
文章采集api
文章采集api( 前往韦世东的技术专栏收获爬虫架构/爬虫逆向/存储引擎/消息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-10-15 06:04
前往韦世东的技术专栏收获爬虫架构/爬虫逆向/存储引擎/消息)
去魏世东的技术专栏收获爬虫架构/爬虫逆向/存储引擎/消息队列/Python/Golang相关知识
这个文章的主要目的是告诉你如何配置Prometheus,使其可以使用指定的Web Api接口采集指标数据。文章中使用的case是NGINX的采集配置。从设置了用户名和密码的NGINX数据索引页中的采集数据来看,这是这个文章的副标题,可能是nginx的prometheus 采集配置或者prometheus 采集@ > 基本身份验证的 nginx。
上图展示了配置完成后在Grafana中配置模板的效果。
用过Prometheus的朋友一定知道如何配置address:port服务。比如在采集某个Redis的信息时,配置可以这样写:
- job_name: 'redis'
static_configs:
- targets: ['11.22.33.58:6087']
注:以上情况假设Redis Exporter的地址和端口为11.22.33.58:6087。
这是最简单也是最广为人知的方法。但是如果要监控指定的Web API,就不能这样写了。如果你没有看到这个 文章,你可能会在搜索引擎中搜索这样的:
但是很遗憾,没有找到有效的信息(现在是2021年3月),基本上所有的坑都能找到。
条件假设
假设我们现在需要从带有地址的接口中采集相关Prometheus监控指标,并且该接口使用basic auth(假设用户名为weishidong,密码为0099887kk)进行基本授权验证。
配置实践
如果填写之前看到的Prometheus配置,很可能这样写配置:
- job_name: 'web'
static_configs:
- targets: ['http://www.weishidong.com/status/format/prometheus']
basic_auth:
username: weishidong
password: 0099887kk
保存配置文件,重启服务后,你会发现这种方式无法采集数据,太可怕了。
官方配置指南
刚才的手术实在是太可怕了。当我们遇到不明白的问题时,我们当然去官方文档-> Prometheus Configuration。建议从上往下阅读,但如果你赶时间,可以直接进入采集配置部分。官方示例如下(内容太多,这里只保留与本文相关的部分,建议大家阅读原文):
# The job name assigned to scraped metrics by default.
job_name:
# How frequently to scrape targets from this job.
[ scrape_interval: | default = ]
# Per-scrape timeout when scraping this job.
[ scrape_timeout: | default = ]
# The HTTP resource path on which to fetch metrics from targets.
[ metrics_path: | default = /metrics ]
# honor_labels controls how Prometheus handles conflicts between labels that are
# already present in scraped data and labels that Prometheus would attach
# server-side ("job" and "instance" labels, manually configured target
# labels, and labels generated by service discovery implementations).
#
# If honor_labels is set to "true", label conflicts are resolved by keeping label
# values from the scraped data and ignoring the conflicting server-side labels.
#
# If honor_labels is set to "false", label conflicts are resolved by renaming
# conflicting labels in the scraped data to "exported_" (for
# example "exported_instance", "exported_job") and then attaching server-side
# labels.
#
# Setting honor_labels to "true" is useful for use cases such as federation and
# scraping the Pushgateway, where all labels specified in the target should be
# preserved.
#
# Note that any globally configured "external_labels" are unaffected by this
# setting. In communication with external systems, they are always applied only
# when a time series does not have a given label yet and are ignored otherwise.
[ honor_labels: | default = false ]
# honor_timestamps controls whether Prometheus respects the timestamps present
# in scraped data.
#
# If honor_timestamps is set to "true", the timestamps of the metrics exposed
# by the target will be used.
#
# If honor_timestamps is set to "false", the timestamps of the metrics exposed
# by the target will be ignored.
[ honor_timestamps: | default = true ]
# Configures the protocol scheme used for requests.
[ scheme: | default = http ]
# Optional HTTP URL parameters.
params:
[ : [, ...] ]
# Sets the `Authorization` header on every scrape request with the
# configured username and password.
# password and password_file are mutually exclusive.
basic_auth:
[ username: ]
[ password: ]
[ password_file: ]
# Sets the `Authorization` header on every scrape request with
# the configured bearer token. It is mutually exclusive with `bearer_token_file`.
[ bearer_token: ]
# Sets the `Authorization` header on every scrape request with the bearer token
# read from the configured file. It is mutually exclusive with `bearer_token`.
[ bearer_token_file: ]
如果仔细看,应该注意几个关键信息:metrics_path 和 basic_auth。其中,metrics_path用于指定HTTP类型指示符信息采集时的路由地址,默认值为/metrics;字段basic_auth用于授权验证,这里的password可以指定一个密码文件,而不是直接填写明文(一般来说,指定的密码文件的安全性稍高,明文)。
有效配置
根据官方文档的指引,我们可以快速推导出正确的配置写法:
- job_name: 'web'
metrics_path: /status/format/prometheus
static_configs:
- targets: ['www.weishidong.com']
basic_auth:
username: weishidong
password: 0099887kk
需要注意的是这里的字不用填,因为Prometheus默认的Scheme是http。如果地址的scheme是https,我们需要根据文档指引添加scheme字段,对应的配置为:
- job_name: 'web'
metrics_path: /status/format/prometheus
static_configs:
- targets: ['www.weishidong.com']
scheme: https
basic_auth:
username: weishidong
password: 0099887kk
配置完成后,Prometheus应该可以成功采集获取数据。用Grafana,可以看到开头给出的监控效果图。 查看全部
文章采集api(
前往韦世东的技术专栏收获爬虫架构/爬虫逆向/存储引擎/消息)

去魏世东的技术专栏收获爬虫架构/爬虫逆向/存储引擎/消息队列/Python/Golang相关知识
这个文章的主要目的是告诉你如何配置Prometheus,使其可以使用指定的Web Api接口采集指标数据。文章中使用的case是NGINX的采集配置。从设置了用户名和密码的NGINX数据索引页中的采集数据来看,这是这个文章的副标题,可能是nginx的prometheus 采集配置或者prometheus 采集@ > 基本身份验证的 nginx。

上图展示了配置完成后在Grafana中配置模板的效果。
用过Prometheus的朋友一定知道如何配置address:port服务。比如在采集某个Redis的信息时,配置可以这样写:
- job_name: 'redis'
static_configs:
- targets: ['11.22.33.58:6087']
注:以上情况假设Redis Exporter的地址和端口为11.22.33.58:6087。
这是最简单也是最广为人知的方法。但是如果要监控指定的Web API,就不能这样写了。如果你没有看到这个 文章,你可能会在搜索引擎中搜索这样的:
但是很遗憾,没有找到有效的信息(现在是2021年3月),基本上所有的坑都能找到。
条件假设
假设我们现在需要从带有地址的接口中采集相关Prometheus监控指标,并且该接口使用basic auth(假设用户名为weishidong,密码为0099887kk)进行基本授权验证。
配置实践
如果填写之前看到的Prometheus配置,很可能这样写配置:
- job_name: 'web'
static_configs:
- targets: ['http://www.weishidong.com/status/format/prometheus']
basic_auth:
username: weishidong
password: 0099887kk
保存配置文件,重启服务后,你会发现这种方式无法采集数据,太可怕了。
官方配置指南
刚才的手术实在是太可怕了。当我们遇到不明白的问题时,我们当然去官方文档-> Prometheus Configuration。建议从上往下阅读,但如果你赶时间,可以直接进入采集配置部分。官方示例如下(内容太多,这里只保留与本文相关的部分,建议大家阅读原文):
# The job name assigned to scraped metrics by default.
job_name:
# How frequently to scrape targets from this job.
[ scrape_interval: | default = ]
# Per-scrape timeout when scraping this job.
[ scrape_timeout: | default = ]
# The HTTP resource path on which to fetch metrics from targets.
[ metrics_path: | default = /metrics ]
# honor_labels controls how Prometheus handles conflicts between labels that are
# already present in scraped data and labels that Prometheus would attach
# server-side ("job" and "instance" labels, manually configured target
# labels, and labels generated by service discovery implementations).
#
# If honor_labels is set to "true", label conflicts are resolved by keeping label
# values from the scraped data and ignoring the conflicting server-side labels.
#
# If honor_labels is set to "false", label conflicts are resolved by renaming
# conflicting labels in the scraped data to "exported_" (for
# example "exported_instance", "exported_job") and then attaching server-side
# labels.
#
# Setting honor_labels to "true" is useful for use cases such as federation and
# scraping the Pushgateway, where all labels specified in the target should be
# preserved.
#
# Note that any globally configured "external_labels" are unaffected by this
# setting. In communication with external systems, they are always applied only
# when a time series does not have a given label yet and are ignored otherwise.
[ honor_labels: | default = false ]
# honor_timestamps controls whether Prometheus respects the timestamps present
# in scraped data.
#
# If honor_timestamps is set to "true", the timestamps of the metrics exposed
# by the target will be used.
#
# If honor_timestamps is set to "false", the timestamps of the metrics exposed
# by the target will be ignored.
[ honor_timestamps: | default = true ]
# Configures the protocol scheme used for requests.
[ scheme: | default = http ]
# Optional HTTP URL parameters.
params:
[ : [, ...] ]
# Sets the `Authorization` header on every scrape request with the
# configured username and password.
# password and password_file are mutually exclusive.
basic_auth:
[ username: ]
[ password: ]
[ password_file: ]
# Sets the `Authorization` header on every scrape request with
# the configured bearer token. It is mutually exclusive with `bearer_token_file`.
[ bearer_token: ]
# Sets the `Authorization` header on every scrape request with the bearer token
# read from the configured file. It is mutually exclusive with `bearer_token`.
[ bearer_token_file: ]
如果仔细看,应该注意几个关键信息:metrics_path 和 basic_auth。其中,metrics_path用于指定HTTP类型指示符信息采集时的路由地址,默认值为/metrics;字段basic_auth用于授权验证,这里的password可以指定一个密码文件,而不是直接填写明文(一般来说,指定的密码文件的安全性稍高,明文)。
有效配置
根据官方文档的指引,我们可以快速推导出正确的配置写法:
- job_name: 'web'
metrics_path: /status/format/prometheus
static_configs:
- targets: ['www.weishidong.com']
basic_auth:
username: weishidong
password: 0099887kk
需要注意的是这里的字不用填,因为Prometheus默认的Scheme是http。如果地址的scheme是https,我们需要根据文档指引添加scheme字段,对应的配置为:
- job_name: 'web'
metrics_path: /status/format/prometheus
static_configs:
- targets: ['www.weishidong.com']
scheme: https
basic_auth:
username: weishidong
password: 0099887kk
配置完成后,Prometheus应该可以成功采集获取数据。用Grafana,可以看到开头给出的监控效果图。
文章采集api(2019seo优化超级蜘蛛池自动采集网站优化必备安装教程 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-10-09 03:31
)
内容
蜘蛛池引流站群蜘蛛池2019 seo优化超级蜘蛛池自动采集网站优化必备
安装教程:
上传后直接访问域名或域名/install进行安装。
建议安装条件:
1、推荐使用Apache
2、PHP 5.4.0 及以上
3、数据库版本不低于Mysql 5.0
蜘蛛池是一个利用大平台权重获取百度收录和排名的程序。程序员常称其为“蜘蛛池”。这是一个可以快速提升网站排名的程序。值得一提的是,它自动提升了网站的网站和收录的排名。这个效果非常出色。蜘蛛池程序能为我们做什么?我不想收录如果我发了外部链接,但我的竞争对手发到同一个网站,他们不发外部链接收录,对吧!答:(因为他们有大量的百度收录蜘蛛爬虫,可以用蜘蛛池做)
seo优化站群功能
安全、高效、优化使用PHP性能,运行流畅稳定
原内容刷新无缓存,节省硬盘。防止搜索引擎识别蜘蛛池
蜘蛛池算法,轻松建站(电影、新闻、图片、论坛等)
可以个性化每个网站的风格、内容、站点模式、关键词、外链等(自定义tkd、自定义外链关键词、自定义通用域名前缀)
____________________
有老手会说我也有百度蜘蛛,为什么不用我的收录?
答:(因为你的百度收录蜘蛛不多,不够宽,来回就是那些低质量的百度收录爬虫,收录慢,甚至一点都没有收录!——-蜘蛛池多服务器,多域名,常规内容站点支持百度收录蜘蛛,分布广泛,多域名,团队化蜘蛛,多源站点,高质量,每一天有新的蜘蛛爬取 收录 你推断的帖子)
超强蜘蛛池功能,全自动采集,支持api二次开发!
也可以作为站群的源程序。
支持用户开户,自动释放,可租用蜘蛛池,释放外链使用!
支持关键词跳转,全局跳转!
自动采集(腾讯新闻(国内、军事)、新浪新闻(国际、军事))
新闻伪原创,加速收录!
支持导入txt外推网址、蜘蛛日记、索引池、权重池等,更多功能可以自己发现!
查看全部
文章采集api(2019seo优化超级蜘蛛池自动采集网站优化必备安装教程
)
内容
蜘蛛池引流站群蜘蛛池2019 seo优化超级蜘蛛池自动采集网站优化必备
安装教程:
上传后直接访问域名或域名/install进行安装。
建议安装条件:
1、推荐使用Apache
2、PHP 5.4.0 及以上
3、数据库版本不低于Mysql 5.0
蜘蛛池是一个利用大平台权重获取百度收录和排名的程序。程序员常称其为“蜘蛛池”。这是一个可以快速提升网站排名的程序。值得一提的是,它自动提升了网站的网站和收录的排名。这个效果非常出色。蜘蛛池程序能为我们做什么?我不想收录如果我发了外部链接,但我的竞争对手发到同一个网站,他们不发外部链接收录,对吧!答:(因为他们有大量的百度收录蜘蛛爬虫,可以用蜘蛛池做)
seo优化站群功能
安全、高效、优化使用PHP性能,运行流畅稳定
原内容刷新无缓存,节省硬盘。防止搜索引擎识别蜘蛛池
蜘蛛池算法,轻松建站(电影、新闻、图片、论坛等)
可以个性化每个网站的风格、内容、站点模式、关键词、外链等(自定义tkd、自定义外链关键词、自定义通用域名前缀)
____________________
有老手会说我也有百度蜘蛛,为什么不用我的收录?
答:(因为你的百度收录蜘蛛不多,不够宽,来回就是那些低质量的百度收录爬虫,收录慢,甚至一点都没有收录!——-蜘蛛池多服务器,多域名,常规内容站点支持百度收录蜘蛛,分布广泛,多域名,团队化蜘蛛,多源站点,高质量,每一天有新的蜘蛛爬取 收录 你推断的帖子)
超强蜘蛛池功能,全自动采集,支持api二次开发!
也可以作为站群的源程序。
支持用户开户,自动释放,可租用蜘蛛池,释放外链使用!
支持关键词跳转,全局跳转!
自动采集(腾讯新闻(国内、军事)、新浪新闻(国际、军事))
新闻伪原创,加速收录!
支持导入txt外推网址、蜘蛛日记、索引池、权重池等,更多功能可以自己发现!
 https://www.chb66.com/wp-conte ... 4.png 416w, https://www.chb66.com/wp-conte ... 6.png 300w, https://www.chb66.com/wp-conte ... 2.png 768w" />
https://www.chb66.com/wp-conte ... 4.png 416w, https://www.chb66.com/wp-conte ... 6.png 300w, https://www.chb66.com/wp-conte ... 2.png 768w" /> 文章采集api(这款zblog-php优采云采集发布接口源码介绍:采集功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-10-09 03:29
来源介绍:
优采云采集器 大家都知道,采集非常强大,支持PHP发布接口,也就是说你在优采云采集中的网页数据可以自动更新到你自己的网站,那么这个zblog-php优采云接口此时就可以满足你的需求了,配置很简单,还有百度推送功能,发布和提交同时进行时间,如果你找人定制一个zblog系统的优采云发布模块,价格300元起,功能非常有限,一些发布参数是固定的,如果你想改变或添加,你需要花钱找人改,一点都不划算,但是如果安装这个“zblog-php优采云采集发布界面”插件,完全可以省去这些步骤,更不用说强大的功能了,而且简单易用。
特色:
下载链接:
链接:提取码:uwx5
安装教程:
1、Locoy_Pub.zip 上传到/zb_users/plugin 目录,然后解压
2、进入后端插件页面启用zblog-php 优采云采集发布接口
3、打开插件,然后下载release模块,将下载的release模块放在优采云的\Module目录下
4、进入优采云>网页发布设置的模块管理,选择zrblog php -hui sem- locoy pub -3. 0,然后编辑
5、在zrblog php -hui sem-locoy pub -3. 0的模块编辑框中点击内容发布参数,然后修改post-post-post地址和post-的参数值源地址的发布地址为正确的值。例如“?1ocoy=sH!pc2Vt”,红色参数值必须与发布接口校验码一致。
6、 然后是配置post数据的步骤,这个可以按照下面提供的表格来设置
7、 设置后点击保存,记得覆盖原来的模块,否则修改的东西不会生效~
其他补充:
求助:请配合优采云。优采云如果不能用请自行百度。
获取分类接口:?locoy_getcate
内容发布参数:(已在发布模块中设置,此处仅作说明,红色必填字段):
表单名称表单值描述
标题 查看全部
文章采集api(这款zblog-php优采云采集发布接口源码介绍:采集功能)
来源介绍:
优采云采集器 大家都知道,采集非常强大,支持PHP发布接口,也就是说你在优采云采集中的网页数据可以自动更新到你自己的网站,那么这个zblog-php优采云接口此时就可以满足你的需求了,配置很简单,还有百度推送功能,发布和提交同时进行时间,如果你找人定制一个zblog系统的优采云发布模块,价格300元起,功能非常有限,一些发布参数是固定的,如果你想改变或添加,你需要花钱找人改,一点都不划算,但是如果安装这个“zblog-php优采云采集发布界面”插件,完全可以省去这些步骤,更不用说强大的功能了,而且简单易用。
特色:
下载链接:
链接:提取码:uwx5
安装教程:
1、Locoy_Pub.zip 上传到/zb_users/plugin 目录,然后解压
2、进入后端插件页面启用zblog-php 优采云采集发布接口
3、打开插件,然后下载release模块,将下载的release模块放在优采云的\Module目录下
4、进入优采云>网页发布设置的模块管理,选择zrblog php -hui sem- locoy pub -3. 0,然后编辑
5、在zrblog php -hui sem-locoy pub -3. 0的模块编辑框中点击内容发布参数,然后修改post-post-post地址和post-的参数值源地址的发布地址为正确的值。例如“?1ocoy=sH!pc2Vt”,红色参数值必须与发布接口校验码一致。
6、 然后是配置post数据的步骤,这个可以按照下面提供的表格来设置
7、 设置后点击保存,记得覆盖原来的模块,否则修改的东西不会生效~
其他补充:
求助:请配合优采云。优采云如果不能用请自行百度。
获取分类接口:?locoy_getcate
内容发布参数:(已在发布模块中设置,此处仅作说明,红色必填字段):
表单名称表单值描述
标题
文章采集api(PHP安装Github地址(截图安装)(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-10-09 03:24
截屏
安装
Github地址:
环境要求:PHP 5.6-7.2、MySQL >= 5.7、Redis,Redis扩展
1、安装环境
这里还是简单的路线,使用宝塔面板进行演示,使用命令:
#CentOS系统
wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh
#Ubuntu系统
wget -O install.sh http://download.bt.cn/install/ ... .0.sh && sudo bash install.sh
#Debian系统
wget -O install.sh http://download.bt.cn/install/ ... .0.sh && bash install.sh
安装完成后进入面板,点击左侧的软件管理,然后安装PHP7.2、Nginx、Mysql5.7+、Redis。
接下来,找到左侧的软件管理-PHP管理-设置-安装Redis扩展。
2、安装步骤
我们先点击左边的网站添加域名;然后点击左边的database-add database。
运行命令:
#进入网站根目录,将路径修改成自己的再运行
cd /www/wwwroot/www.moerats.com
#拉取源码
git clone https://github.com/hiliqi/hanman.git
#将源码移动到根目录
mv hanman/{,.}* ./
#授权用户组
chown -R www:www ./
3、设置伪静态
点击域名设置-网站目录,运行目录选择public,去掉跨站防范检查,重启PHP。然后点击伪静态并输入以下代码:
if (!-e $request_filename) {
rewrite ^(.*)$ /index.php?s=/$1 last;
break;
}
然后打开域名启动安装程序。
如果要启用404而不显示cms错误信息,需要修改config/app.php文件:
#去掉第一排的//即可
'exception_tmpl' => Env::get('app_path') . 'index/view/pub/404.html',
'exception_tmpl' => Env::get('think_path') . 'tpl/think_exception.tpl',
采集
一般情况下,漫画站的图片资源有两种,一种是本地化的,一种是盗链的。建议对图片进行本地化,这样可以保证网站资源的稳定性,同时程序还提供了优采云采集器的API,可以方便地与优采云采集器 用于漫画和章节图片 采集。
首先,我们需要一个优采云采集器,官网→门户,但是分为免费版和付费版,但是免费版由于某些原因不能满足图片本地化的需要功能限制,暂时不适用,有钱可以买付费版,没钱可以直接用优采云V7.6企业破解版版本。大概目前最新的破解版也能满足程序采集的具体要求,如何下载请自行百度。许多 网站 提供下载链接。
注:由于优采云V7和V8没有URL编解码功能,不能采集有中文链接的漫画网站,但V9版本可以,直接上传即可如果你有钱。
采集api 说明:
采集api地址:域名/api/index/save。
请求方式:post
表单字段及说明:
book_name 漫画名
nick_name 漫画别名
tags 分类,多个分类用|隔开
author 作者名字
src 采集源
end 状态,1代表完结,0代表连载中
cover_url 封面图远程地址
chapter_name 章节名
images 由图片标签组成的字符串,示例:
api_key 用于身份验证,要和后台配置的api密钥相同
summary 漫画简介
详细的采集参数说明可查看→门户。
由于采集的过程有点复杂,不太容易发帖,有兴趣不知道如何采集的可以看官方教程→传送门。一般步骤是打开优采云采集器主界面-Publish-New-Content发布参数,然后写好发布模块后,开始寻找目标站并编写采集规则,最后采集 发布。 查看全部
文章采集api(PHP安装Github地址(截图安装)(图))
截屏




安装
Github地址:
环境要求:PHP 5.6-7.2、MySQL >= 5.7、Redis,Redis扩展
1、安装环境
这里还是简单的路线,使用宝塔面板进行演示,使用命令:
#CentOS系统
wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh
#Ubuntu系统
wget -O install.sh http://download.bt.cn/install/ ... .0.sh && sudo bash install.sh
#Debian系统
wget -O install.sh http://download.bt.cn/install/ ... .0.sh && bash install.sh
安装完成后进入面板,点击左侧的软件管理,然后安装PHP7.2、Nginx、Mysql5.7+、Redis。
接下来,找到左侧的软件管理-PHP管理-设置-安装Redis扩展。
2、安装步骤
我们先点击左边的网站添加域名;然后点击左边的database-add database。
运行命令:
#进入网站根目录,将路径修改成自己的再运行
cd /www/wwwroot/www.moerats.com
#拉取源码
git clone https://github.com/hiliqi/hanman.git
#将源码移动到根目录
mv hanman/{,.}* ./
#授权用户组
chown -R www:www ./
3、设置伪静态
点击域名设置-网站目录,运行目录选择public,去掉跨站防范检查,重启PHP。然后点击伪静态并输入以下代码:
if (!-e $request_filename) {
rewrite ^(.*)$ /index.php?s=/$1 last;
break;
}
然后打开域名启动安装程序。
如果要启用404而不显示cms错误信息,需要修改config/app.php文件:
#去掉第一排的//即可
'exception_tmpl' => Env::get('app_path') . 'index/view/pub/404.html',
'exception_tmpl' => Env::get('think_path') . 'tpl/think_exception.tpl',
采集
一般情况下,漫画站的图片资源有两种,一种是本地化的,一种是盗链的。建议对图片进行本地化,这样可以保证网站资源的稳定性,同时程序还提供了优采云采集器的API,可以方便地与优采云采集器 用于漫画和章节图片 采集。
首先,我们需要一个优采云采集器,官网→门户,但是分为免费版和付费版,但是免费版由于某些原因不能满足图片本地化的需要功能限制,暂时不适用,有钱可以买付费版,没钱可以直接用优采云V7.6企业破解版版本。大概目前最新的破解版也能满足程序采集的具体要求,如何下载请自行百度。许多 网站 提供下载链接。
注:由于优采云V7和V8没有URL编解码功能,不能采集有中文链接的漫画网站,但V9版本可以,直接上传即可如果你有钱。
采集api 说明:
采集api地址:域名/api/index/save。
请求方式:post
表单字段及说明:
book_name 漫画名
nick_name 漫画别名
tags 分类,多个分类用|隔开
author 作者名字
src 采集源
end 状态,1代表完结,0代表连载中
cover_url 封面图远程地址
chapter_name 章节名
images 由图片标签组成的字符串,示例:



api_key 用于身份验证,要和后台配置的api密钥相同
summary 漫画简介
详细的采集参数说明可查看→门户。
由于采集的过程有点复杂,不太容易发帖,有兴趣不知道如何采集的可以看官方教程→传送门。一般步骤是打开优采云采集器主界面-Publish-New-Content发布参数,然后写好发布模块后,开始寻找目标站并编写采集规则,最后采集 发布。
文章采集api(一个微信公众号采集程序API的功能特点及功能介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-10-05 17:00
我专注于信息采集,自动化测试。去年做了一个微信公众号采集程序。下半年,微信升级了加密算法,根本停不下来。
前段时间在我们平台偶尔看到这个文章被鼓励,所以在近半个月后,我开发了一个自己的新算法采集。无奈之前的功力太差了,只好在别人的基础上改进UI,增加了很多功能。【感谢你爱上Geek的UI,我哥抄袭你的风格】
本程序API的特点:
1. 支持微信公众号ID和微信公众号中文名称输入
2.返回的内容
微信现在是一个使用非常广泛的社交平台。它的微信公众平台也发挥着重要作用,很多企业和互联网公司都用它来进行推广和分享。后面的需求是采集上面的内容,使用或阅读。比如通过微信公众号采集,他们发布的优秀文章可以被阅读采集,或者转载,供更多人学习交流。
目前,既然微信是腾讯旗下的,谷奇文章当然是不允许外界爬行的。文章的获取方式主要有两种:一、与腾讯合作,开放独立接口。二、 通过腾讯搜狗搜索的微信搜索功能爬取。
本文介绍一个实现良好的微信文章在线采集工具,为文章采集提供指定公众号,获取文章的标题和地址链接@> 批量,并提供第三方API供使用和二次开发。
微信现在是一个使用非常广泛的社交平台。它的微信公众平台也发挥着重要作用,很多企业和互联网公司都用它来进行推广和分享。后面的需求是采集上面的内容,使用或阅读。比如通过微信公众号采集,他们发布的优秀文章可以被阅读采集,或者转载,供更多人学习交流。
目前,既然微信是腾讯旗下的,谷奇文章当然是不允许外人爬的。
本文介绍一个实现良好的微信文章在线采集工具,为文章采集提供指定公众号,获取文章的标题和地址链接@> 批量,并提供第三方API供使用和二次开发。
在线使用
特征
通过微信公众号(订阅号),无需任何登录即可获取公众号发布的所有文章标题和地址,结果可以JSON形式反馈或以TABLE形式在线阅读,同时提供外部API。
支持二次开发:每天自动抓取关注最新微信公众号文章,更新至自营微信公众号、论坛(DISCUZ、PHPWIND)、博客(WORDPRESS)、订阅信息(RSS)等.
指示
登录微信公众号提取网站
接口使用
以POST/GET形式提交微信公众号weixin和用户key,以JSON/JSONP形式返回数据
请求网址:
请求参数:wxID={$wxID}&key={$key}
返回数据:输入网站查看,这里不允许发代码
测试:采集《人民日报》微信公众号
网页显示示例:
API 返回 JSON 示例:+iIR+5Ab52dVh73DsX/XYLlT/kHU9LNL6F71o0yGcChSEq
注:以上内容仅供研究使用,请勿用于非法用途。
【为防止过度使用资源或不必要的麻烦,页面设有临时KEY(有效期2分钟,可刷新重新获取)。】 查看全部
文章采集api(一个微信公众号采集程序API的功能特点及功能介绍)
我专注于信息采集,自动化测试。去年做了一个微信公众号采集程序。下半年,微信升级了加密算法,根本停不下来。
前段时间在我们平台偶尔看到这个文章被鼓励,所以在近半个月后,我开发了一个自己的新算法采集。无奈之前的功力太差了,只好在别人的基础上改进UI,增加了很多功能。【感谢你爱上Geek的UI,我哥抄袭你的风格】
本程序API的特点:
1. 支持微信公众号ID和微信公众号中文名称输入
2.返回的内容
微信现在是一个使用非常广泛的社交平台。它的微信公众平台也发挥着重要作用,很多企业和互联网公司都用它来进行推广和分享。后面的需求是采集上面的内容,使用或阅读。比如通过微信公众号采集,他们发布的优秀文章可以被阅读采集,或者转载,供更多人学习交流。
目前,既然微信是腾讯旗下的,谷奇文章当然是不允许外界爬行的。文章的获取方式主要有两种:一、与腾讯合作,开放独立接口。二、 通过腾讯搜狗搜索的微信搜索功能爬取。
本文介绍一个实现良好的微信文章在线采集工具,为文章采集提供指定公众号,获取文章的标题和地址链接@> 批量,并提供第三方API供使用和二次开发。



微信现在是一个使用非常广泛的社交平台。它的微信公众平台也发挥着重要作用,很多企业和互联网公司都用它来进行推广和分享。后面的需求是采集上面的内容,使用或阅读。比如通过微信公众号采集,他们发布的优秀文章可以被阅读采集,或者转载,供更多人学习交流。
目前,既然微信是腾讯旗下的,谷奇文章当然是不允许外人爬的。
本文介绍一个实现良好的微信文章在线采集工具,为文章采集提供指定公众号,获取文章的标题和地址链接@> 批量,并提供第三方API供使用和二次开发。
在线使用

特征
通过微信公众号(订阅号),无需任何登录即可获取公众号发布的所有文章标题和地址,结果可以JSON形式反馈或以TABLE形式在线阅读,同时提供外部API。
支持二次开发:每天自动抓取关注最新微信公众号文章,更新至自营微信公众号、论坛(DISCUZ、PHPWIND)、博客(WORDPRESS)、订阅信息(RSS)等.
指示
登录微信公众号提取网站
接口使用
以POST/GET形式提交微信公众号weixin和用户key,以JSON/JSONP形式返回数据
请求网址:
请求参数:wxID={$wxID}&key={$key}
返回数据:输入网站查看,这里不允许发代码
测试:采集《人民日报》微信公众号
网页显示示例:
API 返回 JSON 示例:+iIR+5Ab52dVh73DsX/XYLlT/kHU9LNL6F71o0yGcChSEq
注:以上内容仅供研究使用,请勿用于非法用途。
【为防止过度使用资源或不必要的麻烦,页面设有临时KEY(有效期2分钟,可刷新重新获取)。】
文章采集api(抖音爬虫教程,AndServer+Service打造Android服务器实现so文件调用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2021-10-04 14:14
抖音爬虫教程,AndServer+Service搭建Android服务器实现so文件调用so文件调用
随着Android手机安全的飞速发展,无论是为了执行效率还是程序安全,关键代码下沉到native层已经成为一项基本操作。
native层的开发参考JNI/NDK开发。通过JNI,Java层和native层(主要是C/C++)可以相互调用。本机层编译生成so动态链接库,so文件具有可移植性广、执行效率高、保密性强等优点。
那么问题来了,如何调用so文件是极其重要的。当然你也可以直接分析so文件的伪代码,用强大的编程技巧直接模拟按键操作,不过我觉得对于普通人来说头发还是比较重要的。
目前主流的调用so文件的操作应该是: 1.基于Unicorn的各种实现(还在学习中,暂不列出) 2. Android服务器搭建,在App中启动http服务完成调用so的需求(当然前提是经过so等验证)
至于为什么选择AndServer,嗯,不是为什么,只是因为我发现了它为什么要和Service结合,我在学习Android开发的时候就了解了Service的生命周期,个人理解还是用Service来做比较好创建 Http 服务。
当然也有Application的简单使用,因为在正式环境下,so文件的大部分逻辑都有上下文的一些包名,签名验证等,如果自定义Application,就可以得到传递参数的上下文。
短视频直播数据采集接口SDK,请点击查看接口文档libyemu.so介绍
这是我编译的so文件,根据输入参数进行简单的字符串拼接(以下是native层编译前的c代码)
extern "C"
JNIEXPORT jstring JNICALL
Java_com_fw_myapplication_ndktest_NdkTest_stringFromUTF(JNIEnv *env, jobject instance, jstring str_) {
jclass String_clazz = env->FindClass("java/lang/String");
jmethodID concat_methodID = env->GetMethodID(String_clazz, "concat", "(Ljava/lang/String;)Ljava/lang/String;");
jstring str = env->NewStringUTF(" from so --[NightTeam夜幕]");
jobject str1 = env->CallObjectMethod(str_, concat_methodID, str);
const char *chars = env->GetStringUTFChars((jstring)str1, 0);
return env->NewStringUTF(chars);
}
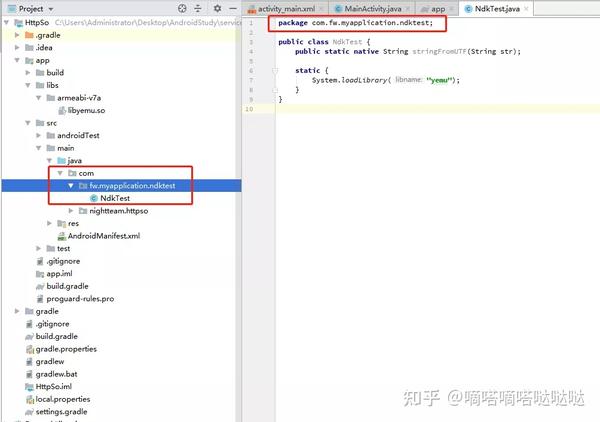
这部分代码还需要贴出来。简单的静态配准使用了反射的思想。反之,反射是至关重要的。接下来是java代码,它定义了native函数。
package com.fw.myapplication.ndktest;
public class NdkTest {
public static native String stringFromUTF(String str);
static {
System.loadLibrary("yemu");
}
}
如果你在这里有点困惑,你可能需要补上Android开发的基础。
Android项目测试so
先说一下我的环境,因为这个环境影响太大了 1、AndroidStudio 3.4 2、手机Android 6架构 armeabi-v7a 打开AndroidStudio新建项目
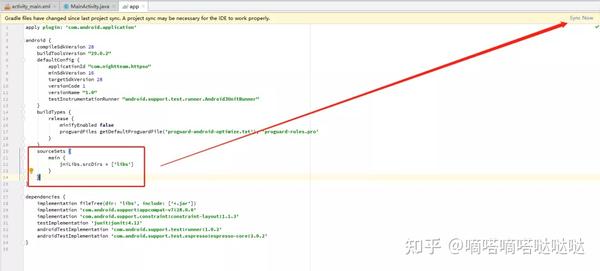
在模块的build中加入这句话,然后同步
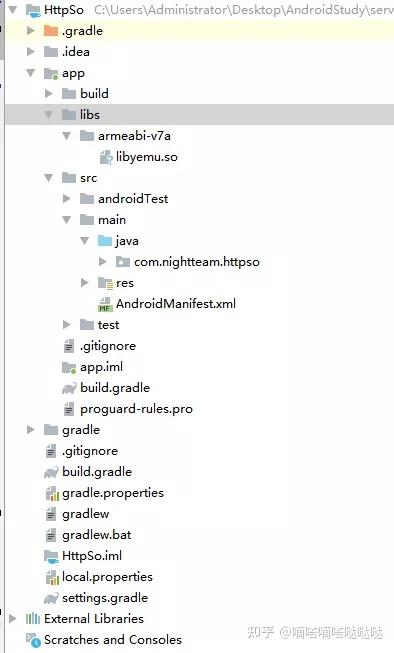
将编译好的so文件复制到libs文件夹(对应刚才的jniLibs.srcDirs)
复制so对应的java代码,注意包名和类名的一致性
打开activity_main.xml文件,给TextView添加一个id
打开 MainActiviy.java 开始编码
这两行的意思是,先从layout中找到id对应的TextView,然后为其设置Text(调用原生函数的返回值)。让我们测试一下我们的通话情况。
可以看到我们的so文件调用成功了(这里我们的so无效,测试一下app是否可以正常调用)
AndServer代码编写
AndServer官方文档:/AndServer/ 打开官方文档,看看别人的介绍,新建一个java文件
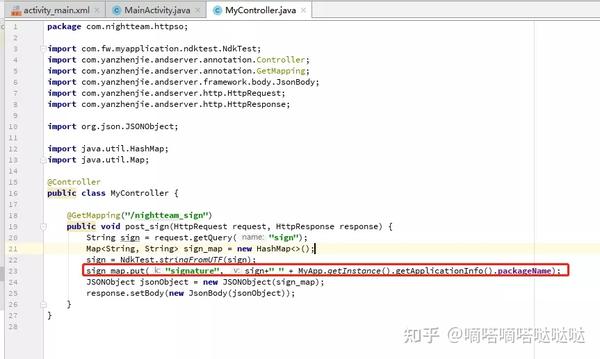
如图,写了经典的MVC C,定义了一个nightteam_sign接口,请求方法为get,请求参数为sign,调用native函数,然后返回json,但是这里我想用Application获取上下文对象并去掉包名,然后自定义Applictaion
package com.nightteam.httpso;
import android.app.Application;
public class MyApp extends Application {
private static MyApp myApp;
public static MyApp getInstance() {
return myApp;
}
@Override
public void onCreate() {
super.onCreate();
myApp = this;
}
}
然后在清单文件中指定要启动的应用程序
然后修改MyController.java的代码
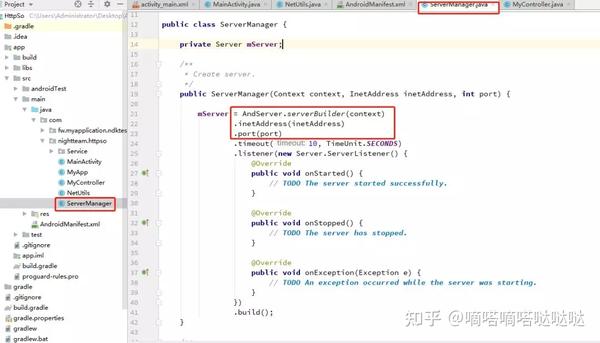
接下来复制官方文档服务器的代码导入一些包,修改部分代码如下
AndServer.serverBuilder 的新版本已经需要传递上下文。这里也修改了网络地址和端口号,从构造参数中获取。至此,AndServer 的东西基本完成了。其实我们会搭建一个界面来调整so。业务逻辑比较多,所以代码最简单好用
服务代码编写
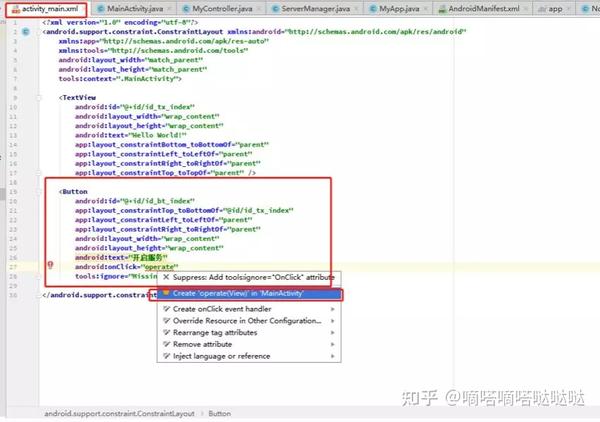
这里我们用按钮的点击事件启动Service,所以在activity_main.xml中添加一个按钮并指定点击事件
接下来编写自定义Service代码
package com.nightteam.httpso.Service;
import android.app.Service;
import android.content.Intent;
import android.os.IBinder;
import android.util.Log;
import com.nightteam.httpso.ServerManager;
import java.net.InetAddress;
import java.net.UnknownHostException;
public class MyService extends Service {
private static final String TAG = "NigthTeam";
@Override
public void onCreate() {
super.onCreate();
Log.d(TAG, "onCreate: MyService");
new Thread() {
@Override
public void run() {
super.run();
InetAddress inetAddress = null;
try {
inetAddress = InetAddress.getByName("0.0.0.0");
Log.d(TAG, "onCreate: " + inetAddress.getHostAddress());
ServerManager serverManager = new ServerManager(getApplicationContext(), inetAddress, 8005);
serverManager.startServer();
} catch (UnknownHostException e) {
e.printStackTrace();
}
}
}.start();
}
@Override
public IBinder onBind(Intent intent) {
return null;
}
}
我打印了几条日志,在子线程中启动了AndServer服务(什么时候使用UI线程和子线程是Android的基础,这里不再赘述)。注意,这里从 0.0.0.0 获取inetAddress,别搞错了,localhost和0.0.0.的区别0,请移至搜索引擎,然后将context、inetAddress、port传递给ServerManager的构造函数用于新建对象,然后启动服务最后注意查看manifest文件中Service的声明
打开Service,获取本地ip
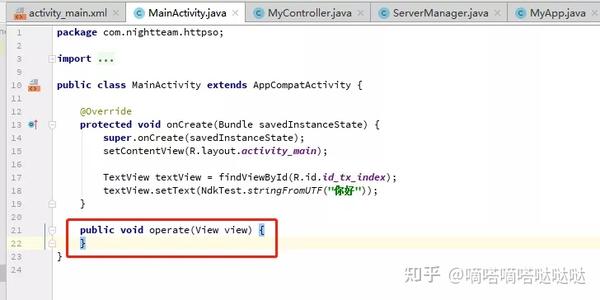
回到我们MainActivity.java的操作(按钮点击事件)编写启动Service的代码
public void operate(View view) {
switch (view.getId()){
case R.id.id_bt_index:
//启动服务:创建-->启动-->销毁
//如果服务已经创建了,后续重复启动,操作的都是同一个服务,不会再重新创建了,除非你先销毁它
Intent it1 = new Intent(this, MyService.class);
Log.d(TAG, "operate: button");
startService(it1);
((Button) view).setText("服务已开启");
break;
}
}
至此,我们的服务基本设置好了,但是为了方便,我想在App上显示我们本地的IP,这样我们就不用再设置和检查了。我在网上找到了一个获取IP地址的工具。,源码如下:
package com.nightteam.httpso;
import java.net.InetAddress;
import java.net.NetworkInterface;
import java.net.SocketException;
import java.util.Enumeration;
import java.util.regex.Pattern;
public class NetUtils {
private static final Pattern IPV4_PATTERN = Pattern.compile("^(" +
"([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\\.){3}" +
"([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])$");
private static boolean isIPv4Address(String input) {
return IPV4_PATTERN.matcher(input).matches();
}
//获取本机IP地址
public static InetAddress getLocalIPAddress() {
Enumeration enumeration = null;
try {
enumeration = NetworkInterface.getNetworkInterfaces();
} catch (SocketException e) {
e.printStackTrace();
}
if (enumeration != null) {
while (enumeration.hasMoreElements()) {
NetworkInterface nif = enumeration.nextElement();
Enumeration inetAddresses = nif.getInetAddresses();
if (inetAddresses != null)
while (inetAddresses.hasMoreElements()) {
InetAddress inetAddress = inetAddresses.nextElement();
if (!inetAddress.isLoopbackAddress() && isIPv4Address(inetAddress.getHostAddress())) {
return inetAddress;
}
}
}
}
return null;
}
}
将工具类复制到我们的 Android 项目中,并在 MainActivity.java 中继续编码
获取本地地址和Android SDK版本(Android 8之后启动Service的方式不同)
申请权限,启动App
最后一步是为应用申请网络权限
然后连接我们的手机,运行项目,测试一下,点击启动服务
查看AndroidStudio日志
好像一切正常,在浏览器访问下试试(ip是App中显示的ip地址)
如图,我们访问到了我们想要的内容。回去再说Service,打开我们手机的设置,找到应用管理-运行服务(不同的手机,不同的方法)
可以看到我们的程序运行了一个服务,这个服务就是我们编码的MyService
接下来,杀死App进程并再次检查正在运行的服务
这里我在权限管理中设置了自动运行,可以保持服务运行。(这个地方还是根据系统大小不同) 到此为止,可以使用App启动http服务并调整so。 查看全部
文章采集api(抖音爬虫教程,AndServer+Service打造Android服务器实现so文件调用)
抖音爬虫教程,AndServer+Service搭建Android服务器实现so文件调用so文件调用
随着Android手机安全的飞速发展,无论是为了执行效率还是程序安全,关键代码下沉到native层已经成为一项基本操作。
native层的开发参考JNI/NDK开发。通过JNI,Java层和native层(主要是C/C++)可以相互调用。本机层编译生成so动态链接库,so文件具有可移植性广、执行效率高、保密性强等优点。
那么问题来了,如何调用so文件是极其重要的。当然你也可以直接分析so文件的伪代码,用强大的编程技巧直接模拟按键操作,不过我觉得对于普通人来说头发还是比较重要的。
目前主流的调用so文件的操作应该是: 1.基于Unicorn的各种实现(还在学习中,暂不列出) 2. Android服务器搭建,在App中启动http服务完成调用so的需求(当然前提是经过so等验证)
至于为什么选择AndServer,嗯,不是为什么,只是因为我发现了它为什么要和Service结合,我在学习Android开发的时候就了解了Service的生命周期,个人理解还是用Service来做比较好创建 Http 服务。
当然也有Application的简单使用,因为在正式环境下,so文件的大部分逻辑都有上下文的一些包名,签名验证等,如果自定义Application,就可以得到传递参数的上下文。
短视频直播数据采集接口SDK,请点击查看接口文档libyemu.so介绍
这是我编译的so文件,根据输入参数进行简单的字符串拼接(以下是native层编译前的c代码)
extern "C"
JNIEXPORT jstring JNICALL
Java_com_fw_myapplication_ndktest_NdkTest_stringFromUTF(JNIEnv *env, jobject instance, jstring str_) {
jclass String_clazz = env->FindClass("java/lang/String");
jmethodID concat_methodID = env->GetMethodID(String_clazz, "concat", "(Ljava/lang/String;)Ljava/lang/String;");
jstring str = env->NewStringUTF(" from so --[NightTeam夜幕]");
jobject str1 = env->CallObjectMethod(str_, concat_methodID, str);
const char *chars = env->GetStringUTFChars((jstring)str1, 0);
return env->NewStringUTF(chars);
}
这部分代码还需要贴出来。简单的静态配准使用了反射的思想。反之,反射是至关重要的。接下来是java代码,它定义了native函数。
package com.fw.myapplication.ndktest;
public class NdkTest {
public static native String stringFromUTF(String str);
static {
System.loadLibrary("yemu");
}
}
如果你在这里有点困惑,你可能需要补上Android开发的基础。
Android项目测试so
先说一下我的环境,因为这个环境影响太大了 1、AndroidStudio 3.4 2、手机Android 6架构 armeabi-v7a 打开AndroidStudio新建项目
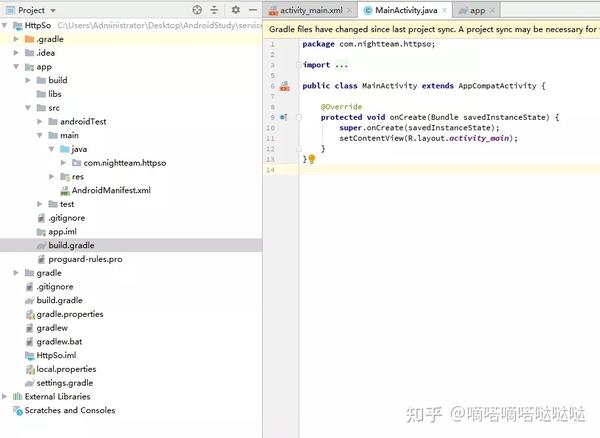
在模块的build中加入这句话,然后同步
将编译好的so文件复制到libs文件夹(对应刚才的jniLibs.srcDirs)
复制so对应的java代码,注意包名和类名的一致性
打开activity_main.xml文件,给TextView添加一个id
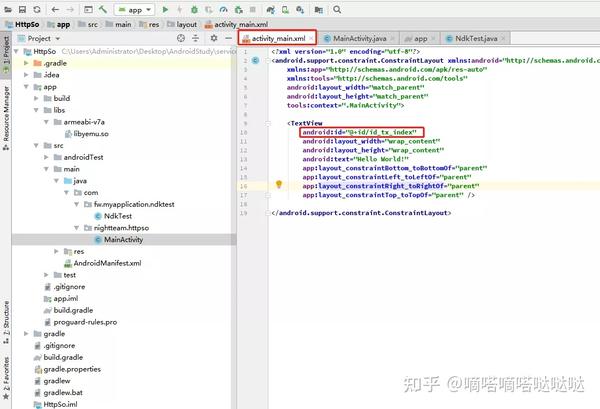
打开 MainActiviy.java 开始编码
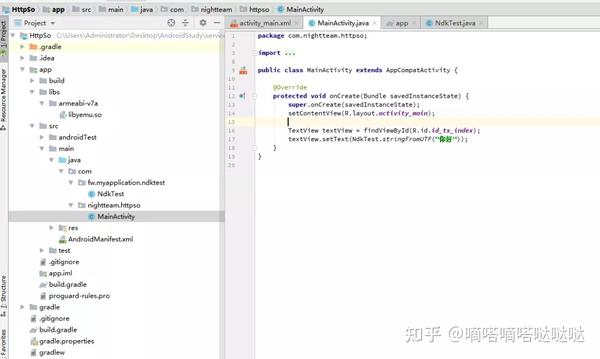
这两行的意思是,先从layout中找到id对应的TextView,然后为其设置Text(调用原生函数的返回值)。让我们测试一下我们的通话情况。

