
文章采集api
文章采集api Python 爬取人人视频
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2022-05-14 20:49
hello,小伙伴们,又见面了,距离上一次发布文章的时间,也算是久别重逢了。期间也发生了很多的事情,导致博文断更,也是笔者不愿意的,但是确实是比较忙,不再过多赘述,希望大家能够体谅。
平时不断的在后台收到小伙伴的私信,问是不是不更了,答案当然是否定的,有着这么多人的支持,小编还是要继续努力下去的,再次谢谢大家的支持。
这次给大家带来的文章是爬取人人视频,之前多是分享一些爬取数据,图片,音乐,还没怎么分享过爬取过视频的,那么想要爬取视频的话该怎么爬取呢?
其实不管是图片,还是音乐,或者是其他的文档,大部分都是一个文件读写的过程,当然视频也不例外,只是文件的格式不同而已。所以我们也可以试着以常规的手段去尝试下爬取视频,没错还是熟悉的套路与配方,即python常用函数 open()和 write()。
不过这次略微不同的是我们会使用到iter_content来获取请求的原始响应数据,普通情况可以用r.raw,在初始请求中设置stream=True,来获取服务器的原始套接字响应,在这里我们使用iter_content更加方便一些,因为requests.get(url) 默认是下载在内存中的,下载完成才存到硬盘上,但Response.iter_content可以边下载边存硬盘中,所以在这视频下载方面更具有优势。
当然说到 iter_content 的话,不得不提下chunk_size,因为流式请求就是像流水一样,不是一次过来而是一点一点“流”过来。处理流式数据也是一点一点处理。
而chunk_size会直接返回从当前位置往后读取 chunk_size 大小的文件内容,且迭代响应数据。这避免了立即将内容读入内存以获得较大的响应。chunk_size是它应该读入内存的字节数。chunk_size的类型必须是int或None。None的值将根据流的值发挥不同的作用。
做了引荐与讲解后,那么就开始上我们的主菜了,即目标网站:
https://m.rr.tv/
介于代码偏基础化,且主要知识点做过分析就直接上代码了,具体请看代码:
单线程:
import requestsimport jsonimport reimport osheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}ep_list =[]vod_list = []def get_vod(url): response = requests.get(url = url,headers = headers)#请求url ep= re.compile(r'sid:"(.*?)",')#提取ep链接 ep_list = re.findall(ep,response.text) vod= re.compile(r'data:\[{id:(.*?),title:"')#提取vod链接 vod_list = re.findall(vod,response.text) vod= re.compile(r',title:"(.*?)",desc:"')#提取视频标题 vod_name = re.findall(vod,response.text) ep = 1 os.mkdir('./'+vod_name[0])#创建视频保存目录 for i in ep_list: print("开始下载"+vod_name[0]+"第"+str(ep)+"集") url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers)#下载请求 r = requests.get(str(json.loads(response.text)['data']['url']), stream=True)#解析出下载链接并发起下载请求 f = open("./"+vod_name[0]+"/第"+str(ep)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk) ep = ep+1if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxxx?snum=1&episode=1'#目标视频链接 get_vod(url)
多线程:
import requestsimport jsonimport reimport osfrom concurrent.futures import ThreadPoolExecutorheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}vod_list = []#存储视频链接vod_name = []#存储视频标题get_down_url =[]#存储下载直链def get_vod(url): response = requests.get(url = url,headers = headers)#请求url vod_list.append(re.findall(re.compile(r'data:\[{id:(.*?),title:"'),response.text)[0])#找找视频链接 vod_name.append(re.findall(re.compile(r',title:"(.*?)",desc:"'),response.text)[0])#找找视频标题 for i in re.findall(re.compile(r'{sid:"(.*?)",key:'),response.text): url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers) get_down_url.append(str(json.loads(response.text)['data']['url']))#拿下载直链进listdef down_begin(url,i): print("开始多线程下载"+vod_name[0]+"第"+str(i)+"集") r = requests.get(url = url,headers = headers)#下载请求 f = open("./"+vod_name[0]+"/第"+str(i)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk)if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxx?snum=1&episode=1'#进入rr.tv自行获取 get_vod(url) os.mkdir('./'+vod_name[0])#创建视频保存目录 with ThreadPoolExecutor(10) as f:#这里写多线程参数,适合几十集的电视剧使用 for i,url in enumerate(get_down_url): i=int(i)+1 f.submit(down_begin,url = url,i=i)
把案例里面的链接改成你想要下载的链接,然后右击运行代码,即可成功的下载你想要的视频了。代码获取后台回复:”人人视频“。
在文章的最后给大家来一波福利,因为前一段时间小编在爬取百度相关关键词以及文章采集时,经常触发百度的验证机制,这种情况很明显要使用到代理IP,后来群里一个小伙伴推荐了品赞代理IP,小编测试了下,完美解决了爬取中存在的问题。
如果大家后续有需要使用到代理方面的业务的话,可以扫码添加下方的二维码。国内外的IP都有,新用户可以免费测试。
查看全部
文章采集api Python 爬取人人视频
hello,小伙伴们,又见面了,距离上一次发布文章的时间,也算是久别重逢了。期间也发生了很多的事情,导致博文断更,也是笔者不愿意的,但是确实是比较忙,不再过多赘述,希望大家能够体谅。
平时不断的在后台收到小伙伴的私信,问是不是不更了,答案当然是否定的,有着这么多人的支持,小编还是要继续努力下去的,再次谢谢大家的支持。
这次给大家带来的文章是爬取人人视频,之前多是分享一些爬取数据,图片,音乐,还没怎么分享过爬取过视频的,那么想要爬取视频的话该怎么爬取呢?
其实不管是图片,还是音乐,或者是其他的文档,大部分都是一个文件读写的过程,当然视频也不例外,只是文件的格式不同而已。所以我们也可以试着以常规的手段去尝试下爬取视频,没错还是熟悉的套路与配方,即python常用函数 open()和 write()。
不过这次略微不同的是我们会使用到iter_content来获取请求的原始响应数据,普通情况可以用r.raw,在初始请求中设置stream=True,来获取服务器的原始套接字响应,在这里我们使用iter_content更加方便一些,因为requests.get(url) 默认是下载在内存中的,下载完成才存到硬盘上,但Response.iter_content可以边下载边存硬盘中,所以在这视频下载方面更具有优势。
当然说到 iter_content 的话,不得不提下chunk_size,因为流式请求就是像流水一样,不是一次过来而是一点一点“流”过来。处理流式数据也是一点一点处理。
而chunk_size会直接返回从当前位置往后读取 chunk_size 大小的文件内容,且迭代响应数据。这避免了立即将内容读入内存以获得较大的响应。chunk_size是它应该读入内存的字节数。chunk_size的类型必须是int或None。None的值将根据流的值发挥不同的作用。
做了引荐与讲解后,那么就开始上我们的主菜了,即目标网站:
https://m.rr.tv/
介于代码偏基础化,且主要知识点做过分析就直接上代码了,具体请看代码:
单线程:
import requestsimport jsonimport reimport osheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}ep_list =[]vod_list = []def get_vod(url): response = requests.get(url = url,headers = headers)#请求url ep= re.compile(r'sid:"(.*?)",')#提取ep链接 ep_list = re.findall(ep,response.text) vod= re.compile(r'data:\[{id:(.*?),title:"')#提取vod链接 vod_list = re.findall(vod,response.text) vod= re.compile(r',title:"(.*?)",desc:"')#提取视频标题 vod_name = re.findall(vod,response.text) ep = 1 os.mkdir('./'+vod_name[0])#创建视频保存目录 for i in ep_list: print("开始下载"+vod_name[0]+"第"+str(ep)+"集") url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers)#下载请求 r = requests.get(str(json.loads(response.text)['data']['url']), stream=True)#解析出下载链接并发起下载请求 f = open("./"+vod_name[0]+"/第"+str(ep)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk) ep = ep+1if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxxx?snum=1&episode=1'#目标视频链接 get_vod(url)
多线程:
import requestsimport jsonimport reimport osfrom concurrent.futures import ThreadPoolExecutorheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}vod_list = []#存储视频链接vod_name = []#存储视频标题get_down_url =[]#存储下载直链def get_vod(url): response = requests.get(url = url,headers = headers)#请求url vod_list.append(re.findall(re.compile(r'data:\[{id:(.*?),title:"'),response.text)[0])#找找视频链接 vod_name.append(re.findall(re.compile(r',title:"(.*?)",desc:"'),response.text)[0])#找找视频标题 for i in re.findall(re.compile(r'{sid:"(.*?)",key:'),response.text): url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers) get_down_url.append(str(json.loads(response.text)['data']['url']))#拿下载直链进listdef down_begin(url,i): print("开始多线程下载"+vod_name[0]+"第"+str(i)+"集") r = requests.get(url = url,headers = headers)#下载请求 f = open("./"+vod_name[0]+"/第"+str(i)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk)if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxx?snum=1&episode=1'#进入rr.tv自行获取 get_vod(url) os.mkdir('./'+vod_name[0])#创建视频保存目录 with ThreadPoolExecutor(10) as f:#这里写多线程参数,适合几十集的电视剧使用 for i,url in enumerate(get_down_url): i=int(i)+1 f.submit(down_begin,url = url,i=i)
把案例里面的链接改成你想要下载的链接,然后右击运行代码,即可成功的下载你想要的视频了。代码获取后台回复:”人人视频“。
在文章的最后给大家来一波福利,因为前一段时间小编在爬取百度相关关键词以及文章采集时,经常触发百度的验证机制,这种情况很明显要使用到代理IP,后来群里一个小伙伴推荐了品赞代理IP,小编测试了下,完美解决了爬取中存在的问题。
如果大家后续有需要使用到代理方面的业务的话,可以扫码添加下方的二维码。国内外的IP都有,新用户可以免费测试。
文章采集api Python 爬取人人视频
采集交流 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-05-13 16:48
hello,小伙伴们,又见面了,距离上一次发布文章的时间,也算是久别重逢了。期间也发生了很多的事情,导致博文断更,也是笔者不愿意的,但是确实是比较忙,不再过多赘述,希望大家能够体谅。
平时不断的在后台收到小伙伴的私信,问是不是不更了,答案当然是否定的,有着这么多人的支持,小编还是要继续努力下去的,再次谢谢大家的支持。
这次给大家带来的文章是爬取人人视频,之前多是分享一些爬取数据,图片,音乐,还没怎么分享过爬取过视频的,那么想要爬取视频的话该怎么爬取呢?
其实不管是图片,还是音乐,或者是其他的文档,大部分都是一个文件读写的过程,当然视频也不例外,只是文件的格式不同而已。所以我们也可以试着以常规的手段去尝试下爬取视频,没错还是熟悉的套路与配方,即python常用函数 open()和 write()。
不过这次略微不同的是我们会使用到iter_content来获取请求的原始响应数据,普通情况可以用r.raw,在初始请求中设置stream=True,来获取服务器的原始套接字响应,在这里我们使用iter_content更加方便一些,因为requests.get(url) 默认是下载在内存中的,下载完成才存到硬盘上,但Response.iter_content可以边下载边存硬盘中,所以在这视频下载方面更具有优势。
当然说到 iter_content 的话,不得不提下chunk_size,因为流式请求就是像流水一样,不是一次过来而是一点一点“流”过来。处理流式数据也是一点一点处理。
而chunk_size会直接返回从当前位置往后读取 chunk_size 大小的文件内容,且迭代响应数据。这避免了立即将内容读入内存以获得较大的响应。chunk_size是它应该读入内存的字节数。chunk_size的类型必须是int或None。None的值将根据流的值发挥不同的作用。
做了引荐与讲解后,那么就开始上我们的主菜了,即目标网站:
https://m.rr.tv/
介于代码偏基础化,且主要知识点做过分析就直接上代码了,具体请看代码:
单线程:
import requestsimport jsonimport reimport osheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}ep_list =[]vod_list = []def get_vod(url): response = requests.get(url = url,headers = headers)#请求url ep= re.compile(r'sid:"(.*?)",')#提取ep链接 ep_list = re.findall(ep,response.text) vod= re.compile(r'data:\[{id:(.*?),title:"')#提取vod链接 vod_list = re.findall(vod,response.text) vod= re.compile(r',title:"(.*?)",desc:"')#提取视频标题 vod_name = re.findall(vod,response.text) ep = 1 os.mkdir('./'+vod_name[0])#创建视频保存目录 for i in ep_list: print("开始下载"+vod_name[0]+"第"+str(ep)+"集") url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers)#下载请求 r = requests.get(str(json.loads(response.text)['data']['url']), stream=True)#解析出下载链接并发起下载请求 f = open("./"+vod_name[0]+"/第"+str(ep)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk) ep = ep+1if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxxx?snum=1&episode=1'#目标视频链接 get_vod(url)
多线程:
import requestsimport jsonimport reimport osfrom concurrent.futures import ThreadPoolExecutorheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}vod_list = []#存储视频链接vod_name = []#存储视频标题get_down_url =[]#存储下载直链def get_vod(url): response = requests.get(url = url,headers = headers)#请求url vod_list.append(re.findall(re.compile(r'data:\[{id:(.*?),title:"'),response.text)[0])#找找视频链接 vod_name.append(re.findall(re.compile(r',title:"(.*?)",desc:"'),response.text)[0])#找找视频标题 for i in re.findall(re.compile(r'{sid:"(.*?)",key:'),response.text): url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers) get_down_url.append(str(json.loads(response.text)['data']['url']))#拿下载直链进listdef down_begin(url,i): print("开始多线程下载"+vod_name[0]+"第"+str(i)+"集") r = requests.get(url = url,headers = headers)#下载请求 f = open("./"+vod_name[0]+"/第"+str(i)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk)if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxx?snum=1&episode=1'#进入rr.tv自行获取 get_vod(url) os.mkdir('./'+vod_name[0])#创建视频保存目录 with ThreadPoolExecutor(10) as f:#这里写多线程参数,适合几十集的电视剧使用 for i,url in enumerate(get_down_url): i=int(i)+1 f.submit(down_begin,url = url,i=i)
把案例里面的链接改成你想要下载的链接,然后右击运行代码,即可成功的下载你想要的视频了。代码获取后台回复:”人人视频“。
在文章的最后给大家来一波福利,因为前一段时间小编在爬取百度相关关键词以及文章采集时,经常触发百度的验证机制,这种情况很明显要使用到代理IP,后来群里一个小伙伴推荐了品赞代理IP,小编测试了下,完美解决了爬取中存在的问题。
如果大家后续有需要使用到代理方面的业务的话,可以扫码添加下方的二维码。国内外的IP都有,新用户可以免费测试。
查看全部
文章采集api Python 爬取人人视频
hello,小伙伴们,又见面了,距离上一次发布文章的时间,也算是久别重逢了。期间也发生了很多的事情,导致博文断更,也是笔者不愿意的,但是确实是比较忙,不再过多赘述,希望大家能够体谅。
平时不断的在后台收到小伙伴的私信,问是不是不更了,答案当然是否定的,有着这么多人的支持,小编还是要继续努力下去的,再次谢谢大家的支持。
这次给大家带来的文章是爬取人人视频,之前多是分享一些爬取数据,图片,音乐,还没怎么分享过爬取过视频的,那么想要爬取视频的话该怎么爬取呢?
其实不管是图片,还是音乐,或者是其他的文档,大部分都是一个文件读写的过程,当然视频也不例外,只是文件的格式不同而已。所以我们也可以试着以常规的手段去尝试下爬取视频,没错还是熟悉的套路与配方,即python常用函数 open()和 write()。
不过这次略微不同的是我们会使用到iter_content来获取请求的原始响应数据,普通情况可以用r.raw,在初始请求中设置stream=True,来获取服务器的原始套接字响应,在这里我们使用iter_content更加方便一些,因为requests.get(url) 默认是下载在内存中的,下载完成才存到硬盘上,但Response.iter_content可以边下载边存硬盘中,所以在这视频下载方面更具有优势。
当然说到 iter_content 的话,不得不提下chunk_size,因为流式请求就是像流水一样,不是一次过来而是一点一点“流”过来。处理流式数据也是一点一点处理。
而chunk_size会直接返回从当前位置往后读取 chunk_size 大小的文件内容,且迭代响应数据。这避免了立即将内容读入内存以获得较大的响应。chunk_size是它应该读入内存的字节数。chunk_size的类型必须是int或None。None的值将根据流的值发挥不同的作用。
做了引荐与讲解后,那么就开始上我们的主菜了,即目标网站:
https://m.rr.tv/
介于代码偏基础化,且主要知识点做过分析就直接上代码了,具体请看代码:
单线程:
import requestsimport jsonimport reimport osheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}ep_list =[]vod_list = []def get_vod(url): response = requests.get(url = url,headers = headers)#请求url ep= re.compile(r'sid:"(.*?)",')#提取ep链接 ep_list = re.findall(ep,response.text) vod= re.compile(r'data:\[{id:(.*?),title:"')#提取vod链接 vod_list = re.findall(vod,response.text) vod= re.compile(r',title:"(.*?)",desc:"')#提取视频标题 vod_name = re.findall(vod,response.text) ep = 1 os.mkdir('./'+vod_name[0])#创建视频保存目录 for i in ep_list: print("开始下载"+vod_name[0]+"第"+str(ep)+"集") url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers)#下载请求 r = requests.get(str(json.loads(response.text)['data']['url']), stream=True)#解析出下载链接并发起下载请求 f = open("./"+vod_name[0]+"/第"+str(ep)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk) ep = ep+1if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxxx?snum=1&episode=1'#目标视频链接 get_vod(url)
多线程:
import requestsimport jsonimport reimport osfrom concurrent.futures import ThreadPoolExecutorheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}vod_list = []#存储视频链接vod_name = []#存储视频标题get_down_url =[]#存储下载直链def get_vod(url): response = requests.get(url = url,headers = headers)#请求url vod_list.append(re.findall(re.compile(r'data:\[{id:(.*?),title:"'),response.text)[0])#找找视频链接 vod_name.append(re.findall(re.compile(r',title:"(.*?)",desc:"'),response.text)[0])#找找视频标题 for i in re.findall(re.compile(r'{sid:"(.*?)",key:'),response.text): url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers) get_down_url.append(str(json.loads(response.text)['data']['url']))#拿下载直链进listdef down_begin(url,i): print("开始多线程下载"+vod_name[0]+"第"+str(i)+"集") r = requests.get(url = url,headers = headers)#下载请求 f = open("./"+vod_name[0]+"/第"+str(i)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk)if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxx?snum=1&episode=1'#进入rr.tv自行获取 get_vod(url) os.mkdir('./'+vod_name[0])#创建视频保存目录 with ThreadPoolExecutor(10) as f:#这里写多线程参数,适合几十集的电视剧使用 for i,url in enumerate(get_down_url): i=int(i)+1 f.submit(down_begin,url = url,i=i)
把案例里面的链接改成你想要下载的链接,然后右击运行代码,即可成功的下载你想要的视频了。代码获取后台回复:”人人视频“。
在文章的最后给大家来一波福利,因为前一段时间小编在爬取百度相关关键词以及文章采集时,经常触发百度的验证机制,这种情况很明显要使用到代理IP,后来群里一个小伙伴推荐了品赞代理IP,小编测试了下,完美解决了爬取中存在的问题。
如果大家后续有需要使用到代理方面的业务的话,可以扫码添加下方的二维码。国内外的IP都有,新用户可以免费测试。
文章采集api Python 爬取人人视频
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-05-09 10:00
hello,小伙伴们,又见面了,距离上一次发布文章的时间,也算是久别重逢了。期间也发生了很多的事情,导致博文断更,也是笔者不愿意的,但是确实是比较忙,不再过多赘述,希望大家能够体谅。
平时不断的在后台收到小伙伴的私信,问是不是不更了,答案当然是否定的,有着这么多人的支持,小编还是要继续努力下去的,再次谢谢大家的支持。
这次给大家带来的文章是爬取人人视频,之前多是分享一些爬取数据,图片,音乐,还没怎么分享过爬取过视频的,那么想要爬取视频的话该怎么爬取呢?
其实不管是图片,还是音乐,或者是其他的文档,大部分都是一个文件读写的过程,当然视频也不例外,只是文件的格式不同而已。所以我们也可以试着以常规的手段去尝试下爬取视频,没错还是熟悉的套路与配方,即python常用函数 open()和 write()。
不过这次略微不同的是我们会使用到iter_content来获取请求的原始响应数据,普通情况可以用r.raw,在初始请求中设置stream=True,来获取服务器的原始套接字响应,在这里我们使用iter_content更加方便一些,因为requests.get(url) 默认是下载在内存中的,下载完成才存到硬盘上,但Response.iter_content可以边下载边存硬盘中,所以在这视频下载方面更具有优势。
当然说到 iter_content 的话,不得不提下chunk_size,因为流式请求就是像流水一样,不是一次过来而是一点一点“流”过来。处理流式数据也是一点一点处理。
而chunk_size会直接返回从当前位置往后读取 chunk_size 大小的文件内容,且迭代响应数据。这避免了立即将内容读入内存以获得较大的响应。chunk_size是它应该读入内存的字节数。chunk_size的类型必须是int或None。None的值将根据流的值发挥不同的作用。
做了引荐与讲解后,那么就开始上我们的主菜了,即目标网站:
https://m.rr.tv/
介于代码偏基础化,且主要知识点做过分析就直接上代码了,具体请看代码:
单线程:
import requestsimport jsonimport reimport osheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}ep_list =[]vod_list = []def get_vod(url): response = requests.get(url = url,headers = headers)#请求url ep= re.compile(r'sid:"(.*?)",')#提取ep链接 ep_list = re.findall(ep,response.text) vod= re.compile(r'data:\[{id:(.*?),title:"')#提取vod链接 vod_list = re.findall(vod,response.text) vod= re.compile(r',title:"(.*?)",desc:"')#提取视频标题 vod_name = re.findall(vod,response.text) ep = 1 os.mkdir('./'+vod_name[0])#创建视频保存目录 for i in ep_list: print("开始下载"+vod_name[0]+"第"+str(ep)+"集") url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers)#下载请求 r = requests.get(str(json.loads(response.text)['data']['url']), stream=True)#解析出下载链接并发起下载请求 f = open("./"+vod_name[0]+"/第"+str(ep)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk) ep = ep+1if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxxx?snum=1&episode=1'#目标视频链接 get_vod(url)
多线程:
import requestsimport jsonimport reimport osfrom concurrent.futures import ThreadPoolExecutorheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}vod_list = []#存储视频链接vod_name = []#存储视频标题get_down_url =[]#存储下载直链def get_vod(url): response = requests.get(url = url,headers = headers)#请求url vod_list.append(re.findall(re.compile(r'data:\[{id:(.*?),title:"'),response.text)[0])#找找视频链接 vod_name.append(re.findall(re.compile(r',title:"(.*?)",desc:"'),response.text)[0])#找找视频标题 for i in re.findall(re.compile(r'{sid:"(.*?)",key:'),response.text): url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers) get_down_url.append(str(json.loads(response.text)['data']['url']))#拿下载直链进listdef down_begin(url,i): print("开始多线程下载"+vod_name[0]+"第"+str(i)+"集") r = requests.get(url = url,headers = headers)#下载请求 f = open("./"+vod_name[0]+"/第"+str(i)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk)if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxx?snum=1&episode=1'#进入rr.tv自行获取 get_vod(url) os.mkdir('./'+vod_name[0])#创建视频保存目录 with ThreadPoolExecutor(10) as f:#这里写多线程参数,适合几十集的电视剧使用 for i,url in enumerate(get_down_url): i=int(i)+1 f.submit(down_begin,url = url,i=i)
把案例里面的链接改成你想要下载的链接,然后右击运行代码,即可成功的下载你想要的视频了。代码获取后台回复:”人人视频“。
在文章的最后给大家来一波福利,因为前一段时间小编在爬取百度相关关键词以及文章采集时,经常触发百度的验证机制,这种情况很明显要使用到代理IP,后来群里一个小伙伴推荐了品赞代理IP,小编测试了下,完美解决了爬取中存在的问题。
如果大家后续有需要使用到代理方面的业务的话,可以扫码添加下方的二维码。国内外的IP都有,新用户可以免费测试。
查看全部
文章采集api Python 爬取人人视频
hello,小伙伴们,又见面了,距离上一次发布文章的时间,也算是久别重逢了。期间也发生了很多的事情,导致博文断更,也是笔者不愿意的,但是确实是比较忙,不再过多赘述,希望大家能够体谅。
平时不断的在后台收到小伙伴的私信,问是不是不更了,答案当然是否定的,有着这么多人的支持,小编还是要继续努力下去的,再次谢谢大家的支持。
这次给大家带来的文章是爬取人人视频,之前多是分享一些爬取数据,图片,音乐,还没怎么分享过爬取过视频的,那么想要爬取视频的话该怎么爬取呢?
其实不管是图片,还是音乐,或者是其他的文档,大部分都是一个文件读写的过程,当然视频也不例外,只是文件的格式不同而已。所以我们也可以试着以常规的手段去尝试下爬取视频,没错还是熟悉的套路与配方,即python常用函数 open()和 write()。
不过这次略微不同的是我们会使用到iter_content来获取请求的原始响应数据,普通情况可以用r.raw,在初始请求中设置stream=True,来获取服务器的原始套接字响应,在这里我们使用iter_content更加方便一些,因为requests.get(url) 默认是下载在内存中的,下载完成才存到硬盘上,但Response.iter_content可以边下载边存硬盘中,所以在这视频下载方面更具有优势。
当然说到 iter_content 的话,不得不提下chunk_size,因为流式请求就是像流水一样,不是一次过来而是一点一点“流”过来。处理流式数据也是一点一点处理。
而chunk_size会直接返回从当前位置往后读取 chunk_size 大小的文件内容,且迭代响应数据。这避免了立即将内容读入内存以获得较大的响应。chunk_size是它应该读入内存的字节数。chunk_size的类型必须是int或None。None的值将根据流的值发挥不同的作用。
做了引荐与讲解后,那么就开始上我们的主菜了,即目标网站:
https://m.rr.tv/
介于代码偏基础化,且主要知识点做过分析就直接上代码了,具体请看代码:
单线程:
import requestsimport jsonimport reimport osheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}ep_list =[]vod_list = []def get_vod(url): response = requests.get(url = url,headers = headers)#请求url ep= re.compile(r'sid:"(.*?)",')#提取ep链接 ep_list = re.findall(ep,response.text) vod= re.compile(r'data:\[{id:(.*?),title:"')#提取vod链接 vod_list = re.findall(vod,response.text) vod= re.compile(r',title:"(.*?)",desc:"')#提取视频标题 vod_name = re.findall(vod,response.text) ep = 1 os.mkdir('./'+vod_name[0])#创建视频保存目录 for i in ep_list: print("开始下载"+vod_name[0]+"第"+str(ep)+"集") url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers)#下载请求 r = requests.get(str(json.loads(response.text)['data']['url']), stream=True)#解析出下载链接并发起下载请求 f = open("./"+vod_name[0]+"/第"+str(ep)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk) ep = ep+1if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxxx?snum=1&episode=1'#目标视频链接 get_vod(url)
多线程:
import requestsimport jsonimport reimport osfrom concurrent.futures import ThreadPoolExecutorheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}vod_list = []#存储视频链接vod_name = []#存储视频标题get_down_url =[]#存储下载直链def get_vod(url): response = requests.get(url = url,headers = headers)#请求url vod_list.append(re.findall(re.compile(r'data:\[{id:(.*?),title:"'),response.text)[0])#找找视频链接 vod_name.append(re.findall(re.compile(r',title:"(.*?)",desc:"'),response.text)[0])#找找视频标题 for i in re.findall(re.compile(r'{sid:"(.*?)",key:'),response.text): url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers) get_down_url.append(str(json.loads(response.text)['data']['url']))#拿下载直链进listdef down_begin(url,i): print("开始多线程下载"+vod_name[0]+"第"+str(i)+"集") r = requests.get(url = url,headers = headers)#下载请求 f = open("./"+vod_name[0]+"/第"+str(i)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk)if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxx?snum=1&episode=1'#进入rr.tv自行获取 get_vod(url) os.mkdir('./'+vod_name[0])#创建视频保存目录 with ThreadPoolExecutor(10) as f:#这里写多线程参数,适合几十集的电视剧使用 for i,url in enumerate(get_down_url): i=int(i)+1 f.submit(down_begin,url = url,i=i)
把案例里面的链接改成你想要下载的链接,然后右击运行代码,即可成功的下载你想要的视频了。代码获取后台回复:”人人视频“。
在文章的最后给大家来一波福利,因为前一段时间小编在爬取百度相关关键词以及文章采集时,经常触发百度的验证机制,这种情况很明显要使用到代理IP,后来群里一个小伙伴推荐了品赞代理IP,小编测试了下,完美解决了爬取中存在的问题。
如果大家后续有需要使用到代理方面的业务的话,可以扫码添加下方的二维码。国内外的IP都有,新用户可以免费测试。
干掉 Swagger + Postman?测试接口直接生成API文档
采集交流 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-05-09 04:25
② 点击右上角的【+】按钮,我们来新建一个页面,编写一个用户注册的 API 接口文档。
新建页面
③ 点击【API 接口模板】按钮,ShowDoc 会帮我们生成 API 接口文档的示例,采用的是 Markdown 的格式。
API 接口模板
④ 简单修改 Markdown 的内容,然后点击右上角的【保存】按钮,生成文档。
保存接口
⑤ 点击右上角的【返回】按钮,可以看到刚创建的 API 接口文档。
接口预览
在右边,艿艿圈了【分享】【目录】【历史版本】三个按钮,胖友可以自己去体验下。
ShowDoc 提供 API 接口的 Mock 功能,方便后端在定义 API 接口后,提供模拟数据。
① 点击需要 Mock 的 API 接口文档的右边的【编辑页面】按钮,然后点击【Mock】按钮,我们可以看到一个 Mock 的弹窗。
Mock 弹窗
② 填写 Mock 的返回结果,设置 Mock Url 的路径,然后点击【保存】按钮。
设置 Mock
③ 点击【复制】按钮,复制 Mock Url 的路径,然后使用浏览器访问,可以看到 Mock 的返回结果。
请求 Mock 接口
友情提示:ShowDoc 提供的 Mock 能力还是比较基础的,实际项目中,我们可能希望根据不同的请求参数,返回不同的 Mock 结果。
如果胖友有这块需求,可以看看 YApi: 。
通过手写 Markdown 的方式,生成 API 文档的方式,是非常非常非常繁琐 的!!!所以,ShowDoc 自己也不推荐采用这种方式,而是主推 RunApi 工具,一边调试接口,一边自动生成 。
咱先看看 RunApi 的自我介绍,也是贼长一大串:
RunApi 是一个以接口为核心的开发测试工具(功能上类似 Postman)。
目前有客户端版(推荐,支持 Win/Mac/Linux全平台)和在线精简版 ,包含接口测试 / 自动流程测试 / Mock 数据 / 项目协作等功能。
它和 ShowDoc 相辅相成:
相信使用 ShowDoc + RunApi 这两个工具组合,能够极大地提高IT团队的效率。
管你看没看懂,跟着艿艿一起,体验一下就完事了!
① 在 地址下,提供了不同操作系统的 RunApi 客户端的下载。
客户端
② 下载并安装完成后,使用 ShowDoc 注册的账号,进行登陆。
Runapi 登陆
虽然我们在 ShowDoc 中,已经新建了项目,但是我们在 RunApi 中是无法看到的。因此,我们需要重新新建属于 RunApi 的项目。
项目对比
① 点击 RunApi 客户端的【新建项目】按钮,填写项目名和描述,然后点击【确认】按钮进行保存。
新建项目
② 浏览器刷新 ShowDoc 页面,可以看到刚创建的项目。
查看项目
① 点击【+】按钮,选择要新增的类型为“带调试功能的API接口”。
新建 API 接口
② 启动一个 Spring Boot 项目,提供一个需要调试的 API 接口。
友情提示:胖友可以克隆 项目,使用 lab-24/lab-24-apidoc-showdoc 示例。
嘿嘿,顺手求个 Star 关注,艿艿写了 40000+ Spring Boot 和 Spring Cloud 的使用示例代码。
启动 Spring Boot 项目
③ 使用 RunApi 调试下 /users/login 接口。
调试 API 接口
④ 点击【返回示例和参数说明】,补全返回结果的接口文档。
补全响应结果
⑤ 点击【保存】按钮,生成 API 接口文档。
⑥ 点击【文档链接】按钮,获得 API 接口文档的地址。
文档链接
⑦ 点击 API 文档的访问链接,查看 API 文档。
RunAPI 文档预览
当然,我们也可以在 ShowDoc 中,进行访问。
ShowDoc 文档预览
有一点要注意,使用 RunApi 生成的 API 接口文档,无法在使用 Markdown 进行编辑噢!原因也很简单,编写后的 Markdown 文件,可能会导致无法逆向被 RunApi 使用,格式被破坏了!
① 点击需要 Mock 的 API 接口文档的下边的【Mock】按钮,我们可以看到一个 Mock 的界面。
Mock 界面
② 填写 Mock 的返回结果,设置 Mock Url 的路径,然后点击【保存】按钮。
设置 Mock
③ 点击【复制】按钮,复制 Mock Url 的路径,然后使用浏览器访问,可以看到 Mock 的返回结果。
请求 Mock 接口
RunApi 还提供了 3 个高级特性,胖友后面可以自己体验下。
强烈推荐 !!!
环境变量
例如说,设置“本地环境”、“测试环境”等多套环境变量,方便模拟请求不通过环境下的 API 噢。
前执行脚本
例如说,可以模拟登陆,获得用户的访问 token 令牌。
后执行脚本
例如说,断言响应的结果,是否为期望的 200 。
RunApi 提供的自动 生成 API 接口文档的方式,确实能够避免一部分烦琐 的手写 Markdown 的过程。同时,它能够结合我们日常开发,模拟调用 API 接口的时,复用了请求参数与响应结果。
但是我们如果仔细去思考,这是不是意味着可能此时此刻,我们已经开发完 API 接口了?!那么,假如团队采用的是前后端分离的架构,并且前端和后端是两拨人,那么前端会希望后端提前就定义好 API 接口的文档,而不是在后端具体完成好 API 接口的开发后,再提供接口文档。
所以我们在使用 RunApi 的时候,有可能是先使用它来**“手动”** 定义好 API 接口文档,然后复用它来模拟测试 API 接口。
嘿嘿~胖友也可以思考下,结合 RunApi 的这种模式,怎么结合到我们的日常开发流程中,欢迎留言讨论。
ShowDoc 支持通过扫描代码注释的方式,自动生成 API 接口文档,目前自持 Java、C++、PHP、Node 等等主流的编程语言。
艿艿看了下官方文档 对这块功能的介绍,感受上使用体验会非常不好。一起来看下官方提供的示例:
/**<br /> * showdoc<br /> * @catalog 测试文档/用户相关<br /> * @title 用户登录<br /> * @description 用户登录的接口<br /> * @method get<br /> * @url https://www.showdoc.cc/home/user/login<br /> * @header token 可选 string 设备token <br /> * @param username 必选 string 用户名 <br /> * @param password 必选 string 密码 <br /> * @param name 可选 string 用户昵称 <br /> * @return {"error_code":0,"data":{"uid":"1","username":"12154545","name":"吴系挂","groupid":2,"reg_time":"1436864169","last_login_time":"0"}}<br /> * @return_param groupid int 用户组id<br /> * @return_param name string 用户昵称<br /> * @remark 这里是备注信息<br /> * @number 99<br /> */<br /> public Object login(String username, String password, String name) {<br /> // ... 省略具体代码<br /> }<br />
需要使用到 @catalog、@title 等等自定义的注释标签,且原有的 @param 需要安装一定的格式来保证 API 接口的参数的说明,@return 的示例会导致注释非常长。
自定义注释
这样就导致,虽然只使用代码注释的方式,实际对代码还是有一定的入侵,影响代码的可读性。
还是老样子,我们使用 项目,lab-24/lab-24-apidoc-showdoc 示例,编写一个 users/login2 接口,并使用 ShowDoc 扫码 Java代码注释,生成 API 接口文档。
① 下载 脚本,到项目的根目录。
下载 showdoc_api 脚本
② 在项目的设置页,获得 ShowDoc 的开放 API 的 api_key 和 api_token 秘钥对。
进入项目的设置页获得 api_key 和 api_token 秘钥对
③ 修改 showdoc_api.sh 脚本,设置刚获得的 api_key 和 api_token 秘钥对。
设置 api_key 和 api_token 秘钥对
④ 编写 users/login2 接口,添加 ShowDoc 所需的注释。
编写 users/login2 接口
是不是看着就蛮乱的,IDEA 还报错 @param 找不到 username 和 password 参数。
⑤ 执行 showdoc_api.sh 脚本,扫描 Java代码注释,生成 API 接口文档。
生成 API 接口文档
⑥ 查看生成 API 接口文档。
查看 API 接口文档
如果胖友希望基于 Java 注释生成 API 接口文档,艿艿还是相对 JApiDocs 工具。具体的,可以看看艿艿写的 《芋道 Spring Boot API 接口文档 JApiDocs 入门》 文章。
JApiDocs 效果
ShowDoc 提供给了开放 API 的方式,导入 Markdown 文档。所以,我们可以编写程序,调用它的 API 接口,创建或更新 API 接口文档。
开放 API 的官方文档文档地址是, 。
接口地址 :
接口参数 :
接口参数
我们来导入一个简单的文档,效果如下图所示:
{<br /> "api_key": "60fc53cea6af4758c1686cb22ba20566472255580",<br /> "api_token": "0bbb5f564a9ee66333115b1abb8f8d541979489118",<br /> "page_title": "公众号",<br /> "page_content": "芋道源码,求一波关注呀~"<br />}<br />
友情提示:api_key 和 api_token 参数,记得改成自己的秘钥对,不然就导入到艿艿的项目里啦~~~
调用开放 API文档效果
在新建项目时,ShowDoc 支持导入 Swagger 或者 Postman 的 JSON 文档,方便我们快速迁移到 ShowDoc 作为 API 接口的平台。
我们来体验下 ShowDoc 提供的导入 Swagger 文档的功能,使用 项目,lab-24/lab-24-apidoc-swagger-starter 示例,提供的 Swagger JSON 文件。
① 启动 Spring Boot 项目,获得其 Swagger JSON 文件。
下载 Swagger JSON 文件
友情提示:胖友也可以访问 地址,直接进行下载!
② 新建 ShowDoc 项目,点击【导入文件】,选择 Swagger JSON 文件。
导入 Swagger JSON 文件
③ 导入完成后,点击自动新建的项目,查看下导入的 API 文档的效果。
导入 Swagger JSON 文件
接口都成功导入了,可惜 Swagger 中的 example 都缺失了,这就导致我们需要手动补全下接口的示例。
ShowDoc 目前只支持新建项目时,导入 Swagger 接口文档。但是如果 Swagger 接口文档变更时,无法进行更新 ShowDoc 中的文档。
如果我们仅仅是把 Swagger 迁移到 ShowDoc 中,肯定是基本能够满足。但是,如果我们希望使用 Swagger 编写接口文档,手动或者自动导入 ShowDoc 进行展示,这样就无法满足了。
这里艿艿推荐下 YApi 工具,支持定时采集 Swagger 接口,智能 合并 API 接口文档。具体的,可以看看艿艿写的 《芋道 Spring Boot API 接口文档 YApi 入门》 文章。
YApi + Swagger
在上家公司,艿艿就采用 Swagger + YApi 的组合,Swagger 方便后端编写 API 接口文档,YApi 提供接口的展示 、编辑 、Mock 、调试 、自动化测试 。
ShowDoc 支持通过扫描数据库,自动生成表结构的数据库文档。
对应的官方文档地址是, 。
下面, 我们来把艿艿的一个开源项目 的数据库,导入 ShowDoc 生成数据库文档。
① 下载 脚本,并设置数据库相关的参数。
下载 show_db 脚本
② 执行 show_db 脚本,看到“成功”说明成功。查看数据库文档的效果,效果还是还不错。
查看数据库文档
国内还有一款不错的数据库文档的生成工具 Screw,具体可以看看艿艿写的《芋道 Spring Boot 数据表结构文档》,地址是 。
演示效果
至此,我们已经完成 ShowDoc 的入门,还是蛮不错的一个工具。做个简单的小总结:
Talk is Cheap,胖友可以选择动手玩玩 ShowDoc 工具。
- END -
欢迎加入我的知识星球,一起探讨架构,交流源码。加入方式,长按下方二维码噢:
已在知识星球更新源码解析如下:
最近更新《芋道 SpringBoot 2.X 入门》系列,已经 101 余篇,覆盖了MyBatis、Redis、MongoDB、ES、分库分表、读写分离、SpringMVC、Webflux、权限、WebSocket、Dubbo、RabbitMQ、RocketMQ、Kafka、性能测试等等内容。
提供近 3W 行代码的 SpringBoot 示例,以及超 4W 行代码的电商微服务项目。 查看全部
干掉 Swagger + Postman?测试接口直接生成API文档
② 点击右上角的【+】按钮,我们来新建一个页面,编写一个用户注册的 API 接口文档。
新建页面
③ 点击【API 接口模板】按钮,ShowDoc 会帮我们生成 API 接口文档的示例,采用的是 Markdown 的格式。
API 接口模板
④ 简单修改 Markdown 的内容,然后点击右上角的【保存】按钮,生成文档。
保存接口
⑤ 点击右上角的【返回】按钮,可以看到刚创建的 API 接口文档。
接口预览
在右边,艿艿圈了【分享】【目录】【历史版本】三个按钮,胖友可以自己去体验下。
ShowDoc 提供 API 接口的 Mock 功能,方便后端在定义 API 接口后,提供模拟数据。
① 点击需要 Mock 的 API 接口文档的右边的【编辑页面】按钮,然后点击【Mock】按钮,我们可以看到一个 Mock 的弹窗。
Mock 弹窗
② 填写 Mock 的返回结果,设置 Mock Url 的路径,然后点击【保存】按钮。
设置 Mock
③ 点击【复制】按钮,复制 Mock Url 的路径,然后使用浏览器访问,可以看到 Mock 的返回结果。
请求 Mock 接口
友情提示:ShowDoc 提供的 Mock 能力还是比较基础的,实际项目中,我们可能希望根据不同的请求参数,返回不同的 Mock 结果。
如果胖友有这块需求,可以看看 YApi: 。
通过手写 Markdown 的方式,生成 API 文档的方式,是非常非常非常繁琐 的!!!所以,ShowDoc 自己也不推荐采用这种方式,而是主推 RunApi 工具,一边调试接口,一边自动生成 。
咱先看看 RunApi 的自我介绍,也是贼长一大串:
RunApi 是一个以接口为核心的开发测试工具(功能上类似 Postman)。
目前有客户端版(推荐,支持 Win/Mac/Linux全平台)和在线精简版 ,包含接口测试 / 自动流程测试 / Mock 数据 / 项目协作等功能。
它和 ShowDoc 相辅相成:
相信使用 ShowDoc + RunApi 这两个工具组合,能够极大地提高IT团队的效率。
管你看没看懂,跟着艿艿一起,体验一下就完事了!
① 在 地址下,提供了不同操作系统的 RunApi 客户端的下载。
客户端
② 下载并安装完成后,使用 ShowDoc 注册的账号,进行登陆。
Runapi 登陆
虽然我们在 ShowDoc 中,已经新建了项目,但是我们在 RunApi 中是无法看到的。因此,我们需要重新新建属于 RunApi 的项目。
项目对比
① 点击 RunApi 客户端的【新建项目】按钮,填写项目名和描述,然后点击【确认】按钮进行保存。
新建项目
② 浏览器刷新 ShowDoc 页面,可以看到刚创建的项目。
查看项目
① 点击【+】按钮,选择要新增的类型为“带调试功能的API接口”。
新建 API 接口
② 启动一个 Spring Boot 项目,提供一个需要调试的 API 接口。
友情提示:胖友可以克隆 项目,使用 lab-24/lab-24-apidoc-showdoc 示例。
嘿嘿,顺手求个 Star 关注,艿艿写了 40000+ Spring Boot 和 Spring Cloud 的使用示例代码。
启动 Spring Boot 项目
③ 使用 RunApi 调试下 /users/login 接口。
调试 API 接口
④ 点击【返回示例和参数说明】,补全返回结果的接口文档。
补全响应结果
⑤ 点击【保存】按钮,生成 API 接口文档。
⑥ 点击【文档链接】按钮,获得 API 接口文档的地址。
文档链接
⑦ 点击 API 文档的访问链接,查看 API 文档。
RunAPI 文档预览
当然,我们也可以在 ShowDoc 中,进行访问。
ShowDoc 文档预览
有一点要注意,使用 RunApi 生成的 API 接口文档,无法在使用 Markdown 进行编辑噢!原因也很简单,编写后的 Markdown 文件,可能会导致无法逆向被 RunApi 使用,格式被破坏了!
① 点击需要 Mock 的 API 接口文档的下边的【Mock】按钮,我们可以看到一个 Mock 的界面。
Mock 界面
② 填写 Mock 的返回结果,设置 Mock Url 的路径,然后点击【保存】按钮。
设置 Mock
③ 点击【复制】按钮,复制 Mock Url 的路径,然后使用浏览器访问,可以看到 Mock 的返回结果。
请求 Mock 接口
RunApi 还提供了 3 个高级特性,胖友后面可以自己体验下。
强烈推荐 !!!
环境变量
例如说,设置“本地环境”、“测试环境”等多套环境变量,方便模拟请求不通过环境下的 API 噢。
前执行脚本
例如说,可以模拟登陆,获得用户的访问 token 令牌。
后执行脚本
例如说,断言响应的结果,是否为期望的 200 。
RunApi 提供的自动 生成 API 接口文档的方式,确实能够避免一部分烦琐 的手写 Markdown 的过程。同时,它能够结合我们日常开发,模拟调用 API 接口的时,复用了请求参数与响应结果。
但是我们如果仔细去思考,这是不是意味着可能此时此刻,我们已经开发完 API 接口了?!那么,假如团队采用的是前后端分离的架构,并且前端和后端是两拨人,那么前端会希望后端提前就定义好 API 接口的文档,而不是在后端具体完成好 API 接口的开发后,再提供接口文档。
所以我们在使用 RunApi 的时候,有可能是先使用它来**“手动”** 定义好 API 接口文档,然后复用它来模拟测试 API 接口。
嘿嘿~胖友也可以思考下,结合 RunApi 的这种模式,怎么结合到我们的日常开发流程中,欢迎留言讨论。
ShowDoc 支持通过扫描代码注释的方式,自动生成 API 接口文档,目前自持 Java、C++、PHP、Node 等等主流的编程语言。
艿艿看了下官方文档 对这块功能的介绍,感受上使用体验会非常不好。一起来看下官方提供的示例:
/**<br /> * showdoc<br /> * @catalog 测试文档/用户相关<br /> * @title 用户登录<br /> * @description 用户登录的接口<br /> * @method get<br /> * @url https://www.showdoc.cc/home/user/login<br /> * @header token 可选 string 设备token <br /> * @param username 必选 string 用户名 <br /> * @param password 必选 string 密码 <br /> * @param name 可选 string 用户昵称 <br /> * @return {"error_code":0,"data":{"uid":"1","username":"12154545","name":"吴系挂","groupid":2,"reg_time":"1436864169","last_login_time":"0"}}<br /> * @return_param groupid int 用户组id<br /> * @return_param name string 用户昵称<br /> * @remark 这里是备注信息<br /> * @number 99<br /> */<br /> public Object login(String username, String password, String name) {<br /> // ... 省略具体代码<br /> }<br />
需要使用到 @catalog、@title 等等自定义的注释标签,且原有的 @param 需要安装一定的格式来保证 API 接口的参数的说明,@return 的示例会导致注释非常长。
自定义注释
这样就导致,虽然只使用代码注释的方式,实际对代码还是有一定的入侵,影响代码的可读性。
还是老样子,我们使用 项目,lab-24/lab-24-apidoc-showdoc 示例,编写一个 users/login2 接口,并使用 ShowDoc 扫码 Java代码注释,生成 API 接口文档。
① 下载 脚本,到项目的根目录。
下载 showdoc_api 脚本
② 在项目的设置页,获得 ShowDoc 的开放 API 的 api_key 和 api_token 秘钥对。
进入项目的设置页获得 api_key 和 api_token 秘钥对
③ 修改 showdoc_api.sh 脚本,设置刚获得的 api_key 和 api_token 秘钥对。
设置 api_key 和 api_token 秘钥对
④ 编写 users/login2 接口,添加 ShowDoc 所需的注释。
编写 users/login2 接口
是不是看着就蛮乱的,IDEA 还报错 @param 找不到 username 和 password 参数。
⑤ 执行 showdoc_api.sh 脚本,扫描 Java代码注释,生成 API 接口文档。
生成 API 接口文档
⑥ 查看生成 API 接口文档。
查看 API 接口文档
如果胖友希望基于 Java 注释生成 API 接口文档,艿艿还是相对 JApiDocs 工具。具体的,可以看看艿艿写的 《芋道 Spring Boot API 接口文档 JApiDocs 入门》 文章。
JApiDocs 效果
ShowDoc 提供给了开放 API 的方式,导入 Markdown 文档。所以,我们可以编写程序,调用它的 API 接口,创建或更新 API 接口文档。
开放 API 的官方文档文档地址是, 。
接口地址 :
接口参数 :
接口参数
我们来导入一个简单的文档,效果如下图所示:
{<br /> "api_key": "60fc53cea6af4758c1686cb22ba20566472255580",<br /> "api_token": "0bbb5f564a9ee66333115b1abb8f8d541979489118",<br /> "page_title": "公众号",<br /> "page_content": "芋道源码,求一波关注呀~"<br />}<br />
友情提示:api_key 和 api_token 参数,记得改成自己的秘钥对,不然就导入到艿艿的项目里啦~~~
调用开放 API文档效果
在新建项目时,ShowDoc 支持导入 Swagger 或者 Postman 的 JSON 文档,方便我们快速迁移到 ShowDoc 作为 API 接口的平台。
我们来体验下 ShowDoc 提供的导入 Swagger 文档的功能,使用 项目,lab-24/lab-24-apidoc-swagger-starter 示例,提供的 Swagger JSON 文件。
① 启动 Spring Boot 项目,获得其 Swagger JSON 文件。
下载 Swagger JSON 文件
友情提示:胖友也可以访问 地址,直接进行下载!
② 新建 ShowDoc 项目,点击【导入文件】,选择 Swagger JSON 文件。
导入 Swagger JSON 文件
③ 导入完成后,点击自动新建的项目,查看下导入的 API 文档的效果。
导入 Swagger JSON 文件
接口都成功导入了,可惜 Swagger 中的 example 都缺失了,这就导致我们需要手动补全下接口的示例。
ShowDoc 目前只支持新建项目时,导入 Swagger 接口文档。但是如果 Swagger 接口文档变更时,无法进行更新 ShowDoc 中的文档。
如果我们仅仅是把 Swagger 迁移到 ShowDoc 中,肯定是基本能够满足。但是,如果我们希望使用 Swagger 编写接口文档,手动或者自动导入 ShowDoc 进行展示,这样就无法满足了。
这里艿艿推荐下 YApi 工具,支持定时采集 Swagger 接口,智能 合并 API 接口文档。具体的,可以看看艿艿写的 《芋道 Spring Boot API 接口文档 YApi 入门》 文章。
YApi + Swagger
在上家公司,艿艿就采用 Swagger + YApi 的组合,Swagger 方便后端编写 API 接口文档,YApi 提供接口的展示 、编辑 、Mock 、调试 、自动化测试 。
ShowDoc 支持通过扫描数据库,自动生成表结构的数据库文档。
对应的官方文档地址是, 。
下面, 我们来把艿艿的一个开源项目 的数据库,导入 ShowDoc 生成数据库文档。
① 下载 脚本,并设置数据库相关的参数。
下载 show_db 脚本
② 执行 show_db 脚本,看到“成功”说明成功。查看数据库文档的效果,效果还是还不错。
查看数据库文档
国内还有一款不错的数据库文档的生成工具 Screw,具体可以看看艿艿写的《芋道 Spring Boot 数据表结构文档》,地址是 。
演示效果
至此,我们已经完成 ShowDoc 的入门,还是蛮不错的一个工具。做个简单的小总结:
Talk is Cheap,胖友可以选择动手玩玩 ShowDoc 工具。
- END -
欢迎加入我的知识星球,一起探讨架构,交流源码。加入方式,长按下方二维码噢:
已在知识星球更新源码解析如下:
最近更新《芋道 SpringBoot 2.X 入门》系列,已经 101 余篇,覆盖了MyBatis、Redis、MongoDB、ES、分库分表、读写分离、SpringMVC、Webflux、权限、WebSocket、Dubbo、RabbitMQ、RocketMQ、Kafka、性能测试等等内容。
提供近 3W 行代码的 SpringBoot 示例,以及超 4W 行代码的电商微服务项目。
文章采集api Python 爬取人人视频
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-05-09 04:23
hello,小伙伴们,又见面了,距离上一次发布文章的时间,也算是久别重逢了。期间也发生了很多的事情,导致博文断更,也是笔者不愿意的,但是确实是比较忙,不再过多赘述,希望大家能够体谅。
平时不断的在后台收到小伙伴的私信,问是不是不更了,答案当然是否定的,有着这么多人的支持,小编还是要继续努力下去的,再次谢谢大家的支持。
这次给大家带来的文章是爬取人人视频,之前多是分享一些爬取数据,图片,音乐,还没怎么分享过爬取过视频的,那么想要爬取视频的话该怎么爬取呢?
其实不管是图片,还是音乐,或者是其他的文档,大部分都是一个文件读写的过程,当然视频也不例外,只是文件的格式不同而已。所以我们也可以试着以常规的手段去尝试下爬取视频,没错还是熟悉的套路与配方,即python常用函数 open()和 write()。
不过这次略微不同的是我们会使用到iter_content来获取请求的原始响应数据,普通情况可以用r.raw,在初始请求中设置stream=True,来获取服务器的原始套接字响应,在这里我们使用iter_content更加方便一些,因为requests.get(url) 默认是下载在内存中的,下载完成才存到硬盘上,但Response.iter_content可以边下载边存硬盘中,所以在这视频下载方面更具有优势。
当然说到 iter_content 的话,不得不提下chunk_size,因为流式请求就是像流水一样,不是一次过来而是一点一点“流”过来。处理流式数据也是一点一点处理。
而chunk_size会直接返回从当前位置往后读取 chunk_size 大小的文件内容,且迭代响应数据。这避免了立即将内容读入内存以获得较大的响应。chunk_size是它应该读入内存的字节数。chunk_size的类型必须是int或None。None的值将根据流的值发挥不同的作用。
做了引荐与讲解后,那么就开始上我们的主菜了,即目标网站:
https://m.rr.tv/
介于代码偏基础化,且主要知识点做过分析就直接上代码了,具体请看代码:
单线程:
import requestsimport jsonimport reimport osheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}ep_list =[]vod_list = []def get_vod(url): response = requests.get(url = url,headers = headers)#请求url ep= re.compile(r'sid:"(.*?)",')#提取ep链接 ep_list = re.findall(ep,response.text) vod= re.compile(r'data:\[{id:(.*?),title:"')#提取vod链接 vod_list = re.findall(vod,response.text) vod= re.compile(r',title:"(.*?)",desc:"')#提取视频标题 vod_name = re.findall(vod,response.text) ep = 1 os.mkdir('./'+vod_name[0])#创建视频保存目录 for i in ep_list: print("开始下载"+vod_name[0]+"第"+str(ep)+"集") url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers)#下载请求 r = requests.get(str(json.loads(response.text)['data']['url']), stream=True)#解析出下载链接并发起下载请求 f = open("./"+vod_name[0]+"/第"+str(ep)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk) ep = ep+1if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxxx?snum=1&episode=1'#目标视频链接 get_vod(url)
多线程:
import requestsimport jsonimport reimport osfrom concurrent.futures import ThreadPoolExecutorheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}vod_list = []#存储视频链接vod_name = []#存储视频标题get_down_url =[]#存储下载直链def get_vod(url): response = requests.get(url = url,headers = headers)#请求url vod_list.append(re.findall(re.compile(r'data:\[{id:(.*?),title:"'),response.text)[0])#找找视频链接 vod_name.append(re.findall(re.compile(r',title:"(.*?)",desc:"'),response.text)[0])#找找视频标题 for i in re.findall(re.compile(r'{sid:"(.*?)",key:'),response.text): url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers) get_down_url.append(str(json.loads(response.text)['data']['url']))#拿下载直链进listdef down_begin(url,i): print("开始多线程下载"+vod_name[0]+"第"+str(i)+"集") r = requests.get(url = url,headers = headers)#下载请求 f = open("./"+vod_name[0]+"/第"+str(i)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk)if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxx?snum=1&episode=1'#进入rr.tv自行获取 get_vod(url) os.mkdir('./'+vod_name[0])#创建视频保存目录 with ThreadPoolExecutor(10) as f:#这里写多线程参数,适合几十集的电视剧使用 for i,url in enumerate(get_down_url): i=int(i)+1 f.submit(down_begin,url = url,i=i)
把案例里面的链接改成你想要下载的链接,然后右击运行代码,即可成功的下载你想要的视频了。代码获取后台回复:”人人视频“。
在文章的最后给大家来一波福利,因为前一段时间小编在爬取百度相关关键词以及文章采集时,经常触发百度的验证机制,这种情况很明显要使用到代理IP,后来群里一个小伙伴推荐了品赞代理IP,小编测试了下,完美解决了爬取中存在的问题。
如果大家后续有需要使用到代理方面的业务的话,可以扫码添加下方的二维码。国内外的IP都有,新用户可以免费测试。
查看全部
文章采集api Python 爬取人人视频
hello,小伙伴们,又见面了,距离上一次发布文章的时间,也算是久别重逢了。期间也发生了很多的事情,导致博文断更,也是笔者不愿意的,但是确实是比较忙,不再过多赘述,希望大家能够体谅。
平时不断的在后台收到小伙伴的私信,问是不是不更了,答案当然是否定的,有着这么多人的支持,小编还是要继续努力下去的,再次谢谢大家的支持。
这次给大家带来的文章是爬取人人视频,之前多是分享一些爬取数据,图片,音乐,还没怎么分享过爬取过视频的,那么想要爬取视频的话该怎么爬取呢?
其实不管是图片,还是音乐,或者是其他的文档,大部分都是一个文件读写的过程,当然视频也不例外,只是文件的格式不同而已。所以我们也可以试着以常规的手段去尝试下爬取视频,没错还是熟悉的套路与配方,即python常用函数 open()和 write()。
不过这次略微不同的是我们会使用到iter_content来获取请求的原始响应数据,普通情况可以用r.raw,在初始请求中设置stream=True,来获取服务器的原始套接字响应,在这里我们使用iter_content更加方便一些,因为requests.get(url) 默认是下载在内存中的,下载完成才存到硬盘上,但Response.iter_content可以边下载边存硬盘中,所以在这视频下载方面更具有优势。
当然说到 iter_content 的话,不得不提下chunk_size,因为流式请求就是像流水一样,不是一次过来而是一点一点“流”过来。处理流式数据也是一点一点处理。
而chunk_size会直接返回从当前位置往后读取 chunk_size 大小的文件内容,且迭代响应数据。这避免了立即将内容读入内存以获得较大的响应。chunk_size是它应该读入内存的字节数。chunk_size的类型必须是int或None。None的值将根据流的值发挥不同的作用。
做了引荐与讲解后,那么就开始上我们的主菜了,即目标网站:
https://m.rr.tv/
介于代码偏基础化,且主要知识点做过分析就直接上代码了,具体请看代码:
单线程:
import requestsimport jsonimport reimport osheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}ep_list =[]vod_list = []def get_vod(url): response = requests.get(url = url,headers = headers)#请求url ep= re.compile(r'sid:"(.*?)",')#提取ep链接 ep_list = re.findall(ep,response.text) vod= re.compile(r'data:\[{id:(.*?),title:"')#提取vod链接 vod_list = re.findall(vod,response.text) vod= re.compile(r',title:"(.*?)",desc:"')#提取视频标题 vod_name = re.findall(vod,response.text) ep = 1 os.mkdir('./'+vod_name[0])#创建视频保存目录 for i in ep_list: print("开始下载"+vod_name[0]+"第"+str(ep)+"集") url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers)#下载请求 r = requests.get(str(json.loads(response.text)['data']['url']), stream=True)#解析出下载链接并发起下载请求 f = open("./"+vod_name[0]+"/第"+str(ep)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk) ep = ep+1if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxxx?snum=1&episode=1'#目标视频链接 get_vod(url)
多线程:
import requestsimport jsonimport reimport osfrom concurrent.futures import ThreadPoolExecutorheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}vod_list = []#存储视频链接vod_name = []#存储视频标题get_down_url =[]#存储下载直链def get_vod(url): response = requests.get(url = url,headers = headers)#请求url vod_list.append(re.findall(re.compile(r'data:\[{id:(.*?),title:"'),response.text)[0])#找找视频链接 vod_name.append(re.findall(re.compile(r',title:"(.*?)",desc:"'),response.text)[0])#找找视频标题 for i in re.findall(re.compile(r'{sid:"(.*?)",key:'),response.text): url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers) get_down_url.append(str(json.loads(response.text)['data']['url']))#拿下载直链进listdef down_begin(url,i): print("开始多线程下载"+vod_name[0]+"第"+str(i)+"集") r = requests.get(url = url,headers = headers)#下载请求 f = open("./"+vod_name[0]+"/第"+str(i)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk)if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxx?snum=1&episode=1'#进入rr.tv自行获取 get_vod(url) os.mkdir('./'+vod_name[0])#创建视频保存目录 with ThreadPoolExecutor(10) as f:#这里写多线程参数,适合几十集的电视剧使用 for i,url in enumerate(get_down_url): i=int(i)+1 f.submit(down_begin,url = url,i=i)
把案例里面的链接改成你想要下载的链接,然后右击运行代码,即可成功的下载你想要的视频了。代码获取后台回复:”人人视频“。
在文章的最后给大家来一波福利,因为前一段时间小编在爬取百度相关关键词以及文章采集时,经常触发百度的验证机制,这种情况很明显要使用到代理IP,后来群里一个小伙伴推荐了品赞代理IP,小编测试了下,完美解决了爬取中存在的问题。
如果大家后续有需要使用到代理方面的业务的话,可以扫码添加下方的二维码。国内外的IP都有,新用户可以免费测试。
如何使用新一代轻量级分布式日志管理神器 Graylog 来收集日志
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-05-04 14:05
公众号关注「奇妙的 Linux 世界」
设为「星标」,每天带你玩转 Linux !
当我们公司内部部署很多服务以及测试、正式环境的时候,查看日志就变成了一个非常刚需的需求了。是多个环境的日志统一收集,然后使用 Nginx 对外提供服务,还是使用专用的日志收集服务 ELK 呢?
这就变成了一个问题!而 Graylog 作为整合方案,使用 Elasticsearch 来存储,使用 MongoDB 来缓存,并且还有带流量控制的(throttling),同时其界面查询简单易用且易于扩展。所以,使用 Graylog 成为了不二之选,为我们省了不少心。
1Filebeat 工具介绍
Filebeat 日志文件托运服务
Filebeat 是一个日志文件托运工具,在你的服务器上安装客户端后,Filebeat 会自动监控给定的日志目录或者指定的日志文件,追踪读取这些文件,不停的读取,并且转发这些信息到 Elasticsearch 或者 Logstarsh 或者 Graylog 中存放。
Filebeat 工作流程介绍
当你安装并启用 Filebeat 程序的时候,它会启动一个或多个探测器(prospectors)去检测你指定的日志目录或文件,对于探测器找出的每一个日志文件,Filebeat 都会启动一个收割进程(harvester),每一个收割进程读取一个日志文件的最新内容,并发送这些新的日志数据到处理程序(spooler),处理程序会集合这些事件,最后 Filebeat 会发送集合的数据到你指定的地址上去(我们这里就是发送给 Graylog 服务了)。
Filebeat 图示理解记忆
我们这里不适用 Logstash 服务,主要是因为 Filebeat 相比于 Logstash 更加轻量级。当我们需要收集信息的机器配置或资源并不是特别多时,且并没有那么复杂的时候,还是建议使用 Filebeat 来收集日志。日常使用中,Filebeat 的安装部署方式多样且运行十分稳定。
图示服务架构理解记忆2Filebeat 配置文件
配置 Filebeat 工具的核心就是如何编写其对应的配置文件!
对应 Filebeat 工具的配置主要是通过编写其配置文件来控制的,对于通过 rpm 或者 deb 包来安装的情况,配置文件默认会存储在,/etc/filebeat/filebeat.yml 这个路径下面。而对于,对于 MAC 或者 Win 系统来说,请查看解压文件中相关文件,其中都有涉及。
下面展示了 Filebeat 工具的主配置文件,注释信息中都对其各个字段含义进行了详细的解释,我这里就不再赘述了。需要注意的是,我们将日志的输入来源统统定义去读取 inputs.d 目录下的所有 yml 配置。所以,我们可以更加不用的服务(测试、正式服务)来定义不同的配置文件,根据物理机部署的实际情况具体配置。
# 配置输入来源的日志信息<br /># 我们合理将其配置到了inputs.d目录下的所有yml文件<br />filebeat.config.inputs:<br /> enabled: true<br /> path: ${path.config}/inputs.d/*.yml<br /> # 若收取日志格式为json的log请开启此配置<br /> # json.keys_under_root: true<br /><br /># 配置filebeat需要加载的模块<br />filebeat.config.modules:<br /> path: ${path.config}/modules.d/*.yml<br /> reload.enabled: false<br /><br />setup.template.settings:<br /> index.number_of_shards: 1<br /><br /># 配置将日志信息发送那个地址上面<br />output.logstash:<br /> hosts: ["11.22.33.44:5500"]<br /><br /># output.file:<br /># enable: true<br /><br />processors:<br /> - add_host_metadata: ~<br /> - rename:<br /> fields:<br /> - from: "log"<br /> to: "message"<br /> - add_fields:<br /> target: ""<br /> fields:<br /> # 加token是为了防止无认证的服务上Graylog服务发送数据<br /> token: "0uxxxxaM-1111-2222-3333-VQZJxxxxxwgX "<br /><br />
下面展示一个简单的 inputs.d 目录下面的 yml 配置文件的具体内容,其主要作用就是配置单独服务的独立日志数据,以及追加不同的数据 tag 类型。
# 配置输入来源的日志信息<br /># 我们合理将其配置到了inputs.d目录下的所有yml文件<br />filebeat.config.inputs:<br /> enabled: true<br /> path: ${path.config}/inputs.d/*.yml<br /> # 若收取日志格式为json的log请开启此配置<br /> # json.keys_under_root: true<br /><br /># 配置filebeat需要加载的模块<br />filebeat.config.modules:<br /> path: ${path.config}/modules.d/*.yml<br /> reload.enabled: false<br /><br />setup.template.settings:<br /> index.number_of_shards: 1<br /><br /># 配置将日志信息发送那个地址上面<br />output.logstash:<br /> hosts: ["11.22.33.44:5500"]<br /><br /># output.file:<br /># enable: true<br /><br />processors:<br /> - add_host_metadata: ~<br /> - rename:<br /> fields:<br /> - from: "log"<br /> to: "message"<br /> - add_fields:<br /> target: ""<br /> fields:<br /> # 加token是为了防止无认证的服务上Graylog服务发送数据<br /> token: "0uxxxxaM-1111-2222-3333-VQZJxxxxxwgX "<br />
需要注意的是,针对于不同的日志类型,filebeat 还提供了不同了模块来配置不同的服务日志以及其不同的模块特性,比如我们常见的 PostgreSQl、Redis、Iptables 等。
# iptables<br />- module: iptables<br /> log:<br /> enabled: true<br /> var.paths: ["/var/log/iptables.log"]<br /> var.input: "file"<br /><br /># postgres<br />- module: postgresql<br /> log:<br /> enabled: true<br /> var.paths: ["/path/to/log/postgres/*.log*"]<br /><br /># nginx<br />- module: nginx<br /> access:<br /> enabled: true<br /> var.paths: ["/path/to/log/nginx/access.log*"]<br /> error:<br /> enabled: true<br /> var.paths: ["/path/to/log/nginx/error.log*"]<br />
3Graylog 服务介绍
服务日志收集方案:Filebeat + Graylog!
Graylog 日志监控系统
Graylog 是一个开源的日志聚合、分析、审计、展现和预警工具。在功能上来说,和 ELK 类似,但又比 ELK 要简单很多。依靠着更加简洁,高效,部署使用简单的优势很快受到许多人的青睐。当然,在扩展性上面确实没有比 ELK 好,但是其有商业版本可以选择。
Graylog 工作流程介绍
部署 Graylog 最简单的架构就是单机部署,复杂的也是部署集群模式,架构图示如下所示。我们可以看到其中包含了三个组件,分别是 Elasticsearch、MongoDb 和 Graylog。其中,Elasticsearch 用来持久化存储和检索日志文件数据(IO 密集),MongoDb 用来存储关于 Graylog 的相关配置,而 Graylog 来提供 Web 界面和对外接口的(CPU 密集)。
最小化单机部署
最优化集群部署4Graylog 组件功能
配置 Graylog 服务的核心就是理解对应组件的功能以及其运作方式!
