UnsupportedLookAndFeelException;
public class MainFrm extends JFrame implements ActionListener {
private static final long serialVersionUID = 1L;
static int count=1;
static int countUrl=1;
JFrame frame;
JButton b1;
JButton b2;
JTextArea t1;
JTextField tf;
JPanel panel;
JScrollPane jScrollPane1;
JLabel label;
JComboBox comb;
PopupMenu pm;
List t = new ArrayList();
static int m = 0;
MainFrm into() {
pm = new PopupMenu();
MenuItem openItem = new MenuItem("1.打 开");
MenuItem closeItem = new MenuItem("2.退 出");
MenuItem aboutItem = new MenuItem("3.关 于");
openItem.addActionListener(this);
closeItem.addActionListener(this);
aboutItem.addActionListener(this);
pm.add(openItem);
pm.add(closeItem);
pm.add(aboutItem);
String[] petStrings = { "Baidu", "Google", "Yahoo", "Bing", "Sogou" };
comb = new JComboBox(petStrings);
java.net.URL imgURL = MainFrm.class.getResource("mail.png");
ImageIcon imageicon = new ImageIcon(imgURL);
panel = new JPanel();
tf = new JTextField(50);
tf.setText("留下邮箱");
label = new JLabel("关键字:");
frame = new JFrame("邮箱抓取(注:抓取深度暂时默认为2) QQ:三二八二四七六七六");
frame.setIconImage(imageicon.getImage());
b1 = new JButton("提取邮箱");
b1.addActionListener(this);
b2 = new JButton("停止抓取");
b2.addActionListener(this);
t1 = new JTextArea();
t1.setLineWrap(true);
jScrollPane1 = new JScrollPane(t1);
jScrollPane1.setPreferredSize(new Dimension(200, 200));
this.setDefaultCloseOperation(DO_NOTHING_ON_CLOSE);
frame.addWindowListener(new WindowAdapter() { // 窗口关闭事件
public void windowClosing(WindowEvent e) {
System.exit(0);
};
public void windowIconified(WindowEvent e) { // 窗口最小化事件
frame.setVisible(false);
systemTray();
}
});
panel.add(label);
panel.add(tf);
panel.add(comb);
panel.add(b1);
panel.add(b2);
frame.getContentPane().add(panel, BorderLayout.NORTH);
frame.getContentPane().add(jScrollPane1, BorderLayout.CENTER);
frame.setSize(300, 400);
frame.pack();
frame.setVisible(true);
Dimension winSize = Toolkit.getDefaultToolkit().getScreenSize();
frame.setLocation((winSize.width - frame.getWidth()) / 2,
(winSize.height - frame.getHeight()) / 2);
frame.setAlwaysOnTop(true);
return this;
}
public static void main(String[] args) throws ClassNotFoundException,
InstantiationException, IllegalAccessException,
UnsupportedLookAndFeelException {
// TODO Auto-generated method stub
UIManager.setLookAndFeel(UIManager.getSystemLookAndFeelClassName());
new MainFrm().into().systemTray();
}
@SuppressWarnings({ "unchecked", "deprecation", "static-access" })
@Override
public void actionPerformed(ActionEvent e) {
if ("提取邮箱".equals(e.getActionCommand())) {
count=1;
t1.setText("");
// get("http://dzh.mop.com/whbm/200601 ... 6quot;);
String http = "";
int combo = (comb.getSelectedIndex());
switch (combo) {
case 0:
http = "http://www.baidu.com/s?wd=";
break;
case 1:
http = "http://www.google.com.hk/searc ... 3B%3B
break;
case 2:
http = "http://www.yahoo.cn/s?q=";
break;
case 3:
http = "http://cn.bing.com/search?q=";
break;
case 4:
http = "http://www.sogou.com/web?query=";
break;
default:
http = "http://www.baidu.com/s?wd=";
break;
}
final List list = get(http + tf.getText());
m = list.size();
for (int i = 0, n = list.size(); i < n; i++) {
final Map map = list.get(i);
Thread tt = new Thread() {
public void run() {
Iterator iterator = map.values().iterator();
while (iterator.hasNext()) {
String u=iterator.next();
get(u);
}
}
};
t.add(tt);
tt.start();
}
} else if ("终止抓取".equals(e.getActionCommand())) {
for (int i = 0; i < t.size(); i++) {
t.get(i).stop();
}
} else if ("1.打 开".equals(e.getActionCommand())) {
frame.setVisible(true);
frame.setExtendedState(frame.NORMAL);
} else if ("2.退 出".equals(e.getActionCommand())) {
System.exit(0);
}else if ("3.关 于".equals(e.getActionCommand())) {
JOptionPane.showMessageDialog(null, "本程序仅供初学参考 QQ:三二八二四七六七六");
}
}
@SuppressWarnings("unchecked")
public List get(String urlStr) {
List list = new ArrayList();
try {
URL url = new URL(urlStr);
URLConnection rulConnection = url.openConnection();
HttpURLConnection httpUrlConnection = (HttpURLConnection) rulConnection;
httpUrlConnection.setRequestProperty("User-Agent",
"Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
BufferedReader br = new BufferedReader(new InputStreamReader(
httpUrlConnection.getInputStream()));
String line = "";
while ((line = br.readLine()) != null) {
Map map = pr(line);
list.add(map);
}
} catch (FileNotFoundException e) {
//e.printStackTrace();
} catch (IOException e) {
//e.printStackTrace();
} finally {
m--;
if (m 查看全部
网页源代码抓取工具(
网络爬虫java实现抓取邮箱邮箱的小工具,你知道吗?
)
简单的webmail抓包工具(附源码)
为了使他们的数据库足够强大,网络爬虫和搜索引擎不分昼夜地在互联网上搜索信息,以使他们的信息更加全面。我们都知道,互联网上的信息是无限的、爆炸式的增长。他们不可能手动获取信息。他们编写小程序不断获取互联网上的信息,因此网络爬虫诞生了。
下面我实现了一个简单的java抓取邮箱的小工具,很粗糙,仅供大家参考。
这是渲染图
不说什么,直接上代码
<p>
import java.awt.BorderLayout;
import java.awt.Dimension;
import java.awt.Image;
import java.awt.MenuItem;
import java.awt.PopupMenu;
import java.awt.Toolkit;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import java.awt.event.WindowAdapter;
import java.awt.event.WindowEvent;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import javax.swing.ImageIcon;
import javax.swing.JButton;
import javax.swing.JComboBox;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JOptionPane;
import javax.swing.JPanel;
import javax.swing.JScrollPane;
import javax.swing.JTextArea;
import javax.swing.JTextField;
import javax.swing.UIManager;
import javax.swing.UnsupportedLookAndFeelException;
public class MainFrm extends JFrame implements ActionListener {
private static final long serialVersionUID = 1L;
static int count=1;
static int countUrl=1;
JFrame frame;
JButton b1;
JButton b2;
JTextArea t1;
JTextField tf;
JPanel panel;
JScrollPane jScrollPane1;
JLabel label;
JComboBox comb;
PopupMenu pm;
List t = new ArrayList();
static int m = 0;
MainFrm into() {
pm = new PopupMenu();
MenuItem openItem = new MenuItem("1.打 开");
MenuItem closeItem = new MenuItem("2.退 出");
MenuItem aboutItem = new MenuItem("3.关 于");
openItem.addActionListener(this);
closeItem.addActionListener(this);
aboutItem.addActionListener(this);
pm.add(openItem);
pm.add(closeItem);
pm.add(aboutItem);
String[] petStrings = { "Baidu", "Google", "Yahoo", "Bing", "Sogou" };
comb = new JComboBox(petStrings);
java.net.URL imgURL = MainFrm.class.getResource("mail.png");
ImageIcon imageicon = new ImageIcon(imgURL);
panel = new JPanel();
tf = new JTextField(50);
tf.setText("留下邮箱");
label = new JLabel("关键字:");
frame = new JFrame("邮箱抓取(注:抓取深度暂时默认为2) QQ:三二八二四七六七六");
frame.setIconImage(imageicon.getImage());
b1 = new JButton("提取邮箱");
b1.addActionListener(this);
b2 = new JButton("停止抓取");
b2.addActionListener(this);
t1 = new JTextArea();
t1.setLineWrap(true);
jScrollPane1 = new JScrollPane(t1);
jScrollPane1.setPreferredSize(new Dimension(200, 200));
this.setDefaultCloseOperation(DO_NOTHING_ON_CLOSE);
frame.addWindowListener(new WindowAdapter() { // 窗口关闭事件
public void windowClosing(WindowEvent e) {
System.exit(0);
};
public void windowIconified(WindowEvent e) { // 窗口最小化事件
frame.setVisible(false);
systemTray();
}
});
panel.add(label);
panel.add(tf);
panel.add(comb);
panel.add(b1);
panel.add(b2);
frame.getContentPane().add(panel, BorderLayout.NORTH);
frame.getContentPane().add(jScrollPane1, BorderLayout.CENTER);
frame.setSize(300, 400);
frame.pack();
frame.setVisible(true);
Dimension winSize = Toolkit.getDefaultToolkit().getScreenSize();
frame.setLocation((winSize.width - frame.getWidth()) / 2,
(winSize.height - frame.getHeight()) / 2);
frame.setAlwaysOnTop(true);
return this;
}
public static void main(String[] args) throws ClassNotFoundException,
InstantiationException, IllegalAccessException,
UnsupportedLookAndFeelException {
// TODO Auto-generated method stub
UIManager.setLookAndFeel(UIManager.getSystemLookAndFeelClassName());
new MainFrm().into().systemTray();
}
@SuppressWarnings({ "unchecked", "deprecation", "static-access" })
@Override
public void actionPerformed(ActionEvent e) {
if ("提取邮箱".equals(e.getActionCommand())) {
count=1;
t1.setText("");
// get("http://dzh.mop.com/whbm/200601 ... 6quot;);
String http = "";
int combo = (comb.getSelectedIndex());
switch (combo) {
case 0:
http = "http://www.baidu.com/s?wd=";
break;
case 1:
http = "http://www.google.com.hk/searc ... 3B%3B
break;
case 2:
http = "http://www.yahoo.cn/s?q=";
break;
case 3:
http = "http://cn.bing.com/search?q=";
break;
case 4:
http = "http://www.sogou.com/web?query=";
break;
default:
http = "http://www.baidu.com/s?wd=";
break;
}
final List list = get(http + tf.getText());
m = list.size();
for (int i = 0, n = list.size(); i < n; i++) {
final Map map = list.get(i);
Thread tt = new Thread() {
public void run() {
Iterator iterator = map.values().iterator();
while (iterator.hasNext()) {
String u=iterator.next();
get(u);
}
}
};
t.add(tt);
tt.start();
}
} else if ("终止抓取".equals(e.getActionCommand())) {
for (int i = 0; i < t.size(); i++) {
t.get(i).stop();
}
} else if ("1.打 开".equals(e.getActionCommand())) {
frame.setVisible(true);
frame.setExtendedState(frame.NORMAL);
} else if ("2.退 出".equals(e.getActionCommand())) {
System.exit(0);
}else if ("3.关 于".equals(e.getActionCommand())) {
JOptionPane.showMessageDialog(null, "本程序仅供初学参考 QQ:三二八二四七六七六");
}
}
@SuppressWarnings("unchecked")
public List get(String urlStr) {
List list = new ArrayList();
try {
URL url = new URL(urlStr);
URLConnection rulConnection = url.openConnection();
HttpURLConnection httpUrlConnection = (HttpURLConnection) rulConnection;
httpUrlConnection.setRequestProperty("User-Agent",
"Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
