
文章采集api
开源免费小鹦苈画CMS漫画连载系统源码带采集API资源
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-08-04 18:50
[资源属性]:
资源名称:开源免费小鹦鹉绘画cms漫画系列系统源码 with采集API
资源大小:5.2MB
资源类别:源码下载》php源码
更新时间:2021-07-05
资源语言:简体中文
授权方式:免费下载
使用平台:Windows/Linux/Mac
资源介绍:
最近想开个漫画站玩玩,找了个不错的系统小平花华cms,开源免费,基于ThinkPHP5.1和Redis缓存,自带优采云api方便我们采集Release,功能我就不多说了,大家可以看下面的截图,几乎漫画系统都差不多。作者也在积极更新中,看来是打算加入会员系统等功能了,就贴在这里吧。
环境要求:PHP5.6-7.2、MySQL >=5.7、Redis,Redis扩展
这里是一个简单的路线,使用宝塔面板进行演示
宝塔安装好后,进入面板,点击左边的软件管理,然后安装PHP7.2、Nginx,Mysql5.7+,Redis。
2、installer
我们先点击左边的网站,添加网站!这个不用我教!!!
如果不能,请稍后观看我的视频教程!!!
设置伪静态
点击域名设置-网站目录,运行目录选择public,去掉反跨站勾选,重启PHP。
一般情况下,漫画中的图片资源有两种,一种是本地化,一种是盗链。建议对图片进行本地化,这样可以保证网站resources的稳定性,同时程序还提供了优采云采集器的API可以方便的连接优采云采集器进行漫画和章节图片采集。
首先我们需要一个优采云采集器,但是它分为免费版和付费版,但是免费版由于一些功能限制不能满足图片本地化的需要,所以暂时不适用有钱可以买付费版,没钱可以直接用优采云V7.6企业破解版,大概是最新的破解版,也可以满足采集程序需求 查看全部
开源免费小鹦苈画CMS漫画连载系统源码带采集API资源
[资源属性]:
资源名称:开源免费小鹦鹉绘画cms漫画系列系统源码 with采集API
资源大小:5.2MB
资源类别:源码下载》php源码
更新时间:2021-07-05
资源语言:简体中文
授权方式:免费下载
使用平台:Windows/Linux/Mac
资源介绍:
最近想开个漫画站玩玩,找了个不错的系统小平花华cms,开源免费,基于ThinkPHP5.1和Redis缓存,自带优采云api方便我们采集Release,功能我就不多说了,大家可以看下面的截图,几乎漫画系统都差不多。作者也在积极更新中,看来是打算加入会员系统等功能了,就贴在这里吧。
环境要求:PHP5.6-7.2、MySQL >=5.7、Redis,Redis扩展
这里是一个简单的路线,使用宝塔面板进行演示
宝塔安装好后,进入面板,点击左边的软件管理,然后安装PHP7.2、Nginx,Mysql5.7+,Redis。
2、installer
我们先点击左边的网站,添加网站!这个不用我教!!!
如果不能,请稍后观看我的视频教程!!!
设置伪静态
点击域名设置-网站目录,运行目录选择public,去掉反跨站勾选,重启PHP。
一般情况下,漫画中的图片资源有两种,一种是本地化,一种是盗链。建议对图片进行本地化,这样可以保证网站resources的稳定性,同时程序还提供了优采云采集器的API可以方便的连接优采云采集器进行漫画和章节图片采集。
首先我们需要一个优采云采集器,但是它分为免费版和付费版,但是免费版由于一些功能限制不能满足图片本地化的需要,所以暂时不适用有钱可以买付费版,没钱可以直接用优采云V7.6企业破解版,大概是最新的破解版,也可以满足采集程序需求
很早以前收集类似功能性的代码文章,结果准确度基本都是OK的
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-08-03 18:23
其实已经很久没有采集类似的功能代码了文章。今天就来记录一下吧。很久以前试过“百度收录detection”这个功能,不管是WP还是TP。所有方法都经过测试,代码基本一致。我用crl通过php中科院模拟搜索请求,分析返回数据判断是否为收录。之前在Typecho中添加“百度收录”确定方法”文章提到因为成功率太低所以放弃了这个功能。
我今天在wfblog上看到了一篇文章的文章。我最初认为它和以前一样。看了一眼,才发现自己升级到了API版本。我通过模拟UA绕过了百度的反爬虫,然后我用curl来模拟header。成功实现了“百度收录”的查询,结果准确率基本OK。
1、来电查询
在模板post.php中添加(自行修改CSS样式)
加载中
2、JQ 评委收录
还是在post.php中添加(必须引入jquery),这里修改提示文本。
3、API 调用源码
为了防止第三方API调用挂断,wfblog贡献了API代码。你可以创建一个php页面自己调用。如果你不想给伟峰打电话,你可以自己做。
整体来看,测试结果的准确度提升非常高。点击几个是准确的。当然,这个判断理论上适用于大多数网站、TP或WP。自己写的PHP很好。
查看全部
很早以前收集类似功能性的代码文章,结果准确度基本都是OK的
其实已经很久没有采集类似的功能代码了文章。今天就来记录一下吧。很久以前试过“百度收录detection”这个功能,不管是WP还是TP。所有方法都经过测试,代码基本一致。我用crl通过php中科院模拟搜索请求,分析返回数据判断是否为收录。之前在Typecho中添加“百度收录”确定方法”文章提到因为成功率太低所以放弃了这个功能。
我今天在wfblog上看到了一篇文章的文章。我最初认为它和以前一样。看了一眼,才发现自己升级到了API版本。我通过模拟UA绕过了百度的反爬虫,然后我用curl来模拟header。成功实现了“百度收录”的查询,结果准确率基本OK。

1、来电查询
在模板post.php中添加(自行修改CSS样式)
加载中
2、JQ 评委收录
还是在post.php中添加(必须引入jquery),这里修改提示文本。
3、API 调用源码
为了防止第三方API调用挂断,wfblog贡献了API代码。你可以创建一个php页面自己调用。如果你不想给伟峰打电话,你可以自己做。
整体来看,测试结果的准确度提升非常高。点击几个是准确的。当然,这个判断理论上适用于大多数网站、TP或WP。自己写的PHP很好。

京东联盟、京东宙斯两个平台如何快速获取自定义推广链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 472 次浏览 • 2021-07-24 23:29
本文创建于3年前,内容陈旧,京东页面也已改版,请进群了解更多。
欢迎加入京东联盟技术讨论群(379480469):
界面没有权限?请看这篇文章《调用京东联盟接口的权限问题》
最新:使用联盟API做的一个查看京东商品佣金的chrome扩展,可以直接在商品详情页查看佣金信息。
【有困难的孩子请参考最新的文章,并贴出当前demo的后台代码】
本文将简要介绍京东联盟和京东宙斯两大平台,以及如何使用京东宙斯平台的京东联盟API快速获取自定义推广链接。
关于京东联盟
京东联盟(查看官网)是一个CPS模式的营销平台。我们可以使用我们的网站置联盟的推广链接为京东推广产品。当用户点击我们的一个网站推广链接,推广真实订单,那么我们就会得到一定的佣金。
申请京东联盟的条件是必须有国内注册网站,这是重点。使用京东账号登录后,填写网站信息,等待审核。
强烈建议先看联盟介绍和规则:
关于京东宙斯
京东Zeus(查看官网)是京东提供的API接口平台(基于oauth2验证)。通过API,我们可以创建各种网站和无线应用来读取京东产品信息和事件信息。等待。商家可以通过API将自己的信息系统嵌入到京东的各种服务系统中。
本文将介绍如何在京东宙斯中使用京东联盟API获取京东联盟定制推广链接。
京东联盟定制推广链接
自定义推广链接,可以使用京东各种商品的链接和各种活动页面。范围很广,也很实用。
在联盟管理界面中,我们可以看到生成自定义推广链接的操作非常简单:
自定义推广链接支持的链接有:京东首页、商品详情页、活动页、店铺页。
点击Get Code按钮后,会生成union开头的链接。我们可以把这个链接放在网站上(这个链接只能在注册的网站上使用,其他方式打开无效)。
我们可以自己点这个链接,在京东上买东西也能拿到佣金! (更多信息,请参见)
在京东 Zeus 平台注册成为京东开发者
我们可以在京东联盟管理界面上获取推广链接,但是每次登录都很麻烦!好在京东已经开放了京东联盟API,我们可以使用代码自动获取!
首先用京东账号登录京东Zeus平台(打开官网),然后填写开发者基本信息完成开发者注册(开发者无需认证),然后授权服务页面申请京东宙斯服务。
完成后会显示您已授权的服务:
创建应用程序
当我们成为注册开发者并授权京东Zeus服务时,我们需要创建一个应用,因为使用API需要授权(access_token),而这个token是由我们创建的应用的APP key和App Secret生成的我们的 API 请求记录将记录在此应用程序下。
在创建应用界面,我们选择【买家】【无线应用】:
完成后,我们还需要填写申请信息,填写回调地址。回调地址的作用是在访问API授权码(accecc_token)时获取中间地址:
接下来,再提交审核,应用状态变为online and running,然后我们就可以正式开始使用应用证书中的APP key获取Token了!
使用APPkey和APPSecrect获取Token
首先提供官网的文档:有能力的可以自己研究~
这里,我使用第一种:授权码获取Token。优点是Token有效期可以维持1年,每天30万个请求!我们现在只需要得到一次!
因为是基于Oauth2.0,所以流程很简单,先用APPKey获取Code,再结合Code获取Token!
代码是通过京东登录页面获取的。输入您的京东账户信息后,授权后将返回我们的回调地址。这时候回调地址会有一个code参数,这就是我们需要的!
获取Code的请求(GET请求)链接:
https://oauth.jd.com/oauth/authorize
有几个参数需要带:
参数名称参数选项说明
响应类型
必填
在这个过程中,值被固定为代码
client_id
必填
创建应用时的Appkey(从JOS控制台获取->管理应用)
redirect_uri
必填
应用的回调地址,必须与创建应用时填写的回调页面的url一致
状态
可选
状态参数,ISV自定义,授权发布后原样返回
范围
可选
权限参数,API 组名称字符串。当有多个组名时,用“,”分隔,目前支持参数取值:read
查看
可选
移动端授权,值固定为wap;非手机终端授权,无需传值
排序后的完整请求链接为:
https://oauth.jd.com/oauth/aut ... mp%3B redirect_uri=YOUR_REGISTERED_REDIRECT_URI
只需要修改client_id(即APP Key)和redirect_uri(回调地址,必须与创建应用时写的一致)。
使用浏览器访问此链接,您将被定向到登录页面:
登录成功后会跳转到我们写的回调地址,这时候就可以拿到code参数值了!
现在我们可以使用 Code 值来获取令牌。
请求链接以获取令牌:
https://oauth.jd.com/oauth/token
参数为:
参数名称参数选项说明
grant_type
必填
授权类型。在这个过程中,该值固定为authorization_code
代码
必填
授权请求返回的授权码
redirect_uri
必填
应用的回调地址必须与创建应用时填写的回调页面的url一致
client_id
必填
创建应用时的Appkey(从JOS控制台获取->管理应用)
client_secret
必填
应用创建时的Appsecret(从JOS控制台获取->管理应用)
状态
可选
状态参数,ISV自定义,授权发布后原样返回
排序后的完整请求链接为:
https://oauth.jd.com/oauth/tok ... mp%3B
redirect_uri=YOUR_REGISTERED_REDIRECT_URI&code=GET_CODE&client_secret= YOUR_APP_SECRET
用浏览器访问这个链接,返回的是标准的json格式:
{
"access_token": "您的Token值",
"code": 0,
"expires_in": 31622400,
"refresh_token": "4a07031d-5122-4100-a60d-4ab982a55307",
"time": "1435499129281",
"token_type": "bearer",
"uid": "您的京东帐号ID",
"user_nick": "您的京东帐号昵称"
}
从那时起,一个理论过程就完成了!现在我们使用php自动下载,即获取code后自动发送获取token的请求,然后显示token的内容。
PHP 实现自动获取令牌的简单演示
直接看代码,很简单,一个php文件:
<p> 查看全部
京东联盟、京东宙斯两个平台如何快速获取自定义推广链接
本文创建于3年前,内容陈旧,京东页面也已改版,请进群了解更多。
欢迎加入京东联盟技术讨论群(379480469):

界面没有权限?请看这篇文章《调用京东联盟接口的权限问题》
最新:使用联盟API做的一个查看京东商品佣金的chrome扩展,可以直接在商品详情页查看佣金信息。
【有困难的孩子请参考最新的文章,并贴出当前demo的后台代码】
本文将简要介绍京东联盟和京东宙斯两大平台,以及如何使用京东宙斯平台的京东联盟API快速获取自定义推广链接。
关于京东联盟
京东联盟(查看官网)是一个CPS模式的营销平台。我们可以使用我们的网站置联盟的推广链接为京东推广产品。当用户点击我们的一个网站推广链接,推广真实订单,那么我们就会得到一定的佣金。
申请京东联盟的条件是必须有国内注册网站,这是重点。使用京东账号登录后,填写网站信息,等待审核。
强烈建议先看联盟介绍和规则:
关于京东宙斯
京东Zeus(查看官网)是京东提供的API接口平台(基于oauth2验证)。通过API,我们可以创建各种网站和无线应用来读取京东产品信息和事件信息。等待。商家可以通过API将自己的信息系统嵌入到京东的各种服务系统中。
本文将介绍如何在京东宙斯中使用京东联盟API获取京东联盟定制推广链接。
京东联盟定制推广链接
自定义推广链接,可以使用京东各种商品的链接和各种活动页面。范围很广,也很实用。
在联盟管理界面中,我们可以看到生成自定义推广链接的操作非常简单:
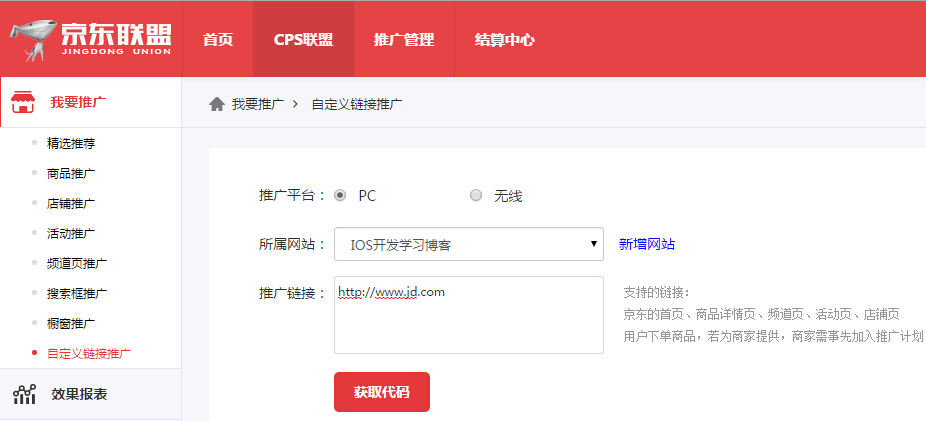
自定义推广链接支持的链接有:京东首页、商品详情页、活动页、店铺页。
点击Get Code按钮后,会生成union开头的链接。我们可以把这个链接放在网站上(这个链接只能在注册的网站上使用,其他方式打开无效)。
我们可以自己点这个链接,在京东上买东西也能拿到佣金! (更多信息,请参见)
在京东 Zeus 平台注册成为京东开发者
我们可以在京东联盟管理界面上获取推广链接,但是每次登录都很麻烦!好在京东已经开放了京东联盟API,我们可以使用代码自动获取!
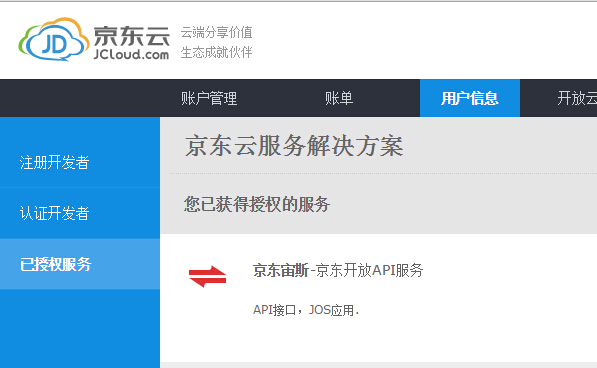
首先用京东账号登录京东Zeus平台(打开官网),然后填写开发者基本信息完成开发者注册(开发者无需认证),然后授权服务页面申请京东宙斯服务。
完成后会显示您已授权的服务:
创建应用程序
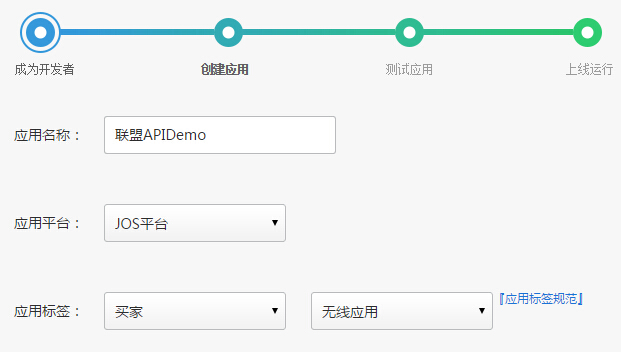
当我们成为注册开发者并授权京东Zeus服务时,我们需要创建一个应用,因为使用API需要授权(access_token),而这个token是由我们创建的应用的APP key和App Secret生成的我们的 API 请求记录将记录在此应用程序下。
在创建应用界面,我们选择【买家】【无线应用】:
完成后,我们还需要填写申请信息,填写回调地址。回调地址的作用是在访问API授权码(accecc_token)时获取中间地址:
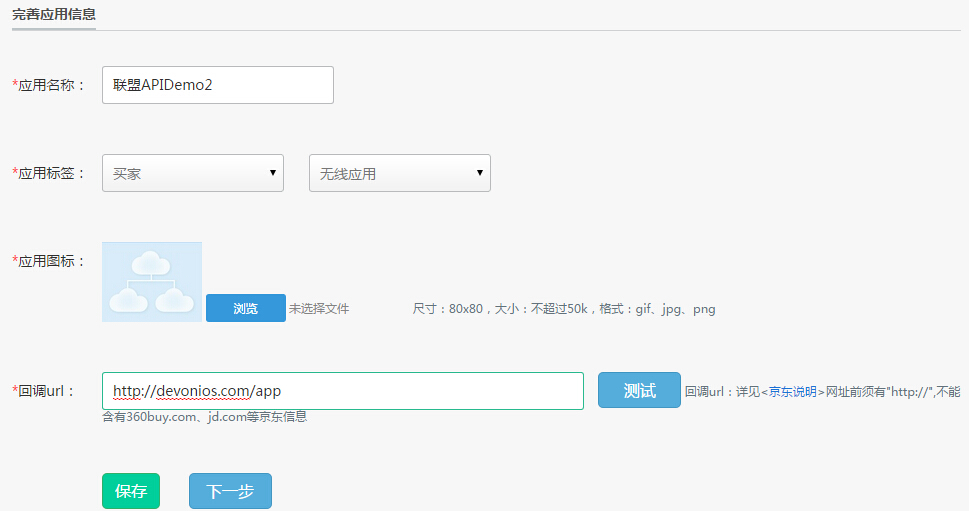
接下来,再提交审核,应用状态变为online and running,然后我们就可以正式开始使用应用证书中的APP key获取Token了!
使用APPkey和APPSecrect获取Token
首先提供官网的文档:有能力的可以自己研究~
这里,我使用第一种:授权码获取Token。优点是Token有效期可以维持1年,每天30万个请求!我们现在只需要得到一次!
因为是基于Oauth2.0,所以流程很简单,先用APPKey获取Code,再结合Code获取Token!
代码是通过京东登录页面获取的。输入您的京东账户信息后,授权后将返回我们的回调地址。这时候回调地址会有一个code参数,这就是我们需要的!
获取Code的请求(GET请求)链接:
https://oauth.jd.com/oauth/authorize
有几个参数需要带:
参数名称参数选项说明
响应类型
必填
在这个过程中,值被固定为代码
client_id
必填
创建应用时的Appkey(从JOS控制台获取->管理应用)
redirect_uri
必填
应用的回调地址,必须与创建应用时填写的回调页面的url一致
状态
可选
状态参数,ISV自定义,授权发布后原样返回
范围
可选
权限参数,API 组名称字符串。当有多个组名时,用“,”分隔,目前支持参数取值:read
查看
可选
移动端授权,值固定为wap;非手机终端授权,无需传值
排序后的完整请求链接为:
https://oauth.jd.com/oauth/aut ... mp%3B redirect_uri=YOUR_REGISTERED_REDIRECT_URI
只需要修改client_id(即APP Key)和redirect_uri(回调地址,必须与创建应用时写的一致)。
使用浏览器访问此链接,您将被定向到登录页面:
登录成功后会跳转到我们写的回调地址,这时候就可以拿到code参数值了!
现在我们可以使用 Code 值来获取令牌。
请求链接以获取令牌:
https://oauth.jd.com/oauth/token
参数为:
参数名称参数选项说明
grant_type
必填
授权类型。在这个过程中,该值固定为authorization_code
代码
必填
授权请求返回的授权码
redirect_uri
必填
应用的回调地址必须与创建应用时填写的回调页面的url一致
client_id
必填
创建应用时的Appkey(从JOS控制台获取->管理应用)
client_secret
必填
应用创建时的Appsecret(从JOS控制台获取->管理应用)
状态
可选
状态参数,ISV自定义,授权发布后原样返回
排序后的完整请求链接为:
https://oauth.jd.com/oauth/tok ... mp%3B
redirect_uri=YOUR_REGISTERED_REDIRECT_URI&code=GET_CODE&client_secret= YOUR_APP_SECRET
用浏览器访问这个链接,返回的是标准的json格式:
{
"access_token": "您的Token值",
"code": 0,
"expires_in": 31622400,
"refresh_token": "4a07031d-5122-4100-a60d-4ab982a55307",
"time": "1435499129281",
"token_type": "bearer",
"uid": "您的京东帐号ID",
"user_nick": "您的京东帐号昵称"
}
从那时起,一个理论过程就完成了!现在我们使用php自动下载,即获取code后自动发送获取token的请求,然后显示token的内容。
PHP 实现自动获取令牌的简单演示
直接看代码,很简单,一个php文件:
<p>
优采云采集软件能生产原创内容吗?能略微低质量的原创
采集交流 • 优采云 发表了文章 • 0 个评论 • 490 次浏览 • 2021-07-24 04:25
优采云采集software 是一个非常好用的文章采集软件,能产生原创内容吗?是的,但只是质量略低原创。今天错误博客()分享的内容是“优采云采集Build原创文章Three Methods”。希望能帮到你。
一、优采云 和原创
优采云没有原创的能力,但优采云确实可以创建原创内容。错误博客先介绍三种使用优采云创原创文章的方式,当然以后会有更多的方式,就看大家的头脑风暴了。
1、English to Chinese plugin
采集一些英文网站文章,然后用优采云的英文转中文插件,可以得到很多伪原创文章,这样文章甚至可以叫原创,不过可能读不完,不过原创度还好,除非两个人是采集同文章中文文章,否则这种模式下得到的内容收录率还行本站有部分谷歌搜索引擎优化文章就是通过这种方式获取的。
目前这种插件一般都是收费的。你可以找到免费的插件,但通常你必须得到百度翻译API。如果超过免费使用量,则需要另行付费。
2、伪原创plugin
伪原创插件基本上都是在线伪原创搞的人做的,大部分都是收费的。毕竟这是大量的伪原创,一定程度上消耗了对方的服务器资源。 .
对于伪原创,错误博客不是特别推荐。毕竟这东西可读性真的很差,搜索引擎也不友好。如果你网站friendliness 好,即使你没有太多的文字,你也可以做到。是收录,但伪原创的内容可能不是收录。
而且伪原创大部分来自同义词和同义词的替换。市面上基本没有AI伪原创。如果确实存在,那就给关键词,其他人自己写吧。市面上的伪原创提供者大多替换同义词和同义词,所以最好不要这样做。
3、建建文章
用大量的词来构建文章,比如把十万个相关词做成一个表格文章页面,把词句排列起来,看起来没有任何意义违反。看到很多这样的方法网站收到了很多流量,错误的博客本身就收到了几万收录。
二、优采云Build文章
优采云Build文章方式很简单,错误博客会一一告诉你。
1、优采云import 模板
下载优采云,即优采云采集,创建一个字符列表组,右键单击该组,然后导入准备好的“.ljobx”文件,即@的模板优采云采集 .
2、内容采集rules
导入后双击打开,直接跳过“URL采集Rules”,直接进入“Content采集Rules”。然后,我们需要构建原创的标题、页面关键词、页面描述、作者、缩略图、标签等,这些内容都来自txt文件,里面有几万行数据txt 文件内存,这样就可以构造原创文章。当然,这只是一种模式。如果你想有更好的收录效果,你需要考虑如何使用这种模式来制作更好的内容,或者使用另一种模式来制作更像原创的内容。
以上是错误博客()分享的“优采云采集Build原创文章Three Ways”的内容。感谢您的阅读。更多原创文章搜索“错误博客”。 查看全部
优采云采集软件能生产原创内容吗?能略微低质量的原创
优采云采集software 是一个非常好用的文章采集软件,能产生原创内容吗?是的,但只是质量略低原创。今天错误博客()分享的内容是“优采云采集Build原创文章Three Methods”。希望能帮到你。

一、优采云 和原创
优采云没有原创的能力,但优采云确实可以创建原创内容。错误博客先介绍三种使用优采云创原创文章的方式,当然以后会有更多的方式,就看大家的头脑风暴了。
1、English to Chinese plugin
采集一些英文网站文章,然后用优采云的英文转中文插件,可以得到很多伪原创文章,这样文章甚至可以叫原创,不过可能读不完,不过原创度还好,除非两个人是采集同文章中文文章,否则这种模式下得到的内容收录率还行本站有部分谷歌搜索引擎优化文章就是通过这种方式获取的。
目前这种插件一般都是收费的。你可以找到免费的插件,但通常你必须得到百度翻译API。如果超过免费使用量,则需要另行付费。

2、伪原创plugin
伪原创插件基本上都是在线伪原创搞的人做的,大部分都是收费的。毕竟这是大量的伪原创,一定程度上消耗了对方的服务器资源。 .
对于伪原创,错误博客不是特别推荐。毕竟这东西可读性真的很差,搜索引擎也不友好。如果你网站friendliness 好,即使你没有太多的文字,你也可以做到。是收录,但伪原创的内容可能不是收录。
而且伪原创大部分来自同义词和同义词的替换。市面上基本没有AI伪原创。如果确实存在,那就给关键词,其他人自己写吧。市面上的伪原创提供者大多替换同义词和同义词,所以最好不要这样做。
3、建建文章
用大量的词来构建文章,比如把十万个相关词做成一个表格文章页面,把词句排列起来,看起来没有任何意义违反。看到很多这样的方法网站收到了很多流量,错误的博客本身就收到了几万收录。
二、优采云Build文章
优采云Build文章方式很简单,错误博客会一一告诉你。
1、优采云import 模板
下载优采云,即优采云采集,创建一个字符列表组,右键单击该组,然后导入准备好的“.ljobx”文件,即@的模板优采云采集 .

2、内容采集rules
导入后双击打开,直接跳过“URL采集Rules”,直接进入“Content采集Rules”。然后,我们需要构建原创的标题、页面关键词、页面描述、作者、缩略图、标签等,这些内容都来自txt文件,里面有几万行数据txt 文件内存,这样就可以构造原创文章。当然,这只是一种模式。如果你想有更好的收录效果,你需要考虑如何使用这种模式来制作更好的内容,或者使用另一种模式来制作更像原创的内容。