简单来讲,Input 表示日志数据的来源,对不同来源的日志可以通过 Extractors 来进行日志的字段转换,比如将 Nginx 的状态码变成对应的英文表述等。然后,通过不同的标签类型分组成不用的 Stream,并将这些日志数据存储到指定的 Index 库中进行持久化保存。
Graylog中的核心服务组件
Graylog 通过 Input 搜集日志,每个 Input 单独配置 Extractors 用来做字段转换。Graylog 中日志搜索的基本单位是 Stream,每个 Stream 可以有自己单独的 Elastic Index Set,也可以共享一个 Index Set。
Extractor 在 System/Input 中配置。Graylog 中很方便的一点就是可以加载一条日志,然后基于这个实际的例子进行配置并能直接看到结果。内置的 Extractor 基本可以完成各种字段提取和转换的任务,但是也有些限制,在应用里写日志的时候就需要考虑到这些限制。Input 可以配置多个 Extractors,按照顺序依次执行。
系统会有一个默认的 Stream,所有日志默认都会保存到这个 Stream 中,除非匹配了某个 Stream,并且这个 Stream 里配置了不保存日志到默认 Stream。可以通过菜单 Streams 创建更多的 Stream,新创建的 Stream 是暂停状态,需要在配置完成后手动启动。Stream 通过配置条件匹配日志,满足条件的日志添加 stream ID 标识字段并保存到对应的 Elastic Index Set 中。
Index Set 通过菜单 System/Indices 创建。日志存储的性能,可靠性和过期策略都通过 Index Set 来配置。性能和可靠性就是配置 Elastic Index 的一些参数,主要参数包括,Shards 和 Replicas。
除了上面提到的日志处理流程,Graylog 还提供了 Pipeline 脚本实现更灵活的日志处理方案。这里不详细阐述,只介绍如果使用 Pipelines 来过滤不需要的日志。下面是丢弃 level > 6 的所有日志的 Pipeline Rule 的例子。从数据采集(input),字段解析(extractor),分流到 stream,再到 Pipeline 的清洗,一气呵成,无需在通过其他方式进行二次加工。
Sidecar 是一个轻量级的日志采集器,通过访问 Graylog 进行集中式管理,支持 Linux 和 windows 系统。Sidecar 守护进程会定期访问 Graylog 的 REST API 接口获取 Sidecar 配置文件中定义的标签(tag),Sidecar 在首次运行时会从 Graylog 服务器拉取配置文件中指定标签(tag)的配置信息同步到本地。目前 Sidecar 支持 NXLog,Filebeat 和 Winlogbeat。他们都通过 Graylog 中的 web 界面进行统一配置,支持 Beats、CEF、Gelf、Json API、NetFlow 等输出类型。Graylog 最厉害的在于可以在配置文件中指定 Sidecar 把日志发送到哪个 Graylog 群集,并对 Graylog 群集中的多个 input 进行负载均衡,这样在遇到日志量非常庞大的时候,Graylog 也能应付自如。
rule "discard debug messages"<br />when<br /> to_long($message.level) > 6<br />then<br /> drop_message();<br />end<br />
日志集中保存到 Graylog 后就可以方便的使用搜索了。不过有时候还是需要对数据进行近一步的处理。主要有两个途径,分别是直接访问 Elastic 中保存的数据,或者通过 Graylog 的 Output 转发到其它服务。
5服务安装和部署
主要介绍部署 Filebeat + Graylog 的安装步骤和注意事项!
使用 Graylog 来收集日志
部署 Filebeat 工具
官方提供了多种的部署方式,包括通过 rpm 和 deb 包安装服务,以及源代码编译的方式安装服务,同时包括了使用 Docker 或者 kubernetes 的方式安装服务。我们根据自己的实际需要,进行安装即可。
# Ubuntu(deb)<br />$ curl -L -O https://artifacts.elastic.co/d ... %3Bbr />$ sudo dpkg -i filebeat-7.8.1-amd64.deb<br />$ sudo systemctl enable filebeat<br />$ sudo service filebeat start<br /><br /># 使用docker启动<br />docker run -d --name=filebeat --user=root \<br /> --volume="./filebeat.docker.yml:/usr/share/filebeat/filebeat.yml:ro" \<br /> --volume="/var/lib/docker/containers:/var/lib/docker/containers:ro" \<br /> --volume="/var/run/docker.sock:/var/run/docker.sock:ro" \<br /> docker.elastic.co/beats/filebeat:7.8.1 filebeat -e -strict.perms=false \<br /> -E output.elasticsearch.hosts=["elasticsearch:9200"]<br />
使用 Graylog 来收集日志
部署 Graylog 服务
我们这里主要介绍使用 Docker 容器来部署服务,如果你需要使用其他方式来部署的话,请自行查看官方文档对应章节的安装部署步骤。在服务部署之前,我们需要给 Graylog 服务生成等相关信息,生成部署如下所示:
<p># 生成password_secret密码(最少16位)<br />$ sudo apt install -y pwgen<br />$ pwgen -N 1 -s 16<br />zscMb65...FxR9ag<br /><br /># 生成后续Web登录时所需要使用的密码<br />$ echo -n "Enter Password: " && head -1 查看全部
如何使用新一代轻量级分布式日志管理神器 Graylog 来收集日志
公众号关注「奇妙的 Linux 世界」
设为「星标」,每天带你玩转 Linux !
当我们公司内部部署很多服务以及测试、正式环境的时候,查看日志就变成了一个非常刚需的需求了。是多个环境的日志统一收集,然后使用 Nginx 对外提供服务,还是使用专用的日志收集服务 ELK 呢?
这就变成了一个问题!而 Graylog 作为整合方案,使用 Elasticsearch 来存储,使用 MongoDB 来缓存,并且还有带流量控制的(throttling),同时其界面查询简单易用且易于扩展。所以,使用 Graylog 成为了不二之选,为我们省了不少心。
1Filebeat 工具介绍
Filebeat 日志文件托运服务
Filebeat 是一个日志文件托运工具,在你的服务器上安装客户端后,Filebeat 会自动监控给定的日志目录或者指定的日志文件,追踪读取这些文件,不停的读取,并且转发这些信息到 Elasticsearch 或者 Logstarsh 或者 Graylog 中存放。
Filebeat 工作流程介绍
当你安装并启用 Filebeat 程序的时候,它会启动一个或多个探测器(prospectors)去检测你指定的日志目录或文件,对于探测器找出的每一个日志文件,Filebeat 都会启动一个收割进程(harvester),每一个收割进程读取一个日志文件的最新内容,并发送这些新的日志数据到处理程序(spooler),处理程序会集合这些事件,最后 Filebeat 会发送集合的数据到你指定的地址上去(我们这里就是发送给 Graylog 服务了)。
Filebeat 图示理解记忆
我们这里不适用 Logstash 服务,主要是因为 Filebeat 相比于 Logstash 更加轻量级。当我们需要收集信息的机器配置或资源并不是特别多时,且并没有那么复杂的时候,还是建议使用 Filebeat 来收集日志。日常使用中,Filebeat 的安装部署方式多样且运行十分稳定。
图示服务架构理解记忆2Filebeat 配置文件
配置 Filebeat 工具的核心就是如何编写其对应的配置文件!
对应 Filebeat 工具的配置主要是通过编写其配置文件来控制的,对于通过 rpm 或者 deb 包来安装的情况,配置文件默认会存储在,/etc/filebeat/filebeat.yml 这个路径下面。而对于,对于 MAC 或者 Win 系统来说,请查看解压文件中相关文件,其中都有涉及。
下面展示了 Filebeat 工具的主配置文件,注释信息中都对其各个字段含义进行了详细的解释,我这里就不再赘述了。需要注意的是,我们将日志的输入来源统统定义去读取 inputs.d 目录下的所有 yml 配置。所以,我们可以更加不用的服务(测试、正式服务)来定义不同的配置文件,根据物理机部署的实际情况具体配置。
# 配置输入来源的日志信息<br /># 我们合理将其配置到了inputs.d目录下的所有yml文件<br />filebeat.config.inputs:<br /> enabled: true<br /> path: ${path.config}/inputs.d/*.yml<br /> # 若收取日志格式为json的log请开启此配置<br /> # json.keys_under_root: true<br /><br /># 配置filebeat需要加载的模块<br />filebeat.config.modules:<br /> path: ${path.config}/modules.d/*.yml<br /> reload.enabled: false<br /><br />setup.template.settings:<br /> index.number_of_shards: 1<br /><br /># 配置将日志信息发送那个地址上面<br />output.logstash:<br /> hosts: ["11.22.33.44:5500"]<br /><br /># output.file:<br /># enable: true<br /><br />processors:<br /> - add_host_metadata: ~<br /> - rename:<br /> fields:<br /> - from: "log"<br /> to: "message"<br /> - add_fields:<br /> target: ""<br /> fields:<br /> # 加token是为了防止无认证的服务上Graylog服务发送数据<br /> token: "0uxxxxaM-1111-2222-3333-VQZJxxxxxwgX "<br /><br />
下面展示一个简单的 inputs.d 目录下面的 yml 配置文件的具体内容,其主要作用就是配置单独服务的独立日志数据,以及追加不同的数据 tag 类型。
# 配置输入来源的日志信息<br /># 我们合理将其配置到了inputs.d目录下的所有yml文件<br />filebeat.config.inputs:<br /> enabled: true<br /> path: ${path.config}/inputs.d/*.yml<br /> # 若收取日志格式为json的log请开启此配置<br /> # json.keys_under_root: true<br /><br /># 配置filebeat需要加载的模块<br />filebeat.config.modules:<br /> path: ${path.config}/modules.d/*.yml<br /> reload.enabled: false<br /><br />setup.template.settings:<br /> index.number_of_shards: 1<br /><br /># 配置将日志信息发送那个地址上面<br />output.logstash:<br /> hosts: ["11.22.33.44:5500"]<br /><br /># output.file:<br /># enable: true<br /><br />processors:<br /> - add_host_metadata: ~<br /> - rename:<br /> fields:<br /> - from: "log"<br /> to: "message"<br /> - add_fields:<br /> target: ""<br /> fields:<br /> # 加token是为了防止无认证的服务上Graylog服务发送数据<br /> token: "0uxxxxaM-1111-2222-3333-VQZJxxxxxwgX "<br />
需要注意的是,针对于不同的日志类型,filebeat 还提供了不同了模块来配置不同的服务日志以及其不同的模块特性,比如我们常见的 PostgreSQl、Redis、Iptables 等。
# iptables<br />- module: iptables<br /> log:<br /> enabled: true<br /> var.paths: ["/var/log/iptables.log"]<br /> var.input: "file"<br /><br /># postgres<br />- module: postgresql<br /> log:<br /> enabled: true<br /> var.paths: ["/path/to/log/postgres/*.log*"]<br /><br /># nginx<br />- module: nginx<br /> access:<br /> enabled: true<br /> var.paths: ["/path/to/log/nginx/access.log*"]<br /> error:<br /> enabled: true<br /> var.paths: ["/path/to/log/nginx/error.log*"]<br />
3Graylog 服务介绍
服务日志收集方案:Filebeat + Graylog!
Graylog 日志监控系统
Graylog 是一个开源的日志聚合、分析、审计、展现和预警工具。在功能上来说,和 ELK 类似,但又比 ELK 要简单很多。依靠着更加简洁,高效,部署使用简单的优势很快受到许多人的青睐。当然,在扩展性上面确实没有比 ELK 好,但是其有商业版本可以选择。
Graylog 工作流程介绍
部署 Graylog 最简单的架构就是单机部署,复杂的也是部署集群模式,架构图示如下所示。我们可以看到其中包含了三个组件,分别是 Elasticsearch、MongoDb 和 Graylog。其中,Elasticsearch 用来持久化存储和检索日志文件数据(IO 密集),MongoDb 用来存储关于 Graylog 的相关配置,而 Graylog 来提供 Web 界面和对外接口的(CPU 密集)。
最小化单机部署
最优化集群部署4Graylog 组件功能
配置 Graylog 服务的核心就是理解对应组件的功能以及其运作方式!
简单来讲,Input 表示日志数据的来源,对不同来源的日志可以通过 Extractors 来进行日志的字段转换,比如将 Nginx 的状态码变成对应的英文表述等。然后,通过不同的标签类型分组成不用的 Stream,并将这些日志数据存储到指定的 Index 库中进行持久化保存。
Graylog中的核心服务组件
Graylog 通过 Input 搜集日志,每个 Input 单独配置 Extractors 用来做字段转换。Graylog 中日志搜索的基本单位是 Stream,每个 Stream 可以有自己单独的 Elastic Index Set,也可以共享一个 Index Set。
Extractor 在 System/Input 中配置。Graylog 中很方便的一点就是可以加载一条日志,然后基于这个实际的例子进行配置并能直接看到结果。内置的 Extractor 基本可以完成各种字段提取和转换的任务,但是也有些限制,在应用里写日志的时候就需要考虑到这些限制。Input 可以配置多个 Extractors,按照顺序依次执行。
系统会有一个默认的 Stream,所有日志默认都会保存到这个 Stream 中,除非匹配了某个 Stream,并且这个 Stream 里配置了不保存日志到默认 Stream。可以通过菜单 Streams 创建更多的 Stream,新创建的 Stream 是暂停状态,需要在配置完成后手动启动。Stream 通过配置条件匹配日志,满足条件的日志添加 stream ID 标识字段并保存到对应的 Elastic Index Set 中。
Index Set 通过菜单 System/Indices 创建。日志存储的性能,可靠性和过期策略都通过 Index Set 来配置。性能和可靠性就是配置 Elastic Index 的一些参数,主要参数包括,Shards 和 Replicas。
除了上面提到的日志处理流程,Graylog 还提供了 Pipeline 脚本实现更灵活的日志处理方案。这里不详细阐述,只介绍如果使用 Pipelines 来过滤不需要的日志。下面是丢弃 level > 6 的所有日志的 Pipeline Rule 的例子。从数据采集(input),字段解析(extractor),分流到 stream,再到 Pipeline 的清洗,一气呵成,无需在通过其他方式进行二次加工。
Sidecar 是一个轻量级的日志采集器,通过访问 Graylog 进行集中式管理,支持 Linux 和 windows 系统。Sidecar 守护进程会定期访问 Graylog 的 REST API 接口获取 Sidecar 配置文件中定义的标签(tag),Sidecar 在首次运行时会从 Graylog 服务器拉取配置文件中指定标签(tag)的配置信息同步到本地。目前 Sidecar 支持 NXLog,Filebeat 和 Winlogbeat。他们都通过 Graylog 中的 web 界面进行统一配置,支持 Beats、CEF、Gelf、Json API、NetFlow 等输出类型。Graylog 最厉害的在于可以在配置文件中指定 Sidecar 把日志发送到哪个 Graylog 群集,并对 Graylog 群集中的多个 input 进行负载均衡,这样在遇到日志量非常庞大的时候,Graylog 也能应付自如。
rule "discard debug messages"<br />when<br /> to_long($message.level) > 6<br />then<br /> drop_message();<br />end<br />
日志集中保存到 Graylog 后就可以方便的使用搜索了。不过有时候还是需要对数据进行近一步的处理。主要有两个途径,分别是直接访问 Elastic 中保存的数据,或者通过 Graylog 的 Output 转发到其它服务。
5服务安装和部署
主要介绍部署 Filebeat + Graylog 的安装步骤和注意事项!
使用 Graylog 来收集日志
部署 Filebeat 工具
官方提供了多种的部署方式,包括通过 rpm 和 deb 包安装服务,以及源代码编译的方式安装服务,同时包括了使用 Docker 或者 kubernetes 的方式安装服务。我们根据自己的实际需要,进行安装即可。
# Ubuntu(deb)<br />$ curl -L -O https://artifacts.elastic.co/d ... %3Bbr />$ sudo dpkg -i filebeat-7.8.1-amd64.deb<br />$ sudo systemctl enable filebeat<br />$ sudo service filebeat start<br /><br /># 使用docker启动<br />docker run -d --name=filebeat --user=root \<br /> --volume="./filebeat.docker.yml:/usr/share/filebeat/filebeat.yml:ro" \<br /> --volume="/var/lib/docker/containers:/var/lib/docker/containers:ro" \<br /> --volume="/var/run/docker.sock:/var/run/docker.sock:ro" \<br /> docker.elastic.co/beats/filebeat:7.8.1 filebeat -e -strict.perms=false \<br /> -E output.elasticsearch.hosts=["elasticsearch:9200"]<br />
使用 Graylog 来收集日志
部署 Graylog 服务
我们这里主要介绍使用 Docker 容器来部署服务,如果你需要使用其他方式来部署的话,请自行查看官方文档对应章节的安装部署步骤。在服务部署之前,我们需要给 Graylog 服务生成等相关信息,生成部署如下所示:
<p># 生成password_secret密码(最少16位)<br />$ sudo apt install -y pwgen<br />$ pwgen -N 1 -s 16<br />zscMb65...FxR9ag<br /><br /># 生成后续Web登录时所需要使用的密码<br />$ echo -n "Enter Password: " && head -1
超好用的收集信息工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-05-04 14:00
什么是 OSINT?
如果您听说过这个名字,OSINT代表开源情报,它指的是可以从免费公共来源合法收集的有关个人或组织的任何信息。在实践中,这往往意味着在互联网上找到的信息,但从技术上讲,任何公共信息都属于OSINT类别,无论是公共图书馆的书籍或报告,报纸上的文章还是新闻稿中的声明。
OSINT 还包括可在不同类型的介质中找到的信息。虽然我们通常认为它是基于文本的,但图像,视频,网络研讨会,公开演讲和会议中的信息都属于该术语。
OSINT的用途是什么?
通过收集有关特定目标的公开可用信息源,以更好地了解其特征并缩小搜索区域以查找可能的漏洞。数据信息可以生成的情报来构建威胁模型。或者有针对性的网络攻击,如军事攻击,从侦察开始,数字侦察的第一阶段是被动地获取情报,而不向目标发出警报。一旦可以从公共来源收集有关您的情报类型,就可以使用它来帮助您或您的安全团队制定更好的防御策略。
OSINT工具
用于情报收集的最明显的工具之一是Google,Bing等网络搜索引擎。事实上,有几十个搜索引擎,对于特定类型的查询,有些搜索引擎可能会返回比其他搜索引擎更好的结果。那么,问题是,如何以有效的方式查询这许多引擎呢?
Searx是解决此问题并使Web查询更有效的一个很好的工具。Searx是元搜索引擎,允许您匿名并同时收集来自70多个搜索服务的结果。Searx是免费的,您甚至可以托管自己的实例,以获得最终的隐私。用户既不会被跟踪,也不会被分析,并且默认情况下禁用cookie。Searx也可以通过Tor用于在线匿名。
有很多人一直在为OSINT开发新工具,当然,跟上他们以及网络安全世界中其他任何事情的好地方就是在Twitter上关注人们。然而,在Twitter上跟踪事情可能很困难。幸运的是,还有一个名为Twint的OSINT工具。
Twint是一个用Python编写的Twitter报废工具,可以很容易地在Twitter上匿名收集和搜索信息,而无需注册Twitter服务本身或使用API密钥,就像使用Recon-ng这样的工具一样。使用 Twint,根本不需要身份验证或 API。只需安装工具并开始搜索即可。您可以按用户,地理位置和时间范围以及其他可能性进行搜索。这只是Twint的一些选择,但也有许多其他选择。
那么,如何使用 Twint 来帮助您跟上 OSINT 的发展呢?嗯,这很容易,是Twint在行动中的一个很好的例子。由于 Twint 允许你指定一个--因为选项,以便仅从某个日期开始拉取推文,因此你可以将其与 Twint 的搜索动词相结合,每天抓取标记有#OSINT的新推文。您可以使用 Twint 的--database选项(保存为 SQLite 格式)自动执行该脚本并将结果馈送到数据库中,以便在方便时查看。
另一个可以用来收集公共信息的好工具是Metagaofil。此工具使用Google搜索引擎从给定域中检索公共PDF,Word文档,Powerpoint和Excel文件。然后,它可以自主地从这些文档中提取元数据,以生成列出用户名、软件版本、服务器和计算机名称等信息的报告。
查看全部
超好用的收集信息工具
什么是 OSINT?
如果您听说过这个名字,OSINT代表开源情报,它指的是可以从免费公共来源合法收集的有关个人或组织的任何信息。在实践中,这往往意味着在互联网上找到的信息,但从技术上讲,任何公共信息都属于OSINT类别,无论是公共图书馆的书籍或报告,报纸上的文章还是新闻稿中的声明。
OSINT 还包括可在不同类型的介质中找到的信息。虽然我们通常认为它是基于文本的,但图像,视频,网络研讨会,公开演讲和会议中的信息都属于该术语。
OSINT的用途是什么?
通过收集有关特定目标的公开可用信息源,以更好地了解其特征并缩小搜索区域以查找可能的漏洞。数据信息可以生成的情报来构建威胁模型。或者有针对性的网络攻击,如军事攻击,从侦察开始,数字侦察的第一阶段是被动地获取情报,而不向目标发出警报。一旦可以从公共来源收集有关您的情报类型,就可以使用它来帮助您或您的安全团队制定更好的防御策略。
OSINT工具
用于情报收集的最明显的工具之一是Google,Bing等网络搜索引擎。事实上,有几十个搜索引擎,对于特定类型的查询,有些搜索引擎可能会返回比其他搜索引擎更好的结果。那么,问题是,如何以有效的方式查询这许多引擎呢?
Searx是解决此问题并使Web查询更有效的一个很好的工具。Searx是元搜索引擎,允许您匿名并同时收集来自70多个搜索服务的结果。Searx是免费的,您甚至可以托管自己的实例,以获得最终的隐私。用户既不会被跟踪,也不会被分析,并且默认情况下禁用cookie。Searx也可以通过Tor用于在线匿名。
有很多人一直在为OSINT开发新工具,当然,跟上他们以及网络安全世界中其他任何事情的好地方就是在Twitter上关注人们。然而,在Twitter上跟踪事情可能很困难。幸运的是,还有一个名为Twint的OSINT工具。
Twint是一个用Python编写的Twitter报废工具,可以很容易地在Twitter上匿名收集和搜索信息,而无需注册Twitter服务本身或使用API密钥,就像使用Recon-ng这样的工具一样。使用 Twint,根本不需要身份验证或 API。只需安装工具并开始搜索即可。您可以按用户,地理位置和时间范围以及其他可能性进行搜索。这只是Twint的一些选择,但也有许多其他选择。
那么,如何使用 Twint 来帮助您跟上 OSINT 的发展呢?嗯,这很容易,是Twint在行动中的一个很好的例子。由于 Twint 允许你指定一个--因为选项,以便仅从某个日期开始拉取推文,因此你可以将其与 Twint 的搜索动词相结合,每天抓取标记有#OSINT的新推文。您可以使用 Twint 的--database选项(保存为 SQLite 格式)自动执行该脚本并将结果馈送到数据库中,以便在方便时查看。
另一个可以用来收集公共信息的好工具是Metagaofil。此工具使用Google搜索引擎从给定域中检索公共PDF,Word文档,Powerpoint和Excel文件。然后,它可以自主地从这些文档中提取元数据,以生成列出用户名、软件版本、服务器和计算机名称等信息的报告。
文章采集api Python 爬取人人视频
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-05-04 13:08
hello,小伙伴们,又见面了,距离上一次发布文章的时间,也算是久别重逢了。期间也发生了很多的事情,导致博文断更,也是笔者不愿意的,但是确实是比较忙,不再过多赘述,希望大家能够体谅。
平时不断的在后台收到小伙伴的私信,问是不是不更了,答案当然是否定的,有着这么多人的支持,小编还是要继续努力下去的,再次谢谢大家的支持。
这次给大家带来的文章是爬取人人视频,之前多是分享一些爬取数据,图片,音乐,还没怎么分享过爬取过视频的,那么想要爬取视频的话该怎么爬取呢?
其实不管是图片,还是音乐,或者是其他的文档,大部分都是一个文件读写的过程,当然视频也不例外,只是文件的格式不同而已。所以我们也可以试着以常规的手段去尝试下爬取视频,没错还是熟悉的套路与配方,即python常用函数 open()和 write()。
不过这次略微不同的是我们会使用到iter_content来获取请求的原始响应数据,普通情况可以用r.raw,在初始请求中设置stream=True,来获取服务器的原始套接字响应,在这里我们使用iter_content更加方便一些,因为requests.get(url) 默认是下载在内存中的,下载完成才存到硬盘上,但Response.iter_content可以边下载边存硬盘中,所以在这视频下载方面更具有优势。
当然说到 iter_content 的话,不得不提下chunk_size,因为流式请求就是像流水一样,不是一次过来而是一点一点“流”过来。处理流式数据也是一点一点处理。
而chunk_size会直接返回从当前位置往后读取 chunk_size 大小的文件内容,且迭代响应数据。这避免了立即将内容读入内存以获得较大的响应。chunk_size是它应该读入内存的字节数。chunk_size的类型必须是int或None。None的值将根据流的值发挥不同的作用。
做了引荐与讲解后,那么就开始上我们的主菜了,即目标网站:
https://m.rr.tv/
介于代码偏基础化,且主要知识点做过分析就直接上代码了,具体请看代码:
单线程:
import requestsimport jsonimport reimport osheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}ep_list =[]vod_list = []def get_vod(url): response = requests.get(url = url,headers = headers)#请求url ep= re.compile(r'sid:"(.*?)",')#提取ep链接 ep_list = re.findall(ep,response.text) vod= re.compile(r'data:\[{id:(.*?),title:"')#提取vod链接 vod_list = re.findall(vod,response.text) vod= re.compile(r',title:"(.*?)",desc:"')#提取视频标题 vod_name = re.findall(vod,response.text) ep = 1 os.mkdir('./'+vod_name[0])#创建视频保存目录 for i in ep_list: print("开始下载"+vod_name[0]+"第"+str(ep)+"集") url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers)#下载请求 r = requests.get(str(json.loads(response.text)['data']['url']), stream=True)#解析出下载链接并发起下载请求 f = open("./"+vod_name[0]+"/第"+str(ep)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk) ep = ep+1if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxxx?snum=1&episode=1'#目标视频链接 get_vod(url)
多线程:
import requestsimport jsonimport reimport osfrom concurrent.futures import ThreadPoolExecutorheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}vod_list = []#存储视频链接vod_name = []#存储视频标题get_down_url =[]#存储下载直链def get_vod(url): response = requests.get(url = url,headers = headers)#请求url vod_list.append(re.findall(re.compile(r'data:\[{id:(.*?),title:"'),response.text)[0])#找找视频链接 vod_name.append(re.findall(re.compile(r',title:"(.*?)",desc:"'),response.text)[0])#找找视频标题 for i in re.findall(re.compile(r'{sid:"(.*?)",key:'),response.text): url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers) get_down_url.append(str(json.loads(response.text)['data']['url']))#拿下载直链进listdef down_begin(url,i): print("开始多线程下载"+vod_name[0]+"第"+str(i)+"集") r = requests.get(url = url,headers = headers)#下载请求 f = open("./"+vod_name[0]+"/第"+str(i)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk)if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxx?snum=1&episode=1'#进入rr.tv自行获取 get_vod(url) os.mkdir('./'+vod_name[0])#创建视频保存目录 with ThreadPoolExecutor(10) as f:#这里写多线程参数,适合几十集的电视剧使用 for i,url in enumerate(get_down_url): i=int(i)+1 f.submit(down_begin,url = url,i=i)
把案例里面的链接改成你想要下载的链接,然后右击运行代码,即可成功的下载你想要的视频了。代码获取后台回复:”人人视频“。
在文章的最后给大家来一波福利,因为前一段时间小编在爬取百度相关关键词以及文章采集时,经常触发百度的验证机制,这种情况很明显要使用到代理IP,后来群里一个小伙伴推荐了品赞代理IP,小编测试了下,完美解决了爬取中存在的问题。
如果大家后续有需要使用到代理方面的业务的话,可以扫码添加下方的二维码。国内外的IP都有,新用户可以免费测试。
查看全部
文章采集api Python 爬取人人视频
hello,小伙伴们,又见面了,距离上一次发布文章的时间,也算是久别重逢了。期间也发生了很多的事情,导致博文断更,也是笔者不愿意的,但是确实是比较忙,不再过多赘述,希望大家能够体谅。
平时不断的在后台收到小伙伴的私信,问是不是不更了,答案当然是否定的,有着这么多人的支持,小编还是要继续努力下去的,再次谢谢大家的支持。
这次给大家带来的文章是爬取人人视频,之前多是分享一些爬取数据,图片,音乐,还没怎么分享过爬取过视频的,那么想要爬取视频的话该怎么爬取呢?
其实不管是图片,还是音乐,或者是其他的文档,大部分都是一个文件读写的过程,当然视频也不例外,只是文件的格式不同而已。所以我们也可以试着以常规的手段去尝试下爬取视频,没错还是熟悉的套路与配方,即python常用函数 open()和 write()。
不过这次略微不同的是我们会使用到iter_content来获取请求的原始响应数据,普通情况可以用r.raw,在初始请求中设置stream=True,来获取服务器的原始套接字响应,在这里我们使用iter_content更加方便一些,因为requests.get(url) 默认是下载在内存中的,下载完成才存到硬盘上,但Response.iter_content可以边下载边存硬盘中,所以在这视频下载方面更具有优势。
当然说到 iter_content 的话,不得不提下chunk_size,因为流式请求就是像流水一样,不是一次过来而是一点一点“流”过来。处理流式数据也是一点一点处理。
而chunk_size会直接返回从当前位置往后读取 chunk_size 大小的文件内容,且迭代响应数据。这避免了立即将内容读入内存以获得较大的响应。chunk_size是它应该读入内存的字节数。chunk_size的类型必须是int或None。None的值将根据流的值发挥不同的作用。
做了引荐与讲解后,那么就开始上我们的主菜了,即目标网站:
https://m.rr.tv/
介于代码偏基础化,且主要知识点做过分析就直接上代码了,具体请看代码:
单线程:
import requestsimport jsonimport reimport osheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}ep_list =[]vod_list = []def get_vod(url): response = requests.get(url = url,headers = headers)#请求url ep= re.compile(r'sid:"(.*?)",')#提取ep链接 ep_list = re.findall(ep,response.text) vod= re.compile(r'data:\[{id:(.*?),title:"')#提取vod链接 vod_list = re.findall(vod,response.text) vod= re.compile(r',title:"(.*?)",desc:"')#提取视频标题 vod_name = re.findall(vod,response.text) ep = 1 os.mkdir('./'+vod_name[0])#创建视频保存目录 for i in ep_list: print("开始下载"+vod_name[0]+"第"+str(ep)+"集") url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers)#下载请求 r = requests.get(str(json.loads(response.text)['data']['url']), stream=True)#解析出下载链接并发起下载请求 f = open("./"+vod_name[0]+"/第"+str(ep)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk) ep = ep+1if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxxx?snum=1&episode=1'#目标视频链接 get_vod(url)
多线程:
import requestsimport jsonimport reimport osfrom concurrent.futures import ThreadPoolExecutorheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}vod_list = []#存储视频链接vod_name = []#存储视频标题get_down_url =[]#存储下载直链def get_vod(url): response = requests.get(url = url,headers = headers)#请求url vod_list.append(re.findall(re.compile(r'data:\[{id:(.*?),title:"'),response.text)[0])#找找视频链接 vod_name.append(re.findall(re.compile(r',title:"(.*?)",desc:"'),response.text)[0])#找找视频标题 for i in re.findall(re.compile(r'{sid:"(.*?)",key:'),response.text): url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers) get_down_url.append(str(json.loads(response.text)['data']['url']))#拿下载直链进listdef down_begin(url,i): print("开始多线程下载"+vod_name[0]+"第"+str(i)+"集") r = requests.get(url = url,headers = headers)#下载请求 f = open("./"+vod_name[0]+"/第"+str(i)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk)if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxx?snum=1&episode=1'#进入rr.tv自行获取 get_vod(url) os.mkdir('./'+vod_name[0])#创建视频保存目录 with ThreadPoolExecutor(10) as f:#这里写多线程参数,适合几十集的电视剧使用 for i,url in enumerate(get_down_url): i=int(i)+1 f.submit(down_begin,url = url,i=i)
把案例里面的链接改成你想要下载的链接,然后右击运行代码,即可成功的下载你想要的视频了。代码获取后台回复:”人人视频“。
在文章的最后给大家来一波福利,因为前一段时间小编在爬取百度相关关键词以及文章采集时,经常触发百度的验证机制,这种情况很明显要使用到代理IP,后来群里一个小伙伴推荐了品赞代理IP,小编测试了下,完美解决了爬取中存在的问题。
如果大家后续有需要使用到代理方面的业务的话,可以扫码添加下方的二维码。国内外的IP都有,新用户可以免费测试。
深入浅出前端监控
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-05-02 22:02
重写 fetch 方法
当然了,重写上述方法后除了异常请求可以被监控到之外,正常响应的请求状态自然也能被采集到,比如 APM 会将对所有上报请求的持续时间进行分析从而得出慢请求的占比:
PS:如果通过 XHR 或 fetch 来上报监控数据的话,上报请求也会被被拦截,可以有选择地做一层过滤处理。
卡顿异常
卡顿指的是显示器刷新时下一帧的画面还没有准备好,导致连续多次展示同样的画面,从而让用户感觉到页面不流畅,也就是所谓的掉帧,衡量一个页面是否卡顿的指标就是我们熟知的 FPS。
如何获取 FPS
Chrome DevTool 中有一栏 Rendering 中包含 FPS 指标,但目前浏览器标准中暂时没有提供相应 API ,只能手动实现。这里需要借助 requestAnimationFrame 方法模拟实现,浏览器会在下一次重绘之前执行 rAF 的回调,因此可以通过计算每秒内 rAF 的执行次数来计算当前页面的 FPS。
通过 rAF 计算 FPS
如何上报“真实卡顿”
从技术角度看 FPS 低于 60 即视为卡顿,但在真实环境中用户很多行为都可能造成 FPS 的波动,并不能无脑地把 FPS 低于 60 以下的 case 全部上报,会造成非常多无效数据,因此需要结合实际的用户体验重新定义“真正的卡顿”,这里贴一下司内 APM 平台的上报策略:
页面 FPS 持续低于预期:当前页面连续 3s FPS 低于 20。用户操作带来的卡顿:当用户进行交互行为后,渲染新的一帧的时间超过 16ms + 100ms。崩溃异常
Web 页面崩溃指在网页运行过程页面完全无响应的现象,通常有两种情况会造成页面崩溃:
JS 主线程出现无限循环,触发浏览器的保护策略,结束当前页面的进程。内存不足
发生崩溃时主线程被阻塞,因此对崩溃的监控只能在独立于 JS 主线程的 Worker 线程中进行,我们可以采用 Web Worker 心跳检测的方式来对主线程进行不断的探测,如果主线程崩溃,就不会有任何响应,那就可以在 Worker 线程中进行崩溃异常的上报。这里继续贴一下 APM 的检测策略:
Web Worker:
崩溃检测
性能监控
性能监控并不只是简单的监控“页面速度有多快”,需要从用户体验的角度全面衡量性能指标。(就是所谓的 RUM 指标)目前业界主流标准是 Google 最新定义的 Core Web Vitals:
可以看到最新标准中,以往熟知的 FP、FCP、FMP、TTI 等指标都被移除了,个人认为这些指标还是具备一定的参考价值,因此下文还是会将这些指标进行相关介绍。(谷歌的话不听不听)
Loading 加载
和 Loading 相关的指标有 FP 、FCP 、FMP 和 LCP,首先来看一下我们相对熟悉的几个指标:
FP/FCP/FMP
一张流传已久的图
这两个指标都通过 PerformancePaintTiming API 获取:
通过 PerformancePaintTiming 获取 FP 和 FCP
下面再来看 FMP 的定义和获取方式:
FMP 的计算相对复杂,因为浏览器并未提供相应的 API,在此之前我们先看一组图:
从图中可以发现页面渲染过程中的一些规律:
在 1.577 秒,页面渲染了一个搜索框,此时已经有 60 个布局对象被添加到了布局树中。在 1.760 秒,页面头部整体渲染完成,此时布局对象总数是 103 个。在 1.907 秒,页面主体内容已经绘制完成,此时有 261 个布局对象被添加到布局树中从用户体验的角度看,此时的时间点就是是 FMP。
可以看到布局对象的数量与页面完成度高度相关。业界目前比较认可的一个计算 FMP 的方式就是——「页面在加载和渲染过程中最大布局变动之后的那个绘制时间即为当前页面的 FMP 」
实现原理则需要通过 MutationObserver 监听 document 整体的 DOM 变化,在回调计算出当前 DOM 树的分数,分数变化最剧烈的时刻,即为 FMP 的时间点。
至于如何计算当前页面 DOM 的分数,LightHouse 的源码中会根据当前节点深度作为变量做一个权重的计算,具体实现可以参考 LightHouse 源码。
const curNodeScore = 1 + 0.5 * depth;<br />const domScore = 所有子节点分数求和<br />
上述计算方式性能开销大且未必准确,LightHouse 6.0 已明确废弃了 FMP 打分项,建议在具体业务场景中根据实际情况手动埋点来确定 FMP 具体的值,更准确也更高效。
LCP
没错,LCP (Largest Contentful Paint) 是就是用来代替 FMP 的一个性能指标 ,用于度量视口中最大的内容元素何时可见,可以用来确定页面的主要内容何时在屏幕上完成渲染。
使用 Largest Contentful Paint API 和 PerformanceObserver 即可获取 LCP 指标的值:
获取 LCP
Interactivity 交互TTI
TTI(Time To Interactive) 表示从页面加载开始到页面处于完全可交互状态所花费的时间, TTI 值越小,代表用户可以更早地操作页面,用户体验就更好。
这里定义一下什么是完全可交互状态的页面:
页面已经显示有用内容。页面上的可见元素关联的事件响应函数已经完成注册。事件响应函数可以在事件发生后的 50ms 内开始执行(主线程无 Long Task)。
TTI 的算法略有些复杂,结合下图看一下具体步骤:
TTI 示意图
Long Task: 阻塞主线程达 50 毫秒或以上的任务。
从 FCP 时间开始,向前搜索一个不小于 5s 的静默窗口期。(静默窗口期定义:窗口所对应的时间内没有 Long Task,且进行中的网络请求数不超过 2 个)找到静默窗口期后,从静默窗口期向后搜索到最近的一个 Long Task,Long Task 的结束时间即为 TTI。如果一直找到 FCP 时刻仍然没有找到 Long Task,以 FCP 时间作为 TTI。
其实现需要支持 Long Tasks API 和 Resource Timing API,具体实现感兴趣的同学可以按照上述流程尝试手动实现。
FID
FID(First Input Delay) 用于度量用户第一次与页面交互的延迟时间,是用户第一次与页面交互到浏览器真正能够开始处理事件处理程序以响应该交互的时间。
其实现使用简洁的 PerformanceEventTiming API 即可,回调的触发时机是用户首次与页面发生交互并得到浏览器响应(点击链接、输入文字等)。
获取 FID
至于为何新的标准中采用 FID 而非 TTI,可能存在以下几个因素:
Visual Stability 视觉稳定CLS
CLS(Cumulative Layout Shift) 是对在页面的整个生命周期中发生的每一次意外布局变化的最大布局变化得分的度量,布局变化得分越小证明你的页面越稳定。
听起来有点复杂,这里做一个简单的解释:
举个例子,一个占据页面高度 50% 的元素,向下偏移了 25%,那么其得分为 0.75 * 0.25,大于标准定义的 0.1 分,该页面就视为视觉上没那么稳定的页面。
使用 Layout Instability API 和 PerformanceObserver 来获取 CLS:
获取 CLS
一点感受:在翻阅诸多参考资料后,私以为性能监控是一件长期实践、以实际业务为导向的事情,业内主流标准日新月异,到底监控什么指标是最贴合用户体验的我们不得而知,对于 FMP、FPS 这类浏览器未提供 API 获取方式的指标花费大量力气去探索实现是否有足够的收益也存在一定的疑问,但毋容置疑的是从自身页面的业务属性出发,结合一些用户反馈再进行相关手段的优化可能是更好的选择。(更推荐深入了解浏览器渲染原理,写出性能极佳的页面,让 APM 同学失业
数据上报
得到所有错误、性能、用户行为以及相应的环境信息后就要考虑如何进行数据上报,理论上正常使用ajax 即可,但有一些数据上报可能出现在页面关闭 (unload) 的时刻,这些请求会被浏览器的策略 cancel 掉,因此出现了以下几种解决方案:
优先使用 Navigator.sendBeacon,这个 API 就是为了解决上述问题而诞生,它通过 HTTP POST 将数据异步传输到服务器且不会影响页面卸载。如果不支持上述 API,动态创建一个
/ > 标签将数据通过 url 拼接的方式传递。使用同步 XHR 进行上报以延迟页面卸载,不过现在很多浏览器禁止了该行为。
APM 采取了第一种方式,不支持 sendBeacon 则使用 XHR,偶尔丢日志的原因找到了。
由于监控数据通常量级都十分庞大,因此不能简单地采集一个就上报一个,需要一些优化手段:
总结
本文旨在提供一个相对体系的前端监控视图,帮助各位了解前端监控领域我们能做什么、需要做什么。此外,如果能对页面性能和异常处理有着更深入的认知,无论是在开发应用时的自我管理(减少 bug、有意识地书写高性能代码),还是自研监控 SDK 都有所裨益。
如何设计监控 SDK 不是本文的重点,部分监控指标的定义和实现细节也可能存在其他解法,实现一个完善且健壮的前端监控 SDK 还有很多技术细节,例如每个指标可以提供哪些配置项、如何设计上报的维度、如何做好兼容性等等,这些都需要在真实的业务场景中不断打磨和优化才能趋于成熟。
参考
Google Developer
❤️ 谢谢支持
以上便是本次分享的全部内容,希望对你有所帮助^_^ 查看全部
深入浅出前端监控
重写 fetch 方法
当然了,重写上述方法后除了异常请求可以被监控到之外,正常响应的请求状态自然也能被采集到,比如 APM 会将对所有上报请求的持续时间进行分析从而得出慢请求的占比:
PS:如果通过 XHR 或 fetch 来上报监控数据的话,上报请求也会被被拦截,可以有选择地做一层过滤处理。
卡顿异常
卡顿指的是显示器刷新时下一帧的画面还没有准备好,导致连续多次展示同样的画面,从而让用户感觉到页面不流畅,也就是所谓的掉帧,衡量一个页面是否卡顿的指标就是我们熟知的 FPS。
如何获取 FPS
Chrome DevTool 中有一栏 Rendering 中包含 FPS 指标,但目前浏览器标准中暂时没有提供相应 API ,只能手动实现。这里需要借助 requestAnimationFrame 方法模拟实现,浏览器会在下一次重绘之前执行 rAF 的回调,因此可以通过计算每秒内 rAF 的执行次数来计算当前页面的 FPS。
通过 rAF 计算 FPS
如何上报“真实卡顿”
从技术角度看 FPS 低于 60 即视为卡顿,但在真实环境中用户很多行为都可能造成 FPS 的波动,并不能无脑地把 FPS 低于 60 以下的 case 全部上报,会造成非常多无效数据,因此需要结合实际的用户体验重新定义“真正的卡顿”,这里贴一下司内 APM 平台的上报策略:
页面 FPS 持续低于预期:当前页面连续 3s FPS 低于 20。用户操作带来的卡顿:当用户进行交互行为后,渲染新的一帧的时间超过 16ms + 100ms。崩溃异常
Web 页面崩溃指在网页运行过程页面完全无响应的现象,通常有两种情况会造成页面崩溃:
JS 主线程出现无限循环,触发浏览器的保护策略,结束当前页面的进程。内存不足
发生崩溃时主线程被阻塞,因此对崩溃的监控只能在独立于 JS 主线程的 Worker 线程中进行,我们可以采用 Web Worker 心跳检测的方式来对主线程进行不断的探测,如果主线程崩溃,就不会有任何响应,那就可以在 Worker 线程中进行崩溃异常的上报。这里继续贴一下 APM 的检测策略:
Web Worker:
崩溃检测
性能监控
性能监控并不只是简单的监控“页面速度有多快”,需要从用户体验的角度全面衡量性能指标。(就是所谓的 RUM 指标)目前业界主流标准是 Google 最新定义的 Core Web Vitals:
可以看到最新标准中,以往熟知的 FP、FCP、FMP、TTI 等指标都被移除了,个人认为这些指标还是具备一定的参考价值,因此下文还是会将这些指标进行相关介绍。(谷歌的话不听不听)
Loading 加载
和 Loading 相关的指标有 FP 、FCP 、FMP 和 LCP,首先来看一下我们相对熟悉的几个指标:
FP/FCP/FMP
一张流传已久的图
这两个指标都通过 PerformancePaintTiming API 获取:
通过 PerformancePaintTiming 获取 FP 和 FCP
下面再来看 FMP 的定义和获取方式:
FMP 的计算相对复杂,因为浏览器并未提供相应的 API,在此之前我们先看一组图:
从图中可以发现页面渲染过程中的一些规律:
在 1.577 秒,页面渲染了一个搜索框,此时已经有 60 个布局对象被添加到了布局树中。在 1.760 秒,页面头部整体渲染完成,此时布局对象总数是 103 个。在 1.907 秒,页面主体内容已经绘制完成,此时有 261 个布局对象被添加到布局树中从用户体验的角度看,此时的时间点就是是 FMP。
可以看到布局对象的数量与页面完成度高度相关。业界目前比较认可的一个计算 FMP 的方式就是——「页面在加载和渲染过程中最大布局变动之后的那个绘制时间即为当前页面的 FMP 」
实现原理则需要通过 MutationObserver 监听 document 整体的 DOM 变化,在回调计算出当前 DOM 树的分数,分数变化最剧烈的时刻,即为 FMP 的时间点。
至于如何计算当前页面 DOM 的分数,LightHouse 的源码中会根据当前节点深度作为变量做一个权重的计算,具体实现可以参考 LightHouse 源码。
const curNodeScore = 1 + 0.5 * depth;<br />const domScore = 所有子节点分数求和<br />
上述计算方式性能开销大且未必准确,LightHouse 6.0 已明确废弃了 FMP 打分项,建议在具体业务场景中根据实际情况手动埋点来确定 FMP 具体的值,更准确也更高效。
LCP
没错,LCP (Largest Contentful Paint) 是就是用来代替 FMP 的一个性能指标 ,用于度量视口中最大的内容元素何时可见,可以用来确定页面的主要内容何时在屏幕上完成渲染。
使用 Largest Contentful Paint API 和 PerformanceObserver 即可获取 LCP 指标的值:
获取 LCP
Interactivity 交互TTI
TTI(Time To Interactive) 表示从页面加载开始到页面处于完全可交互状态所花费的时间, TTI 值越小,代表用户可以更早地操作页面,用户体验就更好。
这里定义一下什么是完全可交互状态的页面:
页面已经显示有用内容。页面上的可见元素关联的事件响应函数已经完成注册。事件响应函数可以在事件发生后的 50ms 内开始执行(主线程无 Long Task)。
TTI 的算法略有些复杂,结合下图看一下具体步骤:
TTI 示意图
Long Task: 阻塞主线程达 50 毫秒或以上的任务。
从 FCP 时间开始,向前搜索一个不小于 5s 的静默窗口期。(静默窗口期定义:窗口所对应的时间内没有 Long Task,且进行中的网络请求数不超过 2 个)找到静默窗口期后,从静默窗口期向后搜索到最近的一个 Long Task,Long Task 的结束时间即为 TTI。如果一直找到 FCP 时刻仍然没有找到 Long Task,以 FCP 时间作为 TTI。
其实现需要支持 Long Tasks API 和 Resource Timing API,具体实现感兴趣的同学可以按照上述流程尝试手动实现。
FID
FID(First Input Delay) 用于度量用户第一次与页面交互的延迟时间,是用户第一次与页面交互到浏览器真正能够开始处理事件处理程序以响应该交互的时间。
其实现使用简洁的 PerformanceEventTiming API 即可,回调的触发时机是用户首次与页面发生交互并得到浏览器响应(点击链接、输入文字等)。
获取 FID
至于为何新的标准中采用 FID 而非 TTI,可能存在以下几个因素:
Visual Stability 视觉稳定CLS
CLS(Cumulative Layout Shift) 是对在页面的整个生命周期中发生的每一次意外布局变化的最大布局变化得分的度量,布局变化得分越小证明你的页面越稳定。
听起来有点复杂,这里做一个简单的解释:
举个例子,一个占据页面高度 50% 的元素,向下偏移了 25%,那么其得分为 0.75 * 0.25,大于标准定义的 0.1 分,该页面就视为视觉上没那么稳定的页面。
使用 Layout Instability API 和 PerformanceObserver 来获取 CLS:
获取 CLS
一点感受:在翻阅诸多参考资料后,私以为性能监控是一件长期实践、以实际业务为导向的事情,业内主流标准日新月异,到底监控什么指标是最贴合用户体验的我们不得而知,对于 FMP、FPS 这类浏览器未提供 API 获取方式的指标花费大量力气去探索实现是否有足够的收益也存在一定的疑问,但毋容置疑的是从自身页面的业务属性出发,结合一些用户反馈再进行相关手段的优化可能是更好的选择。(更推荐深入了解浏览器渲染原理,写出性能极佳的页面,让 APM 同学失业
数据上报
得到所有错误、性能、用户行为以及相应的环境信息后就要考虑如何进行数据上报,理论上正常使用ajax 即可,但有一些数据上报可能出现在页面关闭 (unload) 的时刻,这些请求会被浏览器的策略 cancel 掉,因此出现了以下几种解决方案:
优先使用 Navigator.sendBeacon,这个 API 就是为了解决上述问题而诞生,它通过 HTTP POST 将数据异步传输到服务器且不会影响页面卸载。如果不支持上述 API,动态创建一个
/ > 标签将数据通过 url 拼接的方式传递。使用同步 XHR 进行上报以延迟页面卸载,不过现在很多浏览器禁止了该行为。
APM 采取了第一种方式,不支持 sendBeacon 则使用 XHR,偶尔丢日志的原因找到了。
由于监控数据通常量级都十分庞大,因此不能简单地采集一个就上报一个,需要一些优化手段:
总结
本文旨在提供一个相对体系的前端监控视图,帮助各位了解前端监控领域我们能做什么、需要做什么。此外,如果能对页面性能和异常处理有着更深入的认知,无论是在开发应用时的自我管理(减少 bug、有意识地书写高性能代码),还是自研监控 SDK 都有所裨益。
如何设计监控 SDK 不是本文的重点,部分监控指标的定义和实现细节也可能存在其他解法,实现一个完善且健壮的前端监控 SDK 还有很多技术细节,例如每个指标可以提供哪些配置项、如何设计上报的维度、如何做好兼容性等等,这些都需要在真实的业务场景中不断打磨和优化才能趋于成熟。
参考
Google Developer
❤️ 谢谢支持
以上便是本次分享的全部内容,希望对你有所帮助^_^
文章采集api Python 爬取人人视频
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-05-02 21:59
hello,小伙伴们,又见面了,距离上一次发布文章的时间,也算是久别重逢了。期间也发生了很多的事情,导致博文断更,也是笔者不愿意的,但是确实是比较忙,不再过多赘述,希望大家能够体谅。
平时不断的在后台收到小伙伴的私信,问是不是不更了,答案当然是否定的,有着这么多人的支持,小编还是要继续努力下去的,再次谢谢大家的支持。
这次给大家带来的文章是爬取人人视频,之前多是分享一些爬取数据,图片,音乐,还没怎么分享过爬取过视频的,那么想要爬取视频的话该怎么爬取呢?
其实不管是图片,还是音乐,或者是其他的文档,大部分都是一个文件读写的过程,当然视频也不例外,只是文件的格式不同而已。所以我们也可以试着以常规的手段去尝试下爬取视频,没错还是熟悉的套路与配方,即python常用函数 open()和 write()。
不过这次略微不同的是我们会使用到iter_content来获取请求的原始响应数据,普通情况可以用r.raw,在初始请求中设置stream=True,来获取服务器的原始套接字响应,在这里我们使用iter_content更加方便一些,因为requests.get(url) 默认是下载在内存中的,下载完成才存到硬盘上,但Response.iter_content可以边下载边存硬盘中,所以在这视频下载方面更具有优势。
当然说到 iter_content 的话,不得不提下chunk_size,因为流式请求就是像流水一样,不是一次过来而是一点一点“流”过来。处理流式数据也是一点一点处理。
而chunk_size会直接返回从当前位置往后读取 chunk_size 大小的文件内容,且迭代响应数据。这避免了立即将内容读入内存以获得较大的响应。chunk_size是它应该读入内存的字节数。chunk_size的类型必须是int或None。None的值将根据流的值发挥不同的作用。
做了引荐与讲解后,那么就开始上我们的主菜了,即目标网站:
https://m.rr.tv/
介于代码偏基础化,且主要知识点做过分析就直接上代码了,具体请看代码:
单线程:
import requestsimport jsonimport reimport osheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}ep_list =[]vod_list = []def get_vod(url): response = requests.get(url = url,headers = headers)#请求url ep= re.compile(r'sid:"(.*?)",')#提取ep链接 ep_list = re.findall(ep,response.text) vod= re.compile(r'data:\[{id:(.*?),title:"')#提取vod链接 vod_list = re.findall(vod,response.text) vod= re.compile(r',title:"(.*?)",desc:"')#提取视频标题 vod_name = re.findall(vod,response.text) ep = 1 os.mkdir('./'+vod_name[0])#创建视频保存目录 for i in ep_list: print("开始下载"+vod_name[0]+"第"+str(ep)+"集") url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers)#下载请求 r = requests.get(str(json.loads(response.text)['data']['url']), stream=True)#解析出下载链接并发起下载请求 f = open("./"+vod_name[0]+"/第"+str(ep)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk) ep = ep+1if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxxx?snum=1&episode=1'#目标视频链接 get_vod(url)
多线程:
import requestsimport jsonimport reimport osfrom concurrent.futures import ThreadPoolExecutorheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}vod_list = []#存储视频链接vod_name = []#存储视频标题get_down_url =[]#存储下载直链def get_vod(url): response = requests.get(url = url,headers = headers)#请求url vod_list.append(re.findall(re.compile(r'data:\[{id:(.*?),title:"'),response.text)[0])#找找视频链接 vod_name.append(re.findall(re.compile(r',title:"(.*?)",desc:"'),response.text)[0])#找找视频标题 for i in re.findall(re.compile(r'{sid:"(.*?)",key:'),response.text): url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers) get_down_url.append(str(json.loads(response.text)['data']['url']))#拿下载直链进listdef down_begin(url,i): print("开始多线程下载"+vod_name[0]+"第"+str(i)+"集") r = requests.get(url = url,headers = headers)#下载请求 f = open("./"+vod_name[0]+"/第"+str(i)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk)if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxx?snum=1&episode=1'#进入rr.tv自行获取 get_vod(url) os.mkdir('./'+vod_name[0])#创建视频保存目录 with ThreadPoolExecutor(10) as f:#这里写多线程参数,适合几十集的电视剧使用 for i,url in enumerate(get_down_url): i=int(i)+1 f.submit(down_begin,url = url,i=i)
把案例里面的链接改成你想要下载的链接,然后右击运行代码,即可成功的下载你想要的视频了。代码获取后台回复:”人人视频“。
在文章的最后给大家来一波福利,因为前一段时间小编在爬取百度相关关键词以及文章采集时,经常触发百度的验证机制,这种情况很明显要使用到代理IP,后来群里一个小伙伴推荐了品赞代理IP,小编测试了下,完美解决了爬取中存在的问题。
如果大家后续有需要使用到代理方面的业务的话,可以扫码添加下方的二维码。国内外的IP都有,新用户可以免费测试。
查看全部
文章采集api Python 爬取人人视频
hello,小伙伴们,又见面了,距离上一次发布文章的时间,也算是久别重逢了。期间也发生了很多的事情,导致博文断更,也是笔者不愿意的,但是确实是比较忙,不再过多赘述,希望大家能够体谅。
平时不断的在后台收到小伙伴的私信,问是不是不更了,答案当然是否定的,有着这么多人的支持,小编还是要继续努力下去的,再次谢谢大家的支持。
这次给大家带来的文章是爬取人人视频,之前多是分享一些爬取数据,图片,音乐,还没怎么分享过爬取过视频的,那么想要爬取视频的话该怎么爬取呢?
其实不管是图片,还是音乐,或者是其他的文档,大部分都是一个文件读写的过程,当然视频也不例外,只是文件的格式不同而已。所以我们也可以试着以常规的手段去尝试下爬取视频,没错还是熟悉的套路与配方,即python常用函数 open()和 write()。
不过这次略微不同的是我们会使用到iter_content来获取请求的原始响应数据,普通情况可以用r.raw,在初始请求中设置stream=True,来获取服务器的原始套接字响应,在这里我们使用iter_content更加方便一些,因为requests.get(url) 默认是下载在内存中的,下载完成才存到硬盘上,但Response.iter_content可以边下载边存硬盘中,所以在这视频下载方面更具有优势。
当然说到 iter_content 的话,不得不提下chunk_size,因为流式请求就是像流水一样,不是一次过来而是一点一点“流”过来。处理流式数据也是一点一点处理。
而chunk_size会直接返回从当前位置往后读取 chunk_size 大小的文件内容,且迭代响应数据。这避免了立即将内容读入内存以获得较大的响应。chunk_size是它应该读入内存的字节数。chunk_size的类型必须是int或None。None的值将根据流的值发挥不同的作用。
做了引荐与讲解后,那么就开始上我们的主菜了,即目标网站:
https://m.rr.tv/
介于代码偏基础化,且主要知识点做过分析就直接上代码了,具体请看代码:
单线程:
import requestsimport jsonimport reimport osheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}ep_list =[]vod_list = []def get_vod(url): response = requests.get(url = url,headers = headers)#请求url ep= re.compile(r'sid:"(.*?)",')#提取ep链接 ep_list = re.findall(ep,response.text) vod= re.compile(r'data:\[{id:(.*?),title:"')#提取vod链接 vod_list = re.findall(vod,response.text) vod= re.compile(r',title:"(.*?)",desc:"')#提取视频标题 vod_name = re.findall(vod,response.text) ep = 1 os.mkdir('./'+vod_name[0])#创建视频保存目录 for i in ep_list: print("开始下载"+vod_name[0]+"第"+str(ep)+"集") url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers)#下载请求 r = requests.get(str(json.loads(response.text)['data']['url']), stream=True)#解析出下载链接并发起下载请求 f = open("./"+vod_name[0]+"/第"+str(ep)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk) ep = ep+1if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxxx?snum=1&episode=1'#目标视频链接 get_vod(url)
多线程:
import requestsimport jsonimport reimport osfrom concurrent.futures import ThreadPoolExecutorheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}vod_list = []#存储视频链接vod_name = []#存储视频标题get_down_url =[]#存储下载直链def get_vod(url): response = requests.get(url = url,headers = headers)#请求url vod_list.append(re.findall(re.compile(r'data:\[{id:(.*?),title:"'),response.text)[0])#找找视频链接 vod_name.append(re.findall(re.compile(r',title:"(.*?)",desc:"'),response.text)[0])#找找视频标题 for i in re.findall(re.compile(r'{sid:"(.*?)",key:'),response.text): url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers) get_down_url.append(str(json.loads(response.text)['data']['url']))#拿下载直链进listdef down_begin(url,i): print("开始多线程下载"+vod_name[0]+"第"+str(i)+"集") r = requests.get(url = url,headers = headers)#下载请求 f = open("./"+vod_name[0]+"/第"+str(i)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk)if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxx?snum=1&episode=1'#进入rr.tv自行获取 get_vod(url) os.mkdir('./'+vod_name[0])#创建视频保存目录 with ThreadPoolExecutor(10) as f:#这里写多线程参数,适合几十集的电视剧使用 for i,url in enumerate(get_down_url): i=int(i)+1 f.submit(down_begin,url = url,i=i)
把案例里面的链接改成你想要下载的链接,然后右击运行代码,即可成功的下载你想要的视频了。代码获取后台回复:”人人视频“。
在文章的最后给大家来一波福利,因为前一段时间小编在爬取百度相关关键词以及文章采集时,经常触发百度的验证机制,这种情况很明显要使用到代理IP,后来群里一个小伙伴推荐了品赞代理IP,小编测试了下,完美解决了爬取中存在的问题。
如果大家后续有需要使用到代理方面的业务的话,可以扫码添加下方的二维码。国内外的IP都有,新用户可以免费测试。
文章采集api 性能指标的信仰危机
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-05-02 19:45
正在阅读这篇文章的你,或多或者接触过前端性能优化,这样的接触可能是来自你的阅读体验也可能是来自工作经验。那我们不妨从一个非常简单的思想实验开始,请你借助你对这个领域的理解,来回答下面的几个问题:
不要有压力,你可以慢慢思考并回答这几个问题,你关于第一个问题的答案可能会随着二三问题的出现而不断的调整。
这篇文章的目的就是对上面三个问题的探索和尝试性的解答,希望我的答案能带给你一些启发。
一次复盘
目前我所在的项目上长时间都依赖都 GA (Google Analytic) 作为衡量页面性能的唯一工具,在 GA 的生态圈中,我们最为重视的是 Avg Page Load Time (以下简称为 APLT),通过它来断定我们站点当前的性能状态如何。
但是在定期收集该指标数据的过程中,我们发现用户的感受和数据的展示可能并不一致,具体来说数据看上去波澜不惊,但用户体验却直线下降。
所以我们不得不要回答一个至关重要的问题,APLT 衡量的究竟是什么?
什么这个问题之所以至关重要,是因为它的答案决定我们接下来要解决的问题和需要采取的行动:
然而官方文档对于这个指标的解释是很暧昧的:
Avg Page Load Time : The average amount of time (in seconds) it takes that page to load, from initiation of the pageview (e.g., click on a page link) to load completion in the browser.
Avg. Page Load Time consists of two components: 1) network and server time, and 2) browser time. The Technical section of the Explorer tab provides details about the network and remaining time is the browser overhead for parsing and executing the JavaScript and rendering the page.
对于它的解释,我们产生了几点疑问:
GA 的实现
GA 底层是通过 Navigation Timing API 在采集性能数据
GA 不会统计每一个阶段的数据,它将某些合并后重新命名成新的指标,而其中的某些指标比如 Document Interactive Loaded 其实是某些阶段的统计之和:
GA 统计的仅仅是与 DOM 文档有关的数据。APLT 定义里所说的 load completion 时刻指的就是 loadEventEnd 事件的发生时机,即 onLoad 事件触发完毕(load 事件触发时意味着所有的外部资源,包括 iframe、图片、脚本、样式都已经加载完毕)。所以 APLT 值是 GA 里所有指标里横跨时间范围最广的。
脚本对 Avg Page Load Time 的影响是什么
如上图所示,当浏览器自上而下解析 DOM 树时,它会遇见很多外联资源,比如图片、样式和脚本。于是它需要从缓存或者网络中请求这些资源。
页面的解析是同步的,所以脚本的加载会导致页面解析的暂停。浏览器需要在脚本加载、编译、执行完毕之后才会继续之后的解析工作,这么做是有道理的,因为 JavaScript 可能会使用诸如 document.write() 方法来改变 DOM 的结构。你可能听说过在 script 标签上添加 async 或者 defer 属性来异步的加载和执行脚本。但是它在我们的产品中是不适用的,因为 async 无法保证脚本执行的顺序。但这则方案不一定适用于所有页面,因为 async 无法保证脚本的执行顺序,如果你的应用对脚本的执行顺序有严格要求,那么它对你爱莫能助。
目前浏览器都配备preloader机制来提前扫面页面中的外联元素提前加载,但这个机制并无统一的标准也无法衡量效果,所以暂时不考虑它对我们的影响。
脚本下载之后需要经过解析(parse / compile)和执行(run / execute)。解析阶段首先将 javascript 代码编译为机器语言,执行阶段才会真正的运行我们编写的代码。脚本的解析和执行也会阻塞页面的解析
所以综上,我们可以得出脚本确实能够影响 APLT 。
但抛弃计量谈危害都是刷流氓,它的影响范围究竟有多大?也就是说如果 APLT 是 2 秒的话,其中多少时间耗费在了脚本上?
这里没有一个具体的数字,但它不容小觑,以及足够影响到性能。Addy Osmani 在 2017 年的一篇文章中指出 Chrome 的脚本引擎花费在编译时间上
虽然此后 Chrome 对编译过程进行了优化,但执行脚本过长的困恼依然存在。同时这只是 Chrome 下的情况,我们无法确认其他浏览器在编译脚本时也可以保证同样的效率
如果说 APLT 是由不同的阶段组成,那么我们有没有可能计算出每一个阶段的具体时间?
回顾上面关于 GA 指标的定义,至少我们现在能分离出 server time 和 browser time. 但是在 browser time 之下呢?比如说脚本的下载时间和执行时间,这些我们就无从得知了。这些是需要额外计算和采集的。
综上,我们完全依赖 APLT 来对站点的性能问题进行诊断是不靠谱,我们单纯的认为脚本负担拖慢了性能也是不完整的。
一场关于指标的信仰危机
我想你大概明白了为什么我在上一节中花了这么大段的篇幅来解释仅仅一个指标的含义。因为一个指标能透露的信息可能会比你想象的要复杂,引导和误导并存。
首先要声明我并不反对使用常见指标,这篇文章也不是对它们的批评,它们在帮助我们排查性能问题方面给了非常大的帮助。在这里我想探讨的是,如果常规指标是性能监控的底线的话,它的上限在哪?
从上面的描述中我们不难看出 APLT 的涉猎的维度过于宽泛,它更偏向于一个技术向的综合性指标,它展示给我们是趋势而非细节。这样带来的问题有两个:
接下来我们深入的聊聊这两个问题。
以用户为中心
你或许有留意到,目前前端性能监测的趋势逐渐在向以用户为中心的指标 (User-Centric Performance Metrics) 靠拢。为什么会出现这样的情况?因为随着单页面应用的普及以及前端功能变“重”,经典的以资源为中心的性能指标(例如 Onload, DOMContentLoaded)越来越不能准确地反馈真实用户的体验与产品性能。在传统后端渲染的多页面应用模式下,资源加载完毕即意味着页面对用户可用;而在单页面模式下,资源加载完毕距离产品可用存在一定的差距,因为此时应用才能真正地请求用户个性化的数据,渲染定制化的页面。
总的来说,越来越多重要且耗时的工作都发生在资源加载之后,我们需要把这部分工作的性能也监控起来。
好消息是浏览器原生的在提供给予我们这方面的支持,例如 Chrome 就在 Performace API 中提供了 Paint Timing API 诸如 first paint (FP) 、 first contentful paint (FCP)、time to interact(tti) 等指标数据。顾名思义的这些指标尝试站在用户体验的视角展现应用在浏览器中被呈现时的性能;坏消息是,这些指标依然在测量真实的用户体验方面依然存在误差。
就以上面提到的 FP、FCP、TTI 这三个指标为例,我用一个简单的例子说明这三个指标是如何不够准确的:在单页面的初始化过程中,我们通常会提供类似于「加载中」视图,通常是一个 placeholder 或者 skeleton 样式,在数据请求完毕之后才会将实际的视图渲染出来:
如果加载时间过长,浏览器会以为「加载中」视图就是对用户可用的最终产品形态,并以它为基准计算那上述的三个指标
下面这段代码模拟的就是包含上面所说情况的日常情况:在组件加载时模拟发出两个请求,其中一个需要5秒较长的等待时间,只有当两个请求都返回时才能开始渲染数据,否则一直提示用户加载中。
function App() {<br /> const [data, setState] = useState([]);<br /> useEffect(() => {<br /> const longRequest = new Promise((resolve, reject) => {<br /> setTimeout(() => {<br /> resolve([]);<br /> }, 1000 * 5)<br /> });<br /> const shortRequest = Promise.resolve([]);<br /> <br /> Promise.all([longRequest, shortRequest]).then(([longRequestResponse, shortRequestResponse]) => {<br /> setState([<br /> ['', 'Tesla', 'Mercedes', 'Toyota', 'Volvo'],<br /> ['2019', 10, 11, 12, 13],<br /> ['2020', 20, 11, 14, 13],<br /> ['2021', 30, 15, 12, 13]<br /> ])<br /> })<br /> }, []);<br /> return (<br /> <br /> {data && data.length<br /> ? <br /> : }<br /> <br /> )<br />}
如果你尝试在浏览器中运行上述 App, 通过 Devtools 观测到的各个指标如下:
你能通过开发者工具够观测到各种指标比如 DCL (DOMContentLoaded Event), FP, FCP, FMP (first meaningful paint), L(Onload Event) 都发生在页面加载后一秒左右以内。然而从代码里我们非常肯定至少五秒后用户才能看到真实内容。所以上述指标并不能真的反馈用户感受到的性能问题
我已经把这个应用部署到了 站点上,可以在线访问。并且可以使用 对它做更详细的性能检测,也会得出和 devtools 相同的结果。webpagetest 是一个开源免费对网站性能进行检测的工具。早在 2012 年还没有诸如 FP 一类的指标时,它独创的 Speed Index 指标就能够衡量用户体验。
总的来说如上图所示,目前浏览器提供的 API 能够测量的只是 D 阶段的性能,对 E 和 F 阶段爱莫能助。
这只是其中一个说明原生指标不够准确的例子,可以归纳为后端接口延迟过长。然而还有一种情况是前端渲染时间过长。例如我们在使用 Handsontable 组件渲染上千行数据表格的时候,甚至导致了浏览器的假死,这种场景对 Paint Timing API 也是免疫的。
那 tti 这个指标怎么样?它不是听上去能够检测页面是否可以交互吗?它是不是能够检测页面的假死?
