
网页源代码抓取工具
网页源代码抓取工具(就是自动判断网页编码格式,解决乱码问题(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-19 04:07
)
拿到代码后,首先需要从网上下载一个HTMLParser.NET。最高版本是2003,记住你的VS版本一定不能是2010的,2005和2008都可以。找到动态链接库,然后添加对项目的引用就OK了。
源代码:
<p>using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.IO;
using System.Net;
using Winista.Text.HtmlParser;
using Winista.Text.HtmlParser.Lex;
using Winista.Text.HtmlParser.Visitors;
namespace 抓取网页源代码
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
//textBox1.Text = "http://imgsrc.baidu.com/baike/ ... %3B//抓取文件放到指定地点
}
private void button1_Click(object sender, EventArgs e)
{
//抓取文件放到指定的地点
//try
//{
// //WebClient webclient=new WebClient ();
// WebClient web = new WebClient();
// web.DownloadFile(textBox1.Text, "c://1.jpg");
//}
//catch (Exception ex)
//{
// MessageBox.Show(ex.Message);
//}
textBox2.Text = downhtml_1(textBox1.Text );
}
private string downhtml_1(string WebUrl)//抓取网页源代码方法一
{
string htmlText = "";
try
{
WebClient myWebClient =new WebClient();
myWebClient.Encoding = System.Text.Encoding.Default;//获取和设置用于上载和下载字符串的encoding,默认值是default
//myWebClient.Encoding = System.Text.Encoding.Default;
htmlText = myWebClient.DownloadString(WebUrl );//将下载的资源付给字符串
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
if (htmlText.Trim() == "")
htmlText = "失败!";
return htmlText;
}
//private WebClient WebClient()
//{
// throw new NotImplementedException();
//}
private string downhtml_2(string WebUrl)//抓取网页源代码方法二
{
string responseData = "";
string string1 = "";
try
{
//httpWebRequest是webRequest的子类,httpWebRequest是基于http协议的 .
//HttpWebRequest 是 WebRequest 的实例化使用,单独的 WebRequest 是不能使用的
HttpWebRequest Req = (HttpWebRequest)WebRequest.Create(new System.Uri(WebUrl));
Req.UserAgent = "Mozilla/4.0(compatible;MSIE 6.0;Windows NT 5.0; .NET CLR 1.1.4322)";//声明了浏览器用于 HTTP 请求的用户代理头的值。
Req.Timeout = 30000;
//StreamReader responseReader = new StreamReader(Req.GetResponse().GetResponseStream(), Encoding.Default); //方法一
//方法二,建议使用二
HttpWebResponse response = (HttpWebResponse)Req.GetResponse();//决不要直接创建 HttpWebResponse 类的实例。而应当使用通过调用 HttpWebRequest.GetResponse 所返回的实例
Stream receiveStream = response.GetResponseStream();
StreamReader responseReader = new StreamReader(receiveStream, Encoding.Default);
response.Close();//记得调用close方法关闭 HttpWebResponse,释放连接,以重用
responseData = responseReader.ReadToEnd();
responseReader.Close();
//Lexer lexer = new Lexer(filterScript (responseData ));
//Parser parser=new Parser (lexer );//用一个URL或者string页面做一个parser
//TextExtractingVisitor textvisitor=new TextExtractingVisitor ();用这个parser做一个visitor
//parser .VisitAllNodesWith (textvisitor );//使用parser.visitallnudeswith(visitor)来遍历节点
//string1 =textvisitor .ExtractedText .ToString ();
string1=filterScript(responseData );
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
if (responseData.Trim() == "")
responseData = "失败!";
//return responseData;
return string1;
}
public string filterScript(string str1)//去除代码中的javascript
{
// string str1 = "new TextParser('/posts/05/B1/B3/9E/content_html.txt', 'content_tree');";
if (str1.Contains(" 查看全部
网页源代码抓取工具(就是自动判断网页编码格式,解决乱码问题(图)
)
拿到代码后,首先需要从网上下载一个HTMLParser.NET。最高版本是2003,记住你的VS版本一定不能是2010的,2005和2008都可以。找到动态链接库,然后添加对项目的引用就OK了。
源代码:
<p>using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.IO;
using System.Net;
using Winista.Text.HtmlParser;
using Winista.Text.HtmlParser.Lex;
using Winista.Text.HtmlParser.Visitors;
namespace 抓取网页源代码
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
//textBox1.Text = "http://imgsrc.baidu.com/baike/ ... %3B//抓取文件放到指定地点
}
private void button1_Click(object sender, EventArgs e)
{
//抓取文件放到指定的地点
//try
//{
// //WebClient webclient=new WebClient ();
// WebClient web = new WebClient();
// web.DownloadFile(textBox1.Text, "c://1.jpg");
//}
//catch (Exception ex)
//{
// MessageBox.Show(ex.Message);
//}
textBox2.Text = downhtml_1(textBox1.Text );
}
private string downhtml_1(string WebUrl)//抓取网页源代码方法一
{
string htmlText = "";
try
{
WebClient myWebClient =new WebClient();
myWebClient.Encoding = System.Text.Encoding.Default;//获取和设置用于上载和下载字符串的encoding,默认值是default
//myWebClient.Encoding = System.Text.Encoding.Default;
htmlText = myWebClient.DownloadString(WebUrl );//将下载的资源付给字符串
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
if (htmlText.Trim() == "")
htmlText = "失败!";
return htmlText;
}
//private WebClient WebClient()
//{
// throw new NotImplementedException();
//}
private string downhtml_2(string WebUrl)//抓取网页源代码方法二
{
string responseData = "";
string string1 = "";
try
{
//httpWebRequest是webRequest的子类,httpWebRequest是基于http协议的 .
//HttpWebRequest 是 WebRequest 的实例化使用,单独的 WebRequest 是不能使用的
HttpWebRequest Req = (HttpWebRequest)WebRequest.Create(new System.Uri(WebUrl));
Req.UserAgent = "Mozilla/4.0(compatible;MSIE 6.0;Windows NT 5.0; .NET CLR 1.1.4322)";//声明了浏览器用于 HTTP 请求的用户代理头的值。
Req.Timeout = 30000;
//StreamReader responseReader = new StreamReader(Req.GetResponse().GetResponseStream(), Encoding.Default); //方法一
//方法二,建议使用二
HttpWebResponse response = (HttpWebResponse)Req.GetResponse();//决不要直接创建 HttpWebResponse 类的实例。而应当使用通过调用 HttpWebRequest.GetResponse 所返回的实例
Stream receiveStream = response.GetResponseStream();
StreamReader responseReader = new StreamReader(receiveStream, Encoding.Default);
response.Close();//记得调用close方法关闭 HttpWebResponse,释放连接,以重用
responseData = responseReader.ReadToEnd();
responseReader.Close();
//Lexer lexer = new Lexer(filterScript (responseData ));
//Parser parser=new Parser (lexer );//用一个URL或者string页面做一个parser
//TextExtractingVisitor textvisitor=new TextExtractingVisitor ();用这个parser做一个visitor
//parser .VisitAllNodesWith (textvisitor );//使用parser.visitallnudeswith(visitor)来遍历节点
//string1 =textvisitor .ExtractedText .ToString ();
string1=filterScript(responseData );
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
if (responseData.Trim() == "")
responseData = "失败!";
//return responseData;
return string1;
}
public string filterScript(string str1)//去除代码中的javascript
{
// string str1 = "new TextParser('/posts/05/B1/B3/9E/content_html.txt', 'content_tree');";
if (str1.Contains("
网页源代码抓取工具(网页源代码抓取工具大全:技术python爬虫工具书籍知识总结之)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-16 10:02
网页源代码抓取工具大全:技术python爬虫工具书籍python知识总结之网页抓取一网页抓取工具大全:程序员学习必备工具链接很多...
推荐一些我常用的
推荐:1:(以ueb为例)获取网页详情页评论/结构化数据?2:导出excel到大数据文件
djangoaiohttpredis比较常用,基本上都用得到,
抓包
web相关:抓包1.log4j2.web服务器编程3.getpost4.http协议
你可以尝试使用魔趣、w3cschool、加速猪学习计算机知识。
推荐这个网站学习一下web开发的基础
推荐你看看这个视频
charlessecurecrtpowershell
推荐你看看这个入门
beautifulsoup
推荐看看这个图片,
多看看这个了解下web入门你必须知道的一些web技术概念
linux命令推荐看看linux命令安装与使用命令tab源码篇:zsh入门与安装:pyenvgit手册与学习1:实战篇
web的,
python的话你可以看看libbody
selenium或者selenium+flask。web相关的,看看加速猪:强烈推荐一个精通python开发的网站有什么要求啊,这个下面有什么资料啥的都可以看看。
python都可以百度搜索一下, 查看全部
网页源代码抓取工具(网页源代码抓取工具大全:技术python爬虫工具书籍知识总结之)
网页源代码抓取工具大全:技术python爬虫工具书籍python知识总结之网页抓取一网页抓取工具大全:程序员学习必备工具链接很多...
推荐一些我常用的
推荐:1:(以ueb为例)获取网页详情页评论/结构化数据?2:导出excel到大数据文件
djangoaiohttpredis比较常用,基本上都用得到,
抓包
web相关:抓包1.log4j2.web服务器编程3.getpost4.http协议
你可以尝试使用魔趣、w3cschool、加速猪学习计算机知识。
推荐这个网站学习一下web开发的基础
推荐你看看这个视频
charlessecurecrtpowershell
推荐你看看这个入门
beautifulsoup
推荐看看这个图片,
多看看这个了解下web入门你必须知道的一些web技术概念
linux命令推荐看看linux命令安装与使用命令tab源码篇:zsh入门与安装:pyenvgit手册与学习1:实战篇
web的,
python的话你可以看看libbody
selenium或者selenium+flask。web相关的,看看加速猪:强烈推荐一个精通python开发的网站有什么要求啊,这个下面有什么资料啥的都可以看看。
python都可以百度搜索一下,
网页源代码抓取工具(Python项目案例开发从入门到实战(清华大学出版社郑秋生夏敏捷主编))
网站优化 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-10-14 17:26
来自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生、夏敏毅主编)爬虫应用-抓取百度图片
抓取指定网页中的图片主要需要以下三个步骤:
(1)指定网站链接,获取网站的源码(如果使用google浏览器,鼠标右键->Inspect->Elements中的html内容)
(2) 根据你要爬取的内容设置正则表达式匹配你要爬取的内容
(3)设置循环列表,反复抓取保存内容
下面介绍两种抓取指定网页图片的方法
(1)方法一:使用正则表达式过滤捕获的html内容字符串
1 # 第一个简单的爬取图片的程序
2 import urllib.request # python自带的爬操作url的库
3 import re # 正则表达式
4
5
6 # 该方法传入url,返回url的html的源代码
7 def getHtmlCode(url):
8 # 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求
9 headers = {
10 \'User-Agent\': \'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \
11 AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36\'
12 }
13 # 将headers头部添加到url,模拟浏览器访问
14 url = urllib.request.Request(url, headers=headers)
15
16 # 将url页面的源代码保存成字符串
17 page = urllib.request.urlopen(url).read()
18 # 字符串转码
19 page = page.decode(\'UTF-8\')
20 return page
21
22
23 # 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
24 def getImage(page):
25 # [^\s]*? 表示最小匹配, 两个括号表示列表中有两个元组
26 # imageList = re.findall(r\'(https:[^\s]*?(png))"\', page)
27 imageList = re.findall(r\'(https:[^\s]*?(jpg|png|gif))"\', page)
28 x = 0
29 # 循环列表
30 for imageUrl in imageList:
31 try:
32 print(\'正在下载: %s\' % imageUrl[0])
33 # 这个image文件夹需要先创建好才能看到结果
34 image_save_path = \'./image/%d.png\' % x
35 # 下载图片并且保存到指定文件夹中
36 urllib.request.urlretrieve(imageUrl[0], image_save_path)
37 x = x + 1
38 except:
39 continue
40
41 pass
42
43
44 if __name__ == \'__main__\':
45 # 指定要爬取的网站
46 url = "https://www.cnblogs.com/ttweix ... ot%3B
47 # 得到该网站的源代码
48 page = getHtmlCode(url)
49 # 爬取该网站的图片并且保存
50 getImage(page)
51 # print(page)
注意代码中需要修改的是 imageList = re.findall(r\'(https:[^\s]*?(jpg|png|gif))"\', page) 这一段内容,如何设计正则表达式需要根据你要爬取的内容进行设置,我的设计源码如下:
可以看到,因为这个页面的图片都是png格式,所以也可以写成imageList = re.findall(r\'(https:[^\s]*?(png))"\', page )。
(2)方法二:使用BeautifulSoup库解析html网页
1 from bs4 import BeautifulSoup # BeautifulSoup是python处理HTML/XML的函数库,是Python内置的网页分析工具
2 import urllib # python自带的爬操作url的库
3
4
5 # 该方法传入url,返回url的html的源代码
6 def getHtmlCode(url):
7 # 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求
8 headers = {
9 \'User-Agent\': \'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \
10 AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36\'
11 }
12 # 将headers头部添加到url,模拟浏览器访问
13 url = urllib.request.Request(url, headers=headers)
14
15 # 将url页面的源代码保存成字符串
16 page = urllib.request.urlopen(url).read()
17 # 字符串转码
18 page = page.decode(\'UTF-8\')
19 return page
20
21
22 # 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
23 def getImage(page):
24 # 按照html格式解析页面
25 soup = BeautifulSoup(page, \'html.parser\')
26 # 格式化输出DOM树的内容
27 print(soup.prettify())
28 # 返回所有包含img标签的列表,因为在Html文件中图片的插入呈现形式是...
29 imgList = soup.find_all(\'img\')
30 x = 0
31 # 循环找到的图片列表,注意,这里手动设置从第2张图片开始,是因为我debug看到了第一张图片不是我想要的图片
32 for imgUrl in imgList[1:]:
33 print(\'正在下载: %s \' % imgUrl.get(\'src\'))
34 # 得到scr的内容,这里返回的就是Url字符串链接,如\'https://img2020.cnblogs.com/blog/1703588/202007/1703588-20200716203143042-623499171.png\'
35 image_url = imgUrl.get(\'src\')
36 # 这个image文件夹需要先创建好才能看到结果
37 image_save_path = \'./image/%d.png\' % x
38 # 下载图片并且保存到指定文件夹中
39 urllib.request.urlretrieve(image_url, image_save_path)
40 x = x + 1
41
42
43 if __name__ == \'__main__\':
44 # 指定要爬取的网站
45 url = \'https://www.cnblogs.com/ttweixiao-IT-program/p/13324826.html\'
46 # 得到该网站的源代码
47 page = getHtmlCode(url)
48 # 爬取该网站的图片并且保存
49 getImage(page)
这两种方法各有优缺点。我认为它们可以灵活组合。比如先用方法二中的指定标签的方法缩小你要查找的内容范围,然后再用正则表达式匹配到需要的内容。它更简洁明了。 查看全部
网页源代码抓取工具(Python项目案例开发从入门到实战(清华大学出版社郑秋生夏敏捷主编))
来自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生、夏敏毅主编)爬虫应用-抓取百度图片
抓取指定网页中的图片主要需要以下三个步骤:
(1)指定网站链接,获取网站的源码(如果使用google浏览器,鼠标右键->Inspect->Elements中的html内容)
(2) 根据你要爬取的内容设置正则表达式匹配你要爬取的内容
(3)设置循环列表,反复抓取保存内容
下面介绍两种抓取指定网页图片的方法
(1)方法一:使用正则表达式过滤捕获的html内容字符串
1 # 第一个简单的爬取图片的程序
2 import urllib.request # python自带的爬操作url的库
3 import re # 正则表达式
4
5
6 # 该方法传入url,返回url的html的源代码
7 def getHtmlCode(url):
8 # 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求
9 headers = {
10 \'User-Agent\': \'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \
11 AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36\'
12 }
13 # 将headers头部添加到url,模拟浏览器访问
14 url = urllib.request.Request(url, headers=headers)
15
16 # 将url页面的源代码保存成字符串
17 page = urllib.request.urlopen(url).read()
18 # 字符串转码
19 page = page.decode(\'UTF-8\')
20 return page
21
22
23 # 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
24 def getImage(page):
25 # [^\s]*? 表示最小匹配, 两个括号表示列表中有两个元组
26 # imageList = re.findall(r\'(https:[^\s]*?(png))"\', page)
27 imageList = re.findall(r\'(https:[^\s]*?(jpg|png|gif))"\', page)
28 x = 0
29 # 循环列表
30 for imageUrl in imageList:
31 try:
32 print(\'正在下载: %s\' % imageUrl[0])
33 # 这个image文件夹需要先创建好才能看到结果
34 image_save_path = \'./image/%d.png\' % x
35 # 下载图片并且保存到指定文件夹中
36 urllib.request.urlretrieve(imageUrl[0], image_save_path)
37 x = x + 1
38 except:
39 continue
40
41 pass
42
43
44 if __name__ == \'__main__\':
45 # 指定要爬取的网站
46 url = "https://www.cnblogs.com/ttweix ... ot%3B
47 # 得到该网站的源代码
48 page = getHtmlCode(url)
49 # 爬取该网站的图片并且保存
50 getImage(page)
51 # print(page)
注意代码中需要修改的是 imageList = re.findall(r\'(https:[^\s]*?(jpg|png|gif))"\', page) 这一段内容,如何设计正则表达式需要根据你要爬取的内容进行设置,我的设计源码如下:
可以看到,因为这个页面的图片都是png格式,所以也可以写成imageList = re.findall(r\'(https:[^\s]*?(png))"\', page )。
(2)方法二:使用BeautifulSoup库解析html网页
1 from bs4 import BeautifulSoup # BeautifulSoup是python处理HTML/XML的函数库,是Python内置的网页分析工具
2 import urllib # python自带的爬操作url的库
3
4
5 # 该方法传入url,返回url的html的源代码
6 def getHtmlCode(url):
7 # 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求
8 headers = {
9 \'User-Agent\': \'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \
10 AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36\'
11 }
12 # 将headers头部添加到url,模拟浏览器访问
13 url = urllib.request.Request(url, headers=headers)
14
15 # 将url页面的源代码保存成字符串
16 page = urllib.request.urlopen(url).read()
17 # 字符串转码
18 page = page.decode(\'UTF-8\')
19 return page
20
21
22 # 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
23 def getImage(page):
24 # 按照html格式解析页面
25 soup = BeautifulSoup(page, \'html.parser\')
26 # 格式化输出DOM树的内容
27 print(soup.prettify())
28 # 返回所有包含img标签的列表,因为在Html文件中图片的插入呈现形式是...
29 imgList = soup.find_all(\'img\')
30 x = 0
31 # 循环找到的图片列表,注意,这里手动设置从第2张图片开始,是因为我debug看到了第一张图片不是我想要的图片
32 for imgUrl in imgList[1:]:
33 print(\'正在下载: %s \' % imgUrl.get(\'src\'))
34 # 得到scr的内容,这里返回的就是Url字符串链接,如\'https://img2020.cnblogs.com/blog/1703588/202007/1703588-20200716203143042-623499171.png\'
35 image_url = imgUrl.get(\'src\')
36 # 这个image文件夹需要先创建好才能看到结果
37 image_save_path = \'./image/%d.png\' % x
38 # 下载图片并且保存到指定文件夹中
39 urllib.request.urlretrieve(image_url, image_save_path)
40 x = x + 1
41
42
43 if __name__ == \'__main__\':
44 # 指定要爬取的网站
45 url = \'https://www.cnblogs.com/ttweixiao-IT-program/p/13324826.html\'
46 # 得到该网站的源代码
47 page = getHtmlCode(url)
48 # 爬取该网站的图片并且保存
49 getImage(page)
这两种方法各有优缺点。我认为它们可以灵活组合。比如先用方法二中的指定标签的方法缩小你要查找的内容范围,然后再用正则表达式匹配到需要的内容。它更简洁明了。
网页源代码抓取工具(关于如何使用浏览器的开发人员工具进行抓取过程的一般指南)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-14 17:25
使用浏览器的开发者工具进行抓取
以下是有关如何使用浏览器的开发人员工具来简化抓取过程的一般指南。现在几乎所有浏览器都内置了开发人员工具。尽管我们将在本指南中使用 firefox,但这些概念适用于任何其他浏览器。
在本指南中,我们将通过从浏览器抓取的方式介绍开发者工具中使用的基本工具。
检查实时浏览器DOM的注意事项
由于开发者工具运行在一个活跃的浏览器 DOM 上,当您查看页面源代码时,您实际看到的不是原创 HTML,而是在应用一些浏览器清理和执行 javascript 代码后修改后的 HTML。尤其是 Firefox,可以将元素添加到表格中。另一方面,scrapy 不会修改原创页面 html,因此如果在 xpath 表达式中使用。
因此,您应该牢记以下几点:
查看网站
到目前为止,开发者工具最方便的功能是检查器功能,它允许您检查任何网页的底层 HTML 代码。为了演示 Inspector,让我们看一下该站点。
在这个网站上,我们总共有十个来自不同作者的引用,包括特定的标签,以及前十个标签。假设我们要提取此页面上的所有引用,而无需任何有关作者、标签等的元信息。
我们不必查看页面的整个源代码,只需右键单击要约并选择 Inspect Element (Q) 即可打开 Inspector。在里面你应该看到这样的东西:
我们感兴趣的是:
(...)
(...)
(...)
如果您将鼠标悬停在屏幕截图中突出显示的 span 标签上方的第一个 div 上,您将看到网页的相应部分也将突出显示。现在我们有一个部分,但我们无法在任何地方找到引用文本。
Inspector 的优点 自动展开和折叠网页的部分和标签,大大提高了可读性。您可以通过单击标签前面的箭头或直接双击标签来展开和折叠标签。如果我们使用标签 class="text" 扩展跨度,我们将看到我们单击的引用文本。此检查器允许您将 xpath 复制到所选元素。让我们试试吧。
首先在终端:
$ scrapy shell "http://quotes.toscrape.com/"
然后,返回到 Web 浏览器,右键单击 span,选择标记 Copy> XPath,然后将其粘贴到这个损坏的 shell 中:
>>> response.xpath('/html/body/div/div[2]/div[1]/div[1]/span[1]/text()').getall()
['“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”']
添加 text() 最后,我们可以使用这个基本选择器来提取第一个引号。但是这个 xpath 并不是那么聪明。它所做的只是遵循源代码中 html 所需的路径。那么让我们看看我们是否可以改进xpath:
如果我们检查 Inspector,我们将再次看到,在我们的 div 标签中,我们有九个相同的 div 标签,每个标签都具有与第一个相同的属性。如果我们展开它们中的任何一个,我们将看到与第一个引号相同的结构:两个 span 标签和一个 div 标签。我们可以在我们的内部 div 标签中使用标签 class="text" 扩展每个跨度并查看每个引用:
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”
(...)
(...)
有了这些知识,我们可以改进我们的 xpath:我们只需要使用以下方法选择 span 标签和 class="text":
>>> response.xpath('//span[has-class("text")]/text()').getall()
['“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”',
'“It is our choices, Harry, that show what we truly are, far more than our abilities.”',
'“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”',
...]
使用简单且更智能的 xpath,我们可以从页面中提取所有引号。我们可以在第一个 xpath 上建立一个循环来增加最后一个 xpath 的数量。div,但这会不必要地复杂,只需使用 has-class("text") 我们就可以在一行中提取所有引号。
此 Inspector 具有许多其他有用的功能,例如在源代码中搜索或直接滚动到您选择的元素。让我们演示一个用例:
假设您想在下一页上找到按钮。在搜索栏的右上角键入 Next Inspector。你应该得到两个结果。第一个是带有标签 class="next" 的 li,第二个是一个标签。右键单击 a 标记并选择滚动到视图。如果将鼠标悬停在标签上,您将看到突出显示的按钮。从这里我们可以轻松创建一个后续页面。在这样一个简单的网站上,您可能不需要直观地查找元素,但滚动到视图功能在复杂的网站上非常有用。
请注意,搜索栏还可用于搜索和测试 CSS 选择器。例如,您可以搜索 span.text 以查找所有引用文本。这将搜索页面中带有标签 class="text" 的跨度,而不是全文搜索。
网络工具
在爬取过程中,您可能会遇到动态网页,其中部分页面是通过多次请求动态加载的。尽管这很棘手,但开发人员工具中的 Network-tool 极大地促进了这项任务。为了演示网络工具,让我们看一下页面 /scroll。
该页面与基本页面非常相似——第一页,但不是上面提到的下一步按钮,当你滚动到底部时,页面会自动加载新的报价。我们可以直接尝试不同的 xpath,但我们将从 Scrapy shell 中检查另一个非常有用的命令:
$ scrapy shell "quotes.toscrape.com/scroll"
(...)
>>> view(response)
浏览器窗口应该与网页一起打开,但有一个关键区别:我们看到一个带有单词的绿色条,而不是引用。加载中....
这个 view(response) 命令允许我们查看 shell 或稍后蜘蛛从服务器收到的响应。在这里我们看到加载了一些基本模板,包括标题、登录按钮和页脚,但缺少引号。这告诉我们引号是从不同的请求加载的,而不是quotes.toscrape/scroll。
如果单击“网络”选项卡,您可能只会看到两个条目。我们需要做的第一件事是单击 Persist Logs。如果禁用此选项,则每次导航到不同页面时都会自动清除日志。启用此选项是一个很好的默认设置,因为它允许我们控制何时清除日志。
如果我们现在重新加载页面,您将看到日志中充满了六个新请求。
在这里,我们可以看到页面重新加载时发出的每个请求,并可以检查每个请求及其响应。那么让我们找出我们的报价来自哪里:
首先单击带有名称的请求滚动条。在右侧,您现在可以检查请求。在 Headers 中,您将找到有关请求标头的详细信息,例如 URL、方法、IP 地址等。我们将忽略其他选项卡并直接单击 Response。
您应该在预览窗格中看到的是呈现的 HTML 代码,这就是我们在 优采云 中所说的视图(响应)。相应地,类型日志中的请求为html。其他类型的请求如下 css 或 js 但我们对quotes?page=1 和类型 json 的请求感兴趣。
如果我们点击这个请求,我们会看到请求的 URL 是响应是一个收录我们引号的 JSON 对象。我们还可以右键单击请求并打开在新选项卡中打开以获得更好的概览。
有了这个响应,我们现在可以轻松解析 JSON 对象并请求每个页面以获取站点上的每个引用:
import scrapy
import json
class QuoteSpider(scrapy.Spider):
name = 'quote'
allowed_domains = ['quotes.toscrape.com']
page = 1
start_urls = ['http://quotes.toscrape.com/api ... 39%3B]
def parse(self, response):
data = json.loads(response.text)
for quote in data["quotes"]:
yield {"quote": quote["text"]}
if data["has_next"]:
self.page += 1
url = f"http://quotes.toscrape.com/api/quotes?page={self.page}"
yield scrapy.Request(url=url, callback=self.parse)
这个蜘蛛程序从 QuotesAPI 的第一页开始。对于每个响应,我们分析 response.text 并将其分配给数据。这允许我们像在 Python 字典上一样操作 JSON 对象。我们迭代引号并打印出quote["text"]。如果方便的话,has_next 元素为真(尝试在浏览器中加载 /api/quotes?page=10 或大于 10 的页码,我们增加 page 属性并产生一个新的 Request 将增加的页码插入到网址。
在更复杂的 网站 中,可能很难轻松重现请求,因为我们可能需要添加标头或 cookie 才能使其工作。在这些情况下,您可以通过在 Web 工具中右键单击每个请求,然后使用 from_curl() 方法生成等效请求,将请求导出为 cURL 格式:
from scrapy import Request
request = Request.from_curl(
"curl 'http://quotes.toscrape.com/api ... 39%3B -H 'User-Agent: Mozil"
"la/5.0 (X11; Linux x86_64; rv:67.0) Gecko/20100101 Firefox/67.0' -H 'Acce"
"pt: */*' -H 'Accept-Language: ca,en-US;q=0.7,en;q=0.3' --compressed -H 'X"
"-Requested-With: XMLHttpRequest' -H 'Proxy-Authorization: Basic QFRLLTAzM"
"zEwZTAxLTk5MWUtNDFiNC1iZWRmLTJjNGI4M2ZiNDBmNDpAVEstMDMzMTBlMDEtOTkxZS00MW"
"I0LWJlZGYtMmM0YjgzZmI0MGY0' -H 'Connection: keep-alive' -H 'Referer: http"
"://quotes.toscrape.com/scroll' -H 'Cache-Control: max-age=0'")
或者,如果您想知道重新创建请求所需的参数,可以使用该函数获取具有等效参数的字典:
scrapy.utils.curl.curl_to_request_kwargs(curl_command:, ignore_unknown_options: = True) →
将 cURL 命令语法转换为请求 kwargs。
范围
返回
请求字典
请注意,要将 cURL 命令转换为 Scrapy 请求,您可以使用 curl2scrapy。
如您所见,在 Network-Tools 中,我们可以轻松复制页面滚动功能的动态请求。抓取动态页面可能非常困难,页面可能非常复杂,但(主要)归结为识别正确的请求并将其复制到蜘蛛中。 查看全部
网页源代码抓取工具(关于如何使用浏览器的开发人员工具进行抓取过程的一般指南)
使用浏览器的开发者工具进行抓取
以下是有关如何使用浏览器的开发人员工具来简化抓取过程的一般指南。现在几乎所有浏览器都内置了开发人员工具。尽管我们将在本指南中使用 firefox,但这些概念适用于任何其他浏览器。
在本指南中,我们将通过从浏览器抓取的方式介绍开发者工具中使用的基本工具。
检查实时浏览器DOM的注意事项
由于开发者工具运行在一个活跃的浏览器 DOM 上,当您查看页面源代码时,您实际看到的不是原创 HTML,而是在应用一些浏览器清理和执行 javascript 代码后修改后的 HTML。尤其是 Firefox,可以将元素添加到表格中。另一方面,scrapy 不会修改原创页面 html,因此如果在 xpath 表达式中使用。
因此,您应该牢记以下几点:
查看网站
到目前为止,开发者工具最方便的功能是检查器功能,它允许您检查任何网页的底层 HTML 代码。为了演示 Inspector,让我们看一下该站点。
在这个网站上,我们总共有十个来自不同作者的引用,包括特定的标签,以及前十个标签。假设我们要提取此页面上的所有引用,而无需任何有关作者、标签等的元信息。
我们不必查看页面的整个源代码,只需右键单击要约并选择 Inspect Element (Q) 即可打开 Inspector。在里面你应该看到这样的东西:

我们感兴趣的是:
(...)
(...)
(...)
如果您将鼠标悬停在屏幕截图中突出显示的 span 标签上方的第一个 div 上,您将看到网页的相应部分也将突出显示。现在我们有一个部分,但我们无法在任何地方找到引用文本。
Inspector 的优点 自动展开和折叠网页的部分和标签,大大提高了可读性。您可以通过单击标签前面的箭头或直接双击标签来展开和折叠标签。如果我们使用标签 class="text" 扩展跨度,我们将看到我们单击的引用文本。此检查器允许您将 xpath 复制到所选元素。让我们试试吧。
首先在终端:
$ scrapy shell "http://quotes.toscrape.com/"
然后,返回到 Web 浏览器,右键单击 span,选择标记 Copy> XPath,然后将其粘贴到这个损坏的 shell 中:
>>> response.xpath('/html/body/div/div[2]/div[1]/div[1]/span[1]/text()').getall()
['“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”']
添加 text() 最后,我们可以使用这个基本选择器来提取第一个引号。但是这个 xpath 并不是那么聪明。它所做的只是遵循源代码中 html 所需的路径。那么让我们看看我们是否可以改进xpath:
如果我们检查 Inspector,我们将再次看到,在我们的 div 标签中,我们有九个相同的 div 标签,每个标签都具有与第一个相同的属性。如果我们展开它们中的任何一个,我们将看到与第一个引号相同的结构:两个 span 标签和一个 div 标签。我们可以在我们的内部 div 标签中使用标签 class="text" 扩展每个跨度并查看每个引用:
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”
(...)
(...)
有了这些知识,我们可以改进我们的 xpath:我们只需要使用以下方法选择 span 标签和 class="text":
>>> response.xpath('//span[has-class("text")]/text()').getall()
['“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”',
'“It is our choices, Harry, that show what we truly are, far more than our abilities.”',
'“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”',
...]
使用简单且更智能的 xpath,我们可以从页面中提取所有引号。我们可以在第一个 xpath 上建立一个循环来增加最后一个 xpath 的数量。div,但这会不必要地复杂,只需使用 has-class("text") 我们就可以在一行中提取所有引号。
此 Inspector 具有许多其他有用的功能,例如在源代码中搜索或直接滚动到您选择的元素。让我们演示一个用例:
假设您想在下一页上找到按钮。在搜索栏的右上角键入 Next Inspector。你应该得到两个结果。第一个是带有标签 class="next" 的 li,第二个是一个标签。右键单击 a 标记并选择滚动到视图。如果将鼠标悬停在标签上,您将看到突出显示的按钮。从这里我们可以轻松创建一个后续页面。在这样一个简单的网站上,您可能不需要直观地查找元素,但滚动到视图功能在复杂的网站上非常有用。
请注意,搜索栏还可用于搜索和测试 CSS 选择器。例如,您可以搜索 span.text 以查找所有引用文本。这将搜索页面中带有标签 class="text" 的跨度,而不是全文搜索。
网络工具
在爬取过程中,您可能会遇到动态网页,其中部分页面是通过多次请求动态加载的。尽管这很棘手,但开发人员工具中的 Network-tool 极大地促进了这项任务。为了演示网络工具,让我们看一下页面 /scroll。
该页面与基本页面非常相似——第一页,但不是上面提到的下一步按钮,当你滚动到底部时,页面会自动加载新的报价。我们可以直接尝试不同的 xpath,但我们将从 Scrapy shell 中检查另一个非常有用的命令:
$ scrapy shell "quotes.toscrape.com/scroll"
(...)
>>> view(response)
浏览器窗口应该与网页一起打开,但有一个关键区别:我们看到一个带有单词的绿色条,而不是引用。加载中....

