
网页源代码抓取工具
网页源代码抓取工具(Python用做数据处理还是相当不错的,你知道吗?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-10-04 05:00
Python非常适合数据处理。如果你想做爬虫,Python 是个不错的选择。它有许多已编写的包。只需调用它们就可以完成许多复杂的功能。本文中的所有功能均基于 BeautifulSoup 包。
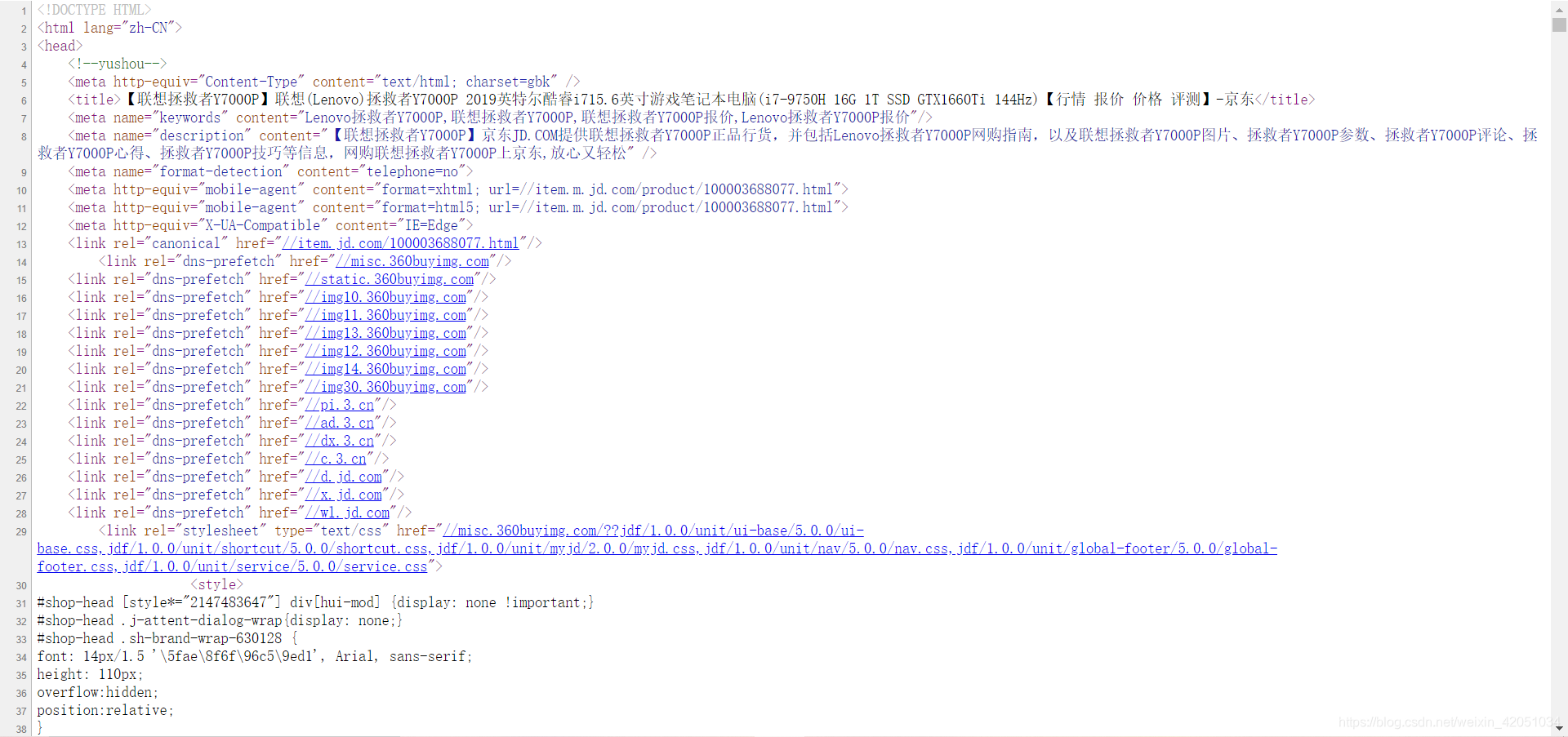
1 Pyhton获取网页内容(即源码)
page = urllib2.urlopen(url)
contents = page.read()
#获得了整个网页的内容也就是源代码
print(contents)
url代表网址,contents代表网址对应的源码,urllib2是需要用到的包,通过上面三句代码就可以得到网页的整个源码
2 获取网页中想要的内容(先获取网页的源代码,然后分析网页的源代码,找到对应的标签,然后提取标签中的内容)
2.1 以豆瓣电影排名为例
网址是,输入网址后会出现下图
现在我需要获取当前页面上所有电影的名称、评分、评论数量、链接
从上图中,红色圆圈是我想要获取的内容,蓝色横线是对应的标签,这样分析就完成了,现在就是写代码来实现,Python提供了很多获取想要的方法内容,这里我使用BeautifulSoup来实现,很简单
#coding:utf-8
'''''
@author: jsjxy
'''
import urllib2
import re
from bs4 import BeautifulSoup
from distutils.filelist import findall
page = urllib2.urlopen('http://movie.douban.com/top250?format=text')
contents = page.read()
#print(contents)
soup = BeautifulSoup(contents,"html.parser")
print("豆瓣电影TOP250" + "\n" +" 影片名 评分 评价人数 链接 ")
for tag in soup.find_all('div', class_='info'):
# print tag
m_name = tag.find('span', class_='title').get_text()
m_rating_score = float(tag.find('span',class_='rating_num').get_text())
m_people = tag.find('div',class_="star")
m_span = m_people.findAll('span')
m_peoplecount = m_span[3].contents[0]
m_url=tag.find('a').get('href')
print( m_name+" " + str(m_rating_score) + " " + m_peoplecount + " " + m_url )
控制台输出,也可以写入文件
前三行代码获取整个网页的源码,然后开始使用BeautifulSoup进行标签分析。find_all 方法就是找到这个标签的所有内容,然后在这个标签中继续搜索。如果标签有特殊属性声明,可以一步找到出来,如果没有特殊属性声明像这张图中求值者数量前面的标签只有一个'span',那么所有的span找到标签,并依次选择相应的标签。在这张图中,它是第三个,所以这个方法可以找到特定行或列的内容。代码比较简单,易于实现。如有不对的地方请大家指出,共同学习。
源代码地址: 查看全部
网页源代码抓取工具(Python用做数据处理还是相当不错的,你知道吗?(上))
Python非常适合数据处理。如果你想做爬虫,Python 是个不错的选择。它有许多已编写的包。只需调用它们就可以完成许多复杂的功能。本文中的所有功能均基于 BeautifulSoup 包。
1 Pyhton获取网页内容(即源码)
page = urllib2.urlopen(url)
contents = page.read()
#获得了整个网页的内容也就是源代码
print(contents)
url代表网址,contents代表网址对应的源码,urllib2是需要用到的包,通过上面三句代码就可以得到网页的整个源码
2 获取网页中想要的内容(先获取网页的源代码,然后分析网页的源代码,找到对应的标签,然后提取标签中的内容)
2.1 以豆瓣电影排名为例
网址是,输入网址后会出现下图
现在我需要获取当前页面上所有电影的名称、评分、评论数量、链接

从上图中,红色圆圈是我想要获取的内容,蓝色横线是对应的标签,这样分析就完成了,现在就是写代码来实现,Python提供了很多获取想要的方法内容,这里我使用BeautifulSoup来实现,很简单

#coding:utf-8
'''''
@author: jsjxy
'''
import urllib2
import re
from bs4 import BeautifulSoup
from distutils.filelist import findall
page = urllib2.urlopen('http://movie.douban.com/top250?format=text')
contents = page.read()
#print(contents)
soup = BeautifulSoup(contents,"html.parser")
print("豆瓣电影TOP250" + "\n" +" 影片名 评分 评价人数 链接 ")
for tag in soup.find_all('div', class_='info'):
# print tag
m_name = tag.find('span', class_='title').get_text()
m_rating_score = float(tag.find('span',class_='rating_num').get_text())
m_people = tag.find('div',class_="star")
m_span = m_people.findAll('span')
m_peoplecount = m_span[3].contents[0]
m_url=tag.find('a').get('href')
print( m_name+" " + str(m_rating_score) + " " + m_peoplecount + " " + m_url )
控制台输出,也可以写入文件

前三行代码获取整个网页的源码,然后开始使用BeautifulSoup进行标签分析。find_all 方法就是找到这个标签的所有内容,然后在这个标签中继续搜索。如果标签有特殊属性声明,可以一步找到出来,如果没有特殊属性声明像这张图中求值者数量前面的标签只有一个'span',那么所有的span找到标签,并依次选择相应的标签。在这张图中,它是第三个,所以这个方法可以找到特定行或列的内容。代码比较简单,易于实现。如有不对的地方请大家指出,共同学习。
源代码地址:
网页源代码抓取工具( 本文协议是互联网中应用最多的协议,如何防止被抓包 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-04 04:24
本文协议是互联网中应用最多的协议,如何防止被抓包
)
本文来自作者吉比贝克,在GitChat上分享了“Fiddler2抓包工具,让你的信息不再被隐藏”,“阅读原文”查看交流记录。
《文末,高能》
编辑 | 爱好
http协议是Internet上使用最广泛的协议。几乎所有的 Web 应用程序和移动应用程序都使用 http 协议。
作为一款基于http协议的免费抓包工具,Fiddler2非常强大。它可以捕获通过http协议传输的数据包,让您的信息无处藏身。
本文将简单讲解Fiddler2的下载安装,具体应用,以及如何防止抓包。
一、为什么Fiddler2的名字后面是2,而不是Fiddler?
虽然这是一个看似无聊的问题,但确实让我纠结了一阵子,或许有点强迫症吧。
当我第一次使用 Fiddler 时,我总是这样写和调用 Fiddler2。但有一天我发现还有另一个 Fiddler4。我瞬间明白是怎么回事了。原来,数字 2 并不是 Fiddler 名字的一部分,而是一个很大的数字。版本号。
但是在全网找了半天,包括去官网都找不到Fiddler3。最新的是 Fiddler4。全网使用最多的是Fiddler2和Fiddler4。至于为什么没有Fiddler和Fiddler3,我也懒得去找了。
二、Fiddler的本质是服务器的代理
启动Fiddler后,Fiddler默认会代理当前电脑或服务器的地址和端口为127.0.0.1:8888,所以http请求发送到当前电脑或服务器将首先发送。127.0.0.1:8888这个代理地址后,再转发到真实访问地址。
Fiddler相当于在客户端和服务器之间安装了一个中继,这个中继负责转发。然后,Fiddler 获取到客户端和服务端的交互数据后,通过数据整理和分析,结果从 Fiddler 客户端显示出来,甚至可以通过 Fiddler 修改请求数据。
当 Fiddler 关闭时,Fiddler 会自动退出代理。这就是Fiddler实现抓包的基本原理。
三、Fiddler的下载安装
可以通过地址下载Fiddler客户端。
只需选择使用原因,输入您的电子邮件地址,选中“我接受 Fiddler 最终用户许可协议”选项,然后单击下载。
下载的安装包:
一路下一步即可完成安装,最新版本为Fiddler4。
四、使用Fiddler基于http协议抓取网页网站数据
打开Fiddler,整个界面分为三块,块1是当前计算机与外网交互的地址信息,有请求结果,请求协议,访问域名,url地址,返回的字节数。
第二块是请求信息,包括头信息、请求地址、请求参数等,第三块是服务器响应信息。根据返回结果的形式不同,可以分为返回网页和返回数据两种。
返回的结果是一个 HTML 页面
我们以访问热门聊天为例进行分析。
从图中可以看到,host栏代表要访问的域名,这里是,Protocol列表显示协议,这里是http,URL栏显示请求路径,这里是/gitchat/hot, Body列代表返回的结果word段数,Content-Type列表示返回内容的类型,这里是html,最后Process列表示进程名称。
一般情况下,我们只需要关注Host、URL、Body和Content-Type列。从Body列的字节大小,我们可以快速判断哪些请求返回的数据量较大,然后根据Content-Type类型判断返回的内容。
在上面有红色图标的那一行,我们可以看到从热门列表页面返回了大量的内容,返回类型为html页面。让我们看看块 3 的结果。
我们切到“SyntaxView”选项卡,可以看到热门聊天的html页面源码,说明请求这个地址后,服务器返回的是html。
返回结果是数据
访问百度网页时,发现红框标注的请求返回了大量数据,返回类型为“application/javascript”,于是查看返回结果,切入“SyntaxView”选项卡,可以看到一堆可识别的数据,如下:
我们选择以“JSON”格式查看,如下:
一般情况下,我们在目标不是很明确的情况下使用Fiddler抓包,也就是说我们不知道这个网站的哪个地址会被抓到,也不知道它将被捕获。在浏览这个网站的过程中,刚刚通过Fiddler的请求分析了哪些数据,哪些数据可能有用。
这些数据往往是在网站或者APP上正常运行时看不到的数据,而这些隐藏的数据可以通过Fiddler的抓包来抓到。
Fiddler 也经常被用作爬虫的辅助工具。首先使用Fiddler过滤目标网站或APP,抓取可以获取目标数据的URL和参数,然后通过爬虫程序访问这些URL和参数。爬到目标数据。
一般APP通过接口返回数据是很常见的。比如这个链接“”是一个APP爬取得到的数据接口,直接访问这个链接,可以看到JSON格式的数据源。
五、 基于https协议使用Fiddler抓取新浪微博
fiddler除了可以抓取http协议的数据外,还可以抓取https协议的数据,但需要额外配置。方法如下:
依次打开菜单栏中的工具>选项>HTTPS选项卡,勾选“解密HTTPS流量”选项和“忽略服务器证书错误(不安全)”选项,重启Fiddler。这时候如果基于https协议访问网站,就可以抓取到网站的信息。我们以新浪微博为例。
可以看到,大部分抓拍的图片都是图片,其中一张返回2907字节。我们来看看返回的结果。
从备注来看,这应该是服务器的一些证书信息。让我们来看看图片。
张一山?
爱极光?
奇门遁甲?
当然,这些照片都是新浪微博首页的照片。想看的话直接上首页。你不需要使用 Fiddler 来抓取它。这只是一个例子。你已经掌握了抓取https协议数据的方法,就可以看到网页显示的内容了。数据,当然也可以看到网页无法显示的隐藏数据。这取决于个人。
剑法已经交给你了。至于你用它来杀猪还是执行骑士正义,你说了算。
六、 使用Fiddler抓取手机APP的通讯数据
要抓取手机的通讯数据,需要同时配置Fiddler和手机端。过程稍微复杂一些。下面我会详细解释。
第一步是配置Fiddler允许远程连接,如图:
依次打开菜单栏中的工具>选项>连接选项卡,勾选“允许远程计算机连接”选项允许远程服务器连接,重启Fiddler。
第二步,在手机上设置安装Fiddler的电脑为手机的代理地址。
找到手机连接的wifi网络,点击弹出修改,在高级代理中找到代理设置,将代理设置改为手动,然后会出现设置代理地址和端口的输入框(不同手机的操作过程会略有不同,最终目的是设置手机的代理地址,可以根据不同品牌型号的手机在百度中搜索相关设置方法)。
设置代理地址。
代理地址是你打开Fiddler的电脑的内网IP地址。window系统可以在cmd命令模式下输入ipconfig查看当前电脑的内网IP地址。我电脑的IP地址是192.168.1.34。
填写代理端口8888,点击保存,如下图:
第三步,访问代理地址,下载安装证书,完成配置。
下载并安装证书:
至此,所有配置完成。现在,所有通过手机与外网通信的数据都可以被 Fiddler 捕获。比如我们通过微信打开gitchat的微信公众号,可以在Fiddler中看到gitchat公众号的标题文章的图片数据,如图。
这是在 Fiddler 中捕获的数据:
GitChat微信公众号中的图文:
同样,网页上可以抓取到的数据也可以在APP上抓取,在APP上抓取的隐藏数据就更多了,因为大部分APP都是以接口的形式与服务器进行通信的。其中会收录大量数据。如果直接抓取接口地址和参数,就可以直接调用接口获取数据。
本文主要讲解Fiddler的用法和场景,所以例子中尽量避免敏感内容。Fiddler 是一把双刃剑,可以用来抓取合法数据,也可以用来抓取私人数据。在使用中请务必遵守规则。
七、使用Fiddler设置断点和修改Response
Fiddler 不仅可以用来抓取通信数据,还可以用来修改请求内容和服务器响应结果。这个功能一般用的比较少,一般在前期的开发调试中使用,这里简单介绍一下。
在菜单栏中,点击规则->自动断点->选择断点方法。有两种方式,一种是在请求前进入断点,i是在服务器响应后设置断点,其实就是返回请求内容和服务器在结果两种情况下都设置断点。
比如我们选择在请求之前输入一个断点。这时候,一旦我们用浏览器访问一个页面,发送请求后,就会停留在Fiddler中。这时候我们就可以修改请求中的数据,然后再进行后续的操作,让服务端接收到的请求被修改。
同理,服务器响应后修改数据,就是直接修改服务器返回的结果。
这种技术在实践中很少使用。如果有人对这篇文章感兴趣,你可以把它放在评论中。我会在后续的交流中详细解释这块。
八、反Fiddler爬取的一些思考
由于Fiddler非常强大,所以我们在做产品开发的时候,尤其是APP和服务器端通信的时候,应该尽量避免Fiddler的爬行,更加注意界面的严谨性和安全性。可以考虑从以下几点入手:
在制作APP界面时,与界面通信的数据在传输前应尽可能加密。不要使用纯文本,这将在很大程度上避免数据被捕获;
接口返回的数据尽量少,也就是APP只返回什么数据。不要因为偷懒把数据全部返回,这样一旦数据被抓到,泄露的会比当前接口业务的数据还多;
必须严格验证参数,防止有人恶意猜测构造参数,非法访问服务器。
本次Fiddler数据采集的话题就到这里。有问题的同学可以留言提问,也可以在阅读圈提问。我看到后,会尽量尽快回复你。感谢大家的参与。
九、备注
在使用Fiddler抓取网页和传输数据时,经常会遇到无法抓取的问题,尤其是https协议网站,数据在Fiddler上根本不显示。
经过反复尝试,我发现问题出在浏览器上。某些浏览器可能会阻止代理。通过这些浏览器访问的网页不会在 Fiddler 上显示数据。感觉代理失败了。
目前测试发现360浏览器100%屏蔽Fiddler,谷歌Chrome屏蔽了一部分。具体的屏蔽规则还没有深入研究。另外IE浏览器完全支持Fiddler,几乎没有屏蔽。上面例子中的数据捕获是通过IE浏览器演示的。
因此,在实际使用中,建议先使用IE浏览器抓取数据。
近期热门文章
“”
“”
“”
“”
“”
“”
“”
查看全部
网页源代码抓取工具(
本文协议是互联网中应用最多的协议,如何防止被抓包
)

本文来自作者吉比贝克,在GitChat上分享了“Fiddler2抓包工具,让你的信息不再被隐藏”,“阅读原文”查看交流记录。
《文末,高能》
编辑 | 爱好
http协议是Internet上使用最广泛的协议。几乎所有的 Web 应用程序和移动应用程序都使用 http 协议。
作为一款基于http协议的免费抓包工具,Fiddler2非常强大。它可以捕获通过http协议传输的数据包,让您的信息无处藏身。
本文将简单讲解Fiddler2的下载安装,具体应用,以及如何防止抓包。
一、为什么Fiddler2的名字后面是2,而不是Fiddler?

虽然这是一个看似无聊的问题,但确实让我纠结了一阵子,或许有点强迫症吧。
当我第一次使用 Fiddler 时,我总是这样写和调用 Fiddler2。但有一天我发现还有另一个 Fiddler4。我瞬间明白是怎么回事了。原来,数字 2 并不是 Fiddler 名字的一部分,而是一个很大的数字。版本号。
但是在全网找了半天,包括去官网都找不到Fiddler3。最新的是 Fiddler4。全网使用最多的是Fiddler2和Fiddler4。至于为什么没有Fiddler和Fiddler3,我也懒得去找了。
二、Fiddler的本质是服务器的代理

启动Fiddler后,Fiddler默认会代理当前电脑或服务器的地址和端口为127.0.0.1:8888,所以http请求发送到当前电脑或服务器将首先发送。127.0.0.1:8888这个代理地址后,再转发到真实访问地址。
Fiddler相当于在客户端和服务器之间安装了一个中继,这个中继负责转发。然后,Fiddler 获取到客户端和服务端的交互数据后,通过数据整理和分析,结果从 Fiddler 客户端显示出来,甚至可以通过 Fiddler 修改请求数据。
当 Fiddler 关闭时,Fiddler 会自动退出代理。这就是Fiddler实现抓包的基本原理。
三、Fiddler的下载安装
可以通过地址下载Fiddler客户端。

只需选择使用原因,输入您的电子邮件地址,选中“我接受 Fiddler 最终用户许可协议”选项,然后单击下载。

下载的安装包:

一路下一步即可完成安装,最新版本为Fiddler4。
四、使用Fiddler基于http协议抓取网页网站数据

打开Fiddler,整个界面分为三块,块1是当前计算机与外网交互的地址信息,有请求结果,请求协议,访问域名,url地址,返回的字节数。
第二块是请求信息,包括头信息、请求地址、请求参数等,第三块是服务器响应信息。根据返回结果的形式不同,可以分为返回网页和返回数据两种。
返回的结果是一个 HTML 页面
我们以访问热门聊天为例进行分析。

从图中可以看到,host栏代表要访问的域名,这里是,Protocol列表显示协议,这里是http,URL栏显示请求路径,这里是/gitchat/hot, Body列代表返回的结果word段数,Content-Type列表示返回内容的类型,这里是html,最后Process列表示进程名称。
一般情况下,我们只需要关注Host、URL、Body和Content-Type列。从Body列的字节大小,我们可以快速判断哪些请求返回的数据量较大,然后根据Content-Type类型判断返回的内容。
在上面有红色图标的那一行,我们可以看到从热门列表页面返回了大量的内容,返回类型为html页面。让我们看看块 3 的结果。

我们切到“SyntaxView”选项卡,可以看到热门聊天的html页面源码,说明请求这个地址后,服务器返回的是html。
返回结果是数据

访问百度网页时,发现红框标注的请求返回了大量数据,返回类型为“application/javascript”,于是查看返回结果,切入“SyntaxView”选项卡,可以看到一堆可识别的数据,如下:

我们选择以“JSON”格式查看,如下:

一般情况下,我们在目标不是很明确的情况下使用Fiddler抓包,也就是说我们不知道这个网站的哪个地址会被抓到,也不知道它将被捕获。在浏览这个网站的过程中,刚刚通过Fiddler的请求分析了哪些数据,哪些数据可能有用。
这些数据往往是在网站或者APP上正常运行时看不到的数据,而这些隐藏的数据可以通过Fiddler的抓包来抓到。
Fiddler 也经常被用作爬虫的辅助工具。首先使用Fiddler过滤目标网站或APP,抓取可以获取目标数据的URL和参数,然后通过爬虫程序访问这些URL和参数。爬到目标数据。
一般APP通过接口返回数据是很常见的。比如这个链接“”是一个APP爬取得到的数据接口,直接访问这个链接,可以看到JSON格式的数据源。

五、 基于https协议使用Fiddler抓取新浪微博
fiddler除了可以抓取http协议的数据外,还可以抓取https协议的数据,但需要额外配置。方法如下:

依次打开菜单栏中的工具>选项>HTTPS选项卡,勾选“解密HTTPS流量”选项和“忽略服务器证书错误(不安全)”选项,重启Fiddler。这时候如果基于https协议访问网站,就可以抓取到网站的信息。我们以新浪微博为例。

可以看到,大部分抓拍的图片都是图片,其中一张返回2907字节。我们来看看返回的结果。

从备注来看,这应该是服务器的一些证书信息。让我们来看看图片。

张一山?

爱极光?

奇门遁甲?
当然,这些照片都是新浪微博首页的照片。想看的话直接上首页。你不需要使用 Fiddler 来抓取它。这只是一个例子。你已经掌握了抓取https协议数据的方法,就可以看到网页显示的内容了。数据,当然也可以看到网页无法显示的隐藏数据。这取决于个人。
剑法已经交给你了。至于你用它来杀猪还是执行骑士正义,你说了算。
六、 使用Fiddler抓取手机APP的通讯数据
要抓取手机的通讯数据,需要同时配置Fiddler和手机端。过程稍微复杂一些。下面我会详细解释。
第一步是配置Fiddler允许远程连接,如图:

依次打开菜单栏中的工具>选项>连接选项卡,勾选“允许远程计算机连接”选项允许远程服务器连接,重启Fiddler。
第二步,在手机上设置安装Fiddler的电脑为手机的代理地址。
找到手机连接的wifi网络,点击弹出修改,在高级代理中找到代理设置,将代理设置改为手动,然后会出现设置代理地址和端口的输入框(不同手机的操作过程会略有不同,最终目的是设置手机的代理地址,可以根据不同品牌型号的手机在百度中搜索相关设置方法)。

设置代理地址。

代理地址是你打开Fiddler的电脑的内网IP地址。window系统可以在cmd命令模式下输入ipconfig查看当前电脑的内网IP地址。我电脑的IP地址是192.168.1.34。
填写代理端口8888,点击保存,如下图:

第三步,访问代理地址,下载安装证书,完成配置。

下载并安装证书:

至此,所有配置完成。现在,所有通过手机与外网通信的数据都可以被 Fiddler 捕获。比如我们通过微信打开gitchat的微信公众号,可以在Fiddler中看到gitchat公众号的标题文章的图片数据,如图。
这是在 Fiddler 中捕获的数据:

GitChat微信公众号中的图文:

同样,网页上可以抓取到的数据也可以在APP上抓取,在APP上抓取的隐藏数据就更多了,因为大部分APP都是以接口的形式与服务器进行通信的。其中会收录大量数据。如果直接抓取接口地址和参数,就可以直接调用接口获取数据。
本文主要讲解Fiddler的用法和场景,所以例子中尽量避免敏感内容。Fiddler 是一把双刃剑,可以用来抓取合法数据,也可以用来抓取私人数据。在使用中请务必遵守规则。
七、使用Fiddler设置断点和修改Response
Fiddler 不仅可以用来抓取通信数据,还可以用来修改请求内容和服务器响应结果。这个功能一般用的比较少,一般在前期的开发调试中使用,这里简单介绍一下。
在菜单栏中,点击规则->自动断点->选择断点方法。有两种方式,一种是在请求前进入断点,i是在服务器响应后设置断点,其实就是返回请求内容和服务器在结果两种情况下都设置断点。
比如我们选择在请求之前输入一个断点。这时候,一旦我们用浏览器访问一个页面,发送请求后,就会停留在Fiddler中。这时候我们就可以修改请求中的数据,然后再进行后续的操作,让服务端接收到的请求被修改。
同理,服务器响应后修改数据,就是直接修改服务器返回的结果。
这种技术在实践中很少使用。如果有人对这篇文章感兴趣,你可以把它放在评论中。我会在后续的交流中详细解释这块。
八、反Fiddler爬取的一些思考
由于Fiddler非常强大,所以我们在做产品开发的时候,尤其是APP和服务器端通信的时候,应该尽量避免Fiddler的爬行,更加注意界面的严谨性和安全性。可以考虑从以下几点入手:
在制作APP界面时,与界面通信的数据在传输前应尽可能加密。不要使用纯文本,这将在很大程度上避免数据被捕获;
接口返回的数据尽量少,也就是APP只返回什么数据。不要因为偷懒把数据全部返回,这样一旦数据被抓到,泄露的会比当前接口业务的数据还多;
必须严格验证参数,防止有人恶意猜测构造参数,非法访问服务器。
本次Fiddler数据采集的话题就到这里。有问题的同学可以留言提问,也可以在阅读圈提问。我看到后,会尽量尽快回复你。感谢大家的参与。
九、备注
在使用Fiddler抓取网页和传输数据时,经常会遇到无法抓取的问题,尤其是https协议网站,数据在Fiddler上根本不显示。
经过反复尝试,我发现问题出在浏览器上。某些浏览器可能会阻止代理。通过这些浏览器访问的网页不会在 Fiddler 上显示数据。感觉代理失败了。
目前测试发现360浏览器100%屏蔽Fiddler,谷歌Chrome屏蔽了一部分。具体的屏蔽规则还没有深入研究。另外IE浏览器完全支持Fiddler,几乎没有屏蔽。上面例子中的数据捕获是通过IE浏览器演示的。
因此,在实际使用中,建议先使用IE浏览器抓取数据。
近期热门文章
“”
“”
“”
“”
“”
“”
“”

