
网页源代码抓取工具
网页源代码抓取工具(网络库urlliburllib库是4个模块详细解析(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-30 23:18
网络库 urllib
urllib库是Python3内置的HTTP请求库,不需要单独安装。默认下载的 Python 已经收录该库。
urllib 库有 4 个模块:
1.request:最基本的HTTP请求模块,可以用来发送HTTP请求和接收来自服务器的响应数据。这个过程就像在浏览器地址栏中输入一个 URL。
2.parse:工具模块,提供了很多处理URL的API,如拆分、解析、合并等。
3.robotparser:用于识别网站的robots.txt文件,进而判断哪些网站可以爬取,哪些不能爬取。
4.错误:异常处理。如果发生请求错误,可以捕获这些异常,然后根据代码的需要进行处理。
下面,我们将介绍 urllib 库的 4 个模块。
要求
请求模块收录发送请求、获取响应、cookies、代理等相关API。在这里,我们将分别介绍如何使用它们。
发送 GET 请求
首先,我们一般在编写爬虫程序的时候,需要在开始时发送请求,然后得到响应进行处理。例如通过GET请求获取网页的源码,示例如下:
import urllib.request
response=urllib.request.urlopen("https://www.csdn.net/")
print(response.read().decode("UTF-8"))
如上代码所示,运行后,我们将得到网页的html源代码。
这里的 response 是一个 HTTPResponse 对象。通过调用它的各种方法和属性,可以进行各种处理。
比如这里我们获取CSDN主页,调用它的属性和方法,示例如下:
import urllib.request
response = urllib.request.urlopen("https://www.csdn.net/")
print("status:", response.status, " msg:", response.msg, " version:", response.version)
print(response.getheaders())
在这里,我们输出CSDN首页的响应状态码、响应消息和HTTP版本的属性,还打印了完整的响应头信息。
发送 POST 请求
request.urlopen()函数默认发送GET请求,如果需要发送POST请求,我们需要使用data命令参数,参数类型为bytes。示例代码如下:
import urllib.request
import urllib.parse
data = bytes(urllib.parse.urlencode({'username': 'name', 'age': '123456'}), encoding="UTF-8")
response = urllib.request.urlopen("http://httpbin.org/post", data=data)
print(response.read().decode("UTF-8"))
运行后,如果请求成功,会返回很多字符串数据。
请求超时处理
在实际爬虫项目中,我们都需要考虑一个关键问题,即请求超时。如果请求的URL长时间没有响应,卡在这里往往会浪费很多资源。
因此,我们需要设置一个超时时间。如果在限定时间内没有响应,我们应该重新获取或停止获取。示例代码如下:
import urllib.request
import urllib.parse
import urllib.error
import socket
data = bytes(urllib.parse.urlencode({'username': 'name', 'age': '123456'}), encoding="UTF-8")
try:
response = urllib.request.urlopen("http://httpbin.org/post", data=data, timeout=0.1)
print(response.read().decode("UTF-8"))
except urllib.error.URLError as e:
if isinstance(e.reason,socket.timeout):
print("超时处理")
finally:
print("继续爬虫的工作")
爬行动物伪装
现在任何知名的网站 都有明确的反爬虫技术。因此,我们在开发爬虫程序时,需要将我们的请求伪装成浏览器。
但是, urlopen() 没有头请求头参数。我们需要使用 request.Request() 来构造请求。示例代码如下:
import urllib.request
import urllib.parse
data = bytes(urllib.parse.urlencode({'username': 'name', 'age': '123456'}), encoding="UTF-8")
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
req = urllib.request.Request("http://httpbin.org/post", data=data, headers=headers)
response = urllib.request.urlopen(req)
print(response.read().decode("UTF-8"))
在这里,我们将爬虫程序伪装成来自 Firefox 浏览器的请求。
当然,Request 类还有很多其他的信息。下表由博主列出,供读者参考。
范围
意义
网址
用于发送请求的 URl,一个必选参数(除此参数外,其他参数可选)
数据
要提交的表单数据必须是字节类型
标题
请求头
origin_req_host
请求方的主机名或 IP 地址
无法核实
指示是否无法验证此请求。默认为False,主要表示用户没有足够的权限选择接收本次请求的结果。比如请求一个HTML图片,但是没有权限自动抓取图片,此时参数为True。
方法
用于指定请求,如GET、POST、PUT等,如果指定了data,则默认为POST请求
需要注意的是最后一个参数方法,如果在程序中指定请求是GET,并且还有数据表单数据,那么默认表单不会提交到服务器。
演戏
其实,除了根据请求头判断服务器是否是爬虫,判断爬虫最简单的方法就是判断是否是短时间内来自同一个IP的大量访问。
如果同一IP短时间内被大量访问,可以直接识别为爬虫。这时候我们就可以通过代理来伪装了。当然,在使用代理时,您应该不断更改代理服务器。
示例代码如下:
import urllib.error
from urllib.request import ProxyHandler, build_opener
proxy_handler = ProxyHandler({
'http': 'http://183.47.138.80:8888',
'http': 'http://125.78.226.217:8888'
})
opener = build_opener(proxy_handler)
try:
response = opener.open('https://www.csdn.net/')
print(response.read().decode('UTF-8'))
except urllib.error.URLError as e:
print(e.reason)
运行后,返回到CSDN首页的源代码和之前一样。不过需要注意的是,这个code IP在博主写博客的时候是有效的,但是如果你看了这篇博文,可能是无效的。你需要找一个免费的代理服务器来自己测试。
获取饼干
一般来说,当我们使用爬虫登录网站时,会使用服务器返回的cookie进行操作。有了这个cookie,服务器就知道我们已经登录了。
那么如何获取cookie数据呢?示例如下:
import urllib.error
from urllib.request import ProxyHandler
import http.cookiejar
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
try:
response = opener.open('https://www.csdn.net/')
for item in cookie:
print("name=", item.name, " value=", item.value)
except urllib.error.URLError as e:
print(e.reason)
如上代码所示,我们可以通过http.cookiejar库进行操作,返回cookie的键值对,并打印输出。效果如下:
如果网站本身的cookie时长比较长,那么在爬虫之后,我们可以将其保存起来使用。这时候会用到 MozillaCookieJar 类和 LWPCookieJar 类。
这两个类会在获取cookie的同时以Mozilla浏览器格式和libwww-perl(LWP)格式保存cookie。示例代码如下:
import urllib.error
from urllib.request import ProxyHandler
import http.cookiejar
cookie = http.cookiejar.MozillaCookieJar('cookies.txt')
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
try:
response = opener.open('https://www.csdn.net/')
cookie.save(ignore_discard=True,ignore_expires=True)
except urllib.error.URLError as e:
print(e.reason)
运行后会生成一个cookies.txt文件,具体内容如下:
LWPCookieJar 类的使用与上面的 MozillaCookieJar 类似,这里不再赘述。至于读取,通过 cookie.load() 方法加载 Cookie。
解析
在实际爬虫处理中,我们经常会遇到各种编码问题。这些问题都可以通过 Parse 来解决。
中文编解码
比如在一些网址的请求头中,一些网站请求头会收录中文。但是默认不做任何处理,肯定会报UnicodeEncodeError。
读者可以用上面的代码在headers字典中添加一个键值对,让值取中文试试。接下来,我们需要对其进行编码,示例如下:
import urllib.parse
import base64
value = urllib.parse.urlencode({'name': '安踏'})
print("编码后的中文:", value)
print("解码后的中文:", urllib.parse.unquote(value))
#base64编码与解码
base64Value=base64.b64encode(bytes('学习网络urllib库',encoding="UTF-8"))
print("编码后的中文:", base64Value)
print("解码后的中文:", str(base64.b64decode(base64Value),"UTF-8"))
运行后效果如下:
需要注意的是,urlencode只能对url参数进行编码。例如,headers 请求头在此处编码。网站 中的一些数据是由 base64 编码的。这时候我们还需要掌握base64的解码和编码。
引用和取消引用
quote 函数也是一种编码函数,但它与 urlencode 的不同之处在于 urlencode 只能对 URL 进行编码。并且quote 可以编码任何字符串。
至于unquote是编码(解码)的逆过程,示例如下:
from urllib.parse import quote, unquote
url = 'https://www.baidu.com/s?wd=' + quote("王者荣耀")
print(url)
url = unquote(url)
print(url)
运行后效果如下:
网址解析
在前面的介绍中,我们也说过解析模块可以对 URL 进行分解、分析和合并。下面,我们就通过这些函数,举一些例子,读者就明白了。
from urllib import parse
url = 'https://www.csdn.net/'
split_result=parse.urlsplit(url);
print(split_result)
result = parse.urlparse(url)
print('scheme:', result.scheme) # 网络协议
print('netloc:', result.netloc) # 域名
print('path:', result.path) # 文件存放路径
print('query:', result.query) # 查询字符
print('fragment:', result.fragment) # 拆分文档中的特殊猫
运行后效果如下:
连接网址
对于 URL,有时我们需要组合 URL 的多个部分。比如我们在网站下爬取某张图片时,默认的前面部分基本一致,可能只是ID不同。
那么这时候我们就需要拼接第一部分的URL和ID。示例代码如下:
import urllib.parse
print(urllib.parse.urljoin('https://blog.csdn.net','liyuanjinglyj'))
print(urllib.parse.urljoin('https://blog.csdn.net','https://www.baidu.com'))
print(urllib.parse.urljoin('https://blog.csdn.net','index.html'))
print(urllib.parse.urljoin('https://blog.csdn.net/index.php','?name=30'))
运行后效果如下:
urljoin使用规则:第一个参数是base_url,是一个base URL。只能设置scheme、netloc 和path。第二个参数是url。
如果第二个参数不是完整的URL,第二个参数的值会加在第一个参数的后面,会自动加上斜线“/”。
如果第二个参数是完整的 URL,则直接返回第二个 URL。
参数转换(parse_qs 和 parse_qsl)
parse_qs 函数将多个参数拆分成一个字典,其中key为参数名,value为参数值。
parse_qsl 函数返回一个列表,每个元素是一个收录 2 个元素值的元组,第一个元素代表键,第二个元素代表值。
示例如下:
from urllib.parse import parse_qs, parse_qsl
query = "name=李元静&age=29"
print(parse_qs(query))
print(parse_qsl(query))
运行后效果如下:
两个函数只是返回形式不同的参数,内容基本匹配。同时,无论这两个函数是什么类型,转换结果都是字符串。
机器人协议
Robots协议也叫爬虫协议、机器人协议,全称是Robots Exclusing Protocol。
用于告诉爬虫和搜索引擎哪些页面可以爬取,哪些页面不能爬取。该协议通常放在一个名为robots.txt 的文本文件中,该文件位于网站 的根目录中。
需要特别注意的是,robots.txt文件只是在开发过程中用来判断哪些数据可以爬取,哪些数据不能爬取,并不阻止开发过程中的爬取操作。但是作为一个有良知的程序员,你应该尽可能地尊重这些规则。
Robots协议定义规则
robots.txt的文本文件一般有3个值:
1.User-agent:如果是*,表示对所有爬虫都有效。2. Disallow:不能爬取哪些目录资源,如Disallow:/index/,则禁止爬取索引文件中的所有资源。如果是/,则表示无法捕获网站。3.Allow:表示可以爬取哪些目录资源。例如Allow:/,表示可以捕获所有网站。该值与 Disallow 相同,但含义相反。
当然User-agent也可以禁止某些爬虫爬取,比如百度爬虫:User-agent:BaiduSpider。常用的爬虫名称如下:
爬虫名称
搜索引擎
谷歌机器人
谷歌
360蜘蛛
360搜索
宾博
必须
百度蜘蛛
百度
Robots协议分析
当然,我们在获取Robots协议的时候,一定要获取哪些资源是不可爬取的。不过,虽然可以直接通过字符串解析来完成,但是稍微复杂一些。
urllib 库的robotparser 模块提供了相应的解析API,即RobotFileParser 类。示例如下:
from urllib.robotparser import RobotFileParser
#一种解析方式
robot = RobotFileParser()
robot.set_url('https://www.csdn.net/robots.txt')
robot.read()
print(robot.can_fetch('*', 'https://blog.csdn.net/rank/list'))
#另一种解析方式
robot = RobotFileParser('https://www.csdn.net/robots.txt')
print(robot.can_fetch('*', 'https://blog.csdn.net/rank/list'))
这里使用can_fetch方法来判断是否可以根据Robots协议获取URL。这里的判断是CSDN排行榜是否可以爬取,返回True。
错误
我们已经在上面的代码中使用了异常处理。例如,在解释请求超时时,我们使用了 URLError。但它也有一个子类 HTTPError。 查看全部
网页源代码抓取工具(网络库urlliburllib库是4个模块详细解析(组图))
网络库 urllib
urllib库是Python3内置的HTTP请求库,不需要单独安装。默认下载的 Python 已经收录该库。
urllib 库有 4 个模块:
1.request:最基本的HTTP请求模块,可以用来发送HTTP请求和接收来自服务器的响应数据。这个过程就像在浏览器地址栏中输入一个 URL。
2.parse:工具模块,提供了很多处理URL的API,如拆分、解析、合并等。
3.robotparser:用于识别网站的robots.txt文件,进而判断哪些网站可以爬取,哪些不能爬取。
4.错误:异常处理。如果发生请求错误,可以捕获这些异常,然后根据代码的需要进行处理。
下面,我们将介绍 urllib 库的 4 个模块。
要求
请求模块收录发送请求、获取响应、cookies、代理等相关API。在这里,我们将分别介绍如何使用它们。
发送 GET 请求
首先,我们一般在编写爬虫程序的时候,需要在开始时发送请求,然后得到响应进行处理。例如通过GET请求获取网页的源码,示例如下:
import urllib.request
response=urllib.request.urlopen("https://www.csdn.net/";)
print(response.read().decode("UTF-8"))
如上代码所示,运行后,我们将得到网页的html源代码。
这里的 response 是一个 HTTPResponse 对象。通过调用它的各种方法和属性,可以进行各种处理。
比如这里我们获取CSDN主页,调用它的属性和方法,示例如下:
import urllib.request
response = urllib.request.urlopen("https://www.csdn.net/";)
print("status:", response.status, " msg:", response.msg, " version:", response.version)
print(response.getheaders())
在这里,我们输出CSDN首页的响应状态码、响应消息和HTTP版本的属性,还打印了完整的响应头信息。
发送 POST 请求
request.urlopen()函数默认发送GET请求,如果需要发送POST请求,我们需要使用data命令参数,参数类型为bytes。示例代码如下:
import urllib.request
import urllib.parse
data = bytes(urllib.parse.urlencode({'username': 'name', 'age': '123456'}), encoding="UTF-8")
response = urllib.request.urlopen("http://httpbin.org/post", data=data)
print(response.read().decode("UTF-8"))
运行后,如果请求成功,会返回很多字符串数据。
请求超时处理
在实际爬虫项目中,我们都需要考虑一个关键问题,即请求超时。如果请求的URL长时间没有响应,卡在这里往往会浪费很多资源。
因此,我们需要设置一个超时时间。如果在限定时间内没有响应,我们应该重新获取或停止获取。示例代码如下:
import urllib.request
import urllib.parse
import urllib.error
import socket
data = bytes(urllib.parse.urlencode({'username': 'name', 'age': '123456'}), encoding="UTF-8")
try:
response = urllib.request.urlopen("http://httpbin.org/post", data=data, timeout=0.1)
print(response.read().decode("UTF-8"))
except urllib.error.URLError as e:
if isinstance(e.reason,socket.timeout):
print("超时处理")
finally:
print("继续爬虫的工作")
爬行动物伪装
现在任何知名的网站 都有明确的反爬虫技术。因此,我们在开发爬虫程序时,需要将我们的请求伪装成浏览器。
但是, urlopen() 没有头请求头参数。我们需要使用 request.Request() 来构造请求。示例代码如下:
import urllib.request
import urllib.parse
data = bytes(urllib.parse.urlencode({'username': 'name', 'age': '123456'}), encoding="UTF-8")
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
req = urllib.request.Request("http://httpbin.org/post", data=data, headers=headers)
response = urllib.request.urlopen(req)
print(response.read().decode("UTF-8"))
在这里,我们将爬虫程序伪装成来自 Firefox 浏览器的请求。
当然,Request 类还有很多其他的信息。下表由博主列出,供读者参考。
范围
意义
网址
用于发送请求的 URl,一个必选参数(除此参数外,其他参数可选)
数据
要提交的表单数据必须是字节类型
标题
请求头
origin_req_host
请求方的主机名或 IP 地址
无法核实
指示是否无法验证此请求。默认为False,主要表示用户没有足够的权限选择接收本次请求的结果。比如请求一个HTML图片,但是没有权限自动抓取图片,此时参数为True。
方法
用于指定请求,如GET、POST、PUT等,如果指定了data,则默认为POST请求
需要注意的是最后一个参数方法,如果在程序中指定请求是GET,并且还有数据表单数据,那么默认表单不会提交到服务器。
演戏
其实,除了根据请求头判断服务器是否是爬虫,判断爬虫最简单的方法就是判断是否是短时间内来自同一个IP的大量访问。
如果同一IP短时间内被大量访问,可以直接识别为爬虫。这时候我们就可以通过代理来伪装了。当然,在使用代理时,您应该不断更改代理服务器。
示例代码如下:
import urllib.error
from urllib.request import ProxyHandler, build_opener
proxy_handler = ProxyHandler({
'http': 'http://183.47.138.80:8888',
'http': 'http://125.78.226.217:8888'
})
opener = build_opener(proxy_handler)
try:
response = opener.open('https://www.csdn.net/')
print(response.read().decode('UTF-8'))
except urllib.error.URLError as e:
print(e.reason)
运行后,返回到CSDN首页的源代码和之前一样。不过需要注意的是,这个code IP在博主写博客的时候是有效的,但是如果你看了这篇博文,可能是无效的。你需要找一个免费的代理服务器来自己测试。
获取饼干
一般来说,当我们使用爬虫登录网站时,会使用服务器返回的cookie进行操作。有了这个cookie,服务器就知道我们已经登录了。
那么如何获取cookie数据呢?示例如下:
import urllib.error
from urllib.request import ProxyHandler
import http.cookiejar
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
try:
response = opener.open('https://www.csdn.net/')
for item in cookie:
print("name=", item.name, " value=", item.value)
except urllib.error.URLError as e:
print(e.reason)
如上代码所示,我们可以通过http.cookiejar库进行操作,返回cookie的键值对,并打印输出。效果如下:
如果网站本身的cookie时长比较长,那么在爬虫之后,我们可以将其保存起来使用。这时候会用到 MozillaCookieJar 类和 LWPCookieJar 类。
这两个类会在获取cookie的同时以Mozilla浏览器格式和libwww-perl(LWP)格式保存cookie。示例代码如下:
import urllib.error
from urllib.request import ProxyHandler
import http.cookiejar
cookie = http.cookiejar.MozillaCookieJar('cookies.txt')
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
try:
response = opener.open('https://www.csdn.net/')
cookie.save(ignore_discard=True,ignore_expires=True)
except urllib.error.URLError as e:
print(e.reason)
运行后会生成一个cookies.txt文件,具体内容如下:
LWPCookieJar 类的使用与上面的 MozillaCookieJar 类似,这里不再赘述。至于读取,通过 cookie.load() 方法加载 Cookie。
解析
在实际爬虫处理中,我们经常会遇到各种编码问题。这些问题都可以通过 Parse 来解决。
中文编解码
比如在一些网址的请求头中,一些网站请求头会收录中文。但是默认不做任何处理,肯定会报UnicodeEncodeError。
读者可以用上面的代码在headers字典中添加一个键值对,让值取中文试试。接下来,我们需要对其进行编码,示例如下:
import urllib.parse
import base64
value = urllib.parse.urlencode({'name': '安踏'})
print("编码后的中文:", value)
print("解码后的中文:", urllib.parse.unquote(value))
#base64编码与解码
base64Value=base64.b64encode(bytes('学习网络urllib库',encoding="UTF-8"))
print("编码后的中文:", base64Value)
print("解码后的中文:", str(base64.b64decode(base64Value),"UTF-8"))
运行后效果如下:
需要注意的是,urlencode只能对url参数进行编码。例如,headers 请求头在此处编码。网站 中的一些数据是由 base64 编码的。这时候我们还需要掌握base64的解码和编码。
引用和取消引用
quote 函数也是一种编码函数,但它与 urlencode 的不同之处在于 urlencode 只能对 URL 进行编码。并且quote 可以编码任何字符串。
至于unquote是编码(解码)的逆过程,示例如下:
from urllib.parse import quote, unquote
url = 'https://www.baidu.com/s?wd=' + quote("王者荣耀")
print(url)
url = unquote(url)
print(url)
运行后效果如下:
网址解析
在前面的介绍中,我们也说过解析模块可以对 URL 进行分解、分析和合并。下面,我们就通过这些函数,举一些例子,读者就明白了。
from urllib import parse
url = 'https://www.csdn.net/'
split_result=parse.urlsplit(url);
print(split_result)
result = parse.urlparse(url)
print('scheme:', result.scheme) # 网络协议
print('netloc:', result.netloc) # 域名
print('path:', result.path) # 文件存放路径
print('query:', result.query) # 查询字符
print('fragment:', result.fragment) # 拆分文档中的特殊猫
运行后效果如下:
连接网址
对于 URL,有时我们需要组合 URL 的多个部分。比如我们在网站下爬取某张图片时,默认的前面部分基本一致,可能只是ID不同。
那么这时候我们就需要拼接第一部分的URL和ID。示例代码如下:
import urllib.parse
print(urllib.parse.urljoin('https://blog.csdn.net','liyuanjinglyj'))
print(urllib.parse.urljoin('https://blog.csdn.net','https://www.baidu.com'))
print(urllib.parse.urljoin('https://blog.csdn.net','index.html'))
print(urllib.parse.urljoin('https://blog.csdn.net/index.php','?name=30'))
运行后效果如下:
urljoin使用规则:第一个参数是base_url,是一个base URL。只能设置scheme、netloc 和path。第二个参数是url。
如果第二个参数不是完整的URL,第二个参数的值会加在第一个参数的后面,会自动加上斜线“/”。
如果第二个参数是完整的 URL,则直接返回第二个 URL。
参数转换(parse_qs 和 parse_qsl)
parse_qs 函数将多个参数拆分成一个字典,其中key为参数名,value为参数值。
parse_qsl 函数返回一个列表,每个元素是一个收录 2 个元素值的元组,第一个元素代表键,第二个元素代表值。
示例如下:
from urllib.parse import parse_qs, parse_qsl
query = "name=李元静&age=29"
print(parse_qs(query))
print(parse_qsl(query))
运行后效果如下:
两个函数只是返回形式不同的参数,内容基本匹配。同时,无论这两个函数是什么类型,转换结果都是字符串。
机器人协议
Robots协议也叫爬虫协议、机器人协议,全称是Robots Exclusing Protocol。
用于告诉爬虫和搜索引擎哪些页面可以爬取,哪些页面不能爬取。该协议通常放在一个名为robots.txt 的文本文件中,该文件位于网站 的根目录中。
需要特别注意的是,robots.txt文件只是在开发过程中用来判断哪些数据可以爬取,哪些数据不能爬取,并不阻止开发过程中的爬取操作。但是作为一个有良知的程序员,你应该尽可能地尊重这些规则。
Robots协议定义规则
robots.txt的文本文件一般有3个值:
1.User-agent:如果是*,表示对所有爬虫都有效。2. Disallow:不能爬取哪些目录资源,如Disallow:/index/,则禁止爬取索引文件中的所有资源。如果是/,则表示无法捕获网站。3.Allow:表示可以爬取哪些目录资源。例如Allow:/,表示可以捕获所有网站。该值与 Disallow 相同,但含义相反。
当然User-agent也可以禁止某些爬虫爬取,比如百度爬虫:User-agent:BaiduSpider。常用的爬虫名称如下:
爬虫名称
搜索引擎
谷歌机器人
谷歌
360蜘蛛
360搜索
宾博
必须
百度蜘蛛
百度
Robots协议分析
当然,我们在获取Robots协议的时候,一定要获取哪些资源是不可爬取的。不过,虽然可以直接通过字符串解析来完成,但是稍微复杂一些。
urllib 库的robotparser 模块提供了相应的解析API,即RobotFileParser 类。示例如下:
from urllib.robotparser import RobotFileParser
#一种解析方式
robot = RobotFileParser()
robot.set_url('https://www.csdn.net/robots.txt')
robot.read()
print(robot.can_fetch('*', 'https://blog.csdn.net/rank/list'))
#另一种解析方式
robot = RobotFileParser('https://www.csdn.net/robots.txt')
print(robot.can_fetch('*', 'https://blog.csdn.net/rank/list'))
这里使用can_fetch方法来判断是否可以根据Robots协议获取URL。这里的判断是CSDN排行榜是否可以爬取,返回True。
错误
我们已经在上面的代码中使用了异常处理。例如,在解释请求超时时,我们使用了 URLError。但它也有一个子类 HTTPError。
网页源代码抓取工具(美女图片镇场子,免得你们说我光说不练假把式!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-29 13:41
首先,爬取镇上美女的图片,免得你说我刚才讲了!
话不多说,开始吧!首先了解需要额外安装的第三方库
由于淘女郎网站收录
AJAX技术,因此只需与后台交换少量数据即可实时更新,这意味着直接抓取网页源代码并分析信息的方法行不通。
对于这类网站,一般有两种抓取方式:
使用selenium库模拟浏览器的用户行为,使服务器认为真实用户在浏览网页,从而获得完整的网页源代码
使用Chrome等浏览器自带的分析工具对网页的网络进行监控,分析数据交换API,利用API捕获数据交换的JSON数据,然后进行捕获。
从效率上看,第一种方法比较慢,也占用系统资源,所以我们用第二种方法来实现。
先写请求,然后从淘女孩网站获取JSON文件。
将请求发送到服务器。然后获取服务端的JSON数据,对返回的数据进行处理,再转换成Python字典类型返回。具体代码如下:
def getInfo(paeNum):
tao_datas ('vievFiag':"A", "currentPage": pageNum)
try:
r=requests. post ("http://nn. taobao. com/tatar/seateh/tatar_nodel. do?_input_charset=utf-8*, data = tao. data)
except:
return None
rav_datas = json. loads(r.text)
datas rav_datas['data']['searchDoList']
returh dat as
返回后,我们连接MongoDB,保存返回的信息。
def main():
client = MongoClient ()
db =client. TaoBao
col = db. TaoLady
for pageNun in range(I,411): 淘女郎一共有410页,所以我们抓取从1到第411页的内容。
print (pageNun)
datas=getInfo(pageNun)
if datas;
col.insert_nany(datas)
if__nane__='__main__';
main()
分析返回的信息,然后提取消息中的图片URL信息,将过度使用的图片保存到PIC文件夹中:
def downPic():
client=HongoClient()
db = client.TaoBao
col=db.TaoLady
for data in col, find():
nane = data['realName']
url =“http:" + data[" avatarUr1']
pie=urlopen(url)
vith, open("pic/" + name +",jpa,vb”) as file:
print(name)
file.vrite(pic. read())
if __nane__='__main__':
downPic()
OK,大功告成,原图全部超清晰,不过由于图片数量多,我的16G U盘几乎装不下,这里就不一一展示了,只截了一部分大家来看看。如果觉得文章还行,不妨点个赞。任何意见或意见,欢迎评论!
我是python开发工程师,整理了一套python学习资料。如果你想提升自己,对编程感兴趣,请关注我,私信后台编辑:《08》可免费领取素材!希望能帮到你! 查看全部
网页源代码抓取工具(美女图片镇场子,免得你们说我光说不练假把式!)
首先,爬取镇上美女的图片,免得你说我刚才讲了!
话不多说,开始吧!首先了解需要额外安装的第三方库
由于淘女郎网站收录
AJAX技术,因此只需与后台交换少量数据即可实时更新,这意味着直接抓取网页源代码并分析信息的方法行不通。
对于这类网站,一般有两种抓取方式:
使用selenium库模拟浏览器的用户行为,使服务器认为真实用户在浏览网页,从而获得完整的网页源代码
使用Chrome等浏览器自带的分析工具对网页的网络进行监控,分析数据交换API,利用API捕获数据交换的JSON数据,然后进行捕获。
从效率上看,第一种方法比较慢,也占用系统资源,所以我们用第二种方法来实现。
先写请求,然后从淘女孩网站获取JSON文件。
将请求发送到服务器。然后获取服务端的JSON数据,对返回的数据进行处理,再转换成Python字典类型返回。具体代码如下:
def getInfo(paeNum):
tao_datas ('vievFiag':"A", "currentPage": pageNum)
try:
r=requests. post ("http://nn. taobao. com/tatar/seateh/tatar_nodel. do?_input_charset=utf-8*, data = tao. data)
except:
return None
rav_datas = json. loads(r.text)
datas rav_datas['data']['searchDoList']
returh dat as
返回后,我们连接MongoDB,保存返回的信息。
def main():
client = MongoClient ()
db =client. TaoBao
col = db. TaoLady
for pageNun in range(I,411): 淘女郎一共有410页,所以我们抓取从1到第411页的内容。
print (pageNun)
datas=getInfo(pageNun)
if datas;
col.insert_nany(datas)
if__nane__='__main__';
main()
分析返回的信息,然后提取消息中的图片URL信息,将过度使用的图片保存到PIC文件夹中:
def downPic():
client=HongoClient()
db = client.TaoBao
col=db.TaoLady
for data in col, find():
nane = data['realName']
url =“http:" + data[" avatarUr1']
pie=urlopen(url)
vith, open("pic/" + name +",jpa,vb”) as file:
print(name)
file.vrite(pic. read())
if __nane__='__main__':
downPic()
OK,大功告成,原图全部超清晰,不过由于图片数量多,我的16G U盘几乎装不下,这里就不一一展示了,只截了一部分大家来看看。如果觉得文章还行,不妨点个赞。任何意见或意见,欢迎评论!
我是python开发工程师,整理了一套python学习资料。如果你想提升自己,对编程感兴趣,请关注我,私信后台编辑:《08》可免费领取素材!希望能帮到你!
网页源代码抓取工具(几年前大数据带着一层神秘面纱(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-29 13:39
几年前,大数据带着神秘的面纱走进人们的视野。在“大数据”[Big Data Observation:]这个词达到顶峰的时候,人们甚至谈到了大数据。如今,大数据的发展越来越扎实,在各个行业开发相关应用的可行性也比以前高很多。但是,在大数据的发展过程中,如果要将其转化为基础能力,基础数据建设仍然是一个不可忽视的环节。一款能够轻松抓取和分析全球网络数据的网络爬虫工具更是不可或缺。不够。
什么是网络爬虫?我们每天需要的大部分大数据来自开放的互联网和其他输入型设备。对于其中最大的互联网,网络抓取工具用于从互联网中提取数据。
基于互联网数据海量的特点,网络爬虫必须满足的条件之一就是高效。因此,市面上最高效的网络爬虫工具“优采云
采集
V9”【】采用的是源码抽取的方式。这种提取方式不需要浏览器解析数据,直接提取网页结构。此外,优采云
Collector V9简化了整个数据提取流程,在提取速度提升的基础上,可以更高效地运行。
网络爬虫是免费的吗?除了效率和易用性,大数据需求群体最大的担忧是工具是否可以免费使用。网页抓取工具优采云
Collector V9 免费版,已累计超过40万用户,每天响应超过10,000个客户。这也从侧面解释了优采云
采集
器软件和服务器。稳定性。
网络爬虫还有其他用途吗?不同于一些小众的采集工具,优采云
collector V9不仅提供了强大的数据采集功能,还有强大的数据处理和发布功能。这些特殊用途的操作非常简单易用。教程的指导快速上手,帮助我们在技术知识相对薄弱的情况下也能轻松高效地处理和发布数据。无需研究代码或寻求其他技术支持,因此选择一个易于使用的网络爬虫工具是非常有必要的。
学习了网络爬虫工具后,未来大数据的基础数据构建在它的协同下可以变得轻松高效。为了更好地适应大数据生态系统的发展需求,我们必须紧跟时代潮流,及时拓展和发散思维,不拘泥于规则,以前瞻性的眼光探索,以执行与执行。坚定的信念。 查看全部
网页源代码抓取工具(几年前大数据带着一层神秘面纱(图))
几年前,大数据带着神秘的面纱走进人们的视野。在“大数据”[Big Data Observation:]这个词达到顶峰的时候,人们甚至谈到了大数据。如今,大数据的发展越来越扎实,在各个行业开发相关应用的可行性也比以前高很多。但是,在大数据的发展过程中,如果要将其转化为基础能力,基础数据建设仍然是一个不可忽视的环节。一款能够轻松抓取和分析全球网络数据的网络爬虫工具更是不可或缺。不够。
什么是网络爬虫?我们每天需要的大部分大数据来自开放的互联网和其他输入型设备。对于其中最大的互联网,网络抓取工具用于从互联网中提取数据。
基于互联网数据海量的特点,网络爬虫必须满足的条件之一就是高效。因此,市面上最高效的网络爬虫工具“优采云
采集
V9”【】采用的是源码抽取的方式。这种提取方式不需要浏览器解析数据,直接提取网页结构。此外,优采云
Collector V9简化了整个数据提取流程,在提取速度提升的基础上,可以更高效地运行。
网络爬虫是免费的吗?除了效率和易用性,大数据需求群体最大的担忧是工具是否可以免费使用。网页抓取工具优采云
Collector V9 免费版,已累计超过40万用户,每天响应超过10,000个客户。这也从侧面解释了优采云
采集
器软件和服务器。稳定性。
网络爬虫还有其他用途吗?不同于一些小众的采集工具,优采云
collector V9不仅提供了强大的数据采集功能,还有强大的数据处理和发布功能。这些特殊用途的操作非常简单易用。教程的指导快速上手,帮助我们在技术知识相对薄弱的情况下也能轻松高效地处理和发布数据。无需研究代码或寻求其他技术支持,因此选择一个易于使用的网络爬虫工具是非常有必要的。
学习了网络爬虫工具后,未来大数据的基础数据构建在它的协同下可以变得轻松高效。为了更好地适应大数据生态系统的发展需求,我们必须紧跟时代潮流,及时拓展和发散思维,不拘泥于规则,以前瞻性的眼光探索,以执行与执行。坚定的信念。
网页源代码抓取工具(一个网站抓站中遇到的奇特网站,分享思路和抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-29 13:38
在我们的学习过程中,我们想在打开网站的时候抓取一次数据,但并不是所有的网站都可以通过一种方式抓取数据。有的有特殊的网页结构,有的有不同的json数据包。慢慢写一些。与我在爬虫过程中遇到的奇葩网站分享爬虫的思路和方法!
工具、目标
工具:pycharm、python3.6 版本
库:请求库
目标:普世网热门图片直播页面,所有图片信息
注意:本网站有一个流行的图片页面,其中收录
活动的相关照片。所有图片信息根据事件写入txt文件(不下载图片,以免影响服务器)!
目标分析
首先,打开如上图所示的主页。不要担心其他人。只需单击右上角。选项出现后,点击进入热图直播选项(注意:部分浏览器需要放大页面才能看到热图直播选项),进入后页面是这样的
在这里,我已放大到 30%。下面是一页一页的活动现场图片。随便点击一个事件,让我们看一下页面
看到页面上的图片加载这么慢,应该是动态加载的,右键查看源码,果然如此!
没有任何图片信息,那我们就需要使用浏览器的页面审核工具了!我这里用的是火狐浏览器,按F12打开,然后点击网络,清除内容,刷新页面,看看加载了哪些数据。
经过简单的检查,我们发现了2个数据,收录
了我们想要的数据
一个是activity相关的信息,一个是image相关的信息,都是json格式加载的。这个很简单,通过请求就可以得到相关的URL。这时候突然想到,如果之前的多个活动页面也是动态加载的,那么是否可以通过这种方式捕获所有活动呢?来看看
这个json数据收录
了页面加载的所有活动信息!没有翻页。. . 难怪加载这么慢【手动申诉】。
代码
通过上面的分析,我们了解了目标数据的位置,接下来就可以开始尝试写代码了
导入requests库,然后直接请求真实的URL,得到名称和对应的URL(真实的URL在消息头中),然后在页面中构造真实的URL。上面得到的网址实际上是网页的网址,而不是网页的网址。如何获取json包所在的真实地址?我们对比一下获取到的几个页面的真实URL,不难发现其规律性。
通过对比发现activityNo的值其实是不一样的,而且这个值也存在于上面抓到的json包中!
构造下一个页面的真实请求地址,然后抓取json包获取所有图片url!至此,核心代码已经写好,完善一下,整体代码和效果如下:
不到1分钟,这个页面上的所有活动和活动图片的url都被保存了,整体代码不到20行,一个非常简单的网站!如果要下载图片,可以把所有的url复制到下载工具,批量下载!
后记
本网站整体结构较为清晰,数据易于获取。今天之所以用这个网站来分享,是因为当我开始抓包的时候,我简直不敢相信。一页之间加载了400多张图片。. . . 而且看页面结构,没想到这么简单!
总的来说,这个网站比较适合新手学习抓包和获取数据。希望对大家有帮助,加油! 查看全部
网页源代码抓取工具(一个网站抓站中遇到的奇特网站,分享思路和抓取方法)
在我们的学习过程中,我们想在打开网站的时候抓取一次数据,但并不是所有的网站都可以通过一种方式抓取数据。有的有特殊的网页结构,有的有不同的json数据包。慢慢写一些。与我在爬虫过程中遇到的奇葩网站分享爬虫的思路和方法!
工具、目标
工具:pycharm、python3.6 版本
库:请求库
目标:普世网热门图片直播页面,所有图片信息
注意:本网站有一个流行的图片页面,其中收录
活动的相关照片。所有图片信息根据事件写入txt文件(不下载图片,以免影响服务器)!
目标分析
首先,打开如上图所示的主页。不要担心其他人。只需单击右上角。选项出现后,点击进入热图直播选项(注意:部分浏览器需要放大页面才能看到热图直播选项),进入后页面是这样的
在这里,我已放大到 30%。下面是一页一页的活动现场图片。随便点击一个事件,让我们看一下页面
看到页面上的图片加载这么慢,应该是动态加载的,右键查看源码,果然如此!
没有任何图片信息,那我们就需要使用浏览器的页面审核工具了!我这里用的是火狐浏览器,按F12打开,然后点击网络,清除内容,刷新页面,看看加载了哪些数据。
经过简单的检查,我们发现了2个数据,收录
了我们想要的数据
一个是activity相关的信息,一个是image相关的信息,都是json格式加载的。这个很简单,通过请求就可以得到相关的URL。这时候突然想到,如果之前的多个活动页面也是动态加载的,那么是否可以通过这种方式捕获所有活动呢?来看看
这个json数据收录
了页面加载的所有活动信息!没有翻页。. . 难怪加载这么慢【手动申诉】。
代码
通过上面的分析,我们了解了目标数据的位置,接下来就可以开始尝试写代码了
导入requests库,然后直接请求真实的URL,得到名称和对应的URL(真实的URL在消息头中),然后在页面中构造真实的URL。上面得到的网址实际上是网页的网址,而不是网页的网址。如何获取json包所在的真实地址?我们对比一下获取到的几个页面的真实URL,不难发现其规律性。
通过对比发现activityNo的值其实是不一样的,而且这个值也存在于上面抓到的json包中!
构造下一个页面的真实请求地址,然后抓取json包获取所有图片url!至此,核心代码已经写好,完善一下,整体代码和效果如下:
不到1分钟,这个页面上的所有活动和活动图片的url都被保存了,整体代码不到20行,一个非常简单的网站!如果要下载图片,可以把所有的url复制到下载工具,批量下载!
后记
本网站整体结构较为清晰,数据易于获取。今天之所以用这个网站来分享,是因为当我开始抓包的时候,我简直不敢相信。一页之间加载了400多张图片。. . . 而且看页面结构,没想到这么简单!
总的来说,这个网站比较适合新手学习抓包和获取数据。希望对大家有帮助,加油!
网页源代码抓取工具( 目标网页用关键字在源代码中查找最终代码验证结果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-29 13:06
目标网页用关键字在源代码中查找最终代码验证结果)
概括
根据网站结构和数据类型制作头条视频爬虫,重点关注数据在网站上的位置和爬取方式
并介绍一个类似的网站,简单讲解一下数据抓取的方法
使用工具:python3.6 + pycharm + requests 库 + re 库
目标情况
这次我们的目标网站是Ajax加载的数据。首先打开网页后,直接使用浏览器自带的开发者工具(火狐),点击网页,然后将网页向下滑动,点击xhr,找到json数据,可以看到大约有100条内容
每个视频都有相关信息,我们只需要取出每个视频的url即可!然后去查看详情页
很容易就能找到视频的真实地址!复制地址,重新打开网页验证,确认地址正确,然后去源码查看地址是否存在
很明显,这个网站不是静态网站,数据应该是存放在一个js文件中的,那我们怎么获取呢~?我需要分析js文件还是使用selenium?别担心,我偶然发现了这个
有没有发现网页源代码中存在url中的关键字,虽然不完全一样,但是我们可以和上一个标签中的内容进行比较
可以确定,这里的值是网页渲染后出现在html标签中的值,在源码中有两个不同格式的视频地址!,很简单,我们来写代码吧!
代码
简单写,直接用requests请求内容,然后用re匹配,取出目标url
类似网站
其实还有一个网站和这种情况很相似,就是第二个视频,但是如果你想看更多的视频,还是需要打开客户端,所以我们就简单的以一个视频为例,抓取它。真实地址!具体过程就不一一讲解了,直接看结果,先看登陆页面
使用关键字在源代码中搜索
最终代码
验证结果
以上文章如有错误,请在留言区指出。如果这篇文章对你有用,请点赞转发。 查看全部
网页源代码抓取工具(
目标网页用关键字在源代码中查找最终代码验证结果)
概括
根据网站结构和数据类型制作头条视频爬虫,重点关注数据在网站上的位置和爬取方式
并介绍一个类似的网站,简单讲解一下数据抓取的方法
使用工具:python3.6 + pycharm + requests 库 + re 库
目标情况
这次我们的目标网站是Ajax加载的数据。首先打开网页后,直接使用浏览器自带的开发者工具(火狐),点击网页,然后将网页向下滑动,点击xhr,找到json数据,可以看到大约有100条内容
每个视频都有相关信息,我们只需要取出每个视频的url即可!然后去查看详情页
很容易就能找到视频的真实地址!复制地址,重新打开网页验证,确认地址正确,然后去源码查看地址是否存在
很明显,这个网站不是静态网站,数据应该是存放在一个js文件中的,那我们怎么获取呢~?我需要分析js文件还是使用selenium?别担心,我偶然发现了这个
有没有发现网页源代码中存在url中的关键字,虽然不完全一样,但是我们可以和上一个标签中的内容进行比较
可以确定,这里的值是网页渲染后出现在html标签中的值,在源码中有两个不同格式的视频地址!,很简单,我们来写代码吧!
代码
简单写,直接用requests请求内容,然后用re匹配,取出目标url
类似网站
其实还有一个网站和这种情况很相似,就是第二个视频,但是如果你想看更多的视频,还是需要打开客户端,所以我们就简单的以一个视频为例,抓取它。真实地址!具体过程就不一一讲解了,直接看结果,先看登陆页面
使用关键字在源代码中搜索
最终代码
验证结果
以上文章如有错误,请在留言区指出。如果这篇文章对你有用,请点赞转发。
网页源代码抓取工具(网页源代码抓取工具最主要的的源等工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-12-29 01:03
网页源代码抓取工具最主要的源代码抓取工具是urllib,shellhub等,网页源代码抓取工具可以抓取html5,css3,javascript等,但是对于一些前端爬虫而言,网页源代码抓取工具的爬取效率没有静态网页高,因为html5和css3会隐藏部分结构,有时候源代码抓取工具就不能解析出明显的结构,而无法达到预期的效果。
所以我们需要能从页面中提取出需要的部分结构。我们最常用的页面源代码抓取工具是selenium,虽然它也能抓取静态网页,但是它抓取html5页面会出现bug,需要用到dom类,dom类中隐藏了结构,所以需要用到equery或者是selenium2才能完全抓取html5页面,用equery就必须要用到javascript,至于如何给出javascript选择器,selenium是使用ajax对html5页面进行请求,所以要用到javascript,一般页面比较简单,使用selenium可以完全抓取html5页面。
然后随着爬虫工具越来越强大,效率越来越高,于是selenium,selenium2等工具大行其道,他们可以抓取javascript,也可以抓取css3,javascript就是一种内嵌式的结构,没有关闭动作,而css3有关闭动作,一般来说就会有缓存机制,爬虫工具只抓取内嵌的css3结构,然后结构提取出来然后渲染到页面上。
接下来介绍如何爬取阿里巴巴的图片。在阿里巴巴网站上有很多图片,经常遇到图片文件打不开的情况,而你在爬取其他网站图片的时候是打开了图片,这时候就说明你要用图片抓取工具抓取的那个图片有问题,这时候就需要提取出这个图片,把它爬下来就可以拿来作为源代码抓取工具爬取。这时我们可以使用selenium2来爬取图片。
步骤如下:1.获取阿里巴巴的图片链接2.打开提取出的图片地址如下:,我们把get_image.jpg(),login_url换成提取出来的链接。3.打开浏览器,一个个的尝试抓取。通过以上三步,我们就爬取到了这个图片地址,如下图:该图片其实就是html5标签中的link(“.html5”),因为在爬取其他网站图片的时候,只能看到一个或者数个link标签,只能提取出这个link,因为其他网站就没有html5标签,所以这个html5地址我们就可以拿来爬取了。
接下来我们给图片属性赋值,图片的属性都是一些固定的,例如:像这个jpg是gray,我们就给gray值赋值一个byte数组listgray即可。也可以给图片赋值另外一个数组的元素对象,这样就可以在这个list中随意取了。对图片的属性赋值很简单,我们只需要根据提取出来的属性名称赋值给图片即可。完整代码如下:[url](url),{url:'/',}。 查看全部
网页源代码抓取工具(网页源代码抓取工具最主要的的源等工具)
网页源代码抓取工具最主要的源代码抓取工具是urllib,shellhub等,网页源代码抓取工具可以抓取html5,css3,javascript等,但是对于一些前端爬虫而言,网页源代码抓取工具的爬取效率没有静态网页高,因为html5和css3会隐藏部分结构,有时候源代码抓取工具就不能解析出明显的结构,而无法达到预期的效果。
所以我们需要能从页面中提取出需要的部分结构。我们最常用的页面源代码抓取工具是selenium,虽然它也能抓取静态网页,但是它抓取html5页面会出现bug,需要用到dom类,dom类中隐藏了结构,所以需要用到equery或者是selenium2才能完全抓取html5页面,用equery就必须要用到javascript,至于如何给出javascript选择器,selenium是使用ajax对html5页面进行请求,所以要用到javascript,一般页面比较简单,使用selenium可以完全抓取html5页面。
然后随着爬虫工具越来越强大,效率越来越高,于是selenium,selenium2等工具大行其道,他们可以抓取javascript,也可以抓取css3,javascript就是一种内嵌式的结构,没有关闭动作,而css3有关闭动作,一般来说就会有缓存机制,爬虫工具只抓取内嵌的css3结构,然后结构提取出来然后渲染到页面上。
接下来介绍如何爬取阿里巴巴的图片。在阿里巴巴网站上有很多图片,经常遇到图片文件打不开的情况,而你在爬取其他网站图片的时候是打开了图片,这时候就说明你要用图片抓取工具抓取的那个图片有问题,这时候就需要提取出这个图片,把它爬下来就可以拿来作为源代码抓取工具爬取。这时我们可以使用selenium2来爬取图片。
步骤如下:1.获取阿里巴巴的图片链接2.打开提取出的图片地址如下:,我们把get_image.jpg(),login_url换成提取出来的链接。3.打开浏览器,一个个的尝试抓取。通过以上三步,我们就爬取到了这个图片地址,如下图:该图片其实就是html5标签中的link(“.html5”),因为在爬取其他网站图片的时候,只能看到一个或者数个link标签,只能提取出这个link,因为其他网站就没有html5标签,所以这个html5地址我们就可以拿来爬取了。
接下来我们给图片属性赋值,图片的属性都是一些固定的,例如:像这个jpg是gray,我们就给gray值赋值一个byte数组listgray即可。也可以给图片赋值另外一个数组的元素对象,这样就可以在这个list中随意取了。对图片的属性赋值很简单,我们只需要根据提取出来的属性名称赋值给图片即可。完整代码如下:[url](url),{url:'/',}。
网页源代码抓取工具(代码比较工具(Diffuse)的特色可视化比较,支持两相比较和三相比较)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-24 14:05
【总体介绍】
一个代码比较工具。
【基本介绍】
代码对比工具,小巧强大,支持windows和linxu两种工作环境!支持命令行提示和基于 GUI 的窗口工具包。在命令行下速度非常快,支持C++、Python、Java、XML等语言的语法高亮。
视觉比较非常直观,支持两相比较和三相比较。这意味着使用 Diffuse 您可以同时比较两个或三个文本文件。最吸引人的是他是开源的。我们不需要支付任何费用。您可以下载他们的在线帮助手册进行练习。Diffuse 默认带有中文界面。代码对比工具(Diffuse)的特色视觉对比非常直观。支持两相比较和三相比较。这意味着使用 Diffuse 您可以同时比较两个或三个文本文件。支持常见的版本控制工具,包括CVS、subversion、git、mercurial等,可以通过Diffuse直接从版本控制系统中获取源代码进行比较合并。支持 C++、Python、Java、XML 等语言中的语法高亮。能够在 Diffuse 中直接编辑文件。支持UTF-8编码。您可以使用快捷键轻松导航。
【软件功能】
1、快速跳转到两个文本的不同之处。使用视图菜单中的菜单项或快捷键CTRL+在所有差异之间快速切换。
2、被比较的两个文件窗口可以互换。如果您习惯于默认将原文放在左侧,您可以使用此功能快速切换是否颠倒。3、快速跳转到某一行。
4、 合并菜单中有很多左右复制的功能,在编辑代码的时候也能提高不少效率。 查看全部
网页源代码抓取工具(代码比较工具(Diffuse)的特色可视化比较,支持两相比较和三相比较)
【总体介绍】
一个代码比较工具。
【基本介绍】
代码对比工具,小巧强大,支持windows和linxu两种工作环境!支持命令行提示和基于 GUI 的窗口工具包。在命令行下速度非常快,支持C++、Python、Java、XML等语言的语法高亮。
视觉比较非常直观,支持两相比较和三相比较。这意味着使用 Diffuse 您可以同时比较两个或三个文本文件。最吸引人的是他是开源的。我们不需要支付任何费用。您可以下载他们的在线帮助手册进行练习。Diffuse 默认带有中文界面。代码对比工具(Diffuse)的特色视觉对比非常直观。支持两相比较和三相比较。这意味着使用 Diffuse 您可以同时比较两个或三个文本文件。支持常见的版本控制工具,包括CVS、subversion、git、mercurial等,可以通过Diffuse直接从版本控制系统中获取源代码进行比较合并。支持 C++、Python、Java、XML 等语言中的语法高亮。能够在 Diffuse 中直接编辑文件。支持UTF-8编码。您可以使用快捷键轻松导航。
【软件功能】
1、快速跳转到两个文本的不同之处。使用视图菜单中的菜单项或快捷键CTRL+在所有差异之间快速切换。
2、被比较的两个文件窗口可以互换。如果您习惯于默认将原文放在左侧,您可以使用此功能快速切换是否颠倒。3、快速跳转到某一行。
4、 合并菜单中有很多左右复制的功能,在编辑代码的时候也能提高不少效率。
网页源代码抓取工具(知乎话题『美女』下所有问题中回答所出现的图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2021-12-23 08:21
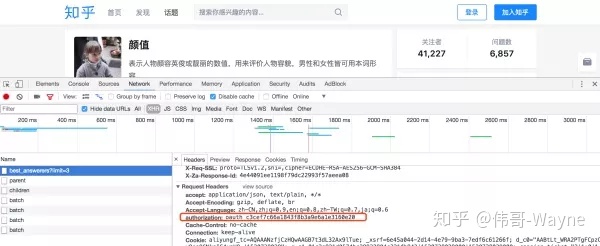
免责声明:所有直接或间接、明示或暗示的文字、图片及相关外部链接,涉及性别、颜值得分等信息均由相关人脸检测界面给出。没有任何客观性,仅供参考。
1 数据来源
知乎“美女”主题下所有问题的答案中出现的图片
2 履带
Python 3,并使用第三方库Requests、lxml、AipFace,共100+行代码
3 必要的环境
Mac / Linux / Windows(Linux没有测试过,理论上,Windows之前反应过异常,但检查后发现Windows限制了本地文件名中的字符并使用了常规过滤),无需登录知乎(即无需提供知乎账号密码),人脸检测服务需要百度云账号(即百度云盘/贴吧账号)
4 人脸检测库
百度云AI开放平台提供的AipFace是一个可以进行人脸检测的Python SDK。可以直接通过HTTP访问,免费使用
5 测试过滤条件
6 实现逻辑
7 抓取结果
直接存放在文件夹中(angelababy实力出国)。另外,目前拍摄的照片中,除了baby,88分是最高分。我个人反对排名,我老婆也不是最高分。
8码
这篇文章中的代码有一百行。针对微信公众号代码阅读体验不佳,小编已将源码保存。请到微信公众号后台回复关键词“知乎爬虫”获取。
微信后台入口
9 操作准备
{
"error": {
"message": "ZERR_NO_AUTH_TOKEN",
"code": 100,
"name": "AuthenticationInvalidRequest"
}
}
10 结论
❈ 查看全部
网页源代码抓取工具(知乎话题『美女』下所有问题中回答所出现的图片)
免责声明:所有直接或间接、明示或暗示的文字、图片及相关外部链接,涉及性别、颜值得分等信息均由相关人脸检测界面给出。没有任何客观性,仅供参考。
1 数据来源
知乎“美女”主题下所有问题的答案中出现的图片
2 履带
Python 3,并使用第三方库Requests、lxml、AipFace,共100+行代码
3 必要的环境
Mac / Linux / Windows(Linux没有测试过,理论上,Windows之前反应过异常,但检查后发现Windows限制了本地文件名中的字符并使用了常规过滤),无需登录知乎(即无需提供知乎账号密码),人脸检测服务需要百度云账号(即百度云盘/贴吧账号)
4 人脸检测库
百度云AI开放平台提供的AipFace是一个可以进行人脸检测的Python SDK。可以直接通过HTTP访问,免费使用
5 测试过滤条件
6 实现逻辑
7 抓取结果
直接存放在文件夹中(angelababy实力出国)。另外,目前拍摄的照片中,除了baby,88分是最高分。我个人反对排名,我老婆也不是最高分。