这个 view(response) 命令允许我们查看 shell 或稍后蜘蛛从服务器收到的响应。在这里我们看到加载了一些基本模板,包括标题、登录按钮和页脚,但缺少引号。这告诉我们引号是从不同的请求加载的,而不是quotes.toscrape/scroll。
如果单击“网络”选项卡,您可能只会看到两个条目。我们需要做的第一件事是单击 Persist Logs。如果禁用此选项,则每次导航到不同页面时都会自动清除日志。启用此选项是一个很好的默认设置,因为它允许我们控制何时清除日志。
如果我们现在重新加载页面,您将看到日志中充满了六个新请求。

在这里,我们可以看到页面重新加载时发出的每个请求,并可以检查每个请求及其响应。那么让我们找出我们的报价来自哪里:
首先单击带有名称的请求滚动条。在右侧,您现在可以检查请求。在 Headers 中,您将找到有关请求标头的详细信息,例如 URL、方法、IP 地址等。我们将忽略其他选项卡并直接单击 Response。
您应该在预览窗格中看到的是呈现的 HTML 代码,这就是我们在 优采云 中所说的视图(响应)。相应地,类型日志中的请求为html。其他类型的请求如下 css 或 js 但我们对quotes?page=1 和类型 json 的请求感兴趣。
如果我们点击这个请求,我们会看到请求的 URL 是响应是一个收录我们引号的 JSON 对象。我们还可以右键单击请求并打开在新选项卡中打开以获得更好的概览。

有了这个响应,我们现在可以轻松解析 JSON 对象并请求每个页面以获取站点上的每个引用:
import scrapy
import json
class QuoteSpider(scrapy.Spider):
name = 'quote'
allowed_domains = ['quotes.toscrape.com']
page = 1
start_urls = ['http://quotes.toscrape.com/api ... 39%3B]
def parse(self, response):
data = json.loads(response.text)
for quote in data["quotes"]:
yield {"quote": quote["text"]}
if data["has_next"]:
self.page += 1
url = f"http://quotes.toscrape.com/api/quotes?page={self.page}"
yield scrapy.Request(url=url, callback=self.parse)
这个蜘蛛程序从 QuotesAPI 的第一页开始。对于每个响应,我们分析 response.text 并将其分配给数据。这允许我们像在 Python 字典上一样操作 JSON 对象。我们迭代引号并打印出quote["text"]。如果方便的话,has_next 元素为真(尝试在浏览器中加载 /api/quotes?page=10 或大于 10 的页码,我们增加 page 属性并产生一个新的 Request 将增加的页码插入到网址。
在更复杂的 网站 中,可能很难轻松重现请求,因为我们可能需要添加标头或 cookie 才能使其工作。在这些情况下,您可以通过在 Web 工具中右键单击每个请求,然后使用 from_curl() 方法生成等效请求,将请求导出为 cURL 格式:
from scrapy import Request
request = Request.from_curl(
"curl 'http://quotes.toscrape.com/api ... 39%3B -H 'User-Agent: Mozil"
"la/5.0 (X11; Linux x86_64; rv:67.0) Gecko/20100101 Firefox/67.0' -H 'Acce"
"pt: */*' -H 'Accept-Language: ca,en-US;q=0.7,en;q=0.3' --compressed -H 'X"
"-Requested-With: XMLHttpRequest' -H 'Proxy-Authorization: Basic QFRLLTAzM"
"zEwZTAxLTk5MWUtNDFiNC1iZWRmLTJjNGI4M2ZiNDBmNDpAVEstMDMzMTBlMDEtOTkxZS00MW"
"I0LWJlZGYtMmM0YjgzZmI0MGY0' -H 'Connection: keep-alive' -H 'Referer: http"
"://quotes.toscrape.com/scroll' -H 'Cache-Control: max-age=0'")
或者,如果您想知道重新创建请求所需的参数,可以使用该函数获取具有等效参数的字典:
scrapy.utils.curl.curl_to_request_kwargs(curl_command:, ignore_unknown_options: = True) →
将 cURL 命令语法转换为请求 kwargs。
范围
返回
请求字典
请注意,要将 cURL 命令转换为 Scrapy 请求,您可以使用 curl2scrapy。
如您所见,在 Network-Tools 中,我们可以轻松复制页面滚动功能的动态请求。抓取动态页面可能非常困难,页面可能非常复杂,但(主要)归结为识别正确的请求并将其复制到蜘蛛中。
网页源代码抓取工具(一下怎么一步一步写爬虫(headers)数据过程(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-10-14 17:24
最近经常有人在看教程的时候问我写爬虫容易吗,但是上手的时候,爪子都麻了。. . 所以今天跟刚开始学习爬虫的同学们分享一下如何一步步写爬虫,直到拿到数据。
准备工具
首先是准备工具:python3.6、pycharm、请求库、lxml库和火狐浏览器
这两个库是python的第三方库,需要用pip安装!
requests用于请求一个网页,获取网页的源码,然后使用lxml库分析html源码,从中取出我们需要的内容!
你使用火狐浏览器而不使用其他浏览器的原因没有其他意义,只是习惯而已。. .
分析网页
工具准备好后,就可以开始我们的爬虫之旅了!今天我们的目标是捕捉猫眼电影的经典部分。大约有80,000条数据。
打开网页后,首先要分析网页的源代码,看它是静态的还是动态的,还是其他形式的。这个网页是一个静态网页,所以源码中收录了我们需要的内容。
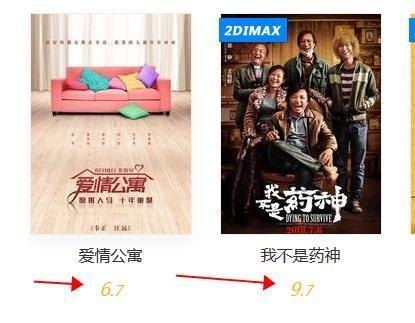
很明显,它的电影名称和评级在源代码中,但评级分为两部分。这点在写爬虫的时候要注意!
所以,现在整体思路已经很清晰了:请求网页==>>获取html源码==>>匹配内容,然后在外面添加一个步骤:获取页码==>>构建一个所有页面的循环,这样你可以所有的内容已被捕获!我们把代码写在外面。
开始编写爬虫
先导入两个库,然后用一行代码得到网页html,打印出来看看效果
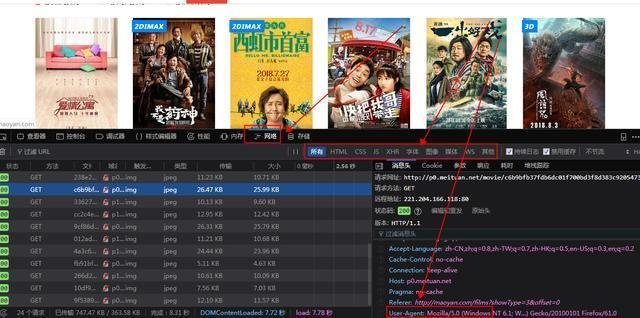
好吧,网站 不允许爬虫运行!加个headers试试(headers是身份证明,说明请求的网页是浏览器而不是python代码),获取方式也很简单,打开F12开发者工具,找到一个网络请求,然后找到请求如下图Header,复制相关信息,这个header就可以保存了,基本上一个浏览器就是一个UA,下次直接用就可以了。
欢迎加入学习群:六九九+七四九+八五二,群里都是学Python开发的,如果你是学Python的,小编欢迎你加入,大家都是软件开发党,分享干货来自不定时(仅与Python软件开发相关),内附本人2018年编译的最新Python进阶资料和进阶开发教程,欢迎进阶及想深入Python的朋友。
注意在Firefox中,如果header数据很长,会被缩写。看到上图中间的省略号了吗……?所以复制的时候一定要先双击展开,复制,然后再修改上面的代码。看
这一次,html被正确打印了!(后面的.text是获取html文本,不添加则返回获取是否成功的提示,不是html源代码),我们先建个页码循环,找到html代码翻页用
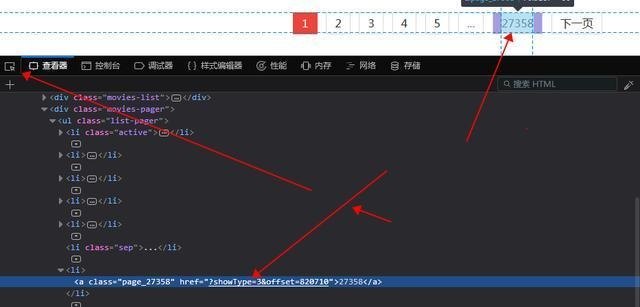
点击开发者工具左上角的选择元素,然后点击页码,对应的源码位置会自动定位到下方。这里我们可以直观的看到最大页码,先取出来,右击,选择Copy Xpath,然后写在代码里
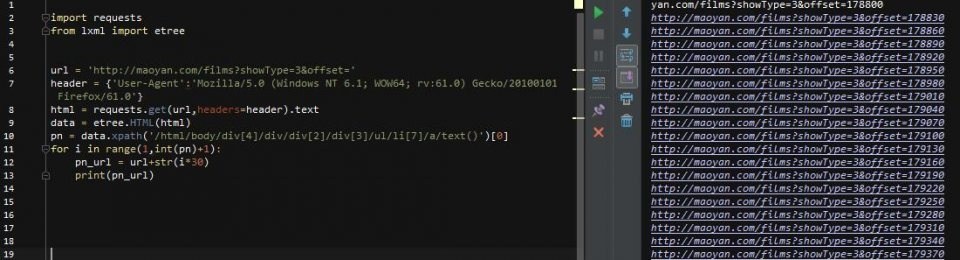
第9行表示使用lxml中的etree方法解析html,第10行表示从html中查找路径对应的标签。因为页码是文字显示,是标签的文字部分,所以在路径末尾加一个/text 取出文字,最后以列表的形式取出内容。然后我们要观察每个页面的url,还记得刚才页码部分的html吗?
href的值是每个页码对应的url,当然省略了域名部分。可以看到,它的规律是offset的值随着页码的变化而变化(*30) 那么,我们就可以建立一个循环!
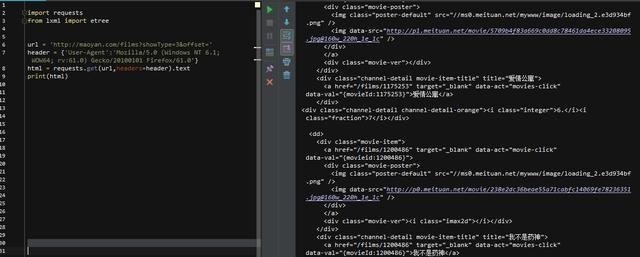
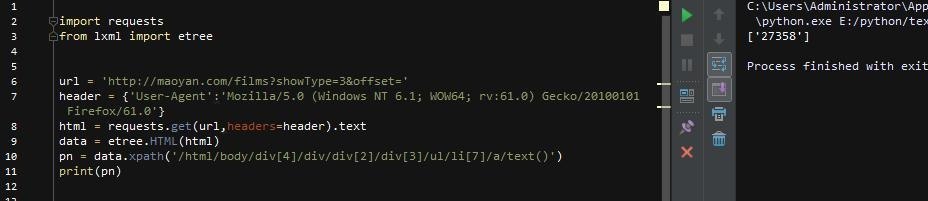
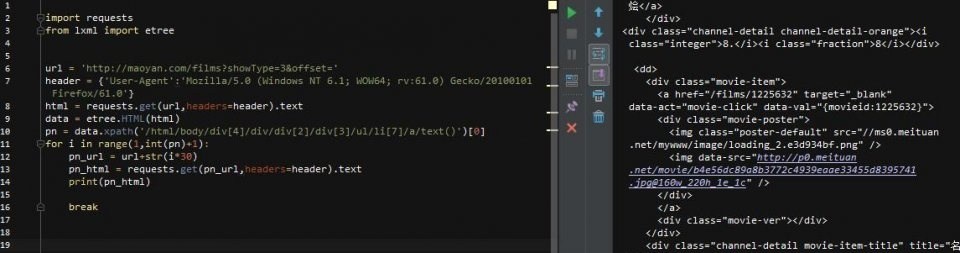
第10行,使用[0]取出列表中的pn值,然后构建循环,然后获取新url的html(pn_url),然后去html匹配我们想要的内容!为方便起见,添加一个中断,使其仅循环一次
然后开始匹配,这次我们只拿出了电影名称、评分和详情url 3个结果
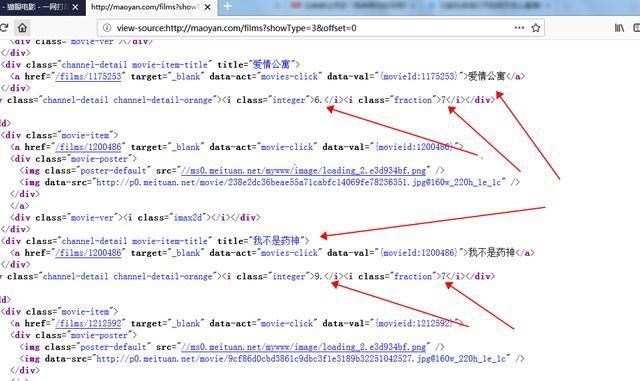
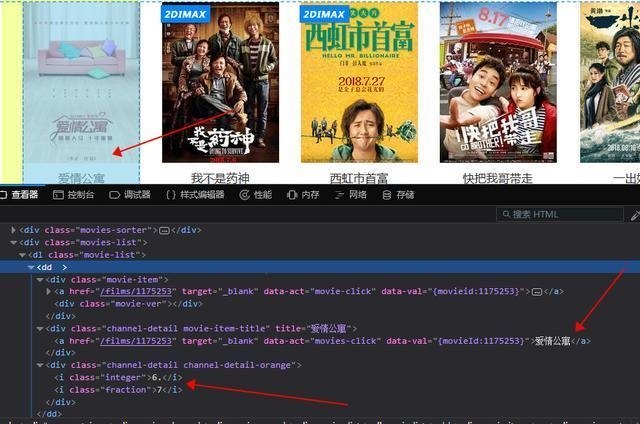
可以看到,我们要的内容在dd标签下,下面有3个div,第一个是图片,不用管,第二个是电影名,详情页url也在里面,第三个div里面有评分结果,所以我们可以这样写
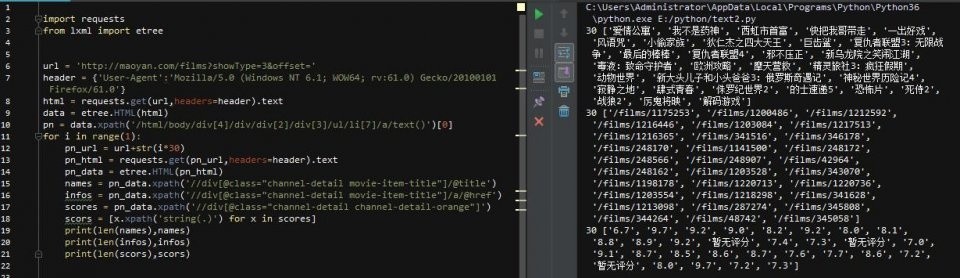
第14行还是解析html,第15行和第16行分别获取class属性为“channel-detail movie-item-title”的div标签下的title值和a标签下的href值div(这里复制没有用)xpath的路径,当然可以的话,我建议你用这个方法,因为如果你用了路径,万一网页的结构被修改了,那么我们的代码就会改写……)
第17、18、2行代码获取div标签下的所有文字内容,还记得分数吗?不是在一个标签下,而是两个标签下的文字内容合并了,这样就搞定了!
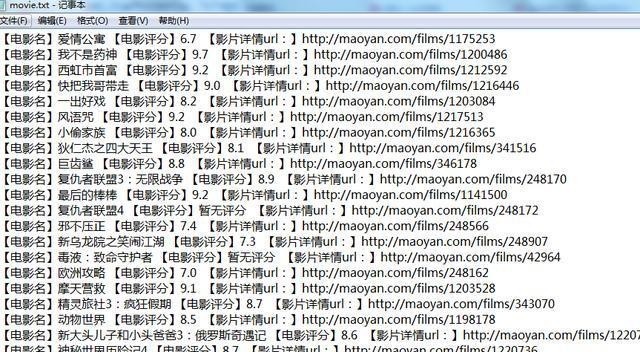
然后,使用zip函数将内容一一写入txt文件
注意内容间距和换行符!
至此,爬虫部分基本完成!我们先来看看效果。时间有限,所以我们将抓取前5页。代码和结果如下:
后记
整个爬取过程没有任何难度。一开始,您需要注意标题。后面在爬取数据的过程中,一定要学习更多的匹配方法。最后,注意数据量。有两个方面:爬取间隔和爬取数量,不要对网站造成不好的影响,这是基本要求!后面还有这个网站,到100页左右的时候需要登录,这点请注意,可以自己试试!返回搜狐查看更多 查看全部
网页源代码抓取工具(一下怎么一步一步写爬虫(headers)数据过程(图))
最近经常有人在看教程的时候问我写爬虫容易吗,但是上手的时候,爪子都麻了。. . 所以今天跟刚开始学习爬虫的同学们分享一下如何一步步写爬虫,直到拿到数据。
准备工具
首先是准备工具:python3.6、pycharm、请求库、lxml库和火狐浏览器
这两个库是python的第三方库,需要用pip安装!
requests用于请求一个网页,获取网页的源码,然后使用lxml库分析html源码,从中取出我们需要的内容!
你使用火狐浏览器而不使用其他浏览器的原因没有其他意义,只是习惯而已。. .

分析网页
工具准备好后,就可以开始我们的爬虫之旅了!今天我们的目标是捕捉猫眼电影的经典部分。大约有80,000条数据。
打开网页后,首先要分析网页的源代码,看它是静态的还是动态的,还是其他形式的。这个网页是一个静态网页,所以源码中收录了我们需要的内容。
很明显,它的电影名称和评级在源代码中,但评级分为两部分。这点在写爬虫的时候要注意!
所以,现在整体思路已经很清晰了:请求网页==>>获取html源码==>>匹配内容,然后在外面添加一个步骤:获取页码==>>构建一个所有页面的循环,这样你可以所有的内容已被捕获!我们把代码写在外面。
开始编写爬虫
先导入两个库,然后用一行代码得到网页html,打印出来看看效果
好吧,网站 不允许爬虫运行!加个headers试试(headers是身份证明,说明请求的网页是浏览器而不是python代码),获取方式也很简单,打开F12开发者工具,找到一个网络请求,然后找到请求如下图Header,复制相关信息,这个header就可以保存了,基本上一个浏览器就是一个UA,下次直接用就可以了。
欢迎加入学习群:六九九+七四九+八五二,群里都是学Python开发的,如果你是学Python的,小编欢迎你加入,大家都是软件开发党,分享干货来自不定时(仅与Python软件开发相关),内附本人2018年编译的最新Python进阶资料和进阶开发教程,欢迎进阶及想深入Python的朋友。
注意在Firefox中,如果header数据很长,会被缩写。看到上图中间的省略号了吗……?所以复制的时候一定要先双击展开,复制,然后再修改上面的代码。看
这一次,html被正确打印了!(后面的.text是获取html文本,不添加则返回获取是否成功的提示,不是html源代码),我们先建个页码循环,找到html代码翻页用
点击开发者工具左上角的选择元素,然后点击页码,对应的源码位置会自动定位到下方。这里我们可以直观的看到最大页码,先取出来,右击,选择Copy Xpath,然后写在代码里
第9行表示使用lxml中的etree方法解析html,第10行表示从html中查找路径对应的标签。因为页码是文字显示,是标签的文字部分,所以在路径末尾加一个/text 取出文字,最后以列表的形式取出内容。然后我们要观察每个页面的url,还记得刚才页码部分的html吗?
href的值是每个页码对应的url,当然省略了域名部分。可以看到,它的规律是offset的值随着页码的变化而变化(*30) 那么,我们就可以建立一个循环!
第10行,使用[0]取出列表中的pn值,然后构建循环,然后获取新url的html(pn_url),然后去html匹配我们想要的内容!为方便起见,添加一个中断,使其仅循环一次
然后开始匹配,这次我们只拿出了电影名称、评分和详情url 3个结果
可以看到,我们要的内容在dd标签下,下面有3个div,第一个是图片,不用管,第二个是电影名,详情页url也在里面,第三个div里面有评分结果,所以我们可以这样写
第14行还是解析html,第15行和第16行分别获取class属性为“channel-detail movie-item-title”的div标签下的title值和a标签下的href值div(这里复制没有用)xpath的路径,当然可以的话,我建议你用这个方法,因为如果你用了路径,万一网页的结构被修改了,那么我们的代码就会改写……)
第17、18、2行代码获取div标签下的所有文字内容,还记得分数吗?不是在一个标签下,而是两个标签下的文字内容合并了,这样就搞定了!
然后,使用zip函数将内容一一写入txt文件
注意内容间距和换行符!
至此,爬虫部分基本完成!我们先来看看效果。时间有限,所以我们将抓取前5页。代码和结果如下:
后记
整个爬取过程没有任何难度。一开始,您需要注意标题。后面在爬取数据的过程中,一定要学习更多的匹配方法。最后,注意数据量。有两个方面:爬取间隔和爬取数量,不要对网站造成不好的影响,这是基本要求!后面还有这个网站,到100页左右的时候需要登录,这点请注意,可以自己试试!返回搜狐查看更多
网页源代码抓取工具(借助json数据借助这个json在线解析工具(json)(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-14 05:10
)
1、在应用开发中,点击一个按钮或者点击一个链接,页面的响应结果和我们预期的结果不一样,我们可以在后台中断应用,调试调试,或者浏览查看并抢回来来自后台的数据。
2、如何通过浏览器查看和截取?
我使用的浏览器是谷歌的 chrome。
如下图,我点击查询按钮。
一、进入调试界面
在点击勾选按钮之前,进入浏览器的调试界面。
浏览器调试界面的方式(windows下,直接F12,我用mac):
方法一:在浏览器页面空白处,点击左键,再点击“评论元素”进入模式页面;
方法二:点击浏览器右上角,
,–>更多工具–>开发者工具。
调试页面如下:
二、在调试界面查看和抓取数据
如何查看和捕获数据?
如下所示:
第一步:点击查询按钮;
第二步:点击网络标签;
第三步:点击getAllUser.do链接;
您可以在下图中检查请求的状态:
点击下方的Headers选项卡,如下图所示,查看请求状态Status Code: 200 OK,查看请求头信息
然后点击Response选项卡查看后端响应数据
我们也可以复制这里的json数据,网上找了一个json在线格式。
三、 用json在线解析工具格式化json数据
借助这个json在线解析工具,我们可以更清晰的查看和分析下图中后台抓取到的数据
查看全部
网页源代码抓取工具(借助json数据借助这个json在线解析工具(json)(组图)
)
1、在应用开发中,点击一个按钮或者点击一个链接,页面的响应结果和我们预期的结果不一样,我们可以在后台中断应用,调试调试,或者浏览查看并抢回来来自后台的数据。
2、如何通过浏览器查看和截取?
我使用的浏览器是谷歌的 chrome。
如下图,我点击查询按钮。

一、进入调试界面
在点击勾选按钮之前,进入浏览器的调试界面。
浏览器调试界面的方式(windows下,直接F12,我用mac):
方法一:在浏览器页面空白处,点击左键,再点击“评论元素”进入模式页面;
方法二:点击浏览器右上角,

,–>更多工具–>开发者工具。
调试页面如下:

二、在调试界面查看和抓取数据
如何查看和捕获数据?
如下所示:
第一步:点击查询按钮;
第二步:点击网络标签;
第三步:点击getAllUser.do链接;

您可以在下图中检查请求的状态:
点击下方的Headers选项卡,如下图所示,查看请求状态Status Code: 200 OK,查看请求头信息

然后点击Response选项卡查看后端响应数据

我们也可以复制这里的json数据,网上找了一个json在线格式。

三、 用json在线解析工具格式化json数据
借助这个json在线解析工具,我们可以更清晰的查看和分析下图中后台抓取到的数据

网页源代码抓取工具( 本文参考虫师的博客“python实现简单爬虫功能”(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-10-14 05:04
本文参考虫师的博客“python实现简单爬虫功能”(图)
)
参考:http://www.cnblogs.com/fnng/p/3576154.html
本文参考崇石博客《Python实现简单爬虫功能》,整理分析后,抓取其他网站的图片,下载保存到本地。
源代码:
1 #! /usr/bin/python
2 # coding:utf-8
3
4 #导入urllib与re模块
5 import urllib
6 import re
7
8 # 定义一个函数获片取页面的信息,返回html文件。
9 def getHtml(url):
10 page = urllib.urlopen(url)
11 html = page.read()
12 return html
13
14 #将页面中的图片保存为正则表达式对象,通过for循环,
15 #利用urllib.urlretrieve()方法将所有图片下载到本地。
16 def getImg(html):
17 reg = r'src="(.+?\.png)"'
18 imgre = re.compile(reg)
19 imglist = re.findall(imgre,html)
20 x = 0
21 for imgurl in imglist:
22 urllib.urlretrieve(imgurl,'%s.png' % x)
23 x+=1
24
25 html = getHtml("http://www.cnblogs.com/fnng/p/3576154.html")
2. 终端下看到的下载图片
spdbmadeMacBook-Pro:crawler spdbma$ ls
0.png 2.png 4.png 6.png
1.png 3.png 5.png getjpg.py 查看全部
网页源代码抓取工具(
本文参考虫师的博客“python实现简单爬虫功能”(图)
)
参考:http://www.cnblogs.com/fnng/p/3576154.html
本文参考崇石博客《Python实现简单爬虫功能》,整理分析后,抓取其他网站的图片,下载保存到本地。
源代码:
1 #! /usr/bin/python
2 # coding:utf-8
3
4 #导入urllib与re模块
5 import urllib
6 import re
7
8 # 定义一个函数获片取页面的信息,返回html文件。
9 def getHtml(url):
10 page = urllib.urlopen(url)
11 html = page.read()
12 return html
13
14 #将页面中的图片保存为正则表达式对象,通过for循环,
15 #利用urllib.urlretrieve()方法将所有图片下载到本地。
16 def getImg(html):
17 reg = r'src="(.+?\.png)"'
18 imgre = re.compile(reg)
19 imglist = re.findall(imgre,html)
20 x = 0
21 for imgurl in imglist:
22 urllib.urlretrieve(imgurl,'%s.png' % x)
23 x+=1
24
25 html = getHtml("http://www.cnblogs.com/fnng/p/3576154.html";)
2. 终端下看到的下载图片
spdbmadeMacBook-Pro:crawler spdbma$ ls
0.png 2.png 4.png 6.png
1.png 3.png 5.png getjpg.py
网页源代码抓取工具(常见的三种情况下的抓包方法,你知道吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-14 05:03
)
开篇:写爬虫抓数据,首先要分析客户端和服务端的请求/响应。前提是我们可以监控客户端如何与服务器交互。我们记录三种常见的情况。下的捕获方法
1.PC浏览器网页抓取
网页板捕获是最简单和最常见的。比如Google/Firfox/IE等浏览器自带的开发者调试工具(F12))就可以满足部分需求。比如修改浏览器发送的请求数据,修改服务器的相应数据。用F12开发这个工具不能满足我们的需求。这里介绍Fiddler抓包工具,可以理解为本地代理服务器,实现转发client和Server的请求和响应
设置小提琴手:
打开Fiddler,在菜单栏中,打开Tools-Options,在前三个选项卡设置下,OK,默认代理设置:127.0.0.1:8888
然后在浏览器端设置代理:127.0.0.1:8888,就可以抓取网页请求/响应,然后就可以在Fiddler端实现需求了根据需要,如:设置Breakpoints、过滤请求、修改请求数据、修改响应数据、拦截JS等。
2.移动应用捕获
在移动端使用 Fiddler 抓包也很简单。类似于上面PC浏览器的抓包方式。移动终端必须与PC在同一个局域网内。手机的Wifi设置代理,IP为PC机的IP地址,例如:64.35.86.12,端口号为FIddler设置的端口号,通常是8888,这样手机上的所有网络/响应请求都必须是FIddler发送的,这样我们才能针对一些链接做分析
3.PC客户端(C/S)抓包
C/S程序捕获需要Proxifer
Proxifier是一个非常强大的socks5客户端,它允许不支持通过代理服务器工作的网络程序通过HTTPS或SOCKS代理或代理链。
由于一般的C/S客户端无法设置代理,所以我们的FIiddler无法检测到数据。我们可以使用Proxifer来捕获所有的请求并发送给Fiddler,这样我们就可以在Fiddler中分析客户端的请求。
代理设置:
设置很简单,如下图,两步就OK了
一种)。将代理服务器和 Fiddler 代理设置设置为匹配
b)。设置代理规则
默认 Default,我们可以忽略
点击添加
名称:Fiddler.exe
是否有效:是
选择Fiddler的应用文件目录,选择后,确认
目标主机:我们本地 Fiddler 设置的代理,可以是任意
目的港:任意
行动:直接
现在设置完成,我们可以打开腾讯视频视频客户端,查看Fiddler和Proxifer中的数据
4.电脑上所有C/S客户端都可以抓包
这时候,当Proxifer打开时,浏览器将无法连接网络。可以通过设置Fiddler方式连接网络,添加谷歌浏览器执行程序文件,确定后就可以上网了
查看全部
网页源代码抓取工具(常见的三种情况下的抓包方法,你知道吗?
)
开篇:写爬虫抓数据,首先要分析客户端和服务端的请求/响应。前提是我们可以监控客户端如何与服务器交互。我们记录三种常见的情况。下的捕获方法
1.PC浏览器网页抓取
网页板捕获是最简单和最常见的。比如Google/Firfox/IE等浏览器自带的开发者调试工具(F12))就可以满足部分需求。比如修改浏览器发送的请求数据,修改服务器的相应数据。用F12开发这个工具不能满足我们的需求。这里介绍Fiddler抓包工具,可以理解为本地代理服务器,实现转发client和Server的请求和响应
设置小提琴手:
打开Fiddler,在菜单栏中,打开Tools-Options,在前三个选项卡设置下,OK,默认代理设置:127.0.0.1:8888



然后在浏览器端设置代理:127.0.0.1:8888,就可以抓取网页请求/响应,然后就可以在Fiddler端实现需求了根据需要,如:设置Breakpoints、过滤请求、修改请求数据、修改响应数据、拦截JS等。
2.移动应用捕获
在移动端使用 Fiddler 抓包也很简单。类似于上面PC浏览器的抓包方式。移动终端必须与PC在同一个局域网内。手机的Wifi设置代理,IP为PC机的IP地址,例如:64.35.86.12,端口号为FIddler设置的端口号,通常是8888,这样手机上的所有网络/响应请求都必须是FIddler发送的,这样我们才能针对一些链接做分析
3.PC客户端(C/S)抓包
C/S程序捕获需要Proxifer
Proxifier是一个非常强大的socks5客户端,它允许不支持通过代理服务器工作的网络程序通过HTTPS或SOCKS代理或代理链。
由于一般的C/S客户端无法设置代理,所以我们的FIiddler无法检测到数据。我们可以使用Proxifer来捕获所有的请求并发送给Fiddler,这样我们就可以在Fiddler中分析客户端的请求。
代理设置:
设置很简单,如下图,两步就OK了

一种)。将代理服务器和 Fiddler 代理设置设置为匹配

b)。设置代理规则
默认 Default,我们可以忽略

点击添加
名称:Fiddler.exe
是否有效:是
选择Fiddler的应用文件目录,选择后,确认

目标主机:我们本地 Fiddler 设置的代理,可以是任意
目的港:任意
行动:直接
现在设置完成,我们可以打开腾讯视频视频客户端,查看Fiddler和Proxifer中的数据


4.电脑上所有C/S客户端都可以抓包
这时候,当Proxifer打开时,浏览器将无法连接网络。可以通过设置Fiddler方式连接网络,添加谷歌浏览器执行程序文件,确定后就可以上网了

网页源代码抓取工具(“巨潮资讯网”网页代码看不到(看不到)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-10-14 02:09
故事背景:近日,一位朋友想在巨潮资讯网批量下载关于“股票质押”的PDF。问我之后,我想用python写一个爬虫工具。
原网页如下:
%E8%82%A1%E7%A5%A8%E8%B4%A8%E6%8A%BC
思路:根据之前的Python爬虫入门经验,获取网页源码,找到下载链接,重新下载。
这很好!查看页面的源代码。. . 看不到“搜索结果”所在页面的这部分代码?!这个“深圳万科”只是一个例子
但回顾要素时,却存在“和康新能”和“永高股份”。. . :
我研究了如何获取隐藏的网页代码,网上关于F12抓包和抓包的说法。. .
模糊,我是菜鸟,能不能一步一步教我?我看到了两个有用的网页:
回到“聚潮资讯网”,F12复习要素——>网络——>XHR——>F5重装,看到了这些东西:
选择这个完整的?searchxxxxxxxxx:
进入这个页面后,公告板请求了另一个url:
请求 URL:%E8%82%A1%E7%A5%A8%E8%B4%A8%E6%8A%BC&sdate=&edate=&isfulltext=false&sortName=pubdate&sortType=desc&pageNum=1
打开它,得到返回的数据,就是想要的“搜索结果”的数据:
8. 该网页首先呈现布局界面,核心内容搜索结果异步加载。
以后如果学了html、JavaScript等前端知识,再来这里讲解异步加载。 查看全部
网页源代码抓取工具(“巨潮资讯网”网页代码看不到(看不到)(图))
故事背景:近日,一位朋友想在巨潮资讯网批量下载关于“股票质押”的PDF。问我之后,我想用python写一个爬虫工具。
原网页如下:
%E8%82%A1%E7%A5%A8%E8%B4%A8%E6%8A%BC

思路:根据之前的Python爬虫入门经验,获取网页源码,找到下载链接,重新下载。
这很好!查看页面的源代码。. . 看不到“搜索结果”所在页面的这部分代码?!这个“深圳万科”只是一个例子

但回顾要素时,却存在“和康新能”和“永高股份”。. . :

我研究了如何获取隐藏的网页代码,网上关于F12抓包和抓包的说法。. .
模糊,我是菜鸟,能不能一步一步教我?我看到了两个有用的网页:


回到“聚潮资讯网”,F12复习要素——>网络——>XHR——>F5重装,看到了这些东西:

选择这个完整的?searchxxxxxxxxx:

进入这个页面后,公告板请求了另一个url:
请求 URL:%E8%82%A1%E7%A5%A8%E8%B4%A8%E6%8A%BC&sdate=&edate=&isfulltext=false&sortName=pubdate&sortType=desc&pageNum=1
打开它,得到返回的数据,就是想要的“搜索结果”的数据:

8. 该网页首先呈现布局界面,核心内容搜索结果异步加载。
以后如果学了html、JavaScript等前端知识,再来这里讲解异步加载。
网页源代码抓取工具( html源代码翻译软件通过分析,提取源代码需要汉化的文本 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 236 次浏览 • 2021-10-13 00:13
html源代码翻译软件通过分析,提取源代码需要汉化的文本
)
html源代码翻译工具官方版是一款非常专业的html源代码翻译软件。官方版html源代码翻译工具可以将用户的htm添加到软件中直接翻译。官方版html源代码翻译工具可以批量翻译文件,也可以翻译所有网页。软件支持中英文转换功能,软件可以保证翻译结果的准确性。该软件非常适合需要查看网页代码的用户。
软件介绍
官方版html源代码翻译工具分析html,提取源代码需要汉化的文字,可以在电脑中完整翻译源代码,批量在线翻译。
软件功能
1、html源码翻译工具提供简单的文本内容翻译功能
2、在软件中添加代码文本进行翻译
3、支持自动备份功能,可以备份原创网页文件
4、 默认支持保存,翻译结果可以在原地址找到
5、快速识别htm内容,实现汉英转换
6、 可以帮助用户翻译国外网页模板
软件特点
1、html源码翻译工具提供简单的网页内容翻译功能
2、把网上下载的源代码翻译成中文
3、 将国外下载的英文网页源代码翻译成中文
4、还支持中英文转换,满足不同用户的需求
5、软件基于谷歌翻译,所以翻译结果还是很准确的
安装方法
下载html源代码翻译工具官方软件包
解压到当前文件夹
双击打开文件夹中的应用程序
查看全部
网页源代码抓取工具(
html源代码翻译软件通过分析,提取源代码需要汉化的文本
)

html源代码翻译工具官方版是一款非常专业的html源代码翻译软件。官方版html源代码翻译工具可以将用户的htm添加到软件中直接翻译。官方版html源代码翻译工具可以批量翻译文件,也可以翻译所有网页。软件支持中英文转换功能,软件可以保证翻译结果的准确性。该软件非常适合需要查看网页代码的用户。
软件介绍
官方版html源代码翻译工具分析html,提取源代码需要汉化的文字,可以在电脑中完整翻译源代码,批量在线翻译。
软件功能
1、html源码翻译工具提供简单的文本内容翻译功能
2、在软件中添加代码文本进行翻译
3、支持自动备份功能,可以备份原创网页文件
4、 默认支持保存,翻译结果可以在原地址找到
5、快速识别htm内容,实现汉英转换
6、 可以帮助用户翻译国外网页模板
软件特点
1、html源码翻译工具提供简单的网页内容翻译功能
2、把网上下载的源代码翻译成中文
3、 将国外下载的英文网页源代码翻译成中文
4、还支持中英文转换,满足不同用户的需求
5、软件基于谷歌翻译,所以翻译结果还是很准确的
安装方法
下载html源代码翻译工具官方软件包

解压到当前文件夹
双击打开文件夹中的应用程序
网页源代码抓取工具(JS加密/解密(HTML/JS互转代码转换工具))
网站优化 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-10-11 12:25
1、JS加密/解密(以js的形式对代码进行加密或解密。)
2、UTF-8 编码转换工具(UTF-8 编码转换。)
3、Unicode 编码转换工具(Unicode 编码转换。)
4、友情链接(该工具可以批量查询百度收录中指定的网站友情链接,百度快照,PR,对方是否链接到本站,你可以识别欺诈链接。)
5. META信息检测(该工具可以快速检测网页的META标签,分析标题、关键词、描述等是否对搜索引擎收录有利。)
6、MD5加密工具(对字符串进行MD5加密。)
7.身份证号码值查询(查询身份证位置、性别和出生日期。)
8、HTML/UBB 代码转换工具(HTML/UBB 代码转换。)
9、HTML/JS 转换工具(HTML/JS 转换。)
10.搜索蜘蛛和机器人模拟工具(该工具可以快速模拟搜索引擎蜘蛛访问页面时抓取的内容信息!)
11、关键词密度检测(该工具可以快速检测关键词出现的页面的数量和密度,更适合蜘蛛搜索。)
12、国家域名查看(查看所有国家的域名。)
13、邮编区号查询(查询各区的邮编区号,支持模糊查询。)
14、域名Whois查询工具(Whois简单来说就是一个数据库,用来查询一个域名是否已经注册以及注册域名的详细信息(如域名拥有者、域名注册商、域名注册商)日期和有效期)日期等)。通过域名Whois查询,可以查询到域名拥有者的联系方式,以及注册和过期时间。)
15、死链检测/全站PR查询(该工具可以快速检测网站的死链。死链-也叫无效链接,即那些不可达的链接。A 网站死链接的存在不是什么好事,首先,如果死链接数量众多,对网站的整体形象会造成很大的损害。其次,搜索引擎蜘蛛爬取通过链接,如果链接太多无法到达,不仅收录的页面数量会减少,而且你的网站在搜索引擎中的权重也会大大降低。这个查询可以遍历所有的链接在指定的网页上并分析每个链接的有效性,找出死链接。)
16、搜索引擎收录查询(此工具可以快速查询网站各大搜索引擎的收录数量!)
17、搜索引擎反向链接(此工具可以快速查询各大搜索引擎到网站的反向链接数量!)
18、查询手机号码归属地(查询手机号码归属地和手机号码类型。)
19、SEO综合查询(SEO综合查询。)
标签:搜索工具网站SEO 查看全部
网页源代码抓取工具(JS加密/解密(HTML/JS互转代码转换工具))
1、JS加密/解密(以js的形式对代码进行加密或解密。)
2、UTF-8 编码转换工具(UTF-8 编码转换。)
3、Unicode 编码转换工具(Unicode 编码转换。)
4、友情链接(该工具可以批量查询百度收录中指定的网站友情链接,百度快照,PR,对方是否链接到本站,你可以识别欺诈链接。)
5. META信息检测(该工具可以快速检测网页的META标签,分析标题、关键词、描述等是否对搜索引擎收录有利。)
6、MD5加密工具(对字符串进行MD5加密。)
7.身份证号码值查询(查询身份证位置、性别和出生日期。)
8、HTML/UBB 代码转换工具(HTML/UBB 代码转换。)
9、HTML/JS 转换工具(HTML/JS 转换。)
10.搜索蜘蛛和机器人模拟工具(该工具可以快速模拟搜索引擎蜘蛛访问页面时抓取的内容信息!)
11、关键词密度检测(该工具可以快速检测关键词出现的页面的数量和密度,更适合蜘蛛搜索。)
12、国家域名查看(查看所有国家的域名。)
13、邮编区号查询(查询各区的邮编区号,支持模糊查询。)
14、域名Whois查询工具(Whois简单来说就是一个数据库,用来查询一个域名是否已经注册以及注册域名的详细信息(如域名拥有者、域名注册商、域名注册商)日期和有效期)日期等)。通过域名Whois查询,可以查询到域名拥有者的联系方式,以及注册和过期时间。)
15、死链检测/全站PR查询(该工具可以快速检测网站的死链。死链-也叫无效链接,即那些不可达的链接。A 网站死链接的存在不是什么好事,首先,如果死链接数量众多,对网站的整体形象会造成很大的损害。其次,搜索引擎蜘蛛爬取通过链接,如果链接太多无法到达,不仅收录的页面数量会减少,而且你的网站在搜索引擎中的权重也会大大降低。这个查询可以遍历所有的链接在指定的网页上并分析每个链接的有效性,找出死链接。)
16、搜索引擎收录查询(此工具可以快速查询网站各大搜索引擎的收录数量!)
17、搜索引擎反向链接(此工具可以快速查询各大搜索引擎到网站的反向链接数量!)
18、查询手机号码归属地(查询手机号码归属地和手机号码类型。)
19、SEO综合查询(SEO综合查询。)
标签:搜索工具网站SEO
网页源代码抓取工具(手机显示的画面截图插件可以直接整屏Command网页的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-08 05:02
说到截取整个网站页面,很多朋友第一时间就想到了用哪个chrome插件。确实,我们网站之前已经引入了一些截图插件,比如:
1.很棒的截图,
2.网页截图,
3.Smartshot:支持滚动的谷歌浏览器截图插件
4.Joxi 全屏截屏:全屏截屏插件
但实际上,现在很多浏览器都有自己的截图功能。尤其是像chrome这样强大的浏览器,很可惜Chrome并没有明显的显示出这个功能,所以今天给大家分享一个不用任何软件、插件就可以直接全屏截取的网页。事情是这样的!
第一步:打开chrome开发者工具。
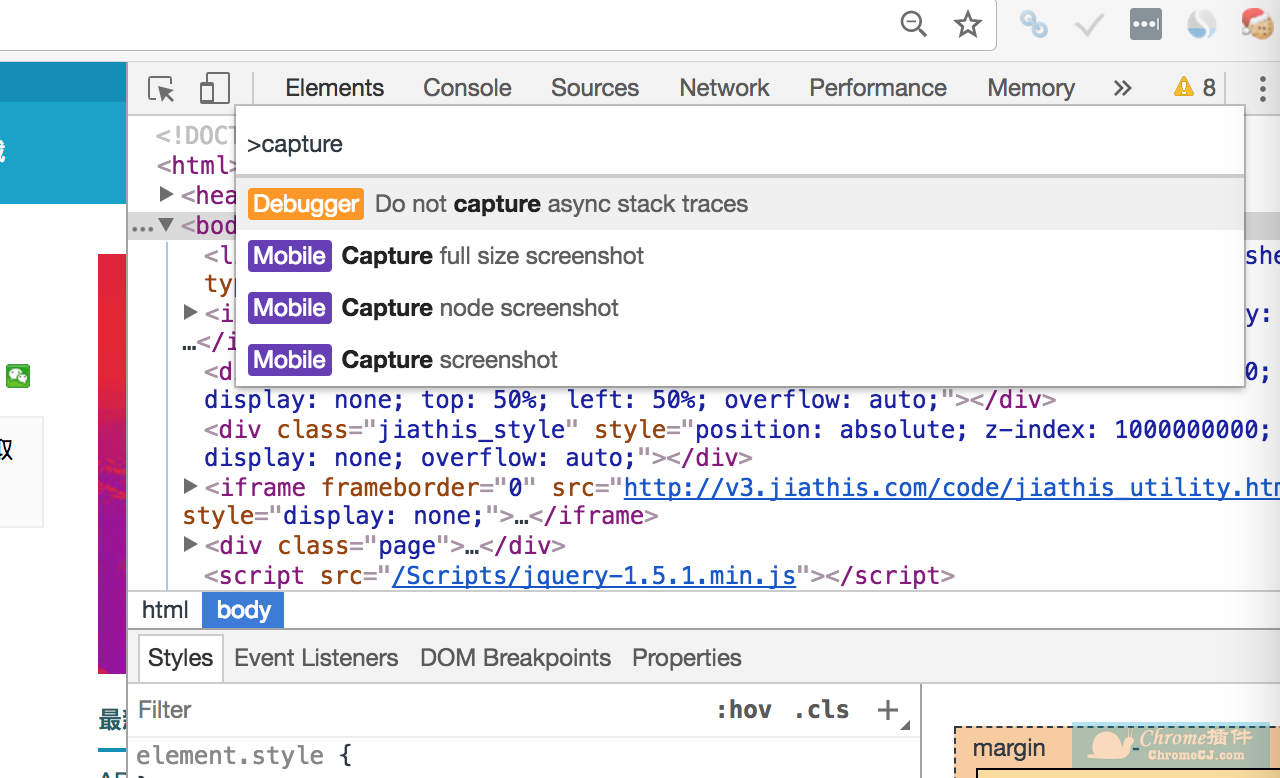
打开要截屏的网页,然后按 F12(对于 macOS 为 option + command + i)调出开发者工具,然后按“Ctrl + Shift + P”(对于 macOS 为 command + Shift + P)。然后输入命令capture,会提示三个选项,如下图:
它们是捕捉全屏、节点模式和当前范围,用鼠标单击或用键盘选择相应的。
第二步:截取手机版网页的截图。如果您想在手机等移动设备上对网页进行截图,可以使用快捷键Ctrl + Shift + M(⌘Command + ⇧Shift + M for Mac)启动模拟工具。在iPhone、iPad、Nexus、Galaxy等设备上切换网页的显示状态,然后使用上面介绍的截图功能对手机上显示的网页进行截图。
是不是特别简单?相比使用扩展程序截屏,这种方式当然更加复杂和简陋,但是当您急需使用扩展程序又不方便下载扩展程序时,它也是一个不错的选择。当然,您也可以选择网页截图插件。 查看全部
网页源代码抓取工具(手机显示的画面截图插件可以直接整屏Command网页的方法)
说到截取整个网站页面,很多朋友第一时间就想到了用哪个chrome插件。确实,我们网站之前已经引入了一些截图插件,比如:
1.很棒的截图,
2.网页截图,
3.Smartshot:支持滚动的谷歌浏览器截图插件
4.Joxi 全屏截屏:全屏截屏插件
但实际上,现在很多浏览器都有自己的截图功能。尤其是像chrome这样强大的浏览器,很可惜Chrome并没有明显的显示出这个功能,所以今天给大家分享一个不用任何软件、插件就可以直接全屏截取的网页。事情是这样的!
第一步:打开chrome开发者工具。
打开要截屏的网页,然后按 F12(对于 macOS 为 option + command + i)调出开发者工具,然后按“Ctrl + Shift + P”(对于 macOS 为 command + Shift + P)。然后输入命令capture,会提示三个选项,如下图:
它们是捕捉全屏、节点模式和当前范围,用鼠标单击或用键盘选择相应的。
第二步:截取手机版网页的截图。如果您想在手机等移动设备上对网页进行截图,可以使用快捷键Ctrl + Shift + M(⌘Command + ⇧Shift + M for Mac)启动模拟工具。在iPhone、iPad、Nexus、Galaxy等设备上切换网页的显示状态,然后使用上面介绍的截图功能对手机上显示的网页进行截图。
是不是特别简单?相比使用扩展程序截屏,这种方式当然更加复杂和简陋,但是当您急需使用扩展程序又不方便下载扩展程序时,它也是一个不错的选择。当然,您也可以选择网页截图插件。
网页源代码抓取工具(网页数据结构化抓取工具(:Powercap网页化))
网站优化 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-10-08 04:33
软件名称:Powercap web数据结构化爬虫工具绿色版
软件版本:1.6
软件大小:5.6mb
授权方式:试用版
作品类型:国产软件
应用平台:Win2000/XP/2003/Win7/Vista
软件语言:简体中文
开发者网址:
开发者邮箱:
下载链接:
软件界面图:
软件介绍:
PowerCap是一款专业的网络信息采集解决方案,可以采集任何类型的网站采集信息,如新闻网站、电子商务网站、论坛、求职网站等支持登录采集、跨页采集、多页合并、增量采集、点击导航、POST 采集、脚本支持、内置人体提取算法,自动采集图片、flash等附件。可以发布到任何ODBC数据库、Excel、Access中,也可以通过Web在线发布。
最新的1.6 版本目前支持以下功能:
* 自动登录或手动登录后采集页面
* 支持Javascript脚本生成的页面
* 定时自动爬行
* 正文提取算法自动去除页面中的广告
* 增量采集
* 多页合并功能
* 自动提取分布在多个页面上的信息
* 自动提取图片、flash等附件
* 点击导航
* 向导式定义抽取规则,抽取方式丰富(前后符号、正则表达式、智能字段、内置字段等)
* POST采集
* 采集页面保存为单个文件
* 使用插件处理采集页面
* 支持VBScript、JavaScript处理采集结果
* 输出到文本文件、Excel、Access、任何支持ODBC的数据库,并在网页上在线发布
* 全局替换抓取的内容
* 意外退出保护,服务器无人值守抓取
与以往爬虫软件相比的优势:
* 采集Anti-leech网站:目前很多网站采用了anti-leech技术来防止采集,PowerCap有效支持anti-leech采集技术
* JavaScript 输出网站:对于使用大量脚本输出页面内容的网页,传统的采集技术无能为力。在PowerCap中,我们独有的脚本支持技术可以应对这种网站
* 脚本跳转:PowerCap可以完美支持使用脚本进行页面导航的网站
* POST采集:传统软件只能在一级起始URL上使用POST采集,而Powercap可以在任何一级进行POST采集
* 限速采集:可以限制网站的爬取速度,防止被某些网站拦截
官方 网站: 查看全部
网页源代码抓取工具(网页数据结构化抓取工具(:Powercap网页化))
软件名称:Powercap web数据结构化爬虫工具绿色版
软件版本:1.6
软件大小:5.6mb
授权方式:试用版
作品类型:国产软件
应用平台:Win2000/XP/2003/Win7/Vista
软件语言:简体中文
开发者网址:
开发者邮箱:
下载链接:
软件界面图:
软件介绍:
PowerCap是一款专业的网络信息采集解决方案,可以采集任何类型的网站采集信息,如新闻网站、电子商务网站、论坛、求职网站等支持登录采集、跨页采集、多页合并、增量采集、点击导航、POST 采集、脚本支持、内置人体提取算法,自动采集图片、flash等附件。可以发布到任何ODBC数据库、Excel、Access中,也可以通过Web在线发布。
最新的1.6 版本目前支持以下功能:
* 自动登录或手动登录后采集页面
* 支持Javascript脚本生成的页面
* 定时自动爬行
* 正文提取算法自动去除页面中的广告
* 增量采集
* 多页合并功能
* 自动提取分布在多个页面上的信息
* 自动提取图片、flash等附件
* 点击导航
* 向导式定义抽取规则,抽取方式丰富(前后符号、正则表达式、智能字段、内置字段等)
* POST采集
* 采集页面保存为单个文件
* 使用插件处理采集页面
* 支持VBScript、JavaScript处理采集结果
* 输出到文本文件、Excel、Access、任何支持ODBC的数据库,并在网页上在线发布
* 全局替换抓取的内容
* 意外退出保护,服务器无人值守抓取
与以往爬虫软件相比的优势:
* 采集Anti-leech网站:目前很多网站采用了anti-leech技术来防止采集,PowerCap有效支持anti-leech采集技术
* JavaScript 输出网站:对于使用大量脚本输出页面内容的网页,传统的采集技术无能为力。在PowerCap中,我们独有的脚本支持技术可以应对这种网站
* 脚本跳转:PowerCap可以完美支持使用脚本进行页面导航的网站
* POST采集:传统软件只能在一级起始URL上使用POST采集,而Powercap可以在任何一级进行POST采集
* 限速采集:可以限制网站的爬取速度,防止被某些网站拦截
官方 网站:
网页源代码抓取工具(蜘蛛协议风铃虫的原理简单使用提取器的作用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-10-07 06:13
风铃介绍
风铃是一款轻量级爬虫工具,像风铃一样灵敏,像蜘蛛一样敏捷,任何细小的风和草都可以感知,轻松抓取网络内容。是一个对目标服务器比较友好的蜘蛛程序。内置20多个常用或不常用的浏览器标识,可自动处理cookies和网页源信息,轻松绕过服务器限制,智能调整请求间隔,动态调整请求频率,防止干扰目标服务器。此外,Windchime 也是一个非常人性化的工具。它提供了大量的链接提取器和内容提取器,让用户可以根据自己的需要快速配置,甚至可以通过提供起始请求地址来配置自己的爬虫。同时,Windchime 还开放了很多自定义界面,让高级用户可以根据需要自定义爬虫功能。最后,风铃自然也支持分布式和集群功能,让你突破单机环境的束缚,释放你的爬虫能力。可以说风铃几乎可以抓取当前网站中的所有内容。
【声明】请不要将风铃应用于任何可能违反法律和道德限制的工作。请友好使用风铃,遵守蜘蛛协议,不要将风铃用于任何非法用途。如果您选择使用风铃,即表示您遵守本协议。作者不承担因您违反本协议而造成的任何法律风险和损失,一切后果由您自行承担。
快速使用
com.yishuifengxiao.common
crawler
2.1.0
交流群:
(群号624646260)
使用简单
从雅虎财经内容页面中提取电子货币名称
// 创建一个提取属性规则
// 该提取规则标识XPATH表示使用XPATH提取器进行提取,
// 该XPATH提取器的XPATH表达式为 //h1/text() , 该提取提取器的作用顺序是0
ExtractFieldRule extractFieldRule = new ExtractFieldRule(Rule.XPATH, "//h1/text()", "", 0);
// 创建一个提取项
ExtractRule extractRule = new ExtractRule();
extractRule
// 提取项代码,不能为空,同一组提取规则之内每一个提取项的编码必须唯一
.setCode("code")
// 提取项名字,可以不设置
.setName("加密电子货币名字")
// 设置提取属性规则
.setRules(Arrays.asList(extractFieldRule));
// 创建一个风铃虫实例
Crawler crawler = CrawlerBuilder.create()
// 风铃虫的起始链接
.startUrl("https://hk.finance.yahoo.com/cryptocurrencies")
// 风铃虫会将请求到的网页中的URL先全部提取出来
// 然后将匹配链接提取规则的链接过滤出来,放入请求池中
// 请求池中的链接会作为下次抓取请求的种子链接
// 可以以添加多个链接提取规则,多个规则之间是并列(或连接)的关系
// 如果不设置则表示提取链接中所有包含域名关键字(例如此例中的yahoo)的链接放入链接池
// 此例中表示符合该正则表达式的链接都会被提取出来
.addLinkRule(new MatcherRule(Pattern.REGEX, "https://hk.finance.yahoo.com/quote/.+"))
// 内容页地址规则是告诉风铃虫哪些页面是内容页
// 对于复杂情况下,可以与 内容匹配规则 配合使用
// 只有符合内容页规则的页面才会被提取数据
// 对于非内容页,风铃虫不会尝试从中提取数据
// 此例中表示符合该正则表达式的网页都是内容页,风铃虫会从这些页面里提取数据
.contentPageRule(new MatcherRule(Pattern.REGEX, "https://hk.finance.yahoo.com/quote/.+"))
// 风铃虫可以设置多个提取项,这里为了演示只设置了一个提取项
// 增加一个提取项规则
.addExtractRule(extractRule)
// 请求间隔时间
// 如果不设置则使用默认时间10秒,此值是为了防止抓取频率太高被服务器封杀
.interval(3000)// 每次进行爬取时的平均间隔时间,单位为毫秒,
.creatCrawler();
// 启动爬虫实例
crawler.start();
// 这里没有设置信息输出器,表示使用默认的信息输出器
// 默认的信息输出器使用的logback日志输出方法,因此需要看控制台信息
// 由于风铃虫是异步运行的,所以演示时这里加入循环
while (Statu.STOP != crawler.getStatu()) {
try {
Thread.sleep(1000 * 20);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
上面例子的功能是在雅虎财经的内容页面上提取电子货币的名称。用户若想提取其他信息,只需根据规则配置其他提取规则即可。
请注意,以上示例仅用于学习和演示目的。Windchime 用户在抓取网页内容时应严格遵守相关法律规定和目标网站蜘蛛协议。
风铃原理
风铃的原理很简单,主要由资源调度器、网页下载器、链接解析器、内容解析器、信息输出器组成。
它们的作用和功能如下:
链接解析器由一系列链接提取器组成。目前,链接提取器主要支持常规提取。
内容解析器由一系列内容提取器组成。不同的内容提取器功能不同,适用于不同的分析场景,支持重复、循环等多种提取器的多种组合。
以上组件都提供了自定义配置接口,让用户可以根据实际需要自定义配置,满足各种复杂甚至异常场景的需求。
内置的风铃内容提取器包括:
原文抽取器、中文抽取器、常量抽取器、CSS内容抽取器、CSS文本抽取器、邮箱抽取器、号码抽取器、正则抽取器、字符删除抽取器、字符替换抽取器、字符串截取抽取器、XPATH抽取器数组截取...
在提取文本内容时,用户可以自由组合这些提取器来提取他们需要的内容。关于提取器的更多具体用法,请参考内容提取器的使用。
Windchime 内置的浏览器标志为:
Google Chrome(windows版、linux版) Opera浏览器(windows版、MAC版) Firefox(windows版、linux版、MAC版) IE浏览器(IE9、IE11)EDAG Safari浏览器(windows版) , MAC 版)...
抓取js渲染网站
核心代码如下:
Crawler crawler = ...
crawler .setDownloader(new SeleniumDownloader("C:\\Users\\yishui\\Desktop\\geckodriver\\win32.exe",3000L))
分布式支持
核心代码如下:
....
//省略其他代码
....
//创建redis资源调度器
Scheduler scheduler=new RedisScheduler("唯一的名字",redisTemplate)
//创建一个redis资源缓存器
RequestCache requestCache = new RedisRequestCache(redisTemplate);
crawler
.setRequestCache(requestCache) //设置使用redis资源缓存器
.setScheduler(scheduler); //设置使用redis资源调度器
....
//省略其他代码
....
//启动爬虫实例
crawler.start();
状态监控
风铃还提供强大的状态监控和事件监控功能。通过状态监听器和事件监听器,风铃可以让你很好的了解任务的运行情况,实时控制实例运行过程中遇到的各种问题,真正做到洞察运行情况任务,方便操作和维护。
解析模拟器
由于风铃强大的解析功能,规则的定义非常灵活,为了直观地了解配置的规则定义的作用,风铃提供了解析模拟器,让用户快速了解自己设置的规则定义符合预期目标,及时调整规则定义,方便风铃实例的配置。
风铃平台效果演示
配置基本信息
配置爬虫名称、使用线程数、超时停止时间
配置链接爬取信息
配置爬虫的起始种子链接和从网页里提取下一次抓取时的链接的提取规则
配置站点信息
此步骤一般可以省略,但是对于某些会校验cookie和请求头参数的网站,此配置非常有用
提取项目配置
配置需要从网站里提取出来的数据,例如新闻标题和网页正文等信息
属性抽取配置
调用内容提取器进行任意组合,以根据需要提取出需要的数据
属性抽取测试
提前检查提取项的配置是否正确,提取的数据是否符合预期目标
相关资源的链接
文件地址:
API 文档:
官方文件: 查看全部
网页源代码抓取工具(蜘蛛协议风铃虫的原理简单使用提取器的作用)
风铃介绍
风铃是一款轻量级爬虫工具,像风铃一样灵敏,像蜘蛛一样敏捷,任何细小的风和草都可以感知,轻松抓取网络内容。是一个对目标服务器比较友好的蜘蛛程序。内置20多个常用或不常用的浏览器标识,可自动处理cookies和网页源信息,轻松绕过服务器限制,智能调整请求间隔,动态调整请求频率,防止干扰目标服务器。此外,Windchime 也是一个非常人性化的工具。它提供了大量的链接提取器和内容提取器,让用户可以根据自己的需要快速配置,甚至可以通过提供起始请求地址来配置自己的爬虫。同时,Windchime 还开放了很多自定义界面,让高级用户可以根据需要自定义爬虫功能。最后,风铃自然也支持分布式和集群功能,让你突破单机环境的束缚,释放你的爬虫能力。可以说风铃几乎可以抓取当前网站中的所有内容。
【声明】请不要将风铃应用于任何可能违反法律和道德限制的工作。请友好使用风铃,遵守蜘蛛协议,不要将风铃用于任何非法用途。如果您选择使用风铃,即表示您遵守本协议。作者不承担因您违反本协议而造成的任何法律风险和损失,一切后果由您自行承担。
快速使用
com.yishuifengxiao.common
crawler
2.1.0
交流群:

(群号624646260)
使用简单
从雅虎财经内容页面中提取电子货币名称
// 创建一个提取属性规则
// 该提取规则标识XPATH表示使用XPATH提取器进行提取,
// 该XPATH提取器的XPATH表达式为 //h1/text() , 该提取提取器的作用顺序是0
ExtractFieldRule extractFieldRule = new ExtractFieldRule(Rule.XPATH, "//h1/text()", "", 0);
// 创建一个提取项
ExtractRule extractRule = new ExtractRule();
extractRule
// 提取项代码,不能为空,同一组提取规则之内每一个提取项的编码必须唯一
.setCode("code")
// 提取项名字,可以不设置
.setName("加密电子货币名字")
// 设置提取属性规则
.setRules(Arrays.asList(extractFieldRule));
// 创建一个风铃虫实例
Crawler crawler = CrawlerBuilder.create()
// 风铃虫的起始链接
.startUrl("https://hk.finance.yahoo.com/cryptocurrencies";)
// 风铃虫会将请求到的网页中的URL先全部提取出来
// 然后将匹配链接提取规则的链接过滤出来,放入请求池中
// 请求池中的链接会作为下次抓取请求的种子链接
// 可以以添加多个链接提取规则,多个规则之间是并列(或连接)的关系
// 如果不设置则表示提取链接中所有包含域名关键字(例如此例中的yahoo)的链接放入链接池
// 此例中表示符合该正则表达式的链接都会被提取出来
.addLinkRule(new MatcherRule(Pattern.REGEX, "https://hk.finance.yahoo.com/quote/.+";))
// 内容页地址规则是告诉风铃虫哪些页面是内容页
// 对于复杂情况下,可以与 内容匹配规则 配合使用
// 只有符合内容页规则的页面才会被提取数据
// 对于非内容页,风铃虫不会尝试从中提取数据
// 此例中表示符合该正则表达式的网页都是内容页,风铃虫会从这些页面里提取数据
.contentPageRule(new MatcherRule(Pattern.REGEX, "https://hk.finance.yahoo.com/quote/.+";))
// 风铃虫可以设置多个提取项,这里为了演示只设置了一个提取项
// 增加一个提取项规则
.addExtractRule(extractRule)
// 请求间隔时间
// 如果不设置则使用默认时间10秒,此值是为了防止抓取频率太高被服务器封杀
.interval(3000)// 每次进行爬取时的平均间隔时间,单位为毫秒,
.creatCrawler();
// 启动爬虫实例
crawler.start();
// 这里没有设置信息输出器,表示使用默认的信息输出器
// 默认的信息输出器使用的logback日志输出方法,因此需要看控制台信息
// 由于风铃虫是异步运行的,所以演示时这里加入循环
while (Statu.STOP != crawler.getStatu()) {
try {
Thread.sleep(1000 * 20);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
上面例子的功能是在雅虎财经的内容页面上提取电子货币的名称。用户若想提取其他信息,只需根据规则配置其他提取规则即可。
请注意,以上示例仅用于学习和演示目的。Windchime 用户在抓取网页内容时应严格遵守相关法律规定和目标网站蜘蛛协议。
风铃原理

风铃的原理很简单,主要由资源调度器、网页下载器、链接解析器、内容解析器、信息输出器组成。
它们的作用和功能如下:
链接解析器由一系列链接提取器组成。目前,链接提取器主要支持常规提取。
内容解析器由一系列内容提取器组成。不同的内容提取器功能不同,适用于不同的分析场景,支持重复、循环等多种提取器的多种组合。
以上组件都提供了自定义配置接口,让用户可以根据实际需要自定义配置,满足各种复杂甚至异常场景的需求。
内置的风铃内容提取器包括:
原文抽取器、中文抽取器、常量抽取器、CSS内容抽取器、CSS文本抽取器、邮箱抽取器、号码抽取器、正则抽取器、字符删除抽取器、字符替换抽取器、字符串截取抽取器、XPATH抽取器数组截取...
在提取文本内容时,用户可以自由组合这些提取器来提取他们需要的内容。关于提取器的更多具体用法,请参考内容提取器的使用。
Windchime 内置的浏览器标志为:
Google Chrome(windows版、linux版) Opera浏览器(windows版、MAC版) Firefox(windows版、linux版、MAC版) IE浏览器(IE9、IE11)EDAG Safari浏览器(windows版) , MAC 版)...
抓取js渲染网站
核心代码如下:
Crawler crawler = ...
crawler .setDownloader(new SeleniumDownloader("C:\\Users\\yishui\\Desktop\\geckodriver\\win32.exe",3000L))
分布式支持
核心代码如下:
....
//省略其他代码
....
//创建redis资源调度器
Scheduler scheduler=new RedisScheduler("唯一的名字",redisTemplate)
//创建一个redis资源缓存器
RequestCache requestCache = new RedisRequestCache(redisTemplate);
crawler
.setRequestCache(requestCache) //设置使用redis资源缓存器
.setScheduler(scheduler); //设置使用redis资源调度器
....
//省略其他代码
....
//启动爬虫实例
crawler.start();
状态监控
风铃还提供强大的状态监控和事件监控功能。通过状态监听器和事件监听器,风铃可以让你很好的了解任务的运行情况,实时控制实例运行过程中遇到的各种问题,真正做到洞察运行情况任务,方便操作和维护。
解析模拟器
由于风铃强大的解析功能,规则的定义非常灵活,为了直观地了解配置的规则定义的作用,风铃提供了解析模拟器,让用户快速了解自己设置的规则定义符合预期目标,及时调整规则定义,方便风铃实例的配置。
风铃平台效果演示
配置基本信息
配置爬虫名称、使用线程数、超时停止时间

配置链接爬取信息
配置爬虫的起始种子链接和从网页里提取下一次抓取时的链接的提取规则

配置站点信息
此步骤一般可以省略,但是对于某些会校验cookie和请求头参数的网站,此配置非常有用

提取项目配置
配置需要从网站里提取出来的数据,例如新闻标题和网页正文等信息

属性抽取配置
调用内容提取器进行任意组合,以根据需要提取出需要的数据

属性抽取测试
提前检查提取项的配置是否正确,提取的数据是否符合预期目标

相关资源的链接
文件地址:
API 文档:
官方文件:
网页源代码抓取工具(Python模拟浏览器发起请求并解析内容代码:正则的好处)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-07 06:07
用 Python 编写爬虫工具现在已经司空见惯。每个人都希望能够编写一个程序来获取互联网上的一些信息进行数据分析或其他事情。
我们知道,爬虫的原理无非就是下载目标URL的内容并存入内存。这时候它的内容其实就是一堆HTML,然后对HTML内容进行解析,按照自己的想法提取出想要的数据。,所以今天我们主要讲四种在Python中解析网页HTML内容的方法,各有千秋,适合不同的场合使用。
首先,我们随机找了一个网站,然后豆瓣网站闪过我的脑海。好吧,网站毕竟是用Python构建的,所以我们用它作为演示。
我们找到了豆瓣的Python爬虫群主页,如下图。
让我们使用浏览器开发人员工具查看 HTML 代码并找到所需的内容。我们要获取讨论组中的所有帖子标题和链接
通过分析,我们发现其实我们想要的内容就在整个HTML代码的这个区域,那么我们只需要想办法取出这个区域的内容即可。
现在开始编写代码。
1:正则表达式大法
正则表达式通常用于检索和替换符合某种模式的文本,因此我们可以利用这个原理来提取我们想要的信息。
参考以下代码。
代码第6、7行,需要手动指定header的内容,假装这个请求是浏览器请求。否则,豆瓣会将我们的请求视为正常请求并返回 HTTP 418 错误。
在第 7 行中,我们直接使用 requests 库的 get 方法发出请求。获取到内容后,我们需要进行编码格式转换。这也是豆瓣页面渲染机制的问题。一般情况下,可以直接获取requests内容的内容。.
Python模拟浏览器发起请求并解析内容代码:
url = 'https://www.douban.com/group/4 ... aders =
{"User-Agent":"Mozilla/5.0 (Macintosh;
Intel Mac OS X 10.14; rv:71.0) Gecko/20100101
Firefox/71.0"}response = requests.get(url=url,headers=headers).
content.decode('utf-8')
正则化的优点是写起来麻烦,不容易理解,但是匹配效率很高。但是,在如今现成的HTMl内容解析库太多之后,我个人不建议使用正则化来手动匹配内容,费时费力。.
主要分析代码:
<p>re_div = r'[\W|\w]+'
pattern = re.compile(re_div)content = re.findall
(pattern, str(response))re_link = r'<a .*?>(.*?)</a>'mm
= re.findall(re_link, str(content), re.S|re.M)urls=
re.findall(r" 查看全部
网页源代码抓取工具(Python模拟浏览器发起请求并解析内容代码:正则的好处)
用 Python 编写爬虫工具现在已经司空见惯。每个人都希望能够编写一个程序来获取互联网上的一些信息进行数据分析或其他事情。