网页源代码抓取工具(自动模式检测WebHarvy自动识别允许您在网页中发生的数据模式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-10-02 20:12
WebHarvy 是一款用户界面简单、操作简单的网页数据抓取工具。它具有自动检测模式。它可以从任何页面中提取数据,包括文本、图片等,输入网址即可打开。默认使用内部浏览器提取数据,可以导出到数据库或文件夹。
特征
点击界面
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这很简单!
自动模式检测
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
导出捕获的数据
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvyWebScraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
从多个页面中提取数据
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvyWebScraper 就会自动从所有页面中抓取数据。
基于关键字的抓取
通过在搜索表单中自动提交输入关键字列表来抓取数据。可以将任意数量的输入关键字提交到多个输入文本字段以执行搜索。可以提取输入关键字组合的所有搜索结果数据。
通过代理服务器
为了匿名抓取,防止网页抓取软件被网页服务器拦截,您可以选择通过代理服务器或VPN网站访问目标。可以使用单个代理服务器地址或代理服务器地址列表。
类别提取
WebHarvyWebScraper 允许您从链接列表中获取数据,从而在 网站 中生成相似的页面/列表。这允许您使用单个配置来抓取 网站 内的类别和子类别。
正则表达式
WebHarvy 允许您在网页的文本或 HTML 源代码上应用正则表达式 (RegEx) 并删除匹配的部分。这种强大的技术为您在抓取数据时提供了更大的灵活性。
运行 JavaScript
在提取数据之前在浏览器中运行您自己的 JavaScript 代码。这可用于与页面元素交互或调用已在目标页面中实现的 JavaScript 函数。
下载图片
您可以下载图像或提取图像 URL。WebHarvy 可以自动提取显示在电子商务网站的商品详情页面中的多张图片。
自动浏览器交互
WebHarvy 可以轻松配置为执行任务,例如单击链接、选择列表/下拉选项、在字段中输入文本、滚动页面等。
更新日志
修复了页面启动时连接可能被禁用的可能性。
您可以为寻呼模式配置专用的连接方式。
可以自动搜索可以在 HTML 上配置的资源。 查看全部
网页源代码抓取工具(自动模式检测WebHarvy自动识别允许您在网页中发生的数据模式)
WebHarvy 是一款用户界面简单、操作简单的网页数据抓取工具。它具有自动检测模式。它可以从任何页面中提取数据,包括文本、图片等,输入网址即可打开。默认使用内部浏览器提取数据,可以导出到数据库或文件夹。
特征
点击界面
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这很简单!
自动模式检测
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
导出捕获的数据
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvyWebScraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
从多个页面中提取数据
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvyWebScraper 就会自动从所有页面中抓取数据。
基于关键字的抓取
通过在搜索表单中自动提交输入关键字列表来抓取数据。可以将任意数量的输入关键字提交到多个输入文本字段以执行搜索。可以提取输入关键字组合的所有搜索结果数据。
通过代理服务器
为了匿名抓取,防止网页抓取软件被网页服务器拦截,您可以选择通过代理服务器或VPN网站访问目标。可以使用单个代理服务器地址或代理服务器地址列表。
类别提取
WebHarvyWebScraper 允许您从链接列表中获取数据,从而在 网站 中生成相似的页面/列表。这允许您使用单个配置来抓取 网站 内的类别和子类别。
正则表达式
WebHarvy 允许您在网页的文本或 HTML 源代码上应用正则表达式 (RegEx) 并删除匹配的部分。这种强大的技术为您在抓取数据时提供了更大的灵活性。
运行 JavaScript
在提取数据之前在浏览器中运行您自己的 JavaScript 代码。这可用于与页面元素交互或调用已在目标页面中实现的 JavaScript 函数。
下载图片
您可以下载图像或提取图像 URL。WebHarvy 可以自动提取显示在电子商务网站的商品详情页面中的多张图片。
自动浏览器交互
WebHarvy 可以轻松配置为执行任务,例如单击链接、选择列表/下拉选项、在字段中输入文本、滚动页面等。
更新日志
修复了页面启动时连接可能被禁用的可能性。
您可以为寻呼模式配置专用的连接方式。
可以自动搜索可以在 HTML 上配置的资源。
网页源代码抓取工具(自动模式检测WebHarvy自动识别允许您在网页中发生的数据模式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-01 06:10
WebHarvy 是一款用户界面简单、操作简单的网页数据抓取工具。它具有自动检测模式。它可以从任何页面中提取数据,包括文本、图片等,输入网址即可打开。默认使用内部浏览器提取数据,可以导出到数据库或文件夹。
特征
点击界面
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这很简单!
自动模式检测
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
导出捕获的数据
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvyWebScraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
从多个页面中提取数据
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvyWebScraper 就会自动从所有页面中抓取数据。
基于关键字的抓取
通过在搜索表单中自动提交输入关键字列表来抓取数据。可以将任意数量的输入关键字提交到多个输入文本字段以执行搜索。可以提取输入的关键字组合的所有搜索结果数据。
通过代理服务器
为了匿名抓取,防止网页抓取软件被网页服务器拦截,您可以选择通过代理服务器或VPN网站访问目标。可以使用单个代理服务器地址或代理服务器地址列表。
类别提取
WebHarvyWebScraper 允许您从链接列表中获取数据,从而在 网站 中生成相似的页面/列表。这允许您使用单个配置来抓取 网站 内的类别和子类别。
正则表达式
WebHarvy 允许您在网页的文本或 HTML 源代码上应用正则表达式 (RegEx) 并删除匹配的部分。这种强大的技术为您在抓取数据时提供了更大的灵活性。
运行 JavaScript
在提取数据之前在浏览器中运行您自己的 JavaScript 代码。这可用于与页面元素交互或调用已在目标页面中实现的 JavaScript 函数。
下载图片
您可以下载图像或提取图像 URL。WebHarvy 可以自动提取显示在电子商务网站的商品详情页面中的多张图片。
自动浏览器交互
WebHarvy 可以轻松配置为执行任务,例如单击链接、选择列表/下拉选项、在字段中输入文本、滚动页面等。
更新日志
修复了页面启动时连接可能被禁用的可能性。
您可以为寻呼模式配置专用的连接方式。
可以自动搜索可以在 HTML 上配置的资源。 查看全部
网页源代码抓取工具(自动模式检测WebHarvy自动识别允许您在网页中发生的数据模式)
WebHarvy 是一款用户界面简单、操作简单的网页数据抓取工具。它具有自动检测模式。它可以从任何页面中提取数据,包括文本、图片等,输入网址即可打开。默认使用内部浏览器提取数据,可以导出到数据库或文件夹。
特征
点击界面
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这很简单!
自动模式检测
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
导出捕获的数据
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvyWebScraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
从多个页面中提取数据
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvyWebScraper 就会自动从所有页面中抓取数据。
基于关键字的抓取
通过在搜索表单中自动提交输入关键字列表来抓取数据。可以将任意数量的输入关键字提交到多个输入文本字段以执行搜索。可以提取输入的关键字组合的所有搜索结果数据。
通过代理服务器
为了匿名抓取,防止网页抓取软件被网页服务器拦截,您可以选择通过代理服务器或VPN网站访问目标。可以使用单个代理服务器地址或代理服务器地址列表。
类别提取
WebHarvyWebScraper 允许您从链接列表中获取数据,从而在 网站 中生成相似的页面/列表。这允许您使用单个配置来抓取 网站 内的类别和子类别。
正则表达式
WebHarvy 允许您在网页的文本或 HTML 源代码上应用正则表达式 (RegEx) 并删除匹配的部分。这种强大的技术为您在抓取数据时提供了更大的灵活性。
运行 JavaScript
在提取数据之前在浏览器中运行您自己的 JavaScript 代码。这可用于与页面元素交互或调用已在目标页面中实现的 JavaScript 函数。
下载图片
您可以下载图像或提取图像 URL。WebHarvy 可以自动提取显示在电子商务网站的商品详情页面中的多张图片。
自动浏览器交互
WebHarvy 可以轻松配置为执行任务,例如单击链接、选择列表/下拉选项、在字段中输入文本、滚动页面等。
更新日志
修复了页面启动时连接可能被禁用的可能性。
您可以为寻呼模式配置专用的连接方式。
可以自动搜索可以在 HTML 上配置的资源。
网页源代码抓取工具(Source对iOS8Extensions的巧妙利用,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-10-01 06:09
如果您是网站管理员或网络开发人员,在浏览器中查看网页源代码(HTML、CSS 和 JavaScript)是每天必不可少的操作。这种在桌面上的轻松操作已经变成了移动端。一件麻烦事。现在有了View Source对iOS 8 Extensions的巧妙运用,在移动端浏览和操作网页源代码将变得非常容易。
安装完查看源代码后,使用Safari分享按钮打开查看源代码开关,即可显示当前网页源代码。如果你不想这样做,你也可以使用View Source作为一个独立的应用程序来打开你想要查看的网站源代码 当然,这种情况下View Source不会显示内容页面,而是直接显示页面源代码。
在这里你可以看到少数派网页的源代码。例如,通常的 SEO 人员会为网页定义 Title 和 Meta 标签关键字,以使 网站 更好地保持搜索引擎。
在View Source中,通过DOM节点树可以直观的看到当前网页的结构,方便查找和访问节点。还有一个很酷的地方就是View Source还可以通过inject JS来编写自定义的JS代码,退出插件的时候输出的JS效果会显示在网页上。比如在小众页面下的Script中输入:
警报(文件。标题);
退出插件,在Safari中显示关于少数网站 Title标签的提示弹窗,效果如图。
当然,如果你想在弹出窗口中显示一个句子,你可以在Script中输入:
警报(我爱斯派);
当然,这些只是普通的 JavaScript 警报代码。如果你有更有趣的玩法或者更实用的功能,也可以在评论中告诉我。
右上角有更多选项可以调用更多功能,比如将代码复制到剪贴板并继续在其他应用程序上编辑,还可以发送电子邮件、选择亮点等更多主题。这里我再多说一下,查看源提供了很多亮色的主题供选择,笔者个人比较喜欢蓝屏的主题。
View Source 目前售价 6 元。 查看全部
网页源代码抓取工具(Source对iOS8Extensions的巧妙利用,你知道吗?)
如果您是网站管理员或网络开发人员,在浏览器中查看网页源代码(HTML、CSS 和 JavaScript)是每天必不可少的操作。这种在桌面上的轻松操作已经变成了移动端。一件麻烦事。现在有了View Source对iOS 8 Extensions的巧妙运用,在移动端浏览和操作网页源代码将变得非常容易。

安装完查看源代码后,使用Safari分享按钮打开查看源代码开关,即可显示当前网页源代码。如果你不想这样做,你也可以使用View Source作为一个独立的应用程序来打开你想要查看的网站源代码 当然,这种情况下View Source不会显示内容页面,而是直接显示页面源代码。

在这里你可以看到少数派网页的源代码。例如,通常的 SEO 人员会为网页定义 Title 和 Meta 标签关键字,以使 网站 更好地保持搜索引擎。

在View Source中,通过DOM节点树可以直观的看到当前网页的结构,方便查找和访问节点。还有一个很酷的地方就是View Source还可以通过inject JS来编写自定义的JS代码,退出插件的时候输出的JS效果会显示在网页上。比如在小众页面下的Script中输入:
警报(文件。标题);
退出插件,在Safari中显示关于少数网站 Title标签的提示弹窗,效果如图。

当然,如果你想在弹出窗口中显示一个句子,你可以在Script中输入:
警报(我爱斯派);

当然,这些只是普通的 JavaScript 警报代码。如果你有更有趣的玩法或者更实用的功能,也可以在评论中告诉我。

右上角有更多选项可以调用更多功能,比如将代码复制到剪贴板并继续在其他应用程序上编辑,还可以发送电子邮件、选择亮点等更多主题。这里我再多说一下,查看源提供了很多亮色的主题供选择,笔者个人比较喜欢蓝屏的主题。
View Source 目前售价 6 元。
网页源代码抓取工具(想要爬取指定网页中的图片主要需要以下三个步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-10-01 06:08
抓取指定网页中的图片主要需要以下三个步骤:
(1)指定网站链接,获取网站的源码(如果使用谷歌浏览器,鼠标右键->检查->Elements中的html内容)
(2) 根据要爬取的内容设置正则表达式,匹配到要爬取的内容
(3)设置循环列表,重复抓取保存内容
下面介绍两种抓取指定网页图片的方法
(1)方法一:使用正则表达式过滤捕获的html内容字符串
# 第一个简单的爬取图片的程序
import urllib.request # python自带的爬操作url的库
import re # 正则表达式
# 该方法传入url,返回url的html的源代码
def getHtmlCode(url):
# 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求
headers = {
'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \
AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36'
}
# 将headers头部添加到url,模拟浏览器访问
url = urllib.request.Request(url, headers=headers)
# 将url页面的源代码保存成字符串
page = urllib.request.urlopen(url).read()
# 字符串转码
page = page.decode('UTF-8')
return page
# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
def getImage(page):
# [^\s]*? 表示最小匹配, 两个括号表示列表中有两个元组
# imageList = re.findall(r'(https:[^\s]*?(png))"', page)
imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page)
x = 0
# 循环列表
for imageUrl in imageList:
try:
print('正在下载: %s' % imageUrl[0])
# 这个image文件夹需要先创建好才能看到结果
image_save_path = './image/%d.png' % x
# 下载图片并且保存到指定文件夹中
urllib.request.urlretrieve(imageUrl[0], image_save_path)
x = x + 1
except:
continue
pass
if __name__ == '__main__':
# 指定要爬取的网站
url = "https://www.cnblogs.com/ttweix ... ot%3B
# 得到该网站的源代码
page = getHtmlCode(url)
# 爬取该网站的图片并且保存
getImage(page)
# print(page)
注意代码中需要修改的是 imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page) 这一段内容,怎么设计正则表达式需要根据你要爬取的内容设置我的设计源码如下:
可以看到,因为这个页面的图片都是png格式,所以也可以写成imageList = re.findall(r'(https:[^\s]*?(png))"', page)
(2)方法二:使用BeautifulSoup库解析html网页
from bs4 import BeautifulSoup # BeautifulSoup是python处理HTML/XML的函数库,是Python内置的网页分析工具
import urllib # python自带的爬操作url的库
# 该方法传入url,返回url的html的源代码
def getHtmlCode(url):
# 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求
headers = {
'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \
AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36'
}
# 将headers头部添加到url,模拟浏览器访问
url = urllib.request.Request(url, headers=headers)
# 将url页面的源代码保存成字符串
page = urllib.request.urlopen(url).read()
# 字符串转码
page = page.decode('UTF-8')
return page
# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
def getImage(page):
# 按照html格式解析页面
soup = BeautifulSoup(page, 'html.parser')
# 格式化输出DOM树的内容
print(soup.prettify())
# 返回所有包含img标签的列表,因为在Html文件中图片的插入呈现形式是...
imgList = soup.find_all('img')
x = 0
# 循环找到的图片列表,注意,这里手动设置从第2张图片开始,是因为我debug看到了第一张图片不是我想要的图片
for imgUrl in imgList[1:]:
print('正在下载: %s ' % imgUrl.get('src'))
# 得到scr的内容,这里返回的就是Url字符串链接,如'https://img2020.cnblogs.com/blog/1703588/202007/1703588-20200716203143042-623499171.png'
image_url = imgUrl.get('src')
# 这个image文件夹需要先创建好才能看到结果
image_save_path = './image/%d.png' % x
# 下载图片并且保存到指定文件夹中
urllib.request.urlretrieve(image_url, image_save_path)
x = x + 1
if __name__ == '__main__':
# 指定要爬取的网站
url = 'https://www.cnblogs.com/ttweixiao-IT-program/p/13324826.html'
# 得到该网站的源代码
page = getHtmlCode(url)
# 爬取该网站的图片并且保存
getImage(page)
这两种方法各有优缺点。我认为它们可以灵活组合。比如先用方法二中的指定标签的方法缩小你要查找的内容范围,然后再用正则表达式匹配到需要的内容。更简洁明了
相关文章 查看全部
网页源代码抓取工具(想要爬取指定网页中的图片主要需要以下三个步骤)
抓取指定网页中的图片主要需要以下三个步骤:
(1)指定网站链接,获取网站的源码(如果使用谷歌浏览器,鼠标右键->检查->Elements中的html内容)
(2) 根据要爬取的内容设置正则表达式,匹配到要爬取的内容
(3)设置循环列表,重复抓取保存内容
下面介绍两种抓取指定网页图片的方法
(1)方法一:使用正则表达式过滤捕获的html内容字符串
# 第一个简单的爬取图片的程序
import urllib.request # python自带的爬操作url的库
import re # 正则表达式
# 该方法传入url,返回url的html的源代码
def getHtmlCode(url):
# 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求
headers = {
'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \
AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36'
}
# 将headers头部添加到url,模拟浏览器访问
url = urllib.request.Request(url, headers=headers)
# 将url页面的源代码保存成字符串
page = urllib.request.urlopen(url).read()
# 字符串转码
page = page.decode('UTF-8')
return page
# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
def getImage(page):
# [^\s]*? 表示最小匹配, 两个括号表示列表中有两个元组
# imageList = re.findall(r'(https:[^\s]*?(png))"', page)
imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page)
x = 0
# 循环列表
for imageUrl in imageList:
try:
print('正在下载: %s' % imageUrl[0])
# 这个image文件夹需要先创建好才能看到结果
image_save_path = './image/%d.png' % x
# 下载图片并且保存到指定文件夹中
urllib.request.urlretrieve(imageUrl[0], image_save_path)
x = x + 1
except:
continue
pass
if __name__ == '__main__':
# 指定要爬取的网站
url = "https://www.cnblogs.com/ttweix ... ot%3B
# 得到该网站的源代码
page = getHtmlCode(url)
# 爬取该网站的图片并且保存
getImage(page)
# print(page)
注意代码中需要修改的是 imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page) 这一段内容,怎么设计正则表达式需要根据你要爬取的内容设置我的设计源码如下:

可以看到,因为这个页面的图片都是png格式,所以也可以写成imageList = re.findall(r'(https:[^\s]*?(png))"', page)
(2)方法二:使用BeautifulSoup库解析html网页
from bs4 import BeautifulSoup # BeautifulSoup是python处理HTML/XML的函数库,是Python内置的网页分析工具
import urllib # python自带的爬操作url的库
# 该方法传入url,返回url的html的源代码
def getHtmlCode(url):
# 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求
headers = {
'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \
AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36'
}
# 将headers头部添加到url,模拟浏览器访问
url = urllib.request.Request(url, headers=headers)
# 将url页面的源代码保存成字符串
page = urllib.request.urlopen(url).read()
# 字符串转码
page = page.decode('UTF-8')
return page
# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
def getImage(page):
# 按照html格式解析页面
soup = BeautifulSoup(page, 'html.parser')
# 格式化输出DOM树的内容
print(soup.prettify())
# 返回所有包含img标签的列表,因为在Html文件中图片的插入呈现形式是...
imgList = soup.find_all('img')
x = 0
# 循环找到的图片列表,注意,这里手动设置从第2张图片开始,是因为我debug看到了第一张图片不是我想要的图片
for imgUrl in imgList[1:]:
print('正在下载: %s ' % imgUrl.get('src'))
# 得到scr的内容,这里返回的就是Url字符串链接,如'https://img2020.cnblogs.com/blog/1703588/202007/1703588-20200716203143042-623499171.png'
image_url = imgUrl.get('src')
# 这个image文件夹需要先创建好才能看到结果
image_save_path = './image/%d.png' % x
# 下载图片并且保存到指定文件夹中
urllib.request.urlretrieve(image_url, image_save_path)
x = x + 1
if __name__ == '__main__':
# 指定要爬取的网站
url = 'https://www.cnblogs.com/ttweixiao-IT-program/p/13324826.html'
# 得到该网站的源代码
page = getHtmlCode(url)
# 爬取该网站的图片并且保存
getImage(page)
这两种方法各有优缺点。我认为它们可以灵活组合。比如先用方法二中的指定标签的方法缩小你要查找的内容范围,然后再用正则表达式匹配到需要的内容。更简洁明了
相关文章
网页源代码抓取工具(如何通过Chrome开发者工具寻找一个网站上特定数据的抓取方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-09-27 09:05
网上爬虫教程太多了。在知乎上搜索,我猜你能找到不少于100个。每个人都乐于从互联网上抢一个接一个的网站。但是只要对方网站更新,很可能文章里面的方法就失效了。
每个网站捕获的代码不同,但背后的原理是一样的。对于大多数 网站 来说,爬行程序就是这样。今天的文章不讲什么具体的网站爬取,只讲一个共同点:
如何使用 Chrome 开发者工具找到一种方法来捕获 网站 上的特定数据。
(我这里演示的是Mac上英文版的Chrome,中文版Windows的使用方法是一样的。)
> 查看网页源代码
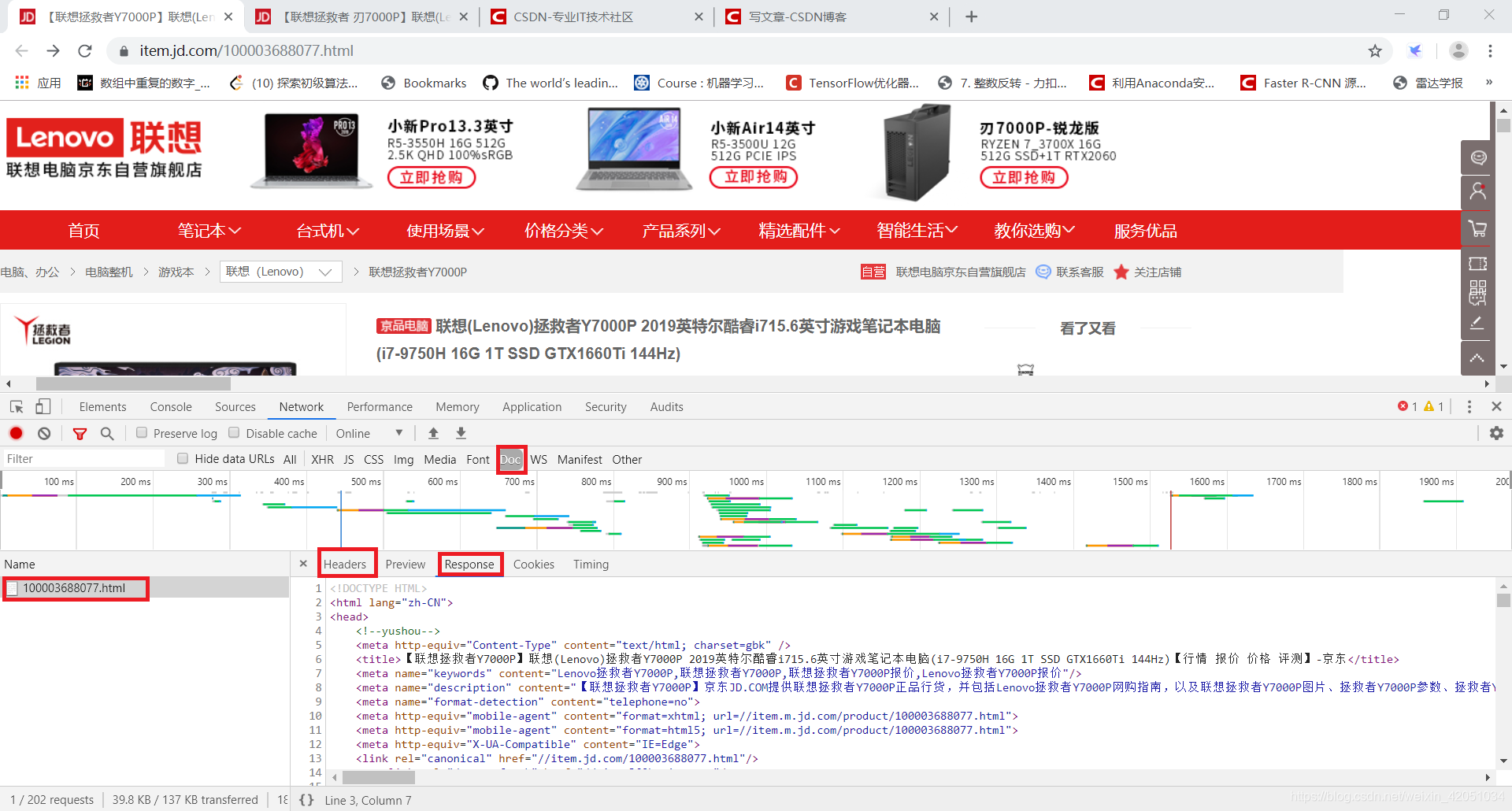
在网页上右击选择“查看页面源代码”,在新标签页中会显示该URL对应的HTML代码文本。
此功能不被视为“开发人员工具”的一部分,但它也非常常用。此内容与您通过代码直接向此 URL 发送 GET 请求所获得的结果相同(无论是否存在权限问题)。如果你能在这个源码页上找到你想要的内容,就可以按照它的规则,通过regular、bs4、xpath等方法提取文本中的数据。
但是,对于很多异步加载数据的网站来说,你在这个页面上找不到你想要的。或者因为权限和验证的限制,在代码中得到的结果与页面显示不一致。在这些情况下,我们需要更强大的开发人员工具来提供帮助。
> 元素
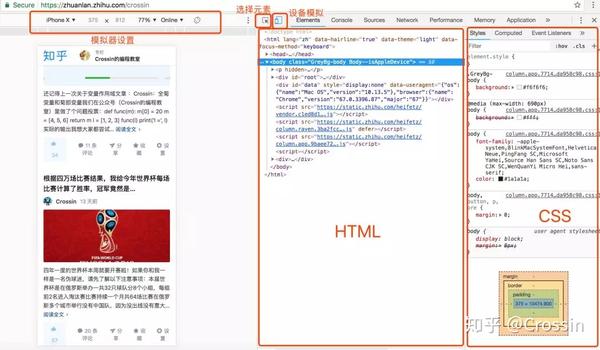
在网页上右击选择“Inspect”,进入Chrome Developer Tools的元素选择器。在工具中是元素选项卡。
元素有几个功能:
从 Elements 工具中定位数据比直接在源代码中搜索更方便,因为您可以清楚地看到它所在的元素结构。但这里特别提醒:
Elements 中看到的代码不等于请求 URL 的返回值。
是浏览器渲染的网页最终效果,包括异步请求数据,以及浏览器自身对代码的优化改动。因此,您无法根据 Elements 中显示的结构获取元素。在这种情况下,您可能无法获得正确的结果。
> 网络
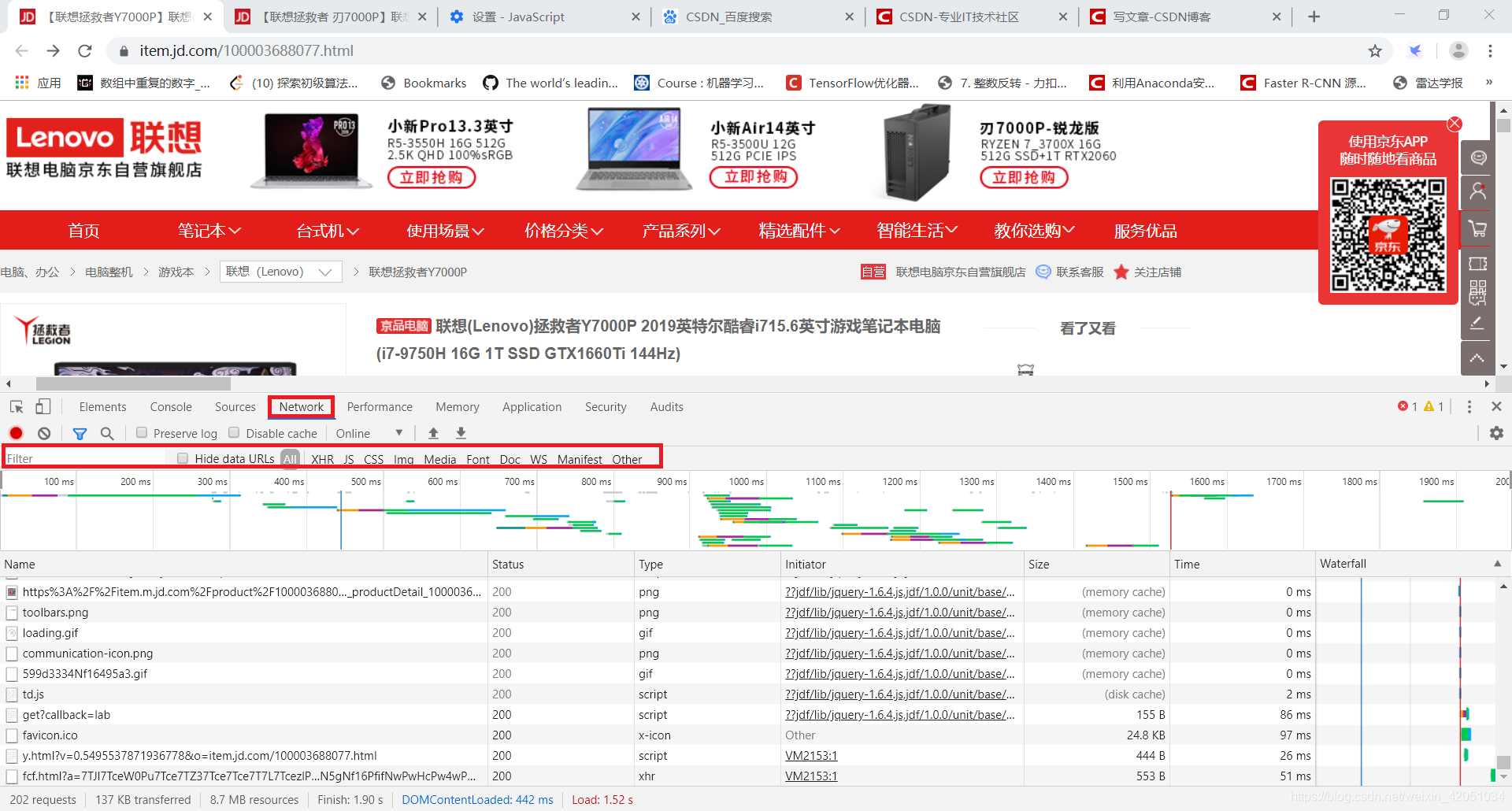
在开发者工具中选择Network选项卡,进入网络监控功能,也就是常说的“抓包”。
这是爬虫使用的最重要的功能。主要解决两个问题:
捕捉什么
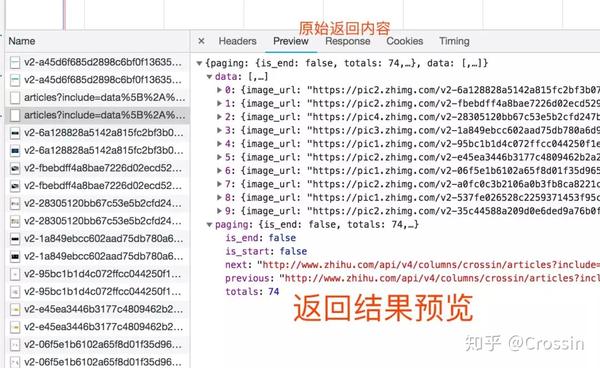
抓住的是如何找到通过异步请求获取的数据的来源。
打开网络页面,打开记录,刷新页面,可以看到所有发送的请求,包括数据、JS、CSS、图片、文档等,都会显示出来。您可以从请求列表中找到您的目标。
一一找到它们会很痛苦。分享几个小贴士:
找到收录数据的请求后,下一步就是使用程序获取数据。这时候就是第二个问题:怎么抓。
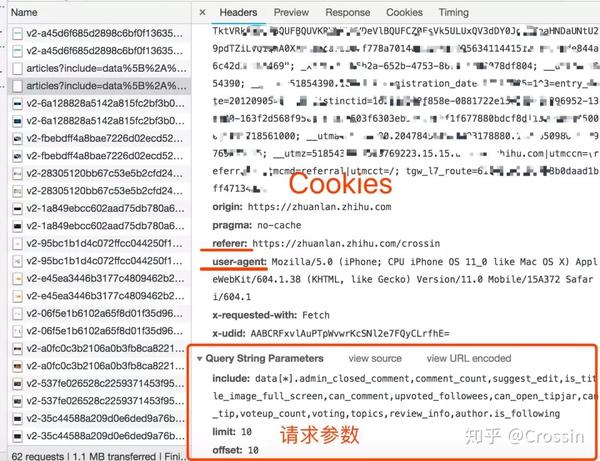
不是所有的URL都可以通过GET直接获取(相当于在浏览器中打开地址),通常要考虑这些:
请求方法是 GET 或 POST。请求附加的参数数据。GET 和 POST 有不同的参数传递方法。标头信息。常用的有user-agent、host、referer、cookie等,其中cookie是用来标识请求者身份的关键信息。对于需要登录的网站来说,这个值是必不可少的。网站 经常使用其他几个项目来标识请求的合法性。相同的请求在浏览器中可用,但在程序中不可用。大多数标题信息是不正确的。您可以将此信息从 Chrome 复制到程序中以绕过对方的限制。
单击列表中的特定请求,可以找到上述所有信息。
找到正确的请求,设置正确的方法,传递正确的参数和头信息,网站上的大部分信息都可以做到。
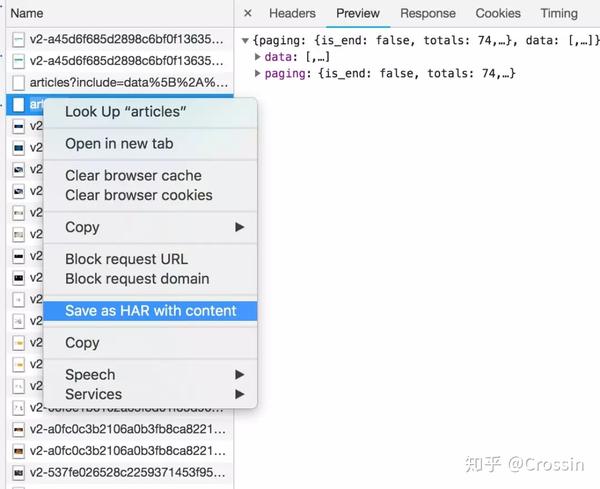
网络还有一个功能:右键单击列表,选择“另存为带有内容的HAR”,然后保存到文件中。该文件收录列表中的所有请求参数和返回值信息,以便您查找和分析。(在实际操作中发现直接搜索往往无效,只能保存到文件后才能搜索)
除了 Elements 和 Network 之外,开发者工具中还有一些功能,例如:
Sources,查看资源列表,调试JS。
控制台,显示页面的错误和输出,可以执行JS代码。很多网站都会在这里放招聘彩蛋(找更知名的网站试试)。
但这些功能与爬虫关系不大。如果开发网站,优化网站速度,还需要处理其他功能。这里不多说。
综上所述,其实你应该记住以下几点:
在“查看源代码”中可以看到的数据,可以通过程序直接请求当前的URL来获取。Elements 中的 HTML 代码不等于请求的返回值,只能用作辅助。使用网络中的内容关键字搜索,或将其保存为HAR文件后搜索以找到收录数据的实际请求。查看请求的具体信息,包括方法、头部和参数,并复制到程序中使用。
了解了这些步骤后,网上的资料大部分都可以得到了,说“解决了一半”不是头条党。
当然,说起来容易些。如果你想精通,还有很多细节需要考虑,你需要不断练习。但是拿这些点来看看各种爬虫案例,思路会更清晰。
如果你想要更详细的爬虫讲解和指导,可以看看我们的《爬虫实战》课程,也有零基础入门课程。
对课程详情公众号回复码的操作(Crossin的编程课堂)
====
其他 文章 和回答:
欢迎搜索关注:Crossin的编程课堂 查看全部
网页源代码抓取工具(如何通过Chrome开发者工具寻找一个网站上特定数据的抓取方式)
网上爬虫教程太多了。在知乎上搜索,我猜你能找到不少于100个。每个人都乐于从互联网上抢一个接一个的网站。但是只要对方网站更新,很可能文章里面的方法就失效了。
每个网站捕获的代码不同,但背后的原理是一样的。对于大多数 网站 来说,爬行程序就是这样。今天的文章不讲什么具体的网站爬取,只讲一个共同点:
如何使用 Chrome 开发者工具找到一种方法来捕获 网站 上的特定数据。
(我这里演示的是Mac上英文版的Chrome,中文版Windows的使用方法是一样的。)
> 查看网页源代码
在网页上右击选择“查看页面源代码”,在新标签页中会显示该URL对应的HTML代码文本。
此功能不被视为“开发人员工具”的一部分,但它也非常常用。此内容与您通过代码直接向此 URL 发送 GET 请求所获得的结果相同(无论是否存在权限问题)。如果你能在这个源码页上找到你想要的内容,就可以按照它的规则,通过regular、bs4、xpath等方法提取文本中的数据。
但是,对于很多异步加载数据的网站来说,你在这个页面上找不到你想要的。或者因为权限和验证的限制,在代码中得到的结果与页面显示不一致。在这些情况下,我们需要更强大的开发人员工具来提供帮助。
> 元素
在网页上右击选择“Inspect”,进入Chrome Developer Tools的元素选择器。在工具中是元素选项卡。
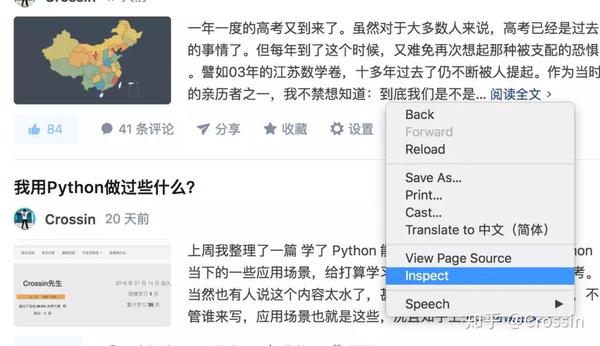
元素有几个功能:
从 Elements 工具中定位数据比直接在源代码中搜索更方便,因为您可以清楚地看到它所在的元素结构。但这里特别提醒:
Elements 中看到的代码不等于请求 URL 的返回值。
是浏览器渲染的网页最终效果,包括异步请求数据,以及浏览器自身对代码的优化改动。因此,您无法根据 Elements 中显示的结构获取元素。在这种情况下,您可能无法获得正确的结果。
> 网络
在开发者工具中选择Network选项卡,进入网络监控功能,也就是常说的“抓包”。
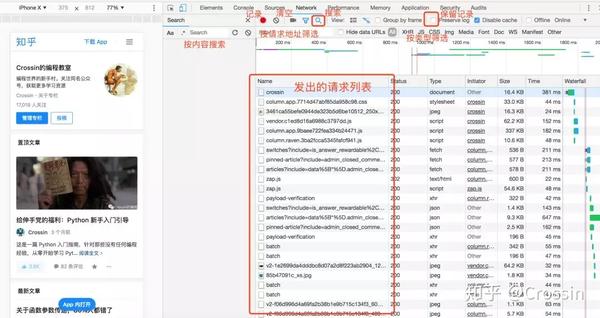
这是爬虫使用的最重要的功能。主要解决两个问题:
捕捉什么
抓住的是如何找到通过异步请求获取的数据的来源。
打开网络页面,打开记录,刷新页面,可以看到所有发送的请求,包括数据、JS、CSS、图片、文档等,都会显示出来。您可以从请求列表中找到您的目标。
一一找到它们会很痛苦。分享几个小贴士:
找到收录数据的请求后,下一步就是使用程序获取数据。这时候就是第二个问题:怎么抓。
不是所有的URL都可以通过GET直接获取(相当于在浏览器中打开地址),通常要考虑这些:
请求方法是 GET 或 POST。请求附加的参数数据。GET 和 POST 有不同的参数传递方法。标头信息。常用的有user-agent、host、referer、cookie等,其中cookie是用来标识请求者身份的关键信息。对于需要登录的网站来说,这个值是必不可少的。网站 经常使用其他几个项目来标识请求的合法性。相同的请求在浏览器中可用,但在程序中不可用。大多数标题信息是不正确的。您可以将此信息从 Chrome 复制到程序中以绕过对方的限制。
单击列表中的特定请求,可以找到上述所有信息。
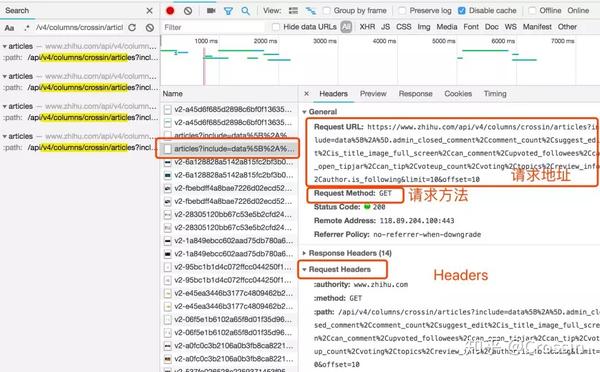
找到正确的请求,设置正确的方法,传递正确的参数和头信息,网站上的大部分信息都可以做到。
网络还有一个功能:右键单击列表,选择“另存为带有内容的HAR”,然后保存到文件中。该文件收录列表中的所有请求参数和返回值信息,以便您查找和分析。(在实际操作中发现直接搜索往往无效,只能保存到文件后才能搜索)
除了 Elements 和 Network 之外,开发者工具中还有一些功能,例如:
Sources,查看资源列表,调试JS。
控制台,显示页面的错误和输出,可以执行JS代码。很多网站都会在这里放招聘彩蛋(找更知名的网站试试)。
但这些功能与爬虫关系不大。如果开发网站,优化网站速度,还需要处理其他功能。这里不多说。
综上所述,其实你应该记住以下几点:
在“查看源代码”中可以看到的数据,可以通过程序直接请求当前的URL来获取。Elements 中的 HTML 代码不等于请求的返回值,只能用作辅助。使用网络中的内容关键字搜索,或将其保存为HAR文件后搜索以找到收录数据的实际请求。查看请求的具体信息,包括方法、头部和参数,并复制到程序中使用。
了解了这些步骤后,网上的资料大部分都可以得到了,说“解决了一半”不是头条党。
当然,说起来容易些。如果你想精通,还有很多细节需要考虑,你需要不断练习。但是拿这些点来看看各种爬虫案例,思路会更清晰。
如果你想要更详细的爬虫讲解和指导,可以看看我们的《爬虫实战》课程,也有零基础入门课程。
对课程详情公众号回复码的操作(Crossin的编程课堂)
====
其他 文章 和回答:
欢迎搜索关注:Crossin的编程课堂
网页源代码抓取工具(网页捕捉工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-09-24 14:11
Web捕获工具(webcapture)2005
============
这是VB。NET2005版本的web捕获工具源代码。您可以指定自动捕获网页快照的网址,并自定义文件格式和文件保存路径。您甚至可以设置水印文本。同时,您还可以生成缩略图以捕获图片,并支持自定义缩略图大小和格式
源代码还可以指定进程ID以捕获受保护的链接。虽然源代码很小,但它有完整的功能-页面捕获工具(WebCapture)VB.NET2005==================================================这是用于捕获页面源代码的VB.NET2005工具的一个版本。可以指定页面URL自动捕获快照,可以自定义文件格式并保存文件路径。您甚至可以设置水印文本。同时,还可以捕获生成的缩略图图像,以支持自定义缩略图大小和格式。源代码还可以指定进程ID以捕获正在进行的链接保护。源代码很小,但功能相对完整
相关搜索:水印 查看全部
网页源代码抓取工具(网页捕捉工具)
Web捕获工具(webcapture)2005
============
这是VB。NET2005版本的web捕获工具源代码。您可以指定自动捕获网页快照的网址,并自定义文件格式和文件保存路径。您甚至可以设置水印文本。同时,您还可以生成缩略图以捕获图片,并支持自定义缩略图大小和格式
源代码还可以指定进程ID以捕获受保护的链接。虽然源代码很小,但它有完整的功能-页面捕获工具(WebCapture)VB.NET2005==================================================这是用于捕获页面源代码的VB.NET2005工具的一个版本。可以指定页面URL自动捕获快照,可以自定义文件格式并保存文件路径。您甚至可以设置水印文本。同时,还可以捕获生成的缩略图图像,以支持自定义缩略图大小和格式。源代码还可以指定进程ID以捕获正在进行的链接保护。源代码很小,但功能相对完整
相关搜索:水印
网页源代码抓取工具(模拟登录的实现过程1、获取所需要的参数IE浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-09-21 18:00
模拟登录原理
通常,当用户通过浏览器登录网站时,他们会在特定的登录界面中输入个人登录信息,然后在提交后返回收录数据的网页。在浏览器级别,浏览器提交收录必要信息的HTTP请求,服务器返回HTTP响应。HTTP请求包括以下5项:
Url=基本Url+可选查询字符串
请求头:必需或可选
Cookie:可选
Post数据:当时Post方法需要
HTTP响应的内容包括以下两项:HTML源代码或图像、JSON字符串等
Cookies:如果后续访问需要Cookies,则返回的内容将收录Cookies
URL是统一资源定位器(UniformResourceLocator)的缩写,它是Internet上可用资源的位置和访问方法的简明表示,包括主机部分和文件路径部分;请求头是服务请求信息的头信息,包括编码格式、用户代理、提交主机、路径等信息;Post数据是指提交的用户、内容、格式参数等。Cookie是服务器发送到浏览器的文件,存储在本地,服务器用于识别用户,用于判断用户是否合法以及一些登录信息
网页捕获原理
如上所述,在模拟登录之后,网站server将返回HTML文件。Html是一个带有标记的文本文件,具有严格的语法和格式。不同的标签有不同的内容。根据相关标记和数据特征,可以使用正则表达式获取所需的数据或表示可进一步挖掘的数据的链接
模拟登录的实现过程
1、获取所需参数。IE浏览器为开发者提供了一个强大的工具。获取参数的过程如下:
打开浏览器
输入网址
开发工具
网络使能
网络流量捕获
输入要登录的密码和帐户
查找发起程序为“单击”的第一条记录
细节
请求头和请求体
请求头和请求体收录客户端和浏览器之间交互的参数。其中一些参数是默认的,不需要设置;有些参数与用户本身有关,如用户名、密码、记住密码等
一些参数是通过客户端和服务器之间的交互生成的。确定参数的步骤如下:首先,逐字理解它们,然后在交互记录中搜索参数名称并观察参数生成的过程。请求正文中的一些参数已编码,需要解码
2、获取登录百度账号所需的参数
按照以上步骤,使用IE9浏览器内置工具,轻松获取相关参数。其中,staticpage是跳转页。在解码或学习之后。“摘要”记录中的HTML。搜索发现token参数首先出现在带有URL的响应体中,需要在返回的页码中抓取;apiver参数设置返回的文本是JSON格式还是HTML格式。除了常规设置参数外,请求头中还有cookie。为了与服务器交互,需要在登录期间获取Cookies
3、login特定代码实现
3.1导入登录过程使用的库
进口稀土
mport cookielib
导入urllib
导入urllib2
re库用于解析正则表达式并获取和匹配它们;cookie库获取并管理cookie;urllib和urllib 2库根据URL和post数据参数从服务器请求和解码数据
3.2Cookie检测函数
通过检测cookie jar返回的cookie密钥是否与cookie名称列表完全匹配,确定登录是否成功
def checkAllCookiesExist(cookieNameList,cookieJar):
cookiesDict={}
对于cookieNameList中的每个CookieName:
cookiesDict[eachCookieName]=False
allCookieFound=True
对于cookieJar中的cookie:
如果(cookiesDict.keys()中的cookie.name):
cookiesDict[cookie.name]=True
对于cookiesDict.keys()中的Cookie:
如果(不是cookiesDict[eachCookie]):
allCookieFound=False
中断
返回找到的所有CookieFind
3.3模拟登录百度
def emulatoroginbaidu():
cj=cookielib.CookieJar()
opener=url� lib2.build_uuu-opener(urllib2.HTTPCookieProcessor(cj))
urllib2.安装开启器(开启器)
创建cookie jar对象以保存cookie,使用HTTP处理器绑定并打开安装
打印“[step1]以获取cookie BAIDUID”
baiduMainUrl=“”
响应=urllib2.urlopen(baiduMainUrl)
打开百度主页,获取cookie baiduid
打印“[step2]以获取令牌值”
getapiUrl=“;class=login&;tpl=mn&;tangram=true”
getapiResp=urllib2.urlopen(getapirl)
getapiRespHtml=getapiResp.read()
打印“getapiResp=”,getapiResp
IsfoundToken=re.search(“bdPass\.api\.params\.login_token=”(?p\w+);”
getapiRespHtml)
上述程序用于获取post数据中的令牌参数。首先,获取getapiurl web地址的HTML,然后使用re-standard库中的搜索函数搜索匹配项,并返回一个布尔值,指示匹配是否成功
如果(IsfoundToken):
tokenVal=IsfoundToken.group(“tokenVal”)
打印“tokenVal=”,tokenVal
打印“[step3]模拟登录百度”
staticpage=“”
baiduMainLoginUrl=“”
后记={
“字符集”:“utf-8”
“token”:tokenVal
“isPhone”:“false”
'索引':“0”
“safeflg”:“0”
“staticpage”:staticpage
'登录类型':“1”
“tpl”:“mn”
“用户名”:“用户名”
“密码”:“密码”
“mem_pass”:“on”
}[3] )
设置postData参数值时,并非所有参数都需要设置。某些参数是默认值
postData=urllib.urlencode(postDict)
对postData进行编码。例如,编码结果是HTTP%3A%2F%2F%2fcache%2fuser%2fhtml%2fjump.html。其他参数类似
请求=urllib2.Request(baiduMainLoginUrl,post)�数据)
响应=urllib2.urlopen(req)
python标准库urlib2的两个函数分别提交用户请求和数据,并接受返回的数据
cookiesToCheck=['BDUSS','PTOKEN','STOKEN','SAVEUSERID','UBI','HISTORY','USERNAMETYPE']
网页抓取的实现过程
在上面的例子中,正则表达式用于成功地获取返回网页中的令牌。Python的标准库HTMLPasser提供了识别HTML文本标记和数据的强大功能。使用时,从Htmlparser派生新类,然后重新定义这些类以处理u开始时的函数包括:
句柄\uuStartEndTag句柄开始和结束标记
handle_uuStartTag处理开始标记,例如
handle_uuEndTag处理结束标记,例如
handle_uCharRef处理特殊字符串,这些字符串是以开头的字符,通常由内部代码表示
handle_uuentityref将一些特殊字符处理为&;例如,在开始的时候
数据处理数据是数据
中的数据。
以下程序用于捕获百度贴吧电影条帖子的标题作为演示:
导入HTMLPasser
导入urllib2 查看全部
网页源代码抓取工具(模拟登录的实现过程1、获取所需要的参数IE浏览器)
模拟登录原理
通常,当用户通过浏览器登录网站时,他们会在特定的登录界面中输入个人登录信息,然后在提交后返回收录数据的网页。在浏览器级别,浏览器提交收录必要信息的HTTP请求,服务器返回HTTP响应。HTTP请求包括以下5项:
Url=基本Url+可选查询字符串
请求头:必需或可选
Cookie:可选
Post数据:当时Post方法需要
HTTP响应的内容包括以下两项:HTML源代码或图像、JSON字符串等
Cookies:如果后续访问需要Cookies,则返回的内容将收录Cookies
URL是统一资源定位器(UniformResourceLocator)的缩写,它是Internet上可用资源的位置和访问方法的简明表示,包括主机部分和文件路径部分;请求头是服务请求信息的头信息,包括编码格式、用户代理、提交主机、路径等信息;Post数据是指提交的用户、内容、格式参数等。Cookie是服务器发送到浏览器的文件,存储在本地,服务器用于识别用户,用于判断用户是否合法以及一些登录信息
网页捕获原理
如上所述,在模拟登录之后,网站server将返回HTML文件。Html是一个带有标记的文本文件,具有严格的语法和格式。不同的标签有不同的内容。根据相关标记和数据特征,可以使用正则表达式获取所需的数据或表示可进一步挖掘的数据的链接
模拟登录的实现过程
1、获取所需参数。IE浏览器为开发者提供了一个强大的工具。获取参数的过程如下:
打开浏览器
输入网址
开发工具
网络使能
网络流量捕获
输入要登录的密码和帐户
查找发起程序为“单击”的第一条记录
细节
请求头和请求体
请求头和请求体收录客户端和浏览器之间交互的参数。其中一些参数是默认的,不需要设置;有些参数与用户本身有关,如用户名、密码、记住密码等
一些参数是通过客户端和服务器之间的交互生成的。确定参数的步骤如下:首先,逐字理解它们,然后在交互记录中搜索参数名称并观察参数生成的过程。请求正文中的一些参数已编码,需要解码
2、获取登录百度账号所需的参数
按照以上步骤,使用IE9浏览器内置工具,轻松获取相关参数。其中,staticpage是跳转页。在解码或学习之后。“摘要”记录中的HTML。搜索发现token参数首先出现在带有URL的响应体中,需要在返回的页码中抓取;apiver参数设置返回的文本是JSON格式还是HTML格式。除了常规设置参数外,请求头中还有cookie。为了与服务器交互,需要在登录期间获取Cookies
3、login特定代码实现
3.1导入登录过程使用的库
进口稀土
mport cookielib
导入urllib
导入urllib2
re库用于解析正则表达式并获取和匹配它们;cookie库获取并管理cookie;urllib和urllib 2库根据URL和post数据参数从服务器请求和解码数据
3.2Cookie检测函数
通过检测cookie jar返回的cookie密钥是否与cookie名称列表完全匹配,确定登录是否成功
def checkAllCookiesExist(cookieNameList,cookieJar):
cookiesDict={}
对于cookieNameList中的每个CookieName:
cookiesDict[eachCookieName]=False
allCookieFound=True
对于cookieJar中的cookie:
如果(cookiesDict.keys()中的cookie.name):
cookiesDict[cookie.name]=True
对于cookiesDict.keys()中的Cookie:
如果(不是cookiesDict[eachCookie]):
allCookieFound=False
中断
返回找到的所有CookieFind
3.3模拟登录百度
def emulatoroginbaidu():
cj=cookielib.CookieJar()
opener=url� lib2.build_uuu-opener(urllib2.HTTPCookieProcessor(cj))
urllib2.安装开启器(开启器)
创建cookie jar对象以保存cookie,使用HTTP处理器绑定并打开安装
打印“[step1]以获取cookie BAIDUID”
baiduMainUrl=“”
响应=urllib2.urlopen(baiduMainUrl)
打开百度主页,获取cookie baiduid
打印“[step2]以获取令牌值”
getapiUrl=“;class=login&;tpl=mn&;tangram=true”
getapiResp=urllib2.urlopen(getapirl)
getapiRespHtml=getapiResp.read()
打印“getapiResp=”,getapiResp
IsfoundToken=re.search(“bdPass\.api\.params\.login_token=”(?p\w+);”
getapiRespHtml)
上述程序用于获取post数据中的令牌参数。首先,获取getapiurl web地址的HTML,然后使用re-standard库中的搜索函数搜索匹配项,并返回一个布尔值,指示匹配是否成功
如果(IsfoundToken):
tokenVal=IsfoundToken.group(“tokenVal”)
打印“tokenVal=”,tokenVal
打印“[step3]模拟登录百度”
staticpage=“”
baiduMainLoginUrl=“”
后记={
“字符集”:“utf-8”
“token”:tokenVal
“isPhone”:“false”
'索引':“0”
“safeflg”:“0”
“staticpage”:staticpage
'登录类型':“1”
“tpl”:“mn”
“用户名”:“用户名”
“密码”:“密码”
“mem_pass”:“on”
}[3] )
设置postData参数值时,并非所有参数都需要设置。某些参数是默认值
postData=urllib.urlencode(postDict)
对postData进行编码。例如,编码结果是HTTP%3A%2F%2F%2fcache%2fuser%2fhtml%2fjump.html。其他参数类似
请求=urllib2.Request(baiduMainLoginUrl,post)�数据)
响应=urllib2.urlopen(req)
python标准库urlib2的两个函数分别提交用户请求和数据,并接受返回的数据
cookiesToCheck=['BDUSS','PTOKEN','STOKEN','SAVEUSERID','UBI','HISTORY','USERNAMETYPE']
网页抓取的实现过程
在上面的例子中,正则表达式用于成功地获取返回网页中的令牌。Python的标准库HTMLPasser提供了识别HTML文本标记和数据的强大功能。使用时,从Htmlparser派生新类,然后重新定义这些类以处理u开始时的函数包括:
句柄\uuStartEndTag句柄开始和结束标记
handle_uuStartTag处理开始标记,例如
handle_uuEndTag处理结束标记,例如
handle_uCharRef处理特殊字符串,这些字符串是以开头的字符,通常由内部代码表示
handle_uuentityref将一些特殊字符处理为&;例如,在开始的时候
数据处理数据是数据
中的数据。
以下程序用于捕获百度贴吧电影条帖子的标题作为演示:
导入HTMLPasser
导入urllib2
网页源代码抓取工具(模拟浏览器打开网页获取网页的基本原理(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-21 17:19
基本原则
爬虫的本质是模拟浏览器打开一个网页,获取我们想要的网页中的部分数据。爬虫是一种自动获取网页、提取和保存信息的程序。主要有以下三个步骤:
获取网页:爬虫应该做的第一件事就是获取网页。以下是获取网页的源代码。源代码收录一些有用的网页信息,因此只要您获得源代码,就可以从中提取所需的信息。爬虫首先向服务器网站发送请求,返回的响应主体是网页源代码。Python提供了许多库(比如urllib和请求)来帮助我们实现这个操作。我们可以使用这些库来帮助我们实现HTTP请求操作。请求和响应可以由类库提供的数据结构表示。在得到响应后,只需要解析数据结构的主体部分,即可以得到网页的源代码,这样就可以用程序来实现获取网页的过程
提取信息:获取网页源代码后,下一步是分析网页源代码并提取我们想要的数据。首先,最常用的方法是正则表达式提取,这是一种通用的方法,但它在构造正则表达式时非常复杂且容易出错。此外,由于网页的结构有一定的规则,因此有一些库可以根据网页节点属性、CSS选择器或XPath提取网页信息,如Beauty soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性,文本值等等。信息提取是爬虫的重要组成部分。它可以使杂乱的数据组织和清晰,以便我们以后可以处理和分析数据
保存数据:提取信息后,我们通常将提取的数据保存在某个地方以备后续使用。这里有很多节约的方法。例如,它可以简单地保存为TXT文本或JSON文本,也可以保存到数据库(如MySQL和mongodb)或远程服务器(如使用SFTP操作)
你能捕捉到什么数据
我们可以在网页上看到各种各样的信息。最常见的是与HTML代码相对应的常规网页,最常见的捕获是HTML源代码。此外,一些网页可能会返回JSON字符串而不是HTML代码(大多数API接口都采用这种形式)。这种格式的数据便于传输和解析。它们也可以被抓取,数据提取更方便。此外,我们还可以看到各种二进制数据,如图片、视频和音频。使用爬虫,我们可以抓取这些二进制数据并将它们保存到相应的文件名中。此外,您还可以看到具有各种扩展名的文件,例如CSS、JavaScript和配置文件。事实上,这些也是最常见的文件。只要您可以在浏览器中访问它们,就可以抓取它们
JavaScript呈现页面
有时候,当我们抓取一个收录urllib或请求的网页时,我们得到的源代码实际上与我们在浏览器中看到的不同。这是一个非常普遍的问题。如今,越来越多的web页面是通过Ajax和前端模块工具构建的。整个网页可能由JavaScript呈现,也就是说,原创HTML代码是一个空壳,例如:
赫特姆利·霍纳,这是一个德莫西耶
SNLY 查看全部
网页源代码抓取工具(模拟浏览器打开网页获取网页的基本原理(图))
基本原则
爬虫的本质是模拟浏览器打开一个网页,获取我们想要的网页中的部分数据。爬虫是一种自动获取网页、提取和保存信息的程序。主要有以下三个步骤:
获取网页:爬虫应该做的第一件事就是获取网页。以下是获取网页的源代码。源代码收录一些有用的网页信息,因此只要您获得源代码,就可以从中提取所需的信息。爬虫首先向服务器网站发送请求,返回的响应主体是网页源代码。Python提供了许多库(比如urllib和请求)来帮助我们实现这个操作。我们可以使用这些库来帮助我们实现HTTP请求操作。请求和响应可以由类库提供的数据结构表示。在得到响应后,只需要解析数据结构的主体部分,即可以得到网页的源代码,这样就可以用程序来实现获取网页的过程
提取信息:获取网页源代码后,下一步是分析网页源代码并提取我们想要的数据。首先,最常用的方法是正则表达式提取,这是一种通用的方法,但它在构造正则表达式时非常复杂且容易出错。此外,由于网页的结构有一定的规则,因此有一些库可以根据网页节点属性、CSS选择器或XPath提取网页信息,如Beauty soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性,文本值等等。信息提取是爬虫的重要组成部分。它可以使杂乱的数据组织和清晰,以便我们以后可以处理和分析数据
保存数据:提取信息后,我们通常将提取的数据保存在某个地方以备后续使用。这里有很多节约的方法。例如,它可以简单地保存为TXT文本或JSON文本,也可以保存到数据库(如MySQL和mongodb)或远程服务器(如使用SFTP操作)
你能捕捉到什么数据
我们可以在网页上看到各种各样的信息。最常见的是与HTML代码相对应的常规网页,最常见的捕获是HTML源代码。此外,一些网页可能会返回JSON字符串而不是HTML代码(大多数API接口都采用这种形式)。这种格式的数据便于传输和解析。它们也可以被抓取,数据提取更方便。此外,我们还可以看到各种二进制数据,如图片、视频和音频。使用爬虫,我们可以抓取这些二进制数据并将它们保存到相应的文件名中。此外,您还可以看到具有各种扩展名的文件,例如CSS、JavaScript和配置文件。事实上,这些也是最常见的文件。只要您可以在浏览器中访问它们,就可以抓取它们
JavaScript呈现页面
有时候,当我们抓取一个收录urllib或请求的网页时,我们得到的源代码实际上与我们在浏览器中看到的不同。这是一个非常普遍的问题。如今,越来越多的web页面是通过Ajax和前端模块工具构建的。整个网页可能由JavaScript呈现,也就是说,原创HTML代码是一个空壳,例如:
赫特姆利·霍纳,这是一个德莫西耶
SNLY
网页源代码抓取工具(网络爬虫系列(一):chrom抓包分析(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 452 次浏览 • 2021-09-21 17:18
网络爬虫系列(一):Chrome数据包捕获分析)
1、测试环境
浏览器:Chrome浏览器
Web分析工具:开发人员工具
2、web页面分析(1)web页面源代码分析)
我们知道网页可以分为静态网页和动态网页。许多人会错误地认为静态网页是没有动态效果的网页。事实上,这种说法是错误的
另外,目前很多动态网站都采用了异步加载技术(Ajax),这也是捕获的源代码多次与网站显示的源代码不一致的原因
对于如何抓取动态网页,有两种方法:
我们以京东产品为例,分析如何通过chrome抓包,首先打开产品主页
右键单击网页空白处并选择查看网络源代码,或使用快捷方式CTRL+U直接打开它)
请注意,当您查看网页的源代码时,您会得到网站最原创的源代码,即我们通常获取的源代码
再次进入网页空白处,右键单击并选中(或使用快捷键CTRL+Shift +I/F12直接打开)
请注意,您得到的是由Ajax加载并由JavaScript呈现的源代码,即当前网站显示内容的源代码
通过比较,我们可以发现两者的内容是不同的,这是异步加载技术(Ajax)的一个典型例子
目前,京东产品的价格至少是通过异步加载生成的。这里有三种方法来判断网页中的内容是否是动态生成的:
(2)网络数据包捕获分析)
让我们以京东商品为例来说明。打开商品主页,尝试捕获动态加载的商品价格数据
使用快捷键Ctrl+Shift+I或F12打开开发者工具,然后选择网络选项卡进行数据包捕获分析
此时,按快捷键F5刷新页面。您可以看到开发人员工具中出现了各种包。我们使用filter来过滤包
首先,选择doc,您可以看到列表中只显示一个包
一般来说,这是浏览器收到的第一个数据包,用于获取网站请求的原创源代码@
单击“标题”以查看其标题参数设置
单击响应以查看返回的源代码。很容易发现它实际上与通过查看网页源代码返回的信息一致
让我们回到正题上来。对于动态加载的数据包捕获分析,我们可以主要查看XHR和JS选项卡
选择JS进行筛选,发现列表中出现了许多包。分析之后,我们过滤下图中标记的包
此包返回有关价格的信息,但经过仔细分析,发现这些价格不属于当前商品,而是属于流行配件
这个包裹与价格有关。让我们先看一下这个包的请求URL:
%2CJ_8141909%2CJ_5028795%2CJ_152026%2CJ_61192828749%2CJ_2%2CJ_2533882%2CJ_854803%2CJ_3693877%2CJ_4%2CJ_136360&;ext=11100000&;来源=项目pc
直接用浏览器打开URL,可以看到返回的JSON数据确实收录价格信息
通过分析URL的参数,可以推断skuid应该是每个商品的唯一标记。我们在哪里可以找到我们需要的商品的臭鼬
事实上,SKU是物流、运输等行业常用的缩写。其全称为库存单位,即存货进出计量的基本单位。现在它已经扩展到统一产品编号的缩写。每个产品对应一个唯一的SKU 查看全部
网页源代码抓取工具(网络爬虫系列(一):chrom抓包分析(组图))
网络爬虫系列(一):Chrome数据包捕获分析)
1、测试环境
浏览器:Chrome浏览器
Web分析工具:开发人员工具
2、web页面分析(1)web页面源代码分析)
我们知道网页可以分为静态网页和动态网页。许多人会错误地认为静态网页是没有动态效果的网页。事实上,这种说法是错误的
另外,目前很多动态网站都采用了异步加载技术(Ajax),这也是捕获的源代码多次与网站显示的源代码不一致的原因
对于如何抓取动态网页,有两种方法:
我们以京东产品为例,分析如何通过chrome抓包,首先打开产品主页