很遗憾依然不行。
如果你有心去查看 tti 这个指标的定义的话, 你会发现 tti 本质上是一种算法:
并且目前的原生 API 并不支持 tti 指标,需要通过 polyfill 实现,按照官方的说明,目前并不能适配所有的 web app。
双向指标
这是知乎创作者中心页面的一个截图
在这个页面中,知乎每天都会为你更新过去七天内文章阅读数、赞同数、评论数等数据的汇总。上图中的折线就是阅读数。
我知道它的用意是想给予创作者数据上的反馈帮助他们更好的输出内容,但至少对我来说一点用也没有。因为我更想知道的是究竟增长来自于哪里,这样我才能有针对性的输出带来点击量的内容。但它带给我的总是汇总数据。
这个需求对于性能监控也是同样的成立的,监控的目的主要是为了及时发现问题,解决问题。所以在审视数据的过程中,我们更关心的是异常波动值发生在何时何地,我们也希望数据能给予我这方面的帮助。
当然我们不可能无中生有的将一组汇总数据还原成细节数据,但在这个问题上我们可以往两个方向努力:
在 Web Performance Calendar 2020 Edition 中 A wish list for web performance tools 一文中,作者提出了关于他理想性能工具应该满足的四则功能,分别是:
其中的第二三则对于我们选择指标来说也是成立的,与我在上面的强调的不谋而合
最后再一次强调这里不是对传统指标的否定。数据带来的效果一定是聊胜于无,指标越多越是能精确的描绘出性能画像。这里探讨的是如何在这些基础上继续事半功倍提升我们洞察问题的效率。
在选择衡量指标上的一些建议
上下文驱动 (Context Driven)
之所以我无法在这里给你一个大而全的解决方案,是因为我认为这种东西并不存在,一切都要依赖你的上下文而定。
你也许更熟悉的是上下文驱动测试(Context Driven Testing),但在我看来,上下文驱动在你选择性能指标或者工具时也是同样成立的。我们不妨看一看上下文测试七条原则中的头两条:
想象一下如果你把两句话中的 practice 理解为指标(metric),甚至直接替换为指标,是不是也没有任何违和感呢?
“上下文驱动”初看上去不过是正反话,但实际上它是我们提升监测效率的有效出路。指标本身不会有对错之分,但不同人群对于指标的视角是割裂的:业务分析师希望得到的是能直接彰显业务价值的数据,例如点击率,弹出率,用户转化;DevOps 同学他们可能关心的是网站的“心跳”,资源的消耗,后端接口的快慢;所以不同指标在不同人群中是一种此消彼长的状态。这种割裂还可以从技术角度上划分,有的指标更侧重于资源,有的指标更侧重于用户感受。
指标只是发现问题的一种手段,现在我们有无数种手段任君挑选:APM (Application Performance Management)、日志分析、RUM (Real-User Monitoring)、TTFB (Time to First Byte)……最终它迫使你回到了问题的起点:我究竟想衡量什么?我想衡量的物体是否可以通过已有的指标表达出来?我只是想 monitor 吗?如果我想 debug 或者是 analyze 的话是否还有其他的选择?
“Good software testing is a challenging intellectual process.” (请把 testing 替换为 performance tuning)上下文驱动测试中的第六条原则如是说。
追踪元素
如果说“资源加载完毕”这件事不靠谱,“浏览器开始绘制”也不靠谱的话,我想唯一靠谱的事情就是用户的所见所得了。不需要用各种数据来展示你的页面加载有多快,如果用户每次都要等待十秒才能看到他想看到的信息,那么这些数字无非是自欺欺人而已。所以我们不妨可以追踪用户关注信息所对应元素的出现的时机。
这不是创新,从早些年的 Speed Index,“above the fold” 到如今的 web vitals 都是这种思想的延续,指标的进化过程像一个不断收缩过程中圆圈,在不断的像用户本身靠拢。只不过出于技术手段的限制,它们只能走到那么远,而如今我们有了 MutationObserver 和 Perforamce API, 则可以精确的定位到元素,甚至元素上属性的改变,自然也就不会被上面例子中的 placeholder 所欺骗。
抱歉我要在这里再次强调一下上下文:我们不能只关注“元素出现的时机”,更要从时间的范畴和从代码延展上看关注形成它的原因,这依然需要我们结合问题所处的环境和它的运转机制而定。举两个例子:
在上图中,如果 Component D 是向客户展示关键信息的关键元素,那么 request 到达 router 的时间,由 router 渲染出 Component C 的时间,都会对 D 元素产生影响;从另一个维度上看:
脚本以及请求加载的快慢和执行的效率,同样也会对元素的出现产生影响。如果你需要对问题进行诊断,对这些背后工作机制的了解必不可少。
但追踪元素也存在另一个问题就是它难以大规模的应用。因为它是侵入式的,因为它需要你识别不同页面上的不同关键元素,用近似于 hard code 的方式对它们一一追踪。这类工作产生的维护成本接近于维护前端的 E2E 测试。诚然我们可以通过分配统一的 id 或者 class name 的方式来减少我们的维护成本,但是相比统一的 GA 代码这样的维护成本依然偏高。所以我建议使用最简单的方法去监控最直接的元素,不要 case by case 的去编写你的监控代码,不要让你的实现代码被监控代码束缚住。
让工具为你所用
你可以在市面上找到各类数不胜数号称能够协助你改善性能的工具。但首先你要小心,它们所宣扬的,并非是你真正需要的。
例如 site24x7 是一家专业提供用户行为监控解决方案的公司。在它们有关 APM 的帮助页面上,开宗明义的指出了监控捕获 SAP(Single Page Application) 性能数据以目前的技术来说其实是一项颇具挑战的工作:
In case of Single Page Applications, the time taken for page load completion cannot be obtained by page onload event since the data are dynamically obtained from the server using
Hence, for each SPA framework, the page load metrics are calculated by listening to particular events specific to the framework.
所以对于此种类型的页面,它们捕获指标也只有:
For every dynamic page load, the corresponding URL, it's respective AJAX calls, response time of each AJAX call, response codes and errors (if any) are captured.
但要知道在如今 SPA 大行其道的今天,如此的收集功能略显的苍白无力了。
同理如果你去看 Azure Application Insights 旗下 JavaScript SDK 默认收集的页面信息:
Network Dependency Requests made by your app XHR and Fetch (fetch collection is disabled by default) requests, include information on
User information (for example, Location, network, IP)
Device information (for example, Browser, OS, version, language, model)
Session information
我不认为这些指标和其他平台提供的相比能带来额外的价值,它能真的给我带来多少真正的 “insights”。
另一方面,不要让你的思维被工具限制住:不要“因为 xx 工具只能做到这些,所以我只能收集这些指标”;而要“我想收集这些指标,所以我需要 xx 工具”。在这里我列举一个我们在探索中的例子:用 OpenTracing 工具 Jaeger 去可视化前端性能图表。
在这里我首先必须赞颂 Chrome 内置 Performance 工具给我们调教性能带来了极大的便利。但我们始终有一些额外的需求无法满足。例如我希望能够在结果呈现中做一些自定义的标记,又或者在 Performance Tab 下展示每一个请求从 connect 到 resposne 每个阶段的状态。
如下图所示,于是我们跨界的使用了 Jaeger 开源工具来用于自定义指标的收集和展示,可以说是将不同纬度的指标以时间为线索将它们联系起来,这样一来页面加载阶段的状态并能一览无余的尽收眼底。便于定位问题的所在。
结束语
我观察到对于大部分前端工程师而言,又或者曾经的自己而言,在做性能监控时是一个被“喂”的过程,即会惯性的不假思索的收集已有指标和利用已有工具。又因为性能优化工作过程前置结果后置的关系,等到我们有需求发生时才会发现当下的结果并非是我们想要的。多一些思考才会让我们的工作少一分浪费。 查看全部
文章采集api 性能指标的信仰危机
正在阅读这篇文章的你,或多或者接触过前端性能优化,这样的接触可能是来自你的阅读体验也可能是来自工作经验。那我们不妨从一个非常简单的思想实验开始,请你借助你对这个领域的理解,来回答下面的几个问题:
不要有压力,你可以慢慢思考并回答这几个问题,你关于第一个问题的答案可能会随着二三问题的出现而不断的调整。
这篇文章的目的就是对上面三个问题的探索和尝试性的解答,希望我的答案能带给你一些启发。
一次复盘
目前我所在的项目上长时间都依赖都 GA (Google Analytic) 作为衡量页面性能的唯一工具,在 GA 的生态圈中,我们最为重视的是 Avg Page Load Time (以下简称为 APLT),通过它来断定我们站点当前的性能状态如何。
但是在定期收集该指标数据的过程中,我们发现用户的感受和数据的展示可能并不一致,具体来说数据看上去波澜不惊,但用户体验却直线下降。
所以我们不得不要回答一个至关重要的问题,APLT 衡量的究竟是什么?
什么这个问题之所以至关重要,是因为它的答案决定我们接下来要解决的问题和需要采取的行动:
然而官方文档对于这个指标的解释是很暧昧的:
Avg Page Load Time : The average amount of time (in seconds) it takes that page to load, from initiation of the pageview (e.g., click on a page link) to load completion in the browser.
Avg. Page Load Time consists of two components: 1) network and server time, and 2) browser time. The Technical section of the Explorer tab provides details about the network and remaining time is the browser overhead for parsing and executing the JavaScript and rendering the page.
对于它的解释,我们产生了几点疑问:
GA 的实现
GA 底层是通过 Navigation Timing API 在采集性能数据
GA 不会统计每一个阶段的数据,它将某些合并后重新命名成新的指标,而其中的某些指标比如 Document Interactive Loaded 其实是某些阶段的统计之和:
GA 统计的仅仅是与 DOM 文档有关的数据。APLT 定义里所说的 load completion 时刻指的就是 loadEventEnd 事件的发生时机,即 onLoad 事件触发完毕(load 事件触发时意味着所有的外部资源,包括 iframe、图片、脚本、样式都已经加载完毕)。所以 APLT 值是 GA 里所有指标里横跨时间范围最广的。
脚本对 Avg Page Load Time 的影响是什么
如上图所示,当浏览器自上而下解析 DOM 树时,它会遇见很多外联资源,比如图片、样式和脚本。于是它需要从缓存或者网络中请求这些资源。
页面的解析是同步的,所以脚本的加载会导致页面解析的暂停。浏览器需要在脚本加载、编译、执行完毕之后才会继续之后的解析工作,这么做是有道理的,因为 JavaScript 可能会使用诸如 document.write() 方法来改变 DOM 的结构。你可能听说过在 script 标签上添加 async 或者 defer 属性来异步的加载和执行脚本。但是它在我们的产品中是不适用的,因为 async 无法保证脚本执行的顺序。但这则方案不一定适用于所有页面,因为 async 无法保证脚本的执行顺序,如果你的应用对脚本的执行顺序有严格要求,那么它对你爱莫能助。
目前浏览器都配备preloader机制来提前扫面页面中的外联元素提前加载,但这个机制并无统一的标准也无法衡量效果,所以暂时不考虑它对我们的影响。
脚本下载之后需要经过解析(parse / compile)和执行(run / execute)。解析阶段首先将 javascript 代码编译为机器语言,执行阶段才会真正的运行我们编写的代码。脚本的解析和执行也会阻塞页面的解析
所以综上,我们可以得出脚本确实能够影响 APLT 。
但抛弃计量谈危害都是刷流氓,它的影响范围究竟有多大?也就是说如果 APLT 是 2 秒的话,其中多少时间耗费在了脚本上?
这里没有一个具体的数字,但它不容小觑,以及足够影响到性能。Addy Osmani 在 2017 年的一篇文章中指出 Chrome 的脚本引擎花费在编译时间上
虽然此后 Chrome 对编译过程进行了优化,但执行脚本过长的困恼依然存在。同时这只是 Chrome 下的情况,我们无法确认其他浏览器在编译脚本时也可以保证同样的效率
如果说 APLT 是由不同的阶段组成,那么我们有没有可能计算出每一个阶段的具体时间?
回顾上面关于 GA 指标的定义,至少我们现在能分离出 server time 和 browser time. 但是在 browser time 之下呢?比如说脚本的下载时间和执行时间,这些我们就无从得知了。这些是需要额外计算和采集的。
综上,我们完全依赖 APLT 来对站点的性能问题进行诊断是不靠谱,我们单纯的认为脚本负担拖慢了性能也是不完整的。
一场关于指标的信仰危机
我想你大概明白了为什么我在上一节中花了这么大段的篇幅来解释仅仅一个指标的含义。因为一个指标能透露的信息可能会比你想象的要复杂,引导和误导并存。
首先要声明我并不反对使用常见指标,这篇文章也不是对它们的批评,它们在帮助我们排查性能问题方面给了非常大的帮助。在这里我想探讨的是,如果常规指标是性能监控的底线的话,它的上限在哪?
从上面的描述中我们不难看出 APLT 的涉猎的维度过于宽泛,它更偏向于一个技术向的综合性指标,它展示给我们是趋势而非细节。这样带来的问题有两个:
接下来我们深入的聊聊这两个问题。
以用户为中心
你或许有留意到,目前前端性能监测的趋势逐渐在向以用户为中心的指标 (User-Centric Performance Metrics) 靠拢。为什么会出现这样的情况?因为随着单页面应用的普及以及前端功能变“重”,经典的以资源为中心的性能指标(例如 Onload, DOMContentLoaded)越来越不能准确地反馈真实用户的体验与产品性能。在传统后端渲染的多页面应用模式下,资源加载完毕即意味着页面对用户可用;而在单页面模式下,资源加载完毕距离产品可用存在一定的差距,因为此时应用才能真正地请求用户个性化的数据,渲染定制化的页面。
总的来说,越来越多重要且耗时的工作都发生在资源加载之后,我们需要把这部分工作的性能也监控起来。
好消息是浏览器原生的在提供给予我们这方面的支持,例如 Chrome 就在 Performace API 中提供了 Paint Timing API 诸如 first paint (FP) 、 first contentful paint (FCP)、time to interact(tti) 等指标数据。顾名思义的这些指标尝试站在用户体验的视角展现应用在浏览器中被呈现时的性能;坏消息是,这些指标依然在测量真实的用户体验方面依然存在误差。
就以上面提到的 FP、FCP、TTI 这三个指标为例,我用一个简单的例子说明这三个指标是如何不够准确的:在单页面的初始化过程中,我们通常会提供类似于「加载中」视图,通常是一个 placeholder 或者 skeleton 样式,在数据请求完毕之后才会将实际的视图渲染出来:
如果加载时间过长,浏览器会以为「加载中」视图就是对用户可用的最终产品形态,并以它为基准计算那上述的三个指标
下面这段代码模拟的就是包含上面所说情况的日常情况:在组件加载时模拟发出两个请求,其中一个需要5秒较长的等待时间,只有当两个请求都返回时才能开始渲染数据,否则一直提示用户加载中。
function App() {<br /> const [data, setState] = useState([]);<br /> useEffect(() => {<br /> const longRequest = new Promise((resolve, reject) => {<br /> setTimeout(() => {<br /> resolve([]);<br /> }, 1000 * 5)<br /> });<br /> const shortRequest = Promise.resolve([]);<br /> <br /> Promise.all([longRequest, shortRequest]).then(([longRequestResponse, shortRequestResponse]) => {<br /> setState([<br /> ['', 'Tesla', 'Mercedes', 'Toyota', 'Volvo'],<br /> ['2019', 10, 11, 12, 13],<br /> ['2020', 20, 11, 14, 13],<br /> ['2021', 30, 15, 12, 13]<br /> ])<br /> })<br /> }, []);<br /> return (<br /> <br /> {data && data.length<br /> ? <br /> : }<br /> <br /> )<br />}
如果你尝试在浏览器中运行上述 App, 通过 Devtools 观测到的各个指标如下:
你能通过开发者工具够观测到各种指标比如 DCL (DOMContentLoaded Event), FP, FCP, FMP (first meaningful paint), L(Onload Event) 都发生在页面加载后一秒左右以内。然而从代码里我们非常肯定至少五秒后用户才能看到真实内容。所以上述指标并不能真的反馈用户感受到的性能问题
我已经把这个应用部署到了 站点上,可以在线访问。并且可以使用 对它做更详细的性能检测,也会得出和 devtools 相同的结果。webpagetest 是一个开源免费对网站性能进行检测的工具。早在 2012 年还没有诸如 FP 一类的指标时,它独创的 Speed Index 指标就能够衡量用户体验。
总的来说如上图所示,目前浏览器提供的 API 能够测量的只是 D 阶段的性能,对 E 和 F 阶段爱莫能助。
这只是其中一个说明原生指标不够准确的例子,可以归纳为后端接口延迟过长。然而还有一种情况是前端渲染时间过长。例如我们在使用 Handsontable 组件渲染上千行数据表格的时候,甚至导致了浏览器的假死,这种场景对 Paint Timing API 也是免疫的。
那 tti 这个指标怎么样?它不是听上去能够检测页面是否可以交互吗?它是不是能够检测页面的假死?
很遗憾依然不行。
如果你有心去查看 tti 这个指标的定义的话, 你会发现 tti 本质上是一种算法:
并且目前的原生 API 并不支持 tti 指标,需要通过 polyfill 实现,按照官方的说明,目前并不能适配所有的 web app。
双向指标
这是知乎创作者中心页面的一个截图
在这个页面中,知乎每天都会为你更新过去七天内文章阅读数、赞同数、评论数等数据的汇总。上图中的折线就是阅读数。
我知道它的用意是想给予创作者数据上的反馈帮助他们更好的输出内容,但至少对我来说一点用也没有。因为我更想知道的是究竟增长来自于哪里,这样我才能有针对性的输出带来点击量的内容。但它带给我的总是汇总数据。
这个需求对于性能监控也是同样的成立的,监控的目的主要是为了及时发现问题,解决问题。所以在审视数据的过程中,我们更关心的是异常波动值发生在何时何地,我们也希望数据能给予我这方面的帮助。
当然我们不可能无中生有的将一组汇总数据还原成细节数据,但在这个问题上我们可以往两个方向努力:
在 Web Performance Calendar 2020 Edition 中 A wish list for web performance tools 一文中,作者提出了关于他理想性能工具应该满足的四则功能,分别是:
其中的第二三则对于我们选择指标来说也是成立的,与我在上面的强调的不谋而合
最后再一次强调这里不是对传统指标的否定。数据带来的效果一定是聊胜于无,指标越多越是能精确的描绘出性能画像。这里探讨的是如何在这些基础上继续事半功倍提升我们洞察问题的效率。
在选择衡量指标上的一些建议
上下文驱动 (Context Driven)
之所以我无法在这里给你一个大而全的解决方案,是因为我认为这种东西并不存在,一切都要依赖你的上下文而定。
你也许更熟悉的是上下文驱动测试(Context Driven Testing),但在我看来,上下文驱动在你选择性能指标或者工具时也是同样成立的。我们不妨看一看上下文测试七条原则中的头两条:
想象一下如果你把两句话中的 practice 理解为指标(metric),甚至直接替换为指标,是不是也没有任何违和感呢?
“上下文驱动”初看上去不过是正反话,但实际上它是我们提升监测效率的有效出路。指标本身不会有对错之分,但不同人群对于指标的视角是割裂的:业务分析师希望得到的是能直接彰显业务价值的数据,例如点击率,弹出率,用户转化;DevOps 同学他们可能关心的是网站的“心跳”,资源的消耗,后端接口的快慢;所以不同指标在不同人群中是一种此消彼长的状态。这种割裂还可以从技术角度上划分,有的指标更侧重于资源,有的指标更侧重于用户感受。
指标只是发现问题的一种手段,现在我们有无数种手段任君挑选:APM (Application Performance Management)、日志分析、RUM (Real-User Monitoring)、TTFB (Time to First Byte)……最终它迫使你回到了问题的起点:我究竟想衡量什么?我想衡量的物体是否可以通过已有的指标表达出来?我只是想 monitor 吗?如果我想 debug 或者是 analyze 的话是否还有其他的选择?
“Good software testing is a challenging intellectual process.” (请把 testing 替换为 performance tuning)上下文驱动测试中的第六条原则如是说。
追踪元素
如果说“资源加载完毕”这件事不靠谱,“浏览器开始绘制”也不靠谱的话,我想唯一靠谱的事情就是用户的所见所得了。不需要用各种数据来展示你的页面加载有多快,如果用户每次都要等待十秒才能看到他想看到的信息,那么这些数字无非是自欺欺人而已。所以我们不妨可以追踪用户关注信息所对应元素的出现的时机。
这不是创新,从早些年的 Speed Index,“above the fold” 到如今的 web vitals 都是这种思想的延续,指标的进化过程像一个不断收缩过程中圆圈,在不断的像用户本身靠拢。只不过出于技术手段的限制,它们只能走到那么远,而如今我们有了 MutationObserver 和 Perforamce API, 则可以精确的定位到元素,甚至元素上属性的改变,自然也就不会被上面例子中的 placeholder 所欺骗。
抱歉我要在这里再次强调一下上下文:我们不能只关注“元素出现的时机”,更要从时间的范畴和从代码延展上看关注形成它的原因,这依然需要我们结合问题所处的环境和它的运转机制而定。举两个例子:
在上图中,如果 Component D 是向客户展示关键信息的关键元素,那么 request 到达 router 的时间,由 router 渲染出 Component C 的时间,都会对 D 元素产生影响;从另一个维度上看:
脚本以及请求加载的快慢和执行的效率,同样也会对元素的出现产生影响。如果你需要对问题进行诊断,对这些背后工作机制的了解必不可少。
但追踪元素也存在另一个问题就是它难以大规模的应用。因为它是侵入式的,因为它需要你识别不同页面上的不同关键元素,用近似于 hard code 的方式对它们一一追踪。这类工作产生的维护成本接近于维护前端的 E2E 测试。诚然我们可以通过分配统一的 id 或者 class name 的方式来减少我们的维护成本,但是相比统一的 GA 代码这样的维护成本依然偏高。所以我建议使用最简单的方法去监控最直接的元素,不要 case by case 的去编写你的监控代码,不要让你的实现代码被监控代码束缚住。
让工具为你所用
你可以在市面上找到各类数不胜数号称能够协助你改善性能的工具。但首先你要小心,它们所宣扬的,并非是你真正需要的。
例如 site24x7 是一家专业提供用户行为监控解决方案的公司。在它们有关 APM 的帮助页面上,开宗明义的指出了监控捕获 SAP(Single Page Application) 性能数据以目前的技术来说其实是一项颇具挑战的工作:
In case of Single Page Applications, the time taken for page load completion cannot be obtained by page onload event since the data are dynamically obtained from the server using
Hence, for each SPA framework, the page load metrics are calculated by listening to particular events specific to the framework.
所以对于此种类型的页面,它们捕获指标也只有:
For every dynamic page load, the corresponding URL, it's respective AJAX calls, response time of each AJAX call, response codes and errors (if any) are captured.
但要知道在如今 SPA 大行其道的今天,如此的收集功能略显的苍白无力了。
同理如果你去看 Azure Application Insights 旗下 JavaScript SDK 默认收集的页面信息:
Network Dependency Requests made by your app XHR and Fetch (fetch collection is disabled by default) requests, include information on
User information (for example, Location, network, IP)
Device information (for example, Browser, OS, version, language, model)
Session information
我不认为这些指标和其他平台提供的相比能带来额外的价值,它能真的给我带来多少真正的 “insights”。
另一方面,不要让你的思维被工具限制住:不要“因为 xx 工具只能做到这些,所以我只能收集这些指标”;而要“我想收集这些指标,所以我需要 xx 工具”。在这里我列举一个我们在探索中的例子:用 OpenTracing 工具 Jaeger 去可视化前端性能图表。
在这里我首先必须赞颂 Chrome 内置 Performance 工具给我们调教性能带来了极大的便利。但我们始终有一些额外的需求无法满足。例如我希望能够在结果呈现中做一些自定义的标记,又或者在 Performance Tab 下展示每一个请求从 connect 到 resposne 每个阶段的状态。
如下图所示,于是我们跨界的使用了 Jaeger 开源工具来用于自定义指标的收集和展示,可以说是将不同纬度的指标以时间为线索将它们联系起来,这样一来页面加载阶段的状态并能一览无余的尽收眼底。便于定位问题的所在。
结束语
我观察到对于大部分前端工程师而言,又或者曾经的自己而言,在做性能监控时是一个被“喂”的过程,即会惯性的不假思索的收集已有指标和利用已有工具。又因为性能优化工作过程前置结果后置的关系,等到我们有需求发生时才会发现当下的结果并非是我们想要的。多一些思考才会让我们的工作少一分浪费。
文章采集api 性能指标的信仰危机
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-05-02 02:40
正在阅读这篇文章的你,或多或者接触过前端性能优化,这样的接触可能是来自你的阅读体验也可能是来自工作经验。那我们不妨从一个非常简单的思想实验开始,请你借助你对这个领域的理解,来回答下面的几个问题:
不要有压力,你可以慢慢思考并回答这几个问题,你关于第一个问题的答案可能会随着二三问题的出现而不断的调整。
这篇文章的目的就是对上面三个问题的探索和尝试性的解答,希望我的答案能带给你一些启发。
一次复盘
目前我所在的项目上长时间都依赖都 GA (Google Analytic) 作为衡量页面性能的唯一工具,在 GA 的生态圈中,我们最为重视的是 Avg Page Load Time (以下简称为 APLT),通过它来断定我们站点当前的性能状态如何。
但是在定期收集该指标数据的过程中,我们发现用户的感受和数据的展示可能并不一致,具体来说数据看上去波澜不惊,但用户体验却直线下降。
所以我们不得不要回答一个至关重要的问题,APLT 衡量的究竟是什么?
什么这个问题之所以至关重要,是因为它的答案决定我们接下来要解决的问题和需要采取的行动:
然而官方文档对于这个指标的解释是很暧昧的:
Avg Page Load Time : The average amount of time (in seconds) it takes that page to load, from initiation of the pageview (e.g., click on a page link) to load completion in the browser.
Avg. Page Load Time consists of two components: 1) network and server time, and 2) browser time. The Technical section of the Explorer tab provides details about the network and remaining time is the browser overhead for parsing and executing the JavaScript and rendering the page.
对于它的解释,我们产生了几点疑问:
GA 的实现
GA 底层是通过 Navigation Timing API 在采集性能数据
GA 不会统计每一个阶段的数据,它将某些合并后重新命名成新的指标,而其中的某些指标比如 Document Interactive Loaded 其实是某些阶段的统计之和:
GA 统计的仅仅是与 DOM 文档有关的数据。APLT 定义里所说的 load completion 时刻指的就是 loadEventEnd 事件的发生时机,即 onLoad 事件触发完毕(load 事件触发时意味着所有的外部资源,包括 iframe、图片、脚本、样式都已经加载完毕)。所以 APLT 值是 GA 里所有指标里横跨时间范围最广的。
脚本对 Avg Page Load Time 的影响是什么
如上图所示,当浏览器自上而下解析 DOM 树时,它会遇见很多外联资源,比如图片、样式和脚本。于是它需要从缓存或者网络中请求这些资源。
页面的解析是同步的,所以脚本的加载会导致页面解析的暂停。浏览器需要在脚本加载、编译、执行完毕之后才会继续之后的解析工作,这么做是有道理的,因为 JavaScript 可能会使用诸如 document.write() 方法来改变 DOM 的结构。你可能听说过在 script 标签上添加 async 或者 defer 属性来异步的加载和执行脚本。但是它在我们的产品中是不适用的,因为 async 无法保证脚本执行的顺序。但这则方案不一定适用于所有页面,因为 async 无法保证脚本的执行顺序,如果你的应用对脚本的执行顺序有严格要求,那么它对你爱莫能助。
目前浏览器都配备preloader机制来提前扫面页面中的外联元素提前加载,但这个机制并无统一的标准也无法衡量效果,所以暂时不考虑它对我们的影响。
脚本下载之后需要经过解析(parse / compile)和执行(run / execute)。解析阶段首先将 javascript 代码编译为机器语言,执行阶段才会真正的运行我们编写的代码。脚本的解析和执行也会阻塞页面的解析
所以综上,我们可以得出脚本确实能够影响 APLT 。
但抛弃计量谈危害都是刷流氓,它的影响范围究竟有多大?也就是说如果 APLT 是 2 秒的话,其中多少时间耗费在了脚本上?
这里没有一个具体的数字,但它不容小觑,以及足够影响到性能。Addy Osmani 在 2017 年的一篇文章中指出 Chrome 的脚本引擎花费在编译时间上
虽然此后 Chrome 对编译过程进行了优化,但执行脚本过长的困恼依然存在。同时这只是 Chrome 下的情况,我们无法确认其他浏览器在编译脚本时也可以保证同样的效率
如果说 APLT 是由不同的阶段组成,那么我们有没有可能计算出每一个阶段的具体时间?
回顾上面关于 GA 指标的定义,至少我们现在能分离出 server time 和 browser time. 但是在 browser time 之下呢?比如说脚本的下载时间和执行时间,这些我们就无从得知了。这些是需要额外计算和采集的。
综上,我们完全依赖 APLT 来对站点的性能问题进行诊断是不靠谱,我们单纯的认为脚本负担拖慢了性能也是不完整的。
一场关于指标的信仰危机
我想你大概明白了为什么我在上一节中花了这么大段的篇幅来解释仅仅一个指标的含义。因为一个指标能透露的信息可能会比你想象的要复杂,引导和误导并存。
首先要声明我并不反对使用常见指标,这篇文章也不是对它们的批评,它们在帮助我们排查性能问题方面给了非常大的帮助。在这里我想探讨的是,如果常规指标是性能监控的底线的话,它的上限在哪?
从上面的描述中我们不难看出 APLT 的涉猎的维度过于宽泛,它更偏向于一个技术向的综合性指标,它展示给我们是趋势而非细节。这样带来的问题有两个:
接下来我们深入的聊聊这两个问题。
以用户为中心
你或许有留意到,目前前端性能监测的趋势逐渐在向以用户为中心的指标 (User-Centric Performance Metrics) 靠拢。为什么会出现这样的情况?因为随着单页面应用的普及以及前端功能变“重”,经典的以资源为中心的性能指标(例如 Onload, DOMContentLoaded)越来越不能准确地反馈真实用户的体验与产品性能。在传统后端渲染的多页面应用模式下,资源加载完毕即意味着页面对用户可用;而在单页面模式下,资源加载完毕距离产品可用存在一定的差距,因为此时应用才能真正地请求用户个性化的数据,渲染定制化的页面。
总的来说,越来越多重要且耗时的工作都发生在资源加载之后,我们需要把这部分工作的性能也监控起来。
好消息是浏览器原生的在提供给予我们这方面的支持,例如 Chrome 就在 Performace API 中提供了 Paint Timing API 诸如 first paint (FP) 、 first contentful paint (FCP)、time to interact(tti) 等指标数据。顾名思义的这些指标尝试站在用户体验的视角展现应用在浏览器中被呈现时的性能;坏消息是,这些指标依然在测量真实的用户体验方面依然存在误差。
就以上面提到的 FP、FCP、TTI 这三个指标为例,我用一个简单的例子说明这三个指标是如何不够准确的:在单页面的初始化过程中,我们通常会提供类似于「加载中」视图,通常是一个 placeholder 或者 skeleton 样式,在数据请求完毕之后才会将实际的视图渲染出来:
如果加载时间过长,浏览器会以为「加载中」视图就是对用户可用的最终产品形态,并以它为基准计算那上述的三个指标
下面这段代码模拟的就是包含上面所说情况的日常情况:在组件加载时模拟发出两个请求,其中一个需要5秒较长的等待时间,只有当两个请求都返回时才能开始渲染数据,否则一直提示用户加载中。
function App() {<br /> const [data, setState] = useState([]);<br /> useEffect(() => {<br /> const longRequest = new Promise((resolve, reject) => {<br /> setTimeout(() => {<br /> resolve([]);<br /> }, 1000 * 5)<br /> });<br /> const shortRequest = Promise.resolve([]);<br /> <br /> Promise.all([longRequest, shortRequest]).then(([longRequestResponse, shortRequestResponse]) => {<br /> setState([<br /> ['', 'Tesla', 'Mercedes', 'Toyota', 'Volvo'],<br /> ['2019', 10, 11, 12, 13],<br /> ['2020', 20, 11, 14, 13],<br /> ['2021', 30, 15, 12, 13]<br /> ])<br /> })<br /> }, []);<br /> return (<br /> <br /> {data && data.length<br /> ? <br /> : }<br /> <br /> )<br />}
如果你尝试在浏览器中运行上述 App, 通过 Devtools 观测到的各个指标如下:
你能通过开发者工具够观测到各种指标比如 DCL (DOMContentLoaded Event), FP, FCP, FMP (first meaningful paint), L(Onload Event) 都发生在页面加载后一秒左右以内。然而从代码里我们非常肯定至少五秒后用户才能看到真实内容。所以上述指标并不能真的反馈用户感受到的性能问题
我已经把这个应用部署到了 站点上,可以在线访问。并且可以使用 对它做更详细的性能检测,也会得出和 devtools 相同的结果。webpagetest 是一个开源免费对网站性能进行检测的工具。早在 2012 年还没有诸如 FP 一类的指标时,它独创的 Speed Index 指标就能够衡量用户体验。
总的来说如上图所示,目前浏览器提供的 API 能够测量的只是 D 阶段的性能,对 E 和 F 阶段爱莫能助。
这只是其中一个说明原生指标不够准确的例子,可以归纳为后端接口延迟过长。然而还有一种情况是前端渲染时间过长。例如我们在使用 Handsontable 组件渲染上千行数据表格的时候,甚至导致了浏览器的假死,这种场景对 Paint Timing API 也是免疫的。
那 tti 这个指标怎么样?它不是听上去能够检测页面是否可以交互吗?它是不是能够检测页面的假死?
很遗憾依然不行。
如果你有心去查看 tti 这个指标的定义的话, 你会发现 tti 本质上是一种算法:
并且目前的原生 API 并不支持 tti 指标,需要通过 polyfill 实现,按照官方的说明,目前并不能适配所有的 web app。
双向指标
这是知乎创作者中心页面的一个截图
在这个页面中,知乎每天都会为你更新过去七天内文章阅读数、赞同数、评论数等数据的汇总。上图中的折线就是阅读数。
我知道它的用意是想给予创作者数据上的反馈帮助他们更好的输出内容,但至少对我来说一点用也没有。因为我更想知道的是究竟增长来自于哪里,这样我才能有针对性的输出带来点击量的内容。但它带给我的总是汇总数据。
这个需求对于性能监控也是同样的成立的,监控的目的主要是为了及时发现问题,解决问题。所以在审视数据的过程中,我们更关心的是异常波动值发生在何时何地,我们也希望数据能给予我这方面的帮助。
当然我们不可能无中生有的将一组汇总数据还原成细节数据,但在这个问题上我们可以往两个方向努力:
在 Web Performance Calendar 2020 Edition 中 A wish list for web performance tools 一文中,作者提出了关于他理想性能工具应该满足的四则功能,分别是:
其中的第二三则对于我们选择指标来说也是成立的,与我在上面的强调的不谋而合
最后再一次强调这里不是对传统指标的否定。数据带来的效果一定是聊胜于无,指标越多越是能精确的描绘出性能画像。这里探讨的是如何在这些基础上继续事半功倍提升我们洞察问题的效率。
在选择衡量指标上的一些建议
上下文驱动 (Context Driven)
之所以我无法在这里给你一个大而全的解决方案,是因为我认为这种东西并不存在,一切都要依赖你的上下文而定。
你也许更熟悉的是上下文驱动测试(Context Driven Testing),但在我看来,上下文驱动在你选择性能指标或者工具时也是同样成立的。我们不妨看一看上下文测试七条原则中的头两条:
想象一下如果你把两句话中的 practice 理解为指标(metric),甚至直接替换为指标,是不是也没有任何违和感呢?
“上下文驱动”初看上去不过是正反话,但实际上它是我们提升监测效率的有效出路。指标本身不会有对错之分,但不同人群对于指标的视角是割裂的:业务分析师希望得到的是能直接彰显业务价值的数据,例如点击率,弹出率,用户转化;DevOps 同学他们可能关心的是网站的“心跳”,资源的消耗,后端接口的快慢;所以不同指标在不同人群中是一种此消彼长的状态。这种割裂还可以从技术角度上划分,有的指标更侧重于资源,有的指标更侧重于用户感受。
指标只是发现问题的一种手段,现在我们有无数种手段任君挑选:APM (Application Performance Management)、日志分析、RUM (Real-User Monitoring)、TTFB (Time to First Byte)……最终它迫使你回到了问题的起点:我究竟想衡量什么?我想衡量的物体是否可以通过已有的指标表达出来?我只是想 monitor 吗?如果我想 debug 或者是 analyze 的话是否还有其他的选择?
“Good software testing is a challenging intellectual process.” (请把 testing 替换为 performance tuning)上下文驱动测试中的第六条原则如是说。
追踪元素
如果说“资源加载完毕”这件事不靠谱,“浏览器开始绘制”也不靠谱的话,我想唯一靠谱的事情就是用户的所见所得了。不需要用各种数据来展示你的页面加载有多快,如果用户每次都要等待十秒才能看到他想看到的信息,那么这些数字无非是自欺欺人而已。所以我们不妨可以追踪用户关注信息所对应元素的出现的时机。
这不是创新,从早些年的 Speed Index,“above the fold” 到如今的 web vitals 都是这种思想的延续,指标的进化过程像一个不断收缩过程中圆圈,在不断的像用户本身靠拢。只不过出于技术手段的限制,它们只能走到那么远,而如今我们有了 MutationObserver 和 Perforamce API, 则可以精确的定位到元素,甚至元素上属性的改变,自然也就不会被上面例子中的 placeholder 所欺骗。
抱歉我要在这里再次强调一下上下文:我们不能只关注“元素出现的时机”,更要从时间的范畴和从代码延展上看关注形成它的原因,这依然需要我们结合问题所处的环境和它的运转机制而定。举两个例子:
在上图中,如果 Component D 是向客户展示关键信息的关键元素,那么 request 到达 router 的时间,由 router 渲染出 Component C 的时间,都会对 D 元素产生影响;从另一个维度上看:
脚本以及请求加载的快慢和执行的效率,同样也会对元素的出现产生影响。如果你需要对问题进行诊断,对这些背后工作机制的了解必不可少。
但追踪元素也存在另一个问题就是它难以大规模的应用。因为它是侵入式的,因为它需要你识别不同页面上的不同关键元素,用近似于 hard code 的方式对它们一一追踪。这类工作产生的维护成本接近于维护前端的 E2E 测试。诚然我们可以通过分配统一的 id 或者 class name 的方式来减少我们的维护成本,但是相比统一的 GA 代码这样的维护成本依然偏高。所以我建议使用最简单的方法去监控最直接的元素,不要 case by case 的去编写你的监控代码,不要让你的实现代码被监控代码束缚住。
让工具为你所用
你可以在市面上找到各类数不胜数号称能够协助你改善性能的工具。但首先你要小心,它们所宣扬的,并非是你真正需要的。
例如 site24x7 是一家专业提供用户行为监控解决方案的公司。在它们有关 APM 的帮助页面上,开宗明义的指出了监控捕获 SAP(Single Page Application) 性能数据以目前的技术来说其实是一项颇具挑战的工作:
In case of Single Page Applications, the time taken for page load completion cannot be obtained by page onload event since the data are dynamically obtained from the server using
Hence, for each SPA framework, the page load metrics are calculated by listening to particular events specific to the framework.
所以对于此种类型的页面,它们捕获指标也只有:
For every dynamic page load, the corresponding URL, it's respective AJAX calls, response time of each AJAX call, response codes and errors (if any) are captured.
但要知道在如今 SPA 大行其道的今天,如此的收集功能略显的苍白无力了。
同理如果你去看 Azure Application Insights 旗下 JavaScript SDK 默认收集的页面信息:
Network Dependency Requests made by your app XHR and Fetch (fetch collection is disabled by default) requests, include information on
User information (for example, Location, network, IP)
Device information (for example, Browser, OS, version, language, model)
Session information
我不认为这些指标和其他平台提供的相比能带来额外的价值,它能真的给我带来多少真正的 “insights”。
另一方面,不要让你的思维被工具限制住:不要“因为 xx 工具只能做到这些,所以我只能收集这些指标”;而要“我想收集这些指标,所以我需要 xx 工具”。在这里我列举一个我们在探索中的例子:用 OpenTracing 工具 Jaeger 去可视化前端性能图表。
在这里我首先必须赞颂 Chrome 内置 Performance 工具给我们调教性能带来了极大的便利。但我们始终有一些额外的需求无法满足。例如我希望能够在结果呈现中做一些自定义的标记,又或者在 Performance Tab 下展示每一个请求从 connect 到 resposne 每个阶段的状态。
如下图所示,于是我们跨界的使用了 Jaeger 开源工具来用于自定义指标的收集和展示,可以说是将不同纬度的指标以时间为线索将它们联系起来,这样一来页面加载阶段的状态并能一览无余的尽收眼底。便于定位问题的所在。
结束语
我观察到对于大部分前端工程师而言,又或者曾经的自己而言,在做性能监控时是一个被“喂”的过程,即会惯性的不假思索的收集已有指标和利用已有工具。又因为性能优化工作过程前置结果后置的关系,等到我们有需求发生时才会发现当下的结果并非是我们想要的。多一些思考才会让我们的工作少一分浪费。 查看全部
文章采集api 性能指标的信仰危机
正在阅读这篇文章的你,或多或者接触过前端性能优化,这样的接触可能是来自你的阅读体验也可能是来自工作经验。那我们不妨从一个非常简单的思想实验开始,请你借助你对这个领域的理解,来回答下面的几个问题:
不要有压力,你可以慢慢思考并回答这几个问题,你关于第一个问题的答案可能会随着二三问题的出现而不断的调整。
这篇文章的目的就是对上面三个问题的探索和尝试性的解答,希望我的答案能带给你一些启发。
一次复盘
目前我所在的项目上长时间都依赖都 GA (Google Analytic) 作为衡量页面性能的唯一工具,在 GA 的生态圈中,我们最为重视的是 Avg Page Load Time (以下简称为 APLT),通过它来断定我们站点当前的性能状态如何。
但是在定期收集该指标数据的过程中,我们发现用户的感受和数据的展示可能并不一致,具体来说数据看上去波澜不惊,但用户体验却直线下降。
所以我们不得不要回答一个至关重要的问题,APLT 衡量的究竟是什么?
什么这个问题之所以至关重要,是因为它的答案决定我们接下来要解决的问题和需要采取的行动:
然而官方文档对于这个指标的解释是很暧昧的:
Avg Page Load Time : The average amount of time (in seconds) it takes that page to load, from initiation of the pageview (e.g., click on a page link) to load completion in the browser.
Avg. Page Load Time consists of two components: 1) network and server time, and 2) browser time. The Technical section of the Explorer tab provides details about the network and remaining time is the browser overhead for parsing and executing the JavaScript and rendering the page.
对于它的解释,我们产生了几点疑问:
GA 的实现
GA 底层是通过 Navigation Timing API 在采集性能数据
GA 不会统计每一个阶段的数据,它将某些合并后重新命名成新的指标,而其中的某些指标比如 Document Interactive Loaded 其实是某些阶段的统计之和:
GA 统计的仅仅是与 DOM 文档有关的数据。APLT 定义里所说的 load completion 时刻指的就是 loadEventEnd 事件的发生时机,即 onLoad 事件触发完毕(load 事件触发时意味着所有的外部资源,包括 iframe、图片、脚本、样式都已经加载完毕)。所以 APLT 值是 GA 里所有指标里横跨时间范围最广的。
脚本对 Avg Page Load Time 的影响是什么
如上图所示,当浏览器自上而下解析 DOM 树时,它会遇见很多外联资源,比如图片、样式和脚本。于是它需要从缓存或者网络中请求这些资源。
页面的解析是同步的,所以脚本的加载会导致页面解析的暂停。浏览器需要在脚本加载、编译、执行完毕之后才会继续之后的解析工作,这么做是有道理的,因为 JavaScript 可能会使用诸如 document.write() 方法来改变 DOM 的结构。你可能听说过在 script 标签上添加 async 或者 defer 属性来异步的加载和执行脚本。但是它在我们的产品中是不适用的,因为 async 无法保证脚本执行的顺序。但这则方案不一定适用于所有页面,因为 async 无法保证脚本的执行顺序,如果你的应用对脚本的执行顺序有严格要求,那么它对你爱莫能助。
目前浏览器都配备preloader机制来提前扫面页面中的外联元素提前加载,但这个机制并无统一的标准也无法衡量效果,所以暂时不考虑它对我们的影响。
脚本下载之后需要经过解析(parse / compile)和执行(run / execute)。解析阶段首先将 javascript 代码编译为机器语言,执行阶段才会真正的运行我们编写的代码。脚本的解析和执行也会阻塞页面的解析
所以综上,我们可以得出脚本确实能够影响 APLT 。
但抛弃计量谈危害都是刷流氓,它的影响范围究竟有多大?也就是说如果 APLT 是 2 秒的话,其中多少时间耗费在了脚本上?
这里没有一个具体的数字,但它不容小觑,以及足够影响到性能。Addy Osmani 在 2017 年的一篇文章中指出 Chrome 的脚本引擎花费在编译时间上
虽然此后 Chrome 对编译过程进行了优化,但执行脚本过长的困恼依然存在。同时这只是 Chrome 下的情况,我们无法确认其他浏览器在编译脚本时也可以保证同样的效率
如果说 APLT 是由不同的阶段组成,那么我们有没有可能计算出每一个阶段的具体时间?
回顾上面关于 GA 指标的定义,至少我们现在能分离出 server time 和 browser time. 但是在 browser time 之下呢?比如说脚本的下载时间和执行时间,这些我们就无从得知了。这些是需要额外计算和采集的。
综上,我们完全依赖 APLT 来对站点的性能问题进行诊断是不靠谱,我们单纯的认为脚本负担拖慢了性能也是不完整的。
一场关于指标的信仰危机
我想你大概明白了为什么我在上一节中花了这么大段的篇幅来解释仅仅一个指标的含义。因为一个指标能透露的信息可能会比你想象的要复杂,引导和误导并存。
首先要声明我并不反对使用常见指标,这篇文章也不是对它们的批评,它们在帮助我们排查性能问题方面给了非常大的帮助。在这里我想探讨的是,如果常规指标是性能监控的底线的话,它的上限在哪?
从上面的描述中我们不难看出 APLT 的涉猎的维度过于宽泛,它更偏向于一个技术向的综合性指标,它展示给我们是趋势而非细节。这样带来的问题有两个:
接下来我们深入的聊聊这两个问题。
以用户为中心
你或许有留意到,目前前端性能监测的趋势逐渐在向以用户为中心的指标 (User-Centric Performance Metrics) 靠拢。为什么会出现这样的情况?因为随着单页面应用的普及以及前端功能变“重”,经典的以资源为中心的性能指标(例如 Onload, DOMContentLoaded)越来越不能准确地反馈真实用户的体验与产品性能。在传统后端渲染的多页面应用模式下,资源加载完毕即意味着页面对用户可用;而在单页面模式下,资源加载完毕距离产品可用存在一定的差距,因为此时应用才能真正地请求用户个性化的数据,渲染定制化的页面。
总的来说,越来越多重要且耗时的工作都发生在资源加载之后,我们需要把这部分工作的性能也监控起来。
好消息是浏览器原生的在提供给予我们这方面的支持,例如 Chrome 就在 Performace API 中提供了 Paint Timing API 诸如 first paint (FP) 、 first contentful paint (FCP)、time to interact(tti) 等指标数据。顾名思义的这些指标尝试站在用户体验的视角展现应用在浏览器中被呈现时的性能;坏消息是,这些指标依然在测量真实的用户体验方面依然存在误差。
就以上面提到的 FP、FCP、TTI 这三个指标为例,我用一个简单的例子说明这三个指标是如何不够准确的:在单页面的初始化过程中,我们通常会提供类似于「加载中」视图,通常是一个 placeholder 或者 skeleton 样式,在数据请求完毕之后才会将实际的视图渲染出来:
如果加载时间过长,浏览器会以为「加载中」视图就是对用户可用的最终产品形态,并以它为基准计算那上述的三个指标
下面这段代码模拟的就是包含上面所说情况的日常情况:在组件加载时模拟发出两个请求,其中一个需要5秒较长的等待时间,只有当两个请求都返回时才能开始渲染数据,否则一直提示用户加载中。
function App() {<br /> const [data, setState] = useState([]);<br /> useEffect(() => {<br /> const longRequest = new Promise((resolve, reject) => {<br /> setTimeout(() => {<br /> resolve([]);<br /> }, 1000 * 5)<br /> });<br /> const shortRequest = Promise.resolve([]);<br /> <br /> Promise.all([longRequest, shortRequest]).then(([longRequestResponse, shortRequestResponse]) => {<br /> setState([<br /> ['', 'Tesla', 'Mercedes', 'Toyota', 'Volvo'],<br /> ['2019', 10, 11, 12, 13],<br /> ['2020', 20, 11, 14, 13],<br /> ['2021', 30, 15, 12, 13]<br /> ])<br /> })<br /> }, []);<br /> return (<br /> <br /> {data && data.length<br /> ? <br /> : }<br /> <br /> )<br />}
如果你尝试在浏览器中运行上述 App, 通过 Devtools 观测到的各个指标如下:
你能通过开发者工具够观测到各种指标比如 DCL (DOMContentLoaded Event), FP, FCP, FMP (first meaningful paint), L(Onload Event) 都发生在页面加载后一秒左右以内。然而从代码里我们非常肯定至少五秒后用户才能看到真实内容。所以上述指标并不能真的反馈用户感受到的性能问题
我已经把这个应用部署到了 站点上,可以在线访问。并且可以使用 对它做更详细的性能检测,也会得出和 devtools 相同的结果。webpagetest 是一个开源免费对网站性能进行检测的工具。早在 2012 年还没有诸如 FP 一类的指标时,它独创的 Speed Index 指标就能够衡量用户体验。
总的来说如上图所示,目前浏览器提供的 API 能够测量的只是 D 阶段的性能,对 E 和 F 阶段爱莫能助。
这只是其中一个说明原生指标不够准确的例子,可以归纳为后端接口延迟过长。然而还有一种情况是前端渲染时间过长。例如我们在使用 Handsontable 组件渲染上千行数据表格的时候,甚至导致了浏览器的假死,这种场景对 Paint Timing API 也是免疫的。
那 tti 这个指标怎么样?它不是听上去能够检测页面是否可以交互吗?它是不是能够检测页面的假死?
很遗憾依然不行。
如果你有心去查看 tti 这个指标的定义的话, 你会发现 tti 本质上是一种算法:
并且目前的原生 API 并不支持 tti 指标,需要通过 polyfill 实现,按照官方的说明,目前并不能适配所有的 web app。
双向指标
这是知乎创作者中心页面的一个截图
在这个页面中,知乎每天都会为你更新过去七天内文章阅读数、赞同数、评论数等数据的汇总。上图中的折线就是阅读数。
我知道它的用意是想给予创作者数据上的反馈帮助他们更好的输出内容,但至少对我来说一点用也没有。因为我更想知道的是究竟增长来自于哪里,这样我才能有针对性的输出带来点击量的内容。但它带给我的总是汇总数据。
这个需求对于性能监控也是同样的成立的,监控的目的主要是为了及时发现问题,解决问题。所以在审视数据的过程中,我们更关心的是异常波动值发生在何时何地,我们也希望数据能给予我这方面的帮助。
当然我们不可能无中生有的将一组汇总数据还原成细节数据,但在这个问题上我们可以往两个方向努力:
在 Web Performance Calendar 2020 Edition 中 A wish list for web performance tools 一文中,作者提出了关于他理想性能工具应该满足的四则功能,分别是:
其中的第二三则对于我们选择指标来说也是成立的,与我在上面的强调的不谋而合
最后再一次强调这里不是对传统指标的否定。数据带来的效果一定是聊胜于无,指标越多越是能精确的描绘出性能画像。这里探讨的是如何在这些基础上继续事半功倍提升我们洞察问题的效率。
在选择衡量指标上的一些建议
上下文驱动 (Context Driven)
之所以我无法在这里给你一个大而全的解决方案,是因为我认为这种东西并不存在,一切都要依赖你的上下文而定。
你也许更熟悉的是上下文驱动测试(Context Driven Testing),但在我看来,上下文驱动在你选择性能指标或者工具时也是同样成立的。我们不妨看一看上下文测试七条原则中的头两条:
想象一下如果你把两句话中的 practice 理解为指标(metric),甚至直接替换为指标,是不是也没有任何违和感呢?
“上下文驱动”初看上去不过是正反话,但实际上它是我们提升监测效率的有效出路。指标本身不会有对错之分,但不同人群对于指标的视角是割裂的:业务分析师希望得到的是能直接彰显业务价值的数据,例如点击率,弹出率,用户转化;DevOps 同学他们可能关心的是网站的“心跳”,资源的消耗,后端接口的快慢;所以不同指标在不同人群中是一种此消彼长的状态。这种割裂还可以从技术角度上划分,有的指标更侧重于资源,有的指标更侧重于用户感受。
指标只是发现问题的一种手段,现在我们有无数种手段任君挑选:APM (Application Performance Management)、日志分析、RUM (Real-User Monitoring)、TTFB (Time to First Byte)……最终它迫使你回到了问题的起点:我究竟想衡量什么?我想衡量的物体是否可以通过已有的指标表达出来?我只是想 monitor 吗?如果我想 debug 或者是 analyze 的话是否还有其他的选择?
“Good software testing is a challenging intellectual process.” (请把 testing 替换为 performance tuning)上下文驱动测试中的第六条原则如是说。
追踪元素
如果说“资源加载完毕”这件事不靠谱,“浏览器开始绘制”也不靠谱的话,我想唯一靠谱的事情就是用户的所见所得了。不需要用各种数据来展示你的页面加载有多快,如果用户每次都要等待十秒才能看到他想看到的信息,那么这些数字无非是自欺欺人而已。所以我们不妨可以追踪用户关注信息所对应元素的出现的时机。
这不是创新,从早些年的 Speed Index,“above the fold” 到如今的 web vitals 都是这种思想的延续,指标的进化过程像一个不断收缩过程中圆圈,在不断的像用户本身靠拢。只不过出于技术手段的限制,它们只能走到那么远,而如今我们有了 MutationObserver 和 Perforamce API, 则可以精确的定位到元素,甚至元素上属性的改变,自然也就不会被上面例子中的 placeholder 所欺骗。
抱歉我要在这里再次强调一下上下文:我们不能只关注“元素出现的时机”,更要从时间的范畴和从代码延展上看关注形成它的原因,这依然需要我们结合问题所处的环境和它的运转机制而定。举两个例子:
在上图中,如果 Component D 是向客户展示关键信息的关键元素,那么 request 到达 router 的时间,由 router 渲染出 Component C 的时间,都会对 D 元素产生影响;从另一个维度上看:
脚本以及请求加载的快慢和执行的效率,同样也会对元素的出现产生影响。如果你需要对问题进行诊断,对这些背后工作机制的了解必不可少。
但追踪元素也存在另一个问题就是它难以大规模的应用。因为它是侵入式的,因为它需要你识别不同页面上的不同关键元素,用近似于 hard code 的方式对它们一一追踪。这类工作产生的维护成本接近于维护前端的 E2E 测试。诚然我们可以通过分配统一的 id 或者 class name 的方式来减少我们的维护成本,但是相比统一的 GA 代码这样的维护成本依然偏高。所以我建议使用最简单的方法去监控最直接的元素,不要 case by case 的去编写你的监控代码,不要让你的实现代码被监控代码束缚住。
让工具为你所用
你可以在市面上找到各类数不胜数号称能够协助你改善性能的工具。但首先你要小心,它们所宣扬的,并非是你真正需要的。
例如 site24x7 是一家专业提供用户行为监控解决方案的公司。在它们有关 APM 的帮助页面上,开宗明义的指出了监控捕获 SAP(Single Page Application) 性能数据以目前的技术来说其实是一项颇具挑战的工作:
In case of Single Page Applications, the time taken for page load completion cannot be obtained by page onload event since the data are dynamically obtained from the server using
Hence, for each SPA framework, the page load metrics are calculated by listening to particular events specific to the framework.
所以对于此种类型的页面,它们捕获指标也只有:
For every dynamic page load, the corresponding URL, it's respective AJAX calls, response time of each AJAX call, response codes and errors (if any) are captured.
