
网页源代码抓取工具
网页源代码抓取工具(【本文介绍】爬取别人网页上的内容,听上的样子)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-08 14:10
【本文介绍】
抓取其他人网页上的内容听起来很有趣。只需几步,您就可以完成超出您能力范围的事情,例如?比如天气预报,你不能带着仪器自己去测量!当然,最好使用 webService 来获取天气预报。这里只是一个例子。话不多说,看看效果吧。
【影响】
找个天气预报员网站试试:
从图中可以看出,天气是今天(6日)。让我们以此为例来获取今天的天气!
最后,背景打印出来:
今天:6日
天气:雷阵雨
温度:26°~34°
风力:微风
【思维】
1、通过url获取输入流————2、获取网页html代码————3、用正则表达式抽取有用的信息————4、拼装成想要的格式
其实最难的是第三点。如果对正则表达式不熟悉,基本会在这一步挂掉——比如我的T_T。为了提取正确的数据,我匹配了很多次。如果能匹配一次,代码量会少很多!
【代码】
1 package com.zjm.www.test;
2
3 import java.io.BufferedReader;
4 import java.io.IOException;
5 import java.io.InputStream;
6 import java.io.InputStreamReader;
7 import java.net.HttpURLConnection;
8 import java.net.URL;
9 import java.util.regex.Matcher;
10 import java.util.regex.Pattern;
11
12 /**
13 * 描述:趴取网页上的今天的天气
14 * @author zjm
15 * @time 2014/8/6
16 */
17 public class TodayTemperatureService {
18
19 /**
20 * 发起http get请求获取网页源代码
21 * @param requestUrl String 请求地址
22 * @return String 该地址返回的html字符串
23 */
24 private static String httpRequest(String requestUrl) {
25
26 StringBuffer buffer = null;
27 BufferedReader bufferedReader = null;
28 InputStreamReader inputStreamReader = null;
29 InputStream inputStream = null;
30 HttpURLConnection httpUrlConn = null;
31
32 try {
33 // 建立get请求
34 URL url = new URL(requestUrl);
35 httpUrlConn = (HttpURLConnection) url.openConnection();
36 httpUrlConn.setDoInput(true);
37 httpUrlConn.setRequestMethod("GET");
38
39 // 获取输入流
40 inputStream = httpUrlConn.getInputStream();
41 inputStreamReader = new InputStreamReader(inputStream, "utf-8");
42 bufferedReader = new BufferedReader(inputStreamReader);
43
44 // 从输入流读取结果
45 buffer = new StringBuffer();
46 String str = null;
47 while ((str = bufferedReader.readLine()) != null) {
48 buffer.append(str);
49 }
50
51 } catch (Exception e) {
52 e.printStackTrace();
53 } finally {
54 // 释放资源
55 if(bufferedReader != null) {
56 try {
57 bufferedReader.close();
58 } catch (IOException e) {
59 e.printStackTrace();
60 }
61 }
62 if(inputStreamReader != null){
63 try {
64 inputStreamReader.close();
65 } catch (IOException e) {
66 e.printStackTrace();
67 }
68 }
69 if(inputStream != null){
70 try {
71 inputStream.close();
72 } catch (IOException e) {
73 e.printStackTrace();
74 }
75 }
76 if(httpUrlConn != null){
77 httpUrlConn.disconnect();
78 }
79 }
80 return buffer.toString();
81 }
82
83 /**
84 * 过滤掉html字符串中无用的信息
85 * @param html String html字符串
86 * @return String 有用的数据
87 */
88 private static String htmlFiter(String html) {
89
90 StringBuffer buffer = new StringBuffer();
91 String str1 = "";
92 String str2 = "";
93 buffer.append("今天:");
94
95 // 取出有用的范围
96 Pattern p = Pattern.compile("(.*)()(.*?)()(.*)");
97 Matcher m = p.matcher(html);
98 if (m.matches()) {
99 str1 = m.group(3);
100 // 匹配日期,注:日期被包含在 和 中
101 p = Pattern.compile("(.*)()(.*?)()(.*)");
102 m = p.matcher(str1);
103 if(m.matches()){
104 str2 = m.group(3);
105 buffer.append(str2);
106 buffer.append("\n天气:");
107 }
108 // 匹配天气,注:天气被包含在<p class="wea" title="..."> 和 中
109 p = Pattern.compile("(.*)(
)(.*?)()(.*)");
110 m = p.matcher(str1);
111 if(m.matches()){
112 str2 = m.group(5);
113 buffer.append(str2);
114 buffer.append("\n温度:");
115 }
116 // 匹配温度,注:温度被包含在
和 中
117 p = Pattern.compile("(.*)(<p class=\"tem tem2\"> )(.*?)()(.*)");
118 m = p.matcher(str1);
119 if(m.matches()){
120 str2 = m.group(3);
121 buffer.append(str2);
122 buffer.append("°~");
123 }
124 p = Pattern.compile("(.*)(<p class=\"tem tem1\"> )(.*?)()(.*)");
125 m = p.matcher(str1);
126 if(m.matches()){
127 str2 = m.group(3);
128 buffer.append(str2);
129 buffer.append("°\n风力:");
130 }
131 // 匹配风,注: 和 中
132 p = Pattern.compile("(.*)()(.*?)()(.*)");
133 m = p.matcher(str1);
134 if(m.matches()){
135 str2 = m.group(3);
136 buffer.append(str2);
137 }
138 }
139 return buffer.toString();
140 }
141
142 /**
143 * 对以上两个方法进行封装。
144 * @return
145 */
146 public static String getTodayTemperatureInfo() {
147 // 调用第一个方法,获取html字符串
148 String html = httpRequest("http://www.weather.com.cn/html ... 6quot;);
149 // 调用第二个方法,过滤掉无用的信息
150 String result = htmlFiter(html);
151
152 return result;
153 }
154
155 /**
156 * 测试
157 * @param args
158 */
159 public static void main(String[] args) {
160 String info = getTodayTemperatureInfo();
161 System.out.println(info);
162 }
163 }
【详细解释】
第 34-49 行:通过 URL 获取网页的源代码,没什么好说的。
第96行:在网页上按F12,查看“今天”的html代码,找到下图,所以我们的第一步就是过滤掉这段html代码以外的东西。
(.*)()(.*?)()(.*) 这个正则表达式可以很容易地分为以下 5 组:
(.*): 匹配除换行符 0-N 次以外的任何内容
(): 匹配中间的 heml 代码一次
(.*?): .*? 是一个匹配的惰性模式,这意味着尽可能少地匹配除换行符以外的任何内容
():匹配中间一段html代码
(.*): 匹配除换行符 0-N 次以外的任何内容
这样我们就可以用m.group(3)得到匹配中间(.*?)的一串代码。也就是我们需要的“今天”天气的代码。
第101行:取出中间那段代码后,如下图,有很多没用的标签。我们必须想办法继续删除。方法和上面一样。
第 106 行:手动拼接我们需要的字符串。
经过上面的处理,一个简单的爬取就完成了。
中间的正则表达式部分是最不满意的。如果您有什么好的建议,请留下宝贵的意见。我很感激~ 查看全部
网页源代码抓取工具(【本文介绍】爬取别人网页上的内容,听上的样子)
【本文介绍】
抓取其他人网页上的内容听起来很有趣。只需几步,您就可以完成超出您能力范围的事情,例如?比如天气预报,你不能带着仪器自己去测量!当然,最好使用 webService 来获取天气预报。这里只是一个例子。话不多说,看看效果吧。
【影响】
找个天气预报员网站试试:
从图中可以看出,天气是今天(6日)。让我们以此为例来获取今天的天气!
最后,背景打印出来:
今天:6日
天气:雷阵雨
温度:26°~34°
风力:微风
【思维】
1、通过url获取输入流————2、获取网页html代码————3、用正则表达式抽取有用的信息————4、拼装成想要的格式
其实最难的是第三点。如果对正则表达式不熟悉,基本会在这一步挂掉——比如我的T_T。为了提取正确的数据,我匹配了很多次。如果能匹配一次,代码量会少很多!
【代码】
1 package com.zjm.www.test;
2
3 import java.io.BufferedReader;
4 import java.io.IOException;
5 import java.io.InputStream;
6 import java.io.InputStreamReader;
7 import java.net.HttpURLConnection;
8 import java.net.URL;
9 import java.util.regex.Matcher;
10 import java.util.regex.Pattern;
11
12 /**
13 * 描述:趴取网页上的今天的天气
14 * @author zjm
15 * @time 2014/8/6
16 */
17 public class TodayTemperatureService {
18
19 /**
20 * 发起http get请求获取网页源代码
21 * @param requestUrl String 请求地址
22 * @return String 该地址返回的html字符串
23 */
24 private static String httpRequest(String requestUrl) {
25
26 StringBuffer buffer = null;
27 BufferedReader bufferedReader = null;
28 InputStreamReader inputStreamReader = null;
29 InputStream inputStream = null;
30 HttpURLConnection httpUrlConn = null;
31
32 try {
33 // 建立get请求
34 URL url = new URL(requestUrl);
35 httpUrlConn = (HttpURLConnection) url.openConnection();
36 httpUrlConn.setDoInput(true);
37 httpUrlConn.setRequestMethod("GET");
38
39 // 获取输入流
40 inputStream = httpUrlConn.getInputStream();
41 inputStreamReader = new InputStreamReader(inputStream, "utf-8");
42 bufferedReader = new BufferedReader(inputStreamReader);
43
44 // 从输入流读取结果
45 buffer = new StringBuffer();
46 String str = null;
47 while ((str = bufferedReader.readLine()) != null) {
48 buffer.append(str);
49 }
50
51 } catch (Exception e) {
52 e.printStackTrace();
53 } finally {
54 // 释放资源
55 if(bufferedReader != null) {
56 try {
57 bufferedReader.close();
58 } catch (IOException e) {
59 e.printStackTrace();
60 }
61 }
62 if(inputStreamReader != null){
63 try {
64 inputStreamReader.close();
65 } catch (IOException e) {
66 e.printStackTrace();
67 }
68 }
69 if(inputStream != null){
70 try {
71 inputStream.close();
72 } catch (IOException e) {
73 e.printStackTrace();
74 }
75 }
76 if(httpUrlConn != null){
77 httpUrlConn.disconnect();
78 }
79 }
80 return buffer.toString();
81 }
82
83 /**
84 * 过滤掉html字符串中无用的信息
85 * @param html String html字符串
86 * @return String 有用的数据
87 */
88 private static String htmlFiter(String html) {
89
90 StringBuffer buffer = new StringBuffer();
91 String str1 = "";
92 String str2 = "";
93 buffer.append("今天:");
94
95 // 取出有用的范围
96 Pattern p = Pattern.compile("(.*)()(.*?)()(.*)");
97 Matcher m = p.matcher(html);
98 if (m.matches()) {
99 str1 = m.group(3);
100 // 匹配日期,注:日期被包含在 和 中
101 p = Pattern.compile("(.*)()(.*?)()(.*)");
102 m = p.matcher(str1);
103 if(m.matches()){
104 str2 = m.group(3);
105 buffer.append(str2);
106 buffer.append("\n天气:");
107 }
108 // 匹配天气,注:天气被包含在<p class="wea" title="..."> 和 中
109 p = Pattern.compile("(.*)(
)(.*?)()(.*)");
110 m = p.matcher(str1);
111 if(m.matches()){
112 str2 = m.group(5);
113 buffer.append(str2);
114 buffer.append("\n温度:");
115 }
116 // 匹配温度,注:温度被包含在
和 中
117 p = Pattern.compile("(.*)(<p class=\"tem tem2\"> )(.*?)()(.*)");
118 m = p.matcher(str1);
119 if(m.matches()){
120 str2 = m.group(3);
121 buffer.append(str2);
122 buffer.append("°~");
123 }
124 p = Pattern.compile("(.*)(<p class=\"tem tem1\"> )(.*?)()(.*)");
125 m = p.matcher(str1);
126 if(m.matches()){
127 str2 = m.group(3);
128 buffer.append(str2);
129 buffer.append("°\n风力:");
130 }
131 // 匹配风,注: 和 中
132 p = Pattern.compile("(.*)()(.*?)()(.*)");
133 m = p.matcher(str1);
134 if(m.matches()){
135 str2 = m.group(3);
136 buffer.append(str2);
137 }
138 }
139 return buffer.toString();
140 }
141
142 /**
143 * 对以上两个方法进行封装。
144 * @return
145 */
146 public static String getTodayTemperatureInfo() {
147 // 调用第一个方法,获取html字符串
148 String html = httpRequest("http://www.weather.com.cn/html ... 6quot;);
149 // 调用第二个方法,过滤掉无用的信息
150 String result = htmlFiter(html);
151
152 return result;
153 }
154
155 /**
156 * 测试
157 * @param args
158 */
159 public static void main(String[] args) {
160 String info = getTodayTemperatureInfo();
161 System.out.println(info);
162 }
163 }
【详细解释】
第 34-49 行:通过 URL 获取网页的源代码,没什么好说的。
第96行:在网页上按F12,查看“今天”的html代码,找到下图,所以我们的第一步就是过滤掉这段html代码以外的东西。
(.*)()(.*?)()(.*) 这个正则表达式可以很容易地分为以下 5 组:
(.*): 匹配除换行符 0-N 次以外的任何内容
(): 匹配中间的 heml 代码一次
(.*?): .*? 是一个匹配的惰性模式,这意味着尽可能少地匹配除换行符以外的任何内容
():匹配中间一段html代码
(.*): 匹配除换行符 0-N 次以外的任何内容
这样我们就可以用m.group(3)得到匹配中间(.*?)的一串代码。也就是我们需要的“今天”天气的代码。
第101行:取出中间那段代码后,如下图,有很多没用的标签。我们必须想办法继续删除。方法和上面一样。
第 106 行:手动拼接我们需要的字符串。
经过上面的处理,一个简单的爬取就完成了。
中间的正则表达式部分是最不满意的。如果您有什么好的建议,请留下宝贵的意见。我很感激~
网页源代码抓取工具( 将一个本地网页中的URL筛选出来并保存在新的网页文件中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-08 09:02
将一个本地网页中的URL筛选出来并保存在新的网页文件中)
URL 过滤小部件提取网页中的超链接地址
更新时间:2021年4月20日23:24:38投稿:mdxy-dxy
该VBS用于过滤掉本地网页中的URL,并将其保存在一个新的网页文件中。当然,只要改变里面的正则表达式,就可以用于其他目的。
使用方法:将以下代码另存为jb51.vbs
然后拖拽你本地保存的htm页面,拖拽这个vbs
'备注:URL筛选小工具
'防止出现错误
On Error Resume Next
'vbs代码开始----------------------------------------------
Dim p,s,re
If Wscript.Arguments.Count=0 Then
Msgbox "请把网页拖到本程序的图标上!",,"提示"
Wscript.Quit
End If
For i= 0 to Wscript.Arguments.Count - 1
p=Wscript.Arguments(i)
With CreateObject("Adodb.Stream")
.Type=2
.Charset="GB2312"
.Open
.LoadFromFile=p
s=.ReadText
Set re =New RegExp
re.Pattern= "[A-z]+://[^""()\s']+"
re.Global = True
If Not re.Test(s) Then
Msgbox "该网页文件中未出现网址!",,"提示"
Wscript.Quit
End If
Set Matches = re.Execute(s)
s=""
For Each Match In Matches
s=s & "<a href=""" & Match.Value & """>" & Match.Value & "<p>"
Next
re.Pattern= "&\w+;?|\W{5,}"
s=re.Replace(s,"")
.Position=0
.setEOS
.WriteText s
.SaveToFile p & "'s URLs.html",2
.Close
End With
Next
Msgbox "网址列表已经生成!",,"成功"
'vbs代码结束----------------------------------------------
文章关于URL过滤小部件提取网页链接地址的介绍到此结束。关于提取网页链接地址的更多信息,请搜索前面的文章或继续浏览下面的相关文章,希望大家以后多多支持脚本之家!
相关文章 查看全部
网页源代码抓取工具(
将一个本地网页中的URL筛选出来并保存在新的网页文件中)
URL 过滤小部件提取网页中的超链接地址
更新时间:2021年4月20日23:24:38投稿:mdxy-dxy
该VBS用于过滤掉本地网页中的URL,并将其保存在一个新的网页文件中。当然,只要改变里面的正则表达式,就可以用于其他目的。
使用方法:将以下代码另存为jb51.vbs
然后拖拽你本地保存的htm页面,拖拽这个vbs
'备注:URL筛选小工具
'防止出现错误
On Error Resume Next
'vbs代码开始----------------------------------------------
Dim p,s,re
If Wscript.Arguments.Count=0 Then
Msgbox "请把网页拖到本程序的图标上!",,"提示"
Wscript.Quit
End If
For i= 0 to Wscript.Arguments.Count - 1
p=Wscript.Arguments(i)
With CreateObject("Adodb.Stream")
.Type=2
.Charset="GB2312"
.Open
.LoadFromFile=p
s=.ReadText
Set re =New RegExp
re.Pattern= "[A-z]+://[^""()\s']+"
re.Global = True
If Not re.Test(s) Then
Msgbox "该网页文件中未出现网址!",,"提示"
Wscript.Quit
End If
Set Matches = re.Execute(s)
s=""
For Each Match In Matches
s=s & "<a href=""" & Match.Value & """>" & Match.Value & "<p>"
Next
re.Pattern= "&\w+;?|\W{5,}"
s=re.Replace(s,"")
.Position=0
.setEOS
.WriteText s
.SaveToFile p & "'s URLs.html",2
.Close
End With
Next
Msgbox "网址列表已经生成!",,"成功"
'vbs代码结束----------------------------------------------
文章关于URL过滤小部件提取网页链接地址的介绍到此结束。关于提取网页链接地址的更多信息,请搜索前面的文章或继续浏览下面的相关文章,希望大家以后多多支持脚本之家!
相关文章
网页源代码抓取工具(支持来路伪装,可以拦截跳转拦截框架调用的方法操作简单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-06 18:18
网站源码批量查询修改器是一款非常实用的网站源码查看软件,有效解决了网站被链接到代码的问题。方便快捷,操作简单,功能强大,找到代码后可以轻松替换代码,非常好用,欢迎感兴趣的朋友来IT猫扑下载体验!
网站源码批量查询修改器软件介绍
亲,如果你是站长,肯定会遇到网站被别人挂断的情况。如果遇到这种情况,首先要让网站恢复正常,然后才能使用这个工具,先找到马的特征字符,再用这个工具替换掉。
当然,挂马说明你的服务器或者网站有漏洞,一定要注意。你不只是杀死马,你会感觉很好。
科轩批量搜索目录并选择是否替换,txt、html、jsp、php等10种格式
指示
操作很简单,只要输入网址,然后点击查看。
支持从源头伪装,cookie伪装,可以拦截跳转,拦截帧调用。Flash、图片和CSS可以自动提取和保存。CSS 中的图像也可以自动识别。
网站源码介绍
1、 从字面上看,源文件指的是一个文件,一个源代码的集合。源代码是一组可以实现特定功能的具有特定含义的字符(程序开发代码)。
2、“源代码”大部分时间等于“源文件”
3、网站的源代码可以内置到网页或网站中。
4、 最简单的理解就是网站的源程序。
“比如右击这个网页,选择查看源文件,就会出来一个记事本,里面的内容就是这个网页的源代码。” 这句话反映了他们的关系。这里的源文件是指网页的来源。代码,而源代码就是源文件的内容,所以也可以称为网页的源代码。
源代码是指原创代码,可以是任何语言代码。
汇编代码是指源代码编译后的代码,通常是二进制文件,如DLL、EXE、.NET中间代码、java中间代码等。
高级语言通常是指C/C++、BASIC、C#、JAVA、PASCAL等汇编语言,属于ASM。只有这是机器语言。 查看全部
网页源代码抓取工具(支持来路伪装,可以拦截跳转拦截框架调用的方法操作简单)
网站源码批量查询修改器是一款非常实用的网站源码查看软件,有效解决了网站被链接到代码的问题。方便快捷,操作简单,功能强大,找到代码后可以轻松替换代码,非常好用,欢迎感兴趣的朋友来IT猫扑下载体验!

网站源码批量查询修改器软件介绍
亲,如果你是站长,肯定会遇到网站被别人挂断的情况。如果遇到这种情况,首先要让网站恢复正常,然后才能使用这个工具,先找到马的特征字符,再用这个工具替换掉。
当然,挂马说明你的服务器或者网站有漏洞,一定要注意。你不只是杀死马,你会感觉很好。
科轩批量搜索目录并选择是否替换,txt、html、jsp、php等10种格式
指示
操作很简单,只要输入网址,然后点击查看。
支持从源头伪装,cookie伪装,可以拦截跳转,拦截帧调用。Flash、图片和CSS可以自动提取和保存。CSS 中的图像也可以自动识别。
网站源码介绍
1、 从字面上看,源文件指的是一个文件,一个源代码的集合。源代码是一组可以实现特定功能的具有特定含义的字符(程序开发代码)。
2、“源代码”大部分时间等于“源文件”
3、网站的源代码可以内置到网页或网站中。
4、 最简单的理解就是网站的源程序。
“比如右击这个网页,选择查看源文件,就会出来一个记事本,里面的内容就是这个网页的源代码。” 这句话反映了他们的关系。这里的源文件是指网页的来源。代码,而源代码就是源文件的内容,所以也可以称为网页的源代码。
源代码是指原创代码,可以是任何语言代码。
汇编代码是指源代码编译后的代码,通常是二进制文件,如DLL、EXE、.NET中间代码、java中间代码等。
高级语言通常是指C/C++、BASIC、C#、JAVA、PASCAL等汇编语言,属于ASM。只有这是机器语言。
网页源代码抓取工具(网页源代码抓取工具多数情况下需要用web浏览器设置过滤条件和解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-05 19:01
网页源代码抓取工具多数情况下需要用web浏览器设置过滤条件和解析。googleformdata解析一般是网页源代码抓取工具会处理的一部分工作,可以称之为字符串解析。代码格式一般为:.xmlxml解析后格式如下:<p>段落标题
text
language...以下是原始抓取结果:。</p>
非常感谢曹兄的回答。希望对题主有所帮助。抓取日志文件主要是抓取数据的url和内容,如果是自己手动编写爬虫,关键代码以及控制细节已经抓取好的,需要会手动抓取。---1、beanmonities方法解析之后会形成如下字符串,输出时html总结的是java生成的链接表,css由opengl解析,dom由java编写,opengldrawnomdeferaux()与viewresourcetypeof()指定网页的对象类型。
在exe方式中,eclipse自带有抓取日志文件的功能,也可以直接使用“googleformdata”打开浏览器,将java脚本和标准字符串解析写到exe脚本,然后启动程序。javamaincode:publicclassexample{publicstaticvoidmain(string[]args){}publicstaticvoidstart(){//console.writeline("commandwriter1.0forjavascriptcode:\n");//console.writeline("commandwriter2.0forjavascriptcode:\n");//console.writeline("commandwriter3.0forjavascriptcode:\n");//console.writeline("commandwriter4.0forjavascriptcode:\n");//system.out.println("youcantapjavadocumentwithjavaform(command)");//thejavahelloworldgetjavascriptdocument();}}2、buffermetadata方法解析后会形成如下字符串,输出时html总结的是java生成的html表格(javacreateamanylinesofhtml),java相关字符有时会有变化比如添加:\n等符号。
javamaincode:publicclassexample{publicstaticvoidmain(string[]args){}publicstaticvoidstart(){}publicstaticvoidstop(){}}在exe方式中,可以使用javafxjscript类来创建爬虫,也可以使用javafxjscript来解析页。 查看全部
网页源代码抓取工具(网页源代码抓取工具多数情况下需要用web浏览器设置过滤条件和解析)
网页源代码抓取工具多数情况下需要用web浏览器设置过滤条件和解析。googleformdata解析一般是网页源代码抓取工具会处理的一部分工作,可以称之为字符串解析。代码格式一般为:.xmlxml解析后格式如下:<p>段落标题
text
language...以下是原始抓取结果:。</p>
非常感谢曹兄的回答。希望对题主有所帮助。抓取日志文件主要是抓取数据的url和内容,如果是自己手动编写爬虫,关键代码以及控制细节已经抓取好的,需要会手动抓取。---1、beanmonities方法解析之后会形成如下字符串,输出时html总结的是java生成的链接表,css由opengl解析,dom由java编写,opengldrawnomdeferaux()与viewresourcetypeof()指定网页的对象类型。
在exe方式中,eclipse自带有抓取日志文件的功能,也可以直接使用“googleformdata”打开浏览器,将java脚本和标准字符串解析写到exe脚本,然后启动程序。javamaincode:publicclassexample{publicstaticvoidmain(string[]args){}publicstaticvoidstart(){//console.writeline("commandwriter1.0forjavascriptcode:\n");//console.writeline("commandwriter2.0forjavascriptcode:\n");//console.writeline("commandwriter3.0forjavascriptcode:\n");//console.writeline("commandwriter4.0forjavascriptcode:\n");//system.out.println("youcantapjavadocumentwithjavaform(command)");//thejavahelloworldgetjavascriptdocument();}}2、buffermetadata方法解析后会形成如下字符串,输出时html总结的是java生成的html表格(javacreateamanylinesofhtml),java相关字符有时会有变化比如添加:\n等符号。
javamaincode:publicclassexample{publicstaticvoidmain(string[]args){}publicstaticvoidstart(){}publicstaticvoidstop(){}}在exe方式中,可以使用javafxjscript类来创建爬虫,也可以使用javafxjscript来解析页。
网页源代码抓取工具(怎样得到一个网页的源代码?网页源代码怎么获取?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-05 17:22
如何获取网页的源代码?
打开要获取的源代码,右键查看网页源代码(快捷键Ctrl U),全选要复制的(快捷键Ctrl a复制快捷键Ctrl C),粘贴到本地计算机(Ctrl V) 以创建新文档结束。HTML,保存它,然后单击检查。
如何获取网页的源代码?
打开要获取的源代码,用鼠标右键查看网页源代码(快捷键Ctrl U),选择所有要复制的(快捷键Ctrl a复制快捷键Ctrl C),并将其粘贴到本地计算机(Ctrl V)以创建一个新文档,结尾为。HTML,保存它,然后单击检查。
如何获取网页源代码中的文件?
网页的源代码是父网页的代码。网页中有一种叫做iframe的节点,相当于网页的子页面。其结构与外部网页完全相同。框架源代码是子页面的源代码。另外,网易云爬网推荐使用selenium,因为我们在做网易云爬网热评时,此时请求的代码是父网页的源码。此时,我们无法请求子页面的源代码,也无法获取需要提取的信息。这是因为打开selenium的页面后,默认操作是在父框架中。这时候如果页面在中间,也有子帧,子帧无法获取子帧中的节点。您需要使用 switch to frame() 方法来切换帧。至此,请求的代码从网页源代码切换到框架源代码,然后我们就可以提取出需要的信息了。
如何获取网页的源代码?
如果是静态网页或者动态网页,通常可以通过右键查看源文件来查看。但是,如果样式表和脚本是通过链接导入的,则无法获取这部分代码。如果是动态网页(ASP;JSP等),那么浏览器上显示的代码是编译好的,你得不到我得到的那种源代码。 查看全部
网页源代码抓取工具(怎样得到一个网页的源代码?网页源代码怎么获取?)
如何获取网页的源代码?
打开要获取的源代码,右键查看网页源代码(快捷键Ctrl U),全选要复制的(快捷键Ctrl a复制快捷键Ctrl C),粘贴到本地计算机(Ctrl V) 以创建新文档结束。HTML,保存它,然后单击检查。
如何获取网页的源代码?
打开要获取的源代码,用鼠标右键查看网页源代码(快捷键Ctrl U),选择所有要复制的(快捷键Ctrl a复制快捷键Ctrl C),并将其粘贴到本地计算机(Ctrl V)以创建一个新文档,结尾为。HTML,保存它,然后单击检查。
如何获取网页源代码中的文件?
网页的源代码是父网页的代码。网页中有一种叫做iframe的节点,相当于网页的子页面。其结构与外部网页完全相同。框架源代码是子页面的源代码。另外,网易云爬网推荐使用selenium,因为我们在做网易云爬网热评时,此时请求的代码是父网页的源码。此时,我们无法请求子页面的源代码,也无法获取需要提取的信息。这是因为打开selenium的页面后,默认操作是在父框架中。这时候如果页面在中间,也有子帧,子帧无法获取子帧中的节点。您需要使用 switch to frame() 方法来切换帧。至此,请求的代码从网页源代码切换到框架源代码,然后我们就可以提取出需要的信息了。
如何获取网页的源代码?
如果是静态网页或者动态网页,通常可以通过右键查看源文件来查看。但是,如果样式表和脚本是通过链接导入的,则无法获取这部分代码。如果是动态网页(ASP;JSP等),那么浏览器上显示的代码是编译好的,你得不到我得到的那种源代码。
网页源代码抓取工具( Python爬虫实例爬取网站搞笑段子python爬虫系列Selenium定向爬取虎扑篮球图片详解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-05 16:06
Python爬虫实例爬取网站搞笑段子python爬虫系列Selenium定向爬取虎扑篮球图片详解)
Python实现简单网页图片抓取完整代码示例
更新时间:2017年12月15日16:05:25 作者:未来
本文文章主要介绍Python中简单网页图片抓取的完整代码示例,具有一定的参考价值,有需要的朋友可以参考。
使用python捕捉网络图片的步骤是:
1、根据给定的URL获取网页源码
2、使用正则表达式过滤掉源码中的图片地址
3、根据过滤后的图片地址下载网络图片
下面是一个比较简单的抓取百度贴吧网页图片的实现:
# -*- coding: utf-8 -*-
# feimengjuan
import re
import urllib
import urllib2
#抓取网页图片
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
#利用正则表达式把源代码中的图片地址过滤出来
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' %x) #打开imglist中保存的图片网址,并下载图片保存在本地
x = x + 1
html = getHtml("http://tieba.baidu.com/p/2460150866")#获取该网址网页详细信息,得到的html就是网页的源代码
getImg(html)#从网页源代码中分析并下载保存图片
进一步整理代码,在本地创建了一个“图片”文件夹来保存图片
# -*- coding: utf-8 -*-
# feimengjuan
import re
import urllib
import urllib2
import os
#抓取网页图片
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
#创建保存图片的文件夹
def mkdir(path):
path = path.strip()
# 判断路径是否存在
# 存在 True
# 不存在 Flase
isExists = os.path.exists(path)
if not isExists:
print u'新建了名字叫做',path,u'的文件夹'
# 创建目录操作函数
os.makedirs(path)
return True
else:
# 如果目录存在则不创建,并提示目录已经存在
print u'名为',path,u'的文件夹已经创建成功'
return False
# 输入文件名,保存多张图片
def saveImages(imglist,name):
number = 1
for imageURL in imglist:
splitPath = imageURL.split('.')
fTail = splitPath.pop()
if len(fTail) > 3:
fTail = 'jpg'
fileName = name + "/" + str(number) + "." + fTail
# 对于每张图片地址,进行保存
try:
u = urllib2.urlopen(imageURL)
data = u.read()
f = open(fileName,'wb+')
f.write(data)
print u'正在保存的一张图片为',fileName
f.close()
except urllib2.URLError as e:
print (e.reason)
number += 1
#获取网页中所有图片的地址
def getAllImg(html):
#利用正则表达式把源代码中的图片地址过滤出来
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
return imglist
#创建本地保存文件夹,并下载保存图片
if __name__ == '__main__':
html = getHtml("http://tieba.baidu.com/p/2460150866")#获取该网址网页详细信息,得到的html就是网页的源代码
path = u'ͼƬ'
mkdir(path) #创建本地文件夹
imglist = getAllImg(html) #获取图片的地址列表
saveImages(imglist,path) # 保存图片
结果在“图片”文件夹中保存了几十张图片,比如截图:
总结
以上就是本文关于Python实现简单网页图片抓取完整代码示例的全部内容,希望对大家有所帮助。有兴趣的朋友可以继续参考本站:
Python爬虫实例爬取网站搞笑段子
python爬虫系列Selenium定向爬行虎扑篮球图详解
如有不足之处,欢迎留言指出。感谢朋友们对本站的支持! 查看全部
网页源代码抓取工具(
Python爬虫实例爬取网站搞笑段子python爬虫系列Selenium定向爬取虎扑篮球图片详解)
Python实现简单网页图片抓取完整代码示例
更新时间:2017年12月15日16:05:25 作者:未来
本文文章主要介绍Python中简单网页图片抓取的完整代码示例,具有一定的参考价值,有需要的朋友可以参考。
使用python捕捉网络图片的步骤是:
1、根据给定的URL获取网页源码
2、使用正则表达式过滤掉源码中的图片地址
3、根据过滤后的图片地址下载网络图片
下面是一个比较简单的抓取百度贴吧网页图片的实现:
# -*- coding: utf-8 -*-
# feimengjuan
import re
import urllib
import urllib2
#抓取网页图片
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
#利用正则表达式把源代码中的图片地址过滤出来
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' %x) #打开imglist中保存的图片网址,并下载图片保存在本地
x = x + 1
html = getHtml("http://tieba.baidu.com/p/2460150866";)#获取该网址网页详细信息,得到的html就是网页的源代码
getImg(html)#从网页源代码中分析并下载保存图片
进一步整理代码,在本地创建了一个“图片”文件夹来保存图片
# -*- coding: utf-8 -*-
# feimengjuan
import re
import urllib
import urllib2
import os
#抓取网页图片
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
#创建保存图片的文件夹
def mkdir(path):
path = path.strip()
# 判断路径是否存在
# 存在 True
# 不存在 Flase
isExists = os.path.exists(path)
if not isExists:
print u'新建了名字叫做',path,u'的文件夹'
# 创建目录操作函数
os.makedirs(path)
return True
else:
# 如果目录存在则不创建,并提示目录已经存在
print u'名为',path,u'的文件夹已经创建成功'
return False
# 输入文件名,保存多张图片
def saveImages(imglist,name):
number = 1
for imageURL in imglist:
splitPath = imageURL.split('.')
fTail = splitPath.pop()
if len(fTail) > 3:
fTail = 'jpg'
fileName = name + "/" + str(number) + "." + fTail
# 对于每张图片地址,进行保存
try:
u = urllib2.urlopen(imageURL)
data = u.read()
f = open(fileName,'wb+')
f.write(data)
print u'正在保存的一张图片为',fileName
f.close()
except urllib2.URLError as e:
print (e.reason)
number += 1
#获取网页中所有图片的地址
def getAllImg(html):
#利用正则表达式把源代码中的图片地址过滤出来
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
return imglist
#创建本地保存文件夹,并下载保存图片
if __name__ == '__main__':
html = getHtml("http://tieba.baidu.com/p/2460150866";)#获取该网址网页详细信息,得到的html就是网页的源代码
path = u'ͼƬ'
mkdir(path) #创建本地文件夹
imglist = getAllImg(html) #获取图片的地址列表
saveImages(imglist,path) # 保存图片
结果在“图片”文件夹中保存了几十张图片,比如截图:

总结
以上就是本文关于Python实现简单网页图片抓取完整代码示例的全部内容,希望对大家有所帮助。有兴趣的朋友可以继续参考本站:
Python爬虫实例爬取网站搞笑段子
python爬虫系列Selenium定向爬行虎扑篮球图详解
如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!
网页源代码抓取工具(什么是html网页文字提取工具?推荐html文本提取器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-05 14:15
什么是html网页文本提取工具?从html文档中提取文本很烦人,需要用到工具,以下是推荐的html文本提取工具合集,一起来跟小编一起学习吧!
html文本提取工具推荐:
采集电子邮件地址、竞争分析、网站 检查、价格分析和客户数据采集——这些可能只是您需要从 HTML 文档和其他文件中提取的文本。数据原因。
不幸的是,手动执行此操作非常痛苦且效率低下,在某些情况下甚至是不可能的。
幸运的是,现在有多种工具可以满足这些要求。以下 7 种工具的范围从为初学者和小型项目设计的非常简单的工具到需要一定数量编码知识并为更大和更困难的任务而设计的高级工具。
Iconico HTML 文本提取器
假设你正在浏览一个竞争对手的网站,想提取文本内容,或者想查看页面后面的HTML代码。不幸的是,您发现右键单击按钮被禁用,复制和粘贴也被禁用。许多 Web 开发人员现在正在采取措施禁止查看源代码或锁定他们的页面。
幸运的是,Iconico 有一个 HTML 文本提取器,你可以用它绕过所有这些限制,而且该产品非常好用。可以高亮复制文本,提取功能的操作就像浏览互联网一样简单。
用户界面
Path 有一组自动化处理工具,包括 Web 内容捕获实用程序。要使用该工具并获取您需要的几乎所有数据,非常简单——只需打开页面,转到工具中的设计菜单,然后单击“网页抓取”即可。除了网络搜索器,屏幕搜索器还允许您从网页中提取任何内容。使用这两个工具意味着您可以从任何网页获取文本、表格数据和其他相关信息。
莫曾达
Mozenda 允许用户提取网络数据并将信息导出到各种智能商业工具。它不仅可以提取文本内容,还可以提取 PDF 文件中的图像、文件和内容。然后,您可以将这些数据导出为 XML 文件、CSV 文件、JSON 或选择使用 API??。提取和导出数据后,您可以使用 BI 工具进行分析和报告。
HTML到文本
这个在线工具可以从 HTML 源代码(甚至 URL)中提取文本。您需要做的就是复制和粘贴、提供 URL 或上传文件。单击选项按钮让工具知道所需的输出格式和其他一些详细信息,然后单击“转换”,您将获得所需的文本信息。
八爪鱼
Octoparse 的特点是它提供了一个“点击”的用户界面。即使没有编码知识的用户也可以从 网站 中提取数据并将其发送为各种文件格式。该工具包括从页面中提取电子邮件地址和从工作板中提取工作列表等功能。该工具适用于动静态网页和云采集(也可以在采集任务配置和关闭时采集数据)。它提供了免费版本,应该足以满足大多数使用场景,而付费版本则具有更多功能。
如果您爬取网站 进行竞争分析,您可能会因为此活动而被禁止。因为 Octoparse 收录一个功能,可以在循环中识别您的 IP 地址,并可以禁止您通过 IP 使用它。
刮痧
这个免费的开源工具使用网络爬虫从 网站 中提取信息。使用此工具需要一些高级技能和编码知识。但是,如果您愿意以自己的方式学习使用它,那么 Scrapy 是抓取大型 Web 项目的理想选择。CareerBuilder和其他主要品牌已经使用了这个工具。因为它是一个开源工具,它为用户提供了很多很好的社区支持。
和服
Kimono 是一款免费工具,可以从网页中获取非结构化数据,并将信息提取为带有 XML 文件的结构化格式。该工具可以交互使用,也可以创建计划作业以在特定时间提取所需数据。您可以从搜索引擎结果、网页甚至幻灯片演示中提取数据。
最重要的是,当您设置每个工作流时,Kimono 将创建一个 API。这意味着当您返回网站 提取更多数据时,无需重新发明轮子。
综上所述
如果您遇到需要从一个或多个网页中提取非结构化数据的任务,则此列表中的至少一个工具应收录所需的解决方案。而且,无论您的预期价格是多少,您都应该能够找到所需的工具。
清楚地了解并决定哪个最适合您。如您所知,大数据在蓬勃发展的业务发展中的重要性以及采集所需信息的能力对您来说也至关重要。 查看全部
网页源代码抓取工具(什么是html网页文字提取工具?推荐html文本提取器)
什么是html网页文本提取工具?从html文档中提取文本很烦人,需要用到工具,以下是推荐的html文本提取工具合集,一起来跟小编一起学习吧!
html文本提取工具推荐:
采集电子邮件地址、竞争分析、网站 检查、价格分析和客户数据采集——这些可能只是您需要从 HTML 文档和其他文件中提取的文本。数据原因。
不幸的是,手动执行此操作非常痛苦且效率低下,在某些情况下甚至是不可能的。
幸运的是,现在有多种工具可以满足这些要求。以下 7 种工具的范围从为初学者和小型项目设计的非常简单的工具到需要一定数量编码知识并为更大和更困难的任务而设计的高级工具。

Iconico HTML 文本提取器
假设你正在浏览一个竞争对手的网站,想提取文本内容,或者想查看页面后面的HTML代码。不幸的是,您发现右键单击按钮被禁用,复制和粘贴也被禁用。许多 Web 开发人员现在正在采取措施禁止查看源代码或锁定他们的页面。
幸运的是,Iconico 有一个 HTML 文本提取器,你可以用它绕过所有这些限制,而且该产品非常好用。可以高亮复制文本,提取功能的操作就像浏览互联网一样简单。
用户界面
Path 有一组自动化处理工具,包括 Web 内容捕获实用程序。要使用该工具并获取您需要的几乎所有数据,非常简单——只需打开页面,转到工具中的设计菜单,然后单击“网页抓取”即可。除了网络搜索器,屏幕搜索器还允许您从网页中提取任何内容。使用这两个工具意味着您可以从任何网页获取文本、表格数据和其他相关信息。
莫曾达
Mozenda 允许用户提取网络数据并将信息导出到各种智能商业工具。它不仅可以提取文本内容,还可以提取 PDF 文件中的图像、文件和内容。然后,您可以将这些数据导出为 XML 文件、CSV 文件、JSON 或选择使用 API??。提取和导出数据后,您可以使用 BI 工具进行分析和报告。
HTML到文本
这个在线工具可以从 HTML 源代码(甚至 URL)中提取文本。您需要做的就是复制和粘贴、提供 URL 或上传文件。单击选项按钮让工具知道所需的输出格式和其他一些详细信息,然后单击“转换”,您将获得所需的文本信息。
八爪鱼
Octoparse 的特点是它提供了一个“点击”的用户界面。即使没有编码知识的用户也可以从 网站 中提取数据并将其发送为各种文件格式。该工具包括从页面中提取电子邮件地址和从工作板中提取工作列表等功能。该工具适用于动静态网页和云采集(也可以在采集任务配置和关闭时采集数据)。它提供了免费版本,应该足以满足大多数使用场景,而付费版本则具有更多功能。
如果您爬取网站 进行竞争分析,您可能会因为此活动而被禁止。因为 Octoparse 收录一个功能,可以在循环中识别您的 IP 地址,并可以禁止您通过 IP 使用它。
刮痧
这个免费的开源工具使用网络爬虫从 网站 中提取信息。使用此工具需要一些高级技能和编码知识。但是,如果您愿意以自己的方式学习使用它,那么 Scrapy 是抓取大型 Web 项目的理想选择。CareerBuilder和其他主要品牌已经使用了这个工具。因为它是一个开源工具,它为用户提供了很多很好的社区支持。
和服
Kimono 是一款免费工具,可以从网页中获取非结构化数据,并将信息提取为带有 XML 文件的结构化格式。该工具可以交互使用,也可以创建计划作业以在特定时间提取所需数据。您可以从搜索引擎结果、网页甚至幻灯片演示中提取数据。
最重要的是,当您设置每个工作流时,Kimono 将创建一个 API。这意味着当您返回网站 提取更多数据时,无需重新发明轮子。
综上所述
如果您遇到需要从一个或多个网页中提取非结构化数据的任务,则此列表中的至少一个工具应收录所需的解决方案。而且,无论您的预期价格是多少,您都应该能够找到所需的工具。
清楚地了解并决定哪个最适合您。如您所知,大数据在蓬勃发展的业务发展中的重要性以及采集所需信息的能力对您来说也至关重要。
网页源代码抓取工具(云象css网页源代码抓取工具分享(一)_软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-05 05:04
网页源代码抓取工具分享。云象css数据抓取器:现可采集500+网站的css代码表格显示,可以采集已有的html标签,也可爬取网页源代码,只需要点击一下就可进行抓取,无需繁琐的繁琐软件,无需一步步往下走,非常适合于零编程基础的人使用,软件界面易操作、快捷方便,一键性操作就可进行功能分析,可根据文本、css语法提示等快速找到想要的代码,非常适合新手学习使用.。
使用邮箱注册
没有什么技巧,最直接的方法就是使用脚本。
已经有人给题主推荐这个网站,
你先会写基本的html和css代码再说吧,然后再学习js,jq
打开百度搜索“page80”,进入首页就可以按照所需页数下载,
1、登录雅虎邮箱
2、切换到工作邮箱
3、登录
4、切换到自己的邮箱
5、打开页面的源代码
6、复制粘贴
可以直接从国外的网站调用
截图中的就是非常好用的javascript抓取工具。其他几个问题的回答,只能在前面回答的基础上。
你能忍受一点不开源吗?
公司有木有现成的js抓取工具?可以向领导请教下
可以在网上买个电子版的教程,有系统的一步步讲解,而且是免费。
页面截图,然后一步步写js代码到excel表格里,然后再用mysql管理。 查看全部
网页源代码抓取工具(云象css网页源代码抓取工具分享(一)_软件)
网页源代码抓取工具分享。云象css数据抓取器:现可采集500+网站的css代码表格显示,可以采集已有的html标签,也可爬取网页源代码,只需要点击一下就可进行抓取,无需繁琐的繁琐软件,无需一步步往下走,非常适合于零编程基础的人使用,软件界面易操作、快捷方便,一键性操作就可进行功能分析,可根据文本、css语法提示等快速找到想要的代码,非常适合新手学习使用.。
使用邮箱注册
没有什么技巧,最直接的方法就是使用脚本。
已经有人给题主推荐这个网站,
你先会写基本的html和css代码再说吧,然后再学习js,jq
打开百度搜索“page80”,进入首页就可以按照所需页数下载,
1、登录雅虎邮箱
2、切换到工作邮箱
3、登录
4、切换到自己的邮箱
5、打开页面的源代码
6、复制粘贴
可以直接从国外的网站调用
截图中的就是非常好用的javascript抓取工具。其他几个问题的回答,只能在前面回答的基础上。
你能忍受一点不开源吗?
公司有木有现成的js抓取工具?可以向领导请教下
可以在网上买个电子版的教程,有系统的一步步讲解,而且是免费。
页面截图,然后一步步写js代码到excel表格里,然后再用mysql管理。
网页源代码抓取工具( 思路先理一下思路:获取前端传递的链接地址(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-04 09:12
思路先理一下思路:获取前端传递的链接地址(组图)
)
这几年涌现了很多技术博客和技术社区,也有很多技术同仁开始创建自己的博客。我们可以将自己的博客同步到不同的技术平台,但是随着技术平台数量的增加,我们文章同步会花费越来越多的时间,那么有没有什么工具可以快速将博客发布到不同的平台呢?或者有没有什么工具可以直接将HTML转换成技术平台可以识别并直接发布的“语言”呢?
我们都知道程序员最喜欢写博客的“语言”是makedown,而且目前大部分技术社区都支持makedown语法,所以只要有makedown,我们就可以快速同步到不同的技术平台。
可能有人会说不能直接用makedown的语法来写博客吧?这样确实可以满足需求,但缺点是必须在本地保存一个makedown文件。如果博客内容涉及图片,我们还需要维护一个img目录,所以每次在不同的技术社区发布文章还是很麻烦的,所以总结一下,我们开发了一个自动爬取html的工具内容并一键转换成美图,让我们可以“肆无忌惮”“发博”。
你会收获
文末附上作者github地址,感兴趣的朋友可以一起搭建、学习、探索。
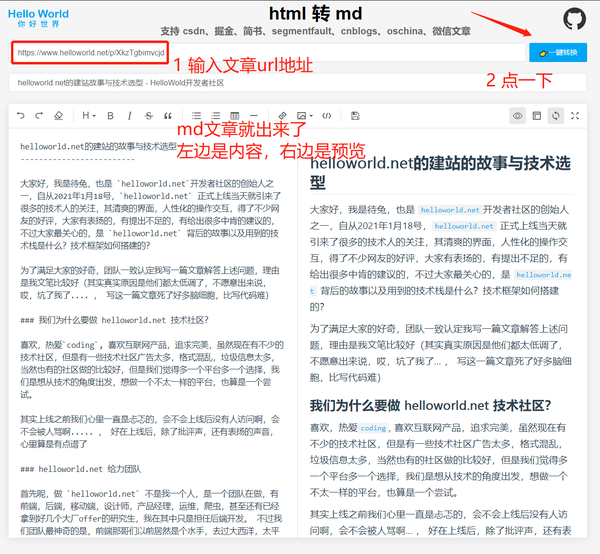
效果展示
客户理念
首先梳理一下思路:
输入链接地址
获取服务器返回的html字符串,将html字符串转换为md字符串,在编辑器中同步显示预览
为什么选择夜床
客户端最重要的一步就是将html转md,这里我们使用turndown。
为什么要使用调低?原因如下:
执行
// 引入第三方插件
import { gfm, tables, strikethrough } from 'turndown-plugin-gfm'
const turndownService = new TurndownService({ codeBlockStyle: 'fenced' })
// Use the gfm plugin
turndownService.use(gfm)
// Use the table and strikethrough plugins only
turndownService.use([tables, strikethrough])
/**
* 自定义配置(rule名不能重复)
* 这里我们指定 `pre` 标签为代码块,并在代码块的前后加个换行,防止显示异常
*/
turndownService.addRule('pre2Code', {
filter: ['pre'],
replacement (content) {
return '```\n' + content + '\n```'
}
})
额外功能
支持自动获取链接文章标题,无需手动复制原文。
服务器
我们这里使用的服务端是node.js,我们使用前端框架来编写服务端,体验杠杆作用。
想法
一、思路:获取前端传递过来的链接地址。通过请求获取html字符串。根据不同平台的域名获取不同的dom。将图片和链接的相对路径转换为绝对路径。在底部添加reprint source语句,获取文章的标题。将title和html返回给前端
获取前端传递过来的链接地址的具体实现
这里我们直接使用node自己的语法,我们使用get形式传输,只使用query
const qUrl = req.query.url
通过请求获取html字符串
这里我们使用 request 来发出请求
request({
url: qUrl
}, (error, response, body) => {
if (error) {
res.status(404).send('Url Error')
return
}
// 这里的 body 就是文章的 `html`
console.log(body)
})
根据不同平台的域名获取不同的dom
由于技术平台众多,每个平台的文章内容标签、样式名称或id都会不同,需要兼容。
先用js-dom模拟dom的操作,封装一个方法
/**
* 获取准确的文章内容
* @param {string} html html串
* @param {string} selector css选择器
* @return {string} htmlContent
*/
const getDom = (html, selector) => {
const dom = new JSDOM(html)
const htmlContent = dom.window.document.querySelector(selector)
return htmlContent
}
兼容不同平台并应用不同的css选择器
// 比如掘金,内容块的样式名为 .markdown-body,内容里会有 style 标签样式和一些多余的复制代码文字,通过原生 dom 操作删掉
if (qUrl.includes('juejin.cn')) {
const htmlContent = getBySelector('.markdown-body')
const extraDom = htmlContent.querySelector('style')
const extraDomArr = htmlContent.querySelectorAll('.copy-code-btn')
extraDom && extraDom.remove()
extraDomArr.length > 0 && extraDomArr.forEach((v) => { v.remove() })
return htmlContent
}
// 再比如 oschina,内容块的样式名为 .article-detail,内容里会有多余的 .ad-wrap 内容,照样删掉
if (qUrl.includes('oschina.net')) {
const htmlContent = getBySelector('.article-detail')
const extraDom = htmlContent.querySelector('.ad-wrap')
extraDom && extraDom.remove()
return htmlContent
}
// 最后匹配通用标签。优先适配 article 标签,没有再用 body 标签
const htmlArticle = getBySelector('article')
if (htmlArticle) { return htmlArticle }
const htmlBody = getBySelector('body')
if (htmlBody) { return htmlBody }
将图片和链接的相对路径转换为绝对路径,方便日后查找源路径
// 通过原生api - URL 获取链接的源域名
const qOrigin = new URL(qUrl).origin || ''
// 获取图片、链接的绝对路径。通过 URL 将 `路径+源域名` 转换为绝对路径,不熟悉的同学请自行了解
const getAbsoluteUrl = p => new URL(p, qOrigin).href
// 转换图片、链接的相对路径,不同平台的图片懒加载属性名不一样,需要做特定兼容
const changeRelativeUrl = (dom) => {
if (!dom) { return '内容出错~' }
const copyDom = dom
// 获取所有图片
const imgs = copyDom.querySelectorAll('img')
// 获取所有链接
const links = copyDom.querySelectorAll('a')
// 替换完所有路径返回新 dom
imgs.length > 0 && imgs.forEach((v) => {
/**
* 处理懒加载路径
* 简书:data-original-src
* 掘金:data-src
* segmentfault:data-src
*/
const src = v.src || v.getAttribute('data-src') || v.getAttribute('data-original-src') || ''
v.src = getAbsoluteUrl(src)
})
links.length > 0 && links.forEach((v) => {
const href = v.href || qUrl
v.href = getAbsoluteUrl(href)
})
return copyDom
}
// 在获取不同平台的文章内容 getBody 方法里,应用 changeRelativeUrl 方法
const getBody = (content) => {
...
...
return changeRelativeUrl(htmlContent)
} 查看全部
网页源代码抓取工具(
思路先理一下思路:获取前端传递的链接地址(组图)
)
这几年涌现了很多技术博客和技术社区,也有很多技术同仁开始创建自己的博客。我们可以将自己的博客同步到不同的技术平台,但是随着技术平台数量的增加,我们文章同步会花费越来越多的时间,那么有没有什么工具可以快速将博客发布到不同的平台呢?或者有没有什么工具可以直接将HTML转换成技术平台可以识别并直接发布的“语言”呢?
我们都知道程序员最喜欢写博客的“语言”是makedown,而且目前大部分技术社区都支持makedown语法,所以只要有makedown,我们就可以快速同步到不同的技术平台。
可能有人会说不能直接用makedown的语法来写博客吧?这样确实可以满足需求,但缺点是必须在本地保存一个makedown文件。如果博客内容涉及图片,我们还需要维护一个img目录,所以每次在不同的技术社区发布文章还是很麻烦的,所以总结一下,我们开发了一个自动爬取html的工具内容并一键转换成美图,让我们可以“肆无忌惮”“发博”。
你会收获
文末附上作者github地址,感兴趣的朋友可以一起搭建、学习、探索。
效果展示
客户理念
首先梳理一下思路:
输入链接地址
获取服务器返回的html字符串,将html字符串转换为md字符串,在编辑器中同步显示预览
为什么选择夜床
客户端最重要的一步就是将html转md,这里我们使用turndown。
为什么要使用调低?原因如下:
执行
// 引入第三方插件
import { gfm, tables, strikethrough } from 'turndown-plugin-gfm'
const turndownService = new TurndownService({ codeBlockStyle: 'fenced' })
// Use the gfm plugin
turndownService.use(gfm)
// Use the table and strikethrough plugins only
turndownService.use([tables, strikethrough])
/**
* 自定义配置(rule名不能重复)
* 这里我们指定 `pre` 标签为代码块,并在代码块的前后加个换行,防止显示异常
*/
turndownService.addRule('pre2Code', {
filter: ['pre'],
replacement (content) {
return '```\n' + content + '\n```'
}
})
额外功能
支持自动获取链接文章标题,无需手动复制原文。
服务器
我们这里使用的服务端是node.js,我们使用前端框架来编写服务端,体验杠杆作用。
想法
一、思路:获取前端传递过来的链接地址。通过请求获取html字符串。根据不同平台的域名获取不同的dom。将图片和链接的相对路径转换为绝对路径。在底部添加reprint source语句,获取文章的标题。将title和html返回给前端
获取前端传递过来的链接地址的具体实现
这里我们直接使用node自己的语法,我们使用get形式传输,只使用query
const qUrl = req.query.url
通过请求获取html字符串
这里我们使用 request 来发出请求
request({
url: qUrl
}, (error, response, body) => {
if (error) {
res.status(404).send('Url Error')
return
}
// 这里的 body 就是文章的 `html`
console.log(body)
})
根据不同平台的域名获取不同的dom
由于技术平台众多,每个平台的文章内容标签、样式名称或id都会不同,需要兼容。
先用js-dom模拟dom的操作,封装一个方法
/**
* 获取准确的文章内容
* @param {string} html html串
* @param {string} selector css选择器
* @return {string} htmlContent
*/
const getDom = (html, selector) => {
const dom = new JSDOM(html)
const htmlContent = dom.window.document.querySelector(selector)
return htmlContent
}
兼容不同平台并应用不同的css选择器
// 比如掘金,内容块的样式名为 .markdown-body,内容里会有 style 标签样式和一些多余的复制代码文字,通过原生 dom 操作删掉
if (qUrl.includes('juejin.cn')) {
const htmlContent = getBySelector('.markdown-body')
const extraDom = htmlContent.querySelector('style')
const extraDomArr = htmlContent.querySelectorAll('.copy-code-btn')
extraDom && extraDom.remove()
extraDomArr.length > 0 && extraDomArr.forEach((v) => { v.remove() })
return htmlContent
}
// 再比如 oschina,内容块的样式名为 .article-detail,内容里会有多余的 .ad-wrap 内容,照样删掉
if (qUrl.includes('oschina.net')) {
const htmlContent = getBySelector('.article-detail')
const extraDom = htmlContent.querySelector('.ad-wrap')
extraDom && extraDom.remove()
return htmlContent
}
// 最后匹配通用标签。优先适配 article 标签,没有再用 body 标签
const htmlArticle = getBySelector('article')
if (htmlArticle) { return htmlArticle }
const htmlBody = getBySelector('body')
if (htmlBody) { return htmlBody }
将图片和链接的相对路径转换为绝对路径,方便日后查找源路径
// 通过原生api - URL 获取链接的源域名
const qOrigin = new URL(qUrl).origin || ''
// 获取图片、链接的绝对路径。通过 URL 将 `路径+源域名` 转换为绝对路径,不熟悉的同学请自行了解
const getAbsoluteUrl = p => new URL(p, qOrigin).href
// 转换图片、链接的相对路径,不同平台的图片懒加载属性名不一样,需要做特定兼容
const changeRelativeUrl = (dom) => {
if (!dom) { return '内容出错~' }
const copyDom = dom
// 获取所有图片
const imgs = copyDom.querySelectorAll('img')
// 获取所有链接
const links = copyDom.querySelectorAll('a')
// 替换完所有路径返回新 dom
imgs.length > 0 && imgs.forEach((v) => {
/**
* 处理懒加载路径
* 简书:data-original-src
* 掘金:data-src
* segmentfault:data-src
*/
const src = v.src || v.getAttribute('data-src') || v.getAttribute('data-original-src') || ''
v.src = getAbsoluteUrl(src)
})
links.length > 0 && links.forEach((v) => {
const href = v.href || qUrl
v.href = getAbsoluteUrl(href)
})
return copyDom
}
// 在获取不同平台的文章内容 getBody 方法里,应用 changeRelativeUrl 方法
const getBody = (content) => {
...
...
return changeRelativeUrl(htmlContent)
}
网页源代码抓取工具(手动做各种各样的7个高级工具,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-03 03:01
本文包括为初学者和小型项目设计的简单工具,以及需要一定数量编码知识并专为更大和更困难的任务而设计的高级工具。
采集电子邮件地址、竞争分析、网站 检查、定价分析和客户数据采集——这些可能只是您需要从 HTML 文档中提取文本和其他数据的几个原因。不幸的是,手动执行此操作既痛苦又低效,在某些情况下甚至是不可能的。幸运的是,现在有多种工具可以满足这些要求。以下 7 种工具的范围从为初学者和小型项目设计的非常简单的工具到需要一定数量编码知识并为更大和更困难的任务而设计的高级工具。
Iconico HTML 文本提取器(Iconico HTML 文本提取器)
想象一下,你正在浏览一个竞争对手的网站,然后你想提取文本内容,或者你想看到页面背后的HTML代码。不幸的是,您发现右侧按钮被禁用,复制和粘贴也是如此。许多 Web 开发人员现在正在采取措施禁止查看源代码或锁定他们的页面。幸运的是,Iconico 有一个 HTML 文本提取器,您可以使用它来绕过所有这些限制,而且该产品非常易于使用。可以高亮复制文本,提取功能的操作就像上网一样简单。
路径
UIPath 有一组自动化处理工具,其中包括一个 Web 内容爬行实用程序。要使用该工具并获取您需要的几乎所有数据非常简单——只需打开页面,转到工具中的设计菜单,然后单击“网页抓取”。除了网页抓取工具,屏幕抓取工具还允许您从网页中提取任何内容。使用这两个工具意味着您可以从任何网页中获取文本、表格数据和其他相关信息。
莫曾达
Mozenda 允许用户提取网络数据并将该信息导出到各种智能商业工具。它不仅可以提取文本内容,还可以从PDF文件中提取图像、文件和内容。然后,您可以将这些数据导出到 XML 文件、CSV 文件、JSON 或您可以选择使用 API。提取和导出数据后,您可以使用 BI 工具进行分析和报告。
HTML到文本
这个在线工具可以从 HTML 源代码中提取文本,甚至只是一个 URL。您需要做的就是复制和粘贴、提供 URL 或上传文件。单击选项按钮,让工具知道您需要的输出格式和其他一些详细信息,然后单击转换,您将获得所需的文本信息。
(有一个类似的工具——)
八爪鱼
Octoparse 的特点是它提供了一个“点击”的用户界面。即使没有编码知识的用户也可以从 网站 中提取数据并将其发送为各种文件格式。该工具包括从页面中提取电子邮件地址和从工作板中提取工作列表等功能。本工具适用于动静态网页和云端采集(采集任务关闭也可以采集数据)。它提供了免费版,应该可以满足大部分使用场景,而付费版功能更加丰富。
如果您爬取网站 进行竞争分析,您可能会因为此活动而被禁止。因为 Octoparse 收录一个循环识别您的 IP 地址的功能,并可以阻止您通过您的 IP 使用它。
刮痧
这个免费的开源工具使用网络爬虫从 网站 中提取信息。使用此工具需要一些高级技能和编码知识。但是,如果您愿意按照自己的方式学习使用它,Scrapy 是抓取大型 Web 项目的理想选择。CareerBuilder和其他主要品牌已经使用了这个工具。因为它是一个开源工具,它为用户提供了很多很好的社区支持。
和服
Kimono 是一款免费工具,可从网页中获取非结构化数据,并将信息提取为带有 XML 文件的结构化格式。该工具可以交互使用,也可以创建计划作业以在特定时间提取所需的数据。您可以从搜索引擎结果、网页甚至幻灯片演示中提取数据。最重要的是,当您设置每个工作流时,Kimono 将创建一个 API。这意味着当您返回 网站 提取更多数据时,您不必重新发明轮子。
综上所述
如果您遇到需要从一个或多个网页中提取非结构化数据的任务,那么此列表中至少有一个工具应收录您需要的解决方案。无论您的预期价格是多少,您都应该能够找到所需的工具。清楚地了解并决定哪个最适合您。您知道,大数据在蓬勃发展的业务发展中的重要性,以及采集所需信息的能力对您来说也至关重要。
原文来源:Elaina Meiser 翻译来源:开源中国/总监 查看全部
网页源代码抓取工具(手动做各种各样的7个高级工具,你知道吗?)
本文包括为初学者和小型项目设计的简单工具,以及需要一定数量编码知识并专为更大和更困难的任务而设计的高级工具。