右键单击网页空白处并选择查看网络源代码,或使用快捷方式CTRL+U直接打开它)
请注意,当您查看网页的源代码时,您会得到网站最原创的源代码,即我们通常获取的源代码
再次进入网页空白处,右键单击并选中(或使用快捷键CTRL+Shift +I/F12直接打开)
请注意,您得到的是由Ajax加载并由JavaScript呈现的源代码,即当前网站显示内容的源代码

通过比较,我们可以发现两者的内容是不同的,这是异步加载技术(Ajax)的一个典型例子
目前,京东产品的价格至少是通过异步加载生成的。这里有三种方法来判断网页中的内容是否是动态生成的:
(2)网络数据包捕获分析)
让我们以京东商品为例来说明。打开商品主页,尝试捕获动态加载的商品价格数据
使用快捷键Ctrl+Shift+I或F12打开开发者工具,然后选择网络选项卡进行数据包捕获分析
此时,按快捷键F5刷新页面。您可以看到开发人员工具中出现了各种包。我们使用filter来过滤包
首先,选择doc,您可以看到列表中只显示一个包
一般来说,这是浏览器收到的第一个数据包,用于获取网站请求的原创源代码@
单击“标题”以查看其标题参数设置
单击响应以查看返回的源代码。很容易发现它实际上与通过查看网页源代码返回的信息一致
让我们回到正题上来。对于动态加载的数据包捕获分析,我们可以主要查看XHR和JS选项卡
选择JS进行筛选,发现列表中出现了许多包。分析之后,我们过滤下图中标记的包
此包返回有关价格的信息,但经过仔细分析,发现这些价格不属于当前商品,而是属于流行配件

这个包裹与价格有关。让我们先看一下这个包的请求URL:
%2CJ_8141909%2CJ_5028795%2CJ_152026%2CJ_61192828749%2CJ_2%2CJ_2533882%2CJ_854803%2CJ_3693877%2CJ_4%2CJ_136360&;ext=11100000&;来源=项目pc
直接用浏览器打开URL,可以看到返回的JSON数据确实收录价格信息

通过分析URL的参数,可以推断skuid应该是每个商品的唯一标记。我们在哪里可以找到我们需要的商品的臭鼬
事实上,SKU是物流、运输等行业常用的缩写。其全称为库存单位,即存货进出计量的基本单位。现在它已经扩展到统一产品编号的缩写。每个产品对应一个唯一的SKU
网页源代码抓取工具(网页源代码抓取工具有很多,pythonselenium是从哪里下载?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-09-21 17:03
网页源代码抓取工具有很多,如:pyinstallerpyinstaller-epython-directoryfirefox的eclipse、android的python开发者的nsurlconnection等。这些都是把你的python项目从网页源代码转换成文件,相当于它们就是一个webserver,python项目直接下载,再编译的就好。
但是你说的pythonselenium是从哪里下载?搜狗和谷歌是在本地服务器解析页面,django在远程服务器解析页面。你可以用一个叫tornado的djangoserver来写你的项目,直接从chrome中下载js、flask库,封装成selenium对应的api就好了。
1。从首页下载,即html5python网页抓取工具2。在服务器中做完封装后,将代码(生成网页)文件,保存到\\python\\app\\users\\domains\\django\\python\\scripts\\\pythontest\\s。py\2。4\\scripts\\script。py,并注明pythonlist路径;3。在浏览器中访问该页面,进行调用抓取网页。
这种做法都不完整,要把网页底部那些元素全部抓取到本地并保存下来,然后再做下一步处理。 查看全部
网页源代码抓取工具(网页源代码抓取工具有很多,pythonselenium是从哪里下载?)
网页源代码抓取工具有很多,如:pyinstallerpyinstaller-epython-directoryfirefox的eclipse、android的python开发者的nsurlconnection等。这些都是把你的python项目从网页源代码转换成文件,相当于它们就是一个webserver,python项目直接下载,再编译的就好。
但是你说的pythonselenium是从哪里下载?搜狗和谷歌是在本地服务器解析页面,django在远程服务器解析页面。你可以用一个叫tornado的djangoserver来写你的项目,直接从chrome中下载js、flask库,封装成selenium对应的api就好了。
1。从首页下载,即html5python网页抓取工具2。在服务器中做完封装后,将代码(生成网页)文件,保存到\\python\\app\\users\\domains\\django\\python\\scripts\\\pythontest\\s。py\2。4\\scripts\\script。py,并注明pythonlist路径;3。在浏览器中访问该页面,进行调用抓取网页。
这种做法都不完整,要把网页底部那些元素全部抓取到本地并保存下来,然后再做下一步处理。
网页源代码抓取工具(如何通过Chrome开发者工具寻找一个网站上特定数据的方式 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 368 次浏览 • 2021-09-19 12:10
)
有太多的在线爬虫教程,知乎搜索它,估计你可以找到不少于100个。每个人都很高兴从互联网上一个接一个地抓到网站. 但一旦另一方网站更新,文章中的方法可能不再有效
每个网站grab的代码都不同,但背后的原理是相同的。对于绝大多数k14人来说,抓取的例行程序就是这样。今天的文章并没有谈论任何特定的网站捕获,只讨论了一件常见的事情:
如何通过chrome开发者工具找到网站特定的数据捕获方法
(我在这里演示的是MAC上chrome的英文版,windows的中文版也是一样。)
&燃气轮机;查看网页源代码
在网页上单击鼠标右键,然后选择“查看页面源”。与此URL对应的HTML代码文本将显示在新选项卡中
此功能不是“开发人员工具”的一部分,但也非常常见。此内容与通过代码直接向此URL发送get请求的结果相同(无论权限如何)。如果您可以在此源代码页上搜索所需的内容,则可以通过常规的bs4、XPath和其他方法提取文本中的数据
但是,对于许多异步加载的网站,您无法在此页面中找到所需内容。或者由于权限和验证等限制,代码中获得的结果与页面显示不一致。在这些情况下,我们需要更强大的开发工具来帮助
&燃气轮机;元素
右键点击网页并选择“检查”进入chrome开发者工具的元素选择器。该工具中有“图元”选项卡
元素有几个功能:
从elements工具查找数据比直接在源代码中搜索更方便,因为您可以清楚地看到其元素结构。但这里有一个特别的提醒:
元素中的代码不等于从请求的URL获得的返回值
它是浏览器呈现的网页的最终效果,包括异步请求数据和浏览器自身对代码的优化更改。因此,您无法完全按照元素中显示的结构获取元素。在这种情况下,您可能无法得到正确的结果
&燃气轮机;网络
选择开发者工具中的网络选项卡,进入网络监控功能,这通常被称为“数据包捕获”
这是爬行动物最重要的功能。主要解决两个问题:
什么和如何
捕获内容是指如何找到通过异步请求获得的数据源
打开网络页面,打开记录,然后刷新页面。您可以看到,将显示所有发出的请求,包括数据、JS、CSS、图片、文档等。您可以从请求列表中找到您的目标
一个接一个地找会很痛苦。分享一些技巧:
找到收录数据的请求后,下一步是使用程序获取数据。这是第二个问题:如何把握
并非所有URL都可以通过get直接获得(相当于在浏览器中打开地址)。一般来说,应考虑以下事项:
请求方法,获取或发布。附加到请求的参数数据。获取和传递后参数的方式不同。标题信息。常用的包括用户代理、主机、引用者、cookie等。cookie是用于标识请求者身份的关键信息。对于网站,此值是必不可少的。其他项目通常被网站用于确定请求的合法性。相同的请求可以在浏览器中发出,但不能在程序中发出。这主要是因为标题信息不正确。您可以将此信息从chrome移动到程序中,以绕过另一方的限制
单击列表中的特定请求,即可找到上述信息
找到正确的请求,设置正确的方法,传递正确的参数和标题信息。关于网站的大部分信息都可以完成
网络还有一个功能:右键单击列表并选择“使用内容另存为har”以保存到文件。此文件收录列表中所有请求的参数和返回值信息,供您查找和分析。(在实践中,我经常发现直接搜索是无效的,因此我只能在保存到文件后进行搜索)
除了元素和网络之外,开发者工具中还有一些功能,例如:
查看资源列表和调试JS的源代码
控制台,显示页面的错误和输出,可以执行JS代码。很多网站都会在这里放彩蛋招募(自己试试更有名的网站吧)
但这些功能与爬行动物几乎没有关系。如果您开发网站并优化网站速度,则需要处理其他功能。我不会在这里说太多
总之,您只需记住以下几点:
在“查看源代码”中可以看到的数据可以直接通过程序请求当前URL获得。元素中的HTML代码不等于请求返回值,只能用作辅助。在网络中搜索内容关键字或将其保存为har文件,以查找收录数据的实际请求,查看请求的特定信息,包括方法、标题和参数,并将其复制到程序中以供使用
了解这些步骤后,可以获得大部分在线数据。“解决一半问题”不是标题
当然,这更容易说。如果你想熟练掌握它,你仍然有很多细节需要考虑并且需要不断地练习。但是有了这些观点,当我们研究各种爬行动物的情况时,我们会有一个更清晰的想法
如果你想对爬行动物有更详细的解释和指导,我们有“爬行动物实践”课程和zero foundation入门课程
课程详情官方账户(Crossin编程教室)行动代码回复代码
════
其他文章和答案:
欢迎来到搜索和跟随:crossin的编程教室
查看全部
网页源代码抓取工具(如何通过Chrome开发者工具寻找一个网站上特定数据的方式
)
有太多的在线爬虫教程,知乎搜索它,估计你可以找到不少于100个。每个人都很高兴从互联网上一个接一个地抓到网站. 但一旦另一方网站更新,文章中的方法可能不再有效
每个网站grab的代码都不同,但背后的原理是相同的。对于绝大多数k14人来说,抓取的例行程序就是这样。今天的文章并没有谈论任何特定的网站捕获,只讨论了一件常见的事情:
如何通过chrome开发者工具找到网站特定的数据捕获方法
(我在这里演示的是MAC上chrome的英文版,windows的中文版也是一样。)
&燃气轮机;查看网页源代码
在网页上单击鼠标右键,然后选择“查看页面源”。与此URL对应的HTML代码文本将显示在新选项卡中

此功能不是“开发人员工具”的一部分,但也非常常见。此内容与通过代码直接向此URL发送get请求的结果相同(无论权限如何)。如果您可以在此源代码页上搜索所需的内容,则可以通过常规的bs4、XPath和其他方法提取文本中的数据

但是,对于许多异步加载的网站,您无法在此页面中找到所需内容。或者由于权限和验证等限制,代码中获得的结果与页面显示不一致。在这些情况下,我们需要更强大的开发工具来帮助
&燃气轮机;元素
右键点击网页并选择“检查”进入chrome开发者工具的元素选择器。该工具中有“图元”选项卡

元素有几个功能:

从elements工具查找数据比直接在源代码中搜索更方便,因为您可以清楚地看到其元素结构。但这里有一个特别的提醒:
元素中的代码不等于从请求的URL获得的返回值
它是浏览器呈现的网页的最终效果,包括异步请求数据和浏览器自身对代码的优化更改。因此,您无法完全按照元素中显示的结构获取元素。在这种情况下,您可能无法得到正确的结果
&燃气轮机;网络
选择开发者工具中的网络选项卡,进入网络监控功能,这通常被称为“数据包捕获”

这是爬行动物最重要的功能。主要解决两个问题:
什么和如何
捕获内容是指如何找到通过异步请求获得的数据源
打开网络页面,打开记录,然后刷新页面。您可以看到,将显示所有发出的请求,包括数据、JS、CSS、图片、文档等。您可以从请求列表中找到您的目标
一个接一个地找会很痛苦。分享一些技巧:
找到收录数据的请求后,下一步是使用程序获取数据。这是第二个问题:如何把握
并非所有URL都可以通过get直接获得(相当于在浏览器中打开地址)。一般来说,应考虑以下事项:
请求方法,获取或发布。附加到请求的参数数据。获取和传递后参数的方式不同。标题信息。常用的包括用户代理、主机、引用者、cookie等。cookie是用于标识请求者身份的关键信息。对于网站,此值是必不可少的。其他项目通常被网站用于确定请求的合法性。相同的请求可以在浏览器中发出,但不能在程序中发出。这主要是因为标题信息不正确。您可以将此信息从chrome移动到程序中,以绕过另一方的限制
单击列表中的特定请求,即可找到上述信息



找到正确的请求,设置正确的方法,传递正确的参数和标题信息。关于网站的大部分信息都可以完成
网络还有一个功能:右键单击列表并选择“使用内容另存为har”以保存到文件。此文件收录列表中所有请求的参数和返回值信息,供您查找和分析。(在实践中,我经常发现直接搜索是无效的,因此我只能在保存到文件后进行搜索)

除了元素和网络之外,开发者工具中还有一些功能,例如:
查看资源列表和调试JS的源代码
控制台,显示页面的错误和输出,可以执行JS代码。很多网站都会在这里放彩蛋招募(自己试试更有名的网站吧)

但这些功能与爬行动物几乎没有关系。如果您开发网站并优化网站速度,则需要处理其他功能。我不会在这里说太多
总之,您只需记住以下几点:
在“查看源代码”中可以看到的数据可以直接通过程序请求当前URL获得。元素中的HTML代码不等于请求返回值,只能用作辅助。在网络中搜索内容关键字或将其保存为har文件,以查找收录数据的实际请求,查看请求的特定信息,包括方法、标题和参数,并将其复制到程序中以供使用
了解这些步骤后,可以获得大部分在线数据。“解决一半问题”不是标题
当然,这更容易说。如果你想熟练掌握它,你仍然有很多细节需要考虑并且需要不断地练习。但是有了这些观点,当我们研究各种爬行动物的情况时,我们会有一个更清晰的想法
如果你想对爬行动物有更详细的解释和指导,我们有“爬行动物实践”课程和zero foundation入门课程
课程详情官方账户(Crossin编程教室)行动代码回复代码
════
其他文章和答案:
欢迎来到搜索和跟随:crossin的编程教室

网页源代码抓取工具(智能识别模式自动识别网页数据抓取工具的功能介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 361 次浏览 • 2021-09-15 13:25
Webhard是一个网页数据捕获工具。该软件可以提取网页中的文本和图片,并通过输入网址将其打开。默认情况下,它使用内部浏览器,支持扩展分析,并可以自动获取类似链接的列表。软件界面直观,易于操作
功能介绍
智能识别模式
Webhard自动识别网页中出现的数据模式。因此,如果您需要从网页中获取项目列表(名称、地址、电子邮件、价格等),则无需进行任何其他配置。如果数据重复,webharvy将自动刮取数据
导出捕获的数据
您可以以各种格式保存从网页提取的数据。WebHarvy网站当前版本的scraper允许您将scraper数据导出为XML、CSV、JSON或TSV文件。您还可以刮取数据并将其导出到SQL数据库
从多个页面中提取
通常web页面显示数据,例如多个页面中的产品目录。Webhard可以自动从多个网页中获取和提取数据。只是指出“链接到下一页”和WebHarvy网站刮板将自动从所有页面中刮取数据
直观的操作界面
Webharvy是一个可视化的网页提取工具。事实上,不需要编写任何脚本或代码来提取数据。使用webharvy的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。这太容易了
基于关键词的抽取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字列表数据。挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
提取分类
WebHarvy网站scraper允许您从链接列表中提取数据,从而在网站. 这允许您使用单个配置刮取网站内的类别或部分
使用正则表达式提取
Webhard可以在文本或网页的HTML源代码中应用正则表达式(正则表达式),并提取匹配的部分。这项功能强大的技术为您提供了更大的灵活性,同时还可以对数据进行争用
软件特性
Webharvy是一个可视化的web刮板。绝对不需要编写任何脚本或代码来捕获数据。您将使用webharvy的内置浏览器浏览web。您可以选择要单击的数据。这很容易
Webharvy自动识别网页中出现的数据模式。因此,如果您需要从网页中删除项目列表(名称、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,webharvy将自动删除它
您可以以多种格式保存从网页提取的数据。当前版本的webhard web scraper允许您将捕获的数据导出为excel、XML、CSV、JSON或TSV文件。您还可以将捕获的数据导出到SQL数据库
通常,web页面在多个页面上显示产品列表等数据。Webhard可以自动从多个页面抓取和提取数据。只要指出“链接到下一页”,webhard web scraper就会自动从所有页面抓取数据
更新日志
修复了页面启动时连接可能被禁用的问题
您可以为页面模式配置独占连接模式
您可以自动搜索可以在HTML上配置的资源 查看全部
网页源代码抓取工具(智能识别模式自动识别网页数据抓取工具的功能介绍)
Webhard是一个网页数据捕获工具。该软件可以提取网页中的文本和图片,并通过输入网址将其打开。默认情况下,它使用内部浏览器,支持扩展分析,并可以自动获取类似链接的列表。软件界面直观,易于操作

功能介绍
智能识别模式
Webhard自动识别网页中出现的数据模式。因此,如果您需要从网页中获取项目列表(名称、地址、电子邮件、价格等),则无需进行任何其他配置。如果数据重复,webharvy将自动刮取数据
导出捕获的数据
您可以以各种格式保存从网页提取的数据。WebHarvy网站当前版本的scraper允许您将scraper数据导出为XML、CSV、JSON或TSV文件。您还可以刮取数据并将其导出到SQL数据库
从多个页面中提取
通常web页面显示数据,例如多个页面中的产品目录。Webhard可以自动从多个网页中获取和提取数据。只是指出“链接到下一页”和WebHarvy网站刮板将自动从所有页面中刮取数据
直观的操作界面
Webharvy是一个可视化的网页提取工具。事实上,不需要编写任何脚本或代码来提取数据。使用webharvy的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。这太容易了
基于关键词的抽取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字列表数据。挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
提取分类
WebHarvy网站scraper允许您从链接列表中提取数据,从而在网站. 这允许您使用单个配置刮取网站内的类别或部分
使用正则表达式提取
Webhard可以在文本或网页的HTML源代码中应用正则表达式(正则表达式),并提取匹配的部分。这项功能强大的技术为您提供了更大的灵活性,同时还可以对数据进行争用

软件特性
Webharvy是一个可视化的web刮板。绝对不需要编写任何脚本或代码来捕获数据。您将使用webharvy的内置浏览器浏览web。您可以选择要单击的数据。这很容易
Webharvy自动识别网页中出现的数据模式。因此,如果您需要从网页中删除项目列表(名称、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,webharvy将自动删除它
您可以以多种格式保存从网页提取的数据。当前版本的webhard web scraper允许您将捕获的数据导出为excel、XML、CSV、JSON或TSV文件。您还可以将捕获的数据导出到SQL数据库
通常,web页面在多个页面上显示产品列表等数据。Webhard可以自动从多个页面抓取和提取数据。只要指出“链接到下一页”,webhard web scraper就会自动从所有页面抓取数据
更新日志
修复了页面启动时连接可能被禁用的问题
您可以为页面模式配置独占连接模式
您可以自动搜索可以在HTML上配置的资源
网页源代码抓取工具( 用Python编写爬虫的基础,需要的朋友们注意了 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-13 18:13
用Python编写爬虫的基础,需要的朋友们注意了
)
一个用Python程序抓取网页HTML信息的小例子
更新时间:2015-05-02 15:02:49 作者:cyqian
这个文章主要介绍一个使用Python程序抓取网页HTML信息的小例子。使用的方法也是用Python编写爬虫的基础。有需要的朋友可以参考
抓取网页数据的思路很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等,本文不考虑复杂情况,并放了一个读取简单网页数据的小例子:
目标数据
将所有这些玩家的超链接保存在 ittf网站 上。
数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接获取网页文字,可以一句话搞定:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/WR_Table_3_A2.asp?Age_category_1=&Age_category_2=&Age_category_3=&Age_category_4=&Age_category_5=&Category=100W&Cont=&Country=&Gender=W&Month1=4&Year1=2015&s_Player_Name=&Formv_WR_Table_3_Page='+str(page)
doc = requests.get(url).text
soup = BeautifulSoup(doc)
atags = soup.find_all('a')
rank_link_pre = 'http://www.ittf.com/ittf_ranking/'
mlfile = open(linkfile,'a')
for atag in atags:
#print atag
if atag!=None and atag.get('href') != None:
if "WR_Table_3_A2_Details.asp" in atag['href']:
link = rank_link_pre + atag['href']
links.append(link)
mlfile.write(link+'\n')
print 'fetch link: '+link
mlfile.close() 查看全部
网页源代码抓取工具(
用Python编写爬虫的基础,需要的朋友们注意了
)
一个用Python程序抓取网页HTML信息的小例子
更新时间:2015-05-02 15:02:49 作者:cyqian
这个文章主要介绍一个使用Python程序抓取网页HTML信息的小例子。使用的方法也是用Python编写爬虫的基础。有需要的朋友可以参考
抓取网页数据的思路很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等,本文不考虑复杂情况,并放了一个读取简单网页数据的小例子:
目标数据
将所有这些玩家的超链接保存在 ittf网站 上。