可以看到我们的so文件调用成功了(这里我们的so无效,测试一下app是否可以正常调用)
AndServer代码编写
AndServer官方文档:/AndServer/ 打开官方文档,看看别人的介绍,新建一个java文件
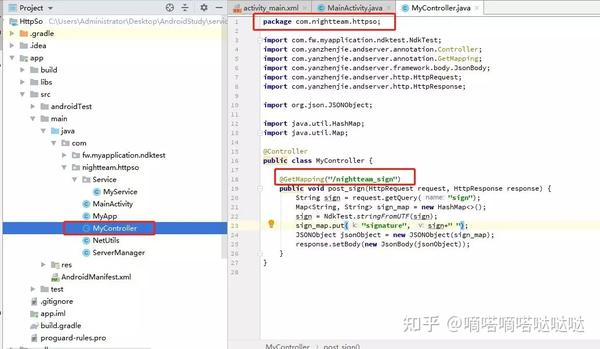
如图,写了经典的MVC C,定义了一个nightteam_sign接口,请求方法为get,请求参数为sign,调用native函数,然后返回json,但是这里我想用Application获取上下文对象并去掉包名,然后自定义Applictaion
package com.nightteam.httpso;
import android.app.Application;
public class MyApp extends Application {
private static MyApp myApp;
public static MyApp getInstance() {
return myApp;
}
@Override
public void onCreate() {
super.onCreate();
myApp = this;
}
}
然后在清单文件中指定要启动的应用程序
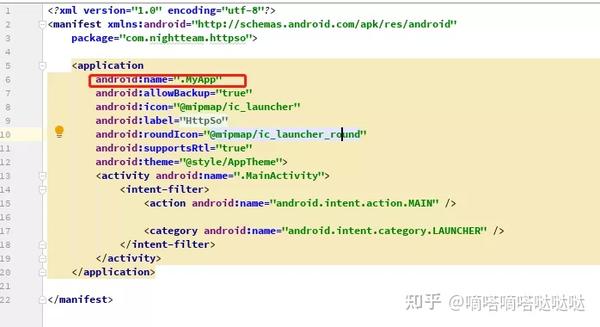
然后修改MyController.java的代码
接下来复制官方文档服务器的代码导入一些包,修改部分代码如下
AndServer.serverBuilder 的新版本已经需要传递上下文。这里也修改了网络地址和端口号,从构造参数中获取。至此,AndServer 的东西基本完成了。其实我们会搭建一个界面来调整so。业务逻辑比较多,所以代码最简单好用
服务代码编写
这里我们用按钮的点击事件启动Service,所以在activity_main.xml中添加一个按钮并指定点击事件
接下来编写自定义Service代码
package com.nightteam.httpso.Service;
import android.app.Service;
import android.content.Intent;
import android.os.IBinder;
import android.util.Log;
import com.nightteam.httpso.ServerManager;
import java.net.InetAddress;
import java.net.UnknownHostException;
public class MyService extends Service {
private static final String TAG = "NigthTeam";
@Override
public void onCreate() {
super.onCreate();
Log.d(TAG, "onCreate: MyService");
new Thread() {
@Override
public void run() {
super.run();
InetAddress inetAddress = null;
try {
inetAddress = InetAddress.getByName("0.0.0.0");
Log.d(TAG, "onCreate: " + inetAddress.getHostAddress());
ServerManager serverManager = new ServerManager(getApplicationContext(), inetAddress, 8005);
serverManager.startServer();
} catch (UnknownHostException e) {
e.printStackTrace();
}
}
}.start();
}
@Override
public IBinder onBind(Intent intent) {
return null;
}
}
我打印了几条日志,在子线程中启动了AndServer服务(什么时候使用UI线程和子线程是Android的基础,这里不再赘述)。注意,这里从 0.0.0.0 获取inetAddress,别搞错了,localhost和0.0.0.的区别0,请移至搜索引擎,然后将context、inetAddress、port传递给ServerManager的构造函数用于新建对象,然后启动服务最后注意查看manifest文件中Service的声明
打开Service,获取本地ip
回到我们MainActivity.java的操作(按钮点击事件)编写启动Service的代码
public void operate(View view) {
switch (view.getId()){
case R.id.id_bt_index:
//启动服务:创建-->启动-->销毁
//如果服务已经创建了,后续重复启动,操作的都是同一个服务,不会再重新创建了,除非你先销毁它
Intent it1 = new Intent(this, MyService.class);
Log.d(TAG, "operate: button");
startService(it1);
((Button) view).setText("服务已开启");
break;
}
}
至此,我们的服务基本设置好了,但是为了方便,我想在App上显示我们本地的IP,这样我们就不用再设置和检查了。我在网上找到了一个获取IP地址的工具。,源码如下:
package com.nightteam.httpso;
import java.net.InetAddress;
import java.net.NetworkInterface;
import java.net.SocketException;
import java.util.Enumeration;
import java.util.regex.Pattern;
public class NetUtils {
private static final Pattern IPV4_PATTERN = Pattern.compile("^(" +
"([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\\.){3}" +
"([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])$");
private static boolean isIPv4Address(String input) {
return IPV4_PATTERN.matcher(input).matches();
}
//获取本机IP地址
public static InetAddress getLocalIPAddress() {
Enumeration enumeration = null;
try {
enumeration = NetworkInterface.getNetworkInterfaces();
} catch (SocketException e) {
e.printStackTrace();
}
if (enumeration != null) {
while (enumeration.hasMoreElements()) {
NetworkInterface nif = enumeration.nextElement();
Enumeration inetAddresses = nif.getInetAddresses();
if (inetAddresses != null)
while (inetAddresses.hasMoreElements()) {
InetAddress inetAddress = inetAddresses.nextElement();
if (!inetAddress.isLoopbackAddress() && isIPv4Address(inetAddress.getHostAddress())) {
return inetAddress;
}
}
}
}
return null;
}
}
将工具类复制到我们的 Android 项目中,并在 MainActivity.java 中继续编码
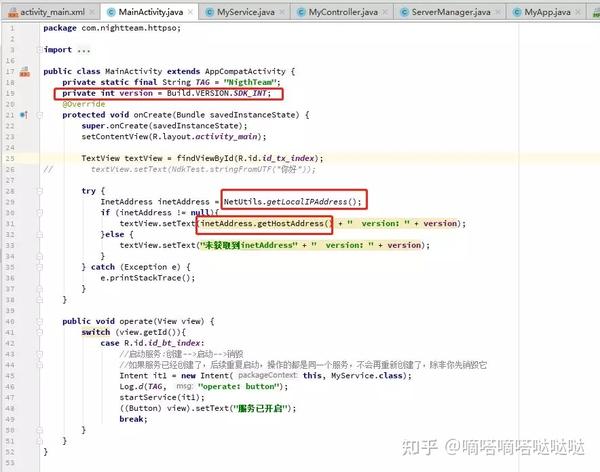
获取本地地址和Android SDK版本(Android 8之后启动Service的方式不同)
申请权限,启动App
最后一步是为应用申请网络权限
然后连接我们的手机,运行项目,测试一下,点击启动服务