8码
这篇文章中的代码有一百行。针对微信公众号代码阅读体验不佳,小编已将源码保存。请到微信公众号后台回复关键词“知乎爬虫”获取。

微信后台入口
9 操作准备
{
"error": {
"message": "ZERR_NO_AUTH_TOKEN",
"code": 100,
"name": "AuthenticationInvalidRequest"
}
}
10 结论
❈
网页源代码抓取工具(如何应对数据匮乏的问题?最简单的方法在这里)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-12-23 08:20
作者 | 拉克夏阿罗拉
编译|弗林
来源|analyticsvidhya
概述介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!希望得到更多的数据来训练我们的机器学习模型是一直困扰着人们的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吗?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络爬行。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 采集数据。现在,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这是网页抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接学习 Python 以了解如何使用流行且高效的 BeautifulSoup 库进行网页抓取。
我们还为本文创建了一个免费课程:
请注意,网络抓取受许多准则和规则的约束。并不是每一个网站都允许用户抓取内容,所以有一定的法律限制。在尝试此操作之前,请确保您已阅读 网站 的 网站 条款和条件。
3 个流行的 Python 网络爬虫工具和库
网络爬虫组件
CrawlParse 和 TransformStore 从网页中抓取 URL 和电子邮件 ID。抓取图片。页面加载时抓取数据。3 个流行的 Python 网络爬虫工具和库。
您将在 Python 中遇到多个用于网页抓取的库和框架。以下是三种用于高效完成任务的流行工具:
美汤
刮痧
硒
网络爬虫组件
这是构成网络爬行的三个主要组件的极好说明:
让我们详细了解这些组件。我们将使用goibibo网站来抓取酒店的详细信息,比如酒店名称和每个房间的价格,以达到这个目的:
注意:请始终遵循目标网站的robots.txt文件,也称为robots排除协议。这可以告诉网络机器人不抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴编写我们的网络机器人脚本。开始吧!
第 1 步:爬网
网络爬虫的第一步是导航到目标网站并下载网页的源代码。我们将使用请求库来做到这一点。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页源代码后,我们需要过滤需要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换
网络抓取的下一步是将此数据解析为 HTML 解析器。为此,我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,就像大多数页面一样,特定酒店的详细信息位于不同的卡片上。
因此,下一步将是从完整的源代码中过滤卡片数据。接下来,我们将选择卡片,然后单击“检查元素”选项以获取该特定卡片的源代码。您将获得以下信息:
所有卡片的类名都是一样的。我们可以通过传递标签名称和属性(例如标签)来获取这些卡片的列表。名称如下:
# find all the sections with specifiedd class name
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,这里的每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在,对于每张卡,我们必须找到上面的酒店名称,这些名称只能来自
从标签中提取。这是因为每张卡和费率只有一个标签、标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)
第 3 步:Store(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后,我们最终将其添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络爬虫。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的类别和地址。现在,让我们看看如何在页面加载时执行一些常见任务,例如抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试使用网页抓取功能抓取的两个最常见的功能是 网站 URL 和电子邮件 ID。我相信你参与过一个需要大量电子邮件 ID 提取的项目或挑战。那么,让我们看看如何在 Python 中抓取这些内容。
使用网络浏览器的控制台 查看全部
网页源代码抓取工具(如何应对数据匮乏的问题?最简单的方法在这里)
作者 | 拉克夏阿罗拉
编译|弗林
来源|analyticsvidhya
概述介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!希望得到更多的数据来训练我们的机器学习模型是一直困扰着人们的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吗?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络爬行。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 采集数据。现在,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。