数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接获取网页文字,可以一句话搞定:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/WR_Table_3_A2.asp?Age_category_1=&Age_category_2=&Age_category_3=&Age_category_4=&Age_category_5=&Category=100W&Cont=&Country=&Gender=W&Month1=4&Year1=2015&s_Player_Name=&Formv_WR_Table_3_Page='+str(page)
doc = requests.get(url).text
soup = BeautifulSoup(doc)
atags = soup.find_all('a')
rank_link_pre = 'http://www.ittf.com/ittf_ranking/'
mlfile = open(linkfile,'a')
for atag in atags:
#print atag
if atag!=None and atag.get('href') != None:
if "WR_Table_3_A2_Details.asp" in atag['href']:
link = rank_link_pre + atag['href']
links.append(link)
mlfile.write(link+'\n')
print 'fetch link: '+link
mlfile.close()
网页源代码抓取工具( 优采云采集器V9http模拟请求可以设置如何发起一个http请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-09-13 18:08
优采云采集器V9http模拟请求可以设置如何发起一个http请求)
网络爬虫工具如何进行http模拟请求?使用网页爬虫工具采集网页就是进行http模拟请求。可以通过浏览器自动获取登录cookie返回头信息查看源码等操作方法,在此分享给大家。爬虫工具优采云采集器V9中的http模拟请求很多请求工具都是仿照优采云采集器中的请求工具建模的,所以可以以此为例来了解一下http模拟请求。可以设置如何发起一个http请求,包括设置请求信息、返回头信息等,具有自动提交的功能。该工具主要收录两部分:一个MDI父表单和一个请求配置表单。 1 一般设置 ① 源页面正确填写请求页面源页面地址 ② 发送方式 get 和 post 选择 post 时,请在发送数据文本框中正确填写 post 数据 ③ 客户端在此处选择或粘贴浏览器类型 ④ Cookie 值读取本地登录信息和自定义两个选项。高级设置包括图中所示的一系列设置。当不需要上述高级设置时,单击关闭按钮。 ①网页压缩选择压缩方式,选择请求头信息对应的所有Accept-Encoding。 ②网页编码自动识别和自定义两个选项。如果选择自定义,选择自定义后会出现一个编码选择框。在选择框中选择请求的编码 ③Keep-Alive 判断当前请求是否为intern
et resources 建立持久链接 ④自动跳转判断当前请求是否应该重定向响应。 ⑤基于Windows认证类型表、党员人数调查表和毫米对照表教师职称等级表员工考核分数表普通年金现值系数表可以正确填写用户名和密码字段,不需要填写无需身份验证的字段。 ⑥显示更多标题信息。发送的头部信息以列表的形式显示。了解请求的头部信息更加清晰直观。此处提供了标题信息。如果用户选择请求某个名称的标头信息,则选中该标头名称对应的复选框。标题名称和标题值都是可编辑的。 13 Return header information 会列出请求成功后返回的header信息。如图14所示,在请求源代码后,工具会自动跳转到源代码选项。在这里可以查看请求成功后返回的页面的源码信息。 15 本次预览请求成功后可以返回预览。启用此操作后,该工具会以一定的时间间隔和运行次数自动向服务器请求。如果要取消这个操作,点击后面的停止按钮配置以上信息,点击开始查看按钮查看请求信息返回头部信息等,为了避免填写请求信息,可以点击Paste External Monitoring HTTP Request Data按钮粘贴请求的头部信息,然后点击Start View按钮。 Tips box 更多关于网络爬虫工具或者网页采集的教程可以在优采云采集器系列教程中学习 查看全部
网页源代码抓取工具(
优采云采集器V9http模拟请求可以设置如何发起一个http请求)

网络爬虫工具如何进行http模拟请求?使用网页爬虫工具采集网页就是进行http模拟请求。可以通过浏览器自动获取登录cookie返回头信息查看源码等操作方法,在此分享给大家。爬虫工具优采云采集器V9中的http模拟请求很多请求工具都是仿照优采云采集器中的请求工具建模的,所以可以以此为例来了解一下http模拟请求。可以设置如何发起一个http请求,包括设置请求信息、返回头信息等,具有自动提交的功能。该工具主要收录两部分:一个MDI父表单和一个请求配置表单。 1 一般设置 ① 源页面正确填写请求页面源页面地址 ② 发送方式 get 和 post 选择 post 时,请在发送数据文本框中正确填写 post 数据 ③ 客户端在此处选择或粘贴浏览器类型 ④ Cookie 值读取本地登录信息和自定义两个选项。高级设置包括图中所示的一系列设置。当不需要上述高级设置时,单击关闭按钮。 ①网页压缩选择压缩方式,选择请求头信息对应的所有Accept-Encoding。 ②网页编码自动识别和自定义两个选项。如果选择自定义,选择自定义后会出现一个编码选择框。在选择框中选择请求的编码 ③Keep-Alive 判断当前请求是否为intern

et resources 建立持久链接 ④自动跳转判断当前请求是否应该重定向响应。 ⑤基于Windows认证类型表、党员人数调查表和毫米对照表教师职称等级表员工考核分数表普通年金现值系数表可以正确填写用户名和密码字段,不需要填写无需身份验证的字段。 ⑥显示更多标题信息。发送的头部信息以列表的形式显示。了解请求的头部信息更加清晰直观。此处提供了标题信息。如果用户选择请求某个名称的标头信息,则选中该标头名称对应的复选框。标题名称和标题值都是可编辑的。 13 Return header information 会列出请求成功后返回的header信息。如图14所示,在请求源代码后,工具会自动跳转到源代码选项。在这里可以查看请求成功后返回的页面的源码信息。 15 本次预览请求成功后可以返回预览。启用此操作后,该工具会以一定的时间间隔和运行次数自动向服务器请求。如果要取消这个操作,点击后面的停止按钮配置以上信息,点击开始查看按钮查看请求信息返回头部信息等,为了避免填写请求信息,可以点击Paste External Monitoring HTTP Request Data按钮粘贴请求的头部信息,然后点击Start View按钮。 Tips box 更多关于网络爬虫工具或者网页采集的教程可以在优采云采集器系列教程中学习
网页源代码抓取工具(完美者()网站改版后的网站对功能性板块进行扩充)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-09-08 22:17
Perfect()网站基于软件下载,修改后的网站扩展了功能部分,以解决用户在使用软件过程中遇到的所有问题。 网站增加了“软件百科”、“小贴士”等频道,可以更好的为用户提供软件使用全周期更专业的服务。
客鼎网页抓包工具,这是一款小巧实用的抓包工具,支持网页摘要、cookies管理、缓存管理等功能,可以帮助用户分析网页数据,功能非常强大。
科鼎网页抓取工具基本介绍
客鼎网页抓取工具是一款功能强大的网页数据分析工具,集成在Internet Explorer工具栏中,包括网页摘要、Cookies管理、缓存管理、消息头发送/接收、字符查询、POST数据和目录管理等功能强大的日常网页抓取软件。
开鼎网页抓取工具使用说明
作为Web开发人员/测试人员,您需要经常分析网页发送的数据包。作为一款强大的IE插件,Keding网页抓取工具短小精悍,能够很好的完成对URL请求的分析。它可以监控和分析通过浏览器发送的http请求。当你在浏览器的地址栏上请求一个URL或者提交一个表单时,它会帮你分析http请求的头部信息,访问页面的cookie信息,以及Get And Post详细的包分析。
注意:部分杀毒软件可能会报病毒,请加信任!
“Tips & Miao Skills”栏目是全网软件使用技巧的合集或软件使用过程中各种问题的解答文章。专栏成立伊始,小编欢迎各位软件大神朋友踊跃投稿。分享每个人独特技能的平台。
本站文章素材来自网络,文章作者姓名大部分缺失。为了让用户更容易阅读和使用,它们已被重新格式化并根据需要进行了部分调整。本站收录文章只是为了帮助用户解决实际问题,如有版权问题,请联系编辑修改或删除,谢谢合作。 查看全部
网页源代码抓取工具(完美者()网站改版后的网站对功能性板块进行扩充)
Perfect()网站基于软件下载,修改后的网站扩展了功能部分,以解决用户在使用软件过程中遇到的所有问题。 网站增加了“软件百科”、“小贴士”等频道,可以更好的为用户提供软件使用全周期更专业的服务。