我们知道,爬虫的原理无非就是下载目标URL的内容并存入内存。这时候它的内容其实就是一堆HTML,然后对HTML内容进行解析,按照自己的想法提取出想要的数据。,所以今天我们主要讲四种在Python中解析网页HTML内容的方法,各有千秋,适合不同的场合使用。
首先,我们随机找了一个网站,然后豆瓣网站闪过我的脑海。好吧,网站毕竟是用Python构建的,所以我们用它作为演示。
我们找到了豆瓣的Python爬虫群主页,如下图。
让我们使用浏览器开发人员工具查看 HTML 代码并找到所需的内容。我们要获取讨论组中的所有帖子标题和链接
通过分析,我们发现其实我们想要的内容就在整个HTML代码的这个区域,那么我们只需要想办法取出这个区域的内容即可。
现在开始编写代码。
1:正则表达式大法
正则表达式通常用于检索和替换符合某种模式的文本,因此我们可以利用这个原理来提取我们想要的信息。
参考以下代码。

代码第6、7行,需要手动指定header的内容,假装这个请求是浏览器请求。否则,豆瓣会将我们的请求视为正常请求并返回 HTTP 418 错误。
在第 7 行中,我们直接使用 requests 库的 get 方法发出请求。获取到内容后,我们需要进行编码格式转换。这也是豆瓣页面渲染机制的问题。一般情况下,可以直接获取requests内容的内容。.
Python模拟浏览器发起请求并解析内容代码:
url = 'https://www.douban.com/group/4 ... aders =
{"User-Agent":"Mozilla/5.0 (Macintosh;
Intel Mac OS X 10.14; rv:71.0) Gecko/20100101
Firefox/71.0"}response = requests.get(url=url,headers=headers).
content.decode('utf-8')
正则化的优点是写起来麻烦,不容易理解,但是匹配效率很高。但是,在如今现成的HTMl内容解析库太多之后,我个人不建议使用正则化来手动匹配内容,费时费力。.
主要分析代码:
<p>re_div = r'[\W|\w]+'
pattern = re.compile(re_div)content = re.findall
(pattern, str(response))re_link = r'<a .*?>(.*?)</a>'mm
= re.findall(re_link, str(content), re.S|re.M)urls=
re.findall(r"
网页源代码抓取工具(如何能够获取到指定网页的源码呢?的小工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-06 20:18
在C#中,我们如何获取指定网页的源代码?比如我们想做一个带有文章抓取功能的小工具。这样的功能是必不可少的。小编做了一个可以获取网页源代码的小工具,并分享了主要代码,希望能给新手一点帮助。
首先看下面的代码:
private string GetWebContent(string url)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
HttpWebResponse respone = (HttpWebResponse)request.GetResponse();
Stream stream = respone.GetResponseStream();
Encoding encoding = Encoding.Default;
if (this.ddlEncoding.SelectedItem != null && this.ddlEncoding.SelectedItem.ToString() != "" && this.ddlEncoding.SelectedItem.ToString() != "Default")
{
encoding = Encoding.GetEncoding(this.ddlEncoding.SelectedItem.ToString());
}
StreamReader streamReader = new StreamReader(stream, encoding);
return streamReader.ReadToEnd();
}
上述方法的作用是将传入参数(url地址)的网页源码返回给调用者,但这只是全部源码,我们不能去掉网站标题, 网站body 元素等,这些元素需要正确读取,我们还要进行下一步。
Encoding encoding = Encoding.Default;
if (this.ddlEncoding.SelectedItem != null && this.ddlEncoding.SelectedItem.ToString() != "" && this.ddlEncoding.SelectedItem.ToString() != "Default")
{
encoding = Encoding.GetEncoding(this.ddlEncoding.SelectedItem.ToString());
}
主要用于处理网站的不同编码。不同的 网站 有不同的编码。如果我们在读取时使用了错误的编码,返回结果中的所有汉字都会变成乱码。因此,提供了一个功能供用户选择编码。如果源代码有误,可以使用其他编码重试。ddlEncoding(ComboBox 控件)提供所有 网站 编码选项。
下面是处理GetWebContent(stringurl)方法正确读取网站的title和body的元素的结果。
private void button1_Click(object sender, EventArgs e)
{
try
{
if (this.txtUrl.Text.Trim().Length == 0)
{
("请输入主入口地址!");
}
else
{
//这里获取GetWebContent方法的结果
string webContent = GetWebContent(this.txtUrl.Text.Trim());
//声明一个WebBrowser
WebBrowser webBrowser = new WebBrowser();
webBrowser.Navigate("about:blank");
//将GetWebContent方法返回的结果转化为HtmlDocument,就可以正确处理网页中的元素了。
HtmlDocument htmlDoc = webBrowser.Document.OpenNew(true);
htmlDoc.Write(webContent);
//获取网页中Body中的Html代码
string outerHtml = htmlDoc.Body.OuterHtml;
//获取网页的标题
string outerTitle=htmlDoc.Title;
this.txtDocumentTitle.Text = outerTitle;
this.txtDocumentConent.Text = outerHtml;
}
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
}
通过以上两步,我们就可以正确读取指定网页中的元素了。当然,在实际处理中,我们可能会遇到很多问题。比如我们需要获取需要用户名的网站的源码。与密码认证相同,但足以处理一般网页。我们也可以从得到的源代码中解析出A标签,然后根据解析出的A标签继续读取源代码,就可以实现自动爬取的功能。 查看全部
网页源代码抓取工具(如何能够获取到指定网页的源码呢?的小工具)
在C#中,我们如何获取指定网页的源代码?比如我们想做一个带有文章抓取功能的小工具。这样的功能是必不可少的。小编做了一个可以获取网页源代码的小工具,并分享了主要代码,希望能给新手一点帮助。
首先看下面的代码:
private string GetWebContent(string url)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
HttpWebResponse respone = (HttpWebResponse)request.GetResponse();
Stream stream = respone.GetResponseStream();
Encoding encoding = Encoding.Default;
if (this.ddlEncoding.SelectedItem != null && this.ddlEncoding.SelectedItem.ToString() != "" && this.ddlEncoding.SelectedItem.ToString() != "Default")
{
encoding = Encoding.GetEncoding(this.ddlEncoding.SelectedItem.ToString());
}
StreamReader streamReader = new StreamReader(stream, encoding);
return streamReader.ReadToEnd();
}
上述方法的作用是将传入参数(url地址)的网页源码返回给调用者,但这只是全部源码,我们不能去掉网站标题, 网站body 元素等,这些元素需要正确读取,我们还要进行下一步。
Encoding encoding = Encoding.Default;
if (this.ddlEncoding.SelectedItem != null && this.ddlEncoding.SelectedItem.ToString() != "" && this.ddlEncoding.SelectedItem.ToString() != "Default")
{
encoding = Encoding.GetEncoding(this.ddlEncoding.SelectedItem.ToString());
}
主要用于处理网站的不同编码。不同的 网站 有不同的编码。如果我们在读取时使用了错误的编码,返回结果中的所有汉字都会变成乱码。因此,提供了一个功能供用户选择编码。如果源代码有误,可以使用其他编码重试。ddlEncoding(ComboBox 控件)提供所有 网站 编码选项。
下面是处理GetWebContent(stringurl)方法正确读取网站的title和body的元素的结果。
private void button1_Click(object sender, EventArgs e)
{
try
{
if (this.txtUrl.Text.Trim().Length == 0)
{
("请输入主入口地址!");
}
else
{
//这里获取GetWebContent方法的结果
string webContent = GetWebContent(this.txtUrl.Text.Trim());
//声明一个WebBrowser
WebBrowser webBrowser = new WebBrowser();
webBrowser.Navigate("about:blank");
//将GetWebContent方法返回的结果转化为HtmlDocument,就可以正确处理网页中的元素了。
HtmlDocument htmlDoc = webBrowser.Document.OpenNew(true);
htmlDoc.Write(webContent);
//获取网页中Body中的Html代码
string outerHtml = htmlDoc.Body.OuterHtml;
//获取网页的标题
string outerTitle=htmlDoc.Title;
this.txtDocumentTitle.Text = outerTitle;
this.txtDocumentConent.Text = outerHtml;
}
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
}
通过以上两步,我们就可以正确读取指定网页中的元素了。当然,在实际处理中,我们可能会遇到很多问题。比如我们需要获取需要用户名的网站的源码。与密码认证相同,但足以处理一般网页。我们也可以从得到的源代码中解析出A标签,然后根据解析出的A标签继续读取源代码,就可以实现自动爬取的功能。
网页源代码抓取工具(网页分析(Chrome开发者工具)对网页抓包分析的本质与内涵)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-10-04 11:14
在这个文章中,我们将尝试使用一个直观的网页分析工具(Chrome Developer Tools)来抓取和分析网页,以更深入地了解网络爬虫的本质和内涵
1、测试环境
浏览器:Chrome 浏览器
浏览器版本:67.0.3396.99(正式版)(32位)
Web 分析工具:开发人员工具
2、网页分析(1)网页源码分析
我们知道网页分为静态网页和动态网页。很多人误以为静态网页就是没有动态效果的网页。事实上,这种说法是错误的。
另外,很多动态网站采用异步加载技术(Ajax)。这就是捕获的源代码和网站显示的源代码不一致的原因。至于如何抓取动态网页,这里有两种方法:
下面以京东产品为例,分析一下如何通过Chrome抓包。首先,我们打开某个产品的主页。
/.html
到网页空白处点击鼠标右键,选择查看网页源码(或使用快捷键Ctrl+U直接打开)
请注意网站的最原创源码是通过查看网页源码获得的,也就是我们平时抓取的源码
再次进入网页空白区域,点击鼠标右键,选择勾选(或使用快捷键Ctrl+Shift+I/F12直接打开)
请注意,检查得到的源代码是Ajax加载并JavaScript渲染的源代码,即当前网站显示内容的源代码
经过比较,我们可以发现两者的内容是不同的。这是异步加载技术(Ajax)的典型例子
目前,至少京东产品的价格是通过异步加载生成的。下面介绍三种判断网页中某个内容是否是动态生成的方法:
(2)网页抓取分析
下面以京东产品为例进行说明。打开一个产品的首页,尝试抓取动态加载的产品价格数据。
/.html
使用快捷键Ctrl+Shift+I或F12打开开发者工具,然后选择Network选项卡进行抓包分析
这时候按快捷键F5刷新页面,可以看到开发者工具里面有各种包,我们用Filter过滤包
首先我们选择Doc,可以看到列表中只出现了一个包
一般来说,这是浏览器收到的第一个包,获取请求的原创源码网站
点击Header查看其头部参数设置
单击响应以查看返回的源代码。不难发现,其实和查看网页源码返回的信息是一样的。
让我们回到下面的话题。对于动态加载的数据包的分析,我们主要看XHR和JS选项卡。
选择JS进行过滤,发现列表中有很多包。经过分析,我们过滤掉下图中标记的包
这个包返回的是价格信息,但是经过仔细分析,发现这些价格不属于当前产品,而是与产品相关。
但是怎么说这个包还是跟价格有关的,我们先来看看这个包的请求地址。
https://p.3.cn/prices/mgets%3F ... em-pc
过滤掉回调等不需要的参数,得到一个简单有效的URL
https://p.3.cn/prices/mgets%3F ... 49638
直接用浏览器打开网址,可以看到返回的JSON数据确实收录价格信息(可惜是其他商品的价格)
分析URL的参数,我们可以推断skuId应该是每个产品的唯一符号。那么在哪里可以找到我们需要的产品的skuId呢?
实际上,SKU是物流、运输等行业常用的缩写。它的全称是Stock Keeping Unit,是库存计量的基本单位。每个产品都有一个独特的 SKU
回顾我们刚刚进入的产品主页,/.html
不是隐藏了当前产品的唯一编号标识()吗?试一试!
果然,我们可以得到产品价格的完整网址,/prices/mgets?skuIds=
我们可以直接访问网站获取当前产品的价格信息
其实我们也可以对URL进行适当的泛化,以适应京东所有商品的价格爬取
很简单,把skuIds作为参数独立分开,{ID}
通过广义的URL,理论上只要能获取到商品的skuId,就可以访问到对应商品的价格 查看全部
网页源代码抓取工具(网页分析(Chrome开发者工具)对网页抓包分析的本质与内涵)
在这个文章中,我们将尝试使用一个直观的网页分析工具(Chrome Developer Tools)来抓取和分析网页,以更深入地了解网络爬虫的本质和内涵
1、测试环境
浏览器:Chrome 浏览器
浏览器版本:67.0.3396.99(正式版)(32位)
Web 分析工具:开发人员工具
2、网页分析(1)网页源码分析
我们知道网页分为静态网页和动态网页。很多人误以为静态网页就是没有动态效果的网页。事实上,这种说法是错误的。
另外,很多动态网站采用异步加载技术(Ajax)。这就是捕获的源代码和网站显示的源代码不一致的原因。至于如何抓取动态网页,这里有两种方法:
下面以京东产品为例,分析一下如何通过Chrome抓包。首先,我们打开某个产品的主页。
/.html
到网页空白处点击鼠标右键,选择查看网页源码(或使用快捷键Ctrl+U直接打开)
请注意网站的最原创源码是通过查看网页源码获得的,也就是我们平时抓取的源码
再次进入网页空白区域,点击鼠标右键,选择勾选(或使用快捷键Ctrl+Shift+I/F12直接打开)
请注意,检查得到的源代码是Ajax加载并JavaScript渲染的源代码,即当前网站显示内容的源代码
经过比较,我们可以发现两者的内容是不同的。这是异步加载技术(Ajax)的典型例子
目前,至少京东产品的价格是通过异步加载生成的。下面介绍三种判断网页中某个内容是否是动态生成的方法:
(2)网页抓取分析
下面以京东产品为例进行说明。打开一个产品的首页,尝试抓取动态加载的产品价格数据。
/.html
使用快捷键Ctrl+Shift+I或F12打开开发者工具,然后选择Network选项卡进行抓包分析
这时候按快捷键F5刷新页面,可以看到开发者工具里面有各种包,我们用Filter过滤包
首先我们选择Doc,可以看到列表中只出现了一个包
一般来说,这是浏览器收到的第一个包,获取请求的原创源码网站
点击Header查看其头部参数设置
单击响应以查看返回的源代码。不难发现,其实和查看网页源码返回的信息是一样的。
让我们回到下面的话题。对于动态加载的数据包的分析,我们主要看XHR和JS选项卡。
选择JS进行过滤,发现列表中有很多包。经过分析,我们过滤掉下图中标记的包
这个包返回的是价格信息,但是经过仔细分析,发现这些价格不属于当前产品,而是与产品相关。
但是怎么说这个包还是跟价格有关的,我们先来看看这个包的请求地址。
https://p.3.cn/prices/mgets%3F ... em-pc
过滤掉回调等不需要的参数,得到一个简单有效的URL
https://p.3.cn/prices/mgets%3F ... 49638
直接用浏览器打开网址,可以看到返回的JSON数据确实收录价格信息(可惜是其他商品的价格)

分析URL的参数,我们可以推断skuId应该是每个产品的唯一符号。那么在哪里可以找到我们需要的产品的skuId呢?
实际上,SKU是物流、运输等行业常用的缩写。它的全称是Stock Keeping Unit,是库存计量的基本单位。每个产品都有一个独特的 SKU
回顾我们刚刚进入的产品主页,/.html
不是隐藏了当前产品的唯一编号标识()吗?试一试!
果然,我们可以得到产品价格的完整网址,/prices/mgets?skuIds=
我们可以直接访问网站获取当前产品的价格信息

其实我们也可以对URL进行适当的泛化,以适应京东所有商品的价格爬取
很简单,把skuIds作为参数独立分开,{ID}
通过广义的URL,理论上只要能获取到商品的skuId,就可以访问到对应商品的价格
网页源代码抓取工具(易语言如何读取网页源码_被单击事件子程序下的讲解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2021-10-04 08:11
信息爆炸时代也引领着软件行业的不断变革。目前,对软件的需求不再是从单一面走向复杂,不仅仅是考虑某一方面的需求,而是多方面需求的综合。那么,一郎是如何读取网页源代码的呢?接下来就让MovieClip为大家讲解一下吧!
1、首先运行“易语言”主程序,弹出“新建项目对话框”,选择“Windows Window程序”,点击“确定”按钮,进入“Windows Window程序设计界面”。如下所示:
2、接下来拖放一个标签组件,两个编辑框组件,一个按钮组件,一个分组框组件。将它们放置在合适的位置,并将窗口的宽度和高度设置为合适的大小。确保橱窗简洁美观。如下所示:
3、界面调整完成后,将窗口标题、标签标题、分组框标题、按钮标题修改为对应的内容,并对编辑框和按钮组件进行标准化命名。准备编写程序代码。
4、 下一步就是写代码了。在“_button_get source code_clicked”事件子程序下,编写如下代码[编辑框_网页源代码. content = to text(HTTP读取文件(编辑框)_URL.Content))】如下图:
5、代码写好后,进入调试阶段。按“F5”快捷键运行程序。我们以百度体验的网址为例,然后点击“获取源码”按钮,等待程序执行。如图:
6、从网页源码编辑框得到的反馈结果分析,如果源码中有乱码,一般是编码方式有问题。这时候我们需要转码才能看到正常的代码。然后,我们的代码也需要做一些小的改动。如图:
7、 重新测试程序。从网页源代码编辑框的反馈结果可以看出,本次读取的网页源代码是正确的。因此,MovieClip在这里提醒大家,在编写软件或程序时,一定要反复调试。至此,易语言阅读网页源代码的讲解结束。谢谢大家阅读。
总结:以上是通过易语言获取网页源代码的相关步骤内容。感谢您的阅读和学习。 查看全部
网页源代码抓取工具(易语言如何读取网页源码_被单击事件子程序下的讲解)
信息爆炸时代也引领着软件行业的不断变革。目前,对软件的需求不再是从单一面走向复杂,不仅仅是考虑某一方面的需求,而是多方面需求的综合。那么,一郎是如何读取网页源代码的呢?接下来就让MovieClip为大家讲解一下吧!
1、首先运行“易语言”主程序,弹出“新建项目对话框”,选择“Windows Window程序”,点击“确定”按钮,进入“Windows Window程序设计界面”。如下所示:

2、接下来拖放一个标签组件,两个编辑框组件,一个按钮组件,一个分组框组件。将它们放置在合适的位置,并将窗口的宽度和高度设置为合适的大小。确保橱窗简洁美观。如下所示:

3、界面调整完成后,将窗口标题、标签标题、分组框标题、按钮标题修改为对应的内容,并对编辑框和按钮组件进行标准化命名。准备编写程序代码。

4、 下一步就是写代码了。在“_button_get source code_clicked”事件子程序下,编写如下代码[编辑框_网页源代码. content = to text(HTTP读取文件(编辑框)_URL.Content))】如下图:

5、代码写好后,进入调试阶段。按“F5”快捷键运行程序。我们以百度体验的网址为例,然后点击“获取源码”按钮,等待程序执行。如图:

6、从网页源码编辑框得到的反馈结果分析,如果源码中有乱码,一般是编码方式有问题。这时候我们需要转码才能看到正常的代码。然后,我们的代码也需要做一些小的改动。如图:

7、 重新测试程序。从网页源代码编辑框的反馈结果可以看出,本次读取的网页源代码是正确的。因此,MovieClip在这里提醒大家,在编写软件或程序时,一定要反复调试。至此,易语言阅读网页源代码的讲解结束。谢谢大家阅读。

总结:以上是通过易语言获取网页源代码的相关步骤内容。感谢您的阅读和学习。
网页源代码抓取工具( WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2021-10-04 08:03
WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
我要分享的工具是一个Chrome插件,叫做:Web Scraper,这是一个Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以将其用作爬虫工具。
也是因为最近在整理36氪文章的一些标签,打算看看其他网站风投相关的标准,所以找了一家公司,名字叫:“Keiu Data” 网站,它提供的一套“行业系统”标签很有参考价值,所以我想抓取页面上的数据,集成到我们自己的标签库中,如红字部分所示下图:
如果是规则中显示的数据,也可以用鼠标选中并复制粘贴,但还是需要想办法将其嵌入到页面中。这时候想起之前安装过Web Scraper,就试了一下。使用起来相当方便,采集效率一下子提高了。也给大家安利~
一年前在一个三班的公开课上看到了Chrome插件Web Scraper。号称是不懂编程也能实现爬虫爬虫的黑科技,但是在三类的官网上好像找不到。你可以百度:“三课爬虫”还是可以搜索到的。名字叫《人人都能学的数据爬虫类》,不过好像要收费100元。我觉得这个东西可以看网上的文章,比如我的文章~
简单的说,Web Scraper是一个基于Chrome的网页元素解析器,可以通过可视化的点击操作,实现自定义区域的数据/元素提取。同时,它还提供了定时自动提取功能,使用该功能可以作为一个简单的爬虫工具。
这里顺便解释一下网页提取器爬虫和真正写代码爬虫的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它首先让您定义要在页面上抓取的元素。,以及抓取哪些页面,然后让机器代人操作;而如果你用Python写爬虫,更多的是用网页请求命令下载整个网页,然后用代码解析HTML页面元素,提取你想要的内容,然后不断循环。相比之下,使用代码会更灵活,但解析的成本会更高。如果是简单的页面内容提取,我也推荐使用Web Scraper。
关于Web Scraper的具体安装过程以及完整功能的使用方法,今天的文章不再赘述。一是我只用了自己需要的部分,二是市面上的Web Scraper教程太多了,你可以自己找。
这里只是一个实际的过程,给大家简单介绍一下我的使用方法。
第一步是创建站点地图
打开Chrome浏览器,按F12调出开发者工具。单击最后一个选项卡上的 Web Scraper 后,选择“创建站点地图”菜单并单击“创建站点地图”选项。
首先输入你要爬取的网站 URL,以及你自定义的爬取任务的名称。比如我取的名字是:xiniulevel,网址是:
第二步,创建抓取节点
我要抓取的是一级标签和二级标签,所以先点击进入我刚刚创建的Sitemap,然后点击“添加新选择器”进入抓取节点选择器配置页面,点击“选择”按钮。当你会看到一个浮动层
此时,当您将鼠标移入网页时,它会自动以绿色突出显示您悬停的某个位置。这时候你可以先点击一个你想选择的方块,你会发现方块变成了红色。如果要选择同一层级的所有块,可以继续点击相邻的下一个块,工具会默认选中所有同层级的块,如下图:
我们会发现下面浮动窗口的文本输入框自动填充了块的XPATH路径,然后点击“完成选择!” 结束选择,浮动框消失,选中的XPATH自动填入下面的Selector行。另外,一定要选择“Multiple”来声明要选择多个块。最后,单击保存选择器按钮结束。
第三步,获取元素值
完成Selector的创建后,回到上一页,你会发现Selector表多了一行。然后就可以直接点击Action中的Data preview,查看所有想要获取的元素值。
上图所示的部分是我添加了两个Selector,一个主标签和一个次标签的情况。点击数据预览的弹窗内容其实就是我想要的,复制到EXCEL就好了,不需要太复杂。自动抓取处理。
以上是对Web Scraper的使用过程的简单介绍。当然,我的使用并不是完全高效,因为每次想要获取二级标签时,都需要先手动切换一级标签,然后再执行抓取指令。应该有更好的方法,但对我来说已经足够了。本文文章主要想和大家普及一下这个工具。这不是教程。更多功能根据自己的需要去探索吧~
怎么样,对你有帮助吗? 查看全部
网页源代码抓取工具(
WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)

我要分享的工具是一个Chrome插件,叫做:Web Scraper,这是一个Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以将其用作爬虫工具。
也是因为最近在整理36氪文章的一些标签,打算看看其他网站风投相关的标准,所以找了一家公司,名字叫:“Keiu Data” 网站,它提供的一套“行业系统”标签很有参考价值,所以我想抓取页面上的数据,集成到我们自己的标签库中,如红字部分所示下图:

如果是规则中显示的数据,也可以用鼠标选中并复制粘贴,但还是需要想办法将其嵌入到页面中。这时候想起之前安装过Web Scraper,就试了一下。使用起来相当方便,采集效率一下子提高了。也给大家安利~
一年前在一个三班的公开课上看到了Chrome插件Web Scraper。号称是不懂编程也能实现爬虫爬虫的黑科技,但是在三类的官网上好像找不到。你可以百度:“三课爬虫”还是可以搜索到的。名字叫《人人都能学的数据爬虫类》,不过好像要收费100元。我觉得这个东西可以看网上的文章,比如我的文章~
简单的说,Web Scraper是一个基于Chrome的网页元素解析器,可以通过可视化的点击操作,实现自定义区域的数据/元素提取。同时,它还提供了定时自动提取功能,使用该功能可以作为一个简单的爬虫工具。
这里顺便解释一下网页提取器爬虫和真正写代码爬虫的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它首先让您定义要在页面上抓取的元素。,以及抓取哪些页面,然后让机器代人操作;而如果你用Python写爬虫,更多的是用网页请求命令下载整个网页,然后用代码解析HTML页面元素,提取你想要的内容,然后不断循环。相比之下,使用代码会更灵活,但解析的成本会更高。如果是简单的页面内容提取,我也推荐使用Web Scraper。
关于Web Scraper的具体安装过程以及完整功能的使用方法,今天的文章不再赘述。一是我只用了自己需要的部分,二是市面上的Web Scraper教程太多了,你可以自己找。
这里只是一个实际的过程,给大家简单介绍一下我的使用方法。
第一步是创建站点地图
打开Chrome浏览器,按F12调出开发者工具。单击最后一个选项卡上的 Web Scraper 后,选择“创建站点地图”菜单并单击“创建站点地图”选项。

首先输入你要爬取的网站 URL,以及你自定义的爬取任务的名称。比如我取的名字是:xiniulevel,网址是:
第二步,创建抓取节点
我要抓取的是一级标签和二级标签,所以先点击进入我刚刚创建的Sitemap,然后点击“添加新选择器”进入抓取节点选择器配置页面,点击“选择”按钮。当你会看到一个浮动层

此时,当您将鼠标移入网页时,它会自动以绿色突出显示您悬停的某个位置。这时候你可以先点击一个你想选择的方块,你会发现方块变成了红色。如果要选择同一层级的所有块,可以继续点击相邻的下一个块,工具会默认选中所有同层级的块,如下图:

我们会发现下面浮动窗口的文本输入框自动填充了块的XPATH路径,然后点击“完成选择!” 结束选择,浮动框消失,选中的XPATH自动填入下面的Selector行。另外,一定要选择“Multiple”来声明要选择多个块。最后,单击保存选择器按钮结束。

第三步,获取元素值
完成Selector的创建后,回到上一页,你会发现Selector表多了一行。然后就可以直接点击Action中的Data preview,查看所有想要获取的元素值。