但有时您可能需要从不提供特定 API 的 网站 采集数据。这是网页抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接学习 Python 以了解如何使用流行且高效的 BeautifulSoup 库进行网页抓取。
我们还为本文创建了一个免费课程:
请注意,网络抓取受许多准则和规则的约束。并不是每一个网站都允许用户抓取内容,所以有一定的法律限制。在尝试此操作之前,请确保您已阅读 网站 的 网站 条款和条件。
3 个流行的 Python 网络爬虫工具和库
网络爬虫组件
CrawlParse 和 TransformStore 从网页中抓取 URL 和电子邮件 ID。抓取图片。页面加载时抓取数据。3 个流行的 Python 网络爬虫工具和库。
您将在 Python 中遇到多个用于网页抓取的库和框架。以下是三种用于高效完成任务的流行工具:
美汤
刮痧
硒
网络爬虫组件
这是构成网络爬行的三个主要组件的极好说明:

让我们详细了解这些组件。我们将使用goibibo网站来抓取酒店的详细信息,比如酒店名称和每个房间的价格,以达到这个目的:

注意:请始终遵循目标网站的robots.txt文件,也称为robots排除协议。这可以告诉网络机器人不抓取哪些页面。

因此,我们可以从目标 URL 中抓取数据。我们很高兴编写我们的网络机器人脚本。开始吧!
第 1 步:爬网
网络爬虫的第一步是导航到目标网站并下载网页的源代码。我们将使用请求库来做到这一点。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页源代码后,我们需要过滤需要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换
网络抓取的下一步是将此数据解析为 HTML 解析器。为此,我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,就像大多数页面一样,特定酒店的详细信息位于不同的卡片上。
因此,下一步将是从完整的源代码中过滤卡片数据。接下来,我们将选择卡片,然后单击“检查元素”选项以获取该特定卡片的源代码。您将获得以下信息:

所有卡片的类名都是一样的。我们可以通过传递标签名称和属性(例如标签)来获取这些卡片的列表。名称如下:
# find all the sections with specifiedd class name
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)

我们从网页的完整源代码中过滤掉了卡片数据,这里的每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:

现在,对于每张卡,我们必须找到上面的酒店名称,这些名称只能来自
从标签中提取。这是因为每张卡和费率只有一个标签、标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)

第 3 步:Store(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后,我们最终将其添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)

恭喜!我们已经成功创建了一个基本的网络爬虫。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的类别和地址。现在,让我们看看如何在页面加载时执行一些常见任务,例如抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试使用网页抓取功能抓取的两个最常见的功能是 网站 URL 和电子邮件 ID。我相信你参与过一个需要大量电子邮件 ID 提取的项目或挑战。那么,让我们看看如何在 Python 中抓取这些内容。
使用网络浏览器的控制台
网页源代码抓取工具(WebSpider蓝蜘蛛网页抓取工具5.1可以抓取、MySQL、适用范围)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-21 06:11
WebSpider 蓝蜘蛛爬网工具5.1 可以爬取互联网上的任何网页,wap网站,包括登录后才能访问的页面。分析爬取的页面内容,获取结构化信息,如如新闻标题、作者、来源、正文等。支持列表页自动翻页抓取、文本页多页合并、图片和文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。
用户指定要爬取的网站、要爬取的网页类型(固定页面、分页展示页面等),并配置如何解析数据项(如新闻标题、作者、来源、 body等),系统可以根据配置信息自动实时采集数据,也可以通过配置设置开始采集的时间,真正做到“按需采集,一个配置,和永久捕获”。捕获的数据可以保存在数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等。
该工具可以完全取代传统的编辑人工信息处理模式。能够实时、准确、24*60全天为企业提供最新的信息和情报,真正为企业降低成本,提高竞争力。
该工具的主要特点如下:
*适用范围广,可以抓取任何网页(包括登录后可以访问的网页)
*处理速度快。网络畅通,1小时可抓取解析10000个网页
*采用独特的重复数据过滤技术,支持增量数据采集,可实时采集数据,如:股票交易信息、天气预报等。
*抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性
*支持断点连续抓取。发生崩溃或异常情况后,可恢复抓取,继续后续抓取工作,提高系统抓取效率
*对于列表页,支持翻页,可以读取所有列表页中的数据。对于body页面,可以自动合并页面显示的内容;
*支持页面深度爬取,可在页面之间逐层爬取。比如通过列表页面抓取body页面的URL,然后再抓取body页面。各级页面可单独存放;
*WEB操作界面,一站式安装,随处使用
*分步分析,分步存储
* 配置一次,永久抓取,一劳永逸 查看全部
网页源代码抓取工具(WebSpider蓝蜘蛛网页抓取工具5.1可以抓取、MySQL、适用范围)
WebSpider 蓝蜘蛛爬网工具5.1 可以爬取互联网上的任何网页,wap网站,包括登录后才能访问的页面。分析爬取的页面内容,获取结构化信息,如如新闻标题、作者、来源、正文等。支持列表页自动翻页抓取、文本页多页合并、图片和文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。
用户指定要爬取的网站、要爬取的网页类型(固定页面、分页展示页面等),并配置如何解析数据项(如新闻标题、作者、来源、 body等),系统可以根据配置信息自动实时采集数据,也可以通过配置设置开始采集的时间,真正做到“按需采集,一个配置,和永久捕获”。捕获的数据可以保存在数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等。
该工具可以完全取代传统的编辑人工信息处理模式。能够实时、准确、24*60全天为企业提供最新的信息和情报,真正为企业降低成本,提高竞争力。
该工具的主要特点如下:
*适用范围广,可以抓取任何网页(包括登录后可以访问的网页)
*处理速度快。网络畅通,1小时可抓取解析10000个网页
*采用独特的重复数据过滤技术,支持增量数据采集,可实时采集数据,如:股票交易信息、天气预报等。
*抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性
*支持断点连续抓取。发生崩溃或异常情况后,可恢复抓取,继续后续抓取工作,提高系统抓取效率
*对于列表页,支持翻页,可以读取所有列表页中的数据。对于body页面,可以自动合并页面显示的内容;
*支持页面深度爬取,可在页面之间逐层爬取。比如通过列表页面抓取body页面的URL,然后再抓取body页面。各级页面可单独存放;
*WEB操作界面,一站式安装,随处使用
*分步分析,分步存储
* 配置一次,永久抓取,一劳永逸
网页源代码抓取工具(网站数据采集工具哪个好用?的爬虫软件可以直接使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-12-20 20:05
网站数据采集 哪个工具好用?
网站数据采集,现成的爬虫软件有很多可以直接使用,下面我就简单介绍三个,分别是优采云、章鱼和优采云,操作简单,易学明白了,有兴趣的朋友可以试试:
这是一款非常智能的网络爬虫软件,支持跨平台,个人使用非常方便,完全免费。对于大多数网站,只需输入URL,软件会自动识别并提取相关字段信息,包括列表、表格、链接、图片等,无需配置任何采集规则,一个-click采用,支持自动翻页和数据导出功能,对于小白来说,非常方便,易学易掌握:这是一款非常好的对比优采云采集器,八达通< @采集器目前只支持windows平台,需要手动设置采集字段和配置规则,所以比较复杂灵活。内置海量数据采集模板,方便采集京东,天猫等热门网站。官方教程很详细,小白很容易掌握:
当然,除了以上三个爬虫软件,它还有很多功能,很多其他软件也支持网站data采集,比如做号,申请保单等等。如果您熟悉 Python、Java 和其他编程语言,您还可以编写抓取数据的程序。网上也有相关的教程和资料,讲的很详细。如果你有兴趣,你可以搜索它们。希望以上分享的内容对您有所帮助,也欢迎大家留言补充。
有没有可以批量解析下载视频的软件?自动抓取网络视频的那种?
一般来说,不同的视频平台有不同的数据处理算法,只有经过一次分析才能实现批量处理。
代码软件代码编程下载网站源代码 查看全部
网页源代码抓取工具(网站数据采集工具哪个好用?的爬虫软件可以直接使用)
网站数据采集 哪个工具好用?
网站数据采集,现成的爬虫软件有很多可以直接使用,下面我就简单介绍三个,分别是优采云、章鱼和优采云,操作简单,易学明白了,有兴趣的朋友可以试试:
这是一款非常智能的网络爬虫软件,支持跨平台,个人使用非常方便,完全免费。对于大多数网站,只需输入URL,软件会自动识别并提取相关字段信息,包括列表、表格、链接、图片等,无需配置任何采集规则,一个-click采用,支持自动翻页和数据导出功能,对于小白来说,非常方便,易学易掌握:这是一款非常好的对比优采云采集器,八达通< @采集器目前只支持windows平台,需要手动设置采集字段和配置规则,所以比较复杂灵活。内置海量数据采集模板,方便采集京东,天猫等热门网站。官方教程很详细,小白很容易掌握:
当然,除了以上三个爬虫软件,它还有很多功能,很多其他软件也支持网站data采集,比如做号,申请保单等等。如果您熟悉 Python、Java 和其他编程语言,您还可以编写抓取数据的程序。网上也有相关的教程和资料,讲的很详细。如果你有兴趣,你可以搜索它们。希望以上分享的内容对您有所帮助,也欢迎大家留言补充。
有没有可以批量解析下载视频的软件?自动抓取网络视频的那种?
一般来说,不同的视频平台有不同的数据处理算法,只有经过一次分析才能实现批量处理。
代码软件代码编程下载网站源代码
网页源代码抓取工具(Python用做数据处理还是相当不错的,你知道吗?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-12-20 13:10
Python非常适合数据处理。如果你想做爬虫,Python 是个不错的选择。它有许多已编写的包。只需调用它们就可以完成许多复杂的功能。本文所有功能均基于 BeautifulSoup 包。
1 Pyhton获取网页内容(即源码)
page = urllib2.urlopen(url)
contents = page.read()
#获得了整个网页的内容也就是源代码
print(contents)
url代表网址,contents代表网址对应的源码,urllib2是需要用到的包,上面三句代码就可以得到网页的整个源码
2 获取网页中想要的内容(先获取网页的源代码,然后分析网页的源代码,找到对应的标签,然后提取标签中的内容)
2.1 以豆瓣电影排名为例
网址是,输入网址后会出现下图
现在我需要获取当前页面上所有电影的名称、评分、评论数量、链接
从上图中,红色圆圈是我想要获取的内容,蓝色横线是对应的标签,这样分析就完成了,现在就是写代码来实现,Python提供了很多获取想要的方法内容,这里我使用BeautifulSoup来实现,很简单
#coding:utf-8
'''
Created on 2016��5��17��
@author: jsjxy
'''
import urllib2
import re
from bs4 import BeautifulSoup
from distutils.filelist import findall
page = urllib2.urlopen('http://movie.douban.com/top250?format=text')
contents = page.read()
#print(contents)
soup = BeautifulSoup(contents,"html.parser")
print("豆瓣电影TOP250" + "\n" +" 影片名 评分 评价人数 链接 ")
for tag in soup.find_all('div', class_='info'):
# print tag
m_name = tag.find('span', class_='title').get_text()
m_rating_score = float(tag.find('span',class_='rating_num').get_text())
m_people = tag.find('div',class_="star")
m_span = m_people.findAll('span')
m_peoplecount = m_span[3].contents[0]
m_url=tag.find('a').get('href')
print( m_name+" " + str(m_rating_score) + " " + m_peoplecount + " " + m_url )
控制台输出,也可以写入文件
前三行代码获取整个网页的源码,然后开始使用BeautifulSoup进行标签分析。find_all 方法就是找到这个标签的所有内容,然后在这个标签中继续搜索。如果标签有特殊的属性声明,可以一步找到出来,如果没有特殊的属性声明,像这张图中求值人数前面的标签,就只有一个'span',那么找到所有span标签,依次选择对应的标签。在这张图中,它是第三个,所以这个方法可以找到特定行或列的内容。代码比较简单,易于实现。如有不对的地方请大家指出,共同学习。
源代码地址: 查看全部
网页源代码抓取工具(Python用做数据处理还是相当不错的,你知道吗?(上))
Python非常适合数据处理。如果你想做爬虫,Python 是个不错的选择。它有许多已编写的包。只需调用它们就可以完成许多复杂的功能。本文所有功能均基于 BeautifulSoup 包。
1 Pyhton获取网页内容(即源码)
page = urllib2.urlopen(url)
contents = page.read()
#获得了整个网页的内容也就是源代码
print(contents)
url代表网址,contents代表网址对应的源码,urllib2是需要用到的包,上面三句代码就可以得到网页的整个源码
2 获取网页中想要的内容(先获取网页的源代码,然后分析网页的源代码,找到对应的标签,然后提取标签中的内容)
2.1 以豆瓣电影排名为例
网址是,输入网址后会出现下图
现在我需要获取当前页面上所有电影的名称、评分、评论数量、链接

从上图中,红色圆圈是我想要获取的内容,蓝色横线是对应的标签,这样分析就完成了,现在就是写代码来实现,Python提供了很多获取想要的方法内容,这里我使用BeautifulSoup来实现,很简单
#coding:utf-8
'''
Created on 2016��5��17��
@author: jsjxy
'''
import urllib2
import re
from bs4 import BeautifulSoup
from distutils.filelist import findall
page = urllib2.urlopen('http://movie.douban.com/top250?format=text')
contents = page.read()
#print(contents)
soup = BeautifulSoup(contents,"html.parser")
print("豆瓣电影TOP250" + "\n" +" 影片名 评分 评价人数 链接 ")
for tag in soup.find_all('div', class_='info'):
# print tag
m_name = tag.find('span', class_='title').get_text()
m_rating_score = float(tag.find('span',class_='rating_num').get_text())
m_people = tag.find('div',class_="star")
m_span = m_people.findAll('span')
m_peoplecount = m_span[3].contents[0]
m_url=tag.find('a').get('href')
print( m_name+" " + str(m_rating_score) + " " + m_peoplecount + " " + m_url )
控制台输出,也可以写入文件

前三行代码获取整个网页的源码,然后开始使用BeautifulSoup进行标签分析。find_all 方法就是找到这个标签的所有内容,然后在这个标签中继续搜索。如果标签有特殊的属性声明,可以一步找到出来,如果没有特殊的属性声明,像这张图中求值人数前面的标签,就只有一个'span',那么找到所有span标签,依次选择对应的标签。在这张图中,它是第三个,所以这个方法可以找到特定行或列的内容。代码比较简单,易于实现。如有不对的地方请大家指出,共同学习。
源代码地址:
网页源代码抓取工具(豆瓣电影排行榜基础教程:请求载体的身份标识(用啥发送的请求) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-18 19:07
)
请求:
请求行 -> 请求方式(get/post) 请求url地址 协议
请求头 -> 放一些服务器要使用的附加信息
请求体 -> 一般放一些请求参数
回复:
状态行 -> 协议 状态码
响应头 -> 放一些客户端要使用的附加信息
响应体 -> 服务器返回的真正客户端要用的内容(HTML, json)等
需要额外注意请求头和响应头,它们一般隐藏了一些重要的内容
请求头中常用的一些重要内容:
1. User-Agent:请求载体的身份(请求由什么发送)
2. Referer: Anti-hotlinking(这个请求来自哪个页面?会用于反爬)
3. cookie:本地字符串数据信息(用户登录信息、反爬取令牌)
响应头中常用的一些重要内容:
1. cookie:本地字符串数据信息(用户登录信息、反爬取令牌)
2. 各种奇怪的字符串(根据经验判断,一般都是防止各种攻击和反爬的令牌)
请求方法:(在爬虫中不重要)
GET:显示提交
2. POST:隐式提交
开始使用请求:
安装:
pip install requests
案例一:获取搜狗搜索结果
import requests
url = 'https://www.sogou.com/web?query=周杰伦'
#所有地址栏里的请求方式一定为get
#需要修改User-Agent避免拦截
dic = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36'
}
resp = requests.get(url, headers=dic)
print(resp) #响应状态码
print(resp.text) #页面源代码
resp.close()
案例二:获取百度翻译结果
import requests
url = 'https://fanyi.baidu.com/sug'
s = input('请输入要翻译的英文单词:')
#post方式
dat = {
'kw':s
}
# 发送post请求,发送的数据必须放在字典中,通过data参数进行传递
resp = requests.post(url, data=dat)
#print(resp.text) #返回乱码
print(resp.json()) # 将服务器返回的内容直接处理成json() => dict
resp.close()
案例三:获取豆瓣分类电影排名
import requests
# 原url:?type=5&interval_id=100%3A90&action=&start=0&limit=20 太复杂,重新封装参数
url = 'https://movie.douban.com/j/chart/top_list'
# 重新封装参数
param = {
'type': '5',
'interval_id': '100:90',
'action': '',
'start': '0',
'limit': '20'
}
# User-Agent
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36'
}
resp = requests.get(url=url, params=param, headers=headers)
print(resp.json())
resp.close() 查看全部
网页源代码抓取工具(豆瓣电影排行榜基础教程:请求载体的身份标识(用啥发送的请求)
)
请求:
请求行 -> 请求方式(get/post) 请求url地址 协议
请求头 -> 放一些服务器要使用的附加信息
请求体 -> 一般放一些请求参数
回复:
状态行 -> 协议 状态码
响应头 -> 放一些客户端要使用的附加信息
响应体 -> 服务器返回的真正客户端要用的内容(HTML, json)等
需要额外注意请求头和响应头,它们一般隐藏了一些重要的内容
请求头中常用的一些重要内容:
1. User-Agent:请求载体的身份(请求由什么发送)
2. Referer: Anti-hotlinking(这个请求来自哪个页面?会用于反爬)
3. cookie:本地字符串数据信息(用户登录信息、反爬取令牌)
响应头中常用的一些重要内容:
1. cookie:本地字符串数据信息(用户登录信息、反爬取令牌)
2. 各种奇怪的字符串(根据经验判断,一般都是防止各种攻击和反爬的令牌)
请求方法:(在爬虫中不重要)
GET:显示提交
2. POST:隐式提交
开始使用请求:
安装:
pip install requests
案例一:获取搜狗搜索结果
import requests
url = 'https://www.sogou.com/web?query=周杰伦'
#所有地址栏里的请求方式一定为get
#需要修改User-Agent避免拦截
dic = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36'
}
resp = requests.get(url, headers=dic)
print(resp) #响应状态码
print(resp.text) #页面源代码
resp.close()
案例二:获取百度翻译结果
import requests
url = 'https://fanyi.baidu.com/sug'
s = input('请输入要翻译的英文单词:')
#post方式
dat = {
'kw':s
}
# 发送post请求,发送的数据必须放在字典中,通过data参数进行传递
resp = requests.post(url, data=dat)
#print(resp.text) #返回乱码
print(resp.json()) # 将服务器返回的内容直接处理成json() => dict
resp.close()
案例三:获取豆瓣分类电影排名
import requests
# 原url:?type=5&interval_id=100%3A90&action=&start=0&limit=20 太复杂,重新封装参数
url = 'https://movie.douban.com/j/chart/top_list'
# 重新封装参数
param = {
'type': '5',
'interval_id': '100:90',
'action': '',
'start': '0',
'limit': '20'
}
# User-Agent
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36'
}
resp = requests.get(url=url, params=param, headers=headers)
print(resp.json())
resp.close()
网页源代码抓取工具(站长工具源码v2.0PHP版.rar站长功能简介)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-12-18 08:01
站长工具源码v2.0 PHP版.rar
站长工具功能介绍1、JS加密/解密(对js形式的代码进行加密或解密。)2、UTF-8编码转换工具(UTF-8编码转换。)< @3、 Unicode 编码转换工具(Unicode 编码转换。)4、友情链接(该工具可用于批量查询百度收录、百度中指定网站的友情链接快照、PR、对方是否链接本站可以检测欺诈链接。) 5、META信息检测(该工具可以快速检测网页的META标签,分析是否有标题、关键词、描述、等有利于搜索引擎收录。)6、MD5加密工具(用MD5加密字符串。) 7、sfz数值查询(查询sfz位置,性别和出生日期。)8、HTML/UBB 代码转换工具(HTML/UBB 代码转换。)9、HTML/JS 相互转换工具(HTML/JS 相互转换。) 10. 搜索蜘蛛,机器人模拟工具(该工具可以快速模拟搜索引擎蜘蛛访问页面的内容信息!) 11、关键词 密度检测(该工具可以快速检测页面的数量和密度关键词 出现,更适合蜘蛛搜索。) 12、 国家域名查看(查看所有国家的域名。) 1.) 30、Unix时间戳转换工具(什么是Unix时间戳):Unix时间戳,或Unix时间,POSIX时间,是一种时间表示,定义为从00:00:00开始的总秒数从格林威治标准时间 1970 年 1 月 1 日到现在。Unix 时间戳不仅在 Unix 系统和类 Unix 系统中使用,而且在许多其他操作系统中也被采用。)
现在下载 查看全部
网页源代码抓取工具(站长工具源码v2.0PHP版.rar站长功能简介)
站长工具源码v2.0 PHP版.rar
站长工具功能介绍1、JS加密/解密(对js形式的代码进行加密或解密。)2、UTF-8编码转换工具(UTF-8编码转换。)< @3、 Unicode 编码转换工具(Unicode 编码转换。)4、友情链接(该工具可用于批量查询百度收录、百度中指定网站的友情链接快照、PR、对方是否链接本站可以检测欺诈链接。) 5、META信息检测(该工具可以快速检测网页的META标签,分析是否有标题、关键词、描述、等有利于搜索引擎收录。)6、MD5加密工具(用MD5加密字符串。) 7、sfz数值查询(查询sfz位置,性别和出生日期。)8、HTML/UBB 代码转换工具(HTML/UBB 代码转换。)9、HTML/JS 相互转换工具(HTML/JS 相互转换。) 10. 搜索蜘蛛,机器人模拟工具(该工具可以快速模拟搜索引擎蜘蛛访问页面的内容信息!) 11、关键词 密度检测(该工具可以快速检测页面的数量和密度关键词 出现,更适合蜘蛛搜索。) 12、 国家域名查看(查看所有国家的域名。) 1.) 30、Unix时间戳转换工具(什么是Unix时间戳):Unix时间戳,或Unix时间,POSIX时间,是一种时间表示,定义为从00:00:00开始的总秒数从格林威治标准时间 1970 年 1 月 1 日到现在。Unix 时间戳不仅在 Unix 系统和类 Unix 系统中使用,而且在许多其他操作系统中也被采用。)
现在下载
网页源代码抓取工具( 免费获取bShare代码bSharePlus代码bSharebSharePlus分享方式(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-18 04:01
免费获取bShare代码bSharePlus代码bSharebSharePlus分享方式(组图))
bShare 拥有多种自定义按钮,让您可以根据需要自定义您想要的模式,给您最大的设计空间。同时bShare代码最轻,采用异步加载的概念,不会对网站本身的加载产生任何影响。强大的一键通话功能,一键分享至20个主流社交平台,大大节省您的账号管理时间。另外,在数据统计方面,可以清晰的看到点击、分享、回流、转化的详细数据,清晰洞察分享的每一个细节。
免费获取 bShare 代码
为了避免分享时网页重定向对网友的影响,bShare Plus特意采用了OAuth技术,让分享操作的整个过程都可以在当前页面完成。有效防止网民因跳转页面的吸引力而流失,还增加了人性化功能,分享完成后自动提示关注您的微博账号,进一步增加了用户在微博中的关注度,从而有效提升了关注度。用户对微博平台的影响。
免费获取 bShare Plus 代码
bSharebShare Plus
分享方式
除了一键点击,都是通过打开一个新的浏览器页面,用户跳转到目标平台的分享页面进行分享。
对于具有开放 API 的平台(例如 Oauth),共享是通过 API 调用完成的。以 Oauth 为例。首次分享时,用户需要打开平台页面进行连接。但是以后共享将不再需要连接,即不会离开当前页面。
分享图片
部分平台(如新浪微博、QQ空间、好友等)在分享时会抓取当前页面图片供用户选择,但这些都是平台本身的处理,bShare无法控制平台抓取的方式。
对于支持Open API图片分享的平台(如新浪微博、QQ空间、腾讯微博等),bShare会抓取页面中收录的主要图片,用户在当前页面。
分享后关注
分享后支持新浪微博关注功能。
对于微博平台,您可以设置分享后的关注功能。
统计数据
bShare统计用户点击分享的次数,跳转到平台分享页面,但bShare无法统计用户是否分享成功,所以分享次数会比实际次数多。
对于Open API的分享,bShare可以准确统计分享成功的次数。
分享优化功能设置
支持修改APP KEY、添加@和话题、分享模板、各种回流设置和数据分析等。
支持修改APP KEY、添加@和话题、分享模板、各种回流设置和数据分析等。
平台支持
不支持只能通过 Open API 共享的平台,例如 Wordpress。
支持所有平台。
获取 bShare!获取 bShare Plus! 查看全部
网页源代码抓取工具(
免费获取bShare代码bSharePlus代码bSharebSharePlus分享方式(组图))

bShare 拥有多种自定义按钮,让您可以根据需要自定义您想要的模式,给您最大的设计空间。同时bShare代码最轻,采用异步加载的概念,不会对网站本身的加载产生任何影响。强大的一键通话功能,一键分享至20个主流社交平台,大大节省您的账号管理时间。另外,在数据统计方面,可以清晰的看到点击、分享、回流、转化的详细数据,清晰洞察分享的每一个细节。
免费获取 bShare 代码