客鼎网页抓包工具,这是一款小巧实用的抓包工具,支持网页摘要、cookies管理、缓存管理等功能,可以帮助用户分析网页数据,功能非常强大。
科鼎网页抓取工具基本介绍
客鼎网页抓取工具是一款功能强大的网页数据分析工具,集成在Internet Explorer工具栏中,包括网页摘要、Cookies管理、缓存管理、消息头发送/接收、字符查询、POST数据和目录管理等功能强大的日常网页抓取软件。
开鼎网页抓取工具使用说明
作为Web开发人员/测试人员,您需要经常分析网页发送的数据包。作为一款强大的IE插件,Keding网页抓取工具短小精悍,能够很好的完成对URL请求的分析。它可以监控和分析通过浏览器发送的http请求。当你在浏览器的地址栏上请求一个URL或者提交一个表单时,它会帮你分析http请求的头部信息,访问页面的cookie信息,以及Get And Post详细的包分析。
注意:部分杀毒软件可能会报病毒,请加信任!
“Tips & Miao Skills”栏目是全网软件使用技巧的合集或软件使用过程中各种问题的解答文章。专栏成立伊始,小编欢迎各位软件大神朋友踊跃投稿。分享每个人独特技能的平台。
本站文章素材来自网络,文章作者姓名大部分缺失。为了让用户更容易阅读和使用,它们已被重新格式化并根据需要进行了部分调整。本站收录文章只是为了帮助用户解决实际问题,如有版权问题,请联系编辑修改或删除,谢谢合作。
网页源代码抓取工具(Python用做数据处理还是相当不错的,你知道吗?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-10-04 05:00
Python非常适合数据处理。如果你想做爬虫,Python 是个不错的选择。它有许多已编写的包。只需调用它们就可以完成许多复杂的功能。本文中的所有功能均基于 BeautifulSoup 包。
1 Pyhton获取网页内容(即源码)
page = urllib2.urlopen(url)
contents = page.read()
#获得了整个网页的内容也就是源代码
print(contents)
url代表网址,contents代表网址对应的源码,urllib2是需要用到的包,通过上面三句代码就可以得到网页的整个源码
2 获取网页中想要的内容(先获取网页的源代码,然后分析网页的源代码,找到对应的标签,然后提取标签中的内容)
2.1 以豆瓣电影排名为例
网址是,输入网址后会出现下图
现在我需要获取当前页面上所有电影的名称、评分、评论数量、链接
从上图中,红色圆圈是我想要获取的内容,蓝色横线是对应的标签,这样分析就完成了,现在就是写代码来实现,Python提供了很多获取想要的方法内容,这里我使用BeautifulSoup来实现,很简单
#coding:utf-8
'''''
@author: jsjxy
'''
import urllib2
import re
from bs4 import BeautifulSoup
from distutils.filelist import findall
page = urllib2.urlopen('http://movie.douban.com/top250?format=text')
contents = page.read()
#print(contents)
soup = BeautifulSoup(contents,"html.parser")
print("豆瓣电影TOP250" + "\n" +" 影片名 评分 评价人数 链接 ")
for tag in soup.find_all('div', class_='info'):
# print tag
m_name = tag.find('span', class_='title').get_text()
m_rating_score = float(tag.find('span',class_='rating_num').get_text())
m_people = tag.find('div',class_="star")
m_span = m_people.findAll('span')
m_peoplecount = m_span[3].contents[0]
m_url=tag.find('a').get('href')
print( m_name+" " + str(m_rating_score) + " " + m_peoplecount + " " + m_url )
控制台输出,也可以写入文件
前三行代码获取整个网页的源码,然后开始使用BeautifulSoup进行标签分析。find_all 方法就是找到这个标签的所有内容,然后在这个标签中继续搜索。如果标签有特殊属性声明,可以一步找到出来,如果没有特殊属性声明像这张图中求值者数量前面的标签只有一个'span',那么所有的span找到标签,并依次选择相应的标签。在这张图中,它是第三个,所以这个方法可以找到特定行或列的内容。代码比较简单,易于实现。如有不对的地方请大家指出,共同学习。
源代码地址: 查看全部
网页源代码抓取工具(Python用做数据处理还是相当不错的,你知道吗?(上))
Python非常适合数据处理。如果你想做爬虫,Python 是个不错的选择。它有许多已编写的包。只需调用它们就可以完成许多复杂的功能。本文中的所有功能均基于 BeautifulSoup 包。
1 Pyhton获取网页内容(即源码)
page = urllib2.urlopen(url)
contents = page.read()
#获得了整个网页的内容也就是源代码
print(contents)
url代表网址,contents代表网址对应的源码,urllib2是需要用到的包,通过上面三句代码就可以得到网页的整个源码
2 获取网页中想要的内容(先获取网页的源代码,然后分析网页的源代码,找到对应的标签,然后提取标签中的内容)
2.1 以豆瓣电影排名为例
网址是,输入网址后会出现下图
现在我需要获取当前页面上所有电影的名称、评分、评论数量、链接
从上图中,红色圆圈是我想要获取的内容,蓝色横线是对应的标签,这样分析就完成了,现在就是写代码来实现,Python提供了很多获取想要的方法内容,这里我使用BeautifulSoup来实现,很简单
#coding:utf-8
'''''
@author: jsjxy
'''
import urllib2
import re
from bs4 import BeautifulSoup
from distutils.filelist import findall
page = urllib2.urlopen('http://movie.douban.com/top250?format=text')
contents = page.read()
#print(contents)
soup = BeautifulSoup(contents,"html.parser")
print("豆瓣电影TOP250" + "\n" +" 影片名 评分 评价人数 链接 ")
for tag in soup.find_all('div', class_='info'):
# print tag
m_name = tag.find('span', class_='title').get_text()
m_rating_score = float(tag.find('span',class_='rating_num').get_text())
m_people = tag.find('div',class_="star")
m_span = m_people.findAll('span')
m_peoplecount = m_span[3].contents[0]
m_url=tag.find('a').get('href')
print( m_name+" " + str(m_rating_score) + " " + m_peoplecount + " " + m_url )
控制台输出,也可以写入文件
前三行代码获取整个网页的源码,然后开始使用BeautifulSoup进行标签分析。find_all 方法就是找到这个标签的所有内容,然后在这个标签中继续搜索。如果标签有特殊属性声明,可以一步找到出来,如果没有特殊属性声明像这张图中求值者数量前面的标签只有一个'span',那么所有的span找到标签,并依次选择相应的标签。在这张图中,它是第三个,所以这个方法可以找到特定行或列的内容。代码比较简单,易于实现。如有不对的地方请大家指出,共同学习。
源代码地址:
网页源代码抓取工具( 本文协议是互联网中应用最多的协议,如何防止被抓包 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-04 04:24
本文协议是互联网中应用最多的协议,如何防止被抓包
)
本文来自作者吉比贝克,在GitChat上分享了“Fiddler2抓包工具,让你的信息不再被隐藏”,“阅读原文”查看交流记录。
《文末,高能》
编辑 | 爱好
http协议是Internet上使用最广泛的协议。几乎所有的 Web 应用程序和移动应用程序都使用 http 协议。
作为一款基于http协议的免费抓包工具,Fiddler2非常强大。它可以捕获通过http协议传输的数据包,让您的信息无处藏身。
本文将简单讲解Fiddler2的下载安装,具体应用,以及如何防止抓包。
一、为什么Fiddler2的名字后面是2,而不是Fiddler?
虽然这是一个看似无聊的问题,但确实让我纠结了一阵子,或许有点强迫症吧。
当我第一次使用 Fiddler 时,我总是这样写和调用 Fiddler2。但有一天我发现还有另一个 Fiddler4。我瞬间明白是怎么回事了。原来,数字 2 并不是 Fiddler 名字的一部分,而是一个很大的数字。版本号。
但是在全网找了半天,包括去官网都找不到Fiddler3。最新的是 Fiddler4。全网使用最多的是Fiddler2和Fiddler4。至于为什么没有Fiddler和Fiddler3,我也懒得去找了。
二、Fiddler的本质是服务器的代理
启动Fiddler后,Fiddler默认会代理当前电脑或服务器的地址和端口为127.0.0.1:8888,所以http请求发送到当前电脑或服务器将首先发送。127.0.0.1:8888这个代理地址后,再转发到真实访问地址。
Fiddler相当于在客户端和服务器之间安装了一个中继,这个中继负责转发。然后,Fiddler 获取到客户端和服务端的交互数据后,通过数据整理和分析,结果从 Fiddler 客户端显示出来,甚至可以通过 Fiddler 修改请求数据。
当 Fiddler 关闭时,Fiddler 会自动退出代理。这就是Fiddler实现抓包的基本原理。
三、Fiddler的下载安装
可以通过地址下载Fiddler客户端。
只需选择使用原因,输入您的电子邮件地址,选中“我接受 Fiddler 最终用户许可协议”选项,然后单击下载。
下载的安装包:
一路下一步即可完成安装,最新版本为Fiddler4。
四、使用Fiddler基于http协议抓取网页网站数据
打开Fiddler,整个界面分为三块,块1是当前计算机与外网交互的地址信息,有请求结果,请求协议,访问域名,url地址,返回的字节数。
第二块是请求信息,包括头信息、请求地址、请求参数等,第三块是服务器响应信息。根据返回结果的形式不同,可以分为返回网页和返回数据两种。
返回的结果是一个 HTML 页面
我们以访问热门聊天为例进行分析。
从图中可以看到,host栏代表要访问的域名,这里是,Protocol列表显示协议,这里是http,URL栏显示请求路径,这里是/gitchat/hot, Body列代表返回的结果word段数,Content-Type列表示返回内容的类型,这里是html,最后Process列表示进程名称。
一般情况下,我们只需要关注Host、URL、Body和Content-Type列。从Body列的字节大小,我们可以快速判断哪些请求返回的数据量较大,然后根据Content-Type类型判断返回的内容。
在上面有红色图标的那一行,我们可以看到从热门列表页面返回了大量的内容,返回类型为html页面。让我们看看块 3 的结果。
我们切到“SyntaxView”选项卡,可以看到热门聊天的html页面源码,说明请求这个地址后,服务器返回的是html。
返回结果是数据
访问百度网页时,发现红框标注的请求返回了大量数据,返回类型为“application/javascript”,于是查看返回结果,切入“SyntaxView”选项卡,可以看到一堆可识别的数据,如下:
我们选择以“JSON”格式查看,如下:
一般情况下,我们在目标不是很明确的情况下使用Fiddler抓包,也就是说我们不知道这个网站的哪个地址会被抓到,也不知道它将被捕获。在浏览这个网站的过程中,刚刚通过Fiddler的请求分析了哪些数据,哪些数据可能有用。
这些数据往往是在网站或者APP上正常运行时看不到的数据,而这些隐藏的数据可以通过Fiddler的抓包来抓到。
Fiddler 也经常被用作爬虫的辅助工具。首先使用Fiddler过滤目标网站或APP,抓取可以获取目标数据的URL和参数,然后通过爬虫程序访问这些URL和参数。爬到目标数据。
一般APP通过接口返回数据是很常见的。比如这个链接“”是一个APP爬取得到的数据接口,直接访问这个链接,可以看到JSON格式的数据源。
五、 基于https协议使用Fiddler抓取新浪微博
fiddler除了可以抓取http协议的数据外,还可以抓取https协议的数据,但需要额外配置。方法如下:
依次打开菜单栏中的工具>选项>HTTPS选项卡,勾选“解密HTTPS流量”选项和“忽略服务器证书错误(不安全)”选项,重启Fiddler。这时候如果基于https协议访问网站,就可以抓取到网站的信息。我们以新浪微博为例。
可以看到,大部分抓拍的图片都是图片,其中一张返回2907字节。我们来看看返回的结果。
从备注来看,这应该是服务器的一些证书信息。让我们来看看图片。
张一山?
爱极光?
奇门遁甲?
当然,这些照片都是新浪微博首页的照片。想看的话直接上首页。你不需要使用 Fiddler 来抓取它。这只是一个例子。你已经掌握了抓取https协议数据的方法,就可以看到网页显示的内容了。数据,当然也可以看到网页无法显示的隐藏数据。这取决于个人。
剑法已经交给你了。至于你用它来杀猪还是执行骑士正义,你说了算。
六、 使用Fiddler抓取手机APP的通讯数据
要抓取手机的通讯数据,需要同时配置Fiddler和手机端。过程稍微复杂一些。下面我会详细解释。
第一步是配置Fiddler允许远程连接,如图:
依次打开菜单栏中的工具>选项>连接选项卡,勾选“允许远程计算机连接”选项允许远程服务器连接,重启Fiddler。
第二步,在手机上设置安装Fiddler的电脑为手机的代理地址。
找到手机连接的wifi网络,点击弹出修改,在高级代理中找到代理设置,将代理设置改为手动,然后会出现设置代理地址和端口的输入框(不同手机的操作过程会略有不同,最终目的是设置手机的代理地址,可以根据不同品牌型号的手机在百度中搜索相关设置方法)。
设置代理地址。
代理地址是你打开Fiddler的电脑的内网IP地址。window系统可以在cmd命令模式下输入ipconfig查看当前电脑的内网IP地址。我电脑的IP地址是192.168.1.34。
填写代理端口8888,点击保存,如下图:
第三步,访问代理地址,下载安装证书,完成配置。
下载并安装证书:
至此,所有配置完成。现在,所有通过手机与外网通信的数据都可以被 Fiddler 捕获。比如我们通过微信打开gitchat的微信公众号,可以在Fiddler中看到gitchat公众号的标题文章的图片数据,如图。
这是在 Fiddler 中捕获的数据:
GitChat微信公众号中的图文:
同样,网页上可以抓取到的数据也可以在APP上抓取,在APP上抓取的隐藏数据就更多了,因为大部分APP都是以接口的形式与服务器进行通信的。其中会收录大量数据。如果直接抓取接口地址和参数,就可以直接调用接口获取数据。
本文主要讲解Fiddler的用法和场景,所以例子中尽量避免敏感内容。Fiddler 是一把双刃剑,可以用来抓取合法数据,也可以用来抓取私人数据。在使用中请务必遵守规则。
七、使用Fiddler设置断点和修改Response
Fiddler 不仅可以用来抓取通信数据,还可以用来修改请求内容和服务器响应结果。这个功能一般用的比较少,一般在前期的开发调试中使用,这里简单介绍一下。
在菜单栏中,点击规则->自动断点->选择断点方法。有两种方式,一种是在请求前进入断点,i是在服务器响应后设置断点,其实就是返回请求内容和服务器在结果两种情况下都设置断点。
比如我们选择在请求之前输入一个断点。这时候,一旦我们用浏览器访问一个页面,发送请求后,就会停留在Fiddler中。这时候我们就可以修改请求中的数据,然后再进行后续的操作,让服务端接收到的请求被修改。
同理,服务器响应后修改数据,就是直接修改服务器返回的结果。
这种技术在实践中很少使用。如果有人对这篇文章感兴趣,你可以把它放在评论中。我会在后续的交流中详细解释这块。
八、反Fiddler爬取的一些思考
由于Fiddler非常强大,所以我们在做产品开发的时候,尤其是APP和服务器端通信的时候,应该尽量避免Fiddler的爬行,更加注意界面的严谨性和安全性。可以考虑从以下几点入手:
在制作APP界面时,与界面通信的数据在传输前应尽可能加密。不要使用纯文本,这将在很大程度上避免数据被捕获;
接口返回的数据尽量少,也就是APP只返回什么数据。不要因为偷懒把数据全部返回,这样一旦数据被抓到,泄露的会比当前接口业务的数据还多;
必须严格验证参数,防止有人恶意猜测构造参数,非法访问服务器。
本次Fiddler数据采集的话题就到这里。有问题的同学可以留言提问,也可以在阅读圈提问。我看到后,会尽量尽快回复你。感谢大家的参与。
九、备注
在使用Fiddler抓取网页和传输数据时,经常会遇到无法抓取的问题,尤其是https协议网站,数据在Fiddler上根本不显示。
经过反复尝试,我发现问题出在浏览器上。某些浏览器可能会阻止代理。通过这些浏览器访问的网页不会在 Fiddler 上显示数据。感觉代理失败了。
目前测试发现360浏览器100%屏蔽Fiddler,谷歌Chrome屏蔽了一部分。具体的屏蔽规则还没有深入研究。另外IE浏览器完全支持Fiddler,几乎没有屏蔽。上面例子中的数据捕获是通过IE浏览器演示的。
因此,在实际使用中,建议先使用IE浏览器抓取数据。
近期热门文章
“”
“”
“”
“”
“”
“”
“”
查看全部
网页源代码抓取工具(
本文协议是互联网中应用最多的协议,如何防止被抓包
)
本文来自作者吉比贝克,在GitChat上分享了“Fiddler2抓包工具,让你的信息不再被隐藏”,“阅读原文”查看交流记录。
《文末,高能》
编辑 | 爱好
http协议是Internet上使用最广泛的协议。几乎所有的 Web 应用程序和移动应用程序都使用 http 协议。
作为一款基于http协议的免费抓包工具,Fiddler2非常强大。它可以捕获通过http协议传输的数据包,让您的信息无处藏身。
本文将简单讲解Fiddler2的下载安装,具体应用,以及如何防止抓包。
一、为什么Fiddler2的名字后面是2,而不是Fiddler?
虽然这是一个看似无聊的问题,但确实让我纠结了一阵子,或许有点强迫症吧。
当我第一次使用 Fiddler 时,我总是这样写和调用 Fiddler2。但有一天我发现还有另一个 Fiddler4。我瞬间明白是怎么回事了。原来,数字 2 并不是 Fiddler 名字的一部分,而是一个很大的数字。版本号。
但是在全网找了半天,包括去官网都找不到Fiddler3。最新的是 Fiddler4。全网使用最多的是Fiddler2和Fiddler4。至于为什么没有Fiddler和Fiddler3,我也懒得去找了。
二、Fiddler的本质是服务器的代理
启动Fiddler后,Fiddler默认会代理当前电脑或服务器的地址和端口为127.0.0.1:8888,所以http请求发送到当前电脑或服务器将首先发送。127.0.0.1:8888这个代理地址后,再转发到真实访问地址。
Fiddler相当于在客户端和服务器之间安装了一个中继,这个中继负责转发。然后,Fiddler 获取到客户端和服务端的交互数据后,通过数据整理和分析,结果从 Fiddler 客户端显示出来,甚至可以通过 Fiddler 修改请求数据。
当 Fiddler 关闭时,Fiddler 会自动退出代理。这就是Fiddler实现抓包的基本原理。
三、Fiddler的下载安装
可以通过地址下载Fiddler客户端。
只需选择使用原因,输入您的电子邮件地址,选中“我接受 Fiddler 最终用户许可协议”选项,然后单击下载。
下载的安装包:
一路下一步即可完成安装,最新版本为Fiddler4。
四、使用Fiddler基于http协议抓取网页网站数据
打开Fiddler,整个界面分为三块,块1是当前计算机与外网交互的地址信息,有请求结果,请求协议,访问域名,url地址,返回的字节数。
第二块是请求信息,包括头信息、请求地址、请求参数等,第三块是服务器响应信息。根据返回结果的形式不同,可以分为返回网页和返回数据两种。
返回的结果是一个 HTML 页面
我们以访问热门聊天为例进行分析。
从图中可以看到,host栏代表要访问的域名,这里是,Protocol列表显示协议,这里是http,URL栏显示请求路径,这里是/gitchat/hot, Body列代表返回的结果word段数,Content-Type列表示返回内容的类型,这里是html,最后Process列表示进程名称。
一般情况下,我们只需要关注Host、URL、Body和Content-Type列。从Body列的字节大小,我们可以快速判断哪些请求返回的数据量较大,然后根据Content-Type类型判断返回的内容。
在上面有红色图标的那一行,我们可以看到从热门列表页面返回了大量的内容,返回类型为html页面。让我们看看块 3 的结果。
我们切到“SyntaxView”选项卡,可以看到热门聊天的html页面源码,说明请求这个地址后,服务器返回的是html。
返回结果是数据
访问百度网页时,发现红框标注的请求返回了大量数据,返回类型为“application/javascript”,于是查看返回结果,切入“SyntaxView”选项卡,可以看到一堆可识别的数据,如下:
我们选择以“JSON”格式查看,如下:
一般情况下,我们在目标不是很明确的情况下使用Fiddler抓包,也就是说我们不知道这个网站的哪个地址会被抓到,也不知道它将被捕获。在浏览这个网站的过程中,刚刚通过Fiddler的请求分析了哪些数据,哪些数据可能有用。
这些数据往往是在网站或者APP上正常运行时看不到的数据,而这些隐藏的数据可以通过Fiddler的抓包来抓到。
Fiddler 也经常被用作爬虫的辅助工具。首先使用Fiddler过滤目标网站或APP,抓取可以获取目标数据的URL和参数,然后通过爬虫程序访问这些URL和参数。爬到目标数据。
一般APP通过接口返回数据是很常见的。比如这个链接“”是一个APP爬取得到的数据接口,直接访问这个链接,可以看到JSON格式的数据源。
五、 基于https协议使用Fiddler抓取新浪微博
fiddler除了可以抓取http协议的数据外,还可以抓取https协议的数据,但需要额外配置。方法如下:
依次打开菜单栏中的工具>选项>HTTPS选项卡,勾选“解密HTTPS流量”选项和“忽略服务器证书错误(不安全)”选项,重启Fiddler。这时候如果基于https协议访问网站,就可以抓取到网站的信息。我们以新浪微博为例。
可以看到,大部分抓拍的图片都是图片,其中一张返回2907字节。我们来看看返回的结果。
从备注来看,这应该是服务器的一些证书信息。让我们来看看图片。
张一山?
爱极光?
奇门遁甲?
当然,这些照片都是新浪微博首页的照片。想看的话直接上首页。你不需要使用 Fiddler 来抓取它。这只是一个例子。你已经掌握了抓取https协议数据的方法,就可以看到网页显示的内容了。数据,当然也可以看到网页无法显示的隐藏数据。这取决于个人。
剑法已经交给你了。至于你用它来杀猪还是执行骑士正义,你说了算。
六、 使用Fiddler抓取手机APP的通讯数据
要抓取手机的通讯数据,需要同时配置Fiddler和手机端。过程稍微复杂一些。下面我会详细解释。
第一步是配置Fiddler允许远程连接,如图:
依次打开菜单栏中的工具>选项>连接选项卡,勾选“允许远程计算机连接”选项允许远程服务器连接,重启Fiddler。
第二步,在手机上设置安装Fiddler的电脑为手机的代理地址。
找到手机连接的wifi网络,点击弹出修改,在高级代理中找到代理设置,将代理设置改为手动,然后会出现设置代理地址和端口的输入框(不同手机的操作过程会略有不同,最终目的是设置手机的代理地址,可以根据不同品牌型号的手机在百度中搜索相关设置方法)。
设置代理地址。
代理地址是你打开Fiddler的电脑的内网IP地址。window系统可以在cmd命令模式下输入ipconfig查看当前电脑的内网IP地址。我电脑的IP地址是192.168.1.34。
填写代理端口8888,点击保存,如下图:
第三步,访问代理地址,下载安装证书,完成配置。
下载并安装证书:
至此,所有配置完成。现在,所有通过手机与外网通信的数据都可以被 Fiddler 捕获。比如我们通过微信打开gitchat的微信公众号,可以在Fiddler中看到gitchat公众号的标题文章的图片数据,如图。
这是在 Fiddler 中捕获的数据:
GitChat微信公众号中的图文:
同样,网页上可以抓取到的数据也可以在APP上抓取,在APP上抓取的隐藏数据就更多了,因为大部分APP都是以接口的形式与服务器进行通信的。其中会收录大量数据。如果直接抓取接口地址和参数,就可以直接调用接口获取数据。
本文主要讲解Fiddler的用法和场景,所以例子中尽量避免敏感内容。Fiddler 是一把双刃剑,可以用来抓取合法数据,也可以用来抓取私人数据。在使用中请务必遵守规则。
七、使用Fiddler设置断点和修改Response
Fiddler 不仅可以用来抓取通信数据,还可以用来修改请求内容和服务器响应结果。这个功能一般用的比较少,一般在前期的开发调试中使用,这里简单介绍一下。
在菜单栏中,点击规则->自动断点->选择断点方法。有两种方式,一种是在请求前进入断点,i是在服务器响应后设置断点,其实就是返回请求内容和服务器在结果两种情况下都设置断点。
比如我们选择在请求之前输入一个断点。这时候,一旦我们用浏览器访问一个页面,发送请求后,就会停留在Fiddler中。这时候我们就可以修改请求中的数据,然后再进行后续的操作,让服务端接收到的请求被修改。
同理,服务器响应后修改数据,就是直接修改服务器返回的结果。
这种技术在实践中很少使用。如果有人对这篇文章感兴趣,你可以把它放在评论中。我会在后续的交流中详细解释这块。
八、反Fiddler爬取的一些思考
由于Fiddler非常强大,所以我们在做产品开发的时候,尤其是APP和服务器端通信的时候,应该尽量避免Fiddler的爬行,更加注意界面的严谨性和安全性。可以考虑从以下几点入手:
在制作APP界面时,与界面通信的数据在传输前应尽可能加密。不要使用纯文本,这将在很大程度上避免数据被捕获;
接口返回的数据尽量少,也就是APP只返回什么数据。不要因为偷懒把数据全部返回,这样一旦数据被抓到,泄露的会比当前接口业务的数据还多;
必须严格验证参数,防止有人恶意猜测构造参数,非法访问服务器。
本次Fiddler数据采集的话题就到这里。有问题的同学可以留言提问,也可以在阅读圈提问。我看到后,会尽量尽快回复你。感谢大家的参与。
九、备注
在使用Fiddler抓取网页和传输数据时,经常会遇到无法抓取的问题,尤其是https协议网站,数据在Fiddler上根本不显示。
经过反复尝试,我发现问题出在浏览器上。某些浏览器可能会阻止代理。通过这些浏览器访问的网页不会在 Fiddler 上显示数据。感觉代理失败了。
目前测试发现360浏览器100%屏蔽Fiddler,谷歌Chrome屏蔽了一部分。具体的屏蔽规则还没有深入研究。另外IE浏览器完全支持Fiddler,几乎没有屏蔽。上面例子中的数据捕获是通过IE浏览器演示的。
因此,在实际使用中,建议先使用IE浏览器抓取数据。
近期热门文章
“”
“”
“”
“”
“”
“”
“”
网页源代码抓取工具(自动模式检测WebHarvy自动识别允许您在网页中发生的数据模式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-10-02 20:12
WebHarvy 是一款用户界面简单、操作简单的网页数据抓取工具。它具有自动检测模式。它可以从任何页面中提取数据,包括文本、图片等,输入网址即可打开。默认使用内部浏览器提取数据,可以导出到数据库或文件夹。
特征
点击界面
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这很简单!
自动模式检测
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
导出捕获的数据
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvyWebScraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
从多个页面中提取数据
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvyWebScraper 就会自动从所有页面中抓取数据。
基于关键字的抓取
通过在搜索表单中自动提交输入关键字列表来抓取数据。可以将任意数量的输入关键字提交到多个输入文本字段以执行搜索。可以提取输入关键字组合的所有搜索结果数据。
通过代理服务器
为了匿名抓取,防止网页抓取软件被网页服务器拦截,您可以选择通过代理服务器或VPN网站访问目标。可以使用单个代理服务器地址或代理服务器地址列表。
类别提取
WebHarvyWebScraper 允许您从链接列表中获取数据,从而在 网站 中生成相似的页面/列表。这允许您使用单个配置来抓取 网站 内的类别和子类别。
正则表达式
WebHarvy 允许您在网页的文本或 HTML 源代码上应用正则表达式 (RegEx) 并删除匹配的部分。这种强大的技术为您在抓取数据时提供了更大的灵活性。
运行 JavaScript
在提取数据之前在浏览器中运行您自己的 JavaScript 代码。这可用于与页面元素交互或调用已在目标页面中实现的 JavaScript 函数。
下载图片
您可以下载图像或提取图像 URL。WebHarvy 可以自动提取显示在电子商务网站的商品详情页面中的多张图片。
自动浏览器交互
WebHarvy 可以轻松配置为执行任务,例如单击链接、选择列表/下拉选项、在字段中输入文本、滚动页面等。
更新日志
修复了页面启动时连接可能被禁用的可能性。
您可以为寻呼模式配置专用的连接方式。
可以自动搜索可以在 HTML 上配置的资源。 查看全部
网页源代码抓取工具(自动模式检测WebHarvy自动识别允许您在网页中发生的数据模式)
WebHarvy 是一款用户界面简单、操作简单的网页数据抓取工具。它具有自动检测模式。它可以从任何页面中提取数据,包括文本、图片等,输入网址即可打开。默认使用内部浏览器提取数据,可以导出到数据库或文件夹。
特征
点击界面
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这很简单!
自动模式检测
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
导出捕获的数据
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvyWebScraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
从多个页面中提取数据
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvyWebScraper 就会自动从所有页面中抓取数据。
基于关键字的抓取
通过在搜索表单中自动提交输入关键字列表来抓取数据。可以将任意数量的输入关键字提交到多个输入文本字段以执行搜索。可以提取输入关键字组合的所有搜索结果数据。
通过代理服务器
为了匿名抓取,防止网页抓取软件被网页服务器拦截,您可以选择通过代理服务器或VPN网站访问目标。可以使用单个代理服务器地址或代理服务器地址列表。
类别提取
WebHarvyWebScraper 允许您从链接列表中获取数据,从而在 网站 中生成相似的页面/列表。这允许您使用单个配置来抓取 网站 内的类别和子类别。
正则表达式
WebHarvy 允许您在网页的文本或 HTML 源代码上应用正则表达式 (RegEx) 并删除匹配的部分。这种强大的技术为您在抓取数据时提供了更大的灵活性。
运行 JavaScript
在提取数据之前在浏览器中运行您自己的 JavaScript 代码。这可用于与页面元素交互或调用已在目标页面中实现的 JavaScript 函数。
下载图片
您可以下载图像或提取图像 URL。WebHarvy 可以自动提取显示在电子商务网站的商品详情页面中的多张图片。
自动浏览器交互
WebHarvy 可以轻松配置为执行任务,例如单击链接、选择列表/下拉选项、在字段中输入文本、滚动页面等。
更新日志
修复了页面启动时连接可能被禁用的可能性。
您可以为寻呼模式配置专用的连接方式。
可以自动搜索可以在 HTML 上配置的资源。
网页源代码抓取工具(自动模式检测WebHarvy自动识别允许您在网页中发生的数据模式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-01 06:10
WebHarvy 是一款用户界面简单、操作简单的网页数据抓取工具。它具有自动检测模式。它可以从任何页面中提取数据,包括文本、图片等,输入网址即可打开。默认使用内部浏览器提取数据,可以导出到数据库或文件夹。
特征
点击界面
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这很简单!
自动模式检测
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
导出捕获的数据
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvyWebScraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
从多个页面中提取数据
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvyWebScraper 就会自动从所有页面中抓取数据。
基于关键字的抓取
通过在搜索表单中自动提交输入关键字列表来抓取数据。可以将任意数量的输入关键字提交到多个输入文本字段以执行搜索。可以提取输入的关键字组合的所有搜索结果数据。
通过代理服务器
为了匿名抓取,防止网页抓取软件被网页服务器拦截,您可以选择通过代理服务器或VPN网站访问目标。可以使用单个代理服务器地址或代理服务器地址列表。
类别提取
WebHarvyWebScraper 允许您从链接列表中获取数据,从而在 网站 中生成相似的页面/列表。这允许您使用单个配置来抓取 网站 内的类别和子类别。
正则表达式
WebHarvy 允许您在网页的文本或 HTML 源代码上应用正则表达式 (RegEx) 并删除匹配的部分。这种强大的技术为您在抓取数据时提供了更大的灵活性。
运行 JavaScript
在提取数据之前在浏览器中运行您自己的 JavaScript 代码。这可用于与页面元素交互或调用已在目标页面中实现的 JavaScript 函数。
下载图片
您可以下载图像或提取图像 URL。WebHarvy 可以自动提取显示在电子商务网站的商品详情页面中的多张图片。
自动浏览器交互
WebHarvy 可以轻松配置为执行任务,例如单击链接、选择列表/下拉选项、在字段中输入文本、滚动页面等。
更新日志
修复了页面启动时连接可能被禁用的可能性。
您可以为寻呼模式配置专用的连接方式。
可以自动搜索可以在 HTML 上配置的资源。 查看全部
网页源代码抓取工具(自动模式检测WebHarvy自动识别允许您在网页中发生的数据模式)
WebHarvy 是一款用户界面简单、操作简单的网页数据抓取工具。它具有自动检测模式。它可以从任何页面中提取数据,包括文本、图片等,输入网址即可打开。默认使用内部浏览器提取数据,可以导出到数据库或文件夹。
特征
点击界面
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这很简单!
自动模式检测
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
导出捕获的数据
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvyWebScraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
从多个页面中提取数据
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvyWebScraper 就会自动从所有页面中抓取数据。
基于关键字的抓取
通过在搜索表单中自动提交输入关键字列表来抓取数据。可以将任意数量的输入关键字提交到多个输入文本字段以执行搜索。可以提取输入的关键字组合的所有搜索结果数据。
通过代理服务器
为了匿名抓取,防止网页抓取软件被网页服务器拦截,您可以选择通过代理服务器或VPN网站访问目标。可以使用单个代理服务器地址或代理服务器地址列表。
类别提取
WebHarvyWebScraper 允许您从链接列表中获取数据,从而在 网站 中生成相似的页面/列表。这允许您使用单个配置来抓取 网站 内的类别和子类别。
正则表达式
WebHarvy 允许您在网页的文本或 HTML 源代码上应用正则表达式 (RegEx) 并删除匹配的部分。这种强大的技术为您在抓取数据时提供了更大的灵活性。
运行 JavaScript
在提取数据之前在浏览器中运行您自己的 JavaScript 代码。这可用于与页面元素交互或调用已在目标页面中实现的 JavaScript 函数。
下载图片
您可以下载图像或提取图像 URL。WebHarvy 可以自动提取显示在电子商务网站的商品详情页面中的多张图片。
自动浏览器交互
WebHarvy 可以轻松配置为执行任务,例如单击链接、选择列表/下拉选项、在字段中输入文本、滚动页面等。
更新日志
修复了页面启动时连接可能被禁用的可能性。
您可以为寻呼模式配置专用的连接方式。
可以自动搜索可以在 HTML 上配置的资源。
网页源代码抓取工具(Source对iOS8Extensions的巧妙利用,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-10-01 06:09
如果您是网站管理员或网络开发人员,在浏览器中查看网页源代码(HTML、CSS 和 JavaScript)是每天必不可少的操作。这种在桌面上的轻松操作已经变成了移动端。一件麻烦事。现在有了View Source对iOS 8 Extensions的巧妙运用,在移动端浏览和操作网页源代码将变得非常容易。
安装完查看源代码后,使用Safari分享按钮打开查看源代码开关,即可显示当前网页源代码。如果你不想这样做,你也可以使用View Source作为一个独立的应用程序来打开你想要查看的网站源代码 当然,这种情况下View Source不会显示内容页面,而是直接显示页面源代码。
在这里你可以看到少数派网页的源代码。例如,通常的 SEO 人员会为网页定义 Title 和 Meta 标签关键字,以使 网站 更好地保持搜索引擎。
在View Source中,通过DOM节点树可以直观的看到当前网页的结构,方便查找和访问节点。还有一个很酷的地方就是View Source还可以通过inject JS来编写自定义的JS代码,退出插件的时候输出的JS效果会显示在网页上。比如在小众页面下的Script中输入:
警报(文件。标题);
退出插件,在Safari中显示关于少数网站 Title标签的提示弹窗,效果如图。
当然,如果你想在弹出窗口中显示一个句子,你可以在Script中输入:
警报(我爱斯派);
当然,这些只是普通的 JavaScript 警报代码。如果你有更有趣的玩法或者更实用的功能,也可以在评论中告诉我。
右上角有更多选项可以调用更多功能,比如将代码复制到剪贴板并继续在其他应用程序上编辑,还可以发送电子邮件、选择亮点等更多主题。这里我再多说一下,查看源提供了很多亮色的主题供选择,笔者个人比较喜欢蓝屏的主题。
View Source 目前售价 6 元。 查看全部
网页源代码抓取工具(Source对iOS8Extensions的巧妙利用,你知道吗?)
如果您是网站管理员或网络开发人员,在浏览器中查看网页源代码(HTML、CSS 和 JavaScript)是每天必不可少的操作。这种在桌面上的轻松操作已经变成了移动端。一件麻烦事。现在有了View Source对iOS 8 Extensions的巧妙运用,在移动端浏览和操作网页源代码将变得非常容易。
安装完查看源代码后,使用Safari分享按钮打开查看源代码开关,即可显示当前网页源代码。如果你不想这样做,你也可以使用View Source作为一个独立的应用程序来打开你想要查看的网站源代码 当然,这种情况下View Source不会显示内容页面,而是直接显示页面源代码。
在这里你可以看到少数派网页的源代码。例如,通常的 SEO 人员会为网页定义 Title 和 Meta 标签关键字,以使 网站 更好地保持搜索引擎。
在View Source中,通过DOM节点树可以直观的看到当前网页的结构,方便查找和访问节点。还有一个很酷的地方就是View Source还可以通过inject JS来编写自定义的JS代码,退出插件的时候输出的JS效果会显示在网页上。比如在小众页面下的Script中输入:
警报(文件。标题);
退出插件,在Safari中显示关于少数网站 Title标签的提示弹窗,效果如图。
当然,如果你想在弹出窗口中显示一个句子,你可以在Script中输入:
警报(我爱斯派);
当然,这些只是普通的 JavaScript 警报代码。如果你有更有趣的玩法或者更实用的功能,也可以在评论中告诉我。
