
文章采集api
文章采集api(一个博客小站来说的收录方式文章目录资源前言)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-03-01 01:25
typechoSEO网站收录插件推荐百度提交
文章目录
资源前言
我们在建一个小站点的时候,可能会遇到如何让搜索引擎抓取我们的文章的问题,当然你可以选择不让搜索引擎抓取你的站点。这时候,你就需要SEO(“搜索引擎优化”)。其实涉及的内容很多,但作为我这种小博客网站,没必要。无非就是让你的网站在搜索引擎中的排名更高,让运维来做。在这篇文章中,我主要讲一下我在SEO方面采取的一些做法,主要是百度收录,其他搜索引擎的收录方法类似,大家可以自行搜索理解
安装
把下载好的插件解压到typecho主目录下的插件目录下,一般是/usr/plugins
然后就可以在typecho的后台插件中看到了
百度站长网站设置
百度搜索引擎提供了站长网站,这样我们就可以主动让百度去收录自己的站点,下面是传送门
门户网站
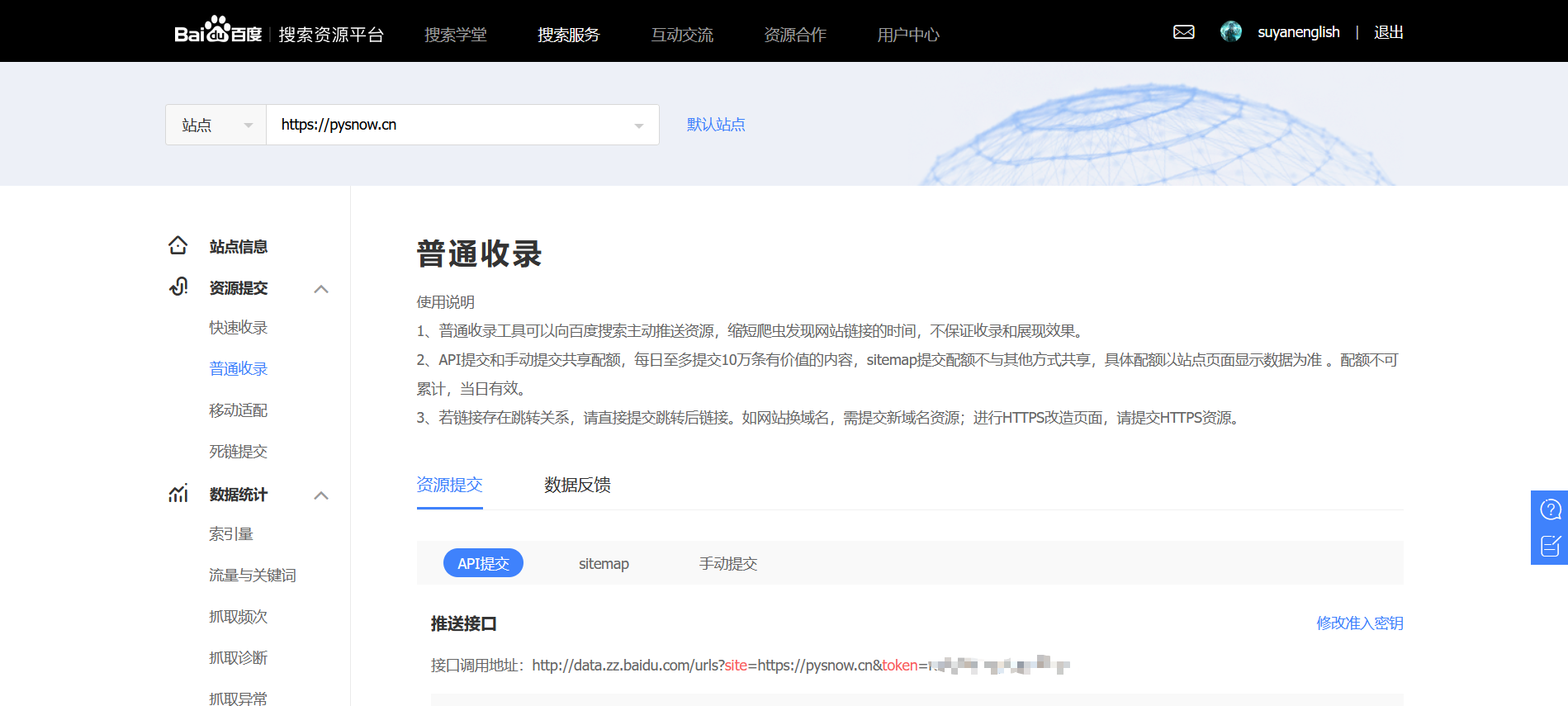
他提供了几种不同的收录方法,比如quick收录,可以让你主动提供你网站的一些资源,比如sitemap等,缩短搜索引擎爬虫爬取你的时间地点。具体方法有API提交、站点地图、手动提交。这次推荐的插件主要是API提交。
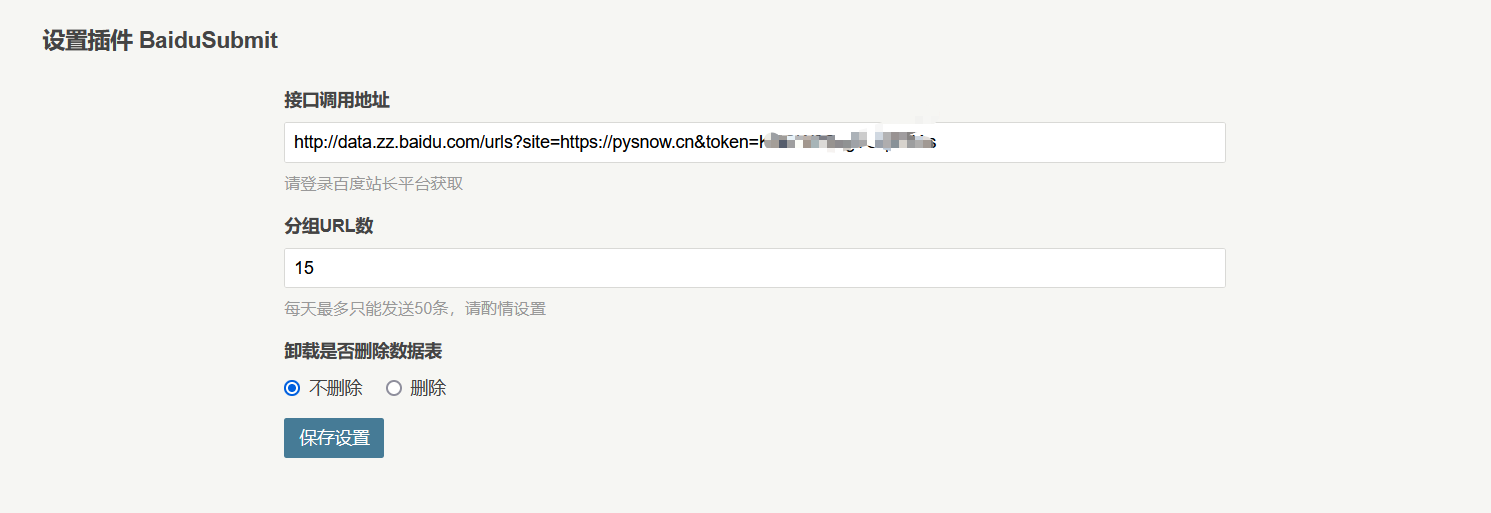
API 提交
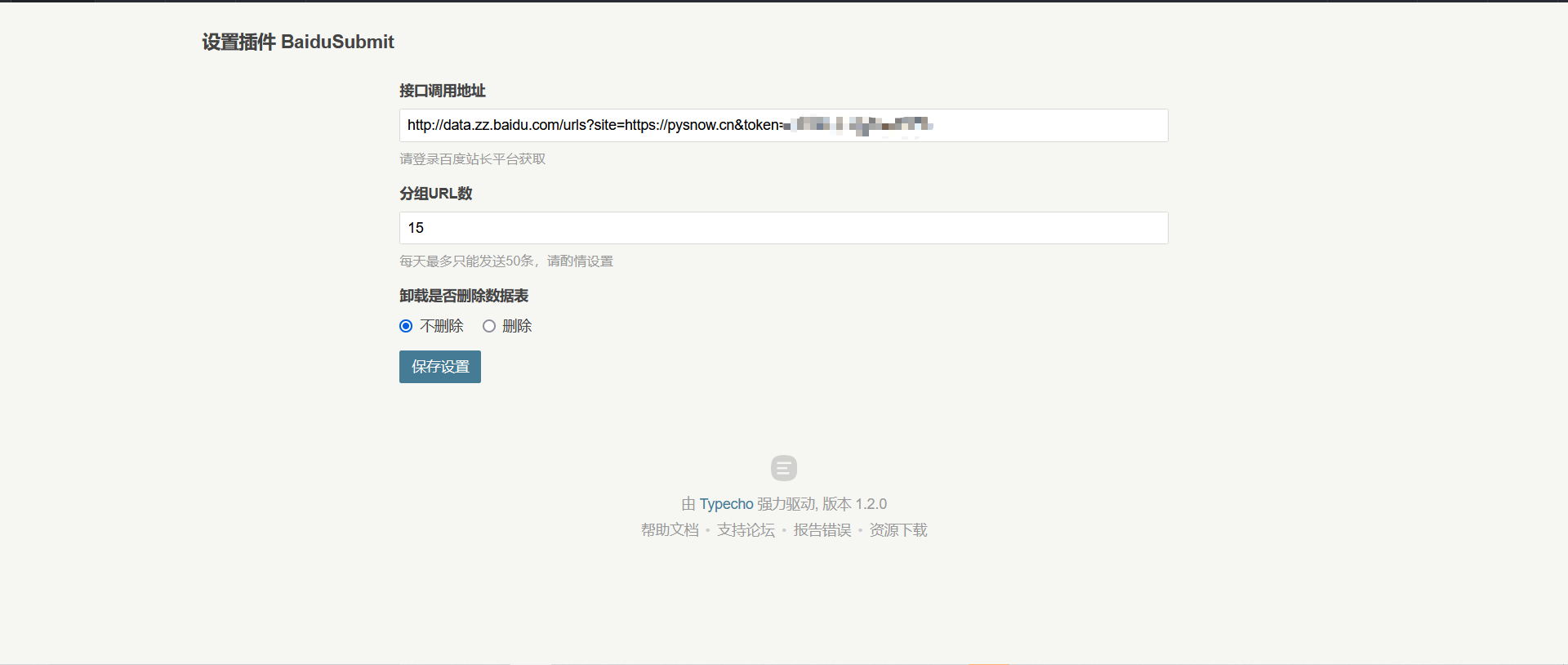
推送接口、推送实例、推送反馈如上所示。我们只需要关注推送接口即可。后两者在实现代码时需要注意。显然,插件作者已经做到了这一点。以下是API接口的样式。
http://data.zz.baidu.com/urls?site={您的站点}&token={验证token,相当于密码}
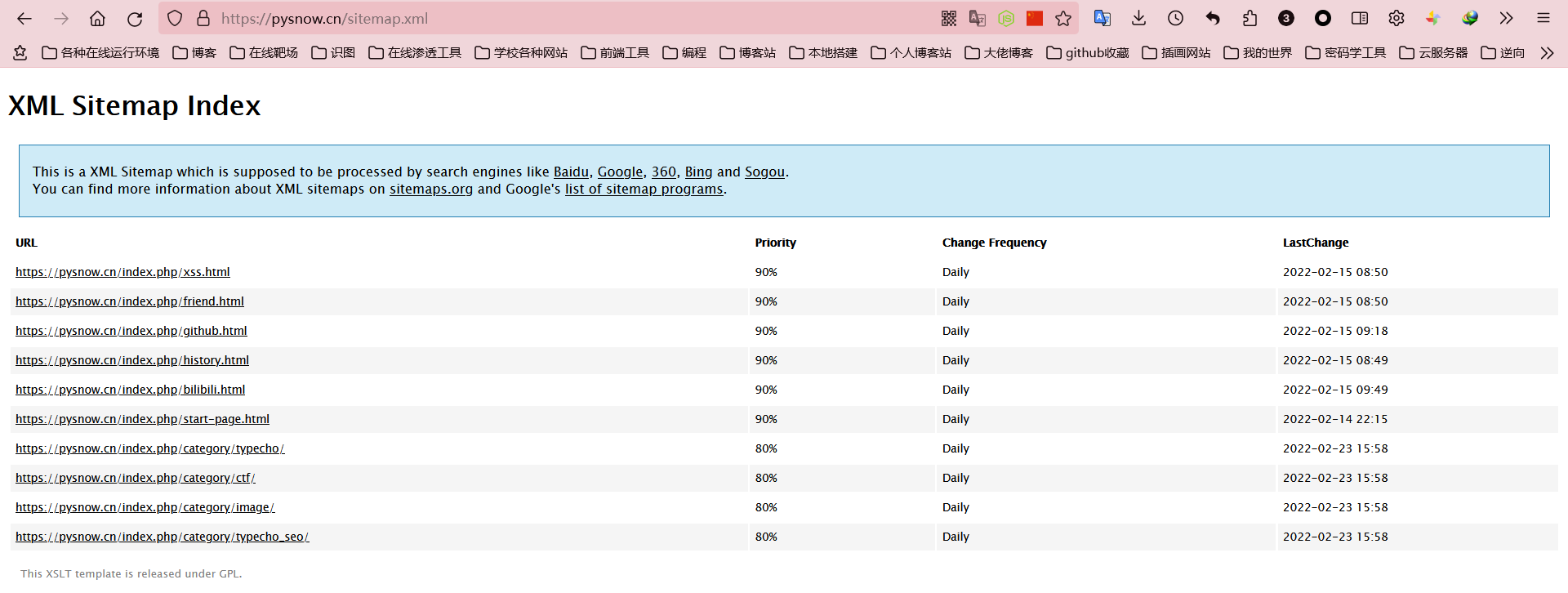
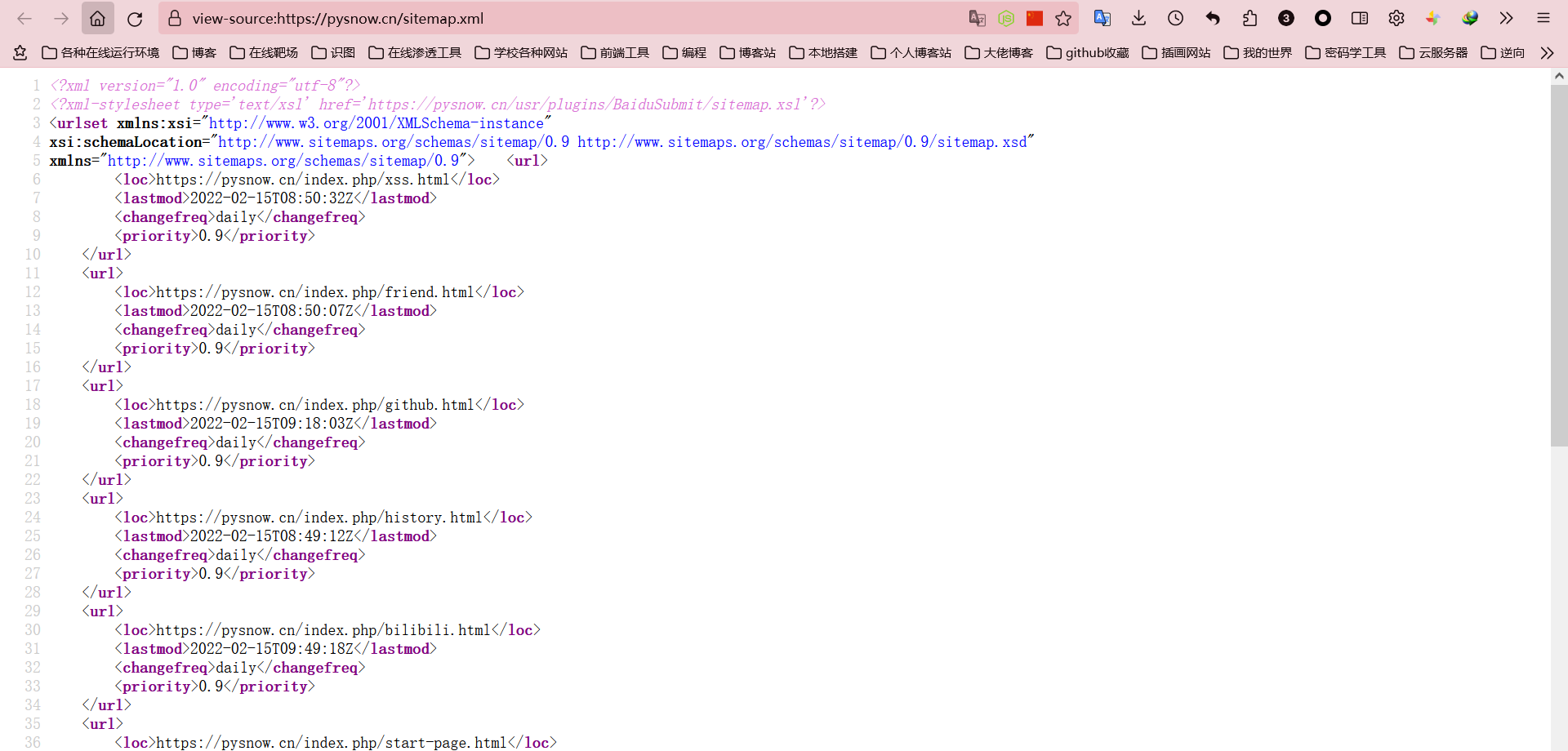
网站地图
要提交站点地图,您可以使用 txt 或 xml 格式。这里可以直接使用这个插件生成的xml文件,大部分搜索引擎都识别sitemaps(我不知道),比如你可以看一下我的站点自动生成的xml。文档
如果您熟悉 XML,很容易发现大部分站点地图实际上是由这些多个 url 元素组成的。
所以我们可以填写对应的
不仅可以在这里使用站点的路径,而且在这里这样做更方便。另外,这个站点地图一天最多只能推送十次。
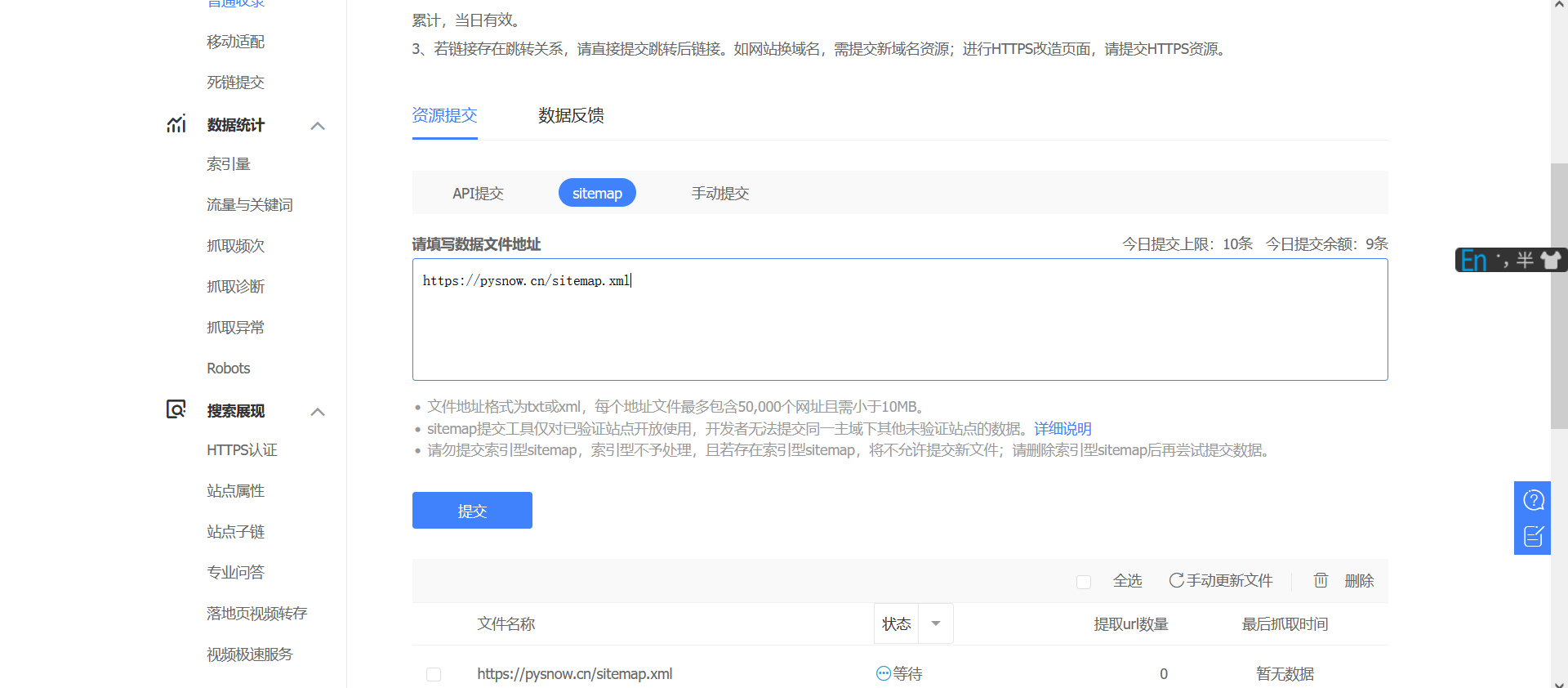
手动提交
也就是提交你网站上写的文章的链接,也就是把sitemap.xml内容中的url链接一个一个提交,这个方法可以保证你的一个文章可以很好收录(不一定,还是看百度吧),自己决定
百度站长其他工具
喜欢什么移动适配,死链接提交可以自己看懂,什么都写清楚了哈哈
插件介绍功能使用
很简单,直接填一个api,发布的时候会自动提交类似这个api的更新文章
机器人文件
使用爬虫的人应该对此非常熟悉。简而言之,是爬虫的“君子协定”。虽然我们平时不遵守君子协定,但百度、搜狗、谷歌等大搜索引擎还是会遵守的。是的,这个约束只是对它们的约束。哈哈,由于这个插件没有自动生成robots.txt的功能,所以需要我们自己创建。方法也很简单。步骤如下
创建一个名为 robots.txt 的新文件
输入内容
User-agent: *
Allow: /
Disallow: /admin/
Disallow: /install/
Sitemap: https://你的网站地址/sitemap.xml
这个语法很简单,可以根据自己网站的需要进行修改
保存并上传文件到 网站 根目录
最后,访问自己 网站 进行验证
好的,你完成了
查看您的网站是否被 收录 阻止
最常用的方法是在搜索引擎上搜索您的一篇文章文章。如果你找到了,说明你已经收录
这里推荐一个查看你整个站点的收录情况的方法(使用搜索语法site:xxx),具体示例如下
可以看到百度收录已经添加了我以前的站点,所以这里有一点你可以知道的是,百度收录并不是你提交资源后就可以立即更新的东西,他会是定期更新,可能是一周或一个月(废话)
总结
其实搜索引擎的收录只需要提交一个链接,搜索引擎就会自动抓取你的链接。这个插件自动生成sitemap.xml文件,可以很方便的让其他搜索引擎收录,所以一个sitemap插件就够了。下面我将给出各大搜索引擎站长的网站地址。你可以直接写你的网站地址,让他们自己爬。, 收录不会马上成功的。这主要取决于不同的搜索引擎,以及您网站的各种结果,其中涉及到 SEO 问题。我对此一无所知。问运维老板。. 最后,祝你折腾网站开心! 查看全部
文章采集api(一个博客小站来说的收录方式文章目录资源前言)
typechoSEO网站收录插件推荐百度提交
文章目录
资源前言
我们在建一个小站点的时候,可能会遇到如何让搜索引擎抓取我们的文章的问题,当然你可以选择不让搜索引擎抓取你的站点。这时候,你就需要SEO(“搜索引擎优化”)。其实涉及的内容很多,但作为我这种小博客网站,没必要。无非就是让你的网站在搜索引擎中的排名更高,让运维来做。在这篇文章中,我主要讲一下我在SEO方面采取的一些做法,主要是百度收录,其他搜索引擎的收录方法类似,大家可以自行搜索理解
安装
把下载好的插件解压到typecho主目录下的插件目录下,一般是/usr/plugins
然后就可以在typecho的后台插件中看到了
百度站长网站设置
百度搜索引擎提供了站长网站,这样我们就可以主动让百度去收录自己的站点,下面是传送门
门户网站
他提供了几种不同的收录方法,比如quick收录,可以让你主动提供你网站的一些资源,比如sitemap等,缩短搜索引擎爬虫爬取你的时间地点。具体方法有API提交、站点地图、手动提交。这次推荐的插件主要是API提交。
API 提交
推送接口、推送实例、推送反馈如上所示。我们只需要关注推送接口即可。后两者在实现代码时需要注意。显然,插件作者已经做到了这一点。以下是API接口的样式。
http://data.zz.baidu.com/urls?site={您的站点}&token={验证token,相当于密码}
网站地图
要提交站点地图,您可以使用 txt 或 xml 格式。这里可以直接使用这个插件生成的xml文件,大部分搜索引擎都识别sitemaps(我不知道),比如你可以看一下我的站点自动生成的xml。文档
如果您熟悉 XML,很容易发现大部分站点地图实际上是由这些多个 url 元素组成的。
所以我们可以填写对应的
不仅可以在这里使用站点的路径,而且在这里这样做更方便。另外,这个站点地图一天最多只能推送十次。
手动提交

也就是提交你网站上写的文章的链接,也就是把sitemap.xml内容中的url链接一个一个提交,这个方法可以保证你的一个文章可以很好收录(不一定,还是看百度吧),自己决定
百度站长其他工具
喜欢什么移动适配,死链接提交可以自己看懂,什么都写清楚了哈哈
插件介绍功能使用
很简单,直接填一个api,发布的时候会自动提交类似这个api的更新文章
机器人文件
使用爬虫的人应该对此非常熟悉。简而言之,是爬虫的“君子协定”。虽然我们平时不遵守君子协定,但百度、搜狗、谷歌等大搜索引擎还是会遵守的。是的,这个约束只是对它们的约束。哈哈,由于这个插件没有自动生成robots.txt的功能,所以需要我们自己创建。方法也很简单。步骤如下
创建一个名为 robots.txt 的新文件
输入内容
User-agent: *
Allow: /
Disallow: /admin/
Disallow: /install/
Sitemap: https://你的网站地址/sitemap.xml
这个语法很简单,可以根据自己网站的需要进行修改
保存并上传文件到 网站 根目录
最后,访问自己 网站 进行验证

好的,你完成了
查看您的网站是否被 收录 阻止
最常用的方法是在搜索引擎上搜索您的一篇文章文章。如果你找到了,说明你已经收录
这里推荐一个查看你整个站点的收录情况的方法(使用搜索语法site:xxx),具体示例如下
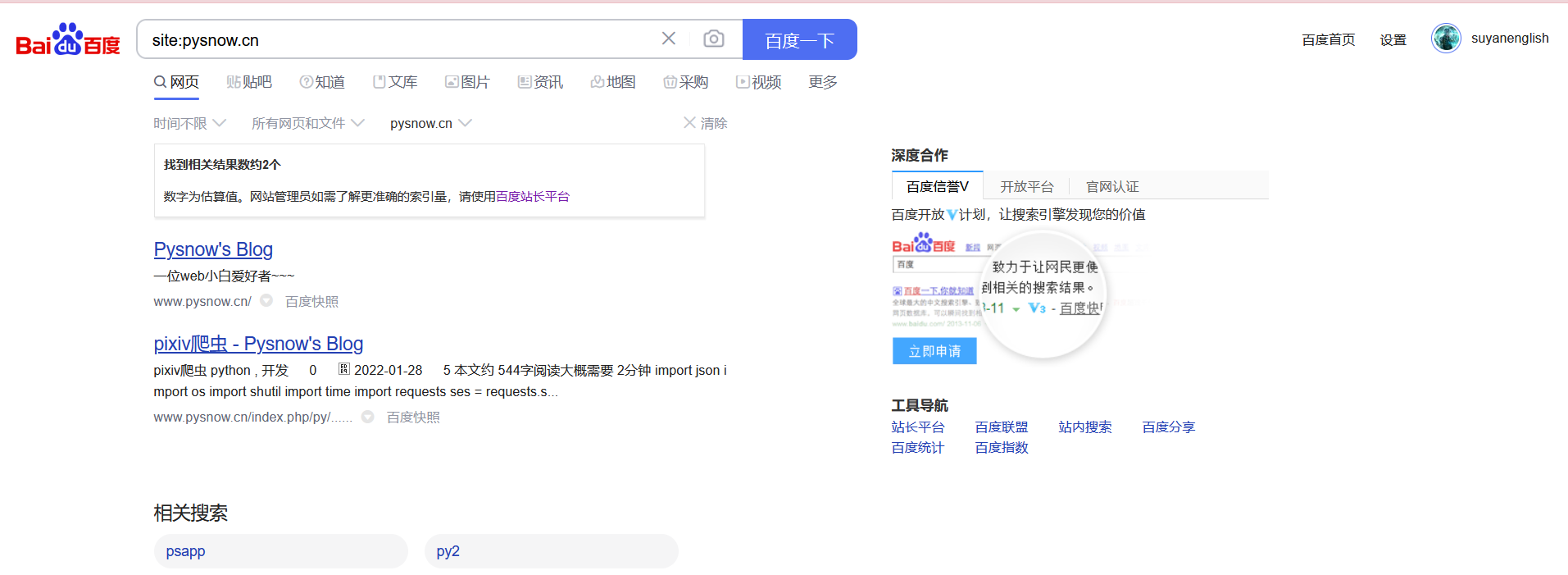
可以看到百度收录已经添加了我以前的站点,所以这里有一点你可以知道的是,百度收录并不是你提交资源后就可以立即更新的东西,他会是定期更新,可能是一周或一个月(废话)
总结
其实搜索引擎的收录只需要提交一个链接,搜索引擎就会自动抓取你的链接。这个插件自动生成sitemap.xml文件,可以很方便的让其他搜索引擎收录,所以一个sitemap插件就够了。下面我将给出各大搜索引擎站长的网站地址。你可以直接写你的网站地址,让他们自己爬。, 收录不会马上成功的。这主要取决于不同的搜索引擎,以及您网站的各种结果,其中涉及到 SEO 问题。我对此一无所知。问运维老板。. 最后,祝你折腾网站开心!
文章采集api(如何用R调用API,提取和整理你需要的免费Web数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2022-02-27 00:28
API是获取Web数据的重要方式之一。想了解如何使用 R 调用 API 来提取和组织您需要的免费 Web 数据吗?本文将逐步向您展示操作过程。
交易
俗话说,“聪明的女人,没有饭难煮”。就算你掌握了数据分析十八门武功,没有数据也是一件麻烦的事情。“拔刀而去,茫然不知所措”,大概就是这样。
有很多数据来源。Web 数据是数量庞大且相对容易获取的类型之一。更好的是,很多网络数据都是免费的。
在这个所谓的大数据时代,如何获取网络数据?
许多人使用由他人编译和发布的数据集。
他们很幸运,他们的工作可以建立在其他人的基础上。这是最有效的。
但并不是每个人都这么幸运。如果您需要的数据从未被组织和发布过怎么办?
事实上,这样的数据量更大。我们是否对他们视而不见?
如果您考虑爬行动物,那么您的想法是正确的。爬虫可以为您获取几乎所有可见(甚至不可见)的网络数据。然而,编写和使用爬虫的成本很高。包括时间资源、技术能力等。如果你遇到任何网络数据获取问题,你不要想“大锤”,有时可能是“刀枪不入”。
在“别人准备的数据”和“需要自己爬取的数据”之间,还有一个广阔的领域,这就是API的世界。
什么是 API?
它是应用程序编程接口的缩写。具体来说,某个网站的数据在不断的积累和变化。如果对这些数据进行整理,不仅费时,而且占用空间,而且还有刚整理完就过时的危险。大多数人需要的数据其实只是其中的一小部分,但时效性要求可能非常强。因此,组织存储并将其提供给公众以供下载是不经济的。
但是,如果数据不能以某种方式打通,就会面临无数爬虫的骚扰。这会对网站的正常运行造成很大的困扰。折衷方案是 网站 主动提供通道。当你需要某部分数据时,虽然没有现成的数据集,但你只需要用这个通道描述你想要的数据,然后网站审核后(一般是自动化的,瞬间完成),认为我可以给你,我会立即发送你明确要求的数据。双方都很高兴。
以后在找数据的时候,不妨看看目标网站有没有提供API,避免无用的努力。
在这个github项目中,有一个非常详细的列表,涵盖了当前常见的主流网站API资源状况。作者还在整理和修改中,大家可以采集起来慢慢看。
如果我们知道某个网站提供了API,通过查看文档知道我们需要的数据在那里,那么问题就变成了——如何通过API获取数据?
下面我们用一个实际的例子来向您展示整个操作步骤。
资源
我们正在寻找的例子是维基百科。
有关 Wikipedia API 的概述,请参阅此页面。
假设我们关心特定时间段内对指定维基百科 文章 页面的访问次数。
维基百科为我们提供了一种称为指标的数据,它涵盖了页面访问的关键价值。对应API的介绍页面在这里。
页面上有一个示例。假设需要获取2015年10月爱因斯坦入口页面的访问次数,可以这样调用:
GET http://wikimedia.org/api/rest_ ... %3Bbr style="box-sizing:border-box;margin:0px;padding:0px;" />
我们可以在浏览器的地址栏中输入GET后的一长串URL,然后回车看看我们得到了什么结果。
在浏览器中,我们看到了上图中的一长串文字。您可能想知道 - 这是什么?
恭喜,这是我们需要得到的数据。但是,它使用一种称为 JSON 的特殊数据格式。
JSON是互联网上数据交互的主流格式之一。如果你想了解 JSON 的含义和用法,可以参考这篇教程。
在浏览器中,我们最初只能看到数据的第一部分。但它已经收录了有价值的内容:
{"items":[{"project":"en.wikipedia","article":"Albert_Einstein","granularity":"daily","timestamp":"2015100100","access":"all-access","agent":"all-agents","views":18860}<br style="box-sizing:border-box;margin:0px;padding:0px;" />
在本段中,我们看到项目名称(en.wikipedia)、文章 标题(Albert Einstein)、统计粒度(天)、时间戳(10/1/2015)、访问类型(全部)、终端类型(全部) 和访问次数 (18860).
我们使用滑块将返回的文本拖到最后,我们会看到如下信息:
{"project":"en.wikipedia","article":"Albert_Einstein","granularity":"daily","timestamp":"2015103100","access":"all-access","agent":"all-agents","views":16380}]}<br style="box-sizing:border-box;margin:0px;padding:0px;" />
与 10 月 1 日的数据相比,只有时间戳(2015 年 10 月 31 日)和访问次数(16380))发生了变化。
在中间,我们跳过了 10 月 2 日至 10 月 30 日之间的数据。存储格式相同,只是日期和访问次数的数据值在变化。
您需要的所有数据都在这里,您只需提取相应的信息即可。但是如果手动进行(比如将需要的项目复制粘贴到Excel中),显然效率低下,容易出错。让我们展示如何使用 R 编程环境自动化这个过程。
准备
在正式用 R 调用 API 之前,我们需要做一些必要的准备工作。
首先是安装R。
请到本网站下载R基础安装包。
R的下载位置比较多,建议选择清华镜像,下载速度比较快。
请根据您的操作系统平台选择对应的版本进行下载。我正在使用 macOS 版本。
下载 pkg 文件。双击安装。
安装完基础包后,我们继续安装集成开发环境RStudio。它可以帮助您轻松和交互式地与 R 进行交流。RStudio的下载地址在这里。
根据你的操作系统,选择对应的安装包。macOS 安装包是一个 dmg 文件。双击打开后,将RStudio.app图标拖到Applications文件夹下,安装完成。
下面我们双击从应用程序目录运行RStudio。
我们先在 RStudio 的 Console 中运行以下语句来安装一些需要的包:
install.packages("tidyverse")<br style="box-sizing:border-box;margin:0px;padding:0px;" />install.packages("rlist")<br style="box-sizing:border-box;margin:0px;padding:0px;" />
安装完成后,在菜单中选择File->New,在如下界面中选择R Notebook。
R Notebook 默认为我们提供了一个带有一些基本使用说明的模板。
让我们尝试在编辑区域(左)的代码部分(灰色)中单击运行按钮。
情节的结果可以立即看到。
我们点击菜单栏上的Preview按钮来查看整个代码的效果。操作的结果将以带有图片和文本的 HTML 文件的形式显示。
现在我们已经熟悉了环境,是时候实际运行我们的代码了。我们把编辑区的开头描述区保留在左边,删除其余的,把文件名改成有意义的web-data-api-with-R。
至此,准备工作就绪。现在我们要开始实际操作了。
操作
在实际操作过程中,我们以维基百科的另一个wiki文章为例来证明这种操作方法的通用性。选中的文章就是我们介绍词云制作时使用的那个,叫做“Yes, Minisiter”。这是一部 1980 年代的英国喜剧。
我们先在浏览器中试一下,看看能否修改 API 示例中的参数,获取“是,部长”文章 的访问统计信息。作为测试,我们仅采集 2017 年 10 月 1 日至 2017 年 10 月 3 日 3 天的数据。
与示例相反,我们需要替换的内容包括开始和结束时间以及 文章 标题。
我们在浏览器的地址栏中输入:
https://wikimedia.org/api/rest ... %3Bbr style="box-sizing:border-box;margin:0px;padding:0px;" />
返回结果如下:
数据可以正常返回。接下来,我们使用语句方法在 RStudio 中调用。
请注意,在下面的代码中,程序的输出部分会在开头带有## 标记,以区别于执行代码本身。
启动后,我们需要设置时区。否则,您稍后在处理时间数据时会遇到错误。
Sys.setenv(TZ="Asia/Shanghai")<br style="box-sizing:border-box;margin:0px;padding:0px;" />
然后,我们调用 tidyverse 包,它是一个可以同时加载许多函数的集合,我们稍后会用到。
library(tidyverse)<br style="box-sizing:border-box;margin:0px;padding:0px;" /><br style="box-sizing:border-box;margin:0px;padding:0px;" />## Loading tidyverse: ggplot2<br style="box-sizing:border-box;margin:0px;padding:0px;" />## Loading tidyverse: tibble<br style="box-sizing:border-box;margin:0px;padding:0px;" />## Loading tidyverse: tidyr<br style="box-sizing:border-box;margin:0px;padding:0px;" />## Loading tidyverse: readr<br style="box-sizing:border-box;margin:0px;padding:0px;" />## Loading tidyverse: purrr<br style="box-sizing:border-box;margin:0px;padding:0px;" />## Loading tidyverse: dplyr<br style="box-sizing:border-box;margin:0px;padding:0px;" /><br style="box-sizing:border-box;margin:0px;padding:0px;" />## Conflicts with tidy packages ----------------------------------------------<br style="box-sizing:border-box;margin:0px;padding:0px;" /><br style="box-sizing:border-box;margin:0px;padding:0px;" />## filter(): dplyr, stats<br style="box-sizing:border-box;margin:0px;padding:0px;" />## lag(): dplyr, stats<br style="box-sizing:border-box;margin:0px;padding:0px;" />
这里可能有一些警告,请忽略它们。它对我们的运营没有影响。
根据前面的例子,我们定义要查询的时间跨度,并指定要查找的wiki文章的名称。
请注意,与 Python 不同,在 R 中,赋值采用标记,而不是 =。不过,R 语言其实很容易上手。如果你坚持使用=,它也能识别,不会报错。
<p>starting 查看全部
文章采集api(如何用R调用API,提取和整理你需要的免费Web数据)
API是获取Web数据的重要方式之一。想了解如何使用 R 调用 API 来提取和组织您需要的免费 Web 数据吗?本文将逐步向您展示操作过程。

交易
俗话说,“聪明的女人,没有饭难煮”。就算你掌握了数据分析十八门武功,没有数据也是一件麻烦的事情。“拔刀而去,茫然不知所措”,大概就是这样。
有很多数据来源。Web 数据是数量庞大且相对容易获取的类型之一。更好的是,很多网络数据都是免费的。
在这个所谓的大数据时代,如何获取网络数据?
许多人使用由他人编译和发布的数据集。
他们很幸运,他们的工作可以建立在其他人的基础上。这是最有效的。
但并不是每个人都这么幸运。如果您需要的数据从未被组织和发布过怎么办?
事实上,这样的数据量更大。我们是否对他们视而不见?
如果您考虑爬行动物,那么您的想法是正确的。爬虫可以为您获取几乎所有可见(甚至不可见)的网络数据。然而,编写和使用爬虫的成本很高。包括时间资源、技术能力等。如果你遇到任何网络数据获取问题,你不要想“大锤”,有时可能是“刀枪不入”。
在“别人准备的数据”和“需要自己爬取的数据”之间,还有一个广阔的领域,这就是API的世界。
什么是 API?
它是应用程序编程接口的缩写。具体来说,某个网站的数据在不断的积累和变化。如果对这些数据进行整理,不仅费时,而且占用空间,而且还有刚整理完就过时的危险。大多数人需要的数据其实只是其中的一小部分,但时效性要求可能非常强。因此,组织存储并将其提供给公众以供下载是不经济的。
但是,如果数据不能以某种方式打通,就会面临无数爬虫的骚扰。这会对网站的正常运行造成很大的困扰。折衷方案是 网站 主动提供通道。当你需要某部分数据时,虽然没有现成的数据集,但你只需要用这个通道描述你想要的数据,然后网站审核后(一般是自动化的,瞬间完成),认为我可以给你,我会立即发送你明确要求的数据。双方都很高兴。
以后在找数据的时候,不妨看看目标网站有没有提供API,避免无用的努力。
在这个github项目中,有一个非常详细的列表,涵盖了当前常见的主流网站API资源状况。作者还在整理和修改中,大家可以采集起来慢慢看。

如果我们知道某个网站提供了API,通过查看文档知道我们需要的数据在那里,那么问题就变成了——如何通过API获取数据?
下面我们用一个实际的例子来向您展示整个操作步骤。
资源
我们正在寻找的例子是维基百科。
有关 Wikipedia API 的概述,请参阅此页面。

假设我们关心特定时间段内对指定维基百科 文章 页面的访问次数。
维基百科为我们提供了一种称为指标的数据,它涵盖了页面访问的关键价值。对应API的介绍页面在这里。

页面上有一个示例。假设需要获取2015年10月爱因斯坦入口页面的访问次数,可以这样调用:
GET http://wikimedia.org/api/rest_ ... %3Bbr style="box-sizing:border-box;margin:0px;padding:0px;" />
我们可以在浏览器的地址栏中输入GET后的一长串URL,然后回车看看我们得到了什么结果。

在浏览器中,我们看到了上图中的一长串文字。您可能想知道 - 这是什么?
恭喜,这是我们需要得到的数据。但是,它使用一种称为 JSON 的特殊数据格式。
JSON是互联网上数据交互的主流格式之一。如果你想了解 JSON 的含义和用法,可以参考这篇教程。
在浏览器中,我们最初只能看到数据的第一部分。但它已经收录了有价值的内容:
{"items":[{"project":"en.wikipedia","article":"Albert_Einstein","granularity":"daily","timestamp":"2015100100","access":"all-access","agent":"all-agents","views":18860}<br style="box-sizing:border-box;margin:0px;padding:0px;" />
在本段中,我们看到项目名称(en.wikipedia)、文章 标题(Albert Einstein)、统计粒度(天)、时间戳(10/1/2015)、访问类型(全部)、终端类型(全部) 和访问次数 (18860).
我们使用滑块将返回的文本拖到最后,我们会看到如下信息:
{"project":"en.wikipedia","article":"Albert_Einstein","granularity":"daily","timestamp":"2015103100","access":"all-access","agent":"all-agents","views":16380}]}<br style="box-sizing:border-box;margin:0px;padding:0px;" />
与 10 月 1 日的数据相比,只有时间戳(2015 年 10 月 31 日)和访问次数(16380))发生了变化。
在中间,我们跳过了 10 月 2 日至 10 月 30 日之间的数据。存储格式相同,只是日期和访问次数的数据值在变化。
您需要的所有数据都在这里,您只需提取相应的信息即可。但是如果手动进行(比如将需要的项目复制粘贴到Excel中),显然效率低下,容易出错。让我们展示如何使用 R 编程环境自动化这个过程。
准备
在正式用 R 调用 API 之前,我们需要做一些必要的准备工作。
首先是安装R。
请到本网站下载R基础安装包。

R的下载位置比较多,建议选择清华镜像,下载速度比较快。

请根据您的操作系统平台选择对应的版本进行下载。我正在使用 macOS 版本。
下载 pkg 文件。双击安装。
安装完基础包后,我们继续安装集成开发环境RStudio。它可以帮助您轻松和交互式地与 R 进行交流。RStudio的下载地址在这里。

根据你的操作系统,选择对应的安装包。macOS 安装包是一个 dmg 文件。双击打开后,将RStudio.app图标拖到Applications文件夹下,安装完成。

下面我们双击从应用程序目录运行RStudio。

我们先在 RStudio 的 Console 中运行以下语句来安装一些需要的包:
install.packages("tidyverse")<br style="box-sizing:border-box;margin:0px;padding:0px;" />install.packages("rlist")<br style="box-sizing:border-box;margin:0px;padding:0px;" />
安装完成后,在菜单中选择File->New,在如下界面中选择R Notebook。

R Notebook 默认为我们提供了一个带有一些基本使用说明的模板。

让我们尝试在编辑区域(左)的代码部分(灰色)中单击运行按钮。

情节的结果可以立即看到。
我们点击菜单栏上的Preview按钮来查看整个代码的效果。操作的结果将以带有图片和文本的 HTML 文件的形式显示。

现在我们已经熟悉了环境,是时候实际运行我们的代码了。我们把编辑区的开头描述区保留在左边,删除其余的,把文件名改成有意义的web-data-api-with-R。

至此,准备工作就绪。现在我们要开始实际操作了。
操作
在实际操作过程中,我们以维基百科的另一个wiki文章为例来证明这种操作方法的通用性。选中的文章就是我们介绍词云制作时使用的那个,叫做“Yes, Minisiter”。这是一部 1980 年代的英国喜剧。

我们先在浏览器中试一下,看看能否修改 API 示例中的参数,获取“是,部长”文章 的访问统计信息。作为测试,我们仅采集 2017 年 10 月 1 日至 2017 年 10 月 3 日 3 天的数据。
与示例相反,我们需要替换的内容包括开始和结束时间以及 文章 标题。
我们在浏览器的地址栏中输入:
https://wikimedia.org/api/rest ... %3Bbr style="box-sizing:border-box;margin:0px;padding:0px;" />
返回结果如下:

