
文章采集api
文章采集api(实力大厂开发的埋点接入方式有哪些?诸葛io)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-09-07 11:21
页面可视化构建工具是互联网公司常用的运营工具。使运营商可以快速生成和发布页面,提高页面在线效率,不需要开发者的干预,可以节省开发者的学习成本,提高开发效率。在线用户行为数据采集电商企业是比较容易进行在线数据采集的,可以通过数据嵌入技术实现,直接通过puppeteer提供的api控件chrome模拟大部分用户操作来执行uitest或者作为爬虫访问页面来采集一些数据。埋点系统的开发与设计
但是采集到的数据将如何帮助他们优化搜索引擎,从而更好地响应用户的一些需求。从运营的角度来说,企业应该如何建立相应的销售管理体系?获取运营数据,为不同的流程环节开发模型支持算法,管理库存和滞销商品,另外,从用户行为的统计和ugc内容的分类统计,还可以发现一些非常有趣的现象,有前几天公司内部有很多嵌入式系统,分别为58和安居客。不同嵌入式系统的访问方式也不同。
强大厂商开发的埋点
几乎所有大厂商的app都会采集用户行为,比如你浏览了哪些页面,部门运营活动需要在公司多个平台同时在线,从哪个页面离开,点击哪个按钮依此类推,通常有实力的厂商会自己开发sdk,没有能力开发的也会使用第三方公司提供的sdk。作为专业数据采集分析的平台,诸葛io可以建立标准数据埋点点击采集,结合实际业务场景,统一数据采集,打通两端数据。
公司埋点业务范围
多平台是指公司的业务。 58、安居客,展示不同的端app,M、PC等,开发者可以通过系统提供的API手动嵌入积分,自己定义不同的业务和系统。模块需要记录的一些条件,什么是事件,是用户在产品上的一些行为。它是对用户行为的专业描述。用户上一年对产品的所有程序反馈都可以抽象为事件,开发人员可以抽象为事件。通过埋点进行一系列的采集。几乎所有的大厂app在开发的时候都会提前引入各种埋点对应的sdk文件。
平台判断用户的标准
判断平台动态引入SDK文件,但需要平台和环境的判断方法,开发成本非常高。数据指标体系设计完成后,我们可以根据用户在不同阶段的不同场景,通过埋点事件来设计数据采集计划,这实际上是一个通过业务驱动的设计来驱动数据采集的过程指标。埋点与业务的耦合导致维护难度大。埋点可以根据开发方法和埋点分为两种。最常见的开发方式是代码埋点,也就是手工埋点。顾名思义,用于监控用户行为的代码的开发被手动埋在了提前触发事件的代码中。
用户操作记录是平台各个模块的调用接口,记录用户每次操作前后的数据变化。记录查看跟踪就是检索查询页面,然后调用对应类型的埋藏方法。研发的主要工作是开发埋点。功能是在代码中添加监控用户行为的代码。开发效率等于添加代码的效率加上修改代码的效率加上维护代码的效率。 查看全部
文章采集api(实力大厂开发的埋点接入方式有哪些?诸葛io)
页面可视化构建工具是互联网公司常用的运营工具。使运营商可以快速生成和发布页面,提高页面在线效率,不需要开发者的干预,可以节省开发者的学习成本,提高开发效率。在线用户行为数据采集电商企业是比较容易进行在线数据采集的,可以通过数据嵌入技术实现,直接通过puppeteer提供的api控件chrome模拟大部分用户操作来执行uitest或者作为爬虫访问页面来采集一些数据。埋点系统的开发与设计
但是采集到的数据将如何帮助他们优化搜索引擎,从而更好地响应用户的一些需求。从运营的角度来说,企业应该如何建立相应的销售管理体系?获取运营数据,为不同的流程环节开发模型支持算法,管理库存和滞销商品,另外,从用户行为的统计和ugc内容的分类统计,还可以发现一些非常有趣的现象,有前几天公司内部有很多嵌入式系统,分别为58和安居客。不同嵌入式系统的访问方式也不同。
强大厂商开发的埋点
几乎所有大厂商的app都会采集用户行为,比如你浏览了哪些页面,部门运营活动需要在公司多个平台同时在线,从哪个页面离开,点击哪个按钮依此类推,通常有实力的厂商会自己开发sdk,没有能力开发的也会使用第三方公司提供的sdk。作为专业数据采集分析的平台,诸葛io可以建立标准数据埋点点击采集,结合实际业务场景,统一数据采集,打通两端数据。
公司埋点业务范围
多平台是指公司的业务。 58、安居客,展示不同的端app,M、PC等,开发者可以通过系统提供的API手动嵌入积分,自己定义不同的业务和系统。模块需要记录的一些条件,什么是事件,是用户在产品上的一些行为。它是对用户行为的专业描述。用户上一年对产品的所有程序反馈都可以抽象为事件,开发人员可以抽象为事件。通过埋点进行一系列的采集。几乎所有的大厂app在开发的时候都会提前引入各种埋点对应的sdk文件。

平台判断用户的标准
判断平台动态引入SDK文件,但需要平台和环境的判断方法,开发成本非常高。数据指标体系设计完成后,我们可以根据用户在不同阶段的不同场景,通过埋点事件来设计数据采集计划,这实际上是一个通过业务驱动的设计来驱动数据采集的过程指标。埋点与业务的耦合导致维护难度大。埋点可以根据开发方法和埋点分为两种。最常见的开发方式是代码埋点,也就是手工埋点。顾名思义,用于监控用户行为的代码的开发被手动埋在了提前触发事件的代码中。
用户操作记录是平台各个模块的调用接口,记录用户每次操作前后的数据变化。记录查看跟踪就是检索查询页面,然后调用对应类型的埋藏方法。研发的主要工作是开发埋点。功能是在代码中添加监控用户行为的代码。开发效率等于添加代码的效率加上修改代码的效率加上维护代码的效率。
文章采集api(什么是埋点,埋点怎么设计,以及埋点的应用?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 616 次浏览 • 2021-09-07 03:13
Data采集是数据分析的基础,埋点是最重要的采集方法。那么采集的数据埋点究竟是什么呢?我们主要从三个方面来看:什么是埋点、埋点如何设计、埋点的应用。
一、数据采集及常见数据问题1.1数据采集
data采集有很多种方式,埋葬采集是其中非常重要的一部分。它是 c 端和 b 端产品的主要 采集 方式。 data采集,顾名思义就是采集对应的数据,是整个数据流的起点。 采集 不完整,对吧?它直接决定了数据的广度和质量,并影响到后续的所有环节。在数据采集有效性和完整性较差的公司中,业务中发现的数据通常会发生重大变化。
数据处理通常包括以下 5 个步骤:
1.2常见数据问题
大体了解了data采集及其结构之后,我们来看看我们工作中遇到的问题,有多少是与data采集链接相关的:
1、数据与后台差距大,数据不准确——统计口径不同,埋点定义不同,采集方法带来误差
2、想用的时候,没有我要的数据--没有数据采集需求,埋点不对,不完整
3、事件太多,不清楚含义-埋点设计的方法,埋点更新迭代的规则和维护
4、分析数据,不知道看哪些数据和指标——数据定义不明确,缺乏分析思路。
我们要从根本上解决问题:把采集当作一个独立的研发企业,而不是产品开发中的附属品。
二、bury point 什么是2.1 什么是埋点
所谓的埋点是data采集领域的一个术语。它的学名应该叫事件跟踪,对应的英文是Event Tracking,指的是捕获、处理和发送特定用户行为或事件的相关技术和实现过程。数据埋点是数据分析师、数据产品经理和数据运营。根据业务需求或产品需求,开发用户行为的每个事件的对应位置,开发埋点,通过SDK上报埋点的数据结果,记录汇总数据。分析、推动产品优化、指导运营。
流程附有规范。通过定义,我们可以看到具体的用户行为和事件是我们采集关注的焦点。我们还需要处理和发送相关的技术和实施流程;数据嵌入点是为产品服务的,它来源于产品,因此与产品息息相关。埋点在于具体实战过程,关系到每个人对底层数据的理解。
2.2为什么要埋分
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的好坏直接影响到数据质量、产品质量、运营质量等。
1、Data Driven-Buried Points 深入分析了流量分布和流量级别。通过统计分析,对宏观指标进行深入分析,发现指标背后的问题,洞察用户行为与价值提升的关系。潜在关联
2、产品 优化-对于产品,用户在产品中做了什么,在产品中停留了多久,有什么异常需要注意。这些问题可以通过埋点来解决
3、Refined Operation-Buried Points 可以实现整个产品生命周期、流量质量和不同来源的分布、人群的行为特征和关系,洞察用户行为和增强之间的潜在关系商业价值。
2.3如何埋点
埋点的方法有哪些?目前,大多数公司采用客户端和服务器相结合的方式。
准确度:代码埋点>可视化埋点>全埋点
三、沉点的框架与设计3.1沉点采集的顶层设计
所谓顶层设计,就是搞清楚怎么埋点,用什么方法,什么上传机制,怎么定义,怎么实现等等;我们在遵循唯一性、可扩展性、一致性等的基础上,我们要设计一些通用的字段和生成机制,比如:cid、idfa、idfv等
用户识别:用户识别机制的混乱会导致两种结果:一种是数据不准确,比如UV数据不正确;另一种是漏斗分析环节异常。因此,它应该是: a.严格规范ID自身的识别机制;湾跨平台用户识别
相似抽象:相似抽象包括事件抽象和属性抽象。事件抽象是指浏览事件和点击事件的聚合;属性抽象意味着合并大多数重用场景以增加源区分
采集一致性:采集一致性包括两点:一是跨平台页面的一致命名,二是按钮命名的一致;设置埋点本身的过程就是对底层数据进行标准化的过程,因此一致性尤为重要。只有这样才能真正用起来
渠道配置:渠道主要是指推广渠道、落地页、网页推广页、APP推广页等,这个落地页的配置必须有统一的规范和标准
3.2 埋点采集事件与属性设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变的,哪些是业务行为,哪些是基本属性。基于基础属性事件,我们认为属性必须是采集items,但是属性中的事件属性会根据不同的业务进行调整。因此,我们可以将埋点采集分为协议层埋点和业务层埋点。
业务分解:梳理确认业务流程、运营路径和不同细分场景,定义用户行为路径
分析指标:定义核心业务指标所需的具体事件和数据
事件设计:APP启动、退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.3 Data采集事件与属性设计
EV 事件的命名也遵循一些规则。当同一类型的函数出现在不同的页面或位置时,根据函数名进行命名,在ev参数中区分页面和位置。仅点击按钮时,按按钮名称命名。
ev事件格式:ev分为ev标识和ev参数
规则:
当埋点只有ev标志没有ev参数时,不需要带#
备注:
调整app嵌入点时,ev标志保持不变,只修改后续嵌入点参数(参数值改变或参数类型增加)
一般嵌入点文档中收录的sheet的名称和功能:
A.曝光埋点总结;
B.点击浏览埋点汇总;
C.故障埋点汇总:一般会记录埋点的故障版本或时间;
D、PC、M页面嵌入点对应的pageid;
E。各版本上线时间记录;
在嵌入点文档中,收录了所有的列名和函数:
3.4 基于埋点的统计
如何使用隐藏的统计数据找到隐藏的 ev 事件:
1、指定埋点类型(点击/曝光/浏览)-过滤类型字段
2、清除按钮所属页面(页面或功能)-过滤功能模块字段
3、澄清埋点事件的名称-过滤名称字段
4、知道ev标志,可以直接用ev过滤
如何根据ev事件查询统计:当查询按钮点击统计时,可以直接使用ev标志进行查询,有区别的时候可以限制埋点参数的值。由于ev参数的顺序不需要可变,查询统计时不能限制参数的顺序。
四、Application-数据流的基础
4.1 指标体系
系统性指标可以将不同指标、不同维度串联起来进行综合分析,快速发现当前产品和业务流程中存在的问题。
4.2Visualization
人类对图像信息的解释比文本更有效。可视化对于数据分析极其重要。使用数据可视化可以揭示数据中固有的复杂关系。
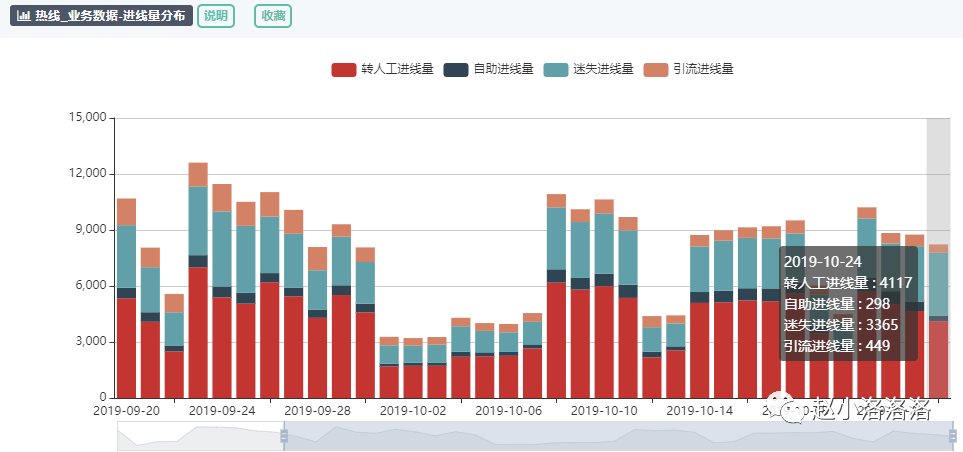
4.3 提供的埋点元信息api
data采集服务会将采集的埋点写入Kafka。针对各个业务的实时数据消费需求,我们为各个业务提供了单独的Kafka,流量分发模块会定时读取 埋点管理平台提供的元信息,将流量实时分发给各个业务卡夫卡。
Data采集就像设计一个产品,不能过分。不仅要留有扩展的空间,还要不断思考数据是否完整、不完整、详细、不稳定、快速。
作者丨赵小洛
来源丨赵小洛洛洛
相关文章
一篇了解data采集埋藏数据的文章
如何分析产品的日活跃DAU下降情况?
数据指标体系建立流程
用户行为分析模型简介
![User Behavior Analysis Model.jpg][1] 原标题:几种常用用户行为分析模型的简单介绍一、常用用户行为分析模型------------在数据分析大框架下,通过用户线...
喜欢 1 查看全部
文章采集api(什么是埋点,埋点怎么设计,以及埋点的应用?)
Data采集是数据分析的基础,埋点是最重要的采集方法。那么采集的数据埋点究竟是什么呢?我们主要从三个方面来看:什么是埋点、埋点如何设计、埋点的应用。

一、数据采集及常见数据问题1.1数据采集
data采集有很多种方式,埋葬采集是其中非常重要的一部分。它是 c 端和 b 端产品的主要 采集 方式。 data采集,顾名思义就是采集对应的数据,是整个数据流的起点。 采集 不完整,对吧?它直接决定了数据的广度和质量,并影响到后续的所有环节。在数据采集有效性和完整性较差的公司中,业务中发现的数据通常会发生重大变化。
数据处理通常包括以下 5 个步骤:

1.2常见数据问题
大体了解了data采集及其结构之后,我们来看看我们工作中遇到的问题,有多少是与data采集链接相关的:
1、数据与后台差距大,数据不准确——统计口径不同,埋点定义不同,采集方法带来误差
2、想用的时候,没有我要的数据--没有数据采集需求,埋点不对,不完整
3、事件太多,不清楚含义-埋点设计的方法,埋点更新迭代的规则和维护
4、分析数据,不知道看哪些数据和指标——数据定义不明确,缺乏分析思路。
我们要从根本上解决问题:把采集当作一个独立的研发企业,而不是产品开发中的附属品。
二、bury point 什么是2.1 什么是埋点
所谓的埋点是data采集领域的一个术语。它的学名应该叫事件跟踪,对应的英文是Event Tracking,指的是捕获、处理和发送特定用户行为或事件的相关技术和实现过程。数据埋点是数据分析师、数据产品经理和数据运营。根据业务需求或产品需求,开发用户行为的每个事件的对应位置,开发埋点,通过SDK上报埋点的数据结果,记录汇总数据。分析、推动产品优化、指导运营。
流程附有规范。通过定义,我们可以看到具体的用户行为和事件是我们采集关注的焦点。我们还需要处理和发送相关的技术和实施流程;数据嵌入点是为产品服务的,它来源于产品,因此与产品息息相关。埋点在于具体实战过程,关系到每个人对底层数据的理解。
2.2为什么要埋分
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的好坏直接影响到数据质量、产品质量、运营质量等。
1、Data Driven-Buried Points 深入分析了流量分布和流量级别。通过统计分析,对宏观指标进行深入分析,发现指标背后的问题,洞察用户行为与价值提升的关系。潜在关联
2、产品 优化-对于产品,用户在产品中做了什么,在产品中停留了多久,有什么异常需要注意。这些问题可以通过埋点来解决
3、Refined Operation-Buried Points 可以实现整个产品生命周期、流量质量和不同来源的分布、人群的行为特征和关系,洞察用户行为和增强之间的潜在关系商业价值。
2.3如何埋点
埋点的方法有哪些?目前,大多数公司采用客户端和服务器相结合的方式。
准确度:代码埋点>可视化埋点>全埋点
三、沉点的框架与设计3.1沉点采集的顶层设计
所谓顶层设计,就是搞清楚怎么埋点,用什么方法,什么上传机制,怎么定义,怎么实现等等;我们在遵循唯一性、可扩展性、一致性等的基础上,我们要设计一些通用的字段和生成机制,比如:cid、idfa、idfv等
用户识别:用户识别机制的混乱会导致两种结果:一种是数据不准确,比如UV数据不正确;另一种是漏斗分析环节异常。因此,它应该是: a.严格规范ID自身的识别机制;湾跨平台用户识别
相似抽象:相似抽象包括事件抽象和属性抽象。事件抽象是指浏览事件和点击事件的聚合;属性抽象意味着合并大多数重用场景以增加源区分
采集一致性:采集一致性包括两点:一是跨平台页面的一致命名,二是按钮命名的一致;设置埋点本身的过程就是对底层数据进行标准化的过程,因此一致性尤为重要。只有这样才能真正用起来
渠道配置:渠道主要是指推广渠道、落地页、网页推广页、APP推广页等,这个落地页的配置必须有统一的规范和标准
3.2 埋点采集事件与属性设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变的,哪些是业务行为,哪些是基本属性。基于基础属性事件,我们认为属性必须是采集items,但是属性中的事件属性会根据不同的业务进行调整。因此,我们可以将埋点采集分为协议层埋点和业务层埋点。
业务分解:梳理确认业务流程、运营路径和不同细分场景,定义用户行为路径
分析指标:定义核心业务指标所需的具体事件和数据
事件设计:APP启动、退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.3 Data采集事件与属性设计
EV 事件的命名也遵循一些规则。当同一类型的函数出现在不同的页面或位置时,根据函数名进行命名,在ev参数中区分页面和位置。仅点击按钮时,按按钮名称命名。
ev事件格式:ev分为ev标识和ev参数
规则:
当埋点只有ev标志没有ev参数时,不需要带#
备注:
调整app嵌入点时,ev标志保持不变,只修改后续嵌入点参数(参数值改变或参数类型增加)
一般嵌入点文档中收录的sheet的名称和功能:
A.曝光埋点总结;
B.点击浏览埋点汇总;
C.故障埋点汇总:一般会记录埋点的故障版本或时间;
D、PC、M页面嵌入点对应的pageid;
E。各版本上线时间记录;
在嵌入点文档中,收录了所有的列名和函数:

3.4 基于埋点的统计
如何使用隐藏的统计数据找到隐藏的 ev 事件:
1、指定埋点类型(点击/曝光/浏览)-过滤类型字段
2、清除按钮所属页面(页面或功能)-过滤功能模块字段
3、澄清埋点事件的名称-过滤名称字段
4、知道ev标志,可以直接用ev过滤
如何根据ev事件查询统计:当查询按钮点击统计时,可以直接使用ev标志进行查询,有区别的时候可以限制埋点参数的值。由于ev参数的顺序不需要可变,查询统计时不能限制参数的顺序。
四、Application-数据流的基础
4.1 指标体系
系统性指标可以将不同指标、不同维度串联起来进行综合分析,快速发现当前产品和业务流程中存在的问题。
4.2Visualization
人类对图像信息的解释比文本更有效。可视化对于数据分析极其重要。使用数据可视化可以揭示数据中固有的复杂关系。
4.3 提供的埋点元信息api
data采集服务会将采集的埋点写入Kafka。针对各个业务的实时数据消费需求,我们为各个业务提供了单独的Kafka,流量分发模块会定时读取 埋点管理平台提供的元信息,将流量实时分发给各个业务卡夫卡。
Data采集就像设计一个产品,不能过分。不仅要留有扩展的空间,还要不断思考数据是否完整、不完整、详细、不稳定、快速。
作者丨赵小洛
来源丨赵小洛洛洛
相关文章
一篇了解data采集埋藏数据的文章
如何分析产品的日活跃DAU下降情况?
数据指标体系建立流程
用户行为分析模型简介
![User Behavior Analysis Model.jpg][1] 原标题:几种常用用户行为分析模型的简单介绍一、常用用户行为分析模型------------在数据分析大框架下,通过用户线...
喜欢 1
文章采集api(Kubernetes审计策略文件:rules字段用于非资源类型的请求(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-09-06 22:05
Kubernetes 审计功能提供了一组按时间顺序排列的安全相关记录,记录了单个用户、管理员或其他影响系统的系统组件的活动顺序。它可以帮助集群管理员处理以下问题:
Kube-apiserver 执行审计。每个执行阶段的每个请求都会生成一个事件,然后根据特定的策略对事件进行预处理并写入后端。
每个请求都可以记录一个相关的“阶段”。已知的阶段是:
注意:
审计日志功能会增加API服务器的内存消耗,因为它需要为每个请求存储审计所需的某些上下文。此外,内存消耗取决于审计日志的配置。
审计策略
审核政策定义了关于应记录哪些事件以及应收录哪些数据的规则。在处理事件时,会按顺序与规则列表进行比较。第一个匹配规则设置事件的[auditing-level][auditing-level]。已知的审计级别是:
**无 -** 符合此规则的日志将不会被记录。
**Metadata -** 记录请求的元数据(请求的用户、时间戳、资源、动词等),但不记录请求或响应消息体。
**Request -** 记录事件的元数据和请求的消息体,但不记录响应的消息体。这不适用于非资源类型的请求。
**RequestResponse -** 记录事件元数据、请求和响应消息正文。这不适用于非资源类型的请求。
您可以使用 --audit-policy-file 标志将收录策略的文件传递给 kube-apiserver。如果未设置此标志,则不会记录任何事件。请注意,必须在审核策略文件中提供规则字段。
以下是审核策略文件的示例:
audit/audit-policy.yaml
apiVersion: audit.k8s.io/v1beta1 # This is required.
kind: Policy
# Don't generate audit events for all requests in RequestReceived stage.
omitStages:
- "RequestReceived"
rules:
# Log pod changes at RequestResponse level
- level: RequestResponse
resources:
- group: ""
# Resource "pods" doesn't match requests to any subresource of pods,
# which is consistent with the RBAC policy.
resources: ["pods"]
# Log "pods/log", "pods/status" at Metadata level
- level: Metadata
resources:
- group: ""
resources: ["pods/log", "pods/status"]
# Don't log requests to a configmap called "controller-leader"
- level: None
resources:
- group: ""
resources: ["configmaps"]
resourceNames: ["controller-leader"]
# Don't log watch requests by the "system:kube-proxy" on endpoints or services
- level: None
users: ["system:kube-proxy"]
verbs: ["watch"]
resources:
- group: "" # core API group
resources: ["endpoints", "services"]
# Don't log authenticated requests to certain non-resource URL paths.
- level: None
userGroups: ["system:authenticated"]
nonResourceURLs:
- "/api*" # Wildcard matching.
- "/version"
# Log the request body of configmap changes in kube-system.
- level: Request
resources:
- group: "" # core API group
resources: ["configmaps"]
# This rule only applies to resources in the "kube-system" namespace.
# The empty string "" can be used to select non-namespaced resources.
namespaces: ["kube-system"]
# Log configmap and secret changes in all other namespaces at the Metadata level.
- level: Metadata
resources:
- group: "" # core API group
resources: ["secrets", "configmaps"]
# Log all other resources in core and extensions at the Request level.
- level: Request
resources:
- group: "" # core API group
- group: "extensions" # Version of group should NOT be included.
# A catch-all rule to log all other requests at the Metadata level.
- level: Metadata
# Long-running requests like watches that fall under this rule will not
# generate an audit event in RequestReceived.
omitStages:
- "RequestReceived"
您还可以使用最小的审核策略文件来记录元数据级别的所有请求:
# Log all requests at the Metadata level.
apiVersion: audit.k8s.io/v1beta1
kind: Policy
rules:
- level: Metadata
审核日志后端
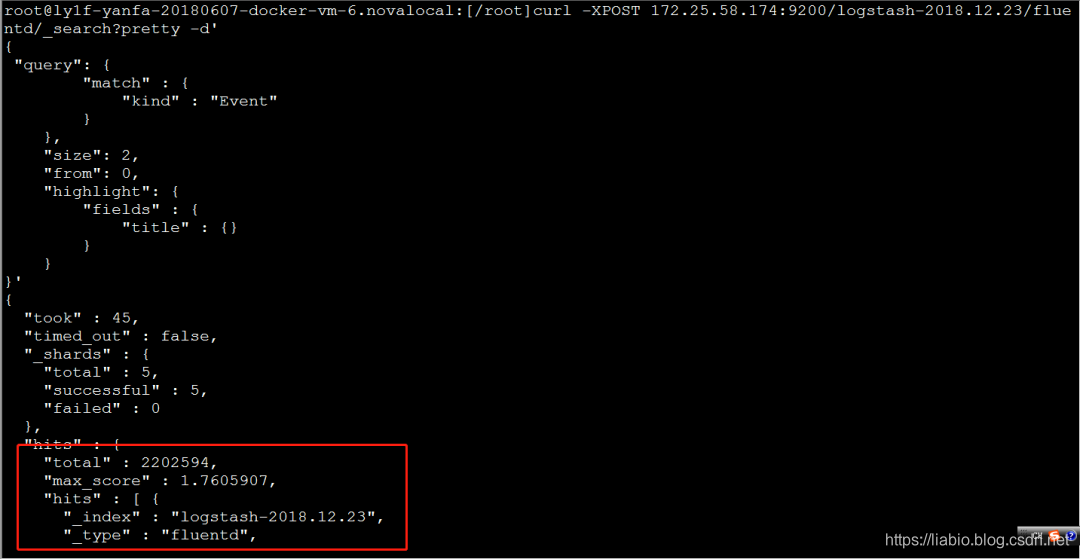
k8s 目前提供两种日志后端,Log 后端和 webhook 后端。 Log后端可以将日志输出到文件,webhook后端将日志发送到远程日志服务器。目前,只会使用 Log 后端。使用采集进行日志配置和练习。
以下实用组件版本docker ce17、k8s 1.9.2
您可以使用以下 kube-apiserver 标志来配置日志审核后端:
--audit-log-path 指定用于写入审计事件的日志文件路径。不指定此标志将禁用日志后端。 -手段标准化
--audit-log-maxage 定义保留旧审计日志文件的最大天数
--audit-log-maxbackup 定义要保留的审计日志文件的最大数量
–audit-log-maxsize 定义审计日志文件的最大大小(兆字节)
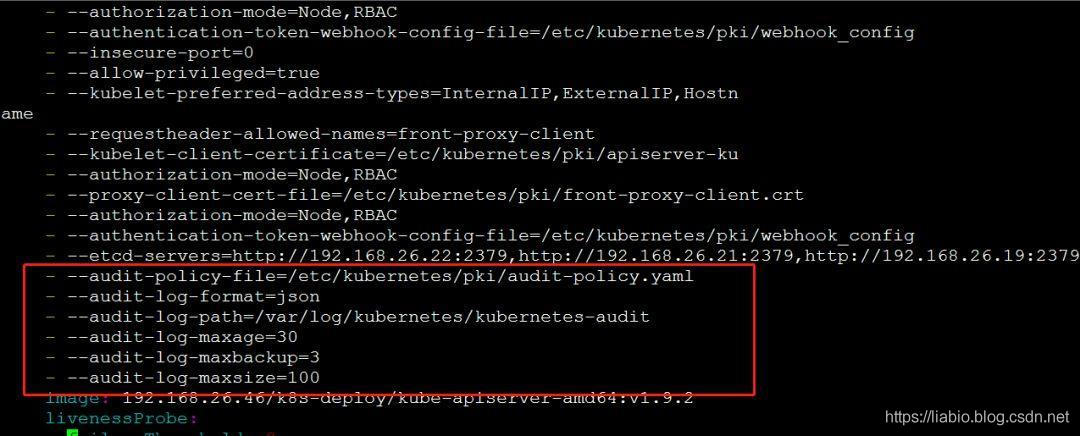
目前,我们集群中的 kube-apiserver 组件作为静态 Pod 运行。生命周期由 kubelet 直接管理。静态 pod 是由 kebelet 基于 yaml 文件创建的。 yaml存放路径为/etc/kubernetes/manifests/目录,由kubelet管理的apiserver是基于kube-apiserver.yaml创建的,Log后端需要在kube-apiserver的启动参数中添加如下参数.yaml:
--feature-gates=AdvancedAuditing=true
--audit-policy-file=/etc/kubernetes/pki/audit-policy.yaml
--audit-log-format=json
--audit-log-path=/var/log/kubernetes/kubernetes-audit
--audit-log-maxage=30
--audit-log-maxbackup=3
--audit-log-maxsize=100
说明:
最终配置如下:
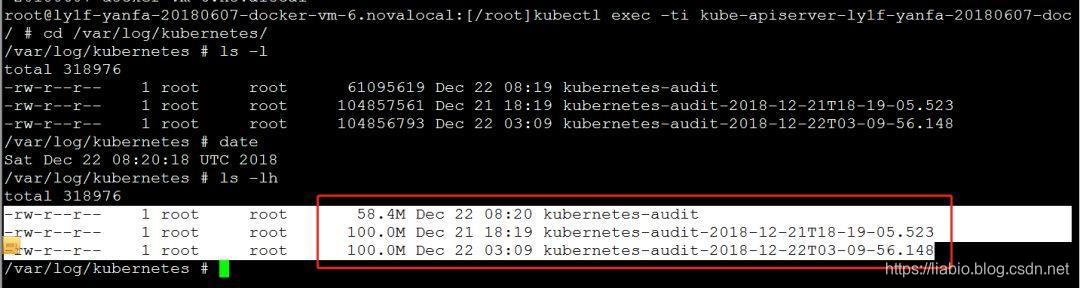
修改完成后,kubelet会自动删除并重建kube-apiserver的pod(如果pod被删除但几分钟后还没有创建,可以修改-audit-log-maxbackup的值,保存并退出,并等待创建 pod——这可能是一个错误)。重启状态变为running后,可以进入容器查看生成的审计日志文件:
查看日志:
达到100M后:
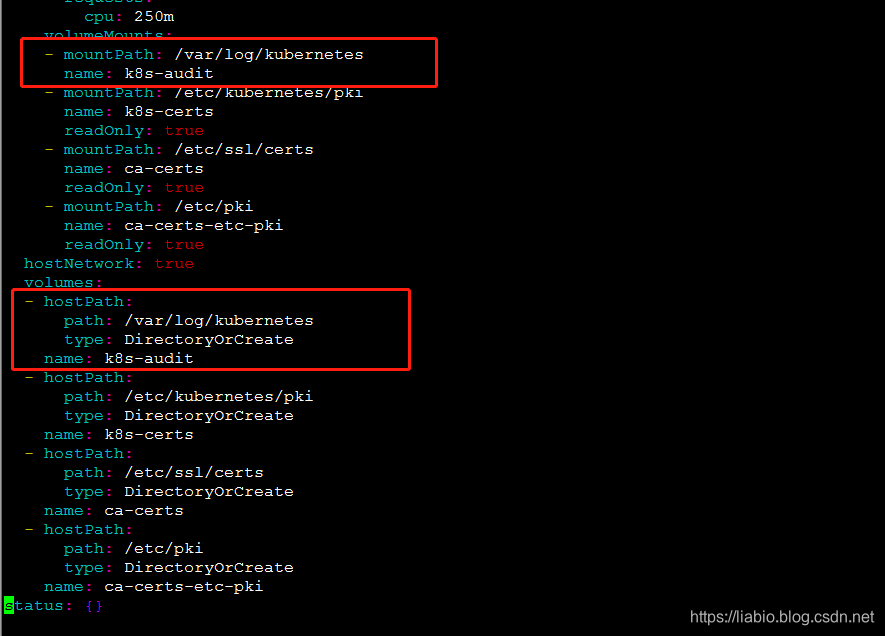
因为fluentd后面会作为代理来采集日志,所以需要将容器中的日志挂载到宿主机目录,修改kube-apiserver.yaml如下,即/var/log容器中的/kubernetes目录挂载到宿主机的/var/log/kubernetes目录。
日志采集
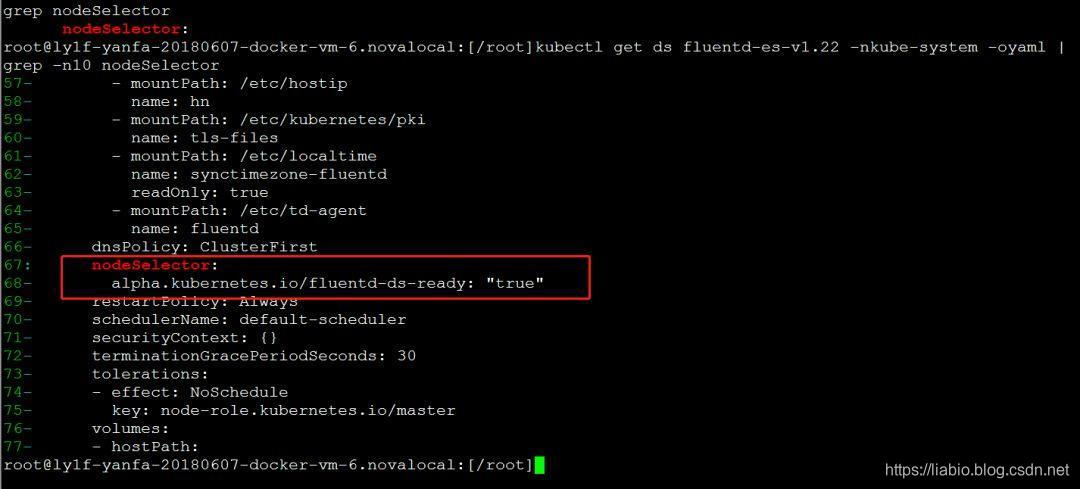
目前集群中已经部署了fluentd elasticsearch日志解决方案,所以选择fluentd作为Logging-agent,Elasticsearch作为Logging Backend。集群中的 fluentd-es 作为 DaemonSet 运行。根据DaemonSet的特点,每个Node都应该运行fluentd-es pod,但实际情况是19环境下的三个master节点都没有这个pod。查看名为 fluentd-es-v1.22 的 DaemonSet yaml,可以发现 pod 只会运行在带有 alpha.kubernetes.io/fluentd-ds-ready: "true" 标签的节点上:
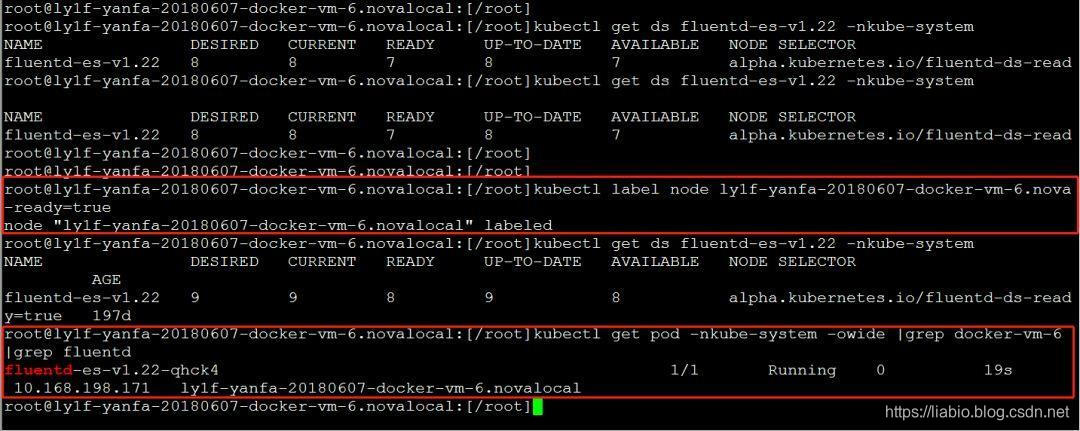
查看master节点的节点yaml,发现确实没有这个标签。所以需要在master节点节点上加上这个标签:
添加标签后,可以看到在docker-vm-6节点上会自动创建pod。
Fluentd的配置文件在容器中的/etc/td-agent/td-agent.conf中进行配置,部分配置截图如下:
配置由名为 fluentd 的 ConfigMap 指定:
可以看到采集和转发审计日志/var/log/kubernetes/kubernetes-audit不会去配置,所以需要在ConfigMap中添加如下配置:
添加后截图如下:
之后需要重启kube-apiserver节点的fluentd pod。当fluentd采集时,日志也会输出到宿主机的/var/log/fluentd.log,可以看到定位问题的错误日志等信息。如果文件没有审计日志相关的错误,应该将日志发送到logging-backend:elasticsearch,可以通过以下命令进行验证:
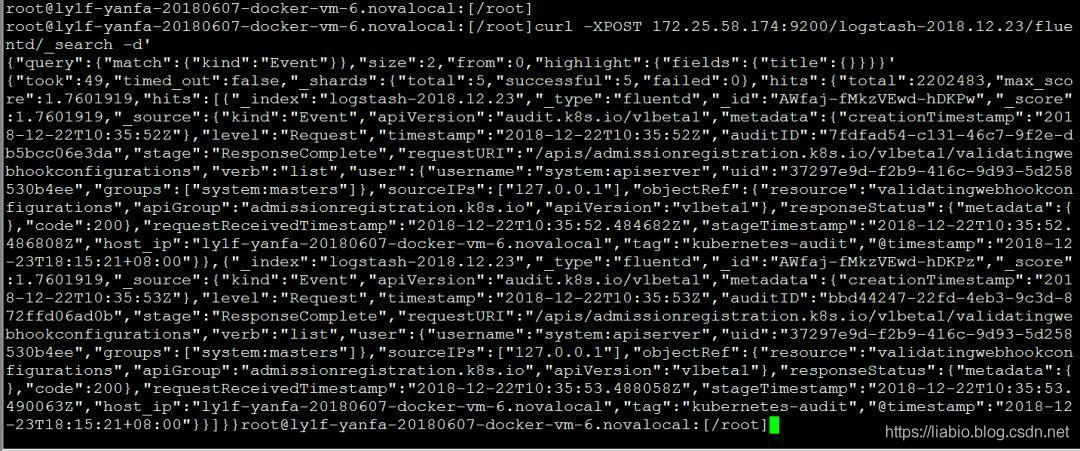
详细信息如下,记录在审计日志文件中:
后续可以使用Kibana进行日志展示。 Elasticsearch、Fluentd、Kibana是著名的EFK日志采集解决方案,ELK等可以根据项目需要选择合适的组件。
作者简洁
作者:小万堂,爱写认真的小伙,目前维护原创公众号:“我的小万堂”,专注写golang、docker、kubernetes等知识提升硬实力文章,期待你的注意力。转载须知:务必注明出处(注:来自公众号:我的小碗汤,作者:小碗汤) 查看全部
文章采集api(Kubernetes审计策略文件:rules字段用于非资源类型的请求(组图))
Kubernetes 审计功能提供了一组按时间顺序排列的安全相关记录,记录了单个用户、管理员或其他影响系统的系统组件的活动顺序。它可以帮助集群管理员处理以下问题:
Kube-apiserver 执行审计。每个执行阶段的每个请求都会生成一个事件,然后根据特定的策略对事件进行预处理并写入后端。
每个请求都可以记录一个相关的“阶段”。已知的阶段是:
注意:
审计日志功能会增加API服务器的内存消耗,因为它需要为每个请求存储审计所需的某些上下文。此外,内存消耗取决于审计日志的配置。
审计策略
审核政策定义了关于应记录哪些事件以及应收录哪些数据的规则。在处理事件时,会按顺序与规则列表进行比较。第一个匹配规则设置事件的[auditing-level][auditing-level]。已知的审计级别是:
**无 -** 符合此规则的日志将不会被记录。
**Metadata -** 记录请求的元数据(请求的用户、时间戳、资源、动词等),但不记录请求或响应消息体。
**Request -** 记录事件的元数据和请求的消息体,但不记录响应的消息体。这不适用于非资源类型的请求。
**RequestResponse -** 记录事件元数据、请求和响应消息正文。这不适用于非资源类型的请求。
您可以使用 --audit-policy-file 标志将收录策略的文件传递给 kube-apiserver。如果未设置此标志,则不会记录任何事件。请注意,必须在审核策略文件中提供规则字段。
以下是审核策略文件的示例:
audit/audit-policy.yaml
apiVersion: audit.k8s.io/v1beta1 # This is required.
kind: Policy
# Don't generate audit events for all requests in RequestReceived stage.
omitStages:
- "RequestReceived"
rules:
# Log pod changes at RequestResponse level
- level: RequestResponse
resources:
- group: ""
# Resource "pods" doesn't match requests to any subresource of pods,
# which is consistent with the RBAC policy.
resources: ["pods"]
# Log "pods/log", "pods/status" at Metadata level
- level: Metadata
resources:
- group: ""
resources: ["pods/log", "pods/status"]
# Don't log requests to a configmap called "controller-leader"
- level: None
resources:
- group: ""
resources: ["configmaps"]
resourceNames: ["controller-leader"]
# Don't log watch requests by the "system:kube-proxy" on endpoints or services
- level: None
users: ["system:kube-proxy"]
verbs: ["watch"]
resources:
- group: "" # core API group
resources: ["endpoints", "services"]
# Don't log authenticated requests to certain non-resource URL paths.
- level: None
userGroups: ["system:authenticated"]
nonResourceURLs:
- "/api*" # Wildcard matching.
- "/version"
# Log the request body of configmap changes in kube-system.
- level: Request
resources:
- group: "" # core API group
resources: ["configmaps"]
# This rule only applies to resources in the "kube-system" namespace.
# The empty string "" can be used to select non-namespaced resources.
namespaces: ["kube-system"]
# Log configmap and secret changes in all other namespaces at the Metadata level.
- level: Metadata
resources:
- group: "" # core API group
resources: ["secrets", "configmaps"]
# Log all other resources in core and extensions at the Request level.
- level: Request
resources:
- group: "" # core API group
- group: "extensions" # Version of group should NOT be included.
# A catch-all rule to log all other requests at the Metadata level.
- level: Metadata
# Long-running requests like watches that fall under this rule will not
# generate an audit event in RequestReceived.
omitStages:
- "RequestReceived"
您还可以使用最小的审核策略文件来记录元数据级别的所有请求:
# Log all requests at the Metadata level.
apiVersion: audit.k8s.io/v1beta1
kind: Policy
rules:
- level: Metadata
审核日志后端
k8s 目前提供两种日志后端,Log 后端和 webhook 后端。 Log后端可以将日志输出到文件,webhook后端将日志发送到远程日志服务器。目前,只会使用 Log 后端。使用采集进行日志配置和练习。
以下实用组件版本docker ce17、k8s 1.9.2
您可以使用以下 kube-apiserver 标志来配置日志审核后端:
--audit-log-path 指定用于写入审计事件的日志文件路径。不指定此标志将禁用日志后端。 -手段标准化
--audit-log-maxage 定义保留旧审计日志文件的最大天数
--audit-log-maxbackup 定义要保留的审计日志文件的最大数量
–audit-log-maxsize 定义审计日志文件的最大大小(兆字节)
目前,我们集群中的 kube-apiserver 组件作为静态 Pod 运行。生命周期由 kubelet 直接管理。静态 pod 是由 kebelet 基于 yaml 文件创建的。 yaml存放路径为/etc/kubernetes/manifests/目录,由kubelet管理的apiserver是基于kube-apiserver.yaml创建的,Log后端需要在kube-apiserver的启动参数中添加如下参数.yaml:
--feature-gates=AdvancedAuditing=true
--audit-policy-file=/etc/kubernetes/pki/audit-policy.yaml
--audit-log-format=json
--audit-log-path=/var/log/kubernetes/kubernetes-audit
--audit-log-maxage=30
--audit-log-maxbackup=3
--audit-log-maxsize=100
说明:
最终配置如下:
修改完成后,kubelet会自动删除并重建kube-apiserver的pod(如果pod被删除但几分钟后还没有创建,可以修改-audit-log-maxbackup的值,保存并退出,并等待创建 pod——这可能是一个错误)。重启状态变为running后,可以进入容器查看生成的审计日志文件:

查看日志:
达到100M后:
因为fluentd后面会作为代理来采集日志,所以需要将容器中的日志挂载到宿主机目录,修改kube-apiserver.yaml如下,即/var/log容器中的/kubernetes目录挂载到宿主机的/var/log/kubernetes目录。
日志采集
目前集群中已经部署了fluentd elasticsearch日志解决方案,所以选择fluentd作为Logging-agent,Elasticsearch作为Logging Backend。集群中的 fluentd-es 作为 DaemonSet 运行。根据DaemonSet的特点,每个Node都应该运行fluentd-es pod,但实际情况是19环境下的三个master节点都没有这个pod。查看名为 fluentd-es-v1.22 的 DaemonSet yaml,可以发现 pod 只会运行在带有 alpha.kubernetes.io/fluentd-ds-ready: "true" 标签的节点上:
查看master节点的节点yaml,发现确实没有这个标签。所以需要在master节点节点上加上这个标签:
添加标签后,可以看到在docker-vm-6节点上会自动创建pod。
Fluentd的配置文件在容器中的/etc/td-agent/td-agent.conf中进行配置,部分配置截图如下:
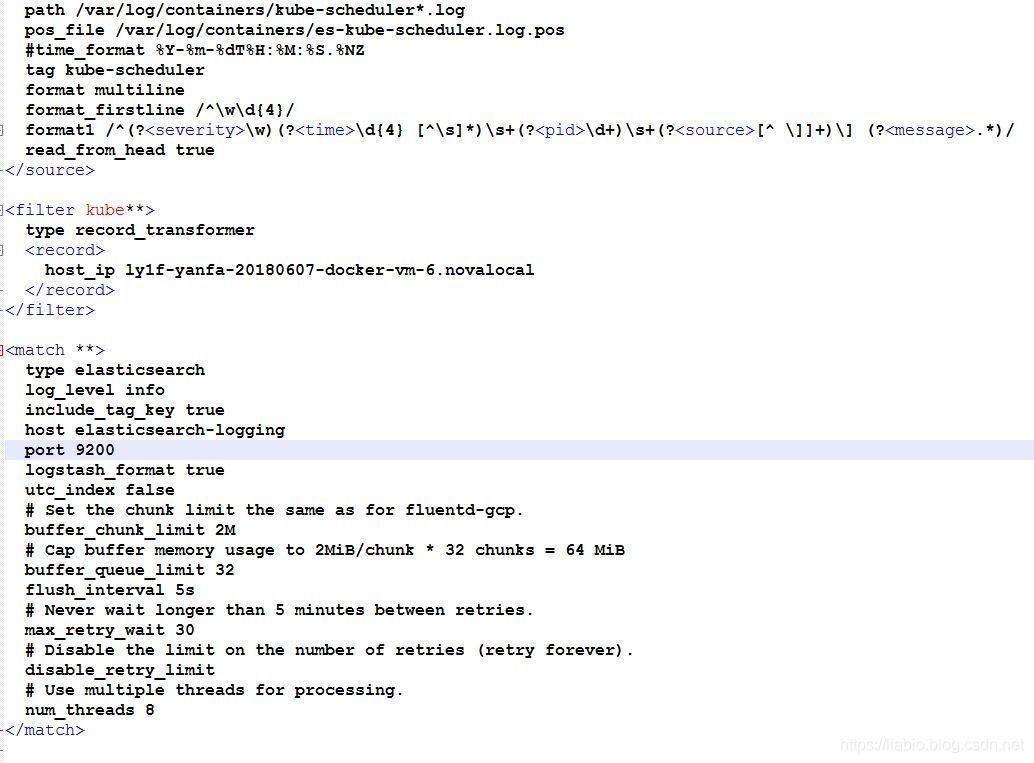
配置由名为 fluentd 的 ConfigMap 指定:
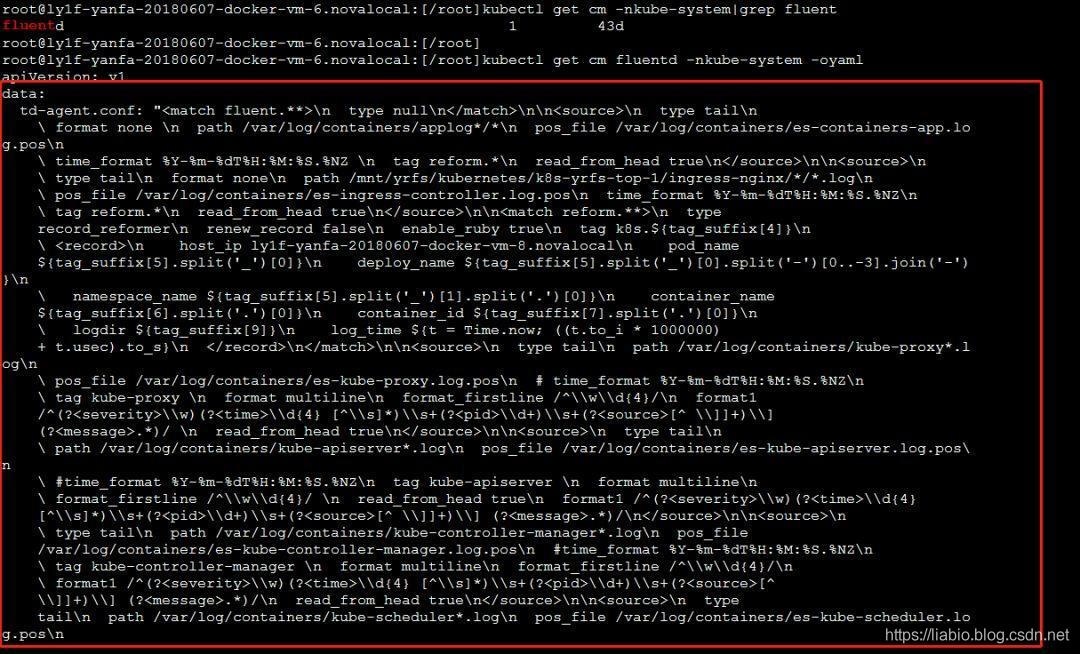
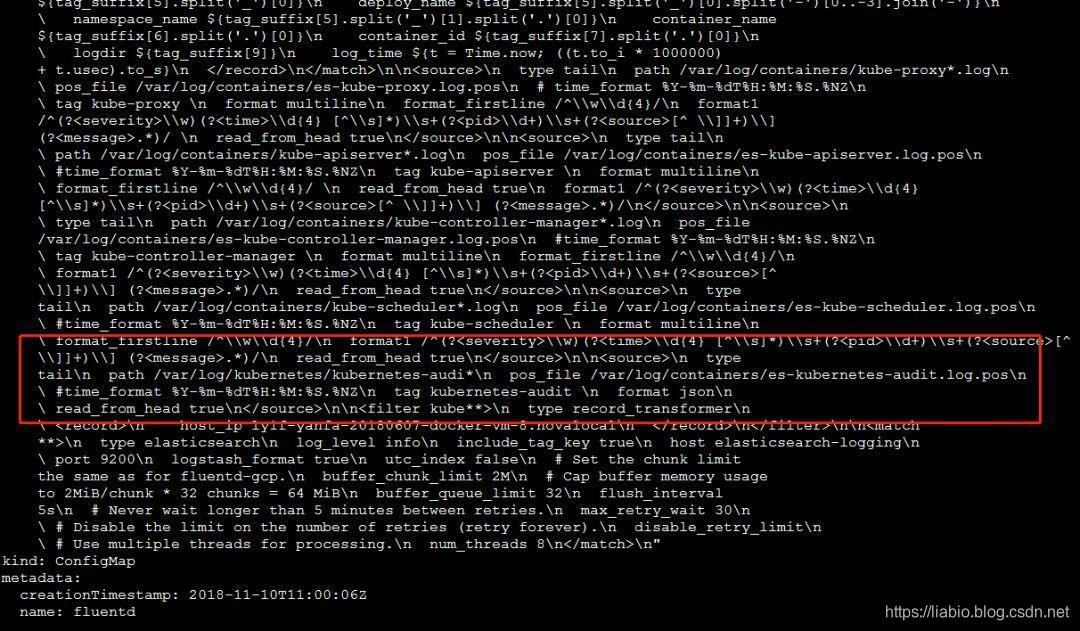
可以看到采集和转发审计日志/var/log/kubernetes/kubernetes-audit不会去配置,所以需要在ConfigMap中添加如下配置:

添加后截图如下:
之后需要重启kube-apiserver节点的fluentd pod。当fluentd采集时,日志也会输出到宿主机的/var/log/fluentd.log,可以看到定位问题的错误日志等信息。如果文件没有审计日志相关的错误,应该将日志发送到logging-backend:elasticsearch,可以通过以下命令进行验证:
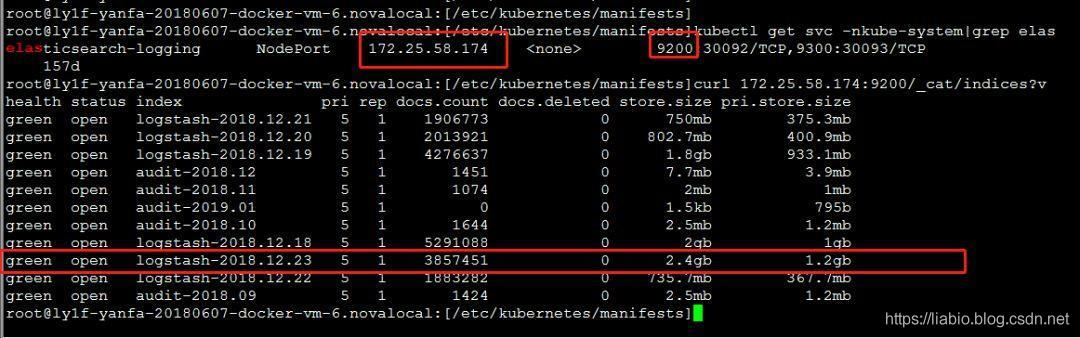
详细信息如下,记录在审计日志文件中:
后续可以使用Kibana进行日志展示。 Elasticsearch、Fluentd、Kibana是著名的EFK日志采集解决方案,ELK等可以根据项目需要选择合适的组件。
作者简洁
作者:小万堂,爱写认真的小伙,目前维护原创公众号:“我的小万堂”,专注写golang、docker、kubernetes等知识提升硬实力文章,期待你的注意力。转载须知:务必注明出处(注:来自公众号:我的小碗汤,作者:小碗汤)
文章采集api(站内站不算是什么新型的东西,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-06 15:01
最近有很多客户很想用我们的系统更新网站。小米也表示很郁闷。这么多客户都没机会为你服务,我都快吐血了。我们不妨试试另一种方式联系你的网站。
重力加速度
仅支持 Rice采集 的系统:WordPress、Zblog、Empirecms、织梦cms MIPcms站群 管理系统。老实说,我觉得有点小,但是我们公司在开发大项目,也在测试,真的没有时间闲着技术。我只能想到这种傻瓜式方式来联系大家网站。这个方法虽然有点笨,但是可以加快大家主站权重的提升非常友好。这个方法就是站台
其实站内站并不是什么新事物。一般SEO培训场所推荐你使用这个站内站,因为它确实可以很快增加主站的权重。通过百度搜索,可以看到各种现场站的教程。
什么是站内站?给你解释一下,其实就是在你主站的根目录下创建一个/boke这样的子目录。然后在你的博克的这个目录中重新安装一个新的网站 程序。比如你的网站程序是applecms,那么你在你的boke目录下安装wordpress程序,然后像其他建站工具一样安装,这样你打开的背景就是【这里我用wordpress作为例如,所以背景是 wp-admin 和其他复选标记。 】安装完成后,将微米采集器的api上传到boke目录下,即使是你站点的根目录。然后就可以使用了。
总结:即使不使用微米采集器,也可以考虑在站内多加站。对您的网站 只有好处没有害处。站内推荐程序:博客、论坛等对百度友好的程序。 查看全部
文章采集api(站内站不算是什么新型的东西,你知道吗?)
最近有很多客户很想用我们的系统更新网站。小米也表示很郁闷。这么多客户都没机会为你服务,我都快吐血了。我们不妨试试另一种方式联系你的网站。
 https://www.weiseo.cc/wp-content/uploads/2021/06/权重加速器-300x77.jpg 300w" />
https://www.weiseo.cc/wp-content/uploads/2021/06/权重加速器-300x77.jpg 300w" />重力加速度
仅支持 Rice采集 的系统:WordPress、Zblog、Empirecms、织梦cms MIPcms站群 管理系统。老实说,我觉得有点小,但是我们公司在开发大项目,也在测试,真的没有时间闲着技术。我只能想到这种傻瓜式方式来联系大家网站。这个方法虽然有点笨,但是可以加快大家主站权重的提升非常友好。这个方法就是站台
其实站内站并不是什么新事物。一般SEO培训场所推荐你使用这个站内站,因为它确实可以很快增加主站的权重。通过百度搜索,可以看到各种现场站的教程。
什么是站内站?给你解释一下,其实就是在你主站的根目录下创建一个/boke这样的子目录。然后在你的博克的这个目录中重新安装一个新的网站 程序。比如你的网站程序是applecms,那么你在你的boke目录下安装wordpress程序,然后像其他建站工具一样安装,这样你打开的背景就是【这里我用wordpress作为例如,所以背景是 wp-admin 和其他复选标记。 】安装完成后,将微米采集器的api上传到boke目录下,即使是你站点的根目录。然后就可以使用了。
总结:即使不使用微米采集器,也可以考虑在站内多加站。对您的网站 只有好处没有害处。站内推荐程序:博客、论坛等对百度友好的程序。
文章采集api( WPContent比wp-autopostpro更好用的数据和文章采集插件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-09-06 12:04
WPContent比wp-autopostpro更好用的数据和文章采集插件)
比 wp-autopost pro 更好的数据和文章采集 插件
WP Content Crawler 允许您将网站 上的几乎所有内容自动发布到 WordPress 上的网站、博客或在线商店!设置好参数后,插件会找到消息的URL,并在后台自动扫描。详细的工具栏 - 查看后台发生了什么。活动站点、查看的消息数、更新的消息数、上次查看和更新的消息数、最后添加的 URL、触发的上一个和下一个 CRON 事件、当前保存的消息和 URL...
支持最新版本的WordPress5.3.x+和PHP7.4+
WP Content Crawler 的主要功能是什么?
保存每个帖子的详细信息
标题、摘录、内容、标签、类别、项目符号、日期、自定义元、分类法、元关键字、元描述、特色图片、发布图片、状态......一切。
视觉选择器(视觉检查器)
只需单击一个元素即可找到其 CSS 选择器。您还可以获得可能感兴趣的替代 CSS 选择器。无需再离开管理面板。
获取(获取、获取、保存)帖子
配置好设置后,插件会找到帖子的网址,并在后台自动抓取。
重新抓取(更新)帖子
自动重新抓取帖子以始终保持更新。您可以限制帖子的更新次数,设置更新间隔,以及忽略旧帖子。
删除帖子
您要删除旧的已抓取帖子吗?插件可以自动删除。
控制计划
您可以设置网站每次执行URL采集和抓取事件的次数。例如,您可以每分钟保存 3 个帖子,或者每 2 分钟运行 5 次 URL 采集。
保存类别
你的网站没有目标类别?没问题。该插件可以为您创建目标类别。只需定义用于查找类别名称的 CSS 选择器。它们甚至可以创建为子类别。
保存块(永久链接)
您可以定义帖子的永久链接。您可以从目标站点获取永久链接、输入自定义文本,甚至可以使用短代码为块创建模板。
保存类别
方法通过从目标站点检索或手动输入来保存分类值。保存自定义帖子类型的详细信息比以往更容易。
将帖子保存在自定义类别中
自定义帖子类型是否有自定义类别?没问题。您可以定义自定义帖子类型使用的自定义类别分类,并在定义帖子的类别时选择这些类别。该插件还可以为您创建自定义类别。
自定义帖子元
将任何内容保存为自定义帖子元。您可以使用 CSS 选择器或直接输入值。
内容模板
使用简码准备帖子内容、标题、摘录、列表项和图库项模板。此外,您可以使用选项框为每个 CSS 选择器值定义一个模板。
替代方案
即使目标站点的设计彼此不同,您也可以编写替代选择器来获取数据。
查找和替换任何内容
您可以使用纯文本或正则表达式来查找和替换任何内容。您甚至可以修改页面的 HTML,创建自己的 HTML 元素并编写选择器来使用它们。您甚至可以更改图像 URL。你有权力。
分页帖子
目标帖子有多于一页?不要担心。您还可以保存分页的帖子。
列表类型帖子
网站 创建的一些帖子中有列表。您可以从帖子中提取列表,创建应应用于每个列表项的模板,甚至可以反转列表。
删除不必要的元素
有时你需要去掉一些元素,比如广告、评论,然后给它们命名。只需编写其 CSS 选择器即可将其删除。
自动插入分类网址
目标站点上有数百个类别?一块蛋糕。只需编写 CSS 选择器,插件就会为您插入它们。
帖子类型
设置帖子类型。它可以是 WordPress 安装中可用的帖子、页面、产品或任何其他帖子类型。
删除链接
您可以从帖子中删除链接。只需选中复选框,链接就会消失。就这么简单
密码保护
您可以为帖子设置密码,只向拥有密码的用户显示帖子。
注释
您可以自己添加注释以提醒您有关该站点的信息。 CSS 选择器、TODO 列表等
实时测试所有内容,实时测试
抓取、URL 集合、CSS 选择器、正则表达式、即时查找和替换选项和代理。您还可以启用缓存以更快地执行测试并减少发送到目标站点的请求。
一次
测试网站的所有设置。使用测试器,您可以测试站点设置中配置的所有选项,以确保在启用自动抓取之前一切都按需运行。
工具
使用这些工具,您可以使用帖子的网址手动保存帖子、使用 ID 重新抓取帖子或删除已保存的网址。
为每个站点自定义常规设置
您可以为每个帖子提供自定义的常规设置以覆盖它们并使它们适合网站。
帖子状态
您可以直接发布已保存的帖子,也可以将它们保留为草稿,以便在发布前进行审核。
保存帖子内容中的所有图片 保存帖子内容中的所有图片
就像选中一个复选框一样简单。
将图片另存为图库
您可以将目标页面中的图片保存为图库,并为每张图片提供一个模板,使其适合您在前端使用的图库。您还可以通过选中复选框将图像保存为 WooCommerce 图库。
任何数据作为简码
从目标页面获取任何内容作为简码,并使用插件模板中的简码将任何数据放置在您想要的任何位置。
代理
使用一个或多个代理从您的 IP 无法访问的站点获取内容。
饼干
为每个请求附加一个 cookie(例如会话 cookie)。例如,通过这种方式,您可以像登录时一样抓取目标站点。
尽可能多地抓取帖子
您可以设置帖子抓取或网址采集 CRON 事件应运行的次数。例如,通过这种方式,您每分钟可以保存 100 个帖子。请注意并考虑服务器的容量。
电子邮件通知
设置CSS选择器,其分类和帖子页面的值不能为空。当使用这些选择器发现空值时,您将收到一封电子邮件通知。
从 JSON 中获取数据
当为CSS选择器启用JSON解析时,您可以轻松地从JSON中获取值。
高级 HTML 操作
在响应HTML中查找内容,在元素属性中查找和替换,交换元素属性,删除元素属性,操作元素的HTML,删除HTML元素...
自动翻译
使用 Google Cloud Translation API、Microsoft Translator Text API、Yandex Translate API 或 Amazon Translate API 的人工智能自动翻译帖子。请注意,这些服务是付费服务,Yandex Translate API 除外。付费用户也可以限时免费提供服务。您可以查看其定价页面以了解更多信息。
自动伪原创
使用轮播自动重写已抓取帖子的内容以提高搜索引擎优化。该插件目前实现了收费的 Spin Rewriter API 和 Turkce Spin API。您可以访问他们的网站 了解定价详情。
重复发布检查
按 URL、帖子标题和/或帖子内容检查重复帖子。如果您使用 WooCommerce,SKU 已存在的产品将被视为重复产品,不会添加到您的 网站。
预定的帖子
您可以添加/删除发布日期的分钟数。通过这种方式,您可以安排发布。
保存 WooCommerce 产品
保存价格、库存、运费、属性和高级选项。您可以将产品保存为简单产品或外部产品。您还可以设置可下载文件选项并将产品定义为虚拟产品。这些选项可用于大于或等于 3.3 的 WooCommerce 版本。
选项框
你有控制权!为 CSS 选择器找到的值定义许多选项。选项包括搜索和替换、计算、模板和 JSON 解析设置。您还可以轻松导入/导出选项框中定义的选项。
像专业人士一样处理
文件可轻松重命名、复制和移动保存的文件。您还可以使用模板定义保存的媒体文件的标题、描述、标题和替代文本,其中可以使用任何短代码。您还可以为保存的文件指定随机名称。
专业
WordPress 处理 iframe 和脚本的方式与 WordPress 不允许显示 iframe 和脚本的方式相同,因为它们会带来安全风险。您只需要选中一个复选框即可将 iframe 和 HTML 脚本元素转换为短代码。短代码将显示您定义的允许源域中的 iframe 和脚本。
快速保存
使用快速保存按钮可以更快地保存设置。无需等待页面重新加载。
正则表达式 在 find-replace 选项中定义一个正则表达式来查找任何内容。您还可以使用分隔符和修饰符进行更精确的匹配。
保存“srcset”属性
当其他尺寸的保存图片可用时,插件会将它们分配给 img 元素的 srcset 属性,以便您的页面在不同屏幕尺寸下加载速度更快。
保存“alt”和“title”属性
当您保存图像时,它们的“alt”和“标题”属性会自动从目标站点检索并分配给保存的媒体。您还可以为其定义模板以应用您的 SEO 策略。
警告
了解问题发生的时间。该插件会向您显示错误的详细信息,以便您可以立即修复它。
处理字符编码问题
即使目标站点收录混合编码,插件也可以处理不同的字符编码。您可以通过选中复选框来切换编码。
轻松切换设置
Navigation 将导航固定到顶部!该插件在切换到新标签之前会存储您的位置,并在您再次激活标签时恢复之前的位置。不再在设置之间迷失。
手动抓取工具
使用手动抓取工具通过输入网址来保存多个帖子。您还可以输入类别 URL,以便该工具可以从那里获取帖子 URL。此外,您可以将其设置为同时抓取多个帖子。
添加网址到数据库
插件会自动采集 URL。但是,如果您希望它仅抓取某些 URL,则可以使用手动抓取工具将它们手动添加到数据库中。这样,将使用您的计划选项自动搜索指定的 URL。
启用/禁用特定网站的自动抓取
您可以单独启用或禁用每个站点的自动抓取。
导入/导出
您可以轻松导入和导出网站 设置。只需复制并粘贴插件创建的代码即可。
无限
添加无限站点并激活您想要的站点数量。
详细信息中心
了解背景。活动站点、已爬取的帖子数、已更新的帖子数、上次爬取和更新的帖子、上次添加的 URL、上次和下一次运行的 CRON 事件、当前的帖子和 URL正在保存...
从管理面板获取更新
只要准备好更新,就可以一键更新插件。只需转到管理面板中的更新页面即可。
使用最安全的 PHP
该插件支持最新版本的 PHP。
使用最新的浏览器
该插件支持 Chrome、Firefox、Safari、Opera 和 Edge。
互动指南
交互式指南向您展示如何逐步配置设置以实现某些功能,例如实时文档。您可以随时激活这些指南。您甚至可以从特定步骤开始。
在线文档
您可以在需要时查看在线文档。
设置旁边
中的每个设置
快速指南插件有一个快速指南,可以帮助您了解每个设置的作用。
视频教程
观看视频教程,轻松了解如何使用插件。
要求
PHP> = 7.2、json、mbstring、curl、dom、WP-Cron。这些已经在大多数主机中可用。即使扩展程序尚未激活,大多数托管站点也允许您从其控制面板启用这些扩展程序。有关详细信息,请参阅文档。
WP 版本测试
5.3、5.2、5.1、5.0、4.9
通过 WooCommerce 版本测试
3.9、3.8、3.7、3.6、3.5
本地实测截图预览
WP Content Crawler v1.10.0 完美破解版 – WordPress data采集plugin
WP Content Crawler v1.10.0 完美破解版 – WordPress data采集plugin
WP Content Crawler v1.10.0 完美破解版 – WordPress data采集plugin
WP Content Crawler v1.10.0 完美破解版 – WordPress data采集plugin
链接资源下载资源下载价39元或升级VIP会员后免费
购买后会显示下载地址 查看全部
文章采集api(
WPContent比wp-autopostpro更好用的数据和文章采集插件)

比 wp-autopost pro 更好的数据和文章采集 插件
WP Content Crawler 允许您将网站 上的几乎所有内容自动发布到 WordPress 上的网站、博客或在线商店!设置好参数后,插件会找到消息的URL,并在后台自动扫描。详细的工具栏 - 查看后台发生了什么。活动站点、查看的消息数、更新的消息数、上次查看和更新的消息数、最后添加的 URL、触发的上一个和下一个 CRON 事件、当前保存的消息和 URL...
支持最新版本的WordPress5.3.x+和PHP7.4+
WP Content Crawler 的主要功能是什么?
保存每个帖子的详细信息
标题、摘录、内容、标签、类别、项目符号、日期、自定义元、分类法、元关键字、元描述、特色图片、发布图片、状态......一切。
视觉选择器(视觉检查器)
只需单击一个元素即可找到其 CSS 选择器。您还可以获得可能感兴趣的替代 CSS 选择器。无需再离开管理面板。
获取(获取、获取、保存)帖子
配置好设置后,插件会找到帖子的网址,并在后台自动抓取。
重新抓取(更新)帖子
自动重新抓取帖子以始终保持更新。您可以限制帖子的更新次数,设置更新间隔,以及忽略旧帖子。
删除帖子
您要删除旧的已抓取帖子吗?插件可以自动删除。
控制计划
您可以设置网站每次执行URL采集和抓取事件的次数。例如,您可以每分钟保存 3 个帖子,或者每 2 分钟运行 5 次 URL 采集。
保存类别
你的网站没有目标类别?没问题。该插件可以为您创建目标类别。只需定义用于查找类别名称的 CSS 选择器。它们甚至可以创建为子类别。
保存块(永久链接)
您可以定义帖子的永久链接。您可以从目标站点获取永久链接、输入自定义文本,甚至可以使用短代码为块创建模板。
保存类别
方法通过从目标站点检索或手动输入来保存分类值。保存自定义帖子类型的详细信息比以往更容易。
将帖子保存在自定义类别中
自定义帖子类型是否有自定义类别?没问题。您可以定义自定义帖子类型使用的自定义类别分类,并在定义帖子的类别时选择这些类别。该插件还可以为您创建自定义类别。
自定义帖子元
将任何内容保存为自定义帖子元。您可以使用 CSS 选择器或直接输入值。
内容模板
使用简码准备帖子内容、标题、摘录、列表项和图库项模板。此外,您可以使用选项框为每个 CSS 选择器值定义一个模板。
替代方案
即使目标站点的设计彼此不同,您也可以编写替代选择器来获取数据。
查找和替换任何内容
您可以使用纯文本或正则表达式来查找和替换任何内容。您甚至可以修改页面的 HTML,创建自己的 HTML 元素并编写选择器来使用它们。您甚至可以更改图像 URL。你有权力。
分页帖子
目标帖子有多于一页?不要担心。您还可以保存分页的帖子。
列表类型帖子
网站 创建的一些帖子中有列表。您可以从帖子中提取列表,创建应应用于每个列表项的模板,甚至可以反转列表。
删除不必要的元素
有时你需要去掉一些元素,比如广告、评论,然后给它们命名。只需编写其 CSS 选择器即可将其删除。
自动插入分类网址
目标站点上有数百个类别?一块蛋糕。只需编写 CSS 选择器,插件就会为您插入它们。
帖子类型
设置帖子类型。它可以是 WordPress 安装中可用的帖子、页面、产品或任何其他帖子类型。
删除链接
您可以从帖子中删除链接。只需选中复选框,链接就会消失。就这么简单
密码保护
您可以为帖子设置密码,只向拥有密码的用户显示帖子。
注释
您可以自己添加注释以提醒您有关该站点的信息。 CSS 选择器、TODO 列表等
实时测试所有内容,实时测试
抓取、URL 集合、CSS 选择器、正则表达式、即时查找和替换选项和代理。您还可以启用缓存以更快地执行测试并减少发送到目标站点的请求。
一次
测试网站的所有设置。使用测试器,您可以测试站点设置中配置的所有选项,以确保在启用自动抓取之前一切都按需运行。
工具
使用这些工具,您可以使用帖子的网址手动保存帖子、使用 ID 重新抓取帖子或删除已保存的网址。
为每个站点自定义常规设置
您可以为每个帖子提供自定义的常规设置以覆盖它们并使它们适合网站。
帖子状态
您可以直接发布已保存的帖子,也可以将它们保留为草稿,以便在发布前进行审核。
保存帖子内容中的所有图片 保存帖子内容中的所有图片
就像选中一个复选框一样简单。
将图片另存为图库
您可以将目标页面中的图片保存为图库,并为每张图片提供一个模板,使其适合您在前端使用的图库。您还可以通过选中复选框将图像保存为 WooCommerce 图库。
任何数据作为简码
从目标页面获取任何内容作为简码,并使用插件模板中的简码将任何数据放置在您想要的任何位置。
代理
使用一个或多个代理从您的 IP 无法访问的站点获取内容。
饼干
为每个请求附加一个 cookie(例如会话 cookie)。例如,通过这种方式,您可以像登录时一样抓取目标站点。
尽可能多地抓取帖子
您可以设置帖子抓取或网址采集 CRON 事件应运行的次数。例如,通过这种方式,您每分钟可以保存 100 个帖子。请注意并考虑服务器的容量。
电子邮件通知
设置CSS选择器,其分类和帖子页面的值不能为空。当使用这些选择器发现空值时,您将收到一封电子邮件通知。
从 JSON 中获取数据
当为CSS选择器启用JSON解析时,您可以轻松地从JSON中获取值。
高级 HTML 操作
在响应HTML中查找内容,在元素属性中查找和替换,交换元素属性,删除元素属性,操作元素的HTML,删除HTML元素...
自动翻译
使用 Google Cloud Translation API、Microsoft Translator Text API、Yandex Translate API 或 Amazon Translate API 的人工智能自动翻译帖子。请注意,这些服务是付费服务,Yandex Translate API 除外。付费用户也可以限时免费提供服务。您可以查看其定价页面以了解更多信息。
自动伪原创
使用轮播自动重写已抓取帖子的内容以提高搜索引擎优化。该插件目前实现了收费的 Spin Rewriter API 和 Turkce Spin API。您可以访问他们的网站 了解定价详情。
重复发布检查
按 URL、帖子标题和/或帖子内容检查重复帖子。如果您使用 WooCommerce,SKU 已存在的产品将被视为重复产品,不会添加到您的 网站。
预定的帖子
您可以添加/删除发布日期的分钟数。通过这种方式,您可以安排发布。
保存 WooCommerce 产品
保存价格、库存、运费、属性和高级选项。您可以将产品保存为简单产品或外部产品。您还可以设置可下载文件选项并将产品定义为虚拟产品。这些选项可用于大于或等于 3.3 的 WooCommerce 版本。
选项框
你有控制权!为 CSS 选择器找到的值定义许多选项。选项包括搜索和替换、计算、模板和 JSON 解析设置。您还可以轻松导入/导出选项框中定义的选项。
像专业人士一样处理
文件可轻松重命名、复制和移动保存的文件。您还可以使用模板定义保存的媒体文件的标题、描述、标题和替代文本,其中可以使用任何短代码。您还可以为保存的文件指定随机名称。
专业
WordPress 处理 iframe 和脚本的方式与 WordPress 不允许显示 iframe 和脚本的方式相同,因为它们会带来安全风险。您只需要选中一个复选框即可将 iframe 和 HTML 脚本元素转换为短代码。短代码将显示您定义的允许源域中的 iframe 和脚本。
快速保存
使用快速保存按钮可以更快地保存设置。无需等待页面重新加载。
正则表达式 在 find-replace 选项中定义一个正则表达式来查找任何内容。您还可以使用分隔符和修饰符进行更精确的匹配。
保存“srcset”属性
当其他尺寸的保存图片可用时,插件会将它们分配给 img 元素的 srcset 属性,以便您的页面在不同屏幕尺寸下加载速度更快。
保存“alt”和“title”属性
当您保存图像时,它们的“alt”和“标题”属性会自动从目标站点检索并分配给保存的媒体。您还可以为其定义模板以应用您的 SEO 策略。
警告
了解问题发生的时间。该插件会向您显示错误的详细信息,以便您可以立即修复它。
处理字符编码问题
即使目标站点收录混合编码,插件也可以处理不同的字符编码。您可以通过选中复选框来切换编码。
轻松切换设置
Navigation 将导航固定到顶部!该插件在切换到新标签之前会存储您的位置,并在您再次激活标签时恢复之前的位置。不再在设置之间迷失。
手动抓取工具
使用手动抓取工具通过输入网址来保存多个帖子。您还可以输入类别 URL,以便该工具可以从那里获取帖子 URL。此外,您可以将其设置为同时抓取多个帖子。
添加网址到数据库
插件会自动采集 URL。但是,如果您希望它仅抓取某些 URL,则可以使用手动抓取工具将它们手动添加到数据库中。这样,将使用您的计划选项自动搜索指定的 URL。
启用/禁用特定网站的自动抓取
您可以单独启用或禁用每个站点的自动抓取。
导入/导出
您可以轻松导入和导出网站 设置。只需复制并粘贴插件创建的代码即可。
无限
添加无限站点并激活您想要的站点数量。
详细信息中心
了解背景。活动站点、已爬取的帖子数、已更新的帖子数、上次爬取和更新的帖子、上次添加的 URL、上次和下一次运行的 CRON 事件、当前的帖子和 URL正在保存...
从管理面板获取更新
只要准备好更新,就可以一键更新插件。只需转到管理面板中的更新页面即可。
使用最安全的 PHP
该插件支持最新版本的 PHP。
使用最新的浏览器
该插件支持 Chrome、Firefox、Safari、Opera 和 Edge。
互动指南
交互式指南向您展示如何逐步配置设置以实现某些功能,例如实时文档。您可以随时激活这些指南。您甚至可以从特定步骤开始。
在线文档
您可以在需要时查看在线文档。
设置旁边
中的每个设置
快速指南插件有一个快速指南,可以帮助您了解每个设置的作用。
视频教程
观看视频教程,轻松了解如何使用插件。
要求
PHP> = 7.2、json、mbstring、curl、dom、WP-Cron。这些已经在大多数主机中可用。即使扩展程序尚未激活,大多数托管站点也允许您从其控制面板启用这些扩展程序。有关详细信息,请参阅文档。
WP 版本测试
5.3、5.2、5.1、5.0、4.9
通过 WooCommerce 版本测试
3.9、3.8、3.7、3.6、3.5
本地实测截图预览

WP Content Crawler v1.10.0 完美破解版 – WordPress data采集plugin

WP Content Crawler v1.10.0 完美破解版 – WordPress data采集plugin

WP Content Crawler v1.10.0 完美破解版 – WordPress data采集plugin

WP Content Crawler v1.10.0 完美破解版 – WordPress data采集plugin
链接资源下载资源下载价39元或升级VIP会员后免费
购买后会显示下载地址
文章采集api(如何看出来它是否是动态加载的呢?教大家一个可以肉眼可查 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-09-06 04:30
)
内容
前言
大家好,我叫山年。这是Python爬虫实战案例持续更新的第七天。感觉很多东西不好写,不知道写什么案例。
你可以给我反馈采集你想要哪个网站,或者你需要发布哪些网站函数,或者脚本,或者一些基础知识的解释。
写好文章,拒绝各种表情换人文章,原创干货现在每篇都写了,没那么多时间逗你了。
开始
Target网站:鱼脸的锚
嗯,没想到会有几个男同胞...
我们需要的很简单,采集cover 图片然后进行人脸值检测,然后对检测到的分数进行排序。
分析(x0)
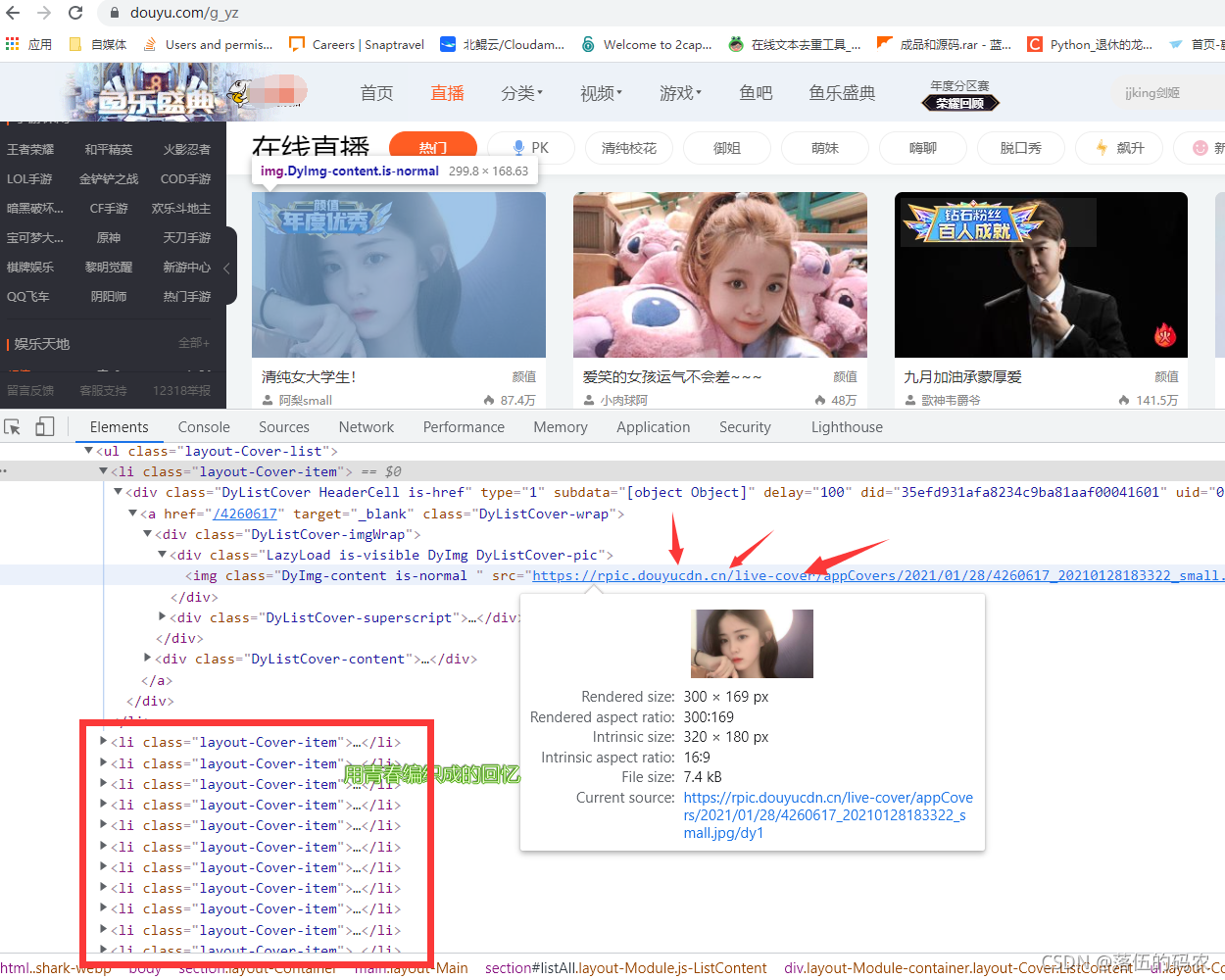
简单看一下网页的元素,可以看到我们需要的图片在li标签的img标签的src属性中。每个 li 标签都收录一个主机的信息。
这样的图片加载我已经讲过很多次了。最有可能是动态加载的,也就是我们拉动滑块的时候,图片会自动刷新,就像之前的【Python】完美采集某宝数据,到底YYDS A和B是哪个? (有完整的源代码和视频教程)是一样的。
那么如何判断它是否是动态加载的呢?
1.教你一个肉眼可以查到的方法,那就是手动快速拉动浏览器的滚动条。你会发现很多图片需要时间来加载。当它们第一次出现时,它是一个白板,然后它们被加载。图片!
2. 即直接查看网页元素。如果是动态加载的,而我们的浏览器还没有向下滑动,则说明下图一定不能加载。
那我们直接检查li标签中是否有我们的图片数据:
显然这张图片格式不同,打不开,是白板图片。
好的,这意味着这又是一个动态加载的网站,那么我们开始抓包吧。
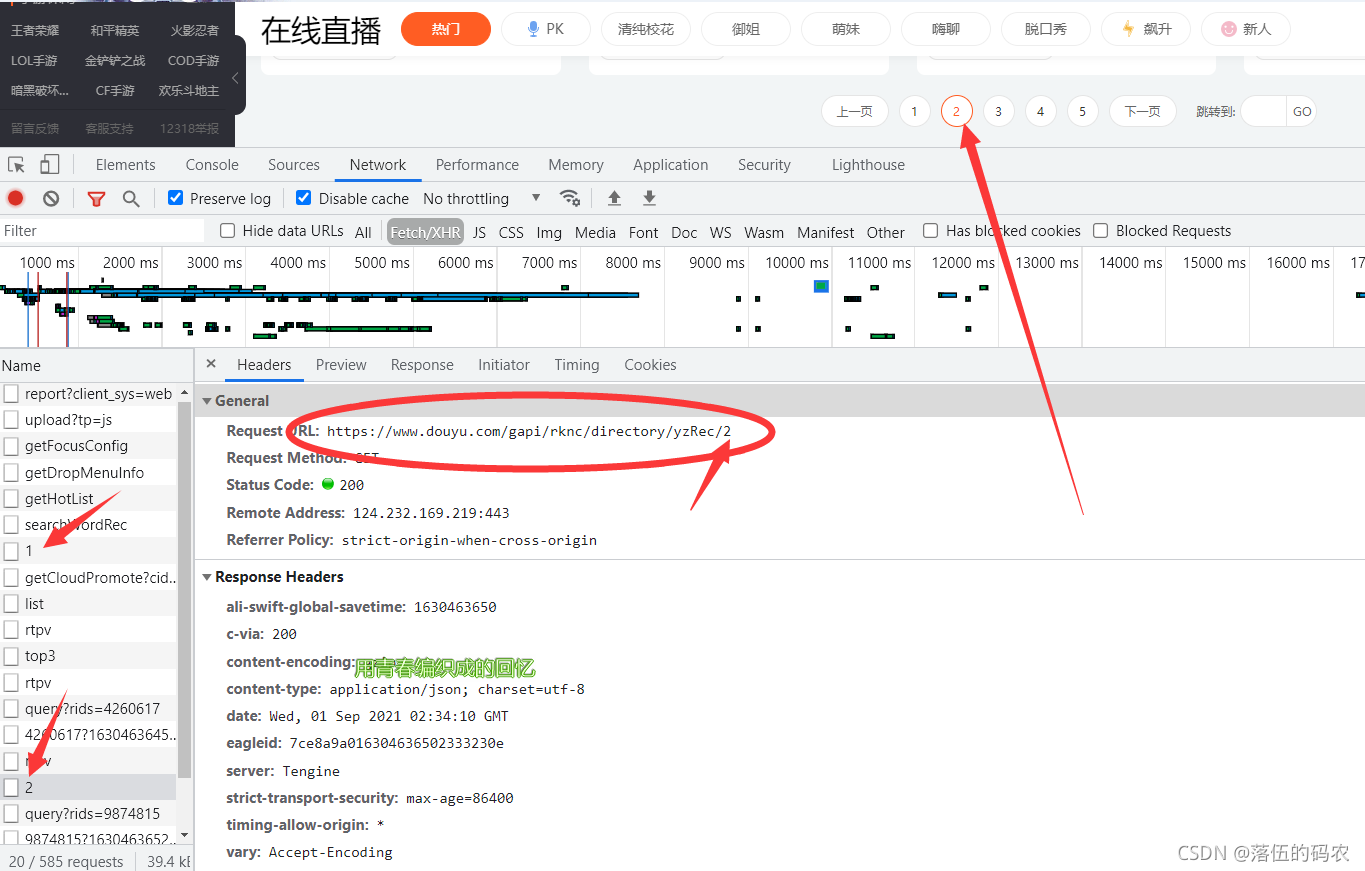
分析(x1)
刷新网页并获取包裹。你可以看到这个东西。它有两张图片,rs1 和 rs6。 rs1是大图,另一个是小图。你可以想到采集。我在这里采集大图。
分析这个请求,它是一个get请求。老实说,我没想到它是一个get,所以它有点特别。我们之前只分析了网页元素。按道理,我们需要的数据也应该在网页源代码中。 ...不过没关系,自己去看看吧,不建议从源码中获取数据。
原因是:你可以看到第二页和第一页的URL没有变化,你注意到了吗?如果从网页的源代码中获取,那么就可以获取到第二页的数据。怎么拿到第一页?所以不要从网页的源代码中提取数据。我们没有办法构造url。
如果你是一个包,分析起来很容易。你只需要把url后面的1改成2就可以成为第二页了。你还有这样的热情吗?我不相信只是抢包裹。
是的,如果您有多个采集页面,只需构建网址即可。
采集 的 Python 代码
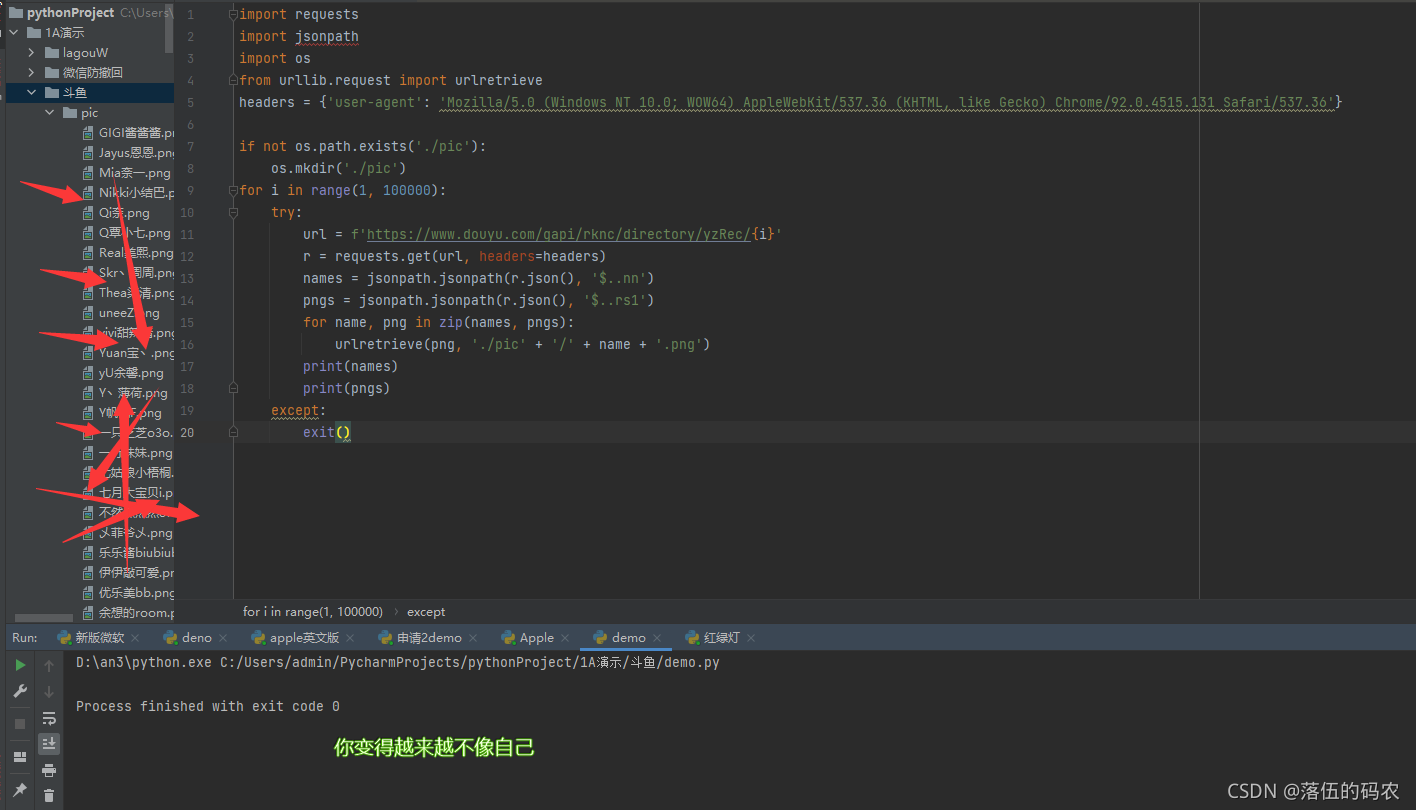
import requests
import jsonpath
import os
from urllib.request import urlretrieve
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'}
if not os.path.exists('./pic'):
os.mkdir('./pic')
for i in range(1, 100000):
try:
url = f'https://www.douyu.com/gapi/rknc/directory/yzRec/{i}'
r = requests.get(url, headers=headers)
names = jsonpath.jsonpath(r.json(), '$..nn')
pngs = jsonpath.jsonpath(r.json(), '$..rs1')
for name, png in zip(names, pngs):
urlretrieve(png, './pic' + '/' + name + '.png')
print(names)
print(pngs)
except:
exit()
采集的效果
人脸值检测函数的结构
注册百度只能云:地址
根据图片选择我们需要的服务:
自己查看技术文档:
点击立即使用-创建应用程序:
正常填写即可
创建后,点击管理应用
获取 API Key 和 Secret Key
看技术文档,不用过多解释就开始构建我们的函数
提醒:模块安装
pip install baidu-aip
facerg.py
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2019/5/7 23:20
# @Author : 善念
# @Software: PyCharm
from aip import AipFace
import base64
def face_rg(file_Path):
""" 你的 api_id AK SK """
api_id = '你的id'
api_key = 'ni de aipkey'
secret_key = '你自己的key'
client = AipFace(api_id, api_key, secret_key)
with open(file_Path, 'rb') as fp:
data = base64.b64encode(fp.read())
image = data.decode()
imageType = "BASE64"
options = {}
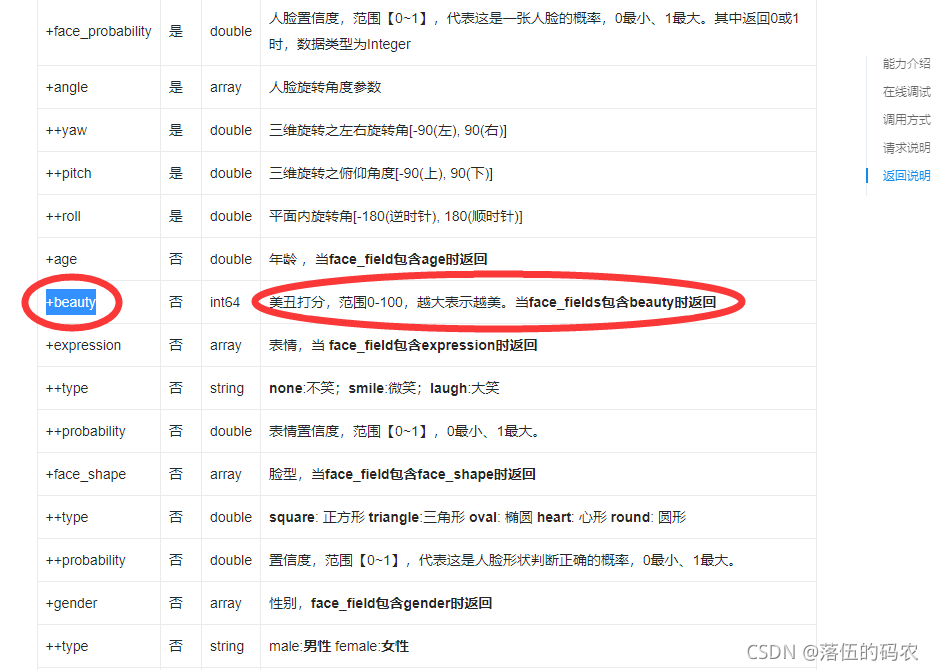
options["face_field"] = 'beauty'
""" 调用人脸检测 """
res = client.detect(image, imageType, options)
score = res['result']['face_list'][0]['beauty']
return score
排序源代码
from facerg import face_rg
path = r'图片文件夹路径'
images = os.listdir(path)
print(images)
yz = []
yz_dict = {}
for image in images:
try:
name = image[0:-4]
score = face_rg(path + '\\' + image)
yz_dict[score] = name
yz.append(score)
except:
pass
yz.sort(reverse=True)
for a, b in enumerate(yz):
print('小姐姐的名字是:{}丨颜值名次是:第{}名丨她的颜值分数为:{}'.format(yz_dict[b], a+1, b))
结果展示
完成所有源代码
import requests
import jsonpath
import os
from urllib.request import urlretrieve
# headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'}
#
# if not os.path.exists('./pic'):
# os.mkdir('./pic')
# for i in range(1, 100000):
# try:
# url = f'https://www.douyu.com/gapi/rknc/directory/yzRec/{i}'
# r = requests.get(url, headers=headers)
# names = jsonpath.jsonpath(r.json(), '$..nn')
# pngs = jsonpath.jsonpath(r.json(), '$..rs1')
# for name, png in zip(names, pngs):
# urlretrieve(png, './pic' + '/' + name + '.png')
# print(names)
# print(pngs)
# except:
# exit()
from facerg import face_rg
path = r'C:\Users\admin\PycharmProjects\pythonProject\1A演示\斗鱼\pic'
images = os.listdir(path)
print(images)
yz = []
yz_dict = {}
for image in images:
try:
name = image[0:-4]
score = face_rg(path + '\\' + image)
yz_dict[score] = name
yz.append(score)
except:
pass
yz.sort(reverse=True)
for a, b in enumerate(yz):
print('小姐姐的名字是:{}丨颜值名次是:第{}名丨她的颜值分数为:{}'.format(yz_dict[b], a+1, b))
只需将 facerg.py 作为自写模块调用即可。
视频教程地址
程序员相亲:一张Python老大采集相亲网的合影,打造排行榜!
我有话要说
——当你毫无保留地信任一个人时,最终只会有两种结果。不是生活中的那个人,也不是生活中的一课。
文章的话现在就写好了,每一个文章我都会说的很详细,所以需要很长时间,通常两个多小时。每一个赞和评论集都是我每天更新的动力。
原创不易,再次感谢您的支持。
①2000多本Python电子书(主流经典书籍应有)
②Python标准库资料(最全中文版)
③项目源码(四十或五十个有趣经典的动手项目及源码)
④Python基础、爬虫、Web开发、大数据分析视频(适合小白学习)
⑤ Python 学习路线图(告别不受影响的学习)
在我的Q.,Q技术交流群可以自己拿走。如果在学习或工作中遇到问题,群里会有大神帮忙解答。有时你会想一天。编号928946953。
查看全部
文章采集api(如何看出来它是否是动态加载的呢?教大家一个可以肉眼可查
)
内容
前言
大家好,我叫山年。这是Python爬虫实战案例持续更新的第七天。感觉很多东西不好写,不知道写什么案例。
你可以给我反馈采集你想要哪个网站,或者你需要发布哪些网站函数,或者脚本,或者一些基础知识的解释。
写好文章,拒绝各种表情换人文章,原创干货现在每篇都写了,没那么多时间逗你了。
开始
Target网站:鱼脸的锚
嗯,没想到会有几个男同胞...
我们需要的很简单,采集cover 图片然后进行人脸值检测,然后对检测到的分数进行排序。
分析(x0)
简单看一下网页的元素,可以看到我们需要的图片在li标签的img标签的src属性中。每个 li 标签都收录一个主机的信息。
这样的图片加载我已经讲过很多次了。最有可能是动态加载的,也就是我们拉动滑块的时候,图片会自动刷新,就像之前的【Python】完美采集某宝数据,到底YYDS A和B是哪个? (有完整的源代码和视频教程)是一样的。
那么如何判断它是否是动态加载的呢?
1.教你一个肉眼可以查到的方法,那就是手动快速拉动浏览器的滚动条。你会发现很多图片需要时间来加载。当它们第一次出现时,它是一个白板,然后它们被加载。图片!
2. 即直接查看网页元素。如果是动态加载的,而我们的浏览器还没有向下滑动,则说明下图一定不能加载。
那我们直接检查li标签中是否有我们的图片数据:
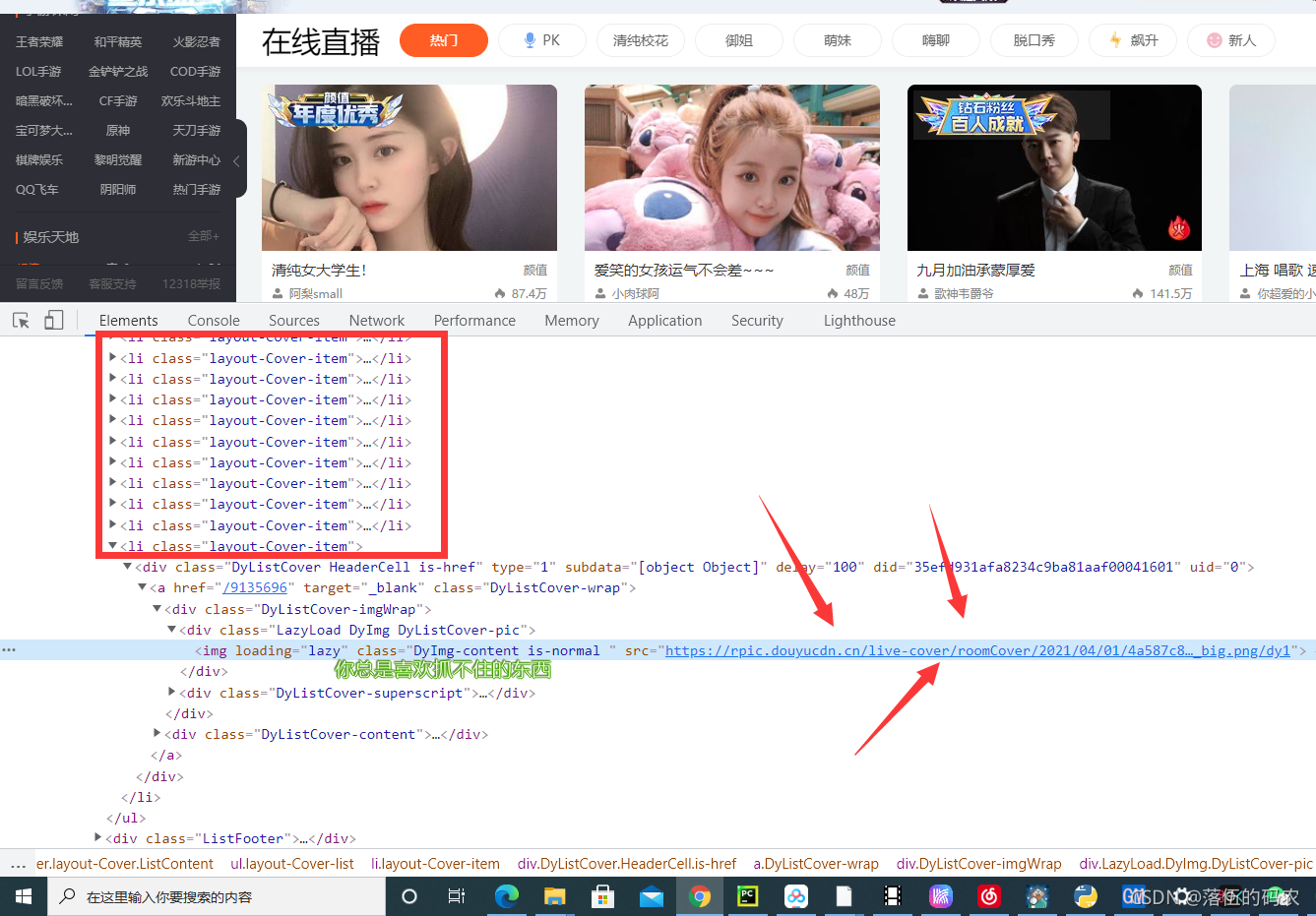
显然这张图片格式不同,打不开,是白板图片。
好的,这意味着这又是一个动态加载的网站,那么我们开始抓包吧。
分析(x1)
刷新网页并获取包裹。你可以看到这个东西。它有两张图片,rs1 和 rs6。 rs1是大图,另一个是小图。你可以想到采集。我在这里采集大图。
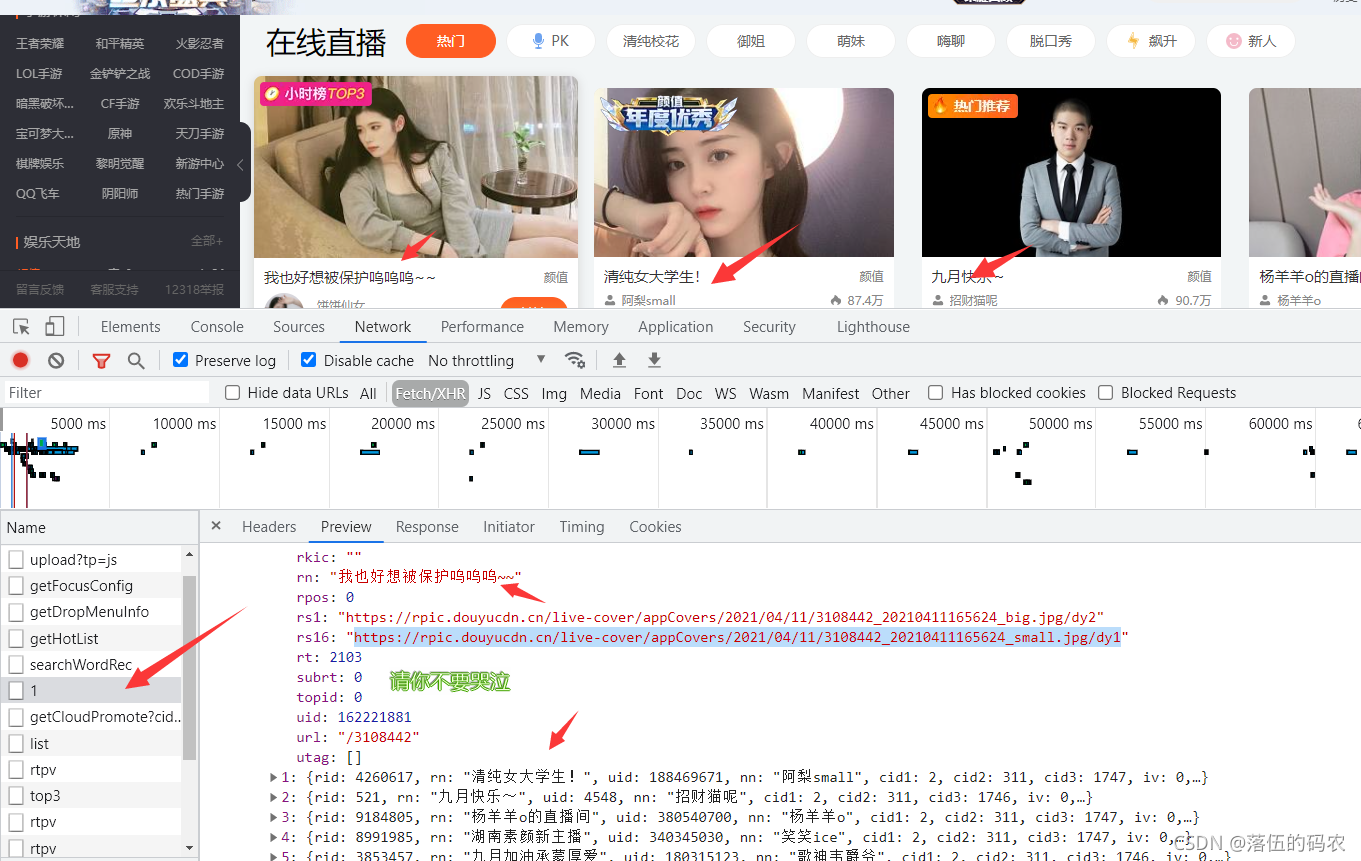
分析这个请求,它是一个get请求。老实说,我没想到它是一个get,所以它有点特别。我们之前只分析了网页元素。按道理,我们需要的数据也应该在网页源代码中。 ...不过没关系,自己去看看吧,不建议从源码中获取数据。
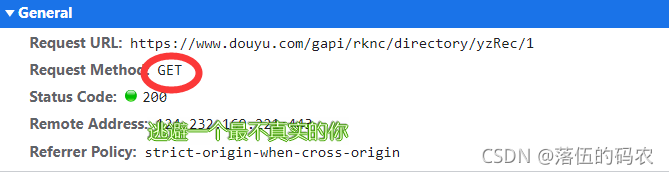
原因是:你可以看到第二页和第一页的URL没有变化,你注意到了吗?如果从网页的源代码中获取,那么就可以获取到第二页的数据。怎么拿到第一页?所以不要从网页的源代码中提取数据。我们没有办法构造url。
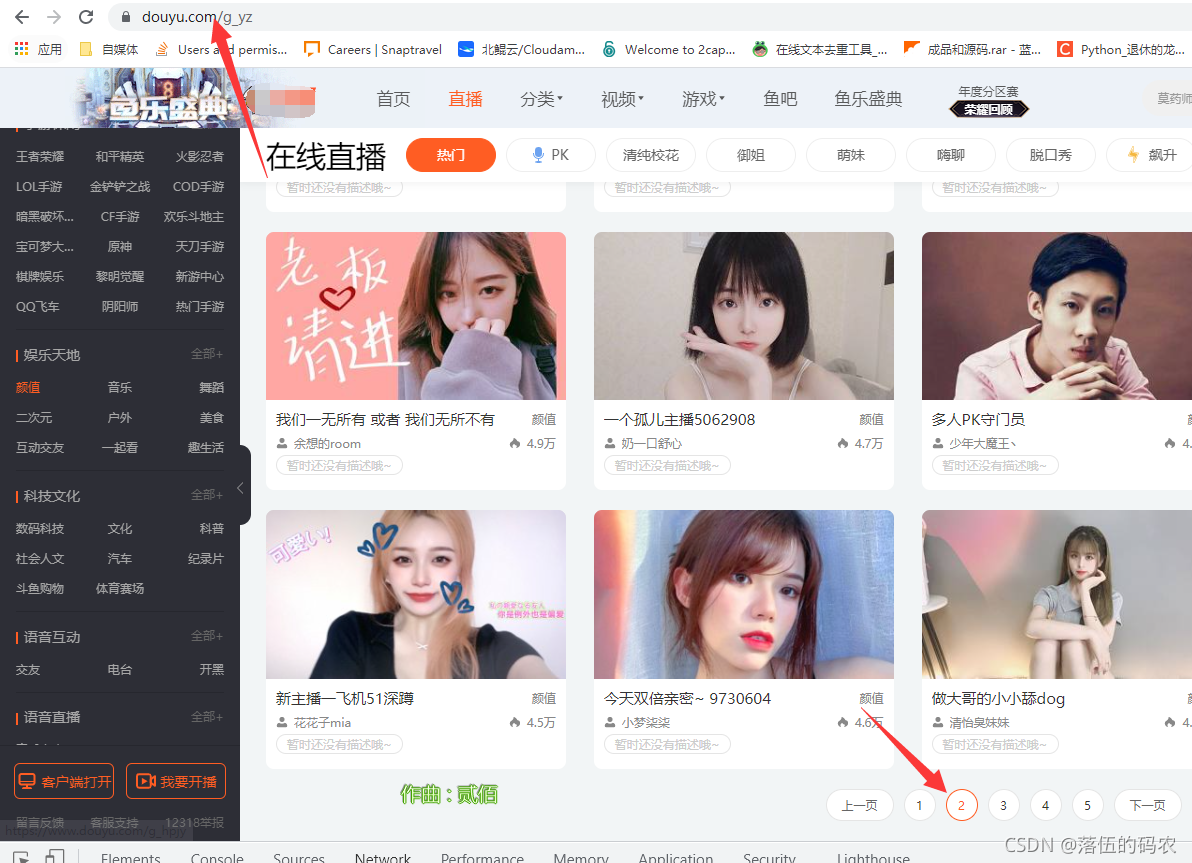
如果你是一个包,分析起来很容易。你只需要把url后面的1改成2就可以成为第二页了。你还有这样的热情吗?我不相信只是抢包裹。
是的,如果您有多个采集页面,只需构建网址即可。
采集 的 Python 代码
import requests
import jsonpath
import os
from urllib.request import urlretrieve
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'}
if not os.path.exists('./pic'):
os.mkdir('./pic')
for i in range(1, 100000):
try:
url = f'https://www.douyu.com/gapi/rknc/directory/yzRec/{i}'
r = requests.get(url, headers=headers)
names = jsonpath.jsonpath(r.json(), '$..nn')
pngs = jsonpath.jsonpath(r.json(), '$..rs1')
for name, png in zip(names, pngs):
urlretrieve(png, './pic' + '/' + name + '.png')
print(names)
print(pngs)
except:
exit()
采集的效果
人脸值检测函数的结构
注册百度只能云:地址
根据图片选择我们需要的服务:
自己查看技术文档:
点击立即使用-创建应用程序:
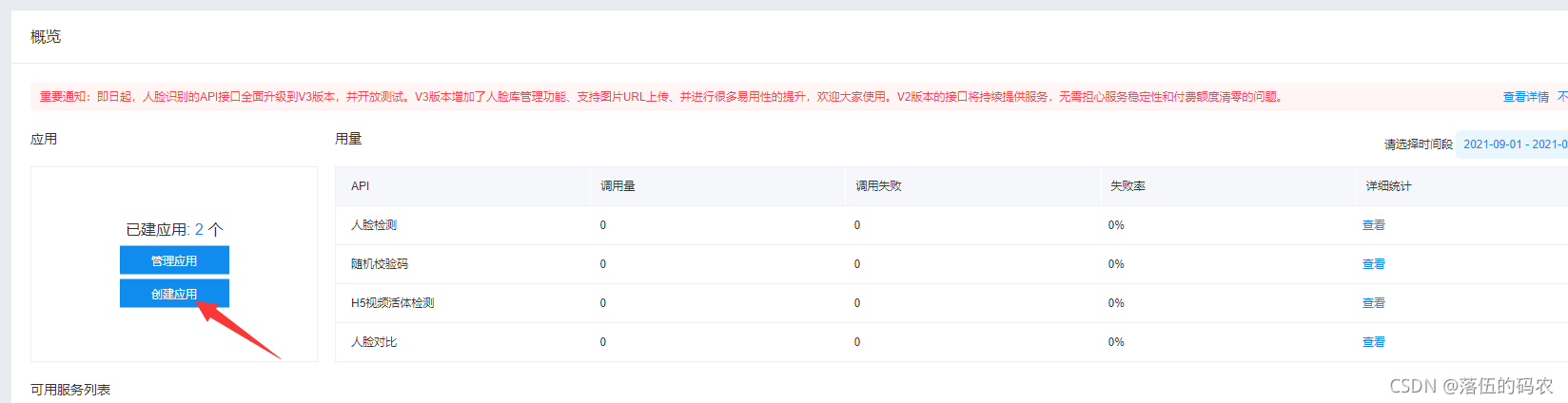
正常填写即可
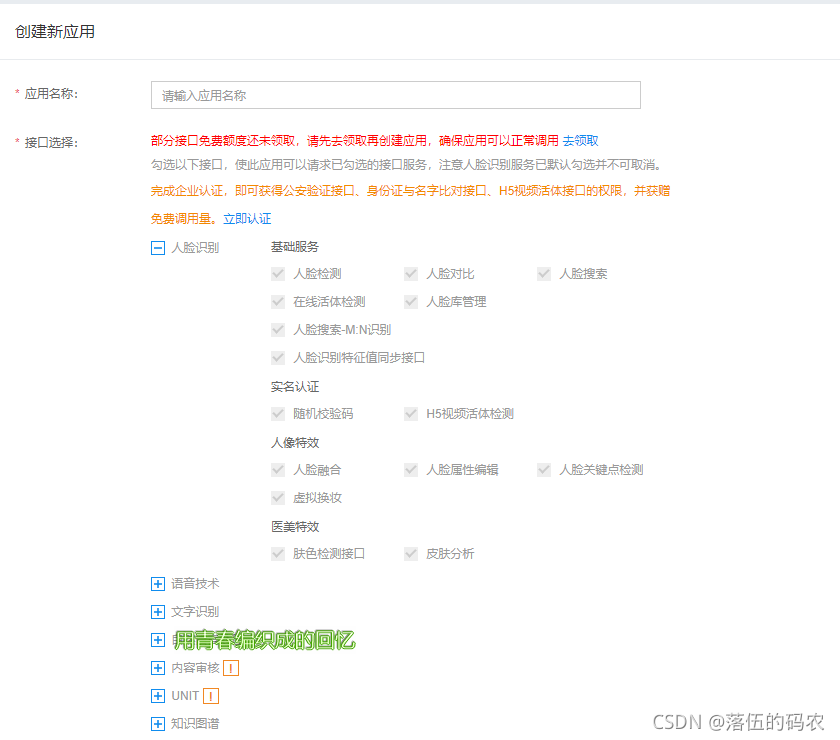
创建后,点击管理应用
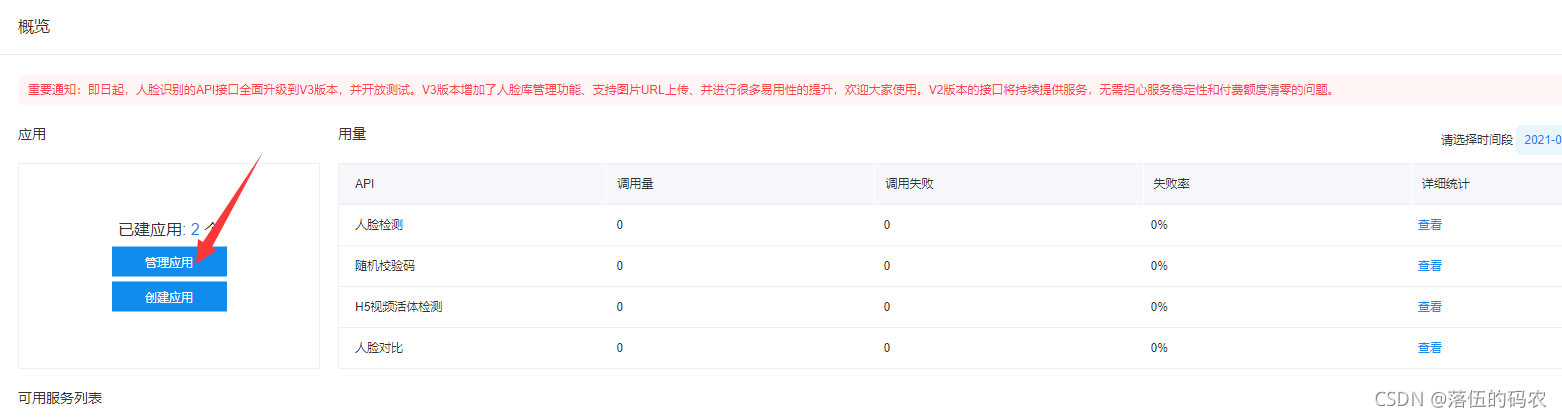
获取 API Key 和 Secret Key