右上角有更多选项可以调用更多功能,比如将代码复制到剪贴板并继续在其他应用程序上编辑,还可以发送电子邮件、选择亮点等更多主题。这里我再多说一下,查看源提供了很多亮色的主题供选择,笔者个人比较喜欢蓝屏的主题。
View Source 目前售价 6 元。
网页源代码抓取工具(想要爬取指定网页中的图片主要需要以下三个步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-10-01 06:08
抓取指定网页中的图片主要需要以下三个步骤:
(1)指定网站链接,获取网站的源码(如果使用谷歌浏览器,鼠标右键->检查->Elements中的html内容)
(2) 根据要爬取的内容设置正则表达式,匹配到要爬取的内容
(3)设置循环列表,重复抓取保存内容
下面介绍两种抓取指定网页图片的方法
(1)方法一:使用正则表达式过滤捕获的html内容字符串
# 第一个简单的爬取图片的程序
import urllib.request # python自带的爬操作url的库
import re # 正则表达式
# 该方法传入url,返回url的html的源代码
def getHtmlCode(url):
# 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求
headers = {
'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \
AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36'
}
# 将headers头部添加到url,模拟浏览器访问
url = urllib.request.Request(url, headers=headers)
# 将url页面的源代码保存成字符串
page = urllib.request.urlopen(url).read()
# 字符串转码
page = page.decode('UTF-8')
return page
# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
def getImage(page):
# [^\s]*? 表示最小匹配, 两个括号表示列表中有两个元组
# imageList = re.findall(r'(https:[^\s]*?(png))"', page)
imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page)
x = 0
# 循环列表
for imageUrl in imageList:
try:
print('正在下载: %s' % imageUrl[0])
# 这个image文件夹需要先创建好才能看到结果
image_save_path = './image/%d.png' % x
# 下载图片并且保存到指定文件夹中
urllib.request.urlretrieve(imageUrl[0], image_save_path)
x = x + 1
except:
continue
pass
if __name__ == '__main__':
# 指定要爬取的网站
url = "https://www.cnblogs.com/ttweix ... ot%3B
# 得到该网站的源代码
page = getHtmlCode(url)
# 爬取该网站的图片并且保存
getImage(page)
# print(page)
注意代码中需要修改的是 imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page) 这一段内容,怎么设计正则表达式需要根据你要爬取的内容设置我的设计源码如下:
可以看到,因为这个页面的图片都是png格式,所以也可以写成imageList = re.findall(r'(https:[^\s]*?(png))"', page)
(2)方法二:使用BeautifulSoup库解析html网页
from bs4 import BeautifulSoup # BeautifulSoup是python处理HTML/XML的函数库,是Python内置的网页分析工具
import urllib # python自带的爬操作url的库
# 该方法传入url,返回url的html的源代码
def getHtmlCode(url):
# 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求
headers = {
'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \
AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36'
}
# 将headers头部添加到url,模拟浏览器访问
url = urllib.request.Request(url, headers=headers)
# 将url页面的源代码保存成字符串
page = urllib.request.urlopen(url).read()
# 字符串转码
page = page.decode('UTF-8')
return page
# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
def getImage(page):
# 按照html格式解析页面
soup = BeautifulSoup(page, 'html.parser')
# 格式化输出DOM树的内容
print(soup.prettify())
# 返回所有包含img标签的列表,因为在Html文件中图片的插入呈现形式是...
imgList = soup.find_all('img')
x = 0
# 循环找到的图片列表,注意,这里手动设置从第2张图片开始,是因为我debug看到了第一张图片不是我想要的图片
for imgUrl in imgList[1:]:
print('正在下载: %s ' % imgUrl.get('src'))
# 得到scr的内容,这里返回的就是Url字符串链接,如'https://img2020.cnblogs.com/blog/1703588/202007/1703588-20200716203143042-623499171.png'
image_url = imgUrl.get('src')
# 这个image文件夹需要先创建好才能看到结果
image_save_path = './image/%d.png' % x
# 下载图片并且保存到指定文件夹中
urllib.request.urlretrieve(image_url, image_save_path)
x = x + 1
if __name__ == '__main__':
# 指定要爬取的网站
url = 'https://www.cnblogs.com/ttweixiao-IT-program/p/13324826.html'
# 得到该网站的源代码
page = getHtmlCode(url)
# 爬取该网站的图片并且保存
getImage(page)
这两种方法各有优缺点。我认为它们可以灵活组合。比如先用方法二中的指定标签的方法缩小你要查找的内容范围,然后再用正则表达式匹配到需要的内容。更简洁明了
相关文章 查看全部
网页源代码抓取工具(想要爬取指定网页中的图片主要需要以下三个步骤)
抓取指定网页中的图片主要需要以下三个步骤:
(1)指定网站链接,获取网站的源码(如果使用谷歌浏览器,鼠标右键->检查->Elements中的html内容)
(2) 根据要爬取的内容设置正则表达式,匹配到要爬取的内容
(3)设置循环列表,重复抓取保存内容
下面介绍两种抓取指定网页图片的方法
(1)方法一:使用正则表达式过滤捕获的html内容字符串
# 第一个简单的爬取图片的程序
import urllib.request # python自带的爬操作url的库
import re # 正则表达式
# 该方法传入url,返回url的html的源代码
def getHtmlCode(url):
# 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求
headers = {
'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \
AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36'
}
# 将headers头部添加到url,模拟浏览器访问
url = urllib.request.Request(url, headers=headers)
# 将url页面的源代码保存成字符串
page = urllib.request.urlopen(url).read()
# 字符串转码
page = page.decode('UTF-8')
return page
# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
def getImage(page):
# [^\s]*? 表示最小匹配, 两个括号表示列表中有两个元组
# imageList = re.findall(r'(https:[^\s]*?(png))"', page)
imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page)
x = 0
# 循环列表
for imageUrl in imageList:
try:
print('正在下载: %s' % imageUrl[0])
# 这个image文件夹需要先创建好才能看到结果
image_save_path = './image/%d.png' % x
# 下载图片并且保存到指定文件夹中
urllib.request.urlretrieve(imageUrl[0], image_save_path)
x = x + 1
except:
continue
pass
if __name__ == '__main__':
# 指定要爬取的网站
url = "https://www.cnblogs.com/ttweix ... ot%3B
# 得到该网站的源代码
page = getHtmlCode(url)
# 爬取该网站的图片并且保存
getImage(page)
# print(page)
注意代码中需要修改的是 imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page) 这一段内容,怎么设计正则表达式需要根据你要爬取的内容设置我的设计源码如下:
可以看到,因为这个页面的图片都是png格式,所以也可以写成imageList = re.findall(r'(https:[^\s]*?(png))"', page)
(2)方法二:使用BeautifulSoup库解析html网页
from bs4 import BeautifulSoup # BeautifulSoup是python处理HTML/XML的函数库,是Python内置的网页分析工具
import urllib # python自带的爬操作url的库
# 该方法传入url,返回url的html的源代码
def getHtmlCode(url):
# 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求
headers = {
'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \
AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36'
}
# 将headers头部添加到url,模拟浏览器访问
url = urllib.request.Request(url, headers=headers)
# 将url页面的源代码保存成字符串
page = urllib.request.urlopen(url).read()
# 字符串转码
page = page.decode('UTF-8')
return page
# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
def getImage(page):
# 按照html格式解析页面
soup = BeautifulSoup(page, 'html.parser')
# 格式化输出DOM树的内容
print(soup.prettify())
# 返回所有包含img标签的列表,因为在Html文件中图片的插入呈现形式是...
imgList = soup.find_all('img')
x = 0
# 循环找到的图片列表,注意,这里手动设置从第2张图片开始,是因为我debug看到了第一张图片不是我想要的图片
for imgUrl in imgList[1:]:
print('正在下载: %s ' % imgUrl.get('src'))
# 得到scr的内容,这里返回的就是Url字符串链接,如'https://img2020.cnblogs.com/blog/1703588/202007/1703588-20200716203143042-623499171.png'
image_url = imgUrl.get('src')
# 这个image文件夹需要先创建好才能看到结果
image_save_path = './image/%d.png' % x
# 下载图片并且保存到指定文件夹中
urllib.request.urlretrieve(image_url, image_save_path)
x = x + 1
if __name__ == '__main__':
# 指定要爬取的网站
url = 'https://www.cnblogs.com/ttweixiao-IT-program/p/13324826.html'
# 得到该网站的源代码
page = getHtmlCode(url)
# 爬取该网站的图片并且保存
getImage(page)
这两种方法各有优缺点。我认为它们可以灵活组合。比如先用方法二中的指定标签的方法缩小你要查找的内容范围,然后再用正则表达式匹配到需要的内容。更简洁明了
相关文章
网页源代码抓取工具(如何通过Chrome开发者工具寻找一个网站上特定数据的抓取方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-09-27 09:05
网上爬虫教程太多了。在知乎上搜索,我猜你能找到不少于100个。每个人都乐于从互联网上抢一个接一个的网站。但是只要对方网站更新,很可能文章里面的方法就失效了。
每个网站捕获的代码不同,但背后的原理是一样的。对于大多数 网站 来说,爬行程序就是这样。今天的文章不讲什么具体的网站爬取,只讲一个共同点:
如何使用 Chrome 开发者工具找到一种方法来捕获 网站 上的特定数据。
(我这里演示的是Mac上英文版的Chrome,中文版Windows的使用方法是一样的。)
> 查看网页源代码
在网页上右击选择“查看页面源代码”,在新标签页中会显示该URL对应的HTML代码文本。
此功能不被视为“开发人员工具”的一部分,但它也非常常用。此内容与您通过代码直接向此 URL 发送 GET 请求所获得的结果相同(无论是否存在权限问题)。如果你能在这个源码页上找到你想要的内容,就可以按照它的规则,通过regular、bs4、xpath等方法提取文本中的数据。
但是,对于很多异步加载数据的网站来说,你在这个页面上找不到你想要的。或者因为权限和验证的限制,在代码中得到的结果与页面显示不一致。在这些情况下,我们需要更强大的开发人员工具来提供帮助。
> 元素
在网页上右击选择“Inspect”,进入Chrome Developer Tools的元素选择器。在工具中是元素选项卡。
元素有几个功能:
从 Elements 工具中定位数据比直接在源代码中搜索更方便,因为您可以清楚地看到它所在的元素结构。但这里特别提醒:
Elements 中看到的代码不等于请求 URL 的返回值。
是浏览器渲染的网页最终效果,包括异步请求数据,以及浏览器自身对代码的优化改动。因此,您无法根据 Elements 中显示的结构获取元素。在这种情况下,您可能无法获得正确的结果。
> 网络
在开发者工具中选择Network选项卡,进入网络监控功能,也就是常说的“抓包”。
这是爬虫使用的最重要的功能。主要解决两个问题:
捕捉什么
抓住的是如何找到通过异步请求获取的数据的来源。
打开网络页面,打开记录,刷新页面,可以看到所有发送的请求,包括数据、JS、CSS、图片、文档等,都会显示出来。您可以从请求列表中找到您的目标。
一一找到它们会很痛苦。分享几个小贴士:
找到收录数据的请求后,下一步就是使用程序获取数据。这时候就是第二个问题:怎么抓。
不是所有的URL都可以通过GET直接获取(相当于在浏览器中打开地址),通常要考虑这些:
请求方法是 GET 或 POST。请求附加的参数数据。GET 和 POST 有不同的参数传递方法。标头信息。常用的有user-agent、host、referer、cookie等,其中cookie是用来标识请求者身份的关键信息。对于需要登录的网站来说,这个值是必不可少的。网站 经常使用其他几个项目来标识请求的合法性。相同的请求在浏览器中可用,但在程序中不可用。大多数标题信息是不正确的。您可以将此信息从 Chrome 复制到程序中以绕过对方的限制。
单击列表中的特定请求,可以找到上述所有信息。
找到正确的请求,设置正确的方法,传递正确的参数和头信息,网站上的大部分信息都可以做到。
网络还有一个功能:右键单击列表,选择“另存为带有内容的HAR”,然后保存到文件中。该文件收录列表中的所有请求参数和返回值信息,以便您查找和分析。(在实际操作中发现直接搜索往往无效,只能保存到文件后才能搜索)
除了 Elements 和 Network 之外,开发者工具中还有一些功能,例如:
Sources,查看资源列表,调试JS。
控制台,显示页面的错误和输出,可以执行JS代码。很多网站都会在这里放招聘彩蛋(找更知名的网站试试)。
但这些功能与爬虫关系不大。如果开发网站,优化网站速度,还需要处理其他功能。这里不多说。
综上所述,其实你应该记住以下几点:
在“查看源代码”中可以看到的数据,可以通过程序直接请求当前的URL来获取。Elements 中的 HTML 代码不等于请求的返回值,只能用作辅助。使用网络中的内容关键字搜索,或将其保存为HAR文件后搜索以找到收录数据的实际请求。查看请求的具体信息,包括方法、头部和参数,并复制到程序中使用。
了解了这些步骤后,网上的资料大部分都可以得到了,说“解决了一半”不是头条党。
当然,说起来容易些。如果你想精通,还有很多细节需要考虑,你需要不断练习。但是拿这些点来看看各种爬虫案例,思路会更清晰。
如果你想要更详细的爬虫讲解和指导,可以看看我们的《爬虫实战》课程,也有零基础入门课程。
对课程详情公众号回复码的操作(Crossin的编程课堂)
====
其他 文章 和回答:
欢迎搜索关注:Crossin的编程课堂 查看全部
网页源代码抓取工具(如何通过Chrome开发者工具寻找一个网站上特定数据的抓取方式)
网上爬虫教程太多了。在知乎上搜索,我猜你能找到不少于100个。每个人都乐于从互联网上抢一个接一个的网站。但是只要对方网站更新,很可能文章里面的方法就失效了。
每个网站捕获的代码不同,但背后的原理是一样的。对于大多数 网站 来说,爬行程序就是这样。今天的文章不讲什么具体的网站爬取,只讲一个共同点:
如何使用 Chrome 开发者工具找到一种方法来捕获 网站 上的特定数据。
(我这里演示的是Mac上英文版的Chrome,中文版Windows的使用方法是一样的。)
> 查看网页源代码
在网页上右击选择“查看页面源代码”,在新标签页中会显示该URL对应的HTML代码文本。
此功能不被视为“开发人员工具”的一部分,但它也非常常用。此内容与您通过代码直接向此 URL 发送 GET 请求所获得的结果相同(无论是否存在权限问题)。如果你能在这个源码页上找到你想要的内容,就可以按照它的规则,通过regular、bs4、xpath等方法提取文本中的数据。
但是,对于很多异步加载数据的网站来说,你在这个页面上找不到你想要的。或者因为权限和验证的限制,在代码中得到的结果与页面显示不一致。在这些情况下,我们需要更强大的开发人员工具来提供帮助。
> 元素
在网页上右击选择“Inspect”,进入Chrome Developer Tools的元素选择器。在工具中是元素选项卡。
元素有几个功能:
从 Elements 工具中定位数据比直接在源代码中搜索更方便,因为您可以清楚地看到它所在的元素结构。但这里特别提醒:
Elements 中看到的代码不等于请求 URL 的返回值。
是浏览器渲染的网页最终效果,包括异步请求数据,以及浏览器自身对代码的优化改动。因此,您无法根据 Elements 中显示的结构获取元素。在这种情况下,您可能无法获得正确的结果。
> 网络
在开发者工具中选择Network选项卡,进入网络监控功能,也就是常说的“抓包”。
这是爬虫使用的最重要的功能。主要解决两个问题:
捕捉什么
抓住的是如何找到通过异步请求获取的数据的来源。
打开网络页面,打开记录,刷新页面,可以看到所有发送的请求,包括数据、JS、CSS、图片、文档等,都会显示出来。您可以从请求列表中找到您的目标。
一一找到它们会很痛苦。分享几个小贴士:
找到收录数据的请求后,下一步就是使用程序获取数据。这时候就是第二个问题:怎么抓。
不是所有的URL都可以通过GET直接获取(相当于在浏览器中打开地址),通常要考虑这些:
请求方法是 GET 或 POST。请求附加的参数数据。GET 和 POST 有不同的参数传递方法。标头信息。常用的有user-agent、host、referer、cookie等,其中cookie是用来标识请求者身份的关键信息。对于需要登录的网站来说,这个值是必不可少的。网站 经常使用其他几个项目来标识请求的合法性。相同的请求在浏览器中可用,但在程序中不可用。大多数标题信息是不正确的。您可以将此信息从 Chrome 复制到程序中以绕过对方的限制。
单击列表中的特定请求,可以找到上述所有信息。
找到正确的请求,设置正确的方法,传递正确的参数和头信息,网站上的大部分信息都可以做到。
网络还有一个功能:右键单击列表,选择“另存为带有内容的HAR”,然后保存到文件中。该文件收录列表中的所有请求参数和返回值信息,以便您查找和分析。(在实际操作中发现直接搜索往往无效,只能保存到文件后才能搜索)
除了 Elements 和 Network 之外,开发者工具中还有一些功能,例如:
Sources,查看资源列表,调试JS。
控制台,显示页面的错误和输出,可以执行JS代码。很多网站都会在这里放招聘彩蛋(找更知名的网站试试)。
但这些功能与爬虫关系不大。如果开发网站,优化网站速度,还需要处理其他功能。这里不多说。
综上所述,其实你应该记住以下几点:
在“查看源代码”中可以看到的数据,可以通过程序直接请求当前的URL来获取。Elements 中的 HTML 代码不等于请求的返回值,只能用作辅助。使用网络中的内容关键字搜索,或将其保存为HAR文件后搜索以找到收录数据的实际请求。查看请求的具体信息,包括方法、头部和参数,并复制到程序中使用。
了解了这些步骤后,网上的资料大部分都可以得到了,说“解决了一半”不是头条党。
当然,说起来容易些。如果你想精通,还有很多细节需要考虑,你需要不断练习。但是拿这些点来看看各种爬虫案例,思路会更清晰。
如果你想要更详细的爬虫讲解和指导,可以看看我们的《爬虫实战》课程,也有零基础入门课程。
对课程详情公众号回复码的操作(Crossin的编程课堂)
====
其他 文章 和回答:
欢迎搜索关注:Crossin的编程课堂
网页源代码抓取工具(网页捕捉工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-09-24 14:11
Web捕获工具(webcapture)2005
============
这是VB。NET2005版本的web捕获工具源代码。您可以指定自动捕获网页快照的网址,并自定义文件格式和文件保存路径。您甚至可以设置水印文本。同时,您还可以生成缩略图以捕获图片,并支持自定义缩略图大小和格式
源代码还可以指定进程ID以捕获受保护的链接。虽然源代码很小,但它有完整的功能-页面捕获工具(WebCapture)VB.NET2005==================================================这是用于捕获页面源代码的VB.NET2005工具的一个版本。可以指定页面URL自动捕获快照,可以自定义文件格式并保存文件路径。您甚至可以设置水印文本。同时,还可以捕获生成的缩略图图像,以支持自定义缩略图大小和格式。源代码还可以指定进程ID以捕获正在进行的链接保护。源代码很小,但功能相对完整
相关搜索:水印 查看全部
网页源代码抓取工具(网页捕捉工具)
Web捕获工具(webcapture)2005
============
这是VB。NET2005版本的web捕获工具源代码。您可以指定自动捕获网页快照的网址,并自定义文件格式和文件保存路径。您甚至可以设置水印文本。同时,您还可以生成缩略图以捕获图片,并支持自定义缩略图大小和格式
源代码还可以指定进程ID以捕获受保护的链接。虽然源代码很小,但它有完整的功能-页面捕获工具(WebCapture)VB.NET2005==================================================这是用于捕获页面源代码的VB.NET2005工具的一个版本。可以指定页面URL自动捕获快照,可以自定义文件格式并保存文件路径。您甚至可以设置水印文本。同时,还可以捕获生成的缩略图图像,以支持自定义缩略图大小和格式。源代码还可以指定进程ID以捕获正在进行的链接保护。源代码很小,但功能相对完整
相关搜索:水印
网页源代码抓取工具(模拟登录的实现过程1、获取所需要的参数IE浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-09-21 18:00
模拟登录原理
通常,当用户通过浏览器登录网站时,他们会在特定的登录界面中输入个人登录信息,然后在提交后返回收录数据的网页。在浏览器级别,浏览器提交收录必要信息的HTTP请求,服务器返回HTTP响应。HTTP请求包括以下5项:
Url=基本Url+可选查询字符串
请求头:必需或可选
Cookie:可选
Post数据:当时Post方法需要
HTTP响应的内容包括以下两项:HTML源代码或图像、JSON字符串等
Cookies:如果后续访问需要Cookies,则返回的内容将收录Cookies
URL是统一资源定位器(UniformResourceLocator)的缩写,它是Internet上可用资源的位置和访问方法的简明表示,包括主机部分和文件路径部分;请求头是服务请求信息的头信息,包括编码格式、用户代理、提交主机、路径等信息;Post数据是指提交的用户、内容、格式参数等。Cookie是服务器发送到浏览器的文件,存储在本地,服务器用于识别用户,用于判断用户是否合法以及一些登录信息
网页捕获原理
如上所述,在模拟登录之后,网站server将返回HTML文件。Html是一个带有标记的文本文件,具有严格的语法和格式。不同的标签有不同的内容。根据相关标记和数据特征,可以使用正则表达式获取所需的数据或表示可进一步挖掘的数据的链接
模拟登录的实现过程
1、获取所需参数。IE浏览器为开发者提供了一个强大的工具。获取参数的过程如下:
打开浏览器
输入网址
开发工具
网络使能
网络流量捕获
输入要登录的密码和帐户
查找发起程序为“单击”的第一条记录
细节
请求头和请求体
请求头和请求体收录客户端和浏览器之间交互的参数。其中一些参数是默认的,不需要设置;有些参数与用户本身有关,如用户名、密码、记住密码等
一些参数是通过客户端和服务器之间的交互生成的。确定参数的步骤如下:首先,逐字理解它们,然后在交互记录中搜索参数名称并观察参数生成的过程。请求正文中的一些参数已编码,需要解码
2、获取登录百度账号所需的参数
按照以上步骤,使用IE9浏览器内置工具,轻松获取相关参数。其中,staticpage是跳转页。在解码或学习之后。“摘要”记录中的HTML。搜索发现token参数首先出现在带有URL的响应体中,需要在返回的页码中抓取;apiver参数设置返回的文本是JSON格式还是HTML格式。除了常规设置参数外,请求头中还有cookie。为了与服务器交互,需要在登录期间获取Cookies
3、login特定代码实现
3.1导入登录过程使用的库
进口稀土
mport cookielib
导入urllib
导入urllib2
re库用于解析正则表达式并获取和匹配它们;cookie库获取并管理cookie;urllib和urllib 2库根据URL和post数据参数从服务器请求和解码数据
3.2Cookie检测函数
通过检测cookie jar返回的cookie密钥是否与cookie名称列表完全匹配,确定登录是否成功
def checkAllCookiesExist(cookieNameList,cookieJar):
cookiesDict={}
对于cookieNameList中的每个CookieName:
cookiesDict[eachCookieName]=False
allCookieFound=True
对于cookieJar中的cookie:
如果(cookiesDict.keys()中的cookie.name):
cookiesDict[cookie.name]=True
对于cookiesDict.keys()中的Cookie:
如果(不是cookiesDict[eachCookie]):
allCookieFound=False
中断
返回找到的所有CookieFind
3.3模拟登录百度
def emulatoroginbaidu():
cj=cookielib.CookieJar()
opener=url� lib2.build_uuu-opener(urllib2.HTTPCookieProcessor(cj))
urllib2.安装开启器(开启器)
创建cookie jar对象以保存cookie,使用HTTP处理器绑定并打开安装
打印“[step1]以获取cookie BAIDUID”
baiduMainUrl=“”
响应=urllib2.urlopen(baiduMainUrl)
打开百度主页,获取cookie baiduid
打印“[step2]以获取令牌值”
getapiUrl=“;class=login&;tpl=mn&;tangram=true”
getapiResp=urllib2.urlopen(getapirl)
getapiRespHtml=getapiResp.read()
打印“getapiResp=”,getapiResp
IsfoundToken=re.search(“bdPass\.api\.params\.login_token=”(?p\w+);”
getapiRespHtml)
上述程序用于获取post数据中的令牌参数。首先,获取getapiurl web地址的HTML,然后使用re-standard库中的搜索函数搜索匹配项,并返回一个布尔值,指示匹配是否成功
如果(IsfoundToken):
tokenVal=IsfoundToken.group(“tokenVal”)
打印“tokenVal=”,tokenVal
打印“[step3]模拟登录百度”
staticpage=“”
baiduMainLoginUrl=“”
后记={
“字符集”:“utf-8”
“token”:tokenVal
“isPhone”:“false”
'索引':“0”
“safeflg”:“0”
“staticpage”:staticpage
'登录类型':“1”
“tpl”:“mn”
“用户名”:“用户名”
“密码”:“密码”
“mem_pass”:“on”
}[3] )
设置postData参数值时,并非所有参数都需要设置。某些参数是默认值
postData=urllib.urlencode(postDict)
对postData进行编码。例如,编码结果是HTTP%3A%2F%2F%2fcache%2fuser%2fhtml%2fjump.html。其他参数类似
请求=urllib2.Request(baiduMainLoginUrl,post)�数据)
响应=urllib2.urlopen(req)
python标准库urlib2的两个函数分别提交用户请求和数据,并接受返回的数据
cookiesToCheck=['BDUSS','PTOKEN','STOKEN','SAVEUSERID','UBI','HISTORY','USERNAMETYPE']
网页抓取的实现过程
在上面的例子中,正则表达式用于成功地获取返回网页中的令牌。Python的标准库HTMLPasser提供了识别HTML文本标记和数据的强大功能。使用时,从Htmlparser派生新类,然后重新定义这些类以处理u开始时的函数包括:
句柄\uuStartEndTag句柄开始和结束标记
handle_uuStartTag处理开始标记,例如
handle_uuEndTag处理结束标记,例如
handle_uCharRef处理特殊字符串,这些字符串是以开头的字符,通常由内部代码表示
handle_uuentityref将一些特殊字符处理为&;例如,在开始的时候
数据处理数据是数据
中的数据。
以下程序用于捕获百度贴吧电影条帖子的标题作为演示:
导入HTMLPasser
导入urllib2 查看全部
网页源代码抓取工具(模拟登录的实现过程1、获取所需要的参数IE浏览器)
模拟登录原理
通常,当用户通过浏览器登录网站时,他们会在特定的登录界面中输入个人登录信息,然后在提交后返回收录数据的网页。在浏览器级别,浏览器提交收录必要信息的HTTP请求,服务器返回HTTP响应。HTTP请求包括以下5项:
Url=基本Url+可选查询字符串
请求头:必需或可选
Cookie:可选
Post数据:当时Post方法需要
HTTP响应的内容包括以下两项:HTML源代码或图像、JSON字符串等
Cookies:如果后续访问需要Cookies,则返回的内容将收录Cookies
URL是统一资源定位器(UniformResourceLocator)的缩写,它是Internet上可用资源的位置和访问方法的简明表示,包括主机部分和文件路径部分;请求头是服务请求信息的头信息,包括编码格式、用户代理、提交主机、路径等信息;Post数据是指提交的用户、内容、格式参数等。Cookie是服务器发送到浏览器的文件,存储在本地,服务器用于识别用户,用于判断用户是否合法以及一些登录信息
网页捕获原理
如上所述,在模拟登录之后,网站server将返回HTML文件。Html是一个带有标记的文本文件,具有严格的语法和格式。不同的标签有不同的内容。根据相关标记和数据特征,可以使用正则表达式获取所需的数据或表示可进一步挖掘的数据的链接
模拟登录的实现过程
1、获取所需参数。IE浏览器为开发者提供了一个强大的工具。获取参数的过程如下:
打开浏览器
输入网址
开发工具
网络使能
网络流量捕获
输入要登录的密码和帐户
查找发起程序为“单击”的第一条记录
细节
请求头和请求体
请求头和请求体收录客户端和浏览器之间交互的参数。其中一些参数是默认的,不需要设置;有些参数与用户本身有关,如用户名、密码、记住密码等
一些参数是通过客户端和服务器之间的交互生成的。确定参数的步骤如下:首先,逐字理解它们,然后在交互记录中搜索参数名称并观察参数生成的过程。请求正文中的一些参数已编码,需要解码
2、获取登录百度账号所需的参数
按照以上步骤,使用IE9浏览器内置工具,轻松获取相关参数。其中,staticpage是跳转页。在解码或学习之后。“摘要”记录中的HTML。搜索发现token参数首先出现在带有URL的响应体中,需要在返回的页码中抓取;apiver参数设置返回的文本是JSON格式还是HTML格式。除了常规设置参数外,请求头中还有cookie。为了与服务器交互,需要在登录期间获取Cookies
3、login特定代码实现
3.1导入登录过程使用的库
进口稀土
mport cookielib
导入urllib
导入urllib2
re库用于解析正则表达式并获取和匹配它们;cookie库获取并管理cookie;urllib和urllib 2库根据URL和post数据参数从服务器请求和解码数据
3.2Cookie检测函数
通过检测cookie jar返回的cookie密钥是否与cookie名称列表完全匹配,确定登录是否成功
def checkAllCookiesExist(cookieNameList,cookieJar):
cookiesDict={}
对于cookieNameList中的每个CookieName:
cookiesDict[eachCookieName]=False
allCookieFound=True
对于cookieJar中的cookie:
如果(cookiesDict.keys()中的cookie.name):
cookiesDict[cookie.name]=True
对于cookiesDict.keys()中的Cookie:
如果(不是cookiesDict[eachCookie]):
allCookieFound=False
中断
返回找到的所有CookieFind
3.3模拟登录百度
def emulatoroginbaidu():
cj=cookielib.CookieJar()
opener=url� lib2.build_uuu-opener(urllib2.HTTPCookieProcessor(cj))
urllib2.安装开启器(开启器)
创建cookie jar对象以保存cookie,使用HTTP处理器绑定并打开安装
打印“[step1]以获取cookie BAIDUID”
baiduMainUrl=“”
响应=urllib2.urlopen(baiduMainUrl)
打开百度主页,获取cookie baiduid
打印“[step2]以获取令牌值”
getapiUrl=“;class=login&;tpl=mn&;tangram=true”
getapiResp=urllib2.urlopen(getapirl)
getapiRespHtml=getapiResp.read()
打印“getapiResp=”,getapiResp
IsfoundToken=re.search(“bdPass\.api\.params\.login_token=”(?p\w+);”
getapiRespHtml)
上述程序用于获取post数据中的令牌参数。首先,获取getapiurl web地址的HTML,然后使用re-standard库中的搜索函数搜索匹配项,并返回一个布尔值,指示匹配是否成功
如果(IsfoundToken):
tokenVal=IsfoundToken.group(“tokenVal”)
打印“tokenVal=”,tokenVal
打印“[step3]模拟登录百度”
staticpage=“”
baiduMainLoginUrl=“”
后记={
“字符集”:“utf-8”
“token”:tokenVal
“isPhone”:“false”
'索引':“0”
“safeflg”:“0”
“staticpage”:staticpage
'登录类型':“1”
“tpl”:“mn”
“用户名”:“用户名”
“密码”:“密码”
“mem_pass”:“on”
}[3] )
设置postData参数值时,并非所有参数都需要设置。某些参数是默认值
postData=urllib.urlencode(postDict)
对postData进行编码。例如,编码结果是HTTP%3A%2F%2F%2fcache%2fuser%2fhtml%2fjump.html。其他参数类似
请求=urllib2.Request(baiduMainLoginUrl,post)�数据)
响应=urllib2.urlopen(req)
python标准库urlib2的两个函数分别提交用户请求和数据,并接受返回的数据
cookiesToCheck=['BDUSS','PTOKEN','STOKEN','SAVEUSERID','UBI','HISTORY','USERNAMETYPE']
网页抓取的实现过程
在上面的例子中,正则表达式用于成功地获取返回网页中的令牌。Python的标准库HTMLPasser提供了识别HTML文本标记和数据的强大功能。使用时,从Htmlparser派生新类,然后重新定义这些类以处理u开始时的函数包括:
句柄\uuStartEndTag句柄开始和结束标记
handle_uuStartTag处理开始标记,例如
handle_uuEndTag处理结束标记,例如
handle_uCharRef处理特殊字符串,这些字符串是以开头的字符,通常由内部代码表示
handle_uuentityref将一些特殊字符处理为&;例如,在开始的时候
数据处理数据是数据
中的数据。
以下程序用于捕获百度贴吧电影条帖子的标题作为演示:
导入HTMLPasser
导入urllib2
网页源代码抓取工具(模拟浏览器打开网页获取网页的基本原理(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-21 17:19
基本原则
爬虫的本质是模拟浏览器打开一个网页,获取我们想要的网页中的部分数据。爬虫是一种自动获取网页、提取和保存信息的程序。主要有以下三个步骤:
获取网页:爬虫应该做的第一件事就是获取网页。以下是获取网页的源代码。源代码收录一些有用的网页信息,因此只要您获得源代码,就可以从中提取所需的信息。爬虫首先向服务器网站发送请求,返回的响应主体是网页源代码。Python提供了许多库(比如urllib和请求)来帮助我们实现这个操作。我们可以使用这些库来帮助我们实现HTTP请求操作。请求和响应可以由类库提供的数据结构表示。在得到响应后,只需要解析数据结构的主体部分,即可以得到网页的源代码,这样就可以用程序来实现获取网页的过程
