
文章采集api
文章采集api(数据具体的采集方案是什么?四种数据采集方法对比)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-01-21 21:13
根据企业在生产和管理过程中会产生的数据类型,提供链接标记、SDK和API三种采集方法,以及基于UTSE数据采集模型对用户的整个生命周期。
那么,数据的具体采集计划是什么?
四种数据采集方法对比
Data采集是通过埋点实现的。诸葛io提供了非常完善的数据访问解决方案,支持代码埋、全埋、可视埋、服务器埋等数据采集方式。
1.代码被埋没
说明:嵌入SDK定义事件和添加事件代码是一种常用的数据采集方法,主要包括网页和h5页面的JS嵌入、移动端的iOS和Android嵌入、微信小程序等。
优点:按需采集,业务信息更全,数据分析更专注,数据采集全面准确,便于后续深入分析。
缺点:需要研发人员配合,有一定的工作量。
2.全葬
说明:通过SDK自动采集页面所有可点击元素的操作数据,无需定义事件,适用于活动页面、登陆页面、关键页面的设计体验测量。
优点:更简单快捷,可以看到页面元素的点击量,更好的了解自己的产品特点。
缺点:采集的数据太多,只要是可点击的元素,就会是采集,上传数据很多,消耗流量很大。无法采集到更深层次的维度信息,比如事件的属性、用户的属性等。
3.可视化埋点
注意:视觉嵌入是基于完整嵌入的。技术同事整合后,业务同事需要圈出页面的元素,选中的元素会是采集。
优点:基于接口配置,无需开发,易于更新,快速生效。
缺点:自定义属性的支持范围比较有限;重构或页面更改时需要重新配置。
4.服务器埋点
说明:通过API对存储在服务器上的数据进行结构化处理,通过接口调用其他业务数据采集和集成,比如CRM等用户数据,对数据进行结构化处理,即适合拥有 采集 @采集 能力客户端的用户。
优点:服务端embedding更有针对性,数据更准确,减少编码embedding的发布过程,数据上传更及时。
缺点:用户的一些简单操作,比如点击按钮、切换模块,这些数据不能采集,用户行为不够完整。
总结:以上是诸葛io提供的四种data采集解决方案:code embedding、full embedding、visual embedding、server embedding,data采集目的是为了满足采集详细分析和操作然后执行需求。只有能够达到这个目标,才有可能选择一种或多种采集形式的组合。在企业业务中,选择哪种采集方式要根据企业自身的具体业务需求来决定。 查看全部
文章采集api(数据具体的采集方案是什么?四种数据采集方法对比)
根据企业在生产和管理过程中会产生的数据类型,提供链接标记、SDK和API三种采集方法,以及基于UTSE数据采集模型对用户的整个生命周期。
那么,数据的具体采集计划是什么?
四种数据采集方法对比
Data采集是通过埋点实现的。诸葛io提供了非常完善的数据访问解决方案,支持代码埋、全埋、可视埋、服务器埋等数据采集方式。
1.代码被埋没
说明:嵌入SDK定义事件和添加事件代码是一种常用的数据采集方法,主要包括网页和h5页面的JS嵌入、移动端的iOS和Android嵌入、微信小程序等。
优点:按需采集,业务信息更全,数据分析更专注,数据采集全面准确,便于后续深入分析。
缺点:需要研发人员配合,有一定的工作量。
2.全葬
说明:通过SDK自动采集页面所有可点击元素的操作数据,无需定义事件,适用于活动页面、登陆页面、关键页面的设计体验测量。
优点:更简单快捷,可以看到页面元素的点击量,更好的了解自己的产品特点。
缺点:采集的数据太多,只要是可点击的元素,就会是采集,上传数据很多,消耗流量很大。无法采集到更深层次的维度信息,比如事件的属性、用户的属性等。
3.可视化埋点
注意:视觉嵌入是基于完整嵌入的。技术同事整合后,业务同事需要圈出页面的元素,选中的元素会是采集。
优点:基于接口配置,无需开发,易于更新,快速生效。
缺点:自定义属性的支持范围比较有限;重构或页面更改时需要重新配置。
4.服务器埋点
说明:通过API对存储在服务器上的数据进行结构化处理,通过接口调用其他业务数据采集和集成,比如CRM等用户数据,对数据进行结构化处理,即适合拥有 采集 @采集 能力客户端的用户。
优点:服务端embedding更有针对性,数据更准确,减少编码embedding的发布过程,数据上传更及时。
缺点:用户的一些简单操作,比如点击按钮、切换模块,这些数据不能采集,用户行为不够完整。
总结:以上是诸葛io提供的四种data采集解决方案:code embedding、full embedding、visual embedding、server embedding,data采集目的是为了满足采集详细分析和操作然后执行需求。只有能够达到这个目标,才有可能选择一种或多种采集形式的组合。在企业业务中,选择哪种采集方式要根据企业自身的具体业务需求来决定。
文章采集api(猫眼电影API接口(从猫眼电影网爬取爬取)开源版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 289 次浏览 • 2022-01-21 17:10
API(ApplicationProgrammingInterface,应用程序编程接口)是一组用来控制Windows的组件(从桌面的外观看。
猫眼电影API接口(从猫眼电影网爬取) Hope771:热门电影:request to total=20,但是movieList只有12个,怎么再获取8个数据?猫眼电影API接口(从猫眼电影网爬取) 刘子凡 11:有没有选座。vscode:Windows 找不到文件“chrome”。请确保文件名正确,然后重试。
智云影视资源开源版简介采集V1.1:采集全网各大资源网(各资源站的飞飞接口地址基本通用) 不是 采集360 。
添加采集网站的接口地址并命名,接口类型选择xml,资源类型选择video。然后选择测试,如图表示成功,保存。保存。
根据电影名称,获取资源链接,并且必须兼容自己的QQ电影资源机器人,根据电影。
最近在做微信小程序“豆瓣电影”。当我尝试调用豆瓣API的时候,发现官方的豆瓣API已经不再对外开放了。在网上找了很多博客,找到了一些解决办法。本来想直接新建一个服务器,但是服务器的价格对学生党不友好,所以用另一种界面解决了:有的老板自己配置了服务器,恢复了官方界面。用作。
网站api域名授权码,我有一个电影资源网站,我想实现域名授权采集,谁能帮忙写代码?一共1个回答。
很多朋友都说要建电影网站,大家都知道电影资源去某影视资源网找接口。首先苹果cms的采集接口api是。 查看全部
文章采集api(猫眼电影API接口(从猫眼电影网爬取爬取)开源版)
API(ApplicationProgrammingInterface,应用程序编程接口)是一组用来控制Windows的组件(从桌面的外观看。
猫眼电影API接口(从猫眼电影网爬取) Hope771:热门电影:request to total=20,但是movieList只有12个,怎么再获取8个数据?猫眼电影API接口(从猫眼电影网爬取) 刘子凡 11:有没有选座。vscode:Windows 找不到文件“chrome”。请确保文件名正确,然后重试。
智云影视资源开源版简介采集V1.1:采集全网各大资源网(各资源站的飞飞接口地址基本通用) 不是 采集360 。

添加采集网站的接口地址并命名,接口类型选择xml,资源类型选择video。然后选择测试,如图表示成功,保存。保存。
根据电影名称,获取资源链接,并且必须兼容自己的QQ电影资源机器人,根据电影。

最近在做微信小程序“豆瓣电影”。当我尝试调用豆瓣API的时候,发现官方的豆瓣API已经不再对外开放了。在网上找了很多博客,找到了一些解决办法。本来想直接新建一个服务器,但是服务器的价格对学生党不友好,所以用另一种界面解决了:有的老板自己配置了服务器,恢复了官方界面。用作。
网站api域名授权码,我有一个电影资源网站,我想实现域名授权采集,谁能帮忙写代码?一共1个回答。
很多朋友都说要建电影网站,大家都知道电影资源去某影视资源网找接口。首先苹果cms的采集接口api是。
文章采集api(苹果cms采集视频可以在后台联盟资源库里直接设置采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2022-01-16 18:06
苹果cms采集视频可以直接在后台联盟资源库中设置采集,也可以配置自己自定义的采集库,关于文章信息采集,Applecms后台没有专门的采集库,所以文章采集我们需要添加采集@ > 自己接口,或者是使用第三方采集工具,不懂代码的小白完全不知道。前期,目前80%的影视站都是靠采集来扩充自己的视频库,比如之前的大站电影天堂、BT站等最新电影的下载。这一切都始于 采集。先丰富视频源再做网站收录,网站收录是由文章信息驱动的。今天我们将介绍使用免费的自动采集发布工具来让Apple cms网站启动并运行!
由于各种视频站的兴起,cms模板泛滥。大量的网站模板都是类似的。除了 采集 规则外,视频站的内容是重复的。多年来,我一直是视频站的老手。车站会叹息! “苹果cms采集电视台越来越难做”,各大搜索引擎收录越来越少。如果依赖cms自带的采集功能,就很难提升了。视频站无非就是一个标题、内容和内容介绍。苹果80%的cms站都是这样的结构,我们该怎么办?为了在众多影视台中脱颖而出?
一、苹果cms网站怎么样原创?
1、标题选择插入品牌词
2、播放的集数(例如:第一集改为在线第一集)
3、剧情简介(插入关键词,采集电影介绍)
4、依靠SEO技术提升网站原创度
SEO 优化可访问性设置:
1、标题前缀和后缀设置(标题的区别更好收录)
2、内容关键词插入(合理增加关键词密度)
3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后主动推送文章到搜索引擎,保证新链接能够被搜索引擎收录及时搜索到)
5、随机点赞-随机阅读-随机作者(增加页面原创度数)
6、内容与标题一致(使内容与标题100%相关)
7、自动内链(在执行发布任务时自动在文章内容中生成内链,帮助引导页面蜘蛛抓取,提高页面权重)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期抓取网页的习惯,从而提升网站的收录)
9、设置批量发布数量(可以设置发布间隔/单日发布总数)
10、可以设置不同的类型发布不同的栏目
11、工具设置锁定词(文章原创文章可读性和核心词不会原创时自动锁定品牌词和产品词)
12、工具还可以批量管理不同的cms网站数据(无论你的网站是Empire, Yiyou, ZBLOG, 织梦, WP,小旋风、站群、PB、Apple、搜外等各大cms电影网站,都可以同时管理和批量发布)
二、苹果cms采集设置
1、只需输入核心关键词,软件会自动生成下拉词、相关搜索词、长尾词,并自动过滤不相关的关键词核心关键词。全自动采集,可同时创建数十个或数百个采集任务(一个任务可支持上传1000个关键词),可同时执行多域任务时间!
2、自动过滤文章已经是采集的,
3、多平台支持采集(资讯、问答、视频频道、电影频道等)
4、可设置关键词采集文章条数,软件可直接查看多任务状态采集-支持本地预览-支持采集链接预览
5、自动批量挂机采集,无缝连接各大cms出版商,采集自动发帖推送到搜索引擎
以上是我个人测试后发现非常有用的所有内容。 文章采集工具与 Apple 的cms自己的数据源采集 无缝协作!目前网站交通还不错!看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力! 查看全部
文章采集api(苹果cms采集视频可以在后台联盟资源库里直接设置采集)
苹果cms采集视频可以直接在后台联盟资源库中设置采集,也可以配置自己自定义的采集库,关于文章信息采集,Applecms后台没有专门的采集库,所以文章采集我们需要添加采集@ > 自己接口,或者是使用第三方采集工具,不懂代码的小白完全不知道。前期,目前80%的影视站都是靠采集来扩充自己的视频库,比如之前的大站电影天堂、BT站等最新电影的下载。这一切都始于 采集。先丰富视频源再做网站收录,网站收录是由文章信息驱动的。今天我们将介绍使用免费的自动采集发布工具来让Apple cms网站启动并运行!

由于各种视频站的兴起,cms模板泛滥。大量的网站模板都是类似的。除了 采集 规则外,视频站的内容是重复的。多年来,我一直是视频站的老手。车站会叹息! “苹果cms采集电视台越来越难做”,各大搜索引擎收录越来越少。如果依赖cms自带的采集功能,就很难提升了。视频站无非就是一个标题、内容和内容介绍。苹果80%的cms站都是这样的结构,我们该怎么办?为了在众多影视台中脱颖而出?
一、苹果cms网站怎么样原创?
1、标题选择插入品牌词
2、播放的集数(例如:第一集改为在线第一集)
3、剧情简介(插入关键词,采集电影介绍)
4、依靠SEO技术提升网站原创度
SEO 优化可访问性设置:
1、标题前缀和后缀设置(标题的区别更好收录)
2、内容关键词插入(合理增加关键词密度)
3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后主动推送文章到搜索引擎,保证新链接能够被搜索引擎收录及时搜索到)
5、随机点赞-随机阅读-随机作者(增加页面原创度数)
6、内容与标题一致(使内容与标题100%相关)
7、自动内链(在执行发布任务时自动在文章内容中生成内链,帮助引导页面蜘蛛抓取,提高页面权重)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期抓取网页的习惯,从而提升网站的收录)
9、设置批量发布数量(可以设置发布间隔/单日发布总数)
10、可以设置不同的类型发布不同的栏目
11、工具设置锁定词(文章原创文章可读性和核心词不会原创时自动锁定品牌词和产品词)
12、工具还可以批量管理不同的cms网站数据(无论你的网站是Empire, Yiyou, ZBLOG, 织梦, WP,小旋风、站群、PB、Apple、搜外等各大cms电影网站,都可以同时管理和批量发布)
二、苹果cms采集设置
1、只需输入核心关键词,软件会自动生成下拉词、相关搜索词、长尾词,并自动过滤不相关的关键词核心关键词。全自动采集,可同时创建数十个或数百个采集任务(一个任务可支持上传1000个关键词),可同时执行多域任务时间!
2、自动过滤文章已经是采集的,
3、多平台支持采集(资讯、问答、视频频道、电影频道等)
4、可设置关键词采集文章条数,软件可直接查看多任务状态采集-支持本地预览-支持采集链接预览
5、自动批量挂机采集,无缝连接各大cms出版商,采集自动发帖推送到搜索引擎
以上是我个人测试后发现非常有用的所有内容。 文章采集工具与 Apple 的cms自己的数据源采集 无缝协作!目前网站交通还不错!看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
文章采集api(Python标准库之外的第三方库(一)库工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-12 17:00
上一期我们讲解了数据归一化的相关内容。首先对词的频率进行排序,然后转换一些大小写以减少 2-gram 序列的重复内容。
当我们真正走出网络数据基础采集的大门时,我们可能会遇到的第一个问题是:“如何获取登录窗口背后的信息?” 如今,网络正朝着页面交互、社交网络媒体、用户生成内容的趋势不断发展。表单和登录窗口是许多 网站 的组成部分。但是,这些都相对容易处理。
到目前为止,在前面的示例中,当网络爬虫与大多数 网站 服务器交互时,它们使用 HTTP 协议的 GET 方法来请求信息。在本文文章中,我们重点介绍POST方法,它将信息推送到Web服务器进行存储和分析。
页面表单基本上可以看成是用户提交POST请求的一种方式,但是这种请求方式是被服务器理解和使用的。正如 网站 URL 链接帮助用户发出 GET 请求一样,HTML 表单帮助用户发出 POST 请求。当然,我们也可以用一点点麻麻自己创建这些请求,然后通过网络爬虫提交给服务器。
Python 请求库
虽然可以使用 Python 标准库控制 Web 表单,但有时一点语法糖可以让生活更甜蜜。但是当你想要做的不仅仅是 urllib 可以做的基本 GET 请求时,请查看 Python 标准库之外的第三方库。
Requests库就是这样一个Python第三方库,擅长处理复杂的HTTP请求、cookies、headers(响应头和请求头)等。
以下是 Requests 创建者 Kenneth Retiz 对 Python 标准库工具的评价:
Python 标准库 urllib2 为您提供了大部分 HTTP 功能,但它的 API 很差。这是因为它是多年来一步步建立起来的——不同的时代要面对不同的网络环境。所以为了完成最简单的任务,他需要花费大量的工作(甚至写完整的方法)。
事情不应该这么复杂,也不应该发生在 Python 中。
与任何第三方 Python 库一样,Requests 库也可以与其他第三方 Python 库管理器(例如 pip)一起安装,或者直接下载 Requests 库源代码。
提交基本表格
大多数 Web 表单由一些 HTML 字段、一个提交按钮和一个“结果”(表单操作的值)页面组成,该页面在表单处理完毕后跳转。虽然这些 HTML 字段通常由文本内容组成,但也可以实现文件上传或其他非文本内容。
因为大部分主流网站都会在他们的robots.txt文件中注明禁止爬虫访问登录表单,相关介绍可以参考这篇文章:爬虫系列:爬虫带来的道德风险和法律责任。
例如,这里是一个表单的源代码:
用户名
密码
这里有几点需要注意:首先,两个输入字段命名为 username 和 passwd 很重要。字段的名称决定了表单验证后将发送到服务器的变量名称。如果你想模拟从表单提交数据的行为,你需要确保你的变量名与字段名相对应。
还要求表单的实际行为实际发生在 index.php?c=session&a=login 中。对表单的任何 POST 请求实际上都发生在此页面上,而不是表单本身所在的页面上。请记住:HTML 表单的目的只是为了帮助 网站 的访问者向服务器发送格式正确的请求以获取未出现的页面。除非您正在研究请求的设计风格,否则不要在表单所在的页面上花费太多时间。
使用 Requests 库提交表单只需几行代码即可完成,包括导入库文件和打印内容的语句:
import requests
params = {'username': 'admin', 'passwd': '5e_KR&pXJ9=J(c7d9P-twt9:'}
r = requests.post("http://www.test.com/admin/inde ... ot%3B, data=params)
print(r.text)
表单提交后,程序返回执行页面的源码,如下:
您的浏览器不支持框架!
由于我们通过Requests提交了内容,并没有在浏览器中提交,所以会出现上面的提示,但是我们已经登录成功了。后面我们需要用到浏览器采集的内容时,我们会详细介绍这部分。
这边的代码可以处理很多简单的表格。以下是邮件订阅的表单代码,如下:
Marketing
Email Address
虽然第一次看到有点吓人,但大多数情况下我们只需要关注两件事:
单选按钮、复选按钮和其他输入
显然,并非所有页面都只是一堆文本字段和一个提交按钮。HTML 标准提供了大量可用的表单字段:单选按钮、复选按钮、下拉选项等。在 HTML5 中,还有其他控件,如滚动条(范围输入字段)、邮箱、日期等。自定义 Javascript 字段是无所不能的,实现了颜色选择器、日历以及开发人员能想到的任何东西。
无论表单的字段看起来多么复杂,仍然只有两件事需要关心:字段名称和值。字段名可以通过查看源码,查找name属性轻松获取。字段值有时比较复杂,可能在表单提交之前由Javascript生成。颜色选择器是一个奇怪的表单字段,它可能使用像 #f5c26b 这样的值。
如果您不确定输入字段值的数据格式,有一些工具可以跟踪浏览器通过 网站 发出或接收的 GET 和 POST 请求的内容。如前所述,跟踪 GET 请求的最佳和最直接的方法是查看 网站 URL 链接,如果 URL 链接如下所示:
https://pdf-lib.org/Home/Searc ... abbix
那么请求的表单可能如下所示:
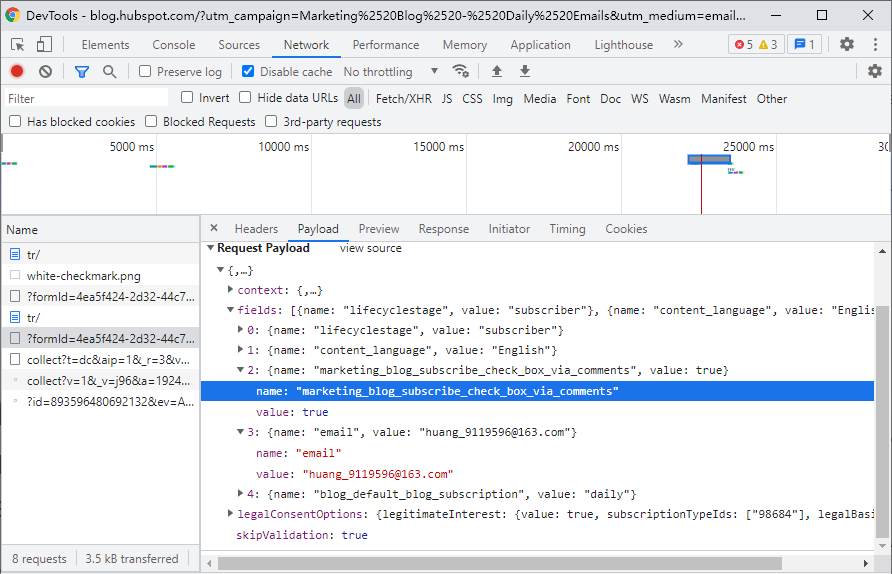
下面是一个更复杂的表单提交示例:
如果您遇到一个看起来很复杂的 POST 表单,并且看起来浏览器正在将这些参数传递给服务器,那么最简单的方法是使用 Chrome 的检查器或开发人员工具。
总结
由于篇幅原因,今天只讲解基本的表单、单选按钮、复选框等表单输入,以及如何通过Requests提交给服务器。
在下一篇文章 文章 中,我们将介绍提交文件、图像、处理登录、cookie、HTTP 基本访问身份验证以及其他与表单相关的问题。
源代码已托管在 Github 上:
如果您有任何问题,欢迎提出。 查看全部
文章采集api(Python标准库之外的第三方库(一)库工具)
上一期我们讲解了数据归一化的相关内容。首先对词的频率进行排序,然后转换一些大小写以减少 2-gram 序列的重复内容。
当我们真正走出网络数据基础采集的大门时,我们可能会遇到的第一个问题是:“如何获取登录窗口背后的信息?” 如今,网络正朝着页面交互、社交网络媒体、用户生成内容的趋势不断发展。表单和登录窗口是许多 网站 的组成部分。但是,这些都相对容易处理。
到目前为止,在前面的示例中,当网络爬虫与大多数 网站 服务器交互时,它们使用 HTTP 协议的 GET 方法来请求信息。在本文文章中,我们重点介绍POST方法,它将信息推送到Web服务器进行存储和分析。
页面表单基本上可以看成是用户提交POST请求的一种方式,但是这种请求方式是被服务器理解和使用的。正如 网站 URL 链接帮助用户发出 GET 请求一样,HTML 表单帮助用户发出 POST 请求。当然,我们也可以用一点点麻麻自己创建这些请求,然后通过网络爬虫提交给服务器。
Python 请求库
虽然可以使用 Python 标准库控制 Web 表单,但有时一点语法糖可以让生活更甜蜜。但是当你想要做的不仅仅是 urllib 可以做的基本 GET 请求时,请查看 Python 标准库之外的第三方库。
Requests库就是这样一个Python第三方库,擅长处理复杂的HTTP请求、cookies、headers(响应头和请求头)等。
以下是 Requests 创建者 Kenneth Retiz 对 Python 标准库工具的评价:
Python 标准库 urllib2 为您提供了大部分 HTTP 功能,但它的 API 很差。这是因为它是多年来一步步建立起来的——不同的时代要面对不同的网络环境。所以为了完成最简单的任务,他需要花费大量的工作(甚至写完整的方法)。
事情不应该这么复杂,也不应该发生在 Python 中。
与任何第三方 Python 库一样,Requests 库也可以与其他第三方 Python 库管理器(例如 pip)一起安装,或者直接下载 Requests 库源代码。
提交基本表格
大多数 Web 表单由一些 HTML 字段、一个提交按钮和一个“结果”(表单操作的值)页面组成,该页面在表单处理完毕后跳转。虽然这些 HTML 字段通常由文本内容组成,但也可以实现文件上传或其他非文本内容。
因为大部分主流网站都会在他们的robots.txt文件中注明禁止爬虫访问登录表单,相关介绍可以参考这篇文章:爬虫系列:爬虫带来的道德风险和法律责任。
例如,这里是一个表单的源代码:
用户名
密码
这里有几点需要注意:首先,两个输入字段命名为 username 和 passwd 很重要。字段的名称决定了表单验证后将发送到服务器的变量名称。如果你想模拟从表单提交数据的行为,你需要确保你的变量名与字段名相对应。
还要求表单的实际行为实际发生在 index.php?c=session&a=login 中。对表单的任何 POST 请求实际上都发生在此页面上,而不是表单本身所在的页面上。请记住:HTML 表单的目的只是为了帮助 网站 的访问者向服务器发送格式正确的请求以获取未出现的页面。除非您正在研究请求的设计风格,否则不要在表单所在的页面上花费太多时间。
使用 Requests 库提交表单只需几行代码即可完成,包括导入库文件和打印内容的语句:
import requests
params = {'username': 'admin', 'passwd': '5e_KR&pXJ9=J(c7d9P-twt9:'}
r = requests.post("http://www.test.com/admin/inde ... ot%3B, data=params)
print(r.text)
表单提交后,程序返回执行页面的源码,如下:
您的浏览器不支持框架!
由于我们通过Requests提交了内容,并没有在浏览器中提交,所以会出现上面的提示,但是我们已经登录成功了。后面我们需要用到浏览器采集的内容时,我们会详细介绍这部分。
这边的代码可以处理很多简单的表格。以下是邮件订阅的表单代码,如下:
Marketing
Email Address
虽然第一次看到有点吓人,但大多数情况下我们只需要关注两件事:
单选按钮、复选按钮和其他输入
显然,并非所有页面都只是一堆文本字段和一个提交按钮。HTML 标准提供了大量可用的表单字段:单选按钮、复选按钮、下拉选项等。在 HTML5 中,还有其他控件,如滚动条(范围输入字段)、邮箱、日期等。自定义 Javascript 字段是无所不能的,实现了颜色选择器、日历以及开发人员能想到的任何东西。
无论表单的字段看起来多么复杂,仍然只有两件事需要关心:字段名称和值。字段名可以通过查看源码,查找name属性轻松获取。字段值有时比较复杂,可能在表单提交之前由Javascript生成。颜色选择器是一个奇怪的表单字段,它可能使用像 #f5c26b 这样的值。
如果您不确定输入字段值的数据格式,有一些工具可以跟踪浏览器通过 网站 发出或接收的 GET 和 POST 请求的内容。如前所述,跟踪 GET 请求的最佳和最直接的方法是查看 网站 URL 链接,如果 URL 链接如下所示:
https://pdf-lib.org/Home/Searc ... abbix
那么请求的表单可能如下所示:
下面是一个更复杂的表单提交示例:
如果您遇到一个看起来很复杂的 POST 表单,并且看起来浏览器正在将这些参数传递给服务器,那么最简单的方法是使用 Chrome 的检查器或开发人员工具。
总结
由于篇幅原因,今天只讲解基本的表单、单选按钮、复选框等表单输入,以及如何通过Requests提交给服务器。
在下一篇文章 文章 中,我们将介绍提交文件、图像、处理登录、cookie、HTTP 基本访问身份验证以及其他与表单相关的问题。
源代码已托管在 Github 上:
如果您有任何问题,欢迎提出。
文章采集api(基于百度地图API的门店信息搜集系统的互联网应用成果)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-01-11 05:17
摘要:互联网的快速发展为互联网的各种应用提供了强大的技术支撑,网络地图服务作为一项基础服务应运而生。随着我国科技水平逐步接近国际先进水平,手机移动互联网呈现快速发展趋势,基于网络地图服务的互联网应用被认为是互联网行业的下一个宝地。百度地图API是一套基于百度地图服务的应用接口,免费提供给开发者。功能非常强大,满足地图应用开发的需要。据统计,基于百度地图API的网络应用数量已超过100万。而基于百度地图API的各种Web应用结果表明,百度地图API可以解决Web地图应用开发中遇到的数据源问题,可以降低企业的开发成本,具有广阔的发展前景。根据“基于百度地图API的店铺信息采集系统”课题,结合当前企业业务销售市场对业务相关店铺信息的需求和垂直搜索引擎的专业特点,“京商传媒店铺信息采集系统” 《系统》在实际项目的背景下,基于百度地图提供的开放式JavaScript API,实现了一个业务相关的店铺信息采集系统。系统的主要功能是采集企业业务销售市场中与业务相关的店铺信息,然后将其结构化提取并存储在企业数据库中,并提供检索和导出到Excel的功能。另外,业务员验证店铺信息并反馈给管理员,管理员更新数据库中的店铺信息。对该系统进行了功能和性能测试,测试结果表明该系统达到了预期的功能效果,性能平稳。业务员验证店铺信息并反馈给管理员,管理员更新数据库中的店铺信息。对该系统进行了功能和性能测试,测试结果表明该系统达到了预期的功能效果,性能平稳。业务员验证店铺信息并反馈给管理员,管理员更新数据库中的店铺信息。对该系统进行了功能和性能测试,测试结果表明该系统达到了预期的功能效果,性能平稳。 查看全部
文章采集api(基于百度地图API的门店信息搜集系统的互联网应用成果)
摘要:互联网的快速发展为互联网的各种应用提供了强大的技术支撑,网络地图服务作为一项基础服务应运而生。随着我国科技水平逐步接近国际先进水平,手机移动互联网呈现快速发展趋势,基于网络地图服务的互联网应用被认为是互联网行业的下一个宝地。百度地图API是一套基于百度地图服务的应用接口,免费提供给开发者。功能非常强大,满足地图应用开发的需要。据统计,基于百度地图API的网络应用数量已超过100万。而基于百度地图API的各种Web应用结果表明,百度地图API可以解决Web地图应用开发中遇到的数据源问题,可以降低企业的开发成本,具有广阔的发展前景。根据“基于百度地图API的店铺信息采集系统”课题,结合当前企业业务销售市场对业务相关店铺信息的需求和垂直搜索引擎的专业特点,“京商传媒店铺信息采集系统” 《系统》在实际项目的背景下,基于百度地图提供的开放式JavaScript API,实现了一个业务相关的店铺信息采集系统。系统的主要功能是采集企业业务销售市场中与业务相关的店铺信息,然后将其结构化提取并存储在企业数据库中,并提供检索和导出到Excel的功能。另外,业务员验证店铺信息并反馈给管理员,管理员更新数据库中的店铺信息。对该系统进行了功能和性能测试,测试结果表明该系统达到了预期的功能效果,性能平稳。业务员验证店铺信息并反馈给管理员,管理员更新数据库中的店铺信息。对该系统进行了功能和性能测试,测试结果表明该系统达到了预期的功能效果,性能平稳。业务员验证店铺信息并反馈给管理员,管理员更新数据库中的店铺信息。对该系统进行了功能和性能测试,测试结果表明该系统达到了预期的功能效果,性能平稳。
文章采集api( 【PostmanPostman】API接口())
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-01-10 14:13
【PostmanPostman】API接口())
本节主题:1.2 阅读API接口文档
课程讲师:查理
观看地址:点我进入
1 本节重点
2 课前准备2.1 接口测试工具
提前准备一个接口测试工具,选择以下工具之一:
POSTMAN 是最好的接口测试工具!
点击此链接邮递员 | 下载Postman App进入Postman官网下载页面,选择对应版本(操作系统和32位/64位)并安装;
如果正常,浏览器会自动识别你的电脑系统。本教程用macOS电脑打开,图中圈出的地方会自动识别电脑系统;
Windows用户需要选择32位还是64位版本,需要先检查你使用的电脑是32位还是64位处理器,如果不确定,可以在电脑里查看设置;
点击下载,直接打开压缩包进行安装。
安装后需要注册才能打开软件,分别填写邮箱、用户名、密码。您需要选中接下来的两个框,然后单击橙色按钮注册一个免费帐户。
是一款免费开源、轻量级、快速美观的 API 调试工具,用于替代 Postman。可以帮助程序员节省时间,提高工作效率;
无需下载,访问官网即可使用!
点击访问:POSTWOMAN官网
极客专属的界面协作管理工具;
点击访问:
ApiPost是一个API调试和管理工具,支持团队协作,可以直接生成文档。它支持模拟常见的请求,如 POST、GET 和 PUT。是后端接口开发人员或前端和接口测试人员不可多得的工具;
点击访问:ApiPost官网
2.2 接口准备
- 在上课前找两个API接口,可以是建道云,公司内部系统,也可以是第三方API接口(不知道在哪里找?有很多第三方接口可以测试阿里云市场免费~点击查看)
3 课程内容3.1 如何阅读接口文档?
API接口文档一般分为接口描述、接口地址、请求方法、请求参数、响应内容、错误码、实例:
接口描述:简要描述接口的逻辑和功能。例如,这是一个发送消息和查询天气的接口;
接口地址:这个地址代表网络地址,即url,我们需要调用接口url来获取响应内容;
请求方式:常见的请求方式有GET和POST,其他方式如下图所示;
请求参数:用于传递信息的变量。即需要请求的字段名称的名称和规则:哪些字段都是,字段的类型是什么,是否需要字段等;
响应内容:接口返回的字段名和规则;
错误码:对接口的错误码进行分类,以便快速查找错误原因并解决问题;
示例:实际调用时响应的内容。
这里需要重点掌握GET和POST请求方法!
3.2 个 GET 请求
GET 通常用于获取服务器端数据:
GET请求可以传递参数,一般的传递方式是URL传递参数,例如:
百度知道搜索地址:
搜索后地址:ct=17&pn=0&tn=ikaslist&rn=10&fr=wwwt&word=%E6%B5%8B%E8%AF%95
拆分网址:
/搜索
lm=0
&rn=10
&pn=0
&fr=搜索
&ie=gbk
&word=%BC%F2%B5%C0%D4%C6
网址解析:
(有些文档需要自己的域名+路径,有些文档会提供完整的接口地址,比如剑道云/钉钉)
参数名称值
流明
rn
10
PN
FR
搜索
IE
gbk
单词
%BC%F2%B5%C0%D4%C6
在GET请求中,参数/Params/Querys是以URL参数的形式传递的!
注意在POSTMAN中可以直接使用URL传参,也可以在Params中填写KEY和VALUE,拼接(演示)会自动进行!
3.3 POST 请求
POST 请求一般由 Url、Headers 和 Body 组成。如果在POST请求的接口文档中遇到Params/Querys,需要像GET请求一样使用URL参数来传递参数,而POST请求的接口文档中的参数一般参考Body!
使用 URL 传递参数的接口:
接口地址
使用 Body 传递参数的接口:
POST 请求有不同的请求格式:
{"name":"ziv","password":"123"}
{"data_id":"5398d19a9318483922"}
text/plain(理解),纯文本格式,一般使用raw-Text;
name:ziv,password:123
ziv
123
application/x-www-from-urlencoded(理解),将表单中的数据转换成键值对,用&分隔。
3.4 文档
以钉钉文档为例说明接口(GET方法):
以阿里云API市场为例说明接口(POST方式):点击查看 查看全部
文章采集api(
【PostmanPostman】API接口())

本节主题:1.2 阅读API接口文档
课程讲师:查理
观看地址:点我进入
1 本节重点
2 课前准备2.1 接口测试工具
提前准备一个接口测试工具,选择以下工具之一:
POSTMAN 是最好的接口测试工具!
点击此链接邮递员 | 下载Postman App进入Postman官网下载页面,选择对应版本(操作系统和32位/64位)并安装;
如果正常,浏览器会自动识别你的电脑系统。本教程用macOS电脑打开,图中圈出的地方会自动识别电脑系统;
Windows用户需要选择32位还是64位版本,需要先检查你使用的电脑是32位还是64位处理器,如果不确定,可以在电脑里查看设置;

点击下载,直接打开压缩包进行安装。

安装后需要注册才能打开软件,分别填写邮箱、用户名、密码。您需要选中接下来的两个框,然后单击橙色按钮注册一个免费帐户。
是一款免费开源、轻量级、快速美观的 API 调试工具,用于替代 Postman。可以帮助程序员节省时间,提高工作效率;
无需下载,访问官网即可使用!
点击访问:POSTWOMAN官网
极客专属的界面协作管理工具;
点击访问:
ApiPost是一个API调试和管理工具,支持团队协作,可以直接生成文档。它支持模拟常见的请求,如 POST、GET 和 PUT。是后端接口开发人员或前端和接口测试人员不可多得的工具;
点击访问:ApiPost官网
2.2 接口准备
- 在上课前找两个API接口,可以是建道云,公司内部系统,也可以是第三方API接口(不知道在哪里找?有很多第三方接口可以测试阿里云市场免费~点击查看)
3 课程内容3.1 如何阅读接口文档?
API接口文档一般分为接口描述、接口地址、请求方法、请求参数、响应内容、错误码、实例:
接口描述:简要描述接口的逻辑和功能。例如,这是一个发送消息和查询天气的接口;
接口地址:这个地址代表网络地址,即url,我们需要调用接口url来获取响应内容;
请求方式:常见的请求方式有GET和POST,其他方式如下图所示;
请求参数:用于传递信息的变量。即需要请求的字段名称的名称和规则:哪些字段都是,字段的类型是什么,是否需要字段等;
响应内容:接口返回的字段名和规则;
错误码:对接口的错误码进行分类,以便快速查找错误原因并解决问题;
示例:实际调用时响应的内容。
这里需要重点掌握GET和POST请求方法!
3.2 个 GET 请求
GET 通常用于获取服务器端数据:
GET请求可以传递参数,一般的传递方式是URL传递参数,例如:
百度知道搜索地址:
搜索后地址:ct=17&pn=0&tn=ikaslist&rn=10&fr=wwwt&word=%E6%B5%8B%E8%AF%95
拆分网址:
/搜索
lm=0
&rn=10
&pn=0
&fr=搜索
&ie=gbk
&word=%BC%F2%B5%C0%D4%C6
网址解析:
(有些文档需要自己的域名+路径,有些文档会提供完整的接口地址,比如剑道云/钉钉)
参数名称值
流明
rn
10
PN
FR
搜索
IE
gbk
单词
%BC%F2%B5%C0%D4%C6
在GET请求中,参数/Params/Querys是以URL参数的形式传递的!