数据可以正常返回。接下来,我们使用语句方法在 RStudio 中调用。
请注意,在下面的代码中,程序的输出部分会在开头带有## 标记,以区别于执行代码本身。
启动后,我们需要设置时区。否则,您稍后在处理时间数据时会遇到错误。
Sys.setenv(TZ="Asia/Shanghai")<br style="box-sizing:border-box;margin:0px;padding:0px;" />
然后,我们调用 tidyverse 包,它是一个可以同时加载许多函数的集合,我们稍后会用到。
library(tidyverse)<br style="box-sizing:border-box;margin:0px;padding:0px;" /><br style="box-sizing:border-box;margin:0px;padding:0px;" />## Loading tidyverse: ggplot2<br style="box-sizing:border-box;margin:0px;padding:0px;" />## Loading tidyverse: tibble<br style="box-sizing:border-box;margin:0px;padding:0px;" />## Loading tidyverse: tidyr<br style="box-sizing:border-box;margin:0px;padding:0px;" />## Loading tidyverse: readr<br style="box-sizing:border-box;margin:0px;padding:0px;" />## Loading tidyverse: purrr<br style="box-sizing:border-box;margin:0px;padding:0px;" />## Loading tidyverse: dplyr<br style="box-sizing:border-box;margin:0px;padding:0px;" /><br style="box-sizing:border-box;margin:0px;padding:0px;" />## Conflicts with tidy packages ----------------------------------------------<br style="box-sizing:border-box;margin:0px;padding:0px;" /><br style="box-sizing:border-box;margin:0px;padding:0px;" />## filter(): dplyr, stats<br style="box-sizing:border-box;margin:0px;padding:0px;" />## lag(): dplyr, stats<br style="box-sizing:border-box;margin:0px;padding:0px;" />
这里可能有一些警告,请忽略它们。它对我们的运营没有影响。
根据前面的例子,我们定义要查询的时间跨度,并指定要查找的wiki文章的名称。
请注意,与 Python 不同,在 R 中,赋值采用标记,而不是 =。不过,R 语言其实很容易上手。如果你坚持使用=,它也能识别,不会报错。
<p>starting
文章采集api(在之前的文章中Python实现“维基百科六度分隔理论”)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-02-24 21:13
在之前的文章 Python实现“维基百科六度分离理论”基础爬虫中,我们实现了一个网站随机从一个链接到另一个链接,但是如果我们需要系统对整个< @网站 分类,或者要搜索 网站 上的每一页,我们该怎么办?我们需要采集整个网站,但这是一个非常占用内存的过程,尤其是在处理大的网站时,更合适的工具是使用数据库来存储< @k11 资源为@>,之前也说过。这是如何做到的。网站地图站点地图网站地图,也称为站点地图,是一个页面,上面放置了网站上所有需要被搜索引擎抓取的页面(注:不是所有页面,所有 文章 链接。大多数人在 网站 上找不到所需信息时,可能会求助于 网站 地图。搜索引擎蜘蛛我非常喜欢 网站maps。对于 SEO,网站maps 的好处: 1. 为搜索引擎蜘蛛提供可以浏览整个 网站 的链接,简单地反映 网站 的整体框架 2. 为搜索引擎提供一些链接蜘蛛指向动态页面或其他方法更难访问的页面;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。当他们在 网站 上找不到他们需要的信息时,地图作为一种补救措施。搜索引擎蜘蛛我非常喜欢 网站maps。对于 SEO,网站maps 的好处: 1. 为搜索引擎蜘蛛提供可以浏览整个 网站 的链接,简单地反映 网站 的整体框架 2. 为搜索引擎提供一些链接蜘蛛指向动态页面或其他方法更难访问的页面;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。当他们在 网站 上找不到他们需要的信息时,地图作为一种补救措施。搜索引擎蜘蛛我非常喜欢 网站maps。对于 SEO,网站maps 的好处: 1. 为搜索引擎蜘蛛提供可以浏览整个 网站 的链接,简单地反映 网站 的整体框架 2. 为搜索引擎提供一些链接蜘蛛指向动态页面或其他方法更难访问的页面;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。@网站。搜索引擎蜘蛛我非常喜欢 网站maps。对于 SEO,网站maps 的好处: 1. 为搜索引擎蜘蛛提供可以浏览整个 网站 的链接,简单地反映 网站 的整体框架 2. 为搜索引擎提供一些链接蜘蛛指向动态页面或其他方法更难访问的页面;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。@网站。搜索引擎蜘蛛我非常喜欢 网站maps。对于 SEO,网站maps 的好处: 1. 为搜索引擎蜘蛛提供可以浏览整个 网站 的链接,简单地反映 网站 的整体框架 2. 为搜索引擎提供一些链接蜘蛛指向动态页面或其他方法更难访问的页面;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。为搜索引擎蜘蛛提供可以浏览整个网站的链接,简单反映网站的整体框架 2. 为搜索引擎蜘蛛提供一些链接,指向动态页面或更难到达的页面其他方法;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。为搜索引擎蜘蛛提供可以浏览整个网站的链接,简单反映网站的整体框架 2. 为搜索引擎蜘蛛提供一些链接,指向动态页面或更难到达的页面其他方法;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。作为一个潜在的着陆页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。作为一个潜在的着陆页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。
数据采集采集网站数据不难,但需要爬虫有足够的深度。我们创建了一个爬虫,它递归地遍历每个 网站 并且只采集那些 网站 页面上的数据。通常耗时的 网站采集 方法从顶层页面(通常是 网站 主页)开始,然后搜索页面上的所有链接,形成一个列表,然后去到采集到这些链接的页面,继续采集到每个页面的链接形成一个新列表,重复执行。显然,这是一个复杂性迅速增长的过程。每页添加 10 个链接,在 网站 上添加 5 个页面深度。如果采集 整个网站,则采集 页的总数为105,即100,000 页。因为很多网站的内部链接都是重复的,为了避免重复的采集,需要链接和去重。在 Python 中,最常用的去重方法是使用内置的集合采集方法。只有“新”链接是 采集。看一下代码示例: from urllib.request import urlopenfrom bs4 import BeautifulSoup import repages = set()def getLinks(pageurl):globalpageshtml= urlopen("" + pageurl)soup= BeautifulSoup(html)forlink in soup.findAll( "a", href=pile("^(/wiki/)")):if'href' in link.attrs:iflink.attrs['href'] not in pages:#这是一个新页面 newPage= 链接。属性[' @采集。看一下代码示例: from urllib.request import urlopenfrom bs4 import BeautifulSoup import repages = set()def getLinks(pageurl):globalpageshtml= urlopen("" + pageurl)soup= BeautifulSoup(html)forlink in soup.findAll( "a", href=pile("^(/wiki/)")):if'href' in link.attrs:iflink.attrs['href'] not in pages:#这是一个新页面 newPage= 链接。属性[' @采集。看一下代码示例: from urllib.request import urlopenfrom bs4 import BeautifulSoup import repages = set()def getLinks(pageurl):globalpageshtml= urlopen("" + pageurl)soup= BeautifulSoup(html)forlink in soup.findAll( "a", href=pile("^(/wiki/)")):if'href' in link.attrs:iflink.attrs['href'] not in pages:#这是一个新页面 newPage= 链接。属性['
递归警告:Python 的默认递归*为 1000 次,因为维基百科的链接太多,所以程序在达到递归*时停止。如果你不想让它停止,你可以设置一个递归计数器或其他东西。采集整个网站数据为了有效地使用爬虫,我们在使用爬虫时需要在页面上做一些事情。让我们创建一个爬虫来采集有关页面标题、正文第一段和编辑页面的链接(如果有的话)的信息。第一步,我们需要在网站上观察页面,然后制定采集模式,通过F12(一般情况下)检查元素,就可以看到页面的构成了。查看维基百科页面,包括入口和非入口页面,例如隐私政策页面,可以得出以下规则:所有标题都在h1→span标签中,页面上只有一个h1标签。所有正文都在 div#bodyContent 标记中。如果要获取第一段文字,可以使用div#mw-content-text→p。此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href' 并且页面上只有一个 h1 标签。所有正文都在 div#bodyContent 标记中。如果要获取第一段文字,可以使用div#mw-content-text→p。此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href' 并且页面上只有一个 h1 标签。所有正文都在 div#bodyContent 标记中。如果要获取第一段文字,可以使用div#mw-content-text→p。此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href' 所有正文都在 div#bodyContent 标记中。如果要获取第一段文字,可以使用div#mw-content-text→p。此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href' 所有正文都在 div#bodyContent 标记中。如果要获取第一段文字,可以使用div#mw-content-text→p。此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href' 此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href' 此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href'
<p>在数据存储到 MySQL 之前,数据已经被获取。直接打印出来比较麻烦,所以我们可以直接存入MySQL。这里只存储链接是没有意义的,所以我们存储页面的标题和内容。我之前有两篇文章 文章 介绍了如何在 MySQL 中存储数据。数据表为pages,代码如下: import reimport datetimeimport randomimport pymysqlconn = pymysql.connect(host = '127.< @0. 查看全部
文章采集api(在之前的文章中Python实现“维基百科六度分隔理论”)
在之前的文章 Python实现“维基百科六度分离理论”基础爬虫中,我们实现了一个网站随机从一个链接到另一个链接,但是如果我们需要系统对整个< @网站 分类,或者要搜索 网站 上的每一页,我们该怎么办?我们需要采集整个网站,但这是一个非常占用内存的过程,尤其是在处理大的网站时,更合适的工具是使用数据库来存储< @k11 资源为@>,之前也说过。这是如何做到的。网站地图站点地图网站地图,也称为站点地图,是一个页面,上面放置了网站上所有需要被搜索引擎抓取的页面(注:不是所有页面,所有 文章 链接。大多数人在 网站 上找不到所需信息时,可能会求助于 网站 地图。搜索引擎蜘蛛我非常喜欢 网站maps。对于 SEO,网站maps 的好处: 1. 为搜索引擎蜘蛛提供可以浏览整个 网站 的链接,简单地反映 网站 的整体框架 2. 为搜索引擎提供一些链接蜘蛛指向动态页面或其他方法更难访问的页面;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。当他们在 网站 上找不到他们需要的信息时,地图作为一种补救措施。搜索引擎蜘蛛我非常喜欢 网站maps。对于 SEO,网站maps 的好处: 1. 为搜索引擎蜘蛛提供可以浏览整个 网站 的链接,简单地反映 网站 的整体框架 2. 为搜索引擎提供一些链接蜘蛛指向动态页面或其他方法更难访问的页面;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。当他们在 网站 上找不到他们需要的信息时,地图作为一种补救措施。搜索引擎蜘蛛我非常喜欢 网站maps。对于 SEO,网站maps 的好处: 1. 为搜索引擎蜘蛛提供可以浏览整个 网站 的链接,简单地反映 网站 的整体框架 2. 为搜索引擎提供一些链接蜘蛛指向动态页面或其他方法更难访问的页面;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。@网站。搜索引擎蜘蛛我非常喜欢 网站maps。对于 SEO,网站maps 的好处: 1. 为搜索引擎蜘蛛提供可以浏览整个 网站 的链接,简单地反映 网站 的整体框架 2. 为搜索引擎提供一些链接蜘蛛指向动态页面或其他方法更难访问的页面;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。@网站。搜索引擎蜘蛛我非常喜欢 网站maps。对于 SEO,网站maps 的好处: 1. 为搜索引擎蜘蛛提供可以浏览整个 网站 的链接,简单地反映 网站 的整体框架 2. 为搜索引擎提供一些链接蜘蛛指向动态页面或其他方法更难访问的页面;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。为搜索引擎蜘蛛提供可以浏览整个网站的链接,简单反映网站的整体框架 2. 为搜索引擎蜘蛛提供一些链接,指向动态页面或更难到达的页面其他方法;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。为搜索引擎蜘蛛提供可以浏览整个网站的链接,简单反映网站的整体框架 2. 为搜索引擎蜘蛛提供一些链接,指向动态页面或更难到达的页面其他方法;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。作为一个潜在的着陆页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。作为一个潜在的着陆页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。
数据采集采集网站数据不难,但需要爬虫有足够的深度。我们创建了一个爬虫,它递归地遍历每个 网站 并且只采集那些 网站 页面上的数据。通常耗时的 网站采集 方法从顶层页面(通常是 网站 主页)开始,然后搜索页面上的所有链接,形成一个列表,然后去到采集到这些链接的页面,继续采集到每个页面的链接形成一个新列表,重复执行。显然,这是一个复杂性迅速增长的过程。每页添加 10 个链接,在 网站 上添加 5 个页面深度。如果采集 整个网站,则采集 页的总数为105,即100,000 页。因为很多网站的内部链接都是重复的,为了避免重复的采集,需要链接和去重。在 Python 中,最常用的去重方法是使用内置的集合采集方法。只有“新”链接是 采集。看一下代码示例: from urllib.request import urlopenfrom bs4 import BeautifulSoup import repages = set()def getLinks(pageurl):globalpageshtml= urlopen("" + pageurl)soup= BeautifulSoup(html)forlink in soup.findAll( "a", href=pile("^(/wiki/)")):if'href' in link.attrs:iflink.attrs['href'] not in pages:#这是一个新页面 newPage= 链接。属性[' @采集。看一下代码示例: from urllib.request import urlopenfrom bs4 import BeautifulSoup import repages = set()def getLinks(pageurl):globalpageshtml= urlopen("" + pageurl)soup= BeautifulSoup(html)forlink in soup.findAll( "a", href=pile("^(/wiki/)")):if'href' in link.attrs:iflink.attrs['href'] not in pages:#这是一个新页面 newPage= 链接。属性[' @采集。看一下代码示例: from urllib.request import urlopenfrom bs4 import BeautifulSoup import repages = set()def getLinks(pageurl):globalpageshtml= urlopen("" + pageurl)soup= BeautifulSoup(html)forlink in soup.findAll( "a", href=pile("^(/wiki/)")):if'href' in link.attrs:iflink.attrs['href'] not in pages:#这是一个新页面 newPage= 链接。属性['
递归警告:Python 的默认递归*为 1000 次,因为维基百科的链接太多,所以程序在达到递归*时停止。如果你不想让它停止,你可以设置一个递归计数器或其他东西。采集整个网站数据为了有效地使用爬虫,我们在使用爬虫时需要在页面上做一些事情。让我们创建一个爬虫来采集有关页面标题、正文第一段和编辑页面的链接(如果有的话)的信息。第一步,我们需要在网站上观察页面,然后制定采集模式,通过F12(一般情况下)检查元素,就可以看到页面的构成了。查看维基百科页面,包括入口和非入口页面,例如隐私政策页面,可以得出以下规则:所有标题都在h1→span标签中,页面上只有一个h1标签。所有正文都在 div#bodyContent 标记中。如果要获取第一段文字,可以使用div#mw-content-text→p。此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href' 并且页面上只有一个 h1 标签。所有正文都在 div#bodyContent 标记中。如果要获取第一段文字,可以使用div#mw-content-text→p。此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href' 并且页面上只有一个 h1 标签。所有正文都在 div#bodyContent 标记中。如果要获取第一段文字,可以使用div#mw-content-text→p。此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href' 所有正文都在 div#bodyContent 标记中。如果要获取第一段文字,可以使用div#mw-content-text→p。此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href' 所有正文都在 div#bodyContent 标记中。如果要获取第一段文字,可以使用div#mw-content-text→p。此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href' 此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href' 此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href'
<p>在数据存储到 MySQL 之前,数据已经被获取。直接打印出来比较麻烦,所以我们可以直接存入MySQL。这里只存储链接是没有意义的,所以我们存储页面的标题和内容。我之前有两篇文章 文章 介绍了如何在 MySQL 中存储数据。数据表为pages,代码如下: import reimport datetimeimport randomimport pymysqlconn = pymysql.connect(host = '127.< @0.
文章采集api(大数据搜集体系有哪些分类?搜集日志数据分类)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-02-24 21:11
【摘要】大数据采集技术对数据进行ETL运算,提取、转换、加载数据,最终挖掘数据的潜在价值,进而为用户提供解决方案或决策参考。那么,大数据采集系统的分类有哪些呢?今天就和小编一起来了解一下吧!
1、系统日志采集系统
采集和采集日志数据信息,然后进行数据分析,挖掘日志数据在公司交易渠道中的潜在价值。总之,采集日志数据提供了离线和在线的实时分析应用。目前常用的开源日志采集系统是 Flume。
2、网络数据采集系统
通过网络爬虫和一些网站渠道提供的公共API(如推特和新浪微博API)从网站获取数据。它可以从网页中提取非结构化数据和半结构化数据的网页数据,提取、清洗并转换为结构化数据,并存储为一致的本地文件数据。
目前常用的网络爬虫系统包括Apache Nutch、Crawler4j、Scrapy等结构。
3、数据库采集系统
数据库采集系统直接与企业事务后台服务器结合后,在企业事务后台每时每刻都将大量事务记录写入数据库,最终由特定的处理系统对系统进行分析。
目前,存储数据常用MySQL、Oracle等关系型数据库,采集数据也常用Redis、MongoDB等NoSQL数据库。
关于大数据采集系统的分类,青腾小编就在这里跟大家分享一下。如果你对大数据工程有浓厚的兴趣,希望这篇文章可以帮助到你。如果想了解更多数据分析师和大数据工程师的技能和资料,可以点击本站其他文章进行学习。 查看全部
文章采集api(大数据搜集体系有哪些分类?搜集日志数据分类)
【摘要】大数据采集技术对数据进行ETL运算,提取、转换、加载数据,最终挖掘数据的潜在价值,进而为用户提供解决方案或决策参考。那么,大数据采集系统的分类有哪些呢?今天就和小编一起来了解一下吧!