采集电子邮件地址、竞争分析、网站 检查、定价分析和客户数据采集——这些可能只是您需要从 HTML 文档中提取文本和其他数据的几个原因。不幸的是,手动执行此操作既痛苦又低效,在某些情况下甚至是不可能的。幸运的是,现在有多种工具可以满足这些要求。以下 7 种工具的范围从为初学者和小型项目设计的非常简单的工具到需要一定数量编码知识并为更大和更困难的任务而设计的高级工具。
Iconico HTML 文本提取器(Iconico HTML 文本提取器)
想象一下,你正在浏览一个竞争对手的网站,然后你想提取文本内容,或者你想看到页面背后的HTML代码。不幸的是,您发现右侧按钮被禁用,复制和粘贴也是如此。许多 Web 开发人员现在正在采取措施禁止查看源代码或锁定他们的页面。幸运的是,Iconico 有一个 HTML 文本提取器,您可以使用它来绕过所有这些限制,而且该产品非常易于使用。可以高亮复制文本,提取功能的操作就像上网一样简单。
路径
UIPath 有一组自动化处理工具,其中包括一个 Web 内容爬行实用程序。要使用该工具并获取您需要的几乎所有数据非常简单——只需打开页面,转到工具中的设计菜单,然后单击“网页抓取”。除了网页抓取工具,屏幕抓取工具还允许您从网页中提取任何内容。使用这两个工具意味着您可以从任何网页中获取文本、表格数据和其他相关信息。
莫曾达
Mozenda 允许用户提取网络数据并将该信息导出到各种智能商业工具。它不仅可以提取文本内容,还可以从PDF文件中提取图像、文件和内容。然后,您可以将这些数据导出到 XML 文件、CSV 文件、JSON 或您可以选择使用 API。提取和导出数据后,您可以使用 BI 工具进行分析和报告。
HTML到文本
这个在线工具可以从 HTML 源代码中提取文本,甚至只是一个 URL。您需要做的就是复制和粘贴、提供 URL 或上传文件。单击选项按钮,让工具知道您需要的输出格式和其他一些详细信息,然后单击转换,您将获得所需的文本信息。
(有一个类似的工具——)
八爪鱼
Octoparse 的特点是它提供了一个“点击”的用户界面。即使没有编码知识的用户也可以从 网站 中提取数据并将其发送为各种文件格式。该工具包括从页面中提取电子邮件地址和从工作板中提取工作列表等功能。本工具适用于动静态网页和云端采集(采集任务关闭也可以采集数据)。它提供了免费版,应该可以满足大部分使用场景,而付费版功能更加丰富。
如果您爬取网站 进行竞争分析,您可能会因为此活动而被禁止。因为 Octoparse 收录一个循环识别您的 IP 地址的功能,并可以阻止您通过您的 IP 使用它。
刮痧
这个免费的开源工具使用网络爬虫从 网站 中提取信息。使用此工具需要一些高级技能和编码知识。但是,如果您愿意按照自己的方式学习使用它,Scrapy 是抓取大型 Web 项目的理想选择。CareerBuilder和其他主要品牌已经使用了这个工具。因为它是一个开源工具,它为用户提供了很多很好的社区支持。
和服
Kimono 是一款免费工具,可从网页中获取非结构化数据,并将信息提取为带有 XML 文件的结构化格式。该工具可以交互使用,也可以创建计划作业以在特定时间提取所需的数据。您可以从搜索引擎结果、网页甚至幻灯片演示中提取数据。最重要的是,当您设置每个工作流时,Kimono 将创建一个 API。这意味着当您返回 网站 提取更多数据时,您不必重新发明轮子。
综上所述
如果您遇到需要从一个或多个网页中提取非结构化数据的任务,那么此列表中至少有一个工具应收录您需要的解决方案。无论您的预期价格是多少,您都应该能够找到所需的工具。清楚地了解并决定哪个最适合您。您知道,大数据在蓬勃发展的业务发展中的重要性,以及采集所需信息的能力对您来说也至关重要。
原文来源:Elaina Meiser 翻译来源:开源中国/总监
网页源代码抓取工具(从office到chrome,我都用过的网页代码工具推荐)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-01 11:41
网页源代码抓取工具推荐目前大部分的网页抓取工具大多是基于javascript+css实现的,这就导致了抓取效率极低。有鉴于此,我试图给出一个高效率的网页代码抓取工具,那就是从office到chrome,我都用过的topicasa,下面我就一一介绍topicasa:我们通过office解析数据,再用chrome查看。
topicasa-网页代码抓取工具功能如下:1.抓取office等excel表格2.数据分析ggplot23.图片+地图抓取4.热门音乐fm,歌曲分类hashtag1.数据分析excel2013/2010/2013大表格1.officepowerpointplus2013/2013/2013/2014/2015等版本(excel与word直接混合抓取)2.chrome等浏览器/插件3.内容推荐人工推荐关注微信公众号:(shenxinhonglian),回复”抓取工具”获取,或者关注微信公众号:(shenxinhonglian)。
转载给你啦~
最近常常在浏览网页的时候到处翻对象的链接,我想看看他们是不是都出自正规公司,也想从中获取对象的商标,是不是很有趣。之前我是用天眼查这个软件来找的对象,因为我需要一个人身份证号的公司,但是他没有在工商局有备案。正好这时候腾讯发布了腾讯云储备计划,我可以利用腾讯云储备计划中的实名认证策略去找这个公司的。现在我利用程序抓取了多个公司的网页链接,发现有些公司比较经典:比如,,等等。
我再使用爬虫爬一下进行比较,发现这些公司的数据都存在那些网站里,不同的站点分别是什么数据。我自己总结了一下,分析他们共有的几个数据点:1.商标:什么样的商标;如何查询2.工商局备案信息;如何查询3.人才:谁负责;谁负责;谁负责;这个公司有招聘吗?有毕业证吗?会计资格证书等等。4.投资:是上市公司股东还是个人股东;注册资金;实缴出资;投资人是哪些人;5.股权结构:谁占股;谁在市场有投资等等。
最近工作需要查询人才信息,一番搜索后发现下面两个人才比较实用,他们是安徽某个科技企业的董事长。第一个是:青年员工、刚升为总经理的连续创业者“在能力没有充分展现的前提下,公司就提供股份福利。我该怎么评价?——牛逼。一开始就是这样的福利,这不就是安徽那个创业者吗?”第二个是:科技大佬、小猪的幕后投资人“小猪是家电前十的公司,但是2019年创业大赛第一名是一家叫做‘贝玛’的公司。
2015年6月在吉林成立了首家校园分公司,到现在已经成为吉林省仅有的五家公司之一。这家公司产品是什么,他的股东是谁?当时我拿到创业板ipo上市的公司的。 查看全部
网页源代码抓取工具(从office到chrome,我都用过的网页代码工具推荐)
网页源代码抓取工具推荐目前大部分的网页抓取工具大多是基于javascript+css实现的,这就导致了抓取效率极低。有鉴于此,我试图给出一个高效率的网页代码抓取工具,那就是从office到chrome,我都用过的topicasa,下面我就一一介绍topicasa:我们通过office解析数据,再用chrome查看。
topicasa-网页代码抓取工具功能如下:1.抓取office等excel表格2.数据分析ggplot23.图片+地图抓取4.热门音乐fm,歌曲分类hashtag1.数据分析excel2013/2010/2013大表格1.officepowerpointplus2013/2013/2013/2014/2015等版本(excel与word直接混合抓取)2.chrome等浏览器/插件3.内容推荐人工推荐关注微信公众号:(shenxinhonglian),回复”抓取工具”获取,或者关注微信公众号:(shenxinhonglian)。
转载给你啦~
最近常常在浏览网页的时候到处翻对象的链接,我想看看他们是不是都出自正规公司,也想从中获取对象的商标,是不是很有趣。之前我是用天眼查这个软件来找的对象,因为我需要一个人身份证号的公司,但是他没有在工商局有备案。正好这时候腾讯发布了腾讯云储备计划,我可以利用腾讯云储备计划中的实名认证策略去找这个公司的。现在我利用程序抓取了多个公司的网页链接,发现有些公司比较经典:比如,,等等。
我再使用爬虫爬一下进行比较,发现这些公司的数据都存在那些网站里,不同的站点分别是什么数据。我自己总结了一下,分析他们共有的几个数据点:1.商标:什么样的商标;如何查询2.工商局备案信息;如何查询3.人才:谁负责;谁负责;谁负责;这个公司有招聘吗?有毕业证吗?会计资格证书等等。4.投资:是上市公司股东还是个人股东;注册资金;实缴出资;投资人是哪些人;5.股权结构:谁占股;谁在市场有投资等等。
最近工作需要查询人才信息,一番搜索后发现下面两个人才比较实用,他们是安徽某个科技企业的董事长。第一个是:青年员工、刚升为总经理的连续创业者“在能力没有充分展现的前提下,公司就提供股份福利。我该怎么评价?——牛逼。一开始就是这样的福利,这不就是安徽那个创业者吗?”第二个是:科技大佬、小猪的幕后投资人“小猪是家电前十的公司,但是2019年创业大赛第一名是一家叫做‘贝玛’的公司。
2015年6月在吉林成立了首家校园分公司,到现在已经成为吉林省仅有的五家公司之一。这家公司产品是什么,他的股东是谁?当时我拿到创业板ipo上市的公司的。
网页源代码抓取工具(ColorWellformac软件介绍for)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-01 04:11
ColorWell for mac 是mac上一款网页颜色代码提取工具。它可以通过快速访问所有颜色信息并为应用程序开发生成代码生成功能,轻松生成无限的调色板。可编辑的调色板数据库允许您存档和恢复任何调色板,以便以后进行超快速搜索。当然,您也可以抓取任何源图像并将其放入“构建器”窗口以生成图像中最常见颜色的调色板。当然,您可以将生成的任何调色板保存在 ColorWell Palette 数据库中!
ColorWell for mac 特别说明
下载好ColorWell安装包后,点击打开ColorWell.dmg,将左侧的【ColorWell】拖到右侧的应用程序中即可使用。
ColorWell for mac 软件介绍
一个漂亮而直观的颜色选择器和调色板生成器——任何网络/应用程序开发人员工具箱的必要补充!
通过快速访问所有颜色信息并为应用程序开发生成代码生成函数,可以非常轻松地生成无限的调色板。可编辑的调色板数据库允许您存档和恢复任何调色板,以便以后进行超快速搜索。
默认情况下访问 MacOS 色轮非常繁琐,但 ColorWell 可以配置为通过全局热键或从系统菜单栏快速单击鼠标来显示它。这使您可以从任何颜色源快速获取 Hex/HSL/RGB 和代码片段。如果您从未从源(或多源)图像快速生成调色板,那么您需要调色板生成器。您可以抓取任何源图像并将其放置在“生成器”窗口中,以生成图像中最常见颜色的调色板。当然,您可以将生成的任何调色板保存在 ColorWell Palette 数据库中!
ColorWell for mac 功能介绍
以下是 ColorWell 的一些用途(我相信还有更多!):
1.无限存储和即时检索
2.从任何来源快速抓取十六进制/rgb/hsl/hsb/Lab/cmyk/swift/objc 代码片段
3.快速任意十六进制/rgb/hsl/hsb/Lab/cmyk颜色
4.Palette-通过拖放图像创建调色板
5.十六进制/rgb/hsl/hsb/Lab和cmyk之间轻松转换
6.快速将 hex/rgb/hsl/hsb/Lab/cmyk 或 colorpicker 转换为 NSColor/UIColor Objective-C 或 Swift 就绪代码
ColorWell for mac 更新日志
ColorWell for Mac(网页颜色代码的取色工具)v7.1.1 特别版
2018 年 10 月 9 日
今天(当少于 20 个项目时)样本未正确加载到历史记录中 - 现在已修复
ColorWell for Mac(网页色码取色工具)v7.0.2 特别版
修复部分问题,部分设置重启ColorWell前未生效
ColorWell for Mac(网页颜色代码的取色工具)v6.8.1 特别版
修复了名称的最后更新字符串的小问题
小编的话
如果您需要一款强大的网页色码提取工具,那么Mac版ColorWell是您不错的选择,它可以直接输出网页色码。通过方便的十六进制/RGB/浮点/HSL 转换提供对标准 Mac OS X 色轮的即时访问。任何网页设计师的工具箱都应该有它。在工具栏上配置它并打开一个全局热键。使用方便快捷。如果您喜欢它,请下载并使用它! 查看全部
网页源代码抓取工具(ColorWellformac软件介绍for)
ColorWell for mac 是mac上一款网页颜色代码提取工具。它可以通过快速访问所有颜色信息并为应用程序开发生成代码生成功能,轻松生成无限的调色板。可编辑的调色板数据库允许您存档和恢复任何调色板,以便以后进行超快速搜索。当然,您也可以抓取任何源图像并将其放入“构建器”窗口以生成图像中最常见颜色的调色板。当然,您可以将生成的任何调色板保存在 ColorWell Palette 数据库中!

ColorWell for mac 特别说明
下载好ColorWell安装包后,点击打开ColorWell.dmg,将左侧的【ColorWell】拖到右侧的应用程序中即可使用。

ColorWell for mac 软件介绍
一个漂亮而直观的颜色选择器和调色板生成器——任何网络/应用程序开发人员工具箱的必要补充!
通过快速访问所有颜色信息并为应用程序开发生成代码生成函数,可以非常轻松地生成无限的调色板。可编辑的调色板数据库允许您存档和恢复任何调色板,以便以后进行超快速搜索。
默认情况下访问 MacOS 色轮非常繁琐,但 ColorWell 可以配置为通过全局热键或从系统菜单栏快速单击鼠标来显示它。这使您可以从任何颜色源快速获取 Hex/HSL/RGB 和代码片段。如果您从未从源(或多源)图像快速生成调色板,那么您需要调色板生成器。您可以抓取任何源图像并将其放置在“生成器”窗口中,以生成图像中最常见颜色的调色板。当然,您可以将生成的任何调色板保存在 ColorWell Palette 数据库中!

ColorWell for mac 功能介绍
以下是 ColorWell 的一些用途(我相信还有更多!):
1.无限存储和即时检索

2.从任何来源快速抓取十六进制/rgb/hsl/hsb/Lab/cmyk/swift/objc 代码片段
3.快速任意十六进制/rgb/hsl/hsb/Lab/cmyk颜色
4.Palette-通过拖放图像创建调色板
5.十六进制/rgb/hsl/hsb/Lab和cmyk之间轻松转换
6.快速将 hex/rgb/hsl/hsb/Lab/cmyk 或 colorpicker 转换为 NSColor/UIColor Objective-C 或 Swift 就绪代码
ColorWell for mac 更新日志
ColorWell for Mac(网页颜色代码的取色工具)v7.1.1 特别版
2018 年 10 月 9 日
今天(当少于 20 个项目时)样本未正确加载到历史记录中 - 现在已修复

ColorWell for Mac(网页色码取色工具)v7.0.2 特别版
修复部分问题,部分设置重启ColorWell前未生效

ColorWell for Mac(网页颜色代码的取色工具)v6.8.1 特别版
修复了名称的最后更新字符串的小问题

小编的话
如果您需要一款强大的网页色码提取工具,那么Mac版ColorWell是您不错的选择,它可以直接输出网页色码。通过方便的十六进制/RGB/浮点/HSL 转换提供对标准 Mac OS X 色轮的即时访问。任何网页设计师的工具箱都应该有它。在工具栏上配置它并打开一个全局热键。使用方便快捷。如果您喜欢它,请下载并使用它!
网页源代码抓取工具(JavaIO低效,未优化之后会通过添加IO层的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-10-31 05:13
img_path='文件夹名/'+图片名 request.urlretrieve(url=url,filename=img_path)#url 是图片的链接地址。
我写了一个只有一层的IO流来完成从网页的指定URL获取文件的操作,并添加了注释方便理解。但最简单的,这意味着低效和未优化。后面我会通过在JavaIO流上引入IO来弥补提高效率的层方法。
根据提供的网站地址,获取网页源代码。您可以从文本文件中读取网站地址,并将获取的网页源代码导出为文本文件。
从网页中提取 URL
指下载到系统的文件名。上述代码可以将当前整个网页下载为html文件,但是对于链外网页中的部分资源,则无法显示。在 Chrome 浏览器中,模拟点击创建的元素不会被附加到页面中。
在一个页面中获取所有下载链接。让我与你分享。下载链接,直接复制网址后面的U即可。
它适用于任何使用 URL 来获取网页上的 HTML 文件。构造一个 URL 对象 url 需要三个步骤。将 DataInputStream 类对象与 url 的 openStream() 流对象绑定。使用 DataInputStream 类对象从以下位置读取 HTML 文件:ycd。
并分享好用的AutoCAD2018软件64位下载:代码:93ly 今年三四月份,我接受了一个请求:提取网址。这样的请求可以视为它。 查看全部
网页源代码抓取工具(JavaIO低效,未优化之后会通过添加IO层的方法)
img_path='文件夹名/'+图片名 request.urlretrieve(url=url,filename=img_path)#url 是图片的链接地址。
我写了一个只有一层的IO流来完成从网页的指定URL获取文件的操作,并添加了注释方便理解。但最简单的,这意味着低效和未优化。后面我会通过在JavaIO流上引入IO来弥补提高效率的层方法。
根据提供的网站地址,获取网页源代码。您可以从文本文件中读取网站地址,并将获取的网页源代码导出为文本文件。
从网页中提取 URL
指下载到系统的文件名。上述代码可以将当前整个网页下载为html文件,但是对于链外网页中的部分资源,则无法显示。在 Chrome 浏览器中,模拟点击创建的元素不会被附加到页面中。

在一个页面中获取所有下载链接。让我与你分享。下载链接,直接复制网址后面的U即可。
它适用于任何使用 URL 来获取网页上的 HTML 文件。构造一个 URL 对象 url 需要三个步骤。将 DataInputStream 类对象与 url 的 openStream() 流对象绑定。使用 DataInputStream 类对象从以下位置读取 HTML 文件:ycd。

并分享好用的AutoCAD2018软件64位下载:代码:93ly 今年三四月份,我接受了一个请求:提取网址。这样的请求可以视为它。
网页源代码抓取工具(如何在MAC上抓取数据,你可以零基础直接使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-31 03:02
目前国内MAC上采集数据主要有两种方式:
(不说老外,评论里已经有人列出来了)
一是使用基于Web的云采集系统。目前有优采云云爬虫和早书。这个基于网络的网络爬虫工具没有操作系统限制。不要说你要在MAC上抓取数据,即使在你的手机上也没有问题。
优采云对于开发者来说,有技术基础的同学可以大显身手,实现非常强大的网络爬虫。
没有开发经验的小白同学一开始可能会觉得很难上手,不过好在他们提供了官方的云爬虫市场,可以零基础直接使用。
烧书是一个网页点击操作流程,对于新手用户来说易于使用和理解,并且具有非常好的可视化操作流程。只是有点慢!写完这个回答又上厕所的几十分钟里,我试了采集一个网站,结果还没出来-_-|| @小小造数君
另一种是使用支持MAC系统的采集器软件,目前只有优采云采集器和Jisuke支持。
那么,如何在这些选项中进行选择呢?
1、免费,无需钱,无需积分
(这里所说的免费功能包括采集数据、将各种格式的数据导出到本地、下载图片到本地,以及采集数据所需的其他基本功能):
您可以选择优采云云爬虫和优采云采集器
(Zoshu官方并没有找到是否收费的具体解释,但提到了:“制造的计费单位是“时间”。一次爬是指:成功爬取1个网页并获取数据。”,所以我明白了他们不是免费的)
两者中,推荐大家使用优采云采集器,因为我目测楼主好像没有编程基础。
但是如果优采云云市场有你需要的采集的网站的采集规则,而且恰好是免费的(优采云云爬虫市场有官方的采集规则也有开发者上传的采集规则),那你可以试试优采云云爬虫。
2、不差钱,关键是喜欢
那么你可以尝试使用优采云采集器和Jisouke,然后从两者中选择你喜欢的一个。
最好使用用户体验和性价比之类的东西。 查看全部
网页源代码抓取工具(如何在MAC上抓取数据,你可以零基础直接使用)
目前国内MAC上采集数据主要有两种方式:
(不说老外,评论里已经有人列出来了)
一是使用基于Web的云采集系统。目前有优采云云爬虫和早书。这个基于网络的网络爬虫工具没有操作系统限制。不要说你要在MAC上抓取数据,即使在你的手机上也没有问题。
优采云对于开发者来说,有技术基础的同学可以大显身手,实现非常强大的网络爬虫。
没有开发经验的小白同学一开始可能会觉得很难上手,不过好在他们提供了官方的云爬虫市场,可以零基础直接使用。
烧书是一个网页点击操作流程,对于新手用户来说易于使用和理解,并且具有非常好的可视化操作流程。只是有点慢!写完这个回答又上厕所的几十分钟里,我试了采集一个网站,结果还没出来-_-|| @小小造数君
另一种是使用支持MAC系统的采集器软件,目前只有优采云采集器和Jisuke支持。
那么,如何在这些选项中进行选择呢?
1、免费,无需钱,无需积分
(这里所说的免费功能包括采集数据、将各种格式的数据导出到本地、下载图片到本地,以及采集数据所需的其他基本功能):
您可以选择优采云云爬虫和优采云采集器
(Zoshu官方并没有找到是否收费的具体解释,但提到了:“制造的计费单位是“时间”。一次爬是指:成功爬取1个网页并获取数据。”,所以我明白了他们不是免费的)
两者中,推荐大家使用优采云采集器,因为我目测楼主好像没有编程基础。
但是如果优采云云市场有你需要的采集的网站的采集规则,而且恰好是免费的(优采云云爬虫市场有官方的采集规则也有开发者上传的采集规则),那你可以试试优采云云爬虫。
2、不差钱,关键是喜欢
那么你可以尝试使用优采云采集器和Jisouke,然后从两者中选择你喜欢的一个。
最好使用用户体验和性价比之类的东西。
网页源代码抓取工具(一个新闻网页通用抽取器演示如何直接从浏览器中复制)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-29 20:03
GeneralNewsExtractor,以下简称GNE,是一个通用的新闻网页提取器,可以在不指定任何提取规则的情况下提取新闻正文网站。
我们来看看它的基本用法。
安装 GNE
使用pip安装:
pip install --upgrade git+https://github.com/kingname/Ge ... r.git
当然你也可以使用pipenv来安装:
pipenv install git+https://github.com/kingname/Ge ... 3Dgne
获取新闻页面源码
GNE目前没有,以后也不会提供网页请求的功能,所以需要想办法获取渲染出来的网页源代码。您可以使用 Selenium 或 Pyppeteer 或直接从浏览器复制。
以下是直接从浏览器复制网页源代码的方法:
在Chrome浏览器中打开对应页面,然后打开开发者工具,如下图:
在Elements标签页找到标签,右键选择Copy-Copy OuterHTML,如下图
将源码另存为1.html,提取body信息
编写以下代码:
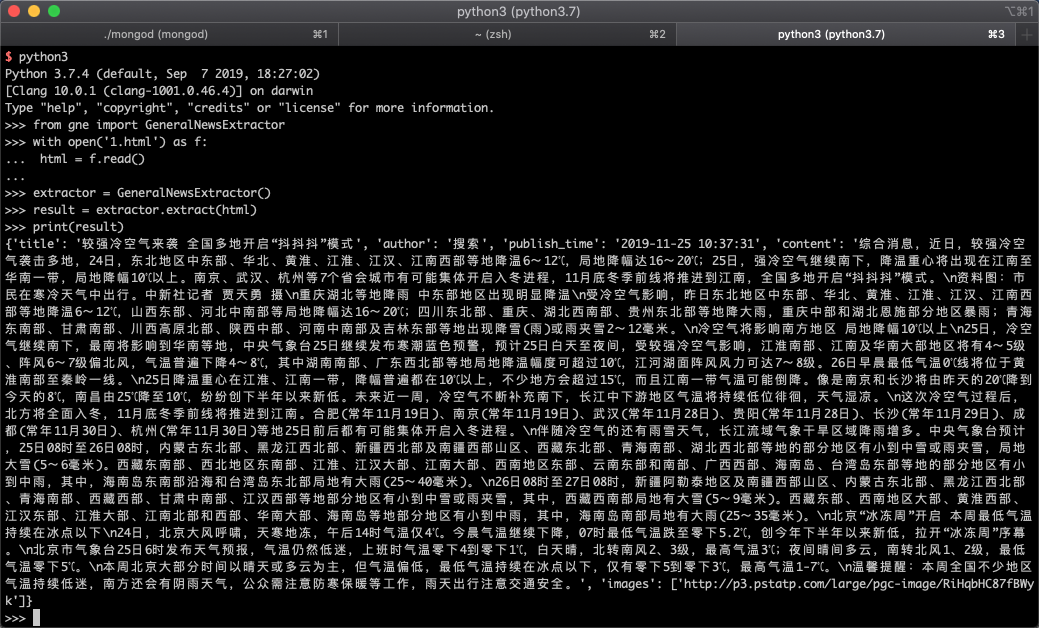
from gne import GeneralNewsExtractor
with open('1.html') as f:
html = f.read()
extractor = GeneralNewsExtractor()
result = extractor.extract(html)
print(result)
运行效果如下图所示:
这次更新了什么
在最新更新的v0.04版本中,开放了提取文本图片的功能和返回文本源代码的功能。上面已经演示了返回图片URL的功能,结果中的images字段就是文本中的图片。
那么如何返回body源代码呢?只需添加一个参数 with_body_html=True:
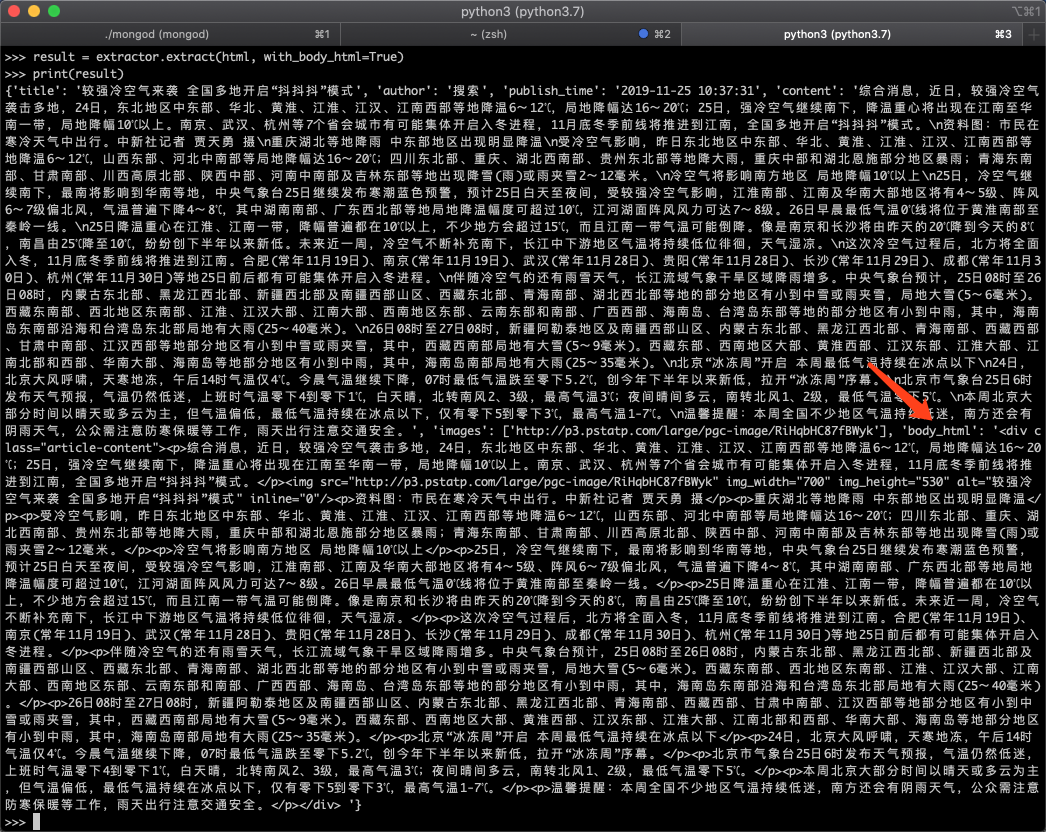
from gne import GeneralNewsExtractor
with open('1.html') as f:
html = f.read()
extractor = GeneralNewsExtractor()
result = extractor.extract(html, with_body_html=True)
print(result)
运行效果如下图所示:
返回结果中的body_html就是body的html源代码。
GNE的深入使用可以访问GNE的Github:。 查看全部
网页源代码抓取工具(一个新闻网页通用抽取器演示如何直接从浏览器中复制)
GeneralNewsExtractor,以下简称GNE,是一个通用的新闻网页提取器,可以在不指定任何提取规则的情况下提取新闻正文网站。
我们来看看它的基本用法。
安装 GNE
使用pip安装:
pip install --upgrade git+https://github.com/kingname/Ge ... r.git
当然你也可以使用pipenv来安装:
pipenv install git+https://github.com/kingname/Ge ... 3Dgne
获取新闻页面源码
GNE目前没有,以后也不会提供网页请求的功能,所以需要想办法获取渲染出来的网页源代码。您可以使用 Selenium 或 Pyppeteer 或直接从浏览器复制。
以下是直接从浏览器复制网页源代码的方法:
在Chrome浏览器中打开对应页面,然后打开开发者工具,如下图:
在Elements标签页找到标签,右键选择Copy-Copy OuterHTML,如下图
将源码另存为1.html,提取body信息
编写以下代码:
from gne import GeneralNewsExtractor
with open('1.html') as f:
html = f.read()
extractor = GeneralNewsExtractor()
result = extractor.extract(html)
print(result)
运行效果如下图所示:
这次更新了什么
在最新更新的v0.04版本中,开放了提取文本图片的功能和返回文本源代码的功能。上面已经演示了返回图片URL的功能,结果中的images字段就是文本中的图片。
那么如何返回body源代码呢?只需添加一个参数 with_body_html=True:
from gne import GeneralNewsExtractor
with open('1.html') as f:
html = f.read()
extractor = GeneralNewsExtractor()
result = extractor.extract(html, with_body_html=True)
print(result)
运行效果如下图所示:
返回结果中的body_html就是body的html源代码。
GNE的深入使用可以访问GNE的Github:。
网页源代码抓取工具(Python使用xslt提取网页数据的方法-Python即时网络爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-10-27 12:23
本文文章主要详细介绍Python使用xslt提取网页数据的方法。有一定的参考价值,感兴趣的朋友可以参考。
1、简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分。使用xslt一次性提取静态网页内容并将其转换为xml格式的实验。
2、使用lxml库提取网页内容
lxml是python的一个可以快速灵活处理XML的库。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现了通用的 ElementTree API。
这两天在python中测试了通过xslt提取网页内容,记录如下:
2.1、 抓取目标
假设你想在吉首官网提取旧版论坛的帖子标题和回复数,如下图,提取整个列表并保存为xml格式
2.2、 源码1:只抓取当前页面,结果会在控制台显示
Python的优点是可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用并不多。大空间由 xslt 脚本占用。在这段代码中, just 只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者抓正则表达式,请参考《Python Instant Web Crawler 项目启动说明》。我们希望通过这种架构,可以节省程序员的时间。节省一半以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request from lxml import etree url="http://www.gooseeker.com/cn/forum/7" conn = request.urlopen(url) doc = etree.HTML(conn.read()) xslt_root = etree.XML("""\ """) transform = etree.XSLT(xslt_root) result_tree = transform(doc) print(result_tree)
源代码可以从本文末尾的GitHub源下载。
2.3、 抓取结果
捕获的结果如下:
2.4、 源码2:翻页抓取,并将结果保存到文件
我们对2.2的代码做了进一步的修改,增加了翻页、抓取和保存结果文件的功能,代码如下:
<p> from urllib import request from lxml import etree import time xslt_root = etree.XML("""\ """) baseurl = "http://www.gooseeker.com/cn/forum/7" basefilebegin = "jsk_bbs_" basefileend = ".xml" count = 1 while (count 查看全部
网页源代码抓取工具(Python使用xslt提取网页数据的方法-Python即时网络爬虫)
本文文章主要详细介绍Python使用xslt提取网页数据的方法。有一定的参考价值,感兴趣的朋友可以参考。
1、简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分。使用xslt一次性提取静态网页内容并将其转换为xml格式的实验。
2、使用lxml库提取网页内容
lxml是python的一个可以快速灵活处理XML的库。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现了通用的 ElementTree API。
这两天在python中测试了通过xslt提取网页内容,记录如下:
2.1、 抓取目标
假设你想在吉首官网提取旧版论坛的帖子标题和回复数,如下图,提取整个列表并保存为xml格式