查看AndroidStudio日志

好像一切正常,在浏览器访问下试试(ip是App中显示的ip地址)
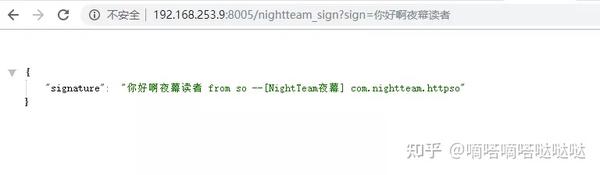
如图,我们访问到了我们想要的内容。回去再说Service,打开我们手机的设置,找到应用管理-运行服务(不同的手机,不同的方法)
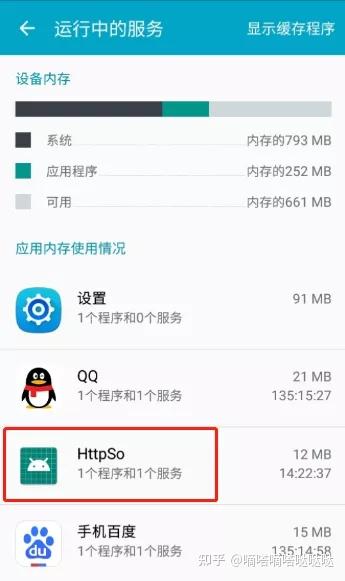
可以看到我们的程序运行了一个服务,这个服务就是我们编码的MyService
接下来,杀死App进程并再次检查正在运行的服务
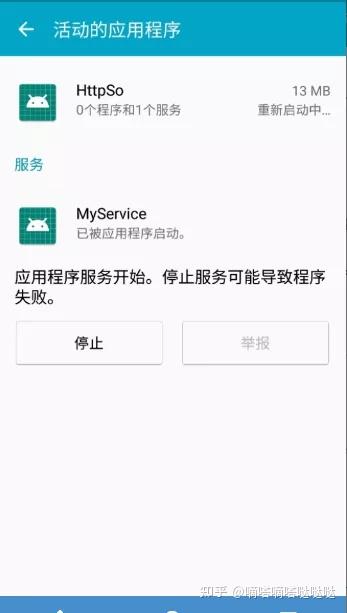
这里我在权限管理中设置了自动运行,可以保持服务运行。(这个地方还是根据系统大小不同) 到此为止,可以使用App启动http服务并调整so。
文章采集api(小涴熊CMS漫画源码的安装和采集教程,文字比较多)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-03 00:30
本文文章将给大家讲解安装小传熊的cms漫画源码和采集教程。有很多文字。你还需要一点耐心,仔细研究。祝大家“车站交通兴旺,客流量日益增加!”
环境要求:PHP 7.0-7.2、MySQL >= 5.7、Redis,Redis扩展(官方要求为PHP 5.6 - 7.2,因为经过测试发现7.0不好用,所以这里修改了一下,直接改成7.0-7.2)。
1、安装环境
这里还是简单的路线,使用宝塔面板进行演示,使用命令:
#CentOS系统
wget -O install.sh && sh install.sh
#Ubuntu系统
wget -O install.sh && sudo bash install.sh
#Debian系统
wget -O install.sh && bash install.sh
安装完成后,进入面板,点击左侧的软件管理,然后安装PHP7.2、Nginx、Mysql5.7+、Redis。
接下来,找到左侧的软件管理-PHP管理-设置-安装Redis扩展。
2、安装步骤
这里有一个简单的路线,使用宝塔面板进行演示
1、宝塔安装好后,进入面板,点击左侧的软件管理,然后安装PHP7.2、Nginx、Mysql5.7+、Redis。
2.我们先点击左边的网站,添加网站!我不需要教这个!!!
3.设置伪静态规则:
如果(!-e $request_filename){
最后重写 ^(.*)$ /index.php?s=/$1;
休息;
}
4、点击域名设置-网站目录,运行目录选择public,去掉跨站防护的勾选,重启PHP。
5.最后浏览器运行你的网站+/install进入安装页面,根据页面提示输入相关信息完成安装!
注意:如果要启用404而不显示cms错误信息,需要修改config/app.php文件:
#删除第一行的//
'exception_tmpl' => Env::get('app_path').'index/view/pub/404.html',
'exception_tmpl' => Env::get('think_path').'tpl/think_exception.tpl',
采集教程
一般情况下,漫画站的图片资源有两种,一种是本地化的,一种是盗链的。建议对图片进行本地化,这样可以保证网站资源的稳定性,同时程序还提供了优采云采集器的API,可以方便地与优采云采集器 用于漫画和章节图片 采集。
首先,我们需要一个优采云采集器,官网→门户,但是分为免费版和付费版,但是免费版由于某些原因不能满足图片本地化的需要功能限制,暂时不适用,有钱可以买付费版,没钱可以直接用优采云V7.6企业版破解版,可能是最新的破解版,也能满足程序采集的具体要求,如何下载请百度。许多 网站 提供下载链接。
注意:由于火车头V7和V8没有url编码解码功能,所以不能采集带有中文链接的漫画网站,但V9版本可以,有钱可以直接上。
采集api 说明:
采集api地址:域名/api/index/save
请求方式:post
表单字段及说明:
book_name 漫画名
nick_name 漫画别名
tags 分类,多个分类用|隔开
author 作者名字
src 采集源
end 状态,1代表完结,0代表连载中
cover_url 封面图远程地址
chapter_name 章节名
images 由图片标签组成的字符串,示例:
api_key 用于身份验证,要和后台配置的api密钥相同
summary 漫画简介
注:由于优采云V7和V8没有URL编解码功能,不能采集有中文链接的漫画网站,但V9版本可以,直接上传即可如果你有钱。
由于采集的过程有点复杂,不太容易发帖,有兴趣和不了解采集的朋友可以到本站下载源码,查看中给出的在线教程地址源代码复制粘贴到浏览器打开,一般步骤是打开优采云采集器主界面-publish-new-content发布参数,然后写好发布模块后,开始找目标站,写采集规则,最后采集发布就行了。
本文由网友投稿或由居马武整理于网络。如转载请注明出处:;
如果本站发布的内容侵犯了您的权益,请发送邮件至cnzz8#删除,我们会及时处理!
本站下载资源大部分采集于互联网,不保证其完整性和安全性。下载后请自行测试。
本站资源仅供学习交流之用。版权属于资源的原作者。请在下载后24小时内自觉删除。
商业用途请购买正版。未及时购买及支付造成的侵权与本站无关。 查看全部
文章采集api(小涴熊CMS漫画源码的安装和采集教程,文字比较多)
本文文章将给大家讲解安装小传熊的cms漫画源码和采集教程。有很多文字。你还需要一点耐心,仔细研究。祝大家“车站交通兴旺,客流量日益增加!”
环境要求:PHP 7.0-7.2、MySQL >= 5.7、Redis,Redis扩展(官方要求为PHP 5.6 - 7.2,因为经过测试发现7.0不好用,所以这里修改了一下,直接改成7.0-7.2)。
1、安装环境
这里还是简单的路线,使用宝塔面板进行演示,使用命令:
#CentOS系统
wget -O install.sh && sh install.sh
#Ubuntu系统
wget -O install.sh && sudo bash install.sh
#Debian系统
wget -O install.sh && bash install.sh
安装完成后,进入面板,点击左侧的软件管理,然后安装PHP7.2、Nginx、Mysql5.7+、Redis。
接下来,找到左侧的软件管理-PHP管理-设置-安装Redis扩展。
2、安装步骤
这里有一个简单的路线,使用宝塔面板进行演示
1、宝塔安装好后,进入面板,点击左侧的软件管理,然后安装PHP7.2、Nginx、Mysql5.7+、Redis。
2.我们先点击左边的网站,添加网站!我不需要教这个!!!
3.设置伪静态规则:
如果(!-e $request_filename){
最后重写 ^(.*)$ /index.php?s=/$1;
休息;
}
4、点击域名设置-网站目录,运行目录选择public,去掉跨站防护的勾选,重启PHP。
5.最后浏览器运行你的网站+/install进入安装页面,根据页面提示输入相关信息完成安装!
注意:如果要启用404而不显示cms错误信息,需要修改config/app.php文件:
#删除第一行的//
'exception_tmpl' => Env::get('app_path').'index/view/pub/404.html',
'exception_tmpl' => Env::get('think_path').'tpl/think_exception.tpl',
采集教程
一般情况下,漫画站的图片资源有两种,一种是本地化的,一种是盗链的。建议对图片进行本地化,这样可以保证网站资源的稳定性,同时程序还提供了优采云采集器的API,可以方便地与优采云采集器 用于漫画和章节图片 采集。
首先,我们需要一个优采云采集器,官网→门户,但是分为免费版和付费版,但是免费版由于某些原因不能满足图片本地化的需要功能限制,暂时不适用,有钱可以买付费版,没钱可以直接用优采云V7.6企业版破解版,可能是最新的破解版,也能满足程序采集的具体要求,如何下载请百度。许多 网站 提供下载链接。
注意:由于火车头V7和V8没有url编码解码功能,所以不能采集带有中文链接的漫画网站,但V9版本可以,有钱可以直接上。
采集api 说明:
采集api地址:域名/api/index/save
请求方式:post
表单字段及说明:
book_name 漫画名
nick_name 漫画别名
tags 分类,多个分类用|隔开
author 作者名字
src 采集源
end 状态,1代表完结,0代表连载中
cover_url 封面图远程地址
chapter_name 章节名
images 由图片标签组成的字符串,示例:
api_key 用于身份验证,要和后台配置的api密钥相同
summary 漫画简介
注:由于优采云V7和V8没有URL编解码功能,不能采集有中文链接的漫画网站,但V9版本可以,直接上传即可如果你有钱。
由于采集的过程有点复杂,不太容易发帖,有兴趣和不了解采集的朋友可以到本站下载源码,查看中给出的在线教程地址源代码复制粘贴到浏览器打开,一般步骤是打开优采云采集器主界面-publish-new-content发布参数,然后写好发布模块后,开始找目标站,写采集规则,最后采集发布就行了。
本文由网友投稿或由居马武整理于网络。如转载请注明出处:;
如果本站发布的内容侵犯了您的权益,请发送邮件至cnzz8#删除,我们会及时处理!
本站下载资源大部分采集于互联网,不保证其完整性和安全性。下载后请自行测试。
本站资源仅供学习交流之用。版权属于资源的原作者。请在下载后24小时内自觉删除。
商业用途请购买正版。未及时购买及支付造成的侵权与本站无关。
文章采集api(介于tapd跨项目统计的困难,开发了基于tapdAPI的数据同步的工具TapdCollect)
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-10-01 10:21
前言:
由于tapd跨项目统计的难度,我们开发了基于tapd API的数据同步工具TapdCollect,可以将数据传输到本地数据库,然后进行分析统计。Net Core 用于开发,可以定期跨平台部署。任务排期采集,支持项目、需求、缺陷、用例、测试计划、变更历史等数据采集,可选择是否保存历史记录、失败自动重试等辅助职能。
下载链接:
源地址:
特征
01、 输入【01】,启动【同步项目】
同步项目列表,对应数据库表名:tapd_project
02、 输入【02】,开始【同步工作流状态中英文名称对应】
同步工作流状态中英文名称对应关系,对应数据库表名:tapd_statusmap
03、 输入【03】,开始【同步自定义字段配置】
同步自定义字段配置,对应数据库表名:tapd_custom_fields_settings
04、 进入【04】,开始【同步需求分类】
同步需求分类,对应数据库表名:tapd_story_categories
05、 进入【05】,开始【同步测试用例分类】
同步测试用例分类,对应数据库表名:tapd_tcase_categories
06、 进入【06】,开始【同步需求】
同步需求,对应数据库表名:tapd_stories
07、 输入【07】,启动【同步缺陷】
同步缺陷,对应数据库表名:tapd_bugs
08、 输入【08】开始【同步任务】
同步任务,对应数据库表名:tapd_tasks
09、 进入【09】,开始【同步测试计划】
同步测试计划,对应数据库表名:tapd_test_plans
10、 输入【10】,开始【同步测试用例】
同步测试用例,对应数据库表名:tapd_tcases
11、 进入【11】,开始【同步需求变化历史】
同步需求变更历史,对应数据库表名:tapd_story_changes
12、 进入【12】,开始【同步缺陷变更历史】
同步缺陷变更历史,对应数据库表名:tapd_bug_changes
13、进入【13】开始【同步发布审核】
同步发布审核,对应数据库表名:tapd_launch_forms
14、输入【14】开始【同步发布计划】
同步发布计划,对应数据库表名:tapd_releases
15、 输入【97】,开始【删除配置文件】
删除配置文件,之前的配置文件会被删除
16、 输入【98】,启动【重置配置文件】
重置配置参数,可以在修改用户名和密码时使用
17、 输入【99】启动【初始化数据库】
第一次使用时,可以调用该方法初始化数据库
默认会在配置文件重置后调用,需要手动确认
配置文件设置
>>>>>>>>>> 1、Api_User-API 账号
>>>>>>>>>> 2、Api_Password-API密码
>>>>>>>>>> 3、CompanyId-公司ID
>>>>>>>>>> 4、PageLimit-每个请求的最大数量(1-200)
>>>>>>>>>> 5、RetryLimit-出错后的重试次数(1-10)
>>>>>>>>>> 6、IsKeepHistory-是否保留历史(0-不保留,1-保留)
>>>>>>>>>> 7、DataBaseConn-数据库连接配置(数据库仅支持Mysql,其他数据库请自行开发)
DataBaseConn 请参考如下配置: Server=xx;Database=Tapd;User=xx;Password=xx;pooling=False;port=xx;Charset=utf8;Allow Zero Datetime=True;
预防措施:
1、 请务必通过本程序设置
2、设置后参数为加密参数,不支持手动修改
3、如需修改参数,请重置配置文件
4、重置配置文件时,请根据自己的情况决定是否初始化数据库
5、 深度使用6个月后,可以联系客服申请api内测资质。申请通过后可以在公司管理-api open申请api账号
采集日志
采集的所有动作都会被记录在对应的日志中,在程序目录的日志文件夹中
1、log.log 带时间戳的日志,可以查看具体操作详情对应的时间
2、log_console.log 控制台日志,可以查看具体操作详情
3、log_error.log 错误日志,错误后可以查看错误对应的内容
4、log_debug.log 调试日志,默认不输出,需要调整NLog.config进行配置,具体数据内容
关于程序的调用(仅供参考,请根据实际情况进行配置)
需要提前安装.net Core Runtime
跳转到目录:cd %TapdCollect%\手动执行:dotnet TapdCollect.dll 自动执行(单功能):dotnet TapdCollect.dll 1 自动执行(多功能):dotnet TapdCollect.dll 1 2 3 4 5 6 7 8 13 对于超过14个功能的配置,请在每个功能参数后加一个空格
.Net Core 运行时下载链接
视窗:
其他平台:请到MicroSoft网站查找
定时任务配置(仅供参考)
1、首先配置bat脚本
2、设置定时任务
预防措施:
1) 开始填写程序所在目录,否则配置文件会被%windows%\system32\下的计划任务配置
2) 以双引号开头,否则无效
3)程序或脚本选择之前配置好的bat文件,建议选择自动运行的脚本
3、 设置触发条件(建议根据实际情况和需要设置)
预防措施:
1) 建议根据实际情况设置。它可以每天同步一次或几个小时同步一次。
2)但是建议不要在一个小时以内同步一次,因为Tapd请求是有时间限制的,理论上是1Req/S
3)tapd 请求过多会抛出过多请求错误 查看全部
文章采集api(介于tapd跨项目统计的困难,开发了基于tapdAPI的数据同步的工具TapdCollect)
前言:
由于tapd跨项目统计的难度,我们开发了基于tapd API的数据同步工具TapdCollect,可以将数据传输到本地数据库,然后进行分析统计。Net Core 用于开发,可以定期跨平台部署。任务排期采集,支持项目、需求、缺陷、用例、测试计划、变更历史等数据采集,可选择是否保存历史记录、失败自动重试等辅助职能。
下载链接:
源地址:
特征
01、 输入【01】,启动【同步项目】
同步项目列表,对应数据库表名:tapd_project
02、 输入【02】,开始【同步工作流状态中英文名称对应】
同步工作流状态中英文名称对应关系,对应数据库表名:tapd_statusmap
03、 输入【03】,开始【同步自定义字段配置】
同步自定义字段配置,对应数据库表名:tapd_custom_fields_settings
04、 进入【04】,开始【同步需求分类】
同步需求分类,对应数据库表名:tapd_story_categories
05、 进入【05】,开始【同步测试用例分类】
同步测试用例分类,对应数据库表名:tapd_tcase_categories
06、 进入【06】,开始【同步需求】
同步需求,对应数据库表名:tapd_stories
07、 输入【07】,启动【同步缺陷】
同步缺陷,对应数据库表名:tapd_bugs
08、 输入【08】开始【同步任务】
同步任务,对应数据库表名:tapd_tasks
09、 进入【09】,开始【同步测试计划】
同步测试计划,对应数据库表名:tapd_test_plans
10、 输入【10】,开始【同步测试用例】
同步测试用例,对应数据库表名:tapd_tcases
11、 进入【11】,开始【同步需求变化历史】
同步需求变更历史,对应数据库表名:tapd_story_changes
12、 进入【12】,开始【同步缺陷变更历史】
同步缺陷变更历史,对应数据库表名:tapd_bug_changes
13、进入【13】开始【同步发布审核】
同步发布审核,对应数据库表名:tapd_launch_forms
14、输入【14】开始【同步发布计划】
同步发布计划,对应数据库表名:tapd_releases
15、 输入【97】,开始【删除配置文件】
删除配置文件,之前的配置文件会被删除
16、 输入【98】,启动【重置配置文件】
重置配置参数,可以在修改用户名和密码时使用
17、 输入【99】启动【初始化数据库】
第一次使用时,可以调用该方法初始化数据库
默认会在配置文件重置后调用,需要手动确认
配置文件设置
>>>>>>>>>> 1、Api_User-API 账号
>>>>>>>>>> 2、Api_Password-API密码
>>>>>>>>>> 3、CompanyId-公司ID
>>>>>>>>>> 4、PageLimit-每个请求的最大数量(1-200)
>>>>>>>>>> 5、RetryLimit-出错后的重试次数(1-10)
>>>>>>>>>> 6、IsKeepHistory-是否保留历史(0-不保留,1-保留)
>>>>>>>>>> 7、DataBaseConn-数据库连接配置(数据库仅支持Mysql,其他数据库请自行开发)
DataBaseConn 请参考如下配置: Server=xx;Database=Tapd;User=xx;Password=xx;pooling=False;port=xx;Charset=utf8;Allow Zero Datetime=True;
预防措施:
1、 请务必通过本程序设置
2、设置后参数为加密参数,不支持手动修改
3、如需修改参数,请重置配置文件
4、重置配置文件时,请根据自己的情况决定是否初始化数据库
5、 深度使用6个月后,可以联系客服申请api内测资质。申请通过后可以在公司管理-api open申请api账号
采集日志
采集的所有动作都会被记录在对应的日志中,在程序目录的日志文件夹中
1、log.log 带时间戳的日志,可以查看具体操作详情对应的时间
2、log_console.log 控制台日志,可以查看具体操作详情
3、log_error.log 错误日志,错误后可以查看错误对应的内容
4、log_debug.log 调试日志,默认不输出,需要调整NLog.config进行配置,具体数据内容
关于程序的调用(仅供参考,请根据实际情况进行配置)
需要提前安装.net Core Runtime
跳转到目录:cd %TapdCollect%\手动执行:dotnet TapdCollect.dll 自动执行(单功能):dotnet TapdCollect.dll 1 自动执行(多功能):dotnet TapdCollect.dll 1 2 3 4 5 6 7 8 13 对于超过14个功能的配置,请在每个功能参数后加一个空格
.Net Core 运行时下载链接
视窗:
其他平台:请到MicroSoft网站查找
定时任务配置(仅供参考)
1、首先配置bat脚本
2、设置定时任务
预防措施:
1) 开始填写程序所在目录,否则配置文件会被%windows%\system32\下的计划任务配置
2) 以双引号开头,否则无效
3)程序或脚本选择之前配置好的bat文件,建议选择自动运行的脚本
3、 设置触发条件(建议根据实际情况和需要设置)
预防措施:
1) 建议根据实际情况设置。它可以每天同步一次或几个小时同步一次。
2)但是建议不要在一个小时以内同步一次,因为Tapd请求是有时间限制的,理论上是1Req/S
3)tapd 请求过多会抛出过多请求错误
文章采集api(接入优采云(小狗AI)API教程-优采云采集支持)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-09-29 14:18
访问优采云(Puppy AI)API教程-优采云采集
优采云采集 支持调用优采云(Puppy AI)API接口处理采集的数据标题和内容;
提示:第三方API接入功能需要优采云旗舰包支持使用,用户需要提供第三方接口账号信息(即用户需要注册第三方接口,调用第三方接口所产生的一切费用由用户自行承担。);
购买优采云(Puppy AI)API,请先联系优采云(Puppy AI)客服告知是在优采云采集平台使用;
详细步骤
1. 创建优采云 API 接口配置
一、API配置入口:
点击【第三方服务配置】==》点击【第三方内容API访问】==》点击控制台左侧列表中的【第三方API配置管理】==》,最后点击【优采云API] 创建接口配置;
二、配置API接口信息:
购买优采云(Puppy AI)API,请先联系优采云(Puppy AI)客服,告知在优采云采集平台使用。
【API key】是从优采云(Puppy AI)后台获取对应的API key,填写优采云;
注意:优采云每次调用限制为6000个字符(包括html代码),所以当内容长度超过时,优采云会被多次分割调用。这个操作会增加api调用次数,费用也会相应增加,这是用户需要承担的费用,使用前一定要注意!!!
2. 创建 API 处理规则
API处理规则,可设置调用API接口处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》进入【API处理规则管理】页面,最后点击【+添加】 API 处理规则] 创建 API 处理规则;
二、API处理规则配置:
规则名称:用户可以自己命名;
字段名:填写的字段名的内容将由API接口处理。默认为title和content字段,可以修改、添加或删除;(可以添加其他字段,点击添加内容字段,修改字段名称,但必须在【Detail Extractor】中已经定义,如作者、关键字、描述字段)
使用的API:选择已经设置好的API接口配置,执行时会调用该接口,多个字段可以选择不同的API接口配置;
处理顺序:执行顺序是按照数量从小到大执行;
注意:API处理1个字段时,API接口会调用一次,所以建议不要添加不需要的字段!
3. API 处理规则使用
API处理规则的使用方式有两种:手动执行和自动执行:
手动执行:data采集后,在【Result Data & Release】中使用第三方API执行;
自动执行:自动化配置完成后,任务采集数据完成后,系统会自动执行指定的API处理规则,无需人工操作。
一、手动执行API处理规则:
在任务的【结果&发布】选项卡中,点击【SEO&API&翻译工具】按钮==》选择【第三方API执行】栏==》选择对应的API处理规则==》执行(有两种执行方式对于数据范围,根据发布状态批量执行,根据列表中选择的数据执行);
二、自动执行API处理规则:
启用 API 处理的自动执行。任务完成采集后,会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡中,【自动执行第三方API配置】==》勾选【采集,自动执行API】选项==》选择要执行的API处理规则==》选择API接口处理的数据范围(一般选择“待发布”,都会导致所有数据被多次执行),最后点击保存;
4. API 处理结果及发布
一、查看API接口处理结果:
API接口处理的内容会保存为一个新的字段,如:标题处理后的新字段:title_优采云,内容处理后的新字段:content_优采云,在[Result Data & Release]和数据预览界面可以查看。
提示:API处理规则执行需要一段时间,执行后页面会自动刷新,API接口处理的新字段会出现;
二、API接口处理后的内容发布
在发布文章之前,修改发布目标第二步的映射字段,在API接口处理后将title和content改为新的对应字段title_优采云和content_优采云;
提示:如果无法在发布目标中选择新字段,请在此任务下复制或创建新的发布目标,然后您可以在新的发布目标中选择新字段。详细教程可以查看发布目标中不能选择的字段;
5. 优采云-API接口常见问题及解决方法
一、API处理规则和SEO规则如何搭配使用?
系统默认对title和content字段进行SEO功能,需要修改为SEO规则中的title_优采云和content_优采云字段; 查看全部
文章采集api(接入优采云(小狗AI)API教程-优采云采集支持)
访问优采云(Puppy AI)API教程-优采云采集
优采云采集 支持调用优采云(Puppy AI)API接口处理采集的数据标题和内容;
提示:第三方API接入功能需要优采云旗舰包支持使用,用户需要提供第三方接口账号信息(即用户需要注册第三方接口,调用第三方接口所产生的一切费用由用户自行承担。);
购买优采云(Puppy AI)API,请先联系优采云(Puppy AI)客服告知是在优采云采集平台使用;
详细步骤
1. 创建优采云 API 接口配置
一、API配置入口:
点击【第三方服务配置】==》点击【第三方内容API访问】==》点击控制台左侧列表中的【第三方API配置管理】==》,最后点击【优采云API] 创建接口配置;
二、配置API接口信息:
购买优采云(Puppy AI)API,请先联系优采云(Puppy AI)客服,告知在优采云采集平台使用。
【API key】是从优采云(Puppy AI)后台获取对应的API key,填写优采云;
注意:优采云每次调用限制为6000个字符(包括html代码),所以当内容长度超过时,优采云会被多次分割调用。这个操作会增加api调用次数,费用也会相应增加,这是用户需要承担的费用,使用前一定要注意!!!
2. 创建 API 处理规则
API处理规则,可设置调用API接口处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》进入【API处理规则管理】页面,最后点击【+添加】 API 处理规则] 创建 API 处理规则;
二、API处理规则配置:
规则名称:用户可以自己命名;
字段名:填写的字段名的内容将由API接口处理。默认为title和content字段,可以修改、添加或删除;(可以添加其他字段,点击添加内容字段,修改字段名称,但必须在【Detail Extractor】中已经定义,如作者、关键字、描述字段)
使用的API:选择已经设置好的API接口配置,执行时会调用该接口,多个字段可以选择不同的API接口配置;
处理顺序:执行顺序是按照数量从小到大执行;
注意:API处理1个字段时,API接口会调用一次,所以建议不要添加不需要的字段!
3. API 处理规则使用
API处理规则的使用方式有两种:手动执行和自动执行:
手动执行:data采集后,在【Result Data & Release】中使用第三方API执行;
自动执行:自动化配置完成后,任务采集数据完成后,系统会自动执行指定的API处理规则,无需人工操作。
一、手动执行API处理规则:
在任务的【结果&发布】选项卡中,点击【SEO&API&翻译工具】按钮==》选择【第三方API执行】栏==》选择对应的API处理规则==》执行(有两种执行方式对于数据范围,根据发布状态批量执行,根据列表中选择的数据执行);
二、自动执行API处理规则:
启用 API 处理的自动执行。任务完成采集后,会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡中,【自动执行第三方API配置】==》勾选【采集,自动执行API】选项==》选择要执行的API处理规则==》选择API接口处理的数据范围(一般选择“待发布”,都会导致所有数据被多次执行),最后点击保存;
4. API 处理结果及发布
一、查看API接口处理结果:
API接口处理的内容会保存为一个新的字段,如:标题处理后的新字段:title_优采云,内容处理后的新字段:content_优采云,在[Result Data & Release]和数据预览界面可以查看。
提示:API处理规则执行需要一段时间,执行后页面会自动刷新,API接口处理的新字段会出现;
二、API接口处理后的内容发布
在发布文章之前,修改发布目标第二步的映射字段,在API接口处理后将title和content改为新的对应字段title_优采云和content_优采云;
提示:如果无法在发布目标中选择新字段,请在此任务下复制或创建新的发布目标,然后您可以在新的发布目标中选择新字段。详细教程可以查看发布目标中不能选择的字段;
5. 优采云-API接口常见问题及解决方法
一、API处理规则和SEO规则如何搭配使用?
系统默认对title和content字段进行SEO功能,需要修改为SEO规则中的title_优采云和content_优采云字段;
文章采集api(数据埋点采集到底都是哪些事呢?的应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-09-24 15:03
数据采集是数据分析的基础,埋点是最重要的采集方法。那么数据埋点采集究竟是什么?我们主要从三个方面来看:什么是埋点,埋点如何设计,埋点的应用。
一、数据采集及常见数据问题
1.1Data采集
数据采集的方式有很多种,埋点采集是其中非常重要的一部分,无论是对于c端还是b端产品,都是主要的采集方法,数据采集 ,顾名思义,采集对应的数据是整个数据流的起点。采集 不完整吧?它直接决定了数据的广度和质量,并影响到后续的所有环节;在数据采集 效率和完整性较差的公司通常会在其业务发现数据中发生重大变化。
数据处理通常包括以下5个步骤:
1.2常见数据问题
在大致了解了数据采集及其结构之后,我们来看看我们工作中遇到的问题,有多少是与数据采集链接相关的
1、数据与后台差距大,数据不准确——统计口径不同,埋点定义不同,采集的方法带来误差
2、想用的时候,没有我要的数据--没有提到数据。采集需求,埋点不对,不完整
3、 事件太多,意思不清楚——埋点设计的方法,埋点更新迭代的规则和维护
4、分析数据,不知道看哪些数据和指标——数据定义不明确,缺乏分析思路
我们要从根本上解决问题:把采集当作一个独立的研发企业,而不是产品开发的附属品
二、什么是埋点
2.1 什么是埋点
所谓埋点,是数据领域的一个术语采集。它的学名应该叫事件跟踪,对应的英文是Event Tracking,指的是捕获、处理和发送特定用户行为或事件的相关技术和实现过程。数据埋点是数据分析师、数据产品经理和数据运营。根据业务需求或产品需求,开发用户行为的每个事件的对应位置,开发埋点,通过SDK上报埋点的数据结果,记录汇总数据。分析、推动产品优化、指导运营。
该过程附有规范。通过定义,我们看到具体的用户行为和事件是我们采集的重点,我们也需要处理发送相关的技术和实现流程;数据嵌入点是为产品服务的,它来自于产品。,所以跟产品息息相关,埋点在于具体实战过程,关系到大家对底层数据的理解。
2.2 为什么要埋点?
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的好坏直接影响到数据质量、产品质量、运营质量等。
1、数据驱动——深入分析,深入到流量分布和流量层面,通过统计分析,宏观指标深入分析,发现指标背后的问题,洞察潜力用户行为与价值提升之间的关联
2、产品优化——对于产品,用户在产品中做了什么,在产品中停留了多久,有什么异常需要注意。这些问题可以通过埋点来实现
3、 精细化运营-埋点可以实现整个产品生命周期、流量质量和不同来源的分布、人群的行为特征和关系,洞察用户行为与提升业务的潜在关系价值。
2.3种埋点方法
埋点的方法有哪些?目前,大多数公司使用客户端和服务器的组合
准确度:编码埋点>可视化埋点>全埋点
三、埋点的框架和设计
3.1 埋点采集的顶层设计
所谓顶层设计,就是搞清楚怎么做点,怎么用,上传机制是什么,怎么定义,怎么实现等等;我们在设计的基础上遵循唯一性、可扩展性、一致性等一些常见的字段和生成机制,例如:cid、idfa、idfv等。
用户识别:用户识别机制的混乱会导致两种结果:一是数据不准确,比如UV数据没有对齐;另一个是漏斗分析有异常。因此,它应该是: a.严格规范ID自身的识别机制;湾 跨平台用户识别
相似抽象:相似抽象包括事件抽象和属性抽象。事件抽象是指浏览事件和点击事件的聚合;属性抽象意味着合并大多数重用场景以增加源区分
采集 一致性:采集 一致性包括两点:一是跨平台页面的一致命名,二是按钮命名的一致;设置埋点本身的过程就是对底层数据进行标准化的过程,所以一致性尤为重要,只有这样才能真正发挥作用
渠道配置:渠道主要是指推广渠道、落地页、网页推广页、APP推广页等,这个落地页的配置必须有统一的规范和标准
3.2埋点采集事件和属性设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变的,哪些是业务行为,哪些是基本属性。基于基础属性事件,我们认为属性是必填采集项,但是属性中的事件属性会根据不同的业务进行调整。因此,我们可以将埋点采集分为协议层和业务层埋点。
业务分解:梳理确认业务流程、运营路径和不同细分场景,定义用户行为路径
分析指标:定义特定事件和核心业务指标所需的数据
事件设计:APP启动、退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.3 数据采集事件和属性设计
Ev 事件的命名也遵循一些规则。当同一类型的函数出现在不同的页面或位置时,根据函数名进行命名,在ev参数中区分页面和位置。仅点击按钮时,按按钮名称命名。
ev事件格式:ev分为ev标识和ev参数
规则:
ev标志和ev参数之间用“#”连接(一级连接器);
ev参数和ev参数之间用“/”连接(二级连接器);
ev 参数使用 key=value 的结构。当一个key对应多个value值时,value1和value2之间用“,”连接(三级连接器);
当埋点只有ev标志,没有ev参数时,不需要带#;
评论:
ev ID:作为埋点的唯一ID,用于区分埋点的位置和属性。它是不可变的,不能被修改;
ev参数:需要返回埋点的参数,ev参数的顺序是可变的,可以修改;
调整app埋点时ev标志不变,只修改后续埋点参数(参数值改变或参数类型增加)
通用嵌入点文档中收录的sheet的名称和功能:
A.暴露埋点汇总;
B.点击浏览埋点汇总;
C、故障埋点总结:一般会记录埋点的故障版本或时间;
D、PC和M页面嵌入点对应的pageid;
E、各版本上线时间记录;
在嵌入点文档中,所有列名和函数包括:
3.4 基于埋点的统计
如何使用埋点统计查找埋点 ev 事件:
1. 指定埋点类型(点击/曝光/浏览)-过滤类型字段
2. 指定按钮所属的页面(页面或功能)-过滤功能模块字段
3. 指定埋藏事件的名称-过滤名称字段
4. 知道ev logo,可以直接用ev过滤
如何根据ev事件进行计数统计:查询按钮点击统计时,可以直接使用ev标志进行查询,有区别时,可以限制埋点参数的取值;因为ev参数的顺序不需要可变,查询统计,不能限制参数的顺序;
四、应用-数据流的基础
4.1 指标体系
系统指标可以将不同指标、不同维度串联起来进行综合分析,快速发现当前产品和业务流程中存在的问题。
4.2 可视化
人类对图像信息的解释比文本更有效。可视化对于数据分析极其重要。数据可视化的使用可以揭示数据中错综复杂的关系。
4.3 api提供
数据采集服务会将采集的埋点写入Kafka。针对每个业务的实时数据消费需求,我们为每个业务提供单独的Kafka,流量分配模块会定时读取。将埋点管理平台提供的元信息实时分发到各个业务Kafka。
数据采集就像设计一个产品。不能过火,留有扩展空间,但要时刻考虑数据是否完整、详细、不稳定、快速与否。 查看全部
文章采集api(数据埋点采集到底都是哪些事呢?的应用)
数据采集是数据分析的基础,埋点是最重要的采集方法。那么数据埋点采集究竟是什么?我们主要从三个方面来看:什么是埋点,埋点如何设计,埋点的应用。
一、数据采集及常见数据问题
1.1Data采集
数据采集的方式有很多种,埋点采集是其中非常重要的一部分,无论是对于c端还是b端产品,都是主要的采集方法,数据采集 ,顾名思义,采集对应的数据是整个数据流的起点。采集 不完整吧?它直接决定了数据的广度和质量,并影响到后续的所有环节;在数据采集 效率和完整性较差的公司通常会在其业务发现数据中发生重大变化。
数据处理通常包括以下5个步骤:
1.2常见数据问题
在大致了解了数据采集及其结构之后,我们来看看我们工作中遇到的问题,有多少是与数据采集链接相关的
1、数据与后台差距大,数据不准确——统计口径不同,埋点定义不同,采集的方法带来误差
2、想用的时候,没有我要的数据--没有提到数据。采集需求,埋点不对,不完整
3、 事件太多,意思不清楚——埋点设计的方法,埋点更新迭代的规则和维护
4、分析数据,不知道看哪些数据和指标——数据定义不明确,缺乏分析思路
我们要从根本上解决问题:把采集当作一个独立的研发企业,而不是产品开发的附属品
二、什么是埋点
2.1 什么是埋点
所谓埋点,是数据领域的一个术语采集。它的学名应该叫事件跟踪,对应的英文是Event Tracking,指的是捕获、处理和发送特定用户行为或事件的相关技术和实现过程。数据埋点是数据分析师、数据产品经理和数据运营。根据业务需求或产品需求,开发用户行为的每个事件的对应位置,开发埋点,通过SDK上报埋点的数据结果,记录汇总数据。分析、推动产品优化、指导运营。
该过程附有规范。通过定义,我们看到具体的用户行为和事件是我们采集的重点,我们也需要处理发送相关的技术和实现流程;数据嵌入点是为产品服务的,它来自于产品。,所以跟产品息息相关,埋点在于具体实战过程,关系到大家对底层数据的理解。
2.2 为什么要埋点?
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的好坏直接影响到数据质量、产品质量、运营质量等。
1、数据驱动——深入分析,深入到流量分布和流量层面,通过统计分析,宏观指标深入分析,发现指标背后的问题,洞察潜力用户行为与价值提升之间的关联
2、产品优化——对于产品,用户在产品中做了什么,在产品中停留了多久,有什么异常需要注意。这些问题可以通过埋点来实现
3、 精细化运营-埋点可以实现整个产品生命周期、流量质量和不同来源的分布、人群的行为特征和关系,洞察用户行为与提升业务的潜在关系价值。
2.3种埋点方法
埋点的方法有哪些?目前,大多数公司使用客户端和服务器的组合
准确度:编码埋点>可视化埋点>全埋点
三、埋点的框架和设计
3.1 埋点采集的顶层设计
所谓顶层设计,就是搞清楚怎么做点,怎么用,上传机制是什么,怎么定义,怎么实现等等;我们在设计的基础上遵循唯一性、可扩展性、一致性等一些常见的字段和生成机制,例如:cid、idfa、idfv等。
用户识别:用户识别机制的混乱会导致两种结果:一是数据不准确,比如UV数据没有对齐;另一个是漏斗分析有异常。因此,它应该是: a.严格规范ID自身的识别机制;湾 跨平台用户识别
相似抽象:相似抽象包括事件抽象和属性抽象。事件抽象是指浏览事件和点击事件的聚合;属性抽象意味着合并大多数重用场景以增加源区分
采集 一致性:采集 一致性包括两点:一是跨平台页面的一致命名,二是按钮命名的一致;设置埋点本身的过程就是对底层数据进行标准化的过程,所以一致性尤为重要,只有这样才能真正发挥作用
渠道配置:渠道主要是指推广渠道、落地页、网页推广页、APP推广页等,这个落地页的配置必须有统一的规范和标准
3.2埋点采集事件和属性设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变的,哪些是业务行为,哪些是基本属性。基于基础属性事件,我们认为属性是必填采集项,但是属性中的事件属性会根据不同的业务进行调整。因此,我们可以将埋点采集分为协议层和业务层埋点。
业务分解:梳理确认业务流程、运营路径和不同细分场景,定义用户行为路径
分析指标:定义特定事件和核心业务指标所需的数据
事件设计:APP启动、退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.3 数据采集事件和属性设计
Ev 事件的命名也遵循一些规则。当同一类型的函数出现在不同的页面或位置时,根据函数名进行命名,在ev参数中区分页面和位置。仅点击按钮时,按按钮名称命名。
ev事件格式:ev分为ev标识和ev参数
规则:
ev标志和ev参数之间用“#”连接(一级连接器);
ev参数和ev参数之间用“/”连接(二级连接器);
ev 参数使用 key=value 的结构。当一个key对应多个value值时,value1和value2之间用“,”连接(三级连接器);
当埋点只有ev标志,没有ev参数时,不需要带#;
评论:
ev ID:作为埋点的唯一ID,用于区分埋点的位置和属性。它是不可变的,不能被修改;
ev参数:需要返回埋点的参数,ev参数的顺序是可变的,可以修改;
调整app埋点时ev标志不变,只修改后续埋点参数(参数值改变或参数类型增加)
通用嵌入点文档中收录的sheet的名称和功能:
A.暴露埋点汇总;
B.点击浏览埋点汇总;
C、故障埋点总结:一般会记录埋点的故障版本或时间;
D、PC和M页面嵌入点对应的pageid;
E、各版本上线时间记录;
在嵌入点文档中,所有列名和函数包括:
3.4 基于埋点的统计
如何使用埋点统计查找埋点 ev 事件:
1. 指定埋点类型(点击/曝光/浏览)-过滤类型字段
2. 指定按钮所属的页面(页面或功能)-过滤功能模块字段
3. 指定埋藏事件的名称-过滤名称字段
4. 知道ev logo,可以直接用ev过滤
如何根据ev事件进行计数统计:查询按钮点击统计时,可以直接使用ev标志进行查询,有区别时,可以限制埋点参数的取值;因为ev参数的顺序不需要可变,查询统计,不能限制参数的顺序;
四、应用-数据流的基础
4.1 指标体系
系统指标可以将不同指标、不同维度串联起来进行综合分析,快速发现当前产品和业务流程中存在的问题。
4.2 可视化
人类对图像信息的解释比文本更有效。可视化对于数据分析极其重要。数据可视化的使用可以揭示数据中错综复杂的关系。
4.3 api提供
数据采集服务会将采集的埋点写入Kafka。针对每个业务的实时数据消费需求,我们为每个业务提供单独的Kafka,流量分配模块会定时读取。将埋点管理平台提供的元信息实时分发到各个业务Kafka。
数据采集就像设计一个产品。不能过火,留有扩展空间,但要时刻考虑数据是否完整、详细、不稳定、快速与否。
文章采集api(一种基于网络爬虫和新浪API相结合的微博数据采集方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-09-24 15:01
本发明涉及微博数据采集技术领域,尤其涉及一种基于网络爬虫与新浪API相结合的微博数据采集方法。
背景技术:
采集对于微博中的数据非常重要,也可以为微博社会安全事件的检测提供重要的数据依据。目前微博数据采集主要有两种方式:基于新浪API和针对新浪微博平台的网络爬虫。基于新浪API的方案可以获取相对规范格式的数据,但调用次数有限,无法进行大规模数据爬取,无法获取部分信息;基于网络爬虫的方法虽然可以获得海量数据,但其页面的分析处理过程较为复杂,其爬取的数据格式不规范,噪声数据较多。
技术实现要素:
本发明的目的在于解决现有技术的不足,提供一种基于网络爬虫与新浪API相结合的微博数据获取方法。
为实现上述目的,本发明是按照以下技术方案实施的:
一种基于网络爬虫和新浪API结合的微博数据采集方法,包括以下步骤:
Step1:基于新浪API从微博名人榜中获取种子用户及其对应的粉丝用户和关注用户,并添加到种子列表中;
Step2:将种子列表转换为种子URL,并判断种子用户列表是否为空,如果为空,转步骤4,否则转步骤3;
Step3:遍历种子列表,利用网络爬虫的方法抓取种子用户的相关微博信息、微博评论信息和用户个人信息,将微博评论用户加入种子列表;
第四步:结束。
具体来说,Step3包括:
获取种子列表中待爬取的URL,进行URL分析和信息获取,包括:获取用户信息URL,进入对应页面抓取用户粉丝、关注者等用户相关信息;获取用户微博URL并进入对应页面爬取微博转发赞、评论用户、爬取微博评论文字、爬取其他微博相关信息;并抓取用户、关注者、关注者、用户、微博转发点赞、评论用户、抓取微博评论文本、抓取其他相关微博数据等相关信息,建立相应的微博数据资源库;同时,将抓取到的用户、粉丝、用户和关注用户、抓取到的微博转发给赞、评论用户加入种子列表。
与现有技术相比,本发明将新浪API与新浪微博平台的网络爬虫相结合,不仅可以获取相对规范格式的微博数据,还可以进行大规模的数据爬取。数据格式更加规范,噪声数据更少,可为微博社会安全事件的检测提供重要的数据依据。
图纸说明
图1是本发明的流程图。
详细方法
下面结合具体实施例对本发明作进一步说明。本发明的示例性实施例和描述用于解释本发明,但并不用于限制本发明。
如图所示。1、本实施例基于网络爬虫与新浪API结合的微博数据采集方法包括以下步骤:
Step1:基于新浪API从微博名人榜中获取种子用户及其对应的粉丝用户和关注用户,并添加到种子列表中;
Step2:将种子列表转换为种子URL,并判断种子用户列表是否为空,如果为空,转步骤4,否则转步骤3;
Step3:遍历种子列表,利用网络爬虫的方法抓取种子用户的相关微博信息、微博评论信息和用户个人信息,将微博评论用户加入种子列表。具体步骤为: 获取种子列表 待爬媒体中待爬取的URL,以及URL分析和信息获取,包括:获取用户信息URL并进入相应页面,从微博抓取用户粉丝用户和关注用户数据资源库,抓取用户其他相关信息;用户的微博网址,进入对应页面,从微博数据资源库中抓取微博,转发赞、评论用户、抓取微博评论文字、抓取微博其他相关信息;同时,被抓取的用户和粉丝关注的用户,
第四步:结束。
根据本实施例的方法采集完成微博数据后,可以对采集接收到的微博文本数据进行处理,去除其中的异常数据和噪声数据,数据格式可以构建相应的微博资源库,可以为微博社会安全事件的检测提供重要的数据基础。
本发明的技术方案并不限于上述具体实施例的限定,凡根据本发明的技术方案所作的技术修改,都属于本发明的保护范围。 查看全部
文章采集api(一种基于网络爬虫和新浪API相结合的微博数据采集方法)
本发明涉及微博数据采集技术领域,尤其涉及一种基于网络爬虫与新浪API相结合的微博数据采集方法。
背景技术:
采集对于微博中的数据非常重要,也可以为微博社会安全事件的检测提供重要的数据依据。目前微博数据采集主要有两种方式:基于新浪API和针对新浪微博平台的网络爬虫。基于新浪API的方案可以获取相对规范格式的数据,但调用次数有限,无法进行大规模数据爬取,无法获取部分信息;基于网络爬虫的方法虽然可以获得海量数据,但其页面的分析处理过程较为复杂,其爬取的数据格式不规范,噪声数据较多。
技术实现要素:
本发明的目的在于解决现有技术的不足,提供一种基于网络爬虫与新浪API相结合的微博数据获取方法。
为实现上述目的,本发明是按照以下技术方案实施的:
一种基于网络爬虫和新浪API结合的微博数据采集方法,包括以下步骤:
Step1:基于新浪API从微博名人榜中获取种子用户及其对应的粉丝用户和关注用户,并添加到种子列表中;
Step2:将种子列表转换为种子URL,并判断种子用户列表是否为空,如果为空,转步骤4,否则转步骤3;
Step3:遍历种子列表,利用网络爬虫的方法抓取种子用户的相关微博信息、微博评论信息和用户个人信息,将微博评论用户加入种子列表;
第四步:结束。
具体来说,Step3包括:
获取种子列表中待爬取的URL,进行URL分析和信息获取,包括:获取用户信息URL,进入对应页面抓取用户粉丝、关注者等用户相关信息;获取用户微博URL并进入对应页面爬取微博转发赞、评论用户、爬取微博评论文字、爬取其他微博相关信息;并抓取用户、关注者、关注者、用户、微博转发点赞、评论用户、抓取微博评论文本、抓取其他相关微博数据等相关信息,建立相应的微博数据资源库;同时,将抓取到的用户、粉丝、用户和关注用户、抓取到的微博转发给赞、评论用户加入种子列表。
与现有技术相比,本发明将新浪API与新浪微博平台的网络爬虫相结合,不仅可以获取相对规范格式的微博数据,还可以进行大规模的数据爬取。数据格式更加规范,噪声数据更少,可为微博社会安全事件的检测提供重要的数据依据。
图纸说明
图1是本发明的流程图。
详细方法
下面结合具体实施例对本发明作进一步说明。本发明的示例性实施例和描述用于解释本发明,但并不用于限制本发明。
如图所示。1、本实施例基于网络爬虫与新浪API结合的微博数据采集方法包括以下步骤:
Step1:基于新浪API从微博名人榜中获取种子用户及其对应的粉丝用户和关注用户,并添加到种子列表中;
Step2:将种子列表转换为种子URL,并判断种子用户列表是否为空,如果为空,转步骤4,否则转步骤3;
Step3:遍历种子列表,利用网络爬虫的方法抓取种子用户的相关微博信息、微博评论信息和用户个人信息,将微博评论用户加入种子列表。具体步骤为: 获取种子列表 待爬媒体中待爬取的URL,以及URL分析和信息获取,包括:获取用户信息URL并进入相应页面,从微博抓取用户粉丝用户和关注用户数据资源库,抓取用户其他相关信息;用户的微博网址,进入对应页面,从微博数据资源库中抓取微博,转发赞、评论用户、抓取微博评论文字、抓取微博其他相关信息;同时,被抓取的用户和粉丝关注的用户,
第四步:结束。
根据本实施例的方法采集完成微博数据后,可以对采集接收到的微博文本数据进行处理,去除其中的异常数据和噪声数据,数据格式可以构建相应的微博资源库,可以为微博社会安全事件的检测提供重要的数据基础。
本发明的技术方案并不限于上述具体实施例的限定,凡根据本发明的技术方案所作的技术修改,都属于本发明的保护范围。
文章采集api(互联网大数据时代网络爬虫采集舆情数据获取的方案 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-09-23 23:29
)
简单来说,网络爬虫是指通过爬虫程序访问@k14@API连接获取数据信息。爬虫程序可以从网页中检索所需的数据信息,然后将其存储在新创建的文档中。网络爬虫支持@k15@各种数据、文件、图片。视频等可以@k15@,但不能@k15@非法经营。互联网大数据时代,网络爬虫主要为搜索引擎提供最全面、最新的数据,网络爬虫也是从@k15@互联网上的数据爬取而来。
我们还可以使用网络爬虫@k15@舆情数据,以及@k15@新闻、社交、论坛、博客等信息数据。这也是获取舆情数据的常用方案之一。一般爬虫程序使用爬虫代理IP对一些有意义的@k14@进行数据@k15@。舆情数据也可以在数据交换市场购买,或者从专业的舆情分析团队获取,但一般来说,专业的舆情分析团队也是使用代理IP通过爬虫程序去@k15@的。用于舆情数据分析的数据。
由于短视频的流行,@k16@和快手是两大主流短视频应用。我们也可以使用爬虫程序@k15@@k16@来分析舆情数据。生成统计数据表,作为数据报告提供给大家。也可以参考以下@k15@程序代码:
@k21@ 查看全部
文章采集api(互联网大数据时代网络爬虫采集舆情数据获取的方案
)
简单来说,网络爬虫是指通过爬虫程序访问@k14@API连接获取数据信息。爬虫程序可以从网页中检索所需的数据信息,然后将其存储在新创建的文档中。网络爬虫支持@k15@各种数据、文件、图片。视频等可以@k15@,但不能@k15@非法经营。互联网大数据时代,网络爬虫主要为搜索引擎提供最全面、最新的数据,网络爬虫也是从@k15@互联网上的数据爬取而来。
我们还可以使用网络爬虫@k15@舆情数据,以及@k15@新闻、社交、论坛、博客等信息数据。这也是获取舆情数据的常用方案之一。一般爬虫程序使用爬虫代理IP对一些有意义的@k14@进行数据@k15@。舆情数据也可以在数据交换市场购买,或者从专业的舆情分析团队获取,但一般来说,专业的舆情分析团队也是使用代理IP通过爬虫程序去@k15@的。用于舆情数据分析的数据。
由于短视频的流行,@k16@和快手是两大主流短视频应用。我们也可以使用爬虫程序@k15@@k16@来分析舆情数据。生成统计数据表,作为数据报告提供给大家。也可以参考以下@k15@程序代码:
@k21@
文章采集api(MetricsAPI介绍之前,必须要提一下API的概念)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-09-21 01:23
概述
从V 1. 8,资源使用的监测可以通过度量API来获得。的具体组分是度量服务器,其用于取代先前Heapster,和Heapster将逐渐被从1. 11丢弃。
度量 - 服务器是的簇核监测数据,从Kubernetes 1. 8,其被用作在由kube-up.sh脚本创建的集群部署对象默认部署开始聚合,如果是其他的部署,需要是单独的安装,或咨询相应的云厂商。
度量API
引入度量服务器之前,必须提度量API的概念
指标API是上次的监视采集法(Hepaster)一个新的想法是一个新的想法,官方希望应该是稳定的,版本控制,可以由用户(如直接访问通过使用kubectl TOP命令),或者通过所述集群中的控制器(如HPA),和类似的其它Kubernetes的API。
官方处置Heapster项目是把核心资源监测作为一等公民,也就是像POD,服务通过API的服务器或客户端直接直接访问,不再安装HEPater聚集并通过Heapster分别管理它
假设每个POD和节点采集10个指标,从K8S 1. 6开始,支持5000个节点,每个节点30种荚,假设采集度1分钟,然后:
10 x 5000 x 30 / 60 = 25000 平均每分钟2万多个采集指标
由于K8S的API-服务器保存所有的数据到ETCD,很显然,K8S本身不能处理采集这个频率,而这种监测数据是快速和临时数据,所以你需要有一个组件成分。分开处理它们,所述K8S版本只存储在存储器中,所以度量 - 服务器的概念是天生的。
事实上,Hepaster已经有了公开的API,但用户和Kubernetes的其他部件都必须通过主代理服务器访问,而且Heapster接口并不像API的服务器,具有完整的身份验证和客户端集成。这个API是处于alpha阶段(8月18日),希望能去GA阶段。写作类的API - 服务器风格:通用API服务器
具有度量服务器组件,和采集的数据,但也暴露了API,但由于API要统一,如何转发该请求到API-服务器/蜜蜂/度量请求度量服务器,解决该溶液:库贝-aggrecator,在K8S 1. 7已经完成,前度量服务器尚未以外,是在步骤-aggrecator延迟
KUBE-aggrecator(聚集API)主要提供:
详细设计文档:参考链接
公制API:
如:
http://127.0.0.1:8001/apis/met ... nodes
http://127.0.0.1:8001/apis/met ... odes/
http://127.0.0.1:8001/apis/met ... pods/
度量服务器
度量服务器定时从Kubelet的总结API(Simmary)采集索引信息,这些聚集的数据将被存储在存储器中并且在公制-API的形式将其暴露。
度量服务器复API-Server库来实现自己的功能,如身份认证,版本等,以便在内存中执行数据,删除默认ETCD存储,引入存储器(例如,实现存储接口。由于存储在存储器中,监测数据是不持久的,可以通过第三方存储,这与Heapster一致扩展。
image.png
度量服务器出现后,将新Kubernetes监视模式将成为图像
官方地址:
使用
如上所述,度量 - 服务器是一个扩展的API服务器,取决于库贝-聚合,因此需要以开启在API服务器相关参数。
--requestheader-client-ca-file=/etc/kubernetes/certs/proxy-ca.crt
--proxy-client-cert-file=/etc/kubernetes/certs/proxy.crt
--proxy-client-key-file=/etc/kubernetes/certs/proxy.key
--requestheader-allowed-names=aggregator
--requestheader-extra-headers-prefix=X-Remote-Extra-
--requestheader-group-headers=X-Remote-Group
--requestheader-username-headers=X-Remote-User
安装文件下载地址:// 1.+ 8,注意更换镜像地址为国内反光镜
kubectl创建-f度量服务器/
图像
安装成功之后,接入地址API地址是:
图像
度量服务器的资源占用将继续上升为荚果的集群中的数目不断上升,所以有必要需要
ADDON-大小调整垂直扩展此容器。插件,调整器线性按照集群中节点的数量扩大度量服务器,以确保它可以提供完整的度量API服务。具体参考:链路
其他
HPA基于度量服务器上:参考链接
在Kubernetes的新监视系统,度量 - 服务器所属的核心指标,提供API metrics.k8s.io,仅提供节点和POD的CPU和内存使用情况。其他自定义指标(自定义指数)是通过组分如普罗米修斯完成,后续文章将解析自定义指标。
这文章是一个容器监督实践系列文章,全内容请参见:集装箱监视器图书 查看全部
文章采集api(MetricsAPI介绍之前,必须要提一下API的概念)
概述
从V 1. 8,资源使用的监测可以通过度量API来获得。的具体组分是度量服务器,其用于取代先前Heapster,和Heapster将逐渐被从1. 11丢弃。
度量 - 服务器是的簇核监测数据,从Kubernetes 1. 8,其被用作在由kube-up.sh脚本创建的集群部署对象默认部署开始聚合,如果是其他的部署,需要是单独的安装,或咨询相应的云厂商。
度量API
引入度量服务器之前,必须提度量API的概念
指标API是上次的监视采集法(Hepaster)一个新的想法是一个新的想法,官方希望应该是稳定的,版本控制,可以由用户(如直接访问通过使用kubectl TOP命令),或者通过所述集群中的控制器(如HPA),和类似的其它Kubernetes的API。
官方处置Heapster项目是把核心资源监测作为一等公民,也就是像POD,服务通过API的服务器或客户端直接直接访问,不再安装HEPater聚集并通过Heapster分别管理它
假设每个POD和节点采集10个指标,从K8S 1. 6开始,支持5000个节点,每个节点30种荚,假设采集度1分钟,然后:
10 x 5000 x 30 / 60 = 25000 平均每分钟2万多个采集指标
由于K8S的API-服务器保存所有的数据到ETCD,很显然,K8S本身不能处理采集这个频率,而这种监测数据是快速和临时数据,所以你需要有一个组件成分。分开处理它们,所述K8S版本只存储在存储器中,所以度量 - 服务器的概念是天生的。
事实上,Hepaster已经有了公开的API,但用户和Kubernetes的其他部件都必须通过主代理服务器访问,而且Heapster接口并不像API的服务器,具有完整的身份验证和客户端集成。这个API是处于alpha阶段(8月18日),希望能去GA阶段。写作类的API - 服务器风格:通用API服务器
具有度量服务器组件,和采集的数据,但也暴露了API,但由于API要统一,如何转发该请求到API-服务器/蜜蜂/度量请求度量服务器,解决该溶液:库贝-aggrecator,在K8S 1. 7已经完成,前度量服务器尚未以外,是在步骤-aggrecator延迟
KUBE-aggrecator(聚集API)主要提供:
详细设计文档:参考链接
公制API:
如:
http://127.0.0.1:8001/apis/met ... nodes
http://127.0.0.1:8001/apis/met ... odes/
http://127.0.0.1:8001/apis/met ... pods/
度量服务器
度量服务器定时从Kubelet的总结API(Simmary)采集索引信息,这些聚集的数据将被存储在存储器中并且在公制-API的形式将其暴露。
度量服务器复API-Server库来实现自己的功能,如身份认证,版本等,以便在内存中执行数据,删除默认ETCD存储,引入存储器(例如,实现存储接口。由于存储在存储器中,监测数据是不持久的,可以通过第三方存储,这与Heapster一致扩展。

image.png
度量服务器出现后,将新Kubernetes监视模式将成为图像
官方地址:
使用
如上所述,度量 - 服务器是一个扩展的API服务器,取决于库贝-聚合,因此需要以开启在API服务器相关参数。
--requestheader-client-ca-file=/etc/kubernetes/certs/proxy-ca.crt
--proxy-client-cert-file=/etc/kubernetes/certs/proxy.crt
--proxy-client-key-file=/etc/kubernetes/certs/proxy.key
--requestheader-allowed-names=aggregator
--requestheader-extra-headers-prefix=X-Remote-Extra-
--requestheader-group-headers=X-Remote-Group
--requestheader-username-headers=X-Remote-User
安装文件下载地址:// 1.+ 8,注意更换镜像地址为国内反光镜
kubectl创建-f度量服务器/

图像
安装成功之后,接入地址API地址是:
图像
度量服务器的资源占用将继续上升为荚果的集群中的数目不断上升,所以有必要需要
ADDON-大小调整垂直扩展此容器。插件,调整器线性按照集群中节点的数量扩大度量服务器,以确保它可以提供完整的度量API服务。具体参考:链路
其他
HPA基于度量服务器上:参考链接
在Kubernetes的新监视系统,度量 - 服务器所属的核心指标,提供API metrics.k8s.io,仅提供节点和POD的CPU和内存使用情况。其他自定义指标(自定义指数)是通过组分如普罗米修斯完成,后续文章将解析自定义指标。
这文章是一个容器监督实践系列文章,全内容请参见:集装箱监视器图书
文章采集api(咕咕数据预览:/news/wxarticlecover()(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-09-19 20:14
请求示例:/news/wxarticlecover?Appkey=您的Appkey&;url=您的值
数据预览:/preview/wxarticlecover
接口测试:/news/wxarticlecover/demo
3.request参数(如果是post请求,则以JSON格式传递参数)
4.返回参数
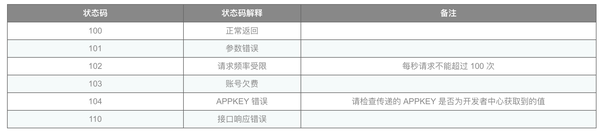
5.接口响应状态代码
6.开发语言请求示例代码
示例代码收录开发语言:c#、go、Java、jQuery、node.js、Objective-c、PHP、python、ruby、swift等。其他语言可以实现相应的restful API请求
Gugu data是一家专业的数据提供商,提供专业全面的数据接口和业务数据分析,使数据成为您的生产原材料
基于我们过去五年为企业客户提供的海量数据支持,goo data将一些通用数据和通用功能抽象为产品级API,极大地满足了用户在产品开发过程中对基础数据的需求,降低了复杂功能的实现门槛和人工成本
除了我们已经打开的分类数据和接口,海量数据正在被分类、清理、集成和构建。在后期,将为用户打开更多的数据和云功能接口
开放数据接口API 查看全部
文章采集api(咕咕数据预览:/news/wxarticlecover()(图))
请求示例:/news/wxarticlecover?Appkey=您的Appkey&;url=您的值
数据预览:/preview/wxarticlecover
接口测试:/news/wxarticlecover/demo
3.request参数(如果是post请求,则以JSON格式传递参数)

4.返回参数

5.接口响应状态代码
6.开发语言请求示例代码
示例代码收录开发语言:c#、go、Java、jQuery、node.js、Objective-c、PHP、python、ruby、swift等。其他语言可以实现相应的restful API请求
Gugu data是一家专业的数据提供商,提供专业全面的数据接口和业务数据分析,使数据成为您的生产原材料

基于我们过去五年为企业客户提供的海量数据支持,goo data将一些通用数据和通用功能抽象为产品级API,极大地满足了用户在产品开发过程中对基础数据的需求,降低了复杂功能的实现门槛和人工成本
除了我们已经打开的分类数据和接口,海量数据正在被分类、清理、集成和构建。在后期,将为用户打开更多的数据和云功能接口
开放数据接口API
文章采集api(咕咕数据预览:/news/wxarticlecover()(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-09-19 20:09
请求示例:/news/wxarticlecover?Appkey=您的Appkey&;url=您的值
数据预览:/preview/wxarticlecover
接口测试:/news/wxarticlecover/demo
3.request参数(如果是post请求,则以JSON格式传递参数)
4.返回参数
5.接口响应状态代码
6.开发语言请求示例代码
示例代码收录开发语言:c#、go、Java、jQuery、node.js、Objective-c、PHP、python、ruby、swift等。其他语言可以实现相应的restful API请求
Gugu data是一家专业的数据提供商,提供专业全面的数据接口和业务数据分析,使数据成为您的生产原材料
基于我们过去五年为企业客户提供的海量数据支持,goo data将一些通用数据和通用功能抽象为产品级API,极大地满足了用户在产品开发过程中对基础数据的需求,降低了复杂功能的实现门槛和人工成本
除了我们已经打开的分类数据和接口,海量数据正在被分类、清理、集成和构建。在后期,将为用户打开更多的数据和云功能接口
开放数据接口API 查看全部
文章采集api(咕咕数据预览:/news/wxarticlecover()(图))
请求示例:/news/wxarticlecover?Appkey=您的Appkey&;url=您的值
数据预览:/preview/wxarticlecover
接口测试:/news/wxarticlecover/demo
3.request参数(如果是post请求,则以JSON格式传递参数)

4.返回参数

5.接口响应状态代码
6.开发语言请求示例代码
示例代码收录开发语言:c#、go、Java、jQuery、node.js、Objective-c、PHP、python、ruby、swift等。其他语言可以实现相应的restful API请求
Gugu data是一家专业的数据提供商,提供专业全面的数据接口和业务数据分析,使数据成为您的生产原材料
基于我们过去五年为企业客户提供的海量数据支持,goo data将一些通用数据和通用功能抽象为产品级API,极大地满足了用户在产品开发过程中对基础数据的需求,降低了复杂功能的实现门槛和人工成本
除了我们已经打开的分类数据和接口,海量数据正在被分类、清理、集成和构建。在后期,将为用户打开更多的数据和云功能接口
开放数据接口API
文章采集api(咕咕数据接口API请求示例(示例代码示例)(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-19 20:06
请求示例:/news/techlogs?Appkey=您的Appkey&;pagesize=10&;pageindex=1
接口测试:/news/techlogs/demo
3.request参数(如果是post请求,则以JSON格式传递参数)
4.返回参数
5.接口响应状态代码
6.开发语言请求示例代码
示例代码收录开发语言:c#、go、Java、jQuery、node.js、Objective-c、PHP、python、ruby、swift等。其他语言可以实现相应的restful API请求
Gugu data是一家专业的数据提供商,提供专业全面的数据接口和业务数据分析,使数据成为您的生产原材料
基于我们过去五年为企业客户提供的海量数据支持,goo data将一些通用数据和通用功能抽象为产品级API,极大地满足了用户在产品开发过程中对基础数据的需求,降低了复杂功能的实现门槛和人工成本
除了我们已经打开的分类数据和接口,海量数据正在被分类、清理、集成和构建。在后期,将为用户打开更多的数据和云功能接口
开放数据接口API 查看全部
文章采集api(咕咕数据接口API请求示例(示例代码示例)(图))
请求示例:/news/techlogs?Appkey=您的Appkey&;pagesize=10&;pageindex=1
接口测试:/news/techlogs/demo
3.request参数(如果是post请求,则以JSON格式传递参数)