1、系统日志采集系统
采集和采集日志数据信息,然后进行数据分析,挖掘日志数据在公司交易渠道中的潜在价值。总之,采集日志数据提供了离线和在线的实时分析应用。目前常用的开源日志采集系统是 Flume。
2、网络数据采集系统
通过网络爬虫和一些网站渠道提供的公共API(如推特和新浪微博API)从网站获取数据。它可以从网页中提取非结构化数据和半结构化数据的网页数据,提取、清洗并转换为结构化数据,并存储为一致的本地文件数据。
目前常用的网络爬虫系统包括Apache Nutch、Crawler4j、Scrapy等结构。
3、数据库采集系统
数据库采集系统直接与企业事务后台服务器结合后,在企业事务后台每时每刻都将大量事务记录写入数据库,最终由特定的处理系统对系统进行分析。
目前,存储数据常用MySQL、Oracle等关系型数据库,采集数据也常用Redis、MongoDB等NoSQL数据库。
关于大数据采集系统的分类,青腾小编就在这里跟大家分享一下。如果你对大数据工程有浓厚的兴趣,希望这篇文章可以帮助到你。如果想了解更多数据分析师和大数据工程师的技能和资料,可以点击本站其他文章进行学习。
文章采集api(Scrapy一个 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2022-02-23 07:17
)
内容
架构介绍
Scrapy 是一个开源和协作框架,最初是为页面抓取(更准确地说是网页抓取)而设计的,它允许您以快速、简单和可扩展的方式从所需数据中提取所有信息。但目前,Scrapy 的用途非常广泛,例如数据挖掘、监控和自动化测试,也可以用来获取 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
Scrapy 是基于 twisted 框架开发的,这是一个流行的事件驱动的 Python 网络框架。所以 Scrapy 使用非阻塞(又名异步)代码来实现并发。整体结构大致如下
IO多路复用
# 引擎(EGINE)(大总管)
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。有关详细信息,请参见上面的数据流部分。
# 调度器(SCHEDULER)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
# 下载器(DOWLOADER)
用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的
# 爬虫(SPIDERS)
SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求
# 项目管道(ITEM PIPLINES)
在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作
# 两个中间件
-爬虫中间件
-下载中间件(用的最多,加头,加代理,加cookie,集成selenium)
安装创建和启动
# 1 框架 不是 模块
# 2 号称爬虫界的django(你会发现,跟django很多地方一样)
# 3 安装
-mac,linux平台:pip3 install scrapy
-windows平台:pip3 install scrapy(大部分人可以)
- 如果失败:
1、pip3 install wheel #安装后,便支持通过wheel文件安装软件,wheel文件官网:https://www.lfd.uci.edu/~gohlke/pythonlibs
3、pip3 install lxml
4、pip3 install pyopenssl
5、下载并安装pywin32:https://sourceforge.net/projec ... in32/
6、下载twisted的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
7、执行pip3 install 下载目录\Twisted-17.9.0-cp36-cp36m-win_amd64.whl
8、pip3 install scrapy
# 4 在script文件夹下会有scrapy.exe可执行文件
-创建scrapy项目:scrapy startproject 项目名 (django创建项目)
-创建爬虫:scrapy genspider 爬虫名 要爬取的网站地址 # 可以创建多个爬虫
# 5 命令启动爬虫
-scrapy crawl 爬虫名字
-scrapy crawl 爬虫名字 --nolog # 没有日志输出启动
# 6 文件执行爬虫(推荐使用)
-在项目路径下创建一个main.py,右键执行即可
from scrapy.cmdline import execute
# execute(['scrapy','crawl','chouti','--nolog']) # 没有设置日志级别
execute(['scrapy','crawl','chouti']) # 设置了日志级别
配置文件目录介绍
-crawl_chouti # 项目名
-crawl_chouti # 跟项目一个名,文件夹
-spiders # spiders:放着爬虫 genspider生成的爬虫,都放在这下面
-__init__.py
-chouti.py # 抽屉爬虫
-cnblogs.py # cnblogs 爬虫
-items.py # 对比django中的models.py文件 ,写一个个的模型类
-middlewares.py # 中间件(爬虫中间件,下载中间件),中间件写在这
-pipelines.py # 写持久化的地方(持久化到文件,mysql,redis,mongodb)
-settings.py # 配置文件
-scrapy.cfg # 不用关注,上线相关的
# 配置文件settings.py
ROBOTSTXT_OBEY = False # 是否遵循爬虫协议,强行运行
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36' # 请求头中的ua,去浏览器复制,或者用ua池拿
LOG_LEVEL='ERROR' # 这样配置,程序错误信息才会打印,
#启动爬虫直接 scrapy crawl 爬虫名 就没有日志输出
# scrapy crawl 爬虫名 --nolog # 配置了就不需要这样启动了
# 爬虫文件
class ChoutiSpider(scrapy.Spider):
name = 'chouti' # 爬虫名字
allowed_domains = ['https://dig.chouti.com/'] # 允许爬取的域,想要多爬就注释掉
start_urls = ['https://dig.chouti.com/'] # 起始爬取的位置,爬虫一启动,会先向它发请求
def parse(self, response): # 解析,请求回来,自动执行parser,在这个方法中做解析
print('---------------------------',response)
抓取数据并解析
# 1 解析,可以使用bs4解析
from bs4 import BeautifulSoup
soup=BeautifulSoup(response.text,'lxml')
soup.find_all() # bs4解析
soup.select() # css解析
# 2 内置的解析器
response.css
response.xpath
# 内置解析
# 所有用css或者xpath选择出来的都放在列表中
# 取第一个:extract_first()
# 取出所有extract()
# css选择器取文本和属性:
# .link-title::text # 取文本,数据都在data中
# .link-title::attr(href) # 取属性,数据都在data中
# xpath选择器取文本和属性
# .//a[contains(@class,"link-title")/text()]
#.//a[contains(@class,"link-title")/@href]
# 内置css选择期,取所有
div_list = response.css('.link-con .link-item')
for div in div_list:
content = div.css('.link-title').extract()
print(content)
数据持久化
# 方式一(不推荐)
-1 parser解析函数,return 列表,列表套字典
# 命令 (支持:('json', 'jsonlines', 'jl', 'csv', 'xml', 'marshal', 'pickle')
# 数据到aa.json文件中
-2 scrapy crawl chouti -o aa.json
# 代码:
lis = []
for div in div_list:
content = div.select('.link-title')[0].text
lis.append({'title':content})
return lis
# 方式二 pipline的方式(管道)
-1 在items.py中创建模型类
-2 在爬虫中chouti.py,引入,把解析的数据放到item对象中(要用中括号)
-3 yield item对象
-4 配置文件配置管道
ITEM_PIPELINES = {
# 数字表示优先级(数字越小,优先级越大)
'crawl_chouti.pipelines.CrawlChoutiPipeline': 300,
'crawl_chouti.pipelines.CrawlChoutiRedisPipeline': 301,
}
-5 pipline.py中写持久化的类
spider_open # 方法,一开始就打开文件
process_item # 方法,写入文件
spider_close # 方法,关闭文件
保存到文件
# choutiaa.py 爬虫文件
import scrapy
from chouti.items import ChoutiItem # 导入模型类
class ChoutiaaSpider(scrapy.Spider):
name = 'choutiaa'
# allowed_domains = ['https://dig.chouti.com/'] # 允许爬取的域
start_urls = ['https://dig.chouti.com//'] # 起始爬取位置
# 解析,请求回来,自动执行parse,在这个方法中解析
def parse(self, response):
print('----------------',response)
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text,'lxml')
div_list = soup.select('.link-con .link-item')
for div in div_list:
content = div.select('.link-title')[0].text
href = div.select('.link-title')[0].attrs['href']
item = ChoutiItem() # 生成模型对象
item['content'] = content # 添加值
item['href'] = href
yield item # 必须用yield
# items.py 模型类文件
import scrapy
class ChoutiItem(scrapy.Item):
content = scrapy.Field()
href = scrapy.Field()
# pipelines.py 数据持久化文件
class ChoutiPipeline(object):
def open_spider(self, spider):
# 一开始就打开文件
self.f = open('a.txt', 'w', encoding='utf-8')
def process_item(self, item, spider):
# print(item)
# 写入文件的操作 查看全部
文章采集api(Scrapy一个
)
内容
架构介绍
Scrapy 是一个开源和协作框架,最初是为页面抓取(更准确地说是网页抓取)而设计的,它允许您以快速、简单和可扩展的方式从所需数据中提取所有信息。但目前,Scrapy 的用途非常广泛,例如数据挖掘、监控和自动化测试,也可以用来获取 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
Scrapy 是基于 twisted 框架开发的,这是一个流行的事件驱动的 Python 网络框架。所以 Scrapy 使用非阻塞(又名异步)代码来实现并发。整体结构大致如下
IO多路复用
# 引擎(EGINE)(大总管)
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。有关详细信息,请参见上面的数据流部分。
# 调度器(SCHEDULER)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
# 下载器(DOWLOADER)
用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的
# 爬虫(SPIDERS)
SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求
# 项目管道(ITEM PIPLINES)
在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作
# 两个中间件
-爬虫中间件
-下载中间件(用的最多,加头,加代理,加cookie,集成selenium)
安装创建和启动
# 1 框架 不是 模块
# 2 号称爬虫界的django(你会发现,跟django很多地方一样)
# 3 安装
-mac,linux平台:pip3 install scrapy
-windows平台:pip3 install scrapy(大部分人可以)
- 如果失败:
1、pip3 install wheel #安装后,便支持通过wheel文件安装软件,wheel文件官网:https://www.lfd.uci.edu/~gohlke/pythonlibs
3、pip3 install lxml
4、pip3 install pyopenssl
5、下载并安装pywin32:https://sourceforge.net/projec ... in32/
6、下载twisted的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
7、执行pip3 install 下载目录\Twisted-17.9.0-cp36-cp36m-win_amd64.whl
8、pip3 install scrapy
# 4 在script文件夹下会有scrapy.exe可执行文件
-创建scrapy项目:scrapy startproject 项目名 (django创建项目)
-创建爬虫:scrapy genspider 爬虫名 要爬取的网站地址 # 可以创建多个爬虫
# 5 命令启动爬虫
-scrapy crawl 爬虫名字
-scrapy crawl 爬虫名字 --nolog # 没有日志输出启动
# 6 文件执行爬虫(推荐使用)
-在项目路径下创建一个main.py,右键执行即可
from scrapy.cmdline import execute
# execute(['scrapy','crawl','chouti','--nolog']) # 没有设置日志级别
execute(['scrapy','crawl','chouti']) # 设置了日志级别
配置文件目录介绍
-crawl_chouti # 项目名
-crawl_chouti # 跟项目一个名,文件夹
-spiders # spiders:放着爬虫 genspider生成的爬虫,都放在这下面
-__init__.py
-chouti.py # 抽屉爬虫
-cnblogs.py # cnblogs 爬虫
-items.py # 对比django中的models.py文件 ,写一个个的模型类
-middlewares.py # 中间件(爬虫中间件,下载中间件),中间件写在这
-pipelines.py # 写持久化的地方(持久化到文件,mysql,redis,mongodb)
-settings.py # 配置文件
-scrapy.cfg # 不用关注,上线相关的
# 配置文件settings.py
ROBOTSTXT_OBEY = False # 是否遵循爬虫协议,强行运行
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36' # 请求头中的ua,去浏览器复制,或者用ua池拿
LOG_LEVEL='ERROR' # 这样配置,程序错误信息才会打印,
#启动爬虫直接 scrapy crawl 爬虫名 就没有日志输出
# scrapy crawl 爬虫名 --nolog # 配置了就不需要这样启动了
# 爬虫文件
class ChoutiSpider(scrapy.Spider):
name = 'chouti' # 爬虫名字
allowed_domains = ['https://dig.chouti.com/'] # 允许爬取的域,想要多爬就注释掉
start_urls = ['https://dig.chouti.com/'] # 起始爬取的位置,爬虫一启动,会先向它发请求
def parse(self, response): # 解析,请求回来,自动执行parser,在这个方法中做解析
print('---------------------------',response)
抓取数据并解析
# 1 解析,可以使用bs4解析
from bs4 import BeautifulSoup
soup=BeautifulSoup(response.text,'lxml')
soup.find_all() # bs4解析
soup.select() # css解析
# 2 内置的解析器
response.css
response.xpath
# 内置解析
# 所有用css或者xpath选择出来的都放在列表中
# 取第一个:extract_first()
# 取出所有extract()
# css选择器取文本和属性:
# .link-title::text # 取文本,数据都在data中
# .link-title::attr(href) # 取属性,数据都在data中
# xpath选择器取文本和属性
# .//a[contains(@class,"link-title")/text()]
#.//a[contains(@class,"link-title")/@href]
# 内置css选择期,取所有
div_list = response.css('.link-con .link-item')
for div in div_list:
content = div.css('.link-title').extract()
print(content)
数据持久化
# 方式一(不推荐)
-1 parser解析函数,return 列表,列表套字典
# 命令 (支持:('json', 'jsonlines', 'jl', 'csv', 'xml', 'marshal', 'pickle')
# 数据到aa.json文件中
-2 scrapy crawl chouti -o aa.json
# 代码:
lis = []
for div in div_list:
content = div.select('.link-title')[0].text
lis.append({'title':content})
return lis
# 方式二 pipline的方式(管道)
-1 在items.py中创建模型类
-2 在爬虫中chouti.py,引入,把解析的数据放到item对象中(要用中括号)
-3 yield item对象
-4 配置文件配置管道
ITEM_PIPELINES = {
# 数字表示优先级(数字越小,优先级越大)
'crawl_chouti.pipelines.CrawlChoutiPipeline': 300,
'crawl_chouti.pipelines.CrawlChoutiRedisPipeline': 301,
}
-5 pipline.py中写持久化的类
spider_open # 方法,一开始就打开文件
process_item # 方法,写入文件
spider_close # 方法,关闭文件
保存到文件
# choutiaa.py 爬虫文件
import scrapy
from chouti.items import ChoutiItem # 导入模型类
class ChoutiaaSpider(scrapy.Spider):
name = 'choutiaa'
# allowed_domains = ['https://dig.chouti.com/'] # 允许爬取的域
start_urls = ['https://dig.chouti.com//'] # 起始爬取位置
# 解析,请求回来,自动执行parse,在这个方法中解析
def parse(self, response):
print('----------------',response)
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text,'lxml')
div_list = soup.select('.link-con .link-item')
for div in div_list:
content = div.select('.link-title')[0].text
href = div.select('.link-title')[0].attrs['href']
item = ChoutiItem() # 生成模型对象
item['content'] = content # 添加值
item['href'] = href
yield item # 必须用yield
# items.py 模型类文件
import scrapy
class ChoutiItem(scrapy.Item):
content = scrapy.Field()
href = scrapy.Field()
# pipelines.py 数据持久化文件
class ChoutiPipeline(object):
def open_spider(self, spider):
# 一开始就打开文件
self.f = open('a.txt', 'w', encoding='utf-8')
def process_item(self, item, spider):
# print(item)
# 写入文件的操作
文章采集api( 爬虫海外网站获取ip之前,请检查是否添加白名单?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2022-02-21 19:03
爬虫海外网站获取ip之前,请检查是否添加白名单?)
海外网站如何使用代理IP采集?
我们在做爬虫的时候,经常会遇到这种情况。爬虫第一次运行时,可以正常获取数据,一切看起来都是那么美好。但是过一会可能会出现403 Forbidden,然后你会打开网站查看一下,你可能会看到“你的IP访问频率太高,请稍后再试”。遇到这种情况,通常这种情况下,我们会使用代理IP隐藏自己的IP,实现大量爬取。国内代理常用的产品有几十种,而我们需要在海外爬的时候网站这些代理都用不上,所以我们今天用的是Ipidea全球代理。
用法与国内相差不大。可以根据需要选择在指定国家或全球播放,通过api接口调用,指定提取次数,也可以指定接口返回数据格式,如txt、json、html、等等,这里以全局混合和json格式为例,获取一个代理,一次一个,python代码如下:
import requestsurl = "http://tiqu.linksocket.com:81/ ... Bresp = requests.get(url)# 成功获取到的数据为:{'code': 0, 'data': [{'ip': '47.74.232.57', 'port': 21861}], 'msg': '0', 'success': True}data = resp.json().get('data')[0]proxy = { "http": "http://%s:%d" % (data.get("ip"), data.get("port")), "https": "https://%s:%d" % (data.get("ip"), data.get("port"))}
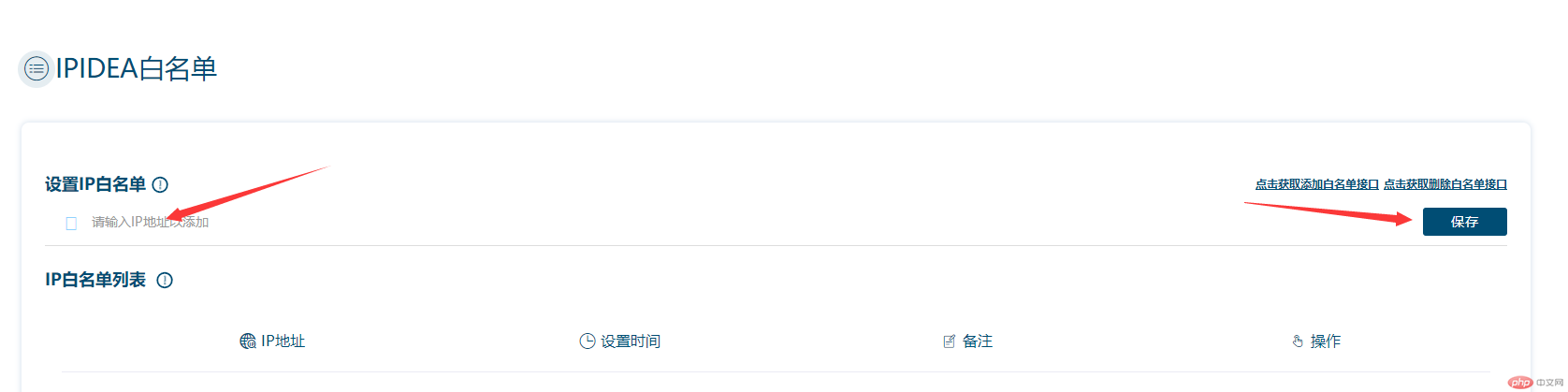
在获取IP之前,我们需要通过个人中心设置IP白名单,否则无法获取数据。
只需填写你本地的公网并保存即可(官方界面也提供了添加或删除白名单的界面)。如果不知道公网IP是什么,可以通过百度搜索IP。
爬虫演示如下。以下是六度新闻的示例:
import requestsurl = "http://tiqu.linksocket.com:81/ ... 3Bdef get_proxy(): """ 获取代理 """ resp = requests.get(url) data = resp.json().get('data')[0] proxy = { "http": "http://%s:%d" % (data.get("ip"), data.get("port")), "https": "https://%s:%d" % (data.get("ip"), data.get("port")) } return proxydef download_html(url): """ 获取url接口数据 """ resp = requests.get(url,proxies=get_proxy()) return resp.json()def run(): """ 主程序 :return: """ url = "https://6do.news/api/tag/114?page=1" content = download_html(url) # 数据处理略if __name__ == '__main__': run()
数据如图:
前后端分离的界面对爬虫比较友好,提取数据也比较方便。这里不需要做太多处理,可以根据需要提取数据。
如果代理不能挂在爬虫中,请检查是否添加白名单。
本次海外网站的采集教程到此结束,详细交流请联系我。
本文章仅供交流分享,【未经许可,请拒绝转载】 查看全部
文章采集api(
爬虫海外网站获取ip之前,请检查是否添加白名单?)
海外网站如何使用代理IP采集?
我们在做爬虫的时候,经常会遇到这种情况。爬虫第一次运行时,可以正常获取数据,一切看起来都是那么美好。但是过一会可能会出现403 Forbidden,然后你会打开网站查看一下,你可能会看到“你的IP访问频率太高,请稍后再试”。遇到这种情况,通常这种情况下,我们会使用代理IP隐藏自己的IP,实现大量爬取。国内代理常用的产品有几十种,而我们需要在海外爬的时候网站这些代理都用不上,所以我们今天用的是Ipidea全球代理。
用法与国内相差不大。可以根据需要选择在指定国家或全球播放,通过api接口调用,指定提取次数,也可以指定接口返回数据格式,如txt、json、html、等等,这里以全局混合和json格式为例,获取一个代理,一次一个,python代码如下:
import requestsurl = "http://tiqu.linksocket.com:81/ ... Bresp = requests.get(url)# 成功获取到的数据为:{'code': 0, 'data': [{'ip': '47.74.232.57', 'port': 21861}], 'msg': '0', 'success': True}data = resp.json().get('data')[0]proxy = { "http": "http://%s:%d" % (data.get("ip"), data.get("port")), "https": "https://%s:%d" % (data.get("ip"), data.get("port"))}
在获取IP之前,我们需要通过个人中心设置IP白名单,否则无法获取数据。
只需填写你本地的公网并保存即可(官方界面也提供了添加或删除白名单的界面)。如果不知道公网IP是什么,可以通过百度搜索IP。
爬虫演示如下。以下是六度新闻的示例:
import requestsurl = "http://tiqu.linksocket.com:81/ ... 3Bdef get_proxy(): """ 获取代理 """ resp = requests.get(url) data = resp.json().get('data')[0] proxy = { "http": "http://%s:%d" % (data.get("ip"), data.get("port")), "https": "https://%s:%d" % (data.get("ip"), data.get("port")) } return proxydef download_html(url): """ 获取url接口数据 """ resp = requests.get(url,proxies=get_proxy()) return resp.json()def run(): """ 主程序 :return: """ url = "https://6do.news/api/tag/114?page=1" content = download_html(url) # 数据处理略if __name__ == '__main__': run()
数据如图:
前后端分离的界面对爬虫比较友好,提取数据也比较方便。这里不需要做太多处理,可以根据需要提取数据。
如果代理不能挂在爬虫中,请检查是否添加白名单。
本次海外网站的采集教程到此结束,详细交流请联系我。
本文章仅供交流分享,【未经许可,请拒绝转载】
文章采集api(如何通过MySQL存储采集到的数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-02-21 06:08
MySQL是目前最流行的开源关系数据库管理系统。令人惊讶的是,一个开源项目的竞争力如此之强,以至于它的受欢迎程度不断接近另外两个闭源商业数据库系统:微软的 SQL Server 和甲骨文的甲骨文数据库(MySQL 于 2010 年被甲骨文收购)。)。
它的受欢迎程度不辜负它的名字。对于大多数应用程序,MySQL 是显而易见的选择。它是一个非常灵活、稳定、功能齐全的 DBMS,许多顶级 网站 都在使用它:Youtube、Twitter、Facebook 等。
由于使用广泛、免费、开箱即用,是web data采集项目中常用的数据库,在此文章我们介绍如何存储数据采集 通过 MySQL。
安装 MySQL
如果您是 MySQL 新手,您可能会觉得它有点麻烦。其实安装方法和安装其他软件一样简单。归根结底,MySQL 是由一系列数据文件组成的,存储在你的远程服务器或本地计算机上,其中收录了存储在数据库中的所有信息。
在Windows上安装MySQL,在Ubuntu上安装MySQL,在MAC上安装MySQL具体步骤在这里:在所有平台上安装MySQL
此处无需过多解释,按照视频操作即可。
基本命令
MySQL服务器启动后,与数据库服务器交互的方式有很多种。因为许多工具都是图形界面,所以您可以不使用 MySQL 的命令行(或很少使用)来管理数据库。phpMyAdmin 和 MySQL Workbench 等工具可以轻松查看、排序和创建数据库。但是,掌握命令行操作数据库还是很重要的。
除了用户定义的变量名,MySQL 不区分大小写。例如,SELECT 与 select 相同,但习惯上所有 MySQL 关键词 的 MySQL 语句都以大写形式编写。大多数开发人员还喜欢使用小写字母作为数据库和数据表名称。
首次登录 MySQL 数据库时,没有数据库来存储数据。我们需要创建一个数据库:
CREATE DATABASE scraping_article DEFAULT CHARACTER SET UTF8 COLLATE UTF8_GENERAL_CI;
因为每个 MySQL 实例可以有多个数据库,所以在使用数据库之前需要指定数据库名称:
使用scraping_article
从现在开始(直到关闭 MySQL 链接或切换到另一个数据库),所有命令都在这个新的“scraping_article”数据库中运行。
所有的操作看起来都很简单。那么在数据库中新建表的操作方法应该也差不多吧?我们在库中新建一个表来存储采集的网页文章的数据:
创建表文章;
结果显示错误:
错误 1113 (42000): 一个表必须至少有 1 列
与数据库不同,MySQL 数据表必须有列,否则无法创建。要在 MySQL 中定义字段(数据列),我们还必须将字段定义放在 CREATE TABLE 语句之后的带括号的逗号分隔列表中:
create table articles
(
id int auto_increment
primary key,
title varchar(64) null,
body text null,
summary varchar(256) null,
body_html text null,
create_time datetime default CURRENT_TIMESTAMP null,
time_updated datetime null,
link_text varchar(128) null
);
每个字段定义由三部分组成:
在字段定义列表的最后,还定义了一个“主键”(key)。MySQL使用这个主键来组织表的内容,方便以后快速查询。以后文章会介绍如何通过这些主键来提高数据库的查询速度,不过目前我们可以使用表的id列作为主键。
语句执行完毕后,我们可以使用DESCRIBE查看数据表的结构:
+--------------+--------------+------+-----+-------------------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+--------------+------+-----+-------------------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| title | varchar(64) | YES | | NULL | |
| body | text | YES | | NULL | |
| summary | varchar(256) | YES | | NULL | |
| body_html | text | YES | | NULL | |
| create_time | datetime | YES | | CURRENT_TIMESTAMP | |
| time_updated | datetime | YES | | NULL | |
| link_text | varchar(128) | YES | | NULL | |
+--------------+--------------+------+-----+-------------------+----------------+
8 rows in set (0.03 sec)
现在这张表是空表,我们插入数据看看,如下图:
INSERT INTO articles(title,body,summary,body_html,link_text) VALUES ("Test page title","Test page body.","Test page summary.","<p>Test page body.","test-page");</p>
这里需要注意,虽然articles表有8个字段(id、title、body、summary、body_html、create_time、time_update、link_text),但实际上我们只插入了5个字段(title、body、summary、body_html、link_text) ) ) 数据。因为id字段是自动递增的(MySQL每次插入数据时默认递增1),一般不需要处理。另外create_time字段的类型是current_timestamp,时间戳是通过插入的默认。
当然,我们也可以自定义字段内容来插入数据:
INSERT INTO articles(id,title,body,summary,body_html,create_time,link_text) VALUES (4,"Test page title","Test page body.","Test page summary.","<p>Test page body.","2021-11-20 15:51:45","test-page");</p>
只要你定义的整数不在数据表的id字段中,就可以插入到数据表中。但是,这非常糟糕;除非绝对必要(比如程序中缺少一行数据),否则让 MySQL 自己处理 id 和 timestamp 字段。
现在表中有一些数据,我们可以通过多种方式查询这些数据。以下是 SELECT 语句的一些示例:
SELECT * FROM articles WHERE id=1;
该语句告诉 MySQL “从文章表中选择 id 等于 2 的所有数据”。此星号 (*) 是通配符,表示所有字段。这行语句将显示所有满足条件的字段(其中 id=1))。如果没有 id 等于 1 的行,它将返回一个空集。例如,以下不区分大小写的查询将返回标题字段中收录“test”的所有行的所有字段(% 符号表示 MySQL 字符串通配符):
SELECT * FROM articles WHERE title LIKE "%test%";
但是如果你有很多字段并且你只想返回其中的一部分呢?您可以使用以下命令代替星号:
SELECT title, body FROM articles WHERE body LIKE "%test%";
这将只返回正文内容收录“test”的所有行的标题和正文字段。
DELETE 语句的语法类似于 SELECT 语句:
DELETE FROM articles WHERE id=1;
由于数据库的数据删除无法恢复,建议在执行DELETE语句前使用SELECT确认要删除的数据(上述删除语句可以使用SELECT * FROM文章WHERE id=1;查看),以及然后将 SELECT * 替换为 DELETE 就可以了,这是一个好习惯。很多程序员都有过 DELETE 误操作的悲惨故事,也有一些恐怖的故事是有人惊慌失措的忘记在语句中输入 WHERE,结果所有客户数据都被删除了。不要让这种事情发生在你身上!
要介绍的另一件事是 UPDATE 语句:
UPDATE articles SET title="A new title", body="Some new body." WHERE id=4;
以上只使用了最基本的 MySQL 语句来做一些简单的数据查询、创建和更新。
与 Python 集成
Python 没有对 MySQL 的内置支持。但是,有很多开源的可以用来和 MySQL 交互,Python 2.x 和 Python 3.x 版本都支持。最著名的一个是 PyMySQL。
我们可以使用pip来安装,执行如下命令:
python3 -m pip 安装 PyMySQL
安装完成后,我们就可以使用 PyMySQL 包了。如果您的 MySQL 服务器正在运行,您应该能够成功执行以下命令:
import pymysql
import os
from dotenv import load_dotenv
class DataSaveToMySQL(object):
def __init__(self):
# loading env config file
dotenv_path = os.path.join(os.getcwd(), '.env')
if os.path.exists(dotenv_path):
load_dotenv(dotenv_path)
conn = pymysql.connect(host=os.environ.get('MYSQL_HOST'), port=os.environ.get('MYSQL_PORT'),
user=os.environ.get('MYSQL_USER'), password=os.environ.get('MYSQL_PASSWORD'),
db=os.environ.get('MYSQL_DATABASES'))
cur = conn.cursor()
cur.execute("SELECT * FROM articles WHERE id=4;")
print(cur.fetchone())
cur.close()
conn.close()
这个程序有两个对象:一个连接对象(conn)和一个游标对象(cur)。
连接/游标模式是数据库编程中常用的模式。当您不熟悉数据库时,有时很难区分这两种模式之间的区别。连接方式除了连接数据库外,还发送数据库信息,处理回滚操作(当一个查询或一组查询中断时,数据库需要回到初始状态,一般使用事务来实现状态回滚),创建新游标等
一个连接可以有很多游标,一个游标跟踪一种状态信息,比如跟踪数据库的使用状态。如果您有多个数据库,并且需要写入所有数据库,则需要多个游标来处理。游标还可以收录上次查询执行的结果。查询结果可以通过调用cur.fetchone()等游标函数获得。
请记住在使用完连接和游标后关闭它们。如果不关闭,会导致连接泄漏(connection leak),造成连接关闭现象,即连接不再使用,但是数据库无法关闭,因为数据库不确定是否你想继续使用它。这种现象会一直消耗数据库资源,所以使用数据库后记得关闭连接!
刚开始时,您要做的就是将 采集 的数据保存到数据库中。我们继续采集blog文章的例子来演示如何实现数据存储。
import pymysql
import os
from dotenv import load_dotenv
from config import logger_config
from utils import connection_util
class DataSaveToMySQL(object):
def __init__(self):
# loading env config file
dotenv_path = os.path.join(os.getcwd(), '.env')
if os.path.exists(dotenv_path):
load_dotenv(dotenv_path)
# MySQL config
self._host = os.environ.get('MYSQL_HOST')
self._port = int(os.environ.get('MYSQL_PORT'))
self._user = os.environ.get('MYSQL_USER')
self._password = os.environ.get('MYSQL_PASSWORD')
self._db = os.environ.get('MYSQL_DATABASES')
self._target_url = 'https://www.scrapingbee.com/blog/'
self._baseUrl = 'https://www.scrapingbee.com'
self._init_connection = connection_util.ProcessConnection()
logging_name = 'store_mysql'
init_logging = logger_config.LoggingConfig()
self._logging = init_logging.init_logging(logging_name)
def scrape_data(self):
get_content = self._init_connection.init_connection(self._target_url)
if get_content:
parent = get_content.findAll("section", {"class": "section-sm"})[0]
get_row = parent.findAll("div", {"class": "col-lg-12 mb-5 mb-lg-0"})[0]
get_child_item = get_row.findAll("div", {"class": "col-md-4 mb-4"})
for item in get_child_item:
# 获取标题文字
get_title = item.find("a", {"class": "h5 d-block mb-3 post-title"}).get_text()
# 获取发布时间
get_release_date = item.find("div", {"class": "mb-3 mt-2"}).findAll("span")[1].get_text()
# 获取文章描述
get_description = item.find("p", {"class": "card-text post-description"}).get_text()
self.article_save_mysql(title=get_title, description=get_description, release_date=get_release_date)
else:
self._logging.warning('未获取到文章任何内容,请检查!')
def article_save_mysql(self, title, description, release_date):
connection = pymysql.connect(host=self._host, port=self._port, user=self._user, password=self._password,
db=self._db, charset='utf-8')
with connection.cursor() as cursor:
# Create a new record
sql = "INSERT INTO articles (title,summary,create_time) VALUES (%s,%s,%s);"
cursor.execute(sql, (title, description, release_date))
# connection is not autocommit by default. So you must commit to save
# your changes.
connection.commit()
这里需要注意几点:首先,将 charset='utf-8' 添加到连接字符串中。这是为了让conn把所有发送到数据库的信息都当作utf-8编码格式(当然前提是数据库默认编码设置为UTF-8)。
然后需要注意article_save_mysql函数。它有3个参数:title、description和release_date,并将这两个参数添加到INSERT语句中并用游标执行,然后用游标确认。这是将光标与连接分开的一个很好的例子;当游标存储一些数据库和数据库上下文信息时,需要通过连接确认才能将信息传递到数据库中,然后再将信息插入到数据库中。
上述代码没有使用 try...finally 语句关闭数据库,而是使用 with() 关闭数据库连接。在上一期中,我们也使用了 with() 来关闭 CSV 文件。
PyMySQL的规模虽然不大,但里面有一些非常实用的功能,在本文章中就不演示了。具体请参考 Python DBAPI 标准文档。
以上是关于将采集的内容保存到MySQL。本示例的所有代码都托管在 github 上。
github: 查看全部
文章采集api(如何通过MySQL存储采集到的数据)
MySQL是目前最流行的开源关系数据库管理系统。令人惊讶的是,一个开源项目的竞争力如此之强,以至于它的受欢迎程度不断接近另外两个闭源商业数据库系统:微软的 SQL Server 和甲骨文的甲骨文数据库(MySQL 于 2010 年被甲骨文收购)。)。
它的受欢迎程度不辜负它的名字。对于大多数应用程序,MySQL 是显而易见的选择。它是一个非常灵活、稳定、功能齐全的 DBMS,许多顶级 网站 都在使用它:Youtube、Twitter、Facebook 等。
由于使用广泛、免费、开箱即用,是web data采集项目中常用的数据库,在此文章我们介绍如何存储数据采集 通过 MySQL。
安装 MySQL
如果您是 MySQL 新手,您可能会觉得它有点麻烦。其实安装方法和安装其他软件一样简单。归根结底,MySQL 是由一系列数据文件组成的,存储在你的远程服务器或本地计算机上,其中收录了存储在数据库中的所有信息。
在Windows上安装MySQL,在Ubuntu上安装MySQL,在MAC上安装MySQL具体步骤在这里:在所有平台上安装MySQL
此处无需过多解释,按照视频操作即可。
基本命令
MySQL服务器启动后,与数据库服务器交互的方式有很多种。因为许多工具都是图形界面,所以您可以不使用 MySQL 的命令行(或很少使用)来管理数据库。phpMyAdmin 和 MySQL Workbench 等工具可以轻松查看、排序和创建数据库。但是,掌握命令行操作数据库还是很重要的。
除了用户定义的变量名,MySQL 不区分大小写。例如,SELECT 与 select 相同,但习惯上所有 MySQL 关键词 的 MySQL 语句都以大写形式编写。大多数开发人员还喜欢使用小写字母作为数据库和数据表名称。
首次登录 MySQL 数据库时,没有数据库来存储数据。我们需要创建一个数据库:
CREATE DATABASE scraping_article DEFAULT CHARACTER SET UTF8 COLLATE UTF8_GENERAL_CI;
因为每个 MySQL 实例可以有多个数据库,所以在使用数据库之前需要指定数据库名称:
使用scraping_article
从现在开始(直到关闭 MySQL 链接或切换到另一个数据库),所有命令都在这个新的“scraping_article”数据库中运行。
所有的操作看起来都很简单。那么在数据库中新建表的操作方法应该也差不多吧?我们在库中新建一个表来存储采集的网页文章的数据:
创建表文章;
结果显示错误:
错误 1113 (42000): 一个表必须至少有 1 列
与数据库不同,MySQL 数据表必须有列,否则无法创建。要在 MySQL 中定义字段(数据列),我们还必须将字段定义放在 CREATE TABLE 语句之后的带括号的逗号分隔列表中:
create table articles
(
id int auto_increment
primary key,
title varchar(64) null,
body text null,
summary varchar(256) null,
body_html text null,
create_time datetime default CURRENT_TIMESTAMP null,
time_updated datetime null,
link_text varchar(128) null
);
每个字段定义由三部分组成:
在字段定义列表的最后,还定义了一个“主键”(key)。MySQL使用这个主键来组织表的内容,方便以后快速查询。以后文章会介绍如何通过这些主键来提高数据库的查询速度,不过目前我们可以使用表的id列作为主键。
语句执行完毕后,我们可以使用DESCRIBE查看数据表的结构:
+--------------+--------------+------+-----+-------------------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+--------------+------+-----+-------------------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| title | varchar(64) | YES | | NULL | |
| body | text | YES | | NULL | |
| summary | varchar(256) | YES | | NULL | |
| body_html | text | YES | | NULL | |
| create_time | datetime | YES | | CURRENT_TIMESTAMP | |
| time_updated | datetime | YES | | NULL | |
| link_text | varchar(128) | YES | | NULL | |
+--------------+--------------+------+-----+-------------------+----------------+
8 rows in set (0.03 sec)
现在这张表是空表,我们插入数据看看,如下图:
INSERT INTO articles(title,body,summary,body_html,link_text) VALUES ("Test page title","Test page body.","Test page summary.","<p>Test page body.","test-page");</p>
这里需要注意,虽然articles表有8个字段(id、title、body、summary、body_html、create_time、time_update、link_text),但实际上我们只插入了5个字段(title、body、summary、body_html、link_text) ) ) 数据。因为id字段是自动递增的(MySQL每次插入数据时默认递增1),一般不需要处理。另外create_time字段的类型是current_timestamp,时间戳是通过插入的默认。
当然,我们也可以自定义字段内容来插入数据:
INSERT INTO articles(id,title,body,summary,body_html,create_time,link_text) VALUES (4,"Test page title","Test page body.","Test page summary.","<p>Test page body.","2021-11-20 15:51:45","test-page");</p>
只要你定义的整数不在数据表的id字段中,就可以插入到数据表中。但是,这非常糟糕;除非绝对必要(比如程序中缺少一行数据),否则让 MySQL 自己处理 id 和 timestamp 字段。
现在表中有一些数据,我们可以通过多种方式查询这些数据。以下是 SELECT 语句的一些示例:
SELECT * FROM articles WHERE id=1;
该语句告诉 MySQL “从文章表中选择 id 等于 2 的所有数据”。此星号 (*) 是通配符,表示所有字段。这行语句将显示所有满足条件的字段(其中 id=1))。如果没有 id 等于 1 的行,它将返回一个空集。例如,以下不区分大小写的查询将返回标题字段中收录“test”的所有行的所有字段(% 符号表示 MySQL 字符串通配符):
SELECT * FROM articles WHERE title LIKE "%test%";
但是如果你有很多字段并且你只想返回其中的一部分呢?您可以使用以下命令代替星号:
SELECT title, body FROM articles WHERE body LIKE "%test%";
这将只返回正文内容收录“test”的所有行的标题和正文字段。
DELETE 语句的语法类似于 SELECT 语句:
DELETE FROM articles WHERE id=1;
由于数据库的数据删除无法恢复,建议在执行DELETE语句前使用SELECT确认要删除的数据(上述删除语句可以使用SELECT * FROM文章WHERE id=1;查看),以及然后将 SELECT * 替换为 DELETE 就可以了,这是一个好习惯。很多程序员都有过 DELETE 误操作的悲惨故事,也有一些恐怖的故事是有人惊慌失措的忘记在语句中输入 WHERE,结果所有客户数据都被删除了。不要让这种事情发生在你身上!
要介绍的另一件事是 UPDATE 语句:
UPDATE articles SET title="A new title", body="Some new body." WHERE id=4;
以上只使用了最基本的 MySQL 语句来做一些简单的数据查询、创建和更新。
与 Python 集成
Python 没有对 MySQL 的内置支持。但是,有很多开源的可以用来和 MySQL 交互,Python 2.x 和 Python 3.x 版本都支持。最著名的一个是 PyMySQL。
我们可以使用pip来安装,执行如下命令:
python3 -m pip 安装 PyMySQL
安装完成后,我们就可以使用 PyMySQL 包了。如果您的 MySQL 服务器正在运行,您应该能够成功执行以下命令:
import pymysql
import os
from dotenv import load_dotenv
class DataSaveToMySQL(object):
def __init__(self):
# loading env config file
dotenv_path = os.path.join(os.getcwd(), '.env')
if os.path.exists(dotenv_path):
load_dotenv(dotenv_path)
conn = pymysql.connect(host=os.environ.get('MYSQL_HOST'), port=os.environ.get('MYSQL_PORT'),
user=os.environ.get('MYSQL_USER'), password=os.environ.get('MYSQL_PASSWORD'),
db=os.environ.get('MYSQL_DATABASES'))
cur = conn.cursor()
cur.execute("SELECT * FROM articles WHERE id=4;")
print(cur.fetchone())
cur.close()
conn.close()
这个程序有两个对象:一个连接对象(conn)和一个游标对象(cur)。
连接/游标模式是数据库编程中常用的模式。当您不熟悉数据库时,有时很难区分这两种模式之间的区别。连接方式除了连接数据库外,还发送数据库信息,处理回滚操作(当一个查询或一组查询中断时,数据库需要回到初始状态,一般使用事务来实现状态回滚),创建新游标等
一个连接可以有很多游标,一个游标跟踪一种状态信息,比如跟踪数据库的使用状态。如果您有多个数据库,并且需要写入所有数据库,则需要多个游标来处理。游标还可以收录上次查询执行的结果。查询结果可以通过调用cur.fetchone()等游标函数获得。
请记住在使用完连接和游标后关闭它们。如果不关闭,会导致连接泄漏(connection leak),造成连接关闭现象,即连接不再使用,但是数据库无法关闭,因为数据库不确定是否你想继续使用它。这种现象会一直消耗数据库资源,所以使用数据库后记得关闭连接!
刚开始时,您要做的就是将 采集 的数据保存到数据库中。我们继续采集blog文章的例子来演示如何实现数据存储。
import pymysql
import os
from dotenv import load_dotenv
from config import logger_config
from utils import connection_util
class DataSaveToMySQL(object):
def __init__(self):
# loading env config file
dotenv_path = os.path.join(os.getcwd(), '.env')
if os.path.exists(dotenv_path):
load_dotenv(dotenv_path)
# MySQL config
self._host = os.environ.get('MYSQL_HOST')
self._port = int(os.environ.get('MYSQL_PORT'))
self._user = os.environ.get('MYSQL_USER')
self._password = os.environ.get('MYSQL_PASSWORD')
self._db = os.environ.get('MYSQL_DATABASES')
self._target_url = 'https://www.scrapingbee.com/blog/'
self._baseUrl = 'https://www.scrapingbee.com'
self._init_connection = connection_util.ProcessConnection()
logging_name = 'store_mysql'
init_logging = logger_config.LoggingConfig()
self._logging = init_logging.init_logging(logging_name)
def scrape_data(self):
get_content = self._init_connection.init_connection(self._target_url)
if get_content:
parent = get_content.findAll("section", {"class": "section-sm"})[0]
get_row = parent.findAll("div", {"class": "col-lg-12 mb-5 mb-lg-0"})[0]
get_child_item = get_row.findAll("div", {"class": "col-md-4 mb-4"})
for item in get_child_item:
# 获取标题文字
get_title = item.find("a", {"class": "h5 d-block mb-3 post-title"}).get_text()
# 获取发布时间
get_release_date = item.find("div", {"class": "mb-3 mt-2"}).findAll("span")[1].get_text()
# 获取文章描述
get_description = item.find("p", {"class": "card-text post-description"}).get_text()
self.article_save_mysql(title=get_title, description=get_description, release_date=get_release_date)
else:
self._logging.warning('未获取到文章任何内容,请检查!')
def article_save_mysql(self, title, description, release_date):
connection = pymysql.connect(host=self._host, port=self._port, user=self._user, password=self._password,
db=self._db, charset='utf-8')
with connection.cursor() as cursor:
# Create a new record
sql = "INSERT INTO articles (title,summary,create_time) VALUES (%s,%s,%s);"
cursor.execute(sql, (title, description, release_date))
# connection is not autocommit by default. So you must commit to save
# your changes.
connection.commit()
这里需要注意几点:首先,将 charset='utf-8' 添加到连接字符串中。这是为了让conn把所有发送到数据库的信息都当作utf-8编码格式(当然前提是数据库默认编码设置为UTF-8)。
然后需要注意article_save_mysql函数。它有3个参数:title、description和release_date,并将这两个参数添加到INSERT语句中并用游标执行,然后用游标确认。这是将光标与连接分开的一个很好的例子;当游标存储一些数据库和数据库上下文信息时,需要通过连接确认才能将信息传递到数据库中,然后再将信息插入到数据库中。
上述代码没有使用 try...finally 语句关闭数据库,而是使用 with() 关闭数据库连接。在上一期中,我们也使用了 with() 来关闭 CSV 文件。
PyMySQL的规模虽然不大,但里面有一些非常实用的功能,在本文章中就不演示了。具体请参考 Python DBAPI 标准文档。
以上是关于将采集的内容保存到MySQL。本示例的所有代码都托管在 github 上。
github:
文章采集api(【干货】Kubernetes日志采集难点分析(一)——Kubernetes)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-02-21 06:02
前言
上一期主要介绍了Kubernetes日志输出的一些注意事项。日志输出的最终目的是做统一的采集和分析。在 Kubernetes 中,记录采集的方式与普通虚拟机有很大不同,相对实现难度和部署成本也略高。但是,如果使用得当,可以实现比传统方式更高的自动化程度和更低的运维成本。
Kubernetes 日志采集 难点
在 Kubernetes 中,log采集 比传统的虚拟机和物理机要复杂得多。最根本的原因是Kubernetes屏蔽了底层异常,提供了更细粒度的资源调度,向上提供了一个稳定动态的环境。因此,日志采集面临着更丰富、更动态的环境,需要考虑的点也更多。
例如:
对于一个运行时间很短的Job应用,从启动到停止只需要几秒,如何保证日志采集的实时性能跟得上,数据不丢失?K8s 一般推荐使用大型节点。每个节点可以运行 10-100+ 个容器。如何以尽可能低的资源消耗采集100+ 个容器?在K8s中,应用以yaml的形式部署,日志采集主要是手动配置文件的形式。日志采集如何以K8s的方式部署?
Kubernetes传统日志类型文件、stdout、host文件、journal文件、journal日志源业务容器、系统组件、宿主业务、宿主采集方法代理(Sidecar、DaemonSet)、直写(DockerEngine、业务)代理、直接-write 单机应用号 10-1001-10 应用动态高低 节点动态高低 采集 部署方式手动、Yaml手动、自定义
采集模式:主动或被动
日志采集方法有两种:被动采集和主动推送。在K8s中,被动采集一般分为Sidecar和DaemonSet两种方式。主动推送包括 DockerEngine 推送和业务直推。写两种方式。
总结:DockerEngine直接写一般不推荐;日志量大的场景推荐业务直写;DaemonSet 一般用于中小型集群;建议在非常大的集群中使用 Sidecar。各种采集方法的详细对比如下:
DockerEngine业务直接写入DaemonSet方法Sidecar方法采集日志类型标准输出业务日志标准输出+部分文件文件部署运维低,原生支持低,只需要维护配置文件正常,需要为了维护 DaemonSet 高,每个需要 采集 日志的 POD 都需要部署一个 sidecar 容器。日志分类和存储无法实现业务无关的配置。一般来说,每个POD都可以通过容器/路径映射来单独配置,灵活性高,多租户隔离性较弱。日志直写一般会和业务逻辑竞争资源。只能通过强配置隔离,通过容器隔离,资源可独立分配,支持集群规模无限本地存储。如果使用 syslog 和 fluentd,根据配置会有单点限制和无限制。无限资源数量低,dockerengine提供整体最低,节省采集的成本,每个节点运行一个容器高,每个POD运行一个容器,查询便利性低,只有grep raw日志高,可根据业务特点定制高,可定制查询,高统计,可根据业务特点定制低高可定制性,可自由扩展低高,每个POD单独配置高耦合,并且强绑定 DockerEngine 固定,修改需要重启 DockerEngine 高,<
日志输出:标准输出或文件
与虚拟机/物理机不同,K8s 容器提供标准输出和文件。在容器中,标准输出直接将日志输出到stdout或stderr,DockerEngine接管stdout和stderr文件描述符,收到日志后根据DockerEngine配置的LogDriver规则进行处理;日志打印到文件的方式与虚拟机/物理机不同。基本类似,只是日志可以使用不同的存储方式,比如默认存储、EmptyDir、HostVolume、NFS等。
虽然 Docker 官方推荐使用 Stdout 打印日志,但需要注意的是,这个推荐是基于容器仅作为简单应用使用的场景。在实际业务场景中,我们还是建议大家尽量使用文件方式。主要原因如下。观点:
stdout性能问题,从应用输出stdout到服务器,会有几个过程(比如常用的JSON LogDriver):应用stdout -> DockerEngine -> LogDriver -> 序列化成JSON -> 保存到文件 -> Agent< @采集文件 -> 解析 JSON -> 上传服务器。整个过程需要比文件更多的开销。压力测试时,每秒输出 10 万行日志会占用 DockerEngine 的额外 CPU 内核。stdout 不支持分类,即所有输出混合在一个流中,不能像文件一样分类输出。通常,一个应用程序包括AccessLog、ErrorLog、InterfaceLog(调用外部接口的日志)、TraceLog等。这些日志的格式和用途不,会很难采集 如果在同一流中混合,则进行分析。stdout 只支持容器主程序的输出。如果是 daemon/fork 模式下运行的程序,则无法使用 stdout。文件转储方式支持多种策略,如同步/异步写入、缓存大小、文件轮换策略、压缩策略、清除策略等,相对更加灵活。
因此,我们建议在线应用使用文件输出日志,而Stdout仅用于功能单一或部分K8s系统/运维组件的应用。
CICD 集成:日志记录操作员
Kubernetes提供了标准化的业务部署方式,可以通过yaml(K8s API)声明路由规则、暴露服务、挂载存储、运行业务、定义伸缩规则等,因此Kubernetes很容易与CICD系统集成。日志采集也是运维监控过程的重要组成部分。必须实时采集业务上线后的所有日志。
原来的方法是在发布后手动部署log采集的逻辑。这种方式需要人工干预,违背了CICD自动化的目的;为了实现自动化,已经有人开始基于日志包装API/SDK采集一个自动部署的服务,发布后通过CICD的webhook触发调用,但是这种方式开发成本高。
在 Kubernetes 中,集成日志最标准的方式是在 Kubernetes 系统中注册一个新资源,并以 Operator(CRD)的形式对其进行管理和维护。这样CICD系统就不需要额外开发,部署到Kubernetes系统时只需要附加日志相关的配置即可。
Kubernetes 日志采集 方案
早在 Kubernetes 出现之前,我们就开始为容器环境开发 log采集 解决方案。随着K8s的逐渐稳定,我们开始将很多业务迁移到K8s平台上,所以我们也在之前的基础上开发了一套。K8s 上的 log采集 方案。主要功能有:
支持各种数据的实时采集,包括容器文件、容器Stdout、宿主文件、Journal、Event等;支持多种采集部署方式,包括DaemonSet、Sidecar、DockerEngine LogDriver等;日志数据丰富,包括Namespace、Pod、Container、Image、Node等附加信息;稳定高可靠,基于阿里巴巴自研Logtail采集Agent实现。目前,全网部署实例数以百万计。; 基于CRD扩展,日志采集规则可以以Kubernetes部署发布的方式部署,与CICD完美集成。
安装日志采集组件
目前,这个采集解决方案已经对外开放。我们提供 Helm 安装包,收录 Logtail 的 DaemonSet、AliyunlogConfig 的 CRD 声明和 CRD Controller。安装后直接使用DaemonS优采云采集器即可,CRD配置完毕。安装方法如下:
阿里云Kubernetes集群在激活的时候就可以安装,这样在创建集群的时候会自动安装以上的组件。如果激活的时候没有安装,可以手动安装。如果是自建Kubernetes,无论是自建在阿里云上还是在其他云上还是离线,都可以使用这个采集方案。具体安装方法请参考【自建Kubernetes安装】()。
上述组件安装完成后,Logtail和对应的Controller会在集群中运行,但默认这些组件不会采集任何日志,需要配置日志采集规则为采集@ > 指定各种日志的Pod。
采集规则配置:环境变量或CRD
除了在日志服务控制台手动配置外,Kubernetes 还支持另外两种配置方式:环境变量和 CRD。
环境变量是自swarm时代以来一直使用的配置方式。你只需要在你想要采集的容器环境变量上声明需要采集的数据地址,Logtail会自动采集这个数据>到服务器。该方法部署简单,学习成本低,易于使用;但是可以支持的配置规则很少,很多高级配置(如解析方式、过滤方式、黑白名单等)都不支持,而且这种声明方式也不支持修改/删除,每个修改实际上创建了一个新的 采集 配置。历史采集配置需要手动清理,否则会造成资源浪费。
CRD的配置方式非常符合Kubernetes官方推荐的标准扩展方式,允许采集配置以K8s资源的形式进行管理,通过部署特殊的CRD资源AliyunLogConfig到Kubernetes来声明数据这需要 采集。例如,下面的例子是部署一个容器的标准输出采集,其中定义需要Stdout和Stderr 采集,并且排除环境变量收录COLLEXT_STDOUT_FLAG: false的容器。基于CRD的配置方式以Kubernetes标准扩展资源的方式进行管理,支持配置的完整语义的增删改查,支持各种高级配置。
采集推荐的规则配置方式
在实际应用场景中,一般使用 DaemonSet 或者 DaemonSet 和 Sidecar 的混合。DaemonSet 的优点是资源利用率高。但是存在一个问题,DaemonSet的所有Logtail共享全局配置,单个Logtail有配置支持上限。因此,它无法支持具有大量应用程序的集群。以上是我们给出的推荐配置方式。核心思想是:
一个尽可能多的采集相似数据的配置,减少了配置的数量,减轻了DaemonSet的压力;核心应用 采集 需要获得足够的资源,并且可以使用 Sidecar 方法;配置方式尽量使用CRD方式;Sidecar 由于每个Logtail都是独立配置的,所以配置数量没有限制,适用于非常大的集群。
练习 1 - 中小型集群
大多数 Kubernetes 集群都是中小型的。中小企业没有明确的定义。一般应用数量小于500,节点规模小于1000。没有功能清晰的Kubernetes平台运维。这个场景的应用数量不是特别多,DaemonSet可以支持所有的采集配置:
大部分业务应用的数据使用DaemonS优采云采集器方式,核心应用(对于可靠性要求较高的采集,如订单/交易系统)单独使用Sidecar方式采集 @>
练习 2 - 大型集群
对于一些用作PAAS平台的大型/超大型集群,一般业务在1000以上,节点规模也在1000以上。有专门的Kubernetes平台运维人员。这种场景下应用的数量没有限制,DaemonSet 无法支持。因此,必须使用 Sidecar 方法。总体规划如下:
Kubernetes平台的系统组件日志和内核日志的类型是比较固定的。这部分日志使用了DaemonS优采云采集器,主要为平台的运维人员提供服务;每个业务的日志使用Sidecar方式采集,每个业务可以独立设置Sidecar的采集目的地址,为业务的DevOps人员提供了足够的灵活性。 查看全部
文章采集api(【干货】Kubernetes日志采集难点分析(一)——Kubernetes)
前言
上一期主要介绍了Kubernetes日志输出的一些注意事项。日志输出的最终目的是做统一的采集和分析。在 Kubernetes 中,记录采集的方式与普通虚拟机有很大不同,相对实现难度和部署成本也略高。但是,如果使用得当,可以实现比传统方式更高的自动化程度和更低的运维成本。
Kubernetes 日志采集 难点
在 Kubernetes 中,log采集 比传统的虚拟机和物理机要复杂得多。最根本的原因是Kubernetes屏蔽了底层异常,提供了更细粒度的资源调度,向上提供了一个稳定动态的环境。因此,日志采集面临着更丰富、更动态的环境,需要考虑的点也更多。
例如:
对于一个运行时间很短的Job应用,从启动到停止只需要几秒,如何保证日志采集的实时性能跟得上,数据不丢失?K8s 一般推荐使用大型节点。每个节点可以运行 10-100+ 个容器。如何以尽可能低的资源消耗采集100+ 个容器?在K8s中,应用以yaml的形式部署,日志采集主要是手动配置文件的形式。日志采集如何以K8s的方式部署?
Kubernetes传统日志类型文件、stdout、host文件、journal文件、journal日志源业务容器、系统组件、宿主业务、宿主采集方法代理(Sidecar、DaemonSet)、直写(DockerEngine、业务)代理、直接-write 单机应用号 10-1001-10 应用动态高低 节点动态高低 采集 部署方式手动、Yaml手动、自定义
采集模式:主动或被动
日志采集方法有两种:被动采集和主动推送。在K8s中,被动采集一般分为Sidecar和DaemonSet两种方式。主动推送包括 DockerEngine 推送和业务直推。写两种方式。
总结:DockerEngine直接写一般不推荐;日志量大的场景推荐业务直写;DaemonSet 一般用于中小型集群;建议在非常大的集群中使用 Sidecar。各种采集方法的详细对比如下:
DockerEngine业务直接写入DaemonSet方法Sidecar方法采集日志类型标准输出业务日志标准输出+部分文件文件部署运维低,原生支持低,只需要维护配置文件正常,需要为了维护 DaemonSet 高,每个需要 采集 日志的 POD 都需要部署一个 sidecar 容器。日志分类和存储无法实现业务无关的配置。一般来说,每个POD都可以通过容器/路径映射来单独配置,灵活性高,多租户隔离性较弱。日志直写一般会和业务逻辑竞争资源。只能通过强配置隔离,通过容器隔离,资源可独立分配,支持集群规模无限本地存储。如果使用 syslog 和 fluentd,根据配置会有单点限制和无限制。无限资源数量低,dockerengine提供整体最低,节省采集的成本,每个节点运行一个容器高,每个POD运行一个容器,查询便利性低,只有grep raw日志高,可根据业务特点定制高,可定制查询,高统计,可根据业务特点定制低高可定制性,可自由扩展低高,每个POD单独配置高耦合,并且强绑定 DockerEngine 固定,修改需要重启 DockerEngine 高,<
日志输出:标准输出或文件
与虚拟机/物理机不同,K8s 容器提供标准输出和文件。在容器中,标准输出直接将日志输出到stdout或stderr,DockerEngine接管stdout和stderr文件描述符,收到日志后根据DockerEngine配置的LogDriver规则进行处理;日志打印到文件的方式与虚拟机/物理机不同。基本类似,只是日志可以使用不同的存储方式,比如默认存储、EmptyDir、HostVolume、NFS等。
虽然 Docker 官方推荐使用 Stdout 打印日志,但需要注意的是,这个推荐是基于容器仅作为简单应用使用的场景。在实际业务场景中,我们还是建议大家尽量使用文件方式。主要原因如下。观点:
stdout性能问题,从应用输出stdout到服务器,会有几个过程(比如常用的JSON LogDriver):应用stdout -> DockerEngine -> LogDriver -> 序列化成JSON -> 保存到文件 -> Agent< @采集文件 -> 解析 JSON -> 上传服务器。整个过程需要比文件更多的开销。压力测试时,每秒输出 10 万行日志会占用 DockerEngine 的额外 CPU 内核。stdout 不支持分类,即所有输出混合在一个流中,不能像文件一样分类输出。通常,一个应用程序包括AccessLog、ErrorLog、InterfaceLog(调用外部接口的日志)、TraceLog等。这些日志的格式和用途不,会很难采集 如果在同一流中混合,则进行分析。stdout 只支持容器主程序的输出。如果是 daemon/fork 模式下运行的程序,则无法使用 stdout。文件转储方式支持多种策略,如同步/异步写入、缓存大小、文件轮换策略、压缩策略、清除策略等,相对更加灵活。
因此,我们建议在线应用使用文件输出日志,而Stdout仅用于功能单一或部分K8s系统/运维组件的应用。
CICD 集成:日志记录操作员
Kubernetes提供了标准化的业务部署方式,可以通过yaml(K8s API)声明路由规则、暴露服务、挂载存储、运行业务、定义伸缩规则等,因此Kubernetes很容易与CICD系统集成。日志采集也是运维监控过程的重要组成部分。必须实时采集业务上线后的所有日志。
原来的方法是在发布后手动部署log采集的逻辑。这种方式需要人工干预,违背了CICD自动化的目的;为了实现自动化,已经有人开始基于日志包装API/SDK采集一个自动部署的服务,发布后通过CICD的webhook触发调用,但是这种方式开发成本高。
在 Kubernetes 中,集成日志最标准的方式是在 Kubernetes 系统中注册一个新资源,并以 Operator(CRD)的形式对其进行管理和维护。这样CICD系统就不需要额外开发,部署到Kubernetes系统时只需要附加日志相关的配置即可。
Kubernetes 日志采集 方案
早在 Kubernetes 出现之前,我们就开始为容器环境开发 log采集 解决方案。随着K8s的逐渐稳定,我们开始将很多业务迁移到K8s平台上,所以我们也在之前的基础上开发了一套。K8s 上的 log采集 方案。主要功能有:
支持各种数据的实时采集,包括容器文件、容器Stdout、宿主文件、Journal、Event等;支持多种采集部署方式,包括DaemonSet、Sidecar、DockerEngine LogDriver等;日志数据丰富,包括Namespace、Pod、Container、Image、Node等附加信息;稳定高可靠,基于阿里巴巴自研Logtail采集Agent实现。目前,全网部署实例数以百万计。; 基于CRD扩展,日志采集规则可以以Kubernetes部署发布的方式部署,与CICD完美集成。
安装日志采集组件
目前,这个采集解决方案已经对外开放。我们提供 Helm 安装包,收录 Logtail 的 DaemonSet、AliyunlogConfig 的 CRD 声明和 CRD Controller。安装后直接使用DaemonS优采云采集器即可,CRD配置完毕。安装方法如下:
阿里云Kubernetes集群在激活的时候就可以安装,这样在创建集群的时候会自动安装以上的组件。如果激活的时候没有安装,可以手动安装。如果是自建Kubernetes,无论是自建在阿里云上还是在其他云上还是离线,都可以使用这个采集方案。具体安装方法请参考【自建Kubernetes安装】()。
上述组件安装完成后,Logtail和对应的Controller会在集群中运行,但默认这些组件不会采集任何日志,需要配置日志采集规则为采集@ > 指定各种日志的Pod。
采集规则配置:环境变量或CRD
除了在日志服务控制台手动配置外,Kubernetes 还支持另外两种配置方式:环境变量和 CRD。
环境变量是自swarm时代以来一直使用的配置方式。你只需要在你想要采集的容器环境变量上声明需要采集的数据地址,Logtail会自动采集这个数据>到服务器。该方法部署简单,学习成本低,易于使用;但是可以支持的配置规则很少,很多高级配置(如解析方式、过滤方式、黑白名单等)都不支持,而且这种声明方式也不支持修改/删除,每个修改实际上创建了一个新的 采集 配置。历史采集配置需要手动清理,否则会造成资源浪费。
CRD的配置方式非常符合Kubernetes官方推荐的标准扩展方式,允许采集配置以K8s资源的形式进行管理,通过部署特殊的CRD资源AliyunLogConfig到Kubernetes来声明数据这需要 采集。例如,下面的例子是部署一个容器的标准输出采集,其中定义需要Stdout和Stderr 采集,并且排除环境变量收录COLLEXT_STDOUT_FLAG: false的容器。基于CRD的配置方式以Kubernetes标准扩展资源的方式进行管理,支持配置的完整语义的增删改查,支持各种高级配置。
采集推荐的规则配置方式
在实际应用场景中,一般使用 DaemonSet 或者 DaemonSet 和 Sidecar 的混合。DaemonSet 的优点是资源利用率高。但是存在一个问题,DaemonSet的所有Logtail共享全局配置,单个Logtail有配置支持上限。因此,它无法支持具有大量应用程序的集群。以上是我们给出的推荐配置方式。核心思想是:
一个尽可能多的采集相似数据的配置,减少了配置的数量,减轻了DaemonSet的压力;核心应用 采集 需要获得足够的资源,并且可以使用 Sidecar 方法;配置方式尽量使用CRD方式;Sidecar 由于每个Logtail都是独立配置的,所以配置数量没有限制,适用于非常大的集群。
练习 1 - 中小型集群
大多数 Kubernetes 集群都是中小型的。中小企业没有明确的定义。一般应用数量小于500,节点规模小于1000。没有功能清晰的Kubernetes平台运维。这个场景的应用数量不是特别多,DaemonSet可以支持所有的采集配置:
大部分业务应用的数据使用DaemonS优采云采集器方式,核心应用(对于可靠性要求较高的采集,如订单/交易系统)单独使用Sidecar方式采集 @>
练习 2 - 大型集群
对于一些用作PAAS平台的大型/超大型集群,一般业务在1000以上,节点规模也在1000以上。有专门的Kubernetes平台运维人员。这种场景下应用的数量没有限制,DaemonSet 无法支持。因此,必须使用 Sidecar 方法。总体规划如下:
Kubernetes平台的系统组件日志和内核日志的类型是比较固定的。这部分日志使用了DaemonS优采云采集器,主要为平台的运维人员提供服务;每个业务的日志使用Sidecar方式采集,每个业务可以独立设置Sidecar的采集目的地址,为业务的DevOps人员提供了足够的灵活性。
文章采集api(来说获得用户专栏文章的链接信息,此乃神器!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2022-02-17 05:24
目前还没有官方API支持。或许最有用的就是用户的“个性化URL”(好别扭,以下简称UID),比如黄继新老师的UID:jixin,不过可以用户自己修改,但是每个用户都必须是独特的。
将对应的 UID 替换为 {{%UID}}。
1. 获取用户列条目:
URI: http://www.zhihu.com/people/{{%UID}}/posts GET/HTTP 1.1
XPATH: //div[@id='zh-profile-list-container']
通过解析上述内容,可以得到用户的所有列入口地址。
2. 获取列 文章 信息:
URI: http://zhuanlan.zhihu.com/api/columns/{{%UID}}/posts?limit={{%LIMIT}}&offset={{%OFFSET}} GET/HTTP 1.1
{{%LIMIT}}:表示本次GET请求获取的数据项个数,即文章列信息的个数。我没有具体测试过最大值是多少,但是可以设置大于默认值。默认值为 10。
{{%OFFSET}}:表示本次GET请求获取的数据项的起始偏移量。
通过分析以上内容,可以得到每一列文章的信息,如标题、题图、列文章摘要、发布时间、批准数等。请求返回JSON数据。
注意:解析该信息时,可以得到该列文章的链接信息。
3. 获取列 文章:
URI: http://zhuanlan.zhihu.com/api/columns/{{%UID}}/posts/{{%SLUG}} GET/HTTP 1.1
{{%SLUG}}:是2中得到的文章链接信息,目前是8位数字。
通过分析以上内容,可以得到文章栏的内容,以及文章的一些相关信息。请求返回 JSON 数据。
以上应该足以满足题主的要求。最重要的是用好Chrome调试工具,这是神器!
* * * * * * * * * *
这里有一些零散的更新来记录 知乎 爬虫的想法。当然,相关实现还是需要尊重ROBOTS协议,可以通过
/机器人.txt
检查相关参数。
UID是用户所有信息的入口。
虽然用户信息有修改间隔限制(一般为几个月不等),但考虑到即使是修改用户名的操作也会导致UID发生变化,从而使之前的存储失效。当然,这也可以破解:用户哈希。这个哈希值是一个 32 位的字符串,对于每个账户来说都是唯一且不变的。
通过 UID 获取哈希:
URI: http://www.zhihu.com/people/%{{UID}} GET/HTTP 1.1
XPATH: //body/div[@class='zg-wrap zu-main']//div[@class='zm-profile-header-op-btns clearfix']/button/@data-id
通过解析上面的内容,可以得到UID对应的hash值。(是的,该值存储在“关注/取消关注”按钮中。)这唯一地标识了用户。
目前没有办法通过hash_id获取UID,但是有间接方法可以参考:定期通过关注列表查看用户信息是否发生变化,当然关注/取消关注操作也可以自动化:
关注操作
URI: http://www.zhihu.com/node/MemberFollowBaseV2 POST/HTTP 1.1
Form Data
method: follow_member
params: {"hash_id": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"}
_xsrf:
取消关注操作
URI: http://www.zhihu.com/node/MemberFollowBaseV2 POST/HTTP 1.1
Form Data
method: unfollow_member
params: {"hash_id": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"}
_xsrf:
知乎爬虫需要一个UID列表才能正常运行,如何获取这个列表是需要考虑的问题。目前一个可行的思路是选择几个大V用户,批量爬取他们的关注列表。比如张老师目前跟随着58W+,通过:
URI: http://www.zhihu.com/node/ProfileFollowersListV2 POST/HTTP 1.1
Form Data
method: next
params: {"offset": {{%OFFSET}}, "order_by": "hash_id", "hash_id": "{{%HASHID}}"}
_xsrf:
每次可以获得20个关注者的用户信息。此信息包括 hash_id、用户名、UID、关注者/关注者数量、问题数量、答案数量等。 查看全部
文章采集api(来说获得用户专栏文章的链接信息,此乃神器!)
目前还没有官方API支持。或许最有用的就是用户的“个性化URL”(好别扭,以下简称UID),比如黄继新老师的UID:jixin,不过可以用户自己修改,但是每个用户都必须是独特的。
将对应的 UID 替换为 {{%UID}}。
1. 获取用户列条目:
URI: http://www.zhihu.com/people/{{%UID}}/posts GET/HTTP 1.1
XPATH: //div[@id='zh-profile-list-container']
通过解析上述内容,可以得到用户的所有列入口地址。
2. 获取列 文章 信息:
URI: http://zhuanlan.zhihu.com/api/columns/{{%UID}}/posts?limit={{%LIMIT}}&offset={{%OFFSET}} GET/HTTP 1.1
{{%LIMIT}}:表示本次GET请求获取的数据项个数,即文章列信息的个数。我没有具体测试过最大值是多少,但是可以设置大于默认值。默认值为 10。
{{%OFFSET}}:表示本次GET请求获取的数据项的起始偏移量。
通过分析以上内容,可以得到每一列文章的信息,如标题、题图、列文章摘要、发布时间、批准数等。请求返回JSON数据。
注意:解析该信息时,可以得到该列文章的链接信息。
3. 获取列 文章:
URI: http://zhuanlan.zhihu.com/api/columns/{{%UID}}/posts/{{%SLUG}} GET/HTTP 1.1
{{%SLUG}}:是2中得到的文章链接信息,目前是8位数字。
通过分析以上内容,可以得到文章栏的内容,以及文章的一些相关信息。请求返回 JSON 数据。
以上应该足以满足题主的要求。最重要的是用好Chrome调试工具,这是神器!
* * * * * * * * * *
这里有一些零散的更新来记录 知乎 爬虫的想法。当然,相关实现还是需要尊重ROBOTS协议,可以通过
/机器人.txt
检查相关参数。
UID是用户所有信息的入口。
虽然用户信息有修改间隔限制(一般为几个月不等),但考虑到即使是修改用户名的操作也会导致UID发生变化,从而使之前的存储失效。当然,这也可以破解:用户哈希。这个哈希值是一个 32 位的字符串,对于每个账户来说都是唯一且不变的。
通过 UID 获取哈希:
URI: http://www.zhihu.com/people/%{{UID}} GET/HTTP 1.1
XPATH: //body/div[@class='zg-wrap zu-main']//div[@class='zm-profile-header-op-btns clearfix']/button/@data-id
通过解析上面的内容,可以得到UID对应的hash值。(是的,该值存储在“关注/取消关注”按钮中。)这唯一地标识了用户。
目前没有办法通过hash_id获取UID,但是有间接方法可以参考:定期通过关注列表查看用户信息是否发生变化,当然关注/取消关注操作也可以自动化:
关注操作
URI: http://www.zhihu.com/node/MemberFollowBaseV2 POST/HTTP 1.1
Form Data
method: follow_member
params: {"hash_id": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"}
_xsrf:
取消关注操作
URI: http://www.zhihu.com/node/MemberFollowBaseV2 POST/HTTP 1.1
Form Data
method: unfollow_member
params: {"hash_id": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"}
_xsrf:
知乎爬虫需要一个UID列表才能正常运行,如何获取这个列表是需要考虑的问题。目前一个可行的思路是选择几个大V用户,批量爬取他们的关注列表。比如张老师目前跟随着58W+,通过:
URI: http://www.zhihu.com/node/ProfileFollowersListV2 POST/HTTP 1.1
Form Data
method: next
params: {"offset": {{%OFFSET}}, "order_by": "hash_id", "hash_id": "{{%HASHID}}"}
_xsrf:
每次可以获得20个关注者的用户信息。此信息包括 hash_id、用户名、UID、关注者/关注者数量、问题数量、答案数量等。
文章采集api(什么是zhihu-articles-api(.json)。。)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-02-16 14:20
简介:知乎-articles-api
将您的 知乎文章 导出为可用的 API (.json)。
什么是知乎文章API?
知乎-articles-api 是一个基于 JavaScript DOM 的脚本,通过 DOM 将你的 知乎文章 导出为 json 格式的 API 文档,其中收录标题、链接、标题图等信息。这些 API 可用于其他网站或您自己来显示您创建的内容。当用户访问这些内容时,用户会跳转到知乎,从而批准和评论您的内容。
如何使用知乎文章API?
与其他 JavaScript 脚本一样,您需要使用浏览器的调试功能来执行这些脚本。
首先,您需要访问您的个人主页。
知乎的个人主页一般是:
您的个人域名
如果您不知道自己的个人域名,可以从首页右上角的头像访问“我的首页”。
切换到“文章”选项卡
zaa 只能在该选项卡下工作。
如果您希望导出其他内容,请务必仔细阅读源代码并修改相关内容。
在这个选项卡下,通过调试脚本的执行,浏览器会自动下载一个名为username.json的文件。
脚本:
例子:
{
"Article_0": {
"headline": "为K100 Pro更换更大容量的电池",
"url": "zhuanlan.zhihu.com/p/205607070",
"dateP": "2020-08-29T14:22:15.000Z",
"dateM": "2020-09-01T17:17:49.000Z",
"img": "https://pic4.zhimg.com/v2-8ac0 ... ot%3B
},
"Article_1": {
"headline": "ES6动态计算属性名的另外一种用法/属性名表达式",
"url": "zhuanlan.zhihu.com/p/199698763",
"dateP": "2020-08-26T15:24:06.000Z",
"dateM": "2020-08-27T02:42:41.000Z",
"img": "https://pic4.zhimg.com/v2-8ac0 ... ot%3B
},
"Article_2": {
"headline": "为Vuetify的UI组件添加滚动条",
"url": "zhuanlan.zhihu.com/p/196736891",
"dateP": "2020-08-24T10:25:53.000Z",
"dateM": "2020-08-24T10:25:53.000Z",
"img": "https://pic4.zhimg.com/v2-8ac0 ... ot%3B
},
"Article_3": {
"headline": "解决移动端左右滑动/溢出问题",
"url": "zhuanlan.zhihu.com/p/194403402",
"dateP": "2020-08-22T16:20:05.000Z",
"dateM": "2020-08-22T16:20:05.000Z",
"img": "https://pic4.zhimg.com/v2-8ac0 ... ot%3B
},
知乎-articles-api 合法吗?
与所有爬虫、API 等一样,请确保您在相关用户协议的规范范围内使用您获取的内容。
由于 知乎-articles-api 在 DOM 上运行,获取的内容是公开可用的,并且已经加载到用户端,我认为这不会导致非法行为。
但是,请不要将本脚本用于非您创作的内容,也不要将本脚本获得的内容用于商业目的,本人对本脚本的任何使用概不负责。
我还是不明白这个脚本是做什么的
对于托管在 Github 上的静态页面,如何动态生成博文是一个非常棘手的问题。如果使用普通的静态页面生成器(markdown),虽然可行,但还是不方便更新维护。个人网站的流量往往比较少,不利于创意内容的传播。
通过知乎-articles-api,将你的文章转换成API,生成json文件。将此文件部署到对象存储并进行 CDN 分发。根据这个json文件生成文章的列表,可以实现创作内容的迁移。只要在云端修改json文件,就可以动态修改静态页面的内容,无需重新生成静态页面。
简单来说,你将自己创建的内容托管在知乎上,相关的静态资源也托管在知乎的服务器上。
已知问题和版本更新:
版本 1.00:
如果你的标题图片是.png格式的透明文件,知乎可能会在服务器上生成两个文件,白色背景和源文件。通过知乎-articles-api生成json文件时,只能访问前者。如果您的网站使用深色主题或夜间模式,则可能值得考虑将 知乎 源文件替换为其他来源的 .png 文件。
感激:
将对象导出为 JSON:
根据自定义属性获取元素(原文已过期,这是转载链接): 查看全部
文章采集api(什么是zhihu-articles-api(.json)。。)
简介:知乎-articles-api
将您的 知乎文章 导出为可用的 API (.json)。
什么是知乎文章API?
知乎-articles-api 是一个基于 JavaScript DOM 的脚本,通过 DOM 将你的 知乎文章 导出为 json 格式的 API 文档,其中收录标题、链接、标题图等信息。这些 API 可用于其他网站或您自己来显示您创建的内容。当用户访问这些内容时,用户会跳转到知乎,从而批准和评论您的内容。
如何使用知乎文章API?
与其他 JavaScript 脚本一样,您需要使用浏览器的调试功能来执行这些脚本。
首先,您需要访问您的个人主页。
知乎的个人主页一般是:
您的个人域名
如果您不知道自己的个人域名,可以从首页右上角的头像访问“我的首页”。
切换到“文章”选项卡
zaa 只能在该选项卡下工作。
如果您希望导出其他内容,请务必仔细阅读源代码并修改相关内容。
在这个选项卡下,通过调试脚本的执行,浏览器会自动下载一个名为username.json的文件。
脚本:
例子:
{
"Article_0": {
"headline": "为K100 Pro更换更大容量的电池",
"url": "zhuanlan.zhihu.com/p/205607070",
"dateP": "2020-08-29T14:22:15.000Z",
"dateM": "2020-09-01T17:17:49.000Z",
"img": "https://pic4.zhimg.com/v2-8ac0 ... ot%3B
},
"Article_1": {
"headline": "ES6动态计算属性名的另外一种用法/属性名表达式",
"url": "zhuanlan.zhihu.com/p/199698763",
"dateP": "2020-08-26T15:24:06.000Z",
"dateM": "2020-08-27T02:42:41.000Z",
"img": "https://pic4.zhimg.com/v2-8ac0 ... ot%3B
},
"Article_2": {
"headline": "为Vuetify的UI组件添加滚动条",
"url": "zhuanlan.zhihu.com/p/196736891",
"dateP": "2020-08-24T10:25:53.000Z",
"dateM": "2020-08-24T10:25:53.000Z",
"img": "https://pic4.zhimg.com/v2-8ac0 ... ot%3B
},
"Article_3": {
"headline": "解决移动端左右滑动/溢出问题",
"url": "zhuanlan.zhihu.com/p/194403402",
"dateP": "2020-08-22T16:20:05.000Z",
"dateM": "2020-08-22T16:20:05.000Z",
"img": "https://pic4.zhimg.com/v2-8ac0 ... ot%3B
},
知乎-articles-api 合法吗?
与所有爬虫、API 等一样,请确保您在相关用户协议的规范范围内使用您获取的内容。
由于 知乎-articles-api 在 DOM 上运行,获取的内容是公开可用的,并且已经加载到用户端,我认为这不会导致非法行为。
但是,请不要将本脚本用于非您创作的内容,也不要将本脚本获得的内容用于商业目的,本人对本脚本的任何使用概不负责。
我还是不明白这个脚本是做什么的
对于托管在 Github 上的静态页面,如何动态生成博文是一个非常棘手的问题。如果使用普通的静态页面生成器(markdown),虽然可行,但还是不方便更新维护。个人网站的流量往往比较少,不利于创意内容的传播。
通过知乎-articles-api,将你的文章转换成API,生成json文件。将此文件部署到对象存储并进行 CDN 分发。根据这个json文件生成文章的列表,可以实现创作内容的迁移。只要在云端修改json文件,就可以动态修改静态页面的内容,无需重新生成静态页面。
简单来说,你将自己创建的内容托管在知乎上,相关的静态资源也托管在知乎的服务器上。
已知问题和版本更新:
版本 1.00:
如果你的标题图片是.png格式的透明文件,知乎可能会在服务器上生成两个文件,白色背景和源文件。通过知乎-articles-api生成json文件时,只能访问前者。如果您的网站使用深色主题或夜间模式,则可能值得考虑将 知乎 源文件替换为其他来源的 .png 文件。
感激:
将对象导出为 JSON:
根据自定义属性获取元素(原文已过期,这是转载链接):
文章采集api(网站权重越高是不是收录速度就越快,是不是DedeCMS采集 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2022-02-16 06:26
)
网站权重越高收录速度越快,有没有可能只要网站权重足够高网站内容可以秒做< @收录? 对于新站点,低权限站点是否无法实现快速内容收录?这样想是一厢情愿的想法,也是不成熟的想法。
决定网站内容爬取速度的因素,以及搜索引擎影响网站爬取速度的核心因素,还是取决于你内容的属性。对于咨询等具有一定时效性内容属性的网站,可以实现较好的收录速度,秒级收录即可。基于搜索引擎,意思是给用户他们需要的信息。但信息化信息属于优质内容,类似重复内容的概率相对较小,因此更有价值。今天教大家一个快速的采集优质文章Dedecms采集(很多大佬都在用)。
这个dedecms采集不需要学习更专业的技术,简单几步就可以轻松采集内容数据,用户只需要dedecms采集@对>进行简单的设置,完成后dedecms采集会根据用户设置的关键词匹配内容和图片的准确率,可以选择保存在本地或者选择< @k1@ >发布后,提供方便快捷的内容采集伪原创发布服务!!
和其他的Dedecms采集相比,这个Dedecms采集基本没有什么门槛,也不需要花很多时间去学习正则表达式或者html标签,一分钟只需要输入关键词即可实现采集(dedecms采集也自带关键词采集的功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这类Dedecms采集发布插件工具还配备了很多SEO功能。通过采集伪原创软件发布时,还可以提升很多SEO优化。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、内容或标题插入,以及网站内容插入或随机作者、随机阅读等,形成一个“高原创”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
比如当大家看到一个引起你注意的热搜,当你需要了解相关信息的时候,如果搜索引擎不能快速抓取并展示相关内容,那么就是非常糟糕的用户体验。.
这再次建立在上述观点之上,如果高权重 网站 可以获得良好的 收录 速度,那么会发生什么?一般来说,很多高权重的网站信息量很大。如果权重高再去快速收录,很有可能搜索引擎抓取压力太大,所以显示很不切实际的快速收录对于很多< @网站。
比如图库网站,很多这类网站网站的权重很高,每天的内容可能会增加成百上千。但是,这类网站的特点就是内容在网络上并不特殊,也没有时效性,那么秒收这些网站又有什么意义呢。不仅不是秒收录,这种类型的网站很多页面都不是收录。
很多人会惊讶,权重这么高,怎么可能不是收录?首先,例如,图像 网站 的权重为 7,而另一个新闻类 网站 的权重仅为 5。
基本上基于以上两点,新闻网站的收录速度比较快。一是权重不是决定收录的因素,二是所谓权重只是第三方工具根据关键词预测流量。根据预估的站点流量,根据流量大小确定网站的权重评价。对于搜索引擎来说,根本就没有所谓的权重,所以很多时候,权重高的网站在各方面的表现并不一定比搜索引擎好。重量轻 网站 有利于速度。
权重只能作为优化程度的参考,所以单纯认为权重高网站可以快收录就更加荒谬了。
可以低权重网站秒收录吗?答案是肯定的,我体验过很多权重只有1的网站,还可以优化到秒。基本上只要内容质量还可以,秒级接收还可以的文字内容还是比较容易的。收录是SEO优化的基本开始,网站内容秒数并不决定你的内容能否上榜。
网站即使你能做到内容秒收录,并不代表你能获得好的排名,即使你有排名,也不一定意味着你有流量。
更多流量仍然取决于您的内容的受欢迎程度。许多网站非常擅长在几秒钟内采集内容。事实上,这类内容的竞争很小,本身也不是很受欢迎,所以很容易成为比较。易收录内容,快收录不是什么难技巧。
如果能在竞争激烈的内容下实现快速收录,那可以说是非常不错了。在同样的内容网站下,大致可以认为此时的权重较高。收录速度越快,此时越科学。快并不代表秒收,只是凸显了一个时间的速度。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。每天跟着博主为你展示各种SEO经验,打通你的两条血脉!
查看全部
文章采集api(网站权重越高是不是收录速度就越快,是不是DedeCMS采集
)
网站权重越高收录速度越快,有没有可能只要网站权重足够高网站内容可以秒做< @收录? 对于新站点,低权限站点是否无法实现快速内容收录?这样想是一厢情愿的想法,也是不成熟的想法。

决定网站内容爬取速度的因素,以及搜索引擎影响网站爬取速度的核心因素,还是取决于你内容的属性。对于咨询等具有一定时效性内容属性的网站,可以实现较好的收录速度,秒级收录即可。基于搜索引擎,意思是给用户他们需要的信息。但信息化信息属于优质内容,类似重复内容的概率相对较小,因此更有价值。今天教大家一个快速的采集优质文章Dedecms采集(很多大佬都在用)。

这个dedecms采集不需要学习更专业的技术,简单几步就可以轻松采集内容数据,用户只需要dedecms采集@对>进行简单的设置,完成后dedecms采集会根据用户设置的关键词匹配内容和图片的准确率,可以选择保存在本地或者选择< @k1@ >发布后,提供方便快捷的内容采集伪原创发布服务!!