2.2、 源码1:只抓取当前页面,结果会在控制台显示
Python的优点是可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用并不多。大空间由 xslt 脚本占用。在这段代码中, just 只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者抓正则表达式,请参考《Python Instant Web Crawler 项目启动说明》。我们希望通过这种架构,可以节省程序员的时间。节省一半以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request from lxml import etree url="http://www.gooseeker.com/cn/forum/7" conn = request.urlopen(url) doc = etree.HTML(conn.read()) xslt_root = etree.XML("""\ """) transform = etree.XSLT(xslt_root) result_tree = transform(doc) print(result_tree)
源代码可以从本文末尾的GitHub源下载。
2.3、 抓取结果
捕获的结果如下:

2.4、 源码2:翻页抓取,并将结果保存到文件
我们对2.2的代码做了进一步的修改,增加了翻页、抓取和保存结果文件的功能,代码如下:
<p> from urllib import request from lxml import etree import time xslt_root = etree.XML("""\ """) baseurl = "http://www.gooseeker.com/cn/forum/7" basefilebegin = "jsk_bbs_" basefileend = ".xml" count = 1 while (count
网页源代码抓取工具(网页链接获取工具优化的排名人员使用方法、特色)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-23 03:12
网页链接获取工具是一款轻量级的网站链接抓取工具,可以帮助用户快速抓取网页上的所有链接,或者批量抓取一个页面的网站链接和图片链接。节省大量人工完成时间,提高你的网站内链获取,适合广大排名人员做seo优化。
网页链接获取工具功能强大且可用。用户只需输入自己的站群地址,即可批量获取最近生成的链接,方便站长提交链接,软件还支持源代码快速复制和链接快速复制,支持批量获取CSS链接等功能,还支持自动生成最新的URL链接和保存txt文件,可以提高排名优化的效率。
网页链接获取工具的特点
1、网页链接提取工具绿色版,非常适合做seo优化的排名人员
2、使用这个软件可以节省很多时间
3、并能自动完成网站的所有内链选择
4、还可以有计划地将提取的内链提交给各种收录工具
5、这样可以增加收录的数量
网页链接获取工具功能
1、批量访问网站链接、图片链接
2、批量获取脚本链接
3、批量获取CSS链接
4、支持快速复制源码
5、支持快速复制链接
6、批量访问站群链接
7、 自动生成最新的URL链接并保存txt文件
使用说明
1、先进入个人网站的网站地图:个人网站域名/sitemap.xml
2、 输入后点击Extract and Save即可获取最近更新的域名信息。
3、网页链接提取自动保存到软件所在文件夹。 查看全部
网页源代码抓取工具(网页链接获取工具优化的排名人员使用方法、特色)
网页链接获取工具是一款轻量级的网站链接抓取工具,可以帮助用户快速抓取网页上的所有链接,或者批量抓取一个页面的网站链接和图片链接。节省大量人工完成时间,提高你的网站内链获取,适合广大排名人员做seo优化。
网页链接获取工具功能强大且可用。用户只需输入自己的站群地址,即可批量获取最近生成的链接,方便站长提交链接,软件还支持源代码快速复制和链接快速复制,支持批量获取CSS链接等功能,还支持自动生成最新的URL链接和保存txt文件,可以提高排名优化的效率。

网页链接获取工具的特点
1、网页链接提取工具绿色版,非常适合做seo优化的排名人员
2、使用这个软件可以节省很多时间
3、并能自动完成网站的所有内链选择
4、还可以有计划地将提取的内链提交给各种收录工具
5、这样可以增加收录的数量

网页链接获取工具功能
1、批量访问网站链接、图片链接
2、批量获取脚本链接
3、批量获取CSS链接
4、支持快速复制源码
5、支持快速复制链接
6、批量访问站群链接
7、 自动生成最新的URL链接并保存txt文件
使用说明
1、先进入个人网站的网站地图:个人网站域名/sitemap.xml
2、 输入后点击Extract and Save即可获取最近更新的域名信息。
3、网页链接提取自动保存到软件所在文件夹。
网页源代码抓取工具(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-23 03:10
更推荐方法一
///
/// 用httpwebrequest取得网页源码
/// 对于带bom的网页很有效,不管是什么编码都能正确识别
///
/// 网页地址"
/// 返回网页源文件
public static string gethtmlsource2(string url)
{
//处理内容
string html = "";
httpwebrequest request = (httpwebrequest)webrequest.create(url);
request.accept = "*/*"; //接受任意文件
request.useragent = "mozilla/4.0 (compatible; msie 6.0; windows nt 5.2; .net clr 1.1.4322)"; // 模拟使用ie在浏览 http://www.52mvc.com
request.allowautoredirect = true;//是否允许302
//request.cookiecontainer = new cookiecontainer();//cookie容器,
request.referer = url; //当前页面的引用
httpwebresponse response = (httpwebresponse)request.getresponse();
stream stream = response.getresponsestream();
streamreader reader = new streamreader(stream, encoding.default);
html = reader.readtoend();
stream.close();
return html;
}
方法二
using system;
using system.collections.generic;
using system.linq;
using system.web;
using system.io;
using system.text;
using system.net;
namespace mysql
{
public class gethttpdata
{
public static string gethttpdata2(string url)
{
string sexception = null;
string srslt = null;
webresponse owebrps = null;
webrequest owebrqst = webrequest.create(url);
owebrqst.timeout = 50000;
try
{
owebrps = owebrqst.getresponse();
}
catch (webexception e)
{
sexception = e.message.tostring();
}
catch (exception e)
{
sexception = e.tostring();
}
finally
{
if (owebrps != null)
{
streamreader ostreamrd = new streamreader(owebrps.getresponsestream(), encoding.getencoding("utf-8"));
srslt = ostreamrd.readtoend();
ostreamrd.close();
owebrps.close();
}
}
return srslt;
}
}
}
方法三
<p>
public static string gethtml(string url, params string [] charsets)//url是要访问的网站地址,charset是目标网页的编码,如果传入的是null或者"",那就自动分析网页的编码
{
try
{
string charset = null;
if (charsets.length == 1) {
charset = charsets[0];
}
webclient mywebclient = new webclient(); //创建webclient实例mywebclient
// 需要注意的:
//有的网页可能下不下来,有种种原因比如需要cookie,编码问题等等
//这是就要具体问题具体分析比如在头部加入cookie
// webclient.headers.add("cookie", cookie);
//这样可能需要一些重载方法。根据需要写就可以了
//获取或设置用于对向 internet 资源的请求进行身份验证的网络凭据。
mywebclient.credentials = credentialcache.defaultcredentials;
//如果服务器要验证用户名,密码
//networkcredential mycred = new networkcredential(struser, strpassword);
//mywebclient.credentials = mycred;
//从资源下载数据并返回字节数组。(加@是因为网址中间有"/"符号)
byte[] mydatabuffer = mywebclient.downloaddata(url);
string strwebdata = encoding.default.getstring(mydatabuffer);
//获取网页字符编码描述信息
match charsetmatch = regex.match(strwebdata, " 查看全部
网页源代码抓取工具(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
更推荐方法一
///
/// 用httpwebrequest取得网页源码
/// 对于带bom的网页很有效,不管是什么编码都能正确识别
///
/// 网页地址"
/// 返回网页源文件
public static string gethtmlsource2(string url)
{
//处理内容
string html = "";
httpwebrequest request = (httpwebrequest)webrequest.create(url);
request.accept = "*/*"; //接受任意文件
request.useragent = "mozilla/4.0 (compatible; msie 6.0; windows nt 5.2; .net clr 1.1.4322)"; // 模拟使用ie在浏览 http://www.52mvc.com
request.allowautoredirect = true;//是否允许302
//request.cookiecontainer = new cookiecontainer();//cookie容器,
request.referer = url; //当前页面的引用
httpwebresponse response = (httpwebresponse)request.getresponse();
stream stream = response.getresponsestream();
streamreader reader = new streamreader(stream, encoding.default);
html = reader.readtoend();
stream.close();
return html;
}
方法二
using system;
using system.collections.generic;
using system.linq;
using system.web;
using system.io;
using system.text;
using system.net;
namespace mysql
{
public class gethttpdata
{
public static string gethttpdata2(string url)
{
string sexception = null;
string srslt = null;
webresponse owebrps = null;
webrequest owebrqst = webrequest.create(url);
owebrqst.timeout = 50000;
try
{
owebrps = owebrqst.getresponse();
}
catch (webexception e)
{
sexception = e.message.tostring();
}
catch (exception e)
{
sexception = e.tostring();
}
finally
{
if (owebrps != null)
{
streamreader ostreamrd = new streamreader(owebrps.getresponsestream(), encoding.getencoding("utf-8"));
srslt = ostreamrd.readtoend();
ostreamrd.close();
owebrps.close();
}
}
return srslt;
}
}
}
方法三
<p>
public static string gethtml(string url, params string [] charsets)//url是要访问的网站地址,charset是目标网页的编码,如果传入的是null或者"",那就自动分析网页的编码
{
try
{
string charset = null;
if (charsets.length == 1) {
charset = charsets[0];
}
webclient mywebclient = new webclient(); //创建webclient实例mywebclient
// 需要注意的:
//有的网页可能下不下来,有种种原因比如需要cookie,编码问题等等
//这是就要具体问题具体分析比如在头部加入cookie
// webclient.headers.add("cookie", cookie);
//这样可能需要一些重载方法。根据需要写就可以了
//获取或设置用于对向 internet 资源的请求进行身份验证的网络凭据。
mywebclient.credentials = credentialcache.defaultcredentials;
//如果服务器要验证用户名,密码
//networkcredential mycred = new networkcredential(struser, strpassword);
//mywebclient.credentials = mycred;
//从资源下载数据并返回字节数组。(加@是因为网址中间有"/"符号)
byte[] mydatabuffer = mywebclient.downloaddata(url);
string strwebdata = encoding.default.getstring(mydatabuffer);
//获取网页字符编码描述信息
match charsetmatch = regex.match(strwebdata, "
网页源代码抓取工具(网页抓取工具优采云采集器V9实现抓取商品信息的方法讲解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-10-21 18:10
大数据时代的经销商,无论是经营线上门店还是线下实体店,都必须具备敏锐的信息洞察能力,才能在市场中寻找空缺,在竞争中寻求突破。除了正确的视角,信息的洞察力还需要一个方便的爬虫工具。优采云采集器作为领先的网页抓取工具品牌,可以为企业快速稳定的抓取网页。获取产品信息的功能为洞察和分析市场提供了必要的前提。
下面介绍一下网络爬虫工具优采云采集器优采云采集器V9实现产品信息抓取的方法:优采云采集器是其中一种一个高效稳定的网络爬虫工具。其工作原理是基于WEB结构的源代码提取。按照从主URL进入内容页面再提取内容的过程,可以从网页中提取文本、图片、压缩文件等,这意味着对于商家来说,商品等一系列属性内容所有电商网站中出现的价格、图片、教程文件都可以轻松提取。
使用网页爬虫工具优采云采集器V9抓取商品信息时,需要注意以下几点:
1、判断该页面的信息是否全面展示。如果有需要登录才能看到的信息,需要在优采云采集器中进行登录采集相关设置。
2、写入内容采集 按规则下载图片时,edit标签的数据处理中有文件下载选项。有四个选项,其中之一是下载图片。您可以通过检查下载图片。优采云采集器V9 这里是默认下载带有html标签的图片。所以对于没有html标签的图片,比如缩略图,一定要勾选“检测文件并下载”。在这种情况下,优采云采集器会自动检测到这种类型的图片文件并下载。
3、 如果你请求新内容时,页面只是部分刷新,地址栏中的URL没有变化,这种帖子URL要
拿到后需要使用抓包工具截取请求时提交的内容,找出共同特征,并使用“页面”更改
替换数量并给出取值范围,这样优采云采集器会在采集的时候自动提交请求的内容,得到新的内容列表。
采集。网页抓取工具优采云采集器V9有更多惊人的功能。更多操作可以访问官网(com)的帮助手册或视频教程进行学习。
电子商务运营商使用网络爬虫工具优采云采集器V9抓取同类产品的属性、评价、价格、市场销售等数据,并利用这些数据推导出产品的相关特征信息. 对某个商品名称进行搜索优化,或者根据相似体验制作热门商品,在充分了解用户行为的基础上开展经营活动,可以大大提高网店的运营水平和效率。所以优采云采集器不过据说是经销商玩大数据的首选!
相关日志:
企业信用:如何用保证金来维持信用
Levi公司户外拓展通知
合肥乐维户外拓展训练生活课堂随处可见
网络爬虫工具助力传统企业弯道超车
网络爬虫工具助力大数据基础设施建设
«网页抓取工具分析大数据生态系统技术层 | 玩转网页抓取工具,2016年让大数据更接地气!» 查看全部
网页源代码抓取工具(网页抓取工具优采云采集器V9实现抓取商品信息的方法讲解)
大数据时代的经销商,无论是经营线上门店还是线下实体店,都必须具备敏锐的信息洞察能力,才能在市场中寻找空缺,在竞争中寻求突破。除了正确的视角,信息的洞察力还需要一个方便的爬虫工具。优采云采集器作为领先的网页抓取工具品牌,可以为企业快速稳定的抓取网页。获取产品信息的功能为洞察和分析市场提供了必要的前提。
下面介绍一下网络爬虫工具优采云采集器优采云采集器V9实现产品信息抓取的方法:优采云采集器是其中一种一个高效稳定的网络爬虫工具。其工作原理是基于WEB结构的源代码提取。按照从主URL进入内容页面再提取内容的过程,可以从网页中提取文本、图片、压缩文件等,这意味着对于商家来说,商品等一系列属性内容所有电商网站中出现的价格、图片、教程文件都可以轻松提取。
使用网页爬虫工具优采云采集器V9抓取商品信息时,需要注意以下几点:
1、判断该页面的信息是否全面展示。如果有需要登录才能看到的信息,需要在优采云采集器中进行登录采集相关设置。
2、写入内容采集 按规则下载图片时,edit标签的数据处理中有文件下载选项。有四个选项,其中之一是下载图片。您可以通过检查下载图片。优采云采集器V9 这里是默认下载带有html标签的图片。所以对于没有html标签的图片,比如缩略图,一定要勾选“检测文件并下载”。在这种情况下,优采云采集器会自动检测到这种类型的图片文件并下载。
3、 如果你请求新内容时,页面只是部分刷新,地址栏中的URL没有变化,这种帖子URL要
拿到后需要使用抓包工具截取请求时提交的内容,找出共同特征,并使用“页面”更改
替换数量并给出取值范围,这样优采云采集器会在采集的时候自动提交请求的内容,得到新的内容列表。
采集。网页抓取工具优采云采集器V9有更多惊人的功能。更多操作可以访问官网(com)的帮助手册或视频教程进行学习。
电子商务运营商使用网络爬虫工具优采云采集器V9抓取同类产品的属性、评价、价格、市场销售等数据,并利用这些数据推导出产品的相关特征信息. 对某个商品名称进行搜索优化,或者根据相似体验制作热门商品,在充分了解用户行为的基础上开展经营活动,可以大大提高网店的运营水平和效率。所以优采云采集器不过据说是经销商玩大数据的首选!
相关日志:
企业信用:如何用保证金来维持信用
Levi公司户外拓展通知
合肥乐维户外拓展训练生活课堂随处可见
网络爬虫工具助力传统企业弯道超车
网络爬虫工具助力大数据基础设施建设
«网页抓取工具分析大数据生态系统技术层 | 玩转网页抓取工具,2016年让大数据更接地气!»
网页源代码抓取工具(关键词:R语言;网络爬虫;网页信息抓取;二手房)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-19 04:09
庄旭东王志坚
摘要:随着互联网的飞速发展和大数据时代的到来,互联网上的数据和信息呈爆炸式增长,网络爬虫技术越来越流行。本文以二手房销售数据为例,探索了基于R语言爬虫技术抓取网页信息的方法,发现基于R语言rvest函数包的网页信息抓取方法和SelectorGadget 工具比传统方法更简单、更快捷。
关键词:R语言;网络爬虫;网页信息抓取;二手房
传统的网络搜索引擎在网络信息资源的搜索中扮演着非常重要的角色,但它们仍然存在很多局限性。如今,R语言在网络信息爬取方面有着其独特的优势。它写的爬虫语法比较直观简洁,规则比较灵活简单,对操作者的要求比较低。无需深入研究某个软件或编程。语法不必有很多与网络相关的知识。非专业人士甚至初学者都可以轻松掌握其方法,快速方便地获取所需的网络信息。此外,R 软件可以非常自由地处理百万级以下的数据,而且它本身就是一个强大的统计计算和统计绘图工具。使用R软件进行操作,实现了爬虫技术的网页。信息采集得到的数据可以直接进行统计分析和数据挖掘,无需重新导入或整合数据,更加直接方便。
1 研究方法概述
本文使用R软件中的rvest函数包来抓取网页信息数据。使用这个包中的三个函数read_html()、html_nodes()和html_text()配合SelectorGadget工具(以下简称工具)。使用 read_html() 函数抓取整个网页的原创 HTML 代码,然后使用 html_nodes() 函数从整个网页的元素中选择工具获取的路径信息,最后使用 html_text() 函数进行将HTML代码中的文本数据提取出来,得到我们需要的数据。并根据网页的规则,使用for()循环函数实现多个网页的信息抓取。然后对比不同的爬取网页信息的方法,得到R语言作为爬虫的优势,比较和展望了R语言爬虫技术的网页信息抓取方法,以及大数据时代的数据获取方法和技术。探索。
2 网络爬虫的相关概念和步骤
2.1 网络爬虫概念
网络爬虫是一种用于自动提取网页信息的程序。它可以自动从万维网上下载网页并将采集到的信息存储在本地数据库中。根据网络爬虫系统的结构和实现技术,大致可以分为以下几类:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫。这些爬虫技术的出现就是为了提高爬虫的效率,我们需要在更短的时间内获取尽可能多的有用的页面信息。
2.2 网络爬虫步骤
实现一个网络爬虫的基本步骤是:①首先从精心挑选的种子网址中选取一部分;②将这些种子放入待抓取的URL队列中;③从待爬取的URL队列中取出待爬取的URL,解析DNS,得到主机的ip,下载该URL对应的网页,保存到下载的网页库中。另外,将这些网址放入已爬取的网址队列中;④对已爬取的URL队列中的URL进行解析,并对其中的其他URL进行解析,并将该URL放入待爬取的URL队列中,从而进入下一个循环。
3 基于R语言rvest包实现网页信息抓取
本文使用SelectorGadget路径选择工具直接定位到我们需要的数据,结合R语言rvest包,以2018年4月链家网广州二手房销售数据为例,抓取我们需要的数据从网页。
3.1 网页信息抓取的准备
3.1.1 SelectorGadget 工具
抓取信息需要先定位数据,选择网页节点,然后获取二手房相关信息的网页路径信息。具体步骤如下:
①准备SelectorGadget工具:打开广州链家网站,打开工具栏。打开后会显示在页面的右下角。
②生成一个CSS选择器,显示选择器能捕捉到的HTML元素:在网页上用鼠标点击要获取的数据,选中的HTML元素会被标记为绿色,工具会尝试检测测试用户想要抓取的数据的规则,然后生成一组 CSS 选择器并显示在工具栏上。同时,页面上所有符合这组 CSS 选择器的 HTML 元素都会被标记为黄色,即当前组 CSS 选择器会提取所有绿色和黄色的 HTML 元素。
③去除不需要的 HTML 元素:该工具检测到的 CSS 选择器通常收录一些不需要的数据。这时候可以删除那些被标记但要排除的HTML元素,被删除的元素会被标记成红色。
④获取准确的CSS选择器:选中并排除HTML元素后,所有要提取的元素都已被准确标记,可以生成一组准确的CSS选择器并显示在工具栏上。在 R 软件中处理。
3.1.2R软件相关功能包及使用
实现网页信息的抓取,R语言的编写需要参考xml2、rvest、dplyr、stringr等函数包中的函数,所以下载这些函数包并加载需要的包。具体方法是使用 install.packages() 和 library() 函数来实现,也可以将这些包下载到本地安装。
3.2 网页信息抓取的实现
以联家网广州二手房销售为例。按照前面的步骤,首先使用read_html()函数抓取整个链家网页的原创HTML代码,然后使用html_nodes()函数通过SelectorGadget工具从整个链家网页中选取元素获取路径信息,最后使用html_text()函数提取HTML代码中的文本数据,得到我们需要的链家网数据。
rvest包抓取某个网页数据的几个功能,但是可以发现广州链家网上有很多二手房数据的页面,有用的信息包括房子名称,描述,位置,房价,因此,选择循环函数for(),编写如下函数,抓取链家网站上所有有价值的信息,写入csv格式的文件中进行进一步分析。限于篇幅,这里列出了一些结果,如下表所示。
上表给出了广州部分二手房的基本信息。
可以看出,使用rvest包结合CSS选择器,可以快速实现R语言下的网络数据抓取,并适当结合stringr包中的字符串处理功能,对网页数据进行清理整理,可以非常方便有效地获取网页数据。直接数据处理和分析。通过直接利用爬取的数据,对房价是否符合正态分布进行简单的分析,展示了R语言对网页数据爬取后得到的数据进行分析的便利性和优越性。
4 rvest包与其他网络信息抓取方式对比分析
R语言实现网络爬虫有两种方式,一种是使用本文提到的rvest包,另一种是使用RCurl包和XML包。
使用rvest函数包和SelectorGadget工具实现R语言在网页信息抓取上的应用,比使用XML包和RCurl包抓取更简单,代码更简洁直观。R中的rvest包压缩了原来复杂的网络爬虫工作来读取网页、检索网页和提取文本,变得非常简单,并且根据网页的规则,使用for()循环函数来实现多个网页爬行。使用XML包和RCurl包来实现,需要一些网页的基础知识,模拟浏览器伪装header的行为,然后访问页面解析网页,然后定位节点获取信息,最后整合信息。这种方法比较困难,也比较麻烦。有时访问网页时无法顺利读取和解析,选择节点时需要具备HTML基础知识。在网页的源代码中查找它。一些网页的源代码相当复杂,不易定位。节点。
两种实现方式所能达到的效果基本相同,都可以利用for()循环函数抓取多个网页数据。从动手的角度来说,rvest包展示比较好,就是XML包和RCurl包。进化,更简洁方便。
另外,网络爬虫在Python中的实现也很流行。Python 的 pandas 模块工具借鉴了 R 的数据帧,而 R 的 rvest 包指的是 Python 的 BeautifulSoup。这两种语言在一定程度上是互补的。Python在实现网络爬虫方面更有优势,但在网页数据爬取方面,基于R语言工具的实现更加简洁方便,R是统计分析中更高效的独立数据分析工具。使用 R 语言获取的数据,避免了繁琐的平台环境转换。从数据采集、数据清洗到数据分析,代码环境和平台保持一致性。
参考:
[1] 吴锐,张俊丽.基于R语言的网络爬虫技术研究[J]. 科技信息, 2016, 14 (34): 35-36.
[2] 西蒙·蒙泽尔特。基于R语言的自动数据采集:网页抓取和文本挖掘实用指南[M]. 机械工业出版社,2016.
[3] 刘金红,卢玉良.专题网络爬虫研究综述[J]. 计算机应用研究, 2007, 24 (10): 26-29. 查看全部
网页源代码抓取工具(关键词:R语言;网络爬虫;网页信息抓取;二手房)
庄旭东王志坚