以上是错误博客()分享的“优采云采集Build原创文章Three Ways”的内容。感谢您的阅读。更多原创文章搜索“错误博客”。
API供开发者获取数据用,通常返回的数据为JSON格式
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-07-11 07:32
很多网站为开发者提供了获取数据的API。通常返回的数据是JSON格式。本文以百度Opener平台为例,通过API进行数据采集实验。由于百度API接口较多,后续会陆续添加实验接口。它们都是非常简单的程序,可以作为以后编写更全面的应用程序的基础。
使用百度API的步骤类似。百度开发者平台注册->免费获取AppID和Key->构建开发者文档中提供的URL->GET获取Json数据->分析展示。下面这个小程序干脆就不解释了,把自己的AppID和Key屏蔽了。
1、百度翻译使用
支持26种语言翻译,翻译准确度还是很好的。
import requests
import random
import hashlib
import json
import pprint
appid = '12345678'
key = 'dasd457dawgjj54j01qf'
url = 'http://api.fanyi.baidu.com/api ... 39%3B
#需要翻译的文本
q = '建设中国特色社会主义'
#原语言
from_language ='zh'
#目的语言
to_language = 'en'
#随机数
salt = random.randint(32768, 65536)
#签名
sign = appid+q+str(salt)+key
sign = sign.encode('utf-8')
sign_new = hashlib.md5(sign).hexdigest()
#生成URL
new_url = url + 'q='+q+'&from='+from_language+'&to='+to_language+'&appid='+appid+'&salt='+str(salt)+'&sign='+sign_new
res = requests.get(new_url)
print(res.text)
json_data = json.loads(res.text)
#translate_result = json_data["trans_result"]["dst"]
pprint.pprint(json_data["trans_result"])
[{'dst':'建设有中国特色的社会主义',
'src':'建设有中国特色的社会主义'}]
2.百度图获取位置经纬度
import json
import requests
from urllib.request import urlopen,quote
import pprint
address = quote("长沙")
key = "dajskjda1231390kjbnreitie1043"
url = "http://api.map.baidu.com/geocoder/v2/"
new_url = url+"?address="+address+"&output=json"+"&ak="+key
url = "http://restapi.amap.com/v3/geocode/geo"
res = requests.get(new_url)
json_data = json.loads(res.text)
print('经度是:'+str(json_data['result']['location']['lat']))
print('维度是:'+str(json_data['result']['location']['lng']))
经度为:28.222
维度为:112.9793527876505 查看全部
API供开发者获取数据用,通常返回的数据为JSON格式
很多网站为开发者提供了获取数据的API。通常返回的数据是JSON格式。本文以百度Opener平台为例,通过API进行数据采集实验。由于百度API接口较多,后续会陆续添加实验接口。它们都是非常简单的程序,可以作为以后编写更全面的应用程序的基础。
使用百度API的步骤类似。百度开发者平台注册->免费获取AppID和Key->构建开发者文档中提供的URL->GET获取Json数据->分析展示。下面这个小程序干脆就不解释了,把自己的AppID和Key屏蔽了。
1、百度翻译使用
支持26种语言翻译,翻译准确度还是很好的。
import requests
import random
import hashlib
import json
import pprint
appid = '12345678'
key = 'dasd457dawgjj54j01qf'
url = 'http://api.fanyi.baidu.com/api ... 39%3B
#需要翻译的文本
q = '建设中国特色社会主义'
#原语言
from_language ='zh'
#目的语言
to_language = 'en'
#随机数
salt = random.randint(32768, 65536)
#签名
sign = appid+q+str(salt)+key
sign = sign.encode('utf-8')
sign_new = hashlib.md5(sign).hexdigest()
#生成URL
new_url = url + 'q='+q+'&from='+from_language+'&to='+to_language+'&appid='+appid+'&salt='+str(salt)+'&sign='+sign_new
res = requests.get(new_url)
print(res.text)
json_data = json.loads(res.text)
#translate_result = json_data["trans_result"]["dst"]
pprint.pprint(json_data["trans_result"])
[{'dst':'建设有中国特色的社会主义',
'src':'建设有中国特色的社会主义'}]
2.百度图获取位置经纬度
import json
import requests
from urllib.request import urlopen,quote
import pprint
address = quote("长沙")
key = "dajskjda1231390kjbnreitie1043"
url = "http://api.map.baidu.com/geocoder/v2/"
new_url = url+"?address="+address+"&output=json"+"&ak="+key
url = "http://restapi.amap.com/v3/geocode/geo"
res = requests.get(new_url)
json_data = json.loads(res.text)
print('经度是:'+str(json_data['result']['location']['lat']))
print('维度是:'+str(json_data['result']['location']['lng']))
经度为:28.222
维度为:112.9793527876505
添加ApiBoot统一版本依赖广告超强,超多装备超强回收,
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-07-04 19:11
可以通过ApiBoot Logging获取每个请求的详细信息。在分布式部署模式下,一个请求可能经过多个服务。如果每个服务独立保存请求日志信息,我们是做不到的。统一控制,日志库和业务库会出现不一致(可能会使用多数据源配置)。因为这个问题,ApiBoot Logging提供了Admin的概念,客户端采集到每个日志都会上报给Admin,Admin会分析、保存等操作。
创建日志管理项目
ApiBoot Logging Admin可以汇总各个业务服务的请求日志(ApiBoot Logging),所以我们需要将各个业务服务的日志采集单上报给Admin,所以我们应该使用独立的方式进行部署。创建单独的服务专门采集请求日志然后保存。
初始化日志管理项目依赖
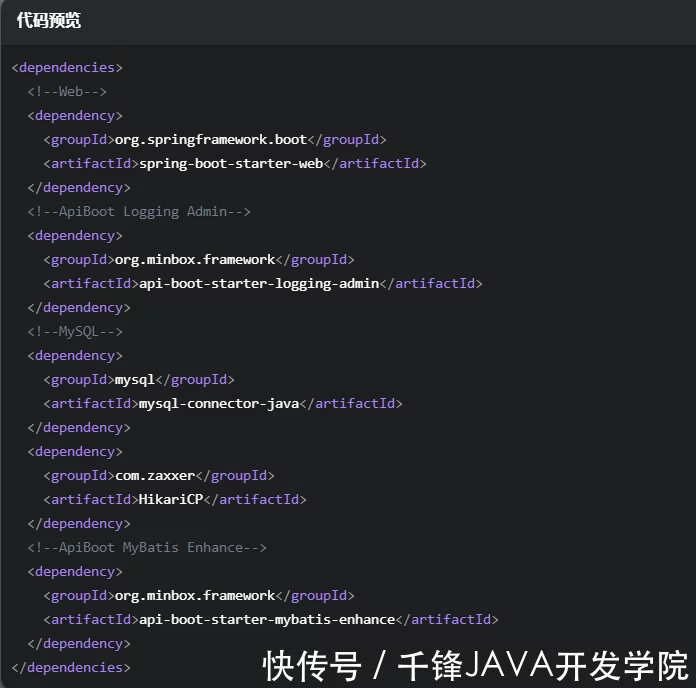
使用idea创建一个SpringBoot项目,pom.xml配置文件中的依赖如下:
广告每天一勺三七粉,50岁的阿姨有死的危险。必须了解三七的禁忌症
我们需要将采集收到的请求日志保存到数据库中,所以需要在项目中添加数据库驱动和数据库连接池相关的依赖。 ApiBoot Logging Admin 通过DataSource 操作数据,依赖ApiBoot MyBatis Enhance。可以自动创建DataSource,摆脱手动创建,加入Spring IOC容器。
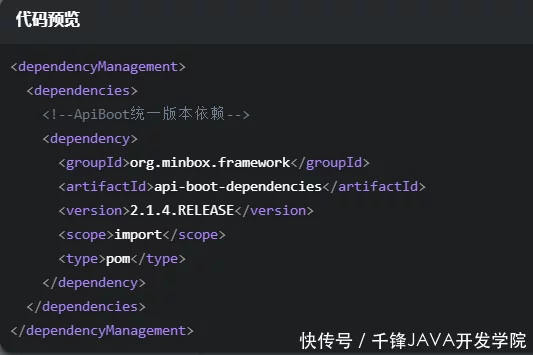
添加ApiBoot统一版本依赖
广告超强魂,超多装备,超回复,无限Boss
最新版本的ApiBoot请访问::api-boot-dependencies查询。
启用日志管理
添加ApiBoot Logging Admin依赖后,无法完全使用Admin功能。我们需要通过@EnableLoggingAdmin 注释来启用它。这个注解会自动将Logging Admin中需要的一些类注册到Spring IOC中,并在入口类中添加注解如下图:
广告每天一勺三七粉,50岁大妈惊呆了。你必须了解三七的禁忌症
配置日志数据源
广告枸杞和它绝配,天天泡水,老样子,方便实用!
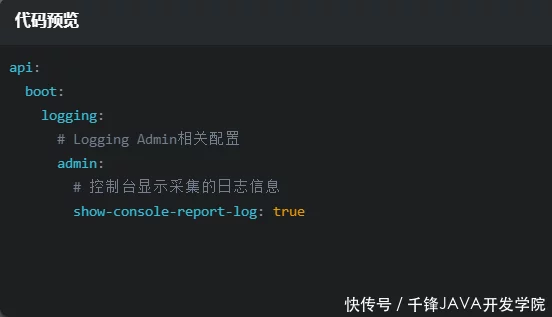
控制台打印报告日志
ApiBoot Logging Admin可以通过配置文件控制是否在控制台打印采集收到的请求日志信息,并在application.yml配置文件中添加如下内容:
五十岁以后的广告,如果你不想长得太快,用灵芝粉泡水就等于清洁你的身体!
注意:这不应与 ApiBoot Logging 提供的 api.boot.logging.show-console-log 配置混淆。
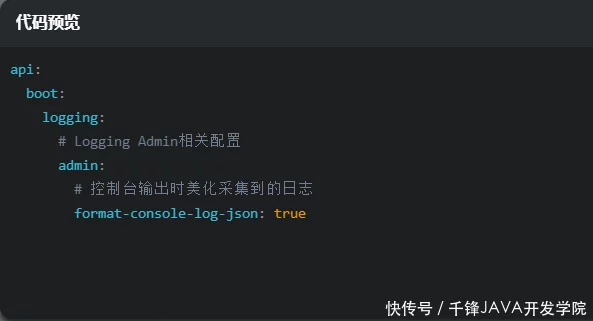
美化控制台打印的报告日志
广告是每天一片肉苁蓉。 50岁的阿姨震惊了。有必要了解肉苁蓉的禁忌症。
注意:不要与这里的 api.boot.logging.format-console-log-json 配置混淆。
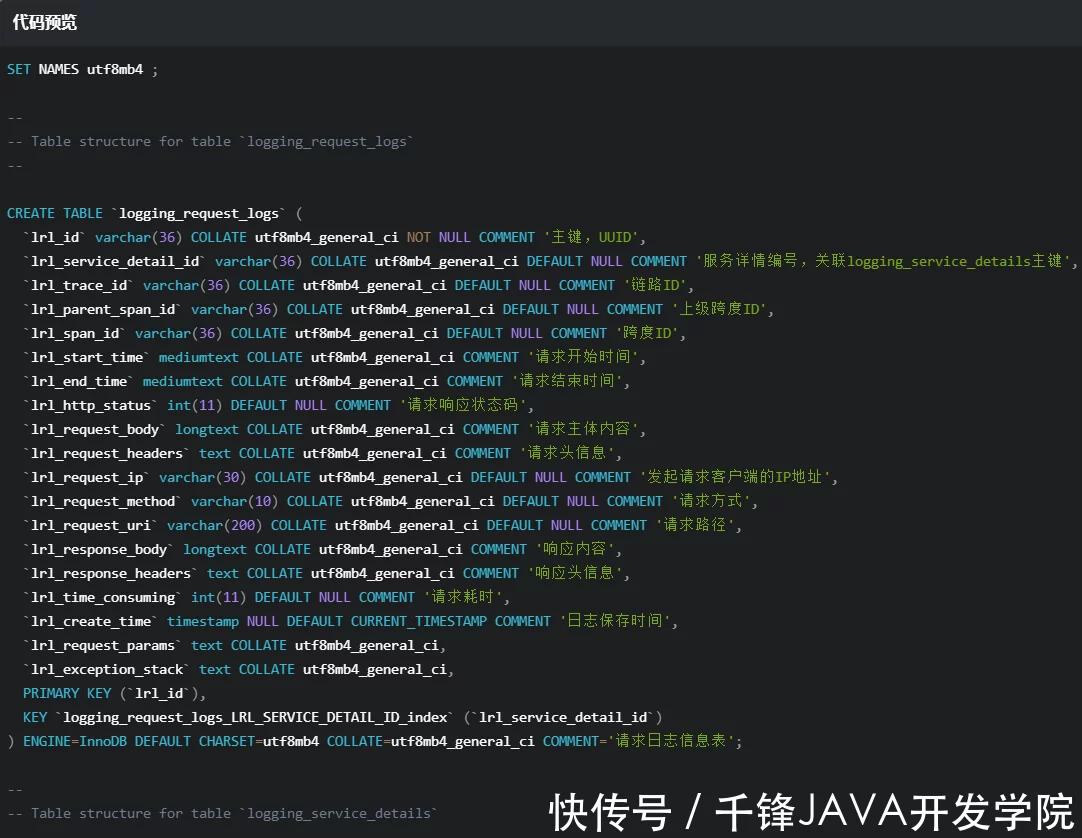
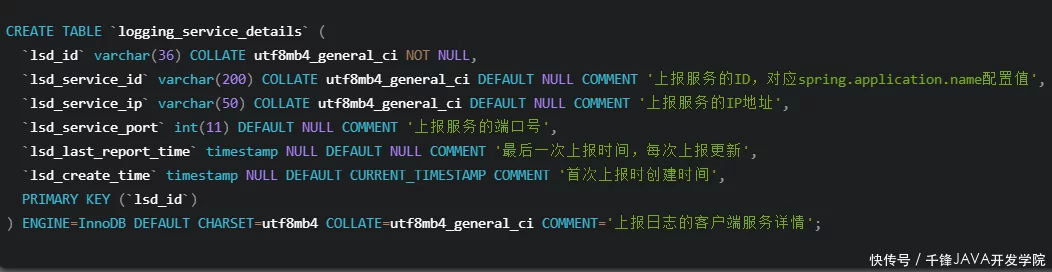
初始化日志表结构
ApiBoot Logging Admin 使用固定的表结构来存储请求日志和服务信息。建表语句如下:
广告中的有害吸烟太多?赶紧学起来,再忙也能看! ! !
广告中很多人认为冬虫夏草很贵。其实藏族直接提供一手价,一年可以吃80克
ApiBoot Logging Admin 到目前为止已经准备就绪。接下来,我们需要修改业务服务以将请求日志报告给 Logging Admin。
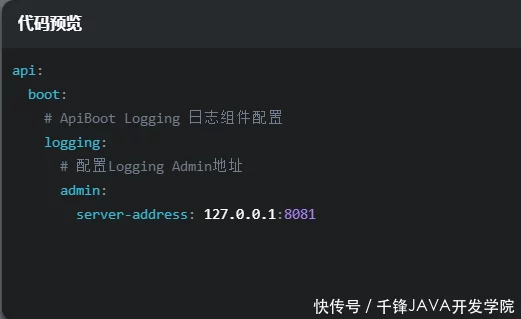
向指定的日志管理员报告日志
我们将修改使用ApiBoot Logging统一管理请求日志文章的源码,并将Logging Admin的地址添加到application.yml中,如下图:
广告五十年后,注意三关。每天用它泡水,睡好吃好!
api.boot.logging.admin-service-address 的配置格式是:Ip:Port,我们只需要修改这一个地方,其他的所有任务内部交给ApiBoot Logging。
测试
我们以应用程序的形式启动 ApiBoot 日志管理和业务服务。
使用curl访问测试地址如下:
广告肺病的“大克星”来了,老烟民用它泡水喝,排烟解毒。
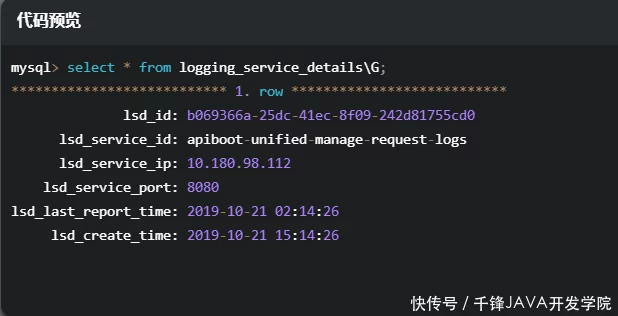
我们已经看到了Logging Admin控制台打印的报告请求日志,这个请求的日志是否已经保存到数据库中还不确定。接下来,我将使用命令行查看数据库的日志信息。
查看logging_service_details表中的数据
广告三斤枸杞还不如1两,天天泡在水里,不显老,方便实用
logging_service_details 存储了每个上报请求日志的业务服务的基本信息。每个服务的基本信息都会缓存在Logging Admin内存中,方便获取service_id用于存储日志。唯一性根据ip端口service_id确定。该服务仅保存一次。
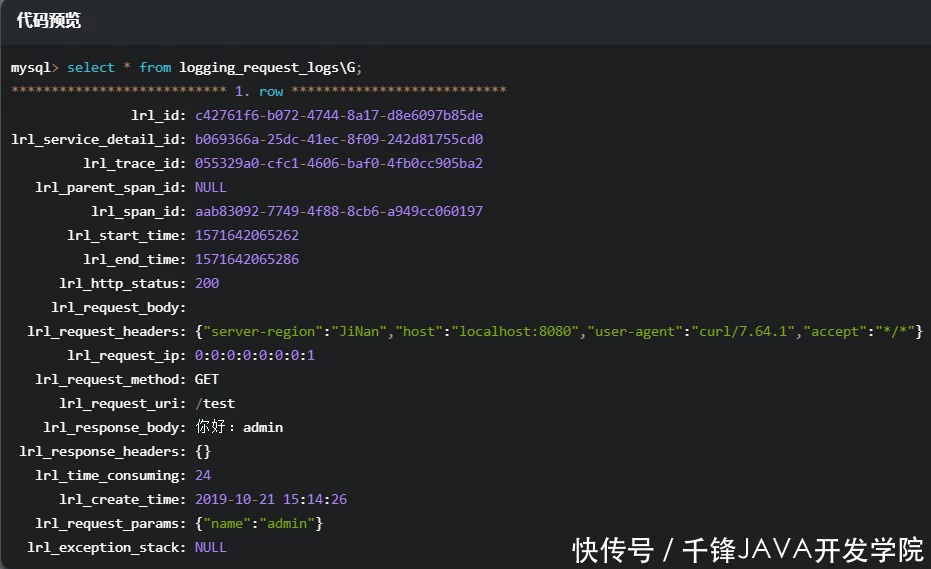
查看logging_request_logs表中的数据
广告五十岁后,注意三关,每天坚持这件事,睡好吃好
敲黑板画重点
本章我们集成了ApiBoot Logging Admin,将业务服务的每一个请求日志上报给Logging Admin,并通过数据库保存请求日志,然后通过其他方法,并通过spanId和traceId查看日志——每个请求链路的从属关系以及每个请求中消耗时间最多的跨度,以准确优化服务性能。 查看全部
添加ApiBoot统一版本依赖广告超强,超多装备超强回收,
可以通过ApiBoot Logging获取每个请求的详细信息。在分布式部署模式下,一个请求可能经过多个服务。如果每个服务独立保存请求日志信息,我们是做不到的。统一控制,日志库和业务库会出现不一致(可能会使用多数据源配置)。因为这个问题,ApiBoot Logging提供了Admin的概念,客户端采集到每个日志都会上报给Admin,Admin会分析、保存等操作。
创建日志管理项目
ApiBoot Logging Admin可以汇总各个业务服务的请求日志(ApiBoot Logging),所以我们需要将各个业务服务的日志采集单上报给Admin,所以我们应该使用独立的方式进行部署。创建单独的服务专门采集请求日志然后保存。
初始化日志管理项目依赖
使用idea创建一个SpringBoot项目,pom.xml配置文件中的依赖如下:
广告每天一勺三七粉,50岁的阿姨有死的危险。必须了解三七的禁忌症
我们需要将采集收到的请求日志保存到数据库中,所以需要在项目中添加数据库驱动和数据库连接池相关的依赖。 ApiBoot Logging Admin 通过DataSource 操作数据,依赖ApiBoot MyBatis Enhance。可以自动创建DataSource,摆脱手动创建,加入Spring IOC容器。
添加ApiBoot统一版本依赖
广告超强魂,超多装备,超回复,无限Boss
最新版本的ApiBoot请访问::api-boot-dependencies查询。
启用日志管理
添加ApiBoot Logging Admin依赖后,无法完全使用Admin功能。我们需要通过@EnableLoggingAdmin 注释来启用它。这个注解会自动将Logging Admin中需要的一些类注册到Spring IOC中,并在入口类中添加注解如下图:
广告每天一勺三七粉,50岁大妈惊呆了。你必须了解三七的禁忌症
配置日志数据源

广告枸杞和它绝配,天天泡水,老样子,方便实用!
控制台打印报告日志
ApiBoot Logging Admin可以通过配置文件控制是否在控制台打印采集收到的请求日志信息,并在application.yml配置文件中添加如下内容:
五十岁以后的广告,如果你不想长得太快,用灵芝粉泡水就等于清洁你的身体!
注意:这不应与 ApiBoot Logging 提供的 api.boot.logging.show-console-log 配置混淆。
美化控制台打印的报告日志
广告是每天一片肉苁蓉。 50岁的阿姨震惊了。有必要了解肉苁蓉的禁忌症。
注意:不要与这里的 api.boot.logging.format-console-log-json 配置混淆。
初始化日志表结构
ApiBoot Logging Admin 使用固定的表结构来存储请求日志和服务信息。建表语句如下:
广告中的有害吸烟太多?赶紧学起来,再忙也能看! ! !
广告中很多人认为冬虫夏草很贵。其实藏族直接提供一手价,一年可以吃80克
ApiBoot Logging Admin 到目前为止已经准备就绪。接下来,我们需要修改业务服务以将请求日志报告给 Logging Admin。
向指定的日志管理员报告日志
我们将修改使用ApiBoot Logging统一管理请求日志文章的源码,并将Logging Admin的地址添加到application.yml中,如下图:
广告五十年后,注意三关。每天用它泡水,睡好吃好!
api.boot.logging.admin-service-address 的配置格式是:Ip:Port,我们只需要修改这一个地方,其他的所有任务内部交给ApiBoot Logging。
测试
我们以应用程序的形式启动 ApiBoot 日志管理和业务服务。
使用curl访问测试地址如下:

广告肺病的“大克星”来了,老烟民用它泡水喝,排烟解毒。
我们已经看到了Logging Admin控制台打印的报告请求日志,这个请求的日志是否已经保存到数据库中还不确定。接下来,我将使用命令行查看数据库的日志信息。
查看logging_service_details表中的数据
广告三斤枸杞还不如1两,天天泡在水里,不显老,方便实用
logging_service_details 存储了每个上报请求日志的业务服务的基本信息。每个服务的基本信息都会缓存在Logging Admin内存中,方便获取service_id用于存储日志。唯一性根据ip端口service_id确定。该服务仅保存一次。
查看logging_request_logs表中的数据
广告五十岁后,注意三关,每天坚持这件事,睡好吃好
敲黑板画重点
本章我们集成了ApiBoot Logging Admin,将业务服务的每一个请求日志上报给Logging Admin,并通过数据库保存请求日志,然后通过其他方法,并通过spanId和traceId查看日志——每个请求链路的从属关系以及每个请求中消耗时间最多的跨度,以准确优化服务性能。
php采集相关的博客百度地图API位置偏移的校准算法
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-06-18 06:29
php 采集api 相关博客
百度地图API位置偏移校准算法
转自百度地图API位置偏移校准算法的客文原文。当您开始使用百度地图API进行开发时,您可能会遇到一个比较奇怪的事情。百度定位的经纬度在地图上显示的很不准确。我在微信开发和Android之初遇到的一个问题。微信开发第一次使用百度地图api获取位置并显示在地图上
橘子是红的 3年前2639
【百度地图API】JS版本FAQ
原文:【百度地图API】JS版FAQ【新手必读】APIFAQ 2011-12-12 1、 如何在百度地图上标注我的店铺?我可以成为区域代理吗?可以在百度地图上免费标注吗?答:这里只负责API技术咨询,不解决任何地图标注问题。在一百
Jack Chen 6 年前 1323
[Map API] 为什么你的坐标不正确?如何纠正偏差?
原文:[Map API] 为什么你的坐标不正确?如何纠正偏差?总结:如何在各种坐标系之间进行转换?有哪些坐标系?什么是火星坐标?为什么我的坐标显示在地图偏移量上?本文详细回答了上述问题。最后给出坐标拾取工具。 -----------------------------
Jack Chen 6 年前 1446
“时序数据库硬件API”打造智能医疗设备
第一次接触 API 应该是 2000 年左右。当时我还在大二。在我开始编程后不久,我还在用 VB 编写程序。我想在打开文件的对话框中添加一个预览功能。这花了很多精力,我写了很多代码。它总是没有人们想要的那么好。后来偶然发现,通过系统的API,几行代码就解决了问题。
仙游3年前2106
从零开始 K8s |可观察性:监控和记录
作者 |莫元阿里巴巴技术专家一、Background 监控和日志是大规模分布式系统的重要**基础设施**。监控可以帮助开发者查看系统的运行状态,日志可以辅助排查和诊断。在Kubernetes中,监控和日志是生态的一部分,不是核心组件,所以大部分功能
阿里云原生助手1年前3882
【技术干货】如果你想高效的将采集数据发送到阿里云Elasticsearch,这些方法你知道吗?
简介:本文全面介绍了Elastic Beats、Logstash、语言客户端、Kibana开发者工具采集对阿里云Elasticsearch(简称ES)服务的特性和数据。帮助您充分理解原理,选择适合您业务特点的数据采集方案。字符数:276
工程师 A 1 年前 1279
日志服务-一站式配置采集Apache访问日志
自日志服务推出数据访问向导(Wizard)功能以来,不断优化访问向导功能,支持采集、各种数据的存储、分析、离线交付,降低用户使用门槛日志服务。本文介绍了数据访问向导采集Apache 日志和索引设置的一站式配置。同时也可以通过默认仪表盘和查询分析语句网站
进行实时分析
从 2 年前的 Mu 2422
CrazyReading项目开发过程直播(开源到github)
作为一个在IT行业10多年的老码农,我计划启动一个开源新闻订阅项目,目标有3个:1.综合利用近年来学到的各种开发知识来提升自己; 2. 分享近年来学到的各种开发知识,帮助有需要的程序员; 3. 为普通用户做一个实用的项目。 -------------
于尔武3年前799
php 采集api 相关问答
php采集高手进: 用curl模拟登录取数据遇到json调用问题,不成功,求帮助!
我在抓取一个页面的信息(假设a.php),这个页面只是一些基本的html框架,其他关键信息通过ajax请求(b.php)返回,返回的是json,然后通过页面js解析json并绘制在页面上。问题关键是ajax请求信息里有手机号需要登录才能显示完整
杨东方4年前906 查看全部
php采集相关的博客百度地图API位置偏移的校准算法
php 采集api 相关博客
百度地图API位置偏移校准算法

转自百度地图API位置偏移校准算法的客文原文。当您开始使用百度地图API进行开发时,您可能会遇到一个比较奇怪的事情。百度定位的经纬度在地图上显示的很不准确。我在微信开发和Android之初遇到的一个问题。微信开发第一次使用百度地图api获取位置并显示在地图上
橘子是红的 3年前2639
【百度地图API】JS版本FAQ

原文:【百度地图API】JS版FAQ【新手必读】APIFAQ 2011-12-12 1、 如何在百度地图上标注我的店铺?我可以成为区域代理吗?可以在百度地图上免费标注吗?答:这里只负责API技术咨询,不解决任何地图标注问题。在一百

Jack Chen 6 年前 1323
[Map API] 为什么你的坐标不正确?如何纠正偏差?

原文:[Map API] 为什么你的坐标不正确?如何纠正偏差?总结:如何在各种坐标系之间进行转换?有哪些坐标系?什么是火星坐标?为什么我的坐标显示在地图偏移量上?本文详细回答了上述问题。最后给出坐标拾取工具。 -----------------------------
Jack Chen 6 年前 1446
“时序数据库硬件API”打造智能医疗设备

第一次接触 API 应该是 2000 年左右。当时我还在大二。在我开始编程后不久,我还在用 VB 编写程序。我想在打开文件的对话框中添加一个预览功能。这花了很多精力,我写了很多代码。它总是没有人们想要的那么好。后来偶然发现,通过系统的API,几行代码就解决了问题。

仙游3年前2106
从零开始 K8s |可观察性:监控和记录

作者 |莫元阿里巴巴技术专家一、Background 监控和日志是大规模分布式系统的重要**基础设施**。监控可以帮助开发者查看系统的运行状态,日志可以辅助排查和诊断。在Kubernetes中,监控和日志是生态的一部分,不是核心组件,所以大部分功能

阿里云原生助手1年前3882
【技术干货】如果你想高效的将采集数据发送到阿里云Elasticsearch,这些方法你知道吗?

简介:本文全面介绍了Elastic Beats、Logstash、语言客户端、Kibana开发者工具采集对阿里云Elasticsearch(简称ES)服务的特性和数据。帮助您充分理解原理,选择适合您业务特点的数据采集方案。字符数:276

工程师 A 1 年前 1279
日志服务-一站式配置采集Apache访问日志

自日志服务推出数据访问向导(Wizard)功能以来,不断优化访问向导功能,支持采集、各种数据的存储、分析、离线交付,降低用户使用门槛日志服务。本文介绍了数据访问向导采集Apache 日志和索引设置的一站式配置。同时也可以通过默认仪表盘和查询分析语句网站
进行实时分析

从 2 年前的 Mu 2422
CrazyReading项目开发过程直播(开源到github)

作为一个在IT行业10多年的老码农,我计划启动一个开源新闻订阅项目,目标有3个:1.综合利用近年来学到的各种开发知识来提升自己; 2. 分享近年来学到的各种开发知识,帮助有需要的程序员; 3. 为普通用户做一个实用的项目。 -------------
于尔武3年前799
php 采集api 相关问答
php采集高手进: 用curl模拟登录取数据遇到json调用问题,不成功,求帮助!

我在抓取一个页面的信息(假设a.php),这个页面只是一些基本的html框架,其他关键信息通过ajax请求(b.php)返回,返回的是json,然后通过页面js解析json并绘制在页面上。问题关键是ajax请求信息里有手机号需要登录才能显示完整
杨东方4年前906
文章采集api 2021年5月30日更新无言给大家争取了一个福利(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 230 次浏览 • 2021-06-06 05:28
2021 年 5 月 30 日更新,无言为大家赢得了一份福利。使用无言提供的优惠码购买插件,最高可享5折优惠。在购买页面输入dc-3035750即可获得优惠,如下图
今天我要推荐一个很棒的 WordPress采集 插件。自从我建网站以来,这个插件已经使用了四年多。我从单站升级到无限版,做网站用这个采集真的超级舒服。
这个QQWorld采集插件据说是采集插件,但其实我更愿意把它定位为网站必备工具插件。下面就默默给大家分析一下QQ世界的各种功能。
QQWorld采集插件功能
以上是使用时间最长的函数。其实还有一些小而实用的功能可以玩。最常用的是采集文章+保存附件+云存储+伪原创+搜索引擎,开启这些功能后,即可实现无人值守操作。
文章采集来后->伪原创功能自动修改文章->自动同时保存附件和水印->从云存储上传附件(可实现不保存到网站media library) ->提交链接到搜索引擎。
万一我写不出采集rules怎么办?
完全不用担心,采集商店里已经有1468条采集规则,可以使用了。不是你想要的网站,你也可以在作者网站提交写作规则
反正QQWorld Collector是一款增值、可定制的爬虫,一款集截图、水印、云存储等功能于一体的WordPress万能云采集插件,可以采集绝大大部分网站,如微信公众号、知乎等,还有采集品商店,上千条采集规则免费使用!
查看全部
文章采集api 2021年5月30日更新无言给大家争取了一个福利(图)
2021 年 5 月 30 日更新,无言为大家赢得了一份福利。使用无言提供的优惠码购买插件,最高可享5折优惠。在购买页面输入dc-3035750即可获得优惠,如下图

今天我要推荐一个很棒的 WordPress采集 插件。自从我建网站以来,这个插件已经使用了四年多。我从单站升级到无限版,做网站用这个采集真的超级舒服。
这个QQWorld采集插件据说是采集插件,但其实我更愿意把它定位为网站必备工具插件。下面就默默给大家分析一下QQ世界的各种功能。
QQWorld采集插件功能
以上是使用时间最长的函数。其实还有一些小而实用的功能可以玩。最常用的是采集文章+保存附件+云存储+伪原创+搜索引擎,开启这些功能后,即可实现无人值守操作。
文章采集来后->伪原创功能自动修改文章->自动同时保存附件和水印->从云存储上传附件(可实现不保存到网站media library) ->提交链接到搜索引擎。
万一我写不出采集rules怎么办?
完全不用担心,采集商店里已经有1468条采集规则,可以使用了。不是你想要的网站,你也可以在作者网站提交写作规则
反正QQWorld Collector是一款增值、可定制的爬虫,一款集截图、水印、云存储等功能于一体的WordPress万能云采集插件,可以采集绝大大部分网站,如微信公众号、知乎等,还有采集品商店,上千条采集规则免费使用!