和其他的Dedecms采集相比,这个Dedecms采集基本没有什么门槛,也不需要花很多时间去学习正则表达式或者html标签,一分钟只需要输入关键词即可实现采集(dedecms采集也自带关键词采集的功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。

几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。

这类Dedecms采集发布插件工具还配备了很多SEO功能。通过采集伪原创软件发布时,还可以提升很多SEO优化。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、内容或标题插入,以及网站内容插入或随机作者、随机阅读等,形成一个“高原创”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
比如当大家看到一个引起你注意的热搜,当你需要了解相关信息的时候,如果搜索引擎不能快速抓取并展示相关内容,那么就是非常糟糕的用户体验。.
这再次建立在上述观点之上,如果高权重 网站 可以获得良好的 收录 速度,那么会发生什么?一般来说,很多高权重的网站信息量很大。如果权重高再去快速收录,很有可能搜索引擎抓取压力太大,所以显示很不切实际的快速收录对于很多< @网站。
比如图库网站,很多这类网站网站的权重很高,每天的内容可能会增加成百上千。但是,这类网站的特点就是内容在网络上并不特殊,也没有时效性,那么秒收这些网站又有什么意义呢。不仅不是秒收录,这种类型的网站很多页面都不是收录。
很多人会惊讶,权重这么高,怎么可能不是收录?首先,例如,图像 网站 的权重为 7,而另一个新闻类 网站 的权重仅为 5。
基本上基于以上两点,新闻网站的收录速度比较快。一是权重不是决定收录的因素,二是所谓权重只是第三方工具根据关键词预测流量。根据预估的站点流量,根据流量大小确定网站的权重评价。对于搜索引擎来说,根本就没有所谓的权重,所以很多时候,权重高的网站在各方面的表现并不一定比搜索引擎好。重量轻 网站 有利于速度。
权重只能作为优化程度的参考,所以单纯认为权重高网站可以快收录就更加荒谬了。
可以低权重网站秒收录吗?答案是肯定的,我体验过很多权重只有1的网站,还可以优化到秒。基本上只要内容质量还可以,秒级接收还可以的文字内容还是比较容易的。收录是SEO优化的基本开始,网站内容秒数并不决定你的内容能否上榜。
网站即使你能做到内容秒收录,并不代表你能获得好的排名,即使你有排名,也不一定意味着你有流量。
更多流量仍然取决于您的内容的受欢迎程度。许多网站非常擅长在几秒钟内采集内容。事实上,这类内容的竞争很小,本身也不是很受欢迎,所以很容易成为比较。易收录内容,快收录不是什么难技巧。

如果能在竞争激烈的内容下实现快速收录,那可以说是非常不错了。在同样的内容网站下,大致可以认为此时的权重较高。收录速度越快,此时越科学。快并不代表秒收,只是凸显了一个时间的速度。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。每天跟着博主为你展示各种SEO经验,打通你的两条血脉!

文章采集api(4.1API通用规则API用一套非常标准的规则生成数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-02-12 10:13
一般情况下,程序员可以使用HTPP协议向API发起请求,获取一定的信息,API会以XML或JSON格式返回服务器响应信息。
API 使用通常不被视为网络数据采集,但实际上使用的许多技术(都发送 HTTP 请求)和结果(都获取信息)是相似的;两者经常有重叠的相容关系。
例如,结合 Wikipedia 编辑历史记录(其中收录编辑者的 IP 地址)和 IP 地址解析 API 以获取 Wikipedia 条目的编辑者的地理位置。
4.1 API 概述
谷歌 API
4.2 API 通用规则
API 使用一套非常标准的规则来生成数据,并且生成的数据以非常标准的方式组织。
四种方式:GET、POST、PUT、DELETE
验证:需要客户端验证
4.3 服务器响应
大多数反馈数据格式是 XML 和 JSON
过去,服务器端使用 PHP 和 .NET 等程序作为 API 的接收端。现在,服务器端也使用一些 JavaScript 框架作为 API 的发送和接收端,例如 Angular 或 Backbone。
接口调用:
4.4 回声巢穴
回声巢音乐资料网站
4.5 推特 API
点安装推特
from twitter import Twitter
t = Twitter(auth=OAuth(,,,))
pythonTweets = t.search.tweets(q = "#python")
print(pythonTweets)
鸣叫 4.6 个 Google API
无论您想使用哪种信息,包括语言翻译、地理位置、日历,甚至基因数据,Google 都提供 API。Google 还为其一些知名应用程序提供 API,例如 Gmail、YouTube 和 Blogger。
4.7 解析 JSON 数据
import json
from urllib.request import urlopen
def getCountry(ipAddress):
response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
responseJson = json.loads(response)
return responseJson.get("country_code")
print(getCountry("50.78.253.58"))
4.8 返回主题
将多个数据源组合成新的形式,或者使用 API 作为工具从新的角度解释数据采集。
先做一个采集维基百科的基础程序,找到编辑历史页面,然后在编辑历史中找出IP地址
# -*- coding: utf-8 -*-
from urllib.request import urlopen
from bs4 import BeautifulSoup
import datetime
import random
import re
import json
random.seed(datetime.datetime.now())
# https://en.wikipedia.org/wiki/Python_(programming_language)
def getLinks(articleUrl):
html = urlopen("http://en.wikipedia.org"+articleUrl)
bsObj = BeautifulSoup(html)
return bsObj.find("div",{"id":"bodyContent"}).findAll("a", href=re.compile("^(/wiki/)((?!:).)*$"))
def getHistoryIPs(pageUrl):
# 编辑历史页面URL链接格式是:
# https://en.wikipedia.org/w/index.php?title=Python_(programming_language)&action=history
pageUrl = pageUrl.replace("/wiki/", "")
historyUrl = "https://en.wikipedia.org/w/ind ... ot%3B
print("history url is: "+historyUrl)
html = urlopen(historyUrl)
bsObj = BeautifulSoup(html)
# 找出class属性是"mw-anonuserlink"的链接
# 它们用IP地址代替用户名
ipAddresses = bsObj.findAll("a", {"class":"mw-anonuserlink"})
addressList = set()
for ipAddress in ipAddresses:
addressList.add(ipAddress.get_text())
return addressList
links = getLinks("/wiki/Python_(programming_language)")
def getCountry(ipAddress):
try:
response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
except HTTPError:
return None
responseJson = json.loads(response)
return responseJson.get("country_code")
while (len(links) > 0):
for link in links:
print("-------------------")
historyIPs = getHistoryIPs(link.attrs["href"])
for historyIP in historyIPs:
#print(historyIP)
country = getCountry(historyIP)
if country is not None:
print(historyIP+" is from "+country)
newLink = links[random.randint(0, len(links)-1)].attrs["href"]
links = getLinks(newLink)
4.9 更多 API
Leonard Richardson、Mike Amundsen 和 Sam Ruby 的 RESTful Web APIs ( ) 为使用 Web APIs 提供了非常全面的理论和实践指南。此外,Mike Amundsen 的精彩视频教程 Designing APIs for the Web() 教您如何创建自己的 API。如果您想以方便的方式分享您的 采集 数据,他的视频非常有用 查看全部
文章采集api(4.1API通用规则API用一套非常标准的规则生成数据)
一般情况下,程序员可以使用HTPP协议向API发起请求,获取一定的信息,API会以XML或JSON格式返回服务器响应信息。
API 使用通常不被视为网络数据采集,但实际上使用的许多技术(都发送 HTTP 请求)和结果(都获取信息)是相似的;两者经常有重叠的相容关系。
例如,结合 Wikipedia 编辑历史记录(其中收录编辑者的 IP 地址)和 IP 地址解析 API 以获取 Wikipedia 条目的编辑者的地理位置。
4.1 API 概述
谷歌 API
4.2 API 通用规则
API 使用一套非常标准的规则来生成数据,并且生成的数据以非常标准的方式组织。
四种方式:GET、POST、PUT、DELETE
验证:需要客户端验证
4.3 服务器响应
大多数反馈数据格式是 XML 和 JSON
过去,服务器端使用 PHP 和 .NET 等程序作为 API 的接收端。现在,服务器端也使用一些 JavaScript 框架作为 API 的发送和接收端,例如 Angular 或 Backbone。
接口调用:
4.4 回声巢穴
回声巢音乐资料网站
4.5 推特 API
点安装推特
from twitter import Twitter
t = Twitter(auth=OAuth(,,,))
pythonTweets = t.search.tweets(q = "#python")
print(pythonTweets)
鸣叫 4.6 个 Google API
无论您想使用哪种信息,包括语言翻译、地理位置、日历,甚至基因数据,Google 都提供 API。Google 还为其一些知名应用程序提供 API,例如 Gmail、YouTube 和 Blogger。
4.7 解析 JSON 数据
import json
from urllib.request import urlopen
def getCountry(ipAddress):
response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
responseJson = json.loads(response)
return responseJson.get("country_code")
print(getCountry("50.78.253.58"))
4.8 返回主题
将多个数据源组合成新的形式,或者使用 API 作为工具从新的角度解释数据采集。
先做一个采集维基百科的基础程序,找到编辑历史页面,然后在编辑历史中找出IP地址
# -*- coding: utf-8 -*-
from urllib.request import urlopen
from bs4 import BeautifulSoup
import datetime
import random
import re
import json
random.seed(datetime.datetime.now())
# https://en.wikipedia.org/wiki/Python_(programming_language)
def getLinks(articleUrl):
html = urlopen("http://en.wikipedia.org"+articleUrl)
bsObj = BeautifulSoup(html)
return bsObj.find("div",{"id":"bodyContent"}).findAll("a", href=re.compile("^(/wiki/)((?!:).)*$"))
def getHistoryIPs(pageUrl):
# 编辑历史页面URL链接格式是:
# https://en.wikipedia.org/w/index.php?title=Python_(programming_language)&action=history
pageUrl = pageUrl.replace("/wiki/", "")
historyUrl = "https://en.wikipedia.org/w/ind ... ot%3B
print("history url is: "+historyUrl)
html = urlopen(historyUrl)
bsObj = BeautifulSoup(html)
# 找出class属性是"mw-anonuserlink"的链接
# 它们用IP地址代替用户名
ipAddresses = bsObj.findAll("a", {"class":"mw-anonuserlink"})
addressList = set()
for ipAddress in ipAddresses:
addressList.add(ipAddress.get_text())
return addressList
links = getLinks("/wiki/Python_(programming_language)")
def getCountry(ipAddress):
try:
response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
except HTTPError:
return None
responseJson = json.loads(response)
return responseJson.get("country_code")
while (len(links) > 0):
for link in links:
print("-------------------")
historyIPs = getHistoryIPs(link.attrs["href"])
for historyIP in historyIPs:
#print(historyIP)
country = getCountry(historyIP)
if country is not None:
print(historyIP+" is from "+country)
newLink = links[random.randint(0, len(links)-1)].attrs["href"]
links = getLinks(newLink)
4.9 更多 API
Leonard Richardson、Mike Amundsen 和 Sam Ruby 的 RESTful Web APIs ( ) 为使用 Web APIs 提供了非常全面的理论和实践指南。此外,Mike Amundsen 的精彩视频教程 Designing APIs for the Web() 教您如何创建自己的 API。如果您想以方便的方式分享您的 采集 数据,他的视频非常有用
文章采集api(终于找到解决方案了,这是一个值得庆祝的事情..)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-02-11 00:09
终于找到了解决办法,值得庆贺....
原来是因为微信在源码中添加了反采集代码,把文章源码中的这一段去掉就好了!
具体代码如下:
public function getCon(){<br style="margin:0px;padding:0px;" /> header('Content-type: text/html; charset=utf-8');<br style="margin:0px;padding:0px;" /> import('Vendor.QL.QueryList');<br style="margin:0px;padding:0px;" /> $w_url=$_POST['wurl']; //接收到的文章地址<br style="margin:0px;padding:0px;" />// 测试文章地址<br style="margin:0px;padding:0px;" />// $w_url='http://mp.weixin.qq.com/s%3F__ ... %3Bbr style="margin:0px;padding:0px;" />// echo "alert('".$w_url."');";<br style="margin:0px;padding:0px;" /> $html = file_get_contents($w_url); //获取文章源码并保存到参数中<br style="margin:0px;padding:0px;" />// echo "alert('".$html."');";<br style="margin:0px;padding:0px;" /> $html = str_replace("", "", $html); //去除微信中的抓取干扰代码<br style="margin:0px;padding:0px;" />// die($w_url);<br style="margin:0px;padding:0px;" /><br style="margin:0px;padding:0px;" />// var_dump($html);<br style="margin:0px;padding:0px;" /> $data = \QueryList::Query($html,array(<br style="margin:0px;padding:0px;" /> //采集规则库<br style="margin:0px;padding:0px;" /> //'规则名' => array('jQuery选择器','要采集的属性'),<br style="margin:0px;padding:0px;" /> 'titleTag' => array('title','text'),<br style="margin:0px;padding:0px;" />// 'title' => array('#activity-name','text'),<br style="margin:0px;padding:0px;" /> 'content' => array('body','text'),<br style="margin:0px;padding:0px;" />// 'image' => array('img','src'),<br style="margin:0px;padding:0px;" /> //微信规则<br style="margin:0px;padding:0px;" /> 'contentWx' => array('#js_content','text'),<br style="margin:0px;padding:0px;" />// 'imageWx' => array('img','data-src'),<br style="margin:0px;padding:0px;" />// 'conText' => array('.rich_media_content>p','text'),<br style="margin:0px;padding:0px;" /> ))->data;<br style="margin:0px;padding:0px;" /> foreach ($data as $k => $v) {<br style="margin:0px;padding:0px;" /> $data[$k]['imageWx'] = $this->cut_str($v['imageWx'],'?',0);<br style="margin:0px;padding:0px;" /> }<br style="margin:0px;padding:0px;" />//打印结果<br style="margin:0px;padding:0px;" />// print_r($data);<br style="margin:0px;padding:0px;" /> $this->assign('conD',$data);<br style="margin:0px;padding:0px;" /> $this->display();<br style="margin:0px;padding:0px;" /><br style="margin:0px;padding:0px;" /> }
String token = AccessTokenTool.getAccessToken();
String URL = "https://api.weixin.qq.com/cgi- ... 3B%3B
// 原始json
String jsonResult = HttpUtil.sendGet(URL.replace("OPENID", openid).replace("ACCESS_TOKEN", token));
System.out.println(jsonResult);
// 编码后的json
String json = new String(jsonResult.getBytes("ISO-8859-1"), "UTF-8");
System.out.println(json);
坐下来输入代码。没有什么技能不经过多年的深思熟虑就能轻易做到的 查看全部
文章采集api(终于找到解决方案了,这是一个值得庆祝的事情..)
终于找到了解决办法,值得庆贺....
原来是因为微信在源码中添加了反采集代码,把文章源码中的这一段去掉就好了!
具体代码如下:
public function getCon(){<br style="margin:0px;padding:0px;" /> header('Content-type: text/html; charset=utf-8');<br style="margin:0px;padding:0px;" /> import('Vendor.QL.QueryList');<br style="margin:0px;padding:0px;" /> $w_url=$_POST['wurl']; //接收到的文章地址<br style="margin:0px;padding:0px;" />// 测试文章地址<br style="margin:0px;padding:0px;" />// $w_url='http://mp.weixin.qq.com/s%3F__ ... %3Bbr style="margin:0px;padding:0px;" />// echo "alert('".$w_url."');";<br style="margin:0px;padding:0px;" /> $html = file_get_contents($w_url); //获取文章源码并保存到参数中<br style="margin:0px;padding:0px;" />// echo "alert('".$html."');";<br style="margin:0px;padding:0px;" /> $html = str_replace("", "", $html); //去除微信中的抓取干扰代码<br style="margin:0px;padding:0px;" />// die($w_url);<br style="margin:0px;padding:0px;" /><br style="margin:0px;padding:0px;" />// var_dump($html);<br style="margin:0px;padding:0px;" /> $data = \QueryList::Query($html,array(<br style="margin:0px;padding:0px;" /> //采集规则库<br style="margin:0px;padding:0px;" /> //'规则名' => array('jQuery选择器','要采集的属性'),<br style="margin:0px;padding:0px;" /> 'titleTag' => array('title','text'),<br style="margin:0px;padding:0px;" />// 'title' => array('#activity-name','text'),<br style="margin:0px;padding:0px;" /> 'content' => array('body','text'),<br style="margin:0px;padding:0px;" />// 'image' => array('img','src'),<br style="margin:0px;padding:0px;" /> //微信规则<br style="margin:0px;padding:0px;" /> 'contentWx' => array('#js_content','text'),<br style="margin:0px;padding:0px;" />// 'imageWx' => array('img','data-src'),<br style="margin:0px;padding:0px;" />// 'conText' => array('.rich_media_content>p','text'),<br style="margin:0px;padding:0px;" /> ))->data;<br style="margin:0px;padding:0px;" /> foreach ($data as $k => $v) {<br style="margin:0px;padding:0px;" /> $data[$k]['imageWx'] = $this->cut_str($v['imageWx'],'?',0);<br style="margin:0px;padding:0px;" /> }<br style="margin:0px;padding:0px;" />//打印结果<br style="margin:0px;padding:0px;" />// print_r($data);<br style="margin:0px;padding:0px;" /> $this->assign('conD',$data);<br style="margin:0px;padding:0px;" /> $this->display();<br style="margin:0px;padding:0px;" /><br style="margin:0px;padding:0px;" /> }
String token = AccessTokenTool.getAccessToken();
String URL = "https://api.weixin.qq.com/cgi- ... 3B%3B
// 原始json
String jsonResult = HttpUtil.sendGet(URL.replace("OPENID", openid).replace("ACCESS_TOKEN", token));
System.out.println(jsonResult);
// 编码后的json
String json = new String(jsonResult.getBytes("ISO-8859-1"), "UTF-8");
System.out.println(json);
坐下来输入代码。没有什么技能不经过多年的深思熟虑就能轻易做到的
文章采集api(cms如何添加采集api接口快速建站,网站模板建站平台)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-02-07 13:20
cms如何添加api采集接口快速建站,网站模板建站平台
高端网站设计cms如何添加api采集接口平台值得您免费注册使用,您可以放心点击使用!
▶1、 网站模板免费使用,3000套海量网站行业模板任你选择,所见即所得。
▶2、易于维护。如果有错,可以修改,直到合适为止。
▶3、覆盖范围广、产品稳定、每周持续更新、专人专职、优质服务让您满意
▶4、覆盖电脑网站、手机网站、小程序、微网站等多平台终端,无需担心流量曝光
▶5、高性价比企业网站施工方案,买三年送三年,还在犹豫吗?
cms如何添加api采集界面网站免费提供各行各业的网站模板供你选择,总有一款适合你,有都是各种素材图片,完全不用担心没有素材可做网站。
▶1、cms如何添加api采集接口网站服务,或者免费模板自建
▶2、怎么做网站,只要你会用电脑制作网站,客服兄妹耐心教你
▶3、我们如何制作自己的网站,cms如何添加api采集接口来帮助你实现你的网站梦想
▶4、不用自己写代码,建个网站其实是很简单的事情
▶5、提供建站+空间+域名+备案一站式服务,让您无后顾之忧
▶6、一键免费注册建站,丰富的功能控件拖拽自由操作,快速编辑,网站可生成预览
▶7、新手会用网站build,不信可以试试
▶8、网站四合一【电脑、手机、微网站、小程序】 查看全部
文章采集api(cms如何添加采集api接口快速建站,网站模板建站平台)
cms如何添加api采集接口快速建站,网站模板建站平台

高端网站设计cms如何添加api采集接口平台值得您免费注册使用,您可以放心点击使用!
▶1、 网站模板免费使用,3000套海量网站行业模板任你选择,所见即所得。
▶2、易于维护。如果有错,可以修改,直到合适为止。
▶3、覆盖范围广、产品稳定、每周持续更新、专人专职、优质服务让您满意
▶4、覆盖电脑网站、手机网站、小程序、微网站等多平台终端,无需担心流量曝光
▶5、高性价比企业网站施工方案,买三年送三年,还在犹豫吗?

cms如何添加api采集界面网站免费提供各行各业的网站模板供你选择,总有一款适合你,有都是各种素材图片,完全不用担心没有素材可做网站。
▶1、cms如何添加api采集接口网站服务,或者免费模板自建
▶2、怎么做网站,只要你会用电脑制作网站,客服兄妹耐心教你
▶3、我们如何制作自己的网站,cms如何添加api采集接口来帮助你实现你的网站梦想
▶4、不用自己写代码,建个网站其实是很简单的事情
▶5、提供建站+空间+域名+备案一站式服务,让您无后顾之忧
▶6、一键免费注册建站,丰富的功能控件拖拽自由操作,快速编辑,网站可生成预览
▶7、新手会用网站build,不信可以试试
▶8、网站四合一【电脑、手机、微网站、小程序】
文章采集api(离线文档查阅Dash的优势是什么?工具集成介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-02-01 16:09
对于软件开发领域的新手和绝大多数计算机科学专业的学生来说,API 文档是众多硬骨头之一。大多数文档存在交互不友好和索引不方便的问题。本着解决人民群众需求的精神,介绍了本期的主角Dash。
Dash 将自己定位为开发人员的文档查询工具。事实上,Dash 在易用性和实用性方面都非常强大。简要总结如下:
可以说,Dash 绝对对得起它的定位。用了之后,很有可能没有它就活不下去了。
离线文档审核
Dash首先是一个文档查询工具,也是它的核心。它基本上涵盖了所有主流和一些非主流语言、框架和库的文档。大部分文档来自这些语言的官方语言,所以也收录了很多官方的介绍。
让我们专注于 API 查询。在 Dash 中查询 API 非常简单。您可以根据需要搜索所有下载的文档,或双击选择特定文档,然后输入关键字进行搜索。在这种情况下,搜索范围将被锁定在该特定文档中。文档内。Dash的检索效率非常高,基本秒出结果。
以 JavaScript 文档为例,它被合理地划分为“类”、“方法”、“事件”、“函数”、“关键字”以及来自 MDN 的非常实用的介绍。与在线版本相比,像Dash这样的离线文档库的优势不仅在于它可以处理更多的场景,而且所有内容一目了然,而且很容易检索,无需忍受快速和慢速的外国服务器。
这是画布教程,这部分来自 MDN(Mozilla 开发者网络,Web 标准的主要开发和推广组织之一一)。
第三方工具集成
由于其作为开发和生产力工具的定位,Dash 与许多工具和 IDE 无缝集成。基本上,您使用和将使用的工具都得到官方支持。插件的安装方法在其GitHub对应的各个Repository上都有详细的安装说明,点击上方对应的工具图标即可找到。
以Alfred为例,即使没有额外的步骤,点击图标后会自动跳转到Alfred,点击import即可安装。集成 Dash 后,索引甚至不需要打开应用程序本身,不太方便。
感受触手可及的阅读乐趣。
自定义数据源
如果你觉得 Dash 的官方库不能满足你的所有需求,你想自定义它作为文档源!
没问题,Google Stack Overflow 已经集成。您还可以将任何您喜欢的社区用作自定义搜索库,并且很容易添加。以Medium为例,直接在上面搜索东西后,复制URL。
可以看到搜索关键词是网址的q后面的段落。在 Dash 的偏好设置中点击网页搜索栏左下角的 +,在名称字段中输入搜索源的名称;将 URL 粘贴到 Search URL 字段中,然后输入关键字只需将其替换为 {query}。
添加注释
Dash还自带注释工具,可以在文档的任意部分添加注释,对学习有很大帮助,也符合大学做笔记的风格。
此外,您还可以将 Mark 学了一半时间的章节或 API 添加到书签中,并将其添加到书签中以供将来参考。
总的来说,Dash是一款在文档的广度和质量上可以满足大部分人使用场景的工具,同时还提供了包括自定义数据源、添加注释等个性化功能,对于学习和工作都有很大的帮助. 明显地。学习搜索是技术发展道路上不可或缺的一步,你也是吗?
除了 Mac 端,Dash 还有一个 iOS 版本。iOS 版本完全免费,还支持离线文档。此外,它还支持 URL Schemes 等功能。您可以从 App Store 或 GitHub 下载源文件。 查看全部
文章采集api(离线文档查阅Dash的优势是什么?工具集成介绍)
对于软件开发领域的新手和绝大多数计算机科学专业的学生来说,API 文档是众多硬骨头之一。大多数文档存在交互不友好和索引不方便的问题。本着解决人民群众需求的精神,介绍了本期的主角Dash。
Dash 将自己定位为开发人员的文档查询工具。事实上,Dash 在易用性和实用性方面都非常强大。简要总结如下:
可以说,Dash 绝对对得起它的定位。用了之后,很有可能没有它就活不下去了。
离线文档审核
Dash首先是一个文档查询工具,也是它的核心。它基本上涵盖了所有主流和一些非主流语言、框架和库的文档。大部分文档来自这些语言的官方语言,所以也收录了很多官方的介绍。
让我们专注于 API 查询。在 Dash 中查询 API 非常简单。您可以根据需要搜索所有下载的文档,或双击选择特定文档,然后输入关键字进行搜索。在这种情况下,搜索范围将被锁定在该特定文档中。文档内。Dash的检索效率非常高,基本秒出结果。
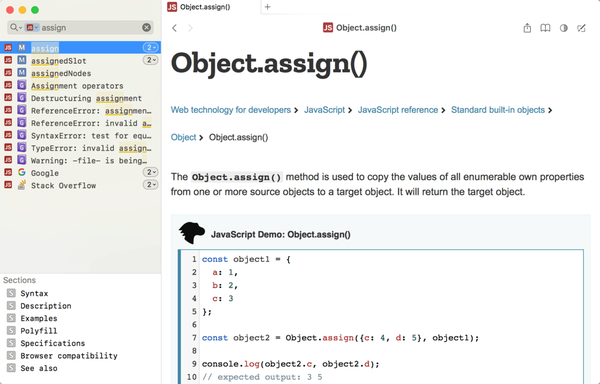
以 JavaScript 文档为例,它被合理地划分为“类”、“方法”、“事件”、“函数”、“关键字”以及来自 MDN 的非常实用的介绍。与在线版本相比,像Dash这样的离线文档库的优势不仅在于它可以处理更多的场景,而且所有内容一目了然,而且很容易检索,无需忍受快速和慢速的外国服务器。
这是画布教程,这部分来自 MDN(Mozilla 开发者网络,Web 标准的主要开发和推广组织之一一)。
第三方工具集成
由于其作为开发和生产力工具的定位,Dash 与许多工具和 IDE 无缝集成。基本上,您使用和将使用的工具都得到官方支持。插件的安装方法在其GitHub对应的各个Repository上都有详细的安装说明,点击上方对应的工具图标即可找到。

以Alfred为例,即使没有额外的步骤,点击图标后会自动跳转到Alfred,点击import即可安装。集成 Dash 后,索引甚至不需要打开应用程序本身,不太方便。
感受触手可及的阅读乐趣。

自定义数据源
如果你觉得 Dash 的官方库不能满足你的所有需求,你想自定义它作为文档源!
没问题,Google Stack Overflow 已经集成。您还可以将任何您喜欢的社区用作自定义搜索库,并且很容易添加。以Medium为例,直接在上面搜索东西后,复制URL。
可以看到搜索关键词是网址的q后面的段落。在 Dash 的偏好设置中点击网页搜索栏左下角的 +,在名称字段中输入搜索源的名称;将 URL 粘贴到 Search URL 字段中,然后输入关键字只需将其替换为 {query}。
添加注释
Dash还自带注释工具,可以在文档的任意部分添加注释,对学习有很大帮助,也符合大学做笔记的风格。
此外,您还可以将 Mark 学了一半时间的章节或 API 添加到书签中,并将其添加到书签中以供将来参考。
总的来说,Dash是一款在文档的广度和质量上可以满足大部分人使用场景的工具,同时还提供了包括自定义数据源、添加注释等个性化功能,对于学习和工作都有很大的帮助. 明显地。学习搜索是技术发展道路上不可或缺的一步,你也是吗?
除了 Mac 端,Dash 还有一个 iOS 版本。iOS 版本完全免费,还支持离线文档。此外,它还支持 URL Schemes 等功能。您可以从 App Store 或 GitHub 下载源文件。
文章采集api(Java开发中常见的纯文本解析方法-乐题库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-01-29 00:21
其他可用的 python http 请求模块:
你的频率
你请求
其中frequests和grequests的使用方式相同,frequests的稳定性高于grequests;简单使用如下:
2.响应结果数据格式
常见的响应结果格式为:
3.各种数据格式的分析方法3.1 Html分析方法
常见的html数据解析方式有:
3.2 纯文本解析方法
常见的纯文本解析方法有:
3.3 网页正文提取
网页正文提取的重要性:
正则表达式可以准确提取某种固定格式的页面,但面对各种HTML,难免要用规则来处理。能否高效、准确地提取页面文本,使其在大规模网页范围内通用,是直接关系到上层应用的难题。
研究计划:
JoyHTML的目的是解析HTML文本中的链接和文本,采用超链接密度法作为标记窗口算法的主要判断依据,采用DOM树解析方式。
这个 Java 类库提供了检测和删除网页主要文本内容旁边的冗余重复内容的算法。它已经提供了特殊的策略来处理一些常见的功能,例如新闻文章提取。
该算法首次将网页文本提取问题转化为寻找页面的行块分布函数,并将其与HTML标签完全分离。通过线性时间建立线块分布函数图,该图可以直接、高效、准确地定位网页文本。同时采用统计与规则相结合的方法解决系统的一般性问题。
这里我们只使用 cx-extractor 和可读性;这里是cx-extractor和可读性的对比,如下:
cx-extractor的使用示例如下图所示:
cx-extractor 和可读性比较
4.数据解析详解
建议: 查看全部
文章采集api(Java开发中常见的纯文本解析方法-乐题库)
其他可用的 python http 请求模块:
你的频率
你请求
其中frequests和grequests的使用方式相同,frequests的稳定性高于grequests;简单使用如下:
2.响应结果数据格式
常见的响应结果格式为:
3.各种数据格式的分析方法3.1 Html分析方法
常见的html数据解析方式有:
3.2 纯文本解析方法
常见的纯文本解析方法有:
3.3 网页正文提取
网页正文提取的重要性:
正则表达式可以准确提取某种固定格式的页面,但面对各种HTML,难免要用规则来处理。能否高效、准确地提取页面文本,使其在大规模网页范围内通用,是直接关系到上层应用的难题。
研究计划:
JoyHTML的目的是解析HTML文本中的链接和文本,采用超链接密度法作为标记窗口算法的主要判断依据,采用DOM树解析方式。
这个 Java 类库提供了检测和删除网页主要文本内容旁边的冗余重复内容的算法。它已经提供了特殊的策略来处理一些常见的功能,例如新闻文章提取。
该算法首次将网页文本提取问题转化为寻找页面的行块分布函数,并将其与HTML标签完全分离。通过线性时间建立线块分布函数图,该图可以直接、高效、准确地定位网页文本。同时采用统计与规则相结合的方法解决系统的一般性问题。
这里我们只使用 cx-extractor 和可读性;这里是cx-extractor和可读性的对比,如下:
cx-extractor的使用示例如下图所示:
cx-extractor 和可读性比较
4.数据解析详解
建议:
文章采集api(优采云采集器官网-网页抓取工具优采云采集器免费网站采集软件 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2022-01-25 08:13
)
免责声明:本教程没有任何盈利目的,仅供学习使用,不会对网站的操作造成负担。请不要将其用于任何商业目的。
优采云简介
优采云采集器官网-网页抓取工具优采云采集器免费网站采集软件
优采云采集器,专业的互联网数据采集、处理、分析、挖掘软件,可以灵活快速的抓取网页上零散的数据信息,并通过一系列的分析处理,精准挖掘出来所需的数据。优采云采集器历经十二年的升级更新,积累了大量的用户和良好的口碑,是目前最受欢迎的网络数据采集软件。
简单来说,就是用软件来简化我们的爬取过程。整个过程无需编写代码即可实现爬虫逻辑。
示例爬取任务
需要爬取分页中的所有页面,并进一步爬取页面上所有有趣条目的二级URL
新任务 添加任务
URL采集规则 - URL 获取
URL采集规则-分页设置
分页规则主要设置在这里,也就是说不仅要抓取当前页面,还需要抓取所有页面。
内容采集规则
这里设置了将URL中的内容提取到前面的采集的规则,即每个商品详情页的内容
内容发布规则
用于指定如何处理采集发送的内容,这里设置为发送到一个api
单击 + 号以添加规则
新发布模块
这里指定要发送给api的参数,其中name为[Content 采集Rule]部分获取的信息,参数为规则名称。
您可以保存其他设置而不更改它们。
然后填写请求的主机
其他设置
以下是一些常用设置,可选。
查看爬取的数据
计划任务设置
这里可以指定任务重复运行的规则
发送通知
可以使用ios软件bark来接受通知,其内容就是爬取的规则。在这里,使用 Golang 简单地创建了一个新的 api。当软件爬取完成后,将信息发送到api【在内容发布规则中设置】,然后将消息发送到api。推送到ios
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
package main
import (
"github.com/gogf/gf/frame/g"
"github.com/gogf/gf/net/ghttp"
"github.com/gogf/gf/os/glog"
"github.com/gogf/gf/util/gconv"
"github.com/gogf/gf/util/grand"
)
type Info struct {
Url string `json:"url"`
Name string `json:"name"`
TaskType string `json:"task_type"`
}
func main() {
s := g.Server()
s.SetPort(8080)
_ = glog.SetConfigWithMap(g.Map{
"path": "log",
"level": "all",
"file": "{Y-m-d}.log",
"flags": glog.F_TIME_DATE | glog.F_TIME_MILLI | glog.F_FILE_LONG,
})
s.BindHandler("/send_info", func(r *ghttp.Request){
requestId := grand.Letters(16)
var info Info
if err := r.ParseForm(&info); err != nil {
glog.Error(requestId, err)
_ = r.Response.WriteJsonExit(nil)
}
glog.Info(requestId, info)
bark := "https://api.day.app/{xxxxxxxxxxxx}"
body := gconv.String(g.Map{
"device_key": "xxxxxxxxxxxxx",
"body": gconv.String(info),
"title": "商品信息",
"ext_params": g.Map{"url": info.Url},
})
glog.Info(requestId, body)
if _, err := g.Client().Post(bark, body); err != nil{
glog.Error(err)
}
})
s.Run()
} 查看全部
文章采集api(优采云采集器官网-网页抓取工具优采云采集器免费网站采集软件
)
免责声明:本教程没有任何盈利目的,仅供学习使用,不会对网站的操作造成负担。请不要将其用于任何商业目的。
优采云简介
优采云采集器官网-网页抓取工具优采云采集器免费网站采集软件
优采云采集器,专业的互联网数据采集、处理、分析、挖掘软件,可以灵活快速的抓取网页上零散的数据信息,并通过一系列的分析处理,精准挖掘出来所需的数据。优采云采集器历经十二年的升级更新,积累了大量的用户和良好的口碑,是目前最受欢迎的网络数据采集软件。
简单来说,就是用软件来简化我们的爬取过程。整个过程无需编写代码即可实现爬虫逻辑。
示例爬取任务
需要爬取分页中的所有页面,并进一步爬取页面上所有有趣条目的二级URL
新任务 添加任务
URL采集规则 - URL 获取
URL采集规则-分页设置
分页规则主要设置在这里,也就是说不仅要抓取当前页面,还需要抓取所有页面。
内容采集规则
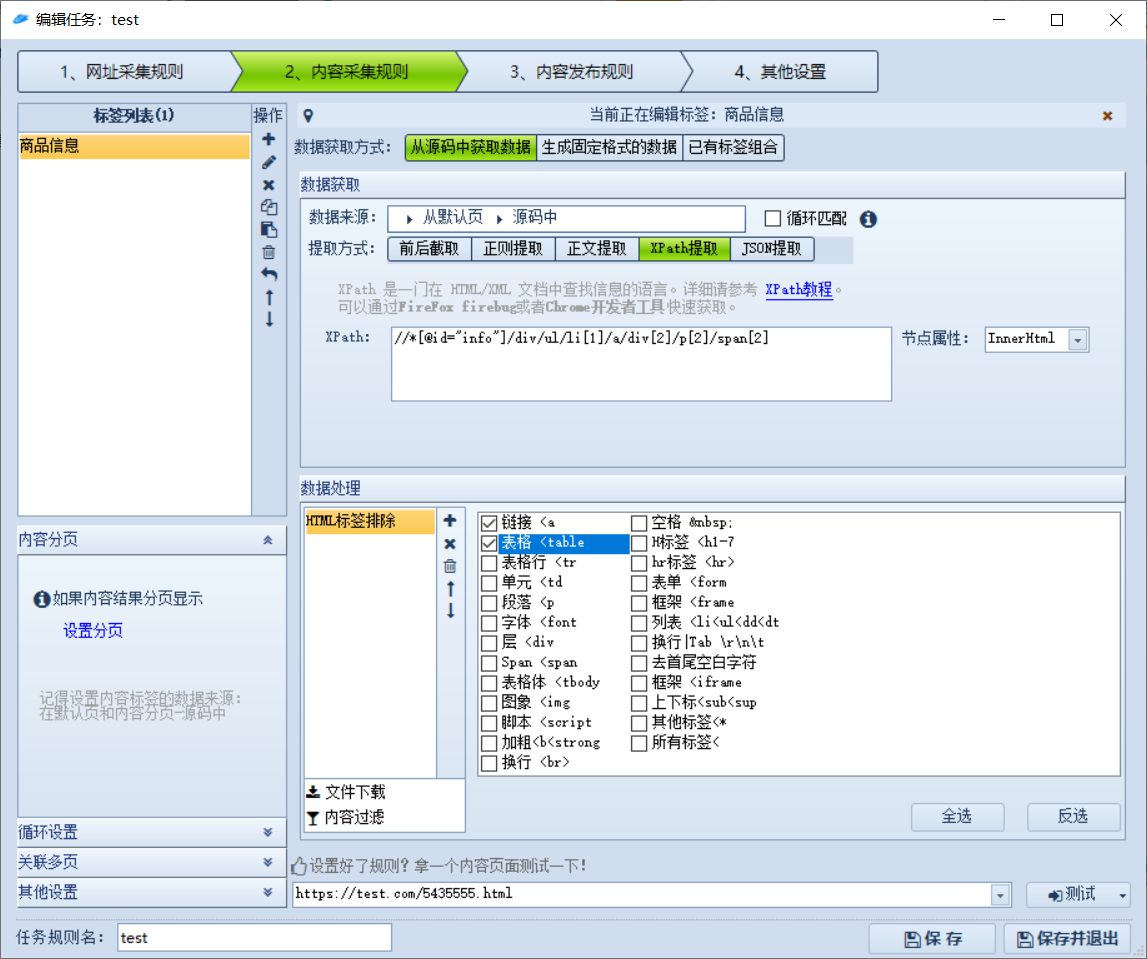
这里设置了将URL中的内容提取到前面的采集的规则,即每个商品详情页的内容
内容发布规则
用于指定如何处理采集发送的内容,这里设置为发送到一个api
单击 + 号以添加规则
新发布模块
这里指定要发送给api的参数,其中name为[Content 采集Rule]部分获取的信息,参数为规则名称。
您可以保存其他设置而不更改它们。
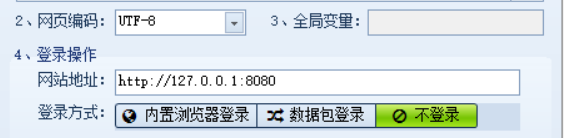
然后填写请求的主机
其他设置
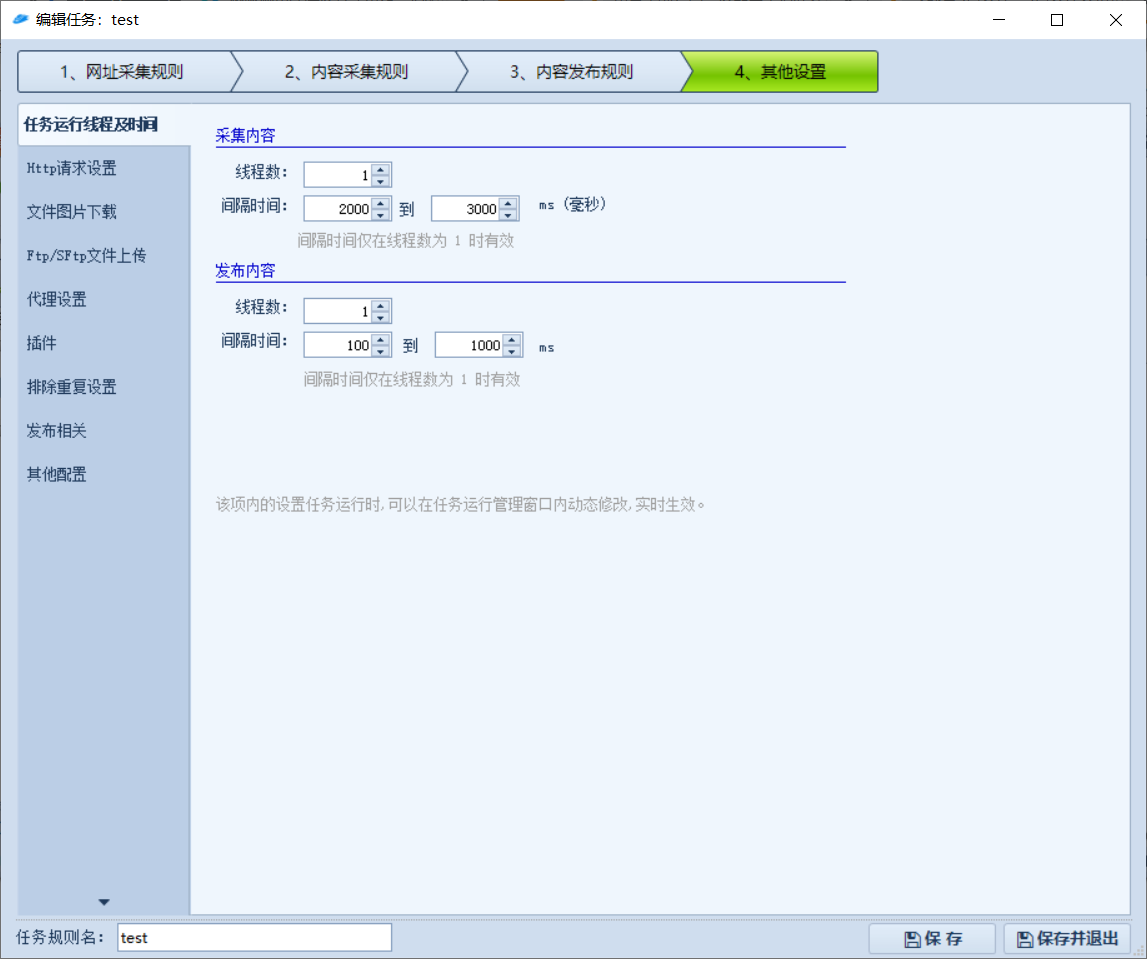
以下是一些常用设置,可选。
查看爬取的数据
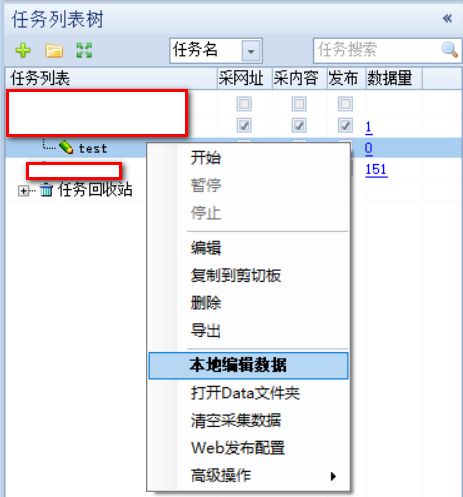
计划任务设置
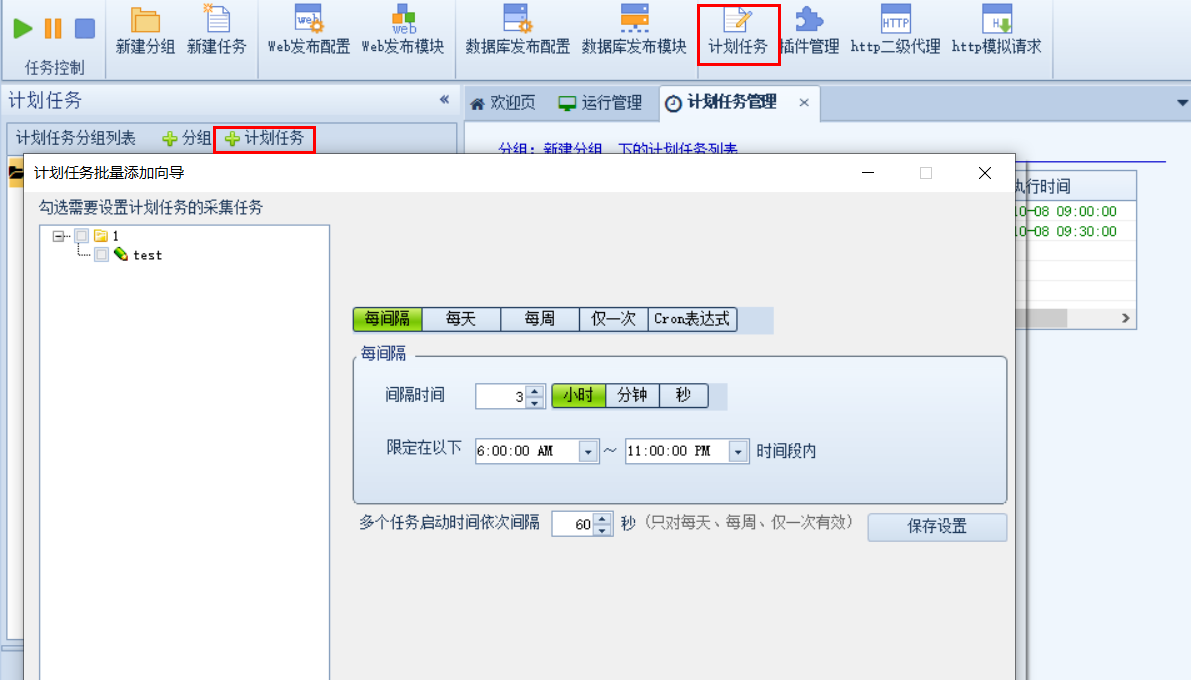
这里可以指定任务重复运行的规则
发送通知
可以使用ios软件bark来接受通知,其内容就是爬取的规则。在这里,使用 Golang 简单地创建了一个新的 api。当软件爬取完成后,将信息发送到api【在内容发布规则中设置】,然后将消息发送到api。推送到ios
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
package main
import (
"github.com/gogf/gf/frame/g"
"github.com/gogf/gf/net/ghttp"
"github.com/gogf/gf/os/glog"
"github.com/gogf/gf/util/gconv"
"github.com/gogf/gf/util/grand"
)
type Info struct {
Url string `json:"url"`
Name string `json:"name"`
TaskType string `json:"task_type"`
}
func main() {
s := g.Server()
s.SetPort(8080)
_ = glog.SetConfigWithMap(g.Map{
"path": "log",
"level": "all",
"file": "{Y-m-d}.log",
"flags": glog.F_TIME_DATE | glog.F_TIME_MILLI | glog.F_FILE_LONG,
})
s.BindHandler("/send_info", func(r *ghttp.Request){
requestId := grand.Letters(16)
var info Info
if err := r.ParseForm(&info); err != nil {
glog.Error(requestId, err)
_ = r.Response.WriteJsonExit(nil)
}
glog.Info(requestId, info)
bark := "https://api.day.app/{xxxxxxxxxxxx}"
body := gconv.String(g.Map{
"device_key": "xxxxxxxxxxxxx",
"body": gconv.String(info),
"title": "商品信息",
"ext_params": g.Map{"url": info.Url},
})
glog.Info(requestId, body)
if _, err := g.Client().Post(bark, body); err != nil{
glog.Error(err)
}
})
s.Run()
}
文章采集api(优采云采集支持调用5118一键智能换词API接口(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2022-01-25 04:20
)
优采云采集 支持调用5118一键智能换字API接口,处理采集的数据标题和内容等,可处理文章@ > 对搜索引擎更有吸引力;
具体步骤如下
1. 5118 一键智能换词API接口配置 I,API配置入口:
点击控制台左侧列表中的【第三方服务配置】==点击【第三方内容API接入】==点击【第三方API配置管理】==最后点击[+5118 一键智能原创API]创建接口配置;
二。配置API接口信息:
【API-Key值】是从5118后端获取的一键智能换词API对应的key值,填写后记得保存;
2. 创建 API 处理规则
API处理规则,可以通过调用API接口设置处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==点击【第三方内容API接入】==进入【API处理规则管理】页面,最后点击[+添加API处理规则]创建API处理规则;
二、API处理规则配置:
规则名称:用户可以命名;
字段名称:填写的字段名称内容将由API接口处理,默认为标题和内容字段,可修改、添加或删除字段;
API used:选择配置的API接口配置,执行时会调用该接口,不同的字段可以选择不同的API接口配置;
处理顺序:执行顺序按照数量从小到大执行;
3.API处理规则使用
API处理规则有两种使用方式:手动执行和自动执行:
手动执行:数据采集后,使用[Result Data & Release]中的第三方API执行;
自动执行:配置自动化后,任务采集数据完成后,系统会自动执行指定的API处理规则,无需人工操作。
我。手动执行API处理规则:
点击采集任务的【结果数据&发布】选项卡中的【SEO&API&翻译等工具】按钮==选择【第三方API执行】栏==选择对应的API处理规则== "Execute;
二。自动执行API处理规则:
启用 API 处理的自动执行。任务完成后采集会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡【自动执行第三方API配置】==勾选【采集,自动执行API】选项==选择执行的API处理rules=="选择API接口处理的数据范围(一般选择‘待发布’,全部会导致所有数据重复执行),最后点击保存;
4.API处理结果并发布 I,查看API接口处理结果:
API接口处理后的内容会保存为新字段,如:标题处理后的新字段:title_5118,内容处理后的新字段:content_5118,可在【结果数据&发布】中查看和数据预览界面。
二。发布API接口处理后的内容:
发布前文章@>修改发布目标第二步的映射字段,重新选择标题和内容作为API接口处理后添加的对应字段title_5118和content_5118;
查看全部
文章采集api(优采云采集支持调用5118一键智能换词API接口(组图)
)
优采云采集 支持调用5118一键智能换字API接口,处理采集的数据标题和内容等,可处理文章@ > 对搜索引擎更有吸引力;
具体步骤如下
1. 5118 一键智能换词API接口配置 I,API配置入口:
点击控制台左侧列表中的【第三方服务配置】==点击【第三方内容API接入】==点击【第三方API配置管理】==最后点击[+5118 一键智能原创API]创建接口配置;