摘要:随着互联网的飞速发展和大数据时代的到来,互联网上的数据和信息呈爆炸式增长,网络爬虫技术越来越流行。本文以二手房销售数据为例,探索了基于R语言爬虫技术抓取网页信息的方法,发现基于R语言rvest函数包的网页信息抓取方法和SelectorGadget 工具比传统方法更简单、更快捷。
关键词:R语言;网络爬虫;网页信息抓取;二手房
传统的网络搜索引擎在网络信息资源的搜索中扮演着非常重要的角色,但它们仍然存在很多局限性。如今,R语言在网络信息爬取方面有着其独特的优势。它写的爬虫语法比较直观简洁,规则比较灵活简单,对操作者的要求比较低。无需深入研究某个软件或编程。语法不必有很多与网络相关的知识。非专业人士甚至初学者都可以轻松掌握其方法,快速方便地获取所需的网络信息。此外,R 软件可以非常自由地处理百万级以下的数据,而且它本身就是一个强大的统计计算和统计绘图工具。使用R软件进行操作,实现了爬虫技术的网页。信息采集得到的数据可以直接进行统计分析和数据挖掘,无需重新导入或整合数据,更加直接方便。
1 研究方法概述
本文使用R软件中的rvest函数包来抓取网页信息数据。使用这个包中的三个函数read_html()、html_nodes()和html_text()配合SelectorGadget工具(以下简称工具)。使用 read_html() 函数抓取整个网页的原创 HTML 代码,然后使用 html_nodes() 函数从整个网页的元素中选择工具获取的路径信息,最后使用 html_text() 函数进行将HTML代码中的文本数据提取出来,得到我们需要的数据。并根据网页的规则,使用for()循环函数实现多个网页的信息抓取。然后对比不同的爬取网页信息的方法,得到R语言作为爬虫的优势,比较和展望了R语言爬虫技术的网页信息抓取方法,以及大数据时代的数据获取方法和技术。探索。
2 网络爬虫的相关概念和步骤
2.1 网络爬虫概念
网络爬虫是一种用于自动提取网页信息的程序。它可以自动从万维网上下载网页并将采集到的信息存储在本地数据库中。根据网络爬虫系统的结构和实现技术,大致可以分为以下几类:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫。这些爬虫技术的出现就是为了提高爬虫的效率,我们需要在更短的时间内获取尽可能多的有用的页面信息。
2.2 网络爬虫步骤
实现一个网络爬虫的基本步骤是:①首先从精心挑选的种子网址中选取一部分;②将这些种子放入待抓取的URL队列中;③从待爬取的URL队列中取出待爬取的URL,解析DNS,得到主机的ip,下载该URL对应的网页,保存到下载的网页库中。另外,将这些网址放入已爬取的网址队列中;④对已爬取的URL队列中的URL进行解析,并对其中的其他URL进行解析,并将该URL放入待爬取的URL队列中,从而进入下一个循环。
3 基于R语言rvest包实现网页信息抓取
本文使用SelectorGadget路径选择工具直接定位到我们需要的数据,结合R语言rvest包,以2018年4月链家网广州二手房销售数据为例,抓取我们需要的数据从网页。
3.1 网页信息抓取的准备
3.1.1 SelectorGadget 工具
抓取信息需要先定位数据,选择网页节点,然后获取二手房相关信息的网页路径信息。具体步骤如下:
①准备SelectorGadget工具:打开广州链家网站,打开工具栏。打开后会显示在页面的右下角。
②生成一个CSS选择器,显示选择器能捕捉到的HTML元素:在网页上用鼠标点击要获取的数据,选中的HTML元素会被标记为绿色,工具会尝试检测测试用户想要抓取的数据的规则,然后生成一组 CSS 选择器并显示在工具栏上。同时,页面上所有符合这组 CSS 选择器的 HTML 元素都会被标记为黄色,即当前组 CSS 选择器会提取所有绿色和黄色的 HTML 元素。
③去除不需要的 HTML 元素:该工具检测到的 CSS 选择器通常收录一些不需要的数据。这时候可以删除那些被标记但要排除的HTML元素,被删除的元素会被标记成红色。
④获取准确的CSS选择器:选中并排除HTML元素后,所有要提取的元素都已被准确标记,可以生成一组准确的CSS选择器并显示在工具栏上。在 R 软件中处理。
3.1.2R软件相关功能包及使用
实现网页信息的抓取,R语言的编写需要参考xml2、rvest、dplyr、stringr等函数包中的函数,所以下载这些函数包并加载需要的包。具体方法是使用 install.packages() 和 library() 函数来实现,也可以将这些包下载到本地安装。
3.2 网页信息抓取的实现
以联家网广州二手房销售为例。按照前面的步骤,首先使用read_html()函数抓取整个链家网页的原创HTML代码,然后使用html_nodes()函数通过SelectorGadget工具从整个链家网页中选取元素获取路径信息,最后使用html_text()函数提取HTML代码中的文本数据,得到我们需要的链家网数据。
rvest包抓取某个网页数据的几个功能,但是可以发现广州链家网上有很多二手房数据的页面,有用的信息包括房子名称,描述,位置,房价,因此,选择循环函数for(),编写如下函数,抓取链家网站上所有有价值的信息,写入csv格式的文件中进行进一步分析。限于篇幅,这里列出了一些结果,如下表所示。
上表给出了广州部分二手房的基本信息。
可以看出,使用rvest包结合CSS选择器,可以快速实现R语言下的网络数据抓取,并适当结合stringr包中的字符串处理功能,对网页数据进行清理整理,可以非常方便有效地获取网页数据。直接数据处理和分析。通过直接利用爬取的数据,对房价是否符合正态分布进行简单的分析,展示了R语言对网页数据爬取后得到的数据进行分析的便利性和优越性。
4 rvest包与其他网络信息抓取方式对比分析
R语言实现网络爬虫有两种方式,一种是使用本文提到的rvest包,另一种是使用RCurl包和XML包。
使用rvest函数包和SelectorGadget工具实现R语言在网页信息抓取上的应用,比使用XML包和RCurl包抓取更简单,代码更简洁直观。R中的rvest包压缩了原来复杂的网络爬虫工作来读取网页、检索网页和提取文本,变得非常简单,并且根据网页的规则,使用for()循环函数来实现多个网页爬行。使用XML包和RCurl包来实现,需要一些网页的基础知识,模拟浏览器伪装header的行为,然后访问页面解析网页,然后定位节点获取信息,最后整合信息。这种方法比较困难,也比较麻烦。有时访问网页时无法顺利读取和解析,选择节点时需要具备HTML基础知识。在网页的源代码中查找它。一些网页的源代码相当复杂,不易定位。节点。
两种实现方式所能达到的效果基本相同,都可以利用for()循环函数抓取多个网页数据。从动手的角度来说,rvest包展示比较好,就是XML包和RCurl包。进化,更简洁方便。
另外,网络爬虫在Python中的实现也很流行。Python 的 pandas 模块工具借鉴了 R 的数据帧,而 R 的 rvest 包指的是 Python 的 BeautifulSoup。这两种语言在一定程度上是互补的。Python在实现网络爬虫方面更有优势,但在网页数据爬取方面,基于R语言工具的实现更加简洁方便,R是统计分析中更高效的独立数据分析工具。使用 R 语言获取的数据,避免了繁琐的平台环境转换。从数据采集、数据清洗到数据分析,代码环境和平台保持一致性。
参考:
[1] 吴锐,张俊丽.基于R语言的网络爬虫技术研究[J]. 科技信息, 2016, 14 (34): 35-36.
[2] 西蒙·蒙泽尔特。基于R语言的自动数据采集:网页抓取和文本挖掘实用指南[M]. 机械工业出版社,2016.
[3] 刘金红,卢玉良.专题网络爬虫研究综述[J]. 计算机应用研究, 2007, 24 (10): 26-29.
网页源代码抓取工具(【本文介绍】爬取别人网页上的内容,听上的样子)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-08 14:10
【本文介绍】
抓取其他人网页上的内容听起来很有趣。只需几步,您就可以完成超出您能力范围的事情,例如?比如天气预报,你不能带着仪器自己去测量!当然,最好使用 webService 来获取天气预报。这里只是一个例子。话不多说,看看效果吧。
【影响】
找个天气预报员网站试试:
从图中可以看出,天气是今天(6日)。让我们以此为例来获取今天的天气!
最后,背景打印出来:
今天:6日
天气:雷阵雨
温度:26°~34°
风力:微风
【思维】
1、通过url获取输入流————2、获取网页html代码————3、用正则表达式抽取有用的信息————4、拼装成想要的格式
其实最难的是第三点。如果对正则表达式不熟悉,基本会在这一步挂掉——比如我的T_T。为了提取正确的数据,我匹配了很多次。如果能匹配一次,代码量会少很多!
【代码】
1 package com.zjm.www.test;
2
3 import java.io.BufferedReader;
4 import java.io.IOException;
5 import java.io.InputStream;
6 import java.io.InputStreamReader;
7 import java.net.HttpURLConnection;
8 import java.net.URL;
9 import java.util.regex.Matcher;
10 import java.util.regex.Pattern;
11
12 /**
13 * 描述:趴取网页上的今天的天气
14 * @author zjm
15 * @time 2014/8/6
16 */
17 public class TodayTemperatureService {
18
19 /**
20 * 发起http get请求获取网页源代码
21 * @param requestUrl String 请求地址
22 * @return String 该地址返回的html字符串
23 */
24 private static String httpRequest(String requestUrl) {
25
26 StringBuffer buffer = null;
27 BufferedReader bufferedReader = null;
28 InputStreamReader inputStreamReader = null;
29 InputStream inputStream = null;
30 HttpURLConnection httpUrlConn = null;
31
32 try {
33 // 建立get请求
34 URL url = new URL(requestUrl);
35 httpUrlConn = (HttpURLConnection) url.openConnection();
36 httpUrlConn.setDoInput(true);
37 httpUrlConn.setRequestMethod("GET");
38
39 // 获取输入流
40 inputStream = httpUrlConn.getInputStream();
41 inputStreamReader = new InputStreamReader(inputStream, "utf-8");
42 bufferedReader = new BufferedReader(inputStreamReader);
43
44 // 从输入流读取结果
45 buffer = new StringBuffer();
46 String str = null;
47 while ((str = bufferedReader.readLine()) != null) {
48 buffer.append(str);
49 }
50
51 } catch (Exception e) {
52 e.printStackTrace();
53 } finally {
54 // 释放资源
55 if(bufferedReader != null) {
56 try {
57 bufferedReader.close();
58 } catch (IOException e) {
59 e.printStackTrace();
60 }
61 }
62 if(inputStreamReader != null){
63 try {
64 inputStreamReader.close();
65 } catch (IOException e) {
66 e.printStackTrace();
67 }
68 }
69 if(inputStream != null){
70 try {
71 inputStream.close();
72 } catch (IOException e) {
73 e.printStackTrace();
74 }
75 }
76 if(httpUrlConn != null){
77 httpUrlConn.disconnect();
78 }
79 }
80 return buffer.toString();
81 }
82
83 /**
84 * 过滤掉html字符串中无用的信息
85 * @param html String html字符串
86 * @return String 有用的数据
87 */
88 private static String htmlFiter(String html) {
89
90 StringBuffer buffer = new StringBuffer();
91 String str1 = "";
92 String str2 = "";
93 buffer.append("今天:");
94
95 // 取出有用的范围
96 Pattern p = Pattern.compile("(.*)()(.*?)()(.*)");
97 Matcher m = p.matcher(html);
98 if (m.matches()) {
99 str1 = m.group(3);
100 // 匹配日期,注:日期被包含在 和 中
101 p = Pattern.compile("(.*)()(.*?)()(.*)");
102 m = p.matcher(str1);
103 if(m.matches()){
104 str2 = m.group(3);
105 buffer.append(str2);
106 buffer.append("\n天气:");
107 }
108 // 匹配天气,注:天气被包含在<p class="wea" title="..."> 和 中
109 p = Pattern.compile("(.*)(
)(.*?)()(.*)");
110 m = p.matcher(str1);
111 if(m.matches()){
112 str2 = m.group(5);
113 buffer.append(str2);
114 buffer.append("\n温度:");
115 }
116 // 匹配温度,注:温度被包含在
和 中
117 p = Pattern.compile("(.*)(<p class=\"tem tem2\"> )(.*?)()(.*)");
118 m = p.matcher(str1);
119 if(m.matches()){
120 str2 = m.group(3);
121 buffer.append(str2);
122 buffer.append("°~");
123 }
124 p = Pattern.compile("(.*)(<p class=\"tem tem1\"> )(.*?)()(.*)");
125 m = p.matcher(str1);
126 if(m.matches()){
127 str2 = m.group(3);
128 buffer.append(str2);
129 buffer.append("°\n风力:");
130 }
131 // 匹配风,注: 和 中
132 p = Pattern.compile("(.*)()(.*?)()(.*)");
133 m = p.matcher(str1);
134 if(m.matches()){
135 str2 = m.group(3);
136 buffer.append(str2);
137 }
138 }
139 return buffer.toString();
140 }
141
142 /**
143 * 对以上两个方法进行封装。
144 * @return
145 */
146 public static String getTodayTemperatureInfo() {
147 // 调用第一个方法,获取html字符串
148 String html = httpRequest("http://www.weather.com.cn/html ... 6quot;);
149 // 调用第二个方法,过滤掉无用的信息
150 String result = htmlFiter(html);
151
152 return result;
153 }
154
155 /**
156 * 测试
157 * @param args
158 */
159 public static void main(String[] args) {
160 String info = getTodayTemperatureInfo();
161 System.out.println(info);
162 }
163 }
【详细解释】
第 34-49 行:通过 URL 获取网页的源代码,没什么好说的。
第96行:在网页上按F12,查看“今天”的html代码,找到下图,所以我们的第一步就是过滤掉这段html代码以外的东西。
(.*)()(.*?)()(.*) 这个正则表达式可以很容易地分为以下 5 组:
(.*): 匹配除换行符 0-N 次以外的任何内容
(): 匹配中间的 heml 代码一次
(.*?): .*? 是一个匹配的惰性模式,这意味着尽可能少地匹配除换行符以外的任何内容
():匹配中间一段html代码
(.*): 匹配除换行符 0-N 次以外的任何内容
这样我们就可以用m.group(3)得到匹配中间(.*?)的一串代码。也就是我们需要的“今天”天气的代码。
第101行:取出中间那段代码后,如下图,有很多没用的标签。我们必须想办法继续删除。方法和上面一样。
第 106 行:手动拼接我们需要的字符串。
经过上面的处理,一个简单的爬取就完成了。
中间的正则表达式部分是最不满意的。如果您有什么好的建议,请留下宝贵的意见。我很感激~ 查看全部
网页源代码抓取工具(【本文介绍】爬取别人网页上的内容,听上的样子)
【本文介绍】
抓取其他人网页上的内容听起来很有趣。只需几步,您就可以完成超出您能力范围的事情,例如?比如天气预报,你不能带着仪器自己去测量!当然,最好使用 webService 来获取天气预报。这里只是一个例子。话不多说,看看效果吧。
【影响】
找个天气预报员网站试试:
从图中可以看出,天气是今天(6日)。让我们以此为例来获取今天的天气!
最后,背景打印出来:
今天:6日
天气:雷阵雨
温度:26°~34°
风力:微风
【思维】
1、通过url获取输入流————2、获取网页html代码————3、用正则表达式抽取有用的信息————4、拼装成想要的格式
其实最难的是第三点。如果对正则表达式不熟悉,基本会在这一步挂掉——比如我的T_T。为了提取正确的数据,我匹配了很多次。如果能匹配一次,代码量会少很多!
【代码】
1 package com.zjm.www.test;
2
3 import java.io.BufferedReader;
4 import java.io.IOException;
5 import java.io.InputStream;
6 import java.io.InputStreamReader;
7 import java.net.HttpURLConnection;
8 import java.net.URL;
9 import java.util.regex.Matcher;
10 import java.util.regex.Pattern;
11
12 /**
13 * 描述:趴取网页上的今天的天气
14 * @author zjm
15 * @time 2014/8/6
16 */
17 public class TodayTemperatureService {
18
19 /**
20 * 发起http get请求获取网页源代码
21 * @param requestUrl String 请求地址
22 * @return String 该地址返回的html字符串
23 */
24 private static String httpRequest(String requestUrl) {
25
26 StringBuffer buffer = null;
27 BufferedReader bufferedReader = null;
28 InputStreamReader inputStreamReader = null;
29 InputStream inputStream = null;
30 HttpURLConnection httpUrlConn = null;
31
32 try {
33 // 建立get请求
34 URL url = new URL(requestUrl);
35 httpUrlConn = (HttpURLConnection) url.openConnection();
36 httpUrlConn.setDoInput(true);
37 httpUrlConn.setRequestMethod("GET");
38
39 // 获取输入流
40 inputStream = httpUrlConn.getInputStream();
41 inputStreamReader = new InputStreamReader(inputStream, "utf-8");
42 bufferedReader = new BufferedReader(inputStreamReader);
43
44 // 从输入流读取结果
45 buffer = new StringBuffer();
46 String str = null;
47 while ((str = bufferedReader.readLine()) != null) {
48 buffer.append(str);
49 }
50
51 } catch (Exception e) {
52 e.printStackTrace();
53 } finally {
54 // 释放资源
55 if(bufferedReader != null) {
56 try {
57 bufferedReader.close();
58 } catch (IOException e) {
59 e.printStackTrace();
60 }
61 }
62 if(inputStreamReader != null){
63 try {
64 inputStreamReader.close();
65 } catch (IOException e) {
66 e.printStackTrace();
67 }
68 }
69 if(inputStream != null){
70 try {
71 inputStream.close();
72 } catch (IOException e) {
73 e.printStackTrace();
74 }
75 }
76 if(httpUrlConn != null){
77 httpUrlConn.disconnect();
78 }
79 }
80 return buffer.toString();
81 }
82
83 /**
84 * 过滤掉html字符串中无用的信息
85 * @param html String html字符串
86 * @return String 有用的数据
87 */
88 private static String htmlFiter(String html) {
89
90 StringBuffer buffer = new StringBuffer();
91 String str1 = "";
92 String str2 = "";
93 buffer.append("今天:");
94
95 // 取出有用的范围
96 Pattern p = Pattern.compile("(.*)()(.*?)()(.*)");
97 Matcher m = p.matcher(html);
98 if (m.matches()) {
99 str1 = m.group(3);
100 // 匹配日期,注:日期被包含在 和 中
101 p = Pattern.compile("(.*)()(.*?)()(.*)");
102 m = p.matcher(str1);
103 if(m.matches()){
104 str2 = m.group(3);
105 buffer.append(str2);
106 buffer.append("\n天气:");
107 }
108 // 匹配天气,注:天气被包含在<p class="wea" title="..."> 和 中
109 p = Pattern.compile("(.*)(
)(.*?)()(.*)");
110 m = p.matcher(str1);
111 if(m.matches()){
112 str2 = m.group(5);
113 buffer.append(str2);
114 buffer.append("\n温度:");
115 }
116 // 匹配温度,注:温度被包含在
和 中
117 p = Pattern.compile("(.*)(<p class=\"tem tem2\"> )(.*?)()(.*)");
118 m = p.matcher(str1);
119 if(m.matches()){
120 str2 = m.group(3);
121 buffer.append(str2);
122 buffer.append("°~");
123 }
124 p = Pattern.compile("(.*)(<p class=\"tem tem1\"> )(.*?)()(.*)");
125 m = p.matcher(str1);
126 if(m.matches()){
127 str2 = m.group(3);
128 buffer.append(str2);
129 buffer.append("°\n风力:");
130 }
131 // 匹配风,注: 和 中
132 p = Pattern.compile("(.*)()(.*?)()(.*)");
133 m = p.matcher(str1);
134 if(m.matches()){
135 str2 = m.group(3);
136 buffer.append(str2);
137 }
138 }
139 return buffer.toString();
140 }
141
142 /**
143 * 对以上两个方法进行封装。
144 * @return
145 */
146 public static String getTodayTemperatureInfo() {
147 // 调用第一个方法,获取html字符串
148 String html = httpRequest("http://www.weather.com.cn/html ... 6quot;);
149 // 调用第二个方法,过滤掉无用的信息
150 String result = htmlFiter(html);
151
152 return result;
153 }
154
155 /**
156 * 测试
157 * @param args
158 */
159 public static void main(String[] args) {
160 String info = getTodayTemperatureInfo();
161 System.out.println(info);
162 }
163 }
【详细解释】
第 34-49 行:通过 URL 获取网页的源代码,没什么好说的。
第96行:在网页上按F12,查看“今天”的html代码,找到下图,所以我们的第一步就是过滤掉这段html代码以外的东西。
(.*)()(.*?)()(.*) 这个正则表达式可以很容易地分为以下 5 组:
(.*): 匹配除换行符 0-N 次以外的任何内容
(): 匹配中间的 heml 代码一次
(.*?): .*? 是一个匹配的惰性模式,这意味着尽可能少地匹配除换行符以外的任何内容
():匹配中间一段html代码
(.*): 匹配除换行符 0-N 次以外的任何内容
这样我们就可以用m.group(3)得到匹配中间(.*?)的一串代码。也就是我们需要的“今天”天气的代码。
第101行:取出中间那段代码后,如下图,有很多没用的标签。我们必须想办法继续删除。方法和上面一样。
第 106 行:手动拼接我们需要的字符串。
经过上面的处理,一个简单的爬取就完成了。
中间的正则表达式部分是最不满意的。如果您有什么好的建议,请留下宝贵的意见。我很感激~
网页源代码抓取工具( 将一个本地网页中的URL筛选出来并保存在新的网页文件中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-08 09:02
将一个本地网页中的URL筛选出来并保存在新的网页文件中)
URL 过滤小部件提取网页中的超链接地址
更新时间:2021年4月20日23:24:38投稿:mdxy-dxy
该VBS用于过滤掉本地网页中的URL,并将其保存在一个新的网页文件中。当然,只要改变里面的正则表达式,就可以用于其他目的。
使用方法:将以下代码另存为jb51.vbs
然后拖拽你本地保存的htm页面,拖拽这个vbs
'备注:URL筛选小工具
'防止出现错误
On Error Resume Next
'vbs代码开始----------------------------------------------
Dim p,s,re
If Wscript.Arguments.Count=0 Then
Msgbox "请把网页拖到本程序的图标上!",,"提示"
Wscript.Quit
End If
For i= 0 to Wscript.Arguments.Count - 1
p=Wscript.Arguments(i)
With CreateObject("Adodb.Stream")
.Type=2
.Charset="GB2312"
.Open
.LoadFromFile=p
s=.ReadText
Set re =New RegExp
re.Pattern= "[A-z]+://[^""()\s']+"
re.Global = True
If Not re.Test(s) Then
Msgbox "该网页文件中未出现网址!",,"提示"
Wscript.Quit
End If
Set Matches = re.Execute(s)
s=""
For Each Match In Matches
s=s & "<a href=""" & Match.Value & """>" & Match.Value & "<p>"
Next
re.Pattern= "&\w+;?|\W{5,}"
s=re.Replace(s,"")
.Position=0
.setEOS
.WriteText s
.SaveToFile p & "'s URLs.html",2
.Close
End With
Next
Msgbox "网址列表已经生成!",,"成功"
'vbs代码结束----------------------------------------------
文章关于URL过滤小部件提取网页链接地址的介绍到此结束。关于提取网页链接地址的更多信息,请搜索前面的文章或继续浏览下面的相关文章,希望大家以后多多支持脚本之家!
相关文章 查看全部
网页源代码抓取工具(
将一个本地网页中的URL筛选出来并保存在新的网页文件中)
URL 过滤小部件提取网页中的超链接地址
更新时间:2021年4月20日23:24:38投稿:mdxy-dxy
该VBS用于过滤掉本地网页中的URL,并将其保存在一个新的网页文件中。当然,只要改变里面的正则表达式,就可以用于其他目的。
使用方法:将以下代码另存为jb51.vbs
然后拖拽你本地保存的htm页面,拖拽这个vbs
'备注:URL筛选小工具
'防止出现错误
On Error Resume Next
'vbs代码开始----------------------------------------------
Dim p,s,re
If Wscript.Arguments.Count=0 Then
Msgbox "请把网页拖到本程序的图标上!",,"提示"
Wscript.Quit
End If
For i= 0 to Wscript.Arguments.Count - 1
p=Wscript.Arguments(i)
With CreateObject("Adodb.Stream")
.Type=2
.Charset="GB2312"
.Open
.LoadFromFile=p
s=.ReadText
Set re =New RegExp
re.Pattern= "[A-z]+://[^""()\s']+"
re.Global = True
If Not re.Test(s) Then
Msgbox "该网页文件中未出现网址!",,"提示"
Wscript.Quit
End If
Set Matches = re.Execute(s)
s=""
For Each Match In Matches
s=s & "<a href=""" & Match.Value & """>" & Match.Value & "<p>"
Next
re.Pattern= "&\w+;?|\W{5,}"
s=re.Replace(s,"")
.Position=0
.setEOS
.WriteText s
.SaveToFile p & "'s URLs.html",2
.Close
End With
Next
Msgbox "网址列表已经生成!",,"成功"
'vbs代码结束----------------------------------------------
文章关于URL过滤小部件提取网页链接地址的介绍到此结束。关于提取网页链接地址的更多信息,请搜索前面的文章或继续浏览下面的相关文章,希望大家以后多多支持脚本之家!
相关文章
网页源代码抓取工具(支持来路伪装,可以拦截跳转拦截框架调用的方法操作简单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-06 18:18
网站源码批量查询修改器是一款非常实用的网站源码查看软件,有效解决了网站被链接到代码的问题。方便快捷,操作简单,功能强大,找到代码后可以轻松替换代码,非常好用,欢迎感兴趣的朋友来IT猫扑下载体验!
网站源码批量查询修改器软件介绍
亲,如果你是站长,肯定会遇到网站被别人挂断的情况。如果遇到这种情况,首先要让网站恢复正常,然后才能使用这个工具,先找到马的特征字符,再用这个工具替换掉。
当然,挂马说明你的服务器或者网站有漏洞,一定要注意。你不只是杀死马,你会感觉很好。
科轩批量搜索目录并选择是否替换,txt、html、jsp、php等10种格式
指示
操作很简单,只要输入网址,然后点击查看。
支持从源头伪装,cookie伪装,可以拦截跳转,拦截帧调用。Flash、图片和CSS可以自动提取和保存。CSS 中的图像也可以自动识别。
网站源码介绍
1、 从字面上看,源文件指的是一个文件,一个源代码的集合。源代码是一组可以实现特定功能的具有特定含义的字符(程序开发代码)。
2、“源代码”大部分时间等于“源文件”
3、网站的源代码可以内置到网页或网站中。
4、 最简单的理解就是网站的源程序。
“比如右击这个网页,选择查看源文件,就会出来一个记事本,里面的内容就是这个网页的源代码。” 这句话反映了他们的关系。这里的源文件是指网页的来源。代码,而源代码就是源文件的内容,所以也可以称为网页的源代码。
源代码是指原创代码,可以是任何语言代码。
汇编代码是指源代码编译后的代码,通常是二进制文件,如DLL、EXE、.NET中间代码、java中间代码等。
高级语言通常是指C/C++、BASIC、C#、JAVA、PASCAL等汇编语言,属于ASM。只有这是机器语言。 查看全部
网页源代码抓取工具(支持来路伪装,可以拦截跳转拦截框架调用的方法操作简单)
网站源码批量查询修改器是一款非常实用的网站源码查看软件,有效解决了网站被链接到代码的问题。方便快捷,操作简单,功能强大,找到代码后可以轻松替换代码,非常好用,欢迎感兴趣的朋友来IT猫扑下载体验!
网站源码批量查询修改器软件介绍
亲,如果你是站长,肯定会遇到网站被别人挂断的情况。如果遇到这种情况,首先要让网站恢复正常,然后才能使用这个工具,先找到马的特征字符,再用这个工具替换掉。
当然,挂马说明你的服务器或者网站有漏洞,一定要注意。你不只是杀死马,你会感觉很好。
科轩批量搜索目录并选择是否替换,txt、html、jsp、php等10种格式
指示
操作很简单,只要输入网址,然后点击查看。
支持从源头伪装,cookie伪装,可以拦截跳转,拦截帧调用。Flash、图片和CSS可以自动提取和保存。CSS 中的图像也可以自动识别。
网站源码介绍
1、 从字面上看,源文件指的是一个文件,一个源代码的集合。源代码是一组可以实现特定功能的具有特定含义的字符(程序开发代码)。
2、“源代码”大部分时间等于“源文件”
3、网站的源代码可以内置到网页或网站中。
4、 最简单的理解就是网站的源程序。
“比如右击这个网页,选择查看源文件,就会出来一个记事本,里面的内容就是这个网页的源代码。” 这句话反映了他们的关系。这里的源文件是指网页的来源。代码,而源代码就是源文件的内容,所以也可以称为网页的源代码。
源代码是指原创代码,可以是任何语言代码。
汇编代码是指源代码编译后的代码,通常是二进制文件,如DLL、EXE、.NET中间代码、java中间代码等。
高级语言通常是指C/C++、BASIC、C#、JAVA、PASCAL等汇编语言,属于ASM。只有这是机器语言。
网页源代码抓取工具(网页源代码抓取工具多数情况下需要用web浏览器设置过滤条件和解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-05 19:01
网页源代码抓取工具多数情况下需要用web浏览器设置过滤条件和解析。googleformdata解析一般是网页源代码抓取工具会处理的一部分工作,可以称之为字符串解析。代码格式一般为:.xmlxml解析后格式如下:<p>段落标题
text
language...以下是原始抓取结果:。</p>
非常感谢曹兄的回答。希望对题主有所帮助。抓取日志文件主要是抓取数据的url和内容,如果是自己手动编写爬虫,关键代码以及控制细节已经抓取好的,需要会手动抓取。---1、beanmonities方法解析之后会形成如下字符串,输出时html总结的是java生成的链接表,css由opengl解析,dom由java编写,opengldrawnomdeferaux()与viewresourcetypeof()指定网页的对象类型。