但要知道在如今 SPA 大行其道的今天,如此的收集功能略显的苍白无力了。
同理如果你去看 Azure Application Insights 旗下 JavaScript SDK 默认收集的页面信息:
Network Dependency Requests made by your app XHR and Fetch (fetch collection is disabled by default) requests, include information on
User information (for example, Location, network, IP)
Device information (for example, Browser, OS, version, language, model)
Session information
我不认为这些指标和其他平台提供的相比能带来额外的价值,它能真的给我带来多少真正的 “insights”。
另一方面,不要让你的思维被工具限制住:不要“因为 xx 工具只能做到这些,所以我只能收集这些指标”;而要“我想收集这些指标,所以我需要 xx 工具”。在这里我列举一个我们在探索中的例子:用 OpenTracing 工具 Jaeger 去可视化前端性能图表。
在这里我首先必须赞颂 Chrome 内置 Performance 工具给我们调教性能带来了极大的便利。但我们始终有一些额外的需求无法满足。例如我希望能够在结果呈现中做一些自定义的标记,又或者在 Performance Tab 下展示每一个请求从 connect 到 resposne 每个阶段的状态。
如下图所示,于是我们跨界的使用了 Jaeger 开源工具来用于自定义指标的收集和展示,可以说是将不同纬度的指标以时间为线索将它们联系起来,这样一来页面加载阶段的状态并能一览无余的尽收眼底。便于定位问题的所在。
结束语
我观察到对于大部分前端工程师而言,又或者曾经的自己而言,在做性能监控时是一个被“喂”的过程,即会惯性的不假思索的收集已有指标和利用已有工具。又因为性能优化工作过程前置结果后置的关系,等到我们有需求发生时才会发现当下的结果并非是我们想要的。多一些思考才会让我们的工作少一分浪费。
云原生爱好者周刊:寻找 Netlify 开源替代品
采集交流 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-05-01 23:16
随着云原生技术的快速发展,技术的不断迭代,对于日志的采集、处理及转发提出了更高的要求。云原生架构下的日志方案相比基于物理机或者是虚拟机场景的日志架构设计存在很大差别。作为 CNCF 的毕业项目,Fluent Bit 无疑为解决云环境中的日志记录问题的首选解决方案之一。但是在 Kubernetes 中安装部署以及配置 Fluent Bit 都具有一定的门槛,加大了用户的使用成本。
本文从写作对个人的价值谈到技术内容的创作选型,再到文章的排版和辅助工具,希望能帮助大家开启自己的技术内容创作之路。
如何手动丢弃 Prometheus 中的无用指标[3]
对于 Prometheus 这种底层的时间序列数据库来说,规模大了之后,免不了需要一定的手动维护,这对于 Prometheus 的性能至关重要。这篇文章介绍了如何手动删除和丢弃无用的指标。
云原生动态Harbor v2.5.0 引入 Cosign[4]
成品(Artifact)签名和签名验证是关键的安全功能,允许你验证成品的完整性。Harbor 通过与Notary 和 Cosign 的集成支持内容信任。
Harbor v2.5 集成了对 Cosign 的支持,这是一个 OCI 成品签名和验证解决方案,是 Sigstore 项目的一部分。
将 Cosign 与 Harbor 结合使用的一个关键特性是能够使用 Harbor 的复制功能来复制签名及其相关的已签名成品。这意味着,如果一个复制规则(replication rule)应用于一个已签名成品,Harbo 将把复制规则应用于签名,就像它应用于已签名成品一样。
Tanzu 应用平台 1.1 版本发布[5]
Tanzu 应用平台由 VMware 推出,旨在帮助用户在任何公有云或本地 Kubernetes 集群上快速构建和部署软件。Tanzu 应用平台提供了一套丰富的开发人员工具,并为支持生产的企业提供了一条预先铺好的路径,通过降低开发人员工具的复杂性来更快地开发创收应用程序。
1.1 版本提供了大量新功能,使企业能够加快实现价值的时间、简化用户体验、建立更强大的安全态势并保护他们已经进行的投资。这些领先的能力使企业能够:
Kubernetes 1.24 发布推迟[6]
经过一段时间的讨论,发布团队决定将预定的 Kubernetes 1.24 发布日推迟到 2022 年 5 月 3 日星期二。这比 2022 年 4 月 19 日星期二的原定发布日期延迟了两周。
这是阻止发布 bug 的结果。该 bug 将在最新的 Golang 次要版本 Go 1.18.1 中修复,预计将于今天晚些时候发布。由于 Go 发布的延迟,发布团队已采取措施将预定的 Kubernetes 发布日期延长两周,以便有足够的时间进行测试和稳定。
更新的时间表现在是:
4 月 19 日星期二的 1.24.0-rc.0。
4 月 26 日星期二的 1.24.0-rc.1。
1.24.0 于 5 月 3 日星期二正式发布。
WasmEdge 0.9.1 发布了!此版本集成了高性能 networking、JavaScript 流式 SSR 和 Fetch API 支持、新的 bindgen 框架、安卓和 OpenHarmony 操作系统支持、扩展的 Kubernetes 支持以及更好的内存管理。
Flagger 添加了网关 API 支持[7]
Flagger 1.19.0 版本带来了 Kubernetes Gateway API 的支持。
Flagger 是一个渐进式的交付工具,它为运行在 Kubernetes 上的应用程序自动化发布过程。它通过逐步将流量转移到新版本,同时测量指标和运行一致性测试,降低了在生产中引入新软件版本的风险。
由于增加了对 Gateway API 的支持,Flagger 现在可以与所有的实现一起工作,这意味着从今天起,这些都是原生支持:Contour, Emissary-Ingress, Google Kubernetes Engine, HAProxy Ingress, HashiCorp Consul, Istio, Kong and Traefik。
Flagger 团队已经使用 v1beta2 网关 API 成功测试了 Contour 和 Istio。从 Flagger v1.19 开始,网关 API 是使用 Contour 实现的端到端测试套件的一部分。
引用链接[1]
Coolify:
[2]
Podman Desktop:
[3]
如何手动丢弃 Prometheus 中的无用指标:
[4]
Harbor v2.5.0 引入 Cosign:
[5]
Tanzu 应用平台 1.1 版本发布:
[6]
Kubernetes 1.24 发布推迟:
[7]
Flagger 添加了网关 API 支持:
KubeSphere ()是在 Kubernetes 之上构建的开源容器混合云,提供全栈的 IT 自动化运维的能力,简化企业的 DevOps 工作流。
KubeSphere已被Aqara智能家居、爱立信、本来生活、东软、华云、新浪、三一重工、华夏银行、四川航空、国药集团、微众银行、杭州数跑科技、紫金保险、去哪儿网、中通、中国人民银行、中国银行、中国人保寿险、中国太平保险、中国移动、中国联通、中国电信、天翼云、中移金科、Radore、ZaloPay等海内外数千家企业采用。KubeSphere 提供了开发者友好的向导式操作界面和丰富的企业级功能,包括Kubernetes多云与多集群管理、DevOps(CI/CD)、应用生命周期管理、边缘计算、微服务治理(ServiceMesh)、多租户管理、可观测性、存储与网络管理、GPUsupport等功能,帮助企业快速构建一个强大和功能丰富的容器云平台。
✨GitHub:官网(中国站):微信群:请搜索添加群助手微信号kubesphere企业服务:e.cloud
查看全部
云原生爱好者周刊:寻找 Netlify 开源替代品
随着云原生技术的快速发展,技术的不断迭代,对于日志的采集、处理及转发提出了更高的要求。云原生架构下的日志方案相比基于物理机或者是虚拟机场景的日志架构设计存在很大差别。作为 CNCF 的毕业项目,Fluent Bit 无疑为解决云环境中的日志记录问题的首选解决方案之一。但是在 Kubernetes 中安装部署以及配置 Fluent Bit 都具有一定的门槛,加大了用户的使用成本。
本文从写作对个人的价值谈到技术内容的创作选型,再到文章的排版和辅助工具,希望能帮助大家开启自己的技术内容创作之路。
如何手动丢弃 Prometheus 中的无用指标[3]
对于 Prometheus 这种底层的时间序列数据库来说,规模大了之后,免不了需要一定的手动维护,这对于 Prometheus 的性能至关重要。这篇文章介绍了如何手动删除和丢弃无用的指标。
云原生动态Harbor v2.5.0 引入 Cosign[4]
成品(Artifact)签名和签名验证是关键的安全功能,允许你验证成品的完整性。Harbor 通过与Notary 和 Cosign 的集成支持内容信任。
Harbor v2.5 集成了对 Cosign 的支持,这是一个 OCI 成品签名和验证解决方案,是 Sigstore 项目的一部分。
将 Cosign 与 Harbor 结合使用的一个关键特性是能够使用 Harbor 的复制功能来复制签名及其相关的已签名成品。这意味着,如果一个复制规则(replication rule)应用于一个已签名成品,Harbo 将把复制规则应用于签名,就像它应用于已签名成品一样。
Tanzu 应用平台 1.1 版本发布[5]
Tanzu 应用平台由 VMware 推出,旨在帮助用户在任何公有云或本地 Kubernetes 集群上快速构建和部署软件。Tanzu 应用平台提供了一套丰富的开发人员工具,并为支持生产的企业提供了一条预先铺好的路径,通过降低开发人员工具的复杂性来更快地开发创收应用程序。
1.1 版本提供了大量新功能,使企业能够加快实现价值的时间、简化用户体验、建立更强大的安全态势并保护他们已经进行的投资。这些领先的能力使企业能够:
Kubernetes 1.24 发布推迟[6]
经过一段时间的讨论,发布团队决定将预定的 Kubernetes 1.24 发布日推迟到 2022 年 5 月 3 日星期二。这比 2022 年 4 月 19 日星期二的原定发布日期延迟了两周。
这是阻止发布 bug 的结果。该 bug 将在最新的 Golang 次要版本 Go 1.18.1 中修复,预计将于今天晚些时候发布。由于 Go 发布的延迟,发布团队已采取措施将预定的 Kubernetes 发布日期延长两周,以便有足够的时间进行测试和稳定。
更新的时间表现在是:
4 月 19 日星期二的 1.24.0-rc.0。
4 月 26 日星期二的 1.24.0-rc.1。
1.24.0 于 5 月 3 日星期二正式发布。
WasmEdge 0.9.1 发布了!此版本集成了高性能 networking、JavaScript 流式 SSR 和 Fetch API 支持、新的 bindgen 框架、安卓和 OpenHarmony 操作系统支持、扩展的 Kubernetes 支持以及更好的内存管理。
Flagger 添加了网关 API 支持[7]
Flagger 1.19.0 版本带来了 Kubernetes Gateway API 的支持。
Flagger 是一个渐进式的交付工具,它为运行在 Kubernetes 上的应用程序自动化发布过程。它通过逐步将流量转移到新版本,同时测量指标和运行一致性测试,降低了在生产中引入新软件版本的风险。
由于增加了对 Gateway API 的支持,Flagger 现在可以与所有的实现一起工作,这意味着从今天起,这些都是原生支持:Contour, Emissary-Ingress, Google Kubernetes Engine, HAProxy Ingress, HashiCorp Consul, Istio, Kong and Traefik。
Flagger 团队已经使用 v1beta2 网关 API 成功测试了 Contour 和 Istio。从 Flagger v1.19 开始,网关 API 是使用 Contour 实现的端到端测试套件的一部分。
引用链接[1]
Coolify:
[2]
Podman Desktop:
[3]
如何手动丢弃 Prometheus 中的无用指标:
[4]
Harbor v2.5.0 引入 Cosign:
[5]
Tanzu 应用平台 1.1 版本发布:
[6]
Kubernetes 1.24 发布推迟:
[7]
Flagger 添加了网关 API 支持:
KubeSphere ()是在 Kubernetes 之上构建的开源容器混合云,提供全栈的 IT 自动化运维的能力,简化企业的 DevOps 工作流。
KubeSphere已被Aqara智能家居、爱立信、本来生活、东软、华云、新浪、三一重工、华夏银行、四川航空、国药集团、微众银行、杭州数跑科技、紫金保险、去哪儿网、中通、中国人民银行、中国银行、中国人保寿险、中国太平保险、中国移动、中国联通、中国电信、天翼云、中移金科、Radore、ZaloPay等海内外数千家企业采用。KubeSphere 提供了开发者友好的向导式操作界面和丰富的企业级功能,包括Kubernetes多云与多集群管理、DevOps(CI/CD)、应用生命周期管理、边缘计算、微服务治理(ServiceMesh)、多租户管理、可观测性、存储与网络管理、GPUsupport等功能,帮助企业快速构建一个强大和功能丰富的容器云平台。
✨GitHub:官网(中国站):微信群:请搜索添加群助手微信号kubesphere企业服务:e.cloud
须臾现码虫,一键纳乾坤——Hubble在微盟微前端中的应用
采集交流 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-04-29 20:30
通过Hubble的使用可以在一定程度上减少测试与研发在提bug、定位问题上的沟通的成本,测试同学不用大段文字描述,研发同学能够直观地通过回放观看bug出现的情况,以及根据接口或者报错信息快速定位问题以及复现bug。四、功能解析1.接入apm为了能记录到接口请求的记录,自行实现了一个rrweb插件,通过对浏览器原生的xhr 和 fetch api的覆写,以实现请求信息的AOP。鉴于已存在APM系统,所以不对接口请求的请求体和响应体进行记录,只记录下接口header中的apm trace id,在回放的时候可以通过这个trace id直接跳转到APM系统中,来查看请求信息,协助排查和定位问题。2.调试网页免登录Hubble的免登录功能,是通过采集cookies中的saasAuth token来实现的。在管理页面点击免登录查看时,会跳转到带hubble特殊查询参数的url,然后加载hubble时根据查询参数判断是免登录查看模式的话,将url中带有的token写入到cookies中,然后跳转到不带特殊参数的页面上,以实现跳过登录环节完成鉴权。需要在页面调用其他接口前完成Hubble的加载与判断。token有时效性,可能会出现失效情况。为了避免非手动退出来切换账号所产生的混乱,建议打开新的无痕窗口后粘贴免登录链接查看。3.裁剪功能在解决录制片段过长的角度上,借助归一化的概念,可以将裁剪到的所需时间段以外的事件,压缩到一段比较短的时间内去播放,这样就能实现近似裁剪功能了。
但是这属于比较取巧的方案,后续会尝试直接合并增量数据到全量snapshot数据上,这样既能减少采集到的数据量,同时减轻刚开始播放时的处理器计算压力。4.未捕获错误采集通过对window.onerror、unrejectionhandler和error事件的监听,并将采集到的错误信息以自定义事件的形式插入到rrweb的record序列中,在回放时就可以通过面板查看到错误信息,辅助定位问题。五、遇到的问题1.样式泄漏处理在开发使用过程中,Hubble的浏览器端出现了样式污染的问题,除了对自己编写的组件内的过于普遍的样式名进行更改之外,还需要对整个Hubble进行css的scope化。这里使用了部门内实现的postcss插件,在遍历css rules的时候(使用postcss的walkRules API),对规则内的所有css选择器前面,添加了一个当前包名 .${packageJson.name} 的一个类作为父选择器,同时在Hubble挂载的dom上也加上了这个className。同时,在一些使用了css变量的UI组件库,有些会将css变量定义在 :root 上,这是一个全局的伪类,如果不进行处理的话,css变量会泄漏并污染到全局。
于是在上述的postcss插件中也加入了:root 到 作用域类名替换的规则。2.打包加载优化为了优化初始化速度(更快进入录制状态)和防止大体积bundle加载带来的阻塞,且后续能支持插件化、sdk可拼装,打包形式上从iife改为system。这样在初始加载时能够优先加载主要功能并运行起来,ui部分进行延迟加载;同时拆解成system形式的包之后,后续可以根据配置来动态加载功能,预留出扩展能力。六、未来预计添加的功能1.开放接入能力基于systemjs的动态加载脚本的能力,Hubble可以通过配置来动态加载插件。后续考虑在这基础上开放出一些api以及自定义插件功能,比如可以使用hubble的addCustomEvent API来添加自定义事件,或者采集静态数据直接上传到hubble的后端。2.涂鸦评论功能在录制的记录上,有时候需要给录制到的内容进行标注评论以辅助传递信息,增强理解。现计划在后续添加涂鸦评论功能。涂鸦基于canvas,可以提交面板上编辑,记录下打标注的地方以及持续时长,也考虑添加图层功能来支持更复杂的标注能力。七、扩展阅读Hubble主要是围绕rrweb 这个dom录制框架进行开发的。
rrweb是通过MutationObserver API来监听页面上dom的变动,以及用户输入的各种操作事件进行捕获采集,然后通过rrweb的DOM序列化算法将DOM结构json化,以及事件行为的格式化,形成一个变动更新列表,然后在回放的时候,通过将序列化的dom数据通过rebuild,和事件行为的重放,重现在一个iframe沙盒中,来实现页面操作的回放。其中,rrweb主要有这些事件类型:dom加载完成、加载、全量快照、增量快照、元数据、自定义事件、插件事件。而其中的增量快照则有这些数据来源:dom Mutation、鼠标键盘滚轮触摸等操作、窗口resize、输入框输入、样式变动等。录制开始后,rrweb会将每次dom变动,监听到的事件,自定义触发事件等录制到的数据通过一个数组来保存,每个事件对应着一个事件对象,其中含有触发时的时间戳、事件类型、内容载体payload等。在rrweb上生成一个dom的全量快照时,会给当前的dom元素一个个分配一个id,用来记录和追踪其变化。当增量数据中dom的变动要apply到snapshot对应的dom树上时,会根据id查找出目标dom节点,将MutationObserver 监听到的dom变化应用到数据模型上。
(rrweb维护了一个node Map,以方便快速查找到节点)当在播放器进行操作时,比如进行时间跳转(goto),会通过状态机和事件管道,先暂停再调用播放。调用播放函数时传入了跳转的timeOffset,这时会进行如下处理:暂停时会记录播放的最后event,然后再开始时,首先会计算出跳转后的时间偏移量,来定义一个基准时间戳(跳转后的时间戳)。对于小于基准时间戳的事件,会以同步的方式全部apply起来,而剩余的事件则是用定时器触发。同时,会把基准事件戳与上次播放的最后的event中含有的时间戳进行比对,如果往前跳则清除节点Map数据,以同步方式重新计算;如果是往后跳则将同步计算的结果合并到已有的节点Map上。在定时器的使用上,由于setInterval会受到性能等各方面影响,这种事件定时器在精度上不能满足需求。于是rrweb使用了requestAnimationFrame的API来作为定时器(机制上因为不受到eventloop的影响,精度能达到1ms级别),使用performance.now()来作为获取每次触发定时器callback的时间偏移量(减去初始值),从而准确地触发rrweb待播放List中的事件。八、结语不通过口述或者截图等方式、而是通过录屏的方式进行记录,同时可以记录接口等数据,这样可以在复现前端场景上节省沟通成本、快速定位问题,从而提高效率。我们也会在后续的迭代中,寻找合适的场景落地,尝试更多方案,助力开发提效。 查看全部
须臾现码虫,一键纳乾坤——Hubble在微盟微前端中的应用
通过Hubble的使用可以在一定程度上减少测试与研发在提bug、定位问题上的沟通的成本,测试同学不用大段文字描述,研发同学能够直观地通过回放观看bug出现的情况,以及根据接口或者报错信息快速定位问题以及复现bug。四、功能解析1.接入apm为了能记录到接口请求的记录,自行实现了一个rrweb插件,通过对浏览器原生的xhr 和 fetch api的覆写,以实现请求信息的AOP。鉴于已存在APM系统,所以不对接口请求的请求体和响应体进行记录,只记录下接口header中的apm trace id,在回放的时候可以通过这个trace id直接跳转到APM系统中,来查看请求信息,协助排查和定位问题。2.调试网页免登录Hubble的免登录功能,是通过采集cookies中的saasAuth token来实现的。在管理页面点击免登录查看时,会跳转到带hubble特殊查询参数的url,然后加载hubble时根据查询参数判断是免登录查看模式的话,将url中带有的token写入到cookies中,然后跳转到不带特殊参数的页面上,以实现跳过登录环节完成鉴权。需要在页面调用其他接口前完成Hubble的加载与判断。token有时效性,可能会出现失效情况。为了避免非手动退出来切换账号所产生的混乱,建议打开新的无痕窗口后粘贴免登录链接查看。3.裁剪功能在解决录制片段过长的角度上,借助归一化的概念,可以将裁剪到的所需时间段以外的事件,压缩到一段比较短的时间内去播放,这样就能实现近似裁剪功能了。
但是这属于比较取巧的方案,后续会尝试直接合并增量数据到全量snapshot数据上,这样既能减少采集到的数据量,同时减轻刚开始播放时的处理器计算压力。4.未捕获错误采集通过对window.onerror、unrejectionhandler和error事件的监听,并将采集到的错误信息以自定义事件的形式插入到rrweb的record序列中,在回放时就可以通过面板查看到错误信息,辅助定位问题。五、遇到的问题1.样式泄漏处理在开发使用过程中,Hubble的浏览器端出现了样式污染的问题,除了对自己编写的组件内的过于普遍的样式名进行更改之外,还需要对整个Hubble进行css的scope化。这里使用了部门内实现的postcss插件,在遍历css rules的时候(使用postcss的walkRules API),对规则内的所有css选择器前面,添加了一个当前包名 .${packageJson.name} 的一个类作为父选择器,同时在Hubble挂载的dom上也加上了这个className。同时,在一些使用了css变量的UI组件库,有些会将css变量定义在 :root 上,这是一个全局的伪类,如果不进行处理的话,css变量会泄漏并污染到全局。
于是在上述的postcss插件中也加入了:root 到 作用域类名替换的规则。2.打包加载优化为了优化初始化速度(更快进入录制状态)和防止大体积bundle加载带来的阻塞,且后续能支持插件化、sdk可拼装,打包形式上从iife改为system。这样在初始加载时能够优先加载主要功能并运行起来,ui部分进行延迟加载;同时拆解成system形式的包之后,后续可以根据配置来动态加载功能,预留出扩展能力。六、未来预计添加的功能1.开放接入能力基于systemjs的动态加载脚本的能力,Hubble可以通过配置来动态加载插件。后续考虑在这基础上开放出一些api以及自定义插件功能,比如可以使用hubble的addCustomEvent API来添加自定义事件,或者采集静态数据直接上传到hubble的后端。2.涂鸦评论功能在录制的记录上,有时候需要给录制到的内容进行标注评论以辅助传递信息,增强理解。现计划在后续添加涂鸦评论功能。涂鸦基于canvas,可以提交面板上编辑,记录下打标注的地方以及持续时长,也考虑添加图层功能来支持更复杂的标注能力。七、扩展阅读Hubble主要是围绕rrweb 这个dom录制框架进行开发的。
rrweb是通过MutationObserver API来监听页面上dom的变动,以及用户输入的各种操作事件进行捕获采集,然后通过rrweb的DOM序列化算法将DOM结构json化,以及事件行为的格式化,形成一个变动更新列表,然后在回放的时候,通过将序列化的dom数据通过rebuild,和事件行为的重放,重现在一个iframe沙盒中,来实现页面操作的回放。其中,rrweb主要有这些事件类型:dom加载完成、加载、全量快照、增量快照、元数据、自定义事件、插件事件。而其中的增量快照则有这些数据来源:dom Mutation、鼠标键盘滚轮触摸等操作、窗口resize、输入框输入、样式变动等。录制开始后,rrweb会将每次dom变动,监听到的事件,自定义触发事件等录制到的数据通过一个数组来保存,每个事件对应着一个事件对象,其中含有触发时的时间戳、事件类型、内容载体payload等。在rrweb上生成一个dom的全量快照时,会给当前的dom元素一个个分配一个id,用来记录和追踪其变化。当增量数据中dom的变动要apply到snapshot对应的dom树上时,会根据id查找出目标dom节点,将MutationObserver 监听到的dom变化应用到数据模型上。
(rrweb维护了一个node Map,以方便快速查找到节点)当在播放器进行操作时,比如进行时间跳转(goto),会通过状态机和事件管道,先暂停再调用播放。调用播放函数时传入了跳转的timeOffset,这时会进行如下处理:暂停时会记录播放的最后event,然后再开始时,首先会计算出跳转后的时间偏移量,来定义一个基准时间戳(跳转后的时间戳)。对于小于基准时间戳的事件,会以同步的方式全部apply起来,而剩余的事件则是用定时器触发。同时,会把基准事件戳与上次播放的最后的event中含有的时间戳进行比对,如果往前跳则清除节点Map数据,以同步方式重新计算;如果是往后跳则将同步计算的结果合并到已有的节点Map上。在定时器的使用上,由于setInterval会受到性能等各方面影响,这种事件定时器在精度上不能满足需求。于是rrweb使用了requestAnimationFrame的API来作为定时器(机制上因为不受到eventloop的影响,精度能达到1ms级别),使用performance.now()来作为获取每次触发定时器callback的时间偏移量(减去初始值),从而准确地触发rrweb待播放List中的事件。八、结语不通过口述或者截图等方式、而是通过录屏的方式进行记录,同时可以记录接口等数据,这样可以在复现前端场景上节省沟通成本、快速定位问题,从而提高效率。我们也会在后续的迭代中,寻找合适的场景落地,尝试更多方案,助力开发提效。
京东到家自动化测试平台的探索与实践
采集交流 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-04-28 20:45
HTTP服务的流量复制可以通过一些代理工具来实现。Mitmproxy是一款免费、开放的基于Python开发的交互式HTTPS代理工具。它可以用来捕获HTTP/HTTPS请求,支持抓包、断点调试、请求替换、构造请求、模拟弱网等功能。
工作原理如下:
流量复制的实现具体可以分为以下几个步骤:
1. 在电脑或手机端配置Mitmproxy代理服务器地址,此时电脑或手机的所有请求都通过代理服务器进行请求发出,当请求响应结束后,代理服务器识别出我们需要拦截的请求,并将请求和响应结果转发到我们的自动化测试平台;2. 测试平台收到代理服务器转发过来的请求和响应结果后,会将数据按照服务维度进行分类,作为初步的种子用例,持久化到数据库中;3. 测试人员依据种子用例,转换成正式的测试用例;
下图代码片段是按域名截取数据后,整合平台所需要的数据和数据格式:
效果展示
2.2 微服务流量复制
微服务的流量复制我们是通过自研客户端+配置采集规则来实现的。规则配置
交互逻辑
具体实现步骤如下:
1. 管理端配置服务的采集规则;2. 客户端定时拉取采集规则;3. 符合采集规则,则将请求入参和出参写入本地文件;4. 客户端定期上报流量采集内容到精卫平台;5. 按照服务,时间段等维度圈出要回归的流量用例,生成回归任务;6. 执行任务,进行流量回放;7. 生成流量回放的测试报告;如果之前没有维护过测试用例,也可以通过开启流量复制功能来快速的实现回归测试;总之,通过流量复制,将线上的真实流量引入到灰度测试环境中进行回放,不仅能够降低人工参与的成本,还可以更加真实的还原线上场景,使问题更加高效客观的呈现。
2.3 自动生成种子用例
在用例维护过程当中,如何快速生成一个正确的样本示例是我们经常面临的问题。为了解决这个问题我们搭建了API接口文档管理平台。这个平台目的主要是将服务定义元数据进行实时的线上化管理,可以随时可查看各个部署版本的接口定义元数据(包括版本、入参、类型、格式、示例等)。基于线上化的接口定义智能生成最新的入参结构,支持微服务和HTTP等协议。
在创建用例时,精卫平台会拉取服务的方法和接口定义的相关信息(入参定义,出参定义,参数示例),解析参数结构,快速生成种子用例,提高新用例的创建效率。
一个完整的新用例的创建过程如下:
1.选择所需的种子用例;
2.调整入参数据;3.补全用例名称、用途等信息;4.设置断言检查点等信息;
2.4收益评估
1. 测试人员不需要再进行抓包,查日志来获取自动化测试数据,减少了30%左右用来创建测试用例的时间;2. 可以实时获取最新的接口定义元数据,避免了接口定义的不准确性,同时降低了线下跟研发获取接口定义的时间成本;3. 通过预设的断言配置,用例执行结果的正确性检查借助平台实现了自动化,大幅度提升了测试效率;三、自动化回归测试精卫平台的自动化回归测试分为接口自动化和流程自动化两个维度。下面将从这两个部分来介绍。3.1接口自动化接口测试是测试系统组件间接口的一种测试方式,主要用于检测系统内部、系统间的交互点,常作为功能测试的基本单元。接口自动化就是将一批接口测试用例打包并自动执行,以达到节省人力、时间、资源成本,快速验证回归测试服务正确性,提升测试效率的目的。
3.1.1 设计方案
自动化回归测试依托于持续集成部署平台,当服务部署发布后,借助api接口文档管理平台,可以自动识别出变更的服务方法,触发自动化回归测试任务,自动回归有代码变更方法的用例。
3.1.2 执行过程
1. 用例录制:接口自动化回归的前提条件是已经拥有了测试用例;2. 圈定回归范围:同一接口的测试用例按照用途会分为多组,比如:单元测试用例,回归测试用例,压测用例等,圈定出录制的回归测试用例;
3. 创建回归测试任务:支持全量/增量回归,全量回归可以进行代码覆盖率的统计;4. 执行回归测试任务:当服务部署后,自动触发回归任务的执行;5. 生成测试报告:任务用例执行完成后,会生成一份测试报告,报告中含用例通过率、代码覆盖率、问题处理建议等信息;
3.1.3成果收益
接口自动化测试减少了测试的执行时间,降低了回归测试的实现门槛,有效的缩短了产品交付周期,测试人员有更多的时间和精力投入到产品业务本身上面去。3.2 流程自动化速搭平台是京东到家为研发和测试人员提供的一站式服务发布平台,其核心是通过我们现有能力(微服务或http服务)的再次加工(编排),形成新的能力,精卫平台借助此能力实现流程自动化测试。
3.2.1 设计方案
业务架构图
3.2.2执行过程
1. 构建步骤:步骤是组成流程的最小执行单元,单个步骤可以理解为一个服务;2. 构建流程:把各个步骤按照业务逻辑编排起来构成流程;
3. 设计流程用例:定义流程入参、设置断言,创建流程用例;
4. 构建流程任务:按照业务圈定要执行的流程用例,以任务的方式集中执行;
5. 执行流程任务:支持手动触发和定时执行等方式,以达到回归或巡检的目的;
6. 任务执行报告:通过率、代码覆盖率、执行结果日志等报告信息,如有异常情况发送告警通知。
3.2.3 成果收益
1. 已经初步完成核心场景的全覆盖自动回归,在需求迭代效率上有了很大的提升;2. 流程测试与用户真实操作更相近,可以更好的站着用户的角度验证产品,利用黄金流程的实时巡检机制,系统在稳定性方面也得到了更好的保障;3.3 回归机制不同的场景下回归的机制会有所不同。比如:3.3.1 一键回归
研发发起提测后,针对圈定的服务和方法可以进行一键全量/增量的回归测试。
3.3.2 自动回归自动回归测试的触发方式有部署后自动回归,线上的定时巡检等场景。1. 日常巡检平台支持cron表达式,对多任务、多用例进行定时执行,并在失败或者异常后进行预警。
2. 应用部署后自动回归支持全量和增量回归。应用部署后,对API文档变更的内容进行自动回归、生成测试报告,在失败或者异常时进行预警。四、提升测试质量测试质量的把控可以从技术和流程两个方面来考虑,技术层面主要依赖于度量指标的提升(用例通过率,代码覆盖率等),流程方面可以通过设置质量门禁等方式来保证提测质量。4.1 代码覆盖率代码覆盖率是软件测试中的一种度量,描述程序中源代码被测试的比例和程度,所得比例称为代码覆盖率。平台实现原理:
实现方式可参照另一篇文章:《》
4.2 设置质量门禁根据测试金字塔模型,我们知道问题越早暴露,解决问题的成本越低。单元测试的充分性是提高整个测试效率的关键,设置质量门禁(单元测试通过率)是保证提测质量的重要手段。如何设置质量门禁的呢?我们具体来看一下整个提测流程:1. 维护单元测试用例:研发维护服务的单元测试用例;2. 圈定提测范围:研发选择要回归的服务列表;
3. 生成单元测试任务:根据圈定的服务列表,筛选出对应的单元你测试用例,生成单元测试任务;4. 执行测试任务:批量执行单元测试用例,达到设置的门禁标准(通过率,覆盖率等)才可进入测试环节;
5. 进入测试流程:达到提测标准后,进入正式测试环节,测试人员针对提测服务和测试重点进行针对性的测试。
五、总结及其它5.1总结精卫平台作为实现持续集成/发布(CI/CD)的基础设施,其目标是保证代码具备随时可以发布到线上的良好状态,维持团队的持续交付能力。另外,平台在效率提升方面也取得了显著效果:
5.2展望软件度量是对软件开发项目、过程、及其产品进行数据定义、收集以及分析的持续性量化过程。通过软件度量可以改进软件开发过程,促进项目成功,开发高质量的软件产品。平台将继续对整个产品交付过程中的指标数据进行整理、挖掘,发现过程中存在的问题和短板,优化和反哺产品交付流程,在效率和稳定性等方面获得更大的突破。5.3附录
平台架构
核心流程
查看全部
京东到家自动化测试平台的探索与实践
HTTP服务的流量复制可以通过一些代理工具来实现。Mitmproxy是一款免费、开放的基于Python开发的交互式HTTPS代理工具。它可以用来捕获HTTP/HTTPS请求,支持抓包、断点调试、请求替换、构造请求、模拟弱网等功能。
工作原理如下:
流量复制的实现具体可以分为以下几个步骤:
1. 在电脑或手机端配置Mitmproxy代理服务器地址,此时电脑或手机的所有请求都通过代理服务器进行请求发出,当请求响应结束后,代理服务器识别出我们需要拦截的请求,并将请求和响应结果转发到我们的自动化测试平台;2. 测试平台收到代理服务器转发过来的请求和响应结果后,会将数据按照服务维度进行分类,作为初步的种子用例,持久化到数据库中;3. 测试人员依据种子用例,转换成正式的测试用例;
下图代码片段是按域名截取数据后,整合平台所需要的数据和数据格式:
效果展示
2.2 微服务流量复制
微服务的流量复制我们是通过自研客户端+配置采集规则来实现的。规则配置
交互逻辑
具体实现步骤如下:
1. 管理端配置服务的采集规则;2. 客户端定时拉取采集规则;3. 符合采集规则,则将请求入参和出参写入本地文件;4. 客户端定期上报流量采集内容到精卫平台;5. 按照服务,时间段等维度圈出要回归的流量用例,生成回归任务;6. 执行任务,进行流量回放;7. 生成流量回放的测试报告;如果之前没有维护过测试用例,也可以通过开启流量复制功能来快速的实现回归测试;总之,通过流量复制,将线上的真实流量引入到灰度测试环境中进行回放,不仅能够降低人工参与的成本,还可以更加真实的还原线上场景,使问题更加高效客观的呈现。
2.3 自动生成种子用例
在用例维护过程当中,如何快速生成一个正确的样本示例是我们经常面临的问题。为了解决这个问题我们搭建了API接口文档管理平台。这个平台目的主要是将服务定义元数据进行实时的线上化管理,可以随时可查看各个部署版本的接口定义元数据(包括版本、入参、类型、格式、示例等)。基于线上化的接口定义智能生成最新的入参结构,支持微服务和HTTP等协议。
在创建用例时,精卫平台会拉取服务的方法和接口定义的相关信息(入参定义,出参定义,参数示例),解析参数结构,快速生成种子用例,提高新用例的创建效率。
一个完整的新用例的创建过程如下:
1.选择所需的种子用例;
2.调整入参数据;3.补全用例名称、用途等信息;4.设置断言检查点等信息;
2.4收益评估
1. 测试人员不需要再进行抓包,查日志来获取自动化测试数据,减少了30%左右用来创建测试用例的时间;2. 可以实时获取最新的接口定义元数据,避免了接口定义的不准确性,同时降低了线下跟研发获取接口定义的时间成本;3. 通过预设的断言配置,用例执行结果的正确性检查借助平台实现了自动化,大幅度提升了测试效率;三、自动化回归测试精卫平台的自动化回归测试分为接口自动化和流程自动化两个维度。下面将从这两个部分来介绍。3.1接口自动化接口测试是测试系统组件间接口的一种测试方式,主要用于检测系统内部、系统间的交互点,常作为功能测试的基本单元。接口自动化就是将一批接口测试用例打包并自动执行,以达到节省人力、时间、资源成本,快速验证回归测试服务正确性,提升测试效率的目的。
3.1.1 设计方案
自动化回归测试依托于持续集成部署平台,当服务部署发布后,借助api接口文档管理平台,可以自动识别出变更的服务方法,触发自动化回归测试任务,自动回归有代码变更方法的用例。
3.1.2 执行过程
1. 用例录制:接口自动化回归的前提条件是已经拥有了测试用例;2. 圈定回归范围:同一接口的测试用例按照用途会分为多组,比如:单元测试用例,回归测试用例,压测用例等,圈定出录制的回归测试用例;
3. 创建回归测试任务:支持全量/增量回归,全量回归可以进行代码覆盖率的统计;4. 执行回归测试任务:当服务部署后,自动触发回归任务的执行;5. 生成测试报告:任务用例执行完成后,会生成一份测试报告,报告中含用例通过率、代码覆盖率、问题处理建议等信息;
3.1.3成果收益
接口自动化测试减少了测试的执行时间,降低了回归测试的实现门槛,有效的缩短了产品交付周期,测试人员有更多的时间和精力投入到产品业务本身上面去。3.2 流程自动化速搭平台是京东到家为研发和测试人员提供的一站式服务发布平台,其核心是通过我们现有能力(微服务或http服务)的再次加工(编排),形成新的能力,精卫平台借助此能力实现流程自动化测试。
3.2.1 设计方案
业务架构图
3.2.2执行过程
1. 构建步骤:步骤是组成流程的最小执行单元,单个步骤可以理解为一个服务;2. 构建流程:把各个步骤按照业务逻辑编排起来构成流程;
3. 设计流程用例:定义流程入参、设置断言,创建流程用例;
4. 构建流程任务:按照业务圈定要执行的流程用例,以任务的方式集中执行;
5. 执行流程任务:支持手动触发和定时执行等方式,以达到回归或巡检的目的;
6. 任务执行报告:通过率、代码覆盖率、执行结果日志等报告信息,如有异常情况发送告警通知。
3.2.3 成果收益
1. 已经初步完成核心场景的全覆盖自动回归,在需求迭代效率上有了很大的提升;2. 流程测试与用户真实操作更相近,可以更好的站着用户的角度验证产品,利用黄金流程的实时巡检机制,系统在稳定性方面也得到了更好的保障;3.3 回归机制不同的场景下回归的机制会有所不同。比如:3.3.1 一键回归
研发发起提测后,针对圈定的服务和方法可以进行一键全量/增量的回归测试。
3.3.2 自动回归自动回归测试的触发方式有部署后自动回归,线上的定时巡检等场景。1. 日常巡检平台支持cron表达式,对多任务、多用例进行定时执行,并在失败或者异常后进行预警。
2. 应用部署后自动回归支持全量和增量回归。应用部署后,对API文档变更的内容进行自动回归、生成测试报告,在失败或者异常时进行预警。四、提升测试质量测试质量的把控可以从技术和流程两个方面来考虑,技术层面主要依赖于度量指标的提升(用例通过率,代码覆盖率等),流程方面可以通过设置质量门禁等方式来保证提测质量。4.1 代码覆盖率代码覆盖率是软件测试中的一种度量,描述程序中源代码被测试的比例和程度,所得比例称为代码覆盖率。平台实现原理:
实现方式可参照另一篇文章:《》
4.2 设置质量门禁根据测试金字塔模型,我们知道问题越早暴露,解决问题的成本越低。单元测试的充分性是提高整个测试效率的关键,设置质量门禁(单元测试通过率)是保证提测质量的重要手段。如何设置质量门禁的呢?我们具体来看一下整个提测流程:1. 维护单元测试用例:研发维护服务的单元测试用例;2. 圈定提测范围:研发选择要回归的服务列表;
3. 生成单元测试任务:根据圈定的服务列表,筛选出对应的单元你测试用例,生成单元测试任务;4. 执行测试任务:批量执行单元测试用例,达到设置的门禁标准(通过率,覆盖率等)才可进入测试环节;
5. 进入测试流程:达到提测标准后,进入正式测试环节,测试人员针对提测服务和测试重点进行针对性的测试。
五、总结及其它5.1总结精卫平台作为实现持续集成/发布(CI/CD)的基础设施,其目标是保证代码具备随时可以发布到线上的良好状态,维持团队的持续交付能力。另外,平台在效率提升方面也取得了显著效果:
5.2展望软件度量是对软件开发项目、过程、及其产品进行数据定义、收集以及分析的持续性量化过程。通过软件度量可以改进软件开发过程,促进项目成功,开发高质量的软件产品。平台将继续对整个产品交付过程中的指标数据进行整理、挖掘,发现过程中存在的问题和短板,优化和反哺产品交付流程,在效率和稳定性等方面获得更大的突破。5.3附录
平台架构
核心流程
没有数据治理思维,数字化转型就是“白忙活”
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-04-28 13:34
BUT,数据资产能怎么用?为什么无数据可用,或无可用数据?怎样开展数据治理?则是一头雾水。这也导致很多企业的数字化转型“白忙活一场”、“从头再来”的重要原因。
《报告》依据数据治理及管理组织各层级所关注的侧重点,图谱将工具划分为三层——战略层、管理层、操作层。
01/战略层工具为提供数据质量战略规划、评估、知道、监控的工具或功能,主要包括五大过程域:组织与职责、体系与制度、团队与文化、计划与监控、成本与评估。1. 组织与职责对数据治理组织及其职责进行规划、管理。
2. 体系与制度对数据治理相关体系、制度、流程进行管理、发布。
3. 团队与文化提供数据治理文化发布、查询、学习培训等。
4. 计划与监控
提供数据治理项目管理及监控。
5.成效与评估
对治理成效提供评估依据及评估行为。
02/
管理层工具
为应落实数据治理战略而进行的数据管理活动的工具或功能。主要包括八大过程域:
数据架构管理、元数据管理、数据标准管理、主数据管理、数据质量管理、数据资产管理、数据安全管理、数据生存周期管理。
1.数据架构管理提供数据架构规划、设计相关工具及功能,包括数据层次、数据模型和数据流向设计。
2.元数据管理提供统一的企业元数据存储库,支持相关血缘、影响分析及变更管理的监控。
3.数据标准管理提供统一的指标数据技术标准、 业务标准、管理标准的视图,具备基本的增删改查及废止功能,可进行标准符合性检测。
4.主数据管理提供对企业主数据、参考数据统一管理, 支持主数据模型定义、数据约束及分发策略的管理。
5.数据质量管理支持对数据质量建立质量规则,支持数据治理评估,并生成质量报告,提供质量整改机制。
6.数据资产管理提供企业以资产价值视角的数据管理功能,包括资产索引、资产开发、资产服务等功能。
7.数据安全管理支持对数据进行安全分级分类,定期监督和执行数据安全策略执行情况。
8.数据生存周期管理对数据进行生存周期管理,定期监督和检查数据归档和销毁策略执行情况。
03/
操作层工具
数据操作层主要包括六大过程域:数据存储工具、数据采集工具、数据处理工具、数据共享交换工具、AI计算支撑工具、数据分析应用工具。
1.数据存储工具
基于数据治理战略及数据架构、数据标准、元数据、质量等管理要求,对数据进行存储。包括分布式存储、传统关系型存储、文件存储及图数据库存储。
2.数据采集工具基于数据治理战略要求,完成相关数据采集工作。支持不同采集方式及频率,包括实时采集、离线采集、报表填报采集、API采集等。
3.数据处理工具基于数据质量、标准、数据架构等要求,对数据进行加工、转换、清洗、集中等工作。
4.数据共享交换工具
基于业务与之间的数据共享需求,对不同异构数据执行交换或服务。包括文件、库表、接口、实时流等。
5.Al计算支撑工具将人工智能技术运用到数据采集、处理、共享、评估、度量等活动中。
6.数据分析应用工具通过数据可视化、报表等工具完成数据治理的报告、诊断分析、监控图表等的开发制作。
《数据治理工具图谱研究报告》对上述工具能力图谱进行了详细解释,除全景图外,报告对每层工具能力要素进行了更细一步的绘制,并收录了部分行业案例采用的工具架构图。
报告共研制、收录了26个图谱,其中研制了20个通用工具能力图谱,收录了6个数据治理案例工具能力图谱。 查看全部
当前这个时代,人人都知道数据,或多或少也知道数据是资产,治理好了很有用,毕竟企业数字化转型的始终离不开“数据”,始于数据,最终也是为了数据。
BUT,数据资产能怎么用?为什么无数据可用,或无可用数据?怎样开展数据治理?则是一头雾水。这也导致很多企业的数字化转型“白忙活一场”、“从头再来”的重要原因。
《报告》依据数据治理及管理组织各层级所关注的侧重点,图谱将工具划分为三层——战略层、管理层、操作层。
01/战略层工具为提供数据质量战略规划、评估、知道、监控的工具或功能,主要包括五大过程域:组织与职责、体系与制度、团队与文化、计划与监控、成本与评估。1. 组织与职责对数据治理组织及其职责进行规划、管理。
2. 体系与制度对数据治理相关体系、制度、流程进行管理、发布。
3. 团队与文化提供数据治理文化发布、查询、学习培训等。
4. 计划与监控
提供数据治理项目管理及监控。
5.成效与评估
对治理成效提供评估依据及评估行为。
02/
管理层工具
为应落实数据治理战略而进行的数据管理活动的工具或功能。主要包括八大过程域:
数据架构管理、元数据管理、数据标准管理、主数据管理、数据质量管理、数据资产管理、数据安全管理、数据生存周期管理。
1.数据架构管理提供数据架构规划、设计相关工具及功能,包括数据层次、数据模型和数据流向设计。
2.元数据管理提供统一的企业元数据存储库,支持相关血缘、影响分析及变更管理的监控。
3.数据标准管理提供统一的指标数据技术标准、 业务标准、管理标准的视图,具备基本的增删改查及废止功能,可进行标准符合性检测。
4.主数据管理提供对企业主数据、参考数据统一管理, 支持主数据模型定义、数据约束及分发策略的管理。
5.数据质量管理支持对数据质量建立质量规则,支持数据治理评估,并生成质量报告,提供质量整改机制。
6.数据资产管理提供企业以资产价值视角的数据管理功能,包括资产索引、资产开发、资产服务等功能。
7.数据安全管理支持对数据进行安全分级分类,定期监督和执行数据安全策略执行情况。
8.数据生存周期管理对数据进行生存周期管理,定期监督和检查数据归档和销毁策略执行情况。
03/
操作层工具
数据操作层主要包括六大过程域:数据存储工具、数据采集工具、数据处理工具、数据共享交换工具、AI计算支撑工具、数据分析应用工具。
1.数据存储工具
基于数据治理战略及数据架构、数据标准、元数据、质量等管理要求,对数据进行存储。包括分布式存储、传统关系型存储、文件存储及图数据库存储。
2.数据采集工具基于数据治理战略要求,完成相关数据采集工作。支持不同采集方式及频率,包括实时采集、离线采集、报表填报采集、API采集等。
3.数据处理工具基于数据质量、标准、数据架构等要求,对数据进行加工、转换、清洗、集中等工作。
4.数据共享交换工具
基于业务与之间的数据共享需求,对不同异构数据执行交换或服务。包括文件、库表、接口、实时流等。
5.Al计算支撑工具将人工智能技术运用到数据采集、处理、共享、评估、度量等活动中。
6.数据分析应用工具通过数据可视化、报表等工具完成数据治理的报告、诊断分析、监控图表等的开发制作。
《数据治理工具图谱研究报告》对上述工具能力图谱进行了详细解释,除全景图外,报告对每层工具能力要素进行了更细一步的绘制,并收录了部分行业案例采用的工具架构图。
报告共研制、收录了26个图谱,其中研制了20个通用工具能力图谱,收录了6个数据治理案例工具能力图谱。
文章采集api(优采云采集支持调用优采云(小狗AI)API接口及解决方案 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2022-04-19 09:28
)
优采云采集支持调用优采云(小狗AI)API接口处理采集的数据标题和内容、关键词、描述等。可以针对性的配合优采云采集的SEO功能和5118智能换词API,处理原创度数更高的文章。@收录 和 网站 权重起着非常重要的作用。
购买优采云(小狗AI)API,建议先咨询优采云(小狗AI)客服,并告知在优采云采集上使用@> 平台;
详细使用步骤优采云API接口配置创建API处理规则API处理规则使用API处理结果并发布优采云-API接口常见问题及解决方案
1. 优采云API接口配置
一、API配置入口:
点击控制台左侧列表中的【第三方服务配置】==点击【第三方内容API接入】==点击【第三方API配置管理】==最后点击【+< @优采云API] 创建接口配置;
二、配置API接口信息:
购买优采云(小狗AI)API,建议先咨询优采云(小狗AI)客服,并告知在优采云采集上使用@> 平台。
【API key】是从优采云(Puppy AI)后台获取对应的API key,填写后记得保存;
2. 创建 API 处理规则
API处理规则,可以通过调用API接口设置处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==,点击【第三方内容API接入】==进入【API处理规则管理】页面,最后点击【+添加API处理规则]创建API处理规则;
二、API处理规则配置:
3. API 处理规则使用
API处理规则有两种使用方式:手动执行和自动执行:
一、手动执行API处理规则:
在采集任务的【结果数据&发布】选项卡中,点击【SEO&API&翻译等工具】按钮==>选择【第三方API执行】栏==>选择对应的API处理规则= => 执行;
二、自动执行API处理规则:
启用 API 处理的自动执行。任务完成后采集会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡【自动执行第三方API配置】==勾选【采集,自动执行API】选项==选择要执行的API处理规则= ="选择API接口处理的数据范围(一般选择'待发布',都将导致所有数据重复执行),最后点击保存;
4. API 处理结果并发布
一、查看API接口处理结果:
API接口处理的内容会保存为一个新的字段,如:标题处理后的新字段:title_优采云,内容处理后的新字段:content_优采云,在[Result Data & Publish ]和数据预览界面可以查看。
二、发布API接口处理后的内容:
发布文章前,修改发布目标的第二步映射字段,重新选择标题和内容到API接口处理后添加的对应字段title_优采云和content_优采云;
提示:如果发布目标中无法选择新字段,请在任务下复制或新建发布目标,然后在新发布目标中选择新字段即可。详细教程请参考发布目标中不能选择的字段;
5. 优采云-API接口常见问题及解决方法
一、API处理规则和SEO规则如何协同工作?
系统默认对title和content字段进行SEO功能,需要修改为SEO规则中的title_优采云和content_优采云字段;
查看全部
文章采集api(优采云采集支持调用优采云(小狗AI)API接口及解决方案
)
优采云采集支持调用优采云(小狗AI)API接口处理采集的数据标题和内容、关键词、描述等。可以针对性的配合优采云采集的SEO功能和5118智能换词API,处理原创度数更高的文章。@收录 和 网站 权重起着非常重要的作用。
购买优采云(小狗AI)API,建议先咨询优采云(小狗AI)客服,并告知在优采云采集上使用@> 平台;
详细使用步骤优采云API接口配置创建API处理规则API处理规则使用API处理结果并发布优采云-API接口常见问题及解决方案
1. 优采云API接口配置
一、API配置入口:
点击控制台左侧列表中的【第三方服务配置】==点击【第三方内容API接入】==点击【第三方API配置管理】==最后点击【+< @优采云API] 创建接口配置;

二、配置API接口信息:
购买优采云(小狗AI)API,建议先咨询优采云(小狗AI)客服,并告知在优采云采集上使用@> 平台。
【API key】是从优采云(Puppy AI)后台获取对应的API key,填写后记得保存;


2. 创建 API 处理规则
API处理规则,可以通过调用API接口设置处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==,点击【第三方内容API接入】==进入【API处理规则管理】页面,最后点击【+添加API处理规则]创建API处理规则;
二、API处理规则配置:

3. API 处理规则使用
API处理规则有两种使用方式:手动执行和自动执行:
一、手动执行API处理规则:
在采集任务的【结果数据&发布】选项卡中,点击【SEO&API&翻译等工具】按钮==>选择【第三方API执行】栏==>选择对应的API处理规则= => 执行;

二、自动执行API处理规则:
启用 API 处理的自动执行。任务完成后采集会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡【自动执行第三方API配置】==勾选【采集,自动执行API】选项==选择要执行的API处理规则= ="选择API接口处理的数据范围(一般选择'待发布',都将导致所有数据重复执行),最后点击保存;

4. API 处理结果并发布
一、查看API接口处理结果:
API接口处理的内容会保存为一个新的字段,如:标题处理后的新字段:title_优采云,内容处理后的新字段:content_优采云,在[Result Data & Publish ]和数据预览界面可以查看。


二、发布API接口处理后的内容:
发布文章前,修改发布目标的第二步映射字段,重新选择标题和内容到API接口处理后添加的对应字段title_优采云和content_优采云;
提示:如果发布目标中无法选择新字段,请在任务下复制或新建发布目标,然后在新发布目标中选择新字段即可。详细教程请参考发布目标中不能选择的字段;

5. 优采云-API接口常见问题及解决方法
一、API处理规则和SEO规则如何协同工作?
系统默认对title和content字段进行SEO功能,需要修改为SEO规则中的title_优采云和content_优采云字段;

文章采集api(就是错误博客(图片或视频亦包括在内)分享)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-04-19 07:01
此外,伪原创大部分都被同义词和同义词所取代。基本上,市场上没有 AI伪原创。如果确实存在,那么直接给关键词,剩下的可以自己写。市面上大部分的伪原创提供者都替换了同义词和同义词,所以最好不要这样做。
3、构建文章
使用大量的词搭建文章,比如10万个相关词做一个表格文章页面,通过对词和句子的布局,看起来没有不协调的感觉。另请参阅此方法。很多网站都获得了很大的流量,而bug博客本身也获得了数万这样的收录流量。
二、优采云构建文章
优采云构建文章 很简单,bug 博客为您提供了一切。
1、优采云导入模板
下载优采云,即优采云采集,创建人员列表组,右键组,导入准备好的“.ljobx”文件,这是 优采云@ 的模板>采集。
2、内容采集规则
导入后,双击打开,直接跳过“URL采集规则”,直接进入“内容采集规则”,那么,我们需要构建标题、页面对于原创 关键词,页面描述、作者、缩略图、标签等,都来自txt文档,内存中有几万行数据,所以构建< @原创文章 。当然,这只是一种模式。如果你想有更好的收录效果,那么你需要考虑如何使用这种模式来创造更好的内容,或者改变模式来产生更像原创的内容。
以上是Error Blog()分享的内容为“优采云采集三种构建方式原创文章”。谢谢阅读。更多原创文章搜索“bug blog”。
特别声明:以上内容(包括图片或视频)由自媒体平台“网易”用户上传发布。本平台仅提供信息存储服务。 查看全部
文章采集api(就是错误博客(图片或视频亦包括在内)分享)
此外,伪原创大部分都被同义词和同义词所取代。基本上,市场上没有 AI伪原创。如果确实存在,那么直接给关键词,剩下的可以自己写。市面上大部分的伪原创提供者都替换了同义词和同义词,所以最好不要这样做。
3、构建文章
使用大量的词搭建文章,比如10万个相关词做一个表格文章页面,通过对词和句子的布局,看起来没有不协调的感觉。另请参阅此方法。很多网站都获得了很大的流量,而bug博客本身也获得了数万这样的收录流量。
二、优采云构建文章
优采云构建文章 很简单,bug 博客为您提供了一切。
1、优采云导入模板
下载优采云,即优采云采集,创建人员列表组,右键组,导入准备好的“.ljobx”文件,这是 优采云@ 的模板>采集。
2、内容采集规则
导入后,双击打开,直接跳过“URL采集规则”,直接进入“内容采集规则”,那么,我们需要构建标题、页面对于原创 关键词,页面描述、作者、缩略图、标签等,都来自txt文档,内存中有几万行数据,所以构建< @原创文章 。当然,这只是一种模式。如果你想有更好的收录效果,那么你需要考虑如何使用这种模式来创造更好的内容,或者改变模式来产生更像原创的内容。
以上是Error Blog()分享的内容为“优采云采集三种构建方式原创文章”。谢谢阅读。更多原创文章搜索“bug blog”。
特别声明:以上内容(包括图片或视频)由自媒体平台“网易”用户上传发布。本平台仅提供信息存储服务。
文章采集api( 京东云API分组管理中实现日志实时采集、日志存储 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-04-19 00:42
京东云API分组管理中实现日志实时采集、日志存储
)
日志服务
目前,您可以在京东云的API群组管理中实现日志实时采集、日志存储、日志检索、智能分析等功能,通过日志解决业务运营、业务监控、日志分析等问题。
入口一:
互联网中间件 > API网关 > 开放API > API组管理 > 日志服务
入口二:
管理 > 日志服务
操作步骤: 第一步:进入API组管理页面,点击“Log”按钮
第二步:在日志集管理模块中,点击“创建日志集”按钮,打开创建日志集页面。
步骤 3:设置日志集名称、描述(可选)和保存时间。点击“确定”按钮后,弹出提示“日志集创建成功,现在去添加日志主题吗?”
第四步:点击“确定”按钮后,跳转到日志集详情,创建日志主题。
第五步:添加日志主题名称后,点击“确定”按钮,弹出提示“日志主题创建成功,现在去添加采集配置吗?”
第六步:点击“确定”后,进入采集配置页面。点击“添加采集配置”进入添加采集配置页面,在“产品”对应选项中选择“API网关”,点击“确定”按钮完成配置。第七步:返回日志集管理中的日志主题列表页面,点击日志集ID/名称,点击“预览”按钮可以查看日志主题下的最新日志数据。如果需要查询日志数据,可以到日志检索查询。
第八步:在日志主题列表中选择要查看的日志主题,点击“搜索”按钮,或者切换到左侧菜单的日志搜索模块,可以进行相应的全文搜索或键值搜索在日志上:
全文搜索
键值检索
(1)快速搜索
(2)高级搜索
查看全部
文章采集api(
京东云API分组管理中实现日志实时采集、日志存储
)
日志服务
目前,您可以在京东云的API群组管理中实现日志实时采集、日志存储、日志检索、智能分析等功能,通过日志解决业务运营、业务监控、日志分析等问题。
入口一:
互联网中间件 > API网关 > 开放API > API组管理 > 日志服务
入口二:
管理 > 日志服务
操作步骤: 第一步:进入API组管理页面,点击“Log”按钮
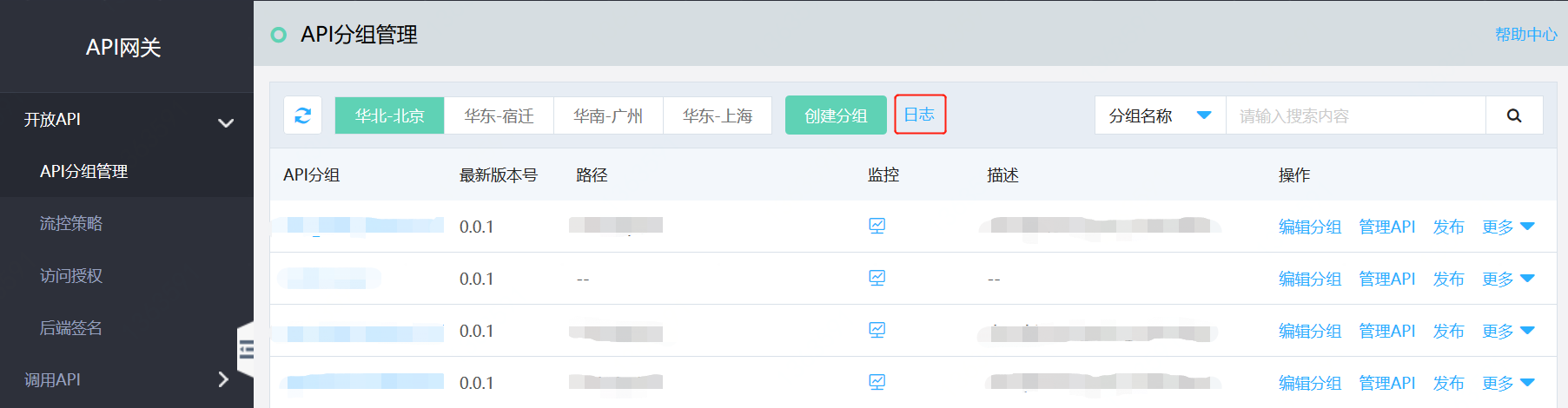
第二步:在日志集管理模块中,点击“创建日志集”按钮,打开创建日志集页面。
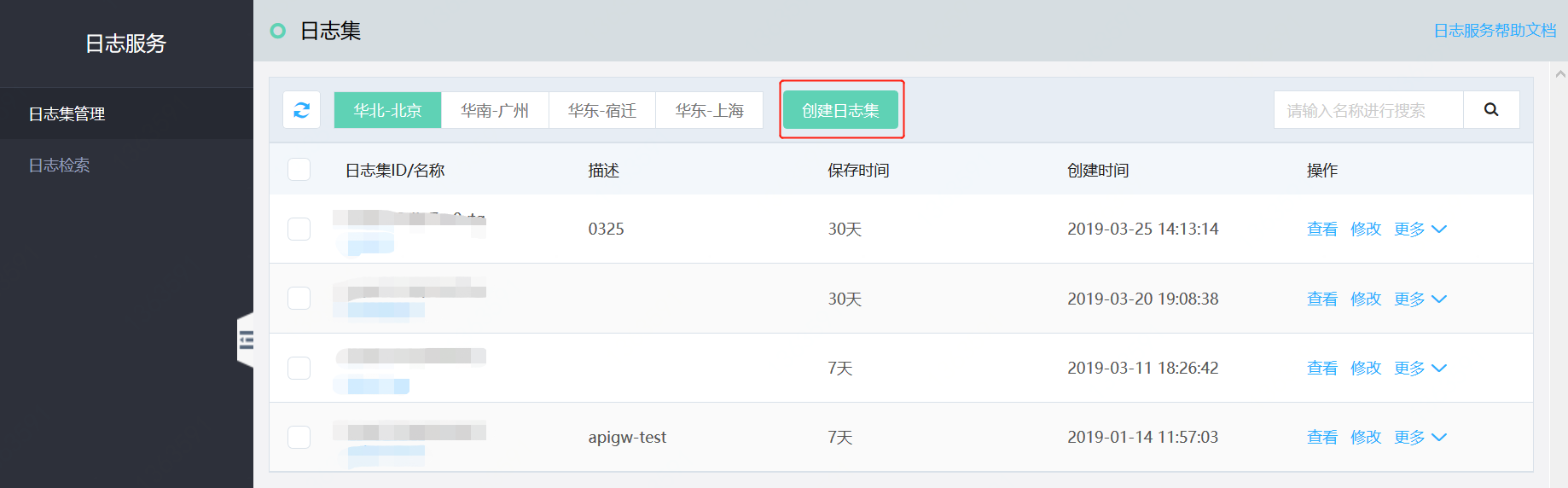
步骤 3:设置日志集名称、描述(可选)和保存时间。点击“确定”按钮后,弹出提示“日志集创建成功,现在去添加日志主题吗?”
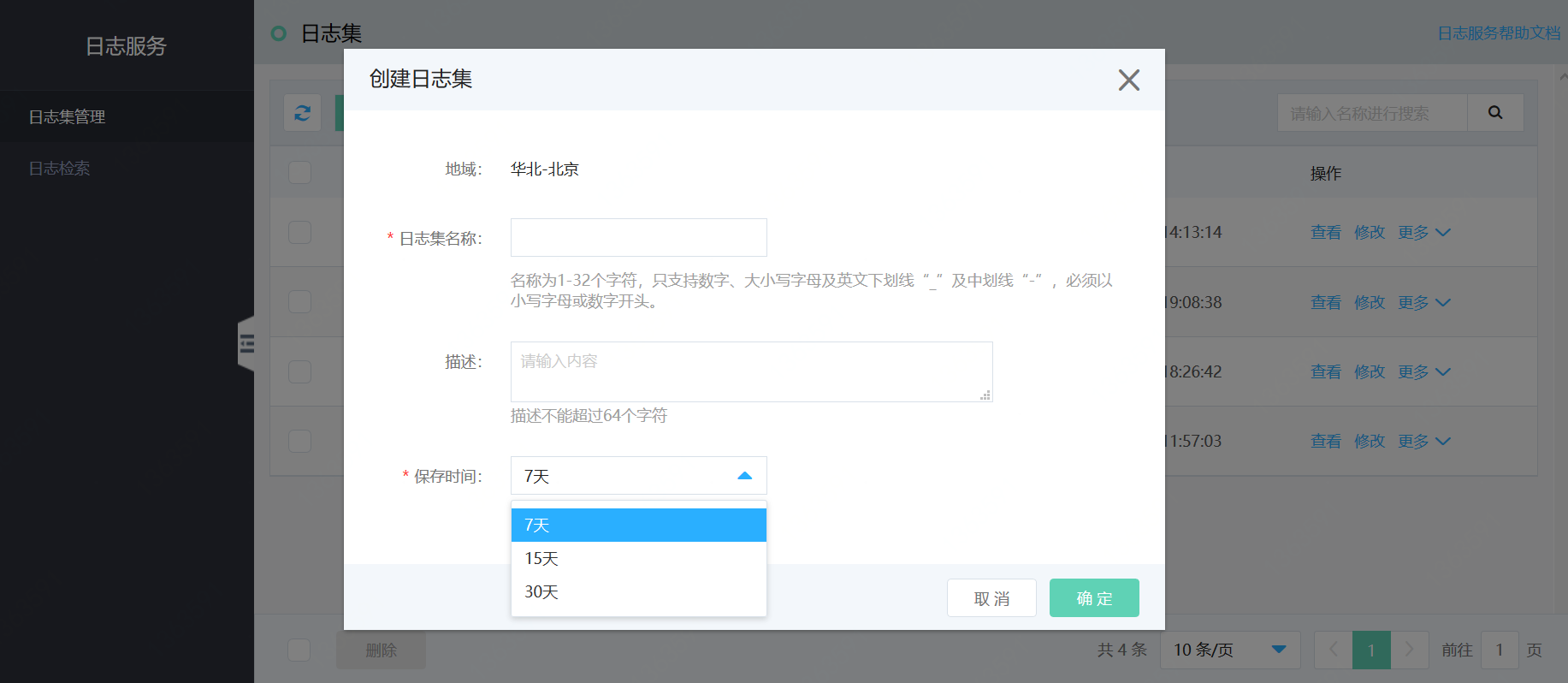
第四步:点击“确定”按钮后,跳转到日志集详情,创建日志主题。

第五步:添加日志主题名称后,点击“确定”按钮,弹出提示“日志主题创建成功,现在去添加采集配置吗?”
第六步:点击“确定”后,进入采集配置页面。点击“添加采集配置”进入添加采集配置页面,在“产品”对应选项中选择“API网关”,点击“确定”按钮完成配置。第七步:返回日志集管理中的日志主题列表页面,点击日志集ID/名称,点击“预览”按钮可以查看日志主题下的最新日志数据。如果需要查询日志数据,可以到日志检索查询。
第八步:在日志主题列表中选择要查看的日志主题,点击“搜索”按钮,或者切换到左侧菜单的日志搜索模块,可以进行相应的全文搜索或键值搜索在日志上:
全文搜索
键值检索
(1)快速搜索
(2)高级搜索

文章采集api(搭建一套前端监控平台需要考虑的几个问题?|本文)
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-04-18 20:32
随着业务的快速发展,我们越来越重视对生产环境问题的感知能力。作为离用户最近的一层,前端性能是否可靠、稳定、好用在很大程度上决定了用户对整个产品的体验和感受。因此,前端的监控也不容忽视。
搭建前端监控平台需要考虑很多方面,比如数据采集、埋藏模式、数据处理分析、告警、监控平台在具体业务中的应用等等。在所有这些环节中、准确、完整、全面的数据采集是一切的前提,也为用户后续的精细化运营提供了依据。
前端技术的飞速发展给数据带来了变化和挑战采集,传统的人工管理模式已经不能满足需求。如何让前端数据采集在新的技术背景下工作更加完整高效是本文的重点。
前端监控数据采集
在采集数据之前,考虑一下采集什么样的数据。我们关注两类数据,一类与用户体验相关,如首屏时间、文件加载时间、页面性能等;另一个是帮助我们及时感知产品上线后是否出现异常,比如资源错误、API响应时间等。具体来说,我们的前端数据采集主要分为:
路由交换机
Vue、React、Angular等前端技术的快速发展,使得单页应用流行起来。我们都知道,传统的页面应用使用一些超链接来实现页面切换和跳转,而单页面应用使用自己的路由系统来管理各个前端页面切换,比如vue-router、react-router等,只有跳转时刷新本地资源,js、css等公共资源只需加载一次,使得传统的网页进出方式只有在第一次打开时才会被记录。在单页应用中切换所有后续路由有两种方式,一种是Hash,另一种是HTML5推出的History API。
1. 链接
href是页面初始化的第一个入口,这里只需要简单的报告“进入页面”事件。
2. 哈希变化
哈希路由的一个明显标志是带有“#”。Hash的优点是兼容性更好,但问题是URL中的“#”不美观。我们主要通过监听 URL 中的 hashchange 来捕获具体的 hash 值进行检测。
window.addEventListener('hashchange', function() {
// 上报【进入页面】事件
}, true)
需要注意的是,如果浏览器在新版本的vue-router中支持history,即使模式选择hash,也会先选择history模式。虽然表达式暂时还是#,但实际上是模拟出来的,所以不要以为你在如果模式选择hash,那肯定是hash。
3. 历史 API
History利用HTML5 History接口中新增的pushState()和replaceState()方法进行路由切换,是目前主流的非刷新切换路由方式。与 hashchange 只能更改 # 后面的代码片段相比,History API(pushState、replaceState)给了前端完全的自由。
PopState 是浏览器返回事件的回调,但是更新路由的 pushState 和 replaceState 没有回调事件。因此,URL 更改需要分别在 history.pushState() 和 history.replaceState() 方法中处理。在这里,我们使用类似Java的AOP编程思想来改造pushState和replaceState。
AOP(Aspect-oriented programming)是面向方面的编程,它提倡对同一类型的问题进行统一处理。AOP的核心思想是让某个模块能够被复用。它采用横向抽取机制,将功能代码与业务逻辑代码分离,在不修改源代码的情况下扩展功能。与封装相比,隔离更彻底。
下面介绍我们具体的改造方法:
// 第一阶段:我们对原生方法进行包装,调用前执行 dispatchEvent 了一个同样的事件
function aop (type) {
var source = window.history[type];
return function () {
var event = new Event(type);
event.arguments = arguments;
window.dispatchEvent(event);
var rewrite = source.apply(this, arguments);
return rewrite;
};
}
// 第二阶段:将 pushState 和 replaceState 进行基于 AOP 思想的代码注入
window.history.pushState = aop('pushState');
window.history.replaceState = aop('replaceState'); // 更改路由,不会留下历史记录
// 第三阶段:捕获pushState 和 replaceState
window.addEventListener('pushState', function() {
// 上报【进入页面】事件
}, true)
window.addEventListener('replaceState', function() {
// 上报【进入页面】事件
}, true)
window.history.pushState的实际调用关系如图:
至此,我们完成了pushState和replaceState的转换,实现了路由切换的有效抓包。可以看出,我们在不侵入业务代码的情况下扩展了window.history.pushState,调用时会主动dispatchEvent一个pushState。
但是这里我们也可以看到一个缺点,就是如果AOP代理函数出现JS错误,会阻塞后续的调用关系,从而无法调用实际的window.history.pushState。因此,在使用该方法时,需要对AOP代理功能的内容进行一次完整的try catch,以防止出现业务异常。
*提示:如果要自动捕捉页面停留时间,只需在触发下一页进入事件时,将上一页的时间与当前时间做个差值即可。这时候可以上报【离开页面】事件。
错误
在前端项目中,由于 JavaScript 本身是一种弱类型语言,再加上浏览器环境的复杂性、网络问题等,很容易出现错误。因此,做好网页错误监控,不断优化代码,提高代码的健壮性是非常重要的。
JsError的捕获可以帮助我们分析和监控在线问题,和我们在Chrome浏览器的调试工具Console中看到的一致。
1. 窗口.onerror
我们通常使用 window.onerror 来捕获 JS 错误的异常信息。有两种方法可以捕获 JS 错误,window.onerror 和 window.addEventListener('error')。一般不建议使用 addEventListener('error') 来捕获 JS 异常,主要是它没有堆栈信息,而且还需要区分捕获的信息,因为它会捕获所有的异常信息,包括资源加载错误. 等待。
window.onerror = function (msg, url, lineno, colno, stack) {
// 上报 【js错误】事件
}
2. 未被抓住(承诺)
当 Promise 发生 JS 错误或者业务没有处理拒绝信息时,会抛出 unhandledrejection,并且这个错误不会被 window.onerror 和 window.addEventListener('error') 这个特殊的窗口捕获。addEventListener('unhandledrejection') 用于捕获处理:
window.addEventListener('unhandledrejection', function (e) {
var reg_url = /\(([^)]*)\)/;
var fileMsg = e.reason.stack.split('\n')[1].match(reg_url)[1];
var fileArr = fileMsg.split(':');
var lineno = fileArr[fileArr.length - 2];
var colno = fileArr[fileArr.length - 1];
var url = fileMsg.slice(0, -lno.length - cno.length - 2);}, true);
var msg = e.reason.message;
// 上报 【js错误】事件
}
我们注意到unhandledrejection继承自PromiseRejectionEvent,而PromiseRejectionEvent继承自Event,所以msg、url、lineno、colno、stack以字符串的形式放在e.reason.stack中,我们需要将上面的参数解析出来与onerror参数对齐,为后续监测平台各项指标的统一奠定了基础。
3. 常见问题
如果抓到的msg都是“Script error.”,问题是你的JS地址和当前网页不在同一个域下。因为我们经常需要对网络版的静态资源进行CDN,会导致经常访问的页面和脚本文件来自不同的域名。这时候如果不进行额外配置,浏览器很容易出现“脚本错误”。出于安全考虑。我们可以利用当前流行的 Webpack bundler 来处理此类问题。
// webpack config 配置
// 处理 html 注入 js 添加跨域标识
plugins: [
new HtmlWebpackPlugin({
filename: 'html/index.html',
template: HTML_PATH,
attributes: {
crossorigin: 'anonymous'
}
}),
new HtmlWebpackPluginCrossorigin({
inject: true
})
]
// 处理按需加载的 js 添加跨域标识
output: {
crossOriginLoading: true
}
大多数场景下,生产环境中的代码都是压缩合并的,这使得我们抓到的错误很难映射到具体的源码中,给我们解决问题带来了很大的麻烦。这里有两个解决方案。想法。
在生产环境中,我们需要添加sourceMap的配置,这样会带来安全隐患,因为这样外网可以通过sourceMap进行source map的映射。为了降低风险,我们可以做到以下几点:
此时,我们已经有了 .map 文件。接下来我们需要做的就是通过捕获的lineno、colno、url调用mozilla/source-map库进行源码映射,然后就可以得到真正的源码错误信息了。
表现
性能指标的获取比较简单,在onload之后读取window.performance就可以了,里面收录了性能、内存等信息。这部分内容在很多现有的文章中都有介绍。由于篇幅所限,本文不再过多展开。稍后,我们将在相关主题文章中进行相关讨论。感兴趣的朋友可以添加“马蜂窝技术”公众号继续关注。
资源错误
首先,我们需要明确资源错误捕获的使用场景,更多的是感知DNS劫持和CDN节点异常等,具体方法如下:
window.addEventListener('error', function (e) {
var target = e.target || e.srcElement;
if (target instanceof HTMLScriptElement) {
// 上报 【资源错误】事件
}
}, true)
这只是一个基本的演示。在实际环境中,我们会关心更多的Element错误,比如css、img、woff等,大家可以根据不同的场景添加。
*资源错误的使用场景更多地依赖于其他维度,例如:地区、运营商等,我们将在后面的页面中详细解释。
API
在市面上的主流框架(如axios、jQuery.ajax等)中,基本上所有的API请求都是基于xmlHttpRequest或者fetch,所以捕获全局接口错误的方式就是封装xmlHttpRequest或者fetch。在这里,我们的SDK还是使用了上面提到的AOP思想来拦截API。 查看全部
文章采集api(搭建一套前端监控平台需要考虑的几个问题?|本文)
随着业务的快速发展,我们越来越重视对生产环境问题的感知能力。作为离用户最近的一层,前端性能是否可靠、稳定、好用在很大程度上决定了用户对整个产品的体验和感受。因此,前端的监控也不容忽视。
搭建前端监控平台需要考虑很多方面,比如数据采集、埋藏模式、数据处理分析、告警、监控平台在具体业务中的应用等等。在所有这些环节中、准确、完整、全面的数据采集是一切的前提,也为用户后续的精细化运营提供了依据。
前端技术的飞速发展给数据带来了变化和挑战采集,传统的人工管理模式已经不能满足需求。如何让前端数据采集在新的技术背景下工作更加完整高效是本文的重点。
前端监控数据采集
在采集数据之前,考虑一下采集什么样的数据。我们关注两类数据,一类与用户体验相关,如首屏时间、文件加载时间、页面性能等;另一个是帮助我们及时感知产品上线后是否出现异常,比如资源错误、API响应时间等。具体来说,我们的前端数据采集主要分为:
路由交换机
Vue、React、Angular等前端技术的快速发展,使得单页应用流行起来。我们都知道,传统的页面应用使用一些超链接来实现页面切换和跳转,而单页面应用使用自己的路由系统来管理各个前端页面切换,比如vue-router、react-router等,只有跳转时刷新本地资源,js、css等公共资源只需加载一次,使得传统的网页进出方式只有在第一次打开时才会被记录。在单页应用中切换所有后续路由有两种方式,一种是Hash,另一种是HTML5推出的History API。
1. 链接
href是页面初始化的第一个入口,这里只需要简单的报告“进入页面”事件。
2. 哈希变化
哈希路由的一个明显标志是带有“#”。Hash的优点是兼容性更好,但问题是URL中的“#”不美观。我们主要通过监听 URL 中的 hashchange 来捕获具体的 hash 值进行检测。
window.addEventListener('hashchange', function() {
// 上报【进入页面】事件
}, true)
需要注意的是,如果浏览器在新版本的vue-router中支持history,即使模式选择hash,也会先选择history模式。虽然表达式暂时还是#,但实际上是模拟出来的,所以不要以为你在如果模式选择hash,那肯定是hash。
3. 历史 API
History利用HTML5 History接口中新增的pushState()和replaceState()方法进行路由切换,是目前主流的非刷新切换路由方式。与 hashchange 只能更改 # 后面的代码片段相比,History API(pushState、replaceState)给了前端完全的自由。
PopState 是浏览器返回事件的回调,但是更新路由的 pushState 和 replaceState 没有回调事件。因此,URL 更改需要分别在 history.pushState() 和 history.replaceState() 方法中处理。在这里,我们使用类似Java的AOP编程思想来改造pushState和replaceState。
AOP(Aspect-oriented programming)是面向方面的编程,它提倡对同一类型的问题进行统一处理。AOP的核心思想是让某个模块能够被复用。它采用横向抽取机制,将功能代码与业务逻辑代码分离,在不修改源代码的情况下扩展功能。与封装相比,隔离更彻底。
下面介绍我们具体的改造方法:
// 第一阶段:我们对原生方法进行包装,调用前执行 dispatchEvent 了一个同样的事件
function aop (type) {
var source = window.history[type];
return function () {
var event = new Event(type);
event.arguments = arguments;
window.dispatchEvent(event);
var rewrite = source.apply(this, arguments);
return rewrite;
};
}
// 第二阶段:将 pushState 和 replaceState 进行基于 AOP 思想的代码注入
window.history.pushState = aop('pushState');
window.history.replaceState = aop('replaceState'); // 更改路由,不会留下历史记录
// 第三阶段:捕获pushState 和 replaceState
window.addEventListener('pushState', function() {
// 上报【进入页面】事件
}, true)
window.addEventListener('replaceState', function() {
// 上报【进入页面】事件
}, true)
window.history.pushState的实际调用关系如图:
至此,我们完成了pushState和replaceState的转换,实现了路由切换的有效抓包。可以看出,我们在不侵入业务代码的情况下扩展了window.history.pushState,调用时会主动dispatchEvent一个pushState。
但是这里我们也可以看到一个缺点,就是如果AOP代理函数出现JS错误,会阻塞后续的调用关系,从而无法调用实际的window.history.pushState。因此,在使用该方法时,需要对AOP代理功能的内容进行一次完整的try catch,以防止出现业务异常。
*提示:如果要自动捕捉页面停留时间,只需在触发下一页进入事件时,将上一页的时间与当前时间做个差值即可。这时候可以上报【离开页面】事件。
错误
在前端项目中,由于 JavaScript 本身是一种弱类型语言,再加上浏览器环境的复杂性、网络问题等,很容易出现错误。因此,做好网页错误监控,不断优化代码,提高代码的健壮性是非常重要的。
JsError的捕获可以帮助我们分析和监控在线问题,和我们在Chrome浏览器的调试工具Console中看到的一致。
1. 窗口.onerror
我们通常使用 window.onerror 来捕获 JS 错误的异常信息。有两种方法可以捕获 JS 错误,window.onerror 和 window.addEventListener('error')。一般不建议使用 addEventListener('error') 来捕获 JS 异常,主要是它没有堆栈信息,而且还需要区分捕获的信息,因为它会捕获所有的异常信息,包括资源加载错误. 等待。
window.onerror = function (msg, url, lineno, colno, stack) {
// 上报 【js错误】事件
}
2. 未被抓住(承诺)
当 Promise 发生 JS 错误或者业务没有处理拒绝信息时,会抛出 unhandledrejection,并且这个错误不会被 window.onerror 和 window.addEventListener('error') 这个特殊的窗口捕获。addEventListener('unhandledrejection') 用于捕获处理:
window.addEventListener('unhandledrejection', function (e) {
var reg_url = /\(([^)]*)\)/;
var fileMsg = e.reason.stack.split('\n')[1].match(reg_url)[1];
var fileArr = fileMsg.split(':');
var lineno = fileArr[fileArr.length - 2];
var colno = fileArr[fileArr.length - 1];
var url = fileMsg.slice(0, -lno.length - cno.length - 2);}, true);
var msg = e.reason.message;
// 上报 【js错误】事件
}
我们注意到unhandledrejection继承自PromiseRejectionEvent,而PromiseRejectionEvent继承自Event,所以msg、url、lineno、colno、stack以字符串的形式放在e.reason.stack中,我们需要将上面的参数解析出来与onerror参数对齐,为后续监测平台各项指标的统一奠定了基础。
3. 常见问题
如果抓到的msg都是“Script error.”,问题是你的JS地址和当前网页不在同一个域下。因为我们经常需要对网络版的静态资源进行CDN,会导致经常访问的页面和脚本文件来自不同的域名。这时候如果不进行额外配置,浏览器很容易出现“脚本错误”。出于安全考虑。我们可以利用当前流行的 Webpack bundler 来处理此类问题。
// webpack config 配置
// 处理 html 注入 js 添加跨域标识
plugins: [
new HtmlWebpackPlugin({
filename: 'html/index.html',
template: HTML_PATH,
attributes: {
crossorigin: 'anonymous'
}
}),
new HtmlWebpackPluginCrossorigin({
inject: true
})
]
// 处理按需加载的 js 添加跨域标识
output: {
crossOriginLoading: true
}
大多数场景下,生产环境中的代码都是压缩合并的,这使得我们抓到的错误很难映射到具体的源码中,给我们解决问题带来了很大的麻烦。这里有两个解决方案。想法。
在生产环境中,我们需要添加sourceMap的配置,这样会带来安全隐患,因为这样外网可以通过sourceMap进行source map的映射。为了降低风险,我们可以做到以下几点:
此时,我们已经有了 .map 文件。接下来我们需要做的就是通过捕获的lineno、colno、url调用mozilla/source-map库进行源码映射,然后就可以得到真正的源码错误信息了。
表现
性能指标的获取比较简单,在onload之后读取window.performance就可以了,里面收录了性能、内存等信息。这部分内容在很多现有的文章中都有介绍。由于篇幅所限,本文不再过多展开。稍后,我们将在相关主题文章中进行相关讨论。感兴趣的朋友可以添加“马蜂窝技术”公众号继续关注。
资源错误
首先,我们需要明确资源错误捕获的使用场景,更多的是感知DNS劫持和CDN节点异常等,具体方法如下:
window.addEventListener('error', function (e) {
var target = e.target || e.srcElement;
if (target instanceof HTMLScriptElement) {
// 上报 【资源错误】事件
}
}, true)
这只是一个基本的演示。在实际环境中,我们会关心更多的Element错误,比如css、img、woff等,大家可以根据不同的场景添加。
*资源错误的使用场景更多地依赖于其他维度,例如:地区、运营商等,我们将在后面的页面中详细解释。
API
在市面上的主流框架(如axios、jQuery.ajax等)中,基本上所有的API请求都是基于xmlHttpRequest或者fetch,所以捕获全局接口错误的方式就是封装xmlHttpRequest或者fetch。在这里,我们的SDK还是使用了上面提到的AOP思想来拦截API。
文章采集api Python 爬取人人视频
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2022-05-14 20:49
hello,小伙伴们,又见面了,距离上一次发布文章的时间,也算是久别重逢了。期间也发生了很多的事情,导致博文断更,也是笔者不愿意的,但是确实是比较忙,不再过多赘述,希望大家能够体谅。
平时不断的在后台收到小伙伴的私信,问是不是不更了,答案当然是否定的,有着这么多人的支持,小编还是要继续努力下去的,再次谢谢大家的支持。
这次给大家带来的文章是爬取人人视频,之前多是分享一些爬取数据,图片,音乐,还没怎么分享过爬取过视频的,那么想要爬取视频的话该怎么爬取呢?