注意在POSTMAN中可以直接使用URL传参,也可以在Params中填写KEY和VALUE,拼接(演示)会自动进行!
3.3 POST 请求
POST 请求一般由 Url、Headers 和 Body 组成。如果在POST请求的接口文档中遇到Params/Querys,需要像GET请求一样使用URL参数来传递参数,而POST请求的接口文档中的参数一般参考Body!
使用 URL 传递参数的接口:
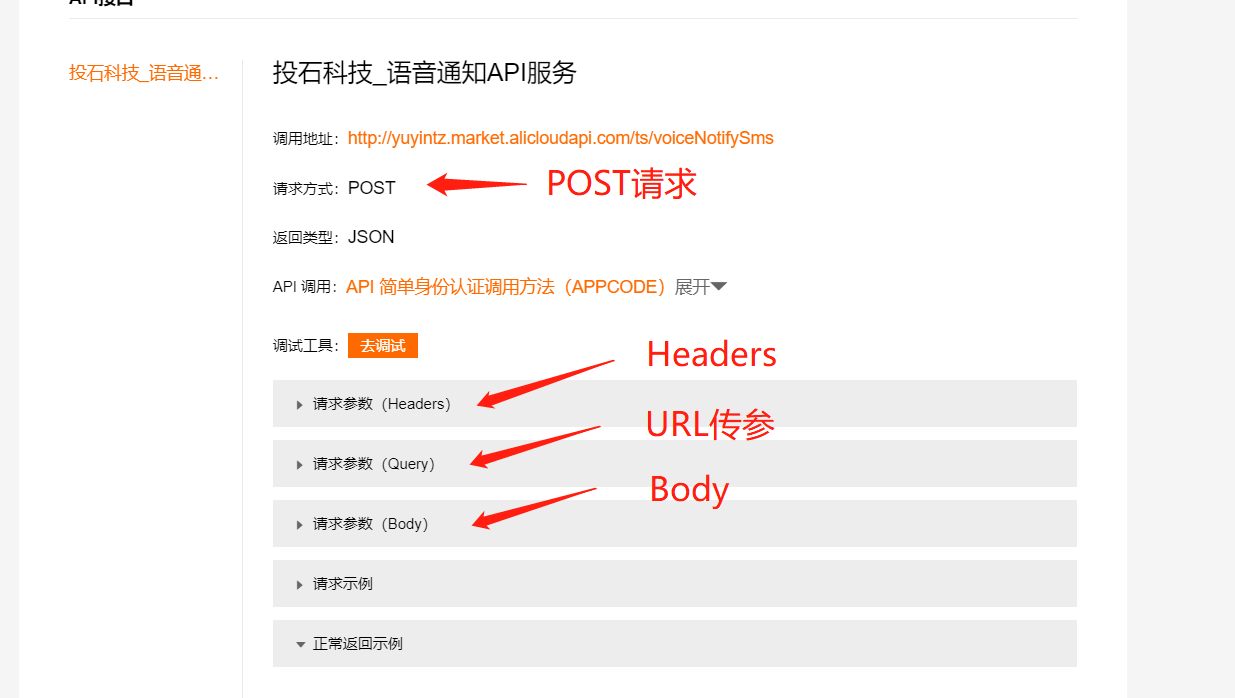
接口地址
使用 Body 传递参数的接口:
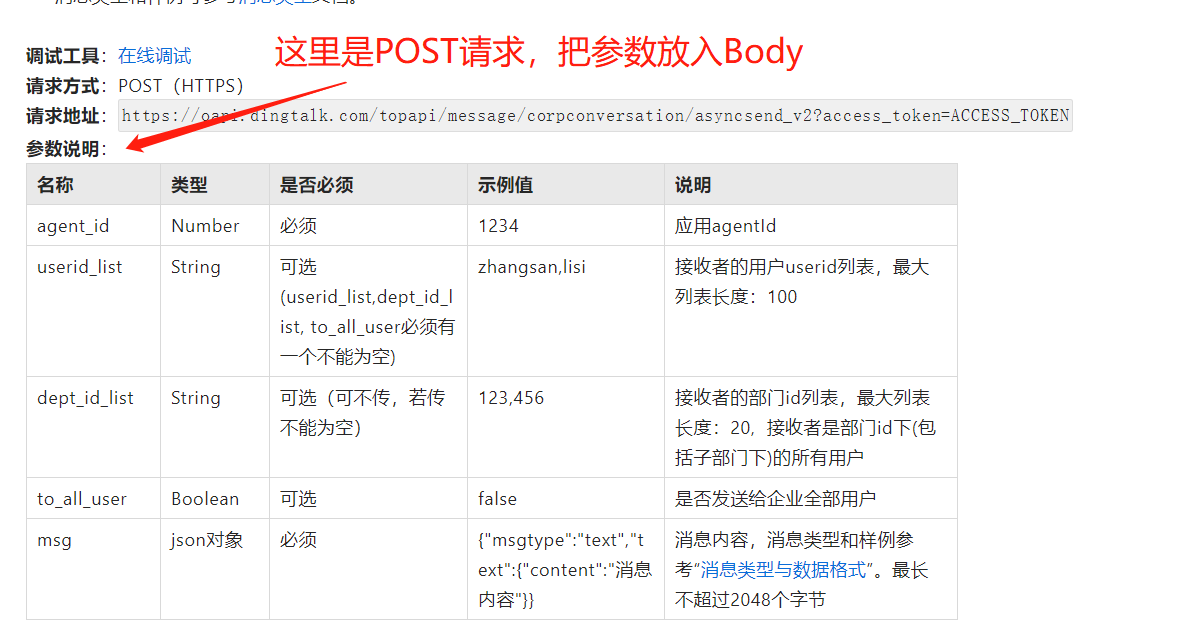
POST 请求有不同的请求格式:
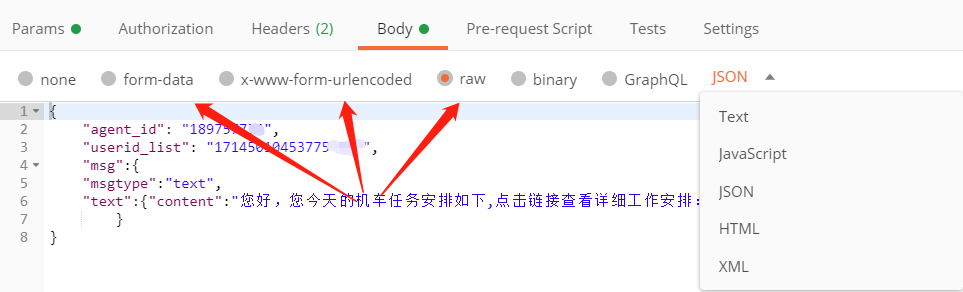
{"name":"ziv","password":"123"}
{"data_id":"5398d19a9318483922"}
text/plain(理解),纯文本格式,一般使用raw-Text;
name:ziv,password:123
ziv
123
application/x-www-from-urlencoded(理解),将表单中的数据转换成键值对,用&分隔。
3.4 文档
以钉钉文档为例说明接口(GET方法):
以阿里云API市场为例说明接口(POST方式):点击查看
文章采集api(一个的API文档是什么?如何正确使用?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-01-07 14:16
对于程序员来说,API 文档对于程序员来说是很熟悉的东西,几乎每天都要和他们打交道。在大多数开发团队中,只要有前后端合作,API文档就会作为两方之间的桥梁存在。API 文档是对后端提供的服务的描述。前端开发人员通常是 API 文档的消费者。下面我从消费者的角度来谈谈什么样的API文档是有用的。
什么是 API 文档?
简单的说就是对所有API调用和涉及的参数进行了清晰的说明。更具体地说,就是每个API可以做什么,以及API中每个参数的解释,包括它们的类型、格式、可能的值、验证规则,以及它们是否有必要。
什么是 API 文档?
欢迎页面
有些人经常忽视这个页面的重要性。当然,如果是内部项目,欢迎页面有时不是那么重要,但是如果API文档是外部的,比如各个公司的开放平台文档,那么详细的欢迎页面甚至可以决定一个开发者是否是愿意访问您的平台。
欢迎页面可以收录的内容:
(Spotify 的 API 文档欢迎页面)
具有完整上下文的示例
想象一个我们阅读 API 文档的场景。我们会像小说一样从头开始阅读吗?大多数情况下不是。一般我们会根据名称直接从API列表跳转到我们需要查看的API,直接读取。因此,对于内容的组织,所有必要的信息和相关的解释都必须收录在每个 API 的解释中。例如,GitHub 的 REST API 文档的 commits 部分,详细给出了每个 API 的部分:
常见类型的例子
可以使用一些工具直接从项目代码中生成文档示例,例如 api blueprint。这样做的好处是在修改源代码时,文档的内容会同步更新,避免了不及时更新文档的问题。但是,建议不要完全依赖自动化工具。生成内容后,还需要手动补充必要的指令,使文档的内容更容易理解。
没有什么比 API 在实际项目中的应用更直观了。真实的示例项目代码可以帮助用户了解各个API的使用方式以及连接方式。通常可以在文档中提供指向示例项目的 GitHub 存储库的链接。如果代码量不大,也可以直接贴在文档中。
顾名思义,该方法就是在客户端模块中封装API调用,包括鉴权、配置等过程,用户可以在项目中直接引用调用封装的方法。这种方式可以简化客户端调用API的工作复杂度,但同时会增加API提供者的工作量。更新后端服务时,客户端模块也需要同步更新。例如,GitHub 提供了不同语言的客户端模块。
错误相关信息
另外,一旦在调试过程中出现错误,详细的错误信息文档可以降低解决错误的难度,应该包括:
事实上,能够做到这一点的文档会少得多。GitHub 的 API 文档在这方面更为通用。Context.IO的文档在错误信息方面表现更好,可以作为参考。
与全球内容相关的话题
这是指任何 API 文档中常见且必要的内容,包括:
至于这些部分的内容,会根据后端服务的不同而有所差异。同时,在每个具体的API讲解中,当有与这些内容相关的概念时,可以给出具体章节的链接,方便开发者随时跳转。查看。
一些可用性建议
API 文档可以提供一些小功能来改善用户体验。比如在代码示例旁边设置了一个复制代码的按钮,方便用户一键复制代码;调用API的代码示例提供多语言支持,用户可以查看不同语言的API调用示例。借助复制功能,可以减少编写重复代码的工作。数量。
API 文档是什么样的?
一个好的API文档,除了内容合理详尽外,风格和交互方式也应该简单易用。目前的API文档基本都是基于网页展示的。利用网页的显示特性,有一些常用的设计方法。以下是一些适合作为 API 文档呈现元素的最佳实践。
只要API文档不是特别大,建议单页展示。在单个页面中查找任何内容(无论是浏览器中的网络搜索还是文档提供的导航)都会非常快,加上页面上的设置,共享一个API记录的位置也非常方便。当然,如果API文档的内容太多,强行在单个页面上会影响页面体验,应该果断拆分文档,但记得要保留每个子页面的全局导航信息,方便用户跳转在每一页上。改变。
在使用API文档的过程中,由于需要频繁搜索内容,页面固定导航栏是非常有必要的。用户可以随时通过导航栏查找文档内容。
既然使用了固定位置的导航栏,那么同时使用多列布局是合乎逻辑的。在宽屏桌面网页上,多栏布局可以很好地组织文档内容,导航、API描述和代码示例可以各占一栏。
API文档维护
维护 API 文档应该和维护一个独立的项目一样。每次更新都以 pull 分支的形式完成。编辑检查文档内容的正确性和简洁性后,项目成员将对其进行审核。
API文档发布后,后期维护同样重要。主要有两个方面:
新的和过时的功能。在发布新功能之前,您应该发布文档并确保该文档已经通过标准审核流程。对于过时的旧功能,应从文档中删除它们。同时,建议在相应位置提供过时功能的提示和升级指南,方便使用老功能的开发者进行升级工作。文档的投稿条目应保留在文档页面。如果文档托管在 GitHub 等平台上,则会提供指向存储库的链接,以便每个阅读文档的用户都可以向文档提交 Issue 或 PR。如果文档是闭源的,至少应该有一个地方可以提供反馈。
以上是项目开发合作中编写友好API文档的一些想法和建议,欢迎讨论。 查看全部
文章采集api(一个的API文档是什么?如何正确使用?(组图))
对于程序员来说,API 文档对于程序员来说是很熟悉的东西,几乎每天都要和他们打交道。在大多数开发团队中,只要有前后端合作,API文档就会作为两方之间的桥梁存在。API 文档是对后端提供的服务的描述。前端开发人员通常是 API 文档的消费者。下面我从消费者的角度来谈谈什么样的API文档是有用的。
什么是 API 文档?
简单的说就是对所有API调用和涉及的参数进行了清晰的说明。更具体地说,就是每个API可以做什么,以及API中每个参数的解释,包括它们的类型、格式、可能的值、验证规则,以及它们是否有必要。
什么是 API 文档?
欢迎页面
有些人经常忽视这个页面的重要性。当然,如果是内部项目,欢迎页面有时不是那么重要,但是如果API文档是外部的,比如各个公司的开放平台文档,那么详细的欢迎页面甚至可以决定一个开发者是否是愿意访问您的平台。
欢迎页面可以收录的内容:
(Spotify 的 API 文档欢迎页面)
具有完整上下文的示例
想象一个我们阅读 API 文档的场景。我们会像小说一样从头开始阅读吗?大多数情况下不是。一般我们会根据名称直接从API列表跳转到我们需要查看的API,直接读取。因此,对于内容的组织,所有必要的信息和相关的解释都必须收录在每个 API 的解释中。例如,GitHub 的 REST API 文档的 commits 部分,详细给出了每个 API 的部分:
常见类型的例子
可以使用一些工具直接从项目代码中生成文档示例,例如 api blueprint。这样做的好处是在修改源代码时,文档的内容会同步更新,避免了不及时更新文档的问题。但是,建议不要完全依赖自动化工具。生成内容后,还需要手动补充必要的指令,使文档的内容更容易理解。
没有什么比 API 在实际项目中的应用更直观了。真实的示例项目代码可以帮助用户了解各个API的使用方式以及连接方式。通常可以在文档中提供指向示例项目的 GitHub 存储库的链接。如果代码量不大,也可以直接贴在文档中。
顾名思义,该方法就是在客户端模块中封装API调用,包括鉴权、配置等过程,用户可以在项目中直接引用调用封装的方法。这种方式可以简化客户端调用API的工作复杂度,但同时会增加API提供者的工作量。更新后端服务时,客户端模块也需要同步更新。例如,GitHub 提供了不同语言的客户端模块。
错误相关信息
另外,一旦在调试过程中出现错误,详细的错误信息文档可以降低解决错误的难度,应该包括:
事实上,能够做到这一点的文档会少得多。GitHub 的 API 文档在这方面更为通用。Context.IO的文档在错误信息方面表现更好,可以作为参考。

与全球内容相关的话题
这是指任何 API 文档中常见且必要的内容,包括:
至于这些部分的内容,会根据后端服务的不同而有所差异。同时,在每个具体的API讲解中,当有与这些内容相关的概念时,可以给出具体章节的链接,方便开发者随时跳转。查看。
一些可用性建议
API 文档可以提供一些小功能来改善用户体验。比如在代码示例旁边设置了一个复制代码的按钮,方便用户一键复制代码;调用API的代码示例提供多语言支持,用户可以查看不同语言的API调用示例。借助复制功能,可以减少编写重复代码的工作。数量。
API 文档是什么样的?
一个好的API文档,除了内容合理详尽外,风格和交互方式也应该简单易用。目前的API文档基本都是基于网页展示的。利用网页的显示特性,有一些常用的设计方法。以下是一些适合作为 API 文档呈现元素的最佳实践。
只要API文档不是特别大,建议单页展示。在单个页面中查找任何内容(无论是浏览器中的网络搜索还是文档提供的导航)都会非常快,加上页面上的设置,共享一个API记录的位置也非常方便。当然,如果API文档的内容太多,强行在单个页面上会影响页面体验,应该果断拆分文档,但记得要保留每个子页面的全局导航信息,方便用户跳转在每一页上。改变。
在使用API文档的过程中,由于需要频繁搜索内容,页面固定导航栏是非常有必要的。用户可以随时通过导航栏查找文档内容。
既然使用了固定位置的导航栏,那么同时使用多列布局是合乎逻辑的。在宽屏桌面网页上,多栏布局可以很好地组织文档内容,导航、API描述和代码示例可以各占一栏。
API文档维护
维护 API 文档应该和维护一个独立的项目一样。每次更新都以 pull 分支的形式完成。编辑检查文档内容的正确性和简洁性后,项目成员将对其进行审核。
API文档发布后,后期维护同样重要。主要有两个方面:
新的和过时的功能。在发布新功能之前,您应该发布文档并确保该文档已经通过标准审核流程。对于过时的旧功能,应从文档中删除它们。同时,建议在相应位置提供过时功能的提示和升级指南,方便使用老功能的开发者进行升级工作。文档的投稿条目应保留在文档页面。如果文档托管在 GitHub 等平台上,则会提供指向存储库的链接,以便每个阅读文档的用户都可以向文档提交 Issue 或 PR。如果文档是闭源的,至少应该有一个地方可以提供反馈。
以上是项目开发合作中编写友好API文档的一些想法和建议,欢迎讨论。
文章采集api(七个步骤逐步介绍如何阅读API文档和测试?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-01-06 13:01
随着API在互联网时代越来越普遍,不仅程序员会使用,现在产品经理或者互联网运营商也需要调试和对接API。阅读这个 文章 你可能会使用或开发 API,或者两者兼而有之。因此,不仅要了解如何编写,还要了解如何阅读 API 文档和测试。
什么是 API 文档?您也可以将 API 文档视为双方之间的服务协议。该文档概述了当第一方发送某种类型的请求时第二方及其软件将如何响应。文档中描述了这些类型的请求(称为 API 调用),以便开发人员知道他们可以使用 API 做什么以及如何做。
好的 API 文档描述了它们的端点,解释了为什么应该使用它们,并提供了非常具体的示例来说明如何使用它们——所有这些方法对于初学者和高级用户来说都同样清楚。带有未知说明的 API 文档过于技术性和文本化,因此并非所有用户都能正确使用。
下面,我们将通过七步一步一步介绍如何编写高质量的API文档。
了解谁在使用您的 API
描绘您的用户旅程
从基本函数语句开始
添加代码示例
列出您的状态代码和错误消息
用白话写和设计API文档
使 API 文档始终保持最新
1.了解使用你API的用户
与影响战略规划或 UI 设计过程的任何内容一样,编写 API 文档的第一步是了解目标受众。这需要了解您所针对的用户类型、内容需要为他们提供的实用价值,以及他们适合实际场景的方式。
在编写 API 文档时,需要牢记两个主要的用户组。一组用户是API文档的直接用户,因此他们只需要查看教程和代码示例。这个群体主要是开发者。另一组用户将评估 API 功能、价格、速率限制、安全性和其他因素,以了解 API 如何与其业务需求和目标保持一致。团队主要由CTO和产品经理,以及一些开发人员组成。
您必须牢记这两个角色,以确保文档为每位读者提供良好的体验。
2.描述您的用户旅程
与任何产品一样,API 必须在买家旅程的每个阶段提供内容。这意味着文档应该解释 API 可以做什么(或它可以解决什么问题)、它提供的各种功能和端点,以及它与竞争对手的不同之处。
API 文档应该回答的一些基本问题是:
1.为什么要使用这个API?
2.如何访问不同的工具和端点?
3.获得许可后下一步是什么?
4.如何使用一些特定的功能?
3.从基本的函数语句开始
每个 API 和功能都是唯一的或唯一的。例如,一些API可以将微博照片嵌入到电子商务平台的详细信息页面中。一些API可以让你通过B站旅游UP主访问上千家推荐的酒店。网站 上甚至还有一个用于集成 Yoda 翻译器的 API。虽然每个 API 的作用不同,但是每个 API 文档都应该涵盖一些基础知识。让我们看看下面的一些例子。
验证
由于认证对于保护API数据以及开发者和最终用户的数据安全非常重要,API通常有多种认证方案,因此API文档中必须对每一种认证方式进行说明,以便用户能够正确获取Authorize并使用API。例如,YouTube 数据 API 支持两种类型的授权凭据。它的文档解释了如何使用 OAuth 2.0 以及如何获取 API 密钥,以便用户可以选择他们更熟悉的身份验证方法。
速率限制
与用户身份验证一样,速率限制可以帮助防止意外传输或 API 滥用。API 速率限制是您在给定时间内可以向 API 发送请求的次数。这些限制必须在 API 文档中明确说明,以便用户了解如何正确使用 API 及其功能。此信息最常出现在“使用条款”中。
使用条款
使用(或服务)条款是服务提供者与需要服务的用户之间的法律协议。后者必须同意遵守这些条款才能使用服务。在 API 文档中,使用条款必须明确定义 API 用户在理想情况下应该如何使用 API。这将有助于确保服务用户充分利用 API 平台和功能。
内容变更日志
API 用户了解他们使用的 API 的任何折旧是很重要的。更改文档可以帮助他们妥善维护自己的应用程序,并充分利用 API 平台的功能。案例:Twitter 的 API 文档有一个变更日志,其中记录了对 Twitter 开发者平台所做的所有变更,包括新功能和新产品。
4.添加代码示例
API 文档有两个主要目标:使开发人员尽可能轻松地使用 API,并使他们能够快速了解 API 的全部功能。实现这两个目标的一个好方法是为每个 API 端点提供代码示例。这样,开发者就可以了解端点最关键的功能,从一些案例代码入手,然后直接调整案例代码上的参数,以满足自己的实际需求和对接规范。
5.列出您的状态代码和错误消息
API 文档应清楚地概述用户在进行 API 调用时可能期望的状态代码和错误消息。理想情况下,每个响应都应附有简短的描述,以便用户知道 API 何时成功调用、API 何时未成功调用,并能够解决他们遇到的任何错误。通常,此信息放置在其自己的页面上。这是 Express 100 API 文档中的一个示例。
6.用白话写和设计API文档
如果您想以易于用户阅读和浏览的方式编写、构建和设计 API 文档。这意味着根据用户的使用场景和需求来呈现和组织文档的内容信息。用户的使用场景是与用户在哪里、何时、为什么以及如何找到内容并与之交互相关的所有内容。他们的需求还包括他们的目标、行为和期望。
最好的 API 文档是为不熟悉 API 的初学者和非常熟悉 API 的开发人员编写的。本文档应尽可能避免使用过多的技术术语,并尽可能提供附加的上下文信息或文档的内部链接。它还需要提供,比如“入门”以及示例和教程,这些是新手用户需要的内容,更高级的用户可以跳过它。
为了保证用户可以选择自己需要的东西,在设计API文档的时候一定要做好导航。最佳做法是使用标题和侧边栏,以便用户可以导航到文档的另一部分并提供搜索功能,而无需在页面上上下滚动。其他设计考虑因素包括排版、配色方案和布局。三列布局被认为是收录大量代码示例的文档的理想选择。无衬线字体和对比色链接也是不错的设计选择。
7.保持 API 文档始终是最新的
为了保证 API 用户能够获得最佳体验并不断吸引新用户,API 提供商必须不时维护自己的 API 文档。过去,API 文档以PDF 或静态网页的形式存在,这使得文档更新变得困难。现在,有一些工具可以帮助您创建可以自动更新的动态和交互式文档。Redocly 和 SwaggerUI 是两个比较常见的实际例子。
如何阅读 API 文档
如果你只是一个 API 用户,而不是 API 服务提供者,那么你需要知道如何阅读 API 文档。虽然写法和读法都差不多(找基本原理、试代码示例等),但并不完全一样。让我们仔细看看如何阅读 API 文档以了解使用特定 API 可能实现的功能。
从文档概览开始
大多数API文档会首先概述API的功能,如何连接API,以及如何正确使用API。当然,你不需要了解概览的每一个细节,但你应该粗略地浏览一遍。
以Express 100的API文档为例。首先,Express 100 的 API 文档解释了 Express 100 的 API 的用途,使用的协议和语言,以及它的认证方案。在左侧边栏的“快速链接”部分,您将找到指向其使用指南和速率限制、测试帐户、更改日志以及开始使用 API 所需的所有其他内容的重要链接。
对函数的深入理解
了解 API 概述后,请浏览 API 参考文档,其中列出了 API 的所有功能(也称为方法)。此时,无需彻底阅读或记住所有内容。相反,请仔细研究您特别感兴趣的功能。通过查看其参数和示例,您可以了解是否可以成功使用该 API 执行您想要执行的确切操作。
例如,假设您想通过快递100的API实现如下物流查询功能:-在电商网页/APP/小程序中,客户在订单详情中查看所购商品的物流地图轨迹,并显示物流跟踪文字信息一起。顾客
在这种需求的驱动下,您可以导航到“接口文档”,然后查看其代码语言、参数、响应和错误消息等。
通读 API 文档教程
现在您知道是否可以使用 API 来实现您的需求,请查看教程。由于最好的 API 文档应该可以帮助用户快速入门,因此大多数文档都会收录完成任务的详细教程。您应该至少通读一个教程,以了解需要仔细研究哪些级别的细节和示例。如果你想了解电商快递物流API的好处,这里有一篇文章《什么是电商API?这是它能给商家带来的12个运营效益》一文,介绍了它们的优点和缺点详细。有兴趣的可以去看看,说不定你会发现意想不到的惊喜。
记录 API 信息更改
随着越来越多的公司提供 API 服务以形成高度集成的用户体验,知道如何编写和阅读 API 文档变得越来越有价值。在创建或评估 API 文档时,请确保您的 API 稳定且易于阅读和浏览,并向开发人员和非开发人员清楚地传达 API 的价值。这确保了技术出身的用户可以快速正确地开始使用您的 API,而同事必须确保他们可以与其他非技术同事一起使用它。 查看全部
文章采集api(七个步骤逐步介绍如何阅读API文档和测试?(组图))
随着API在互联网时代越来越普遍,不仅程序员会使用,现在产品经理或者互联网运营商也需要调试和对接API。阅读这个 文章 你可能会使用或开发 API,或者两者兼而有之。因此,不仅要了解如何编写,还要了解如何阅读 API 文档和测试。
什么是 API 文档?您也可以将 API 文档视为双方之间的服务协议。该文档概述了当第一方发送某种类型的请求时第二方及其软件将如何响应。文档中描述了这些类型的请求(称为 API 调用),以便开发人员知道他们可以使用 API 做什么以及如何做。
好的 API 文档描述了它们的端点,解释了为什么应该使用它们,并提供了非常具体的示例来说明如何使用它们——所有这些方法对于初学者和高级用户来说都同样清楚。带有未知说明的 API 文档过于技术性和文本化,因此并非所有用户都能正确使用。
下面,我们将通过七步一步一步介绍如何编写高质量的API文档。