为了避免分享时网页重定向对网友的影响,bShare Plus特意采用了OAuth技术,让分享操作的整个过程都可以在当前页面完成。有效防止网民因跳转页面的吸引力而流失,还增加了人性化功能,分享完成后自动提示关注您的微博账号,进一步增加了用户在微博中的关注度,从而有效提升了关注度。用户对微博平台的影响。
免费获取 bShare Plus 代码

bSharebShare Plus
分享方式
除了一键点击,都是通过打开一个新的浏览器页面,用户跳转到目标平台的分享页面进行分享。
对于具有开放 API 的平台(例如 Oauth),共享是通过 API 调用完成的。以 Oauth 为例。首次分享时,用户需要打开平台页面进行连接。但是以后共享将不再需要连接,即不会离开当前页面。
分享图片
部分平台(如新浪微博、QQ空间、好友等)在分享时会抓取当前页面图片供用户选择,但这些都是平台本身的处理,bShare无法控制平台抓取的方式。
对于支持Open API图片分享的平台(如新浪微博、QQ空间、腾讯微博等),bShare会抓取页面中收录的主要图片,用户在当前页面。
分享后关注
分享后支持新浪微博关注功能。
对于微博平台,您可以设置分享后的关注功能。
统计数据
bShare统计用户点击分享的次数,跳转到平台分享页面,但bShare无法统计用户是否分享成功,所以分享次数会比实际次数多。
对于Open API的分享,bShare可以准确统计分享成功的次数。
分享优化功能设置
支持修改APP KEY、添加@和话题、分享模板、各种回流设置和数据分析等。
支持修改APP KEY、添加@和话题、分享模板、各种回流设置和数据分析等。
平台支持
不支持只能通过 Open API 共享的平台,例如 Wordpress。
支持所有平台。
获取 bShare!获取 bShare Plus!
网页源代码抓取工具(网页邮箱地址采集工具逗号分隔效率效率分隔分隔)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-12-18 02:02
网页邮箱地址采集工具是一款绿色免费便携软件,可以从网页中提取邮箱地址。例如,可以检索常见的 贴吧 电子邮件页面。
邮箱地址采集 工具功能:
输入采集的URL并点击执行按钮,支持逗号和分号分隔邮件地址,支持采集完成邮件发送提醒。
<IMG border=0 src="/uploadfiles/2014-12-11/20141211_163555_976.png">
使用说明:
1.在地址栏输入邮箱地址,点击“提取”
优点:提取多个唯一邮箱只需要一个URL
如何使用“多任务处理”:
1.检查多任务处理
2.在地址栏输入邮箱地址,点击“提取”,再次输入不同的网址,再次点击“提取”,像一些循环
优点:多次检索邮箱,保存一次
如何使用“提取邮箱”选项:
1. 在文本框中输入带有邮箱的网页源代码或邮箱的文本片段与其他文本混合,点击“执行”
优点:快速提取邮箱中的杂乱文字,网页源码等杂乱文字,其他文章等。
如何使用“组”和“逗号”选项:
1. 提取邮箱后,点击分组,设置每个分组的邮箱数量,然后根据需要添加逗号,点击“执行”
优点:根据需要对大量邮箱进行分组,并添加逗号,可用于批量/捆绑单显示同时发送给多个收件人。
如何使用“正常”选项”:
提取邮箱后,当您想在提取的邮箱中添加备注时,选择“普通”,添加备注内容,选择“将结果发送到邮箱”,然后单击“执行”,即可将添加了带有处理过的邮箱的注释发送到邮箱
解决这个问题:
1. 手动从网页中提取多个邮箱,速度太慢
2.重复邮箱太多,手动一一删除耗时太长
3. 群发/捆绑单发时,必须手动一一输入收信人邮箱,用逗号隔开,效率太低
4. 经常不在同一台电脑上,想开发客户端,没有数据和工具,数据不方便保存 查看全部
网页源代码抓取工具(网页邮箱地址采集工具逗号分隔效率效率分隔分隔)
网页邮箱地址采集工具是一款绿色免费便携软件,可以从网页中提取邮箱地址。例如,可以检索常见的 贴吧 电子邮件页面。
邮箱地址采集 工具功能:
输入采集的URL并点击执行按钮,支持逗号和分号分隔邮件地址,支持采集完成邮件发送提醒。
<IMG border=0 src="/uploadfiles/2014-12-11/20141211_163555_976.png">
使用说明:
1.在地址栏输入邮箱地址,点击“提取”
优点:提取多个唯一邮箱只需要一个URL
如何使用“多任务处理”:
1.检查多任务处理
2.在地址栏输入邮箱地址,点击“提取”,再次输入不同的网址,再次点击“提取”,像一些循环
优点:多次检索邮箱,保存一次
如何使用“提取邮箱”选项:
1. 在文本框中输入带有邮箱的网页源代码或邮箱的文本片段与其他文本混合,点击“执行”
优点:快速提取邮箱中的杂乱文字,网页源码等杂乱文字,其他文章等。
如何使用“组”和“逗号”选项:
1. 提取邮箱后,点击分组,设置每个分组的邮箱数量,然后根据需要添加逗号,点击“执行”
优点:根据需要对大量邮箱进行分组,并添加逗号,可用于批量/捆绑单显示同时发送给多个收件人。
如何使用“正常”选项”:
提取邮箱后,当您想在提取的邮箱中添加备注时,选择“普通”,添加备注内容,选择“将结果发送到邮箱”,然后单击“执行”,即可将添加了带有处理过的邮箱的注释发送到邮箱
解决这个问题:
1. 手动从网页中提取多个邮箱,速度太慢
2.重复邮箱太多,手动一一删除耗时太长
3. 群发/捆绑单发时,必须手动一一输入收信人邮箱,用逗号隔开,效率太低
4. 经常不在同一台电脑上,想开发客户端,没有数据和工具,数据不方便保存
网页源代码抓取工具(“百度蜘蛛模拟抓取工具”这款工具支持多个搜索引擎)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-18 02:01
类别:网站管理员工具/插件(专业测试)
资源大小:140KB
资源格式:EXE
存储方式:百度云
点击下载
注:本站提供的资源均为优质资源。均由站长本人或原创的资源测试并提供。确保资源的完整性、可用性和实用性!此外,所有资源均附有相关视频教程或指导文件,欢迎下载!
今天和大家分享的是一款“百度蜘蛛模拟爬虫工具”。本工具支持多种搜索引擎的模拟爬取,如:百度搜索引擎、360搜索引擎、搜狗搜索引擎等。本工具可以模拟爬取网页的风格和爬取源代码,作为SEO工作者,这款软件对我们很有帮助,让我们专注于这一点。
蜘蛛模拟爬虫有哪些功能?
1. 有没有被欺骗的链接?
我们在换友情链接的时候,正常看网页代码,但其实有些人会用劫持技术阻止百度看到这种友情链接,我们就会被骗,所以这个一定要注意,所以以免被链接白费。
2. 网站 被劫持了吗?
如果我们的网站被黑了,很容易被黑客劫持。我们正常看源码是没有问题的,但是百度抓取源码可能有问题,所以如果你的网站排名持续下降,你还是找不到问题,你需要用这个软件排查,有的黑客很聪明,他们不会占用你的百度排名,他们会去你的360,搜狗,因为百度的站长工具可以查,但是一般人在360、搜狗很少去查,所以有些人网站360很容易被K,部分是因为这个操作造成的。
3.检查网站蜘蛛爬行是否正常!
第三点是检查自己的页面。一些功能站点js太多,百度抓取的页面,可能不完整,或者我们用源码测试一下,看看百度可以抓取哪些部分,可以用这个软件测试。非常方便。这个软件可以说是seor必备的软件之一!
如何使用蜘蛛模拟爬虫!
1.下载软件并打开软件
2.输入你的网址,选择引擎,点击模拟爬取
3、点击查看源码,可以看到蜘蛛爬取的源码。
这个软件使用起来非常简单,但是非常好用。用于检查页面是否被黑,是否被骗,网页中是否有百度抓不到的内容,还可以调度360搜索引擎和搜狗搜索。引擎、必应搜索引擎等等!而且我们可以用这个软件来测试,比如我们开发的源代码,用这个软件测试爬取率,是否有问题等等,好的,今天就给大家讲解一下,希望这个软件帮助大家。 查看全部
网页源代码抓取工具(“百度蜘蛛模拟抓取工具”这款工具支持多个搜索引擎)
类别:网站管理员工具/插件(专业测试)
资源大小:140KB
资源格式:EXE
存储方式:百度云
点击下载
注:本站提供的资源均为优质资源。均由站长本人或原创的资源测试并提供。确保资源的完整性、可用性和实用性!此外,所有资源均附有相关视频教程或指导文件,欢迎下载!
今天和大家分享的是一款“百度蜘蛛模拟爬虫工具”。本工具支持多种搜索引擎的模拟爬取,如:百度搜索引擎、360搜索引擎、搜狗搜索引擎等。本工具可以模拟爬取网页的风格和爬取源代码,作为SEO工作者,这款软件对我们很有帮助,让我们专注于这一点。
蜘蛛模拟爬虫有哪些功能?
1. 有没有被欺骗的链接?
我们在换友情链接的时候,正常看网页代码,但其实有些人会用劫持技术阻止百度看到这种友情链接,我们就会被骗,所以这个一定要注意,所以以免被链接白费。
2. 网站 被劫持了吗?
如果我们的网站被黑了,很容易被黑客劫持。我们正常看源码是没有问题的,但是百度抓取源码可能有问题,所以如果你的网站排名持续下降,你还是找不到问题,你需要用这个软件排查,有的黑客很聪明,他们不会占用你的百度排名,他们会去你的360,搜狗,因为百度的站长工具可以查,但是一般人在360、搜狗很少去查,所以有些人网站360很容易被K,部分是因为这个操作造成的。
3.检查网站蜘蛛爬行是否正常!
第三点是检查自己的页面。一些功能站点js太多,百度抓取的页面,可能不完整,或者我们用源码测试一下,看看百度可以抓取哪些部分,可以用这个软件测试。非常方便。这个软件可以说是seor必备的软件之一!
如何使用蜘蛛模拟爬虫!
1.下载软件并打开软件
2.输入你的网址,选择引擎,点击模拟爬取
3、点击查看源码,可以看到蜘蛛爬取的源码。
这个软件使用起来非常简单,但是非常好用。用于检查页面是否被黑,是否被骗,网页中是否有百度抓不到的内容,还可以调度360搜索引擎和搜狗搜索。引擎、必应搜索引擎等等!而且我们可以用这个软件来测试,比如我们开发的源代码,用这个软件测试爬取率,是否有问题等等,好的,今天就给大家讲解一下,希望这个软件帮助大家。
网页源代码抓取工具(网络爬虫的专门邮箱邮箱的功能(待续)(下))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-17 14:25
网络爬虫和搜索引擎日以继夜地在互联网上搜索信息,以使其数据库足够强大,使自己的信息更加全面。大家都知道,互联网信息是无穷无尽的,爆炸式的增长。他们无法手动获取信息。他们编写了一个小程序,不断地获取互联网上的信息,于是产生了网络爬虫。
下面我用java实现了一个简单的专门抓邮箱的小工具,很粗糙,仅供大家参考。
这是渲染图
什么都不说,直接上代码
<p>
import java.awt.BorderLayout;
import java.awt.Dimension;
import java.awt.Image;
import java.awt.MenuItem;
import java.awt.PopupMenu;
import java.awt.Toolkit;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import java.awt.event.WindowAdapter;
import java.awt.event.WindowEvent;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import javax.swing.ImageIcon;
import javax.swing.JButton;
import javax.swing.JComboBox;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JOptionPane;
import javax.swing.JPanel;
import javax.swing.JScrollPane;
import javax.swing.JTextArea;
import javax.swing.JTextField;
import javax.swing.UIManager;
import javax.swing.UnsupportedLookAndFeelException;
public class MainFrm extends JFrame implements ActionListener {
private static final long serialVersionUID = 1L;
static int count=1;
static int countUrl=1;
JFrame frame;
JButton b1;
JButton b2;
JTextArea t1;
JTextField tf;
JPanel panel;
JScrollPane jScrollPane1;
JLabel label;
JComboBox comb;
PopupMenu pm;
List t = new ArrayList();
static int m = 0;
MainFrm into() {
pm = new PopupMenu();
MenuItem openItem = new MenuItem("1.打 开");
MenuItem closeItem = new MenuItem("2.退 出");
MenuItem aboutItem = new MenuItem("3.关 于");
openItem.addActionListener(this);
closeItem.addActionListener(this);
aboutItem.addActionListener(this);
pm.add(openItem);
pm.add(closeItem);
pm.add(aboutItem);
String[] petStrings = { "Baidu", "Google", "Yahoo", "Bing", "Sogou" };
comb = new JComboBox(petStrings);
java.net.URL imgURL = MainFrm.class.getResource("mail.png");
ImageIcon imageicon = new ImageIcon(imgURL);
panel = new JPanel();
tf = new JTextField(50);
tf.setText("留下邮箱");
label = new JLabel("关键字:");
frame = new JFrame("邮箱抓取(注:抓取深度暂时默认为2) QQ:三二八二四七六七六");
frame.setIconImage(imageicon.getImage());
b1 = new JButton("提取邮箱");
b1.addActionListener(this);
b2 = new JButton("停止抓取");
b2.addActionListener(this);
t1 = new JTextArea();
t1.setLineWrap(true);
jScrollPane1 = new JScrollPane(t1);
jScrollPane1.setPreferredSize(new Dimension(200, 200));
this.setDefaultCloseOperation(DO_NOTHING_ON_CLOSE);
frame.addWindowListener(new WindowAdapter() { // 窗口关闭事件
public void windowClosing(WindowEvent e) {
System.exit(0);
};
public void windowIconified(WindowEvent e) { // 窗口最小化事件
frame.setVisible(false);
systemTray();
}
});
panel.add(label);
panel.add(tf);
panel.add(comb);
panel.add(b1);
panel.add(b2);
frame.getContentPane().add(panel, BorderLayout.NORTH);
frame.getContentPane().add(jScrollPane1, BorderLayout.CENTER);
frame.setSize(300, 400);
frame.pack();
frame.setVisible(true);
Dimension winSize = Toolkit.getDefaultToolkit().getScreenSize();
frame.setLocation((winSize.width - frame.getWidth()) / 2,
(winSize.height - frame.getHeight()) / 2);
frame.setAlwaysOnTop(true);
return this;
}
public static void main(String[] args) throws ClassNotFoundException,
InstantiationException, IllegalAccessException,
UnsupportedLookAndFeelException {
// TODO Auto-generated method stub
UIManager.setLookAndFeel(UIManager.getSystemLookAndFeelClassName());
new MainFrm().into().systemTray();
}
@SuppressWarnings({ "unchecked", "deprecation", "static-access" })
@Override
public void actionPerformed(ActionEvent e) {
if ("提取邮箱".equals(e.getActionCommand())) {
count=1;
t1.setText("");
// get("http://dzh.mop.com/whbm/200601 ... 6quot;);
String http = "";
int combo = (comb.getSelectedIndex());
switch (combo) {
case 0:
http = "http://www.baidu.com/s?wd=";
break;
case 1:
http = "http://www.google.com.hk/searc ... 3B%3B
break;
case 2:
http = "http://www.yahoo.cn/s?q=";
break;
case 3:
http = "http://cn.bing.com/search?q=";
break;
case 4:
http = "http://www.sogou.com/web?query=";
break;
default:
http = "http://www.baidu.com/s?wd=";
break;
}
final List list = get(http + tf.getText());
m = list.size();
for (int i = 0, n = list.size(); i < n; i++) {
final Map map = list.get(i);
Thread tt = new Thread() {
public void run() {
Iterator iterator = map.values().iterator();
while (iterator.hasNext()) {
String u=iterator.next();
get(u);
}
}
};
t.add(tt);
tt.start();
}
} else if ("终止抓取".equals(e.getActionCommand())) {
for (int i = 0; i < t.size(); i++) {
t.get(i).stop();
}
} else if ("1.打 开".equals(e.getActionCommand())) {
frame.setVisible(true);
frame.setExtendedState(frame.NORMAL);
} else if ("2.退 出".equals(e.getActionCommand())) {
System.exit(0);
}else if ("3.关 于".equals(e.getActionCommand())) {
JOptionPane.showMessageDialog(null, "本程序仅供初学参考 QQ:三二八二四七六七六");
}
}
@SuppressWarnings("unchecked")
public List get(String urlStr) {
List list = new ArrayList();
try {
URL url = new URL(urlStr);
URLConnection rulConnection = url.openConnection();
HttpURLConnection httpUrlConnection = (HttpURLConnection) rulConnection;
httpUrlConnection.setRequestProperty("User-Agent",
"Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
BufferedReader br = new BufferedReader(new InputStreamReader(
httpUrlConnection.getInputStream()));
String line = "";
while ((line = br.readLine()) != null) {
Map map = pr(line);
list.add(map);
}
} catch (FileNotFoundException e) {
//e.printStackTrace();
} catch (IOException e) {
//e.printStackTrace();
} finally {
m--;
if (m 查看全部
网页源代码抓取工具(网络爬虫的专门邮箱邮箱的功能(待续)(下))
网络爬虫和搜索引擎日以继夜地在互联网上搜索信息,以使其数据库足够强大,使自己的信息更加全面。大家都知道,互联网信息是无穷无尽的,爆炸式的增长。他们无法手动获取信息。他们编写了一个小程序,不断地获取互联网上的信息,于是产生了网络爬虫。
下面我用java实现了一个简单的专门抓邮箱的小工具,很粗糙,仅供大家参考。
这是渲染图

什么都不说,直接上代码
<p>
import java.awt.BorderLayout;
import java.awt.Dimension;
import java.awt.Image;
import java.awt.MenuItem;
import java.awt.PopupMenu;
import java.awt.Toolkit;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import java.awt.event.WindowAdapter;
import java.awt.event.WindowEvent;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import javax.swing.ImageIcon;
import javax.swing.JButton;
import javax.swing.JComboBox;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JOptionPane;
import javax.swing.JPanel;
import javax.swing.JScrollPane;
import javax.swing.JTextArea;
import javax.swing.JTextField;
import javax.swing.UIManager;
import javax.swing.UnsupportedLookAndFeelException;
public class MainFrm extends JFrame implements ActionListener {
private static final long serialVersionUID = 1L;
static int count=1;
static int countUrl=1;
JFrame frame;
JButton b1;
JButton b2;
JTextArea t1;
JTextField tf;
JPanel panel;
JScrollPane jScrollPane1;
JLabel label;
JComboBox comb;
PopupMenu pm;
List t = new ArrayList();
static int m = 0;
MainFrm into() {
pm = new PopupMenu();
MenuItem openItem = new MenuItem("1.打 开");
MenuItem closeItem = new MenuItem("2.退 出");
MenuItem aboutItem = new MenuItem("3.关 于");
openItem.addActionListener(this);
closeItem.addActionListener(this);
aboutItem.addActionListener(this);
pm.add(openItem);
pm.add(closeItem);
pm.add(aboutItem);
String[] petStrings = { "Baidu", "Google", "Yahoo", "Bing", "Sogou" };
comb = new JComboBox(petStrings);
java.net.URL imgURL = MainFrm.class.getResource("mail.png");
ImageIcon imageicon = new ImageIcon(imgURL);
panel = new JPanel();
tf = new JTextField(50);
tf.setText("留下邮箱");
label = new JLabel("关键字:");
frame = new JFrame("邮箱抓取(注:抓取深度暂时默认为2) QQ:三二八二四七六七六");
frame.setIconImage(imageicon.getImage());
b1 = new JButton("提取邮箱");
b1.addActionListener(this);
b2 = new JButton("停止抓取");
b2.addActionListener(this);
t1 = new JTextArea();
t1.setLineWrap(true);
jScrollPane1 = new JScrollPane(t1);
jScrollPane1.setPreferredSize(new Dimension(200, 200));
this.setDefaultCloseOperation(DO_NOTHING_ON_CLOSE);
frame.addWindowListener(new WindowAdapter() { // 窗口关闭事件
public void windowClosing(WindowEvent e) {
System.exit(0);
};
public void windowIconified(WindowEvent e) { // 窗口最小化事件
frame.setVisible(false);
systemTray();
}
});
panel.add(label);
panel.add(tf);
panel.add(comb);
panel.add(b1);
panel.add(b2);
frame.getContentPane().add(panel, BorderLayout.NORTH);
frame.getContentPane().add(jScrollPane1, BorderLayout.CENTER);
frame.setSize(300, 400);
frame.pack();
frame.setVisible(true);
Dimension winSize = Toolkit.getDefaultToolkit().getScreenSize();
frame.setLocation((winSize.width - frame.getWidth()) / 2,
(winSize.height - frame.getHeight()) / 2);
frame.setAlwaysOnTop(true);
return this;
}
public static void main(String[] args) throws ClassNotFoundException,
InstantiationException, IllegalAccessException,
UnsupportedLookAndFeelException {
// TODO Auto-generated method stub
UIManager.setLookAndFeel(UIManager.getSystemLookAndFeelClassName());
new MainFrm().into().systemTray();
}
@SuppressWarnings({ "unchecked", "deprecation", "static-access" })
@Override
public void actionPerformed(ActionEvent e) {
if ("提取邮箱".equals(e.getActionCommand())) {
count=1;
t1.setText("");
// get("http://dzh.mop.com/whbm/200601 ... 6quot;);
String http = "";
int combo = (comb.getSelectedIndex());
switch (combo) {
case 0:
http = "http://www.baidu.com/s?wd=";
break;
case 1:
http = "http://www.google.com.hk/searc ... 3B%3B
break;
case 2:
http = "http://www.yahoo.cn/s?q=";
break;
case 3:
http = "http://cn.bing.com/search?q=";
break;
case 4:
http = "http://www.sogou.com/web?query=";
break;
default:
http = "http://www.baidu.com/s?wd=";
break;
}
final List list = get(http + tf.getText());
m = list.size();
for (int i = 0, n = list.size(); i < n; i++) {
final Map map = list.get(i);
Thread tt = new Thread() {
public void run() {
Iterator iterator = map.values().iterator();
while (iterator.hasNext()) {
String u=iterator.next();
get(u);
}
}
};
t.add(tt);
tt.start();
}
} else if ("终止抓取".equals(e.getActionCommand())) {
for (int i = 0; i < t.size(); i++) {
t.get(i).stop();
}
} else if ("1.打 开".equals(e.getActionCommand())) {
frame.setVisible(true);
frame.setExtendedState(frame.NORMAL);
} else if ("2.退 出".equals(e.getActionCommand())) {
System.exit(0);
}else if ("3.关 于".equals(e.getActionCommand())) {
JOptionPane.showMessageDialog(null, "本程序仅供初学参考 QQ:三二八二四七六七六");
}
}
@SuppressWarnings("unchecked")
public List get(String urlStr) {
List list = new ArrayList();
try {
URL url = new URL(urlStr);
URLConnection rulConnection = url.openConnection();
HttpURLConnection httpUrlConnection = (HttpURLConnection) rulConnection;
httpUrlConnection.setRequestProperty("User-Agent",
"Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
BufferedReader br = new BufferedReader(new InputStreamReader(
httpUrlConnection.getInputStream()));
String line = "";
while ((line = br.readLine()) != null) {
Map map = pr(line);
list.add(map);
}
} catch (FileNotFoundException e) {
//e.printStackTrace();
} catch (IOException e) {
//e.printStackTrace();
} finally {
m--;
if (m
网页源代码抓取工具(提取的数据还不能直接拿来用?文件还不符合要求?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-16 00:16
提取出来的数据不能直接使用吗?文件还没有下载?格式等不符合要求?不用担心,网页抓取工具优采云采集器 有自己的解决方案-数据处理。
图片1.png
网络爬虫的数据处理功能包括内容处理、文件下载和内容过滤三部分。下面我依次给大家介绍一下:
1、内容处理:对内容页面中提取的数据进行进一步的处理,如替换、标签过滤、分词等,我们可以同时添加多个操作,但这里需要注意的是,如果有多个操作,按照上面的顺序执行,也就是将上一步的结果作为下一步的参数。
下面我们一一介绍:
①提取内容为空:如果通过前面的规则无法准确提取提取内容或提取内容为空,请选择此选项。此应用程序后,将使用正则匹配从原创页面中再次提取。
②内容替换/排除:用字符串替换采集的内容。如果需要排除,请用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数替换字符串(不同于工具栏中的同义词替换)。
③html标签过滤:过滤指定的html标签,如④字符截取:通过开始和结束字符串截取内容。适用于提取内容的截取和调整。
⑤纯替换:如果某些内容(如单次出现的文本)无法通过一般的内容替换进行操作,则需要通过强大的正则表达式进行复杂的替换。
例如“最受欢迎的美国餐馆在这里”,我们将其替换为“美国餐馆”,正则表达式如下:
图片2.png
⑥数据转换:包括将结果简转繁、将结果繁转简、自动转化为拼音和时间修正转化,共计四项处理。
⑦智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取。
⑧高级功能:包括自动摘要、自动分词、自动分类、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串A长度等一系列函数。
⑨补全单个网址:将当前内容补全为一个网址。
2、文件下载:可以自动检测下载文件,可以设置下载路径和文件名样式。
注:文件下载中所指的下载图片为源代码中的标准样式
标签的图片地址。
例如,如果是直接的图片地址或不规则的图片源代码,采集器 将被视为文件下载。
①将相对地址补全为绝对地址:勾选后,标签采集的相对地址补全为绝对地址。
②下载图片:经核对,源码收录标准样式
将下载代码图像。
③检测文件的真实地址但不下载:有时采集到达附件下载地址而不是实际下载地址。点击之后,会有一个跳转。在这种情况下,如果勾选此选项,将显示真实地址采集,但不会仅下载下载地址。
④检测文件并下载:勾选后可以从采集下载任意格式的文件附件。
3、内容过滤:一些不符合条件的记录可以通过设置内容过滤被删除或标记为不接受。有几种方法可以处理内容过滤:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件即可。
②采集 结果不能为空:该功能可以防止某个字段出现空内容。
③采集 结果不能重复:该功能可以防止某个字段出现重复的内容。设置此项前请确保没有采集数据,否则需要先清除采集数据。
④内容长度小于(大于、等于、不等于)时过滤 N:符号或字母或数字或汉字算一个。
注意:如果满足以上四项中的任何一项或多项,您可以在采集器的其他设置功能中直接删除该记录,或者将该记录标记为不在采集采集将在下次运行任务时重复。
在网页抓取工具优采云采集器中进行一系列数据处理的好处是,当我们只需要做一个小操作时,我们不需要编写插件、生成和编译它们,并且可以一键将数据处理成我们需要的数据。 查看全部
网页源代码抓取工具(提取的数据还不能直接拿来用?文件还不符合要求?)
提取出来的数据不能直接使用吗?文件还没有下载?格式等不符合要求?不用担心,网页抓取工具优采云采集器 有自己的解决方案-数据处理。
图片1.png
网络爬虫的数据处理功能包括内容处理、文件下载和内容过滤三部分。下面我依次给大家介绍一下:
1、内容处理:对内容页面中提取的数据进行进一步的处理,如替换、标签过滤、分词等,我们可以同时添加多个操作,但这里需要注意的是,如果有多个操作,按照上面的顺序执行,也就是将上一步的结果作为下一步的参数。
下面我们一一介绍:
①提取内容为空:如果通过前面的规则无法准确提取提取内容或提取内容为空,请选择此选项。此应用程序后,将使用正则匹配从原创页面中再次提取。
②内容替换/排除:用字符串替换采集的内容。如果需要排除,请用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数替换字符串(不同于工具栏中的同义词替换)。
③html标签过滤:过滤指定的html标签,如④字符截取:通过开始和结束字符串截取内容。适用于提取内容的截取和调整。
⑤纯替换:如果某些内容(如单次出现的文本)无法通过一般的内容替换进行操作,则需要通过强大的正则表达式进行复杂的替换。
例如“最受欢迎的美国餐馆在这里”,我们将其替换为“美国餐馆”,正则表达式如下:
图片2.png
⑥数据转换:包括将结果简转繁、将结果繁转简、自动转化为拼音和时间修正转化,共计四项处理。
⑦智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取。
⑧高级功能:包括自动摘要、自动分词、自动分类、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串A长度等一系列函数。
⑨补全单个网址:将当前内容补全为一个网址。
2、文件下载:可以自动检测下载文件,可以设置下载路径和文件名样式。
注:文件下载中所指的下载图片为源代码中的标准样式
标签的图片地址。
例如,如果是直接的图片地址或不规则的图片源代码,采集器 将被视为文件下载。
①将相对地址补全为绝对地址:勾选后,标签采集的相对地址补全为绝对地址。
②下载图片:经核对,源码收录标准样式
将下载代码图像。
③检测文件的真实地址但不下载:有时采集到达附件下载地址而不是实际下载地址。点击之后,会有一个跳转。在这种情况下,如果勾选此选项,将显示真实地址采集,但不会仅下载下载地址。
④检测文件并下载:勾选后可以从采集下载任意格式的文件附件。
3、内容过滤:一些不符合条件的记录可以通过设置内容过滤被删除或标记为不接受。有几种方法可以处理内容过滤:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件即可。
②采集 结果不能为空:该功能可以防止某个字段出现空内容。
③采集 结果不能重复:该功能可以防止某个字段出现重复的内容。设置此项前请确保没有采集数据,否则需要先清除采集数据。
④内容长度小于(大于、等于、不等于)时过滤 N:符号或字母或数字或汉字算一个。
注意:如果满足以上四项中的任何一项或多项,您可以在采集器的其他设置功能中直接删除该记录,或者将该记录标记为不在采集采集将在下次运行任务时重复。
在网页抓取工具优采云采集器中进行一系列数据处理的好处是,当我们只需要做一个小操作时,我们不需要编写插件、生成和编译它们,并且可以一键将数据处理成我们需要的数据。
网页源代码抓取工具(Source对iOS8Extensions的巧妙利用,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-16 00:14
如果您是网站管理员或网络开发人员,在浏览器中查看网页源代码(HTML、CSS 和 JavaScript)是每天必不可少的操作。这种在桌面上的轻松操作已经变成了移动端。一件麻烦事。现在有了View Source对iOS 8 Extensions的巧妙运用,在移动端浏览和操作网页源代码将变得非常容易。
安装完查看源代码后,通过Safari分享按钮打开查看源代码开关,即可显示当前网页源代码。如果不想这样做,也可以将View Source作为一个独立的应用程序打开要查看的网站源代码当然,这种情况下View Source不会显示内容页面,而是直接显示页面源代码。
在这里你可以看到少数派网页的源代码。例如,通常的 SEO 人员会为网页定义 Title 和 Meta 标签关键字,以使 网站 更好地保持搜索引擎。
在View Source中,通过DOM节点树可以直观的看到当前网页的结构,方便查找和访问节点。还有一个很酷的地方就是View Source还可以通过inject JS来编写自定义的JS代码,退出插件的时候输出的JS效果会在网页上显示出来。比如在小众页面下的Script中输入:
警报(文件。标题);
退出插件,在Safari中显示关于少数网站 Title标签的提示弹窗,效果如图。
当然,如果你想在弹出的窗口中显示一个句子,你可以在脚本中输入:
警报(我爱斯派);
当然,这些只是普通的 JavaScript 警报代码。如果你有更有趣的玩法或者更实用的功能,也可以在评论中告诉我。
右上角有更多选项可以调用更多功能,比如将代码复制到剪贴板并继续在其他应用程序上编辑,还可以发送电子邮件、选择亮点等更多主题。这里多说一下,查看源码提供了很多亮色的主题供选择,笔者个人比较喜欢蓝屏的主题。
View Source 目前售价 6 元。 查看全部
网页源代码抓取工具(Source对iOS8Extensions的巧妙利用,你知道吗?)
如果您是网站管理员或网络开发人员,在浏览器中查看网页源代码(HTML、CSS 和 JavaScript)是每天必不可少的操作。这种在桌面上的轻松操作已经变成了移动端。一件麻烦事。现在有了View Source对iOS 8 Extensions的巧妙运用,在移动端浏览和操作网页源代码将变得非常容易。

安装完查看源代码后,通过Safari分享按钮打开查看源代码开关,即可显示当前网页源代码。如果不想这样做,也可以将View Source作为一个独立的应用程序打开要查看的网站源代码当然,这种情况下View Source不会显示内容页面,而是直接显示页面源代码。

在这里你可以看到少数派网页的源代码。例如,通常的 SEO 人员会为网页定义 Title 和 Meta 标签关键字,以使 网站 更好地保持搜索引擎。

在View Source中,通过DOM节点树可以直观的看到当前网页的结构,方便查找和访问节点。还有一个很酷的地方就是View Source还可以通过inject JS来编写自定义的JS代码,退出插件的时候输出的JS效果会在网页上显示出来。比如在小众页面下的Script中输入:
警报(文件。标题);
退出插件,在Safari中显示关于少数网站 Title标签的提示弹窗,效果如图。

当然,如果你想在弹出的窗口中显示一个句子,你可以在脚本中输入:
警报(我爱斯派);