4.返回参数
5.接口响应状态代码
6.开发语言请求示例代码
示例代码收录开发语言:c#、go、Java、jQuery、node.js、Objective-c、PHP、python、ruby、swift等。其他语言可以实现相应的restful API请求
Gugu data是一家专业的数据提供商,提供专业全面的数据接口和业务数据分析,使数据成为您的生产原材料
基于我们过去五年为企业客户提供的海量数据支持,goo data将一些通用数据和通用功能抽象为产品级API,极大地满足了用户在产品开发过程中对基础数据的需求,降低了复杂功能的实现门槛和人工成本
除了我们已经打开的分类数据和接口,海量数据正在被分类、清理、集成和构建。在后期,将为用户打开更多的数据和云功能接口
开放数据接口API
文章采集api(青苹果影视系统(MacCms)可以快速搭建一个免更新、免维护的影视聚合、影视导航、影视点播网站)
采集交流 • 优采云 发表了文章 • 0 个评论 • 465 次浏览 • 2021-09-17 14:12
使用绿苹果影视系统(Maccms)可以快速构建免更新、免维护的影视聚合、影视导航和影视点播网站.绿苹果影视系统( Maccms)功能列表1、数据模块一键连接市场上影视资源站的API接口,现已支持FeiFeicms、 Maccms、 Maxcms、 Seacms等常用影视cmsinterfaces2、手机模板计算机系统支持一套模板tes适应计算机、手机、平板电脑、官方账号等终端入口,也可以将移动终端与PC模板分离。3、VOD模块是视频模块的基本在线VOD功能。H5播放器采用著名的dplayer,包括mp4、 m3u8、Flv、MP3和其他格式支持4、微信公众号可用于连接微信公众号开发者工具(视频机器人系统).对接后,微信用户可以通过回答关键词搜索相应的视频点播。5、图片延迟加载网站前台图片列表采用图片点播加载技术,加快用户访问网站的速度,节省服务器带宽6、简单传统转换网站前台集成了简单繁体中文自动转换功能,网页加载后会根据浏览器区域自动转换语言,是传统点播站的首选7、focus map模块可以通过ugh焦点地图模块,移动终端和PC终端独立管理,支持手机滑动8、广告模块系统预留多个广告位,由移动终端和PC终端独立管理,只需在相应的广告位i中添加广告代码即可n后台,可通过标记在模板中扩展和调用
9、link模块系统保留主页链接和全站链接。友情链接用于站长之间的交流。全站链接主要用于一系列关键词主题的内部链接。10、导航模块是基于daicuo后台开发框架的导航组件调用的on是系统全站的频道链接,图标导航是移动终端的首页图标小部件。11、分类模块基于大厝后台开发框架的分类组件设计,支持一级分类和二级分类,支持不同的分类ent分类调用不同的资源站进行独立设计。12、搜索模块支持同一关键词呼叫对不同资源站的搜索结果。搜索条件需要基于资源站支持的类型,通常包括明星、电影标题和导演搜索。绿苹果电影电视系统( Maccms)项目优势1、开源和免费:我们传播开源的概念Maccms这是一个免费开源的PHP电影程序,没有任何加密代码,源代码完全开放,安全可靠,没有后门2、稳定性和安全隐患:内核安全稳定,PHP+MySQL架构和跨平台操作。ThinkPHP+jQuery+bootstrap组合和超级负载能力帮助您轻松操作数百万个网站@3、回归自然:没有那些花哨的鸡肋功能,回归电影和视频站“免费观看”的核心精髓。本节目试图以最简单的方式4、auto站群免费为互联网用户提供点播服务功能:如果您已经拥有影视聚合和点播网站,您可以通过其API接口直接与用户通信Maccms停靠、主站更新和自动同步所有站群系统的自动化
@5、多插件:系统基于daicuo后台开发框架开发,在网站后台,可通过daicuo的应用市场6、在线安装和管理多个实用插件,免维护:可一次性安装,并随影视资源st自动更新全天24小时运行,省去了采集和生成等复杂的锁定工作,只需专注于操作网站和流程实现7、伪静态:系统依托thinkphp5强大的路由模块,通过后台可以设计出非常有利于搜索引擎ac的目录结构根据站长8、云解析需求:系统提供的云播放器使用dplayer集成主流视频的点播和解析功能网站.您还可以在后台通过单击设置9、strong caching调用第三方解析接口服务:系统依赖于thinkphp5强大的缓存模块,可通过后台随时切换到文件缓存、Xcache、memcached、redis等缓存方式。绿苹果影视系统( Maccms)安装说明1、将文件夹下的所有文件上载到您的网站space2、如果您的主机是Windows操作系统,请向以下文件夹@3、的IIS用户添加写入权限如果您的主机是Linux操作系统,请将以下文件夹权限设置为777./data/*system operation cache目录4、通过浏览器访问网站basic配置的后台(强烈建议将admin.php更改为不易猜测的名称)您的域名/admin.php,默认用户名为admin,密码为admin888@5、系统默认为SQLite3数据库,如果需要转换成MySQL,可以通过后台的数据库转换功能完成 查看全部
文章采集api(青苹果影视系统(MacCms)可以快速搭建一个免更新、免维护的影视聚合、影视导航、影视点播网站)
使用绿苹果影视系统(Maccms)可以快速构建免更新、免维护的影视聚合、影视导航和影视点播网站.绿苹果影视系统( Maccms)功能列表1、数据模块一键连接市场上影视资源站的API接口,现已支持FeiFeicms、 Maccms、 Maxcms、 Seacms等常用影视cmsinterfaces2、手机模板计算机系统支持一套模板tes适应计算机、手机、平板电脑、官方账号等终端入口,也可以将移动终端与PC模板分离。3、VOD模块是视频模块的基本在线VOD功能。H5播放器采用著名的dplayer,包括mp4、 m3u8、Flv、MP3和其他格式支持4、微信公众号可用于连接微信公众号开发者工具(视频机器人系统).对接后,微信用户可以通过回答关键词搜索相应的视频点播。5、图片延迟加载网站前台图片列表采用图片点播加载技术,加快用户访问网站的速度,节省服务器带宽6、简单传统转换网站前台集成了简单繁体中文自动转换功能,网页加载后会根据浏览器区域自动转换语言,是传统点播站的首选7、focus map模块可以通过ugh焦点地图模块,移动终端和PC终端独立管理,支持手机滑动8、广告模块系统预留多个广告位,由移动终端和PC终端独立管理,只需在相应的广告位i中添加广告代码即可n后台,可通过标记在模板中扩展和调用
9、link模块系统保留主页链接和全站链接。友情链接用于站长之间的交流。全站链接主要用于一系列关键词主题的内部链接。10、导航模块是基于daicuo后台开发框架的导航组件调用的on是系统全站的频道链接,图标导航是移动终端的首页图标小部件。11、分类模块基于大厝后台开发框架的分类组件设计,支持一级分类和二级分类,支持不同的分类ent分类调用不同的资源站进行独立设计。12、搜索模块支持同一关键词呼叫对不同资源站的搜索结果。搜索条件需要基于资源站支持的类型,通常包括明星、电影标题和导演搜索。绿苹果电影电视系统( Maccms)项目优势1、开源和免费:我们传播开源的概念Maccms这是一个免费开源的PHP电影程序,没有任何加密代码,源代码完全开放,安全可靠,没有后门2、稳定性和安全隐患:内核安全稳定,PHP+MySQL架构和跨平台操作。ThinkPHP+jQuery+bootstrap组合和超级负载能力帮助您轻松操作数百万个网站@3、回归自然:没有那些花哨的鸡肋功能,回归电影和视频站“免费观看”的核心精髓。本节目试图以最简单的方式4、auto站群免费为互联网用户提供点播服务功能:如果您已经拥有影视聚合和点播网站,您可以通过其API接口直接与用户通信Maccms停靠、主站更新和自动同步所有站群系统的自动化
@5、多插件:系统基于daicuo后台开发框架开发,在网站后台,可通过daicuo的应用市场6、在线安装和管理多个实用插件,免维护:可一次性安装,并随影视资源st自动更新全天24小时运行,省去了采集和生成等复杂的锁定工作,只需专注于操作网站和流程实现7、伪静态:系统依托thinkphp5强大的路由模块,通过后台可以设计出非常有利于搜索引擎ac的目录结构根据站长8、云解析需求:系统提供的云播放器使用dplayer集成主流视频的点播和解析功能网站.您还可以在后台通过单击设置9、strong caching调用第三方解析接口服务:系统依赖于thinkphp5强大的缓存模块,可通过后台随时切换到文件缓存、Xcache、memcached、redis等缓存方式。绿苹果影视系统( Maccms)安装说明1、将文件夹下的所有文件上载到您的网站space2、如果您的主机是Windows操作系统,请向以下文件夹@3、的IIS用户添加写入权限如果您的主机是Linux操作系统,请将以下文件夹权限设置为777./data/*system operation cache目录4、通过浏览器访问网站basic配置的后台(强烈建议将admin.php更改为不易猜测的名称)您的域名/admin.php,默认用户名为admin,密码为admin888@5、系统默认为SQLite3数据库,如果需要转换成MySQL,可以通过后台的数据库转换功能完成
文章采集api(数据埋点采集到底包括哪些问题?作者从什么是埋点、埋点的应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-09-12 21:15
Data采集是数据分析的基础,埋点是最重要的采集方法。那么,数据埋点采集涉及哪些问题呢?本文作者从什么是埋点、埋点如何设计、埋点的应用三个方面梳理了这个问题,与大家分享。
一、数据采集及常见数据问题
1.data采集
数据采集的方式有很多种,埋点采集是其中非常重要的一部分。这是c端和b端产品的主要采集方式。
数据采集,顾名思义采集,对应的数据是整个数据流的起点。 采集不完整,对不对,直接决定数据的广度和质量,影响后续所有环节。在数据采集有效性和完整性较差的公司中,业务中发现的数据通常会发生重大变化。
数据处理通常包括以下 5 个步骤:
2. 常见数据问题
大体了解了data采集及其结构之后,我们来看看我们工作中遇到的问题,有多少是与data采集链接相关的:
数据与背景差距大,数据不准确——统计口径不同,埋点定义不同,采集方法带来误差;
想用的时候,没有我想要的数据——没有数据采集需求,埋点不正确,不完整;
事件太多,含义不明确——埋点设计的方法,埋点更新迭代的规则和维护;
分析数据,不知道看哪些数据和指标——数据定义不明确,缺乏分析思路。
我们要从根本上解决问题:把采集当作一个独立的研发企业,而不是产品开发中的附属品
二、什么是埋点
1.什么是埋点
所谓的埋点是data采集领域的一个术语。它的学名应该叫事件跟踪,对应的英文是Event Tracking,指的是捕获、处理和发送特定用户行为或事件的相关技术和实现过程。
数据埋点是数据分析师、数据产品经理和数据运营。根据业务需求或产品需求,开发用户行为的每个事件对应的位置和埋点,通过SDK上报埋点的数据结果,汇总记录。数据分析后,推动产品优化,指导运营。
流程附有规范。通过定义,我们可以看到具体的用户行为和事件是我们采集关注的焦点。我们还需要处理和发送相关的技术和实施流程;数据嵌入的意义在于服务于产品,它来自于产品。因此,它与产品密切相关。埋点在于具体实战过程,关系到每个人对底层数据的理解。
2.为什么要埋地
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的好坏直接影响到数据质量、产品质量、运营质量等。
数据驱动的埋点将分析深度下钻到流量分布和流量级别。通过统计分析,对宏观指标进行深入分析,发现指标背后的问题,洞察用户行为与价值提升的潜在关系;
产品优化——对于产品,用户在产品中做了什么,用户在产品中停留了多久,有什么异常需要注意。这些问题都可以通过埋点来解决;
精细化的运营-购买点可以实现整个产品生命周期、流量质量和不同来源的分布、人群的行为特征和关系,以及用户行为与提升商业价值之间的潜在关联。
3.如何埋点
埋点的方法有哪些?目前,大多数公司采用客户端和服务器的组合:
准确度:代码埋点>可视化埋点>全埋点
三、Median 的框架和设计
1.埋点采集的顶层设计
所谓顶层设计,就是搞清楚怎么埋点,用什么方法,上传机制是什么,怎么定义,怎么实现等等;我们在遵循唯一性、可扩展性、一致性等的基础上,我们要设计一些通用的字段和生成机制,比如:cid、idfa、idfv等
用户识别:用户识别机制的混乱会导致两种结果:一种是数据不准确,比如UV数据不正确;另一种是漏斗分析环节异常。因此,它应该是: a.严格规范ID自身的识别机制;湾跨平台用户识别;
相似抽象:相似抽象包括事件抽象和属性抽象。事件抽象是指浏览事件和点击事件的聚合;属性抽象意味着合并大部分重用场景以增加源区分;
采集一致性:采集一致性包括两点:一是跨平台页面的一致命名,二是按钮命名的一致;建立嵌入点本身的过程就是对底层数据进行标准化的过程,因此一致性尤为重要。只有这样才能真正用上;
渠道配置:渠道主要是指推广渠道、落地页、网页推广页、APP推广页等,这个落地页的配置必须有统一的规范和标准。
2.埋点采集事件与属性设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变的,哪些是业务行为,哪些是基本属性。
基于基础属性事件,我们认为属性必须是采集items,但是属性中的事件属性会根据不同的业务进行调整。因此,我们可以将埋点采集分为协议层和业务层。点。
业务分解:梳理确认业务流程、运营路径和不同细分场景,定义用户行为路径
分析指标:定义核心业务指标所需的具体事件和数据
事件设计:APP启动、退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.Data采集事件与属性设计
EV 事件的命名也遵循一些规则。当同一类型的函数出现在不同的页面或位置时,根据函数名进行命名,在ev参数中区分页面和位置。仅点击按钮时,按按钮名称命名。
ev事件格式:ev分为ev标识和ev参数
规则:
ev标识符和ev参数之间用“#”连接(一级连接器);
ev参数和ev参数之间用“/”连接(二级连接器);
ev 参数使用 key=value 的结构。当一个key对应多个value值时,value1和value2之间用“,”连接(三级连接器);
当埋点只有ev标志没有ev参数时,不需要带#;
备注:
ev identifier:作为埋点的唯一标识符,用于区分埋点的位置和属性,不可变,不可修改;
ev参数:埋点需要返回的参数,ev参数的顺序是可变的,可以修改;)
调整app嵌入点时,ev标志保持不变,只修改后续嵌入点参数(参数值改变或参数类型增加)
eg:通用嵌入点文档中收录的sheet的名称和功能:
A.曝光埋点总结;
B.点击浏览埋点汇总;
C.故障埋点汇总:一般会记录埋点的故障版本或时间;
D、PC、M页面嵌入点对应的pageid;
E。各版本上线时间记录;
在嵌入点文档中,收录了所有的列名和函数:
4.基于埋点的统计
如何使用隐藏的统计数据找到隐藏的 ev 事件:
指定埋点类型(点击/曝光/浏览)-过滤类型字段
明确按钮所属的页面(页面或功能)-过滤功能模块字段
指定埋藏事件的名称-过滤名称字段
知道ev标识符,可以直接用ev过滤
如何根据ev事件进行计数统计:当查询按钮点击统计时,可以直接使用ev标志进行查询。有区别时,可以限制埋点参数的取值;因为ev参数的顺序不需要可变,所以在查询统计时,不能限制参数的顺序;
四、Application-数据流的基础
1.指标体系
系统性指标可以将不同指标、不同维度串联起来进行综合分析,快速发现当前产品和业务流程中存在的问题。
2. 可视化
人类对图像信息的解释比文本更有效。可视化对于数据分析极其重要。使用数据可视化可以揭示数据中固有的复杂关系。
3.埋点元信息api提供
data采集服务会将采集的埋点写入Kafka。针对各个业务的实时数据消费需求,我们为各个业务提供了单独的Kafka,流量分发模块会定时读取 埋点管理平台提供的元信息,将流量实时分发给各个业务卡夫卡。
Data采集 就像设计一个产品。不能过分,留有扩展的余地,但要时刻考虑数据是否完整、详细、不稳定、快速。 查看全部
文章采集api(数据埋点采集到底包括哪些问题?作者从什么是埋点、埋点的应用)
Data采集是数据分析的基础,埋点是最重要的采集方法。那么,数据埋点采集涉及哪些问题呢?本文作者从什么是埋点、埋点如何设计、埋点的应用三个方面梳理了这个问题,与大家分享。
一、数据采集及常见数据问题
1.data采集
数据采集的方式有很多种,埋点采集是其中非常重要的一部分。这是c端和b端产品的主要采集方式。
数据采集,顾名思义采集,对应的数据是整个数据流的起点。 采集不完整,对不对,直接决定数据的广度和质量,影响后续所有环节。在数据采集有效性和完整性较差的公司中,业务中发现的数据通常会发生重大变化。
数据处理通常包括以下 5 个步骤:
2. 常见数据问题
大体了解了data采集及其结构之后,我们来看看我们工作中遇到的问题,有多少是与data采集链接相关的:
数据与背景差距大,数据不准确——统计口径不同,埋点定义不同,采集方法带来误差;
想用的时候,没有我想要的数据——没有数据采集需求,埋点不正确,不完整;
事件太多,含义不明确——埋点设计的方法,埋点更新迭代的规则和维护;
分析数据,不知道看哪些数据和指标——数据定义不明确,缺乏分析思路。
我们要从根本上解决问题:把采集当作一个独立的研发企业,而不是产品开发中的附属品
二、什么是埋点
1.什么是埋点
所谓的埋点是data采集领域的一个术语。它的学名应该叫事件跟踪,对应的英文是Event Tracking,指的是捕获、处理和发送特定用户行为或事件的相关技术和实现过程。
数据埋点是数据分析师、数据产品经理和数据运营。根据业务需求或产品需求,开发用户行为的每个事件对应的位置和埋点,通过SDK上报埋点的数据结果,汇总记录。数据分析后,推动产品优化,指导运营。
流程附有规范。通过定义,我们可以看到具体的用户行为和事件是我们采集关注的焦点。我们还需要处理和发送相关的技术和实施流程;数据嵌入的意义在于服务于产品,它来自于产品。因此,它与产品密切相关。埋点在于具体实战过程,关系到每个人对底层数据的理解。
2.为什么要埋地
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的好坏直接影响到数据质量、产品质量、运营质量等。
数据驱动的埋点将分析深度下钻到流量分布和流量级别。通过统计分析,对宏观指标进行深入分析,发现指标背后的问题,洞察用户行为与价值提升的潜在关系;
产品优化——对于产品,用户在产品中做了什么,用户在产品中停留了多久,有什么异常需要注意。这些问题都可以通过埋点来解决;
精细化的运营-购买点可以实现整个产品生命周期、流量质量和不同来源的分布、人群的行为特征和关系,以及用户行为与提升商业价值之间的潜在关联。
3.如何埋点
埋点的方法有哪些?目前,大多数公司采用客户端和服务器的组合:
准确度:代码埋点>可视化埋点>全埋点
三、Median 的框架和设计
1.埋点采集的顶层设计
所谓顶层设计,就是搞清楚怎么埋点,用什么方法,上传机制是什么,怎么定义,怎么实现等等;我们在遵循唯一性、可扩展性、一致性等的基础上,我们要设计一些通用的字段和生成机制,比如:cid、idfa、idfv等
用户识别:用户识别机制的混乱会导致两种结果:一种是数据不准确,比如UV数据不正确;另一种是漏斗分析环节异常。因此,它应该是: a.严格规范ID自身的识别机制;湾跨平台用户识别;
相似抽象:相似抽象包括事件抽象和属性抽象。事件抽象是指浏览事件和点击事件的聚合;属性抽象意味着合并大部分重用场景以增加源区分;
采集一致性:采集一致性包括两点:一是跨平台页面的一致命名,二是按钮命名的一致;建立嵌入点本身的过程就是对底层数据进行标准化的过程,因此一致性尤为重要。只有这样才能真正用上;
渠道配置:渠道主要是指推广渠道、落地页、网页推广页、APP推广页等,这个落地页的配置必须有统一的规范和标准。
2.埋点采集事件与属性设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变的,哪些是业务行为,哪些是基本属性。
基于基础属性事件,我们认为属性必须是采集items,但是属性中的事件属性会根据不同的业务进行调整。因此,我们可以将埋点采集分为协议层和业务层。点。
业务分解:梳理确认业务流程、运营路径和不同细分场景,定义用户行为路径
分析指标:定义核心业务指标所需的具体事件和数据
事件设计:APP启动、退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.Data采集事件与属性设计
EV 事件的命名也遵循一些规则。当同一类型的函数出现在不同的页面或位置时,根据函数名进行命名,在ev参数中区分页面和位置。仅点击按钮时,按按钮名称命名。
ev事件格式:ev分为ev标识和ev参数
规则:
ev标识符和ev参数之间用“#”连接(一级连接器);
ev参数和ev参数之间用“/”连接(二级连接器);
ev 参数使用 key=value 的结构。当一个key对应多个value值时,value1和value2之间用“,”连接(三级连接器);
当埋点只有ev标志没有ev参数时,不需要带#;
备注:
ev identifier:作为埋点的唯一标识符,用于区分埋点的位置和属性,不可变,不可修改;
ev参数:埋点需要返回的参数,ev参数的顺序是可变的,可以修改;)
调整app嵌入点时,ev标志保持不变,只修改后续嵌入点参数(参数值改变或参数类型增加)
eg:通用嵌入点文档中收录的sheet的名称和功能:
A.曝光埋点总结;
B.点击浏览埋点汇总;
C.故障埋点汇总:一般会记录埋点的故障版本或时间;
D、PC、M页面嵌入点对应的pageid;
E。各版本上线时间记录;
在嵌入点文档中,收录了所有的列名和函数:
4.基于埋点的统计
如何使用隐藏的统计数据找到隐藏的 ev 事件:
指定埋点类型(点击/曝光/浏览)-过滤类型字段
明确按钮所属的页面(页面或功能)-过滤功能模块字段
指定埋藏事件的名称-过滤名称字段
知道ev标识符,可以直接用ev过滤
如何根据ev事件进行计数统计:当查询按钮点击统计时,可以直接使用ev标志进行查询。有区别时,可以限制埋点参数的取值;因为ev参数的顺序不需要可变,所以在查询统计时,不能限制参数的顺序;
四、Application-数据流的基础
1.指标体系
系统性指标可以将不同指标、不同维度串联起来进行综合分析,快速发现当前产品和业务流程中存在的问题。
2. 可视化
人类对图像信息的解释比文本更有效。可视化对于数据分析极其重要。使用数据可视化可以揭示数据中固有的复杂关系。
3.埋点元信息api提供
data采集服务会将采集的埋点写入Kafka。针对各个业务的实时数据消费需求,我们为各个业务提供了单独的Kafka,流量分发模块会定时读取 埋点管理平台提供的元信息,将流量实时分发给各个业务卡夫卡。
Data采集 就像设计一个产品。不能过分,留有扩展的余地,但要时刻考虑数据是否完整、详细、不稳定、快速。
文章采集api(如何用R调用API,提取和整理你需要的免费Web数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 276 次浏览 • 2021-09-09 22:13
API 是获取网络数据的重要途径之一。您想知道如何使用R调用API来提取和组织您需要的免费网络数据吗?本文将一步步为您详细介绍操作流程。
权衡
俗话说,“聪明的女人做饭没有米饭很难。”就算你掌握了数据分析的18个武功,没有数据也是一件苦恼的事情。 “拔剑望心”大概就是这种情况吧。
数据来源很多。 Web数据是一种数量大、获取相对容易的类型。更好的是,很多网络数据都是免费的。
在这个大数据时代,如何获取网络数据?
许多人会使用其他人编译和发布的数据集。
他们很幸运,他们的工作可以建立在其他人的基础上。这是最有效的。
但并不是每个人都这么幸运。如果你需要没有人编译和发布的数据怎么办?
其实这样的数据量更大。我们是否对他们视而不见?
如果您想到爬虫,那么您的思考方向是正确的。爬虫可以为您获取几乎所有可见(甚至不可见)的 Web 数据。但是,编写和使用爬虫的成本很高。包括时间资源、技术能力等。如果你面对任何网络数据采集问题,你甚至都不会想到“大锤”,有时可能就是“大锤杀鸡”。
在“别人准备的数据”和“需要自己爬取的数据”之间,有一个非常广阔的领域。这就是 API 的世界。
API 是什么?
是Application Programming Interface的缩写。具体来说,就是某个网站积累了变化的数据。如果把这些数据整理出来,不仅费时,而且占用空间,刚整理出来就有过期的危险。大多数人需要的数据其实只是其中的一小部分,但对时效性的要求可能非常强。因此,组织存储并提供给公众下载既不经济也不划算。
但是,如果数据不能以某种方式发布,你将面临无数爬虫的骚扰。这会给网站的正常运行带来很大的麻烦。妥协是网站主动提供了一个渠道。当你需要某部分数据时,虽然没有现成的数据集,你只需要用这个渠道描述你想要的数据,然后网站review(一般是自动化的,瞬间完成),认为可以给你,立即发送你明确要求的数据。双方都很开心。
以后找数据的时候,不妨看看目标网站是否提供了API,避免做无用功。
在这个github项目中,有一个非常详细的列表,涵盖了当前常见的主流网站API资源状态。作者还在整理修改中,大家可以采集慢慢看。
如果我们了解到某个网站提供了API,并且通过查看文档,知道里面有我们需要的数据,那么问题就变成了——如何通过API获取数据?
下面我们通过一个实际的例子向您展示整个过程的步骤。
来源
我们正在寻找的样本是维基百科。
有关维基百科 API 的概述,请参阅此页面。
假设我们关心特定时间段内对指定维基百科文章页面的访问次数。
维基百科专门为我们提供了一种称为指标的数据,它涵盖了页面访问的关键价值。对应的API介绍页面在这里。
页面上有一个示例。假设你需要获取2015年10月爱因斯坦的入口页面的访问次数,可以这样调用:
GET http://wikimedia.org/api/rest_ ... 03100
我们可以在浏览器的地址栏中输入GET后的一长串网址,按回车查看得到的结果。
在浏览器中,我们看到上图中的一长串文本。你可能会觉得奇怪——这是什么?
恭喜,这是我们需要获取的数据。但是,它使用一种称为 JSON 的特殊数据格式。
JSON 是目前互联网上数据交互的主流格式之一。如果你想了解JSON的含义和用法,可以参考这个教程。
在浏览器中,我们最初只能看到数据的第一部分。但它已经收录了有价值的内容:
{"items":[{"project":"en.wikipedia","article":"Albert_Einstein","granularity":"daily","timestamp":"2015100100","access":"all-access","agent":"all-agents","views":18860}
在这一段中,我们看到了项目名称(en.wikipedia)、文章title(阿尔伯特·爱因斯坦)、统计粒度(天)、时间戳(2015 年 10 月 1 日)、访问类型(全部)、终端类型( all),以及访问次数(18860)。
我们使用滑块将返回的文本拖到最后,我们会看到如下信息:
{"project":"en.wikipedia","article":"Albert_Einstein","granularity":"daily","timestamp":"2015103100","access":"all-access","agent":"all-agents","views":16380}]}
与10月1日的数据相比,只有时间戳(2015年10月31日)和访问量(16380))发生了变化。
我们中间跳过的数据是10月2日到10月30日之间的数据。存储格式相同,只有date和visits这两个数据值在变化。
所有需要的数据都在这里,你只需要提取相应的信息,就是这样。但是如果让你手动去做(比如复制需要的项目,然后粘贴到Excel中),显然效率很低,容易出错。让我们展示如何使用 R 编程环境来自动化这个过程。
准备
在使用 R 调用 API 之前,我们需要做一些必要的准备。
第一步是安装 R。
请先从本站下载R基础安装包。
R的下载位置比较多,建议选择清华大学的镜像,下载速度比较快。
请根据您的操作系统平台选择相应的版本进行下载。我使用的是 macOS 版本。
下载 pkg 文件。双击安装。
安装完基础包后,我们继续安装集成开发环境RStudio。它可以帮助您轻松地与 R 进行交互。 RStudio的下载地址在这里。
根据您的操作系统,选择对应的安装包。 macOS 安装包是一个 dmg 文件。双击打开后,将其中的RStudio.app图标拖到Applications文件夹,安装完成。
接下来,我们双击从应用程序目录运行 RStudio。
我们先在RStudio的Console中运行如下语句来安装一些需要用到的软件包:
install.packages("tidyverse")
install.packages("rlist")
安装完成后,在菜单中选择File->New,在如下界面选择R Notebook。
R Notebook 默认为我们提供了一个模板,其中收录一些基本的使用说明。
我们尝试点击编辑区(左侧)代码部分(灰色)中的运行按钮。
您可以立即看到绘图结果。
我们点击菜单栏上的Preview按钮来查看整个代码的结果。操作结果会显示在HTML文件中,图片和文字都可以。
熟悉环境后,是时候实际运行我们自己的代码了。我们保留左侧编辑区开头的描述区,删除其余部分,将文件名改为有意义的web-data-api-with-R。
到此,准备工作就做好了。现在我们就要开始实际操作了。
操作
在实际操作过程中,我们从维基百科中换了一个Wiki文章作为样本,以证明这种操作方法的通用性。选择的文章是我们在介绍词云制作时使用的那个,叫做“Yes, Minisiter”。这是一部 1980 年代的英国喜剧。
我们先在浏览器中试试看能否通过修改API示例中的参数来获取“是,部长”文章访问统计。作为测试,我们仅采集了 2017 年 10 月 1 日至 2017 年 10 月 3 日的 3 天数据。
与示例相比,我们需要替换的内容包括起止时间和文章title。
我们在浏览器的地址栏中输入:
https://wikimedia.org/api/rest ... 00300
返回结果如下:
数据可以正常返回。下面我们将使用statement方法在RStudio中进行调用。
注意,在下面的代码中,程序输出的开头会有一个##标记,以区别于执行代码本身。
一出现,我们就需要设置时区。以后不处理时间数据时,会遇到错误。
Sys.setenv(TZ="Asia/Shanghai")
然后,我们调用 tidyverse 包,它是一个集合,加载了我们稍后将使用的许多函数。
library(tidyverse)
## Loading tidyverse: ggplot2
## Loading tidyverse: tibble
## Loading tidyverse: tidyr
## Loading tidyverse: readr
## Loading tidyverse: purrr
## Loading tidyverse: dplyr
## Conflicts with tidy packages ----------------------------------------------
## filter(): dplyr, stats
## lag(): dplyr, stats
这里可能会遇到一些警告,忽略即可。它对我们的运营没有影响。
根据前面的例子,我们定义了要查询的时间跨度,并指定了要搜索的wiki名称文章。
注意,与 Python 不同的是,在 R 语言中,使用了赋值
<p>starting 查看全部
文章采集api(如何用R调用API,提取和整理你需要的免费Web数据)
API 是获取网络数据的重要途径之一。您想知道如何使用R调用API来提取和组织您需要的免费网络数据吗?本文将一步步为您详细介绍操作流程。

权衡
俗话说,“聪明的女人做饭没有米饭很难。”就算你掌握了数据分析的18个武功,没有数据也是一件苦恼的事情。 “拔剑望心”大概就是这种情况吧。
数据来源很多。 Web数据是一种数量大、获取相对容易的类型。更好的是,很多网络数据都是免费的。
在这个大数据时代,如何获取网络数据?
许多人会使用其他人编译和发布的数据集。
他们很幸运,他们的工作可以建立在其他人的基础上。这是最有效的。
但并不是每个人都这么幸运。如果你需要没有人编译和发布的数据怎么办?
其实这样的数据量更大。我们是否对他们视而不见?
如果您想到爬虫,那么您的思考方向是正确的。爬虫可以为您获取几乎所有可见(甚至不可见)的 Web 数据。但是,编写和使用爬虫的成本很高。包括时间资源、技术能力等。如果你面对任何网络数据采集问题,你甚至都不会想到“大锤”,有时可能就是“大锤杀鸡”。
在“别人准备的数据”和“需要自己爬取的数据”之间,有一个非常广阔的领域。这就是 API 的世界。
API 是什么?
是Application Programming Interface的缩写。具体来说,就是某个网站积累了变化的数据。如果把这些数据整理出来,不仅费时,而且占用空间,刚整理出来就有过期的危险。大多数人需要的数据其实只是其中的一小部分,但对时效性的要求可能非常强。因此,组织存储并提供给公众下载既不经济也不划算。
但是,如果数据不能以某种方式发布,你将面临无数爬虫的骚扰。这会给网站的正常运行带来很大的麻烦。妥协是网站主动提供了一个渠道。当你需要某部分数据时,虽然没有现成的数据集,你只需要用这个渠道描述你想要的数据,然后网站review(一般是自动化的,瞬间完成),认为可以给你,立即发送你明确要求的数据。双方都很开心。
以后找数据的时候,不妨看看目标网站是否提供了API,避免做无用功。
在这个github项目中,有一个非常详细的列表,涵盖了当前常见的主流网站API资源状态。作者还在整理修改中,大家可以采集慢慢看。
如果我们了解到某个网站提供了API,并且通过查看文档,知道里面有我们需要的数据,那么问题就变成了——如何通过API获取数据?
下面我们通过一个实际的例子向您展示整个过程的步骤。
来源
我们正在寻找的样本是维基百科。
有关维基百科 API 的概述,请参阅此页面。
假设我们关心特定时间段内对指定维基百科文章页面的访问次数。
维基百科专门为我们提供了一种称为指标的数据,它涵盖了页面访问的关键价值。对应的API介绍页面在这里。
页面上有一个示例。假设你需要获取2015年10月爱因斯坦的入口页面的访问次数,可以这样调用:
GET http://wikimedia.org/api/rest_ ... 03100
我们可以在浏览器的地址栏中输入GET后的一长串网址,按回车查看得到的结果。
在浏览器中,我们看到上图中的一长串文本。你可能会觉得奇怪——这是什么?
恭喜,这是我们需要获取的数据。但是,它使用一种称为 JSON 的特殊数据格式。
JSON 是目前互联网上数据交互的主流格式之一。如果你想了解JSON的含义和用法,可以参考这个教程。
在浏览器中,我们最初只能看到数据的第一部分。但它已经收录了有价值的内容:
{"items":[{"project":"en.wikipedia","article":"Albert_Einstein","granularity":"daily","timestamp":"2015100100","access":"all-access","agent":"all-agents","views":18860}
在这一段中,我们看到了项目名称(en.wikipedia)、文章title(阿尔伯特·爱因斯坦)、统计粒度(天)、时间戳(2015 年 10 月 1 日)、访问类型(全部)、终端类型( all),以及访问次数(18860)。
我们使用滑块将返回的文本拖到最后,我们会看到如下信息:
{"project":"en.wikipedia","article":"Albert_Einstein","granularity":"daily","timestamp":"2015103100","access":"all-access","agent":"all-agents","views":16380}]}
与10月1日的数据相比,只有时间戳(2015年10月31日)和访问量(16380))发生了变化。
我们中间跳过的数据是10月2日到10月30日之间的数据。存储格式相同,只有date和visits这两个数据值在变化。
所有需要的数据都在这里,你只需要提取相应的信息,就是这样。但是如果让你手动去做(比如复制需要的项目,然后粘贴到Excel中),显然效率很低,容易出错。让我们展示如何使用 R 编程环境来自动化这个过程。
准备
在使用 R 调用 API 之前,我们需要做一些必要的准备。
第一步是安装 R。
请先从本站下载R基础安装包。