了解谁在使用您的 API
描绘您的用户旅程
从基本函数语句开始
添加代码示例
列出您的状态代码和错误消息
用白话写和设计API文档
使 API 文档始终保持最新
1.了解使用你API的用户
与影响战略规划或 UI 设计过程的任何内容一样,编写 API 文档的第一步是了解目标受众。这需要了解您所针对的用户类型、内容需要为他们提供的实用价值,以及他们适合实际场景的方式。
在编写 API 文档时,需要牢记两个主要的用户组。一组用户是API文档的直接用户,因此他们只需要查看教程和代码示例。这个群体主要是开发者。另一组用户将评估 API 功能、价格、速率限制、安全性和其他因素,以了解 API 如何与其业务需求和目标保持一致。团队主要由CTO和产品经理,以及一些开发人员组成。
您必须牢记这两个角色,以确保文档为每位读者提供良好的体验。
2.描述您的用户旅程
与任何产品一样,API 必须在买家旅程的每个阶段提供内容。这意味着文档应该解释 API 可以做什么(或它可以解决什么问题)、它提供的各种功能和端点,以及它与竞争对手的不同之处。
API 文档应该回答的一些基本问题是:
1.为什么要使用这个API?
2.如何访问不同的工具和端点?
3.获得许可后下一步是什么?
4.如何使用一些特定的功能?
3.从基本的函数语句开始
每个 API 和功能都是唯一的或唯一的。例如,一些API可以将微博照片嵌入到电子商务平台的详细信息页面中。一些API可以让你通过B站旅游UP主访问上千家推荐的酒店。网站 上甚至还有一个用于集成 Yoda 翻译器的 API。虽然每个 API 的作用不同,但是每个 API 文档都应该涵盖一些基础知识。让我们看看下面的一些例子。
验证
由于认证对于保护API数据以及开发者和最终用户的数据安全非常重要,API通常有多种认证方案,因此API文档中必须对每一种认证方式进行说明,以便用户能够正确获取Authorize并使用API。例如,YouTube 数据 API 支持两种类型的授权凭据。它的文档解释了如何使用 OAuth 2.0 以及如何获取 API 密钥,以便用户可以选择他们更熟悉的身份验证方法。
速率限制
与用户身份验证一样,速率限制可以帮助防止意外传输或 API 滥用。API 速率限制是您在给定时间内可以向 API 发送请求的次数。这些限制必须在 API 文档中明确说明,以便用户了解如何正确使用 API 及其功能。此信息最常出现在“使用条款”中。
使用条款
使用(或服务)条款是服务提供者与需要服务的用户之间的法律协议。后者必须同意遵守这些条款才能使用服务。在 API 文档中,使用条款必须明确定义 API 用户在理想情况下应该如何使用 API。这将有助于确保服务用户充分利用 API 平台和功能。
内容变更日志
API 用户了解他们使用的 API 的任何折旧是很重要的。更改文档可以帮助他们妥善维护自己的应用程序,并充分利用 API 平台的功能。案例:Twitter 的 API 文档有一个变更日志,其中记录了对 Twitter 开发者平台所做的所有变更,包括新功能和新产品。
4.添加代码示例
API 文档有两个主要目标:使开发人员尽可能轻松地使用 API,并使他们能够快速了解 API 的全部功能。实现这两个目标的一个好方法是为每个 API 端点提供代码示例。这样,开发者就可以了解端点最关键的功能,从一些案例代码入手,然后直接调整案例代码上的参数,以满足自己的实际需求和对接规范。
5.列出您的状态代码和错误消息
API 文档应清楚地概述用户在进行 API 调用时可能期望的状态代码和错误消息。理想情况下,每个响应都应附有简短的描述,以便用户知道 API 何时成功调用、API 何时未成功调用,并能够解决他们遇到的任何错误。通常,此信息放置在其自己的页面上。这是 Express 100 API 文档中的一个示例。
6.用白话写和设计API文档
如果您想以易于用户阅读和浏览的方式编写、构建和设计 API 文档。这意味着根据用户的使用场景和需求来呈现和组织文档的内容信息。用户的使用场景是与用户在哪里、何时、为什么以及如何找到内容并与之交互相关的所有内容。他们的需求还包括他们的目标、行为和期望。
最好的 API 文档是为不熟悉 API 的初学者和非常熟悉 API 的开发人员编写的。本文档应尽可能避免使用过多的技术术语,并尽可能提供附加的上下文信息或文档的内部链接。它还需要提供,比如“入门”以及示例和教程,这些是新手用户需要的内容,更高级的用户可以跳过它。
为了保证用户可以选择自己需要的东西,在设计API文档的时候一定要做好导航。最佳做法是使用标题和侧边栏,以便用户可以导航到文档的另一部分并提供搜索功能,而无需在页面上上下滚动。其他设计考虑因素包括排版、配色方案和布局。三列布局被认为是收录大量代码示例的文档的理想选择。无衬线字体和对比色链接也是不错的设计选择。
7.保持 API 文档始终是最新的
为了保证 API 用户能够获得最佳体验并不断吸引新用户,API 提供商必须不时维护自己的 API 文档。过去,API 文档以PDF 或静态网页的形式存在,这使得文档更新变得困难。现在,有一些工具可以帮助您创建可以自动更新的动态和交互式文档。Redocly 和 SwaggerUI 是两个比较常见的实际例子。
如何阅读 API 文档
如果你只是一个 API 用户,而不是 API 服务提供者,那么你需要知道如何阅读 API 文档。虽然写法和读法都差不多(找基本原理、试代码示例等),但并不完全一样。让我们仔细看看如何阅读 API 文档以了解使用特定 API 可能实现的功能。
从文档概览开始
大多数API文档会首先概述API的功能,如何连接API,以及如何正确使用API。当然,你不需要了解概览的每一个细节,但你应该粗略地浏览一遍。
以Express 100的API文档为例。首先,Express 100 的 API 文档解释了 Express 100 的 API 的用途,使用的协议和语言,以及它的认证方案。在左侧边栏的“快速链接”部分,您将找到指向其使用指南和速率限制、测试帐户、更改日志以及开始使用 API 所需的所有其他内容的重要链接。
对函数的深入理解
了解 API 概述后,请浏览 API 参考文档,其中列出了 API 的所有功能(也称为方法)。此时,无需彻底阅读或记住所有内容。相反,请仔细研究您特别感兴趣的功能。通过查看其参数和示例,您可以了解是否可以成功使用该 API 执行您想要执行的确切操作。
例如,假设您想通过快递100的API实现如下物流查询功能:-在电商网页/APP/小程序中,客户在订单详情中查看所购商品的物流地图轨迹,并显示物流跟踪文字信息一起。顾客
在这种需求的驱动下,您可以导航到“接口文档”,然后查看其代码语言、参数、响应和错误消息等。
通读 API 文档教程
现在您知道是否可以使用 API 来实现您的需求,请查看教程。由于最好的 API 文档应该可以帮助用户快速入门,因此大多数文档都会收录完成任务的详细教程。您应该至少通读一个教程,以了解需要仔细研究哪些级别的细节和示例。如果你想了解电商快递物流API的好处,这里有一篇文章《什么是电商API?这是它能给商家带来的12个运营效益》一文,介绍了它们的优点和缺点详细。有兴趣的可以去看看,说不定你会发现意想不到的惊喜。
记录 API 信息更改
随着越来越多的公司提供 API 服务以形成高度集成的用户体验,知道如何编写和阅读 API 文档变得越来越有价值。在创建或评估 API 文档时,请确保您的 API 稳定且易于阅读和浏览,并向开发人员和非开发人员清楚地传达 API 的价值。这确保了技术出身的用户可以快速正确地开始使用您的 API,而同事必须确保他们可以与其他非技术同事一起使用它。
文章采集api(数据埋点采集到底包括哪些问题?作者从什么是埋点、埋点的应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-12-30 23:22
数据采集是数据分析的基础,埋点是采集最重要的方法。那么数据埋点采集涉及哪些问题呢?本文作者从什么是埋点、埋点如何设计、埋点的应用三个方面梳理了这个问题,与大家分享。
一、数据采集及常见数据问题1.数据采集
数据采集的方式有很多种,埋点采集是其中非常重要的一部分。是c端和b端产品采集的主要方式。
数据采集,顾名思义,采集对应的数据是整个数据流的起点。采集的不完整性,对与错,直接决定了数据的广度和质量,并影响到后续的所有环节。在数据采集有效性和完整性较差的公司中,业务中发现的数据通常会发生重大变化。
数据处理通常包括以下5个步骤:
2. 常见数据问题
在大致了解了数据采集及其结构之后,我们来看看我们工作中遇到的问题,有多少是与数据采集链接相关的:
数据与后台差距大,数据不准确——统计口径不同,埋点定义不同,采集的方法带来误差;想用的时候,没有我想要的数据——没有数据。采集需求,埋点不正确,不完整;事件太多,意义不明——埋点设计方法,埋点更新迭代规则和维护;数据分析不知道看哪些数据和指标——数据定义不清,缺乏分析思路。
我们要从根本上解决问题:把采集当作一个独立的研发企业,而不是产品开发的附属品
二、什么是埋点1. 什么是埋点
所谓埋点,是数据领域的一个术语采集。它的学名应该叫Event Tracking,对应的英文是Event Tracking,指的是捕获、处理和发送特定用户行为或事件的相关技术和实现过程。
数据埋点是数据分析师、数据产品经理和数据运营。根据业务需求或产品需求,开发用户行为的每个事件的对应位置,开发埋点,通过SDK上报埋点的数据结果,并记录汇总数据。分析、推动产品优化、指导运营。
该过程附有规范。通过定义,我们看到特定的用户行为和事件是我们的采集关注点。我们还需要处理和发送相关的技术和实施流程;数据嵌入点是为产品服务的,它来自于产品。,所以跟产品息息相关,埋点在于具体的实战过程,这关系到每个人对底层数据的理解。
2. 为什么要埋分
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的好坏直接影响到数据质量、产品质量、运营质量等。
数据驱动的埋点将分析深度下钻到流量分布和流量级别。通过统计分析,对宏观指标进行深入分析,发现指标背后的问题,洞察用户行为与价值提升的潜在关系;产品优化——对于产品,用户在产品中做了什么,在产品中停留了多久,有什么异常需要注意。这些问题都可以通过埋点的方式来解决;精细化运营——埋点可以实现整个产品生命周期、流量质量和不同来源的分布、人群的行为特征和关系,洞察用户行为与提升商业价值之间的潜在关联。3.
埋点的方法有哪些?目前,大多数公司使用客户端和服务器的组合:
准确度:编码埋点>可视化埋点>全埋点
三、埋点框架及设计1.埋点顶层设计采集
所谓顶层设计,就是搞清楚怎么埋点,用什么方法,上传机制是什么,怎么定义,怎么实现等等;我们在设计的基础上遵循唯一性、可扩展性、一致性等一些常见的字段和生成机制,例如:cid、idfa、idfv等。
2. 埋点 采集 事件和属性设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变的,哪些是业务行为,哪些是基本属性。
基于基础属性事件,我们认为属性一定是采集项,但是属性中的事件属性根据业务进行了调整。因此,我们可以将埋点采集分为协议层和业务层埋点。
3. 数据采集事件和属性设计
Ev 事件的命名也遵循一些规则。当同一类型的函数出现在不同的页面或位置时,根据函数名进行命名,在ev参数中区分页面和位置。仅点击按钮时,按按钮名称命名。
ev事件格式:ev分为ev标识和ev参数
规则:
ev标志和ev参数之间用“#”连接(一级连接器);
ev参数和ev参数之间用“/”连接(二级连接器);
ev 参数使用key=value 的结构。当一个key对应多个value值时,value1和value2之间用“,”连接(三级连接器);
当埋点只有ev标志,没有ev参数时,不需要带#;
评论:
ev标识:作为埋点的唯一标识,用于区分埋点的位置和属性,不可变,不可修改;
ev参数:需要返回埋点的参数,ev参数的顺序是可变的,可以修改;)
调整app埋点时ev标志不变,只修改后续埋点参数(参数值改变或参数类型增加)
eg:一般嵌入点文档中收录的sheet的名称和功能:
A.暴露埋点汇总;
B.点击浏览埋点汇总;
C.故障埋点总结:一般会记录埋点的故障版本或时间;
D、PC和M页面嵌入点对应的pageid;
E、各版本上线时间记录;
在嵌入点文档中,所有列名和函数包括:
4. 基于埋点的统计
如何使用埋点统计查找埋点 ev 事件:
明确埋点类型(点击/曝光/浏览)-过滤类型字段,清除埋点所属页面(页面或功能)-过滤功能模块字段,指定埋点事件名称-过滤name字段知道ev标志,可以直接用ev过滤
如何根据ev事件进行计数统计:查询按钮点击统计时,可以直接使用ev标志进行查询,有区别时,可以限制埋点参数的取值;因为ev参数的顺序不需要可变,查询统计的时候,不能限制参数的顺序;
四、应用-数据流的基础
1. 指标系统
系统化的指标可以将不同指标、不同维度串联起来进行综合分析,快速发现当前产品和业务流程中存在的问题。
2. 可视化
人类对图像信息的解释比文本更有效。可视化对于数据分析极其重要。使用数据可视化可以揭示数据中错综复杂的关系。
3. 埋点元信息api提供
数据采集服务会将采集的埋点写入Kafka。针对每个业务的实时数据消费需求,我们为每个业务提供了单独的Kafka,流量分发模块会定时读取它 取埋点管理平台提供的元信息,实时分发流量各业务时间卡夫卡。
数据采集就像设计一个产品。不能过火,留有扩展空间,但要时刻考虑数据是否完整、详细、不稳定、快速与否。 查看全部
文章采集api(数据埋点采集到底包括哪些问题?作者从什么是埋点、埋点的应用)
数据采集是数据分析的基础,埋点是采集最重要的方法。那么数据埋点采集涉及哪些问题呢?本文作者从什么是埋点、埋点如何设计、埋点的应用三个方面梳理了这个问题,与大家分享。
一、数据采集及常见数据问题1.数据采集
数据采集的方式有很多种,埋点采集是其中非常重要的一部分。是c端和b端产品采集的主要方式。
数据采集,顾名思义,采集对应的数据是整个数据流的起点。采集的不完整性,对与错,直接决定了数据的广度和质量,并影响到后续的所有环节。在数据采集有效性和完整性较差的公司中,业务中发现的数据通常会发生重大变化。
数据处理通常包括以下5个步骤:
2. 常见数据问题
在大致了解了数据采集及其结构之后,我们来看看我们工作中遇到的问题,有多少是与数据采集链接相关的:
数据与后台差距大,数据不准确——统计口径不同,埋点定义不同,采集的方法带来误差;想用的时候,没有我想要的数据——没有数据。采集需求,埋点不正确,不完整;事件太多,意义不明——埋点设计方法,埋点更新迭代规则和维护;数据分析不知道看哪些数据和指标——数据定义不清,缺乏分析思路。
我们要从根本上解决问题:把采集当作一个独立的研发企业,而不是产品开发的附属品
二、什么是埋点1. 什么是埋点
所谓埋点,是数据领域的一个术语采集。它的学名应该叫Event Tracking,对应的英文是Event Tracking,指的是捕获、处理和发送特定用户行为或事件的相关技术和实现过程。
数据埋点是数据分析师、数据产品经理和数据运营。根据业务需求或产品需求,开发用户行为的每个事件的对应位置,开发埋点,通过SDK上报埋点的数据结果,并记录汇总数据。分析、推动产品优化、指导运营。
该过程附有规范。通过定义,我们看到特定的用户行为和事件是我们的采集关注点。我们还需要处理和发送相关的技术和实施流程;数据嵌入点是为产品服务的,它来自于产品。,所以跟产品息息相关,埋点在于具体的实战过程,这关系到每个人对底层数据的理解。
2. 为什么要埋分
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的好坏直接影响到数据质量、产品质量、运营质量等。
数据驱动的埋点将分析深度下钻到流量分布和流量级别。通过统计分析,对宏观指标进行深入分析,发现指标背后的问题,洞察用户行为与价值提升的潜在关系;产品优化——对于产品,用户在产品中做了什么,在产品中停留了多久,有什么异常需要注意。这些问题都可以通过埋点的方式来解决;精细化运营——埋点可以实现整个产品生命周期、流量质量和不同来源的分布、人群的行为特征和关系,洞察用户行为与提升商业价值之间的潜在关联。3.
埋点的方法有哪些?目前,大多数公司使用客户端和服务器的组合:
准确度:编码埋点>可视化埋点>全埋点
三、埋点框架及设计1.埋点顶层设计采集
所谓顶层设计,就是搞清楚怎么埋点,用什么方法,上传机制是什么,怎么定义,怎么实现等等;我们在设计的基础上遵循唯一性、可扩展性、一致性等一些常见的字段和生成机制,例如:cid、idfa、idfv等。
2. 埋点 采集 事件和属性设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变的,哪些是业务行为,哪些是基本属性。
基于基础属性事件,我们认为属性一定是采集项,但是属性中的事件属性根据业务进行了调整。因此,我们可以将埋点采集分为协议层和业务层埋点。
3. 数据采集事件和属性设计
Ev 事件的命名也遵循一些规则。当同一类型的函数出现在不同的页面或位置时,根据函数名进行命名,在ev参数中区分页面和位置。仅点击按钮时,按按钮名称命名。
ev事件格式:ev分为ev标识和ev参数
规则:
ev标志和ev参数之间用“#”连接(一级连接器);
ev参数和ev参数之间用“/”连接(二级连接器);
ev 参数使用key=value 的结构。当一个key对应多个value值时,value1和value2之间用“,”连接(三级连接器);
当埋点只有ev标志,没有ev参数时,不需要带#;
评论:
ev标识:作为埋点的唯一标识,用于区分埋点的位置和属性,不可变,不可修改;
ev参数:需要返回埋点的参数,ev参数的顺序是可变的,可以修改;)
调整app埋点时ev标志不变,只修改后续埋点参数(参数值改变或参数类型增加)
eg:一般嵌入点文档中收录的sheet的名称和功能:
A.暴露埋点汇总;
B.点击浏览埋点汇总;
C.故障埋点总结:一般会记录埋点的故障版本或时间;
D、PC和M页面嵌入点对应的pageid;
E、各版本上线时间记录;
在嵌入点文档中,所有列名和函数包括:
4. 基于埋点的统计
如何使用埋点统计查找埋点 ev 事件:
明确埋点类型(点击/曝光/浏览)-过滤类型字段,清除埋点所属页面(页面或功能)-过滤功能模块字段,指定埋点事件名称-过滤name字段知道ev标志,可以直接用ev过滤
如何根据ev事件进行计数统计:查询按钮点击统计时,可以直接使用ev标志进行查询,有区别时,可以限制埋点参数的取值;因为ev参数的顺序不需要可变,查询统计的时候,不能限制参数的顺序;
四、应用-数据流的基础
1. 指标系统
系统化的指标可以将不同指标、不同维度串联起来进行综合分析,快速发现当前产品和业务流程中存在的问题。
2. 可视化
人类对图像信息的解释比文本更有效。可视化对于数据分析极其重要。使用数据可视化可以揭示数据中错综复杂的关系。
3. 埋点元信息api提供
数据采集服务会将采集的埋点写入Kafka。针对每个业务的实时数据消费需求,我们为每个业务提供了单独的Kafka,流量分发模块会定时读取它 取埋点管理平台提供的元信息,实时分发流量各业务时间卡夫卡。
数据采集就像设计一个产品。不能过火,留有扩展空间,但要时刻考虑数据是否完整、详细、不稳定、快速与否。
文章采集api(【干货】大数据采集系统的分为操作建议及注意事项)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-12-30 14:08
大数据采集系统:
用于采集
各种数据,并提取、转换和加载数据。
大数据采集技术:
对数据进行ETL操作,提取、转换、加载数据,最终挖掘数据的潜在价值。然后为用户提供解决方案或决策参考。
大数据采集系统主要分为三类:
1、系统日志采集
系统
日志采集和日志数据信息的采集,然后进行数据分析,挖掘公司业务平台日志数据的潜在价值。总之,采集
日志数据提供了离线和在线实时分析。目前常用的开源日志采集
系统是Flume。
2、网络数据采集系统
通过网络爬虫和一些网站平台(如推特、新浪微博API)提供的公共API从网站获取数据。可以从网页中提取非结构化数据和半结构化数据的网页数据,提取、清洗、转换成结构化数据,作为统一的本地文件数据存储。
目前常用的网络爬虫系统包括Apache Nutch、Crawler4j、Scrapy等框架。
3、数据库采集系统
数据库采集系统直接与企业业务后端服务器集成,每时每刻都会在企业业务后端产生大量的业务记录写入数据库。最后,由特定的处理和分配系统进行系统分析。
目前常用MySQL、Oracle等关系型数据库来存储数据,也常用Redis、MongoDB等NoSQL数据库进行数据采集。
一个简单易用的大数据采集平台:
1.数据超市
基于云平台的大数据计算分析系统。拥有丰富优质的数据资源,通过自有渠道资源获得100余项版权大数据资源。所有数据都经过审计,以确保数据的高可用性。
2. 快速矿工
数据科学软件平台为数据准备、机器学习、深度学习、文本挖掘和预测分析提供了一个集成环境。
3. Oracle 数据挖掘
它是 Oracle 高级分析数据库的代表。市场领先的公司使用它来最大限度地发挥数据的潜力并做出准确的预测。
4. IBM SPSS Modeler
适用于大型项目。在这个建模器中,文本分析及其最先进的可视化界面非常有价值。有助于生成数据挖掘算法,基本不需要编程。
5. KNIME
开源数据分析平台。您可以快速部署、扩展并熟悉其中的数据。
6. Python
一种免费的开源语言。
大数据平台:
是指一组主要处理海量数据存储、计算、不间断流数据实时计算等场景的基础设施。既可以使用开源平台,也可以使用华为、Transwarp等商业解决方案。它们可以部署在私有云或公共云上。
任何一个完整的大数据平台,一般都包括以下流程:
数据采集->数据存储->数据处理->数据展示(可视化、报告和监控)
其中,数据采集对于所有数据系统都是必不可少的。随着大数据越来越受到重视,数据采集的挑战就显得尤为突出。 查看全部
文章采集api(【干货】大数据采集系统的分为操作建议及注意事项)
大数据采集系统:
用于采集
各种数据,并提取、转换和加载数据。
大数据采集技术:
对数据进行ETL操作,提取、转换、加载数据,最终挖掘数据的潜在价值。然后为用户提供解决方案或决策参考。
大数据采集系统主要分为三类:
1、系统日志采集
系统
日志采集和日志数据信息的采集,然后进行数据分析,挖掘公司业务平台日志数据的潜在价值。总之,采集
日志数据提供了离线和在线实时分析。目前常用的开源日志采集
系统是Flume。
2、网络数据采集系统
通过网络爬虫和一些网站平台(如推特、新浪微博API)提供的公共API从网站获取数据。可以从网页中提取非结构化数据和半结构化数据的网页数据,提取、清洗、转换成结构化数据,作为统一的本地文件数据存储。
目前常用的网络爬虫系统包括Apache Nutch、Crawler4j、Scrapy等框架。
3、数据库采集系统
数据库采集系统直接与企业业务后端服务器集成,每时每刻都会在企业业务后端产生大量的业务记录写入数据库。最后,由特定的处理和分配系统进行系统分析。
目前常用MySQL、Oracle等关系型数据库来存储数据,也常用Redis、MongoDB等NoSQL数据库进行数据采集。
一个简单易用的大数据采集平台:
1.数据超市
基于云平台的大数据计算分析系统。拥有丰富优质的数据资源,通过自有渠道资源获得100余项版权大数据资源。所有数据都经过审计,以确保数据的高可用性。
2. 快速矿工
数据科学软件平台为数据准备、机器学习、深度学习、文本挖掘和预测分析提供了一个集成环境。
3. Oracle 数据挖掘
它是 Oracle 高级分析数据库的代表。市场领先的公司使用它来最大限度地发挥数据的潜力并做出准确的预测。
4. IBM SPSS Modeler
适用于大型项目。在这个建模器中,文本分析及其最先进的可视化界面非常有价值。有助于生成数据挖掘算法,基本不需要编程。
5. KNIME
开源数据分析平台。您可以快速部署、扩展并熟悉其中的数据。
6. Python
一种免费的开源语言。
大数据平台:
是指一组主要处理海量数据存储、计算、不间断流数据实时计算等场景的基础设施。既可以使用开源平台,也可以使用华为、Transwarp等商业解决方案。它们可以部署在私有云或公共云上。
任何一个完整的大数据平台,一般都包括以下流程:
数据采集->数据存储->数据处理->数据展示(可视化、报告和监控)
其中,数据采集对于所有数据系统都是必不可少的。随着大数据越来越受到重视,数据采集的挑战就显得尤为突出。
文章采集api( 公众号数据下载有哪些值得推荐的微信数据分析技巧?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-12-30 07:15
公众号数据下载有哪些值得推荐的微信数据分析技巧?)
公众号资料下载服务内容
账号搜索和扩展数据,根据需要查找微信、微博、今日头条、抖音等新媒体平台账号并发布内容。自定义列表,根据提供的账号计算新的列表索引,并以列表的形式展示。定制化支持,还有更多其他数据需求?我们的技术服务人员可以为您提供完全定制的支持和咨询服务。公众号、微博、今日头条、抖音等新媒体账号海量数据采集、历史发布内容海量采集和评论区数据采集。API深度定制,除了在线API接口外,还为开发者提供微信、微博、抖音等新媒体平台数据。
公众号资料下载
微信公众号推荐的数据分析技术有哪些?
目前,公众号拖图数据后台自带的数据包括用户分析、图形分析、菜单分析、消息分析、界面分析、网页分析六大模块。其中,界面分析和网页分析是公众号二次开发后的数据分析(本文未提及)
一、用户分析
在微信公众平台->统计->用户分析中,用户分析数据包括用户增长和用户属性两个数据,通过它可以查看粉丝数量的变化和当前公众平台用户画像。
1、用户增长
(1)核心数据指标
①新关注数:新关注用户数(不包括当天重复关注的用户);
②取消关注的用户数:取消关注的用户数(不包括当天重复取消关注的用户);
③关注人数净增:新增关注人数与未关注人数之差
④ 累计关注数:当前关注的用户总数。
公众号资料下载 查看全部
文章采集api(
公众号数据下载有哪些值得推荐的微信数据分析技巧?)
公众号资料下载服务内容
账号搜索和扩展数据,根据需要查找微信、微博、今日头条、抖音等新媒体平台账号并发布内容。自定义列表,根据提供的账号计算新的列表索引,并以列表的形式展示。定制化支持,还有更多其他数据需求?我们的技术服务人员可以为您提供完全定制的支持和咨询服务。公众号、微博、今日头条、抖音等新媒体账号海量数据采集、历史发布内容海量采集和评论区数据采集。API深度定制,除了在线API接口外,还为开发者提供微信、微博、抖音等新媒体平台数据。
公众号资料下载
微信公众号推荐的数据分析技术有哪些?
目前,公众号拖图数据后台自带的数据包括用户分析、图形分析、菜单分析、消息分析、界面分析、网页分析六大模块。其中,界面分析和网页分析是公众号二次开发后的数据分析(本文未提及)
一、用户分析
在微信公众平台->统计->用户分析中,用户分析数据包括用户增长和用户属性两个数据,通过它可以查看粉丝数量的变化和当前公众平台用户画像。
1、用户增长
(1)核心数据指标
①新关注数:新关注用户数(不包括当天重复关注的用户);
②取消关注的用户数:取消关注的用户数(不包括当天重复取消关注的用户);
③关注人数净增:新增关注人数与未关注人数之差
④ 累计关注数:当前关注的用户总数。
公众号资料下载
文章采集api( 学Python,学Vba?不需要!(一)!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-12-30 07:14
学Python,学Vba?不需要!(一)!)
爬虫,听起来是不是又高又高?
需要学习专业的网络知识吗?需要学Python,学Vba?不必要!
这篇文章教你零基础用Excel完成,
废话少说,直接上实操步骤!
一、注册并获得您自己的密钥
1、禾丰天气是一个开放的网站,你可以直接在百度上搜索。
鹤峰天气网站:
2、新用户注册账号
3、 注册并激活获取密钥后,只需按照以下步骤操作即可。
这样我们就得到了密钥:a684c431c6b840c196a4a2962630b736,作者的账号密钥,读者可以免费申请。
二、阅读API接口文档
1、打开和风天气网站,找到如下页面:
下面会有一个示例请求 URL
#获取北京实时天气
这是付费版本的一个例子。对于免费版,我们需要在api前加上free-,如下图:
2、 我们来看看需要哪些参数,
我们可以看到location和key这两个参数是必须的。
3、返回参数说明
拿到数据后,我们需要了解返回的是什么信息。下面有详细说明供参考:
了解了这些信息后,我们就可以开始使用EXCEL来获取天气信息了。
三、用EXCEL的PQ工具获取结果
1、打开EXCEL 2016,如下输入你要获取的城市名称,插入表格
2、导入表格到POWER QUERY
如果有读者还没有加载这个工具,我们可以在设置中加载:
3、导入后添加自定义列
添加自定义列:
=Web.Contents(""&[区域]&"&Key=a684c431c6b840c196a4a2962630b736")
4、添加自定义列并分析
= Json.Document([自定义])
您将获得以下图片:
我们扩展数据并组织数据。
5、 我们需要的是当前数据,现在展开,然后依次展开
网页上有参数说明,修改请参考网页说明,详细参数及取值说明:
根据上图中的描述,我们把title改成了中文(具体属性根据需要保留)
数据的逆向透视,便于我们观察
只需关闭并上传。
让我们试试吧。将“上海”添加到城市并刷新数据。
完美成功获取上海实时天气情况。
是不是没有你想的那么难,记得自己练习哦!
网站上还有历史天气和风景天气的界面。有兴趣的读者也可以尝试一下。 查看全部
文章采集api(
学Python,学Vba?不需要!(一)!)
爬虫,听起来是不是又高又高?
需要学习专业的网络知识吗?需要学Python,学Vba?不必要!
这篇文章教你零基础用Excel完成,
废话少说,直接上实操步骤!
一、注册并获得您自己的密钥
1、禾丰天气是一个开放的网站,你可以直接在百度上搜索。
鹤峰天气网站:
2、新用户注册账号
3、 注册并激活获取密钥后,只需按照以下步骤操作即可。
这样我们就得到了密钥:a684c431c6b840c196a4a2962630b736,作者的账号密钥,读者可以免费申请。
二、阅读API接口文档
1、打开和风天气网站,找到如下页面:
下面会有一个示例请求 URL
#获取北京实时天气
这是付费版本的一个例子。对于免费版,我们需要在api前加上free-,如下图:
2、 我们来看看需要哪些参数,
我们可以看到location和key这两个参数是必须的。
3、返回参数说明
拿到数据后,我们需要了解返回的是什么信息。下面有详细说明供参考:
了解了这些信息后,我们就可以开始使用EXCEL来获取天气信息了。
三、用EXCEL的PQ工具获取结果
1、打开EXCEL 2016,如下输入你要获取的城市名称,插入表格
2、导入表格到POWER QUERY
如果有读者还没有加载这个工具,我们可以在设置中加载:
3、导入后添加自定义列
添加自定义列:
=Web.Contents(""&[区域]&"&Key=a684c431c6b840c196a4a2962630b736")
4、添加自定义列并分析
= Json.Document([自定义])
您将获得以下图片:
我们扩展数据并组织数据。
5、 我们需要的是当前数据,现在展开,然后依次展开
网页上有参数说明,修改请参考网页说明,详细参数及取值说明:
根据上图中的描述,我们把title改成了中文(具体属性根据需要保留)
数据的逆向透视,便于我们观察
只需关闭并上传。
让我们试试吧。将“上海”添加到城市并刷新数据。
完美成功获取上海实时天气情况。
是不是没有你想的那么难,记得自己练习哦!
网站上还有历史天气和风景天气的界面。有兴趣的读者也可以尝试一下。
文章采集api(数据资产治理(详情见)——元数据提取)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-12-27 08:10
来源:
一、简介
数据资产治理(详见:数据资产、赞智治理)需要数据。它要求数据类型齐全,数量大,并尽可能覆盖数据流通的方方面面。元数据采集
变得尤为重要,它是数据资产治理的核心基础。
在早期的采集系统中,我们主要使用数据仓库通过“API直连方式”采集Hive/Mysql表的元数据。随着业务的快速发展,对数据运营和成本管理的需求越来越强烈。元数据需要覆盖整个数据链路,包括离线计算平台、实时计算平台、内部工具、任务元数据等。在采集
元数据的过程中,我们遇到了以下困难:
本文主要从元数据的意义、提取、采集、监控告警等方面介绍了我们所做的一些事情。
二、元数据2.1 什么是元数据
什么是元数据?元数据是“用于描述数据的数据”。例如:我用手机拍了一张照片,查看了照片的详细信息,如下图:
照片信息
文件名:IMG_20201217_114115
时间:2020年12月17号 11:30:01
分辨率:4608X2592
文件大小:2.69MB
相机制造商:OnePlus
相机型号:ONEPLUS A5000
闪光灯:未使用闪光灯
焦距:4.10mm
白平衡:自动
光圈:f/1.7
曝光时间:1/50
ISO:1250
这些是数码照片的元数据,用于描述图片。在资产管理平台,我们采集
Hive组件的元数据,包括:表名、字段列表、负责人、任务调度信息等。
采集
整个链接的数据(各种元数据)可以帮助数据平台回答:我们有什么数据?有多少人在使用它?什么是数据存储?如何找到这些数据?什么是数据流?结合血缘关系分析问题根源,分析影响。
2.2 采集
了哪些元数据
如下图所示,是一个数据流图。我们主要采集
了各种平台组件:
到目前为止,采集
到的平台组件覆盖了整个数据链路。涵盖10种数据+,基础元数据量10w+。主要包括:
三、元数据提取
如何从众多平台组件中提取元数据?大致有这几个方面:
计算任务通过分析任务的输入/输出依赖配置来获取血缘关系。 SQL类任务使用“Sql Parser”(ANTLR4系统实现的sql重写工具)工具解析SQL脚本,获取表/字段级血缘关系。 3.1个线下平台
主要采集
Hive/RDS表的元数据。
Hive组件的元数据存储在Metastore中,通过JDBC访问Mysql获取数据库表的元数据。根据Hive表信息组装HDFS地址,通过FileSystem API获取文件状态、文件编号、文件大小、数据更新时间等趋势数据。
RDS平台提供Mysql服务的管理,通过平台提供的服务接口获取表元数据、趋势数据、访问状态等信息。
3.2 实时平台
主要是Flume/Hbase/Kafka等组件的元数据。
例如:我们访问KP平台的工单数据,获取topic的基本元数据信息,定时消费topic获取样本数据,解析字段列表。平台本身提供集群状态和业务监控指标,通过平台服务获取集群资源的使用情况。
3.3 个内部工具
主要是BI报表系统的血缘关系(一个BI报表查询的Hive表和Mysql表的关系)、指标库(Hive表和指标关联字段的关系)、OneService服务(哪个数据库表的关系数据)由接口访问)数据。
这些内部系统在产品的不断迭代中积累了大量的元数据。在不考虑元数据的时效性的情况下,我们一般将这些系统的数据同步到Hive数据库中,离线处理后获取元数据。
3.4 任务元数据
元数据任务主要是DP离线任务、Flink计算服务、Flume任务。
这些计算任务都放在磁盘上,通过Binlog同步或者离线同步获取任务列表,获取任务的元数据。
四、数据采集
元数据提取后,我们可以得到整个数据链中各个平台组件的元数据。数据采集是指将这些元数据存储到数据资产管理系统的数据库中。
4.1种采集方式
采集
数据的方式主要有三种。下表列出了三种方式的优缺点:
一般情况下,我们建议业务方使用收购SDK。主动上报元数据,访问时只需要关注上报数据格式和SDK初始化,即可快速完成上报。
4.2采集SDK设计
采集SDK支持基础元数据、趋势数据、血缘关系数据的上报,主要包括客户端SDK和采集服务器两部分。客户端SDK主要实现通用报表模型的定义和报表功能,采集服务器主要实现不同的适配器完成数据的统一存储。
4.2.1 架构
获取SDK客户端
定义了基本元数据(MetaSchema)、趋势数据(TrendSchema)、血缘关系数据(LineageSchema)的通用模型,并支持扩展新的报告模型(XXXSchema)。 ReportService实现了向Kafka推送数据的功能。
采集
服务器
数据鉴权服务器消费Kafka,获取数据后,对每条记录的签名进行鉴权(获取记录中的appId、appName、token信息,重新生成token,比较值的过程)。统一仓储服务定义了统一的数据仓储模型,包括表基础元数据、趋势数据、血缘关系数据、趋势数据,实现不同数据类型的仓储服务。数据适配器Bridge获取Kafka的数据,根据不同的数据类型转换成“统一存储模型”,触发“统一存储服务”完成数据写入。 4.2.2 通用模型
采集
了很多平台组件。我们参考Hive“表模型”的定义,抽象出一套通用的数据上报模型,保证数据上报和数据存储的可扩展性。
通用血缘模型主要包括血缘模型定义和任务血缘模型定义,支持用户分别上报血缘关系和任务血缘关系。模型定义如下:
/**
* 表血缘模型定义
*/
@Data
public class TableLineageSchema {
/**
* 当前节点
*/
private T current;
/**
* 父节点
*/
private List parents;
/**
* 子节点
*/
private List childs;
/**
* 表级别血缘扩展信息,json对象,kv结构
*/
private String extParam;
}
/**
* 表任务血缘定义
*
*/
@Data
public class JobLineageSchema {
/**
* 任务节点对象
*/
private Job task;
/**
* 输入对象列表
*/
private List inputs;
/**
* 输出对象列表
*/
private List outputs;
/**
* 任务级别血缘扩展信息,json对象,kv结构
*/
private String extParam;
}
每个模型定义都有一个扩展字段(常规的 json 格式)。不在定义中的指标可以放在扩展字段中。数据上报后,也会存储在元数据表的扩展字段中。访问新的类型,索引定义大不相同,元数据上报是通过扩展新的数据模型定义来完成的。
4.2.3 访问、验证、限流
如何保证用户上报的数据安全?我们设计了一组签名:访问方Id(appId)、访问名称(appName)、访问标识(token)。管理员填写基本接入方信息,生成随机的appId和token信息。业务方在初始化SDK集合时,指定了签名信息,每上报的数据都会携带签名。在采集服务器上,每条数据都经过签名和认证,保证了数据的安全性。
采集SDK会对每一条上报的数据执行通用规则来检查数据的有效性,比如表名不为空,负责人的有效性,表的大小,趋势数据不能为负数等。如果检测到非法数据,将被过滤掉并触发报警通知。
在采集SDK服务器上,每隔一定时间(每两秒)消费一批Kafka数据。支持设置消费数据的时间间隔和拉取件数,不会因为上报数据的流量高峰而增加下游存储压力。 ,起到限流作用。
4.3 触发获取
我们支持多种元数据采集
方法。如何触发数据采集
?总体思路是:
基于Apollo配置系统(见:Apollo's Praise in Practice)和Linux系统的Crontab功能,实现任务调度。数据采集任务在Apollo上配置。更改配置后,Apollo会发布,配置信息会实时同步到在线节点的Crontab文件中。
4.3.1 增量任务,准实时
支持获取组件最近变化的元数据,配置增量任务,提高元数据采集的实时性。比如增量采集
Hive表元数据,每1分钟查询一次metastore,获取最近变化的元数据列表,并更新元数据。
4.3.2个满任务,走底线
增量采集
可能会出现数据丢失的情况。每 1 天或更多天完成一次完整采集
,作为确保元数据完整性的底线计划。
4.3.3 采集SDK并实时上报
采集SDK支持实时和全量上报模式。一般要求接入方数据实时变化,不定期上报一次满量。
4.4 数据存储、更新
数据采集后,需要考虑如何存储,以及元数据发生变化时如何同步和更新。我们对采集
到的元数据进行分类统一,抽象出“表模型”,分类存储。
4.4.1 数据存储
我们评估了每个组件的元数据量(共10w+),估计了数据可能的使用场景,最终选择了Mysql来存储。为了满足用户个性化的查询需求,构建了Es宽表。表粒度主要包括:表名、备注、负责人、字段列表、趋势信息、业务领域信息、任务信息等,在数据采集过程中同步更新Es表,保证元数据查询的实时性。定期更新(构建离线模型表,每天同步更新Es表),保证元数据的完整性。
元数据中的表不是孤立存在的。一般有关联任务(离线任务、实时任务)输出表,表和任务之间的流向关系也会在数据图中显示。那么如何在众多平台组件中唯一区分一个表呢?我们通过表所在的集群名称、项目名称、表类型(它来自哪个平台组件)和表名称的组合来唯一区分。
数据分类存储,最终形成:基础元数据表、趋势数据表、任务元数据表、血缘关系数据表。
4.4.2 数据更新
元数据表离线,如何更新?
五、监控和警告
完成数据采集后,就全部完成了吗?答案是否定的。在采集过程中,数据种类繁多,删除方式多样,删除链接长度。任何环节的任何问题都会导致结果不准确。我们通过以下方式来保证采集服务的稳定性。
5.1 采集
链路监控告警5.1.1 接口监控
我们将系统的所有服务接口分为核心、重要、通用三个层次,并支持标注接口和责任人的注解。异常会触发不同级别的警报通知。核心业务异常直接触发电话报警,重要或一般业务异常触发电子邮件报警。系统会存储接口请求和执行状态并删除,每天向接口服务负责人发送服务日报。通过将元数据采集服务标记为核心重要服务,“API直连方式”接口异常感知。
如下图是服务接口的告警通知:
[Warning][prod][data-dict] - 数据资产平台告警
你负责的[元信息采集]模块(backup为XXX)出现[重要]等级问题, 方法名:[com.youzan.bigdata.crystal.controller.HiveMetaController.getHiveDb], 异常信息:null
host:XXXXXX
处理地址:https://XXXX
如下图是服务接口的每日报警报表:
[Warning][prod][data-dict] - 数据资产平台告警
[shunfengche]今日问题汇总
请及时收敛今日问题,总问题数 1 个,出现 2 次
【核心】问题 0 个:
【重要】问题 0 个:
【一般】问题 1 个:
[数据采集]com.youzan.bigdata.crystal.controller.HiveMetaController.getHiveDb 今日出现 2 次, 已存在 5 天, 历史出现 8 次
host:XXXXXX
处理地址:https://XXXX
5.1.2 采集过程监控
对于每个元数据采集服务,如果采集过程中出现异常,都会发出警报通知。
如下图,是采集过程中出现异常触发的告警:
[Warning][prod][data-dict] - 数据资产平台告警
你负责的[元信息采集]模块(backup为XXX)出现[一般]等级问题, 方法名:[com.youzan.bigdata.crystal.asyncworker.work.AsyncAllRdsDDLWorker.run], 异常信息:/n
### Error updating database. Cause: com.mysql.jdbc.exceptions.jdbc4.MySQLQueryInterruptedException: Query execution was interrupted
5.1.3 Kafka 消息积压警告
消费Kafka数据,通过kp平台配置消息backlog告警,实现SDK服务采集异常感知。
5.2 结果数据对比
主要用于事后监测预警,定期探索采集的元数据量异常波动。针对不同类型的元数据,通过将当天采集的金额与过去7天的历史平均金额进行比较,设置异常波动的告警阈值,超过阈值时触发告警通知。
根据采集到的元数据结果表,配置一些数据质量检测规则,定期执行异常规则,发现问题数据触发告警通知。这保证了对结果数据的异常感知。例如定义的数据质量规则:
5.3 项目迭代机制,集合问题收敛
通过事前、事中、事后的监测预警机制,及时发现和感知采集异常。对于异常问题,我们一般以项目迭代的方式发起jira,组织相关人员进行审核。追根溯源,讨论改进方案,制定行动,关注并持续收敛问题。
六、总结与展望6.1 结论
我们定义了一套通用的数据采集和存储模型,支持访问不同数据类型的元数据,支持多种访问方式。采集SDK提高了数据的访问效率和时效性。
如下图所示,已经访问了各个组件的元数据,统一管理数据,提供数据字典、数据地图、资产盘点、全局成本计费等元数据应用。
如果将数据资产治理比作高层建筑的建设,那么不同构件的元数据是原材料,数据采集是基础。只有夯实了基础,数据治理的建设才能越来越稳固。
6.2 展望
在数据采集
的过程中,我们也遇到了很多问题。在后续工作中,我们需要不断的优化和功能迭代,包括但不限于: 查看全部
文章采集api(数据资产治理(详情见)——元数据提取)
来源:
一、简介
数据资产治理(详见:数据资产、赞智治理)需要数据。它要求数据类型齐全,数量大,并尽可能覆盖数据流通的方方面面。元数据采集
变得尤为重要,它是数据资产治理的核心基础。
在早期的采集系统中,我们主要使用数据仓库通过“API直连方式”采集Hive/Mysql表的元数据。随着业务的快速发展,对数据运营和成本管理的需求越来越强烈。元数据需要覆盖整个数据链路,包括离线计算平台、实时计算平台、内部工具、任务元数据等。在采集
元数据的过程中,我们遇到了以下困难:
本文主要从元数据的意义、提取、采集、监控告警等方面介绍了我们所做的一些事情。
二、元数据2.1 什么是元数据
什么是元数据?元数据是“用于描述数据的数据”。例如:我用手机拍了一张照片,查看了照片的详细信息,如下图:
照片信息
文件名:IMG_20201217_114115
时间:2020年12月17号 11:30:01
分辨率:4608X2592
文件大小:2.69MB
相机制造商:OnePlus
相机型号:ONEPLUS A5000
闪光灯:未使用闪光灯
焦距:4.10mm
白平衡:自动
光圈:f/1.7
曝光时间:1/50
ISO:1250
这些是数码照片的元数据,用于描述图片。在资产管理平台,我们采集
Hive组件的元数据,包括:表名、字段列表、负责人、任务调度信息等。
采集
整个链接的数据(各种元数据)可以帮助数据平台回答:我们有什么数据?有多少人在使用它?什么是数据存储?如何找到这些数据?什么是数据流?结合血缘关系分析问题根源,分析影响。
2.2 采集
了哪些元数据
如下图所示,是一个数据流图。我们主要采集
了各种平台组件:
到目前为止,采集
到的平台组件覆盖了整个数据链路。涵盖10种数据+,基础元数据量10w+。主要包括:
三、元数据提取
如何从众多平台组件中提取元数据?大致有这几个方面:
计算任务通过分析任务的输入/输出依赖配置来获取血缘关系。 SQL类任务使用“Sql Parser”(ANTLR4系统实现的sql重写工具)工具解析SQL脚本,获取表/字段级血缘关系。 3.1个线下平台
主要采集
Hive/RDS表的元数据。
Hive组件的元数据存储在Metastore中,通过JDBC访问Mysql获取数据库表的元数据。根据Hive表信息组装HDFS地址,通过FileSystem API获取文件状态、文件编号、文件大小、数据更新时间等趋势数据。
RDS平台提供Mysql服务的管理,通过平台提供的服务接口获取表元数据、趋势数据、访问状态等信息。
3.2 实时平台
主要是Flume/Hbase/Kafka等组件的元数据。
例如:我们访问KP平台的工单数据,获取topic的基本元数据信息,定时消费topic获取样本数据,解析字段列表。平台本身提供集群状态和业务监控指标,通过平台服务获取集群资源的使用情况。
3.3 个内部工具
主要是BI报表系统的血缘关系(一个BI报表查询的Hive表和Mysql表的关系)、指标库(Hive表和指标关联字段的关系)、OneService服务(哪个数据库表的关系数据)由接口访问)数据。
这些内部系统在产品的不断迭代中积累了大量的元数据。在不考虑元数据的时效性的情况下,我们一般将这些系统的数据同步到Hive数据库中,离线处理后获取元数据。
3.4 任务元数据
元数据任务主要是DP离线任务、Flink计算服务、Flume任务。
这些计算任务都放在磁盘上,通过Binlog同步或者离线同步获取任务列表,获取任务的元数据。
四、数据采集
元数据提取后,我们可以得到整个数据链中各个平台组件的元数据。数据采集是指将这些元数据存储到数据资产管理系统的数据库中。
4.1种采集方式
采集
数据的方式主要有三种。下表列出了三种方式的优缺点:
一般情况下,我们建议业务方使用收购SDK。主动上报元数据,访问时只需要关注上报数据格式和SDK初始化,即可快速完成上报。
4.2采集SDK设计
采集SDK支持基础元数据、趋势数据、血缘关系数据的上报,主要包括客户端SDK和采集服务器两部分。客户端SDK主要实现通用报表模型的定义和报表功能,采集服务器主要实现不同的适配器完成数据的统一存储。
4.2.1 架构
获取SDK客户端
定义了基本元数据(MetaSchema)、趋势数据(TrendSchema)、血缘关系数据(LineageSchema)的通用模型,并支持扩展新的报告模型(XXXSchema)。 ReportService实现了向Kafka推送数据的功能。
采集
服务器
数据鉴权服务器消费Kafka,获取数据后,对每条记录的签名进行鉴权(获取记录中的appId、appName、token信息,重新生成token,比较值的过程)。统一仓储服务定义了统一的数据仓储模型,包括表基础元数据、趋势数据、血缘关系数据、趋势数据,实现不同数据类型的仓储服务。数据适配器Bridge获取Kafka的数据,根据不同的数据类型转换成“统一存储模型”,触发“统一存储服务”完成数据写入。 4.2.2 通用模型
采集
了很多平台组件。我们参考Hive“表模型”的定义,抽象出一套通用的数据上报模型,保证数据上报和数据存储的可扩展性。
通用血缘模型主要包括血缘模型定义和任务血缘模型定义,支持用户分别上报血缘关系和任务血缘关系。模型定义如下:
/**
* 表血缘模型定义
*/
@Data
public class TableLineageSchema {
/**
* 当前节点
*/
private T current;
/**
* 父节点
*/
private List parents;
/**
* 子节点
*/
private List childs;
/**
* 表级别血缘扩展信息,json对象,kv结构
*/
private String extParam;
}
/**
* 表任务血缘定义
*
*/
@Data
public class JobLineageSchema {
/**
* 任务节点对象
*/
private Job task;
/**
* 输入对象列表
*/
private List inputs;
/**
* 输出对象列表
*/
private List outputs;
/**
* 任务级别血缘扩展信息,json对象,kv结构
*/
private String extParam;
}
每个模型定义都有一个扩展字段(常规的 json 格式)。不在定义中的指标可以放在扩展字段中。数据上报后,也会存储在元数据表的扩展字段中。访问新的类型,索引定义大不相同,元数据上报是通过扩展新的数据模型定义来完成的。
4.2.3 访问、验证、限流
如何保证用户上报的数据安全?我们设计了一组签名:访问方Id(appId)、访问名称(appName)、访问标识(token)。管理员填写基本接入方信息,生成随机的appId和token信息。业务方在初始化SDK集合时,指定了签名信息,每上报的数据都会携带签名。在采集服务器上,每条数据都经过签名和认证,保证了数据的安全性。
采集SDK会对每一条上报的数据执行通用规则来检查数据的有效性,比如表名不为空,负责人的有效性,表的大小,趋势数据不能为负数等。如果检测到非法数据,将被过滤掉并触发报警通知。
在采集SDK服务器上,每隔一定时间(每两秒)消费一批Kafka数据。支持设置消费数据的时间间隔和拉取件数,不会因为上报数据的流量高峰而增加下游存储压力。 ,起到限流作用。
4.3 触发获取
我们支持多种元数据采集
方法。如何触发数据采集
?总体思路是:
基于Apollo配置系统(见:Apollo's Praise in Practice)和Linux系统的Crontab功能,实现任务调度。数据采集任务在Apollo上配置。更改配置后,Apollo会发布,配置信息会实时同步到在线节点的Crontab文件中。
4.3.1 增量任务,准实时
支持获取组件最近变化的元数据,配置增量任务,提高元数据采集的实时性。比如增量采集
Hive表元数据,每1分钟查询一次metastore,获取最近变化的元数据列表,并更新元数据。
4.3.2个满任务,走底线
增量采集
可能会出现数据丢失的情况。每 1 天或更多天完成一次完整采集
,作为确保元数据完整性的底线计划。
4.3.3 采集SDK并实时上报
采集SDK支持实时和全量上报模式。一般要求接入方数据实时变化,不定期上报一次满量。
4.4 数据存储、更新
数据采集后,需要考虑如何存储,以及元数据发生变化时如何同步和更新。我们对采集
到的元数据进行分类统一,抽象出“表模型”,分类存储。
4.4.1 数据存储
我们评估了每个组件的元数据量(共10w+),估计了数据可能的使用场景,最终选择了Mysql来存储。为了满足用户个性化的查询需求,构建了Es宽表。表粒度主要包括:表名、备注、负责人、字段列表、趋势信息、业务领域信息、任务信息等,在数据采集过程中同步更新Es表,保证元数据查询的实时性。定期更新(构建离线模型表,每天同步更新Es表),保证元数据的完整性。
元数据中的表不是孤立存在的。一般有关联任务(离线任务、实时任务)输出表,表和任务之间的流向关系也会在数据图中显示。那么如何在众多平台组件中唯一区分一个表呢?我们通过表所在的集群名称、项目名称、表类型(它来自哪个平台组件)和表名称的组合来唯一区分。
数据分类存储,最终形成:基础元数据表、趋势数据表、任务元数据表、血缘关系数据表。
4.4.2 数据更新
元数据表离线,如何更新?
五、监控和警告
完成数据采集后,就全部完成了吗?答案是否定的。在采集过程中,数据种类繁多,删除方式多样,删除链接长度。任何环节的任何问题都会导致结果不准确。我们通过以下方式来保证采集服务的稳定性。
5.1 采集
链路监控告警5.1.1 接口监控
我们将系统的所有服务接口分为核心、重要、通用三个层次,并支持标注接口和责任人的注解。异常会触发不同级别的警报通知。核心业务异常直接触发电话报警,重要或一般业务异常触发电子邮件报警。系统会存储接口请求和执行状态并删除,每天向接口服务负责人发送服务日报。通过将元数据采集服务标记为核心重要服务,“API直连方式”接口异常感知。
如下图是服务接口的告警通知:
[Warning][prod][data-dict] - 数据资产平台告警
你负责的[元信息采集]模块(backup为XXX)出现[重要]等级问题, 方法名:[com.youzan.bigdata.crystal.controller.HiveMetaController.getHiveDb], 异常信息:null
host:XXXXXX
处理地址:https://XXXX
如下图是服务接口的每日报警报表:
[Warning][prod][data-dict] - 数据资产平台告警
[shunfengche]今日问题汇总
请及时收敛今日问题,总问题数 1 个,出现 2 次
【核心】问题 0 个:
【重要】问题 0 个:
【一般】问题 1 个:
[数据采集]com.youzan.bigdata.crystal.controller.HiveMetaController.getHiveDb 今日出现 2 次, 已存在 5 天, 历史出现 8 次
host:XXXXXX
处理地址:https://XXXX
5.1.2 采集过程监控
对于每个元数据采集服务,如果采集过程中出现异常,都会发出警报通知。
如下图,是采集过程中出现异常触发的告警:
[Warning][prod][data-dict] - 数据资产平台告警
你负责的[元信息采集]模块(backup为XXX)出现[一般]等级问题, 方法名:[com.youzan.bigdata.crystal.asyncworker.work.AsyncAllRdsDDLWorker.run], 异常信息:/n
### Error updating database. Cause: com.mysql.jdbc.exceptions.jdbc4.MySQLQueryInterruptedException: Query execution was interrupted
5.1.3 Kafka 消息积压警告
消费Kafka数据,通过kp平台配置消息backlog告警,实现SDK服务采集异常感知。
5.2 结果数据对比
主要用于事后监测预警,定期探索采集的元数据量异常波动。针对不同类型的元数据,通过将当天采集的金额与过去7天的历史平均金额进行比较,设置异常波动的告警阈值,超过阈值时触发告警通知。
根据采集到的元数据结果表,配置一些数据质量检测规则,定期执行异常规则,发现问题数据触发告警通知。这保证了对结果数据的异常感知。例如定义的数据质量规则:
5.3 项目迭代机制,集合问题收敛
通过事前、事中、事后的监测预警机制,及时发现和感知采集异常。对于异常问题,我们一般以项目迭代的方式发起jira,组织相关人员进行审核。追根溯源,讨论改进方案,制定行动,关注并持续收敛问题。
六、总结与展望6.1 结论
我们定义了一套通用的数据采集和存储模型,支持访问不同数据类型的元数据,支持多种访问方式。采集SDK提高了数据的访问效率和时效性。
如下图所示,已经访问了各个组件的元数据,统一管理数据,提供数据字典、数据地图、资产盘点、全局成本计费等元数据应用。
如果将数据资产治理比作高层建筑的建设,那么不同构件的元数据是原材料,数据采集是基础。只有夯实了基础,数据治理的建设才能越来越稳固。
6.2 展望
在数据采集
的过程中,我们也遇到了很多问题。在后续工作中,我们需要不断的优化和功能迭代,包括但不限于:
文章采集api(数据科学:Python好用框架的目的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-12-27 08:08
说到ApacheSPark框架,数据科学(网络)社区分为两大阵营:有的认为Scala好用,有的认为Python好用。本文旨在比较两者的优缺点,供大家参考。
ApacheSPark 是目前最流行的大数据分析框架(一)。它可以提供对 Scala、Python、Java 和 R 语言的 API 支持,但本文只讨论前两种语言。因为 Java 没有支持读写-评估-输出这个循环,R语言的普及度不高。前两个认为Scala好用的人说用Scala写ApacheSPark非常快。而且,作为静态类型的语音,Scala已经被编译并收录
在JVM(Java虚拟机)中。笔者认为每种方法都有其优缺点,最终的选择应该取决于应用程序的类型。
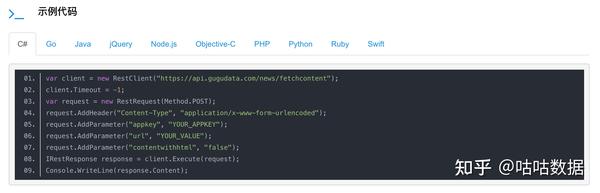
性能
Scala 通常比 Python 快 10 倍左右。 (因为JVM技术支持Scala语言的操作。)相比之下,Python作为动态语言,速度要慢很多。因为在 Python 中调用 ApacheSPark 库需要大量的代码处理。所以在性能上,Scala更适合调用有限的数据库。
另外,Scala基于JVM技术,植根于Hadoop框架下的HDFS文件系统,因此与Hadoop框架具有非常好的交互和兼容性。相比之下,Python 和 Hadoop 框架之间的交互是可怕的。开发者甚至不得不使用第三方插件(如hadopy)。
学习曲线
两种语言都是函数式的、面向对象的语言,而且它们的语法结构相似。与 Python 相比,Scala 可能更复杂,因为它具有更高级的功能。 Python 适合于简单的逻辑处理,而 Scala 更适合于复杂的工作流。但是Python也不是没用,因为Python的语法简单,库也比较标准。
并发
Scala 拥有多个标准库,支持大数据生态系统中数据库的快速集成。它可以使用多个并发原语来编写代码,而 Python 不支持并发或多线程编写代码。但是,Python 支持重量级进程分支。只是一次只能激活一个线程。而且每次写新代码,都必须重启其他进程,这无疑会增加内存使用。
实用性
Python 的特点是简单易用。 Scala 在框架、库、隐式和宏方面有很大的优势。这也是 Scala 在 MapReduce 框架中表现出色的原因。由于 Scala 的 API 集合是一致的,因此许多 Scala 数据框架都遵循相似的数据类型。开发者只需学习其常用的标准库,即可轻松掌握其他库。 ApacheSPark 是用 Scala 编写的,所以了解 Scala 也可以帮助你认识和修改 ApacheSPark 的内部功能。但是对于 NLP,Python 是首选。 (因为 Scala 缺少机器学习或 NLP 的工具。)此外,Python 也是 GraphX、GraphFrames 和 MLLib 的最佳选择。 Python 的可视化库是对 Pyspark 的补充。这是 ApacheSPark 和 Scala 都没有的东西。
代码恢复和安全
Scala 是一种静态语言,它支持我们在编译过程中发现错误。而 Python 是一种动态语言。换句话说,每次更改现有代码时,Python 语音都更容易出错。因此,在 Scala 中重构代码比在 Python 中重构更容易。
结论
Python 运行缓慢,但很容易上手。 Scala 是最快的编程语言,学习能力中等。 Scala 可以帮助您更全面地了解 ApacheSPark,因为 ApacheSPark 是用 Scala 编写的(但并非绝对)。要知道,编程语言的选择取决于项目的特点,我们要根据项目的特点灵活选择。 Python面向分析,Scala面向工程,但这两种语言都是构建数据科学应用的优秀语言。总的来说,Scala 可以充分利用 ApacheSPark 的特性。 查看全部
文章采集api(数据科学:Python好用框架的目的)
说到ApacheSPark框架,数据科学(网络)社区分为两大阵营:有的认为Scala好用,有的认为Python好用。本文旨在比较两者的优缺点,供大家参考。
ApacheSPark 是目前最流行的大数据分析框架(一)。它可以提供对 Scala、Python、Java 和 R 语言的 API 支持,但本文只讨论前两种语言。因为 Java 没有支持读写-评估-输出这个循环,R语言的普及度不高。前两个认为Scala好用的人说用Scala写ApacheSPark非常快。而且,作为静态类型的语音,Scala已经被编译并收录
在JVM(Java虚拟机)中。笔者认为每种方法都有其优缺点,最终的选择应该取决于应用程序的类型。
性能
Scala 通常比 Python 快 10 倍左右。 (因为JVM技术支持Scala语言的操作。)相比之下,Python作为动态语言,速度要慢很多。因为在 Python 中调用 ApacheSPark 库需要大量的代码处理。所以在性能上,Scala更适合调用有限的数据库。
另外,Scala基于JVM技术,植根于Hadoop框架下的HDFS文件系统,因此与Hadoop框架具有非常好的交互和兼容性。相比之下,Python 和 Hadoop 框架之间的交互是可怕的。开发者甚至不得不使用第三方插件(如hadopy)。
学习曲线
两种语言都是函数式的、面向对象的语言,而且它们的语法结构相似。与 Python 相比,Scala 可能更复杂,因为它具有更高级的功能。 Python 适合于简单的逻辑处理,而 Scala 更适合于复杂的工作流。但是Python也不是没用,因为Python的语法简单,库也比较标准。
并发
Scala 拥有多个标准库,支持大数据生态系统中数据库的快速集成。它可以使用多个并发原语来编写代码,而 Python 不支持并发或多线程编写代码。但是,Python 支持重量级进程分支。只是一次只能激活一个线程。而且每次写新代码,都必须重启其他进程,这无疑会增加内存使用。
实用性
Python 的特点是简单易用。 Scala 在框架、库、隐式和宏方面有很大的优势。这也是 Scala 在 MapReduce 框架中表现出色的原因。由于 Scala 的 API 集合是一致的,因此许多 Scala 数据框架都遵循相似的数据类型。开发者只需学习其常用的标准库,即可轻松掌握其他库。 ApacheSPark 是用 Scala 编写的,所以了解 Scala 也可以帮助你认识和修改 ApacheSPark 的内部功能。但是对于 NLP,Python 是首选。 (因为 Scala 缺少机器学习或 NLP 的工具。)此外,Python 也是 GraphX、GraphFrames 和 MLLib 的最佳选择。 Python 的可视化库是对 Pyspark 的补充。这是 ApacheSPark 和 Scala 都没有的东西。
代码恢复和安全
Scala 是一种静态语言,它支持我们在编译过程中发现错误。而 Python 是一种动态语言。换句话说,每次更改现有代码时,Python 语音都更容易出错。因此,在 Scala 中重构代码比在 Python 中重构更容易。
结论
Python 运行缓慢,但很容易上手。 Scala 是最快的编程语言,学习能力中等。 Scala 可以帮助您更全面地了解 ApacheSPark,因为 ApacheSPark 是用 Scala 编写的(但并非绝对)。要知道,编程语言的选择取决于项目的特点,我们要根据项目的特点灵活选择。 Python面向分析,Scala面向工程,但这两种语言都是构建数据科学应用的优秀语言。总的来说,Scala 可以充分利用 ApacheSPark 的特性。
文章采集api(数据具体的采集方案是什么?四种数据采集方法对比 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-12-20 16:07
)
根据企业生产经营过程中产生的数据类型,提供链接标记、SDK、API三种采集方法,以及基于UTSE数据采集模型用户的全生命周期。
那么,对于数据的具体采集计划是什么?
四种数据采集方法的比较
数据采集是通过埋点实现的。诸葛io提供了非常完善的数据访问方案,支持代码埋点、全埋点、可视化埋点、服务端埋点等多种数据方式。
1.代码埋点
说明:嵌入SDK定义事件并添加事件代码是常用的数据采集方法,主要包括网页和h5页面的JS嵌入点、移动iOS、Android嵌入点、微信小程序等。
优点:按需采集,业务信息更完整,数据分析更有针对性,数据采集全面准确,便于后续深入分析。
缺点:需要研发人员配合,有一定的工作量。
2.所有埋点
说明:通过SDK,自动采集页面上所有可点击元素的操作数据,无需定义事件,适用于衡量事件页面、登陆页面、关键页面的设计体验。
优点:更简单快捷,可以看到页面元素的点击量,更好的了解自己产品的特点。
缺点:采集中数据太多,只要是可点击元素,就会采集,上传大量数据,消耗大量流量。无法通过采集获取更深的维度信息,比如事件的属性、用户的属性等。
3.埋点可视化
注:目视埋点以全埋点为准。技术同事整合后,业务同事需要圈出页面的元素,选中的元素为采集。
优点:界面化配置,无需开发,内嵌点更新方便,见效快。
缺点:对自定义属性的支持范围比较有限;重构或页面变化时需要重新配置。
4.服务端埋点
说明:通过API,将存储在服务器上的数据结构化,支持其他业务数据采集和集成,如CRM等用户数据,通过接口调用,将数据结构化,适合其自己使用采集能力客户。
优点:服务器埋点更有针对性,数据更准确,减少了代码埋点发布版本的过程,数据上传更及时。
缺点:用户一些简单的操作,比如点击按钮、切换模块,数据不能采集,用户行为不完整。
总结:以上是诸葛io提供的四种数据采集方案:代码埋点、全埋点、可视化埋点、服务端埋点,数据采集的目的是满足< @采集 然后进行精细化分析和运营需求。只有达到这个目标,才有可能选择一种或多种采集形式的组合。在企业业务中,选择哪种采集方式要根据企业的具体业务需求来决定。.
查看全部
文章采集api(数据具体的采集方案是什么?四种数据采集方法对比
)
根据企业生产经营过程中产生的数据类型,提供链接标记、SDK、API三种采集方法,以及基于UTSE数据采集模型用户的全生命周期。
那么,对于数据的具体采集计划是什么?