其实不管是图片,还是音乐,或者是其他的文档,大部分都是一个文件读写的过程,当然视频也不例外,只是文件的格式不同而已。所以我们也可以试着以常规的手段去尝试下爬取视频,没错还是熟悉的套路与配方,即python常用函数 open()和 write()。
不过这次略微不同的是我们会使用到iter_content来获取请求的原始响应数据,普通情况可以用r.raw,在初始请求中设置stream=True,来获取服务器的原始套接字响应,在这里我们使用iter_content更加方便一些,因为requests.get(url) 默认是下载在内存中的,下载完成才存到硬盘上,但Response.iter_content可以边下载边存硬盘中,所以在这视频下载方面更具有优势。
当然说到 iter_content 的话,不得不提下chunk_size,因为流式请求就是像流水一样,不是一次过来而是一点一点“流”过来。处理流式数据也是一点一点处理。
而chunk_size会直接返回从当前位置往后读取 chunk_size 大小的文件内容,且迭代响应数据。这避免了立即将内容读入内存以获得较大的响应。chunk_size是它应该读入内存的字节数。chunk_size的类型必须是int或None。None的值将根据流的值发挥不同的作用。
做了引荐与讲解后,那么就开始上我们的主菜了,即目标网站:
https://m.rr.tv/
介于代码偏基础化,且主要知识点做过分析就直接上代码了,具体请看代码:
单线程:
import requestsimport jsonimport reimport osheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}ep_list =[]vod_list = []def get_vod(url): response = requests.get(url = url,headers = headers)#请求url ep= re.compile(r'sid:"(.*?)",')#提取ep链接 ep_list = re.findall(ep,response.text) vod= re.compile(r'data:\[{id:(.*?),title:"')#提取vod链接 vod_list = re.findall(vod,response.text) vod= re.compile(r',title:"(.*?)",desc:"')#提取视频标题 vod_name = re.findall(vod,response.text) ep = 1 os.mkdir('./'+vod_name[0])#创建视频保存目录 for i in ep_list: print("开始下载"+vod_name[0]+"第"+str(ep)+"集") url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers)#下载请求 r = requests.get(str(json.loads(response.text)['data']['url']), stream=True)#解析出下载链接并发起下载请求 f = open("./"+vod_name[0]+"/第"+str(ep)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk) ep = ep+1if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxxx?snum=1&episode=1'#目标视频链接 get_vod(url)
多线程:
import requestsimport jsonimport reimport osfrom concurrent.futures import ThreadPoolExecutorheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}vod_list = []#存储视频链接vod_name = []#存储视频标题get_down_url =[]#存储下载直链def get_vod(url): response = requests.get(url = url,headers = headers)#请求url vod_list.append(re.findall(re.compile(r'data:\[{id:(.*?),title:"'),response.text)[0])#找找视频链接 vod_name.append(re.findall(re.compile(r',title:"(.*?)",desc:"'),response.text)[0])#找找视频标题 for i in re.findall(re.compile(r'{sid:"(.*?)",key:'),response.text): url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers) get_down_url.append(str(json.loads(response.text)['data']['url']))#拿下载直链进listdef down_begin(url,i): print("开始多线程下载"+vod_name[0]+"第"+str(i)+"集") r = requests.get(url = url,headers = headers)#下载请求 f = open("./"+vod_name[0]+"/第"+str(i)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk)if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxx?snum=1&episode=1'#进入rr.tv自行获取 get_vod(url) os.mkdir('./'+vod_name[0])#创建视频保存目录 with ThreadPoolExecutor(10) as f:#这里写多线程参数,适合几十集的电视剧使用 for i,url in enumerate(get_down_url): i=int(i)+1 f.submit(down_begin,url = url,i=i)
把案例里面的链接改成你想要下载的链接,然后右击运行代码,即可成功的下载你想要的视频了。代码获取后台回复:”人人视频“。
在文章的最后给大家来一波福利,因为前一段时间小编在爬取百度相关关键词以及文章采集时,经常触发百度的验证机制,这种情况很明显要使用到代理IP,后来群里一个小伙伴推荐了品赞代理IP,小编测试了下,完美解决了爬取中存在的问题。
如果大家后续有需要使用到代理方面的业务的话,可以扫码添加下方的二维码。国内外的IP都有,新用户可以免费测试。
查看全部
文章采集api Python 爬取人人视频
hello,小伙伴们,又见面了,距离上一次发布文章的时间,也算是久别重逢了。期间也发生了很多的事情,导致博文断更,也是笔者不愿意的,但是确实是比较忙,不再过多赘述,希望大家能够体谅。
平时不断的在后台收到小伙伴的私信,问是不是不更了,答案当然是否定的,有着这么多人的支持,小编还是要继续努力下去的,再次谢谢大家的支持。
这次给大家带来的文章是爬取人人视频,之前多是分享一些爬取数据,图片,音乐,还没怎么分享过爬取过视频的,那么想要爬取视频的话该怎么爬取呢?
其实不管是图片,还是音乐,或者是其他的文档,大部分都是一个文件读写的过程,当然视频也不例外,只是文件的格式不同而已。所以我们也可以试着以常规的手段去尝试下爬取视频,没错还是熟悉的套路与配方,即python常用函数 open()和 write()。
不过这次略微不同的是我们会使用到iter_content来获取请求的原始响应数据,普通情况可以用r.raw,在初始请求中设置stream=True,来获取服务器的原始套接字响应,在这里我们使用iter_content更加方便一些,因为requests.get(url) 默认是下载在内存中的,下载完成才存到硬盘上,但Response.iter_content可以边下载边存硬盘中,所以在这视频下载方面更具有优势。
当然说到 iter_content 的话,不得不提下chunk_size,因为流式请求就是像流水一样,不是一次过来而是一点一点“流”过来。处理流式数据也是一点一点处理。
而chunk_size会直接返回从当前位置往后读取 chunk_size 大小的文件内容,且迭代响应数据。这避免了立即将内容读入内存以获得较大的响应。chunk_size是它应该读入内存的字节数。chunk_size的类型必须是int或None。None的值将根据流的值发挥不同的作用。
做了引荐与讲解后,那么就开始上我们的主菜了,即目标网站:
https://m.rr.tv/
介于代码偏基础化,且主要知识点做过分析就直接上代码了,具体请看代码:
单线程:
import requestsimport jsonimport reimport osheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}ep_list =[]vod_list = []def get_vod(url): response = requests.get(url = url,headers = headers)#请求url ep= re.compile(r'sid:"(.*?)",')#提取ep链接 ep_list = re.findall(ep,response.text) vod= re.compile(r'data:\[{id:(.*?),title:"')#提取vod链接 vod_list = re.findall(vod,response.text) vod= re.compile(r',title:"(.*?)",desc:"')#提取视频标题 vod_name = re.findall(vod,response.text) ep = 1 os.mkdir('./'+vod_name[0])#创建视频保存目录 for i in ep_list: print("开始下载"+vod_name[0]+"第"+str(ep)+"集") url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers)#下载请求 r = requests.get(str(json.loads(response.text)['data']['url']), stream=True)#解析出下载链接并发起下载请求 f = open("./"+vod_name[0]+"/第"+str(ep)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk) ep = ep+1if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxxx?snum=1&episode=1'#目标视频链接 get_vod(url)
多线程:
import requestsimport jsonimport reimport osfrom concurrent.futures import ThreadPoolExecutorheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}vod_list = []#存储视频链接vod_name = []#存储视频标题get_down_url =[]#存储下载直链def get_vod(url): response = requests.get(url = url,headers = headers)#请求url vod_list.append(re.findall(re.compile(r'data:\[{id:(.*?),title:"'),response.text)[0])#找找视频链接 vod_name.append(re.findall(re.compile(r',title:"(.*?)",desc:"'),response.text)[0])#找找视频标题 for i in re.findall(re.compile(r'{sid:"(.*?)",key:'),response.text): url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers) get_down_url.append(str(json.loads(response.text)['data']['url']))#拿下载直链进listdef down_begin(url,i): print("开始多线程下载"+vod_name[0]+"第"+str(i)+"集") r = requests.get(url = url,headers = headers)#下载请求 f = open("./"+vod_name[0]+"/第"+str(i)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk)if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxx?snum=1&episode=1'#进入rr.tv自行获取 get_vod(url) os.mkdir('./'+vod_name[0])#创建视频保存目录 with ThreadPoolExecutor(10) as f:#这里写多线程参数,适合几十集的电视剧使用 for i,url in enumerate(get_down_url): i=int(i)+1 f.submit(down_begin,url = url,i=i)
把案例里面的链接改成你想要下载的链接,然后右击运行代码,即可成功的下载你想要的视频了。代码获取后台回复:”人人视频“。
在文章的最后给大家来一波福利,因为前一段时间小编在爬取百度相关关键词以及文章采集时,经常触发百度的验证机制,这种情况很明显要使用到代理IP,后来群里一个小伙伴推荐了品赞代理IP,小编测试了下,完美解决了爬取中存在的问题。
如果大家后续有需要使用到代理方面的业务的话,可以扫码添加下方的二维码。国内外的IP都有,新用户可以免费测试。
文章采集api Python 爬取人人视频
采集交流 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-05-13 16:48
hello,小伙伴们,又见面了,距离上一次发布文章的时间,也算是久别重逢了。期间也发生了很多的事情,导致博文断更,也是笔者不愿意的,但是确实是比较忙,不再过多赘述,希望大家能够体谅。
平时不断的在后台收到小伙伴的私信,问是不是不更了,答案当然是否定的,有着这么多人的支持,小编还是要继续努力下去的,再次谢谢大家的支持。
这次给大家带来的文章是爬取人人视频,之前多是分享一些爬取数据,图片,音乐,还没怎么分享过爬取过视频的,那么想要爬取视频的话该怎么爬取呢?
其实不管是图片,还是音乐,或者是其他的文档,大部分都是一个文件读写的过程,当然视频也不例外,只是文件的格式不同而已。所以我们也可以试着以常规的手段去尝试下爬取视频,没错还是熟悉的套路与配方,即python常用函数 open()和 write()。
不过这次略微不同的是我们会使用到iter_content来获取请求的原始响应数据,普通情况可以用r.raw,在初始请求中设置stream=True,来获取服务器的原始套接字响应,在这里我们使用iter_content更加方便一些,因为requests.get(url) 默认是下载在内存中的,下载完成才存到硬盘上,但Response.iter_content可以边下载边存硬盘中,所以在这视频下载方面更具有优势。
当然说到 iter_content 的话,不得不提下chunk_size,因为流式请求就是像流水一样,不是一次过来而是一点一点“流”过来。处理流式数据也是一点一点处理。
而chunk_size会直接返回从当前位置往后读取 chunk_size 大小的文件内容,且迭代响应数据。这避免了立即将内容读入内存以获得较大的响应。chunk_size是它应该读入内存的字节数。chunk_size的类型必须是int或None。None的值将根据流的值发挥不同的作用。
做了引荐与讲解后,那么就开始上我们的主菜了,即目标网站:
https://m.rr.tv/
介于代码偏基础化,且主要知识点做过分析就直接上代码了,具体请看代码:
单线程:
import requestsimport jsonimport reimport osheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}ep_list =[]vod_list = []def get_vod(url): response = requests.get(url = url,headers = headers)#请求url ep= re.compile(r'sid:"(.*?)",')#提取ep链接 ep_list = re.findall(ep,response.text) vod= re.compile(r'data:\[{id:(.*?),title:"')#提取vod链接 vod_list = re.findall(vod,response.text) vod= re.compile(r',title:"(.*?)",desc:"')#提取视频标题 vod_name = re.findall(vod,response.text) ep = 1 os.mkdir('./'+vod_name[0])#创建视频保存目录 for i in ep_list: print("开始下载"+vod_name[0]+"第"+str(ep)+"集") url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers)#下载请求 r = requests.get(str(json.loads(response.text)['data']['url']), stream=True)#解析出下载链接并发起下载请求 f = open("./"+vod_name[0]+"/第"+str(ep)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk) ep = ep+1if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxxx?snum=1&episode=1'#目标视频链接 get_vod(url)
多线程:
import requestsimport jsonimport reimport osfrom concurrent.futures import ThreadPoolExecutorheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}vod_list = []#存储视频链接vod_name = []#存储视频标题get_down_url =[]#存储下载直链def get_vod(url): response = requests.get(url = url,headers = headers)#请求url vod_list.append(re.findall(re.compile(r'data:\[{id:(.*?),title:"'),response.text)[0])#找找视频链接 vod_name.append(re.findall(re.compile(r',title:"(.*?)",desc:"'),response.text)[0])#找找视频标题 for i in re.findall(re.compile(r'{sid:"(.*?)",key:'),response.text): url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers) get_down_url.append(str(json.loads(response.text)['data']['url']))#拿下载直链进listdef down_begin(url,i): print("开始多线程下载"+vod_name[0]+"第"+str(i)+"集") r = requests.get(url = url,headers = headers)#下载请求 f = open("./"+vod_name[0]+"/第"+str(i)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk)if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxx?snum=1&episode=1'#进入rr.tv自行获取 get_vod(url) os.mkdir('./'+vod_name[0])#创建视频保存目录 with ThreadPoolExecutor(10) as f:#这里写多线程参数,适合几十集的电视剧使用 for i,url in enumerate(get_down_url): i=int(i)+1 f.submit(down_begin,url = url,i=i)
把案例里面的链接改成你想要下载的链接,然后右击运行代码,即可成功的下载你想要的视频了。代码获取后台回复:”人人视频“。
在文章的最后给大家来一波福利,因为前一段时间小编在爬取百度相关关键词以及文章采集时,经常触发百度的验证机制,这种情况很明显要使用到代理IP,后来群里一个小伙伴推荐了品赞代理IP,小编测试了下,完美解决了爬取中存在的问题。
如果大家后续有需要使用到代理方面的业务的话,可以扫码添加下方的二维码。国内外的IP都有,新用户可以免费测试。
查看全部
文章采集api Python 爬取人人视频
hello,小伙伴们,又见面了,距离上一次发布文章的时间,也算是久别重逢了。期间也发生了很多的事情,导致博文断更,也是笔者不愿意的,但是确实是比较忙,不再过多赘述,希望大家能够体谅。
平时不断的在后台收到小伙伴的私信,问是不是不更了,答案当然是否定的,有着这么多人的支持,小编还是要继续努力下去的,再次谢谢大家的支持。
这次给大家带来的文章是爬取人人视频,之前多是分享一些爬取数据,图片,音乐,还没怎么分享过爬取过视频的,那么想要爬取视频的话该怎么爬取呢?
其实不管是图片,还是音乐,或者是其他的文档,大部分都是一个文件读写的过程,当然视频也不例外,只是文件的格式不同而已。所以我们也可以试着以常规的手段去尝试下爬取视频,没错还是熟悉的套路与配方,即python常用函数 open()和 write()。
不过这次略微不同的是我们会使用到iter_content来获取请求的原始响应数据,普通情况可以用r.raw,在初始请求中设置stream=True,来获取服务器的原始套接字响应,在这里我们使用iter_content更加方便一些,因为requests.get(url) 默认是下载在内存中的,下载完成才存到硬盘上,但Response.iter_content可以边下载边存硬盘中,所以在这视频下载方面更具有优势。
当然说到 iter_content 的话,不得不提下chunk_size,因为流式请求就是像流水一样,不是一次过来而是一点一点“流”过来。处理流式数据也是一点一点处理。
而chunk_size会直接返回从当前位置往后读取 chunk_size 大小的文件内容,且迭代响应数据。这避免了立即将内容读入内存以获得较大的响应。chunk_size是它应该读入内存的字节数。chunk_size的类型必须是int或None。None的值将根据流的值发挥不同的作用。
做了引荐与讲解后,那么就开始上我们的主菜了,即目标网站:
https://m.rr.tv/
介于代码偏基础化,且主要知识点做过分析就直接上代码了,具体请看代码:
单线程:
import requestsimport jsonimport reimport osheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}ep_list =[]vod_list = []def get_vod(url): response = requests.get(url = url,headers = headers)#请求url ep= re.compile(r'sid:"(.*?)",')#提取ep链接 ep_list = re.findall(ep,response.text) vod= re.compile(r'data:\[{id:(.*?),title:"')#提取vod链接 vod_list = re.findall(vod,response.text) vod= re.compile(r',title:"(.*?)",desc:"')#提取视频标题 vod_name = re.findall(vod,response.text) ep = 1 os.mkdir('./'+vod_name[0])#创建视频保存目录 for i in ep_list: print("开始下载"+vod_name[0]+"第"+str(ep)+"集") url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers)#下载请求 r = requests.get(str(json.loads(response.text)['data']['url']), stream=True)#解析出下载链接并发起下载请求 f = open("./"+vod_name[0]+"/第"+str(ep)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk) ep = ep+1if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxxx?snum=1&episode=1'#目标视频链接 get_vod(url)
多线程:
import requestsimport jsonimport reimport osfrom concurrent.futures import ThreadPoolExecutorheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}vod_list = []#存储视频链接vod_name = []#存储视频标题get_down_url =[]#存储下载直链def get_vod(url): response = requests.get(url = url,headers = headers)#请求url vod_list.append(re.findall(re.compile(r'data:\[{id:(.*?),title:"'),response.text)[0])#找找视频链接 vod_name.append(re.findall(re.compile(r',title:"(.*?)",desc:"'),response.text)[0])#找找视频标题 for i in re.findall(re.compile(r'{sid:"(.*?)",key:'),response.text): url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers) get_down_url.append(str(json.loads(response.text)['data']['url']))#拿下载直链进listdef down_begin(url,i): print("开始多线程下载"+vod_name[0]+"第"+str(i)+"集") r = requests.get(url = url,headers = headers)#下载请求 f = open("./"+vod_name[0]+"/第"+str(i)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk)if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxx?snum=1&episode=1'#进入rr.tv自行获取 get_vod(url) os.mkdir('./'+vod_name[0])#创建视频保存目录 with ThreadPoolExecutor(10) as f:#这里写多线程参数,适合几十集的电视剧使用 for i,url in enumerate(get_down_url): i=int(i)+1 f.submit(down_begin,url = url,i=i)
把案例里面的链接改成你想要下载的链接,然后右击运行代码,即可成功的下载你想要的视频了。代码获取后台回复:”人人视频“。
在文章的最后给大家来一波福利,因为前一段时间小编在爬取百度相关关键词以及文章采集时,经常触发百度的验证机制,这种情况很明显要使用到代理IP,后来群里一个小伙伴推荐了品赞代理IP,小编测试了下,完美解决了爬取中存在的问题。
如果大家后续有需要使用到代理方面的业务的话,可以扫码添加下方的二维码。国内外的IP都有,新用户可以免费测试。
文章采集api Python 爬取人人视频
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-05-09 10:00
hello,小伙伴们,又见面了,距离上一次发布文章的时间,也算是久别重逢了。期间也发生了很多的事情,导致博文断更,也是笔者不愿意的,但是确实是比较忙,不再过多赘述,希望大家能够体谅。
平时不断的在后台收到小伙伴的私信,问是不是不更了,答案当然是否定的,有着这么多人的支持,小编还是要继续努力下去的,再次谢谢大家的支持。
这次给大家带来的文章是爬取人人视频,之前多是分享一些爬取数据,图片,音乐,还没怎么分享过爬取过视频的,那么想要爬取视频的话该怎么爬取呢?
其实不管是图片,还是音乐,或者是其他的文档,大部分都是一个文件读写的过程,当然视频也不例外,只是文件的格式不同而已。所以我们也可以试着以常规的手段去尝试下爬取视频,没错还是熟悉的套路与配方,即python常用函数 open()和 write()。
不过这次略微不同的是我们会使用到iter_content来获取请求的原始响应数据,普通情况可以用r.raw,在初始请求中设置stream=True,来获取服务器的原始套接字响应,在这里我们使用iter_content更加方便一些,因为requests.get(url) 默认是下载在内存中的,下载完成才存到硬盘上,但Response.iter_content可以边下载边存硬盘中,所以在这视频下载方面更具有优势。
当然说到 iter_content 的话,不得不提下chunk_size,因为流式请求就是像流水一样,不是一次过来而是一点一点“流”过来。处理流式数据也是一点一点处理。
而chunk_size会直接返回从当前位置往后读取 chunk_size 大小的文件内容,且迭代响应数据。这避免了立即将内容读入内存以获得较大的响应。chunk_size是它应该读入内存的字节数。chunk_size的类型必须是int或None。None的值将根据流的值发挥不同的作用。
做了引荐与讲解后,那么就开始上我们的主菜了,即目标网站:
https://m.rr.tv/
介于代码偏基础化,且主要知识点做过分析就直接上代码了,具体请看代码:
单线程:
import requestsimport jsonimport reimport osheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}ep_list =[]vod_list = []def get_vod(url): response = requests.get(url = url,headers = headers)#请求url ep= re.compile(r'sid:"(.*?)",')#提取ep链接 ep_list = re.findall(ep,response.text) vod= re.compile(r'data:\[{id:(.*?),title:"')#提取vod链接 vod_list = re.findall(vod,response.text) vod= re.compile(r',title:"(.*?)",desc:"')#提取视频标题 vod_name = re.findall(vod,response.text) ep = 1 os.mkdir('./'+vod_name[0])#创建视频保存目录 for i in ep_list: print("开始下载"+vod_name[0]+"第"+str(ep)+"集") url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers)#下载请求 r = requests.get(str(json.loads(response.text)['data']['url']), stream=True)#解析出下载链接并发起下载请求 f = open("./"+vod_name[0]+"/第"+str(ep)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk) ep = ep+1if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxxx?snum=1&episode=1'#目标视频链接 get_vod(url)
多线程:
import requestsimport jsonimport reimport osfrom concurrent.futures import ThreadPoolExecutorheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}vod_list = []#存储视频链接vod_name = []#存储视频标题get_down_url =[]#存储下载直链def get_vod(url): response = requests.get(url = url,headers = headers)#请求url vod_list.append(re.findall(re.compile(r'data:\[{id:(.*?),title:"'),response.text)[0])#找找视频链接 vod_name.append(re.findall(re.compile(r',title:"(.*?)",desc:"'),response.text)[0])#找找视频标题 for i in re.findall(re.compile(r'{sid:"(.*?)",key:'),response.text): url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers) get_down_url.append(str(json.loads(response.text)['data']['url']))#拿下载直链进listdef down_begin(url,i): print("开始多线程下载"+vod_name[0]+"第"+str(i)+"集") r = requests.get(url = url,headers = headers)#下载请求 f = open("./"+vod_name[0]+"/第"+str(i)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk)if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxx?snum=1&episode=1'#进入rr.tv自行获取 get_vod(url) os.mkdir('./'+vod_name[0])#创建视频保存目录 with ThreadPoolExecutor(10) as f:#这里写多线程参数,适合几十集的电视剧使用 for i,url in enumerate(get_down_url): i=int(i)+1 f.submit(down_begin,url = url,i=i)
把案例里面的链接改成你想要下载的链接,然后右击运行代码,即可成功的下载你想要的视频了。代码获取后台回复:”人人视频“。
在文章的最后给大家来一波福利,因为前一段时间小编在爬取百度相关关键词以及文章采集时,经常触发百度的验证机制,这种情况很明显要使用到代理IP,后来群里一个小伙伴推荐了品赞代理IP,小编测试了下,完美解决了爬取中存在的问题。
如果大家后续有需要使用到代理方面的业务的话,可以扫码添加下方的二维码。国内外的IP都有,新用户可以免费测试。
查看全部
文章采集api Python 爬取人人视频
hello,小伙伴们,又见面了,距离上一次发布文章的时间,也算是久别重逢了。期间也发生了很多的事情,导致博文断更,也是笔者不愿意的,但是确实是比较忙,不再过多赘述,希望大家能够体谅。
平时不断的在后台收到小伙伴的私信,问是不是不更了,答案当然是否定的,有着这么多人的支持,小编还是要继续努力下去的,再次谢谢大家的支持。
这次给大家带来的文章是爬取人人视频,之前多是分享一些爬取数据,图片,音乐,还没怎么分享过爬取过视频的,那么想要爬取视频的话该怎么爬取呢?
其实不管是图片,还是音乐,或者是其他的文档,大部分都是一个文件读写的过程,当然视频也不例外,只是文件的格式不同而已。所以我们也可以试着以常规的手段去尝试下爬取视频,没错还是熟悉的套路与配方,即python常用函数 open()和 write()。
不过这次略微不同的是我们会使用到iter_content来获取请求的原始响应数据,普通情况可以用r.raw,在初始请求中设置stream=True,来获取服务器的原始套接字响应,在这里我们使用iter_content更加方便一些,因为requests.get(url) 默认是下载在内存中的,下载完成才存到硬盘上,但Response.iter_content可以边下载边存硬盘中,所以在这视频下载方面更具有优势。
当然说到 iter_content 的话,不得不提下chunk_size,因为流式请求就是像流水一样,不是一次过来而是一点一点“流”过来。处理流式数据也是一点一点处理。
而chunk_size会直接返回从当前位置往后读取 chunk_size 大小的文件内容,且迭代响应数据。这避免了立即将内容读入内存以获得较大的响应。chunk_size是它应该读入内存的字节数。chunk_size的类型必须是int或None。None的值将根据流的值发挥不同的作用。
做了引荐与讲解后,那么就开始上我们的主菜了,即目标网站:
https://m.rr.tv/
介于代码偏基础化,且主要知识点做过分析就直接上代码了,具体请看代码:
单线程:
import requestsimport jsonimport reimport osheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}ep_list =[]vod_list = []def get_vod(url): response = requests.get(url = url,headers = headers)#请求url ep= re.compile(r'sid:"(.*?)",')#提取ep链接 ep_list = re.findall(ep,response.text) vod= re.compile(r'data:\[{id:(.*?),title:"')#提取vod链接 vod_list = re.findall(vod,response.text) vod= re.compile(r',title:"(.*?)",desc:"')#提取视频标题 vod_name = re.findall(vod,response.text) ep = 1 os.mkdir('./'+vod_name[0])#创建视频保存目录 for i in ep_list: print("开始下载"+vod_name[0]+"第"+str(ep)+"集") url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers)#下载请求 r = requests.get(str(json.loads(response.text)['data']['url']), stream=True)#解析出下载链接并发起下载请求 f = open("./"+vod_name[0]+"/第"+str(ep)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk) ep = ep+1if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxxx?snum=1&episode=1'#目标视频链接 get_vod(url)
多线程:
import requestsimport jsonimport reimport osfrom concurrent.futures import ThreadPoolExecutorheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}vod_list = []#存储视频链接vod_name = []#存储视频标题get_down_url =[]#存储下载直链def get_vod(url): response = requests.get(url = url,headers = headers)#请求url vod_list.append(re.findall(re.compile(r'data:\[{id:(.*?),title:"'),response.text)[0])#找找视频链接 vod_name.append(re.findall(re.compile(r',title:"(.*?)",desc:"'),response.text)[0])#找找视频标题 for i in re.findall(re.compile(r'{sid:"(.*?)",key:'),response.text): url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers) get_down_url.append(str(json.loads(response.text)['data']['url']))#拿下载直链进listdef down_begin(url,i): print("开始多线程下载"+vod_name[0]+"第"+str(i)+"集") r = requests.get(url = url,headers = headers)#下载请求 f = open("./"+vod_name[0]+"/第"+str(i)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk)if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxx?snum=1&episode=1'#进入rr.tv自行获取 get_vod(url) os.mkdir('./'+vod_name[0])#创建视频保存目录 with ThreadPoolExecutor(10) as f:#这里写多线程参数,适合几十集的电视剧使用 for i,url in enumerate(get_down_url): i=int(i)+1 f.submit(down_begin,url = url,i=i)
把案例里面的链接改成你想要下载的链接,然后右击运行代码,即可成功的下载你想要的视频了。代码获取后台回复:”人人视频“。
在文章的最后给大家来一波福利,因为前一段时间小编在爬取百度相关关键词以及文章采集时,经常触发百度的验证机制,这种情况很明显要使用到代理IP,后来群里一个小伙伴推荐了品赞代理IP,小编测试了下,完美解决了爬取中存在的问题。
如果大家后续有需要使用到代理方面的业务的话,可以扫码添加下方的二维码。国内外的IP都有,新用户可以免费测试。
干掉 Swagger + Postman?测试接口直接生成API文档
采集交流 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-05-09 04:25
② 点击右上角的【+】按钮,我们来新建一个页面,编写一个用户注册的 API 接口文档。
新建页面
③ 点击【API 接口模板】按钮,ShowDoc 会帮我们生成 API 接口文档的示例,采用的是 Markdown 的格式。
API 接口模板
④ 简单修改 Markdown 的内容,然后点击右上角的【保存】按钮,生成文档。
保存接口
⑤ 点击右上角的【返回】按钮,可以看到刚创建的 API 接口文档。
接口预览
在右边,艿艿圈了【分享】【目录】【历史版本】三个按钮,胖友可以自己去体验下。
ShowDoc 提供 API 接口的 Mock 功能,方便后端在定义 API 接口后,提供模拟数据。
① 点击需要 Mock 的 API 接口文档的右边的【编辑页面】按钮,然后点击【Mock】按钮,我们可以看到一个 Mock 的弹窗。
Mock 弹窗
② 填写 Mock 的返回结果,设置 Mock Url 的路径,然后点击【保存】按钮。
设置 Mock
③ 点击【复制】按钮,复制 Mock Url 的路径,然后使用浏览器访问,可以看到 Mock 的返回结果。
请求 Mock 接口
友情提示:ShowDoc 提供的 Mock 能力还是比较基础的,实际项目中,我们可能希望根据不同的请求参数,返回不同的 Mock 结果。
如果胖友有这块需求,可以看看 YApi: 。
通过手写 Markdown 的方式,生成 API 文档的方式,是非常非常非常繁琐 的!!!所以,ShowDoc 自己也不推荐采用这种方式,而是主推 RunApi 工具,一边调试接口,一边自动生成 。
咱先看看 RunApi 的自我介绍,也是贼长一大串:
RunApi 是一个以接口为核心的开发测试工具(功能上类似 Postman)。
目前有客户端版(推荐,支持 Win/Mac/Linux全平台)和在线精简版 ,包含接口测试 / 自动流程测试 / Mock 数据 / 项目协作等功能。
它和 ShowDoc 相辅相成:
相信使用 ShowDoc + RunApi 这两个工具组合,能够极大地提高IT团队的效率。
管你看没看懂,跟着艿艿一起,体验一下就完事了!
① 在 地址下,提供了不同操作系统的 RunApi 客户端的下载。
客户端
② 下载并安装完成后,使用 ShowDoc 注册的账号,进行登陆。
Runapi 登陆
虽然我们在 ShowDoc 中,已经新建了项目,但是我们在 RunApi 中是无法看到的。因此,我们需要重新新建属于 RunApi 的项目。
项目对比
① 点击 RunApi 客户端的【新建项目】按钮,填写项目名和描述,然后点击【确认】按钮进行保存。
新建项目
② 浏览器刷新 ShowDoc 页面,可以看到刚创建的项目。
查看项目
① 点击【+】按钮,选择要新增的类型为“带调试功能的API接口”。
新建 API 接口
② 启动一个 Spring Boot 项目,提供一个需要调试的 API 接口。
友情提示:胖友可以克隆 项目,使用 lab-24/lab-24-apidoc-showdoc 示例。
嘿嘿,顺手求个 Star 关注,艿艿写了 40000+ Spring Boot 和 Spring Cloud 的使用示例代码。
启动 Spring Boot 项目
③ 使用 RunApi 调试下 /users/login 接口。
调试 API 接口
④ 点击【返回示例和参数说明】,补全返回结果的接口文档。
补全响应结果
⑤ 点击【保存】按钮,生成 API 接口文档。
⑥ 点击【文档链接】按钮,获得 API 接口文档的地址。
文档链接
⑦ 点击 API 文档的访问链接,查看 API 文档。
RunAPI 文档预览
当然,我们也可以在 ShowDoc 中,进行访问。
ShowDoc 文档预览
有一点要注意,使用 RunApi 生成的 API 接口文档,无法在使用 Markdown 进行编辑噢!原因也很简单,编写后的 Markdown 文件,可能会导致无法逆向被 RunApi 使用,格式被破坏了!
① 点击需要 Mock 的 API 接口文档的下边的【Mock】按钮,我们可以看到一个 Mock 的界面。
Mock 界面
② 填写 Mock 的返回结果,设置 Mock Url 的路径,然后点击【保存】按钮。
设置 Mock
③ 点击【复制】按钮,复制 Mock Url 的路径,然后使用浏览器访问,可以看到 Mock 的返回结果。
请求 Mock 接口
RunApi 还提供了 3 个高级特性,胖友后面可以自己体验下。
强烈推荐 !!!
环境变量
例如说,设置“本地环境”、“测试环境”等多套环境变量,方便模拟请求不通过环境下的 API 噢。
前执行脚本
例如说,可以模拟登陆,获得用户的访问 token 令牌。
后执行脚本
例如说,断言响应的结果,是否为期望的 200 。
RunApi 提供的自动 生成 API 接口文档的方式,确实能够避免一部分烦琐 的手写 Markdown 的过程。同时,它能够结合我们日常开发,模拟调用 API 接口的时,复用了请求参数与响应结果。
但是我们如果仔细去思考,这是不是意味着可能此时此刻,我们已经开发完 API 接口了?!那么,假如团队采用的是前后端分离的架构,并且前端和后端是两拨人,那么前端会希望后端提前就定义好 API 接口的文档,而不是在后端具体完成好 API 接口的开发后,再提供接口文档。
所以我们在使用 RunApi 的时候,有可能是先使用它来**“手动”** 定义好 API 接口文档,然后复用它来模拟测试 API 接口。
嘿嘿~胖友也可以思考下,结合 RunApi 的这种模式,怎么结合到我们的日常开发流程中,欢迎留言讨论。
ShowDoc 支持通过扫描代码注释的方式,自动生成 API 接口文档,目前自持 Java、C++、PHP、Node 等等主流的编程语言。
艿艿看了下官方文档 对这块功能的介绍,感受上使用体验会非常不好。一起来看下官方提供的示例:
/**<br /> * showdoc<br /> * @catalog 测试文档/用户相关<br /> * @title 用户登录<br /> * @description 用户登录的接口<br /> * @method get<br /> * @url https://www.showdoc.cc/home/user/login<br /> * @header token 可选 string 设备token <br /> * @param username 必选 string 用户名 <br /> * @param password 必选 string 密码 <br /> * @param name 可选 string 用户昵称 <br /> * @return {"error_code":0,"data":{"uid":"1","username":"12154545","name":"吴系挂","groupid":2,"reg_time":"1436864169","last_login_time":"0"}}<br /> * @return_param groupid int 用户组id<br /> * @return_param name string 用户昵称<br /> * @remark 这里是备注信息<br /> * @number 99<br /> */<br /> public Object login(String username, String password, String name) {<br /> // ... 省略具体代码<br /> }<br />
需要使用到 @catalog、@title 等等自定义的注释标签,且原有的 @param 需要安装一定的格式来保证 API 接口的参数的说明,@return 的示例会导致注释非常长。
自定义注释
这样就导致,虽然只使用代码注释的方式,实际对代码还是有一定的入侵,影响代码的可读性。
还是老样子,我们使用 项目,lab-24/lab-24-apidoc-showdoc 示例,编写一个 users/login2 接口,并使用 ShowDoc 扫码 Java代码注释,生成 API 接口文档。
① 下载 脚本,到项目的根目录。
下载 showdoc_api 脚本
② 在项目的设置页,获得 ShowDoc 的开放 API 的 api_key 和 api_token 秘钥对。
进入项目的设置页获得 api_key 和 api_token 秘钥对
③ 修改 showdoc_api.sh 脚本,设置刚获得的 api_key 和 api_token 秘钥对。
设置 api_key 和 api_token 秘钥对
④ 编写 users/login2 接口,添加 ShowDoc 所需的注释。
编写 users/login2 接口
是不是看着就蛮乱的,IDEA 还报错 @param 找不到 username 和 password 参数。
⑤ 执行 showdoc_api.sh 脚本,扫描 Java代码注释,生成 API 接口文档。
生成 API 接口文档
⑥ 查看生成 API 接口文档。
查看 API 接口文档
如果胖友希望基于 Java 注释生成 API 接口文档,艿艿还是相对 JApiDocs 工具。具体的,可以看看艿艿写的 《芋道 Spring Boot API 接口文档 JApiDocs 入门》 文章。
JApiDocs 效果
ShowDoc 提供给了开放 API 的方式,导入 Markdown 文档。所以,我们可以编写程序,调用它的 API 接口,创建或更新 API 接口文档。
开放 API 的官方文档文档地址是, 。
接口地址 :
接口参数 :
接口参数
我们来导入一个简单的文档,效果如下图所示:
{<br /> "api_key": "60fc53cea6af4758c1686cb22ba20566472255580",<br /> "api_token": "0bbb5f564a9ee66333115b1abb8f8d541979489118",<br /> "page_title": "公众号",<br /> "page_content": "芋道源码,求一波关注呀~"<br />}<br />
友情提示:api_key 和 api_token 参数,记得改成自己的秘钥对,不然就导入到艿艿的项目里啦~~~
调用开放 API文档效果
在新建项目时,ShowDoc 支持导入 Swagger 或者 Postman 的 JSON 文档,方便我们快速迁移到 ShowDoc 作为 API 接口的平台。
我们来体验下 ShowDoc 提供的导入 Swagger 文档的功能,使用 项目,lab-24/lab-24-apidoc-swagger-starter 示例,提供的 Swagger JSON 文件。
① 启动 Spring Boot 项目,获得其 Swagger JSON 文件。
下载 Swagger JSON 文件
友情提示:胖友也可以访问 地址,直接进行下载!
② 新建 ShowDoc 项目,点击【导入文件】,选择 Swagger JSON 文件。
导入 Swagger JSON 文件
③ 导入完成后,点击自动新建的项目,查看下导入的 API 文档的效果。
导入 Swagger JSON 文件
接口都成功导入了,可惜 Swagger 中的 example 都缺失了,这就导致我们需要手动补全下接口的示例。
ShowDoc 目前只支持新建项目时,导入 Swagger 接口文档。但是如果 Swagger 接口文档变更时,无法进行更新 ShowDoc 中的文档。
如果我们仅仅是把 Swagger 迁移到 ShowDoc 中,肯定是基本能够满足。但是,如果我们希望使用 Swagger 编写接口文档,手动或者自动导入 ShowDoc 进行展示,这样就无法满足了。
这里艿艿推荐下 YApi 工具,支持定时采集 Swagger 接口,智能 合并 API 接口文档。具体的,可以看看艿艿写的 《芋道 Spring Boot API 接口文档 YApi 入门》 文章。
YApi + Swagger
在上家公司,艿艿就采用 Swagger + YApi 的组合,Swagger 方便后端编写 API 接口文档,YApi 提供接口的展示 、编辑 、Mock 、调试 、自动化测试 。
ShowDoc 支持通过扫描数据库,自动生成表结构的数据库文档。
对应的官方文档地址是, 。
下面, 我们来把艿艿的一个开源项目 的数据库,导入 ShowDoc 生成数据库文档。
① 下载 脚本,并设置数据库相关的参数。
下载 show_db 脚本
② 执行 show_db 脚本,看到“成功”说明成功。查看数据库文档的效果,效果还是还不错。
查看数据库文档
国内还有一款不错的数据库文档的生成工具 Screw,具体可以看看艿艿写的《芋道 Spring Boot 数据表结构文档》,地址是 。
演示效果
至此,我们已经完成 ShowDoc 的入门,还是蛮不错的一个工具。做个简单的小总结:
Talk is Cheap,胖友可以选择动手玩玩 ShowDoc 工具。
- END -
欢迎加入我的知识星球,一起探讨架构,交流源码。加入方式,长按下方二维码噢:
已在知识星球更新源码解析如下:
最近更新《芋道 SpringBoot 2.X 入门》系列,已经 101 余篇,覆盖了MyBatis、Redis、MongoDB、ES、分库分表、读写分离、SpringMVC、Webflux、权限、WebSocket、Dubbo、RabbitMQ、RocketMQ、Kafka、性能测试等等内容。
提供近 3W 行代码的 SpringBoot 示例,以及超 4W 行代码的电商微服务项目。 查看全部
干掉 Swagger + Postman?测试接口直接生成API文档
② 点击右上角的【+】按钮,我们来新建一个页面,编写一个用户注册的 API 接口文档。
新建页面
③ 点击【API 接口模板】按钮,ShowDoc 会帮我们生成 API 接口文档的示例,采用的是 Markdown 的格式。
API 接口模板
④ 简单修改 Markdown 的内容,然后点击右上角的【保存】按钮,生成文档。
保存接口
⑤ 点击右上角的【返回】按钮,可以看到刚创建的 API 接口文档。
接口预览
在右边,艿艿圈了【分享】【目录】【历史版本】三个按钮,胖友可以自己去体验下。
ShowDoc 提供 API 接口的 Mock 功能,方便后端在定义 API 接口后,提供模拟数据。
① 点击需要 Mock 的 API 接口文档的右边的【编辑页面】按钮,然后点击【Mock】按钮,我们可以看到一个 Mock 的弹窗。
Mock 弹窗
② 填写 Mock 的返回结果,设置 Mock Url 的路径,然后点击【保存】按钮。
设置 Mock
③ 点击【复制】按钮,复制 Mock Url 的路径,然后使用浏览器访问,可以看到 Mock 的返回结果。
请求 Mock 接口
友情提示:ShowDoc 提供的 Mock 能力还是比较基础的,实际项目中,我们可能希望根据不同的请求参数,返回不同的 Mock 结果。
如果胖友有这块需求,可以看看 YApi: 。
通过手写 Markdown 的方式,生成 API 文档的方式,是非常非常非常繁琐 的!!!所以,ShowDoc 自己也不推荐采用这种方式,而是主推 RunApi 工具,一边调试接口,一边自动生成 。
咱先看看 RunApi 的自我介绍,也是贼长一大串:
RunApi 是一个以接口为核心的开发测试工具(功能上类似 Postman)。
目前有客户端版(推荐,支持 Win/Mac/Linux全平台)和在线精简版 ,包含接口测试 / 自动流程测试 / Mock 数据 / 项目协作等功能。
它和 ShowDoc 相辅相成:
相信使用 ShowDoc + RunApi 这两个工具组合,能够极大地提高IT团队的效率。
管你看没看懂,跟着艿艿一起,体验一下就完事了!
① 在 地址下,提供了不同操作系统的 RunApi 客户端的下载。
客户端
② 下载并安装完成后,使用 ShowDoc 注册的账号,进行登陆。
Runapi 登陆
虽然我们在 ShowDoc 中,已经新建了项目,但是我们在 RunApi 中是无法看到的。因此,我们需要重新新建属于 RunApi 的项目。
项目对比
① 点击 RunApi 客户端的【新建项目】按钮,填写项目名和描述,然后点击【确认】按钮进行保存。
新建项目
② 浏览器刷新 ShowDoc 页面,可以看到刚创建的项目。
查看项目
① 点击【+】按钮,选择要新增的类型为“带调试功能的API接口”。
新建 API 接口
② 启动一个 Spring Boot 项目,提供一个需要调试的 API 接口。
友情提示:胖友可以克隆 项目,使用 lab-24/lab-24-apidoc-showdoc 示例。
嘿嘿,顺手求个 Star 关注,艿艿写了 40000+ Spring Boot 和 Spring Cloud 的使用示例代码。
启动 Spring Boot 项目
③ 使用 RunApi 调试下 /users/login 接口。
调试 API 接口
④ 点击【返回示例和参数说明】,补全返回结果的接口文档。
补全响应结果
⑤ 点击【保存】按钮,生成 API 接口文档。
⑥ 点击【文档链接】按钮,获得 API 接口文档的地址。
文档链接
⑦ 点击 API 文档的访问链接,查看 API 文档。
RunAPI 文档预览
当然,我们也可以在 ShowDoc 中,进行访问。
ShowDoc 文档预览
有一点要注意,使用 RunApi 生成的 API 接口文档,无法在使用 Markdown 进行编辑噢!原因也很简单,编写后的 Markdown 文件,可能会导致无法逆向被 RunApi 使用,格式被破坏了!
① 点击需要 Mock 的 API 接口文档的下边的【Mock】按钮,我们可以看到一个 Mock 的界面。
Mock 界面
② 填写 Mock 的返回结果,设置 Mock Url 的路径,然后点击【保存】按钮。
设置 Mock
③ 点击【复制】按钮,复制 Mock Url 的路径,然后使用浏览器访问,可以看到 Mock 的返回结果。
请求 Mock 接口
RunApi 还提供了 3 个高级特性,胖友后面可以自己体验下。
强烈推荐 !!!
环境变量
例如说,设置“本地环境”、“测试环境”等多套环境变量,方便模拟请求不通过环境下的 API 噢。
前执行脚本
例如说,可以模拟登陆,获得用户的访问 token 令牌。
后执行脚本
例如说,断言响应的结果,是否为期望的 200 。
RunApi 提供的自动 生成 API 接口文档的方式,确实能够避免一部分烦琐 的手写 Markdown 的过程。同时,它能够结合我们日常开发,模拟调用 API 接口的时,复用了请求参数与响应结果。
但是我们如果仔细去思考,这是不是意味着可能此时此刻,我们已经开发完 API 接口了?!那么,假如团队采用的是前后端分离的架构,并且前端和后端是两拨人,那么前端会希望后端提前就定义好 API 接口的文档,而不是在后端具体完成好 API 接口的开发后,再提供接口文档。
所以我们在使用 RunApi 的时候,有可能是先使用它来**“手动”** 定义好 API 接口文档,然后复用它来模拟测试 API 接口。
嘿嘿~胖友也可以思考下,结合 RunApi 的这种模式,怎么结合到我们的日常开发流程中,欢迎留言讨论。
ShowDoc 支持通过扫描代码注释的方式,自动生成 API 接口文档,目前自持 Java、C++、PHP、Node 等等主流的编程语言。
艿艿看了下官方文档 对这块功能的介绍,感受上使用体验会非常不好。一起来看下官方提供的示例:
/**<br /> * showdoc<br /> * @catalog 测试文档/用户相关<br /> * @title 用户登录<br /> * @description 用户登录的接口<br /> * @method get<br /> * @url https://www.showdoc.cc/home/user/login<br /> * @header token 可选 string 设备token <br /> * @param username 必选 string 用户名 <br /> * @param password 必选 string 密码 <br /> * @param name 可选 string 用户昵称 <br /> * @return {"error_code":0,"data":{"uid":"1","username":"12154545","name":"吴系挂","groupid":2,"reg_time":"1436864169","last_login_time":"0"}}<br /> * @return_param groupid int 用户组id<br /> * @return_param name string 用户昵称<br /> * @remark 这里是备注信息<br /> * @number 99<br /> */<br /> public Object login(String username, String password, String name) {<br /> // ... 省略具体代码<br /> }<br />
需要使用到 @catalog、@title 等等自定义的注释标签,且原有的 @param 需要安装一定的格式来保证 API 接口的参数的说明,@return 的示例会导致注释非常长。
自定义注释
这样就导致,虽然只使用代码注释的方式,实际对代码还是有一定的入侵,影响代码的可读性。
还是老样子,我们使用 项目,lab-24/lab-24-apidoc-showdoc 示例,编写一个 users/login2 接口,并使用 ShowDoc 扫码 Java代码注释,生成 API 接口文档。
① 下载 脚本,到项目的根目录。
下载 showdoc_api 脚本
② 在项目的设置页,获得 ShowDoc 的开放 API 的 api_key 和 api_token 秘钥对。
进入项目的设置页获得 api_key 和 api_token 秘钥对
③ 修改 showdoc_api.sh 脚本,设置刚获得的 api_key 和 api_token 秘钥对。
设置 api_key 和 api_token 秘钥对
④ 编写 users/login2 接口,添加 ShowDoc 所需的注释。
编写 users/login2 接口
是不是看着就蛮乱的,IDEA 还报错 @param 找不到 username 和 password 参数。
⑤ 执行 showdoc_api.sh 脚本,扫描 Java代码注释,生成 API 接口文档。
生成 API 接口文档
⑥ 查看生成 API 接口文档。
查看 API 接口文档
如果胖友希望基于 Java 注释生成 API 接口文档,艿艿还是相对 JApiDocs 工具。具体的,可以看看艿艿写的 《芋道 Spring Boot API 接口文档 JApiDocs 入门》 文章。
JApiDocs 效果
ShowDoc 提供给了开放 API 的方式,导入 Markdown 文档。所以,我们可以编写程序,调用它的 API 接口,创建或更新 API 接口文档。
开放 API 的官方文档文档地址是, 。
接口地址 :
接口参数 :
接口参数
我们来导入一个简单的文档,效果如下图所示:
{<br /> "api_key": "60fc53cea6af4758c1686cb22ba20566472255580",<br /> "api_token": "0bbb5f564a9ee66333115b1abb8f8d541979489118",<br /> "page_title": "公众号",<br /> "page_content": "芋道源码,求一波关注呀~"<br />}<br />
友情提示:api_key 和 api_token 参数,记得改成自己的秘钥对,不然就导入到艿艿的项目里啦~~~
调用开放 API文档效果
在新建项目时,ShowDoc 支持导入 Swagger 或者 Postman 的 JSON 文档,方便我们快速迁移到 ShowDoc 作为 API 接口的平台。
我们来体验下 ShowDoc 提供的导入 Swagger 文档的功能,使用 项目,lab-24/lab-24-apidoc-swagger-starter 示例,提供的 Swagger JSON 文件。
① 启动 Spring Boot 项目,获得其 Swagger JSON 文件。
下载 Swagger JSON 文件
友情提示:胖友也可以访问 地址,直接进行下载!
② 新建 ShowDoc 项目,点击【导入文件】,选择 Swagger JSON 文件。
导入 Swagger JSON 文件
③ 导入完成后,点击自动新建的项目,查看下导入的 API 文档的效果。
导入 Swagger JSON 文件
接口都成功导入了,可惜 Swagger 中的 example 都缺失了,这就导致我们需要手动补全下接口的示例。
ShowDoc 目前只支持新建项目时,导入 Swagger 接口文档。但是如果 Swagger 接口文档变更时,无法进行更新 ShowDoc 中的文档。
如果我们仅仅是把 Swagger 迁移到 ShowDoc 中,肯定是基本能够满足。但是,如果我们希望使用 Swagger 编写接口文档,手动或者自动导入 ShowDoc 进行展示,这样就无法满足了。
这里艿艿推荐下 YApi 工具,支持定时采集 Swagger 接口,智能 合并 API 接口文档。具体的,可以看看艿艿写的 《芋道 Spring Boot API 接口文档 YApi 入门》 文章。
YApi + Swagger
在上家公司,艿艿就采用 Swagger + YApi 的组合,Swagger 方便后端编写 API 接口文档,YApi 提供接口的展示 、编辑 、Mock 、调试 、自动化测试 。
ShowDoc 支持通过扫描数据库,自动生成表结构的数据库文档。
对应的官方文档地址是, 。
下面, 我们来把艿艿的一个开源项目 的数据库,导入 ShowDoc 生成数据库文档。
① 下载 脚本,并设置数据库相关的参数。
下载 show_db 脚本
② 执行 show_db 脚本,看到“成功”说明成功。查看数据库文档的效果,效果还是还不错。
查看数据库文档
国内还有一款不错的数据库文档的生成工具 Screw,具体可以看看艿艿写的《芋道 Spring Boot 数据表结构文档》,地址是 。
演示效果
至此,我们已经完成 ShowDoc 的入门,还是蛮不错的一个工具。做个简单的小总结:
Talk is Cheap,胖友可以选择动手玩玩 ShowDoc 工具。
- END -
欢迎加入我的知识星球,一起探讨架构,交流源码。加入方式,长按下方二维码噢:
已在知识星球更新源码解析如下:
最近更新《芋道 SpringBoot 2.X 入门》系列,已经 101 余篇,覆盖了MyBatis、Redis、MongoDB、ES、分库分表、读写分离、SpringMVC、Webflux、权限、WebSocket、Dubbo、RabbitMQ、RocketMQ、Kafka、性能测试等等内容。
提供近 3W 行代码的 SpringBoot 示例,以及超 4W 行代码的电商微服务项目。
文章采集api Python 爬取人人视频
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-05-09 04:23
hello,小伙伴们,又见面了,距离上一次发布文章的时间,也算是久别重逢了。期间也发生了很多的事情,导致博文断更,也是笔者不愿意的,但是确实是比较忙,不再过多赘述,希望大家能够体谅。
平时不断的在后台收到小伙伴的私信,问是不是不更了,答案当然是否定的,有着这么多人的支持,小编还是要继续努力下去的,再次谢谢大家的支持。
这次给大家带来的文章是爬取人人视频,之前多是分享一些爬取数据,图片,音乐,还没怎么分享过爬取过视频的,那么想要爬取视频的话该怎么爬取呢?
其实不管是图片,还是音乐,或者是其他的文档,大部分都是一个文件读写的过程,当然视频也不例外,只是文件的格式不同而已。所以我们也可以试着以常规的手段去尝试下爬取视频,没错还是熟悉的套路与配方,即python常用函数 open()和 write()。
不过这次略微不同的是我们会使用到iter_content来获取请求的原始响应数据,普通情况可以用r.raw,在初始请求中设置stream=True,来获取服务器的原始套接字响应,在这里我们使用iter_content更加方便一些,因为requests.get(url) 默认是下载在内存中的,下载完成才存到硬盘上,但Response.iter_content可以边下载边存硬盘中,所以在这视频下载方面更具有优势。
当然说到 iter_content 的话,不得不提下chunk_size,因为流式请求就是像流水一样,不是一次过来而是一点一点“流”过来。处理流式数据也是一点一点处理。
而chunk_size会直接返回从当前位置往后读取 chunk_size 大小的文件内容,且迭代响应数据。这避免了立即将内容读入内存以获得较大的响应。chunk_size是它应该读入内存的字节数。chunk_size的类型必须是int或None。None的值将根据流的值发挥不同的作用。
做了引荐与讲解后,那么就开始上我们的主菜了,即目标网站:
https://m.rr.tv/
介于代码偏基础化,且主要知识点做过分析就直接上代码了,具体请看代码:
单线程:
import requestsimport jsonimport reimport osheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}ep_list =[]vod_list = []def get_vod(url): response = requests.get(url = url,headers = headers)#请求url ep= re.compile(r'sid:"(.*?)",')#提取ep链接 ep_list = re.findall(ep,response.text) vod= re.compile(r'data:\[{id:(.*?),title:"')#提取vod链接 vod_list = re.findall(vod,response.text) vod= re.compile(r',title:"(.*?)",desc:"')#提取视频标题 vod_name = re.findall(vod,response.text) ep = 1 os.mkdir('./'+vod_name[0])#创建视频保存目录 for i in ep_list: print("开始下载"+vod_name[0]+"第"+str(ep)+"集") url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers)#下载请求 r = requests.get(str(json.loads(response.text)['data']['url']), stream=True)#解析出下载链接并发起下载请求 f = open("./"+vod_name[0]+"/第"+str(ep)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk) ep = ep+1if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxxx?snum=1&episode=1'#目标视频链接 get_vod(url)
多线程:
import requestsimport jsonimport reimport osfrom concurrent.futures import ThreadPoolExecutorheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}vod_list = []#存储视频链接vod_name = []#存储视频标题get_down_url =[]#存储下载直链def get_vod(url): response = requests.get(url = url,headers = headers)#请求url vod_list.append(re.findall(re.compile(r'data:\[{id:(.*?),title:"'),response.text)[0])#找找视频链接 vod_name.append(re.findall(re.compile(r',title:"(.*?)",desc:"'),response.text)[0])#找找视频标题 for i in re.findall(re.compile(r'{sid:"(.*?)",key:'),response.text): url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers) get_down_url.append(str(json.loads(response.text)['data']['url']))#拿下载直链进listdef down_begin(url,i): print("开始多线程下载"+vod_name[0]+"第"+str(i)+"集") r = requests.get(url = url,headers = headers)#下载请求 f = open("./"+vod_name[0]+"/第"+str(i)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk)if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxx?snum=1&episode=1'#进入rr.tv自行获取 get_vod(url) os.mkdir('./'+vod_name[0])#创建视频保存目录 with ThreadPoolExecutor(10) as f:#这里写多线程参数,适合几十集的电视剧使用 for i,url in enumerate(get_down_url): i=int(i)+1 f.submit(down_begin,url = url,i=i)
把案例里面的链接改成你想要下载的链接,然后右击运行代码,即可成功的下载你想要的视频了。代码获取后台回复:”人人视频“。
在文章的最后给大家来一波福利,因为前一段时间小编在爬取百度相关关键词以及文章采集时,经常触发百度的验证机制,这种情况很明显要使用到代理IP,后来群里一个小伙伴推荐了品赞代理IP,小编测试了下,完美解决了爬取中存在的问题。
如果大家后续有需要使用到代理方面的业务的话,可以扫码添加下方的二维码。国内外的IP都有,新用户可以免费测试。
查看全部
文章采集api Python 爬取人人视频
hello,小伙伴们,又见面了,距离上一次发布文章的时间,也算是久别重逢了。期间也发生了很多的事情,导致博文断更,也是笔者不愿意的,但是确实是比较忙,不再过多赘述,希望大家能够体谅。
平时不断的在后台收到小伙伴的私信,问是不是不更了,答案当然是否定的,有着这么多人的支持,小编还是要继续努力下去的,再次谢谢大家的支持。
这次给大家带来的文章是爬取人人视频,之前多是分享一些爬取数据,图片,音乐,还没怎么分享过爬取过视频的,那么想要爬取视频的话该怎么爬取呢?
其实不管是图片,还是音乐,或者是其他的文档,大部分都是一个文件读写的过程,当然视频也不例外,只是文件的格式不同而已。所以我们也可以试着以常规的手段去尝试下爬取视频,没错还是熟悉的套路与配方,即python常用函数 open()和 write()。
不过这次略微不同的是我们会使用到iter_content来获取请求的原始响应数据,普通情况可以用r.raw,在初始请求中设置stream=True,来获取服务器的原始套接字响应,在这里我们使用iter_content更加方便一些,因为requests.get(url) 默认是下载在内存中的,下载完成才存到硬盘上,但Response.iter_content可以边下载边存硬盘中,所以在这视频下载方面更具有优势。
当然说到 iter_content 的话,不得不提下chunk_size,因为流式请求就是像流水一样,不是一次过来而是一点一点“流”过来。处理流式数据也是一点一点处理。
而chunk_size会直接返回从当前位置往后读取 chunk_size 大小的文件内容,且迭代响应数据。这避免了立即将内容读入内存以获得较大的响应。chunk_size是它应该读入内存的字节数。chunk_size的类型必须是int或None。None的值将根据流的值发挥不同的作用。
做了引荐与讲解后,那么就开始上我们的主菜了,即目标网站:
https://m.rr.tv/
介于代码偏基础化,且主要知识点做过分析就直接上代码了,具体请看代码:
单线程:
import requestsimport jsonimport reimport osheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}ep_list =[]vod_list = []def get_vod(url): response = requests.get(url = url,headers = headers)#请求url ep= re.compile(r'sid:"(.*?)",')#提取ep链接 ep_list = re.findall(ep,response.text) vod= re.compile(r'data:\[{id:(.*?),title:"')#提取vod链接 vod_list = re.findall(vod,response.text) vod= re.compile(r',title:"(.*?)",desc:"')#提取视频标题 vod_name = re.findall(vod,response.text) ep = 1 os.mkdir('./'+vod_name[0])#创建视频保存目录 for i in ep_list: print("开始下载"+vod_name[0]+"第"+str(ep)+"集") url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers)#下载请求 r = requests.get(str(json.loads(response.text)['data']['url']), stream=True)#解析出下载链接并发起下载请求 f = open("./"+vod_name[0]+"/第"+str(ep)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk) ep = ep+1if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxxx?snum=1&episode=1'#目标视频链接 get_vod(url)
多线程:
import requestsimport jsonimport reimport osfrom concurrent.futures import ThreadPoolExecutorheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}vod_list = []#存储视频链接vod_name = []#存储视频标题get_down_url =[]#存储下载直链def get_vod(url): response = requests.get(url = url,headers = headers)#请求url vod_list.append(re.findall(re.compile(r'data:\[{id:(.*?),title:"'),response.text)[0])#找找视频链接 vod_name.append(re.findall(re.compile(r',title:"(.*?)",desc:"'),response.text)[0])#找找视频标题 for i in re.findall(re.compile(r'{sid:"(.*?)",key:'),response.text): url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers) get_down_url.append(str(json.loads(response.text)['data']['url']))#拿下载直链进listdef down_begin(url,i): print("开始多线程下载"+vod_name[0]+"第"+str(i)+"集") r = requests.get(url = url,headers = headers)#下载请求 f = open("./"+vod_name[0]+"/第"+str(i)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk)if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxx?snum=1&episode=1'#进入rr.tv自行获取 get_vod(url) os.mkdir('./'+vod_name[0])#创建视频保存目录 with ThreadPoolExecutor(10) as f:#这里写多线程参数,适合几十集的电视剧使用 for i,url in enumerate(get_down_url): i=int(i)+1 f.submit(down_begin,url = url,i=i)
把案例里面的链接改成你想要下载的链接,然后右击运行代码,即可成功的下载你想要的视频了。代码获取后台回复:”人人视频“。
在文章的最后给大家来一波福利,因为前一段时间小编在爬取百度相关关键词以及文章采集时,经常触发百度的验证机制,这种情况很明显要使用到代理IP,后来群里一个小伙伴推荐了品赞代理IP,小编测试了下,完美解决了爬取中存在的问题。
如果大家后续有需要使用到代理方面的业务的话,可以扫码添加下方的二维码。国内外的IP都有,新用户可以免费测试。
如何使用新一代轻量级分布式日志管理神器 Graylog 来收集日志
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-05-04 14:05
公众号关注「奇妙的 Linux 世界」
设为「星标」,每天带你玩转 Linux !
当我们公司内部部署很多服务以及测试、正式环境的时候,查看日志就变成了一个非常刚需的需求了。是多个环境的日志统一收集,然后使用 Nginx 对外提供服务,还是使用专用的日志收集服务 ELK 呢?
这就变成了一个问题!而 Graylog 作为整合方案,使用 Elasticsearch 来存储,使用 MongoDB 来缓存,并且还有带流量控制的(throttling),同时其界面查询简单易用且易于扩展。所以,使用 Graylog 成为了不二之选,为我们省了不少心。
1Filebeat 工具介绍
Filebeat 日志文件托运服务
Filebeat 是一个日志文件托运工具,在你的服务器上安装客户端后,Filebeat 会自动监控给定的日志目录或者指定的日志文件,追踪读取这些文件,不停的读取,并且转发这些信息到 Elasticsearch 或者 Logstarsh 或者 Graylog 中存放。
Filebeat 工作流程介绍
当你安装并启用 Filebeat 程序的时候,它会启动一个或多个探测器(prospectors)去检测你指定的日志目录或文件,对于探测器找出的每一个日志文件,Filebeat 都会启动一个收割进程(harvester),每一个收割进程读取一个日志文件的最新内容,并发送这些新的日志数据到处理程序(spooler),处理程序会集合这些事件,最后 Filebeat 会发送集合的数据到你指定的地址上去(我们这里就是发送给 Graylog 服务了)。
Filebeat 图示理解记忆
我们这里不适用 Logstash 服务,主要是因为 Filebeat 相比于 Logstash 更加轻量级。当我们需要收集信息的机器配置或资源并不是特别多时,且并没有那么复杂的时候,还是建议使用 Filebeat 来收集日志。日常使用中,Filebeat 的安装部署方式多样且运行十分稳定。
图示服务架构理解记忆2Filebeat 配置文件
配置 Filebeat 工具的核心就是如何编写其对应的配置文件!