路由器的源码:retrieve方法获取需序列化的对象
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-05-29 03:25
文章中涉及的示例代码已经更新到HelloGitHub-Team仓库[2]
一旦我们使用了视图集,并实现了HTTP请求对应的action方法(对应规则的描述见使用视图集的简化代码),在路由器中注册后,django-restframework会自动为我们生成对应的API接口。
到目前为止,我们只实现了GET请求对应的action-list方法,所以路由器只为我们生成了一个API,这个API返回的是文章资源列表。 GET请求也可以用于获取单个资源,对应的动作是retrieve。因此,我们只要在视图集中实现retrieve方法的逻辑,就可以直接生成API接口获取单个资源文章。
贴心的,django-rest-framework帮我们在mixins.RetrieveModelMixin中写了检索的逻辑,可以直接混入视图集:
class PostViewSet(
mixins.ListModelMixin, mixins.RetrieveModelMixin, viewsets.GenericViewSet
):
serializer_class = PostListSerializer
queryset = Post.objects.all()
permission_classes = [AllowAny]
现在,路由会自动添加一个 URL 模式 /posts/:pk/,其中 pk 是 文章 的 id。访问该API接口获取指定文章 id的资源。
实际上,实现每个动作逻辑的混入类非常简单。以 RetrieveModelMixin 为例,我们来看看它的源码:
class RetrieveModelMixin:
"""
Retrieve a model instance.
"""
def retrieve(self, request, *args, **kwargs):
instance = self.get_object()
serializer = self.get_serializer(instance)
return Response(serializer.data)
retrieve 方法首先调用get_object 方法获取要序列化的对象。 get_object 方法通常基于以下两点过滤掉单个资源对象:
get_queryset方法返回的资源列表对象(或queryset属性,get_queryset方法返回的值优先)。 lookup_field 属性指定的资源过滤字段(默认为pk)。 django-rest-framework 使用该字段的值从 get_queryset 返回的资源列表中过滤出单个资源对象。 lookup_field字段的值会从请求的URL中抓取,所以你看到文章接口的url模式是/posts/:pk/,假设lookup_field被指定为title,url模式是/posts/ :title/, this 根据文章的标题,我们会得到一个文章资源。 文章详细的序列化器
<p>现在假设我们要获取id为1的文章资源,访问获取单个文章资源的API接口:10000/api/posts/1/,得到如下返回结果: 查看全部
路由器的源码:retrieve方法获取需序列化的对象
文章中涉及的示例代码已经更新到HelloGitHub-Team仓库[2]
一旦我们使用了视图集,并实现了HTTP请求对应的action方法(对应规则的描述见使用视图集的简化代码),在路由器中注册后,django-restframework会自动为我们生成对应的API接口。
到目前为止,我们只实现了GET请求对应的action-list方法,所以路由器只为我们生成了一个API,这个API返回的是文章资源列表。 GET请求也可以用于获取单个资源,对应的动作是retrieve。因此,我们只要在视图集中实现retrieve方法的逻辑,就可以直接生成API接口获取单个资源文章。
贴心的,django-rest-framework帮我们在mixins.RetrieveModelMixin中写了检索的逻辑,可以直接混入视图集:
class PostViewSet(
mixins.ListModelMixin, mixins.RetrieveModelMixin, viewsets.GenericViewSet
):
serializer_class = PostListSerializer
queryset = Post.objects.all()
permission_classes = [AllowAny]
现在,路由会自动添加一个 URL 模式 /posts/:pk/,其中 pk 是 文章 的 id。访问该API接口获取指定文章 id的资源。
实际上,实现每个动作逻辑的混入类非常简单。以 RetrieveModelMixin 为例,我们来看看它的源码:
class RetrieveModelMixin:
"""
Retrieve a model instance.
"""
def retrieve(self, request, *args, **kwargs):
instance = self.get_object()
serializer = self.get_serializer(instance)
return Response(serializer.data)
retrieve 方法首先调用get_object 方法获取要序列化的对象。 get_object 方法通常基于以下两点过滤掉单个资源对象:
get_queryset方法返回的资源列表对象(或queryset属性,get_queryset方法返回的值优先)。 lookup_field 属性指定的资源过滤字段(默认为pk)。 django-rest-framework 使用该字段的值从 get_queryset 返回的资源列表中过滤出单个资源对象。 lookup_field字段的值会从请求的URL中抓取,所以你看到文章接口的url模式是/posts/:pk/,假设lookup_field被指定为title,url模式是/posts/ :title/, this 根据文章的标题,我们会得到一个文章资源。 文章详细的序列化器
<p>现在假设我们要获取id为1的文章资源,访问获取单个文章资源的API接口:10000/api/posts/1/,得到如下返回结果:
前往韦世东的技术专栏收获爬虫架构/爬虫逆向/存储引擎/消息
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-05-17 01:28
前往韦世东的技术专栏收获爬虫架构/爬虫逆向/存储引擎/消息
转到Wei Shidong的技术专栏,以获取爬虫架构/爬虫反向/存储引擎/消息队列/ Python / Golang相关知识
本文文章的主要目的是告诉您如何配置Prometheus,以便它可以使用指定的Web Api接口采集索引数据。 文章中使用的情况是NGINX的采集配置。从设置了用户名和密码的NGINX数据索引页中的采集数据中,本文文章的标题可能是nginx的prometheus 采集配置nginx或prometheus 采集基本身份验证。
上图显示了配置完成后在Grafana中配置模板的效果。
曾经使用Prometheus的朋友必须知道如何配置address:port服务。例如,当采集有关某个Redis的信息时,可以这样编写配置:
- job_name: 'redis'
static_configs:
- targets: ['11.22.33.58:6087']
注意:在上述情况下,假设Redis Exporter的地址和端口为1 1. 2 2. 3 3. 58:6087。
这是最简单,最知名的方法。但是,如果您要监视指定的Web API,则不能以这种方式编写。如果您没有看到此文章,则可以在这样的搜索引擎中进行搜索:
不幸的是,我找不到任何有效的信息(现在是2021年3月),基本上我只能找到坑。
条件假设
假设我们现在需要从具有地址的界面中采集相关的Prometheus监视指标,并且该界面使用基本身份验证(假设用户名为weishidong并且密码为0099887kk)进行基本授权验证。
配置练习操作
如果您填写之前看到的Prometheus配置,则很有可能这样编写配置:
- job_name: 'web'
static_configs:
- targets: ['http://www.weishidong.com/status/format/prometheus']
basic_auth:
username: weishidong
password: 0099887kk
保存配置文件并重新启动服务后,您将发现无法以这种方式采集数据,这很糟糕。
官方配置指南
刚才的操作真的很糟糕。当我们遇到无法理解的问题时,我们当然会转到官方文档-> Prometheus Configuration。建议从上至下阅读,但是如果您急于忙,可以直接进入本节。官方示例如下(内容太多,这里仅是与本文相关的部分,建议您阅读原文):
# The job name assigned to scraped metrics by default.
job_name:
# How frequently to scrape targets from this job.
[ scrape_interval: | default = ]
# Per-scrape timeout when scraping this job.
[ scrape_timeout: | default = ]
# The HTTP resource path on which to fetch metrics from targets.
[ metrics_path: | default = /metrics ]
# honor_labels controls how Prometheus handles conflicts between labels that are
# already present in scraped data and labels that Prometheus would attach
# server-side ("job" and "instance" labels, manually configured target
# labels, and labels generated by service discovery implementations).
#
# If honor_labels is set to "true", label conflicts are resolved by keeping label
# values from the scraped data and ignoring the conflicting server-side labels.
#
# If honor_labels is set to "false", label conflicts are resolved by renaming
# conflicting labels in the scraped data to "exported_" (for
# example "exported_instance", "exported_job") and then attaching server-side
# labels.
#
# Setting honor_labels to "true" is useful for use cases such as federation and
# scraping the Pushgateway, where all labels specified in the target should be
# preserved.
#
# Note that any globally configured "external_labels" are unaffected by this
# setting. In communication with external systems, they are always applied only
# when a time series does not have a given label yet and are ignored otherwise.
[ honor_labels: | default = false ]
# honor_timestamps controls whether Prometheus respects the timestamps present
# in scraped data.
#
# If honor_timestamps is set to "true", the timestamps of the metrics exposed
# by the target will be used.
#
# If honor_timestamps is set to "false", the timestamps of the metrics exposed
# by the target will be ignored.
[ honor_timestamps: | default = true ]
# Configures the protocol scheme used for requests.
[ scheme: | default = http ]
# Optional HTTP URL parameters.
params:
[ : [, ...] ]
# Sets the `Authorization` header on every scrape request with the
# configured username and password.
# password and password_file are mutually exclusive.
basic_auth:
[ username: ]
[ password: ]
[ password_file: ]
# Sets the `Authorization` header on every scrape request with
# the configured bearer token. It is mutually exclusive with `bearer_token_file`.
[ bearer_token: ]
# Sets the `Authorization` header on every scrape request with the bearer token
# read from the configured file. It is mutually exclusive with `bearer_token`.
[ bearer_token_file: ]
<p>如果仔细看,应该注意一些关键信息:metrics_path和basic_auth。其中,metrics_path用于在使用HTTP类型指示符信息采集时指定路由地址,默认值为/ metrics;默认值为/ metrics。字段basic_auth用于授权验证,此处的密码可以指定密码文件,而不是直接填写纯文本(通常,指定密码文件的安全性比纯文本的安全性高)。 查看全部
前往韦世东的技术专栏收获爬虫架构/爬虫逆向/存储引擎/消息

转到Wei Shidong的技术专栏,以获取爬虫架构/爬虫反向/存储引擎/消息队列/ Python / Golang相关知识
本文文章的主要目的是告诉您如何配置Prometheus,以便它可以使用指定的Web Api接口采集索引数据。 文章中使用的情况是NGINX的采集配置。从设置了用户名和密码的NGINX数据索引页中的采集数据中,本文文章的标题可能是nginx的prometheus 采集配置nginx或prometheus 采集基本身份验证。

上图显示了配置完成后在Grafana中配置模板的效果。
曾经使用Prometheus的朋友必须知道如何配置address:port服务。例如,当采集有关某个Redis的信息时,可以这样编写配置:
- job_name: 'redis'
static_configs:
- targets: ['11.22.33.58:6087']
注意:在上述情况下,假设Redis Exporter的地址和端口为1 1. 2 2. 3 3. 58:6087。
这是最简单,最知名的方法。但是,如果您要监视指定的Web API,则不能以这种方式编写。如果您没有看到此文章,则可以在这样的搜索引擎中进行搜索:
不幸的是,我找不到任何有效的信息(现在是2021年3月),基本上我只能找到坑。
条件假设
假设我们现在需要从具有地址的界面中采集相关的Prometheus监视指标,并且该界面使用基本身份验证(假设用户名为weishidong并且密码为0099887kk)进行基本授权验证。
配置练习操作
如果您填写之前看到的Prometheus配置,则很有可能这样编写配置:
- job_name: 'web'
static_configs:
- targets: ['http://www.weishidong.com/status/format/prometheus']
basic_auth:
username: weishidong
password: 0099887kk
保存配置文件并重新启动服务后,您将发现无法以这种方式采集数据,这很糟糕。
官方配置指南
刚才的操作真的很糟糕。当我们遇到无法理解的问题时,我们当然会转到官方文档-> Prometheus Configuration。建议从上至下阅读,但是如果您急于忙,可以直接进入本节。官方示例如下(内容太多,这里仅是与本文相关的部分,建议您阅读原文):
# The job name assigned to scraped metrics by default.
job_name:
# How frequently to scrape targets from this job.
[ scrape_interval: | default = ]
# Per-scrape timeout when scraping this job.
[ scrape_timeout: | default = ]
# The HTTP resource path on which to fetch metrics from targets.
[ metrics_path: | default = /metrics ]
# honor_labels controls how Prometheus handles conflicts between labels that are
# already present in scraped data and labels that Prometheus would attach
# server-side ("job" and "instance" labels, manually configured target
# labels, and labels generated by service discovery implementations).
#
# If honor_labels is set to "true", label conflicts are resolved by keeping label
# values from the scraped data and ignoring the conflicting server-side labels.
#
# If honor_labels is set to "false", label conflicts are resolved by renaming
# conflicting labels in the scraped data to "exported_" (for
# example "exported_instance", "exported_job") and then attaching server-side
# labels.
#
# Setting honor_labels to "true" is useful for use cases such as federation and
# scraping the Pushgateway, where all labels specified in the target should be
# preserved.
#
# Note that any globally configured "external_labels" are unaffected by this
# setting. In communication with external systems, they are always applied only
# when a time series does not have a given label yet and are ignored otherwise.
[ honor_labels: | default = false ]
# honor_timestamps controls whether Prometheus respects the timestamps present
# in scraped data.
#
# If honor_timestamps is set to "true", the timestamps of the metrics exposed
# by the target will be used.
#
# If honor_timestamps is set to "false", the timestamps of the metrics exposed
# by the target will be ignored.
[ honor_timestamps: | default = true ]
# Configures the protocol scheme used for requests.
[ scheme: | default = http ]
# Optional HTTP URL parameters.
params:
[ : [, ...] ]
# Sets the `Authorization` header on every scrape request with the
# configured username and password.
# password and password_file are mutually exclusive.
basic_auth:
[ username: ]
[ password: ]
[ password_file: ]
# Sets the `Authorization` header on every scrape request with
# the configured bearer token. It is mutually exclusive with `bearer_token_file`.
[ bearer_token: ]
# Sets the `Authorization` header on every scrape request with the bearer token
# read from the configured file. It is mutually exclusive with `bearer_token`.
[ bearer_token_file: ]
<p>如果仔细看,应该注意一些关键信息:metrics_path和basic_auth。其中,metrics_path用于在使用HTTP类型指示符信息采集时指定路由地址,默认值为/ metrics;默认值为/ metrics。字段basic_auth用于授权验证,此处的密码可以指定密码文件,而不是直接填写纯文本(通常,指定密码文件的安全性比纯文本的安全性高)。
的数据库API调用API的经验分享
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-05-03 03:07
内容
背景
许多Internet公司通常都有存储自己的用户信息的数据库,而数据库中的数据基本上是由工程部门非常干净地解析的(使用采集器技术或对基础数据的分析主要是开发部门或数据采集工程部工作),因此许多业务数据分析人员仅使用HSQL和其他工具即可轻松获取所需的大量数据。
但是市场上有一些。他们不像B2C公司那样依靠自己的用户信息来进行产品迭代或业务增长。他们主要依靠工程部门解析第三方数据,并将结果发送给产品开发部门以构建和可视化业务平台。获取第三方数据的过程要求使用第三方API接口,这就是为什么这些公司要求申请多个职位的候选人具有调用API的经验,因为即使公司拥有自己的数据库,它也是所有工程部门。在选择性地对结果进行爬网和排序之后,您可能会面临数据库没有所需数据的困境。目前,您需要使用类似的方法来使用自己的采集数据。
API简介
调用API的过程也是一种爬虫。在抓取工具中,通常会在两个地方提到API,一个是库API,另一个是数据API。
库API
库API通常意味着开发人员已经开发了一个库(例如python库)并为用户提供了调用该库的接口。就像,我们要去包裹储物柜取走我们的快递。我们必须输入正确的信息才能表达我们的意思。此信息是一个API接口,可帮助我们准确定位该库并进行调用。
数据API
在产品开发或Web开发中,数据API就像一条从后端传递到前端的数据线。后端人员已经整理出他们想要显示的数据,只需要通过此数据线将其传输给前端开发人员,前端就可以根据需要对其进行可视化处理。而且该界面也可以被外界使用。
与网络采集器不同,数据API的设计更简单,更高效。此界面已经存储了您需要的数据,因此我们无需花费太多精力来解析网页。网页数据爬网经常给服务器带来压力。如果您的代码未设置合理的类似于人类的Web浏览频率,则存在IP被阻止的风险。
但是数据API也有一些缺点。尽管市场上有许多可以由外界使用的API产品,但是许多免费接口对爬网量有很大的限制。如果您的抓取需求很大,则需要付费。
简单的API采集器示例
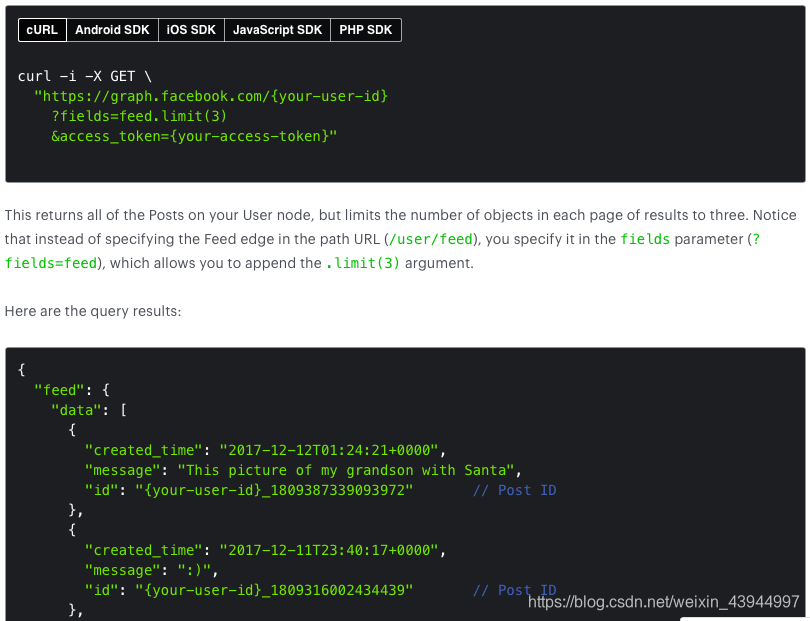
下面,我将使用Facebook Graph API抓取数据作为大致记录通用数据API调用过程的示例。
调用界面信息:提供API调用地址(通常为URL格式)。此地址类似于帮助我们找到要领取的储物柜的行和列。请求获取数据:使用HTTP协议请求传输数据,通常在python的请求包中调用get函数。设置请求参数:您需要提供请求参数,也就是说,您需要告诉API接口要获取的信息类型。例如,在此示例中,我需要created_time(博客发布时间),post_id(博客post_id)和其他信息。 Facebook Graph API简介文件
尽管get函数可以帮助我们实现HTTP协议请求,但多次请求此URL需要身份验证。例如,以下代码将报告错误:
import requests
r = requests.get('https://facebook.com/user_id')
r.json()
并返回:需要身份许可。因此,在使用任何API接口时,最好事先阅读网站使用文档,以了解请求协议需要哪些特定信息。
{'documentation_url': ''https://facebook.com/user_id/% ... 39%3B,
'message': 'Requires authentication'}
它也可以在Facebook API的官方用户手册中看到。如果要获取Facebook帐户的发帖信息,则需要获取该帐户的令牌。如果您想获取自己以外的帐户信息,则还需要提前获取他们的令牌。将会有相应的获取令牌的介绍->如何获取Facebook帐户的访问令牌。
获取令牌后,测试以上代码以获取以下结果:
代码示例
目的:要获得从202 0. 0 3. 01到202 0. 0 3. 07的每个视频博客帖子的观看次数,请查看每个国家/地区的观看时间,性别和年龄段某个帐户,分析本周博客作者的视频内容的效果。
1. 首先我需要拿到3.1至3.7之间每条博文的ID(post_id)
2. 筛选出仅为视频的博文ID
3. 需要获取每条视频博文的观看次数,各个国家的观看时长
4. 将json格式的数据整理成dataframe格式
5. 将观看时长可视化
1.导入所需的软件包
import pandas as pd
import json, datetime, requests
from datetime import date, timedelta, datetime
import numpy as np
from pandas.core.frame import DataFrame
2.创建用于抓取数据的函数
<p>def get_list_of_fb_post_ids(fb_page_id, fb_token, START, END):
'''
Function to get all the post_ids from a given facebook page during certain time range
'''
posts=[] #用来存储所有博文的post_id
graph_output = requests.get('https://graph.facebook.com/%26 ... limit(10){created_time}',params=fb_token).json()
posts+=graph_output['posts']['data']
graph_output = requests.get(graph_output['posts']['paging']['next']).json()
posts+=graph_output['data']
while True: #一直读取next_page,直到某次读取的记录的时间小于你设置的开始时间
try:
graph_output = requests.get(graph_output['paging']['next']).json()
posts+=graph_output['data']
if graph_output['data'][-1]['created_time']=START)&(df_posts.created_time 查看全部
的数据库API调用API的经验分享
内容
背景
许多Internet公司通常都有存储自己的用户信息的数据库,而数据库中的数据基本上是由工程部门非常干净地解析的(使用采集器技术或对基础数据的分析主要是开发部门或数据采集工程部工作),因此许多业务数据分析人员仅使用HSQL和其他工具即可轻松获取所需的大量数据。
但是市场上有一些。他们不像B2C公司那样依靠自己的用户信息来进行产品迭代或业务增长。他们主要依靠工程部门解析第三方数据,并将结果发送给产品开发部门以构建和可视化业务平台。获取第三方数据的过程要求使用第三方API接口,这就是为什么这些公司要求申请多个职位的候选人具有调用API的经验,因为即使公司拥有自己的数据库,它也是所有工程部门。在选择性地对结果进行爬网和排序之后,您可能会面临数据库没有所需数据的困境。目前,您需要使用类似的方法来使用自己的采集数据。

API简介
调用API的过程也是一种爬虫。在抓取工具中,通常会在两个地方提到API,一个是库API,另一个是数据API。
库API
库API通常意味着开发人员已经开发了一个库(例如python库)并为用户提供了调用该库的接口。就像,我们要去包裹储物柜取走我们的快递。我们必须输入正确的信息才能表达我们的意思。此信息是一个API接口,可帮助我们准确定位该库并进行调用。
数据API
在产品开发或Web开发中,数据API就像一条从后端传递到前端的数据线。后端人员已经整理出他们想要显示的数据,只需要通过此数据线将其传输给前端开发人员,前端就可以根据需要对其进行可视化处理。而且该界面也可以被外界使用。
与网络采集器不同,数据API的设计更简单,更高效。此界面已经存储了您需要的数据,因此我们无需花费太多精力来解析网页。网页数据爬网经常给服务器带来压力。如果您的代码未设置合理的类似于人类的Web浏览频率,则存在IP被阻止的风险。
但是数据API也有一些缺点。尽管市场上有许多可以由外界使用的API产品,但是许多免费接口对爬网量有很大的限制。如果您的抓取需求很大,则需要付费。
简单的API采集器示例
下面,我将使用Facebook Graph API抓取数据作为大致记录通用数据API调用过程的示例。
调用界面信息:提供API调用地址(通常为URL格式)。此地址类似于帮助我们找到要领取的储物柜的行和列。请求获取数据:使用HTTP协议请求传输数据,通常在python的请求包中调用get函数。设置请求参数:您需要提供请求参数,也就是说,您需要告诉API接口要获取的信息类型。例如,在此示例中,我需要created_time(博客发布时间),post_id(博客post_id)和其他信息。 Facebook Graph API简介文件
尽管get函数可以帮助我们实现HTTP协议请求,但多次请求此URL需要身份验证。例如,以下代码将报告错误:
import requests
r = requests.get('https://facebook.com/user_id')
r.json()
并返回:需要身份许可。因此,在使用任何API接口时,最好事先阅读网站使用文档,以了解请求协议需要哪些特定信息。
{'documentation_url': ''https://facebook.com/user_id/% ... 39%3B,
'message': 'Requires authentication'}
它也可以在Facebook API的官方用户手册中看到。如果要获取Facebook帐户的发帖信息,则需要获取该帐户的令牌。如果您想获取自己以外的帐户信息,则还需要提前获取他们的令牌。将会有相应的获取令牌的介绍->如何获取Facebook帐户的访问令牌。
获取令牌后,测试以上代码以获取以下结果:
代码示例
目的:要获得从202 0. 0 3. 01到202 0. 0 3. 07的每个视频博客帖子的观看次数,请查看每个国家/地区的观看时间,性别和年龄段某个帐户,分析本周博客作者的视频内容的效果。
1. 首先我需要拿到3.1至3.7之间每条博文的ID(post_id)
2. 筛选出仅为视频的博文ID
3. 需要获取每条视频博文的观看次数,各个国家的观看时长
4. 将json格式的数据整理成dataframe格式
5. 将观看时长可视化
1.导入所需的软件包
import pandas as pd
import json, datetime, requests
from datetime import date, timedelta, datetime
import numpy as np
from pandas.core.frame import DataFrame
2.创建用于抓取数据的函数
<p>def get_list_of_fb_post_ids(fb_page_id, fb_token, START, END):
'''
Function to get all the post_ids from a given facebook page during certain time range
'''
posts=[] #用来存储所有博文的post_id
graph_output = requests.get('https://graph.facebook.com/%26 ... limit(10){created_time}',params=fb_token).json()
posts+=graph_output['posts']['data']
graph_output = requests.get(graph_output['posts']['paging']['next']).json()
posts+=graph_output['data']
while True: #一直读取next_page,直到某次读取的记录的时间小于你设置的开始时间
try:
graph_output = requests.get(graph_output['paging']['next']).json()
posts+=graph_output['data']
if graph_output['data'][-1]['created_time']=START)&(df_posts.created_time
优采云采集支持调用5118一键智能换词API接口(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 429 次浏览 • 2021-05-02 00:17
优采云 采集支持调用5118一键式智能单词更改API接口,处理采集数据标题和内容等,以及处理文章,对搜索引擎更具吸引力;
详细的使用步骤如下
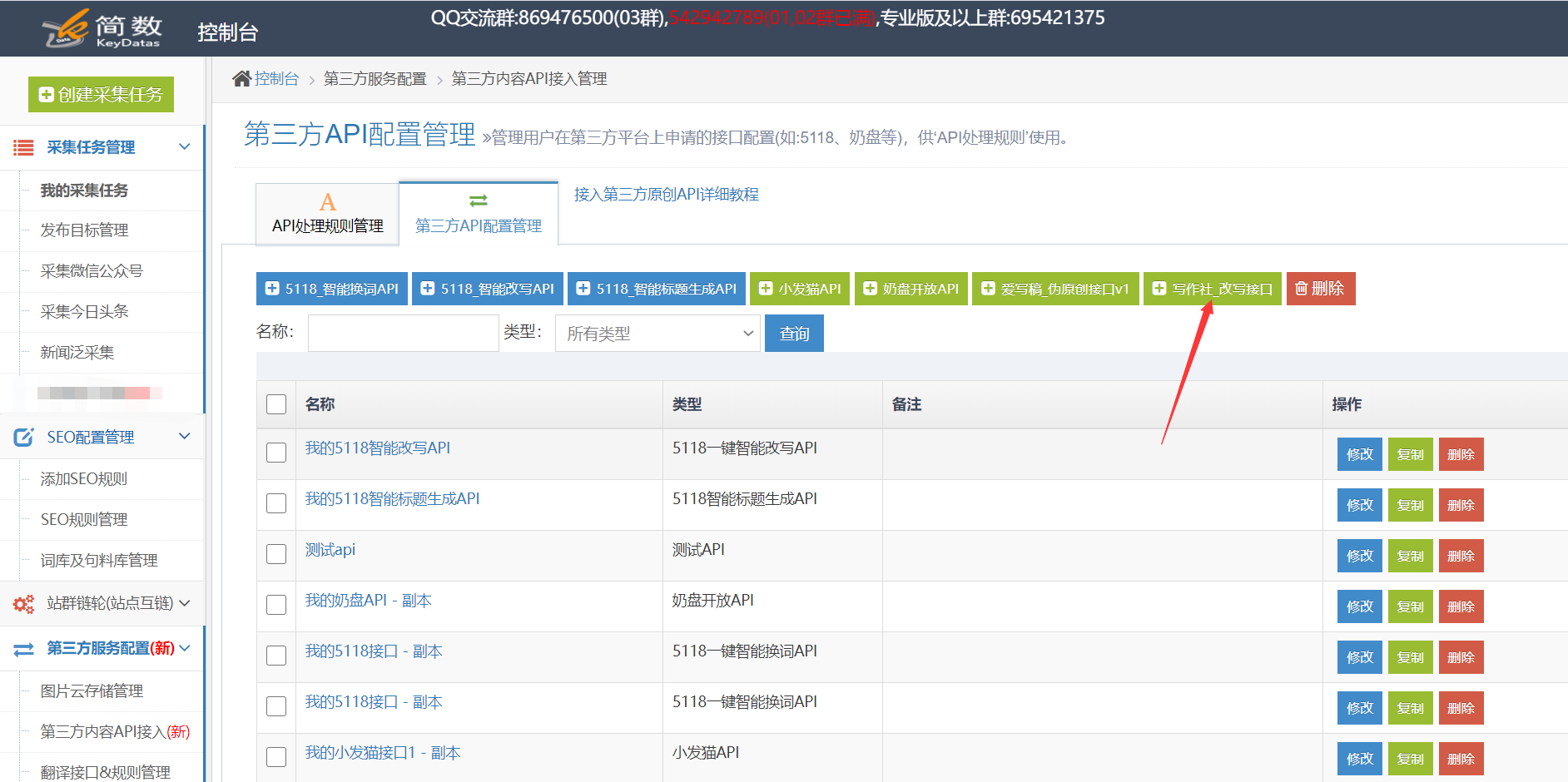
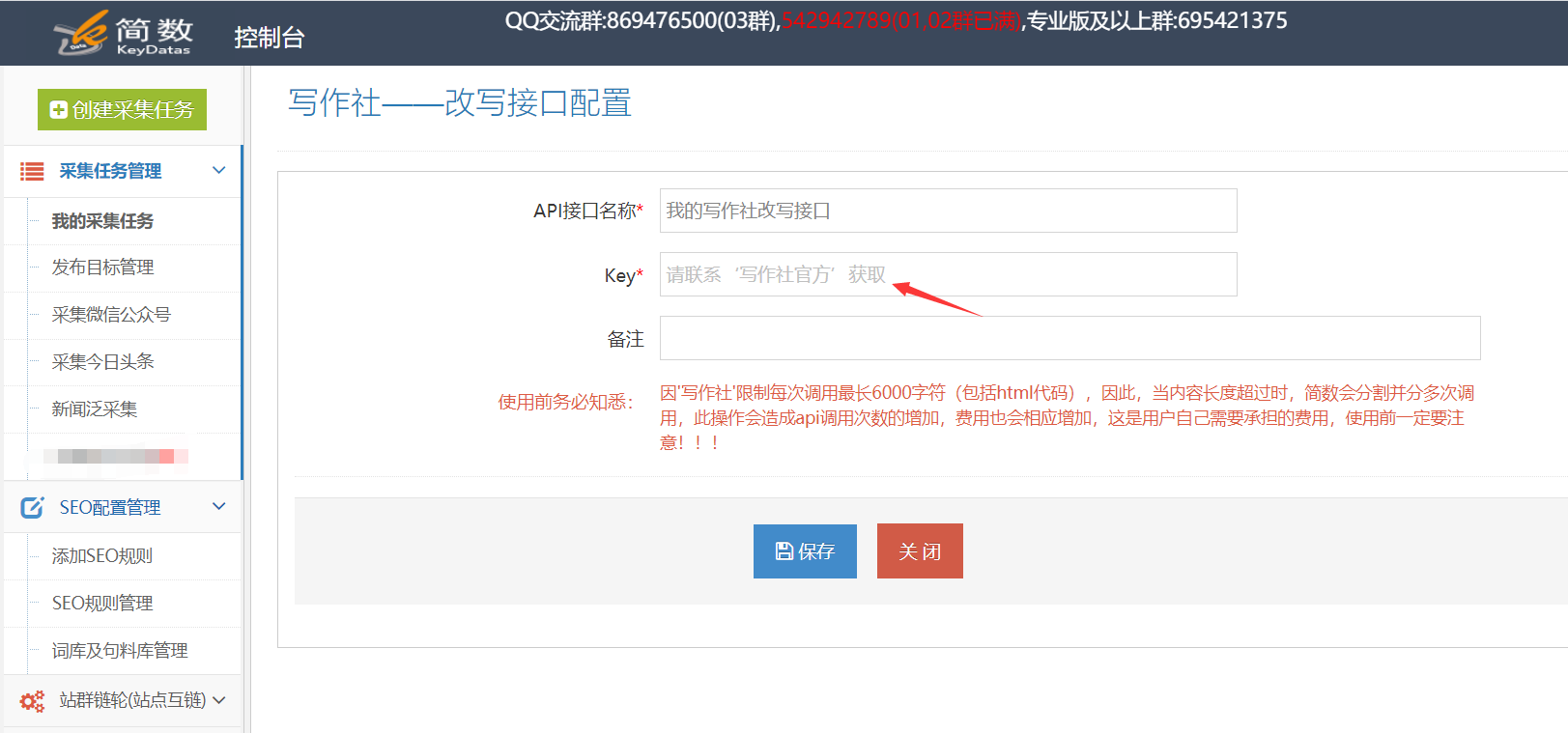
1. 5118一键式智能单词更改API接口配置I,API配置条目:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问权限] ==”单击[第三方API配置管理] ==“最后单击[+5118一键式智能原创 API]创建接口配置;
II。配置API接口信息:
[API-Key value]用于从5118背景中获取与一键智能单词更改API对应的密钥值,并记住填写后保存;
2.创建API处理规则
API处理规则,可以将其设置为调用API接口以处理哪些字段的内容;
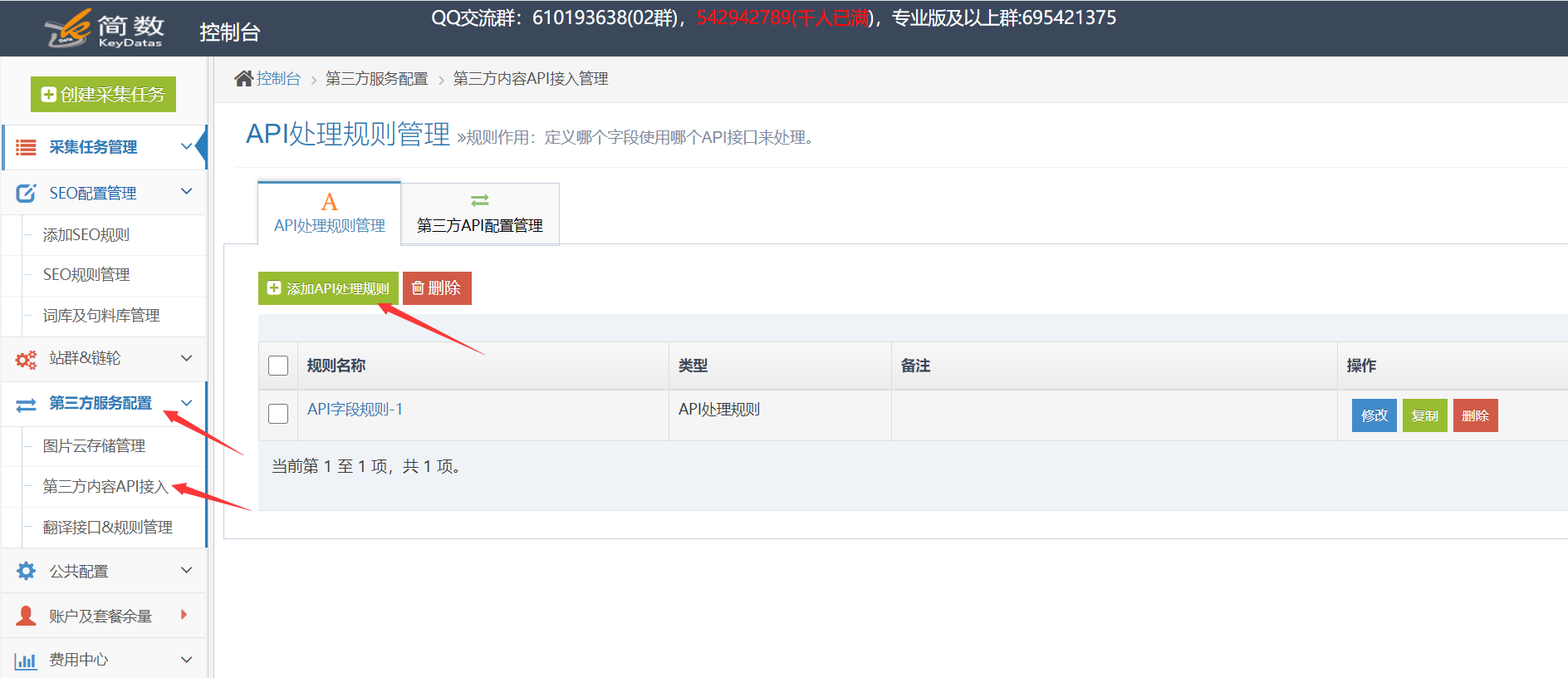
I。 API处理规则条目:
单击[第三方服务配置] ==“单击控制台左侧列表中的[第三方内容API访问权限] ==”,进入[API处理规则管理]页面,最后单击[+添加API处理规则]创建API处理规则;
II,API处理规则配置:
规则名称:用户可以自己命名;
字段名称:填充的字段名称的内容将由API接口处理,默认为标题和内容字段,可以对其进行修改,添加或删除;
使用的API:选择已设置的API接口配置,执行时将调用该接口,并且可以为不同的字段选择不同的API接口配置;
处理顺序:执行顺序按从小到大的顺序执行;
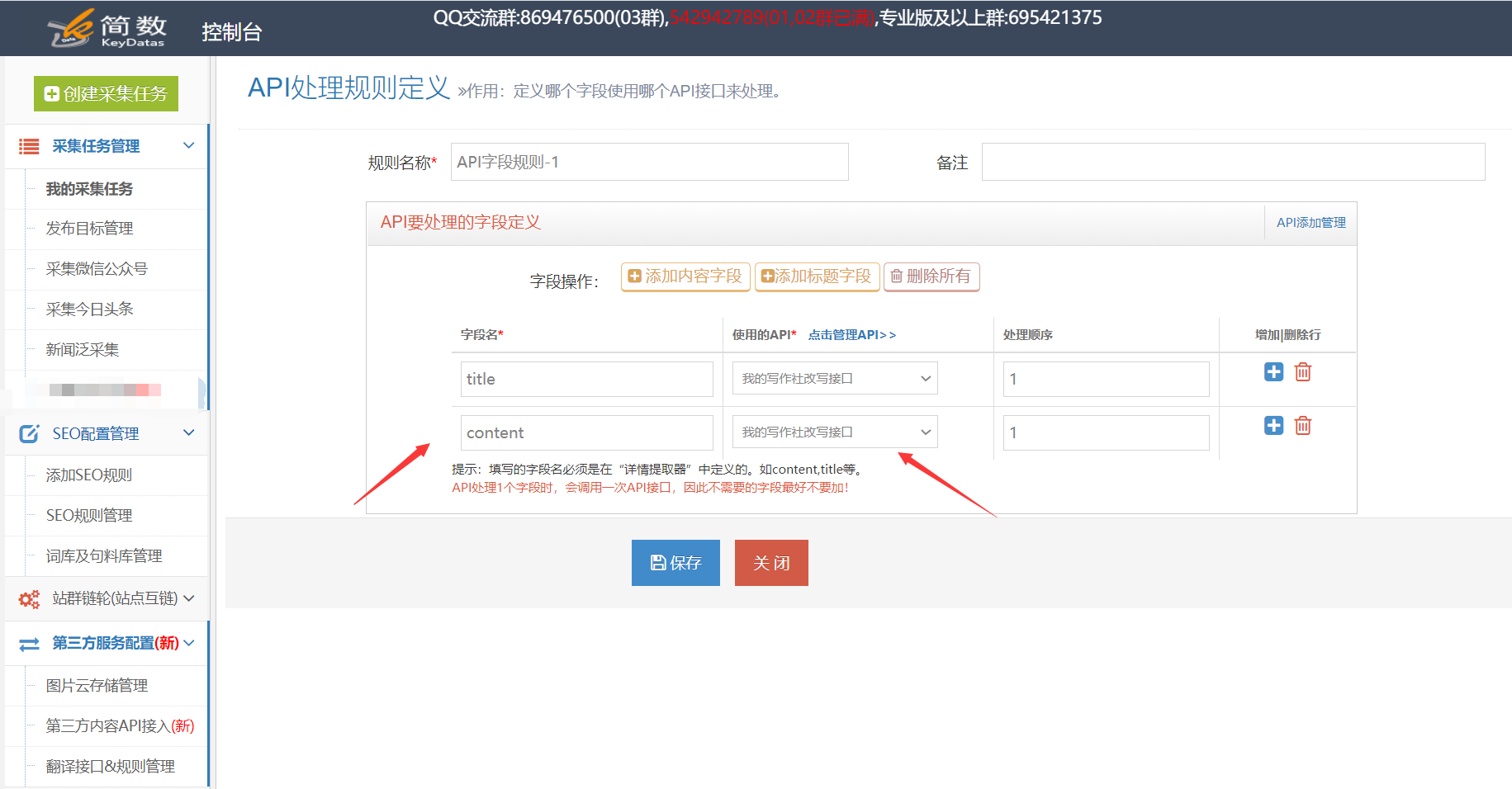
3. API处理规则的用法
使用API处理规则的方式有两种:手动执行和自动执行:
手动执行:在采集数据之后,使用第三方API在[结果数据和发布]中执行;
自动执行:配置自动化后,完成任务采集数据后,系统将自动执行指定的API处理规则,而无需人工操作。
I。手动执行API处理规则:
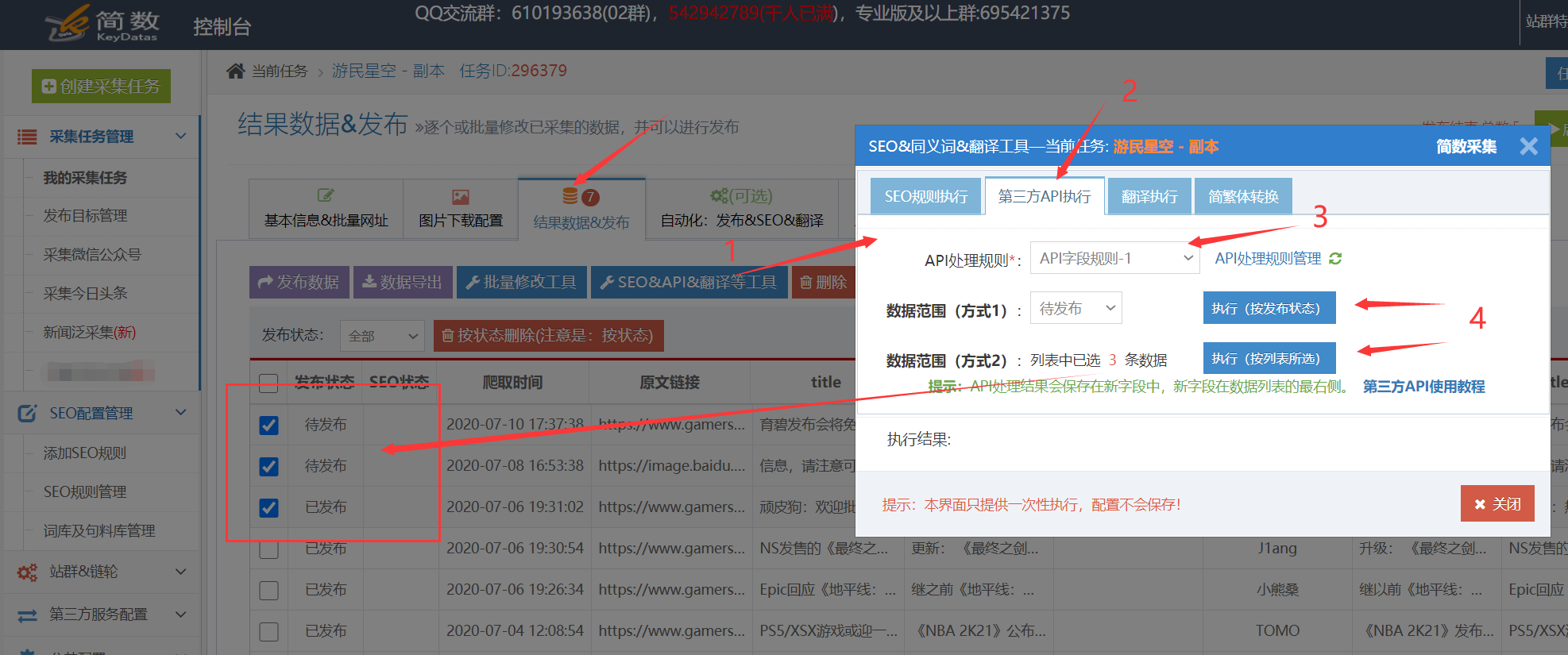
在采集任务的[结果数据和发布]选项卡中,单击[SEO&API&翻译工具]按钮==“选择[第三方API执行]列==”选择相应的API处理规则==“执行;
II。自动执行API处理规则:
启用API处理的自动执行。任务完成采集后,API处理将自动执行。通常,可以使用计时采集和自动发布功能;
在任务的[自动化:发布和SEO和翻译]选项卡中,[自动执行第三方API配置] ==“检查[采集,自动执行API]选项==”选择要执行的API处理规则==“选择由API接口处理的数据范围(通常选择”要发布“,所有将导致所有数据被多次执行),最后单击保存;
4. API处理结果和发布,查看API接口处理结果:
API接口处理的内容将另存为新字段,例如标题处理后的新字段title_5118和内容处理后的新字段content_5118,可以在[结果数据和发布中查看]和数据预览界面。
II。发布API接口的处理后内容:
发布文章之前,请在发布目标的第二步中修改映射字段,并在API接口处理之后将标题和内容更改为新的对应字段title_5118和content_5118;
查看全部
优采云采集支持调用5118一键智能换词API接口(图)
优采云 采集支持调用5118一键式智能单词更改API接口,处理采集数据标题和内容等,以及处理文章,对搜索引擎更具吸引力;
详细的使用步骤如下
1. 5118一键式智能单词更改API接口配置I,API配置条目:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问权限] ==”单击[第三方API配置管理] ==“最后单击[+5118一键式智能原创 API]创建接口配置;