BufferedReader br = new BufferedReader(new InputStreamReader(
httpUrlConnection.getInputStream()));
String line = "";
while ((line = br.readLine()) != null) {
Map map = pr(line);
list.add(map);
}
} catch (FileNotFoundException e) {
//e.printStackTrace();
} catch (IOException e) {
//e.printStackTrace();
} finally {
m--;
if (m
网页源代码抓取工具(网页内容抓取工具做网站指定采集伪原创发布,你知道吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-04-12 01:17
网页内容抓取工具。最近有很多做网站的朋友问我有没有什么有用的网页内容爬取。我可以批量采集网站内容到网站指定采集伪原创发布,因为他们站很多,每天网站内容更新是一件很麻烦的事情。SEO是“内容为王”的时代,优质内容的稳定输出将有利于网站的SEO收录和SEO排名。
当网页内容爬虫做网站时,你需要选择一个好的模板。对于 网站 优化,一个好的模板通常会事半功倍。除了基本要求之外,一个好的模板应该有很好的插图,有时间线,没有太多的页面链接,没有杂乱的章节。
采集速度快,数据完整性高。采集网页内容抓取器的速度是最快的采集软件之一。独有的多模板功能+智能纠错模式,保证结果数据100%完整性。任何网页都可以是采集,只要你能在浏览器中看到内容,几乎可以做到你需要的格式采集。采集 支持 JS 输出内容。
有节奏地更新网站 内容,维护原创,并使用适当的伪原创 工具。一开始,要不断给搜索引擎一个好的形象,不要被判断为采集网站。这是很多人一开始并没有注意到的。网站网页内容爬取到一定规模后,为了增加网站的收录,每天添加网站的外部链接。然后可以使用网页内容爬虫的一键批量自动推送工具,将网站链接批量提交到百度、搜狗、360、神马等搜索引擎。推送是 SEO 的重要组成部分。推送主动向搜索引擎公开链接以增加蜘蛛爬行,从而促进网站收录。
当网站为收录,稳定且有一定关键词排名时,可以通过网页内容爬取不断增加网站内容。当然,如果你有资源,可以在网站收录首页后交换链接。主要是因为没有排名的 网站 很难切换到正确的链接。网页内容抓取可以通过站外推广不断增加网站的曝光率,可以间接提高网站的自然点击率,从而提升和稳定网站的排名。
很多时候我们会发现我们的网站代码有一些优化问题,比如一些模板链接错误,或者我们对网站做了一些微调。如果看不懂代码,往往只能自己操心。如果你懂html和div+css,就可以很好的解决这些小问题。
我们都知道网站空间的稳定性很重要,打开速度也是衡量网站排名的一个很重要的指标,所以一旦百度站长平台有这样的优化建议,往往需要自己解决。
做过SEO的人都离不开程序背景。通常,很多工作都在其中完成。尤其是想要做好结构优化的修改和设置,不看懂这个程序是不可能的。如果做得不好,很容易犯各种严重的错误。
当前网站安全形势非常严峻。我们经常看到有人在网站上抱怨因为排名好被黑客打开,或者被黑了,服务器甚至被别人炸了。这无疑会对他们的网站排名产生非常负面的影响,所以一些安全知识是必要的。
网页内容爬虫基于高度智能的文本识别算法。网页内容爬虫只需将关键词输入到采集内容,无需编写采集规则。覆盖六大搜索引擎和各大新闻源,内容取之不尽,优先采集最新最热的文章信息,自动过滤采集到的信息,拒绝重复采集。这就是今天对 网站 内容抓取工具的介绍。返回搜狐,查看更多 查看全部
网页源代码抓取工具(网页内容抓取工具做网站指定采集伪原创发布,你知道吗)
网页内容抓取工具。最近有很多做网站的朋友问我有没有什么有用的网页内容爬取。我可以批量采集网站内容到网站指定采集伪原创发布,因为他们站很多,每天网站内容更新是一件很麻烦的事情。SEO是“内容为王”的时代,优质内容的稳定输出将有利于网站的SEO收录和SEO排名。
当网页内容爬虫做网站时,你需要选择一个好的模板。对于 网站 优化,一个好的模板通常会事半功倍。除了基本要求之外,一个好的模板应该有很好的插图,有时间线,没有太多的页面链接,没有杂乱的章节。
采集速度快,数据完整性高。采集网页内容抓取器的速度是最快的采集软件之一。独有的多模板功能+智能纠错模式,保证结果数据100%完整性。任何网页都可以是采集,只要你能在浏览器中看到内容,几乎可以做到你需要的格式采集。采集 支持 JS 输出内容。
有节奏地更新网站 内容,维护原创,并使用适当的伪原创 工具。一开始,要不断给搜索引擎一个好的形象,不要被判断为采集网站。这是很多人一开始并没有注意到的。网站网页内容爬取到一定规模后,为了增加网站的收录,每天添加网站的外部链接。然后可以使用网页内容爬虫的一键批量自动推送工具,将网站链接批量提交到百度、搜狗、360、神马等搜索引擎。推送是 SEO 的重要组成部分。推送主动向搜索引擎公开链接以增加蜘蛛爬行,从而促进网站收录。
当网站为收录,稳定且有一定关键词排名时,可以通过网页内容爬取不断增加网站内容。当然,如果你有资源,可以在网站收录首页后交换链接。主要是因为没有排名的 网站 很难切换到正确的链接。网页内容抓取可以通过站外推广不断增加网站的曝光率,可以间接提高网站的自然点击率,从而提升和稳定网站的排名。
很多时候我们会发现我们的网站代码有一些优化问题,比如一些模板链接错误,或者我们对网站做了一些微调。如果看不懂代码,往往只能自己操心。如果你懂html和div+css,就可以很好的解决这些小问题。
我们都知道网站空间的稳定性很重要,打开速度也是衡量网站排名的一个很重要的指标,所以一旦百度站长平台有这样的优化建议,往往需要自己解决。
做过SEO的人都离不开程序背景。通常,很多工作都在其中完成。尤其是想要做好结构优化的修改和设置,不看懂这个程序是不可能的。如果做得不好,很容易犯各种严重的错误。
当前网站安全形势非常严峻。我们经常看到有人在网站上抱怨因为排名好被黑客打开,或者被黑了,服务器甚至被别人炸了。这无疑会对他们的网站排名产生非常负面的影响,所以一些安全知识是必要的。
网页内容爬虫基于高度智能的文本识别算法。网页内容爬虫只需将关键词输入到采集内容,无需编写采集规则。覆盖六大搜索引擎和各大新闻源,内容取之不尽,优先采集最新最热的文章信息,自动过滤采集到的信息,拒绝重复采集。这就是今天对 网站 内容抓取工具的介绍。返回搜狐,查看更多
网页源代码抓取工具( 能快速获取网上数据的工具吗?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2022-04-11 23:14
能快速获取网上数据的工具吗?(组图))
前天,有同学加我微信咨询我:“猴哥,我想抓取最近的5000条新闻数据,但是我是文科生,不会写代码,怎么办?”
猴哥会回答每一个问题。我会安排这位同学的问题。
首先说一下获取数据的方式:首先,使用现成的工具,我们只需要知道如何使用工具来获取数据,不需要关心工具是如何实现的。比如我们在岸上,要去海上的一个小岛,岸上有船,我们首先想到的就是选择船去那里,而不是想着造船去那里。二是针对场景需求做一些定制化的工具,这需要一点编程基础。比如我们还是要去海里的一个小岛,我们也要求30分钟内有货送到岛上。
所以前期只是单纯的想获取数据,如果没有其他需求,首选现有的工具。可能是Python这几年很火,我们经常会看到别人用Python做网络爬虫爬取数据。因此,有些学生有这样的误解。如果你想从网上抓取数据,你必须学习 Python 并编写代码。
其实并不是。猴哥介绍几个可以快速获取在线数据的工具。
1.微软 Excel
你没看错,是 Excel,Office 三剑客之一。Excel 是一个强大的工具,能够捕获数据是它的功能之一。我用耳机作为关键词来抓取京东的产品列表。
几秒钟后,Excel 会将页面上的所有文本信息抓取到一个表格中。这个方法确实可以捕获数据,但是也会引入一些我们不需要的数据。如果你有更高的要求,你可以选择后者的工具。
2.优采云采集器
优采云 是爬虫界的老字号。它是目前使用最多的互联网数据采集、处理、分析和挖掘软件。它的优点是采集不限于网页和内容,也分布式采集,效率会更高。缺点是对新手用户不太友好,有一定的知识门槛(如网页知识、HTTP协议等),熟悉工具操作需要一定的时间。
由于学习门槛的关系,掌握了工具后,采集的数据限制会非常高。有时间和精力的同学可以去折腾折腾。
官网地址:
3.优采云采集器
优采云采集器对于初学者来说是一个很棒的采集器。它简单易用,因此您可以在几分钟内启动并运行。优采云提供一些常用抓取的模板网站,使用模板快速抓取数据。如果你想在没有模板的情况下抓取网站,官网也提供了非常详细的图文教程和视频教程。
优采云是基于浏览器内核实现数据的可视化抓取,所以有滞后和采集数据慢的特点。不过这个缺陷也掩盖不了弱点,基本可以满足新手在短时间内抓取数据的场景,比如翻页查询、Ajax动态加载数据等。
网站:
4.GooSeeker
Jisouke也是一个易于使用的可视化采集数据工具。它还可以捕获动态网页,以及捕获移动网站上的数据,以及捕获在索引图表上悬浮显示的数据。Jisouke 以浏览器插件的形式捕获数据。尽管它具有上述优点,但也有缺点。多线程 采集 数据是不可能的,浏览器冻结是不可避免的。
网站:
5.Scrapinghub
如果想抓取国外的网站数据,可以考虑Scrapinghub。Scrapinghub 是一个基于 Python 的 Scrapy 框架的云爬虫平台。Scrapehub 是市面上一个非常复杂且功能强大的网页抓取平台,提供数据抓取的解决方案提供商。
地址:
6.WebScraper
WebScraper 是一款优秀的国外浏览器插件。它也是一个适合初学者抓取数据的可视化工具。我们只需设置一些抓取规则,让浏览器完成工作。
地址: 查看全部
网页源代码抓取工具(
能快速获取网上数据的工具吗?(组图))
前天,有同学加我微信咨询我:“猴哥,我想抓取最近的5000条新闻数据,但是我是文科生,不会写代码,怎么办?”
猴哥会回答每一个问题。我会安排这位同学的问题。
首先说一下获取数据的方式:首先,使用现成的工具,我们只需要知道如何使用工具来获取数据,不需要关心工具是如何实现的。比如我们在岸上,要去海上的一个小岛,岸上有船,我们首先想到的就是选择船去那里,而不是想着造船去那里。二是针对场景需求做一些定制化的工具,这需要一点编程基础。比如我们还是要去海里的一个小岛,我们也要求30分钟内有货送到岛上。
所以前期只是单纯的想获取数据,如果没有其他需求,首选现有的工具。可能是Python这几年很火,我们经常会看到别人用Python做网络爬虫爬取数据。因此,有些学生有这样的误解。如果你想从网上抓取数据,你必须学习 Python 并编写代码。
其实并不是。猴哥介绍几个可以快速获取在线数据的工具。
1.微软 Excel
你没看错,是 Excel,Office 三剑客之一。Excel 是一个强大的工具,能够捕获数据是它的功能之一。我用耳机作为关键词来抓取京东的产品列表。
几秒钟后,Excel 会将页面上的所有文本信息抓取到一个表格中。这个方法确实可以捕获数据,但是也会引入一些我们不需要的数据。如果你有更高的要求,你可以选择后者的工具。
2.优采云采集器
优采云 是爬虫界的老字号。它是目前使用最多的互联网数据采集、处理、分析和挖掘软件。它的优点是采集不限于网页和内容,也分布式采集,效率会更高。缺点是对新手用户不太友好,有一定的知识门槛(如网页知识、HTTP协议等),熟悉工具操作需要一定的时间。
由于学习门槛的关系,掌握了工具后,采集的数据限制会非常高。有时间和精力的同学可以去折腾折腾。
官网地址:
3.优采云采集器
优采云采集器对于初学者来说是一个很棒的采集器。它简单易用,因此您可以在几分钟内启动并运行。优采云提供一些常用抓取的模板网站,使用模板快速抓取数据。如果你想在没有模板的情况下抓取网站,官网也提供了非常详细的图文教程和视频教程。
优采云是基于浏览器内核实现数据的可视化抓取,所以有滞后和采集数据慢的特点。不过这个缺陷也掩盖不了弱点,基本可以满足新手在短时间内抓取数据的场景,比如翻页查询、Ajax动态加载数据等。
网站:
4.GooSeeker
Jisouke也是一个易于使用的可视化采集数据工具。它还可以捕获动态网页,以及捕获移动网站上的数据,以及捕获在索引图表上悬浮显示的数据。Jisouke 以浏览器插件的形式捕获数据。尽管它具有上述优点,但也有缺点。多线程 采集 数据是不可能的,浏览器冻结是不可避免的。
网站:
5.Scrapinghub
如果想抓取国外的网站数据,可以考虑Scrapinghub。Scrapinghub 是一个基于 Python 的 Scrapy 框架的云爬虫平台。Scrapehub 是市面上一个非常复杂且功能强大的网页抓取平台,提供数据抓取的解决方案提供商。
地址:
6.WebScraper
WebScraper 是一款优秀的国外浏览器插件。它也是一个适合初学者抓取数据的可视化工具。我们只需设置一些抓取规则,让浏览器完成工作。
地址:
网页源代码抓取工具(celrityC/C++源代码源码查看工具功能强大的C/源代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-04-11 23:11
celrityC/C++源代码查看工具
一款功能强大的C/C++源代码分析软件。可以处理数百万行源代码。支持标准和 K&R 风格的 C/C++。对于每一个源代码项目,通过建立一个收录丰富交叉引用关系的数据库,展示其中收录的各种信息:所有源文件、所有头文件、词汇索引、文件收录关系、宏定义、数据结构和函数定义、函数调用关系、诊断输出等。一键扩展各种类型的定义和调用关系非常方便。所有这些结合起来可以非常有效地帮助用户快速理解和维护大型源代码项目。收录各种友好的用户界面效果,如窗口的选项卡式排列、任意分隔、自动隐藏、浮动,拖动等。它允许用户快速找到每个功能窗口并以各种格式重新组合它们。收录一个通用的文本和十六进制编辑器。可以设置多个文件定义来指定文件的处理、颜色和样式。当前或以前打开的文件可以相对快速地定位。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。它允许用户快速找到每个功能窗口并以各种格式重新组合它们。收录一个通用的文本和十六进制编辑器。可以设置多个文件定义来指定文件的处理、颜色和样式。当前或以前打开的文件可以相对快速地定位。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。它允许用户快速找到每个功能窗口并以各种格式重新组合它们。收录一个通用的文本和十六进制编辑器。可以设置多个文件定义来指定文件的处理、颜色和样式。当前或以前打开的文件可以相对快速地定位。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。收录一个通用的文本和十六进制编辑器。可以设置多个文件定义来指定文件的处理、颜色和样式。当前或以前打开的文件可以相对快速地定位。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。收录一个通用的文本和十六进制编辑器。可以设置多个文件定义来指定文件的处理、颜色和样式。当前或以前打开的文件可以相对快速地定位。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。
立即下载 查看全部
网页源代码抓取工具(celrityC/C++源代码源码查看工具功能强大的C/源代码)
celrityC/C++源代码查看工具
一款功能强大的C/C++源代码分析软件。可以处理数百万行源代码。支持标准和 K&R 风格的 C/C++。对于每一个源代码项目,通过建立一个收录丰富交叉引用关系的数据库,展示其中收录的各种信息:所有源文件、所有头文件、词汇索引、文件收录关系、宏定义、数据结构和函数定义、函数调用关系、诊断输出等。一键扩展各种类型的定义和调用关系非常方便。所有这些结合起来可以非常有效地帮助用户快速理解和维护大型源代码项目。收录各种友好的用户界面效果,如窗口的选项卡式排列、任意分隔、自动隐藏、浮动,拖动等。它允许用户快速找到每个功能窗口并以各种格式重新组合它们。收录一个通用的文本和十六进制编辑器。可以设置多个文件定义来指定文件的处理、颜色和样式。当前或以前打开的文件可以相对快速地定位。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。它允许用户快速找到每个功能窗口并以各种格式重新组合它们。收录一个通用的文本和十六进制编辑器。可以设置多个文件定义来指定文件的处理、颜色和样式。当前或以前打开的文件可以相对快速地定位。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。它允许用户快速找到每个功能窗口并以各种格式重新组合它们。收录一个通用的文本和十六进制编辑器。可以设置多个文件定义来指定文件的处理、颜色和样式。当前或以前打开的文件可以相对快速地定位。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。收录一个通用的文本和十六进制编辑器。可以设置多个文件定义来指定文件的处理、颜色和样式。当前或以前打开的文件可以相对快速地定位。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。收录一个通用的文本和十六进制编辑器。可以设置多个文件定义来指定文件的处理、颜色和样式。当前或以前打开的文件可以相对快速地定位。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。收录一个可以同时打开多个项目的工作区,并且有许多命令可以处理一个或所有项目。强大的功能可以同时在多个文件、文件夹和项目中进行后台搜索和替换。收录一个强大的比较模块,可以在文件之间或文件夹之间进行背景比较。提供了许多命令来显示目标之间的差异。
立即下载
网页源代码抓取工具(如何用web浏览器的内置工具去分析客户端的源码?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-04-11 23:04
翻译自:@_bl4de/how-to-perform-the-static-analysis-of-website-source-code-with-the-browser-the-beginners-bug-d674828c8d9a
译:聂新明
在本手册中,我将展示如何使用 Web 浏览器的内置工具分析客户端源代码。可能会有一些奇怪的声音,浏览器可能不是这个任务的最佳选择,但在你继续之前,让我们打开 Burp Suite 来拦截 http 请求,无论是在这里还是用 alert(1) 继续xss,首先知道你的目标总是一个好主意
这个 文章 主要针对对 HTML 和 JavaScript 代码经验很少或没有经验的赏金猎人,但我希望更有经验的黑客能找到一些有趣的东西。
在我最近关于基本操作的推文引起了社区的广泛关注之后,我认为是时候写出类似 文章 的东西了。
这个简单的想法只是冰山一角,如果我把所有这些技巧都发到推特上,其他人很容易错过它们,所以我决定采集它们并写博客。我希望你们能找到一些有用的东西。
好吧,让我们开始吧
工具集
每个现代浏览器都有内置的开发人员工具,为了启动它们,您可以使用 Ctrl+Shift+I、CMD+Option+I (macOS)、F12 或浏览器右侧的菜单选项 - 这取决于您正在使用操作系统和浏览器。虽然在这个 文章 我使用的是最新版本的 Chromium,但如果你使用 Firefox、Safari、Chrome 或 Edge,它们除了 UI 没有什么不同。你可以选择任何你喜欢的浏览器,但你会发现 Chrome DevTools 是最强大的(Chrome DevTools 或 Lightweight DevTools 兼容 Chrome、Chromium、Brave、Opera 或其他基于 Chromium 的浏览器)
您需要安装 IDE(集成开发环境)或任何带有 html 和 JavaScript 代码突出显示的编辑器。这些都是基于你自己的偏好,但我发现 Visual Studio Code 特别有用(顺便说一句,我在所有事情上都使用 VSCode,包括在我的工作中)。您可以使用下面的链接为您的系统下载 VSCode
安装 NodeJS 也是一个好主意(如果你经常使用它,你会更加熟悉它——互联网上有成千上万的资源)。更有用的
python对我来说也是必备工具(如果你使用基于*NIX的系统,你有机会使用它,它已经安装了。如果你是windows用户,你必须自己手动安装Python)。用 Python 编写代码的能力是无价的,我建议那些从未编写过代码的人尝试一下 Python
NodeJS 对于在终端中运行和测试 JavaScript 代码非常有用(您也可以在浏览器中进行,但我们稍后会讨论它们的优缺点)。您可以在 Python 中创建自己的脚本工具来快速验证漏洞并实际利用它——我还将在本文中介绍我自己的工具 文章。如果你解释其他解释型语言(如Ruby、PHP、Perl、Bash等),你也可以使用它们。上述语言的主要优点是无需编译即可运行,也可以直接从命令行执行。它们是 100% 跨平台的,您可以在网络上使用许多库和模块。
好的,现在终于想通了
查看 HTML 源代码
让我们回到我刚刚引用的推文。您可能会注意到,被筛选的网页似乎没有内容,并且似乎只是一个空白页面。
但是如果你查看网页的源代码(在 mac 上使用 CTRL+U 或 CMD+Option+U)你会看到很多代码(不幸的是我无法提供那个 网站 的 url在屏幕截图中),因为那是公测项目的私有项目)。为什么这些元素不显示在浏览器中?