R的下载位置比较多,建议选择清华大学的镜像,下载速度比较快。

请根据您的操作系统平台选择相应的版本进行下载。我使用的是 macOS 版本。
下载 pkg 文件。双击安装。
安装完基础包后,我们继续安装集成开发环境RStudio。它可以帮助您轻松地与 R 进行交互。 RStudio的下载地址在这里。
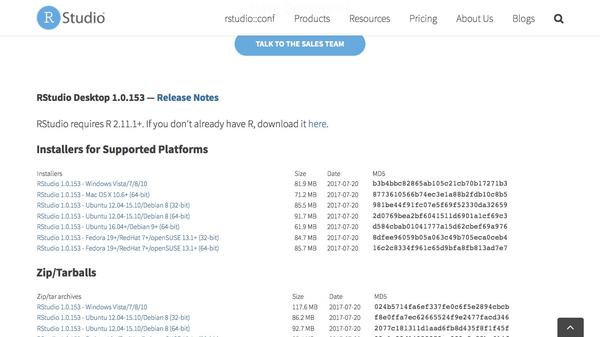
根据您的操作系统,选择对应的安装包。 macOS 安装包是一个 dmg 文件。双击打开后,将其中的RStudio.app图标拖到Applications文件夹,安装完成。
接下来,我们双击从应用程序目录运行 RStudio。
我们先在RStudio的Console中运行如下语句来安装一些需要用到的软件包:
install.packages("tidyverse")
install.packages("rlist")
安装完成后,在菜单中选择File->New,在如下界面选择R Notebook。
R Notebook 默认为我们提供了一个模板,其中收录一些基本的使用说明。
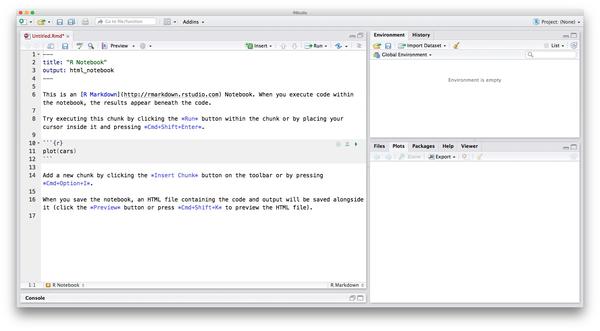
我们尝试点击编辑区(左侧)代码部分(灰色)中的运行按钮。
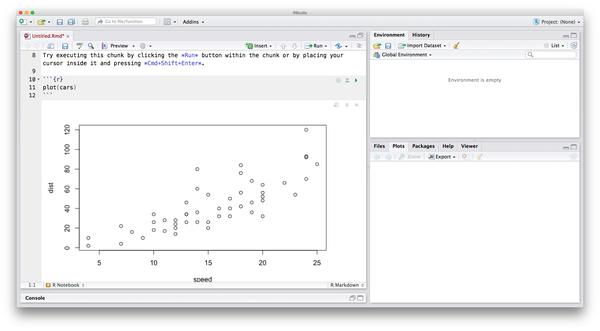
您可以立即看到绘图结果。
我们点击菜单栏上的Preview按钮来查看整个代码的结果。操作结果会显示在HTML文件中,图片和文字都可以。
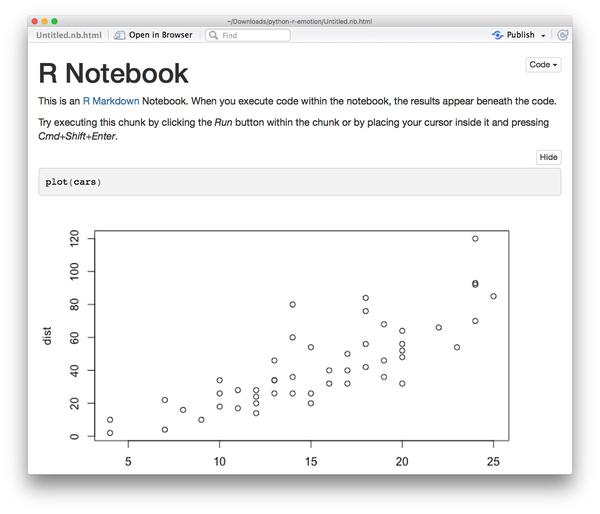
熟悉环境后,是时候实际运行我们自己的代码了。我们保留左侧编辑区开头的描述区,删除其余部分,将文件名改为有意义的web-data-api-with-R。
到此,准备工作就做好了。现在我们就要开始实际操作了。
操作
在实际操作过程中,我们从维基百科中换了一个Wiki文章作为样本,以证明这种操作方法的通用性。选择的文章是我们在介绍词云制作时使用的那个,叫做“Yes, Minisiter”。这是一部 1980 年代的英国喜剧。
我们先在浏览器中试试看能否通过修改API示例中的参数来获取“是,部长”文章访问统计。作为测试,我们仅采集了 2017 年 10 月 1 日至 2017 年 10 月 3 日的 3 天数据。
与示例相比,我们需要替换的内容包括起止时间和文章title。
我们在浏览器的地址栏中输入:
https://wikimedia.org/api/rest ... 00300
返回结果如下:
数据可以正常返回。下面我们将使用statement方法在RStudio中进行调用。
注意,在下面的代码中,程序输出的开头会有一个##标记,以区别于执行代码本身。
一出现,我们就需要设置时区。以后不处理时间数据时,会遇到错误。
Sys.setenv(TZ="Asia/Shanghai")
然后,我们调用 tidyverse 包,它是一个集合,加载了我们稍后将使用的许多函数。
library(tidyverse)
## Loading tidyverse: ggplot2
## Loading tidyverse: tibble
## Loading tidyverse: tidyr
## Loading tidyverse: readr
## Loading tidyverse: purrr
## Loading tidyverse: dplyr
## Conflicts with tidy packages ----------------------------------------------
## filter(): dplyr, stats
## lag(): dplyr, stats
这里可能会遇到一些警告,忽略即可。它对我们的运营没有影响。
根据前面的例子,我们定义了要查询的时间跨度,并指定了要搜索的wiki名称文章。
注意,与 Python 不同的是,在 R 语言中,使用了赋值
<p>starting
文章采集api(ApiPost支持团队协作,可直接生成文档的API调试、管理工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-09-09 22:11
ApiPost 是一个 API 调试和管理工具,支持团队协作,可以直接生成文档。支持POST、GET、PUT等常见请求的模拟,是后端接口开发人员或前端和接口测试人员不可多得的工具。用户不仅可以使用apiopst调试界面,还可以编写相关注释(界面文档),轻松生成可读性好、界面美观的在线界面文档。
本文主要收录以下内容:
介绍 ApiPost 工具及其功能
如何下载和安装
一些常见的操作
介绍一些技巧
前言:apipost 能做什么?
ApiPost 是一个 API 调试和管理工具,支持团队协作,可以直接生成文档。支持模拟POST、GET、PUT等postman等常见请求,快速生成接口文档。是后端接口开发人员或前端和接口测试人员不可多得的工具。先看它的界面风格。
下载并安装apipost
ApiPost 的安装和下载非常简单。可以直接到官网(自行百度)下载对应操作系统(支持window、mac、linux)的安装包并安装。官网还提供了丰富的安装文档,这里不再赘述。
一些常见的操作
ApiPost 支持常用的接口发送、文档生成等,作为开发者,相信你从上面的截图基本可以看出怎么使用了。下面是一些其他常见的操作。但是第一次使用需要注册账号,创建项目,然后点击左侧的APIS菜单栏进入控制台。
下图是对目录的常用操作
总之,使用基本上很简单,看到就下载安装。如有疑问,可以到官网查看文档或到社区提问。
一些操作技巧
提示:快速导入参数
apipost支持多种格式的参数导入,如下图所示,再也不用一一慢慢写了:
导入格式支持 key-value 和 json 格式:
1-1:键值格式导入示例:
常见的key-value格式为浏览器(控制台的F12)数据格式,见下图:
我们,复制上面的请求头参数,然后粘贴到apipost中,点击import
参数瞬间导入到请求参数中,如下图:
上面的例子只是展示了如何快速导入header参数,其他的query、body操作等参数完全一样。
1-2:json格式导入示例:
apipost 也支持json格式的参数导入,参数格式可以如下:
{ "id": 123, "title": "我就是标题" }
如图,点击Import,参数快速导入到请求参数中。
提示:自动识别参数注释
上面我们写了如何快速导入参数。实际上,参数描述(注释)是生成接口文档最可怕的。对于一直很忙的程序员来说,花大量时间写文档实在是太累了。 !
幸运的是,apipost 为我们节省了大量时间。对于一个参数,只要写一次注释,下次就可以选择同一个参数。示例:
在上图中,我们为id和title写了相应的注释:
id:“我是文章Id”
title:“我是文章title”
当我们新建一个界面的时候,如果界面还使用了id或者title等参数,点击参数说明会显示刚刚输入的参数说明,选择就可以了,不用再麻烦打字了。
这个小功能是否为开发者节省了大量时间?
提示:快速定位当前界面目录
左边的目录默认关闭。有时我们不知道当前正在编辑的界面属于哪个目录,查找起来很头疼。 Apipost 提供了“定位到当前界面目录”功能(见下图),可以快速打开当前正在编辑界面和文档的目录。它解决了你的大问题吗?
其实apipost还有很多更符合中国人操作习惯的小功能,等你去发现。 查看全部
文章采集api(ApiPost支持团队协作,可直接生成文档的API调试、管理工具)
ApiPost 是一个 API 调试和管理工具,支持团队协作,可以直接生成文档。支持POST、GET、PUT等常见请求的模拟,是后端接口开发人员或前端和接口测试人员不可多得的工具。用户不仅可以使用apiopst调试界面,还可以编写相关注释(界面文档),轻松生成可读性好、界面美观的在线界面文档。
本文主要收录以下内容:
介绍 ApiPost 工具及其功能
如何下载和安装
一些常见的操作
介绍一些技巧
前言:apipost 能做什么?
ApiPost 是一个 API 调试和管理工具,支持团队协作,可以直接生成文档。支持模拟POST、GET、PUT等postman等常见请求,快速生成接口文档。是后端接口开发人员或前端和接口测试人员不可多得的工具。先看它的界面风格。
下载并安装apipost
ApiPost 的安装和下载非常简单。可以直接到官网(自行百度)下载对应操作系统(支持window、mac、linux)的安装包并安装。官网还提供了丰富的安装文档,这里不再赘述。
一些常见的操作
ApiPost 支持常用的接口发送、文档生成等,作为开发者,相信你从上面的截图基本可以看出怎么使用了。下面是一些其他常见的操作。但是第一次使用需要注册账号,创建项目,然后点击左侧的APIS菜单栏进入控制台。
下图是对目录的常用操作
总之,使用基本上很简单,看到就下载安装。如有疑问,可以到官网查看文档或到社区提问。
一些操作技巧
提示:快速导入参数
apipost支持多种格式的参数导入,如下图所示,再也不用一一慢慢写了:
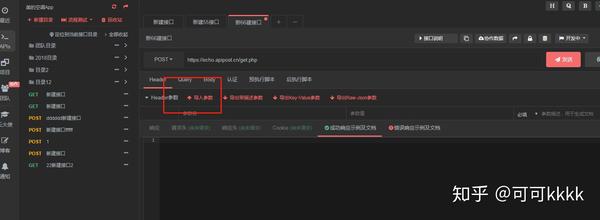
导入格式支持 key-value 和 json 格式:
1-1:键值格式导入示例:
常见的key-value格式为浏览器(控制台的F12)数据格式,见下图:
我们,复制上面的请求头参数,然后粘贴到apipost中,点击import
参数瞬间导入到请求参数中,如下图:
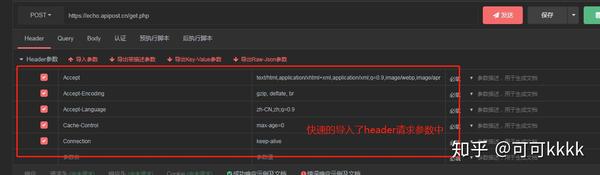
上面的例子只是展示了如何快速导入header参数,其他的query、body操作等参数完全一样。
1-2:json格式导入示例:
apipost 也支持json格式的参数导入,参数格式可以如下:
{ "id": 123, "title": "我就是标题" }
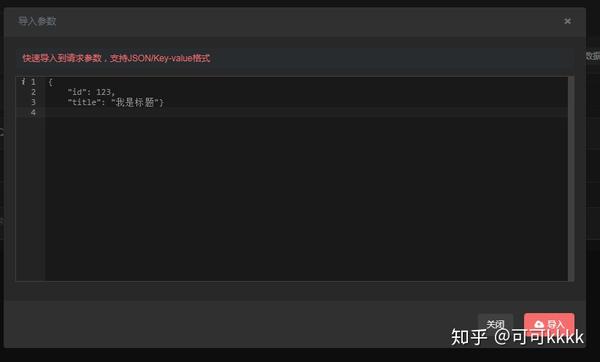
如图,点击Import,参数快速导入到请求参数中。
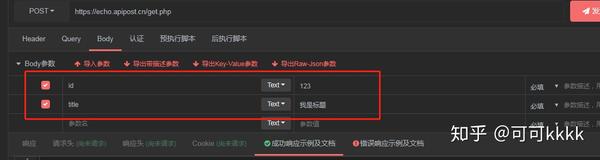
提示:自动识别参数注释
上面我们写了如何快速导入参数。实际上,参数描述(注释)是生成接口文档最可怕的。对于一直很忙的程序员来说,花大量时间写文档实在是太累了。 !
幸运的是,apipost 为我们节省了大量时间。对于一个参数,只要写一次注释,下次就可以选择同一个参数。示例:
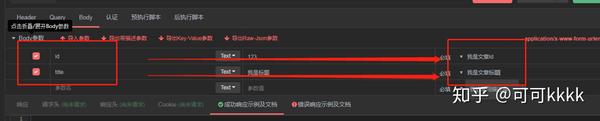
在上图中,我们为id和title写了相应的注释:
id:“我是文章Id”
title:“我是文章title”
当我们新建一个界面的时候,如果界面还使用了id或者title等参数,点击参数说明会显示刚刚输入的参数说明,选择就可以了,不用再麻烦打字了。
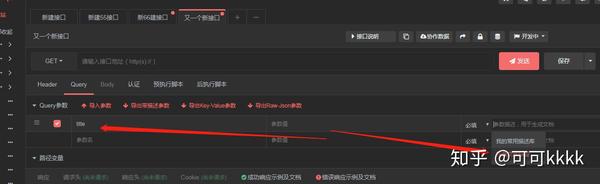
这个小功能是否为开发者节省了大量时间?
提示:快速定位当前界面目录
左边的目录默认关闭。有时我们不知道当前正在编辑的界面属于哪个目录,查找起来很头疼。 Apipost 提供了“定位到当前界面目录”功能(见下图),可以快速打开当前正在编辑界面和文档的目录。它解决了你的大问题吗?
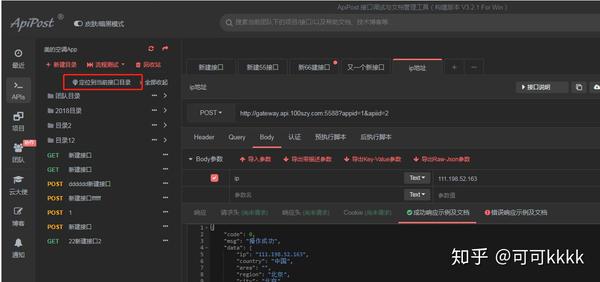
其实apipost还有很多更符合中国人操作习惯的小功能,等你去发现。
文章采集api( 前往韦世东的技术专栏收获爬虫架构/爬虫逆向/存储引擎/消息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-10-15 06:04
前往韦世东的技术专栏收获爬虫架构/爬虫逆向/存储引擎/消息)
去魏世东的技术专栏收获爬虫架构/爬虫逆向/存储引擎/消息队列/Python/Golang相关知识
这个文章的主要目的是告诉你如何配置Prometheus,使其可以使用指定的Web Api接口采集指标数据。文章中使用的case是NGINX的采集配置。从设置了用户名和密码的NGINX数据索引页中的采集数据来看,这是这个文章的副标题,可能是nginx的prometheus 采集配置或者prometheus 采集@ > 基本身份验证的 nginx。
上图展示了配置完成后在Grafana中配置模板的效果。
用过Prometheus的朋友一定知道如何配置address:port服务。比如在采集某个Redis的信息时,配置可以这样写:
- job_name: 'redis'
static_configs:
- targets: ['11.22.33.58:6087']
注:以上情况假设Redis Exporter的地址和端口为11.22.33.58:6087。
这是最简单也是最广为人知的方法。但是如果要监控指定的Web API,就不能这样写了。如果你没有看到这个 文章,你可能会在搜索引擎中搜索这样的:
但是很遗憾,没有找到有效的信息(现在是2021年3月),基本上所有的坑都能找到。
条件假设
假设我们现在需要从带有地址的接口中采集相关Prometheus监控指标,并且该接口使用basic auth(假设用户名为weishidong,密码为0099887kk)进行基本授权验证。
配置实践
如果填写之前看到的Prometheus配置,很可能这样写配置:
- job_name: 'web'
static_configs:
- targets: ['http://www.weishidong.com/status/format/prometheus']
basic_auth:
username: weishidong
password: 0099887kk
保存配置文件,重启服务后,你会发现这种方式无法采集数据,太可怕了。
官方配置指南
刚才的手术实在是太可怕了。当我们遇到不明白的问题时,我们当然去官方文档-> Prometheus Configuration。建议从上往下阅读,但如果你赶时间,可以直接进入采集配置部分。官方示例如下(内容太多,这里只保留与本文相关的部分,建议大家阅读原文):
# The job name assigned to scraped metrics by default.
job_name:
# How frequently to scrape targets from this job.
[ scrape_interval: | default = ]
# Per-scrape timeout when scraping this job.
[ scrape_timeout: | default = ]
# The HTTP resource path on which to fetch metrics from targets.
[ metrics_path: | default = /metrics ]
# honor_labels controls how Prometheus handles conflicts between labels that are
# already present in scraped data and labels that Prometheus would attach
# server-side ("job" and "instance" labels, manually configured target
# labels, and labels generated by service discovery implementations).
#
# If honor_labels is set to "true", label conflicts are resolved by keeping label
# values from the scraped data and ignoring the conflicting server-side labels.
#
# If honor_labels is set to "false", label conflicts are resolved by renaming
# conflicting labels in the scraped data to "exported_" (for
# example "exported_instance", "exported_job") and then attaching server-side
# labels.
#
# Setting honor_labels to "true" is useful for use cases such as federation and
# scraping the Pushgateway, where all labels specified in the target should be
# preserved.
#
# Note that any globally configured "external_labels" are unaffected by this
# setting. In communication with external systems, they are always applied only
# when a time series does not have a given label yet and are ignored otherwise.
[ honor_labels: | default = false ]
# honor_timestamps controls whether Prometheus respects the timestamps present
# in scraped data.
#
# If honor_timestamps is set to "true", the timestamps of the metrics exposed
# by the target will be used.
#
# If honor_timestamps is set to "false", the timestamps of the metrics exposed
# by the target will be ignored.
[ honor_timestamps: | default = true ]
# Configures the protocol scheme used for requests.
[ scheme: | default = http ]
# Optional HTTP URL parameters.
params:
[ : [, ...] ]
# Sets the `Authorization` header on every scrape request with the
# configured username and password.
# password and password_file are mutually exclusive.
basic_auth:
[ username: ]
[ password: ]
[ password_file: ]
# Sets the `Authorization` header on every scrape request with
# the configured bearer token. It is mutually exclusive with `bearer_token_file`.
[ bearer_token: ]
# Sets the `Authorization` header on every scrape request with the bearer token
# read from the configured file. It is mutually exclusive with `bearer_token`.
[ bearer_token_file: ]
如果仔细看,应该注意几个关键信息:metrics_path 和 basic_auth。其中,metrics_path用于指定HTTP类型指示符信息采集时的路由地址,默认值为/metrics;字段basic_auth用于授权验证,这里的password可以指定一个密码文件,而不是直接填写明文(一般来说,指定的密码文件的安全性稍高,明文)。
有效配置
根据官方文档的指引,我们可以快速推导出正确的配置写法:
- job_name: 'web'
metrics_path: /status/format/prometheus
static_configs:
- targets: ['www.weishidong.com']
basic_auth:
username: weishidong
password: 0099887kk
需要注意的是这里的字不用填,因为Prometheus默认的Scheme是http。如果地址的scheme是https,我们需要根据文档指引添加scheme字段,对应的配置为:
- job_name: 'web'
metrics_path: /status/format/prometheus
static_configs:
- targets: ['www.weishidong.com']
scheme: https
basic_auth:
username: weishidong
password: 0099887kk
配置完成后,Prometheus应该可以成功采集获取数据。用Grafana,可以看到开头给出的监控效果图。 查看全部
文章采集api(
前往韦世东的技术专栏收获爬虫架构/爬虫逆向/存储引擎/消息)
去魏世东的技术专栏收获爬虫架构/爬虫逆向/存储引擎/消息队列/Python/Golang相关知识
这个文章的主要目的是告诉你如何配置Prometheus,使其可以使用指定的Web Api接口采集指标数据。文章中使用的case是NGINX的采集配置。从设置了用户名和密码的NGINX数据索引页中的采集数据来看,这是这个文章的副标题,可能是nginx的prometheus 采集配置或者prometheus 采集@ > 基本身份验证的 nginx。
上图展示了配置完成后在Grafana中配置模板的效果。
用过Prometheus的朋友一定知道如何配置address:port服务。比如在采集某个Redis的信息时,配置可以这样写:
- job_name: 'redis'
static_configs:
- targets: ['11.22.33.58:6087']
注:以上情况假设Redis Exporter的地址和端口为11.22.33.58:6087。
这是最简单也是最广为人知的方法。但是如果要监控指定的Web API,就不能这样写了。如果你没有看到这个 文章,你可能会在搜索引擎中搜索这样的:
但是很遗憾,没有找到有效的信息(现在是2021年3月),基本上所有的坑都能找到。
条件假设
假设我们现在需要从带有地址的接口中采集相关Prometheus监控指标,并且该接口使用basic auth(假设用户名为weishidong,密码为0099887kk)进行基本授权验证。
配置实践
如果填写之前看到的Prometheus配置,很可能这样写配置:
- job_name: 'web'
static_configs:
- targets: ['http://www.weishidong.com/status/format/prometheus']
basic_auth:
username: weishidong
password: 0099887kk
保存配置文件,重启服务后,你会发现这种方式无法采集数据,太可怕了。
官方配置指南
刚才的手术实在是太可怕了。当我们遇到不明白的问题时,我们当然去官方文档-> Prometheus Configuration。建议从上往下阅读,但如果你赶时间,可以直接进入采集配置部分。官方示例如下(内容太多,这里只保留与本文相关的部分,建议大家阅读原文):
# The job name assigned to scraped metrics by default.
job_name:
# How frequently to scrape targets from this job.
[ scrape_interval: | default = ]
# Per-scrape timeout when scraping this job.
[ scrape_timeout: | default = ]
# The HTTP resource path on which to fetch metrics from targets.
[ metrics_path: | default = /metrics ]
# honor_labels controls how Prometheus handles conflicts between labels that are
# already present in scraped data and labels that Prometheus would attach
# server-side ("job" and "instance" labels, manually configured target
# labels, and labels generated by service discovery implementations).
#
# If honor_labels is set to "true", label conflicts are resolved by keeping label
# values from the scraped data and ignoring the conflicting server-side labels.
#
# If honor_labels is set to "false", label conflicts are resolved by renaming
# conflicting labels in the scraped data to "exported_" (for
# example "exported_instance", "exported_job") and then attaching server-side
# labels.
#
# Setting honor_labels to "true" is useful for use cases such as federation and
# scraping the Pushgateway, where all labels specified in the target should be
# preserved.
#
# Note that any globally configured "external_labels" are unaffected by this
# setting. In communication with external systems, they are always applied only
# when a time series does not have a given label yet and are ignored otherwise.
[ honor_labels: | default = false ]
# honor_timestamps controls whether Prometheus respects the timestamps present
# in scraped data.
#
# If honor_timestamps is set to "true", the timestamps of the metrics exposed
# by the target will be used.
#
# If honor_timestamps is set to "false", the timestamps of the metrics exposed
# by the target will be ignored.
[ honor_timestamps: | default = true ]
# Configures the protocol scheme used for requests.
[ scheme: | default = http ]
# Optional HTTP URL parameters.
params:
[ : [, ...] ]
# Sets the `Authorization` header on every scrape request with the
# configured username and password.
# password and password_file are mutually exclusive.
basic_auth:
[ username: ]
[ password: ]
[ password_file: ]
# Sets the `Authorization` header on every scrape request with
# the configured bearer token. It is mutually exclusive with `bearer_token_file`.
[ bearer_token: ]
# Sets the `Authorization` header on every scrape request with the bearer token
# read from the configured file. It is mutually exclusive with `bearer_token`.
[ bearer_token_file: ]
如果仔细看,应该注意几个关键信息:metrics_path 和 basic_auth。其中,metrics_path用于指定HTTP类型指示符信息采集时的路由地址,默认值为/metrics;字段basic_auth用于授权验证,这里的password可以指定一个密码文件,而不是直接填写明文(一般来说,指定的密码文件的安全性稍高,明文)。
有效配置
根据官方文档的指引,我们可以快速推导出正确的配置写法:
- job_name: 'web'
metrics_path: /status/format/prometheus
static_configs:
- targets: ['www.weishidong.com']
basic_auth:
username: weishidong
password: 0099887kk
需要注意的是这里的字不用填,因为Prometheus默认的Scheme是http。如果地址的scheme是https,我们需要根据文档指引添加scheme字段,对应的配置为:
- job_name: 'web'
metrics_path: /status/format/prometheus
static_configs:
- targets: ['www.weishidong.com']
scheme: https
basic_auth:
username: weishidong
password: 0099887kk
配置完成后,Prometheus应该可以成功采集获取数据。用Grafana,可以看到开头给出的监控效果图。
文章采集api(2019seo优化超级蜘蛛池自动采集网站优化必备安装教程 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-10-09 03:31
)
内容
蜘蛛池引流站群蜘蛛池2019 seo优化超级蜘蛛池自动采集网站优化必备
安装教程:
上传后直接访问域名或域名/install进行安装。
建议安装条件:
1、推荐使用Apache
2、PHP 5.4.0 及以上
3、数据库版本不低于Mysql 5.0
蜘蛛池是一个利用大平台权重获取百度收录和排名的程序。程序员常称其为“蜘蛛池”。这是一个可以快速提升网站排名的程序。值得一提的是,它自动提升了网站的网站和收录的排名。这个效果非常出色。蜘蛛池程序能为我们做什么?我不想收录如果我发了外部链接,但我的竞争对手发到同一个网站,他们不发外部链接收录,对吧!答:(因为他们有大量的百度收录蜘蛛爬虫,可以用蜘蛛池做)
seo优化站群功能
安全、高效、优化使用PHP性能,运行流畅稳定
原内容刷新无缓存,节省硬盘。防止搜索引擎识别蜘蛛池
蜘蛛池算法,轻松建站(电影、新闻、图片、论坛等)
可以个性化每个网站的风格、内容、站点模式、关键词、外链等(自定义tkd、自定义外链关键词、自定义通用域名前缀)
____________________
有老手会说我也有百度蜘蛛,为什么不用我的收录?
答:(因为你的百度收录蜘蛛不多,不够宽,来回就是那些低质量的百度收录爬虫,收录慢,甚至一点都没有收录!——-蜘蛛池多服务器,多域名,常规内容站点支持百度收录蜘蛛,分布广泛,多域名,团队化蜘蛛,多源站点,高质量,每一天有新的蜘蛛爬取 收录 你推断的帖子)
超强蜘蛛池功能,全自动采集,支持api二次开发!
也可以作为站群的源程序。
支持用户开户,自动释放,可租用蜘蛛池,释放外链使用!
支持关键词跳转,全局跳转!
自动采集(腾讯新闻(国内、军事)、新浪新闻(国际、军事))
新闻伪原创,加速收录!
支持导入txt外推网址、蜘蛛日记、索引池、权重池等,更多功能可以自己发现!
查看全部
文章采集api(2019seo优化超级蜘蛛池自动采集网站优化必备安装教程
)
内容
蜘蛛池引流站群蜘蛛池2019 seo优化超级蜘蛛池自动采集网站优化必备
安装教程:
上传后直接访问域名或域名/install进行安装。
建议安装条件:
1、推荐使用Apache
2、PHP 5.4.0 及以上
3、数据库版本不低于Mysql 5.0
蜘蛛池是一个利用大平台权重获取百度收录和排名的程序。程序员常称其为“蜘蛛池”。这是一个可以快速提升网站排名的程序。值得一提的是,它自动提升了网站的网站和收录的排名。这个效果非常出色。蜘蛛池程序能为我们做什么?我不想收录如果我发了外部链接,但我的竞争对手发到同一个网站,他们不发外部链接收录,对吧!答:(因为他们有大量的百度收录蜘蛛爬虫,可以用蜘蛛池做)
seo优化站群功能
安全、高效、优化使用PHP性能,运行流畅稳定
原内容刷新无缓存,节省硬盘。防止搜索引擎识别蜘蛛池
蜘蛛池算法,轻松建站(电影、新闻、图片、论坛等)
可以个性化每个网站的风格、内容、站点模式、关键词、外链等(自定义tkd、自定义外链关键词、自定义通用域名前缀)
____________________
有老手会说我也有百度蜘蛛,为什么不用我的收录?
答:(因为你的百度收录蜘蛛不多,不够宽,来回就是那些低质量的百度收录爬虫,收录慢,甚至一点都没有收录!——-蜘蛛池多服务器,多域名,常规内容站点支持百度收录蜘蛛,分布广泛,多域名,团队化蜘蛛,多源站点,高质量,每一天有新的蜘蛛爬取 收录 你推断的帖子)
超强蜘蛛池功能,全自动采集,支持api二次开发!
也可以作为站群的源程序。
支持用户开户,自动释放,可租用蜘蛛池,释放外链使用!
支持关键词跳转,全局跳转!
自动采集(腾讯新闻(国内、军事)、新浪新闻(国际、军事))
新闻伪原创,加速收录!
支持导入txt外推网址、蜘蛛日记、索引池、权重池等,更多功能可以自己发现!
https://www.chb66.com/wp-conte ... 4.png 416w, https://www.chb66.com/wp-conte ... 6.png 300w, https://www.chb66.com/wp-conte ... 2.png 768w" /> 文章采集api(这款zblog-php优采云采集发布接口源码介绍:采集功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-10-09 03:29
来源介绍:
优采云采集器 大家都知道,采集非常强大,支持PHP发布接口,也就是说你在优采云采集中的网页数据可以自动更新到你自己的网站,那么这个zblog-php优采云接口此时就可以满足你的需求了,配置很简单,还有百度推送功能,发布和提交同时进行时间,如果你找人定制一个zblog系统的优采云发布模块,价格300元起,功能非常有限,一些发布参数是固定的,如果你想改变或添加,你需要花钱找人改,一点都不划算,但是如果安装这个“zblog-php优采云采集发布界面”插件,完全可以省去这些步骤,更不用说强大的功能了,而且简单易用。
特色:
下载链接:
链接:提取码:uwx5
安装教程:
1、Locoy_Pub.zip 上传到/zb_users/plugin 目录,然后解压
2、进入后端插件页面启用zblog-php 优采云采集发布接口
3、打开插件,然后下载release模块,将下载的release模块放在优采云的\Module目录下
4、进入优采云>网页发布设置的模块管理,选择zrblog php -hui sem- locoy pub -3. 0,然后编辑
5、在zrblog php -hui sem-locoy pub -3. 0的模块编辑框中点击内容发布参数,然后修改post-post-post地址和post-的参数值源地址的发布地址为正确的值。例如“?1ocoy=sH!pc2Vt”,红色参数值必须与发布接口校验码一致。
6、 然后是配置post数据的步骤,这个可以按照下面提供的表格来设置
7、 设置后点击保存,记得覆盖原来的模块,否则修改的东西不会生效~
其他补充:
求助:请配合优采云。优采云如果不能用请自行百度。
获取分类接口:?locoy_getcate
内容发布参数:(已在发布模块中设置,此处仅作说明,红色必填字段):
表单名称表单值描述
标题 查看全部
文章采集api(这款zblog-php优采云采集发布接口源码介绍:采集功能)
来源介绍:
优采云采集器 大家都知道,采集非常强大,支持PHP发布接口,也就是说你在优采云采集中的网页数据可以自动更新到你自己的网站,那么这个zblog-php优采云接口此时就可以满足你的需求了,配置很简单,还有百度推送功能,发布和提交同时进行时间,如果你找人定制一个zblog系统的优采云发布模块,价格300元起,功能非常有限,一些发布参数是固定的,如果你想改变或添加,你需要花钱找人改,一点都不划算,但是如果安装这个“zblog-php优采云采集发布界面”插件,完全可以省去这些步骤,更不用说强大的功能了,而且简单易用。
特色:
下载链接:
链接:提取码:uwx5
安装教程:
1、Locoy_Pub.zip 上传到/zb_users/plugin 目录,然后解压
2、进入后端插件页面启用zblog-php 优采云采集发布接口
3、打开插件,然后下载release模块,将下载的release模块放在优采云的\Module目录下
4、进入优采云>网页发布设置的模块管理,选择zrblog php -hui sem- locoy pub -3. 0,然后编辑
5、在zrblog php -hui sem-locoy pub -3. 0的模块编辑框中点击内容发布参数,然后修改post-post-post地址和post-的参数值源地址的发布地址为正确的值。例如“?1ocoy=sH!pc2Vt”,红色参数值必须与发布接口校验码一致。
6、 然后是配置post数据的步骤,这个可以按照下面提供的表格来设置
7、 设置后点击保存,记得覆盖原来的模块,否则修改的东西不会生效~
其他补充:
求助:请配合优采云。优采云如果不能用请自行百度。
获取分类接口:?locoy_getcate
内容发布参数:(已在发布模块中设置,此处仅作说明,红色必填字段):
表单名称表单值描述
标题
文章采集api(PHP安装Github地址(截图安装)(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-10-09 03:24
截屏
安装
Github地址:
环境要求:PHP 5.6-7.2、MySQL >= 5.7、Redis,Redis扩展
1、安装环境
这里还是简单的路线,使用宝塔面板进行演示,使用命令:
#CentOS系统
wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh
#Ubuntu系统
wget -O install.sh http://download.bt.cn/install/ ... .0.sh && sudo bash install.sh
#Debian系统
wget -O install.sh http://download.bt.cn/install/ ... .0.sh && bash install.sh
安装完成后进入面板,点击左侧的软件管理,然后安装PHP7.2、Nginx、Mysql5.7+、Redis。
接下来,找到左侧的软件管理-PHP管理-设置-安装Redis扩展。
2、安装步骤
我们先点击左边的网站添加域名;然后点击左边的database-add database。
运行命令:
#进入网站根目录,将路径修改成自己的再运行
cd /www/wwwroot/www.moerats.com
#拉取源码
git clone https://github.com/hiliqi/hanman.git
#将源码移动到根目录
mv hanman/{,.}* ./
#授权用户组
chown -R www:www ./
3、设置伪静态
点击域名设置-网站目录,运行目录选择public,去掉跨站防范检查,重启PHP。然后点击伪静态并输入以下代码:
if (!-e $request_filename) {
rewrite ^(.*)$ /index.php?s=/$1 last;
break;
}
然后打开域名启动安装程序。
如果要启用404而不显示cms错误信息,需要修改config/app.php文件:
#去掉第一排的//即可
'exception_tmpl' => Env::get('app_path') . 'index/view/pub/404.html',
'exception_tmpl' => Env::get('think_path') . 'tpl/think_exception.tpl',
采集
一般情况下,漫画站的图片资源有两种,一种是本地化的,一种是盗链的。建议对图片进行本地化,这样可以保证网站资源的稳定性,同时程序还提供了优采云采集器的API,可以方便地与优采云采集器 用于漫画和章节图片 采集。
首先,我们需要一个优采云采集器,官网→门户,但是分为免费版和付费版,但是免费版由于某些原因不能满足图片本地化的需要功能限制,暂时不适用,有钱可以买付费版,没钱可以直接用优采云V7.6企业破解版版本。大概目前最新的破解版也能满足程序采集的具体要求,如何下载请自行百度。许多 网站 提供下载链接。
注:由于优采云V7和V8没有URL编解码功能,不能采集有中文链接的漫画网站,但V9版本可以,直接上传即可如果你有钱。
采集api 说明:
采集api地址:域名/api/index/save。
请求方式:post
表单字段及说明:
book_name 漫画名
nick_name 漫画别名
tags 分类,多个分类用|隔开
author 作者名字
src 采集源
end 状态,1代表完结,0代表连载中
cover_url 封面图远程地址
chapter_name 章节名
images 由图片标签组成的字符串,示例:
api_key 用于身份验证,要和后台配置的api密钥相同
summary 漫画简介
详细的采集参数说明可查看→门户。
由于采集的过程有点复杂,不太容易发帖,有兴趣不知道如何采集的可以看官方教程→传送门。一般步骤是打开优采云采集器主界面-Publish-New-Content发布参数,然后写好发布模块后,开始寻找目标站并编写采集规则,最后采集 发布。 查看全部
文章采集api(PHP安装Github地址(截图安装)(图))
截屏
安装
Github地址:
环境要求:PHP 5.6-7.2、MySQL >= 5.7、Redis,Redis扩展
1、安装环境
这里还是简单的路线,使用宝塔面板进行演示,使用命令:
#CentOS系统
wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh
#Ubuntu系统
wget -O install.sh http://download.bt.cn/install/ ... .0.sh && sudo bash install.sh
#Debian系统
wget -O install.sh http://download.bt.cn/install/ ... .0.sh && bash install.sh
安装完成后进入面板,点击左侧的软件管理,然后安装PHP7.2、Nginx、Mysql5.7+、Redis。
接下来,找到左侧的软件管理-PHP管理-设置-安装Redis扩展。
2、安装步骤
我们先点击左边的网站添加域名;然后点击左边的database-add database。
运行命令:
#进入网站根目录,将路径修改成自己的再运行
cd /www/wwwroot/www.moerats.com
#拉取源码
git clone https://github.com/hiliqi/hanman.git
#将源码移动到根目录
mv hanman/{,.}* ./
#授权用户组
chown -R www:www ./
3、设置伪静态
点击域名设置-网站目录,运行目录选择public,去掉跨站防范检查,重启PHP。然后点击伪静态并输入以下代码:
if (!-e $request_filename) {
rewrite ^(.*)$ /index.php?s=/$1 last;
break;
}
然后打开域名启动安装程序。
如果要启用404而不显示cms错误信息,需要修改config/app.php文件:
#去掉第一排的//即可
'exception_tmpl' => Env::get('app_path') . 'index/view/pub/404.html',
'exception_tmpl' => Env::get('think_path') . 'tpl/think_exception.tpl',
采集
一般情况下,漫画站的图片资源有两种,一种是本地化的,一种是盗链的。建议对图片进行本地化,这样可以保证网站资源的稳定性,同时程序还提供了优采云采集器的API,可以方便地与优采云采集器 用于漫画和章节图片 采集。
首先,我们需要一个优采云采集器,官网→门户,但是分为免费版和付费版,但是免费版由于某些原因不能满足图片本地化的需要功能限制,暂时不适用,有钱可以买付费版,没钱可以直接用优采云V7.6企业破解版版本。大概目前最新的破解版也能满足程序采集的具体要求,如何下载请自行百度。许多 网站 提供下载链接。
注:由于优采云V7和V8没有URL编解码功能,不能采集有中文链接的漫画网站,但V9版本可以,直接上传即可如果你有钱。
采集api 说明:
采集api地址:域名/api/index/save。
请求方式:post
表单字段及说明:
book_name 漫画名
nick_name 漫画别名
tags 分类,多个分类用|隔开
author 作者名字
src 采集源
end 状态,1代表完结,0代表连载中
cover_url 封面图远程地址
chapter_name 章节名
images 由图片标签组成的字符串,示例:
api_key 用于身份验证,要和后台配置的api密钥相同
summary 漫画简介
详细的采集参数说明可查看→门户。
由于采集的过程有点复杂,不太容易发帖,有兴趣不知道如何采集的可以看官方教程→传送门。一般步骤是打开优采云采集器主界面-Publish-New-Content发布参数,然后写好发布模块后,开始寻找目标站并编写采集规则,最后采集 发布。
文章采集api(一个微信公众号采集程序API的功能特点及功能介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-10-05 17:00
我专注于信息采集,自动化测试。去年做了一个微信公众号采集程序。下半年,微信升级了加密算法,根本停不下来。
前段时间在我们平台偶尔看到这个文章被鼓励,所以在近半个月后,我开发了一个自己的新算法采集。无奈之前的功力太差了,只好在别人的基础上改进UI,增加了很多功能。【感谢你爱上Geek的UI,我哥抄袭你的风格】
本程序API的特点:
1. 支持微信公众号ID和微信公众号中文名称输入
2.返回的内容
微信现在是一个使用非常广泛的社交平台。它的微信公众平台也发挥着重要作用,很多企业和互联网公司都用它来进行推广和分享。后面的需求是采集上面的内容,使用或阅读。比如通过微信公众号采集,他们发布的优秀文章可以被阅读采集,或者转载,供更多人学习交流。
目前,既然微信是腾讯旗下的,谷奇文章当然是不允许外界爬行的。文章的获取方式主要有两种:一、与腾讯合作,开放独立接口。二、 通过腾讯搜狗搜索的微信搜索功能爬取。
本文介绍一个实现良好的微信文章在线采集工具,为文章采集提供指定公众号,获取文章的标题和地址链接@> 批量,并提供第三方API供使用和二次开发。
微信现在是一个使用非常广泛的社交平台。它的微信公众平台也发挥着重要作用,很多企业和互联网公司都用它来进行推广和分享。后面的需求是采集上面的内容,使用或阅读。比如通过微信公众号采集,他们发布的优秀文章可以被阅读采集,或者转载,供更多人学习交流。