四种数据采集方法的比较
数据采集是通过埋点实现的。诸葛io提供了非常完善的数据访问方案,支持代码埋点、全埋点、可视化埋点、服务端埋点等多种数据方式。
1.代码埋点
说明:嵌入SDK定义事件并添加事件代码是常用的数据采集方法,主要包括网页和h5页面的JS嵌入点、移动iOS、Android嵌入点、微信小程序等。
优点:按需采集,业务信息更完整,数据分析更有针对性,数据采集全面准确,便于后续深入分析。
缺点:需要研发人员配合,有一定的工作量。
2.所有埋点
说明:通过SDK,自动采集页面上所有可点击元素的操作数据,无需定义事件,适用于衡量事件页面、登陆页面、关键页面的设计体验。
优点:更简单快捷,可以看到页面元素的点击量,更好的了解自己产品的特点。
缺点:采集中数据太多,只要是可点击元素,就会采集,上传大量数据,消耗大量流量。无法通过采集获取更深的维度信息,比如事件的属性、用户的属性等。
3.埋点可视化
注:目视埋点以全埋点为准。技术同事整合后,业务同事需要圈出页面的元素,选中的元素为采集。
优点:界面化配置,无需开发,内嵌点更新方便,见效快。
缺点:对自定义属性的支持范围比较有限;重构或页面变化时需要重新配置。
4.服务端埋点
说明:通过API,将存储在服务器上的数据结构化,支持其他业务数据采集和集成,如CRM等用户数据,通过接口调用,将数据结构化,适合其自己使用采集能力客户。
优点:服务器埋点更有针对性,数据更准确,减少了代码埋点发布版本的过程,数据上传更及时。
缺点:用户一些简单的操作,比如点击按钮、切换模块,数据不能采集,用户行为不完整。
总结:以上是诸葛io提供的四种数据采集方案:代码埋点、全埋点、可视化埋点、服务端埋点,数据采集的目的是满足< @采集 然后进行精细化分析和运营需求。只有达到这个目标,才有可能选择一种或多种采集形式的组合。在企业业务中,选择哪种采集方式要根据企业的具体业务需求来决定。.

文章采集api(咕咕数据预览:/news/wxarticlecover()(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-19 21:04
请求示例:/news/wxarticlecover?appkey=YOUR_APPKEY&url=YOUR_VALUE
数据预览:/preview/wxarticlecover
界面测试:/news/wxarticlecover/demo
3. 请求参数(如果是POST请求,参数以JSON格式传递)
4. 返回参数
5. 接口响应状态码
6. 开发语言请求示例代码
示例代码中收录的开发语言:C#、Go、Java、jQuery、Node.js、Objective-C、PHP、Python、Ruby、Swift等,其他语言可以通过相应的RESTful API请求实现。
布谷鸟数据,专业的数据提供商,提供专业全面的数据接口和业务数据分析,让数据成为您的生产原材料。
布谷鸟数据基于我们过去五年为企业客户提供的海量数据支持。将一些通用数据和通用功能抽象为产品级API,极大地满足了用户在产品开发过程中对基础数据的需求,降低了复杂功能的复杂度。实现门槛和人工成本。
除了我们开放的分类数据和接口,还有海量的数据在整理、清洗、整合、构建。后续会开放更多的数据和云功能接口供用户使用。
目前开放的数据接口API 查看全部
文章采集api(咕咕数据预览:/news/wxarticlecover()(图))
请求示例:/news/wxarticlecover?appkey=YOUR_APPKEY&url=YOUR_VALUE
数据预览:/preview/wxarticlecover
界面测试:/news/wxarticlecover/demo
3. 请求参数(如果是POST请求,参数以JSON格式传递)

4. 返回参数

5. 接口响应状态码
6. 开发语言请求示例代码
示例代码中收录的开发语言:C#、Go、Java、jQuery、Node.js、Objective-C、PHP、Python、Ruby、Swift等,其他语言可以通过相应的RESTful API请求实现。
布谷鸟数据,专业的数据提供商,提供专业全面的数据接口和业务数据分析,让数据成为您的生产原材料。

布谷鸟数据基于我们过去五年为企业客户提供的海量数据支持。将一些通用数据和通用功能抽象为产品级API,极大地满足了用户在产品开发过程中对基础数据的需求,降低了复杂功能的复杂度。实现门槛和人工成本。
除了我们开放的分类数据和接口,还有海量的数据在整理、清洗、整合、构建。后续会开放更多的数据和云功能接口供用户使用。
目前开放的数据接口API
文章采集api(搭建一套前端监控平台需要考虑的几个问题?|本文)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-11-29 02:05
随着业务的快速发展,我们越来越重视生产环境中的问题感知能力。作为离用户最近的一层,前端性能是否可靠、稳定、易用,在很大程度上决定了用户对整个产品的体验和感受。因此,前端的监控不容忽视。
搭建前端监控平台需要考虑的方面有很多,比如数据采集、埋点模式、数据处理分析、告警、监控平台在具体业务中的应用等。在所有这些环节中,准确、完整、全面的数据采集是一切的前提,也为用户后续精细化操作提供了基础。
前端技术的飞速发展也给数据带来了变化和挑战采集。传统的人工管理模式已不能满足需求。如何让前端数据采集在新的技术背景下工作更完整、更高效,是本文的重点。
前端监控数据采集
在采集数据之前,我们首先要考虑采集是什么样的数据。我们关注两类数据,一类是与用户体验相关的数据,比如首屏时间、文件加载时间、页面性能等;另一个是帮助我们及时感知产品上线后是否有异常,比如资源错误、API响应时间等。具体来说,我们的前端数据采集具体分为:
路由交换机
Vue、React、Angular 等前端技术的快速发展,使得单页应用大行其道。我们都知道传统的页面应用使用一些超链接来实现页面切换和跳转,而单页面应用则使用自己的路由系统来管理前端的各个页面切换,比如vue-router、react-router等,跳转时只刷新部分资源,js、css等公共资源只需要加载一次,这就使得传统网页的进出方式只能在第一次打开时记录。单页应用所有后续路由的切换有两种方式,一种是Hash,一种是HTML5推出的History API。
1. href
href是页面初始化的第一个入口,这里只需要上报“页面入口”事件即可。
2. 哈希变化
哈希路由的一个明显标志是带有“#”。Hash 的优点是兼容性比较好,但问题是 URL 中总有一个“#”,不美观。我们主要是监控URL中的hashchange,捕获具体的hash值进行检测。
window.addEventListener('hashchange', function() {
// 上报【进入页面】事件
}, true)
需要注意的是,在新版本的vue-router中,如果浏览器支持history,即使选择了hash模式,也会先选择history模式。虽然表达式暂时还是#,但实际上是模拟的,所以不要以为你在模式选择hash的时候就会是hash。
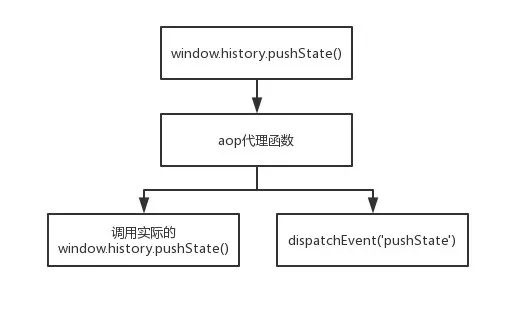
3. 历史 API
History使用HTML5 History Interface中新增的pushState()和replaceState()方法进行路由切换,是目前主流的非刷新切换路由方式。相比hashchange后面的代码片段只能改#,History API(pushState、replaceState)给了前端完全的自由。
PopState是浏览器返回事件的回调,但是update路由的pushState和replaceState没有回调事件。因此,需要分别在 history.pushState() 和 history.replaceState() 方法中处理 URL 更改。在这里,我们使用了类似Java的AOP编程思想来转换pushState和replaceState。
AOP(Aspect-Oriented Programming)是指面向方面的编程,主张对同一类型的问题进行统一处理。AOP的核心思想是允许某个模块被复用。它采用横向抽取机制,将功能代码与业务逻辑代码分离,在不修改源代码的情况下扩展功能,隔离比封装更彻底。
下面介绍我们具体的改造方法:
// 第一阶段:我们对原生方法进行包装,调用前执行 dispatchEvent 了一个同样的事件
function aop (type) {
var source = window.history[type];
return function () {
var event = new Event(type);
event.arguments = arguments;
window.dispatchEvent(event);
var rewrite = source.apply(this, arguments);
return rewrite;
};
}
// 第二阶段:将 pushState 和 replaceState 进行基于 AOP 思想的代码注入
window.history.pushState = aop('pushState');
window.history.replaceState = aop('replaceState'); // 更改路由,不会留下历史记录
// 第三阶段:捕获pushState 和 replaceState
window.addEventListener('pushState', function() {
// 上报【进入页面】事件
}, true)
window.addEventListener('replaceState', function() {
// 上报【进入页面】事件
}, true)
window.history.pushState的实际调用关系如图:
至此,我们就完成了pushState和replaceState的转换,实现了路由切换的有效捕获。可以看出,我们在不侵入业务代码的情况下扩展了window.history.pushState,调用时会主动dispatchEvent一个pushState。
但是这里我们也可以看到一个缺点,就是如果AOP代理函数出现JS错误,会阻塞后续的调用关系,导致无法调用实际的window.history.pushState。所以在使用这种方式的时候,应该对AOP代理功能的内容做一个完整的try catch,防止业务出现异常。
_*_Tips:如果要自动捕捉页面停留时间,只需要计算下一页进入事件触发时上一页的tick时间与当前时间的差值即可。这时候可以举报【离开页面】事件。
错误
在前端项目中,由于JavaScript本身是弱类型语言,加上浏览器环境的复杂、网络问题等,容易出现错误。因此,做好网页错误的监控,不断优化代码,提高代码的健壮性是非常重要的。
JsError的捕获可以帮助我们分析和监控在线问题,与我们在Chrome浏览器的调试工具Console中看到的一致。
1. window.onerror
我们一般使用 window.onerror 来捕获 JS 错误的异常信息。有两种方法可以捕获 JS 错误,window.onerror 和 window.addEventListener('error')。一般情况下,不推荐使用addEventListener('error')来捕捉JS异常,主要是它没有栈信息,需要区分捕捉到的信息,因为它会捕捉到所有的异常信息,包括资源加载错误等等。
window.onerror = function (msg, url, lineno, colno, stack) {
// 上报 【js错误】事件
}
2. 未捕获(承诺)
当Promise发生JS错误或者业务没有处理reject信息时,会抛出unhandledrejection,window.onerror和window.addEventListener('error')不会捕捉到这个错误。这里需要一个特殊的窗口。addEventListener('unhandledrejection') 用于捕获处理:
window.addEventListener('unhandledrejection', function (e) {
var reg_url = /\(([^)]*)\)/;
var fileMsg = e.reason.stack.split('\n')[1].match(reg_url)[1];
var fileArr = fileMsg.split(':');
var lineno = fileArr[fileArr.length - 2];
var colno = fileArr[fileArr.length - 1];
var url = fileMsg.slice(0, -lno.length - cno.length - 2);}, true);
var msg = e.reason.message;
// 上报 【js错误】事件
}
我们注意到,因为 unhandledrejection 继承自 PromiseRejectionEvent 和 PromiseRejectionEvent 继承自 Event,msg、url、lineno、colno、stack 以字符串的形式放在 e.reason.stack 中。我们需要解析出上面的参数来与 onerror 参数对齐。为后续监测平台各项指标的统一奠定基础。
3.常见问题
如果抓到的msg都是“Script error.”,问题是你的JS地址和当前网页不在同一个域。因为我们经常需要对网络版做静态资源CDN化,会导致经常访问的页面和脚本文件来自不同的域名。如果此时不进行额外的配置,浏览器很容易出现“脚本错误”。由于安全设计。我们可以使用目前流行的Webpack打包工具来处理此类问题。
// webpack config 配置
// 处理 html 注入 js 添加跨域标识
plugins: [
new HtmlWebpackPlugin({
filename: 'html/index.html',
template: HTML_PATH,
attributes: {
crossorigin: 'anonymous'
}
}),
new HtmlWebpackPluginCrossorigin({
inject: true
})
]
// 处理按需加载的 js 添加跨域标识
output: {
crossOriginLoading: true
}
大多数场景下,生产环境中的代码都是经过压缩和合并的,这使得我们捕捉到的错误很难映射到具体的源代码上,给我们解决问题带来了很大的麻烦。这里简单介绍2个解决思路。
在生产环境中,我们需要添加sourceMap的配置,这会造成安全隐患,因为外网可以通过sourceMap映射源代码。为了降低风险,我们可以做到以下几点:
设置sourceMap生成的.map文件访问公司内网,降低源代码安全风险
将代码发布到CDN时,将.map文件存放在公司内网下
这时候我们已经有了 .map 文件。后面我们要做的就是调用mozilla/source-map库,通过抓到的lineno、colno、url来映射源码,然后我们就可以得到真正的源码错误信息了。
表现
性能指标的获取比较简单,只需要在onload后读取window.performance,里面收录性能、内存等信息。这部分内容在很多现有的文章中都有介绍。限于篇幅,本文不会展开过多。稍后我们将在相关话题文章中进行相关讨论。感兴趣的朋友可以添加“马蜂窝技术”公众号继续关注。
资源错误
首先需要明确资源错误捕获的使用场景,更多的是感知DNS劫持、CDN节点异常等,具体方法如下:
window.addEventListener('error', function (e) {
var target = e.target || e.srcElement;
if (target instanceof HTMLScriptElement) {
// 上报 【资源错误】事件
}
}, true)
这里只是一个基本的演示。在实际环境中,我们会关心更多的Element错误,比如css、img、woff等,可以根据不同的场景添加。
_*资源错误的使用场景更多地依赖于其他几个维度,例如:_region、operator等,我们将在后面的页面中详细说明。
应用程序接口
在市面上的主流框架(如Axios、jQuery.ajax等)中,基本上所有的API请求都是基于xmlHttpRequest或者fetch,所以捕获全局接口错误的方式是封装xmlHttpRequest或者fetch。在这里,我们的SDK还是采用了上面提到的AOP思想来拦截API。 查看全部
文章采集api(搭建一套前端监控平台需要考虑的几个问题?|本文)
随着业务的快速发展,我们越来越重视生产环境中的问题感知能力。作为离用户最近的一层,前端性能是否可靠、稳定、易用,在很大程度上决定了用户对整个产品的体验和感受。因此,前端的监控不容忽视。
搭建前端监控平台需要考虑的方面有很多,比如数据采集、埋点模式、数据处理分析、告警、监控平台在具体业务中的应用等。在所有这些环节中,准确、完整、全面的数据采集是一切的前提,也为用户后续精细化操作提供了基础。
前端技术的飞速发展也给数据带来了变化和挑战采集。传统的人工管理模式已不能满足需求。如何让前端数据采集在新的技术背景下工作更完整、更高效,是本文的重点。
前端监控数据采集
在采集数据之前,我们首先要考虑采集是什么样的数据。我们关注两类数据,一类是与用户体验相关的数据,比如首屏时间、文件加载时间、页面性能等;另一个是帮助我们及时感知产品上线后是否有异常,比如资源错误、API响应时间等。具体来说,我们的前端数据采集具体分为:
路由交换机
Vue、React、Angular 等前端技术的快速发展,使得单页应用大行其道。我们都知道传统的页面应用使用一些超链接来实现页面切换和跳转,而单页面应用则使用自己的路由系统来管理前端的各个页面切换,比如vue-router、react-router等,跳转时只刷新部分资源,js、css等公共资源只需要加载一次,这就使得传统网页的进出方式只能在第一次打开时记录。单页应用所有后续路由的切换有两种方式,一种是Hash,一种是HTML5推出的History API。
1. href
href是页面初始化的第一个入口,这里只需要上报“页面入口”事件即可。
2. 哈希变化
哈希路由的一个明显标志是带有“#”。Hash 的优点是兼容性比较好,但问题是 URL 中总有一个“#”,不美观。我们主要是监控URL中的hashchange,捕获具体的hash值进行检测。
window.addEventListener('hashchange', function() {
// 上报【进入页面】事件
}, true)
需要注意的是,在新版本的vue-router中,如果浏览器支持history,即使选择了hash模式,也会先选择history模式。虽然表达式暂时还是#,但实际上是模拟的,所以不要以为你在模式选择hash的时候就会是hash。
3. 历史 API
History使用HTML5 History Interface中新增的pushState()和replaceState()方法进行路由切换,是目前主流的非刷新切换路由方式。相比hashchange后面的代码片段只能改#,History API(pushState、replaceState)给了前端完全的自由。
PopState是浏览器返回事件的回调,但是update路由的pushState和replaceState没有回调事件。因此,需要分别在 history.pushState() 和 history.replaceState() 方法中处理 URL 更改。在这里,我们使用了类似Java的AOP编程思想来转换pushState和replaceState。
AOP(Aspect-Oriented Programming)是指面向方面的编程,主张对同一类型的问题进行统一处理。AOP的核心思想是允许某个模块被复用。它采用横向抽取机制,将功能代码与业务逻辑代码分离,在不修改源代码的情况下扩展功能,隔离比封装更彻底。
下面介绍我们具体的改造方法:
// 第一阶段:我们对原生方法进行包装,调用前执行 dispatchEvent 了一个同样的事件
function aop (type) {
var source = window.history[type];
return function () {
var event = new Event(type);
event.arguments = arguments;
window.dispatchEvent(event);
var rewrite = source.apply(this, arguments);
return rewrite;
};
}
// 第二阶段:将 pushState 和 replaceState 进行基于 AOP 思想的代码注入
window.history.pushState = aop('pushState');
window.history.replaceState = aop('replaceState'); // 更改路由,不会留下历史记录
// 第三阶段:捕获pushState 和 replaceState
window.addEventListener('pushState', function() {
// 上报【进入页面】事件
}, true)
window.addEventListener('replaceState', function() {
// 上报【进入页面】事件
}, true)
window.history.pushState的实际调用关系如图:
至此,我们就完成了pushState和replaceState的转换,实现了路由切换的有效捕获。可以看出,我们在不侵入业务代码的情况下扩展了window.history.pushState,调用时会主动dispatchEvent一个pushState。
但是这里我们也可以看到一个缺点,就是如果AOP代理函数出现JS错误,会阻塞后续的调用关系,导致无法调用实际的window.history.pushState。所以在使用这种方式的时候,应该对AOP代理功能的内容做一个完整的try catch,防止业务出现异常。
_*_Tips:如果要自动捕捉页面停留时间,只需要计算下一页进入事件触发时上一页的tick时间与当前时间的差值即可。这时候可以举报【离开页面】事件。
错误
在前端项目中,由于JavaScript本身是弱类型语言,加上浏览器环境的复杂、网络问题等,容易出现错误。因此,做好网页错误的监控,不断优化代码,提高代码的健壮性是非常重要的。
JsError的捕获可以帮助我们分析和监控在线问题,与我们在Chrome浏览器的调试工具Console中看到的一致。
1. window.onerror
我们一般使用 window.onerror 来捕获 JS 错误的异常信息。有两种方法可以捕获 JS 错误,window.onerror 和 window.addEventListener('error')。一般情况下,不推荐使用addEventListener('error')来捕捉JS异常,主要是它没有栈信息,需要区分捕捉到的信息,因为它会捕捉到所有的异常信息,包括资源加载错误等等。
window.onerror = function (msg, url, lineno, colno, stack) {
// 上报 【js错误】事件
}
2. 未捕获(承诺)
当Promise发生JS错误或者业务没有处理reject信息时,会抛出unhandledrejection,window.onerror和window.addEventListener('error')不会捕捉到这个错误。这里需要一个特殊的窗口。addEventListener('unhandledrejection') 用于捕获处理:
window.addEventListener('unhandledrejection', function (e) {
var reg_url = /\(([^)]*)\)/;
var fileMsg = e.reason.stack.split('\n')[1].match(reg_url)[1];
var fileArr = fileMsg.split(':');
var lineno = fileArr[fileArr.length - 2];
var colno = fileArr[fileArr.length - 1];
var url = fileMsg.slice(0, -lno.length - cno.length - 2);}, true);
var msg = e.reason.message;
// 上报 【js错误】事件
}
我们注意到,因为 unhandledrejection 继承自 PromiseRejectionEvent 和 PromiseRejectionEvent 继承自 Event,msg、url、lineno、colno、stack 以字符串的形式放在 e.reason.stack 中。我们需要解析出上面的参数来与 onerror 参数对齐。为后续监测平台各项指标的统一奠定基础。
3.常见问题
如果抓到的msg都是“Script error.”,问题是你的JS地址和当前网页不在同一个域。因为我们经常需要对网络版做静态资源CDN化,会导致经常访问的页面和脚本文件来自不同的域名。如果此时不进行额外的配置,浏览器很容易出现“脚本错误”。由于安全设计。我们可以使用目前流行的Webpack打包工具来处理此类问题。
// webpack config 配置
// 处理 html 注入 js 添加跨域标识
plugins: [
new HtmlWebpackPlugin({
filename: 'html/index.html',
template: HTML_PATH,
attributes: {
crossorigin: 'anonymous'
}
}),
new HtmlWebpackPluginCrossorigin({
inject: true
})
]
// 处理按需加载的 js 添加跨域标识
output: {
crossOriginLoading: true
}
大多数场景下,生产环境中的代码都是经过压缩和合并的,这使得我们捕捉到的错误很难映射到具体的源代码上,给我们解决问题带来了很大的麻烦。这里简单介绍2个解决思路。
在生产环境中,我们需要添加sourceMap的配置,这会造成安全隐患,因为外网可以通过sourceMap映射源代码。为了降低风险,我们可以做到以下几点:
设置sourceMap生成的.map文件访问公司内网,降低源代码安全风险
将代码发布到CDN时,将.map文件存放在公司内网下
这时候我们已经有了 .map 文件。后面我们要做的就是调用mozilla/source-map库,通过抓到的lineno、colno、url来映射源码,然后我们就可以得到真正的源码错误信息了。
表现
性能指标的获取比较简单,只需要在onload后读取window.performance,里面收录性能、内存等信息。这部分内容在很多现有的文章中都有介绍。限于篇幅,本文不会展开过多。稍后我们将在相关话题文章中进行相关讨论。感兴趣的朋友可以添加“马蜂窝技术”公众号继续关注。
资源错误
首先需要明确资源错误捕获的使用场景,更多的是感知DNS劫持、CDN节点异常等,具体方法如下:
window.addEventListener('error', function (e) {
var target = e.target || e.srcElement;
if (target instanceof HTMLScriptElement) {
// 上报 【资源错误】事件
}
}, true)
这里只是一个基本的演示。在实际环境中,我们会关心更多的Element错误,比如css、img、woff等,可以根据不同的场景添加。
_*资源错误的使用场景更多地依赖于其他几个维度,例如:_region、operator等,我们将在后面的页面中详细说明。
应用程序接口
在市面上的主流框架(如Axios、jQuery.ajax等)中,基本上所有的API请求都是基于xmlHttpRequest或者fetch,所以捕获全局接口错误的方式是封装xmlHttpRequest或者fetch。在这里,我们的SDK还是采用了上面提到的AOP思想来拦截API。
文章采集api(今日未采集资产列表:已访问过得加密,明天加上)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-11-26 17:17
获取今天不是 采集 的资产列表:
关键点:
1、server表增加了两个字段:latest_date(可以为空);服务器状态信息;
2、什么情况下会获取采集服务器信息?
①latest_date为空时,如未上报的资产的初始创建;
②今天还没到采集,关注latest_date__date__lt
③服务器状态在线
3、设置current_date=datetime.datetime.now(); 当服务器更新资产时
4、get_host_list 函数:
注:内容放在response.text部分(response=request.get(url))
代码区:
###############服务端###############
@csrf_exempt
def server(request):
'''
requests不能发送字典类型数据,纵观我们学的form表单提交数据,
ajax发送数据,均是不支持字典类型数据的发送的。
具体原因百度知晓。
:param request:
:return:
'''
if request.method == 'GET':
# 获取今日未采集主机列表[latest_date为None或者latest_date不为今日且服务器状态为在线]
current_date = date.today()
host_list = models.Server.objects.filter(
Q(Q(latest_date=None) | Q(latest_date__date__lt=current_date)) & Q(server_status_id=2)).values('hostname')
'''
['hostname':'c1.com']
'''
host_list = list(host_list)
print(host_list)
return HttpResponse(json.dumps(host_list))
#############客户端#############
class SshSaltClient(BaseClient):
def get_host_list(self):
response=requests.get(self.api) #
# print(response.text) # [{"hostname": "c1.com"}]注意这种用法
return json.loads(response.text)
接口验证
要点:过三关
第一关:时间限制(超出客户端时间和服务器之间的时间间隔,我们团队要求限制)
第二关:加密规则限制(主要应用MD5加密)
第三遍:我们为已访问过的加密str设置访问列表。普通用户不可能再用这个访问过的数据向服务器请求。如果列表中没有str,则证明是普通用户访问,记得将此数据加入到访问列表中。
这个内容会越来越大,实际会应用到memcache和redis上。
后三个级别基本可以达到防止黑客攻击的效果,但不排除黑客的网速比我们快。我们不妨对要发送的数据进行加密,然后尽快将黑客的网速提交给服务器。这不是一个坏主意吗?
代码区:
##############客户端##############
import requests
import time
import hashlib
def md5(arg):
md5 = hashlib.md5()
md5.update(arg.encode('utf-8'))
return md5.hexdigest()
key = 'asdfghjklmnbvcxz'
ctime = str(time.time())
client_str = '%s|%s' % (key, ctime)
client_md5_str = md5(client_str)
client_header_str = '%s|%s' % (client_md5_str, ctime)
print(client_header_str)
response = requests.get(url='http://127.0.0.1:8000/api/tests.html', headers={'auth-api': 'cae76146bfa06482cfee7e4f899cc414|1506956350.973326'})
print(response.text)
##############服务端##############
def md5(arg):
md5 = hashlib.md5()
md5.update(arg.encode('utf-8'))
return md5.hexdigest()
key = 'asdfghjklmnbvcxz'
vistied_str_dict={}
def tests(request):
client_header_str = request.META.get('HTTP_AUTH_API')
print(client_header_str)
client_md5_str, client_ctime = client_header_str.split('|', maxsplit=1)
client_float_ctime = float(client_ctime)
server_float_ctime = float(time.time())
# 第一关
if (client_float_ctime + 20) < server_float_ctime:
return HttpResponse("太慢了")
# 第二关
server_str = '%s|%s' % (key, client_ctime)
server_md5_str = md5(server_str)
if client_md5_str != server_md5_str:
return HttpResponse('休想')
# 第三关
if vistied_str_dict.get(client_md5_str):
return HttpResponse('放弃吧')
else:
vistied_str_dict[client_md5_str] = client_ctime
return HttpResponse('你得到我了')
最后,没有使用装饰器,明天将添加。 查看全部
文章采集api(今日未采集资产列表:已访问过得加密,明天加上)
获取今天不是 采集 的资产列表:
关键点:
1、server表增加了两个字段:latest_date(可以为空);服务器状态信息;
2、什么情况下会获取采集服务器信息?
①latest_date为空时,如未上报的资产的初始创建;
②今天还没到采集,关注latest_date__date__lt
③服务器状态在线
3、设置current_date=datetime.datetime.now(); 当服务器更新资产时
4、get_host_list 函数:
注:内容放在response.text部分(response=request.get(url))
代码区:
###############服务端###############
@csrf_exempt
def server(request):
'''
requests不能发送字典类型数据,纵观我们学的form表单提交数据,
ajax发送数据,均是不支持字典类型数据的发送的。
具体原因百度知晓。
:param request:
:return:
'''
if request.method == 'GET':
# 获取今日未采集主机列表[latest_date为None或者latest_date不为今日且服务器状态为在线]
current_date = date.today()
host_list = models.Server.objects.filter(
Q(Q(latest_date=None) | Q(latest_date__date__lt=current_date)) & Q(server_status_id=2)).values('hostname')
'''
['hostname':'c1.com']
'''
host_list = list(host_list)
print(host_list)
return HttpResponse(json.dumps(host_list))
#############客户端#############
class SshSaltClient(BaseClient):
def get_host_list(self):
response=requests.get(self.api) #
# print(response.text) # [{"hostname": "c1.com"}]注意这种用法
return json.loads(response.text)
接口验证
要点:过三关
第一关:时间限制(超出客户端时间和服务器之间的时间间隔,我们团队要求限制)
第二关:加密规则限制(主要应用MD5加密)
第三遍:我们为已访问过的加密str设置访问列表。普通用户不可能再用这个访问过的数据向服务器请求。如果列表中没有str,则证明是普通用户访问,记得将此数据加入到访问列表中。
这个内容会越来越大,实际会应用到memcache和redis上。
后三个级别基本可以达到防止黑客攻击的效果,但不排除黑客的网速比我们快。我们不妨对要发送的数据进行加密,然后尽快将黑客的网速提交给服务器。这不是一个坏主意吗?
代码区:
##############客户端##############
import requests
import time
import hashlib
def md5(arg):
md5 = hashlib.md5()
md5.update(arg.encode('utf-8'))
return md5.hexdigest()
key = 'asdfghjklmnbvcxz'
ctime = str(time.time())
client_str = '%s|%s' % (key, ctime)
client_md5_str = md5(client_str)
client_header_str = '%s|%s' % (client_md5_str, ctime)
print(client_header_str)
response = requests.get(url='http://127.0.0.1:8000/api/tests.html', headers={'auth-api': 'cae76146bfa06482cfee7e4f899cc414|1506956350.973326'})
print(response.text)
##############服务端##############
def md5(arg):
md5 = hashlib.md5()
md5.update(arg.encode('utf-8'))
return md5.hexdigest()
key = 'asdfghjklmnbvcxz'
vistied_str_dict={}
def tests(request):
client_header_str = request.META.get('HTTP_AUTH_API')
print(client_header_str)
client_md5_str, client_ctime = client_header_str.split('|', maxsplit=1)
client_float_ctime = float(client_ctime)
server_float_ctime = float(time.time())
# 第一关
if (client_float_ctime + 20) < server_float_ctime:
return HttpResponse("太慢了")
# 第二关
server_str = '%s|%s' % (key, client_ctime)
server_md5_str = md5(server_str)
if client_md5_str != server_md5_str:
return HttpResponse('休想')
# 第三关
if vistied_str_dict.get(client_md5_str):
return HttpResponse('放弃吧')
else:
vistied_str_dict[client_md5_str] = client_ctime
return HttpResponse('你得到我了')
最后,没有使用装饰器,明天将添加。
文章采集api(基于ApaChe-Tomcat+JAVA+MySql全网独家+全新二开的API开奖数据采集接口源码)
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-11-24 23:15
本次分享的是我们基于ApaChe-Tomcat+JAVA+MySql全网独家+全新开放API抽奖数据采集接口源码,稳定运行一年多,我们的源码同时使用。许多修订和功能性的两个开口。对于大家关心的安全性和运行稳定性,那就是博一Thinkphp5版的源码。手术; 在界面美化方面,我们从最初的版本到现在的改进不下10倍。模板已优化,运行稳定,近期不再优化;用户中心的功能包括:个人中心、IP白名单、修改密码、赞助我们、我的界面,您可以看下面的截图或到我们的演示站点查看;对于颜色类型,您可以添加或删除某种类型的界面或某种颜色类型,也可以自行定义颜色类型的缩写没有限制;系统背景介绍等一些方面,可以查看截图演示或我们的演示站点;此外,所有修改后的.jar采集 包也已经打包了源码。购买前请再次确认,本源代码为我们独家二流资源,并非部分用于充值的二流、三流资源;最后,如果你只需要这个源码,可以在本页右上角下单购买。然后就可以看到解压出来的密码了!或者你可以自己定义颜色类型的缩写没有限制;系统背景介绍等一些方面,可以查看截图演示或我们的演示站点;此外,所有修改后的.jar采集 包也已经打包了源码。购买前请再次确认,本源代码为我们独家二流资源,并非部分用于充值的二流、三流资源;最后,如果你只需要这个源码,可以在本页右上角下单购买。然后就可以看到解压出来的密码了!或者你可以自己定义颜色类型的缩写没有限制;系统背景介绍等一些方面,可以查看截图演示或我们的演示站点;此外,所有修改后的.jar采集 包也已经打包了源码。购买前请再次确认,本源代码为我们独家二流资源,并非部分用于充值的二流、三流资源;最后,如果你只需要这个源码,可以在本页右上角下单购买。然后就可以看到解压出来的密码了!包也与源代码一起打包。购买前请再次确认,本源代码为我们独家二流资源,并非部分用于充值的二流、三流资源;最后,如果你只需要这个源码,可以在本页右上角下单购买。然后就可以看到解压出来的密码了!包也与源代码一起打包。购买前请再次确认,本源代码为我们独家二流资源,并非部分用于充值的二流、三流资源;最后,如果你只需要这个源码,可以在本页右上角下单购买。然后就可以看到解压出来的密码了!
示范站:目前所有高频都停止服务,所以只有低频、海外和极速是正常的
后台演示:操作现场不提供,请查看演示截图。
更多信息有待更新...
本源码附有视频详细安装说明:
Kaku亲测环境:ApaChe-Tomcat+JAVA+MySql5.7(必填)
付费安装范围包括:将您购买的程序安装到您的服务器上!!
不包括:修改程序中的文字/版权/图片/或某些特定信息,我们将根据您的修改程度适当收取费用!
需要注意的是,系统开通账户使用权限后,所有接口都有调用权限,而不是单个接口。
注意:我们打包的.jar采集 包中收录自定义接口,您可以按照说明连接第三方接口。
注意:由于源代码开发环境的特殊性,请严格按照我们的安装说明进行安装。如果没有,请找我们付费安装。
注:虽然程序压缩包中有详细的安装说明,但还是推荐给有一定建站基础的朋友使用。本网站不想引起恶名,所以请谨慎!
注:源代码仅供下载者在个人本地电脑学习研究,上传服务器不可运行,否则后果自负。
有关常见安装问题的摘要,请参阅:
免责声明:用户在使用本站资源时,必须禁止将其用于国家相关法律法规范围内的一切违法活动。使用仅限于测试、实验和研究目的。禁止在所有商业操作中使用。本站对用户在使用过程中的任何违法行为不承担任何责任。
爪哇
卡库克斯平民 查看全部
文章采集api(基于ApaChe-Tomcat+JAVA+MySql全网独家+全新二开的API开奖数据采集接口源码)
本次分享的是我们基于ApaChe-Tomcat+JAVA+MySql全网独家+全新开放API抽奖数据采集接口源码,稳定运行一年多,我们的源码同时使用。许多修订和功能性的两个开口。对于大家关心的安全性和运行稳定性,那就是博一Thinkphp5版的源码。手术; 在界面美化方面,我们从最初的版本到现在的改进不下10倍。模板已优化,运行稳定,近期不再优化;用户中心的功能包括:个人中心、IP白名单、修改密码、赞助我们、我的界面,您可以看下面的截图或到我们的演示站点查看;对于颜色类型,您可以添加或删除某种类型的界面或某种颜色类型,也可以自行定义颜色类型的缩写没有限制;系统背景介绍等一些方面,可以查看截图演示或我们的演示站点;此外,所有修改后的.jar采集 包也已经打包了源码。购买前请再次确认,本源代码为我们独家二流资源,并非部分用于充值的二流、三流资源;最后,如果你只需要这个源码,可以在本页右上角下单购买。然后就可以看到解压出来的密码了!或者你可以自己定义颜色类型的缩写没有限制;系统背景介绍等一些方面,可以查看截图演示或我们的演示站点;此外,所有修改后的.jar采集 包也已经打包了源码。购买前请再次确认,本源代码为我们独家二流资源,并非部分用于充值的二流、三流资源;最后,如果你只需要这个源码,可以在本页右上角下单购买。然后就可以看到解压出来的密码了!或者你可以自己定义颜色类型的缩写没有限制;系统背景介绍等一些方面,可以查看截图演示或我们的演示站点;此外,所有修改后的.jar采集 包也已经打包了源码。购买前请再次确认,本源代码为我们独家二流资源,并非部分用于充值的二流、三流资源;最后,如果你只需要这个源码,可以在本页右上角下单购买。然后就可以看到解压出来的密码了!包也与源代码一起打包。购买前请再次确认,本源代码为我们独家二流资源,并非部分用于充值的二流、三流资源;最后,如果你只需要这个源码,可以在本页右上角下单购买。然后就可以看到解压出来的密码了!包也与源代码一起打包。购买前请再次确认,本源代码为我们独家二流资源,并非部分用于充值的二流、三流资源;最后,如果你只需要这个源码,可以在本页右上角下单购买。然后就可以看到解压出来的密码了!
示范站:目前所有高频都停止服务,所以只有低频、海外和极速是正常的
后台演示:操作现场不提供,请查看演示截图。
更多信息有待更新...
本源码附有视频详细安装说明:
Kaku亲测环境:ApaChe-Tomcat+JAVA+MySql5.7(必填)
付费安装范围包括:将您购买的程序安装到您的服务器上!!
不包括:修改程序中的文字/版权/图片/或某些特定信息,我们将根据您的修改程度适当收取费用!
需要注意的是,系统开通账户使用权限后,所有接口都有调用权限,而不是单个接口。
注意:我们打包的.jar采集 包中收录自定义接口,您可以按照说明连接第三方接口。
注意:由于源代码开发环境的特殊性,请严格按照我们的安装说明进行安装。如果没有,请找我们付费安装。
注:虽然程序压缩包中有详细的安装说明,但还是推荐给有一定建站基础的朋友使用。本网站不想引起恶名,所以请谨慎!
注:源代码仅供下载者在个人本地电脑学习研究,上传服务器不可运行,否则后果自负。
有关常见安装问题的摘要,请参阅:
免责声明:用户在使用本站资源时,必须禁止将其用于国家相关法律法规范围内的一切违法活动。使用仅限于测试、实验和研究目的。禁止在所有商业操作中使用。本站对用户在使用过程中的任何违法行为不承担任何责任。
爪哇
卡库克斯平民
文章采集api( PHP+fiddler抓包操作实例PHP编程技术本文实例讲述框架数据库操作)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-11-19 14:20
PHP+fiddler抓包操作实例PHP编程技术本文实例讲述框架数据库操作)
2. 截取这个接口转发到自己的服务器,点击规则-自定义规则添加到OnBeforeRequest中(正式请求前执行的函数)
if (oSession.fullUrl.Contains("mp.weixin.qq.com/mp/getappmsgext"))
{
oSession.oRequest["Host"]= 'ccc.aaa.com' ;
}
效果,可以看到这个接口已经转发了
3.服务端缓存key,代码以PHP为例
public function saveKey(Request $request)
{
$__biz = $request->param('__biz',0);
$data['uin'] = $request->param('uin',0);
$data['key'] = $request->param('key',0);
Cache::set($__biz,$data,30 * 60);
return 'ok';
}
4.提交文章查询API代码链接
public function getReadNum(Request $request)
{
$url = $request->param('url');
parse_str(parse_url($url)['query'], $param);
$__biz = $param['__biz'];
$key_data = Cache::get($__biz);
if (empty($key_data))
return 'no key';
$uin = $key_data['uin'];
$key = $key_data['key'];
$param['uin'] = $uin;
$param['key'] = $key;
$param['wxtoken'] = "777";
$wechat_url = "https://mp.weixin.qq.com/mp/getappmsgext?" . http_build_query($param);
//dump($wechat_url);
$data = array(
'is_only_read' => 1,
'is_temp_url' => 0,
'appmsg_type' => 9,
);
$res = $this->get_url($wechat_url,$data);
return $res;
}
function get_url($url,$data)
{
$ifpost = 1;//是否post请求
$datafields = $data;//post数据
$cookiefile = '';//cookie文件
$cookie = '';//cookie变量
$v = false;
//模拟http请求header头
$header = array("Connection: Keep-Alive","Accept: text/html, application/xhtml+xml, */*", "Pragma: no-cache", "Accept-Language: zh-Hans-CN,zh-Hans;q=0.8,en-US;q=0.5,en;q=0.3","User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36 QBCore/4.0.1278.400 QQBrowser/9.0.2524.400 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2875.116 Safari/537.36 NetType/WIFI MicroMessenger/7.0.5 WindowsWechat");
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, $v);
curl_setopt($ch, CURLOPT_HTTPHEADER, $header);
$ifpost && curl_setopt($ch, CURLOPT_POST, $ifpost);
$ifpost && curl_setopt($ch, CURLOPT_POSTFIELDS, $datafields);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
$cookie && curl_setopt($ch, CURLOPT_COOKIE, $cookie);//发送cookie变量
$cookiefile && curl_setopt($ch, CURLOPT_COOKIEFILE, $cookiefile);//发送cookie文件
$cookiefile && curl_setopt($ch, CURLOPT_COOKIEJAR, $cookiefile);//写入cookie到文件
curl_setopt($ch,CURLOPT_TIMEOUT,60); //允许执行的最长秒数
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
$ok = curl_exec($ch);
curl_close($ch);
unset($ch);
return $ok;
}
5.通知客户端重定向页面(这部分不写了,看我另外一篇关于socket的文字文章)
6.使用fiddler修改微信文章还有jsj脚本,
在OnBeforeResponse(返回客户端之前执行的方法)中,添加跳转到中间页面的代码
影响
总结
以上就是小编为大家介绍的PHP+fiddler抓包。采集微信文章 看了几个赞,希望对你有帮助,有什么问题请给我留言,肖小编会及时回复大家。非常感谢您对编程宝库网站的支持!
下一节:laravel框架数据库操作的PHP编程技术、查询生成器、Eloquent ORM操作实例
本文介绍了 Laravel 框架数据库操作、查询构建器和 Eloquent ORM 操作。分享给大家,供大家参考,如下:1、连接数据库laravel连接数据库配置文件... 查看全部
文章采集api(
PHP+fiddler抓包操作实例PHP编程技术本文实例讲述框架数据库操作)