重要的是有些 HTML 标签在页面中没有显示任何内容,HTML 中有很多这样的标签,我将在这里给出一些基本示例, , , 或 查看全部
网页源代码抓取工具(如何用web浏览器的内置工具去分析客户端的源码?)
翻译自:@_bl4de/how-to-perform-the-static-analysis-of-website-source-code-with-the-browser-the-beginners-bug-d674828c8d9a
译:聂新明
在本手册中,我将展示如何使用 Web 浏览器的内置工具分析客户端源代码。可能会有一些奇怪的声音,浏览器可能不是这个任务的最佳选择,但在你继续之前,让我们打开 Burp Suite 来拦截 http 请求,无论是在这里还是用 alert(1) 继续xss,首先知道你的目标总是一个好主意
这个 文章 主要针对对 HTML 和 JavaScript 代码经验很少或没有经验的赏金猎人,但我希望更有经验的黑客能找到一些有趣的东西。
在我最近关于基本操作的推文引起了社区的广泛关注之后,我认为是时候写出类似 文章 的东西了。
这个简单的想法只是冰山一角,如果我把所有这些技巧都发到推特上,其他人很容易错过它们,所以我决定采集它们并写博客。我希望你们能找到一些有用的东西。
好吧,让我们开始吧
工具集
每个现代浏览器都有内置的开发人员工具,为了启动它们,您可以使用 Ctrl+Shift+I、CMD+Option+I (macOS)、F12 或浏览器右侧的菜单选项 - 这取决于您正在使用操作系统和浏览器。虽然在这个 文章 我使用的是最新版本的 Chromium,但如果你使用 Firefox、Safari、Chrome 或 Edge,它们除了 UI 没有什么不同。你可以选择任何你喜欢的浏览器,但你会发现 Chrome DevTools 是最强大的(Chrome DevTools 或 Lightweight DevTools 兼容 Chrome、Chromium、Brave、Opera 或其他基于 Chromium 的浏览器)
您需要安装 IDE(集成开发环境)或任何带有 html 和 JavaScript 代码突出显示的编辑器。这些都是基于你自己的偏好,但我发现 Visual Studio Code 特别有用(顺便说一句,我在所有事情上都使用 VSCode,包括在我的工作中)。您可以使用下面的链接为您的系统下载 VSCode
安装 NodeJS 也是一个好主意(如果你经常使用它,你会更加熟悉它——互联网上有成千上万的资源)。更有用的
python对我来说也是必备工具(如果你使用基于*NIX的系统,你有机会使用它,它已经安装了。如果你是windows用户,你必须自己手动安装Python)。用 Python 编写代码的能力是无价的,我建议那些从未编写过代码的人尝试一下 Python
NodeJS 对于在终端中运行和测试 JavaScript 代码非常有用(您也可以在浏览器中进行,但我们稍后会讨论它们的优缺点)。您可以在 Python 中创建自己的脚本工具来快速验证漏洞并实际利用它——我还将在本文中介绍我自己的工具 文章。如果你解释其他解释型语言(如Ruby、PHP、Perl、Bash等),你也可以使用它们。上述语言的主要优点是无需编译即可运行,也可以直接从命令行执行。它们是 100% 跨平台的,您可以在网络上使用许多库和模块。
好的,现在终于想通了
查看 HTML 源代码
让我们回到我刚刚引用的推文。您可能会注意到,被筛选的网页似乎没有内容,并且似乎只是一个空白页面。
但是如果你查看网页的源代码(在 mac 上使用 CTRL+U 或 CMD+Option+U)你会看到很多代码(不幸的是我无法提供那个 网站 的 url在屏幕截图中),因为那是公测项目的私有项目)。为什么这些元素不显示在浏览器中?
重要的是有些 HTML 标签在页面中没有显示任何内容,HTML 中有很多这样的标签,我将在这里给出一些基本示例, , , 或
网页源代码抓取工具(请求头注意携带4、请求体如果是是get方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-04-11 23:03
请求:用户通过浏览器(socket client)将自己的信息发送到服务器(socket server)
响应:服务器收到请求,分析用户发送的请求信息,然后返回数据(返回的数据可能收录其他链接,如:图片、js、css等)
ps:浏览器收到Response后,会解析其内容展示给用户,爬虫模拟浏览器发送请求后提取有用数据,然后接收Response。
四、 请求
1、请求方法:
常见的请求方式:GET / POST
2、请求的网址
url 全局统一资源定位器,用于定义互联网上唯一的资源 例如:图片、文件、视频都可以通过url唯一标识
网址编码
图片
图像将被编码(见示例代码)
一个网页的加载过程是:
加载网页通常会先加载文档,
在解析document文档时,如果遇到链接,则对该超链接发起图片下载请求
3、请求头
User-agent:如果请求头中没有user-agent客户端配置,服务器可能会将你视为非法用户主机;
cookies:cookies用于存储登录信息
注意:一般爬虫会添加请求头
请求头中需要注意的参数:
(1)Referrer:访问源从哪里来(有些大的网站,会使用Referrer做防盗链策略;所有爬虫也要注意模拟)
(2)User-Agent: 访问的浏览器(需添加否则视为爬虫)
(3)cookie: 请注意请求头
4、请求正文
如果请求体在get方法中,则请求体是没有内容的(get请求的请求体放在url后面的参数中,可以直接看到)。如果是在post方法中,请求体为格式dataps:1、登录窗口,文件上传等,信息会附在请求体2、登录,输入错误的用户名和输入密码,然后提交,就可以看到帖子了,正确登录后,页面一般会跳转,帖子无法被抓取
五、 响应
1、响应状态码
200:代表成功
301:代表跳转
404: 文件不存在
403:未经授权的访问
502:服务器错误
2、响应头
响应头中需要注意的参数:
(1)Set-Cookie:BDSVRTM=0; path=/: 可能不止一个,就是告诉浏览器保存cookie
(2)Content-Location:服务器响应头收录Location返回浏览器后,浏览器会重新访问另一个页面
3、预览是网页的源代码
JSO 数据
如网页html、图片
二进制数据等
1、爬虫流程总结:
爬取--->解析--->存储
2、爬虫需要的工具:
请求库:requests、selenium(可以驱动浏览器解析和渲染CSS和JS,但有性能劣势(会加载有用和无用的网页);)
解析库:regular、beautifulsoup、pyquery
存储库:文件、MySQL、Mongodb、Redis 查看全部
网页源代码抓取工具(请求头注意携带4、请求体如果是是get方式)
请求:用户通过浏览器(socket client)将自己的信息发送到服务器(socket server)
响应:服务器收到请求,分析用户发送的请求信息,然后返回数据(返回的数据可能收录其他链接,如:图片、js、css等)
ps:浏览器收到Response后,会解析其内容展示给用户,爬虫模拟浏览器发送请求后提取有用数据,然后接收Response。
四、 请求
1、请求方法:
常见的请求方式:GET / POST
2、请求的网址
url 全局统一资源定位器,用于定义互联网上唯一的资源 例如:图片、文件、视频都可以通过url唯一标识
网址编码
图片
图像将被编码(见示例代码)
一个网页的加载过程是:
加载网页通常会先加载文档,
在解析document文档时,如果遇到链接,则对该超链接发起图片下载请求
3、请求头
User-agent:如果请求头中没有user-agent客户端配置,服务器可能会将你视为非法用户主机;
cookies:cookies用于存储登录信息
注意:一般爬虫会添加请求头
请求头中需要注意的参数:
(1)Referrer:访问源从哪里来(有些大的网站,会使用Referrer做防盗链策略;所有爬虫也要注意模拟)
(2)User-Agent: 访问的浏览器(需添加否则视为爬虫)
(3)cookie: 请注意请求头
4、请求正文
如果请求体在get方法中,则请求体是没有内容的(get请求的请求体放在url后面的参数中,可以直接看到)。如果是在post方法中,请求体为格式dataps:1、登录窗口,文件上传等,信息会附在请求体2、登录,输入错误的用户名和输入密码,然后提交,就可以看到帖子了,正确登录后,页面一般会跳转,帖子无法被抓取
五、 响应
1、响应状态码
200:代表成功
301:代表跳转
404: 文件不存在
403:未经授权的访问
502:服务器错误
2、响应头
响应头中需要注意的参数:
(1)Set-Cookie:BDSVRTM=0; path=/: 可能不止一个,就是告诉浏览器保存cookie
(2)Content-Location:服务器响应头收录Location返回浏览器后,浏览器会重新访问另一个页面
3、预览是网页的源代码
JSO 数据
如网页html、图片
二进制数据等
1、爬虫流程总结:
爬取--->解析--->存储
2、爬虫需要的工具:
请求库:requests、selenium(可以驱动浏览器解析和渲染CSS和JS,但有性能劣势(会加载有用和无用的网页);)
解析库:regular、beautifulsoup、pyquery
存储库:文件、MySQL、Mongodb、Redis
网页源代码抓取工具(分享一个微信小程序前端代码提取工具提取码:zfhn推荐)
网站优化 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2022-04-11 15:06
分享一个微信小程序前端代码提取工具
提取码:zfhn
建议安装安卓模拟器,本次分享使用“夜游模拟器”
安装夜神模拟器,安装地址:在模拟器上安装微信QQ在模拟器上设置超级管理员权限在模拟器上登录微信,访问需要解压代码的小程序小程序运行正常后,返回主page 界面在“文件管理器”中根据如下目录找到pkg文件(这里需要获取root权限,按照4步即可获取root权限)。具体目录位置如下: /data/data/com.tencent.mm/MicroMsg/********/appbrand/pkg/ 在这个目录下,你会发现一些xxxxxxx.wxapkg类型的文件,这些是微信小程序的封装,微信小程序的格式为.wxapkg。你可以根据使用时间来判断你刚刚从服务器下载的是哪一个。一般来说,小程序的文件不是太大,可以根据时间来判断,长按压缩选中的文件,然后通过QQ把压缩包发到我的电脑上。如果不压缩,是不可能通过QQ发送这个文件的。所以QQ的这个功能让我们可以很方便的拿到源文件,而不必去电脑目录找模拟器的文件目录。在这一步,您将获得小程序文件。接下来只需要将小程序文件放到工具解压目录的wxapkg目录下,返回运行CrackMinApp.exe,在选择界面选择需要解压的小程序文件,运行等待进度条后加载后,可以在小程序文件目录中找到对应的文件夹。恭喜,你已经拿到了源代码。
亲测可用,技术共享,请勿用于非法经营活动。 查看全部
网页源代码抓取工具(分享一个微信小程序前端代码提取工具提取码:zfhn推荐)
分享一个微信小程序前端代码提取工具
提取码:zfhn
建议安装安卓模拟器,本次分享使用“夜游模拟器”
安装夜神模拟器,安装地址:在模拟器上安装微信QQ在模拟器上设置超级管理员权限在模拟器上登录微信,访问需要解压代码的小程序小程序运行正常后,返回主page 界面在“文件管理器”中根据如下目录找到pkg文件(这里需要获取root权限,按照4步即可获取root权限)。具体目录位置如下: /data/data/com.tencent.mm/MicroMsg/********/appbrand/pkg/ 在这个目录下,你会发现一些xxxxxxx.wxapkg类型的文件,这些是微信小程序的封装,微信小程序的格式为.wxapkg。你可以根据使用时间来判断你刚刚从服务器下载的是哪一个。一般来说,小程序的文件不是太大,可以根据时间来判断,长按压缩选中的文件,然后通过QQ把压缩包发到我的电脑上。如果不压缩,是不可能通过QQ发送这个文件的。所以QQ的这个功能让我们可以很方便的拿到源文件,而不必去电脑目录找模拟器的文件目录。在这一步,您将获得小程序文件。接下来只需要将小程序文件放到工具解压目录的wxapkg目录下,返回运行CrackMinApp.exe,在选择界面选择需要解压的小程序文件,运行等待进度条后加载后,可以在小程序文件目录中找到对应的文件夹。恭喜,你已经拿到了源代码。
亲测可用,技术共享,请勿用于非法经营活动。
网页源代码抓取工具(一套网站首页幻灯片大图功能和图片管理以及销售功能介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-04-09 10:38
专为摄影相关单位和个人设计的自助网站系统。它集成了文章管理功能和强大的图片管理和销售功能。还预留了系统集成接口。
主要功能:
1、无限分类功能,可以自定义文章和图片的分类;
2、强大的图片保护功能(需要aspjpeg组件的支持):上传图片时,程序会自动生成两个缩略图:一个是170像素宽的小图片,用于预览,另一个是是宽度为600,用于进一步预览,中间图片自动加水印,具有商业价值的原图需要授权查看或下载,这样可以完全保护你的图片不被盗版;
3、图片销售功能:具有商业价值的原创图片需要授权才能下载,并且有详细的下载记录,可以进行图片销售。形象销售方面,我们即将整合线上支付功能,付费用户可免费升级;
4、集成黑、白、蓝三种风格,用户可自由切换;
5、强大的JS调用功能:让有一定代码知识的朋友轻松自定义网站界面;
6、用户组权限自定义功能:默认有5个用户组。管理员可以自定义每个用户组的权限。可管理的权限包括:发布文章、上传图片、下载原图、评分评论、查看隐藏图片等;
7、自动水印功能(需要aspjpeg组件支持):上传图片时,程序会自动加水印,水印内容管理员可以自己定义,可以是文字也可以是图片,省去了上传图片之前加水印的麻烦;
8、模板管理功能:有一定代码的可以在线修改模板;
9、预留系统集成接口,可以轻松集成各种文章、论坛或博客系统,共享用户数据;(例如:动态网络论坛)
10、如果是数码照片,可以自动读取EXIF参数。
其他功能:
1、自定义网站首页幻灯片大图功能:
2、文章评论功能和图片评分评论功能;
3、图片推荐功能:管理员可以任意推荐自己认为值得推荐的好图;
4、后台设置在线咨询QQ号;
5、自定义是否限制鼠标右键的功能;
6、后台添加“统计码”,用户可以在免费盘点网站申请统计码,然后添加到后台“统计码”框内,实现统计功能;
7、您可以随时在线修改存储图片的文件夹名称,以保护图片的版权不受侵犯;
8、设备管理功能:可以后台管理摄影器材的品牌;
9、广告管理功能:可以发布自己的广告,也可以插入其他广告网络的广告;
10、备份、压缩和恢复数据库功能。 查看全部
网页源代码抓取工具(一套网站首页幻灯片大图功能和图片管理以及销售功能介绍)
专为摄影相关单位和个人设计的自助网站系统。它集成了文章管理功能和强大的图片管理和销售功能。还预留了系统集成接口。
主要功能:
1、无限分类功能,可以自定义文章和图片的分类;
2、强大的图片保护功能(需要aspjpeg组件的支持):上传图片时,程序会自动生成两个缩略图:一个是170像素宽的小图片,用于预览,另一个是是宽度为600,用于进一步预览,中间图片自动加水印,具有商业价值的原图需要授权查看或下载,这样可以完全保护你的图片不被盗版;
3、图片销售功能:具有商业价值的原创图片需要授权才能下载,并且有详细的下载记录,可以进行图片销售。形象销售方面,我们即将整合线上支付功能,付费用户可免费升级;
4、集成黑、白、蓝三种风格,用户可自由切换;
5、强大的JS调用功能:让有一定代码知识的朋友轻松自定义网站界面;
6、用户组权限自定义功能:默认有5个用户组。管理员可以自定义每个用户组的权限。可管理的权限包括:发布文章、上传图片、下载原图、评分评论、查看隐藏图片等;
7、自动水印功能(需要aspjpeg组件支持):上传图片时,程序会自动加水印,水印内容管理员可以自己定义,可以是文字也可以是图片,省去了上传图片之前加水印的麻烦;
8、模板管理功能:有一定代码的可以在线修改模板;
9、预留系统集成接口,可以轻松集成各种文章、论坛或博客系统,共享用户数据;(例如:动态网络论坛)