在exe方式中,eclipse自带有抓取日志文件的功能,也可以直接使用“googleformdata”打开浏览器,将java脚本和标准字符串解析写到exe脚本,然后启动程序。javamaincode:publicclassexample{publicstaticvoidmain(string[]args){}publicstaticvoidstart(){//console.writeline("commandwriter1.0forjavascriptcode:\n");//console.writeline("commandwriter2.0forjavascriptcode:\n");//console.writeline("commandwriter3.0forjavascriptcode:\n");//console.writeline("commandwriter4.0forjavascriptcode:\n");//system.out.println("youcantapjavadocumentwithjavaform(command)");//thejavahelloworldgetjavascriptdocument();}}2、buffermetadata方法解析后会形成如下字符串,输出时html总结的是java生成的html表格(javacreateamanylinesofhtml),java相关字符有时会有变化比如添加:\n等符号。
javamaincode:publicclassexample{publicstaticvoidmain(string[]args){}publicstaticvoidstart(){}publicstaticvoidstop(){}}在exe方式中,可以使用javafxjscript类来创建爬虫,也可以使用javafxjscript来解析页。 查看全部
网页源代码抓取工具(网页源代码抓取工具多数情况下需要用web浏览器设置过滤条件和解析)
网页源代码抓取工具多数情况下需要用web浏览器设置过滤条件和解析。googleformdata解析一般是网页源代码抓取工具会处理的一部分工作,可以称之为字符串解析。代码格式一般为:.xmlxml解析后格式如下:<p>段落标题
text
language...以下是原始抓取结果:。</p>
非常感谢曹兄的回答。希望对题主有所帮助。抓取日志文件主要是抓取数据的url和内容,如果是自己手动编写爬虫,关键代码以及控制细节已经抓取好的,需要会手动抓取。---1、beanmonities方法解析之后会形成如下字符串,输出时html总结的是java生成的链接表,css由opengl解析,dom由java编写,opengldrawnomdeferaux()与viewresourcetypeof()指定网页的对象类型。
在exe方式中,eclipse自带有抓取日志文件的功能,也可以直接使用“googleformdata”打开浏览器,将java脚本和标准字符串解析写到exe脚本,然后启动程序。javamaincode:publicclassexample{publicstaticvoidmain(string[]args){}publicstaticvoidstart(){//console.writeline("commandwriter1.0forjavascriptcode:\n");//console.writeline("commandwriter2.0forjavascriptcode:\n");//console.writeline("commandwriter3.0forjavascriptcode:\n");//console.writeline("commandwriter4.0forjavascriptcode:\n");//system.out.println("youcantapjavadocumentwithjavaform(command)");//thejavahelloworldgetjavascriptdocument();}}2、buffermetadata方法解析后会形成如下字符串,输出时html总结的是java生成的html表格(javacreateamanylinesofhtml),java相关字符有时会有变化比如添加:\n等符号。
javamaincode:publicclassexample{publicstaticvoidmain(string[]args){}publicstaticvoidstart(){}publicstaticvoidstop(){}}在exe方式中,可以使用javafxjscript类来创建爬虫,也可以使用javafxjscript来解析页。
网页源代码抓取工具(怎样得到一个网页的源代码?网页源代码怎么获取?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-05 17:22
如何获取网页的源代码?
打开要获取的源代码,右键查看网页源代码(快捷键Ctrl U),全选要复制的(快捷键Ctrl a复制快捷键Ctrl C),粘贴到本地计算机(Ctrl V) 以创建新文档结束。HTML,保存它,然后单击检查。
如何获取网页的源代码?
打开要获取的源代码,用鼠标右键查看网页源代码(快捷键Ctrl U),选择所有要复制的(快捷键Ctrl a复制快捷键Ctrl C),并将其粘贴到本地计算机(Ctrl V)以创建一个新文档,结尾为。HTML,保存它,然后单击检查。
如何获取网页源代码中的文件?
网页的源代码是父网页的代码。网页中有一种叫做iframe的节点,相当于网页的子页面。其结构与外部网页完全相同。框架源代码是子页面的源代码。另外,网易云爬网推荐使用selenium,因为我们在做网易云爬网热评时,此时请求的代码是父网页的源码。此时,我们无法请求子页面的源代码,也无法获取需要提取的信息。这是因为打开selenium的页面后,默认操作是在父框架中。这时候如果页面在中间,也有子帧,子帧无法获取子帧中的节点。您需要使用 switch to frame() 方法来切换帧。至此,请求的代码从网页源代码切换到框架源代码,然后我们就可以提取出需要的信息了。
如何获取网页的源代码?
如果是静态网页或者动态网页,通常可以通过右键查看源文件来查看。但是,如果样式表和脚本是通过链接导入的,则无法获取这部分代码。如果是动态网页(ASP;JSP等),那么浏览器上显示的代码是编译好的,你得不到我得到的那种源代码。 查看全部
网页源代码抓取工具(怎样得到一个网页的源代码?网页源代码怎么获取?)
如何获取网页的源代码?
打开要获取的源代码,右键查看网页源代码(快捷键Ctrl U),全选要复制的(快捷键Ctrl a复制快捷键Ctrl C),粘贴到本地计算机(Ctrl V) 以创建新文档结束。HTML,保存它,然后单击检查。
如何获取网页的源代码?
打开要获取的源代码,用鼠标右键查看网页源代码(快捷键Ctrl U),选择所有要复制的(快捷键Ctrl a复制快捷键Ctrl C),并将其粘贴到本地计算机(Ctrl V)以创建一个新文档,结尾为。HTML,保存它,然后单击检查。
如何获取网页源代码中的文件?
网页的源代码是父网页的代码。网页中有一种叫做iframe的节点,相当于网页的子页面。其结构与外部网页完全相同。框架源代码是子页面的源代码。另外,网易云爬网推荐使用selenium,因为我们在做网易云爬网热评时,此时请求的代码是父网页的源码。此时,我们无法请求子页面的源代码,也无法获取需要提取的信息。这是因为打开selenium的页面后,默认操作是在父框架中。这时候如果页面在中间,也有子帧,子帧无法获取子帧中的节点。您需要使用 switch to frame() 方法来切换帧。至此,请求的代码从网页源代码切换到框架源代码,然后我们就可以提取出需要的信息了。
如何获取网页的源代码?
如果是静态网页或者动态网页,通常可以通过右键查看源文件来查看。但是,如果样式表和脚本是通过链接导入的,则无法获取这部分代码。如果是动态网页(ASP;JSP等),那么浏览器上显示的代码是编译好的,你得不到我得到的那种源代码。
网页源代码抓取工具( Python爬虫实例爬取网站搞笑段子python爬虫系列Selenium定向爬取虎扑篮球图片详解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-05 16:06
Python爬虫实例爬取网站搞笑段子python爬虫系列Selenium定向爬取虎扑篮球图片详解)
Python实现简单网页图片抓取完整代码示例
更新时间:2017年12月15日16:05:25 作者:未来
本文文章主要介绍Python中简单网页图片抓取的完整代码示例,具有一定的参考价值,有需要的朋友可以参考。
使用python捕捉网络图片的步骤是:
1、根据给定的URL获取网页源码
2、使用正则表达式过滤掉源码中的图片地址
3、根据过滤后的图片地址下载网络图片
下面是一个比较简单的抓取百度贴吧网页图片的实现:
# -*- coding: utf-8 -*-
# feimengjuan
import re
import urllib
import urllib2
#抓取网页图片
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
#利用正则表达式把源代码中的图片地址过滤出来
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' %x) #打开imglist中保存的图片网址,并下载图片保存在本地
x = x + 1
html = getHtml("http://tieba.baidu.com/p/2460150866")#获取该网址网页详细信息,得到的html就是网页的源代码
getImg(html)#从网页源代码中分析并下载保存图片
进一步整理代码,在本地创建了一个“图片”文件夹来保存图片
# -*- coding: utf-8 -*-
# feimengjuan
import re
import urllib
import urllib2
import os
#抓取网页图片
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
#创建保存图片的文件夹
def mkdir(path):
path = path.strip()
# 判断路径是否存在
# 存在 True
# 不存在 Flase
isExists = os.path.exists(path)
if not isExists:
print u'新建了名字叫做',path,u'的文件夹'
# 创建目录操作函数
os.makedirs(path)
return True
else:
# 如果目录存在则不创建,并提示目录已经存在
print u'名为',path,u'的文件夹已经创建成功'
return False
# 输入文件名,保存多张图片
def saveImages(imglist,name):
number = 1
for imageURL in imglist:
splitPath = imageURL.split('.')
fTail = splitPath.pop()
if len(fTail) > 3:
fTail = 'jpg'
fileName = name + "/" + str(number) + "." + fTail
# 对于每张图片地址,进行保存
try:
u = urllib2.urlopen(imageURL)
data = u.read()
f = open(fileName,'wb+')
f.write(data)
print u'正在保存的一张图片为',fileName
f.close()
except urllib2.URLError as e:
print (e.reason)
number += 1
#获取网页中所有图片的地址
def getAllImg(html):
#利用正则表达式把源代码中的图片地址过滤出来
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
return imglist
#创建本地保存文件夹,并下载保存图片
if __name__ == '__main__':
html = getHtml("http://tieba.baidu.com/p/2460150866")#获取该网址网页详细信息,得到的html就是网页的源代码
path = u'ͼƬ'
mkdir(path) #创建本地文件夹
imglist = getAllImg(html) #获取图片的地址列表
saveImages(imglist,path) # 保存图片
结果在“图片”文件夹中保存了几十张图片,比如截图:
总结
以上就是本文关于Python实现简单网页图片抓取完整代码示例的全部内容,希望对大家有所帮助。有兴趣的朋友可以继续参考本站:
Python爬虫实例爬取网站搞笑段子
python爬虫系列Selenium定向爬行虎扑篮球图详解
如有不足之处,欢迎留言指出。感谢朋友们对本站的支持! 查看全部
网页源代码抓取工具(
Python爬虫实例爬取网站搞笑段子python爬虫系列Selenium定向爬取虎扑篮球图片详解)
Python实现简单网页图片抓取完整代码示例
更新时间:2017年12月15日16:05:25 作者:未来
本文文章主要介绍Python中简单网页图片抓取的完整代码示例,具有一定的参考价值,有需要的朋友可以参考。
使用python捕捉网络图片的步骤是:
1、根据给定的URL获取网页源码
2、使用正则表达式过滤掉源码中的图片地址
3、根据过滤后的图片地址下载网络图片
下面是一个比较简单的抓取百度贴吧网页图片的实现:
# -*- coding: utf-8 -*-
# feimengjuan
import re
import urllib
import urllib2
#抓取网页图片
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
#利用正则表达式把源代码中的图片地址过滤出来
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' %x) #打开imglist中保存的图片网址,并下载图片保存在本地
x = x + 1
html = getHtml("http://tieba.baidu.com/p/2460150866";)#获取该网址网页详细信息,得到的html就是网页的源代码
getImg(html)#从网页源代码中分析并下载保存图片
进一步整理代码,在本地创建了一个“图片”文件夹来保存图片
# -*- coding: utf-8 -*-
# feimengjuan
import re
import urllib
import urllib2
import os
#抓取网页图片
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
#创建保存图片的文件夹
def mkdir(path):
path = path.strip()
# 判断路径是否存在
# 存在 True
# 不存在 Flase
isExists = os.path.exists(path)
if not isExists:
print u'新建了名字叫做',path,u'的文件夹'
# 创建目录操作函数
os.makedirs(path)
return True
else:
# 如果目录存在则不创建,并提示目录已经存在
print u'名为',path,u'的文件夹已经创建成功'
return False
# 输入文件名,保存多张图片
def saveImages(imglist,name):
number = 1
for imageURL in imglist:
splitPath = imageURL.split('.')
fTail = splitPath.pop()
if len(fTail) > 3:
fTail = 'jpg'
fileName = name + "/" + str(number) + "." + fTail
# 对于每张图片地址,进行保存
try:
u = urllib2.urlopen(imageURL)
data = u.read()
f = open(fileName,'wb+')
f.write(data)
print u'正在保存的一张图片为',fileName
f.close()
except urllib2.URLError as e:
print (e.reason)
number += 1
#获取网页中所有图片的地址
def getAllImg(html):
#利用正则表达式把源代码中的图片地址过滤出来
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
return imglist
#创建本地保存文件夹,并下载保存图片
if __name__ == '__main__':
html = getHtml("http://tieba.baidu.com/p/2460150866";)#获取该网址网页详细信息,得到的html就是网页的源代码
path = u'ͼƬ'
mkdir(path) #创建本地文件夹
imglist = getAllImg(html) #获取图片的地址列表
saveImages(imglist,path) # 保存图片
结果在“图片”文件夹中保存了几十张图片,比如截图:
总结
以上就是本文关于Python实现简单网页图片抓取完整代码示例的全部内容,希望对大家有所帮助。有兴趣的朋友可以继续参考本站:
Python爬虫实例爬取网站搞笑段子
python爬虫系列Selenium定向爬行虎扑篮球图详解
如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!
网页源代码抓取工具(什么是html网页文字提取工具?推荐html文本提取器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-05 14:15
什么是html网页文本提取工具?从html文档中提取文本很烦人,需要用到工具,以下是推荐的html文本提取工具合集,一起来跟小编一起学习吧!
html文本提取工具推荐:
采集电子邮件地址、竞争分析、网站 检查、价格分析和客户数据采集——这些可能只是您需要从 HTML 文档和其他文件中提取的文本。数据原因。
不幸的是,手动执行此操作非常痛苦且效率低下,在某些情况下甚至是不可能的。
幸运的是,现在有多种工具可以满足这些要求。以下 7 种工具的范围从为初学者和小型项目设计的非常简单的工具到需要一定数量编码知识并为更大和更困难的任务而设计的高级工具。
Iconico HTML 文本提取器
假设你正在浏览一个竞争对手的网站,想提取文本内容,或者想查看页面后面的HTML代码。不幸的是,您发现右键单击按钮被禁用,复制和粘贴也被禁用。许多 Web 开发人员现在正在采取措施禁止查看源代码或锁定他们的页面。
幸运的是,Iconico 有一个 HTML 文本提取器,你可以用它绕过所有这些限制,而且该产品非常好用。可以高亮复制文本,提取功能的操作就像浏览互联网一样简单。
用户界面
Path 有一组自动化处理工具,包括 Web 内容捕获实用程序。要使用该工具并获取您需要的几乎所有数据,非常简单——只需打开页面,转到工具中的设计菜单,然后单击“网页抓取”即可。除了网络搜索器,屏幕搜索器还允许您从网页中提取任何内容。使用这两个工具意味着您可以从任何网页获取文本、表格数据和其他相关信息。
莫曾达
Mozenda 允许用户提取网络数据并将信息导出到各种智能商业工具。它不仅可以提取文本内容,还可以提取 PDF 文件中的图像、文件和内容。然后,您可以将这些数据导出为 XML 文件、CSV 文件、JSON 或选择使用 API??。提取和导出数据后,您可以使用 BI 工具进行分析和报告。
HTML到文本
这个在线工具可以从 HTML 源代码(甚至 URL)中提取文本。您需要做的就是复制和粘贴、提供 URL 或上传文件。单击选项按钮让工具知道所需的输出格式和其他一些详细信息,然后单击“转换”,您将获得所需的文本信息。
八爪鱼
Octoparse 的特点是它提供了一个“点击”的用户界面。即使没有编码知识的用户也可以从 网站 中提取数据并将其发送为各种文件格式。该工具包括从页面中提取电子邮件地址和从工作板中提取工作列表等功能。该工具适用于动静态网页和云采集(也可以在采集任务配置和关闭时采集数据)。它提供了免费版本,应该足以满足大多数使用场景,而付费版本则具有更多功能。
如果您爬取网站 进行竞争分析,您可能会因为此活动而被禁止。因为 Octoparse 收录一个功能,可以在循环中识别您的 IP 地址,并可以禁止您通过 IP 使用它。
刮痧
这个免费的开源工具使用网络爬虫从 网站 中提取信息。使用此工具需要一些高级技能和编码知识。但是,如果您愿意以自己的方式学习使用它,那么 Scrapy 是抓取大型 Web 项目的理想选择。CareerBuilder和其他主要品牌已经使用了这个工具。因为它是一个开源工具,它为用户提供了很多很好的社区支持。
和服
Kimono 是一款免费工具,可以从网页中获取非结构化数据,并将信息提取为带有 XML 文件的结构化格式。该工具可以交互使用,也可以创建计划作业以在特定时间提取所需数据。您可以从搜索引擎结果、网页甚至幻灯片演示中提取数据。
最重要的是,当您设置每个工作流时,Kimono 将创建一个 API。这意味着当您返回网站 提取更多数据时,无需重新发明轮子。
综上所述
如果您遇到需要从一个或多个网页中提取非结构化数据的任务,则此列表中的至少一个工具应收录所需的解决方案。而且,无论您的预期价格是多少,您都应该能够找到所需的工具。
清楚地了解并决定哪个最适合您。如您所知,大数据在蓬勃发展的业务发展中的重要性以及采集所需信息的能力对您来说也至关重要。 查看全部
网页源代码抓取工具(什么是html网页文字提取工具?推荐html文本提取器)
什么是html网页文本提取工具?从html文档中提取文本很烦人,需要用到工具,以下是推荐的html文本提取工具合集,一起来跟小编一起学习吧!
html文本提取工具推荐:
采集电子邮件地址、竞争分析、网站 检查、价格分析和客户数据采集——这些可能只是您需要从 HTML 文档和其他文件中提取的文本。数据原因。
不幸的是,手动执行此操作非常痛苦且效率低下,在某些情况下甚至是不可能的。
幸运的是,现在有多种工具可以满足这些要求。以下 7 种工具的范围从为初学者和小型项目设计的非常简单的工具到需要一定数量编码知识并为更大和更困难的任务而设计的高级工具。
Iconico HTML 文本提取器
假设你正在浏览一个竞争对手的网站,想提取文本内容,或者想查看页面后面的HTML代码。不幸的是,您发现右键单击按钮被禁用,复制和粘贴也被禁用。许多 Web 开发人员现在正在采取措施禁止查看源代码或锁定他们的页面。
幸运的是,Iconico 有一个 HTML 文本提取器,你可以用它绕过所有这些限制,而且该产品非常好用。可以高亮复制文本,提取功能的操作就像浏览互联网一样简单。
用户界面
Path 有一组自动化处理工具,包括 Web 内容捕获实用程序。要使用该工具并获取您需要的几乎所有数据,非常简单——只需打开页面,转到工具中的设计菜单,然后单击“网页抓取”即可。除了网络搜索器,屏幕搜索器还允许您从网页中提取任何内容。使用这两个工具意味着您可以从任何网页获取文本、表格数据和其他相关信息。
莫曾达
Mozenda 允许用户提取网络数据并将信息导出到各种智能商业工具。它不仅可以提取文本内容,还可以提取 PDF 文件中的图像、文件和内容。然后,您可以将这些数据导出为 XML 文件、CSV 文件、JSON 或选择使用 API??。提取和导出数据后,您可以使用 BI 工具进行分析和报告。
HTML到文本
这个在线工具可以从 HTML 源代码(甚至 URL)中提取文本。您需要做的就是复制和粘贴、提供 URL 或上传文件。单击选项按钮让工具知道所需的输出格式和其他一些详细信息,然后单击“转换”,您将获得所需的文本信息。
八爪鱼
Octoparse 的特点是它提供了一个“点击”的用户界面。即使没有编码知识的用户也可以从 网站 中提取数据并将其发送为各种文件格式。该工具包括从页面中提取电子邮件地址和从工作板中提取工作列表等功能。该工具适用于动静态网页和云采集(也可以在采集任务配置和关闭时采集数据)。它提供了免费版本,应该足以满足大多数使用场景,而付费版本则具有更多功能。
如果您爬取网站 进行竞争分析,您可能会因为此活动而被禁止。因为 Octoparse 收录一个功能,可以在循环中识别您的 IP 地址,并可以禁止您通过 IP 使用它。
刮痧
这个免费的开源工具使用网络爬虫从 网站 中提取信息。使用此工具需要一些高级技能和编码知识。但是,如果您愿意以自己的方式学习使用它,那么 Scrapy 是抓取大型 Web 项目的理想选择。CareerBuilder和其他主要品牌已经使用了这个工具。因为它是一个开源工具,它为用户提供了很多很好的社区支持。
和服
Kimono 是一款免费工具,可以从网页中获取非结构化数据,并将信息提取为带有 XML 文件的结构化格式。该工具可以交互使用,也可以创建计划作业以在特定时间提取所需数据。您可以从搜索引擎结果、网页甚至幻灯片演示中提取数据。
最重要的是,当您设置每个工作流时,Kimono 将创建一个 API。这意味着当您返回网站 提取更多数据时,无需重新发明轮子。
综上所述
如果您遇到需要从一个或多个网页中提取非结构化数据的任务,则此列表中的至少一个工具应收录所需的解决方案。而且,无论您的预期价格是多少,您都应该能够找到所需的工具。
清楚地了解并决定哪个最适合您。如您所知,大数据在蓬勃发展的业务发展中的重要性以及采集所需信息的能力对您来说也至关重要。
网页源代码抓取工具(云象css网页源代码抓取工具分享(一)_软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-05 05:04
网页源代码抓取工具分享。云象css数据抓取器:现可采集500+网站的css代码表格显示,可以采集已有的html标签,也可爬取网页源代码,只需要点击一下就可进行抓取,无需繁琐的繁琐软件,无需一步步往下走,非常适合于零编程基础的人使用,软件界面易操作、快捷方便,一键性操作就可进行功能分析,可根据文本、css语法提示等快速找到想要的代码,非常适合新手学习使用.。
使用邮箱注册
没有什么技巧,最直接的方法就是使用脚本。
已经有人给题主推荐这个网站,
你先会写基本的html和css代码再说吧,然后再学习js,jq
打开百度搜索“page80”,进入首页就可以按照所需页数下载,
1、登录雅虎邮箱
2、切换到工作邮箱
3、登录
4、切换到自己的邮箱
5、打开页面的源代码
6、复制粘贴
可以直接从国外的网站调用
截图中的就是非常好用的javascript抓取工具。其他几个问题的回答,只能在前面回答的基础上。
你能忍受一点不开源吗?
公司有木有现成的js抓取工具?可以向领导请教下
可以在网上买个电子版的教程,有系统的一步步讲解,而且是免费。
页面截图,然后一步步写js代码到excel表格里,然后再用mysql管理。 查看全部
网页源代码抓取工具(云象css网页源代码抓取工具分享(一)_软件)
网页源代码抓取工具分享。云象css数据抓取器:现可采集500+网站的css代码表格显示,可以采集已有的html标签,也可爬取网页源代码,只需要点击一下就可进行抓取,无需繁琐的繁琐软件,无需一步步往下走,非常适合于零编程基础的人使用,软件界面易操作、快捷方便,一键性操作就可进行功能分析,可根据文本、css语法提示等快速找到想要的代码,非常适合新手学习使用.。
使用邮箱注册
没有什么技巧,最直接的方法就是使用脚本。
已经有人给题主推荐这个网站,
你先会写基本的html和css代码再说吧,然后再学习js,jq
打开百度搜索“page80”,进入首页就可以按照所需页数下载,
1、登录雅虎邮箱
2、切换到工作邮箱
3、登录
4、切换到自己的邮箱
5、打开页面的源代码
6、复制粘贴
可以直接从国外的网站调用
截图中的就是非常好用的javascript抓取工具。其他几个问题的回答,只能在前面回答的基础上。
你能忍受一点不开源吗?
公司有木有现成的js抓取工具?可以向领导请教下
可以在网上买个电子版的教程,有系统的一步步讲解,而且是免费。
页面截图,然后一步步写js代码到excel表格里,然后再用mysql管理。
网页源代码抓取工具( 思路先理一下思路:获取前端传递的链接地址(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-04 09:12
思路先理一下思路:获取前端传递的链接地址(组图)
)
这几年涌现了很多技术博客和技术社区,也有很多技术同仁开始创建自己的博客。我们可以将自己的博客同步到不同的技术平台,但是随着技术平台数量的增加,我们文章同步会花费越来越多的时间,那么有没有什么工具可以快速将博客发布到不同的平台呢?或者有没有什么工具可以直接将HTML转换成技术平台可以识别并直接发布的“语言”呢?
我们都知道程序员最喜欢写博客的“语言”是makedown,而且目前大部分技术社区都支持makedown语法,所以只要有makedown,我们就可以快速同步到不同的技术平台。
可能有人会说不能直接用makedown的语法来写博客吧?这样确实可以满足需求,但缺点是必须在本地保存一个makedown文件。如果博客内容涉及图片,我们还需要维护一个img目录,所以每次在不同的技术社区发布文章还是很麻烦的,所以总结一下,我们开发了一个自动爬取html的工具内容并一键转换成美图,让我们可以“肆无忌惮”“发博”。
你会收获
文末附上作者github地址,感兴趣的朋友可以一起搭建、学习、探索。
效果展示
客户理念
首先梳理一下思路:
输入链接地址
获取服务器返回的html字符串,将html字符串转换为md字符串,在编辑器中同步显示预览
为什么选择夜床
客户端最重要的一步就是将html转md,这里我们使用turndown。
为什么要使用调低?原因如下:
执行
// 引入第三方插件
import { gfm, tables, strikethrough } from 'turndown-plugin-gfm'
const turndownService = new TurndownService({ codeBlockStyle: 'fenced' })
// Use the gfm plugin
turndownService.use(gfm)
// Use the table and strikethrough plugins only
turndownService.use([tables, strikethrough])
/**
* 自定义配置(rule名不能重复)
* 这里我们指定 `pre` 标签为代码块,并在代码块的前后加个换行,防止显示异常
*/
turndownService.addRule('pre2Code', {
filter: ['pre'],
replacement (content) {
return '```\n' + content + '\n```'
}
})
额外功能
支持自动获取链接文章标题,无需手动复制原文。
服务器
我们这里使用的服务端是node.js,我们使用前端框架来编写服务端,体验杠杆作用。
想法
一、思路:获取前端传递过来的链接地址。通过请求获取html字符串。根据不同平台的域名获取不同的dom。将图片和链接的相对路径转换为绝对路径。在底部添加reprint source语句,获取文章的标题。将title和html返回给前端
获取前端传递过来的链接地址的具体实现
这里我们直接使用node自己的语法,我们使用get形式传输,只使用query
const qUrl = req.query.url
通过请求获取html字符串
这里我们使用 request 来发出请求
request({
url: qUrl
}, (error, response, body) => {
if (error) {
res.status(404).send('Url Error')
return
}
// 这里的 body 就是文章的 `html`
console.log(body)
})
根据不同平台的域名获取不同的dom
由于技术平台众多,每个平台的文章内容标签、样式名称或id都会不同,需要兼容。
先用js-dom模拟dom的操作,封装一个方法
/**
* 获取准确的文章内容
* @param {string} html html串
* @param {string} selector css选择器
* @return {string} htmlContent
*/
const getDom = (html, selector) => {
const dom = new JSDOM(html)
const htmlContent = dom.window.document.querySelector(selector)
return htmlContent
}
兼容不同平台并应用不同的css选择器
// 比如掘金,内容块的样式名为 .markdown-body,内容里会有 style 标签样式和一些多余的复制代码文字,通过原生 dom 操作删掉
if (qUrl.includes('juejin.cn')) {
const htmlContent = getBySelector('.markdown-body')
const extraDom = htmlContent.querySelector('style')
const extraDomArr = htmlContent.querySelectorAll('.copy-code-btn')
extraDom && extraDom.remove()
extraDomArr.length > 0 && extraDomArr.forEach((v) => { v.remove() })
return htmlContent
}
// 再比如 oschina,内容块的样式名为 .article-detail,内容里会有多余的 .ad-wrap 内容,照样删掉
if (qUrl.includes('oschina.net')) {
const htmlContent = getBySelector('.article-detail')
const extraDom = htmlContent.querySelector('.ad-wrap')
extraDom && extraDom.remove()
return htmlContent
}
// 最后匹配通用标签。优先适配 article 标签,没有再用 body 标签
const htmlArticle = getBySelector('article')
if (htmlArticle) { return htmlArticle }
const htmlBody = getBySelector('body')
if (htmlBody) { return htmlBody }
将图片和链接的相对路径转换为绝对路径,方便日后查找源路径
// 通过原生api - URL 获取链接的源域名
const qOrigin = new URL(qUrl).origin || ''
// 获取图片、链接的绝对路径。通过 URL 将 `路径+源域名` 转换为绝对路径,不熟悉的同学请自行了解
const getAbsoluteUrl = p => new URL(p, qOrigin).href
// 转换图片、链接的相对路径,不同平台的图片懒加载属性名不一样,需要做特定兼容
const changeRelativeUrl = (dom) => {
if (!dom) { return '内容出错~' }
const copyDom = dom
// 获取所有图片
const imgs = copyDom.querySelectorAll('img')
// 获取所有链接
const links = copyDom.querySelectorAll('a')
// 替换完所有路径返回新 dom
imgs.length > 0 && imgs.forEach((v) => {
/**
* 处理懒加载路径
* 简书:data-original-src
* 掘金:data-src
* segmentfault:data-src
*/
const src = v.src || v.getAttribute('data-src') || v.getAttribute('data-original-src') || ''
v.src = getAbsoluteUrl(src)
})
links.length > 0 && links.forEach((v) => {
const href = v.href || qUrl
v.href = getAbsoluteUrl(href)
})
return copyDom
}
// 在获取不同平台的文章内容 getBody 方法里,应用 changeRelativeUrl 方法
const getBody = (content) => {
...
...
return changeRelativeUrl(htmlContent)
} 查看全部
网页源代码抓取工具(
思路先理一下思路:获取前端传递的链接地址(组图)
)
这几年涌现了很多技术博客和技术社区,也有很多技术同仁开始创建自己的博客。我们可以将自己的博客同步到不同的技术平台,但是随着技术平台数量的增加,我们文章同步会花费越来越多的时间,那么有没有什么工具可以快速将博客发布到不同的平台呢?或者有没有什么工具可以直接将HTML转换成技术平台可以识别并直接发布的“语言”呢?
我们都知道程序员最喜欢写博客的“语言”是makedown,而且目前大部分技术社区都支持makedown语法,所以只要有makedown,我们就可以快速同步到不同的技术平台。
可能有人会说不能直接用makedown的语法来写博客吧?这样确实可以满足需求,但缺点是必须在本地保存一个makedown文件。如果博客内容涉及图片,我们还需要维护一个img目录,所以每次在不同的技术社区发布文章还是很麻烦的,所以总结一下,我们开发了一个自动爬取html的工具内容并一键转换成美图,让我们可以“肆无忌惮”“发博”。
你会收获
文末附上作者github地址,感兴趣的朋友可以一起搭建、学习、探索。
效果展示
客户理念
首先梳理一下思路:
输入链接地址
获取服务器返回的html字符串,将html字符串转换为md字符串,在编辑器中同步显示预览
为什么选择夜床
客户端最重要的一步就是将html转md,这里我们使用turndown。
为什么要使用调低?原因如下:
执行
// 引入第三方插件
import { gfm, tables, strikethrough } from 'turndown-plugin-gfm'
const turndownService = new TurndownService({ codeBlockStyle: 'fenced' })
// Use the gfm plugin
turndownService.use(gfm)
// Use the table and strikethrough plugins only
turndownService.use([tables, strikethrough])
/**
* 自定义配置(rule名不能重复)
* 这里我们指定 `pre` 标签为代码块,并在代码块的前后加个换行,防止显示异常
*/
turndownService.addRule('pre2Code', {