当然,这些只是普通的 JavaScript 警报代码。如果你有更有趣的玩法或者更实用的功能,也可以在评论中告诉我。

右上角有更多选项可以调用更多功能,比如将代码复制到剪贴板并继续在其他应用程序上编辑,还可以发送电子邮件、选择亮点等更多主题。这里多说一下,查看源码提供了很多亮色的主题供选择,笔者个人比较喜欢蓝屏的主题。
View Source 目前售价 6 元。
网页源代码抓取工具(网络库urlliburllib库是4个模块详细解析(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-30 23:18
网络库 urllib
urllib库是Python3内置的HTTP请求库,不需要单独安装。默认下载的 Python 已经收录该库。
urllib 库有 4 个模块:
1.request:最基本的HTTP请求模块,可以用来发送HTTP请求和接收来自服务器的响应数据。这个过程就像在浏览器地址栏中输入一个 URL。
2.parse:工具模块,提供了很多处理URL的API,如拆分、解析、合并等。
3.robotparser:用于识别网站的robots.txt文件,进而判断哪些网站可以爬取,哪些不能爬取。
4.错误:异常处理。如果发生请求错误,可以捕获这些异常,然后根据代码的需要进行处理。
下面,我们将介绍 urllib 库的 4 个模块。
要求
请求模块收录发送请求、获取响应、cookies、代理等相关API。在这里,我们将分别介绍如何使用它们。
发送 GET 请求
首先,我们一般在编写爬虫程序的时候,需要在开始时发送请求,然后得到响应进行处理。例如通过GET请求获取网页的源码,示例如下:
import urllib.request
response=urllib.request.urlopen("https://www.csdn.net/")
print(response.read().decode("UTF-8"))
如上代码所示,运行后,我们将得到网页的html源代码。
这里的 response 是一个 HTTPResponse 对象。通过调用它的各种方法和属性,可以进行各种处理。
比如这里我们获取CSDN主页,调用它的属性和方法,示例如下:
import urllib.request
response = urllib.request.urlopen("https://www.csdn.net/")
print("status:", response.status, " msg:", response.msg, " version:", response.version)
print(response.getheaders())
在这里,我们输出CSDN首页的响应状态码、响应消息和HTTP版本的属性,还打印了完整的响应头信息。
发送 POST 请求
request.urlopen()函数默认发送GET请求,如果需要发送POST请求,我们需要使用data命令参数,参数类型为bytes。示例代码如下:
import urllib.request
import urllib.parse
data = bytes(urllib.parse.urlencode({'username': 'name', 'age': '123456'}), encoding="UTF-8")
response = urllib.request.urlopen("http://httpbin.org/post", data=data)
print(response.read().decode("UTF-8"))
运行后,如果请求成功,会返回很多字符串数据。
请求超时处理
在实际爬虫项目中,我们都需要考虑一个关键问题,即请求超时。如果请求的URL长时间没有响应,卡在这里往往会浪费很多资源。
因此,我们需要设置一个超时时间。如果在限定时间内没有响应,我们应该重新获取或停止获取。示例代码如下:
import urllib.request
import urllib.parse
import urllib.error
import socket
data = bytes(urllib.parse.urlencode({'username': 'name', 'age': '123456'}), encoding="UTF-8")
try:
response = urllib.request.urlopen("http://httpbin.org/post", data=data, timeout=0.1)
print(response.read().decode("UTF-8"))
except urllib.error.URLError as e:
if isinstance(e.reason,socket.timeout):
print("超时处理")
finally:
print("继续爬虫的工作")
爬行动物伪装
现在任何知名的网站 都有明确的反爬虫技术。因此,我们在开发爬虫程序时,需要将我们的请求伪装成浏览器。
但是, urlopen() 没有头请求头参数。我们需要使用 request.Request() 来构造请求。示例代码如下:
import urllib.request
import urllib.parse
data = bytes(urllib.parse.urlencode({'username': 'name', 'age': '123456'}), encoding="UTF-8")
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
req = urllib.request.Request("http://httpbin.org/post", data=data, headers=headers)
response = urllib.request.urlopen(req)
print(response.read().decode("UTF-8"))
在这里,我们将爬虫程序伪装成来自 Firefox 浏览器的请求。
当然,Request 类还有很多其他的信息。下表由博主列出,供读者参考。
范围
意义
网址
用于发送请求的 URl,一个必选参数(除此参数外,其他参数可选)
数据
要提交的表单数据必须是字节类型
标题
请求头
origin_req_host
请求方的主机名或 IP 地址
无法核实
指示是否无法验证此请求。默认为False,主要表示用户没有足够的权限选择接收本次请求的结果。比如请求一个HTML图片,但是没有权限自动抓取图片,此时参数为True。
方法
用于指定请求,如GET、POST、PUT等,如果指定了data,则默认为POST请求
需要注意的是最后一个参数方法,如果在程序中指定请求是GET,并且还有数据表单数据,那么默认表单不会提交到服务器。
演戏
其实,除了根据请求头判断服务器是否是爬虫,判断爬虫最简单的方法就是判断是否是短时间内来自同一个IP的大量访问。
如果同一IP短时间内被大量访问,可以直接识别为爬虫。这时候我们就可以通过代理来伪装了。当然,在使用代理时,您应该不断更改代理服务器。
示例代码如下:
import urllib.error
from urllib.request import ProxyHandler, build_opener
proxy_handler = ProxyHandler({
'http': 'http://183.47.138.80:8888',
'http': 'http://125.78.226.217:8888'
})
opener = build_opener(proxy_handler)
try:
response = opener.open('https://www.csdn.net/')
print(response.read().decode('UTF-8'))
except urllib.error.URLError as e:
print(e.reason)
运行后,返回到CSDN首页的源代码和之前一样。不过需要注意的是,这个code IP在博主写博客的时候是有效的,但是如果你看了这篇博文,可能是无效的。你需要找一个免费的代理服务器来自己测试。
获取饼干
一般来说,当我们使用爬虫登录网站时,会使用服务器返回的cookie进行操作。有了这个cookie,服务器就知道我们已经登录了。
那么如何获取cookie数据呢?示例如下:
import urllib.error
from urllib.request import ProxyHandler
import http.cookiejar
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
try:
response = opener.open('https://www.csdn.net/')
for item in cookie:
print("name=", item.name, " value=", item.value)
except urllib.error.URLError as e:
print(e.reason)
如上代码所示,我们可以通过http.cookiejar库进行操作,返回cookie的键值对,并打印输出。效果如下:
如果网站本身的cookie时长比较长,那么在爬虫之后,我们可以将其保存起来使用。这时候会用到 MozillaCookieJar 类和 LWPCookieJar 类。
这两个类会在获取cookie的同时以Mozilla浏览器格式和libwww-perl(LWP)格式保存cookie。示例代码如下:
import urllib.error
from urllib.request import ProxyHandler
import http.cookiejar
cookie = http.cookiejar.MozillaCookieJar('cookies.txt')
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
try:
response = opener.open('https://www.csdn.net/')
cookie.save(ignore_discard=True,ignore_expires=True)
except urllib.error.URLError as e:
print(e.reason)
运行后会生成一个cookies.txt文件,具体内容如下:
LWPCookieJar 类的使用与上面的 MozillaCookieJar 类似,这里不再赘述。至于读取,通过 cookie.load() 方法加载 Cookie。
解析
在实际爬虫处理中,我们经常会遇到各种编码问题。这些问题都可以通过 Parse 来解决。
中文编解码
比如在一些网址的请求头中,一些网站请求头会收录中文。但是默认不做任何处理,肯定会报UnicodeEncodeError。
读者可以用上面的代码在headers字典中添加一个键值对,让值取中文试试。接下来,我们需要对其进行编码,示例如下:
import urllib.parse
import base64
value = urllib.parse.urlencode({'name': '安踏'})
print("编码后的中文:", value)
print("解码后的中文:", urllib.parse.unquote(value))
#base64编码与解码
base64Value=base64.b64encode(bytes('学习网络urllib库',encoding="UTF-8"))
print("编码后的中文:", base64Value)
print("解码后的中文:", str(base64.b64decode(base64Value),"UTF-8"))
运行后效果如下:
需要注意的是,urlencode只能对url参数进行编码。例如,headers 请求头在此处编码。网站 中的一些数据是由 base64 编码的。这时候我们还需要掌握base64的解码和编码。
引用和取消引用
quote 函数也是一种编码函数,但它与 urlencode 的不同之处在于 urlencode 只能对 URL 进行编码。并且quote 可以编码任何字符串。
至于unquote是编码(解码)的逆过程,示例如下:
from urllib.parse import quote, unquote
url = 'https://www.baidu.com/s?wd=' + quote("王者荣耀")
print(url)
url = unquote(url)
print(url)
运行后效果如下:
网址解析
在前面的介绍中,我们也说过解析模块可以对 URL 进行分解、分析和合并。下面,我们就通过这些函数,举一些例子,读者就明白了。
from urllib import parse
url = 'https://www.csdn.net/'
split_result=parse.urlsplit(url);
print(split_result)
result = parse.urlparse(url)
print('scheme:', result.scheme) # 网络协议
print('netloc:', result.netloc) # 域名
print('path:', result.path) # 文件存放路径
print('query:', result.query) # 查询字符
print('fragment:', result.fragment) # 拆分文档中的特殊猫
运行后效果如下:
连接网址
对于 URL,有时我们需要组合 URL 的多个部分。比如我们在网站下爬取某张图片时,默认的前面部分基本一致,可能只是ID不同。
那么这时候我们就需要拼接第一部分的URL和ID。示例代码如下:
import urllib.parse
print(urllib.parse.urljoin('https://blog.csdn.net','liyuanjinglyj'))
print(urllib.parse.urljoin('https://blog.csdn.net','https://www.baidu.com'))
print(urllib.parse.urljoin('https://blog.csdn.net','index.html'))
print(urllib.parse.urljoin('https://blog.csdn.net/index.php','?name=30'))
运行后效果如下:
urljoin使用规则:第一个参数是base_url,是一个base URL。只能设置scheme、netloc 和path。第二个参数是url。
如果第二个参数不是完整的URL,第二个参数的值会加在第一个参数的后面,会自动加上斜线“/”。
如果第二个参数是完整的 URL,则直接返回第二个 URL。
参数转换(parse_qs 和 parse_qsl)
parse_qs 函数将多个参数拆分成一个字典,其中key为参数名,value为参数值。
parse_qsl 函数返回一个列表,每个元素是一个收录 2 个元素值的元组,第一个元素代表键,第二个元素代表值。
示例如下:
from urllib.parse import parse_qs, parse_qsl
query = "name=李元静&age=29"
print(parse_qs(query))
print(parse_qsl(query))
运行后效果如下:
两个函数只是返回形式不同的参数,内容基本匹配。同时,无论这两个函数是什么类型,转换结果都是字符串。
机器人协议
Robots协议也叫爬虫协议、机器人协议,全称是Robots Exclusing Protocol。
用于告诉爬虫和搜索引擎哪些页面可以爬取,哪些页面不能爬取。该协议通常放在一个名为robots.txt 的文本文件中,该文件位于网站 的根目录中。
需要特别注意的是,robots.txt文件只是在开发过程中用来判断哪些数据可以爬取,哪些数据不能爬取,并不阻止开发过程中的爬取操作。但是作为一个有良知的程序员,你应该尽可能地尊重这些规则。
Robots协议定义规则
robots.txt的文本文件一般有3个值:
1.User-agent:如果是*,表示对所有爬虫都有效。2. Disallow:不能爬取哪些目录资源,如Disallow:/index/,则禁止爬取索引文件中的所有资源。如果是/,则表示无法捕获网站。3.Allow:表示可以爬取哪些目录资源。例如Allow:/,表示可以捕获所有网站。该值与 Disallow 相同,但含义相反。
当然User-agent也可以禁止某些爬虫爬取,比如百度爬虫:User-agent:BaiduSpider。常用的爬虫名称如下:
爬虫名称
搜索引擎
谷歌机器人
谷歌
360蜘蛛
360搜索
宾博
必须
百度蜘蛛
百度
Robots协议分析
当然,我们在获取Robots协议的时候,一定要获取哪些资源是不可爬取的。不过,虽然可以直接通过字符串解析来完成,但是稍微复杂一些。
urllib 库的robotparser 模块提供了相应的解析API,即RobotFileParser 类。示例如下:
from urllib.robotparser import RobotFileParser
#一种解析方式
robot = RobotFileParser()
robot.set_url('https://www.csdn.net/robots.txt')
robot.read()
print(robot.can_fetch('*', 'https://blog.csdn.net/rank/list'))
#另一种解析方式
robot = RobotFileParser('https://www.csdn.net/robots.txt')
print(robot.can_fetch('*', 'https://blog.csdn.net/rank/list'))
这里使用can_fetch方法来判断是否可以根据Robots协议获取URL。这里的判断是CSDN排行榜是否可以爬取,返回True。
错误
我们已经在上面的代码中使用了异常处理。例如,在解释请求超时时,我们使用了 URLError。但它也有一个子类 HTTPError。 查看全部
网页源代码抓取工具(网络库urlliburllib库是4个模块详细解析(组图))
网络库 urllib
urllib库是Python3内置的HTTP请求库,不需要单独安装。默认下载的 Python 已经收录该库。
urllib 库有 4 个模块:
1.request:最基本的HTTP请求模块,可以用来发送HTTP请求和接收来自服务器的响应数据。这个过程就像在浏览器地址栏中输入一个 URL。
2.parse:工具模块,提供了很多处理URL的API,如拆分、解析、合并等。
3.robotparser:用于识别网站的robots.txt文件,进而判断哪些网站可以爬取,哪些不能爬取。
4.错误:异常处理。如果发生请求错误,可以捕获这些异常,然后根据代码的需要进行处理。
下面,我们将介绍 urllib 库的 4 个模块。
要求
请求模块收录发送请求、获取响应、cookies、代理等相关API。在这里,我们将分别介绍如何使用它们。
发送 GET 请求
首先,我们一般在编写爬虫程序的时候,需要在开始时发送请求,然后得到响应进行处理。例如通过GET请求获取网页的源码,示例如下:
import urllib.request
response=urllib.request.urlopen("https://www.csdn.net/";)
print(response.read().decode("UTF-8"))
如上代码所示,运行后,我们将得到网页的html源代码。
这里的 response 是一个 HTTPResponse 对象。通过调用它的各种方法和属性,可以进行各种处理。
比如这里我们获取CSDN主页,调用它的属性和方法,示例如下:
import urllib.request
response = urllib.request.urlopen("https://www.csdn.net/";)
print("status:", response.status, " msg:", response.msg, " version:", response.version)
print(response.getheaders())
在这里,我们输出CSDN首页的响应状态码、响应消息和HTTP版本的属性,还打印了完整的响应头信息。
发送 POST 请求
request.urlopen()函数默认发送GET请求,如果需要发送POST请求,我们需要使用data命令参数,参数类型为bytes。示例代码如下:
import urllib.request
import urllib.parse
data = bytes(urllib.parse.urlencode({'username': 'name', 'age': '123456'}), encoding="UTF-8")
response = urllib.request.urlopen("http://httpbin.org/post", data=data)
print(response.read().decode("UTF-8"))
运行后,如果请求成功,会返回很多字符串数据。
请求超时处理
在实际爬虫项目中,我们都需要考虑一个关键问题,即请求超时。如果请求的URL长时间没有响应,卡在这里往往会浪费很多资源。
因此,我们需要设置一个超时时间。如果在限定时间内没有响应,我们应该重新获取或停止获取。示例代码如下:
import urllib.request
import urllib.parse
import urllib.error
import socket
data = bytes(urllib.parse.urlencode({'username': 'name', 'age': '123456'}), encoding="UTF-8")
try:
response = urllib.request.urlopen("http://httpbin.org/post", data=data, timeout=0.1)
print(response.read().decode("UTF-8"))
except urllib.error.URLError as e:
if isinstance(e.reason,socket.timeout):
print("超时处理")
finally:
print("继续爬虫的工作")
爬行动物伪装
现在任何知名的网站 都有明确的反爬虫技术。因此,我们在开发爬虫程序时,需要将我们的请求伪装成浏览器。
但是, urlopen() 没有头请求头参数。我们需要使用 request.Request() 来构造请求。示例代码如下:
import urllib.request
import urllib.parse
data = bytes(urllib.parse.urlencode({'username': 'name', 'age': '123456'}), encoding="UTF-8")
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
req = urllib.request.Request("http://httpbin.org/post", data=data, headers=headers)
response = urllib.request.urlopen(req)
print(response.read().decode("UTF-8"))
在这里,我们将爬虫程序伪装成来自 Firefox 浏览器的请求。
当然,Request 类还有很多其他的信息。下表由博主列出,供读者参考。
范围
意义
网址
用于发送请求的 URl,一个必选参数(除此参数外,其他参数可选)
数据
要提交的表单数据必须是字节类型
标题
请求头
origin_req_host
请求方的主机名或 IP 地址
无法核实
指示是否无法验证此请求。默认为False,主要表示用户没有足够的权限选择接收本次请求的结果。比如请求一个HTML图片,但是没有权限自动抓取图片,此时参数为True。
方法
用于指定请求,如GET、POST、PUT等,如果指定了data,则默认为POST请求
需要注意的是最后一个参数方法,如果在程序中指定请求是GET,并且还有数据表单数据,那么默认表单不会提交到服务器。
演戏
其实,除了根据请求头判断服务器是否是爬虫,判断爬虫最简单的方法就是判断是否是短时间内来自同一个IP的大量访问。
如果同一IP短时间内被大量访问,可以直接识别为爬虫。这时候我们就可以通过代理来伪装了。当然,在使用代理时,您应该不断更改代理服务器。
示例代码如下:
import urllib.error
from urllib.request import ProxyHandler, build_opener
proxy_handler = ProxyHandler({
'http': 'http://183.47.138.80:8888',
'http': 'http://125.78.226.217:8888'
})
opener = build_opener(proxy_handler)
try:
response = opener.open('https://www.csdn.net/')
print(response.read().decode('UTF-8'))
except urllib.error.URLError as e:
print(e.reason)
运行后,返回到CSDN首页的源代码和之前一样。不过需要注意的是,这个code IP在博主写博客的时候是有效的,但是如果你看了这篇博文,可能是无效的。你需要找一个免费的代理服务器来自己测试。
获取饼干
一般来说,当我们使用爬虫登录网站时,会使用服务器返回的cookie进行操作。有了这个cookie,服务器就知道我们已经登录了。
那么如何获取cookie数据呢?示例如下:
import urllib.error
from urllib.request import ProxyHandler
import http.cookiejar
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
try:
response = opener.open('https://www.csdn.net/')
for item in cookie:
print("name=", item.name, " value=", item.value)
except urllib.error.URLError as e:
print(e.reason)
如上代码所示,我们可以通过http.cookiejar库进行操作,返回cookie的键值对,并打印输出。效果如下:
如果网站本身的cookie时长比较长,那么在爬虫之后,我们可以将其保存起来使用。这时候会用到 MozillaCookieJar 类和 LWPCookieJar 类。
这两个类会在获取cookie的同时以Mozilla浏览器格式和libwww-perl(LWP)格式保存cookie。示例代码如下:
import urllib.error
from urllib.request import ProxyHandler
import http.cookiejar
cookie = http.cookiejar.MozillaCookieJar('cookies.txt')
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
try:
response = opener.open('https://www.csdn.net/')
cookie.save(ignore_discard=True,ignore_expires=True)
except urllib.error.URLError as e:
print(e.reason)
运行后会生成一个cookies.txt文件,具体内容如下:
LWPCookieJar 类的使用与上面的 MozillaCookieJar 类似,这里不再赘述。至于读取,通过 cookie.load() 方法加载 Cookie。
解析
在实际爬虫处理中,我们经常会遇到各种编码问题。这些问题都可以通过 Parse 来解决。
中文编解码
比如在一些网址的请求头中,一些网站请求头会收录中文。但是默认不做任何处理,肯定会报UnicodeEncodeError。
读者可以用上面的代码在headers字典中添加一个键值对,让值取中文试试。接下来,我们需要对其进行编码,示例如下:
import urllib.parse
import base64
value = urllib.parse.urlencode({'name': '安踏'})
print("编码后的中文:", value)
print("解码后的中文:", urllib.parse.unquote(value))
#base64编码与解码
base64Value=base64.b64encode(bytes('学习网络urllib库',encoding="UTF-8"))
print("编码后的中文:", base64Value)
print("解码后的中文:", str(base64.b64decode(base64Value),"UTF-8"))
运行后效果如下:
需要注意的是,urlencode只能对url参数进行编码。例如,headers 请求头在此处编码。网站 中的一些数据是由 base64 编码的。这时候我们还需要掌握base64的解码和编码。
引用和取消引用
quote 函数也是一种编码函数,但它与 urlencode 的不同之处在于 urlencode 只能对 URL 进行编码。并且quote 可以编码任何字符串。
至于unquote是编码(解码)的逆过程,示例如下:
from urllib.parse import quote, unquote
url = 'https://www.baidu.com/s?wd=' + quote("王者荣耀")
print(url)
url = unquote(url)
print(url)
运行后效果如下:
网址解析
在前面的介绍中,我们也说过解析模块可以对 URL 进行分解、分析和合并。下面,我们就通过这些函数,举一些例子,读者就明白了。
from urllib import parse
url = 'https://www.csdn.net/'
split_result=parse.urlsplit(url);
print(split_result)
result = parse.urlparse(url)
print('scheme:', result.scheme) # 网络协议
print('netloc:', result.netloc) # 域名
print('path:', result.path) # 文件存放路径
print('query:', result.query) # 查询字符
print('fragment:', result.fragment) # 拆分文档中的特殊猫
运行后效果如下:
连接网址
对于 URL,有时我们需要组合 URL 的多个部分。比如我们在网站下爬取某张图片时,默认的前面部分基本一致,可能只是ID不同。
那么这时候我们就需要拼接第一部分的URL和ID。示例代码如下:
import urllib.parse
print(urllib.parse.urljoin('https://blog.csdn.net','liyuanjinglyj'))
print(urllib.parse.urljoin('https://blog.csdn.net','https://www.baidu.com'))
print(urllib.parse.urljoin('https://blog.csdn.net','index.html'))
print(urllib.parse.urljoin('https://blog.csdn.net/index.php','?name=30'))
运行后效果如下:
urljoin使用规则:第一个参数是base_url,是一个base URL。只能设置scheme、netloc 和path。第二个参数是url。
如果第二个参数不是完整的URL,第二个参数的值会加在第一个参数的后面,会自动加上斜线“/”。
如果第二个参数是完整的 URL,则直接返回第二个 URL。
参数转换(parse_qs 和 parse_qsl)
parse_qs 函数将多个参数拆分成一个字典,其中key为参数名,value为参数值。
parse_qsl 函数返回一个列表,每个元素是一个收录 2 个元素值的元组,第一个元素代表键,第二个元素代表值。
示例如下:
from urllib.parse import parse_qs, parse_qsl
query = "name=李元静&age=29"
print(parse_qs(query))
print(parse_qsl(query))
运行后效果如下:
两个函数只是返回形式不同的参数,内容基本匹配。同时,无论这两个函数是什么类型,转换结果都是字符串。
机器人协议
Robots协议也叫爬虫协议、机器人协议,全称是Robots Exclusing Protocol。
用于告诉爬虫和搜索引擎哪些页面可以爬取,哪些页面不能爬取。该协议通常放在一个名为robots.txt 的文本文件中,该文件位于网站 的根目录中。
需要特别注意的是,robots.txt文件只是在开发过程中用来判断哪些数据可以爬取,哪些数据不能爬取,并不阻止开发过程中的爬取操作。但是作为一个有良知的程序员,你应该尽可能地尊重这些规则。
Robots协议定义规则
robots.txt的文本文件一般有3个值:
1.User-agent:如果是*,表示对所有爬虫都有效。2. Disallow:不能爬取哪些目录资源,如Disallow:/index/,则禁止爬取索引文件中的所有资源。如果是/,则表示无法捕获网站。3.Allow:表示可以爬取哪些目录资源。例如Allow:/,表示可以捕获所有网站。该值与 Disallow 相同,但含义相反。
当然User-agent也可以禁止某些爬虫爬取,比如百度爬虫:User-agent:BaiduSpider。常用的爬虫名称如下:
爬虫名称
搜索引擎
谷歌机器人
谷歌
360蜘蛛
360搜索
宾博
必须
百度蜘蛛
百度
Robots协议分析
当然,我们在获取Robots协议的时候,一定要获取哪些资源是不可爬取的。不过,虽然可以直接通过字符串解析来完成,但是稍微复杂一些。
urllib 库的robotparser 模块提供了相应的解析API,即RobotFileParser 类。示例如下:
from urllib.robotparser import RobotFileParser
#一种解析方式
robot = RobotFileParser()
robot.set_url('https://www.csdn.net/robots.txt')
robot.read()
print(robot.can_fetch('*', 'https://blog.csdn.net/rank/list'))
#另一种解析方式
robot = RobotFileParser('https://www.csdn.net/robots.txt')
print(robot.can_fetch('*', 'https://blog.csdn.net/rank/list'))
这里使用can_fetch方法来判断是否可以根据Robots协议获取URL。这里的判断是CSDN排行榜是否可以爬取,返回True。
错误
我们已经在上面的代码中使用了异常处理。例如,在解释请求超时时,我们使用了 URLError。但它也有一个子类 HTTPError。
网页源代码抓取工具(美女图片镇场子,免得你们说我光说不练假把式!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-29 13:41
首先,爬取镇上美女的图片,免得你说我刚才讲了!
话不多说,开始吧!首先了解需要额外安装的第三方库
由于淘女郎网站收录
AJAX技术,因此只需与后台交换少量数据即可实时更新,这意味着直接抓取网页源代码并分析信息的方法行不通。
对于这类网站,一般有两种抓取方式:
使用selenium库模拟浏览器的用户行为,使服务器认为真实用户在浏览网页,从而获得完整的网页源代码
使用Chrome等浏览器自带的分析工具对网页的网络进行监控,分析数据交换API,利用API捕获数据交换的JSON数据,然后进行捕获。
从效率上看,第一种方法比较慢,也占用系统资源,所以我们用第二种方法来实现。
先写请求,然后从淘女孩网站获取JSON文件。
将请求发送到服务器。然后获取服务端的JSON数据,对返回的数据进行处理,再转换成Python字典类型返回。具体代码如下:
def getInfo(paeNum):
tao_datas ('vievFiag':"A", "currentPage": pageNum)
try:
r=requests. post ("http://nn. taobao. com/tatar/seateh/tatar_nodel. do?_input_charset=utf-8*, data = tao. data)
except:
return None
rav_datas = json. loads(r.text)
datas rav_datas['data']['searchDoList']
returh dat as
返回后,我们连接MongoDB,保存返回的信息。