10、如果是数码照片,可以自动读取EXIF参数。
其他功能:
1、自定义网站首页幻灯片大图功能:
2、文章评论功能和图片评分评论功能;
3、图片推荐功能:管理员可以任意推荐自己认为值得推荐的好图;
4、后台设置在线咨询QQ号;
5、自定义是否限制鼠标右键的功能;
6、后台添加“统计码”,用户可以在免费盘点网站申请统计码,然后添加到后台“统计码”框内,实现统计功能;
7、您可以随时在线修改存储图片的文件夹名称,以保护图片的版权不受侵犯;
8、设备管理功能:可以后台管理摄影器材的品牌;
9、广告管理功能:可以发布自己的广告,也可以插入其他广告网络的广告;
10、备份、压缩和恢复数据库功能。
网页源代码抓取工具(爬虫网页中有的调试与源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 416 次浏览 • 2022-04-09 08:09
爬虫的主要目的是过滤掉网页中的无用信息,抓取网页中的有用信息。
一般的爬虫架构是:
在python爬虫之前,你必须对网页的结构知识有一定的了解,比如网页的标签,网页的语言等,推荐去W3School:
W3school 链接查找
爬取前还有一些工具:
1.首先是Python的开发环境:这里我选择了python2.7。开发的IDE为了安装调试方便,选择在VS2013上使用python插件在VS上开发(python程序的调试和c的调试差不多);
2.查看网页源代码的工具:虽然每个浏览器都可以查看网页源代码,但我还是推荐使用火狐浏览器和FirBug插件(同时这两个也是web开发者的工具必须使用) of 一);
FirBug插件的安装可以在右侧的插件组件中安装;
接下来,让我们尝试查看网页的源代码。这里我以我们要爬取的篮球数据为例:
比如我要爬取网页中Team Comparison表的内容:
首先,右键选择我要爬取的分数32-49,右键选择查看带有firBug的元素,(FirBug的另一个好处是网页上会显示源码显示的样式查看源代码时,网页底部会弹出网页源代码和32-49分的位置和源代码,如下图:
可以看到32-49是网页的源代码:
32-49
其中,td为标签名,class为类名,align为格式,32-49为标签内容,即我们要爬取的内容;
但是,在同一个网页中有很多相似的标签和类名,单靠这两个元素是爬不下我们需要的数据的。这时候我们需要查看这个标签的父标签,或者上一层的标签。提取我们要爬取的数据的更多特征,过滤掉其他不想爬取的数据,比如我们选择这张表所在的标签作为我们过滤的第二个。
特征:
Team Comparison
我们再分析一下网页的URL:
比如我们要爬取的网页的网址是:
http://www.covers.com/pageLoad ... .html
因为有骑网站的经验,可以去这里
是一个域名;
/pageLoader/pageLoader.aspxpage=/data/nba/matchups/g5_preview_12.html,可能是网页根目录下/pageLoader/pageLoader.aspx?page=/data/nba/matchups/的地址中的服务器页面上的页面,
为方便管理,相同类型的网页会放在同一个文件夹下,并以类似的方式命名:例如这里的网页命名为g5_preview_12.html,所以类似的网页会改变g5 中的 5 ,或者_12 中的 12 ,通过改变这两个数字,我们发现类似的网页可以改变 12 的数字得到,
让我们了解爬行动物:
这里主要使用python爬虫
urllib2
美丽汤
这两个库,BeautifulSoup的详细文档可以在下面的网站中查看:
抓取网页时:
先打开网页,然后调用beautifulSoup库对网页进行分析,然后使用.find函数找到我们刚才分析的特征的位置,使用.text获取标签的内容,也就是我们要抓取的数据
例如,我们分析以下代码:
response=urllib2.urlopen(url)
print response.getcode()
soup=BeautifulSoup(
response,
‘html.parser‘,
from_encoding=‘utf-8‘
)
links2=soup.find_all(‘div‘,class_="sdi-so",limit=2)
cishu=0
for i in links2:
if(cishu==1):
two=i.find_all(‘td‘,class_="sdi-datacell")
for q in two:
print q.text
table.write(row,col,q.text)
col=(col+1)%9
if(col==0):
row=row+1
row=row+1
file.save(‘NBA.xls‘)
cishu=cishu+1
urllib2.urlopen(url) 是打开一个网页;
print response.getcode() 是测试网页是否可以打开;
汤=美丽汤(
回复,
'html.parser',
from_encoding='utf-8'
)
代表 Beautiful 进行网页分析;
links2=soup.find_all('div',class_=”sdi-so”,limit=2) 用于特征值的查询和返回
其中,我们要找'div'的label,class_=”sdi-so”,limit=2就是找两个为limit(这是为了过滤其他相似的label)
for i in links2:
if(cishu==1):
two=i.find_all(‘td‘,class_="sdi-datacell")
for q in two:
print q.text
table.write(row,col,q.text)
col=(col+1)%9
if(col==0):
row=row+1
row=row+1
为了找到'div',class_=”sdi-so”,然后搜索对应的标签如'td', class_=”sdi-datacell”;
q.text 返回我们想要的数据
这里row=row+1,row=row+1是用来组织我们将数据写入excel文件时的文件格式;
下一步是保存抓取的数据:
这里我们使用excel使用包保存数据:
xdrlib,系统,xlwt
功能:
文件=xlwt.Workbook()
table=file.add_sheet('shuju',cell_overwrite_ok=True)
table.write(0,0,'team')
table.write(0,1,'W/L')
table.write(行,列,q.text)
file.save('NBA.xls')
为最基本的excel写函数,这里不再赘述;
最后,我们爬下来,将数据保存为以下格式:
好的
我想,最深的爱是分开后,我会像你一样活出自己。 查看全部
网页源代码抓取工具(爬虫网页中有的调试与源码)
爬虫的主要目的是过滤掉网页中的无用信息,抓取网页中的有用信息。
一般的爬虫架构是:
在python爬虫之前,你必须对网页的结构知识有一定的了解,比如网页的标签,网页的语言等,推荐去W3School:
W3school 链接查找
爬取前还有一些工具:
1.首先是Python的开发环境:这里我选择了python2.7。开发的IDE为了安装调试方便,选择在VS2013上使用python插件在VS上开发(python程序的调试和c的调试差不多);
2.查看网页源代码的工具:虽然每个浏览器都可以查看网页源代码,但我还是推荐使用火狐浏览器和FirBug插件(同时这两个也是web开发者的工具必须使用) of 一);
FirBug插件的安装可以在右侧的插件组件中安装;
接下来,让我们尝试查看网页的源代码。这里我以我们要爬取的篮球数据为例:
比如我要爬取网页中Team Comparison表的内容:
首先,右键选择我要爬取的分数32-49,右键选择查看带有firBug的元素,(FirBug的另一个好处是网页上会显示源码显示的样式查看源代码时,网页底部会弹出网页源代码和32-49分的位置和源代码,如下图:
可以看到32-49是网页的源代码:
32-49
其中,td为标签名,class为类名,align为格式,32-49为标签内容,即我们要爬取的内容;
但是,在同一个网页中有很多相似的标签和类名,单靠这两个元素是爬不下我们需要的数据的。这时候我们需要查看这个标签的父标签,或者上一层的标签。提取我们要爬取的数据的更多特征,过滤掉其他不想爬取的数据,比如我们选择这张表所在的标签作为我们过滤的第二个。
特征:
Team Comparison
我们再分析一下网页的URL:
比如我们要爬取的网页的网址是:
http://www.covers.com/pageLoad ... .html
因为有骑网站的经验,可以去这里
是一个域名;
/pageLoader/pageLoader.aspxpage=/data/nba/matchups/g5_preview_12.html,可能是网页根目录下/pageLoader/pageLoader.aspx?page=/data/nba/matchups/的地址中的服务器页面上的页面,
为方便管理,相同类型的网页会放在同一个文件夹下,并以类似的方式命名:例如这里的网页命名为g5_preview_12.html,所以类似的网页会改变g5 中的 5 ,或者_12 中的 12 ,通过改变这两个数字,我们发现类似的网页可以改变 12 的数字得到,
让我们了解爬行动物:
这里主要使用python爬虫
urllib2
美丽汤
这两个库,BeautifulSoup的详细文档可以在下面的网站中查看:
抓取网页时:
先打开网页,然后调用beautifulSoup库对网页进行分析,然后使用.find函数找到我们刚才分析的特征的位置,使用.text获取标签的内容,也就是我们要抓取的数据
例如,我们分析以下代码:
response=urllib2.urlopen(url)
print response.getcode()
soup=BeautifulSoup(
response,
‘html.parser‘,
from_encoding=‘utf-8‘
)
links2=soup.find_all(‘div‘,class_="sdi-so",limit=2)
cishu=0
for i in links2:
if(cishu==1):
two=i.find_all(‘td‘,class_="sdi-datacell")
for q in two:
print q.text
table.write(row,col,q.text)
col=(col+1)%9
if(col==0):
row=row+1
row=row+1
file.save(‘NBA.xls‘)
cishu=cishu+1
urllib2.urlopen(url) 是打开一个网页;
print response.getcode() 是测试网页是否可以打开;
汤=美丽汤(
回复,
'html.parser',
from_encoding='utf-8'
)
代表 Beautiful 进行网页分析;
links2=soup.find_all('div',class_=”sdi-so”,limit=2) 用于特征值的查询和返回
其中,我们要找'div'的label,class_=”sdi-so”,limit=2就是找两个为limit(这是为了过滤其他相似的label)
for i in links2:
if(cishu==1):
two=i.find_all(‘td‘,class_="sdi-datacell")
for q in two:
print q.text
table.write(row,col,q.text)
col=(col+1)%9
if(col==0):
row=row+1
row=row+1
为了找到'div',class_=”sdi-so”,然后搜索对应的标签如'td', class_=”sdi-datacell”;
q.text 返回我们想要的数据
这里row=row+1,row=row+1是用来组织我们将数据写入excel文件时的文件格式;
下一步是保存抓取的数据:
这里我们使用excel使用包保存数据:
xdrlib,系统,xlwt
功能:
文件=xlwt.Workbook()
table=file.add_sheet('shuju',cell_overwrite_ok=True)
table.write(0,0,'team')
table.write(0,1,'W/L')
table.write(行,列,q.text)
file.save('NBA.xls')
为最基本的excel写函数,这里不再赘述;
最后,我们爬下来,将数据保存为以下格式:
好的
我想,最深的爱是分开后,我会像你一样活出自己。
网页源代码抓取工具( 图12预览视频下载的多种方法和使用到的工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-04-09 08:06
图12预览视频下载的多种方法和使用到的工具)
图9 快速输入视频网站 在“选项”中,我们可以设置视频文件的相关参数,包括输出视频格式、视频大小、音频码率等。可以将视频转换为AVI, MPEG或PSP格式,操作比较简单。
图10 相关设置选项六、在线播放视频下载
除了通过工具下载在线视频外,我们还可以借助一些在线网站下载视频,连软件都不需要安装,省事!登录FLV下载器网站,目前这个网站支持120个视频的资源下载网站。在上方的“输入视频页面地址”框中,复制您正在观看的视频的页面地址,然后点击“获取地址”按钮,真实的下载地址将被快速解析并显示在下方。这里我们以著名的youtube网络为例:
图11 FLV Downloader网站 获取视频地址后,我们可以将下载地址复制到其他工具下载,直接下载视频,预览视频。预览视频功能很有特色。
图12 预览视频总结: 以上,我们介绍了FLV视频下载的各种方法和工具。其中,在临时文件中查找FLV视频的方法是最简单的,但是在查找的时候,需要眼睛和手快。》,并注意技巧,否则从众多的临时文件中查找会比较麻烦;而我们推荐的四款FLV视频下载工具体积都比较小,操作也比较简单,是大家下载FLV视频最主要的途径。虽然需要安装一次,但安装后可以轻松下载;在没有安装软件的情况下,通过网站在线下载视频是一种替代方案,可以解决您的燃眉之急! 查看全部
网页源代码抓取工具(
图12预览视频下载的多种方法和使用到的工具)
图9 快速输入视频网站 在“选项”中,我们可以设置视频文件的相关参数,包括输出视频格式、视频大小、音频码率等。可以将视频转换为AVI, MPEG或PSP格式,操作比较简单。
图10 相关设置选项六、在线播放视频下载
除了通过工具下载在线视频外,我们还可以借助一些在线网站下载视频,连软件都不需要安装,省事!登录FLV下载器网站,目前这个网站支持120个视频的资源下载网站。在上方的“输入视频页面地址”框中,复制您正在观看的视频的页面地址,然后点击“获取地址”按钮,真实的下载地址将被快速解析并显示在下方。这里我们以著名的youtube网络为例:
图11 FLV Downloader网站 获取视频地址后,我们可以将下载地址复制到其他工具下载,直接下载视频,预览视频。预览视频功能很有特色。
图12 预览视频总结: 以上,我们介绍了FLV视频下载的各种方法和工具。其中,在临时文件中查找FLV视频的方法是最简单的,但是在查找的时候,需要眼睛和手快。》,并注意技巧,否则从众多的临时文件中查找会比较麻烦;而我们推荐的四款FLV视频下载工具体积都比较小,操作也比较简单,是大家下载FLV视频最主要的途径。虽然需要安装一次,但安装后可以轻松下载;在没有安装软件的情况下,通过网站在线下载视频是一种替代方案,可以解决您的燃眉之急!
网页源代码抓取工具(ColorWellformac破解版安装教程mac安装包破解版安装包安装包下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-04-09 03:38
ColorWell 是一个强大的 mac 调色板,支持与 macOS 系统调色板同步。您可以导入/导出 Adobe .ase 和 Apple .clr 调色板文件,拥有无限的历史记录,支持 Swift/Objective-C 颜色代码生成,支持按名称、十六进制、RGB、HSL、HSB、Lab 和 CMYK 更改颜色,支持提取颜色从图片和生成配色方案。
ColorWell for mac 破解版安装教程