filter: ['pre'],
replacement (content) {
return '```\n' + content + '\n```'
}
})
额外功能
支持自动获取链接文章标题,无需手动复制原文。
服务器
我们这里使用的服务端是node.js,我们使用前端框架来编写服务端,体验杠杆作用。
想法
一、思路:获取前端传递过来的链接地址。通过请求获取html字符串。根据不同平台的域名获取不同的dom。将图片和链接的相对路径转换为绝对路径。在底部添加reprint source语句,获取文章的标题。将title和html返回给前端
获取前端传递过来的链接地址的具体实现
这里我们直接使用node自己的语法,我们使用get形式传输,只使用query
const qUrl = req.query.url
通过请求获取html字符串
这里我们使用 request 来发出请求
request({
url: qUrl
}, (error, response, body) => {
if (error) {
res.status(404).send('Url Error')
return
}
// 这里的 body 就是文章的 `html`
console.log(body)
})
根据不同平台的域名获取不同的dom
由于技术平台众多,每个平台的文章内容标签、样式名称或id都会不同,需要兼容。
先用js-dom模拟dom的操作,封装一个方法
/**
* 获取准确的文章内容
* @param {string} html html串
* @param {string} selector css选择器
* @return {string} htmlContent
*/
const getDom = (html, selector) => {
const dom = new JSDOM(html)
const htmlContent = dom.window.document.querySelector(selector)
return htmlContent
}
兼容不同平台并应用不同的css选择器
// 比如掘金,内容块的样式名为 .markdown-body,内容里会有 style 标签样式和一些多余的复制代码文字,通过原生 dom 操作删掉
if (qUrl.includes('juejin.cn')) {
const htmlContent = getBySelector('.markdown-body')
const extraDom = htmlContent.querySelector('style')
const extraDomArr = htmlContent.querySelectorAll('.copy-code-btn')
extraDom && extraDom.remove()
extraDomArr.length > 0 && extraDomArr.forEach((v) => { v.remove() })
return htmlContent
}
// 再比如 oschina,内容块的样式名为 .article-detail,内容里会有多余的 .ad-wrap 内容,照样删掉
if (qUrl.includes('oschina.net')) {
const htmlContent = getBySelector('.article-detail')
const extraDom = htmlContent.querySelector('.ad-wrap')
extraDom && extraDom.remove()
return htmlContent
}
// 最后匹配通用标签。优先适配 article 标签,没有再用 body 标签
const htmlArticle = getBySelector('article')
if (htmlArticle) { return htmlArticle }
const htmlBody = getBySelector('body')
if (htmlBody) { return htmlBody }
将图片和链接的相对路径转换为绝对路径,方便日后查找源路径
// 通过原生api - URL 获取链接的源域名
const qOrigin = new URL(qUrl).origin || ''
// 获取图片、链接的绝对路径。通过 URL 将 `路径+源域名` 转换为绝对路径,不熟悉的同学请自行了解
const getAbsoluteUrl = p => new URL(p, qOrigin).href
// 转换图片、链接的相对路径,不同平台的图片懒加载属性名不一样,需要做特定兼容
const changeRelativeUrl = (dom) => {
if (!dom) { return '内容出错~' }
const copyDom = dom
// 获取所有图片
const imgs = copyDom.querySelectorAll('img')
// 获取所有链接
const links = copyDom.querySelectorAll('a')
// 替换完所有路径返回新 dom
imgs.length > 0 && imgs.forEach((v) => {
/**
* 处理懒加载路径
* 简书:data-original-src
* 掘金:data-src
* segmentfault:data-src
*/
const src = v.src || v.getAttribute('data-src') || v.getAttribute('data-original-src') || ''
v.src = getAbsoluteUrl(src)
})
links.length > 0 && links.forEach((v) => {
const href = v.href || qUrl
v.href = getAbsoluteUrl(href)
})
return copyDom
}
// 在获取不同平台的文章内容 getBody 方法里,应用 changeRelativeUrl 方法
const getBody = (content) => {
...
...
return changeRelativeUrl(htmlContent)
}
网页源代码抓取工具(手动做各种各样的7个高级工具,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-03 03:01
本文包括为初学者和小型项目设计的简单工具,以及需要一定数量编码知识并专为更大和更困难的任务而设计的高级工具。
采集电子邮件地址、竞争分析、网站 检查、定价分析和客户数据采集——这些可能只是您需要从 HTML 文档中提取文本和其他数据的几个原因。不幸的是,手动执行此操作既痛苦又低效,在某些情况下甚至是不可能的。幸运的是,现在有多种工具可以满足这些要求。以下 7 种工具的范围从为初学者和小型项目设计的非常简单的工具到需要一定数量编码知识并为更大和更困难的任务而设计的高级工具。
Iconico HTML 文本提取器(Iconico HTML 文本提取器)
想象一下,你正在浏览一个竞争对手的网站,然后你想提取文本内容,或者你想看到页面背后的HTML代码。不幸的是,您发现右侧按钮被禁用,复制和粘贴也是如此。许多 Web 开发人员现在正在采取措施禁止查看源代码或锁定他们的页面。幸运的是,Iconico 有一个 HTML 文本提取器,您可以使用它来绕过所有这些限制,而且该产品非常易于使用。可以高亮复制文本,提取功能的操作就像上网一样简单。
路径
UIPath 有一组自动化处理工具,其中包括一个 Web 内容爬行实用程序。要使用该工具并获取您需要的几乎所有数据非常简单——只需打开页面,转到工具中的设计菜单,然后单击“网页抓取”。除了网页抓取工具,屏幕抓取工具还允许您从网页中提取任何内容。使用这两个工具意味着您可以从任何网页中获取文本、表格数据和其他相关信息。
莫曾达
Mozenda 允许用户提取网络数据并将该信息导出到各种智能商业工具。它不仅可以提取文本内容,还可以从PDF文件中提取图像、文件和内容。然后,您可以将这些数据导出到 XML 文件、CSV 文件、JSON 或您可以选择使用 API。提取和导出数据后,您可以使用 BI 工具进行分析和报告。
HTML到文本
这个在线工具可以从 HTML 源代码中提取文本,甚至只是一个 URL。您需要做的就是复制和粘贴、提供 URL 或上传文件。单击选项按钮,让工具知道您需要的输出格式和其他一些详细信息,然后单击转换,您将获得所需的文本信息。
(有一个类似的工具——)
八爪鱼
Octoparse 的特点是它提供了一个“点击”的用户界面。即使没有编码知识的用户也可以从 网站 中提取数据并将其发送为各种文件格式。该工具包括从页面中提取电子邮件地址和从工作板中提取工作列表等功能。本工具适用于动静态网页和云端采集(采集任务关闭也可以采集数据)。它提供了免费版,应该可以满足大部分使用场景,而付费版功能更加丰富。
如果您爬取网站 进行竞争分析,您可能会因为此活动而被禁止。因为 Octoparse 收录一个循环识别您的 IP 地址的功能,并可以阻止您通过您的 IP 使用它。
刮痧
这个免费的开源工具使用网络爬虫从 网站 中提取信息。使用此工具需要一些高级技能和编码知识。但是,如果您愿意按照自己的方式学习使用它,Scrapy 是抓取大型 Web 项目的理想选择。CareerBuilder和其他主要品牌已经使用了这个工具。因为它是一个开源工具,它为用户提供了很多很好的社区支持。
和服
Kimono 是一款免费工具,可从网页中获取非结构化数据,并将信息提取为带有 XML 文件的结构化格式。该工具可以交互使用,也可以创建计划作业以在特定时间提取所需的数据。您可以从搜索引擎结果、网页甚至幻灯片演示中提取数据。最重要的是,当您设置每个工作流时,Kimono 将创建一个 API。这意味着当您返回 网站 提取更多数据时,您不必重新发明轮子。
综上所述
如果您遇到需要从一个或多个网页中提取非结构化数据的任务,那么此列表中至少有一个工具应收录您需要的解决方案。无论您的预期价格是多少,您都应该能够找到所需的工具。清楚地了解并决定哪个最适合您。您知道,大数据在蓬勃发展的业务发展中的重要性,以及采集所需信息的能力对您来说也至关重要。
原文来源:Elaina Meiser 翻译来源:开源中国/总监 查看全部
网页源代码抓取工具(手动做各种各样的7个高级工具,你知道吗?)
本文包括为初学者和小型项目设计的简单工具,以及需要一定数量编码知识并专为更大和更困难的任务而设计的高级工具。
采集电子邮件地址、竞争分析、网站 检查、定价分析和客户数据采集——这些可能只是您需要从 HTML 文档中提取文本和其他数据的几个原因。不幸的是,手动执行此操作既痛苦又低效,在某些情况下甚至是不可能的。幸运的是,现在有多种工具可以满足这些要求。以下 7 种工具的范围从为初学者和小型项目设计的非常简单的工具到需要一定数量编码知识并为更大和更困难的任务而设计的高级工具。
Iconico HTML 文本提取器(Iconico HTML 文本提取器)
想象一下,你正在浏览一个竞争对手的网站,然后你想提取文本内容,或者你想看到页面背后的HTML代码。不幸的是,您发现右侧按钮被禁用,复制和粘贴也是如此。许多 Web 开发人员现在正在采取措施禁止查看源代码或锁定他们的页面。幸运的是,Iconico 有一个 HTML 文本提取器,您可以使用它来绕过所有这些限制,而且该产品非常易于使用。可以高亮复制文本,提取功能的操作就像上网一样简单。
路径
UIPath 有一组自动化处理工具,其中包括一个 Web 内容爬行实用程序。要使用该工具并获取您需要的几乎所有数据非常简单——只需打开页面,转到工具中的设计菜单,然后单击“网页抓取”。除了网页抓取工具,屏幕抓取工具还允许您从网页中提取任何内容。使用这两个工具意味着您可以从任何网页中获取文本、表格数据和其他相关信息。
莫曾达
Mozenda 允许用户提取网络数据并将该信息导出到各种智能商业工具。它不仅可以提取文本内容,还可以从PDF文件中提取图像、文件和内容。然后,您可以将这些数据导出到 XML 文件、CSV 文件、JSON 或您可以选择使用 API。提取和导出数据后,您可以使用 BI 工具进行分析和报告。
HTML到文本
这个在线工具可以从 HTML 源代码中提取文本,甚至只是一个 URL。您需要做的就是复制和粘贴、提供 URL 或上传文件。单击选项按钮,让工具知道您需要的输出格式和其他一些详细信息,然后单击转换,您将获得所需的文本信息。
(有一个类似的工具——)
八爪鱼
Octoparse 的特点是它提供了一个“点击”的用户界面。即使没有编码知识的用户也可以从 网站 中提取数据并将其发送为各种文件格式。该工具包括从页面中提取电子邮件地址和从工作板中提取工作列表等功能。本工具适用于动静态网页和云端采集(采集任务关闭也可以采集数据)。它提供了免费版,应该可以满足大部分使用场景,而付费版功能更加丰富。
如果您爬取网站 进行竞争分析,您可能会因为此活动而被禁止。因为 Octoparse 收录一个循环识别您的 IP 地址的功能,并可以阻止您通过您的 IP 使用它。
刮痧
这个免费的开源工具使用网络爬虫从 网站 中提取信息。使用此工具需要一些高级技能和编码知识。但是,如果您愿意按照自己的方式学习使用它,Scrapy 是抓取大型 Web 项目的理想选择。CareerBuilder和其他主要品牌已经使用了这个工具。因为它是一个开源工具,它为用户提供了很多很好的社区支持。
和服
Kimono 是一款免费工具,可从网页中获取非结构化数据,并将信息提取为带有 XML 文件的结构化格式。该工具可以交互使用,也可以创建计划作业以在特定时间提取所需的数据。您可以从搜索引擎结果、网页甚至幻灯片演示中提取数据。最重要的是,当您设置每个工作流时,Kimono 将创建一个 API。这意味着当您返回 网站 提取更多数据时,您不必重新发明轮子。
综上所述
如果您遇到需要从一个或多个网页中提取非结构化数据的任务,那么此列表中至少有一个工具应收录您需要的解决方案。无论您的预期价格是多少,您都应该能够找到所需的工具。清楚地了解并决定哪个最适合您。您知道,大数据在蓬勃发展的业务发展中的重要性,以及采集所需信息的能力对您来说也至关重要。
原文来源:Elaina Meiser 翻译来源:开源中国/总监
网页源代码抓取工具(从office到chrome,我都用过的网页代码工具推荐)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-01 11:41
网页源代码抓取工具推荐目前大部分的网页抓取工具大多是基于javascript+css实现的,这就导致了抓取效率极低。有鉴于此,我试图给出一个高效率的网页代码抓取工具,那就是从office到chrome,我都用过的topicasa,下面我就一一介绍topicasa:我们通过office解析数据,再用chrome查看。
topicasa-网页代码抓取工具功能如下:1.抓取office等excel表格2.数据分析ggplot23.图片+地图抓取4.热门音乐fm,歌曲分类hashtag1.数据分析excel2013/2010/2013大表格1.officepowerpointplus2013/2013/2013/2014/2015等版本(excel与word直接混合抓取)2.chrome等浏览器/插件3.内容推荐人工推荐关注微信公众号:(shenxinhonglian),回复”抓取工具”获取,或者关注微信公众号:(shenxinhonglian)。
转载给你啦~
最近常常在浏览网页的时候到处翻对象的链接,我想看看他们是不是都出自正规公司,也想从中获取对象的商标,是不是很有趣。之前我是用天眼查这个软件来找的对象,因为我需要一个人身份证号的公司,但是他没有在工商局有备案。正好这时候腾讯发布了腾讯云储备计划,我可以利用腾讯云储备计划中的实名认证策略去找这个公司的。现在我利用程序抓取了多个公司的网页链接,发现有些公司比较经典:比如,,等等。
我再使用爬虫爬一下进行比较,发现这些公司的数据都存在那些网站里,不同的站点分别是什么数据。我自己总结了一下,分析他们共有的几个数据点:1.商标:什么样的商标;如何查询2.工商局备案信息;如何查询3.人才:谁负责;谁负责;谁负责;这个公司有招聘吗?有毕业证吗?会计资格证书等等。4.投资:是上市公司股东还是个人股东;注册资金;实缴出资;投资人是哪些人;5.股权结构:谁占股;谁在市场有投资等等。
最近工作需要查询人才信息,一番搜索后发现下面两个人才比较实用,他们是安徽某个科技企业的董事长。第一个是:青年员工、刚升为总经理的连续创业者“在能力没有充分展现的前提下,公司就提供股份福利。我该怎么评价?——牛逼。一开始就是这样的福利,这不就是安徽那个创业者吗?”第二个是:科技大佬、小猪的幕后投资人“小猪是家电前十的公司,但是2019年创业大赛第一名是一家叫做‘贝玛’的公司。
2015年6月在吉林成立了首家校园分公司,到现在已经成为吉林省仅有的五家公司之一。这家公司产品是什么,他的股东是谁?当时我拿到创业板ipo上市的公司的。 查看全部
网页源代码抓取工具(从office到chrome,我都用过的网页代码工具推荐)
网页源代码抓取工具推荐目前大部分的网页抓取工具大多是基于javascript+css实现的,这就导致了抓取效率极低。有鉴于此,我试图给出一个高效率的网页代码抓取工具,那就是从office到chrome,我都用过的topicasa,下面我就一一介绍topicasa:我们通过office解析数据,再用chrome查看。
topicasa-网页代码抓取工具功能如下:1.抓取office等excel表格2.数据分析ggplot23.图片+地图抓取4.热门音乐fm,歌曲分类hashtag1.数据分析excel2013/2010/2013大表格1.officepowerpointplus2013/2013/2013/2014/2015等版本(excel与word直接混合抓取)2.chrome等浏览器/插件3.内容推荐人工推荐关注微信公众号:(shenxinhonglian),回复”抓取工具”获取,或者关注微信公众号:(shenxinhonglian)。
转载给你啦~
最近常常在浏览网页的时候到处翻对象的链接,我想看看他们是不是都出自正规公司,也想从中获取对象的商标,是不是很有趣。之前我是用天眼查这个软件来找的对象,因为我需要一个人身份证号的公司,但是他没有在工商局有备案。正好这时候腾讯发布了腾讯云储备计划,我可以利用腾讯云储备计划中的实名认证策略去找这个公司的。现在我利用程序抓取了多个公司的网页链接,发现有些公司比较经典:比如,,等等。
我再使用爬虫爬一下进行比较,发现这些公司的数据都存在那些网站里,不同的站点分别是什么数据。我自己总结了一下,分析他们共有的几个数据点:1.商标:什么样的商标;如何查询2.工商局备案信息;如何查询3.人才:谁负责;谁负责;谁负责;这个公司有招聘吗?有毕业证吗?会计资格证书等等。4.投资:是上市公司股东还是个人股东;注册资金;实缴出资;投资人是哪些人;5.股权结构:谁占股;谁在市场有投资等等。
最近工作需要查询人才信息,一番搜索后发现下面两个人才比较实用,他们是安徽某个科技企业的董事长。第一个是:青年员工、刚升为总经理的连续创业者“在能力没有充分展现的前提下,公司就提供股份福利。我该怎么评价?——牛逼。一开始就是这样的福利,这不就是安徽那个创业者吗?”第二个是:科技大佬、小猪的幕后投资人“小猪是家电前十的公司,但是2019年创业大赛第一名是一家叫做‘贝玛’的公司。
2015年6月在吉林成立了首家校园分公司,到现在已经成为吉林省仅有的五家公司之一。这家公司产品是什么,他的股东是谁?当时我拿到创业板ipo上市的公司的。
网页源代码抓取工具(ColorWellformac软件介绍for)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-01 04:11
ColorWell for mac 是mac上一款网页颜色代码提取工具。它可以通过快速访问所有颜色信息并为应用程序开发生成代码生成功能,轻松生成无限的调色板。可编辑的调色板数据库允许您存档和恢复任何调色板,以便以后进行超快速搜索。当然,您也可以抓取任何源图像并将其放入“构建器”窗口以生成图像中最常见颜色的调色板。当然,您可以将生成的任何调色板保存在 ColorWell Palette 数据库中!
ColorWell for mac 特别说明
下载好ColorWell安装包后,点击打开ColorWell.dmg,将左侧的【ColorWell】拖到右侧的应用程序中即可使用。
ColorWell for mac 软件介绍
一个漂亮而直观的颜色选择器和调色板生成器——任何网络/应用程序开发人员工具箱的必要补充!
通过快速访问所有颜色信息并为应用程序开发生成代码生成函数,可以非常轻松地生成无限的调色板。可编辑的调色板数据库允许您存档和恢复任何调色板,以便以后进行超快速搜索。
默认情况下访问 MacOS 色轮非常繁琐,但 ColorWell 可以配置为通过全局热键或从系统菜单栏快速单击鼠标来显示它。这使您可以从任何颜色源快速获取 Hex/HSL/RGB 和代码片段。如果您从未从源(或多源)图像快速生成调色板,那么您需要调色板生成器。您可以抓取任何源图像并将其放置在“生成器”窗口中,以生成图像中最常见颜色的调色板。当然,您可以将生成的任何调色板保存在 ColorWell Palette 数据库中!
ColorWell for mac 功能介绍
以下是 ColorWell 的一些用途(我相信还有更多!):
1.无限存储和即时检索
2.从任何来源快速抓取十六进制/rgb/hsl/hsb/Lab/cmyk/swift/objc 代码片段
3.快速任意十六进制/rgb/hsl/hsb/Lab/cmyk颜色
4.Palette-通过拖放图像创建调色板
5.十六进制/rgb/hsl/hsb/Lab和cmyk之间轻松转换
6.快速将 hex/rgb/hsl/hsb/Lab/cmyk 或 colorpicker 转换为 NSColor/UIColor Objective-C 或 Swift 就绪代码
ColorWell for mac 更新日志
ColorWell for Mac(网页颜色代码的取色工具)v7.1.1 特别版
2018 年 10 月 9 日
今天(当少于 20 个项目时)样本未正确加载到历史记录中 - 现在已修复
ColorWell for Mac(网页色码取色工具)v7.0.2 特别版
修复部分问题,部分设置重启ColorWell前未生效
ColorWell for Mac(网页颜色代码的取色工具)v6.8.1 特别版
修复了名称的最后更新字符串的小问题
小编的话
如果您需要一款强大的网页色码提取工具,那么Mac版ColorWell是您不错的选择,它可以直接输出网页色码。通过方便的十六进制/RGB/浮点/HSL 转换提供对标准 Mac OS X 色轮的即时访问。任何网页设计师的工具箱都应该有它。在工具栏上配置它并打开一个全局热键。使用方便快捷。如果您喜欢它,请下载并使用它! 查看全部
网页源代码抓取工具(ColorWellformac软件介绍for)
ColorWell for mac 是mac上一款网页颜色代码提取工具。它可以通过快速访问所有颜色信息并为应用程序开发生成代码生成功能,轻松生成无限的调色板。可编辑的调色板数据库允许您存档和恢复任何调色板,以便以后进行超快速搜索。当然,您也可以抓取任何源图像并将其放入“构建器”窗口以生成图像中最常见颜色的调色板。当然,您可以将生成的任何调色板保存在 ColorWell Palette 数据库中!
ColorWell for mac 特别说明
下载好ColorWell安装包后,点击打开ColorWell.dmg,将左侧的【ColorWell】拖到右侧的应用程序中即可使用。
ColorWell for mac 软件介绍
一个漂亮而直观的颜色选择器和调色板生成器——任何网络/应用程序开发人员工具箱的必要补充!
通过快速访问所有颜色信息并为应用程序开发生成代码生成函数,可以非常轻松地生成无限的调色板。可编辑的调色板数据库允许您存档和恢复任何调色板,以便以后进行超快速搜索。
默认情况下访问 MacOS 色轮非常繁琐,但 ColorWell 可以配置为通过全局热键或从系统菜单栏快速单击鼠标来显示它。这使您可以从任何颜色源快速获取 Hex/HSL/RGB 和代码片段。如果您从未从源(或多源)图像快速生成调色板,那么您需要调色板生成器。您可以抓取任何源图像并将其放置在“生成器”窗口中,以生成图像中最常见颜色的调色板。当然,您可以将生成的任何调色板保存在 ColorWell Palette 数据库中!
ColorWell for mac 功能介绍
以下是 ColorWell 的一些用途(我相信还有更多!):
1.无限存储和即时检索
2.从任何来源快速抓取十六进制/rgb/hsl/hsb/Lab/cmyk/swift/objc 代码片段
3.快速任意十六进制/rgb/hsl/hsb/Lab/cmyk颜色
4.Palette-通过拖放图像创建调色板
5.十六进制/rgb/hsl/hsb/Lab和cmyk之间轻松转换
6.快速将 hex/rgb/hsl/hsb/Lab/cmyk 或 colorpicker 转换为 NSColor/UIColor Objective-C 或 Swift 就绪代码
ColorWell for mac 更新日志
ColorWell for Mac(网页颜色代码的取色工具)v7.1.1 特别版
2018 年 10 月 9 日
今天(当少于 20 个项目时)样本未正确加载到历史记录中 - 现在已修复
ColorWell for Mac(网页色码取色工具)v7.0.2 特别版
修复部分问题,部分设置重启ColorWell前未生效
ColorWell for Mac(网页颜色代码的取色工具)v6.8.1 特别版
修复了名称的最后更新字符串的小问题
小编的话
如果您需要一款强大的网页色码提取工具,那么Mac版ColorWell是您不错的选择,它可以直接输出网页色码。通过方便的十六进制/RGB/浮点/HSL 转换提供对标准 Mac OS X 色轮的即时访问。任何网页设计师的工具箱都应该有它。在工具栏上配置它并打开一个全局热键。使用方便快捷。如果您喜欢它,请下载并使用它!
网页源代码抓取工具(JavaIO低效,未优化之后会通过添加IO层的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-10-31 05:13
img_path='文件夹名/'+图片名 request.urlretrieve(url=url,filename=img_path)#url 是图片的链接地址。
我写了一个只有一层的IO流来完成从网页的指定URL获取文件的操作,并添加了注释方便理解。但最简单的,这意味着低效和未优化。后面我会通过在JavaIO流上引入IO来弥补提高效率的层方法。
根据提供的网站地址,获取网页源代码。您可以从文本文件中读取网站地址,并将获取的网页源代码导出为文本文件。
从网页中提取 URL
指下载到系统的文件名。上述代码可以将当前整个网页下载为html文件,但是对于链外网页中的部分资源,则无法显示。在 Chrome 浏览器中,模拟点击创建的元素不会被附加到页面中。
在一个页面中获取所有下载链接。让我与你分享。下载链接,直接复制网址后面的U即可。
它适用于任何使用 URL 来获取网页上的 HTML 文件。构造一个 URL 对象 url 需要三个步骤。将 DataInputStream 类对象与 url 的 openStream() 流对象绑定。使用 DataInputStream 类对象从以下位置读取 HTML 文件:ycd。
并分享好用的AutoCAD2018软件64位下载:代码:93ly 今年三四月份,我接受了一个请求:提取网址。这样的请求可以视为它。 查看全部
网页源代码抓取工具(JavaIO低效,未优化之后会通过添加IO层的方法)
img_path='文件夹名/'+图片名 request.urlretrieve(url=url,filename=img_path)#url 是图片的链接地址。
我写了一个只有一层的IO流来完成从网页的指定URL获取文件的操作,并添加了注释方便理解。但最简单的,这意味着低效和未优化。后面我会通过在JavaIO流上引入IO来弥补提高效率的层方法。
根据提供的网站地址,获取网页源代码。您可以从文本文件中读取网站地址,并将获取的网页源代码导出为文本文件。
从网页中提取 URL
指下载到系统的文件名。上述代码可以将当前整个网页下载为html文件,但是对于链外网页中的部分资源,则无法显示。在 Chrome 浏览器中,模拟点击创建的元素不会被附加到页面中。
在一个页面中获取所有下载链接。让我与你分享。下载链接,直接复制网址后面的U即可。
它适用于任何使用 URL 来获取网页上的 HTML 文件。构造一个 URL 对象 url 需要三个步骤。将 DataInputStream 类对象与 url 的 openStream() 流对象绑定。使用 DataInputStream 类对象从以下位置读取 HTML 文件:ycd。
并分享好用的AutoCAD2018软件64位下载:代码:93ly 今年三四月份,我接受了一个请求:提取网址。这样的请求可以视为它。
网页源代码抓取工具(如何在MAC上抓取数据,你可以零基础直接使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-31 03:02
目前国内MAC上采集数据主要有两种方式:
(不说老外,评论里已经有人列出来了)
一是使用基于Web的云采集系统。目前有优采云云爬虫和早书。这个基于网络的网络爬虫工具没有操作系统限制。不要说你要在MAC上抓取数据,即使在你的手机上也没有问题。
优采云对于开发者来说,有技术基础的同学可以大显身手,实现非常强大的网络爬虫。
没有开发经验的小白同学一开始可能会觉得很难上手,不过好在他们提供了官方的云爬虫市场,可以零基础直接使用。
烧书是一个网页点击操作流程,对于新手用户来说易于使用和理解,并且具有非常好的可视化操作流程。只是有点慢!写完这个回答又上厕所的几十分钟里,我试了采集一个网站,结果还没出来-_-|| @小小造数君
另一种是使用支持MAC系统的采集器软件,目前只有优采云采集器和Jisuke支持。
那么,如何在这些选项中进行选择呢?
1、免费,无需钱,无需积分
(这里所说的免费功能包括采集数据、将各种格式的数据导出到本地、下载图片到本地,以及采集数据所需的其他基本功能):
您可以选择优采云云爬虫和优采云采集器
(Zoshu官方并没有找到是否收费的具体解释,但提到了:“制造的计费单位是“时间”。一次爬是指:成功爬取1个网页并获取数据。”,所以我明白了他们不是免费的)
两者中,推荐大家使用优采云采集器,因为我目测楼主好像没有编程基础。
但是如果优采云云市场有你需要的采集的网站的采集规则,而且恰好是免费的(优采云云爬虫市场有官方的采集规则也有开发者上传的采集规则),那你可以试试优采云云爬虫。
2、不差钱,关键是喜欢
那么你可以尝试使用优采云采集器和Jisouke,然后从两者中选择你喜欢的一个。
最好使用用户体验和性价比之类的东西。 查看全部
网页源代码抓取工具(如何在MAC上抓取数据,你可以零基础直接使用)
目前国内MAC上采集数据主要有两种方式:
(不说老外,评论里已经有人列出来了)
一是使用基于Web的云采集系统。目前有优采云云爬虫和早书。这个基于网络的网络爬虫工具没有操作系统限制。不要说你要在MAC上抓取数据,即使在你的手机上也没有问题。
优采云对于开发者来说,有技术基础的同学可以大显身手,实现非常强大的网络爬虫。
没有开发经验的小白同学一开始可能会觉得很难上手,不过好在他们提供了官方的云爬虫市场,可以零基础直接使用。
烧书是一个网页点击操作流程,对于新手用户来说易于使用和理解,并且具有非常好的可视化操作流程。只是有点慢!写完这个回答又上厕所的几十分钟里,我试了采集一个网站,结果还没出来-_-|| @小小造数君
另一种是使用支持MAC系统的采集器软件,目前只有优采云采集器和Jisuke支持。
那么,如何在这些选项中进行选择呢?
1、免费,无需钱,无需积分
(这里所说的免费功能包括采集数据、将各种格式的数据导出到本地、下载图片到本地,以及采集数据所需的其他基本功能):
您可以选择优采云云爬虫和优采云采集器
(Zoshu官方并没有找到是否收费的具体解释,但提到了:“制造的计费单位是“时间”。一次爬是指:成功爬取1个网页并获取数据。”,所以我明白了他们不是免费的)
两者中,推荐大家使用优采云采集器,因为我目测楼主好像没有编程基础。
但是如果优采云云市场有你需要的采集的网站的采集规则,而且恰好是免费的(优采云云爬虫市场有官方的采集规则也有开发者上传的采集规则),那你可以试试优采云云爬虫。
2、不差钱,关键是喜欢
那么你可以尝试使用优采云采集器和Jisouke,然后从两者中选择你喜欢的一个。
最好使用用户体验和性价比之类的东西。
网页源代码抓取工具(一个新闻网页通用抽取器演示如何直接从浏览器中复制)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-29 20:03
GeneralNewsExtractor,以下简称GNE,是一个通用的新闻网页提取器,可以在不指定任何提取规则的情况下提取新闻正文网站。
我们来看看它的基本用法。
安装 GNE
使用pip安装:
pip install --upgrade git+https://github.com/kingname/Ge ... r.git
当然你也可以使用pipenv来安装:
pipenv install git+https://github.com/kingname/Ge ... 3Dgne
获取新闻页面源码
GNE目前没有,以后也不会提供网页请求的功能,所以需要想办法获取渲染出来的网页源代码。您可以使用 Selenium 或 Pyppeteer 或直接从浏览器复制。
以下是直接从浏览器复制网页源代码的方法:
在Chrome浏览器中打开对应页面,然后打开开发者工具,如下图:
在Elements标签页找到标签,右键选择Copy-Copy OuterHTML,如下图
将源码另存为1.html,提取body信息
编写以下代码:
from gne import GeneralNewsExtractor
with open('1.html') as f:
html = f.read()
extractor = GeneralNewsExtractor()
result = extractor.extract(html)
print(result)
运行效果如下图所示:
这次更新了什么
在最新更新的v0.04版本中,开放了提取文本图片的功能和返回文本源代码的功能。上面已经演示了返回图片URL的功能,结果中的images字段就是文本中的图片。
那么如何返回body源代码呢?只需添加一个参数 with_body_html=True:
from gne import GeneralNewsExtractor
with open('1.html') as f:
html = f.read()
extractor = GeneralNewsExtractor()
result = extractor.extract(html, with_body_html=True)
print(result)
运行效果如下图所示:
返回结果中的body_html就是body的html源代码。
GNE的深入使用可以访问GNE的Github:。 查看全部
网页源代码抓取工具(一个新闻网页通用抽取器演示如何直接从浏览器中复制)
GeneralNewsExtractor,以下简称GNE,是一个通用的新闻网页提取器,可以在不指定任何提取规则的情况下提取新闻正文网站。
我们来看看它的基本用法。
安装 GNE
使用pip安装:
pip install --upgrade git+https://github.com/kingname/Ge ... r.git
当然你也可以使用pipenv来安装:
pipenv install git+https://github.com/kingname/Ge ... 3Dgne
获取新闻页面源码
GNE目前没有,以后也不会提供网页请求的功能,所以需要想办法获取渲染出来的网页源代码。您可以使用 Selenium 或 Pyppeteer 或直接从浏览器复制。
以下是直接从浏览器复制网页源代码的方法:
在Chrome浏览器中打开对应页面,然后打开开发者工具,如下图:
在Elements标签页找到标签,右键选择Copy-Copy OuterHTML,如下图
将源码另存为1.html,提取body信息
编写以下代码:
from gne import GeneralNewsExtractor
with open('1.html') as f:
html = f.read()
extractor = GeneralNewsExtractor()
result = extractor.extract(html)
print(result)
运行效果如下图所示:
这次更新了什么
在最新更新的v0.04版本中,开放了提取文本图片的功能和返回文本源代码的功能。上面已经演示了返回图片URL的功能,结果中的images字段就是文本中的图片。
那么如何返回body源代码呢?只需添加一个参数 with_body_html=True:
from gne import GeneralNewsExtractor
with open('1.html') as f:
html = f.read()
extractor = GeneralNewsExtractor()
result = extractor.extract(html, with_body_html=True)
print(result)
运行效果如下图所示:
返回结果中的body_html就是body的html源代码。
GNE的深入使用可以访问GNE的Github:。
网页源代码抓取工具(Python使用xslt提取网页数据的方法-Python即时网络爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-10-27 12:23
本文文章主要详细介绍Python使用xslt提取网页数据的方法。有一定的参考价值,感兴趣的朋友可以参考。
1、简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分。使用xslt一次性提取静态网页内容并将其转换为xml格式的实验。
2、使用lxml库提取网页内容
lxml是python的一个可以快速灵活处理XML的库。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现了通用的 ElementTree API。
这两天在python中测试了通过xslt提取网页内容,记录如下:
2.1、 抓取目标
假设你想在吉首官网提取旧版论坛的帖子标题和回复数,如下图,提取整个列表并保存为xml格式
2.2、 源码1:只抓取当前页面,结果会在控制台显示