目前,既然微信是腾讯旗下的,谷奇文章当然是不允许外人爬的。
本文介绍一个实现良好的微信文章在线采集工具,为文章采集提供指定公众号,获取文章的标题和地址链接@> 批量,并提供第三方API供使用和二次开发。
在线使用
特征
通过微信公众号(订阅号),无需任何登录即可获取公众号发布的所有文章标题和地址,结果可以JSON形式反馈或以TABLE形式在线阅读,同时提供外部API。
支持二次开发:每天自动抓取关注最新微信公众号文章,更新至自营微信公众号、论坛(DISCUZ、PHPWIND)、博客(WORDPRESS)、订阅信息(RSS)等.
指示
登录微信公众号提取网站
接口使用
以POST/GET形式提交微信公众号weixin和用户key,以JSON/JSONP形式返回数据
请求网址:
请求参数:wxID={$wxID}&key={$key}
返回数据:输入网站查看,这里不允许发代码
测试:采集《人民日报》微信公众号
网页显示示例:
API 返回 JSON 示例:+iIR+5Ab52dVh73DsX/XYLlT/kHU9LNL6F71o0yGcChSEq
注:以上内容仅供研究使用,请勿用于非法用途。
【为防止过度使用资源或不必要的麻烦,页面设有临时KEY(有效期2分钟,可刷新重新获取)。】 查看全部
文章采集api(一个微信公众号采集程序API的功能特点及功能介绍)
我专注于信息采集,自动化测试。去年做了一个微信公众号采集程序。下半年,微信升级了加密算法,根本停不下来。
前段时间在我们平台偶尔看到这个文章被鼓励,所以在近半个月后,我开发了一个自己的新算法采集。无奈之前的功力太差了,只好在别人的基础上改进UI,增加了很多功能。【感谢你爱上Geek的UI,我哥抄袭你的风格】
本程序API的特点:
1. 支持微信公众号ID和微信公众号中文名称输入
2.返回的内容
微信现在是一个使用非常广泛的社交平台。它的微信公众平台也发挥着重要作用,很多企业和互联网公司都用它来进行推广和分享。后面的需求是采集上面的内容,使用或阅读。比如通过微信公众号采集,他们发布的优秀文章可以被阅读采集,或者转载,供更多人学习交流。
目前,既然微信是腾讯旗下的,谷奇文章当然是不允许外界爬行的。文章的获取方式主要有两种:一、与腾讯合作,开放独立接口。二、 通过腾讯搜狗搜索的微信搜索功能爬取。
本文介绍一个实现良好的微信文章在线采集工具,为文章采集提供指定公众号,获取文章的标题和地址链接@> 批量,并提供第三方API供使用和二次开发。
微信现在是一个使用非常广泛的社交平台。它的微信公众平台也发挥着重要作用,很多企业和互联网公司都用它来进行推广和分享。后面的需求是采集上面的内容,使用或阅读。比如通过微信公众号采集,他们发布的优秀文章可以被阅读采集,或者转载,供更多人学习交流。
目前,既然微信是腾讯旗下的,谷奇文章当然是不允许外人爬的。
本文介绍一个实现良好的微信文章在线采集工具,为文章采集提供指定公众号,获取文章的标题和地址链接@> 批量,并提供第三方API供使用和二次开发。
在线使用
特征
通过微信公众号(订阅号),无需任何登录即可获取公众号发布的所有文章标题和地址,结果可以JSON形式反馈或以TABLE形式在线阅读,同时提供外部API。
支持二次开发:每天自动抓取关注最新微信公众号文章,更新至自营微信公众号、论坛(DISCUZ、PHPWIND)、博客(WORDPRESS)、订阅信息(RSS)等.
指示
登录微信公众号提取网站
接口使用
以POST/GET形式提交微信公众号weixin和用户key,以JSON/JSONP形式返回数据
请求网址:
请求参数:wxID={$wxID}&key={$key}
返回数据:输入网站查看,这里不允许发代码
测试:采集《人民日报》微信公众号
网页显示示例:
API 返回 JSON 示例:+iIR+5Ab52dVh73DsX/XYLlT/kHU9LNL6F71o0yGcChSEq
注:以上内容仅供研究使用,请勿用于非法用途。
【为防止过度使用资源或不必要的麻烦,页面设有临时KEY(有效期2分钟,可刷新重新获取)。】
文章采集api(抖音爬虫教程,AndServer+Service打造Android服务器实现so文件调用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2021-10-04 14:14
抖音爬虫教程,AndServer+Service搭建Android服务器实现so文件调用so文件调用
随着Android手机安全的飞速发展,无论是为了执行效率还是程序安全,关键代码下沉到native层已经成为一项基本操作。
native层的开发参考JNI/NDK开发。通过JNI,Java层和native层(主要是C/C++)可以相互调用。本机层编译生成so动态链接库,so文件具有可移植性广、执行效率高、保密性强等优点。
那么问题来了,如何调用so文件是极其重要的。当然你也可以直接分析so文件的伪代码,用强大的编程技巧直接模拟按键操作,不过我觉得对于普通人来说头发还是比较重要的。
目前主流的调用so文件的操作应该是: 1.基于Unicorn的各种实现(还在学习中,暂不列出) 2. Android服务器搭建,在App中启动http服务完成调用so的需求(当然前提是经过so等验证)
至于为什么选择AndServer,嗯,不是为什么,只是因为我发现了它为什么要和Service结合,我在学习Android开发的时候就了解了Service的生命周期,个人理解还是用Service来做比较好创建 Http 服务。
当然也有Application的简单使用,因为在正式环境下,so文件的大部分逻辑都有上下文的一些包名,签名验证等,如果自定义Application,就可以得到传递参数的上下文。
短视频直播数据采集接口SDK,请点击查看接口文档libyemu.so介绍
这是我编译的so文件,根据输入参数进行简单的字符串拼接(以下是native层编译前的c代码)
extern "C"
JNIEXPORT jstring JNICALL
Java_com_fw_myapplication_ndktest_NdkTest_stringFromUTF(JNIEnv *env, jobject instance, jstring str_) {
jclass String_clazz = env->FindClass("java/lang/String");
jmethodID concat_methodID = env->GetMethodID(String_clazz, "concat", "(Ljava/lang/String;)Ljava/lang/String;");
jstring str = env->NewStringUTF(" from so --[NightTeam夜幕]");
jobject str1 = env->CallObjectMethod(str_, concat_methodID, str);
const char *chars = env->GetStringUTFChars((jstring)str1, 0);
return env->NewStringUTF(chars);
}
这部分代码还需要贴出来。简单的静态配准使用了反射的思想。反之,反射是至关重要的。接下来是java代码,它定义了native函数。
package com.fw.myapplication.ndktest;
public class NdkTest {
public static native String stringFromUTF(String str);
static {
System.loadLibrary("yemu");
}
}
如果你在这里有点困惑,你可能需要补上Android开发的基础。
Android项目测试so
先说一下我的环境,因为这个环境影响太大了 1、AndroidStudio 3.4 2、手机Android 6架构 armeabi-v7a 打开AndroidStudio新建项目
在模块的build中加入这句话,然后同步
将编译好的so文件复制到libs文件夹(对应刚才的jniLibs.srcDirs)
复制so对应的java代码,注意包名和类名的一致性
打开activity_main.xml文件,给TextView添加一个id
打开 MainActiviy.java 开始编码
这两行的意思是,先从layout中找到id对应的TextView,然后为其设置Text(调用原生函数的返回值)。让我们测试一下我们的通话情况。
可以看到我们的so文件调用成功了(这里我们的so无效,测试一下app是否可以正常调用)
AndServer代码编写
AndServer官方文档:/AndServer/ 打开官方文档,看看别人的介绍,新建一个java文件
如图,写了经典的MVC C,定义了一个nightteam_sign接口,请求方法为get,请求参数为sign,调用native函数,然后返回json,但是这里我想用Application获取上下文对象并去掉包名,然后自定义Applictaion
package com.nightteam.httpso;
import android.app.Application;
public class MyApp extends Application {
private static MyApp myApp;
public static MyApp getInstance() {
return myApp;
}
@Override
public void onCreate() {
super.onCreate();
myApp = this;
}
}
然后在清单文件中指定要启动的应用程序
然后修改MyController.java的代码
接下来复制官方文档服务器的代码导入一些包,修改部分代码如下
AndServer.serverBuilder 的新版本已经需要传递上下文。这里也修改了网络地址和端口号,从构造参数中获取。至此,AndServer 的东西基本完成了。其实我们会搭建一个界面来调整so。业务逻辑比较多,所以代码最简单好用
服务代码编写
这里我们用按钮的点击事件启动Service,所以在activity_main.xml中添加一个按钮并指定点击事件
接下来编写自定义Service代码
package com.nightteam.httpso.Service;
import android.app.Service;
import android.content.Intent;
import android.os.IBinder;
import android.util.Log;
import com.nightteam.httpso.ServerManager;
import java.net.InetAddress;
import java.net.UnknownHostException;
public class MyService extends Service {
private static final String TAG = "NigthTeam";
@Override
public void onCreate() {
super.onCreate();
Log.d(TAG, "onCreate: MyService");
new Thread() {
@Override
public void run() {
super.run();
InetAddress inetAddress = null;
try {
inetAddress = InetAddress.getByName("0.0.0.0");
Log.d(TAG, "onCreate: " + inetAddress.getHostAddress());
ServerManager serverManager = new ServerManager(getApplicationContext(), inetAddress, 8005);
serverManager.startServer();
} catch (UnknownHostException e) {
e.printStackTrace();
}
}
}.start();
}
@Override
public IBinder onBind(Intent intent) {
return null;
}
}
我打印了几条日志,在子线程中启动了AndServer服务(什么时候使用UI线程和子线程是Android的基础,这里不再赘述)。注意,这里从 0.0.0.0 获取inetAddress,别搞错了,localhost和0.0.0.的区别0,请移至搜索引擎,然后将context、inetAddress、port传递给ServerManager的构造函数用于新建对象,然后启动服务最后注意查看manifest文件中Service的声明
打开Service,获取本地ip
回到我们MainActivity.java的操作(按钮点击事件)编写启动Service的代码
public void operate(View view) {
switch (view.getId()){
case R.id.id_bt_index:
//启动服务:创建-->启动-->销毁
//如果服务已经创建了,后续重复启动,操作的都是同一个服务,不会再重新创建了,除非你先销毁它
Intent it1 = new Intent(this, MyService.class);
Log.d(TAG, "operate: button");
startService(it1);
((Button) view).setText("服务已开启");
break;
}
}
至此,我们的服务基本设置好了,但是为了方便,我想在App上显示我们本地的IP,这样我们就不用再设置和检查了。我在网上找到了一个获取IP地址的工具。,源码如下:
package com.nightteam.httpso;
import java.net.InetAddress;
import java.net.NetworkInterface;
import java.net.SocketException;
import java.util.Enumeration;
import java.util.regex.Pattern;
public class NetUtils {
private static final Pattern IPV4_PATTERN = Pattern.compile("^(" +
"([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\\.){3}" +
"([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])$");
private static boolean isIPv4Address(String input) {
return IPV4_PATTERN.matcher(input).matches();
}
//获取本机IP地址
public static InetAddress getLocalIPAddress() {
Enumeration enumeration = null;
try {
enumeration = NetworkInterface.getNetworkInterfaces();
} catch (SocketException e) {
e.printStackTrace();
}
if (enumeration != null) {
while (enumeration.hasMoreElements()) {
NetworkInterface nif = enumeration.nextElement();
Enumeration inetAddresses = nif.getInetAddresses();
if (inetAddresses != null)
while (inetAddresses.hasMoreElements()) {
InetAddress inetAddress = inetAddresses.nextElement();
if (!inetAddress.isLoopbackAddress() && isIPv4Address(inetAddress.getHostAddress())) {
return inetAddress;
}
}
}
}
return null;
}
}
将工具类复制到我们的 Android 项目中,并在 MainActivity.java 中继续编码
获取本地地址和Android SDK版本(Android 8之后启动Service的方式不同)
申请权限,启动App
最后一步是为应用申请网络权限
然后连接我们的手机,运行项目,测试一下,点击启动服务
查看AndroidStudio日志
好像一切正常,在浏览器访问下试试(ip是App中显示的ip地址)
如图,我们访问到了我们想要的内容。回去再说Service,打开我们手机的设置,找到应用管理-运行服务(不同的手机,不同的方法)
可以看到我们的程序运行了一个服务,这个服务就是我们编码的MyService
接下来,杀死App进程并再次检查正在运行的服务
这里我在权限管理中设置了自动运行,可以保持服务运行。(这个地方还是根据系统大小不同) 到此为止,可以使用App启动http服务并调整so。 查看全部
文章采集api(抖音爬虫教程,AndServer+Service打造Android服务器实现so文件调用)
抖音爬虫教程,AndServer+Service搭建Android服务器实现so文件调用so文件调用
随着Android手机安全的飞速发展,无论是为了执行效率还是程序安全,关键代码下沉到native层已经成为一项基本操作。
native层的开发参考JNI/NDK开发。通过JNI,Java层和native层(主要是C/C++)可以相互调用。本机层编译生成so动态链接库,so文件具有可移植性广、执行效率高、保密性强等优点。
那么问题来了,如何调用so文件是极其重要的。当然你也可以直接分析so文件的伪代码,用强大的编程技巧直接模拟按键操作,不过我觉得对于普通人来说头发还是比较重要的。
目前主流的调用so文件的操作应该是: 1.基于Unicorn的各种实现(还在学习中,暂不列出) 2. Android服务器搭建,在App中启动http服务完成调用so的需求(当然前提是经过so等验证)
至于为什么选择AndServer,嗯,不是为什么,只是因为我发现了它为什么要和Service结合,我在学习Android开发的时候就了解了Service的生命周期,个人理解还是用Service来做比较好创建 Http 服务。
当然也有Application的简单使用,因为在正式环境下,so文件的大部分逻辑都有上下文的一些包名,签名验证等,如果自定义Application,就可以得到传递参数的上下文。
短视频直播数据采集接口SDK,请点击查看接口文档libyemu.so介绍
这是我编译的so文件,根据输入参数进行简单的字符串拼接(以下是native层编译前的c代码)
extern "C"
JNIEXPORT jstring JNICALL
Java_com_fw_myapplication_ndktest_NdkTest_stringFromUTF(JNIEnv *env, jobject instance, jstring str_) {
jclass String_clazz = env->FindClass("java/lang/String");
jmethodID concat_methodID = env->GetMethodID(String_clazz, "concat", "(Ljava/lang/String;)Ljava/lang/String;");
jstring str = env->NewStringUTF(" from so --[NightTeam夜幕]");
jobject str1 = env->CallObjectMethod(str_, concat_methodID, str);
const char *chars = env->GetStringUTFChars((jstring)str1, 0);
return env->NewStringUTF(chars);
}
这部分代码还需要贴出来。简单的静态配准使用了反射的思想。反之,反射是至关重要的。接下来是java代码,它定义了native函数。
package com.fw.myapplication.ndktest;
public class NdkTest {
public static native String stringFromUTF(String str);
static {
System.loadLibrary("yemu");
}
}
如果你在这里有点困惑,你可能需要补上Android开发的基础。
Android项目测试so
先说一下我的环境,因为这个环境影响太大了 1、AndroidStudio 3.4 2、手机Android 6架构 armeabi-v7a 打开AndroidStudio新建项目
在模块的build中加入这句话,然后同步
将编译好的so文件复制到libs文件夹(对应刚才的jniLibs.srcDirs)
复制so对应的java代码,注意包名和类名的一致性
打开activity_main.xml文件,给TextView添加一个id
打开 MainActiviy.java 开始编码
这两行的意思是,先从layout中找到id对应的TextView,然后为其设置Text(调用原生函数的返回值)。让我们测试一下我们的通话情况。
可以看到我们的so文件调用成功了(这里我们的so无效,测试一下app是否可以正常调用)
AndServer代码编写
AndServer官方文档:/AndServer/ 打开官方文档,看看别人的介绍,新建一个java文件
如图,写了经典的MVC C,定义了一个nightteam_sign接口,请求方法为get,请求参数为sign,调用native函数,然后返回json,但是这里我想用Application获取上下文对象并去掉包名,然后自定义Applictaion
package com.nightteam.httpso;
import android.app.Application;
public class MyApp extends Application {
private static MyApp myApp;
public static MyApp getInstance() {
return myApp;
}
@Override
public void onCreate() {
super.onCreate();
myApp = this;
}
}
然后在清单文件中指定要启动的应用程序
然后修改MyController.java的代码
接下来复制官方文档服务器的代码导入一些包,修改部分代码如下
AndServer.serverBuilder 的新版本已经需要传递上下文。这里也修改了网络地址和端口号,从构造参数中获取。至此,AndServer 的东西基本完成了。其实我们会搭建一个界面来调整so。业务逻辑比较多,所以代码最简单好用
服务代码编写
这里我们用按钮的点击事件启动Service,所以在activity_main.xml中添加一个按钮并指定点击事件
接下来编写自定义Service代码
package com.nightteam.httpso.Service;
import android.app.Service;
import android.content.Intent;
import android.os.IBinder;
import android.util.Log;
import com.nightteam.httpso.ServerManager;
import java.net.InetAddress;
import java.net.UnknownHostException;
public class MyService extends Service {
private static final String TAG = "NigthTeam";
@Override
public void onCreate() {
super.onCreate();
Log.d(TAG, "onCreate: MyService");
new Thread() {
@Override
public void run() {
super.run();
InetAddress inetAddress = null;
try {
inetAddress = InetAddress.getByName("0.0.0.0");
Log.d(TAG, "onCreate: " + inetAddress.getHostAddress());
ServerManager serverManager = new ServerManager(getApplicationContext(), inetAddress, 8005);
serverManager.startServer();
} catch (UnknownHostException e) {
e.printStackTrace();
}
}
}.start();
}
@Override
public IBinder onBind(Intent intent) {
return null;
}
}
我打印了几条日志,在子线程中启动了AndServer服务(什么时候使用UI线程和子线程是Android的基础,这里不再赘述)。注意,这里从 0.0.0.0 获取inetAddress,别搞错了,localhost和0.0.0.的区别0,请移至搜索引擎,然后将context、inetAddress、port传递给ServerManager的构造函数用于新建对象,然后启动服务最后注意查看manifest文件中Service的声明
打开Service,获取本地ip
回到我们MainActivity.java的操作(按钮点击事件)编写启动Service的代码
public void operate(View view) {
switch (view.getId()){
case R.id.id_bt_index:
//启动服务:创建-->启动-->销毁
//如果服务已经创建了,后续重复启动,操作的都是同一个服务,不会再重新创建了,除非你先销毁它
Intent it1 = new Intent(this, MyService.class);
Log.d(TAG, "operate: button");
startService(it1);
((Button) view).setText("服务已开启");
break;
}
}
至此,我们的服务基本设置好了,但是为了方便,我想在App上显示我们本地的IP,这样我们就不用再设置和检查了。我在网上找到了一个获取IP地址的工具。,源码如下:
package com.nightteam.httpso;
import java.net.InetAddress;
import java.net.NetworkInterface;
import java.net.SocketException;
import java.util.Enumeration;
import java.util.regex.Pattern;
public class NetUtils {
private static final Pattern IPV4_PATTERN = Pattern.compile("^(" +
"([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\\.){3}" +
"([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])$");
private static boolean isIPv4Address(String input) {
return IPV4_PATTERN.matcher(input).matches();
}
//获取本机IP地址
public static InetAddress getLocalIPAddress() {
Enumeration enumeration = null;
try {
enumeration = NetworkInterface.getNetworkInterfaces();
} catch (SocketException e) {
e.printStackTrace();
}
if (enumeration != null) {
while (enumeration.hasMoreElements()) {
NetworkInterface nif = enumeration.nextElement();
Enumeration inetAddresses = nif.getInetAddresses();
if (inetAddresses != null)
while (inetAddresses.hasMoreElements()) {
InetAddress inetAddress = inetAddresses.nextElement();
if (!inetAddress.isLoopbackAddress() && isIPv4Address(inetAddress.getHostAddress())) {
return inetAddress;
}
}
}
}
return null;
}
}
将工具类复制到我们的 Android 项目中,并在 MainActivity.java 中继续编码
获取本地地址和Android SDK版本(Android 8之后启动Service的方式不同)
申请权限,启动App
最后一步是为应用申请网络权限
然后连接我们的手机,运行项目,测试一下,点击启动服务
查看AndroidStudio日志
好像一切正常,在浏览器访问下试试(ip是App中显示的ip地址)
如图,我们访问到了我们想要的内容。回去再说Service,打开我们手机的设置,找到应用管理-运行服务(不同的手机,不同的方法)
可以看到我们的程序运行了一个服务,这个服务就是我们编码的MyService
接下来,杀死App进程并再次检查正在运行的服务
这里我在权限管理中设置了自动运行,可以保持服务运行。(这个地方还是根据系统大小不同) 到此为止,可以使用App启动http服务并调整so。
文章采集api(小涴熊CMS漫画源码的安装和采集教程,文字比较多)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-03 00:30
本文文章将给大家讲解安装小传熊的cms漫画源码和采集教程。有很多文字。你还需要一点耐心,仔细研究。祝大家“车站交通兴旺,客流量日益增加!”
环境要求:PHP 7.0-7.2、MySQL >= 5.7、Redis,Redis扩展(官方要求为PHP 5.6 - 7.2,因为经过测试发现7.0不好用,所以这里修改了一下,直接改成7.0-7.2)。
1、安装环境
这里还是简单的路线,使用宝塔面板进行演示,使用命令:
#CentOS系统
wget -O install.sh && sh install.sh
#Ubuntu系统
wget -O install.sh && sudo bash install.sh
#Debian系统
wget -O install.sh && bash install.sh
安装完成后,进入面板,点击左侧的软件管理,然后安装PHP7.2、Nginx、Mysql5.7+、Redis。
接下来,找到左侧的软件管理-PHP管理-设置-安装Redis扩展。
2、安装步骤
这里有一个简单的路线,使用宝塔面板进行演示
1、宝塔安装好后,进入面板,点击左侧的软件管理,然后安装PHP7.2、Nginx、Mysql5.7+、Redis。
2.我们先点击左边的网站,添加网站!我不需要教这个!!!
3.设置伪静态规则:
如果(!-e $request_filename){
最后重写 ^(.*)$ /index.php?s=/$1;
休息;
}
4、点击域名设置-网站目录,运行目录选择public,去掉跨站防护的勾选,重启PHP。
5.最后浏览器运行你的网站+/install进入安装页面,根据页面提示输入相关信息完成安装!
注意:如果要启用404而不显示cms错误信息,需要修改config/app.php文件:
#删除第一行的//
'exception_tmpl' => Env::get('app_path').'index/view/pub/404.html',
'exception_tmpl' => Env::get('think_path').'tpl/think_exception.tpl',
采集教程
一般情况下,漫画站的图片资源有两种,一种是本地化的,一种是盗链的。建议对图片进行本地化,这样可以保证网站资源的稳定性,同时程序还提供了优采云采集器的API,可以方便地与优采云采集器 用于漫画和章节图片 采集。
首先,我们需要一个优采云采集器,官网→门户,但是分为免费版和付费版,但是免费版由于某些原因不能满足图片本地化的需要功能限制,暂时不适用,有钱可以买付费版,没钱可以直接用优采云V7.6企业版破解版,可能是最新的破解版,也能满足程序采集的具体要求,如何下载请百度。许多 网站 提供下载链接。
注意:由于火车头V7和V8没有url编码解码功能,所以不能采集带有中文链接的漫画网站,但V9版本可以,有钱可以直接上。
采集api 说明:
采集api地址:域名/api/index/save
请求方式:post
表单字段及说明:
book_name 漫画名
nick_name 漫画别名
tags 分类,多个分类用|隔开
author 作者名字
src 采集源
end 状态,1代表完结,0代表连载中
cover_url 封面图远程地址
chapter_name 章节名
images 由图片标签组成的字符串,示例:
api_key 用于身份验证,要和后台配置的api密钥相同
summary 漫画简介
注:由于优采云V7和V8没有URL编解码功能,不能采集有中文链接的漫画网站,但V9版本可以,直接上传即可如果你有钱。
由于采集的过程有点复杂,不太容易发帖,有兴趣和不了解采集的朋友可以到本站下载源码,查看中给出的在线教程地址源代码复制粘贴到浏览器打开,一般步骤是打开优采云采集器主界面-publish-new-content发布参数,然后写好发布模块后,开始找目标站,写采集规则,最后采集发布就行了。
本文由网友投稿或由居马武整理于网络。如转载请注明出处:;
如果本站发布的内容侵犯了您的权益,请发送邮件至cnzz8#删除,我们会及时处理!
本站下载资源大部分采集于互联网,不保证其完整性和安全性。下载后请自行测试。
本站资源仅供学习交流之用。版权属于资源的原作者。请在下载后24小时内自觉删除。
商业用途请购买正版。未及时购买及支付造成的侵权与本站无关。 查看全部
文章采集api(小涴熊CMS漫画源码的安装和采集教程,文字比较多)
本文文章将给大家讲解安装小传熊的cms漫画源码和采集教程。有很多文字。你还需要一点耐心,仔细研究。祝大家“车站交通兴旺,客流量日益增加!”
环境要求:PHP 7.0-7.2、MySQL >= 5.7、Redis,Redis扩展(官方要求为PHP 5.6 - 7.2,因为经过测试发现7.0不好用,所以这里修改了一下,直接改成7.0-7.2)。
1、安装环境
这里还是简单的路线,使用宝塔面板进行演示,使用命令:
#CentOS系统
wget -O install.sh && sh install.sh
#Ubuntu系统
wget -O install.sh && sudo bash install.sh
#Debian系统
wget -O install.sh && bash install.sh
安装完成后,进入面板,点击左侧的软件管理,然后安装PHP7.2、Nginx、Mysql5.7+、Redis。
接下来,找到左侧的软件管理-PHP管理-设置-安装Redis扩展。
2、安装步骤
这里有一个简单的路线,使用宝塔面板进行演示
1、宝塔安装好后,进入面板,点击左侧的软件管理,然后安装PHP7.2、Nginx、Mysql5.7+、Redis。
2.我们先点击左边的网站,添加网站!我不需要教这个!!!
3.设置伪静态规则:
如果(!-e $request_filename){
最后重写 ^(.*)$ /index.php?s=/$1;
休息;
}
4、点击域名设置-网站目录,运行目录选择public,去掉跨站防护的勾选,重启PHP。
5.最后浏览器运行你的网站+/install进入安装页面,根据页面提示输入相关信息完成安装!
注意:如果要启用404而不显示cms错误信息,需要修改config/app.php文件:
#删除第一行的//
'exception_tmpl' => Env::get('app_path').'index/view/pub/404.html',
'exception_tmpl' => Env::get('think_path').'tpl/think_exception.tpl',
采集教程
一般情况下,漫画站的图片资源有两种,一种是本地化的,一种是盗链的。建议对图片进行本地化,这样可以保证网站资源的稳定性,同时程序还提供了优采云采集器的API,可以方便地与优采云采集器 用于漫画和章节图片 采集。
首先,我们需要一个优采云采集器,官网→门户,但是分为免费版和付费版,但是免费版由于某些原因不能满足图片本地化的需要功能限制,暂时不适用,有钱可以买付费版,没钱可以直接用优采云V7.6企业版破解版,可能是最新的破解版,也能满足程序采集的具体要求,如何下载请百度。许多 网站 提供下载链接。
注意:由于火车头V7和V8没有url编码解码功能,所以不能采集带有中文链接的漫画网站,但V9版本可以,有钱可以直接上。
采集api 说明:
采集api地址:域名/api/index/save
请求方式:post
表单字段及说明:
book_name 漫画名
nick_name 漫画别名
tags 分类,多个分类用|隔开
author 作者名字
src 采集源
end 状态,1代表完结,0代表连载中
cover_url 封面图远程地址
chapter_name 章节名
images 由图片标签组成的字符串,示例:
api_key 用于身份验证,要和后台配置的api密钥相同
summary 漫画简介
注:由于优采云V7和V8没有URL编解码功能,不能采集有中文链接的漫画网站,但V9版本可以,直接上传即可如果你有钱。
由于采集的过程有点复杂,不太容易发帖,有兴趣和不了解采集的朋友可以到本站下载源码,查看中给出的在线教程地址源代码复制粘贴到浏览器打开,一般步骤是打开优采云采集器主界面-publish-new-content发布参数,然后写好发布模块后,开始找目标站,写采集规则,最后采集发布就行了。
本文由网友投稿或由居马武整理于网络。如转载请注明出处:;
如果本站发布的内容侵犯了您的权益,请发送邮件至cnzz8#删除,我们会及时处理!
本站下载资源大部分采集于互联网,不保证其完整性和安全性。下载后请自行测试。
本站资源仅供学习交流之用。版权属于资源的原作者。请在下载后24小时内自觉删除。
商业用途请购买正版。未及时购买及支付造成的侵权与本站无关。
文章采集api(介于tapd跨项目统计的困难,开发了基于tapdAPI的数据同步的工具TapdCollect)
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-10-01 10:21
前言:
由于tapd跨项目统计的难度,我们开发了基于tapd API的数据同步工具TapdCollect,可以将数据传输到本地数据库,然后进行分析统计。Net Core 用于开发,可以定期跨平台部署。任务排期采集,支持项目、需求、缺陷、用例、测试计划、变更历史等数据采集,可选择是否保存历史记录、失败自动重试等辅助职能。
下载链接:
源地址:
特征
01、 输入【01】,启动【同步项目】
同步项目列表,对应数据库表名:tapd_project
02、 输入【02】,开始【同步工作流状态中英文名称对应】
同步工作流状态中英文名称对应关系,对应数据库表名:tapd_statusmap
03、 输入【03】,开始【同步自定义字段配置】
同步自定义字段配置,对应数据库表名:tapd_custom_fields_settings
04、 进入【04】,开始【同步需求分类】
同步需求分类,对应数据库表名:tapd_story_categories
05、 进入【05】,开始【同步测试用例分类】
同步测试用例分类,对应数据库表名:tapd_tcase_categories
06、 进入【06】,开始【同步需求】
同步需求,对应数据库表名:tapd_stories
07、 输入【07】,启动【同步缺陷】
同步缺陷,对应数据库表名:tapd_bugs
08、 输入【08】开始【同步任务】
同步任务,对应数据库表名:tapd_tasks
09、 进入【09】,开始【同步测试计划】
同步测试计划,对应数据库表名:tapd_test_plans
10、 输入【10】,开始【同步测试用例】
同步测试用例,对应数据库表名:tapd_tcases
11、 进入【11】,开始【同步需求变化历史】
同步需求变更历史,对应数据库表名:tapd_story_changes
12、 进入【12】,开始【同步缺陷变更历史】
同步缺陷变更历史,对应数据库表名:tapd_bug_changes
13、进入【13】开始【同步发布审核】
同步发布审核,对应数据库表名:tapd_launch_forms
14、输入【14】开始【同步发布计划】
同步发布计划,对应数据库表名:tapd_releases
15、 输入【97】,开始【删除配置文件】
删除配置文件,之前的配置文件会被删除
16、 输入【98】,启动【重置配置文件】
重置配置参数,可以在修改用户名和密码时使用
17、 输入【99】启动【初始化数据库】
第一次使用时,可以调用该方法初始化数据库
默认会在配置文件重置后调用,需要手动确认
配置文件设置
>>>>>>>>>> 1、Api_User-API 账号
>>>>>>>>>> 2、Api_Password-API密码
>>>>>>>>>> 3、CompanyId-公司ID
>>>>>>>>>> 4、PageLimit-每个请求的最大数量(1-200)
>>>>>>>>>> 5、RetryLimit-出错后的重试次数(1-10)
>>>>>>>>>> 6、IsKeepHistory-是否保留历史(0-不保留,1-保留)
>>>>>>>>>> 7、DataBaseConn-数据库连接配置(数据库仅支持Mysql,其他数据库请自行开发)
DataBaseConn 请参考如下配置: Server=xx;Database=Tapd;User=xx;Password=xx;pooling=False;port=xx;Charset=utf8;Allow Zero Datetime=True;
预防措施:
1、 请务必通过本程序设置
2、设置后参数为加密参数,不支持手动修改
3、如需修改参数,请重置配置文件
4、重置配置文件时,请根据自己的情况决定是否初始化数据库
5、 深度使用6个月后,可以联系客服申请api内测资质。申请通过后可以在公司管理-api open申请api账号
采集日志
采集的所有动作都会被记录在对应的日志中,在程序目录的日志文件夹中
1、log.log 带时间戳的日志,可以查看具体操作详情对应的时间
2、log_console.log 控制台日志,可以查看具体操作详情
3、log_error.log 错误日志,错误后可以查看错误对应的内容
4、log_debug.log 调试日志,默认不输出,需要调整NLog.config进行配置,具体数据内容
关于程序的调用(仅供参考,请根据实际情况进行配置)
需要提前安装.net Core Runtime
跳转到目录:cd %TapdCollect%\手动执行:dotnet TapdCollect.dll 自动执行(单功能):dotnet TapdCollect.dll 1 自动执行(多功能):dotnet TapdCollect.dll 1 2 3 4 5 6 7 8 13 对于超过14个功能的配置,请在每个功能参数后加一个空格
.Net Core 运行时下载链接
视窗:
其他平台:请到MicroSoft网站查找
定时任务配置(仅供参考)
1、首先配置bat脚本
2、设置定时任务
预防措施:
1) 开始填写程序所在目录,否则配置文件会被%windows%\system32\下的计划任务配置
2) 以双引号开头,否则无效
3)程序或脚本选择之前配置好的bat文件,建议选择自动运行的脚本
3、 设置触发条件(建议根据实际情况和需要设置)
预防措施:
1) 建议根据实际情况设置。它可以每天同步一次或几个小时同步一次。
2)但是建议不要在一个小时以内同步一次,因为Tapd请求是有时间限制的,理论上是1Req/S
3)tapd 请求过多会抛出过多请求错误 查看全部
文章采集api(介于tapd跨项目统计的困难,开发了基于tapdAPI的数据同步的工具TapdCollect)
前言:
由于tapd跨项目统计的难度,我们开发了基于tapd API的数据同步工具TapdCollect,可以将数据传输到本地数据库,然后进行分析统计。Net Core 用于开发,可以定期跨平台部署。任务排期采集,支持项目、需求、缺陷、用例、测试计划、变更历史等数据采集,可选择是否保存历史记录、失败自动重试等辅助职能。
下载链接:
源地址:
特征
01、 输入【01】,启动【同步项目】
同步项目列表,对应数据库表名:tapd_project
02、 输入【02】,开始【同步工作流状态中英文名称对应】
同步工作流状态中英文名称对应关系,对应数据库表名:tapd_statusmap
03、 输入【03】,开始【同步自定义字段配置】
同步自定义字段配置,对应数据库表名:tapd_custom_fields_settings
04、 进入【04】,开始【同步需求分类】
同步需求分类,对应数据库表名:tapd_story_categories
05、 进入【05】,开始【同步测试用例分类】
同步测试用例分类,对应数据库表名:tapd_tcase_categories
06、 进入【06】,开始【同步需求】
同步需求,对应数据库表名:tapd_stories
07、 输入【07】,启动【同步缺陷】
同步缺陷,对应数据库表名:tapd_bugs
08、 输入【08】开始【同步任务】
同步任务,对应数据库表名:tapd_tasks
09、 进入【09】,开始【同步测试计划】
同步测试计划,对应数据库表名:tapd_test_plans
10、 输入【10】,开始【同步测试用例】
同步测试用例,对应数据库表名:tapd_tcases
11、 进入【11】,开始【同步需求变化历史】
同步需求变更历史,对应数据库表名:tapd_story_changes
12、 进入【12】,开始【同步缺陷变更历史】
同步缺陷变更历史,对应数据库表名:tapd_bug_changes
13、进入【13】开始【同步发布审核】
同步发布审核,对应数据库表名:tapd_launch_forms
14、输入【14】开始【同步发布计划】
同步发布计划,对应数据库表名:tapd_releases
15、 输入【97】,开始【删除配置文件】
删除配置文件,之前的配置文件会被删除
16、 输入【98】,启动【重置配置文件】
重置配置参数,可以在修改用户名和密码时使用
17、 输入【99】启动【初始化数据库】
第一次使用时,可以调用该方法初始化数据库
默认会在配置文件重置后调用,需要手动确认
配置文件设置
>>>>>>>>>> 1、Api_User-API 账号
>>>>>>>>>> 2、Api_Password-API密码
>>>>>>>>>> 3、CompanyId-公司ID
>>>>>>>>>> 4、PageLimit-每个请求的最大数量(1-200)
>>>>>>>>>> 5、RetryLimit-出错后的重试次数(1-10)
>>>>>>>>>> 6、IsKeepHistory-是否保留历史(0-不保留,1-保留)
>>>>>>>>>> 7、DataBaseConn-数据库连接配置(数据库仅支持Mysql,其他数据库请自行开发)
DataBaseConn 请参考如下配置: Server=xx;Database=Tapd;User=xx;Password=xx;pooling=False;port=xx;Charset=utf8;Allow Zero Datetime=True;
预防措施:
1、 请务必通过本程序设置
2、设置后参数为加密参数,不支持手动修改
3、如需修改参数,请重置配置文件
4、重置配置文件时,请根据自己的情况决定是否初始化数据库
5、 深度使用6个月后,可以联系客服申请api内测资质。申请通过后可以在公司管理-api open申请api账号