colorwell mac 破解版安装包下载后打开,将【ColorWell】拖入应用程序。
ColorWell for mac 破解版官方介绍
ColorWell Mac版是Mac os平台上帮助用户提取WEB页面颜色代码的工具。ColorWell Mac版使用非常方便,功能非常强大。您也可以自行设置提取的快捷键,加快操作速度。顶部的工具栏也可以最小化以方便使用。默认情况下,访问 MacOS 色轮非常繁琐,但可以将 ColorWell 配置为通过全局热键或系统菜单栏中的快速鼠标单击来显示它。这使您可以从任何颜色源快速获取 Hex/HSL/RGB 和代码片段。如果您从未从源(或多源)图像快速生成调色板,那么调色板生成器就是您所需要的。您可以抓取任何源图像并将其放入 Builder 窗口以生成图像中最常见颜色的调色板。
ColorWell mac破解版功能
- 存储并立即检索无限的调色板
- 通过拖放图像创建调色板
- 从任何来源快速获取 hex/rgb/hsl/h***/swift/objc 代码片段。
- 在 hex/rgb/hsl 和 h*** 之间轻松转换。
- 快速查看任何 hex/rgb/hsl/h*** 颜色。
- 快速将 hex/rgb/hsl/h*** 或颜色选择器转换为 NSColor/UIColor Objective-C 或 Swift 就绪代码。
小编的话
ColorWell 是一个很棒的网络颜色代码提取工具,可以很容易地生成无限的调色板,并且可编辑的调色板数据库允许您存档和恢复任何调色板,以便以后进行超快速搜索。 查看全部
网页源代码抓取工具(ColorWellformac破解版安装教程mac安装包破解版安装包安装包下载)
ColorWell 是一个强大的 mac 调色板,支持与 macOS 系统调色板同步。您可以导入/导出 Adobe .ase 和 Apple .clr 调色板文件,拥有无限的历史记录,支持 Swift/Objective-C 颜色代码生成,支持按名称、十六进制、RGB、HSL、HSB、Lab 和 CMYK 更改颜色,支持提取颜色从图片和生成配色方案。
ColorWell for mac 破解版安装教程
colorwell mac 破解版安装包下载后打开,将【ColorWell】拖入应用程序。
ColorWell for mac 破解版官方介绍
ColorWell Mac版是Mac os平台上帮助用户提取WEB页面颜色代码的工具。ColorWell Mac版使用非常方便,功能非常强大。您也可以自行设置提取的快捷键,加快操作速度。顶部的工具栏也可以最小化以方便使用。默认情况下,访问 MacOS 色轮非常繁琐,但可以将 ColorWell 配置为通过全局热键或系统菜单栏中的快速鼠标单击来显示它。这使您可以从任何颜色源快速获取 Hex/HSL/RGB 和代码片段。如果您从未从源(或多源)图像快速生成调色板,那么调色板生成器就是您所需要的。您可以抓取任何源图像并将其放入 Builder 窗口以生成图像中最常见颜色的调色板。
ColorWell mac破解版功能
- 存储并立即检索无限的调色板
- 通过拖放图像创建调色板
- 从任何来源快速获取 hex/rgb/hsl/h***/swift/objc 代码片段。
- 在 hex/rgb/hsl 和 h*** 之间轻松转换。
- 快速查看任何 hex/rgb/hsl/h*** 颜色。
- 快速将 hex/rgb/hsl/h*** 或颜色选择器转换为 NSColor/UIColor Objective-C 或 Swift 就绪代码。
小编的话
ColorWell 是一个很棒的网络颜色代码提取工具,可以很容易地生成无限的调色板,并且可编辑的调色板数据库允许您存档和恢复任何调色板,以便以后进行超快速搜索。
网页源代码抓取工具(Python自带的HTMLParser示例程序 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-04-08 03:23
)
本程序使用Python自带的HTMLParser,从Yahoo Finance的指定页面抓取几个字段。代码30行左右,简单实用,居家旅行必备:)
代码由官方文档中HTMLParser的示例程序修改
完整的代码和介绍在:
代码如下:
import urllibimport sysimport stringfrom HTMLParser import HTMLParserticker_list = ["ibb", "socl", "pnqi", "qqq", "vbk", "eirl", "ewi", "pbd", "ita", "dfe"]ticker = ticker_list[0]class MyHTMLParser(HTMLParser): def handle_data(self, data): starttag_text = self.get_starttag_text() ticker_str = "(%s)" % ticker if -1!=string.find(data, ticker_str.upper()) and -1!=string.find(starttag_text, ""): sys.stdout.write(data) if -1!=string.find(str(starttag_text), "yfs_g53_%s" % ticker.lower()) and -1==string.find(data, "-"): sys.stdout.write("\t") sys.stdout.write(data) if -1!=string.find(str(starttag_text), "yfs_h53_%s" % ticker.lower()): print "\t", datafor t in ticker_list: ticker = t parser = MyHTMLParser() f = urllib.urlopen("http://finance.yahoo.com/q?s=%s" % ticker) html_string = f.read() parser.feed(html_string)
样本输出:
iShares Nasdaq Biotechnology (IBB) 228.14 234.90Global X Social Media Index ETF (SOCL) 17.38 17.92PowerShares NASDAQ Internet (PNQI) 61.73 63.17PowerShares QQQ (QQQ) 87.31 88.15Vanguard Small Cap Growth ETF (VBK) 118.53 120.54iShares MSCI Ireland Capped (EIRL) 38.37 38.84iShares MSCI Italy Capped (EWI) 17.95 18.09PowerShares Global Clean Energy (PBD) 12.95 13.12 Defense (ITA) 107.93 109.36WisdomTree Europe SmallCap Dividend (DFE) 62.08 62.64 查看全部
网页源代码抓取工具(Python自带的HTMLParser示例程序
)
本程序使用Python自带的HTMLParser,从Yahoo Finance的指定页面抓取几个字段。代码30行左右,简单实用,居家旅行必备:)
代码由官方文档中HTMLParser的示例程序修改
完整的代码和介绍在:
代码如下:
import urllibimport sysimport stringfrom HTMLParser import HTMLParserticker_list = ["ibb", "socl", "pnqi", "qqq", "vbk", "eirl", "ewi", "pbd", "ita", "dfe"]ticker = ticker_list[0]class MyHTMLParser(HTMLParser): def handle_data(self, data): starttag_text = self.get_starttag_text() ticker_str = "(%s)" % ticker if -1!=string.find(data, ticker_str.upper()) and -1!=string.find(starttag_text, ""): sys.stdout.write(data) if -1!=string.find(str(starttag_text), "yfs_g53_%s" % ticker.lower()) and -1==string.find(data, "-"): sys.stdout.write("\t") sys.stdout.write(data) if -1!=string.find(str(starttag_text), "yfs_h53_%s" % ticker.lower()): print "\t", datafor t in ticker_list: ticker = t parser = MyHTMLParser() f = urllib.urlopen("http://finance.yahoo.com/q?s=%s" % ticker) html_string = f.read() parser.feed(html_string)
样本输出:
iShares Nasdaq Biotechnology (IBB) 228.14 234.90Global X Social Media Index ETF (SOCL) 17.38 17.92PowerShares NASDAQ Internet (PNQI) 61.73 63.17PowerShares QQQ (QQQ) 87.31 88.15Vanguard Small Cap Growth ETF (VBK) 118.53 120.54iShares MSCI Ireland Capped (EIRL) 38.37 38.84iShares MSCI Italy Capped (EWI) 17.95 18.09PowerShares Global Clean Energy (PBD) 12.95 13.12 Defense (ITA) 107.93 109.36WisdomTree Europe SmallCap Dividend (DFE) 62.08 62.64
网页源代码抓取工具(网页内容抓取工具做网站指定采集伪原创发布,你知道吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-04-08 01:06
网页内容抓取工具。最近有很多做网站的朋友问我有没有什么有用的网页内容爬取。我可以批量采集网站内容到网站指定采集伪原创发布,因为他们站很多,每天网站内容更新是一件很麻烦的事情。SEO是“内容为王”的时代,优质内容的稳定输出将有利于网站的SEO收录和SEO排名。
当网页内容爬虫做网站时,你需要选择一个好的模板。对于 网站 优化,一个好的模板通常会事半功倍。除了基本要求之外,一个好的模板应该有很好的插图,有时间线,没有太多的页面链接,没有杂乱的章节。
采集速度快,数据完整性高。采集网页内容抓取器的速度是最快的采集软件之一。独有的多模板功能+智能纠错模式,保证结果数据100%完整性。任何网页都可以是采集,只要你能在浏览器中看到内容,几乎可以做到你需要的格式采集。采集 支持 JS 输出内容。
有节奏地更新网站 内容,维护原创,并使用适当的伪原创 工具。一开始,要不断给搜索引擎一个好的形象,不要被判断为采集网站。这是很多人一开始并没有注意到的。网站网页内容爬取到一定规模后,为了增加网站的收录,每天添加网站的外部链接。然后可以使用网页内容爬虫的一键批量自动推送工具,将网站链接批量提交到百度、搜狗、360、神马等搜索引擎。推送是 SEO 的重要组成部分。推送主动向搜索引擎公开链接以增加蜘蛛爬行,从而促进网站收录。
当网站为收录,稳定且有一定关键词排名时,可以通过网页内容爬取不断增加网站内容。当然,如果你有资源,可以在网站收录首页后交换链接。主要是因为没有排名的 网站 很难切换到正确的链接。网页内容爬取可以通过站外推广不断增加网站的曝光率,可以间接提高网站的自然点击率,从而提升和稳定网站的排名。
很多时候我们会发现我们的网站代码有一些优化问题,比如一些模板链接错误,或者我们对网站做了一些微调。如果看不懂代码,往往只能自己操心。如果你懂html和div+css,就可以很好的解决这些小问题。
我们都知道网站空间的稳定性很重要,打开速度也是衡量网站排名的一个非常重要的指标,所以一旦百度站长平台有这样的优化建议,往往需要自己解决。
做过SEO的人都离不开程序背景。通常,很多工作都在其中完成。尤其是想要做好结构优化的修改和设置,不看懂这个程序是不可能的。如果做得不好,很容易犯各种严重的错误。
当前网站安全形势非常严峻。我们经常看到有人在网站上抱怨因为排名好被黑客打开,或者被黑了,服务器甚至被别人炸了。这无疑会对他们的网站排名产生非常负面的影响,所以一些安全知识是必要的。
网页内容爬虫基于高度智能的文本识别算法。网页内容爬虫只需将关键词输入到采集内容,无需编写采集规则。覆盖六大搜索引擎和各大新闻源,内容取之不尽,优先采集最新最热的文章信息,自动过滤采集到的信息,拒绝重复采集。这就是今天对 网站 内容抓取工具的介绍。返回搜狐,查看更多 查看全部
网页源代码抓取工具(网页内容抓取工具做网站指定采集伪原创发布,你知道吗)
网页内容抓取工具。最近有很多做网站的朋友问我有没有什么有用的网页内容爬取。我可以批量采集网站内容到网站指定采集伪原创发布,因为他们站很多,每天网站内容更新是一件很麻烦的事情。SEO是“内容为王”的时代,优质内容的稳定输出将有利于网站的SEO收录和SEO排名。
当网页内容爬虫做网站时,你需要选择一个好的模板。对于 网站 优化,一个好的模板通常会事半功倍。除了基本要求之外,一个好的模板应该有很好的插图,有时间线,没有太多的页面链接,没有杂乱的章节。
采集速度快,数据完整性高。采集网页内容抓取器的速度是最快的采集软件之一。独有的多模板功能+智能纠错模式,保证结果数据100%完整性。任何网页都可以是采集,只要你能在浏览器中看到内容,几乎可以做到你需要的格式采集。采集 支持 JS 输出内容。
有节奏地更新网站 内容,维护原创,并使用适当的伪原创 工具。一开始,要不断给搜索引擎一个好的形象,不要被判断为采集网站。这是很多人一开始并没有注意到的。网站网页内容爬取到一定规模后,为了增加网站的收录,每天添加网站的外部链接。然后可以使用网页内容爬虫的一键批量自动推送工具,将网站链接批量提交到百度、搜狗、360、神马等搜索引擎。推送是 SEO 的重要组成部分。推送主动向搜索引擎公开链接以增加蜘蛛爬行,从而促进网站收录。
当网站为收录,稳定且有一定关键词排名时,可以通过网页内容爬取不断增加网站内容。当然,如果你有资源,可以在网站收录首页后交换链接。主要是因为没有排名的 网站 很难切换到正确的链接。网页内容爬取可以通过站外推广不断增加网站的曝光率,可以间接提高网站的自然点击率,从而提升和稳定网站的排名。
很多时候我们会发现我们的网站代码有一些优化问题,比如一些模板链接错误,或者我们对网站做了一些微调。如果看不懂代码,往往只能自己操心。如果你懂html和div+css,就可以很好的解决这些小问题。
我们都知道网站空间的稳定性很重要,打开速度也是衡量网站排名的一个非常重要的指标,所以一旦百度站长平台有这样的优化建议,往往需要自己解决。
做过SEO的人都离不开程序背景。通常,很多工作都在其中完成。尤其是想要做好结构优化的修改和设置,不看懂这个程序是不可能的。如果做得不好,很容易犯各种严重的错误。
当前网站安全形势非常严峻。我们经常看到有人在网站上抱怨因为排名好被黑客打开,或者被黑了,服务器甚至被别人炸了。这无疑会对他们的网站排名产生非常负面的影响,所以一些安全知识是必要的。
网页内容爬虫基于高度智能的文本识别算法。网页内容爬虫只需将关键词输入到采集内容,无需编写采集规则。覆盖六大搜索引擎和各大新闻源,内容取之不尽,优先采集最新最热的文章信息,自动过滤采集到的信息,拒绝重复采集。这就是今天对 网站 内容抓取工具的介绍。返回搜狐,查看更多
网页源代码抓取工具(使用PyQt5爬虫小工具方便他的操作可视化(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-07 20:13