Python的优点是可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用并不多。大空间由 xslt 脚本占用。在这段代码中, just 只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者抓正则表达式,请参考《Python Instant Web Crawler 项目启动说明》。我们希望通过这种架构,可以节省程序员的时间。节省一半以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request from lxml import etree url="http://www.gooseeker.com/cn/forum/7" conn = request.urlopen(url) doc = etree.HTML(conn.read()) xslt_root = etree.XML("""\ """) transform = etree.XSLT(xslt_root) result_tree = transform(doc) print(result_tree)
源代码可以从本文末尾的GitHub源下载。
2.3、 抓取结果
捕获的结果如下:
2.4、 源码2:翻页抓取,并将结果保存到文件
我们对2.2的代码做了进一步的修改,增加了翻页、抓取和保存结果文件的功能,代码如下:
<p> from urllib import request from lxml import etree import time xslt_root = etree.XML("""\ """) baseurl = "http://www.gooseeker.com/cn/forum/7" basefilebegin = "jsk_bbs_" basefileend = ".xml" count = 1 while (count 查看全部
网页源代码抓取工具(Python使用xslt提取网页数据的方法-Python即时网络爬虫)
本文文章主要详细介绍Python使用xslt提取网页数据的方法。有一定的参考价值,感兴趣的朋友可以参考。
1、简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分。使用xslt一次性提取静态网页内容并将其转换为xml格式的实验。
2、使用lxml库提取网页内容
lxml是python的一个可以快速灵活处理XML的库。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现了通用的 ElementTree API。
这两天在python中测试了通过xslt提取网页内容,记录如下:
2.1、 抓取目标
假设你想在吉首官网提取旧版论坛的帖子标题和回复数,如下图,提取整个列表并保存为xml格式
2.2、 源码1:只抓取当前页面,结果会在控制台显示
Python的优点是可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用并不多。大空间由 xslt 脚本占用。在这段代码中, just 只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者抓正则表达式,请参考《Python Instant Web Crawler 项目启动说明》。我们希望通过这种架构,可以节省程序员的时间。节省一半以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request from lxml import etree url="http://www.gooseeker.com/cn/forum/7" conn = request.urlopen(url) doc = etree.HTML(conn.read()) xslt_root = etree.XML("""\ """) transform = etree.XSLT(xslt_root) result_tree = transform(doc) print(result_tree)
源代码可以从本文末尾的GitHub源下载。
2.3、 抓取结果
捕获的结果如下:
2.4、 源码2:翻页抓取,并将结果保存到文件
我们对2.2的代码做了进一步的修改,增加了翻页、抓取和保存结果文件的功能,代码如下:
<p> from urllib import request from lxml import etree import time xslt_root = etree.XML("""\ """) baseurl = "http://www.gooseeker.com/cn/forum/7" basefilebegin = "jsk_bbs_" basefileend = ".xml" count = 1 while (count
网页源代码抓取工具(网页链接获取工具优化的排名人员使用方法、特色)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-23 03:12
网页链接获取工具是一款轻量级的网站链接抓取工具,可以帮助用户快速抓取网页上的所有链接,或者批量抓取一个页面的网站链接和图片链接。节省大量人工完成时间,提高你的网站内链获取,适合广大排名人员做seo优化。
网页链接获取工具功能强大且可用。用户只需输入自己的站群地址,即可批量获取最近生成的链接,方便站长提交链接,软件还支持源代码快速复制和链接快速复制,支持批量获取CSS链接等功能,还支持自动生成最新的URL链接和保存txt文件,可以提高排名优化的效率。
网页链接获取工具的特点
1、网页链接提取工具绿色版,非常适合做seo优化的排名人员
2、使用这个软件可以节省很多时间
3、并能自动完成网站的所有内链选择
4、还可以有计划地将提取的内链提交给各种收录工具
5、这样可以增加收录的数量
网页链接获取工具功能
1、批量访问网站链接、图片链接
2、批量获取脚本链接
3、批量获取CSS链接
4、支持快速复制源码
5、支持快速复制链接
6、批量访问站群链接
7、 自动生成最新的URL链接并保存txt文件
使用说明
1、先进入个人网站的网站地图:个人网站域名/sitemap.xml
2、 输入后点击Extract and Save即可获取最近更新的域名信息。
3、网页链接提取自动保存到软件所在文件夹。 查看全部
网页源代码抓取工具(网页链接获取工具优化的排名人员使用方法、特色)
网页链接获取工具是一款轻量级的网站链接抓取工具,可以帮助用户快速抓取网页上的所有链接,或者批量抓取一个页面的网站链接和图片链接。节省大量人工完成时间,提高你的网站内链获取,适合广大排名人员做seo优化。
网页链接获取工具功能强大且可用。用户只需输入自己的站群地址,即可批量获取最近生成的链接,方便站长提交链接,软件还支持源代码快速复制和链接快速复制,支持批量获取CSS链接等功能,还支持自动生成最新的URL链接和保存txt文件,可以提高排名优化的效率。
网页链接获取工具的特点
1、网页链接提取工具绿色版,非常适合做seo优化的排名人员
2、使用这个软件可以节省很多时间
3、并能自动完成网站的所有内链选择
4、还可以有计划地将提取的内链提交给各种收录工具
5、这样可以增加收录的数量
网页链接获取工具功能
1、批量访问网站链接、图片链接
2、批量获取脚本链接
3、批量获取CSS链接
4、支持快速复制源码
5、支持快速复制链接
6、批量访问站群链接
7、 自动生成最新的URL链接并保存txt文件
使用说明
1、先进入个人网站的网站地图:个人网站域名/sitemap.xml
2、 输入后点击Extract and Save即可获取最近更新的域名信息。
3、网页链接提取自动保存到软件所在文件夹。
网页源代码抓取工具(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-23 03:10
更推荐方法一
///
/// 用httpwebrequest取得网页源码
/// 对于带bom的网页很有效,不管是什么编码都能正确识别
///
/// 网页地址"
/// 返回网页源文件
public static string gethtmlsource2(string url)
{
//处理内容
string html = "";
httpwebrequest request = (httpwebrequest)webrequest.create(url);
request.accept = "*/*"; //接受任意文件
request.useragent = "mozilla/4.0 (compatible; msie 6.0; windows nt 5.2; .net clr 1.1.4322)"; // 模拟使用ie在浏览 http://www.52mvc.com
request.allowautoredirect = true;//是否允许302
//request.cookiecontainer = new cookiecontainer();//cookie容器,
request.referer = url; //当前页面的引用
httpwebresponse response = (httpwebresponse)request.getresponse();
stream stream = response.getresponsestream();
streamreader reader = new streamreader(stream, encoding.default);
html = reader.readtoend();
stream.close();
return html;
}
方法二
using system;
using system.collections.generic;
using system.linq;
using system.web;
using system.io;
using system.text;
using system.net;
namespace mysql
{
public class gethttpdata
{
public static string gethttpdata2(string url)
{
string sexception = null;
string srslt = null;
webresponse owebrps = null;
webrequest owebrqst = webrequest.create(url);
owebrqst.timeout = 50000;
try
{
owebrps = owebrqst.getresponse();
}
catch (webexception e)
{
sexception = e.message.tostring();
}
catch (exception e)
{
sexception = e.tostring();
}
finally
{
if (owebrps != null)
{
streamreader ostreamrd = new streamreader(owebrps.getresponsestream(), encoding.getencoding("utf-8"));
srslt = ostreamrd.readtoend();
ostreamrd.close();
owebrps.close();
}
}
return srslt;
}
}
}
方法三
<p>
public static string gethtml(string url, params string [] charsets)//url是要访问的网站地址,charset是目标网页的编码,如果传入的是null或者"",那就自动分析网页的编码
{
try
{
string charset = null;
if (charsets.length == 1) {
charset = charsets[0];
}
webclient mywebclient = new webclient(); //创建webclient实例mywebclient
// 需要注意的:
//有的网页可能下不下来,有种种原因比如需要cookie,编码问题等等
//这是就要具体问题具体分析比如在头部加入cookie
// webclient.headers.add("cookie", cookie);
//这样可能需要一些重载方法。根据需要写就可以了
//获取或设置用于对向 internet 资源的请求进行身份验证的网络凭据。
mywebclient.credentials = credentialcache.defaultcredentials;
//如果服务器要验证用户名,密码
//networkcredential mycred = new networkcredential(struser, strpassword);
//mywebclient.credentials = mycred;
//从资源下载数据并返回字节数组。(加@是因为网址中间有"/"符号)
byte[] mydatabuffer = mywebclient.downloaddata(url);
string strwebdata = encoding.default.getstring(mydatabuffer);
//获取网页字符编码描述信息
match charsetmatch = regex.match(strwebdata, " 查看全部
网页源代码抓取工具(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
更推荐方法一
///
/// 用httpwebrequest取得网页源码
/// 对于带bom的网页很有效,不管是什么编码都能正确识别
///
/// 网页地址"
/// 返回网页源文件
public static string gethtmlsource2(string url)
{
//处理内容
string html = "";
httpwebrequest request = (httpwebrequest)webrequest.create(url);
request.accept = "*/*"; //接受任意文件
request.useragent = "mozilla/4.0 (compatible; msie 6.0; windows nt 5.2; .net clr 1.1.4322)"; // 模拟使用ie在浏览 http://www.52mvc.com
request.allowautoredirect = true;//是否允许302
//request.cookiecontainer = new cookiecontainer();//cookie容器,
request.referer = url; //当前页面的引用
httpwebresponse response = (httpwebresponse)request.getresponse();
stream stream = response.getresponsestream();
streamreader reader = new streamreader(stream, encoding.default);
html = reader.readtoend();
stream.close();
return html;
}
方法二
using system;
using system.collections.generic;
using system.linq;
using system.web;
using system.io;
using system.text;
using system.net;
namespace mysql
{
public class gethttpdata
{
public static string gethttpdata2(string url)
{
string sexception = null;
string srslt = null;
webresponse owebrps = null;
webrequest owebrqst = webrequest.create(url);
owebrqst.timeout = 50000;
try
{
owebrps = owebrqst.getresponse();
}
catch (webexception e)
{
sexception = e.message.tostring();
}
catch (exception e)
{
sexception = e.tostring();
}
finally
{
if (owebrps != null)
{
streamreader ostreamrd = new streamreader(owebrps.getresponsestream(), encoding.getencoding("utf-8"));
srslt = ostreamrd.readtoend();
ostreamrd.close();
owebrps.close();
}
}
return srslt;
}
}
}
方法三
<p>
public static string gethtml(string url, params string [] charsets)//url是要访问的网站地址,charset是目标网页的编码,如果传入的是null或者"",那就自动分析网页的编码
{
try
{
string charset = null;
if (charsets.length == 1) {
charset = charsets[0];
}
webclient mywebclient = new webclient(); //创建webclient实例mywebclient
// 需要注意的:
//有的网页可能下不下来,有种种原因比如需要cookie,编码问题等等
//这是就要具体问题具体分析比如在头部加入cookie
// webclient.headers.add("cookie", cookie);
//这样可能需要一些重载方法。根据需要写就可以了
//获取或设置用于对向 internet 资源的请求进行身份验证的网络凭据。
mywebclient.credentials = credentialcache.defaultcredentials;
//如果服务器要验证用户名,密码
//networkcredential mycred = new networkcredential(struser, strpassword);
//mywebclient.credentials = mycred;
//从资源下载数据并返回字节数组。(加@是因为网址中间有"/"符号)
byte[] mydatabuffer = mywebclient.downloaddata(url);
string strwebdata = encoding.default.getstring(mydatabuffer);
//获取网页字符编码描述信息
match charsetmatch = regex.match(strwebdata, "
网页源代码抓取工具(网页抓取工具优采云采集器V9实现抓取商品信息的方法讲解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-10-21 18:10
大数据时代的经销商,无论是经营线上门店还是线下实体店,都必须具备敏锐的信息洞察能力,才能在市场中寻找空缺,在竞争中寻求突破。除了正确的视角,信息的洞察力还需要一个方便的爬虫工具。优采云采集器作为领先的网页抓取工具品牌,可以为企业快速稳定的抓取网页。获取产品信息的功能为洞察和分析市场提供了必要的前提。
下面介绍一下网络爬虫工具优采云采集器优采云采集器V9实现产品信息抓取的方法:优采云采集器是其中一种一个高效稳定的网络爬虫工具。其工作原理是基于WEB结构的源代码提取。按照从主URL进入内容页面再提取内容的过程,可以从网页中提取文本、图片、压缩文件等,这意味着对于商家来说,商品等一系列属性内容所有电商网站中出现的价格、图片、教程文件都可以轻松提取。
使用网页爬虫工具优采云采集器V9抓取商品信息时,需要注意以下几点:
1、判断该页面的信息是否全面展示。如果有需要登录才能看到的信息,需要在优采云采集器中进行登录采集相关设置。
2、写入内容采集 按规则下载图片时,edit标签的数据处理中有文件下载选项。有四个选项,其中之一是下载图片。您可以通过检查下载图片。优采云采集器V9 这里是默认下载带有html标签的图片。所以对于没有html标签的图片,比如缩略图,一定要勾选“检测文件并下载”。在这种情况下,优采云采集器会自动检测到这种类型的图片文件并下载。
3、 如果你请求新内容时,页面只是部分刷新,地址栏中的URL没有变化,这种帖子URL要
拿到后需要使用抓包工具截取请求时提交的内容,找出共同特征,并使用“页面”更改
替换数量并给出取值范围,这样优采云采集器会在采集的时候自动提交请求的内容,得到新的内容列表。
采集。网页抓取工具优采云采集器V9有更多惊人的功能。更多操作可以访问官网(com)的帮助手册或视频教程进行学习。
电子商务运营商使用网络爬虫工具优采云采集器V9抓取同类产品的属性、评价、价格、市场销售等数据,并利用这些数据推导出产品的相关特征信息. 对某个商品名称进行搜索优化,或者根据相似体验制作热门商品,在充分了解用户行为的基础上开展经营活动,可以大大提高网店的运营水平和效率。所以优采云采集器不过据说是经销商玩大数据的首选!
相关日志:
企业信用:如何用保证金来维持信用
Levi公司户外拓展通知
合肥乐维户外拓展训练生活课堂随处可见
网络爬虫工具助力传统企业弯道超车
网络爬虫工具助力大数据基础设施建设
«网页抓取工具分析大数据生态系统技术层 | 玩转网页抓取工具,2016年让大数据更接地气!» 查看全部
网页源代码抓取工具(网页抓取工具优采云采集器V9实现抓取商品信息的方法讲解)
大数据时代的经销商,无论是经营线上门店还是线下实体店,都必须具备敏锐的信息洞察能力,才能在市场中寻找空缺,在竞争中寻求突破。除了正确的视角,信息的洞察力还需要一个方便的爬虫工具。优采云采集器作为领先的网页抓取工具品牌,可以为企业快速稳定的抓取网页。获取产品信息的功能为洞察和分析市场提供了必要的前提。
下面介绍一下网络爬虫工具优采云采集器优采云采集器V9实现产品信息抓取的方法:优采云采集器是其中一种一个高效稳定的网络爬虫工具。其工作原理是基于WEB结构的源代码提取。按照从主URL进入内容页面再提取内容的过程,可以从网页中提取文本、图片、压缩文件等,这意味着对于商家来说,商品等一系列属性内容所有电商网站中出现的价格、图片、教程文件都可以轻松提取。
使用网页爬虫工具优采云采集器V9抓取商品信息时,需要注意以下几点:
1、判断该页面的信息是否全面展示。如果有需要登录才能看到的信息,需要在优采云采集器中进行登录采集相关设置。
2、写入内容采集 按规则下载图片时,edit标签的数据处理中有文件下载选项。有四个选项,其中之一是下载图片。您可以通过检查下载图片。优采云采集器V9 这里是默认下载带有html标签的图片。所以对于没有html标签的图片,比如缩略图,一定要勾选“检测文件并下载”。在这种情况下,优采云采集器会自动检测到这种类型的图片文件并下载。
3、 如果你请求新内容时,页面只是部分刷新,地址栏中的URL没有变化,这种帖子URL要
拿到后需要使用抓包工具截取请求时提交的内容,找出共同特征,并使用“页面”更改
替换数量并给出取值范围,这样优采云采集器会在采集的时候自动提交请求的内容,得到新的内容列表。
采集。网页抓取工具优采云采集器V9有更多惊人的功能。更多操作可以访问官网(com)的帮助手册或视频教程进行学习。
电子商务运营商使用网络爬虫工具优采云采集器V9抓取同类产品的属性、评价、价格、市场销售等数据,并利用这些数据推导出产品的相关特征信息. 对某个商品名称进行搜索优化,或者根据相似体验制作热门商品,在充分了解用户行为的基础上开展经营活动,可以大大提高网店的运营水平和效率。所以优采云采集器不过据说是经销商玩大数据的首选!
相关日志:
企业信用:如何用保证金来维持信用
Levi公司户外拓展通知
合肥乐维户外拓展训练生活课堂随处可见
网络爬虫工具助力传统企业弯道超车
网络爬虫工具助力大数据基础设施建设
«网页抓取工具分析大数据生态系统技术层 | 玩转网页抓取工具,2016年让大数据更接地气!»
网页源代码抓取工具(关键词:R语言;网络爬虫;网页信息抓取;二手房)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-19 04:09
庄旭东王志坚
摘要:随着互联网的飞速发展和大数据时代的到来,互联网上的数据和信息呈爆炸式增长,网络爬虫技术越来越流行。本文以二手房销售数据为例,探索了基于R语言爬虫技术抓取网页信息的方法,发现基于R语言rvest函数包的网页信息抓取方法和SelectorGadget 工具比传统方法更简单、更快捷。
关键词:R语言;网络爬虫;网页信息抓取;二手房
传统的网络搜索引擎在网络信息资源的搜索中扮演着非常重要的角色,但它们仍然存在很多局限性。如今,R语言在网络信息爬取方面有着其独特的优势。它写的爬虫语法比较直观简洁,规则比较灵活简单,对操作者的要求比较低。无需深入研究某个软件或编程。语法不必有很多与网络相关的知识。非专业人士甚至初学者都可以轻松掌握其方法,快速方便地获取所需的网络信息。此外,R 软件可以非常自由地处理百万级以下的数据,而且它本身就是一个强大的统计计算和统计绘图工具。使用R软件进行操作,实现了爬虫技术的网页。信息采集得到的数据可以直接进行统计分析和数据挖掘,无需重新导入或整合数据,更加直接方便。
1 研究方法概述
本文使用R软件中的rvest函数包来抓取网页信息数据。使用这个包中的三个函数read_html()、html_nodes()和html_text()配合SelectorGadget工具(以下简称工具)。使用 read_html() 函数抓取整个网页的原创 HTML 代码,然后使用 html_nodes() 函数从整个网页的元素中选择工具获取的路径信息,最后使用 html_text() 函数进行将HTML代码中的文本数据提取出来,得到我们需要的数据。并根据网页的规则,使用for()循环函数实现多个网页的信息抓取。然后对比不同的爬取网页信息的方法,得到R语言作为爬虫的优势,比较和展望了R语言爬虫技术的网页信息抓取方法,以及大数据时代的数据获取方法和技术。探索。
2 网络爬虫的相关概念和步骤
2.1 网络爬虫概念
网络爬虫是一种用于自动提取网页信息的程序。它可以自动从万维网上下载网页并将采集到的信息存储在本地数据库中。根据网络爬虫系统的结构和实现技术,大致可以分为以下几类:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫。这些爬虫技术的出现就是为了提高爬虫的效率,我们需要在更短的时间内获取尽可能多的有用的页面信息。
2.2 网络爬虫步骤
实现一个网络爬虫的基本步骤是:①首先从精心挑选的种子网址中选取一部分;②将这些种子放入待抓取的URL队列中;③从待爬取的URL队列中取出待爬取的URL,解析DNS,得到主机的ip,下载该URL对应的网页,保存到下载的网页库中。另外,将这些网址放入已爬取的网址队列中;④对已爬取的URL队列中的URL进行解析,并对其中的其他URL进行解析,并将该URL放入待爬取的URL队列中,从而进入下一个循环。
3 基于R语言rvest包实现网页信息抓取
本文使用SelectorGadget路径选择工具直接定位到我们需要的数据,结合R语言rvest包,以2018年4月链家网广州二手房销售数据为例,抓取我们需要的数据从网页。
3.1 网页信息抓取的准备
3.1.1 SelectorGadget 工具
抓取信息需要先定位数据,选择网页节点,然后获取二手房相关信息的网页路径信息。具体步骤如下:
①准备SelectorGadget工具:打开广州链家网站,打开工具栏。打开后会显示在页面的右下角。
②生成一个CSS选择器,显示选择器能捕捉到的HTML元素:在网页上用鼠标点击要获取的数据,选中的HTML元素会被标记为绿色,工具会尝试检测测试用户想要抓取的数据的规则,然后生成一组 CSS 选择器并显示在工具栏上。同时,页面上所有符合这组 CSS 选择器的 HTML 元素都会被标记为黄色,即当前组 CSS 选择器会提取所有绿色和黄色的 HTML 元素。
③去除不需要的 HTML 元素:该工具检测到的 CSS 选择器通常收录一些不需要的数据。这时候可以删除那些被标记但要排除的HTML元素,被删除的元素会被标记成红色。
④获取准确的CSS选择器:选中并排除HTML元素后,所有要提取的元素都已被准确标记,可以生成一组准确的CSS选择器并显示在工具栏上。在 R 软件中处理。
3.1.2R软件相关功能包及使用
实现网页信息的抓取,R语言的编写需要参考xml2、rvest、dplyr、stringr等函数包中的函数,所以下载这些函数包并加载需要的包。具体方法是使用 install.packages() 和 library() 函数来实现,也可以将这些包下载到本地安装。
3.2 网页信息抓取的实现
以联家网广州二手房销售为例。按照前面的步骤,首先使用read_html()函数抓取整个链家网页的原创HTML代码,然后使用html_nodes()函数通过SelectorGadget工具从整个链家网页中选取元素获取路径信息,最后使用html_text()函数提取HTML代码中的文本数据,得到我们需要的链家网数据。
rvest包抓取某个网页数据的几个功能,但是可以发现广州链家网上有很多二手房数据的页面,有用的信息包括房子名称,描述,位置,房价,因此,选择循环函数for(),编写如下函数,抓取链家网站上所有有价值的信息,写入csv格式的文件中进行进一步分析。限于篇幅,这里列出了一些结果,如下表所示。
上表给出了广州部分二手房的基本信息。
可以看出,使用rvest包结合CSS选择器,可以快速实现R语言下的网络数据抓取,并适当结合stringr包中的字符串处理功能,对网页数据进行清理整理,可以非常方便有效地获取网页数据。直接数据处理和分析。通过直接利用爬取的数据,对房价是否符合正态分布进行简单的分析,展示了R语言对网页数据爬取后得到的数据进行分析的便利性和优越性。
4 rvest包与其他网络信息抓取方式对比分析
R语言实现网络爬虫有两种方式,一种是使用本文提到的rvest包,另一种是使用RCurl包和XML包。
使用rvest函数包和SelectorGadget工具实现R语言在网页信息抓取上的应用,比使用XML包和RCurl包抓取更简单,代码更简洁直观。R中的rvest包压缩了原来复杂的网络爬虫工作来读取网页、检索网页和提取文本,变得非常简单,并且根据网页的规则,使用for()循环函数来实现多个网页爬行。使用XML包和RCurl包来实现,需要一些网页的基础知识,模拟浏览器伪装header的行为,然后访问页面解析网页,然后定位节点获取信息,最后整合信息。这种方法比较困难,也比较麻烦。有时访问网页时无法顺利读取和解析,选择节点时需要具备HTML基础知识。在网页的源代码中查找它。一些网页的源代码相当复杂,不易定位。节点。
两种实现方式所能达到的效果基本相同,都可以利用for()循环函数抓取多个网页数据。从动手的角度来说,rvest包展示比较好,就是XML包和RCurl包。进化,更简洁方便。
另外,网络爬虫在Python中的实现也很流行。Python 的 pandas 模块工具借鉴了 R 的数据帧,而 R 的 rvest 包指的是 Python 的 BeautifulSoup。这两种语言在一定程度上是互补的。Python在实现网络爬虫方面更有优势,但在网页数据爬取方面,基于R语言工具的实现更加简洁方便,R是统计分析中更高效的独立数据分析工具。使用 R 语言获取的数据,避免了繁琐的平台环境转换。从数据采集、数据清洗到数据分析,代码环境和平台保持一致性。
参考:
[1] 吴锐,张俊丽.基于R语言的网络爬虫技术研究[J]. 科技信息, 2016, 14 (34): 35-36.
[2] 西蒙·蒙泽尔特。基于R语言的自动数据采集:网页抓取和文本挖掘实用指南[M]. 机械工业出版社,2016.
[3] 刘金红,卢玉良.专题网络爬虫研究综述[J]. 计算机应用研究, 2007, 24 (10): 26-29. 查看全部
网页源代码抓取工具(关键词:R语言;网络爬虫;网页信息抓取;二手房)
庄旭东王志坚
摘要:随着互联网的飞速发展和大数据时代的到来,互联网上的数据和信息呈爆炸式增长,网络爬虫技术越来越流行。本文以二手房销售数据为例,探索了基于R语言爬虫技术抓取网页信息的方法,发现基于R语言rvest函数包的网页信息抓取方法和SelectorGadget 工具比传统方法更简单、更快捷。
关键词:R语言;网络爬虫;网页信息抓取;二手房
传统的网络搜索引擎在网络信息资源的搜索中扮演着非常重要的角色,但它们仍然存在很多局限性。如今,R语言在网络信息爬取方面有着其独特的优势。它写的爬虫语法比较直观简洁,规则比较灵活简单,对操作者的要求比较低。无需深入研究某个软件或编程。语法不必有很多与网络相关的知识。非专业人士甚至初学者都可以轻松掌握其方法,快速方便地获取所需的网络信息。此外,R 软件可以非常自由地处理百万级以下的数据,而且它本身就是一个强大的统计计算和统计绘图工具。使用R软件进行操作,实现了爬虫技术的网页。信息采集得到的数据可以直接进行统计分析和数据挖掘,无需重新导入或整合数据,更加直接方便。
1 研究方法概述
本文使用R软件中的rvest函数包来抓取网页信息数据。使用这个包中的三个函数read_html()、html_nodes()和html_text()配合SelectorGadget工具(以下简称工具)。使用 read_html() 函数抓取整个网页的原创 HTML 代码,然后使用 html_nodes() 函数从整个网页的元素中选择工具获取的路径信息,最后使用 html_text() 函数进行将HTML代码中的文本数据提取出来,得到我们需要的数据。并根据网页的规则,使用for()循环函数实现多个网页的信息抓取。然后对比不同的爬取网页信息的方法,得到R语言作为爬虫的优势,比较和展望了R语言爬虫技术的网页信息抓取方法,以及大数据时代的数据获取方法和技术。探索。
2 网络爬虫的相关概念和步骤
2.1 网络爬虫概念
网络爬虫是一种用于自动提取网页信息的程序。它可以自动从万维网上下载网页并将采集到的信息存储在本地数据库中。根据网络爬虫系统的结构和实现技术,大致可以分为以下几类:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫。这些爬虫技术的出现就是为了提高爬虫的效率,我们需要在更短的时间内获取尽可能多的有用的页面信息。
2.2 网络爬虫步骤
实现一个网络爬虫的基本步骤是:①首先从精心挑选的种子网址中选取一部分;②将这些种子放入待抓取的URL队列中;③从待爬取的URL队列中取出待爬取的URL,解析DNS,得到主机的ip,下载该URL对应的网页,保存到下载的网页库中。另外,将这些网址放入已爬取的网址队列中;④对已爬取的URL队列中的URL进行解析,并对其中的其他URL进行解析,并将该URL放入待爬取的URL队列中,从而进入下一个循环。
3 基于R语言rvest包实现网页信息抓取
本文使用SelectorGadget路径选择工具直接定位到我们需要的数据,结合R语言rvest包,以2018年4月链家网广州二手房销售数据为例,抓取我们需要的数据从网页。
3.1 网页信息抓取的准备
3.1.1 SelectorGadget 工具
抓取信息需要先定位数据,选择网页节点,然后获取二手房相关信息的网页路径信息。具体步骤如下:
①准备SelectorGadget工具:打开广州链家网站,打开工具栏。打开后会显示在页面的右下角。
②生成一个CSS选择器,显示选择器能捕捉到的HTML元素:在网页上用鼠标点击要获取的数据,选中的HTML元素会被标记为绿色,工具会尝试检测测试用户想要抓取的数据的规则,然后生成一组 CSS 选择器并显示在工具栏上。同时,页面上所有符合这组 CSS 选择器的 HTML 元素都会被标记为黄色,即当前组 CSS 选择器会提取所有绿色和黄色的 HTML 元素。
③去除不需要的 HTML 元素:该工具检测到的 CSS 选择器通常收录一些不需要的数据。这时候可以删除那些被标记但要排除的HTML元素,被删除的元素会被标记成红色。
④获取准确的CSS选择器:选中并排除HTML元素后,所有要提取的元素都已被准确标记,可以生成一组准确的CSS选择器并显示在工具栏上。在 R 软件中处理。
3.1.2R软件相关功能包及使用
实现网页信息的抓取,R语言的编写需要参考xml2、rvest、dplyr、stringr等函数包中的函数,所以下载这些函数包并加载需要的包。具体方法是使用 install.packages() 和 library() 函数来实现,也可以将这些包下载到本地安装。
3.2 网页信息抓取的实现
以联家网广州二手房销售为例。按照前面的步骤,首先使用read_html()函数抓取整个链家网页的原创HTML代码,然后使用html_nodes()函数通过SelectorGadget工具从整个链家网页中选取元素获取路径信息,最后使用html_text()函数提取HTML代码中的文本数据,得到我们需要的链家网数据。
rvest包抓取某个网页数据的几个功能,但是可以发现广州链家网上有很多二手房数据的页面,有用的信息包括房子名称,描述,位置,房价,因此,选择循环函数for(),编写如下函数,抓取链家网站上所有有价值的信息,写入csv格式的文件中进行进一步分析。限于篇幅,这里列出了一些结果,如下表所示。
上表给出了广州部分二手房的基本信息。
可以看出,使用rvest包结合CSS选择器,可以快速实现R语言下的网络数据抓取,并适当结合stringr包中的字符串处理功能,对网页数据进行清理整理,可以非常方便有效地获取网页数据。直接数据处理和分析。通过直接利用爬取的数据,对房价是否符合正态分布进行简单的分析,展示了R语言对网页数据爬取后得到的数据进行分析的便利性和优越性。
4 rvest包与其他网络信息抓取方式对比分析
R语言实现网络爬虫有两种方式,一种是使用本文提到的rvest包,另一种是使用RCurl包和XML包。
使用rvest函数包和SelectorGadget工具实现R语言在网页信息抓取上的应用,比使用XML包和RCurl包抓取更简单,代码更简洁直观。R中的rvest包压缩了原来复杂的网络爬虫工作来读取网页、检索网页和提取文本,变得非常简单,并且根据网页的规则,使用for()循环函数来实现多个网页爬行。使用XML包和RCurl包来实现,需要一些网页的基础知识,模拟浏览器伪装header的行为,然后访问页面解析网页,然后定位节点获取信息,最后整合信息。这种方法比较困难,也比较麻烦。有时访问网页时无法顺利读取和解析,选择节点时需要具备HTML基础知识。在网页的源代码中查找它。一些网页的源代码相当复杂,不易定位。节点。
两种实现方式所能达到的效果基本相同,都可以利用for()循环函数抓取多个网页数据。从动手的角度来说,rvest包展示比较好,就是XML包和RCurl包。进化,更简洁方便。
另外,网络爬虫在Python中的实现也很流行。Python 的 pandas 模块工具借鉴了 R 的数据帧,而 R 的 rvest 包指的是 Python 的 BeautifulSoup。这两种语言在一定程度上是互补的。Python在实现网络爬虫方面更有优势,但在网页数据爬取方面,基于R语言工具的实现更加简洁方便,R是统计分析中更高效的独立数据分析工具。使用 R 语言获取的数据,避免了繁琐的平台环境转换。从数据采集、数据清洗到数据分析,代码环境和平台保持一致性。
参考:
[1] 吴锐,张俊丽.基于R语言的网络爬虫技术研究[J]. 科技信息, 2016, 14 (34): 35-36.
[2] 西蒙·蒙泽尔特。基于R语言的自动数据采集:网页抓取和文本挖掘实用指南[M]. 机械工业出版社,2016.
[3] 刘金红,卢玉良.专题网络爬虫研究综述[J]. 计算机应用研究, 2007, 24 (10): 26-29.