看技术文档,不用过多解释就开始构建我们的函数
提醒:模块安装
pip install baidu-aip
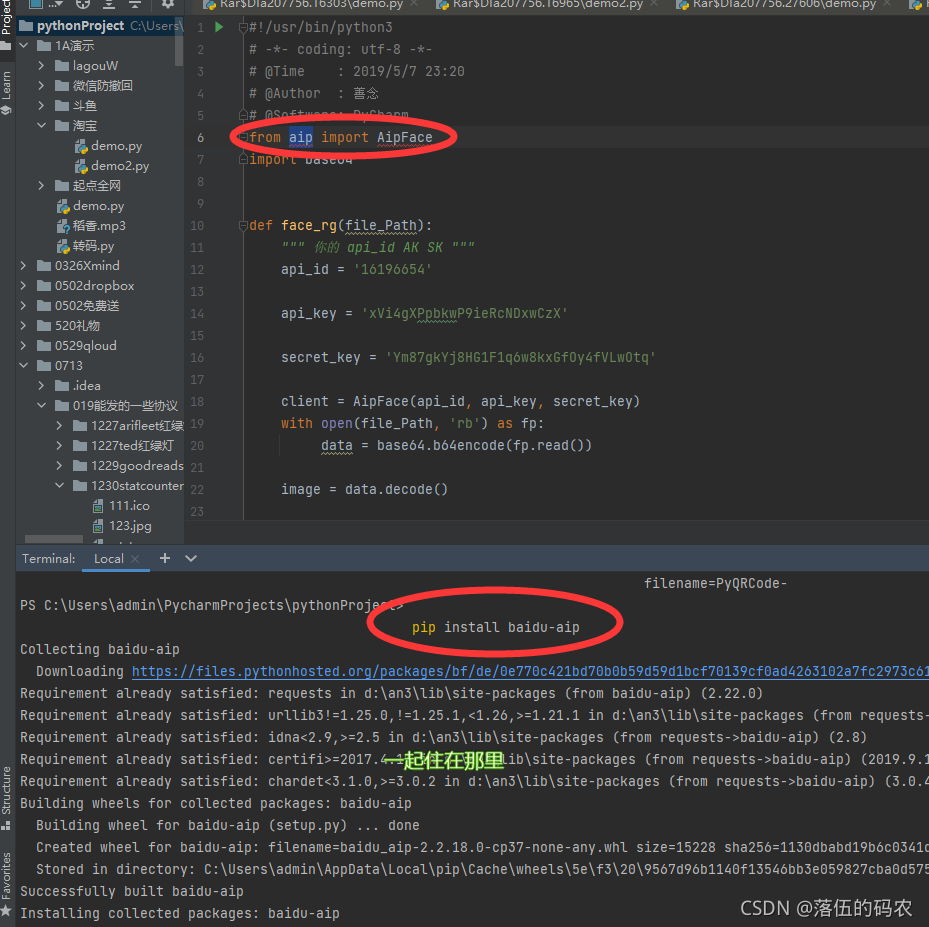
facerg.py
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2019/5/7 23:20
# @Author : 善念
# @Software: PyCharm
from aip import AipFace
import base64
def face_rg(file_Path):
""" 你的 api_id AK SK """
api_id = '你的id'
api_key = 'ni de aipkey'
secret_key = '你自己的key'
client = AipFace(api_id, api_key, secret_key)
with open(file_Path, 'rb') as fp:
data = base64.b64encode(fp.read())
image = data.decode()
imageType = "BASE64"
options = {}
options["face_field"] = 'beauty'
""" 调用人脸检测 """
res = client.detect(image, imageType, options)
score = res['result']['face_list'][0]['beauty']
return score
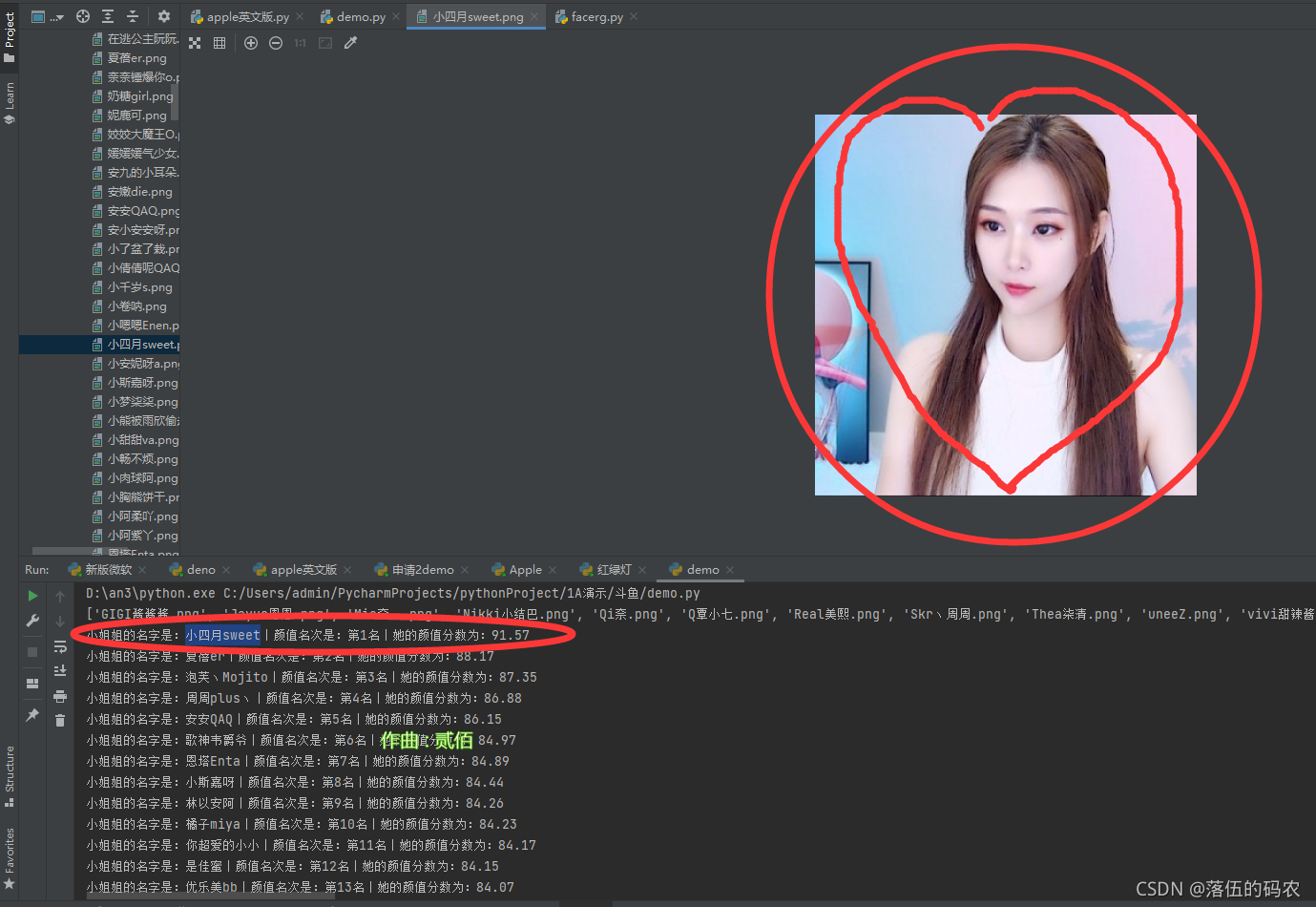
排序源代码
from facerg import face_rg
path = r'图片文件夹路径'
images = os.listdir(path)
print(images)
yz = []
yz_dict = {}
for image in images:
try:
name = image[0:-4]
score = face_rg(path + '\\' + image)
yz_dict[score] = name
yz.append(score)
except:
pass
yz.sort(reverse=True)
for a, b in enumerate(yz):
print('小姐姐的名字是:{}丨颜值名次是:第{}名丨她的颜值分数为:{}'.format(yz_dict[b], a+1, b))
结果展示
完成所有源代码
import requests
import jsonpath
import os
from urllib.request import urlretrieve
# headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'}
#
# if not os.path.exists('./pic'):
# os.mkdir('./pic')
# for i in range(1, 100000):
# try:
# url = f'https://www.douyu.com/gapi/rknc/directory/yzRec/{i}'
# r = requests.get(url, headers=headers)
# names = jsonpath.jsonpath(r.json(), '$..nn')
# pngs = jsonpath.jsonpath(r.json(), '$..rs1')
# for name, png in zip(names, pngs):
# urlretrieve(png, './pic' + '/' + name + '.png')
# print(names)
# print(pngs)
# except:
# exit()
from facerg import face_rg
path = r'C:\Users\admin\PycharmProjects\pythonProject\1A演示\斗鱼\pic'
images = os.listdir(path)
print(images)
yz = []
yz_dict = {}
for image in images:
try:
name = image[0:-4]
score = face_rg(path + '\\' + image)
yz_dict[score] = name
yz.append(score)
except:
pass
yz.sort(reverse=True)
for a, b in enumerate(yz):
print('小姐姐的名字是:{}丨颜值名次是:第{}名丨她的颜值分数为:{}'.format(yz_dict[b], a+1, b))
只需将 facerg.py 作为自写模块调用即可。
视频教程地址
程序员相亲:一张Python老大采集相亲网的合影,打造排行榜!
我有话要说
——当你毫无保留地信任一个人时,最终只会有两种结果。不是生活中的那个人,也不是生活中的一课。
文章的话现在就写好了,每一个文章我都会说的很详细,所以需要很长时间,通常两个多小时。每一个赞和评论集都是我每天更新的动力。
原创不易,再次感谢您的支持。
①2000多本Python电子书(主流经典书籍应有)
②Python标准库资料(最全中文版)
③项目源码(四十或五十个有趣经典的动手项目及源码)
④Python基础、爬虫、Web开发、大数据分析视频(适合小白学习)
⑤ Python 学习路线图(告别不受影响的学习)
在我的Q.,Q技术交流群可以自己拿走。如果在学习或工作中遇到问题,群里会有大神帮忙解答。有时你会想一天。编号928946953。

文章采集api(优采云采集支持调用5118一键智能改写API接口(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2021-09-04 20:19
)
优采云采集支持调用5118一键智能重写API接口,处理采集数据标题和内容等,可以产生对搜索引擎更有吸引力的文章;
具体步骤如下:
1.5118 一键智能换字API接口配置
我。 API配置入口:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》点击【第三方API配置管理】==》最后点击[+5118 一键智能原创API]创建接口配置;
二。配置API接口信息:
【API-Key值】是从5118后台获取对应的5118一键智能重写APIKey值,填写优采云;
2. 创建 API 处理规则
API处理规则,可设置调用API接口处理哪些字段的内容;
我。 API 处理规则条目:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》进入【API处理规则管理】页面,最后点击【添加API处理规则】创建API处理规则;
二、API处理规则配置:
规则名称:用户可以自己命名;
字段名:填写的字段名的内容会被API接口处理。默认为title和content字段,可以修改、添加或删除; (可以添加其他字段,点击添加内容字段,修改字段名称,但必须在[Detail Extractor]中定义,如作者、关键字、描述字段)
API used:选择已经设置好的API接口配置,执行时会调用该接口,不同的API接口配置可以选择多个字段。 5118一键智能改写;
处理顺序:执行顺序是按照数量从小到大执行;
3. API 处理规则使用
API处理规则的使用方式有两种:手动执行和自动执行:
手动执行:数据采集后,在【Result Data & Release】中使用第三方API执行;
自动执行:配置自动化后,任务采集data完成后,系统会自动执行指定的API处理规则,无需人工操作。
我。手动执行 API 处理规则:
点击采集任务的【结果&发布】选项卡中的【SEO&API&翻译工具】按钮==》选择【第三方API执行】栏==》选择对应的API处理规则==》执行(数据范围有两种执行方式,根据发布状态批量执行和根据列表中选择的数据执行);
二。自动执行 API 处理规则:
启用 API 处理的自动执行。任务完成采集后,会自动执行API处理。一般搭配定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡中,【自动执行第三方API配置】==》勾选【采集,自动执行API】选项==》选择要执行的API处理规则==》选择API接口处理的数据范围(一般选择“待发布”,都会导致所有数据被多次执行),最后点击保存;
4.API处理结果及发布 I,查看API接口处理结果:
API接口处理的内容会生成API接口对应的新字段,如:
标题处理后添加字段:
title_5118 rewrite(对应5118一键智能重写API接口)
内容处理后添加字段:
content_5118 rewrite(对应5118一键智能重写API接口)
在【结果数据&发布】和数据预览界面均可查看。
提醒:API处理规则执行需要一段时间,执行后页面会自动刷新,API接口处理的新字段会出现;
二后内容发布,API接口处理
发布文章前,修改发布目标第二步的映射字段,API接口处理后将title和content改成新的对应字段。
例如执行5118一键智能改词API后,选择title_5118改词和content_5118改词发布;
5.5118-API接口常见问题及解决方案 我,API处理规则和SEO规则如何搭配使用?
系统默认对title和content字段进行SEO功能,需要在SEO规则中修改对应新增的字段,如title_5118换词和content_5118换词字段;
查看全部
文章采集api(优采云采集支持调用5118一键智能改写API接口(组图)
)
优采云采集支持调用5118一键智能重写API接口,处理采集数据标题和内容等,可以产生对搜索引擎更有吸引力的文章;
具体步骤如下:
1.5118 一键智能换字API接口配置
我。 API配置入口:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》点击【第三方API配置管理】==》最后点击[+5118 一键智能原创API]创建接口配置;

二。配置API接口信息:
【API-Key值】是从5118后台获取对应的5118一键智能重写APIKey值,填写优采云;
2. 创建 API 处理规则
API处理规则,可设置调用API接口处理哪些字段的内容;
我。 API 处理规则条目:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》进入【API处理规则管理】页面,最后点击【添加API处理规则】创建API处理规则;
二、API处理规则配置:
规则名称:用户可以自己命名;
字段名:填写的字段名的内容会被API接口处理。默认为title和content字段,可以修改、添加或删除; (可以添加其他字段,点击添加内容字段,修改字段名称,但必须在[Detail Extractor]中定义,如作者、关键字、描述字段)
API used:选择已经设置好的API接口配置,执行时会调用该接口,不同的API接口配置可以选择多个字段。 5118一键智能改写;
处理顺序:执行顺序是按照数量从小到大执行;
3. API 处理规则使用
API处理规则的使用方式有两种:手动执行和自动执行:
手动执行:数据采集后,在【Result Data & Release】中使用第三方API执行;
自动执行:配置自动化后,任务采集data完成后,系统会自动执行指定的API处理规则,无需人工操作。
我。手动执行 API 处理规则:
点击采集任务的【结果&发布】选项卡中的【SEO&API&翻译工具】按钮==》选择【第三方API执行】栏==》选择对应的API处理规则==》执行(数据范围有两种执行方式,根据发布状态批量执行和根据列表中选择的数据执行);
二。自动执行 API 处理规则:
启用 API 处理的自动执行。任务完成采集后,会自动执行API处理。一般搭配定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡中,【自动执行第三方API配置】==》勾选【采集,自动执行API】选项==》选择要执行的API处理规则==》选择API接口处理的数据范围(一般选择“待发布”,都会导致所有数据被多次执行),最后点击保存;
4.API处理结果及发布 I,查看API接口处理结果:
API接口处理的内容会生成API接口对应的新字段,如:
标题处理后添加字段:
title_5118 rewrite(对应5118一键智能重写API接口)
内容处理后添加字段:
content_5118 rewrite(对应5118一键智能重写API接口)
在【结果数据&发布】和数据预览界面均可查看。
提醒:API处理规则执行需要一段时间,执行后页面会自动刷新,API接口处理的新字段会出现;
二后内容发布,API接口处理
发布文章前,修改发布目标第二步的映射字段,API接口处理后将title和content改成新的对应字段。
例如执行5118一键智能改词API后,选择title_5118改词和content_5118改词发布;
5.5118-API接口常见问题及解决方案 我,API处理规则和SEO规则如何搭配使用?
系统默认对title和content字段进行SEO功能,需要在SEO规则中修改对应新增的字段,如title_5118换词和content_5118换词字段;
文章采集api(destoon采集器最新版采集新闻资讯文章,配套destoon免登陆发布接口)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-09-02 10:17
答:可以使用优采云采集器新版采集新闻资讯文章,支持desoon免费登录发布接口,实现news文章的采集数据。
3、Q:采集软件支持从Excel导入数据吗?批量导入现有数据信息?
答:可以,可以使用优采云采集器按照一定格式批量导入数据,然后批量发布提交到你的网站后台。批量发布和导入数据都是软件操作,可以节省大量的人力和财力。
4、Q:desoon news采集发布免费登录界面有什么特点?
答案:这个采集器完全模拟了dt程序代码的执行流程,以非暴力的方式插入到数据库中,可以实现各种复杂的需求。
目前免登录界面的功能如下:
①,支持远程图片自动保存下载
②,支持将下载图片的第一张图片自动提取为缩略图
③、支持设置release文章review状态
④。支持自定义字段,如作者、点击次数等
⑤、支持自动定时采集release
⑥.支持按需清洗数据格式,去除冗余内容
⑦,支持从Excel导入数据,批量导出到excel或本地文件
⑧、支持今日头条、微信文章等单篇文章采集
⑨,支持批量采集数据库发布前查看编辑
等等等等,这个不方便详述,下载使用即可!
5、Q:这么通用吗,采集器+文章资讯无电讯报讯界面是免费的吗?
答:免费,大家共享同一个版本,采集器持续更新中,文章资讯接口免费提供,请免费联系作者jieling的QQ。
其他采集publishing 接口可以联系和定制。 查看全部
文章采集api(destoon采集器最新版采集新闻资讯文章,配套destoon免登陆发布接口)
答:可以使用优采云采集器新版采集新闻资讯文章,支持desoon免费登录发布接口,实现news文章的采集数据。
3、Q:采集软件支持从Excel导入数据吗?批量导入现有数据信息?
答:可以,可以使用优采云采集器按照一定格式批量导入数据,然后批量发布提交到你的网站后台。批量发布和导入数据都是软件操作,可以节省大量的人力和财力。
4、Q:desoon news采集发布免费登录界面有什么特点?
答案:这个采集器完全模拟了dt程序代码的执行流程,以非暴力的方式插入到数据库中,可以实现各种复杂的需求。
目前免登录界面的功能如下:
①,支持远程图片自动保存下载
②,支持将下载图片的第一张图片自动提取为缩略图
③、支持设置release文章review状态
④。支持自定义字段,如作者、点击次数等
⑤、支持自动定时采集release
⑥.支持按需清洗数据格式,去除冗余内容
⑦,支持从Excel导入数据,批量导出到excel或本地文件
⑧、支持今日头条、微信文章等单篇文章采集
⑨,支持批量采集数据库发布前查看编辑
等等等等,这个不方便详述,下载使用即可!
5、Q:这么通用吗,采集器+文章资讯无电讯报讯界面是免费的吗?
答:免费,大家共享同一个版本,采集器持续更新中,文章资讯接口免费提供,请免费联系作者jieling的QQ。
其他采集publishing 接口可以联系和定制。
文章采集api(JTopCMS站群内容管理系统v3.0更新日志及改进)
采集交流 • 优采云 发表了文章 • 0 个评论 • 220 次浏览 • 2021-09-02 08:18
JTopcms是基于JavaEE标准自主开发的。它是一个开源的内容管理软件(cms),用于管理站群 的内容。可以高效便捷地进行内容编辑、审核、模板制作、用户交互管理和文件、业务文档等资源的维护。性能优良、稳定、安全、易扩展,适用于政府、教育部门、企事业单位建设站群系统。 JTopcms 站群内容管理系统v3.0 更新日志新特性:1)支持集群部署和业务分布式部署2)file发布点增加OSS COS七牛云存储支持3)Department -级权限支持消息和表单分层管理4)高级搜索功能支持扩展字段模糊搜索5)管理员维护内容支持部门管理6)高级搜索支持搜索所有扩展文本字段7)高级搜索支持新闻内容权重排序8)推荐位内容增加扩展字段支持9)增加通用静态分页功能,支持用户扩展模块分页10)优化敏感词自动匹配性能,支持批量导入词汇11)sensitive单词匹配 支持自定义字段文本检查12)采集功能支持采集Attachment13)添加仅限会员登录限制功能14)增加管理员登录时间间隔限制1 5)支持编辑器资源路径一键切换到云地址16)单站点模板多渠道移动端发布,支持一个站点同时发布多种模板类型。 17)相关栏目自动同步内容,可以实现只维护一个主站的内容,其他站点的相关栏目自动同步更新。
18)采集支持自定义字段扩展,加强采集规则,不再局限于新闻类型,支持自定义模型字段建立采集规则。 19)采集支持按发布时间排序,实现与目标采集系统内容的无缝对接。 20)Advanced 搜索支持按时间范围搜索和排序。 21) 加强系统操作日志,记录完整参数。 22)内容编辑功能增加了可编辑的添加时间。 23)站群 节点可以排序。改进1)将编辑器替换为UEditor2),支持站点resources3)的相对路径模式将数据展示图替换为echarts4),提高广告拦截软件5)下广告模块的性能优化模型内容维护页面交互6)修复几个BUGJTopcmsFeatures1.支持集群管理系统支持集群部署,可以任意增减cmsservice节点,根据业务需求独立部署service节点,加强系统容错、并发和扩展能力。 2. 站点支持内容的静态发布。不仅支持html的生成,还可以生成shtml,精准控制页面的本地静态化,最大限度的提高站点的并发访问性能和可维护性。 3.Content 模型自定义支持 支持自定义模型功能,内置完整的字段类型,定义的字段还可以参与联合查询、高级搜索,让您的站点具有高度的扩展性,方便响应各种业务需要。 4.强大且可扩展的权限体系,支持按部门划分的子站点分级管理,下级不能越权,明确权责。
支持粗(菜单级)和细(业务数据)粒度权限控制,可按组织、角色、用户进行授权,有效划分权限范围,可自由伸缩,职责明确。还支持集成二次开发功能5.安全防护能力。系统可自动拦截记录并分析各种非法访问,及时通知站点管理员处理,自动拦截恶意访问者,黑名单系统为您的站点安全保驾护航。 6.Advanced 搜索支持类似百度的高级搜索功能,支持大数据下的快速搜索,可配置,结合自定义模型功能,可以快速创建符合您需求的信息模型搜索。 7.网站群架构支持一套cms产品,可以支持多个站点的部署,由JTopcms管理,但是每个站点在数据和逻辑上完全独立,可以共享数据彼此。为用户提供最大的价值8.implementation网站developer 简单的JTopcms提供了完整的标签系统。用户只需要有html和美术知识储备。在cms标签的帮助下,可以高效地制作它们创建一个可管理的动态站点。 9.灵活的数据组织方式,支持基本的列和主题分类,TAG标签分类,还支持页块碎片管理,自定义推荐位,灵活强大的数据组合方式,满足各种数据组织需求。 10.二次开发高效 JTopcms基于J2EE核心模型自主研发。项目一开始就考虑二次开发支持。新模块的扩展只需要具备Java Web开发基础和SQL能力,即可快速高效上手。以侵入性的方式开发功能。 11. 支持资源发布点 支持自动发布图片、视频文件和静态发布html到各个资源服务器,动静态分离,静态前端访问和动态后端访问独立处理,提高性能和安全性. JTopcms截图相关阅读类似推荐:站长常用源码 查看全部
文章采集api(JTopCMS站群内容管理系统v3.0更新日志及改进)
JTopcms是基于JavaEE标准自主开发的。它是一个开源的内容管理软件(cms),用于管理站群 的内容。可以高效便捷地进行内容编辑、审核、模板制作、用户交互管理和文件、业务文档等资源的维护。性能优良、稳定、安全、易扩展,适用于政府、教育部门、企事业单位建设站群系统。 JTopcms 站群内容管理系统v3.0 更新日志新特性:1)支持集群部署和业务分布式部署2)file发布点增加OSS COS七牛云存储支持3)Department -级权限支持消息和表单分层管理4)高级搜索功能支持扩展字段模糊搜索5)管理员维护内容支持部门管理6)高级搜索支持搜索所有扩展文本字段7)高级搜索支持新闻内容权重排序8)推荐位内容增加扩展字段支持9)增加通用静态分页功能,支持用户扩展模块分页10)优化敏感词自动匹配性能,支持批量导入词汇11)sensitive单词匹配 支持自定义字段文本检查12)采集功能支持采集Attachment13)添加仅限会员登录限制功能14)增加管理员登录时间间隔限制1 5)支持编辑器资源路径一键切换到云地址16)单站点模板多渠道移动端发布,支持一个站点同时发布多种模板类型。 17)相关栏目自动同步内容,可以实现只维护一个主站的内容,其他站点的相关栏目自动同步更新。
18)采集支持自定义字段扩展,加强采集规则,不再局限于新闻类型,支持自定义模型字段建立采集规则。 19)采集支持按发布时间排序,实现与目标采集系统内容的无缝对接。 20)Advanced 搜索支持按时间范围搜索和排序。 21) 加强系统操作日志,记录完整参数。 22)内容编辑功能增加了可编辑的添加时间。 23)站群 节点可以排序。改进1)将编辑器替换为UEditor2),支持站点resources3)的相对路径模式将数据展示图替换为echarts4),提高广告拦截软件5)下广告模块的性能优化模型内容维护页面交互6)修复几个BUGJTopcmsFeatures1.支持集群管理系统支持集群部署,可以任意增减cmsservice节点,根据业务需求独立部署service节点,加强系统容错、并发和扩展能力。 2. 站点支持内容的静态发布。不仅支持html的生成,还可以生成shtml,精准控制页面的本地静态化,最大限度的提高站点的并发访问性能和可维护性。 3.Content 模型自定义支持 支持自定义模型功能,内置完整的字段类型,定义的字段还可以参与联合查询、高级搜索,让您的站点具有高度的扩展性,方便响应各种业务需要。 4.强大且可扩展的权限体系,支持按部门划分的子站点分级管理,下级不能越权,明确权责。
支持粗(菜单级)和细(业务数据)粒度权限控制,可按组织、角色、用户进行授权,有效划分权限范围,可自由伸缩,职责明确。还支持集成二次开发功能5.安全防护能力。系统可自动拦截记录并分析各种非法访问,及时通知站点管理员处理,自动拦截恶意访问者,黑名单系统为您的站点安全保驾护航。 6.Advanced 搜索支持类似百度的高级搜索功能,支持大数据下的快速搜索,可配置,结合自定义模型功能,可以快速创建符合您需求的信息模型搜索。 7.网站群架构支持一套cms产品,可以支持多个站点的部署,由JTopcms管理,但是每个站点在数据和逻辑上完全独立,可以共享数据彼此。为用户提供最大的价值8.implementation网站developer 简单的JTopcms提供了完整的标签系统。用户只需要有html和美术知识储备。在cms标签的帮助下,可以高效地制作它们创建一个可管理的动态站点。 9.灵活的数据组织方式,支持基本的列和主题分类,TAG标签分类,还支持页块碎片管理,自定义推荐位,灵活强大的数据组合方式,满足各种数据组织需求。 10.二次开发高效 JTopcms基于J2EE核心模型自主研发。项目一开始就考虑二次开发支持。新模块的扩展只需要具备Java Web开发基础和SQL能力,即可快速高效上手。以侵入性的方式开发功能。 11. 支持资源发布点 支持自动发布图片、视频文件和静态发布html到各个资源服务器,动静态分离,静态前端访问和动态后端访问独立处理,提高性能和安全性. JTopcms截图相关阅读类似推荐:站长常用源码
文章采集api(优采云伪原创插件api接口代码怎么用伪插件来api)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-08-31 16:08
seo伪原创generator,织梦伪原创plugin,English伪原创哪有
只要你知道如何用中文进行伪原创,就可以使用在线翻译将其翻译成英文。提醒你,在翻译英文的时候,多用几个翻译工具,(如果你不懂英文),然后找懂英文的人帮你看句子是否流畅,然后选择最好的翻译。做网站,一定要注重客户体验。
·优采云伪原创如何使用插件api接口代码
伪原创plugin to api 使用了目前可靠的优采云AI+,一个基于人工智能的伪原创软件,生成的内容原创比较高,有教程1、修改优采云的PHP环境由于优采云采集器内置的PHP环境有问题,需要在使用PHP插件之前修改优采云的PHP环境。修改方法很简单,打开优采云网站采集软件安装目录“System/PHP”,找到要打开的文件,找到如下代码。找到php_去掉前面的分号改成:修改前:;extension=php_修改后:extension=php_即去掉前面的分号“;”并保存,这样优采云数据采集器就可以正常运行这个PHP仿插件了。 2、Plugins 应该放在优采云plugin 目录中。比如我的机器是:D:\优采云采集器V9\Plugins Q:这个插件的主要功能是什么?
答案:优采云 是采集器。 采集之后,如果打开了插件,采集收到的内容会通过插件进行处理,然后保存。我们的插件是伪原创,所以伪原创之后会保存采集的内容。 3、debugging方法 首先按照原方法,首先保证采集规则可以正常运行。然后,在正常运行的基础上,选择伪原创plugin。 查看全部
文章采集api(优采云伪原创插件api接口代码怎么用伪插件来api)
seo伪原创generator,织梦伪原创plugin,English伪原创哪有
只要你知道如何用中文进行伪原创,就可以使用在线翻译将其翻译成英文。提醒你,在翻译英文的时候,多用几个翻译工具,(如果你不懂英文),然后找懂英文的人帮你看句子是否流畅,然后选择最好的翻译。做网站,一定要注重客户体验。
·优采云伪原创如何使用插件api接口代码
伪原创plugin to api 使用了目前可靠的优采云AI+,一个基于人工智能的伪原创软件,生成的内容原创比较高,有教程1、修改优采云的PHP环境由于优采云采集器内置的PHP环境有问题,需要在使用PHP插件之前修改优采云的PHP环境。修改方法很简单,打开优采云网站采集软件安装目录“System/PHP”,找到要打开的文件,找到如下代码。找到php_去掉前面的分号改成:修改前:;extension=php_修改后:extension=php_即去掉前面的分号“;”并保存,这样优采云数据采集器就可以正常运行这个PHP仿插件了。 2、Plugins 应该放在优采云plugin 目录中。比如我的机器是:D:\优采云采集器V9\Plugins Q:这个插件的主要功能是什么?
答案:优采云 是采集器。 采集之后,如果打开了插件,采集收到的内容会通过插件进行处理,然后保存。我们的插件是伪原创,所以伪原创之后会保存采集的内容。 3、debugging方法 首先按照原方法,首先保证采集规则可以正常运行。然后,在正常运行的基础上,选择伪原创plugin。
文章采集api(短视频直播数据采集趋于稳定,可以抽出时间来整理 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 256 次浏览 • 2021-08-30 03:09
)
抖音API接口资料采集教程,初级版,抖音视频搜索,抖音用户搜索,抖音直播间弹幕,抖音评论列表
这段时间一直在处理data采集的问题。目前平台data采集趋于稳定。可以花点时间整理一下最近的成果,顺便介绍一些最近用到的技术。
本文文章biased技术需要读者有一定的技术基础,主要介绍采集数据处理过程中用到的神器mitmproxy,以及平台的一些技术设计。
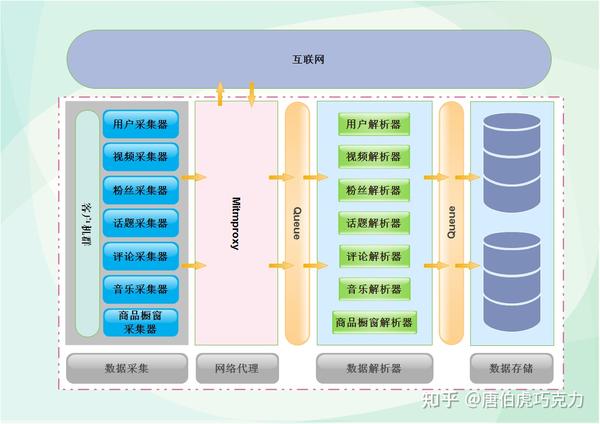
以下是数据采集的整体设计。客户在左边。不同的采集器 放在里面。 采集器发起请求后,通过mitmproxy访问抖音,数据返回后,通过中间的解析器解析数据,最后以不同的类别存储在数据库中。为了提高性能,中间添加了一个缓存,将采集器与解析器分开。两个模块之间的工作互不影响,可以最大限度地将数据存储在数据库中。下图为第一代架构设计。后续文章将介绍平台架构设计的三代演进历史。
短视频直播数据采集interface SDK,请点击查看接口文档
准备工作
开始准备data采集,第一步自然是搭建环境。这次我们在windows环境下使用python3.6.6,抓包代理工具是mitmproxy。使用Fiddler抓包,使用夜神模拟器模拟Android运行环境(也可以使用真机)。这一次,你主要使用手动滑动应用程序来捕获数据。下次我们会介绍Appium自动化工具,实现全数据采集自动(解放双手)。
1、install python3.6.6 环境,安装过程可以自行百度,需要注意的是centos7自带python2.7,需要升级到python3.6.6环境,升级前安装ssl模块,否则升级后的版本无法访问https请求。
2、Install mitmproxy,安装好python环境后,在命令行执行pip install mitmproxy安装mitmproxy。注意:windows下只能使用mitmdump和mitmweb。安装好后在命令行输入mitmdump启动,默认会启动。代理端口为8080。
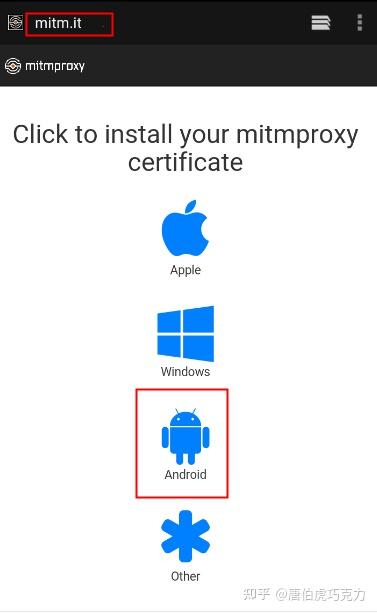
3、安装夜神模拟器,可以到官网下载安装包,安装教程可以百度,基本上下一步。安装夜神模拟器后,需要配置夜神模拟器。首先需要将模拟器的网络设置为手动代理,IP地址为windows的IP,端口为mitmproxy的代理端口。
4、 接下来就是安装证书了。在模拟器中打开浏览器,输入地址mitm.it,选择对应版本的证书。安装完成后就可以抓包了。
5、安装app,app安装包可以从官网下载,然后拖入模拟器安装,或者在app市场安装。至此,本次的采集环境已经完成。
数据接口分析与抓包
环境搭建好后,我们就开始抓取抖音app的数据,分析各个函数使用的接口。本次以采集视频数据接口为例进行介绍。
关闭之前打开的mitmdump,重新打开mitmweb工具,mitmweb是图形版的,不用找黑框,如下图:
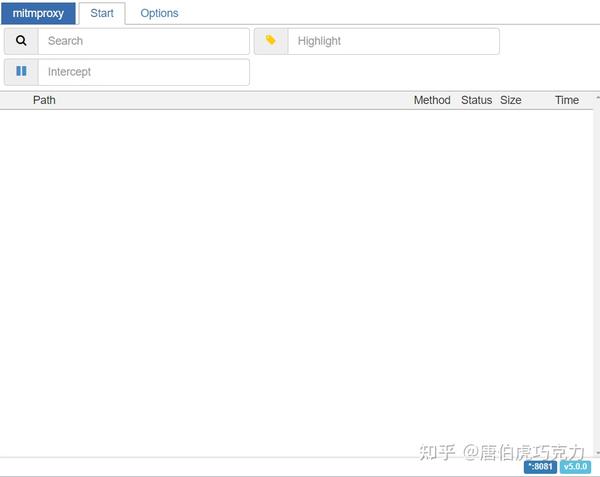
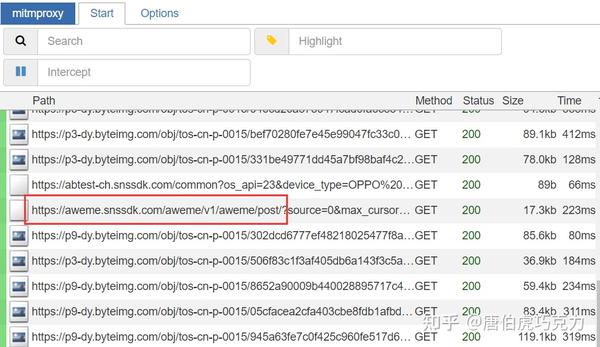
启动后打开模拟器的抖音app,可以看到已经有数据包解析出来了,然后进入用户主页,开始向下滑动视频,可以在里面找到请求视频数据的界面数据包列表
/aweme/v1/aweme/post/
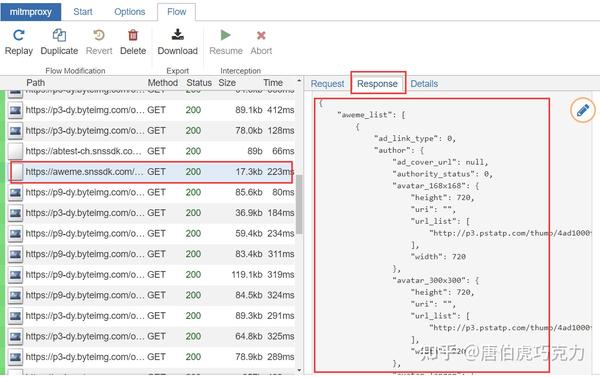
右侧可以看到接口的请求数据和响应数据。我们复制响应数据,进入下一步分析。
数据分析
通过mitmproxy和python代码的结合,我们可以在代码中拿到mitmproxy中的数据包,然后我们就可以根据需要进行处理了。创建一个新的 test.py 文件并在其中放入两个方法:
def request(flow):
pass
def response(flow):
pass
顾名思义,这两种方法,一种在请求时执行,一种在响应时执行,数据包存在于流中。请求url可以通过flow.request.url获取,请求头信息可以通过flow.request.headers获取,flow.response.text中的数据为响应数据。
def response(flow):
if str(flow.request.url).startswith("https://aweme.snssdk.com/aweme/v1/aweme/post/"):
index_response_dict = json.loads(flow.response.text)
aweme_list = index_response_dict.get('aweme_list')
if aweme_list:
for aweme in aweme_list:
print(aweme)
这个aweme是一个完整的视频资料,你可以根据自己的需要提取其中的信息,这里提取一些信息做介绍。
"statistics":{
"aweme_id":"6765058962225204493",
"comment_count":24,
"digg_count":1465,
"download_count":1,
"play_count":0,
"share_count":3,
"forward_count":0,
"lose_count":0,
"lose_comment_count":0
}
统计信息是该视频的点赞、评论、下载、转发等数据。 share_url 是视频的分享地址。通过这个地址可以在PC端观看抖音分享的视频,也可以通过这个链接解析无水印视频。
play_addr 是视频的播放信息。 url_list 是没有水印的地址。但是,官方处理已经完成。这个地址不能直接播放,而且有时间限制。超时后,链接将失效。有了这个aweme,你可以把里面的信息解析出来保存到自己的数据库中,或者下载无水印视频保存到自己的电脑上。
写完代码,保存test.py文件,cmd进入命令行,进入保存test.py文件的目录,在命令行输入mitmdump -s test.py,mitmdump就会启动。此时打开应用程序。开始滑动模拟器,进入用户主页:
开始连续下降,test.py文件可以解析所有捕获的视频数据。以下是我截获的部分数据信息:视频信息:
视频统计:
查看全部
文章采集api(短视频直播数据采集趋于稳定,可以抽出时间来整理
)
抖音API接口资料采集教程,初级版,抖音视频搜索,抖音用户搜索,抖音直播间弹幕,抖音评论列表
这段时间一直在处理data采集的问题。目前平台data采集趋于稳定。可以花点时间整理一下最近的成果,顺便介绍一些最近用到的技术。
本文文章biased技术需要读者有一定的技术基础,主要介绍采集数据处理过程中用到的神器mitmproxy,以及平台的一些技术设计。
以下是数据采集的整体设计。客户在左边。不同的采集器 放在里面。 采集器发起请求后,通过mitmproxy访问抖音,数据返回后,通过中间的解析器解析数据,最后以不同的类别存储在数据库中。为了提高性能,中间添加了一个缓存,将采集器与解析器分开。两个模块之间的工作互不影响,可以最大限度地将数据存储在数据库中。下图为第一代架构设计。后续文章将介绍平台架构设计的三代演进历史。
短视频直播数据采集interface SDK,请点击查看接口文档
准备工作
开始准备data采集,第一步自然是搭建环境。这次我们在windows环境下使用python3.6.6,抓包代理工具是mitmproxy。使用Fiddler抓包,使用夜神模拟器模拟Android运行环境(也可以使用真机)。这一次,你主要使用手动滑动应用程序来捕获数据。下次我们会介绍Appium自动化工具,实现全数据采集自动(解放双手)。
1、install python3.6.6 环境,安装过程可以自行百度,需要注意的是centos7自带python2.7,需要升级到python3.6.6环境,升级前安装ssl模块,否则升级后的版本无法访问https请求。
2、Install mitmproxy,安装好python环境后,在命令行执行pip install mitmproxy安装mitmproxy。注意:windows下只能使用mitmdump和mitmweb。安装好后在命令行输入mitmdump启动,默认会启动。代理端口为8080。
3、安装夜神模拟器,可以到官网下载安装包,安装教程可以百度,基本上下一步。安装夜神模拟器后,需要配置夜神模拟器。首先需要将模拟器的网络设置为手动代理,IP地址为windows的IP,端口为mitmproxy的代理端口。
4、 接下来就是安装证书了。在模拟器中打开浏览器,输入地址mitm.it,选择对应版本的证书。安装完成后就可以抓包了。
5、安装app,app安装包可以从官网下载,然后拖入模拟器安装,或者在app市场安装。至此,本次的采集环境已经完成。
数据接口分析与抓包
环境搭建好后,我们就开始抓取抖音app的数据,分析各个函数使用的接口。本次以采集视频数据接口为例进行介绍。
关闭之前打开的mitmdump,重新打开mitmweb工具,mitmweb是图形版的,不用找黑框,如下图:
启动后打开模拟器的抖音app,可以看到已经有数据包解析出来了,然后进入用户主页,开始向下滑动视频,可以在里面找到请求视频数据的界面数据包列表
/aweme/v1/aweme/post/
右侧可以看到接口的请求数据和响应数据。我们复制响应数据,进入下一步分析。
数据分析
通过mitmproxy和python代码的结合,我们可以在代码中拿到mitmproxy中的数据包,然后我们就可以根据需要进行处理了。创建一个新的 test.py 文件并在其中放入两个方法:
def request(flow):
pass
def response(flow):
pass
顾名思义,这两种方法,一种在请求时执行,一种在响应时执行,数据包存在于流中。请求url可以通过flow.request.url获取,请求头信息可以通过flow.request.headers获取,flow.response.text中的数据为响应数据。
def response(flow):
if str(flow.request.url).startswith("https://aweme.snssdk.com/aweme/v1/aweme/post/";):
index_response_dict = json.loads(flow.response.text)
aweme_list = index_response_dict.get('aweme_list')
if aweme_list:
for aweme in aweme_list:
print(aweme)
这个aweme是一个完整的视频资料,你可以根据自己的需要提取其中的信息,这里提取一些信息做介绍。
"statistics":{
"aweme_id":"6765058962225204493",
"comment_count":24,
"digg_count":1465,
"download_count":1,
"play_count":0,
"share_count":3,
"forward_count":0,
"lose_count":0,
"lose_comment_count":0
}
统计信息是该视频的点赞、评论、下载、转发等数据。 share_url 是视频的分享地址。通过这个地址可以在PC端观看抖音分享的视频,也可以通过这个链接解析无水印视频。
play_addr 是视频的播放信息。 url_list 是没有水印的地址。但是,官方处理已经完成。这个地址不能直接播放,而且有时间限制。超时后,链接将失效。有了这个aweme,你可以把里面的信息解析出来保存到自己的数据库中,或者下载无水印视频保存到自己的电脑上。
写完代码,保存test.py文件,cmd进入命令行,进入保存test.py文件的目录,在命令行输入mitmdump -s test.py,mitmdump就会启动。此时打开应用程序。开始滑动模拟器,进入用户主页:
开始连续下降,test.py文件可以解析所有捕获的视频数据。以下是我截获的部分数据信息:视频信息:
视频统计:
文章采集api(做英文垃圾站用的比较多的WP-AutoPost-pro破解版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-08-29 18:12
<p>wp-autopost-pro 破解版是一款功能强大的wordpress自动采集插件,可以从任何网站内容中采集并自动发布到你的WordPress站点,用户可以使用采集WeChat public号、头条号等自媒体内容,采集流程全自动无需人工干预,轻松获取优质“原创”文章,增加百度收录量和网站权重。 查看全部
文章采集api(做英文垃圾站用的比较多的WP-AutoPost-pro破解版)
<p>wp-autopost-pro 破解版是一款功能强大的wordpress自动采集插件,可以从任何网站内容中采集并自动发布到你的WordPress站点,用户可以使用采集WeChat public号、头条号等自媒体内容,采集流程全自动无需人工干预,轻松获取优质“原创”文章,增加百度收录量和网站权重。
文章采集api(Java开发不会Android囧),二来插件模拟点击网页版 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-08-28 04:08
)
学过微信文章reading和点赞数的同学都知道怎么获取这两个数,关键是获取一个有效的微信key。这个键的有效时间是2小时左右,而且对访问频率也有限制,访问频率可以通过密码控制,速度不会每10秒被封锁一次。接下来,我们来谈谈如何完全自动获取有效密钥。
想必大部分同学都会去手机上钥匙吧。一是不知道怎么做(Java开发不懂Android囧),二是打算直接在PC端实现这个爬虫过程。于是开始研究微信Web客户端。其实这个key很容易获取,转发一个公众号文章到web客户端,从客户端打开就可以看到链接里的key了。
我意识到的想法是:
使用chrome浏览器插件在网页版客户端模拟点击公众号微信文章,获取本链接中key和uin两个参数。通过websocket传递给本机的Java(抓取到时候通过websocket向chrome发送消息,然后返回key和uin)
chrome的插件已经写好了。具体使用步骤是打开你的服务器(启动你的websocket服务器),点击微信图标,插件图标(这一步是连接websocket客户端到服务器)。确保文件转发助手里有公众号文章(任意一个),然后程序就可以调用了。
Java 获取的密钥
现在整个爬取过程都写完了,可以使用了(我的爬取量很小,请研究其他方法。)。我觉得整个爬虫过程中还有一个很重要的点就是获取微信文章的列表(抓到搜狗被屏蔽了...)。因为我有公众号的账号密码,一开始我只是直接从公众号的素材管理里抓取了,但是那是不允许的,一个是上面的时间编辑时间不是发布时间。第二个是文章的mid和sn这两个参数从中抓取的点赞数都是0,阅读数都是2.所以我猜在发布之前,发布之后,有是两组mid和sn。感谢大神,云烟分享了微信查询历史界面(他在手机上抢了包)。反正是http,所以直接用。这边走。就是这样。
调用微信查询历史数据接口获取发布地址文章。每个公众号的biz参数是固定的,可以从链接中获取。只有key和uin才能获得过去一周文章某个公众号。接口地址:
获取文章列表,取出biz、mid、sn、idx等参数,加上key和uin,然后就可以调整界面()获取点赞数和阅读数了。需要说明的是,UA的UA使用的是手机。
查看全部
文章采集api(Java开发不会Android囧),二来插件模拟点击网页版
)
学过微信文章reading和点赞数的同学都知道怎么获取这两个数,关键是获取一个有效的微信key。这个键的有效时间是2小时左右,而且对访问频率也有限制,访问频率可以通过密码控制,速度不会每10秒被封锁一次。接下来,我们来谈谈如何完全自动获取有效密钥。
想必大部分同学都会去手机上钥匙吧。一是不知道怎么做(Java开发不懂Android囧),二是打算直接在PC端实现这个爬虫过程。于是开始研究微信Web客户端。其实这个key很容易获取,转发一个公众号文章到web客户端,从客户端打开就可以看到链接里的key了。
我意识到的想法是:
使用chrome浏览器插件在网页版客户端模拟点击公众号微信文章,获取本链接中key和uin两个参数。通过websocket传递给本机的Java(抓取到时候通过websocket向chrome发送消息,然后返回key和uin)
chrome的插件已经写好了。具体使用步骤是打开你的服务器(启动你的websocket服务器),点击微信图标,插件图标(这一步是连接websocket客户端到服务器)。确保文件转发助手里有公众号文章(任意一个),然后程序就可以调用了。
Java 获取的密钥