II。配置API接口信息:
[API-Key value]用于从5118背景中获取与一键智能单词更改API对应的密钥值,并记住填写后保存;
2.创建API处理规则
API处理规则,可以将其设置为调用API接口以处理哪些字段的内容;
I。 API处理规则条目:
单击[第三方服务配置] ==“单击控制台左侧列表中的[第三方内容API访问权限] ==”,进入[API处理规则管理]页面,最后单击[+添加API处理规则]创建API处理规则;
II,API处理规则配置:
规则名称:用户可以自己命名;
字段名称:填充的字段名称的内容将由API接口处理,默认为标题和内容字段,可以对其进行修改,添加或删除;
使用的API:选择已设置的API接口配置,执行时将调用该接口,并且可以为不同的字段选择不同的API接口配置;
处理顺序:执行顺序按从小到大的顺序执行;
3. API处理规则的用法
使用API处理规则的方式有两种:手动执行和自动执行:
手动执行:在采集数据之后,使用第三方API在[结果数据和发布]中执行;
自动执行:配置自动化后,完成任务采集数据后,系统将自动执行指定的API处理规则,而无需人工操作。
I。手动执行API处理规则:
在采集任务的[结果数据和发布]选项卡中,单击[SEO&API&翻译工具]按钮==“选择[第三方API执行]列==”选择相应的API处理规则==“执行;
II。自动执行API处理规则:
启用API处理的自动执行。任务完成采集后,API处理将自动执行。通常,可以使用计时采集和自动发布功能;
在任务的[自动化:发布和SEO和翻译]选项卡中,[自动执行第三方API配置] ==“检查[采集,自动执行API]选项==”选择要执行的API处理规则==“选择由API接口处理的数据范围(通常选择”要发布“,所有将导致所有数据被多次执行),最后单击保存;
4. API处理结果和发布,查看API接口处理结果:
API接口处理的内容将另存为新字段,例如标题处理后的新字段title_5118和内容处理后的新字段content_5118,可以在[结果数据和发布中查看]和数据预览界面。
II。发布API接口的处理后内容:
发布文章之前,请在发布目标的第二步中修改映射字段,并在API接口处理之后将标题和内容更改为新的对应字段title_5118和content_5118;
小涴熊CMS漫画源码的安装和采集教程,文字比较多
采集交流 • 优采云 发表了文章 • 0 个评论 • 260 次浏览 • 2021-03-26 00:09
在本文文章中,我将说明Xiaoxiong cms漫画源代码和采集教程的安装。文本很多,您仍然需要一点耐心并仔细研究。在此祝大家长隆“停运”,交通流量不断增加!
环境要求:PHP 7. 0- 7. 2、 MySQL> = 5. 7、 Redis,Redis扩展(官方要求是PHP 5. 6- 7. 2,因为我测试过我发现7. 0不容易使用,因此我在这里进行了修改,并将其直接更改为7. 0- 7. 2)。
1、安装环境
这里仍然是一条简单的路线,使用宝塔面板进行演示,请使用以下命令:
#CentOS系统
wget -O install.sh && sh install.sh
#Ubuntu系统
wget -O install.sh && sudo bash install.sh
#Debian系统
wget -O install.sh && bash install.sh
安装完成后,进入面板,单击左侧的软件管理,然后安装PHP 7. 2、 Nginx,Mysql 5. 7 +,Redis。
接下来,在左侧找到“软件管理-PHP管理-设置-安装Redis扩展”。
2、安装程序
这是一条简单的路线,使用宝塔面板进行演示
1。安装宝塔后,进入面板,单击左侧的软件管理,然后安装PHP 7. 2、 Nginx,Mysql 5. 7 +,Redis。
2,让我们单击左侧的网站并添加网站!我不需要教这个!!!
3,设置伪静态规则:
if(!-e $ request_filename){
最后重写^(。*)$ /index.php?s = / $ 1;
休息;
}
4,单击域名设置-网站目录,运行该目录并选择public,取消对反跨站点的检查,然后重新启动PHP。
5,最后浏览器运行您的网站+ / install进入安装页面,并根据页面提示输入相关信息以完成安装!
注意:如果要在不显示cms错误消息的情况下启用404,则需要修改config / app.php文件:
#删除第一行中的//。
'exception_tmpl'=> Env :: get('app_path')。'index / view / pub / 40 4. html',
'exception_tmpl'=> Env :: get('think_path')。'tpl / think_exception.tpl',
采集教程
在正常情况下,漫画工作站中有两种类型的图片资源,一种是本地化的,另一种是热链接的。建议对图片进行本地化以确保网站资源的稳定性,并且程序还提供网站 k6] 采集器的API可以轻松连接到优采云 采集器,用于漫画和章节图片采集。
首先我们需要一个优采云 采集器官方网站→门户,但是它分为免费版和付费版,但是由于某些功能限制,免费版不能满足图像本地化的需求,因此暂时不适用。如果您有钱,可以购买付费版本,但如果没有钱,则可以直接使用优采云 V 7. 6企业破解版。当前最新的破解版本可能也可以满足程序的采集需求。 ,有关如何下载,请使用百度。许多网站提供下载链接。
注意:由于火车头V7和V8没有url编码解码功能,所以不能采集带有中文链接的漫画网站,但V9版本可以,有钱可以直接上。
采集 api描述:
采集api地址:域名/api/index/save
请求方式:post
表单字段及说明:
book_name 漫画名
nick_name 漫画别名
tags 分类,多个分类用|隔开
author 作者名字
src 采集源
end 状态,1代表完结,0代表连载中
cover_url 封面图远程地址
chapter_name 章节名
images 由图片标签组成的字符串,示例:
api_key 用于身份验证,要和后台配置的api密钥相同
summary 漫画简介
注意:由于优采云 V7和V8不具有URL编码和解码功能,因此采集具有中文链接网站的漫画不可用,但是V9版本还可以。如果有钱,可以直接上传。
由于采集的过程有点复杂且不易发布,有兴趣和不知道采集的朋友可以从此站点下载源代码,请查看源代码并复制并粘贴以进行浏览打开浏览器,一般步骤是打开优采云 采集器主界面-publish-new-content发布参数,然后在编写发布模块之后,开始查找目标电台并编写采集规则,最后采集发布。
这篇文章是由网民提供的,或者是由Jumawu在互联网上编写的。如果转载,请注明出处:;
如果在本网站上发布的内容侵犯了您的权利,请发送电子邮件至cnzz8#将其删除,我们将及时处理!
此站点上的大多数下载资源都采集在Internet上,并且不能保证其完整性和安全性。下载后请自己进行测试。
此网站上的资源仅用于学习和交流目的。版权属于资源的原创作者。请在下载后的24小时内有意识地删除它们。
出于商业目的,请购买正版。由于未能购买和付款而导致的侵权行为与本网站无关。 查看全部
小涴熊CMS漫画源码的安装和采集教程,文字比较多
在本文文章中,我将说明Xiaoxiong cms漫画源代码和采集教程的安装。文本很多,您仍然需要一点耐心并仔细研究。在此祝大家长隆“停运”,交通流量不断增加!
环境要求:PHP 7. 0- 7. 2、 MySQL> = 5. 7、 Redis,Redis扩展(官方要求是PHP 5. 6- 7. 2,因为我测试过我发现7. 0不容易使用,因此我在这里进行了修改,并将其直接更改为7. 0- 7. 2)。
1、安装环境
这里仍然是一条简单的路线,使用宝塔面板进行演示,请使用以下命令:
#CentOS系统
wget -O install.sh && sh install.sh
#Ubuntu系统
wget -O install.sh && sudo bash install.sh
#Debian系统
wget -O install.sh && bash install.sh
安装完成后,进入面板,单击左侧的软件管理,然后安装PHP 7. 2、 Nginx,Mysql 5. 7 +,Redis。
接下来,在左侧找到“软件管理-PHP管理-设置-安装Redis扩展”。
2、安装程序
这是一条简单的路线,使用宝塔面板进行演示
1。安装宝塔后,进入面板,单击左侧的软件管理,然后安装PHP 7. 2、 Nginx,Mysql 5. 7 +,Redis。
2,让我们单击左侧的网站并添加网站!我不需要教这个!!!
3,设置伪静态规则:
if(!-e $ request_filename){
最后重写^(。*)$ /index.php?s = / $ 1;
休息;
}
4,单击域名设置-网站目录,运行该目录并选择public,取消对反跨站点的检查,然后重新启动PHP。
5,最后浏览器运行您的网站+ / install进入安装页面,并根据页面提示输入相关信息以完成安装!
注意:如果要在不显示cms错误消息的情况下启用404,则需要修改config / app.php文件:
#删除第一行中的//。
'exception_tmpl'=> Env :: get('app_path')。'index / view / pub / 40 4. html',
'exception_tmpl'=> Env :: get('think_path')。'tpl / think_exception.tpl',
采集教程
在正常情况下,漫画工作站中有两种类型的图片资源,一种是本地化的,另一种是热链接的。建议对图片进行本地化以确保网站资源的稳定性,并且程序还提供网站 k6] 采集器的API可以轻松连接到优采云 采集器,用于漫画和章节图片采集。
首先我们需要一个优采云 采集器官方网站→门户,但是它分为免费版和付费版,但是由于某些功能限制,免费版不能满足图像本地化的需求,因此暂时不适用。如果您有钱,可以购买付费版本,但如果没有钱,则可以直接使用优采云 V 7. 6企业破解版。当前最新的破解版本可能也可以满足程序的采集需求。 ,有关如何下载,请使用百度。许多网站提供下载链接。
注意:由于火车头V7和V8没有url编码解码功能,所以不能采集带有中文链接的漫画网站,但V9版本可以,有钱可以直接上。
采集 api描述:
采集api地址:域名/api/index/save
请求方式:post
表单字段及说明:
book_name 漫画名
nick_name 漫画别名
tags 分类,多个分类用|隔开
author 作者名字
src 采集源
end 状态,1代表完结,0代表连载中
cover_url 封面图远程地址
chapter_name 章节名
images 由图片标签组成的字符串,示例:



api_key 用于身份验证,要和后台配置的api密钥相同
summary 漫画简介
注意:由于优采云 V7和V8不具有URL编码和解码功能,因此采集具有中文链接网站的漫画不可用,但是V9版本还可以。如果有钱,可以直接上传。
由于采集的过程有点复杂且不易发布,有兴趣和不知道采集的朋友可以从此站点下载源代码,请查看源代码并复制并粘贴以进行浏览打开浏览器,一般步骤是打开优采云 采集器主界面-publish-new-content发布参数,然后在编写发布模块之后,开始查找目标电台并编写采集规则,最后采集发布。
这篇文章是由网民提供的,或者是由Jumawu在互联网上编写的。如果转载,请注明出处:;
如果在本网站上发布的内容侵犯了您的权利,请发送电子邮件至cnzz8#将其删除,我们将及时处理!
此站点上的大多数下载资源都采集在Internet上,并且不能保证其完整性和安全性。下载后请自己进行测试。
此网站上的资源仅用于学习和交流目的。版权属于资源的原创作者。请在下载后的24小时内有意识地删除它们。
出于商业目的,请购买正版。由于未能购买和付款而导致的侵权行为与本网站无关。
UI,小弟照抄了你们的风格]本程序API的功能特点
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-03-20 21:15
我专注于信息采集,即自动测试。去年,我做了一个微信公众号程序采集。下半年,微信对加密算法进行了升级,因此无法停止。
前一段时间,我偶尔在我们的平台上看到此文章,对此我感到非常鼓舞。因此,在将近半个月之后,我开发了一种新的采集算法。 Wunai以前的技能太差了,因此我不得不在其他基础上改进UI,并添加了许多功能。 [感谢您爱上了怪胎的用户界面,我的兄弟复制了您的风格]
该程序的API功能:
1.支持微信公众号和微信中文名输入
2.返回的内容有
微信现在是一个广泛使用和广泛使用的社交平台。它的微信公众平台也起着重要作用,许多公司和互联网公司都在使用它进行推广和共享。接下来的需求是采集其上要使用或阅读的内容。例如,通过微信帐户采集,可以阅读和采集由其发布的优秀文章或重新打印,以使更多的人学习和交流。
目前,由于微信归腾讯所有,因此古琦文章当然不允许外界爬行。获得文章的主要方法有两种:一、与腾讯合作并打开独立的界面。 二、通过腾讯搜狗搜索的微信搜索功能进行爬网。
本文介绍了一种易于实现的在线微信文章工具文章,该工具为文章 采集提供了一个指定的官方帐户,并批量获取了文章的标题和地址链接,并提供了第三个方API。使用和二次开发。
微信现在是一个广泛使用和广泛使用的社交平台。它的微信公众平台也起着重要作用,许多公司和互联网公司都在使用它进行推广和共享。接下来的需求是采集其上要使用或阅读的内容。例如,通过微信帐户采集,可以阅读和采集由其发布的优秀文章,或将其重新打印以供更多人学习和交流。
目前,由于微信归腾讯所有,因此古琦文章当然不允许外界爬行。
本文介绍了一种易于实现的在线微信文章工具文章,该工具为文章 采集提供了一个指定的官方帐户,并批量获取了文章的标题和地址链接,并提供了第三个方API。使用和二次开发。
在线使用
功能介绍
您无需登录即可获取微信官方帐户(订阅帐户)发布的所有文章标题和地址,并且结果可以JSON格式反馈并可以TABLE格式在线读取,并且可以使用外部API同时提供。
支持二次开发:每天自动获取最新的微信官方帐户文章,更新为自营微信官方帐户,论坛(DISCUZ,PHPWIND),博客(WORDPRESS),订阅信息(RSS)等。
使用方法
登录微信公众号提取网站
API使用率
以POST / GET形式提交微信公众号weixin和用户密钥,以JSON / JSONP形式返回数据
请求网址:
请求参数:wxID = {$ wxID}&key = {$ key}
返回数据:转到网站查看,此处不会发布任何代码
测试:采集《人民日报》微信官方帐户
网页显示示例:
API返回JSON的示例:+ iIR + 5Ab52dVh73DsX / XYLlT / kHU9LNL6F71o0yGcChSEq
注意:以上内容仅供研究使用,请勿将其用于非法目的。
[为了防止过度使用资源或不必要的麻烦,该页面具有一个临时KEY(有效期为2分钟,可以刷新并重新获得)。 ) 查看全部
UI,小弟照抄了你们的风格]本程序API的功能特点
我专注于信息采集,即自动测试。去年,我做了一个微信公众号程序采集。下半年,微信对加密算法进行了升级,因此无法停止。
前一段时间,我偶尔在我们的平台上看到此文章,对此我感到非常鼓舞。因此,在将近半个月之后,我开发了一种新的采集算法。 Wunai以前的技能太差了,因此我不得不在其他基础上改进UI,并添加了许多功能。 [感谢您爱上了怪胎的用户界面,我的兄弟复制了您的风格]
该程序的API功能:
1.支持微信公众号和微信中文名输入
2.返回的内容有
微信现在是一个广泛使用和广泛使用的社交平台。它的微信公众平台也起着重要作用,许多公司和互联网公司都在使用它进行推广和共享。接下来的需求是采集其上要使用或阅读的内容。例如,通过微信帐户采集,可以阅读和采集由其发布的优秀文章或重新打印,以使更多的人学习和交流。
目前,由于微信归腾讯所有,因此古琦文章当然不允许外界爬行。获得文章的主要方法有两种:一、与腾讯合作并打开独立的界面。 二、通过腾讯搜狗搜索的微信搜索功能进行爬网。
本文介绍了一种易于实现的在线微信文章工具文章,该工具为文章 采集提供了一个指定的官方帐户,并批量获取了文章的标题和地址链接,并提供了第三个方API。使用和二次开发。



微信现在是一个广泛使用和广泛使用的社交平台。它的微信公众平台也起着重要作用,许多公司和互联网公司都在使用它进行推广和共享。接下来的需求是采集其上要使用或阅读的内容。例如,通过微信帐户采集,可以阅读和采集由其发布的优秀文章,或将其重新打印以供更多人学习和交流。
目前,由于微信归腾讯所有,因此古琦文章当然不允许外界爬行。
本文介绍了一种易于实现的在线微信文章工具文章,该工具为文章 采集提供了一个指定的官方帐户,并批量获取了文章的标题和地址链接,并提供了第三个方API。使用和二次开发。
在线使用

功能介绍
您无需登录即可获取微信官方帐户(订阅帐户)发布的所有文章标题和地址,并且结果可以JSON格式反馈并可以TABLE格式在线读取,并且可以使用外部API同时提供。
支持二次开发:每天自动获取最新的微信官方帐户文章,更新为自营微信官方帐户,论坛(DISCUZ,PHPWIND),博客(WORDPRESS),订阅信息(RSS)等。
使用方法
登录微信公众号提取网站
API使用率
以POST / GET形式提交微信公众号weixin和用户密钥,以JSON / JSONP形式返回数据
请求网址:
请求参数:wxID = {$ wxID}&key = {$ key}
返回数据:转到网站查看,此处不会发布任何代码
测试:采集《人民日报》微信官方帐户
网页显示示例:
API返回JSON的示例:+ iIR + 5Ab52dVh73DsX / XYLlT / kHU9LNL6F71o0yGcChSEq
注意:以上内容仅供研究使用,请勿将其用于非法目的。
[为了防止过度使用资源或不必要的麻烦,该页面具有一个临时KEY(有效期为2分钟,可以刷新并重新获得)。 )
今日头条采集接入写作社API教程-优采云控制台如何使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 1293 次浏览 • 2021-01-17 12:11
优采云导航:优采云 采集优采云控制台如何使用优采云 SEO工具微信公众号文章采集今天的标题采集
访问写作机构API教程-优采云 采集
优采云 采集支持调用书写机构API接口来处理采集等的数据标题和内容;
提醒:第三方API访问功能需要优采云旗舰软件包来支持使用,并且用户需要提供第三方接口帐户信息(即,用户需要注册第三方界面,并且调用第三方界面所产生的所有费用均由用户承担);
请联系写作机构的客户服务(QQ:193650808)以购买写作机构API,并告知其已在优采云 采集平台上使用。
详细的使用步骤1.创建书写机构API接口配置I,API配置入口:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问] ==”单击[第三方API配置管理] ==“最后单击[编写Club_Rewrite接口API]创建接口配置;
II。配置API接口信息:
要购买写作机构的API,请联系写作机构的客户服务(QQ:193650808),并告知其已在优采云 采集平台上使用。
[API密钥],请联系写作机构的客户服务部门以获取相应的API密钥,并填写优采云;
注意:写作机构将每次调用的最大长度限制为6000个字符(包括html代码),因此,如果内容长度超出限制,则优采云将被分割并多次调用。此操作将增加api调用的次数和成本,也将相应增加。这是用户需要承担的费用。使用前请小心! ! !
2.创建API处理规则
API处理规则,可以将其设置为调用API接口以处理哪些字段的内容;
I。 API处理规则条目:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问权限] ==进入[API处理规则管理]页面,最后单击[添加API处理规则]创建API处理规则;
II,API处理规则配置:
注意:当API处理1个字段时,API接口将被调用一次,因此建议不要添加不需要的字段!
3.API处理规则的用法
使用API处理规则的方式有两种:手动执行和自动执行:
I。手动执行API处理规则:
在采集任务的[结果和发布]选项卡中,单击[SEO&API&翻译和其他工具]按钮==“选择[第三方API执行]列==”选择相应的API处理规则==“执行(数据范围有两种执行方法,根据发布状态批量执行和根据列表中选择的数据执行);
II。自动执行API处理规则:
启用API处理的自动执行。任务完成采集后,API处理将自动执行。定时采集和自动发布功能通常很方便;
在任务的[自动化:发布和SEO和翻译]选项卡中,[自动执行第三方API配置] ==“选中[采集,自动执行API]选项==”选择要执行的API处理==“选择由API接口处理的数据范围(通常选择”要发布“,所有将导致所有数据被执行多次),最后单击保存;
4.API处理结果和发布,查看API接口处理结果:
API接口处理的内容将另存为新字段,例如:
可以在[结果数据和发布]和数据预览界面中查看它。
提醒:执行API处理规则需要花费一些时间。执行后,页面将自动刷新,并在API接口处理后显示新字段;
II,API接口处理后的内容发布
发布文章之前,请在发布目标的第二步中修改映射字段,并在经过API接口处理后将标题和内容更改为新的对应字段title_写作俱乐部和content_写作俱乐部;
提醒:如果无法在发布目标中选择新字段,请在此任务下复制或创建新的发布目标,然后可以在新发布目标中选择新字段。可以查看详细的教程;
5.编写代理程序-API接口的常见问题和解决方法I,如何一起使用API处理规则和SEO规则?
系统默认对标题和内容字段执行SEO功能,需要将其修改为SEO规则中的title_写作俱乐部和content_写作俱乐部字段;
优采云导航:优采云 采集优采云控制台如何使用优采云 SEO工具微信公众号文章采集今天的标题采集 查看全部
今日头条采集接入写作社API教程-优采云控制台如何使用
优采云导航:优采云 采集优采云控制台如何使用优采云 SEO工具微信公众号文章采集今天的标题采集
访问写作机构API教程-优采云 采集
优采云 采集支持调用书写机构API接口来处理采集等的数据标题和内容;
提醒:第三方API访问功能需要优采云旗舰软件包来支持使用,并且用户需要提供第三方接口帐户信息(即,用户需要注册第三方界面,并且调用第三方界面所产生的所有费用均由用户承担);
请联系写作机构的客户服务(QQ:193650808)以购买写作机构API,并告知其已在优采云 采集平台上使用。
详细的使用步骤1.创建书写机构API接口配置I,API配置入口:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问] ==”单击[第三方API配置管理] ==“最后单击[编写Club_Rewrite接口API]创建接口配置;

II。配置API接口信息:
要购买写作机构的API,请联系写作机构的客户服务(QQ:193650808),并告知其已在优采云 采集平台上使用。
[API密钥],请联系写作机构的客户服务部门以获取相应的API密钥,并填写优采云;

注意:写作机构将每次调用的最大长度限制为6000个字符(包括html代码),因此,如果内容长度超出限制,则优采云将被分割并多次调用。此操作将增加api调用的次数和成本,也将相应增加。这是用户需要承担的费用。使用前请小心! ! !
2.创建API处理规则
API处理规则,可以将其设置为调用API接口以处理哪些字段的内容;
I。 API处理规则条目:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问权限] ==进入[API处理规则管理]页面,最后单击[添加API处理规则]创建API处理规则;

II,API处理规则配置:

注意:当API处理1个字段时,API接口将被调用一次,因此建议不要添加不需要的字段!
3.API处理规则的用法
使用API处理规则的方式有两种:手动执行和自动执行:
I。手动执行API处理规则:
在采集任务的[结果和发布]选项卡中,单击[SEO&API&翻译和其他工具]按钮==“选择[第三方API执行]列==”选择相应的API处理规则==“执行(数据范围有两种执行方法,根据发布状态批量执行和根据列表中选择的数据执行);

II。自动执行API处理规则:

启用API处理的自动执行。任务完成采集后,API处理将自动执行。定时采集和自动发布功能通常很方便;
在任务的[自动化:发布和SEO和翻译]选项卡中,[自动执行第三方API配置] ==“选中[采集,自动执行API]选项==”选择要执行的API处理==“选择由API接口处理的数据范围(通常选择”要发布“,所有将导致所有数据被执行多次),最后单击保存;
4.API处理结果和发布,查看API接口处理结果:
API接口处理的内容将另存为新字段,例如:
可以在[结果数据和发布]和数据预览界面中查看它。

提醒:执行API处理规则需要花费一些时间。执行后,页面将自动刷新,并在API接口处理后显示新字段;
II,API接口处理后的内容发布
发布文章之前,请在发布目标的第二步中修改映射字段,并在经过API接口处理后将标题和内容更改为新的对应字段title_写作俱乐部和content_写作俱乐部;

提醒:如果无法在发布目标中选择新字段,请在此任务下复制或创建新的发布目标,然后可以在新发布目标中选择新字段。可以查看详细的教程;
5.编写代理程序-API接口的常见问题和解决方法I,如何一起使用API处理规则和SEO规则?
系统默认对标题和内容字段执行SEO功能,需要将其修改为SEO规则中的title_写作俱乐部和content_写作俱乐部字段;