二。配置API接口信息:
【API-Key值】是从5118后端获取的一键智能换词API对应的key值,填写后记得保存;
2. 创建 API 处理规则
API处理规则,可以通过调用API接口设置处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==点击【第三方内容API接入】==进入【API处理规则管理】页面,最后点击[+添加API处理规则]创建API处理规则;
二、API处理规则配置:
规则名称:用户可以命名;
字段名称:填写的字段名称内容将由API接口处理,默认为标题和内容字段,可修改、添加或删除字段;
API used:选择配置的API接口配置,执行时会调用该接口,不同的字段可以选择不同的API接口配置;
处理顺序:执行顺序按照数量从小到大执行;
3.API处理规则使用
API处理规则有两种使用方式:手动执行和自动执行:
手动执行:数据采集后,使用[Result Data & Release]中的第三方API执行;
自动执行:配置自动化后,任务采集数据完成后,系统会自动执行指定的API处理规则,无需人工操作。
我。手动执行API处理规则:
点击采集任务的【结果数据&发布】选项卡中的【SEO&API&翻译等工具】按钮==选择【第三方API执行】栏==选择对应的API处理规则== "Execute;
二。自动执行API处理规则:
启用 API 处理的自动执行。任务完成后采集会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡【自动执行第三方API配置】==勾选【采集,自动执行API】选项==选择执行的API处理rules=="选择API接口处理的数据范围(一般选择‘待发布’,全部会导致所有数据重复执行),最后点击保存;
4.API处理结果并发布 I,查看API接口处理结果:
API接口处理后的内容会保存为新字段,如:标题处理后的新字段:title_5118,内容处理后的新字段:content_5118,可在【结果数据&发布】中查看和数据预览界面。
二。发布API接口处理后的内容:
发布前文章@>修改发布目标第二步的映射字段,重新选择标题和内容作为API接口处理后添加的对应字段title_5118和content_5118;
文章采集api( 如何查询prometheus采集job中指标下数据量的情况过滤?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-01-22 12:25
如何查询prometheus采集job中指标下数据量的情况过滤?)
如何在普罗米修斯中过滤不需要的指标
在prometheus的采集中,你会发现一个job可能收录几十个甚至上百个指标,每个指标下的数据量也非常大。在生产环境中,我们实际上可能只用到了几十个指标,而那些我们没有用过的指标,prometheus采集就成了浪费部署资源的罪魁祸首。
这时候就需要考虑过滤prometheus采集的job中的指标了。
如何查询指标下的数据量
1
2
3
4
5
# 展现数据量前50的指标
topk(50, count by (__name__, job)({__name__=~".+"}))
# prometheus中的指标数据量
sum(count by (__name__, job)({__name__=~".+"}))
在 prometheus 采集Job 上过滤指标
以下是 cadvice采集job 的示例。目前使用metric_relabel_configs下的drop操作丢弃不需要的指标(感觉不是特别方便)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
- job_name: kubernetes-cadvisor
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
metric_relabel_configs:
- action: replace
source_labels: [id]
regex: '^/machine\.slice/machine-rkt\\x2d([^\\]+)\\.+/([^/]+)\.service$'
target_label: rkt_container_name
replacement: '${2}-${1}'
- action: replace
source_labels: [id]
regex: '^/system\.slice/(.+)\.service$'
target_label: systemd_service_name
replacement: '${1}'
# 丢弃掉container_network_tcp_usage_total指标
- action: drop
source_labels: [__name__]
regex: 'container_network_tcp_usage_total'
- action: drop
source_labels: [__name__]
regex: 'container_tasks_state'
- action: drop
source_labels: [__name__]
regex: 'container_network_udp_usage_total'
- action: drop
source_labels: [__name__]
regex: 'container_memory_failures_total'
在 prometheus-opretor 中过滤 Servicemonit 配置的作业指标
在使用prometheus-opretor部署监控环境时,会发现很多监控作业都是使用Servicemonit定义的。您还可以在 Servicemonit 中配置 drop to drop 指示器。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
serviceMonitors:
- name: foundation-prometheus
namespaceSelector:
matchNames:
- monitoring
selector:
matchLabels:
cluster: foundation
endpoints:
- port: foundation-port
honorLabels: true
path: /federate
params:
'match[]':
- '{__name__=~".+"}'
# 配置丢弃container_memory_failures_total指标
metricRelabelings:
- action: drop
source_labels: [__name__]
regex: 'container_memory_failures_total'
在每个 采集export 中配置不需要的指标
最好的处理方法是在prometheus采集指标之前控制每个export提供的指标,只给prometheus提供我们需要监控的指标。我们以节点导出为例。在 node-export 中,有一个应用程序的官方描述。您可以使用--no-collector。用于控制不需要 采集 的模块的标志 查看全部
文章采集api(
如何查询prometheus采集job中指标下数据量的情况过滤?)
如何在普罗米修斯中过滤不需要的指标
在prometheus的采集中,你会发现一个job可能收录几十个甚至上百个指标,每个指标下的数据量也非常大。在生产环境中,我们实际上可能只用到了几十个指标,而那些我们没有用过的指标,prometheus采集就成了浪费部署资源的罪魁祸首。
这时候就需要考虑过滤prometheus采集的job中的指标了。
如何查询指标下的数据量
1
2
3
4
5
# 展现数据量前50的指标
topk(50, count by (__name__, job)({__name__=~".+"}))
# prometheus中的指标数据量
sum(count by (__name__, job)({__name__=~".+"}))
在 prometheus 采集Job 上过滤指标
以下是 cadvice采集job 的示例。目前使用metric_relabel_configs下的drop操作丢弃不需要的指标(感觉不是特别方便)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
- job_name: kubernetes-cadvisor
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
metric_relabel_configs:
- action: replace
source_labels: [id]
regex: '^/machine\.slice/machine-rkt\\x2d([^\\]+)\\.+/([^/]+)\.service$'
target_label: rkt_container_name
replacement: '${2}-${1}'
- action: replace
source_labels: [id]
regex: '^/system\.slice/(.+)\.service$'
target_label: systemd_service_name
replacement: '${1}'
# 丢弃掉container_network_tcp_usage_total指标
- action: drop
source_labels: [__name__]
regex: 'container_network_tcp_usage_total'
- action: drop
source_labels: [__name__]
regex: 'container_tasks_state'
- action: drop
source_labels: [__name__]
regex: 'container_network_udp_usage_total'
- action: drop
source_labels: [__name__]
regex: 'container_memory_failures_total'
在 prometheus-opretor 中过滤 Servicemonit 配置的作业指标
在使用prometheus-opretor部署监控环境时,会发现很多监控作业都是使用Servicemonit定义的。您还可以在 Servicemonit 中配置 drop to drop 指示器。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
serviceMonitors:
- name: foundation-prometheus
namespaceSelector:
matchNames:
- monitoring
selector:
matchLabels:
cluster: foundation
endpoints:
- port: foundation-port
honorLabels: true
path: /federate
params:
'match[]':
- '{__name__=~".+"}'
# 配置丢弃container_memory_failures_total指标
metricRelabelings:
- action: drop
source_labels: [__name__]
regex: 'container_memory_failures_total'
在每个 采集export 中配置不需要的指标
最好的处理方法是在prometheus采集指标之前控制每个export提供的指标,只给prometheus提供我们需要监控的指标。我们以节点导出为例。在 node-export 中,有一个应用程序的官方描述。您可以使用--no-collector。用于控制不需要 采集 的模块的标志
文章采集api( 传cookie )
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-01-21 21:15
传cookie
)
在api采集的过程中,有些接口不通过cookie就不能让你访问该接口。然后我们需要把cookie带入到cookie传递的地方。
cookie 的来源,例如访问或登录。当服务器响应时,它会为你生成。
卷曲方法:
// 初始化CURL
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
// 获取头部信息
curl_setopt($ch, CURLOPT_HEADER, 1);
// 返回原生的(Raw)输出
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
// 执行并获取返回结果
$content = curl_exec($ch);
// 关闭CURL
curl_close($ch);
// 解析HTTP数据流
list($header, $body) = explode("\r\n\r\n", $content);
// 解析COOKIE
preg_match("/set\-cookie:([^\r\n]*)/i", $header, $matches);
// 后面用CURL提交的时候可以直接使用
// curl_setopt($ch, CURLOPT_COOKIE, $cookie);
$cookie = $matches[1];
// 初始化CURL
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url2);
// 获取头部信息
curl_setopt($ch, CURLOPT_HEADER, 1);
// 返回原生的(Raw)输出
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_COOKIE, $cookie);//设置cookie
// 执行并获取返回结果
$content = curl_exec($ch);
// 关闭CURL
curl_close($ch); 查看全部
文章采集api(
传cookie
)
在api采集的过程中,有些接口不通过cookie就不能让你访问该接口。然后我们需要把cookie带入到cookie传递的地方。
cookie 的来源,例如访问或登录。当服务器响应时,它会为你生成。
卷曲方法:
// 初始化CURL
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
// 获取头部信息
curl_setopt($ch, CURLOPT_HEADER, 1);
// 返回原生的(Raw)输出
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
// 执行并获取返回结果
$content = curl_exec($ch);
// 关闭CURL
curl_close($ch);
// 解析HTTP数据流
list($header, $body) = explode("\r\n\r\n", $content);
// 解析COOKIE
preg_match("/set\-cookie:([^\r\n]*)/i", $header, $matches);
// 后面用CURL提交的时候可以直接使用
// curl_setopt($ch, CURLOPT_COOKIE, $cookie);
$cookie = $matches[1];
// 初始化CURL
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url2);
// 获取头部信息
curl_setopt($ch, CURLOPT_HEADER, 1);
// 返回原生的(Raw)输出
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_COOKIE, $cookie);//设置cookie
// 执行并获取返回结果
$content = curl_exec($ch);
// 关闭CURL
curl_close($ch);
文章采集api(一个博客小站来说的收录方式文章目录资源前言)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-03-01 01:25
typechoSEO网站收录插件推荐百度提交
文章目录
资源前言
我们在建一个小站点的时候,可能会遇到如何让搜索引擎抓取我们的文章的问题,当然你可以选择不让搜索引擎抓取你的站点。这时候,你就需要SEO(“搜索引擎优化”)。其实涉及的内容很多,但作为我这种小博客网站,没必要。无非就是让你的网站在搜索引擎中的排名更高,让运维来做。在这篇文章中,我主要讲一下我在SEO方面采取的一些做法,主要是百度收录,其他搜索引擎的收录方法类似,大家可以自行搜索理解
安装
把下载好的插件解压到typecho主目录下的插件目录下,一般是/usr/plugins
然后就可以在typecho的后台插件中看到了
百度站长网站设置
百度搜索引擎提供了站长网站,这样我们就可以主动让百度去收录自己的站点,下面是传送门
门户网站
他提供了几种不同的收录方法,比如quick收录,可以让你主动提供你网站的一些资源,比如sitemap等,缩短搜索引擎爬虫爬取你的时间地点。具体方法有API提交、站点地图、手动提交。这次推荐的插件主要是API提交。
API 提交
推送接口、推送实例、推送反馈如上所示。我们只需要关注推送接口即可。后两者在实现代码时需要注意。显然,插件作者已经做到了这一点。以下是API接口的样式。
http://data.zz.baidu.com/urls?site={您的站点}&token={验证token,相当于密码}
网站地图
要提交站点地图,您可以使用 txt 或 xml 格式。这里可以直接使用这个插件生成的xml文件,大部分搜索引擎都识别sitemaps(我不知道),比如你可以看一下我的站点自动生成的xml。文档
如果您熟悉 XML,很容易发现大部分站点地图实际上是由这些多个 url 元素组成的。
所以我们可以填写对应的
不仅可以在这里使用站点的路径,而且在这里这样做更方便。另外,这个站点地图一天最多只能推送十次。
手动提交
也就是提交你网站上写的文章的链接,也就是把sitemap.xml内容中的url链接一个一个提交,这个方法可以保证你的一个文章可以很好收录(不一定,还是看百度吧),自己决定
百度站长其他工具
喜欢什么移动适配,死链接提交可以自己看懂,什么都写清楚了哈哈
插件介绍功能使用
很简单,直接填一个api,发布的时候会自动提交类似这个api的更新文章
机器人文件
使用爬虫的人应该对此非常熟悉。简而言之,是爬虫的“君子协定”。虽然我们平时不遵守君子协定,但百度、搜狗、谷歌等大搜索引擎还是会遵守的。是的,这个约束只是对它们的约束。哈哈,由于这个插件没有自动生成robots.txt的功能,所以需要我们自己创建。方法也很简单。步骤如下
创建一个名为 robots.txt 的新文件
输入内容
User-agent: *
Allow: /
Disallow: /admin/
Disallow: /install/
Sitemap: https://你的网站地址/sitemap.xml
这个语法很简单,可以根据自己网站的需要进行修改
保存并上传文件到 网站 根目录
最后,访问自己 网站 进行验证
好的,你完成了
查看您的网站是否被 收录 阻止
最常用的方法是在搜索引擎上搜索您的一篇文章文章。如果你找到了,说明你已经收录
这里推荐一个查看你整个站点的收录情况的方法(使用搜索语法site:xxx),具体示例如下
可以看到百度收录已经添加了我以前的站点,所以这里有一点你可以知道的是,百度收录并不是你提交资源后就可以立即更新的东西,他会是定期更新,可能是一周或一个月(废话)
总结
其实搜索引擎的收录只需要提交一个链接,搜索引擎就会自动抓取你的链接。这个插件自动生成sitemap.xml文件,可以很方便的让其他搜索引擎收录,所以一个sitemap插件就够了。下面我将给出各大搜索引擎站长的网站地址。你可以直接写你的网站地址,让他们自己爬。, 收录不会马上成功的。这主要取决于不同的搜索引擎,以及您网站的各种结果,其中涉及到 SEO 问题。我对此一无所知。问运维老板。. 最后,祝你折腾网站开心! 查看全部
文章采集api(一个博客小站来说的收录方式文章目录资源前言)
typechoSEO网站收录插件推荐百度提交
文章目录
资源前言
我们在建一个小站点的时候,可能会遇到如何让搜索引擎抓取我们的文章的问题,当然你可以选择不让搜索引擎抓取你的站点。这时候,你就需要SEO(“搜索引擎优化”)。其实涉及的内容很多,但作为我这种小博客网站,没必要。无非就是让你的网站在搜索引擎中的排名更高,让运维来做。在这篇文章中,我主要讲一下我在SEO方面采取的一些做法,主要是百度收录,其他搜索引擎的收录方法类似,大家可以自行搜索理解
安装
把下载好的插件解压到typecho主目录下的插件目录下,一般是/usr/plugins
然后就可以在typecho的后台插件中看到了
百度站长网站设置
百度搜索引擎提供了站长网站,这样我们就可以主动让百度去收录自己的站点,下面是传送门
门户网站
他提供了几种不同的收录方法,比如quick收录,可以让你主动提供你网站的一些资源,比如sitemap等,缩短搜索引擎爬虫爬取你的时间地点。具体方法有API提交、站点地图、手动提交。这次推荐的插件主要是API提交。
API 提交
推送接口、推送实例、推送反馈如上所示。我们只需要关注推送接口即可。后两者在实现代码时需要注意。显然,插件作者已经做到了这一点。以下是API接口的样式。
http://data.zz.baidu.com/urls?site={您的站点}&token={验证token,相当于密码}
网站地图
要提交站点地图,您可以使用 txt 或 xml 格式。这里可以直接使用这个插件生成的xml文件,大部分搜索引擎都识别sitemaps(我不知道),比如你可以看一下我的站点自动生成的xml。文档
如果您熟悉 XML,很容易发现大部分站点地图实际上是由这些多个 url 元素组成的。
所以我们可以填写对应的
不仅可以在这里使用站点的路径,而且在这里这样做更方便。另外,这个站点地图一天最多只能推送十次。
手动提交
也就是提交你网站上写的文章的链接,也就是把sitemap.xml内容中的url链接一个一个提交,这个方法可以保证你的一个文章可以很好收录(不一定,还是看百度吧),自己决定
百度站长其他工具
喜欢什么移动适配,死链接提交可以自己看懂,什么都写清楚了哈哈
插件介绍功能使用
很简单,直接填一个api,发布的时候会自动提交类似这个api的更新文章
机器人文件
使用爬虫的人应该对此非常熟悉。简而言之,是爬虫的“君子协定”。虽然我们平时不遵守君子协定,但百度、搜狗、谷歌等大搜索引擎还是会遵守的。是的,这个约束只是对它们的约束。哈哈,由于这个插件没有自动生成robots.txt的功能,所以需要我们自己创建。方法也很简单。步骤如下
创建一个名为 robots.txt 的新文件
输入内容
User-agent: *
Allow: /
Disallow: /admin/
Disallow: /install/
Sitemap: https://你的网站地址/sitemap.xml
这个语法很简单,可以根据自己网站的需要进行修改
保存并上传文件到 网站 根目录
最后,访问自己 网站 进行验证
好的,你完成了
查看您的网站是否被 收录 阻止
最常用的方法是在搜索引擎上搜索您的一篇文章文章。如果你找到了,说明你已经收录
这里推荐一个查看你整个站点的收录情况的方法(使用搜索语法site:xxx),具体示例如下
可以看到百度收录已经添加了我以前的站点,所以这里有一点你可以知道的是,百度收录并不是你提交资源后就可以立即更新的东西,他会是定期更新,可能是一周或一个月(废话)
总结
其实搜索引擎的收录只需要提交一个链接,搜索引擎就会自动抓取你的链接。这个插件自动生成sitemap.xml文件,可以很方便的让其他搜索引擎收录,所以一个sitemap插件就够了。下面我将给出各大搜索引擎站长的网站地址。你可以直接写你的网站地址,让他们自己爬。, 收录不会马上成功的。这主要取决于不同的搜索引擎,以及您网站的各种结果,其中涉及到 SEO 问题。我对此一无所知。问运维老板。. 最后,祝你折腾网站开心!
文章采集api(如何用R调用API,提取和整理你需要的免费Web数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2022-02-27 00:28
API是获取Web数据的重要方式之一。想了解如何使用 R 调用 API 来提取和组织您需要的免费 Web 数据吗?本文将逐步向您展示操作过程。
交易
俗话说,“聪明的女人,没有饭难煮”。就算你掌握了数据分析十八门武功,没有数据也是一件麻烦的事情。“拔刀而去,茫然不知所措”,大概就是这样。
有很多数据来源。Web 数据是数量庞大且相对容易获取的类型之一。更好的是,很多网络数据都是免费的。
在这个所谓的大数据时代,如何获取网络数据?
许多人使用由他人编译和发布的数据集。
他们很幸运,他们的工作可以建立在其他人的基础上。这是最有效的。
但并不是每个人都这么幸运。如果您需要的数据从未被组织和发布过怎么办?
事实上,这样的数据量更大。我们是否对他们视而不见?
如果您考虑爬行动物,那么您的想法是正确的。爬虫可以为您获取几乎所有可见(甚至不可见)的网络数据。然而,编写和使用爬虫的成本很高。包括时间资源、技术能力等。如果你遇到任何网络数据获取问题,你不要想“大锤”,有时可能是“刀枪不入”。
在“别人准备的数据”和“需要自己爬取的数据”之间,还有一个广阔的领域,这就是API的世界。
什么是 API?
它是应用程序编程接口的缩写。具体来说,某个网站的数据在不断的积累和变化。如果对这些数据进行整理,不仅费时,而且占用空间,而且还有刚整理完就过时的危险。大多数人需要的数据其实只是其中的一小部分,但时效性要求可能非常强。因此,组织存储并将其提供给公众以供下载是不经济的。
但是,如果数据不能以某种方式打通,就会面临无数爬虫的骚扰。这会对网站的正常运行造成很大的困扰。折衷方案是 网站 主动提供通道。当你需要某部分数据时,虽然没有现成的数据集,但你只需要用这个通道描述你想要的数据,然后网站审核后(一般是自动化的,瞬间完成),认为我可以给你,我会立即发送你明确要求的数据。双方都很高兴。
以后在找数据的时候,不妨看看目标网站有没有提供API,避免无用的努力。
在这个github项目中,有一个非常详细的列表,涵盖了当前常见的主流网站API资源状况。作者还在整理和修改中,大家可以采集起来慢慢看。
如果我们知道某个网站提供了API,通过查看文档知道我们需要的数据在那里,那么问题就变成了——如何通过API获取数据?
下面我们用一个实际的例子来向您展示整个操作步骤。
资源
我们正在寻找的例子是维基百科。
有关 Wikipedia API 的概述,请参阅此页面。
假设我们关心特定时间段内对指定维基百科 文章 页面的访问次数。
维基百科为我们提供了一种称为指标的数据,它涵盖了页面访问的关键价值。对应API的介绍页面在这里。
页面上有一个示例。假设需要获取2015年10月爱因斯坦入口页面的访问次数,可以这样调用:
GET http://wikimedia.org/api/rest_ ... %3Bbr style="box-sizing:border-box;margin:0px;padding:0px;" />
我们可以在浏览器的地址栏中输入GET后的一长串URL,然后回车看看我们得到了什么结果。
在浏览器中,我们看到了上图中的一长串文字。您可能想知道 - 这是什么?
恭喜,这是我们需要得到的数据。但是,它使用一种称为 JSON 的特殊数据格式。
JSON是互联网上数据交互的主流格式之一。如果你想了解 JSON 的含义和用法,可以参考这篇教程。
在浏览器中,我们最初只能看到数据的第一部分。但它已经收录了有价值的内容:
{"items":[{"project":"en.wikipedia","article":"Albert_Einstein","granularity":"daily","timestamp":"2015100100","access":"all-access","agent":"all-agents","views":18860}<br style="box-sizing:border-box;margin:0px;padding:0px;" />
在本段中,我们看到项目名称(en.wikipedia)、文章 标题(Albert Einstein)、统计粒度(天)、时间戳(10/1/2015)、访问类型(全部)、终端类型(全部) 和访问次数 (18860).
我们使用滑块将返回的文本拖到最后,我们会看到如下信息:
{"project":"en.wikipedia","article":"Albert_Einstein","granularity":"daily","timestamp":"2015103100","access":"all-access","agent":"all-agents","views":16380}]}<br style="box-sizing:border-box;margin:0px;padding:0px;" />
与 10 月 1 日的数据相比,只有时间戳(2015 年 10 月 31 日)和访问次数(16380))发生了变化。
在中间,我们跳过了 10 月 2 日至 10 月 30 日之间的数据。存储格式相同,只是日期和访问次数的数据值在变化。
您需要的所有数据都在这里,您只需提取相应的信息即可。但是如果手动进行(比如将需要的项目复制粘贴到Excel中),显然效率低下,容易出错。让我们展示如何使用 R 编程环境自动化这个过程。
准备
在正式用 R 调用 API 之前,我们需要做一些必要的准备工作。
首先是安装R。
请到本网站下载R基础安装包。
R的下载位置比较多,建议选择清华镜像,下载速度比较快。
请根据您的操作系统平台选择对应的版本进行下载。我正在使用 macOS 版本。
下载 pkg 文件。双击安装。
安装完基础包后,我们继续安装集成开发环境RStudio。它可以帮助您轻松和交互式地与 R 进行交流。RStudio的下载地址在这里。
根据你的操作系统,选择对应的安装包。macOS 安装包是一个 dmg 文件。双击打开后,将RStudio.app图标拖到Applications文件夹下,安装完成。
下面我们双击从应用程序目录运行RStudio。
我们先在 RStudio 的 Console 中运行以下语句来安装一些需要的包:
install.packages("tidyverse")<br style="box-sizing:border-box;margin:0px;padding:0px;" />install.packages("rlist")<br style="box-sizing:border-box;margin:0px;padding:0px;" />
安装完成后,在菜单中选择File->New,在如下界面中选择R Notebook。
R Notebook 默认为我们提供了一个带有一些基本使用说明的模板。
让我们尝试在编辑区域(左)的代码部分(灰色)中单击运行按钮。
情节的结果可以立即看到。
我们点击菜单栏上的Preview按钮来查看整个代码的效果。操作的结果将以带有图片和文本的 HTML 文件的形式显示。
现在我们已经熟悉了环境,是时候实际运行我们的代码了。我们把编辑区的开头描述区保留在左边,删除其余的,把文件名改成有意义的web-data-api-with-R。
至此,准备工作就绪。现在我们要开始实际操作了。
操作
在实际操作过程中,我们以维基百科的另一个wiki文章为例来证明这种操作方法的通用性。选中的文章就是我们介绍词云制作时使用的那个,叫做“Yes, Minisiter”。这是一部 1980 年代的英国喜剧。
我们先在浏览器中试一下,看看能否修改 API 示例中的参数,获取“是,部长”文章 的访问统计信息。作为测试,我们仅采集 2017 年 10 月 1 日至 2017 年 10 月 3 日 3 天的数据。
与示例相反,我们需要替换的内容包括开始和结束时间以及 文章 标题。
我们在浏览器的地址栏中输入:
https://wikimedia.org/api/rest ... %3Bbr style="box-sizing:border-box;margin:0px;padding:0px;" />
返回结果如下:
数据可以正常返回。接下来,我们使用语句方法在 RStudio 中调用。
请注意,在下面的代码中,程序的输出部分会在开头带有## 标记,以区别于执行代码本身。
启动后,我们需要设置时区。否则,您稍后在处理时间数据时会遇到错误。
Sys.setenv(TZ="Asia/Shanghai")<br style="box-sizing:border-box;margin:0px;padding:0px;" />
然后,我们调用 tidyverse 包,它是一个可以同时加载许多函数的集合,我们稍后会用到。
library(tidyverse)<br style="box-sizing:border-box;margin:0px;padding:0px;" /><br style="box-sizing:border-box;margin:0px;padding:0px;" />## Loading tidyverse: ggplot2<br style="box-sizing:border-box;margin:0px;padding:0px;" />## Loading tidyverse: tibble<br style="box-sizing:border-box;margin:0px;padding:0px;" />## Loading tidyverse: tidyr<br style="box-sizing:border-box;margin:0px;padding:0px;" />## Loading tidyverse: readr<br style="box-sizing:border-box;margin:0px;padding:0px;" />## Loading tidyverse: purrr<br style="box-sizing:border-box;margin:0px;padding:0px;" />## Loading tidyverse: dplyr<br style="box-sizing:border-box;margin:0px;padding:0px;" /><br style="box-sizing:border-box;margin:0px;padding:0px;" />## Conflicts with tidy packages ----------------------------------------------<br style="box-sizing:border-box;margin:0px;padding:0px;" /><br style="box-sizing:border-box;margin:0px;padding:0px;" />## filter(): dplyr, stats<br style="box-sizing:border-box;margin:0px;padding:0px;" />## lag(): dplyr, stats<br style="box-sizing:border-box;margin:0px;padding:0px;" />
这里可能有一些警告,请忽略它们。它对我们的运营没有影响。
根据前面的例子,我们定义要查询的时间跨度,并指定要查找的wiki文章的名称。
请注意,与 Python 不同,在 R 中,赋值采用标记,而不是 =。不过,R 语言其实很容易上手。如果你坚持使用=,它也能识别,不会报错。
<p>starting 查看全部
文章采集api(如何用R调用API,提取和整理你需要的免费Web数据)
API是获取Web数据的重要方式之一。想了解如何使用 R 调用 API 来提取和组织您需要的免费 Web 数据吗?本文将逐步向您展示操作过程。
交易
俗话说,“聪明的女人,没有饭难煮”。就算你掌握了数据分析十八门武功,没有数据也是一件麻烦的事情。“拔刀而去,茫然不知所措”,大概就是这样。
有很多数据来源。Web 数据是数量庞大且相对容易获取的类型之一。更好的是,很多网络数据都是免费的。
在这个所谓的大数据时代,如何获取网络数据?
许多人使用由他人编译和发布的数据集。
他们很幸运,他们的工作可以建立在其他人的基础上。这是最有效的。
但并不是每个人都这么幸运。如果您需要的数据从未被组织和发布过怎么办?
事实上,这样的数据量更大。我们是否对他们视而不见?
如果您考虑爬行动物,那么您的想法是正确的。爬虫可以为您获取几乎所有可见(甚至不可见)的网络数据。然而,编写和使用爬虫的成本很高。包括时间资源、技术能力等。如果你遇到任何网络数据获取问题,你不要想“大锤”,有时可能是“刀枪不入”。
在“别人准备的数据”和“需要自己爬取的数据”之间,还有一个广阔的领域,这就是API的世界。
什么是 API?
它是应用程序编程接口的缩写。具体来说,某个网站的数据在不断的积累和变化。如果对这些数据进行整理,不仅费时,而且占用空间,而且还有刚整理完就过时的危险。大多数人需要的数据其实只是其中的一小部分,但时效性要求可能非常强。因此,组织存储并将其提供给公众以供下载是不经济的。
但是,如果数据不能以某种方式打通,就会面临无数爬虫的骚扰。这会对网站的正常运行造成很大的困扰。折衷方案是 网站 主动提供通道。当你需要某部分数据时,虽然没有现成的数据集,但你只需要用这个通道描述你想要的数据,然后网站审核后(一般是自动化的,瞬间完成),认为我可以给你,我会立即发送你明确要求的数据。双方都很高兴。
以后在找数据的时候,不妨看看目标网站有没有提供API,避免无用的努力。
在这个github项目中,有一个非常详细的列表,涵盖了当前常见的主流网站API资源状况。作者还在整理和修改中,大家可以采集起来慢慢看。
如果我们知道某个网站提供了API,通过查看文档知道我们需要的数据在那里,那么问题就变成了——如何通过API获取数据?
下面我们用一个实际的例子来向您展示整个操作步骤。
资源
我们正在寻找的例子是维基百科。
有关 Wikipedia API 的概述,请参阅此页面。
假设我们关心特定时间段内对指定维基百科 文章 页面的访问次数。
维基百科为我们提供了一种称为指标的数据,它涵盖了页面访问的关键价值。对应API的介绍页面在这里。
页面上有一个示例。假设需要获取2015年10月爱因斯坦入口页面的访问次数,可以这样调用:
GET http://wikimedia.org/api/rest_ ... %3Bbr style="box-sizing:border-box;margin:0px;padding:0px;" />
我们可以在浏览器的地址栏中输入GET后的一长串URL,然后回车看看我们得到了什么结果。
在浏览器中,我们看到了上图中的一长串文字。您可能想知道 - 这是什么?
恭喜,这是我们需要得到的数据。但是,它使用一种称为 JSON 的特殊数据格式。
JSON是互联网上数据交互的主流格式之一。如果你想了解 JSON 的含义和用法,可以参考这篇教程。
在浏览器中,我们最初只能看到数据的第一部分。但它已经收录了有价值的内容:
{"items":[{"project":"en.wikipedia","article":"Albert_Einstein","granularity":"daily","timestamp":"2015100100","access":"all-access","agent":"all-agents","views":18860}<br style="box-sizing:border-box;margin:0px;padding:0px;" />
在本段中,我们看到项目名称(en.wikipedia)、文章 标题(Albert Einstein)、统计粒度(天)、时间戳(10/1/2015)、访问类型(全部)、终端类型(全部) 和访问次数 (18860).
我们使用滑块将返回的文本拖到最后,我们会看到如下信息:
{"project":"en.wikipedia","article":"Albert_Einstein","granularity":"daily","timestamp":"2015103100","access":"all-access","agent":"all-agents","views":16380}]}<br style="box-sizing:border-box;margin:0px;padding:0px;" />
与 10 月 1 日的数据相比,只有时间戳(2015 年 10 月 31 日)和访问次数(16380))发生了变化。
在中间,我们跳过了 10 月 2 日至 10 月 30 日之间的数据。存储格式相同,只是日期和访问次数的数据值在变化。
您需要的所有数据都在这里,您只需提取相应的信息即可。但是如果手动进行(比如将需要的项目复制粘贴到Excel中),显然效率低下,容易出错。让我们展示如何使用 R 编程环境自动化这个过程。
准备
在正式用 R 调用 API 之前,我们需要做一些必要的准备工作。
首先是安装R。
请到本网站下载R基础安装包。
R的下载位置比较多,建议选择清华镜像,下载速度比较快。
请根据您的操作系统平台选择对应的版本进行下载。我正在使用 macOS 版本。
下载 pkg 文件。双击安装。
安装完基础包后,我们继续安装集成开发环境RStudio。它可以帮助您轻松和交互式地与 R 进行交流。RStudio的下载地址在这里。
根据你的操作系统,选择对应的安装包。macOS 安装包是一个 dmg 文件。双击打开后,将RStudio.app图标拖到Applications文件夹下,安装完成。
下面我们双击从应用程序目录运行RStudio。
我们先在 RStudio 的 Console 中运行以下语句来安装一些需要的包:
install.packages("tidyverse")<br style="box-sizing:border-box;margin:0px;padding:0px;" />install.packages("rlist")<br style="box-sizing:border-box;margin:0px;padding:0px;" />
安装完成后,在菜单中选择File->New,在如下界面中选择R Notebook。
R Notebook 默认为我们提供了一个带有一些基本使用说明的模板。
让我们尝试在编辑区域(左)的代码部分(灰色)中单击运行按钮。
情节的结果可以立即看到。
我们点击菜单栏上的Preview按钮来查看整个代码的效果。操作的结果将以带有图片和文本的 HTML 文件的形式显示。
现在我们已经熟悉了环境,是时候实际运行我们的代码了。我们把编辑区的开头描述区保留在左边,删除其余的,把文件名改成有意义的web-data-api-with-R。
至此,准备工作就绪。现在我们要开始实际操作了。
操作
在实际操作过程中,我们以维基百科的另一个wiki文章为例来证明这种操作方法的通用性。选中的文章就是我们介绍词云制作时使用的那个,叫做“Yes, Minisiter”。这是一部 1980 年代的英国喜剧。
我们先在浏览器中试一下,看看能否修改 API 示例中的参数,获取“是,部长”文章 的访问统计信息。作为测试,我们仅采集 2017 年 10 月 1 日至 2017 年 10 月 3 日 3 天的数据。
与示例相反,我们需要替换的内容包括开始和结束时间以及 文章 标题。
我们在浏览器的地址栏中输入:
https://wikimedia.org/api/rest ... %3Bbr style="box-sizing:border-box;margin:0px;padding:0px;" />
返回结果如下:
数据可以正常返回。接下来,我们使用语句方法在 RStudio 中调用。
请注意,在下面的代码中,程序的输出部分会在开头带有## 标记,以区别于执行代码本身。
启动后,我们需要设置时区。否则,您稍后在处理时间数据时会遇到错误。
Sys.setenv(TZ="Asia/Shanghai")<br style="box-sizing:border-box;margin:0px;padding:0px;" />
然后,我们调用 tidyverse 包,它是一个可以同时加载许多函数的集合,我们稍后会用到。
library(tidyverse)<br style="box-sizing:border-box;margin:0px;padding:0px;" /><br style="box-sizing:border-box;margin:0px;padding:0px;" />## Loading tidyverse: ggplot2<br style="box-sizing:border-box;margin:0px;padding:0px;" />## Loading tidyverse: tibble<br style="box-sizing:border-box;margin:0px;padding:0px;" />## Loading tidyverse: tidyr<br style="box-sizing:border-box;margin:0px;padding:0px;" />## Loading tidyverse: readr<br style="box-sizing:border-box;margin:0px;padding:0px;" />## Loading tidyverse: purrr<br style="box-sizing:border-box;margin:0px;padding:0px;" />## Loading tidyverse: dplyr<br style="box-sizing:border-box;margin:0px;padding:0px;" /><br style="box-sizing:border-box;margin:0px;padding:0px;" />## Conflicts with tidy packages ----------------------------------------------<br style="box-sizing:border-box;margin:0px;padding:0px;" /><br style="box-sizing:border-box;margin:0px;padding:0px;" />## filter(): dplyr, stats<br style="box-sizing:border-box;margin:0px;padding:0px;" />## lag(): dplyr, stats<br style="box-sizing:border-box;margin:0px;padding:0px;" />
这里可能有一些警告,请忽略它们。它对我们的运营没有影响。
根据前面的例子,我们定义要查询的时间跨度,并指定要查找的wiki文章的名称。
请注意,与 Python 不同,在 R 中,赋值采用标记,而不是 =。不过,R 语言其实很容易上手。如果你坚持使用=,它也能识别,不会报错。
<p>starting
文章采集api(在之前的文章中Python实现“维基百科六度分隔理论”)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-02-24 21:13
在之前的文章 Python实现“维基百科六度分离理论”基础爬虫中,我们实现了一个网站随机从一个链接到另一个链接,但是如果我们需要系统对整个< @网站 分类,或者要搜索 网站 上的每一页,我们该怎么办?我们需要采集整个网站,但这是一个非常占用内存的过程,尤其是在处理大的网站时,更合适的工具是使用数据库来存储< @k11 资源为@>,之前也说过。这是如何做到的。网站地图站点地图网站地图,也称为站点地图,是一个页面,上面放置了网站上所有需要被搜索引擎抓取的页面(注:不是所有页面,所有 文章 链接。大多数人在 网站 上找不到所需信息时,可能会求助于 网站 地图。搜索引擎蜘蛛我非常喜欢 网站maps。对于 SEO,网站maps 的好处: 1. 为搜索引擎蜘蛛提供可以浏览整个 网站 的链接,简单地反映 网站 的整体框架 2. 为搜索引擎提供一些链接蜘蛛指向动态页面或其他方法更难访问的页面;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。当他们在 网站 上找不到他们需要的信息时,地图作为一种补救措施。搜索引擎蜘蛛我非常喜欢 网站maps。对于 SEO,网站maps 的好处: 1. 为搜索引擎蜘蛛提供可以浏览整个 网站 的链接,简单地反映 网站 的整体框架 2. 为搜索引擎提供一些链接蜘蛛指向动态页面或其他方法更难访问的页面;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。当他们在 网站 上找不到他们需要的信息时,地图作为一种补救措施。搜索引擎蜘蛛我非常喜欢 网站maps。对于 SEO,网站maps 的好处: 1. 为搜索引擎蜘蛛提供可以浏览整个 网站 的链接,简单地反映 网站 的整体框架 2. 为搜索引擎提供一些链接蜘蛛指向动态页面或其他方法更难访问的页面;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。@网站。搜索引擎蜘蛛我非常喜欢 网站maps。对于 SEO,网站maps 的好处: 1. 为搜索引擎蜘蛛提供可以浏览整个 网站 的链接,简单地反映 网站 的整体框架 2. 为搜索引擎提供一些链接蜘蛛指向动态页面或其他方法更难访问的页面;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。@网站。搜索引擎蜘蛛我非常喜欢 网站maps。对于 SEO,网站maps 的好处: 1. 为搜索引擎蜘蛛提供可以浏览整个 网站 的链接,简单地反映 网站 的整体框架 2. 为搜索引擎提供一些链接蜘蛛指向动态页面或其他方法更难访问的页面;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。为搜索引擎蜘蛛提供可以浏览整个网站的链接,简单反映网站的整体框架 2. 为搜索引擎蜘蛛提供一些链接,指向动态页面或更难到达的页面其他方法;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。为搜索引擎蜘蛛提供可以浏览整个网站的链接,简单反映网站的整体框架 2. 为搜索引擎蜘蛛提供一些链接,指向动态页面或更难到达的页面其他方法;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。作为一个潜在的着陆页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。作为一个潜在的着陆页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。
数据采集采集网站数据不难,但需要爬虫有足够的深度。我们创建了一个爬虫,它递归地遍历每个 网站 并且只采集那些 网站 页面上的数据。通常耗时的 网站采集 方法从顶层页面(通常是 网站 主页)开始,然后搜索页面上的所有链接,形成一个列表,然后去到采集到这些链接的页面,继续采集到每个页面的链接形成一个新列表,重复执行。显然,这是一个复杂性迅速增长的过程。每页添加 10 个链接,在 网站 上添加 5 个页面深度。如果采集 整个网站,则采集 页的总数为105,即100,000 页。因为很多网站的内部链接都是重复的,为了避免重复的采集,需要链接和去重。在 Python 中,最常用的去重方法是使用内置的集合采集方法。只有“新”链接是 采集。看一下代码示例: from urllib.request import urlopenfrom bs4 import BeautifulSoup import repages = set()def getLinks(pageurl):globalpageshtml= urlopen("" + pageurl)soup= BeautifulSoup(html)forlink in soup.findAll( "a", href=pile("^(/wiki/)")):if'href' in link.attrs:iflink.attrs['href'] not in pages:#这是一个新页面 newPage= 链接。属性[' @采集。看一下代码示例: from urllib.request import urlopenfrom bs4 import BeautifulSoup import repages = set()def getLinks(pageurl):globalpageshtml= urlopen("" + pageurl)soup= BeautifulSoup(html)forlink in soup.findAll( "a", href=pile("^(/wiki/)")):if'href' in link.attrs:iflink.attrs['href'] not in pages:#这是一个新页面 newPage= 链接。属性[' @采集。看一下代码示例: from urllib.request import urlopenfrom bs4 import BeautifulSoup import repages = set()def getLinks(pageurl):globalpageshtml= urlopen("" + pageurl)soup= BeautifulSoup(html)forlink in soup.findAll( "a", href=pile("^(/wiki/)")):if'href' in link.attrs:iflink.attrs['href'] not in pages:#这是一个新页面 newPage= 链接。属性['
递归警告:Python 的默认递归*为 1000 次,因为维基百科的链接太多,所以程序在达到递归*时停止。如果你不想让它停止,你可以设置一个递归计数器或其他东西。采集整个网站数据为了有效地使用爬虫,我们在使用爬虫时需要在页面上做一些事情。让我们创建一个爬虫来采集有关页面标题、正文第一段和编辑页面的链接(如果有的话)的信息。第一步,我们需要在网站上观察页面,然后制定采集模式,通过F12(一般情况下)检查元素,就可以看到页面的构成了。查看维基百科页面,包括入口和非入口页面,例如隐私政策页面,可以得出以下规则:所有标题都在h1→span标签中,页面上只有一个h1标签。所有正文都在 div#bodyContent 标记中。如果要获取第一段文字,可以使用div#mw-content-text→p。此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href' 并且页面上只有一个 h1 标签。所有正文都在 div#bodyContent 标记中。如果要获取第一段文字,可以使用div#mw-content-text→p。此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href' 并且页面上只有一个 h1 标签。所有正文都在 div#bodyContent 标记中。如果要获取第一段文字,可以使用div#mw-content-text→p。此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href' 所有正文都在 div#bodyContent 标记中。如果要获取第一段文字,可以使用div#mw-content-text→p。此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href' 所有正文都在 div#bodyContent 标记中。如果要获取第一段文字,可以使用div#mw-content-text→p。此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href' 此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href' 此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href'
<p>在数据存储到 MySQL 之前,数据已经被获取。直接打印出来比较麻烦,所以我们可以直接存入MySQL。这里只存储链接是没有意义的,所以我们存储页面的标题和内容。我之前有两篇文章 文章 介绍了如何在 MySQL 中存储数据。数据表为pages,代码如下: import reimport datetimeimport randomimport pymysqlconn = pymysql.connect(host = '127.< @0. 查看全部
文章采集api(在之前的文章中Python实现“维基百科六度分隔理论”)
在之前的文章 Python实现“维基百科六度分离理论”基础爬虫中,我们实现了一个网站随机从一个链接到另一个链接,但是如果我们需要系统对整个< @网站 分类,或者要搜索 网站 上的每一页,我们该怎么办?我们需要采集整个网站,但这是一个非常占用内存的过程,尤其是在处理大的网站时,更合适的工具是使用数据库来存储< @k11 资源为@>,之前也说过。这是如何做到的。网站地图站点地图网站地图,也称为站点地图,是一个页面,上面放置了网站上所有需要被搜索引擎抓取的页面(注:不是所有页面,所有 文章 链接。大多数人在 网站 上找不到所需信息时,可能会求助于 网站 地图。搜索引擎蜘蛛我非常喜欢 网站maps。对于 SEO,网站maps 的好处: 1. 为搜索引擎蜘蛛提供可以浏览整个 网站 的链接,简单地反映 网站 的整体框架 2. 为搜索引擎提供一些链接蜘蛛指向动态页面或其他方法更难访问的页面;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。当他们在 网站 上找不到他们需要的信息时,地图作为一种补救措施。搜索引擎蜘蛛我非常喜欢 网站maps。对于 SEO,网站maps 的好处: 1. 为搜索引擎蜘蛛提供可以浏览整个 网站 的链接,简单地反映 网站 的整体框架 2. 为搜索引擎提供一些链接蜘蛛指向动态页面或其他方法更难访问的页面;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。当他们在 网站 上找不到他们需要的信息时,地图作为一种补救措施。搜索引擎蜘蛛我非常喜欢 网站maps。对于 SEO,网站maps 的好处: 1. 为搜索引擎蜘蛛提供可以浏览整个 网站 的链接,简单地反映 网站 的整体框架 2. 为搜索引擎提供一些链接蜘蛛指向动态页面或其他方法更难访问的页面;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。@网站。搜索引擎蜘蛛我非常喜欢 网站maps。对于 SEO,网站maps 的好处: 1. 为搜索引擎蜘蛛提供可以浏览整个 网站 的链接,简单地反映 网站 的整体框架 2. 为搜索引擎提供一些链接蜘蛛指向动态页面或其他方法更难访问的页面;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。@网站。搜索引擎蜘蛛我非常喜欢 网站maps。对于 SEO,网站maps 的好处: 1. 为搜索引擎蜘蛛提供可以浏览整个 网站 的链接,简单地反映 网站 的整体框架 2. 为搜索引擎提供一些链接蜘蛛指向动态页面或其他方法更难访问的页面;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。为搜索引擎蜘蛛提供可以浏览整个网站的链接,简单反映网站的整体框架 2. 为搜索引擎蜘蛛提供一些链接,指向动态页面或更难到达的页面其他方法;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。为搜索引擎蜘蛛提供可以浏览整个网站的链接,简单反映网站的整体框架 2. 为搜索引擎蜘蛛提供一些链接,指向动态页面或更难到达的页面其他方法;3、作为潜在的落地页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。作为一个潜在的着陆页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。作为一个潜在的着陆页,可以针对搜索流量进行优化;4. 如果您访问如果访问者试图访问一个在 网站 域中不存在的 URL,访问者将被重定向到“找不到文件”错误页面,并且 网站 映射可以用作该页面的“准”内容。
数据采集采集网站数据不难,但需要爬虫有足够的深度。我们创建了一个爬虫,它递归地遍历每个 网站 并且只采集那些 网站 页面上的数据。通常耗时的 网站采集 方法从顶层页面(通常是 网站 主页)开始,然后搜索页面上的所有链接,形成一个列表,然后去到采集到这些链接的页面,继续采集到每个页面的链接形成一个新列表,重复执行。显然,这是一个复杂性迅速增长的过程。每页添加 10 个链接,在 网站 上添加 5 个页面深度。如果采集 整个网站,则采集 页的总数为105,即100,000 页。因为很多网站的内部链接都是重复的,为了避免重复的采集,需要链接和去重。在 Python 中,最常用的去重方法是使用内置的集合采集方法。只有“新”链接是 采集。看一下代码示例: from urllib.request import urlopenfrom bs4 import BeautifulSoup import repages = set()def getLinks(pageurl):globalpageshtml= urlopen("" + pageurl)soup= BeautifulSoup(html)forlink in soup.findAll( "a", href=pile("^(/wiki/)")):if'href' in link.attrs:iflink.attrs['href'] not in pages:#这是一个新页面 newPage= 链接。属性[' @采集。看一下代码示例: from urllib.request import urlopenfrom bs4 import BeautifulSoup import repages = set()def getLinks(pageurl):globalpageshtml= urlopen("" + pageurl)soup= BeautifulSoup(html)forlink in soup.findAll( "a", href=pile("^(/wiki/)")):if'href' in link.attrs:iflink.attrs['href'] not in pages:#这是一个新页面 newPage= 链接。属性[' @采集。看一下代码示例: from urllib.request import urlopenfrom bs4 import BeautifulSoup import repages = set()def getLinks(pageurl):globalpageshtml= urlopen("" + pageurl)soup= BeautifulSoup(html)forlink in soup.findAll( "a", href=pile("^(/wiki/)")):if'href' in link.attrs:iflink.attrs['href'] not in pages:#这是一个新页面 newPage= 链接。属性['