对应 Filebeat 工具的配置主要是通过编写其配置文件来控制的,对于通过 rpm 或者 deb 包来安装的情况,配置文件默认会存储在,/etc/filebeat/filebeat.yml 这个路径下面。而对于,对于 MAC 或者 Win 系统来说,请查看解压文件中相关文件,其中都有涉及。
下面展示了 Filebeat 工具的主配置文件,注释信息中都对其各个字段含义进行了详细的解释,我这里就不再赘述了。需要注意的是,我们将日志的输入来源统统定义去读取 inputs.d 目录下的所有 yml 配置。所以,我们可以更加不用的服务(测试、正式服务)来定义不同的配置文件,根据物理机部署的实际情况具体配置。
# 配置输入来源的日志信息<br /># 我们合理将其配置到了inputs.d目录下的所有yml文件<br />filebeat.config.inputs:<br /> enabled: true<br /> path: ${path.config}/inputs.d/*.yml<br /> # 若收取日志格式为json的log请开启此配置<br /> # json.keys_under_root: true<br /><br /># 配置filebeat需要加载的模块<br />filebeat.config.modules:<br /> path: ${path.config}/modules.d/*.yml<br /> reload.enabled: false<br /><br />setup.template.settings:<br /> index.number_of_shards: 1<br /><br /># 配置将日志信息发送那个地址上面<br />output.logstash:<br /> hosts: ["11.22.33.44:5500"]<br /><br /># output.file:<br /># enable: true<br /><br />processors:<br /> - add_host_metadata: ~<br /> - rename:<br /> fields:<br /> - from: "log"<br /> to: "message"<br /> - add_fields:<br /> target: ""<br /> fields:<br /> # 加token是为了防止无认证的服务上Graylog服务发送数据<br /> token: "0uxxxxaM-1111-2222-3333-VQZJxxxxxwgX "<br /><br />
下面展示一个简单的 inputs.d 目录下面的 yml 配置文件的具体内容,其主要作用就是配置单独服务的独立日志数据,以及追加不同的数据 tag 类型。
# 配置输入来源的日志信息<br /># 我们合理将其配置到了inputs.d目录下的所有yml文件<br />filebeat.config.inputs:<br /> enabled: true<br /> path: ${path.config}/inputs.d/*.yml<br /> # 若收取日志格式为json的log请开启此配置<br /> # json.keys_under_root: true<br /><br /># 配置filebeat需要加载的模块<br />filebeat.config.modules:<br /> path: ${path.config}/modules.d/*.yml<br /> reload.enabled: false<br /><br />setup.template.settings:<br /> index.number_of_shards: 1<br /><br /># 配置将日志信息发送那个地址上面<br />output.logstash:<br /> hosts: ["11.22.33.44:5500"]<br /><br /># output.file:<br /># enable: true<br /><br />processors:<br /> - add_host_metadata: ~<br /> - rename:<br /> fields:<br /> - from: "log"<br /> to: "message"<br /> - add_fields:<br /> target: ""<br /> fields:<br /> # 加token是为了防止无认证的服务上Graylog服务发送数据<br /> token: "0uxxxxaM-1111-2222-3333-VQZJxxxxxwgX "<br />
需要注意的是,针对于不同的日志类型,filebeat 还提供了不同了模块来配置不同的服务日志以及其不同的模块特性,比如我们常见的 PostgreSQl、Redis、Iptables 等。
# iptables<br />- module: iptables<br /> log:<br /> enabled: true<br /> var.paths: ["/var/log/iptables.log"]<br /> var.input: "file"<br /><br /># postgres<br />- module: postgresql<br /> log:<br /> enabled: true<br /> var.paths: ["/path/to/log/postgres/*.log*"]<br /><br /># nginx<br />- module: nginx<br /> access:<br /> enabled: true<br /> var.paths: ["/path/to/log/nginx/access.log*"]<br /> error:<br /> enabled: true<br /> var.paths: ["/path/to/log/nginx/error.log*"]<br />
3Graylog 服务介绍
服务日志收集方案:Filebeat + Graylog!
Graylog 日志监控系统
Graylog 是一个开源的日志聚合、分析、审计、展现和预警工具。在功能上来说,和 ELK 类似,但又比 ELK 要简单很多。依靠着更加简洁,高效,部署使用简单的优势很快受到许多人的青睐。当然,在扩展性上面确实没有比 ELK 好,但是其有商业版本可以选择。
Graylog 工作流程介绍
部署 Graylog 最简单的架构就是单机部署,复杂的也是部署集群模式,架构图示如下所示。我们可以看到其中包含了三个组件,分别是 Elasticsearch、MongoDb 和 Graylog。其中,Elasticsearch 用来持久化存储和检索日志文件数据(IO 密集),MongoDb 用来存储关于 Graylog 的相关配置,而 Graylog 来提供 Web 界面和对外接口的(CPU 密集)。
最小化单机部署
最优化集群部署4Graylog 组件功能
配置 Graylog 服务的核心就是理解对应组件的功能以及其运作方式!
简单来讲,Input 表示日志数据的来源,对不同来源的日志可以通过 Extractors 来进行日志的字段转换,比如将 Nginx 的状态码变成对应的英文表述等。然后,通过不同的标签类型分组成不用的 Stream,并将这些日志数据存储到指定的 Index 库中进行持久化保存。
Graylog中的核心服务组件
Graylog 通过 Input 搜集日志,每个 Input 单独配置 Extractors 用来做字段转换。Graylog 中日志搜索的基本单位是 Stream,每个 Stream 可以有自己单独的 Elastic Index Set,也可以共享一个 Index Set。
Extractor 在 System/Input 中配置。Graylog 中很方便的一点就是可以加载一条日志,然后基于这个实际的例子进行配置并能直接看到结果。内置的 Extractor 基本可以完成各种字段提取和转换的任务,但是也有些限制,在应用里写日志的时候就需要考虑到这些限制。Input 可以配置多个 Extractors,按照顺序依次执行。
系统会有一个默认的 Stream,所有日志默认都会保存到这个 Stream 中,除非匹配了某个 Stream,并且这个 Stream 里配置了不保存日志到默认 Stream。可以通过菜单 Streams 创建更多的 Stream,新创建的 Stream 是暂停状态,需要在配置完成后手动启动。Stream 通过配置条件匹配日志,满足条件的日志添加 stream ID 标识字段并保存到对应的 Elastic Index Set 中。
Index Set 通过菜单 System/Indices 创建。日志存储的性能,可靠性和过期策略都通过 Index Set 来配置。性能和可靠性就是配置 Elastic Index 的一些参数,主要参数包括,Shards 和 Replicas。
除了上面提到的日志处理流程,Graylog 还提供了 Pipeline 脚本实现更灵活的日志处理方案。这里不详细阐述,只介绍如果使用 Pipelines 来过滤不需要的日志。下面是丢弃 level > 6 的所有日志的 Pipeline Rule 的例子。从数据采集(input),字段解析(extractor),分流到 stream,再到 Pipeline 的清洗,一气呵成,无需在通过其他方式进行二次加工。
Sidecar 是一个轻量级的日志采集器,通过访问 Graylog 进行集中式管理,支持 Linux 和 windows 系统。Sidecar 守护进程会定期访问 Graylog 的 REST API 接口获取 Sidecar 配置文件中定义的标签(tag),Sidecar 在首次运行时会从 Graylog 服务器拉取配置文件中指定标签(tag)的配置信息同步到本地。目前 Sidecar 支持 NXLog,Filebeat 和 Winlogbeat。他们都通过 Graylog 中的 web 界面进行统一配置,支持 Beats、CEF、Gelf、Json API、NetFlow 等输出类型。Graylog 最厉害的在于可以在配置文件中指定 Sidecar 把日志发送到哪个 Graylog 群集,并对 Graylog 群集中的多个 input 进行负载均衡,这样在遇到日志量非常庞大的时候,Graylog 也能应付自如。
rule "discard debug messages"<br />when<br /> to_long($message.level) > 6<br />then<br /> drop_message();<br />end<br />
日志集中保存到 Graylog 后就可以方便的使用搜索了。不过有时候还是需要对数据进行近一步的处理。主要有两个途径,分别是直接访问 Elastic 中保存的数据,或者通过 Graylog 的 Output 转发到其它服务。
5服务安装和部署
主要介绍部署 Filebeat + Graylog 的安装步骤和注意事项!
使用 Graylog 来收集日志
部署 Filebeat 工具
官方提供了多种的部署方式,包括通过 rpm 和 deb 包安装服务,以及源代码编译的方式安装服务,同时包括了使用 Docker 或者 kubernetes 的方式安装服务。我们根据自己的实际需要,进行安装即可。
# Ubuntu(deb)<br />$ curl -L -O https://artifacts.elastic.co/d ... %3Bbr />$ sudo dpkg -i filebeat-7.8.1-amd64.deb<br />$ sudo systemctl enable filebeat<br />$ sudo service filebeat start<br /><br /># 使用docker启动<br />docker run -d --name=filebeat --user=root \<br /> --volume="./filebeat.docker.yml:/usr/share/filebeat/filebeat.yml:ro" \<br /> --volume="/var/lib/docker/containers:/var/lib/docker/containers:ro" \<br /> --volume="/var/run/docker.sock:/var/run/docker.sock:ro" \<br /> docker.elastic.co/beats/filebeat:7.8.1 filebeat -e -strict.perms=false \<br /> -E output.elasticsearch.hosts=["elasticsearch:9200"]<br />
使用 Graylog 来收集日志
部署 Graylog 服务
我们这里主要介绍使用 Docker 容器来部署服务,如果你需要使用其他方式来部署的话,请自行查看官方文档对应章节的安装部署步骤。在服务部署之前,我们需要给 Graylog 服务生成等相关信息,生成部署如下所示:
<p># 生成password_secret密码(最少16位)<br />$ sudo apt install -y pwgen<br />$ pwgen -N 1 -s 16<br />zscMb65...FxR9ag<br /><br /># 生成后续Web登录时所需要使用的密码<br />$ echo -n "Enter Password: " && head -1 查看全部
如何使用新一代轻量级分布式日志管理神器 Graylog 来收集日志
公众号关注「奇妙的 Linux 世界」
设为「星标」,每天带你玩转 Linux !
当我们公司内部部署很多服务以及测试、正式环境的时候,查看日志就变成了一个非常刚需的需求了。是多个环境的日志统一收集,然后使用 Nginx 对外提供服务,还是使用专用的日志收集服务 ELK 呢?
这就变成了一个问题!而 Graylog 作为整合方案,使用 Elasticsearch 来存储,使用 MongoDB 来缓存,并且还有带流量控制的(throttling),同时其界面查询简单易用且易于扩展。所以,使用 Graylog 成为了不二之选,为我们省了不少心。
1Filebeat 工具介绍
Filebeat 日志文件托运服务
Filebeat 是一个日志文件托运工具,在你的服务器上安装客户端后,Filebeat 会自动监控给定的日志目录或者指定的日志文件,追踪读取这些文件,不停的读取,并且转发这些信息到 Elasticsearch 或者 Logstarsh 或者 Graylog 中存放。
Filebeat 工作流程介绍
当你安装并启用 Filebeat 程序的时候,它会启动一个或多个探测器(prospectors)去检测你指定的日志目录或文件,对于探测器找出的每一个日志文件,Filebeat 都会启动一个收割进程(harvester),每一个收割进程读取一个日志文件的最新内容,并发送这些新的日志数据到处理程序(spooler),处理程序会集合这些事件,最后 Filebeat 会发送集合的数据到你指定的地址上去(我们这里就是发送给 Graylog 服务了)。
Filebeat 图示理解记忆
我们这里不适用 Logstash 服务,主要是因为 Filebeat 相比于 Logstash 更加轻量级。当我们需要收集信息的机器配置或资源并不是特别多时,且并没有那么复杂的时候,还是建议使用 Filebeat 来收集日志。日常使用中,Filebeat 的安装部署方式多样且运行十分稳定。
图示服务架构理解记忆2Filebeat 配置文件
配置 Filebeat 工具的核心就是如何编写其对应的配置文件!
对应 Filebeat 工具的配置主要是通过编写其配置文件来控制的,对于通过 rpm 或者 deb 包来安装的情况,配置文件默认会存储在,/etc/filebeat/filebeat.yml 这个路径下面。而对于,对于 MAC 或者 Win 系统来说,请查看解压文件中相关文件,其中都有涉及。
下面展示了 Filebeat 工具的主配置文件,注释信息中都对其各个字段含义进行了详细的解释,我这里就不再赘述了。需要注意的是,我们将日志的输入来源统统定义去读取 inputs.d 目录下的所有 yml 配置。所以,我们可以更加不用的服务(测试、正式服务)来定义不同的配置文件,根据物理机部署的实际情况具体配置。
# 配置输入来源的日志信息<br /># 我们合理将其配置到了inputs.d目录下的所有yml文件<br />filebeat.config.inputs:<br /> enabled: true<br /> path: ${path.config}/inputs.d/*.yml<br /> # 若收取日志格式为json的log请开启此配置<br /> # json.keys_under_root: true<br /><br /># 配置filebeat需要加载的模块<br />filebeat.config.modules:<br /> path: ${path.config}/modules.d/*.yml<br /> reload.enabled: false<br /><br />setup.template.settings:<br /> index.number_of_shards: 1<br /><br /># 配置将日志信息发送那个地址上面<br />output.logstash:<br /> hosts: ["11.22.33.44:5500"]<br /><br /># output.file:<br /># enable: true<br /><br />processors:<br /> - add_host_metadata: ~<br /> - rename:<br /> fields:<br /> - from: "log"<br /> to: "message"<br /> - add_fields:<br /> target: ""<br /> fields:<br /> # 加token是为了防止无认证的服务上Graylog服务发送数据<br /> token: "0uxxxxaM-1111-2222-3333-VQZJxxxxxwgX "<br /><br />
下面展示一个简单的 inputs.d 目录下面的 yml 配置文件的具体内容,其主要作用就是配置单独服务的独立日志数据,以及追加不同的数据 tag 类型。
# 配置输入来源的日志信息<br /># 我们合理将其配置到了inputs.d目录下的所有yml文件<br />filebeat.config.inputs:<br /> enabled: true<br /> path: ${path.config}/inputs.d/*.yml<br /> # 若收取日志格式为json的log请开启此配置<br /> # json.keys_under_root: true<br /><br /># 配置filebeat需要加载的模块<br />filebeat.config.modules:<br /> path: ${path.config}/modules.d/*.yml<br /> reload.enabled: false<br /><br />setup.template.settings:<br /> index.number_of_shards: 1<br /><br /># 配置将日志信息发送那个地址上面<br />output.logstash:<br /> hosts: ["11.22.33.44:5500"]<br /><br /># output.file:<br /># enable: true<br /><br />processors:<br /> - add_host_metadata: ~<br /> - rename:<br /> fields:<br /> - from: "log"<br /> to: "message"<br /> - add_fields:<br /> target: ""<br /> fields:<br /> # 加token是为了防止无认证的服务上Graylog服务发送数据<br /> token: "0uxxxxaM-1111-2222-3333-VQZJxxxxxwgX "<br />
需要注意的是,针对于不同的日志类型,filebeat 还提供了不同了模块来配置不同的服务日志以及其不同的模块特性,比如我们常见的 PostgreSQl、Redis、Iptables 等。
# iptables<br />- module: iptables<br /> log:<br /> enabled: true<br /> var.paths: ["/var/log/iptables.log"]<br /> var.input: "file"<br /><br /># postgres<br />- module: postgresql<br /> log:<br /> enabled: true<br /> var.paths: ["/path/to/log/postgres/*.log*"]<br /><br /># nginx<br />- module: nginx<br /> access:<br /> enabled: true<br /> var.paths: ["/path/to/log/nginx/access.log*"]<br /> error:<br /> enabled: true<br /> var.paths: ["/path/to/log/nginx/error.log*"]<br />
3Graylog 服务介绍
服务日志收集方案:Filebeat + Graylog!
Graylog 日志监控系统
Graylog 是一个开源的日志聚合、分析、审计、展现和预警工具。在功能上来说,和 ELK 类似,但又比 ELK 要简单很多。依靠着更加简洁,高效,部署使用简单的优势很快受到许多人的青睐。当然,在扩展性上面确实没有比 ELK 好,但是其有商业版本可以选择。
Graylog 工作流程介绍
部署 Graylog 最简单的架构就是单机部署,复杂的也是部署集群模式,架构图示如下所示。我们可以看到其中包含了三个组件,分别是 Elasticsearch、MongoDb 和 Graylog。其中,Elasticsearch 用来持久化存储和检索日志文件数据(IO 密集),MongoDb 用来存储关于 Graylog 的相关配置,而 Graylog 来提供 Web 界面和对外接口的(CPU 密集)。
最小化单机部署
最优化集群部署4Graylog 组件功能
配置 Graylog 服务的核心就是理解对应组件的功能以及其运作方式!
简单来讲,Input 表示日志数据的来源,对不同来源的日志可以通过 Extractors 来进行日志的字段转换,比如将 Nginx 的状态码变成对应的英文表述等。然后,通过不同的标签类型分组成不用的 Stream,并将这些日志数据存储到指定的 Index 库中进行持久化保存。
Graylog中的核心服务组件
Graylog 通过 Input 搜集日志,每个 Input 单独配置 Extractors 用来做字段转换。Graylog 中日志搜索的基本单位是 Stream,每个 Stream 可以有自己单独的 Elastic Index Set,也可以共享一个 Index Set。
Extractor 在 System/Input 中配置。Graylog 中很方便的一点就是可以加载一条日志,然后基于这个实际的例子进行配置并能直接看到结果。内置的 Extractor 基本可以完成各种字段提取和转换的任务,但是也有些限制,在应用里写日志的时候就需要考虑到这些限制。Input 可以配置多个 Extractors,按照顺序依次执行。
系统会有一个默认的 Stream,所有日志默认都会保存到这个 Stream 中,除非匹配了某个 Stream,并且这个 Stream 里配置了不保存日志到默认 Stream。可以通过菜单 Streams 创建更多的 Stream,新创建的 Stream 是暂停状态,需要在配置完成后手动启动。Stream 通过配置条件匹配日志,满足条件的日志添加 stream ID 标识字段并保存到对应的 Elastic Index Set 中。
Index Set 通过菜单 System/Indices 创建。日志存储的性能,可靠性和过期策略都通过 Index Set 来配置。性能和可靠性就是配置 Elastic Index 的一些参数,主要参数包括,Shards 和 Replicas。
除了上面提到的日志处理流程,Graylog 还提供了 Pipeline 脚本实现更灵活的日志处理方案。这里不详细阐述,只介绍如果使用 Pipelines 来过滤不需要的日志。下面是丢弃 level > 6 的所有日志的 Pipeline Rule 的例子。从数据采集(input),字段解析(extractor),分流到 stream,再到 Pipeline 的清洗,一气呵成,无需在通过其他方式进行二次加工。
Sidecar 是一个轻量级的日志采集器,通过访问 Graylog 进行集中式管理,支持 Linux 和 windows 系统。Sidecar 守护进程会定期访问 Graylog 的 REST API 接口获取 Sidecar 配置文件中定义的标签(tag),Sidecar 在首次运行时会从 Graylog 服务器拉取配置文件中指定标签(tag)的配置信息同步到本地。目前 Sidecar 支持 NXLog,Filebeat 和 Winlogbeat。他们都通过 Graylog 中的 web 界面进行统一配置,支持 Beats、CEF、Gelf、Json API、NetFlow 等输出类型。Graylog 最厉害的在于可以在配置文件中指定 Sidecar 把日志发送到哪个 Graylog 群集,并对 Graylog 群集中的多个 input 进行负载均衡,这样在遇到日志量非常庞大的时候,Graylog 也能应付自如。
rule "discard debug messages"<br />when<br /> to_long($message.level) > 6<br />then<br /> drop_message();<br />end<br />
日志集中保存到 Graylog 后就可以方便的使用搜索了。不过有时候还是需要对数据进行近一步的处理。主要有两个途径,分别是直接访问 Elastic 中保存的数据,或者通过 Graylog 的 Output 转发到其它服务。
5服务安装和部署
主要介绍部署 Filebeat + Graylog 的安装步骤和注意事项!
使用 Graylog 来收集日志
部署 Filebeat 工具
官方提供了多种的部署方式,包括通过 rpm 和 deb 包安装服务,以及源代码编译的方式安装服务,同时包括了使用 Docker 或者 kubernetes 的方式安装服务。我们根据自己的实际需要,进行安装即可。
# Ubuntu(deb)<br />$ curl -L -O https://artifacts.elastic.co/d ... %3Bbr />$ sudo dpkg -i filebeat-7.8.1-amd64.deb<br />$ sudo systemctl enable filebeat<br />$ sudo service filebeat start<br /><br /># 使用docker启动<br />docker run -d --name=filebeat --user=root \<br /> --volume="./filebeat.docker.yml:/usr/share/filebeat/filebeat.yml:ro" \<br /> --volume="/var/lib/docker/containers:/var/lib/docker/containers:ro" \<br /> --volume="/var/run/docker.sock:/var/run/docker.sock:ro" \<br /> docker.elastic.co/beats/filebeat:7.8.1 filebeat -e -strict.perms=false \<br /> -E output.elasticsearch.hosts=["elasticsearch:9200"]<br />
使用 Graylog 来收集日志
部署 Graylog 服务
我们这里主要介绍使用 Docker 容器来部署服务,如果你需要使用其他方式来部署的话,请自行查看官方文档对应章节的安装部署步骤。在服务部署之前,我们需要给 Graylog 服务生成等相关信息,生成部署如下所示:
<p># 生成password_secret密码(最少16位)<br />$ sudo apt install -y pwgen<br />$ pwgen -N 1 -s 16<br />zscMb65...FxR9ag<br /><br /># 生成后续Web登录时所需要使用的密码<br />$ echo -n "Enter Password: " && head -1
超好用的收集信息工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-05-04 14:00
什么是 OSINT?
如果您听说过这个名字,OSINT代表开源情报,它指的是可以从免费公共来源合法收集的有关个人或组织的任何信息。在实践中,这往往意味着在互联网上找到的信息,但从技术上讲,任何公共信息都属于OSINT类别,无论是公共图书馆的书籍或报告,报纸上的文章还是新闻稿中的声明。
OSINT 还包括可在不同类型的介质中找到的信息。虽然我们通常认为它是基于文本的,但图像,视频,网络研讨会,公开演讲和会议中的信息都属于该术语。
OSINT的用途是什么?
通过收集有关特定目标的公开可用信息源,以更好地了解其特征并缩小搜索区域以查找可能的漏洞。数据信息可以生成的情报来构建威胁模型。或者有针对性的网络攻击,如军事攻击,从侦察开始,数字侦察的第一阶段是被动地获取情报,而不向目标发出警报。一旦可以从公共来源收集有关您的情报类型,就可以使用它来帮助您或您的安全团队制定更好的防御策略。
OSINT工具
用于情报收集的最明显的工具之一是Google,Bing等网络搜索引擎。事实上,有几十个搜索引擎,对于特定类型的查询,有些搜索引擎可能会返回比其他搜索引擎更好的结果。那么,问题是,如何以有效的方式查询这许多引擎呢?
Searx是解决此问题并使Web查询更有效的一个很好的工具。Searx是元搜索引擎,允许您匿名并同时收集来自70多个搜索服务的结果。Searx是免费的,您甚至可以托管自己的实例,以获得最终的隐私。用户既不会被跟踪,也不会被分析,并且默认情况下禁用cookie。Searx也可以通过Tor用于在线匿名。
有很多人一直在为OSINT开发新工具,当然,跟上他们以及网络安全世界中其他任何事情的好地方就是在Twitter上关注人们。然而,在Twitter上跟踪事情可能很困难。幸运的是,还有一个名为Twint的OSINT工具。
Twint是一个用Python编写的Twitter报废工具,可以很容易地在Twitter上匿名收集和搜索信息,而无需注册Twitter服务本身或使用API密钥,就像使用Recon-ng这样的工具一样。使用 Twint,根本不需要身份验证或 API。只需安装工具并开始搜索即可。您可以按用户,地理位置和时间范围以及其他可能性进行搜索。这只是Twint的一些选择,但也有许多其他选择。
那么,如何使用 Twint 来帮助您跟上 OSINT 的发展呢?嗯,这很容易,是Twint在行动中的一个很好的例子。由于 Twint 允许你指定一个--因为选项,以便仅从某个日期开始拉取推文,因此你可以将其与 Twint 的搜索动词相结合,每天抓取标记有#OSINT的新推文。您可以使用 Twint 的--database选项(保存为 SQLite 格式)自动执行该脚本并将结果馈送到数据库中,以便在方便时查看。
另一个可以用来收集公共信息的好工具是Metagaofil。此工具使用Google搜索引擎从给定域中检索公共PDF,Word文档,Powerpoint和Excel文件。然后,它可以自主地从这些文档中提取元数据,以生成列出用户名、软件版本、服务器和计算机名称等信息的报告。
查看全部
超好用的收集信息工具
什么是 OSINT?
如果您听说过这个名字,OSINT代表开源情报,它指的是可以从免费公共来源合法收集的有关个人或组织的任何信息。在实践中,这往往意味着在互联网上找到的信息,但从技术上讲,任何公共信息都属于OSINT类别,无论是公共图书馆的书籍或报告,报纸上的文章还是新闻稿中的声明。
OSINT 还包括可在不同类型的介质中找到的信息。虽然我们通常认为它是基于文本的,但图像,视频,网络研讨会,公开演讲和会议中的信息都属于该术语。
OSINT的用途是什么?
通过收集有关特定目标的公开可用信息源,以更好地了解其特征并缩小搜索区域以查找可能的漏洞。数据信息可以生成的情报来构建威胁模型。或者有针对性的网络攻击,如军事攻击,从侦察开始,数字侦察的第一阶段是被动地获取情报,而不向目标发出警报。一旦可以从公共来源收集有关您的情报类型,就可以使用它来帮助您或您的安全团队制定更好的防御策略。
OSINT工具
用于情报收集的最明显的工具之一是Google,Bing等网络搜索引擎。事实上,有几十个搜索引擎,对于特定类型的查询,有些搜索引擎可能会返回比其他搜索引擎更好的结果。那么,问题是,如何以有效的方式查询这许多引擎呢?
Searx是解决此问题并使Web查询更有效的一个很好的工具。Searx是元搜索引擎,允许您匿名并同时收集来自70多个搜索服务的结果。Searx是免费的,您甚至可以托管自己的实例,以获得最终的隐私。用户既不会被跟踪,也不会被分析,并且默认情况下禁用cookie。Searx也可以通过Tor用于在线匿名。
有很多人一直在为OSINT开发新工具,当然,跟上他们以及网络安全世界中其他任何事情的好地方就是在Twitter上关注人们。然而,在Twitter上跟踪事情可能很困难。幸运的是,还有一个名为Twint的OSINT工具。
Twint是一个用Python编写的Twitter报废工具,可以很容易地在Twitter上匿名收集和搜索信息,而无需注册Twitter服务本身或使用API密钥,就像使用Recon-ng这样的工具一样。使用 Twint,根本不需要身份验证或 API。只需安装工具并开始搜索即可。您可以按用户,地理位置和时间范围以及其他可能性进行搜索。这只是Twint的一些选择,但也有许多其他选择。
那么,如何使用 Twint 来帮助您跟上 OSINT 的发展呢?嗯,这很容易,是Twint在行动中的一个很好的例子。由于 Twint 允许你指定一个--因为选项,以便仅从某个日期开始拉取推文,因此你可以将其与 Twint 的搜索动词相结合,每天抓取标记有#OSINT的新推文。您可以使用 Twint 的--database选项(保存为 SQLite 格式)自动执行该脚本并将结果馈送到数据库中,以便在方便时查看。
另一个可以用来收集公共信息的好工具是Metagaofil。此工具使用Google搜索引擎从给定域中检索公共PDF,Word文档,Powerpoint和Excel文件。然后,它可以自主地从这些文档中提取元数据,以生成列出用户名、软件版本、服务器和计算机名称等信息的报告。
文章采集api Python 爬取人人视频
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-05-04 13:08
hello,小伙伴们,又见面了,距离上一次发布文章的时间,也算是久别重逢了。期间也发生了很多的事情,导致博文断更,也是笔者不愿意的,但是确实是比较忙,不再过多赘述,希望大家能够体谅。
平时不断的在后台收到小伙伴的私信,问是不是不更了,答案当然是否定的,有着这么多人的支持,小编还是要继续努力下去的,再次谢谢大家的支持。
这次给大家带来的文章是爬取人人视频,之前多是分享一些爬取数据,图片,音乐,还没怎么分享过爬取过视频的,那么想要爬取视频的话该怎么爬取呢?
其实不管是图片,还是音乐,或者是其他的文档,大部分都是一个文件读写的过程,当然视频也不例外,只是文件的格式不同而已。所以我们也可以试着以常规的手段去尝试下爬取视频,没错还是熟悉的套路与配方,即python常用函数 open()和 write()。
不过这次略微不同的是我们会使用到iter_content来获取请求的原始响应数据,普通情况可以用r.raw,在初始请求中设置stream=True,来获取服务器的原始套接字响应,在这里我们使用iter_content更加方便一些,因为requests.get(url) 默认是下载在内存中的,下载完成才存到硬盘上,但Response.iter_content可以边下载边存硬盘中,所以在这视频下载方面更具有优势。
当然说到 iter_content 的话,不得不提下chunk_size,因为流式请求就是像流水一样,不是一次过来而是一点一点“流”过来。处理流式数据也是一点一点处理。
而chunk_size会直接返回从当前位置往后读取 chunk_size 大小的文件内容,且迭代响应数据。这避免了立即将内容读入内存以获得较大的响应。chunk_size是它应该读入内存的字节数。chunk_size的类型必须是int或None。None的值将根据流的值发挥不同的作用。
做了引荐与讲解后,那么就开始上我们的主菜了,即目标网站:
https://m.rr.tv/
介于代码偏基础化,且主要知识点做过分析就直接上代码了,具体请看代码:
单线程:
import requestsimport jsonimport reimport osheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}ep_list =[]vod_list = []def get_vod(url): response = requests.get(url = url,headers = headers)#请求url ep= re.compile(r'sid:"(.*?)",')#提取ep链接 ep_list = re.findall(ep,response.text) vod= re.compile(r'data:\[{id:(.*?),title:"')#提取vod链接 vod_list = re.findall(vod,response.text) vod= re.compile(r',title:"(.*?)",desc:"')#提取视频标题 vod_name = re.findall(vod,response.text) ep = 1 os.mkdir('./'+vod_name[0])#创建视频保存目录 for i in ep_list: print("开始下载"+vod_name[0]+"第"+str(ep)+"集") url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers)#下载请求 r = requests.get(str(json.loads(response.text)['data']['url']), stream=True)#解析出下载链接并发起下载请求 f = open("./"+vod_name[0]+"/第"+str(ep)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk) ep = ep+1if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxxx?snum=1&episode=1'#目标视频链接 get_vod(url)
多线程:
import requestsimport jsonimport reimport osfrom concurrent.futures import ThreadPoolExecutorheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}vod_list = []#存储视频链接vod_name = []#存储视频标题get_down_url =[]#存储下载直链def get_vod(url): response = requests.get(url = url,headers = headers)#请求url vod_list.append(re.findall(re.compile(r'data:\[{id:(.*?),title:"'),response.text)[0])#找找视频链接 vod_name.append(re.findall(re.compile(r',title:"(.*?)",desc:"'),response.text)[0])#找找视频标题 for i in re.findall(re.compile(r'{sid:"(.*?)",key:'),response.text): url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers) get_down_url.append(str(json.loads(response.text)['data']['url']))#拿下载直链进listdef down_begin(url,i): print("开始多线程下载"+vod_name[0]+"第"+str(i)+"集") r = requests.get(url = url,headers = headers)#下载请求 f = open("./"+vod_name[0]+"/第"+str(i)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk)if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxx?snum=1&episode=1'#进入rr.tv自行获取 get_vod(url) os.mkdir('./'+vod_name[0])#创建视频保存目录 with ThreadPoolExecutor(10) as f:#这里写多线程参数,适合几十集的电视剧使用 for i,url in enumerate(get_down_url): i=int(i)+1 f.submit(down_begin,url = url,i=i)
把案例里面的链接改成你想要下载的链接,然后右击运行代码,即可成功的下载你想要的视频了。代码获取后台回复:”人人视频“。
在文章的最后给大家来一波福利,因为前一段时间小编在爬取百度相关关键词以及文章采集时,经常触发百度的验证机制,这种情况很明显要使用到代理IP,后来群里一个小伙伴推荐了品赞代理IP,小编测试了下,完美解决了爬取中存在的问题。
如果大家后续有需要使用到代理方面的业务的话,可以扫码添加下方的二维码。国内外的IP都有,新用户可以免费测试。
查看全部
文章采集api Python 爬取人人视频
hello,小伙伴们,又见面了,距离上一次发布文章的时间,也算是久别重逢了。期间也发生了很多的事情,导致博文断更,也是笔者不愿意的,但是确实是比较忙,不再过多赘述,希望大家能够体谅。
平时不断的在后台收到小伙伴的私信,问是不是不更了,答案当然是否定的,有着这么多人的支持,小编还是要继续努力下去的,再次谢谢大家的支持。
这次给大家带来的文章是爬取人人视频,之前多是分享一些爬取数据,图片,音乐,还没怎么分享过爬取过视频的,那么想要爬取视频的话该怎么爬取呢?
其实不管是图片,还是音乐,或者是其他的文档,大部分都是一个文件读写的过程,当然视频也不例外,只是文件的格式不同而已。所以我们也可以试着以常规的手段去尝试下爬取视频,没错还是熟悉的套路与配方,即python常用函数 open()和 write()。
不过这次略微不同的是我们会使用到iter_content来获取请求的原始响应数据,普通情况可以用r.raw,在初始请求中设置stream=True,来获取服务器的原始套接字响应,在这里我们使用iter_content更加方便一些,因为requests.get(url) 默认是下载在内存中的,下载完成才存到硬盘上,但Response.iter_content可以边下载边存硬盘中,所以在这视频下载方面更具有优势。
当然说到 iter_content 的话,不得不提下chunk_size,因为流式请求就是像流水一样,不是一次过来而是一点一点“流”过来。处理流式数据也是一点一点处理。
而chunk_size会直接返回从当前位置往后读取 chunk_size 大小的文件内容,且迭代响应数据。这避免了立即将内容读入内存以获得较大的响应。chunk_size是它应该读入内存的字节数。chunk_size的类型必须是int或None。None的值将根据流的值发挥不同的作用。
做了引荐与讲解后,那么就开始上我们的主菜了,即目标网站:
https://m.rr.tv/
介于代码偏基础化,且主要知识点做过分析就直接上代码了,具体请看代码:
单线程:
import requestsimport jsonimport reimport osheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}ep_list =[]vod_list = []def get_vod(url): response = requests.get(url = url,headers = headers)#请求url ep= re.compile(r'sid:"(.*?)",')#提取ep链接 ep_list = re.findall(ep,response.text) vod= re.compile(r'data:\[{id:(.*?),title:"')#提取vod链接 vod_list = re.findall(vod,response.text) vod= re.compile(r',title:"(.*?)",desc:"')#提取视频标题 vod_name = re.findall(vod,response.text) ep = 1 os.mkdir('./'+vod_name[0])#创建视频保存目录 for i in ep_list: print("开始下载"+vod_name[0]+"第"+str(ep)+"集") url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers)#下载请求 r = requests.get(str(json.loads(response.text)['data']['url']), stream=True)#解析出下载链接并发起下载请求 f = open("./"+vod_name[0]+"/第"+str(ep)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk) ep = ep+1if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxxx?snum=1&episode=1'#目标视频链接 get_vod(url)
多线程:
import requestsimport jsonimport reimport osfrom concurrent.futures import ThreadPoolExecutorheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}vod_list = []#存储视频链接vod_name = []#存储视频标题get_down_url =[]#存储下载直链def get_vod(url): response = requests.get(url = url,headers = headers)#请求url vod_list.append(re.findall(re.compile(r'data:\[{id:(.*?),title:"'),response.text)[0])#找找视频链接 vod_name.append(re.findall(re.compile(r',title:"(.*?)",desc:"'),response.text)[0])#找找视频标题 for i in re.findall(re.compile(r'{sid:"(.*?)",key:'),response.text): url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers) get_down_url.append(str(json.loads(response.text)['data']['url']))#拿下载直链进listdef down_begin(url,i): print("开始多线程下载"+vod_name[0]+"第"+str(i)+"集") r = requests.get(url = url,headers = headers)#下载请求 f = open("./"+vod_name[0]+"/第"+str(i)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk)if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxx?snum=1&episode=1'#进入rr.tv自行获取 get_vod(url) os.mkdir('./'+vod_name[0])#创建视频保存目录 with ThreadPoolExecutor(10) as f:#这里写多线程参数,适合几十集的电视剧使用 for i,url in enumerate(get_down_url): i=int(i)+1 f.submit(down_begin,url = url,i=i)
把案例里面的链接改成你想要下载的链接,然后右击运行代码,即可成功的下载你想要的视频了。代码获取后台回复:”人人视频“。
在文章的最后给大家来一波福利,因为前一段时间小编在爬取百度相关关键词以及文章采集时,经常触发百度的验证机制,这种情况很明显要使用到代理IP,后来群里一个小伙伴推荐了品赞代理IP,小编测试了下,完美解决了爬取中存在的问题。
如果大家后续有需要使用到代理方面的业务的话,可以扫码添加下方的二维码。国内外的IP都有,新用户可以免费测试。
深入浅出前端监控
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-05-02 22:02
重写 fetch 方法
当然了,重写上述方法后除了异常请求可以被监控到之外,正常响应的请求状态自然也能被采集到,比如 APM 会将对所有上报请求的持续时间进行分析从而得出慢请求的占比:
PS:如果通过 XHR 或 fetch 来上报监控数据的话,上报请求也会被被拦截,可以有选择地做一层过滤处理。
卡顿异常
卡顿指的是显示器刷新时下一帧的画面还没有准备好,导致连续多次展示同样的画面,从而让用户感觉到页面不流畅,也就是所谓的掉帧,衡量一个页面是否卡顿的指标就是我们熟知的 FPS。
如何获取 FPS
Chrome DevTool 中有一栏 Rendering 中包含 FPS 指标,但目前浏览器标准中暂时没有提供相应 API ,只能手动实现。这里需要借助 requestAnimationFrame 方法模拟实现,浏览器会在下一次重绘之前执行 rAF 的回调,因此可以通过计算每秒内 rAF 的执行次数来计算当前页面的 FPS。
通过 rAF 计算 FPS
如何上报“真实卡顿”
从技术角度看 FPS 低于 60 即视为卡顿,但在真实环境中用户很多行为都可能造成 FPS 的波动,并不能无脑地把 FPS 低于 60 以下的 case 全部上报,会造成非常多无效数据,因此需要结合实际的用户体验重新定义“真正的卡顿”,这里贴一下司内 APM 平台的上报策略:
页面 FPS 持续低于预期:当前页面连续 3s FPS 低于 20。用户操作带来的卡顿:当用户进行交互行为后,渲染新的一帧的时间超过 16ms + 100ms。崩溃异常
Web 页面崩溃指在网页运行过程页面完全无响应的现象,通常有两种情况会造成页面崩溃:
JS 主线程出现无限循环,触发浏览器的保护策略,结束当前页面的进程。内存不足
发生崩溃时主线程被阻塞,因此对崩溃的监控只能在独立于 JS 主线程的 Worker 线程中进行,我们可以采用 Web Worker 心跳检测的方式来对主线程进行不断的探测,如果主线程崩溃,就不会有任何响应,那就可以在 Worker 线程中进行崩溃异常的上报。这里继续贴一下 APM 的检测策略:
Web Worker:
崩溃检测
性能监控
性能监控并不只是简单的监控“页面速度有多快”,需要从用户体验的角度全面衡量性能指标。(就是所谓的 RUM 指标)目前业界主流标准是 Google 最新定义的 Core Web Vitals:
可以看到最新标准中,以往熟知的 FP、FCP、FMP、TTI 等指标都被移除了,个人认为这些指标还是具备一定的参考价值,因此下文还是会将这些指标进行相关介绍。(谷歌的话不听不听)
Loading 加载
和 Loading 相关的指标有 FP 、FCP 、FMP 和 LCP,首先来看一下我们相对熟悉的几个指标:
FP/FCP/FMP
一张流传已久的图
这两个指标都通过 PerformancePaintTiming API 获取:
通过 PerformancePaintTiming 获取 FP 和 FCP
下面再来看 FMP 的定义和获取方式:
FMP 的计算相对复杂,因为浏览器并未提供相应的 API,在此之前我们先看一组图:
从图中可以发现页面渲染过程中的一些规律:
在 1.577 秒,页面渲染了一个搜索框,此时已经有 60 个布局对象被添加到了布局树中。在 1.760 秒,页面头部整体渲染完成,此时布局对象总数是 103 个。在 1.907 秒,页面主体内容已经绘制完成,此时有 261 个布局对象被添加到布局树中从用户体验的角度看,此时的时间点就是是 FMP。
可以看到布局对象的数量与页面完成度高度相关。业界目前比较认可的一个计算 FMP 的方式就是——「页面在加载和渲染过程中最大布局变动之后的那个绘制时间即为当前页面的 FMP 」
实现原理则需要通过 MutationObserver 监听 document 整体的 DOM 变化,在回调计算出当前 DOM 树的分数,分数变化最剧烈的时刻,即为 FMP 的时间点。
至于如何计算当前页面 DOM 的分数,LightHouse 的源码中会根据当前节点深度作为变量做一个权重的计算,具体实现可以参考 LightHouse 源码。
const curNodeScore = 1 + 0.5 * depth;<br />const domScore = 所有子节点分数求和<br />
上述计算方式性能开销大且未必准确,LightHouse 6.0 已明确废弃了 FMP 打分项,建议在具体业务场景中根据实际情况手动埋点来确定 FMP 具体的值,更准确也更高效。
LCP
没错,LCP (Largest Contentful Paint) 是就是用来代替 FMP 的一个性能指标 ,用于度量视口中最大的内容元素何时可见,可以用来确定页面的主要内容何时在屏幕上完成渲染。
使用 Largest Contentful Paint API 和 PerformanceObserver 即可获取 LCP 指标的值:
获取 LCP
Interactivity 交互TTI
TTI(Time To Interactive) 表示从页面加载开始到页面处于完全可交互状态所花费的时间, TTI 值越小,代表用户可以更早地操作页面,用户体验就更好。
这里定义一下什么是完全可交互状态的页面:
页面已经显示有用内容。页面上的可见元素关联的事件响应函数已经完成注册。事件响应函数可以在事件发生后的 50ms 内开始执行(主线程无 Long Task)。
TTI 的算法略有些复杂,结合下图看一下具体步骤:
TTI 示意图
Long Task: 阻塞主线程达 50 毫秒或以上的任务。
从 FCP 时间开始,向前搜索一个不小于 5s 的静默窗口期。(静默窗口期定义:窗口所对应的时间内没有 Long Task,且进行中的网络请求数不超过 2 个)找到静默窗口期后,从静默窗口期向后搜索到最近的一个 Long Task,Long Task 的结束时间即为 TTI。如果一直找到 FCP 时刻仍然没有找到 Long Task,以 FCP 时间作为 TTI。
其实现需要支持 Long Tasks API 和 Resource Timing API,具体实现感兴趣的同学可以按照上述流程尝试手动实现。
FID
FID(First Input Delay) 用于度量用户第一次与页面交互的延迟时间,是用户第一次与页面交互到浏览器真正能够开始处理事件处理程序以响应该交互的时间。
其实现使用简洁的 PerformanceEventTiming API 即可,回调的触发时机是用户首次与页面发生交互并得到浏览器响应(点击链接、输入文字等)。
获取 FID
至于为何新的标准中采用 FID 而非 TTI,可能存在以下几个因素:
Visual Stability 视觉稳定CLS
CLS(Cumulative Layout Shift) 是对在页面的整个生命周期中发生的每一次意外布局变化的最大布局变化得分的度量,布局变化得分越小证明你的页面越稳定。
听起来有点复杂,这里做一个简单的解释:
举个例子,一个占据页面高度 50% 的元素,向下偏移了 25%,那么其得分为 0.75 * 0.25,大于标准定义的 0.1 分,该页面就视为视觉上没那么稳定的页面。
使用 Layout Instability API 和 PerformanceObserver 来获取 CLS:
获取 CLS
一点感受:在翻阅诸多参考资料后,私以为性能监控是一件长期实践、以实际业务为导向的事情,业内主流标准日新月异,到底监控什么指标是最贴合用户体验的我们不得而知,对于 FMP、FPS 这类浏览器未提供 API 获取方式的指标花费大量力气去探索实现是否有足够的收益也存在一定的疑问,但毋容置疑的是从自身页面的业务属性出发,结合一些用户反馈再进行相关手段的优化可能是更好的选择。(更推荐深入了解浏览器渲染原理,写出性能极佳的页面,让 APM 同学失业
数据上报
得到所有错误、性能、用户行为以及相应的环境信息后就要考虑如何进行数据上报,理论上正常使用ajax 即可,但有一些数据上报可能出现在页面关闭 (unload) 的时刻,这些请求会被浏览器的策略 cancel 掉,因此出现了以下几种解决方案:
优先使用 Navigator.sendBeacon,这个 API 就是为了解决上述问题而诞生,它通过 HTTP POST 将数据异步传输到服务器且不会影响页面卸载。如果不支持上述 API,动态创建一个
/ > 标签将数据通过 url 拼接的方式传递。使用同步 XHR 进行上报以延迟页面卸载,不过现在很多浏览器禁止了该行为。
APM 采取了第一种方式,不支持 sendBeacon 则使用 XHR,偶尔丢日志的原因找到了。
由于监控数据通常量级都十分庞大,因此不能简单地采集一个就上报一个,需要一些优化手段:
总结
本文旨在提供一个相对体系的前端监控视图,帮助各位了解前端监控领域我们能做什么、需要做什么。此外,如果能对页面性能和异常处理有着更深入的认知,无论是在开发应用时的自我管理(减少 bug、有意识地书写高性能代码),还是自研监控 SDK 都有所裨益。
如何设计监控 SDK 不是本文的重点,部分监控指标的定义和实现细节也可能存在其他解法,实现一个完善且健壮的前端监控 SDK 还有很多技术细节,例如每个指标可以提供哪些配置项、如何设计上报的维度、如何做好兼容性等等,这些都需要在真实的业务场景中不断打磨和优化才能趋于成熟。
参考
Google Developer
❤️ 谢谢支持
以上便是本次分享的全部内容,希望对你有所帮助^_^ 查看全部
深入浅出前端监控
重写 fetch 方法
当然了,重写上述方法后除了异常请求可以被监控到之外,正常响应的请求状态自然也能被采集到,比如 APM 会将对所有上报请求的持续时间进行分析从而得出慢请求的占比:
PS:如果通过 XHR 或 fetch 来上报监控数据的话,上报请求也会被被拦截,可以有选择地做一层过滤处理。
卡顿异常
卡顿指的是显示器刷新时下一帧的画面还没有准备好,导致连续多次展示同样的画面,从而让用户感觉到页面不流畅,也就是所谓的掉帧,衡量一个页面是否卡顿的指标就是我们熟知的 FPS。
如何获取 FPS
Chrome DevTool 中有一栏 Rendering 中包含 FPS 指标,但目前浏览器标准中暂时没有提供相应 API ,只能手动实现。这里需要借助 requestAnimationFrame 方法模拟实现,浏览器会在下一次重绘之前执行 rAF 的回调,因此可以通过计算每秒内 rAF 的执行次数来计算当前页面的 FPS。
通过 rAF 计算 FPS
如何上报“真实卡顿”
从技术角度看 FPS 低于 60 即视为卡顿,但在真实环境中用户很多行为都可能造成 FPS 的波动,并不能无脑地把 FPS 低于 60 以下的 case 全部上报,会造成非常多无效数据,因此需要结合实际的用户体验重新定义“真正的卡顿”,这里贴一下司内 APM 平台的上报策略:
页面 FPS 持续低于预期:当前页面连续 3s FPS 低于 20。用户操作带来的卡顿:当用户进行交互行为后,渲染新的一帧的时间超过 16ms + 100ms。崩溃异常
Web 页面崩溃指在网页运行过程页面完全无响应的现象,通常有两种情况会造成页面崩溃:
JS 主线程出现无限循环,触发浏览器的保护策略,结束当前页面的进程。内存不足
发生崩溃时主线程被阻塞,因此对崩溃的监控只能在独立于 JS 主线程的 Worker 线程中进行,我们可以采用 Web Worker 心跳检测的方式来对主线程进行不断的探测,如果主线程崩溃,就不会有任何响应,那就可以在 Worker 线程中进行崩溃异常的上报。这里继续贴一下 APM 的检测策略:
Web Worker:
崩溃检测
性能监控
性能监控并不只是简单的监控“页面速度有多快”,需要从用户体验的角度全面衡量性能指标。(就是所谓的 RUM 指标)目前业界主流标准是 Google 最新定义的 Core Web Vitals:
可以看到最新标准中,以往熟知的 FP、FCP、FMP、TTI 等指标都被移除了,个人认为这些指标还是具备一定的参考价值,因此下文还是会将这些指标进行相关介绍。(谷歌的话不听不听)
Loading 加载
和 Loading 相关的指标有 FP 、FCP 、FMP 和 LCP,首先来看一下我们相对熟悉的几个指标:
FP/FCP/FMP
一张流传已久的图
这两个指标都通过 PerformancePaintTiming API 获取:
通过 PerformancePaintTiming 获取 FP 和 FCP
下面再来看 FMP 的定义和获取方式:
FMP 的计算相对复杂,因为浏览器并未提供相应的 API,在此之前我们先看一组图:
从图中可以发现页面渲染过程中的一些规律:
在 1.577 秒,页面渲染了一个搜索框,此时已经有 60 个布局对象被添加到了布局树中。在 1.760 秒,页面头部整体渲染完成,此时布局对象总数是 103 个。在 1.907 秒,页面主体内容已经绘制完成,此时有 261 个布局对象被添加到布局树中从用户体验的角度看,此时的时间点就是是 FMP。
可以看到布局对象的数量与页面完成度高度相关。业界目前比较认可的一个计算 FMP 的方式就是——「页面在加载和渲染过程中最大布局变动之后的那个绘制时间即为当前页面的 FMP 」
实现原理则需要通过 MutationObserver 监听 document 整体的 DOM 变化,在回调计算出当前 DOM 树的分数,分数变化最剧烈的时刻,即为 FMP 的时间点。
至于如何计算当前页面 DOM 的分数,LightHouse 的源码中会根据当前节点深度作为变量做一个权重的计算,具体实现可以参考 LightHouse 源码。
const curNodeScore = 1 + 0.5 * depth;<br />const domScore = 所有子节点分数求和<br />
上述计算方式性能开销大且未必准确,LightHouse 6.0 已明确废弃了 FMP 打分项,建议在具体业务场景中根据实际情况手动埋点来确定 FMP 具体的值,更准确也更高效。
LCP
没错,LCP (Largest Contentful Paint) 是就是用来代替 FMP 的一个性能指标 ,用于度量视口中最大的内容元素何时可见,可以用来确定页面的主要内容何时在屏幕上完成渲染。
使用 Largest Contentful Paint API 和 PerformanceObserver 即可获取 LCP 指标的值:
获取 LCP
Interactivity 交互TTI
TTI(Time To Interactive) 表示从页面加载开始到页面处于完全可交互状态所花费的时间, TTI 值越小,代表用户可以更早地操作页面,用户体验就更好。
这里定义一下什么是完全可交互状态的页面:
页面已经显示有用内容。页面上的可见元素关联的事件响应函数已经完成注册。事件响应函数可以在事件发生后的 50ms 内开始执行(主线程无 Long Task)。
TTI 的算法略有些复杂,结合下图看一下具体步骤:
TTI 示意图
Long Task: 阻塞主线程达 50 毫秒或以上的任务。
从 FCP 时间开始,向前搜索一个不小于 5s 的静默窗口期。(静默窗口期定义:窗口所对应的时间内没有 Long Task,且进行中的网络请求数不超过 2 个)找到静默窗口期后,从静默窗口期向后搜索到最近的一个 Long Task,Long Task 的结束时间即为 TTI。如果一直找到 FCP 时刻仍然没有找到 Long Task,以 FCP 时间作为 TTI。
其实现需要支持 Long Tasks API 和 Resource Timing API,具体实现感兴趣的同学可以按照上述流程尝试手动实现。
FID
FID(First Input Delay) 用于度量用户第一次与页面交互的延迟时间,是用户第一次与页面交互到浏览器真正能够开始处理事件处理程序以响应该交互的时间。
其实现使用简洁的 PerformanceEventTiming API 即可,回调的触发时机是用户首次与页面发生交互并得到浏览器响应(点击链接、输入文字等)。
获取 FID
至于为何新的标准中采用 FID 而非 TTI,可能存在以下几个因素:
Visual Stability 视觉稳定CLS
CLS(Cumulative Layout Shift) 是对在页面的整个生命周期中发生的每一次意外布局变化的最大布局变化得分的度量,布局变化得分越小证明你的页面越稳定。
听起来有点复杂,这里做一个简单的解释:
举个例子,一个占据页面高度 50% 的元素,向下偏移了 25%,那么其得分为 0.75 * 0.25,大于标准定义的 0.1 分,该页面就视为视觉上没那么稳定的页面。
使用 Layout Instability API 和 PerformanceObserver 来获取 CLS:
获取 CLS
一点感受:在翻阅诸多参考资料后,私以为性能监控是一件长期实践、以实际业务为导向的事情,业内主流标准日新月异,到底监控什么指标是最贴合用户体验的我们不得而知,对于 FMP、FPS 这类浏览器未提供 API 获取方式的指标花费大量力气去探索实现是否有足够的收益也存在一定的疑问,但毋容置疑的是从自身页面的业务属性出发,结合一些用户反馈再进行相关手段的优化可能是更好的选择。(更推荐深入了解浏览器渲染原理,写出性能极佳的页面,让 APM 同学失业
数据上报
得到所有错误、性能、用户行为以及相应的环境信息后就要考虑如何进行数据上报,理论上正常使用ajax 即可,但有一些数据上报可能出现在页面关闭 (unload) 的时刻,这些请求会被浏览器的策略 cancel 掉,因此出现了以下几种解决方案:
优先使用 Navigator.sendBeacon,这个 API 就是为了解决上述问题而诞生,它通过 HTTP POST 将数据异步传输到服务器且不会影响页面卸载。如果不支持上述 API,动态创建一个
/ > 标签将数据通过 url 拼接的方式传递。使用同步 XHR 进行上报以延迟页面卸载,不过现在很多浏览器禁止了该行为。
APM 采取了第一种方式,不支持 sendBeacon 则使用 XHR,偶尔丢日志的原因找到了。
由于监控数据通常量级都十分庞大,因此不能简单地采集一个就上报一个,需要一些优化手段:
总结
本文旨在提供一个相对体系的前端监控视图,帮助各位了解前端监控领域我们能做什么、需要做什么。此外,如果能对页面性能和异常处理有着更深入的认知,无论是在开发应用时的自我管理(减少 bug、有意识地书写高性能代码),还是自研监控 SDK 都有所裨益。
如何设计监控 SDK 不是本文的重点,部分监控指标的定义和实现细节也可能存在其他解法,实现一个完善且健壮的前端监控 SDK 还有很多技术细节,例如每个指标可以提供哪些配置项、如何设计上报的维度、如何做好兼容性等等,这些都需要在真实的业务场景中不断打磨和优化才能趋于成熟。
参考
Google Developer
❤️ 谢谢支持
以上便是本次分享的全部内容,希望对你有所帮助^_^
文章采集api Python 爬取人人视频
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-05-02 21:59
hello,小伙伴们,又见面了,距离上一次发布文章的时间,也算是久别重逢了。期间也发生了很多的事情,导致博文断更,也是笔者不愿意的,但是确实是比较忙,不再过多赘述,希望大家能够体谅。
平时不断的在后台收到小伙伴的私信,问是不是不更了,答案当然是否定的,有着这么多人的支持,小编还是要继续努力下去的,再次谢谢大家的支持。
这次给大家带来的文章是爬取人人视频,之前多是分享一些爬取数据,图片,音乐,还没怎么分享过爬取过视频的,那么想要爬取视频的话该怎么爬取呢?
其实不管是图片,还是音乐,或者是其他的文档,大部分都是一个文件读写的过程,当然视频也不例外,只是文件的格式不同而已。所以我们也可以试着以常规的手段去尝试下爬取视频,没错还是熟悉的套路与配方,即python常用函数 open()和 write()。
不过这次略微不同的是我们会使用到iter_content来获取请求的原始响应数据,普通情况可以用r.raw,在初始请求中设置stream=True,来获取服务器的原始套接字响应,在这里我们使用iter_content更加方便一些,因为requests.get(url) 默认是下载在内存中的,下载完成才存到硬盘上,但Response.iter_content可以边下载边存硬盘中,所以在这视频下载方面更具有优势。
当然说到 iter_content 的话,不得不提下chunk_size,因为流式请求就是像流水一样,不是一次过来而是一点一点“流”过来。处理流式数据也是一点一点处理。
而chunk_size会直接返回从当前位置往后读取 chunk_size 大小的文件内容,且迭代响应数据。这避免了立即将内容读入内存以获得较大的响应。chunk_size是它应该读入内存的字节数。chunk_size的类型必须是int或None。None的值将根据流的值发挥不同的作用。
做了引荐与讲解后,那么就开始上我们的主菜了,即目标网站:
https://m.rr.tv/
介于代码偏基础化,且主要知识点做过分析就直接上代码了,具体请看代码:
单线程:
import requestsimport jsonimport reimport osheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}ep_list =[]vod_list = []def get_vod(url): response = requests.get(url = url,headers = headers)#请求url ep= re.compile(r'sid:"(.*?)",')#提取ep链接 ep_list = re.findall(ep,response.text) vod= re.compile(r'data:\[{id:(.*?),title:"')#提取vod链接 vod_list = re.findall(vod,response.text) vod= re.compile(r',title:"(.*?)",desc:"')#提取视频标题 vod_name = re.findall(vod,response.text) ep = 1 os.mkdir('./'+vod_name[0])#创建视频保存目录 for i in ep_list: print("开始下载"+vod_name[0]+"第"+str(ep)+"集") url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers)#下载请求 r = requests.get(str(json.loads(response.text)['data']['url']), stream=True)#解析出下载链接并发起下载请求 f = open("./"+vod_name[0]+"/第"+str(ep)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk) ep = ep+1if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxxx?snum=1&episode=1'#目标视频链接 get_vod(url)
多线程:
import requestsimport jsonimport reimport osfrom concurrent.futures import ThreadPoolExecutorheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}vod_list = []#存储视频链接vod_name = []#存储视频标题get_down_url =[]#存储下载直链def get_vod(url): response = requests.get(url = url,headers = headers)#请求url vod_list.append(re.findall(re.compile(r'data:\[{id:(.*?),title:"'),response.text)[0])#找找视频链接 vod_name.append(re.findall(re.compile(r',title:"(.*?)",desc:"'),response.text)[0])#找找视频标题 for i in re.findall(re.compile(r'{sid:"(.*?)",key:'),response.text): url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers) get_down_url.append(str(json.loads(response.text)['data']['url']))#拿下载直链进listdef down_begin(url,i): print("开始多线程下载"+vod_name[0]+"第"+str(i)+"集") r = requests.get(url = url,headers = headers)#下载请求 f = open("./"+vod_name[0]+"/第"+str(i)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk)if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxx?snum=1&episode=1'#进入rr.tv自行获取 get_vod(url) os.mkdir('./'+vod_name[0])#创建视频保存目录 with ThreadPoolExecutor(10) as f:#这里写多线程参数,适合几十集的电视剧使用 for i,url in enumerate(get_down_url): i=int(i)+1 f.submit(down_begin,url = url,i=i)
把案例里面的链接改成你想要下载的链接,然后右击运行代码,即可成功的下载你想要的视频了。代码获取后台回复:”人人视频“。
在文章的最后给大家来一波福利,因为前一段时间小编在爬取百度相关关键词以及文章采集时,经常触发百度的验证机制,这种情况很明显要使用到代理IP,后来群里一个小伙伴推荐了品赞代理IP,小编测试了下,完美解决了爬取中存在的问题。
如果大家后续有需要使用到代理方面的业务的话,可以扫码添加下方的二维码。国内外的IP都有,新用户可以免费测试。
查看全部
文章采集api Python 爬取人人视频
hello,小伙伴们,又见面了,距离上一次发布文章的时间,也算是久别重逢了。期间也发生了很多的事情,导致博文断更,也是笔者不愿意的,但是确实是比较忙,不再过多赘述,希望大家能够体谅。
平时不断的在后台收到小伙伴的私信,问是不是不更了,答案当然是否定的,有着这么多人的支持,小编还是要继续努力下去的,再次谢谢大家的支持。
这次给大家带来的文章是爬取人人视频,之前多是分享一些爬取数据,图片,音乐,还没怎么分享过爬取过视频的,那么想要爬取视频的话该怎么爬取呢?
其实不管是图片,还是音乐,或者是其他的文档,大部分都是一个文件读写的过程,当然视频也不例外,只是文件的格式不同而已。所以我们也可以试着以常规的手段去尝试下爬取视频,没错还是熟悉的套路与配方,即python常用函数 open()和 write()。
不过这次略微不同的是我们会使用到iter_content来获取请求的原始响应数据,普通情况可以用r.raw,在初始请求中设置stream=True,来获取服务器的原始套接字响应,在这里我们使用iter_content更加方便一些,因为requests.get(url) 默认是下载在内存中的,下载完成才存到硬盘上,但Response.iter_content可以边下载边存硬盘中,所以在这视频下载方面更具有优势。
当然说到 iter_content 的话,不得不提下chunk_size,因为流式请求就是像流水一样,不是一次过来而是一点一点“流”过来。处理流式数据也是一点一点处理。
而chunk_size会直接返回从当前位置往后读取 chunk_size 大小的文件内容,且迭代响应数据。这避免了立即将内容读入内存以获得较大的响应。chunk_size是它应该读入内存的字节数。chunk_size的类型必须是int或None。None的值将根据流的值发挥不同的作用。
做了引荐与讲解后,那么就开始上我们的主菜了,即目标网站:
https://m.rr.tv/
介于代码偏基础化,且主要知识点做过分析就直接上代码了,具体请看代码:
单线程:
import requestsimport jsonimport reimport osheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}ep_list =[]vod_list = []def get_vod(url): response = requests.get(url = url,headers = headers)#请求url ep= re.compile(r'sid:"(.*?)",')#提取ep链接 ep_list = re.findall(ep,response.text) vod= re.compile(r'data:\[{id:(.*?),title:"')#提取vod链接 vod_list = re.findall(vod,response.text) vod= re.compile(r',title:"(.*?)",desc:"')#提取视频标题 vod_name = re.findall(vod,response.text) ep = 1 os.mkdir('./'+vod_name[0])#创建视频保存目录 for i in ep_list: print("开始下载"+vod_name[0]+"第"+str(ep)+"集") url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers)#下载请求 r = requests.get(str(json.loads(response.text)['data']['url']), stream=True)#解析出下载链接并发起下载请求 f = open("./"+vod_name[0]+"/第"+str(ep)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk) ep = ep+1if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxxx?snum=1&episode=1'#目标视频链接 get_vod(url)
多线程:
import requestsimport jsonimport reimport osfrom concurrent.futures import ThreadPoolExecutorheaders = {'Referer':'https://m.rr.tv/',#全局设置'User-Agent':'Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36'}vod_list = []#存储视频链接vod_name = []#存储视频标题get_down_url =[]#存储下载直链def get_vod(url): response = requests.get(url = url,headers = headers)#请求url vod_list.append(re.findall(re.compile(r'data:\[{id:(.*?),title:"'),response.text)[0])#找找视频链接 vod_name.append(re.findall(re.compile(r',title:"(.*?)",desc:"'),response.text)[0])#找找视频标题 for i in re.findall(re.compile(r'{sid:"(.*?)",key:'),response.text): url ="https://web-api.rr.tv/web/dram ... _list[0]+"&episodeId="+i+"&2-7-17xx"#拼接地址 response = requests.get(url = url,headers = headers) get_down_url.append(str(json.loads(response.text)['data']['url']))#拿下载直链进listdef down_begin(url,i): print("开始多线程下载"+vod_name[0]+"第"+str(i)+"集") r = requests.get(url = url,headers = headers)#下载请求 f = open("./"+vod_name[0]+"/第"+str(i)+"集.MP4", "wb")#保存视频 for chunk in r.iter_content(chunk_size=512): if chunk: f.write(chunk)if __name__ == '__main__': url='https://m.rr.tv/detail/xxxxx?snum=1&episode=1'#进入rr.tv自行获取 get_vod(url) os.mkdir('./'+vod_name[0])#创建视频保存目录 with ThreadPoolExecutor(10) as f:#这里写多线程参数,适合几十集的电视剧使用 for i,url in enumerate(get_down_url): i=int(i)+1 f.submit(down_begin,url = url,i=i)
把案例里面的链接改成你想要下载的链接,然后右击运行代码,即可成功的下载你想要的视频了。代码获取后台回复:”人人视频“。
在文章的最后给大家来一波福利,因为前一段时间小编在爬取百度相关关键词以及文章采集时,经常触发百度的验证机制,这种情况很明显要使用到代理IP,后来群里一个小伙伴推荐了品赞代理IP,小编测试了下,完美解决了爬取中存在的问题。
如果大家后续有需要使用到代理方面的业务的话,可以扫码添加下方的二维码。国内外的IP都有,新用户可以免费测试。
文章采集api 性能指标的信仰危机
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-05-02 19:45
正在阅读这篇文章的你,或多或者接触过前端性能优化,这样的接触可能是来自你的阅读体验也可能是来自工作经验。那我们不妨从一个非常简单的思想实验开始,请你借助你对这个领域的理解,来回答下面的几个问题:
不要有压力,你可以慢慢思考并回答这几个问题,你关于第一个问题的答案可能会随着二三问题的出现而不断的调整。
这篇文章的目的就是对上面三个问题的探索和尝试性的解答,希望我的答案能带给你一些启发。
一次复盘
目前我所在的项目上长时间都依赖都 GA (Google Analytic) 作为衡量页面性能的唯一工具,在 GA 的生态圈中,我们最为重视的是 Avg Page Load Time (以下简称为 APLT),通过它来断定我们站点当前的性能状态如何。
但是在定期收集该指标数据的过程中,我们发现用户的感受和数据的展示可能并不一致,具体来说数据看上去波澜不惊,但用户体验却直线下降。
所以我们不得不要回答一个至关重要的问题,APLT 衡量的究竟是什么?
什么这个问题之所以至关重要,是因为它的答案决定我们接下来要解决的问题和需要采取的行动:
然而官方文档对于这个指标的解释是很暧昧的:
Avg Page Load Time : The average amount of time (in seconds) it takes that page to load, from initiation of the pageview (e.g., click on a page link) to load completion in the browser.
Avg. Page Load Time consists of two components: 1) network and server time, and 2) browser time. The Technical section of the Explorer tab provides details about the network and remaining time is the browser overhead for parsing and executing the JavaScript and rendering the page.
对于它的解释,我们产生了几点疑问:
GA 的实现
GA 底层是通过 Navigation Timing API 在采集性能数据
GA 不会统计每一个阶段的数据,它将某些合并后重新命名成新的指标,而其中的某些指标比如 Document Interactive Loaded 其实是某些阶段的统计之和:
GA 统计的仅仅是与 DOM 文档有关的数据。APLT 定义里所说的 load completion 时刻指的就是 loadEventEnd 事件的发生时机,即 onLoad 事件触发完毕(load 事件触发时意味着所有的外部资源,包括 iframe、图片、脚本、样式都已经加载完毕)。所以 APLT 值是 GA 里所有指标里横跨时间范围最广的。
脚本对 Avg Page Load Time 的影响是什么
如上图所示,当浏览器自上而下解析 DOM 树时,它会遇见很多外联资源,比如图片、样式和脚本。于是它需要从缓存或者网络中请求这些资源。
页面的解析是同步的,所以脚本的加载会导致页面解析的暂停。浏览器需要在脚本加载、编译、执行完毕之后才会继续之后的解析工作,这么做是有道理的,因为 JavaScript 可能会使用诸如 document.write() 方法来改变 DOM 的结构。你可能听说过在 script 标签上添加 async 或者 defer 属性来异步的加载和执行脚本。但是它在我们的产品中是不适用的,因为 async 无法保证脚本执行的顺序。但这则方案不一定适用于所有页面,因为 async 无法保证脚本的执行顺序,如果你的应用对脚本的执行顺序有严格要求,那么它对你爱莫能助。
目前浏览器都配备preloader机制来提前扫面页面中的外联元素提前加载,但这个机制并无统一的标准也无法衡量效果,所以暂时不考虑它对我们的影响。
脚本下载之后需要经过解析(parse / compile)和执行(run / execute)。解析阶段首先将 javascript 代码编译为机器语言,执行阶段才会真正的运行我们编写的代码。脚本的解析和执行也会阻塞页面的解析
所以综上,我们可以得出脚本确实能够影响 APLT 。
但抛弃计量谈危害都是刷流氓,它的影响范围究竟有多大?也就是说如果 APLT 是 2 秒的话,其中多少时间耗费在了脚本上?
这里没有一个具体的数字,但它不容小觑,以及足够影响到性能。Addy Osmani 在 2017 年的一篇文章中指出 Chrome 的脚本引擎花费在编译时间上
虽然此后 Chrome 对编译过程进行了优化,但执行脚本过长的困恼依然存在。同时这只是 Chrome 下的情况,我们无法确认其他浏览器在编译脚本时也可以保证同样的效率
如果说 APLT 是由不同的阶段组成,那么我们有没有可能计算出每一个阶段的具体时间?