def main():
client = MongoClient ()
db =client. TaoBao
col = db. TaoLady
for pageNun in range(I,411): 淘女郎一共有410页,所以我们抓取从1到第411页的内容。
print (pageNun)
datas=getInfo(pageNun)
if datas;
col.insert_nany(datas)
if__nane__='__main__';
main()
分析返回的信息,然后提取消息中的图片URL信息,将过度使用的图片保存到PIC文件夹中:
def downPic():
client=HongoClient()
db = client.TaoBao
col=db.TaoLady
for data in col, find():
nane = data['realName']
url =“http:" + data[" avatarUr1']
pie=urlopen(url)
vith, open("pic/" + name +",jpa,vb”) as file:
print(name)
file.vrite(pic. read())
if __nane__='__main__':
downPic()
OK,大功告成,原图全部超清晰,不过由于图片数量多,我的16G U盘几乎装不下,这里就不一一展示了,只截了一部分大家来看看。如果觉得文章还行,不妨点个赞。任何意见或意见,欢迎评论!
我是python开发工程师,整理了一套python学习资料。如果你想提升自己,对编程感兴趣,请关注我,私信后台编辑:《08》可免费领取素材!希望能帮到你! 查看全部
网页源代码抓取工具(美女图片镇场子,免得你们说我光说不练假把式!)
首先,爬取镇上美女的图片,免得你说我刚才讲了!
话不多说,开始吧!首先了解需要额外安装的第三方库
由于淘女郎网站收录
AJAX技术,因此只需与后台交换少量数据即可实时更新,这意味着直接抓取网页源代码并分析信息的方法行不通。
对于这类网站,一般有两种抓取方式:
使用selenium库模拟浏览器的用户行为,使服务器认为真实用户在浏览网页,从而获得完整的网页源代码
使用Chrome等浏览器自带的分析工具对网页的网络进行监控,分析数据交换API,利用API捕获数据交换的JSON数据,然后进行捕获。
从效率上看,第一种方法比较慢,也占用系统资源,所以我们用第二种方法来实现。
先写请求,然后从淘女孩网站获取JSON文件。
将请求发送到服务器。然后获取服务端的JSON数据,对返回的数据进行处理,再转换成Python字典类型返回。具体代码如下:
def getInfo(paeNum):
tao_datas ('vievFiag':"A", "currentPage": pageNum)
try:
r=requests. post ("http://nn. taobao. com/tatar/seateh/tatar_nodel. do?_input_charset=utf-8*, data = tao. data)
except:
return None
rav_datas = json. loads(r.text)
datas rav_datas['data']['searchDoList']
returh dat as
返回后,我们连接MongoDB,保存返回的信息。
def main():
client = MongoClient ()
db =client. TaoBao
col = db. TaoLady
for pageNun in range(I,411): 淘女郎一共有410页,所以我们抓取从1到第411页的内容。
print (pageNun)
datas=getInfo(pageNun)
if datas;
col.insert_nany(datas)
if__nane__='__main__';
main()
分析返回的信息,然后提取消息中的图片URL信息,将过度使用的图片保存到PIC文件夹中:
def downPic():
client=HongoClient()
db = client.TaoBao
col=db.TaoLady
for data in col, find():
nane = data['realName']
url =“http:" + data[" avatarUr1']
pie=urlopen(url)
vith, open("pic/" + name +",jpa,vb”) as file:
print(name)
file.vrite(pic. read())
if __nane__='__main__':
downPic()
OK,大功告成,原图全部超清晰,不过由于图片数量多,我的16G U盘几乎装不下,这里就不一一展示了,只截了一部分大家来看看。如果觉得文章还行,不妨点个赞。任何意见或意见,欢迎评论!
我是python开发工程师,整理了一套python学习资料。如果你想提升自己,对编程感兴趣,请关注我,私信后台编辑:《08》可免费领取素材!希望能帮到你!
网页源代码抓取工具(几年前大数据带着一层神秘面纱(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-29 13:39
几年前,大数据带着神秘的面纱走进人们的视野。在“大数据”[Big Data Observation:]这个词达到顶峰的时候,人们甚至谈到了大数据。如今,大数据的发展越来越扎实,在各个行业开发相关应用的可行性也比以前高很多。但是,在大数据的发展过程中,如果要将其转化为基础能力,基础数据建设仍然是一个不可忽视的环节。一款能够轻松抓取和分析全球网络数据的网络爬虫工具更是不可或缺。不够。
什么是网络爬虫?我们每天需要的大部分大数据来自开放的互联网和其他输入型设备。对于其中最大的互联网,网络抓取工具用于从互联网中提取数据。
基于互联网数据海量的特点,网络爬虫必须满足的条件之一就是高效。因此,市面上最高效的网络爬虫工具“优采云
采集
V9”【】采用的是源码抽取的方式。这种提取方式不需要浏览器解析数据,直接提取网页结构。此外,优采云
Collector V9简化了整个数据提取流程,在提取速度提升的基础上,可以更高效地运行。
网络爬虫是免费的吗?除了效率和易用性,大数据需求群体最大的担忧是工具是否可以免费使用。网页抓取工具优采云
Collector V9 免费版,已累计超过40万用户,每天响应超过10,000个客户。这也从侧面解释了优采云
采集
器软件和服务器。稳定性。
网络爬虫还有其他用途吗?不同于一些小众的采集工具,优采云
collector V9不仅提供了强大的数据采集功能,还有强大的数据处理和发布功能。这些特殊用途的操作非常简单易用。教程的指导快速上手,帮助我们在技术知识相对薄弱的情况下也能轻松高效地处理和发布数据。无需研究代码或寻求其他技术支持,因此选择一个易于使用的网络爬虫工具是非常有必要的。
学习了网络爬虫工具后,未来大数据的基础数据构建在它的协同下可以变得轻松高效。为了更好地适应大数据生态系统的发展需求,我们必须紧跟时代潮流,及时拓展和发散思维,不拘泥于规则,以前瞻性的眼光探索,以执行与执行。坚定的信念。 查看全部
网页源代码抓取工具(几年前大数据带着一层神秘面纱(图))
几年前,大数据带着神秘的面纱走进人们的视野。在“大数据”[Big Data Observation:]这个词达到顶峰的时候,人们甚至谈到了大数据。如今,大数据的发展越来越扎实,在各个行业开发相关应用的可行性也比以前高很多。但是,在大数据的发展过程中,如果要将其转化为基础能力,基础数据建设仍然是一个不可忽视的环节。一款能够轻松抓取和分析全球网络数据的网络爬虫工具更是不可或缺。不够。
什么是网络爬虫?我们每天需要的大部分大数据来自开放的互联网和其他输入型设备。对于其中最大的互联网,网络抓取工具用于从互联网中提取数据。
基于互联网数据海量的特点,网络爬虫必须满足的条件之一就是高效。因此,市面上最高效的网络爬虫工具“优采云
采集
V9”【】采用的是源码抽取的方式。这种提取方式不需要浏览器解析数据,直接提取网页结构。此外,优采云
Collector V9简化了整个数据提取流程,在提取速度提升的基础上,可以更高效地运行。
网络爬虫是免费的吗?除了效率和易用性,大数据需求群体最大的担忧是工具是否可以免费使用。网页抓取工具优采云
Collector V9 免费版,已累计超过40万用户,每天响应超过10,000个客户。这也从侧面解释了优采云
采集
器软件和服务器。稳定性。
网络爬虫还有其他用途吗?不同于一些小众的采集工具,优采云
collector V9不仅提供了强大的数据采集功能,还有强大的数据处理和发布功能。这些特殊用途的操作非常简单易用。教程的指导快速上手,帮助我们在技术知识相对薄弱的情况下也能轻松高效地处理和发布数据。无需研究代码或寻求其他技术支持,因此选择一个易于使用的网络爬虫工具是非常有必要的。
学习了网络爬虫工具后,未来大数据的基础数据构建在它的协同下可以变得轻松高效。为了更好地适应大数据生态系统的发展需求,我们必须紧跟时代潮流,及时拓展和发散思维,不拘泥于规则,以前瞻性的眼光探索,以执行与执行。坚定的信念。
网页源代码抓取工具(一个网站抓站中遇到的奇特网站,分享思路和抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-29 13:38
在我们的学习过程中,我们想在打开网站的时候抓取一次数据,但并不是所有的网站都可以通过一种方式抓取数据。有的有特殊的网页结构,有的有不同的json数据包。慢慢写一些。与我在爬虫过程中遇到的奇葩网站分享爬虫的思路和方法!
工具、目标
工具:pycharm、python3.6 版本
库:请求库
目标:普世网热门图片直播页面,所有图片信息
注意:本网站有一个流行的图片页面,其中收录
活动的相关照片。所有图片信息根据事件写入txt文件(不下载图片,以免影响服务器)!
目标分析
首先,打开如上图所示的主页。不要担心其他人。只需单击右上角。选项出现后,点击进入热图直播选项(注意:部分浏览器需要放大页面才能看到热图直播选项),进入后页面是这样的
在这里,我已放大到 30%。下面是一页一页的活动现场图片。随便点击一个事件,让我们看一下页面
看到页面上的图片加载这么慢,应该是动态加载的,右键查看源码,果然如此!
没有任何图片信息,那我们就需要使用浏览器的页面审核工具了!我这里用的是火狐浏览器,按F12打开,然后点击网络,清除内容,刷新页面,看看加载了哪些数据。
经过简单的检查,我们发现了2个数据,收录
了我们想要的数据
一个是activity相关的信息,一个是image相关的信息,都是json格式加载的。这个很简单,通过请求就可以得到相关的URL。这时候突然想到,如果之前的多个活动页面也是动态加载的,那么是否可以通过这种方式捕获所有活动呢?来看看
这个json数据收录
了页面加载的所有活动信息!没有翻页。. . 难怪加载这么慢【手动申诉】。
代码
通过上面的分析,我们了解了目标数据的位置,接下来就可以开始尝试写代码了
导入requests库,然后直接请求真实的URL,得到名称和对应的URL(真实的URL在消息头中),然后在页面中构造真实的URL。上面得到的网址实际上是网页的网址,而不是网页的网址。如何获取json包所在的真实地址?我们对比一下获取到的几个页面的真实URL,不难发现其规律性。
通过对比发现activityNo的值其实是不一样的,而且这个值也存在于上面抓到的json包中!
构造下一个页面的真实请求地址,然后抓取json包获取所有图片url!至此,核心代码已经写好,完善一下,整体代码和效果如下:
不到1分钟,这个页面上的所有活动和活动图片的url都被保存了,整体代码不到20行,一个非常简单的网站!如果要下载图片,可以把所有的url复制到下载工具,批量下载!
后记
本网站整体结构较为清晰,数据易于获取。今天之所以用这个网站来分享,是因为当我开始抓包的时候,我简直不敢相信。一页之间加载了400多张图片。. . . 而且看页面结构,没想到这么简单!
总的来说,这个网站比较适合新手学习抓包和获取数据。希望对大家有帮助,加油! 查看全部
网页源代码抓取工具(一个网站抓站中遇到的奇特网站,分享思路和抓取方法)
在我们的学习过程中,我们想在打开网站的时候抓取一次数据,但并不是所有的网站都可以通过一种方式抓取数据。有的有特殊的网页结构,有的有不同的json数据包。慢慢写一些。与我在爬虫过程中遇到的奇葩网站分享爬虫的思路和方法!
工具、目标
工具:pycharm、python3.6 版本
库:请求库
目标:普世网热门图片直播页面,所有图片信息
注意:本网站有一个流行的图片页面,其中收录
活动的相关照片。所有图片信息根据事件写入txt文件(不下载图片,以免影响服务器)!
目标分析
首先,打开如上图所示的主页。不要担心其他人。只需单击右上角。选项出现后,点击进入热图直播选项(注意:部分浏览器需要放大页面才能看到热图直播选项),进入后页面是这样的
在这里,我已放大到 30%。下面是一页一页的活动现场图片。随便点击一个事件,让我们看一下页面
看到页面上的图片加载这么慢,应该是动态加载的,右键查看源码,果然如此!
没有任何图片信息,那我们就需要使用浏览器的页面审核工具了!我这里用的是火狐浏览器,按F12打开,然后点击网络,清除内容,刷新页面,看看加载了哪些数据。
经过简单的检查,我们发现了2个数据,收录
了我们想要的数据
一个是activity相关的信息,一个是image相关的信息,都是json格式加载的。这个很简单,通过请求就可以得到相关的URL。这时候突然想到,如果之前的多个活动页面也是动态加载的,那么是否可以通过这种方式捕获所有活动呢?来看看
这个json数据收录
了页面加载的所有活动信息!没有翻页。. . 难怪加载这么慢【手动申诉】。
代码
通过上面的分析,我们了解了目标数据的位置,接下来就可以开始尝试写代码了
导入requests库,然后直接请求真实的URL,得到名称和对应的URL(真实的URL在消息头中),然后在页面中构造真实的URL。上面得到的网址实际上是网页的网址,而不是网页的网址。如何获取json包所在的真实地址?我们对比一下获取到的几个页面的真实URL,不难发现其规律性。
通过对比发现activityNo的值其实是不一样的,而且这个值也存在于上面抓到的json包中!
构造下一个页面的真实请求地址,然后抓取json包获取所有图片url!至此,核心代码已经写好,完善一下,整体代码和效果如下:
不到1分钟,这个页面上的所有活动和活动图片的url都被保存了,整体代码不到20行,一个非常简单的网站!如果要下载图片,可以把所有的url复制到下载工具,批量下载!
后记
本网站整体结构较为清晰,数据易于获取。今天之所以用这个网站来分享,是因为当我开始抓包的时候,我简直不敢相信。一页之间加载了400多张图片。. . . 而且看页面结构,没想到这么简单!
总的来说,这个网站比较适合新手学习抓包和获取数据。希望对大家有帮助,加油!
网页源代码抓取工具( 目标网页用关键字在源代码中查找最终代码验证结果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-29 13:06
目标网页用关键字在源代码中查找最终代码验证结果)
概括
根据网站结构和数据类型制作头条视频爬虫,重点关注数据在网站上的位置和爬取方式
并介绍一个类似的网站,简单讲解一下数据抓取的方法
使用工具:python3.6 + pycharm + requests 库 + re 库
目标情况
这次我们的目标网站是Ajax加载的数据。首先打开网页后,直接使用浏览器自带的开发者工具(火狐),点击网页,然后将网页向下滑动,点击xhr,找到json数据,可以看到大约有100条内容
每个视频都有相关信息,我们只需要取出每个视频的url即可!然后去查看详情页
很容易就能找到视频的真实地址!复制地址,重新打开网页验证,确认地址正确,然后去源码查看地址是否存在
很明显,这个网站不是静态网站,数据应该是存放在一个js文件中的,那我们怎么获取呢~?我需要分析js文件还是使用selenium?别担心,我偶然发现了这个
有没有发现网页源代码中存在url中的关键字,虽然不完全一样,但是我们可以和上一个标签中的内容进行比较
可以确定,这里的值是网页渲染后出现在html标签中的值,在源码中有两个不同格式的视频地址!,很简单,我们来写代码吧!
代码
简单写,直接用requests请求内容,然后用re匹配,取出目标url
类似网站
其实还有一个网站和这种情况很相似,就是第二个视频,但是如果你想看更多的视频,还是需要打开客户端,所以我们就简单的以一个视频为例,抓取它。真实地址!具体过程就不一一讲解了,直接看结果,先看登陆页面
使用关键字在源代码中搜索
最终代码
验证结果
以上文章如有错误,请在留言区指出。如果这篇文章对你有用,请点赞转发。 查看全部
网页源代码抓取工具(
目标网页用关键字在源代码中查找最终代码验证结果)
概括
根据网站结构和数据类型制作头条视频爬虫,重点关注数据在网站上的位置和爬取方式
并介绍一个类似的网站,简单讲解一下数据抓取的方法
使用工具:python3.6 + pycharm + requests 库 + re 库
目标情况
这次我们的目标网站是Ajax加载的数据。首先打开网页后,直接使用浏览器自带的开发者工具(火狐),点击网页,然后将网页向下滑动,点击xhr,找到json数据,可以看到大约有100条内容
每个视频都有相关信息,我们只需要取出每个视频的url即可!然后去查看详情页
很容易就能找到视频的真实地址!复制地址,重新打开网页验证,确认地址正确,然后去源码查看地址是否存在
很明显,这个网站不是静态网站,数据应该是存放在一个js文件中的,那我们怎么获取呢~?我需要分析js文件还是使用selenium?别担心,我偶然发现了这个
有没有发现网页源代码中存在url中的关键字,虽然不完全一样,但是我们可以和上一个标签中的内容进行比较
可以确定,这里的值是网页渲染后出现在html标签中的值,在源码中有两个不同格式的视频地址!,很简单,我们来写代码吧!
代码
简单写,直接用requests请求内容,然后用re匹配,取出目标url
类似网站
其实还有一个网站和这种情况很相似,就是第二个视频,但是如果你想看更多的视频,还是需要打开客户端,所以我们就简单的以一个视频为例,抓取它。真实地址!具体过程就不一一讲解了,直接看结果,先看登陆页面
使用关键字在源代码中搜索
最终代码
验证结果
以上文章如有错误,请在留言区指出。如果这篇文章对你有用,请点赞转发。
网页源代码抓取工具(网页源代码抓取工具最主要的的源等工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-12-29 01:03
网页源代码抓取工具最主要的源代码抓取工具是urllib,shellhub等,网页源代码抓取工具可以抓取html5,css3,javascript等,但是对于一些前端爬虫而言,网页源代码抓取工具的爬取效率没有静态网页高,因为html5和css3会隐藏部分结构,有时候源代码抓取工具就不能解析出明显的结构,而无法达到预期的效果。
所以我们需要能从页面中提取出需要的部分结构。我们最常用的页面源代码抓取工具是selenium,虽然它也能抓取静态网页,但是它抓取html5页面会出现bug,需要用到dom类,dom类中隐藏了结构,所以需要用到equery或者是selenium2才能完全抓取html5页面,用equery就必须要用到javascript,至于如何给出javascript选择器,selenium是使用ajax对html5页面进行请求,所以要用到javascript,一般页面比较简单,使用selenium可以完全抓取html5页面。
然后随着爬虫工具越来越强大,效率越来越高,于是selenium,selenium2等工具大行其道,他们可以抓取javascript,也可以抓取css3,javascript就是一种内嵌式的结构,没有关闭动作,而css3有关闭动作,一般来说就会有缓存机制,爬虫工具只抓取内嵌的css3结构,然后结构提取出来然后渲染到页面上。
接下来介绍如何爬取阿里巴巴的图片。在阿里巴巴网站上有很多图片,经常遇到图片文件打不开的情况,而你在爬取其他网站图片的时候是打开了图片,这时候就说明你要用图片抓取工具抓取的那个图片有问题,这时候就需要提取出这个图片,把它爬下来就可以拿来作为源代码抓取工具爬取。这时我们可以使用selenium2来爬取图片。
步骤如下:1.获取阿里巴巴的图片链接2.打开提取出的图片地址如下:,我们把get_image.jpg(),login_url换成提取出来的链接。3.打开浏览器,一个个的尝试抓取。通过以上三步,我们就爬取到了这个图片地址,如下图:该图片其实就是html5标签中的link(“.html5”),因为在爬取其他网站图片的时候,只能看到一个或者数个link标签,只能提取出这个link,因为其他网站就没有html5标签,所以这个html5地址我们就可以拿来爬取了。
接下来我们给图片属性赋值,图片的属性都是一些固定的,例如:像这个jpg是gray,我们就给gray值赋值一个byte数组listgray即可。也可以给图片赋值另外一个数组的元素对象,这样就可以在这个list中随意取了。对图片的属性赋值很简单,我们只需要根据提取出来的属性名称赋值给图片即可。完整代码如下:[url](url),{url:'/',}。 查看全部
网页源代码抓取工具(网页源代码抓取工具最主要的的源等工具)
网页源代码抓取工具最主要的源代码抓取工具是urllib,shellhub等,网页源代码抓取工具可以抓取html5,css3,javascript等,但是对于一些前端爬虫而言,网页源代码抓取工具的爬取效率没有静态网页高,因为html5和css3会隐藏部分结构,有时候源代码抓取工具就不能解析出明显的结构,而无法达到预期的效果。
所以我们需要能从页面中提取出需要的部分结构。我们最常用的页面源代码抓取工具是selenium,虽然它也能抓取静态网页,但是它抓取html5页面会出现bug,需要用到dom类,dom类中隐藏了结构,所以需要用到equery或者是selenium2才能完全抓取html5页面,用equery就必须要用到javascript,至于如何给出javascript选择器,selenium是使用ajax对html5页面进行请求,所以要用到javascript,一般页面比较简单,使用selenium可以完全抓取html5页面。
然后随着爬虫工具越来越强大,效率越来越高,于是selenium,selenium2等工具大行其道,他们可以抓取javascript,也可以抓取css3,javascript就是一种内嵌式的结构,没有关闭动作,而css3有关闭动作,一般来说就会有缓存机制,爬虫工具只抓取内嵌的css3结构,然后结构提取出来然后渲染到页面上。
接下来介绍如何爬取阿里巴巴的图片。在阿里巴巴网站上有很多图片,经常遇到图片文件打不开的情况,而你在爬取其他网站图片的时候是打开了图片,这时候就说明你要用图片抓取工具抓取的那个图片有问题,这时候就需要提取出这个图片,把它爬下来就可以拿来作为源代码抓取工具爬取。这时我们可以使用selenium2来爬取图片。
步骤如下:1.获取阿里巴巴的图片链接2.打开提取出的图片地址如下:,我们把get_image.jpg(),login_url换成提取出来的链接。3.打开浏览器,一个个的尝试抓取。通过以上三步,我们就爬取到了这个图片地址,如下图:该图片其实就是html5标签中的link(“.html5”),因为在爬取其他网站图片的时候,只能看到一个或者数个link标签,只能提取出这个link,因为其他网站就没有html5标签,所以这个html5地址我们就可以拿来爬取了。
接下来我们给图片属性赋值,图片的属性都是一些固定的,例如:像这个jpg是gray,我们就给gray值赋值一个byte数组listgray即可。也可以给图片赋值另外一个数组的元素对象,这样就可以在这个list中随意取了。对图片的属性赋值很简单,我们只需要根据提取出来的属性名称赋值给图片即可。完整代码如下:[url](url),{url:'/',}。
网页源代码抓取工具(代码比较工具(Diffuse)的特色可视化比较,支持两相比较和三相比较)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-24 14:05
【总体介绍】
一个代码比较工具。
【基本介绍】
代码对比工具,小巧强大,支持windows和linxu两种工作环境!支持命令行提示和基于 GUI 的窗口工具包。在命令行下速度非常快,支持C++、Python、Java、XML等语言的语法高亮。
视觉比较非常直观,支持两相比较和三相比较。这意味着使用 Diffuse 您可以同时比较两个或三个文本文件。最吸引人的是他是开源的。我们不需要支付任何费用。您可以下载他们的在线帮助手册进行练习。Diffuse 默认带有中文界面。代码对比工具(Diffuse)的特色视觉对比非常直观。支持两相比较和三相比较。这意味着使用 Diffuse 您可以同时比较两个或三个文本文件。支持常见的版本控制工具,包括CVS、subversion、git、mercurial等,可以通过Diffuse直接从版本控制系统中获取源代码进行比较合并。支持 C++、Python、Java、XML 等语言中的语法高亮。能够在 Diffuse 中直接编辑文件。支持UTF-8编码。您可以使用快捷键轻松导航。
【软件功能】
1、快速跳转到两个文本的不同之处。使用视图菜单中的菜单项或快捷键CTRL+在所有差异之间快速切换。
2、被比较的两个文件窗口可以互换。如果您习惯于默认将原文放在左侧,您可以使用此功能快速切换是否颠倒。3、快速跳转到某一行。
4、 合并菜单中有很多左右复制的功能,在编辑代码的时候也能提高不少效率。 查看全部
网页源代码抓取工具(代码比较工具(Diffuse)的特色可视化比较,支持两相比较和三相比较)
【总体介绍】
一个代码比较工具。
【基本介绍】
代码对比工具,小巧强大,支持windows和linxu两种工作环境!支持命令行提示和基于 GUI 的窗口工具包。在命令行下速度非常快,支持C++、Python、Java、XML等语言的语法高亮。
视觉比较非常直观,支持两相比较和三相比较。这意味着使用 Diffuse 您可以同时比较两个或三个文本文件。最吸引人的是他是开源的。我们不需要支付任何费用。您可以下载他们的在线帮助手册进行练习。Diffuse 默认带有中文界面。代码对比工具(Diffuse)的特色视觉对比非常直观。支持两相比较和三相比较。这意味着使用 Diffuse 您可以同时比较两个或三个文本文件。支持常见的版本控制工具,包括CVS、subversion、git、mercurial等,可以通过Diffuse直接从版本控制系统中获取源代码进行比较合并。支持 C++、Python、Java、XML 等语言中的语法高亮。能够在 Diffuse 中直接编辑文件。支持UTF-8编码。您可以使用快捷键轻松导航。
【软件功能】
1、快速跳转到两个文本的不同之处。使用视图菜单中的菜单项或快捷键CTRL+在所有差异之间快速切换。
2、被比较的两个文件窗口可以互换。如果您习惯于默认将原文放在左侧,您可以使用此功能快速切换是否颠倒。3、快速跳转到某一行。
4、 合并菜单中有很多左右复制的功能,在编辑代码的时候也能提高不少效率。
网页源代码抓取工具(知乎话题『美女』下所有问题中回答所出现的图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2021-12-23 08:21
免责声明:所有直接或间接、明示或暗示的文字、图片及相关外部链接,涉及性别、颜值得分等信息均由相关人脸检测界面给出。没有任何客观性,仅供参考。
1 数据来源
知乎“美女”主题下所有问题的答案中出现的图片
2 履带
Python 3,并使用第三方库Requests、lxml、AipFace,共100+行代码
3 必要的环境
Mac / Linux / Windows(Linux没有测试过,理论上,Windows之前反应过异常,但检查后发现Windows限制了本地文件名中的字符并使用了常规过滤),无需登录知乎(即无需提供知乎账号密码),人脸检测服务需要百度云账号(即百度云盘/贴吧账号)
4 人脸检测库
百度云AI开放平台提供的AipFace是一个可以进行人脸检测的Python SDK。可以直接通过HTTP访问,免费使用
5 测试过滤条件
6 实现逻辑
7 抓取结果
直接存放在文件夹中(angelababy实力出国)。另外,目前拍摄的照片中,除了baby,88分是最高分。我个人反对排名,我老婆也不是最高分。
8码
这篇文章中的代码有一百行。针对微信公众号代码阅读体验不佳,小编已将源码保存。请到微信公众号后台回复关键词“知乎爬虫”获取。
微信后台入口
9 操作准备
{
"error": {
"message": "ZERR_NO_AUTH_TOKEN",
"code": 100,
"name": "AuthenticationInvalidRequest"
}
}
10 结论
❈ 查看全部
网页源代码抓取工具(知乎话题『美女』下所有问题中回答所出现的图片)
免责声明:所有直接或间接、明示或暗示的文字、图片及相关外部链接,涉及性别、颜值得分等信息均由相关人脸检测界面给出。没有任何客观性,仅供参考。
1 数据来源
知乎“美女”主题下所有问题的答案中出现的图片
2 履带
Python 3,并使用第三方库Requests、lxml、AipFace,共100+行代码
3 必要的环境
Mac / Linux / Windows(Linux没有测试过,理论上,Windows之前反应过异常,但检查后发现Windows限制了本地文件名中的字符并使用了常规过滤),无需登录知乎(即无需提供知乎账号密码),人脸检测服务需要百度云账号(即百度云盘/贴吧账号)
4 人脸检测库
百度云AI开放平台提供的AipFace是一个可以进行人脸检测的Python SDK。可以直接通过HTTP访问,免费使用
5 测试过滤条件
6 实现逻辑
7 抓取结果
直接存放在文件夹中(angelababy实力出国)。另外,目前拍摄的照片中,除了baby,88分是最高分。我个人反对排名,我老婆也不是最高分。
8码
这篇文章中的代码有一百行。针对微信公众号代码阅读体验不佳,小编已将源码保存。请到微信公众号后台回复关键词“知乎爬虫”获取。
微信后台入口
9 操作准备
{
"error": {
"message": "ZERR_NO_AUTH_TOKEN",
"code": 100,
"name": "AuthenticationInvalidRequest"
}
}
10 结论
❈
网页源代码抓取工具(如何应对数据匮乏的问题?最简单的方法在这里)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-12-23 08:20
作者 | 拉克夏阿罗拉
编译|弗林
来源|analyticsvidhya
概述介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!希望得到更多的数据来训练我们的机器学习模型是一直困扰着人们的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吗?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络爬行。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 采集数据。现在,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这是网页抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接学习 Python 以了解如何使用流行且高效的 BeautifulSoup 库进行网页抓取。
我们还为本文创建了一个免费课程:
请注意,网络抓取受许多准则和规则的约束。并不是每一个网站都允许用户抓取内容,所以有一定的法律限制。在尝试此操作之前,请确保您已阅读 网站 的 网站 条款和条件。
3 个流行的 Python 网络爬虫工具和库
网络爬虫组件
CrawlParse 和 TransformStore 从网页中抓取 URL 和电子邮件 ID。抓取图片。页面加载时抓取数据。3 个流行的 Python 网络爬虫工具和库。
您将在 Python 中遇到多个用于网页抓取的库和框架。以下是三种用于高效完成任务的流行工具:
美汤
刮痧
硒
网络爬虫组件
这是构成网络爬行的三个主要组件的极好说明:
让我们详细了解这些组件。我们将使用goibibo网站来抓取酒店的详细信息,比如酒店名称和每个房间的价格,以达到这个目的:
注意:请始终遵循目标网站的robots.txt文件,也称为robots排除协议。这可以告诉网络机器人不抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴编写我们的网络机器人脚本。开始吧!
第 1 步:爬网
网络爬虫的第一步是导航到目标网站并下载网页的源代码。我们将使用请求库来做到这一点。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页源代码后,我们需要过滤需要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换
网络抓取的下一步是将此数据解析为 HTML 解析器。为此,我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,就像大多数页面一样,特定酒店的详细信息位于不同的卡片上。
因此,下一步将是从完整的源代码中过滤卡片数据。接下来,我们将选择卡片,然后单击“检查元素”选项以获取该特定卡片的源代码。您将获得以下信息:
所有卡片的类名都是一样的。我们可以通过传递标签名称和属性(例如标签)来获取这些卡片的列表。名称如下:
# find all the sections with specifiedd class name
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,这里的每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在,对于每张卡,我们必须找到上面的酒店名称,这些名称只能来自
从标签中提取。这是因为每张卡和费率只有一个标签、标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)
第 3 步:Store(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后,我们最终将其添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络爬虫。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的类别和地址。现在,让我们看看如何在页面加载时执行一些常见任务,例如抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试使用网页抓取功能抓取的两个最常见的功能是 网站 URL 和电子邮件 ID。我相信你参与过一个需要大量电子邮件 ID 提取的项目或挑战。那么,让我们看看如何在 Python 中抓取这些内容。
使用网络浏览器的控制台 查看全部
网页源代码抓取工具(如何应对数据匮乏的问题?最简单的方法在这里)
作者 | 拉克夏阿罗拉
编译|弗林
来源|analyticsvidhya
概述介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!希望得到更多的数据来训练我们的机器学习模型是一直困扰着人们的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吗?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络爬行。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 采集数据。现在,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这是网页抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接学习 Python 以了解如何使用流行且高效的 BeautifulSoup 库进行网页抓取。
我们还为本文创建了一个免费课程:
请注意,网络抓取受许多准则和规则的约束。并不是每一个网站都允许用户抓取内容,所以有一定的法律限制。在尝试此操作之前,请确保您已阅读 网站 的 网站 条款和条件。
3 个流行的 Python 网络爬虫工具和库
网络爬虫组件
CrawlParse 和 TransformStore 从网页中抓取 URL 和电子邮件 ID。抓取图片。页面加载时抓取数据。3 个流行的 Python 网络爬虫工具和库。
您将在 Python 中遇到多个用于网页抓取的库和框架。以下是三种用于高效完成任务的流行工具:
美汤
刮痧
硒
网络爬虫组件
这是构成网络爬行的三个主要组件的极好说明:
让我们详细了解这些组件。我们将使用goibibo网站来抓取酒店的详细信息,比如酒店名称和每个房间的价格,以达到这个目的:
注意:请始终遵循目标网站的robots.txt文件,也称为robots排除协议。这可以告诉网络机器人不抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴编写我们的网络机器人脚本。开始吧!
第 1 步:爬网