优采云导航:优采云 采集优采云控制台如何使用优采云 SEO工具微信公众号文章采集今天的标题采集
技术文章:博易网API接口_免费接口源码_自动采集_php接口网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 329 次浏览 • 2021-01-16 09:01
本网站提供的“ Boyiwang API interface_free接口源代码_auto采集_php接口网站”资源来自Internet。版权纠纷与本网站无关,版权属于原创的所有者!它仅用于学习和研究目的,并且以上内容资源不得用于商业或非法目的。否则,用户应对所有后果负责。
1.本网站上的所有内容均从Internet采集并由网民上传,仅供您参考和学习。没有商业目的或商业用途。
2.如果您需要商业运作或其他商业活动,请购买正版许可证并合法使用。
3.如果您也有不错的源代码或教程,则可以将其发布在审阅区域中,并分享奖励和额外收入!
4.不能保证所有资源都是完整的和可用的,也不排除BUG或不完整的可能性。由于资源的特殊性,下载后将不会将其退回。
5.魔方资源网不提供任何技术支持和安装服务,请您自己评估。
6.如果存在无法下载,无效或带有广告的链接,请联系客服QQ:3420634106尽快为您处理!
7.本网站上的所有资源均不收费。用户只需要登录并登录即可获取相应的魔币,以交换学习和参考。所有会员费网站均用于网站运营和维护成本,与资源无关!
8.如果遇到加密的压缩包,则默认的解压缩密码为“或”,如果无法解压缩,请与管理员联系!
9.如果链接失败或侵犯版权,请首先与我们联系。点击这里给我发消息 查看全部
技术文章:博易网API接口_免费接口源码_自动采集_php接口网站
本网站提供的“ Boyiwang API interface_free接口源代码_auto采集_php接口网站”资源来自Internet。版权纠纷与本网站无关,版权属于原创的所有者!它仅用于学习和研究目的,并且以上内容资源不得用于商业或非法目的。否则,用户应对所有后果负责。
1.本网站上的所有内容均从Internet采集并由网民上传,仅供您参考和学习。没有商业目的或商业用途。
2.如果您需要商业运作或其他商业活动,请购买正版许可证并合法使用。
3.如果您也有不错的源代码或教程,则可以将其发布在审阅区域中,并分享奖励和额外收入!
4.不能保证所有资源都是完整的和可用的,也不排除BUG或不完整的可能性。由于资源的特殊性,下载后将不会将其退回。
5.魔方资源网不提供任何技术支持和安装服务,请您自己评估。
6.如果存在无法下载,无效或带有广告的链接,请联系客服QQ:3420634106尽快为您处理!
7.本网站上的所有资源均不收费。用户只需要登录并登录即可获取相应的魔币,以交换学习和参考。所有会员费网站均用于网站运营和维护成本,与资源无关!
8.如果遇到加密的压缩包,则默认的解压缩密码为“或”,如果无法解压缩,请与管理员联系!
9.如果链接失败或侵犯版权,请首先与我们联系。点击这里给我发消息
汇总:数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2021-01-13 11:10
数据采集
智能云采集器基于自行开发的分布式数据采集引擎,涵盖全球30,000网站平台和500个移动应用程序。各行各业的企业可以利用自身的优势和想象力,使用丰富多样的数据来开发自己的大数据应用程序。通过调用标准的Internet数据接口来完成数据采集的工作,颠覆了传统的Internet数据捕获方法,解决了数据清理麻烦,爬虫维护麻烦等问题
目前,每天超过500万家酒店的500万家互联网新闻文章,1500万个FB用户动态信息,1000万个微博帖子,5000万个商业数据信息以及1000万种房型都在不断更新,从而领先于世界数据采集能力
数据融合
在采集的过程中,大数据将在相同类型的不同平台上遇到数据结构的不一致。 99API智能数据融合,在采集过程中,根据采集平台的类型,选择合适的预定义数据结构进行适配,实现同类型平台的智能异构集成,规范数据结构,大大减少了底层数据,提高了客户清理数据的难度,促进了系统对接和开发人员程序对接
数据分析
通过Hadoop,Spark,TensorFlow和其他数据分析和挖掘框架,为大数据操作提供技术支持。实现数据统计分析,提供多种高级统计分析模型,可根据需要进行复杂的高级统计,并可以多层次,多角度显示数据,支持数据分析的可视化。基于独立知识产权的算法模型实现了文本挖掘的各种功能,包括Internet上非结构化文本数据的结构化处理,实体,关键词,主题,情感倾向和文章类别的智能提取。 ,准确率超过90%
数据管理
在当前流行的EFK(Elasticsearch,Filebeat,Kibana)的基础上,实现数据管理和监控,Internet大数据的分布式存储,提高容错性和并发性,并且适合于Internet异构大数据的集成,即将数据存储到统一JSON(JavaScript对象表示法)中。 JSON是一种标准化,轻量级且Internet通用的数据交换格式。同时实现了数据日志的可视化监控和7 * 24小时的数据监控 查看全部
汇总:数据采集

数据采集
智能云采集器基于自行开发的分布式数据采集引擎,涵盖全球30,000网站平台和500个移动应用程序。各行各业的企业可以利用自身的优势和想象力,使用丰富多样的数据来开发自己的大数据应用程序。通过调用标准的Internet数据接口来完成数据采集的工作,颠覆了传统的Internet数据捕获方法,解决了数据清理麻烦,爬虫维护麻烦等问题
目前,每天超过500万家酒店的500万家互联网新闻文章,1500万个FB用户动态信息,1000万个微博帖子,5000万个商业数据信息以及1000万种房型都在不断更新,从而领先于世界数据采集能力

数据融合
在采集的过程中,大数据将在相同类型的不同平台上遇到数据结构的不一致。 99API智能数据融合,在采集过程中,根据采集平台的类型,选择合适的预定义数据结构进行适配,实现同类型平台的智能异构集成,规范数据结构,大大减少了底层数据,提高了客户清理数据的难度,促进了系统对接和开发人员程序对接

数据分析
通过Hadoop,Spark,TensorFlow和其他数据分析和挖掘框架,为大数据操作提供技术支持。实现数据统计分析,提供多种高级统计分析模型,可根据需要进行复杂的高级统计,并可以多层次,多角度显示数据,支持数据分析的可视化。基于独立知识产权的算法模型实现了文本挖掘的各种功能,包括Internet上非结构化文本数据的结构化处理,实体,关键词,主题,情感倾向和文章类别的智能提取。 ,准确率超过90%

数据管理
在当前流行的EFK(Elasticsearch,Filebeat,Kibana)的基础上,实现数据管理和监控,Internet大数据的分布式存储,提高容错性和并发性,并且适合于Internet异构大数据的集成,即将数据存储到统一JSON(JavaScript对象表示法)中。 JSON是一种标准化,轻量级且Internet通用的数据交换格式。同时实现了数据日志的可视化监控和7 * 24小时的数据监控
解密:基于Python采集爬取微信公众号历史数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 589 次浏览 • 2020-12-27 10:12
基于Python抓取微信公众号的历史数据采集
更新时间:2020年11月27日09:22:47作者:Tempo父亲
本文文章主要介绍了基于Python 采集的微信公众号历史数据的抓取。本文介绍的示例代码非常详细。它对每个人的学习或工作都有一定的参考学习价值。需要它的朋友可以参考
Kun Zhipeng的技术人员将在本文中介绍一种通过操作微信应用程序采集模拟官方帐户的所有历史数据的方法。
通过数据包捕获分析,我们发现微信公众号的历史数据是通过HTTP协议加载的。相应的API接口如下图所示,它具有四个关键参数(__biz,appmsg_token,pass_ticket和Cookie)。
为了能够获得这四个参数,我们需要模拟App的操作,让其生成这些参数,然后捕获数据包。对于模拟的App操作,我们介绍了通过Python模拟Android App的方法(请参阅详细信息)。对于HTTP集成捕获,我们之前已经引入了Mitmproxy(请参阅详细信息)。
我们需要模拟微信的操作以完成以下步骤:
1.启动微信应用程序
2.点击“联系人”
3.点击“官方帐户”
4.单击官方帐户以采集
5.单击右上角的用户图片图标
6.单击“所有消息”
这时,我们可以从响应数据以及请求标头中的Cookie值中捕获__biz,appmsg_token和pass_ticket的三个关键参数。如下所示。
使用上述四个参数,我们可以构造一个API请求以获取历史记录文章列表,并通过调用API接口直接获取数据(无需模拟App操作)。核心参数如下。通过更改offset参数,您可以获得所有历史数据。
# Cookie
headers = {'Cookie': 'rewardsn=; wxtokenkey=777; wxuin=584068438; devicetype=android-19; version=26060736; lang=zh_CN; pass_ticket=Rr8cO5c2******3tKGqe7aVZzV9TupvrK+1uHHmHYQGL2WFdKIE; wap_sid2=COKhxu4KElxckFZQ3QzTHU4WThEUk0zcWdrZjhGcUdYdEVSV3Y1X2NPWHNUakRrd1ZzMnpLTERpdE5rbmxjSTg******dlRBcUNRazZpOGxTZUVEQUTgNQJVO'}
url = 'https://mp.weixin.qq.com/mp/profile_ext?'
data = {}
data['is_ok'] = '1'
data['count'] = '10'
data['wxtoken'] = ''
data['f'] = 'json'
data['scene'] = '124'
data['uin'] = '777'
data['key'] = '777'
data['offset'] = '0'
data['action'] = 'getmsg'
data['x5'] = '0'
# 下面三个参数需要替换
# https://mp.weixin.qq.com/mp/pr ... Dhome应答数据里会暴漏这三个参数
data['__biz'] = 'MjM5MzQyOTM1OQ=='
data['appmsg_token'] = '993_V8%2BEmfVD7g%2FvMZ****4DNUJNFkg~~'
data['pass_ticket'] = 'Rr8cO5c23ZngeQHRGy8E7gv*****pvrK+1uHHmHYQGL2WFdKIE'
url = url + urllib.urlencode(data)
以“数字工厂”的微信公众号为例,采集过程操作的截图如下:
输出结果的屏幕截图如下:
以上是本文的全部内容,希望对大家的学习有所帮助,并希望您能更多地支持Scripthome。 查看全部
解密:基于Python采集爬取微信公众号历史数据
基于Python抓取微信公众号的历史数据采集
更新时间:2020年11月27日09:22:47作者:Tempo父亲
本文文章主要介绍了基于Python 采集的微信公众号历史数据的抓取。本文介绍的示例代码非常详细。它对每个人的学习或工作都有一定的参考学习价值。需要它的朋友可以参考
Kun Zhipeng的技术人员将在本文中介绍一种通过操作微信应用程序采集模拟官方帐户的所有历史数据的方法。
通过数据包捕获分析,我们发现微信公众号的历史数据是通过HTTP协议加载的。相应的API接口如下图所示,它具有四个关键参数(__biz,appmsg_token,pass_ticket和Cookie)。

为了能够获得这四个参数,我们需要模拟App的操作,让其生成这些参数,然后捕获数据包。对于模拟的App操作,我们介绍了通过Python模拟Android App的方法(请参阅详细信息)。对于HTTP集成捕获,我们之前已经引入了Mitmproxy(请参阅详细信息)。
我们需要模拟微信的操作以完成以下步骤:
1.启动微信应用程序
2.点击“联系人”
3.点击“官方帐户”
4.单击官方帐户以采集
5.单击右上角的用户图片图标
6.单击“所有消息”


这时,我们可以从响应数据以及请求标头中的Cookie值中捕获__biz,appmsg_token和pass_ticket的三个关键参数。如下所示。



使用上述四个参数,我们可以构造一个API请求以获取历史记录文章列表,并通过调用API接口直接获取数据(无需模拟App操作)。核心参数如下。通过更改offset参数,您可以获得所有历史数据。
# Cookie
headers = {'Cookie': 'rewardsn=; wxtokenkey=777; wxuin=584068438; devicetype=android-19; version=26060736; lang=zh_CN; pass_ticket=Rr8cO5c2******3tKGqe7aVZzV9TupvrK+1uHHmHYQGL2WFdKIE; wap_sid2=COKhxu4KElxckFZQ3QzTHU4WThEUk0zcWdrZjhGcUdYdEVSV3Y1X2NPWHNUakRrd1ZzMnpLTERpdE5rbmxjSTg******dlRBcUNRazZpOGxTZUVEQUTgNQJVO'}
url = 'https://mp.weixin.qq.com/mp/profile_ext?'
data = {}
data['is_ok'] = '1'
data['count'] = '10'
data['wxtoken'] = ''
data['f'] = 'json'
data['scene'] = '124'
data['uin'] = '777'
data['key'] = '777'
data['offset'] = '0'
data['action'] = 'getmsg'
data['x5'] = '0'
# 下面三个参数需要替换
# https://mp.weixin.qq.com/mp/pr ... Dhome应答数据里会暴漏这三个参数
data['__biz'] = 'MjM5MzQyOTM1OQ=='
data['appmsg_token'] = '993_V8%2BEmfVD7g%2FvMZ****4DNUJNFkg~~'
data['pass_ticket'] = 'Rr8cO5c23ZngeQHRGy8E7gv*****pvrK+1uHHmHYQGL2WFdKIE'
url = url + urllib.urlencode(data)
以“数字工厂”的微信公众号为例,采集过程操作的截图如下:

输出结果的屏幕截图如下:

以上是本文的全部内容,希望对大家的学习有所帮助,并希望您能更多地支持Scripthome。
干货教程:优采云采集接入写作社API详细教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 305 次浏览 • 2020-12-20 09:13
优采云采集支持调用书写机构API接口来处理采集等的数据标题和内容;
详细步骤如下:
1.创建书写代理商API接口配置I,API配置入口:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问权限] ==”单击[第三方API配置管理] ==“最后,单击[Writing Club_Rewrite接口API]创建接口配置;
II。配置API接口信息:
要购买写作机构的API,请联系写作机构的客户服务并告知其已在优采云采集平台上使用。
[API密钥],请联系写作机构的客户服务部门以获取相应的API密钥,并填写优采云;
注意:写作机构将每次调用的最大长度限制为6000个字符(包括html代码),因此,如果内容长度超出限制,则优采云将被分割并多次调用。此操作将增加api调用的次数和成本,也将相应增加。这是用户需要承担的费用。使用前请小心! ! !
2.创建API处理规则
API处理规则,可以将其设置为调用API接口以处理哪些字段的内容;
I。 API处理规则条目:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问] ==”,进入[API处理规则管理]页面,最后单击[添加API处理规则]创建API处理规则;
II,API处理规则配置:
规则名称:用户可以自己命名;
字段名称:填充的字段名称的内容将由API接口处理。默认为标题和内容字段,可以对其进行修改,添加或删除;
使用的API:选择已设置的API接口配置,执行时将调用该接口,并且可以为多个字段选择不同的API接口配置;
处理顺序:执行顺序是按从小到大的顺序执行的;
3.API处理规则的用法
使用API处理规则的方式有两种:手动执行和自动执行:
手动执行:在采集数据之后,使用第三方API在[结果数据和发布]中执行;
自动执行:配置自动化后,完成任务采集数据后,系统将自动执行指定的API处理规则,而无需人工操作。
I。手动执行API处理规则:
在采集任务的[结果数据和发布]选项卡中单击[SEO&API&翻译和其他工具]按钮==“选择[第三方API执行]列==”选择相应的API处理规则==“执行(数据范围有两种执行方法,根据发布状态批量执行和根据列表中选择的数据执行);
II。自动执行API处理规则:
启用API处理的自动执行。任务完成采集后,API处理将自动执行。定时采集和自动发布功能通常很方便;
在任务的[自动化:发布和SEO和翻译]选项卡中,[自动执行第三方API配置] ==“选中[采集,自动执行API]选项==”选择要执行的API处理规则==“选择由API接口处理的数据范围(通常选择”要发布“,所有将导致所有数据被多次执行),最后单击保存;
4.API处理结果和发布,查看API接口处理结果:
API接口处理的内容将另存为新字段,例如:
在标题处理后添加新字段:title_写作俱乐部
在内容处理后添加新字段:content_ Writing club
可以在[结果数据和发布]和数据预览界面中查看它。
提醒:API处理规则需要一段时间才能执行。执行后,页面将自动刷新,并显示由API界面处理的新字段;
II,API接口处理后的内容发布
发布文章之前,请在发布目标的第二步中修改映射字段,并在经过API接口处理后将标题和内容更改为新的对应字段title_写作俱乐部和content_写作俱乐部;
提醒:如果无法在发布目标中选择新字段,请在此任务下复制或创建新的发布目标,然后可以在新发布目标中选择新字段。对于详细的教程,您可以查看发布目标无法选择的字段;
5.编写Club-API接口常见问题和解决方法
I。如何同时使用API处理规则和SEO规则?
系统默认对标题和内容字段执行SEO功能,需要将其修改为SEO规则中的title_写作俱乐部和content_写作俱乐部字段;
查看全部
干货教程:优采云采集接入写作社API详细教程
优采云采集支持调用书写机构API接口来处理采集等的数据标题和内容;
详细步骤如下:
1.创建书写代理商API接口配置I,API配置入口:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问权限] ==”单击[第三方API配置管理] ==“最后,单击[Writing Club_Rewrite接口API]创建接口配置;

II。配置API接口信息:
要购买写作机构的API,请联系写作机构的客户服务并告知其已在优采云采集平台上使用。
[API密钥],请联系写作机构的客户服务部门以获取相应的API密钥,并填写优采云;

注意:写作机构将每次调用的最大长度限制为6000个字符(包括html代码),因此,如果内容长度超出限制,则优采云将被分割并多次调用。此操作将增加api调用的次数和成本,也将相应增加。这是用户需要承担的费用。使用前请小心! ! !
2.创建API处理规则
API处理规则,可以将其设置为调用API接口以处理哪些字段的内容;
I。 API处理规则条目:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问] ==”,进入[API处理规则管理]页面,最后单击[添加API处理规则]创建API处理规则;

II,API处理规则配置:

规则名称:用户可以自己命名;
字段名称:填充的字段名称的内容将由API接口处理。默认为标题和内容字段,可以对其进行修改,添加或删除;
使用的API:选择已设置的API接口配置,执行时将调用该接口,并且可以为多个字段选择不同的API接口配置;
处理顺序:执行顺序是按从小到大的顺序执行的;
3.API处理规则的用法
使用API处理规则的方式有两种:手动执行和自动执行:
手动执行:在采集数据之后,使用第三方API在[结果数据和发布]中执行;
自动执行:配置自动化后,完成任务采集数据后,系统将自动执行指定的API处理规则,而无需人工操作。
I。手动执行API处理规则:
在采集任务的[结果数据和发布]选项卡中单击[SEO&API&翻译和其他工具]按钮==“选择[第三方API执行]列==”选择相应的API处理规则==“执行(数据范围有两种执行方法,根据发布状态批量执行和根据列表中选择的数据执行);

II。自动执行API处理规则:

启用API处理的自动执行。任务完成采集后,API处理将自动执行。定时采集和自动发布功能通常很方便;
在任务的[自动化:发布和SEO和翻译]选项卡中,[自动执行第三方API配置] ==“选中[采集,自动执行API]选项==”选择要执行的API处理规则==“选择由API接口处理的数据范围(通常选择”要发布“,所有将导致所有数据被多次执行),最后单击保存;
4.API处理结果和发布,查看API接口处理结果:
API接口处理的内容将另存为新字段,例如:
在标题处理后添加新字段:title_写作俱乐部
在内容处理后添加新字段:content_ Writing club
可以在[结果数据和发布]和数据预览界面中查看它。

提醒:API处理规则需要一段时间才能执行。执行后,页面将自动刷新,并显示由API界面处理的新字段;
II,API接口处理后的内容发布
发布文章之前,请在发布目标的第二步中修改映射字段,并在经过API接口处理后将标题和内容更改为新的对应字段title_写作俱乐部和content_写作俱乐部;

提醒:如果无法在发布目标中选择新字段,请在此任务下复制或创建新的发布目标,然后可以在新发布目标中选择新字段。对于详细的教程,您可以查看发布目标无法选择的字段;
5.编写Club-API接口常见问题和解决方法
I。如何同时使用API处理规则和SEO规则?
系统默认对标题和内容字段执行SEO功能,需要将其修改为SEO规则中的title_写作俱乐部和content_写作俱乐部字段;