回顾上面关于 GA 指标的定义,至少我们现在能分离出 server time 和 browser time. 但是在 browser time 之下呢?比如说脚本的下载时间和执行时间,这些我们就无从得知了。这些是需要额外计算和采集的。
综上,我们完全依赖 APLT 来对站点的性能问题进行诊断是不靠谱,我们单纯的认为脚本负担拖慢了性能也是不完整的。
一场关于指标的信仰危机
我想你大概明白了为什么我在上一节中花了这么大段的篇幅来解释仅仅一个指标的含义。因为一个指标能透露的信息可能会比你想象的要复杂,引导和误导并存。
首先要声明我并不反对使用常见指标,这篇文章也不是对它们的批评,它们在帮助我们排查性能问题方面给了非常大的帮助。在这里我想探讨的是,如果常规指标是性能监控的底线的话,它的上限在哪?
从上面的描述中我们不难看出 APLT 的涉猎的维度过于宽泛,它更偏向于一个技术向的综合性指标,它展示给我们是趋势而非细节。这样带来的问题有两个:
接下来我们深入的聊聊这两个问题。
以用户为中心
你或许有留意到,目前前端性能监测的趋势逐渐在向以用户为中心的指标 (User-Centric Performance Metrics) 靠拢。为什么会出现这样的情况?因为随着单页面应用的普及以及前端功能变“重”,经典的以资源为中心的性能指标(例如 Onload, DOMContentLoaded)越来越不能准确地反馈真实用户的体验与产品性能。在传统后端渲染的多页面应用模式下,资源加载完毕即意味着页面对用户可用;而在单页面模式下,资源加载完毕距离产品可用存在一定的差距,因为此时应用才能真正地请求用户个性化的数据,渲染定制化的页面。
总的来说,越来越多重要且耗时的工作都发生在资源加载之后,我们需要把这部分工作的性能也监控起来。
好消息是浏览器原生的在提供给予我们这方面的支持,例如 Chrome 就在 Performace API 中提供了 Paint Timing API 诸如 first paint (FP) 、 first contentful paint (FCP)、time to interact(tti) 等指标数据。顾名思义的这些指标尝试站在用户体验的视角展现应用在浏览器中被呈现时的性能;坏消息是,这些指标依然在测量真实的用户体验方面依然存在误差。
就以上面提到的 FP、FCP、TTI 这三个指标为例,我用一个简单的例子说明这三个指标是如何不够准确的:在单页面的初始化过程中,我们通常会提供类似于「加载中」视图,通常是一个 placeholder 或者 skeleton 样式,在数据请求完毕之后才会将实际的视图渲染出来:
如果加载时间过长,浏览器会以为「加载中」视图就是对用户可用的最终产品形态,并以它为基准计算那上述的三个指标
下面这段代码模拟的就是包含上面所说情况的日常情况:在组件加载时模拟发出两个请求,其中一个需要5秒较长的等待时间,只有当两个请求都返回时才能开始渲染数据,否则一直提示用户加载中。
function App() {<br /> const [data, setState] = useState([]);<br /> useEffect(() => {<br /> const longRequest = new Promise((resolve, reject) => {<br /> setTimeout(() => {<br /> resolve([]);<br /> }, 1000 * 5)<br /> });<br /> const shortRequest = Promise.resolve([]);<br /> <br /> Promise.all([longRequest, shortRequest]).then(([longRequestResponse, shortRequestResponse]) => {<br /> setState([<br /> ['', 'Tesla', 'Mercedes', 'Toyota', 'Volvo'],<br /> ['2019', 10, 11, 12, 13],<br /> ['2020', 20, 11, 14, 13],<br /> ['2021', 30, 15, 12, 13]<br /> ])<br /> })<br /> }, []);<br /> return (<br /> <br /> {data && data.length<br /> ? <br /> : }<br /> <br /> )<br />}
如果你尝试在浏览器中运行上述 App, 通过 Devtools 观测到的各个指标如下:
你能通过开发者工具够观测到各种指标比如 DCL (DOMContentLoaded Event), FP, FCP, FMP (first meaningful paint), L(Onload Event) 都发生在页面加载后一秒左右以内。然而从代码里我们非常肯定至少五秒后用户才能看到真实内容。所以上述指标并不能真的反馈用户感受到的性能问题
我已经把这个应用部署到了 站点上,可以在线访问。并且可以使用 对它做更详细的性能检测,也会得出和 devtools 相同的结果。webpagetest 是一个开源免费对网站性能进行检测的工具。早在 2012 年还没有诸如 FP 一类的指标时,它独创的 Speed Index 指标就能够衡量用户体验。
总的来说如上图所示,目前浏览器提供的 API 能够测量的只是 D 阶段的性能,对 E 和 F 阶段爱莫能助。
这只是其中一个说明原生指标不够准确的例子,可以归纳为后端接口延迟过长。然而还有一种情况是前端渲染时间过长。例如我们在使用 Handsontable 组件渲染上千行数据表格的时候,甚至导致了浏览器的假死,这种场景对 Paint Timing API 也是免疫的。
那 tti 这个指标怎么样?它不是听上去能够检测页面是否可以交互吗?它是不是能够检测页面的假死?
很遗憾依然不行。
如果你有心去查看 tti 这个指标的定义的话, 你会发现 tti 本质上是一种算法:
并且目前的原生 API 并不支持 tti 指标,需要通过 polyfill 实现,按照官方的说明,目前并不能适配所有的 web app。
双向指标
这是知乎创作者中心页面的一个截图
在这个页面中,知乎每天都会为你更新过去七天内文章阅读数、赞同数、评论数等数据的汇总。上图中的折线就是阅读数。
我知道它的用意是想给予创作者数据上的反馈帮助他们更好的输出内容,但至少对我来说一点用也没有。因为我更想知道的是究竟增长来自于哪里,这样我才能有针对性的输出带来点击量的内容。但它带给我的总是汇总数据。
这个需求对于性能监控也是同样的成立的,监控的目的主要是为了及时发现问题,解决问题。所以在审视数据的过程中,我们更关心的是异常波动值发生在何时何地,我们也希望数据能给予我这方面的帮助。
当然我们不可能无中生有的将一组汇总数据还原成细节数据,但在这个问题上我们可以往两个方向努力:
在 Web Performance Calendar 2020 Edition 中 A wish list for web performance tools 一文中,作者提出了关于他理想性能工具应该满足的四则功能,分别是:
其中的第二三则对于我们选择指标来说也是成立的,与我在上面的强调的不谋而合
最后再一次强调这里不是对传统指标的否定。数据带来的效果一定是聊胜于无,指标越多越是能精确的描绘出性能画像。这里探讨的是如何在这些基础上继续事半功倍提升我们洞察问题的效率。
在选择衡量指标上的一些建议
上下文驱动 (Context Driven)
之所以我无法在这里给你一个大而全的解决方案,是因为我认为这种东西并不存在,一切都要依赖你的上下文而定。
你也许更熟悉的是上下文驱动测试(Context Driven Testing),但在我看来,上下文驱动在你选择性能指标或者工具时也是同样成立的。我们不妨看一看上下文测试七条原则中的头两条:
想象一下如果你把两句话中的 practice 理解为指标(metric),甚至直接替换为指标,是不是也没有任何违和感呢?
“上下文驱动”初看上去不过是正反话,但实际上它是我们提升监测效率的有效出路。指标本身不会有对错之分,但不同人群对于指标的视角是割裂的:业务分析师希望得到的是能直接彰显业务价值的数据,例如点击率,弹出率,用户转化;DevOps 同学他们可能关心的是网站的“心跳”,资源的消耗,后端接口的快慢;所以不同指标在不同人群中是一种此消彼长的状态。这种割裂还可以从技术角度上划分,有的指标更侧重于资源,有的指标更侧重于用户感受。
指标只是发现问题的一种手段,现在我们有无数种手段任君挑选:APM (Application Performance Management)、日志分析、RUM (Real-User Monitoring)、TTFB (Time to First Byte)……最终它迫使你回到了问题的起点:我究竟想衡量什么?我想衡量的物体是否可以通过已有的指标表达出来?我只是想 monitor 吗?如果我想 debug 或者是 analyze 的话是否还有其他的选择?
“Good software testing is a challenging intellectual process.” (请把 testing 替换为 performance tuning)上下文驱动测试中的第六条原则如是说。
追踪元素
如果说“资源加载完毕”这件事不靠谱,“浏览器开始绘制”也不靠谱的话,我想唯一靠谱的事情就是用户的所见所得了。不需要用各种数据来展示你的页面加载有多快,如果用户每次都要等待十秒才能看到他想看到的信息,那么这些数字无非是自欺欺人而已。所以我们不妨可以追踪用户关注信息所对应元素的出现的时机。
这不是创新,从早些年的 Speed Index,“above the fold” 到如今的 web vitals 都是这种思想的延续,指标的进化过程像一个不断收缩过程中圆圈,在不断的像用户本身靠拢。只不过出于技术手段的限制,它们只能走到那么远,而如今我们有了 MutationObserver 和 Perforamce API, 则可以精确的定位到元素,甚至元素上属性的改变,自然也就不会被上面例子中的 placeholder 所欺骗。
抱歉我要在这里再次强调一下上下文:我们不能只关注“元素出现的时机”,更要从时间的范畴和从代码延展上看关注形成它的原因,这依然需要我们结合问题所处的环境和它的运转机制而定。举两个例子:
在上图中,如果 Component D 是向客户展示关键信息的关键元素,那么 request 到达 router 的时间,由 router 渲染出 Component C 的时间,都会对 D 元素产生影响;从另一个维度上看:
脚本以及请求加载的快慢和执行的效率,同样也会对元素的出现产生影响。如果你需要对问题进行诊断,对这些背后工作机制的了解必不可少。
但追踪元素也存在另一个问题就是它难以大规模的应用。因为它是侵入式的,因为它需要你识别不同页面上的不同关键元素,用近似于 hard code 的方式对它们一一追踪。这类工作产生的维护成本接近于维护前端的 E2E 测试。诚然我们可以通过分配统一的 id 或者 class name 的方式来减少我们的维护成本,但是相比统一的 GA 代码这样的维护成本依然偏高。所以我建议使用最简单的方法去监控最直接的元素,不要 case by case 的去编写你的监控代码,不要让你的实现代码被监控代码束缚住。
让工具为你所用
你可以在市面上找到各类数不胜数号称能够协助你改善性能的工具。但首先你要小心,它们所宣扬的,并非是你真正需要的。
例如 site24x7 是一家专业提供用户行为监控解决方案的公司。在它们有关 APM 的帮助页面上,开宗明义的指出了监控捕获 SAP(Single Page Application) 性能数据以目前的技术来说其实是一项颇具挑战的工作:
In case of Single Page Applications, the time taken for page load completion cannot be obtained by page onload event since the data are dynamically obtained from the server using
Hence, for each SPA framework, the page load metrics are calculated by listening to particular events specific to the framework.
所以对于此种类型的页面,它们捕获指标也只有:
For every dynamic page load, the corresponding URL, it's respective AJAX calls, response time of each AJAX call, response codes and errors (if any) are captured.
但要知道在如今 SPA 大行其道的今天,如此的收集功能略显的苍白无力了。
同理如果你去看 Azure Application Insights 旗下 JavaScript SDK 默认收集的页面信息:
Network Dependency Requests made by your app XHR and Fetch (fetch collection is disabled by default) requests, include information on
User information (for example, Location, network, IP)
Device information (for example, Browser, OS, version, language, model)
Session information
我不认为这些指标和其他平台提供的相比能带来额外的价值,它能真的给我带来多少真正的 “insights”。
另一方面,不要让你的思维被工具限制住:不要“因为 xx 工具只能做到这些,所以我只能收集这些指标”;而要“我想收集这些指标,所以我需要 xx 工具”。在这里我列举一个我们在探索中的例子:用 OpenTracing 工具 Jaeger 去可视化前端性能图表。
在这里我首先必须赞颂 Chrome 内置 Performance 工具给我们调教性能带来了极大的便利。但我们始终有一些额外的需求无法满足。例如我希望能够在结果呈现中做一些自定义的标记,又或者在 Performance Tab 下展示每一个请求从 connect 到 resposne 每个阶段的状态。
如下图所示,于是我们跨界的使用了 Jaeger 开源工具来用于自定义指标的收集和展示,可以说是将不同纬度的指标以时间为线索将它们联系起来,这样一来页面加载阶段的状态并能一览无余的尽收眼底。便于定位问题的所在。
结束语
我观察到对于大部分前端工程师而言,又或者曾经的自己而言,在做性能监控时是一个被“喂”的过程,即会惯性的不假思索的收集已有指标和利用已有工具。又因为性能优化工作过程前置结果后置的关系,等到我们有需求发生时才会发现当下的结果并非是我们想要的。多一些思考才会让我们的工作少一分浪费。 查看全部
文章采集api 性能指标的信仰危机
正在阅读这篇文章的你,或多或者接触过前端性能优化,这样的接触可能是来自你的阅读体验也可能是来自工作经验。那我们不妨从一个非常简单的思想实验开始,请你借助你对这个领域的理解,来回答下面的几个问题:
不要有压力,你可以慢慢思考并回答这几个问题,你关于第一个问题的答案可能会随着二三问题的出现而不断的调整。
这篇文章的目的就是对上面三个问题的探索和尝试性的解答,希望我的答案能带给你一些启发。
一次复盘
目前我所在的项目上长时间都依赖都 GA (Google Analytic) 作为衡量页面性能的唯一工具,在 GA 的生态圈中,我们最为重视的是 Avg Page Load Time (以下简称为 APLT),通过它来断定我们站点当前的性能状态如何。
但是在定期收集该指标数据的过程中,我们发现用户的感受和数据的展示可能并不一致,具体来说数据看上去波澜不惊,但用户体验却直线下降。
所以我们不得不要回答一个至关重要的问题,APLT 衡量的究竟是什么?
什么这个问题之所以至关重要,是因为它的答案决定我们接下来要解决的问题和需要采取的行动:
然而官方文档对于这个指标的解释是很暧昧的:
Avg Page Load Time : The average amount of time (in seconds) it takes that page to load, from initiation of the pageview (e.g., click on a page link) to load completion in the browser.
Avg. Page Load Time consists of two components: 1) network and server time, and 2) browser time. The Technical section of the Explorer tab provides details about the network and remaining time is the browser overhead for parsing and executing the JavaScript and rendering the page.
对于它的解释,我们产生了几点疑问:
GA 的实现
GA 底层是通过 Navigation Timing API 在采集性能数据
GA 不会统计每一个阶段的数据,它将某些合并后重新命名成新的指标,而其中的某些指标比如 Document Interactive Loaded 其实是某些阶段的统计之和:
GA 统计的仅仅是与 DOM 文档有关的数据。APLT 定义里所说的 load completion 时刻指的就是 loadEventEnd 事件的发生时机,即 onLoad 事件触发完毕(load 事件触发时意味着所有的外部资源,包括 iframe、图片、脚本、样式都已经加载完毕)。所以 APLT 值是 GA 里所有指标里横跨时间范围最广的。
脚本对 Avg Page Load Time 的影响是什么
如上图所示,当浏览器自上而下解析 DOM 树时,它会遇见很多外联资源,比如图片、样式和脚本。于是它需要从缓存或者网络中请求这些资源。
页面的解析是同步的,所以脚本的加载会导致页面解析的暂停。浏览器需要在脚本加载、编译、执行完毕之后才会继续之后的解析工作,这么做是有道理的,因为 JavaScript 可能会使用诸如 document.write() 方法来改变 DOM 的结构。你可能听说过在 script 标签上添加 async 或者 defer 属性来异步的加载和执行脚本。但是它在我们的产品中是不适用的,因为 async 无法保证脚本执行的顺序。但这则方案不一定适用于所有页面,因为 async 无法保证脚本的执行顺序,如果你的应用对脚本的执行顺序有严格要求,那么它对你爱莫能助。
目前浏览器都配备preloader机制来提前扫面页面中的外联元素提前加载,但这个机制并无统一的标准也无法衡量效果,所以暂时不考虑它对我们的影响。
脚本下载之后需要经过解析(parse / compile)和执行(run / execute)。解析阶段首先将 javascript 代码编译为机器语言,执行阶段才会真正的运行我们编写的代码。脚本的解析和执行也会阻塞页面的解析
所以综上,我们可以得出脚本确实能够影响 APLT 。
但抛弃计量谈危害都是刷流氓,它的影响范围究竟有多大?也就是说如果 APLT 是 2 秒的话,其中多少时间耗费在了脚本上?
这里没有一个具体的数字,但它不容小觑,以及足够影响到性能。Addy Osmani 在 2017 年的一篇文章中指出 Chrome 的脚本引擎花费在编译时间上
虽然此后 Chrome 对编译过程进行了优化,但执行脚本过长的困恼依然存在。同时这只是 Chrome 下的情况,我们无法确认其他浏览器在编译脚本时也可以保证同样的效率
如果说 APLT 是由不同的阶段组成,那么我们有没有可能计算出每一个阶段的具体时间?
回顾上面关于 GA 指标的定义,至少我们现在能分离出 server time 和 browser time. 但是在 browser time 之下呢?比如说脚本的下载时间和执行时间,这些我们就无从得知了。这些是需要额外计算和采集的。
综上,我们完全依赖 APLT 来对站点的性能问题进行诊断是不靠谱,我们单纯的认为脚本负担拖慢了性能也是不完整的。
一场关于指标的信仰危机
我想你大概明白了为什么我在上一节中花了这么大段的篇幅来解释仅仅一个指标的含义。因为一个指标能透露的信息可能会比你想象的要复杂,引导和误导并存。
首先要声明我并不反对使用常见指标,这篇文章也不是对它们的批评,它们在帮助我们排查性能问题方面给了非常大的帮助。在这里我想探讨的是,如果常规指标是性能监控的底线的话,它的上限在哪?
从上面的描述中我们不难看出 APLT 的涉猎的维度过于宽泛,它更偏向于一个技术向的综合性指标,它展示给我们是趋势而非细节。这样带来的问题有两个:
接下来我们深入的聊聊这两个问题。
以用户为中心
你或许有留意到,目前前端性能监测的趋势逐渐在向以用户为中心的指标 (User-Centric Performance Metrics) 靠拢。为什么会出现这样的情况?因为随着单页面应用的普及以及前端功能变“重”,经典的以资源为中心的性能指标(例如 Onload, DOMContentLoaded)越来越不能准确地反馈真实用户的体验与产品性能。在传统后端渲染的多页面应用模式下,资源加载完毕即意味着页面对用户可用;而在单页面模式下,资源加载完毕距离产品可用存在一定的差距,因为此时应用才能真正地请求用户个性化的数据,渲染定制化的页面。
总的来说,越来越多重要且耗时的工作都发生在资源加载之后,我们需要把这部分工作的性能也监控起来。
好消息是浏览器原生的在提供给予我们这方面的支持,例如 Chrome 就在 Performace API 中提供了 Paint Timing API 诸如 first paint (FP) 、 first contentful paint (FCP)、time to interact(tti) 等指标数据。顾名思义的这些指标尝试站在用户体验的视角展现应用在浏览器中被呈现时的性能;坏消息是,这些指标依然在测量真实的用户体验方面依然存在误差。
就以上面提到的 FP、FCP、TTI 这三个指标为例,我用一个简单的例子说明这三个指标是如何不够准确的:在单页面的初始化过程中,我们通常会提供类似于「加载中」视图,通常是一个 placeholder 或者 skeleton 样式,在数据请求完毕之后才会将实际的视图渲染出来:
如果加载时间过长,浏览器会以为「加载中」视图就是对用户可用的最终产品形态,并以它为基准计算那上述的三个指标
下面这段代码模拟的就是包含上面所说情况的日常情况:在组件加载时模拟发出两个请求,其中一个需要5秒较长的等待时间,只有当两个请求都返回时才能开始渲染数据,否则一直提示用户加载中。
function App() {<br /> const [data, setState] = useState([]);<br /> useEffect(() => {<br /> const longRequest = new Promise((resolve, reject) => {<br /> setTimeout(() => {<br /> resolve([]);<br /> }, 1000 * 5)<br /> });<br /> const shortRequest = Promise.resolve([]);<br /> <br /> Promise.all([longRequest, shortRequest]).then(([longRequestResponse, shortRequestResponse]) => {<br /> setState([<br /> ['', 'Tesla', 'Mercedes', 'Toyota', 'Volvo'],<br /> ['2019', 10, 11, 12, 13],<br /> ['2020', 20, 11, 14, 13],<br /> ['2021', 30, 15, 12, 13]<br /> ])<br /> })<br /> }, []);<br /> return (<br /> <br /> {data && data.length<br /> ? <br /> : }<br /> <br /> )<br />}
如果你尝试在浏览器中运行上述 App, 通过 Devtools 观测到的各个指标如下:
你能通过开发者工具够观测到各种指标比如 DCL (DOMContentLoaded Event), FP, FCP, FMP (first meaningful paint), L(Onload Event) 都发生在页面加载后一秒左右以内。然而从代码里我们非常肯定至少五秒后用户才能看到真实内容。所以上述指标并不能真的反馈用户感受到的性能问题
我已经把这个应用部署到了 站点上,可以在线访问。并且可以使用 对它做更详细的性能检测,也会得出和 devtools 相同的结果。webpagetest 是一个开源免费对网站性能进行检测的工具。早在 2012 年还没有诸如 FP 一类的指标时,它独创的 Speed Index 指标就能够衡量用户体验。
总的来说如上图所示,目前浏览器提供的 API 能够测量的只是 D 阶段的性能,对 E 和 F 阶段爱莫能助。
这只是其中一个说明原生指标不够准确的例子,可以归纳为后端接口延迟过长。然而还有一种情况是前端渲染时间过长。例如我们在使用 Handsontable 组件渲染上千行数据表格的时候,甚至导致了浏览器的假死,这种场景对 Paint Timing API 也是免疫的。
那 tti 这个指标怎么样?它不是听上去能够检测页面是否可以交互吗?它是不是能够检测页面的假死?
很遗憾依然不行。
如果你有心去查看 tti 这个指标的定义的话, 你会发现 tti 本质上是一种算法:
并且目前的原生 API 并不支持 tti 指标,需要通过 polyfill 实现,按照官方的说明,目前并不能适配所有的 web app。
双向指标
这是知乎创作者中心页面的一个截图
在这个页面中,知乎每天都会为你更新过去七天内文章阅读数、赞同数、评论数等数据的汇总。上图中的折线就是阅读数。
我知道它的用意是想给予创作者数据上的反馈帮助他们更好的输出内容,但至少对我来说一点用也没有。因为我更想知道的是究竟增长来自于哪里,这样我才能有针对性的输出带来点击量的内容。但它带给我的总是汇总数据。
这个需求对于性能监控也是同样的成立的,监控的目的主要是为了及时发现问题,解决问题。所以在审视数据的过程中,我们更关心的是异常波动值发生在何时何地,我们也希望数据能给予我这方面的帮助。
当然我们不可能无中生有的将一组汇总数据还原成细节数据,但在这个问题上我们可以往两个方向努力:
在 Web Performance Calendar 2020 Edition 中 A wish list for web performance tools 一文中,作者提出了关于他理想性能工具应该满足的四则功能,分别是:
其中的第二三则对于我们选择指标来说也是成立的,与我在上面的强调的不谋而合
最后再一次强调这里不是对传统指标的否定。数据带来的效果一定是聊胜于无,指标越多越是能精确的描绘出性能画像。这里探讨的是如何在这些基础上继续事半功倍提升我们洞察问题的效率。
在选择衡量指标上的一些建议
上下文驱动 (Context Driven)
之所以我无法在这里给你一个大而全的解决方案,是因为我认为这种东西并不存在,一切都要依赖你的上下文而定。
你也许更熟悉的是上下文驱动测试(Context Driven Testing),但在我看来,上下文驱动在你选择性能指标或者工具时也是同样成立的。我们不妨看一看上下文测试七条原则中的头两条:
想象一下如果你把两句话中的 practice 理解为指标(metric),甚至直接替换为指标,是不是也没有任何违和感呢?
“上下文驱动”初看上去不过是正反话,但实际上它是我们提升监测效率的有效出路。指标本身不会有对错之分,但不同人群对于指标的视角是割裂的:业务分析师希望得到的是能直接彰显业务价值的数据,例如点击率,弹出率,用户转化;DevOps 同学他们可能关心的是网站的“心跳”,资源的消耗,后端接口的快慢;所以不同指标在不同人群中是一种此消彼长的状态。这种割裂还可以从技术角度上划分,有的指标更侧重于资源,有的指标更侧重于用户感受。
指标只是发现问题的一种手段,现在我们有无数种手段任君挑选:APM (Application Performance Management)、日志分析、RUM (Real-User Monitoring)、TTFB (Time to First Byte)……最终它迫使你回到了问题的起点:我究竟想衡量什么?我想衡量的物体是否可以通过已有的指标表达出来?我只是想 monitor 吗?如果我想 debug 或者是 analyze 的话是否还有其他的选择?
“Good software testing is a challenging intellectual process.” (请把 testing 替换为 performance tuning)上下文驱动测试中的第六条原则如是说。
追踪元素
如果说“资源加载完毕”这件事不靠谱,“浏览器开始绘制”也不靠谱的话,我想唯一靠谱的事情就是用户的所见所得了。不需要用各种数据来展示你的页面加载有多快,如果用户每次都要等待十秒才能看到他想看到的信息,那么这些数字无非是自欺欺人而已。所以我们不妨可以追踪用户关注信息所对应元素的出现的时机。
这不是创新,从早些年的 Speed Index,“above the fold” 到如今的 web vitals 都是这种思想的延续,指标的进化过程像一个不断收缩过程中圆圈,在不断的像用户本身靠拢。只不过出于技术手段的限制,它们只能走到那么远,而如今我们有了 MutationObserver 和 Perforamce API, 则可以精确的定位到元素,甚至元素上属性的改变,自然也就不会被上面例子中的 placeholder 所欺骗。
抱歉我要在这里再次强调一下上下文:我们不能只关注“元素出现的时机”,更要从时间的范畴和从代码延展上看关注形成它的原因,这依然需要我们结合问题所处的环境和它的运转机制而定。举两个例子:
在上图中,如果 Component D 是向客户展示关键信息的关键元素,那么 request 到达 router 的时间,由 router 渲染出 Component C 的时间,都会对 D 元素产生影响;从另一个维度上看:
脚本以及请求加载的快慢和执行的效率,同样也会对元素的出现产生影响。如果你需要对问题进行诊断,对这些背后工作机制的了解必不可少。
但追踪元素也存在另一个问题就是它难以大规模的应用。因为它是侵入式的,因为它需要你识别不同页面上的不同关键元素,用近似于 hard code 的方式对它们一一追踪。这类工作产生的维护成本接近于维护前端的 E2E 测试。诚然我们可以通过分配统一的 id 或者 class name 的方式来减少我们的维护成本,但是相比统一的 GA 代码这样的维护成本依然偏高。所以我建议使用最简单的方法去监控最直接的元素,不要 case by case 的去编写你的监控代码,不要让你的实现代码被监控代码束缚住。
让工具为你所用
你可以在市面上找到各类数不胜数号称能够协助你改善性能的工具。但首先你要小心,它们所宣扬的,并非是你真正需要的。
例如 site24x7 是一家专业提供用户行为监控解决方案的公司。在它们有关 APM 的帮助页面上,开宗明义的指出了监控捕获 SAP(Single Page Application) 性能数据以目前的技术来说其实是一项颇具挑战的工作:
In case of Single Page Applications, the time taken for page load completion cannot be obtained by page onload event since the data are dynamically obtained from the server using
Hence, for each SPA framework, the page load metrics are calculated by listening to particular events specific to the framework.
所以对于此种类型的页面,它们捕获指标也只有:
For every dynamic page load, the corresponding URL, it's respective AJAX calls, response time of each AJAX call, response codes and errors (if any) are captured.
但要知道在如今 SPA 大行其道的今天,如此的收集功能略显的苍白无力了。
同理如果你去看 Azure Application Insights 旗下 JavaScript SDK 默认收集的页面信息:
Network Dependency Requests made by your app XHR and Fetch (fetch collection is disabled by default) requests, include information on
User information (for example, Location, network, IP)
Device information (for example, Browser, OS, version, language, model)
Session information
我不认为这些指标和其他平台提供的相比能带来额外的价值,它能真的给我带来多少真正的 “insights”。
另一方面,不要让你的思维被工具限制住:不要“因为 xx 工具只能做到这些,所以我只能收集这些指标”;而要“我想收集这些指标,所以我需要 xx 工具”。在这里我列举一个我们在探索中的例子:用 OpenTracing 工具 Jaeger 去可视化前端性能图表。
在这里我首先必须赞颂 Chrome 内置 Performance 工具给我们调教性能带来了极大的便利。但我们始终有一些额外的需求无法满足。例如我希望能够在结果呈现中做一些自定义的标记,又或者在 Performance Tab 下展示每一个请求从 connect 到 resposne 每个阶段的状态。
如下图所示,于是我们跨界的使用了 Jaeger 开源工具来用于自定义指标的收集和展示,可以说是将不同纬度的指标以时间为线索将它们联系起来,这样一来页面加载阶段的状态并能一览无余的尽收眼底。便于定位问题的所在。
结束语
我观察到对于大部分前端工程师而言,又或者曾经的自己而言,在做性能监控时是一个被“喂”的过程,即会惯性的不假思索的收集已有指标和利用已有工具。又因为性能优化工作过程前置结果后置的关系,等到我们有需求发生时才会发现当下的结果并非是我们想要的。多一些思考才会让我们的工作少一分浪费。
文章采集api 性能指标的信仰危机
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-05-02 02:40
正在阅读这篇文章的你,或多或者接触过前端性能优化,这样的接触可能是来自你的阅读体验也可能是来自工作经验。那我们不妨从一个非常简单的思想实验开始,请你借助你对这个领域的理解,来回答下面的几个问题:
不要有压力,你可以慢慢思考并回答这几个问题,你关于第一个问题的答案可能会随着二三问题的出现而不断的调整。
这篇文章的目的就是对上面三个问题的探索和尝试性的解答,希望我的答案能带给你一些启发。
一次复盘
目前我所在的项目上长时间都依赖都 GA (Google Analytic) 作为衡量页面性能的唯一工具,在 GA 的生态圈中,我们最为重视的是 Avg Page Load Time (以下简称为 APLT),通过它来断定我们站点当前的性能状态如何。
但是在定期收集该指标数据的过程中,我们发现用户的感受和数据的展示可能并不一致,具体来说数据看上去波澜不惊,但用户体验却直线下降。
所以我们不得不要回答一个至关重要的问题,APLT 衡量的究竟是什么?
什么这个问题之所以至关重要,是因为它的答案决定我们接下来要解决的问题和需要采取的行动:
然而官方文档对于这个指标的解释是很暧昧的:
Avg Page Load Time : The average amount of time (in seconds) it takes that page to load, from initiation of the pageview (e.g., click on a page link) to load completion in the browser.
Avg. Page Load Time consists of two components: 1) network and server time, and 2) browser time. The Technical section of the Explorer tab provides details about the network and remaining time is the browser overhead for parsing and executing the JavaScript and rendering the page.
对于它的解释,我们产生了几点疑问:
GA 的实现
GA 底层是通过 Navigation Timing API 在采集性能数据
GA 不会统计每一个阶段的数据,它将某些合并后重新命名成新的指标,而其中的某些指标比如 Document Interactive Loaded 其实是某些阶段的统计之和:
GA 统计的仅仅是与 DOM 文档有关的数据。APLT 定义里所说的 load completion 时刻指的就是 loadEventEnd 事件的发生时机,即 onLoad 事件触发完毕(load 事件触发时意味着所有的外部资源,包括 iframe、图片、脚本、样式都已经加载完毕)。所以 APLT 值是 GA 里所有指标里横跨时间范围最广的。
脚本对 Avg Page Load Time 的影响是什么
如上图所示,当浏览器自上而下解析 DOM 树时,它会遇见很多外联资源,比如图片、样式和脚本。于是它需要从缓存或者网络中请求这些资源。
页面的解析是同步的,所以脚本的加载会导致页面解析的暂停。浏览器需要在脚本加载、编译、执行完毕之后才会继续之后的解析工作,这么做是有道理的,因为 JavaScript 可能会使用诸如 document.write() 方法来改变 DOM 的结构。你可能听说过在 script 标签上添加 async 或者 defer 属性来异步的加载和执行脚本。但是它在我们的产品中是不适用的,因为 async 无法保证脚本执行的顺序。但这则方案不一定适用于所有页面,因为 async 无法保证脚本的执行顺序,如果你的应用对脚本的执行顺序有严格要求,那么它对你爱莫能助。
目前浏览器都配备preloader机制来提前扫面页面中的外联元素提前加载,但这个机制并无统一的标准也无法衡量效果,所以暂时不考虑它对我们的影响。
脚本下载之后需要经过解析(parse / compile)和执行(run / execute)。解析阶段首先将 javascript 代码编译为机器语言,执行阶段才会真正的运行我们编写的代码。脚本的解析和执行也会阻塞页面的解析
所以综上,我们可以得出脚本确实能够影响 APLT 。
但抛弃计量谈危害都是刷流氓,它的影响范围究竟有多大?也就是说如果 APLT 是 2 秒的话,其中多少时间耗费在了脚本上?
这里没有一个具体的数字,但它不容小觑,以及足够影响到性能。Addy Osmani 在 2017 年的一篇文章中指出 Chrome 的脚本引擎花费在编译时间上
虽然此后 Chrome 对编译过程进行了优化,但执行脚本过长的困恼依然存在。同时这只是 Chrome 下的情况,我们无法确认其他浏览器在编译脚本时也可以保证同样的效率
如果说 APLT 是由不同的阶段组成,那么我们有没有可能计算出每一个阶段的具体时间?
回顾上面关于 GA 指标的定义,至少我们现在能分离出 server time 和 browser time. 但是在 browser time 之下呢?比如说脚本的下载时间和执行时间,这些我们就无从得知了。这些是需要额外计算和采集的。
综上,我们完全依赖 APLT 来对站点的性能问题进行诊断是不靠谱,我们单纯的认为脚本负担拖慢了性能也是不完整的。
一场关于指标的信仰危机
我想你大概明白了为什么我在上一节中花了这么大段的篇幅来解释仅仅一个指标的含义。因为一个指标能透露的信息可能会比你想象的要复杂,引导和误导并存。
首先要声明我并不反对使用常见指标,这篇文章也不是对它们的批评,它们在帮助我们排查性能问题方面给了非常大的帮助。在这里我想探讨的是,如果常规指标是性能监控的底线的话,它的上限在哪?
从上面的描述中我们不难看出 APLT 的涉猎的维度过于宽泛,它更偏向于一个技术向的综合性指标,它展示给我们是趋势而非细节。这样带来的问题有两个:
接下来我们深入的聊聊这两个问题。
以用户为中心
你或许有留意到,目前前端性能监测的趋势逐渐在向以用户为中心的指标 (User-Centric Performance Metrics) 靠拢。为什么会出现这样的情况?因为随着单页面应用的普及以及前端功能变“重”,经典的以资源为中心的性能指标(例如 Onload, DOMContentLoaded)越来越不能准确地反馈真实用户的体验与产品性能。在传统后端渲染的多页面应用模式下,资源加载完毕即意味着页面对用户可用;而在单页面模式下,资源加载完毕距离产品可用存在一定的差距,因为此时应用才能真正地请求用户个性化的数据,渲染定制化的页面。
总的来说,越来越多重要且耗时的工作都发生在资源加载之后,我们需要把这部分工作的性能也监控起来。
好消息是浏览器原生的在提供给予我们这方面的支持,例如 Chrome 就在 Performace API 中提供了 Paint Timing API 诸如 first paint (FP) 、 first contentful paint (FCP)、time to interact(tti) 等指标数据。顾名思义的这些指标尝试站在用户体验的视角展现应用在浏览器中被呈现时的性能;坏消息是,这些指标依然在测量真实的用户体验方面依然存在误差。
就以上面提到的 FP、FCP、TTI 这三个指标为例,我用一个简单的例子说明这三个指标是如何不够准确的:在单页面的初始化过程中,我们通常会提供类似于「加载中」视图,通常是一个 placeholder 或者 skeleton 样式,在数据请求完毕之后才会将实际的视图渲染出来:
如果加载时间过长,浏览器会以为「加载中」视图就是对用户可用的最终产品形态,并以它为基准计算那上述的三个指标
下面这段代码模拟的就是包含上面所说情况的日常情况:在组件加载时模拟发出两个请求,其中一个需要5秒较长的等待时间,只有当两个请求都返回时才能开始渲染数据,否则一直提示用户加载中。
function App() {<br /> const [data, setState] = useState([]);<br /> useEffect(() => {<br /> const longRequest = new Promise((resolve, reject) => {<br /> setTimeout(() => {<br /> resolve([]);<br /> }, 1000 * 5)<br /> });<br /> const shortRequest = Promise.resolve([]);<br /> <br /> Promise.all([longRequest, shortRequest]).then(([longRequestResponse, shortRequestResponse]) => {<br /> setState([<br /> ['', 'Tesla', 'Mercedes', 'Toyota', 'Volvo'],<br /> ['2019', 10, 11, 12, 13],<br /> ['2020', 20, 11, 14, 13],<br /> ['2021', 30, 15, 12, 13]<br /> ])<br /> })<br /> }, []);<br /> return (<br /> <br /> {data && data.length<br /> ? <br /> : }<br /> <br /> )<br />}
如果你尝试在浏览器中运行上述 App, 通过 Devtools 观测到的各个指标如下:
你能通过开发者工具够观测到各种指标比如 DCL (DOMContentLoaded Event), FP, FCP, FMP (first meaningful paint), L(Onload Event) 都发生在页面加载后一秒左右以内。然而从代码里我们非常肯定至少五秒后用户才能看到真实内容。所以上述指标并不能真的反馈用户感受到的性能问题
我已经把这个应用部署到了 站点上,可以在线访问。并且可以使用 对它做更详细的性能检测,也会得出和 devtools 相同的结果。webpagetest 是一个开源免费对网站性能进行检测的工具。早在 2012 年还没有诸如 FP 一类的指标时,它独创的 Speed Index 指标就能够衡量用户体验。
总的来说如上图所示,目前浏览器提供的 API 能够测量的只是 D 阶段的性能,对 E 和 F 阶段爱莫能助。
这只是其中一个说明原生指标不够准确的例子,可以归纳为后端接口延迟过长。然而还有一种情况是前端渲染时间过长。例如我们在使用 Handsontable 组件渲染上千行数据表格的时候,甚至导致了浏览器的假死,这种场景对 Paint Timing API 也是免疫的。
那 tti 这个指标怎么样?它不是听上去能够检测页面是否可以交互吗?它是不是能够检测页面的假死?
很遗憾依然不行。
如果你有心去查看 tti 这个指标的定义的话, 你会发现 tti 本质上是一种算法:
并且目前的原生 API 并不支持 tti 指标,需要通过 polyfill 实现,按照官方的说明,目前并不能适配所有的 web app。
双向指标
这是知乎创作者中心页面的一个截图
在这个页面中,知乎每天都会为你更新过去七天内文章阅读数、赞同数、评论数等数据的汇总。上图中的折线就是阅读数。
我知道它的用意是想给予创作者数据上的反馈帮助他们更好的输出内容,但至少对我来说一点用也没有。因为我更想知道的是究竟增长来自于哪里,这样我才能有针对性的输出带来点击量的内容。但它带给我的总是汇总数据。
这个需求对于性能监控也是同样的成立的,监控的目的主要是为了及时发现问题,解决问题。所以在审视数据的过程中,我们更关心的是异常波动值发生在何时何地,我们也希望数据能给予我这方面的帮助。
当然我们不可能无中生有的将一组汇总数据还原成细节数据,但在这个问题上我们可以往两个方向努力:
在 Web Performance Calendar 2020 Edition 中 A wish list for web performance tools 一文中,作者提出了关于他理想性能工具应该满足的四则功能,分别是:
其中的第二三则对于我们选择指标来说也是成立的,与我在上面的强调的不谋而合
最后再一次强调这里不是对传统指标的否定。数据带来的效果一定是聊胜于无,指标越多越是能精确的描绘出性能画像。这里探讨的是如何在这些基础上继续事半功倍提升我们洞察问题的效率。
在选择衡量指标上的一些建议
上下文驱动 (Context Driven)
之所以我无法在这里给你一个大而全的解决方案,是因为我认为这种东西并不存在,一切都要依赖你的上下文而定。
你也许更熟悉的是上下文驱动测试(Context Driven Testing),但在我看来,上下文驱动在你选择性能指标或者工具时也是同样成立的。我们不妨看一看上下文测试七条原则中的头两条:
想象一下如果你把两句话中的 practice 理解为指标(metric),甚至直接替换为指标,是不是也没有任何违和感呢?
“上下文驱动”初看上去不过是正反话,但实际上它是我们提升监测效率的有效出路。指标本身不会有对错之分,但不同人群对于指标的视角是割裂的:业务分析师希望得到的是能直接彰显业务价值的数据,例如点击率,弹出率,用户转化;DevOps 同学他们可能关心的是网站的“心跳”,资源的消耗,后端接口的快慢;所以不同指标在不同人群中是一种此消彼长的状态。这种割裂还可以从技术角度上划分,有的指标更侧重于资源,有的指标更侧重于用户感受。
指标只是发现问题的一种手段,现在我们有无数种手段任君挑选:APM (Application Performance Management)、日志分析、RUM (Real-User Monitoring)、TTFB (Time to First Byte)……最终它迫使你回到了问题的起点:我究竟想衡量什么?我想衡量的物体是否可以通过已有的指标表达出来?我只是想 monitor 吗?如果我想 debug 或者是 analyze 的话是否还有其他的选择?
“Good software testing is a challenging intellectual process.” (请把 testing 替换为 performance tuning)上下文驱动测试中的第六条原则如是说。
追踪元素
如果说“资源加载完毕”这件事不靠谱,“浏览器开始绘制”也不靠谱的话,我想唯一靠谱的事情就是用户的所见所得了。不需要用各种数据来展示你的页面加载有多快,如果用户每次都要等待十秒才能看到他想看到的信息,那么这些数字无非是自欺欺人而已。所以我们不妨可以追踪用户关注信息所对应元素的出现的时机。
这不是创新,从早些年的 Speed Index,“above the fold” 到如今的 web vitals 都是这种思想的延续,指标的进化过程像一个不断收缩过程中圆圈,在不断的像用户本身靠拢。只不过出于技术手段的限制,它们只能走到那么远,而如今我们有了 MutationObserver 和 Perforamce API, 则可以精确的定位到元素,甚至元素上属性的改变,自然也就不会被上面例子中的 placeholder 所欺骗。
抱歉我要在这里再次强调一下上下文:我们不能只关注“元素出现的时机”,更要从时间的范畴和从代码延展上看关注形成它的原因,这依然需要我们结合问题所处的环境和它的运转机制而定。举两个例子:
在上图中,如果 Component D 是向客户展示关键信息的关键元素,那么 request 到达 router 的时间,由 router 渲染出 Component C 的时间,都会对 D 元素产生影响;从另一个维度上看:
脚本以及请求加载的快慢和执行的效率,同样也会对元素的出现产生影响。如果你需要对问题进行诊断,对这些背后工作机制的了解必不可少。
但追踪元素也存在另一个问题就是它难以大规模的应用。因为它是侵入式的,因为它需要你识别不同页面上的不同关键元素,用近似于 hard code 的方式对它们一一追踪。这类工作产生的维护成本接近于维护前端的 E2E 测试。诚然我们可以通过分配统一的 id 或者 class name 的方式来减少我们的维护成本,但是相比统一的 GA 代码这样的维护成本依然偏高。所以我建议使用最简单的方法去监控最直接的元素,不要 case by case 的去编写你的监控代码,不要让你的实现代码被监控代码束缚住。
让工具为你所用
你可以在市面上找到各类数不胜数号称能够协助你改善性能的工具。但首先你要小心,它们所宣扬的,并非是你真正需要的。
例如 site24x7 是一家专业提供用户行为监控解决方案的公司。在它们有关 APM 的帮助页面上,开宗明义的指出了监控捕获 SAP(Single Page Application) 性能数据以目前的技术来说其实是一项颇具挑战的工作:
In case of Single Page Applications, the time taken for page load completion cannot be obtained by page onload event since the data are dynamically obtained from the server using
Hence, for each SPA framework, the page load metrics are calculated by listening to particular events specific to the framework.
所以对于此种类型的页面,它们捕获指标也只有:
For every dynamic page load, the corresponding URL, it's respective AJAX calls, response time of each AJAX call, response codes and errors (if any) are captured.
但要知道在如今 SPA 大行其道的今天,如此的收集功能略显的苍白无力了。
同理如果你去看 Azure Application Insights 旗下 JavaScript SDK 默认收集的页面信息:
Network Dependency Requests made by your app XHR and Fetch (fetch collection is disabled by default) requests, include information on
User information (for example, Location, network, IP)
Device information (for example, Browser, OS, version, language, model)
Session information
我不认为这些指标和其他平台提供的相比能带来额外的价值,它能真的给我带来多少真正的 “insights”。
另一方面,不要让你的思维被工具限制住:不要“因为 xx 工具只能做到这些,所以我只能收集这些指标”;而要“我想收集这些指标,所以我需要 xx 工具”。在这里我列举一个我们在探索中的例子:用 OpenTracing 工具 Jaeger 去可视化前端性能图表。
在这里我首先必须赞颂 Chrome 内置 Performance 工具给我们调教性能带来了极大的便利。但我们始终有一些额外的需求无法满足。例如我希望能够在结果呈现中做一些自定义的标记,又或者在 Performance Tab 下展示每一个请求从 connect 到 resposne 每个阶段的状态。
如下图所示,于是我们跨界的使用了 Jaeger 开源工具来用于自定义指标的收集和展示,可以说是将不同纬度的指标以时间为线索将它们联系起来,这样一来页面加载阶段的状态并能一览无余的尽收眼底。便于定位问题的所在。
结束语
我观察到对于大部分前端工程师而言,又或者曾经的自己而言,在做性能监控时是一个被“喂”的过程,即会惯性的不假思索的收集已有指标和利用已有工具。又因为性能优化工作过程前置结果后置的关系,等到我们有需求发生时才会发现当下的结果并非是我们想要的。多一些思考才会让我们的工作少一分浪费。 查看全部
文章采集api 性能指标的信仰危机
正在阅读这篇文章的你,或多或者接触过前端性能优化,这样的接触可能是来自你的阅读体验也可能是来自工作经验。那我们不妨从一个非常简单的思想实验开始,请你借助你对这个领域的理解,来回答下面的几个问题:
不要有压力,你可以慢慢思考并回答这几个问题,你关于第一个问题的答案可能会随着二三问题的出现而不断的调整。
这篇文章的目的就是对上面三个问题的探索和尝试性的解答,希望我的答案能带给你一些启发。
一次复盘
目前我所在的项目上长时间都依赖都 GA (Google Analytic) 作为衡量页面性能的唯一工具,在 GA 的生态圈中,我们最为重视的是 Avg Page Load Time (以下简称为 APLT),通过它来断定我们站点当前的性能状态如何。
但是在定期收集该指标数据的过程中,我们发现用户的感受和数据的展示可能并不一致,具体来说数据看上去波澜不惊,但用户体验却直线下降。
所以我们不得不要回答一个至关重要的问题,APLT 衡量的究竟是什么?
什么这个问题之所以至关重要,是因为它的答案决定我们接下来要解决的问题和需要采取的行动:
然而官方文档对于这个指标的解释是很暧昧的:
Avg Page Load Time : The average amount of time (in seconds) it takes that page to load, from initiation of the pageview (e.g., click on a page link) to load completion in the browser.
Avg. Page Load Time consists of two components: 1) network and server time, and 2) browser time. The Technical section of the Explorer tab provides details about the network and remaining time is the browser overhead for parsing and executing the JavaScript and rendering the page.
对于它的解释,我们产生了几点疑问:
GA 的实现
GA 底层是通过 Navigation Timing API 在采集性能数据
GA 不会统计每一个阶段的数据,它将某些合并后重新命名成新的指标,而其中的某些指标比如 Document Interactive Loaded 其实是某些阶段的统计之和:
GA 统计的仅仅是与 DOM 文档有关的数据。APLT 定义里所说的 load completion 时刻指的就是 loadEventEnd 事件的发生时机,即 onLoad 事件触发完毕(load 事件触发时意味着所有的外部资源,包括 iframe、图片、脚本、样式都已经加载完毕)。所以 APLT 值是 GA 里所有指标里横跨时间范围最广的。
脚本对 Avg Page Load Time 的影响是什么
如上图所示,当浏览器自上而下解析 DOM 树时,它会遇见很多外联资源,比如图片、样式和脚本。于是它需要从缓存或者网络中请求这些资源。
页面的解析是同步的,所以脚本的加载会导致页面解析的暂停。浏览器需要在脚本加载、编译、执行完毕之后才会继续之后的解析工作,这么做是有道理的,因为 JavaScript 可能会使用诸如 document.write() 方法来改变 DOM 的结构。你可能听说过在 script 标签上添加 async 或者 defer 属性来异步的加载和执行脚本。但是它在我们的产品中是不适用的,因为 async 无法保证脚本执行的顺序。但这则方案不一定适用于所有页面,因为 async 无法保证脚本的执行顺序,如果你的应用对脚本的执行顺序有严格要求,那么它对你爱莫能助。
目前浏览器都配备preloader机制来提前扫面页面中的外联元素提前加载,但这个机制并无统一的标准也无法衡量效果,所以暂时不考虑它对我们的影响。
脚本下载之后需要经过解析(parse / compile)和执行(run / execute)。解析阶段首先将 javascript 代码编译为机器语言,执行阶段才会真正的运行我们编写的代码。脚本的解析和执行也会阻塞页面的解析
所以综上,我们可以得出脚本确实能够影响 APLT 。
但抛弃计量谈危害都是刷流氓,它的影响范围究竟有多大?也就是说如果 APLT 是 2 秒的话,其中多少时间耗费在了脚本上?
这里没有一个具体的数字,但它不容小觑,以及足够影响到性能。Addy Osmani 在 2017 年的一篇文章中指出 Chrome 的脚本引擎花费在编译时间上
虽然此后 Chrome 对编译过程进行了优化,但执行脚本过长的困恼依然存在。同时这只是 Chrome 下的情况,我们无法确认其他浏览器在编译脚本时也可以保证同样的效率
如果说 APLT 是由不同的阶段组成,那么我们有没有可能计算出每一个阶段的具体时间?
回顾上面关于 GA 指标的定义,至少我们现在能分离出 server time 和 browser time. 但是在 browser time 之下呢?比如说脚本的下载时间和执行时间,这些我们就无从得知了。这些是需要额外计算和采集的。
综上,我们完全依赖 APLT 来对站点的性能问题进行诊断是不靠谱,我们单纯的认为脚本负担拖慢了性能也是不完整的。
一场关于指标的信仰危机
我想你大概明白了为什么我在上一节中花了这么大段的篇幅来解释仅仅一个指标的含义。因为一个指标能透露的信息可能会比你想象的要复杂,引导和误导并存。
首先要声明我并不反对使用常见指标,这篇文章也不是对它们的批评,它们在帮助我们排查性能问题方面给了非常大的帮助。在这里我想探讨的是,如果常规指标是性能监控的底线的话,它的上限在哪?
从上面的描述中我们不难看出 APLT 的涉猎的维度过于宽泛,它更偏向于一个技术向的综合性指标,它展示给我们是趋势而非细节。这样带来的问题有两个:
接下来我们深入的聊聊这两个问题。
以用户为中心
你或许有留意到,目前前端性能监测的趋势逐渐在向以用户为中心的指标 (User-Centric Performance Metrics) 靠拢。为什么会出现这样的情况?因为随着单页面应用的普及以及前端功能变“重”,经典的以资源为中心的性能指标(例如 Onload, DOMContentLoaded)越来越不能准确地反馈真实用户的体验与产品性能。在传统后端渲染的多页面应用模式下,资源加载完毕即意味着页面对用户可用;而在单页面模式下,资源加载完毕距离产品可用存在一定的差距,因为此时应用才能真正地请求用户个性化的数据,渲染定制化的页面。
总的来说,越来越多重要且耗时的工作都发生在资源加载之后,我们需要把这部分工作的性能也监控起来。
好消息是浏览器原生的在提供给予我们这方面的支持,例如 Chrome 就在 Performace API 中提供了 Paint Timing API 诸如 first paint (FP) 、 first contentful paint (FCP)、time to interact(tti) 等指标数据。顾名思义的这些指标尝试站在用户体验的视角展现应用在浏览器中被呈现时的性能;坏消息是,这些指标依然在测量真实的用户体验方面依然存在误差。
就以上面提到的 FP、FCP、TTI 这三个指标为例,我用一个简单的例子说明这三个指标是如何不够准确的:在单页面的初始化过程中,我们通常会提供类似于「加载中」视图,通常是一个 placeholder 或者 skeleton 样式,在数据请求完毕之后才会将实际的视图渲染出来:
如果加载时间过长,浏览器会以为「加载中」视图就是对用户可用的最终产品形态,并以它为基准计算那上述的三个指标
下面这段代码模拟的就是包含上面所说情况的日常情况:在组件加载时模拟发出两个请求,其中一个需要5秒较长的等待时间,只有当两个请求都返回时才能开始渲染数据,否则一直提示用户加载中。
function App() {<br /> const [data, setState] = useState([]);<br /> useEffect(() => {<br /> const longRequest = new Promise((resolve, reject) => {<br /> setTimeout(() => {<br /> resolve([]);<br /> }, 1000 * 5)<br /> });<br /> const shortRequest = Promise.resolve([]);<br /> <br /> Promise.all([longRequest, shortRequest]).then(([longRequestResponse, shortRequestResponse]) => {<br /> setState([<br /> ['', 'Tesla', 'Mercedes', 'Toyota', 'Volvo'],<br /> ['2019', 10, 11, 12, 13],<br /> ['2020', 20, 11, 14, 13],<br /> ['2021', 30, 15, 12, 13]<br /> ])<br /> })<br /> }, []);<br /> return (<br /> <br /> {data && data.length<br /> ? <br /> : }<br /> <br /> )<br />}
如果你尝试在浏览器中运行上述 App, 通过 Devtools 观测到的各个指标如下:
你能通过开发者工具够观测到各种指标比如 DCL (DOMContentLoaded Event), FP, FCP, FMP (first meaningful paint), L(Onload Event) 都发生在页面加载后一秒左右以内。然而从代码里我们非常肯定至少五秒后用户才能看到真实内容。所以上述指标并不能真的反馈用户感受到的性能问题
我已经把这个应用部署到了 站点上,可以在线访问。并且可以使用 对它做更详细的性能检测,也会得出和 devtools 相同的结果。webpagetest 是一个开源免费对网站性能进行检测的工具。早在 2012 年还没有诸如 FP 一类的指标时,它独创的 Speed Index 指标就能够衡量用户体验。
总的来说如上图所示,目前浏览器提供的 API 能够测量的只是 D 阶段的性能,对 E 和 F 阶段爱莫能助。
这只是其中一个说明原生指标不够准确的例子,可以归纳为后端接口延迟过长。然而还有一种情况是前端渲染时间过长。例如我们在使用 Handsontable 组件渲染上千行数据表格的时候,甚至导致了浏览器的假死,这种场景对 Paint Timing API 也是免疫的。
那 tti 这个指标怎么样?它不是听上去能够检测页面是否可以交互吗?它是不是能够检测页面的假死?
很遗憾依然不行。
如果你有心去查看 tti 这个指标的定义的话, 你会发现 tti 本质上是一种算法:
并且目前的原生 API 并不支持 tti 指标,需要通过 polyfill 实现,按照官方的说明,目前并不能适配所有的 web app。
双向指标
这是知乎创作者中心页面的一个截图
在这个页面中,知乎每天都会为你更新过去七天内文章阅读数、赞同数、评论数等数据的汇总。上图中的折线就是阅读数。
我知道它的用意是想给予创作者数据上的反馈帮助他们更好的输出内容,但至少对我来说一点用也没有。因为我更想知道的是究竟增长来自于哪里,这样我才能有针对性的输出带来点击量的内容。但它带给我的总是汇总数据。
这个需求对于性能监控也是同样的成立的,监控的目的主要是为了及时发现问题,解决问题。所以在审视数据的过程中,我们更关心的是异常波动值发生在何时何地,我们也希望数据能给予我这方面的帮助。
当然我们不可能无中生有的将一组汇总数据还原成细节数据,但在这个问题上我们可以往两个方向努力:
在 Web Performance Calendar 2020 Edition 中 A wish list for web performance tools 一文中,作者提出了关于他理想性能工具应该满足的四则功能,分别是:
其中的第二三则对于我们选择指标来说也是成立的,与我在上面的强调的不谋而合
最后再一次强调这里不是对传统指标的否定。数据带来的效果一定是聊胜于无,指标越多越是能精确的描绘出性能画像。这里探讨的是如何在这些基础上继续事半功倍提升我们洞察问题的效率。
在选择衡量指标上的一些建议
上下文驱动 (Context Driven)
之所以我无法在这里给你一个大而全的解决方案,是因为我认为这种东西并不存在,一切都要依赖你的上下文而定。
你也许更熟悉的是上下文驱动测试(Context Driven Testing),但在我看来,上下文驱动在你选择性能指标或者工具时也是同样成立的。我们不妨看一看上下文测试七条原则中的头两条:
想象一下如果你把两句话中的 practice 理解为指标(metric),甚至直接替换为指标,是不是也没有任何违和感呢?
“上下文驱动”初看上去不过是正反话,但实际上它是我们提升监测效率的有效出路。指标本身不会有对错之分,但不同人群对于指标的视角是割裂的:业务分析师希望得到的是能直接彰显业务价值的数据,例如点击率,弹出率,用户转化;DevOps 同学他们可能关心的是网站的“心跳”,资源的消耗,后端接口的快慢;所以不同指标在不同人群中是一种此消彼长的状态。这种割裂还可以从技术角度上划分,有的指标更侧重于资源,有的指标更侧重于用户感受。
指标只是发现问题的一种手段,现在我们有无数种手段任君挑选:APM (Application Performance Management)、日志分析、RUM (Real-User Monitoring)、TTFB (Time to First Byte)……最终它迫使你回到了问题的起点:我究竟想衡量什么?我想衡量的物体是否可以通过已有的指标表达出来?我只是想 monitor 吗?如果我想 debug 或者是 analyze 的话是否还有其他的选择?
“Good software testing is a challenging intellectual process.” (请把 testing 替换为 performance tuning)上下文驱动测试中的第六条原则如是说。
追踪元素
如果说“资源加载完毕”这件事不靠谱,“浏览器开始绘制”也不靠谱的话,我想唯一靠谱的事情就是用户的所见所得了。不需要用各种数据来展示你的页面加载有多快,如果用户每次都要等待十秒才能看到他想看到的信息,那么这些数字无非是自欺欺人而已。所以我们不妨可以追踪用户关注信息所对应元素的出现的时机。
这不是创新,从早些年的 Speed Index,“above the fold” 到如今的 web vitals 都是这种思想的延续,指标的进化过程像一个不断收缩过程中圆圈,在不断的像用户本身靠拢。只不过出于技术手段的限制,它们只能走到那么远,而如今我们有了 MutationObserver 和 Perforamce API, 则可以精确的定位到元素,甚至元素上属性的改变,自然也就不会被上面例子中的 placeholder 所欺骗。
抱歉我要在这里再次强调一下上下文:我们不能只关注“元素出现的时机”,更要从时间的范畴和从代码延展上看关注形成它的原因,这依然需要我们结合问题所处的环境和它的运转机制而定。举两个例子:
在上图中,如果 Component D 是向客户展示关键信息的关键元素,那么 request 到达 router 的时间,由 router 渲染出 Component C 的时间,都会对 D 元素产生影响;从另一个维度上看:
脚本以及请求加载的快慢和执行的效率,同样也会对元素的出现产生影响。如果你需要对问题进行诊断,对这些背后工作机制的了解必不可少。
但追踪元素也存在另一个问题就是它难以大规模的应用。因为它是侵入式的,因为它需要你识别不同页面上的不同关键元素,用近似于 hard code 的方式对它们一一追踪。这类工作产生的维护成本接近于维护前端的 E2E 测试。诚然我们可以通过分配统一的 id 或者 class name 的方式来减少我们的维护成本,但是相比统一的 GA 代码这样的维护成本依然偏高。所以我建议使用最简单的方法去监控最直接的元素,不要 case by case 的去编写你的监控代码,不要让你的实现代码被监控代码束缚住。
让工具为你所用
你可以在市面上找到各类数不胜数号称能够协助你改善性能的工具。但首先你要小心,它们所宣扬的,并非是你真正需要的。
例如 site24x7 是一家专业提供用户行为监控解决方案的公司。在它们有关 APM 的帮助页面上,开宗明义的指出了监控捕获 SAP(Single Page Application) 性能数据以目前的技术来说其实是一项颇具挑战的工作:
In case of Single Page Applications, the time taken for page load completion cannot be obtained by page onload event since the data are dynamically obtained from the server using
Hence, for each SPA framework, the page load metrics are calculated by listening to particular events specific to the framework.
所以对于此种类型的页面,它们捕获指标也只有:
For every dynamic page load, the corresponding URL, it's respective AJAX calls, response time of each AJAX call, response codes and errors (if any) are captured.