网络爬虫的第一步是导航到目标网站并下载网页的源代码。我们将使用请求库来做到这一点。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页源代码后,我们需要过滤需要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换
网络抓取的下一步是将此数据解析为 HTML 解析器。为此,我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,就像大多数页面一样,特定酒店的详细信息位于不同的卡片上。
因此,下一步将是从完整的源代码中过滤卡片数据。接下来,我们将选择卡片,然后单击“检查元素”选项以获取该特定卡片的源代码。您将获得以下信息:
所有卡片的类名都是一样的。我们可以通过传递标签名称和属性(例如标签)来获取这些卡片的列表。名称如下:
# find all the sections with specifiedd class name
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,这里的每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在,对于每张卡,我们必须找到上面的酒店名称,这些名称只能来自
从标签中提取。这是因为每张卡和费率只有一个标签、标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)
第 3 步:Store(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后,我们最终将其添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络爬虫。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的类别和地址。现在,让我们看看如何在页面加载时执行一些常见任务,例如抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试使用网页抓取功能抓取的两个最常见的功能是 网站 URL 和电子邮件 ID。我相信你参与过一个需要大量电子邮件 ID 提取的项目或挑战。那么,让我们看看如何在 Python 中抓取这些内容。
使用网络浏览器的控制台
网页源代码抓取工具(WebSpider蓝蜘蛛网页抓取工具5.1可以抓取、MySQL、适用范围)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-21 06:11
WebSpider 蓝蜘蛛爬网工具5.1 可以爬取互联网上的任何网页,wap网站,包括登录后才能访问的页面。分析爬取的页面内容,获取结构化信息,如如新闻标题、作者、来源、正文等。支持列表页自动翻页抓取、文本页多页合并、图片和文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。
用户指定要爬取的网站、要爬取的网页类型(固定页面、分页展示页面等),并配置如何解析数据项(如新闻标题、作者、来源、 body等),系统可以根据配置信息自动实时采集数据,也可以通过配置设置开始采集的时间,真正做到“按需采集,一个配置,和永久捕获”。捕获的数据可以保存在数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等。
该工具可以完全取代传统的编辑人工信息处理模式。能够实时、准确、24*60全天为企业提供最新的信息和情报,真正为企业降低成本,提高竞争力。
该工具的主要特点如下:
*适用范围广,可以抓取任何网页(包括登录后可以访问的网页)
*处理速度快。网络畅通,1小时可抓取解析10000个网页
*采用独特的重复数据过滤技术,支持增量数据采集,可实时采集数据,如:股票交易信息、天气预报等。
*抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性
*支持断点连续抓取。发生崩溃或异常情况后,可恢复抓取,继续后续抓取工作,提高系统抓取效率
*对于列表页,支持翻页,可以读取所有列表页中的数据。对于body页面,可以自动合并页面显示的内容;
*支持页面深度爬取,可在页面之间逐层爬取。比如通过列表页面抓取body页面的URL,然后再抓取body页面。各级页面可单独存放;
*WEB操作界面,一站式安装,随处使用
*分步分析,分步存储
* 配置一次,永久抓取,一劳永逸 查看全部
网页源代码抓取工具(WebSpider蓝蜘蛛网页抓取工具5.1可以抓取、MySQL、适用范围)
WebSpider 蓝蜘蛛爬网工具5.1 可以爬取互联网上的任何网页,wap网站,包括登录后才能访问的页面。分析爬取的页面内容,获取结构化信息,如如新闻标题、作者、来源、正文等。支持列表页自动翻页抓取、文本页多页合并、图片和文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。
用户指定要爬取的网站、要爬取的网页类型(固定页面、分页展示页面等),并配置如何解析数据项(如新闻标题、作者、来源、 body等),系统可以根据配置信息自动实时采集数据,也可以通过配置设置开始采集的时间,真正做到“按需采集,一个配置,和永久捕获”。捕获的数据可以保存在数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等。
该工具可以完全取代传统的编辑人工信息处理模式。能够实时、准确、24*60全天为企业提供最新的信息和情报,真正为企业降低成本,提高竞争力。
该工具的主要特点如下:
*适用范围广,可以抓取任何网页(包括登录后可以访问的网页)
*处理速度快。网络畅通,1小时可抓取解析10000个网页
*采用独特的重复数据过滤技术,支持增量数据采集,可实时采集数据,如:股票交易信息、天气预报等。
*抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性
*支持断点连续抓取。发生崩溃或异常情况后,可恢复抓取,继续后续抓取工作,提高系统抓取效率
*对于列表页,支持翻页,可以读取所有列表页中的数据。对于body页面,可以自动合并页面显示的内容;
*支持页面深度爬取,可在页面之间逐层爬取。比如通过列表页面抓取body页面的URL,然后再抓取body页面。各级页面可单独存放;
*WEB操作界面,一站式安装,随处使用
*分步分析,分步存储
* 配置一次,永久抓取,一劳永逸
网页源代码抓取工具(网站数据采集工具哪个好用?的爬虫软件可以直接使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-12-20 20:05
网站数据采集 哪个工具好用?
网站数据采集,现成的爬虫软件有很多可以直接使用,下面我就简单介绍三个,分别是优采云、章鱼和优采云,操作简单,易学明白了,有兴趣的朋友可以试试:
这是一款非常智能的网络爬虫软件,支持跨平台,个人使用非常方便,完全免费。对于大多数网站,只需输入URL,软件会自动识别并提取相关字段信息,包括列表、表格、链接、图片等,无需配置任何采集规则,一个-click采用,支持自动翻页和数据导出功能,对于小白来说,非常方便,易学易掌握:这是一款非常好的对比优采云采集器,八达通< @采集器目前只支持windows平台,需要手动设置采集字段和配置规则,所以比较复杂灵活。内置海量数据采集模板,方便采集京东,天猫等热门网站。官方教程很详细,小白很容易掌握:
当然,除了以上三个爬虫软件,它还有很多功能,很多其他软件也支持网站data采集,比如做号,申请保单等等。如果您熟悉 Python、Java 和其他编程语言,您还可以编写抓取数据的程序。网上也有相关的教程和资料,讲的很详细。如果你有兴趣,你可以搜索它们。希望以上分享的内容对您有所帮助,也欢迎大家留言补充。
有没有可以批量解析下载视频的软件?自动抓取网络视频的那种?
一般来说,不同的视频平台有不同的数据处理算法,只有经过一次分析才能实现批量处理。
代码软件代码编程下载网站源代码 查看全部
网页源代码抓取工具(网站数据采集工具哪个好用?的爬虫软件可以直接使用)
网站数据采集 哪个工具好用?
网站数据采集,现成的爬虫软件有很多可以直接使用,下面我就简单介绍三个,分别是优采云、章鱼和优采云,操作简单,易学明白了,有兴趣的朋友可以试试:
这是一款非常智能的网络爬虫软件,支持跨平台,个人使用非常方便,完全免费。对于大多数网站,只需输入URL,软件会自动识别并提取相关字段信息,包括列表、表格、链接、图片等,无需配置任何采集规则,一个-click采用,支持自动翻页和数据导出功能,对于小白来说,非常方便,易学易掌握:这是一款非常好的对比优采云采集器,八达通< @采集器目前只支持windows平台,需要手动设置采集字段和配置规则,所以比较复杂灵活。内置海量数据采集模板,方便采集京东,天猫等热门网站。官方教程很详细,小白很容易掌握:
当然,除了以上三个爬虫软件,它还有很多功能,很多其他软件也支持网站data采集,比如做号,申请保单等等。如果您熟悉 Python、Java 和其他编程语言,您还可以编写抓取数据的程序。网上也有相关的教程和资料,讲的很详细。如果你有兴趣,你可以搜索它们。希望以上分享的内容对您有所帮助,也欢迎大家留言补充。
有没有可以批量解析下载视频的软件?自动抓取网络视频的那种?
一般来说,不同的视频平台有不同的数据处理算法,只有经过一次分析才能实现批量处理。
代码软件代码编程下载网站源代码
网页源代码抓取工具(Python用做数据处理还是相当不错的,你知道吗?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-12-20 13:10
Python非常适合数据处理。如果你想做爬虫,Python 是个不错的选择。它有许多已编写的包。只需调用它们就可以完成许多复杂的功能。本文所有功能均基于 BeautifulSoup 包。
1 Pyhton获取网页内容(即源码)
page = urllib2.urlopen(url)
contents = page.read()
#获得了整个网页的内容也就是源代码
print(contents)
url代表网址,contents代表网址对应的源码,urllib2是需要用到的包,上面三句代码就可以得到网页的整个源码
2 获取网页中想要的内容(先获取网页的源代码,然后分析网页的源代码,找到对应的标签,然后提取标签中的内容)
2.1 以豆瓣电影排名为例
网址是,输入网址后会出现下图
现在我需要获取当前页面上所有电影的名称、评分、评论数量、链接
从上图中,红色圆圈是我想要获取的内容,蓝色横线是对应的标签,这样分析就完成了,现在就是写代码来实现,Python提供了很多获取想要的方法内容,这里我使用BeautifulSoup来实现,很简单
#coding:utf-8
'''
Created on 2016��5��17��
@author: jsjxy
'''
import urllib2
import re
from bs4 import BeautifulSoup
from distutils.filelist import findall
page = urllib2.urlopen('http://movie.douban.com/top250?format=text')
contents = page.read()
#print(contents)
soup = BeautifulSoup(contents,"html.parser")
print("豆瓣电影TOP250" + "\n" +" 影片名 评分 评价人数 链接 ")
for tag in soup.find_all('div', class_='info'):
# print tag
m_name = tag.find('span', class_='title').get_text()
m_rating_score = float(tag.find('span',class_='rating_num').get_text())
m_people = tag.find('div',class_="star")
m_span = m_people.findAll('span')
m_peoplecount = m_span[3].contents[0]
m_url=tag.find('a').get('href')
print( m_name+" " + str(m_rating_score) + " " + m_peoplecount + " " + m_url )
控制台输出,也可以写入文件
前三行代码获取整个网页的源码,然后开始使用BeautifulSoup进行标签分析。find_all 方法就是找到这个标签的所有内容,然后在这个标签中继续搜索。如果标签有特殊的属性声明,可以一步找到出来,如果没有特殊的属性声明,像这张图中求值人数前面的标签,就只有一个'span',那么找到所有span标签,依次选择对应的标签。在这张图中,它是第三个,所以这个方法可以找到特定行或列的内容。代码比较简单,易于实现。如有不对的地方请大家指出,共同学习。
源代码地址: 查看全部
网页源代码抓取工具(Python用做数据处理还是相当不错的,你知道吗?(上))
Python非常适合数据处理。如果你想做爬虫,Python 是个不错的选择。它有许多已编写的包。只需调用它们就可以完成许多复杂的功能。本文所有功能均基于 BeautifulSoup 包。
1 Pyhton获取网页内容(即源码)
page = urllib2.urlopen(url)
contents = page.read()
#获得了整个网页的内容也就是源代码
print(contents)
url代表网址,contents代表网址对应的源码,urllib2是需要用到的包,上面三句代码就可以得到网页的整个源码
2 获取网页中想要的内容(先获取网页的源代码,然后分析网页的源代码,找到对应的标签,然后提取标签中的内容)
2.1 以豆瓣电影排名为例
网址是,输入网址后会出现下图
现在我需要获取当前页面上所有电影的名称、评分、评论数量、链接
从上图中,红色圆圈是我想要获取的内容,蓝色横线是对应的标签,这样分析就完成了,现在就是写代码来实现,Python提供了很多获取想要的方法内容,这里我使用BeautifulSoup来实现,很简单
#coding:utf-8
'''
Created on 2016��5��17��
@author: jsjxy
'''
import urllib2
import re
from bs4 import BeautifulSoup
from distutils.filelist import findall
page = urllib2.urlopen('http://movie.douban.com/top250?format=text')
contents = page.read()
#print(contents)
soup = BeautifulSoup(contents,"html.parser")
print("豆瓣电影TOP250" + "\n" +" 影片名 评分 评价人数 链接 ")
for tag in soup.find_all('div', class_='info'):
# print tag
m_name = tag.find('span', class_='title').get_text()
m_rating_score = float(tag.find('span',class_='rating_num').get_text())
m_people = tag.find('div',class_="star")
m_span = m_people.findAll('span')
m_peoplecount = m_span[3].contents[0]
m_url=tag.find('a').get('href')
print( m_name+" " + str(m_rating_score) + " " + m_peoplecount + " " + m_url )
控制台输出,也可以写入文件
前三行代码获取整个网页的源码,然后开始使用BeautifulSoup进行标签分析。find_all 方法就是找到这个标签的所有内容,然后在这个标签中继续搜索。如果标签有特殊的属性声明,可以一步找到出来,如果没有特殊的属性声明,像这张图中求值人数前面的标签,就只有一个'span',那么找到所有span标签,依次选择对应的标签。在这张图中,它是第三个,所以这个方法可以找到特定行或列的内容。代码比较简单,易于实现。如有不对的地方请大家指出,共同学习。
源代码地址:
网页源代码抓取工具(豆瓣电影排行榜基础教程:请求载体的身份标识(用啥发送的请求) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-18 19:07
)
请求:
请求行 -> 请求方式(get/post) 请求url地址 协议
请求头 -> 放一些服务器要使用的附加信息
请求体 -> 一般放一些请求参数
回复:
状态行 -> 协议 状态码
响应头 -> 放一些客户端要使用的附加信息
响应体 -> 服务器返回的真正客户端要用的内容(HTML, json)等
需要额外注意请求头和响应头,它们一般隐藏了一些重要的内容
请求头中常用的一些重要内容:
1. User-Agent:请求载体的身份(请求由什么发送)
2. Referer: Anti-hotlinking(这个请求来自哪个页面?会用于反爬)
3. cookie:本地字符串数据信息(用户登录信息、反爬取令牌)
响应头中常用的一些重要内容:
1. cookie:本地字符串数据信息(用户登录信息、反爬取令牌)
2. 各种奇怪的字符串(根据经验判断,一般都是防止各种攻击和反爬的令牌)
请求方法:(在爬虫中不重要)
GET:显示提交
2. POST:隐式提交
开始使用请求:
安装:
pip install requests
案例一:获取搜狗搜索结果
import requests
url = 'https://www.sogou.com/web?query=周杰伦'
#所有地址栏里的请求方式一定为get
#需要修改User-Agent避免拦截
dic = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36'
}
resp = requests.get(url, headers=dic)
print(resp) #响应状态码
print(resp.text) #页面源代码
resp.close()
案例二:获取百度翻译结果
import requests
url = 'https://fanyi.baidu.com/sug'
s = input('请输入要翻译的英文单词:')
#post方式
dat = {
'kw':s
}
# 发送post请求,发送的数据必须放在字典中,通过data参数进行传递
resp = requests.post(url, data=dat)
#print(resp.text) #返回乱码
print(resp.json()) # 将服务器返回的内容直接处理成json() => dict
resp.close()
案例三:获取豆瓣分类电影排名
import requests
# 原url:?type=5&interval_id=100%3A90&action=&start=0&limit=20 太复杂,重新封装参数
url = 'https://movie.douban.com/j/chart/top_list'
# 重新封装参数
param = {
'type': '5',
'interval_id': '100:90',
'action': '',
'start': '0',
'limit': '20'
}
# User-Agent
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36'
}
resp = requests.get(url=url, params=param, headers=headers)
print(resp.json())
resp.close() 查看全部
网页源代码抓取工具(豆瓣电影排行榜基础教程:请求载体的身份标识(用啥发送的请求)
)
请求:
请求行 -> 请求方式(get/post) 请求url地址 协议
请求头 -> 放一些服务器要使用的附加信息
请求体 -> 一般放一些请求参数
回复:
状态行 -> 协议 状态码
响应头 -> 放一些客户端要使用的附加信息
响应体 -> 服务器返回的真正客户端要用的内容(HTML, json)等
需要额外注意请求头和响应头,它们一般隐藏了一些重要的内容
请求头中常用的一些重要内容:
1. User-Agent:请求载体的身份(请求由什么发送)
2. Referer: Anti-hotlinking(这个请求来自哪个页面?会用于反爬)
3. cookie:本地字符串数据信息(用户登录信息、反爬取令牌)
响应头中常用的一些重要内容:
1. cookie:本地字符串数据信息(用户登录信息、反爬取令牌)
2. 各种奇怪的字符串(根据经验判断,一般都是防止各种攻击和反爬的令牌)
请求方法:(在爬虫中不重要)
GET:显示提交
2. POST:隐式提交
开始使用请求:
安装:
pip install requests
案例一:获取搜狗搜索结果
import requests
url = 'https://www.sogou.com/web?query=周杰伦'
#所有地址栏里的请求方式一定为get
#需要修改User-Agent避免拦截
dic = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36'
}
resp = requests.get(url, headers=dic)
print(resp) #响应状态码
print(resp.text) #页面源代码
resp.close()
案例二:获取百度翻译结果
import requests
url = 'https://fanyi.baidu.com/sug'
s = input('请输入要翻译的英文单词:')
#post方式
dat = {
'kw':s
}
# 发送post请求,发送的数据必须放在字典中,通过data参数进行传递
resp = requests.post(url, data=dat)
#print(resp.text) #返回乱码
print(resp.json()) # 将服务器返回的内容直接处理成json() => dict
resp.close()
案例三:获取豆瓣分类电影排名
import requests
# 原url:?type=5&interval_id=100%3A90&action=&start=0&limit=20 太复杂,重新封装参数
url = 'https://movie.douban.com/j/chart/top_list'
# 重新封装参数
param = {
'type': '5',
'interval_id': '100:90',
'action': '',
'start': '0',
'limit': '20'
}
# User-Agent
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36'
}
resp = requests.get(url=url, params=param, headers=headers)
print(resp.json())
resp.close()
网页源代码抓取工具(站长工具源码v2.0PHP版.rar站长功能简介)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-12-18 08:01
站长工具源码v2.0 PHP版.rar
站长工具功能介绍1、JS加密/解密(对js形式的代码进行加密或解密。)2、UTF-8编码转换工具(UTF-8编码转换。)< @3、 Unicode 编码转换工具(Unicode 编码转换。)4、友情链接(该工具可用于批量查询百度收录、百度中指定网站的友情链接快照、PR、对方是否链接本站可以检测欺诈链接。) 5、META信息检测(该工具可以快速检测网页的META标签,分析是否有标题、关键词、描述、等有利于搜索引擎收录。)6、MD5加密工具(用MD5加密字符串。) 7、sfz数值查询(查询sfz位置,性别和出生日期。)8、HTML/UBB 代码转换工具(HTML/UBB 代码转换。)9、HTML/JS 相互转换工具(HTML/JS 相互转换。) 10. 搜索蜘蛛,机器人模拟工具(该工具可以快速模拟搜索引擎蜘蛛访问页面的内容信息!) 11、关键词 密度检测(该工具可以快速检测页面的数量和密度关键词 出现,更适合蜘蛛搜索。) 12、 国家域名查看(查看所有国家的域名。) 1.) 30、Unix时间戳转换工具(什么是Unix时间戳):Unix时间戳,或Unix时间,POSIX时间,是一种时间表示,定义为从00:00:00开始的总秒数从格林威治标准时间 1970 年 1 月 1 日到现在。Unix 时间戳不仅在 Unix 系统和类 Unix 系统中使用,而且在许多其他操作系统中也被采用。)
现在下载 查看全部
网页源代码抓取工具(站长工具源码v2.0PHP版.rar站长功能简介)
站长工具源码v2.0 PHP版.rar
站长工具功能介绍1、JS加密/解密(对js形式的代码进行加密或解密。)2、UTF-8编码转换工具(UTF-8编码转换。)< @3、 Unicode 编码转换工具(Unicode 编码转换。)4、友情链接(该工具可用于批量查询百度收录、百度中指定网站的友情链接快照、PR、对方是否链接本站可以检测欺诈链接。) 5、META信息检测(该工具可以快速检测网页的META标签,分析是否有标题、关键词、描述、等有利于搜索引擎收录。)6、MD5加密工具(用MD5加密字符串。) 7、sfz数值查询(查询sfz位置,性别和出生日期。)8、HTML/UBB 代码转换工具(HTML/UBB 代码转换。)9、HTML/JS 相互转换工具(HTML/JS 相互转换。) 10. 搜索蜘蛛,机器人模拟工具(该工具可以快速模拟搜索引擎蜘蛛访问页面的内容信息!) 11、关键词 密度检测(该工具可以快速检测页面的数量和密度关键词 出现,更适合蜘蛛搜索。) 12、 国家域名查看(查看所有国家的域名。) 1.) 30、Unix时间戳转换工具(什么是Unix时间戳):Unix时间戳,或Unix时间,POSIX时间,是一种时间表示,定义为从00:00:00开始的总秒数从格林威治标准时间 1970 年 1 月 1 日到现在。Unix 时间戳不仅在 Unix 系统和类 Unix 系统中使用,而且在许多其他操作系统中也被采用。)
现在下载
网页源代码抓取工具( 免费获取bShare代码bSharePlus代码bSharebSharePlus分享方式(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-18 04:01
免费获取bShare代码bSharePlus代码bSharebSharePlus分享方式(组图))
bShare 拥有多种自定义按钮,让您可以根据需要自定义您想要的模式,给您最大的设计空间。同时bShare代码最轻,采用异步加载的概念,不会对网站本身的加载产生任何影响。强大的一键通话功能,一键分享至20个主流社交平台,大大节省您的账号管理时间。另外,在数据统计方面,可以清晰的看到点击、分享、回流、转化的详细数据,清晰洞察分享的每一个细节。
免费获取 bShare 代码
为了避免分享时网页重定向对网友的影响,bShare Plus特意采用了OAuth技术,让分享操作的整个过程都可以在当前页面完成。有效防止网民因跳转页面的吸引力而流失,还增加了人性化功能,分享完成后自动提示关注您的微博账号,进一步增加了用户在微博中的关注度,从而有效提升了关注度。用户对微博平台的影响。
免费获取 bShare Plus 代码
bSharebShare Plus
分享方式
除了一键点击,都是通过打开一个新的浏览器页面,用户跳转到目标平台的分享页面进行分享。
对于具有开放 API 的平台(例如 Oauth),共享是通过 API 调用完成的。以 Oauth 为例。首次分享时,用户需要打开平台页面进行连接。但是以后共享将不再需要连接,即不会离开当前页面。
分享图片
部分平台(如新浪微博、QQ空间、好友等)在分享时会抓取当前页面图片供用户选择,但这些都是平台本身的处理,bShare无法控制平台抓取的方式。
对于支持Open API图片分享的平台(如新浪微博、QQ空间、腾讯微博等),bShare会抓取页面中收录的主要图片,用户在当前页面。
分享后关注
分享后支持新浪微博关注功能。
对于微博平台,您可以设置分享后的关注功能。
统计数据
bShare统计用户点击分享的次数,跳转到平台分享页面,但bShare无法统计用户是否分享成功,所以分享次数会比实际次数多。
对于Open API的分享,bShare可以准确统计分享成功的次数。
分享优化功能设置
支持修改APP KEY、添加@和话题、分享模板、各种回流设置和数据分析等。
支持修改APP KEY、添加@和话题、分享模板、各种回流设置和数据分析等。
平台支持
不支持只能通过 Open API 共享的平台,例如 Wordpress。
支持所有平台。
获取 bShare!获取 bShare Plus! 查看全部
网页源代码抓取工具(
免费获取bShare代码bSharePlus代码bSharebSharePlus分享方式(组图))
bShare 拥有多种自定义按钮,让您可以根据需要自定义您想要的模式,给您最大的设计空间。同时bShare代码最轻,采用异步加载的概念,不会对网站本身的加载产生任何影响。强大的一键通话功能,一键分享至20个主流社交平台,大大节省您的账号管理时间。另外,在数据统计方面,可以清晰的看到点击、分享、回流、转化的详细数据,清晰洞察分享的每一个细节。
免费获取 bShare 代码
为了避免分享时网页重定向对网友的影响,bShare Plus特意采用了OAuth技术,让分享操作的整个过程都可以在当前页面完成。有效防止网民因跳转页面的吸引力而流失,还增加了人性化功能,分享完成后自动提示关注您的微博账号,进一步增加了用户在微博中的关注度,从而有效提升了关注度。用户对微博平台的影响。
免费获取 bShare Plus 代码
bSharebShare Plus
分享方式
除了一键点击,都是通过打开一个新的浏览器页面,用户跳转到目标平台的分享页面进行分享。
对于具有开放 API 的平台(例如 Oauth),共享是通过 API 调用完成的。以 Oauth 为例。首次分享时,用户需要打开平台页面进行连接。但是以后共享将不再需要连接,即不会离开当前页面。
分享图片
部分平台(如新浪微博、QQ空间、好友等)在分享时会抓取当前页面图片供用户选择,但这些都是平台本身的处理,bShare无法控制平台抓取的方式。
对于支持Open API图片分享的平台(如新浪微博、QQ空间、腾讯微博等),bShare会抓取页面中收录的主要图片,用户在当前页面。
分享后关注
分享后支持新浪微博关注功能。
对于微博平台,您可以设置分享后的关注功能。
统计数据
bShare统计用户点击分享的次数,跳转到平台分享页面,但bShare无法统计用户是否分享成功,所以分享次数会比实际次数多。
对于Open API的分享,bShare可以准确统计分享成功的次数。
分享优化功能设置
支持修改APP KEY、添加@和话题、分享模板、各种回流设置和数据分析等。
支持修改APP KEY、添加@和话题、分享模板、各种回流设置和数据分析等。
平台支持
不支持只能通过 Open API 共享的平台,例如 Wordpress。
支持所有平台。
获取 bShare!获取 bShare Plus!
网页源代码抓取工具(网页邮箱地址采集工具逗号分隔效率效率分隔分隔)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-12-18 02:02
网页邮箱地址采集工具是一款绿色免费便携软件,可以从网页中提取邮箱地址。例如,可以检索常见的 贴吧 电子邮件页面。
邮箱地址采集 工具功能:
输入采集的URL并点击执行按钮,支持逗号和分号分隔邮件地址,支持采集完成邮件发送提醒。
<IMG border=0 src="/uploadfiles/2014-12-11/20141211_163555_976.png">
使用说明:
1.在地址栏输入邮箱地址,点击“提取”
优点:提取多个唯一邮箱只需要一个URL
如何使用“多任务处理”:
1.检查多任务处理
2.在地址栏输入邮箱地址,点击“提取”,再次输入不同的网址,再次点击“提取”,像一些循环
优点:多次检索邮箱,保存一次
如何使用“提取邮箱”选项:
1. 在文本框中输入带有邮箱的网页源代码或邮箱的文本片段与其他文本混合,点击“执行”
优点:快速提取邮箱中的杂乱文字,网页源码等杂乱文字,其他文章等。
如何使用“组”和“逗号”选项:
1. 提取邮箱后,点击分组,设置每个分组的邮箱数量,然后根据需要添加逗号,点击“执行”
优点:根据需要对大量邮箱进行分组,并添加逗号,可用于批量/捆绑单显示同时发送给多个收件人。
如何使用“正常”选项”:
提取邮箱后,当您想在提取的邮箱中添加备注时,选择“普通”,添加备注内容,选择“将结果发送到邮箱”,然后单击“执行”,即可将添加了带有处理过的邮箱的注释发送到邮箱
解决这个问题:
1. 手动从网页中提取多个邮箱,速度太慢
2.重复邮箱太多,手动一一删除耗时太长
3. 群发/捆绑单发时,必须手动一一输入收信人邮箱,用逗号隔开,效率太低
4. 经常不在同一台电脑上,想开发客户端,没有数据和工具,数据不方便保存 查看全部
网页源代码抓取工具(网页邮箱地址采集工具逗号分隔效率效率分隔分隔)
网页邮箱地址采集工具是一款绿色免费便携软件,可以从网页中提取邮箱地址。例如,可以检索常见的 贴吧 电子邮件页面。
邮箱地址采集 工具功能:
输入采集的URL并点击执行按钮,支持逗号和分号分隔邮件地址,支持采集完成邮件发送提醒。
<IMG border=0 src="/uploadfiles/2014-12-11/20141211_163555_976.png">
使用说明:
1.在地址栏输入邮箱地址,点击“提取”
优点:提取多个唯一邮箱只需要一个URL
如何使用“多任务处理”:
1.检查多任务处理
2.在地址栏输入邮箱地址,点击“提取”,再次输入不同的网址,再次点击“提取”,像一些循环
优点:多次检索邮箱,保存一次
如何使用“提取邮箱”选项:
1. 在文本框中输入带有邮箱的网页源代码或邮箱的文本片段与其他文本混合,点击“执行”
优点:快速提取邮箱中的杂乱文字,网页源码等杂乱文字,其他文章等。
如何使用“组”和“逗号”选项:
1. 提取邮箱后,点击分组,设置每个分组的邮箱数量,然后根据需要添加逗号,点击“执行”
优点:根据需要对大量邮箱进行分组,并添加逗号,可用于批量/捆绑单显示同时发送给多个收件人。
如何使用“正常”选项”:
提取邮箱后,当您想在提取的邮箱中添加备注时,选择“普通”,添加备注内容,选择“将结果发送到邮箱”,然后单击“执行”,即可将添加了带有处理过的邮箱的注释发送到邮箱
解决这个问题:
1. 手动从网页中提取多个邮箱,速度太慢
2.重复邮箱太多,手动一一删除耗时太长
3. 群发/捆绑单发时,必须手动一一输入收信人邮箱,用逗号隔开,效率太低
4. 经常不在同一台电脑上,想开发客户端,没有数据和工具,数据不方便保存
网页源代码抓取工具(“百度蜘蛛模拟抓取工具”这款工具支持多个搜索引擎)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-18 02:01
类别:网站管理员工具/插件(专业测试)
资源大小:140KB
资源格式:EXE
存储方式:百度云
点击下载
注:本站提供的资源均为优质资源。均由站长本人或原创的资源测试并提供。确保资源的完整性、可用性和实用性!此外,所有资源均附有相关视频教程或指导文件,欢迎下载!
今天和大家分享的是一款“百度蜘蛛模拟爬虫工具”。本工具支持多种搜索引擎的模拟爬取,如:百度搜索引擎、360搜索引擎、搜狗搜索引擎等。本工具可以模拟爬取网页的风格和爬取源代码,作为SEO工作者,这款软件对我们很有帮助,让我们专注于这一点。
蜘蛛模拟爬虫有哪些功能?
1. 有没有被欺骗的链接?
我们在换友情链接的时候,正常看网页代码,但其实有些人会用劫持技术阻止百度看到这种友情链接,我们就会被骗,所以这个一定要注意,所以以免被链接白费。
2. 网站 被劫持了吗?
如果我们的网站被黑了,很容易被黑客劫持。我们正常看源码是没有问题的,但是百度抓取源码可能有问题,所以如果你的网站排名持续下降,你还是找不到问题,你需要用这个软件排查,有的黑客很聪明,他们不会占用你的百度排名,他们会去你的360,搜狗,因为百度的站长工具可以查,但是一般人在360、搜狗很少去查,所以有些人网站360很容易被K,部分是因为这个操作造成的。
3.检查网站蜘蛛爬行是否正常!
第三点是检查自己的页面。一些功能站点js太多,百度抓取的页面,可能不完整,或者我们用源码测试一下,看看百度可以抓取哪些部分,可以用这个软件测试。非常方便。这个软件可以说是seor必备的软件之一!
如何使用蜘蛛模拟爬虫!
1.下载软件并打开软件
2.输入你的网址,选择引擎,点击模拟爬取
3、点击查看源码,可以看到蜘蛛爬取的源码。
这个软件使用起来非常简单,但是非常好用。用于检查页面是否被黑,是否被骗,网页中是否有百度抓不到的内容,还可以调度360搜索引擎和搜狗搜索。引擎、必应搜索引擎等等!而且我们可以用这个软件来测试,比如我们开发的源代码,用这个软件测试爬取率,是否有问题等等,好的,今天就给大家讲解一下,希望这个软件帮助大家。 查看全部
网页源代码抓取工具(“百度蜘蛛模拟抓取工具”这款工具支持多个搜索引擎)