解决方案:优采云采集接入写作社API详细教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 290 次浏览 • 2020-12-19 10:19
优采云采集支持调用书写机构API接口来处理采集,关键词,描述等的数据标题和内容。可以通过优采云采集的SEO功能来定位]和写作机构API来处理原创程度更高的文章,这对于增加文章的收录和网站的权重具有非常重要的作用。
详细的使用步骤
1.创建书写代理商API接口配置
I。 API配置入口:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问权限] ==”单击[第三方API配置管理] ==“最后,单击[Writing Club_Rewrite接口API]创建接口配置;
II。配置API接口信息:
要购买写作机构的API,请联系写作机构的客户服务并告知其已在优采云采集平台上使用。
[API密钥],请联系写作机构的客户服务部门以获取相应的API密钥,并填写优采云;
2.创建API处理规则
API处理规则,可以将其设置为调用API接口以处理哪些字段的内容;
I。 API处理规则条目:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问] ==”,进入[API处理规则管理]页面,最后单击[添加API处理规则]创建API处理规则;
II,API处理规则配置:
3.API处理规则的用法
使用API处理规则的方式有两种:手动执行和自动执行:
I。手动执行API处理规则:
在采集任务的[结果数据和发布]选项卡中单击[SEO&API&翻译和其他工具]按钮==“选择[第三方API执行]列==”选择相应的API处理规则==“执行(数据范围有两种执行方法,根据发布状态批量执行和根据列表中选择的数据执行);
II。自动执行API处理规则:
启用API处理的自动执行。任务完成采集后,API处理将自动执行。定时采集和自动发布功能通常很方便;
在任务的[自动化:发布和SEO和翻译]选项卡中,[自动执行第三方API配置] ==“选中[采集,自动执行API]选项==”选择要执行的API处理规则==“选择由API接口处理的数据范围(通常选择”要发布“,所有将导致所有数据被多次执行),最后单击保存;
4.API处理结果和发布
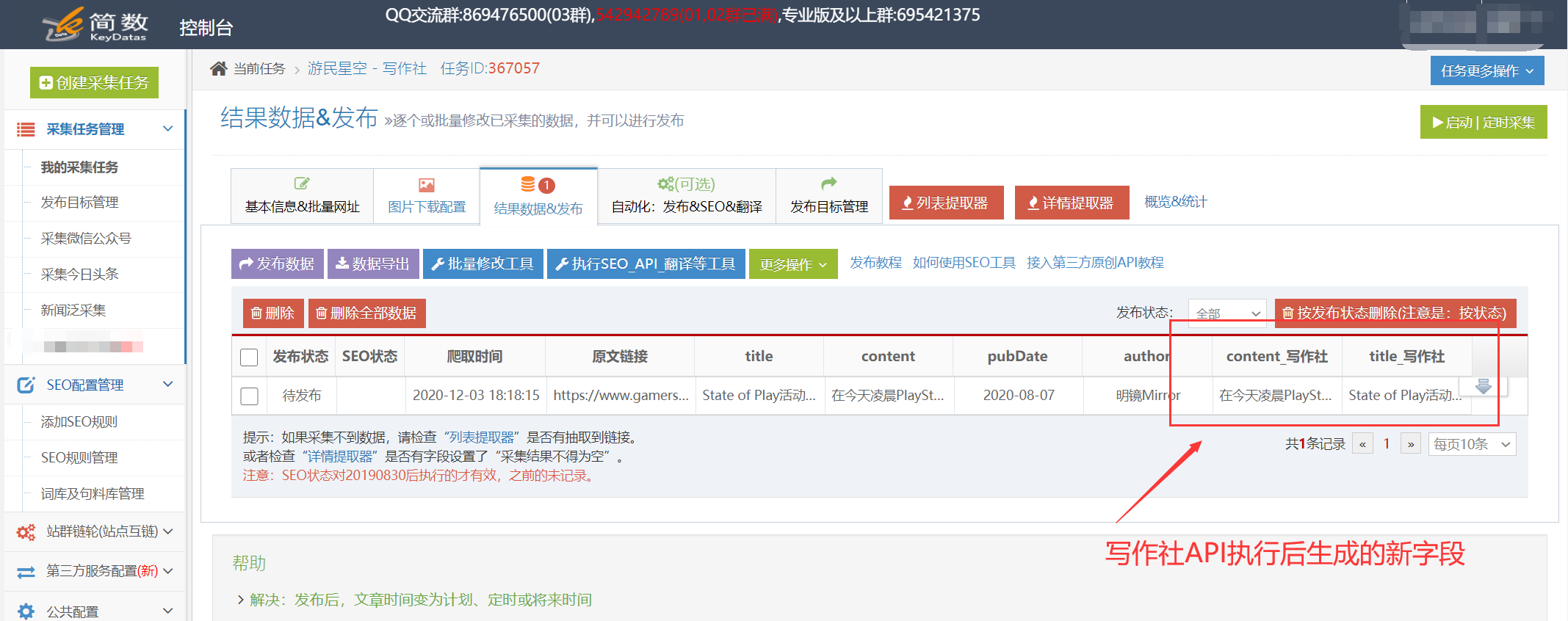
I。查看API接口处理的结果:
API接口处理的内容将另存为新字段,例如:
可以在[结果数据和发布]和数据预览界面中查看它。
提醒:API处理规则需要一段时间才能执行。执行后,页面将自动刷新,并显示由API界面处理的新字段;
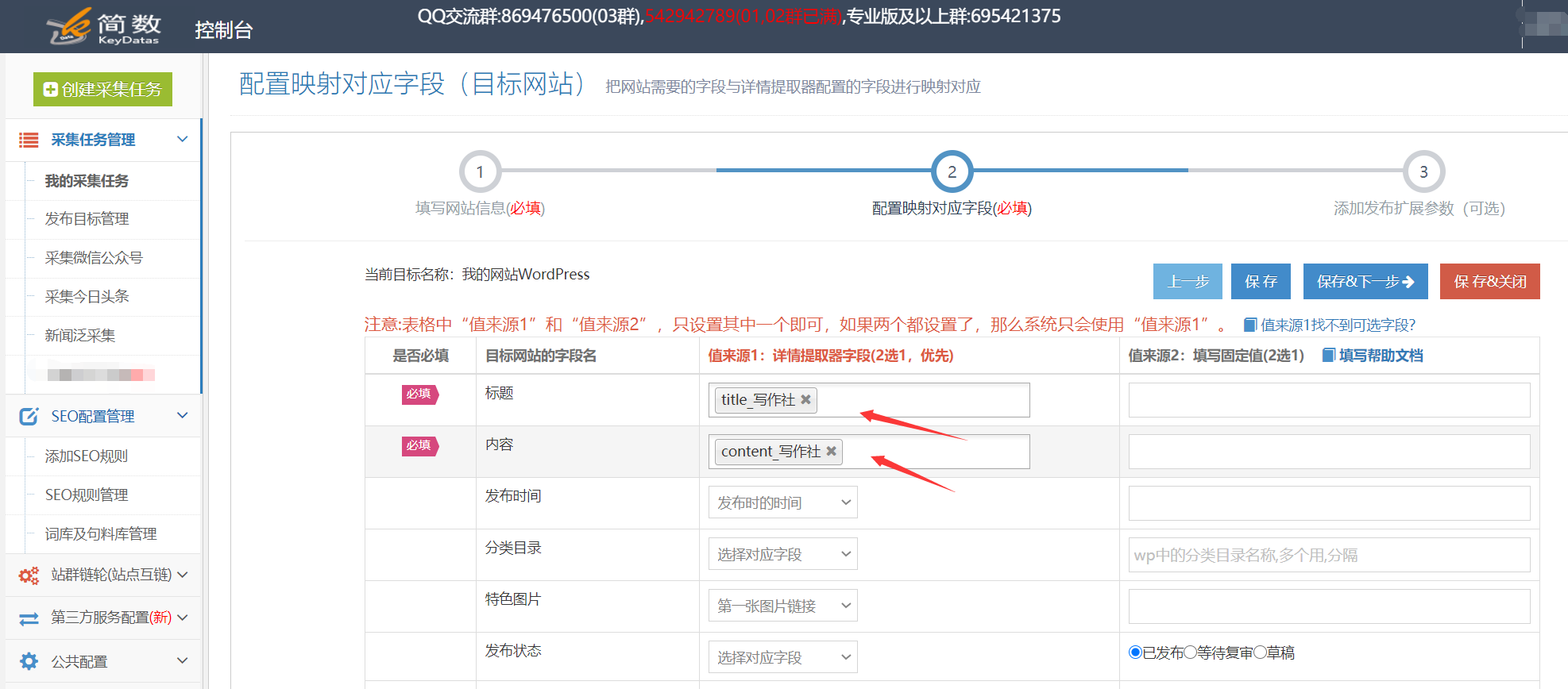
II,API接口处理后的内容发布
发布文章之前,请在发布目标的第二步中修改映射字段,并在经过API接口处理后将标题和内容更改为新的对应字段title_写作俱乐部和content_写作俱乐部;
提醒:如果无法在发布目标中选择新字段,请在此任务下复制或创建新的发布目标,然后可以在新发布目标中选择新字段。可以查看详细的教程;
5.编写Club-API接口常见问题和解决方法
I。如何同时使用API处理规则和SEO规则?
系统默认对标题和内容字段执行SEO功能,需要将其修改为SEO规则中的title_写作俱乐部和content_写作俱乐部字段;
查看全部
解决方案:优采云采集接入写作社API详细教程
优采云采集支持调用书写机构API接口来处理采集,关键词,描述等的数据标题和内容。可以通过优采云采集的SEO功能来定位]和写作机构API来处理原创程度更高的文章,这对于增加文章的收录和网站的权重具有非常重要的作用。
详细的使用步骤
1.创建书写代理商API接口配置
I。 API配置入口:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问权限] ==”单击[第三方API配置管理] ==“最后,单击[Writing Club_Rewrite接口API]创建接口配置;
II。配置API接口信息:
要购买写作机构的API,请联系写作机构的客户服务并告知其已在优采云采集平台上使用。
[API密钥],请联系写作机构的客户服务部门以获取相应的API密钥,并填写优采云;
2.创建API处理规则
API处理规则,可以将其设置为调用API接口以处理哪些字段的内容;
I。 API处理规则条目:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问] ==”,进入[API处理规则管理]页面,最后单击[添加API处理规则]创建API处理规则;
II,API处理规则配置:
3.API处理规则的用法
使用API处理规则的方式有两种:手动执行和自动执行:
I。手动执行API处理规则:
在采集任务的[结果数据和发布]选项卡中单击[SEO&API&翻译和其他工具]按钮==“选择[第三方API执行]列==”选择相应的API处理规则==“执行(数据范围有两种执行方法,根据发布状态批量执行和根据列表中选择的数据执行);
II。自动执行API处理规则:
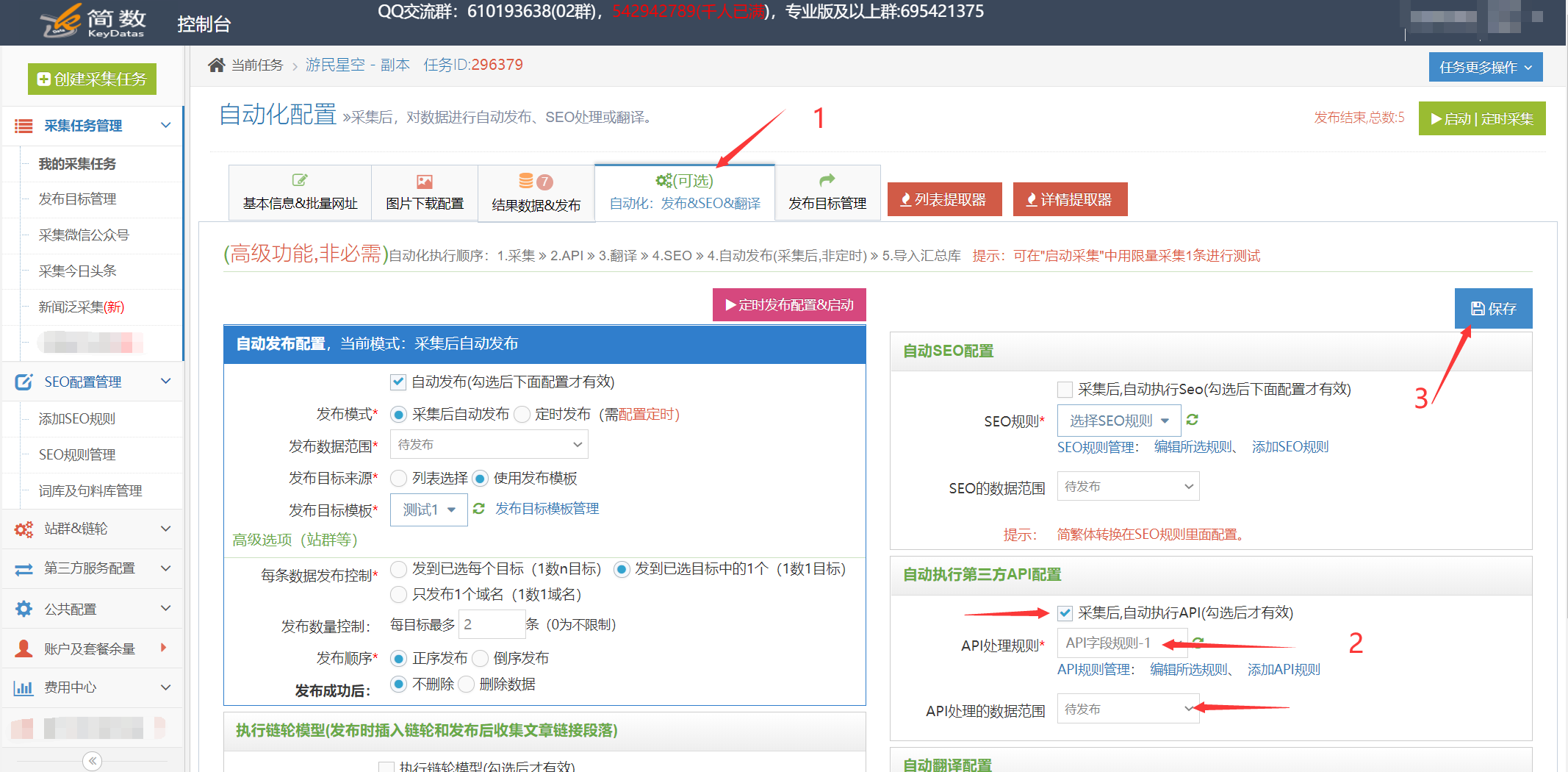
启用API处理的自动执行。任务完成采集后,API处理将自动执行。定时采集和自动发布功能通常很方便;
在任务的[自动化:发布和SEO和翻译]选项卡中,[自动执行第三方API配置] ==“选中[采集,自动执行API]选项==”选择要执行的API处理规则==“选择由API接口处理的数据范围(通常选择”要发布“,所有将导致所有数据被多次执行),最后单击保存;
4.API处理结果和发布
I。查看API接口处理的结果:
API接口处理的内容将另存为新字段,例如:
可以在[结果数据和发布]和数据预览界面中查看它。
提醒:API处理规则需要一段时间才能执行。执行后,页面将自动刷新,并显示由API界面处理的新字段;
II,API接口处理后的内容发布
发布文章之前,请在发布目标的第二步中修改映射字段,并在经过API接口处理后将标题和内容更改为新的对应字段title_写作俱乐部和content_写作俱乐部;
提醒:如果无法在发布目标中选择新字段,请在此任务下复制或创建新的发布目标,然后可以在新发布目标中选择新字段。可以查看详细的教程;
5.编写Club-API接口常见问题和解决方法
I。如何同时使用API处理规则和SEO规则?
系统默认对标题和内容字段执行SEO功能,需要将其修改为SEO规则中的title_写作俱乐部和content_写作俱乐部字段;
开源免费小鹦苈画CMS漫画连载系统源码带采集API资源
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-08-04 18:50
[资源属性]:
资源名称:开源免费小鹦鹉绘画cms漫画系列系统源码 with采集API
资源大小:5.2MB
资源类别:源码下载》php源码
更新时间:2021-07-05
资源语言:简体中文
授权方式:免费下载
使用平台:Windows/Linux/Mac
资源介绍:
最近想开个漫画站玩玩,找了个不错的系统小平花华cms,开源免费,基于ThinkPHP5.1和Redis缓存,自带优采云api方便我们采集Release,功能我就不多说了,大家可以看下面的截图,几乎漫画系统都差不多。作者也在积极更新中,看来是打算加入会员系统等功能了,就贴在这里吧。
环境要求:PHP5.6-7.2、MySQL >=5.7、Redis,Redis扩展
这里是一个简单的路线,使用宝塔面板进行演示
宝塔安装好后,进入面板,点击左边的软件管理,然后安装PHP7.2、Nginx,Mysql5.7+,Redis。
2、installer
我们先点击左边的网站,添加网站!这个不用我教!!!
如果不能,请稍后观看我的视频教程!!!
设置伪静态
点击域名设置-网站目录,运行目录选择public,去掉反跨站勾选,重启PHP。
一般情况下,漫画中的图片资源有两种,一种是本地化,一种是盗链。建议对图片进行本地化,这样可以保证网站resources的稳定性,同时程序还提供了优采云采集器的API可以方便的连接优采云采集器进行漫画和章节图片采集。
首先我们需要一个优采云采集器,但是它分为免费版和付费版,但是免费版由于一些功能限制不能满足图片本地化的需要,所以暂时不适用有钱可以买付费版,没钱可以直接用优采云V7.6企业破解版,大概是最新的破解版,也可以满足采集程序需求 查看全部
开源免费小鹦苈画CMS漫画连载系统源码带采集API资源
[资源属性]:
资源名称:开源免费小鹦鹉绘画cms漫画系列系统源码 with采集API
资源大小:5.2MB
资源类别:源码下载》php源码
更新时间:2021-07-05
资源语言:简体中文
授权方式:免费下载
使用平台:Windows/Linux/Mac
资源介绍:
最近想开个漫画站玩玩,找了个不错的系统小平花华cms,开源免费,基于ThinkPHP5.1和Redis缓存,自带优采云api方便我们采集Release,功能我就不多说了,大家可以看下面的截图,几乎漫画系统都差不多。作者也在积极更新中,看来是打算加入会员系统等功能了,就贴在这里吧。
环境要求:PHP5.6-7.2、MySQL >=5.7、Redis,Redis扩展
这里是一个简单的路线,使用宝塔面板进行演示
宝塔安装好后,进入面板,点击左边的软件管理,然后安装PHP7.2、Nginx,Mysql5.7+,Redis。
2、installer
我们先点击左边的网站,添加网站!这个不用我教!!!
如果不能,请稍后观看我的视频教程!!!
设置伪静态
点击域名设置-网站目录,运行目录选择public,去掉反跨站勾选,重启PHP。
一般情况下,漫画中的图片资源有两种,一种是本地化,一种是盗链。建议对图片进行本地化,这样可以保证网站resources的稳定性,同时程序还提供了优采云采集器的API可以方便的连接优采云采集器进行漫画和章节图片采集。
首先我们需要一个优采云采集器,但是它分为免费版和付费版,但是免费版由于一些功能限制不能满足图片本地化的需要,所以暂时不适用有钱可以买付费版,没钱可以直接用优采云V7.6企业破解版,大概是最新的破解版,也可以满足采集程序需求
很早以前收集类似功能性的代码文章,结果准确度基本都是OK的
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-08-03 18:23
其实已经很久没有采集类似的功能代码了文章。今天就来记录一下吧。很久以前试过“百度收录detection”这个功能,不管是WP还是TP。所有方法都经过测试,代码基本一致。我用crl通过php中科院模拟搜索请求,分析返回数据判断是否为收录。之前在Typecho中添加“百度收录”确定方法”文章提到因为成功率太低所以放弃了这个功能。
我今天在wfblog上看到了一篇文章的文章。我最初认为它和以前一样。看了一眼,才发现自己升级到了API版本。我通过模拟UA绕过了百度的反爬虫,然后我用curl来模拟header。成功实现了“百度收录”的查询,结果准确率基本OK。
1、来电查询
在模板post.php中添加(自行修改CSS样式)
加载中
2、JQ 评委收录
还是在post.php中添加(必须引入jquery),这里修改提示文本。
3、API 调用源码
为了防止第三方API调用挂断,wfblog贡献了API代码。你可以创建一个php页面自己调用。如果你不想给伟峰打电话,你可以自己做。
整体来看,测试结果的准确度提升非常高。点击几个是准确的。当然,这个判断理论上适用于大多数网站、TP或WP。自己写的PHP很好。
查看全部
很早以前收集类似功能性的代码文章,结果准确度基本都是OK的
其实已经很久没有采集类似的功能代码了文章。今天就来记录一下吧。很久以前试过“百度收录detection”这个功能,不管是WP还是TP。所有方法都经过测试,代码基本一致。我用crl通过php中科院模拟搜索请求,分析返回数据判断是否为收录。之前在Typecho中添加“百度收录”确定方法”文章提到因为成功率太低所以放弃了这个功能。
我今天在wfblog上看到了一篇文章的文章。我最初认为它和以前一样。看了一眼,才发现自己升级到了API版本。我通过模拟UA绕过了百度的反爬虫,然后我用curl来模拟header。成功实现了“百度收录”的查询,结果准确率基本OK。
1、来电查询
在模板post.php中添加(自行修改CSS样式)
加载中
2、JQ 评委收录
还是在post.php中添加(必须引入jquery),这里修改提示文本。
3、API 调用源码
为了防止第三方API调用挂断,wfblog贡献了API代码。你可以创建一个php页面自己调用。如果你不想给伟峰打电话,你可以自己做。
整体来看,测试结果的准确度提升非常高。点击几个是准确的。当然,这个判断理论上适用于大多数网站、TP或WP。自己写的PHP很好。
京东联盟、京东宙斯两个平台如何快速获取自定义推广链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 472 次浏览 • 2021-07-24 23:29
本文创建于3年前,内容陈旧,京东页面也已改版,请进群了解更多。
欢迎加入京东联盟技术讨论群(379480469):
界面没有权限?请看这篇文章《调用京东联盟接口的权限问题》
最新:使用联盟API做的一个查看京东商品佣金的chrome扩展,可以直接在商品详情页查看佣金信息。
【有困难的孩子请参考最新的文章,并贴出当前demo的后台代码】
本文将简要介绍京东联盟和京东宙斯两大平台,以及如何使用京东宙斯平台的京东联盟API快速获取自定义推广链接。
关于京东联盟
京东联盟(查看官网)是一个CPS模式的营销平台。我们可以使用我们的网站置联盟的推广链接为京东推广产品。当用户点击我们的一个网站推广链接,推广真实订单,那么我们就会得到一定的佣金。
申请京东联盟的条件是必须有国内注册网站,这是重点。使用京东账号登录后,填写网站信息,等待审核。
强烈建议先看联盟介绍和规则:
关于京东宙斯
京东Zeus(查看官网)是京东提供的API接口平台(基于oauth2验证)。通过API,我们可以创建各种网站和无线应用来读取京东产品信息和事件信息。等待。商家可以通过API将自己的信息系统嵌入到京东的各种服务系统中。
本文将介绍如何在京东宙斯中使用京东联盟API获取京东联盟定制推广链接。
京东联盟定制推广链接
自定义推广链接,可以使用京东各种商品的链接和各种活动页面。范围很广,也很实用。
在联盟管理界面中,我们可以看到生成自定义推广链接的操作非常简单:
自定义推广链接支持的链接有:京东首页、商品详情页、活动页、店铺页。
点击Get Code按钮后,会生成union开头的链接。我们可以把这个链接放在网站上(这个链接只能在注册的网站上使用,其他方式打开无效)。
我们可以自己点这个链接,在京东上买东西也能拿到佣金! (更多信息,请参见)
在京东 Zeus 平台注册成为京东开发者
我们可以在京东联盟管理界面上获取推广链接,但是每次登录都很麻烦!好在京东已经开放了京东联盟API,我们可以使用代码自动获取!
首先用京东账号登录京东Zeus平台(打开官网),然后填写开发者基本信息完成开发者注册(开发者无需认证),然后授权服务页面申请京东宙斯服务。
完成后会显示您已授权的服务:
创建应用程序
当我们成为注册开发者并授权京东Zeus服务时,我们需要创建一个应用,因为使用API需要授权(access_token),而这个token是由我们创建的应用的APP key和App Secret生成的我们的 API 请求记录将记录在此应用程序下。
在创建应用界面,我们选择【买家】【无线应用】:
完成后,我们还需要填写申请信息,填写回调地址。回调地址的作用是在访问API授权码(accecc_token)时获取中间地址:
接下来,再提交审核,应用状态变为online and running,然后我们就可以正式开始使用应用证书中的APP key获取Token了!
使用APPkey和APPSecrect获取Token
首先提供官网的文档:有能力的可以自己研究~
这里,我使用第一种:授权码获取Token。优点是Token有效期可以维持1年,每天30万个请求!我们现在只需要得到一次!
因为是基于Oauth2.0,所以流程很简单,先用APPKey获取Code,再结合Code获取Token!
代码是通过京东登录页面获取的。输入您的京东账户信息后,授权后将返回我们的回调地址。这时候回调地址会有一个code参数,这就是我们需要的!
获取Code的请求(GET请求)链接:
https://oauth.jd.com/oauth/authorize
有几个参数需要带:
参数名称参数选项说明
响应类型
必填
在这个过程中,值被固定为代码
client_id
必填
创建应用时的Appkey(从JOS控制台获取->管理应用)
redirect_uri
必填
应用的回调地址,必须与创建应用时填写的回调页面的url一致
状态
可选
状态参数,ISV自定义,授权发布后原样返回
范围
可选
权限参数,API 组名称字符串。当有多个组名时,用“,”分隔,目前支持参数取值:read
查看
可选
移动端授权,值固定为wap;非手机终端授权,无需传值
排序后的完整请求链接为:
https://oauth.jd.com/oauth/aut ... mp%3B redirect_uri=YOUR_REGISTERED_REDIRECT_URI
只需要修改client_id(即APP Key)和redirect_uri(回调地址,必须与创建应用时写的一致)。
使用浏览器访问此链接,您将被定向到登录页面:
登录成功后会跳转到我们写的回调地址,这时候就可以拿到code参数值了!
现在我们可以使用 Code 值来获取令牌。
请求链接以获取令牌:
https://oauth.jd.com/oauth/token
参数为:
参数名称参数选项说明
grant_type
必填
授权类型。在这个过程中,该值固定为authorization_code
代码
必填
授权请求返回的授权码
redirect_uri
必填
应用的回调地址必须与创建应用时填写的回调页面的url一致
client_id
必填
创建应用时的Appkey(从JOS控制台获取->管理应用)
client_secret
必填
应用创建时的Appsecret(从JOS控制台获取->管理应用)
状态
可选
状态参数,ISV自定义,授权发布后原样返回
排序后的完整请求链接为:
https://oauth.jd.com/oauth/tok ... mp%3B
redirect_uri=YOUR_REGISTERED_REDIRECT_URI&code=GET_CODE&client_secret= YOUR_APP_SECRET
用浏览器访问这个链接,返回的是标准的json格式:
{
"access_token": "您的Token值",
"code": 0,
"expires_in": 31622400,
"refresh_token": "4a07031d-5122-4100-a60d-4ab982a55307",
"time": "1435499129281",
"token_type": "bearer",
"uid": "您的京东帐号ID",
"user_nick": "您的京东帐号昵称"
}
从那时起,一个理论过程就完成了!现在我们使用php自动下载,即获取code后自动发送获取token的请求,然后显示token的内容。
PHP 实现自动获取令牌的简单演示
直接看代码,很简单,一个php文件:
<p> 查看全部
京东联盟、京东宙斯两个平台如何快速获取自定义推广链接
本文创建于3年前,内容陈旧,京东页面也已改版,请进群了解更多。
欢迎加入京东联盟技术讨论群(379480469):
界面没有权限?请看这篇文章《调用京东联盟接口的权限问题》
最新:使用联盟API做的一个查看京东商品佣金的chrome扩展,可以直接在商品详情页查看佣金信息。
【有困难的孩子请参考最新的文章,并贴出当前demo的后台代码】
本文将简要介绍京东联盟和京东宙斯两大平台,以及如何使用京东宙斯平台的京东联盟API快速获取自定义推广链接。
关于京东联盟
京东联盟(查看官网)是一个CPS模式的营销平台。我们可以使用我们的网站置联盟的推广链接为京东推广产品。当用户点击我们的一个网站推广链接,推广真实订单,那么我们就会得到一定的佣金。
申请京东联盟的条件是必须有国内注册网站,这是重点。使用京东账号登录后,填写网站信息,等待审核。
强烈建议先看联盟介绍和规则:
关于京东宙斯
京东Zeus(查看官网)是京东提供的API接口平台(基于oauth2验证)。通过API,我们可以创建各种网站和无线应用来读取京东产品信息和事件信息。等待。商家可以通过API将自己的信息系统嵌入到京东的各种服务系统中。
本文将介绍如何在京东宙斯中使用京东联盟API获取京东联盟定制推广链接。
京东联盟定制推广链接
自定义推广链接,可以使用京东各种商品的链接和各种活动页面。范围很广,也很实用。
在联盟管理界面中,我们可以看到生成自定义推广链接的操作非常简单:
自定义推广链接支持的链接有:京东首页、商品详情页、活动页、店铺页。
点击Get Code按钮后,会生成union开头的链接。我们可以把这个链接放在网站上(这个链接只能在注册的网站上使用,其他方式打开无效)。
我们可以自己点这个链接,在京东上买东西也能拿到佣金! (更多信息,请参见)
在京东 Zeus 平台注册成为京东开发者
我们可以在京东联盟管理界面上获取推广链接,但是每次登录都很麻烦!好在京东已经开放了京东联盟API,我们可以使用代码自动获取!
首先用京东账号登录京东Zeus平台(打开官网),然后填写开发者基本信息完成开发者注册(开发者无需认证),然后授权服务页面申请京东宙斯服务。
完成后会显示您已授权的服务:
创建应用程序
当我们成为注册开发者并授权京东Zeus服务时,我们需要创建一个应用,因为使用API需要授权(access_token),而这个token是由我们创建的应用的APP key和App Secret生成的我们的 API 请求记录将记录在此应用程序下。
在创建应用界面,我们选择【买家】【无线应用】:
完成后,我们还需要填写申请信息,填写回调地址。回调地址的作用是在访问API授权码(accecc_token)时获取中间地址:
接下来,再提交审核,应用状态变为online and running,然后我们就可以正式开始使用应用证书中的APP key获取Token了!
使用APPkey和APPSecrect获取Token
首先提供官网的文档:有能力的可以自己研究~
这里,我使用第一种:授权码获取Token。优点是Token有效期可以维持1年,每天30万个请求!我们现在只需要得到一次!
因为是基于Oauth2.0,所以流程很简单,先用APPKey获取Code,再结合Code获取Token!
代码是通过京东登录页面获取的。输入您的京东账户信息后,授权后将返回我们的回调地址。这时候回调地址会有一个code参数,这就是我们需要的!
获取Code的请求(GET请求)链接:
https://oauth.jd.com/oauth/authorize
有几个参数需要带:
参数名称参数选项说明
响应类型
必填
在这个过程中,值被固定为代码
client_id
必填
创建应用时的Appkey(从JOS控制台获取->管理应用)
redirect_uri
必填
应用的回调地址,必须与创建应用时填写的回调页面的url一致
状态
可选
状态参数,ISV自定义,授权发布后原样返回
范围
可选
权限参数,API 组名称字符串。当有多个组名时,用“,”分隔,目前支持参数取值:read
查看
可选
移动端授权,值固定为wap;非手机终端授权,无需传值
排序后的完整请求链接为:
https://oauth.jd.com/oauth/aut ... mp%3B redirect_uri=YOUR_REGISTERED_REDIRECT_URI
只需要修改client_id(即APP Key)和redirect_uri(回调地址,必须与创建应用时写的一致)。
使用浏览器访问此链接,您将被定向到登录页面:
登录成功后会跳转到我们写的回调地址,这时候就可以拿到code参数值了!
现在我们可以使用 Code 值来获取令牌。
请求链接以获取令牌:
https://oauth.jd.com/oauth/token
参数为:
参数名称参数选项说明
grant_type
必填
授权类型。在这个过程中,该值固定为authorization_code
代码
必填
授权请求返回的授权码
redirect_uri
必填
应用的回调地址必须与创建应用时填写的回调页面的url一致
client_id
必填
创建应用时的Appkey(从JOS控制台获取->管理应用)
client_secret
必填
应用创建时的Appsecret(从JOS控制台获取->管理应用)
状态
可选
状态参数,ISV自定义,授权发布后原样返回
排序后的完整请求链接为:
https://oauth.jd.com/oauth/tok ... mp%3B
redirect_uri=YOUR_REGISTERED_REDIRECT_URI&code=GET_CODE&client_secret= YOUR_APP_SECRET
用浏览器访问这个链接,返回的是标准的json格式:
{
"access_token": "您的Token值",
"code": 0,
"expires_in": 31622400,
"refresh_token": "4a07031d-5122-4100-a60d-4ab982a55307",
"time": "1435499129281",
"token_type": "bearer",
"uid": "您的京东帐号ID",
"user_nick": "您的京东帐号昵称"
}
从那时起,一个理论过程就完成了!现在我们使用php自动下载,即获取code后自动发送获取token的请求,然后显示token的内容。
PHP 实现自动获取令牌的简单演示
直接看代码,很简单,一个php文件:
<p>
优采云采集软件能生产原创内容吗?能略微低质量的原创
采集交流 • 优采云 发表了文章 • 0 个评论 • 490 次浏览 • 2021-07-24 04:25
优采云采集software 是一个非常好用的文章采集软件,能产生原创内容吗?是的,但只是质量略低原创。今天错误博客()分享的内容是“优采云采集Build原创文章Three Methods”。希望能帮到你。
一、优采云 和原创
优采云没有原创的能力,但优采云确实可以创建原创内容。错误博客先介绍三种使用优采云创原创文章的方式,当然以后会有更多的方式,就看大家的头脑风暴了。
1、English to Chinese plugin
采集一些英文网站文章,然后用优采云的英文转中文插件,可以得到很多伪原创文章,这样文章甚至可以叫原创,不过可能读不完,不过原创度还好,除非两个人是采集同文章中文文章,否则这种模式下得到的内容收录率还行本站有部分谷歌搜索引擎优化文章就是通过这种方式获取的。
目前这种插件一般都是收费的。你可以找到免费的插件,但通常你必须得到百度翻译API。如果超过免费使用量,则需要另行付费。
2、伪原创plugin
伪原创插件基本上都是在线伪原创搞的人做的,大部分都是收费的。毕竟这是大量的伪原创,一定程度上消耗了对方的服务器资源。 .
对于伪原创,错误博客不是特别推荐。毕竟这东西可读性真的很差,搜索引擎也不友好。如果你网站friendliness 好,即使你没有太多的文字,你也可以做到。是收录,但伪原创的内容可能不是收录。
而且伪原创大部分来自同义词和同义词的替换。市面上基本没有AI伪原创。如果确实存在,那就给关键词,其他人自己写吧。市面上的伪原创提供者大多替换同义词和同义词,所以最好不要这样做。
3、建建文章
用大量的词来构建文章,比如把十万个相关词做成一个表格文章页面,把词句排列起来,看起来没有任何意义违反。看到很多这样的方法网站收到了很多流量,错误的博客本身就收到了几万收录。
二、优采云Build文章
优采云Build文章方式很简单,错误博客会一一告诉你。
1、优采云import 模板
下载优采云,即优采云采集,创建一个字符列表组,右键单击该组,然后导入准备好的“.ljobx”文件,即@的模板优采云采集 .
2、内容采集rules
导入后双击打开,直接跳过“URL采集Rules”,直接进入“Content采集Rules”。然后,我们需要构建原创的标题、页面关键词、页面描述、作者、缩略图、标签等,这些内容都来自txt文件,里面有几万行数据txt 文件内存,这样就可以构造原创文章。当然,这只是一种模式。如果你想有更好的收录效果,你需要考虑如何使用这种模式来制作更好的内容,或者使用另一种模式来制作更像原创的内容。
以上是错误博客()分享的“优采云采集Build原创文章Three Ways”的内容。感谢您的阅读。更多原创文章搜索“错误博客”。 查看全部
优采云采集软件能生产原创内容吗?能略微低质量的原创
优采云采集software 是一个非常好用的文章采集软件,能产生原创内容吗?是的,但只是质量略低原创。今天错误博客()分享的内容是“优采云采集Build原创文章Three Methods”。希望能帮到你。
一、优采云 和原创
优采云没有原创的能力,但优采云确实可以创建原创内容。错误博客先介绍三种使用优采云创原创文章的方式,当然以后会有更多的方式,就看大家的头脑风暴了。
1、English to Chinese plugin
采集一些英文网站文章,然后用优采云的英文转中文插件,可以得到很多伪原创文章,这样文章甚至可以叫原创,不过可能读不完,不过原创度还好,除非两个人是采集同文章中文文章,否则这种模式下得到的内容收录率还行本站有部分谷歌搜索引擎优化文章就是通过这种方式获取的。
目前这种插件一般都是收费的。你可以找到免费的插件,但通常你必须得到百度翻译API。如果超过免费使用量,则需要另行付费。
2、伪原创plugin
伪原创插件基本上都是在线伪原创搞的人做的,大部分都是收费的。毕竟这是大量的伪原创,一定程度上消耗了对方的服务器资源。 .
对于伪原创,错误博客不是特别推荐。毕竟这东西可读性真的很差,搜索引擎也不友好。如果你网站friendliness 好,即使你没有太多的文字,你也可以做到。是收录,但伪原创的内容可能不是收录。
而且伪原创大部分来自同义词和同义词的替换。市面上基本没有AI伪原创。如果确实存在,那就给关键词,其他人自己写吧。市面上的伪原创提供者大多替换同义词和同义词,所以最好不要这样做。
3、建建文章
用大量的词来构建文章,比如把十万个相关词做成一个表格文章页面,把词句排列起来,看起来没有任何意义违反。看到很多这样的方法网站收到了很多流量,错误的博客本身就收到了几万收录。
二、优采云Build文章
优采云Build文章方式很简单,错误博客会一一告诉你。
1、优采云import 模板
下载优采云,即优采云采集,创建一个字符列表组,右键单击该组,然后导入准备好的“.ljobx”文件,即@的模板优采云采集 .
2、内容采集rules
导入后双击打开,直接跳过“URL采集Rules”,直接进入“Content采集Rules”。然后,我们需要构建原创的标题、页面关键词、页面描述、作者、缩略图、标签等,这些内容都来自txt文件,里面有几万行数据txt 文件内存,这样就可以构造原创文章。当然,这只是一种模式。如果你想有更好的收录效果,你需要考虑如何使用这种模式来制作更好的内容,或者使用另一种模式来制作更像原创的内容。
以上是错误博客()分享的“优采云采集Build原创文章Three Ways”的内容。感谢您的阅读。更多原创文章搜索“错误博客”。
API供开发者获取数据用,通常返回的数据为JSON格式
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-07-11 07:32
很多网站为开发者提供了获取数据的API。通常返回的数据是JSON格式。本文以百度Opener平台为例,通过API进行数据采集实验。由于百度API接口较多,后续会陆续添加实验接口。它们都是非常简单的程序,可以作为以后编写更全面的应用程序的基础。
使用百度API的步骤类似。百度开发者平台注册->免费获取AppID和Key->构建开发者文档中提供的URL->GET获取Json数据->分析展示。下面这个小程序干脆就不解释了,把自己的AppID和Key屏蔽了。
1、百度翻译使用
支持26种语言翻译,翻译准确度还是很好的。
import requests
import random
import hashlib
import json
import pprint
appid = '12345678'
key = 'dasd457dawgjj54j01qf'
url = 'http://api.fanyi.baidu.com/api ... 39%3B
#需要翻译的文本
q = '建设中国特色社会主义'
#原语言
from_language ='zh'
#目的语言
to_language = 'en'
#随机数
salt = random.randint(32768, 65536)
#签名
sign = appid+q+str(salt)+key
sign = sign.encode('utf-8')
sign_new = hashlib.md5(sign).hexdigest()
#生成URL
new_url = url + 'q='+q+'&from='+from_language+'&to='+to_language+'&appid='+appid+'&salt='+str(salt)+'&sign='+sign_new
res = requests.get(new_url)
print(res.text)
json_data = json.loads(res.text)
#translate_result = json_data["trans_result"]["dst"]
pprint.pprint(json_data["trans_result"])
[{'dst':'建设有中国特色的社会主义',
'src':'建设有中国特色的社会主义'}]
2.百度图获取位置经纬度
import json
import requests
from urllib.request import urlopen,quote
import pprint
address = quote("长沙")
key = "dajskjda1231390kjbnreitie1043"
url = "http://api.map.baidu.com/geocoder/v2/"
new_url = url+"?address="+address+"&output=json"+"&ak="+key
url = "http://restapi.amap.com/v3/geocode/geo"
res = requests.get(new_url)
json_data = json.loads(res.text)
print('经度是:'+str(json_data['result']['location']['lat']))
print('维度是:'+str(json_data['result']['location']['lng']))
经度为:28.222
维度为:112.9793527876505 查看全部
API供开发者获取数据用,通常返回的数据为JSON格式
很多网站为开发者提供了获取数据的API。通常返回的数据是JSON格式。本文以百度Opener平台为例,通过API进行数据采集实验。由于百度API接口较多,后续会陆续添加实验接口。它们都是非常简单的程序,可以作为以后编写更全面的应用程序的基础。
使用百度API的步骤类似。百度开发者平台注册->免费获取AppID和Key->构建开发者文档中提供的URL->GET获取Json数据->分析展示。下面这个小程序干脆就不解释了,把自己的AppID和Key屏蔽了。
1、百度翻译使用
支持26种语言翻译,翻译准确度还是很好的。
import requests
import random
import hashlib
import json
import pprint
appid = '12345678'
key = 'dasd457dawgjj54j01qf'
url = 'http://api.fanyi.baidu.com/api ... 39%3B
#需要翻译的文本
q = '建设中国特色社会主义'
#原语言
from_language ='zh'
#目的语言
to_language = 'en'
#随机数
salt = random.randint(32768, 65536)
#签名
sign = appid+q+str(salt)+key
sign = sign.encode('utf-8')
sign_new = hashlib.md5(sign).hexdigest()
#生成URL
new_url = url + 'q='+q+'&from='+from_language+'&to='+to_language+'&appid='+appid+'&salt='+str(salt)+'&sign='+sign_new
res = requests.get(new_url)
print(res.text)
json_data = json.loads(res.text)
#translate_result = json_data["trans_result"]["dst"]
pprint.pprint(json_data["trans_result"])
[{'dst':'建设有中国特色的社会主义',
'src':'建设有中国特色的社会主义'}]
2.百度图获取位置经纬度
import json
import requests
from urllib.request import urlopen,quote
import pprint
address = quote("长沙")
key = "dajskjda1231390kjbnreitie1043"
url = "http://api.map.baidu.com/geocoder/v2/"
new_url = url+"?address="+address+"&output=json"+"&ak="+key
url = "http://restapi.amap.com/v3/geocode/geo"
res = requests.get(new_url)
json_data = json.loads(res.text)
print('经度是:'+str(json_data['result']['location']['lat']))
print('维度是:'+str(json_data['result']['location']['lng']))
经度为:28.222
维度为:112.9793527876505
添加ApiBoot统一版本依赖广告超强,超多装备超强回收,
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-07-04 19:11
可以通过ApiBoot Logging获取每个请求的详细信息。在分布式部署模式下,一个请求可能经过多个服务。如果每个服务独立保存请求日志信息,我们是做不到的。统一控制,日志库和业务库会出现不一致(可能会使用多数据源配置)。因为这个问题,ApiBoot Logging提供了Admin的概念,客户端采集到每个日志都会上报给Admin,Admin会分析、保存等操作。
创建日志管理项目
ApiBoot Logging Admin可以汇总各个业务服务的请求日志(ApiBoot Logging),所以我们需要将各个业务服务的日志采集单上报给Admin,所以我们应该使用独立的方式进行部署。创建单独的服务专门采集请求日志然后保存。
初始化日志管理项目依赖
使用idea创建一个SpringBoot项目,pom.xml配置文件中的依赖如下:
广告每天一勺三七粉,50岁的阿姨有死的危险。必须了解三七的禁忌症
我们需要将采集收到的请求日志保存到数据库中,所以需要在项目中添加数据库驱动和数据库连接池相关的依赖。 ApiBoot Logging Admin 通过DataSource 操作数据,依赖ApiBoot MyBatis Enhance。可以自动创建DataSource,摆脱手动创建,加入Spring IOC容器。
添加ApiBoot统一版本依赖
广告超强魂,超多装备,超回复,无限Boss
最新版本的ApiBoot请访问::api-boot-dependencies查询。
启用日志管理
添加ApiBoot Logging Admin依赖后,无法完全使用Admin功能。我们需要通过@EnableLoggingAdmin 注释来启用它。这个注解会自动将Logging Admin中需要的一些类注册到Spring IOC中,并在入口类中添加注解如下图:
广告每天一勺三七粉,50岁大妈惊呆了。你必须了解三七的禁忌症
配置日志数据源
广告枸杞和它绝配,天天泡水,老样子,方便实用!
控制台打印报告日志
ApiBoot Logging Admin可以通过配置文件控制是否在控制台打印采集收到的请求日志信息,并在application.yml配置文件中添加如下内容:
五十岁以后的广告,如果你不想长得太快,用灵芝粉泡水就等于清洁你的身体!
注意:这不应与 ApiBoot Logging 提供的 api.boot.logging.show-console-log 配置混淆。
美化控制台打印的报告日志
广告是每天一片肉苁蓉。 50岁的阿姨震惊了。有必要了解肉苁蓉的禁忌症。
注意:不要与这里的 api.boot.logging.format-console-log-json 配置混淆。
初始化日志表结构