但要知道在如今 SPA 大行其道的今天,如此的收集功能略显的苍白无力了。
同理如果你去看 Azure Application Insights 旗下 JavaScript SDK 默认收集的页面信息:
Network Dependency Requests made by your app XHR and Fetch (fetch collection is disabled by default) requests, include information on
User information (for example, Location, network, IP)
Device information (for example, Browser, OS, version, language, model)
Session information
我不认为这些指标和其他平台提供的相比能带来额外的价值,它能真的给我带来多少真正的 “insights”。
另一方面,不要让你的思维被工具限制住:不要“因为 xx 工具只能做到这些,所以我只能收集这些指标”;而要“我想收集这些指标,所以我需要 xx 工具”。在这里我列举一个我们在探索中的例子:用 OpenTracing 工具 Jaeger 去可视化前端性能图表。
在这里我首先必须赞颂 Chrome 内置 Performance 工具给我们调教性能带来了极大的便利。但我们始终有一些额外的需求无法满足。例如我希望能够在结果呈现中做一些自定义的标记,又或者在 Performance Tab 下展示每一个请求从 connect 到 resposne 每个阶段的状态。
如下图所示,于是我们跨界的使用了 Jaeger 开源工具来用于自定义指标的收集和展示,可以说是将不同纬度的指标以时间为线索将它们联系起来,这样一来页面加载阶段的状态并能一览无余的尽收眼底。便于定位问题的所在。
结束语
我观察到对于大部分前端工程师而言,又或者曾经的自己而言,在做性能监控时是一个被“喂”的过程,即会惯性的不假思索的收集已有指标和利用已有工具。又因为性能优化工作过程前置结果后置的关系,等到我们有需求发生时才会发现当下的结果并非是我们想要的。多一些思考才会让我们的工作少一分浪费。
云原生爱好者周刊:寻找 Netlify 开源替代品
采集交流 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-05-01 23:16
随着云原生技术的快速发展,技术的不断迭代,对于日志的采集、处理及转发提出了更高的要求。云原生架构下的日志方案相比基于物理机或者是虚拟机场景的日志架构设计存在很大差别。作为 CNCF 的毕业项目,Fluent Bit 无疑为解决云环境中的日志记录问题的首选解决方案之一。但是在 Kubernetes 中安装部署以及配置 Fluent Bit 都具有一定的门槛,加大了用户的使用成本。
本文从写作对个人的价值谈到技术内容的创作选型,再到文章的排版和辅助工具,希望能帮助大家开启自己的技术内容创作之路。
如何手动丢弃 Prometheus 中的无用指标[3]
对于 Prometheus 这种底层的时间序列数据库来说,规模大了之后,免不了需要一定的手动维护,这对于 Prometheus 的性能至关重要。这篇文章介绍了如何手动删除和丢弃无用的指标。
云原生动态Harbor v2.5.0 引入 Cosign[4]
成品(Artifact)签名和签名验证是关键的安全功能,允许你验证成品的完整性。Harbor 通过与Notary 和 Cosign 的集成支持内容信任。
Harbor v2.5 集成了对 Cosign 的支持,这是一个 OCI 成品签名和验证解决方案,是 Sigstore 项目的一部分。
将 Cosign 与 Harbor 结合使用的一个关键特性是能够使用 Harbor 的复制功能来复制签名及其相关的已签名成品。这意味着,如果一个复制规则(replication rule)应用于一个已签名成品,Harbo 将把复制规则应用于签名,就像它应用于已签名成品一样。
Tanzu 应用平台 1.1 版本发布[5]
Tanzu 应用平台由 VMware 推出,旨在帮助用户在任何公有云或本地 Kubernetes 集群上快速构建和部署软件。Tanzu 应用平台提供了一套丰富的开发人员工具,并为支持生产的企业提供了一条预先铺好的路径,通过降低开发人员工具的复杂性来更快地开发创收应用程序。
1.1 版本提供了大量新功能,使企业能够加快实现价值的时间、简化用户体验、建立更强大的安全态势并保护他们已经进行的投资。这些领先的能力使企业能够:
Kubernetes 1.24 发布推迟[6]
经过一段时间的讨论,发布团队决定将预定的 Kubernetes 1.24 发布日推迟到 2022 年 5 月 3 日星期二。这比 2022 年 4 月 19 日星期二的原定发布日期延迟了两周。
这是阻止发布 bug 的结果。该 bug 将在最新的 Golang 次要版本 Go 1.18.1 中修复,预计将于今天晚些时候发布。由于 Go 发布的延迟,发布团队已采取措施将预定的 Kubernetes 发布日期延长两周,以便有足够的时间进行测试和稳定。
更新的时间表现在是:
4 月 19 日星期二的 1.24.0-rc.0。
4 月 26 日星期二的 1.24.0-rc.1。
1.24.0 于 5 月 3 日星期二正式发布。
WasmEdge 0.9.1 发布了!此版本集成了高性能 networking、JavaScript 流式 SSR 和 Fetch API 支持、新的 bindgen 框架、安卓和 OpenHarmony 操作系统支持、扩展的 Kubernetes 支持以及更好的内存管理。
Flagger 添加了网关 API 支持[7]
Flagger 1.19.0 版本带来了 Kubernetes Gateway API 的支持。
Flagger 是一个渐进式的交付工具,它为运行在 Kubernetes 上的应用程序自动化发布过程。它通过逐步将流量转移到新版本,同时测量指标和运行一致性测试,降低了在生产中引入新软件版本的风险。
由于增加了对 Gateway API 的支持,Flagger 现在可以与所有的实现一起工作,这意味着从今天起,这些都是原生支持:Contour, Emissary-Ingress, Google Kubernetes Engine, HAProxy Ingress, HashiCorp Consul, Istio, Kong and Traefik。
Flagger 团队已经使用 v1beta2 网关 API 成功测试了 Contour 和 Istio。从 Flagger v1.19 开始,网关 API 是使用 Contour 实现的端到端测试套件的一部分。
引用链接[1]
Coolify:
[2]
Podman Desktop:
[3]
如何手动丢弃 Prometheus 中的无用指标:
[4]
Harbor v2.5.0 引入 Cosign:
[5]
Tanzu 应用平台 1.1 版本发布:
[6]
Kubernetes 1.24 发布推迟:
[7]
Flagger 添加了网关 API 支持:
KubeSphere ()是在 Kubernetes 之上构建的开源容器混合云,提供全栈的 IT 自动化运维的能力,简化企业的 DevOps 工作流。
KubeSphere已被Aqara智能家居、爱立信、本来生活、东软、华云、新浪、三一重工、华夏银行、四川航空、国药集团、微众银行、杭州数跑科技、紫金保险、去哪儿网、中通、中国人民银行、中国银行、中国人保寿险、中国太平保险、中国移动、中国联通、中国电信、天翼云、中移金科、Radore、ZaloPay等海内外数千家企业采用。KubeSphere 提供了开发者友好的向导式操作界面和丰富的企业级功能,包括Kubernetes多云与多集群管理、DevOps(CI/CD)、应用生命周期管理、边缘计算、微服务治理(ServiceMesh)、多租户管理、可观测性、存储与网络管理、GPUsupport等功能,帮助企业快速构建一个强大和功能丰富的容器云平台。
✨GitHub:官网(中国站):微信群:请搜索添加群助手微信号kubesphere企业服务:e.cloud
查看全部
云原生爱好者周刊:寻找 Netlify 开源替代品
随着云原生技术的快速发展,技术的不断迭代,对于日志的采集、处理及转发提出了更高的要求。云原生架构下的日志方案相比基于物理机或者是虚拟机场景的日志架构设计存在很大差别。作为 CNCF 的毕业项目,Fluent Bit 无疑为解决云环境中的日志记录问题的首选解决方案之一。但是在 Kubernetes 中安装部署以及配置 Fluent Bit 都具有一定的门槛,加大了用户的使用成本。
本文从写作对个人的价值谈到技术内容的创作选型,再到文章的排版和辅助工具,希望能帮助大家开启自己的技术内容创作之路。
如何手动丢弃 Prometheus 中的无用指标[3]
对于 Prometheus 这种底层的时间序列数据库来说,规模大了之后,免不了需要一定的手动维护,这对于 Prometheus 的性能至关重要。这篇文章介绍了如何手动删除和丢弃无用的指标。
云原生动态Harbor v2.5.0 引入 Cosign[4]
成品(Artifact)签名和签名验证是关键的安全功能,允许你验证成品的完整性。Harbor 通过与Notary 和 Cosign 的集成支持内容信任。
Harbor v2.5 集成了对 Cosign 的支持,这是一个 OCI 成品签名和验证解决方案,是 Sigstore 项目的一部分。
将 Cosign 与 Harbor 结合使用的一个关键特性是能够使用 Harbor 的复制功能来复制签名及其相关的已签名成品。这意味着,如果一个复制规则(replication rule)应用于一个已签名成品,Harbo 将把复制规则应用于签名,就像它应用于已签名成品一样。
Tanzu 应用平台 1.1 版本发布[5]
Tanzu 应用平台由 VMware 推出,旨在帮助用户在任何公有云或本地 Kubernetes 集群上快速构建和部署软件。Tanzu 应用平台提供了一套丰富的开发人员工具,并为支持生产的企业提供了一条预先铺好的路径,通过降低开发人员工具的复杂性来更快地开发创收应用程序。
1.1 版本提供了大量新功能,使企业能够加快实现价值的时间、简化用户体验、建立更强大的安全态势并保护他们已经进行的投资。这些领先的能力使企业能够:
Kubernetes 1.24 发布推迟[6]
经过一段时间的讨论,发布团队决定将预定的 Kubernetes 1.24 发布日推迟到 2022 年 5 月 3 日星期二。这比 2022 年 4 月 19 日星期二的原定发布日期延迟了两周。
这是阻止发布 bug 的结果。该 bug 将在最新的 Golang 次要版本 Go 1.18.1 中修复,预计将于今天晚些时候发布。由于 Go 发布的延迟,发布团队已采取措施将预定的 Kubernetes 发布日期延长两周,以便有足够的时间进行测试和稳定。
更新的时间表现在是:
4 月 19 日星期二的 1.24.0-rc.0。
4 月 26 日星期二的 1.24.0-rc.1。
1.24.0 于 5 月 3 日星期二正式发布。
WasmEdge 0.9.1 发布了!此版本集成了高性能 networking、JavaScript 流式 SSR 和 Fetch API 支持、新的 bindgen 框架、安卓和 OpenHarmony 操作系统支持、扩展的 Kubernetes 支持以及更好的内存管理。
Flagger 添加了网关 API 支持[7]
Flagger 1.19.0 版本带来了 Kubernetes Gateway API 的支持。
Flagger 是一个渐进式的交付工具,它为运行在 Kubernetes 上的应用程序自动化发布过程。它通过逐步将流量转移到新版本,同时测量指标和运行一致性测试,降低了在生产中引入新软件版本的风险。
由于增加了对 Gateway API 的支持,Flagger 现在可以与所有的实现一起工作,这意味着从今天起,这些都是原生支持:Contour, Emissary-Ingress, Google Kubernetes Engine, HAProxy Ingress, HashiCorp Consul, Istio, Kong and Traefik。
Flagger 团队已经使用 v1beta2 网关 API 成功测试了 Contour 和 Istio。从 Flagger v1.19 开始,网关 API 是使用 Contour 实现的端到端测试套件的一部分。
引用链接[1]
Coolify:
[2]
Podman Desktop:
[3]
如何手动丢弃 Prometheus 中的无用指标:
[4]
Harbor v2.5.0 引入 Cosign:
[5]
Tanzu 应用平台 1.1 版本发布:
[6]
Kubernetes 1.24 发布推迟:
[7]
Flagger 添加了网关 API 支持:
KubeSphere ()是在 Kubernetes 之上构建的开源容器混合云,提供全栈的 IT 自动化运维的能力,简化企业的 DevOps 工作流。
KubeSphere已被Aqara智能家居、爱立信、本来生活、东软、华云、新浪、三一重工、华夏银行、四川航空、国药集团、微众银行、杭州数跑科技、紫金保险、去哪儿网、中通、中国人民银行、中国银行、中国人保寿险、中国太平保险、中国移动、中国联通、中国电信、天翼云、中移金科、Radore、ZaloPay等海内外数千家企业采用。KubeSphere 提供了开发者友好的向导式操作界面和丰富的企业级功能,包括Kubernetes多云与多集群管理、DevOps(CI/CD)、应用生命周期管理、边缘计算、微服务治理(ServiceMesh)、多租户管理、可观测性、存储与网络管理、GPUsupport等功能,帮助企业快速构建一个强大和功能丰富的容器云平台。
✨GitHub:官网(中国站):微信群:请搜索添加群助手微信号kubesphere企业服务:e.cloud
须臾现码虫,一键纳乾坤——Hubble在微盟微前端中的应用
采集交流 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-04-29 20:30
通过Hubble的使用可以在一定程度上减少测试与研发在提bug、定位问题上的沟通的成本,测试同学不用大段文字描述,研发同学能够直观地通过回放观看bug出现的情况,以及根据接口或者报错信息快速定位问题以及复现bug。四、功能解析1.接入apm为了能记录到接口请求的记录,自行实现了一个rrweb插件,通过对浏览器原生的xhr 和 fetch api的覆写,以实现请求信息的AOP。鉴于已存在APM系统,所以不对接口请求的请求体和响应体进行记录,只记录下接口header中的apm trace id,在回放的时候可以通过这个trace id直接跳转到APM系统中,来查看请求信息,协助排查和定位问题。2.调试网页免登录Hubble的免登录功能,是通过采集cookies中的saasAuth token来实现的。在管理页面点击免登录查看时,会跳转到带hubble特殊查询参数的url,然后加载hubble时根据查询参数判断是免登录查看模式的话,将url中带有的token写入到cookies中,然后跳转到不带特殊参数的页面上,以实现跳过登录环节完成鉴权。需要在页面调用其他接口前完成Hubble的加载与判断。token有时效性,可能会出现失效情况。为了避免非手动退出来切换账号所产生的混乱,建议打开新的无痕窗口后粘贴免登录链接查看。3.裁剪功能在解决录制片段过长的角度上,借助归一化的概念,可以将裁剪到的所需时间段以外的事件,压缩到一段比较短的时间内去播放,这样就能实现近似裁剪功能了。
但是这属于比较取巧的方案,后续会尝试直接合并增量数据到全量snapshot数据上,这样既能减少采集到的数据量,同时减轻刚开始播放时的处理器计算压力。4.未捕获错误采集通过对window.onerror、unrejectionhandler和error事件的监听,并将采集到的错误信息以自定义事件的形式插入到rrweb的record序列中,在回放时就可以通过面板查看到错误信息,辅助定位问题。五、遇到的问题1.样式泄漏处理在开发使用过程中,Hubble的浏览器端出现了样式污染的问题,除了对自己编写的组件内的过于普遍的样式名进行更改之外,还需要对整个Hubble进行css的scope化。这里使用了部门内实现的postcss插件,在遍历css rules的时候(使用postcss的walkRules API),对规则内的所有css选择器前面,添加了一个当前包名 .${packageJson.name} 的一个类作为父选择器,同时在Hubble挂载的dom上也加上了这个className。同时,在一些使用了css变量的UI组件库,有些会将css变量定义在 :root 上,这是一个全局的伪类,如果不进行处理的话,css变量会泄漏并污染到全局。
于是在上述的postcss插件中也加入了:root 到 作用域类名替换的规则。2.打包加载优化为了优化初始化速度(更快进入录制状态)和防止大体积bundle加载带来的阻塞,且后续能支持插件化、sdk可拼装,打包形式上从iife改为system。这样在初始加载时能够优先加载主要功能并运行起来,ui部分进行延迟加载;同时拆解成system形式的包之后,后续可以根据配置来动态加载功能,预留出扩展能力。六、未来预计添加的功能1.开放接入能力基于systemjs的动态加载脚本的能力,Hubble可以通过配置来动态加载插件。后续考虑在这基础上开放出一些api以及自定义插件功能,比如可以使用hubble的addCustomEvent API来添加自定义事件,或者采集静态数据直接上传到hubble的后端。2.涂鸦评论功能在录制的记录上,有时候需要给录制到的内容进行标注评论以辅助传递信息,增强理解。现计划在后续添加涂鸦评论功能。涂鸦基于canvas,可以提交面板上编辑,记录下打标注的地方以及持续时长,也考虑添加图层功能来支持更复杂的标注能力。七、扩展阅读Hubble主要是围绕rrweb 这个dom录制框架进行开发的。
rrweb是通过MutationObserver API来监听页面上dom的变动,以及用户输入的各种操作事件进行捕获采集,然后通过rrweb的DOM序列化算法将DOM结构json化,以及事件行为的格式化,形成一个变动更新列表,然后在回放的时候,通过将序列化的dom数据通过rebuild,和事件行为的重放,重现在一个iframe沙盒中,来实现页面操作的回放。其中,rrweb主要有这些事件类型:dom加载完成、加载、全量快照、增量快照、元数据、自定义事件、插件事件。而其中的增量快照则有这些数据来源:dom Mutation、鼠标键盘滚轮触摸等操作、窗口resize、输入框输入、样式变动等。录制开始后,rrweb会将每次dom变动,监听到的事件,自定义触发事件等录制到的数据通过一个数组来保存,每个事件对应着一个事件对象,其中含有触发时的时间戳、事件类型、内容载体payload等。在rrweb上生成一个dom的全量快照时,会给当前的dom元素一个个分配一个id,用来记录和追踪其变化。当增量数据中dom的变动要apply到snapshot对应的dom树上时,会根据id查找出目标dom节点,将MutationObserver 监听到的dom变化应用到数据模型上。
(rrweb维护了一个node Map,以方便快速查找到节点)当在播放器进行操作时,比如进行时间跳转(goto),会通过状态机和事件管道,先暂停再调用播放。调用播放函数时传入了跳转的timeOffset,这时会进行如下处理:暂停时会记录播放的最后event,然后再开始时,首先会计算出跳转后的时间偏移量,来定义一个基准时间戳(跳转后的时间戳)。对于小于基准时间戳的事件,会以同步的方式全部apply起来,而剩余的事件则是用定时器触发。同时,会把基准事件戳与上次播放的最后的event中含有的时间戳进行比对,如果往前跳则清除节点Map数据,以同步方式重新计算;如果是往后跳则将同步计算的结果合并到已有的节点Map上。在定时器的使用上,由于setInterval会受到性能等各方面影响,这种事件定时器在精度上不能满足需求。于是rrweb使用了requestAnimationFrame的API来作为定时器(机制上因为不受到eventloop的影响,精度能达到1ms级别),使用performance.now()来作为获取每次触发定时器callback的时间偏移量(减去初始值),从而准确地触发rrweb待播放List中的事件。八、结语不通过口述或者截图等方式、而是通过录屏的方式进行记录,同时可以记录接口等数据,这样可以在复现前端场景上节省沟通成本、快速定位问题,从而提高效率。我们也会在后续的迭代中,寻找合适的场景落地,尝试更多方案,助力开发提效。 查看全部
须臾现码虫,一键纳乾坤——Hubble在微盟微前端中的应用
通过Hubble的使用可以在一定程度上减少测试与研发在提bug、定位问题上的沟通的成本,测试同学不用大段文字描述,研发同学能够直观地通过回放观看bug出现的情况,以及根据接口或者报错信息快速定位问题以及复现bug。四、功能解析1.接入apm为了能记录到接口请求的记录,自行实现了一个rrweb插件,通过对浏览器原生的xhr 和 fetch api的覆写,以实现请求信息的AOP。鉴于已存在APM系统,所以不对接口请求的请求体和响应体进行记录,只记录下接口header中的apm trace id,在回放的时候可以通过这个trace id直接跳转到APM系统中,来查看请求信息,协助排查和定位问题。2.调试网页免登录Hubble的免登录功能,是通过采集cookies中的saasAuth token来实现的。在管理页面点击免登录查看时,会跳转到带hubble特殊查询参数的url,然后加载hubble时根据查询参数判断是免登录查看模式的话,将url中带有的token写入到cookies中,然后跳转到不带特殊参数的页面上,以实现跳过登录环节完成鉴权。需要在页面调用其他接口前完成Hubble的加载与判断。token有时效性,可能会出现失效情况。为了避免非手动退出来切换账号所产生的混乱,建议打开新的无痕窗口后粘贴免登录链接查看。3.裁剪功能在解决录制片段过长的角度上,借助归一化的概念,可以将裁剪到的所需时间段以外的事件,压缩到一段比较短的时间内去播放,这样就能实现近似裁剪功能了。
但是这属于比较取巧的方案,后续会尝试直接合并增量数据到全量snapshot数据上,这样既能减少采集到的数据量,同时减轻刚开始播放时的处理器计算压力。4.未捕获错误采集通过对window.onerror、unrejectionhandler和error事件的监听,并将采集到的错误信息以自定义事件的形式插入到rrweb的record序列中,在回放时就可以通过面板查看到错误信息,辅助定位问题。五、遇到的问题1.样式泄漏处理在开发使用过程中,Hubble的浏览器端出现了样式污染的问题,除了对自己编写的组件内的过于普遍的样式名进行更改之外,还需要对整个Hubble进行css的scope化。这里使用了部门内实现的postcss插件,在遍历css rules的时候(使用postcss的walkRules API),对规则内的所有css选择器前面,添加了一个当前包名 .${packageJson.name} 的一个类作为父选择器,同时在Hubble挂载的dom上也加上了这个className。同时,在一些使用了css变量的UI组件库,有些会将css变量定义在 :root 上,这是一个全局的伪类,如果不进行处理的话,css变量会泄漏并污染到全局。
于是在上述的postcss插件中也加入了:root 到 作用域类名替换的规则。2.打包加载优化为了优化初始化速度(更快进入录制状态)和防止大体积bundle加载带来的阻塞,且后续能支持插件化、sdk可拼装,打包形式上从iife改为system。这样在初始加载时能够优先加载主要功能并运行起来,ui部分进行延迟加载;同时拆解成system形式的包之后,后续可以根据配置来动态加载功能,预留出扩展能力。六、未来预计添加的功能1.开放接入能力基于systemjs的动态加载脚本的能力,Hubble可以通过配置来动态加载插件。后续考虑在这基础上开放出一些api以及自定义插件功能,比如可以使用hubble的addCustomEvent API来添加自定义事件,或者采集静态数据直接上传到hubble的后端。2.涂鸦评论功能在录制的记录上,有时候需要给录制到的内容进行标注评论以辅助传递信息,增强理解。现计划在后续添加涂鸦评论功能。涂鸦基于canvas,可以提交面板上编辑,记录下打标注的地方以及持续时长,也考虑添加图层功能来支持更复杂的标注能力。七、扩展阅读Hubble主要是围绕rrweb 这个dom录制框架进行开发的。
rrweb是通过MutationObserver API来监听页面上dom的变动,以及用户输入的各种操作事件进行捕获采集,然后通过rrweb的DOM序列化算法将DOM结构json化,以及事件行为的格式化,形成一个变动更新列表,然后在回放的时候,通过将序列化的dom数据通过rebuild,和事件行为的重放,重现在一个iframe沙盒中,来实现页面操作的回放。其中,rrweb主要有这些事件类型:dom加载完成、加载、全量快照、增量快照、元数据、自定义事件、插件事件。而其中的增量快照则有这些数据来源:dom Mutation、鼠标键盘滚轮触摸等操作、窗口resize、输入框输入、样式变动等。录制开始后,rrweb会将每次dom变动,监听到的事件,自定义触发事件等录制到的数据通过一个数组来保存,每个事件对应着一个事件对象,其中含有触发时的时间戳、事件类型、内容载体payload等。在rrweb上生成一个dom的全量快照时,会给当前的dom元素一个个分配一个id,用来记录和追踪其变化。当增量数据中dom的变动要apply到snapshot对应的dom树上时,会根据id查找出目标dom节点,将MutationObserver 监听到的dom变化应用到数据模型上。
(rrweb维护了一个node Map,以方便快速查找到节点)当在播放器进行操作时,比如进行时间跳转(goto),会通过状态机和事件管道,先暂停再调用播放。调用播放函数时传入了跳转的timeOffset,这时会进行如下处理:暂停时会记录播放的最后event,然后再开始时,首先会计算出跳转后的时间偏移量,来定义一个基准时间戳(跳转后的时间戳)。对于小于基准时间戳的事件,会以同步的方式全部apply起来,而剩余的事件则是用定时器触发。同时,会把基准事件戳与上次播放的最后的event中含有的时间戳进行比对,如果往前跳则清除节点Map数据,以同步方式重新计算;如果是往后跳则将同步计算的结果合并到已有的节点Map上。在定时器的使用上,由于setInterval会受到性能等各方面影响,这种事件定时器在精度上不能满足需求。于是rrweb使用了requestAnimationFrame的API来作为定时器(机制上因为不受到eventloop的影响,精度能达到1ms级别),使用performance.now()来作为获取每次触发定时器callback的时间偏移量(减去初始值),从而准确地触发rrweb待播放List中的事件。八、结语不通过口述或者截图等方式、而是通过录屏的方式进行记录,同时可以记录接口等数据,这样可以在复现前端场景上节省沟通成本、快速定位问题,从而提高效率。我们也会在后续的迭代中,寻找合适的场景落地,尝试更多方案,助力开发提效。
京东到家自动化测试平台的探索与实践
采集交流 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-04-28 20:45
HTTP服务的流量复制可以通过一些代理工具来实现。Mitmproxy是一款免费、开放的基于Python开发的交互式HTTPS代理工具。它可以用来捕获HTTP/HTTPS请求,支持抓包、断点调试、请求替换、构造请求、模拟弱网等功能。
工作原理如下:
流量复制的实现具体可以分为以下几个步骤:
1. 在电脑或手机端配置Mitmproxy代理服务器地址,此时电脑或手机的所有请求都通过代理服务器进行请求发出,当请求响应结束后,代理服务器识别出我们需要拦截的请求,并将请求和响应结果转发到我们的自动化测试平台;2. 测试平台收到代理服务器转发过来的请求和响应结果后,会将数据按照服务维度进行分类,作为初步的种子用例,持久化到数据库中;3. 测试人员依据种子用例,转换成正式的测试用例;
下图代码片段是按域名截取数据后,整合平台所需要的数据和数据格式:
效果展示
2.2 微服务流量复制
微服务的流量复制我们是通过自研客户端+配置采集规则来实现的。规则配置
交互逻辑
具体实现步骤如下:
1. 管理端配置服务的采集规则;2. 客户端定时拉取采集规则;3. 符合采集规则,则将请求入参和出参写入本地文件;4. 客户端定期上报流量采集内容到精卫平台;5. 按照服务,时间段等维度圈出要回归的流量用例,生成回归任务;6. 执行任务,进行流量回放;7. 生成流量回放的测试报告;如果之前没有维护过测试用例,也可以通过开启流量复制功能来快速的实现回归测试;总之,通过流量复制,将线上的真实流量引入到灰度测试环境中进行回放,不仅能够降低人工参与的成本,还可以更加真实的还原线上场景,使问题更加高效客观的呈现。
2.3 自动生成种子用例
在用例维护过程当中,如何快速生成一个正确的样本示例是我们经常面临的问题。为了解决这个问题我们搭建了API接口文档管理平台。这个平台目的主要是将服务定义元数据进行实时的线上化管理,可以随时可查看各个部署版本的接口定义元数据(包括版本、入参、类型、格式、示例等)。基于线上化的接口定义智能生成最新的入参结构,支持微服务和HTTP等协议。
在创建用例时,精卫平台会拉取服务的方法和接口定义的相关信息(入参定义,出参定义,参数示例),解析参数结构,快速生成种子用例,提高新用例的创建效率。
一个完整的新用例的创建过程如下:
1.选择所需的种子用例;
2.调整入参数据;3.补全用例名称、用途等信息;4.设置断言检查点等信息;
2.4收益评估
1. 测试人员不需要再进行抓包,查日志来获取自动化测试数据,减少了30%左右用来创建测试用例的时间;2. 可以实时获取最新的接口定义元数据,避免了接口定义的不准确性,同时降低了线下跟研发获取接口定义的时间成本;3. 通过预设的断言配置,用例执行结果的正确性检查借助平台实现了自动化,大幅度提升了测试效率;三、自动化回归测试精卫平台的自动化回归测试分为接口自动化和流程自动化两个维度。下面将从这两个部分来介绍。3.1接口自动化接口测试是测试系统组件间接口的一种测试方式,主要用于检测系统内部、系统间的交互点,常作为功能测试的基本单元。接口自动化就是将一批接口测试用例打包并自动执行,以达到节省人力、时间、资源成本,快速验证回归测试服务正确性,提升测试效率的目的。
3.1.1 设计方案
自动化回归测试依托于持续集成部署平台,当服务部署发布后,借助api接口文档管理平台,可以自动识别出变更的服务方法,触发自动化回归测试任务,自动回归有代码变更方法的用例。
3.1.2 执行过程
1. 用例录制:接口自动化回归的前提条件是已经拥有了测试用例;2. 圈定回归范围:同一接口的测试用例按照用途会分为多组,比如:单元测试用例,回归测试用例,压测用例等,圈定出录制的回归测试用例;
3. 创建回归测试任务:支持全量/增量回归,全量回归可以进行代码覆盖率的统计;4. 执行回归测试任务:当服务部署后,自动触发回归任务的执行;5. 生成测试报告:任务用例执行完成后,会生成一份测试报告,报告中含用例通过率、代码覆盖率、问题处理建议等信息;
3.1.3成果收益
接口自动化测试减少了测试的执行时间,降低了回归测试的实现门槛,有效的缩短了产品交付周期,测试人员有更多的时间和精力投入到产品业务本身上面去。3.2 流程自动化速搭平台是京东到家为研发和测试人员提供的一站式服务发布平台,其核心是通过我们现有能力(微服务或http服务)的再次加工(编排),形成新的能力,精卫平台借助此能力实现流程自动化测试。
3.2.1 设计方案
业务架构图
3.2.2执行过程
1. 构建步骤:步骤是组成流程的最小执行单元,单个步骤可以理解为一个服务;2. 构建流程:把各个步骤按照业务逻辑编排起来构成流程;
3. 设计流程用例:定义流程入参、设置断言,创建流程用例;
4. 构建流程任务:按照业务圈定要执行的流程用例,以任务的方式集中执行;
5. 执行流程任务:支持手动触发和定时执行等方式,以达到回归或巡检的目的;
6. 任务执行报告:通过率、代码覆盖率、执行结果日志等报告信息,如有异常情况发送告警通知。
3.2.3 成果收益
1. 已经初步完成核心场景的全覆盖自动回归,在需求迭代效率上有了很大的提升;2. 流程测试与用户真实操作更相近,可以更好的站着用户的角度验证产品,利用黄金流程的实时巡检机制,系统在稳定性方面也得到了更好的保障;3.3 回归机制不同的场景下回归的机制会有所不同。比如:3.3.1 一键回归
研发发起提测后,针对圈定的服务和方法可以进行一键全量/增量的回归测试。
3.3.2 自动回归自动回归测试的触发方式有部署后自动回归,线上的定时巡检等场景。1. 日常巡检平台支持cron表达式,对多任务、多用例进行定时执行,并在失败或者异常后进行预警。
2. 应用部署后自动回归支持全量和增量回归。应用部署后,对API文档变更的内容进行自动回归、生成测试报告,在失败或者异常时进行预警。四、提升测试质量测试质量的把控可以从技术和流程两个方面来考虑,技术层面主要依赖于度量指标的提升(用例通过率,代码覆盖率等),流程方面可以通过设置质量门禁等方式来保证提测质量。4.1 代码覆盖率代码覆盖率是软件测试中的一种度量,描述程序中源代码被测试的比例和程度,所得比例称为代码覆盖率。平台实现原理:
实现方式可参照另一篇文章:《》
4.2 设置质量门禁根据测试金字塔模型,我们知道问题越早暴露,解决问题的成本越低。单元测试的充分性是提高整个测试效率的关键,设置质量门禁(单元测试通过率)是保证提测质量的重要手段。如何设置质量门禁的呢?我们具体来看一下整个提测流程:1. 维护单元测试用例:研发维护服务的单元测试用例;2. 圈定提测范围:研发选择要回归的服务列表;
3. 生成单元测试任务:根据圈定的服务列表,筛选出对应的单元你测试用例,生成单元测试任务;4. 执行测试任务:批量执行单元测试用例,达到设置的门禁标准(通过率,覆盖率等)才可进入测试环节;
5. 进入测试流程:达到提测标准后,进入正式测试环节,测试人员针对提测服务和测试重点进行针对性的测试。
五、总结及其它5.1总结精卫平台作为实现持续集成/发布(CI/CD)的基础设施,其目标是保证代码具备随时可以发布到线上的良好状态,维持团队的持续交付能力。另外,平台在效率提升方面也取得了显著效果:
5.2展望软件度量是对软件开发项目、过程、及其产品进行数据定义、收集以及分析的持续性量化过程。通过软件度量可以改进软件开发过程,促进项目成功,开发高质量的软件产品。平台将继续对整个产品交付过程中的指标数据进行整理、挖掘,发现过程中存在的问题和短板,优化和反哺产品交付流程,在效率和稳定性等方面获得更大的突破。5.3附录
平台架构
核心流程
查看全部
京东到家自动化测试平台的探索与实践
HTTP服务的流量复制可以通过一些代理工具来实现。Mitmproxy是一款免费、开放的基于Python开发的交互式HTTPS代理工具。它可以用来捕获HTTP/HTTPS请求,支持抓包、断点调试、请求替换、构造请求、模拟弱网等功能。
工作原理如下:
流量复制的实现具体可以分为以下几个步骤:
1. 在电脑或手机端配置Mitmproxy代理服务器地址,此时电脑或手机的所有请求都通过代理服务器进行请求发出,当请求响应结束后,代理服务器识别出我们需要拦截的请求,并将请求和响应结果转发到我们的自动化测试平台;2. 测试平台收到代理服务器转发过来的请求和响应结果后,会将数据按照服务维度进行分类,作为初步的种子用例,持久化到数据库中;3. 测试人员依据种子用例,转换成正式的测试用例;
下图代码片段是按域名截取数据后,整合平台所需要的数据和数据格式:
效果展示
2.2 微服务流量复制
微服务的流量复制我们是通过自研客户端+配置采集规则来实现的。规则配置
交互逻辑
具体实现步骤如下:
1. 管理端配置服务的采集规则;2. 客户端定时拉取采集规则;3. 符合采集规则,则将请求入参和出参写入本地文件;4. 客户端定期上报流量采集内容到精卫平台;5. 按照服务,时间段等维度圈出要回归的流量用例,生成回归任务;6. 执行任务,进行流量回放;7. 生成流量回放的测试报告;如果之前没有维护过测试用例,也可以通过开启流量复制功能来快速的实现回归测试;总之,通过流量复制,将线上的真实流量引入到灰度测试环境中进行回放,不仅能够降低人工参与的成本,还可以更加真实的还原线上场景,使问题更加高效客观的呈现。
2.3 自动生成种子用例
在用例维护过程当中,如何快速生成一个正确的样本示例是我们经常面临的问题。为了解决这个问题我们搭建了API接口文档管理平台。这个平台目的主要是将服务定义元数据进行实时的线上化管理,可以随时可查看各个部署版本的接口定义元数据(包括版本、入参、类型、格式、示例等)。基于线上化的接口定义智能生成最新的入参结构,支持微服务和HTTP等协议。
在创建用例时,精卫平台会拉取服务的方法和接口定义的相关信息(入参定义,出参定义,参数示例),解析参数结构,快速生成种子用例,提高新用例的创建效率。
一个完整的新用例的创建过程如下:
1.选择所需的种子用例;
2.调整入参数据;3.补全用例名称、用途等信息;4.设置断言检查点等信息;
2.4收益评估
1. 测试人员不需要再进行抓包,查日志来获取自动化测试数据,减少了30%左右用来创建测试用例的时间;2. 可以实时获取最新的接口定义元数据,避免了接口定义的不准确性,同时降低了线下跟研发获取接口定义的时间成本;3. 通过预设的断言配置,用例执行结果的正确性检查借助平台实现了自动化,大幅度提升了测试效率;三、自动化回归测试精卫平台的自动化回归测试分为接口自动化和流程自动化两个维度。下面将从这两个部分来介绍。3.1接口自动化接口测试是测试系统组件间接口的一种测试方式,主要用于检测系统内部、系统间的交互点,常作为功能测试的基本单元。接口自动化就是将一批接口测试用例打包并自动执行,以达到节省人力、时间、资源成本,快速验证回归测试服务正确性,提升测试效率的目的。
3.1.1 设计方案
自动化回归测试依托于持续集成部署平台,当服务部署发布后,借助api接口文档管理平台,可以自动识别出变更的服务方法,触发自动化回归测试任务,自动回归有代码变更方法的用例。
3.1.2 执行过程
1. 用例录制:接口自动化回归的前提条件是已经拥有了测试用例;2. 圈定回归范围:同一接口的测试用例按照用途会分为多组,比如:单元测试用例,回归测试用例,压测用例等,圈定出录制的回归测试用例;
3. 创建回归测试任务:支持全量/增量回归,全量回归可以进行代码覆盖率的统计;4. 执行回归测试任务:当服务部署后,自动触发回归任务的执行;5. 生成测试报告:任务用例执行完成后,会生成一份测试报告,报告中含用例通过率、代码覆盖率、问题处理建议等信息;
3.1.3成果收益
接口自动化测试减少了测试的执行时间,降低了回归测试的实现门槛,有效的缩短了产品交付周期,测试人员有更多的时间和精力投入到产品业务本身上面去。3.2 流程自动化速搭平台是京东到家为研发和测试人员提供的一站式服务发布平台,其核心是通过我们现有能力(微服务或http服务)的再次加工(编排),形成新的能力,精卫平台借助此能力实现流程自动化测试。
3.2.1 设计方案
业务架构图
3.2.2执行过程
1. 构建步骤:步骤是组成流程的最小执行单元,单个步骤可以理解为一个服务;2. 构建流程:把各个步骤按照业务逻辑编排起来构成流程;
3. 设计流程用例:定义流程入参、设置断言,创建流程用例;
4. 构建流程任务:按照业务圈定要执行的流程用例,以任务的方式集中执行;
5. 执行流程任务:支持手动触发和定时执行等方式,以达到回归或巡检的目的;
6. 任务执行报告:通过率、代码覆盖率、执行结果日志等报告信息,如有异常情况发送告警通知。
3.2.3 成果收益
1. 已经初步完成核心场景的全覆盖自动回归,在需求迭代效率上有了很大的提升;2. 流程测试与用户真实操作更相近,可以更好的站着用户的角度验证产品,利用黄金流程的实时巡检机制,系统在稳定性方面也得到了更好的保障;3.3 回归机制不同的场景下回归的机制会有所不同。比如:3.3.1 一键回归
研发发起提测后,针对圈定的服务和方法可以进行一键全量/增量的回归测试。
3.3.2 自动回归自动回归测试的触发方式有部署后自动回归,线上的定时巡检等场景。1. 日常巡检平台支持cron表达式,对多任务、多用例进行定时执行,并在失败或者异常后进行预警。
2. 应用部署后自动回归支持全量和增量回归。应用部署后,对API文档变更的内容进行自动回归、生成测试报告,在失败或者异常时进行预警。四、提升测试质量测试质量的把控可以从技术和流程两个方面来考虑,技术层面主要依赖于度量指标的提升(用例通过率,代码覆盖率等),流程方面可以通过设置质量门禁等方式来保证提测质量。4.1 代码覆盖率代码覆盖率是软件测试中的一种度量,描述程序中源代码被测试的比例和程度,所得比例称为代码覆盖率。平台实现原理:
实现方式可参照另一篇文章:《》
4.2 设置质量门禁根据测试金字塔模型,我们知道问题越早暴露,解决问题的成本越低。单元测试的充分性是提高整个测试效率的关键,设置质量门禁(单元测试通过率)是保证提测质量的重要手段。如何设置质量门禁的呢?我们具体来看一下整个提测流程:1. 维护单元测试用例:研发维护服务的单元测试用例;2. 圈定提测范围:研发选择要回归的服务列表;
3. 生成单元测试任务:根据圈定的服务列表,筛选出对应的单元你测试用例,生成单元测试任务;4. 执行测试任务:批量执行单元测试用例,达到设置的门禁标准(通过率,覆盖率等)才可进入测试环节;
5. 进入测试流程:达到提测标准后,进入正式测试环节,测试人员针对提测服务和测试重点进行针对性的测试。
五、总结及其它5.1总结精卫平台作为实现持续集成/发布(CI/CD)的基础设施,其目标是保证代码具备随时可以发布到线上的良好状态,维持团队的持续交付能力。另外,平台在效率提升方面也取得了显著效果:
5.2展望软件度量是对软件开发项目、过程、及其产品进行数据定义、收集以及分析的持续性量化过程。通过软件度量可以改进软件开发过程,促进项目成功,开发高质量的软件产品。平台将继续对整个产品交付过程中的指标数据进行整理、挖掘,发现过程中存在的问题和短板,优化和反哺产品交付流程,在效率和稳定性等方面获得更大的突破。5.3附录
平台架构
核心流程
没有数据治理思维,数字化转型就是“白忙活”
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-04-28 13:34
BUT,数据资产能怎么用?为什么无数据可用,或无可用数据?怎样开展数据治理?则是一头雾水。这也导致很多企业的数字化转型“白忙活一场”、“从头再来”的重要原因。
《报告》依据数据治理及管理组织各层级所关注的侧重点,图谱将工具划分为三层——战略层、管理层、操作层。
01/战略层工具为提供数据质量战略规划、评估、知道、监控的工具或功能,主要包括五大过程域:组织与职责、体系与制度、团队与文化、计划与监控、成本与评估。1. 组织与职责对数据治理组织及其职责进行规划、管理。
2. 体系与制度对数据治理相关体系、制度、流程进行管理、发布。
3. 团队与文化提供数据治理文化发布、查询、学习培训等。
4. 计划与监控
提供数据治理项目管理及监控。
5.成效与评估
对治理成效提供评估依据及评估行为。
02/
管理层工具
为应落实数据治理战略而进行的数据管理活动的工具或功能。主要包括八大过程域:
数据架构管理、元数据管理、数据标准管理、主数据管理、数据质量管理、数据资产管理、数据安全管理、数据生存周期管理。
1.数据架构管理提供数据架构规划、设计相关工具及功能,包括数据层次、数据模型和数据流向设计。
2.元数据管理提供统一的企业元数据存储库,支持相关血缘、影响分析及变更管理的监控。
3.数据标准管理提供统一的指标数据技术标准、 业务标准、管理标准的视图,具备基本的增删改查及废止功能,可进行标准符合性检测。
4.主数据管理提供对企业主数据、参考数据统一管理, 支持主数据模型定义、数据约束及分发策略的管理。
5.数据质量管理支持对数据质量建立质量规则,支持数据治理评估,并生成质量报告,提供质量整改机制。
6.数据资产管理提供企业以资产价值视角的数据管理功能,包括资产索引、资产开发、资产服务等功能。
7.数据安全管理支持对数据进行安全分级分类,定期监督和执行数据安全策略执行情况。
8.数据生存周期管理对数据进行生存周期管理,定期监督和检查数据归档和销毁策略执行情况。
03/
操作层工具
数据操作层主要包括六大过程域:数据存储工具、数据采集工具、数据处理工具、数据共享交换工具、AI计算支撑工具、数据分析应用工具。
1.数据存储工具
基于数据治理战略及数据架构、数据标准、元数据、质量等管理要求,对数据进行存储。包括分布式存储、传统关系型存储、文件存储及图数据库存储。
2.数据采集工具基于数据治理战略要求,完成相关数据采集工作。支持不同采集方式及频率,包括实时采集、离线采集、报表填报采集、API采集等。
3.数据处理工具基于数据质量、标准、数据架构等要求,对数据进行加工、转换、清洗、集中等工作。
4.数据共享交换工具
基于业务与之间的数据共享需求,对不同异构数据执行交换或服务。包括文件、库表、接口、实时流等。
5.Al计算支撑工具将人工智能技术运用到数据采集、处理、共享、评估、度量等活动中。
6.数据分析应用工具通过数据可视化、报表等工具完成数据治理的报告、诊断分析、监控图表等的开发制作。
《数据治理工具图谱研究报告》对上述工具能力图谱进行了详细解释,除全景图外,报告对每层工具能力要素进行了更细一步的绘制,并收录了部分行业案例采用的工具架构图。
报告共研制、收录了26个图谱,其中研制了20个通用工具能力图谱,收录了6个数据治理案例工具能力图谱。 查看全部
当前这个时代,人人都知道数据,或多或少也知道数据是资产,治理好了很有用,毕竟企业数字化转型的始终离不开“数据”,始于数据,最终也是为了数据。
BUT,数据资产能怎么用?为什么无数据可用,或无可用数据?怎样开展数据治理?则是一头雾水。这也导致很多企业的数字化转型“白忙活一场”、“从头再来”的重要原因。
《报告》依据数据治理及管理组织各层级所关注的侧重点,图谱将工具划分为三层——战略层、管理层、操作层。
01/战略层工具为提供数据质量战略规划、评估、知道、监控的工具或功能,主要包括五大过程域:组织与职责、体系与制度、团队与文化、计划与监控、成本与评估。1. 组织与职责对数据治理组织及其职责进行规划、管理。
2. 体系与制度对数据治理相关体系、制度、流程进行管理、发布。
3. 团队与文化提供数据治理文化发布、查询、学习培训等。
4. 计划与监控
提供数据治理项目管理及监控。
5.成效与评估
对治理成效提供评估依据及评估行为。
02/
管理层工具
为应落实数据治理战略而进行的数据管理活动的工具或功能。主要包括八大过程域:
数据架构管理、元数据管理、数据标准管理、主数据管理、数据质量管理、数据资产管理、数据安全管理、数据生存周期管理。
1.数据架构管理提供数据架构规划、设计相关工具及功能,包括数据层次、数据模型和数据流向设计。
2.元数据管理提供统一的企业元数据存储库,支持相关血缘、影响分析及变更管理的监控。
3.数据标准管理提供统一的指标数据技术标准、 业务标准、管理标准的视图,具备基本的增删改查及废止功能,可进行标准符合性检测。
4.主数据管理提供对企业主数据、参考数据统一管理, 支持主数据模型定义、数据约束及分发策略的管理。
5.数据质量管理支持对数据质量建立质量规则,支持数据治理评估,并生成质量报告,提供质量整改机制。
6.数据资产管理提供企业以资产价值视角的数据管理功能,包括资产索引、资产开发、资产服务等功能。
7.数据安全管理支持对数据进行安全分级分类,定期监督和执行数据安全策略执行情况。
8.数据生存周期管理对数据进行生存周期管理,定期监督和检查数据归档和销毁策略执行情况。
03/
操作层工具
数据操作层主要包括六大过程域:数据存储工具、数据采集工具、数据处理工具、数据共享交换工具、AI计算支撑工具、数据分析应用工具。
1.数据存储工具
基于数据治理战略及数据架构、数据标准、元数据、质量等管理要求,对数据进行存储。包括分布式存储、传统关系型存储、文件存储及图数据库存储。
2.数据采集工具基于数据治理战略要求,完成相关数据采集工作。支持不同采集方式及频率,包括实时采集、离线采集、报表填报采集、API采集等。
3.数据处理工具基于数据质量、标准、数据架构等要求,对数据进行加工、转换、清洗、集中等工作。
4.数据共享交换工具
基于业务与之间的数据共享需求,对不同异构数据执行交换或服务。包括文件、库表、接口、实时流等。
5.Al计算支撑工具将人工智能技术运用到数据采集、处理、共享、评估、度量等活动中。
6.数据分析应用工具通过数据可视化、报表等工具完成数据治理的报告、诊断分析、监控图表等的开发制作。
《数据治理工具图谱研究报告》对上述工具能力图谱进行了详细解释,除全景图外,报告对每层工具能力要素进行了更细一步的绘制,并收录了部分行业案例采用的工具架构图。
报告共研制、收录了26个图谱,其中研制了20个通用工具能力图谱,收录了6个数据治理案例工具能力图谱。
文章采集api(优采云采集支持调用优采云(小狗AI)API接口及解决方案 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2022-04-19 09:28
)
优采云采集支持调用优采云(小狗AI)API接口处理采集的数据标题和内容、关键词、描述等。可以针对性的配合优采云采集的SEO功能和5118智能换词API,处理原创度数更高的文章。@收录 和 网站 权重起着非常重要的作用。
购买优采云(小狗AI)API,建议先咨询优采云(小狗AI)客服,并告知在优采云采集上使用@> 平台;
详细使用步骤优采云API接口配置创建API处理规则API处理规则使用API处理结果并发布优采云-API接口常见问题及解决方案
1. 优采云API接口配置
一、API配置入口:
点击控制台左侧列表中的【第三方服务配置】==点击【第三方内容API接入】==点击【第三方API配置管理】==最后点击【+< @优采云API] 创建接口配置;
二、配置API接口信息:
购买优采云(小狗AI)API,建议先咨询优采云(小狗AI)客服,并告知在优采云采集上使用@> 平台。
【API key】是从优采云(Puppy AI)后台获取对应的API key,填写后记得保存;
2. 创建 API 处理规则
API处理规则,可以通过调用API接口设置处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==,点击【第三方内容API接入】==进入【API处理规则管理】页面,最后点击【+添加API处理规则]创建API处理规则;
二、API处理规则配置:
3. API 处理规则使用
API处理规则有两种使用方式:手动执行和自动执行:
一、手动执行API处理规则:
在采集任务的【结果数据&发布】选项卡中,点击【SEO&API&翻译等工具】按钮==>选择【第三方API执行】栏==>选择对应的API处理规则= => 执行;
二、自动执行API处理规则:
启用 API 处理的自动执行。任务完成后采集会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡【自动执行第三方API配置】==勾选【采集,自动执行API】选项==选择要执行的API处理规则= ="选择API接口处理的数据范围(一般选择'待发布',都将导致所有数据重复执行),最后点击保存;
4. API 处理结果并发布
一、查看API接口处理结果:
API接口处理的内容会保存为一个新的字段,如:标题处理后的新字段:title_优采云,内容处理后的新字段:content_优采云,在[Result Data & Publish ]和数据预览界面可以查看。
二、发布API接口处理后的内容:
发布文章前,修改发布目标的第二步映射字段,重新选择标题和内容到API接口处理后添加的对应字段title_优采云和content_优采云;
提示:如果发布目标中无法选择新字段,请在任务下复制或新建发布目标,然后在新发布目标中选择新字段即可。详细教程请参考发布目标中不能选择的字段;
5. 优采云-API接口常见问题及解决方法
一、API处理规则和SEO规则如何协同工作?
系统默认对title和content字段进行SEO功能,需要修改为SEO规则中的title_优采云和content_优采云字段;
查看全部
文章采集api(优采云采集支持调用优采云(小狗AI)API接口及解决方案
)
优采云采集支持调用优采云(小狗AI)API接口处理采集的数据标题和内容、关键词、描述等。可以针对性的配合优采云采集的SEO功能和5118智能换词API,处理原创度数更高的文章。@收录 和 网站 权重起着非常重要的作用。
购买优采云(小狗AI)API,建议先咨询优采云(小狗AI)客服,并告知在优采云采集上使用@> 平台;
详细使用步骤优采云API接口配置创建API处理规则API处理规则使用API处理结果并发布优采云-API接口常见问题及解决方案
1. 优采云API接口配置
一、API配置入口:
点击控制台左侧列表中的【第三方服务配置】==点击【第三方内容API接入】==点击【第三方API配置管理】==最后点击【+< @优采云API] 创建接口配置;
二、配置API接口信息:
购买优采云(小狗AI)API,建议先咨询优采云(小狗AI)客服,并告知在优采云采集上使用@> 平台。
【API key】是从优采云(Puppy AI)后台获取对应的API key,填写后记得保存;
2. 创建 API 处理规则
API处理规则,可以通过调用API接口设置处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==,点击【第三方内容API接入】==进入【API处理规则管理】页面,最后点击【+添加API处理规则]创建API处理规则;
二、API处理规则配置:
3. API 处理规则使用
API处理规则有两种使用方式:手动执行和自动执行:
一、手动执行API处理规则:
在采集任务的【结果数据&发布】选项卡中,点击【SEO&API&翻译等工具】按钮==>选择【第三方API执行】栏==>选择对应的API处理规则= => 执行;
二、自动执行API处理规则:
启用 API 处理的自动执行。任务完成后采集会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡【自动执行第三方API配置】==勾选【采集,自动执行API】选项==选择要执行的API处理规则= ="选择API接口处理的数据范围(一般选择'待发布',都将导致所有数据重复执行),最后点击保存;
4. API 处理结果并发布
一、查看API接口处理结果:
API接口处理的内容会保存为一个新的字段,如:标题处理后的新字段:title_优采云,内容处理后的新字段:content_优采云,在[Result Data & Publish ]和数据预览界面可以查看。
二、发布API接口处理后的内容:
发布文章前,修改发布目标的第二步映射字段,重新选择标题和内容到API接口处理后添加的对应字段title_优采云和content_优采云;
提示:如果发布目标中无法选择新字段,请在任务下复制或新建发布目标,然后在新发布目标中选择新字段即可。详细教程请参考发布目标中不能选择的字段;
5. 优采云-API接口常见问题及解决方法
一、API处理规则和SEO规则如何协同工作?
系统默认对title和content字段进行SEO功能,需要修改为SEO规则中的title_优采云和content_优采云字段;
文章采集api(就是错误博客(图片或视频亦包括在内)分享)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-04-19 07:01
此外,伪原创大部分都被同义词和同义词所取代。基本上,市场上没有 AI伪原创。如果确实存在,那么直接给关键词,剩下的可以自己写。市面上大部分的伪原创提供者都替换了同义词和同义词,所以最好不要这样做。
3、构建文章
使用大量的词搭建文章,比如10万个相关词做一个表格文章页面,通过对词和句子的布局,看起来没有不协调的感觉。另请参阅此方法。很多网站都获得了很大的流量,而bug博客本身也获得了数万这样的收录流量。
二、优采云构建文章
优采云构建文章 很简单,bug 博客为您提供了一切。
1、优采云导入模板
下载优采云,即优采云采集,创建人员列表组,右键组,导入准备好的“.ljobx”文件,这是 优采云@ 的模板>采集。
2、内容采集规则
导入后,双击打开,直接跳过“URL采集规则”,直接进入“内容采集规则”,那么,我们需要构建标题、页面对于原创 关键词,页面描述、作者、缩略图、标签等,都来自txt文档,内存中有几万行数据,所以构建< @原创文章 。当然,这只是一种模式。如果你想有更好的收录效果,那么你需要考虑如何使用这种模式来创造更好的内容,或者改变模式来产生更像原创的内容。
以上是Error Blog()分享的内容为“优采云采集三种构建方式原创文章”。谢谢阅读。更多原创文章搜索“bug blog”。
特别声明:以上内容(包括图片或视频)由自媒体平台“网易”用户上传发布。本平台仅提供信息存储服务。 查看全部
文章采集api(就是错误博客(图片或视频亦包括在内)分享)
此外,伪原创大部分都被同义词和同义词所取代。基本上,市场上没有 AI伪原创。如果确实存在,那么直接给关键词,剩下的可以自己写。市面上大部分的伪原创提供者都替换了同义词和同义词,所以最好不要这样做。
3、构建文章
使用大量的词搭建文章,比如10万个相关词做一个表格文章页面,通过对词和句子的布局,看起来没有不协调的感觉。另请参阅此方法。很多网站都获得了很大的流量,而bug博客本身也获得了数万这样的收录流量。
二、优采云构建文章
优采云构建文章 很简单,bug 博客为您提供了一切。
1、优采云导入模板
下载优采云,即优采云采集,创建人员列表组,右键组,导入准备好的“.ljobx”文件,这是 优采云@ 的模板>采集。
2、内容采集规则
导入后,双击打开,直接跳过“URL采集规则”,直接进入“内容采集规则”,那么,我们需要构建标题、页面对于原创 关键词,页面描述、作者、缩略图、标签等,都来自txt文档,内存中有几万行数据,所以构建< @原创文章 。当然,这只是一种模式。如果你想有更好的收录效果,那么你需要考虑如何使用这种模式来创造更好的内容,或者改变模式来产生更像原创的内容。
以上是Error Blog()分享的内容为“优采云采集三种构建方式原创文章”。谢谢阅读。更多原创文章搜索“bug blog”。
特别声明:以上内容(包括图片或视频)由自媒体平台“网易”用户上传发布。本平台仅提供信息存储服务。
文章采集api( 京东云API分组管理中实现日志实时采集、日志存储 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-04-19 00:42
京东云API分组管理中实现日志实时采集、日志存储
)
日志服务
目前,您可以在京东云的API群组管理中实现日志实时采集、日志存储、日志检索、智能分析等功能,通过日志解决业务运营、业务监控、日志分析等问题。
入口一:
互联网中间件 > API网关 > 开放API > API组管理 > 日志服务
入口二:
管理 > 日志服务
操作步骤: 第一步:进入API组管理页面,点击“Log”按钮
第二步:在日志集管理模块中,点击“创建日志集”按钮,打开创建日志集页面。
步骤 3:设置日志集名称、描述(可选)和保存时间。点击“确定”按钮后,弹出提示“日志集创建成功,现在去添加日志主题吗?”
第四步:点击“确定”按钮后,跳转到日志集详情,创建日志主题。
第五步:添加日志主题名称后,点击“确定”按钮,弹出提示“日志主题创建成功,现在去添加采集配置吗?”
第六步:点击“确定”后,进入采集配置页面。点击“添加采集配置”进入添加采集配置页面,在“产品”对应选项中选择“API网关”,点击“确定”按钮完成配置。第七步:返回日志集管理中的日志主题列表页面,点击日志集ID/名称,点击“预览”按钮可以查看日志主题下的最新日志数据。如果需要查询日志数据,可以到日志检索查询。
第八步:在日志主题列表中选择要查看的日志主题,点击“搜索”按钮,或者切换到左侧菜单的日志搜索模块,可以进行相应的全文搜索或键值搜索在日志上:
全文搜索
键值检索
(1)快速搜索
(2)高级搜索
查看全部
文章采集api(
京东云API分组管理中实现日志实时采集、日志存储
)
日志服务
目前,您可以在京东云的API群组管理中实现日志实时采集、日志存储、日志检索、智能分析等功能,通过日志解决业务运营、业务监控、日志分析等问题。
入口一:
互联网中间件 > API网关 > 开放API > API组管理 > 日志服务
入口二:
管理 > 日志服务
操作步骤: 第一步:进入API组管理页面,点击“Log”按钮
第二步:在日志集管理模块中,点击“创建日志集”按钮,打开创建日志集页面。
步骤 3:设置日志集名称、描述(可选)和保存时间。点击“确定”按钮后,弹出提示“日志集创建成功,现在去添加日志主题吗?”
第四步:点击“确定”按钮后,跳转到日志集详情,创建日志主题。
第五步:添加日志主题名称后,点击“确定”按钮,弹出提示“日志主题创建成功,现在去添加采集配置吗?”
第六步:点击“确定”后,进入采集配置页面。点击“添加采集配置”进入添加采集配置页面,在“产品”对应选项中选择“API网关”,点击“确定”按钮完成配置。第七步:返回日志集管理中的日志主题列表页面,点击日志集ID/名称,点击“预览”按钮可以查看日志主题下的最新日志数据。如果需要查询日志数据,可以到日志检索查询。
第八步:在日志主题列表中选择要查看的日志主题,点击“搜索”按钮,或者切换到左侧菜单的日志搜索模块,可以进行相应的全文搜索或键值搜索在日志上:
全文搜索
键值检索
(1)快速搜索
(2)高级搜索
文章采集api(搭建一套前端监控平台需要考虑的几个问题?|本文)
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-04-18 20:32
随着业务的快速发展,我们越来越重视对生产环境问题的感知能力。作为离用户最近的一层,前端性能是否可靠、稳定、好用在很大程度上决定了用户对整个产品的体验和感受。因此,前端的监控也不容忽视。
搭建前端监控平台需要考虑很多方面,比如数据采集、埋藏模式、数据处理分析、告警、监控平台在具体业务中的应用等等。在所有这些环节中、准确、完整、全面的数据采集是一切的前提,也为用户后续的精细化运营提供了依据。
前端技术的飞速发展给数据带来了变化和挑战采集,传统的人工管理模式已经不能满足需求。如何让前端数据采集在新的技术背景下工作更加完整高效是本文的重点。
前端监控数据采集
在采集数据之前,考虑一下采集什么样的数据。我们关注两类数据,一类与用户体验相关,如首屏时间、文件加载时间、页面性能等;另一个是帮助我们及时感知产品上线后是否出现异常,比如资源错误、API响应时间等。具体来说,我们的前端数据采集主要分为:
路由交换机
Vue、React、Angular等前端技术的快速发展,使得单页应用流行起来。我们都知道,传统的页面应用使用一些超链接来实现页面切换和跳转,而单页面应用使用自己的路由系统来管理各个前端页面切换,比如vue-router、react-router等,只有跳转时刷新本地资源,js、css等公共资源只需加载一次,使得传统的网页进出方式只有在第一次打开时才会被记录。在单页应用中切换所有后续路由有两种方式,一种是Hash,另一种是HTML5推出的History API。
1. 链接
href是页面初始化的第一个入口,这里只需要简单的报告“进入页面”事件。
2. 哈希变化
哈希路由的一个明显标志是带有“#”。Hash的优点是兼容性更好,但问题是URL中的“#”不美观。我们主要通过监听 URL 中的 hashchange 来捕获具体的 hash 值进行检测。
window.addEventListener('hashchange', function() {
// 上报【进入页面】事件
}, true)
需要注意的是,如果浏览器在新版本的vue-router中支持history,即使模式选择hash,也会先选择history模式。虽然表达式暂时还是#,但实际上是模拟出来的,所以不要以为你在如果模式选择hash,那肯定是hash。
3. 历史 API
History利用HTML5 History接口中新增的pushState()和replaceState()方法进行路由切换,是目前主流的非刷新切换路由方式。与 hashchange 只能更改 # 后面的代码片段相比,History API(pushState、replaceState)给了前端完全的自由。
PopState 是浏览器返回事件的回调,但是更新路由的 pushState 和 replaceState 没有回调事件。因此,URL 更改需要分别在 history.pushState() 和 history.replaceState() 方法中处理。在这里,我们使用类似Java的AOP编程思想来改造pushState和replaceState。
AOP(Aspect-oriented programming)是面向方面的编程,它提倡对同一类型的问题进行统一处理。AOP的核心思想是让某个模块能够被复用。它采用横向抽取机制,将功能代码与业务逻辑代码分离,在不修改源代码的情况下扩展功能。与封装相比,隔离更彻底。
下面介绍我们具体的改造方法:
// 第一阶段:我们对原生方法进行包装,调用前执行 dispatchEvent 了一个同样的事件
function aop (type) {
var source = window.history[type];
return function () {
var event = new Event(type);
event.arguments = arguments;
window.dispatchEvent(event);
var rewrite = source.apply(this, arguments);
return rewrite;
};
}
// 第二阶段:将 pushState 和 replaceState 进行基于 AOP 思想的代码注入
window.history.pushState = aop('pushState');
window.history.replaceState = aop('replaceState'); // 更改路由,不会留下历史记录
// 第三阶段:捕获pushState 和 replaceState
window.addEventListener('pushState', function() {
// 上报【进入页面】事件
}, true)
window.addEventListener('replaceState', function() {
// 上报【进入页面】事件
}, true)
window.history.pushState的实际调用关系如图:
至此,我们完成了pushState和replaceState的转换,实现了路由切换的有效抓包。可以看出,我们在不侵入业务代码的情况下扩展了window.history.pushState,调用时会主动dispatchEvent一个pushState。
但是这里我们也可以看到一个缺点,就是如果AOP代理函数出现JS错误,会阻塞后续的调用关系,从而无法调用实际的window.history.pushState。因此,在使用该方法时,需要对AOP代理功能的内容进行一次完整的try catch,以防止出现业务异常。
*提示:如果要自动捕捉页面停留时间,只需在触发下一页进入事件时,将上一页的时间与当前时间做个差值即可。这时候可以上报【离开页面】事件。
错误
在前端项目中,由于 JavaScript 本身是一种弱类型语言,再加上浏览器环境的复杂性、网络问题等,很容易出现错误。因此,做好网页错误监控,不断优化代码,提高代码的健壮性是非常重要的。
JsError的捕获可以帮助我们分析和监控在线问题,和我们在Chrome浏览器的调试工具Console中看到的一致。
1. 窗口.onerror
我们通常使用 window.onerror 来捕获 JS 错误的异常信息。有两种方法可以捕获 JS 错误,window.onerror 和 window.addEventListener('error')。一般不建议使用 addEventListener('error') 来捕获 JS 异常,主要是它没有堆栈信息,而且还需要区分捕获的信息,因为它会捕获所有的异常信息,包括资源加载错误. 等待。
window.onerror = function (msg, url, lineno, colno, stack) {
// 上报 【js错误】事件
}
2. 未被抓住(承诺)
当 Promise 发生 JS 错误或者业务没有处理拒绝信息时,会抛出 unhandledrejection,并且这个错误不会被 window.onerror 和 window.addEventListener('error') 这个特殊的窗口捕获。addEventListener('unhandledrejection') 用于捕获处理:
window.addEventListener('unhandledrejection', function (e) {
var reg_url = /\(([^)]*)\)/;
var fileMsg = e.reason.stack.split('\n')[1].match(reg_url)[1];
var fileArr = fileMsg.split(':');
var lineno = fileArr[fileArr.length - 2];
var colno = fileArr[fileArr.length - 1];
var url = fileMsg.slice(0, -lno.length - cno.length - 2);}, true);
var msg = e.reason.message;
// 上报 【js错误】事件
}
我们注意到unhandledrejection继承自PromiseRejectionEvent,而PromiseRejectionEvent继承自Event,所以msg、url、lineno、colno、stack以字符串的形式放在e.reason.stack中,我们需要将上面的参数解析出来与onerror参数对齐,为后续监测平台各项指标的统一奠定了基础。
3. 常见问题
如果抓到的msg都是“Script error.”,问题是你的JS地址和当前网页不在同一个域下。因为我们经常需要对网络版的静态资源进行CDN,会导致经常访问的页面和脚本文件来自不同的域名。这时候如果不进行额外配置,浏览器很容易出现“脚本错误”。出于安全考虑。我们可以利用当前流行的 Webpack bundler 来处理此类问题。
// webpack config 配置
// 处理 html 注入 js 添加跨域标识
plugins: [
new HtmlWebpackPlugin({
filename: 'html/index.html',
template: HTML_PATH,
attributes: {
crossorigin: 'anonymous'
}
}),
new HtmlWebpackPluginCrossorigin({
inject: true
})
]
// 处理按需加载的 js 添加跨域标识
output: {
crossOriginLoading: true
}
大多数场景下,生产环境中的代码都是压缩合并的,这使得我们抓到的错误很难映射到具体的源码中,给我们解决问题带来了很大的麻烦。这里有两个解决方案。想法。
在生产环境中,我们需要添加sourceMap的配置,这样会带来安全隐患,因为这样外网可以通过sourceMap进行source map的映射。为了降低风险,我们可以做到以下几点:
此时,我们已经有了 .map 文件。接下来我们需要做的就是通过捕获的lineno、colno、url调用mozilla/source-map库进行源码映射,然后就可以得到真正的源码错误信息了。
表现
性能指标的获取比较简单,在onload之后读取window.performance就可以了,里面收录了性能、内存等信息。这部分内容在很多现有的文章中都有介绍。由于篇幅所限,本文不再过多展开。稍后,我们将在相关主题文章中进行相关讨论。感兴趣的朋友可以添加“马蜂窝技术”公众号继续关注。
资源错误
首先,我们需要明确资源错误捕获的使用场景,更多的是感知DNS劫持和CDN节点异常等,具体方法如下:
window.addEventListener('error', function (e) {
var target = e.target || e.srcElement;
if (target instanceof HTMLScriptElement) {
// 上报 【资源错误】事件
}
}, true)
这只是一个基本的演示。在实际环境中,我们会关心更多的Element错误,比如css、img、woff等,大家可以根据不同的场景添加。
*资源错误的使用场景更多地依赖于其他维度,例如:地区、运营商等,我们将在后面的页面中详细解释。
API
在市面上的主流框架(如axios、jQuery.ajax等)中,基本上所有的API请求都是基于xmlHttpRequest或者fetch,所以捕获全局接口错误的方式就是封装xmlHttpRequest或者fetch。在这里,我们的SDK还是使用了上面提到的AOP思想来拦截API。 查看全部
文章采集api(搭建一套前端监控平台需要考虑的几个问题?|本文)
随着业务的快速发展,我们越来越重视对生产环境问题的感知能力。作为离用户最近的一层,前端性能是否可靠、稳定、好用在很大程度上决定了用户对整个产品的体验和感受。因此,前端的监控也不容忽视。
搭建前端监控平台需要考虑很多方面,比如数据采集、埋藏模式、数据处理分析、告警、监控平台在具体业务中的应用等等。在所有这些环节中、准确、完整、全面的数据采集是一切的前提,也为用户后续的精细化运营提供了依据。
前端技术的飞速发展给数据带来了变化和挑战采集,传统的人工管理模式已经不能满足需求。如何让前端数据采集在新的技术背景下工作更加完整高效是本文的重点。
前端监控数据采集
在采集数据之前,考虑一下采集什么样的数据。我们关注两类数据,一类与用户体验相关,如首屏时间、文件加载时间、页面性能等;另一个是帮助我们及时感知产品上线后是否出现异常,比如资源错误、API响应时间等。具体来说,我们的前端数据采集主要分为:
路由交换机
Vue、React、Angular等前端技术的快速发展,使得单页应用流行起来。我们都知道,传统的页面应用使用一些超链接来实现页面切换和跳转,而单页面应用使用自己的路由系统来管理各个前端页面切换,比如vue-router、react-router等,只有跳转时刷新本地资源,js、css等公共资源只需加载一次,使得传统的网页进出方式只有在第一次打开时才会被记录。在单页应用中切换所有后续路由有两种方式,一种是Hash,另一种是HTML5推出的History API。
1. 链接
href是页面初始化的第一个入口,这里只需要简单的报告“进入页面”事件。
2. 哈希变化
哈希路由的一个明显标志是带有“#”。Hash的优点是兼容性更好,但问题是URL中的“#”不美观。我们主要通过监听 URL 中的 hashchange 来捕获具体的 hash 值进行检测。
window.addEventListener('hashchange', function() {
// 上报【进入页面】事件
}, true)
需要注意的是,如果浏览器在新版本的vue-router中支持history,即使模式选择hash,也会先选择history模式。虽然表达式暂时还是#,但实际上是模拟出来的,所以不要以为你在如果模式选择hash,那肯定是hash。
3. 历史 API
History利用HTML5 History接口中新增的pushState()和replaceState()方法进行路由切换,是目前主流的非刷新切换路由方式。与 hashchange 只能更改 # 后面的代码片段相比,History API(pushState、replaceState)给了前端完全的自由。
PopState 是浏览器返回事件的回调,但是更新路由的 pushState 和 replaceState 没有回调事件。因此,URL 更改需要分别在 history.pushState() 和 history.replaceState() 方法中处理。在这里,我们使用类似Java的AOP编程思想来改造pushState和replaceState。
AOP(Aspect-oriented programming)是面向方面的编程,它提倡对同一类型的问题进行统一处理。AOP的核心思想是让某个模块能够被复用。它采用横向抽取机制,将功能代码与业务逻辑代码分离,在不修改源代码的情况下扩展功能。与封装相比,隔离更彻底。
下面介绍我们具体的改造方法:
// 第一阶段:我们对原生方法进行包装,调用前执行 dispatchEvent 了一个同样的事件
function aop (type) {
var source = window.history[type];
return function () {
var event = new Event(type);
event.arguments = arguments;
window.dispatchEvent(event);
var rewrite = source.apply(this, arguments);
return rewrite;
};
}
// 第二阶段:将 pushState 和 replaceState 进行基于 AOP 思想的代码注入
window.history.pushState = aop('pushState');
window.history.replaceState = aop('replaceState'); // 更改路由,不会留下历史记录
// 第三阶段:捕获pushState 和 replaceState
window.addEventListener('pushState', function() {
// 上报【进入页面】事件
}, true)
window.addEventListener('replaceState', function() {
// 上报【进入页面】事件
}, true)
window.history.pushState的实际调用关系如图:
至此,我们完成了pushState和replaceState的转换,实现了路由切换的有效抓包。可以看出,我们在不侵入业务代码的情况下扩展了window.history.pushState,调用时会主动dispatchEvent一个pushState。
但是这里我们也可以看到一个缺点,就是如果AOP代理函数出现JS错误,会阻塞后续的调用关系,从而无法调用实际的window.history.pushState。因此,在使用该方法时,需要对AOP代理功能的内容进行一次完整的try catch,以防止出现业务异常。
*提示:如果要自动捕捉页面停留时间,只需在触发下一页进入事件时,将上一页的时间与当前时间做个差值即可。这时候可以上报【离开页面】事件。
错误
在前端项目中,由于 JavaScript 本身是一种弱类型语言,再加上浏览器环境的复杂性、网络问题等,很容易出现错误。因此,做好网页错误监控,不断优化代码,提高代码的健壮性是非常重要的。
JsError的捕获可以帮助我们分析和监控在线问题,和我们在Chrome浏览器的调试工具Console中看到的一致。
1. 窗口.onerror
我们通常使用 window.onerror 来捕获 JS 错误的异常信息。有两种方法可以捕获 JS 错误,window.onerror 和 window.addEventListener('error')。一般不建议使用 addEventListener('error') 来捕获 JS 异常,主要是它没有堆栈信息,而且还需要区分捕获的信息,因为它会捕获所有的异常信息,包括资源加载错误. 等待。
window.onerror = function (msg, url, lineno, colno, stack) {
// 上报 【js错误】事件
}
2. 未被抓住(承诺)
当 Promise 发生 JS 错误或者业务没有处理拒绝信息时,会抛出 unhandledrejection,并且这个错误不会被 window.onerror 和 window.addEventListener('error') 这个特殊的窗口捕获。addEventListener('unhandledrejection') 用于捕获处理:
window.addEventListener('unhandledrejection', function (e) {
var reg_url = /\(([^)]*)\)/;
var fileMsg = e.reason.stack.split('\n')[1].match(reg_url)[1];
var fileArr = fileMsg.split(':');
var lineno = fileArr[fileArr.length - 2];
var colno = fileArr[fileArr.length - 1];
var url = fileMsg.slice(0, -lno.length - cno.length - 2);}, true);
var msg = e.reason.message;
// 上报 【js错误】事件
}
我们注意到unhandledrejection继承自PromiseRejectionEvent,而PromiseRejectionEvent继承自Event,所以msg、url、lineno、colno、stack以字符串的形式放在e.reason.stack中,我们需要将上面的参数解析出来与onerror参数对齐,为后续监测平台各项指标的统一奠定了基础。
3. 常见问题
如果抓到的msg都是“Script error.”,问题是你的JS地址和当前网页不在同一个域下。因为我们经常需要对网络版的静态资源进行CDN,会导致经常访问的页面和脚本文件来自不同的域名。这时候如果不进行额外配置,浏览器很容易出现“脚本错误”。出于安全考虑。我们可以利用当前流行的 Webpack bundler 来处理此类问题。
// webpack config 配置
// 处理 html 注入 js 添加跨域标识
plugins: [
new HtmlWebpackPlugin({
filename: 'html/index.html',
template: HTML_PATH,
attributes: {
crossorigin: 'anonymous'
}
}),
new HtmlWebpackPluginCrossorigin({
inject: true
})
]
// 处理按需加载的 js 添加跨域标识
output: {
crossOriginLoading: true
}
大多数场景下,生产环境中的代码都是压缩合并的,这使得我们抓到的错误很难映射到具体的源码中,给我们解决问题带来了很大的麻烦。这里有两个解决方案。想法。
在生产环境中,我们需要添加sourceMap的配置,这样会带来安全隐患,因为这样外网可以通过sourceMap进行source map的映射。为了降低风险,我们可以做到以下几点:
此时,我们已经有了 .map 文件。接下来我们需要做的就是通过捕获的lineno、colno、url调用mozilla/source-map库进行源码映射,然后就可以得到真正的源码错误信息了。
表现
性能指标的获取比较简单,在onload之后读取window.performance就可以了,里面收录了性能、内存等信息。这部分内容在很多现有的文章中都有介绍。由于篇幅所限,本文不再过多展开。稍后,我们将在相关主题文章中进行相关讨论。感兴趣的朋友可以添加“马蜂窝技术”公众号继续关注。
资源错误
首先,我们需要明确资源错误捕获的使用场景,更多的是感知DNS劫持和CDN节点异常等,具体方法如下:
window.addEventListener('error', function (e) {
var target = e.target || e.srcElement;
if (target instanceof HTMLScriptElement) {
// 上报 【资源错误】事件
}
}, true)
这只是一个基本的演示。在实际环境中,我们会关心更多的Element错误,比如css、img、woff等,大家可以根据不同的场景添加。
*资源错误的使用场景更多地依赖于其他维度,例如:地区、运营商等,我们将在后面的页面中详细解释。
API
在市面上的主流框架(如axios、jQuery.ajax等)中,基本上所有的API请求都是基于xmlHttpRequest或者fetch,所以捕获全局接口错误的方式就是封装xmlHttpRequest或者fetch。在这里,我们的SDK还是使用了上面提到的AOP思想来拦截API。