)
最近有朋友需要帮忙写一个爬虫脚本来爬取雪球网一些上市公司的财务数据。锅友希望能够根据自己的选择自由抓取,所以干脆给锅友一个脚本。锅友还需要自己搭建一个python环境,还需要熟悉一些参数修改的操作,想想也麻烦。.
于是,结合我之前做的汇率计算器小工具,我决定用PyQt5为朋友做一个爬虫小工具,方便他的操作可视化。
一、效果演示
二、功能说明三、制作流程
首先导入需要的库
import sys from PyQt5 import QtCore, QtGui, QtWidgets from PyQt5.QtWidgets import QApplication, QMainWindow,QFileDialog import os import requests from fake_useragent import UserAgent import json import logging import time import pandas as pd from openpyxl import load_workbook
新手学习,Python 教程/工具/方法/解疑+V:itz992
Snowball 网页拆解
这一步的目的是获取待爬取数据的真实URL地址模式。
当我选择一只股票查看某类财务数据报告时,点击下一页,网站的地址没有变化。我基本上可以知道这是动态加载的数据。对于这类数据,我可以使用 F12 打开开发者模式。.
开发者模式下选择Network—>XHR查看真实数据获取地址URL和请求方法(General是请求URL和请求方法说明,Request Headers有请求头信息,如cookies,Query String Parameters可用Variable参数项,一般来说,数据源URL是由base URL和这里的可变参数组成)
当我们分析这个 URL 时,我们可以发现它的基本结构如下:
基于以上结构,我们将最终组合的 URL 地址拆分如下
#基础网站
base_url = f'https://stock.xueqiu.com/v5/stock/finance/{ABtype}'
#组合url地址
url = f'{base_url}/{data_type}.json?symbol={ipo_code}&type=all&is_detail=true&count={count_num}×tamp={start_time}'
操作界面设计
操作界面设计使用PyQt5,这里不再详细介绍。我们将在后续对PyQt5的使用进行专门的讲解。
使用QT Designer可视化设计操作界面,参考以下:
Snowball Network Data Extraction.ui中各个组件的相关设置如下:
.ui文件可以使用pyuic5指令编译生成对应的.py文件,也可以直接在vscode中翻译(这里不再赘述,详见后续特别说明)。
本文没有单独使用操作界面定义文件,而是将所有代码集中在同一个.py文件中,所以翻译后的代码可供以后使用。
获取cookies和基本参数获取cookies
为了让小工具可以使用,我们需要自动获取 cookie 地址并将其附加到请求头中,而不是在开发人员模式下手动打开网页并填写 cookie。
自动获取cookies,这里使用的requests库的session会话对象。
requests 库的 session 对象可以跨请求维护某些参数。简单来说,比如你使用session成功登录到某个网站,那么再使用session对象请求网站。其他网页默认使用会话前使用的cookie等参数。
import requests from fake_useragent import UserAgent
url = 'https://xueqiu.com' session = requests.Session()
headers = {"User-Agent": UserAgent(verify_ssl=False).random}
session.get(url, headers=headers) #获取当前的Cookie
Cookie= dict(session.cookies)
基本参数
基本参数用于在请求财务数据时选择原创的 URL 组成参数。我们需要在可视化操作工具中选择财务数据类型,所以这里需要建立一个财务数据类型字典。
#原始网址
original_url = 'https://xueqiu.com'
#财务数据类型字典
dataType = {'全选':'all', '主要指标':'indicator', '利润表':'income', '资产负债表':'balance', '现金流量表':'cash_flow'}
访问各种证券市场的上市目录
因为我们在可视化操作工具上选择了股票代码并抓取了相关数据并导出,导出的文件名预计以股票代码+公司名称的形式存储(SH600000上海浦东发展银行),所以我们需要获取股票代码和名称。对应的字典表。
这实际上是一个简单的网络爬虫和数据格式调整过程。实现代码如下:
1import requests
2import pandas as pd
3import json
4from fake_useragent import UserAgent 5#请求头设置
6headers = {"User-Agent": UserAgent(verify_ssl=False).random} 7#股票清单列表地址解析(通过设置参数size为9999可以只使用1个静态地址,全部股票数量不足5000)
8url = 'https://xueqiu.com/service/v5/ ... 39%3B
9#请求原始数据
10response = requests.get(url,headers = headers) 11#获取股票列表数据
12df = response.text 13#数据格式转化
14data = json.loads(df) 15#获取所需要的股票代码及股票名称数据
16data = data['data']['list'] 17#将数据转化为dataframe格式,并进行相关调整
18data = pd.DataFrame(data)
19data = data[['symbol','name']]
20data['name'] = data['symbol']+' '+data['name']
21data.sort_values(by = ['symbol'],inplace=True)
22data = data.set_index(data['symbol'])['name'] 23#将股票列表转化为字典,键为股票代码,值为股票代码和股票名称的组合
24ipoCodecn = data.to_dict()
A股股票代码和公司名称字典如下:
获取并导出上市公司财务数据
根据可视化操作界面中选择的财报时间间隔、财报数据类型、选择的证券市场类型和输入的股票代码,我们需要根据这些参数形成我们需要请求数据的URL,然后进行数据请求。
由于请求的数据是json格式,所以可以直接转换成dataframe类型再导出。导出数据时,我们需要判断数据文件是否存在,存在则追加,不存在则新建文件。
获取上市公司财务数据
通过选择的参数生成财务数据URL,然后根据是否全部选择来判断后续数据请求的操作,因此可以分为获取数据URL和请求详细数据两部分。
获取数据地址
数据URL根据证券市场类型、金融数据类型、股票代码、单页数和起始时间戳确定,这些参数通过可视化操作界面进行设置。
股市类型控件是radioButton,可以通过你的ischecked()方法判断是否选中,然后使用if-else设置参数;
需要先选择金融数据类型和股票代码,因为它们支持全选(全选的情况下,需要循环获取数据URL,否则只能通过单一方式获取),所以这个部分需要再次拆分;
单页数考虑到每年有4份财报,所以这里默认是年差*4;
时间戳是根据开始时间中的结束时间计算的。由于可视化界面的输入是整数年,我们可以通过mktime()方法获取时间戳。
1def Get_url(self,name,ipo_code): 2 #获取开始结束时间戳(开始和结束时间手动输入)
3 inputstartTime = str(self.start_dateEdit.date().toPyDate().year) 4 inputendTime = str(self.end_dateEdit.date().toPyDate().year) 5 endTime = f'{inputendTime}-12-31 00:00:00'
6 timeArray = time.strptime(endTime, "%Y-%m-%d %H:%M:%S") 7
8 #获取指定的数据类型及股票代码
9 filename = ipo_code 10 data_type =dataType[name] 11 #计算需要采集的数据量(一年以四个算)
12 count_num = (int(inputendTime) - int(inputstartTime) +1) * 4
13 start_time = f'{int(time.mktime(timeArray))}001'
14
15 #证券市场类型
16 if (self.radioButtonCN.isChecked()): 17 ABtype = 'cn'
18 num = 3
19 elif (self.radioButtonUS.isChecked()): 20 ABtype = 'us'
21 num = 6
22 elif (self.radioButtonHK.isChecked()): 23 ABtype = 'hk'
24 num = 6
25 else: 26 ABtype = 'cn'
27 num = 3
28
29 #基础网站
30 base_url = f'https://stock.xueqiu.com/v5/stock/finance/{ABtype}'
31
32 #组合url地址
33 url = f'{base_url}/{data_type}.json?symbol={ipo_code}&type=all&is_detail=true&count={count_num}×tamp={start_time}'
34
35 return url,num
请求详细数据
data采集 方法需要根据用户输入来确定。代码主要根据用户输入进行判断,然后进行详细的数据请求。
1#根据用户输入决定数据采集方式
2def Get_data(self): 3 #name为财务报告数据类型(全选或单个)
4 name = self.Typelist_comboBox.currentText() 5 #股票代码(全选或单个)
6 ipo_code = self.lineEditCode.text() 7 #判断证券市场类型
8 if (self.radioButtonCN.isChecked()): 9 ipoCodex=ipoCodecn 10 elif (self.radioButtonUS.isChecked()): 11 ipoCodex=ipoCodeus 12 elif (self.radioButtonHK.isChecked()): 13 ipoCodex=ipoCodehk 14 else: 15 ipoCodex=ipoCodecn 16#根据财务报告数据类型和股票代码类型决定数据采集的方式
17 if name == '全选' and ipo_code == '全选': 18 for ipo_code in list(ipoCodex.keys()): 19 for name in list(dataType.keys())[1:]: 20 self.re_data(name,ipo_code) 21 elif name == '全选' and ipo_code != '全选': 22 for name in list(dataType.keys())[1:]: 23 self.re_data(name,ipo_code) 24 elif ipo_code == '全选' and name != '全选': 25 for ipo_code in list(ipoCodex.keys()): 26 self.re_data(name,ipo_code) 27 else: 28 self.re_data(name,ipo_code) 29
30#数据采集,需要调用数据网址(Get.url(name,ipo_code)
31def re_data(self,name,ipo_code): 32 name = name 33 #获取url和num(url为详情数据网址,num是详情数据中根据不同证券市场类型决定的需要提取的数据起始位置)
34 url,num = self.Get_url(name,ipo_code) 35 #请求头
36 headers = {"User-Agent": UserAgent(verify_ssl=False).random} 37 #请求数据
38 df = requests.get(url,headers = headers,cookies = cookies) 39
40 df = df.text
41try: 42 data = json.loads(df) 43 pd_df = pd.DataFrame(data['data']['list']) 44 to_xlsx(num,pd_df) 45 except KeyError: 46 log = '该股票此类型报告不存在,请重新选择股票代码或数据类型'
47 self.rizhi_textBrowser.append(log)
财务数据处理和导出
简单的数据导出是一个比较简单的操作,可以直接to_excel()。但是考虑到同一个上市公司有四种类型的财务数据,我们希望它们都存储在同一个文件中,对于可能批量导出的同类型数据,我们希望添加。因此需要特殊处理,使用pd.ExcelWriter()方法进行操作。
新手学习,Python 教程/工具/方法/解疑+V:itz992
1#数据处理并导出
2def to_xlsx(self,num,data): 3 pd_df = data 4 #获取可视化操作界面输入的导出文件保存文件夹目录
5 filepath = self.filepath_lineEdit.text() 6 #获取文件名
7 filename = ipoCode[ipo_code] 8 #组合成文件详情(地址+文件名+文件类型)
9 path = f'{filepath}\{filename}.xlsx'
10 #获取原始数据列字段
11 cols = pd_df.columns.tolist() 12 #创建空dataframe类型用于存储
13 data = pd.DataFrame() 14 #创建报告名称字段
15 data['报告名称'] = pd_df['report_name'] 16 #由于不同证券市场类型下各股票财务报告详情页数据从不同的列才是需要的数据,因此需要用num作为起点
17 for i in range(num,len(cols)): 18 col = cols[i] 19 try: 20 #每列数据中是列表形式,第一个是值,第二个是同比
21 data[col] = pd_df[col].apply(lambda x:x[0]) 22 # data[f'{col}_同比'] = pd_df[col].apply(lambda x:x[1])
23 except TypeError: 24 pass
25 data = data.set_index('报告名称') 26 log = f'{filename}的{name}数据已经爬取成功'
27 self.rizhi_textBrowser.append(log) 28 #由于存储的数据行索引为数据指标,所以需要对采集的数据进行转T处理
29 dataT = data.T 30 dataT.rename(index = eval(f'_{name}'),inplace=True) 31 #以下为判断数据报告文件是否存在,若存在则追加,不存在则重新创建
32 try: 33 if os.path.exists(path): 34 #读取文件全部页签