递归警告:Python 的默认递归*为 1000 次,因为维基百科的链接太多,所以程序在达到递归*时停止。如果你不想让它停止,你可以设置一个递归计数器或其他东西。采集整个网站数据为了有效地使用爬虫,我们在使用爬虫时需要在页面上做一些事情。让我们创建一个爬虫来采集有关页面标题、正文第一段和编辑页面的链接(如果有的话)的信息。第一步,我们需要在网站上观察页面,然后制定采集模式,通过F12(一般情况下)检查元素,就可以看到页面的构成了。查看维基百科页面,包括入口和非入口页面,例如隐私政策页面,可以得出以下规则:所有标题都在h1→span标签中,页面上只有一个h1标签。所有正文都在 div#bodyContent 标记中。如果要获取第一段文字,可以使用div#mw-content-text→p。此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href' 并且页面上只有一个 h1 标签。所有正文都在 div#bodyContent 标记中。如果要获取第一段文字,可以使用div#mw-content-text→p。此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href' 并且页面上只有一个 h1 标签。所有正文都在 div#bodyContent 标记中。如果要获取第一段文字,可以使用div#mw-content-text→p。此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href' 所有正文都在 div#bodyContent 标记中。如果要获取第一段文字,可以使用div#mw-content-text→p。此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href' 所有正文都在 div#bodyContent 标记中。如果要获取第一段文字,可以使用div#mw-content-text→p。此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href' 此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href' 此规则适用于除文件页面之外的所有页面。编辑链接仅出现在入口页面上。如果有编辑链接,则位于li#ca-edit标签的li#ca-edit→span→a中。调整前面的代码,我们可以构建一个爬虫和数据的组合程序采集,代码如下: import redef getLinks(pageUrl):global pageshtml = urlopen("" + pageUrl)soup = BeautifulSoup(html)尝试: print(soup.h1.get_text())print(soup.find(id="mw-content-text").findAll("p")[0])print(soup.find(id =" ca-edit").find("span").find("a").attrs['href'
<p>在数据存储到 MySQL 之前,数据已经被获取。直接打印出来比较麻烦,所以我们可以直接存入MySQL。这里只存储链接是没有意义的,所以我们存储页面的标题和内容。我之前有两篇文章 文章 介绍了如何在 MySQL 中存储数据。数据表为pages,代码如下: import reimport datetimeimport randomimport pymysqlconn = pymysql.connect(host = '127.< @0.
文章采集api(大数据搜集体系有哪些分类?搜集日志数据分类)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-02-24 21:11
【摘要】大数据采集技术对数据进行ETL运算,提取、转换、加载数据,最终挖掘数据的潜在价值,进而为用户提供解决方案或决策参考。那么,大数据采集系统的分类有哪些呢?今天就和小编一起来了解一下吧!
1、系统日志采集系统
采集和采集日志数据信息,然后进行数据分析,挖掘日志数据在公司交易渠道中的潜在价值。总之,采集日志数据提供了离线和在线的实时分析应用。目前常用的开源日志采集系统是 Flume。
2、网络数据采集系统
通过网络爬虫和一些网站渠道提供的公共API(如推特和新浪微博API)从网站获取数据。它可以从网页中提取非结构化数据和半结构化数据的网页数据,提取、清洗并转换为结构化数据,并存储为一致的本地文件数据。
目前常用的网络爬虫系统包括Apache Nutch、Crawler4j、Scrapy等结构。
3、数据库采集系统
数据库采集系统直接与企业事务后台服务器结合后,在企业事务后台每时每刻都将大量事务记录写入数据库,最终由特定的处理系统对系统进行分析。
目前,存储数据常用MySQL、Oracle等关系型数据库,采集数据也常用Redis、MongoDB等NoSQL数据库。
关于大数据采集系统的分类,青腾小编就在这里跟大家分享一下。如果你对大数据工程有浓厚的兴趣,希望这篇文章可以帮助到你。如果想了解更多数据分析师和大数据工程师的技能和资料,可以点击本站其他文章进行学习。 查看全部
文章采集api(大数据搜集体系有哪些分类?搜集日志数据分类)
【摘要】大数据采集技术对数据进行ETL运算,提取、转换、加载数据,最终挖掘数据的潜在价值,进而为用户提供解决方案或决策参考。那么,大数据采集系统的分类有哪些呢?今天就和小编一起来了解一下吧!
1、系统日志采集系统
采集和采集日志数据信息,然后进行数据分析,挖掘日志数据在公司交易渠道中的潜在价值。总之,采集日志数据提供了离线和在线的实时分析应用。目前常用的开源日志采集系统是 Flume。
2、网络数据采集系统
通过网络爬虫和一些网站渠道提供的公共API(如推特和新浪微博API)从网站获取数据。它可以从网页中提取非结构化数据和半结构化数据的网页数据,提取、清洗并转换为结构化数据,并存储为一致的本地文件数据。
目前常用的网络爬虫系统包括Apache Nutch、Crawler4j、Scrapy等结构。
3、数据库采集系统
数据库采集系统直接与企业事务后台服务器结合后,在企业事务后台每时每刻都将大量事务记录写入数据库,最终由特定的处理系统对系统进行分析。
目前,存储数据常用MySQL、Oracle等关系型数据库,采集数据也常用Redis、MongoDB等NoSQL数据库。
关于大数据采集系统的分类,青腾小编就在这里跟大家分享一下。如果你对大数据工程有浓厚的兴趣,希望这篇文章可以帮助到你。如果想了解更多数据分析师和大数据工程师的技能和资料,可以点击本站其他文章进行学习。
文章采集api(Scrapy一个 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2022-02-23 07:17
)
内容
架构介绍
Scrapy 是一个开源和协作框架,最初是为页面抓取(更准确地说是网页抓取)而设计的,它允许您以快速、简单和可扩展的方式从所需数据中提取所有信息。但目前,Scrapy 的用途非常广泛,例如数据挖掘、监控和自动化测试,也可以用来获取 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
Scrapy 是基于 twisted 框架开发的,这是一个流行的事件驱动的 Python 网络框架。所以 Scrapy 使用非阻塞(又名异步)代码来实现并发。整体结构大致如下
IO多路复用
# 引擎(EGINE)(大总管)
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。有关详细信息,请参见上面的数据流部分。
# 调度器(SCHEDULER)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
# 下载器(DOWLOADER)
用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的
# 爬虫(SPIDERS)
SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求
# 项目管道(ITEM PIPLINES)
在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作
# 两个中间件
-爬虫中间件
-下载中间件(用的最多,加头,加代理,加cookie,集成selenium)
安装创建和启动
# 1 框架 不是 模块
# 2 号称爬虫界的django(你会发现,跟django很多地方一样)
# 3 安装
-mac,linux平台:pip3 install scrapy
-windows平台:pip3 install scrapy(大部分人可以)
- 如果失败:
1、pip3 install wheel #安装后,便支持通过wheel文件安装软件,wheel文件官网:https://www.lfd.uci.edu/~gohlke/pythonlibs
3、pip3 install lxml
4、pip3 install pyopenssl
5、下载并安装pywin32:https://sourceforge.net/projec ... in32/
6、下载twisted的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
7、执行pip3 install 下载目录\Twisted-17.9.0-cp36-cp36m-win_amd64.whl
8、pip3 install scrapy
# 4 在script文件夹下会有scrapy.exe可执行文件
-创建scrapy项目:scrapy startproject 项目名 (django创建项目)
-创建爬虫:scrapy genspider 爬虫名 要爬取的网站地址 # 可以创建多个爬虫
# 5 命令启动爬虫
-scrapy crawl 爬虫名字
-scrapy crawl 爬虫名字 --nolog # 没有日志输出启动
# 6 文件执行爬虫(推荐使用)
-在项目路径下创建一个main.py,右键执行即可
from scrapy.cmdline import execute
# execute(['scrapy','crawl','chouti','--nolog']) # 没有设置日志级别
execute(['scrapy','crawl','chouti']) # 设置了日志级别
配置文件目录介绍
-crawl_chouti # 项目名
-crawl_chouti # 跟项目一个名,文件夹
-spiders # spiders:放着爬虫 genspider生成的爬虫,都放在这下面
-__init__.py
-chouti.py # 抽屉爬虫
-cnblogs.py # cnblogs 爬虫
-items.py # 对比django中的models.py文件 ,写一个个的模型类
-middlewares.py # 中间件(爬虫中间件,下载中间件),中间件写在这
-pipelines.py # 写持久化的地方(持久化到文件,mysql,redis,mongodb)
-settings.py # 配置文件
-scrapy.cfg # 不用关注,上线相关的
# 配置文件settings.py
ROBOTSTXT_OBEY = False # 是否遵循爬虫协议,强行运行
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36' # 请求头中的ua,去浏览器复制,或者用ua池拿
LOG_LEVEL='ERROR' # 这样配置,程序错误信息才会打印,
#启动爬虫直接 scrapy crawl 爬虫名 就没有日志输出
# scrapy crawl 爬虫名 --nolog # 配置了就不需要这样启动了
# 爬虫文件
class ChoutiSpider(scrapy.Spider):
name = 'chouti' # 爬虫名字
allowed_domains = ['https://dig.chouti.com/'] # 允许爬取的域,想要多爬就注释掉
start_urls = ['https://dig.chouti.com/'] # 起始爬取的位置,爬虫一启动,会先向它发请求
def parse(self, response): # 解析,请求回来,自动执行parser,在这个方法中做解析
print('---------------------------',response)
抓取数据并解析
# 1 解析,可以使用bs4解析
from bs4 import BeautifulSoup
soup=BeautifulSoup(response.text,'lxml')
soup.find_all() # bs4解析
soup.select() # css解析
# 2 内置的解析器
response.css
response.xpath
# 内置解析
# 所有用css或者xpath选择出来的都放在列表中
# 取第一个:extract_first()
# 取出所有extract()
# css选择器取文本和属性:
# .link-title::text # 取文本,数据都在data中
# .link-title::attr(href) # 取属性,数据都在data中
# xpath选择器取文本和属性
# .//a[contains(@class,"link-title")/text()]
#.//a[contains(@class,"link-title")/@href]
# 内置css选择期,取所有
div_list = response.css('.link-con .link-item')
for div in div_list:
content = div.css('.link-title').extract()
print(content)
数据持久化
# 方式一(不推荐)
-1 parser解析函数,return 列表,列表套字典
# 命令 (支持:('json', 'jsonlines', 'jl', 'csv', 'xml', 'marshal', 'pickle')
# 数据到aa.json文件中
-2 scrapy crawl chouti -o aa.json
# 代码:
lis = []
for div in div_list:
content = div.select('.link-title')[0].text
lis.append({'title':content})
return lis
# 方式二 pipline的方式(管道)
-1 在items.py中创建模型类
-2 在爬虫中chouti.py,引入,把解析的数据放到item对象中(要用中括号)
-3 yield item对象
-4 配置文件配置管道
ITEM_PIPELINES = {
# 数字表示优先级(数字越小,优先级越大)
'crawl_chouti.pipelines.CrawlChoutiPipeline': 300,
'crawl_chouti.pipelines.CrawlChoutiRedisPipeline': 301,
}
-5 pipline.py中写持久化的类
spider_open # 方法,一开始就打开文件
process_item # 方法,写入文件
spider_close # 方法,关闭文件
保存到文件
# choutiaa.py 爬虫文件
import scrapy
from chouti.items import ChoutiItem # 导入模型类
class ChoutiaaSpider(scrapy.Spider):
name = 'choutiaa'
# allowed_domains = ['https://dig.chouti.com/'] # 允许爬取的域
start_urls = ['https://dig.chouti.com//'] # 起始爬取位置
# 解析,请求回来,自动执行parse,在这个方法中解析
def parse(self, response):
print('----------------',response)
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text,'lxml')
div_list = soup.select('.link-con .link-item')
for div in div_list:
content = div.select('.link-title')[0].text
href = div.select('.link-title')[0].attrs['href']
item = ChoutiItem() # 生成模型对象
item['content'] = content # 添加值
item['href'] = href
yield item # 必须用yield
# items.py 模型类文件
import scrapy
class ChoutiItem(scrapy.Item):
content = scrapy.Field()
href = scrapy.Field()
# pipelines.py 数据持久化文件
class ChoutiPipeline(object):
def open_spider(self, spider):
# 一开始就打开文件
self.f = open('a.txt', 'w', encoding='utf-8')
def process_item(self, item, spider):
# print(item)
# 写入文件的操作 查看全部
文章采集api(Scrapy一个
)
内容
架构介绍
Scrapy 是一个开源和协作框架,最初是为页面抓取(更准确地说是网页抓取)而设计的,它允许您以快速、简单和可扩展的方式从所需数据中提取所有信息。但目前,Scrapy 的用途非常广泛,例如数据挖掘、监控和自动化测试,也可以用来获取 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
Scrapy 是基于 twisted 框架开发的,这是一个流行的事件驱动的 Python 网络框架。所以 Scrapy 使用非阻塞(又名异步)代码来实现并发。整体结构大致如下
IO多路复用
# 引擎(EGINE)(大总管)
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。有关详细信息,请参见上面的数据流部分。
# 调度器(SCHEDULER)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
# 下载器(DOWLOADER)
用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的
# 爬虫(SPIDERS)
SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求
# 项目管道(ITEM PIPLINES)
在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作
# 两个中间件
-爬虫中间件
-下载中间件(用的最多,加头,加代理,加cookie,集成selenium)
安装创建和启动
# 1 框架 不是 模块
# 2 号称爬虫界的django(你会发现,跟django很多地方一样)
# 3 安装
-mac,linux平台:pip3 install scrapy
-windows平台:pip3 install scrapy(大部分人可以)
- 如果失败:
1、pip3 install wheel #安装后,便支持通过wheel文件安装软件,wheel文件官网:https://www.lfd.uci.edu/~gohlke/pythonlibs
3、pip3 install lxml
4、pip3 install pyopenssl
5、下载并安装pywin32:https://sourceforge.net/projec ... in32/
6、下载twisted的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
7、执行pip3 install 下载目录\Twisted-17.9.0-cp36-cp36m-win_amd64.whl
8、pip3 install scrapy
# 4 在script文件夹下会有scrapy.exe可执行文件
-创建scrapy项目:scrapy startproject 项目名 (django创建项目)
-创建爬虫:scrapy genspider 爬虫名 要爬取的网站地址 # 可以创建多个爬虫
# 5 命令启动爬虫
-scrapy crawl 爬虫名字
-scrapy crawl 爬虫名字 --nolog # 没有日志输出启动
# 6 文件执行爬虫(推荐使用)
-在项目路径下创建一个main.py,右键执行即可
from scrapy.cmdline import execute
# execute(['scrapy','crawl','chouti','--nolog']) # 没有设置日志级别
execute(['scrapy','crawl','chouti']) # 设置了日志级别
配置文件目录介绍
-crawl_chouti # 项目名
-crawl_chouti # 跟项目一个名,文件夹
-spiders # spiders:放着爬虫 genspider生成的爬虫,都放在这下面
-__init__.py
-chouti.py # 抽屉爬虫
-cnblogs.py # cnblogs 爬虫
-items.py # 对比django中的models.py文件 ,写一个个的模型类
-middlewares.py # 中间件(爬虫中间件,下载中间件),中间件写在这
-pipelines.py # 写持久化的地方(持久化到文件,mysql,redis,mongodb)
-settings.py # 配置文件
-scrapy.cfg # 不用关注,上线相关的
# 配置文件settings.py
ROBOTSTXT_OBEY = False # 是否遵循爬虫协议,强行运行
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36' # 请求头中的ua,去浏览器复制,或者用ua池拿
LOG_LEVEL='ERROR' # 这样配置,程序错误信息才会打印,
#启动爬虫直接 scrapy crawl 爬虫名 就没有日志输出
# scrapy crawl 爬虫名 --nolog # 配置了就不需要这样启动了
# 爬虫文件
class ChoutiSpider(scrapy.Spider):
name = 'chouti' # 爬虫名字
allowed_domains = ['https://dig.chouti.com/'] # 允许爬取的域,想要多爬就注释掉
start_urls = ['https://dig.chouti.com/'] # 起始爬取的位置,爬虫一启动,会先向它发请求
def parse(self, response): # 解析,请求回来,自动执行parser,在这个方法中做解析
print('---------------------------',response)
抓取数据并解析
# 1 解析,可以使用bs4解析
from bs4 import BeautifulSoup
soup=BeautifulSoup(response.text,'lxml')
soup.find_all() # bs4解析
soup.select() # css解析
# 2 内置的解析器
response.css
response.xpath
# 内置解析
# 所有用css或者xpath选择出来的都放在列表中
# 取第一个:extract_first()
# 取出所有extract()
# css选择器取文本和属性:
# .link-title::text # 取文本,数据都在data中
# .link-title::attr(href) # 取属性,数据都在data中
# xpath选择器取文本和属性
# .//a[contains(@class,"link-title")/text()]
#.//a[contains(@class,"link-title")/@href]
# 内置css选择期,取所有
div_list = response.css('.link-con .link-item')
for div in div_list:
content = div.css('.link-title').extract()
print(content)
数据持久化
# 方式一(不推荐)
-1 parser解析函数,return 列表,列表套字典
# 命令 (支持:('json', 'jsonlines', 'jl', 'csv', 'xml', 'marshal', 'pickle')
# 数据到aa.json文件中
-2 scrapy crawl chouti -o aa.json
# 代码:
lis = []
for div in div_list:
content = div.select('.link-title')[0].text
lis.append({'title':content})
return lis
# 方式二 pipline的方式(管道)
-1 在items.py中创建模型类
-2 在爬虫中chouti.py,引入,把解析的数据放到item对象中(要用中括号)
-3 yield item对象
-4 配置文件配置管道
ITEM_PIPELINES = {
# 数字表示优先级(数字越小,优先级越大)
'crawl_chouti.pipelines.CrawlChoutiPipeline': 300,
'crawl_chouti.pipelines.CrawlChoutiRedisPipeline': 301,
}
-5 pipline.py中写持久化的类
spider_open # 方法,一开始就打开文件
process_item # 方法,写入文件
spider_close # 方法,关闭文件
保存到文件
# choutiaa.py 爬虫文件
import scrapy
from chouti.items import ChoutiItem # 导入模型类
class ChoutiaaSpider(scrapy.Spider):
name = 'choutiaa'
# allowed_domains = ['https://dig.chouti.com/'] # 允许爬取的域
start_urls = ['https://dig.chouti.com//'] # 起始爬取位置
# 解析,请求回来,自动执行parse,在这个方法中解析
def parse(self, response):
print('----------------',response)
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text,'lxml')
div_list = soup.select('.link-con .link-item')
for div in div_list:
content = div.select('.link-title')[0].text
href = div.select('.link-title')[0].attrs['href']
item = ChoutiItem() # 生成模型对象
item['content'] = content # 添加值
item['href'] = href
yield item # 必须用yield
# items.py 模型类文件
import scrapy
class ChoutiItem(scrapy.Item):
content = scrapy.Field()
href = scrapy.Field()
# pipelines.py 数据持久化文件
class ChoutiPipeline(object):
def open_spider(self, spider):
# 一开始就打开文件
self.f = open('a.txt', 'w', encoding='utf-8')
def process_item(self, item, spider):
# print(item)
# 写入文件的操作
文章采集api( 爬虫海外网站获取ip之前,请检查是否添加白名单?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2022-02-21 19:03
爬虫海外网站获取ip之前,请检查是否添加白名单?)
海外网站如何使用代理IP采集?
我们在做爬虫的时候,经常会遇到这种情况。爬虫第一次运行时,可以正常获取数据,一切看起来都是那么美好。但是过一会可能会出现403 Forbidden,然后你会打开网站查看一下,你可能会看到“你的IP访问频率太高,请稍后再试”。遇到这种情况,通常这种情况下,我们会使用代理IP隐藏自己的IP,实现大量爬取。国内代理常用的产品有几十种,而我们需要在海外爬的时候网站这些代理都用不上,所以我们今天用的是Ipidea全球代理。
用法与国内相差不大。可以根据需要选择在指定国家或全球播放,通过api接口调用,指定提取次数,也可以指定接口返回数据格式,如txt、json、html、等等,这里以全局混合和json格式为例,获取一个代理,一次一个,python代码如下:
import requestsurl = "http://tiqu.linksocket.com:81/ ... Bresp = requests.get(url)# 成功获取到的数据为:{'code': 0, 'data': [{'ip': '47.74.232.57', 'port': 21861}], 'msg': '0', 'success': True}data = resp.json().get('data')[0]proxy = { "http": "http://%s:%d" % (data.get("ip"), data.get("port")), "https": "https://%s:%d" % (data.get("ip"), data.get("port"))}
在获取IP之前,我们需要通过个人中心设置IP白名单,否则无法获取数据。
只需填写你本地的公网并保存即可(官方界面也提供了添加或删除白名单的界面)。如果不知道公网IP是什么,可以通过百度搜索IP。
爬虫演示如下。以下是六度新闻的示例:
import requestsurl = "http://tiqu.linksocket.com:81/ ... 3Bdef get_proxy(): """ 获取代理 """ resp = requests.get(url) data = resp.json().get('data')[0] proxy = { "http": "http://%s:%d" % (data.get("ip"), data.get("port")), "https": "https://%s:%d" % (data.get("ip"), data.get("port")) } return proxydef download_html(url): """ 获取url接口数据 """ resp = requests.get(url,proxies=get_proxy()) return resp.json()def run(): """ 主程序 :return: """ url = "https://6do.news/api/tag/114?page=1" content = download_html(url) # 数据处理略if __name__ == '__main__': run()
数据如图:
前后端分离的界面对爬虫比较友好,提取数据也比较方便。这里不需要做太多处理,可以根据需要提取数据。
如果代理不能挂在爬虫中,请检查是否添加白名单。
本次海外网站的采集教程到此结束,详细交流请联系我。
本文章仅供交流分享,【未经许可,请拒绝转载】 查看全部
文章采集api(
爬虫海外网站获取ip之前,请检查是否添加白名单?)
海外网站如何使用代理IP采集?
我们在做爬虫的时候,经常会遇到这种情况。爬虫第一次运行时,可以正常获取数据,一切看起来都是那么美好。但是过一会可能会出现403 Forbidden,然后你会打开网站查看一下,你可能会看到“你的IP访问频率太高,请稍后再试”。遇到这种情况,通常这种情况下,我们会使用代理IP隐藏自己的IP,实现大量爬取。国内代理常用的产品有几十种,而我们需要在海外爬的时候网站这些代理都用不上,所以我们今天用的是Ipidea全球代理。
用法与国内相差不大。可以根据需要选择在指定国家或全球播放,通过api接口调用,指定提取次数,也可以指定接口返回数据格式,如txt、json、html、等等,这里以全局混合和json格式为例,获取一个代理,一次一个,python代码如下:
import requestsurl = "http://tiqu.linksocket.com:81/ ... Bresp = requests.get(url)# 成功获取到的数据为:{'code': 0, 'data': [{'ip': '47.74.232.57', 'port': 21861}], 'msg': '0', 'success': True}data = resp.json().get('data')[0]proxy = { "http": "http://%s:%d" % (data.get("ip"), data.get("port")), "https": "https://%s:%d" % (data.get("ip"), data.get("port"))}
在获取IP之前,我们需要通过个人中心设置IP白名单,否则无法获取数据。
只需填写你本地的公网并保存即可(官方界面也提供了添加或删除白名单的界面)。如果不知道公网IP是什么,可以通过百度搜索IP。
爬虫演示如下。以下是六度新闻的示例:
import requestsurl = "http://tiqu.linksocket.com:81/ ... 3Bdef get_proxy(): """ 获取代理 """ resp = requests.get(url) data = resp.json().get('data')[0] proxy = { "http": "http://%s:%d" % (data.get("ip"), data.get("port")), "https": "https://%s:%d" % (data.get("ip"), data.get("port")) } return proxydef download_html(url): """ 获取url接口数据 """ resp = requests.get(url,proxies=get_proxy()) return resp.json()def run(): """ 主程序 :return: """ url = "https://6do.news/api/tag/114?page=1" content = download_html(url) # 数据处理略if __name__ == '__main__': run()
数据如图:
前后端分离的界面对爬虫比较友好,提取数据也比较方便。这里不需要做太多处理,可以根据需要提取数据。
如果代理不能挂在爬虫中,请检查是否添加白名单。
本次海外网站的采集教程到此结束,详细交流请联系我。
本文章仅供交流分享,【未经许可,请拒绝转载】
文章采集api(如何通过MySQL存储采集到的数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-02-21 06:08
MySQL是目前最流行的开源关系数据库管理系统。令人惊讶的是,一个开源项目的竞争力如此之强,以至于它的受欢迎程度不断接近另外两个闭源商业数据库系统:微软的 SQL Server 和甲骨文的甲骨文数据库(MySQL 于 2010 年被甲骨文收购)。)。
它的受欢迎程度不辜负它的名字。对于大多数应用程序,MySQL 是显而易见的选择。它是一个非常灵活、稳定、功能齐全的 DBMS,许多顶级 网站 都在使用它:Youtube、Twitter、Facebook 等。
由于使用广泛、免费、开箱即用,是web data采集项目中常用的数据库,在此文章我们介绍如何存储数据采集 通过 MySQL。
安装 MySQL
如果您是 MySQL 新手,您可能会觉得它有点麻烦。其实安装方法和安装其他软件一样简单。归根结底,MySQL 是由一系列数据文件组成的,存储在你的远程服务器或本地计算机上,其中收录了存储在数据库中的所有信息。
在Windows上安装MySQL,在Ubuntu上安装MySQL,在MAC上安装MySQL具体步骤在这里:在所有平台上安装MySQL
此处无需过多解释,按照视频操作即可。
基本命令
MySQL服务器启动后,与数据库服务器交互的方式有很多种。因为许多工具都是图形界面,所以您可以不使用 MySQL 的命令行(或很少使用)来管理数据库。phpMyAdmin 和 MySQL Workbench 等工具可以轻松查看、排序和创建数据库。但是,掌握命令行操作数据库还是很重要的。
除了用户定义的变量名,MySQL 不区分大小写。例如,SELECT 与 select 相同,但习惯上所有 MySQL 关键词 的 MySQL 语句都以大写形式编写。大多数开发人员还喜欢使用小写字母作为数据库和数据表名称。
首次登录 MySQL 数据库时,没有数据库来存储数据。我们需要创建一个数据库:
CREATE DATABASE scraping_article DEFAULT CHARACTER SET UTF8 COLLATE UTF8_GENERAL_CI;
因为每个 MySQL 实例可以有多个数据库,所以在使用数据库之前需要指定数据库名称:
使用scraping_article
从现在开始(直到关闭 MySQL 链接或切换到另一个数据库),所有命令都在这个新的“scraping_article”数据库中运行。
所有的操作看起来都很简单。那么在数据库中新建表的操作方法应该也差不多吧?我们在库中新建一个表来存储采集的网页文章的数据:
创建表文章;
结果显示错误:
错误 1113 (42000): 一个表必须至少有 1 列
与数据库不同,MySQL 数据表必须有列,否则无法创建。要在 MySQL 中定义字段(数据列),我们还必须将字段定义放在 CREATE TABLE 语句之后的带括号的逗号分隔列表中:
create table articles
(
id int auto_increment
primary key,
title varchar(64) null,
body text null,
summary varchar(256) null,
body_html text null,
create_time datetime default CURRENT_TIMESTAMP null,
time_updated datetime null,
link_text varchar(128) null
);
每个字段定义由三部分组成:
在字段定义列表的最后,还定义了一个“主键”(key)。MySQL使用这个主键来组织表的内容,方便以后快速查询。以后文章会介绍如何通过这些主键来提高数据库的查询速度,不过目前我们可以使用表的id列作为主键。
语句执行完毕后,我们可以使用DESCRIBE查看数据表的结构:
+--------------+--------------+------+-----+-------------------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+--------------+------+-----+-------------------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| title | varchar(64) | YES | | NULL | |
| body | text | YES | | NULL | |
| summary | varchar(256) | YES | | NULL | |
| body_html | text | YES | | NULL | |
| create_time | datetime | YES | | CURRENT_TIMESTAMP | |
| time_updated | datetime | YES | | NULL | |
| link_text | varchar(128) | YES | | NULL | |
+--------------+--------------+------+-----+-------------------+----------------+
8 rows in set (0.03 sec)
现在这张表是空表,我们插入数据看看,如下图:
INSERT INTO articles(title,body,summary,body_html,link_text) VALUES ("Test page title","Test page body.","Test page summary.","<p>Test page body.","test-page");</p>
这里需要注意,虽然articles表有8个字段(id、title、body、summary、body_html、create_time、time_update、link_text),但实际上我们只插入了5个字段(title、body、summary、body_html、link_text) ) ) 数据。因为id字段是自动递增的(MySQL每次插入数据时默认递增1),一般不需要处理。另外create_time字段的类型是current_timestamp,时间戳是通过插入的默认。
当然,我们也可以自定义字段内容来插入数据:
INSERT INTO articles(id,title,body,summary,body_html,create_time,link_text) VALUES (4,"Test page title","Test page body.","Test page summary.","<p>Test page body.","2021-11-20 15:51:45","test-page");</p>
只要你定义的整数不在数据表的id字段中,就可以插入到数据表中。但是,这非常糟糕;除非绝对必要(比如程序中缺少一行数据),否则让 MySQL 自己处理 id 和 timestamp 字段。
现在表中有一些数据,我们可以通过多种方式查询这些数据。以下是 SELECT 语句的一些示例:
SELECT * FROM articles WHERE id=1;
该语句告诉 MySQL “从文章表中选择 id 等于 2 的所有数据”。此星号 (*) 是通配符,表示所有字段。这行语句将显示所有满足条件的字段(其中 id=1))。如果没有 id 等于 1 的行,它将返回一个空集。例如,以下不区分大小写的查询将返回标题字段中收录“test”的所有行的所有字段(% 符号表示 MySQL 字符串通配符):
SELECT * FROM articles WHERE title LIKE "%test%";
但是如果你有很多字段并且你只想返回其中的一部分呢?您可以使用以下命令代替星号:
SELECT title, body FROM articles WHERE body LIKE "%test%";
这将只返回正文内容收录“test”的所有行的标题和正文字段。
DELETE 语句的语法类似于 SELECT 语句:
DELETE FROM articles WHERE id=1;
由于数据库的数据删除无法恢复,建议在执行DELETE语句前使用SELECT确认要删除的数据(上述删除语句可以使用SELECT * FROM文章WHERE id=1;查看),以及然后将 SELECT * 替换为 DELETE 就可以了,这是一个好习惯。很多程序员都有过 DELETE 误操作的悲惨故事,也有一些恐怖的故事是有人惊慌失措的忘记在语句中输入 WHERE,结果所有客户数据都被删除了。不要让这种事情发生在你身上!
要介绍的另一件事是 UPDATE 语句:
UPDATE articles SET title="A new title", body="Some new body." WHERE id=4;
以上只使用了最基本的 MySQL 语句来做一些简单的数据查询、创建和更新。
与 Python 集成
Python 没有对 MySQL 的内置支持。但是,有很多开源的可以用来和 MySQL 交互,Python 2.x 和 Python 3.x 版本都支持。最著名的一个是 PyMySQL。
我们可以使用pip来安装,执行如下命令:
python3 -m pip 安装 PyMySQL
安装完成后,我们就可以使用 PyMySQL 包了。如果您的 MySQL 服务器正在运行,您应该能够成功执行以下命令:
import pymysql
import os
from dotenv import load_dotenv
class DataSaveToMySQL(object):
def __init__(self):
# loading env config file
dotenv_path = os.path.join(os.getcwd(), '.env')
if os.path.exists(dotenv_path):
load_dotenv(dotenv_path)
conn = pymysql.connect(host=os.environ.get('MYSQL_HOST'), port=os.environ.get('MYSQL_PORT'),
user=os.environ.get('MYSQL_USER'), password=os.environ.get('MYSQL_PASSWORD'),
db=os.environ.get('MYSQL_DATABASES'))
cur = conn.cursor()
cur.execute("SELECT * FROM articles WHERE id=4;")
print(cur.fetchone())
cur.close()
conn.close()
这个程序有两个对象:一个连接对象(conn)和一个游标对象(cur)。
连接/游标模式是数据库编程中常用的模式。当您不熟悉数据库时,有时很难区分这两种模式之间的区别。连接方式除了连接数据库外,还发送数据库信息,处理回滚操作(当一个查询或一组查询中断时,数据库需要回到初始状态,一般使用事务来实现状态回滚),创建新游标等
一个连接可以有很多游标,一个游标跟踪一种状态信息,比如跟踪数据库的使用状态。如果您有多个数据库,并且需要写入所有数据库,则需要多个游标来处理。游标还可以收录上次查询执行的结果。查询结果可以通过调用cur.fetchone()等游标函数获得。
请记住在使用完连接和游标后关闭它们。如果不关闭,会导致连接泄漏(connection leak),造成连接关闭现象,即连接不再使用,但是数据库无法关闭,因为数据库不确定是否你想继续使用它。这种现象会一直消耗数据库资源,所以使用数据库后记得关闭连接!
刚开始时,您要做的就是将 采集 的数据保存到数据库中。我们继续采集blog文章的例子来演示如何实现数据存储。
import pymysql
import os
from dotenv import load_dotenv
from config import logger_config
from utils import connection_util
class DataSaveToMySQL(object):
def __init__(self):
# loading env config file
dotenv_path = os.path.join(os.getcwd(), '.env')
if os.path.exists(dotenv_path):
load_dotenv(dotenv_path)
# MySQL config
self._host = os.environ.get('MYSQL_HOST')
self._port = int(os.environ.get('MYSQL_PORT'))
self._user = os.environ.get('MYSQL_USER')
self._password = os.environ.get('MYSQL_PASSWORD')
self._db = os.environ.get('MYSQL_DATABASES')
self._target_url = 'https://www.scrapingbee.com/blog/'
self._baseUrl = 'https://www.scrapingbee.com'
self._init_connection = connection_util.ProcessConnection()
logging_name = 'store_mysql'
init_logging = logger_config.LoggingConfig()
self._logging = init_logging.init_logging(logging_name)
def scrape_data(self):
get_content = self._init_connection.init_connection(self._target_url)
if get_content:
parent = get_content.findAll("section", {"class": "section-sm"})[0]
get_row = parent.findAll("div", {"class": "col-lg-12 mb-5 mb-lg-0"})[0]
get_child_item = get_row.findAll("div", {"class": "col-md-4 mb-4"})
for item in get_child_item:
# 获取标题文字
get_title = item.find("a", {"class": "h5 d-block mb-3 post-title"}).get_text()
# 获取发布时间
get_release_date = item.find("div", {"class": "mb-3 mt-2"}).findAll("span")[1].get_text()
# 获取文章描述
get_description = item.find("p", {"class": "card-text post-description"}).get_text()
self.article_save_mysql(title=get_title, description=get_description, release_date=get_release_date)
else:
self._logging.warning('未获取到文章任何内容,请检查!')
def article_save_mysql(self, title, description, release_date):
connection = pymysql.connect(host=self._host, port=self._port, user=self._user, password=self._password,
db=self._db, charset='utf-8')
with connection.cursor() as cursor:
# Create a new record
sql = "INSERT INTO articles (title,summary,create_time) VALUES (%s,%s,%s);"
cursor.execute(sql, (title, description, release_date))
# connection is not autocommit by default. So you must commit to save
# your changes.
connection.commit()
这里需要注意几点:首先,将 charset='utf-8' 添加到连接字符串中。这是为了让conn把所有发送到数据库的信息都当作utf-8编码格式(当然前提是数据库默认编码设置为UTF-8)。
然后需要注意article_save_mysql函数。它有3个参数:title、description和release_date,并将这两个参数添加到INSERT语句中并用游标执行,然后用游标确认。这是将光标与连接分开的一个很好的例子;当游标存储一些数据库和数据库上下文信息时,需要通过连接确认才能将信息传递到数据库中,然后再将信息插入到数据库中。
上述代码没有使用 try...finally 语句关闭数据库,而是使用 with() 关闭数据库连接。在上一期中,我们也使用了 with() 来关闭 CSV 文件。
PyMySQL的规模虽然不大,但里面有一些非常实用的功能,在本文章中就不演示了。具体请参考 Python DBAPI 标准文档。
以上是关于将采集的内容保存到MySQL。本示例的所有代码都托管在 github 上。
github: 查看全部
文章采集api(如何通过MySQL存储采集到的数据)
MySQL是目前最流行的开源关系数据库管理系统。令人惊讶的是,一个开源项目的竞争力如此之强,以至于它的受欢迎程度不断接近另外两个闭源商业数据库系统:微软的 SQL Server 和甲骨文的甲骨文数据库(MySQL 于 2010 年被甲骨文收购)。)。
它的受欢迎程度不辜负它的名字。对于大多数应用程序,MySQL 是显而易见的选择。它是一个非常灵活、稳定、功能齐全的 DBMS,许多顶级 网站 都在使用它:Youtube、Twitter、Facebook 等。
由于使用广泛、免费、开箱即用,是web data采集项目中常用的数据库,在此文章我们介绍如何存储数据采集 通过 MySQL。
安装 MySQL
如果您是 MySQL 新手,您可能会觉得它有点麻烦。其实安装方法和安装其他软件一样简单。归根结底,MySQL 是由一系列数据文件组成的,存储在你的远程服务器或本地计算机上,其中收录了存储在数据库中的所有信息。
在Windows上安装MySQL,在Ubuntu上安装MySQL,在MAC上安装MySQL具体步骤在这里:在所有平台上安装MySQL
此处无需过多解释,按照视频操作即可。
基本命令
MySQL服务器启动后,与数据库服务器交互的方式有很多种。因为许多工具都是图形界面,所以您可以不使用 MySQL 的命令行(或很少使用)来管理数据库。phpMyAdmin 和 MySQL Workbench 等工具可以轻松查看、排序和创建数据库。但是,掌握命令行操作数据库还是很重要的。
除了用户定义的变量名,MySQL 不区分大小写。例如,SELECT 与 select 相同,但习惯上所有 MySQL 关键词 的 MySQL 语句都以大写形式编写。大多数开发人员还喜欢使用小写字母作为数据库和数据表名称。
首次登录 MySQL 数据库时,没有数据库来存储数据。我们需要创建一个数据库:
CREATE DATABASE scraping_article DEFAULT CHARACTER SET UTF8 COLLATE UTF8_GENERAL_CI;
因为每个 MySQL 实例可以有多个数据库,所以在使用数据库之前需要指定数据库名称:
使用scraping_article
从现在开始(直到关闭 MySQL 链接或切换到另一个数据库),所有命令都在这个新的“scraping_article”数据库中运行。
所有的操作看起来都很简单。那么在数据库中新建表的操作方法应该也差不多吧?我们在库中新建一个表来存储采集的网页文章的数据:
创建表文章;
结果显示错误:
错误 1113 (42000): 一个表必须至少有 1 列
与数据库不同,MySQL 数据表必须有列,否则无法创建。要在 MySQL 中定义字段(数据列),我们还必须将字段定义放在 CREATE TABLE 语句之后的带括号的逗号分隔列表中:
create table articles
(
id int auto_increment
primary key,
title varchar(64) null,
body text null,
summary varchar(256) null,
body_html text null,
create_time datetime default CURRENT_TIMESTAMP null,
time_updated datetime null,
link_text varchar(128) null
);
每个字段定义由三部分组成:
在字段定义列表的最后,还定义了一个“主键”(key)。MySQL使用这个主键来组织表的内容,方便以后快速查询。以后文章会介绍如何通过这些主键来提高数据库的查询速度,不过目前我们可以使用表的id列作为主键。
语句执行完毕后,我们可以使用DESCRIBE查看数据表的结构:
+--------------+--------------+------+-----+-------------------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+--------------+------+-----+-------------------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| title | varchar(64) | YES | | NULL | |
| body | text | YES | | NULL | |
| summary | varchar(256) | YES | | NULL | |
| body_html | text | YES | | NULL | |
| create_time | datetime | YES | | CURRENT_TIMESTAMP | |
| time_updated | datetime | YES | | NULL | |
| link_text | varchar(128) | YES | | NULL | |
+--------------+--------------+------+-----+-------------------+----------------+
8 rows in set (0.03 sec)
现在这张表是空表,我们插入数据看看,如下图:
INSERT INTO articles(title,body,summary,body_html,link_text) VALUES ("Test page title","Test page body.","Test page summary.","<p>Test page body.","test-page");</p>
这里需要注意,虽然articles表有8个字段(id、title、body、summary、body_html、create_time、time_update、link_text),但实际上我们只插入了5个字段(title、body、summary、body_html、link_text) ) ) 数据。因为id字段是自动递增的(MySQL每次插入数据时默认递增1),一般不需要处理。另外create_time字段的类型是current_timestamp,时间戳是通过插入的默认。
当然,我们也可以自定义字段内容来插入数据:
INSERT INTO articles(id,title,body,summary,body_html,create_time,link_text) VALUES (4,"Test page title","Test page body.","Test page summary.","<p>Test page body.","2021-11-20 15:51:45","test-page");</p>
只要你定义的整数不在数据表的id字段中,就可以插入到数据表中。但是,这非常糟糕;除非绝对必要(比如程序中缺少一行数据),否则让 MySQL 自己处理 id 和 timestamp 字段。
现在表中有一些数据,我们可以通过多种方式查询这些数据。以下是 SELECT 语句的一些示例:
SELECT * FROM articles WHERE id=1;
该语句告诉 MySQL “从文章表中选择 id 等于 2 的所有数据”。此星号 (*) 是通配符,表示所有字段。这行语句将显示所有满足条件的字段(其中 id=1))。如果没有 id 等于 1 的行,它将返回一个空集。例如,以下不区分大小写的查询将返回标题字段中收录“test”的所有行的所有字段(% 符号表示 MySQL 字符串通配符):
SELECT * FROM articles WHERE title LIKE "%test%";
但是如果你有很多字段并且你只想返回其中的一部分呢?您可以使用以下命令代替星号:
SELECT title, body FROM articles WHERE body LIKE "%test%";
这将只返回正文内容收录“test”的所有行的标题和正文字段。
DELETE 语句的语法类似于 SELECT 语句:
DELETE FROM articles WHERE id=1;