ApiBoot Logging Admin 使用固定的表结构来存储请求日志和服务信息。建表语句如下:
广告中的有害吸烟太多?赶紧学起来,再忙也能看! ! !
广告中很多人认为冬虫夏草很贵。其实藏族直接提供一手价,一年可以吃80克
ApiBoot Logging Admin 到目前为止已经准备就绪。接下来,我们需要修改业务服务以将请求日志报告给 Logging Admin。
向指定的日志管理员报告日志
我们将修改使用ApiBoot Logging统一管理请求日志文章的源码,并将Logging Admin的地址添加到application.yml中,如下图:
广告五十年后,注意三关。每天用它泡水,睡好吃好!
api.boot.logging.admin-service-address 的配置格式是:Ip:Port,我们只需要修改这一个地方,其他的所有任务内部交给ApiBoot Logging。
测试
我们以应用程序的形式启动 ApiBoot 日志管理和业务服务。
使用curl访问测试地址如下:
广告肺病的“大克星”来了,老烟民用它泡水喝,排烟解毒。
我们已经看到了Logging Admin控制台打印的报告请求日志,这个请求的日志是否已经保存到数据库中还不确定。接下来,我将使用命令行查看数据库的日志信息。
查看logging_service_details表中的数据
广告三斤枸杞还不如1两,天天泡在水里,不显老,方便实用
logging_service_details 存储了每个上报请求日志的业务服务的基本信息。每个服务的基本信息都会缓存在Logging Admin内存中,方便获取service_id用于存储日志。唯一性根据ip端口service_id确定。该服务仅保存一次。
查看logging_request_logs表中的数据
广告五十岁后,注意三关,每天坚持这件事,睡好吃好
敲黑板画重点
本章我们集成了ApiBoot Logging Admin,将业务服务的每一个请求日志上报给Logging Admin,并通过数据库保存请求日志,然后通过其他方法,并通过spanId和traceId查看日志——每个请求链路的从属关系以及每个请求中消耗时间最多的跨度,以准确优化服务性能。 查看全部
添加ApiBoot统一版本依赖广告超强,超多装备超强回收,
可以通过ApiBoot Logging获取每个请求的详细信息。在分布式部署模式下,一个请求可能经过多个服务。如果每个服务独立保存请求日志信息,我们是做不到的。统一控制,日志库和业务库会出现不一致(可能会使用多数据源配置)。因为这个问题,ApiBoot Logging提供了Admin的概念,客户端采集到每个日志都会上报给Admin,Admin会分析、保存等操作。
创建日志管理项目
ApiBoot Logging Admin可以汇总各个业务服务的请求日志(ApiBoot Logging),所以我们需要将各个业务服务的日志采集单上报给Admin,所以我们应该使用独立的方式进行部署。创建单独的服务专门采集请求日志然后保存。
初始化日志管理项目依赖
使用idea创建一个SpringBoot项目,pom.xml配置文件中的依赖如下:
广告每天一勺三七粉,50岁的阿姨有死的危险。必须了解三七的禁忌症
我们需要将采集收到的请求日志保存到数据库中,所以需要在项目中添加数据库驱动和数据库连接池相关的依赖。 ApiBoot Logging Admin 通过DataSource 操作数据,依赖ApiBoot MyBatis Enhance。可以自动创建DataSource,摆脱手动创建,加入Spring IOC容器。
添加ApiBoot统一版本依赖
广告超强魂,超多装备,超回复,无限Boss
最新版本的ApiBoot请访问::api-boot-dependencies查询。
启用日志管理
添加ApiBoot Logging Admin依赖后,无法完全使用Admin功能。我们需要通过@EnableLoggingAdmin 注释来启用它。这个注解会自动将Logging Admin中需要的一些类注册到Spring IOC中,并在入口类中添加注解如下图:
广告每天一勺三七粉,50岁大妈惊呆了。你必须了解三七的禁忌症
配置日志数据源
广告枸杞和它绝配,天天泡水,老样子,方便实用!
控制台打印报告日志
ApiBoot Logging Admin可以通过配置文件控制是否在控制台打印采集收到的请求日志信息,并在application.yml配置文件中添加如下内容:
五十岁以后的广告,如果你不想长得太快,用灵芝粉泡水就等于清洁你的身体!
注意:这不应与 ApiBoot Logging 提供的 api.boot.logging.show-console-log 配置混淆。
美化控制台打印的报告日志
广告是每天一片肉苁蓉。 50岁的阿姨震惊了。有必要了解肉苁蓉的禁忌症。
注意:不要与这里的 api.boot.logging.format-console-log-json 配置混淆。
初始化日志表结构
ApiBoot Logging Admin 使用固定的表结构来存储请求日志和服务信息。建表语句如下:
广告中的有害吸烟太多?赶紧学起来,再忙也能看! ! !
广告中很多人认为冬虫夏草很贵。其实藏族直接提供一手价,一年可以吃80克
ApiBoot Logging Admin 到目前为止已经准备就绪。接下来,我们需要修改业务服务以将请求日志报告给 Logging Admin。
向指定的日志管理员报告日志
我们将修改使用ApiBoot Logging统一管理请求日志文章的源码,并将Logging Admin的地址添加到application.yml中,如下图:
广告五十年后,注意三关。每天用它泡水,睡好吃好!
api.boot.logging.admin-service-address 的配置格式是:Ip:Port,我们只需要修改这一个地方,其他的所有任务内部交给ApiBoot Logging。
测试
我们以应用程序的形式启动 ApiBoot 日志管理和业务服务。
使用curl访问测试地址如下:
广告肺病的“大克星”来了,老烟民用它泡水喝,排烟解毒。
我们已经看到了Logging Admin控制台打印的报告请求日志,这个请求的日志是否已经保存到数据库中还不确定。接下来,我将使用命令行查看数据库的日志信息。
查看logging_service_details表中的数据
广告三斤枸杞还不如1两,天天泡在水里,不显老,方便实用
logging_service_details 存储了每个上报请求日志的业务服务的基本信息。每个服务的基本信息都会缓存在Logging Admin内存中,方便获取service_id用于存储日志。唯一性根据ip端口service_id确定。该服务仅保存一次。
查看logging_request_logs表中的数据
广告五十岁后,注意三关,每天坚持这件事,睡好吃好
敲黑板画重点
本章我们集成了ApiBoot Logging Admin,将业务服务的每一个请求日志上报给Logging Admin,并通过数据库保存请求日志,然后通过其他方法,并通过spanId和traceId查看日志——每个请求链路的从属关系以及每个请求中消耗时间最多的跨度,以准确优化服务性能。
php采集相关的博客百度地图API位置偏移的校准算法
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-06-18 06:29
php 采集api 相关博客
百度地图API位置偏移校准算法
转自百度地图API位置偏移校准算法的客文原文。当您开始使用百度地图API进行开发时,您可能会遇到一个比较奇怪的事情。百度定位的经纬度在地图上显示的很不准确。我在微信开发和Android之初遇到的一个问题。微信开发第一次使用百度地图api获取位置并显示在地图上
橘子是红的 3年前2639
【百度地图API】JS版本FAQ
原文:【百度地图API】JS版FAQ【新手必读】APIFAQ 2011-12-12 1、 如何在百度地图上标注我的店铺?我可以成为区域代理吗?可以在百度地图上免费标注吗?答:这里只负责API技术咨询,不解决任何地图标注问题。在一百
Jack Chen 6 年前 1323
[Map API] 为什么你的坐标不正确?如何纠正偏差?
原文:[Map API] 为什么你的坐标不正确?如何纠正偏差?总结:如何在各种坐标系之间进行转换?有哪些坐标系?什么是火星坐标?为什么我的坐标显示在地图偏移量上?本文详细回答了上述问题。最后给出坐标拾取工具。 -----------------------------
Jack Chen 6 年前 1446
“时序数据库硬件API”打造智能医疗设备
第一次接触 API 应该是 2000 年左右。当时我还在大二。在我开始编程后不久,我还在用 VB 编写程序。我想在打开文件的对话框中添加一个预览功能。这花了很多精力,我写了很多代码。它总是没有人们想要的那么好。后来偶然发现,通过系统的API,几行代码就解决了问题。
仙游3年前2106
从零开始 K8s |可观察性:监控和记录
作者 |莫元阿里巴巴技术专家一、Background 监控和日志是大规模分布式系统的重要**基础设施**。监控可以帮助开发者查看系统的运行状态,日志可以辅助排查和诊断。在Kubernetes中,监控和日志是生态的一部分,不是核心组件,所以大部分功能
阿里云原生助手1年前3882
【技术干货】如果你想高效的将采集数据发送到阿里云Elasticsearch,这些方法你知道吗?
简介:本文全面介绍了Elastic Beats、Logstash、语言客户端、Kibana开发者工具采集对阿里云Elasticsearch(简称ES)服务的特性和数据。帮助您充分理解原理,选择适合您业务特点的数据采集方案。字符数:276
工程师 A 1 年前 1279
日志服务-一站式配置采集Apache访问日志
自日志服务推出数据访问向导(Wizard)功能以来,不断优化访问向导功能,支持采集、各种数据的存储、分析、离线交付,降低用户使用门槛日志服务。本文介绍了数据访问向导采集Apache 日志和索引设置的一站式配置。同时也可以通过默认仪表盘和查询分析语句网站
进行实时分析
从 2 年前的 Mu 2422
CrazyReading项目开发过程直播(开源到github)
作为一个在IT行业10多年的老码农,我计划启动一个开源新闻订阅项目,目标有3个:1.综合利用近年来学到的各种开发知识来提升自己; 2. 分享近年来学到的各种开发知识,帮助有需要的程序员; 3. 为普通用户做一个实用的项目。 -------------
于尔武3年前799
php 采集api 相关问答
php采集高手进: 用curl模拟登录取数据遇到json调用问题,不成功,求帮助!
我在抓取一个页面的信息(假设a.php),这个页面只是一些基本的html框架,其他关键信息通过ajax请求(b.php)返回,返回的是json,然后通过页面js解析json并绘制在页面上。问题关键是ajax请求信息里有手机号需要登录才能显示完整
杨东方4年前906 查看全部
php采集相关的博客百度地图API位置偏移的校准算法
php 采集api 相关博客
百度地图API位置偏移校准算法
转自百度地图API位置偏移校准算法的客文原文。当您开始使用百度地图API进行开发时,您可能会遇到一个比较奇怪的事情。百度定位的经纬度在地图上显示的很不准确。我在微信开发和Android之初遇到的一个问题。微信开发第一次使用百度地图api获取位置并显示在地图上
橘子是红的 3年前2639
【百度地图API】JS版本FAQ
原文:【百度地图API】JS版FAQ【新手必读】APIFAQ 2011-12-12 1、 如何在百度地图上标注我的店铺?我可以成为区域代理吗?可以在百度地图上免费标注吗?答:这里只负责API技术咨询,不解决任何地图标注问题。在一百
Jack Chen 6 年前 1323
[Map API] 为什么你的坐标不正确?如何纠正偏差?
原文:[Map API] 为什么你的坐标不正确?如何纠正偏差?总结:如何在各种坐标系之间进行转换?有哪些坐标系?什么是火星坐标?为什么我的坐标显示在地图偏移量上?本文详细回答了上述问题。最后给出坐标拾取工具。 -----------------------------
Jack Chen 6 年前 1446
“时序数据库硬件API”打造智能医疗设备
第一次接触 API 应该是 2000 年左右。当时我还在大二。在我开始编程后不久,我还在用 VB 编写程序。我想在打开文件的对话框中添加一个预览功能。这花了很多精力,我写了很多代码。它总是没有人们想要的那么好。后来偶然发现,通过系统的API,几行代码就解决了问题。
仙游3年前2106
从零开始 K8s |可观察性:监控和记录
作者 |莫元阿里巴巴技术专家一、Background 监控和日志是大规模分布式系统的重要**基础设施**。监控可以帮助开发者查看系统的运行状态,日志可以辅助排查和诊断。在Kubernetes中,监控和日志是生态的一部分,不是核心组件,所以大部分功能
阿里云原生助手1年前3882
【技术干货】如果你想高效的将采集数据发送到阿里云Elasticsearch,这些方法你知道吗?
简介:本文全面介绍了Elastic Beats、Logstash、语言客户端、Kibana开发者工具采集对阿里云Elasticsearch(简称ES)服务的特性和数据。帮助您充分理解原理,选择适合您业务特点的数据采集方案。字符数:276
工程师 A 1 年前 1279
日志服务-一站式配置采集Apache访问日志
自日志服务推出数据访问向导(Wizard)功能以来,不断优化访问向导功能,支持采集、各种数据的存储、分析、离线交付,降低用户使用门槛日志服务。本文介绍了数据访问向导采集Apache 日志和索引设置的一站式配置。同时也可以通过默认仪表盘和查询分析语句网站
进行实时分析
从 2 年前的 Mu 2422
CrazyReading项目开发过程直播(开源到github)
作为一个在IT行业10多年的老码农,我计划启动一个开源新闻订阅项目,目标有3个:1.综合利用近年来学到的各种开发知识来提升自己; 2. 分享近年来学到的各种开发知识,帮助有需要的程序员; 3. 为普通用户做一个实用的项目。 -------------
于尔武3年前799
php 采集api 相关问答
php采集高手进: 用curl模拟登录取数据遇到json调用问题,不成功,求帮助!
我在抓取一个页面的信息(假设a.php),这个页面只是一些基本的html框架,其他关键信息通过ajax请求(b.php)返回,返回的是json,然后通过页面js解析json并绘制在页面上。问题关键是ajax请求信息里有手机号需要登录才能显示完整
杨东方4年前906
文章采集api 2021年5月30日更新无言给大家争取了一个福利(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 230 次浏览 • 2021-06-06 05:28
2021 年 5 月 30 日更新,无言为大家赢得了一份福利。使用无言提供的优惠码购买插件,最高可享5折优惠。在购买页面输入dc-3035750即可获得优惠,如下图
今天我要推荐一个很棒的 WordPress采集 插件。自从我建网站以来,这个插件已经使用了四年多。我从单站升级到无限版,做网站用这个采集真的超级舒服。
这个QQWorld采集插件据说是采集插件,但其实我更愿意把它定位为网站必备工具插件。下面就默默给大家分析一下QQ世界的各种功能。
QQWorld采集插件功能
以上是使用时间最长的函数。其实还有一些小而实用的功能可以玩。最常用的是采集文章+保存附件+云存储+伪原创+搜索引擎,开启这些功能后,即可实现无人值守操作。
文章采集来后->伪原创功能自动修改文章->自动同时保存附件和水印->从云存储上传附件(可实现不保存到网站media library) ->提交链接到搜索引擎。
万一我写不出采集rules怎么办?
完全不用担心,采集商店里已经有1468条采集规则,可以使用了。不是你想要的网站,你也可以在作者网站提交写作规则
反正QQWorld Collector是一款增值、可定制的爬虫,一款集截图、水印、云存储等功能于一体的WordPress万能云采集插件,可以采集绝大大部分网站,如微信公众号、知乎等,还有采集品商店,上千条采集规则免费使用!
查看全部
文章采集api 2021年5月30日更新无言给大家争取了一个福利(图)
2021 年 5 月 30 日更新,无言为大家赢得了一份福利。使用无言提供的优惠码购买插件,最高可享5折优惠。在购买页面输入dc-3035750即可获得优惠,如下图
今天我要推荐一个很棒的 WordPress采集 插件。自从我建网站以来,这个插件已经使用了四年多。我从单站升级到无限版,做网站用这个采集真的超级舒服。
这个QQWorld采集插件据说是采集插件,但其实我更愿意把它定位为网站必备工具插件。下面就默默给大家分析一下QQ世界的各种功能。
QQWorld采集插件功能
以上是使用时间最长的函数。其实还有一些小而实用的功能可以玩。最常用的是采集文章+保存附件+云存储+伪原创+搜索引擎,开启这些功能后,即可实现无人值守操作。
文章采集来后->伪原创功能自动修改文章->自动同时保存附件和水印->从云存储上传附件(可实现不保存到网站media library) ->提交链接到搜索引擎。
万一我写不出采集rules怎么办?
完全不用担心,采集商店里已经有1468条采集规则,可以使用了。不是你想要的网站,你也可以在作者网站提交写作规则
反正QQWorld Collector是一款增值、可定制的爬虫,一款集截图、水印、云存储等功能于一体的WordPress万能云采集插件,可以采集绝大大部分网站,如微信公众号、知乎等,还有采集品商店,上千条采集规则免费使用!
路由器的源码:retrieve方法获取需序列化的对象
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-05-29 03:25
文章中涉及的示例代码已经更新到HelloGitHub-Team仓库[2]
一旦我们使用了视图集,并实现了HTTP请求对应的action方法(对应规则的描述见使用视图集的简化代码),在路由器中注册后,django-restframework会自动为我们生成对应的API接口。
到目前为止,我们只实现了GET请求对应的action-list方法,所以路由器只为我们生成了一个API,这个API返回的是文章资源列表。 GET请求也可以用于获取单个资源,对应的动作是retrieve。因此,我们只要在视图集中实现retrieve方法的逻辑,就可以直接生成API接口获取单个资源文章。
贴心的,django-rest-framework帮我们在mixins.RetrieveModelMixin中写了检索的逻辑,可以直接混入视图集:
class PostViewSet(
mixins.ListModelMixin, mixins.RetrieveModelMixin, viewsets.GenericViewSet
):
serializer_class = PostListSerializer
queryset = Post.objects.all()
permission_classes = [AllowAny]
现在,路由会自动添加一个 URL 模式 /posts/:pk/,其中 pk 是 文章 的 id。访问该API接口获取指定文章 id的资源。
实际上,实现每个动作逻辑的混入类非常简单。以 RetrieveModelMixin 为例,我们来看看它的源码:
class RetrieveModelMixin:
"""
Retrieve a model instance.
"""
def retrieve(self, request, *args, **kwargs):
instance = self.get_object()
serializer = self.get_serializer(instance)
return Response(serializer.data)
retrieve 方法首先调用get_object 方法获取要序列化的对象。 get_object 方法通常基于以下两点过滤掉单个资源对象:
get_queryset方法返回的资源列表对象(或queryset属性,get_queryset方法返回的值优先)。 lookup_field 属性指定的资源过滤字段(默认为pk)。 django-rest-framework 使用该字段的值从 get_queryset 返回的资源列表中过滤出单个资源对象。 lookup_field字段的值会从请求的URL中抓取,所以你看到文章接口的url模式是/posts/:pk/,假设lookup_field被指定为title,url模式是/posts/ :title/, this 根据文章的标题,我们会得到一个文章资源。 文章详细的序列化器
<p>现在假设我们要获取id为1的文章资源,访问获取单个文章资源的API接口:10000/api/posts/1/,得到如下返回结果: 查看全部
路由器的源码:retrieve方法获取需序列化的对象
文章中涉及的示例代码已经更新到HelloGitHub-Team仓库[2]
一旦我们使用了视图集,并实现了HTTP请求对应的action方法(对应规则的描述见使用视图集的简化代码),在路由器中注册后,django-restframework会自动为我们生成对应的API接口。
到目前为止,我们只实现了GET请求对应的action-list方法,所以路由器只为我们生成了一个API,这个API返回的是文章资源列表。 GET请求也可以用于获取单个资源,对应的动作是retrieve。因此,我们只要在视图集中实现retrieve方法的逻辑,就可以直接生成API接口获取单个资源文章。
贴心的,django-rest-framework帮我们在mixins.RetrieveModelMixin中写了检索的逻辑,可以直接混入视图集:
class PostViewSet(
mixins.ListModelMixin, mixins.RetrieveModelMixin, viewsets.GenericViewSet
):
serializer_class = PostListSerializer
queryset = Post.objects.all()
permission_classes = [AllowAny]
现在,路由会自动添加一个 URL 模式 /posts/:pk/,其中 pk 是 文章 的 id。访问该API接口获取指定文章 id的资源。
实际上,实现每个动作逻辑的混入类非常简单。以 RetrieveModelMixin 为例,我们来看看它的源码:
class RetrieveModelMixin:
"""
Retrieve a model instance.
"""
def retrieve(self, request, *args, **kwargs):
instance = self.get_object()
serializer = self.get_serializer(instance)
return Response(serializer.data)
retrieve 方法首先调用get_object 方法获取要序列化的对象。 get_object 方法通常基于以下两点过滤掉单个资源对象:
get_queryset方法返回的资源列表对象(或queryset属性,get_queryset方法返回的值优先)。 lookup_field 属性指定的资源过滤字段(默认为pk)。 django-rest-framework 使用该字段的值从 get_queryset 返回的资源列表中过滤出单个资源对象。 lookup_field字段的值会从请求的URL中抓取,所以你看到文章接口的url模式是/posts/:pk/,假设lookup_field被指定为title,url模式是/posts/ :title/, this 根据文章的标题,我们会得到一个文章资源。 文章详细的序列化器
<p>现在假设我们要获取id为1的文章资源,访问获取单个文章资源的API接口:10000/api/posts/1/,得到如下返回结果:
前往韦世东的技术专栏收获爬虫架构/爬虫逆向/存储引擎/消息
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-05-17 01:28
前往韦世东的技术专栏收获爬虫架构/爬虫逆向/存储引擎/消息
转到Wei Shidong的技术专栏,以获取爬虫架构/爬虫反向/存储引擎/消息队列/ Python / Golang相关知识
本文文章的主要目的是告诉您如何配置Prometheus,以便它可以使用指定的Web Api接口采集索引数据。 文章中使用的情况是NGINX的采集配置。从设置了用户名和密码的NGINX数据索引页中的采集数据中,本文文章的标题可能是nginx的prometheus 采集配置nginx或prometheus 采集基本身份验证。
上图显示了配置完成后在Grafana中配置模板的效果。
曾经使用Prometheus的朋友必须知道如何配置address:port服务。例如,当采集有关某个Redis的信息时,可以这样编写配置:
- job_name: 'redis'
static_configs:
- targets: ['11.22.33.58:6087']
注意:在上述情况下,假设Redis Exporter的地址和端口为1 1. 2 2. 3 3. 58:6087。
这是最简单,最知名的方法。但是,如果您要监视指定的Web API,则不能以这种方式编写。如果您没有看到此文章,则可以在这样的搜索引擎中进行搜索:
不幸的是,我找不到任何有效的信息(现在是2021年3月),基本上我只能找到坑。
条件假设
假设我们现在需要从具有地址的界面中采集相关的Prometheus监视指标,并且该界面使用基本身份验证(假设用户名为weishidong并且密码为0099887kk)进行基本授权验证。
配置练习操作
如果您填写之前看到的Prometheus配置,则很有可能这样编写配置:
- job_name: 'web'
static_configs:
- targets: ['http://www.weishidong.com/status/format/prometheus']
basic_auth:
username: weishidong
password: 0099887kk
保存配置文件并重新启动服务后,您将发现无法以这种方式采集数据,这很糟糕。
官方配置指南
刚才的操作真的很糟糕。当我们遇到无法理解的问题时,我们当然会转到官方文档-> Prometheus Configuration。建议从上至下阅读,但是如果您急于忙,可以直接进入本节。官方示例如下(内容太多,这里仅是与本文相关的部分,建议您阅读原文):
# The job name assigned to scraped metrics by default.
job_name:
# How frequently to scrape targets from this job.
[ scrape_interval: | default = ]
# Per-scrape timeout when scraping this job.
[ scrape_timeout: | default = ]
# The HTTP resource path on which to fetch metrics from targets.
[ metrics_path: | default = /metrics ]
# honor_labels controls how Prometheus handles conflicts between labels that are
# already present in scraped data and labels that Prometheus would attach
# server-side ("job" and "instance" labels, manually configured target
# labels, and labels generated by service discovery implementations).
#
# If honor_labels is set to "true", label conflicts are resolved by keeping label
# values from the scraped data and ignoring the conflicting server-side labels.
#
# If honor_labels is set to "false", label conflicts are resolved by renaming
# conflicting labels in the scraped data to "exported_" (for
# example "exported_instance", "exported_job") and then attaching server-side
# labels.
#
# Setting honor_labels to "true" is useful for use cases such as federation and
# scraping the Pushgateway, where all labels specified in the target should be
# preserved.
#
# Note that any globally configured "external_labels" are unaffected by this
# setting. In communication with external systems, they are always applied only
# when a time series does not have a given label yet and are ignored otherwise.
[ honor_labels: | default = false ]
# honor_timestamps controls whether Prometheus respects the timestamps present
# in scraped data.
#
# If honor_timestamps is set to "true", the timestamps of the metrics exposed
# by the target will be used.
#
# If honor_timestamps is set to "false", the timestamps of the metrics exposed
# by the target will be ignored.
[ honor_timestamps: | default = true ]
# Configures the protocol scheme used for requests.
[ scheme: | default = http ]
# Optional HTTP URL parameters.
params:
[ : [, ...] ]
# Sets the `Authorization` header on every scrape request with the
# configured username and password.
# password and password_file are mutually exclusive.
basic_auth:
[ username: ]
[ password: ]
[ password_file: ]
# Sets the `Authorization` header on every scrape request with
# the configured bearer token. It is mutually exclusive with `bearer_token_file`.
[ bearer_token: ]
# Sets the `Authorization` header on every scrape request with the bearer token
# read from the configured file. It is mutually exclusive with `bearer_token`.
[ bearer_token_file: ]
<p>如果仔细看,应该注意一些关键信息:metrics_path和basic_auth。其中,metrics_path用于在使用HTTP类型指示符信息采集时指定路由地址,默认值为/ metrics;默认值为/ metrics。字段basic_auth用于授权验证,此处的密码可以指定密码文件,而不是直接填写纯文本(通常,指定密码文件的安全性比纯文本的安全性高)。 查看全部
前往韦世东的技术专栏收获爬虫架构/爬虫逆向/存储引擎/消息
转到Wei Shidong的技术专栏,以获取爬虫架构/爬虫反向/存储引擎/消息队列/ Python / Golang相关知识
本文文章的主要目的是告诉您如何配置Prometheus,以便它可以使用指定的Web Api接口采集索引数据。 文章中使用的情况是NGINX的采集配置。从设置了用户名和密码的NGINX数据索引页中的采集数据中,本文文章的标题可能是nginx的prometheus 采集配置nginx或prometheus 采集基本身份验证。
上图显示了配置完成后在Grafana中配置模板的效果。
曾经使用Prometheus的朋友必须知道如何配置address:port服务。例如,当采集有关某个Redis的信息时,可以这样编写配置:
- job_name: 'redis'
static_configs:
- targets: ['11.22.33.58:6087']
注意:在上述情况下,假设Redis Exporter的地址和端口为1 1. 2 2. 3 3. 58:6087。
这是最简单,最知名的方法。但是,如果您要监视指定的Web API,则不能以这种方式编写。如果您没有看到此文章,则可以在这样的搜索引擎中进行搜索:
不幸的是,我找不到任何有效的信息(现在是2021年3月),基本上我只能找到坑。
条件假设
假设我们现在需要从具有地址的界面中采集相关的Prometheus监视指标,并且该界面使用基本身份验证(假设用户名为weishidong并且密码为0099887kk)进行基本授权验证。
配置练习操作
如果您填写之前看到的Prometheus配置,则很有可能这样编写配置:
- job_name: 'web'
static_configs:
- targets: ['http://www.weishidong.com/status/format/prometheus']
basic_auth:
username: weishidong
password: 0099887kk
保存配置文件并重新启动服务后,您将发现无法以这种方式采集数据,这很糟糕。
官方配置指南
刚才的操作真的很糟糕。当我们遇到无法理解的问题时,我们当然会转到官方文档-> Prometheus Configuration。建议从上至下阅读,但是如果您急于忙,可以直接进入本节。官方示例如下(内容太多,这里仅是与本文相关的部分,建议您阅读原文):
# The job name assigned to scraped metrics by default.
job_name:
# How frequently to scrape targets from this job.
[ scrape_interval: | default = ]
# Per-scrape timeout when scraping this job.
[ scrape_timeout: | default = ]
# The HTTP resource path on which to fetch metrics from targets.
[ metrics_path: | default = /metrics ]
# honor_labels controls how Prometheus handles conflicts between labels that are
# already present in scraped data and labels that Prometheus would attach
# server-side ("job" and "instance" labels, manually configured target
# labels, and labels generated by service discovery implementations).
#
# If honor_labels is set to "true", label conflicts are resolved by keeping label
# values from the scraped data and ignoring the conflicting server-side labels.
#
# If honor_labels is set to "false", label conflicts are resolved by renaming
# conflicting labels in the scraped data to "exported_" (for
# example "exported_instance", "exported_job") and then attaching server-side
# labels.
#
# Setting honor_labels to "true" is useful for use cases such as federation and
# scraping the Pushgateway, where all labels specified in the target should be
# preserved.
#
# Note that any globally configured "external_labels" are unaffected by this
# setting. In communication with external systems, they are always applied only
# when a time series does not have a given label yet and are ignored otherwise.
[ honor_labels: | default = false ]
# honor_timestamps controls whether Prometheus respects the timestamps present
# in scraped data.
#
# If honor_timestamps is set to "true", the timestamps of the metrics exposed
# by the target will be used.
#
# If honor_timestamps is set to "false", the timestamps of the metrics exposed
# by the target will be ignored.
[ honor_timestamps: | default = true ]
# Configures the protocol scheme used for requests.
[ scheme: | default = http ]
# Optional HTTP URL parameters.
params:
[ : [, ...] ]
# Sets the `Authorization` header on every scrape request with the
# configured username and password.
# password and password_file are mutually exclusive.
basic_auth:
[ username: ]
[ password: ]
[ password_file: ]
# Sets the `Authorization` header on every scrape request with
# the configured bearer token. It is mutually exclusive with `bearer_token_file`.
[ bearer_token: ]
# Sets the `Authorization` header on every scrape request with the bearer token
# read from the configured file. It is mutually exclusive with `bearer_token`.
[ bearer_token_file: ]
<p>如果仔细看,应该注意一些关键信息:metrics_path和basic_auth。其中,metrics_path用于在使用HTTP类型指示符信息采集时指定路由地址,默认值为/ metrics;默认值为/ metrics。字段basic_auth用于授权验证,此处的密码可以指定密码文件,而不是直接填写纯文本(通常,指定密码文件的安全性比纯文本的安全性高)。