2. 截取这个接口转发到自己的服务器,点击规则-自定义规则添加到OnBeforeRequest中(正式请求前执行的函数)
if (oSession.fullUrl.Contains("mp.weixin.qq.com/mp/getappmsgext"))
{
oSession.oRequest["Host"]= 'ccc.aaa.com' ;
}

效果,可以看到这个接口已经转发了

3.服务端缓存key,代码以PHP为例
public function saveKey(Request $request)
{
$__biz = $request->param('__biz',0);
$data['uin'] = $request->param('uin',0);
$data['key'] = $request->param('key',0);
Cache::set($__biz,$data,30 * 60);
return 'ok';
}
4.提交文章查询API代码链接
public function getReadNum(Request $request)
{
$url = $request->param('url');
parse_str(parse_url($url)['query'], $param);
$__biz = $param['__biz'];
$key_data = Cache::get($__biz);
if (empty($key_data))
return 'no key';
$uin = $key_data['uin'];
$key = $key_data['key'];
$param['uin'] = $uin;
$param['key'] = $key;
$param['wxtoken'] = "777";
$wechat_url = "https://mp.weixin.qq.com/mp/getappmsgext?" . http_build_query($param);
//dump($wechat_url);
$data = array(
'is_only_read' => 1,
'is_temp_url' => 0,
'appmsg_type' => 9,
);
$res = $this->get_url($wechat_url,$data);
return $res;
}
function get_url($url,$data)
{
$ifpost = 1;//是否post请求
$datafields = $data;//post数据
$cookiefile = '';//cookie文件
$cookie = '';//cookie变量
$v = false;
//模拟http请求header头
$header = array("Connection: Keep-Alive","Accept: text/html, application/xhtml+xml, */*", "Pragma: no-cache", "Accept-Language: zh-Hans-CN,zh-Hans;q=0.8,en-US;q=0.5,en;q=0.3","User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36 QBCore/4.0.1278.400 QQBrowser/9.0.2524.400 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2875.116 Safari/537.36 NetType/WIFI MicroMessenger/7.0.5 WindowsWechat");
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, $v);
curl_setopt($ch, CURLOPT_HTTPHEADER, $header);
$ifpost && curl_setopt($ch, CURLOPT_POST, $ifpost);
$ifpost && curl_setopt($ch, CURLOPT_POSTFIELDS, $datafields);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
$cookie && curl_setopt($ch, CURLOPT_COOKIE, $cookie);//发送cookie变量
$cookiefile && curl_setopt($ch, CURLOPT_COOKIEFILE, $cookiefile);//发送cookie文件
$cookiefile && curl_setopt($ch, CURLOPT_COOKIEJAR, $cookiefile);//写入cookie到文件
curl_setopt($ch,CURLOPT_TIMEOUT,60); //允许执行的最长秒数
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
$ok = curl_exec($ch);
curl_close($ch);
unset($ch);
return $ok;
}
5.通知客户端重定向页面(这部分不写了,看我另外一篇关于socket的文字文章)
6.使用fiddler修改微信文章还有jsj脚本,
在OnBeforeResponse(返回客户端之前执行的方法)中,添加跳转到中间页面的代码
影响