现在整个爬取过程都写完了,可以使用了(我的爬取量很小,请研究其他方法。)。我觉得整个爬虫过程中还有一个很重要的点就是获取微信文章的列表(抓到搜狗被屏蔽了...)。因为我有公众号的账号密码,一开始我只是直接从公众号的素材管理里抓取了,但是那是不允许的,一个是上面的时间编辑时间不是发布时间。第二个是文章的mid和sn这两个参数从中抓取的点赞数都是0,阅读数都是2.所以我猜在发布之前,发布之后,有是两组mid和sn。感谢大神,云烟分享了微信查询历史界面(他在手机上抢了包)。反正是http,所以直接用。这边走。就是这样。
调用微信查询历史数据接口获取发布地址文章。每个公众号的biz参数是固定的,可以从链接中获取。只有key和uin才能获得过去一周文章某个公众号。接口地址:

获取文章列表,取出biz、mid、sn、idx等参数,加上key和uin,然后就可以调整界面()获取点赞数和阅读数了。需要说明的是,UA的UA使用的是手机。
哪里有finecms采集接口可以下载?建站时比较纠结
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-08-24 22:15
finecms采集接口在哪里下载?我们在使用finecms建站的时候比较纠结的是怎么采集文章,finecms商城有售采集插件,价格50元,有的朋友感觉比较贵也不太愿意买,权衡了很久也决定买了。有需要的朋友可以联系ytkah了解一下。价格比官方漂亮多了。添加微信咨询
finecms采集接口插件使用方法:联系ytkah咨询下载finecms采集plug-in
1、覆盖到根目录
2、finecms5.wpm 文件是优采云release 模块
3、本采集接口支持所有自定义字段,
data[status]为内容状态,1为待审核,9为通过
xiaazai = 1 下载附件配置,1 表示下载,0 表示不下载
多文件字段发布标签如下:
具有多个文件字段的文件数据[字段名称][文件]
多个文件字段数据的文件标题[字段名称][标题]
多个文件使用[|]作为间隔如下
*.com/file/upload/201609/09/16-26-06-11-362.jpg[|]*.com/file/upload/201609/08/14-23-20-41 -362.jpg[|]*.com/file/upload/201609/09/14-22-42-61-362.jpg
复选框字段如下
数据[字段名称] = [1,2,3]
联动菜单字段为区域。直接写区域名称,比如北京,会自动匹配区域id进入数据库。 查看全部
哪里有finecms采集接口可以下载?建站时比较纠结
finecms采集接口在哪里下载?我们在使用finecms建站的时候比较纠结的是怎么采集文章,finecms商城有售采集插件,价格50元,有的朋友感觉比较贵也不太愿意买,权衡了很久也决定买了。有需要的朋友可以联系ytkah了解一下。价格比官方漂亮多了。添加微信咨询

finecms采集接口插件使用方法:联系ytkah咨询下载finecms采集plug-in
1、覆盖到根目录
2、finecms5.wpm 文件是优采云release 模块
3、本采集接口支持所有自定义字段,
data[status]为内容状态,1为待审核,9为通过
xiaazai = 1 下载附件配置,1 表示下载,0 表示不下载
多文件字段发布标签如下:
具有多个文件字段的文件数据[字段名称][文件]
多个文件字段数据的文件标题[字段名称][标题]
多个文件使用[|]作为间隔如下
*.com/file/upload/201609/09/16-26-06-11-362.jpg[|]*.com/file/upload/201609/08/14-23-20-41 -362.jpg[|]*.com/file/upload/201609/09/14-22-42-61-362.jpg
复选框字段如下
数据[字段名称] = [1,2,3]
联动菜单字段为区域。直接写区域名称,比如北京,会自动匹配区域id进入数据库。
WordPress5.X优采云免登陆发布接口+模块(增强版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-08-22 20:03
WordPress5.X优采云免登陆发布接口+模块(增强版)
WordPress5.X优采云免登录发布界面+模块(增强版)使用说明
适用于优采云采集器7.6-9.6
优化验证标题重复
优化附件、图片、缩略图的上传生成
增加了多种分类方法的发布参数(post_taxonomy_list),使用方法请参考功能特性
修正BUG:如果分类名称收录数字,会导致分类错误。
重新设计老版本发布界面,新版本号为T1,老版本后续不再升级维护。老版本支持3.X-4.8.2
修复BUG:当模块中的某个参数没有在规则中发布时,会导致发布的数据异常(db:标签名会显示)
优化strtoarray函数
特点
1.category(category):
分类支持分类名称和分类ID,系统自动判断
多分类处理(多分类请用逗号隔开)
自动创建一个类别。如果网站中没有这个分类,会自动创建一个分类。
自动创建父类,适用于设置网站中不存在的父类。使用方法:WEB发布模块/高级功能/内容发布参数/->添加post_parent_cate
添加分类描述使用方法:WEB发布模块/高级功能/内容发布参数/->添加category_description
2.标签:
多标签处理(多个标签请用逗号隔开)
3.作者:
多作者处理,可以设置多个作者随机发文章,发帖参数中指定post_author
自定义作者功能,如果提交的数据是用户名,会自动检测系统中是否存在该用户,如果已经存在则以用户身份发布,如果不存在则将自动新建用户(界面以中文用户名为准。处理)
4.图片和缩略图:
网页图片上传,根据主题或网站背景设置自动生成缩略图,并自动将第一张图片设置为文章的特色图片。使用方法:WEB发布模块/高级功能/文件上传设置/->增加图片所在标签,表格名称:福建自增号
自定义缩略图(特色图片) 使用方法:WEB发布模块/高级功能/文件上传设置/添加缩略图所在标签,表单名称:缩略图增量编号
标准的php.ini单次最大文件上传数为20个,如果发布的内容附件超过20个,会报错。如果遇到这个问题,请修改php.ini的max_file_uploads/2018/03参数。或更改上传方式为FTP
5.时间和预约发布:
正确的时间格式是 2017-10-01 23:45:55 或 2017-10-01 23:45
自动处理服务器时间和博客时间的时差
随机排期和排期发布功能:可以设置排期,启用排期排期功能。开启定时发布后,如果POST的数据中收录时间,则立即根据时间发布,否则时间由接口文件Publish配置。
6.评论:
发表评论,支持评论时间、评论作者、评论内容,需要在优采云->网页发布模块/内容发布参数/->添加三个参数,comment、commentdate、commentauthor,与评论对应内容和评论分别时间,评论作者。三个参数缺一不可
7.其他:
判断标题是否重复,在参数配置中打开$checkTitle,可以判断标题是否重复,重复的结果不会发布
发布文章后自动ping,需要后台设置->撰写->更新服务并填写ping地址
‘pending review’更新文章STATUS pending(审查)发布(所有人可见)
使用说明
将 locoy.php 放在 wordpress 网站的根目录下
编辑任务/选择“网络发布配置管理”下的“第3步:发布内容设置”
将“WordPress免登录发布界面.wpm”放入优采云采集器下的“Module”文件夹,参考下图创建web发布配置
回到第三步,选择“添加发布配置”,选择刚才保存的配置文件。
完成以上步骤后,就可以正常发布数据了,可以发布的内容有:
标题、内容(图片和文件可以在这个标签上传)、类别、作者、时间、摘要、缩略图(系统默认会调用内容的第一张图片作为缩略图,这个标签是可选的)”
如果您不需要某些标签,您可以在“内容发布参数”中编辑发布模块并删除它们。
WordPress优采云advanced 免登录界面教程
关于安全配置、多分类、多标签、自定义字段(post_meta)、自定义分类(category)、自定义文章类型(post_type)、自定义文章表单(post_format)、自定义定义分类方法(taxonomy) , 自定义分类信息(add_term_meta)请往下阅读
模块参数列表:
//以下是代码体...
post_title 必填标题
post_contentRequired 内容
标签可选标签
post_category 可选类别
post_date 可选时间
post_excerpt 可选摘要
post_author 可选作者
category_description 可选类别信息
post_cate_meta[name] 可选,自定义分类信息
post_meta[name] 可选自定义字段
post_type 是可选的文章type 默认是‘post’
post_taxonomy 可选的自定义分类方法
post_format 可选文章FORM
参考函数说明:
自定义字段的使用方法:WEB发布模块/高级功能/内容发布参数/->添加post_meta[‘field name’]
自定义文章type(post_type)用法:WEB发布模块/高级功能/内容发布参数/->添加post_type
自定义文章表单(post_format)使用该功能,需要修改配置参数$postformat=true;并且在优采云->Web发布模块/内容发布参数/->新发布参数post_format中,标签内容必须为:Image:post-format-image Video:post-format-video
自定义分类(taxonomy):使用方法:WEB发布模块/高级特性/内容发布参数/ -> 增加post_taxonomy,使用taxonomy后文章只能在taxonomy所属的category下发布,category name or ID 请填写类别
如何使用自定义分类信息(add_term_meta):WEB发布模块/高级功能/内容发布参数/->添加post_cate_meta['meta_key'],标签内容可以是文本或数组,数组必须引用格式:key$$ value|||key$$value|||key$$value
如何同时发布属于多个类别和多个标签的文章?
多类别和多标签必须用逗号分隔。支持name和id两种方法,模块自动判断。例如名称:科幻、动作、动漫 id:1,3,6,2
如何发布自定义字段?
进入发布界面的编辑模式
新建post_meta[]表单,中间的[]是自定义字段的名称
如何配置安全性?
文件会过滤数据,但为了数据安全,建议:
1.更改通信密钥,更改locoy.php文件的第61行“$secretWord = ‘LilySoftware’;” (注意!这个key必须和Web发布配置中的全局变量一致)
2.将文件重命名为更复杂的名称。重命名后需要修改release模块的以下参数以保持一致性
关于文件上传:
1.发布模块/高级功能/在网页上添加标签名称
2.Tag Editing,“File Download”设置如图:
其他自定义的用法与自定义字段类似,只是表单的名称有所改变。一些自定义属性支持数组。
采取打赏、点赞和微博分享
猜你要找
免责声明1. 本站所有资源均来自用户上传和互联网。如有侵权请联系网站客服!
2.所有资源仅供大家学习交流使用。请不要将它们用于商业或非法目的。由此产生的后果与本站无关!
3.如果你有闲置的源码或者教程,可以在个人中心贡献区发布,会有金币奖励和额外收益!
4. 本站提供的源代码、模板、插件等资源不收录技术服务。请原谅我!
5.如出现无法下载、无效或有广告的链接,请联系网站客服!
6.本站资源价格仅为赞助,收取的费用仅用于维持本站日常运营!
7.如果遇到加密压缩包,默认解压密码为“”,如无法解压请联系客服!
8.如遇到支付或充值失败或充值未到,请不要着急,请及时联系网站客服!
65源码网»WordPress5.X优采云免登录发布界面+模块(含优采云采集器7.6版)
常见问题 常见问题
免费下载或VIP会员专属资源可以直接商业化吗?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多说明请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:可以将下载的压缩包容量与网盘容量进行对比。如果小于网盘指示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言,或者联系我们。
在资源介绍文章中找不到示例图片?
对于PPT、KEY、Mockups、APP、网页模板等类型的素材,文章中用于介绍的图片通常不收录在相应的可下载素材包中。这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
65源网
自助共享下载平台
贵宾
分享到: 查看全部
WordPress5.X优采云免登陆发布接口+模块(增强版)

WordPress5.X优采云免登录发布界面+模块(增强版)使用说明
适用于优采云采集器7.6-9.6
优化验证标题重复
优化附件、图片、缩略图的上传生成
增加了多种分类方法的发布参数(post_taxonomy_list),使用方法请参考功能特性
修正BUG:如果分类名称收录数字,会导致分类错误。
重新设计老版本发布界面,新版本号为T1,老版本后续不再升级维护。老版本支持3.X-4.8.2
修复BUG:当模块中的某个参数没有在规则中发布时,会导致发布的数据异常(db:标签名会显示)
优化strtoarray函数
特点
1.category(category):
分类支持分类名称和分类ID,系统自动判断
多分类处理(多分类请用逗号隔开)
自动创建一个类别。如果网站中没有这个分类,会自动创建一个分类。
自动创建父类,适用于设置网站中不存在的父类。使用方法:WEB发布模块/高级功能/内容发布参数/->添加post_parent_cate
添加分类描述使用方法:WEB发布模块/高级功能/内容发布参数/->添加category_description
2.标签:
多标签处理(多个标签请用逗号隔开)
3.作者:
多作者处理,可以设置多个作者随机发文章,发帖参数中指定post_author
自定义作者功能,如果提交的数据是用户名,会自动检测系统中是否存在该用户,如果已经存在则以用户身份发布,如果不存在则将自动新建用户(界面以中文用户名为准。处理)
4.图片和缩略图:
网页图片上传,根据主题或网站背景设置自动生成缩略图,并自动将第一张图片设置为文章的特色图片。使用方法:WEB发布模块/高级功能/文件上传设置/->增加图片所在标签,表格名称:福建自增号
自定义缩略图(特色图片) 使用方法:WEB发布模块/高级功能/文件上传设置/添加缩略图所在标签,表单名称:缩略图增量编号
标准的php.ini单次最大文件上传数为20个,如果发布的内容附件超过20个,会报错。如果遇到这个问题,请修改php.ini的max_file_uploads/2018/03参数。或更改上传方式为FTP
5.时间和预约发布:
正确的时间格式是 2017-10-01 23:45:55 或 2017-10-01 23:45
自动处理服务器时间和博客时间的时差
随机排期和排期发布功能:可以设置排期,启用排期排期功能。开启定时发布后,如果POST的数据中收录时间,则立即根据时间发布,否则时间由接口文件Publish配置。
6.评论:
发表评论,支持评论时间、评论作者、评论内容,需要在优采云->网页发布模块/内容发布参数/->添加三个参数,comment、commentdate、commentauthor,与评论对应内容和评论分别时间,评论作者。三个参数缺一不可
7.其他:
判断标题是否重复,在参数配置中打开$checkTitle,可以判断标题是否重复,重复的结果不会发布
发布文章后自动ping,需要后台设置->撰写->更新服务并填写ping地址
‘pending review’更新文章STATUS pending(审查)发布(所有人可见)
使用说明
将 locoy.php 放在 wordpress 网站的根目录下
编辑任务/选择“网络发布配置管理”下的“第3步:发布内容设置”
 http://www.65ymz.com/wp-conten ... 1.png 600w, http://www.65ymz.com/wp-conten ... 2.png 768w" />
http://www.65ymz.com/wp-conten ... 1.png 600w, http://www.65ymz.com/wp-conten ... 2.png 768w" />将“WordPress免登录发布界面.wpm”放入优采云采集器下的“Module”文件夹,参考下图创建web发布配置
 http://www.65ymz.com/wp-conten ... 6.png 600w" />
http://www.65ymz.com/wp-conten ... 6.png 600w" />回到第三步,选择“添加发布配置”,选择刚才保存的配置文件。
完成以上步骤后,就可以正常发布数据了,可以发布的内容有:
标题、内容(图片和文件可以在这个标签上传)、类别、作者、时间、摘要、缩略图(系统默认会调用内容的第一张图片作为缩略图,这个标签是可选的)”
如果您不需要某些标签,您可以在“内容发布参数”中编辑发布模块并删除它们。
WordPress优采云advanced 免登录界面教程
关于安全配置、多分类、多标签、自定义字段(post_meta)、自定义分类(category)、自定义文章类型(post_type)、自定义文章表单(post_format)、自定义定义分类方法(taxonomy) , 自定义分类信息(add_term_meta)请往下阅读
模块参数列表:
//以下是代码体...
post_title 必填标题
post_contentRequired 内容
标签可选标签
post_category 可选类别
post_date 可选时间
post_excerpt 可选摘要
post_author 可选作者
category_description 可选类别信息
post_cate_meta[name] 可选,自定义分类信息
post_meta[name] 可选自定义字段
post_type 是可选的文章type 默认是‘post’
post_taxonomy 可选的自定义分类方法
post_format 可选文章FORM
参考函数说明:
自定义字段的使用方法:WEB发布模块/高级功能/内容发布参数/->添加post_meta[‘field name’]
自定义文章type(post_type)用法:WEB发布模块/高级功能/内容发布参数/->添加post_type
自定义文章表单(post_format)使用该功能,需要修改配置参数$postformat=true;并且在优采云->Web发布模块/内容发布参数/->新发布参数post_format中,标签内容必须为:Image:post-format-image Video:post-format-video
自定义分类(taxonomy):使用方法:WEB发布模块/高级特性/内容发布参数/ -> 增加post_taxonomy,使用taxonomy后文章只能在taxonomy所属的category下发布,category name or ID 请填写类别
如何使用自定义分类信息(add_term_meta):WEB发布模块/高级功能/内容发布参数/->添加post_cate_meta['meta_key'],标签内容可以是文本或数组,数组必须引用格式:key$$ value|||key$$value|||key$$value
如何同时发布属于多个类别和多个标签的文章?
多类别和多标签必须用逗号分隔。支持name和id两种方法,模块自动判断。例如名称:科幻、动作、动漫 id:1,3,6,2
如何发布自定义字段?
进入发布界面的编辑模式
 http://www.65ymz.com/wp-conten ... 4.png 600w" />
http://www.65ymz.com/wp-conten ... 4.png 600w" />新建post_meta[]表单,中间的[]是自定义字段的名称
如何配置安全性?
文件会过滤数据,但为了数据安全,建议:
1.更改通信密钥,更改locoy.php文件的第61行“$secretWord = ‘LilySoftware’;” (注意!这个key必须和Web发布配置中的全局变量一致)
2.将文件重命名为更复杂的名称。重命名后需要修改release模块的以下参数以保持一致性

关于文件上传:
1.发布模块/高级功能/在网页上添加标签名称

2.Tag Editing,“File Download”设置如图:
 http://www.65ymz.com/wp-conten ... 4.png 600w, http://www.65ymz.com/wp-conten ... 7.png 768w" />
http://www.65ymz.com/wp-conten ... 4.png 600w, http://www.65ymz.com/wp-conten ... 7.png 768w" />其他自定义的用法与自定义字段类似,只是表单的名称有所改变。一些自定义属性支持数组。
采取打赏、点赞和微博分享
猜你要找
免责声明1. 本站所有资源均来自用户上传和互联网。如有侵权请联系网站客服!
2.所有资源仅供大家学习交流使用。请不要将它们用于商业或非法目的。由此产生的后果与本站无关!
3.如果你有闲置的源码或者教程,可以在个人中心贡献区发布,会有金币奖励和额外收益!
4. 本站提供的源代码、模板、插件等资源不收录技术服务。请原谅我!
5.如出现无法下载、无效或有广告的链接,请联系网站客服!
6.本站资源价格仅为赞助,收取的费用仅用于维持本站日常运营!
7.如果遇到加密压缩包,默认解压密码为“”,如无法解压请联系客服!
8.如遇到支付或充值失败或充值未到,请不要着急,请及时联系网站客服!
65源码网»WordPress5.X优采云免登录发布界面+模块(含优采云采集器7.6版)
常见问题 常见问题
免费下载或VIP会员专属资源可以直接商业化吗?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多说明请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:可以将下载的压缩包容量与网盘容量进行对比。如果小于网盘指示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言,或者联系我们。
在资源介绍文章中找不到示例图片?
对于PPT、KEY、Mockups、APP、网页模板等类型的素材,文章中用于介绍的图片通常不收录在相应的可下载素材包中。这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
65源网
自助共享下载平台
贵宾
分享到:
创建LoggingAdmin项目ApiBootLogging项目依赖使用idea(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-08-19 05:25
可以通过ApiBoot Logging获取每个请求的详细信息。在分布式部署模式下,一个请求可能经过多个服务。如果每个服务独立保存请求日志信息,我们是做不到的。统一控制,日志库和业务库会出现不一致(可能会使用多个数据源配置),因为这个问题ApiBoot Logging提供了Admin的概念,客户端采集到每个日志都报给管理员,管理员会分析、保存等操作。
创建日志管理项目
ApiBoot Logging Admin可以汇总各个业务服务的请求日志(ApiBoot Logging),所以我们需要将各个业务服务的日志采集单上报给Admin,所以我们应该使用独立的方式进行部署。创建单独的服务专门采集请求日志然后保存。
初始化日志管理项目依赖
使用idea创建一个SpringBoot项目,pom.xml配置文件中的依赖如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
org.springframework.boot
spring-boot-starter-web
org.minbox.framework
api-boot-starter-logging-admin
mysql
mysql-connector-java
com.zaxxer
HikariCP
org.minbox.framework
api-boot-starter-mybatis-enhance
我们需要将采集收到的请求日志保存到数据库中,所以需要在项目中添加数据库驱动和数据库连接池相关的依赖。 ApiBoot Logging Admin 通过DataSource 操作数据,依赖ApiBoot MyBatis Enhance。可以自动创建DataSource,摆脱手动创建,加入Spring IOC容器。
添加ApiBoot统一版本依赖
1
2
3
4
5
6
7
8
9
10
11
12
org.minbox.framework
api-boot-dependencies
2.1.4.RELEASE
import
pom
最新版本的ApiBoot请访问::api-boot-dependencies查询。
启用日志管理
添加ApiBoot Logging Admin依赖后,无法完全使用Admin功能。我们需要通过@EnableLoggingAdmin 注释来启用它。这个注解会自动将Logging Admin中需要的一些类注册到Spring IOC中,并在入口类中添加注解如下图:
1
2
3
4
5
6
7
8
9
10
11
12
/**
* ApiBoot Logging Admin入口类
*/
@SpringBootApplication
@EnableLoggingAdmin
public class ApibootReportLogsByLoggingToAdminApplication {
public static void main(String[] args) {
SpringApplication.run(ApibootReportLogsByLoggingToAdminApplication.class, args);
}
}
配置日志数据源
application.yml 配置文件中的数据源配置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# 服务名称
spring:
application:
name: apiboot-report-logs-by-logging-to-admin
# 数据源相关配置
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test
username: root
password: 123456
type: com.zaxxer.hikari.HikariDataSource
# 服务端口号
server:
port: 8081
控制台打印报告日志
ApiBoot Logging Admin可以通过配置文件控制是否在控制台打印采集收到的请求日志信息,并在application.yml配置文件中添加如下内容:
1
2
3
4
5
6
7
api:
boot:
logging:
# Logging Admin相关配置
admin:
# 控制台显示采集的日志信息
show-console-report-log: true
注意:这不应与 ApiBoot Logging 提供的 api.boot.logging.show-console-log 配置混淆。
美化控制台打印的报告日志
1
2
3
4
5
6
7
api:
boot:
logging:
# Logging Admin相关配置
admin:
# 控制台输出时美化采集到的日志
format-console-log-json: true
注意:不要与这里的 api.boot.logging.format-console-log-json 配置混淆。
初始化日志表结构
ApiBoot Logging Admin 使用固定的表结构来存储请求日志和服务信息。建表语句如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
SET NAMES utf8mb4 ;
--
-- Table structure for table `logging_request_logs`
--
CREATE TABLE `logging_request_logs` (
`lrl_id` varchar(36) COLLATE utf8mb4_general_ci NOT NULL COMMENT '主键,UUID',
`lrl_service_detail_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '服务详情编号,关联logging_service_details主键',
`lrl_trace_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '链路ID',
`lrl_parent_span_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上级跨度ID',
`lrl_span_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '跨度ID',
`lrl_start_time` mediumtext COLLATE utf8mb4_general_ci COMMENT '请求开始时间',
`lrl_end_time` mediumtext COLLATE utf8mb4_general_ci COMMENT '请求结束时间',
`lrl_http_status` int(11) DEFAULT NULL COMMENT '请求响应状态码',
`lrl_request_body` longtext COLLATE utf8mb4_general_ci COMMENT '请求主体内容',
`lrl_request_headers` text COLLATE utf8mb4_general_ci COMMENT '请求头信息',
`lrl_request_ip` varchar(30) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '发起请求客户端的IP地址',
`lrl_request_method` varchar(10) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '请求方式',
`lrl_request_uri` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '请求路径',
`lrl_response_body` longtext COLLATE utf8mb4_general_ci COMMENT '响应内容',
`lrl_response_headers` text COLLATE utf8mb4_general_ci COMMENT '响应头信息',
`lrl_time_consuming` int(11) DEFAULT NULL COMMENT '请求耗时',
`lrl_create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '日志保存时间',
`lrl_request_params` text COLLATE utf8mb4_general_ci,
`lrl_exception_stack` text COLLATE utf8mb4_general_ci,
PRIMARY KEY (`lrl_id`),
KEY `logging_request_logs_LRL_SERVICE_DETAIL_ID_index` (`lrl_service_detail_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='请求日志信息表';
--
-- Table structure for table `logging_service_details`
--
CREATE TABLE `logging_service_details` (
`lsd_id` varchar(36) COLLATE utf8mb4_general_ci NOT NULL,
`lsd_service_id` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上报服务的ID,对应spring.application.name配置值',
`lsd_service_ip` varchar(50) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上报服务的IP地址',
`lsd_service_port` int(11) DEFAULT NULL COMMENT '上报服务的端口号',
`lsd_last_report_time` timestamp NULL DEFAULT NULL COMMENT '最后一次上报时间,每次上报更新',
`lsd_create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '首次上报时创建时间',
PRIMARY KEY (`lsd_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='上报日志的客户端服务详情';
ApiBoot Logging Admin 到目前为止已经准备就绪。接下来,我们需要修改业务服务以将请求日志报告给 Logging Admin。
向指定的日志管理员报告日志
我们将修改使用ApiBoot Logging统一管理请求日志文章的源码,并将Logging Admin的地址添加到application.yml中,如下图:
1
2
3
4
5
6
7
api:
boot:
# ApiBoot Logging 日志组件配置
logging:
# 配置Logging Admin地址
admin:
server-address: 127.0.0.1:8081
api.boot.logging.admin-service-address 的配置格式是:Ip:Port,我们只需要修改这一个地方,其他的所有任务内部交给ApiBoot Logging。
测试
我们以应用程序的形式启动 ApiBoot 日志管理和业务服务。
使用curl访问测试地址如下:
1
2
~ curl http://localhost:8080/test\?name\=admin
你好:admin
我们检查 ApiBoot Logging 管理控制台日志如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
Receiving Service: 【apiboot-unified-manage-request-logs -> 127.0.0.1】, Request Log Report,Logging Content:[
{
"endTime":1571641723779,
"httpStatus":200,
"requestBody":"",
"requestHeaders":{
"server-region":"JiNan",
"host":"localhost:8080",
"user-agent":"curl/7.64.1",
"accept":"*/*"
},
"requestIp":"0:0:0:0:0:0:0:1",
"requestMethod":"GET",
"requestParam":"{\"name\":\"admin\"}",
"requestUri":"/test",
"responseBody":"你好:admin",
"responseHeaders":{},
"serviceId":"apiboot-unified-manage-request-logs",
"serviceIp":"127.0.0.1",
"servicePort":"8080",
"spanId":"95a73ca0-831b-45df-aa43-2b5887e8d98d",
"startTime":1571641723776,
"timeConsuming":3,
"traceId":"25a7de96-b3dd-48e5-9854-1a8069a4a681"
}
]
我们已经看到了Logging Admin控制台打印的报告请求日志,这个请求的日志是否已经保存到数据库中还不确定。接下来,我将使用命令行查看数据库的日志信息。
查看logging_service_details表中的数据
1
2
3
4
5
6
7
8
mysql> select * from logging_service_details\G;
*************************** 1. row ***************************
lsd_id: b069366a-25dc-41ec-8f09-242d81755cd0
lsd_service_id: apiboot-unified-manage-request-logs
lsd_service_ip: 10.180.98.112
lsd_service_port: 8080
lsd_last_report_time: 2019-10-21 02:14:26
lsd_create_time: 2019-10-21 15:14:26
logging_service_details 存储了每个上报请求日志的业务服务的基本信息。每个服务的基本信息都会缓存在Logging Admin内存中,方便获取service_id用于存储日志,根据ip+port+service_id确定唯一性。同一个服务只保存一次。
查看logging_request_logs表中的数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
mysql> select * from logging_request_logs\G;
*************************** 1. row ***************************
lrl_id: c42761f6-b072-4744-8a17-d8e6097b85de
lrl_service_detail_id: b069366a-25dc-41ec-8f09-242d81755cd0
lrl_trace_id: 055329a0-cfc1-4606-baf0-4fb0cc905ba2
lrl_parent_span_id: NULL
lrl_span_id: aab83092-7749-4f88-8cb6-a949cc060197
lrl_start_time: 1571642065262
lrl_end_time: 1571642065286
lrl_http_status: 200
lrl_request_body:
lrl_request_headers: {"server-region":"JiNan","host":"localhost:8080","user-agent":"curl/7.64.1","accept":"*/*"}
lrl_request_ip: 0:0:0:0:0:0:0:1
lrl_request_method: GET
lrl_request_uri: /test
lrl_response_body: 你好:admin
lrl_response_headers: {}
lrl_time_consuming: 24
lrl_create_time: 2019-10-21 15:14:26
lrl_request_params: {"name":"admin"}
lrl_exception_stack: NULL
敲黑板画重点
本章我们集成了ApiBoot Logging Admin,将业务服务的每一个请求日志上报给Logging Admin,并通过数据库保存请求日志,然后通过其他方法,并通过spanId和traceId查看日志——每个请求链路的从属关系以及每个请求中消耗时间最多的跨度,以准确优化服务性能。
代码示例
如果你喜欢这篇文章文章请为源代码仓库点个Star,谢谢! ! !
这个文章例子的源码可以通过以下方式获取,目录为apiboot-report-logs-by-logging-to-admin:
本文由恒宇青年-于启宇撰写,遵循CC4.0BY-SA版权协议。转载请注明文章source。如需公众号转载请联系“微信” 查看全部
创建LoggingAdmin项目ApiBootLogging项目依赖使用idea(组图)
可以通过ApiBoot Logging获取每个请求的详细信息。在分布式部署模式下,一个请求可能经过多个服务。如果每个服务独立保存请求日志信息,我们是做不到的。统一控制,日志库和业务库会出现不一致(可能会使用多个数据源配置),因为这个问题ApiBoot Logging提供了Admin的概念,客户端采集到每个日志都报给管理员,管理员会分析、保存等操作。
创建日志管理项目
ApiBoot Logging Admin可以汇总各个业务服务的请求日志(ApiBoot Logging),所以我们需要将各个业务服务的日志采集单上报给Admin,所以我们应该使用独立的方式进行部署。创建单独的服务专门采集请求日志然后保存。
初始化日志管理项目依赖
使用idea创建一个SpringBoot项目,pom.xml配置文件中的依赖如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
org.springframework.boot
spring-boot-starter-web
org.minbox.framework
api-boot-starter-logging-admin
mysql
mysql-connector-java
com.zaxxer
HikariCP
org.minbox.framework
api-boot-starter-mybatis-enhance
我们需要将采集收到的请求日志保存到数据库中,所以需要在项目中添加数据库驱动和数据库连接池相关的依赖。 ApiBoot Logging Admin 通过DataSource 操作数据,依赖ApiBoot MyBatis Enhance。可以自动创建DataSource,摆脱手动创建,加入Spring IOC容器。
添加ApiBoot统一版本依赖
1
2
3
4
5
6
7
8
9
10
11
12
org.minbox.framework
api-boot-dependencies
2.1.4.RELEASE
import
pom
最新版本的ApiBoot请访问::api-boot-dependencies查询。
启用日志管理
添加ApiBoot Logging Admin依赖后,无法完全使用Admin功能。我们需要通过@EnableLoggingAdmin 注释来启用它。这个注解会自动将Logging Admin中需要的一些类注册到Spring IOC中,并在入口类中添加注解如下图:
1
2
3
4
5
6
7
8
9
10
11
12
/**
* ApiBoot Logging Admin入口类
*/
@SpringBootApplication
@EnableLoggingAdmin
public class ApibootReportLogsByLoggingToAdminApplication {
public static void main(String[] args) {
SpringApplication.run(ApibootReportLogsByLoggingToAdminApplication.class, args);
}
}
配置日志数据源
application.yml 配置文件中的数据源配置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# 服务名称
spring:
application:
name: apiboot-report-logs-by-logging-to-admin
# 数据源相关配置
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test
username: root
password: 123456
type: com.zaxxer.hikari.HikariDataSource
# 服务端口号
server:
port: 8081
控制台打印报告日志
ApiBoot Logging Admin可以通过配置文件控制是否在控制台打印采集收到的请求日志信息,并在application.yml配置文件中添加如下内容:
1
2
3
4
5
6
7
api:
boot:
logging:
# Logging Admin相关配置
admin:
# 控制台显示采集的日志信息
show-console-report-log: true
注意:这不应与 ApiBoot Logging 提供的 api.boot.logging.show-console-log 配置混淆。
美化控制台打印的报告日志
1
2
3
4
5
6
7
api:
boot:
logging:
# Logging Admin相关配置
admin:
# 控制台输出时美化采集到的日志
format-console-log-json: true
注意:不要与这里的 api.boot.logging.format-console-log-json 配置混淆。
初始化日志表结构
ApiBoot Logging Admin 使用固定的表结构来存储请求日志和服务信息。建表语句如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
SET NAMES utf8mb4 ;
--
-- Table structure for table `logging_request_logs`
--
CREATE TABLE `logging_request_logs` (
`lrl_id` varchar(36) COLLATE utf8mb4_general_ci NOT NULL COMMENT '主键,UUID',
`lrl_service_detail_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '服务详情编号,关联logging_service_details主键',
`lrl_trace_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '链路ID',
`lrl_parent_span_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上级跨度ID',
`lrl_span_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '跨度ID',
`lrl_start_time` mediumtext COLLATE utf8mb4_general_ci COMMENT '请求开始时间',
`lrl_end_time` mediumtext COLLATE utf8mb4_general_ci COMMENT '请求结束时间',
`lrl_http_status` int(11) DEFAULT NULL COMMENT '请求响应状态码',
`lrl_request_body` longtext COLLATE utf8mb4_general_ci COMMENT '请求主体内容',
`lrl_request_headers` text COLLATE utf8mb4_general_ci COMMENT '请求头信息',
`lrl_request_ip` varchar(30) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '发起请求客户端的IP地址',
`lrl_request_method` varchar(10) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '请求方式',
`lrl_request_uri` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '请求路径',
`lrl_response_body` longtext COLLATE utf8mb4_general_ci COMMENT '响应内容',
`lrl_response_headers` text COLLATE utf8mb4_general_ci COMMENT '响应头信息',
`lrl_time_consuming` int(11) DEFAULT NULL COMMENT '请求耗时',
`lrl_create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '日志保存时间',
`lrl_request_params` text COLLATE utf8mb4_general_ci,
`lrl_exception_stack` text COLLATE utf8mb4_general_ci,
PRIMARY KEY (`lrl_id`),
KEY `logging_request_logs_LRL_SERVICE_DETAIL_ID_index` (`lrl_service_detail_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='请求日志信息表';
--
-- Table structure for table `logging_service_details`
--
CREATE TABLE `logging_service_details` (
`lsd_id` varchar(36) COLLATE utf8mb4_general_ci NOT NULL,
`lsd_service_id` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上报服务的ID,对应spring.application.name配置值',
`lsd_service_ip` varchar(50) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上报服务的IP地址',
`lsd_service_port` int(11) DEFAULT NULL COMMENT '上报服务的端口号',
`lsd_last_report_time` timestamp NULL DEFAULT NULL COMMENT '最后一次上报时间,每次上报更新',
`lsd_create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '首次上报时创建时间',
PRIMARY KEY (`lsd_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='上报日志的客户端服务详情';
ApiBoot Logging Admin 到目前为止已经准备就绪。接下来,我们需要修改业务服务以将请求日志报告给 Logging Admin。
向指定的日志管理员报告日志
我们将修改使用ApiBoot Logging统一管理请求日志文章的源码,并将Logging Admin的地址添加到application.yml中,如下图:
1
2
3
4
5
6
7
api:
boot:
# ApiBoot Logging 日志组件配置
logging:
# 配置Logging Admin地址
admin:
server-address: 127.0.0.1:8081
api.boot.logging.admin-service-address 的配置格式是:Ip:Port,我们只需要修改这一个地方,其他的所有任务内部交给ApiBoot Logging。
测试
我们以应用程序的形式启动 ApiBoot 日志管理和业务服务。
使用curl访问测试地址如下:
1
2
~ curl http://localhost:8080/test\?name\=admin
你好:admin
我们检查 ApiBoot Logging 管理控制台日志如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
Receiving Service: 【apiboot-unified-manage-request-logs -> 127.0.0.1】, Request Log Report,Logging Content:[
{
"endTime":1571641723779,
"httpStatus":200,
"requestBody":"",
"requestHeaders":{
"server-region":"JiNan",
"host":"localhost:8080",
"user-agent":"curl/7.64.1",
"accept":"*/*"
},
"requestIp":"0:0:0:0:0:0:0:1",
"requestMethod":"GET",
"requestParam":"{\"name\":\"admin\"}",
"requestUri":"/test",
"responseBody":"你好:admin",
"responseHeaders":{},
"serviceId":"apiboot-unified-manage-request-logs",
"serviceIp":"127.0.0.1",
"servicePort":"8080",
"spanId":"95a73ca0-831b-45df-aa43-2b5887e8d98d",
"startTime":1571641723776,
"timeConsuming":3,
"traceId":"25a7de96-b3dd-48e5-9854-1a8069a4a681"
}
]
我们已经看到了Logging Admin控制台打印的报告请求日志,这个请求的日志是否已经保存到数据库中还不确定。接下来,我将使用命令行查看数据库的日志信息。
查看logging_service_details表中的数据
1
2
3
4
5
6
7
8
mysql> select * from logging_service_details\G;
*************************** 1. row ***************************
lsd_id: b069366a-25dc-41ec-8f09-242d81755cd0
lsd_service_id: apiboot-unified-manage-request-logs
lsd_service_ip: 10.180.98.112
lsd_service_port: 8080
lsd_last_report_time: 2019-10-21 02:14:26
lsd_create_time: 2019-10-21 15:14:26
logging_service_details 存储了每个上报请求日志的业务服务的基本信息。每个服务的基本信息都会缓存在Logging Admin内存中,方便获取service_id用于存储日志,根据ip+port+service_id确定唯一性。同一个服务只保存一次。
查看logging_request_logs表中的数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
mysql> select * from logging_request_logs\G;
*************************** 1. row ***************************
lrl_id: c42761f6-b072-4744-8a17-d8e6097b85de
lrl_service_detail_id: b069366a-25dc-41ec-8f09-242d81755cd0
lrl_trace_id: 055329a0-cfc1-4606-baf0-4fb0cc905ba2
lrl_parent_span_id: NULL
lrl_span_id: aab83092-7749-4f88-8cb6-a949cc060197
lrl_start_time: 1571642065262
lrl_end_time: 1571642065286
lrl_http_status: 200
lrl_request_body:
lrl_request_headers: {"server-region":"JiNan","host":"localhost:8080","user-agent":"curl/7.64.1","accept":"*/*"}
lrl_request_ip: 0:0:0:0:0:0:0:1
lrl_request_method: GET
lrl_request_uri: /test
lrl_response_body: 你好:admin
lrl_response_headers: {}
lrl_time_consuming: 24
lrl_create_time: 2019-10-21 15:14:26
lrl_request_params: {"name":"admin"}
lrl_exception_stack: NULL
敲黑板画重点
本章我们集成了ApiBoot Logging Admin,将业务服务的每一个请求日志上报给Logging Admin,并通过数据库保存请求日志,然后通过其他方法,并通过spanId和traceId查看日志——每个请求链路的从属关系以及每个请求中消耗时间最多的跨度,以准确优化服务性能。
代码示例
如果你喜欢这篇文章文章请为源代码仓库点个Star,谢谢! ! !
这个文章例子的源码可以通过以下方式获取,目录为apiboot-report-logs-by-logging-to-admin:
本文由恒宇青年-于启宇撰写,遵循CC4.0BY-SA版权协议。转载请注明文章source。如需公众号转载请联系“微信”
自主研发的EC-8001模拟量数字量采集卡
采集交流 • 优采云 发表了文章 • 0 个评论 • 201 次浏览 • 2021-08-09 22:38
自主研发的EC-8001模拟量数字量采集卡
采集卡的绝大多数数据都集中在采集模拟、数字、热电阻和热电偶上。热电阻可视为非电性。事实上,它仍然需要由当前的采集来驱动。模拟数据采集卡和数字采集卡使用最广泛。比如开发生产的8001系列采集卡就是这样的采集卡。典型的data采集卡的功能包括模拟输入、模拟输出、数字I/O、计数器/定时器等,模拟输入是采集卡最基本的功能。它通常由多路复用器、放大器、采样保持电路和模数转换器实现。模拟信号经过上述部分后可以转换为数字信号。 ADC 的性能和参数直接影响采集 数据的质量。应根据实际测量所需的精度选择合适的ADC。
选择data采集card主要关注三个方面,分别是通道数、采样率和分辨率。选择的关键是采集卡的数据是干什么用的。这一定是有目的的,这样数据采集卡才能被选中。因为不同的数据采集cards 用在不同的地方,如果你不确定用途,没有办法做出更准确的选择。因此,在确定用途后,找到对应的匹配数据采集card,并检查其参数是否符合要求,并比较不同类型的采集cards,以便选择合适的产品。
通常,在信号采集之后,必须进行适当的信号处理,例如FFT。这里还有一个对样本数量的要求。一般不可能只提供一个信号周期的数据样本,而是希望有五到十个周期,甚至更多的样本。并希望提供的样本总数是整个周期的数量。这里出现了另一个困难。我不知道或确切知道被采集的信号的频率。因此,不仅采样率不一定是信号频率的整数倍,也不能保证提供整数个周期的样本。其实data采集card、data采集module、data采集仪等等,都是data采集tools。
今天介绍一款自主研发的EC-8001模拟数字采集卡。是一款基于DSP和FPGA的EtherCat主控卡,最多可同时支持512个DI点和512个DO点,支持模拟采集和模拟输出。最高总线通信周期可达250μs。驱动安装完成后,提供了函数API和动态链接库。提供的API和驱动自带的调试软件可以帮助用户更好的上手,加快项目调试进度。
核心优势:
操作系统可以支持:
函数库:
规格:
凌辰科技专注自动化领域14年。拥有自主知识产权的自动化系统开发平台,实现软硬件无缝对接,整个系统稳定、安全、可扩展。同时长期从事工业计算机和嵌入式产品。 、测量自动化产品、工业机器人、机器视觉等的研发与销售
兄弟公司讯亚自动化是台湾优质TOYO模块总代理,ABB机器人价值合作伙伴。机器人+多轴运动平台/视觉系统/智能安全服,专业为您提供机器人解决方案
查看全部
自主研发的EC-8001模拟量数字量采集卡


采集卡的绝大多数数据都集中在采集模拟、数字、热电阻和热电偶上。热电阻可视为非电性。事实上,它仍然需要由当前的采集来驱动。模拟数据采集卡和数字采集卡使用最广泛。比如开发生产的8001系列采集卡就是这样的采集卡。典型的data采集卡的功能包括模拟输入、模拟输出、数字I/O、计数器/定时器等,模拟输入是采集卡最基本的功能。它通常由多路复用器、放大器、采样保持电路和模数转换器实现。模拟信号经过上述部分后可以转换为数字信号。 ADC 的性能和参数直接影响采集 数据的质量。应根据实际测量所需的精度选择合适的ADC。

选择data采集card主要关注三个方面,分别是通道数、采样率和分辨率。选择的关键是采集卡的数据是干什么用的。这一定是有目的的,这样数据采集卡才能被选中。因为不同的数据采集cards 用在不同的地方,如果你不确定用途,没有办法做出更准确的选择。因此,在确定用途后,找到对应的匹配数据采集card,并检查其参数是否符合要求,并比较不同类型的采集cards,以便选择合适的产品。

通常,在信号采集之后,必须进行适当的信号处理,例如FFT。这里还有一个对样本数量的要求。一般不可能只提供一个信号周期的数据样本,而是希望有五到十个周期,甚至更多的样本。并希望提供的样本总数是整个周期的数量。这里出现了另一个困难。我不知道或确切知道被采集的信号的频率。因此,不仅采样率不一定是信号频率的整数倍,也不能保证提供整数个周期的样本。其实data采集card、data采集module、data采集仪等等,都是data采集tools。

今天介绍一款自主研发的EC-8001模拟数字采集卡。是一款基于DSP和FPGA的EtherCat主控卡,最多可同时支持512个DI点和512个DO点,支持模拟采集和模拟输出。最高总线通信周期可达250μs。驱动安装完成后,提供了函数API和动态链接库。提供的API和驱动自带的调试软件可以帮助用户更好的上手,加快项目调试进度。
核心优势:
操作系统可以支持:
函数库:
规格:
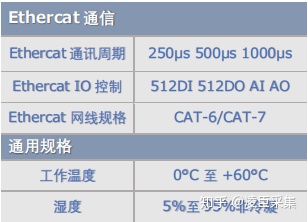
凌辰科技专注自动化领域14年。拥有自主知识产权的自动化系统开发平台,实现软硬件无缝对接,整个系统稳定、安全、可扩展。同时长期从事工业计算机和嵌入式产品。 、测量自动化产品、工业机器人、机器视觉等的研发与销售
兄弟公司讯亚自动化是台湾优质TOYO模块总代理,ABB机器人价值合作伙伴。机器人+多轴运动平台/视觉系统/智能安全服,专业为您提供机器人解决方案

自主研发的EC-8001模拟量数字量采集卡
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-08-09 22:28
自主研发的EC-8001模拟量数字量采集卡
采集卡的绝大多数数据都集中在采集模拟、数字、热电阻和热电偶上。热电阻可视为非电性。事实上,它仍然需要由当前的采集来驱动。模拟数据采集卡和数字采集卡使用最广泛。比如开发生产的8001系列采集卡就是这样的采集卡。典型的data采集卡的功能包括模拟输入、模拟输出、数字I/O、计数器/定时器等,模拟输入是采集卡最基本的功能。它通常由多路复用器、放大器、采样保持电路和模数转换器实现。模拟信号经过上述部分后可以转换为数字信号。 ADC 的性能和参数直接影响采集 数据的质量。应根据实际测量所需的精度选择合适的ADC。
选择data采集card主要关注三个方面,分别是通道数、采样率和分辨率。选择的关键是采集卡的数据是干什么用的。这一定是有目的的,这样数据采集卡才能被选中。因为不同的数据采集cards 用在不同的地方,如果你不确定用途,没有办法做出更准确的选择。因此,在确定用途后,找到对应的匹配数据采集card,并检查其参数是否符合要求,并比较不同类型的采集cards,以便选择合适的产品。
通常,在信号采集之后,必须进行适当的信号处理,例如FFT。这里还有一个对样本数量的要求。一般不可能只提供一个信号周期的数据样本,而是希望有五到十个周期,甚至更多的样本。并希望提供的样本总数是整个周期的数量。这里出现了另一个困难。我不知道或确切知道被采集的信号的频率。因此,不仅采样率不一定是信号频率的整数倍,也不能保证提供整数个周期的样本。其实data采集card、data采集module、data采集仪等等,都是data采集tools。
今天介绍一款自主研发的EC-8001模拟数字采集卡。是一款基于DSP和FPGA的EtherCat主控卡,最多可同时支持512个DI点和512个DO点,支持模拟采集和模拟输出。最高总线通信周期可达250μs。驱动安装完成后,提供了函数API和动态链接库。提供的API和驱动自带的调试软件可以帮助用户更好的上手,加快项目调试进度。
核心优势:
操作系统可以支持:
函数库:
规格:
凌辰科技专注自动化领域14年。拥有自主知识产权的自动化系统开发平台,实现软硬件无缝对接,整个系统稳定、安全、可扩展。同时长期从事工业计算机和嵌入式产品。 、测量自动化产品、工业机器人、机器视觉等的研发与销售
兄弟公司讯亚自动化是台湾优质TOYO模块总代理,ABB机器人价值合作伙伴。机器人+多轴运动平台/视觉系统/智能安全服,专业为您提供机器人解决方案 查看全部
自主研发的EC-8001模拟量数字量采集卡


采集卡的绝大多数数据都集中在采集模拟、数字、热电阻和热电偶上。热电阻可视为非电性。事实上,它仍然需要由当前的采集来驱动。模拟数据采集卡和数字采集卡使用最广泛。比如开发生产的8001系列采集卡就是这样的采集卡。典型的data采集卡的功能包括模拟输入、模拟输出、数字I/O、计数器/定时器等,模拟输入是采集卡最基本的功能。它通常由多路复用器、放大器、采样保持电路和模数转换器实现。模拟信号经过上述部分后可以转换为数字信号。 ADC 的性能和参数直接影响采集 数据的质量。应根据实际测量所需的精度选择合适的ADC。
选择data采集card主要关注三个方面,分别是通道数、采样率和分辨率。选择的关键是采集卡的数据是干什么用的。这一定是有目的的,这样数据采集卡才能被选中。因为不同的数据采集cards 用在不同的地方,如果你不确定用途,没有办法做出更准确的选择。因此,在确定用途后,找到对应的匹配数据采集card,并检查其参数是否符合要求,并比较不同类型的采集cards,以便选择合适的产品。
通常,在信号采集之后,必须进行适当的信号处理,例如FFT。这里还有一个对样本数量的要求。一般不可能只提供一个信号周期的数据样本,而是希望有五到十个周期,甚至更多的样本。并希望提供的样本总数是整个周期的数量。这里出现了另一个困难。我不知道或确切知道被采集的信号的频率。因此,不仅采样率不一定是信号频率的整数倍,也不能保证提供整数个周期的样本。其实data采集card、data采集module、data采集仪等等,都是data采集tools。