采集日志
采集的所有动作都会被记录在对应的日志中,在程序目录的日志文件夹中
1、log.log 带时间戳的日志,可以查看具体操作详情对应的时间
2、log_console.log 控制台日志,可以查看具体操作详情
3、log_error.log 错误日志,错误后可以查看错误对应的内容
4、log_debug.log 调试日志,默认不输出,需要调整NLog.config进行配置,具体数据内容
关于程序的调用(仅供参考,请根据实际情况进行配置)
需要提前安装.net Core Runtime
跳转到目录:cd %TapdCollect%\手动执行:dotnet TapdCollect.dll 自动执行(单功能):dotnet TapdCollect.dll 1 自动执行(多功能):dotnet TapdCollect.dll 1 2 3 4 5 6 7 8 13 对于超过14个功能的配置,请在每个功能参数后加一个空格
.Net Core 运行时下载链接
视窗:
其他平台:请到MicroSoft网站查找
定时任务配置(仅供参考)
1、首先配置bat脚本
2、设置定时任务
预防措施:
1) 开始填写程序所在目录,否则配置文件会被%windows%\system32\下的计划任务配置
2) 以双引号开头,否则无效
3)程序或脚本选择之前配置好的bat文件,建议选择自动运行的脚本
3、 设置触发条件(建议根据实际情况和需要设置)
预防措施:
1) 建议根据实际情况设置。它可以每天同步一次或几个小时同步一次。
2)但是建议不要在一个小时以内同步一次,因为Tapd请求是有时间限制的,理论上是1Req/S
3)tapd 请求过多会抛出过多请求错误
文章采集api(接入优采云(小狗AI)API教程-优采云采集支持)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-09-29 14:18
访问优采云(Puppy AI)API教程-优采云采集
优采云采集 支持调用优采云(Puppy AI)API接口处理采集的数据标题和内容;
提示:第三方API接入功能需要优采云旗舰包支持使用,用户需要提供第三方接口账号信息(即用户需要注册第三方接口,调用第三方接口所产生的一切费用由用户自行承担。);
购买优采云(Puppy AI)API,请先联系优采云(Puppy AI)客服告知是在优采云采集平台使用;
详细步骤
1. 创建优采云 API 接口配置
一、API配置入口:
点击【第三方服务配置】==》点击【第三方内容API访问】==》点击控制台左侧列表中的【第三方API配置管理】==》,最后点击【优采云API] 创建接口配置;
二、配置API接口信息:
购买优采云(Puppy AI)API,请先联系优采云(Puppy AI)客服,告知在优采云采集平台使用。
【API key】是从优采云(Puppy AI)后台获取对应的API key,填写优采云;
注意:优采云每次调用限制为6000个字符(包括html代码),所以当内容长度超过时,优采云会被多次分割调用。这个操作会增加api调用次数,费用也会相应增加,这是用户需要承担的费用,使用前一定要注意!!!
2. 创建 API 处理规则
API处理规则,可设置调用API接口处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》进入【API处理规则管理】页面,最后点击【+添加】 API 处理规则] 创建 API 处理规则;
二、API处理规则配置:
规则名称:用户可以自己命名;
字段名:填写的字段名的内容将由API接口处理。默认为title和content字段,可以修改、添加或删除;(可以添加其他字段,点击添加内容字段,修改字段名称,但必须在【Detail Extractor】中已经定义,如作者、关键字、描述字段)
使用的API:选择已经设置好的API接口配置,执行时会调用该接口,多个字段可以选择不同的API接口配置;
处理顺序:执行顺序是按照数量从小到大执行;
注意:API处理1个字段时,API接口会调用一次,所以建议不要添加不需要的字段!
3. API 处理规则使用
API处理规则的使用方式有两种:手动执行和自动执行:
手动执行:data采集后,在【Result Data & Release】中使用第三方API执行;
自动执行:自动化配置完成后,任务采集数据完成后,系统会自动执行指定的API处理规则,无需人工操作。
一、手动执行API处理规则:
在任务的【结果&发布】选项卡中,点击【SEO&API&翻译工具】按钮==》选择【第三方API执行】栏==》选择对应的API处理规则==》执行(有两种执行方式对于数据范围,根据发布状态批量执行,根据列表中选择的数据执行);
二、自动执行API处理规则:
启用 API 处理的自动执行。任务完成采集后,会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡中,【自动执行第三方API配置】==》勾选【采集,自动执行API】选项==》选择要执行的API处理规则==》选择API接口处理的数据范围(一般选择“待发布”,都会导致所有数据被多次执行),最后点击保存;
4. API 处理结果及发布
一、查看API接口处理结果:
API接口处理的内容会保存为一个新的字段,如:标题处理后的新字段:title_优采云,内容处理后的新字段:content_优采云,在[Result Data & Release]和数据预览界面可以查看。
提示:API处理规则执行需要一段时间,执行后页面会自动刷新,API接口处理的新字段会出现;
二、API接口处理后的内容发布
在发布文章之前,修改发布目标第二步的映射字段,在API接口处理后将title和content改为新的对应字段title_优采云和content_优采云;
提示:如果无法在发布目标中选择新字段,请在此任务下复制或创建新的发布目标,然后您可以在新的发布目标中选择新字段。详细教程可以查看发布目标中不能选择的字段;
5. 优采云-API接口常见问题及解决方法
一、API处理规则和SEO规则如何搭配使用?
系统默认对title和content字段进行SEO功能,需要修改为SEO规则中的title_优采云和content_优采云字段; 查看全部
文章采集api(接入优采云(小狗AI)API教程-优采云采集支持)
访问优采云(Puppy AI)API教程-优采云采集
优采云采集 支持调用优采云(Puppy AI)API接口处理采集的数据标题和内容;
提示:第三方API接入功能需要优采云旗舰包支持使用,用户需要提供第三方接口账号信息(即用户需要注册第三方接口,调用第三方接口所产生的一切费用由用户自行承担。);
购买优采云(Puppy AI)API,请先联系优采云(Puppy AI)客服告知是在优采云采集平台使用;
详细步骤
1. 创建优采云 API 接口配置
一、API配置入口:
点击【第三方服务配置】==》点击【第三方内容API访问】==》点击控制台左侧列表中的【第三方API配置管理】==》,最后点击【优采云API] 创建接口配置;
二、配置API接口信息:
购买优采云(Puppy AI)API,请先联系优采云(Puppy AI)客服,告知在优采云采集平台使用。
【API key】是从优采云(Puppy AI)后台获取对应的API key,填写优采云;
注意:优采云每次调用限制为6000个字符(包括html代码),所以当内容长度超过时,优采云会被多次分割调用。这个操作会增加api调用次数,费用也会相应增加,这是用户需要承担的费用,使用前一定要注意!!!
2. 创建 API 处理规则
API处理规则,可设置调用API接口处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》进入【API处理规则管理】页面,最后点击【+添加】 API 处理规则] 创建 API 处理规则;
二、API处理规则配置:
规则名称:用户可以自己命名;
字段名:填写的字段名的内容将由API接口处理。默认为title和content字段,可以修改、添加或删除;(可以添加其他字段,点击添加内容字段,修改字段名称,但必须在【Detail Extractor】中已经定义,如作者、关键字、描述字段)
使用的API:选择已经设置好的API接口配置,执行时会调用该接口,多个字段可以选择不同的API接口配置;
处理顺序:执行顺序是按照数量从小到大执行;
注意:API处理1个字段时,API接口会调用一次,所以建议不要添加不需要的字段!
3. API 处理规则使用
API处理规则的使用方式有两种:手动执行和自动执行:
手动执行:data采集后,在【Result Data & Release】中使用第三方API执行;
自动执行:自动化配置完成后,任务采集数据完成后,系统会自动执行指定的API处理规则,无需人工操作。
一、手动执行API处理规则:
在任务的【结果&发布】选项卡中,点击【SEO&API&翻译工具】按钮==》选择【第三方API执行】栏==》选择对应的API处理规则==》执行(有两种执行方式对于数据范围,根据发布状态批量执行,根据列表中选择的数据执行);
二、自动执行API处理规则:
启用 API 处理的自动执行。任务完成采集后,会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡中,【自动执行第三方API配置】==》勾选【采集,自动执行API】选项==》选择要执行的API处理规则==》选择API接口处理的数据范围(一般选择“待发布”,都会导致所有数据被多次执行),最后点击保存;
4. API 处理结果及发布
一、查看API接口处理结果:
API接口处理的内容会保存为一个新的字段,如:标题处理后的新字段:title_优采云,内容处理后的新字段:content_优采云,在[Result Data & Release]和数据预览界面可以查看。
提示:API处理规则执行需要一段时间,执行后页面会自动刷新,API接口处理的新字段会出现;
二、API接口处理后的内容发布
在发布文章之前,修改发布目标第二步的映射字段,在API接口处理后将title和content改为新的对应字段title_优采云和content_优采云;
提示:如果无法在发布目标中选择新字段,请在此任务下复制或创建新的发布目标,然后您可以在新的发布目标中选择新字段。详细教程可以查看发布目标中不能选择的字段;
5. 优采云-API接口常见问题及解决方法
一、API处理规则和SEO规则如何搭配使用?
系统默认对title和content字段进行SEO功能,需要修改为SEO规则中的title_优采云和content_优采云字段;
文章采集api(数据埋点采集到底都是哪些事呢?的应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-09-24 15:03
数据采集是数据分析的基础,埋点是最重要的采集方法。那么数据埋点采集究竟是什么?我们主要从三个方面来看:什么是埋点,埋点如何设计,埋点的应用。
一、数据采集及常见数据问题
1.1Data采集
数据采集的方式有很多种,埋点采集是其中非常重要的一部分,无论是对于c端还是b端产品,都是主要的采集方法,数据采集 ,顾名思义,采集对应的数据是整个数据流的起点。采集 不完整吧?它直接决定了数据的广度和质量,并影响到后续的所有环节;在数据采集 效率和完整性较差的公司通常会在其业务发现数据中发生重大变化。
数据处理通常包括以下5个步骤:
1.2常见数据问题
在大致了解了数据采集及其结构之后,我们来看看我们工作中遇到的问题,有多少是与数据采集链接相关的
1、数据与后台差距大,数据不准确——统计口径不同,埋点定义不同,采集的方法带来误差
2、想用的时候,没有我要的数据--没有提到数据。采集需求,埋点不对,不完整
3、 事件太多,意思不清楚——埋点设计的方法,埋点更新迭代的规则和维护
4、分析数据,不知道看哪些数据和指标——数据定义不明确,缺乏分析思路
我们要从根本上解决问题:把采集当作一个独立的研发企业,而不是产品开发的附属品
二、什么是埋点
2.1 什么是埋点
所谓埋点,是数据领域的一个术语采集。它的学名应该叫事件跟踪,对应的英文是Event Tracking,指的是捕获、处理和发送特定用户行为或事件的相关技术和实现过程。数据埋点是数据分析师、数据产品经理和数据运营。根据业务需求或产品需求,开发用户行为的每个事件的对应位置,开发埋点,通过SDK上报埋点的数据结果,记录汇总数据。分析、推动产品优化、指导运营。
该过程附有规范。通过定义,我们看到具体的用户行为和事件是我们采集的重点,我们也需要处理发送相关的技术和实现流程;数据嵌入点是为产品服务的,它来自于产品。,所以跟产品息息相关,埋点在于具体实战过程,关系到大家对底层数据的理解。
2.2 为什么要埋点?
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的好坏直接影响到数据质量、产品质量、运营质量等。
1、数据驱动——深入分析,深入到流量分布和流量层面,通过统计分析,宏观指标深入分析,发现指标背后的问题,洞察潜力用户行为与价值提升之间的关联
2、产品优化——对于产品,用户在产品中做了什么,在产品中停留了多久,有什么异常需要注意。这些问题可以通过埋点来实现
3、 精细化运营-埋点可以实现整个产品生命周期、流量质量和不同来源的分布、人群的行为特征和关系,洞察用户行为与提升业务的潜在关系价值。
2.3种埋点方法
埋点的方法有哪些?目前,大多数公司使用客户端和服务器的组合
准确度:编码埋点>可视化埋点>全埋点
三、埋点的框架和设计
3.1 埋点采集的顶层设计
所谓顶层设计,就是搞清楚怎么做点,怎么用,上传机制是什么,怎么定义,怎么实现等等;我们在设计的基础上遵循唯一性、可扩展性、一致性等一些常见的字段和生成机制,例如:cid、idfa、idfv等。
用户识别:用户识别机制的混乱会导致两种结果:一是数据不准确,比如UV数据没有对齐;另一个是漏斗分析有异常。因此,它应该是: a.严格规范ID自身的识别机制;湾 跨平台用户识别
相似抽象:相似抽象包括事件抽象和属性抽象。事件抽象是指浏览事件和点击事件的聚合;属性抽象意味着合并大多数重用场景以增加源区分
采集 一致性:采集 一致性包括两点:一是跨平台页面的一致命名,二是按钮命名的一致;设置埋点本身的过程就是对底层数据进行标准化的过程,所以一致性尤为重要,只有这样才能真正发挥作用
渠道配置:渠道主要是指推广渠道、落地页、网页推广页、APP推广页等,这个落地页的配置必须有统一的规范和标准
3.2埋点采集事件和属性设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变的,哪些是业务行为,哪些是基本属性。基于基础属性事件,我们认为属性是必填采集项,但是属性中的事件属性会根据不同的业务进行调整。因此,我们可以将埋点采集分为协议层和业务层埋点。
业务分解:梳理确认业务流程、运营路径和不同细分场景,定义用户行为路径
分析指标:定义特定事件和核心业务指标所需的数据
事件设计:APP启动、退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.3 数据采集事件和属性设计
Ev 事件的命名也遵循一些规则。当同一类型的函数出现在不同的页面或位置时,根据函数名进行命名,在ev参数中区分页面和位置。仅点击按钮时,按按钮名称命名。
ev事件格式:ev分为ev标识和ev参数
规则:
ev标志和ev参数之间用“#”连接(一级连接器);
ev参数和ev参数之间用“/”连接(二级连接器);
ev 参数使用 key=value 的结构。当一个key对应多个value值时,value1和value2之间用“,”连接(三级连接器);
当埋点只有ev标志,没有ev参数时,不需要带#;
评论:
ev ID:作为埋点的唯一ID,用于区分埋点的位置和属性。它是不可变的,不能被修改;
ev参数:需要返回埋点的参数,ev参数的顺序是可变的,可以修改;
调整app埋点时ev标志不变,只修改后续埋点参数(参数值改变或参数类型增加)
通用嵌入点文档中收录的sheet的名称和功能:
A.暴露埋点汇总;
B.点击浏览埋点汇总;
C、故障埋点总结:一般会记录埋点的故障版本或时间;
D、PC和M页面嵌入点对应的pageid;
E、各版本上线时间记录;
在嵌入点文档中,所有列名和函数包括:
3.4 基于埋点的统计
如何使用埋点统计查找埋点 ev 事件:
1. 指定埋点类型(点击/曝光/浏览)-过滤类型字段
2. 指定按钮所属的页面(页面或功能)-过滤功能模块字段
3. 指定埋藏事件的名称-过滤名称字段
4. 知道ev logo,可以直接用ev过滤
如何根据ev事件进行计数统计:查询按钮点击统计时,可以直接使用ev标志进行查询,有区别时,可以限制埋点参数的取值;因为ev参数的顺序不需要可变,查询统计,不能限制参数的顺序;
四、应用-数据流的基础
4.1 指标体系
系统指标可以将不同指标、不同维度串联起来进行综合分析,快速发现当前产品和业务流程中存在的问题。
4.2 可视化
人类对图像信息的解释比文本更有效。可视化对于数据分析极其重要。数据可视化的使用可以揭示数据中错综复杂的关系。
4.3 api提供
数据采集服务会将采集的埋点写入Kafka。针对每个业务的实时数据消费需求,我们为每个业务提供单独的Kafka,流量分配模块会定时读取。将埋点管理平台提供的元信息实时分发到各个业务Kafka。
数据采集就像设计一个产品。不能过火,留有扩展空间,但要时刻考虑数据是否完整、详细、不稳定、快速与否。 查看全部
文章采集api(数据埋点采集到底都是哪些事呢?的应用)
数据采集是数据分析的基础,埋点是最重要的采集方法。那么数据埋点采集究竟是什么?我们主要从三个方面来看:什么是埋点,埋点如何设计,埋点的应用。
一、数据采集及常见数据问题
1.1Data采集
数据采集的方式有很多种,埋点采集是其中非常重要的一部分,无论是对于c端还是b端产品,都是主要的采集方法,数据采集 ,顾名思义,采集对应的数据是整个数据流的起点。采集 不完整吧?它直接决定了数据的广度和质量,并影响到后续的所有环节;在数据采集 效率和完整性较差的公司通常会在其业务发现数据中发生重大变化。
数据处理通常包括以下5个步骤:
1.2常见数据问题
在大致了解了数据采集及其结构之后,我们来看看我们工作中遇到的问题,有多少是与数据采集链接相关的
1、数据与后台差距大,数据不准确——统计口径不同,埋点定义不同,采集的方法带来误差
2、想用的时候,没有我要的数据--没有提到数据。采集需求,埋点不对,不完整
3、 事件太多,意思不清楚——埋点设计的方法,埋点更新迭代的规则和维护
4、分析数据,不知道看哪些数据和指标——数据定义不明确,缺乏分析思路
我们要从根本上解决问题:把采集当作一个独立的研发企业,而不是产品开发的附属品
二、什么是埋点
2.1 什么是埋点
所谓埋点,是数据领域的一个术语采集。它的学名应该叫事件跟踪,对应的英文是Event Tracking,指的是捕获、处理和发送特定用户行为或事件的相关技术和实现过程。数据埋点是数据分析师、数据产品经理和数据运营。根据业务需求或产品需求,开发用户行为的每个事件的对应位置,开发埋点,通过SDK上报埋点的数据结果,记录汇总数据。分析、推动产品优化、指导运营。
该过程附有规范。通过定义,我们看到具体的用户行为和事件是我们采集的重点,我们也需要处理发送相关的技术和实现流程;数据嵌入点是为产品服务的,它来自于产品。,所以跟产品息息相关,埋点在于具体实战过程,关系到大家对底层数据的理解。
2.2 为什么要埋点?
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的好坏直接影响到数据质量、产品质量、运营质量等。
1、数据驱动——深入分析,深入到流量分布和流量层面,通过统计分析,宏观指标深入分析,发现指标背后的问题,洞察潜力用户行为与价值提升之间的关联
2、产品优化——对于产品,用户在产品中做了什么,在产品中停留了多久,有什么异常需要注意。这些问题可以通过埋点来实现
3、 精细化运营-埋点可以实现整个产品生命周期、流量质量和不同来源的分布、人群的行为特征和关系,洞察用户行为与提升业务的潜在关系价值。
2.3种埋点方法
埋点的方法有哪些?目前,大多数公司使用客户端和服务器的组合
准确度:编码埋点>可视化埋点>全埋点
三、埋点的框架和设计
3.1 埋点采集的顶层设计
所谓顶层设计,就是搞清楚怎么做点,怎么用,上传机制是什么,怎么定义,怎么实现等等;我们在设计的基础上遵循唯一性、可扩展性、一致性等一些常见的字段和生成机制,例如:cid、idfa、idfv等。
用户识别:用户识别机制的混乱会导致两种结果:一是数据不准确,比如UV数据没有对齐;另一个是漏斗分析有异常。因此,它应该是: a.严格规范ID自身的识别机制;湾 跨平台用户识别
相似抽象:相似抽象包括事件抽象和属性抽象。事件抽象是指浏览事件和点击事件的聚合;属性抽象意味着合并大多数重用场景以增加源区分
采集 一致性:采集 一致性包括两点:一是跨平台页面的一致命名,二是按钮命名的一致;设置埋点本身的过程就是对底层数据进行标准化的过程,所以一致性尤为重要,只有这样才能真正发挥作用
渠道配置:渠道主要是指推广渠道、落地页、网页推广页、APP推广页等,这个落地页的配置必须有统一的规范和标准
3.2埋点采集事件和属性设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变的,哪些是业务行为,哪些是基本属性。基于基础属性事件,我们认为属性是必填采集项,但是属性中的事件属性会根据不同的业务进行调整。因此,我们可以将埋点采集分为协议层和业务层埋点。
业务分解:梳理确认业务流程、运营路径和不同细分场景,定义用户行为路径
分析指标:定义特定事件和核心业务指标所需的数据
事件设计:APP启动、退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.3 数据采集事件和属性设计
Ev 事件的命名也遵循一些规则。当同一类型的函数出现在不同的页面或位置时,根据函数名进行命名,在ev参数中区分页面和位置。仅点击按钮时,按按钮名称命名。
ev事件格式:ev分为ev标识和ev参数
规则:
ev标志和ev参数之间用“#”连接(一级连接器);
ev参数和ev参数之间用“/”连接(二级连接器);
ev 参数使用 key=value 的结构。当一个key对应多个value值时,value1和value2之间用“,”连接(三级连接器);
当埋点只有ev标志,没有ev参数时,不需要带#;
评论:
ev ID:作为埋点的唯一ID,用于区分埋点的位置和属性。它是不可变的,不能被修改;
ev参数:需要返回埋点的参数,ev参数的顺序是可变的,可以修改;
调整app埋点时ev标志不变,只修改后续埋点参数(参数值改变或参数类型增加)
通用嵌入点文档中收录的sheet的名称和功能:
A.暴露埋点汇总;
B.点击浏览埋点汇总;
C、故障埋点总结:一般会记录埋点的故障版本或时间;
D、PC和M页面嵌入点对应的pageid;
E、各版本上线时间记录;
在嵌入点文档中,所有列名和函数包括:
3.4 基于埋点的统计
如何使用埋点统计查找埋点 ev 事件:
1. 指定埋点类型(点击/曝光/浏览)-过滤类型字段
2. 指定按钮所属的页面(页面或功能)-过滤功能模块字段
3. 指定埋藏事件的名称-过滤名称字段
4. 知道ev logo,可以直接用ev过滤
如何根据ev事件进行计数统计:查询按钮点击统计时,可以直接使用ev标志进行查询,有区别时,可以限制埋点参数的取值;因为ev参数的顺序不需要可变,查询统计,不能限制参数的顺序;
四、应用-数据流的基础
4.1 指标体系
系统指标可以将不同指标、不同维度串联起来进行综合分析,快速发现当前产品和业务流程中存在的问题。
4.2 可视化
人类对图像信息的解释比文本更有效。可视化对于数据分析极其重要。数据可视化的使用可以揭示数据中错综复杂的关系。
4.3 api提供
数据采集服务会将采集的埋点写入Kafka。针对每个业务的实时数据消费需求,我们为每个业务提供单独的Kafka,流量分配模块会定时读取。将埋点管理平台提供的元信息实时分发到各个业务Kafka。
数据采集就像设计一个产品。不能过火,留有扩展空间,但要时刻考虑数据是否完整、详细、不稳定、快速与否。
文章采集api(一种基于网络爬虫和新浪API相结合的微博数据采集方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-09-24 15:01
本发明涉及微博数据采集技术领域,尤其涉及一种基于网络爬虫与新浪API相结合的微博数据采集方法。
背景技术:
采集对于微博中的数据非常重要,也可以为微博社会安全事件的检测提供重要的数据依据。目前微博数据采集主要有两种方式:基于新浪API和针对新浪微博平台的网络爬虫。基于新浪API的方案可以获取相对规范格式的数据,但调用次数有限,无法进行大规模数据爬取,无法获取部分信息;基于网络爬虫的方法虽然可以获得海量数据,但其页面的分析处理过程较为复杂,其爬取的数据格式不规范,噪声数据较多。
技术实现要素:
本发明的目的在于解决现有技术的不足,提供一种基于网络爬虫与新浪API相结合的微博数据获取方法。
为实现上述目的,本发明是按照以下技术方案实施的:
一种基于网络爬虫和新浪API结合的微博数据采集方法,包括以下步骤:
Step1:基于新浪API从微博名人榜中获取种子用户及其对应的粉丝用户和关注用户,并添加到种子列表中;
Step2:将种子列表转换为种子URL,并判断种子用户列表是否为空,如果为空,转步骤4,否则转步骤3;
Step3:遍历种子列表,利用网络爬虫的方法抓取种子用户的相关微博信息、微博评论信息和用户个人信息,将微博评论用户加入种子列表;
第四步:结束。
具体来说,Step3包括:
获取种子列表中待爬取的URL,进行URL分析和信息获取,包括:获取用户信息URL,进入对应页面抓取用户粉丝、关注者等用户相关信息;获取用户微博URL并进入对应页面爬取微博转发赞、评论用户、爬取微博评论文字、爬取其他微博相关信息;并抓取用户、关注者、关注者、用户、微博转发点赞、评论用户、抓取微博评论文本、抓取其他相关微博数据等相关信息,建立相应的微博数据资源库;同时,将抓取到的用户、粉丝、用户和关注用户、抓取到的微博转发给赞、评论用户加入种子列表。
与现有技术相比,本发明将新浪API与新浪微博平台的网络爬虫相结合,不仅可以获取相对规范格式的微博数据,还可以进行大规模的数据爬取。数据格式更加规范,噪声数据更少,可为微博社会安全事件的检测提供重要的数据依据。
图纸说明
图1是本发明的流程图。
详细方法
下面结合具体实施例对本发明作进一步说明。本发明的示例性实施例和描述用于解释本发明,但并不用于限制本发明。
如图所示。1、本实施例基于网络爬虫与新浪API结合的微博数据采集方法包括以下步骤:
Step1:基于新浪API从微博名人榜中获取种子用户及其对应的粉丝用户和关注用户,并添加到种子列表中;
Step2:将种子列表转换为种子URL,并判断种子用户列表是否为空,如果为空,转步骤4,否则转步骤3;
Step3:遍历种子列表,利用网络爬虫的方法抓取种子用户的相关微博信息、微博评论信息和用户个人信息,将微博评论用户加入种子列表。具体步骤为: 获取种子列表 待爬媒体中待爬取的URL,以及URL分析和信息获取,包括:获取用户信息URL并进入相应页面,从微博抓取用户粉丝用户和关注用户数据资源库,抓取用户其他相关信息;用户的微博网址,进入对应页面,从微博数据资源库中抓取微博,转发赞、评论用户、抓取微博评论文字、抓取微博其他相关信息;同时,被抓取的用户和粉丝关注的用户,
第四步:结束。
根据本实施例的方法采集完成微博数据后,可以对采集接收到的微博文本数据进行处理,去除其中的异常数据和噪声数据,数据格式可以构建相应的微博资源库,可以为微博社会安全事件的检测提供重要的数据基础。
本发明的技术方案并不限于上述具体实施例的限定,凡根据本发明的技术方案所作的技术修改,都属于本发明的保护范围。 查看全部
文章采集api(一种基于网络爬虫和新浪API相结合的微博数据采集方法)
本发明涉及微博数据采集技术领域,尤其涉及一种基于网络爬虫与新浪API相结合的微博数据采集方法。
背景技术:
采集对于微博中的数据非常重要,也可以为微博社会安全事件的检测提供重要的数据依据。目前微博数据采集主要有两种方式:基于新浪API和针对新浪微博平台的网络爬虫。基于新浪API的方案可以获取相对规范格式的数据,但调用次数有限,无法进行大规模数据爬取,无法获取部分信息;基于网络爬虫的方法虽然可以获得海量数据,但其页面的分析处理过程较为复杂,其爬取的数据格式不规范,噪声数据较多。
技术实现要素:
本发明的目的在于解决现有技术的不足,提供一种基于网络爬虫与新浪API相结合的微博数据获取方法。
为实现上述目的,本发明是按照以下技术方案实施的:
一种基于网络爬虫和新浪API结合的微博数据采集方法,包括以下步骤:
Step1:基于新浪API从微博名人榜中获取种子用户及其对应的粉丝用户和关注用户,并添加到种子列表中;
Step2:将种子列表转换为种子URL,并判断种子用户列表是否为空,如果为空,转步骤4,否则转步骤3;
Step3:遍历种子列表,利用网络爬虫的方法抓取种子用户的相关微博信息、微博评论信息和用户个人信息,将微博评论用户加入种子列表;
第四步:结束。
具体来说,Step3包括:
获取种子列表中待爬取的URL,进行URL分析和信息获取,包括:获取用户信息URL,进入对应页面抓取用户粉丝、关注者等用户相关信息;获取用户微博URL并进入对应页面爬取微博转发赞、评论用户、爬取微博评论文字、爬取其他微博相关信息;并抓取用户、关注者、关注者、用户、微博转发点赞、评论用户、抓取微博评论文本、抓取其他相关微博数据等相关信息,建立相应的微博数据资源库;同时,将抓取到的用户、粉丝、用户和关注用户、抓取到的微博转发给赞、评论用户加入种子列表。
与现有技术相比,本发明将新浪API与新浪微博平台的网络爬虫相结合,不仅可以获取相对规范格式的微博数据,还可以进行大规模的数据爬取。数据格式更加规范,噪声数据更少,可为微博社会安全事件的检测提供重要的数据依据。
图纸说明
图1是本发明的流程图。
详细方法
下面结合具体实施例对本发明作进一步说明。本发明的示例性实施例和描述用于解释本发明,但并不用于限制本发明。
如图所示。1、本实施例基于网络爬虫与新浪API结合的微博数据采集方法包括以下步骤:
Step1:基于新浪API从微博名人榜中获取种子用户及其对应的粉丝用户和关注用户,并添加到种子列表中;
Step2:将种子列表转换为种子URL,并判断种子用户列表是否为空,如果为空,转步骤4,否则转步骤3;
Step3:遍历种子列表,利用网络爬虫的方法抓取种子用户的相关微博信息、微博评论信息和用户个人信息,将微博评论用户加入种子列表。具体步骤为: 获取种子列表 待爬媒体中待爬取的URL,以及URL分析和信息获取,包括:获取用户信息URL并进入相应页面,从微博抓取用户粉丝用户和关注用户数据资源库,抓取用户其他相关信息;用户的微博网址,进入对应页面,从微博数据资源库中抓取微博,转发赞、评论用户、抓取微博评论文字、抓取微博其他相关信息;同时,被抓取的用户和粉丝关注的用户,
第四步:结束。
根据本实施例的方法采集完成微博数据后,可以对采集接收到的微博文本数据进行处理,去除其中的异常数据和噪声数据,数据格式可以构建相应的微博资源库,可以为微博社会安全事件的检测提供重要的数据基础。
本发明的技术方案并不限于上述具体实施例的限定,凡根据本发明的技术方案所作的技术修改,都属于本发明的保护范围。
文章采集api(互联网大数据时代网络爬虫采集舆情数据获取的方案 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-09-23 23:29
)
简单来说,网络爬虫是指通过爬虫程序访问@k14@API连接获取数据信息。爬虫程序可以从网页中检索所需的数据信息,然后将其存储在新创建的文档中。网络爬虫支持@k15@各种数据、文件、图片。视频等可以@k15@,但不能@k15@非法经营。互联网大数据时代,网络爬虫主要为搜索引擎提供最全面、最新的数据,网络爬虫也是从@k15@互联网上的数据爬取而来。
我们还可以使用网络爬虫@k15@舆情数据,以及@k15@新闻、社交、论坛、博客等信息数据。这也是获取舆情数据的常用方案之一。一般爬虫程序使用爬虫代理IP对一些有意义的@k14@进行数据@k15@。舆情数据也可以在数据交换市场购买,或者从专业的舆情分析团队获取,但一般来说,专业的舆情分析团队也是使用代理IP通过爬虫程序去@k15@的。用于舆情数据分析的数据。
由于短视频的流行,@k16@和快手是两大主流短视频应用。我们也可以使用爬虫程序@k15@@k16@来分析舆情数据。生成统计数据表,作为数据报告提供给大家。也可以参考以下@k15@程序代码:
@k21@ 查看全部
文章采集api(互联网大数据时代网络爬虫采集舆情数据获取的方案
)
简单来说,网络爬虫是指通过爬虫程序访问@k14@API连接获取数据信息。爬虫程序可以从网页中检索所需的数据信息,然后将其存储在新创建的文档中。网络爬虫支持@k15@各种数据、文件、图片。视频等可以@k15@,但不能@k15@非法经营。互联网大数据时代,网络爬虫主要为搜索引擎提供最全面、最新的数据,网络爬虫也是从@k15@互联网上的数据爬取而来。
我们还可以使用网络爬虫@k15@舆情数据,以及@k15@新闻、社交、论坛、博客等信息数据。这也是获取舆情数据的常用方案之一。一般爬虫程序使用爬虫代理IP对一些有意义的@k14@进行数据@k15@。舆情数据也可以在数据交换市场购买,或者从专业的舆情分析团队获取,但一般来说,专业的舆情分析团队也是使用代理IP通过爬虫程序去@k15@的。用于舆情数据分析的数据。
由于短视频的流行,@k16@和快手是两大主流短视频应用。我们也可以使用爬虫程序@k15@@k16@来分析舆情数据。生成统计数据表,作为数据报告提供给大家。也可以参考以下@k15@程序代码:
@k21@
文章采集api(MetricsAPI介绍之前,必须要提一下API的概念)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-09-21 01:23
概述
从V 1. 8,资源使用的监测可以通过度量API来获得。的具体组分是度量服务器,其用于取代先前Heapster,和Heapster将逐渐被从1. 11丢弃。
度量 - 服务器是的簇核监测数据,从Kubernetes 1. 8,其被用作在由kube-up.sh脚本创建的集群部署对象默认部署开始聚合,如果是其他的部署,需要是单独的安装,或咨询相应的云厂商。
度量API
引入度量服务器之前,必须提度量API的概念
指标API是上次的监视采集法(Hepaster)一个新的想法是一个新的想法,官方希望应该是稳定的,版本控制,可以由用户(如直接访问通过使用kubectl TOP命令),或者通过所述集群中的控制器(如HPA),和类似的其它Kubernetes的API。
官方处置Heapster项目是把核心资源监测作为一等公民,也就是像POD,服务通过API的服务器或客户端直接直接访问,不再安装HEPater聚集并通过Heapster分别管理它
假设每个POD和节点采集10个指标,从K8S 1. 6开始,支持5000个节点,每个节点30种荚,假设采集度1分钟,然后:
10 x 5000 x 30 / 60 = 25000 平均每分钟2万多个采集指标
由于K8S的API-服务器保存所有的数据到ETCD,很显然,K8S本身不能处理采集这个频率,而这种监测数据是快速和临时数据,所以你需要有一个组件成分。分开处理它们,所述K8S版本只存储在存储器中,所以度量 - 服务器的概念是天生的。
事实上,Hepaster已经有了公开的API,但用户和Kubernetes的其他部件都必须通过主代理服务器访问,而且Heapster接口并不像API的服务器,具有完整的身份验证和客户端集成。这个API是处于alpha阶段(8月18日),希望能去GA阶段。写作类的API - 服务器风格:通用API服务器
具有度量服务器组件,和采集的数据,但也暴露了API,但由于API要统一,如何转发该请求到API-服务器/蜜蜂/度量请求度量服务器,解决该溶液:库贝-aggrecator,在K8S 1. 7已经完成,前度量服务器尚未以外,是在步骤-aggrecator延迟
KUBE-aggrecator(聚集API)主要提供:
详细设计文档:参考链接
公制API:
如:
http://127.0.0.1:8001/apis/met ... nodes
http://127.0.0.1:8001/apis/met ... odes/
http://127.0.0.1:8001/apis/met ... pods/
度量服务器
度量服务器定时从Kubelet的总结API(Simmary)采集索引信息,这些聚集的数据将被存储在存储器中并且在公制-API的形式将其暴露。
度量服务器复API-Server库来实现自己的功能,如身份认证,版本等,以便在内存中执行数据,删除默认ETCD存储,引入存储器(例如,实现存储接口。由于存储在存储器中,监测数据是不持久的,可以通过第三方存储,这与Heapster一致扩展。
image.png
度量服务器出现后,将新Kubernetes监视模式将成为图像
官方地址:
使用
如上所述,度量 - 服务器是一个扩展的API服务器,取决于库贝-聚合,因此需要以开启在API服务器相关参数。
--requestheader-client-ca-file=/etc/kubernetes/certs/proxy-ca.crt
--proxy-client-cert-file=/etc/kubernetes/certs/proxy.crt
--proxy-client-key-file=/etc/kubernetes/certs/proxy.key
--requestheader-allowed-names=aggregator
--requestheader-extra-headers-prefix=X-Remote-Extra-
--requestheader-group-headers=X-Remote-Group
--requestheader-username-headers=X-Remote-User
安装文件下载地址:// 1.+ 8,注意更换镜像地址为国内反光镜
kubectl创建-f度量服务器/
图像
安装成功之后,接入地址API地址是:
图像
度量服务器的资源占用将继续上升为荚果的集群中的数目不断上升,所以有必要需要
ADDON-大小调整垂直扩展此容器。插件,调整器线性按照集群中节点的数量扩大度量服务器,以确保它可以提供完整的度量API服务。具体参考:链路
其他
HPA基于度量服务器上:参考链接
在Kubernetes的新监视系统,度量 - 服务器所属的核心指标,提供API metrics.k8s.io,仅提供节点和POD的CPU和内存使用情况。其他自定义指标(自定义指数)是通过组分如普罗米修斯完成,后续文章将解析自定义指标。
这文章是一个容器监督实践系列文章,全内容请参见:集装箱监视器图书 查看全部
文章采集api(MetricsAPI介绍之前,必须要提一下API的概念)
概述
从V 1. 8,资源使用的监测可以通过度量API来获得。的具体组分是度量服务器,其用于取代先前Heapster,和Heapster将逐渐被从1. 11丢弃。
度量 - 服务器是的簇核监测数据,从Kubernetes 1. 8,其被用作在由kube-up.sh脚本创建的集群部署对象默认部署开始聚合,如果是其他的部署,需要是单独的安装,或咨询相应的云厂商。
度量API
引入度量服务器之前,必须提度量API的概念
指标API是上次的监视采集法(Hepaster)一个新的想法是一个新的想法,官方希望应该是稳定的,版本控制,可以由用户(如直接访问通过使用kubectl TOP命令),或者通过所述集群中的控制器(如HPA),和类似的其它Kubernetes的API。
官方处置Heapster项目是把核心资源监测作为一等公民,也就是像POD,服务通过API的服务器或客户端直接直接访问,不再安装HEPater聚集并通过Heapster分别管理它
假设每个POD和节点采集10个指标,从K8S 1. 6开始,支持5000个节点,每个节点30种荚,假设采集度1分钟,然后:
10 x 5000 x 30 / 60 = 25000 平均每分钟2万多个采集指标
由于K8S的API-服务器保存所有的数据到ETCD,很显然,K8S本身不能处理采集这个频率,而这种监测数据是快速和临时数据,所以你需要有一个组件成分。分开处理它们,所述K8S版本只存储在存储器中,所以度量 - 服务器的概念是天生的。
事实上,Hepaster已经有了公开的API,但用户和Kubernetes的其他部件都必须通过主代理服务器访问,而且Heapster接口并不像API的服务器,具有完整的身份验证和客户端集成。这个API是处于alpha阶段(8月18日),希望能去GA阶段。写作类的API - 服务器风格:通用API服务器
具有度量服务器组件,和采集的数据,但也暴露了API,但由于API要统一,如何转发该请求到API-服务器/蜜蜂/度量请求度量服务器,解决该溶液:库贝-aggrecator,在K8S 1. 7已经完成,前度量服务器尚未以外,是在步骤-aggrecator延迟
KUBE-aggrecator(聚集API)主要提供:
详细设计文档:参考链接
公制API:
如:
http://127.0.0.1:8001/apis/met ... nodes
http://127.0.0.1:8001/apis/met ... odes/
http://127.0.0.1:8001/apis/met ... pods/
度量服务器
度量服务器定时从Kubelet的总结API(Simmary)采集索引信息,这些聚集的数据将被存储在存储器中并且在公制-API的形式将其暴露。
度量服务器复API-Server库来实现自己的功能,如身份认证,版本等,以便在内存中执行数据,删除默认ETCD存储,引入存储器(例如,实现存储接口。由于存储在存储器中,监测数据是不持久的,可以通过第三方存储,这与Heapster一致扩展。
image.png
度量服务器出现后,将新Kubernetes监视模式将成为图像
官方地址:
使用
如上所述,度量 - 服务器是一个扩展的API服务器,取决于库贝-聚合,因此需要以开启在API服务器相关参数。
--requestheader-client-ca-file=/etc/kubernetes/certs/proxy-ca.crt
--proxy-client-cert-file=/etc/kubernetes/certs/proxy.crt
--proxy-client-key-file=/etc/kubernetes/certs/proxy.key
--requestheader-allowed-names=aggregator
--requestheader-extra-headers-prefix=X-Remote-Extra-
--requestheader-group-headers=X-Remote-Group
--requestheader-username-headers=X-Remote-User
安装文件下载地址:// 1.+ 8,注意更换镜像地址为国内反光镜
kubectl创建-f度量服务器/
图像
安装成功之后,接入地址API地址是:
图像
度量服务器的资源占用将继续上升为荚果的集群中的数目不断上升,所以有必要需要
ADDON-大小调整垂直扩展此容器。插件,调整器线性按照集群中节点的数量扩大度量服务器,以确保它可以提供完整的度量API服务。具体参考:链路
其他
HPA基于度量服务器上:参考链接
在Kubernetes的新监视系统,度量 - 服务器所属的核心指标,提供API metrics.k8s.io,仅提供节点和POD的CPU和内存使用情况。其他自定义指标(自定义指数)是通过组分如普罗米修斯完成,后续文章将解析自定义指标。
这文章是一个容器监督实践系列文章,全内容请参见:集装箱监视器图书
文章采集api(咕咕数据预览:/news/wxarticlecover()(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-09-19 20:14
请求示例:/news/wxarticlecover?Appkey=您的Appkey&;url=您的值
数据预览:/preview/wxarticlecover
接口测试:/news/wxarticlecover/demo
3.request参数(如果是post请求,则以JSON格式传递参数)
4.返回参数
5.接口响应状态代码
6.开发语言请求示例代码
示例代码收录开发语言:c#、go、Java、jQuery、node.js、Objective-c、PHP、python、ruby、swift等。其他语言可以实现相应的restful API请求
Gugu data是一家专业的数据提供商,提供专业全面的数据接口和业务数据分析,使数据成为您的生产原材料
基于我们过去五年为企业客户提供的海量数据支持,goo data将一些通用数据和通用功能抽象为产品级API,极大地满足了用户在产品开发过程中对基础数据的需求,降低了复杂功能的实现门槛和人工成本
除了我们已经打开的分类数据和接口,海量数据正在被分类、清理、集成和构建。在后期,将为用户打开更多的数据和云功能接口
开放数据接口API 查看全部
文章采集api(咕咕数据预览:/news/wxarticlecover()(图))
请求示例:/news/wxarticlecover?Appkey=您的Appkey&;url=您的值
数据预览:/preview/wxarticlecover
接口测试:/news/wxarticlecover/demo
3.request参数(如果是post请求,则以JSON格式传递参数)
4.返回参数
5.接口响应状态代码
6.开发语言请求示例代码
示例代码收录开发语言:c#、go、Java、jQuery、node.js、Objective-c、PHP、python、ruby、swift等。其他语言可以实现相应的restful API请求
Gugu data是一家专业的数据提供商,提供专业全面的数据接口和业务数据分析,使数据成为您的生产原材料
基于我们过去五年为企业客户提供的海量数据支持,goo data将一些通用数据和通用功能抽象为产品级API,极大地满足了用户在产品开发过程中对基础数据的需求,降低了复杂功能的实现门槛和人工成本
除了我们已经打开的分类数据和接口,海量数据正在被分类、清理、集成和构建。在后期,将为用户打开更多的数据和云功能接口
开放数据接口API
文章采集api(咕咕数据预览:/news/wxarticlecover()(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-09-19 20:09
请求示例:/news/wxarticlecover?Appkey=您的Appkey&;url=您的值
数据预览:/preview/wxarticlecover
接口测试:/news/wxarticlecover/demo
3.request参数(如果是post请求,则以JSON格式传递参数)
4.返回参数
5.接口响应状态代码
6.开发语言请求示例代码
示例代码收录开发语言:c#、go、Java、jQuery、node.js、Objective-c、PHP、python、ruby、swift等。其他语言可以实现相应的restful API请求
Gugu data是一家专业的数据提供商,提供专业全面的数据接口和业务数据分析,使数据成为您的生产原材料
基于我们过去五年为企业客户提供的海量数据支持,goo data将一些通用数据和通用功能抽象为产品级API,极大地满足了用户在产品开发过程中对基础数据的需求,降低了复杂功能的实现门槛和人工成本
除了我们已经打开的分类数据和接口,海量数据正在被分类、清理、集成和构建。在后期,将为用户打开更多的数据和云功能接口
开放数据接口API 查看全部
文章采集api(咕咕数据预览:/news/wxarticlecover()(图))
请求示例:/news/wxarticlecover?Appkey=您的Appkey&;url=您的值
数据预览:/preview/wxarticlecover
接口测试:/news/wxarticlecover/demo
3.request参数(如果是post请求,则以JSON格式传递参数)
4.返回参数
5.接口响应状态代码
6.开发语言请求示例代码
示例代码收录开发语言:c#、go、Java、jQuery、node.js、Objective-c、PHP、python、ruby、swift等。其他语言可以实现相应的restful API请求
Gugu data是一家专业的数据提供商,提供专业全面的数据接口和业务数据分析,使数据成为您的生产原材料
基于我们过去五年为企业客户提供的海量数据支持,goo data将一些通用数据和通用功能抽象为产品级API,极大地满足了用户在产品开发过程中对基础数据的需求,降低了复杂功能的实现门槛和人工成本