总结
以上就是小编为大家介绍的PHP+fiddler抓包。采集微信文章 看了几个赞,希望对你有帮助,有什么问题请给我留言,肖小编会及时回复大家。非常感谢您对编程宝库网站的支持!
下一节:laravel框架数据库操作的PHP编程技术、查询生成器、Eloquent ORM操作实例
本文介绍了 Laravel 框架数据库操作、查询构建器和 Eloquent ORM 操作。分享给大家,供大家参考,如下:1、连接数据库laravel连接数据库配置文件...
文章采集api(数据具体的采集方案是什么?四种数据采集方法对比)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-01-21 21:13
根据企业在生产和管理过程中会产生的数据类型,提供链接标记、SDK和API三种采集方法,以及基于UTSE数据采集模型对用户的整个生命周期。
那么,数据的具体采集计划是什么?
四种数据采集方法对比
Data采集是通过埋点实现的。诸葛io提供了非常完善的数据访问解决方案,支持代码埋、全埋、可视埋、服务器埋等数据采集方式。
1.代码被埋没
说明:嵌入SDK定义事件和添加事件代码是一种常用的数据采集方法,主要包括网页和h5页面的JS嵌入、移动端的iOS和Android嵌入、微信小程序等。
优点:按需采集,业务信息更全,数据分析更专注,数据采集全面准确,便于后续深入分析。
缺点:需要研发人员配合,有一定的工作量。
2.全葬
说明:通过SDK自动采集页面所有可点击元素的操作数据,无需定义事件,适用于活动页面、登陆页面、关键页面的设计体验测量。
优点:更简单快捷,可以看到页面元素的点击量,更好的了解自己的产品特点。
缺点:采集的数据太多,只要是可点击的元素,就会是采集,上传数据很多,消耗流量很大。无法采集到更深层次的维度信息,比如事件的属性、用户的属性等。
3.可视化埋点
注意:视觉嵌入是基于完整嵌入的。技术同事整合后,业务同事需要圈出页面的元素,选中的元素会是采集。
优点:基于接口配置,无需开发,易于更新,快速生效。
缺点:自定义属性的支持范围比较有限;重构或页面更改时需要重新配置。
4.服务器埋点
说明:通过API对存储在服务器上的数据进行结构化处理,通过接口调用其他业务数据采集和集成,比如CRM等用户数据,对数据进行结构化处理,即适合拥有 采集 @采集 能力客户端的用户。
优点:服务端embedding更有针对性,数据更准确,减少编码embedding的发布过程,数据上传更及时。
缺点:用户的一些简单操作,比如点击按钮、切换模块,这些数据不能采集,用户行为不够完整。
总结:以上是诸葛io提供的四种data采集解决方案:code embedding、full embedding、visual embedding、server embedding,data采集目的是为了满足采集详细分析和操作然后执行需求。只有能够达到这个目标,才有可能选择一种或多种采集形式的组合。在企业业务中,选择哪种采集方式要根据企业自身的具体业务需求来决定。 查看全部
文章采集api(数据具体的采集方案是什么?四种数据采集方法对比)
根据企业在生产和管理过程中会产生的数据类型,提供链接标记、SDK和API三种采集方法,以及基于UTSE数据采集模型对用户的整个生命周期。
那么,数据的具体采集计划是什么?
四种数据采集方法对比
Data采集是通过埋点实现的。诸葛io提供了非常完善的数据访问解决方案,支持代码埋、全埋、可视埋、服务器埋等数据采集方式。
1.代码被埋没
说明:嵌入SDK定义事件和添加事件代码是一种常用的数据采集方法,主要包括网页和h5页面的JS嵌入、移动端的iOS和Android嵌入、微信小程序等。
优点:按需采集,业务信息更全,数据分析更专注,数据采集全面准确,便于后续深入分析。
缺点:需要研发人员配合,有一定的工作量。
2.全葬
说明:通过SDK自动采集页面所有可点击元素的操作数据,无需定义事件,适用于活动页面、登陆页面、关键页面的设计体验测量。
优点:更简单快捷,可以看到页面元素的点击量,更好的了解自己的产品特点。
缺点:采集的数据太多,只要是可点击的元素,就会是采集,上传数据很多,消耗流量很大。无法采集到更深层次的维度信息,比如事件的属性、用户的属性等。
3.可视化埋点
注意:视觉嵌入是基于完整嵌入的。技术同事整合后,业务同事需要圈出页面的元素,选中的元素会是采集。
优点:基于接口配置,无需开发,易于更新,快速生效。
缺点:自定义属性的支持范围比较有限;重构或页面更改时需要重新配置。
4.服务器埋点
说明:通过API对存储在服务器上的数据进行结构化处理,通过接口调用其他业务数据采集和集成,比如CRM等用户数据,对数据进行结构化处理,即适合拥有 采集 @采集 能力客户端的用户。
优点:服务端embedding更有针对性,数据更准确,减少编码embedding的发布过程,数据上传更及时。
缺点:用户的一些简单操作,比如点击按钮、切换模块,这些数据不能采集,用户行为不够完整。
总结:以上是诸葛io提供的四种data采集解决方案:code embedding、full embedding、visual embedding、server embedding,data采集目的是为了满足采集详细分析和操作然后执行需求。只有能够达到这个目标,才有可能选择一种或多种采集形式的组合。在企业业务中,选择哪种采集方式要根据企业自身的具体业务需求来决定。
文章采集api(猫眼电影API接口(从猫眼电影网爬取爬取)开源版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 289 次浏览 • 2022-01-21 17:10
API(ApplicationProgrammingInterface,应用程序编程接口)是一组用来控制Windows的组件(从桌面的外观看。
猫眼电影API接口(从猫眼电影网爬取) Hope771:热门电影:request to total=20,但是movieList只有12个,怎么再获取8个数据?猫眼电影API接口(从猫眼电影网爬取) 刘子凡 11:有没有选座。vscode:Windows 找不到文件“chrome”。请确保文件名正确,然后重试。
智云影视资源开源版简介采集V1.1:采集全网各大资源网(各资源站的飞飞接口地址基本通用) 不是 采集360 。
添加采集网站的接口地址并命名,接口类型选择xml,资源类型选择video。然后选择测试,如图表示成功,保存。保存。
根据电影名称,获取资源链接,并且必须兼容自己的QQ电影资源机器人,根据电影。
最近在做微信小程序“豆瓣电影”。当我尝试调用豆瓣API的时候,发现官方的豆瓣API已经不再对外开放了。在网上找了很多博客,找到了一些解决办法。本来想直接新建一个服务器,但是服务器的价格对学生党不友好,所以用另一种界面解决了:有的老板自己配置了服务器,恢复了官方界面。用作。
网站api域名授权码,我有一个电影资源网站,我想实现域名授权采集,谁能帮忙写代码?一共1个回答。
很多朋友都说要建电影网站,大家都知道电影资源去某影视资源网找接口。首先苹果cms的采集接口api是。 查看全部
文章采集api(猫眼电影API接口(从猫眼电影网爬取爬取)开源版)
API(ApplicationProgrammingInterface,应用程序编程接口)是一组用来控制Windows的组件(从桌面的外观看。
猫眼电影API接口(从猫眼电影网爬取) Hope771:热门电影:request to total=20,但是movieList只有12个,怎么再获取8个数据?猫眼电影API接口(从猫眼电影网爬取) 刘子凡 11:有没有选座。vscode:Windows 找不到文件“chrome”。请确保文件名正确,然后重试。
智云影视资源开源版简介采集V1.1:采集全网各大资源网(各资源站的飞飞接口地址基本通用) 不是 采集360 。
添加采集网站的接口地址并命名,接口类型选择xml,资源类型选择video。然后选择测试,如图表示成功,保存。保存。
根据电影名称,获取资源链接,并且必须兼容自己的QQ电影资源机器人,根据电影。
最近在做微信小程序“豆瓣电影”。当我尝试调用豆瓣API的时候,发现官方的豆瓣API已经不再对外开放了。在网上找了很多博客,找到了一些解决办法。本来想直接新建一个服务器,但是服务器的价格对学生党不友好,所以用另一种界面解决了:有的老板自己配置了服务器,恢复了官方界面。用作。
网站api域名授权码,我有一个电影资源网站,我想实现域名授权采集,谁能帮忙写代码?一共1个回答。
很多朋友都说要建电影网站,大家都知道电影资源去某影视资源网找接口。首先苹果cms的采集接口api是。
文章采集api(苹果cms采集视频可以在后台联盟资源库里直接设置采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2022-01-16 18:06
苹果cms采集视频可以直接在后台联盟资源库中设置采集,也可以配置自己自定义的采集库,关于文章信息采集,Applecms后台没有专门的采集库,所以文章采集我们需要添加采集@ > 自己接口,或者是使用第三方采集工具,不懂代码的小白完全不知道。前期,目前80%的影视站都是靠采集来扩充自己的视频库,比如之前的大站电影天堂、BT站等最新电影的下载。这一切都始于 采集。先丰富视频源再做网站收录,网站收录是由文章信息驱动的。今天我们将介绍使用免费的自动采集发布工具来让Apple cms网站启动并运行!
由于各种视频站的兴起,cms模板泛滥。大量的网站模板都是类似的。除了 采集 规则外,视频站的内容是重复的。多年来,我一直是视频站的老手。车站会叹息! “苹果cms采集电视台越来越难做”,各大搜索引擎收录越来越少。如果依赖cms自带的采集功能,就很难提升了。视频站无非就是一个标题、内容和内容介绍。苹果80%的cms站都是这样的结构,我们该怎么办?为了在众多影视台中脱颖而出?
一、苹果cms网站怎么样原创?
1、标题选择插入品牌词
2、播放的集数(例如:第一集改为在线第一集)
3、剧情简介(插入关键词,采集电影介绍)
4、依靠SEO技术提升网站原创度
SEO 优化可访问性设置:
1、标题前缀和后缀设置(标题的区别更好收录)
2、内容关键词插入(合理增加关键词密度)
3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后主动推送文章到搜索引擎,保证新链接能够被搜索引擎收录及时搜索到)
5、随机点赞-随机阅读-随机作者(增加页面原创度数)
6、内容与标题一致(使内容与标题100%相关)
7、自动内链(在执行发布任务时自动在文章内容中生成内链,帮助引导页面蜘蛛抓取,提高页面权重)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期抓取网页的习惯,从而提升网站的收录)
9、设置批量发布数量(可以设置发布间隔/单日发布总数)
10、可以设置不同的类型发布不同的栏目
11、工具设置锁定词(文章原创文章可读性和核心词不会原创时自动锁定品牌词和产品词)
12、工具还可以批量管理不同的cms网站数据(无论你的网站是Empire, Yiyou, ZBLOG, 织梦, WP,小旋风、站群、PB、Apple、搜外等各大cms电影网站,都可以同时管理和批量发布)
二、苹果cms采集设置
1、只需输入核心关键词,软件会自动生成下拉词、相关搜索词、长尾词,并自动过滤不相关的关键词核心关键词。全自动采集,可同时创建数十个或数百个采集任务(一个任务可支持上传1000个关键词),可同时执行多域任务时间!
2、自动过滤文章已经是采集的,
3、多平台支持采集(资讯、问答、视频频道、电影频道等)
4、可设置关键词采集文章条数,软件可直接查看多任务状态采集-支持本地预览-支持采集链接预览
5、自动批量挂机采集,无缝连接各大cms出版商,采集自动发帖推送到搜索引擎
以上是我个人测试后发现非常有用的所有内容。 文章采集工具与 Apple 的cms自己的数据源采集 无缝协作!目前网站交通还不错!看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力! 查看全部
文章采集api(苹果cms采集视频可以在后台联盟资源库里直接设置采集)
苹果cms采集视频可以直接在后台联盟资源库中设置采集,也可以配置自己自定义的采集库,关于文章信息采集,Applecms后台没有专门的采集库,所以文章采集我们需要添加采集@ > 自己接口,或者是使用第三方采集工具,不懂代码的小白完全不知道。前期,目前80%的影视站都是靠采集来扩充自己的视频库,比如之前的大站电影天堂、BT站等最新电影的下载。这一切都始于 采集。先丰富视频源再做网站收录,网站收录是由文章信息驱动的。今天我们将介绍使用免费的自动采集发布工具来让Apple cms网站启动并运行!
由于各种视频站的兴起,cms模板泛滥。大量的网站模板都是类似的。除了 采集 规则外,视频站的内容是重复的。多年来,我一直是视频站的老手。车站会叹息! “苹果cms采集电视台越来越难做”,各大搜索引擎收录越来越少。如果依赖cms自带的采集功能,就很难提升了。视频站无非就是一个标题、内容和内容介绍。苹果80%的cms站都是这样的结构,我们该怎么办?为了在众多影视台中脱颖而出?
一、苹果cms网站怎么样原创?
1、标题选择插入品牌词
2、播放的集数(例如:第一集改为在线第一集)
3、剧情简介(插入关键词,采集电影介绍)
4、依靠SEO技术提升网站原创度
SEO 优化可访问性设置:
1、标题前缀和后缀设置(标题的区别更好收录)
2、内容关键词插入(合理增加关键词密度)
3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后主动推送文章到搜索引擎,保证新链接能够被搜索引擎收录及时搜索到)
5、随机点赞-随机阅读-随机作者(增加页面原创度数)
6、内容与标题一致(使内容与标题100%相关)
7、自动内链(在执行发布任务时自动在文章内容中生成内链,帮助引导页面蜘蛛抓取,提高页面权重)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期抓取网页的习惯,从而提升网站的收录)
9、设置批量发布数量(可以设置发布间隔/单日发布总数)
10、可以设置不同的类型发布不同的栏目
11、工具设置锁定词(文章原创文章可读性和核心词不会原创时自动锁定品牌词和产品词)
12、工具还可以批量管理不同的cms网站数据(无论你的网站是Empire, Yiyou, ZBLOG, 织梦, WP,小旋风、站群、PB、Apple、搜外等各大cms电影网站,都可以同时管理和批量发布)
二、苹果cms采集设置
1、只需输入核心关键词,软件会自动生成下拉词、相关搜索词、长尾词,并自动过滤不相关的关键词核心关键词。全自动采集,可同时创建数十个或数百个采集任务(一个任务可支持上传1000个关键词),可同时执行多域任务时间!
2、自动过滤文章已经是采集的,
3、多平台支持采集(资讯、问答、视频频道、电影频道等)
4、可设置关键词采集文章条数,软件可直接查看多任务状态采集-支持本地预览-支持采集链接预览
5、自动批量挂机采集,无缝连接各大cms出版商,采集自动发帖推送到搜索引擎
以上是我个人测试后发现非常有用的所有内容。 文章采集工具与 Apple 的cms自己的数据源采集 无缝协作!目前网站交通还不错!看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
文章采集api(Python标准库之外的第三方库(一)库工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-12 17:00
上一期我们讲解了数据归一化的相关内容。首先对词的频率进行排序,然后转换一些大小写以减少 2-gram 序列的重复内容。
当我们真正走出网络数据基础采集的大门时,我们可能会遇到的第一个问题是:“如何获取登录窗口背后的信息?” 如今,网络正朝着页面交互、社交网络媒体、用户生成内容的趋势不断发展。表单和登录窗口是许多 网站 的组成部分。但是,这些都相对容易处理。
到目前为止,在前面的示例中,当网络爬虫与大多数 网站 服务器交互时,它们使用 HTTP 协议的 GET 方法来请求信息。在本文文章中,我们重点介绍POST方法,它将信息推送到Web服务器进行存储和分析。
页面表单基本上可以看成是用户提交POST请求的一种方式,但是这种请求方式是被服务器理解和使用的。正如 网站 URL 链接帮助用户发出 GET 请求一样,HTML 表单帮助用户发出 POST 请求。当然,我们也可以用一点点麻麻自己创建这些请求,然后通过网络爬虫提交给服务器。
Python 请求库
虽然可以使用 Python 标准库控制 Web 表单,但有时一点语法糖可以让生活更甜蜜。但是当你想要做的不仅仅是 urllib 可以做的基本 GET 请求时,请查看 Python 标准库之外的第三方库。
Requests库就是这样一个Python第三方库,擅长处理复杂的HTTP请求、cookies、headers(响应头和请求头)等。
以下是 Requests 创建者 Kenneth Retiz 对 Python 标准库工具的评价:
Python 标准库 urllib2 为您提供了大部分 HTTP 功能,但它的 API 很差。这是因为它是多年来一步步建立起来的——不同的时代要面对不同的网络环境。所以为了完成最简单的任务,他需要花费大量的工作(甚至写完整的方法)。
事情不应该这么复杂,也不应该发生在 Python 中。
与任何第三方 Python 库一样,Requests 库也可以与其他第三方 Python 库管理器(例如 pip)一起安装,或者直接下载 Requests 库源代码。
提交基本表格
大多数 Web 表单由一些 HTML 字段、一个提交按钮和一个“结果”(表单操作的值)页面组成,该页面在表单处理完毕后跳转。虽然这些 HTML 字段通常由文本内容组成,但也可以实现文件上传或其他非文本内容。
因为大部分主流网站都会在他们的robots.txt文件中注明禁止爬虫访问登录表单,相关介绍可以参考这篇文章:爬虫系列:爬虫带来的道德风险和法律责任。
例如,这里是一个表单的源代码:
用户名
密码
这里有几点需要注意:首先,两个输入字段命名为 username 和 passwd 很重要。字段的名称决定了表单验证后将发送到服务器的变量名称。如果你想模拟从表单提交数据的行为,你需要确保你的变量名与字段名相对应。
还要求表单的实际行为实际发生在 index.php?c=session&a=login 中。对表单的任何 POST 请求实际上都发生在此页面上,而不是表单本身所在的页面上。请记住:HTML 表单的目的只是为了帮助 网站 的访问者向服务器发送格式正确的请求以获取未出现的页面。除非您正在研究请求的设计风格,否则不要在表单所在的页面上花费太多时间。
使用 Requests 库提交表单只需几行代码即可完成,包括导入库文件和打印内容的语句:
import requests
params = {'username': 'admin', 'passwd': '5e_KR&pXJ9=J(c7d9P-twt9:'}
r = requests.post("http://www.test.com/admin/inde ... ot%3B, data=params)
print(r.text)
表单提交后,程序返回执行页面的源码,如下:
您的浏览器不支持框架!
由于我们通过Requests提交了内容,并没有在浏览器中提交,所以会出现上面的提示,但是我们已经登录成功了。后面我们需要用到浏览器采集的内容时,我们会详细介绍这部分。
这边的代码可以处理很多简单的表格。以下是邮件订阅的表单代码,如下:
Marketing
Email Address
虽然第一次看到有点吓人,但大多数情况下我们只需要关注两件事:
单选按钮、复选按钮和其他输入
显然,并非所有页面都只是一堆文本字段和一个提交按钮。HTML 标准提供了大量可用的表单字段:单选按钮、复选按钮、下拉选项等。在 HTML5 中,还有其他控件,如滚动条(范围输入字段)、邮箱、日期等。自定义 Javascript 字段是无所不能的,实现了颜色选择器、日历以及开发人员能想到的任何东西。
无论表单的字段看起来多么复杂,仍然只有两件事需要关心:字段名称和值。字段名可以通过查看源码,查找name属性轻松获取。字段值有时比较复杂,可能在表单提交之前由Javascript生成。颜色选择器是一个奇怪的表单字段,它可能使用像 #f5c26b 这样的值。
如果您不确定输入字段值的数据格式,有一些工具可以跟踪浏览器通过 网站 发出或接收的 GET 和 POST 请求的内容。如前所述,跟踪 GET 请求的最佳和最直接的方法是查看 网站 URL 链接,如果 URL 链接如下所示:
https://pdf-lib.org/Home/Searc ... abbix
那么请求的表单可能如下所示:
下面是一个更复杂的表单提交示例:
如果您遇到一个看起来很复杂的 POST 表单,并且看起来浏览器正在将这些参数传递给服务器,那么最简单的方法是使用 Chrome 的检查器或开发人员工具。
总结
由于篇幅原因,今天只讲解基本的表单、单选按钮、复选框等表单输入,以及如何通过Requests提交给服务器。
在下一篇文章 文章 中,我们将介绍提交文件、图像、处理登录、cookie、HTTP 基本访问身份验证以及其他与表单相关的问题。
源代码已托管在 Github 上:
如果您有任何问题,欢迎提出。 查看全部
文章采集api(Python标准库之外的第三方库(一)库工具)
上一期我们讲解了数据归一化的相关内容。首先对词的频率进行排序,然后转换一些大小写以减少 2-gram 序列的重复内容。
当我们真正走出网络数据基础采集的大门时,我们可能会遇到的第一个问题是:“如何获取登录窗口背后的信息?” 如今,网络正朝着页面交互、社交网络媒体、用户生成内容的趋势不断发展。表单和登录窗口是许多 网站 的组成部分。但是,这些都相对容易处理。
到目前为止,在前面的示例中,当网络爬虫与大多数 网站 服务器交互时,它们使用 HTTP 协议的 GET 方法来请求信息。在本文文章中,我们重点介绍POST方法,它将信息推送到Web服务器进行存储和分析。
页面表单基本上可以看成是用户提交POST请求的一种方式,但是这种请求方式是被服务器理解和使用的。正如 网站 URL 链接帮助用户发出 GET 请求一样,HTML 表单帮助用户发出 POST 请求。当然,我们也可以用一点点麻麻自己创建这些请求,然后通过网络爬虫提交给服务器。
Python 请求库
虽然可以使用 Python 标准库控制 Web 表单,但有时一点语法糖可以让生活更甜蜜。但是当你想要做的不仅仅是 urllib 可以做的基本 GET 请求时,请查看 Python 标准库之外的第三方库。
Requests库就是这样一个Python第三方库,擅长处理复杂的HTTP请求、cookies、headers(响应头和请求头)等。
以下是 Requests 创建者 Kenneth Retiz 对 Python 标准库工具的评价:
Python 标准库 urllib2 为您提供了大部分 HTTP 功能,但它的 API 很差。这是因为它是多年来一步步建立起来的——不同的时代要面对不同的网络环境。所以为了完成最简单的任务,他需要花费大量的工作(甚至写完整的方法)。
事情不应该这么复杂,也不应该发生在 Python 中。
与任何第三方 Python 库一样,Requests 库也可以与其他第三方 Python 库管理器(例如 pip)一起安装,或者直接下载 Requests 库源代码。
提交基本表格
大多数 Web 表单由一些 HTML 字段、一个提交按钮和一个“结果”(表单操作的值)页面组成,该页面在表单处理完毕后跳转。虽然这些 HTML 字段通常由文本内容组成,但也可以实现文件上传或其他非文本内容。
因为大部分主流网站都会在他们的robots.txt文件中注明禁止爬虫访问登录表单,相关介绍可以参考这篇文章:爬虫系列:爬虫带来的道德风险和法律责任。
例如,这里是一个表单的源代码:
用户名
密码
这里有几点需要注意:首先,两个输入字段命名为 username 和 passwd 很重要。字段的名称决定了表单验证后将发送到服务器的变量名称。如果你想模拟从表单提交数据的行为,你需要确保你的变量名与字段名相对应。
还要求表单的实际行为实际发生在 index.php?c=session&a=login 中。对表单的任何 POST 请求实际上都发生在此页面上,而不是表单本身所在的页面上。请记住:HTML 表单的目的只是为了帮助 网站 的访问者向服务器发送格式正确的请求以获取未出现的页面。除非您正在研究请求的设计风格,否则不要在表单所在的页面上花费太多时间。
使用 Requests 库提交表单只需几行代码即可完成,包括导入库文件和打印内容的语句:
import requests
params = {'username': 'admin', 'passwd': '5e_KR&pXJ9=J(c7d9P-twt9:'}
r = requests.post("http://www.test.com/admin/inde ... ot%3B, data=params)
print(r.text)
表单提交后,程序返回执行页面的源码,如下:
您的浏览器不支持框架!
由于我们通过Requests提交了内容,并没有在浏览器中提交,所以会出现上面的提示,但是我们已经登录成功了。后面我们需要用到浏览器采集的内容时,我们会详细介绍这部分。
这边的代码可以处理很多简单的表格。以下是邮件订阅的表单代码,如下:
Marketing
Email Address
虽然第一次看到有点吓人,但大多数情况下我们只需要关注两件事:
单选按钮、复选按钮和其他输入
显然,并非所有页面都只是一堆文本字段和一个提交按钮。HTML 标准提供了大量可用的表单字段:单选按钮、复选按钮、下拉选项等。在 HTML5 中,还有其他控件,如滚动条(范围输入字段)、邮箱、日期等。自定义 Javascript 字段是无所不能的,实现了颜色选择器、日历以及开发人员能想到的任何东西。
无论表单的字段看起来多么复杂,仍然只有两件事需要关心:字段名称和值。字段名可以通过查看源码,查找name属性轻松获取。字段值有时比较复杂,可能在表单提交之前由Javascript生成。颜色选择器是一个奇怪的表单字段,它可能使用像 #f5c26b 这样的值。
如果您不确定输入字段值的数据格式,有一些工具可以跟踪浏览器通过 网站 发出或接收的 GET 和 POST 请求的内容。如前所述,跟踪 GET 请求的最佳和最直接的方法是查看 网站 URL 链接,如果 URL 链接如下所示:
https://pdf-lib.org/Home/Searc ... abbix
那么请求的表单可能如下所示:
下面是一个更复杂的表单提交示例:
如果您遇到一个看起来很复杂的 POST 表单,并且看起来浏览器正在将这些参数传递给服务器,那么最简单的方法是使用 Chrome 的检查器或开发人员工具。
总结
由于篇幅原因,今天只讲解基本的表单、单选按钮、复选框等表单输入,以及如何通过Requests提交给服务器。
在下一篇文章 文章 中,我们将介绍提交文件、图像、处理登录、cookie、HTTP 基本访问身份验证以及其他与表单相关的问题。
源代码已托管在 Github 上:
如果您有任何问题,欢迎提出。
文章采集api(基于百度地图API的门店信息搜集系统的互联网应用成果)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-01-11 05:17
摘要:互联网的快速发展为互联网的各种应用提供了强大的技术支撑,网络地图服务作为一项基础服务应运而生。随着我国科技水平逐步接近国际先进水平,手机移动互联网呈现快速发展趋势,基于网络地图服务的互联网应用被认为是互联网行业的下一个宝地。百度地图API是一套基于百度地图服务的应用接口,免费提供给开发者。功能非常强大,满足地图应用开发的需要。据统计,基于百度地图API的网络应用数量已超过100万。而基于百度地图API的各种Web应用结果表明,百度地图API可以解决Web地图应用开发中遇到的数据源问题,可以降低企业的开发成本,具有广阔的发展前景。根据“基于百度地图API的店铺信息采集系统”课题,结合当前企业业务销售市场对业务相关店铺信息的需求和垂直搜索引擎的专业特点,“京商传媒店铺信息采集系统” 《系统》在实际项目的背景下,基于百度地图提供的开放式JavaScript API,实现了一个业务相关的店铺信息采集系统。系统的主要功能是采集企业业务销售市场中与业务相关的店铺信息,然后将其结构化提取并存储在企业数据库中,并提供检索和导出到Excel的功能。另外,业务员验证店铺信息并反馈给管理员,管理员更新数据库中的店铺信息。对该系统进行了功能和性能测试,测试结果表明该系统达到了预期的功能效果,性能平稳。业务员验证店铺信息并反馈给管理员,管理员更新数据库中的店铺信息。对该系统进行了功能和性能测试,测试结果表明该系统达到了预期的功能效果,性能平稳。业务员验证店铺信息并反馈给管理员,管理员更新数据库中的店铺信息。对该系统进行了功能和性能测试,测试结果表明该系统达到了预期的功能效果,性能平稳。 查看全部
文章采集api(基于百度地图API的门店信息搜集系统的互联网应用成果)
摘要:互联网的快速发展为互联网的各种应用提供了强大的技术支撑,网络地图服务作为一项基础服务应运而生。随着我国科技水平逐步接近国际先进水平,手机移动互联网呈现快速发展趋势,基于网络地图服务的互联网应用被认为是互联网行业的下一个宝地。百度地图API是一套基于百度地图服务的应用接口,免费提供给开发者。功能非常强大,满足地图应用开发的需要。据统计,基于百度地图API的网络应用数量已超过100万。而基于百度地图API的各种Web应用结果表明,百度地图API可以解决Web地图应用开发中遇到的数据源问题,可以降低企业的开发成本,具有广阔的发展前景。根据“基于百度地图API的店铺信息采集系统”课题,结合当前企业业务销售市场对业务相关店铺信息的需求和垂直搜索引擎的专业特点,“京商传媒店铺信息采集系统” 《系统》在实际项目的背景下,基于百度地图提供的开放式JavaScript API,实现了一个业务相关的店铺信息采集系统。系统的主要功能是采集企业业务销售市场中与业务相关的店铺信息,然后将其结构化提取并存储在企业数据库中,并提供检索和导出到Excel的功能。另外,业务员验证店铺信息并反馈给管理员,管理员更新数据库中的店铺信息。对该系统进行了功能和性能测试,测试结果表明该系统达到了预期的功能效果,性能平稳。业务员验证店铺信息并反馈给管理员,管理员更新数据库中的店铺信息。对该系统进行了功能和性能测试,测试结果表明该系统达到了预期的功能效果,性能平稳。业务员验证店铺信息并反馈给管理员,管理员更新数据库中的店铺信息。对该系统进行了功能和性能测试,测试结果表明该系统达到了预期的功能效果,性能平稳。
文章采集api( 【PostmanPostman】API接口())
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-01-10 14:13
【PostmanPostman】API接口())
本节主题:1.2 阅读API接口文档
课程讲师:查理
观看地址:点我进入
1 本节重点
2 课前准备2.1 接口测试工具
提前准备一个接口测试工具,选择以下工具之一:
POSTMAN 是最好的接口测试工具!
点击此链接邮递员 | 下载Postman App进入Postman官网下载页面,选择对应版本(操作系统和32位/64位)并安装;
如果正常,浏览器会自动识别你的电脑系统。本教程用macOS电脑打开,图中圈出的地方会自动识别电脑系统;
Windows用户需要选择32位还是64位版本,需要先检查你使用的电脑是32位还是64位处理器,如果不确定,可以在电脑里查看设置;
点击下载,直接打开压缩包进行安装。
安装后需要注册才能打开软件,分别填写邮箱、用户名、密码。您需要选中接下来的两个框,然后单击橙色按钮注册一个免费帐户。
是一款免费开源、轻量级、快速美观的 API 调试工具,用于替代 Postman。可以帮助程序员节省时间,提高工作效率;
无需下载,访问官网即可使用!
点击访问:POSTWOMAN官网
极客专属的界面协作管理工具;
点击访问:
ApiPost是一个API调试和管理工具,支持团队协作,可以直接生成文档。它支持模拟常见的请求,如 POST、GET 和 PUT。是后端接口开发人员或前端和接口测试人员不可多得的工具;
点击访问:ApiPost官网
2.2 接口准备
- 在上课前找两个API接口,可以是建道云,公司内部系统,也可以是第三方API接口(不知道在哪里找?有很多第三方接口可以测试阿里云市场免费~点击查看)
3 课程内容3.1 如何阅读接口文档?
API接口文档一般分为接口描述、接口地址、请求方法、请求参数、响应内容、错误码、实例:
接口描述:简要描述接口的逻辑和功能。例如,这是一个发送消息和查询天气的接口;
接口地址:这个地址代表网络地址,即url,我们需要调用接口url来获取响应内容;
请求方式:常见的请求方式有GET和POST,其他方式如下图所示;
请求参数:用于传递信息的变量。即需要请求的字段名称的名称和规则:哪些字段都是,字段的类型是什么,是否需要字段等;
响应内容:接口返回的字段名和规则;
错误码:对接口的错误码进行分类,以便快速查找错误原因并解决问题;
示例:实际调用时响应的内容。
这里需要重点掌握GET和POST请求方法!
3.2 个 GET 请求
GET 通常用于获取服务器端数据:
GET请求可以传递参数,一般的传递方式是URL传递参数,例如:
百度知道搜索地址:
搜索后地址:ct=17&pn=0&tn=ikaslist&rn=10&fr=wwwt&word=%E6%B5%8B%E8%AF%95
拆分网址:
/搜索
lm=0
&rn=10
&pn=0
&fr=搜索
&ie=gbk
&word=%BC%F2%B5%C0%D4%C6
网址解析:
(有些文档需要自己的域名+路径,有些文档会提供完整的接口地址,比如剑道云/钉钉)
参数名称值
流明
rn
10
PN
FR
搜索
IE
gbk
单词
%BC%F2%B5%C0%D4%C6
在GET请求中,参数/Params/Querys是以URL参数的形式传递的!
注意在POSTMAN中可以直接使用URL传参,也可以在Params中填写KEY和VALUE,拼接(演示)会自动进行!
3.3 POST 请求
POST 请求一般由 Url、Headers 和 Body 组成。如果在POST请求的接口文档中遇到Params/Querys,需要像GET请求一样使用URL参数来传递参数,而POST请求的接口文档中的参数一般参考Body!
使用 URL 传递参数的接口:
接口地址
使用 Body 传递参数的接口:
POST 请求有不同的请求格式:
{"name":"ziv","password":"123"}
{"data_id":"5398d19a9318483922"}
text/plain(理解),纯文本格式,一般使用raw-Text;
name:ziv,password:123
ziv
123
application/x-www-from-urlencoded(理解),将表单中的数据转换成键值对,用&分隔。
3.4 文档
以钉钉文档为例说明接口(GET方法):
以阿里云API市场为例说明接口(POST方式):点击查看 查看全部
文章采集api(
【PostmanPostman】API接口())
本节主题:1.2 阅读API接口文档
课程讲师:查理
观看地址:点我进入
1 本节重点
2 课前准备2.1 接口测试工具
提前准备一个接口测试工具,选择以下工具之一:
POSTMAN 是最好的接口测试工具!
点击此链接邮递员 | 下载Postman App进入Postman官网下载页面,选择对应版本(操作系统和32位/64位)并安装;
如果正常,浏览器会自动识别你的电脑系统。本教程用macOS电脑打开,图中圈出的地方会自动识别电脑系统;
Windows用户需要选择32位还是64位版本,需要先检查你使用的电脑是32位还是64位处理器,如果不确定,可以在电脑里查看设置;
点击下载,直接打开压缩包进行安装。
安装后需要注册才能打开软件,分别填写邮箱、用户名、密码。您需要选中接下来的两个框,然后单击橙色按钮注册一个免费帐户。
是一款免费开源、轻量级、快速美观的 API 调试工具,用于替代 Postman。可以帮助程序员节省时间,提高工作效率;
无需下载,访问官网即可使用!
点击访问:POSTWOMAN官网
极客专属的界面协作管理工具;
点击访问:
ApiPost是一个API调试和管理工具,支持团队协作,可以直接生成文档。它支持模拟常见的请求,如 POST、GET 和 PUT。是后端接口开发人员或前端和接口测试人员不可多得的工具;
点击访问:ApiPost官网
2.2 接口准备
- 在上课前找两个API接口,可以是建道云,公司内部系统,也可以是第三方API接口(不知道在哪里找?有很多第三方接口可以测试阿里云市场免费~点击查看)
3 课程内容3.1 如何阅读接口文档?
API接口文档一般分为接口描述、接口地址、请求方法、请求参数、响应内容、错误码、实例:
接口描述:简要描述接口的逻辑和功能。例如,这是一个发送消息和查询天气的接口;
接口地址:这个地址代表网络地址,即url,我们需要调用接口url来获取响应内容;
请求方式:常见的请求方式有GET和POST,其他方式如下图所示;
请求参数:用于传递信息的变量。即需要请求的字段名称的名称和规则:哪些字段都是,字段的类型是什么,是否需要字段等;
响应内容:接口返回的字段名和规则;
错误码:对接口的错误码进行分类,以便快速查找错误原因并解决问题;
示例:实际调用时响应的内容。
这里需要重点掌握GET和POST请求方法!
3.2 个 GET 请求
GET 通常用于获取服务器端数据:
GET请求可以传递参数,一般的传递方式是URL传递参数,例如:
百度知道搜索地址:
搜索后地址:ct=17&pn=0&tn=ikaslist&rn=10&fr=wwwt&word=%E6%B5%8B%E8%AF%95
拆分网址:
/搜索
lm=0
&rn=10
&pn=0
&fr=搜索
&ie=gbk
&word=%BC%F2%B5%C0%D4%C6
网址解析:
(有些文档需要自己的域名+路径,有些文档会提供完整的接口地址,比如剑道云/钉钉)
参数名称值
流明
rn
10
PN
FR
搜索
IE
gbk
单词
%BC%F2%B5%C0%D4%C6
在GET请求中,参数/Params/Querys是以URL参数的形式传递的!
注意在POSTMAN中可以直接使用URL传参,也可以在Params中填写KEY和VALUE,拼接(演示)会自动进行!
3.3 POST 请求
POST 请求一般由 Url、Headers 和 Body 组成。如果在POST请求的接口文档中遇到Params/Querys,需要像GET请求一样使用URL参数来传递参数,而POST请求的接口文档中的参数一般参考Body!
使用 URL 传递参数的接口:
接口地址
使用 Body 传递参数的接口:
POST 请求有不同的请求格式:
{"name":"ziv","password":"123"}
{"data_id":"5398d19a9318483922"}
text/plain(理解),纯文本格式,一般使用raw-Text;
name:ziv,password:123
ziv
123
application/x-www-from-urlencoded(理解),将表单中的数据转换成键值对,用&分隔。
3.4 文档
以钉钉文档为例说明接口(GET方法):
以阿里云API市场为例说明接口(POST方式):点击查看
文章采集api(一个的API文档是什么?如何正确使用?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-01-07 14:16
对于程序员来说,API 文档对于程序员来说是很熟悉的东西,几乎每天都要和他们打交道。在大多数开发团队中,只要有前后端合作,API文档就会作为两方之间的桥梁存在。API 文档是对后端提供的服务的描述。前端开发人员通常是 API 文档的消费者。下面我从消费者的角度来谈谈什么样的API文档是有用的。
什么是 API 文档?
简单的说就是对所有API调用和涉及的参数进行了清晰的说明。更具体地说,就是每个API可以做什么,以及API中每个参数的解释,包括它们的类型、格式、可能的值、验证规则,以及它们是否有必要。
什么是 API 文档?
欢迎页面
有些人经常忽视这个页面的重要性。当然,如果是内部项目,欢迎页面有时不是那么重要,但是如果API文档是外部的,比如各个公司的开放平台文档,那么详细的欢迎页面甚至可以决定一个开发者是否是愿意访问您的平台。
欢迎页面可以收录的内容:
(Spotify 的 API 文档欢迎页面)
具有完整上下文的示例
想象一个我们阅读 API 文档的场景。我们会像小说一样从头开始阅读吗?大多数情况下不是。一般我们会根据名称直接从API列表跳转到我们需要查看的API,直接读取。因此,对于内容的组织,所有必要的信息和相关的解释都必须收录在每个 API 的解释中。例如,GitHub 的 REST API 文档的 commits 部分,详细给出了每个 API 的部分:
常见类型的例子
可以使用一些工具直接从项目代码中生成文档示例,例如 api blueprint。这样做的好处是在修改源代码时,文档的内容会同步更新,避免了不及时更新文档的问题。但是,建议不要完全依赖自动化工具。生成内容后,还需要手动补充必要的指令,使文档的内容更容易理解。
没有什么比 API 在实际项目中的应用更直观了。真实的示例项目代码可以帮助用户了解各个API的使用方式以及连接方式。通常可以在文档中提供指向示例项目的 GitHub 存储库的链接。如果代码量不大,也可以直接贴在文档中。
顾名思义,该方法就是在客户端模块中封装API调用,包括鉴权、配置等过程,用户可以在项目中直接引用调用封装的方法。这种方式可以简化客户端调用API的工作复杂度,但同时会增加API提供者的工作量。更新后端服务时,客户端模块也需要同步更新。例如,GitHub 提供了不同语言的客户端模块。
错误相关信息
另外,一旦在调试过程中出现错误,详细的错误信息文档可以降低解决错误的难度,应该包括:
事实上,能够做到这一点的文档会少得多。GitHub 的 API 文档在这方面更为通用。Context.IO的文档在错误信息方面表现更好,可以作为参考。
与全球内容相关的话题
这是指任何 API 文档中常见且必要的内容,包括:
至于这些部分的内容,会根据后端服务的不同而有所差异。同时,在每个具体的API讲解中,当有与这些内容相关的概念时,可以给出具体章节的链接,方便开发者随时跳转。查看。
一些可用性建议
API 文档可以提供一些小功能来改善用户体验。比如在代码示例旁边设置了一个复制代码的按钮,方便用户一键复制代码;调用API的代码示例提供多语言支持,用户可以查看不同语言的API调用示例。借助复制功能,可以减少编写重复代码的工作。数量。
API 文档是什么样的?
一个好的API文档,除了内容合理详尽外,风格和交互方式也应该简单易用。目前的API文档基本都是基于网页展示的。利用网页的显示特性,有一些常用的设计方法。以下是一些适合作为 API 文档呈现元素的最佳实践。
只要API文档不是特别大,建议单页展示。在单个页面中查找任何内容(无论是浏览器中的网络搜索还是文档提供的导航)都会非常快,加上页面上的设置,共享一个API记录的位置也非常方便。当然,如果API文档的内容太多,强行在单个页面上会影响页面体验,应该果断拆分文档,但记得要保留每个子页面的全局导航信息,方便用户跳转在每一页上。改变。
在使用API文档的过程中,由于需要频繁搜索内容,页面固定导航栏是非常有必要的。用户可以随时通过导航栏查找文档内容。
既然使用了固定位置的导航栏,那么同时使用多列布局是合乎逻辑的。在宽屏桌面网页上,多栏布局可以很好地组织文档内容,导航、API描述和代码示例可以各占一栏。
API文档维护
维护 API 文档应该和维护一个独立的项目一样。每次更新都以 pull 分支的形式完成。编辑检查文档内容的正确性和简洁性后,项目成员将对其进行审核。
API文档发布后,后期维护同样重要。主要有两个方面:
新的和过时的功能。在发布新功能之前,您应该发布文档并确保该文档已经通过标准审核流程。对于过时的旧功能,应从文档中删除它们。同时,建议在相应位置提供过时功能的提示和升级指南,方便使用老功能的开发者进行升级工作。文档的投稿条目应保留在文档页面。如果文档托管在 GitHub 等平台上,则会提供指向存储库的链接,以便每个阅读文档的用户都可以向文档提交 Issue 或 PR。如果文档是闭源的,至少应该有一个地方可以提供反馈。
以上是项目开发合作中编写友好API文档的一些想法和建议,欢迎讨论。 查看全部
文章采集api(一个的API文档是什么?如何正确使用?(组图))
对于程序员来说,API 文档对于程序员来说是很熟悉的东西,几乎每天都要和他们打交道。在大多数开发团队中,只要有前后端合作,API文档就会作为两方之间的桥梁存在。API 文档是对后端提供的服务的描述。前端开发人员通常是 API 文档的消费者。下面我从消费者的角度来谈谈什么样的API文档是有用的。
什么是 API 文档?
简单的说就是对所有API调用和涉及的参数进行了清晰的说明。更具体地说,就是每个API可以做什么,以及API中每个参数的解释,包括它们的类型、格式、可能的值、验证规则,以及它们是否有必要。
什么是 API 文档?
欢迎页面
有些人经常忽视这个页面的重要性。当然,如果是内部项目,欢迎页面有时不是那么重要,但是如果API文档是外部的,比如各个公司的开放平台文档,那么详细的欢迎页面甚至可以决定一个开发者是否是愿意访问您的平台。
欢迎页面可以收录的内容:
(Spotify 的 API 文档欢迎页面)
具有完整上下文的示例
想象一个我们阅读 API 文档的场景。我们会像小说一样从头开始阅读吗?大多数情况下不是。一般我们会根据名称直接从API列表跳转到我们需要查看的API,直接读取。因此,对于内容的组织,所有必要的信息和相关的解释都必须收录在每个 API 的解释中。例如,GitHub 的 REST API 文档的 commits 部分,详细给出了每个 API 的部分:
常见类型的例子
可以使用一些工具直接从项目代码中生成文档示例,例如 api blueprint。这样做的好处是在修改源代码时,文档的内容会同步更新,避免了不及时更新文档的问题。但是,建议不要完全依赖自动化工具。生成内容后,还需要手动补充必要的指令,使文档的内容更容易理解。
没有什么比 API 在实际项目中的应用更直观了。真实的示例项目代码可以帮助用户了解各个API的使用方式以及连接方式。通常可以在文档中提供指向示例项目的 GitHub 存储库的链接。如果代码量不大,也可以直接贴在文档中。
顾名思义,该方法就是在客户端模块中封装API调用,包括鉴权、配置等过程,用户可以在项目中直接引用调用封装的方法。这种方式可以简化客户端调用API的工作复杂度,但同时会增加API提供者的工作量。更新后端服务时,客户端模块也需要同步更新。例如,GitHub 提供了不同语言的客户端模块。
错误相关信息
另外,一旦在调试过程中出现错误,详细的错误信息文档可以降低解决错误的难度,应该包括:
事实上,能够做到这一点的文档会少得多。GitHub 的 API 文档在这方面更为通用。Context.IO的文档在错误信息方面表现更好,可以作为参考。
与全球内容相关的话题
这是指任何 API 文档中常见且必要的内容,包括:
至于这些部分的内容,会根据后端服务的不同而有所差异。同时,在每个具体的API讲解中,当有与这些内容相关的概念时,可以给出具体章节的链接,方便开发者随时跳转。查看。
一些可用性建议
API 文档可以提供一些小功能来改善用户体验。比如在代码示例旁边设置了一个复制代码的按钮,方便用户一键复制代码;调用API的代码示例提供多语言支持,用户可以查看不同语言的API调用示例。借助复制功能,可以减少编写重复代码的工作。数量。
API 文档是什么样的?
一个好的API文档,除了内容合理详尽外,风格和交互方式也应该简单易用。目前的API文档基本都是基于网页展示的。利用网页的显示特性,有一些常用的设计方法。以下是一些适合作为 API 文档呈现元素的最佳实践。
只要API文档不是特别大,建议单页展示。在单个页面中查找任何内容(无论是浏览器中的网络搜索还是文档提供的导航)都会非常快,加上页面上的设置,共享一个API记录的位置也非常方便。当然,如果API文档的内容太多,强行在单个页面上会影响页面体验,应该果断拆分文档,但记得要保留每个子页面的全局导航信息,方便用户跳转在每一页上。改变。
在使用API文档的过程中,由于需要频繁搜索内容,页面固定导航栏是非常有必要的。用户可以随时通过导航栏查找文档内容。
既然使用了固定位置的导航栏,那么同时使用多列布局是合乎逻辑的。在宽屏桌面网页上,多栏布局可以很好地组织文档内容,导航、API描述和代码示例可以各占一栏。
API文档维护
维护 API 文档应该和维护一个独立的项目一样。每次更新都以 pull 分支的形式完成。编辑检查文档内容的正确性和简洁性后,项目成员将对其进行审核。
API文档发布后,后期维护同样重要。主要有两个方面:
新的和过时的功能。在发布新功能之前,您应该发布文档并确保该文档已经通过标准审核流程。对于过时的旧功能,应从文档中删除它们。同时,建议在相应位置提供过时功能的提示和升级指南,方便使用老功能的开发者进行升级工作。文档的投稿条目应保留在文档页面。如果文档托管在 GitHub 等平台上,则会提供指向存储库的链接,以便每个阅读文档的用户都可以向文档提交 Issue 或 PR。如果文档是闭源的,至少应该有一个地方可以提供反馈。
以上是项目开发合作中编写友好API文档的一些想法和建议,欢迎讨论。
文章采集api(七个步骤逐步介绍如何阅读API文档和测试?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-01-06 13:01
随着API在互联网时代越来越普遍,不仅程序员会使用,现在产品经理或者互联网运营商也需要调试和对接API。阅读这个 文章 你可能会使用或开发 API,或者两者兼而有之。因此,不仅要了解如何编写,还要了解如何阅读 API 文档和测试。
什么是 API 文档?您也可以将 API 文档视为双方之间的服务协议。该文档概述了当第一方发送某种类型的请求时第二方及其软件将如何响应。文档中描述了这些类型的请求(称为 API 调用),以便开发人员知道他们可以使用 API 做什么以及如何做。
好的 API 文档描述了它们的端点,解释了为什么应该使用它们,并提供了非常具体的示例来说明如何使用它们——所有这些方法对于初学者和高级用户来说都同样清楚。带有未知说明的 API 文档过于技术性和文本化,因此并非所有用户都能正确使用。
下面,我们将通过七步一步一步介绍如何编写高质量的API文档。
了解谁在使用您的 API
描绘您的用户旅程
从基本函数语句开始
添加代码示例
列出您的状态代码和错误消息
用白话写和设计API文档
使 API 文档始终保持最新
1.了解使用你API的用户
与影响战略规划或 UI 设计过程的任何内容一样,编写 API 文档的第一步是了解目标受众。这需要了解您所针对的用户类型、内容需要为他们提供的实用价值,以及他们适合实际场景的方式。
在编写 API 文档时,需要牢记两个主要的用户组。一组用户是API文档的直接用户,因此他们只需要查看教程和代码示例。这个群体主要是开发者。另一组用户将评估 API 功能、价格、速率限制、安全性和其他因素,以了解 API 如何与其业务需求和目标保持一致。团队主要由CTO和产品经理,以及一些开发人员组成。
您必须牢记这两个角色,以确保文档为每位读者提供良好的体验。
2.描述您的用户旅程
与任何产品一样,API 必须在买家旅程的每个阶段提供内容。这意味着文档应该解释 API 可以做什么(或它可以解决什么问题)、它提供的各种功能和端点,以及它与竞争对手的不同之处。
API 文档应该回答的一些基本问题是:
1.为什么要使用这个API?
2.如何访问不同的工具和端点?
3.获得许可后下一步是什么?
4.如何使用一些特定的功能?
3.从基本的函数语句开始
每个 API 和功能都是唯一的或唯一的。例如,一些API可以将微博照片嵌入到电子商务平台的详细信息页面中。一些API可以让你通过B站旅游UP主访问上千家推荐的酒店。网站 上甚至还有一个用于集成 Yoda 翻译器的 API。虽然每个 API 的作用不同,但是每个 API 文档都应该涵盖一些基础知识。让我们看看下面的一些例子。
验证
由于认证对于保护API数据以及开发者和最终用户的数据安全非常重要,API通常有多种认证方案,因此API文档中必须对每一种认证方式进行说明,以便用户能够正确获取Authorize并使用API。例如,YouTube 数据 API 支持两种类型的授权凭据。它的文档解释了如何使用 OAuth 2.0 以及如何获取 API 密钥,以便用户可以选择他们更熟悉的身份验证方法。
速率限制
与用户身份验证一样,速率限制可以帮助防止意外传输或 API 滥用。API 速率限制是您在给定时间内可以向 API 发送请求的次数。这些限制必须在 API 文档中明确说明,以便用户了解如何正确使用 API 及其功能。此信息最常出现在“使用条款”中。
使用条款
使用(或服务)条款是服务提供者与需要服务的用户之间的法律协议。后者必须同意遵守这些条款才能使用服务。在 API 文档中,使用条款必须明确定义 API 用户在理想情况下应该如何使用 API。这将有助于确保服务用户充分利用 API 平台和功能。
内容变更日志
API 用户了解他们使用的 API 的任何折旧是很重要的。更改文档可以帮助他们妥善维护自己的应用程序,并充分利用 API 平台的功能。案例:Twitter 的 API 文档有一个变更日志,其中记录了对 Twitter 开发者平台所做的所有变更,包括新功能和新产品。
4.添加代码示例
API 文档有两个主要目标:使开发人员尽可能轻松地使用 API,并使他们能够快速了解 API 的全部功能。实现这两个目标的一个好方法是为每个 API 端点提供代码示例。这样,开发者就可以了解端点最关键的功能,从一些案例代码入手,然后直接调整案例代码上的参数,以满足自己的实际需求和对接规范。
5.列出您的状态代码和错误消息
API 文档应清楚地概述用户在进行 API 调用时可能期望的状态代码和错误消息。理想情况下,每个响应都应附有简短的描述,以便用户知道 API 何时成功调用、API 何时未成功调用,并能够解决他们遇到的任何错误。通常,此信息放置在其自己的页面上。这是 Express 100 API 文档中的一个示例。
6.用白话写和设计API文档
如果您想以易于用户阅读和浏览的方式编写、构建和设计 API 文档。这意味着根据用户的使用场景和需求来呈现和组织文档的内容信息。用户的使用场景是与用户在哪里、何时、为什么以及如何找到内容并与之交互相关的所有内容。他们的需求还包括他们的目标、行为和期望。
最好的 API 文档是为不熟悉 API 的初学者和非常熟悉 API 的开发人员编写的。本文档应尽可能避免使用过多的技术术语,并尽可能提供附加的上下文信息或文档的内部链接。它还需要提供,比如“入门”以及示例和教程,这些是新手用户需要的内容,更高级的用户可以跳过它。
为了保证用户可以选择自己需要的东西,在设计API文档的时候一定要做好导航。最佳做法是使用标题和侧边栏,以便用户可以导航到文档的另一部分并提供搜索功能,而无需在页面上上下滚动。其他设计考虑因素包括排版、配色方案和布局。三列布局被认为是收录大量代码示例的文档的理想选择。无衬线字体和对比色链接也是不错的设计选择。
7.保持 API 文档始终是最新的
为了保证 API 用户能够获得最佳体验并不断吸引新用户,API 提供商必须不时维护自己的 API 文档。过去,API 文档以PDF 或静态网页的形式存在,这使得文档更新变得困难。现在,有一些工具可以帮助您创建可以自动更新的动态和交互式文档。Redocly 和 SwaggerUI 是两个比较常见的实际例子。
如何阅读 API 文档
如果你只是一个 API 用户,而不是 API 服务提供者,那么你需要知道如何阅读 API 文档。虽然写法和读法都差不多(找基本原理、试代码示例等),但并不完全一样。让我们仔细看看如何阅读 API 文档以了解使用特定 API 可能实现的功能。
从文档概览开始
大多数API文档会首先概述API的功能,如何连接API,以及如何正确使用API。当然,你不需要了解概览的每一个细节,但你应该粗略地浏览一遍。
以Express 100的API文档为例。首先,Express 100 的 API 文档解释了 Express 100 的 API 的用途,使用的协议和语言,以及它的认证方案。在左侧边栏的“快速链接”部分,您将找到指向其使用指南和速率限制、测试帐户、更改日志以及开始使用 API 所需的所有其他内容的重要链接。
对函数的深入理解
了解 API 概述后,请浏览 API 参考文档,其中列出了 API 的所有功能(也称为方法)。此时,无需彻底阅读或记住所有内容。相反,请仔细研究您特别感兴趣的功能。通过查看其参数和示例,您可以了解是否可以成功使用该 API 执行您想要执行的确切操作。
例如,假设您想通过快递100的API实现如下物流查询功能:-在电商网页/APP/小程序中,客户在订单详情中查看所购商品的物流地图轨迹,并显示物流跟踪文字信息一起。顾客
在这种需求的驱动下,您可以导航到“接口文档”,然后查看其代码语言、参数、响应和错误消息等。
通读 API 文档教程
现在您知道是否可以使用 API 来实现您的需求,请查看教程。由于最好的 API 文档应该可以帮助用户快速入门,因此大多数文档都会收录完成任务的详细教程。您应该至少通读一个教程,以了解需要仔细研究哪些级别的细节和示例。如果你想了解电商快递物流API的好处,这里有一篇文章《什么是电商API?这是它能给商家带来的12个运营效益》一文,介绍了它们的优点和缺点详细。有兴趣的可以去看看,说不定你会发现意想不到的惊喜。
记录 API 信息更改
随着越来越多的公司提供 API 服务以形成高度集成的用户体验,知道如何编写和阅读 API 文档变得越来越有价值。在创建或评估 API 文档时,请确保您的 API 稳定且易于阅读和浏览,并向开发人员和非开发人员清楚地传达 API 的价值。这确保了技术出身的用户可以快速正确地开始使用您的 API,而同事必须确保他们可以与其他非技术同事一起使用它。 查看全部
文章采集api(七个步骤逐步介绍如何阅读API文档和测试?(组图))
随着API在互联网时代越来越普遍,不仅程序员会使用,现在产品经理或者互联网运营商也需要调试和对接API。阅读这个 文章 你可能会使用或开发 API,或者两者兼而有之。因此,不仅要了解如何编写,还要了解如何阅读 API 文档和测试。
什么是 API 文档?您也可以将 API 文档视为双方之间的服务协议。该文档概述了当第一方发送某种类型的请求时第二方及其软件将如何响应。文档中描述了这些类型的请求(称为 API 调用),以便开发人员知道他们可以使用 API 做什么以及如何做。
好的 API 文档描述了它们的端点,解释了为什么应该使用它们,并提供了非常具体的示例来说明如何使用它们——所有这些方法对于初学者和高级用户来说都同样清楚。带有未知说明的 API 文档过于技术性和文本化,因此并非所有用户都能正确使用。
下面,我们将通过七步一步一步介绍如何编写高质量的API文档。
了解谁在使用您的 API
描绘您的用户旅程
从基本函数语句开始
添加代码示例
列出您的状态代码和错误消息
用白话写和设计API文档
使 API 文档始终保持最新
1.了解使用你API的用户
与影响战略规划或 UI 设计过程的任何内容一样,编写 API 文档的第一步是了解目标受众。这需要了解您所针对的用户类型、内容需要为他们提供的实用价值,以及他们适合实际场景的方式。
在编写 API 文档时,需要牢记两个主要的用户组。一组用户是API文档的直接用户,因此他们只需要查看教程和代码示例。这个群体主要是开发者。另一组用户将评估 API 功能、价格、速率限制、安全性和其他因素,以了解 API 如何与其业务需求和目标保持一致。团队主要由CTO和产品经理,以及一些开发人员组成。
您必须牢记这两个角色,以确保文档为每位读者提供良好的体验。
2.描述您的用户旅程
与任何产品一样,API 必须在买家旅程的每个阶段提供内容。这意味着文档应该解释 API 可以做什么(或它可以解决什么问题)、它提供的各种功能和端点,以及它与竞争对手的不同之处。
API 文档应该回答的一些基本问题是:
1.为什么要使用这个API?
2.如何访问不同的工具和端点?
3.获得许可后下一步是什么?
4.如何使用一些特定的功能?
3.从基本的函数语句开始
每个 API 和功能都是唯一的或唯一的。例如,一些API可以将微博照片嵌入到电子商务平台的详细信息页面中。一些API可以让你通过B站旅游UP主访问上千家推荐的酒店。网站 上甚至还有一个用于集成 Yoda 翻译器的 API。虽然每个 API 的作用不同,但是每个 API 文档都应该涵盖一些基础知识。让我们看看下面的一些例子。
验证
由于认证对于保护API数据以及开发者和最终用户的数据安全非常重要,API通常有多种认证方案,因此API文档中必须对每一种认证方式进行说明,以便用户能够正确获取Authorize并使用API。例如,YouTube 数据 API 支持两种类型的授权凭据。它的文档解释了如何使用 OAuth 2.0 以及如何获取 API 密钥,以便用户可以选择他们更熟悉的身份验证方法。
速率限制
与用户身份验证一样,速率限制可以帮助防止意外传输或 API 滥用。API 速率限制是您在给定时间内可以向 API 发送请求的次数。这些限制必须在 API 文档中明确说明,以便用户了解如何正确使用 API 及其功能。此信息最常出现在“使用条款”中。
使用条款
使用(或服务)条款是服务提供者与需要服务的用户之间的法律协议。后者必须同意遵守这些条款才能使用服务。在 API 文档中,使用条款必须明确定义 API 用户在理想情况下应该如何使用 API。这将有助于确保服务用户充分利用 API 平台和功能。
内容变更日志
API 用户了解他们使用的 API 的任何折旧是很重要的。更改文档可以帮助他们妥善维护自己的应用程序,并充分利用 API 平台的功能。案例:Twitter 的 API 文档有一个变更日志,其中记录了对 Twitter 开发者平台所做的所有变更,包括新功能和新产品。
4.添加代码示例
API 文档有两个主要目标:使开发人员尽可能轻松地使用 API,并使他们能够快速了解 API 的全部功能。实现这两个目标的一个好方法是为每个 API 端点提供代码示例。这样,开发者就可以了解端点最关键的功能,从一些案例代码入手,然后直接调整案例代码上的参数,以满足自己的实际需求和对接规范。
5.列出您的状态代码和错误消息