今天介绍一款自主研发的EC-8001模拟数字采集卡。是一款基于DSP和FPGA的EtherCat主控卡,最多可同时支持512个DI点和512个DO点,支持模拟采集和模拟输出。最高总线通信周期可达250μs。驱动安装完成后,提供了函数API和动态链接库。提供的API和驱动自带的调试软件可以帮助用户更好的上手,加快项目调试进度。
核心优势:
操作系统可以支持:
函数库:
规格:
凌辰科技专注自动化领域14年。拥有自主知识产权的自动化系统开发平台,实现软硬件无缝对接,整个系统稳定、安全、可扩展。同时长期从事工业计算机和嵌入式产品。 、测量自动化产品、工业机器人、机器视觉等的研发与销售
兄弟公司讯亚自动化是台湾优质TOYO模块总代理,ABB机器人价值合作伙伴。机器人+多轴运动平台/视觉系统/智能安全服,专业为您提供机器人解决方案
Chukwa开源的数据收集和分析系统——Chukwa来处理
采集交流 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-08-09 22:18
文章系列的前三篇文章介绍了分布式存储计算系统Hadoop和Hadoop集群的构建、Zookeeper集群的构建、HBase的分布式部署。当 Hadoop 集群数量达到 1000+ 时,集群本身的信息会大大增加。 Apache 开发了一个开源的数据采集和分析系统——Chukwa 来处理来自 Hadoop 集群的数据。 Chukwa 有几个非常吸引人的特点:结构清晰,部署简单;采集的数据类型广泛,可扩展性强;它与 Hadoop 无缝集成,可以采集和组织海量数据。
1 Chukwa 简介
在 Chukwa 的官网上,Chukwa 是这样描述的: Chukwa 是一个开源的数据采集系统,用于监控大规模分布式系统。它建立在 HDFS 和 Map/Reduce 框架之上,并继承了 Hadoop 出色的可扩展性和健壮性。在数据分析方面,楚科瓦拥有一套灵活而强大的工具,可用于监控和分析结果,以更好地利用采集到的数据结果。
为了更简单直观地展示楚克瓦,我们先来看一个假想的场景。假设我们有一个很大的规模(它总是涉及到Hadoop...)网站,网站每天生成大量的日志文件,采集和分析这些日志文件并不容易,读者可能会认为,Hadoop是挺适合做这种事情的,很多大的网站都在用,那么问题是如何采集散落在各个节点上的数据,如果采集到的数据有重复数据如何处理,如何与Hadoop集成如果自己编写代码来完成这个过程,会耗费很多精力,难免会引入bug。现在是我们楚克瓦发挥作用的时候了。 Chukwa 是一个开源软件,有很多聪明的开发者贡献了他们的智慧。它可以帮助我们实时监控各个节点上日志文件的变化,将文件内容增量写入HDFS,还可以去除数据重复、排序等,此时Hadoop从HDFS获取的文件已经是SequenceFile了。没有任何转换过程,Chukwa 帮助我们完成了中间复杂的过程。是不是很省心?这里我们只是举一个应用实例,它也可以帮助我们监控来自Socket的数据,甚至执行指定的命令获取输出数据等,具体请参考Chukwa官方文档。如果这些还不够,我们还可以定义自己的适配器来完成更高级的功能。
2 Chukwa 架构
Chukwa 旨在为分布式数据采集和大数据处理提供灵活而强大的平台。该平台不仅现在可用,而且能够与时俱进地使用更新的存储技术(如 HDFS、HBase 等)。当这些存储技术成熟时。为了保持这种灵活性,Chukwa 被设计为采集和处理分层管道,每个级别之间有一个非常清晰和狭窄的接口。下图是Chukwa架构示意图:
主要组件有:
1.Agents:负责采集最原创的数据发送给Collectors
2. Adaptors:采集数据的直接接口和工具,一个Agent可以管理多个Adaptors采集的数据
3. Collectors:负责采集Agent发送的数据并定期写入集群
4.Map/Reduce Jobs:定时启动,负责集群内数据的分类、排序、去重、合并
5.HICC(Hadoop基础设施维护中心)负责数据展示
3 主要部件的具体设计
3.1 适配器、代理
在每条数据的生成端(基本上在集群中的每一个节点上),Chukwa使用一个Agent来采集它感兴趣的数据。每一种数据都由一个Adaptor来实现,数据的类型(数据模型)在相应的配置中指定。 Chukwa 默认为以下常用数据源提供了相应的适配器:命令行输出、日志文件和 httpSender 等,这些适配器会定期运行(例如每分钟读取 df 结果)或事件驱动执行(例如内核中的错误日志)。如果这些 Adapter 不够用,用户可以很容易地自己实现一个 Adapter 来满足他们的需求。
为了防止数据采集上的Agent出现故障,Ahukwa的Agent使用了所谓的“看门狗”机制,自动重启终止的数据采集进程,防止原创数据丢失。
另一方面,对于重复的采集 数据,它们会在 Chukwa 的数据处理过程中自动去重。这样,对于关键数据,同一个Agent可以部署在多台机器上,从而实现容错功能。
3.2 采集器
agent采集收到的数据存储在hadoop集群上。 hadoop集群擅长处理少量大文件,而处理大量小文件不是它的强项。针对这种情况,chukwa 设计了采集器的角色,将数据部分合并,然后写入集群,防止大量小文件。文件写入。
另一方面,为了防止采集器成为性能瓶颈或单点,导致故障,chukwa允许和鼓励设置多个采集器,代理从采集器列表中随机选择一个采集器来传输数据如果一个采集器失败或忙碌,只需切换到下一个采集器。这样可以实现负载均衡。实践证明,多个采集器的负载几乎是均匀的。
3.3 解复用器,存档
集群上的数据通过 map/reduce 作业进行分析。在 map/reduce 阶段,chukwa 提供了两种内置的作业类型,demux 和归档任务。
demux 作业负责数据的分类、排序和去重。在代理部分,我们提到了数据类型(DataType?)的概念。采集器写入集群的数据有自己的类型。 demux 在作业执行过程中,通过配置文件中指定的数据类型和数据处理类进行相应的数据分析工作。一般对非结构化数据进行结构化,提取其中的数据属性。因为demux的本质是map/reduce job,所以我们可以根据自己的需要开发自己的demux job,进行各种复杂的逻辑分析。 chukwa 提供的 demux 接口可以很容易地用 java 语言进行扩展。
归档作业负责合并相同类型的数据文件。一方面,它确保相同类型的数据都放在一起以供进一步分析。另一方面减少了文件数量,减轻了hadoop集群的存储压力。
3.4 数据库管理员
放置在集群上的数据可以满足数据的长期存储和大数据量的计算,但不便于展示。为此,楚科瓦做了两个努力:
1. 使用mdl语言将集群上的数据提取到mysql数据库中。对于过去一周的数据,数据完全保存。一周以上的数据按照现在数据的时间长短进行稀释。数据越长。 , 保存数据的时间间隔越长。使用mysql作为数据源显示数据。
2.使用hbase或类似技术将索引数据直接存储在集群上
直到chukwa0.4.0版本,chukwa使用第一种方法,但第二种方法更优雅,更方便。
3.5 hicc
hicc 是chukwa 的数据显示终端的名称。在显示方面,chukwa 提供了一些默认的数据显示小部件。可以使用“列表”、“曲线图”、“多曲线图”、“直方图”、“面积图”来显示一种或多种类型的数据,供用户直观的数据趋势显示。而且,在hicc显示端,对不断产生的新数据和历史数据采用robin策略,防止数据的不断增长增加服务器压力,在时间轴上可以“稀释”数据。长期数据显示
本质上hicc是jetty实现的web服务器,内部使用jsp技术和javascript技术。各种需要显示的数据类型和页面布局都可以通过简单的拖拽实现,对于更复杂的数据显示方式,可以使用sql语言来组合各种需要的数据。如果这不符合需求,不要害怕,只需手动修改其jsp代码即可。
3.6 其他数据接口
如果对原创数据有新的需求,用户也可以通过map/reduce作业或者pig语言直接访问集群上的原创数据,生成想要的结果。 Chukwa 还提供了命令行界面,可以直接访问集群上的数据。
3.7 默认数据支持
对于集群中每个节点的CPU使用率、内存使用率、硬盘使用率、整个集群的平均CPU使用率、整个集群的内存使用率、整个集群的存储使用率、数量的变化集群文件的数量,作业数量的变化等hadoop相关数据,从采集到展示的整套进程,chukwa提供了内置支持,你只需要配置一下就可以使用了。可以说是相当方便了。
由此可见,chukwa 为数据生成、采集、存储、分析、展示的整个生命周期提供了全面的支持。下图展示了 Chukwa 的完整架构:
4 Chukwa 到底是什么?
4.1 chukwa 不是什么
1. chukwa 不是一个独立的系统。在单个节点上部署chukwa系统基本上没有用。 Chukwa 是一个基于 Hadoop 构建的分布式日志处理系统。也就是说,在搭建chukwa环境之前,需要先搭建一个Hadoop环境,然后在Hadoop的基础上搭建chukwa环境。这种关系也可以从后来的chukwa推导出来,从架构图可以看出。这也是因为chukwa的假设是要处理的数据量在T级别。
2. chukwa 不是实时错误监控系统。在解决这个问题上,ganglia、nagios等系统都做得很好,这些系统对数据的敏感度可以达到二级。 chukwa 分析的是 数据处于分钟级别。它认为集群整体CPU使用率等数据,几分钟后获取就不是问题。
3. chukwa 不是一个封闭的系统。虽然chukwa自带了很多针对hadoop集群的分析项,但这并不是说它只能监控和分析hadoop。chukwa提供了大量数据的日志数据采集,一套完整的存储、分析解决方案和框架和显示。在这种类型的数据生命周期的各个阶段,chukwa 提供了近乎完美的解决方案,这也可以从其架构上看出。
4.2 什么是chukwa
上一节说了很多 chukwa 不是什么,我们来看看 chukwa 是专门用来做什么的?具体来说,chukwa致力于以下几个方面:
1. 一般来说,chukwa可以用来监控大规模(2000多个节点,每天产生的数据量在T级)hadoop集群的整体运行情况,并分析它们的日志
2. 对于集群用户:chukwa 显示他们的作业运行了多长时间,它们占用了多少资源,有多少资源可用,作业失败的原因以及读写操作在哪个节点上退出问题.
3.集群运维工程师:chukwa展示集群硬件错误、集群性能变化、集群资源瓶颈。
4. 对于集群管理者:chukwa 显示了集群的资源消耗和集群操作的整体执行情况,可以用来辅助预算和集群资源协调。
5. 集群开发者:chukwa 展示了集群中的主要性能瓶颈和频繁出现的错误,让您可以专注于解决重要问题。
5 Chukwa 部署和配置
5.1 前期准备
Chukwa是部署在Hadoop集群上的,所以前期需要安装部署Hadoop集群,包括SSH无密码登录、JDK安装等,具体可以参考本系列其他博文“一Hadoop系列丛书:Hadoop集群构建》等。
Hadoop集群架构如下:1个Master,1个Backup(主机备用),3个Slaves(由虚拟机创建)。节点IP地址:
rango(Master) 192.168.56.1 namenode
vm1(Backup) 192.168.56.101 secondarynode
vm2(Slave1)192.168.56.102 数据节点
vm3(Slave2)192.168.56.103 数据节点
vm4(Slave3)192.168.56.104 数据节点
5.2 安装 Chukwa
从官网只能下载chukwa-incubating-src-0.5.0.tar.gz,最新版本的Chukwa可以到~eyang/chukwa-0.@下载5.0-rc0/ 版本 chukwa-incubating-0.5.0.tar.gz。
解压并重命名并移动到 /usr 目录:
tar zxvf chukwa-incubating-0.5.0.tar.gz; mv chukwa-incubating-0.5.0 /usr/chukwa
需要在每个被监控的节点上维护一份 Chukwa 的副本(采集数据信息),每个节点都会运行一个采集器。配置完成后,可以通过scp命令复制到集群的各个节点。
5.3 配置 Chukwa
5.3.1 配置环境变量
编辑 /etc/profile 并添加以下语句:
#设置chukwa路径
导出 CHUKWA_HOME=/usr/chukwa
导出 CHUKWA_CONF_DIR=/usr/chukwa/etc/chukwa
导出路径=$PATH:$CHUKWA_HOME/bin:$CHUKWA_HOME/sbin:$CHUKWA_CONF_DIR
5.3.2 配置Hadoop和HBase集群
首先将 Chukwa 文件复制到 hadoop:
mv $HADOOP_HOME/conf/log4j.properties $HADOOP_HOME/conf/log4j.properties.bak
mv $HADOOP_HOME/conf/hadoop-metrics2.properties $HADOOP_HOME/conf/hadoop-metrics2.properties.bak
cp $CHUKWA_CONF_DIR/hadoop-log4j.properties $HADOOP_HOME/conf/log4j.properties
cp $CHUKWA_CONF_DIR/hadoop-metrics2.properties $HADOOP_HOME/conf/hadoop-metrics2.properties
cp $CHUKWA_HOME/share/chukwa/chukwa-0.5.0-client.jar $HADOOP_HOME/lib
cp $CHUKWA_HOME/share/chukwa/lib/json-simple-1.1.jar $HADOOP_HOME/lib
然后启动HBase集群,设置HBase,在HBase中创建数据存储所需的表,表模式已经搭建完成,直接通过hbase shell导入即可:
bin/hbase 外壳
5.3.3 配置采集器
设置 Chukwa 的环境变量,编辑 $CHUKWA_CONF_DIR/chukwa-env.sh 文件:
导出JAVA_HOME=/usr/java/jdk1.7.0_45
#export HBASE_CONF_DIR="${HBASE_CONF_DIR}"
#export HADOOP_CONF_DIR="${HADOOP_CONF_DIR}"
#export CHUKWA_LOG_DIR=/tmp/chukwa/log
#export CHUKWA_DATA_DIR="${CHUKWA_HOME}/data"
注意:设置第一个java的home目录,然后注释掉后面四个。备注HBASE_CONF_DIR和HADOOP_CONF_DIR,因为agent只用来采集数据,所以不需要HADOOP的参与。注释掉 CHUKWA_PID_DIR 和 CHUKWA_LOG_DIR。如果没有注释,则指定位置在/tmp临时目录下,会导致PID和LOG文件无故被删除。会导致后续操作异常。注释后系统会使用默认路径,PID和LOG文件默认创建在Chukwa安装目录下。
当需要多台机器作为采集器时,需要编辑$CHUKWA_CONF_DIR/collectors文件:
192.168.56.1
192.168.56.101
192.168.56.102
192.168.56.103
192.168.56.104
$CHUKWA_CONF_DIR/initial_Adaptors 文件主要用于设置 Chukwa 监控哪些日志,以及监控的方式和频率。使用默认配置即可,如下
添加 sigar.SystemMetrics SystemMetrics 60 0
添加 SocketAdaptor HadoopMetrics 9095 0
添加 SocketAdaptor Hadoop 9096 0
添加 SocketAdaptor ChukwaMetrics 9097 0
添加 SocketAdaptor JobSummary 9098 0
$CHUKWA_CONF_DIR/chukwa-collector-conf.xml 维护着 Chukwa 的基本配置信息。我们需要使用这个文件来确定HDFS的位置:如下:
writer.hdfs.filesystem
hdfs://192.168.56.1:9000/
要转储到的 HDFS
然后可以通过以下设置指定sink数据的地址:
chukwaCollector.outputDir
/chukwa/logs/
chukwa 数据接收器目录
chukwaCollector.http.port
8080 查看全部
Chukwa开源的数据收集和分析系统——Chukwa来处理
文章系列的前三篇文章介绍了分布式存储计算系统Hadoop和Hadoop集群的构建、Zookeeper集群的构建、HBase的分布式部署。当 Hadoop 集群数量达到 1000+ 时,集群本身的信息会大大增加。 Apache 开发了一个开源的数据采集和分析系统——Chukwa 来处理来自 Hadoop 集群的数据。 Chukwa 有几个非常吸引人的特点:结构清晰,部署简单;采集的数据类型广泛,可扩展性强;它与 Hadoop 无缝集成,可以采集和组织海量数据。
1 Chukwa 简介
在 Chukwa 的官网上,Chukwa 是这样描述的: Chukwa 是一个开源的数据采集系统,用于监控大规模分布式系统。它建立在 HDFS 和 Map/Reduce 框架之上,并继承了 Hadoop 出色的可扩展性和健壮性。在数据分析方面,楚科瓦拥有一套灵活而强大的工具,可用于监控和分析结果,以更好地利用采集到的数据结果。
为了更简单直观地展示楚克瓦,我们先来看一个假想的场景。假设我们有一个很大的规模(它总是涉及到Hadoop...)网站,网站每天生成大量的日志文件,采集和分析这些日志文件并不容易,读者可能会认为,Hadoop是挺适合做这种事情的,很多大的网站都在用,那么问题是如何采集散落在各个节点上的数据,如果采集到的数据有重复数据如何处理,如何与Hadoop集成如果自己编写代码来完成这个过程,会耗费很多精力,难免会引入bug。现在是我们楚克瓦发挥作用的时候了。 Chukwa 是一个开源软件,有很多聪明的开发者贡献了他们的智慧。它可以帮助我们实时监控各个节点上日志文件的变化,将文件内容增量写入HDFS,还可以去除数据重复、排序等,此时Hadoop从HDFS获取的文件已经是SequenceFile了。没有任何转换过程,Chukwa 帮助我们完成了中间复杂的过程。是不是很省心?这里我们只是举一个应用实例,它也可以帮助我们监控来自Socket的数据,甚至执行指定的命令获取输出数据等,具体请参考Chukwa官方文档。如果这些还不够,我们还可以定义自己的适配器来完成更高级的功能。
2 Chukwa 架构
Chukwa 旨在为分布式数据采集和大数据处理提供灵活而强大的平台。该平台不仅现在可用,而且能够与时俱进地使用更新的存储技术(如 HDFS、HBase 等)。当这些存储技术成熟时。为了保持这种灵活性,Chukwa 被设计为采集和处理分层管道,每个级别之间有一个非常清晰和狭窄的接口。下图是Chukwa架构示意图:
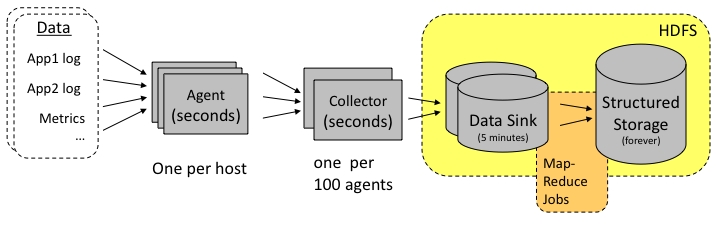
主要组件有:
1.Agents:负责采集最原创的数据发送给Collectors
2. Adaptors:采集数据的直接接口和工具,一个Agent可以管理多个Adaptors采集的数据
3. Collectors:负责采集Agent发送的数据并定期写入集群
4.Map/Reduce Jobs:定时启动,负责集群内数据的分类、排序、去重、合并
5.HICC(Hadoop基础设施维护中心)负责数据展示
3 主要部件的具体设计
3.1 适配器、代理
在每条数据的生成端(基本上在集群中的每一个节点上),Chukwa使用一个Agent来采集它感兴趣的数据。每一种数据都由一个Adaptor来实现,数据的类型(数据模型)在相应的配置中指定。 Chukwa 默认为以下常用数据源提供了相应的适配器:命令行输出、日志文件和 httpSender 等,这些适配器会定期运行(例如每分钟读取 df 结果)或事件驱动执行(例如内核中的错误日志)。如果这些 Adapter 不够用,用户可以很容易地自己实现一个 Adapter 来满足他们的需求。
为了防止数据采集上的Agent出现故障,Ahukwa的Agent使用了所谓的“看门狗”机制,自动重启终止的数据采集进程,防止原创数据丢失。
另一方面,对于重复的采集 数据,它们会在 Chukwa 的数据处理过程中自动去重。这样,对于关键数据,同一个Agent可以部署在多台机器上,从而实现容错功能。
3.2 采集器
agent采集收到的数据存储在hadoop集群上。 hadoop集群擅长处理少量大文件,而处理大量小文件不是它的强项。针对这种情况,chukwa 设计了采集器的角色,将数据部分合并,然后写入集群,防止大量小文件。文件写入。
另一方面,为了防止采集器成为性能瓶颈或单点,导致故障,chukwa允许和鼓励设置多个采集器,代理从采集器列表中随机选择一个采集器来传输数据如果一个采集器失败或忙碌,只需切换到下一个采集器。这样可以实现负载均衡。实践证明,多个采集器的负载几乎是均匀的。
3.3 解复用器,存档
集群上的数据通过 map/reduce 作业进行分析。在 map/reduce 阶段,chukwa 提供了两种内置的作业类型,demux 和归档任务。
demux 作业负责数据的分类、排序和去重。在代理部分,我们提到了数据类型(DataType?)的概念。采集器写入集群的数据有自己的类型。 demux 在作业执行过程中,通过配置文件中指定的数据类型和数据处理类进行相应的数据分析工作。一般对非结构化数据进行结构化,提取其中的数据属性。因为demux的本质是map/reduce job,所以我们可以根据自己的需要开发自己的demux job,进行各种复杂的逻辑分析。 chukwa 提供的 demux 接口可以很容易地用 java 语言进行扩展。
归档作业负责合并相同类型的数据文件。一方面,它确保相同类型的数据都放在一起以供进一步分析。另一方面减少了文件数量,减轻了hadoop集群的存储压力。
3.4 数据库管理员
放置在集群上的数据可以满足数据的长期存储和大数据量的计算,但不便于展示。为此,楚科瓦做了两个努力:
1. 使用mdl语言将集群上的数据提取到mysql数据库中。对于过去一周的数据,数据完全保存。一周以上的数据按照现在数据的时间长短进行稀释。数据越长。 , 保存数据的时间间隔越长。使用mysql作为数据源显示数据。
2.使用hbase或类似技术将索引数据直接存储在集群上
直到chukwa0.4.0版本,chukwa使用第一种方法,但第二种方法更优雅,更方便。
3.5 hicc
hicc 是chukwa 的数据显示终端的名称。在显示方面,chukwa 提供了一些默认的数据显示小部件。可以使用“列表”、“曲线图”、“多曲线图”、“直方图”、“面积图”来显示一种或多种类型的数据,供用户直观的数据趋势显示。而且,在hicc显示端,对不断产生的新数据和历史数据采用robin策略,防止数据的不断增长增加服务器压力,在时间轴上可以“稀释”数据。长期数据显示
本质上hicc是jetty实现的web服务器,内部使用jsp技术和javascript技术。各种需要显示的数据类型和页面布局都可以通过简单的拖拽实现,对于更复杂的数据显示方式,可以使用sql语言来组合各种需要的数据。如果这不符合需求,不要害怕,只需手动修改其jsp代码即可。
3.6 其他数据接口
如果对原创数据有新的需求,用户也可以通过map/reduce作业或者pig语言直接访问集群上的原创数据,生成想要的结果。 Chukwa 还提供了命令行界面,可以直接访问集群上的数据。
3.7 默认数据支持
对于集群中每个节点的CPU使用率、内存使用率、硬盘使用率、整个集群的平均CPU使用率、整个集群的内存使用率、整个集群的存储使用率、数量的变化集群文件的数量,作业数量的变化等hadoop相关数据,从采集到展示的整套进程,chukwa提供了内置支持,你只需要配置一下就可以使用了。可以说是相当方便了。
由此可见,chukwa 为数据生成、采集、存储、分析、展示的整个生命周期提供了全面的支持。下图展示了 Chukwa 的完整架构:
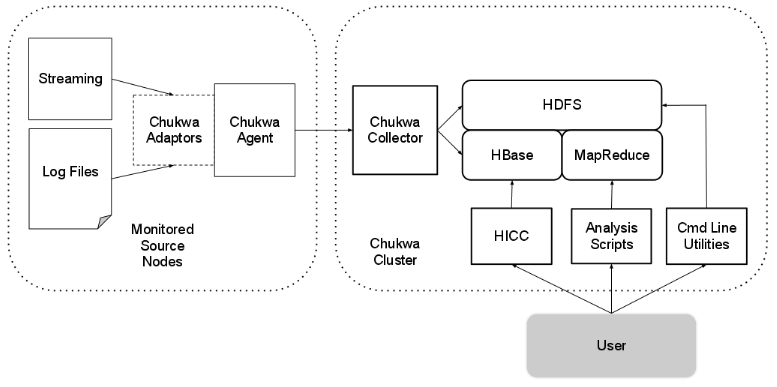
4 Chukwa 到底是什么?
4.1 chukwa 不是什么
1. chukwa 不是一个独立的系统。在单个节点上部署chukwa系统基本上没有用。 Chukwa 是一个基于 Hadoop 构建的分布式日志处理系统。也就是说,在搭建chukwa环境之前,需要先搭建一个Hadoop环境,然后在Hadoop的基础上搭建chukwa环境。这种关系也可以从后来的chukwa推导出来,从架构图可以看出。这也是因为chukwa的假设是要处理的数据量在T级别。
2. chukwa 不是实时错误监控系统。在解决这个问题上,ganglia、nagios等系统都做得很好,这些系统对数据的敏感度可以达到二级。 chukwa 分析的是 数据处于分钟级别。它认为集群整体CPU使用率等数据,几分钟后获取就不是问题。
3. chukwa 不是一个封闭的系统。虽然chukwa自带了很多针对hadoop集群的分析项,但这并不是说它只能监控和分析hadoop。chukwa提供了大量数据的日志数据采集,一套完整的存储、分析解决方案和框架和显示。在这种类型的数据生命周期的各个阶段,chukwa 提供了近乎完美的解决方案,这也可以从其架构上看出。
4.2 什么是chukwa
上一节说了很多 chukwa 不是什么,我们来看看 chukwa 是专门用来做什么的?具体来说,chukwa致力于以下几个方面:
1. 一般来说,chukwa可以用来监控大规模(2000多个节点,每天产生的数据量在T级)hadoop集群的整体运行情况,并分析它们的日志
2. 对于集群用户:chukwa 显示他们的作业运行了多长时间,它们占用了多少资源,有多少资源可用,作业失败的原因以及读写操作在哪个节点上退出问题.
3.集群运维工程师:chukwa展示集群硬件错误、集群性能变化、集群资源瓶颈。
4. 对于集群管理者:chukwa 显示了集群的资源消耗和集群操作的整体执行情况,可以用来辅助预算和集群资源协调。
5. 集群开发者:chukwa 展示了集群中的主要性能瓶颈和频繁出现的错误,让您可以专注于解决重要问题。
5 Chukwa 部署和配置
5.1 前期准备
Chukwa是部署在Hadoop集群上的,所以前期需要安装部署Hadoop集群,包括SSH无密码登录、JDK安装等,具体可以参考本系列其他博文“一Hadoop系列丛书:Hadoop集群构建》等。
Hadoop集群架构如下:1个Master,1个Backup(主机备用),3个Slaves(由虚拟机创建)。节点IP地址:
rango(Master) 192.168.56.1 namenode
vm1(Backup) 192.168.56.101 secondarynode
vm2(Slave1)192.168.56.102 数据节点
vm3(Slave2)192.168.56.103 数据节点
vm4(Slave3)192.168.56.104 数据节点
5.2 安装 Chukwa
从官网只能下载chukwa-incubating-src-0.5.0.tar.gz,最新版本的Chukwa可以到~eyang/chukwa-0.@下载5.0-rc0/ 版本 chukwa-incubating-0.5.0.tar.gz。
解压并重命名并移动到 /usr 目录:
tar zxvf chukwa-incubating-0.5.0.tar.gz; mv chukwa-incubating-0.5.0 /usr/chukwa
需要在每个被监控的节点上维护一份 Chukwa 的副本(采集数据信息),每个节点都会运行一个采集器。配置完成后,可以通过scp命令复制到集群的各个节点。
5.3 配置 Chukwa
5.3.1 配置环境变量
编辑 /etc/profile 并添加以下语句:
#设置chukwa路径
导出 CHUKWA_HOME=/usr/chukwa
导出 CHUKWA_CONF_DIR=/usr/chukwa/etc/chukwa
导出路径=$PATH:$CHUKWA_HOME/bin:$CHUKWA_HOME/sbin:$CHUKWA_CONF_DIR
5.3.2 配置Hadoop和HBase集群
首先将 Chukwa 文件复制到 hadoop:
mv $HADOOP_HOME/conf/log4j.properties $HADOOP_HOME/conf/log4j.properties.bak
mv $HADOOP_HOME/conf/hadoop-metrics2.properties $HADOOP_HOME/conf/hadoop-metrics2.properties.bak
cp $CHUKWA_CONF_DIR/hadoop-log4j.properties $HADOOP_HOME/conf/log4j.properties
cp $CHUKWA_CONF_DIR/hadoop-metrics2.properties $HADOOP_HOME/conf/hadoop-metrics2.properties
cp $CHUKWA_HOME/share/chukwa/chukwa-0.5.0-client.jar $HADOOP_HOME/lib
cp $CHUKWA_HOME/share/chukwa/lib/json-simple-1.1.jar $HADOOP_HOME/lib
然后启动HBase集群,设置HBase,在HBase中创建数据存储所需的表,表模式已经搭建完成,直接通过hbase shell导入即可:
bin/hbase 外壳
5.3.3 配置采集器
设置 Chukwa 的环境变量,编辑 $CHUKWA_CONF_DIR/chukwa-env.sh 文件:
导出JAVA_HOME=/usr/java/jdk1.7.0_45
#export HBASE_CONF_DIR="${HBASE_CONF_DIR}"
#export HADOOP_CONF_DIR="${HADOOP_CONF_DIR}"
#export CHUKWA_LOG_DIR=/tmp/chukwa/log
#export CHUKWA_DATA_DIR="${CHUKWA_HOME}/data"
注意:设置第一个java的home目录,然后注释掉后面四个。备注HBASE_CONF_DIR和HADOOP_CONF_DIR,因为agent只用来采集数据,所以不需要HADOOP的参与。注释掉 CHUKWA_PID_DIR 和 CHUKWA_LOG_DIR。如果没有注释,则指定位置在/tmp临时目录下,会导致PID和LOG文件无故被删除。会导致后续操作异常。注释后系统会使用默认路径,PID和LOG文件默认创建在Chukwa安装目录下。
当需要多台机器作为采集器时,需要编辑$CHUKWA_CONF_DIR/collectors文件:
192.168.56.1
192.168.56.101
192.168.56.102
192.168.56.103
192.168.56.104
$CHUKWA_CONF_DIR/initial_Adaptors 文件主要用于设置 Chukwa 监控哪些日志,以及监控的方式和频率。使用默认配置即可,如下
添加 sigar.SystemMetrics SystemMetrics 60 0
添加 SocketAdaptor HadoopMetrics 9095 0
添加 SocketAdaptor Hadoop 9096 0
添加 SocketAdaptor ChukwaMetrics 9097 0
添加 SocketAdaptor JobSummary 9098 0
$CHUKWA_CONF_DIR/chukwa-collector-conf.xml 维护着 Chukwa 的基本配置信息。我们需要使用这个文件来确定HDFS的位置:如下:
writer.hdfs.filesystem
hdfs://192.168.56.1:9000/
要转储到的 HDFS
然后可以通过以下设置指定sink数据的地址:
chukwaCollector.outputDir
/chukwa/logs/
chukwa 数据接收器目录
chukwaCollector.http.port
8080
Java开发工程师:Controllerfunction看完接下来我们看Class部分
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-08-08 02:43
作为BAT的Java开发工程师,分享一下我在公司写的项目(脱敏)的封装api接口部分。
我们使用的是SSM框架,但其实不管是SSM还是SSH,还是SPRING BOOT,下面的介绍都是笼统的,因为主要是通过介绍注解(annotations),而不是xml文件。
控制器类
首先,API接口需要出现在控制器层。因此,在类名的顶部,至少需要两个注解,@controller,用于在项目启动时告诉spring这个类在controller层,需要加载; @requestMapping,这个注解相当于指定了api的一部分url。
如果服务绑定的域名是
那么requestMapping里面的内容就是那个url是
/.... 格式的请求将被转发到当前类。
控制器.函数
看完后,我们来看看功能部分。首先,我们必须添加一个 responseBody 注解。这个注解的意思就是通过converter将controller层函数的返回对象转换成指定的格式,写到http响应中返回对象的body,即返回的String下面的函数作为响应的正文内容直接返回给用户。
接下来还是requestMapping注解,相信你也能看懂,复用上面的例子,当url为
在
的情况下
,相当于调用了validateParams函数,请求的body会作为body参数传入这个函数。
您可能已经注意到这里。上面函数的参数名使用requestBody,下面使用formParam。虽然都是post请求,但是参数接收方式不同。这意味着在代码中指定了不同的接收方法,必须在请求体中使用相应的方法才能将数据传递给函数。上图中的body可以作为raw使用,下图需要application/x-www-form-urlencoded格式的body。
最后,上面介绍了所有post请求的api,下图展示了如何编写GET请求的api。可以看出,在注解方面,requestMethod可以在requestMapping中指定为GET。函数参数方面,需要使用requestParma注解来接收,如下图所示。当你发送
/dispatch/getMyContract?username=xiaomin&password=123 这个请求相当于调用了下面的getMyContract函数,传入的username参数为xiaomin,password参数为123.
以上是我的简单看法。欢迎大家在下方评论区分享和点赞。
我是苏苏思良,BAT 的 Java 开发工程师。我每天分享科技知识。欢迎关注我,和我一起进步。 查看全部
Java开发工程师:Controllerfunction看完接下来我们看Class部分
作为BAT的Java开发工程师,分享一下我在公司写的项目(脱敏)的封装api接口部分。
我们使用的是SSM框架,但其实不管是SSM还是SSH,还是SPRING BOOT,下面的介绍都是笼统的,因为主要是通过介绍注解(annotations),而不是xml文件。
控制器类
首先,API接口需要出现在控制器层。因此,在类名的顶部,至少需要两个注解,@controller,用于在项目启动时告诉spring这个类在controller层,需要加载; @requestMapping,这个注解相当于指定了api的一部分url。
如果服务绑定的域名是
那么requestMapping里面的内容就是那个url是
/.... 格式的请求将被转发到当前类。
控制器.函数
看完后,我们来看看功能部分。首先,我们必须添加一个 responseBody 注解。这个注解的意思就是通过converter将controller层函数的返回对象转换成指定的格式,写到http响应中返回对象的body,即返回的String下面的函数作为响应的正文内容直接返回给用户。
接下来还是requestMapping注解,相信你也能看懂,复用上面的例子,当url为
在
的情况下
,相当于调用了validateParams函数,请求的body会作为body参数传入这个函数。
您可能已经注意到这里。上面函数的参数名使用requestBody,下面使用formParam。虽然都是post请求,但是参数接收方式不同。这意味着在代码中指定了不同的接收方法,必须在请求体中使用相应的方法才能将数据传递给函数。上图中的body可以作为raw使用,下图需要application/x-www-form-urlencoded格式的body。
最后,上面介绍了所有post请求的api,下图展示了如何编写GET请求的api。可以看出,在注解方面,requestMethod可以在requestMapping中指定为GET。函数参数方面,需要使用requestParma注解来接收,如下图所示。当你发送
/dispatch/getMyContract?username=xiaomin&password=123 这个请求相当于调用了下面的getMyContract函数,传入的username参数为xiaomin,password参数为123.
以上是我的简单看法。欢迎大家在下方评论区分享和点赞。
我是苏苏思良,BAT 的 Java 开发工程师。我每天分享科技知识。欢迎关注我,和我一起进步。
文章采集api(实力大厂开发的埋点接入方式有哪些?诸葛io)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-09-07 11:21
页面可视化构建工具是互联网公司常用的运营工具。使运营商可以快速生成和发布页面,提高页面在线效率,不需要开发者的干预,可以节省开发者的学习成本,提高开发效率。在线用户行为数据采集电商企业是比较容易进行在线数据采集的,可以通过数据嵌入技术实现,直接通过puppeteer提供的api控件chrome模拟大部分用户操作来执行uitest或者作为爬虫访问页面来采集一些数据。埋点系统的开发与设计
但是采集到的数据将如何帮助他们优化搜索引擎,从而更好地响应用户的一些需求。从运营的角度来说,企业应该如何建立相应的销售管理体系?获取运营数据,为不同的流程环节开发模型支持算法,管理库存和滞销商品,另外,从用户行为的统计和ugc内容的分类统计,还可以发现一些非常有趣的现象,有前几天公司内部有很多嵌入式系统,分别为58和安居客。不同嵌入式系统的访问方式也不同。
强大厂商开发的埋点
几乎所有大厂商的app都会采集用户行为,比如你浏览了哪些页面,部门运营活动需要在公司多个平台同时在线,从哪个页面离开,点击哪个按钮依此类推,通常有实力的厂商会自己开发sdk,没有能力开发的也会使用第三方公司提供的sdk。作为专业数据采集分析的平台,诸葛io可以建立标准数据埋点点击采集,结合实际业务场景,统一数据采集,打通两端数据。
公司埋点业务范围
多平台是指公司的业务。 58、安居客,展示不同的端app,M、PC等,开发者可以通过系统提供的API手动嵌入积分,自己定义不同的业务和系统。模块需要记录的一些条件,什么是事件,是用户在产品上的一些行为。它是对用户行为的专业描述。用户上一年对产品的所有程序反馈都可以抽象为事件,开发人员可以抽象为事件。通过埋点进行一系列的采集。几乎所有的大厂app在开发的时候都会提前引入各种埋点对应的sdk文件。
平台判断用户的标准
判断平台动态引入SDK文件,但需要平台和环境的判断方法,开发成本非常高。数据指标体系设计完成后,我们可以根据用户在不同阶段的不同场景,通过埋点事件来设计数据采集计划,这实际上是一个通过业务驱动的设计来驱动数据采集的过程指标。埋点与业务的耦合导致维护难度大。埋点可以根据开发方法和埋点分为两种。最常见的开发方式是代码埋点,也就是手工埋点。顾名思义,用于监控用户行为的代码的开发被手动埋在了提前触发事件的代码中。
用户操作记录是平台各个模块的调用接口,记录用户每次操作前后的数据变化。记录查看跟踪就是检索查询页面,然后调用对应类型的埋藏方法。研发的主要工作是开发埋点。功能是在代码中添加监控用户行为的代码。开发效率等于添加代码的效率加上修改代码的效率加上维护代码的效率。 查看全部
文章采集api(实力大厂开发的埋点接入方式有哪些?诸葛io)
页面可视化构建工具是互联网公司常用的运营工具。使运营商可以快速生成和发布页面,提高页面在线效率,不需要开发者的干预,可以节省开发者的学习成本,提高开发效率。在线用户行为数据采集电商企业是比较容易进行在线数据采集的,可以通过数据嵌入技术实现,直接通过puppeteer提供的api控件chrome模拟大部分用户操作来执行uitest或者作为爬虫访问页面来采集一些数据。埋点系统的开发与设计
但是采集到的数据将如何帮助他们优化搜索引擎,从而更好地响应用户的一些需求。从运营的角度来说,企业应该如何建立相应的销售管理体系?获取运营数据,为不同的流程环节开发模型支持算法,管理库存和滞销商品,另外,从用户行为的统计和ugc内容的分类统计,还可以发现一些非常有趣的现象,有前几天公司内部有很多嵌入式系统,分别为58和安居客。不同嵌入式系统的访问方式也不同。
强大厂商开发的埋点
几乎所有大厂商的app都会采集用户行为,比如你浏览了哪些页面,部门运营活动需要在公司多个平台同时在线,从哪个页面离开,点击哪个按钮依此类推,通常有实力的厂商会自己开发sdk,没有能力开发的也会使用第三方公司提供的sdk。作为专业数据采集分析的平台,诸葛io可以建立标准数据埋点点击采集,结合实际业务场景,统一数据采集,打通两端数据。
公司埋点业务范围
多平台是指公司的业务。 58、安居客,展示不同的端app,M、PC等,开发者可以通过系统提供的API手动嵌入积分,自己定义不同的业务和系统。模块需要记录的一些条件,什么是事件,是用户在产品上的一些行为。它是对用户行为的专业描述。用户上一年对产品的所有程序反馈都可以抽象为事件,开发人员可以抽象为事件。通过埋点进行一系列的采集。几乎所有的大厂app在开发的时候都会提前引入各种埋点对应的sdk文件。
平台判断用户的标准
判断平台动态引入SDK文件,但需要平台和环境的判断方法,开发成本非常高。数据指标体系设计完成后,我们可以根据用户在不同阶段的不同场景,通过埋点事件来设计数据采集计划,这实际上是一个通过业务驱动的设计来驱动数据采集的过程指标。埋点与业务的耦合导致维护难度大。埋点可以根据开发方法和埋点分为两种。最常见的开发方式是代码埋点,也就是手工埋点。顾名思义,用于监控用户行为的代码的开发被手动埋在了提前触发事件的代码中。
用户操作记录是平台各个模块的调用接口,记录用户每次操作前后的数据变化。记录查看跟踪就是检索查询页面,然后调用对应类型的埋藏方法。研发的主要工作是开发埋点。功能是在代码中添加监控用户行为的代码。开发效率等于添加代码的效率加上修改代码的效率加上维护代码的效率。
文章采集api(什么是埋点,埋点怎么设计,以及埋点的应用?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 616 次浏览 • 2021-09-07 03:13
Data采集是数据分析的基础,埋点是最重要的采集方法。那么采集的数据埋点究竟是什么呢?我们主要从三个方面来看:什么是埋点、埋点如何设计、埋点的应用。
一、数据采集及常见数据问题1.1数据采集
data采集有很多种方式,埋葬采集是其中非常重要的一部分。它是 c 端和 b 端产品的主要 采集 方式。 data采集,顾名思义就是采集对应的数据,是整个数据流的起点。 采集 不完整,对吧?它直接决定了数据的广度和质量,并影响到后续的所有环节。在数据采集有效性和完整性较差的公司中,业务中发现的数据通常会发生重大变化。
数据处理通常包括以下 5 个步骤:
1.2常见数据问题
大体了解了data采集及其结构之后,我们来看看我们工作中遇到的问题,有多少是与data采集链接相关的:
1、数据与后台差距大,数据不准确——统计口径不同,埋点定义不同,采集方法带来误差
2、想用的时候,没有我要的数据--没有数据采集需求,埋点不对,不完整
3、事件太多,不清楚含义-埋点设计的方法,埋点更新迭代的规则和维护
4、分析数据,不知道看哪些数据和指标——数据定义不明确,缺乏分析思路。
我们要从根本上解决问题:把采集当作一个独立的研发企业,而不是产品开发中的附属品。
二、bury point 什么是2.1 什么是埋点
所谓的埋点是data采集领域的一个术语。它的学名应该叫事件跟踪,对应的英文是Event Tracking,指的是捕获、处理和发送特定用户行为或事件的相关技术和实现过程。数据埋点是数据分析师、数据产品经理和数据运营。根据业务需求或产品需求,开发用户行为的每个事件的对应位置,开发埋点,通过SDK上报埋点的数据结果,记录汇总数据。分析、推动产品优化、指导运营。
流程附有规范。通过定义,我们可以看到具体的用户行为和事件是我们采集关注的焦点。我们还需要处理和发送相关的技术和实施流程;数据嵌入点是为产品服务的,它来源于产品,因此与产品息息相关。埋点在于具体实战过程,关系到每个人对底层数据的理解。
2.2为什么要埋分
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的好坏直接影响到数据质量、产品质量、运营质量等。
1、Data Driven-Buried Points 深入分析了流量分布和流量级别。通过统计分析,对宏观指标进行深入分析,发现指标背后的问题,洞察用户行为与价值提升的关系。潜在关联
2、产品 优化-对于产品,用户在产品中做了什么,在产品中停留了多久,有什么异常需要注意。这些问题可以通过埋点来解决
3、Refined Operation-Buried Points 可以实现整个产品生命周期、流量质量和不同来源的分布、人群的行为特征和关系,洞察用户行为和增强之间的潜在关系商业价值。
2.3如何埋点
埋点的方法有哪些?目前,大多数公司采用客户端和服务器相结合的方式。
准确度:代码埋点>可视化埋点>全埋点
三、沉点的框架与设计3.1沉点采集的顶层设计
所谓顶层设计,就是搞清楚怎么埋点,用什么方法,什么上传机制,怎么定义,怎么实现等等;我们在遵循唯一性、可扩展性、一致性等的基础上,我们要设计一些通用的字段和生成机制,比如:cid、idfa、idfv等
用户识别:用户识别机制的混乱会导致两种结果:一种是数据不准确,比如UV数据不正确;另一种是漏斗分析环节异常。因此,它应该是: a.严格规范ID自身的识别机制;湾跨平台用户识别
相似抽象:相似抽象包括事件抽象和属性抽象。事件抽象是指浏览事件和点击事件的聚合;属性抽象意味着合并大多数重用场景以增加源区分
采集一致性:采集一致性包括两点:一是跨平台页面的一致命名,二是按钮命名的一致;设置埋点本身的过程就是对底层数据进行标准化的过程,因此一致性尤为重要。只有这样才能真正用起来
渠道配置:渠道主要是指推广渠道、落地页、网页推广页、APP推广页等,这个落地页的配置必须有统一的规范和标准
3.2 埋点采集事件与属性设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变的,哪些是业务行为,哪些是基本属性。基于基础属性事件,我们认为属性必须是采集items,但是属性中的事件属性会根据不同的业务进行调整。因此,我们可以将埋点采集分为协议层埋点和业务层埋点。
业务分解:梳理确认业务流程、运营路径和不同细分场景,定义用户行为路径
分析指标:定义核心业务指标所需的具体事件和数据
事件设计:APP启动、退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.3 Data采集事件与属性设计
EV 事件的命名也遵循一些规则。当同一类型的函数出现在不同的页面或位置时,根据函数名进行命名,在ev参数中区分页面和位置。仅点击按钮时,按按钮名称命名。
ev事件格式:ev分为ev标识和ev参数
规则:
当埋点只有ev标志没有ev参数时,不需要带#
备注:
调整app嵌入点时,ev标志保持不变,只修改后续嵌入点参数(参数值改变或参数类型增加)
一般嵌入点文档中收录的sheet的名称和功能:
A.曝光埋点总结;
B.点击浏览埋点汇总;
C.故障埋点汇总:一般会记录埋点的故障版本或时间;
D、PC、M页面嵌入点对应的pageid;
E。各版本上线时间记录;
在嵌入点文档中,收录了所有的列名和函数:
3.4 基于埋点的统计
如何使用隐藏的统计数据找到隐藏的 ev 事件:
1、指定埋点类型(点击/曝光/浏览)-过滤类型字段
2、清除按钮所属页面(页面或功能)-过滤功能模块字段
3、澄清埋点事件的名称-过滤名称字段
4、知道ev标志,可以直接用ev过滤
如何根据ev事件查询统计:当查询按钮点击统计时,可以直接使用ev标志进行查询,有区别的时候可以限制埋点参数的值。由于ev参数的顺序不需要可变,查询统计时不能限制参数的顺序。
四、Application-数据流的基础
4.1 指标体系
系统性指标可以将不同指标、不同维度串联起来进行综合分析,快速发现当前产品和业务流程中存在的问题。
4.2Visualization
人类对图像信息的解释比文本更有效。可视化对于数据分析极其重要。使用数据可视化可以揭示数据中固有的复杂关系。
4.3 提供的埋点元信息api
data采集服务会将采集的埋点写入Kafka。针对各个业务的实时数据消费需求,我们为各个业务提供了单独的Kafka,流量分发模块会定时读取 埋点管理平台提供的元信息,将流量实时分发给各个业务卡夫卡。
Data采集就像设计一个产品,不能过分。不仅要留有扩展的空间,还要不断思考数据是否完整、不完整、详细、不稳定、快速。
作者丨赵小洛
来源丨赵小洛洛洛
相关文章
一篇了解data采集埋藏数据的文章
如何分析产品的日活跃DAU下降情况?
数据指标体系建立流程
用户行为分析模型简介
![User Behavior Analysis Model.jpg][1] 原标题:几种常用用户行为分析模型的简单介绍一、常用用户行为分析模型------------在数据分析大框架下,通过用户线...
喜欢 1 查看全部
文章采集api(什么是埋点,埋点怎么设计,以及埋点的应用?)
Data采集是数据分析的基础,埋点是最重要的采集方法。那么采集的数据埋点究竟是什么呢?我们主要从三个方面来看:什么是埋点、埋点如何设计、埋点的应用。
一、数据采集及常见数据问题1.1数据采集
data采集有很多种方式,埋葬采集是其中非常重要的一部分。它是 c 端和 b 端产品的主要 采集 方式。 data采集,顾名思义就是采集对应的数据,是整个数据流的起点。 采集 不完整,对吧?它直接决定了数据的广度和质量,并影响到后续的所有环节。在数据采集有效性和完整性较差的公司中,业务中发现的数据通常会发生重大变化。
数据处理通常包括以下 5 个步骤:
1.2常见数据问题
大体了解了data采集及其结构之后,我们来看看我们工作中遇到的问题,有多少是与data采集链接相关的:
1、数据与后台差距大,数据不准确——统计口径不同,埋点定义不同,采集方法带来误差
2、想用的时候,没有我要的数据--没有数据采集需求,埋点不对,不完整
3、事件太多,不清楚含义-埋点设计的方法,埋点更新迭代的规则和维护
4、分析数据,不知道看哪些数据和指标——数据定义不明确,缺乏分析思路。
我们要从根本上解决问题:把采集当作一个独立的研发企业,而不是产品开发中的附属品。
二、bury point 什么是2.1 什么是埋点
所谓的埋点是data采集领域的一个术语。它的学名应该叫事件跟踪,对应的英文是Event Tracking,指的是捕获、处理和发送特定用户行为或事件的相关技术和实现过程。数据埋点是数据分析师、数据产品经理和数据运营。根据业务需求或产品需求,开发用户行为的每个事件的对应位置,开发埋点,通过SDK上报埋点的数据结果,记录汇总数据。分析、推动产品优化、指导运营。
流程附有规范。通过定义,我们可以看到具体的用户行为和事件是我们采集关注的焦点。我们还需要处理和发送相关的技术和实施流程;数据嵌入点是为产品服务的,它来源于产品,因此与产品息息相关。埋点在于具体实战过程,关系到每个人对底层数据的理解。
2.2为什么要埋分
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的好坏直接影响到数据质量、产品质量、运营质量等。
1、Data Driven-Buried Points 深入分析了流量分布和流量级别。通过统计分析,对宏观指标进行深入分析,发现指标背后的问题,洞察用户行为与价值提升的关系。潜在关联
2、产品 优化-对于产品,用户在产品中做了什么,在产品中停留了多久,有什么异常需要注意。这些问题可以通过埋点来解决
3、Refined Operation-Buried Points 可以实现整个产品生命周期、流量质量和不同来源的分布、人群的行为特征和关系,洞察用户行为和增强之间的潜在关系商业价值。
2.3如何埋点
埋点的方法有哪些?目前,大多数公司采用客户端和服务器相结合的方式。
准确度:代码埋点>可视化埋点>全埋点
三、沉点的框架与设计3.1沉点采集的顶层设计
所谓顶层设计,就是搞清楚怎么埋点,用什么方法,什么上传机制,怎么定义,怎么实现等等;我们在遵循唯一性、可扩展性、一致性等的基础上,我们要设计一些通用的字段和生成机制,比如:cid、idfa、idfv等
用户识别:用户识别机制的混乱会导致两种结果:一种是数据不准确,比如UV数据不正确;另一种是漏斗分析环节异常。因此,它应该是: a.严格规范ID自身的识别机制;湾跨平台用户识别
相似抽象:相似抽象包括事件抽象和属性抽象。事件抽象是指浏览事件和点击事件的聚合;属性抽象意味着合并大多数重用场景以增加源区分
采集一致性:采集一致性包括两点:一是跨平台页面的一致命名,二是按钮命名的一致;设置埋点本身的过程就是对底层数据进行标准化的过程,因此一致性尤为重要。只有这样才能真正用起来
渠道配置:渠道主要是指推广渠道、落地页、网页推广页、APP推广页等,这个落地页的配置必须有统一的规范和标准
3.2 埋点采集事件与属性设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变的,哪些是业务行为,哪些是基本属性。基于基础属性事件,我们认为属性必须是采集items,但是属性中的事件属性会根据不同的业务进行调整。因此,我们可以将埋点采集分为协议层埋点和业务层埋点。
业务分解:梳理确认业务流程、运营路径和不同细分场景,定义用户行为路径
分析指标:定义核心业务指标所需的具体事件和数据
事件设计:APP启动、退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.3 Data采集事件与属性设计
EV 事件的命名也遵循一些规则。当同一类型的函数出现在不同的页面或位置时,根据函数名进行命名,在ev参数中区分页面和位置。仅点击按钮时,按按钮名称命名。
ev事件格式:ev分为ev标识和ev参数
规则:
当埋点只有ev标志没有ev参数时,不需要带#
备注:
调整app嵌入点时,ev标志保持不变,只修改后续嵌入点参数(参数值改变或参数类型增加)
一般嵌入点文档中收录的sheet的名称和功能:
A.曝光埋点总结;
B.点击浏览埋点汇总;
C.故障埋点汇总:一般会记录埋点的故障版本或时间;
D、PC、M页面嵌入点对应的pageid;
E。各版本上线时间记录;
在嵌入点文档中,收录了所有的列名和函数:
3.4 基于埋点的统计
如何使用隐藏的统计数据找到隐藏的 ev 事件:
1、指定埋点类型(点击/曝光/浏览)-过滤类型字段
2、清除按钮所属页面(页面或功能)-过滤功能模块字段
3、澄清埋点事件的名称-过滤名称字段
4、知道ev标志,可以直接用ev过滤
如何根据ev事件查询统计:当查询按钮点击统计时,可以直接使用ev标志进行查询,有区别的时候可以限制埋点参数的值。由于ev参数的顺序不需要可变,查询统计时不能限制参数的顺序。
四、Application-数据流的基础
4.1 指标体系
系统性指标可以将不同指标、不同维度串联起来进行综合分析,快速发现当前产品和业务流程中存在的问题。
4.2Visualization
人类对图像信息的解释比文本更有效。可视化对于数据分析极其重要。使用数据可视化可以揭示数据中固有的复杂关系。
4.3 提供的埋点元信息api
data采集服务会将采集的埋点写入Kafka。针对各个业务的实时数据消费需求,我们为各个业务提供了单独的Kafka,流量分发模块会定时读取 埋点管理平台提供的元信息,将流量实时分发给各个业务卡夫卡。
Data采集就像设计一个产品,不能过分。不仅要留有扩展的空间,还要不断思考数据是否完整、不完整、详细、不稳定、快速。
作者丨赵小洛
来源丨赵小洛洛洛
相关文章
一篇了解data采集埋藏数据的文章
如何分析产品的日活跃DAU下降情况?
数据指标体系建立流程
用户行为分析模型简介
![User Behavior Analysis Model.jpg][1] 原标题:几种常用用户行为分析模型的简单介绍一、常用用户行为分析模型------------在数据分析大框架下,通过用户线...
喜欢 1
文章采集api(Kubernetes审计策略文件:rules字段用于非资源类型的请求(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-09-06 22:05
Kubernetes 审计功能提供了一组按时间顺序排列的安全相关记录,记录了单个用户、管理员或其他影响系统的系统组件的活动顺序。它可以帮助集群管理员处理以下问题:
Kube-apiserver 执行审计。每个执行阶段的每个请求都会生成一个事件,然后根据特定的策略对事件进行预处理并写入后端。
每个请求都可以记录一个相关的“阶段”。已知的阶段是:
注意:
审计日志功能会增加API服务器的内存消耗,因为它需要为每个请求存储审计所需的某些上下文。此外,内存消耗取决于审计日志的配置。
审计策略
审核政策定义了关于应记录哪些事件以及应收录哪些数据的规则。在处理事件时,会按顺序与规则列表进行比较。第一个匹配规则设置事件的[auditing-level][auditing-level]。已知的审计级别是:
**无 -** 符合此规则的日志将不会被记录。
**Metadata -** 记录请求的元数据(请求的用户、时间戳、资源、动词等),但不记录请求或响应消息体。
**Request -** 记录事件的元数据和请求的消息体,但不记录响应的消息体。这不适用于非资源类型的请求。
**RequestResponse -** 记录事件元数据、请求和响应消息正文。这不适用于非资源类型的请求。
您可以使用 --audit-policy-file 标志将收录策略的文件传递给 kube-apiserver。如果未设置此标志,则不会记录任何事件。请注意,必须在审核策略文件中提供规则字段。
以下是审核策略文件的示例:
audit/audit-policy.yaml
apiVersion: audit.k8s.io/v1beta1 # This is required.
kind: Policy
# Don't generate audit events for all requests in RequestReceived stage.
omitStages:
- "RequestReceived"
rules:
# Log pod changes at RequestResponse level
- level: RequestResponse
resources:
- group: ""
# Resource "pods" doesn't match requests to any subresource of pods,
# which is consistent with the RBAC policy.
resources: ["pods"]
# Log "pods/log", "pods/status" at Metadata level
- level: Metadata
resources:
- group: ""
resources: ["pods/log", "pods/status"]
# Don't log requests to a configmap called "controller-leader"
- level: None
resources:
- group: ""
resources: ["configmaps"]
resourceNames: ["controller-leader"]
# Don't log watch requests by the "system:kube-proxy" on endpoints or services
- level: None
users: ["system:kube-proxy"]
verbs: ["watch"]
resources:
- group: "" # core API group
resources: ["endpoints", "services"]
# Don't log authenticated requests to certain non-resource URL paths.
- level: None
userGroups: ["system:authenticated"]
nonResourceURLs:
- "/api*" # Wildcard matching.
- "/version"
# Log the request body of configmap changes in kube-system.
- level: Request
resources:
- group: "" # core API group
resources: ["configmaps"]
# This rule only applies to resources in the "kube-system" namespace.
# The empty string "" can be used to select non-namespaced resources.
namespaces: ["kube-system"]
# Log configmap and secret changes in all other namespaces at the Metadata level.
- level: Metadata
resources:
- group: "" # core API group
resources: ["secrets", "configmaps"]
# Log all other resources in core and extensions at the Request level.
- level: Request
resources:
- group: "" # core API group
- group: "extensions" # Version of group should NOT be included.
# A catch-all rule to log all other requests at the Metadata level.
- level: Metadata
# Long-running requests like watches that fall under this rule will not
# generate an audit event in RequestReceived.
omitStages:
- "RequestReceived"
您还可以使用最小的审核策略文件来记录元数据级别的所有请求:
# Log all requests at the Metadata level.
apiVersion: audit.k8s.io/v1beta1
kind: Policy
rules:
- level: Metadata
审核日志后端
k8s 目前提供两种日志后端,Log 后端和 webhook 后端。 Log后端可以将日志输出到文件,webhook后端将日志发送到远程日志服务器。目前,只会使用 Log 后端。使用采集进行日志配置和练习。
以下实用组件版本docker ce17、k8s 1.9.2
您可以使用以下 kube-apiserver 标志来配置日志审核后端:
--audit-log-path 指定用于写入审计事件的日志文件路径。不指定此标志将禁用日志后端。 -手段标准化
--audit-log-maxage 定义保留旧审计日志文件的最大天数
--audit-log-maxbackup 定义要保留的审计日志文件的最大数量
–audit-log-maxsize 定义审计日志文件的最大大小(兆字节)
目前,我们集群中的 kube-apiserver 组件作为静态 Pod 运行。生命周期由 kubelet 直接管理。静态 pod 是由 kebelet 基于 yaml 文件创建的。 yaml存放路径为/etc/kubernetes/manifests/目录,由kubelet管理的apiserver是基于kube-apiserver.yaml创建的,Log后端需要在kube-apiserver的启动参数中添加如下参数.yaml:
--feature-gates=AdvancedAuditing=true
--audit-policy-file=/etc/kubernetes/pki/audit-policy.yaml
--audit-log-format=json
--audit-log-path=/var/log/kubernetes/kubernetes-audit
--audit-log-maxage=30
--audit-log-maxbackup=3
--audit-log-maxsize=100
说明:
最终配置如下:
修改完成后,kubelet会自动删除并重建kube-apiserver的pod(如果pod被删除但几分钟后还没有创建,可以修改-audit-log-maxbackup的值,保存并退出,并等待创建 pod——这可能是一个错误)。重启状态变为running后,可以进入容器查看生成的审计日志文件:
查看日志:
达到100M后:
因为fluentd后面会作为代理来采集日志,所以需要将容器中的日志挂载到宿主机目录,修改kube-apiserver.yaml如下,即/var/log容器中的/kubernetes目录挂载到宿主机的/var/log/kubernetes目录。
日志采集
目前集群中已经部署了fluentd elasticsearch日志解决方案,所以选择fluentd作为Logging-agent,Elasticsearch作为Logging Backend。集群中的 fluentd-es 作为 DaemonSet 运行。根据DaemonSet的特点,每个Node都应该运行fluentd-es pod,但实际情况是19环境下的三个master节点都没有这个pod。查看名为 fluentd-es-v1.22 的 DaemonSet yaml,可以发现 pod 只会运行在带有 alpha.kubernetes.io/fluentd-ds-ready: "true" 标签的节点上:
查看master节点的节点yaml,发现确实没有这个标签。所以需要在master节点节点上加上这个标签:
添加标签后,可以看到在docker-vm-6节点上会自动创建pod。
Fluentd的配置文件在容器中的/etc/td-agent/td-agent.conf中进行配置,部分配置截图如下:
配置由名为 fluentd 的 ConfigMap 指定:
可以看到采集和转发审计日志/var/log/kubernetes/kubernetes-audit不会去配置,所以需要在ConfigMap中添加如下配置:
添加后截图如下:
之后需要重启kube-apiserver节点的fluentd pod。当fluentd采集时,日志也会输出到宿主机的/var/log/fluentd.log,可以看到定位问题的错误日志等信息。如果文件没有审计日志相关的错误,应该将日志发送到logging-backend:elasticsearch,可以通过以下命令进行验证:
详细信息如下,记录在审计日志文件中:
后续可以使用Kibana进行日志展示。 Elasticsearch、Fluentd、Kibana是著名的EFK日志采集解决方案,ELK等可以根据项目需要选择合适的组件。
作者简洁
作者:小万堂,爱写认真的小伙,目前维护原创公众号:“我的小万堂”,专注写golang、docker、kubernetes等知识提升硬实力文章,期待你的注意力。转载须知:务必注明出处(注:来自公众号:我的小碗汤,作者:小碗汤) 查看全部
文章采集api(Kubernetes审计策略文件:rules字段用于非资源类型的请求(组图))
Kubernetes 审计功能提供了一组按时间顺序排列的安全相关记录,记录了单个用户、管理员或其他影响系统的系统组件的活动顺序。它可以帮助集群管理员处理以下问题:
Kube-apiserver 执行审计。每个执行阶段的每个请求都会生成一个事件,然后根据特定的策略对事件进行预处理并写入后端。
每个请求都可以记录一个相关的“阶段”。已知的阶段是:
注意:
审计日志功能会增加API服务器的内存消耗,因为它需要为每个请求存储审计所需的某些上下文。此外,内存消耗取决于审计日志的配置。
审计策略
审核政策定义了关于应记录哪些事件以及应收录哪些数据的规则。在处理事件时,会按顺序与规则列表进行比较。第一个匹配规则设置事件的[auditing-level][auditing-level]。已知的审计级别是:
**无 -** 符合此规则的日志将不会被记录。
**Metadata -** 记录请求的元数据(请求的用户、时间戳、资源、动词等),但不记录请求或响应消息体。
**Request -** 记录事件的元数据和请求的消息体,但不记录响应的消息体。这不适用于非资源类型的请求。
**RequestResponse -** 记录事件元数据、请求和响应消息正文。这不适用于非资源类型的请求。
您可以使用 --audit-policy-file 标志将收录策略的文件传递给 kube-apiserver。如果未设置此标志,则不会记录任何事件。请注意,必须在审核策略文件中提供规则字段。
以下是审核策略文件的示例:
audit/audit-policy.yaml
apiVersion: audit.k8s.io/v1beta1 # This is required.
kind: Policy
# Don't generate audit events for all requests in RequestReceived stage.
omitStages:
- "RequestReceived"
rules:
# Log pod changes at RequestResponse level
- level: RequestResponse
resources:
- group: ""
# Resource "pods" doesn't match requests to any subresource of pods,
# which is consistent with the RBAC policy.
resources: ["pods"]
# Log "pods/log", "pods/status" at Metadata level
- level: Metadata
resources:
- group: ""
resources: ["pods/log", "pods/status"]
# Don't log requests to a configmap called "controller-leader"
- level: None
resources:
- group: ""
resources: ["configmaps"]
resourceNames: ["controller-leader"]
# Don't log watch requests by the "system:kube-proxy" on endpoints or services
- level: None
users: ["system:kube-proxy"]
verbs: ["watch"]
resources:
- group: "" # core API group
resources: ["endpoints", "services"]
# Don't log authenticated requests to certain non-resource URL paths.
- level: None
userGroups: ["system:authenticated"]
nonResourceURLs:
- "/api*" # Wildcard matching.
- "/version"
# Log the request body of configmap changes in kube-system.
- level: Request
resources:
- group: "" # core API group
resources: ["configmaps"]
# This rule only applies to resources in the "kube-system" namespace.
# The empty string "" can be used to select non-namespaced resources.
namespaces: ["kube-system"]
# Log configmap and secret changes in all other namespaces at the Metadata level.
- level: Metadata
resources:
- group: "" # core API group
resources: ["secrets", "configmaps"]
# Log all other resources in core and extensions at the Request level.
- level: Request
resources:
- group: "" # core API group
- group: "extensions" # Version of group should NOT be included.
# A catch-all rule to log all other requests at the Metadata level.
- level: Metadata
# Long-running requests like watches that fall under this rule will not
# generate an audit event in RequestReceived.
omitStages:
- "RequestReceived"
您还可以使用最小的审核策略文件来记录元数据级别的所有请求:
# Log all requests at the Metadata level.
apiVersion: audit.k8s.io/v1beta1
kind: Policy
rules:
- level: Metadata
审核日志后端
k8s 目前提供两种日志后端,Log 后端和 webhook 后端。 Log后端可以将日志输出到文件,webhook后端将日志发送到远程日志服务器。目前,只会使用 Log 后端。使用采集进行日志配置和练习。
以下实用组件版本docker ce17、k8s 1.9.2
您可以使用以下 kube-apiserver 标志来配置日志审核后端:
--audit-log-path 指定用于写入审计事件的日志文件路径。不指定此标志将禁用日志后端。 -手段标准化
--audit-log-maxage 定义保留旧审计日志文件的最大天数
--audit-log-maxbackup 定义要保留的审计日志文件的最大数量
–audit-log-maxsize 定义审计日志文件的最大大小(兆字节)
目前,我们集群中的 kube-apiserver 组件作为静态 Pod 运行。生命周期由 kubelet 直接管理。静态 pod 是由 kebelet 基于 yaml 文件创建的。 yaml存放路径为/etc/kubernetes/manifests/目录,由kubelet管理的apiserver是基于kube-apiserver.yaml创建的,Log后端需要在kube-apiserver的启动参数中添加如下参数.yaml:
--feature-gates=AdvancedAuditing=true
--audit-policy-file=/etc/kubernetes/pki/audit-policy.yaml
--audit-log-format=json
--audit-log-path=/var/log/kubernetes/kubernetes-audit
--audit-log-maxage=30
--audit-log-maxbackup=3
--audit-log-maxsize=100
说明:
最终配置如下:
修改完成后,kubelet会自动删除并重建kube-apiserver的pod(如果pod被删除但几分钟后还没有创建,可以修改-audit-log-maxbackup的值,保存并退出,并等待创建 pod——这可能是一个错误)。重启状态变为running后,可以进入容器查看生成的审计日志文件:
查看日志:
达到100M后:
因为fluentd后面会作为代理来采集日志,所以需要将容器中的日志挂载到宿主机目录,修改kube-apiserver.yaml如下,即/var/log容器中的/kubernetes目录挂载到宿主机的/var/log/kubernetes目录。
日志采集
目前集群中已经部署了fluentd elasticsearch日志解决方案,所以选择fluentd作为Logging-agent,Elasticsearch作为Logging Backend。集群中的 fluentd-es 作为 DaemonSet 运行。根据DaemonSet的特点,每个Node都应该运行fluentd-es pod,但实际情况是19环境下的三个master节点都没有这个pod。查看名为 fluentd-es-v1.22 的 DaemonSet yaml,可以发现 pod 只会运行在带有 alpha.kubernetes.io/fluentd-ds-ready: "true" 标签的节点上:
查看master节点的节点yaml,发现确实没有这个标签。所以需要在master节点节点上加上这个标签:
添加标签后,可以看到在docker-vm-6节点上会自动创建pod。
Fluentd的配置文件在容器中的/etc/td-agent/td-agent.conf中进行配置,部分配置截图如下:
配置由名为 fluentd 的 ConfigMap 指定:
可以看到采集和转发审计日志/var/log/kubernetes/kubernetes-audit不会去配置,所以需要在ConfigMap中添加如下配置:
添加后截图如下:
之后需要重启kube-apiserver节点的fluentd pod。当fluentd采集时,日志也会输出到宿主机的/var/log/fluentd.log,可以看到定位问题的错误日志等信息。如果文件没有审计日志相关的错误,应该将日志发送到logging-backend:elasticsearch,可以通过以下命令进行验证:
详细信息如下,记录在审计日志文件中:
后续可以使用Kibana进行日志展示。 Elasticsearch、Fluentd、Kibana是著名的EFK日志采集解决方案,ELK等可以根据项目需要选择合适的组件。
作者简洁
作者:小万堂,爱写认真的小伙,目前维护原创公众号:“我的小万堂”,专注写golang、docker、kubernetes等知识提升硬实力文章,期待你的注意力。转载须知:务必注明出处(注:来自公众号:我的小碗汤,作者:小碗汤)
文章采集api(站内站不算是什么新型的东西,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-06 15:01
最近有很多客户很想用我们的系统更新网站。小米也表示很郁闷。这么多客户都没机会为你服务,我都快吐血了。我们不妨试试另一种方式联系你的网站。
重力加速度
仅支持 Rice采集 的系统:WordPress、Zblog、Empirecms、织梦cms MIPcms站群 管理系统。老实说,我觉得有点小,但是我们公司在开发大项目,也在测试,真的没有时间闲着技术。我只能想到这种傻瓜式方式来联系大家网站。这个方法虽然有点笨,但是可以加快大家主站权重的提升非常友好。这个方法就是站台
其实站内站并不是什么新事物。一般SEO培训场所推荐你使用这个站内站,因为它确实可以很快增加主站的权重。通过百度搜索,可以看到各种现场站的教程。
什么是站内站?给你解释一下,其实就是在你主站的根目录下创建一个/boke这样的子目录。然后在你的博克的这个目录中重新安装一个新的网站 程序。比如你的网站程序是applecms,那么你在你的boke目录下安装wordpress程序,然后像其他建站工具一样安装,这样你打开的背景就是【这里我用wordpress作为例如,所以背景是 wp-admin 和其他复选标记。 】安装完成后,将微米采集器的api上传到boke目录下,即使是你站点的根目录。然后就可以使用了。
总结:即使不使用微米采集器,也可以考虑在站内多加站。对您的网站 只有好处没有害处。站内推荐程序:博客、论坛等对百度友好的程序。 查看全部
文章采集api(站内站不算是什么新型的东西,你知道吗?)
最近有很多客户很想用我们的系统更新网站。小米也表示很郁闷。这么多客户都没机会为你服务,我都快吐血了。我们不妨试试另一种方式联系你的网站。
https://www.weiseo.cc/wp-content/uploads/2021/06/权重加速器-300x77.jpg 300w" />重力加速度
仅支持 Rice采集 的系统:WordPress、Zblog、Empirecms、织梦cms MIPcms站群 管理系统。老实说,我觉得有点小,但是我们公司在开发大项目,也在测试,真的没有时间闲着技术。我只能想到这种傻瓜式方式来联系大家网站。这个方法虽然有点笨,但是可以加快大家主站权重的提升非常友好。这个方法就是站台
其实站内站并不是什么新事物。一般SEO培训场所推荐你使用这个站内站,因为它确实可以很快增加主站的权重。通过百度搜索,可以看到各种现场站的教程。
什么是站内站?给你解释一下,其实就是在你主站的根目录下创建一个/boke这样的子目录。然后在你的博克的这个目录中重新安装一个新的网站 程序。比如你的网站程序是applecms,那么你在你的boke目录下安装wordpress程序,然后像其他建站工具一样安装,这样你打开的背景就是【这里我用wordpress作为例如,所以背景是 wp-admin 和其他复选标记。 】安装完成后,将微米采集器的api上传到boke目录下,即使是你站点的根目录。然后就可以使用了。
总结:即使不使用微米采集器,也可以考虑在站内多加站。对您的网站 只有好处没有害处。站内推荐程序:博客、论坛等对百度友好的程序。
文章采集api( WPContent比wp-autopostpro更好用的数据和文章采集插件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-09-06 12:04
WPContent比wp-autopostpro更好用的数据和文章采集插件)
比 wp-autopost pro 更好的数据和文章采集 插件
WP Content Crawler 允许您将网站 上的几乎所有内容自动发布到 WordPress 上的网站、博客或在线商店!设置好参数后,插件会找到消息的URL,并在后台自动扫描。详细的工具栏 - 查看后台发生了什么。活动站点、查看的消息数、更新的消息数、上次查看和更新的消息数、最后添加的 URL、触发的上一个和下一个 CRON 事件、当前保存的消息和 URL...
支持最新版本的WordPress5.3.x+和PHP7.4+
WP Content Crawler 的主要功能是什么?
保存每个帖子的详细信息
标题、摘录、内容、标签、类别、项目符号、日期、自定义元、分类法、元关键字、元描述、特色图片、发布图片、状态......一切。
视觉选择器(视觉检查器)
只需单击一个元素即可找到其 CSS 选择器。您还可以获得可能感兴趣的替代 CSS 选择器。无需再离开管理面板。
获取(获取、获取、保存)帖子
配置好设置后,插件会找到帖子的网址,并在后台自动抓取。
重新抓取(更新)帖子
自动重新抓取帖子以始终保持更新。您可以限制帖子的更新次数,设置更新间隔,以及忽略旧帖子。
删除帖子
您要删除旧的已抓取帖子吗?插件可以自动删除。
控制计划
您可以设置网站每次执行URL采集和抓取事件的次数。例如,您可以每分钟保存 3 个帖子,或者每 2 分钟运行 5 次 URL 采集。
保存类别
你的网站没有目标类别?没问题。该插件可以为您创建目标类别。只需定义用于查找类别名称的 CSS 选择器。它们甚至可以创建为子类别。
保存块(永久链接)
您可以定义帖子的永久链接。您可以从目标站点获取永久链接、输入自定义文本,甚至可以使用短代码为块创建模板。
保存类别
方法通过从目标站点检索或手动输入来保存分类值。保存自定义帖子类型的详细信息比以往更容易。
将帖子保存在自定义类别中
自定义帖子类型是否有自定义类别?没问题。您可以定义自定义帖子类型使用的自定义类别分类,并在定义帖子的类别时选择这些类别。该插件还可以为您创建自定义类别。
自定义帖子元
将任何内容保存为自定义帖子元。您可以使用 CSS 选择器或直接输入值。
内容模板
使用简码准备帖子内容、标题、摘录、列表项和图库项模板。此外,您可以使用选项框为每个 CSS 选择器值定义一个模板。
替代方案
即使目标站点的设计彼此不同,您也可以编写替代选择器来获取数据。
查找和替换任何内容
您可以使用纯文本或正则表达式来查找和替换任何内容。您甚至可以修改页面的 HTML,创建自己的 HTML 元素并编写选择器来使用它们。您甚至可以更改图像 URL。你有权力。
分页帖子
目标帖子有多于一页?不要担心。您还可以保存分页的帖子。
列表类型帖子
网站 创建的一些帖子中有列表。您可以从帖子中提取列表,创建应应用于每个列表项的模板,甚至可以反转列表。
删除不必要的元素
有时你需要去掉一些元素,比如广告、评论,然后给它们命名。只需编写其 CSS 选择器即可将其删除。
自动插入分类网址
目标站点上有数百个类别?一块蛋糕。只需编写 CSS 选择器,插件就会为您插入它们。
帖子类型
设置帖子类型。它可以是 WordPress 安装中可用的帖子、页面、产品或任何其他帖子类型。
删除链接
您可以从帖子中删除链接。只需选中复选框,链接就会消失。就这么简单
密码保护
您可以为帖子设置密码,只向拥有密码的用户显示帖子。
注释
您可以自己添加注释以提醒您有关该站点的信息。 CSS 选择器、TODO 列表等
实时测试所有内容,实时测试
抓取、URL 集合、CSS 选择器、正则表达式、即时查找和替换选项和代理。您还可以启用缓存以更快地执行测试并减少发送到目标站点的请求。
一次
测试网站的所有设置。使用测试器,您可以测试站点设置中配置的所有选项,以确保在启用自动抓取之前一切都按需运行。
工具
使用这些工具,您可以使用帖子的网址手动保存帖子、使用 ID 重新抓取帖子或删除已保存的网址。
为每个站点自定义常规设置
您可以为每个帖子提供自定义的常规设置以覆盖它们并使它们适合网站。
帖子状态
您可以直接发布已保存的帖子,也可以将它们保留为草稿,以便在发布前进行审核。
保存帖子内容中的所有图片 保存帖子内容中的所有图片
就像选中一个复选框一样简单。
将图片另存为图库
您可以将目标页面中的图片保存为图库,并为每张图片提供一个模板,使其适合您在前端使用的图库。您还可以通过选中复选框将图像保存为 WooCommerce 图库。
任何数据作为简码
从目标页面获取任何内容作为简码,并使用插件模板中的简码将任何数据放置在您想要的任何位置。
代理
使用一个或多个代理从您的 IP 无法访问的站点获取内容。
饼干
为每个请求附加一个 cookie(例如会话 cookie)。例如,通过这种方式,您可以像登录时一样抓取目标站点。
尽可能多地抓取帖子
您可以设置帖子抓取或网址采集 CRON 事件应运行的次数。例如,通过这种方式,您每分钟可以保存 100 个帖子。请注意并考虑服务器的容量。
电子邮件通知
设置CSS选择器,其分类和帖子页面的值不能为空。当使用这些选择器发现空值时,您将收到一封电子邮件通知。
从 JSON 中获取数据
当为CSS选择器启用JSON解析时,您可以轻松地从JSON中获取值。
高级 HTML 操作
在响应HTML中查找内容,在元素属性中查找和替换,交换元素属性,删除元素属性,操作元素的HTML,删除HTML元素...
自动翻译
使用 Google Cloud Translation API、Microsoft Translator Text API、Yandex Translate API 或 Amazon Translate API 的人工智能自动翻译帖子。请注意,这些服务是付费服务,Yandex Translate API 除外。付费用户也可以限时免费提供服务。您可以查看其定价页面以了解更多信息。
自动伪原创
使用轮播自动重写已抓取帖子的内容以提高搜索引擎优化。该插件目前实现了收费的 Spin Rewriter API 和 Turkce Spin API。您可以访问他们的网站 了解定价详情。
重复发布检查
按 URL、帖子标题和/或帖子内容检查重复帖子。如果您使用 WooCommerce,SKU 已存在的产品将被视为重复产品,不会添加到您的 网站。
预定的帖子
您可以添加/删除发布日期的分钟数。通过这种方式,您可以安排发布。
保存 WooCommerce 产品
保存价格、库存、运费、属性和高级选项。您可以将产品保存为简单产品或外部产品。您还可以设置可下载文件选项并将产品定义为虚拟产品。这些选项可用于大于或等于 3.3 的 WooCommerce 版本。
选项框
你有控制权!为 CSS 选择器找到的值定义许多选项。选项包括搜索和替换、计算、模板和 JSON 解析设置。您还可以轻松导入/导出选项框中定义的选项。
像专业人士一样处理
文件可轻松重命名、复制和移动保存的文件。您还可以使用模板定义保存的媒体文件的标题、描述、标题和替代文本,其中可以使用任何短代码。您还可以为保存的文件指定随机名称。
专业
WordPress 处理 iframe 和脚本的方式与 WordPress 不允许显示 iframe 和脚本的方式相同,因为它们会带来安全风险。您只需要选中一个复选框即可将 iframe 和 HTML 脚本元素转换为短代码。短代码将显示您定义的允许源域中的 iframe 和脚本。
快速保存
使用快速保存按钮可以更快地保存设置。无需等待页面重新加载。
正则表达式 在 find-replace 选项中定义一个正则表达式来查找任何内容。您还可以使用分隔符和修饰符进行更精确的匹配。
保存“srcset”属性
当其他尺寸的保存图片可用时,插件会将它们分配给 img 元素的 srcset 属性,以便您的页面在不同屏幕尺寸下加载速度更快。
保存“alt”和“title”属性
当您保存图像时,它们的“alt”和“标题”属性会自动从目标站点检索并分配给保存的媒体。您还可以为其定义模板以应用您的 SEO 策略。
警告
了解问题发生的时间。该插件会向您显示错误的详细信息,以便您可以立即修复它。
处理字符编码问题
即使目标站点收录混合编码,插件也可以处理不同的字符编码。您可以通过选中复选框来切换编码。
轻松切换设置
Navigation 将导航固定到顶部!该插件在切换到新标签之前会存储您的位置,并在您再次激活标签时恢复之前的位置。不再在设置之间迷失。
手动抓取工具
使用手动抓取工具通过输入网址来保存多个帖子。您还可以输入类别 URL,以便该工具可以从那里获取帖子 URL。此外,您可以将其设置为同时抓取多个帖子。
添加网址到数据库
插件会自动采集 URL。但是,如果您希望它仅抓取某些 URL,则可以使用手动抓取工具将它们手动添加到数据库中。这样,将使用您的计划选项自动搜索指定的 URL。
启用/禁用特定网站的自动抓取
您可以单独启用或禁用每个站点的自动抓取。
导入/导出
您可以轻松导入和导出网站 设置。只需复制并粘贴插件创建的代码即可。
无限
添加无限站点并激活您想要的站点数量。
详细信息中心
了解背景。活动站点、已爬取的帖子数、已更新的帖子数、上次爬取和更新的帖子、上次添加的 URL、上次和下一次运行的 CRON 事件、当前的帖子和 URL正在保存...
从管理面板获取更新
只要准备好更新,就可以一键更新插件。只需转到管理面板中的更新页面即可。
使用最安全的 PHP
该插件支持最新版本的 PHP。
使用最新的浏览器
该插件支持 Chrome、Firefox、Safari、Opera 和 Edge。
互动指南
交互式指南向您展示如何逐步配置设置以实现某些功能,例如实时文档。您可以随时激活这些指南。您甚至可以从特定步骤开始。
在线文档
您可以在需要时查看在线文档。
设置旁边
中的每个设置
快速指南插件有一个快速指南,可以帮助您了解每个设置的作用。
视频教程
观看视频教程,轻松了解如何使用插件。
要求
PHP> = 7.2、json、mbstring、curl、dom、WP-Cron。这些已经在大多数主机中可用。即使扩展程序尚未激活,大多数托管站点也允许您从其控制面板启用这些扩展程序。有关详细信息,请参阅文档。
WP 版本测试
5.3、5.2、5.1、5.0、4.9
通过 WooCommerce 版本测试
3.9、3.8、3.7、3.6、3.5
本地实测截图预览
WP Content Crawler v1.10.0 完美破解版 – WordPress data采集plugin
WP Content Crawler v1.10.0 完美破解版 – WordPress data采集plugin
WP Content Crawler v1.10.0 完美破解版 – WordPress data采集plugin
WP Content Crawler v1.10.0 完美破解版 – WordPress data采集plugin
链接资源下载资源下载价39元或升级VIP会员后免费
购买后会显示下载地址 查看全部
文章采集api(
WPContent比wp-autopostpro更好用的数据和文章采集插件)
比 wp-autopost pro 更好的数据和文章采集 插件
WP Content Crawler 允许您将网站 上的几乎所有内容自动发布到 WordPress 上的网站、博客或在线商店!设置好参数后,插件会找到消息的URL,并在后台自动扫描。详细的工具栏 - 查看后台发生了什么。活动站点、查看的消息数、更新的消息数、上次查看和更新的消息数、最后添加的 URL、触发的上一个和下一个 CRON 事件、当前保存的消息和 URL...
支持最新版本的WordPress5.3.x+和PHP7.4+
WP Content Crawler 的主要功能是什么?
保存每个帖子的详细信息
标题、摘录、内容、标签、类别、项目符号、日期、自定义元、分类法、元关键字、元描述、特色图片、发布图片、状态......一切。
视觉选择器(视觉检查器)
只需单击一个元素即可找到其 CSS 选择器。您还可以获得可能感兴趣的替代 CSS 选择器。无需再离开管理面板。
获取(获取、获取、保存)帖子
配置好设置后,插件会找到帖子的网址,并在后台自动抓取。
重新抓取(更新)帖子
自动重新抓取帖子以始终保持更新。您可以限制帖子的更新次数,设置更新间隔,以及忽略旧帖子。
删除帖子
您要删除旧的已抓取帖子吗?插件可以自动删除。
控制计划
您可以设置网站每次执行URL采集和抓取事件的次数。例如,您可以每分钟保存 3 个帖子,或者每 2 分钟运行 5 次 URL 采集。
保存类别
你的网站没有目标类别?没问题。该插件可以为您创建目标类别。只需定义用于查找类别名称的 CSS 选择器。它们甚至可以创建为子类别。
保存块(永久链接)
您可以定义帖子的永久链接。您可以从目标站点获取永久链接、输入自定义文本,甚至可以使用短代码为块创建模板。
保存类别
方法通过从目标站点检索或手动输入来保存分类值。保存自定义帖子类型的详细信息比以往更容易。
将帖子保存在自定义类别中
自定义帖子类型是否有自定义类别?没问题。您可以定义自定义帖子类型使用的自定义类别分类,并在定义帖子的类别时选择这些类别。该插件还可以为您创建自定义类别。
自定义帖子元
将任何内容保存为自定义帖子元。您可以使用 CSS 选择器或直接输入值。
内容模板
使用简码准备帖子内容、标题、摘录、列表项和图库项模板。此外,您可以使用选项框为每个 CSS 选择器值定义一个模板。
替代方案
即使目标站点的设计彼此不同,您也可以编写替代选择器来获取数据。
查找和替换任何内容
您可以使用纯文本或正则表达式来查找和替换任何内容。您甚至可以修改页面的 HTML,创建自己的 HTML 元素并编写选择器来使用它们。您甚至可以更改图像 URL。你有权力。
分页帖子
目标帖子有多于一页?不要担心。您还可以保存分页的帖子。
列表类型帖子
网站 创建的一些帖子中有列表。您可以从帖子中提取列表,创建应应用于每个列表项的模板,甚至可以反转列表。
删除不必要的元素
有时你需要去掉一些元素,比如广告、评论,然后给它们命名。只需编写其 CSS 选择器即可将其删除。
自动插入分类网址
目标站点上有数百个类别?一块蛋糕。只需编写 CSS 选择器,插件就会为您插入它们。
帖子类型
设置帖子类型。它可以是 WordPress 安装中可用的帖子、页面、产品或任何其他帖子类型。
删除链接
您可以从帖子中删除链接。只需选中复选框,链接就会消失。就这么简单
密码保护
您可以为帖子设置密码,只向拥有密码的用户显示帖子。
注释
您可以自己添加注释以提醒您有关该站点的信息。 CSS 选择器、TODO 列表等
实时测试所有内容,实时测试
抓取、URL 集合、CSS 选择器、正则表达式、即时查找和替换选项和代理。您还可以启用缓存以更快地执行测试并减少发送到目标站点的请求。
一次
测试网站的所有设置。使用测试器,您可以测试站点设置中配置的所有选项,以确保在启用自动抓取之前一切都按需运行。
工具
使用这些工具,您可以使用帖子的网址手动保存帖子、使用 ID 重新抓取帖子或删除已保存的网址。
为每个站点自定义常规设置
您可以为每个帖子提供自定义的常规设置以覆盖它们并使它们适合网站。
帖子状态
您可以直接发布已保存的帖子,也可以将它们保留为草稿,以便在发布前进行审核。
保存帖子内容中的所有图片 保存帖子内容中的所有图片
就像选中一个复选框一样简单。
将图片另存为图库
您可以将目标页面中的图片保存为图库,并为每张图片提供一个模板,使其适合您在前端使用的图库。您还可以通过选中复选框将图像保存为 WooCommerce 图库。
任何数据作为简码
从目标页面获取任何内容作为简码,并使用插件模板中的简码将任何数据放置在您想要的任何位置。
代理
使用一个或多个代理从您的 IP 无法访问的站点获取内容。
饼干
为每个请求附加一个 cookie(例如会话 cookie)。例如,通过这种方式,您可以像登录时一样抓取目标站点。
尽可能多地抓取帖子
您可以设置帖子抓取或网址采集 CRON 事件应运行的次数。例如,通过这种方式,您每分钟可以保存 100 个帖子。请注意并考虑服务器的容量。
电子邮件通知
设置CSS选择器,其分类和帖子页面的值不能为空。当使用这些选择器发现空值时,您将收到一封电子邮件通知。
从 JSON 中获取数据
当为CSS选择器启用JSON解析时,您可以轻松地从JSON中获取值。
高级 HTML 操作
在响应HTML中查找内容,在元素属性中查找和替换,交换元素属性,删除元素属性,操作元素的HTML,删除HTML元素...
自动翻译
使用 Google Cloud Translation API、Microsoft Translator Text API、Yandex Translate API 或 Amazon Translate API 的人工智能自动翻译帖子。请注意,这些服务是付费服务,Yandex Translate API 除外。付费用户也可以限时免费提供服务。您可以查看其定价页面以了解更多信息。
自动伪原创
使用轮播自动重写已抓取帖子的内容以提高搜索引擎优化。该插件目前实现了收费的 Spin Rewriter API 和 Turkce Spin API。您可以访问他们的网站 了解定价详情。
重复发布检查
按 URL、帖子标题和/或帖子内容检查重复帖子。如果您使用 WooCommerce,SKU 已存在的产品将被视为重复产品,不会添加到您的 网站。
预定的帖子
您可以添加/删除发布日期的分钟数。通过这种方式,您可以安排发布。
保存 WooCommerce 产品
保存价格、库存、运费、属性和高级选项。您可以将产品保存为简单产品或外部产品。您还可以设置可下载文件选项并将产品定义为虚拟产品。这些选项可用于大于或等于 3.3 的 WooCommerce 版本。
选项框
你有控制权!为 CSS 选择器找到的值定义许多选项。选项包括搜索和替换、计算、模板和 JSON 解析设置。您还可以轻松导入/导出选项框中定义的选项。
像专业人士一样处理
文件可轻松重命名、复制和移动保存的文件。您还可以使用模板定义保存的媒体文件的标题、描述、标题和替代文本,其中可以使用任何短代码。您还可以为保存的文件指定随机名称。
专业
WordPress 处理 iframe 和脚本的方式与 WordPress 不允许显示 iframe 和脚本的方式相同,因为它们会带来安全风险。您只需要选中一个复选框即可将 iframe 和 HTML 脚本元素转换为短代码。短代码将显示您定义的允许源域中的 iframe 和脚本。
快速保存
使用快速保存按钮可以更快地保存设置。无需等待页面重新加载。
正则表达式 在 find-replace 选项中定义一个正则表达式来查找任何内容。您还可以使用分隔符和修饰符进行更精确的匹配。
保存“srcset”属性
当其他尺寸的保存图片可用时,插件会将它们分配给 img 元素的 srcset 属性,以便您的页面在不同屏幕尺寸下加载速度更快。
保存“alt”和“title”属性
当您保存图像时,它们的“alt”和“标题”属性会自动从目标站点检索并分配给保存的媒体。您还可以为其定义模板以应用您的 SEO 策略。
警告
了解问题发生的时间。该插件会向您显示错误的详细信息,以便您可以立即修复它。
处理字符编码问题
即使目标站点收录混合编码,插件也可以处理不同的字符编码。您可以通过选中复选框来切换编码。
轻松切换设置
Navigation 将导航固定到顶部!该插件在切换到新标签之前会存储您的位置,并在您再次激活标签时恢复之前的位置。不再在设置之间迷失。
手动抓取工具
使用手动抓取工具通过输入网址来保存多个帖子。您还可以输入类别 URL,以便该工具可以从那里获取帖子 URL。此外,您可以将其设置为同时抓取多个帖子。
添加网址到数据库
插件会自动采集 URL。但是,如果您希望它仅抓取某些 URL,则可以使用手动抓取工具将它们手动添加到数据库中。这样,将使用您的计划选项自动搜索指定的 URL。
启用/禁用特定网站的自动抓取
您可以单独启用或禁用每个站点的自动抓取。
导入/导出
您可以轻松导入和导出网站 设置。只需复制并粘贴插件创建的代码即可。
无限
添加无限站点并激活您想要的站点数量。
详细信息中心
了解背景。活动站点、已爬取的帖子数、已更新的帖子数、上次爬取和更新的帖子、上次添加的 URL、上次和下一次运行的 CRON 事件、当前的帖子和 URL正在保存...
从管理面板获取更新
只要准备好更新,就可以一键更新插件。只需转到管理面板中的更新页面即可。
使用最安全的 PHP
该插件支持最新版本的 PHP。
使用最新的浏览器
该插件支持 Chrome、Firefox、Safari、Opera 和 Edge。
互动指南
交互式指南向您展示如何逐步配置设置以实现某些功能,例如实时文档。您可以随时激活这些指南。您甚至可以从特定步骤开始。
在线文档
您可以在需要时查看在线文档。
设置旁边
中的每个设置
快速指南插件有一个快速指南,可以帮助您了解每个设置的作用。
视频教程
观看视频教程,轻松了解如何使用插件。
要求
PHP> = 7.2、json、mbstring、curl、dom、WP-Cron。这些已经在大多数主机中可用。即使扩展程序尚未激活,大多数托管站点也允许您从其控制面板启用这些扩展程序。有关详细信息,请参阅文档。
WP 版本测试
5.3、5.2、5.1、5.0、4.9
通过 WooCommerce 版本测试
3.9、3.8、3.7、3.6、3.5
本地实测截图预览
WP Content Crawler v1.10.0 完美破解版 – WordPress data采集plugin
WP Content Crawler v1.10.0 完美破解版 – WordPress data采集plugin
WP Content Crawler v1.10.0 完美破解版 – WordPress data采集plugin
WP Content Crawler v1.10.0 完美破解版 – WordPress data采集plugin
链接资源下载资源下载价39元或升级VIP会员后免费
购买后会显示下载地址
文章采集api(如何看出来它是否是动态加载的呢?教大家一个可以肉眼可查 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-09-06 04:30
)
内容
前言
大家好,我叫山年。这是Python爬虫实战案例持续更新的第七天。感觉很多东西不好写,不知道写什么案例。
你可以给我反馈采集你想要哪个网站,或者你需要发布哪些网站函数,或者脚本,或者一些基础知识的解释。
写好文章,拒绝各种表情换人文章,原创干货现在每篇都写了,没那么多时间逗你了。
开始
Target网站:鱼脸的锚
嗯,没想到会有几个男同胞...
我们需要的很简单,采集cover 图片然后进行人脸值检测,然后对检测到的分数进行排序。
分析(x0)
简单看一下网页的元素,可以看到我们需要的图片在li标签的img标签的src属性中。每个 li 标签都收录一个主机的信息。
这样的图片加载我已经讲过很多次了。最有可能是动态加载的,也就是我们拉动滑块的时候,图片会自动刷新,就像之前的【Python】完美采集某宝数据,到底YYDS A和B是哪个? (有完整的源代码和视频教程)是一样的。
那么如何判断它是否是动态加载的呢?
1.教你一个肉眼可以查到的方法,那就是手动快速拉动浏览器的滚动条。你会发现很多图片需要时间来加载。当它们第一次出现时,它是一个白板,然后它们被加载。图片!
2. 即直接查看网页元素。如果是动态加载的,而我们的浏览器还没有向下滑动,则说明下图一定不能加载。
那我们直接检查li标签中是否有我们的图片数据:
显然这张图片格式不同,打不开,是白板图片。
好的,这意味着这又是一个动态加载的网站,那么我们开始抓包吧。
分析(x1)
刷新网页并获取包裹。你可以看到这个东西。它有两张图片,rs1 和 rs6。 rs1是大图,另一个是小图。你可以想到采集。我在这里采集大图。
分析这个请求,它是一个get请求。老实说,我没想到它是一个get,所以它有点特别。我们之前只分析了网页元素。按道理,我们需要的数据也应该在网页源代码中。 ...不过没关系,自己去看看吧,不建议从源码中获取数据。
原因是:你可以看到第二页和第一页的URL没有变化,你注意到了吗?如果从网页的源代码中获取,那么就可以获取到第二页的数据。怎么拿到第一页?所以不要从网页的源代码中提取数据。我们没有办法构造url。
如果你是一个包,分析起来很容易。你只需要把url后面的1改成2就可以成为第二页了。你还有这样的热情吗?我不相信只是抢包裹。
是的,如果您有多个采集页面,只需构建网址即可。
采集 的 Python 代码
import requests
import jsonpath
import os
from urllib.request import urlretrieve
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'}
if not os.path.exists('./pic'):
os.mkdir('./pic')
for i in range(1, 100000):
try:
url = f'https://www.douyu.com/gapi/rknc/directory/yzRec/{i}'
r = requests.get(url, headers=headers)
names = jsonpath.jsonpath(r.json(), '$..nn')
pngs = jsonpath.jsonpath(r.json(), '$..rs1')
for name, png in zip(names, pngs):
urlretrieve(png, './pic' + '/' + name + '.png')
print(names)
print(pngs)
except:
exit()
采集的效果
人脸值检测函数的结构
注册百度只能云:地址
根据图片选择我们需要的服务:
自己查看技术文档:
点击立即使用-创建应用程序:
正常填写即可
创建后,点击管理应用
获取 API Key 和 Secret Key
看技术文档,不用过多解释就开始构建我们的函数
提醒:模块安装
pip install baidu-aip
facerg.py
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2019/5/7 23:20
# @Author : 善念
# @Software: PyCharm
from aip import AipFace
import base64
def face_rg(file_Path):
""" 你的 api_id AK SK """
api_id = '你的id'
api_key = 'ni de aipkey'
secret_key = '你自己的key'
client = AipFace(api_id, api_key, secret_key)
with open(file_Path, 'rb') as fp:
data = base64.b64encode(fp.read())
image = data.decode()
imageType = "BASE64"
options = {}
options["face_field"] = 'beauty'
""" 调用人脸检测 """
res = client.detect(image, imageType, options)
score = res['result']['face_list'][0]['beauty']
return score
排序源代码
from facerg import face_rg
path = r'图片文件夹路径'
images = os.listdir(path)
print(images)
yz = []
yz_dict = {}
for image in images:
try:
name = image[0:-4]
score = face_rg(path + '\\' + image)
yz_dict[score] = name
yz.append(score)
except:
pass
yz.sort(reverse=True)
for a, b in enumerate(yz):
print('小姐姐的名字是:{}丨颜值名次是:第{}名丨她的颜值分数为:{}'.format(yz_dict[b], a+1, b))
结果展示
完成所有源代码
import requests
import jsonpath
import os
from urllib.request import urlretrieve
# headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'}
#
# if not os.path.exists('./pic'):
# os.mkdir('./pic')
# for i in range(1, 100000):
# try:
# url = f'https://www.douyu.com/gapi/rknc/directory/yzRec/{i}'
# r = requests.get(url, headers=headers)
# names = jsonpath.jsonpath(r.json(), '$..nn')
# pngs = jsonpath.jsonpath(r.json(), '$..rs1')
# for name, png in zip(names, pngs):
# urlretrieve(png, './pic' + '/' + name + '.png')
# print(names)
# print(pngs)
# except:
# exit()
from facerg import face_rg
path = r'C:\Users\admin\PycharmProjects\pythonProject\1A演示\斗鱼\pic'
images = os.listdir(path)
print(images)
yz = []
yz_dict = {}
for image in images:
try:
name = image[0:-4]
score = face_rg(path + '\\' + image)
yz_dict[score] = name
yz.append(score)
except:
pass
yz.sort(reverse=True)
for a, b in enumerate(yz):
print('小姐姐的名字是:{}丨颜值名次是:第{}名丨她的颜值分数为:{}'.format(yz_dict[b], a+1, b))
只需将 facerg.py 作为自写模块调用即可。
视频教程地址
程序员相亲:一张Python老大采集相亲网的合影,打造排行榜!
我有话要说
——当你毫无保留地信任一个人时,最终只会有两种结果。不是生活中的那个人,也不是生活中的一课。
文章的话现在就写好了,每一个文章我都会说的很详细,所以需要很长时间,通常两个多小时。每一个赞和评论集都是我每天更新的动力。
原创不易,再次感谢您的支持。
①2000多本Python电子书(主流经典书籍应有)
②Python标准库资料(最全中文版)
③项目源码(四十或五十个有趣经典的动手项目及源码)
④Python基础、爬虫、Web开发、大数据分析视频(适合小白学习)
⑤ Python 学习路线图(告别不受影响的学习)
在我的Q.,Q技术交流群可以自己拿走。如果在学习或工作中遇到问题,群里会有大神帮忙解答。有时你会想一天。编号928946953。
查看全部
文章采集api(如何看出来它是否是动态加载的呢?教大家一个可以肉眼可查
)
内容
前言
大家好,我叫山年。这是Python爬虫实战案例持续更新的第七天。感觉很多东西不好写,不知道写什么案例。
你可以给我反馈采集你想要哪个网站,或者你需要发布哪些网站函数,或者脚本,或者一些基础知识的解释。
写好文章,拒绝各种表情换人文章,原创干货现在每篇都写了,没那么多时间逗你了。
开始
Target网站:鱼脸的锚
嗯,没想到会有几个男同胞...
我们需要的很简单,采集cover 图片然后进行人脸值检测,然后对检测到的分数进行排序。
分析(x0)
简单看一下网页的元素,可以看到我们需要的图片在li标签的img标签的src属性中。每个 li 标签都收录一个主机的信息。
这样的图片加载我已经讲过很多次了。最有可能是动态加载的,也就是我们拉动滑块的时候,图片会自动刷新,就像之前的【Python】完美采集某宝数据,到底YYDS A和B是哪个? (有完整的源代码和视频教程)是一样的。
那么如何判断它是否是动态加载的呢?
1.教你一个肉眼可以查到的方法,那就是手动快速拉动浏览器的滚动条。你会发现很多图片需要时间来加载。当它们第一次出现时,它是一个白板,然后它们被加载。图片!
2. 即直接查看网页元素。如果是动态加载的,而我们的浏览器还没有向下滑动,则说明下图一定不能加载。
那我们直接检查li标签中是否有我们的图片数据:
显然这张图片格式不同,打不开,是白板图片。
好的,这意味着这又是一个动态加载的网站,那么我们开始抓包吧。
分析(x1)
刷新网页并获取包裹。你可以看到这个东西。它有两张图片,rs1 和 rs6。 rs1是大图,另一个是小图。你可以想到采集。我在这里采集大图。
分析这个请求,它是一个get请求。老实说,我没想到它是一个get,所以它有点特别。我们之前只分析了网页元素。按道理,我们需要的数据也应该在网页源代码中。 ...不过没关系,自己去看看吧,不建议从源码中获取数据。
原因是:你可以看到第二页和第一页的URL没有变化,你注意到了吗?如果从网页的源代码中获取,那么就可以获取到第二页的数据。怎么拿到第一页?所以不要从网页的源代码中提取数据。我们没有办法构造url。
如果你是一个包,分析起来很容易。你只需要把url后面的1改成2就可以成为第二页了。你还有这样的热情吗?我不相信只是抢包裹。
是的,如果您有多个采集页面,只需构建网址即可。
采集 的 Python 代码
import requests
import jsonpath
import os
from urllib.request import urlretrieve
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'}
if not os.path.exists('./pic'):
os.mkdir('./pic')
for i in range(1, 100000):
try:
url = f'https://www.douyu.com/gapi/rknc/directory/yzRec/{i}'
r = requests.get(url, headers=headers)
names = jsonpath.jsonpath(r.json(), '$..nn')
pngs = jsonpath.jsonpath(r.json(), '$..rs1')
for name, png in zip(names, pngs):
urlretrieve(png, './pic' + '/' + name + '.png')
print(names)
print(pngs)
except:
exit()
采集的效果
人脸值检测函数的结构
注册百度只能云:地址
根据图片选择我们需要的服务:
自己查看技术文档:
点击立即使用-创建应用程序:
正常填写即可
创建后,点击管理应用
获取 API Key 和 Secret Key
看技术文档,不用过多解释就开始构建我们的函数
提醒:模块安装
pip install baidu-aip
facerg.py
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2019/5/7 23:20
# @Author : 善念
# @Software: PyCharm
from aip import AipFace
import base64
def face_rg(file_Path):
""" 你的 api_id AK SK """
api_id = '你的id'
api_key = 'ni de aipkey'
secret_key = '你自己的key'
client = AipFace(api_id, api_key, secret_key)
with open(file_Path, 'rb') as fp:
data = base64.b64encode(fp.read())
image = data.decode()
imageType = "BASE64"
options = {}
options["face_field"] = 'beauty'
""" 调用人脸检测 """
res = client.detect(image, imageType, options)
score = res['result']['face_list'][0]['beauty']
return score
排序源代码
from facerg import face_rg
path = r'图片文件夹路径'
images = os.listdir(path)
print(images)
yz = []
yz_dict = {}
for image in images:
try:
name = image[0:-4]
score = face_rg(path + '\\' + image)
yz_dict[score] = name
yz.append(score)
except:
pass
yz.sort(reverse=True)
for a, b in enumerate(yz):
print('小姐姐的名字是:{}丨颜值名次是:第{}名丨她的颜值分数为:{}'.format(yz_dict[b], a+1, b))
结果展示
完成所有源代码
import requests
import jsonpath
import os
from urllib.request import urlretrieve
# headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'}
#
# if not os.path.exists('./pic'):
# os.mkdir('./pic')
# for i in range(1, 100000):
# try:
# url = f'https://www.douyu.com/gapi/rknc/directory/yzRec/{i}'
# r = requests.get(url, headers=headers)
# names = jsonpath.jsonpath(r.json(), '$..nn')
# pngs = jsonpath.jsonpath(r.json(), '$..rs1')
# for name, png in zip(names, pngs):
# urlretrieve(png, './pic' + '/' + name + '.png')
# print(names)
# print(pngs)
# except:
# exit()
from facerg import face_rg
path = r'C:\Users\admin\PycharmProjects\pythonProject\1A演示\斗鱼\pic'
images = os.listdir(path)
print(images)
yz = []
yz_dict = {}
for image in images:
try:
name = image[0:-4]
score = face_rg(path + '\\' + image)
yz_dict[score] = name
yz.append(score)
except:
pass
yz.sort(reverse=True)
for a, b in enumerate(yz):
print('小姐姐的名字是:{}丨颜值名次是:第{}名丨她的颜值分数为:{}'.format(yz_dict[b], a+1, b))
只需将 facerg.py 作为自写模块调用即可。
视频教程地址
程序员相亲:一张Python老大采集相亲网的合影,打造排行榜!
我有话要说
——当你毫无保留地信任一个人时,最终只会有两种结果。不是生活中的那个人,也不是生活中的一课。
文章的话现在就写好了,每一个文章我都会说的很详细,所以需要很长时间,通常两个多小时。每一个赞和评论集都是我每天更新的动力。
原创不易,再次感谢您的支持。
①2000多本Python电子书(主流经典书籍应有)
②Python标准库资料(最全中文版)
③项目源码(四十或五十个有趣经典的动手项目及源码)
④Python基础、爬虫、Web开发、大数据分析视频(适合小白学习)
⑤ Python 学习路线图(告别不受影响的学习)
在我的Q.,Q技术交流群可以自己拿走。如果在学习或工作中遇到问题,群里会有大神帮忙解答。有时你会想一天。编号928946953。
文章采集api(优采云采集支持调用5118一键智能改写API接口(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2021-09-04 20:19
)
优采云采集支持调用5118一键智能重写API接口,处理采集数据标题和内容等,可以产生对搜索引擎更有吸引力的文章;
具体步骤如下:
1.5118 一键智能换字API接口配置
我。 API配置入口:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》点击【第三方API配置管理】==》最后点击[+5118 一键智能原创API]创建接口配置;
二。配置API接口信息:
【API-Key值】是从5118后台获取对应的5118一键智能重写APIKey值,填写优采云;
2. 创建 API 处理规则
API处理规则,可设置调用API接口处理哪些字段的内容;
我。 API 处理规则条目:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》进入【API处理规则管理】页面,最后点击【添加API处理规则】创建API处理规则;
二、API处理规则配置:
规则名称:用户可以自己命名;
字段名:填写的字段名的内容会被API接口处理。默认为title和content字段,可以修改、添加或删除; (可以添加其他字段,点击添加内容字段,修改字段名称,但必须在[Detail Extractor]中定义,如作者、关键字、描述字段)
API used:选择已经设置好的API接口配置,执行时会调用该接口,不同的API接口配置可以选择多个字段。 5118一键智能改写;
处理顺序:执行顺序是按照数量从小到大执行;
3. API 处理规则使用
API处理规则的使用方式有两种:手动执行和自动执行:
手动执行:数据采集后,在【Result Data & Release】中使用第三方API执行;
自动执行:配置自动化后,任务采集data完成后,系统会自动执行指定的API处理规则,无需人工操作。
我。手动执行 API 处理规则:
点击采集任务的【结果&发布】选项卡中的【SEO&API&翻译工具】按钮==》选择【第三方API执行】栏==》选择对应的API处理规则==》执行(数据范围有两种执行方式,根据发布状态批量执行和根据列表中选择的数据执行);
二。自动执行 API 处理规则:
启用 API 处理的自动执行。任务完成采集后,会自动执行API处理。一般搭配定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡中,【自动执行第三方API配置】==》勾选【采集,自动执行API】选项==》选择要执行的API处理规则==》选择API接口处理的数据范围(一般选择“待发布”,都会导致所有数据被多次执行),最后点击保存;
4.API处理结果及发布 I,查看API接口处理结果:
API接口处理的内容会生成API接口对应的新字段,如:
标题处理后添加字段:
title_5118 rewrite(对应5118一键智能重写API接口)
内容处理后添加字段:
content_5118 rewrite(对应5118一键智能重写API接口)
在【结果数据&发布】和数据预览界面均可查看。
提醒:API处理规则执行需要一段时间,执行后页面会自动刷新,API接口处理的新字段会出现;
二后内容发布,API接口处理
发布文章前,修改发布目标第二步的映射字段,API接口处理后将title和content改成新的对应字段。
例如执行5118一键智能改词API后,选择title_5118改词和content_5118改词发布;
5.5118-API接口常见问题及解决方案 我,API处理规则和SEO规则如何搭配使用?
系统默认对title和content字段进行SEO功能,需要在SEO规则中修改对应新增的字段,如title_5118换词和content_5118换词字段;
查看全部
文章采集api(优采云采集支持调用5118一键智能改写API接口(组图)
)
优采云采集支持调用5118一键智能重写API接口,处理采集数据标题和内容等,可以产生对搜索引擎更有吸引力的文章;
具体步骤如下:
1.5118 一键智能换字API接口配置
我。 API配置入口:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》点击【第三方API配置管理】==》最后点击[+5118 一键智能原创API]创建接口配置;
二。配置API接口信息:
【API-Key值】是从5118后台获取对应的5118一键智能重写APIKey值,填写优采云;
2. 创建 API 处理规则
API处理规则,可设置调用API接口处理哪些字段的内容;
我。 API 处理规则条目:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》进入【API处理规则管理】页面,最后点击【添加API处理规则】创建API处理规则;
二、API处理规则配置:
规则名称:用户可以自己命名;
字段名:填写的字段名的内容会被API接口处理。默认为title和content字段,可以修改、添加或删除; (可以添加其他字段,点击添加内容字段,修改字段名称,但必须在[Detail Extractor]中定义,如作者、关键字、描述字段)
API used:选择已经设置好的API接口配置,执行时会调用该接口,不同的API接口配置可以选择多个字段。 5118一键智能改写;
处理顺序:执行顺序是按照数量从小到大执行;
3. API 处理规则使用
API处理规则的使用方式有两种:手动执行和自动执行:
手动执行:数据采集后,在【Result Data & Release】中使用第三方API执行;
自动执行:配置自动化后,任务采集data完成后,系统会自动执行指定的API处理规则,无需人工操作。
我。手动执行 API 处理规则:
点击采集任务的【结果&发布】选项卡中的【SEO&API&翻译工具】按钮==》选择【第三方API执行】栏==》选择对应的API处理规则==》执行(数据范围有两种执行方式,根据发布状态批量执行和根据列表中选择的数据执行);
二。自动执行 API 处理规则:
启用 API 处理的自动执行。任务完成采集后,会自动执行API处理。一般搭配定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡中,【自动执行第三方API配置】==》勾选【采集,自动执行API】选项==》选择要执行的API处理规则==》选择API接口处理的数据范围(一般选择“待发布”,都会导致所有数据被多次执行),最后点击保存;
4.API处理结果及发布 I,查看API接口处理结果:
API接口处理的内容会生成API接口对应的新字段,如:
标题处理后添加字段:
title_5118 rewrite(对应5118一键智能重写API接口)
内容处理后添加字段:
content_5118 rewrite(对应5118一键智能重写API接口)
在【结果数据&发布】和数据预览界面均可查看。
提醒:API处理规则执行需要一段时间,执行后页面会自动刷新,API接口处理的新字段会出现;
二后内容发布,API接口处理
发布文章前,修改发布目标第二步的映射字段,API接口处理后将title和content改成新的对应字段。
例如执行5118一键智能改词API后,选择title_5118改词和content_5118改词发布;
5.5118-API接口常见问题及解决方案 我,API处理规则和SEO规则如何搭配使用?
系统默认对title和content字段进行SEO功能,需要在SEO规则中修改对应新增的字段,如title_5118换词和content_5118换词字段;
文章采集api(destoon采集器最新版采集新闻资讯文章,配套destoon免登陆发布接口)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-09-02 10:17
答:可以使用优采云采集器新版采集新闻资讯文章,支持desoon免费登录发布接口,实现news文章的采集数据。
3、Q:采集软件支持从Excel导入数据吗?批量导入现有数据信息?
答:可以,可以使用优采云采集器按照一定格式批量导入数据,然后批量发布提交到你的网站后台。批量发布和导入数据都是软件操作,可以节省大量的人力和财力。
4、Q:desoon news采集发布免费登录界面有什么特点?
答案:这个采集器完全模拟了dt程序代码的执行流程,以非暴力的方式插入到数据库中,可以实现各种复杂的需求。
目前免登录界面的功能如下:
①,支持远程图片自动保存下载
②,支持将下载图片的第一张图片自动提取为缩略图
③、支持设置release文章review状态
④。支持自定义字段,如作者、点击次数等
⑤、支持自动定时采集release
⑥.支持按需清洗数据格式,去除冗余内容
⑦,支持从Excel导入数据,批量导出到excel或本地文件
⑧、支持今日头条、微信文章等单篇文章采集
⑨,支持批量采集数据库发布前查看编辑
等等等等,这个不方便详述,下载使用即可!
5、Q:这么通用吗,采集器+文章资讯无电讯报讯界面是免费的吗?
答:免费,大家共享同一个版本,采集器持续更新中,文章资讯接口免费提供,请免费联系作者jieling的QQ。
其他采集publishing 接口可以联系和定制。 查看全部
文章采集api(destoon采集器最新版采集新闻资讯文章,配套destoon免登陆发布接口)
答:可以使用优采云采集器新版采集新闻资讯文章,支持desoon免费登录发布接口,实现news文章的采集数据。
3、Q:采集软件支持从Excel导入数据吗?批量导入现有数据信息?