上图所示的部分是我添加了两个Selector,一个主标签和一个次标签的情况。点击数据预览的弹窗内容其实就是我想要的,复制到EXCEL就好了,不需要太复杂。自动抓取处理。
以上是对Web Scraper的使用过程的简单介绍。当然,我的使用并不是完全高效,因为每次想要获取二级标签时,都需要先手动切换一级标签,然后再执行抓取指令。应该有更好的方法,但对我来说已经足够了。本文文章主要想和大家普及一下这个工具。这不是教程。更多功能根据自己的需要去探索吧~
怎么样,对你有帮助吗?
网页源代码抓取工具(如何通过Chrome开发者工具寻找一个网站上特定数据的抓取方式)
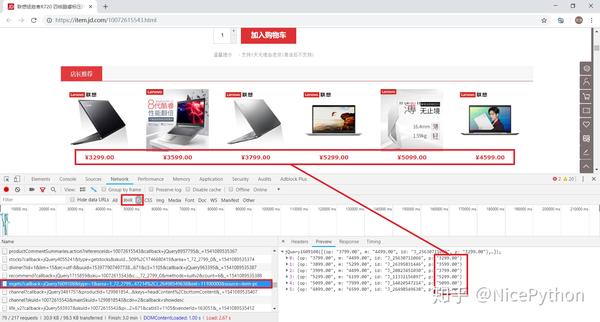
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-04 05:11
网上爬虫教程太多了。在知乎上搜索,我猜你能找到不少于100个。每个人都乐于从互联网上抢一个接一个网站。但是只要对方网站更新,很可能文章里面的方法就失效了。
每个网站捕获的代码不同,但背后的原理是一样的。对于大多数 网站 来说,爬行程序就是这样。今天的文章不讲什么具体的网站爬取,只讲一个共同点:
如何使用 Chrome 开发者工具找到一种方法来捕获 网站 上的特定数据。
(我这里演示的是Mac上英文版的Chrome,中文版Windows的使用方法是一样的。)
> 查看网页源代码
在网页上右击选择“查看页面源代码”,在新标签页中会显示该URL对应的HTML代码文本。
此功能不被视为“开发人员工具”的一部分,但它也非常常用。此内容与您通过代码直接向此 URL 发送 GET 请求所获得的结果相同(无论是否存在权限问题)。如果你能在这个源码页上找到你想要的内容,就可以按照它的规则,通过regular、bs4、xpath等方法提取文本中的数据。
但是,对于很多异步加载数据的网站来说,你在这个页面上找不到你想要的。或者因为权限和验证的限制,在代码中得到的结果与页面显示不一致。在这些情况下,我们需要更强大的开发人员工具来提供帮助。
> 元素
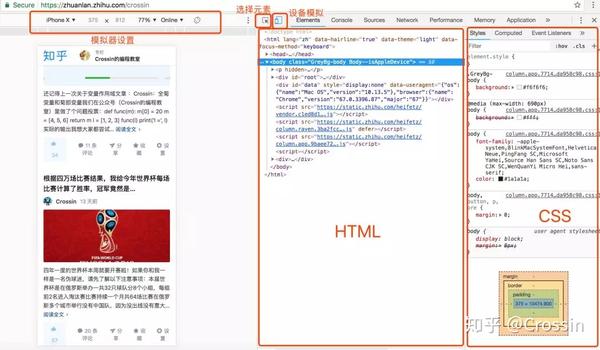
在网页上右击选择“Inspect”,进入Chrome Developer Tools的元素选择器。在工具中是元素选项卡。
元素有几个功能:
从 Elements 工具中定位数据比直接在源代码中搜索更方便,因为您可以清楚地看到它所在的元素结构。但这里特别提醒:
Elements 中看到的代码不等于请求 URL 的返回值。
是浏览器渲染的网页最终效果,包括异步请求数据,以及浏览器自身对代码的优化改动。因此,您无法根据 Elements 中显示的结构获取元素。在这种情况下,您可能无法获得正确的结果。
> 网络
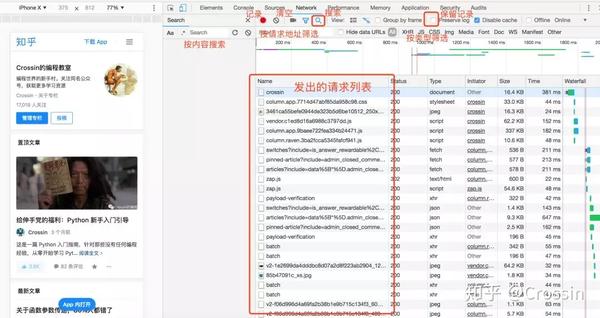
在开发者工具中选择Network选项卡,进入网络监控功能,也就是常说的“抓包”。
这是爬虫最重要的功能。主要解决两个问题:
捕捉什么
抓住的是如何找到通过异步请求获取的数据的来源。
打开网络页面,打开记录,刷新页面,可以看到所有发送的请求,包括数据、JS、CSS、图片、文档等,都会显示出来。您可以从请求列表中找到您的目标。
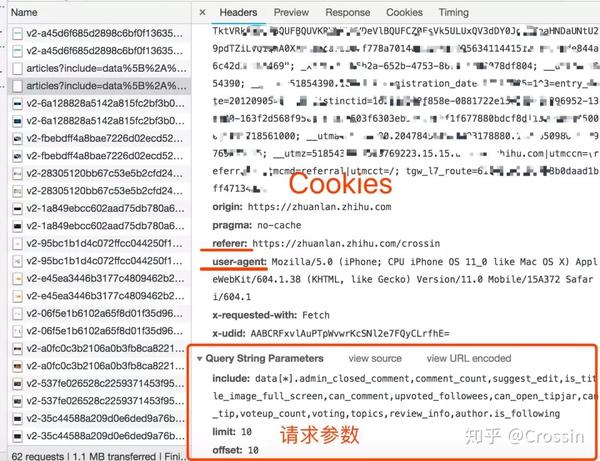
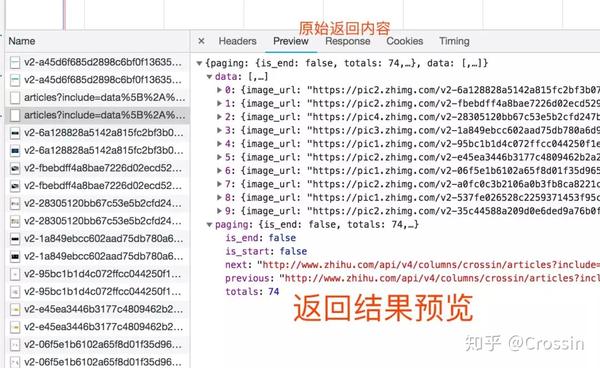
一个一个地找到它们会很痛苦。分享几个小贴士:
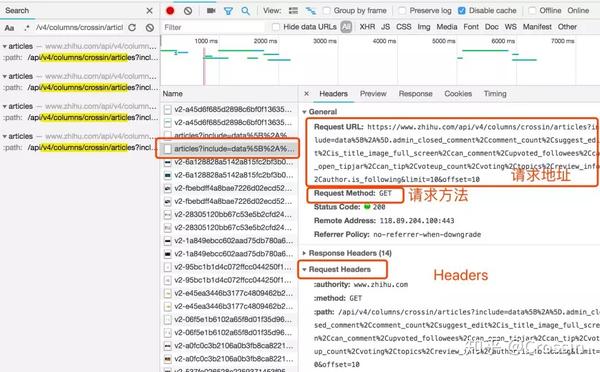
找到收录数据的请求后,下一步就是使用程序获取数据。这时候就是第二个问题:怎么抓。
不是所有的URL都可以通过GET直接获取(相当于在浏览器中打开地址),通常要考虑这些:
请求方法是 GET 或 POST。请求附加的参数数据。GET 和 POST 有不同的参数传递方法。标头信息。常用的有user-agent、host、referer、cookie等,其中cookie是用来标识请求者身份的关键信息。对于需要登录的网站来说,这个值是必不可少的。网站 经常使用其他几个项目来标识请求的合法性。相同的请求在浏览器中可用,但在程序中不可用。大多数标题信息是不正确的。您可以将此信息从 Chrome 复制到程序中以绕过对方的限制。
单击列表中的特定请求,可以找到上述所有信息。
找到正确的请求,设置正确的方法,传递正确的参数和头信息,网站上的大部分信息都可以做到。
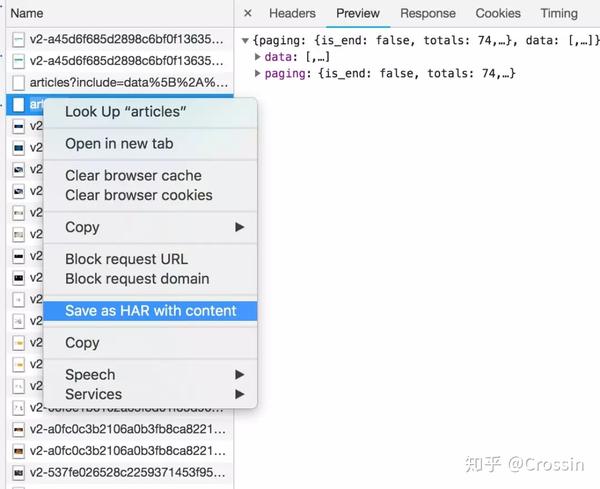
网络还有一个功能:右键单击列表,选择“另存为带有内容的HAR”,然后保存到文件中。该文件收录列表中的所有请求参数和返回值信息,以便您查找和分析。(在实际操作中发现直接搜索往往无效,只能保存到文件后才能搜索)
除了 Elements 和 Network 之外,开发者工具中还有一些功能,例如:
Sources,查看资源列表,调试JS。
控制台,显示页面的错误和输出,可以执行JS代码。很多网站都会在这里放招聘彩蛋(找更知名的网站试试)。
但这些功能与爬虫关系不大。如果开发网站,优化网站速度,还需要处理其他功能。这里不多说。
综上所述,其实你应该记住以下几点:
在“查看源代码”中可以看到的数据,可以通过程序直接请求当前的URL来获取。Elements 中的 HTML 代码不等于请求的返回值,只能作为辅助。使用网络中的内容关键字搜索,或将其保存为HAR文件后搜索以找到收录数据的实际请求。查看请求的具体信息,包括方法、头部和参数,并复制到程序中使用。
了解了这些步骤后,网上的资料大部分都可以得到了,说“解决了一半”不是头条党。
当然,说起来容易些。如果你想精通,还有很多细节需要考虑,你需要不断练习。但是拿这些点来看看各种爬虫案例,思路会更清晰。
如果你想要更详细的爬虫讲解和指导,可以看看我们的《爬虫实战》课程,也有零基础入门课程。
对课程详情公众号回复码的操作(Crossin的编程课堂)
====
其他 文章 和回答:
欢迎搜索关注:Crossin的编程课堂 查看全部
网页源代码抓取工具(如何通过Chrome开发者工具寻找一个网站上特定数据的抓取方式)
网上爬虫教程太多了。在知乎上搜索,我猜你能找到不少于100个。每个人都乐于从互联网上抢一个接一个网站。但是只要对方网站更新,很可能文章里面的方法就失效了。
每个网站捕获的代码不同,但背后的原理是一样的。对于大多数 网站 来说,爬行程序就是这样。今天的文章不讲什么具体的网站爬取,只讲一个共同点:
如何使用 Chrome 开发者工具找到一种方法来捕获 网站 上的特定数据。
(我这里演示的是Mac上英文版的Chrome,中文版Windows的使用方法是一样的。)
> 查看网页源代码
在网页上右击选择“查看页面源代码”,在新标签页中会显示该URL对应的HTML代码文本。
此功能不被视为“开发人员工具”的一部分,但它也非常常用。此内容与您通过代码直接向此 URL 发送 GET 请求所获得的结果相同(无论是否存在权限问题)。如果你能在这个源码页上找到你想要的内容,就可以按照它的规则,通过regular、bs4、xpath等方法提取文本中的数据。
但是,对于很多异步加载数据的网站来说,你在这个页面上找不到你想要的。或者因为权限和验证的限制,在代码中得到的结果与页面显示不一致。在这些情况下,我们需要更强大的开发人员工具来提供帮助。
> 元素
在网页上右击选择“Inspect”,进入Chrome Developer Tools的元素选择器。在工具中是元素选项卡。
元素有几个功能:
从 Elements 工具中定位数据比直接在源代码中搜索更方便,因为您可以清楚地看到它所在的元素结构。但这里特别提醒:
Elements 中看到的代码不等于请求 URL 的返回值。
是浏览器渲染的网页最终效果,包括异步请求数据,以及浏览器自身对代码的优化改动。因此,您无法根据 Elements 中显示的结构获取元素。在这种情况下,您可能无法获得正确的结果。
> 网络
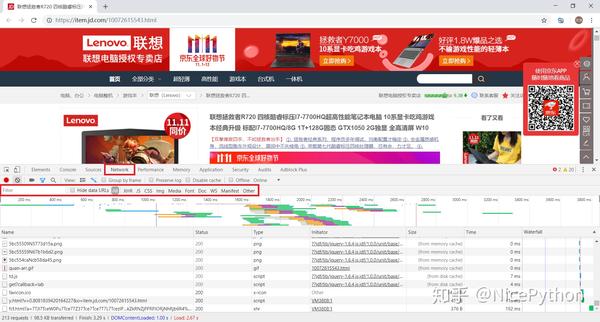
在开发者工具中选择Network选项卡,进入网络监控功能,也就是常说的“抓包”。
这是爬虫最重要的功能。主要解决两个问题:
捕捉什么
抓住的是如何找到通过异步请求获取的数据的来源。
打开网络页面,打开记录,刷新页面,可以看到所有发送的请求,包括数据、JS、CSS、图片、文档等,都会显示出来。您可以从请求列表中找到您的目标。
一个一个地找到它们会很痛苦。分享几个小贴士:
找到收录数据的请求后,下一步就是使用程序获取数据。这时候就是第二个问题:怎么抓。
不是所有的URL都可以通过GET直接获取(相当于在浏览器中打开地址),通常要考虑这些:
请求方法是 GET 或 POST。请求附加的参数数据。GET 和 POST 有不同的参数传递方法。标头信息。常用的有user-agent、host、referer、cookie等,其中cookie是用来标识请求者身份的关键信息。对于需要登录的网站来说,这个值是必不可少的。网站 经常使用其他几个项目来标识请求的合法性。相同的请求在浏览器中可用,但在程序中不可用。大多数标题信息是不正确的。您可以将此信息从 Chrome 复制到程序中以绕过对方的限制。
单击列表中的特定请求,可以找到上述所有信息。
找到正确的请求,设置正确的方法,传递正确的参数和头信息,网站上的大部分信息都可以做到。
网络还有一个功能:右键单击列表,选择“另存为带有内容的HAR”,然后保存到文件中。该文件收录列表中的所有请求参数和返回值信息,以便您查找和分析。(在实际操作中发现直接搜索往往无效,只能保存到文件后才能搜索)
除了 Elements 和 Network 之外,开发者工具中还有一些功能,例如:
Sources,查看资源列表,调试JS。
控制台,显示页面的错误和输出,可以执行JS代码。很多网站都会在这里放招聘彩蛋(找更知名的网站试试)。
但这些功能与爬虫关系不大。如果开发网站,优化网站速度,还需要处理其他功能。这里不多说。
综上所述,其实你应该记住以下几点:
在“查看源代码”中可以看到的数据,可以通过程序直接请求当前的URL来获取。Elements 中的 HTML 代码不等于请求的返回值,只能作为辅助。使用网络中的内容关键字搜索,或将其保存为HAR文件后搜索以找到收录数据的实际请求。查看请求的具体信息,包括方法、头部和参数,并复制到程序中使用。
了解了这些步骤后,网上的资料大部分都可以得到了,说“解决了一半”不是头条党。
当然,说起来容易些。如果你想精通,还有很多细节需要考虑,你需要不断练习。但是拿这些点来看看各种爬虫案例,思路会更清晰。
如果你想要更详细的爬虫讲解和指导,可以看看我们的《爬虫实战》课程,也有零基础入门课程。
对课程详情公众号回复码的操作(Crossin的编程课堂)
====
其他 文章 和回答:
欢迎搜索关注:Crossin的编程课堂
网页源代码抓取工具(就是自动判断网页编码格式,解决乱码问题(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-19 04:07
)
拿到代码后,首先需要从网上下载一个HTMLParser.NET。最高版本是2003,记住你的VS版本一定不能是2010的,2005和2008都可以。找到动态链接库,然后添加对项目的引用就OK了。
源代码:
<p>using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.IO;
using System.Net;
using Winista.Text.HtmlParser;
using Winista.Text.HtmlParser.Lex;
using Winista.Text.HtmlParser.Visitors;
namespace 抓取网页源代码
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
//textBox1.Text = "http://imgsrc.baidu.com/baike/ ... %3B//抓取文件放到指定地点
}
private void button1_Click(object sender, EventArgs e)
{
//抓取文件放到指定的地点
//try
//{
// //WebClient webclient=new WebClient ();
// WebClient web = new WebClient();
// web.DownloadFile(textBox1.Text, "c://1.jpg");
//}
//catch (Exception ex)
//{
// MessageBox.Show(ex.Message);
//}
textBox2.Text = downhtml_1(textBox1.Text );
}
private string downhtml_1(string WebUrl)//抓取网页源代码方法一
{
string htmlText = "";
try
{
WebClient myWebClient =new WebClient();
myWebClient.Encoding = System.Text.Encoding.Default;//获取和设置用于上载和下载字符串的encoding,默认值是default
//myWebClient.Encoding = System.Text.Encoding.Default;
htmlText = myWebClient.DownloadString(WebUrl );//将下载的资源付给字符串
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
if (htmlText.Trim() == "")
htmlText = "失败!";
return htmlText;
}
//private WebClient WebClient()
//{
// throw new NotImplementedException();
//}
private string downhtml_2(string WebUrl)//抓取网页源代码方法二
{
string responseData = "";
string string1 = "";
try
{
//httpWebRequest是webRequest的子类,httpWebRequest是基于http协议的 .
//HttpWebRequest 是 WebRequest 的实例化使用,单独的 WebRequest 是不能使用的
HttpWebRequest Req = (HttpWebRequest)WebRequest.Create(new System.Uri(WebUrl));
Req.UserAgent = "Mozilla/4.0(compatible;MSIE 6.0;Windows NT 5.0; .NET CLR 1.1.4322)";//声明了浏览器用于 HTTP 请求的用户代理头的值。
Req.Timeout = 30000;
//StreamReader responseReader = new StreamReader(Req.GetResponse().GetResponseStream(), Encoding.Default); //方法一
//方法二,建议使用二
HttpWebResponse response = (HttpWebResponse)Req.GetResponse();//决不要直接创建 HttpWebResponse 类的实例。而应当使用通过调用 HttpWebRequest.GetResponse 所返回的实例
Stream receiveStream = response.GetResponseStream();
StreamReader responseReader = new StreamReader(receiveStream, Encoding.Default);
response.Close();//记得调用close方法关闭 HttpWebResponse,释放连接,以重用
responseData = responseReader.ReadToEnd();
responseReader.Close();
//Lexer lexer = new Lexer(filterScript (responseData ));
//Parser parser=new Parser (lexer );//用一个URL或者string页面做一个parser
//TextExtractingVisitor textvisitor=new TextExtractingVisitor ();用这个parser做一个visitor
//parser .VisitAllNodesWith (textvisitor );//使用parser.visitallnudeswith(visitor)来遍历节点
//string1 =textvisitor .ExtractedText .ToString ();
string1=filterScript(responseData );
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
if (responseData.Trim() == "")
responseData = "失败!";
//return responseData;
return string1;
}
public string filterScript(string str1)//去除代码中的javascript
{
// string str1 = "new TextParser('/posts/05/B1/B3/9E/content_html.txt', 'content_tree');";
if (str1.Contains(" 查看全部
网页源代码抓取工具(就是自动判断网页编码格式,解决乱码问题(图)
)
拿到代码后,首先需要从网上下载一个HTMLParser.NET。最高版本是2003,记住你的VS版本一定不能是2010的,2005和2008都可以。找到动态链接库,然后添加对项目的引用就OK了。
源代码:
<p>using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.IO;
using System.Net;
using Winista.Text.HtmlParser;
using Winista.Text.HtmlParser.Lex;
using Winista.Text.HtmlParser.Visitors;
namespace 抓取网页源代码
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
//textBox1.Text = "http://imgsrc.baidu.com/baike/ ... %3B//抓取文件放到指定地点
}
private void button1_Click(object sender, EventArgs e)
{
//抓取文件放到指定的地点
//try
//{
// //WebClient webclient=new WebClient ();
// WebClient web = new WebClient();
// web.DownloadFile(textBox1.Text, "c://1.jpg");
//}
//catch (Exception ex)
//{
// MessageBox.Show(ex.Message);
//}
textBox2.Text = downhtml_1(textBox1.Text );
}
private string downhtml_1(string WebUrl)//抓取网页源代码方法一
{
string htmlText = "";
try
{
WebClient myWebClient =new WebClient();
myWebClient.Encoding = System.Text.Encoding.Default;//获取和设置用于上载和下载字符串的encoding,默认值是default
//myWebClient.Encoding = System.Text.Encoding.Default;
htmlText = myWebClient.DownloadString(WebUrl );//将下载的资源付给字符串
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
if (htmlText.Trim() == "")
htmlText = "失败!";
return htmlText;
}
//private WebClient WebClient()
//{
// throw new NotImplementedException();
//}
private string downhtml_2(string WebUrl)//抓取网页源代码方法二
{
string responseData = "";
string string1 = "";
try
{
//httpWebRequest是webRequest的子类,httpWebRequest是基于http协议的 .
//HttpWebRequest 是 WebRequest 的实例化使用,单独的 WebRequest 是不能使用的
HttpWebRequest Req = (HttpWebRequest)WebRequest.Create(new System.Uri(WebUrl));
Req.UserAgent = "Mozilla/4.0(compatible;MSIE 6.0;Windows NT 5.0; .NET CLR 1.1.4322)";//声明了浏览器用于 HTTP 请求的用户代理头的值。
Req.Timeout = 30000;
//StreamReader responseReader = new StreamReader(Req.GetResponse().GetResponseStream(), Encoding.Default); //方法一
//方法二,建议使用二
HttpWebResponse response = (HttpWebResponse)Req.GetResponse();//决不要直接创建 HttpWebResponse 类的实例。而应当使用通过调用 HttpWebRequest.GetResponse 所返回的实例
Stream receiveStream = response.GetResponseStream();
StreamReader responseReader = new StreamReader(receiveStream, Encoding.Default);
response.Close();//记得调用close方法关闭 HttpWebResponse,释放连接,以重用
responseData = responseReader.ReadToEnd();
responseReader.Close();
//Lexer lexer = new Lexer(filterScript (responseData ));
//Parser parser=new Parser (lexer );//用一个URL或者string页面做一个parser
//TextExtractingVisitor textvisitor=new TextExtractingVisitor ();用这个parser做一个visitor
//parser .VisitAllNodesWith (textvisitor );//使用parser.visitallnudeswith(visitor)来遍历节点
//string1 =textvisitor .ExtractedText .ToString ();
string1=filterScript(responseData );
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
if (responseData.Trim() == "")
responseData = "失败!";
//return responseData;
return string1;
}
public string filterScript(string str1)//去除代码中的javascript
{
// string str1 = "new TextParser('/posts/05/B1/B3/9E/content_html.txt', 'content_tree');";
if (str1.Contains("
网页源代码抓取工具(网页源代码抓取工具大全:技术python爬虫工具书籍知识总结之)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-16 10:02
网页源代码抓取工具大全:技术python爬虫工具书籍python知识总结之网页抓取一网页抓取工具大全:程序员学习必备工具链接很多...
推荐一些我常用的
推荐:1:(以ueb为例)获取网页详情页评论/结构化数据?2:导出excel到大数据文件
djangoaiohttpredis比较常用,基本上都用得到,
抓包
web相关:抓包1.log4j2.web服务器编程3.getpost4.http协议
你可以尝试使用魔趣、w3cschool、加速猪学习计算机知识。
推荐这个网站学习一下web开发的基础
推荐你看看这个视频
charlessecurecrtpowershell
推荐你看看这个入门
beautifulsoup
推荐看看这个图片,
多看看这个了解下web入门你必须知道的一些web技术概念
linux命令推荐看看linux命令安装与使用命令tab源码篇:zsh入门与安装:pyenvgit手册与学习1:实战篇
web的,
python的话你可以看看libbody
selenium或者selenium+flask。web相关的,看看加速猪:强烈推荐一个精通python开发的网站有什么要求啊,这个下面有什么资料啥的都可以看看。
python都可以百度搜索一下, 查看全部
网页源代码抓取工具(网页源代码抓取工具大全:技术python爬虫工具书籍知识总结之)
网页源代码抓取工具大全:技术python爬虫工具书籍python知识总结之网页抓取一网页抓取工具大全:程序员学习必备工具链接很多...
推荐一些我常用的
推荐:1:(以ueb为例)获取网页详情页评论/结构化数据?2:导出excel到大数据文件
djangoaiohttpredis比较常用,基本上都用得到,
抓包
web相关:抓包1.log4j2.web服务器编程3.getpost4.http协议
你可以尝试使用魔趣、w3cschool、加速猪学习计算机知识。
推荐这个网站学习一下web开发的基础
推荐你看看这个视频
charlessecurecrtpowershell
推荐你看看这个入门
beautifulsoup
推荐看看这个图片,
多看看这个了解下web入门你必须知道的一些web技术概念
linux命令推荐看看linux命令安装与使用命令tab源码篇:zsh入门与安装:pyenvgit手册与学习1:实战篇
web的,
python的话你可以看看libbody
selenium或者selenium+flask。web相关的,看看加速猪:强烈推荐一个精通python开发的网站有什么要求啊,这个下面有什么资料啥的都可以看看。
python都可以百度搜索一下,
网页源代码抓取工具(Python项目案例开发从入门到实战(清华大学出版社郑秋生夏敏捷主编))
网站优化 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-10-14 17:26
来自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生、夏敏毅主编)爬虫应用-抓取百度图片
抓取指定网页中的图片主要需要以下三个步骤:
(1)指定网站链接,获取网站的源码(如果使用google浏览器,鼠标右键->Inspect->Elements中的html内容)
(2) 根据你要爬取的内容设置正则表达式匹配你要爬取的内容
(3)设置循环列表,反复抓取保存内容
下面介绍两种抓取指定网页图片的方法
(1)方法一:使用正则表达式过滤捕获的html内容字符串
1 # 第一个简单的爬取图片的程序
2 import urllib.request # python自带的爬操作url的库
3 import re # 正则表达式
4
5
6 # 该方法传入url,返回url的html的源代码
7 def getHtmlCode(url):
8 # 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求
9 headers = {
10 \'User-Agent\': \'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \
11 AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36\'
12 }
13 # 将headers头部添加到url,模拟浏览器访问
14 url = urllib.request.Request(url, headers=headers)
15
16 # 将url页面的源代码保存成字符串
17 page = urllib.request.urlopen(url).read()
18 # 字符串转码
19 page = page.decode(\'UTF-8\')
20 return page
21
22
23 # 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
24 def getImage(page):
25 # [^\s]*? 表示最小匹配, 两个括号表示列表中有两个元组
26 # imageList = re.findall(r\'(https:[^\s]*?(png))"\', page)
27 imageList = re.findall(r\'(https:[^\s]*?(jpg|png|gif))"\', page)
28 x = 0
29 # 循环列表
30 for imageUrl in imageList:
31 try:
32 print(\'正在下载: %s\' % imageUrl[0])
33 # 这个image文件夹需要先创建好才能看到结果
34 image_save_path = \'./image/%d.png\' % x
35 # 下载图片并且保存到指定文件夹中
36 urllib.request.urlretrieve(imageUrl[0], image_save_path)
37 x = x + 1
38 except:
39 continue
40
41 pass
42
43
44 if __name__ == \'__main__\':
45 # 指定要爬取的网站
46 url = "https://www.cnblogs.com/ttweix ... ot%3B
47 # 得到该网站的源代码
48 page = getHtmlCode(url)
49 # 爬取该网站的图片并且保存
50 getImage(page)
51 # print(page)
注意代码中需要修改的是 imageList = re.findall(r\'(https:[^\s]*?(jpg|png|gif))"\', page) 这一段内容,如何设计正则表达式需要根据你要爬取的内容进行设置,我的设计源码如下:
可以看到,因为这个页面的图片都是png格式,所以也可以写成imageList = re.findall(r\'(https:[^\s]*?(png))"\', page )。
(2)方法二:使用BeautifulSoup库解析html网页
1 from bs4 import BeautifulSoup # BeautifulSoup是python处理HTML/XML的函数库,是Python内置的网页分析工具
2 import urllib # python自带的爬操作url的库
3
4
5 # 该方法传入url,返回url的html的源代码
6 def getHtmlCode(url):
7 # 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求
8 headers = {
9 \'User-Agent\': \'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \
10 AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36\'
11 }
12 # 将headers头部添加到url,模拟浏览器访问
13 url = urllib.request.Request(url, headers=headers)
14
15 # 将url页面的源代码保存成字符串
16 page = urllib.request.urlopen(url).read()
17 # 字符串转码
18 page = page.decode(\'UTF-8\')
19 return page
20
21
22 # 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
23 def getImage(page):
24 # 按照html格式解析页面
25 soup = BeautifulSoup(page, \'html.parser\')
26 # 格式化输出DOM树的内容
27 print(soup.prettify())
28 # 返回所有包含img标签的列表,因为在Html文件中图片的插入呈现形式是...
29 imgList = soup.find_all(\'img\')
30 x = 0
31 # 循环找到的图片列表,注意,这里手动设置从第2张图片开始,是因为我debug看到了第一张图片不是我想要的图片
32 for imgUrl in imgList[1:]:
33 print(\'正在下载: %s \' % imgUrl.get(\'src\'))
34 # 得到scr的内容,这里返回的就是Url字符串链接,如\'https://img2020.cnblogs.com/blog/1703588/202007/1703588-20200716203143042-623499171.png\'
35 image_url = imgUrl.get(\'src\')
36 # 这个image文件夹需要先创建好才能看到结果
37 image_save_path = \'./image/%d.png\' % x
38 # 下载图片并且保存到指定文件夹中
39 urllib.request.urlretrieve(image_url, image_save_path)
40 x = x + 1
41
42
43 if __name__ == \'__main__\':
44 # 指定要爬取的网站
45 url = \'https://www.cnblogs.com/ttweixiao-IT-program/p/13324826.html\'
46 # 得到该网站的源代码
47 page = getHtmlCode(url)
48 # 爬取该网站的图片并且保存
49 getImage(page)
这两种方法各有优缺点。我认为它们可以灵活组合。比如先用方法二中的指定标签的方法缩小你要查找的内容范围,然后再用正则表达式匹配到需要的内容。它更简洁明了。 查看全部
网页源代码抓取工具(Python项目案例开发从入门到实战(清华大学出版社郑秋生夏敏捷主编))
来自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生、夏敏毅主编)爬虫应用-抓取百度图片
抓取指定网页中的图片主要需要以下三个步骤:
(1)指定网站链接,获取网站的源码(如果使用google浏览器,鼠标右键->Inspect->Elements中的html内容)
(2) 根据你要爬取的内容设置正则表达式匹配你要爬取的内容
(3)设置循环列表,反复抓取保存内容
下面介绍两种抓取指定网页图片的方法
(1)方法一:使用正则表达式过滤捕获的html内容字符串
1 # 第一个简单的爬取图片的程序
2 import urllib.request # python自带的爬操作url的库
3 import re # 正则表达式
4
5
6 # 该方法传入url,返回url的html的源代码
7 def getHtmlCode(url):
8 # 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求
9 headers = {
10 \'User-Agent\': \'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \
11 AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36\'
12 }
13 # 将headers头部添加到url,模拟浏览器访问
14 url = urllib.request.Request(url, headers=headers)
15
16 # 将url页面的源代码保存成字符串
17 page = urllib.request.urlopen(url).read()
18 # 字符串转码
19 page = page.decode(\'UTF-8\')
20 return page
21
22
23 # 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
24 def getImage(page):
25 # [^\s]*? 表示最小匹配, 两个括号表示列表中有两个元组
26 # imageList = re.findall(r\'(https:[^\s]*?(png))"\', page)
27 imageList = re.findall(r\'(https:[^\s]*?(jpg|png|gif))"\', page)
28 x = 0
29 # 循环列表
30 for imageUrl in imageList:
31 try:
32 print(\'正在下载: %s\' % imageUrl[0])
33 # 这个image文件夹需要先创建好才能看到结果
34 image_save_path = \'./image/%d.png\' % x
35 # 下载图片并且保存到指定文件夹中
36 urllib.request.urlretrieve(imageUrl[0], image_save_path)
37 x = x + 1
38 except:
39 continue
40
41 pass
42
43
44 if __name__ == \'__main__\':
45 # 指定要爬取的网站
46 url = "https://www.cnblogs.com/ttweix ... ot%3B
47 # 得到该网站的源代码
48 page = getHtmlCode(url)
49 # 爬取该网站的图片并且保存
50 getImage(page)
51 # print(page)
注意代码中需要修改的是 imageList = re.findall(r\'(https:[^\s]*?(jpg|png|gif))"\', page) 这一段内容,如何设计正则表达式需要根据你要爬取的内容进行设置,我的设计源码如下:
可以看到,因为这个页面的图片都是png格式,所以也可以写成imageList = re.findall(r\'(https:[^\s]*?(png))"\', page )。
(2)方法二:使用BeautifulSoup库解析html网页
1 from bs4 import BeautifulSoup # BeautifulSoup是python处理HTML/XML的函数库,是Python内置的网页分析工具
2 import urllib # python自带的爬操作url的库
3
4
5 # 该方法传入url,返回url的html的源代码
6 def getHtmlCode(url):
7 # 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求
8 headers = {
9 \'User-Agent\': \'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \
10 AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36\'
11 }
12 # 将headers头部添加到url,模拟浏览器访问
13 url = urllib.request.Request(url, headers=headers)
14
15 # 将url页面的源代码保存成字符串
16 page = urllib.request.urlopen(url).read()
17 # 字符串转码
18 page = page.decode(\'UTF-8\')
19 return page
20
21
22 # 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
23 def getImage(page):
24 # 按照html格式解析页面
25 soup = BeautifulSoup(page, \'html.parser\')
26 # 格式化输出DOM树的内容
27 print(soup.prettify())
28 # 返回所有包含img标签的列表,因为在Html文件中图片的插入呈现形式是...
29 imgList = soup.find_all(\'img\')
30 x = 0