API 文档应清楚地概述用户在进行 API 调用时可能期望的状态代码和错误消息。理想情况下,每个响应都应附有简短的描述,以便用户知道 API 何时成功调用、API 何时未成功调用,并能够解决他们遇到的任何错误。通常,此信息放置在其自己的页面上。这是 Express 100 API 文档中的一个示例。
6.用白话写和设计API文档
如果您想以易于用户阅读和浏览的方式编写、构建和设计 API 文档。这意味着根据用户的使用场景和需求来呈现和组织文档的内容信息。用户的使用场景是与用户在哪里、何时、为什么以及如何找到内容并与之交互相关的所有内容。他们的需求还包括他们的目标、行为和期望。
最好的 API 文档是为不熟悉 API 的初学者和非常熟悉 API 的开发人员编写的。本文档应尽可能避免使用过多的技术术语,并尽可能提供附加的上下文信息或文档的内部链接。它还需要提供,比如“入门”以及示例和教程,这些是新手用户需要的内容,更高级的用户可以跳过它。
为了保证用户可以选择自己需要的东西,在设计API文档的时候一定要做好导航。最佳做法是使用标题和侧边栏,以便用户可以导航到文档的另一部分并提供搜索功能,而无需在页面上上下滚动。其他设计考虑因素包括排版、配色方案和布局。三列布局被认为是收录大量代码示例的文档的理想选择。无衬线字体和对比色链接也是不错的设计选择。
7.保持 API 文档始终是最新的
为了保证 API 用户能够获得最佳体验并不断吸引新用户,API 提供商必须不时维护自己的 API 文档。过去,API 文档以PDF 或静态网页的形式存在,这使得文档更新变得困难。现在,有一些工具可以帮助您创建可以自动更新的动态和交互式文档。Redocly 和 SwaggerUI 是两个比较常见的实际例子。
如何阅读 API 文档
如果你只是一个 API 用户,而不是 API 服务提供者,那么你需要知道如何阅读 API 文档。虽然写法和读法都差不多(找基本原理、试代码示例等),但并不完全一样。让我们仔细看看如何阅读 API 文档以了解使用特定 API 可能实现的功能。
从文档概览开始
大多数API文档会首先概述API的功能,如何连接API,以及如何正确使用API。当然,你不需要了解概览的每一个细节,但你应该粗略地浏览一遍。
以Express 100的API文档为例。首先,Express 100 的 API 文档解释了 Express 100 的 API 的用途,使用的协议和语言,以及它的认证方案。在左侧边栏的“快速链接”部分,您将找到指向其使用指南和速率限制、测试帐户、更改日志以及开始使用 API 所需的所有其他内容的重要链接。
对函数的深入理解
了解 API 概述后,请浏览 API 参考文档,其中列出了 API 的所有功能(也称为方法)。此时,无需彻底阅读或记住所有内容。相反,请仔细研究您特别感兴趣的功能。通过查看其参数和示例,您可以了解是否可以成功使用该 API 执行您想要执行的确切操作。
例如,假设您想通过快递100的API实现如下物流查询功能:-在电商网页/APP/小程序中,客户在订单详情中查看所购商品的物流地图轨迹,并显示物流跟踪文字信息一起。顾客
在这种需求的驱动下,您可以导航到“接口文档”,然后查看其代码语言、参数、响应和错误消息等。
通读 API 文档教程
现在您知道是否可以使用 API 来实现您的需求,请查看教程。由于最好的 API 文档应该可以帮助用户快速入门,因此大多数文档都会收录完成任务的详细教程。您应该至少通读一个教程,以了解需要仔细研究哪些级别的细节和示例。如果你想了解电商快递物流API的好处,这里有一篇文章《什么是电商API?这是它能给商家带来的12个运营效益》一文,介绍了它们的优点和缺点详细。有兴趣的可以去看看,说不定你会发现意想不到的惊喜。
记录 API 信息更改
随着越来越多的公司提供 API 服务以形成高度集成的用户体验,知道如何编写和阅读 API 文档变得越来越有价值。在创建或评估 API 文档时,请确保您的 API 稳定且易于阅读和浏览,并向开发人员和非开发人员清楚地传达 API 的价值。这确保了技术出身的用户可以快速正确地开始使用您的 API,而同事必须确保他们可以与其他非技术同事一起使用它。
文章采集api(数据埋点采集到底包括哪些问题?作者从什么是埋点、埋点的应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-12-30 23:22
数据采集是数据分析的基础,埋点是采集最重要的方法。那么数据埋点采集涉及哪些问题呢?本文作者从什么是埋点、埋点如何设计、埋点的应用三个方面梳理了这个问题,与大家分享。
一、数据采集及常见数据问题1.数据采集
数据采集的方式有很多种,埋点采集是其中非常重要的一部分。是c端和b端产品采集的主要方式。
数据采集,顾名思义,采集对应的数据是整个数据流的起点。采集的不完整性,对与错,直接决定了数据的广度和质量,并影响到后续的所有环节。在数据采集有效性和完整性较差的公司中,业务中发现的数据通常会发生重大变化。
数据处理通常包括以下5个步骤:
2. 常见数据问题
在大致了解了数据采集及其结构之后,我们来看看我们工作中遇到的问题,有多少是与数据采集链接相关的:
数据与后台差距大,数据不准确——统计口径不同,埋点定义不同,采集的方法带来误差;想用的时候,没有我想要的数据——没有数据。采集需求,埋点不正确,不完整;事件太多,意义不明——埋点设计方法,埋点更新迭代规则和维护;数据分析不知道看哪些数据和指标——数据定义不清,缺乏分析思路。
我们要从根本上解决问题:把采集当作一个独立的研发企业,而不是产品开发的附属品
二、什么是埋点1. 什么是埋点
所谓埋点,是数据领域的一个术语采集。它的学名应该叫Event Tracking,对应的英文是Event Tracking,指的是捕获、处理和发送特定用户行为或事件的相关技术和实现过程。
数据埋点是数据分析师、数据产品经理和数据运营。根据业务需求或产品需求,开发用户行为的每个事件的对应位置,开发埋点,通过SDK上报埋点的数据结果,并记录汇总数据。分析、推动产品优化、指导运营。
该过程附有规范。通过定义,我们看到特定的用户行为和事件是我们的采集关注点。我们还需要处理和发送相关的技术和实施流程;数据嵌入点是为产品服务的,它来自于产品。,所以跟产品息息相关,埋点在于具体的实战过程,这关系到每个人对底层数据的理解。
2. 为什么要埋分
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的好坏直接影响到数据质量、产品质量、运营质量等。
数据驱动的埋点将分析深度下钻到流量分布和流量级别。通过统计分析,对宏观指标进行深入分析,发现指标背后的问题,洞察用户行为与价值提升的潜在关系;产品优化——对于产品,用户在产品中做了什么,在产品中停留了多久,有什么异常需要注意。这些问题都可以通过埋点的方式来解决;精细化运营——埋点可以实现整个产品生命周期、流量质量和不同来源的分布、人群的行为特征和关系,洞察用户行为与提升商业价值之间的潜在关联。3.
埋点的方法有哪些?目前,大多数公司使用客户端和服务器的组合:
准确度:编码埋点>可视化埋点>全埋点
三、埋点框架及设计1.埋点顶层设计采集
所谓顶层设计,就是搞清楚怎么埋点,用什么方法,上传机制是什么,怎么定义,怎么实现等等;我们在设计的基础上遵循唯一性、可扩展性、一致性等一些常见的字段和生成机制,例如:cid、idfa、idfv等。
2. 埋点 采集 事件和属性设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变的,哪些是业务行为,哪些是基本属性。
基于基础属性事件,我们认为属性一定是采集项,但是属性中的事件属性根据业务进行了调整。因此,我们可以将埋点采集分为协议层和业务层埋点。
3. 数据采集事件和属性设计
Ev 事件的命名也遵循一些规则。当同一类型的函数出现在不同的页面或位置时,根据函数名进行命名,在ev参数中区分页面和位置。仅点击按钮时,按按钮名称命名。
ev事件格式:ev分为ev标识和ev参数
规则:
ev标志和ev参数之间用“#”连接(一级连接器);
ev参数和ev参数之间用“/”连接(二级连接器);
ev 参数使用key=value 的结构。当一个key对应多个value值时,value1和value2之间用“,”连接(三级连接器);
当埋点只有ev标志,没有ev参数时,不需要带#;
评论:
ev标识:作为埋点的唯一标识,用于区分埋点的位置和属性,不可变,不可修改;
ev参数:需要返回埋点的参数,ev参数的顺序是可变的,可以修改;)
调整app埋点时ev标志不变,只修改后续埋点参数(参数值改变或参数类型增加)
eg:一般嵌入点文档中收录的sheet的名称和功能:
A.暴露埋点汇总;
B.点击浏览埋点汇总;
C.故障埋点总结:一般会记录埋点的故障版本或时间;
D、PC和M页面嵌入点对应的pageid;
E、各版本上线时间记录;
在嵌入点文档中,所有列名和函数包括:
4. 基于埋点的统计
如何使用埋点统计查找埋点 ev 事件:
明确埋点类型(点击/曝光/浏览)-过滤类型字段,清除埋点所属页面(页面或功能)-过滤功能模块字段,指定埋点事件名称-过滤name字段知道ev标志,可以直接用ev过滤
如何根据ev事件进行计数统计:查询按钮点击统计时,可以直接使用ev标志进行查询,有区别时,可以限制埋点参数的取值;因为ev参数的顺序不需要可变,查询统计的时候,不能限制参数的顺序;
四、应用-数据流的基础
1. 指标系统
系统化的指标可以将不同指标、不同维度串联起来进行综合分析,快速发现当前产品和业务流程中存在的问题。
2. 可视化
人类对图像信息的解释比文本更有效。可视化对于数据分析极其重要。使用数据可视化可以揭示数据中错综复杂的关系。
3. 埋点元信息api提供
数据采集服务会将采集的埋点写入Kafka。针对每个业务的实时数据消费需求,我们为每个业务提供了单独的Kafka,流量分发模块会定时读取它 取埋点管理平台提供的元信息,实时分发流量各业务时间卡夫卡。
数据采集就像设计一个产品。不能过火,留有扩展空间,但要时刻考虑数据是否完整、详细、不稳定、快速与否。 查看全部
文章采集api(数据埋点采集到底包括哪些问题?作者从什么是埋点、埋点的应用)
数据采集是数据分析的基础,埋点是采集最重要的方法。那么数据埋点采集涉及哪些问题呢?本文作者从什么是埋点、埋点如何设计、埋点的应用三个方面梳理了这个问题,与大家分享。
一、数据采集及常见数据问题1.数据采集
数据采集的方式有很多种,埋点采集是其中非常重要的一部分。是c端和b端产品采集的主要方式。
数据采集,顾名思义,采集对应的数据是整个数据流的起点。采集的不完整性,对与错,直接决定了数据的广度和质量,并影响到后续的所有环节。在数据采集有效性和完整性较差的公司中,业务中发现的数据通常会发生重大变化。
数据处理通常包括以下5个步骤:
2. 常见数据问题
在大致了解了数据采集及其结构之后,我们来看看我们工作中遇到的问题,有多少是与数据采集链接相关的:
数据与后台差距大,数据不准确——统计口径不同,埋点定义不同,采集的方法带来误差;想用的时候,没有我想要的数据——没有数据。采集需求,埋点不正确,不完整;事件太多,意义不明——埋点设计方法,埋点更新迭代规则和维护;数据分析不知道看哪些数据和指标——数据定义不清,缺乏分析思路。
我们要从根本上解决问题:把采集当作一个独立的研发企业,而不是产品开发的附属品
二、什么是埋点1. 什么是埋点
所谓埋点,是数据领域的一个术语采集。它的学名应该叫Event Tracking,对应的英文是Event Tracking,指的是捕获、处理和发送特定用户行为或事件的相关技术和实现过程。
数据埋点是数据分析师、数据产品经理和数据运营。根据业务需求或产品需求,开发用户行为的每个事件的对应位置,开发埋点,通过SDK上报埋点的数据结果,并记录汇总数据。分析、推动产品优化、指导运营。
该过程附有规范。通过定义,我们看到特定的用户行为和事件是我们的采集关注点。我们还需要处理和发送相关的技术和实施流程;数据嵌入点是为产品服务的,它来自于产品。,所以跟产品息息相关,埋点在于具体的实战过程,这关系到每个人对底层数据的理解。
2. 为什么要埋分
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的好坏直接影响到数据质量、产品质量、运营质量等。
数据驱动的埋点将分析深度下钻到流量分布和流量级别。通过统计分析,对宏观指标进行深入分析,发现指标背后的问题,洞察用户行为与价值提升的潜在关系;产品优化——对于产品,用户在产品中做了什么,在产品中停留了多久,有什么异常需要注意。这些问题都可以通过埋点的方式来解决;精细化运营——埋点可以实现整个产品生命周期、流量质量和不同来源的分布、人群的行为特征和关系,洞察用户行为与提升商业价值之间的潜在关联。3.
埋点的方法有哪些?目前,大多数公司使用客户端和服务器的组合:
准确度:编码埋点>可视化埋点>全埋点
三、埋点框架及设计1.埋点顶层设计采集
所谓顶层设计,就是搞清楚怎么埋点,用什么方法,上传机制是什么,怎么定义,怎么实现等等;我们在设计的基础上遵循唯一性、可扩展性、一致性等一些常见的字段和生成机制,例如:cid、idfa、idfv等。
2. 埋点 采集 事件和属性设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变的,哪些是业务行为,哪些是基本属性。
基于基础属性事件,我们认为属性一定是采集项,但是属性中的事件属性根据业务进行了调整。因此,我们可以将埋点采集分为协议层和业务层埋点。
3. 数据采集事件和属性设计
Ev 事件的命名也遵循一些规则。当同一类型的函数出现在不同的页面或位置时,根据函数名进行命名,在ev参数中区分页面和位置。仅点击按钮时,按按钮名称命名。
ev事件格式:ev分为ev标识和ev参数
规则:
ev标志和ev参数之间用“#”连接(一级连接器);
ev参数和ev参数之间用“/”连接(二级连接器);
ev 参数使用key=value 的结构。当一个key对应多个value值时,value1和value2之间用“,”连接(三级连接器);
当埋点只有ev标志,没有ev参数时,不需要带#;
评论:
ev标识:作为埋点的唯一标识,用于区分埋点的位置和属性,不可变,不可修改;
ev参数:需要返回埋点的参数,ev参数的顺序是可变的,可以修改;)
调整app埋点时ev标志不变,只修改后续埋点参数(参数值改变或参数类型增加)
eg:一般嵌入点文档中收录的sheet的名称和功能:
A.暴露埋点汇总;
B.点击浏览埋点汇总;
C.故障埋点总结:一般会记录埋点的故障版本或时间;
D、PC和M页面嵌入点对应的pageid;
E、各版本上线时间记录;
在嵌入点文档中,所有列名和函数包括:
4. 基于埋点的统计
如何使用埋点统计查找埋点 ev 事件:
明确埋点类型(点击/曝光/浏览)-过滤类型字段,清除埋点所属页面(页面或功能)-过滤功能模块字段,指定埋点事件名称-过滤name字段知道ev标志,可以直接用ev过滤
如何根据ev事件进行计数统计:查询按钮点击统计时,可以直接使用ev标志进行查询,有区别时,可以限制埋点参数的取值;因为ev参数的顺序不需要可变,查询统计的时候,不能限制参数的顺序;
四、应用-数据流的基础
1. 指标系统
系统化的指标可以将不同指标、不同维度串联起来进行综合分析,快速发现当前产品和业务流程中存在的问题。
2. 可视化
人类对图像信息的解释比文本更有效。可视化对于数据分析极其重要。使用数据可视化可以揭示数据中错综复杂的关系。
3. 埋点元信息api提供
数据采集服务会将采集的埋点写入Kafka。针对每个业务的实时数据消费需求,我们为每个业务提供了单独的Kafka,流量分发模块会定时读取它 取埋点管理平台提供的元信息,实时分发流量各业务时间卡夫卡。
数据采集就像设计一个产品。不能过火,留有扩展空间,但要时刻考虑数据是否完整、详细、不稳定、快速与否。
文章采集api(【干货】大数据采集系统的分为操作建议及注意事项)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-12-30 14:08
大数据采集系统:
用于采集
各种数据,并提取、转换和加载数据。
大数据采集技术:
对数据进行ETL操作,提取、转换、加载数据,最终挖掘数据的潜在价值。然后为用户提供解决方案或决策参考。
大数据采集系统主要分为三类:
1、系统日志采集
系统
日志采集和日志数据信息的采集,然后进行数据分析,挖掘公司业务平台日志数据的潜在价值。总之,采集
日志数据提供了离线和在线实时分析。目前常用的开源日志采集
系统是Flume。
2、网络数据采集系统
通过网络爬虫和一些网站平台(如推特、新浪微博API)提供的公共API从网站获取数据。可以从网页中提取非结构化数据和半结构化数据的网页数据,提取、清洗、转换成结构化数据,作为统一的本地文件数据存储。
目前常用的网络爬虫系统包括Apache Nutch、Crawler4j、Scrapy等框架。
3、数据库采集系统
数据库采集系统直接与企业业务后端服务器集成,每时每刻都会在企业业务后端产生大量的业务记录写入数据库。最后,由特定的处理和分配系统进行系统分析。
目前常用MySQL、Oracle等关系型数据库来存储数据,也常用Redis、MongoDB等NoSQL数据库进行数据采集。
一个简单易用的大数据采集平台:
1.数据超市
基于云平台的大数据计算分析系统。拥有丰富优质的数据资源,通过自有渠道资源获得100余项版权大数据资源。所有数据都经过审计,以确保数据的高可用性。
2. 快速矿工
数据科学软件平台为数据准备、机器学习、深度学习、文本挖掘和预测分析提供了一个集成环境。
3. Oracle 数据挖掘
它是 Oracle 高级分析数据库的代表。市场领先的公司使用它来最大限度地发挥数据的潜力并做出准确的预测。
4. IBM SPSS Modeler
适用于大型项目。在这个建模器中,文本分析及其最先进的可视化界面非常有价值。有助于生成数据挖掘算法,基本不需要编程。
5. KNIME
开源数据分析平台。您可以快速部署、扩展并熟悉其中的数据。
6. Python
一种免费的开源语言。
大数据平台:
是指一组主要处理海量数据存储、计算、不间断流数据实时计算等场景的基础设施。既可以使用开源平台,也可以使用华为、Transwarp等商业解决方案。它们可以部署在私有云或公共云上。
任何一个完整的大数据平台,一般都包括以下流程:
数据采集->数据存储->数据处理->数据展示(可视化、报告和监控)
其中,数据采集对于所有数据系统都是必不可少的。随着大数据越来越受到重视,数据采集的挑战就显得尤为突出。 查看全部
文章采集api(【干货】大数据采集系统的分为操作建议及注意事项)
大数据采集系统:
用于采集
各种数据,并提取、转换和加载数据。
大数据采集技术:
对数据进行ETL操作,提取、转换、加载数据,最终挖掘数据的潜在价值。然后为用户提供解决方案或决策参考。
大数据采集系统主要分为三类:
1、系统日志采集
系统
日志采集和日志数据信息的采集,然后进行数据分析,挖掘公司业务平台日志数据的潜在价值。总之,采集
日志数据提供了离线和在线实时分析。目前常用的开源日志采集
系统是Flume。
2、网络数据采集系统
通过网络爬虫和一些网站平台(如推特、新浪微博API)提供的公共API从网站获取数据。可以从网页中提取非结构化数据和半结构化数据的网页数据,提取、清洗、转换成结构化数据,作为统一的本地文件数据存储。
目前常用的网络爬虫系统包括Apache Nutch、Crawler4j、Scrapy等框架。
3、数据库采集系统
数据库采集系统直接与企业业务后端服务器集成,每时每刻都会在企业业务后端产生大量的业务记录写入数据库。最后,由特定的处理和分配系统进行系统分析。
目前常用MySQL、Oracle等关系型数据库来存储数据,也常用Redis、MongoDB等NoSQL数据库进行数据采集。
一个简单易用的大数据采集平台:
1.数据超市
基于云平台的大数据计算分析系统。拥有丰富优质的数据资源,通过自有渠道资源获得100余项版权大数据资源。所有数据都经过审计,以确保数据的高可用性。
2. 快速矿工
数据科学软件平台为数据准备、机器学习、深度学习、文本挖掘和预测分析提供了一个集成环境。
3. Oracle 数据挖掘
它是 Oracle 高级分析数据库的代表。市场领先的公司使用它来最大限度地发挥数据的潜力并做出准确的预测。
4. IBM SPSS Modeler
适用于大型项目。在这个建模器中,文本分析及其最先进的可视化界面非常有价值。有助于生成数据挖掘算法,基本不需要编程。
5. KNIME
开源数据分析平台。您可以快速部署、扩展并熟悉其中的数据。
6. Python
一种免费的开源语言。
大数据平台:
是指一组主要处理海量数据存储、计算、不间断流数据实时计算等场景的基础设施。既可以使用开源平台,也可以使用华为、Transwarp等商业解决方案。它们可以部署在私有云或公共云上。
任何一个完整的大数据平台,一般都包括以下流程:
数据采集->数据存储->数据处理->数据展示(可视化、报告和监控)
其中,数据采集对于所有数据系统都是必不可少的。随着大数据越来越受到重视,数据采集的挑战就显得尤为突出。
文章采集api( 公众号数据下载有哪些值得推荐的微信数据分析技巧?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-12-30 07:15
公众号数据下载有哪些值得推荐的微信数据分析技巧?)
公众号资料下载服务内容
账号搜索和扩展数据,根据需要查找微信、微博、今日头条、抖音等新媒体平台账号并发布内容。自定义列表,根据提供的账号计算新的列表索引,并以列表的形式展示。定制化支持,还有更多其他数据需求?我们的技术服务人员可以为您提供完全定制的支持和咨询服务。公众号、微博、今日头条、抖音等新媒体账号海量数据采集、历史发布内容海量采集和评论区数据采集。API深度定制,除了在线API接口外,还为开发者提供微信、微博、抖音等新媒体平台数据。
公众号资料下载
微信公众号推荐的数据分析技术有哪些?
目前,公众号拖图数据后台自带的数据包括用户分析、图形分析、菜单分析、消息分析、界面分析、网页分析六大模块。其中,界面分析和网页分析是公众号二次开发后的数据分析(本文未提及)
一、用户分析
在微信公众平台->统计->用户分析中,用户分析数据包括用户增长和用户属性两个数据,通过它可以查看粉丝数量的变化和当前公众平台用户画像。
1、用户增长
(1)核心数据指标
①新关注数:新关注用户数(不包括当天重复关注的用户);
②取消关注的用户数:取消关注的用户数(不包括当天重复取消关注的用户);
③关注人数净增:新增关注人数与未关注人数之差
④ 累计关注数:当前关注的用户总数。
公众号资料下载 查看全部
文章采集api(
公众号数据下载有哪些值得推荐的微信数据分析技巧?)
公众号资料下载服务内容
账号搜索和扩展数据,根据需要查找微信、微博、今日头条、抖音等新媒体平台账号并发布内容。自定义列表,根据提供的账号计算新的列表索引,并以列表的形式展示。定制化支持,还有更多其他数据需求?我们的技术服务人员可以为您提供完全定制的支持和咨询服务。公众号、微博、今日头条、抖音等新媒体账号海量数据采集、历史发布内容海量采集和评论区数据采集。API深度定制,除了在线API接口外,还为开发者提供微信、微博、抖音等新媒体平台数据。
公众号资料下载
微信公众号推荐的数据分析技术有哪些?
目前,公众号拖图数据后台自带的数据包括用户分析、图形分析、菜单分析、消息分析、界面分析、网页分析六大模块。其中,界面分析和网页分析是公众号二次开发后的数据分析(本文未提及)
一、用户分析
在微信公众平台->统计->用户分析中,用户分析数据包括用户增长和用户属性两个数据,通过它可以查看粉丝数量的变化和当前公众平台用户画像。
1、用户增长
(1)核心数据指标
①新关注数:新关注用户数(不包括当天重复关注的用户);
②取消关注的用户数:取消关注的用户数(不包括当天重复取消关注的用户);
③关注人数净增:新增关注人数与未关注人数之差
④ 累计关注数:当前关注的用户总数。
公众号资料下载
文章采集api( 学Python,学Vba?不需要!(一)!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-12-30 07:14
学Python,学Vba?不需要!(一)!)
爬虫,听起来是不是又高又高?
需要学习专业的网络知识吗?需要学Python,学Vba?不必要!
这篇文章教你零基础用Excel完成,
废话少说,直接上实操步骤!
一、注册并获得您自己的密钥
1、禾丰天气是一个开放的网站,你可以直接在百度上搜索。
鹤峰天气网站:
2、新用户注册账号
3、 注册并激活获取密钥后,只需按照以下步骤操作即可。
这样我们就得到了密钥:a684c431c6b840c196a4a2962630b736,作者的账号密钥,读者可以免费申请。
二、阅读API接口文档
1、打开和风天气网站,找到如下页面:
下面会有一个示例请求 URL
#获取北京实时天气
这是付费版本的一个例子。对于免费版,我们需要在api前加上free-,如下图:
2、 我们来看看需要哪些参数,
我们可以看到location和key这两个参数是必须的。
3、返回参数说明
拿到数据后,我们需要了解返回的是什么信息。下面有详细说明供参考:
了解了这些信息后,我们就可以开始使用EXCEL来获取天气信息了。
三、用EXCEL的PQ工具获取结果
1、打开EXCEL 2016,如下输入你要获取的城市名称,插入表格
2、导入表格到POWER QUERY
如果有读者还没有加载这个工具,我们可以在设置中加载:
3、导入后添加自定义列
添加自定义列:
=Web.Contents(""&[区域]&"&Key=a684c431c6b840c196a4a2962630b736")
4、添加自定义列并分析
= Json.Document([自定义])
您将获得以下图片:
我们扩展数据并组织数据。
5、 我们需要的是当前数据,现在展开,然后依次展开
网页上有参数说明,修改请参考网页说明,详细参数及取值说明:
根据上图中的描述,我们把title改成了中文(具体属性根据需要保留)
数据的逆向透视,便于我们观察
只需关闭并上传。
让我们试试吧。将“上海”添加到城市并刷新数据。
完美成功获取上海实时天气情况。
是不是没有你想的那么难,记得自己练习哦!
网站上还有历史天气和风景天气的界面。有兴趣的读者也可以尝试一下。 查看全部
文章采集api(
学Python,学Vba?不需要!(一)!)
爬虫,听起来是不是又高又高?
需要学习专业的网络知识吗?需要学Python,学Vba?不必要!
这篇文章教你零基础用Excel完成,
废话少说,直接上实操步骤!
一、注册并获得您自己的密钥
1、禾丰天气是一个开放的网站,你可以直接在百度上搜索。
鹤峰天气网站:
2、新用户注册账号
3、 注册并激活获取密钥后,只需按照以下步骤操作即可。
这样我们就得到了密钥:a684c431c6b840c196a4a2962630b736,作者的账号密钥,读者可以免费申请。
二、阅读API接口文档
1、打开和风天气网站,找到如下页面:
下面会有一个示例请求 URL
#获取北京实时天气
这是付费版本的一个例子。对于免费版,我们需要在api前加上free-,如下图:
2、 我们来看看需要哪些参数,
我们可以看到location和key这两个参数是必须的。
3、返回参数说明
拿到数据后,我们需要了解返回的是什么信息。下面有详细说明供参考:
了解了这些信息后,我们就可以开始使用EXCEL来获取天气信息了。
三、用EXCEL的PQ工具获取结果
1、打开EXCEL 2016,如下输入你要获取的城市名称,插入表格
2、导入表格到POWER QUERY
如果有读者还没有加载这个工具,我们可以在设置中加载:
3、导入后添加自定义列
添加自定义列:
=Web.Contents(""&[区域]&"&Key=a684c431c6b840c196a4a2962630b736")
4、添加自定义列并分析
= Json.Document([自定义])
您将获得以下图片:
我们扩展数据并组织数据。
5、 我们需要的是当前数据,现在展开,然后依次展开
网页上有参数说明,修改请参考网页说明,详细参数及取值说明:
根据上图中的描述,我们把title改成了中文(具体属性根据需要保留)
数据的逆向透视,便于我们观察
只需关闭并上传。
让我们试试吧。将“上海”添加到城市并刷新数据。
完美成功获取上海实时天气情况。
是不是没有你想的那么难,记得自己练习哦!
网站上还有历史天气和风景天气的界面。有兴趣的读者也可以尝试一下。
文章采集api(数据资产治理(详情见)——元数据提取)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-12-27 08:10
来源:
一、简介
数据资产治理(详见:数据资产、赞智治理)需要数据。它要求数据类型齐全,数量大,并尽可能覆盖数据流通的方方面面。元数据采集
变得尤为重要,它是数据资产治理的核心基础。
在早期的采集系统中,我们主要使用数据仓库通过“API直连方式”采集Hive/Mysql表的元数据。随着业务的快速发展,对数据运营和成本管理的需求越来越强烈。元数据需要覆盖整个数据链路,包括离线计算平台、实时计算平台、内部工具、任务元数据等。在采集
元数据的过程中,我们遇到了以下困难:
本文主要从元数据的意义、提取、采集、监控告警等方面介绍了我们所做的一些事情。
二、元数据2.1 什么是元数据
什么是元数据?元数据是“用于描述数据的数据”。例如:我用手机拍了一张照片,查看了照片的详细信息,如下图:
照片信息
文件名:IMG_20201217_114115
时间:2020年12月17号 11:30:01
分辨率:4608X2592
文件大小:2.69MB
相机制造商:OnePlus
相机型号:ONEPLUS A5000
闪光灯:未使用闪光灯
焦距:4.10mm
白平衡:自动
光圈:f/1.7
曝光时间:1/50
ISO:1250
这些是数码照片的元数据,用于描述图片。在资产管理平台,我们采集
Hive组件的元数据,包括:表名、字段列表、负责人、任务调度信息等。
采集
整个链接的数据(各种元数据)可以帮助数据平台回答:我们有什么数据?有多少人在使用它?什么是数据存储?如何找到这些数据?什么是数据流?结合血缘关系分析问题根源,分析影响。
2.2 采集
了哪些元数据
如下图所示,是一个数据流图。我们主要采集
了各种平台组件:
到目前为止,采集
到的平台组件覆盖了整个数据链路。涵盖10种数据+,基础元数据量10w+。主要包括:
三、元数据提取
如何从众多平台组件中提取元数据?大致有这几个方面:
计算任务通过分析任务的输入/输出依赖配置来获取血缘关系。 SQL类任务使用“Sql Parser”(ANTLR4系统实现的sql重写工具)工具解析SQL脚本,获取表/字段级血缘关系。 3.1个线下平台
主要采集
Hive/RDS表的元数据。
Hive组件的元数据存储在Metastore中,通过JDBC访问Mysql获取数据库表的元数据。根据Hive表信息组装HDFS地址,通过FileSystem API获取文件状态、文件编号、文件大小、数据更新时间等趋势数据。
RDS平台提供Mysql服务的管理,通过平台提供的服务接口获取表元数据、趋势数据、访问状态等信息。
3.2 实时平台
主要是Flume/Hbase/Kafka等组件的元数据。
例如:我们访问KP平台的工单数据,获取topic的基本元数据信息,定时消费topic获取样本数据,解析字段列表。平台本身提供集群状态和业务监控指标,通过平台服务获取集群资源的使用情况。
3.3 个内部工具
主要是BI报表系统的血缘关系(一个BI报表查询的Hive表和Mysql表的关系)、指标库(Hive表和指标关联字段的关系)、OneService服务(哪个数据库表的关系数据)由接口访问)数据。
这些内部系统在产品的不断迭代中积累了大量的元数据。在不考虑元数据的时效性的情况下,我们一般将这些系统的数据同步到Hive数据库中,离线处理后获取元数据。
3.4 任务元数据
元数据任务主要是DP离线任务、Flink计算服务、Flume任务。
这些计算任务都放在磁盘上,通过Binlog同步或者离线同步获取任务列表,获取任务的元数据。
四、数据采集
元数据提取后,我们可以得到整个数据链中各个平台组件的元数据。数据采集是指将这些元数据存储到数据资产管理系统的数据库中。
4.1种采集方式
采集
数据的方式主要有三种。下表列出了三种方式的优缺点:
一般情况下,我们建议业务方使用收购SDK。主动上报元数据,访问时只需要关注上报数据格式和SDK初始化,即可快速完成上报。
4.2采集SDK设计
采集SDK支持基础元数据、趋势数据、血缘关系数据的上报,主要包括客户端SDK和采集服务器两部分。客户端SDK主要实现通用报表模型的定义和报表功能,采集服务器主要实现不同的适配器完成数据的统一存储。
4.2.1 架构
获取SDK客户端
定义了基本元数据(MetaSchema)、趋势数据(TrendSchema)、血缘关系数据(LineageSchema)的通用模型,并支持扩展新的报告模型(XXXSchema)。 ReportService实现了向Kafka推送数据的功能。
采集
服务器
数据鉴权服务器消费Kafka,获取数据后,对每条记录的签名进行鉴权(获取记录中的appId、appName、token信息,重新生成token,比较值的过程)。统一仓储服务定义了统一的数据仓储模型,包括表基础元数据、趋势数据、血缘关系数据、趋势数据,实现不同数据类型的仓储服务。数据适配器Bridge获取Kafka的数据,根据不同的数据类型转换成“统一存储模型”,触发“统一存储服务”完成数据写入。 4.2.2 通用模型
采集
了很多平台组件。我们参考Hive“表模型”的定义,抽象出一套通用的数据上报模型,保证数据上报和数据存储的可扩展性。
通用血缘模型主要包括血缘模型定义和任务血缘模型定义,支持用户分别上报血缘关系和任务血缘关系。模型定义如下:
/**
* 表血缘模型定义
*/
@Data
public class TableLineageSchema {
/**
* 当前节点
*/
private T current;
/**
* 父节点
*/
private List parents;
/**
* 子节点
*/
private List childs;
/**
* 表级别血缘扩展信息,json对象,kv结构
*/
private String extParam;
}
/**
* 表任务血缘定义
*
*/
@Data
public class JobLineageSchema {
/**
* 任务节点对象
*/
private Job task;
/**
* 输入对象列表
*/
private List inputs;
/**
* 输出对象列表
*/
private List outputs;
/**
* 任务级别血缘扩展信息,json对象,kv结构
*/
private String extParam;
}
每个模型定义都有一个扩展字段(常规的 json 格式)。不在定义中的指标可以放在扩展字段中。数据上报后,也会存储在元数据表的扩展字段中。访问新的类型,索引定义大不相同,元数据上报是通过扩展新的数据模型定义来完成的。
4.2.3 访问、验证、限流
如何保证用户上报的数据安全?我们设计了一组签名:访问方Id(appId)、访问名称(appName)、访问标识(token)。管理员填写基本接入方信息,生成随机的appId和token信息。业务方在初始化SDK集合时,指定了签名信息,每上报的数据都会携带签名。在采集服务器上,每条数据都经过签名和认证,保证了数据的安全性。
采集SDK会对每一条上报的数据执行通用规则来检查数据的有效性,比如表名不为空,负责人的有效性,表的大小,趋势数据不能为负数等。如果检测到非法数据,将被过滤掉并触发报警通知。
在采集SDK服务器上,每隔一定时间(每两秒)消费一批Kafka数据。支持设置消费数据的时间间隔和拉取件数,不会因为上报数据的流量高峰而增加下游存储压力。 ,起到限流作用。
4.3 触发获取
我们支持多种元数据采集
方法。如何触发数据采集
?总体思路是:
基于Apollo配置系统(见:Apollo's Praise in Practice)和Linux系统的Crontab功能,实现任务调度。数据采集任务在Apollo上配置。更改配置后,Apollo会发布,配置信息会实时同步到在线节点的Crontab文件中。
4.3.1 增量任务,准实时
支持获取组件最近变化的元数据,配置增量任务,提高元数据采集的实时性。比如增量采集
Hive表元数据,每1分钟查询一次metastore,获取最近变化的元数据列表,并更新元数据。
4.3.2个满任务,走底线
增量采集
可能会出现数据丢失的情况。每 1 天或更多天完成一次完整采集
,作为确保元数据完整性的底线计划。
4.3.3 采集SDK并实时上报
采集SDK支持实时和全量上报模式。一般要求接入方数据实时变化,不定期上报一次满量。
4.4 数据存储、更新
数据采集后,需要考虑如何存储,以及元数据发生变化时如何同步和更新。我们对采集
到的元数据进行分类统一,抽象出“表模型”,分类存储。
4.4.1 数据存储
我们评估了每个组件的元数据量(共10w+),估计了数据可能的使用场景,最终选择了Mysql来存储。为了满足用户个性化的查询需求,构建了Es宽表。表粒度主要包括:表名、备注、负责人、字段列表、趋势信息、业务领域信息、任务信息等,在数据采集过程中同步更新Es表,保证元数据查询的实时性。定期更新(构建离线模型表,每天同步更新Es表),保证元数据的完整性。
元数据中的表不是孤立存在的。一般有关联任务(离线任务、实时任务)输出表,表和任务之间的流向关系也会在数据图中显示。那么如何在众多平台组件中唯一区分一个表呢?我们通过表所在的集群名称、项目名称、表类型(它来自哪个平台组件)和表名称的组合来唯一区分。
数据分类存储,最终形成:基础元数据表、趋势数据表、任务元数据表、血缘关系数据表。
4.4.2 数据更新
元数据表离线,如何更新?
五、监控和警告
完成数据采集后,就全部完成了吗?答案是否定的。在采集过程中,数据种类繁多,删除方式多样,删除链接长度。任何环节的任何问题都会导致结果不准确。我们通过以下方式来保证采集服务的稳定性。
5.1 采集
链路监控告警5.1.1 接口监控
我们将系统的所有服务接口分为核心、重要、通用三个层次,并支持标注接口和责任人的注解。异常会触发不同级别的警报通知。核心业务异常直接触发电话报警,重要或一般业务异常触发电子邮件报警。系统会存储接口请求和执行状态并删除,每天向接口服务负责人发送服务日报。通过将元数据采集服务标记为核心重要服务,“API直连方式”接口异常感知。
如下图是服务接口的告警通知:
[Warning][prod][data-dict] - 数据资产平台告警
你负责的[元信息采集]模块(backup为XXX)出现[重要]等级问题, 方法名:[com.youzan.bigdata.crystal.controller.HiveMetaController.getHiveDb], 异常信息:null
host:XXXXXX
处理地址:https://XXXX
如下图是服务接口的每日报警报表:
[Warning][prod][data-dict] - 数据资产平台告警
[shunfengche]今日问题汇总
请及时收敛今日问题,总问题数 1 个,出现 2 次
【核心】问题 0 个:
【重要】问题 0 个:
【一般】问题 1 个:
[数据采集]com.youzan.bigdata.crystal.controller.HiveMetaController.getHiveDb 今日出现 2 次, 已存在 5 天, 历史出现 8 次
host:XXXXXX
处理地址:https://XXXX
5.1.2 采集过程监控
对于每个元数据采集服务,如果采集过程中出现异常,都会发出警报通知。
如下图,是采集过程中出现异常触发的告警:
[Warning][prod][data-dict] - 数据资产平台告警
你负责的[元信息采集]模块(backup为XXX)出现[一般]等级问题, 方法名:[com.youzan.bigdata.crystal.asyncworker.work.AsyncAllRdsDDLWorker.run], 异常信息:/n
### Error updating database. Cause: com.mysql.jdbc.exceptions.jdbc4.MySQLQueryInterruptedException: Query execution was interrupted
5.1.3 Kafka 消息积压警告
消费Kafka数据,通过kp平台配置消息backlog告警,实现SDK服务采集异常感知。
5.2 结果数据对比
主要用于事后监测预警,定期探索采集的元数据量异常波动。针对不同类型的元数据,通过将当天采集的金额与过去7天的历史平均金额进行比较,设置异常波动的告警阈值,超过阈值时触发告警通知。
根据采集到的元数据结果表,配置一些数据质量检测规则,定期执行异常规则,发现问题数据触发告警通知。这保证了对结果数据的异常感知。例如定义的数据质量规则:
5.3 项目迭代机制,集合问题收敛
通过事前、事中、事后的监测预警机制,及时发现和感知采集异常。对于异常问题,我们一般以项目迭代的方式发起jira,组织相关人员进行审核。追根溯源,讨论改进方案,制定行动,关注并持续收敛问题。
六、总结与展望6.1 结论
我们定义了一套通用的数据采集和存储模型,支持访问不同数据类型的元数据,支持多种访问方式。采集SDK提高了数据的访问效率和时效性。
如下图所示,已经访问了各个组件的元数据,统一管理数据,提供数据字典、数据地图、资产盘点、全局成本计费等元数据应用。
如果将数据资产治理比作高层建筑的建设,那么不同构件的元数据是原材料,数据采集是基础。只有夯实了基础,数据治理的建设才能越来越稳固。
6.2 展望
在数据采集
的过程中,我们也遇到了很多问题。在后续工作中,我们需要不断的优化和功能迭代,包括但不限于: 查看全部
文章采集api(数据资产治理(详情见)——元数据提取)
来源:
一、简介
数据资产治理(详见:数据资产、赞智治理)需要数据。它要求数据类型齐全,数量大,并尽可能覆盖数据流通的方方面面。元数据采集
变得尤为重要,它是数据资产治理的核心基础。
在早期的采集系统中,我们主要使用数据仓库通过“API直连方式”采集Hive/Mysql表的元数据。随着业务的快速发展,对数据运营和成本管理的需求越来越强烈。元数据需要覆盖整个数据链路,包括离线计算平台、实时计算平台、内部工具、任务元数据等。在采集
元数据的过程中,我们遇到了以下困难:
本文主要从元数据的意义、提取、采集、监控告警等方面介绍了我们所做的一些事情。
二、元数据2.1 什么是元数据
什么是元数据?元数据是“用于描述数据的数据”。例如:我用手机拍了一张照片,查看了照片的详细信息,如下图:
照片信息
文件名:IMG_20201217_114115
时间:2020年12月17号 11:30:01
分辨率:4608X2592
文件大小:2.69MB
相机制造商:OnePlus
相机型号:ONEPLUS A5000
闪光灯:未使用闪光灯
焦距:4.10mm
白平衡:自动
光圈:f/1.7
曝光时间:1/50
ISO:1250
这些是数码照片的元数据,用于描述图片。在资产管理平台,我们采集
Hive组件的元数据,包括:表名、字段列表、负责人、任务调度信息等。
采集
整个链接的数据(各种元数据)可以帮助数据平台回答:我们有什么数据?有多少人在使用它?什么是数据存储?如何找到这些数据?什么是数据流?结合血缘关系分析问题根源,分析影响。
2.2 采集
了哪些元数据
如下图所示,是一个数据流图。我们主要采集
了各种平台组件:
到目前为止,采集
到的平台组件覆盖了整个数据链路。涵盖10种数据+,基础元数据量10w+。主要包括:
三、元数据提取
如何从众多平台组件中提取元数据?大致有这几个方面:
计算任务通过分析任务的输入/输出依赖配置来获取血缘关系。 SQL类任务使用“Sql Parser”(ANTLR4系统实现的sql重写工具)工具解析SQL脚本,获取表/字段级血缘关系。 3.1个线下平台
主要采集
Hive/RDS表的元数据。
Hive组件的元数据存储在Metastore中,通过JDBC访问Mysql获取数据库表的元数据。根据Hive表信息组装HDFS地址,通过FileSystem API获取文件状态、文件编号、文件大小、数据更新时间等趋势数据。
RDS平台提供Mysql服务的管理,通过平台提供的服务接口获取表元数据、趋势数据、访问状态等信息。
3.2 实时平台
主要是Flume/Hbase/Kafka等组件的元数据。
例如:我们访问KP平台的工单数据,获取topic的基本元数据信息,定时消费topic获取样本数据,解析字段列表。平台本身提供集群状态和业务监控指标,通过平台服务获取集群资源的使用情况。
3.3 个内部工具
主要是BI报表系统的血缘关系(一个BI报表查询的Hive表和Mysql表的关系)、指标库(Hive表和指标关联字段的关系)、OneService服务(哪个数据库表的关系数据)由接口访问)数据。
这些内部系统在产品的不断迭代中积累了大量的元数据。在不考虑元数据的时效性的情况下,我们一般将这些系统的数据同步到Hive数据库中,离线处理后获取元数据。
3.4 任务元数据
元数据任务主要是DP离线任务、Flink计算服务、Flume任务。
这些计算任务都放在磁盘上,通过Binlog同步或者离线同步获取任务列表,获取任务的元数据。
四、数据采集
元数据提取后,我们可以得到整个数据链中各个平台组件的元数据。数据采集是指将这些元数据存储到数据资产管理系统的数据库中。
4.1种采集方式
采集
数据的方式主要有三种。下表列出了三种方式的优缺点:
一般情况下,我们建议业务方使用收购SDK。主动上报元数据,访问时只需要关注上报数据格式和SDK初始化,即可快速完成上报。
4.2采集SDK设计
采集SDK支持基础元数据、趋势数据、血缘关系数据的上报,主要包括客户端SDK和采集服务器两部分。客户端SDK主要实现通用报表模型的定义和报表功能,采集服务器主要实现不同的适配器完成数据的统一存储。
4.2.1 架构
获取SDK客户端
定义了基本元数据(MetaSchema)、趋势数据(TrendSchema)、血缘关系数据(LineageSchema)的通用模型,并支持扩展新的报告模型(XXXSchema)。 ReportService实现了向Kafka推送数据的功能。
采集
服务器
数据鉴权服务器消费Kafka,获取数据后,对每条记录的签名进行鉴权(获取记录中的appId、appName、token信息,重新生成token,比较值的过程)。统一仓储服务定义了统一的数据仓储模型,包括表基础元数据、趋势数据、血缘关系数据、趋势数据,实现不同数据类型的仓储服务。数据适配器Bridge获取Kafka的数据,根据不同的数据类型转换成“统一存储模型”,触发“统一存储服务”完成数据写入。 4.2.2 通用模型
采集
了很多平台组件。我们参考Hive“表模型”的定义,抽象出一套通用的数据上报模型,保证数据上报和数据存储的可扩展性。
通用血缘模型主要包括血缘模型定义和任务血缘模型定义,支持用户分别上报血缘关系和任务血缘关系。模型定义如下:
/**
* 表血缘模型定义
*/
@Data
public class TableLineageSchema {
/**
* 当前节点
*/
private T current;
/**
* 父节点
*/
private List parents;
/**
* 子节点
*/
private List childs;
/**
* 表级别血缘扩展信息,json对象,kv结构
*/
private String extParam;
}
/**
* 表任务血缘定义
*
*/
@Data
public class JobLineageSchema {
/**
* 任务节点对象
*/
private Job task;
/**
* 输入对象列表
*/
private List inputs;
/**
* 输出对象列表
*/
private List outputs;
/**
* 任务级别血缘扩展信息,json对象,kv结构
*/
private String extParam;
}
每个模型定义都有一个扩展字段(常规的 json 格式)。不在定义中的指标可以放在扩展字段中。数据上报后,也会存储在元数据表的扩展字段中。访问新的类型,索引定义大不相同,元数据上报是通过扩展新的数据模型定义来完成的。
4.2.3 访问、验证、限流
如何保证用户上报的数据安全?我们设计了一组签名:访问方Id(appId)、访问名称(appName)、访问标识(token)。管理员填写基本接入方信息,生成随机的appId和token信息。业务方在初始化SDK集合时,指定了签名信息,每上报的数据都会携带签名。在采集服务器上,每条数据都经过签名和认证,保证了数据的安全性。
采集SDK会对每一条上报的数据执行通用规则来检查数据的有效性,比如表名不为空,负责人的有效性,表的大小,趋势数据不能为负数等。如果检测到非法数据,将被过滤掉并触发报警通知。
在采集SDK服务器上,每隔一定时间(每两秒)消费一批Kafka数据。支持设置消费数据的时间间隔和拉取件数,不会因为上报数据的流量高峰而增加下游存储压力。 ,起到限流作用。
4.3 触发获取
我们支持多种元数据采集
方法。如何触发数据采集
?总体思路是:
基于Apollo配置系统(见:Apollo's Praise in Practice)和Linux系统的Crontab功能,实现任务调度。数据采集任务在Apollo上配置。更改配置后,Apollo会发布,配置信息会实时同步到在线节点的Crontab文件中。
4.3.1 增量任务,准实时
支持获取组件最近变化的元数据,配置增量任务,提高元数据采集的实时性。比如增量采集
Hive表元数据,每1分钟查询一次metastore,获取最近变化的元数据列表,并更新元数据。
4.3.2个满任务,走底线
增量采集
可能会出现数据丢失的情况。每 1 天或更多天完成一次完整采集
,作为确保元数据完整性的底线计划。
4.3.3 采集SDK并实时上报
采集SDK支持实时和全量上报模式。一般要求接入方数据实时变化,不定期上报一次满量。
4.4 数据存储、更新
数据采集后,需要考虑如何存储,以及元数据发生变化时如何同步和更新。我们对采集
到的元数据进行分类统一,抽象出“表模型”,分类存储。
4.4.1 数据存储
我们评估了每个组件的元数据量(共10w+),估计了数据可能的使用场景,最终选择了Mysql来存储。为了满足用户个性化的查询需求,构建了Es宽表。表粒度主要包括:表名、备注、负责人、字段列表、趋势信息、业务领域信息、任务信息等,在数据采集过程中同步更新Es表,保证元数据查询的实时性。定期更新(构建离线模型表,每天同步更新Es表),保证元数据的完整性。
元数据中的表不是孤立存在的。一般有关联任务(离线任务、实时任务)输出表,表和任务之间的流向关系也会在数据图中显示。那么如何在众多平台组件中唯一区分一个表呢?我们通过表所在的集群名称、项目名称、表类型(它来自哪个平台组件)和表名称的组合来唯一区分。
数据分类存储,最终形成:基础元数据表、趋势数据表、任务元数据表、血缘关系数据表。
4.4.2 数据更新
元数据表离线,如何更新?
五、监控和警告
完成数据采集后,就全部完成了吗?答案是否定的。在采集过程中,数据种类繁多,删除方式多样,删除链接长度。任何环节的任何问题都会导致结果不准确。我们通过以下方式来保证采集服务的稳定性。
5.1 采集
链路监控告警5.1.1 接口监控
我们将系统的所有服务接口分为核心、重要、通用三个层次,并支持标注接口和责任人的注解。异常会触发不同级别的警报通知。核心业务异常直接触发电话报警,重要或一般业务异常触发电子邮件报警。系统会存储接口请求和执行状态并删除,每天向接口服务负责人发送服务日报。通过将元数据采集服务标记为核心重要服务,“API直连方式”接口异常感知。
如下图是服务接口的告警通知:
[Warning][prod][data-dict] - 数据资产平台告警
你负责的[元信息采集]模块(backup为XXX)出现[重要]等级问题, 方法名:[com.youzan.bigdata.crystal.controller.HiveMetaController.getHiveDb], 异常信息:null
host:XXXXXX
处理地址:https://XXXX
如下图是服务接口的每日报警报表:
[Warning][prod][data-dict] - 数据资产平台告警
[shunfengche]今日问题汇总
请及时收敛今日问题,总问题数 1 个,出现 2 次
【核心】问题 0 个:
【重要】问题 0 个:
【一般】问题 1 个:
[数据采集]com.youzan.bigdata.crystal.controller.HiveMetaController.getHiveDb 今日出现 2 次, 已存在 5 天, 历史出现 8 次
host:XXXXXX
处理地址:https://XXXX
5.1.2 采集过程监控
对于每个元数据采集服务,如果采集过程中出现异常,都会发出警报通知。
如下图,是采集过程中出现异常触发的告警:
[Warning][prod][data-dict] - 数据资产平台告警
你负责的[元信息采集]模块(backup为XXX)出现[一般]等级问题, 方法名:[com.youzan.bigdata.crystal.asyncworker.work.AsyncAllRdsDDLWorker.run], 异常信息:/n
### Error updating database. Cause: com.mysql.jdbc.exceptions.jdbc4.MySQLQueryInterruptedException: Query execution was interrupted
5.1.3 Kafka 消息积压警告
消费Kafka数据,通过kp平台配置消息backlog告警,实现SDK服务采集异常感知。
5.2 结果数据对比
主要用于事后监测预警,定期探索采集的元数据量异常波动。针对不同类型的元数据,通过将当天采集的金额与过去7天的历史平均金额进行比较,设置异常波动的告警阈值,超过阈值时触发告警通知。
根据采集到的元数据结果表,配置一些数据质量检测规则,定期执行异常规则,发现问题数据触发告警通知。这保证了对结果数据的异常感知。例如定义的数据质量规则:
5.3 项目迭代机制,集合问题收敛
通过事前、事中、事后的监测预警机制,及时发现和感知采集异常。对于异常问题,我们一般以项目迭代的方式发起jira,组织相关人员进行审核。追根溯源,讨论改进方案,制定行动,关注并持续收敛问题。
六、总结与展望6.1 结论
我们定义了一套通用的数据采集和存储模型,支持访问不同数据类型的元数据,支持多种访问方式。采集SDK提高了数据的访问效率和时效性。
如下图所示,已经访问了各个组件的元数据,统一管理数据,提供数据字典、数据地图、资产盘点、全局成本计费等元数据应用。
如果将数据资产治理比作高层建筑的建设,那么不同构件的元数据是原材料,数据采集是基础。只有夯实了基础,数据治理的建设才能越来越稳固。
6.2 展望
在数据采集
的过程中,我们也遇到了很多问题。在后续工作中,我们需要不断的优化和功能迭代,包括但不限于:
文章采集api(数据科学:Python好用框架的目的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-12-27 08:08
说到ApacheSPark框架,数据科学(网络)社区分为两大阵营:有的认为Scala好用,有的认为Python好用。本文旨在比较两者的优缺点,供大家参考。
ApacheSPark 是目前最流行的大数据分析框架(一)。它可以提供对 Scala、Python、Java 和 R 语言的 API 支持,但本文只讨论前两种语言。因为 Java 没有支持读写-评估-输出这个循环,R语言的普及度不高。前两个认为Scala好用的人说用Scala写ApacheSPark非常快。而且,作为静态类型的语音,Scala已经被编译并收录
在JVM(Java虚拟机)中。笔者认为每种方法都有其优缺点,最终的选择应该取决于应用程序的类型。
性能
Scala 通常比 Python 快 10 倍左右。 (因为JVM技术支持Scala语言的操作。)相比之下,Python作为动态语言,速度要慢很多。因为在 Python 中调用 ApacheSPark 库需要大量的代码处理。所以在性能上,Scala更适合调用有限的数据库。
另外,Scala基于JVM技术,植根于Hadoop框架下的HDFS文件系统,因此与Hadoop框架具有非常好的交互和兼容性。相比之下,Python 和 Hadoop 框架之间的交互是可怕的。开发者甚至不得不使用第三方插件(如hadopy)。
学习曲线
两种语言都是函数式的、面向对象的语言,而且它们的语法结构相似。与 Python 相比,Scala 可能更复杂,因为它具有更高级的功能。 Python 适合于简单的逻辑处理,而 Scala 更适合于复杂的工作流。但是Python也不是没用,因为Python的语法简单,库也比较标准。
并发
Scala 拥有多个标准库,支持大数据生态系统中数据库的快速集成。它可以使用多个并发原语来编写代码,而 Python 不支持并发或多线程编写代码。但是,Python 支持重量级进程分支。只是一次只能激活一个线程。而且每次写新代码,都必须重启其他进程,这无疑会增加内存使用。
实用性
Python 的特点是简单易用。 Scala 在框架、库、隐式和宏方面有很大的优势。这也是 Scala 在 MapReduce 框架中表现出色的原因。由于 Scala 的 API 集合是一致的,因此许多 Scala 数据框架都遵循相似的数据类型。开发者只需学习其常用的标准库,即可轻松掌握其他库。 ApacheSPark 是用 Scala 编写的,所以了解 Scala 也可以帮助你认识和修改 ApacheSPark 的内部功能。但是对于 NLP,Python 是首选。 (因为 Scala 缺少机器学习或 NLP 的工具。)此外,Python 也是 GraphX、GraphFrames 和 MLLib 的最佳选择。 Python 的可视化库是对 Pyspark 的补充。这是 ApacheSPark 和 Scala 都没有的东西。
代码恢复和安全
Scala 是一种静态语言,它支持我们在编译过程中发现错误。而 Python 是一种动态语言。换句话说,每次更改现有代码时,Python 语音都更容易出错。因此,在 Scala 中重构代码比在 Python 中重构更容易。
结论
Python 运行缓慢,但很容易上手。 Scala 是最快的编程语言,学习能力中等。 Scala 可以帮助您更全面地了解 ApacheSPark,因为 ApacheSPark 是用 Scala 编写的(但并非绝对)。要知道,编程语言的选择取决于项目的特点,我们要根据项目的特点灵活选择。 Python面向分析,Scala面向工程,但这两种语言都是构建数据科学应用的优秀语言。总的来说,Scala 可以充分利用 ApacheSPark 的特性。 查看全部
文章采集api(数据科学:Python好用框架的目的)
说到ApacheSPark框架,数据科学(网络)社区分为两大阵营:有的认为Scala好用,有的认为Python好用。本文旨在比较两者的优缺点,供大家参考。
ApacheSPark 是目前最流行的大数据分析框架(一)。它可以提供对 Scala、Python、Java 和 R 语言的 API 支持,但本文只讨论前两种语言。因为 Java 没有支持读写-评估-输出这个循环,R语言的普及度不高。前两个认为Scala好用的人说用Scala写ApacheSPark非常快。而且,作为静态类型的语音,Scala已经被编译并收录
在JVM(Java虚拟机)中。笔者认为每种方法都有其优缺点,最终的选择应该取决于应用程序的类型。
性能
Scala 通常比 Python 快 10 倍左右。 (因为JVM技术支持Scala语言的操作。)相比之下,Python作为动态语言,速度要慢很多。因为在 Python 中调用 ApacheSPark 库需要大量的代码处理。所以在性能上,Scala更适合调用有限的数据库。
另外,Scala基于JVM技术,植根于Hadoop框架下的HDFS文件系统,因此与Hadoop框架具有非常好的交互和兼容性。相比之下,Python 和 Hadoop 框架之间的交互是可怕的。开发者甚至不得不使用第三方插件(如hadopy)。
学习曲线
两种语言都是函数式的、面向对象的语言,而且它们的语法结构相似。与 Python 相比,Scala 可能更复杂,因为它具有更高级的功能。 Python 适合于简单的逻辑处理,而 Scala 更适合于复杂的工作流。但是Python也不是没用,因为Python的语法简单,库也比较标准。
并发
Scala 拥有多个标准库,支持大数据生态系统中数据库的快速集成。它可以使用多个并发原语来编写代码,而 Python 不支持并发或多线程编写代码。但是,Python 支持重量级进程分支。只是一次只能激活一个线程。而且每次写新代码,都必须重启其他进程,这无疑会增加内存使用。
实用性
Python 的特点是简单易用。 Scala 在框架、库、隐式和宏方面有很大的优势。这也是 Scala 在 MapReduce 框架中表现出色的原因。由于 Scala 的 API 集合是一致的,因此许多 Scala 数据框架都遵循相似的数据类型。开发者只需学习其常用的标准库,即可轻松掌握其他库。 ApacheSPark 是用 Scala 编写的,所以了解 Scala 也可以帮助你认识和修改 ApacheSPark 的内部功能。但是对于 NLP,Python 是首选。 (因为 Scala 缺少机器学习或 NLP 的工具。)此外,Python 也是 GraphX、GraphFrames 和 MLLib 的最佳选择。 Python 的可视化库是对 Pyspark 的补充。这是 ApacheSPark 和 Scala 都没有的东西。
代码恢复和安全
Scala 是一种静态语言,它支持我们在编译过程中发现错误。而 Python 是一种动态语言。换句话说,每次更改现有代码时,Python 语音都更容易出错。因此,在 Scala 中重构代码比在 Python 中重构更容易。
结论
Python 运行缓慢,但很容易上手。 Scala 是最快的编程语言,学习能力中等。 Scala 可以帮助您更全面地了解 ApacheSPark,因为 ApacheSPark 是用 Scala 编写的(但并非绝对)。要知道,编程语言的选择取决于项目的特点,我们要根据项目的特点灵活选择。 Python面向分析,Scala面向工程,但这两种语言都是构建数据科学应用的优秀语言。总的来说,Scala 可以充分利用 ApacheSPark 的特性。
文章采集api(数据具体的采集方案是什么?四种数据采集方法对比 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-12-20 16:07
)
根据企业生产经营过程中产生的数据类型,提供链接标记、SDK、API三种采集方法,以及基于UTSE数据采集模型用户的全生命周期。