类别:网站管理员工具/插件(专业测试)
资源大小:140KB
资源格式:EXE
存储方式:百度云
点击下载
注:本站提供的资源均为优质资源。均由站长本人或原创的资源测试并提供。确保资源的完整性、可用性和实用性!此外,所有资源均附有相关视频教程或指导文件,欢迎下载!
今天和大家分享的是一款“百度蜘蛛模拟爬虫工具”。本工具支持多种搜索引擎的模拟爬取,如:百度搜索引擎、360搜索引擎、搜狗搜索引擎等。本工具可以模拟爬取网页的风格和爬取源代码,作为SEO工作者,这款软件对我们很有帮助,让我们专注于这一点。
蜘蛛模拟爬虫有哪些功能?
1. 有没有被欺骗的链接?
我们在换友情链接的时候,正常看网页代码,但其实有些人会用劫持技术阻止百度看到这种友情链接,我们就会被骗,所以这个一定要注意,所以以免被链接白费。
2. 网站 被劫持了吗?
如果我们的网站被黑了,很容易被黑客劫持。我们正常看源码是没有问题的,但是百度抓取源码可能有问题,所以如果你的网站排名持续下降,你还是找不到问题,你需要用这个软件排查,有的黑客很聪明,他们不会占用你的百度排名,他们会去你的360,搜狗,因为百度的站长工具可以查,但是一般人在360、搜狗很少去查,所以有些人网站360很容易被K,部分是因为这个操作造成的。
3.检查网站蜘蛛爬行是否正常!
第三点是检查自己的页面。一些功能站点js太多,百度抓取的页面,可能不完整,或者我们用源码测试一下,看看百度可以抓取哪些部分,可以用这个软件测试。非常方便。这个软件可以说是seor必备的软件之一!
如何使用蜘蛛模拟爬虫!
1.下载软件并打开软件
2.输入你的网址,选择引擎,点击模拟爬取
3、点击查看源码,可以看到蜘蛛爬取的源码。
这个软件使用起来非常简单,但是非常好用。用于检查页面是否被黑,是否被骗,网页中是否有百度抓不到的内容,还可以调度360搜索引擎和搜狗搜索。引擎、必应搜索引擎等等!而且我们可以用这个软件来测试,比如我们开发的源代码,用这个软件测试爬取率,是否有问题等等,好的,今天就给大家讲解一下,希望这个软件帮助大家。
网页源代码抓取工具(网络爬虫的专门邮箱邮箱的功能(待续)(下))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-17 14:25
网络爬虫和搜索引擎日以继夜地在互联网上搜索信息,以使其数据库足够强大,使自己的信息更加全面。大家都知道,互联网信息是无穷无尽的,爆炸式的增长。他们无法手动获取信息。他们编写了一个小程序,不断地获取互联网上的信息,于是产生了网络爬虫。
下面我用java实现了一个简单的专门抓邮箱的小工具,很粗糙,仅供大家参考。
这是渲染图
什么都不说,直接上代码
<p>
import java.awt.BorderLayout;
import java.awt.Dimension;
import java.awt.Image;
import java.awt.MenuItem;
import java.awt.PopupMenu;
import java.awt.Toolkit;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import java.awt.event.WindowAdapter;
import java.awt.event.WindowEvent;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import javax.swing.ImageIcon;
import javax.swing.JButton;
import javax.swing.JComboBox;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JOptionPane;
import javax.swing.JPanel;
import javax.swing.JScrollPane;
import javax.swing.JTextArea;
import javax.swing.JTextField;
import javax.swing.UIManager;
import javax.swing.UnsupportedLookAndFeelException;
public class MainFrm extends JFrame implements ActionListener {
private static final long serialVersionUID = 1L;
static int count=1;
static int countUrl=1;
JFrame frame;
JButton b1;
JButton b2;
JTextArea t1;
JTextField tf;
JPanel panel;
JScrollPane jScrollPane1;
JLabel label;
JComboBox comb;
PopupMenu pm;
List t = new ArrayList();
static int m = 0;
MainFrm into() {
pm = new PopupMenu();
MenuItem openItem = new MenuItem("1.打 开");
MenuItem closeItem = new MenuItem("2.退 出");
MenuItem aboutItem = new MenuItem("3.关 于");
openItem.addActionListener(this);
closeItem.addActionListener(this);
aboutItem.addActionListener(this);
pm.add(openItem);
pm.add(closeItem);
pm.add(aboutItem);
String[] petStrings = { "Baidu", "Google", "Yahoo", "Bing", "Sogou" };
comb = new JComboBox(petStrings);
java.net.URL imgURL = MainFrm.class.getResource("mail.png");
ImageIcon imageicon = new ImageIcon(imgURL);
panel = new JPanel();
tf = new JTextField(50);
tf.setText("留下邮箱");
label = new JLabel("关键字:");
frame = new JFrame("邮箱抓取(注:抓取深度暂时默认为2) QQ:三二八二四七六七六");
frame.setIconImage(imageicon.getImage());
b1 = new JButton("提取邮箱");
b1.addActionListener(this);
b2 = new JButton("停止抓取");
b2.addActionListener(this);
t1 = new JTextArea();
t1.setLineWrap(true);
jScrollPane1 = new JScrollPane(t1);
jScrollPane1.setPreferredSize(new Dimension(200, 200));
this.setDefaultCloseOperation(DO_NOTHING_ON_CLOSE);
frame.addWindowListener(new WindowAdapter() { // 窗口关闭事件
public void windowClosing(WindowEvent e) {
System.exit(0);
};
public void windowIconified(WindowEvent e) { // 窗口最小化事件
frame.setVisible(false);
systemTray();
}
});
panel.add(label);
panel.add(tf);
panel.add(comb);
panel.add(b1);
panel.add(b2);
frame.getContentPane().add(panel, BorderLayout.NORTH);
frame.getContentPane().add(jScrollPane1, BorderLayout.CENTER);
frame.setSize(300, 400);
frame.pack();
frame.setVisible(true);
Dimension winSize = Toolkit.getDefaultToolkit().getScreenSize();
frame.setLocation((winSize.width - frame.getWidth()) / 2,
(winSize.height - frame.getHeight()) / 2);
frame.setAlwaysOnTop(true);
return this;
}
public static void main(String[] args) throws ClassNotFoundException,
InstantiationException, IllegalAccessException,
UnsupportedLookAndFeelException {
// TODO Auto-generated method stub
UIManager.setLookAndFeel(UIManager.getSystemLookAndFeelClassName());
new MainFrm().into().systemTray();
}
@SuppressWarnings({ "unchecked", "deprecation", "static-access" })
@Override
public void actionPerformed(ActionEvent e) {
if ("提取邮箱".equals(e.getActionCommand())) {
count=1;
t1.setText("");
// get("http://dzh.mop.com/whbm/200601 ... 6quot;);
String http = "";
int combo = (comb.getSelectedIndex());
switch (combo) {
case 0:
http = "http://www.baidu.com/s?wd=";
break;
case 1:
http = "http://www.google.com.hk/searc ... 3B%3B
break;
case 2:
http = "http://www.yahoo.cn/s?q=";
break;
case 3:
http = "http://cn.bing.com/search?q=";
break;
case 4:
http = "http://www.sogou.com/web?query=";
break;
default:
http = "http://www.baidu.com/s?wd=";
break;
}
final List list = get(http + tf.getText());
m = list.size();
for (int i = 0, n = list.size(); i < n; i++) {
final Map map = list.get(i);
Thread tt = new Thread() {
public void run() {
Iterator iterator = map.values().iterator();
while (iterator.hasNext()) {
String u=iterator.next();
get(u);
}
}
};
t.add(tt);
tt.start();
}
} else if ("终止抓取".equals(e.getActionCommand())) {
for (int i = 0; i < t.size(); i++) {
t.get(i).stop();
}
} else if ("1.打 开".equals(e.getActionCommand())) {
frame.setVisible(true);
frame.setExtendedState(frame.NORMAL);
} else if ("2.退 出".equals(e.getActionCommand())) {
System.exit(0);
}else if ("3.关 于".equals(e.getActionCommand())) {
JOptionPane.showMessageDialog(null, "本程序仅供初学参考 QQ:三二八二四七六七六");
}
}
@SuppressWarnings("unchecked")
public List get(String urlStr) {
List list = new ArrayList();
try {
URL url = new URL(urlStr);
URLConnection rulConnection = url.openConnection();
HttpURLConnection httpUrlConnection = (HttpURLConnection) rulConnection;
httpUrlConnection.setRequestProperty("User-Agent",
"Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
BufferedReader br = new BufferedReader(new InputStreamReader(
httpUrlConnection.getInputStream()));
String line = "";
while ((line = br.readLine()) != null) {
Map map = pr(line);
list.add(map);
}
} catch (FileNotFoundException e) {
//e.printStackTrace();
} catch (IOException e) {
//e.printStackTrace();
} finally {
m--;
if (m 查看全部
网页源代码抓取工具(网络爬虫的专门邮箱邮箱的功能(待续)(下))
网络爬虫和搜索引擎日以继夜地在互联网上搜索信息,以使其数据库足够强大,使自己的信息更加全面。大家都知道,互联网信息是无穷无尽的,爆炸式的增长。他们无法手动获取信息。他们编写了一个小程序,不断地获取互联网上的信息,于是产生了网络爬虫。
下面我用java实现了一个简单的专门抓邮箱的小工具,很粗糙,仅供大家参考。
这是渲染图
什么都不说,直接上代码
<p>
import java.awt.BorderLayout;
import java.awt.Dimension;
import java.awt.Image;
import java.awt.MenuItem;
import java.awt.PopupMenu;
import java.awt.Toolkit;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import java.awt.event.WindowAdapter;
import java.awt.event.WindowEvent;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import javax.swing.ImageIcon;
import javax.swing.JButton;
import javax.swing.JComboBox;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JOptionPane;
import javax.swing.JPanel;
import javax.swing.JScrollPane;
import javax.swing.JTextArea;
import javax.swing.JTextField;
import javax.swing.UIManager;
import javax.swing.UnsupportedLookAndFeelException;
public class MainFrm extends JFrame implements ActionListener {
private static final long serialVersionUID = 1L;
static int count=1;
static int countUrl=1;
JFrame frame;
JButton b1;
JButton b2;
JTextArea t1;
JTextField tf;
JPanel panel;
JScrollPane jScrollPane1;
JLabel label;
JComboBox comb;
PopupMenu pm;
List t = new ArrayList();
static int m = 0;
MainFrm into() {
pm = new PopupMenu();
MenuItem openItem = new MenuItem("1.打 开");
MenuItem closeItem = new MenuItem("2.退 出");
MenuItem aboutItem = new MenuItem("3.关 于");
openItem.addActionListener(this);
closeItem.addActionListener(this);
aboutItem.addActionListener(this);
pm.add(openItem);
pm.add(closeItem);
pm.add(aboutItem);
String[] petStrings = { "Baidu", "Google", "Yahoo", "Bing", "Sogou" };
comb = new JComboBox(petStrings);
java.net.URL imgURL = MainFrm.class.getResource("mail.png");
ImageIcon imageicon = new ImageIcon(imgURL);
panel = new JPanel();
tf = new JTextField(50);
tf.setText("留下邮箱");
label = new JLabel("关键字:");
frame = new JFrame("邮箱抓取(注:抓取深度暂时默认为2) QQ:三二八二四七六七六");
frame.setIconImage(imageicon.getImage());
b1 = new JButton("提取邮箱");
b1.addActionListener(this);
b2 = new JButton("停止抓取");
b2.addActionListener(this);
t1 = new JTextArea();
t1.setLineWrap(true);
jScrollPane1 = new JScrollPane(t1);
jScrollPane1.setPreferredSize(new Dimension(200, 200));
this.setDefaultCloseOperation(DO_NOTHING_ON_CLOSE);
frame.addWindowListener(new WindowAdapter() { // 窗口关闭事件
public void windowClosing(WindowEvent e) {
System.exit(0);
};
public void windowIconified(WindowEvent e) { // 窗口最小化事件
frame.setVisible(false);
systemTray();
}
});
panel.add(label);
panel.add(tf);
panel.add(comb);
panel.add(b1);
panel.add(b2);
frame.getContentPane().add(panel, BorderLayout.NORTH);
frame.getContentPane().add(jScrollPane1, BorderLayout.CENTER);
frame.setSize(300, 400);
frame.pack();
frame.setVisible(true);
Dimension winSize = Toolkit.getDefaultToolkit().getScreenSize();
frame.setLocation((winSize.width - frame.getWidth()) / 2,
(winSize.height - frame.getHeight()) / 2);
frame.setAlwaysOnTop(true);
return this;
}
public static void main(String[] args) throws ClassNotFoundException,
InstantiationException, IllegalAccessException,
UnsupportedLookAndFeelException {
// TODO Auto-generated method stub
UIManager.setLookAndFeel(UIManager.getSystemLookAndFeelClassName());
new MainFrm().into().systemTray();
}
@SuppressWarnings({ "unchecked", "deprecation", "static-access" })
@Override
public void actionPerformed(ActionEvent e) {
if ("提取邮箱".equals(e.getActionCommand())) {
count=1;
t1.setText("");
// get("http://dzh.mop.com/whbm/200601 ... 6quot;);
String http = "";
int combo = (comb.getSelectedIndex());
switch (combo) {
case 0:
http = "http://www.baidu.com/s?wd=";
break;
case 1:
http = "http://www.google.com.hk/searc ... 3B%3B
break;
case 2:
http = "http://www.yahoo.cn/s?q=";
break;
case 3:
http = "http://cn.bing.com/search?q=";
break;
case 4:
http = "http://www.sogou.com/web?query=";
break;
default:
http = "http://www.baidu.com/s?wd=";
break;
}
final List list = get(http + tf.getText());
m = list.size();
for (int i = 0, n = list.size(); i < n; i++) {
final Map map = list.get(i);
Thread tt = new Thread() {
public void run() {
Iterator iterator = map.values().iterator();
while (iterator.hasNext()) {
String u=iterator.next();
get(u);
}
}
};
t.add(tt);
tt.start();
}
} else if ("终止抓取".equals(e.getActionCommand())) {
for (int i = 0; i < t.size(); i++) {
t.get(i).stop();
}
} else if ("1.打 开".equals(e.getActionCommand())) {
frame.setVisible(true);
frame.setExtendedState(frame.NORMAL);
} else if ("2.退 出".equals(e.getActionCommand())) {
System.exit(0);
}else if ("3.关 于".equals(e.getActionCommand())) {
JOptionPane.showMessageDialog(null, "本程序仅供初学参考 QQ:三二八二四七六七六");
}
}
@SuppressWarnings("unchecked")
public List get(String urlStr) {
List list = new ArrayList();
try {
URL url = new URL(urlStr);
URLConnection rulConnection = url.openConnection();
HttpURLConnection httpUrlConnection = (HttpURLConnection) rulConnection;
httpUrlConnection.setRequestProperty("User-Agent",
"Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
BufferedReader br = new BufferedReader(new InputStreamReader(
httpUrlConnection.getInputStream()));
String line = "";
while ((line = br.readLine()) != null) {
Map map = pr(line);
list.add(map);
}
} catch (FileNotFoundException e) {
//e.printStackTrace();
} catch (IOException e) {
//e.printStackTrace();
} finally {
m--;
if (m
网页源代码抓取工具(提取的数据还不能直接拿来用?文件还不符合要求?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-16 00:16
提取出来的数据不能直接使用吗?文件还没有下载?格式等不符合要求?不用担心,网页抓取工具优采云采集器 有自己的解决方案-数据处理。
图片1.png
网络爬虫的数据处理功能包括内容处理、文件下载和内容过滤三部分。下面我依次给大家介绍一下:
1、内容处理:对内容页面中提取的数据进行进一步的处理,如替换、标签过滤、分词等,我们可以同时添加多个操作,但这里需要注意的是,如果有多个操作,按照上面的顺序执行,也就是将上一步的结果作为下一步的参数。
下面我们一一介绍:
①提取内容为空:如果通过前面的规则无法准确提取提取内容或提取内容为空,请选择此选项。此应用程序后,将使用正则匹配从原创页面中再次提取。
②内容替换/排除:用字符串替换采集的内容。如果需要排除,请用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数替换字符串(不同于工具栏中的同义词替换)。
③html标签过滤:过滤指定的html标签,如④字符截取:通过开始和结束字符串截取内容。适用于提取内容的截取和调整。
⑤纯替换:如果某些内容(如单次出现的文本)无法通过一般的内容替换进行操作,则需要通过强大的正则表达式进行复杂的替换。
例如“最受欢迎的美国餐馆在这里”,我们将其替换为“美国餐馆”,正则表达式如下:
图片2.png
⑥数据转换:包括将结果简转繁、将结果繁转简、自动转化为拼音和时间修正转化,共计四项处理。
⑦智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取。
⑧高级功能:包括自动摘要、自动分词、自动分类、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串A长度等一系列函数。
⑨补全单个网址:将当前内容补全为一个网址。
2、文件下载:可以自动检测下载文件,可以设置下载路径和文件名样式。
注:文件下载中所指的下载图片为源代码中的标准样式
标签的图片地址。
例如,如果是直接的图片地址或不规则的图片源代码,采集器 将被视为文件下载。
①将相对地址补全为绝对地址:勾选后,标签采集的相对地址补全为绝对地址。
②下载图片:经核对,源码收录标准样式
将下载代码图像。
③检测文件的真实地址但不下载:有时采集到达附件下载地址而不是实际下载地址。点击之后,会有一个跳转。在这种情况下,如果勾选此选项,将显示真实地址采集,但不会仅下载下载地址。
④检测文件并下载:勾选后可以从采集下载任意格式的文件附件。
3、内容过滤:一些不符合条件的记录可以通过设置内容过滤被删除或标记为不接受。有几种方法可以处理内容过滤:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件即可。
②采集 结果不能为空:该功能可以防止某个字段出现空内容。
③采集 结果不能重复:该功能可以防止某个字段出现重复的内容。设置此项前请确保没有采集数据,否则需要先清除采集数据。
④内容长度小于(大于、等于、不等于)时过滤 N:符号或字母或数字或汉字算一个。
注意:如果满足以上四项中的任何一项或多项,您可以在采集器的其他设置功能中直接删除该记录,或者将该记录标记为不在采集采集将在下次运行任务时重复。
在网页抓取工具优采云采集器中进行一系列数据处理的好处是,当我们只需要做一个小操作时,我们不需要编写插件、生成和编译它们,并且可以一键将数据处理成我们需要的数据。 查看全部
网页源代码抓取工具(提取的数据还不能直接拿来用?文件还不符合要求?)
提取出来的数据不能直接使用吗?文件还没有下载?格式等不符合要求?不用担心,网页抓取工具优采云采集器 有自己的解决方案-数据处理。
图片1.png
网络爬虫的数据处理功能包括内容处理、文件下载和内容过滤三部分。下面我依次给大家介绍一下:
1、内容处理:对内容页面中提取的数据进行进一步的处理,如替换、标签过滤、分词等,我们可以同时添加多个操作,但这里需要注意的是,如果有多个操作,按照上面的顺序执行,也就是将上一步的结果作为下一步的参数。
下面我们一一介绍:
①提取内容为空:如果通过前面的规则无法准确提取提取内容或提取内容为空,请选择此选项。此应用程序后,将使用正则匹配从原创页面中再次提取。
②内容替换/排除:用字符串替换采集的内容。如果需要排除,请用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数替换字符串(不同于工具栏中的同义词替换)。
③html标签过滤:过滤指定的html标签,如④字符截取:通过开始和结束字符串截取内容。适用于提取内容的截取和调整。
⑤纯替换:如果某些内容(如单次出现的文本)无法通过一般的内容替换进行操作,则需要通过强大的正则表达式进行复杂的替换。
例如“最受欢迎的美国餐馆在这里”,我们将其替换为“美国餐馆”,正则表达式如下:
图片2.png
⑥数据转换:包括将结果简转繁、将结果繁转简、自动转化为拼音和时间修正转化,共计四项处理。
⑦智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取。
⑧高级功能:包括自动摘要、自动分词、自动分类、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串A长度等一系列函数。
⑨补全单个网址:将当前内容补全为一个网址。
2、文件下载:可以自动检测下载文件,可以设置下载路径和文件名样式。
注:文件下载中所指的下载图片为源代码中的标准样式
标签的图片地址。
例如,如果是直接的图片地址或不规则的图片源代码,采集器 将被视为文件下载。
①将相对地址补全为绝对地址:勾选后,标签采集的相对地址补全为绝对地址。
②下载图片:经核对,源码收录标准样式
将下载代码图像。
③检测文件的真实地址但不下载:有时采集到达附件下载地址而不是实际下载地址。点击之后,会有一个跳转。在这种情况下,如果勾选此选项,将显示真实地址采集,但不会仅下载下载地址。
④检测文件并下载:勾选后可以从采集下载任意格式的文件附件。
3、内容过滤:一些不符合条件的记录可以通过设置内容过滤被删除或标记为不接受。有几种方法可以处理内容过滤:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件即可。
②采集 结果不能为空:该功能可以防止某个字段出现空内容。
③采集 结果不能重复:该功能可以防止某个字段出现重复的内容。设置此项前请确保没有采集数据,否则需要先清除采集数据。
④内容长度小于(大于、等于、不等于)时过滤 N:符号或字母或数字或汉字算一个。
注意:如果满足以上四项中的任何一项或多项,您可以在采集器的其他设置功能中直接删除该记录,或者将该记录标记为不在采集采集将在下次运行任务时重复。
在网页抓取工具优采云采集器中进行一系列数据处理的好处是,当我们只需要做一个小操作时,我们不需要编写插件、生成和编译它们,并且可以一键将数据处理成我们需要的数据。
网页源代码抓取工具(Source对iOS8Extensions的巧妙利用,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-16 00:14
如果您是网站管理员或网络开发人员,在浏览器中查看网页源代码(HTML、CSS 和 JavaScript)是每天必不可少的操作。这种在桌面上的轻松操作已经变成了移动端。一件麻烦事。现在有了View Source对iOS 8 Extensions的巧妙运用,在移动端浏览和操作网页源代码将变得非常容易。
安装完查看源代码后,通过Safari分享按钮打开查看源代码开关,即可显示当前网页源代码。如果不想这样做,也可以将View Source作为一个独立的应用程序打开要查看的网站源代码当然,这种情况下View Source不会显示内容页面,而是直接显示页面源代码。
在这里你可以看到少数派网页的源代码。例如,通常的 SEO 人员会为网页定义 Title 和 Meta 标签关键字,以使 网站 更好地保持搜索引擎。
在View Source中,通过DOM节点树可以直观的看到当前网页的结构,方便查找和访问节点。还有一个很酷的地方就是View Source还可以通过inject JS来编写自定义的JS代码,退出插件的时候输出的JS效果会在网页上显示出来。比如在小众页面下的Script中输入:
警报(文件。标题);
退出插件,在Safari中显示关于少数网站 Title标签的提示弹窗,效果如图。
当然,如果你想在弹出的窗口中显示一个句子,你可以在脚本中输入:
警报(我爱斯派);
当然,这些只是普通的 JavaScript 警报代码。如果你有更有趣的玩法或者更实用的功能,也可以在评论中告诉我。
右上角有更多选项可以调用更多功能,比如将代码复制到剪贴板并继续在其他应用程序上编辑,还可以发送电子邮件、选择亮点等更多主题。这里多说一下,查看源码提供了很多亮色的主题供选择,笔者个人比较喜欢蓝屏的主题。
View Source 目前售价 6 元。 查看全部
网页源代码抓取工具(Source对iOS8Extensions的巧妙利用,你知道吗?)
如果您是网站管理员或网络开发人员,在浏览器中查看网页源代码(HTML、CSS 和 JavaScript)是每天必不可少的操作。这种在桌面上的轻松操作已经变成了移动端。一件麻烦事。现在有了View Source对iOS 8 Extensions的巧妙运用,在移动端浏览和操作网页源代码将变得非常容易。
安装完查看源代码后,通过Safari分享按钮打开查看源代码开关,即可显示当前网页源代码。如果不想这样做,也可以将View Source作为一个独立的应用程序打开要查看的网站源代码当然,这种情况下View Source不会显示内容页面,而是直接显示页面源代码。
在这里你可以看到少数派网页的源代码。例如,通常的 SEO 人员会为网页定义 Title 和 Meta 标签关键字,以使 网站 更好地保持搜索引擎。
在View Source中,通过DOM节点树可以直观的看到当前网页的结构,方便查找和访问节点。还有一个很酷的地方就是View Source还可以通过inject JS来编写自定义的JS代码,退出插件的时候输出的JS效果会在网页上显示出来。比如在小众页面下的Script中输入:
警报(文件。标题);
退出插件,在Safari中显示关于少数网站 Title标签的提示弹窗,效果如图。
当然,如果你想在弹出的窗口中显示一个句子,你可以在脚本中输入:
警报(我爱斯派);
当然,这些只是普通的 JavaScript 警报代码。如果你有更有趣的玩法或者更实用的功能,也可以在评论中告诉我。
右上角有更多选项可以调用更多功能,比如将代码复制到剪贴板并继续在其他应用程序上编辑,还可以发送电子邮件、选择亮点等更多主题。这里多说一下,查看源码提供了很多亮色的主题供选择,笔者个人比较喜欢蓝屏的主题。
View Source 目前售价 6 元。