答:可以,可以使用优采云采集器按照一定格式批量导入数据,然后批量发布提交到你的网站后台。批量发布和导入数据都是软件操作,可以节省大量的人力和财力。
4、Q:desoon news采集发布免费登录界面有什么特点?
答案:这个采集器完全模拟了dt程序代码的执行流程,以非暴力的方式插入到数据库中,可以实现各种复杂的需求。
目前免登录界面的功能如下:
①,支持远程图片自动保存下载
②,支持将下载图片的第一张图片自动提取为缩略图
③、支持设置release文章review状态
④。支持自定义字段,如作者、点击次数等
⑤、支持自动定时采集release
⑥.支持按需清洗数据格式,去除冗余内容
⑦,支持从Excel导入数据,批量导出到excel或本地文件
⑧、支持今日头条、微信文章等单篇文章采集
⑨,支持批量采集数据库发布前查看编辑
等等等等,这个不方便详述,下载使用即可!
5、Q:这么通用吗,采集器+文章资讯无电讯报讯界面是免费的吗?
答:免费,大家共享同一个版本,采集器持续更新中,文章资讯接口免费提供,请免费联系作者jieling的QQ。
其他采集publishing 接口可以联系和定制。
文章采集api(JTopCMS站群内容管理系统v3.0更新日志及改进)
采集交流 • 优采云 发表了文章 • 0 个评论 • 220 次浏览 • 2021-09-02 08:18
JTopcms是基于JavaEE标准自主开发的。它是一个开源的内容管理软件(cms),用于管理站群 的内容。可以高效便捷地进行内容编辑、审核、模板制作、用户交互管理和文件、业务文档等资源的维护。性能优良、稳定、安全、易扩展,适用于政府、教育部门、企事业单位建设站群系统。 JTopcms 站群内容管理系统v3.0 更新日志新特性:1)支持集群部署和业务分布式部署2)file发布点增加OSS COS七牛云存储支持3)Department -级权限支持消息和表单分层管理4)高级搜索功能支持扩展字段模糊搜索5)管理员维护内容支持部门管理6)高级搜索支持搜索所有扩展文本字段7)高级搜索支持新闻内容权重排序8)推荐位内容增加扩展字段支持9)增加通用静态分页功能,支持用户扩展模块分页10)优化敏感词自动匹配性能,支持批量导入词汇11)sensitive单词匹配 支持自定义字段文本检查12)采集功能支持采集Attachment13)添加仅限会员登录限制功能14)增加管理员登录时间间隔限制1 5)支持编辑器资源路径一键切换到云地址16)单站点模板多渠道移动端发布,支持一个站点同时发布多种模板类型。 17)相关栏目自动同步内容,可以实现只维护一个主站的内容,其他站点的相关栏目自动同步更新。
18)采集支持自定义字段扩展,加强采集规则,不再局限于新闻类型,支持自定义模型字段建立采集规则。 19)采集支持按发布时间排序,实现与目标采集系统内容的无缝对接。 20)Advanced 搜索支持按时间范围搜索和排序。 21) 加强系统操作日志,记录完整参数。 22)内容编辑功能增加了可编辑的添加时间。 23)站群 节点可以排序。改进1)将编辑器替换为UEditor2),支持站点resources3)的相对路径模式将数据展示图替换为echarts4),提高广告拦截软件5)下广告模块的性能优化模型内容维护页面交互6)修复几个BUGJTopcmsFeatures1.支持集群管理系统支持集群部署,可以任意增减cmsservice节点,根据业务需求独立部署service节点,加强系统容错、并发和扩展能力。 2. 站点支持内容的静态发布。不仅支持html的生成,还可以生成shtml,精准控制页面的本地静态化,最大限度的提高站点的并发访问性能和可维护性。 3.Content 模型自定义支持 支持自定义模型功能,内置完整的字段类型,定义的字段还可以参与联合查询、高级搜索,让您的站点具有高度的扩展性,方便响应各种业务需要。 4.强大且可扩展的权限体系,支持按部门划分的子站点分级管理,下级不能越权,明确权责。
支持粗(菜单级)和细(业务数据)粒度权限控制,可按组织、角色、用户进行授权,有效划分权限范围,可自由伸缩,职责明确。还支持集成二次开发功能5.安全防护能力。系统可自动拦截记录并分析各种非法访问,及时通知站点管理员处理,自动拦截恶意访问者,黑名单系统为您的站点安全保驾护航。 6.Advanced 搜索支持类似百度的高级搜索功能,支持大数据下的快速搜索,可配置,结合自定义模型功能,可以快速创建符合您需求的信息模型搜索。 7.网站群架构支持一套cms产品,可以支持多个站点的部署,由JTopcms管理,但是每个站点在数据和逻辑上完全独立,可以共享数据彼此。为用户提供最大的价值8.implementation网站developer 简单的JTopcms提供了完整的标签系统。用户只需要有html和美术知识储备。在cms标签的帮助下,可以高效地制作它们创建一个可管理的动态站点。 9.灵活的数据组织方式,支持基本的列和主题分类,TAG标签分类,还支持页块碎片管理,自定义推荐位,灵活强大的数据组合方式,满足各种数据组织需求。 10.二次开发高效 JTopcms基于J2EE核心模型自主研发。项目一开始就考虑二次开发支持。新模块的扩展只需要具备Java Web开发基础和SQL能力,即可快速高效上手。以侵入性的方式开发功能。 11. 支持资源发布点 支持自动发布图片、视频文件和静态发布html到各个资源服务器,动静态分离,静态前端访问和动态后端访问独立处理,提高性能和安全性. JTopcms截图相关阅读类似推荐:站长常用源码 查看全部
文章采集api(JTopCMS站群内容管理系统v3.0更新日志及改进)
JTopcms是基于JavaEE标准自主开发的。它是一个开源的内容管理软件(cms),用于管理站群 的内容。可以高效便捷地进行内容编辑、审核、模板制作、用户交互管理和文件、业务文档等资源的维护。性能优良、稳定、安全、易扩展,适用于政府、教育部门、企事业单位建设站群系统。 JTopcms 站群内容管理系统v3.0 更新日志新特性:1)支持集群部署和业务分布式部署2)file发布点增加OSS COS七牛云存储支持3)Department -级权限支持消息和表单分层管理4)高级搜索功能支持扩展字段模糊搜索5)管理员维护内容支持部门管理6)高级搜索支持搜索所有扩展文本字段7)高级搜索支持新闻内容权重排序8)推荐位内容增加扩展字段支持9)增加通用静态分页功能,支持用户扩展模块分页10)优化敏感词自动匹配性能,支持批量导入词汇11)sensitive单词匹配 支持自定义字段文本检查12)采集功能支持采集Attachment13)添加仅限会员登录限制功能14)增加管理员登录时间间隔限制1 5)支持编辑器资源路径一键切换到云地址16)单站点模板多渠道移动端发布,支持一个站点同时发布多种模板类型。 17)相关栏目自动同步内容,可以实现只维护一个主站的内容,其他站点的相关栏目自动同步更新。
18)采集支持自定义字段扩展,加强采集规则,不再局限于新闻类型,支持自定义模型字段建立采集规则。 19)采集支持按发布时间排序,实现与目标采集系统内容的无缝对接。 20)Advanced 搜索支持按时间范围搜索和排序。 21) 加强系统操作日志,记录完整参数。 22)内容编辑功能增加了可编辑的添加时间。 23)站群 节点可以排序。改进1)将编辑器替换为UEditor2),支持站点resources3)的相对路径模式将数据展示图替换为echarts4),提高广告拦截软件5)下广告模块的性能优化模型内容维护页面交互6)修复几个BUGJTopcmsFeatures1.支持集群管理系统支持集群部署,可以任意增减cmsservice节点,根据业务需求独立部署service节点,加强系统容错、并发和扩展能力。 2. 站点支持内容的静态发布。不仅支持html的生成,还可以生成shtml,精准控制页面的本地静态化,最大限度的提高站点的并发访问性能和可维护性。 3.Content 模型自定义支持 支持自定义模型功能,内置完整的字段类型,定义的字段还可以参与联合查询、高级搜索,让您的站点具有高度的扩展性,方便响应各种业务需要。 4.强大且可扩展的权限体系,支持按部门划分的子站点分级管理,下级不能越权,明确权责。
支持粗(菜单级)和细(业务数据)粒度权限控制,可按组织、角色、用户进行授权,有效划分权限范围,可自由伸缩,职责明确。还支持集成二次开发功能5.安全防护能力。系统可自动拦截记录并分析各种非法访问,及时通知站点管理员处理,自动拦截恶意访问者,黑名单系统为您的站点安全保驾护航。 6.Advanced 搜索支持类似百度的高级搜索功能,支持大数据下的快速搜索,可配置,结合自定义模型功能,可以快速创建符合您需求的信息模型搜索。 7.网站群架构支持一套cms产品,可以支持多个站点的部署,由JTopcms管理,但是每个站点在数据和逻辑上完全独立,可以共享数据彼此。为用户提供最大的价值8.implementation网站developer 简单的JTopcms提供了完整的标签系统。用户只需要有html和美术知识储备。在cms标签的帮助下,可以高效地制作它们创建一个可管理的动态站点。 9.灵活的数据组织方式,支持基本的列和主题分类,TAG标签分类,还支持页块碎片管理,自定义推荐位,灵活强大的数据组合方式,满足各种数据组织需求。 10.二次开发高效 JTopcms基于J2EE核心模型自主研发。项目一开始就考虑二次开发支持。新模块的扩展只需要具备Java Web开发基础和SQL能力,即可快速高效上手。以侵入性的方式开发功能。 11. 支持资源发布点 支持自动发布图片、视频文件和静态发布html到各个资源服务器,动静态分离,静态前端访问和动态后端访问独立处理,提高性能和安全性. JTopcms截图相关阅读类似推荐:站长常用源码
文章采集api(优采云伪原创插件api接口代码怎么用伪插件来api)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-08-31 16:08
seo伪原创generator,织梦伪原创plugin,English伪原创哪有
只要你知道如何用中文进行伪原创,就可以使用在线翻译将其翻译成英文。提醒你,在翻译英文的时候,多用几个翻译工具,(如果你不懂英文),然后找懂英文的人帮你看句子是否流畅,然后选择最好的翻译。做网站,一定要注重客户体验。
·优采云伪原创如何使用插件api接口代码
伪原创plugin to api 使用了目前可靠的优采云AI+,一个基于人工智能的伪原创软件,生成的内容原创比较高,有教程1、修改优采云的PHP环境由于优采云采集器内置的PHP环境有问题,需要在使用PHP插件之前修改优采云的PHP环境。修改方法很简单,打开优采云网站采集软件安装目录“System/PHP”,找到要打开的文件,找到如下代码。找到php_去掉前面的分号改成:修改前:;extension=php_修改后:extension=php_即去掉前面的分号“;”并保存,这样优采云数据采集器就可以正常运行这个PHP仿插件了。 2、Plugins 应该放在优采云plugin 目录中。比如我的机器是:D:\优采云采集器V9\Plugins Q:这个插件的主要功能是什么?
答案:优采云 是采集器。 采集之后,如果打开了插件,采集收到的内容会通过插件进行处理,然后保存。我们的插件是伪原创,所以伪原创之后会保存采集的内容。 3、debugging方法 首先按照原方法,首先保证采集规则可以正常运行。然后,在正常运行的基础上,选择伪原创plugin。 查看全部
文章采集api(优采云伪原创插件api接口代码怎么用伪插件来api)
seo伪原创generator,织梦伪原创plugin,English伪原创哪有
只要你知道如何用中文进行伪原创,就可以使用在线翻译将其翻译成英文。提醒你,在翻译英文的时候,多用几个翻译工具,(如果你不懂英文),然后找懂英文的人帮你看句子是否流畅,然后选择最好的翻译。做网站,一定要注重客户体验。
·优采云伪原创如何使用插件api接口代码
伪原创plugin to api 使用了目前可靠的优采云AI+,一个基于人工智能的伪原创软件,生成的内容原创比较高,有教程1、修改优采云的PHP环境由于优采云采集器内置的PHP环境有问题,需要在使用PHP插件之前修改优采云的PHP环境。修改方法很简单,打开优采云网站采集软件安装目录“System/PHP”,找到要打开的文件,找到如下代码。找到php_去掉前面的分号改成:修改前:;extension=php_修改后:extension=php_即去掉前面的分号“;”并保存,这样优采云数据采集器就可以正常运行这个PHP仿插件了。 2、Plugins 应该放在优采云plugin 目录中。比如我的机器是:D:\优采云采集器V9\Plugins Q:这个插件的主要功能是什么?
答案:优采云 是采集器。 采集之后,如果打开了插件,采集收到的内容会通过插件进行处理,然后保存。我们的插件是伪原创,所以伪原创之后会保存采集的内容。 3、debugging方法 首先按照原方法,首先保证采集规则可以正常运行。然后,在正常运行的基础上,选择伪原创plugin。
文章采集api(短视频直播数据采集趋于稳定,可以抽出时间来整理 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 256 次浏览 • 2021-08-30 03:09
)
抖音API接口资料采集教程,初级版,抖音视频搜索,抖音用户搜索,抖音直播间弹幕,抖音评论列表
这段时间一直在处理data采集的问题。目前平台data采集趋于稳定。可以花点时间整理一下最近的成果,顺便介绍一些最近用到的技术。
本文文章biased技术需要读者有一定的技术基础,主要介绍采集数据处理过程中用到的神器mitmproxy,以及平台的一些技术设计。
以下是数据采集的整体设计。客户在左边。不同的采集器 放在里面。 采集器发起请求后,通过mitmproxy访问抖音,数据返回后,通过中间的解析器解析数据,最后以不同的类别存储在数据库中。为了提高性能,中间添加了一个缓存,将采集器与解析器分开。两个模块之间的工作互不影响,可以最大限度地将数据存储在数据库中。下图为第一代架构设计。后续文章将介绍平台架构设计的三代演进历史。
短视频直播数据采集interface SDK,请点击查看接口文档
准备工作
开始准备data采集,第一步自然是搭建环境。这次我们在windows环境下使用python3.6.6,抓包代理工具是mitmproxy。使用Fiddler抓包,使用夜神模拟器模拟Android运行环境(也可以使用真机)。这一次,你主要使用手动滑动应用程序来捕获数据。下次我们会介绍Appium自动化工具,实现全数据采集自动(解放双手)。
1、install python3.6.6 环境,安装过程可以自行百度,需要注意的是centos7自带python2.7,需要升级到python3.6.6环境,升级前安装ssl模块,否则升级后的版本无法访问https请求。
2、Install mitmproxy,安装好python环境后,在命令行执行pip install mitmproxy安装mitmproxy。注意:windows下只能使用mitmdump和mitmweb。安装好后在命令行输入mitmdump启动,默认会启动。代理端口为8080。
3、安装夜神模拟器,可以到官网下载安装包,安装教程可以百度,基本上下一步。安装夜神模拟器后,需要配置夜神模拟器。首先需要将模拟器的网络设置为手动代理,IP地址为windows的IP,端口为mitmproxy的代理端口。
4、 接下来就是安装证书了。在模拟器中打开浏览器,输入地址mitm.it,选择对应版本的证书。安装完成后就可以抓包了。
5、安装app,app安装包可以从官网下载,然后拖入模拟器安装,或者在app市场安装。至此,本次的采集环境已经完成。
数据接口分析与抓包
环境搭建好后,我们就开始抓取抖音app的数据,分析各个函数使用的接口。本次以采集视频数据接口为例进行介绍。
关闭之前打开的mitmdump,重新打开mitmweb工具,mitmweb是图形版的,不用找黑框,如下图:
启动后打开模拟器的抖音app,可以看到已经有数据包解析出来了,然后进入用户主页,开始向下滑动视频,可以在里面找到请求视频数据的界面数据包列表
/aweme/v1/aweme/post/
右侧可以看到接口的请求数据和响应数据。我们复制响应数据,进入下一步分析。
数据分析
通过mitmproxy和python代码的结合,我们可以在代码中拿到mitmproxy中的数据包,然后我们就可以根据需要进行处理了。创建一个新的 test.py 文件并在其中放入两个方法:
def request(flow):
pass
def response(flow):
pass
顾名思义,这两种方法,一种在请求时执行,一种在响应时执行,数据包存在于流中。请求url可以通过flow.request.url获取,请求头信息可以通过flow.request.headers获取,flow.response.text中的数据为响应数据。
def response(flow):
if str(flow.request.url).startswith("https://aweme.snssdk.com/aweme/v1/aweme/post/"):
index_response_dict = json.loads(flow.response.text)
aweme_list = index_response_dict.get('aweme_list')
if aweme_list:
for aweme in aweme_list:
print(aweme)
这个aweme是一个完整的视频资料,你可以根据自己的需要提取其中的信息,这里提取一些信息做介绍。
"statistics":{
"aweme_id":"6765058962225204493",
"comment_count":24,
"digg_count":1465,
"download_count":1,
"play_count":0,
"share_count":3,
"forward_count":0,
"lose_count":0,
"lose_comment_count":0
}
统计信息是该视频的点赞、评论、下载、转发等数据。 share_url 是视频的分享地址。通过这个地址可以在PC端观看抖音分享的视频,也可以通过这个链接解析无水印视频。
play_addr 是视频的播放信息。 url_list 是没有水印的地址。但是,官方处理已经完成。这个地址不能直接播放,而且有时间限制。超时后,链接将失效。有了这个aweme,你可以把里面的信息解析出来保存到自己的数据库中,或者下载无水印视频保存到自己的电脑上。
写完代码,保存test.py文件,cmd进入命令行,进入保存test.py文件的目录,在命令行输入mitmdump -s test.py,mitmdump就会启动。此时打开应用程序。开始滑动模拟器,进入用户主页:
开始连续下降,test.py文件可以解析所有捕获的视频数据。以下是我截获的部分数据信息:视频信息:
视频统计:
查看全部
文章采集api(短视频直播数据采集趋于稳定,可以抽出时间来整理
)
抖音API接口资料采集教程,初级版,抖音视频搜索,抖音用户搜索,抖音直播间弹幕,抖音评论列表
这段时间一直在处理data采集的问题。目前平台data采集趋于稳定。可以花点时间整理一下最近的成果,顺便介绍一些最近用到的技术。
本文文章biased技术需要读者有一定的技术基础,主要介绍采集数据处理过程中用到的神器mitmproxy,以及平台的一些技术设计。
以下是数据采集的整体设计。客户在左边。不同的采集器 放在里面。 采集器发起请求后,通过mitmproxy访问抖音,数据返回后,通过中间的解析器解析数据,最后以不同的类别存储在数据库中。为了提高性能,中间添加了一个缓存,将采集器与解析器分开。两个模块之间的工作互不影响,可以最大限度地将数据存储在数据库中。下图为第一代架构设计。后续文章将介绍平台架构设计的三代演进历史。
短视频直播数据采集interface SDK,请点击查看接口文档
准备工作
开始准备data采集,第一步自然是搭建环境。这次我们在windows环境下使用python3.6.6,抓包代理工具是mitmproxy。使用Fiddler抓包,使用夜神模拟器模拟Android运行环境(也可以使用真机)。这一次,你主要使用手动滑动应用程序来捕获数据。下次我们会介绍Appium自动化工具,实现全数据采集自动(解放双手)。
1、install python3.6.6 环境,安装过程可以自行百度,需要注意的是centos7自带python2.7,需要升级到python3.6.6环境,升级前安装ssl模块,否则升级后的版本无法访问https请求。
2、Install mitmproxy,安装好python环境后,在命令行执行pip install mitmproxy安装mitmproxy。注意:windows下只能使用mitmdump和mitmweb。安装好后在命令行输入mitmdump启动,默认会启动。代理端口为8080。
3、安装夜神模拟器,可以到官网下载安装包,安装教程可以百度,基本上下一步。安装夜神模拟器后,需要配置夜神模拟器。首先需要将模拟器的网络设置为手动代理,IP地址为windows的IP,端口为mitmproxy的代理端口。
4、 接下来就是安装证书了。在模拟器中打开浏览器,输入地址mitm.it,选择对应版本的证书。安装完成后就可以抓包了。
5、安装app,app安装包可以从官网下载,然后拖入模拟器安装,或者在app市场安装。至此,本次的采集环境已经完成。
数据接口分析与抓包
环境搭建好后,我们就开始抓取抖音app的数据,分析各个函数使用的接口。本次以采集视频数据接口为例进行介绍。
关闭之前打开的mitmdump,重新打开mitmweb工具,mitmweb是图形版的,不用找黑框,如下图:
启动后打开模拟器的抖音app,可以看到已经有数据包解析出来了,然后进入用户主页,开始向下滑动视频,可以在里面找到请求视频数据的界面数据包列表
/aweme/v1/aweme/post/
右侧可以看到接口的请求数据和响应数据。我们复制响应数据,进入下一步分析。
数据分析
通过mitmproxy和python代码的结合,我们可以在代码中拿到mitmproxy中的数据包,然后我们就可以根据需要进行处理了。创建一个新的 test.py 文件并在其中放入两个方法:
def request(flow):
pass
def response(flow):
pass
顾名思义,这两种方法,一种在请求时执行,一种在响应时执行,数据包存在于流中。请求url可以通过flow.request.url获取,请求头信息可以通过flow.request.headers获取,flow.response.text中的数据为响应数据。
def response(flow):
if str(flow.request.url).startswith("https://aweme.snssdk.com/aweme/v1/aweme/post/";):
index_response_dict = json.loads(flow.response.text)
aweme_list = index_response_dict.get('aweme_list')
if aweme_list:
for aweme in aweme_list:
print(aweme)
这个aweme是一个完整的视频资料,你可以根据自己的需要提取其中的信息,这里提取一些信息做介绍。
"statistics":{
"aweme_id":"6765058962225204493",
"comment_count":24,
"digg_count":1465,
"download_count":1,
"play_count":0,
"share_count":3,
"forward_count":0,
"lose_count":0,
"lose_comment_count":0
}
统计信息是该视频的点赞、评论、下载、转发等数据。 share_url 是视频的分享地址。通过这个地址可以在PC端观看抖音分享的视频,也可以通过这个链接解析无水印视频。
play_addr 是视频的播放信息。 url_list 是没有水印的地址。但是,官方处理已经完成。这个地址不能直接播放,而且有时间限制。超时后,链接将失效。有了这个aweme,你可以把里面的信息解析出来保存到自己的数据库中,或者下载无水印视频保存到自己的电脑上。
写完代码,保存test.py文件,cmd进入命令行,进入保存test.py文件的目录,在命令行输入mitmdump -s test.py,mitmdump就会启动。此时打开应用程序。开始滑动模拟器,进入用户主页:
开始连续下降,test.py文件可以解析所有捕获的视频数据。以下是我截获的部分数据信息:视频信息:
视频统计:
文章采集api(做英文垃圾站用的比较多的WP-AutoPost-pro破解版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-08-29 18:12
<p>wp-autopost-pro 破解版是一款功能强大的wordpress自动采集插件,可以从任何网站内容中采集并自动发布到你的WordPress站点,用户可以使用采集WeChat public号、头条号等自媒体内容,采集流程全自动无需人工干预,轻松获取优质“原创”文章,增加百度收录量和网站权重。 查看全部
文章采集api(做英文垃圾站用的比较多的WP-AutoPost-pro破解版)
<p>wp-autopost-pro 破解版是一款功能强大的wordpress自动采集插件,可以从任何网站内容中采集并自动发布到你的WordPress站点,用户可以使用采集WeChat public号、头条号等自媒体内容,采集流程全自动无需人工干预,轻松获取优质“原创”文章,增加百度收录量和网站权重。
文章采集api(Java开发不会Android囧),二来插件模拟点击网页版 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-08-28 04:08
)
学过微信文章reading和点赞数的同学都知道怎么获取这两个数,关键是获取一个有效的微信key。这个键的有效时间是2小时左右,而且对访问频率也有限制,访问频率可以通过密码控制,速度不会每10秒被封锁一次。接下来,我们来谈谈如何完全自动获取有效密钥。
想必大部分同学都会去手机上钥匙吧。一是不知道怎么做(Java开发不懂Android囧),二是打算直接在PC端实现这个爬虫过程。于是开始研究微信Web客户端。其实这个key很容易获取,转发一个公众号文章到web客户端,从客户端打开就可以看到链接里的key了。
我意识到的想法是:
使用chrome浏览器插件在网页版客户端模拟点击公众号微信文章,获取本链接中key和uin两个参数。通过websocket传递给本机的Java(抓取到时候通过websocket向chrome发送消息,然后返回key和uin)
chrome的插件已经写好了。具体使用步骤是打开你的服务器(启动你的websocket服务器),点击微信图标,插件图标(这一步是连接websocket客户端到服务器)。确保文件转发助手里有公众号文章(任意一个),然后程序就可以调用了。
Java 获取的密钥
现在整个爬取过程都写完了,可以使用了(我的爬取量很小,请研究其他方法。)。我觉得整个爬虫过程中还有一个很重要的点就是获取微信文章的列表(抓到搜狗被屏蔽了...)。因为我有公众号的账号密码,一开始我只是直接从公众号的素材管理里抓取了,但是那是不允许的,一个是上面的时间编辑时间不是发布时间。第二个是文章的mid和sn这两个参数从中抓取的点赞数都是0,阅读数都是2.所以我猜在发布之前,发布之后,有是两组mid和sn。感谢大神,云烟分享了微信查询历史界面(他在手机上抢了包)。反正是http,所以直接用。这边走。就是这样。
调用微信查询历史数据接口获取发布地址文章。每个公众号的biz参数是固定的,可以从链接中获取。只有key和uin才能获得过去一周文章某个公众号。接口地址:
获取文章列表,取出biz、mid、sn、idx等参数,加上key和uin,然后就可以调整界面()获取点赞数和阅读数了。需要说明的是,UA的UA使用的是手机。
查看全部
文章采集api(Java开发不会Android囧),二来插件模拟点击网页版
)
学过微信文章reading和点赞数的同学都知道怎么获取这两个数,关键是获取一个有效的微信key。这个键的有效时间是2小时左右,而且对访问频率也有限制,访问频率可以通过密码控制,速度不会每10秒被封锁一次。接下来,我们来谈谈如何完全自动获取有效密钥。
想必大部分同学都会去手机上钥匙吧。一是不知道怎么做(Java开发不懂Android囧),二是打算直接在PC端实现这个爬虫过程。于是开始研究微信Web客户端。其实这个key很容易获取,转发一个公众号文章到web客户端,从客户端打开就可以看到链接里的key了。
我意识到的想法是:
使用chrome浏览器插件在网页版客户端模拟点击公众号微信文章,获取本链接中key和uin两个参数。通过websocket传递给本机的Java(抓取到时候通过websocket向chrome发送消息,然后返回key和uin)
chrome的插件已经写好了。具体使用步骤是打开你的服务器(启动你的websocket服务器),点击微信图标,插件图标(这一步是连接websocket客户端到服务器)。确保文件转发助手里有公众号文章(任意一个),然后程序就可以调用了。
Java 获取的密钥
现在整个爬取过程都写完了,可以使用了(我的爬取量很小,请研究其他方法。)。我觉得整个爬虫过程中还有一个很重要的点就是获取微信文章的列表(抓到搜狗被屏蔽了...)。因为我有公众号的账号密码,一开始我只是直接从公众号的素材管理里抓取了,但是那是不允许的,一个是上面的时间编辑时间不是发布时间。第二个是文章的mid和sn这两个参数从中抓取的点赞数都是0,阅读数都是2.所以我猜在发布之前,发布之后,有是两组mid和sn。感谢大神,云烟分享了微信查询历史界面(他在手机上抢了包)。反正是http,所以直接用。这边走。就是这样。
调用微信查询历史数据接口获取发布地址文章。每个公众号的biz参数是固定的,可以从链接中获取。只有key和uin才能获得过去一周文章某个公众号。接口地址:
获取文章列表,取出biz、mid、sn、idx等参数,加上key和uin,然后就可以调整界面()获取点赞数和阅读数了。需要说明的是,UA的UA使用的是手机。
哪里有finecms采集接口可以下载?建站时比较纠结
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-08-24 22:15
finecms采集接口在哪里下载?我们在使用finecms建站的时候比较纠结的是怎么采集文章,finecms商城有售采集插件,价格50元,有的朋友感觉比较贵也不太愿意买,权衡了很久也决定买了。有需要的朋友可以联系ytkah了解一下。价格比官方漂亮多了。添加微信咨询
finecms采集接口插件使用方法:联系ytkah咨询下载finecms采集plug-in
1、覆盖到根目录
2、finecms5.wpm 文件是优采云release 模块
3、本采集接口支持所有自定义字段,
data[status]为内容状态,1为待审核,9为通过
xiaazai = 1 下载附件配置,1 表示下载,0 表示不下载
多文件字段发布标签如下:
具有多个文件字段的文件数据[字段名称][文件]
多个文件字段数据的文件标题[字段名称][标题]
多个文件使用[|]作为间隔如下
*.com/file/upload/201609/09/16-26-06-11-362.jpg[|]*.com/file/upload/201609/08/14-23-20-41 -362.jpg[|]*.com/file/upload/201609/09/14-22-42-61-362.jpg
复选框字段如下
数据[字段名称] = [1,2,3]
联动菜单字段为区域。直接写区域名称,比如北京,会自动匹配区域id进入数据库。 查看全部
哪里有finecms采集接口可以下载?建站时比较纠结
finecms采集接口在哪里下载?我们在使用finecms建站的时候比较纠结的是怎么采集文章,finecms商城有售采集插件,价格50元,有的朋友感觉比较贵也不太愿意买,权衡了很久也决定买了。有需要的朋友可以联系ytkah了解一下。价格比官方漂亮多了。添加微信咨询
finecms采集接口插件使用方法:联系ytkah咨询下载finecms采集plug-in
1、覆盖到根目录
2、finecms5.wpm 文件是优采云release 模块
3、本采集接口支持所有自定义字段,
data[status]为内容状态,1为待审核,9为通过
xiaazai = 1 下载附件配置,1 表示下载,0 表示不下载
多文件字段发布标签如下:
具有多个文件字段的文件数据[字段名称][文件]
多个文件字段数据的文件标题[字段名称][标题]
多个文件使用[|]作为间隔如下
*.com/file/upload/201609/09/16-26-06-11-362.jpg[|]*.com/file/upload/201609/08/14-23-20-41 -362.jpg[|]*.com/file/upload/201609/09/14-22-42-61-362.jpg
复选框字段如下
数据[字段名称] = [1,2,3]
联动菜单字段为区域。直接写区域名称,比如北京,会自动匹配区域id进入数据库。
WordPress5.X优采云免登陆发布接口+模块(增强版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-08-22 20:03
WordPress5.X优采云免登陆发布接口+模块(增强版)
WordPress5.X优采云免登录发布界面+模块(增强版)使用说明
适用于优采云采集器7.6-9.6
优化验证标题重复
优化附件、图片、缩略图的上传生成
增加了多种分类方法的发布参数(post_taxonomy_list),使用方法请参考功能特性
修正BUG:如果分类名称收录数字,会导致分类错误。
重新设计老版本发布界面,新版本号为T1,老版本后续不再升级维护。老版本支持3.X-4.8.2
修复BUG:当模块中的某个参数没有在规则中发布时,会导致发布的数据异常(db:标签名会显示)
优化strtoarray函数
特点
1.category(category):
分类支持分类名称和分类ID,系统自动判断
多分类处理(多分类请用逗号隔开)
自动创建一个类别。如果网站中没有这个分类,会自动创建一个分类。
自动创建父类,适用于设置网站中不存在的父类。使用方法:WEB发布模块/高级功能/内容发布参数/->添加post_parent_cate
添加分类描述使用方法:WEB发布模块/高级功能/内容发布参数/->添加category_description
2.标签:
多标签处理(多个标签请用逗号隔开)
3.作者:
多作者处理,可以设置多个作者随机发文章,发帖参数中指定post_author
自定义作者功能,如果提交的数据是用户名,会自动检测系统中是否存在该用户,如果已经存在则以用户身份发布,如果不存在则将自动新建用户(界面以中文用户名为准。处理)
4.图片和缩略图:
网页图片上传,根据主题或网站背景设置自动生成缩略图,并自动将第一张图片设置为文章的特色图片。使用方法:WEB发布模块/高级功能/文件上传设置/->增加图片所在标签,表格名称:福建自增号
自定义缩略图(特色图片) 使用方法:WEB发布模块/高级功能/文件上传设置/添加缩略图所在标签,表单名称:缩略图增量编号
标准的php.ini单次最大文件上传数为20个,如果发布的内容附件超过20个,会报错。如果遇到这个问题,请修改php.ini的max_file_uploads/2018/03参数。或更改上传方式为FTP
5.时间和预约发布:
正确的时间格式是 2017-10-01 23:45:55 或 2017-10-01 23:45
自动处理服务器时间和博客时间的时差
随机排期和排期发布功能:可以设置排期,启用排期排期功能。开启定时发布后,如果POST的数据中收录时间,则立即根据时间发布,否则时间由接口文件Publish配置。
6.评论:
发表评论,支持评论时间、评论作者、评论内容,需要在优采云->网页发布模块/内容发布参数/->添加三个参数,comment、commentdate、commentauthor,与评论对应内容和评论分别时间,评论作者。三个参数缺一不可
7.其他:
判断标题是否重复,在参数配置中打开$checkTitle,可以判断标题是否重复,重复的结果不会发布
发布文章后自动ping,需要后台设置->撰写->更新服务并填写ping地址
‘pending review’更新文章STATUS pending(审查)发布(所有人可见)
使用说明
将 locoy.php 放在 wordpress 网站的根目录下
编辑任务/选择“网络发布配置管理”下的“第3步:发布内容设置”
将“WordPress免登录发布界面.wpm”放入优采云采集器下的“Module”文件夹,参考下图创建web发布配置
回到第三步,选择“添加发布配置”,选择刚才保存的配置文件。
完成以上步骤后,就可以正常发布数据了,可以发布的内容有:
标题、内容(图片和文件可以在这个标签上传)、类别、作者、时间、摘要、缩略图(系统默认会调用内容的第一张图片作为缩略图,这个标签是可选的)”
如果您不需要某些标签,您可以在“内容发布参数”中编辑发布模块并删除它们。
WordPress优采云advanced 免登录界面教程
关于安全配置、多分类、多标签、自定义字段(post_meta)、自定义分类(category)、自定义文章类型(post_type)、自定义文章表单(post_format)、自定义定义分类方法(taxonomy) , 自定义分类信息(add_term_meta)请往下阅读
模块参数列表:
//以下是代码体...
post_title 必填标题
post_contentRequired 内容
标签可选标签
post_category 可选类别
post_date 可选时间
post_excerpt 可选摘要
post_author 可选作者
category_description 可选类别信息
post_cate_meta[name] 可选,自定义分类信息
post_meta[name] 可选自定义字段
post_type 是可选的文章type 默认是‘post’
post_taxonomy 可选的自定义分类方法
post_format 可选文章FORM
参考函数说明:
自定义字段的使用方法:WEB发布模块/高级功能/内容发布参数/->添加post_meta[‘field name’]
自定义文章type(post_type)用法:WEB发布模块/高级功能/内容发布参数/->添加post_type
自定义文章表单(post_format)使用该功能,需要修改配置参数$postformat=true;并且在优采云->Web发布模块/内容发布参数/->新发布参数post_format中,标签内容必须为:Image:post-format-image Video:post-format-video
自定义分类(taxonomy):使用方法:WEB发布模块/高级特性/内容发布参数/ -> 增加post_taxonomy,使用taxonomy后文章只能在taxonomy所属的category下发布,category name or ID 请填写类别
如何使用自定义分类信息(add_term_meta):WEB发布模块/高级功能/内容发布参数/->添加post_cate_meta['meta_key'],标签内容可以是文本或数组,数组必须引用格式:key$$ value|||key$$value|||key$$value
如何同时发布属于多个类别和多个标签的文章?
多类别和多标签必须用逗号分隔。支持name和id两种方法,模块自动判断。例如名称:科幻、动作、动漫 id:1,3,6,2
如何发布自定义字段?
进入发布界面的编辑模式
新建post_meta[]表单,中间的[]是自定义字段的名称
如何配置安全性?
文件会过滤数据,但为了数据安全,建议:
1.更改通信密钥,更改locoy.php文件的第61行“$secretWord = ‘LilySoftware’;” (注意!这个key必须和Web发布配置中的全局变量一致)
2.将文件重命名为更复杂的名称。重命名后需要修改release模块的以下参数以保持一致性
关于文件上传:
1.发布模块/高级功能/在网页上添加标签名称
2.Tag Editing,“File Download”设置如图:
其他自定义的用法与自定义字段类似,只是表单的名称有所改变。一些自定义属性支持数组。
采取打赏、点赞和微博分享
猜你要找
免责声明1. 本站所有资源均来自用户上传和互联网。如有侵权请联系网站客服!
2.所有资源仅供大家学习交流使用。请不要将它们用于商业或非法目的。由此产生的后果与本站无关!
3.如果你有闲置的源码或者教程,可以在个人中心贡献区发布,会有金币奖励和额外收益!
4. 本站提供的源代码、模板、插件等资源不收录技术服务。请原谅我!
5.如出现无法下载、无效或有广告的链接,请联系网站客服!
6.本站资源价格仅为赞助,收取的费用仅用于维持本站日常运营!
7.如果遇到加密压缩包,默认解压密码为“”,如无法解压请联系客服!
8.如遇到支付或充值失败或充值未到,请不要着急,请及时联系网站客服!
65源码网»WordPress5.X优采云免登录发布界面+模块(含优采云采集器7.6版)
常见问题 常见问题
免费下载或VIP会员专属资源可以直接商业化吗?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多说明请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:可以将下载的压缩包容量与网盘容量进行对比。如果小于网盘指示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言,或者联系我们。
在资源介绍文章中找不到示例图片?
对于PPT、KEY、Mockups、APP、网页模板等类型的素材,文章中用于介绍的图片通常不收录在相应的可下载素材包中。这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
65源网
自助共享下载平台
贵宾
分享到: 查看全部
WordPress5.X优采云免登陆发布接口+模块(增强版)
WordPress5.X优采云免登录发布界面+模块(增强版)使用说明
适用于优采云采集器7.6-9.6
优化验证标题重复
优化附件、图片、缩略图的上传生成
增加了多种分类方法的发布参数(post_taxonomy_list),使用方法请参考功能特性
修正BUG:如果分类名称收录数字,会导致分类错误。
重新设计老版本发布界面,新版本号为T1,老版本后续不再升级维护。老版本支持3.X-4.8.2
修复BUG:当模块中的某个参数没有在规则中发布时,会导致发布的数据异常(db:标签名会显示)
优化strtoarray函数
特点
1.category(category):
分类支持分类名称和分类ID,系统自动判断
多分类处理(多分类请用逗号隔开)
自动创建一个类别。如果网站中没有这个分类,会自动创建一个分类。
自动创建父类,适用于设置网站中不存在的父类。使用方法:WEB发布模块/高级功能/内容发布参数/->添加post_parent_cate
添加分类描述使用方法:WEB发布模块/高级功能/内容发布参数/->添加category_description
2.标签:
多标签处理(多个标签请用逗号隔开)
3.作者:
多作者处理,可以设置多个作者随机发文章,发帖参数中指定post_author
自定义作者功能,如果提交的数据是用户名,会自动检测系统中是否存在该用户,如果已经存在则以用户身份发布,如果不存在则将自动新建用户(界面以中文用户名为准。处理)
4.图片和缩略图:
网页图片上传,根据主题或网站背景设置自动生成缩略图,并自动将第一张图片设置为文章的特色图片。使用方法:WEB发布模块/高级功能/文件上传设置/->增加图片所在标签,表格名称:福建自增号
自定义缩略图(特色图片) 使用方法:WEB发布模块/高级功能/文件上传设置/添加缩略图所在标签,表单名称:缩略图增量编号
标准的php.ini单次最大文件上传数为20个,如果发布的内容附件超过20个,会报错。如果遇到这个问题,请修改php.ini的max_file_uploads/2018/03参数。或更改上传方式为FTP
5.时间和预约发布:
正确的时间格式是 2017-10-01 23:45:55 或 2017-10-01 23:45
自动处理服务器时间和博客时间的时差
随机排期和排期发布功能:可以设置排期,启用排期排期功能。开启定时发布后,如果POST的数据中收录时间,则立即根据时间发布,否则时间由接口文件Publish配置。
6.评论:
发表评论,支持评论时间、评论作者、评论内容,需要在优采云->网页发布模块/内容发布参数/->添加三个参数,comment、commentdate、commentauthor,与评论对应内容和评论分别时间,评论作者。三个参数缺一不可
7.其他:
判断标题是否重复,在参数配置中打开$checkTitle,可以判断标题是否重复,重复的结果不会发布
发布文章后自动ping,需要后台设置->撰写->更新服务并填写ping地址
‘pending review’更新文章STATUS pending(审查)发布(所有人可见)
使用说明
将 locoy.php 放在 wordpress 网站的根目录下
编辑任务/选择“网络发布配置管理”下的“第3步:发布内容设置”
http://www.65ymz.com/wp-conten ... 1.png 600w, http://www.65ymz.com/wp-conten ... 2.png 768w" />将“WordPress免登录发布界面.wpm”放入优采云采集器下的“Module”文件夹,参考下图创建web发布配置
http://www.65ymz.com/wp-conten ... 6.png 600w" />回到第三步,选择“添加发布配置”,选择刚才保存的配置文件。
完成以上步骤后,就可以正常发布数据了,可以发布的内容有:
标题、内容(图片和文件可以在这个标签上传)、类别、作者、时间、摘要、缩略图(系统默认会调用内容的第一张图片作为缩略图,这个标签是可选的)”
如果您不需要某些标签,您可以在“内容发布参数”中编辑发布模块并删除它们。
WordPress优采云advanced 免登录界面教程
关于安全配置、多分类、多标签、自定义字段(post_meta)、自定义分类(category)、自定义文章类型(post_type)、自定义文章表单(post_format)、自定义定义分类方法(taxonomy) , 自定义分类信息(add_term_meta)请往下阅读
模块参数列表:
//以下是代码体...
post_title 必填标题
post_contentRequired 内容
标签可选标签
post_category 可选类别
post_date 可选时间
post_excerpt 可选摘要
post_author 可选作者
category_description 可选类别信息
post_cate_meta[name] 可选,自定义分类信息
post_meta[name] 可选自定义字段
post_type 是可选的文章type 默认是‘post’
post_taxonomy 可选的自定义分类方法
post_format 可选文章FORM
参考函数说明:
自定义字段的使用方法:WEB发布模块/高级功能/内容发布参数/->添加post_meta[‘field name’]
自定义文章type(post_type)用法:WEB发布模块/高级功能/内容发布参数/->添加post_type
自定义文章表单(post_format)使用该功能,需要修改配置参数$postformat=true;并且在优采云->Web发布模块/内容发布参数/->新发布参数post_format中,标签内容必须为:Image:post-format-image Video:post-format-video
自定义分类(taxonomy):使用方法:WEB发布模块/高级特性/内容发布参数/ -> 增加post_taxonomy,使用taxonomy后文章只能在taxonomy所属的category下发布,category name or ID 请填写类别
如何使用自定义分类信息(add_term_meta):WEB发布模块/高级功能/内容发布参数/->添加post_cate_meta['meta_key'],标签内容可以是文本或数组,数组必须引用格式:key$$ value|||key$$value|||key$$value
如何同时发布属于多个类别和多个标签的文章?
多类别和多标签必须用逗号分隔。支持name和id两种方法,模块自动判断。例如名称:科幻、动作、动漫 id:1,3,6,2
如何发布自定义字段?
进入发布界面的编辑模式
http://www.65ymz.com/wp-conten ... 4.png 600w" />新建post_meta[]表单,中间的[]是自定义字段的名称
如何配置安全性?
文件会过滤数据,但为了数据安全,建议:
1.更改通信密钥,更改locoy.php文件的第61行“$secretWord = ‘LilySoftware’;” (注意!这个key必须和Web发布配置中的全局变量一致)
2.将文件重命名为更复杂的名称。重命名后需要修改release模块的以下参数以保持一致性
关于文件上传:
1.发布模块/高级功能/在网页上添加标签名称
2.Tag Editing,“File Download”设置如图:
http://www.65ymz.com/wp-conten ... 4.png 600w, http://www.65ymz.com/wp-conten ... 7.png 768w" />其他自定义的用法与自定义字段类似,只是表单的名称有所改变。一些自定义属性支持数组。
采取打赏、点赞和微博分享
猜你要找
免责声明1. 本站所有资源均来自用户上传和互联网。如有侵权请联系网站客服!
2.所有资源仅供大家学习交流使用。请不要将它们用于商业或非法目的。由此产生的后果与本站无关!
3.如果你有闲置的源码或者教程,可以在个人中心贡献区发布,会有金币奖励和额外收益!
4. 本站提供的源代码、模板、插件等资源不收录技术服务。请原谅我!
5.如出现无法下载、无效或有广告的链接,请联系网站客服!
6.本站资源价格仅为赞助,收取的费用仅用于维持本站日常运营!
7.如果遇到加密压缩包,默认解压密码为“”,如无法解压请联系客服!
8.如遇到支付或充值失败或充值未到,请不要着急,请及时联系网站客服!
65源码网»WordPress5.X优采云免登录发布界面+模块(含优采云采集器7.6版)
常见问题 常见问题
免费下载或VIP会员专属资源可以直接商业化吗?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多说明请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:可以将下载的压缩包容量与网盘容量进行对比。如果小于网盘指示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言,或者联系我们。
在资源介绍文章中找不到示例图片?
对于PPT、KEY、Mockups、APP、网页模板等类型的素材,文章中用于介绍的图片通常不收录在相应的可下载素材包中。这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
65源网
自助共享下载平台
贵宾
分享到:
创建LoggingAdmin项目ApiBootLogging项目依赖使用idea(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-08-19 05:25
可以通过ApiBoot Logging获取每个请求的详细信息。在分布式部署模式下,一个请求可能经过多个服务。如果每个服务独立保存请求日志信息,我们是做不到的。统一控制,日志库和业务库会出现不一致(可能会使用多个数据源配置),因为这个问题ApiBoot Logging提供了Admin的概念,客户端采集到每个日志都报给管理员,管理员会分析、保存等操作。
创建日志管理项目
ApiBoot Logging Admin可以汇总各个业务服务的请求日志(ApiBoot Logging),所以我们需要将各个业务服务的日志采集单上报给Admin,所以我们应该使用独立的方式进行部署。创建单独的服务专门采集请求日志然后保存。
初始化日志管理项目依赖
使用idea创建一个SpringBoot项目,pom.xml配置文件中的依赖如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
org.springframework.boot
spring-boot-starter-web
org.minbox.framework
api-boot-starter-logging-admin
mysql
mysql-connector-java
com.zaxxer
HikariCP
org.minbox.framework
api-boot-starter-mybatis-enhance
我们需要将采集收到的请求日志保存到数据库中,所以需要在项目中添加数据库驱动和数据库连接池相关的依赖。 ApiBoot Logging Admin 通过DataSource 操作数据,依赖ApiBoot MyBatis Enhance。可以自动创建DataSource,摆脱手动创建,加入Spring IOC容器。
添加ApiBoot统一版本依赖
1
2
3
4
5
6
7
8
9
10
11
12
org.minbox.framework
api-boot-dependencies
2.1.4.RELEASE
import
pom
最新版本的ApiBoot请访问::api-boot-dependencies查询。
启用日志管理
添加ApiBoot Logging Admin依赖后,无法完全使用Admin功能。我们需要通过@EnableLoggingAdmin 注释来启用它。这个注解会自动将Logging Admin中需要的一些类注册到Spring IOC中,并在入口类中添加注解如下图:
1
2
3
4
5
6
7
8
9
10
11
12
/**
* ApiBoot Logging Admin入口类
*/
@SpringBootApplication
@EnableLoggingAdmin
public class ApibootReportLogsByLoggingToAdminApplication {
public static void main(String[] args) {
SpringApplication.run(ApibootReportLogsByLoggingToAdminApplication.class, args);
}
}
配置日志数据源
application.yml 配置文件中的数据源配置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# 服务名称
spring:
application:
name: apiboot-report-logs-by-logging-to-admin
# 数据源相关配置
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test
username: root
password: 123456
type: com.zaxxer.hikari.HikariDataSource
# 服务端口号
server:
port: 8081
控制台打印报告日志
ApiBoot Logging Admin可以通过配置文件控制是否在控制台打印采集收到的请求日志信息,并在application.yml配置文件中添加如下内容:
1
2
3
4
5
6
7
api:
boot:
logging:
# Logging Admin相关配置
admin:
# 控制台显示采集的日志信息
show-console-report-log: true
注意:这不应与 ApiBoot Logging 提供的 api.boot.logging.show-console-log 配置混淆。
美化控制台打印的报告日志
1
2
3
4
5
6
7
api:
boot:
logging:
# Logging Admin相关配置
admin:
# 控制台输出时美化采集到的日志
format-console-log-json: true
注意:不要与这里的 api.boot.logging.format-console-log-json 配置混淆。
初始化日志表结构
ApiBoot Logging Admin 使用固定的表结构来存储请求日志和服务信息。建表语句如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
SET NAMES utf8mb4 ;
--
-- Table structure for table `logging_request_logs`
--
CREATE TABLE `logging_request_logs` (
`lrl_id` varchar(36) COLLATE utf8mb4_general_ci NOT NULL COMMENT '主键,UUID',
`lrl_service_detail_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '服务详情编号,关联logging_service_details主键',
`lrl_trace_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '链路ID',
`lrl_parent_span_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上级跨度ID',
`lrl_span_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '跨度ID',
`lrl_start_time` mediumtext COLLATE utf8mb4_general_ci COMMENT '请求开始时间',
`lrl_end_time` mediumtext COLLATE utf8mb4_general_ci COMMENT '请求结束时间',
`lrl_http_status` int(11) DEFAULT NULL COMMENT '请求响应状态码',
`lrl_request_body` longtext COLLATE utf8mb4_general_ci COMMENT '请求主体内容',
`lrl_request_headers` text COLLATE utf8mb4_general_ci COMMENT '请求头信息',
`lrl_request_ip` varchar(30) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '发起请求客户端的IP地址',
`lrl_request_method` varchar(10) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '请求方式',
`lrl_request_uri` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '请求路径',
`lrl_response_body` longtext COLLATE utf8mb4_general_ci COMMENT '响应内容',
`lrl_response_headers` text COLLATE utf8mb4_general_ci COMMENT '响应头信息',
`lrl_time_consuming` int(11) DEFAULT NULL COMMENT '请求耗时',
`lrl_create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '日志保存时间',
`lrl_request_params` text COLLATE utf8mb4_general_ci,
`lrl_exception_stack` text COLLATE utf8mb4_general_ci,
PRIMARY KEY (`lrl_id`),
KEY `logging_request_logs_LRL_SERVICE_DETAIL_ID_index` (`lrl_service_detail_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='请求日志信息表';
--
-- Table structure for table `logging_service_details`
--
CREATE TABLE `logging_service_details` (
`lsd_id` varchar(36) COLLATE utf8mb4_general_ci NOT NULL,
`lsd_service_id` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上报服务的ID,对应spring.application.name配置值',
`lsd_service_ip` varchar(50) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上报服务的IP地址',
`lsd_service_port` int(11) DEFAULT NULL COMMENT '上报服务的端口号',
`lsd_last_report_time` timestamp NULL DEFAULT NULL COMMENT '最后一次上报时间,每次上报更新',
`lsd_create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '首次上报时创建时间',
PRIMARY KEY (`lsd_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='上报日志的客户端服务详情';
ApiBoot Logging Admin 到目前为止已经准备就绪。接下来,我们需要修改业务服务以将请求日志报告给 Logging Admin。
向指定的日志管理员报告日志
我们将修改使用ApiBoot Logging统一管理请求日志文章的源码,并将Logging Admin的地址添加到application.yml中,如下图:
1
2
3
4
5
6
7
api:
boot:
# ApiBoot Logging 日志组件配置
logging:
# 配置Logging Admin地址
admin:
server-address: 127.0.0.1:8081
api.boot.logging.admin-service-address 的配置格式是:Ip:Port,我们只需要修改这一个地方,其他的所有任务内部交给ApiBoot Logging。
测试
我们以应用程序的形式启动 ApiBoot 日志管理和业务服务。
使用curl访问测试地址如下:
1
2
~ curl http://localhost:8080/test\?name\=admin
你好:admin
我们检查 ApiBoot Logging 管理控制台日志如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
Receiving Service: 【apiboot-unified-manage-request-logs -> 127.0.0.1】, Request Log Report,Logging Content:[
{
"endTime":1571641723779,
"httpStatus":200,
"requestBody":"",
"requestHeaders":{
"server-region":"JiNan",
"host":"localhost:8080",
"user-agent":"curl/7.64.1",
"accept":"*/*"
},
"requestIp":"0:0:0:0:0:0:0:1",
"requestMethod":"GET",
"requestParam":"{\"name\":\"admin\"}",
"requestUri":"/test",
"responseBody":"你好:admin",
"responseHeaders":{},
"serviceId":"apiboot-unified-manage-request-logs",
"serviceIp":"127.0.0.1",
"servicePort":"8080",
"spanId":"95a73ca0-831b-45df-aa43-2b5887e8d98d",
"startTime":1571641723776,
"timeConsuming":3,
"traceId":"25a7de96-b3dd-48e5-9854-1a8069a4a681"
}
]
我们已经看到了Logging Admin控制台打印的报告请求日志,这个请求的日志是否已经保存到数据库中还不确定。接下来,我将使用命令行查看数据库的日志信息。
查看logging_service_details表中的数据
1
2
3
4
5
6
7
8
mysql> select * from logging_service_details\G;
*************************** 1. row ***************************
lsd_id: b069366a-25dc-41ec-8f09-242d81755cd0
lsd_service_id: apiboot-unified-manage-request-logs
lsd_service_ip: 10.180.98.112
lsd_service_port: 8080
lsd_last_report_time: 2019-10-21 02:14:26
lsd_create_time: 2019-10-21 15:14:26
logging_service_details 存储了每个上报请求日志的业务服务的基本信息。每个服务的基本信息都会缓存在Logging Admin内存中,方便获取service_id用于存储日志,根据ip+port+service_id确定唯一性。同一个服务只保存一次。
查看logging_request_logs表中的数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
mysql> select * from logging_request_logs\G;