提取信息:获取网页源代码后,下一步是分析网页源代码并提取我们想要的数据。首先,最常用的方法是正则表达式提取,这是一种通用的方法,但它在构造正则表达式时非常复杂且容易出错。此外,由于网页的结构有一定的规则,因此有一些库可以根据网页节点属性、CSS选择器或XPath提取网页信息,如Beauty soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性,文本值等等。信息提取是爬虫的重要组成部分。它可以使杂乱的数据组织和清晰,以便我们以后可以处理和分析数据
保存数据:提取信息后,我们通常将提取的数据保存在某个地方以备后续使用。这里有很多节约的方法。例如,它可以简单地保存为TXT文本或JSON文本,也可以保存到数据库(如MySQL和mongodb)或远程服务器(如使用SFTP操作)
你能捕捉到什么数据
我们可以在网页上看到各种各样的信息。最常见的是与HTML代码相对应的常规网页,最常见的捕获是HTML源代码。此外,一些网页可能会返回JSON字符串而不是HTML代码(大多数API接口都采用这种形式)。这种格式的数据便于传输和解析。它们也可以被抓取,数据提取更方便。此外,我们还可以看到各种二进制数据,如图片、视频和音频。使用爬虫,我们可以抓取这些二进制数据并将它们保存到相应的文件名中。此外,您还可以看到具有各种扩展名的文件,例如CSS、JavaScript和配置文件。事实上,这些也是最常见的文件。只要您可以在浏览器中访问它们,就可以抓取它们
JavaScript呈现页面
有时候,当我们抓取一个收录urllib或请求的网页时,我们得到的源代码实际上与我们在浏览器中看到的不同。这是一个非常普遍的问题。如今,越来越多的web页面是通过Ajax和前端模块工具构建的。整个网页可能由JavaScript呈现,也就是说,原创HTML代码是一个空壳,例如:
赫特姆利·霍纳,这是一个德莫西耶
SNLY 查看全部
网页源代码抓取工具(模拟浏览器打开网页获取网页的基本原理(图))
基本原则
爬虫的本质是模拟浏览器打开一个网页,获取我们想要的网页中的部分数据。爬虫是一种自动获取网页、提取和保存信息的程序。主要有以下三个步骤:
获取网页:爬虫应该做的第一件事就是获取网页。以下是获取网页的源代码。源代码收录一些有用的网页信息,因此只要您获得源代码,就可以从中提取所需的信息。爬虫首先向服务器网站发送请求,返回的响应主体是网页源代码。Python提供了许多库(比如urllib和请求)来帮助我们实现这个操作。我们可以使用这些库来帮助我们实现HTTP请求操作。请求和响应可以由类库提供的数据结构表示。在得到响应后,只需要解析数据结构的主体部分,即可以得到网页的源代码,这样就可以用程序来实现获取网页的过程
提取信息:获取网页源代码后,下一步是分析网页源代码并提取我们想要的数据。首先,最常用的方法是正则表达式提取,这是一种通用的方法,但它在构造正则表达式时非常复杂且容易出错。此外,由于网页的结构有一定的规则,因此有一些库可以根据网页节点属性、CSS选择器或XPath提取网页信息,如Beauty soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性,文本值等等。信息提取是爬虫的重要组成部分。它可以使杂乱的数据组织和清晰,以便我们以后可以处理和分析数据
保存数据:提取信息后,我们通常将提取的数据保存在某个地方以备后续使用。这里有很多节约的方法。例如,它可以简单地保存为TXT文本或JSON文本,也可以保存到数据库(如MySQL和mongodb)或远程服务器(如使用SFTP操作)
你能捕捉到什么数据
我们可以在网页上看到各种各样的信息。最常见的是与HTML代码相对应的常规网页,最常见的捕获是HTML源代码。此外,一些网页可能会返回JSON字符串而不是HTML代码(大多数API接口都采用这种形式)。这种格式的数据便于传输和解析。它们也可以被抓取,数据提取更方便。此外,我们还可以看到各种二进制数据,如图片、视频和音频。使用爬虫,我们可以抓取这些二进制数据并将它们保存到相应的文件名中。此外,您还可以看到具有各种扩展名的文件,例如CSS、JavaScript和配置文件。事实上,这些也是最常见的文件。只要您可以在浏览器中访问它们,就可以抓取它们
JavaScript呈现页面
有时候,当我们抓取一个收录urllib或请求的网页时,我们得到的源代码实际上与我们在浏览器中看到的不同。这是一个非常普遍的问题。如今,越来越多的web页面是通过Ajax和前端模块工具构建的。整个网页可能由JavaScript呈现,也就是说,原创HTML代码是一个空壳,例如:
赫特姆利·霍纳,这是一个德莫西耶
SNLY
网页源代码抓取工具(网络爬虫系列(一):chrom抓包分析(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 452 次浏览 • 2021-09-21 17:18
网络爬虫系列(一):Chrome数据包捕获分析)
1、测试环境
浏览器:Chrome浏览器
Web分析工具:开发人员工具
2、web页面分析(1)web页面源代码分析)
我们知道网页可以分为静态网页和动态网页。许多人会错误地认为静态网页是没有动态效果的网页。事实上,这种说法是错误的
另外,目前很多动态网站都采用了异步加载技术(Ajax),这也是捕获的源代码多次与网站显示的源代码不一致的原因
对于如何抓取动态网页,有两种方法:
我们以京东产品为例,分析如何通过chrome抓包,首先打开产品主页
右键单击网页空白处并选择查看网络源代码,或使用快捷方式CTRL+U直接打开它)
请注意,当您查看网页的源代码时,您会得到网站最原创的源代码,即我们通常获取的源代码
再次进入网页空白处,右键单击并选中(或使用快捷键CTRL+Shift +I/F12直接打开)
请注意,您得到的是由Ajax加载并由JavaScript呈现的源代码,即当前网站显示内容的源代码
通过比较,我们可以发现两者的内容是不同的,这是异步加载技术(Ajax)的一个典型例子
目前,京东产品的价格至少是通过异步加载生成的。这里有三种方法来判断网页中的内容是否是动态生成的:
(2)网络数据包捕获分析)
让我们以京东商品为例来说明。打开商品主页,尝试捕获动态加载的商品价格数据
使用快捷键Ctrl+Shift+I或F12打开开发者工具,然后选择网络选项卡进行数据包捕获分析
此时,按快捷键F5刷新页面。您可以看到开发人员工具中出现了各种包。我们使用filter来过滤包
首先,选择doc,您可以看到列表中只显示一个包
一般来说,这是浏览器收到的第一个数据包,用于获取网站请求的原创源代码@
单击“标题”以查看其标题参数设置
单击响应以查看返回的源代码。很容易发现它实际上与通过查看网页源代码返回的信息一致
让我们回到正题上来。对于动态加载的数据包捕获分析,我们可以主要查看XHR和JS选项卡
选择JS进行筛选,发现列表中出现了许多包。分析之后,我们过滤下图中标记的包
此包返回有关价格的信息,但经过仔细分析,发现这些价格不属于当前商品,而是属于流行配件
这个包裹与价格有关。让我们先看一下这个包的请求URL:
%2CJ_8141909%2CJ_5028795%2CJ_152026%2CJ_61192828749%2CJ_2%2CJ_2533882%2CJ_854803%2CJ_3693877%2CJ_4%2CJ_136360&;ext=11100000&;来源=项目pc
直接用浏览器打开URL,可以看到返回的JSON数据确实收录价格信息
通过分析URL的参数,可以推断skuid应该是每个商品的唯一标记。我们在哪里可以找到我们需要的商品的臭鼬
事实上,SKU是物流、运输等行业常用的缩写。其全称为库存单位,即存货进出计量的基本单位。现在它已经扩展到统一产品编号的缩写。每个产品对应一个唯一的SKU 查看全部
网页源代码抓取工具(网络爬虫系列(一):chrom抓包分析(组图))
网络爬虫系列(一):Chrome数据包捕获分析)
1、测试环境
浏览器:Chrome浏览器
Web分析工具:开发人员工具
2、web页面分析(1)web页面源代码分析)
我们知道网页可以分为静态网页和动态网页。许多人会错误地认为静态网页是没有动态效果的网页。事实上,这种说法是错误的
另外,目前很多动态网站都采用了异步加载技术(Ajax),这也是捕获的源代码多次与网站显示的源代码不一致的原因
对于如何抓取动态网页,有两种方法:
我们以京东产品为例,分析如何通过chrome抓包,首先打开产品主页
右键单击网页空白处并选择查看网络源代码,或使用快捷方式CTRL+U直接打开它)
请注意,当您查看网页的源代码时,您会得到网站最原创的源代码,即我们通常获取的源代码
再次进入网页空白处,右键单击并选中(或使用快捷键CTRL+Shift +I/F12直接打开)
请注意,您得到的是由Ajax加载并由JavaScript呈现的源代码,即当前网站显示内容的源代码
通过比较,我们可以发现两者的内容是不同的,这是异步加载技术(Ajax)的一个典型例子
目前,京东产品的价格至少是通过异步加载生成的。这里有三种方法来判断网页中的内容是否是动态生成的:
(2)网络数据包捕获分析)
让我们以京东商品为例来说明。打开商品主页,尝试捕获动态加载的商品价格数据
使用快捷键Ctrl+Shift+I或F12打开开发者工具,然后选择网络选项卡进行数据包捕获分析
此时,按快捷键F5刷新页面。您可以看到开发人员工具中出现了各种包。我们使用filter来过滤包
首先,选择doc,您可以看到列表中只显示一个包
一般来说,这是浏览器收到的第一个数据包,用于获取网站请求的原创源代码@
单击“标题”以查看其标题参数设置
单击响应以查看返回的源代码。很容易发现它实际上与通过查看网页源代码返回的信息一致
让我们回到正题上来。对于动态加载的数据包捕获分析,我们可以主要查看XHR和JS选项卡
选择JS进行筛选,发现列表中出现了许多包。分析之后,我们过滤下图中标记的包
此包返回有关价格的信息,但经过仔细分析,发现这些价格不属于当前商品,而是属于流行配件
这个包裹与价格有关。让我们先看一下这个包的请求URL:
%2CJ_8141909%2CJ_5028795%2CJ_152026%2CJ_61192828749%2CJ_2%2CJ_2533882%2CJ_854803%2CJ_3693877%2CJ_4%2CJ_136360&;ext=11100000&;来源=项目pc
直接用浏览器打开URL,可以看到返回的JSON数据确实收录价格信息
通过分析URL的参数,可以推断skuid应该是每个商品的唯一标记。我们在哪里可以找到我们需要的商品的臭鼬
事实上,SKU是物流、运输等行业常用的缩写。其全称为库存单位,即存货进出计量的基本单位。现在它已经扩展到统一产品编号的缩写。每个产品对应一个唯一的SKU
网页源代码抓取工具(网页源代码抓取工具有很多,pythonselenium是从哪里下载?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-09-21 17:03
网页源代码抓取工具有很多,如:pyinstallerpyinstaller-epython-directoryfirefox的eclipse、android的python开发者的nsurlconnection等。这些都是把你的python项目从网页源代码转换成文件,相当于它们就是一个webserver,python项目直接下载,再编译的就好。
但是你说的pythonselenium是从哪里下载?搜狗和谷歌是在本地服务器解析页面,django在远程服务器解析页面。你可以用一个叫tornado的djangoserver来写你的项目,直接从chrome中下载js、flask库,封装成selenium对应的api就好了。
1。从首页下载,即html5python网页抓取工具2。在服务器中做完封装后,将代码(生成网页)文件,保存到\\python\\app\\users\\domains\\django\\python\\scripts\\\pythontest\\s。py\2。4\\scripts\\script。py,并注明pythonlist路径;3。在浏览器中访问该页面,进行调用抓取网页。
这种做法都不完整,要把网页底部那些元素全部抓取到本地并保存下来,然后再做下一步处理。 查看全部
网页源代码抓取工具(网页源代码抓取工具有很多,pythonselenium是从哪里下载?)
网页源代码抓取工具有很多,如:pyinstallerpyinstaller-epython-directoryfirefox的eclipse、android的python开发者的nsurlconnection等。这些都是把你的python项目从网页源代码转换成文件,相当于它们就是一个webserver,python项目直接下载,再编译的就好。
但是你说的pythonselenium是从哪里下载?搜狗和谷歌是在本地服务器解析页面,django在远程服务器解析页面。你可以用一个叫tornado的djangoserver来写你的项目,直接从chrome中下载js、flask库,封装成selenium对应的api就好了。
1。从首页下载,即html5python网页抓取工具2。在服务器中做完封装后,将代码(生成网页)文件,保存到\\python\\app\\users\\domains\\django\\python\\scripts\\\pythontest\\s。py\2。4\\scripts\\script。py,并注明pythonlist路径;3。在浏览器中访问该页面,进行调用抓取网页。
这种做法都不完整,要把网页底部那些元素全部抓取到本地并保存下来,然后再做下一步处理。
网页源代码抓取工具(如何通过Chrome开发者工具寻找一个网站上特定数据的方式 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 368 次浏览 • 2021-09-19 12:10
)
有太多的在线爬虫教程,知乎搜索它,估计你可以找到不少于100个。每个人都很高兴从互联网上一个接一个地抓到网站. 但一旦另一方网站更新,文章中的方法可能不再有效
每个网站grab的代码都不同,但背后的原理是相同的。对于绝大多数k14人来说,抓取的例行程序就是这样。今天的文章并没有谈论任何特定的网站捕获,只讨论了一件常见的事情:
如何通过chrome开发者工具找到网站特定的数据捕获方法
(我在这里演示的是MAC上chrome的英文版,windows的中文版也是一样。)
&燃气轮机;查看网页源代码
在网页上单击鼠标右键,然后选择“查看页面源”。与此URL对应的HTML代码文本将显示在新选项卡中
此功能不是“开发人员工具”的一部分,但也非常常见。此内容与通过代码直接向此URL发送get请求的结果相同(无论权限如何)。如果您可以在此源代码页上搜索所需的内容,则可以通过常规的bs4、XPath和其他方法提取文本中的数据
但是,对于许多异步加载的网站,您无法在此页面中找到所需内容。或者由于权限和验证等限制,代码中获得的结果与页面显示不一致。在这些情况下,我们需要更强大的开发工具来帮助
&燃气轮机;元素
右键点击网页并选择“检查”进入chrome开发者工具的元素选择器。该工具中有“图元”选项卡
元素有几个功能:
从elements工具查找数据比直接在源代码中搜索更方便,因为您可以清楚地看到其元素结构。但这里有一个特别的提醒:
元素中的代码不等于从请求的URL获得的返回值
它是浏览器呈现的网页的最终效果,包括异步请求数据和浏览器自身对代码的优化更改。因此,您无法完全按照元素中显示的结构获取元素。在这种情况下,您可能无法得到正确的结果
&燃气轮机;网络
选择开发者工具中的网络选项卡,进入网络监控功能,这通常被称为“数据包捕获”
这是爬行动物最重要的功能。主要解决两个问题:
什么和如何
捕获内容是指如何找到通过异步请求获得的数据源
打开网络页面,打开记录,然后刷新页面。您可以看到,将显示所有发出的请求,包括数据、JS、CSS、图片、文档等。您可以从请求列表中找到您的目标
一个接一个地找会很痛苦。分享一些技巧:
找到收录数据的请求后,下一步是使用程序获取数据。这是第二个问题:如何把握
并非所有URL都可以通过get直接获得(相当于在浏览器中打开地址)。一般来说,应考虑以下事项:
请求方法,获取或发布。附加到请求的参数数据。获取和传递后参数的方式不同。标题信息。常用的包括用户代理、主机、引用者、cookie等。cookie是用于标识请求者身份的关键信息。对于网站,此值是必不可少的。其他项目通常被网站用于确定请求的合法性。相同的请求可以在浏览器中发出,但不能在程序中发出。这主要是因为标题信息不正确。您可以将此信息从chrome移动到程序中,以绕过另一方的限制
单击列表中的特定请求,即可找到上述信息
找到正确的请求,设置正确的方法,传递正确的参数和标题信息。关于网站的大部分信息都可以完成
网络还有一个功能:右键单击列表并选择“使用内容另存为har”以保存到文件。此文件收录列表中所有请求的参数和返回值信息,供您查找和分析。(在实践中,我经常发现直接搜索是无效的,因此我只能在保存到文件后进行搜索)
除了元素和网络之外,开发者工具中还有一些功能,例如:
查看资源列表和调试JS的源代码
控制台,显示页面的错误和输出,可以执行JS代码。很多网站都会在这里放彩蛋招募(自己试试更有名的网站吧)
但这些功能与爬行动物几乎没有关系。如果您开发网站并优化网站速度,则需要处理其他功能。我不会在这里说太多
总之,您只需记住以下几点:
在“查看源代码”中可以看到的数据可以直接通过程序请求当前URL获得。元素中的HTML代码不等于请求返回值,只能用作辅助。在网络中搜索内容关键字或将其保存为har文件,以查找收录数据的实际请求,查看请求的特定信息,包括方法、标题和参数,并将其复制到程序中以供使用
了解这些步骤后,可以获得大部分在线数据。“解决一半问题”不是标题
当然,这更容易说。如果你想熟练掌握它,你仍然有很多细节需要考虑并且需要不断地练习。但是有了这些观点,当我们研究各种爬行动物的情况时,我们会有一个更清晰的想法
如果你想对爬行动物有更详细的解释和指导,我们有“爬行动物实践”课程和zero foundation入门课程
课程详情官方账户(Crossin编程教室)行动代码回复代码
════
其他文章和答案:
欢迎来到搜索和跟随:crossin的编程教室
查看全部
网页源代码抓取工具(如何通过Chrome开发者工具寻找一个网站上特定数据的方式
)
有太多的在线爬虫教程,知乎搜索它,估计你可以找到不少于100个。每个人都很高兴从互联网上一个接一个地抓到网站. 但一旦另一方网站更新,文章中的方法可能不再有效
每个网站grab的代码都不同,但背后的原理是相同的。对于绝大多数k14人来说,抓取的例行程序就是这样。今天的文章并没有谈论任何特定的网站捕获,只讨论了一件常见的事情:
如何通过chrome开发者工具找到网站特定的数据捕获方法
(我在这里演示的是MAC上chrome的英文版,windows的中文版也是一样。)
&燃气轮机;查看网页源代码
在网页上单击鼠标右键,然后选择“查看页面源”。与此URL对应的HTML代码文本将显示在新选项卡中
此功能不是“开发人员工具”的一部分,但也非常常见。此内容与通过代码直接向此URL发送get请求的结果相同(无论权限如何)。如果您可以在此源代码页上搜索所需的内容,则可以通过常规的bs4、XPath和其他方法提取文本中的数据
但是,对于许多异步加载的网站,您无法在此页面中找到所需内容。或者由于权限和验证等限制,代码中获得的结果与页面显示不一致。在这些情况下,我们需要更强大的开发工具来帮助
&燃气轮机;元素
右键点击网页并选择“检查”进入chrome开发者工具的元素选择器。该工具中有“图元”选项卡
元素有几个功能:
从elements工具查找数据比直接在源代码中搜索更方便,因为您可以清楚地看到其元素结构。但这里有一个特别的提醒:
元素中的代码不等于从请求的URL获得的返回值
它是浏览器呈现的网页的最终效果,包括异步请求数据和浏览器自身对代码的优化更改。因此,您无法完全按照元素中显示的结构获取元素。在这种情况下,您可能无法得到正确的结果
&燃气轮机;网络
选择开发者工具中的网络选项卡,进入网络监控功能,这通常被称为“数据包捕获”
这是爬行动物最重要的功能。主要解决两个问题:
什么和如何
捕获内容是指如何找到通过异步请求获得的数据源
打开网络页面,打开记录,然后刷新页面。您可以看到,将显示所有发出的请求,包括数据、JS、CSS、图片、文档等。您可以从请求列表中找到您的目标
一个接一个地找会很痛苦。分享一些技巧:
找到收录数据的请求后,下一步是使用程序获取数据。这是第二个问题:如何把握
并非所有URL都可以通过get直接获得(相当于在浏览器中打开地址)。一般来说,应考虑以下事项:
请求方法,获取或发布。附加到请求的参数数据。获取和传递后参数的方式不同。标题信息。常用的包括用户代理、主机、引用者、cookie等。cookie是用于标识请求者身份的关键信息。对于网站,此值是必不可少的。其他项目通常被网站用于确定请求的合法性。相同的请求可以在浏览器中发出,但不能在程序中发出。这主要是因为标题信息不正确。您可以将此信息从chrome移动到程序中,以绕过另一方的限制
单击列表中的特定请求,即可找到上述信息
找到正确的请求,设置正确的方法,传递正确的参数和标题信息。关于网站的大部分信息都可以完成
网络还有一个功能:右键单击列表并选择“使用内容另存为har”以保存到文件。此文件收录列表中所有请求的参数和返回值信息,供您查找和分析。(在实践中,我经常发现直接搜索是无效的,因此我只能在保存到文件后进行搜索)
除了元素和网络之外,开发者工具中还有一些功能,例如:
查看资源列表和调试JS的源代码
控制台,显示页面的错误和输出,可以执行JS代码。很多网站都会在这里放彩蛋招募(自己试试更有名的网站吧)
但这些功能与爬行动物几乎没有关系。如果您开发网站并优化网站速度,则需要处理其他功能。我不会在这里说太多
总之,您只需记住以下几点:
在“查看源代码”中可以看到的数据可以直接通过程序请求当前URL获得。元素中的HTML代码不等于请求返回值,只能用作辅助。在网络中搜索内容关键字或将其保存为har文件,以查找收录数据的实际请求,查看请求的特定信息,包括方法、标题和参数,并将其复制到程序中以供使用
了解这些步骤后,可以获得大部分在线数据。“解决一半问题”不是标题
当然,这更容易说。如果你想熟练掌握它,你仍然有很多细节需要考虑并且需要不断地练习。但是有了这些观点,当我们研究各种爬行动物的情况时,我们会有一个更清晰的想法
如果你想对爬行动物有更详细的解释和指导,我们有“爬行动物实践”课程和zero foundation入门课程
课程详情官方账户(Crossin编程教室)行动代码回复代码
════
其他文章和答案:
欢迎来到搜索和跟随:crossin的编程教室
网页源代码抓取工具(智能识别模式自动识别网页数据抓取工具的功能介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 361 次浏览 • 2021-09-15 13:25
Webhard是一个网页数据捕获工具。该软件可以提取网页中的文本和图片,并通过输入网址将其打开。默认情况下,它使用内部浏览器,支持扩展分析,并可以自动获取类似链接的列表。软件界面直观,易于操作
功能介绍
智能识别模式
Webhard自动识别网页中出现的数据模式。因此,如果您需要从网页中获取项目列表(名称、地址、电子邮件、价格等),则无需进行任何其他配置。如果数据重复,webharvy将自动刮取数据
导出捕获的数据
您可以以各种格式保存从网页提取的数据。WebHarvy网站当前版本的scraper允许您将scraper数据导出为XML、CSV、JSON或TSV文件。您还可以刮取数据并将其导出到SQL数据库
从多个页面中提取
通常web页面显示数据,例如多个页面中的产品目录。Webhard可以自动从多个网页中获取和提取数据。只是指出“链接到下一页”和WebHarvy网站刮板将自动从所有页面中刮取数据
直观的操作界面
Webharvy是一个可视化的网页提取工具。事实上,不需要编写任何脚本或代码来提取数据。使用webharvy的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。这太容易了
基于关键词的抽取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字列表数据。挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
提取分类
WebHarvy网站scraper允许您从链接列表中提取数据,从而在网站. 这允许您使用单个配置刮取网站内的类别或部分
使用正则表达式提取
Webhard可以在文本或网页的HTML源代码中应用正则表达式(正则表达式),并提取匹配的部分。这项功能强大的技术为您提供了更大的灵活性,同时还可以对数据进行争用
软件特性
Webharvy是一个可视化的web刮板。绝对不需要编写任何脚本或代码来捕获数据。您将使用webharvy的内置浏览器浏览web。您可以选择要单击的数据。这很容易
Webharvy自动识别网页中出现的数据模式。因此,如果您需要从网页中删除项目列表(名称、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,webharvy将自动删除它
您可以以多种格式保存从网页提取的数据。当前版本的webhard web scraper允许您将捕获的数据导出为excel、XML、CSV、JSON或TSV文件。您还可以将捕获的数据导出到SQL数据库
通常,web页面在多个页面上显示产品列表等数据。Webhard可以自动从多个页面抓取和提取数据。只要指出“链接到下一页”,webhard web scraper就会自动从所有页面抓取数据
更新日志
修复了页面启动时连接可能被禁用的问题
您可以为页面模式配置独占连接模式
您可以自动搜索可以在HTML上配置的资源 查看全部
网页源代码抓取工具(智能识别模式自动识别网页数据抓取工具的功能介绍)
Webhard是一个网页数据捕获工具。该软件可以提取网页中的文本和图片,并通过输入网址将其打开。默认情况下,它使用内部浏览器,支持扩展分析,并可以自动获取类似链接的列表。软件界面直观,易于操作
功能介绍
智能识别模式
Webhard自动识别网页中出现的数据模式。因此,如果您需要从网页中获取项目列表(名称、地址、电子邮件、价格等),则无需进行任何其他配置。如果数据重复,webharvy将自动刮取数据
导出捕获的数据
您可以以各种格式保存从网页提取的数据。WebHarvy网站当前版本的scraper允许您将scraper数据导出为XML、CSV、JSON或TSV文件。您还可以刮取数据并将其导出到SQL数据库
从多个页面中提取
通常web页面显示数据,例如多个页面中的产品目录。Webhard可以自动从多个网页中获取和提取数据。只是指出“链接到下一页”和WebHarvy网站刮板将自动从所有页面中刮取数据
直观的操作界面
Webharvy是一个可视化的网页提取工具。事实上,不需要编写任何脚本或代码来提取数据。使用webharvy的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。这太容易了
基于关键词的抽取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字列表数据。挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
提取分类
WebHarvy网站scraper允许您从链接列表中提取数据,从而在网站. 这允许您使用单个配置刮取网站内的类别或部分
使用正则表达式提取
Webhard可以在文本或网页的HTML源代码中应用正则表达式(正则表达式),并提取匹配的部分。这项功能强大的技术为您提供了更大的灵活性,同时还可以对数据进行争用
软件特性
Webharvy是一个可视化的web刮板。绝对不需要编写任何脚本或代码来捕获数据。您将使用webharvy的内置浏览器浏览web。您可以选择要单击的数据。这很容易
Webharvy自动识别网页中出现的数据模式。因此,如果您需要从网页中删除项目列表(名称、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,webharvy将自动删除它
您可以以多种格式保存从网页提取的数据。当前版本的webhard web scraper允许您将捕获的数据导出为excel、XML、CSV、JSON或TSV文件。您还可以将捕获的数据导出到SQL数据库
通常,web页面在多个页面上显示产品列表等数据。Webhard可以自动从多个页面抓取和提取数据。只要指出“链接到下一页”,webhard web scraper就会自动从所有页面抓取数据
更新日志
修复了页面启动时连接可能被禁用的问题
您可以为页面模式配置独占连接模式
您可以自动搜索可以在HTML上配置的资源
网页源代码抓取工具( 用Python编写爬虫的基础,需要的朋友们注意了 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-13 18:13
用Python编写爬虫的基础,需要的朋友们注意了
)
一个用Python程序抓取网页HTML信息的小例子
更新时间:2015-05-02 15:02:49 作者:cyqian
这个文章主要介绍一个使用Python程序抓取网页HTML信息的小例子。使用的方法也是用Python编写爬虫的基础。有需要的朋友可以参考
抓取网页数据的思路很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等,本文不考虑复杂情况,并放了一个读取简单网页数据的小例子:
目标数据
将所有这些玩家的超链接保存在 ittf网站 上。
数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接获取网页文字,可以一句话搞定:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/WR_Table_3_A2.asp?Age_category_1=&Age_category_2=&Age_category_3=&Age_category_4=&Age_category_5=&Category=100W&Cont=&Country=&Gender=W&Month1=4&Year1=2015&s_Player_Name=&Formv_WR_Table_3_Page='+str(page)
doc = requests.get(url).text
soup = BeautifulSoup(doc)
atags = soup.find_all('a')
rank_link_pre = 'http://www.ittf.com/ittf_ranking/'
mlfile = open(linkfile,'a')
for atag in atags:
#print atag
if atag!=None and atag.get('href') != None:
if "WR_Table_3_A2_Details.asp" in atag['href']:
link = rank_link_pre + atag['href']
links.append(link)
mlfile.write(link+'\n')
print 'fetch link: '+link
mlfile.close() 查看全部
网页源代码抓取工具(
用Python编写爬虫的基础,需要的朋友们注意了
)
一个用Python程序抓取网页HTML信息的小例子
更新时间:2015-05-02 15:02:49 作者:cyqian
这个文章主要介绍一个使用Python程序抓取网页HTML信息的小例子。使用的方法也是用Python编写爬虫的基础。有需要的朋友可以参考
抓取网页数据的思路很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等,本文不考虑复杂情况,并放了一个读取简单网页数据的小例子:
目标数据
将所有这些玩家的超链接保存在 ittf网站 上。
数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接获取网页文字,可以一句话搞定:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/WR_Table_3_A2.asp?Age_category_1=&Age_category_2=&Age_category_3=&Age_category_4=&Age_category_5=&Category=100W&Cont=&Country=&Gender=W&Month1=4&Year1=2015&s_Player_Name=&Formv_WR_Table_3_Page='+str(page)
doc = requests.get(url).text
soup = BeautifulSoup(doc)
atags = soup.find_all('a')
rank_link_pre = 'http://www.ittf.com/ittf_ranking/'
mlfile = open(linkfile,'a')
for atag in atags:
#print atag
if atag!=None and atag.get('href') != None:
if "WR_Table_3_A2_Details.asp" in atag['href']:
link = rank_link_pre + atag['href']
links.append(link)
mlfile.write(link+'\n')
print 'fetch link: '+link
mlfile.close()
网页源代码抓取工具( 优采云采集器V9http模拟请求可以设置如何发起一个http请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-09-13 18:08
优采云采集器V9http模拟请求可以设置如何发起一个http请求)
网络爬虫工具如何进行http模拟请求?使用网页爬虫工具采集网页就是进行http模拟请求。可以通过浏览器自动获取登录cookie返回头信息查看源码等操作方法,在此分享给大家。爬虫工具优采云采集器V9中的http模拟请求很多请求工具都是仿照优采云采集器中的请求工具建模的,所以可以以此为例来了解一下http模拟请求。可以设置如何发起一个http请求,包括设置请求信息、返回头信息等,具有自动提交的功能。该工具主要收录两部分:一个MDI父表单和一个请求配置表单。 1 一般设置 ① 源页面正确填写请求页面源页面地址 ② 发送方式 get 和 post 选择 post 时,请在发送数据文本框中正确填写 post 数据 ③ 客户端在此处选择或粘贴浏览器类型 ④ Cookie 值读取本地登录信息和自定义两个选项。高级设置包括图中所示的一系列设置。当不需要上述高级设置时,单击关闭按钮。 ①网页压缩选择压缩方式,选择请求头信息对应的所有Accept-Encoding。 ②网页编码自动识别和自定义两个选项。如果选择自定义,选择自定义后会出现一个编码选择框。在选择框中选择请求的编码 ③Keep-Alive 判断当前请求是否为intern
et resources 建立持久链接 ④自动跳转判断当前请求是否应该重定向响应。 ⑤基于Windows认证类型表、党员人数调查表和毫米对照表教师职称等级表员工考核分数表普通年金现值系数表可以正确填写用户名和密码字段,不需要填写无需身份验证的字段。 ⑥显示更多标题信息。发送的头部信息以列表的形式显示。了解请求的头部信息更加清晰直观。此处提供了标题信息。如果用户选择请求某个名称的标头信息,则选中该标头名称对应的复选框。标题名称和标题值都是可编辑的。 13 Return header information 会列出请求成功后返回的header信息。如图14所示,在请求源代码后,工具会自动跳转到源代码选项。在这里可以查看请求成功后返回的页面的源码信息。 15 本次预览请求成功后可以返回预览。启用此操作后,该工具会以一定的时间间隔和运行次数自动向服务器请求。如果要取消这个操作,点击后面的停止按钮配置以上信息,点击开始查看按钮查看请求信息返回头部信息等,为了避免填写请求信息,可以点击Paste External Monitoring HTTP Request Data按钮粘贴请求的头部信息,然后点击Start View按钮。 Tips box 更多关于网络爬虫工具或者网页采集的教程可以在优采云采集器系列教程中学习 查看全部
网页源代码抓取工具(
优采云采集器V9http模拟请求可以设置如何发起一个http请求)
网络爬虫工具如何进行http模拟请求?使用网页爬虫工具采集网页就是进行http模拟请求。可以通过浏览器自动获取登录cookie返回头信息查看源码等操作方法,在此分享给大家。爬虫工具优采云采集器V9中的http模拟请求很多请求工具都是仿照优采云采集器中的请求工具建模的,所以可以以此为例来了解一下http模拟请求。可以设置如何发起一个http请求,包括设置请求信息、返回头信息等,具有自动提交的功能。该工具主要收录两部分:一个MDI父表单和一个请求配置表单。 1 一般设置 ① 源页面正确填写请求页面源页面地址 ② 发送方式 get 和 post 选择 post 时,请在发送数据文本框中正确填写 post 数据 ③ 客户端在此处选择或粘贴浏览器类型 ④ Cookie 值读取本地登录信息和自定义两个选项。高级设置包括图中所示的一系列设置。当不需要上述高级设置时,单击关闭按钮。 ①网页压缩选择压缩方式,选择请求头信息对应的所有Accept-Encoding。 ②网页编码自动识别和自定义两个选项。如果选择自定义,选择自定义后会出现一个编码选择框。在选择框中选择请求的编码 ③Keep-Alive 判断当前请求是否为intern
et resources 建立持久链接 ④自动跳转判断当前请求是否应该重定向响应。 ⑤基于Windows认证类型表、党员人数调查表和毫米对照表教师职称等级表员工考核分数表普通年金现值系数表可以正确填写用户名和密码字段,不需要填写无需身份验证的字段。 ⑥显示更多标题信息。发送的头部信息以列表的形式显示。了解请求的头部信息更加清晰直观。此处提供了标题信息。如果用户选择请求某个名称的标头信息,则选中该标头名称对应的复选框。标题名称和标题值都是可编辑的。 13 Return header information 会列出请求成功后返回的header信息。如图14所示,在请求源代码后,工具会自动跳转到源代码选项。在这里可以查看请求成功后返回的页面的源码信息。 15 本次预览请求成功后可以返回预览。启用此操作后,该工具会以一定的时间间隔和运行次数自动向服务器请求。如果要取消这个操作,点击后面的停止按钮配置以上信息,点击开始查看按钮查看请求信息返回头部信息等,为了避免填写请求信息,可以点击Paste External Monitoring HTTP Request Data按钮粘贴请求的头部信息,然后点击Start View按钮。 Tips box 更多关于网络爬虫工具或者网页采集的教程可以在优采云采集器系列教程中学习
网页源代码抓取工具(完美者()网站改版后的网站对功能性板块进行扩充)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-09-08 22:17
Perfect()网站基于软件下载,修改后的网站扩展了功能部分,以解决用户在使用软件过程中遇到的所有问题。 网站增加了“软件百科”、“小贴士”等频道,可以更好的为用户提供软件使用全周期更专业的服务。
客鼎网页抓包工具,这是一款小巧实用的抓包工具,支持网页摘要、cookies管理、缓存管理等功能,可以帮助用户分析网页数据,功能非常强大。
科鼎网页抓取工具基本介绍
客鼎网页抓取工具是一款功能强大的网页数据分析工具,集成在Internet Explorer工具栏中,包括网页摘要、Cookies管理、缓存管理、消息头发送/接收、字符查询、POST数据和目录管理等功能强大的日常网页抓取软件。
开鼎网页抓取工具使用说明
作为Web开发人员/测试人员,您需要经常分析网页发送的数据包。作为一款强大的IE插件,Keding网页抓取工具短小精悍,能够很好的完成对URL请求的分析。它可以监控和分析通过浏览器发送的http请求。当你在浏览器的地址栏上请求一个URL或者提交一个表单时,它会帮你分析http请求的头部信息,访问页面的cookie信息,以及Get And Post详细的包分析。
注意:部分杀毒软件可能会报病毒,请加信任!
“Tips & Miao Skills”栏目是全网软件使用技巧的合集或软件使用过程中各种问题的解答文章。专栏成立伊始,小编欢迎各位软件大神朋友踊跃投稿。分享每个人独特技能的平台。
本站文章素材来自网络,文章作者姓名大部分缺失。为了让用户更容易阅读和使用,它们已被重新格式化并根据需要进行了部分调整。本站收录文章只是为了帮助用户解决实际问题,如有版权问题,请联系编辑修改或删除,谢谢合作。 查看全部
网页源代码抓取工具(完美者()网站改版后的网站对功能性板块进行扩充)
Perfect()网站基于软件下载,修改后的网站扩展了功能部分,以解决用户在使用软件过程中遇到的所有问题。 网站增加了“软件百科”、“小贴士”等频道,可以更好的为用户提供软件使用全周期更专业的服务。
客鼎网页抓包工具,这是一款小巧实用的抓包工具,支持网页摘要、cookies管理、缓存管理等功能,可以帮助用户分析网页数据,功能非常强大。
科鼎网页抓取工具基本介绍
客鼎网页抓取工具是一款功能强大的网页数据分析工具,集成在Internet Explorer工具栏中,包括网页摘要、Cookies管理、缓存管理、消息头发送/接收、字符查询、POST数据和目录管理等功能强大的日常网页抓取软件。
开鼎网页抓取工具使用说明
作为Web开发人员/测试人员,您需要经常分析网页发送的数据包。作为一款强大的IE插件,Keding网页抓取工具短小精悍,能够很好的完成对URL请求的分析。它可以监控和分析通过浏览器发送的http请求。当你在浏览器的地址栏上请求一个URL或者提交一个表单时,它会帮你分析http请求的头部信息,访问页面的cookie信息,以及Get And Post详细的包分析。
注意:部分杀毒软件可能会报病毒,请加信任!
“Tips & Miao Skills”栏目是全网软件使用技巧的合集或软件使用过程中各种问题的解答文章。专栏成立伊始,小编欢迎各位软件大神朋友踊跃投稿。分享每个人独特技能的平台。
本站文章素材来自网络,文章作者姓名大部分缺失。为了让用户更容易阅读和使用,它们已被重新格式化并根据需要进行了部分调整。本站收录文章只是为了帮助用户解决实际问题,如有版权问题,请联系编辑修改或删除,谢谢合作。