35 df_dic = pd.read_excel(path,None) 36 if name not in list(df_dic.keys()): 37 log = f'{filename}的{name}数据页签不存在,创建新页签'
38 self.rizhi_textBrowser.append(log) 39 #追加新的页签
40 with pd.ExcelWriter(path,mode='a') as writer: 41 book = load_workbook(path) 42 writer.book = book 43 dataT.to_excel(writer,sheet_name=name) 44 writer.save() 45 else: 46 log = f'{filename}的{name}数据页签已存在,合并中'
47 self.rizhi_textBrowser.append(log) 48 df = pd.read_excel(path,sheet_name = name,index_col=0) 49 d_ = list(set(list(dataT.columns)) - set(list(df.columns))) 50#使用merge()进行数据合并
51 dataT = pd.merge(df,dataT[d_],how='outer',left_index=True,right_index=True) 52 dataT.sort_index(axis=1,ascending=False,inplace=True) 53 #页签中追加数据不影响其他页签
54 with pd.ExcelWriter(path,engine='openpyxl') as writer: 55 book = load_workbook(path) 56 writer.book = book 57 idx = writer.book.sheetnames.index(name) 58 #删除同名的,然后重新创建一个同名的
59 writer.book.remove(writer.book.worksheets[idx]) 60 writer.book.create_sheet(name, idx) 61 writer.sheets = {ws.title:ws for ws in writer.book.worksheets} 62
63 dataT.to_excel(writer,sheet_name=name,startcol=0) 64 writer.save() 65 else: 66 dataT.to_excel(path,sheet_name=name) 67
68 log = f'{filename}的{name}数据已经保存成功'
69 self.rizhi_textBrowser.append(log) 70
71 except FileNotFoundError: 72 log = '未设置存储目录或存储目录不存在,请重新选择文件夹'
73 self.rizhi_textBrowser.append(log) 查看全部
网页源代码抓取工具(使用PyQt5爬虫小工具方便他的操作可视化(组图)
)
最近有朋友需要帮忙写一个爬虫脚本来爬取雪球网一些上市公司的财务数据。锅友希望能够根据自己的选择自由抓取,所以干脆给锅友一个脚本。锅友还需要自己搭建一个python环境,还需要熟悉一些参数修改的操作,想想也麻烦。.
于是,结合我之前做的汇率计算器小工具,我决定用PyQt5为朋友做一个爬虫小工具,方便他的操作可视化。
一、效果演示
二、功能说明三、制作流程
首先导入需要的库
import sys from PyQt5 import QtCore, QtGui, QtWidgets from PyQt5.QtWidgets import QApplication, QMainWindow,QFileDialog import os import requests from fake_useragent import UserAgent import json import logging import time import pandas as pd from openpyxl import load_workbook
新手学习,Python 教程/工具/方法/解疑+V:itz992
Snowball 网页拆解
这一步的目的是获取待爬取数据的真实URL地址模式。
当我选择一只股票查看某类财务数据报告时,点击下一页,网站的地址没有变化。我基本上可以知道这是动态加载的数据。对于这类数据,我可以使用 F12 打开开发者模式。.
开发者模式下选择Network—>XHR查看真实数据获取地址URL和请求方法(General是请求URL和请求方法说明,Request Headers有请求头信息,如cookies,Query String Parameters可用Variable参数项,一般来说,数据源URL是由base URL和这里的可变参数组成)
当我们分析这个 URL 时,我们可以发现它的基本结构如下:
基于以上结构,我们将最终组合的 URL 地址拆分如下
#基础网站
base_url = f'https://stock.xueqiu.com/v5/stock/finance/{ABtype}'
#组合url地址
url = f'{base_url}/{data_type}.json?symbol={ipo_code}&type=all&is_detail=true&count={count_num}×tamp={start_time}'
操作界面设计
操作界面设计使用PyQt5,这里不再详细介绍。我们将在后续对PyQt5的使用进行专门的讲解。
使用QT Designer可视化设计操作界面,参考以下:
Snowball Network Data Extraction.ui中各个组件的相关设置如下:
.ui文件可以使用pyuic5指令编译生成对应的.py文件,也可以直接在vscode中翻译(这里不再赘述,详见后续特别说明)。
本文没有单独使用操作界面定义文件,而是将所有代码集中在同一个.py文件中,所以翻译后的代码可供以后使用。
获取cookies和基本参数获取cookies
为了让小工具可以使用,我们需要自动获取 cookie 地址并将其附加到请求头中,而不是在开发人员模式下手动打开网页并填写 cookie。
自动获取cookies,这里使用的requests库的session会话对象。
requests 库的 session 对象可以跨请求维护某些参数。简单来说,比如你使用session成功登录到某个网站,那么再使用session对象请求网站。其他网页默认使用会话前使用的cookie等参数。
import requests from fake_useragent import UserAgent
url = 'https://xueqiu.com' session = requests.Session()
headers = {"User-Agent": UserAgent(verify_ssl=False).random}
session.get(url, headers=headers) #获取当前的Cookie
Cookie= dict(session.cookies)
基本参数
基本参数用于在请求财务数据时选择原创的 URL 组成参数。我们需要在可视化操作工具中选择财务数据类型,所以这里需要建立一个财务数据类型字典。
#原始网址
original_url = 'https://xueqiu.com'
#财务数据类型字典
dataType = {'全选':'all', '主要指标':'indicator', '利润表':'income', '资产负债表':'balance', '现金流量表':'cash_flow'}
访问各种证券市场的上市目录
因为我们在可视化操作工具上选择了股票代码并抓取了相关数据并导出,导出的文件名预计以股票代码+公司名称的形式存储(SH600000上海浦东发展银行),所以我们需要获取股票代码和名称。对应的字典表。
这实际上是一个简单的网络爬虫和数据格式调整过程。实现代码如下:
1import requests
2import pandas as pd
3import json
4from fake_useragent import UserAgent 5#请求头设置
6headers = {"User-Agent": UserAgent(verify_ssl=False).random} 7#股票清单列表地址解析(通过设置参数size为9999可以只使用1个静态地址,全部股票数量不足5000)
8url = 'https://xueqiu.com/service/v5/ ... 39%3B
9#请求原始数据
10response = requests.get(url,headers = headers) 11#获取股票列表数据
12df = response.text 13#数据格式转化
14data = json.loads(df) 15#获取所需要的股票代码及股票名称数据
16data = data['data']['list'] 17#将数据转化为dataframe格式,并进行相关调整
18data = pd.DataFrame(data)
19data = data[['symbol','name']]
20data['name'] = data['symbol']+' '+data['name']
21data.sort_values(by = ['symbol'],inplace=True)
22data = data.set_index(data['symbol'])['name'] 23#将股票列表转化为字典,键为股票代码,值为股票代码和股票名称的组合
24ipoCodecn = data.to_dict()
A股股票代码和公司名称字典如下:
获取并导出上市公司财务数据
根据可视化操作界面中选择的财报时间间隔、财报数据类型、选择的证券市场类型和输入的股票代码,我们需要根据这些参数形成我们需要请求数据的URL,然后进行数据请求。
由于请求的数据是json格式,所以可以直接转换成dataframe类型再导出。导出数据时,我们需要判断数据文件是否存在,存在则追加,不存在则新建文件。
获取上市公司财务数据
通过选择的参数生成财务数据URL,然后根据是否全部选择来判断后续数据请求的操作,因此可以分为获取数据URL和请求详细数据两部分。
获取数据地址
数据URL根据证券市场类型、金融数据类型、股票代码、单页数和起始时间戳确定,这些参数通过可视化操作界面进行设置。
股市类型控件是radioButton,可以通过你的ischecked()方法判断是否选中,然后使用if-else设置参数;
需要先选择金融数据类型和股票代码,因为它们支持全选(全选的情况下,需要循环获取数据URL,否则只能通过单一方式获取),所以这个部分需要再次拆分;
单页数考虑到每年有4份财报,所以这里默认是年差*4;
时间戳是根据开始时间中的结束时间计算的。由于可视化界面的输入是整数年,我们可以通过mktime()方法获取时间戳。
1def Get_url(self,name,ipo_code): 2 #获取开始结束时间戳(开始和结束时间手动输入)
3 inputstartTime = str(self.start_dateEdit.date().toPyDate().year) 4 inputendTime = str(self.end_dateEdit.date().toPyDate().year) 5 endTime = f'{inputendTime}-12-31 00:00:00'
6 timeArray = time.strptime(endTime, "%Y-%m-%d %H:%M:%S") 7
8 #获取指定的数据类型及股票代码
9 filename = ipo_code 10 data_type =dataType[name] 11 #计算需要采集的数据量(一年以四个算)
12 count_num = (int(inputendTime) - int(inputstartTime) +1) * 4
13 start_time = f'{int(time.mktime(timeArray))}001'
14
15 #证券市场类型
16 if (self.radioButtonCN.isChecked()): 17 ABtype = 'cn'
18 num = 3
19 elif (self.radioButtonUS.isChecked()): 20 ABtype = 'us'
21 num = 6
22 elif (self.radioButtonHK.isChecked()): 23 ABtype = 'hk'
24 num = 6
25 else: 26 ABtype = 'cn'
27 num = 3
28
29 #基础网站
30 base_url = f'https://stock.xueqiu.com/v5/stock/finance/{ABtype}'
31
32 #组合url地址
33 url = f'{base_url}/{data_type}.json?symbol={ipo_code}&type=all&is_detail=true&count={count_num}×tamp={start_time}'
34
35 return url,num
请求详细数据
data采集 方法需要根据用户输入来确定。代码主要根据用户输入进行判断,然后进行详细的数据请求。
1#根据用户输入决定数据采集方式
2def Get_data(self): 3 #name为财务报告数据类型(全选或单个)
4 name = self.Typelist_comboBox.currentText() 5 #股票代码(全选或单个)
6 ipo_code = self.lineEditCode.text() 7 #判断证券市场类型
8 if (self.radioButtonCN.isChecked()): 9 ipoCodex=ipoCodecn 10 elif (self.radioButtonUS.isChecked()): 11 ipoCodex=ipoCodeus 12 elif (self.radioButtonHK.isChecked()): 13 ipoCodex=ipoCodehk 14 else: 15 ipoCodex=ipoCodecn 16#根据财务报告数据类型和股票代码类型决定数据采集的方式
17 if name == '全选' and ipo_code == '全选': 18 for ipo_code in list(ipoCodex.keys()): 19 for name in list(dataType.keys())[1:]: 20 self.re_data(name,ipo_code) 21 elif name == '全选' and ipo_code != '全选': 22 for name in list(dataType.keys())[1:]: 23 self.re_data(name,ipo_code) 24 elif ipo_code == '全选' and name != '全选': 25 for ipo_code in list(ipoCodex.keys()): 26 self.re_data(name,ipo_code) 27 else: 28 self.re_data(name,ipo_code) 29
30#数据采集,需要调用数据网址(Get.url(name,ipo_code)
31def re_data(self,name,ipo_code): 32 name = name 33 #获取url和num(url为详情数据网址,num是详情数据中根据不同证券市场类型决定的需要提取的数据起始位置)
34 url,num = self.Get_url(name,ipo_code) 35 #请求头
36 headers = {"User-Agent": UserAgent(verify_ssl=False).random} 37 #请求数据
38 df = requests.get(url,headers = headers,cookies = cookies) 39
40 df = df.text