那么,对于数据的具体采集计划是什么?
四种数据采集方法的比较
数据采集是通过埋点实现的。诸葛io提供了非常完善的数据访问方案,支持代码埋点、全埋点、可视化埋点、服务端埋点等多种数据方式。
1.代码埋点
说明:嵌入SDK定义事件并添加事件代码是常用的数据采集方法,主要包括网页和h5页面的JS嵌入点、移动iOS、Android嵌入点、微信小程序等。
优点:按需采集,业务信息更完整,数据分析更有针对性,数据采集全面准确,便于后续深入分析。
缺点:需要研发人员配合,有一定的工作量。
2.所有埋点
说明:通过SDK,自动采集页面上所有可点击元素的操作数据,无需定义事件,适用于衡量事件页面、登陆页面、关键页面的设计体验。
优点:更简单快捷,可以看到页面元素的点击量,更好的了解自己产品的特点。
缺点:采集中数据太多,只要是可点击元素,就会采集,上传大量数据,消耗大量流量。无法通过采集获取更深的维度信息,比如事件的属性、用户的属性等。
3.埋点可视化
注:目视埋点以全埋点为准。技术同事整合后,业务同事需要圈出页面的元素,选中的元素为采集。
优点:界面化配置,无需开发,内嵌点更新方便,见效快。
缺点:对自定义属性的支持范围比较有限;重构或页面变化时需要重新配置。
4.服务端埋点
说明:通过API,将存储在服务器上的数据结构化,支持其他业务数据采集和集成,如CRM等用户数据,通过接口调用,将数据结构化,适合其自己使用采集能力客户。
优点:服务器埋点更有针对性,数据更准确,减少了代码埋点发布版本的过程,数据上传更及时。
缺点:用户一些简单的操作,比如点击按钮、切换模块,数据不能采集,用户行为不完整。
总结:以上是诸葛io提供的四种数据采集方案:代码埋点、全埋点、可视化埋点、服务端埋点,数据采集的目的是满足< @采集 然后进行精细化分析和运营需求。只有达到这个目标,才有可能选择一种或多种采集形式的组合。在企业业务中,选择哪种采集方式要根据企业的具体业务需求来决定。.
查看全部
文章采集api(数据具体的采集方案是什么?四种数据采集方法对比
)
根据企业生产经营过程中产生的数据类型,提供链接标记、SDK、API三种采集方法,以及基于UTSE数据采集模型用户的全生命周期。
那么,对于数据的具体采集计划是什么?
四种数据采集方法的比较
数据采集是通过埋点实现的。诸葛io提供了非常完善的数据访问方案,支持代码埋点、全埋点、可视化埋点、服务端埋点等多种数据方式。
1.代码埋点
说明:嵌入SDK定义事件并添加事件代码是常用的数据采集方法,主要包括网页和h5页面的JS嵌入点、移动iOS、Android嵌入点、微信小程序等。
优点:按需采集,业务信息更完整,数据分析更有针对性,数据采集全面准确,便于后续深入分析。
缺点:需要研发人员配合,有一定的工作量。
2.所有埋点
说明:通过SDK,自动采集页面上所有可点击元素的操作数据,无需定义事件,适用于衡量事件页面、登陆页面、关键页面的设计体验。
优点:更简单快捷,可以看到页面元素的点击量,更好的了解自己产品的特点。
缺点:采集中数据太多,只要是可点击元素,就会采集,上传大量数据,消耗大量流量。无法通过采集获取更深的维度信息,比如事件的属性、用户的属性等。
3.埋点可视化
注:目视埋点以全埋点为准。技术同事整合后,业务同事需要圈出页面的元素,选中的元素为采集。
优点:界面化配置,无需开发,内嵌点更新方便,见效快。
缺点:对自定义属性的支持范围比较有限;重构或页面变化时需要重新配置。
4.服务端埋点
说明:通过API,将存储在服务器上的数据结构化,支持其他业务数据采集和集成,如CRM等用户数据,通过接口调用,将数据结构化,适合其自己使用采集能力客户。
优点:服务器埋点更有针对性,数据更准确,减少了代码埋点发布版本的过程,数据上传更及时。
缺点:用户一些简单的操作,比如点击按钮、切换模块,数据不能采集,用户行为不完整。
总结:以上是诸葛io提供的四种数据采集方案:代码埋点、全埋点、可视化埋点、服务端埋点,数据采集的目的是满足< @采集 然后进行精细化分析和运营需求。只有达到这个目标,才有可能选择一种或多种采集形式的组合。在企业业务中,选择哪种采集方式要根据企业的具体业务需求来决定。.
文章采集api(咕咕数据预览:/news/wxarticlecover()(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-19 21:04
请求示例:/news/wxarticlecover?appkey=YOUR_APPKEY&url=YOUR_VALUE
数据预览:/preview/wxarticlecover
界面测试:/news/wxarticlecover/demo
3. 请求参数(如果是POST请求,参数以JSON格式传递)
4. 返回参数
5. 接口响应状态码
6. 开发语言请求示例代码
示例代码中收录的开发语言:C#、Go、Java、jQuery、Node.js、Objective-C、PHP、Python、Ruby、Swift等,其他语言可以通过相应的RESTful API请求实现。
布谷鸟数据,专业的数据提供商,提供专业全面的数据接口和业务数据分析,让数据成为您的生产原材料。
布谷鸟数据基于我们过去五年为企业客户提供的海量数据支持。将一些通用数据和通用功能抽象为产品级API,极大地满足了用户在产品开发过程中对基础数据的需求,降低了复杂功能的复杂度。实现门槛和人工成本。
除了我们开放的分类数据和接口,还有海量的数据在整理、清洗、整合、构建。后续会开放更多的数据和云功能接口供用户使用。
目前开放的数据接口API 查看全部
文章采集api(咕咕数据预览:/news/wxarticlecover()(图))
请求示例:/news/wxarticlecover?appkey=YOUR_APPKEY&url=YOUR_VALUE
数据预览:/preview/wxarticlecover
界面测试:/news/wxarticlecover/demo
3. 请求参数(如果是POST请求,参数以JSON格式传递)
4. 返回参数
5. 接口响应状态码
6. 开发语言请求示例代码
示例代码中收录的开发语言:C#、Go、Java、jQuery、Node.js、Objective-C、PHP、Python、Ruby、Swift等,其他语言可以通过相应的RESTful API请求实现。
布谷鸟数据,专业的数据提供商,提供专业全面的数据接口和业务数据分析,让数据成为您的生产原材料。
布谷鸟数据基于我们过去五年为企业客户提供的海量数据支持。将一些通用数据和通用功能抽象为产品级API,极大地满足了用户在产品开发过程中对基础数据的需求,降低了复杂功能的复杂度。实现门槛和人工成本。
除了我们开放的分类数据和接口,还有海量的数据在整理、清洗、整合、构建。后续会开放更多的数据和云功能接口供用户使用。
目前开放的数据接口API
文章采集api(搭建一套前端监控平台需要考虑的几个问题?|本文)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-11-29 02:05
随着业务的快速发展,我们越来越重视生产环境中的问题感知能力。作为离用户最近的一层,前端性能是否可靠、稳定、易用,在很大程度上决定了用户对整个产品的体验和感受。因此,前端的监控不容忽视。
搭建前端监控平台需要考虑的方面有很多,比如数据采集、埋点模式、数据处理分析、告警、监控平台在具体业务中的应用等。在所有这些环节中,准确、完整、全面的数据采集是一切的前提,也为用户后续精细化操作提供了基础。
前端技术的飞速发展也给数据带来了变化和挑战采集。传统的人工管理模式已不能满足需求。如何让前端数据采集在新的技术背景下工作更完整、更高效,是本文的重点。
前端监控数据采集
在采集数据之前,我们首先要考虑采集是什么样的数据。我们关注两类数据,一类是与用户体验相关的数据,比如首屏时间、文件加载时间、页面性能等;另一个是帮助我们及时感知产品上线后是否有异常,比如资源错误、API响应时间等。具体来说,我们的前端数据采集具体分为:
路由交换机
Vue、React、Angular 等前端技术的快速发展,使得单页应用大行其道。我们都知道传统的页面应用使用一些超链接来实现页面切换和跳转,而单页面应用则使用自己的路由系统来管理前端的各个页面切换,比如vue-router、react-router等,跳转时只刷新部分资源,js、css等公共资源只需要加载一次,这就使得传统网页的进出方式只能在第一次打开时记录。单页应用所有后续路由的切换有两种方式,一种是Hash,一种是HTML5推出的History API。
1. href
href是页面初始化的第一个入口,这里只需要上报“页面入口”事件即可。
2. 哈希变化
哈希路由的一个明显标志是带有“#”。Hash 的优点是兼容性比较好,但问题是 URL 中总有一个“#”,不美观。我们主要是监控URL中的hashchange,捕获具体的hash值进行检测。
window.addEventListener('hashchange', function() {
// 上报【进入页面】事件
}, true)
需要注意的是,在新版本的vue-router中,如果浏览器支持history,即使选择了hash模式,也会先选择history模式。虽然表达式暂时还是#,但实际上是模拟的,所以不要以为你在模式选择hash的时候就会是hash。
3. 历史 API
History使用HTML5 History Interface中新增的pushState()和replaceState()方法进行路由切换,是目前主流的非刷新切换路由方式。相比hashchange后面的代码片段只能改#,History API(pushState、replaceState)给了前端完全的自由。
PopState是浏览器返回事件的回调,但是update路由的pushState和replaceState没有回调事件。因此,需要分别在 history.pushState() 和 history.replaceState() 方法中处理 URL 更改。在这里,我们使用了类似Java的AOP编程思想来转换pushState和replaceState。
AOP(Aspect-Oriented Programming)是指面向方面的编程,主张对同一类型的问题进行统一处理。AOP的核心思想是允许某个模块被复用。它采用横向抽取机制,将功能代码与业务逻辑代码分离,在不修改源代码的情况下扩展功能,隔离比封装更彻底。
下面介绍我们具体的改造方法:
// 第一阶段:我们对原生方法进行包装,调用前执行 dispatchEvent 了一个同样的事件
function aop (type) {
var source = window.history[type];
return function () {
var event = new Event(type);
event.arguments = arguments;
window.dispatchEvent(event);
var rewrite = source.apply(this, arguments);
return rewrite;
};
}
// 第二阶段:将 pushState 和 replaceState 进行基于 AOP 思想的代码注入
window.history.pushState = aop('pushState');
window.history.replaceState = aop('replaceState'); // 更改路由,不会留下历史记录
// 第三阶段:捕获pushState 和 replaceState
window.addEventListener('pushState', function() {
// 上报【进入页面】事件
}, true)
window.addEventListener('replaceState', function() {
// 上报【进入页面】事件
}, true)
window.history.pushState的实际调用关系如图:
至此,我们就完成了pushState和replaceState的转换,实现了路由切换的有效捕获。可以看出,我们在不侵入业务代码的情况下扩展了window.history.pushState,调用时会主动dispatchEvent一个pushState。
但是这里我们也可以看到一个缺点,就是如果AOP代理函数出现JS错误,会阻塞后续的调用关系,导致无法调用实际的window.history.pushState。所以在使用这种方式的时候,应该对AOP代理功能的内容做一个完整的try catch,防止业务出现异常。
_*_Tips:如果要自动捕捉页面停留时间,只需要计算下一页进入事件触发时上一页的tick时间与当前时间的差值即可。这时候可以举报【离开页面】事件。
错误
在前端项目中,由于JavaScript本身是弱类型语言,加上浏览器环境的复杂、网络问题等,容易出现错误。因此,做好网页错误的监控,不断优化代码,提高代码的健壮性是非常重要的。
JsError的捕获可以帮助我们分析和监控在线问题,与我们在Chrome浏览器的调试工具Console中看到的一致。
1. window.onerror
我们一般使用 window.onerror 来捕获 JS 错误的异常信息。有两种方法可以捕获 JS 错误,window.onerror 和 window.addEventListener('error')。一般情况下,不推荐使用addEventListener('error')来捕捉JS异常,主要是它没有栈信息,需要区分捕捉到的信息,因为它会捕捉到所有的异常信息,包括资源加载错误等等。
window.onerror = function (msg, url, lineno, colno, stack) {
// 上报 【js错误】事件
}
2. 未捕获(承诺)
当Promise发生JS错误或者业务没有处理reject信息时,会抛出unhandledrejection,window.onerror和window.addEventListener('error')不会捕捉到这个错误。这里需要一个特殊的窗口。addEventListener('unhandledrejection') 用于捕获处理:
window.addEventListener('unhandledrejection', function (e) {
var reg_url = /\(([^)]*)\)/;
var fileMsg = e.reason.stack.split('\n')[1].match(reg_url)[1];
var fileArr = fileMsg.split(':');
var lineno = fileArr[fileArr.length - 2];
var colno = fileArr[fileArr.length - 1];
var url = fileMsg.slice(0, -lno.length - cno.length - 2);}, true);
var msg = e.reason.message;
// 上报 【js错误】事件
}
我们注意到,因为 unhandledrejection 继承自 PromiseRejectionEvent 和 PromiseRejectionEvent 继承自 Event,msg、url、lineno、colno、stack 以字符串的形式放在 e.reason.stack 中。我们需要解析出上面的参数来与 onerror 参数对齐。为后续监测平台各项指标的统一奠定基础。
3.常见问题
如果抓到的msg都是“Script error.”,问题是你的JS地址和当前网页不在同一个域。因为我们经常需要对网络版做静态资源CDN化,会导致经常访问的页面和脚本文件来自不同的域名。如果此时不进行额外的配置,浏览器很容易出现“脚本错误”。由于安全设计。我们可以使用目前流行的Webpack打包工具来处理此类问题。
// webpack config 配置
// 处理 html 注入 js 添加跨域标识
plugins: [
new HtmlWebpackPlugin({
filename: 'html/index.html',
template: HTML_PATH,
attributes: {
crossorigin: 'anonymous'
}
}),
new HtmlWebpackPluginCrossorigin({
inject: true
})
]
// 处理按需加载的 js 添加跨域标识
output: {
crossOriginLoading: true
}
大多数场景下,生产环境中的代码都是经过压缩和合并的,这使得我们捕捉到的错误很难映射到具体的源代码上,给我们解决问题带来了很大的麻烦。这里简单介绍2个解决思路。
在生产环境中,我们需要添加sourceMap的配置,这会造成安全隐患,因为外网可以通过sourceMap映射源代码。为了降低风险,我们可以做到以下几点:
设置sourceMap生成的.map文件访问公司内网,降低源代码安全风险
将代码发布到CDN时,将.map文件存放在公司内网下
这时候我们已经有了 .map 文件。后面我们要做的就是调用mozilla/source-map库,通过抓到的lineno、colno、url来映射源码,然后我们就可以得到真正的源码错误信息了。
表现
性能指标的获取比较简单,只需要在onload后读取window.performance,里面收录性能、内存等信息。这部分内容在很多现有的文章中都有介绍。限于篇幅,本文不会展开过多。稍后我们将在相关话题文章中进行相关讨论。感兴趣的朋友可以添加“马蜂窝技术”公众号继续关注。
资源错误
首先需要明确资源错误捕获的使用场景,更多的是感知DNS劫持、CDN节点异常等,具体方法如下:
window.addEventListener('error', function (e) {
var target = e.target || e.srcElement;
if (target instanceof HTMLScriptElement) {
// 上报 【资源错误】事件
}
}, true)
这里只是一个基本的演示。在实际环境中,我们会关心更多的Element错误,比如css、img、woff等,可以根据不同的场景添加。
_*资源错误的使用场景更多地依赖于其他几个维度,例如:_region、operator等,我们将在后面的页面中详细说明。
应用程序接口
在市面上的主流框架(如Axios、jQuery.ajax等)中,基本上所有的API请求都是基于xmlHttpRequest或者fetch,所以捕获全局接口错误的方式是封装xmlHttpRequest或者fetch。在这里,我们的SDK还是采用了上面提到的AOP思想来拦截API。 查看全部
文章采集api(搭建一套前端监控平台需要考虑的几个问题?|本文)
随着业务的快速发展,我们越来越重视生产环境中的问题感知能力。作为离用户最近的一层,前端性能是否可靠、稳定、易用,在很大程度上决定了用户对整个产品的体验和感受。因此,前端的监控不容忽视。
搭建前端监控平台需要考虑的方面有很多,比如数据采集、埋点模式、数据处理分析、告警、监控平台在具体业务中的应用等。在所有这些环节中,准确、完整、全面的数据采集是一切的前提,也为用户后续精细化操作提供了基础。
前端技术的飞速发展也给数据带来了变化和挑战采集。传统的人工管理模式已不能满足需求。如何让前端数据采集在新的技术背景下工作更完整、更高效,是本文的重点。
前端监控数据采集
在采集数据之前,我们首先要考虑采集是什么样的数据。我们关注两类数据,一类是与用户体验相关的数据,比如首屏时间、文件加载时间、页面性能等;另一个是帮助我们及时感知产品上线后是否有异常,比如资源错误、API响应时间等。具体来说,我们的前端数据采集具体分为:
路由交换机
Vue、React、Angular 等前端技术的快速发展,使得单页应用大行其道。我们都知道传统的页面应用使用一些超链接来实现页面切换和跳转,而单页面应用则使用自己的路由系统来管理前端的各个页面切换,比如vue-router、react-router等,跳转时只刷新部分资源,js、css等公共资源只需要加载一次,这就使得传统网页的进出方式只能在第一次打开时记录。单页应用所有后续路由的切换有两种方式,一种是Hash,一种是HTML5推出的History API。
1. href
href是页面初始化的第一个入口,这里只需要上报“页面入口”事件即可。
2. 哈希变化
哈希路由的一个明显标志是带有“#”。Hash 的优点是兼容性比较好,但问题是 URL 中总有一个“#”,不美观。我们主要是监控URL中的hashchange,捕获具体的hash值进行检测。
window.addEventListener('hashchange', function() {
// 上报【进入页面】事件
}, true)
需要注意的是,在新版本的vue-router中,如果浏览器支持history,即使选择了hash模式,也会先选择history模式。虽然表达式暂时还是#,但实际上是模拟的,所以不要以为你在模式选择hash的时候就会是hash。
3. 历史 API
History使用HTML5 History Interface中新增的pushState()和replaceState()方法进行路由切换,是目前主流的非刷新切换路由方式。相比hashchange后面的代码片段只能改#,History API(pushState、replaceState)给了前端完全的自由。
PopState是浏览器返回事件的回调,但是update路由的pushState和replaceState没有回调事件。因此,需要分别在 history.pushState() 和 history.replaceState() 方法中处理 URL 更改。在这里,我们使用了类似Java的AOP编程思想来转换pushState和replaceState。
AOP(Aspect-Oriented Programming)是指面向方面的编程,主张对同一类型的问题进行统一处理。AOP的核心思想是允许某个模块被复用。它采用横向抽取机制,将功能代码与业务逻辑代码分离,在不修改源代码的情况下扩展功能,隔离比封装更彻底。
下面介绍我们具体的改造方法:
// 第一阶段:我们对原生方法进行包装,调用前执行 dispatchEvent 了一个同样的事件
function aop (type) {
var source = window.history[type];
return function () {
var event = new Event(type);
event.arguments = arguments;
window.dispatchEvent(event);
var rewrite = source.apply(this, arguments);
return rewrite;
};
}
// 第二阶段:将 pushState 和 replaceState 进行基于 AOP 思想的代码注入
window.history.pushState = aop('pushState');
window.history.replaceState = aop('replaceState'); // 更改路由,不会留下历史记录
// 第三阶段:捕获pushState 和 replaceState
window.addEventListener('pushState', function() {
// 上报【进入页面】事件
}, true)
window.addEventListener('replaceState', function() {
// 上报【进入页面】事件
}, true)
window.history.pushState的实际调用关系如图:
至此,我们就完成了pushState和replaceState的转换,实现了路由切换的有效捕获。可以看出,我们在不侵入业务代码的情况下扩展了window.history.pushState,调用时会主动dispatchEvent一个pushState。
但是这里我们也可以看到一个缺点,就是如果AOP代理函数出现JS错误,会阻塞后续的调用关系,导致无法调用实际的window.history.pushState。所以在使用这种方式的时候,应该对AOP代理功能的内容做一个完整的try catch,防止业务出现异常。
_*_Tips:如果要自动捕捉页面停留时间,只需要计算下一页进入事件触发时上一页的tick时间与当前时间的差值即可。这时候可以举报【离开页面】事件。
错误
在前端项目中,由于JavaScript本身是弱类型语言,加上浏览器环境的复杂、网络问题等,容易出现错误。因此,做好网页错误的监控,不断优化代码,提高代码的健壮性是非常重要的。
JsError的捕获可以帮助我们分析和监控在线问题,与我们在Chrome浏览器的调试工具Console中看到的一致。
1. window.onerror
我们一般使用 window.onerror 来捕获 JS 错误的异常信息。有两种方法可以捕获 JS 错误,window.onerror 和 window.addEventListener('error')。一般情况下,不推荐使用addEventListener('error')来捕捉JS异常,主要是它没有栈信息,需要区分捕捉到的信息,因为它会捕捉到所有的异常信息,包括资源加载错误等等。
window.onerror = function (msg, url, lineno, colno, stack) {
// 上报 【js错误】事件
}
2. 未捕获(承诺)
当Promise发生JS错误或者业务没有处理reject信息时,会抛出unhandledrejection,window.onerror和window.addEventListener('error')不会捕捉到这个错误。这里需要一个特殊的窗口。addEventListener('unhandledrejection') 用于捕获处理:
window.addEventListener('unhandledrejection', function (e) {
var reg_url = /\(([^)]*)\)/;
var fileMsg = e.reason.stack.split('\n')[1].match(reg_url)[1];
var fileArr = fileMsg.split(':');
var lineno = fileArr[fileArr.length - 2];
var colno = fileArr[fileArr.length - 1];
var url = fileMsg.slice(0, -lno.length - cno.length - 2);}, true);
var msg = e.reason.message;
// 上报 【js错误】事件
}
我们注意到,因为 unhandledrejection 继承自 PromiseRejectionEvent 和 PromiseRejectionEvent 继承自 Event,msg、url、lineno、colno、stack 以字符串的形式放在 e.reason.stack 中。我们需要解析出上面的参数来与 onerror 参数对齐。为后续监测平台各项指标的统一奠定基础。
3.常见问题
如果抓到的msg都是“Script error.”,问题是你的JS地址和当前网页不在同一个域。因为我们经常需要对网络版做静态资源CDN化,会导致经常访问的页面和脚本文件来自不同的域名。如果此时不进行额外的配置,浏览器很容易出现“脚本错误”。由于安全设计。我们可以使用目前流行的Webpack打包工具来处理此类问题。
// webpack config 配置
// 处理 html 注入 js 添加跨域标识
plugins: [
new HtmlWebpackPlugin({
filename: 'html/index.html',
template: HTML_PATH,
attributes: {
crossorigin: 'anonymous'
}
}),
new HtmlWebpackPluginCrossorigin({
inject: true
})
]
// 处理按需加载的 js 添加跨域标识
output: {
crossOriginLoading: true
}
大多数场景下,生产环境中的代码都是经过压缩和合并的,这使得我们捕捉到的错误很难映射到具体的源代码上,给我们解决问题带来了很大的麻烦。这里简单介绍2个解决思路。
在生产环境中,我们需要添加sourceMap的配置,这会造成安全隐患,因为外网可以通过sourceMap映射源代码。为了降低风险,我们可以做到以下几点:
设置sourceMap生成的.map文件访问公司内网,降低源代码安全风险
将代码发布到CDN时,将.map文件存放在公司内网下
这时候我们已经有了 .map 文件。后面我们要做的就是调用mozilla/source-map库,通过抓到的lineno、colno、url来映射源码,然后我们就可以得到真正的源码错误信息了。
表现
性能指标的获取比较简单,只需要在onload后读取window.performance,里面收录性能、内存等信息。这部分内容在很多现有的文章中都有介绍。限于篇幅,本文不会展开过多。稍后我们将在相关话题文章中进行相关讨论。感兴趣的朋友可以添加“马蜂窝技术”公众号继续关注。
资源错误
首先需要明确资源错误捕获的使用场景,更多的是感知DNS劫持、CDN节点异常等,具体方法如下:
window.addEventListener('error', function (e) {
var target = e.target || e.srcElement;
if (target instanceof HTMLScriptElement) {
// 上报 【资源错误】事件
}
}, true)
这里只是一个基本的演示。在实际环境中,我们会关心更多的Element错误,比如css、img、woff等,可以根据不同的场景添加。
_*资源错误的使用场景更多地依赖于其他几个维度,例如:_region、operator等,我们将在后面的页面中详细说明。
应用程序接口
在市面上的主流框架(如Axios、jQuery.ajax等)中,基本上所有的API请求都是基于xmlHttpRequest或者fetch,所以捕获全局接口错误的方式是封装xmlHttpRequest或者fetch。在这里,我们的SDK还是采用了上面提到的AOP思想来拦截API。
文章采集api(今日未采集资产列表:已访问过得加密,明天加上)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-11-26 17:17
获取今天不是 采集 的资产列表:
关键点:
1、server表增加了两个字段:latest_date(可以为空);服务器状态信息;
2、什么情况下会获取采集服务器信息?
①latest_date为空时,如未上报的资产的初始创建;
②今天还没到采集,关注latest_date__date__lt
③服务器状态在线
3、设置current_date=datetime.datetime.now(); 当服务器更新资产时
4、get_host_list 函数:
注:内容放在response.text部分(response=request.get(url))
代码区:
###############服务端###############
@csrf_exempt
def server(request):
'''
requests不能发送字典类型数据,纵观我们学的form表单提交数据,
ajax发送数据,均是不支持字典类型数据的发送的。
具体原因百度知晓。
:param request:
:return:
'''
if request.method == 'GET':
# 获取今日未采集主机列表[latest_date为None或者latest_date不为今日且服务器状态为在线]
current_date = date.today()
host_list = models.Server.objects.filter(
Q(Q(latest_date=None) | Q(latest_date__date__lt=current_date)) & Q(server_status_id=2)).values('hostname')
'''
['hostname':'c1.com']
'''
host_list = list(host_list)
print(host_list)
return HttpResponse(json.dumps(host_list))
#############客户端#############
class SshSaltClient(BaseClient):
def get_host_list(self):
response=requests.get(self.api) #
# print(response.text) # [{"hostname": "c1.com"}]注意这种用法
return json.loads(response.text)
接口验证
要点:过三关
第一关:时间限制(超出客户端时间和服务器之间的时间间隔,我们团队要求限制)
第二关:加密规则限制(主要应用MD5加密)
第三遍:我们为已访问过的加密str设置访问列表。普通用户不可能再用这个访问过的数据向服务器请求。如果列表中没有str,则证明是普通用户访问,记得将此数据加入到访问列表中。
这个内容会越来越大,实际会应用到memcache和redis上。
后三个级别基本可以达到防止黑客攻击的效果,但不排除黑客的网速比我们快。我们不妨对要发送的数据进行加密,然后尽快将黑客的网速提交给服务器。这不是一个坏主意吗?
代码区:
##############客户端##############
import requests
import time
import hashlib
def md5(arg):
md5 = hashlib.md5()
md5.update(arg.encode('utf-8'))
return md5.hexdigest()
key = 'asdfghjklmnbvcxz'
ctime = str(time.time())
client_str = '%s|%s' % (key, ctime)
client_md5_str = md5(client_str)
client_header_str = '%s|%s' % (client_md5_str, ctime)
print(client_header_str)
response = requests.get(url='http://127.0.0.1:8000/api/tests.html', headers={'auth-api': 'cae76146bfa06482cfee7e4f899cc414|1506956350.973326'})
print(response.text)
##############服务端##############
def md5(arg):
md5 = hashlib.md5()
md5.update(arg.encode('utf-8'))
return md5.hexdigest()
key = 'asdfghjklmnbvcxz'
vistied_str_dict={}
def tests(request):
client_header_str = request.META.get('HTTP_AUTH_API')
print(client_header_str)
client_md5_str, client_ctime = client_header_str.split('|', maxsplit=1)
client_float_ctime = float(client_ctime)
server_float_ctime = float(time.time())
# 第一关
if (client_float_ctime + 20) < server_float_ctime:
return HttpResponse("太慢了")
# 第二关
server_str = '%s|%s' % (key, client_ctime)
server_md5_str = md5(server_str)
if client_md5_str != server_md5_str:
return HttpResponse('休想')
# 第三关
if vistied_str_dict.get(client_md5_str):
return HttpResponse('放弃吧')
else:
vistied_str_dict[client_md5_str] = client_ctime
return HttpResponse('你得到我了')
最后,没有使用装饰器,明天将添加。 查看全部
文章采集api(今日未采集资产列表:已访问过得加密,明天加上)
获取今天不是 采集 的资产列表:
关键点:
1、server表增加了两个字段:latest_date(可以为空);服务器状态信息;
2、什么情况下会获取采集服务器信息?
①latest_date为空时,如未上报的资产的初始创建;
②今天还没到采集,关注latest_date__date__lt
③服务器状态在线
3、设置current_date=datetime.datetime.now(); 当服务器更新资产时
4、get_host_list 函数:
注:内容放在response.text部分(response=request.get(url))
代码区:
###############服务端###############
@csrf_exempt
def server(request):
'''
requests不能发送字典类型数据,纵观我们学的form表单提交数据,
ajax发送数据,均是不支持字典类型数据的发送的。
具体原因百度知晓。
:param request:
:return:
'''
if request.method == 'GET':
# 获取今日未采集主机列表[latest_date为None或者latest_date不为今日且服务器状态为在线]
current_date = date.today()
host_list = models.Server.objects.filter(
Q(Q(latest_date=None) | Q(latest_date__date__lt=current_date)) & Q(server_status_id=2)).values('hostname')
'''
['hostname':'c1.com']
'''
host_list = list(host_list)
print(host_list)
return HttpResponse(json.dumps(host_list))
#############客户端#############
class SshSaltClient(BaseClient):
def get_host_list(self):
response=requests.get(self.api) #
# print(response.text) # [{"hostname": "c1.com"}]注意这种用法
return json.loads(response.text)
接口验证
要点:过三关
第一关:时间限制(超出客户端时间和服务器之间的时间间隔,我们团队要求限制)
第二关:加密规则限制(主要应用MD5加密)
第三遍:我们为已访问过的加密str设置访问列表。普通用户不可能再用这个访问过的数据向服务器请求。如果列表中没有str,则证明是普通用户访问,记得将此数据加入到访问列表中。
这个内容会越来越大,实际会应用到memcache和redis上。
后三个级别基本可以达到防止黑客攻击的效果,但不排除黑客的网速比我们快。我们不妨对要发送的数据进行加密,然后尽快将黑客的网速提交给服务器。这不是一个坏主意吗?
代码区:
##############客户端##############
import requests
import time
import hashlib
def md5(arg):
md5 = hashlib.md5()
md5.update(arg.encode('utf-8'))
return md5.hexdigest()
key = 'asdfghjklmnbvcxz'
ctime = str(time.time())
client_str = '%s|%s' % (key, ctime)
client_md5_str = md5(client_str)
client_header_str = '%s|%s' % (client_md5_str, ctime)
print(client_header_str)
response = requests.get(url='http://127.0.0.1:8000/api/tests.html', headers={'auth-api': 'cae76146bfa06482cfee7e4f899cc414|1506956350.973326'})
print(response.text)
##############服务端##############
def md5(arg):
md5 = hashlib.md5()
md5.update(arg.encode('utf-8'))
return md5.hexdigest()
key = 'asdfghjklmnbvcxz'
vistied_str_dict={}
def tests(request):
client_header_str = request.META.get('HTTP_AUTH_API')
print(client_header_str)
client_md5_str, client_ctime = client_header_str.split('|', maxsplit=1)
client_float_ctime = float(client_ctime)
server_float_ctime = float(time.time())
# 第一关
if (client_float_ctime + 20) < server_float_ctime:
return HttpResponse("太慢了")
# 第二关
server_str = '%s|%s' % (key, client_ctime)
server_md5_str = md5(server_str)
if client_md5_str != server_md5_str:
return HttpResponse('休想')
# 第三关
if vistied_str_dict.get(client_md5_str):
return HttpResponse('放弃吧')
else:
vistied_str_dict[client_md5_str] = client_ctime
return HttpResponse('你得到我了')
最后,没有使用装饰器,明天将添加。
文章采集api(基于ApaChe-Tomcat+JAVA+MySql全网独家+全新二开的API开奖数据采集接口源码)
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-11-24 23:15
本次分享的是我们基于ApaChe-Tomcat+JAVA+MySql全网独家+全新开放API抽奖数据采集接口源码,稳定运行一年多,我们的源码同时使用。许多修订和功能性的两个开口。对于大家关心的安全性和运行稳定性,那就是博一Thinkphp5版的源码。手术; 在界面美化方面,我们从最初的版本到现在的改进不下10倍。模板已优化,运行稳定,近期不再优化;用户中心的功能包括:个人中心、IP白名单、修改密码、赞助我们、我的界面,您可以看下面的截图或到我们的演示站点查看;对于颜色类型,您可以添加或删除某种类型的界面或某种颜色类型,也可以自行定义颜色类型的缩写没有限制;系统背景介绍等一些方面,可以查看截图演示或我们的演示站点;此外,所有修改后的.jar采集 包也已经打包了源码。购买前请再次确认,本源代码为我们独家二流资源,并非部分用于充值的二流、三流资源;最后,如果你只需要这个源码,可以在本页右上角下单购买。然后就可以看到解压出来的密码了!或者你可以自己定义颜色类型的缩写没有限制;系统背景介绍等一些方面,可以查看截图演示或我们的演示站点;此外,所有修改后的.jar采集 包也已经打包了源码。购买前请再次确认,本源代码为我们独家二流资源,并非部分用于充值的二流、三流资源;最后,如果你只需要这个源码,可以在本页右上角下单购买。然后就可以看到解压出来的密码了!或者你可以自己定义颜色类型的缩写没有限制;系统背景介绍等一些方面,可以查看截图演示或我们的演示站点;此外,所有修改后的.jar采集 包也已经打包了源码。购买前请再次确认,本源代码为我们独家二流资源,并非部分用于充值的二流、三流资源;最后,如果你只需要这个源码,可以在本页右上角下单购买。然后就可以看到解压出来的密码了!包也与源代码一起打包。购买前请再次确认,本源代码为我们独家二流资源,并非部分用于充值的二流、三流资源;最后,如果你只需要这个源码,可以在本页右上角下单购买。然后就可以看到解压出来的密码了!包也与源代码一起打包。购买前请再次确认,本源代码为我们独家二流资源,并非部分用于充值的二流、三流资源;最后,如果你只需要这个源码,可以在本页右上角下单购买。然后就可以看到解压出来的密码了!
示范站:目前所有高频都停止服务,所以只有低频、海外和极速是正常的
后台演示:操作现场不提供,请查看演示截图。
更多信息有待更新...
本源码附有视频详细安装说明:
Kaku亲测环境:ApaChe-Tomcat+JAVA+MySql5.7(必填)
付费安装范围包括:将您购买的程序安装到您的服务器上!!
不包括:修改程序中的文字/版权/图片/或某些特定信息,我们将根据您的修改程度适当收取费用!
需要注意的是,系统开通账户使用权限后,所有接口都有调用权限,而不是单个接口。
注意:我们打包的.jar采集 包中收录自定义接口,您可以按照说明连接第三方接口。
注意:由于源代码开发环境的特殊性,请严格按照我们的安装说明进行安装。如果没有,请找我们付费安装。
注:虽然程序压缩包中有详细的安装说明,但还是推荐给有一定建站基础的朋友使用。本网站不想引起恶名,所以请谨慎!
注:源代码仅供下载者在个人本地电脑学习研究,上传服务器不可运行,否则后果自负。
有关常见安装问题的摘要,请参阅:
免责声明:用户在使用本站资源时,必须禁止将其用于国家相关法律法规范围内的一切违法活动。使用仅限于测试、实验和研究目的。禁止在所有商业操作中使用。本站对用户在使用过程中的任何违法行为不承担任何责任。
爪哇
卡库克斯平民 查看全部
文章采集api(基于ApaChe-Tomcat+JAVA+MySql全网独家+全新二开的API开奖数据采集接口源码)
本次分享的是我们基于ApaChe-Tomcat+JAVA+MySql全网独家+全新开放API抽奖数据采集接口源码,稳定运行一年多,我们的源码同时使用。许多修订和功能性的两个开口。对于大家关心的安全性和运行稳定性,那就是博一Thinkphp5版的源码。手术; 在界面美化方面,我们从最初的版本到现在的改进不下10倍。模板已优化,运行稳定,近期不再优化;用户中心的功能包括:个人中心、IP白名单、修改密码、赞助我们、我的界面,您可以看下面的截图或到我们的演示站点查看;对于颜色类型,您可以添加或删除某种类型的界面或某种颜色类型,也可以自行定义颜色类型的缩写没有限制;系统背景介绍等一些方面,可以查看截图演示或我们的演示站点;此外,所有修改后的.jar采集 包也已经打包了源码。购买前请再次确认,本源代码为我们独家二流资源,并非部分用于充值的二流、三流资源;最后,如果你只需要这个源码,可以在本页右上角下单购买。然后就可以看到解压出来的密码了!或者你可以自己定义颜色类型的缩写没有限制;系统背景介绍等一些方面,可以查看截图演示或我们的演示站点;此外,所有修改后的.jar采集 包也已经打包了源码。购买前请再次确认,本源代码为我们独家二流资源,并非部分用于充值的二流、三流资源;最后,如果你只需要这个源码,可以在本页右上角下单购买。然后就可以看到解压出来的密码了!或者你可以自己定义颜色类型的缩写没有限制;系统背景介绍等一些方面,可以查看截图演示或我们的演示站点;此外,所有修改后的.jar采集 包也已经打包了源码。购买前请再次确认,本源代码为我们独家二流资源,并非部分用于充值的二流、三流资源;最后,如果你只需要这个源码,可以在本页右上角下单购买。然后就可以看到解压出来的密码了!包也与源代码一起打包。购买前请再次确认,本源代码为我们独家二流资源,并非部分用于充值的二流、三流资源;最后,如果你只需要这个源码,可以在本页右上角下单购买。然后就可以看到解压出来的密码了!包也与源代码一起打包。购买前请再次确认,本源代码为我们独家二流资源,并非部分用于充值的二流、三流资源;最后,如果你只需要这个源码,可以在本页右上角下单购买。然后就可以看到解压出来的密码了!
示范站:目前所有高频都停止服务,所以只有低频、海外和极速是正常的
后台演示:操作现场不提供,请查看演示截图。
更多信息有待更新...
本源码附有视频详细安装说明:
Kaku亲测环境:ApaChe-Tomcat+JAVA+MySql5.7(必填)
付费安装范围包括:将您购买的程序安装到您的服务器上!!
不包括:修改程序中的文字/版权/图片/或某些特定信息,我们将根据您的修改程度适当收取费用!
需要注意的是,系统开通账户使用权限后,所有接口都有调用权限,而不是单个接口。
注意:我们打包的.jar采集 包中收录自定义接口,您可以按照说明连接第三方接口。
注意:由于源代码开发环境的特殊性,请严格按照我们的安装说明进行安装。如果没有,请找我们付费安装。
注:虽然程序压缩包中有详细的安装说明,但还是推荐给有一定建站基础的朋友使用。本网站不想引起恶名,所以请谨慎!
注:源代码仅供下载者在个人本地电脑学习研究,上传服务器不可运行,否则后果自负。
有关常见安装问题的摘要,请参阅:
免责声明:用户在使用本站资源时,必须禁止将其用于国家相关法律法规范围内的一切违法活动。使用仅限于测试、实验和研究目的。禁止在所有商业操作中使用。本站对用户在使用过程中的任何违法行为不承担任何责任。
爪哇
卡库克斯平民
文章采集api( PHP+fiddler抓包操作实例PHP编程技术本文实例讲述框架数据库操作)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-11-19 14:20
PHP+fiddler抓包操作实例PHP编程技术本文实例讲述框架数据库操作)
2. 截取这个接口转发到自己的服务器,点击规则-自定义规则添加到OnBeforeRequest中(正式请求前执行的函数)
if (oSession.fullUrl.Contains("mp.weixin.qq.com/mp/getappmsgext"))
{
oSession.oRequest["Host"]= 'ccc.aaa.com' ;
}
效果,可以看到这个接口已经转发了
3.服务端缓存key,代码以PHP为例
public function saveKey(Request $request)
{
$__biz = $request->param('__biz',0);
$data['uin'] = $request->param('uin',0);
$data['key'] = $request->param('key',0);
Cache::set($__biz,$data,30 * 60);
return 'ok';
}
4.提交文章查询API代码链接
public function getReadNum(Request $request)
{
$url = $request->param('url');
parse_str(parse_url($url)['query'], $param);
$__biz = $param['__biz'];
$key_data = Cache::get($__biz);
if (empty($key_data))
return 'no key';
$uin = $key_data['uin'];
$key = $key_data['key'];
$param['uin'] = $uin;
$param['key'] = $key;
$param['wxtoken'] = "777";
$wechat_url = "https://mp.weixin.qq.com/mp/getappmsgext?" . http_build_query($param);
//dump($wechat_url);
$data = array(
'is_only_read' => 1,
'is_temp_url' => 0,
'appmsg_type' => 9,
);
$res = $this->get_url($wechat_url,$data);
return $res;
}
function get_url($url,$data)
{
$ifpost = 1;//是否post请求
$datafields = $data;//post数据
$cookiefile = '';//cookie文件
$cookie = '';//cookie变量
$v = false;
//模拟http请求header头
$header = array("Connection: Keep-Alive","Accept: text/html, application/xhtml+xml, */*", "Pragma: no-cache", "Accept-Language: zh-Hans-CN,zh-Hans;q=0.8,en-US;q=0.5,en;q=0.3","User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36 QBCore/4.0.1278.400 QQBrowser/9.0.2524.400 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2875.116 Safari/537.36 NetType/WIFI MicroMessenger/7.0.5 WindowsWechat");
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, $v);
curl_setopt($ch, CURLOPT_HTTPHEADER, $header);
$ifpost && curl_setopt($ch, CURLOPT_POST, $ifpost);
$ifpost && curl_setopt($ch, CURLOPT_POSTFIELDS, $datafields);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
$cookie && curl_setopt($ch, CURLOPT_COOKIE, $cookie);//发送cookie变量
$cookiefile && curl_setopt($ch, CURLOPT_COOKIEFILE, $cookiefile);//发送cookie文件
$cookiefile && curl_setopt($ch, CURLOPT_COOKIEJAR, $cookiefile);//写入cookie到文件
curl_setopt($ch,CURLOPT_TIMEOUT,60); //允许执行的最长秒数
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
$ok = curl_exec($ch);
curl_close($ch);
unset($ch);
return $ok;
}
5.通知客户端重定向页面(这部分不写了,看我另外一篇关于socket的文字文章)
6.使用fiddler修改微信文章还有jsj脚本,
在OnBeforeResponse(返回客户端之前执行的方法)中,添加跳转到中间页面的代码
影响
总结
以上就是小编为大家介绍的PHP+fiddler抓包。采集微信文章 看了几个赞,希望对你有帮助,有什么问题请给我留言,肖小编会及时回复大家。非常感谢您对编程宝库网站的支持!
下一节:laravel框架数据库操作的PHP编程技术、查询生成器、Eloquent ORM操作实例
本文介绍了 Laravel 框架数据库操作、查询构建器和 Eloquent ORM 操作。分享给大家,供大家参考,如下:1、连接数据库laravel连接数据库配置文件... 查看全部
文章采集api(
PHP+fiddler抓包操作实例PHP编程技术本文实例讲述框架数据库操作)
2. 截取这个接口转发到自己的服务器,点击规则-自定义规则添加到OnBeforeRequest中(正式请求前执行的函数)
if (oSession.fullUrl.Contains("mp.weixin.qq.com/mp/getappmsgext"))
{
oSession.oRequest["Host"]= 'ccc.aaa.com' ;
}
效果,可以看到这个接口已经转发了
3.服务端缓存key,代码以PHP为例
public function saveKey(Request $request)
{
$__biz = $request->param('__biz',0);
$data['uin'] = $request->param('uin',0);
$data['key'] = $request->param('key',0);
Cache::set($__biz,$data,30 * 60);
return 'ok';
}
4.提交文章查询API代码链接
public function getReadNum(Request $request)
{
$url = $request->param('url');
parse_str(parse_url($url)['query'], $param);
$__biz = $param['__biz'];
$key_data = Cache::get($__biz);
if (empty($key_data))
return 'no key';
$uin = $key_data['uin'];
$key = $key_data['key'];
$param['uin'] = $uin;
$param['key'] = $key;
$param['wxtoken'] = "777";
$wechat_url = "https://mp.weixin.qq.com/mp/getappmsgext?" . http_build_query($param);
//dump($wechat_url);
$data = array(
'is_only_read' => 1,
'is_temp_url' => 0,
'appmsg_type' => 9,
);
$res = $this->get_url($wechat_url,$data);
return $res;
}
function get_url($url,$data)
{
$ifpost = 1;//是否post请求
$datafields = $data;//post数据
$cookiefile = '';//cookie文件
$cookie = '';//cookie变量
$v = false;
//模拟http请求header头
$header = array("Connection: Keep-Alive","Accept: text/html, application/xhtml+xml, */*", "Pragma: no-cache", "Accept-Language: zh-Hans-CN,zh-Hans;q=0.8,en-US;q=0.5,en;q=0.3","User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36 QBCore/4.0.1278.400 QQBrowser/9.0.2524.400 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2875.116 Safari/537.36 NetType/WIFI MicroMessenger/7.0.5 WindowsWechat");
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, $v);
curl_setopt($ch, CURLOPT_HTTPHEADER, $header);
$ifpost && curl_setopt($ch, CURLOPT_POST, $ifpost);
$ifpost && curl_setopt($ch, CURLOPT_POSTFIELDS, $datafields);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
$cookie && curl_setopt($ch, CURLOPT_COOKIE, $cookie);//发送cookie变量
$cookiefile && curl_setopt($ch, CURLOPT_COOKIEFILE, $cookiefile);//发送cookie文件
$cookiefile && curl_setopt($ch, CURLOPT_COOKIEJAR, $cookiefile);//写入cookie到文件
curl_setopt($ch,CURLOPT_TIMEOUT,60); //允许执行的最长秒数
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
$ok = curl_exec($ch);
curl_close($ch);
unset($ch);
return $ok;
}
5.通知客户端重定向页面(这部分不写了,看我另外一篇关于socket的文字文章)
6.使用fiddler修改微信文章还有jsj脚本,
在OnBeforeResponse(返回客户端之前执行的方法)中,添加跳转到中间页面的代码
影响
总结
以上就是小编为大家介绍的PHP+fiddler抓包。采集微信文章 看了几个赞,希望对你有帮助,有什么问题请给我留言,肖小编会及时回复大家。非常感谢您对编程宝库网站的支持!
下一节:laravel框架数据库操作的PHP编程技术、查询生成器、Eloquent ORM操作实例
本文介绍了 Laravel 框架数据库操作、查询构建器和 Eloquent ORM 操作。分享给大家,供大家参考,如下:1、连接数据库laravel连接数据库配置文件...