*************************** 1. row ***************************
lrl_id: c42761f6-b072-4744-8a17-d8e6097b85de
lrl_service_detail_id: b069366a-25dc-41ec-8f09-242d81755cd0
lrl_trace_id: 055329a0-cfc1-4606-baf0-4fb0cc905ba2
lrl_parent_span_id: NULL
lrl_span_id: aab83092-7749-4f88-8cb6-a949cc060197
lrl_start_time: 1571642065262
lrl_end_time: 1571642065286
lrl_http_status: 200
lrl_request_body:
lrl_request_headers: {"server-region":"JiNan","host":"localhost:8080","user-agent":"curl/7.64.1","accept":"*/*"}
lrl_request_ip: 0:0:0:0:0:0:0:1
lrl_request_method: GET
lrl_request_uri: /test
lrl_response_body: 你好:admin
lrl_response_headers: {}
lrl_time_consuming: 24
lrl_create_time: 2019-10-21 15:14:26
lrl_request_params: {"name":"admin"}
lrl_exception_stack: NULL
敲黑板画重点
本章我们集成了ApiBoot Logging Admin,将业务服务的每一个请求日志上报给Logging Admin,并通过数据库保存请求日志,然后通过其他方法,并通过spanId和traceId查看日志——每个请求链路的从属关系以及每个请求中消耗时间最多的跨度,以准确优化服务性能。
代码示例
如果你喜欢这篇文章文章请为源代码仓库点个Star,谢谢! ! !
这个文章例子的源码可以通过以下方式获取,目录为apiboot-report-logs-by-logging-to-admin:
本文由恒宇青年-于启宇撰写,遵循CC4.0BY-SA版权协议。转载请注明文章source。如需公众号转载请联系“微信” 查看全部
创建LoggingAdmin项目ApiBootLogging项目依赖使用idea(组图)
可以通过ApiBoot Logging获取每个请求的详细信息。在分布式部署模式下,一个请求可能经过多个服务。如果每个服务独立保存请求日志信息,我们是做不到的。统一控制,日志库和业务库会出现不一致(可能会使用多个数据源配置),因为这个问题ApiBoot Logging提供了Admin的概念,客户端采集到每个日志都报给管理员,管理员会分析、保存等操作。
创建日志管理项目
ApiBoot Logging Admin可以汇总各个业务服务的请求日志(ApiBoot Logging),所以我们需要将各个业务服务的日志采集单上报给Admin,所以我们应该使用独立的方式进行部署。创建单独的服务专门采集请求日志然后保存。
初始化日志管理项目依赖
使用idea创建一个SpringBoot项目,pom.xml配置文件中的依赖如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
org.springframework.boot
spring-boot-starter-web
org.minbox.framework
api-boot-starter-logging-admin
mysql
mysql-connector-java
com.zaxxer
HikariCP
org.minbox.framework
api-boot-starter-mybatis-enhance
我们需要将采集收到的请求日志保存到数据库中,所以需要在项目中添加数据库驱动和数据库连接池相关的依赖。 ApiBoot Logging Admin 通过DataSource 操作数据,依赖ApiBoot MyBatis Enhance。可以自动创建DataSource,摆脱手动创建,加入Spring IOC容器。
添加ApiBoot统一版本依赖
1
2
3
4
5
6
7
8
9
10
11
12
org.minbox.framework
api-boot-dependencies
2.1.4.RELEASE
import
pom
最新版本的ApiBoot请访问::api-boot-dependencies查询。
启用日志管理
添加ApiBoot Logging Admin依赖后,无法完全使用Admin功能。我们需要通过@EnableLoggingAdmin 注释来启用它。这个注解会自动将Logging Admin中需要的一些类注册到Spring IOC中,并在入口类中添加注解如下图:
1
2
3
4
5
6
7
8
9
10
11
12
/**
* ApiBoot Logging Admin入口类
*/
@SpringBootApplication
@EnableLoggingAdmin
public class ApibootReportLogsByLoggingToAdminApplication {
public static void main(String[] args) {
SpringApplication.run(ApibootReportLogsByLoggingToAdminApplication.class, args);
}
}
配置日志数据源
application.yml 配置文件中的数据源配置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# 服务名称
spring:
application:
name: apiboot-report-logs-by-logging-to-admin
# 数据源相关配置
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test
username: root
password: 123456
type: com.zaxxer.hikari.HikariDataSource
# 服务端口号
server:
port: 8081
控制台打印报告日志
ApiBoot Logging Admin可以通过配置文件控制是否在控制台打印采集收到的请求日志信息,并在application.yml配置文件中添加如下内容:
1
2
3
4
5
6
7
api:
boot:
logging:
# Logging Admin相关配置
admin:
# 控制台显示采集的日志信息
show-console-report-log: true
注意:这不应与 ApiBoot Logging 提供的 api.boot.logging.show-console-log 配置混淆。
美化控制台打印的报告日志
1
2
3
4
5
6
7
api:
boot:
logging:
# Logging Admin相关配置
admin:
# 控制台输出时美化采集到的日志
format-console-log-json: true
注意:不要与这里的 api.boot.logging.format-console-log-json 配置混淆。
初始化日志表结构
ApiBoot Logging Admin 使用固定的表结构来存储请求日志和服务信息。建表语句如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
SET NAMES utf8mb4 ;
--
-- Table structure for table `logging_request_logs`
--
CREATE TABLE `logging_request_logs` (
`lrl_id` varchar(36) COLLATE utf8mb4_general_ci NOT NULL COMMENT '主键,UUID',
`lrl_service_detail_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '服务详情编号,关联logging_service_details主键',
`lrl_trace_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '链路ID',
`lrl_parent_span_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上级跨度ID',
`lrl_span_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '跨度ID',
`lrl_start_time` mediumtext COLLATE utf8mb4_general_ci COMMENT '请求开始时间',
`lrl_end_time` mediumtext COLLATE utf8mb4_general_ci COMMENT '请求结束时间',
`lrl_http_status` int(11) DEFAULT NULL COMMENT '请求响应状态码',
`lrl_request_body` longtext COLLATE utf8mb4_general_ci COMMENT '请求主体内容',
`lrl_request_headers` text COLLATE utf8mb4_general_ci COMMENT '请求头信息',
`lrl_request_ip` varchar(30) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '发起请求客户端的IP地址',
`lrl_request_method` varchar(10) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '请求方式',
`lrl_request_uri` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '请求路径',
`lrl_response_body` longtext COLLATE utf8mb4_general_ci COMMENT '响应内容',
`lrl_response_headers` text COLLATE utf8mb4_general_ci COMMENT '响应头信息',
`lrl_time_consuming` int(11) DEFAULT NULL COMMENT '请求耗时',
`lrl_create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '日志保存时间',
`lrl_request_params` text COLLATE utf8mb4_general_ci,
`lrl_exception_stack` text COLLATE utf8mb4_general_ci,
PRIMARY KEY (`lrl_id`),
KEY `logging_request_logs_LRL_SERVICE_DETAIL_ID_index` (`lrl_service_detail_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='请求日志信息表';
--
-- Table structure for table `logging_service_details`
--
CREATE TABLE `logging_service_details` (
`lsd_id` varchar(36) COLLATE utf8mb4_general_ci NOT NULL,
`lsd_service_id` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上报服务的ID,对应spring.application.name配置值',
`lsd_service_ip` varchar(50) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上报服务的IP地址',
`lsd_service_port` int(11) DEFAULT NULL COMMENT '上报服务的端口号',
`lsd_last_report_time` timestamp NULL DEFAULT NULL COMMENT '最后一次上报时间,每次上报更新',
`lsd_create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '首次上报时创建时间',
PRIMARY KEY (`lsd_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='上报日志的客户端服务详情';
ApiBoot Logging Admin 到目前为止已经准备就绪。接下来,我们需要修改业务服务以将请求日志报告给 Logging Admin。
向指定的日志管理员报告日志
我们将修改使用ApiBoot Logging统一管理请求日志文章的源码,并将Logging Admin的地址添加到application.yml中,如下图:
1
2
3
4
5
6
7
api:
boot:
# ApiBoot Logging 日志组件配置
logging:
# 配置Logging Admin地址
admin:
server-address: 127.0.0.1:8081
api.boot.logging.admin-service-address 的配置格式是:Ip:Port,我们只需要修改这一个地方,其他的所有任务内部交给ApiBoot Logging。
测试
我们以应用程序的形式启动 ApiBoot 日志管理和业务服务。
使用curl访问测试地址如下:
1
2
~ curl http://localhost:8080/test\?name\=admin
你好:admin
我们检查 ApiBoot Logging 管理控制台日志如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
Receiving Service: 【apiboot-unified-manage-request-logs -> 127.0.0.1】, Request Log Report,Logging Content:[
{
"endTime":1571641723779,
"httpStatus":200,
"requestBody":"",
"requestHeaders":{
"server-region":"JiNan",
"host":"localhost:8080",
"user-agent":"curl/7.64.1",
"accept":"*/*"
},
"requestIp":"0:0:0:0:0:0:0:1",
"requestMethod":"GET",
"requestParam":"{\"name\":\"admin\"}",
"requestUri":"/test",
"responseBody":"你好:admin",
"responseHeaders":{},
"serviceId":"apiboot-unified-manage-request-logs",
"serviceIp":"127.0.0.1",
"servicePort":"8080",
"spanId":"95a73ca0-831b-45df-aa43-2b5887e8d98d",
"startTime":1571641723776,
"timeConsuming":3,
"traceId":"25a7de96-b3dd-48e5-9854-1a8069a4a681"
}
]
我们已经看到了Logging Admin控制台打印的报告请求日志,这个请求的日志是否已经保存到数据库中还不确定。接下来,我将使用命令行查看数据库的日志信息。
查看logging_service_details表中的数据
1
2
3
4
5
6
7
8
mysql> select * from logging_service_details\G;
*************************** 1. row ***************************
lsd_id: b069366a-25dc-41ec-8f09-242d81755cd0
lsd_service_id: apiboot-unified-manage-request-logs
lsd_service_ip: 10.180.98.112
lsd_service_port: 8080
lsd_last_report_time: 2019-10-21 02:14:26
lsd_create_time: 2019-10-21 15:14:26
logging_service_details 存储了每个上报请求日志的业务服务的基本信息。每个服务的基本信息都会缓存在Logging Admin内存中,方便获取service_id用于存储日志,根据ip+port+service_id确定唯一性。同一个服务只保存一次。
查看logging_request_logs表中的数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
mysql> select * from logging_request_logs\G;
*************************** 1. row ***************************
lrl_id: c42761f6-b072-4744-8a17-d8e6097b85de
lrl_service_detail_id: b069366a-25dc-41ec-8f09-242d81755cd0
lrl_trace_id: 055329a0-cfc1-4606-baf0-4fb0cc905ba2
lrl_parent_span_id: NULL
lrl_span_id: aab83092-7749-4f88-8cb6-a949cc060197
lrl_start_time: 1571642065262
lrl_end_time: 1571642065286
lrl_http_status: 200
lrl_request_body:
lrl_request_headers: {"server-region":"JiNan","host":"localhost:8080","user-agent":"curl/7.64.1","accept":"*/*"}
lrl_request_ip: 0:0:0:0:0:0:0:1
lrl_request_method: GET
lrl_request_uri: /test
lrl_response_body: 你好:admin
lrl_response_headers: {}
lrl_time_consuming: 24
lrl_create_time: 2019-10-21 15:14:26
lrl_request_params: {"name":"admin"}
lrl_exception_stack: NULL
敲黑板画重点
本章我们集成了ApiBoot Logging Admin,将业务服务的每一个请求日志上报给Logging Admin,并通过数据库保存请求日志,然后通过其他方法,并通过spanId和traceId查看日志——每个请求链路的从属关系以及每个请求中消耗时间最多的跨度,以准确优化服务性能。
代码示例
如果你喜欢这篇文章文章请为源代码仓库点个Star,谢谢! ! !
这个文章例子的源码可以通过以下方式获取,目录为apiboot-report-logs-by-logging-to-admin:
本文由恒宇青年-于启宇撰写,遵循CC4.0BY-SA版权协议。转载请注明文章source。如需公众号转载请联系“微信”
自主研发的EC-8001模拟量数字量采集卡
采集交流 • 优采云 发表了文章 • 0 个评论 • 201 次浏览 • 2021-08-09 22:38
自主研发的EC-8001模拟量数字量采集卡
采集卡的绝大多数数据都集中在采集模拟、数字、热电阻和热电偶上。热电阻可视为非电性。事实上,它仍然需要由当前的采集来驱动。模拟数据采集卡和数字采集卡使用最广泛。比如开发生产的8001系列采集卡就是这样的采集卡。典型的data采集卡的功能包括模拟输入、模拟输出、数字I/O、计数器/定时器等,模拟输入是采集卡最基本的功能。它通常由多路复用器、放大器、采样保持电路和模数转换器实现。模拟信号经过上述部分后可以转换为数字信号。 ADC 的性能和参数直接影响采集 数据的质量。应根据实际测量所需的精度选择合适的ADC。
选择data采集card主要关注三个方面,分别是通道数、采样率和分辨率。选择的关键是采集卡的数据是干什么用的。这一定是有目的的,这样数据采集卡才能被选中。因为不同的数据采集cards 用在不同的地方,如果你不确定用途,没有办法做出更准确的选择。因此,在确定用途后,找到对应的匹配数据采集card,并检查其参数是否符合要求,并比较不同类型的采集cards,以便选择合适的产品。
通常,在信号采集之后,必须进行适当的信号处理,例如FFT。这里还有一个对样本数量的要求。一般不可能只提供一个信号周期的数据样本,而是希望有五到十个周期,甚至更多的样本。并希望提供的样本总数是整个周期的数量。这里出现了另一个困难。我不知道或确切知道被采集的信号的频率。因此,不仅采样率不一定是信号频率的整数倍,也不能保证提供整数个周期的样本。其实data采集card、data采集module、data采集仪等等,都是data采集tools。
今天介绍一款自主研发的EC-8001模拟数字采集卡。是一款基于DSP和FPGA的EtherCat主控卡,最多可同时支持512个DI点和512个DO点,支持模拟采集和模拟输出。最高总线通信周期可达250μs。驱动安装完成后,提供了函数API和动态链接库。提供的API和驱动自带的调试软件可以帮助用户更好的上手,加快项目调试进度。
核心优势:
操作系统可以支持:
函数库:
规格:
凌辰科技专注自动化领域14年。拥有自主知识产权的自动化系统开发平台,实现软硬件无缝对接,整个系统稳定、安全、可扩展。同时长期从事工业计算机和嵌入式产品。 、测量自动化产品、工业机器人、机器视觉等的研发与销售
兄弟公司讯亚自动化是台湾优质TOYO模块总代理,ABB机器人价值合作伙伴。机器人+多轴运动平台/视觉系统/智能安全服,专业为您提供机器人解决方案
查看全部
自主研发的EC-8001模拟量数字量采集卡
采集卡的绝大多数数据都集中在采集模拟、数字、热电阻和热电偶上。热电阻可视为非电性。事实上,它仍然需要由当前的采集来驱动。模拟数据采集卡和数字采集卡使用最广泛。比如开发生产的8001系列采集卡就是这样的采集卡。典型的data采集卡的功能包括模拟输入、模拟输出、数字I/O、计数器/定时器等,模拟输入是采集卡最基本的功能。它通常由多路复用器、放大器、采样保持电路和模数转换器实现。模拟信号经过上述部分后可以转换为数字信号。 ADC 的性能和参数直接影响采集 数据的质量。应根据实际测量所需的精度选择合适的ADC。
选择data采集card主要关注三个方面,分别是通道数、采样率和分辨率。选择的关键是采集卡的数据是干什么用的。这一定是有目的的,这样数据采集卡才能被选中。因为不同的数据采集cards 用在不同的地方,如果你不确定用途,没有办法做出更准确的选择。因此,在确定用途后,找到对应的匹配数据采集card,并检查其参数是否符合要求,并比较不同类型的采集cards,以便选择合适的产品。
通常,在信号采集之后,必须进行适当的信号处理,例如FFT。这里还有一个对样本数量的要求。一般不可能只提供一个信号周期的数据样本,而是希望有五到十个周期,甚至更多的样本。并希望提供的样本总数是整个周期的数量。这里出现了另一个困难。我不知道或确切知道被采集的信号的频率。因此,不仅采样率不一定是信号频率的整数倍,也不能保证提供整数个周期的样本。其实data采集card、data采集module、data采集仪等等,都是data采集tools。
今天介绍一款自主研发的EC-8001模拟数字采集卡。是一款基于DSP和FPGA的EtherCat主控卡,最多可同时支持512个DI点和512个DO点,支持模拟采集和模拟输出。最高总线通信周期可达250μs。驱动安装完成后,提供了函数API和动态链接库。提供的API和驱动自带的调试软件可以帮助用户更好的上手,加快项目调试进度。
核心优势:
操作系统可以支持:
函数库:
规格:
凌辰科技专注自动化领域14年。拥有自主知识产权的自动化系统开发平台,实现软硬件无缝对接,整个系统稳定、安全、可扩展。同时长期从事工业计算机和嵌入式产品。 、测量自动化产品、工业机器人、机器视觉等的研发与销售
兄弟公司讯亚自动化是台湾优质TOYO模块总代理,ABB机器人价值合作伙伴。机器人+多轴运动平台/视觉系统/智能安全服,专业为您提供机器人解决方案
自主研发的EC-8001模拟量数字量采集卡
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-08-09 22:28
自主研发的EC-8001模拟量数字量采集卡
采集卡的绝大多数数据都集中在采集模拟、数字、热电阻和热电偶上。热电阻可视为非电性。事实上,它仍然需要由当前的采集来驱动。模拟数据采集卡和数字采集卡使用最广泛。比如开发生产的8001系列采集卡就是这样的采集卡。典型的data采集卡的功能包括模拟输入、模拟输出、数字I/O、计数器/定时器等,模拟输入是采集卡最基本的功能。它通常由多路复用器、放大器、采样保持电路和模数转换器实现。模拟信号经过上述部分后可以转换为数字信号。 ADC 的性能和参数直接影响采集 数据的质量。应根据实际测量所需的精度选择合适的ADC。
选择data采集card主要关注三个方面,分别是通道数、采样率和分辨率。选择的关键是采集卡的数据是干什么用的。这一定是有目的的,这样数据采集卡才能被选中。因为不同的数据采集cards 用在不同的地方,如果你不确定用途,没有办法做出更准确的选择。因此,在确定用途后,找到对应的匹配数据采集card,并检查其参数是否符合要求,并比较不同类型的采集cards,以便选择合适的产品。
通常,在信号采集之后,必须进行适当的信号处理,例如FFT。这里还有一个对样本数量的要求。一般不可能只提供一个信号周期的数据样本,而是希望有五到十个周期,甚至更多的样本。并希望提供的样本总数是整个周期的数量。这里出现了另一个困难。我不知道或确切知道被采集的信号的频率。因此,不仅采样率不一定是信号频率的整数倍,也不能保证提供整数个周期的样本。其实data采集card、data采集module、data采集仪等等,都是data采集tools。
今天介绍一款自主研发的EC-8001模拟数字采集卡。是一款基于DSP和FPGA的EtherCat主控卡,最多可同时支持512个DI点和512个DO点,支持模拟采集和模拟输出。最高总线通信周期可达250μs。驱动安装完成后,提供了函数API和动态链接库。提供的API和驱动自带的调试软件可以帮助用户更好的上手,加快项目调试进度。
核心优势:
操作系统可以支持:
函数库:
规格:
凌辰科技专注自动化领域14年。拥有自主知识产权的自动化系统开发平台,实现软硬件无缝对接,整个系统稳定、安全、可扩展。同时长期从事工业计算机和嵌入式产品。 、测量自动化产品、工业机器人、机器视觉等的研发与销售
兄弟公司讯亚自动化是台湾优质TOYO模块总代理,ABB机器人价值合作伙伴。机器人+多轴运动平台/视觉系统/智能安全服,专业为您提供机器人解决方案 查看全部
自主研发的EC-8001模拟量数字量采集卡
采集卡的绝大多数数据都集中在采集模拟、数字、热电阻和热电偶上。热电阻可视为非电性。事实上,它仍然需要由当前的采集来驱动。模拟数据采集卡和数字采集卡使用最广泛。比如开发生产的8001系列采集卡就是这样的采集卡。典型的data采集卡的功能包括模拟输入、模拟输出、数字I/O、计数器/定时器等,模拟输入是采集卡最基本的功能。它通常由多路复用器、放大器、采样保持电路和模数转换器实现。模拟信号经过上述部分后可以转换为数字信号。 ADC 的性能和参数直接影响采集 数据的质量。应根据实际测量所需的精度选择合适的ADC。
选择data采集card主要关注三个方面,分别是通道数、采样率和分辨率。选择的关键是采集卡的数据是干什么用的。这一定是有目的的,这样数据采集卡才能被选中。因为不同的数据采集cards 用在不同的地方,如果你不确定用途,没有办法做出更准确的选择。因此,在确定用途后,找到对应的匹配数据采集card,并检查其参数是否符合要求,并比较不同类型的采集cards,以便选择合适的产品。
通常,在信号采集之后,必须进行适当的信号处理,例如FFT。这里还有一个对样本数量的要求。一般不可能只提供一个信号周期的数据样本,而是希望有五到十个周期,甚至更多的样本。并希望提供的样本总数是整个周期的数量。这里出现了另一个困难。我不知道或确切知道被采集的信号的频率。因此,不仅采样率不一定是信号频率的整数倍,也不能保证提供整数个周期的样本。其实data采集card、data采集module、data采集仪等等,都是data采集tools。
今天介绍一款自主研发的EC-8001模拟数字采集卡。是一款基于DSP和FPGA的EtherCat主控卡,最多可同时支持512个DI点和512个DO点,支持模拟采集和模拟输出。最高总线通信周期可达250μs。驱动安装完成后,提供了函数API和动态链接库。提供的API和驱动自带的调试软件可以帮助用户更好的上手,加快项目调试进度。
核心优势:
操作系统可以支持:
函数库:
规格:
凌辰科技专注自动化领域14年。拥有自主知识产权的自动化系统开发平台,实现软硬件无缝对接,整个系统稳定、安全、可扩展。同时长期从事工业计算机和嵌入式产品。 、测量自动化产品、工业机器人、机器视觉等的研发与销售
兄弟公司讯亚自动化是台湾优质TOYO模块总代理,ABB机器人价值合作伙伴。机器人+多轴运动平台/视觉系统/智能安全服,专业为您提供机器人解决方案
Chukwa开源的数据收集和分析系统——Chukwa来处理
采集交流 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-08-09 22:18
文章系列的前三篇文章介绍了分布式存储计算系统Hadoop和Hadoop集群的构建、Zookeeper集群的构建、HBase的分布式部署。当 Hadoop 集群数量达到 1000+ 时,集群本身的信息会大大增加。 Apache 开发了一个开源的数据采集和分析系统——Chukwa 来处理来自 Hadoop 集群的数据。 Chukwa 有几个非常吸引人的特点:结构清晰,部署简单;采集的数据类型广泛,可扩展性强;它与 Hadoop 无缝集成,可以采集和组织海量数据。
1 Chukwa 简介
在 Chukwa 的官网上,Chukwa 是这样描述的: Chukwa 是一个开源的数据采集系统,用于监控大规模分布式系统。它建立在 HDFS 和 Map/Reduce 框架之上,并继承了 Hadoop 出色的可扩展性和健壮性。在数据分析方面,楚科瓦拥有一套灵活而强大的工具,可用于监控和分析结果,以更好地利用采集到的数据结果。
为了更简单直观地展示楚克瓦,我们先来看一个假想的场景。假设我们有一个很大的规模(它总是涉及到Hadoop...)网站,网站每天生成大量的日志文件,采集和分析这些日志文件并不容易,读者可能会认为,Hadoop是挺适合做这种事情的,很多大的网站都在用,那么问题是如何采集散落在各个节点上的数据,如果采集到的数据有重复数据如何处理,如何与Hadoop集成如果自己编写代码来完成这个过程,会耗费很多精力,难免会引入bug。现在是我们楚克瓦发挥作用的时候了。 Chukwa 是一个开源软件,有很多聪明的开发者贡献了他们的智慧。它可以帮助我们实时监控各个节点上日志文件的变化,将文件内容增量写入HDFS,还可以去除数据重复、排序等,此时Hadoop从HDFS获取的文件已经是SequenceFile了。没有任何转换过程,Chukwa 帮助我们完成了中间复杂的过程。是不是很省心?这里我们只是举一个应用实例,它也可以帮助我们监控来自Socket的数据,甚至执行指定的命令获取输出数据等,具体请参考Chukwa官方文档。如果这些还不够,我们还可以定义自己的适配器来完成更高级的功能。
2 Chukwa 架构
Chukwa 旨在为分布式数据采集和大数据处理提供灵活而强大的平台。该平台不仅现在可用,而且能够与时俱进地使用更新的存储技术(如 HDFS、HBase 等)。当这些存储技术成熟时。为了保持这种灵活性,Chukwa 被设计为采集和处理分层管道,每个级别之间有一个非常清晰和狭窄的接口。下图是Chukwa架构示意图:
主要组件有:
1.Agents:负责采集最原创的数据发送给Collectors
2. Adaptors:采集数据的直接接口和工具,一个Agent可以管理多个Adaptors采集的数据
3. Collectors:负责采集Agent发送的数据并定期写入集群
4.Map/Reduce Jobs:定时启动,负责集群内数据的分类、排序、去重、合并
5.HICC(Hadoop基础设施维护中心)负责数据展示
3 主要部件的具体设计
3.1 适配器、代理
在每条数据的生成端(基本上在集群中的每一个节点上),Chukwa使用一个Agent来采集它感兴趣的数据。每一种数据都由一个Adaptor来实现,数据的类型(数据模型)在相应的配置中指定。 Chukwa 默认为以下常用数据源提供了相应的适配器:命令行输出、日志文件和 httpSender 等,这些适配器会定期运行(例如每分钟读取 df 结果)或事件驱动执行(例如内核中的错误日志)。如果这些 Adapter 不够用,用户可以很容易地自己实现一个 Adapter 来满足他们的需求。
为了防止数据采集上的Agent出现故障,Ahukwa的Agent使用了所谓的“看门狗”机制,自动重启终止的数据采集进程,防止原创数据丢失。
另一方面,对于重复的采集 数据,它们会在 Chukwa 的数据处理过程中自动去重。这样,对于关键数据,同一个Agent可以部署在多台机器上,从而实现容错功能。
3.2 采集器
agent采集收到的数据存储在hadoop集群上。 hadoop集群擅长处理少量大文件,而处理大量小文件不是它的强项。针对这种情况,chukwa 设计了采集器的角色,将数据部分合并,然后写入集群,防止大量小文件。文件写入。
另一方面,为了防止采集器成为性能瓶颈或单点,导致故障,chukwa允许和鼓励设置多个采集器,代理从采集器列表中随机选择一个采集器来传输数据如果一个采集器失败或忙碌,只需切换到下一个采集器。这样可以实现负载均衡。实践证明,多个采集器的负载几乎是均匀的。
3.3 解复用器,存档
集群上的数据通过 map/reduce 作业进行分析。在 map/reduce 阶段,chukwa 提供了两种内置的作业类型,demux 和归档任务。
demux 作业负责数据的分类、排序和去重。在代理部分,我们提到了数据类型(DataType?)的概念。采集器写入集群的数据有自己的类型。 demux 在作业执行过程中,通过配置文件中指定的数据类型和数据处理类进行相应的数据分析工作。一般对非结构化数据进行结构化,提取其中的数据属性。因为demux的本质是map/reduce job,所以我们可以根据自己的需要开发自己的demux job,进行各种复杂的逻辑分析。 chukwa 提供的 demux 接口可以很容易地用 java 语言进行扩展。
归档作业负责合并相同类型的数据文件。一方面,它确保相同类型的数据都放在一起以供进一步分析。另一方面减少了文件数量,减轻了hadoop集群的存储压力。
3.4 数据库管理员
放置在集群上的数据可以满足数据的长期存储和大数据量的计算,但不便于展示。为此,楚科瓦做了两个努力:
1. 使用mdl语言将集群上的数据提取到mysql数据库中。对于过去一周的数据,数据完全保存。一周以上的数据按照现在数据的时间长短进行稀释。数据越长。 , 保存数据的时间间隔越长。使用mysql作为数据源显示数据。
2.使用hbase或类似技术将索引数据直接存储在集群上
直到chukwa0.4.0版本,chukwa使用第一种方法,但第二种方法更优雅,更方便。
3.5 hicc
hicc 是chukwa 的数据显示终端的名称。在显示方面,chukwa 提供了一些默认的数据显示小部件。可以使用“列表”、“曲线图”、“多曲线图”、“直方图”、“面积图”来显示一种或多种类型的数据,供用户直观的数据趋势显示。而且,在hicc显示端,对不断产生的新数据和历史数据采用robin策略,防止数据的不断增长增加服务器压力,在时间轴上可以“稀释”数据。长期数据显示
本质上hicc是jetty实现的web服务器,内部使用jsp技术和javascript技术。各种需要显示的数据类型和页面布局都可以通过简单的拖拽实现,对于更复杂的数据显示方式,可以使用sql语言来组合各种需要的数据。如果这不符合需求,不要害怕,只需手动修改其jsp代码即可。
3.6 其他数据接口
如果对原创数据有新的需求,用户也可以通过map/reduce作业或者pig语言直接访问集群上的原创数据,生成想要的结果。 Chukwa 还提供了命令行界面,可以直接访问集群上的数据。
3.7 默认数据支持
对于集群中每个节点的CPU使用率、内存使用率、硬盘使用率、整个集群的平均CPU使用率、整个集群的内存使用率、整个集群的存储使用率、数量的变化集群文件的数量,作业数量的变化等hadoop相关数据,从采集到展示的整套进程,chukwa提供了内置支持,你只需要配置一下就可以使用了。可以说是相当方便了。
由此可见,chukwa 为数据生成、采集、存储、分析、展示的整个生命周期提供了全面的支持。下图展示了 Chukwa 的完整架构:
4 Chukwa 到底是什么?
4.1 chukwa 不是什么
1. chukwa 不是一个独立的系统。在单个节点上部署chukwa系统基本上没有用。 Chukwa 是一个基于 Hadoop 构建的分布式日志处理系统。也就是说,在搭建chukwa环境之前,需要先搭建一个Hadoop环境,然后在Hadoop的基础上搭建chukwa环境。这种关系也可以从后来的chukwa推导出来,从架构图可以看出。这也是因为chukwa的假设是要处理的数据量在T级别。
2. chukwa 不是实时错误监控系统。在解决这个问题上,ganglia、nagios等系统都做得很好,这些系统对数据的敏感度可以达到二级。 chukwa 分析的是 数据处于分钟级别。它认为集群整体CPU使用率等数据,几分钟后获取就不是问题。
3. chukwa 不是一个封闭的系统。虽然chukwa自带了很多针对hadoop集群的分析项,但这并不是说它只能监控和分析hadoop。chukwa提供了大量数据的日志数据采集,一套完整的存储、分析解决方案和框架和显示。在这种类型的数据生命周期的各个阶段,chukwa 提供了近乎完美的解决方案,这也可以从其架构上看出。
4.2 什么是chukwa
上一节说了很多 chukwa 不是什么,我们来看看 chukwa 是专门用来做什么的?具体来说,chukwa致力于以下几个方面:
1. 一般来说,chukwa可以用来监控大规模(2000多个节点,每天产生的数据量在T级)hadoop集群的整体运行情况,并分析它们的日志
2. 对于集群用户:chukwa 显示他们的作业运行了多长时间,它们占用了多少资源,有多少资源可用,作业失败的原因以及读写操作在哪个节点上退出问题.
3.集群运维工程师:chukwa展示集群硬件错误、集群性能变化、集群资源瓶颈。
4. 对于集群管理者:chukwa 显示了集群的资源消耗和集群操作的整体执行情况,可以用来辅助预算和集群资源协调。
5. 集群开发者:chukwa 展示了集群中的主要性能瓶颈和频繁出现的错误,让您可以专注于解决重要问题。
5 Chukwa 部署和配置
5.1 前期准备
Chukwa是部署在Hadoop集群上的,所以前期需要安装部署Hadoop集群,包括SSH无密码登录、JDK安装等,具体可以参考本系列其他博文“一Hadoop系列丛书:Hadoop集群构建》等。
Hadoop集群架构如下:1个Master,1个Backup(主机备用),3个Slaves(由虚拟机创建)。节点IP地址:
rango(Master) 192.168.56.1 namenode
vm1(Backup) 192.168.56.101 secondarynode
vm2(Slave1)192.168.56.102 数据节点
vm3(Slave2)192.168.56.103 数据节点
vm4(Slave3)192.168.56.104 数据节点
5.2 安装 Chukwa
从官网只能下载chukwa-incubating-src-0.5.0.tar.gz,最新版本的Chukwa可以到~eyang/chukwa-0.@下载5.0-rc0/ 版本 chukwa-incubating-0.5.0.tar.gz。
解压并重命名并移动到 /usr 目录:
tar zxvf chukwa-incubating-0.5.0.tar.gz; mv chukwa-incubating-0.5.0 /usr/chukwa
需要在每个被监控的节点上维护一份 Chukwa 的副本(采集数据信息),每个节点都会运行一个采集器。配置完成后,可以通过scp命令复制到集群的各个节点。
5.3 配置 Chukwa
5.3.1 配置环境变量
编辑 /etc/profile 并添加以下语句:
#设置chukwa路径
导出 CHUKWA_HOME=/usr/chukwa
导出 CHUKWA_CONF_DIR=/usr/chukwa/etc/chukwa
导出路径=$PATH:$CHUKWA_HOME/bin:$CHUKWA_HOME/sbin:$CHUKWA_CONF_DIR
5.3.2 配置Hadoop和HBase集群
首先将 Chukwa 文件复制到 hadoop:
mv $HADOOP_HOME/conf/log4j.properties $HADOOP_HOME/conf/log4j.properties.bak
mv $HADOOP_HOME/conf/hadoop-metrics2.properties $HADOOP_HOME/conf/hadoop-metrics2.properties.bak
cp $CHUKWA_CONF_DIR/hadoop-log4j.properties $HADOOP_HOME/conf/log4j.properties
cp $CHUKWA_CONF_DIR/hadoop-metrics2.properties $HADOOP_HOME/conf/hadoop-metrics2.properties
cp $CHUKWA_HOME/share/chukwa/chukwa-0.5.0-client.jar $HADOOP_HOME/lib
cp $CHUKWA_HOME/share/chukwa/lib/json-simple-1.1.jar $HADOOP_HOME/lib
然后启动HBase集群,设置HBase,在HBase中创建数据存储所需的表,表模式已经搭建完成,直接通过hbase shell导入即可:
bin/hbase 外壳
5.3.3 配置采集器
设置 Chukwa 的环境变量,编辑 $CHUKWA_CONF_DIR/chukwa-env.sh 文件:
导出JAVA_HOME=/usr/java/jdk1.7.0_45
#export HBASE_CONF_DIR="${HBASE_CONF_DIR}"
#export HADOOP_CONF_DIR="${HADOOP_CONF_DIR}"
#export CHUKWA_LOG_DIR=/tmp/chukwa/log
#export CHUKWA_DATA_DIR="${CHUKWA_HOME}/data"
注意:设置第一个java的home目录,然后注释掉后面四个。备注HBASE_CONF_DIR和HADOOP_CONF_DIR,因为agent只用来采集数据,所以不需要HADOOP的参与。注释掉 CHUKWA_PID_DIR 和 CHUKWA_LOG_DIR。如果没有注释,则指定位置在/tmp临时目录下,会导致PID和LOG文件无故被删除。会导致后续操作异常。注释后系统会使用默认路径,PID和LOG文件默认创建在Chukwa安装目录下。
当需要多台机器作为采集器时,需要编辑$CHUKWA_CONF_DIR/collectors文件:
192.168.56.1
192.168.56.101
192.168.56.102
192.168.56.103
192.168.56.104
$CHUKWA_CONF_DIR/initial_Adaptors 文件主要用于设置 Chukwa 监控哪些日志,以及监控的方式和频率。使用默认配置即可,如下
添加 sigar.SystemMetrics SystemMetrics 60 0
添加 SocketAdaptor HadoopMetrics 9095 0
添加 SocketAdaptor Hadoop 9096 0
添加 SocketAdaptor ChukwaMetrics 9097 0
添加 SocketAdaptor JobSummary 9098 0
$CHUKWA_CONF_DIR/chukwa-collector-conf.xml 维护着 Chukwa 的基本配置信息。我们需要使用这个文件来确定HDFS的位置:如下:
writer.hdfs.filesystem
hdfs://192.168.56.1:9000/
要转储到的 HDFS
然后可以通过以下设置指定sink数据的地址:
chukwaCollector.outputDir
/chukwa/logs/
chukwa 数据接收器目录
chukwaCollector.http.port
8080 查看全部
Chukwa开源的数据收集和分析系统——Chukwa来处理
文章系列的前三篇文章介绍了分布式存储计算系统Hadoop和Hadoop集群的构建、Zookeeper集群的构建、HBase的分布式部署。当 Hadoop 集群数量达到 1000+ 时,集群本身的信息会大大增加。 Apache 开发了一个开源的数据采集和分析系统——Chukwa 来处理来自 Hadoop 集群的数据。 Chukwa 有几个非常吸引人的特点:结构清晰,部署简单;采集的数据类型广泛,可扩展性强;它与 Hadoop 无缝集成,可以采集和组织海量数据。
1 Chukwa 简介
在 Chukwa 的官网上,Chukwa 是这样描述的: Chukwa 是一个开源的数据采集系统,用于监控大规模分布式系统。它建立在 HDFS 和 Map/Reduce 框架之上,并继承了 Hadoop 出色的可扩展性和健壮性。在数据分析方面,楚科瓦拥有一套灵活而强大的工具,可用于监控和分析结果,以更好地利用采集到的数据结果。
为了更简单直观地展示楚克瓦,我们先来看一个假想的场景。假设我们有一个很大的规模(它总是涉及到Hadoop...)网站,网站每天生成大量的日志文件,采集和分析这些日志文件并不容易,读者可能会认为,Hadoop是挺适合做这种事情的,很多大的网站都在用,那么问题是如何采集散落在各个节点上的数据,如果采集到的数据有重复数据如何处理,如何与Hadoop集成如果自己编写代码来完成这个过程,会耗费很多精力,难免会引入bug。现在是我们楚克瓦发挥作用的时候了。 Chukwa 是一个开源软件,有很多聪明的开发者贡献了他们的智慧。它可以帮助我们实时监控各个节点上日志文件的变化,将文件内容增量写入HDFS,还可以去除数据重复、排序等,此时Hadoop从HDFS获取的文件已经是SequenceFile了。没有任何转换过程,Chukwa 帮助我们完成了中间复杂的过程。是不是很省心?这里我们只是举一个应用实例,它也可以帮助我们监控来自Socket的数据,甚至执行指定的命令获取输出数据等,具体请参考Chukwa官方文档。如果这些还不够,我们还可以定义自己的适配器来完成更高级的功能。
2 Chukwa 架构
Chukwa 旨在为分布式数据采集和大数据处理提供灵活而强大的平台。该平台不仅现在可用,而且能够与时俱进地使用更新的存储技术(如 HDFS、HBase 等)。当这些存储技术成熟时。为了保持这种灵活性,Chukwa 被设计为采集和处理分层管道,每个级别之间有一个非常清晰和狭窄的接口。下图是Chukwa架构示意图:
主要组件有:
1.Agents:负责采集最原创的数据发送给Collectors
2. Adaptors:采集数据的直接接口和工具,一个Agent可以管理多个Adaptors采集的数据
3. Collectors:负责采集Agent发送的数据并定期写入集群
4.Map/Reduce Jobs:定时启动,负责集群内数据的分类、排序、去重、合并
5.HICC(Hadoop基础设施维护中心)负责数据展示
3 主要部件的具体设计
3.1 适配器、代理
在每条数据的生成端(基本上在集群中的每一个节点上),Chukwa使用一个Agent来采集它感兴趣的数据。每一种数据都由一个Adaptor来实现,数据的类型(数据模型)在相应的配置中指定。 Chukwa 默认为以下常用数据源提供了相应的适配器:命令行输出、日志文件和 httpSender 等,这些适配器会定期运行(例如每分钟读取 df 结果)或事件驱动执行(例如内核中的错误日志)。如果这些 Adapter 不够用,用户可以很容易地自己实现一个 Adapter 来满足他们的需求。
为了防止数据采集上的Agent出现故障,Ahukwa的Agent使用了所谓的“看门狗”机制,自动重启终止的数据采集进程,防止原创数据丢失。
另一方面,对于重复的采集 数据,它们会在 Chukwa 的数据处理过程中自动去重。这样,对于关键数据,同一个Agent可以部署在多台机器上,从而实现容错功能。
3.2 采集器
agent采集收到的数据存储在hadoop集群上。 hadoop集群擅长处理少量大文件,而处理大量小文件不是它的强项。针对这种情况,chukwa 设计了采集器的角色,将数据部分合并,然后写入集群,防止大量小文件。文件写入。
另一方面,为了防止采集器成为性能瓶颈或单点,导致故障,chukwa允许和鼓励设置多个采集器,代理从采集器列表中随机选择一个采集器来传输数据如果一个采集器失败或忙碌,只需切换到下一个采集器。这样可以实现负载均衡。实践证明,多个采集器的负载几乎是均匀的。
3.3 解复用器,存档
集群上的数据通过 map/reduce 作业进行分析。在 map/reduce 阶段,chukwa 提供了两种内置的作业类型,demux 和归档任务。
demux 作业负责数据的分类、排序和去重。在代理部分,我们提到了数据类型(DataType?)的概念。采集器写入集群的数据有自己的类型。 demux 在作业执行过程中,通过配置文件中指定的数据类型和数据处理类进行相应的数据分析工作。一般对非结构化数据进行结构化,提取其中的数据属性。因为demux的本质是map/reduce job,所以我们可以根据自己的需要开发自己的demux job,进行各种复杂的逻辑分析。 chukwa 提供的 demux 接口可以很容易地用 java 语言进行扩展。
归档作业负责合并相同类型的数据文件。一方面,它确保相同类型的数据都放在一起以供进一步分析。另一方面减少了文件数量,减轻了hadoop集群的存储压力。
3.4 数据库管理员
放置在集群上的数据可以满足数据的长期存储和大数据量的计算,但不便于展示。为此,楚科瓦做了两个努力:
1. 使用mdl语言将集群上的数据提取到mysql数据库中。对于过去一周的数据,数据完全保存。一周以上的数据按照现在数据的时间长短进行稀释。数据越长。 , 保存数据的时间间隔越长。使用mysql作为数据源显示数据。
2.使用hbase或类似技术将索引数据直接存储在集群上
直到chukwa0.4.0版本,chukwa使用第一种方法,但第二种方法更优雅,更方便。
3.5 hicc
hicc 是chukwa 的数据显示终端的名称。在显示方面,chukwa 提供了一些默认的数据显示小部件。可以使用“列表”、“曲线图”、“多曲线图”、“直方图”、“面积图”来显示一种或多种类型的数据,供用户直观的数据趋势显示。而且,在hicc显示端,对不断产生的新数据和历史数据采用robin策略,防止数据的不断增长增加服务器压力,在时间轴上可以“稀释”数据。长期数据显示
本质上hicc是jetty实现的web服务器,内部使用jsp技术和javascript技术。各种需要显示的数据类型和页面布局都可以通过简单的拖拽实现,对于更复杂的数据显示方式,可以使用sql语言来组合各种需要的数据。如果这不符合需求,不要害怕,只需手动修改其jsp代码即可。
3.6 其他数据接口
如果对原创数据有新的需求,用户也可以通过map/reduce作业或者pig语言直接访问集群上的原创数据,生成想要的结果。 Chukwa 还提供了命令行界面,可以直接访问集群上的数据。
3.7 默认数据支持
对于集群中每个节点的CPU使用率、内存使用率、硬盘使用率、整个集群的平均CPU使用率、整个集群的内存使用率、整个集群的存储使用率、数量的变化集群文件的数量,作业数量的变化等hadoop相关数据,从采集到展示的整套进程,chukwa提供了内置支持,你只需要配置一下就可以使用了。可以说是相当方便了。
由此可见,chukwa 为数据生成、采集、存储、分析、展示的整个生命周期提供了全面的支持。下图展示了 Chukwa 的完整架构:
4 Chukwa 到底是什么?
4.1 chukwa 不是什么
1. chukwa 不是一个独立的系统。在单个节点上部署chukwa系统基本上没有用。 Chukwa 是一个基于 Hadoop 构建的分布式日志处理系统。也就是说,在搭建chukwa环境之前,需要先搭建一个Hadoop环境,然后在Hadoop的基础上搭建chukwa环境。这种关系也可以从后来的chukwa推导出来,从架构图可以看出。这也是因为chukwa的假设是要处理的数据量在T级别。
2. chukwa 不是实时错误监控系统。在解决这个问题上,ganglia、nagios等系统都做得很好,这些系统对数据的敏感度可以达到二级。 chukwa 分析的是 数据处于分钟级别。它认为集群整体CPU使用率等数据,几分钟后获取就不是问题。
3. chukwa 不是一个封闭的系统。虽然chukwa自带了很多针对hadoop集群的分析项,但这并不是说它只能监控和分析hadoop。chukwa提供了大量数据的日志数据采集,一套完整的存储、分析解决方案和框架和显示。在这种类型的数据生命周期的各个阶段,chukwa 提供了近乎完美的解决方案,这也可以从其架构上看出。
4.2 什么是chukwa
上一节说了很多 chukwa 不是什么,我们来看看 chukwa 是专门用来做什么的?具体来说,chukwa致力于以下几个方面:
1. 一般来说,chukwa可以用来监控大规模(2000多个节点,每天产生的数据量在T级)hadoop集群的整体运行情况,并分析它们的日志
2. 对于集群用户:chukwa 显示他们的作业运行了多长时间,它们占用了多少资源,有多少资源可用,作业失败的原因以及读写操作在哪个节点上退出问题.
3.集群运维工程师:chukwa展示集群硬件错误、集群性能变化、集群资源瓶颈。
4. 对于集群管理者:chukwa 显示了集群的资源消耗和集群操作的整体执行情况,可以用来辅助预算和集群资源协调。
5. 集群开发者:chukwa 展示了集群中的主要性能瓶颈和频繁出现的错误,让您可以专注于解决重要问题。
5 Chukwa 部署和配置
5.1 前期准备
Chukwa是部署在Hadoop集群上的,所以前期需要安装部署Hadoop集群,包括SSH无密码登录、JDK安装等,具体可以参考本系列其他博文“一Hadoop系列丛书:Hadoop集群构建》等。
Hadoop集群架构如下:1个Master,1个Backup(主机备用),3个Slaves(由虚拟机创建)。节点IP地址:
rango(Master) 192.168.56.1 namenode
vm1(Backup) 192.168.56.101 secondarynode
vm2(Slave1)192.168.56.102 数据节点
vm3(Slave2)192.168.56.103 数据节点
vm4(Slave3)192.168.56.104 数据节点
5.2 安装 Chukwa
从官网只能下载chukwa-incubating-src-0.5.0.tar.gz,最新版本的Chukwa可以到~eyang/chukwa-0.@下载5.0-rc0/ 版本 chukwa-incubating-0.5.0.tar.gz。
解压并重命名并移动到 /usr 目录:
tar zxvf chukwa-incubating-0.5.0.tar.gz; mv chukwa-incubating-0.5.0 /usr/chukwa
需要在每个被监控的节点上维护一份 Chukwa 的副本(采集数据信息),每个节点都会运行一个采集器。配置完成后,可以通过scp命令复制到集群的各个节点。
5.3 配置 Chukwa
5.3.1 配置环境变量
编辑 /etc/profile 并添加以下语句:
#设置chukwa路径
导出 CHUKWA_HOME=/usr/chukwa
导出 CHUKWA_CONF_DIR=/usr/chukwa/etc/chukwa
导出路径=$PATH:$CHUKWA_HOME/bin:$CHUKWA_HOME/sbin:$CHUKWA_CONF_DIR
5.3.2 配置Hadoop和HBase集群
首先将 Chukwa 文件复制到 hadoop:
mv $HADOOP_HOME/conf/log4j.properties $HADOOP_HOME/conf/log4j.properties.bak
mv $HADOOP_HOME/conf/hadoop-metrics2.properties $HADOOP_HOME/conf/hadoop-metrics2.properties.bak
cp $CHUKWA_CONF_DIR/hadoop-log4j.properties $HADOOP_HOME/conf/log4j.properties
cp $CHUKWA_CONF_DIR/hadoop-metrics2.properties $HADOOP_HOME/conf/hadoop-metrics2.properties
cp $CHUKWA_HOME/share/chukwa/chukwa-0.5.0-client.jar $HADOOP_HOME/lib
cp $CHUKWA_HOME/share/chukwa/lib/json-simple-1.1.jar $HADOOP_HOME/lib
然后启动HBase集群,设置HBase,在HBase中创建数据存储所需的表,表模式已经搭建完成,直接通过hbase shell导入即可:
bin/hbase 外壳
5.3.3 配置采集器
设置 Chukwa 的环境变量,编辑 $CHUKWA_CONF_DIR/chukwa-env.sh 文件:
导出JAVA_HOME=/usr/java/jdk1.7.0_45
#export HBASE_CONF_DIR="${HBASE_CONF_DIR}"
#export HADOOP_CONF_DIR="${HADOOP_CONF_DIR}"
#export CHUKWA_LOG_DIR=/tmp/chukwa/log
#export CHUKWA_DATA_DIR="${CHUKWA_HOME}/data"
注意:设置第一个java的home目录,然后注释掉后面四个。备注HBASE_CONF_DIR和HADOOP_CONF_DIR,因为agent只用来采集数据,所以不需要HADOOP的参与。注释掉 CHUKWA_PID_DIR 和 CHUKWA_LOG_DIR。如果没有注释,则指定位置在/tmp临时目录下,会导致PID和LOG文件无故被删除。会导致后续操作异常。注释后系统会使用默认路径,PID和LOG文件默认创建在Chukwa安装目录下。
当需要多台机器作为采集器时,需要编辑$CHUKWA_CONF_DIR/collectors文件:
192.168.56.1
192.168.56.101
192.168.56.102
192.168.56.103
192.168.56.104
$CHUKWA_CONF_DIR/initial_Adaptors 文件主要用于设置 Chukwa 监控哪些日志,以及监控的方式和频率。使用默认配置即可,如下
添加 sigar.SystemMetrics SystemMetrics 60 0
添加 SocketAdaptor HadoopMetrics 9095 0
添加 SocketAdaptor Hadoop 9096 0
添加 SocketAdaptor ChukwaMetrics 9097 0
添加 SocketAdaptor JobSummary 9098 0
$CHUKWA_CONF_DIR/chukwa-collector-conf.xml 维护着 Chukwa 的基本配置信息。我们需要使用这个文件来确定HDFS的位置:如下:
writer.hdfs.filesystem
hdfs://192.168.56.1:9000/
要转储到的 HDFS
然后可以通过以下设置指定sink数据的地址:
chukwaCollector.outputDir
/chukwa/logs/
chukwa 数据接收器目录
chukwaCollector.http.port
8080
Java开发工程师:Controllerfunction看完接下来我们看Class部分
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-08-08 02:43
作为BAT的Java开发工程师,分享一下我在公司写的项目(脱敏)的封装api接口部分。
我们使用的是SSM框架,但其实不管是SSM还是SSH,还是SPRING BOOT,下面的介绍都是笼统的,因为主要是通过介绍注解(annotations),而不是xml文件。
控制器类
首先,API接口需要出现在控制器层。因此,在类名的顶部,至少需要两个注解,@controller,用于在项目启动时告诉spring这个类在controller层,需要加载; @requestMapping,这个注解相当于指定了api的一部分url。
如果服务绑定的域名是
那么requestMapping里面的内容就是那个url是
/.... 格式的请求将被转发到当前类。
控制器.函数
看完后,我们来看看功能部分。首先,我们必须添加一个 responseBody 注解。这个注解的意思就是通过converter将controller层函数的返回对象转换成指定的格式,写到http响应中返回对象的body,即返回的String下面的函数作为响应的正文内容直接返回给用户。
接下来还是requestMapping注解,相信你也能看懂,复用上面的例子,当url为
在
的情况下
,相当于调用了validateParams函数,请求的body会作为body参数传入这个函数。
您可能已经注意到这里。上面函数的参数名使用requestBody,下面使用formParam。虽然都是post请求,但是参数接收方式不同。这意味着在代码中指定了不同的接收方法,必须在请求体中使用相应的方法才能将数据传递给函数。上图中的body可以作为raw使用,下图需要application/x-www-form-urlencoded格式的body。
最后,上面介绍了所有post请求的api,下图展示了如何编写GET请求的api。可以看出,在注解方面,requestMethod可以在requestMapping中指定为GET。函数参数方面,需要使用requestParma注解来接收,如下图所示。当你发送
/dispatch/getMyContract?username=xiaomin&password=123 这个请求相当于调用了下面的getMyContract函数,传入的username参数为xiaomin,password参数为123.
以上是我的简单看法。欢迎大家在下方评论区分享和点赞。
我是苏苏思良,BAT 的 Java 开发工程师。我每天分享科技知识。欢迎关注我,和我一起进步。 查看全部
Java开发工程师:Controllerfunction看完接下来我们看Class部分
作为BAT的Java开发工程师,分享一下我在公司写的项目(脱敏)的封装api接口部分。
我们使用的是SSM框架,但其实不管是SSM还是SSH,还是SPRING BOOT,下面的介绍都是笼统的,因为主要是通过介绍注解(annotations),而不是xml文件。
控制器类
首先,API接口需要出现在控制器层。因此,在类名的顶部,至少需要两个注解,@controller,用于在项目启动时告诉spring这个类在controller层,需要加载; @requestMapping,这个注解相当于指定了api的一部分url。
如果服务绑定的域名是
那么requestMapping里面的内容就是那个url是
/.... 格式的请求将被转发到当前类。
控制器.函数
看完后,我们来看看功能部分。首先,我们必须添加一个 responseBody 注解。这个注解的意思就是通过converter将controller层函数的返回对象转换成指定的格式,写到http响应中返回对象的body,即返回的String下面的函数作为响应的正文内容直接返回给用户。
接下来还是requestMapping注解,相信你也能看懂,复用上面的例子,当url为
在
的情况下
,相当于调用了validateParams函数,请求的body会作为body参数传入这个函数。
您可能已经注意到这里。上面函数的参数名使用requestBody,下面使用formParam。虽然都是post请求,但是参数接收方式不同。这意味着在代码中指定了不同的接收方法,必须在请求体中使用相应的方法才能将数据传递给函数。上图中的body可以作为raw使用,下图需要application/x-www-form-urlencoded格式的body。
最后,上面介绍了所有post请求的api,下图展示了如何编写GET请求的api。可以看出,在注解方面,requestMethod可以在requestMapping中指定为GET。函数参数方面,需要使用requestParma注解来接收,如下图所示。当你发送
/dispatch/getMyContract?username=xiaomin&password=123 这个请求相当于调用了下面的getMyContract函数,传入的username参数为xiaomin,password参数为123.
以上是我的简单看法。欢迎大家在下方评论区分享和点赞。
我是苏苏思良,BAT 的 Java 开发工程师。我每天分享科技知识。欢迎关注我,和我一起进步。