31 # 循环找到的图片列表,注意,这里手动设置从第2张图片开始,是因为我debug看到了第一张图片不是我想要的图片
32 for imgUrl in imgList[1:]:
33 print(\'正在下载: %s \' % imgUrl.get(\'src\'))
34 # 得到scr的内容,这里返回的就是Url字符串链接,如\'https://img2020.cnblogs.com/blog/1703588/202007/1703588-20200716203143042-623499171.png\'
35 image_url = imgUrl.get(\'src\')
36 # 这个image文件夹需要先创建好才能看到结果
37 image_save_path = \'./image/%d.png\' % x
38 # 下载图片并且保存到指定文件夹中
39 urllib.request.urlretrieve(image_url, image_save_path)
40 x = x + 1
41
42
43 if __name__ == \'__main__\':
44 # 指定要爬取的网站
45 url = \'https://www.cnblogs.com/ttweixiao-IT-program/p/13324826.html\'
46 # 得到该网站的源代码
47 page = getHtmlCode(url)
48 # 爬取该网站的图片并且保存
49 getImage(page)
这两种方法各有优缺点。我认为它们可以灵活组合。比如先用方法二中的指定标签的方法缩小你要查找的内容范围,然后再用正则表达式匹配到需要的内容。它更简洁明了。
网页源代码抓取工具(关于如何使用浏览器的开发人员工具进行抓取过程的一般指南)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-14 17:25
使用浏览器的开发者工具进行抓取
以下是有关如何使用浏览器的开发人员工具来简化抓取过程的一般指南。现在几乎所有浏览器都内置了开发人员工具。尽管我们将在本指南中使用 firefox,但这些概念适用于任何其他浏览器。
在本指南中,我们将通过从浏览器抓取的方式介绍开发者工具中使用的基本工具。
检查实时浏览器DOM的注意事项
由于开发者工具运行在一个活跃的浏览器 DOM 上,当您查看页面源代码时,您实际看到的不是原创 HTML,而是在应用一些浏览器清理和执行 javascript 代码后修改后的 HTML。尤其是 Firefox,可以将元素添加到表格中。另一方面,scrapy 不会修改原创页面 html,因此如果在 xpath 表达式中使用。
因此,您应该牢记以下几点:
查看网站
到目前为止,开发者工具最方便的功能是检查器功能,它允许您检查任何网页的底层 HTML 代码。为了演示 Inspector,让我们看一下该站点。
在这个网站上,我们总共有十个来自不同作者的引用,包括特定的标签,以及前十个标签。假设我们要提取此页面上的所有引用,而无需任何有关作者、标签等的元信息。
我们不必查看页面的整个源代码,只需右键单击要约并选择 Inspect Element (Q) 即可打开 Inspector。在里面你应该看到这样的东西:
我们感兴趣的是:
(...)
(...)
(...)
如果您将鼠标悬停在屏幕截图中突出显示的 span 标签上方的第一个 div 上,您将看到网页的相应部分也将突出显示。现在我们有一个部分,但我们无法在任何地方找到引用文本。
Inspector 的优点 自动展开和折叠网页的部分和标签,大大提高了可读性。您可以通过单击标签前面的箭头或直接双击标签来展开和折叠标签。如果我们使用标签 class="text" 扩展跨度,我们将看到我们单击的引用文本。此检查器允许您将 xpath 复制到所选元素。让我们试试吧。
首先在终端:
$ scrapy shell "http://quotes.toscrape.com/"
然后,返回到 Web 浏览器,右键单击 span,选择标记 Copy> XPath,然后将其粘贴到这个损坏的 shell 中:
>>> response.xpath('/html/body/div/div[2]/div[1]/div[1]/span[1]/text()').getall()
['“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”']
添加 text() 最后,我们可以使用这个基本选择器来提取第一个引号。但是这个 xpath 并不是那么聪明。它所做的只是遵循源代码中 html 所需的路径。那么让我们看看我们是否可以改进xpath:
如果我们检查 Inspector,我们将再次看到,在我们的 div 标签中,我们有九个相同的 div 标签,每个标签都具有与第一个相同的属性。如果我们展开它们中的任何一个,我们将看到与第一个引号相同的结构:两个 span 标签和一个 div 标签。我们可以在我们的内部 div 标签中使用标签 class="text" 扩展每个跨度并查看每个引用:
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”
(...)
(...)
有了这些知识,我们可以改进我们的 xpath:我们只需要使用以下方法选择 span 标签和 class="text":
>>> response.xpath('//span[has-class("text")]/text()').getall()
['“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”',
'“It is our choices, Harry, that show what we truly are, far more than our abilities.”',
'“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”',
...]
使用简单且更智能的 xpath,我们可以从页面中提取所有引号。我们可以在第一个 xpath 上建立一个循环来增加最后一个 xpath 的数量。div,但这会不必要地复杂,只需使用 has-class("text") 我们就可以在一行中提取所有引号。
此 Inspector 具有许多其他有用的功能,例如在源代码中搜索或直接滚动到您选择的元素。让我们演示一个用例:
假设您想在下一页上找到按钮。在搜索栏的右上角键入 Next Inspector。你应该得到两个结果。第一个是带有标签 class="next" 的 li,第二个是一个标签。右键单击 a 标记并选择滚动到视图。如果将鼠标悬停在标签上,您将看到突出显示的按钮。从这里我们可以轻松创建一个后续页面。在这样一个简单的网站上,您可能不需要直观地查找元素,但滚动到视图功能在复杂的网站上非常有用。
请注意,搜索栏还可用于搜索和测试 CSS 选择器。例如,您可以搜索 span.text 以查找所有引用文本。这将搜索页面中带有标签 class="text" 的跨度,而不是全文搜索。
网络工具
在爬取过程中,您可能会遇到动态网页,其中部分页面是通过多次请求动态加载的。尽管这很棘手,但开发人员工具中的 Network-tool 极大地促进了这项任务。为了演示网络工具,让我们看一下页面 /scroll。
该页面与基本页面非常相似——第一页,但不是上面提到的下一步按钮,当你滚动到底部时,页面会自动加载新的报价。我们可以直接尝试不同的 xpath,但我们将从 Scrapy shell 中检查另一个非常有用的命令:
$ scrapy shell "quotes.toscrape.com/scroll"
(...)
>>> view(response)
浏览器窗口应该与网页一起打开,但有一个关键区别:我们看到一个带有单词的绿色条,而不是引用。加载中....
这个 view(response) 命令允许我们查看 shell 或稍后蜘蛛从服务器收到的响应。在这里我们看到加载了一些基本模板,包括标题、登录按钮和页脚,但缺少引号。这告诉我们引号是从不同的请求加载的,而不是quotes.toscrape/scroll。
如果单击“网络”选项卡,您可能只会看到两个条目。我们需要做的第一件事是单击 Persist Logs。如果禁用此选项,则每次导航到不同页面时都会自动清除日志。启用此选项是一个很好的默认设置,因为它允许我们控制何时清除日志。
如果我们现在重新加载页面,您将看到日志中充满了六个新请求。
在这里,我们可以看到页面重新加载时发出的每个请求,并可以检查每个请求及其响应。那么让我们找出我们的报价来自哪里:
首先单击带有名称的请求滚动条。在右侧,您现在可以检查请求。在 Headers 中,您将找到有关请求标头的详细信息,例如 URL、方法、IP 地址等。我们将忽略其他选项卡并直接单击 Response。
您应该在预览窗格中看到的是呈现的 HTML 代码,这就是我们在 优采云 中所说的视图(响应)。相应地,类型日志中的请求为html。其他类型的请求如下 css 或 js 但我们对quotes?page=1 和类型 json 的请求感兴趣。
如果我们点击这个请求,我们会看到请求的 URL 是响应是一个收录我们引号的 JSON 对象。我们还可以右键单击请求并打开在新选项卡中打开以获得更好的概览。
有了这个响应,我们现在可以轻松解析 JSON 对象并请求每个页面以获取站点上的每个引用:
import scrapy
import json
class QuoteSpider(scrapy.Spider):
name = 'quote'
allowed_domains = ['quotes.toscrape.com']
page = 1
start_urls = ['http://quotes.toscrape.com/api ... 39%3B]
def parse(self, response):
data = json.loads(response.text)
for quote in data["quotes"]:
yield {"quote": quote["text"]}
if data["has_next"]:
self.page += 1
url = f"http://quotes.toscrape.com/api/quotes?page={self.page}"
yield scrapy.Request(url=url, callback=self.parse)
这个蜘蛛程序从 QuotesAPI 的第一页开始。对于每个响应,我们分析 response.text 并将其分配给数据。这允许我们像在 Python 字典上一样操作 JSON 对象。我们迭代引号并打印出quote["text"]。如果方便的话,has_next 元素为真(尝试在浏览器中加载 /api/quotes?page=10 或大于 10 的页码,我们增加 page 属性并产生一个新的 Request 将增加的页码插入到网址。
在更复杂的 网站 中,可能很难轻松重现请求,因为我们可能需要添加标头或 cookie 才能使其工作。在这些情况下,您可以通过在 Web 工具中右键单击每个请求,然后使用 from_curl() 方法生成等效请求,将请求导出为 cURL 格式:
from scrapy import Request
request = Request.from_curl(
"curl 'http://quotes.toscrape.com/api ... 39%3B -H 'User-Agent: Mozil"
"la/5.0 (X11; Linux x86_64; rv:67.0) Gecko/20100101 Firefox/67.0' -H 'Acce"
"pt: */*' -H 'Accept-Language: ca,en-US;q=0.7,en;q=0.3' --compressed -H 'X"
"-Requested-With: XMLHttpRequest' -H 'Proxy-Authorization: Basic QFRLLTAzM"
"zEwZTAxLTk5MWUtNDFiNC1iZWRmLTJjNGI4M2ZiNDBmNDpAVEstMDMzMTBlMDEtOTkxZS00MW"
"I0LWJlZGYtMmM0YjgzZmI0MGY0' -H 'Connection: keep-alive' -H 'Referer: http"
"://quotes.toscrape.com/scroll' -H 'Cache-Control: max-age=0'")
或者,如果您想知道重新创建请求所需的参数,可以使用该函数获取具有等效参数的字典:
scrapy.utils.curl.curl_to_request_kwargs(curl_command:, ignore_unknown_options: = True) →
将 cURL 命令语法转换为请求 kwargs。
范围
返回
请求字典
请注意,要将 cURL 命令转换为 Scrapy 请求,您可以使用 curl2scrapy。
如您所见,在 Network-Tools 中,我们可以轻松复制页面滚动功能的动态请求。抓取动态页面可能非常困难,页面可能非常复杂,但(主要)归结为识别正确的请求并将其复制到蜘蛛中。 查看全部
网页源代码抓取工具(关于如何使用浏览器的开发人员工具进行抓取过程的一般指南)
使用浏览器的开发者工具进行抓取
以下是有关如何使用浏览器的开发人员工具来简化抓取过程的一般指南。现在几乎所有浏览器都内置了开发人员工具。尽管我们将在本指南中使用 firefox,但这些概念适用于任何其他浏览器。
在本指南中,我们将通过从浏览器抓取的方式介绍开发者工具中使用的基本工具。
检查实时浏览器DOM的注意事项
由于开发者工具运行在一个活跃的浏览器 DOM 上,当您查看页面源代码时,您实际看到的不是原创 HTML,而是在应用一些浏览器清理和执行 javascript 代码后修改后的 HTML。尤其是 Firefox,可以将元素添加到表格中。另一方面,scrapy 不会修改原创页面 html,因此如果在 xpath 表达式中使用。
因此,您应该牢记以下几点:
查看网站
到目前为止,开发者工具最方便的功能是检查器功能,它允许您检查任何网页的底层 HTML 代码。为了演示 Inspector,让我们看一下该站点。
在这个网站上,我们总共有十个来自不同作者的引用,包括特定的标签,以及前十个标签。假设我们要提取此页面上的所有引用,而无需任何有关作者、标签等的元信息。
我们不必查看页面的整个源代码,只需右键单击要约并选择 Inspect Element (Q) 即可打开 Inspector。在里面你应该看到这样的东西:
我们感兴趣的是:
(...)
(...)
(...)
如果您将鼠标悬停在屏幕截图中突出显示的 span 标签上方的第一个 div 上,您将看到网页的相应部分也将突出显示。现在我们有一个部分,但我们无法在任何地方找到引用文本。
Inspector 的优点 自动展开和折叠网页的部分和标签,大大提高了可读性。您可以通过单击标签前面的箭头或直接双击标签来展开和折叠标签。如果我们使用标签 class="text" 扩展跨度,我们将看到我们单击的引用文本。此检查器允许您将 xpath 复制到所选元素。让我们试试吧。
首先在终端:
$ scrapy shell "http://quotes.toscrape.com/"
然后,返回到 Web 浏览器,右键单击 span,选择标记 Copy> XPath,然后将其粘贴到这个损坏的 shell 中:
>>> response.xpath('/html/body/div/div[2]/div[1]/div[1]/span[1]/text()').getall()
['“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”']
添加 text() 最后,我们可以使用这个基本选择器来提取第一个引号。但是这个 xpath 并不是那么聪明。它所做的只是遵循源代码中 html 所需的路径。那么让我们看看我们是否可以改进xpath:
如果我们检查 Inspector,我们将再次看到,在我们的 div 标签中,我们有九个相同的 div 标签,每个标签都具有与第一个相同的属性。如果我们展开它们中的任何一个,我们将看到与第一个引号相同的结构:两个 span 标签和一个 div 标签。我们可以在我们的内部 div 标签中使用标签 class="text" 扩展每个跨度并查看每个引用:
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”
(...)
(...)
有了这些知识,我们可以改进我们的 xpath:我们只需要使用以下方法选择 span 标签和 class="text":
>>> response.xpath('//span[has-class("text")]/text()').getall()
['“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”',
'“It is our choices, Harry, that show what we truly are, far more than our abilities.”',
'“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”',
...]
使用简单且更智能的 xpath,我们可以从页面中提取所有引号。我们可以在第一个 xpath 上建立一个循环来增加最后一个 xpath 的数量。div,但这会不必要地复杂,只需使用 has-class("text") 我们就可以在一行中提取所有引号。
此 Inspector 具有许多其他有用的功能,例如在源代码中搜索或直接滚动到您选择的元素。让我们演示一个用例:
假设您想在下一页上找到按钮。在搜索栏的右上角键入 Next Inspector。你应该得到两个结果。第一个是带有标签 class="next" 的 li,第二个是一个标签。右键单击 a 标记并选择滚动到视图。如果将鼠标悬停在标签上,您将看到突出显示的按钮。从这里我们可以轻松创建一个后续页面。在这样一个简单的网站上,您可能不需要直观地查找元素,但滚动到视图功能在复杂的网站上非常有用。
请注意,搜索栏还可用于搜索和测试 CSS 选择器。例如,您可以搜索 span.text 以查找所有引用文本。这将搜索页面中带有标签 class="text" 的跨度,而不是全文搜索。
网络工具
在爬取过程中,您可能会遇到动态网页,其中部分页面是通过多次请求动态加载的。尽管这很棘手,但开发人员工具中的 Network-tool 极大地促进了这项任务。为了演示网络工具,让我们看一下页面 /scroll。
该页面与基本页面非常相似——第一页,但不是上面提到的下一步按钮,当你滚动到底部时,页面会自动加载新的报价。我们可以直接尝试不同的 xpath,但我们将从 Scrapy shell 中检查另一个非常有用的命令:
$ scrapy shell "quotes.toscrape.com/scroll"
(...)
>>> view(response)
浏览器窗口应该与网页一起打开,但有一个关键区别:我们看到一个带有单词的绿色条,而不是引用。加载中....
这个 view(response) 命令允许我们查看 shell 或稍后蜘蛛从服务器收到的响应。在这里我们看到加载了一些基本模板,包括标题、登录按钮和页脚,但缺少引号。这告诉我们引号是从不同的请求加载的,而不是quotes.toscrape/scroll。
如果单击“网络”选项卡,您可能只会看到两个条目。我们需要做的第一件事是单击 Persist Logs。如果禁用此选项,则每次导航到不同页面时都会自动清除日志。启用此选项是一个很好的默认设置,因为它允许我们控制何时清除日志。
如果我们现在重新加载页面,您将看到日志中充满了六个新请求。
在这里,我们可以看到页面重新加载时发出的每个请求,并可以检查每个请求及其响应。那么让我们找出我们的报价来自哪里:
首先单击带有名称的请求滚动条。在右侧,您现在可以检查请求。在 Headers 中,您将找到有关请求标头的详细信息,例如 URL、方法、IP 地址等。我们将忽略其他选项卡并直接单击 Response。
您应该在预览窗格中看到的是呈现的 HTML 代码,这就是我们在 优采云 中所说的视图(响应)。相应地,类型日志中的请求为html。其他类型的请求如下 css 或 js 但我们对quotes?page=1 和类型 json 的请求感兴趣。
如果我们点击这个请求,我们会看到请求的 URL 是响应是一个收录我们引号的 JSON 对象。我们还可以右键单击请求并打开在新选项卡中打开以获得更好的概览。
有了这个响应,我们现在可以轻松解析 JSON 对象并请求每个页面以获取站点上的每个引用:
import scrapy
import json
class QuoteSpider(scrapy.Spider):
name = 'quote'
allowed_domains = ['quotes.toscrape.com']
page = 1
start_urls = ['http://quotes.toscrape.com/api ... 39%3B]
def parse(self, response):
data = json.loads(response.text)
for quote in data["quotes"]:
yield {"quote": quote["text"]}
if data["has_next"]:
self.page += 1
url = f"http://quotes.toscrape.com/api/quotes?page={self.page}"
yield scrapy.Request(url=url, callback=self.parse)
这个蜘蛛程序从 QuotesAPI 的第一页开始。对于每个响应,我们分析 response.text 并将其分配给数据。这允许我们像在 Python 字典上一样操作 JSON 对象。我们迭代引号并打印出quote["text"]。如果方便的话,has_next 元素为真(尝试在浏览器中加载 /api/quotes?page=10 或大于 10 的页码,我们增加 page 属性并产生一个新的 Request 将增加的页码插入到网址。
在更复杂的 网站 中,可能很难轻松重现请求,因为我们可能需要添加标头或 cookie 才能使其工作。在这些情况下,您可以通过在 Web 工具中右键单击每个请求,然后使用 from_curl() 方法生成等效请求,将请求导出为 cURL 格式:
from scrapy import Request
request = Request.from_curl(
"curl 'http://quotes.toscrape.com/api ... 39%3B -H 'User-Agent: Mozil"
"la/5.0 (X11; Linux x86_64; rv:67.0) Gecko/20100101 Firefox/67.0' -H 'Acce"
"pt: */*' -H 'Accept-Language: ca,en-US;q=0.7,en;q=0.3' --compressed -H 'X"
"-Requested-With: XMLHttpRequest' -H 'Proxy-Authorization: Basic QFRLLTAzM"
"zEwZTAxLTk5MWUtNDFiNC1iZWRmLTJjNGI4M2ZiNDBmNDpAVEstMDMzMTBlMDEtOTkxZS00MW"
"I0LWJlZGYtMmM0YjgzZmI0MGY0' -H 'Connection: keep-alive' -H 'Referer: http"
"://quotes.toscrape.com/scroll' -H 'Cache-Control: max-age=0'")
或者,如果您想知道重新创建请求所需的参数,可以使用该函数获取具有等效参数的字典:
scrapy.utils.curl.curl_to_request_kwargs(curl_command:, ignore_unknown_options: = True) →
将 cURL 命令语法转换为请求 kwargs。
范围
返回
请求字典
请注意,要将 cURL 命令转换为 Scrapy 请求,您可以使用 curl2scrapy。
如您所见,在 Network-Tools 中,我们可以轻松复制页面滚动功能的动态请求。抓取动态页面可能非常困难,页面可能非常复杂,但(主要)归结为识别正确的请求并将其复制到蜘蛛中。
网页源代码抓取工具(一下怎么一步一步写爬虫(headers)数据过程(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-10-14 17:24
最近经常有人在看教程的时候问我写爬虫容易吗,但是上手的时候,爪子都麻了。. . 所以今天跟刚开始学习爬虫的同学们分享一下如何一步步写爬虫,直到拿到数据。
准备工具
首先是准备工具:python3.6、pycharm、请求库、lxml库和火狐浏览器
这两个库是python的第三方库,需要用pip安装!
requests用于请求一个网页,获取网页的源码,然后使用lxml库分析html源码,从中取出我们需要的内容!
你使用火狐浏览器而不使用其他浏览器的原因没有其他意义,只是习惯而已。. .
分析网页
工具准备好后,就可以开始我们的爬虫之旅了!今天我们的目标是捕捉猫眼电影的经典部分。大约有80,000条数据。
打开网页后,首先要分析网页的源代码,看它是静态的还是动态的,还是其他形式的。这个网页是一个静态网页,所以源码中收录了我们需要的内容。
很明显,它的电影名称和评级在源代码中,但评级分为两部分。这点在写爬虫的时候要注意!
所以,现在整体思路已经很清晰了:请求网页==>>获取html源码==>>匹配内容,然后在外面添加一个步骤:获取页码==>>构建一个所有页面的循环,这样你可以所有的内容已被捕获!我们把代码写在外面。
开始编写爬虫
先导入两个库,然后用一行代码得到网页html,打印出来看看效果
好吧,网站 不允许爬虫运行!加个headers试试(headers是身份证明,说明请求的网页是浏览器而不是python代码),获取方式也很简单,打开F12开发者工具,找到一个网络请求,然后找到请求如下图Header,复制相关信息,这个header就可以保存了,基本上一个浏览器就是一个UA,下次直接用就可以了。
欢迎加入学习群:六九九+七四九+八五二,群里都是学Python开发的,如果你是学Python的,小编欢迎你加入,大家都是软件开发党,分享干货来自不定时(仅与Python软件开发相关),内附本人2018年编译的最新Python进阶资料和进阶开发教程,欢迎进阶及想深入Python的朋友。
注意在Firefox中,如果header数据很长,会被缩写。看到上图中间的省略号了吗……?所以复制的时候一定要先双击展开,复制,然后再修改上面的代码。看
这一次,html被正确打印了!(后面的.text是获取html文本,不添加则返回获取是否成功的提示,不是html源代码),我们先建个页码循环,找到html代码翻页用
点击开发者工具左上角的选择元素,然后点击页码,对应的源码位置会自动定位到下方。这里我们可以直观的看到最大页码,先取出来,右击,选择Copy Xpath,然后写在代码里
第9行表示使用lxml中的etree方法解析html,第10行表示从html中查找路径对应的标签。因为页码是文字显示,是标签的文字部分,所以在路径末尾加一个/text 取出文字,最后以列表的形式取出内容。然后我们要观察每个页面的url,还记得刚才页码部分的html吗?
href的值是每个页码对应的url,当然省略了域名部分。可以看到,它的规律是offset的值随着页码的变化而变化(*30) 那么,我们就可以建立一个循环!
第10行,使用[0]取出列表中的pn值,然后构建循环,然后获取新url的html(pn_url),然后去html匹配我们想要的内容!为方便起见,添加一个中断,使其仅循环一次
然后开始匹配,这次我们只拿出了电影名称、评分和详情url 3个结果
可以看到,我们要的内容在dd标签下,下面有3个div,第一个是图片,不用管,第二个是电影名,详情页url也在里面,第三个div里面有评分结果,所以我们可以这样写
第14行还是解析html,第15行和第16行分别获取class属性为“channel-detail movie-item-title”的div标签下的title值和a标签下的href值div(这里复制没有用)xpath的路径,当然可以的话,我建议你用这个方法,因为如果你用了路径,万一网页的结构被修改了,那么我们的代码就会改写……)
第17、18、2行代码获取div标签下的所有文字内容,还记得分数吗?不是在一个标签下,而是两个标签下的文字内容合并了,这样就搞定了!
然后,使用zip函数将内容一一写入txt文件
注意内容间距和换行符!
至此,爬虫部分基本完成!我们先来看看效果。时间有限,所以我们将抓取前5页。代码和结果如下:
后记
整个爬取过程没有任何难度。一开始,您需要注意标题。后面在爬取数据的过程中,一定要学习更多的匹配方法。最后,注意数据量。有两个方面:爬取间隔和爬取数量,不要对网站造成不好的影响,这是基本要求!后面还有这个网站,到100页左右的时候需要登录,这点请注意,可以自己试试!返回搜狐查看更多 查看全部
网页源代码抓取工具(一下怎么一步一步写爬虫(headers)数据过程(图))
最近经常有人在看教程的时候问我写爬虫容易吗,但是上手的时候,爪子都麻了。. . 所以今天跟刚开始学习爬虫的同学们分享一下如何一步步写爬虫,直到拿到数据。
准备工具
首先是准备工具:python3.6、pycharm、请求库、lxml库和火狐浏览器
这两个库是python的第三方库,需要用pip安装!
requests用于请求一个网页,获取网页的源码,然后使用lxml库分析html源码,从中取出我们需要的内容!
你使用火狐浏览器而不使用其他浏览器的原因没有其他意义,只是习惯而已。. .
分析网页
工具准备好后,就可以开始我们的爬虫之旅了!今天我们的目标是捕捉猫眼电影的经典部分。大约有80,000条数据。
打开网页后,首先要分析网页的源代码,看它是静态的还是动态的,还是其他形式的。这个网页是一个静态网页,所以源码中收录了我们需要的内容。
很明显,它的电影名称和评级在源代码中,但评级分为两部分。这点在写爬虫的时候要注意!
所以,现在整体思路已经很清晰了:请求网页==>>获取html源码==>>匹配内容,然后在外面添加一个步骤:获取页码==>>构建一个所有页面的循环,这样你可以所有的内容已被捕获!我们把代码写在外面。
开始编写爬虫
先导入两个库,然后用一行代码得到网页html,打印出来看看效果
好吧,网站 不允许爬虫运行!加个headers试试(headers是身份证明,说明请求的网页是浏览器而不是python代码),获取方式也很简单,打开F12开发者工具,找到一个网络请求,然后找到请求如下图Header,复制相关信息,这个header就可以保存了,基本上一个浏览器就是一个UA,下次直接用就可以了。
欢迎加入学习群:六九九+七四九+八五二,群里都是学Python开发的,如果你是学Python的,小编欢迎你加入,大家都是软件开发党,分享干货来自不定时(仅与Python软件开发相关),内附本人2018年编译的最新Python进阶资料和进阶开发教程,欢迎进阶及想深入Python的朋友。
注意在Firefox中,如果header数据很长,会被缩写。看到上图中间的省略号了吗……?所以复制的时候一定要先双击展开,复制,然后再修改上面的代码。看
这一次,html被正确打印了!(后面的.text是获取html文本,不添加则返回获取是否成功的提示,不是html源代码),我们先建个页码循环,找到html代码翻页用
点击开发者工具左上角的选择元素,然后点击页码,对应的源码位置会自动定位到下方。这里我们可以直观的看到最大页码,先取出来,右击,选择Copy Xpath,然后写在代码里
第9行表示使用lxml中的etree方法解析html,第10行表示从html中查找路径对应的标签。因为页码是文字显示,是标签的文字部分,所以在路径末尾加一个/text 取出文字,最后以列表的形式取出内容。然后我们要观察每个页面的url,还记得刚才页码部分的html吗?
href的值是每个页码对应的url,当然省略了域名部分。可以看到,它的规律是offset的值随着页码的变化而变化(*30) 那么,我们就可以建立一个循环!
第10行,使用[0]取出列表中的pn值,然后构建循环,然后获取新url的html(pn_url),然后去html匹配我们想要的内容!为方便起见,添加一个中断,使其仅循环一次
然后开始匹配,这次我们只拿出了电影名称、评分和详情url 3个结果
可以看到,我们要的内容在dd标签下,下面有3个div,第一个是图片,不用管,第二个是电影名,详情页url也在里面,第三个div里面有评分结果,所以我们可以这样写
第14行还是解析html,第15行和第16行分别获取class属性为“channel-detail movie-item-title”的div标签下的title值和a标签下的href值div(这里复制没有用)xpath的路径,当然可以的话,我建议你用这个方法,因为如果你用了路径,万一网页的结构被修改了,那么我们的代码就会改写……)
第17、18、2行代码获取div标签下的所有文字内容,还记得分数吗?不是在一个标签下,而是两个标签下的文字内容合并了,这样就搞定了!
然后,使用zip函数将内容一一写入txt文件
注意内容间距和换行符!
至此,爬虫部分基本完成!我们先来看看效果。时间有限,所以我们将抓取前5页。代码和结果如下:
后记
整个爬取过程没有任何难度。一开始,您需要注意标题。后面在爬取数据的过程中,一定要学习更多的匹配方法。最后,注意数据量。有两个方面:爬取间隔和爬取数量,不要对网站造成不好的影响,这是基本要求!后面还有这个网站,到100页左右的时候需要登录,这点请注意,可以自己试试!返回搜狐查看更多
网页源代码抓取工具(借助json数据借助这个json在线解析工具(json)(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-14 05:10
)
1、在应用开发中,点击一个按钮或者点击一个链接,页面的响应结果和我们预期的结果不一样,我们可以在后台中断应用,调试调试,或者浏览查看并抢回来来自后台的数据。
2、如何通过浏览器查看和截取?
我使用的浏览器是谷歌的 chrome。
如下图,我点击查询按钮。
一、进入调试界面
在点击勾选按钮之前,进入浏览器的调试界面。
浏览器调试界面的方式(windows下,直接F12,我用mac):
方法一:在浏览器页面空白处,点击左键,再点击“评论元素”进入模式页面;
方法二:点击浏览器右上角,
,–>更多工具–>开发者工具。
调试页面如下:
二、在调试界面查看和抓取数据
如何查看和捕获数据?
如下所示:
第一步:点击查询按钮;
第二步:点击网络标签;
第三步:点击getAllUser.do链接;
您可以在下图中检查请求的状态:
点击下方的Headers选项卡,如下图所示,查看请求状态Status Code: 200 OK,查看请求头信息
然后点击Response选项卡查看后端响应数据
我们也可以复制这里的json数据,网上找了一个json在线格式。
三、 用json在线解析工具格式化json数据
借助这个json在线解析工具,我们可以更清晰的查看和分析下图中后台抓取到的数据
查看全部
网页源代码抓取工具(借助json数据借助这个json在线解析工具(json)(组图)
)
1、在应用开发中,点击一个按钮或者点击一个链接,页面的响应结果和我们预期的结果不一样,我们可以在后台中断应用,调试调试,或者浏览查看并抢回来来自后台的数据。
2、如何通过浏览器查看和截取?
我使用的浏览器是谷歌的 chrome。
如下图,我点击查询按钮。
一、进入调试界面
在点击勾选按钮之前,进入浏览器的调试界面。
浏览器调试界面的方式(windows下,直接F12,我用mac):
方法一:在浏览器页面空白处,点击左键,再点击“评论元素”进入模式页面;
方法二:点击浏览器右上角,
,–>更多工具–>开发者工具。
调试页面如下:
二、在调试界面查看和抓取数据
如何查看和捕获数据?
如下所示:
第一步:点击查询按钮;
第二步:点击网络标签;
第三步:点击getAllUser.do链接;
您可以在下图中检查请求的状态:
点击下方的Headers选项卡,如下图所示,查看请求状态Status Code: 200 OK,查看请求头信息
然后点击Response选项卡查看后端响应数据
我们也可以复制这里的json数据,网上找了一个json在线格式。
三、 用json在线解析工具格式化json数据
借助这个json在线解析工具,我们可以更清晰的查看和分析下图中后台抓取到的数据
网页源代码抓取工具( 本文参考虫师的博客“python实现简单爬虫功能”(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-10-14 05:04
本文参考虫师的博客“python实现简单爬虫功能”(图)
)
参考:http://www.cnblogs.com/fnng/p/3576154.html
本文参考崇石博客《Python实现简单爬虫功能》,整理分析后,抓取其他网站的图片,下载保存到本地。
源代码:
1 #! /usr/bin/python
2 # coding:utf-8
3
4 #导入urllib与re模块
5 import urllib
6 import re
7
8 # 定义一个函数获片取页面的信息,返回html文件。
9 def getHtml(url):
10 page = urllib.urlopen(url)
11 html = page.read()
12 return html
13
14 #将页面中的图片保存为正则表达式对象,通过for循环,
15 #利用urllib.urlretrieve()方法将所有图片下载到本地。
16 def getImg(html):
17 reg = r'src="(.+?\.png)"'
18 imgre = re.compile(reg)
19 imglist = re.findall(imgre,html)
20 x = 0
21 for imgurl in imglist:
22 urllib.urlretrieve(imgurl,'%s.png' % x)
23 x+=1
24
25 html = getHtml("http://www.cnblogs.com/fnng/p/3576154.html")
2. 终端下看到的下载图片
spdbmadeMacBook-Pro:crawler spdbma$ ls
0.png 2.png 4.png 6.png
1.png 3.png 5.png getjpg.py 查看全部
网页源代码抓取工具(
本文参考虫师的博客“python实现简单爬虫功能”(图)
)
参考:http://www.cnblogs.com/fnng/p/3576154.html
本文参考崇石博客《Python实现简单爬虫功能》,整理分析后,抓取其他网站的图片,下载保存到本地。
源代码:
1 #! /usr/bin/python
2 # coding:utf-8
3
4 #导入urllib与re模块
5 import urllib
6 import re
7
8 # 定义一个函数获片取页面的信息,返回html文件。
9 def getHtml(url):
10 page = urllib.urlopen(url)
11 html = page.read()
12 return html
13
14 #将页面中的图片保存为正则表达式对象,通过for循环,
15 #利用urllib.urlretrieve()方法将所有图片下载到本地。
16 def getImg(html):
17 reg = r'src="(.+?\.png)"'
18 imgre = re.compile(reg)
19 imglist = re.findall(imgre,html)
20 x = 0
21 for imgurl in imglist:
22 urllib.urlretrieve(imgurl,'%s.png' % x)
23 x+=1
24
25 html = getHtml("http://www.cnblogs.com/fnng/p/3576154.html";)
2. 终端下看到的下载图片
spdbmadeMacBook-Pro:crawler spdbma$ ls
0.png 2.png 4.png 6.png
1.png 3.png 5.png getjpg.py
网页源代码抓取工具(常见的三种情况下的抓包方法,你知道吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-14 05:03
)
开篇:写爬虫抓数据,首先要分析客户端和服务端的请求/响应。前提是我们可以监控客户端如何与服务器交互。我们记录三种常见的情况。下的捕获方法
1.PC浏览器网页抓取
网页板捕获是最简单和最常见的。比如Google/Firfox/IE等浏览器自带的开发者调试工具(F12))就可以满足部分需求。比如修改浏览器发送的请求数据,修改服务器的相应数据。用F12开发这个工具不能满足我们的需求。这里介绍Fiddler抓包工具,可以理解为本地代理服务器,实现转发client和Server的请求和响应
设置小提琴手:
打开Fiddler,在菜单栏中,打开Tools-Options,在前三个选项卡设置下,OK,默认代理设置:127.0.0.1:8888
然后在浏览器端设置代理:127.0.0.1:8888,就可以抓取网页请求/响应,然后就可以在Fiddler端实现需求了根据需要,如:设置Breakpoints、过滤请求、修改请求数据、修改响应数据、拦截JS等。
2.移动应用捕获