41try: 42 data = json.loads(df) 43 pd_df = pd.DataFrame(data['data']['list']) 44 to_xlsx(num,pd_df) 45 except KeyError: 46 log = '该股票此类型报告不存在,请重新选择股票代码或数据类型'
47 self.rizhi_textBrowser.append(log)
财务数据处理和导出
简单的数据导出是一个比较简单的操作,可以直接to_excel()。但是考虑到同一个上市公司有四种类型的财务数据,我们希望它们都存储在同一个文件中,对于可能批量导出的同类型数据,我们希望添加。因此需要特殊处理,使用pd.ExcelWriter()方法进行操作。
新手学习,Python 教程/工具/方法/解疑+V:itz992
1#数据处理并导出
2def to_xlsx(self,num,data): 3 pd_df = data 4 #获取可视化操作界面输入的导出文件保存文件夹目录
5 filepath = self.filepath_lineEdit.text() 6 #获取文件名
7 filename = ipoCode[ipo_code] 8 #组合成文件详情(地址+文件名+文件类型)
9 path = f'{filepath}\{filename}.xlsx'
10 #获取原始数据列字段
11 cols = pd_df.columns.tolist() 12 #创建空dataframe类型用于存储
13 data = pd.DataFrame() 14 #创建报告名称字段
15 data['报告名称'] = pd_df['report_name'] 16 #由于不同证券市场类型下各股票财务报告详情页数据从不同的列才是需要的数据,因此需要用num作为起点
17 for i in range(num,len(cols)): 18 col = cols[i] 19 try: 20 #每列数据中是列表形式,第一个是值,第二个是同比
21 data[col] = pd_df[col].apply(lambda x:x[0]) 22 # data[f'{col}_同比'] = pd_df[col].apply(lambda x:x[1])
23 except TypeError: 24 pass
25 data = data.set_index('报告名称') 26 log = f'{filename}的{name}数据已经爬取成功'
27 self.rizhi_textBrowser.append(log) 28 #由于存储的数据行索引为数据指标,所以需要对采集的数据进行转T处理
29 dataT = data.T 30 dataT.rename(index = eval(f'_{name}'),inplace=True) 31 #以下为判断数据报告文件是否存在,若存在则追加,不存在则重新创建
32 try: 33 if os.path.exists(path): 34 #读取文件全部页签
35 df_dic = pd.read_excel(path,None) 36 if name not in list(df_dic.keys()): 37 log = f'{filename}的{name}数据页签不存在,创建新页签'
38 self.rizhi_textBrowser.append(log) 39 #追加新的页签
40 with pd.ExcelWriter(path,mode='a') as writer: 41 book = load_workbook(path) 42 writer.book = book 43 dataT.to_excel(writer,sheet_name=name) 44 writer.save() 45 else: 46 log = f'{filename}的{name}数据页签已存在,合并中'
47 self.rizhi_textBrowser.append(log) 48 df = pd.read_excel(path,sheet_name = name,index_col=0) 49 d_ = list(set(list(dataT.columns)) - set(list(df.columns))) 50#使用merge()进行数据合并
51 dataT = pd.merge(df,dataT[d_],how='outer',left_index=True,right_index=True) 52 dataT.sort_index(axis=1,ascending=False,inplace=True) 53 #页签中追加数据不影响其他页签
54 with pd.ExcelWriter(path,engine='openpyxl') as writer: 55 book = load_workbook(path) 56 writer.book = book 57 idx = writer.book.sheetnames.index(name) 58 #删除同名的,然后重新创建一个同名的
59 writer.book.remove(writer.book.worksheets[idx]) 60 writer.book.create_sheet(name, idx) 61 writer.sheets = {ws.title:ws for ws in writer.book.worksheets} 62
63 dataT.to_excel(writer,sheet_name=name,startcol=0) 64 writer.save() 65 else: 66 dataT.to_excel(path,sheet_name=name) 67
68 log = f'{filename}的{name}数据已经保存成功'
69 self.rizhi_textBrowser.append(log) 70
71 except FileNotFoundError: 72 log = '未设置存储目录或存储目录不存在,请重新选择文件夹'
73 self.rizhi_textBrowser.append(log)
网页源代码抓取工具(安卓手机上查看源代码非常不错的工具帮助用户查看和下载网页源代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 245 次浏览 • 2022-04-07 10:01
小编点评:一个非常好的安卓手机查看源码的工具
帮助用户查看和下载网页源代码的软件。 HTML Source Code是一款解锁高级版的html源码查看器,支持cookie编辑器、javascript评估等。还可以离线保存网站,轻松下载三种独特格式的网页。将网页保存为 PDF、TXT 和 HTML 格式,如有需要欢迎下载。
功能介绍
Cookie 编辑器功能使您能够查看和应用 Cookie、使用编辑器浏览 Cookie、复制它们并应用自定义 Cookie。
Website Inspector 是最新的工具,可让您实时检查网站和编辑网站,您可以轻松地将编辑后的网站保存为 PDF。
在源代码中突出显示和查找单词,查找文本允许您在源代码中查找和突出显示文本,这使您可以轻松地编辑源代码。
代码编辑器支持多种语言,您可以将源代码导入代码编辑器并以完全可访问性的方式进行编辑。 CodeEditor 是一款专业工具,可让您对 HTML、Javascript 和 CSS 进行高级编辑。
Javascript Runner 和 evaluator 将帮助您运行 javascript 和 JS 命令并查看输出,这将帮助您控制台记录整个页面的 javascript 和网络请求。
将 网站 源代码保存为开发人员的 网站 源代码,以帮助您评估和改进 网站。 网站源代码保存选项允许您将网页保存为 HTML、Javascript 和 CSS。
说明
输入网页的网址。
您可以选择保存选项。
之后,系统会要求您选择一种格式(HTML、TXT、PDF)。
完成,现在下载源代码。
软件功能
一键查看HTML源代码
使用 网站 检查器实时编辑网页。
在 HTML 代码中查找或搜索文本
使用查看器和编辑器设置 cookie。
带有网络日志查看器的 Javascript 评估器。
使用导入功能上传网址
导出网站源代码
将网站另存为 PDF、TXT 和 HTML
50.0 更新
查看和保存 网站 的 HTML 源代码
查找文本和编辑源代码,共享源代码
查看 CSS 和 JS,另存为 PDF
评估 JS 并编辑 cookie。 查看全部
网页源代码抓取工具(安卓手机上查看源代码非常不错的工具帮助用户查看和下载网页源代码)
小编点评:一个非常好的安卓手机查看源码的工具
帮助用户查看和下载网页源代码的软件。 HTML Source Code是一款解锁高级版的html源码查看器,支持cookie编辑器、javascript评估等。还可以离线保存网站,轻松下载三种独特格式的网页。将网页保存为 PDF、TXT 和 HTML 格式,如有需要欢迎下载。
功能介绍
Cookie 编辑器功能使您能够查看和应用 Cookie、使用编辑器浏览 Cookie、复制它们并应用自定义 Cookie。
Website Inspector 是最新的工具,可让您实时检查网站和编辑网站,您可以轻松地将编辑后的网站保存为 PDF。
在源代码中突出显示和查找单词,查找文本允许您在源代码中查找和突出显示文本,这使您可以轻松地编辑源代码。
代码编辑器支持多种语言,您可以将源代码导入代码编辑器并以完全可访问性的方式进行编辑。 CodeEditor 是一款专业工具,可让您对 HTML、Javascript 和 CSS 进行高级编辑。
Javascript Runner 和 evaluator 将帮助您运行 javascript 和 JS 命令并查看输出,这将帮助您控制台记录整个页面的 javascript 和网络请求。
将 网站 源代码保存为开发人员的 网站 源代码,以帮助您评估和改进 网站。 网站源代码保存选项允许您将网页保存为 HTML、Javascript 和 CSS。
说明
输入网页的网址。
您可以选择保存选项。
之后,系统会要求您选择一种格式(HTML、TXT、PDF)。
完成,现在下载源代码。
软件功能
一键查看HTML源代码
使用 网站 检查器实时编辑网页。
在 HTML 代码中查找或搜索文本
使用查看器和编辑器设置 cookie。
带有网络日志查看器的 Javascript 评估器。
使用导入功能上传网址
导出网站源代码
将网站另存为 PDF、TXT 和 HTML
50.0 更新
查看和保存 网站 的 HTML 源代码
查找文本和编辑源代码,共享源代码
查看 CSS 和 JS,另存为 PDF
评估 JS 并编辑 cookie。
网页源代码抓取工具( 搭建属于自己的在线工具箱拥有近百种功能合集(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-06 06:05
搭建属于自己的在线工具箱拥有近百种功能合集(组图))
打造自己的在线工具箱 近百个功能合集,可自定义插件程序,操作简单,方便快捷
项目架构
项目主要包括和使用以下框架和开源项目
引导 3.3.7
字体真棒 4.7
层 3.1.1
jQuery 2.1.4
阿里云矢量库
等等……
安装教程
安装请直接上传项目,解压到根目录,然后访问域名安装
安装时请确保是最新版本
请确认支持的功能
完整的数据库信息
填写域名等账号信息
使用说明
内置工具大多基于杨小杰api等网站api接口,不代表可以永久有效使用
至于其他一些开源工具,其中一些也依赖于在线资源的聚合。
如果您想制作自己的工具,请参阅“Q&A”
节目特色
前台支持三组主题切换、ajax点赞、浏览量统计以及站内站外单独跳转功能
内置时间轴功能,可以记录你的网站开发过程和一些重要新闻
关于页面支持消息,内置smtp发送,轻松完成用户沟通
后台使用Unicorn Admin开源项目进行对接,搭建完成。
具体功能如下:
工具管理功能(主页列表)
友情链接的添加、删除等管理功能
时间线发布和管理功能
内置消息管理功能
网站信息设置,内置smtp发送配置
本项目从构建到测试使用5.6,最新版本已经支持php7.2
下载地址:工具箱近百个站长工具网站1.4源码
更多资源可以在川娃资源网找到 查看全部
网页源代码抓取工具(
搭建属于自己的在线工具箱拥有近百种功能合集(组图))
打造自己的在线工具箱 近百个功能合集,可自定义插件程序,操作简单,方便快捷
项目架构
项目主要包括和使用以下框架和开源项目
引导 3.3.7
字体真棒 4.7
层 3.1.1
jQuery 2.1.4
阿里云矢量库
等等……
安装教程
安装请直接上传项目,解压到根目录,然后访问域名安装
安装时请确保是最新版本
请确认支持的功能
完整的数据库信息
填写域名等账号信息
使用说明
内置工具大多基于杨小杰api等网站api接口,不代表可以永久有效使用
至于其他一些开源工具,其中一些也依赖于在线资源的聚合。
如果您想制作自己的工具,请参阅“Q&A”
节目特色
前台支持三组主题切换、ajax点赞、浏览量统计以及站内站外单独跳转功能
内置时间轴功能,可以记录你的网站开发过程和一些重要新闻
关于页面支持消息,内置smtp发送,轻松完成用户沟通
后台使用Unicorn Admin开源项目进行对接,搭建完成。
具体功能如下:
工具管理功能(主页列表)
友情链接的添加、删除等管理功能
时间线发布和管理功能
内置消息管理功能
网站信息设置,内置smtp发送配置
本项目从构建到测试使用5.6,最新版本已经支持php7.2
下载地址:工具箱近百个站长工具网站1.4源码
更多资源可以在川娃资源网找到
网页源代码抓取工具(阿里数据库api,找的是这个么?怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-02 03:08
网页源代码抓取工具有很多,我们学习的时候如果看到很多新的词,大家可以使用w3school在线教程这个网站来学习。这个网站上有很多html,css,javascript以及cookie的讲解以及资源。同时他们还有一个cdn+webrtc教程,学习webrtc这个是很重要的。其实w3school里面的内容有点过时了,但是网上很多资源已经都是过时的,学习还是需要去看老东西。
可以试试我正在用的爬虫工具程序,动态爬取google,百度,搜狗,360等搜索引擎。这个工具在一个python语言文件中已经有了完整的分析工具。包括抓取网页信息,抓取字符串,获取网页数据库信息等功能。
我有一个免费的抓包工具,基本满足你的需求。
阿里数据库的api,
找的是这个么?的确是付费的爬虫。但是如果是免费的话,这种python爬虫/数据分析工具(答主看到的这篇文章里的网址)等这些也很常见。
rst抓取stackoverflow大量教程,也可能有一些比较老的工具,但整体还是很不错的。感觉既然题主在知乎提问,应该也不是做it的,等我学好了技术再来安利python。而且请不要用爬虫来获取用户评论或者回答,对语言本身是一种伤害。
《pythonfordataanalysispythonfordataanalysis(seehelp)》 查看全部
网页源代码抓取工具(阿里数据库api,找的是这个么?怎么办?)
网页源代码抓取工具有很多,我们学习的时候如果看到很多新的词,大家可以使用w3school在线教程这个网站来学习。这个网站上有很多html,css,javascript以及cookie的讲解以及资源。同时他们还有一个cdn+webrtc教程,学习webrtc这个是很重要的。其实w3school里面的内容有点过时了,但是网上很多资源已经都是过时的,学习还是需要去看老东西。
可以试试我正在用的爬虫工具程序,动态爬取google,百度,搜狗,360等搜索引擎。这个工具在一个python语言文件中已经有了完整的分析工具。包括抓取网页信息,抓取字符串,获取网页数据库信息等功能。
我有一个免费的抓包工具,基本满足你的需求。
阿里数据库的api,
找的是这个么?的确是付费的爬虫。但是如果是免费的话,这种python爬虫/数据分析工具(答主看到的这篇文章里的网址)等这些也很常见。
rst抓取stackoverflow大量教程,也可能有一些比较老的工具,但整体还是很不错的。感觉既然题主在知乎提问,应该也不是做it的,等我学好了技术再来安利python。而且请不要用爬虫来获取用户评论或者回答,对语言本身是一种伤害。
《pythonfordataanalysispythonfordataanalysis(seehelp)》