由于数据库的数据删除无法恢复,建议在执行DELETE语句前使用SELECT确认要删除的数据(上述删除语句可以使用SELECT * FROM文章WHERE id=1;查看),以及然后将 SELECT * 替换为 DELETE 就可以了,这是一个好习惯。很多程序员都有过 DELETE 误操作的悲惨故事,也有一些恐怖的故事是有人惊慌失措的忘记在语句中输入 WHERE,结果所有客户数据都被删除了。不要让这种事情发生在你身上!
要介绍的另一件事是 UPDATE 语句:
UPDATE articles SET title="A new title", body="Some new body." WHERE id=4;
以上只使用了最基本的 MySQL 语句来做一些简单的数据查询、创建和更新。
与 Python 集成
Python 没有对 MySQL 的内置支持。但是,有很多开源的可以用来和 MySQL 交互,Python 2.x 和 Python 3.x 版本都支持。最著名的一个是 PyMySQL。
我们可以使用pip来安装,执行如下命令:
python3 -m pip 安装 PyMySQL
安装完成后,我们就可以使用 PyMySQL 包了。如果您的 MySQL 服务器正在运行,您应该能够成功执行以下命令:
import pymysql
import os
from dotenv import load_dotenv
class DataSaveToMySQL(object):
def __init__(self):
# loading env config file
dotenv_path = os.path.join(os.getcwd(), '.env')
if os.path.exists(dotenv_path):
load_dotenv(dotenv_path)
conn = pymysql.connect(host=os.environ.get('MYSQL_HOST'), port=os.environ.get('MYSQL_PORT'),
user=os.environ.get('MYSQL_USER'), password=os.environ.get('MYSQL_PASSWORD'),
db=os.environ.get('MYSQL_DATABASES'))
cur = conn.cursor()
cur.execute("SELECT * FROM articles WHERE id=4;")
print(cur.fetchone())
cur.close()
conn.close()
这个程序有两个对象:一个连接对象(conn)和一个游标对象(cur)。
连接/游标模式是数据库编程中常用的模式。当您不熟悉数据库时,有时很难区分这两种模式之间的区别。连接方式除了连接数据库外,还发送数据库信息,处理回滚操作(当一个查询或一组查询中断时,数据库需要回到初始状态,一般使用事务来实现状态回滚),创建新游标等
一个连接可以有很多游标,一个游标跟踪一种状态信息,比如跟踪数据库的使用状态。如果您有多个数据库,并且需要写入所有数据库,则需要多个游标来处理。游标还可以收录上次查询执行的结果。查询结果可以通过调用cur.fetchone()等游标函数获得。
请记住在使用完连接和游标后关闭它们。如果不关闭,会导致连接泄漏(connection leak),造成连接关闭现象,即连接不再使用,但是数据库无法关闭,因为数据库不确定是否你想继续使用它。这种现象会一直消耗数据库资源,所以使用数据库后记得关闭连接!
刚开始时,您要做的就是将 采集 的数据保存到数据库中。我们继续采集blog文章的例子来演示如何实现数据存储。
import pymysql
import os
from dotenv import load_dotenv
from config import logger_config
from utils import connection_util
class DataSaveToMySQL(object):
def __init__(self):
# loading env config file
dotenv_path = os.path.join(os.getcwd(), '.env')
if os.path.exists(dotenv_path):
load_dotenv(dotenv_path)
# MySQL config
self._host = os.environ.get('MYSQL_HOST')
self._port = int(os.environ.get('MYSQL_PORT'))
self._user = os.environ.get('MYSQL_USER')
self._password = os.environ.get('MYSQL_PASSWORD')
self._db = os.environ.get('MYSQL_DATABASES')
self._target_url = 'https://www.scrapingbee.com/blog/'
self._baseUrl = 'https://www.scrapingbee.com'
self._init_connection = connection_util.ProcessConnection()
logging_name = 'store_mysql'
init_logging = logger_config.LoggingConfig()
self._logging = init_logging.init_logging(logging_name)
def scrape_data(self):
get_content = self._init_connection.init_connection(self._target_url)
if get_content:
parent = get_content.findAll("section", {"class": "section-sm"})[0]
get_row = parent.findAll("div", {"class": "col-lg-12 mb-5 mb-lg-0"})[0]
get_child_item = get_row.findAll("div", {"class": "col-md-4 mb-4"})
for item in get_child_item:
# 获取标题文字
get_title = item.find("a", {"class": "h5 d-block mb-3 post-title"}).get_text()
# 获取发布时间
get_release_date = item.find("div", {"class": "mb-3 mt-2"}).findAll("span")[1].get_text()
# 获取文章描述
get_description = item.find("p", {"class": "card-text post-description"}).get_text()
self.article_save_mysql(title=get_title, description=get_description, release_date=get_release_date)
else:
self._logging.warning('未获取到文章任何内容,请检查!')
def article_save_mysql(self, title, description, release_date):
connection = pymysql.connect(host=self._host, port=self._port, user=self._user, password=self._password,
db=self._db, charset='utf-8')
with connection.cursor() as cursor:
# Create a new record
sql = "INSERT INTO articles (title,summary,create_time) VALUES (%s,%s,%s);"
cursor.execute(sql, (title, description, release_date))
# connection is not autocommit by default. So you must commit to save
# your changes.
connection.commit()
这里需要注意几点:首先,将 charset='utf-8' 添加到连接字符串中。这是为了让conn把所有发送到数据库的信息都当作utf-8编码格式(当然前提是数据库默认编码设置为UTF-8)。
然后需要注意article_save_mysql函数。它有3个参数:title、description和release_date,并将这两个参数添加到INSERT语句中并用游标执行,然后用游标确认。这是将光标与连接分开的一个很好的例子;当游标存储一些数据库和数据库上下文信息时,需要通过连接确认才能将信息传递到数据库中,然后再将信息插入到数据库中。
上述代码没有使用 try...finally 语句关闭数据库,而是使用 with() 关闭数据库连接。在上一期中,我们也使用了 with() 来关闭 CSV 文件。
PyMySQL的规模虽然不大,但里面有一些非常实用的功能,在本文章中就不演示了。具体请参考 Python DBAPI 标准文档。
以上是关于将采集的内容保存到MySQL。本示例的所有代码都托管在 github 上。
github:
文章采集api(【干货】Kubernetes日志采集难点分析(一)——Kubernetes)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-02-21 06:02
前言
上一期主要介绍了Kubernetes日志输出的一些注意事项。日志输出的最终目的是做统一的采集和分析。在 Kubernetes 中,记录采集的方式与普通虚拟机有很大不同,相对实现难度和部署成本也略高。但是,如果使用得当,可以实现比传统方式更高的自动化程度和更低的运维成本。
Kubernetes 日志采集 难点
在 Kubernetes 中,log采集 比传统的虚拟机和物理机要复杂得多。最根本的原因是Kubernetes屏蔽了底层异常,提供了更细粒度的资源调度,向上提供了一个稳定动态的环境。因此,日志采集面临着更丰富、更动态的环境,需要考虑的点也更多。
例如:
对于一个运行时间很短的Job应用,从启动到停止只需要几秒,如何保证日志采集的实时性能跟得上,数据不丢失?K8s 一般推荐使用大型节点。每个节点可以运行 10-100+ 个容器。如何以尽可能低的资源消耗采集100+ 个容器?在K8s中,应用以yaml的形式部署,日志采集主要是手动配置文件的形式。日志采集如何以K8s的方式部署?
Kubernetes传统日志类型文件、stdout、host文件、journal文件、journal日志源业务容器、系统组件、宿主业务、宿主采集方法代理(Sidecar、DaemonSet)、直写(DockerEngine、业务)代理、直接-write 单机应用号 10-1001-10 应用动态高低 节点动态高低 采集 部署方式手动、Yaml手动、自定义
采集模式:主动或被动
日志采集方法有两种:被动采集和主动推送。在K8s中,被动采集一般分为Sidecar和DaemonSet两种方式。主动推送包括 DockerEngine 推送和业务直推。写两种方式。
总结:DockerEngine直接写一般不推荐;日志量大的场景推荐业务直写;DaemonSet 一般用于中小型集群;建议在非常大的集群中使用 Sidecar。各种采集方法的详细对比如下:
DockerEngine业务直接写入DaemonSet方法Sidecar方法采集日志类型标准输出业务日志标准输出+部分文件文件部署运维低,原生支持低,只需要维护配置文件正常,需要为了维护 DaemonSet 高,每个需要 采集 日志的 POD 都需要部署一个 sidecar 容器。日志分类和存储无法实现业务无关的配置。一般来说,每个POD都可以通过容器/路径映射来单独配置,灵活性高,多租户隔离性较弱。日志直写一般会和业务逻辑竞争资源。只能通过强配置隔离,通过容器隔离,资源可独立分配,支持集群规模无限本地存储。如果使用 syslog 和 fluentd,根据配置会有单点限制和无限制。无限资源数量低,dockerengine提供整体最低,节省采集的成本,每个节点运行一个容器高,每个POD运行一个容器,查询便利性低,只有grep raw日志高,可根据业务特点定制高,可定制查询,高统计,可根据业务特点定制低高可定制性,可自由扩展低高,每个POD单独配置高耦合,并且强绑定 DockerEngine 固定,修改需要重启 DockerEngine 高,<
日志输出:标准输出或文件
与虚拟机/物理机不同,K8s 容器提供标准输出和文件。在容器中,标准输出直接将日志输出到stdout或stderr,DockerEngine接管stdout和stderr文件描述符,收到日志后根据DockerEngine配置的LogDriver规则进行处理;日志打印到文件的方式与虚拟机/物理机不同。基本类似,只是日志可以使用不同的存储方式,比如默认存储、EmptyDir、HostVolume、NFS等。
虽然 Docker 官方推荐使用 Stdout 打印日志,但需要注意的是,这个推荐是基于容器仅作为简单应用使用的场景。在实际业务场景中,我们还是建议大家尽量使用文件方式。主要原因如下。观点:
stdout性能问题,从应用输出stdout到服务器,会有几个过程(比如常用的JSON LogDriver):应用stdout -> DockerEngine -> LogDriver -> 序列化成JSON -> 保存到文件 -> Agent< @采集文件 -> 解析 JSON -> 上传服务器。整个过程需要比文件更多的开销。压力测试时,每秒输出 10 万行日志会占用 DockerEngine 的额外 CPU 内核。stdout 不支持分类,即所有输出混合在一个流中,不能像文件一样分类输出。通常,一个应用程序包括AccessLog、ErrorLog、InterfaceLog(调用外部接口的日志)、TraceLog等。这些日志的格式和用途不,会很难采集 如果在同一流中混合,则进行分析。stdout 只支持容器主程序的输出。如果是 daemon/fork 模式下运行的程序,则无法使用 stdout。文件转储方式支持多种策略,如同步/异步写入、缓存大小、文件轮换策略、压缩策略、清除策略等,相对更加灵活。
因此,我们建议在线应用使用文件输出日志,而Stdout仅用于功能单一或部分K8s系统/运维组件的应用。
CICD 集成:日志记录操作员
Kubernetes提供了标准化的业务部署方式,可以通过yaml(K8s API)声明路由规则、暴露服务、挂载存储、运行业务、定义伸缩规则等,因此Kubernetes很容易与CICD系统集成。日志采集也是运维监控过程的重要组成部分。必须实时采集业务上线后的所有日志。
原来的方法是在发布后手动部署log采集的逻辑。这种方式需要人工干预,违背了CICD自动化的目的;为了实现自动化,已经有人开始基于日志包装API/SDK采集一个自动部署的服务,发布后通过CICD的webhook触发调用,但是这种方式开发成本高。
在 Kubernetes 中,集成日志最标准的方式是在 Kubernetes 系统中注册一个新资源,并以 Operator(CRD)的形式对其进行管理和维护。这样CICD系统就不需要额外开发,部署到Kubernetes系统时只需要附加日志相关的配置即可。
Kubernetes 日志采集 方案
早在 Kubernetes 出现之前,我们就开始为容器环境开发 log采集 解决方案。随着K8s的逐渐稳定,我们开始将很多业务迁移到K8s平台上,所以我们也在之前的基础上开发了一套。K8s 上的 log采集 方案。主要功能有:
支持各种数据的实时采集,包括容器文件、容器Stdout、宿主文件、Journal、Event等;支持多种采集部署方式,包括DaemonSet、Sidecar、DockerEngine LogDriver等;日志数据丰富,包括Namespace、Pod、Container、Image、Node等附加信息;稳定高可靠,基于阿里巴巴自研Logtail采集Agent实现。目前,全网部署实例数以百万计。; 基于CRD扩展,日志采集规则可以以Kubernetes部署发布的方式部署,与CICD完美集成。
安装日志采集组件
目前,这个采集解决方案已经对外开放。我们提供 Helm 安装包,收录 Logtail 的 DaemonSet、AliyunlogConfig 的 CRD 声明和 CRD Controller。安装后直接使用DaemonS优采云采集器即可,CRD配置完毕。安装方法如下:
阿里云Kubernetes集群在激活的时候就可以安装,这样在创建集群的时候会自动安装以上的组件。如果激活的时候没有安装,可以手动安装。如果是自建Kubernetes,无论是自建在阿里云上还是在其他云上还是离线,都可以使用这个采集方案。具体安装方法请参考【自建Kubernetes安装】()。
上述组件安装完成后,Logtail和对应的Controller会在集群中运行,但默认这些组件不会采集任何日志,需要配置日志采集规则为采集@ > 指定各种日志的Pod。
采集规则配置:环境变量或CRD
除了在日志服务控制台手动配置外,Kubernetes 还支持另外两种配置方式:环境变量和 CRD。
环境变量是自swarm时代以来一直使用的配置方式。你只需要在你想要采集的容器环境变量上声明需要采集的数据地址,Logtail会自动采集这个数据>到服务器。该方法部署简单,学习成本低,易于使用;但是可以支持的配置规则很少,很多高级配置(如解析方式、过滤方式、黑白名单等)都不支持,而且这种声明方式也不支持修改/删除,每个修改实际上创建了一个新的 采集 配置。历史采集配置需要手动清理,否则会造成资源浪费。
CRD的配置方式非常符合Kubernetes官方推荐的标准扩展方式,允许采集配置以K8s资源的形式进行管理,通过部署特殊的CRD资源AliyunLogConfig到Kubernetes来声明数据这需要 采集。例如,下面的例子是部署一个容器的标准输出采集,其中定义需要Stdout和Stderr 采集,并且排除环境变量收录COLLEXT_STDOUT_FLAG: false的容器。基于CRD的配置方式以Kubernetes标准扩展资源的方式进行管理,支持配置的完整语义的增删改查,支持各种高级配置。
采集推荐的规则配置方式
在实际应用场景中,一般使用 DaemonSet 或者 DaemonSet 和 Sidecar 的混合。DaemonSet 的优点是资源利用率高。但是存在一个问题,DaemonSet的所有Logtail共享全局配置,单个Logtail有配置支持上限。因此,它无法支持具有大量应用程序的集群。以上是我们给出的推荐配置方式。核心思想是:
一个尽可能多的采集相似数据的配置,减少了配置的数量,减轻了DaemonSet的压力;核心应用 采集 需要获得足够的资源,并且可以使用 Sidecar 方法;配置方式尽量使用CRD方式;Sidecar 由于每个Logtail都是独立配置的,所以配置数量没有限制,适用于非常大的集群。
练习 1 - 中小型集群
大多数 Kubernetes 集群都是中小型的。中小企业没有明确的定义。一般应用数量小于500,节点规模小于1000。没有功能清晰的Kubernetes平台运维。这个场景的应用数量不是特别多,DaemonSet可以支持所有的采集配置:
大部分业务应用的数据使用DaemonS优采云采集器方式,核心应用(对于可靠性要求较高的采集,如订单/交易系统)单独使用Sidecar方式采集 @>
练习 2 - 大型集群
对于一些用作PAAS平台的大型/超大型集群,一般业务在1000以上,节点规模也在1000以上。有专门的Kubernetes平台运维人员。这种场景下应用的数量没有限制,DaemonSet 无法支持。因此,必须使用 Sidecar 方法。总体规划如下:
Kubernetes平台的系统组件日志和内核日志的类型是比较固定的。这部分日志使用了DaemonS优采云采集器,主要为平台的运维人员提供服务;每个业务的日志使用Sidecar方式采集,每个业务可以独立设置Sidecar的采集目的地址,为业务的DevOps人员提供了足够的灵活性。 查看全部
文章采集api(【干货】Kubernetes日志采集难点分析(一)——Kubernetes)
前言
上一期主要介绍了Kubernetes日志输出的一些注意事项。日志输出的最终目的是做统一的采集和分析。在 Kubernetes 中,记录采集的方式与普通虚拟机有很大不同,相对实现难度和部署成本也略高。但是,如果使用得当,可以实现比传统方式更高的自动化程度和更低的运维成本。
Kubernetes 日志采集 难点
在 Kubernetes 中,log采集 比传统的虚拟机和物理机要复杂得多。最根本的原因是Kubernetes屏蔽了底层异常,提供了更细粒度的资源调度,向上提供了一个稳定动态的环境。因此,日志采集面临着更丰富、更动态的环境,需要考虑的点也更多。
例如:
对于一个运行时间很短的Job应用,从启动到停止只需要几秒,如何保证日志采集的实时性能跟得上,数据不丢失?K8s 一般推荐使用大型节点。每个节点可以运行 10-100+ 个容器。如何以尽可能低的资源消耗采集100+ 个容器?在K8s中,应用以yaml的形式部署,日志采集主要是手动配置文件的形式。日志采集如何以K8s的方式部署?
Kubernetes传统日志类型文件、stdout、host文件、journal文件、journal日志源业务容器、系统组件、宿主业务、宿主采集方法代理(Sidecar、DaemonSet)、直写(DockerEngine、业务)代理、直接-write 单机应用号 10-1001-10 应用动态高低 节点动态高低 采集 部署方式手动、Yaml手动、自定义
采集模式:主动或被动
日志采集方法有两种:被动采集和主动推送。在K8s中,被动采集一般分为Sidecar和DaemonSet两种方式。主动推送包括 DockerEngine 推送和业务直推。写两种方式。
总结:DockerEngine直接写一般不推荐;日志量大的场景推荐业务直写;DaemonSet 一般用于中小型集群;建议在非常大的集群中使用 Sidecar。各种采集方法的详细对比如下:
DockerEngine业务直接写入DaemonSet方法Sidecar方法采集日志类型标准输出业务日志标准输出+部分文件文件部署运维低,原生支持低,只需要维护配置文件正常,需要为了维护 DaemonSet 高,每个需要 采集 日志的 POD 都需要部署一个 sidecar 容器。日志分类和存储无法实现业务无关的配置。一般来说,每个POD都可以通过容器/路径映射来单独配置,灵活性高,多租户隔离性较弱。日志直写一般会和业务逻辑竞争资源。只能通过强配置隔离,通过容器隔离,资源可独立分配,支持集群规模无限本地存储。如果使用 syslog 和 fluentd,根据配置会有单点限制和无限制。无限资源数量低,dockerengine提供整体最低,节省采集的成本,每个节点运行一个容器高,每个POD运行一个容器,查询便利性低,只有grep raw日志高,可根据业务特点定制高,可定制查询,高统计,可根据业务特点定制低高可定制性,可自由扩展低高,每个POD单独配置高耦合,并且强绑定 DockerEngine 固定,修改需要重启 DockerEngine 高,<
日志输出:标准输出或文件
与虚拟机/物理机不同,K8s 容器提供标准输出和文件。在容器中,标准输出直接将日志输出到stdout或stderr,DockerEngine接管stdout和stderr文件描述符,收到日志后根据DockerEngine配置的LogDriver规则进行处理;日志打印到文件的方式与虚拟机/物理机不同。基本类似,只是日志可以使用不同的存储方式,比如默认存储、EmptyDir、HostVolume、NFS等。
虽然 Docker 官方推荐使用 Stdout 打印日志,但需要注意的是,这个推荐是基于容器仅作为简单应用使用的场景。在实际业务场景中,我们还是建议大家尽量使用文件方式。主要原因如下。观点:
stdout性能问题,从应用输出stdout到服务器,会有几个过程(比如常用的JSON LogDriver):应用stdout -> DockerEngine -> LogDriver -> 序列化成JSON -> 保存到文件 -> Agent< @采集文件 -> 解析 JSON -> 上传服务器。整个过程需要比文件更多的开销。压力测试时,每秒输出 10 万行日志会占用 DockerEngine 的额外 CPU 内核。stdout 不支持分类,即所有输出混合在一个流中,不能像文件一样分类输出。通常,一个应用程序包括AccessLog、ErrorLog、InterfaceLog(调用外部接口的日志)、TraceLog等。这些日志的格式和用途不,会很难采集 如果在同一流中混合,则进行分析。stdout 只支持容器主程序的输出。如果是 daemon/fork 模式下运行的程序,则无法使用 stdout。文件转储方式支持多种策略,如同步/异步写入、缓存大小、文件轮换策略、压缩策略、清除策略等,相对更加灵活。
因此,我们建议在线应用使用文件输出日志,而Stdout仅用于功能单一或部分K8s系统/运维组件的应用。
CICD 集成:日志记录操作员
Kubernetes提供了标准化的业务部署方式,可以通过yaml(K8s API)声明路由规则、暴露服务、挂载存储、运行业务、定义伸缩规则等,因此Kubernetes很容易与CICD系统集成。日志采集也是运维监控过程的重要组成部分。必须实时采集业务上线后的所有日志。
原来的方法是在发布后手动部署log采集的逻辑。这种方式需要人工干预,违背了CICD自动化的目的;为了实现自动化,已经有人开始基于日志包装API/SDK采集一个自动部署的服务,发布后通过CICD的webhook触发调用,但是这种方式开发成本高。
在 Kubernetes 中,集成日志最标准的方式是在 Kubernetes 系统中注册一个新资源,并以 Operator(CRD)的形式对其进行管理和维护。这样CICD系统就不需要额外开发,部署到Kubernetes系统时只需要附加日志相关的配置即可。
Kubernetes 日志采集 方案
早在 Kubernetes 出现之前,我们就开始为容器环境开发 log采集 解决方案。随着K8s的逐渐稳定,我们开始将很多业务迁移到K8s平台上,所以我们也在之前的基础上开发了一套。K8s 上的 log采集 方案。主要功能有:
支持各种数据的实时采集,包括容器文件、容器Stdout、宿主文件、Journal、Event等;支持多种采集部署方式,包括DaemonSet、Sidecar、DockerEngine LogDriver等;日志数据丰富,包括Namespace、Pod、Container、Image、Node等附加信息;稳定高可靠,基于阿里巴巴自研Logtail采集Agent实现。目前,全网部署实例数以百万计。; 基于CRD扩展,日志采集规则可以以Kubernetes部署发布的方式部署,与CICD完美集成。
安装日志采集组件
目前,这个采集解决方案已经对外开放。我们提供 Helm 安装包,收录 Logtail 的 DaemonSet、AliyunlogConfig 的 CRD 声明和 CRD Controller。安装后直接使用DaemonS优采云采集器即可,CRD配置完毕。安装方法如下:
阿里云Kubernetes集群在激活的时候就可以安装,这样在创建集群的时候会自动安装以上的组件。如果激活的时候没有安装,可以手动安装。如果是自建Kubernetes,无论是自建在阿里云上还是在其他云上还是离线,都可以使用这个采集方案。具体安装方法请参考【自建Kubernetes安装】()。
上述组件安装完成后,Logtail和对应的Controller会在集群中运行,但默认这些组件不会采集任何日志,需要配置日志采集规则为采集@ > 指定各种日志的Pod。
采集规则配置:环境变量或CRD
除了在日志服务控制台手动配置外,Kubernetes 还支持另外两种配置方式:环境变量和 CRD。
环境变量是自swarm时代以来一直使用的配置方式。你只需要在你想要采集的容器环境变量上声明需要采集的数据地址,Logtail会自动采集这个数据>到服务器。该方法部署简单,学习成本低,易于使用;但是可以支持的配置规则很少,很多高级配置(如解析方式、过滤方式、黑白名单等)都不支持,而且这种声明方式也不支持修改/删除,每个修改实际上创建了一个新的 采集 配置。历史采集配置需要手动清理,否则会造成资源浪费。
CRD的配置方式非常符合Kubernetes官方推荐的标准扩展方式,允许采集配置以K8s资源的形式进行管理,通过部署特殊的CRD资源AliyunLogConfig到Kubernetes来声明数据这需要 采集。例如,下面的例子是部署一个容器的标准输出采集,其中定义需要Stdout和Stderr 采集,并且排除环境变量收录COLLEXT_STDOUT_FLAG: false的容器。基于CRD的配置方式以Kubernetes标准扩展资源的方式进行管理,支持配置的完整语义的增删改查,支持各种高级配置。
采集推荐的规则配置方式
在实际应用场景中,一般使用 DaemonSet 或者 DaemonSet 和 Sidecar 的混合。DaemonSet 的优点是资源利用率高。但是存在一个问题,DaemonSet的所有Logtail共享全局配置,单个Logtail有配置支持上限。因此,它无法支持具有大量应用程序的集群。以上是我们给出的推荐配置方式。核心思想是:
一个尽可能多的采集相似数据的配置,减少了配置的数量,减轻了DaemonSet的压力;核心应用 采集 需要获得足够的资源,并且可以使用 Sidecar 方法;配置方式尽量使用CRD方式;Sidecar 由于每个Logtail都是独立配置的,所以配置数量没有限制,适用于非常大的集群。
练习 1 - 中小型集群
大多数 Kubernetes 集群都是中小型的。中小企业没有明确的定义。一般应用数量小于500,节点规模小于1000。没有功能清晰的Kubernetes平台运维。这个场景的应用数量不是特别多,DaemonSet可以支持所有的采集配置:
大部分业务应用的数据使用DaemonS优采云采集器方式,核心应用(对于可靠性要求较高的采集,如订单/交易系统)单独使用Sidecar方式采集 @>
练习 2 - 大型集群
对于一些用作PAAS平台的大型/超大型集群,一般业务在1000以上,节点规模也在1000以上。有专门的Kubernetes平台运维人员。这种场景下应用的数量没有限制,DaemonSet 无法支持。因此,必须使用 Sidecar 方法。总体规划如下:
Kubernetes平台的系统组件日志和内核日志的类型是比较固定的。这部分日志使用了DaemonS优采云采集器,主要为平台的运维人员提供服务;每个业务的日志使用Sidecar方式采集,每个业务可以独立设置Sidecar的采集目的地址,为业务的DevOps人员提供了足够的灵活性。
文章采集api(来说获得用户专栏文章的链接信息,此乃神器!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2022-02-17 05:24
目前还没有官方API支持。或许最有用的就是用户的“个性化URL”(好别扭,以下简称UID),比如黄继新老师的UID:jixin,不过可以用户自己修改,但是每个用户都必须是独特的。
将对应的 UID 替换为 {{%UID}}。
1. 获取用户列条目:
URI: http://www.zhihu.com/people/{{%UID}}/posts GET/HTTP 1.1
XPATH: //div[@id='zh-profile-list-container']
通过解析上述内容,可以得到用户的所有列入口地址。
2. 获取列 文章 信息:
URI: http://zhuanlan.zhihu.com/api/columns/{{%UID}}/posts?limit={{%LIMIT}}&offset={{%OFFSET}} GET/HTTP 1.1
{{%LIMIT}}:表示本次GET请求获取的数据项个数,即文章列信息的个数。我没有具体测试过最大值是多少,但是可以设置大于默认值。默认值为 10。
{{%OFFSET}}:表示本次GET请求获取的数据项的起始偏移量。
通过分析以上内容,可以得到每一列文章的信息,如标题、题图、列文章摘要、发布时间、批准数等。请求返回JSON数据。
注意:解析该信息时,可以得到该列文章的链接信息。
3. 获取列 文章:
URI: http://zhuanlan.zhihu.com/api/columns/{{%UID}}/posts/{{%SLUG}} GET/HTTP 1.1
{{%SLUG}}:是2中得到的文章链接信息,目前是8位数字。
通过分析以上内容,可以得到文章栏的内容,以及文章的一些相关信息。请求返回 JSON 数据。
以上应该足以满足题主的要求。最重要的是用好Chrome调试工具,这是神器!
* * * * * * * * * *
这里有一些零散的更新来记录 知乎 爬虫的想法。当然,相关实现还是需要尊重ROBOTS协议,可以通过
/机器人.txt
检查相关参数。
UID是用户所有信息的入口。
虽然用户信息有修改间隔限制(一般为几个月不等),但考虑到即使是修改用户名的操作也会导致UID发生变化,从而使之前的存储失效。当然,这也可以破解:用户哈希。这个哈希值是一个 32 位的字符串,对于每个账户来说都是唯一且不变的。
通过 UID 获取哈希:
URI: http://www.zhihu.com/people/%{{UID}} GET/HTTP 1.1
XPATH: //body/div[@class='zg-wrap zu-main']//div[@class='zm-profile-header-op-btns clearfix']/button/@data-id
通过解析上面的内容,可以得到UID对应的hash值。(是的,该值存储在“关注/取消关注”按钮中。)这唯一地标识了用户。
目前没有办法通过hash_id获取UID,但是有间接方法可以参考:定期通过关注列表查看用户信息是否发生变化,当然关注/取消关注操作也可以自动化:
关注操作
URI: http://www.zhihu.com/node/MemberFollowBaseV2 POST/HTTP 1.1
Form Data
method: follow_member
params: {"hash_id": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"}
_xsrf:
取消关注操作
URI: http://www.zhihu.com/node/MemberFollowBaseV2 POST/HTTP 1.1
Form Data
method: unfollow_member
params: {"hash_id": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"}
_xsrf:
知乎爬虫需要一个UID列表才能正常运行,如何获取这个列表是需要考虑的问题。目前一个可行的思路是选择几个大V用户,批量爬取他们的关注列表。比如张老师目前跟随着58W+,通过:
URI: http://www.zhihu.com/node/ProfileFollowersListV2 POST/HTTP 1.1
Form Data
method: next
params: {"offset": {{%OFFSET}}, "order_by": "hash_id", "hash_id": "{{%HASHID}}"}
_xsrf:
每次可以获得20个关注者的用户信息。此信息包括 hash_id、用户名、UID、关注者/关注者数量、问题数量、答案数量等。 查看全部
文章采集api(来说获得用户专栏文章的链接信息,此乃神器!)
目前还没有官方API支持。或许最有用的就是用户的“个性化URL”(好别扭,以下简称UID),比如黄继新老师的UID:jixin,不过可以用户自己修改,但是每个用户都必须是独特的。
将对应的 UID 替换为 {{%UID}}。
1. 获取用户列条目:
URI: http://www.zhihu.com/people/{{%UID}}/posts GET/HTTP 1.1
XPATH: //div[@id='zh-profile-list-container']
通过解析上述内容,可以得到用户的所有列入口地址。
2. 获取列 文章 信息:
URI: http://zhuanlan.zhihu.com/api/columns/{{%UID}}/posts?limit={{%LIMIT}}&offset={{%OFFSET}} GET/HTTP 1.1
{{%LIMIT}}:表示本次GET请求获取的数据项个数,即文章列信息的个数。我没有具体测试过最大值是多少,但是可以设置大于默认值。默认值为 10。
{{%OFFSET}}:表示本次GET请求获取的数据项的起始偏移量。
通过分析以上内容,可以得到每一列文章的信息,如标题、题图、列文章摘要、发布时间、批准数等。请求返回JSON数据。
注意:解析该信息时,可以得到该列文章的链接信息。
3. 获取列 文章:
URI: http://zhuanlan.zhihu.com/api/columns/{{%UID}}/posts/{{%SLUG}} GET/HTTP 1.1
{{%SLUG}}:是2中得到的文章链接信息,目前是8位数字。
通过分析以上内容,可以得到文章栏的内容,以及文章的一些相关信息。请求返回 JSON 数据。
以上应该足以满足题主的要求。最重要的是用好Chrome调试工具,这是神器!
* * * * * * * * * *
这里有一些零散的更新来记录 知乎 爬虫的想法。当然,相关实现还是需要尊重ROBOTS协议,可以通过
/机器人.txt
检查相关参数。
UID是用户所有信息的入口。
虽然用户信息有修改间隔限制(一般为几个月不等),但考虑到即使是修改用户名的操作也会导致UID发生变化,从而使之前的存储失效。当然,这也可以破解:用户哈希。这个哈希值是一个 32 位的字符串,对于每个账户来说都是唯一且不变的。
通过 UID 获取哈希:
URI: http://www.zhihu.com/people/%{{UID}} GET/HTTP 1.1
XPATH: //body/div[@class='zg-wrap zu-main']//div[@class='zm-profile-header-op-btns clearfix']/button/@data-id
通过解析上面的内容,可以得到UID对应的hash值。(是的,该值存储在“关注/取消关注”按钮中。)这唯一地标识了用户。
目前没有办法通过hash_id获取UID,但是有间接方法可以参考:定期通过关注列表查看用户信息是否发生变化,当然关注/取消关注操作也可以自动化:
关注操作
URI: http://www.zhihu.com/node/MemberFollowBaseV2 POST/HTTP 1.1
Form Data
method: follow_member
params: {"hash_id": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"}
_xsrf:
取消关注操作
URI: http://www.zhihu.com/node/MemberFollowBaseV2 POST/HTTP 1.1
Form Data
method: unfollow_member
params: {"hash_id": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"}
_xsrf:
知乎爬虫需要一个UID列表才能正常运行,如何获取这个列表是需要考虑的问题。目前一个可行的思路是选择几个大V用户,批量爬取他们的关注列表。比如张老师目前跟随着58W+,通过:
URI: http://www.zhihu.com/node/ProfileFollowersListV2 POST/HTTP 1.1
Form Data
method: next
params: {"offset": {{%OFFSET}}, "order_by": "hash_id", "hash_id": "{{%HASHID}}"}
_xsrf:
每次可以获得20个关注者的用户信息。此信息包括 hash_id、用户名、UID、关注者/关注者数量、问题数量、答案数量等。
文章采集api(什么是zhihu-articles-api(.json)。。)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-02-16 14:20
简介:知乎-articles-api
将您的 知乎文章 导出为可用的 API (.json)。
什么是知乎文章API?
知乎-articles-api 是一个基于 JavaScript DOM 的脚本,通过 DOM 将你的 知乎文章 导出为 json 格式的 API 文档,其中收录标题、链接、标题图等信息。这些 API 可用于其他网站或您自己来显示您创建的内容。当用户访问这些内容时,用户会跳转到知乎,从而批准和评论您的内容。
如何使用知乎文章API?
与其他 JavaScript 脚本一样,您需要使用浏览器的调试功能来执行这些脚本。
首先,您需要访问您的个人主页。
知乎的个人主页一般是:
您的个人域名
如果您不知道自己的个人域名,可以从首页右上角的头像访问“我的首页”。
切换到“文章”选项卡
zaa 只能在该选项卡下工作。
如果您希望导出其他内容,请务必仔细阅读源代码并修改相关内容。
在这个选项卡下,通过调试脚本的执行,浏览器会自动下载一个名为username.json的文件。
脚本:
例子:
{
"Article_0": {
"headline": "为K100 Pro更换更大容量的电池",
"url": "zhuanlan.zhihu.com/p/205607070",
"dateP": "2020-08-29T14:22:15.000Z",
"dateM": "2020-09-01T17:17:49.000Z",
"img": "https://pic4.zhimg.com/v2-8ac0 ... ot%3B
},
"Article_1": {
"headline": "ES6动态计算属性名的另外一种用法/属性名表达式",
"url": "zhuanlan.zhihu.com/p/199698763",
"dateP": "2020-08-26T15:24:06.000Z",
"dateM": "2020-08-27T02:42:41.000Z",
"img": "https://pic4.zhimg.com/v2-8ac0 ... ot%3B
},
"Article_2": {
"headline": "为Vuetify的UI组件添加滚动条",
"url": "zhuanlan.zhihu.com/p/196736891",
"dateP": "2020-08-24T10:25:53.000Z",
"dateM": "2020-08-24T10:25:53.000Z",
"img": "https://pic4.zhimg.com/v2-8ac0 ... ot%3B
},
"Article_3": {
"headline": "解决移动端左右滑动/溢出问题",
"url": "zhuanlan.zhihu.com/p/194403402",
"dateP": "2020-08-22T16:20:05.000Z",
"dateM": "2020-08-22T16:20:05.000Z",
"img": "https://pic4.zhimg.com/v2-8ac0 ... ot%3B
},
知乎-articles-api 合法吗?
与所有爬虫、API 等一样,请确保您在相关用户协议的规范范围内使用您获取的内容。
由于 知乎-articles-api 在 DOM 上运行,获取的内容是公开可用的,并且已经加载到用户端,我认为这不会导致非法行为。
但是,请不要将本脚本用于非您创作的内容,也不要将本脚本获得的内容用于商业目的,本人对本脚本的任何使用概不负责。
我还是不明白这个脚本是做什么的
对于托管在 Github 上的静态页面,如何动态生成博文是一个非常棘手的问题。如果使用普通的静态页面生成器(markdown),虽然可行,但还是不方便更新维护。个人网站的流量往往比较少,不利于创意内容的传播。
通过知乎-articles-api,将你的文章转换成API,生成json文件。将此文件部署到对象存储并进行 CDN 分发。根据这个json文件生成文章的列表,可以实现创作内容的迁移。只要在云端修改json文件,就可以动态修改静态页面的内容,无需重新生成静态页面。
简单来说,你将自己创建的内容托管在知乎上,相关的静态资源也托管在知乎的服务器上。
已知问题和版本更新:
版本 1.00:
如果你的标题图片是.png格式的透明文件,知乎可能会在服务器上生成两个文件,白色背景和源文件。通过知乎-articles-api生成json文件时,只能访问前者。如果您的网站使用深色主题或夜间模式,则可能值得考虑将 知乎 源文件替换为其他来源的 .png 文件。
感激:
将对象导出为 JSON:
根据自定义属性获取元素(原文已过期,这是转载链接): 查看全部
文章采集api(什么是zhihu-articles-api(.json)。。)
简介:知乎-articles-api
将您的 知乎文章 导出为可用的 API (.json)。
什么是知乎文章API?
知乎-articles-api 是一个基于 JavaScript DOM 的脚本,通过 DOM 将你的 知乎文章 导出为 json 格式的 API 文档,其中收录标题、链接、标题图等信息。这些 API 可用于其他网站或您自己来显示您创建的内容。当用户访问这些内容时,用户会跳转到知乎,从而批准和评论您的内容。
如何使用知乎文章API?
与其他 JavaScript 脚本一样,您需要使用浏览器的调试功能来执行这些脚本。
首先,您需要访问您的个人主页。
知乎的个人主页一般是:
您的个人域名
如果您不知道自己的个人域名,可以从首页右上角的头像访问“我的首页”。
切换到“文章”选项卡
zaa 只能在该选项卡下工作。
如果您希望导出其他内容,请务必仔细阅读源代码并修改相关内容。
在这个选项卡下,通过调试脚本的执行,浏览器会自动下载一个名为username.json的文件。
脚本:
例子:
{
"Article_0": {
"headline": "为K100 Pro更换更大容量的电池",
"url": "zhuanlan.zhihu.com/p/205607070",
"dateP": "2020-08-29T14:22:15.000Z",
"dateM": "2020-09-01T17:17:49.000Z",
"img": "https://pic4.zhimg.com/v2-8ac0 ... ot%3B
},
"Article_1": {
"headline": "ES6动态计算属性名的另外一种用法/属性名表达式",
"url": "zhuanlan.zhihu.com/p/199698763",
"dateP": "2020-08-26T15:24:06.000Z",
"dateM": "2020-08-27T02:42:41.000Z",
"img": "https://pic4.zhimg.com/v2-8ac0 ... ot%3B
},
"Article_2": {
"headline": "为Vuetify的UI组件添加滚动条",
"url": "zhuanlan.zhihu.com/p/196736891",
"dateP": "2020-08-24T10:25:53.000Z",
"dateM": "2020-08-24T10:25:53.000Z",
"img": "https://pic4.zhimg.com/v2-8ac0 ... ot%3B
},
"Article_3": {
"headline": "解决移动端左右滑动/溢出问题",
"url": "zhuanlan.zhihu.com/p/194403402",
"dateP": "2020-08-22T16:20:05.000Z",
"dateM": "2020-08-22T16:20:05.000Z",
"img": "https://pic4.zhimg.com/v2-8ac0 ... ot%3B
},
知乎-articles-api 合法吗?
与所有爬虫、API 等一样,请确保您在相关用户协议的规范范围内使用您获取的内容。
由于 知乎-articles-api 在 DOM 上运行,获取的内容是公开可用的,并且已经加载到用户端,我认为这不会导致非法行为。
但是,请不要将本脚本用于非您创作的内容,也不要将本脚本获得的内容用于商业目的,本人对本脚本的任何使用概不负责。
我还是不明白这个脚本是做什么的
对于托管在 Github 上的静态页面,如何动态生成博文是一个非常棘手的问题。如果使用普通的静态页面生成器(markdown),虽然可行,但还是不方便更新维护。个人网站的流量往往比较少,不利于创意内容的传播。
通过知乎-articles-api,将你的文章转换成API,生成json文件。将此文件部署到对象存储并进行 CDN 分发。根据这个json文件生成文章的列表,可以实现创作内容的迁移。只要在云端修改json文件,就可以动态修改静态页面的内容,无需重新生成静态页面。
简单来说,你将自己创建的内容托管在知乎上,相关的静态资源也托管在知乎的服务器上。
已知问题和版本更新:
版本 1.00:
如果你的标题图片是.png格式的透明文件,知乎可能会在服务器上生成两个文件,白色背景和源文件。通过知乎-articles-api生成json文件时,只能访问前者。如果您的网站使用深色主题或夜间模式,则可能值得考虑将 知乎 源文件替换为其他来源的 .png 文件。
感激:
将对象导出为 JSON:
根据自定义属性获取元素(原文已过期,这是转载链接):
文章采集api(网站权重越高是不是收录速度就越快,是不是DedeCMS采集 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2022-02-16 06:26
)
网站权重越高收录速度越快,有没有可能只要网站权重足够高网站内容可以秒做< @收录? 对于新站点,低权限站点是否无法实现快速内容收录?这样想是一厢情愿的想法,也是不成熟的想法。
决定网站内容爬取速度的因素,以及搜索引擎影响网站爬取速度的核心因素,还是取决于你内容的属性。对于咨询等具有一定时效性内容属性的网站,可以实现较好的收录速度,秒级收录即可。基于搜索引擎,意思是给用户他们需要的信息。但信息化信息属于优质内容,类似重复内容的概率相对较小,因此更有价值。今天教大家一个快速的采集优质文章Dedecms采集(很多大佬都在用)。
这个dedecms采集不需要学习更专业的技术,简单几步就可以轻松采集内容数据,用户只需要dedecms采集@对>进行简单的设置,完成后dedecms采集会根据用户设置的关键词匹配内容和图片的准确率,可以选择保存在本地或者选择< @k1@ >发布后,提供方便快捷的内容采集伪原创发布服务!!
和其他的Dedecms采集相比,这个Dedecms采集基本没有什么门槛,也不需要花很多时间去学习正则表达式或者html标签,一分钟只需要输入关键词即可实现采集(dedecms采集也自带关键词采集的功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这类Dedecms采集发布插件工具还配备了很多SEO功能。通过采集伪原创软件发布时,还可以提升很多SEO优化。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、内容或标题插入,以及网站内容插入或随机作者、随机阅读等,形成一个“高原创”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
比如当大家看到一个引起你注意的热搜,当你需要了解相关信息的时候,如果搜索引擎不能快速抓取并展示相关内容,那么就是非常糟糕的用户体验。.
这再次建立在上述观点之上,如果高权重 网站 可以获得良好的 收录 速度,那么会发生什么?一般来说,很多高权重的网站信息量很大。如果权重高再去快速收录,很有可能搜索引擎抓取压力太大,所以显示很不切实际的快速收录对于很多< @网站。
比如图库网站,很多这类网站网站的权重很高,每天的内容可能会增加成百上千。但是,这类网站的特点就是内容在网络上并不特殊,也没有时效性,那么秒收这些网站又有什么意义呢。不仅不是秒收录,这种类型的网站很多页面都不是收录。
很多人会惊讶,权重这么高,怎么可能不是收录?首先,例如,图像 网站 的权重为 7,而另一个新闻类 网站 的权重仅为 5。
基本上基于以上两点,新闻网站的收录速度比较快。一是权重不是决定收录的因素,二是所谓权重只是第三方工具根据关键词预测流量。根据预估的站点流量,根据流量大小确定网站的权重评价。对于搜索引擎来说,根本就没有所谓的权重,所以很多时候,权重高的网站在各方面的表现并不一定比搜索引擎好。重量轻 网站 有利于速度。
权重只能作为优化程度的参考,所以单纯认为权重高网站可以快收录就更加荒谬了。
可以低权重网站秒收录吗?答案是肯定的,我体验过很多权重只有1的网站,还可以优化到秒。基本上只要内容质量还可以,秒级接收还可以的文字内容还是比较容易的。收录是SEO优化的基本开始,网站内容秒数并不决定你的内容能否上榜。
网站即使你能做到内容秒收录,并不代表你能获得好的排名,即使你有排名,也不一定意味着你有流量。
更多流量仍然取决于您的内容的受欢迎程度。许多网站非常擅长在几秒钟内采集内容。事实上,这类内容的竞争很小,本身也不是很受欢迎,所以很容易成为比较。易收录内容,快收录不是什么难技巧。
如果能在竞争激烈的内容下实现快速收录,那可以说是非常不错了。在同样的内容网站下,大致可以认为此时的权重较高。收录速度越快,此时越科学。快并不代表秒收,只是凸显了一个时间的速度。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。每天跟着博主为你展示各种SEO经验,打通你的两条血脉!
查看全部
文章采集api(网站权重越高是不是收录速度就越快,是不是DedeCMS采集
)
网站权重越高收录速度越快,有没有可能只要网站权重足够高网站内容可以秒做< @收录? 对于新站点,低权限站点是否无法实现快速内容收录?这样想是一厢情愿的想法,也是不成熟的想法。
决定网站内容爬取速度的因素,以及搜索引擎影响网站爬取速度的核心因素,还是取决于你内容的属性。对于咨询等具有一定时效性内容属性的网站,可以实现较好的收录速度,秒级收录即可。基于搜索引擎,意思是给用户他们需要的信息。但信息化信息属于优质内容,类似重复内容的概率相对较小,因此更有价值。今天教大家一个快速的采集优质文章Dedecms采集(很多大佬都在用)。
这个dedecms采集不需要学习更专业的技术,简单几步就可以轻松采集内容数据,用户只需要dedecms采集@对>进行简单的设置,完成后dedecms采集会根据用户设置的关键词匹配内容和图片的准确率,可以选择保存在本地或者选择< @k1@ >发布后,提供方便快捷的内容采集伪原创发布服务!!
和其他的Dedecms采集相比,这个Dedecms采集基本没有什么门槛,也不需要花很多时间去学习正则表达式或者html标签,一分钟只需要输入关键词即可实现采集(dedecms采集也自带关键词采集的功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这类Dedecms采集发布插件工具还配备了很多SEO功能。通过采集伪原创软件发布时,还可以提升很多SEO优化。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、内容或标题插入,以及网站内容插入或随机作者、随机阅读等,形成一个“高原创”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
比如当大家看到一个引起你注意的热搜,当你需要了解相关信息的时候,如果搜索引擎不能快速抓取并展示相关内容,那么就是非常糟糕的用户体验。.
这再次建立在上述观点之上,如果高权重 网站 可以获得良好的 收录 速度,那么会发生什么?一般来说,很多高权重的网站信息量很大。如果权重高再去快速收录,很有可能搜索引擎抓取压力太大,所以显示很不切实际的快速收录对于很多< @网站。
比如图库网站,很多这类网站网站的权重很高,每天的内容可能会增加成百上千。但是,这类网站的特点就是内容在网络上并不特殊,也没有时效性,那么秒收这些网站又有什么意义呢。不仅不是秒收录,这种类型的网站很多页面都不是收录。
很多人会惊讶,权重这么高,怎么可能不是收录?首先,例如,图像 网站 的权重为 7,而另一个新闻类 网站 的权重仅为 5。
基本上基于以上两点,新闻网站的收录速度比较快。一是权重不是决定收录的因素,二是所谓权重只是第三方工具根据关键词预测流量。根据预估的站点流量,根据流量大小确定网站的权重评价。对于搜索引擎来说,根本就没有所谓的权重,所以很多时候,权重高的网站在各方面的表现并不一定比搜索引擎好。重量轻 网站 有利于速度。
权重只能作为优化程度的参考,所以单纯认为权重高网站可以快收录就更加荒谬了。
可以低权重网站秒收录吗?答案是肯定的,我体验过很多权重只有1的网站,还可以优化到秒。基本上只要内容质量还可以,秒级接收还可以的文字内容还是比较容易的。收录是SEO优化的基本开始,网站内容秒数并不决定你的内容能否上榜。
网站即使你能做到内容秒收录,并不代表你能获得好的排名,即使你有排名,也不一定意味着你有流量。
更多流量仍然取决于您的内容的受欢迎程度。许多网站非常擅长在几秒钟内采集内容。事实上,这类内容的竞争很小,本身也不是很受欢迎,所以很容易成为比较。易收录内容,快收录不是什么难技巧。
如果能在竞争激烈的内容下实现快速收录,那可以说是非常不错了。在同样的内容网站下,大致可以认为此时的权重较高。收录速度越快,此时越科学。快并不代表秒收,只是凸显了一个时间的速度。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。每天跟着博主为你展示各种SEO经验,打通你的两条血脉!
文章采集api(4.1API通用规则API用一套非常标准的规则生成数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-02-12 10:13
一般情况下,程序员可以使用HTPP协议向API发起请求,获取一定的信息,API会以XML或JSON格式返回服务器响应信息。
API 使用通常不被视为网络数据采集,但实际上使用的许多技术(都发送 HTTP 请求)和结果(都获取信息)是相似的;两者经常有重叠的相容关系。
例如,结合 Wikipedia 编辑历史记录(其中收录编辑者的 IP 地址)和 IP 地址解析 API 以获取 Wikipedia 条目的编辑者的地理位置。
4.1 API 概述
谷歌 API
4.2 API 通用规则
API 使用一套非常标准的规则来生成数据,并且生成的数据以非常标准的方式组织。
四种方式:GET、POST、PUT、DELETE
验证:需要客户端验证
4.3 服务器响应
大多数反馈数据格式是 XML 和 JSON
过去,服务器端使用 PHP 和 .NET 等程序作为 API 的接收端。现在,服务器端也使用一些 JavaScript 框架作为 API 的发送和接收端,例如 Angular 或 Backbone。
接口调用:
4.4 回声巢穴
回声巢音乐资料网站
4.5 推特 API
点安装推特
from twitter import Twitter
t = Twitter(auth=OAuth(,,,))
pythonTweets = t.search.tweets(q = "#python")
print(pythonTweets)
鸣叫 4.6 个 Google API
无论您想使用哪种信息,包括语言翻译、地理位置、日历,甚至基因数据,Google 都提供 API。Google 还为其一些知名应用程序提供 API,例如 Gmail、YouTube 和 Blogger。
4.7 解析 JSON 数据
import json
from urllib.request import urlopen
def getCountry(ipAddress):
response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
responseJson = json.loads(response)
return responseJson.get("country_code")
print(getCountry("50.78.253.58"))
4.8 返回主题
将多个数据源组合成新的形式,或者使用 API 作为工具从新的角度解释数据采集。
先做一个采集维基百科的基础程序,找到编辑历史页面,然后在编辑历史中找出IP地址
# -*- coding: utf-8 -*-
from urllib.request import urlopen
from bs4 import BeautifulSoup
import datetime
import random
import re
import json
random.seed(datetime.datetime.now())
# https://en.wikipedia.org/wiki/Python_(programming_language)
def getLinks(articleUrl):
html = urlopen("http://en.wikipedia.org"+articleUrl)
bsObj = BeautifulSoup(html)
return bsObj.find("div",{"id":"bodyContent"}).findAll("a", href=re.compile("^(/wiki/)((?!:).)*$"))
def getHistoryIPs(pageUrl):
# 编辑历史页面URL链接格式是:
# https://en.wikipedia.org/w/index.php?title=Python_(programming_language)&action=history
pageUrl = pageUrl.replace("/wiki/", "")
historyUrl = "https://en.wikipedia.org/w/ind ... ot%3B
print("history url is: "+historyUrl)