除了我们已经打开的分类数据和接口,海量数据正在被分类、清理、集成和构建。在后期,将为用户打开更多的数据和云功能接口
开放数据接口API
文章采集api(咕咕数据接口API请求示例(示例代码示例)(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-19 20:06
请求示例:/news/techlogs?Appkey=您的Appkey&;pagesize=10&;pageindex=1
接口测试:/news/techlogs/demo
3.request参数(如果是post请求,则以JSON格式传递参数)
4.返回参数
5.接口响应状态代码
6.开发语言请求示例代码
示例代码收录开发语言:c#、go、Java、jQuery、node.js、Objective-c、PHP、python、ruby、swift等。其他语言可以实现相应的restful API请求
Gugu data是一家专业的数据提供商,提供专业全面的数据接口和业务数据分析,使数据成为您的生产原材料
基于我们过去五年为企业客户提供的海量数据支持,goo data将一些通用数据和通用功能抽象为产品级API,极大地满足了用户在产品开发过程中对基础数据的需求,降低了复杂功能的实现门槛和人工成本
除了我们已经打开的分类数据和接口,海量数据正在被分类、清理、集成和构建。在后期,将为用户打开更多的数据和云功能接口
开放数据接口API 查看全部
文章采集api(咕咕数据接口API请求示例(示例代码示例)(图))
请求示例:/news/techlogs?Appkey=您的Appkey&;pagesize=10&;pageindex=1
接口测试:/news/techlogs/demo
3.request参数(如果是post请求,则以JSON格式传递参数)
4.返回参数
5.接口响应状态代码
6.开发语言请求示例代码
示例代码收录开发语言:c#、go、Java、jQuery、node.js、Objective-c、PHP、python、ruby、swift等。其他语言可以实现相应的restful API请求
Gugu data是一家专业的数据提供商,提供专业全面的数据接口和业务数据分析,使数据成为您的生产原材料
基于我们过去五年为企业客户提供的海量数据支持,goo data将一些通用数据和通用功能抽象为产品级API,极大地满足了用户在产品开发过程中对基础数据的需求,降低了复杂功能的实现门槛和人工成本
除了我们已经打开的分类数据和接口,海量数据正在被分类、清理、集成和构建。在后期,将为用户打开更多的数据和云功能接口
开放数据接口API
文章采集api(青苹果影视系统(MacCms)可以快速搭建一个免更新、免维护的影视聚合、影视导航、影视点播网站)
采集交流 • 优采云 发表了文章 • 0 个评论 • 465 次浏览 • 2021-09-17 14:12
使用绿苹果影视系统(Maccms)可以快速构建免更新、免维护的影视聚合、影视导航和影视点播网站.绿苹果影视系统( Maccms)功能列表1、数据模块一键连接市场上影视资源站的API接口,现已支持FeiFeicms、 Maccms、 Maxcms、 Seacms等常用影视cmsinterfaces2、手机模板计算机系统支持一套模板tes适应计算机、手机、平板电脑、官方账号等终端入口,也可以将移动终端与PC模板分离。3、VOD模块是视频模块的基本在线VOD功能。H5播放器采用著名的dplayer,包括mp4、 m3u8、Flv、MP3和其他格式支持4、微信公众号可用于连接微信公众号开发者工具(视频机器人系统).对接后,微信用户可以通过回答关键词搜索相应的视频点播。5、图片延迟加载网站前台图片列表采用图片点播加载技术,加快用户访问网站的速度,节省服务器带宽6、简单传统转换网站前台集成了简单繁体中文自动转换功能,网页加载后会根据浏览器区域自动转换语言,是传统点播站的首选7、focus map模块可以通过ugh焦点地图模块,移动终端和PC终端独立管理,支持手机滑动8、广告模块系统预留多个广告位,由移动终端和PC终端独立管理,只需在相应的广告位i中添加广告代码即可n后台,可通过标记在模板中扩展和调用
9、link模块系统保留主页链接和全站链接。友情链接用于站长之间的交流。全站链接主要用于一系列关键词主题的内部链接。10、导航模块是基于daicuo后台开发框架的导航组件调用的on是系统全站的频道链接,图标导航是移动终端的首页图标小部件。11、分类模块基于大厝后台开发框架的分类组件设计,支持一级分类和二级分类,支持不同的分类ent分类调用不同的资源站进行独立设计。12、搜索模块支持同一关键词呼叫对不同资源站的搜索结果。搜索条件需要基于资源站支持的类型,通常包括明星、电影标题和导演搜索。绿苹果电影电视系统( Maccms)项目优势1、开源和免费:我们传播开源的概念Maccms这是一个免费开源的PHP电影程序,没有任何加密代码,源代码完全开放,安全可靠,没有后门2、稳定性和安全隐患:内核安全稳定,PHP+MySQL架构和跨平台操作。ThinkPHP+jQuery+bootstrap组合和超级负载能力帮助您轻松操作数百万个网站@3、回归自然:没有那些花哨的鸡肋功能,回归电影和视频站“免费观看”的核心精髓。本节目试图以最简单的方式4、auto站群免费为互联网用户提供点播服务功能:如果您已经拥有影视聚合和点播网站,您可以通过其API接口直接与用户通信Maccms停靠、主站更新和自动同步所有站群系统的自动化
@5、多插件:系统基于daicuo后台开发框架开发,在网站后台,可通过daicuo的应用市场6、在线安装和管理多个实用插件,免维护:可一次性安装,并随影视资源st自动更新全天24小时运行,省去了采集和生成等复杂的锁定工作,只需专注于操作网站和流程实现7、伪静态:系统依托thinkphp5强大的路由模块,通过后台可以设计出非常有利于搜索引擎ac的目录结构根据站长8、云解析需求:系统提供的云播放器使用dplayer集成主流视频的点播和解析功能网站.您还可以在后台通过单击设置9、strong caching调用第三方解析接口服务:系统依赖于thinkphp5强大的缓存模块,可通过后台随时切换到文件缓存、Xcache、memcached、redis等缓存方式。绿苹果影视系统( Maccms)安装说明1、将文件夹下的所有文件上载到您的网站space2、如果您的主机是Windows操作系统,请向以下文件夹@3、的IIS用户添加写入权限如果您的主机是Linux操作系统,请将以下文件夹权限设置为777./data/*system operation cache目录4、通过浏览器访问网站basic配置的后台(强烈建议将admin.php更改为不易猜测的名称)您的域名/admin.php,默认用户名为admin,密码为admin888@5、系统默认为SQLite3数据库,如果需要转换成MySQL,可以通过后台的数据库转换功能完成 查看全部
文章采集api(青苹果影视系统(MacCms)可以快速搭建一个免更新、免维护的影视聚合、影视导航、影视点播网站)
使用绿苹果影视系统(Maccms)可以快速构建免更新、免维护的影视聚合、影视导航和影视点播网站.绿苹果影视系统( Maccms)功能列表1、数据模块一键连接市场上影视资源站的API接口,现已支持FeiFeicms、 Maccms、 Maxcms、 Seacms等常用影视cmsinterfaces2、手机模板计算机系统支持一套模板tes适应计算机、手机、平板电脑、官方账号等终端入口,也可以将移动终端与PC模板分离。3、VOD模块是视频模块的基本在线VOD功能。H5播放器采用著名的dplayer,包括mp4、 m3u8、Flv、MP3和其他格式支持4、微信公众号可用于连接微信公众号开发者工具(视频机器人系统).对接后,微信用户可以通过回答关键词搜索相应的视频点播。5、图片延迟加载网站前台图片列表采用图片点播加载技术,加快用户访问网站的速度,节省服务器带宽6、简单传统转换网站前台集成了简单繁体中文自动转换功能,网页加载后会根据浏览器区域自动转换语言,是传统点播站的首选7、focus map模块可以通过ugh焦点地图模块,移动终端和PC终端独立管理,支持手机滑动8、广告模块系统预留多个广告位,由移动终端和PC终端独立管理,只需在相应的广告位i中添加广告代码即可n后台,可通过标记在模板中扩展和调用
9、link模块系统保留主页链接和全站链接。友情链接用于站长之间的交流。全站链接主要用于一系列关键词主题的内部链接。10、导航模块是基于daicuo后台开发框架的导航组件调用的on是系统全站的频道链接,图标导航是移动终端的首页图标小部件。11、分类模块基于大厝后台开发框架的分类组件设计,支持一级分类和二级分类,支持不同的分类ent分类调用不同的资源站进行独立设计。12、搜索模块支持同一关键词呼叫对不同资源站的搜索结果。搜索条件需要基于资源站支持的类型,通常包括明星、电影标题和导演搜索。绿苹果电影电视系统( Maccms)项目优势1、开源和免费:我们传播开源的概念Maccms这是一个免费开源的PHP电影程序,没有任何加密代码,源代码完全开放,安全可靠,没有后门2、稳定性和安全隐患:内核安全稳定,PHP+MySQL架构和跨平台操作。ThinkPHP+jQuery+bootstrap组合和超级负载能力帮助您轻松操作数百万个网站@3、回归自然:没有那些花哨的鸡肋功能,回归电影和视频站“免费观看”的核心精髓。本节目试图以最简单的方式4、auto站群免费为互联网用户提供点播服务功能:如果您已经拥有影视聚合和点播网站,您可以通过其API接口直接与用户通信Maccms停靠、主站更新和自动同步所有站群系统的自动化
@5、多插件:系统基于daicuo后台开发框架开发,在网站后台,可通过daicuo的应用市场6、在线安装和管理多个实用插件,免维护:可一次性安装,并随影视资源st自动更新全天24小时运行,省去了采集和生成等复杂的锁定工作,只需专注于操作网站和流程实现7、伪静态:系统依托thinkphp5强大的路由模块,通过后台可以设计出非常有利于搜索引擎ac的目录结构根据站长8、云解析需求:系统提供的云播放器使用dplayer集成主流视频的点播和解析功能网站.您还可以在后台通过单击设置9、strong caching调用第三方解析接口服务:系统依赖于thinkphp5强大的缓存模块,可通过后台随时切换到文件缓存、Xcache、memcached、redis等缓存方式。绿苹果影视系统( Maccms)安装说明1、将文件夹下的所有文件上载到您的网站space2、如果您的主机是Windows操作系统,请向以下文件夹@3、的IIS用户添加写入权限如果您的主机是Linux操作系统,请将以下文件夹权限设置为777./data/*system operation cache目录4、通过浏览器访问网站basic配置的后台(强烈建议将admin.php更改为不易猜测的名称)您的域名/admin.php,默认用户名为admin,密码为admin888@5、系统默认为SQLite3数据库,如果需要转换成MySQL,可以通过后台的数据库转换功能完成
文章采集api(数据埋点采集到底包括哪些问题?作者从什么是埋点、埋点的应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-09-12 21:15
Data采集是数据分析的基础,埋点是最重要的采集方法。那么,数据埋点采集涉及哪些问题呢?本文作者从什么是埋点、埋点如何设计、埋点的应用三个方面梳理了这个问题,与大家分享。
一、数据采集及常见数据问题
1.data采集
数据采集的方式有很多种,埋点采集是其中非常重要的一部分。这是c端和b端产品的主要采集方式。
数据采集,顾名思义采集,对应的数据是整个数据流的起点。 采集不完整,对不对,直接决定数据的广度和质量,影响后续所有环节。在数据采集有效性和完整性较差的公司中,业务中发现的数据通常会发生重大变化。
数据处理通常包括以下 5 个步骤:
2. 常见数据问题
大体了解了data采集及其结构之后,我们来看看我们工作中遇到的问题,有多少是与data采集链接相关的:
数据与背景差距大,数据不准确——统计口径不同,埋点定义不同,采集方法带来误差;
想用的时候,没有我想要的数据——没有数据采集需求,埋点不正确,不完整;
事件太多,含义不明确——埋点设计的方法,埋点更新迭代的规则和维护;
分析数据,不知道看哪些数据和指标——数据定义不明确,缺乏分析思路。
我们要从根本上解决问题:把采集当作一个独立的研发企业,而不是产品开发中的附属品
二、什么是埋点
1.什么是埋点
所谓的埋点是data采集领域的一个术语。它的学名应该叫事件跟踪,对应的英文是Event Tracking,指的是捕获、处理和发送特定用户行为或事件的相关技术和实现过程。
数据埋点是数据分析师、数据产品经理和数据运营。根据业务需求或产品需求,开发用户行为的每个事件对应的位置和埋点,通过SDK上报埋点的数据结果,汇总记录。数据分析后,推动产品优化,指导运营。
流程附有规范。通过定义,我们可以看到具体的用户行为和事件是我们采集关注的焦点。我们还需要处理和发送相关的技术和实施流程;数据嵌入的意义在于服务于产品,它来自于产品。因此,它与产品密切相关。埋点在于具体实战过程,关系到每个人对底层数据的理解。
2.为什么要埋地
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的好坏直接影响到数据质量、产品质量、运营质量等。
数据驱动的埋点将分析深度下钻到流量分布和流量级别。通过统计分析,对宏观指标进行深入分析,发现指标背后的问题,洞察用户行为与价值提升的潜在关系;
产品优化——对于产品,用户在产品中做了什么,用户在产品中停留了多久,有什么异常需要注意。这些问题都可以通过埋点来解决;
精细化的运营-购买点可以实现整个产品生命周期、流量质量和不同来源的分布、人群的行为特征和关系,以及用户行为与提升商业价值之间的潜在关联。
3.如何埋点
埋点的方法有哪些?目前,大多数公司采用客户端和服务器的组合:
准确度:代码埋点>可视化埋点>全埋点
三、Median 的框架和设计
1.埋点采集的顶层设计
所谓顶层设计,就是搞清楚怎么埋点,用什么方法,上传机制是什么,怎么定义,怎么实现等等;我们在遵循唯一性、可扩展性、一致性等的基础上,我们要设计一些通用的字段和生成机制,比如:cid、idfa、idfv等
用户识别:用户识别机制的混乱会导致两种结果:一种是数据不准确,比如UV数据不正确;另一种是漏斗分析环节异常。因此,它应该是: a.严格规范ID自身的识别机制;湾跨平台用户识别;
相似抽象:相似抽象包括事件抽象和属性抽象。事件抽象是指浏览事件和点击事件的聚合;属性抽象意味着合并大部分重用场景以增加源区分;
采集一致性:采集一致性包括两点:一是跨平台页面的一致命名,二是按钮命名的一致;建立嵌入点本身的过程就是对底层数据进行标准化的过程,因此一致性尤为重要。只有这样才能真正用上;
渠道配置:渠道主要是指推广渠道、落地页、网页推广页、APP推广页等,这个落地页的配置必须有统一的规范和标准。
2.埋点采集事件与属性设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变的,哪些是业务行为,哪些是基本属性。
基于基础属性事件,我们认为属性必须是采集items,但是属性中的事件属性会根据不同的业务进行调整。因此,我们可以将埋点采集分为协议层和业务层。点。
业务分解:梳理确认业务流程、运营路径和不同细分场景,定义用户行为路径
分析指标:定义核心业务指标所需的具体事件和数据
事件设计:APP启动、退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.Data采集事件与属性设计
EV 事件的命名也遵循一些规则。当同一类型的函数出现在不同的页面或位置时,根据函数名进行命名,在ev参数中区分页面和位置。仅点击按钮时,按按钮名称命名。
ev事件格式:ev分为ev标识和ev参数
规则:
ev标识符和ev参数之间用“#”连接(一级连接器);
ev参数和ev参数之间用“/”连接(二级连接器);
ev 参数使用 key=value 的结构。当一个key对应多个value值时,value1和value2之间用“,”连接(三级连接器);
当埋点只有ev标志没有ev参数时,不需要带#;
备注:
ev identifier:作为埋点的唯一标识符,用于区分埋点的位置和属性,不可变,不可修改;
ev参数:埋点需要返回的参数,ev参数的顺序是可变的,可以修改;)
调整app嵌入点时,ev标志保持不变,只修改后续嵌入点参数(参数值改变或参数类型增加)
eg:通用嵌入点文档中收录的sheet的名称和功能:
A.曝光埋点总结;
B.点击浏览埋点汇总;
C.故障埋点汇总:一般会记录埋点的故障版本或时间;
D、PC、M页面嵌入点对应的pageid;
E。各版本上线时间记录;
在嵌入点文档中,收录了所有的列名和函数:
4.基于埋点的统计
如何使用隐藏的统计数据找到隐藏的 ev 事件:
指定埋点类型(点击/曝光/浏览)-过滤类型字段
明确按钮所属的页面(页面或功能)-过滤功能模块字段
指定埋藏事件的名称-过滤名称字段
知道ev标识符,可以直接用ev过滤
如何根据ev事件进行计数统计:当查询按钮点击统计时,可以直接使用ev标志进行查询。有区别时,可以限制埋点参数的取值;因为ev参数的顺序不需要可变,所以在查询统计时,不能限制参数的顺序;
四、Application-数据流的基础
1.指标体系
系统性指标可以将不同指标、不同维度串联起来进行综合分析,快速发现当前产品和业务流程中存在的问题。
2. 可视化
人类对图像信息的解释比文本更有效。可视化对于数据分析极其重要。使用数据可视化可以揭示数据中固有的复杂关系。
3.埋点元信息api提供
data采集服务会将采集的埋点写入Kafka。针对各个业务的实时数据消费需求,我们为各个业务提供了单独的Kafka,流量分发模块会定时读取 埋点管理平台提供的元信息,将流量实时分发给各个业务卡夫卡。
Data采集 就像设计一个产品。不能过分,留有扩展的余地,但要时刻考虑数据是否完整、详细、不稳定、快速。 查看全部
文章采集api(数据埋点采集到底包括哪些问题?作者从什么是埋点、埋点的应用)
Data采集是数据分析的基础,埋点是最重要的采集方法。那么,数据埋点采集涉及哪些问题呢?本文作者从什么是埋点、埋点如何设计、埋点的应用三个方面梳理了这个问题,与大家分享。
一、数据采集及常见数据问题
1.data采集
数据采集的方式有很多种,埋点采集是其中非常重要的一部分。这是c端和b端产品的主要采集方式。
数据采集,顾名思义采集,对应的数据是整个数据流的起点。 采集不完整,对不对,直接决定数据的广度和质量,影响后续所有环节。在数据采集有效性和完整性较差的公司中,业务中发现的数据通常会发生重大变化。
数据处理通常包括以下 5 个步骤:
2. 常见数据问题
大体了解了data采集及其结构之后,我们来看看我们工作中遇到的问题,有多少是与data采集链接相关的:
数据与背景差距大,数据不准确——统计口径不同,埋点定义不同,采集方法带来误差;
想用的时候,没有我想要的数据——没有数据采集需求,埋点不正确,不完整;
事件太多,含义不明确——埋点设计的方法,埋点更新迭代的规则和维护;
分析数据,不知道看哪些数据和指标——数据定义不明确,缺乏分析思路。
我们要从根本上解决问题:把采集当作一个独立的研发企业,而不是产品开发中的附属品
二、什么是埋点
1.什么是埋点
所谓的埋点是data采集领域的一个术语。它的学名应该叫事件跟踪,对应的英文是Event Tracking,指的是捕获、处理和发送特定用户行为或事件的相关技术和实现过程。
数据埋点是数据分析师、数据产品经理和数据运营。根据业务需求或产品需求,开发用户行为的每个事件对应的位置和埋点,通过SDK上报埋点的数据结果,汇总记录。数据分析后,推动产品优化,指导运营。
流程附有规范。通过定义,我们可以看到具体的用户行为和事件是我们采集关注的焦点。我们还需要处理和发送相关的技术和实施流程;数据嵌入的意义在于服务于产品,它来自于产品。因此,它与产品密切相关。埋点在于具体实战过程,关系到每个人对底层数据的理解。
2.为什么要埋地
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的好坏直接影响到数据质量、产品质量、运营质量等。
数据驱动的埋点将分析深度下钻到流量分布和流量级别。通过统计分析,对宏观指标进行深入分析,发现指标背后的问题,洞察用户行为与价值提升的潜在关系;
产品优化——对于产品,用户在产品中做了什么,用户在产品中停留了多久,有什么异常需要注意。这些问题都可以通过埋点来解决;
精细化的运营-购买点可以实现整个产品生命周期、流量质量和不同来源的分布、人群的行为特征和关系,以及用户行为与提升商业价值之间的潜在关联。
3.如何埋点
埋点的方法有哪些?目前,大多数公司采用客户端和服务器的组合:
准确度:代码埋点>可视化埋点>全埋点
三、Median 的框架和设计
1.埋点采集的顶层设计
所谓顶层设计,就是搞清楚怎么埋点,用什么方法,上传机制是什么,怎么定义,怎么实现等等;我们在遵循唯一性、可扩展性、一致性等的基础上,我们要设计一些通用的字段和生成机制,比如:cid、idfa、idfv等
用户识别:用户识别机制的混乱会导致两种结果:一种是数据不准确,比如UV数据不正确;另一种是漏斗分析环节异常。因此,它应该是: a.严格规范ID自身的识别机制;湾跨平台用户识别;
相似抽象:相似抽象包括事件抽象和属性抽象。事件抽象是指浏览事件和点击事件的聚合;属性抽象意味着合并大部分重用场景以增加源区分;
采集一致性:采集一致性包括两点:一是跨平台页面的一致命名,二是按钮命名的一致;建立嵌入点本身的过程就是对底层数据进行标准化的过程,因此一致性尤为重要。只有这样才能真正用上;
渠道配置:渠道主要是指推广渠道、落地页、网页推广页、APP推广页等,这个落地页的配置必须有统一的规范和标准。
2.埋点采集事件与属性设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变的,哪些是业务行为,哪些是基本属性。
基于基础属性事件,我们认为属性必须是采集items,但是属性中的事件属性会根据不同的业务进行调整。因此,我们可以将埋点采集分为协议层和业务层。点。
业务分解:梳理确认业务流程、运营路径和不同细分场景,定义用户行为路径
分析指标:定义核心业务指标所需的具体事件和数据
事件设计:APP启动、退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.Data采集事件与属性设计
EV 事件的命名也遵循一些规则。当同一类型的函数出现在不同的页面或位置时,根据函数名进行命名,在ev参数中区分页面和位置。仅点击按钮时,按按钮名称命名。
ev事件格式:ev分为ev标识和ev参数
规则:
ev标识符和ev参数之间用“#”连接(一级连接器);
ev参数和ev参数之间用“/”连接(二级连接器);
ev 参数使用 key=value 的结构。当一个key对应多个value值时,value1和value2之间用“,”连接(三级连接器);
当埋点只有ev标志没有ev参数时,不需要带#;
备注:
ev identifier:作为埋点的唯一标识符,用于区分埋点的位置和属性,不可变,不可修改;
ev参数:埋点需要返回的参数,ev参数的顺序是可变的,可以修改;)
调整app嵌入点时,ev标志保持不变,只修改后续嵌入点参数(参数值改变或参数类型增加)
eg:通用嵌入点文档中收录的sheet的名称和功能:
A.曝光埋点总结;
B.点击浏览埋点汇总;
C.故障埋点汇总:一般会记录埋点的故障版本或时间;
D、PC、M页面嵌入点对应的pageid;
E。各版本上线时间记录;
在嵌入点文档中,收录了所有的列名和函数:
4.基于埋点的统计
如何使用隐藏的统计数据找到隐藏的 ev 事件:
指定埋点类型(点击/曝光/浏览)-过滤类型字段
明确按钮所属的页面(页面或功能)-过滤功能模块字段
指定埋藏事件的名称-过滤名称字段
知道ev标识符,可以直接用ev过滤
如何根据ev事件进行计数统计:当查询按钮点击统计时,可以直接使用ev标志进行查询。有区别时,可以限制埋点参数的取值;因为ev参数的顺序不需要可变,所以在查询统计时,不能限制参数的顺序;
四、Application-数据流的基础
1.指标体系
系统性指标可以将不同指标、不同维度串联起来进行综合分析,快速发现当前产品和业务流程中存在的问题。
2. 可视化
人类对图像信息的解释比文本更有效。可视化对于数据分析极其重要。使用数据可视化可以揭示数据中固有的复杂关系。
3.埋点元信息api提供
data采集服务会将采集的埋点写入Kafka。针对各个业务的实时数据消费需求,我们为各个业务提供了单独的Kafka,流量分发模块会定时读取 埋点管理平台提供的元信息,将流量实时分发给各个业务卡夫卡。
Data采集 就像设计一个产品。不能过分,留有扩展的余地,但要时刻考虑数据是否完整、详细、不稳定、快速。
文章采集api(如何用R调用API,提取和整理你需要的免费Web数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 276 次浏览 • 2021-09-09 22:13
API 是获取网络数据的重要途径之一。您想知道如何使用R调用API来提取和组织您需要的免费网络数据吗?本文将一步步为您详细介绍操作流程。
权衡
俗话说,“聪明的女人做饭没有米饭很难。”就算你掌握了数据分析的18个武功,没有数据也是一件苦恼的事情。 “拔剑望心”大概就是这种情况吧。
数据来源很多。 Web数据是一种数量大、获取相对容易的类型。更好的是,很多网络数据都是免费的。
在这个大数据时代,如何获取网络数据?
许多人会使用其他人编译和发布的数据集。
他们很幸运,他们的工作可以建立在其他人的基础上。这是最有效的。
但并不是每个人都这么幸运。如果你需要没有人编译和发布的数据怎么办?
其实这样的数据量更大。我们是否对他们视而不见?
如果您想到爬虫,那么您的思考方向是正确的。爬虫可以为您获取几乎所有可见(甚至不可见)的 Web 数据。但是,编写和使用爬虫的成本很高。包括时间资源、技术能力等。如果你面对任何网络数据采集问题,你甚至都不会想到“大锤”,有时可能就是“大锤杀鸡”。
在“别人准备的数据”和“需要自己爬取的数据”之间,有一个非常广阔的领域。这就是 API 的世界。
API 是什么?
是Application Programming Interface的缩写。具体来说,就是某个网站积累了变化的数据。如果把这些数据整理出来,不仅费时,而且占用空间,刚整理出来就有过期的危险。大多数人需要的数据其实只是其中的一小部分,但对时效性的要求可能非常强。因此,组织存储并提供给公众下载既不经济也不划算。
但是,如果数据不能以某种方式发布,你将面临无数爬虫的骚扰。这会给网站的正常运行带来很大的麻烦。妥协是网站主动提供了一个渠道。当你需要某部分数据时,虽然没有现成的数据集,你只需要用这个渠道描述你想要的数据,然后网站review(一般是自动化的,瞬间完成),认为可以给你,立即发送你明确要求的数据。双方都很开心。
以后找数据的时候,不妨看看目标网站是否提供了API,避免做无用功。
在这个github项目中,有一个非常详细的列表,涵盖了当前常见的主流网站API资源状态。作者还在整理修改中,大家可以采集慢慢看。
如果我们了解到某个网站提供了API,并且通过查看文档,知道里面有我们需要的数据,那么问题就变成了——如何通过API获取数据?
下面我们通过一个实际的例子向您展示整个过程的步骤。
来源
我们正在寻找的样本是维基百科。
有关维基百科 API 的概述,请参阅此页面。
假设我们关心特定时间段内对指定维基百科文章页面的访问次数。
维基百科专门为我们提供了一种称为指标的数据,它涵盖了页面访问的关键价值。对应的API介绍页面在这里。
页面上有一个示例。假设你需要获取2015年10月爱因斯坦的入口页面的访问次数,可以这样调用:
GET http://wikimedia.org/api/rest_ ... 03100
我们可以在浏览器的地址栏中输入GET后的一长串网址,按回车查看得到的结果。
在浏览器中,我们看到上图中的一长串文本。你可能会觉得奇怪——这是什么?
恭喜,这是我们需要获取的数据。但是,它使用一种称为 JSON 的特殊数据格式。
JSON 是目前互联网上数据交互的主流格式之一。如果你想了解JSON的含义和用法,可以参考这个教程。
在浏览器中,我们最初只能看到数据的第一部分。但它已经收录了有价值的内容:
{"items":[{"project":"en.wikipedia","article":"Albert_Einstein","granularity":"daily","timestamp":"2015100100","access":"all-access","agent":"all-agents","views":18860}
在这一段中,我们看到了项目名称(en.wikipedia)、文章title(阿尔伯特·爱因斯坦)、统计粒度(天)、时间戳(2015 年 10 月 1 日)、访问类型(全部)、终端类型( all),以及访问次数(18860)。
我们使用滑块将返回的文本拖到最后,我们会看到如下信息:
{"project":"en.wikipedia","article":"Albert_Einstein","granularity":"daily","timestamp":"2015103100","access":"all-access","agent":"all-agents","views":16380}]}
与10月1日的数据相比,只有时间戳(2015年10月31日)和访问量(16380))发生了变化。
我们中间跳过的数据是10月2日到10月30日之间的数据。存储格式相同,只有date和visits这两个数据值在变化。
所有需要的数据都在这里,你只需要提取相应的信息,就是这样。但是如果让你手动去做(比如复制需要的项目,然后粘贴到Excel中),显然效率很低,容易出错。让我们展示如何使用 R 编程环境来自动化这个过程。
准备
在使用 R 调用 API 之前,我们需要做一些必要的准备。
第一步是安装 R。
请先从本站下载R基础安装包。
R的下载位置比较多,建议选择清华大学的镜像,下载速度比较快。
请根据您的操作系统平台选择相应的版本进行下载。我使用的是 macOS 版本。
下载 pkg 文件。双击安装。
安装完基础包后,我们继续安装集成开发环境RStudio。它可以帮助您轻松地与 R 进行交互。 RStudio的下载地址在这里。
根据您的操作系统,选择对应的安装包。 macOS 安装包是一个 dmg 文件。双击打开后,将其中的RStudio.app图标拖到Applications文件夹,安装完成。
接下来,我们双击从应用程序目录运行 RStudio。
我们先在RStudio的Console中运行如下语句来安装一些需要用到的软件包:
install.packages("tidyverse")
install.packages("rlist")
安装完成后,在菜单中选择File->New,在如下界面选择R Notebook。
R Notebook 默认为我们提供了一个模板,其中收录一些基本的使用说明。
我们尝试点击编辑区(左侧)代码部分(灰色)中的运行按钮。
您可以立即看到绘图结果。
我们点击菜单栏上的Preview按钮来查看整个代码的结果。操作结果会显示在HTML文件中,图片和文字都可以。
熟悉环境后,是时候实际运行我们自己的代码了。我们保留左侧编辑区开头的描述区,删除其余部分,将文件名改为有意义的web-data-api-with-R。
到此,准备工作就做好了。现在我们就要开始实际操作了。
操作
在实际操作过程中,我们从维基百科中换了一个Wiki文章作为样本,以证明这种操作方法的通用性。选择的文章是我们在介绍词云制作时使用的那个,叫做“Yes, Minisiter”。这是一部 1980 年代的英国喜剧。
我们先在浏览器中试试看能否通过修改API示例中的参数来获取“是,部长”文章访问统计。作为测试,我们仅采集了 2017 年 10 月 1 日至 2017 年 10 月 3 日的 3 天数据。
与示例相比,我们需要替换的内容包括起止时间和文章title。
我们在浏览器的地址栏中输入:
https://wikimedia.org/api/rest ... 00300
返回结果如下:
数据可以正常返回。下面我们将使用statement方法在RStudio中进行调用。
注意,在下面的代码中,程序输出的开头会有一个##标记,以区别于执行代码本身。
一出现,我们就需要设置时区。以后不处理时间数据时,会遇到错误。
Sys.setenv(TZ="Asia/Shanghai")
然后,我们调用 tidyverse 包,它是一个集合,加载了我们稍后将使用的许多函数。
library(tidyverse)
## Loading tidyverse: ggplot2
## Loading tidyverse: tibble
## Loading tidyverse: tidyr
## Loading tidyverse: readr
## Loading tidyverse: purrr
## Loading tidyverse: dplyr
## Conflicts with tidy packages ----------------------------------------------
## filter(): dplyr, stats
## lag(): dplyr, stats
这里可能会遇到一些警告,忽略即可。它对我们的运营没有影响。
根据前面的例子,我们定义了要查询的时间跨度,并指定了要搜索的wiki名称文章。
注意,与 Python 不同的是,在 R 语言中,使用了赋值
<p>starting 查看全部
文章采集api(如何用R调用API,提取和整理你需要的免费Web数据)
API 是获取网络数据的重要途径之一。您想知道如何使用R调用API来提取和组织您需要的免费网络数据吗?本文将一步步为您详细介绍操作流程。
权衡
俗话说,“聪明的女人做饭没有米饭很难。”就算你掌握了数据分析的18个武功,没有数据也是一件苦恼的事情。 “拔剑望心”大概就是这种情况吧。
数据来源很多。 Web数据是一种数量大、获取相对容易的类型。更好的是,很多网络数据都是免费的。
在这个大数据时代,如何获取网络数据?
许多人会使用其他人编译和发布的数据集。
他们很幸运,他们的工作可以建立在其他人的基础上。这是最有效的。
但并不是每个人都这么幸运。如果你需要没有人编译和发布的数据怎么办?
其实这样的数据量更大。我们是否对他们视而不见?
如果您想到爬虫,那么您的思考方向是正确的。爬虫可以为您获取几乎所有可见(甚至不可见)的 Web 数据。但是,编写和使用爬虫的成本很高。包括时间资源、技术能力等。如果你面对任何网络数据采集问题,你甚至都不会想到“大锤”,有时可能就是“大锤杀鸡”。
在“别人准备的数据”和“需要自己爬取的数据”之间,有一个非常广阔的领域。这就是 API 的世界。
API 是什么?
是Application Programming Interface的缩写。具体来说,就是某个网站积累了变化的数据。如果把这些数据整理出来,不仅费时,而且占用空间,刚整理出来就有过期的危险。大多数人需要的数据其实只是其中的一小部分,但对时效性的要求可能非常强。因此,组织存储并提供给公众下载既不经济也不划算。
但是,如果数据不能以某种方式发布,你将面临无数爬虫的骚扰。这会给网站的正常运行带来很大的麻烦。妥协是网站主动提供了一个渠道。当你需要某部分数据时,虽然没有现成的数据集,你只需要用这个渠道描述你想要的数据,然后网站review(一般是自动化的,瞬间完成),认为可以给你,立即发送你明确要求的数据。双方都很开心。
以后找数据的时候,不妨看看目标网站是否提供了API,避免做无用功。
在这个github项目中,有一个非常详细的列表,涵盖了当前常见的主流网站API资源状态。作者还在整理修改中,大家可以采集慢慢看。
如果我们了解到某个网站提供了API,并且通过查看文档,知道里面有我们需要的数据,那么问题就变成了——如何通过API获取数据?
下面我们通过一个实际的例子向您展示整个过程的步骤。
来源
我们正在寻找的样本是维基百科。
有关维基百科 API 的概述,请参阅此页面。
假设我们关心特定时间段内对指定维基百科文章页面的访问次数。
维基百科专门为我们提供了一种称为指标的数据,它涵盖了页面访问的关键价值。对应的API介绍页面在这里。
页面上有一个示例。假设你需要获取2015年10月爱因斯坦的入口页面的访问次数,可以这样调用:
GET http://wikimedia.org/api/rest_ ... 03100
我们可以在浏览器的地址栏中输入GET后的一长串网址,按回车查看得到的结果。
在浏览器中,我们看到上图中的一长串文本。你可能会觉得奇怪——这是什么?
恭喜,这是我们需要获取的数据。但是,它使用一种称为 JSON 的特殊数据格式。
JSON 是目前互联网上数据交互的主流格式之一。如果你想了解JSON的含义和用法,可以参考这个教程。
在浏览器中,我们最初只能看到数据的第一部分。但它已经收录了有价值的内容:
{"items":[{"project":"en.wikipedia","article":"Albert_Einstein","granularity":"daily","timestamp":"2015100100","access":"all-access","agent":"all-agents","views":18860}
在这一段中,我们看到了项目名称(en.wikipedia)、文章title(阿尔伯特·爱因斯坦)、统计粒度(天)、时间戳(2015 年 10 月 1 日)、访问类型(全部)、终端类型( all),以及访问次数(18860)。
我们使用滑块将返回的文本拖到最后,我们会看到如下信息:
{"project":"en.wikipedia","article":"Albert_Einstein","granularity":"daily","timestamp":"2015103100","access":"all-access","agent":"all-agents","views":16380}]}
与10月1日的数据相比,只有时间戳(2015年10月31日)和访问量(16380))发生了变化。
我们中间跳过的数据是10月2日到10月30日之间的数据。存储格式相同,只有date和visits这两个数据值在变化。
所有需要的数据都在这里,你只需要提取相应的信息,就是这样。但是如果让你手动去做(比如复制需要的项目,然后粘贴到Excel中),显然效率很低,容易出错。让我们展示如何使用 R 编程环境来自动化这个过程。
准备
在使用 R 调用 API 之前,我们需要做一些必要的准备。
第一步是安装 R。
请先从本站下载R基础安装包。
R的下载位置比较多,建议选择清华大学的镜像,下载速度比较快。
请根据您的操作系统平台选择相应的版本进行下载。我使用的是 macOS 版本。
下载 pkg 文件。双击安装。
安装完基础包后,我们继续安装集成开发环境RStudio。它可以帮助您轻松地与 R 进行交互。 RStudio的下载地址在这里。
根据您的操作系统,选择对应的安装包。 macOS 安装包是一个 dmg 文件。双击打开后,将其中的RStudio.app图标拖到Applications文件夹,安装完成。
接下来,我们双击从应用程序目录运行 RStudio。
我们先在RStudio的Console中运行如下语句来安装一些需要用到的软件包:
install.packages("tidyverse")
install.packages("rlist")
安装完成后,在菜单中选择File->New,在如下界面选择R Notebook。
R Notebook 默认为我们提供了一个模板,其中收录一些基本的使用说明。
我们尝试点击编辑区(左侧)代码部分(灰色)中的运行按钮。
您可以立即看到绘图结果。
我们点击菜单栏上的Preview按钮来查看整个代码的结果。操作结果会显示在HTML文件中,图片和文字都可以。
熟悉环境后,是时候实际运行我们自己的代码了。我们保留左侧编辑区开头的描述区,删除其余部分,将文件名改为有意义的web-data-api-with-R。
到此,准备工作就做好了。现在我们就要开始实际操作了。
操作
在实际操作过程中,我们从维基百科中换了一个Wiki文章作为样本,以证明这种操作方法的通用性。选择的文章是我们在介绍词云制作时使用的那个,叫做“Yes, Minisiter”。这是一部 1980 年代的英国喜剧。
我们先在浏览器中试试看能否通过修改API示例中的参数来获取“是,部长”文章访问统计。作为测试,我们仅采集了 2017 年 10 月 1 日至 2017 年 10 月 3 日的 3 天数据。
与示例相比,我们需要替换的内容包括起止时间和文章title。
我们在浏览器的地址栏中输入:
https://wikimedia.org/api/rest ... 00300
返回结果如下:
数据可以正常返回。下面我们将使用statement方法在RStudio中进行调用。
注意,在下面的代码中,程序输出的开头会有一个##标记,以区别于执行代码本身。
一出现,我们就需要设置时区。以后不处理时间数据时,会遇到错误。
Sys.setenv(TZ="Asia/Shanghai")
然后,我们调用 tidyverse 包,它是一个集合,加载了我们稍后将使用的许多函数。
library(tidyverse)
## Loading tidyverse: ggplot2
## Loading tidyverse: tibble
## Loading tidyverse: tidyr
## Loading tidyverse: readr
## Loading tidyverse: purrr
## Loading tidyverse: dplyr
## Conflicts with tidy packages ----------------------------------------------
## filter(): dplyr, stats
## lag(): dplyr, stats
这里可能会遇到一些警告,忽略即可。它对我们的运营没有影响。
根据前面的例子,我们定义了要查询的时间跨度,并指定了要搜索的wiki名称文章。
注意,与 Python 不同的是,在 R 语言中,使用了赋值
<p>starting
文章采集api(ApiPost支持团队协作,可直接生成文档的API调试、管理工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-09-09 22:11
ApiPost 是一个 API 调试和管理工具,支持团队协作,可以直接生成文档。支持POST、GET、PUT等常见请求的模拟,是后端接口开发人员或前端和接口测试人员不可多得的工具。用户不仅可以使用apiopst调试界面,还可以编写相关注释(界面文档),轻松生成可读性好、界面美观的在线界面文档。
本文主要收录以下内容:
介绍 ApiPost 工具及其功能
如何下载和安装
一些常见的操作
介绍一些技巧
前言:apipost 能做什么?
ApiPost 是一个 API 调试和管理工具,支持团队协作,可以直接生成文档。支持模拟POST、GET、PUT等postman等常见请求,快速生成接口文档。是后端接口开发人员或前端和接口测试人员不可多得的工具。先看它的界面风格。
下载并安装apipost
ApiPost 的安装和下载非常简单。可以直接到官网(自行百度)下载对应操作系统(支持window、mac、linux)的安装包并安装。官网还提供了丰富的安装文档,这里不再赘述。
一些常见的操作
ApiPost 支持常用的接口发送、文档生成等,作为开发者,相信你从上面的截图基本可以看出怎么使用了。下面是一些其他常见的操作。但是第一次使用需要注册账号,创建项目,然后点击左侧的APIS菜单栏进入控制台。
下图是对目录的常用操作
总之,使用基本上很简单,看到就下载安装。如有疑问,可以到官网查看文档或到社区提问。
一些操作技巧
提示:快速导入参数
apipost支持多种格式的参数导入,如下图所示,再也不用一一慢慢写了:
导入格式支持 key-value 和 json 格式:
1-1:键值格式导入示例:
常见的key-value格式为浏览器(控制台的F12)数据格式,见下图:
我们,复制上面的请求头参数,然后粘贴到apipost中,点击import
参数瞬间导入到请求参数中,如下图:
上面的例子只是展示了如何快速导入header参数,其他的query、body操作等参数完全一样。
1-2:json格式导入示例:
apipost 也支持json格式的参数导入,参数格式可以如下:
{ "id": 123, "title": "我就是标题" }
如图,点击Import,参数快速导入到请求参数中。
提示:自动识别参数注释
上面我们写了如何快速导入参数。实际上,参数描述(注释)是生成接口文档最可怕的。对于一直很忙的程序员来说,花大量时间写文档实在是太累了。 !
幸运的是,apipost 为我们节省了大量时间。对于一个参数,只要写一次注释,下次就可以选择同一个参数。示例:
在上图中,我们为id和title写了相应的注释:
id:“我是文章Id”
title:“我是文章title”
当我们新建一个界面的时候,如果界面还使用了id或者title等参数,点击参数说明会显示刚刚输入的参数说明,选择就可以了,不用再麻烦打字了。
这个小功能是否为开发者节省了大量时间?
提示:快速定位当前界面目录
左边的目录默认关闭。有时我们不知道当前正在编辑的界面属于哪个目录,查找起来很头疼。 Apipost 提供了“定位到当前界面目录”功能(见下图),可以快速打开当前正在编辑界面和文档的目录。它解决了你的大问题吗?
其实apipost还有很多更符合中国人操作习惯的小功能,等你去发现。 查看全部
文章采集api(ApiPost支持团队协作,可直接生成文档的API调试、管理工具)
ApiPost 是一个 API 调试和管理工具,支持团队协作,可以直接生成文档。支持POST、GET、PUT等常见请求的模拟,是后端接口开发人员或前端和接口测试人员不可多得的工具。用户不仅可以使用apiopst调试界面,还可以编写相关注释(界面文档),轻松生成可读性好、界面美观的在线界面文档。
本文主要收录以下内容:
介绍 ApiPost 工具及其功能
如何下载和安装
一些常见的操作
介绍一些技巧
前言:apipost 能做什么?
ApiPost 是一个 API 调试和管理工具,支持团队协作,可以直接生成文档。支持模拟POST、GET、PUT等postman等常见请求,快速生成接口文档。是后端接口开发人员或前端和接口测试人员不可多得的工具。先看它的界面风格。
下载并安装apipost
ApiPost 的安装和下载非常简单。可以直接到官网(自行百度)下载对应操作系统(支持window、mac、linux)的安装包并安装。官网还提供了丰富的安装文档,这里不再赘述。
一些常见的操作
ApiPost 支持常用的接口发送、文档生成等,作为开发者,相信你从上面的截图基本可以看出怎么使用了。下面是一些其他常见的操作。但是第一次使用需要注册账号,创建项目,然后点击左侧的APIS菜单栏进入控制台。
下图是对目录的常用操作
总之,使用基本上很简单,看到就下载安装。如有疑问,可以到官网查看文档或到社区提问。
一些操作技巧
提示:快速导入参数
apipost支持多种格式的参数导入,如下图所示,再也不用一一慢慢写了:
导入格式支持 key-value 和 json 格式:
1-1:键值格式导入示例:
常见的key-value格式为浏览器(控制台的F12)数据格式,见下图:
我们,复制上面的请求头参数,然后粘贴到apipost中,点击import
参数瞬间导入到请求参数中,如下图:
上面的例子只是展示了如何快速导入header参数,其他的query、body操作等参数完全一样。
1-2:json格式导入示例:
apipost 也支持json格式的参数导入,参数格式可以如下:
{ "id": 123, "title": "我就是标题" }
如图,点击Import,参数快速导入到请求参数中。
提示:自动识别参数注释
上面我们写了如何快速导入参数。实际上,参数描述(注释)是生成接口文档最可怕的。对于一直很忙的程序员来说,花大量时间写文档实在是太累了。 !
幸运的是,apipost 为我们节省了大量时间。对于一个参数,只要写一次注释,下次就可以选择同一个参数。示例:
在上图中,我们为id和title写了相应的注释:
id:“我是文章Id”
title:“我是文章title”
当我们新建一个界面的时候,如果界面还使用了id或者title等参数,点击参数说明会显示刚刚输入的参数说明,选择就可以了,不用再麻烦打字了。
这个小功能是否为开发者节省了大量时间?
提示:快速定位当前界面目录
左边的目录默认关闭。有时我们不知道当前正在编辑的界面属于哪个目录,查找起来很头疼。 Apipost 提供了“定位到当前界面目录”功能(见下图),可以快速打开当前正在编辑界面和文档的目录。它解决了你的大问题吗?
其实apipost还有很多更符合中国人操作习惯的小功能,等你去发现。