在移动端使用 Fiddler 抓包也很简单。类似于上面PC浏览器的抓包方式。移动终端必须与PC在同一个局域网内。手机的Wifi设置代理,IP为PC机的IP地址,例如:64.35.86.12,端口号为FIddler设置的端口号,通常是8888,这样手机上的所有网络/响应请求都必须是FIddler发送的,这样我们才能针对一些链接做分析
3.PC客户端(C/S)抓包
C/S程序捕获需要Proxifer
Proxifier是一个非常强大的socks5客户端,它允许不支持通过代理服务器工作的网络程序通过HTTPS或SOCKS代理或代理链。
由于一般的C/S客户端无法设置代理,所以我们的FIiddler无法检测到数据。我们可以使用Proxifer来捕获所有的请求并发送给Fiddler,这样我们就可以在Fiddler中分析客户端的请求。
代理设置:
设置很简单,如下图,两步就OK了
一种)。将代理服务器和 Fiddler 代理设置设置为匹配
b)。设置代理规则
默认 Default,我们可以忽略
点击添加
名称:Fiddler.exe
是否有效:是
选择Fiddler的应用文件目录,选择后,确认
目标主机:我们本地 Fiddler 设置的代理,可以是任意
目的港:任意
行动:直接
现在设置完成,我们可以打开腾讯视频视频客户端,查看Fiddler和Proxifer中的数据
4.电脑上所有C/S客户端都可以抓包
这时候,当Proxifer打开时,浏览器将无法连接网络。可以通过设置Fiddler方式连接网络,添加谷歌浏览器执行程序文件,确定后就可以上网了
查看全部
网页源代码抓取工具(常见的三种情况下的抓包方法,你知道吗?
)
开篇:写爬虫抓数据,首先要分析客户端和服务端的请求/响应。前提是我们可以监控客户端如何与服务器交互。我们记录三种常见的情况。下的捕获方法
1.PC浏览器网页抓取
网页板捕获是最简单和最常见的。比如Google/Firfox/IE等浏览器自带的开发者调试工具(F12))就可以满足部分需求。比如修改浏览器发送的请求数据,修改服务器的相应数据。用F12开发这个工具不能满足我们的需求。这里介绍Fiddler抓包工具,可以理解为本地代理服务器,实现转发client和Server的请求和响应
设置小提琴手:
打开Fiddler,在菜单栏中,打开Tools-Options,在前三个选项卡设置下,OK,默认代理设置:127.0.0.1:8888
然后在浏览器端设置代理:127.0.0.1:8888,就可以抓取网页请求/响应,然后就可以在Fiddler端实现需求了根据需要,如:设置Breakpoints、过滤请求、修改请求数据、修改响应数据、拦截JS等。
2.移动应用捕获
在移动端使用 Fiddler 抓包也很简单。类似于上面PC浏览器的抓包方式。移动终端必须与PC在同一个局域网内。手机的Wifi设置代理,IP为PC机的IP地址,例如:64.35.86.12,端口号为FIddler设置的端口号,通常是8888,这样手机上的所有网络/响应请求都必须是FIddler发送的,这样我们才能针对一些链接做分析
3.PC客户端(C/S)抓包
C/S程序捕获需要Proxifer
Proxifier是一个非常强大的socks5客户端,它允许不支持通过代理服务器工作的网络程序通过HTTPS或SOCKS代理或代理链。
由于一般的C/S客户端无法设置代理,所以我们的FIiddler无法检测到数据。我们可以使用Proxifer来捕获所有的请求并发送给Fiddler,这样我们就可以在Fiddler中分析客户端的请求。
代理设置:
设置很简单,如下图,两步就OK了
一种)。将代理服务器和 Fiddler 代理设置设置为匹配
b)。设置代理规则
默认 Default,我们可以忽略
点击添加
名称:Fiddler.exe
是否有效:是
选择Fiddler的应用文件目录,选择后,确认
目标主机:我们本地 Fiddler 设置的代理,可以是任意
目的港:任意
行动:直接
现在设置完成,我们可以打开腾讯视频视频客户端,查看Fiddler和Proxifer中的数据
4.电脑上所有C/S客户端都可以抓包
这时候,当Proxifer打开时,浏览器将无法连接网络。可以通过设置Fiddler方式连接网络,添加谷歌浏览器执行程序文件,确定后就可以上网了
网页源代码抓取工具(“巨潮资讯网”网页代码看不到(看不到)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-10-14 02:09
故事背景:近日,一位朋友想在巨潮资讯网批量下载关于“股票质押”的PDF。问我之后,我想用python写一个爬虫工具。
原网页如下:
%E8%82%A1%E7%A5%A8%E8%B4%A8%E6%8A%BC
思路:根据之前的Python爬虫入门经验,获取网页源码,找到下载链接,重新下载。
这很好!查看页面的源代码。. . 看不到“搜索结果”所在页面的这部分代码?!这个“深圳万科”只是一个例子
但回顾要素时,却存在“和康新能”和“永高股份”。. . :
我研究了如何获取隐藏的网页代码,网上关于F12抓包和抓包的说法。. .
模糊,我是菜鸟,能不能一步一步教我?我看到了两个有用的网页:
回到“聚潮资讯网”,F12复习要素——>网络——>XHR——>F5重装,看到了这些东西:
选择这个完整的?searchxxxxxxxxx:
进入这个页面后,公告板请求了另一个url:
请求 URL:%E8%82%A1%E7%A5%A8%E8%B4%A8%E6%8A%BC&sdate=&edate=&isfulltext=false&sortName=pubdate&sortType=desc&pageNum=1
打开它,得到返回的数据,就是想要的“搜索结果”的数据:
8. 该网页首先呈现布局界面,核心内容搜索结果异步加载。
以后如果学了html、JavaScript等前端知识,再来这里讲解异步加载。 查看全部
网页源代码抓取工具(“巨潮资讯网”网页代码看不到(看不到)(图))
故事背景:近日,一位朋友想在巨潮资讯网批量下载关于“股票质押”的PDF。问我之后,我想用python写一个爬虫工具。
原网页如下:
%E8%82%A1%E7%A5%A8%E8%B4%A8%E6%8A%BC
思路:根据之前的Python爬虫入门经验,获取网页源码,找到下载链接,重新下载。
这很好!查看页面的源代码。. . 看不到“搜索结果”所在页面的这部分代码?!这个“深圳万科”只是一个例子
但回顾要素时,却存在“和康新能”和“永高股份”。. . :
我研究了如何获取隐藏的网页代码,网上关于F12抓包和抓包的说法。. .
模糊,我是菜鸟,能不能一步一步教我?我看到了两个有用的网页:
回到“聚潮资讯网”,F12复习要素——>网络——>XHR——>F5重装,看到了这些东西:
选择这个完整的?searchxxxxxxxxx:
进入这个页面后,公告板请求了另一个url:
请求 URL:%E8%82%A1%E7%A5%A8%E8%B4%A8%E6%8A%BC&sdate=&edate=&isfulltext=false&sortName=pubdate&sortType=desc&pageNum=1
打开它,得到返回的数据,就是想要的“搜索结果”的数据:
8. 该网页首先呈现布局界面,核心内容搜索结果异步加载。
以后如果学了html、JavaScript等前端知识,再来这里讲解异步加载。
网页源代码抓取工具( html源代码翻译软件通过分析,提取源代码需要汉化的文本 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 236 次浏览 • 2021-10-13 00:13
html源代码翻译软件通过分析,提取源代码需要汉化的文本
)
html源代码翻译工具官方版是一款非常专业的html源代码翻译软件。官方版html源代码翻译工具可以将用户的htm添加到软件中直接翻译。官方版html源代码翻译工具可以批量翻译文件,也可以翻译所有网页。软件支持中英文转换功能,软件可以保证翻译结果的准确性。该软件非常适合需要查看网页代码的用户。
软件介绍
官方版html源代码翻译工具分析html,提取源代码需要汉化的文字,可以在电脑中完整翻译源代码,批量在线翻译。
软件功能
1、html源码翻译工具提供简单的文本内容翻译功能
2、在软件中添加代码文本进行翻译
3、支持自动备份功能,可以备份原创网页文件
4、 默认支持保存,翻译结果可以在原地址找到
5、快速识别htm内容,实现汉英转换
6、 可以帮助用户翻译国外网页模板
软件特点
1、html源码翻译工具提供简单的网页内容翻译功能
2、把网上下载的源代码翻译成中文
3、 将国外下载的英文网页源代码翻译成中文
4、还支持中英文转换,满足不同用户的需求
5、软件基于谷歌翻译,所以翻译结果还是很准确的
安装方法
下载html源代码翻译工具官方软件包
解压到当前文件夹
双击打开文件夹中的应用程序
查看全部
网页源代码抓取工具(
html源代码翻译软件通过分析,提取源代码需要汉化的文本
)
html源代码翻译工具官方版是一款非常专业的html源代码翻译软件。官方版html源代码翻译工具可以将用户的htm添加到软件中直接翻译。官方版html源代码翻译工具可以批量翻译文件,也可以翻译所有网页。软件支持中英文转换功能,软件可以保证翻译结果的准确性。该软件非常适合需要查看网页代码的用户。
软件介绍
官方版html源代码翻译工具分析html,提取源代码需要汉化的文字,可以在电脑中完整翻译源代码,批量在线翻译。
软件功能
1、html源码翻译工具提供简单的文本内容翻译功能
2、在软件中添加代码文本进行翻译
3、支持自动备份功能,可以备份原创网页文件
4、 默认支持保存,翻译结果可以在原地址找到
5、快速识别htm内容,实现汉英转换
6、 可以帮助用户翻译国外网页模板
软件特点
1、html源码翻译工具提供简单的网页内容翻译功能
2、把网上下载的源代码翻译成中文
3、 将国外下载的英文网页源代码翻译成中文
4、还支持中英文转换,满足不同用户的需求
5、软件基于谷歌翻译,所以翻译结果还是很准确的
安装方法
下载html源代码翻译工具官方软件包
解压到当前文件夹
双击打开文件夹中的应用程序
网页源代码抓取工具(JS加密/解密(HTML/JS互转代码转换工具))
网站优化 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-10-11 12:25
1、JS加密/解密(以js的形式对代码进行加密或解密。)
2、UTF-8 编码转换工具(UTF-8 编码转换。)
3、Unicode 编码转换工具(Unicode 编码转换。)
4、友情链接(该工具可以批量查询百度收录中指定的网站友情链接,百度快照,PR,对方是否链接到本站,你可以识别欺诈链接。)
5. META信息检测(该工具可以快速检测网页的META标签,分析标题、关键词、描述等是否对搜索引擎收录有利。)
6、MD5加密工具(对字符串进行MD5加密。)
7.身份证号码值查询(查询身份证位置、性别和出生日期。)
8、HTML/UBB 代码转换工具(HTML/UBB 代码转换。)
9、HTML/JS 转换工具(HTML/JS 转换。)
10.搜索蜘蛛和机器人模拟工具(该工具可以快速模拟搜索引擎蜘蛛访问页面时抓取的内容信息!)
11、关键词密度检测(该工具可以快速检测关键词出现的页面的数量和密度,更适合蜘蛛搜索。)
12、国家域名查看(查看所有国家的域名。)
13、邮编区号查询(查询各区的邮编区号,支持模糊查询。)
14、域名Whois查询工具(Whois简单来说就是一个数据库,用来查询一个域名是否已经注册以及注册域名的详细信息(如域名拥有者、域名注册商、域名注册商)日期和有效期)日期等)。通过域名Whois查询,可以查询到域名拥有者的联系方式,以及注册和过期时间。)
15、死链检测/全站PR查询(该工具可以快速检测网站的死链。死链-也叫无效链接,即那些不可达的链接。A 网站死链接的存在不是什么好事,首先,如果死链接数量众多,对网站的整体形象会造成很大的损害。其次,搜索引擎蜘蛛爬取通过链接,如果链接太多无法到达,不仅收录的页面数量会减少,而且你的网站在搜索引擎中的权重也会大大降低。这个查询可以遍历所有的链接在指定的网页上并分析每个链接的有效性,找出死链接。)
16、搜索引擎收录查询(此工具可以快速查询网站各大搜索引擎的收录数量!)
17、搜索引擎反向链接(此工具可以快速查询各大搜索引擎到网站的反向链接数量!)
18、查询手机号码归属地(查询手机号码归属地和手机号码类型。)
19、SEO综合查询(SEO综合查询。)
标签:搜索工具网站SEO 查看全部
网页源代码抓取工具(JS加密/解密(HTML/JS互转代码转换工具))
1、JS加密/解密(以js的形式对代码进行加密或解密。)
2、UTF-8 编码转换工具(UTF-8 编码转换。)
3、Unicode 编码转换工具(Unicode 编码转换。)
4、友情链接(该工具可以批量查询百度收录中指定的网站友情链接,百度快照,PR,对方是否链接到本站,你可以识别欺诈链接。)
5. META信息检测(该工具可以快速检测网页的META标签,分析标题、关键词、描述等是否对搜索引擎收录有利。)
6、MD5加密工具(对字符串进行MD5加密。)
7.身份证号码值查询(查询身份证位置、性别和出生日期。)
8、HTML/UBB 代码转换工具(HTML/UBB 代码转换。)
9、HTML/JS 转换工具(HTML/JS 转换。)
10.搜索蜘蛛和机器人模拟工具(该工具可以快速模拟搜索引擎蜘蛛访问页面时抓取的内容信息!)
11、关键词密度检测(该工具可以快速检测关键词出现的页面的数量和密度,更适合蜘蛛搜索。)
12、国家域名查看(查看所有国家的域名。)
13、邮编区号查询(查询各区的邮编区号,支持模糊查询。)
14、域名Whois查询工具(Whois简单来说就是一个数据库,用来查询一个域名是否已经注册以及注册域名的详细信息(如域名拥有者、域名注册商、域名注册商)日期和有效期)日期等)。通过域名Whois查询,可以查询到域名拥有者的联系方式,以及注册和过期时间。)
15、死链检测/全站PR查询(该工具可以快速检测网站的死链。死链-也叫无效链接,即那些不可达的链接。A 网站死链接的存在不是什么好事,首先,如果死链接数量众多,对网站的整体形象会造成很大的损害。其次,搜索引擎蜘蛛爬取通过链接,如果链接太多无法到达,不仅收录的页面数量会减少,而且你的网站在搜索引擎中的权重也会大大降低。这个查询可以遍历所有的链接在指定的网页上并分析每个链接的有效性,找出死链接。)
16、搜索引擎收录查询(此工具可以快速查询网站各大搜索引擎的收录数量!)
17、搜索引擎反向链接(此工具可以快速查询各大搜索引擎到网站的反向链接数量!)
18、查询手机号码归属地(查询手机号码归属地和手机号码类型。)
19、SEO综合查询(SEO综合查询。)
标签:搜索工具网站SEO
网页源代码抓取工具(手机显示的画面截图插件可以直接整屏Command网页的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-08 05:02
说到截取整个网站页面,很多朋友第一时间就想到了用哪个chrome插件。确实,我们网站之前已经引入了一些截图插件,比如:
1.很棒的截图,
2.网页截图,
3.Smartshot:支持滚动的谷歌浏览器截图插件
4.Joxi 全屏截屏:全屏截屏插件
但实际上,现在很多浏览器都有自己的截图功能。尤其是像chrome这样强大的浏览器,很可惜Chrome并没有明显的显示出这个功能,所以今天给大家分享一个不用任何软件、插件就可以直接全屏截取的网页。事情是这样的!
第一步:打开chrome开发者工具。
打开要截屏的网页,然后按 F12(对于 macOS 为 option + command + i)调出开发者工具,然后按“Ctrl + Shift + P”(对于 macOS 为 command + Shift + P)。然后输入命令capture,会提示三个选项,如下图:
它们是捕捉全屏、节点模式和当前范围,用鼠标单击或用键盘选择相应的。
第二步:截取手机版网页的截图。如果您想在手机等移动设备上对网页进行截图,可以使用快捷键Ctrl + Shift + M(⌘Command + ⇧Shift + M for Mac)启动模拟工具。在iPhone、iPad、Nexus、Galaxy等设备上切换网页的显示状态,然后使用上面介绍的截图功能对手机上显示的网页进行截图。
是不是特别简单?相比使用扩展程序截屏,这种方式当然更加复杂和简陋,但是当您急需使用扩展程序又不方便下载扩展程序时,它也是一个不错的选择。当然,您也可以选择网页截图插件。 查看全部
网页源代码抓取工具(手机显示的画面截图插件可以直接整屏Command网页的方法)
说到截取整个网站页面,很多朋友第一时间就想到了用哪个chrome插件。确实,我们网站之前已经引入了一些截图插件,比如:
1.很棒的截图,
2.网页截图,
3.Smartshot:支持滚动的谷歌浏览器截图插件
4.Joxi 全屏截屏:全屏截屏插件
但实际上,现在很多浏览器都有自己的截图功能。尤其是像chrome这样强大的浏览器,很可惜Chrome并没有明显的显示出这个功能,所以今天给大家分享一个不用任何软件、插件就可以直接全屏截取的网页。事情是这样的!
第一步:打开chrome开发者工具。
打开要截屏的网页,然后按 F12(对于 macOS 为 option + command + i)调出开发者工具,然后按“Ctrl + Shift + P”(对于 macOS 为 command + Shift + P)。然后输入命令capture,会提示三个选项,如下图:
它们是捕捉全屏、节点模式和当前范围,用鼠标单击或用键盘选择相应的。
第二步:截取手机版网页的截图。如果您想在手机等移动设备上对网页进行截图,可以使用快捷键Ctrl + Shift + M(⌘Command + ⇧Shift + M for Mac)启动模拟工具。在iPhone、iPad、Nexus、Galaxy等设备上切换网页的显示状态,然后使用上面介绍的截图功能对手机上显示的网页进行截图。
是不是特别简单?相比使用扩展程序截屏,这种方式当然更加复杂和简陋,但是当您急需使用扩展程序又不方便下载扩展程序时,它也是一个不错的选择。当然,您也可以选择网页截图插件。
网页源代码抓取工具(网页数据结构化抓取工具(:Powercap网页化))
网站优化 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-10-08 04:33
软件名称:Powercap web数据结构化爬虫工具绿色版
软件版本:1.6
软件大小:5.6mb
授权方式:试用版
作品类型:国产软件
应用平台:Win2000/XP/2003/Win7/Vista
软件语言:简体中文
开发者网址:
开发者邮箱:
下载链接:
软件界面图:
软件介绍:
PowerCap是一款专业的网络信息采集解决方案,可以采集任何类型的网站采集信息,如新闻网站、电子商务网站、论坛、求职网站等支持登录采集、跨页采集、多页合并、增量采集、点击导航、POST 采集、脚本支持、内置人体提取算法,自动采集图片、flash等附件。可以发布到任何ODBC数据库、Excel、Access中,也可以通过Web在线发布。
最新的1.6 版本目前支持以下功能:
* 自动登录或手动登录后采集页面
* 支持Javascript脚本生成的页面
* 定时自动爬行
* 正文提取算法自动去除页面中的广告
* 增量采集
* 多页合并功能
* 自动提取分布在多个页面上的信息
* 自动提取图片、flash等附件
* 点击导航
* 向导式定义抽取规则,抽取方式丰富(前后符号、正则表达式、智能字段、内置字段等)
* POST采集
* 采集页面保存为单个文件
* 使用插件处理采集页面
* 支持VBScript、JavaScript处理采集结果
* 输出到文本文件、Excel、Access、任何支持ODBC的数据库,并在网页上在线发布
* 全局替换抓取的内容
* 意外退出保护,服务器无人值守抓取
与以往爬虫软件相比的优势:
* 采集Anti-leech网站:目前很多网站采用了anti-leech技术来防止采集,PowerCap有效支持anti-leech采集技术
* JavaScript 输出网站:对于使用大量脚本输出页面内容的网页,传统的采集技术无能为力。在PowerCap中,我们独有的脚本支持技术可以应对这种网站
* 脚本跳转:PowerCap可以完美支持使用脚本进行页面导航的网站
* POST采集:传统软件只能在一级起始URL上使用POST采集,而Powercap可以在任何一级进行POST采集
* 限速采集:可以限制网站的爬取速度,防止被某些网站拦截
官方 网站: 查看全部
网页源代码抓取工具(网页数据结构化抓取工具(:Powercap网页化))
软件名称:Powercap web数据结构化爬虫工具绿色版
软件版本:1.6
软件大小:5.6mb
授权方式:试用版
作品类型:国产软件
应用平台:Win2000/XP/2003/Win7/Vista
软件语言:简体中文
开发者网址:
开发者邮箱:
下载链接:
软件界面图:
软件介绍:
PowerCap是一款专业的网络信息采集解决方案,可以采集任何类型的网站采集信息,如新闻网站、电子商务网站、论坛、求职网站等支持登录采集、跨页采集、多页合并、增量采集、点击导航、POST 采集、脚本支持、内置人体提取算法,自动采集图片、flash等附件。可以发布到任何ODBC数据库、Excel、Access中,也可以通过Web在线发布。
最新的1.6 版本目前支持以下功能:
* 自动登录或手动登录后采集页面
* 支持Javascript脚本生成的页面
* 定时自动爬行
* 正文提取算法自动去除页面中的广告
* 增量采集
* 多页合并功能
* 自动提取分布在多个页面上的信息
* 自动提取图片、flash等附件
* 点击导航
* 向导式定义抽取规则,抽取方式丰富(前后符号、正则表达式、智能字段、内置字段等)
* POST采集
* 采集页面保存为单个文件
* 使用插件处理采集页面
* 支持VBScript、JavaScript处理采集结果
* 输出到文本文件、Excel、Access、任何支持ODBC的数据库,并在网页上在线发布
* 全局替换抓取的内容
* 意外退出保护,服务器无人值守抓取
与以往爬虫软件相比的优势:
* 采集Anti-leech网站:目前很多网站采用了anti-leech技术来防止采集,PowerCap有效支持anti-leech采集技术
* JavaScript 输出网站:对于使用大量脚本输出页面内容的网页,传统的采集技术无能为力。在PowerCap中,我们独有的脚本支持技术可以应对这种网站
* 脚本跳转:PowerCap可以完美支持使用脚本进行页面导航的网站
* POST采集:传统软件只能在一级起始URL上使用POST采集,而Powercap可以在任何一级进行POST采集
* 限速采集:可以限制网站的爬取速度,防止被某些网站拦截
官方 网站:
网页源代码抓取工具(蜘蛛协议风铃虫的原理简单使用提取器的作用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-10-07 06:13
风铃介绍
风铃是一款轻量级爬虫工具,像风铃一样灵敏,像蜘蛛一样敏捷,任何细小的风和草都可以感知,轻松抓取网络内容。是一个对目标服务器比较友好的蜘蛛程序。内置20多个常用或不常用的浏览器标识,可自动处理cookies和网页源信息,轻松绕过服务器限制,智能调整请求间隔,动态调整请求频率,防止干扰目标服务器。此外,Windchime 也是一个非常人性化的工具。它提供了大量的链接提取器和内容提取器,让用户可以根据自己的需要快速配置,甚至可以通过提供起始请求地址来配置自己的爬虫。同时,Windchime 还开放了很多自定义界面,让高级用户可以根据需要自定义爬虫功能。最后,风铃自然也支持分布式和集群功能,让你突破单机环境的束缚,释放你的爬虫能力。可以说风铃几乎可以抓取当前网站中的所有内容。
【声明】请不要将风铃应用于任何可能违反法律和道德限制的工作。请友好使用风铃,遵守蜘蛛协议,不要将风铃用于任何非法用途。如果您选择使用风铃,即表示您遵守本协议。作者不承担因您违反本协议而造成的任何法律风险和损失,一切后果由您自行承担。
快速使用
com.yishuifengxiao.common
crawler
2.1.0
交流群:
(群号624646260)
使用简单
从雅虎财经内容页面中提取电子货币名称
// 创建一个提取属性规则
// 该提取规则标识XPATH表示使用XPATH提取器进行提取,
// 该XPATH提取器的XPATH表达式为 //h1/text() , 该提取提取器的作用顺序是0
ExtractFieldRule extractFieldRule = new ExtractFieldRule(Rule.XPATH, "//h1/text()", "", 0);
// 创建一个提取项
ExtractRule extractRule = new ExtractRule();
extractRule
// 提取项代码,不能为空,同一组提取规则之内每一个提取项的编码必须唯一
.setCode("code")
// 提取项名字,可以不设置
.setName("加密电子货币名字")
// 设置提取属性规则
.setRules(Arrays.asList(extractFieldRule));
// 创建一个风铃虫实例
Crawler crawler = CrawlerBuilder.create()
// 风铃虫的起始链接
.startUrl("https://hk.finance.yahoo.com/cryptocurrencies")
// 风铃虫会将请求到的网页中的URL先全部提取出来
// 然后将匹配链接提取规则的链接过滤出来,放入请求池中
// 请求池中的链接会作为下次抓取请求的种子链接
// 可以以添加多个链接提取规则,多个规则之间是并列(或连接)的关系
// 如果不设置则表示提取链接中所有包含域名关键字(例如此例中的yahoo)的链接放入链接池
// 此例中表示符合该正则表达式的链接都会被提取出来
.addLinkRule(new MatcherRule(Pattern.REGEX, "https://hk.finance.yahoo.com/quote/.+"))
// 内容页地址规则是告诉风铃虫哪些页面是内容页
// 对于复杂情况下,可以与 内容匹配规则 配合使用
// 只有符合内容页规则的页面才会被提取数据
// 对于非内容页,风铃虫不会尝试从中提取数据
// 此例中表示符合该正则表达式的网页都是内容页,风铃虫会从这些页面里提取数据
.contentPageRule(new MatcherRule(Pattern.REGEX, "https://hk.finance.yahoo.com/quote/.+"))
// 风铃虫可以设置多个提取项,这里为了演示只设置了一个提取项
// 增加一个提取项规则
.addExtractRule(extractRule)
// 请求间隔时间
// 如果不设置则使用默认时间10秒,此值是为了防止抓取频率太高被服务器封杀
.interval(3000)// 每次进行爬取时的平均间隔时间,单位为毫秒,
.creatCrawler();
// 启动爬虫实例
crawler.start();
// 这里没有设置信息输出器,表示使用默认的信息输出器
// 默认的信息输出器使用的logback日志输出方法,因此需要看控制台信息
// 由于风铃虫是异步运行的,所以演示时这里加入循环
while (Statu.STOP != crawler.getStatu()) {
try {
Thread.sleep(1000 * 20);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
上面例子的功能是在雅虎财经的内容页面上提取电子货币的名称。用户若想提取其他信息,只需根据规则配置其他提取规则即可。
请注意,以上示例仅用于学习和演示目的。Windchime 用户在抓取网页内容时应严格遵守相关法律规定和目标网站蜘蛛协议。
风铃原理
风铃的原理很简单,主要由资源调度器、网页下载器、链接解析器、内容解析器、信息输出器组成。
它们的作用和功能如下:
链接解析器由一系列链接提取器组成。目前,链接提取器主要支持常规提取。
内容解析器由一系列内容提取器组成。不同的内容提取器功能不同,适用于不同的分析场景,支持重复、循环等多种提取器的多种组合。
以上组件都提供了自定义配置接口,让用户可以根据实际需要自定义配置,满足各种复杂甚至异常场景的需求。
内置的风铃内容提取器包括:
原文抽取器、中文抽取器、常量抽取器、CSS内容抽取器、CSS文本抽取器、邮箱抽取器、号码抽取器、正则抽取器、字符删除抽取器、字符替换抽取器、字符串截取抽取器、XPATH抽取器数组截取...
在提取文本内容时,用户可以自由组合这些提取器来提取他们需要的内容。关于提取器的更多具体用法,请参考内容提取器的使用。
Windchime 内置的浏览器标志为:
Google Chrome(windows版、linux版) Opera浏览器(windows版、MAC版) Firefox(windows版、linux版、MAC版) IE浏览器(IE9、IE11)EDAG Safari浏览器(windows版) , MAC 版)...
抓取js渲染网站
核心代码如下:
Crawler crawler = ...
crawler .setDownloader(new SeleniumDownloader("C:\\Users\\yishui\\Desktop\\geckodriver\\win32.exe",3000L))
分布式支持
核心代码如下:
....
//省略其他代码
....
//创建redis资源调度器
Scheduler scheduler=new RedisScheduler("唯一的名字",redisTemplate)
//创建一个redis资源缓存器
RequestCache requestCache = new RedisRequestCache(redisTemplate);
crawler
.setRequestCache(requestCache) //设置使用redis资源缓存器
.setScheduler(scheduler); //设置使用redis资源调度器
....
//省略其他代码
....
//启动爬虫实例
crawler.start();
状态监控
风铃还提供强大的状态监控和事件监控功能。通过状态监听器和事件监听器,风铃可以让你很好的了解任务的运行情况,实时控制实例运行过程中遇到的各种问题,真正做到洞察运行情况任务,方便操作和维护。
解析模拟器
由于风铃强大的解析功能,规则的定义非常灵活,为了直观地了解配置的规则定义的作用,风铃提供了解析模拟器,让用户快速了解自己设置的规则定义符合预期目标,及时调整规则定义,方便风铃实例的配置。
风铃平台效果演示
配置基本信息
配置爬虫名称、使用线程数、超时停止时间
配置链接爬取信息
配置爬虫的起始种子链接和从网页里提取下一次抓取时的链接的提取规则
配置站点信息
此步骤一般可以省略,但是对于某些会校验cookie和请求头参数的网站,此配置非常有用
提取项目配置
配置需要从网站里提取出来的数据,例如新闻标题和网页正文等信息
属性抽取配置
调用内容提取器进行任意组合,以根据需要提取出需要的数据
属性抽取测试
提前检查提取项的配置是否正确,提取的数据是否符合预期目标
相关资源的链接
文件地址:
API 文档:
官方文件: 查看全部
网页源代码抓取工具(蜘蛛协议风铃虫的原理简单使用提取器的作用)
风铃介绍
风铃是一款轻量级爬虫工具,像风铃一样灵敏,像蜘蛛一样敏捷,任何细小的风和草都可以感知,轻松抓取网络内容。是一个对目标服务器比较友好的蜘蛛程序。内置20多个常用或不常用的浏览器标识,可自动处理cookies和网页源信息,轻松绕过服务器限制,智能调整请求间隔,动态调整请求频率,防止干扰目标服务器。此外,Windchime 也是一个非常人性化的工具。它提供了大量的链接提取器和内容提取器,让用户可以根据自己的需要快速配置,甚至可以通过提供起始请求地址来配置自己的爬虫。同时,Windchime 还开放了很多自定义界面,让高级用户可以根据需要自定义爬虫功能。最后,风铃自然也支持分布式和集群功能,让你突破单机环境的束缚,释放你的爬虫能力。可以说风铃几乎可以抓取当前网站中的所有内容。
【声明】请不要将风铃应用于任何可能违反法律和道德限制的工作。请友好使用风铃,遵守蜘蛛协议,不要将风铃用于任何非法用途。如果您选择使用风铃,即表示您遵守本协议。作者不承担因您违反本协议而造成的任何法律风险和损失,一切后果由您自行承担。
快速使用
com.yishuifengxiao.common
crawler
2.1.0
交流群:
(群号624646260)
使用简单
从雅虎财经内容页面中提取电子货币名称
// 创建一个提取属性规则
// 该提取规则标识XPATH表示使用XPATH提取器进行提取,
// 该XPATH提取器的XPATH表达式为 //h1/text() , 该提取提取器的作用顺序是0
ExtractFieldRule extractFieldRule = new ExtractFieldRule(Rule.XPATH, "//h1/text()", "", 0);
// 创建一个提取项
ExtractRule extractRule = new ExtractRule();
extractRule
// 提取项代码,不能为空,同一组提取规则之内每一个提取项的编码必须唯一
.setCode("code")
// 提取项名字,可以不设置
.setName("加密电子货币名字")
// 设置提取属性规则
.setRules(Arrays.asList(extractFieldRule));
// 创建一个风铃虫实例
Crawler crawler = CrawlerBuilder.create()
// 风铃虫的起始链接
.startUrl("https://hk.finance.yahoo.com/cryptocurrencies";)
// 风铃虫会将请求到的网页中的URL先全部提取出来
// 然后将匹配链接提取规则的链接过滤出来,放入请求池中
// 请求池中的链接会作为下次抓取请求的种子链接
// 可以以添加多个链接提取规则,多个规则之间是并列(或连接)的关系
// 如果不设置则表示提取链接中所有包含域名关键字(例如此例中的yahoo)的链接放入链接池
// 此例中表示符合该正则表达式的链接都会被提取出来
.addLinkRule(new MatcherRule(Pattern.REGEX, "https://hk.finance.yahoo.com/quote/.+";))
// 内容页地址规则是告诉风铃虫哪些页面是内容页
// 对于复杂情况下,可以与 内容匹配规则 配合使用
// 只有符合内容页规则的页面才会被提取数据
// 对于非内容页,风铃虫不会尝试从中提取数据
// 此例中表示符合该正则表达式的网页都是内容页,风铃虫会从这些页面里提取数据
.contentPageRule(new MatcherRule(Pattern.REGEX, "https://hk.finance.yahoo.com/quote/.+";))
// 风铃虫可以设置多个提取项,这里为了演示只设置了一个提取项
// 增加一个提取项规则
.addExtractRule(extractRule)
// 请求间隔时间
// 如果不设置则使用默认时间10秒,此值是为了防止抓取频率太高被服务器封杀
.interval(3000)// 每次进行爬取时的平均间隔时间,单位为毫秒,
.creatCrawler();
// 启动爬虫实例
crawler.start();
// 这里没有设置信息输出器,表示使用默认的信息输出器
// 默认的信息输出器使用的logback日志输出方法,因此需要看控制台信息
// 由于风铃虫是异步运行的,所以演示时这里加入循环
while (Statu.STOP != crawler.getStatu()) {
try {
Thread.sleep(1000 * 20);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
上面例子的功能是在雅虎财经的内容页面上提取电子货币的名称。用户若想提取其他信息,只需根据规则配置其他提取规则即可。
请注意,以上示例仅用于学习和演示目的。Windchime 用户在抓取网页内容时应严格遵守相关法律规定和目标网站蜘蛛协议。
风铃原理
风铃的原理很简单,主要由资源调度器、网页下载器、链接解析器、内容解析器、信息输出器组成。
它们的作用和功能如下:
链接解析器由一系列链接提取器组成。目前,链接提取器主要支持常规提取。
内容解析器由一系列内容提取器组成。不同的内容提取器功能不同,适用于不同的分析场景,支持重复、循环等多种提取器的多种组合。
以上组件都提供了自定义配置接口,让用户可以根据实际需要自定义配置,满足各种复杂甚至异常场景的需求。
内置的风铃内容提取器包括:
原文抽取器、中文抽取器、常量抽取器、CSS内容抽取器、CSS文本抽取器、邮箱抽取器、号码抽取器、正则抽取器、字符删除抽取器、字符替换抽取器、字符串截取抽取器、XPATH抽取器数组截取...
在提取文本内容时,用户可以自由组合这些提取器来提取他们需要的内容。关于提取器的更多具体用法,请参考内容提取器的使用。
Windchime 内置的浏览器标志为:
Google Chrome(windows版、linux版) Opera浏览器(windows版、MAC版) Firefox(windows版、linux版、MAC版) IE浏览器(IE9、IE11)EDAG Safari浏览器(windows版) , MAC 版)...
抓取js渲染网站
核心代码如下:
Crawler crawler = ...
crawler .setDownloader(new SeleniumDownloader("C:\\Users\\yishui\\Desktop\\geckodriver\\win32.exe",3000L))
分布式支持
核心代码如下:
....
//省略其他代码
....
//创建redis资源调度器
Scheduler scheduler=new RedisScheduler("唯一的名字",redisTemplate)
//创建一个redis资源缓存器
RequestCache requestCache = new RedisRequestCache(redisTemplate);
crawler
.setRequestCache(requestCache) //设置使用redis资源缓存器
.setScheduler(scheduler); //设置使用redis资源调度器
....
//省略其他代码
....
//启动爬虫实例
crawler.start();
状态监控
风铃还提供强大的状态监控和事件监控功能。通过状态监听器和事件监听器,风铃可以让你很好的了解任务的运行情况,实时控制实例运行过程中遇到的各种问题,真正做到洞察运行情况任务,方便操作和维护。
解析模拟器
由于风铃强大的解析功能,规则的定义非常灵活,为了直观地了解配置的规则定义的作用,风铃提供了解析模拟器,让用户快速了解自己设置的规则定义符合预期目标,及时调整规则定义,方便风铃实例的配置。
风铃平台效果演示
配置基本信息
配置爬虫名称、使用线程数、超时停止时间
配置链接爬取信息
配置爬虫的起始种子链接和从网页里提取下一次抓取时的链接的提取规则
配置站点信息
此步骤一般可以省略,但是对于某些会校验cookie和请求头参数的网站,此配置非常有用
提取项目配置
配置需要从网站里提取出来的数据,例如新闻标题和网页正文等信息
属性抽取配置
调用内容提取器进行任意组合,以根据需要提取出需要的数据
属性抽取测试
提前检查提取项的配置是否正确,提取的数据是否符合预期目标
相关资源的链接
文件地址:
API 文档:
官方文件:
网页源代码抓取工具(Python模拟浏览器发起请求并解析内容代码:正则的好处)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-07 06:07
用 Python 编写爬虫工具现在已经司空见惯。每个人都希望能够编写一个程序来获取互联网上的一些信息进行数据分析或其他事情。
我们知道,爬虫的原理无非就是下载目标URL的内容并存入内存。这时候它的内容其实就是一堆HTML,然后对HTML内容进行解析,按照自己的想法提取出想要的数据。,所以今天我们主要讲四种在Python中解析网页HTML内容的方法,各有千秋,适合不同的场合使用。
首先,我们随机找了一个网站,然后豆瓣网站闪过我的脑海。好吧,网站毕竟是用Python构建的,所以我们用它作为演示。
我们找到了豆瓣的Python爬虫群主页,如下图。
让我们使用浏览器开发人员工具查看 HTML 代码并找到所需的内容。我们要获取讨论组中的所有帖子标题和链接
通过分析,我们发现其实我们想要的内容就在整个HTML代码的这个区域,那么我们只需要想办法取出这个区域的内容即可。
现在开始编写代码。
1:正则表达式大法
正则表达式通常用于检索和替换符合某种模式的文本,因此我们可以利用这个原理来提取我们想要的信息。
参考以下代码。
代码第6、7行,需要手动指定header的内容,假装这个请求是浏览器请求。否则,豆瓣会将我们的请求视为正常请求并返回 HTTP 418 错误。
在第 7 行中,我们直接使用 requests 库的 get 方法发出请求。获取到内容后,我们需要进行编码格式转换。这也是豆瓣页面渲染机制的问题。一般情况下,可以直接获取requests内容的内容。.
Python模拟浏览器发起请求并解析内容代码:
url = 'https://www.douban.com/group/4 ... aders =
{"User-Agent":"Mozilla/5.0 (Macintosh;
Intel Mac OS X 10.14; rv:71.0) Gecko/20100101
Firefox/71.0"}response = requests.get(url=url,headers=headers).
content.decode('utf-8')
正则化的优点是写起来麻烦,不容易理解,但是匹配效率很高。但是,在如今现成的HTMl内容解析库太多之后,我个人不建议使用正则化来手动匹配内容,费时费力。.
主要分析代码:
<p>re_div = r'[\W|\w]+'
pattern = re.compile(re_div)content = re.findall
(pattern, str(response))re_link = r'<a .*?>(.*?)</a>'mm
= re.findall(re_link, str(content), re.S|re.M)urls=
re.findall(r" 查看全部
网页源代码抓取工具(Python模拟浏览器发起请求并解析内容代码:正则的好处)
用 Python 编写爬虫工具现在已经司空见惯。每个人都希望能够编写一个程序来获取互联网上的一些信息进行数据分析或其他事情。
我们知道,爬虫的原理无非就是下载目标URL的内容并存入内存。这时候它的内容其实就是一堆HTML,然后对HTML内容进行解析,按照自己的想法提取出想要的数据。,所以今天我们主要讲四种在Python中解析网页HTML内容的方法,各有千秋,适合不同的场合使用。
首先,我们随机找了一个网站,然后豆瓣网站闪过我的脑海。好吧,网站毕竟是用Python构建的,所以我们用它作为演示。
我们找到了豆瓣的Python爬虫群主页,如下图。
让我们使用浏览器开发人员工具查看 HTML 代码并找到所需的内容。我们要获取讨论组中的所有帖子标题和链接
通过分析,我们发现其实我们想要的内容就在整个HTML代码的这个区域,那么我们只需要想办法取出这个区域的内容即可。
现在开始编写代码。
1:正则表达式大法
正则表达式通常用于检索和替换符合某种模式的文本,因此我们可以利用这个原理来提取我们想要的信息。
参考以下代码。
代码第6、7行,需要手动指定header的内容,假装这个请求是浏览器请求。否则,豆瓣会将我们的请求视为正常请求并返回 HTTP 418 错误。
在第 7 行中,我们直接使用 requests 库的 get 方法发出请求。获取到内容后,我们需要进行编码格式转换。这也是豆瓣页面渲染机制的问题。一般情况下,可以直接获取requests内容的内容。.
Python模拟浏览器发起请求并解析内容代码:
url = 'https://www.douban.com/group/4 ... aders =
{"User-Agent":"Mozilla/5.0 (Macintosh;
Intel Mac OS X 10.14; rv:71.0) Gecko/20100101
Firefox/71.0"}response = requests.get(url=url,headers=headers).
content.decode('utf-8')
正则化的优点是写起来麻烦,不容易理解,但是匹配效率很高。但是,在如今现成的HTMl内容解析库太多之后,我个人不建议使用正则化来手动匹配内容,费时费力。.
主要分析代码:
<p>re_div = r'[\W|\w]+'
pattern = re.compile(re_div)content = re.findall
(pattern, str(response))re_link = r'<a .*?>(.*?)</a>'mm
= re.findall(re_link, str(content), re.S|re.M)urls=
re.findall(r"
网页源代码抓取工具(如何能够获取到指定网页的源码呢?的小工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-06 20:18
在C#中,我们如何获取指定网页的源代码?比如我们想做一个带有文章抓取功能的小工具。这样的功能是必不可少的。小编做了一个可以获取网页源代码的小工具,并分享了主要代码,希望能给新手一点帮助。
首先看下面的代码:
private string GetWebContent(string url)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
HttpWebResponse respone = (HttpWebResponse)request.GetResponse();
Stream stream = respone.GetResponseStream();
Encoding encoding = Encoding.Default;
if (this.ddlEncoding.SelectedItem != null && this.ddlEncoding.SelectedItem.ToString() != "" && this.ddlEncoding.SelectedItem.ToString() != "Default")
{
encoding = Encoding.GetEncoding(this.ddlEncoding.SelectedItem.ToString());
}
StreamReader streamReader = new StreamReader(stream, encoding);
return streamReader.ReadToEnd();
}
上述方法的作用是将传入参数(url地址)的网页源码返回给调用者,但这只是全部源码,我们不能去掉网站标题, 网站body 元素等,这些元素需要正确读取,我们还要进行下一步。
Encoding encoding = Encoding.Default;
if (this.ddlEncoding.SelectedItem != null && this.ddlEncoding.SelectedItem.ToString() != "" && this.ddlEncoding.SelectedItem.ToString() != "Default")
{
encoding = Encoding.GetEncoding(this.ddlEncoding.SelectedItem.ToString());
}
主要用于处理网站的不同编码。不同的 网站 有不同的编码。如果我们在读取时使用了错误的编码,返回结果中的所有汉字都会变成乱码。因此,提供了一个功能供用户选择编码。如果源代码有误,可以使用其他编码重试。ddlEncoding(ComboBox 控件)提供所有 网站 编码选项。
下面是处理GetWebContent(stringurl)方法正确读取网站的title和body的元素的结果。
private void button1_Click(object sender, EventArgs e)
{
try
{
if (this.txtUrl.Text.Trim().Length == 0)
{
("请输入主入口地址!");
}
else
{
//这里获取GetWebContent方法的结果
string webContent = GetWebContent(this.txtUrl.Text.Trim());
//声明一个WebBrowser
WebBrowser webBrowser = new WebBrowser();
webBrowser.Navigate("about:blank");
//将GetWebContent方法返回的结果转化为HtmlDocument,就可以正确处理网页中的元素了。
HtmlDocument htmlDoc = webBrowser.Document.OpenNew(true);
htmlDoc.Write(webContent);
//获取网页中Body中的Html代码
string outerHtml = htmlDoc.Body.OuterHtml;
//获取网页的标题
string outerTitle=htmlDoc.Title;
this.txtDocumentTitle.Text = outerTitle;
this.txtDocumentConent.Text = outerHtml;
}
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
}
通过以上两步,我们就可以正确读取指定网页中的元素了。当然,在实际处理中,我们可能会遇到很多问题。比如我们需要获取需要用户名的网站的源码。与密码认证相同,但足以处理一般网页。我们也可以从得到的源代码中解析出A标签,然后根据解析出的A标签继续读取源代码,就可以实现自动爬取的功能。 查看全部
网页源代码抓取工具(如何能够获取到指定网页的源码呢?的小工具)
在C#中,我们如何获取指定网页的源代码?比如我们想做一个带有文章抓取功能的小工具。这样的功能是必不可少的。小编做了一个可以获取网页源代码的小工具,并分享了主要代码,希望能给新手一点帮助。
首先看下面的代码:
private string GetWebContent(string url)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
HttpWebResponse respone = (HttpWebResponse)request.GetResponse();
Stream stream = respone.GetResponseStream();
Encoding encoding = Encoding.Default;
if (this.ddlEncoding.SelectedItem != null && this.ddlEncoding.SelectedItem.ToString() != "" && this.ddlEncoding.SelectedItem.ToString() != "Default")
{
encoding = Encoding.GetEncoding(this.ddlEncoding.SelectedItem.ToString());
}
StreamReader streamReader = new StreamReader(stream, encoding);
return streamReader.ReadToEnd();
}
上述方法的作用是将传入参数(url地址)的网页源码返回给调用者,但这只是全部源码,我们不能去掉网站标题, 网站body 元素等,这些元素需要正确读取,我们还要进行下一步。
Encoding encoding = Encoding.Default;
if (this.ddlEncoding.SelectedItem != null && this.ddlEncoding.SelectedItem.ToString() != "" && this.ddlEncoding.SelectedItem.ToString() != "Default")
{
encoding = Encoding.GetEncoding(this.ddlEncoding.SelectedItem.ToString());
}
主要用于处理网站的不同编码。不同的 网站 有不同的编码。如果我们在读取时使用了错误的编码,返回结果中的所有汉字都会变成乱码。因此,提供了一个功能供用户选择编码。如果源代码有误,可以使用其他编码重试。ddlEncoding(ComboBox 控件)提供所有 网站 编码选项。
下面是处理GetWebContent(stringurl)方法正确读取网站的title和body的元素的结果。
private void button1_Click(object sender, EventArgs e)
{
try
{
if (this.txtUrl.Text.Trim().Length == 0)
{
("请输入主入口地址!");
}
else
{
//这里获取GetWebContent方法的结果
string webContent = GetWebContent(this.txtUrl.Text.Trim());
//声明一个WebBrowser
WebBrowser webBrowser = new WebBrowser();
webBrowser.Navigate("about:blank");
//将GetWebContent方法返回的结果转化为HtmlDocument,就可以正确处理网页中的元素了。
HtmlDocument htmlDoc = webBrowser.Document.OpenNew(true);
htmlDoc.Write(webContent);
//获取网页中Body中的Html代码
string outerHtml = htmlDoc.Body.OuterHtml;
//获取网页的标题
string outerTitle=htmlDoc.Title;
this.txtDocumentTitle.Text = outerTitle;
this.txtDocumentConent.Text = outerHtml;
}
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
}
通过以上两步,我们就可以正确读取指定网页中的元素了。当然,在实际处理中,我们可能会遇到很多问题。比如我们需要获取需要用户名的网站的源码。与密码认证相同,但足以处理一般网页。我们也可以从得到的源代码中解析出A标签,然后根据解析出的A标签继续读取源代码,就可以实现自动爬取的功能。
网页源代码抓取工具(网页分析(Chrome开发者工具)对网页抓包分析的本质与内涵)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-10-04 11:14
在这个文章中,我们将尝试使用一个直观的网页分析工具(Chrome Developer Tools)来抓取和分析网页,以更深入地了解网络爬虫的本质和内涵
1、测试环境
浏览器:Chrome 浏览器
浏览器版本:67.0.3396.99(正式版)(32位)
Web 分析工具:开发人员工具
2、网页分析(1)网页源码分析
我们知道网页分为静态网页和动态网页。很多人误以为静态网页就是没有动态效果的网页。事实上,这种说法是错误的。
另外,很多动态网站采用异步加载技术(Ajax)。这就是捕获的源代码和网站显示的源代码不一致的原因。至于如何抓取动态网页,这里有两种方法:
下面以京东产品为例,分析一下如何通过Chrome抓包。首先,我们打开某个产品的主页。
/.html
到网页空白处点击鼠标右键,选择查看网页源码(或使用快捷键Ctrl+U直接打开)
请注意网站的最原创源码是通过查看网页源码获得的,也就是我们平时抓取的源码
再次进入网页空白区域,点击鼠标右键,选择勾选(或使用快捷键Ctrl+Shift+I/F12直接打开)
请注意,检查得到的源代码是Ajax加载并JavaScript渲染的源代码,即当前网站显示内容的源代码
经过比较,我们可以发现两者的内容是不同的。这是异步加载技术(Ajax)的典型例子
目前,至少京东产品的价格是通过异步加载生成的。下面介绍三种判断网页中某个内容是否是动态生成的方法:
(2)网页抓取分析
下面以京东产品为例进行说明。打开一个产品的首页,尝试抓取动态加载的产品价格数据。
/.html
使用快捷键Ctrl+Shift+I或F12打开开发者工具,然后选择Network选项卡进行抓包分析
这时候按快捷键F5刷新页面,可以看到开发者工具里面有各种包,我们用Filter过滤包
首先我们选择Doc,可以看到列表中只出现了一个包
一般来说,这是浏览器收到的第一个包,获取请求的原创源码网站
点击Header查看其头部参数设置
单击响应以查看返回的源代码。不难发现,其实和查看网页源码返回的信息是一样的。
让我们回到下面的话题。对于动态加载的数据包的分析,我们主要看XHR和JS选项卡。
选择JS进行过滤,发现列表中有很多包。经过分析,我们过滤掉下图中标记的包
这个包返回的是价格信息,但是经过仔细分析,发现这些价格不属于当前产品,而是与产品相关。
但是怎么说这个包还是跟价格有关的,我们先来看看这个包的请求地址。
https://p.3.cn/prices/mgets%3F ... em-pc
过滤掉回调等不需要的参数,得到一个简单有效的URL
https://p.3.cn/prices/mgets%3F ... 49638
直接用浏览器打开网址,可以看到返回的JSON数据确实收录价格信息(可惜是其他商品的价格)
分析URL的参数,我们可以推断skuId应该是每个产品的唯一符号。那么在哪里可以找到我们需要的产品的skuId呢?
实际上,SKU是物流、运输等行业常用的缩写。它的全称是Stock Keeping Unit,是库存计量的基本单位。每个产品都有一个独特的 SKU
回顾我们刚刚进入的产品主页,/.html
不是隐藏了当前产品的唯一编号标识()吗?试一试!
果然,我们可以得到产品价格的完整网址,/prices/mgets?skuIds=
我们可以直接访问网站获取当前产品的价格信息
其实我们也可以对URL进行适当的泛化,以适应京东所有商品的价格爬取
很简单,把skuIds作为参数独立分开,{ID}
通过广义的URL,理论上只要能获取到商品的skuId,就可以访问到对应商品的价格 查看全部
网页源代码抓取工具(网页分析(Chrome开发者工具)对网页抓包分析的本质与内涵)
在这个文章中,我们将尝试使用一个直观的网页分析工具(Chrome Developer Tools)来抓取和分析网页,以更深入地了解网络爬虫的本质和内涵
1、测试环境
浏览器:Chrome 浏览器
浏览器版本:67.0.3396.99(正式版)(32位)
Web 分析工具:开发人员工具
2、网页分析(1)网页源码分析
我们知道网页分为静态网页和动态网页。很多人误以为静态网页就是没有动态效果的网页。事实上,这种说法是错误的。
另外,很多动态网站采用异步加载技术(Ajax)。这就是捕获的源代码和网站显示的源代码不一致的原因。至于如何抓取动态网页,这里有两种方法:
下面以京东产品为例,分析一下如何通过Chrome抓包。首先,我们打开某个产品的主页。
/.html
到网页空白处点击鼠标右键,选择查看网页源码(或使用快捷键Ctrl+U直接打开)
请注意网站的最原创源码是通过查看网页源码获得的,也就是我们平时抓取的源码
再次进入网页空白区域,点击鼠标右键,选择勾选(或使用快捷键Ctrl+Shift+I/F12直接打开)
请注意,检查得到的源代码是Ajax加载并JavaScript渲染的源代码,即当前网站显示内容的源代码
经过比较,我们可以发现两者的内容是不同的。这是异步加载技术(Ajax)的典型例子
目前,至少京东产品的价格是通过异步加载生成的。下面介绍三种判断网页中某个内容是否是动态生成的方法:
(2)网页抓取分析
下面以京东产品为例进行说明。打开一个产品的首页,尝试抓取动态加载的产品价格数据。
/.html
使用快捷键Ctrl+Shift+I或F12打开开发者工具,然后选择Network选项卡进行抓包分析
这时候按快捷键F5刷新页面,可以看到开发者工具里面有各种包,我们用Filter过滤包
首先我们选择Doc,可以看到列表中只出现了一个包
一般来说,这是浏览器收到的第一个包,获取请求的原创源码网站
点击Header查看其头部参数设置
单击响应以查看返回的源代码。不难发现,其实和查看网页源码返回的信息是一样的。
让我们回到下面的话题。对于动态加载的数据包的分析,我们主要看XHR和JS选项卡。
选择JS进行过滤,发现列表中有很多包。经过分析,我们过滤掉下图中标记的包
这个包返回的是价格信息,但是经过仔细分析,发现这些价格不属于当前产品,而是与产品相关。
但是怎么说这个包还是跟价格有关的,我们先来看看这个包的请求地址。
https://p.3.cn/prices/mgets%3F ... em-pc
过滤掉回调等不需要的参数,得到一个简单有效的URL
https://p.3.cn/prices/mgets%3F ... 49638
直接用浏览器打开网址,可以看到返回的JSON数据确实收录价格信息(可惜是其他商品的价格)
分析URL的参数,我们可以推断skuId应该是每个产品的唯一符号。那么在哪里可以找到我们需要的产品的skuId呢?
实际上,SKU是物流、运输等行业常用的缩写。它的全称是Stock Keeping Unit,是库存计量的基本单位。每个产品都有一个独特的 SKU
回顾我们刚刚进入的产品主页,/.html
不是隐藏了当前产品的唯一编号标识()吗?试一试!
果然,我们可以得到产品价格的完整网址,/prices/mgets?skuIds=
我们可以直接访问网站获取当前产品的价格信息
其实我们也可以对URL进行适当的泛化,以适应京东所有商品的价格爬取
很简单,把skuIds作为参数独立分开,{ID}
通过广义的URL,理论上只要能获取到商品的skuId,就可以访问到对应商品的价格
网页源代码抓取工具(易语言如何读取网页源码_被单击事件子程序下的讲解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2021-10-04 08:11
信息爆炸时代也引领着软件行业的不断变革。目前,对软件的需求不再是从单一面走向复杂,不仅仅是考虑某一方面的需求,而是多方面需求的综合。那么,一郎是如何读取网页源代码的呢?接下来就让MovieClip为大家讲解一下吧!
1、首先运行“易语言”主程序,弹出“新建项目对话框”,选择“Windows Window程序”,点击“确定”按钮,进入“Windows Window程序设计界面”。如下所示:
2、接下来拖放一个标签组件,两个编辑框组件,一个按钮组件,一个分组框组件。将它们放置在合适的位置,并将窗口的宽度和高度设置为合适的大小。确保橱窗简洁美观。如下所示:
3、界面调整完成后,将窗口标题、标签标题、分组框标题、按钮标题修改为对应的内容,并对编辑框和按钮组件进行标准化命名。准备编写程序代码。
4、 下一步就是写代码了。在“_button_get source code_clicked”事件子程序下,编写如下代码[编辑框_网页源代码. content = to text(HTTP读取文件(编辑框)_URL.Content))】如下图:
5、代码写好后,进入调试阶段。按“F5”快捷键运行程序。我们以百度体验的网址为例,然后点击“获取源码”按钮,等待程序执行。如图:
6、从网页源码编辑框得到的反馈结果分析,如果源码中有乱码,一般是编码方式有问题。这时候我们需要转码才能看到正常的代码。然后,我们的代码也需要做一些小的改动。如图:
7、 重新测试程序。从网页源代码编辑框的反馈结果可以看出,本次读取的网页源代码是正确的。因此,MovieClip在这里提醒大家,在编写软件或程序时,一定要反复调试。至此,易语言阅读网页源代码的讲解结束。谢谢大家阅读。
总结:以上是通过易语言获取网页源代码的相关步骤内容。感谢您的阅读和学习。 查看全部
网页源代码抓取工具(易语言如何读取网页源码_被单击事件子程序下的讲解)
信息爆炸时代也引领着软件行业的不断变革。目前,对软件的需求不再是从单一面走向复杂,不仅仅是考虑某一方面的需求,而是多方面需求的综合。那么,一郎是如何读取网页源代码的呢?接下来就让MovieClip为大家讲解一下吧!
1、首先运行“易语言”主程序,弹出“新建项目对话框”,选择“Windows Window程序”,点击“确定”按钮,进入“Windows Window程序设计界面”。如下所示:
2、接下来拖放一个标签组件,两个编辑框组件,一个按钮组件,一个分组框组件。将它们放置在合适的位置,并将窗口的宽度和高度设置为合适的大小。确保橱窗简洁美观。如下所示:
3、界面调整完成后,将窗口标题、标签标题、分组框标题、按钮标题修改为对应的内容,并对编辑框和按钮组件进行标准化命名。准备编写程序代码。
4、 下一步就是写代码了。在“_button_get source code_clicked”事件子程序下,编写如下代码[编辑框_网页源代码. content = to text(HTTP读取文件(编辑框)_URL.Content))】如下图:
5、代码写好后,进入调试阶段。按“F5”快捷键运行程序。我们以百度体验的网址为例,然后点击“获取源码”按钮,等待程序执行。如图:
6、从网页源码编辑框得到的反馈结果分析,如果源码中有乱码,一般是编码方式有问题。这时候我们需要转码才能看到正常的代码。然后,我们的代码也需要做一些小的改动。如图:
7、 重新测试程序。从网页源代码编辑框的反馈结果可以看出,本次读取的网页源代码是正确的。因此,MovieClip在这里提醒大家,在编写软件或程序时,一定要反复调试。至此,易语言阅读网页源代码的讲解结束。谢谢大家阅读。
总结:以上是通过易语言获取网页源代码的相关步骤内容。感谢您的阅读和学习。
网页源代码抓取工具( WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2021-10-04 08:03
WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
我要分享的工具是一个Chrome插件,叫做:Web Scraper,这是一个Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以将其用作爬虫工具。
也是因为最近在整理36氪文章的一些标签,打算看看其他网站风投相关的标准,所以找了一家公司,名字叫:“Keiu Data” 网站,它提供的一套“行业系统”标签很有参考价值,所以我想抓取页面上的数据,集成到我们自己的标签库中,如红字部分所示下图:
如果是规则中显示的数据,也可以用鼠标选中并复制粘贴,但还是需要想办法将其嵌入到页面中。这时候想起之前安装过Web Scraper,就试了一下。使用起来相当方便,采集效率一下子提高了。也给大家安利~
一年前在一个三班的公开课上看到了Chrome插件Web Scraper。号称是不懂编程也能实现爬虫爬虫的黑科技,但是在三类的官网上好像找不到。你可以百度:“三课爬虫”还是可以搜索到的。名字叫《人人都能学的数据爬虫类》,不过好像要收费100元。我觉得这个东西可以看网上的文章,比如我的文章~
简单的说,Web Scraper是一个基于Chrome的网页元素解析器,可以通过可视化的点击操作,实现自定义区域的数据/元素提取。同时,它还提供了定时自动提取功能,使用该功能可以作为一个简单的爬虫工具。
这里顺便解释一下网页提取器爬虫和真正写代码爬虫的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它首先让您定义要在页面上抓取的元素。,以及抓取哪些页面,然后让机器代人操作;而如果你用Python写爬虫,更多的是用网页请求命令下载整个网页,然后用代码解析HTML页面元素,提取你想要的内容,然后不断循环。相比之下,使用代码会更灵活,但解析的成本会更高。如果是简单的页面内容提取,我也推荐使用Web Scraper。
关于Web Scraper的具体安装过程以及完整功能的使用方法,今天的文章不再赘述。一是我只用了自己需要的部分,二是市面上的Web Scraper教程太多了,你可以自己找。
这里只是一个实际的过程,给大家简单介绍一下我的使用方法。
第一步是创建站点地图
打开Chrome浏览器,按F12调出开发者工具。单击最后一个选项卡上的 Web Scraper 后,选择“创建站点地图”菜单并单击“创建站点地图”选项。
首先输入你要爬取的网站 URL,以及你自定义的爬取任务的名称。比如我取的名字是:xiniulevel,网址是:
第二步,创建抓取节点
我要抓取的是一级标签和二级标签,所以先点击进入我刚刚创建的Sitemap,然后点击“添加新选择器”进入抓取节点选择器配置页面,点击“选择”按钮。当你会看到一个浮动层
此时,当您将鼠标移入网页时,它会自动以绿色突出显示您悬停的某个位置。这时候你可以先点击一个你想选择的方块,你会发现方块变成了红色。如果要选择同一层级的所有块,可以继续点击相邻的下一个块,工具会默认选中所有同层级的块,如下图:
我们会发现下面浮动窗口的文本输入框自动填充了块的XPATH路径,然后点击“完成选择!” 结束选择,浮动框消失,选中的XPATH自动填入下面的Selector行。另外,一定要选择“Multiple”来声明要选择多个块。最后,单击保存选择器按钮结束。
第三步,获取元素值
完成Selector的创建后,回到上一页,你会发现Selector表多了一行。然后就可以直接点击Action中的Data preview,查看所有想要获取的元素值。
上图所示的部分是我添加了两个Selector,一个主标签和一个次标签的情况。点击数据预览的弹窗内容其实就是我想要的,复制到EXCEL就好了,不需要太复杂。自动抓取处理。
以上是对Web Scraper的使用过程的简单介绍。当然,我的使用并不是完全高效,因为每次想要获取二级标签时,都需要先手动切换一级标签,然后再执行抓取指令。应该有更好的方法,但对我来说已经足够了。本文文章主要想和大家普及一下这个工具。这不是教程。更多功能根据自己的需要去探索吧~
怎么样,对你有帮助吗? 查看全部
网页源代码抓取工具(
WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
我要分享的工具是一个Chrome插件,叫做:Web Scraper,这是一个Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以将其用作爬虫工具。
也是因为最近在整理36氪文章的一些标签,打算看看其他网站风投相关的标准,所以找了一家公司,名字叫:“Keiu Data” 网站,它提供的一套“行业系统”标签很有参考价值,所以我想抓取页面上的数据,集成到我们自己的标签库中,如红字部分所示下图:
如果是规则中显示的数据,也可以用鼠标选中并复制粘贴,但还是需要想办法将其嵌入到页面中。这时候想起之前安装过Web Scraper,就试了一下。使用起来相当方便,采集效率一下子提高了。也给大家安利~
一年前在一个三班的公开课上看到了Chrome插件Web Scraper。号称是不懂编程也能实现爬虫爬虫的黑科技,但是在三类的官网上好像找不到。你可以百度:“三课爬虫”还是可以搜索到的。名字叫《人人都能学的数据爬虫类》,不过好像要收费100元。我觉得这个东西可以看网上的文章,比如我的文章~
简单的说,Web Scraper是一个基于Chrome的网页元素解析器,可以通过可视化的点击操作,实现自定义区域的数据/元素提取。同时,它还提供了定时自动提取功能,使用该功能可以作为一个简单的爬虫工具。
这里顺便解释一下网页提取器爬虫和真正写代码爬虫的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它首先让您定义要在页面上抓取的元素。,以及抓取哪些页面,然后让机器代人操作;而如果你用Python写爬虫,更多的是用网页请求命令下载整个网页,然后用代码解析HTML页面元素,提取你想要的内容,然后不断循环。相比之下,使用代码会更灵活,但解析的成本会更高。如果是简单的页面内容提取,我也推荐使用Web Scraper。
关于Web Scraper的具体安装过程以及完整功能的使用方法,今天的文章不再赘述。一是我只用了自己需要的部分,二是市面上的Web Scraper教程太多了,你可以自己找。
这里只是一个实际的过程,给大家简单介绍一下我的使用方法。
第一步是创建站点地图
打开Chrome浏览器,按F12调出开发者工具。单击最后一个选项卡上的 Web Scraper 后,选择“创建站点地图”菜单并单击“创建站点地图”选项。
首先输入你要爬取的网站 URL,以及你自定义的爬取任务的名称。比如我取的名字是:xiniulevel,网址是:
第二步,创建抓取节点
我要抓取的是一级标签和二级标签,所以先点击进入我刚刚创建的Sitemap,然后点击“添加新选择器”进入抓取节点选择器配置页面,点击“选择”按钮。当你会看到一个浮动层
此时,当您将鼠标移入网页时,它会自动以绿色突出显示您悬停的某个位置。这时候你可以先点击一个你想选择的方块,你会发现方块变成了红色。如果要选择同一层级的所有块,可以继续点击相邻的下一个块,工具会默认选中所有同层级的块,如下图:
我们会发现下面浮动窗口的文本输入框自动填充了块的XPATH路径,然后点击“完成选择!” 结束选择,浮动框消失,选中的XPATH自动填入下面的Selector行。另外,一定要选择“Multiple”来声明要选择多个块。最后,单击保存选择器按钮结束。
第三步,获取元素值
完成Selector的创建后,回到上一页,你会发现Selector表多了一行。然后就可以直接点击Action中的Data preview,查看所有想要获取的元素值。
上图所示的部分是我添加了两个Selector,一个主标签和一个次标签的情况。点击数据预览的弹窗内容其实就是我想要的,复制到EXCEL就好了,不需要太复杂。自动抓取处理。
以上是对Web Scraper的使用过程的简单介绍。当然,我的使用并不是完全高效,因为每次想要获取二级标签时,都需要先手动切换一级标签,然后再执行抓取指令。应该有更好的方法,但对我来说已经足够了。本文文章主要想和大家普及一下这个工具。这不是教程。更多功能根据自己的需要去探索吧~
怎么样,对你有帮助吗?
网页源代码抓取工具(如何通过Chrome开发者工具寻找一个网站上特定数据的抓取方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-04 05:11
网上爬虫教程太多了。在知乎上搜索,我猜你能找到不少于100个。每个人都乐于从互联网上抢一个接一个网站。但是只要对方网站更新,很可能文章里面的方法就失效了。
每个网站捕获的代码不同,但背后的原理是一样的。对于大多数 网站 来说,爬行程序就是这样。今天的文章不讲什么具体的网站爬取,只讲一个共同点:
如何使用 Chrome 开发者工具找到一种方法来捕获 网站 上的特定数据。
(我这里演示的是Mac上英文版的Chrome,中文版Windows的使用方法是一样的。)
> 查看网页源代码
在网页上右击选择“查看页面源代码”,在新标签页中会显示该URL对应的HTML代码文本。
此功能不被视为“开发人员工具”的一部分,但它也非常常用。此内容与您通过代码直接向此 URL 发送 GET 请求所获得的结果相同(无论是否存在权限问题)。如果你能在这个源码页上找到你想要的内容,就可以按照它的规则,通过regular、bs4、xpath等方法提取文本中的数据。
但是,对于很多异步加载数据的网站来说,你在这个页面上找不到你想要的。或者因为权限和验证的限制,在代码中得到的结果与页面显示不一致。在这些情况下,我们需要更强大的开发人员工具来提供帮助。
> 元素
在网页上右击选择“Inspect”,进入Chrome Developer Tools的元素选择器。在工具中是元素选项卡。
元素有几个功能:
从 Elements 工具中定位数据比直接在源代码中搜索更方便,因为您可以清楚地看到它所在的元素结构。但这里特别提醒:
Elements 中看到的代码不等于请求 URL 的返回值。
是浏览器渲染的网页最终效果,包括异步请求数据,以及浏览器自身对代码的优化改动。因此,您无法根据 Elements 中显示的结构获取元素。在这种情况下,您可能无法获得正确的结果。
> 网络
在开发者工具中选择Network选项卡,进入网络监控功能,也就是常说的“抓包”。
这是爬虫最重要的功能。主要解决两个问题:
捕捉什么
抓住的是如何找到通过异步请求获取的数据的来源。
打开网络页面,打开记录,刷新页面,可以看到所有发送的请求,包括数据、JS、CSS、图片、文档等,都会显示出来。您可以从请求列表中找到您的目标。
一个一个地找到它们会很痛苦。分享几个小贴士:
找到收录数据的请求后,下一步就是使用程序获取数据。这时候就是第二个问题:怎么抓。
不是所有的URL都可以通过GET直接获取(相当于在浏览器中打开地址),通常要考虑这些:
请求方法是 GET 或 POST。请求附加的参数数据。GET 和 POST 有不同的参数传递方法。标头信息。常用的有user-agent、host、referer、cookie等,其中cookie是用来标识请求者身份的关键信息。对于需要登录的网站来说,这个值是必不可少的。网站 经常使用其他几个项目来标识请求的合法性。相同的请求在浏览器中可用,但在程序中不可用。大多数标题信息是不正确的。您可以将此信息从 Chrome 复制到程序中以绕过对方的限制。
单击列表中的特定请求,可以找到上述所有信息。
找到正确的请求,设置正确的方法,传递正确的参数和头信息,网站上的大部分信息都可以做到。
网络还有一个功能:右键单击列表,选择“另存为带有内容的HAR”,然后保存到文件中。该文件收录列表中的所有请求参数和返回值信息,以便您查找和分析。(在实际操作中发现直接搜索往往无效,只能保存到文件后才能搜索)
除了 Elements 和 Network 之外,开发者工具中还有一些功能,例如:
Sources,查看资源列表,调试JS。
控制台,显示页面的错误和输出,可以执行JS代码。很多网站都会在这里放招聘彩蛋(找更知名的网站试试)。
但这些功能与爬虫关系不大。如果开发网站,优化网站速度,还需要处理其他功能。这里不多说。
综上所述,其实你应该记住以下几点:
在“查看源代码”中可以看到的数据,可以通过程序直接请求当前的URL来获取。Elements 中的 HTML 代码不等于请求的返回值,只能作为辅助。使用网络中的内容关键字搜索,或将其保存为HAR文件后搜索以找到收录数据的实际请求。查看请求的具体信息,包括方法、头部和参数,并复制到程序中使用。
了解了这些步骤后,网上的资料大部分都可以得到了,说“解决了一半”不是头条党。
当然,说起来容易些。如果你想精通,还有很多细节需要考虑,你需要不断练习。但是拿这些点来看看各种爬虫案例,思路会更清晰。
如果你想要更详细的爬虫讲解和指导,可以看看我们的《爬虫实战》课程,也有零基础入门课程。
对课程详情公众号回复码的操作(Crossin的编程课堂)
====
其他 文章 和回答:
欢迎搜索关注:Crossin的编程课堂 查看全部
网页源代码抓取工具(如何通过Chrome开发者工具寻找一个网站上特定数据的抓取方式)
网上爬虫教程太多了。在知乎上搜索,我猜你能找到不少于100个。每个人都乐于从互联网上抢一个接一个网站。但是只要对方网站更新,很可能文章里面的方法就失效了。
每个网站捕获的代码不同,但背后的原理是一样的。对于大多数 网站 来说,爬行程序就是这样。今天的文章不讲什么具体的网站爬取,只讲一个共同点:
如何使用 Chrome 开发者工具找到一种方法来捕获 网站 上的特定数据。
(我这里演示的是Mac上英文版的Chrome,中文版Windows的使用方法是一样的。)
> 查看网页源代码
在网页上右击选择“查看页面源代码”,在新标签页中会显示该URL对应的HTML代码文本。
此功能不被视为“开发人员工具”的一部分,但它也非常常用。此内容与您通过代码直接向此 URL 发送 GET 请求所获得的结果相同(无论是否存在权限问题)。如果你能在这个源码页上找到你想要的内容,就可以按照它的规则,通过regular、bs4、xpath等方法提取文本中的数据。
但是,对于很多异步加载数据的网站来说,你在这个页面上找不到你想要的。或者因为权限和验证的限制,在代码中得到的结果与页面显示不一致。在这些情况下,我们需要更强大的开发人员工具来提供帮助。
> 元素
在网页上右击选择“Inspect”,进入Chrome Developer Tools的元素选择器。在工具中是元素选项卡。
元素有几个功能:
从 Elements 工具中定位数据比直接在源代码中搜索更方便,因为您可以清楚地看到它所在的元素结构。但这里特别提醒:
Elements 中看到的代码不等于请求 URL 的返回值。
是浏览器渲染的网页最终效果,包括异步请求数据,以及浏览器自身对代码的优化改动。因此,您无法根据 Elements 中显示的结构获取元素。在这种情况下,您可能无法获得正确的结果。
> 网络
在开发者工具中选择Network选项卡,进入网络监控功能,也就是常说的“抓包”。
这是爬虫最重要的功能。主要解决两个问题:
捕捉什么
抓住的是如何找到通过异步请求获取的数据的来源。
打开网络页面,打开记录,刷新页面,可以看到所有发送的请求,包括数据、JS、CSS、图片、文档等,都会显示出来。您可以从请求列表中找到您的目标。
一个一个地找到它们会很痛苦。分享几个小贴士:
找到收录数据的请求后,下一步就是使用程序获取数据。这时候就是第二个问题:怎么抓。
不是所有的URL都可以通过GET直接获取(相当于在浏览器中打开地址),通常要考虑这些:
请求方法是 GET 或 POST。请求附加的参数数据。GET 和 POST 有不同的参数传递方法。标头信息。常用的有user-agent、host、referer、cookie等,其中cookie是用来标识请求者身份的关键信息。对于需要登录的网站来说,这个值是必不可少的。网站 经常使用其他几个项目来标识请求的合法性。相同的请求在浏览器中可用,但在程序中不可用。大多数标题信息是不正确的。您可以将此信息从 Chrome 复制到程序中以绕过对方的限制。
单击列表中的特定请求,可以找到上述所有信息。
找到正确的请求,设置正确的方法,传递正确的参数和头信息,网站上的大部分信息都可以做到。
网络还有一个功能:右键单击列表,选择“另存为带有内容的HAR”,然后保存到文件中。该文件收录列表中的所有请求参数和返回值信息,以便您查找和分析。(在实际操作中发现直接搜索往往无效,只能保存到文件后才能搜索)
除了 Elements 和 Network 之外,开发者工具中还有一些功能,例如:
Sources,查看资源列表,调试JS。
控制台,显示页面的错误和输出,可以执行JS代码。很多网站都会在这里放招聘彩蛋(找更知名的网站试试)。
但这些功能与爬虫关系不大。如果开发网站,优化网站速度,还需要处理其他功能。这里不多说。
综上所述,其实你应该记住以下几点:
在“查看源代码”中可以看到的数据,可以通过程序直接请求当前的URL来获取。Elements 中的 HTML 代码不等于请求的返回值,只能作为辅助。使用网络中的内容关键字搜索,或将其保存为HAR文件后搜索以找到收录数据的实际请求。查看请求的具体信息,包括方法、头部和参数,并复制到程序中使用。
了解了这些步骤后,网上的资料大部分都可以得到了,说“解决了一半”不是头条党。
当然,说起来容易些。如果你想精通,还有很多细节需要考虑,你需要不断练习。但是拿这些点来看看各种爬虫案例,思路会更清晰。
如果你想要更详细的爬虫讲解和指导,可以看看我们的《爬虫实战》课程,也有零基础入门课程。
对课程详情公众号回复码的操作(Crossin的编程课堂)
====
其他 文章 和回答:
欢迎搜索关注:Crossin的编程课堂