html = urlopen(historyUrl)
bsObj = BeautifulSoup(html)
# 找出class属性是"mw-anonuserlink"的链接
# 它们用IP地址代替用户名
ipAddresses = bsObj.findAll("a", {"class":"mw-anonuserlink"})
addressList = set()
for ipAddress in ipAddresses:
addressList.add(ipAddress.get_text())
return addressList
links = getLinks("/wiki/Python_(programming_language)")
def getCountry(ipAddress):
try:
response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
except HTTPError:
return None
responseJson = json.loads(response)
return responseJson.get("country_code")
while (len(links) > 0):
for link in links:
print("-------------------")
historyIPs = getHistoryIPs(link.attrs["href"])
for historyIP in historyIPs:
#print(historyIP)
country = getCountry(historyIP)
if country is not None:
print(historyIP+" is from "+country)
newLink = links[random.randint(0, len(links)-1)].attrs["href"]
links = getLinks(newLink)
4.9 更多 API
Leonard Richardson、Mike Amundsen 和 Sam Ruby 的 RESTful Web APIs ( ) 为使用 Web APIs 提供了非常全面的理论和实践指南。此外,Mike Amundsen 的精彩视频教程 Designing APIs for the Web() 教您如何创建自己的 API。如果您想以方便的方式分享您的 采集 数据,他的视频非常有用 查看全部
文章采集api(4.1API通用规则API用一套非常标准的规则生成数据)
一般情况下,程序员可以使用HTPP协议向API发起请求,获取一定的信息,API会以XML或JSON格式返回服务器响应信息。
API 使用通常不被视为网络数据采集,但实际上使用的许多技术(都发送 HTTP 请求)和结果(都获取信息)是相似的;两者经常有重叠的相容关系。
例如,结合 Wikipedia 编辑历史记录(其中收录编辑者的 IP 地址)和 IP 地址解析 API 以获取 Wikipedia 条目的编辑者的地理位置。
4.1 API 概述
谷歌 API
4.2 API 通用规则
API 使用一套非常标准的规则来生成数据,并且生成的数据以非常标准的方式组织。
四种方式:GET、POST、PUT、DELETE
验证:需要客户端验证
4.3 服务器响应
大多数反馈数据格式是 XML 和 JSON
过去,服务器端使用 PHP 和 .NET 等程序作为 API 的接收端。现在,服务器端也使用一些 JavaScript 框架作为 API 的发送和接收端,例如 Angular 或 Backbone。
接口调用:
4.4 回声巢穴
回声巢音乐资料网站
4.5 推特 API
点安装推特
from twitter import Twitter
t = Twitter(auth=OAuth(,,,))
pythonTweets = t.search.tweets(q = "#python")
print(pythonTweets)
鸣叫 4.6 个 Google API
无论您想使用哪种信息,包括语言翻译、地理位置、日历,甚至基因数据,Google 都提供 API。Google 还为其一些知名应用程序提供 API,例如 Gmail、YouTube 和 Blogger。
4.7 解析 JSON 数据
import json
from urllib.request import urlopen
def getCountry(ipAddress):
response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
responseJson = json.loads(response)
return responseJson.get("country_code")
print(getCountry("50.78.253.58"))
4.8 返回主题
将多个数据源组合成新的形式,或者使用 API 作为工具从新的角度解释数据采集。
先做一个采集维基百科的基础程序,找到编辑历史页面,然后在编辑历史中找出IP地址
# -*- coding: utf-8 -*-
from urllib.request import urlopen
from bs4 import BeautifulSoup
import datetime
import random
import re
import json
random.seed(datetime.datetime.now())
# https://en.wikipedia.org/wiki/Python_(programming_language)
def getLinks(articleUrl):
html = urlopen("http://en.wikipedia.org"+articleUrl)
bsObj = BeautifulSoup(html)
return bsObj.find("div",{"id":"bodyContent"}).findAll("a", href=re.compile("^(/wiki/)((?!:).)*$"))
def getHistoryIPs(pageUrl):
# 编辑历史页面URL链接格式是:
# https://en.wikipedia.org/w/index.php?title=Python_(programming_language)&action=history
pageUrl = pageUrl.replace("/wiki/", "")
historyUrl = "https://en.wikipedia.org/w/ind ... ot%3B
print("history url is: "+historyUrl)
html = urlopen(historyUrl)
bsObj = BeautifulSoup(html)
# 找出class属性是"mw-anonuserlink"的链接
# 它们用IP地址代替用户名
ipAddresses = bsObj.findAll("a", {"class":"mw-anonuserlink"})
addressList = set()
for ipAddress in ipAddresses:
addressList.add(ipAddress.get_text())
return addressList
links = getLinks("/wiki/Python_(programming_language)")
def getCountry(ipAddress):
try:
response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
except HTTPError:
return None
responseJson = json.loads(response)
return responseJson.get("country_code")
while (len(links) > 0):
for link in links:
print("-------------------")
historyIPs = getHistoryIPs(link.attrs["href"])
for historyIP in historyIPs:
#print(historyIP)
country = getCountry(historyIP)
if country is not None:
print(historyIP+" is from "+country)
newLink = links[random.randint(0, len(links)-1)].attrs["href"]
links = getLinks(newLink)
4.9 更多 API
Leonard Richardson、Mike Amundsen 和 Sam Ruby 的 RESTful Web APIs ( ) 为使用 Web APIs 提供了非常全面的理论和实践指南。此外,Mike Amundsen 的精彩视频教程 Designing APIs for the Web() 教您如何创建自己的 API。如果您想以方便的方式分享您的 采集 数据,他的视频非常有用
文章采集api(终于找到解决方案了,这是一个值得庆祝的事情..)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-02-11 00:09
终于找到了解决办法,值得庆贺....
原来是因为微信在源码中添加了反采集代码,把文章源码中的这一段去掉就好了!
具体代码如下:
public function getCon(){<br style="margin:0px;padding:0px;" /> header('Content-type: text/html; charset=utf-8');<br style="margin:0px;padding:0px;" /> import('Vendor.QL.QueryList');<br style="margin:0px;padding:0px;" /> $w_url=$_POST['wurl']; //接收到的文章地址<br style="margin:0px;padding:0px;" />// 测试文章地址<br style="margin:0px;padding:0px;" />// $w_url='http://mp.weixin.qq.com/s%3F__ ... %3Bbr style="margin:0px;padding:0px;" />// echo "alert('".$w_url."');";<br style="margin:0px;padding:0px;" /> $html = file_get_contents($w_url); //获取文章源码并保存到参数中<br style="margin:0px;padding:0px;" />// echo "alert('".$html."');";<br style="margin:0px;padding:0px;" /> $html = str_replace("", "", $html); //去除微信中的抓取干扰代码<br style="margin:0px;padding:0px;" />// die($w_url);<br style="margin:0px;padding:0px;" /><br style="margin:0px;padding:0px;" />// var_dump($html);<br style="margin:0px;padding:0px;" /> $data = \QueryList::Query($html,array(<br style="margin:0px;padding:0px;" /> //采集规则库<br style="margin:0px;padding:0px;" /> //'规则名' => array('jQuery选择器','要采集的属性'),<br style="margin:0px;padding:0px;" /> 'titleTag' => array('title','text'),<br style="margin:0px;padding:0px;" />// 'title' => array('#activity-name','text'),<br style="margin:0px;padding:0px;" /> 'content' => array('body','text'),<br style="margin:0px;padding:0px;" />// 'image' => array('img','src'),<br style="margin:0px;padding:0px;" /> //微信规则<br style="margin:0px;padding:0px;" /> 'contentWx' => array('#js_content','text'),<br style="margin:0px;padding:0px;" />// 'imageWx' => array('img','data-src'),<br style="margin:0px;padding:0px;" />// 'conText' => array('.rich_media_content>p','text'),<br style="margin:0px;padding:0px;" /> ))->data;<br style="margin:0px;padding:0px;" /> foreach ($data as $k => $v) {<br style="margin:0px;padding:0px;" /> $data[$k]['imageWx'] = $this->cut_str($v['imageWx'],'?',0);<br style="margin:0px;padding:0px;" /> }<br style="margin:0px;padding:0px;" />//打印结果<br style="margin:0px;padding:0px;" />// print_r($data);<br style="margin:0px;padding:0px;" /> $this->assign('conD',$data);<br style="margin:0px;padding:0px;" /> $this->display();<br style="margin:0px;padding:0px;" /><br style="margin:0px;padding:0px;" /> }
String token = AccessTokenTool.getAccessToken();
String URL = "https://api.weixin.qq.com/cgi- ... 3B%3B
// 原始json
String jsonResult = HttpUtil.sendGet(URL.replace("OPENID", openid).replace("ACCESS_TOKEN", token));
System.out.println(jsonResult);
// 编码后的json
String json = new String(jsonResult.getBytes("ISO-8859-1"), "UTF-8");
System.out.println(json);
坐下来输入代码。没有什么技能不经过多年的深思熟虑就能轻易做到的 查看全部
文章采集api(终于找到解决方案了,这是一个值得庆祝的事情..)
终于找到了解决办法,值得庆贺....
原来是因为微信在源码中添加了反采集代码,把文章源码中的这一段去掉就好了!
具体代码如下:
public function getCon(){<br style="margin:0px;padding:0px;" /> header('Content-type: text/html; charset=utf-8');<br style="margin:0px;padding:0px;" /> import('Vendor.QL.QueryList');<br style="margin:0px;padding:0px;" /> $w_url=$_POST['wurl']; //接收到的文章地址<br style="margin:0px;padding:0px;" />// 测试文章地址<br style="margin:0px;padding:0px;" />// $w_url='http://mp.weixin.qq.com/s%3F__ ... %3Bbr style="margin:0px;padding:0px;" />// echo "alert('".$w_url."');";<br style="margin:0px;padding:0px;" /> $html = file_get_contents($w_url); //获取文章源码并保存到参数中<br style="margin:0px;padding:0px;" />// echo "alert('".$html."');";<br style="margin:0px;padding:0px;" /> $html = str_replace("", "", $html); //去除微信中的抓取干扰代码<br style="margin:0px;padding:0px;" />// die($w_url);<br style="margin:0px;padding:0px;" /><br style="margin:0px;padding:0px;" />// var_dump($html);<br style="margin:0px;padding:0px;" /> $data = \QueryList::Query($html,array(<br style="margin:0px;padding:0px;" /> //采集规则库<br style="margin:0px;padding:0px;" /> //'规则名' => array('jQuery选择器','要采集的属性'),<br style="margin:0px;padding:0px;" /> 'titleTag' => array('title','text'),<br style="margin:0px;padding:0px;" />// 'title' => array('#activity-name','text'),<br style="margin:0px;padding:0px;" /> 'content' => array('body','text'),<br style="margin:0px;padding:0px;" />// 'image' => array('img','src'),<br style="margin:0px;padding:0px;" /> //微信规则<br style="margin:0px;padding:0px;" /> 'contentWx' => array('#js_content','text'),<br style="margin:0px;padding:0px;" />// 'imageWx' => array('img','data-src'),<br style="margin:0px;padding:0px;" />// 'conText' => array('.rich_media_content>p','text'),<br style="margin:0px;padding:0px;" /> ))->data;<br style="margin:0px;padding:0px;" /> foreach ($data as $k => $v) {<br style="margin:0px;padding:0px;" /> $data[$k]['imageWx'] = $this->cut_str($v['imageWx'],'?',0);<br style="margin:0px;padding:0px;" /> }<br style="margin:0px;padding:0px;" />//打印结果<br style="margin:0px;padding:0px;" />// print_r($data);<br style="margin:0px;padding:0px;" /> $this->assign('conD',$data);<br style="margin:0px;padding:0px;" /> $this->display();<br style="margin:0px;padding:0px;" /><br style="margin:0px;padding:0px;" /> }
String token = AccessTokenTool.getAccessToken();
String URL = "https://api.weixin.qq.com/cgi- ... 3B%3B
// 原始json
String jsonResult = HttpUtil.sendGet(URL.replace("OPENID", openid).replace("ACCESS_TOKEN", token));
System.out.println(jsonResult);
// 编码后的json
String json = new String(jsonResult.getBytes("ISO-8859-1"), "UTF-8");
System.out.println(json);
坐下来输入代码。没有什么技能不经过多年的深思熟虑就能轻易做到的
文章采集api(cms如何添加采集api接口快速建站,网站模板建站平台)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-02-07 13:20
cms如何添加api采集接口快速建站,网站模板建站平台
高端网站设计cms如何添加api采集接口平台值得您免费注册使用,您可以放心点击使用!
▶1、 网站模板免费使用,3000套海量网站行业模板任你选择,所见即所得。
▶2、易于维护。如果有错,可以修改,直到合适为止。
▶3、覆盖范围广、产品稳定、每周持续更新、专人专职、优质服务让您满意
▶4、覆盖电脑网站、手机网站、小程序、微网站等多平台终端,无需担心流量曝光
▶5、高性价比企业网站施工方案,买三年送三年,还在犹豫吗?
cms如何添加api采集界面网站免费提供各行各业的网站模板供你选择,总有一款适合你,有都是各种素材图片,完全不用担心没有素材可做网站。
▶1、cms如何添加api采集接口网站服务,或者免费模板自建
▶2、怎么做网站,只要你会用电脑制作网站,客服兄妹耐心教你
▶3、我们如何制作自己的网站,cms如何添加api采集接口来帮助你实现你的网站梦想
▶4、不用自己写代码,建个网站其实是很简单的事情
▶5、提供建站+空间+域名+备案一站式服务,让您无后顾之忧
▶6、一键免费注册建站,丰富的功能控件拖拽自由操作,快速编辑,网站可生成预览
▶7、新手会用网站build,不信可以试试
▶8、网站四合一【电脑、手机、微网站、小程序】 查看全部
文章采集api(cms如何添加采集api接口快速建站,网站模板建站平台)
cms如何添加api采集接口快速建站,网站模板建站平台
高端网站设计cms如何添加api采集接口平台值得您免费注册使用,您可以放心点击使用!
▶1、 网站模板免费使用,3000套海量网站行业模板任你选择,所见即所得。
▶2、易于维护。如果有错,可以修改,直到合适为止。
▶3、覆盖范围广、产品稳定、每周持续更新、专人专职、优质服务让您满意
▶4、覆盖电脑网站、手机网站、小程序、微网站等多平台终端,无需担心流量曝光
▶5、高性价比企业网站施工方案,买三年送三年,还在犹豫吗?
cms如何添加api采集界面网站免费提供各行各业的网站模板供你选择,总有一款适合你,有都是各种素材图片,完全不用担心没有素材可做网站。
▶1、cms如何添加api采集接口网站服务,或者免费模板自建
▶2、怎么做网站,只要你会用电脑制作网站,客服兄妹耐心教你
▶3、我们如何制作自己的网站,cms如何添加api采集接口来帮助你实现你的网站梦想
▶4、不用自己写代码,建个网站其实是很简单的事情
▶5、提供建站+空间+域名+备案一站式服务,让您无后顾之忧
▶6、一键免费注册建站,丰富的功能控件拖拽自由操作,快速编辑,网站可生成预览
▶7、新手会用网站build,不信可以试试
▶8、网站四合一【电脑、手机、微网站、小程序】
文章采集api(离线文档查阅Dash的优势是什么?工具集成介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-02-01 16:09
对于软件开发领域的新手和绝大多数计算机科学专业的学生来说,API 文档是众多硬骨头之一。大多数文档存在交互不友好和索引不方便的问题。本着解决人民群众需求的精神,介绍了本期的主角Dash。
Dash 将自己定位为开发人员的文档查询工具。事实上,Dash 在易用性和实用性方面都非常强大。简要总结如下:
可以说,Dash 绝对对得起它的定位。用了之后,很有可能没有它就活不下去了。
离线文档审核
Dash首先是一个文档查询工具,也是它的核心。它基本上涵盖了所有主流和一些非主流语言、框架和库的文档。大部分文档来自这些语言的官方语言,所以也收录了很多官方的介绍。
让我们专注于 API 查询。在 Dash 中查询 API 非常简单。您可以根据需要搜索所有下载的文档,或双击选择特定文档,然后输入关键字进行搜索。在这种情况下,搜索范围将被锁定在该特定文档中。文档内。Dash的检索效率非常高,基本秒出结果。
以 JavaScript 文档为例,它被合理地划分为“类”、“方法”、“事件”、“函数”、“关键字”以及来自 MDN 的非常实用的介绍。与在线版本相比,像Dash这样的离线文档库的优势不仅在于它可以处理更多的场景,而且所有内容一目了然,而且很容易检索,无需忍受快速和慢速的外国服务器。
这是画布教程,这部分来自 MDN(Mozilla 开发者网络,Web 标准的主要开发和推广组织之一一)。
第三方工具集成
由于其作为开发和生产力工具的定位,Dash 与许多工具和 IDE 无缝集成。基本上,您使用和将使用的工具都得到官方支持。插件的安装方法在其GitHub对应的各个Repository上都有详细的安装说明,点击上方对应的工具图标即可找到。
以Alfred为例,即使没有额外的步骤,点击图标后会自动跳转到Alfred,点击import即可安装。集成 Dash 后,索引甚至不需要打开应用程序本身,不太方便。
感受触手可及的阅读乐趣。
自定义数据源
如果你觉得 Dash 的官方库不能满足你的所有需求,你想自定义它作为文档源!
没问题,Google Stack Overflow 已经集成。您还可以将任何您喜欢的社区用作自定义搜索库,并且很容易添加。以Medium为例,直接在上面搜索东西后,复制URL。
可以看到搜索关键词是网址的q后面的段落。在 Dash 的偏好设置中点击网页搜索栏左下角的 +,在名称字段中输入搜索源的名称;将 URL 粘贴到 Search URL 字段中,然后输入关键字只需将其替换为 {query}。
添加注释
Dash还自带注释工具,可以在文档的任意部分添加注释,对学习有很大帮助,也符合大学做笔记的风格。
此外,您还可以将 Mark 学了一半时间的章节或 API 添加到书签中,并将其添加到书签中以供将来参考。
总的来说,Dash是一款在文档的广度和质量上可以满足大部分人使用场景的工具,同时还提供了包括自定义数据源、添加注释等个性化功能,对于学习和工作都有很大的帮助. 明显地。学习搜索是技术发展道路上不可或缺的一步,你也是吗?
除了 Mac 端,Dash 还有一个 iOS 版本。iOS 版本完全免费,还支持离线文档。此外,它还支持 URL Schemes 等功能。您可以从 App Store 或 GitHub 下载源文件。 查看全部
文章采集api(离线文档查阅Dash的优势是什么?工具集成介绍)
对于软件开发领域的新手和绝大多数计算机科学专业的学生来说,API 文档是众多硬骨头之一。大多数文档存在交互不友好和索引不方便的问题。本着解决人民群众需求的精神,介绍了本期的主角Dash。
Dash 将自己定位为开发人员的文档查询工具。事实上,Dash 在易用性和实用性方面都非常强大。简要总结如下:
可以说,Dash 绝对对得起它的定位。用了之后,很有可能没有它就活不下去了。
离线文档审核
Dash首先是一个文档查询工具,也是它的核心。它基本上涵盖了所有主流和一些非主流语言、框架和库的文档。大部分文档来自这些语言的官方语言,所以也收录了很多官方的介绍。
让我们专注于 API 查询。在 Dash 中查询 API 非常简单。您可以根据需要搜索所有下载的文档,或双击选择特定文档,然后输入关键字进行搜索。在这种情况下,搜索范围将被锁定在该特定文档中。文档内。Dash的检索效率非常高,基本秒出结果。
以 JavaScript 文档为例,它被合理地划分为“类”、“方法”、“事件”、“函数”、“关键字”以及来自 MDN 的非常实用的介绍。与在线版本相比,像Dash这样的离线文档库的优势不仅在于它可以处理更多的场景,而且所有内容一目了然,而且很容易检索,无需忍受快速和慢速的外国服务器。
这是画布教程,这部分来自 MDN(Mozilla 开发者网络,Web 标准的主要开发和推广组织之一一)。
第三方工具集成
由于其作为开发和生产力工具的定位,Dash 与许多工具和 IDE 无缝集成。基本上,您使用和将使用的工具都得到官方支持。插件的安装方法在其GitHub对应的各个Repository上都有详细的安装说明,点击上方对应的工具图标即可找到。
以Alfred为例,即使没有额外的步骤,点击图标后会自动跳转到Alfred,点击import即可安装。集成 Dash 后,索引甚至不需要打开应用程序本身,不太方便。
感受触手可及的阅读乐趣。
自定义数据源
如果你觉得 Dash 的官方库不能满足你的所有需求,你想自定义它作为文档源!
没问题,Google Stack Overflow 已经集成。您还可以将任何您喜欢的社区用作自定义搜索库,并且很容易添加。以Medium为例,直接在上面搜索东西后,复制URL。
可以看到搜索关键词是网址的q后面的段落。在 Dash 的偏好设置中点击网页搜索栏左下角的 +,在名称字段中输入搜索源的名称;将 URL 粘贴到 Search URL 字段中,然后输入关键字只需将其替换为 {query}。
添加注释
Dash还自带注释工具,可以在文档的任意部分添加注释,对学习有很大帮助,也符合大学做笔记的风格。
此外,您还可以将 Mark 学了一半时间的章节或 API 添加到书签中,并将其添加到书签中以供将来参考。
总的来说,Dash是一款在文档的广度和质量上可以满足大部分人使用场景的工具,同时还提供了包括自定义数据源、添加注释等个性化功能,对于学习和工作都有很大的帮助. 明显地。学习搜索是技术发展道路上不可或缺的一步,你也是吗?
除了 Mac 端,Dash 还有一个 iOS 版本。iOS 版本完全免费,还支持离线文档。此外,它还支持 URL Schemes 等功能。您可以从 App Store 或 GitHub 下载源文件。
文章采集api(Java开发中常见的纯文本解析方法-乐题库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-01-29 00:21
其他可用的 python http 请求模块:
你的频率
你请求
其中frequests和grequests的使用方式相同,frequests的稳定性高于grequests;简单使用如下:
2.响应结果数据格式
常见的响应结果格式为:
3.各种数据格式的分析方法3.1 Html分析方法
常见的html数据解析方式有:
3.2 纯文本解析方法
常见的纯文本解析方法有:
3.3 网页正文提取
网页正文提取的重要性:
正则表达式可以准确提取某种固定格式的页面,但面对各种HTML,难免要用规则来处理。能否高效、准确地提取页面文本,使其在大规模网页范围内通用,是直接关系到上层应用的难题。
研究计划:
JoyHTML的目的是解析HTML文本中的链接和文本,采用超链接密度法作为标记窗口算法的主要判断依据,采用DOM树解析方式。
这个 Java 类库提供了检测和删除网页主要文本内容旁边的冗余重复内容的算法。它已经提供了特殊的策略来处理一些常见的功能,例如新闻文章提取。
该算法首次将网页文本提取问题转化为寻找页面的行块分布函数,并将其与HTML标签完全分离。通过线性时间建立线块分布函数图,该图可以直接、高效、准确地定位网页文本。同时采用统计与规则相结合的方法解决系统的一般性问题。
这里我们只使用 cx-extractor 和可读性;这里是cx-extractor和可读性的对比,如下:
cx-extractor的使用示例如下图所示:
cx-extractor 和可读性比较
4.数据解析详解
建议: 查看全部
文章采集api(Java开发中常见的纯文本解析方法-乐题库)
其他可用的 python http 请求模块:
你的频率
你请求
其中frequests和grequests的使用方式相同,frequests的稳定性高于grequests;简单使用如下:
2.响应结果数据格式
常见的响应结果格式为:
3.各种数据格式的分析方法3.1 Html分析方法
常见的html数据解析方式有:
3.2 纯文本解析方法
常见的纯文本解析方法有:
3.3 网页正文提取
网页正文提取的重要性:
正则表达式可以准确提取某种固定格式的页面,但面对各种HTML,难免要用规则来处理。能否高效、准确地提取页面文本,使其在大规模网页范围内通用,是直接关系到上层应用的难题。
研究计划:
JoyHTML的目的是解析HTML文本中的链接和文本,采用超链接密度法作为标记窗口算法的主要判断依据,采用DOM树解析方式。
这个 Java 类库提供了检测和删除网页主要文本内容旁边的冗余重复内容的算法。它已经提供了特殊的策略来处理一些常见的功能,例如新闻文章提取。
该算法首次将网页文本提取问题转化为寻找页面的行块分布函数,并将其与HTML标签完全分离。通过线性时间建立线块分布函数图,该图可以直接、高效、准确地定位网页文本。同时采用统计与规则相结合的方法解决系统的一般性问题。
这里我们只使用 cx-extractor 和可读性;这里是cx-extractor和可读性的对比,如下:
cx-extractor的使用示例如下图所示:
cx-extractor 和可读性比较
4.数据解析详解
建议:
文章采集api(优采云采集器官网-网页抓取工具优采云采集器免费网站采集软件 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2022-01-25 08:13
)
免责声明:本教程没有任何盈利目的,仅供学习使用,不会对网站的操作造成负担。请不要将其用于任何商业目的。
优采云简介
优采云采集器官网-网页抓取工具优采云采集器免费网站采集软件
优采云采集器,专业的互联网数据采集、处理、分析、挖掘软件,可以灵活快速的抓取网页上零散的数据信息,并通过一系列的分析处理,精准挖掘出来所需的数据。优采云采集器历经十二年的升级更新,积累了大量的用户和良好的口碑,是目前最受欢迎的网络数据采集软件。
简单来说,就是用软件来简化我们的爬取过程。整个过程无需编写代码即可实现爬虫逻辑。
示例爬取任务
需要爬取分页中的所有页面,并进一步爬取页面上所有有趣条目的二级URL
新任务 添加任务
URL采集规则 - URL 获取
URL采集规则-分页设置
分页规则主要设置在这里,也就是说不仅要抓取当前页面,还需要抓取所有页面。
内容采集规则
这里设置了将URL中的内容提取到前面的采集的规则,即每个商品详情页的内容
内容发布规则
用于指定如何处理采集发送的内容,这里设置为发送到一个api
单击 + 号以添加规则
新发布模块
这里指定要发送给api的参数,其中name为[Content 采集Rule]部分获取的信息,参数为规则名称。
您可以保存其他设置而不更改它们。
然后填写请求的主机
其他设置
以下是一些常用设置,可选。
查看爬取的数据
计划任务设置
这里可以指定任务重复运行的规则
发送通知
可以使用ios软件bark来接受通知,其内容就是爬取的规则。在这里,使用 Golang 简单地创建了一个新的 api。当软件爬取完成后,将信息发送到api【在内容发布规则中设置】,然后将消息发送到api。推送到ios
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
package main
import (
"github.com/gogf/gf/frame/g"
"github.com/gogf/gf/net/ghttp"
"github.com/gogf/gf/os/glog"
"github.com/gogf/gf/util/gconv"
"github.com/gogf/gf/util/grand"
)
type Info struct {
Url string `json:"url"`
Name string `json:"name"`
TaskType string `json:"task_type"`
}
func main() {
s := g.Server()
s.SetPort(8080)
_ = glog.SetConfigWithMap(g.Map{
"path": "log",
"level": "all",
"file": "{Y-m-d}.log",
"flags": glog.F_TIME_DATE | glog.F_TIME_MILLI | glog.F_FILE_LONG,
})
s.BindHandler("/send_info", func(r *ghttp.Request){
requestId := grand.Letters(16)
var info Info
if err := r.ParseForm(&info); err != nil {
glog.Error(requestId, err)
_ = r.Response.WriteJsonExit(nil)
}
glog.Info(requestId, info)
bark := "https://api.day.app/{xxxxxxxxxxxx}"
body := gconv.String(g.Map{
"device_key": "xxxxxxxxxxxxx",
"body": gconv.String(info),
"title": "商品信息",
"ext_params": g.Map{"url": info.Url},
})
glog.Info(requestId, body)
if _, err := g.Client().Post(bark, body); err != nil{
glog.Error(err)
}
})
s.Run()
} 查看全部
文章采集api(优采云采集器官网-网页抓取工具优采云采集器免费网站采集软件
)
免责声明:本教程没有任何盈利目的,仅供学习使用,不会对网站的操作造成负担。请不要将其用于任何商业目的。
优采云简介
优采云采集器官网-网页抓取工具优采云采集器免费网站采集软件
优采云采集器,专业的互联网数据采集、处理、分析、挖掘软件,可以灵活快速的抓取网页上零散的数据信息,并通过一系列的分析处理,精准挖掘出来所需的数据。优采云采集器历经十二年的升级更新,积累了大量的用户和良好的口碑,是目前最受欢迎的网络数据采集软件。
简单来说,就是用软件来简化我们的爬取过程。整个过程无需编写代码即可实现爬虫逻辑。
示例爬取任务
需要爬取分页中的所有页面,并进一步爬取页面上所有有趣条目的二级URL
新任务 添加任务
URL采集规则 - URL 获取
URL采集规则-分页设置
分页规则主要设置在这里,也就是说不仅要抓取当前页面,还需要抓取所有页面。
内容采集规则
这里设置了将URL中的内容提取到前面的采集的规则,即每个商品详情页的内容
内容发布规则
用于指定如何处理采集发送的内容,这里设置为发送到一个api
单击 + 号以添加规则
新发布模块
这里指定要发送给api的参数,其中name为[Content 采集Rule]部分获取的信息,参数为规则名称。
您可以保存其他设置而不更改它们。
然后填写请求的主机
其他设置
以下是一些常用设置,可选。
查看爬取的数据
计划任务设置
这里可以指定任务重复运行的规则
发送通知
可以使用ios软件bark来接受通知,其内容就是爬取的规则。在这里,使用 Golang 简单地创建了一个新的 api。当软件爬取完成后,将信息发送到api【在内容发布规则中设置】,然后将消息发送到api。推送到ios
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
package main
import (
"github.com/gogf/gf/frame/g"
"github.com/gogf/gf/net/ghttp"
"github.com/gogf/gf/os/glog"
"github.com/gogf/gf/util/gconv"
"github.com/gogf/gf/util/grand"
)
type Info struct {
Url string `json:"url"`
Name string `json:"name"`
TaskType string `json:"task_type"`
}
func main() {
s := g.Server()
s.SetPort(8080)
_ = glog.SetConfigWithMap(g.Map{
"path": "log",
"level": "all",
"file": "{Y-m-d}.log",
"flags": glog.F_TIME_DATE | glog.F_TIME_MILLI | glog.F_FILE_LONG,
})
s.BindHandler("/send_info", func(r *ghttp.Request){
requestId := grand.Letters(16)
var info Info
if err := r.ParseForm(&info); err != nil {
glog.Error(requestId, err)
_ = r.Response.WriteJsonExit(nil)
}
glog.Info(requestId, info)
bark := "https://api.day.app/{xxxxxxxxxxxx}"
body := gconv.String(g.Map{
"device_key": "xxxxxxxxxxxxx",
"body": gconv.String(info),
"title": "商品信息",
"ext_params": g.Map{"url": info.Url},
})
glog.Info(requestId, body)
if _, err := g.Client().Post(bark, body); err != nil{
glog.Error(err)
}
})
s.Run()
}
文章采集api(优采云采集支持调用5118一键智能换词API接口(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2022-01-25 04:20
)
优采云采集 支持调用5118一键智能换字API接口,处理采集的数据标题和内容等,可处理文章@ > 对搜索引擎更有吸引力;
具体步骤如下
1. 5118 一键智能换词API接口配置 I,API配置入口:
点击控制台左侧列表中的【第三方服务配置】==点击【第三方内容API接入】==点击【第三方API配置管理】==最后点击[+5118 一键智能原创API]创建接口配置;
二。配置API接口信息:
【API-Key值】是从5118后端获取的一键智能换词API对应的key值,填写后记得保存;
2. 创建 API 处理规则
API处理规则,可以通过调用API接口设置处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==点击【第三方内容API接入】==进入【API处理规则管理】页面,最后点击[+添加API处理规则]创建API处理规则;
二、API处理规则配置:
规则名称:用户可以命名;
字段名称:填写的字段名称内容将由API接口处理,默认为标题和内容字段,可修改、添加或删除字段;
API used:选择配置的API接口配置,执行时会调用该接口,不同的字段可以选择不同的API接口配置;
处理顺序:执行顺序按照数量从小到大执行;
3.API处理规则使用
API处理规则有两种使用方式:手动执行和自动执行:
手动执行:数据采集后,使用[Result Data & Release]中的第三方API执行;
自动执行:配置自动化后,任务采集数据完成后,系统会自动执行指定的API处理规则,无需人工操作。
我。手动执行API处理规则:
点击采集任务的【结果数据&发布】选项卡中的【SEO&API&翻译等工具】按钮==选择【第三方API执行】栏==选择对应的API处理规则== "Execute;
二。自动执行API处理规则:
启用 API 处理的自动执行。任务完成后采集会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡【自动执行第三方API配置】==勾选【采集,自动执行API】选项==选择执行的API处理rules=="选择API接口处理的数据范围(一般选择‘待发布’,全部会导致所有数据重复执行),最后点击保存;
4.API处理结果并发布 I,查看API接口处理结果:
API接口处理后的内容会保存为新字段,如:标题处理后的新字段:title_5118,内容处理后的新字段:content_5118,可在【结果数据&发布】中查看和数据预览界面。
二。发布API接口处理后的内容:
发布前文章@>修改发布目标第二步的映射字段,重新选择标题和内容作为API接口处理后添加的对应字段title_5118和content_5118;
查看全部
文章采集api(优采云采集支持调用5118一键智能换词API接口(组图)
)
优采云采集 支持调用5118一键智能换字API接口,处理采集的数据标题和内容等,可处理文章@ > 对搜索引擎更有吸引力;
具体步骤如下
1. 5118 一键智能换词API接口配置 I,API配置入口:
点击控制台左侧列表中的【第三方服务配置】==点击【第三方内容API接入】==点击【第三方API配置管理】==最后点击[+5118 一键智能原创API]创建接口配置;
二。配置API接口信息:
【API-Key值】是从5118后端获取的一键智能换词API对应的key值,填写后记得保存;
2. 创建 API 处理规则
API处理规则,可以通过调用API接口设置处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==点击【第三方内容API接入】==进入【API处理规则管理】页面,最后点击[+添加API处理规则]创建API处理规则;
二、API处理规则配置:
规则名称:用户可以命名;
字段名称:填写的字段名称内容将由API接口处理,默认为标题和内容字段,可修改、添加或删除字段;
API used:选择配置的API接口配置,执行时会调用该接口,不同的字段可以选择不同的API接口配置;
处理顺序:执行顺序按照数量从小到大执行;
3.API处理规则使用
API处理规则有两种使用方式:手动执行和自动执行:
手动执行:数据采集后,使用[Result Data & Release]中的第三方API执行;
自动执行:配置自动化后,任务采集数据完成后,系统会自动执行指定的API处理规则,无需人工操作。
我。手动执行API处理规则:
点击采集任务的【结果数据&发布】选项卡中的【SEO&API&翻译等工具】按钮==选择【第三方API执行】栏==选择对应的API处理规则== "Execute;
二。自动执行API处理规则:
启用 API 处理的自动执行。任务完成后采集会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡【自动执行第三方API配置】==勾选【采集,自动执行API】选项==选择执行的API处理rules=="选择API接口处理的数据范围(一般选择‘待发布’,全部会导致所有数据重复执行),最后点击保存;
4.API处理结果并发布 I,查看API接口处理结果:
API接口处理后的内容会保存为新字段,如:标题处理后的新字段:title_5118,内容处理后的新字段:content_5118,可在【结果数据&发布】中查看和数据预览界面。
二。发布API接口处理后的内容:
发布前文章@>修改发布目标第二步的映射字段,重新选择标题和内容作为API接口处理后添加的对应字段title_5118和content_5118;
文章采集api( 如何查询prometheus采集job中指标下数据量的情况过滤?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-01-22 12:25
如何查询prometheus采集job中指标下数据量的情况过滤?)
如何在普罗米修斯中过滤不需要的指标
在prometheus的采集中,你会发现一个job可能收录几十个甚至上百个指标,每个指标下的数据量也非常大。在生产环境中,我们实际上可能只用到了几十个指标,而那些我们没有用过的指标,prometheus采集就成了浪费部署资源的罪魁祸首。
这时候就需要考虑过滤prometheus采集的job中的指标了。
如何查询指标下的数据量
1
2
3
4
5
# 展现数据量前50的指标
topk(50, count by (__name__, job)({__name__=~".+"}))
# prometheus中的指标数据量
sum(count by (__name__, job)({__name__=~".+"}))
在 prometheus 采集Job 上过滤指标
以下是 cadvice采集job 的示例。目前使用metric_relabel_configs下的drop操作丢弃不需要的指标(感觉不是特别方便)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
- job_name: kubernetes-cadvisor
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
metric_relabel_configs:
- action: replace
source_labels: [id]
regex: '^/machine\.slice/machine-rkt\\x2d([^\\]+)\\.+/([^/]+)\.service$'
target_label: rkt_container_name
replacement: '${2}-${1}'
- action: replace
source_labels: [id]
regex: '^/system\.slice/(.+)\.service$'
target_label: systemd_service_name
replacement: '${1}'
# 丢弃掉container_network_tcp_usage_total指标
- action: drop
source_labels: [__name__]
regex: 'container_network_tcp_usage_total'
- action: drop
source_labels: [__name__]
regex: 'container_tasks_state'
- action: drop
source_labels: [__name__]
regex: 'container_network_udp_usage_total'
- action: drop
source_labels: [__name__]
regex: 'container_memory_failures_total'
在 prometheus-opretor 中过滤 Servicemonit 配置的作业指标
在使用prometheus-opretor部署监控环境时,会发现很多监控作业都是使用Servicemonit定义的。您还可以在 Servicemonit 中配置 drop to drop 指示器。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
serviceMonitors:
- name: foundation-prometheus
namespaceSelector:
matchNames:
- monitoring
selector:
matchLabels:
cluster: foundation
endpoints:
- port: foundation-port
honorLabels: true
path: /federate
params:
'match[]':
- '{__name__=~".+"}'
# 配置丢弃container_memory_failures_total指标
metricRelabelings:
- action: drop
source_labels: [__name__]
regex: 'container_memory_failures_total'
在每个 采集export 中配置不需要的指标
最好的处理方法是在prometheus采集指标之前控制每个export提供的指标,只给prometheus提供我们需要监控的指标。我们以节点导出为例。在 node-export 中,有一个应用程序的官方描述。您可以使用--no-collector。用于控制不需要 采集 的模块的标志 查看全部
文章采集api(
如何查询prometheus采集job中指标下数据量的情况过滤?)
如何在普罗米修斯中过滤不需要的指标
在prometheus的采集中,你会发现一个job可能收录几十个甚至上百个指标,每个指标下的数据量也非常大。在生产环境中,我们实际上可能只用到了几十个指标,而那些我们没有用过的指标,prometheus采集就成了浪费部署资源的罪魁祸首。
这时候就需要考虑过滤prometheus采集的job中的指标了。
如何查询指标下的数据量
1
2
3
4
5
# 展现数据量前50的指标
topk(50, count by (__name__, job)({__name__=~".+"}))
# prometheus中的指标数据量
sum(count by (__name__, job)({__name__=~".+"}))
在 prometheus 采集Job 上过滤指标
以下是 cadvice采集job 的示例。目前使用metric_relabel_configs下的drop操作丢弃不需要的指标(感觉不是特别方便)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
- job_name: kubernetes-cadvisor
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
metric_relabel_configs:
- action: replace
source_labels: [id]
regex: '^/machine\.slice/machine-rkt\\x2d([^\\]+)\\.+/([^/]+)\.service$'
target_label: rkt_container_name
replacement: '${2}-${1}'
- action: replace
source_labels: [id]
regex: '^/system\.slice/(.+)\.service$'
target_label: systemd_service_name
replacement: '${1}'
# 丢弃掉container_network_tcp_usage_total指标
- action: drop
source_labels: [__name__]
regex: 'container_network_tcp_usage_total'
- action: drop
source_labels: [__name__]
regex: 'container_tasks_state'
- action: drop
source_labels: [__name__]
regex: 'container_network_udp_usage_total'
- action: drop
source_labels: [__name__]
regex: 'container_memory_failures_total'
在 prometheus-opretor 中过滤 Servicemonit 配置的作业指标
在使用prometheus-opretor部署监控环境时,会发现很多监控作业都是使用Servicemonit定义的。您还可以在 Servicemonit 中配置 drop to drop 指示器。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
serviceMonitors:
- name: foundation-prometheus
namespaceSelector:
matchNames:
- monitoring
selector:
matchLabels:
cluster: foundation
endpoints:
- port: foundation-port
honorLabels: true
path: /federate
params:
'match[]':
- '{__name__=~".+"}'
# 配置丢弃container_memory_failures_total指标
metricRelabelings:
- action: drop
source_labels: [__name__]
regex: 'container_memory_failures_total'
在每个 采集export 中配置不需要的指标
最好的处理方法是在prometheus采集指标之前控制每个export提供的指标,只给prometheus提供我们需要监控的指标。我们以节点导出为例。在 node-export 中,有一个应用程序的官方描述。您可以使用--no-collector。用于控制不需要 采集 的模块的标志
文章采集api( 传cookie )
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-01-21 21:15
传cookie
)
在api采集的过程中,有些接口不通过cookie就不能让你访问该接口。然后我们需要把cookie带入到cookie传递的地方。
cookie 的来源,例如访问或登录。当服务器响应时,它会为你生成。
卷曲方法:
// 初始化CURL
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
// 获取头部信息
curl_setopt($ch, CURLOPT_HEADER, 1);
// 返回原生的(Raw)输出
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
// 执行并获取返回结果
$content = curl_exec($ch);
// 关闭CURL
curl_close($ch);
// 解析HTTP数据流
list($header, $body) = explode("\r\n\r\n", $content);
// 解析COOKIE
preg_match("/set\-cookie:([^\r\n]*)/i", $header, $matches);
// 后面用CURL提交的时候可以直接使用
// curl_setopt($ch, CURLOPT_COOKIE, $cookie);
$cookie = $matches[1];
// 初始化CURL
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url2);
// 获取头部信息
curl_setopt($ch, CURLOPT_HEADER, 1);
// 返回原生的(Raw)输出
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_COOKIE, $cookie);//设置cookie
// 执行并获取返回结果
$content = curl_exec($ch);
// 关闭CURL
curl_close($ch); 查看全部
文章采集api(
传cookie
)
在api采集的过程中,有些接口不通过cookie就不能让你访问该接口。然后我们需要把cookie带入到cookie传递的地方。
cookie 的来源,例如访问或登录。当服务器响应时,它会为你生成。
卷曲方法:
// 初始化CURL
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
// 获取头部信息
curl_setopt($ch, CURLOPT_HEADER, 1);
// 返回原生的(Raw)输出
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
// 执行并获取返回结果
$content = curl_exec($ch);
// 关闭CURL
curl_close($ch);
// 解析HTTP数据流
list($header, $body) = explode("\r\n\r\n", $content);
// 解析COOKIE
preg_match("/set\-cookie:([^\r\n]*)/i", $header, $matches);
// 后面用CURL提交的时候可以直接使用
// curl_setopt($ch, CURLOPT_COOKIE, $cookie);
$cookie = $matches[1];
// 初始化CURL
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url2);
// 获取头部信息
curl_setopt($ch, CURLOPT_HEADER, 1);
// 返回原生的(Raw)输出
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_COOKIE, $cookie);//设置cookie
// 执行并获取返回结果
$content = curl_exec($ch);
// 关闭CURL
curl_close($ch);