的数据库API调用API的经验分享
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-05-03 03:07
内容
背景
许多Internet公司通常都有存储自己的用户信息的数据库,而数据库中的数据基本上是由工程部门非常干净地解析的(使用采集器技术或对基础数据的分析主要是开发部门或数据采集工程部工作),因此许多业务数据分析人员仅使用HSQL和其他工具即可轻松获取所需的大量数据。
但是市场上有一些。他们不像B2C公司那样依靠自己的用户信息来进行产品迭代或业务增长。他们主要依靠工程部门解析第三方数据,并将结果发送给产品开发部门以构建和可视化业务平台。获取第三方数据的过程要求使用第三方API接口,这就是为什么这些公司要求申请多个职位的候选人具有调用API的经验,因为即使公司拥有自己的数据库,它也是所有工程部门。在选择性地对结果进行爬网和排序之后,您可能会面临数据库没有所需数据的困境。目前,您需要使用类似的方法来使用自己的采集数据。
API简介
调用API的过程也是一种爬虫。在抓取工具中,通常会在两个地方提到API,一个是库API,另一个是数据API。
库API
库API通常意味着开发人员已经开发了一个库(例如python库)并为用户提供了调用该库的接口。就像,我们要去包裹储物柜取走我们的快递。我们必须输入正确的信息才能表达我们的意思。此信息是一个API接口,可帮助我们准确定位该库并进行调用。
数据API
在产品开发或Web开发中,数据API就像一条从后端传递到前端的数据线。后端人员已经整理出他们想要显示的数据,只需要通过此数据线将其传输给前端开发人员,前端就可以根据需要对其进行可视化处理。而且该界面也可以被外界使用。
与网络采集器不同,数据API的设计更简单,更高效。此界面已经存储了您需要的数据,因此我们无需花费太多精力来解析网页。网页数据爬网经常给服务器带来压力。如果您的代码未设置合理的类似于人类的Web浏览频率,则存在IP被阻止的风险。
但是数据API也有一些缺点。尽管市场上有许多可以由外界使用的API产品,但是许多免费接口对爬网量有很大的限制。如果您的抓取需求很大,则需要付费。
简单的API采集器示例
下面,我将使用Facebook Graph API抓取数据作为大致记录通用数据API调用过程的示例。
调用界面信息:提供API调用地址(通常为URL格式)。此地址类似于帮助我们找到要领取的储物柜的行和列。请求获取数据:使用HTTP协议请求传输数据,通常在python的请求包中调用get函数。设置请求参数:您需要提供请求参数,也就是说,您需要告诉API接口要获取的信息类型。例如,在此示例中,我需要created_time(博客发布时间),post_id(博客post_id)和其他信息。 Facebook Graph API简介文件
尽管get函数可以帮助我们实现HTTP协议请求,但多次请求此URL需要身份验证。例如,以下代码将报告错误:
import requests
r = requests.get('https://facebook.com/user_id')
r.json()
并返回:需要身份许可。因此,在使用任何API接口时,最好事先阅读网站使用文档,以了解请求协议需要哪些特定信息。
{'documentation_url': ''https://facebook.com/user_id/% ... 39%3B,
'message': 'Requires authentication'}
它也可以在Facebook API的官方用户手册中看到。如果要获取Facebook帐户的发帖信息,则需要获取该帐户的令牌。如果您想获取自己以外的帐户信息,则还需要提前获取他们的令牌。将会有相应的获取令牌的介绍->如何获取Facebook帐户的访问令牌。
获取令牌后,测试以上代码以获取以下结果:
代码示例
目的:要获得从202 0. 0 3. 01到202 0. 0 3. 07的每个视频博客帖子的观看次数,请查看每个国家/地区的观看时间,性别和年龄段某个帐户,分析本周博客作者的视频内容的效果。
1. 首先我需要拿到3.1至3.7之间每条博文的ID(post_id)
2. 筛选出仅为视频的博文ID
3. 需要获取每条视频博文的观看次数,各个国家的观看时长
4. 将json格式的数据整理成dataframe格式
5. 将观看时长可视化
1.导入所需的软件包
import pandas as pd
import json, datetime, requests
from datetime import date, timedelta, datetime
import numpy as np
from pandas.core.frame import DataFrame
2.创建用于抓取数据的函数
<p>def get_list_of_fb_post_ids(fb_page_id, fb_token, START, END):
'''
Function to get all the post_ids from a given facebook page during certain time range
'''
posts=[] #用来存储所有博文的post_id
graph_output = requests.get('https://graph.facebook.com/%26 ... limit(10){created_time}',params=fb_token).json()
posts+=graph_output['posts']['data']
graph_output = requests.get(graph_output['posts']['paging']['next']).json()
posts+=graph_output['data']
while True: #一直读取next_page,直到某次读取的记录的时间小于你设置的开始时间
try:
graph_output = requests.get(graph_output['paging']['next']).json()
posts+=graph_output['data']
if graph_output['data'][-1]['created_time']=START)&(df_posts.created_time 查看全部
的数据库API调用API的经验分享
内容
背景
许多Internet公司通常都有存储自己的用户信息的数据库,而数据库中的数据基本上是由工程部门非常干净地解析的(使用采集器技术或对基础数据的分析主要是开发部门或数据采集工程部工作),因此许多业务数据分析人员仅使用HSQL和其他工具即可轻松获取所需的大量数据。
但是市场上有一些。他们不像B2C公司那样依靠自己的用户信息来进行产品迭代或业务增长。他们主要依靠工程部门解析第三方数据,并将结果发送给产品开发部门以构建和可视化业务平台。获取第三方数据的过程要求使用第三方API接口,这就是为什么这些公司要求申请多个职位的候选人具有调用API的经验,因为即使公司拥有自己的数据库,它也是所有工程部门。在选择性地对结果进行爬网和排序之后,您可能会面临数据库没有所需数据的困境。目前,您需要使用类似的方法来使用自己的采集数据。
API简介
调用API的过程也是一种爬虫。在抓取工具中,通常会在两个地方提到API,一个是库API,另一个是数据API。
库API
库API通常意味着开发人员已经开发了一个库(例如python库)并为用户提供了调用该库的接口。就像,我们要去包裹储物柜取走我们的快递。我们必须输入正确的信息才能表达我们的意思。此信息是一个API接口,可帮助我们准确定位该库并进行调用。
数据API
在产品开发或Web开发中,数据API就像一条从后端传递到前端的数据线。后端人员已经整理出他们想要显示的数据,只需要通过此数据线将其传输给前端开发人员,前端就可以根据需要对其进行可视化处理。而且该界面也可以被外界使用。
与网络采集器不同,数据API的设计更简单,更高效。此界面已经存储了您需要的数据,因此我们无需花费太多精力来解析网页。网页数据爬网经常给服务器带来压力。如果您的代码未设置合理的类似于人类的Web浏览频率,则存在IP被阻止的风险。
但是数据API也有一些缺点。尽管市场上有许多可以由外界使用的API产品,但是许多免费接口对爬网量有很大的限制。如果您的抓取需求很大,则需要付费。
简单的API采集器示例
下面,我将使用Facebook Graph API抓取数据作为大致记录通用数据API调用过程的示例。
调用界面信息:提供API调用地址(通常为URL格式)。此地址类似于帮助我们找到要领取的储物柜的行和列。请求获取数据:使用HTTP协议请求传输数据,通常在python的请求包中调用get函数。设置请求参数:您需要提供请求参数,也就是说,您需要告诉API接口要获取的信息类型。例如,在此示例中,我需要created_time(博客发布时间),post_id(博客post_id)和其他信息。 Facebook Graph API简介文件
尽管get函数可以帮助我们实现HTTP协议请求,但多次请求此URL需要身份验证。例如,以下代码将报告错误:
import requests
r = requests.get('https://facebook.com/user_id')
r.json()
并返回:需要身份许可。因此,在使用任何API接口时,最好事先阅读网站使用文档,以了解请求协议需要哪些特定信息。
{'documentation_url': ''https://facebook.com/user_id/% ... 39%3B,
'message': 'Requires authentication'}
它也可以在Facebook API的官方用户手册中看到。如果要获取Facebook帐户的发帖信息,则需要获取该帐户的令牌。如果您想获取自己以外的帐户信息,则还需要提前获取他们的令牌。将会有相应的获取令牌的介绍->如何获取Facebook帐户的访问令牌。
获取令牌后,测试以上代码以获取以下结果:
代码示例
目的:要获得从202 0. 0 3. 01到202 0. 0 3. 07的每个视频博客帖子的观看次数,请查看每个国家/地区的观看时间,性别和年龄段某个帐户,分析本周博客作者的视频内容的效果。
1. 首先我需要拿到3.1至3.7之间每条博文的ID(post_id)
2. 筛选出仅为视频的博文ID
3. 需要获取每条视频博文的观看次数,各个国家的观看时长
4. 将json格式的数据整理成dataframe格式
5. 将观看时长可视化
1.导入所需的软件包
import pandas as pd
import json, datetime, requests
from datetime import date, timedelta, datetime
import numpy as np
from pandas.core.frame import DataFrame
2.创建用于抓取数据的函数
<p>def get_list_of_fb_post_ids(fb_page_id, fb_token, START, END):
'''
Function to get all the post_ids from a given facebook page during certain time range
'''
posts=[] #用来存储所有博文的post_id
graph_output = requests.get('https://graph.facebook.com/%26 ... limit(10){created_time}',params=fb_token).json()
posts+=graph_output['posts']['data']
graph_output = requests.get(graph_output['posts']['paging']['next']).json()
posts+=graph_output['data']
while True: #一直读取next_page,直到某次读取的记录的时间小于你设置的开始时间
try:
graph_output = requests.get(graph_output['paging']['next']).json()
posts+=graph_output['data']
if graph_output['data'][-1]['created_time']=START)&(df_posts.created_time
优采云采集支持调用5118一键智能换词API接口(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 429 次浏览 • 2021-05-02 00:17
优采云 采集支持调用5118一键式智能单词更改API接口,处理采集数据标题和内容等,以及处理文章,对搜索引擎更具吸引力;
详细的使用步骤如下
1. 5118一键式智能单词更改API接口配置I,API配置条目:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问权限] ==”单击[第三方API配置管理] ==“最后单击[+5118一键式智能原创 API]创建接口配置;
II。配置API接口信息:
[API-Key value]用于从5118背景中获取与一键智能单词更改API对应的密钥值,并记住填写后保存;
2.创建API处理规则
API处理规则,可以将其设置为调用API接口以处理哪些字段的内容;
I。 API处理规则条目:
单击[第三方服务配置] ==“单击控制台左侧列表中的[第三方内容API访问权限] ==”,进入[API处理规则管理]页面,最后单击[+添加API处理规则]创建API处理规则;
II,API处理规则配置:
规则名称:用户可以自己命名;
字段名称:填充的字段名称的内容将由API接口处理,默认为标题和内容字段,可以对其进行修改,添加或删除;
使用的API:选择已设置的API接口配置,执行时将调用该接口,并且可以为不同的字段选择不同的API接口配置;
处理顺序:执行顺序按从小到大的顺序执行;
3. API处理规则的用法
使用API处理规则的方式有两种:手动执行和自动执行:
手动执行:在采集数据之后,使用第三方API在[结果数据和发布]中执行;
自动执行:配置自动化后,完成任务采集数据后,系统将自动执行指定的API处理规则,而无需人工操作。
I。手动执行API处理规则:
在采集任务的[结果数据和发布]选项卡中,单击[SEO&API&翻译工具]按钮==“选择[第三方API执行]列==”选择相应的API处理规则==“执行;
II。自动执行API处理规则:
启用API处理的自动执行。任务完成采集后,API处理将自动执行。通常,可以使用计时采集和自动发布功能;
在任务的[自动化:发布和SEO和翻译]选项卡中,[自动执行第三方API配置] ==“检查[采集,自动执行API]选项==”选择要执行的API处理规则==“选择由API接口处理的数据范围(通常选择”要发布“,所有将导致所有数据被多次执行),最后单击保存;
4. API处理结果和发布,查看API接口处理结果:
API接口处理的内容将另存为新字段,例如标题处理后的新字段title_5118和内容处理后的新字段content_5118,可以在[结果数据和发布中查看]和数据预览界面。
II。发布API接口的处理后内容:
发布文章之前,请在发布目标的第二步中修改映射字段,并在API接口处理之后将标题和内容更改为新的对应字段title_5118和content_5118;
查看全部
优采云采集支持调用5118一键智能换词API接口(图)
优采云 采集支持调用5118一键式智能单词更改API接口,处理采集数据标题和内容等,以及处理文章,对搜索引擎更具吸引力;
详细的使用步骤如下
1. 5118一键式智能单词更改API接口配置I,API配置条目:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问权限] ==”单击[第三方API配置管理] ==“最后单击[+5118一键式智能原创 API]创建接口配置;
II。配置API接口信息:
[API-Key value]用于从5118背景中获取与一键智能单词更改API对应的密钥值,并记住填写后保存;
2.创建API处理规则
API处理规则,可以将其设置为调用API接口以处理哪些字段的内容;
I。 API处理规则条目:
单击[第三方服务配置] ==“单击控制台左侧列表中的[第三方内容API访问权限] ==”,进入[API处理规则管理]页面,最后单击[+添加API处理规则]创建API处理规则;
II,API处理规则配置:
规则名称:用户可以自己命名;
字段名称:填充的字段名称的内容将由API接口处理,默认为标题和内容字段,可以对其进行修改,添加或删除;
使用的API:选择已设置的API接口配置,执行时将调用该接口,并且可以为不同的字段选择不同的API接口配置;
处理顺序:执行顺序按从小到大的顺序执行;
3. API处理规则的用法
使用API处理规则的方式有两种:手动执行和自动执行:
手动执行:在采集数据之后,使用第三方API在[结果数据和发布]中执行;
自动执行:配置自动化后,完成任务采集数据后,系统将自动执行指定的API处理规则,而无需人工操作。
I。手动执行API处理规则:
在采集任务的[结果数据和发布]选项卡中,单击[SEO&API&翻译工具]按钮==“选择[第三方API执行]列==”选择相应的API处理规则==“执行;
II。自动执行API处理规则:
启用API处理的自动执行。任务完成采集后,API处理将自动执行。通常,可以使用计时采集和自动发布功能;
在任务的[自动化:发布和SEO和翻译]选项卡中,[自动执行第三方API配置] ==“检查[采集,自动执行API]选项==”选择要执行的API处理规则==“选择由API接口处理的数据范围(通常选择”要发布“,所有将导致所有数据被多次执行),最后单击保存;
4. API处理结果和发布,查看API接口处理结果:
API接口处理的内容将另存为新字段,例如标题处理后的新字段title_5118和内容处理后的新字段content_5118,可以在[结果数据和发布中查看]和数据预览界面。
II。发布API接口的处理后内容:
发布文章之前,请在发布目标的第二步中修改映射字段,并在API接口处理之后将标题和内容更改为新的对应字段title_5118和content_5118;
小涴熊CMS漫画源码的安装和采集教程,文字比较多
采集交流 • 优采云 发表了文章 • 0 个评论 • 260 次浏览 • 2021-03-26 00:09
在本文文章中,我将说明Xiaoxiong cms漫画源代码和采集教程的安装。文本很多,您仍然需要一点耐心并仔细研究。在此祝大家长隆“停运”,交通流量不断增加!
环境要求:PHP 7. 0- 7. 2、 MySQL> = 5. 7、 Redis,Redis扩展(官方要求是PHP 5. 6- 7. 2,因为我测试过我发现7. 0不容易使用,因此我在这里进行了修改,并将其直接更改为7. 0- 7. 2)。
1、安装环境
这里仍然是一条简单的路线,使用宝塔面板进行演示,请使用以下命令:
#CentOS系统
wget -O install.sh && sh install.sh
#Ubuntu系统
wget -O install.sh && sudo bash install.sh
#Debian系统
wget -O install.sh && bash install.sh
安装完成后,进入面板,单击左侧的软件管理,然后安装PHP 7. 2、 Nginx,Mysql 5. 7 +,Redis。
接下来,在左侧找到“软件管理-PHP管理-设置-安装Redis扩展”。
2、安装程序
这是一条简单的路线,使用宝塔面板进行演示
1。安装宝塔后,进入面板,单击左侧的软件管理,然后安装PHP 7. 2、 Nginx,Mysql 5. 7 +,Redis。
2,让我们单击左侧的网站并添加网站!我不需要教这个!!!
3,设置伪静态规则:
if(!-e $ request_filename){
最后重写^(。*)$ /index.php?s = / $ 1;
休息;
}
4,单击域名设置-网站目录,运行该目录并选择public,取消对反跨站点的检查,然后重新启动PHP。
5,最后浏览器运行您的网站+ / install进入安装页面,并根据页面提示输入相关信息以完成安装!
注意:如果要在不显示cms错误消息的情况下启用404,则需要修改config / app.php文件:
#删除第一行中的//。
'exception_tmpl'=> Env :: get('app_path')。'index / view / pub / 40 4. html',
'exception_tmpl'=> Env :: get('think_path')。'tpl / think_exception.tpl',
采集教程
在正常情况下,漫画工作站中有两种类型的图片资源,一种是本地化的,另一种是热链接的。建议对图片进行本地化以确保网站资源的稳定性,并且程序还提供网站 k6] 采集器的API可以轻松连接到优采云 采集器,用于漫画和章节图片采集。
首先我们需要一个优采云 采集器官方网站→门户,但是它分为免费版和付费版,但是由于某些功能限制,免费版不能满足图像本地化的需求,因此暂时不适用。如果您有钱,可以购买付费版本,但如果没有钱,则可以直接使用优采云 V 7. 6企业破解版。当前最新的破解版本可能也可以满足程序的采集需求。 ,有关如何下载,请使用百度。许多网站提供下载链接。
注意:由于火车头V7和V8没有url编码解码功能,所以不能采集带有中文链接的漫画网站,但V9版本可以,有钱可以直接上。
采集 api描述:
采集api地址:域名/api/index/save
请求方式:post
表单字段及说明:
book_name 漫画名
nick_name 漫画别名
tags 分类,多个分类用|隔开
author 作者名字
src 采集源
end 状态,1代表完结,0代表连载中
cover_url 封面图远程地址
chapter_name 章节名
images 由图片标签组成的字符串,示例:
api_key 用于身份验证,要和后台配置的api密钥相同
summary 漫画简介
注意:由于优采云 V7和V8不具有URL编码和解码功能,因此采集具有中文链接网站的漫画不可用,但是V9版本还可以。如果有钱,可以直接上传。
由于采集的过程有点复杂且不易发布,有兴趣和不知道采集的朋友可以从此站点下载源代码,请查看源代码并复制并粘贴以进行浏览打开浏览器,一般步骤是打开优采云 采集器主界面-publish-new-content发布参数,然后在编写发布模块之后,开始查找目标电台并编写采集规则,最后采集发布。
这篇文章是由网民提供的,或者是由Jumawu在互联网上编写的。如果转载,请注明出处:;
如果在本网站上发布的内容侵犯了您的权利,请发送电子邮件至cnzz8#将其删除,我们将及时处理!
此站点上的大多数下载资源都采集在Internet上,并且不能保证其完整性和安全性。下载后请自己进行测试。
此网站上的资源仅用于学习和交流目的。版权属于资源的原创作者。请在下载后的24小时内有意识地删除它们。
出于商业目的,请购买正版。由于未能购买和付款而导致的侵权行为与本网站无关。 查看全部
小涴熊CMS漫画源码的安装和采集教程,文字比较多
在本文文章中,我将说明Xiaoxiong cms漫画源代码和采集教程的安装。文本很多,您仍然需要一点耐心并仔细研究。在此祝大家长隆“停运”,交通流量不断增加!
环境要求:PHP 7. 0- 7. 2、 MySQL> = 5. 7、 Redis,Redis扩展(官方要求是PHP 5. 6- 7. 2,因为我测试过我发现7. 0不容易使用,因此我在这里进行了修改,并将其直接更改为7. 0- 7. 2)。
1、安装环境
这里仍然是一条简单的路线,使用宝塔面板进行演示,请使用以下命令:
#CentOS系统
wget -O install.sh && sh install.sh
#Ubuntu系统
wget -O install.sh && sudo bash install.sh
#Debian系统
wget -O install.sh && bash install.sh
安装完成后,进入面板,单击左侧的软件管理,然后安装PHP 7. 2、 Nginx,Mysql 5. 7 +,Redis。
接下来,在左侧找到“软件管理-PHP管理-设置-安装Redis扩展”。
2、安装程序
这是一条简单的路线,使用宝塔面板进行演示
1。安装宝塔后,进入面板,单击左侧的软件管理,然后安装PHP 7. 2、 Nginx,Mysql 5. 7 +,Redis。
2,让我们单击左侧的网站并添加网站!我不需要教这个!!!
3,设置伪静态规则:
if(!-e $ request_filename){
最后重写^(。*)$ /index.php?s = / $ 1;
休息;
}
4,单击域名设置-网站目录,运行该目录并选择public,取消对反跨站点的检查,然后重新启动PHP。
5,最后浏览器运行您的网站+ / install进入安装页面,并根据页面提示输入相关信息以完成安装!
注意:如果要在不显示cms错误消息的情况下启用404,则需要修改config / app.php文件:
#删除第一行中的//。
'exception_tmpl'=> Env :: get('app_path')。'index / view / pub / 40 4. html',
'exception_tmpl'=> Env :: get('think_path')。'tpl / think_exception.tpl',
采集教程
在正常情况下,漫画工作站中有两种类型的图片资源,一种是本地化的,另一种是热链接的。建议对图片进行本地化以确保网站资源的稳定性,并且程序还提供网站 k6] 采集器的API可以轻松连接到优采云 采集器,用于漫画和章节图片采集。
首先我们需要一个优采云 采集器官方网站→门户,但是它分为免费版和付费版,但是由于某些功能限制,免费版不能满足图像本地化的需求,因此暂时不适用。如果您有钱,可以购买付费版本,但如果没有钱,则可以直接使用优采云 V 7. 6企业破解版。当前最新的破解版本可能也可以满足程序的采集需求。 ,有关如何下载,请使用百度。许多网站提供下载链接。
注意:由于火车头V7和V8没有url编码解码功能,所以不能采集带有中文链接的漫画网站,但V9版本可以,有钱可以直接上。
采集 api描述:
采集api地址:域名/api/index/save
请求方式:post
表单字段及说明:
book_name 漫画名
nick_name 漫画别名
tags 分类,多个分类用|隔开
author 作者名字
src 采集源
end 状态,1代表完结,0代表连载中
cover_url 封面图远程地址
chapter_name 章节名
images 由图片标签组成的字符串,示例:
api_key 用于身份验证,要和后台配置的api密钥相同
summary 漫画简介
注意:由于优采云 V7和V8不具有URL编码和解码功能,因此采集具有中文链接网站的漫画不可用,但是V9版本还可以。如果有钱,可以直接上传。
由于采集的过程有点复杂且不易发布,有兴趣和不知道采集的朋友可以从此站点下载源代码,请查看源代码并复制并粘贴以进行浏览打开浏览器,一般步骤是打开优采云 采集器主界面-publish-new-content发布参数,然后在编写发布模块之后,开始查找目标电台并编写采集规则,最后采集发布。
这篇文章是由网民提供的,或者是由Jumawu在互联网上编写的。如果转载,请注明出处:;
如果在本网站上发布的内容侵犯了您的权利,请发送电子邮件至cnzz8#将其删除,我们将及时处理!
此站点上的大多数下载资源都采集在Internet上,并且不能保证其完整性和安全性。下载后请自己进行测试。
此网站上的资源仅用于学习和交流目的。版权属于资源的原创作者。请在下载后的24小时内有意识地删除它们。
出于商业目的,请购买正版。由于未能购买和付款而导致的侵权行为与本网站无关。
UI,小弟照抄了你们的风格]本程序API的功能特点
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-03-20 21:15
我专注于信息采集,即自动测试。去年,我做了一个微信公众号程序采集。下半年,微信对加密算法进行了升级,因此无法停止。
前一段时间,我偶尔在我们的平台上看到此文章,对此我感到非常鼓舞。因此,在将近半个月之后,我开发了一种新的采集算法。 Wunai以前的技能太差了,因此我不得不在其他基础上改进UI,并添加了许多功能。 [感谢您爱上了怪胎的用户界面,我的兄弟复制了您的风格]
该程序的API功能:
1.支持微信公众号和微信中文名输入
2.返回的内容有
微信现在是一个广泛使用和广泛使用的社交平台。它的微信公众平台也起着重要作用,许多公司和互联网公司都在使用它进行推广和共享。接下来的需求是采集其上要使用或阅读的内容。例如,通过微信帐户采集,可以阅读和采集由其发布的优秀文章或重新打印,以使更多的人学习和交流。
目前,由于微信归腾讯所有,因此古琦文章当然不允许外界爬行。获得文章的主要方法有两种:一、与腾讯合作并打开独立的界面。 二、通过腾讯搜狗搜索的微信搜索功能进行爬网。
本文介绍了一种易于实现的在线微信文章工具文章,该工具为文章 采集提供了一个指定的官方帐户,并批量获取了文章的标题和地址链接,并提供了第三个方API。使用和二次开发。
微信现在是一个广泛使用和广泛使用的社交平台。它的微信公众平台也起着重要作用,许多公司和互联网公司都在使用它进行推广和共享。接下来的需求是采集其上要使用或阅读的内容。例如,通过微信帐户采集,可以阅读和采集由其发布的优秀文章,或将其重新打印以供更多人学习和交流。
目前,由于微信归腾讯所有,因此古琦文章当然不允许外界爬行。
本文介绍了一种易于实现的在线微信文章工具文章,该工具为文章 采集提供了一个指定的官方帐户,并批量获取了文章的标题和地址链接,并提供了第三个方API。使用和二次开发。
在线使用
功能介绍
您无需登录即可获取微信官方帐户(订阅帐户)发布的所有文章标题和地址,并且结果可以JSON格式反馈并可以TABLE格式在线读取,并且可以使用外部API同时提供。
支持二次开发:每天自动获取最新的微信官方帐户文章,更新为自营微信官方帐户,论坛(DISCUZ,PHPWIND),博客(WORDPRESS),订阅信息(RSS)等。
使用方法
登录微信公众号提取网站
API使用率
以POST / GET形式提交微信公众号weixin和用户密钥,以JSON / JSONP形式返回数据
请求网址:
请求参数:wxID = {$ wxID}&key = {$ key}
返回数据:转到网站查看,此处不会发布任何代码
测试:采集《人民日报》微信官方帐户
网页显示示例:
API返回JSON的示例:+ iIR + 5Ab52dVh73DsX / XYLlT / kHU9LNL6F71o0yGcChSEq
注意:以上内容仅供研究使用,请勿将其用于非法目的。
[为了防止过度使用资源或不必要的麻烦,该页面具有一个临时KEY(有效期为2分钟,可以刷新并重新获得)。 ) 查看全部
UI,小弟照抄了你们的风格]本程序API的功能特点
我专注于信息采集,即自动测试。去年,我做了一个微信公众号程序采集。下半年,微信对加密算法进行了升级,因此无法停止。
前一段时间,我偶尔在我们的平台上看到此文章,对此我感到非常鼓舞。因此,在将近半个月之后,我开发了一种新的采集算法。 Wunai以前的技能太差了,因此我不得不在其他基础上改进UI,并添加了许多功能。 [感谢您爱上了怪胎的用户界面,我的兄弟复制了您的风格]
该程序的API功能:
1.支持微信公众号和微信中文名输入
2.返回的内容有
微信现在是一个广泛使用和广泛使用的社交平台。它的微信公众平台也起着重要作用,许多公司和互联网公司都在使用它进行推广和共享。接下来的需求是采集其上要使用或阅读的内容。例如,通过微信帐户采集,可以阅读和采集由其发布的优秀文章或重新打印,以使更多的人学习和交流。
目前,由于微信归腾讯所有,因此古琦文章当然不允许外界爬行。获得文章的主要方法有两种:一、与腾讯合作并打开独立的界面。 二、通过腾讯搜狗搜索的微信搜索功能进行爬网。
本文介绍了一种易于实现的在线微信文章工具文章,该工具为文章 采集提供了一个指定的官方帐户,并批量获取了文章的标题和地址链接,并提供了第三个方API。使用和二次开发。
微信现在是一个广泛使用和广泛使用的社交平台。它的微信公众平台也起着重要作用,许多公司和互联网公司都在使用它进行推广和共享。接下来的需求是采集其上要使用或阅读的内容。例如,通过微信帐户采集,可以阅读和采集由其发布的优秀文章,或将其重新打印以供更多人学习和交流。
目前,由于微信归腾讯所有,因此古琦文章当然不允许外界爬行。
本文介绍了一种易于实现的在线微信文章工具文章,该工具为文章 采集提供了一个指定的官方帐户,并批量获取了文章的标题和地址链接,并提供了第三个方API。使用和二次开发。
在线使用
功能介绍
您无需登录即可获取微信官方帐户(订阅帐户)发布的所有文章标题和地址,并且结果可以JSON格式反馈并可以TABLE格式在线读取,并且可以使用外部API同时提供。
支持二次开发:每天自动获取最新的微信官方帐户文章,更新为自营微信官方帐户,论坛(DISCUZ,PHPWIND),博客(WORDPRESS),订阅信息(RSS)等。
使用方法
登录微信公众号提取网站
API使用率
以POST / GET形式提交微信公众号weixin和用户密钥,以JSON / JSONP形式返回数据
请求网址:
请求参数:wxID = {$ wxID}&key = {$ key}
返回数据:转到网站查看,此处不会发布任何代码
测试:采集《人民日报》微信官方帐户
网页显示示例:
API返回JSON的示例:+ iIR + 5Ab52dVh73DsX / XYLlT / kHU9LNL6F71o0yGcChSEq
注意:以上内容仅供研究使用,请勿将其用于非法目的。
[为了防止过度使用资源或不必要的麻烦,该页面具有一个临时KEY(有效期为2分钟,可以刷新并重新获得)。 )
今日头条采集接入写作社API教程-优采云控制台如何使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 1293 次浏览 • 2021-01-17 12:11
优采云导航:优采云 采集优采云控制台如何使用优采云 SEO工具微信公众号文章采集今天的标题采集
访问写作机构API教程-优采云 采集
优采云 采集支持调用书写机构API接口来处理采集等的数据标题和内容;
提醒:第三方API访问功能需要优采云旗舰软件包来支持使用,并且用户需要提供第三方接口帐户信息(即,用户需要注册第三方界面,并且调用第三方界面所产生的所有费用均由用户承担);
请联系写作机构的客户服务(QQ:193650808)以购买写作机构API,并告知其已在优采云 采集平台上使用。
详细的使用步骤1.创建书写机构API接口配置I,API配置入口:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问] ==”单击[第三方API配置管理] ==“最后单击[编写Club_Rewrite接口API]创建接口配置;
II。配置API接口信息:
要购买写作机构的API,请联系写作机构的客户服务(QQ:193650808),并告知其已在优采云 采集平台上使用。
[API密钥],请联系写作机构的客户服务部门以获取相应的API密钥,并填写优采云;
注意:写作机构将每次调用的最大长度限制为6000个字符(包括html代码),因此,如果内容长度超出限制,则优采云将被分割并多次调用。此操作将增加api调用的次数和成本,也将相应增加。这是用户需要承担的费用。使用前请小心! ! !
2.创建API处理规则
API处理规则,可以将其设置为调用API接口以处理哪些字段的内容;
I。 API处理规则条目:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问权限] ==进入[API处理规则管理]页面,最后单击[添加API处理规则]创建API处理规则;
II,API处理规则配置:
注意:当API处理1个字段时,API接口将被调用一次,因此建议不要添加不需要的字段!
3.API处理规则的用法
使用API处理规则的方式有两种:手动执行和自动执行:
I。手动执行API处理规则:
在采集任务的[结果和发布]选项卡中,单击[SEO&API&翻译和其他工具]按钮==“选择[第三方API执行]列==”选择相应的API处理规则==“执行(数据范围有两种执行方法,根据发布状态批量执行和根据列表中选择的数据执行);
II。自动执行API处理规则:
启用API处理的自动执行。任务完成采集后,API处理将自动执行。定时采集和自动发布功能通常很方便;
在任务的[自动化:发布和SEO和翻译]选项卡中,[自动执行第三方API配置] ==“选中[采集,自动执行API]选项==”选择要执行的API处理==“选择由API接口处理的数据范围(通常选择”要发布“,所有将导致所有数据被执行多次),最后单击保存;
4.API处理结果和发布,查看API接口处理结果:
API接口处理的内容将另存为新字段,例如:
可以在[结果数据和发布]和数据预览界面中查看它。
提醒:执行API处理规则需要花费一些时间。执行后,页面将自动刷新,并在API接口处理后显示新字段;
II,API接口处理后的内容发布
发布文章之前,请在发布目标的第二步中修改映射字段,并在经过API接口处理后将标题和内容更改为新的对应字段title_写作俱乐部和content_写作俱乐部;
提醒:如果无法在发布目标中选择新字段,请在此任务下复制或创建新的发布目标,然后可以在新发布目标中选择新字段。可以查看详细的教程;
5.编写代理程序-API接口的常见问题和解决方法I,如何一起使用API处理规则和SEO规则?
系统默认对标题和内容字段执行SEO功能,需要将其修改为SEO规则中的title_写作俱乐部和content_写作俱乐部字段;
优采云导航:优采云 采集优采云控制台如何使用优采云 SEO工具微信公众号文章采集今天的标题采集 查看全部
今日头条采集接入写作社API教程-优采云控制台如何使用
优采云导航:优采云 采集优采云控制台如何使用优采云 SEO工具微信公众号文章采集今天的标题采集
访问写作机构API教程-优采云 采集
优采云 采集支持调用书写机构API接口来处理采集等的数据标题和内容;
提醒:第三方API访问功能需要优采云旗舰软件包来支持使用,并且用户需要提供第三方接口帐户信息(即,用户需要注册第三方界面,并且调用第三方界面所产生的所有费用均由用户承担);
请联系写作机构的客户服务(QQ:193650808)以购买写作机构API,并告知其已在优采云 采集平台上使用。
详细的使用步骤1.创建书写机构API接口配置I,API配置入口:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问] ==”单击[第三方API配置管理] ==“最后单击[编写Club_Rewrite接口API]创建接口配置;
II。配置API接口信息:
要购买写作机构的API,请联系写作机构的客户服务(QQ:193650808),并告知其已在优采云 采集平台上使用。
[API密钥],请联系写作机构的客户服务部门以获取相应的API密钥,并填写优采云;
注意:写作机构将每次调用的最大长度限制为6000个字符(包括html代码),因此,如果内容长度超出限制,则优采云将被分割并多次调用。此操作将增加api调用的次数和成本,也将相应增加。这是用户需要承担的费用。使用前请小心! ! !
2.创建API处理规则
API处理规则,可以将其设置为调用API接口以处理哪些字段的内容;
I。 API处理规则条目:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问权限] ==进入[API处理规则管理]页面,最后单击[添加API处理规则]创建API处理规则;
II,API处理规则配置:
注意:当API处理1个字段时,API接口将被调用一次,因此建议不要添加不需要的字段!
3.API处理规则的用法
使用API处理规则的方式有两种:手动执行和自动执行:
I。手动执行API处理规则:
在采集任务的[结果和发布]选项卡中,单击[SEO&API&翻译和其他工具]按钮==“选择[第三方API执行]列==”选择相应的API处理规则==“执行(数据范围有两种执行方法,根据发布状态批量执行和根据列表中选择的数据执行);
II。自动执行API处理规则:
启用API处理的自动执行。任务完成采集后,API处理将自动执行。定时采集和自动发布功能通常很方便;
在任务的[自动化:发布和SEO和翻译]选项卡中,[自动执行第三方API配置] ==“选中[采集,自动执行API]选项==”选择要执行的API处理==“选择由API接口处理的数据范围(通常选择”要发布“,所有将导致所有数据被执行多次),最后单击保存;
4.API处理结果和发布,查看API接口处理结果:
API接口处理的内容将另存为新字段,例如:
可以在[结果数据和发布]和数据预览界面中查看它。
提醒:执行API处理规则需要花费一些时间。执行后,页面将自动刷新,并在API接口处理后显示新字段;
II,API接口处理后的内容发布
发布文章之前,请在发布目标的第二步中修改映射字段,并在经过API接口处理后将标题和内容更改为新的对应字段title_写作俱乐部和content_写作俱乐部;
提醒:如果无法在发布目标中选择新字段,请在此任务下复制或创建新的发布目标,然后可以在新发布目标中选择新字段。可以查看详细的教程;
5.编写代理程序-API接口的常见问题和解决方法I,如何一起使用API处理规则和SEO规则?
系统默认对标题和内容字段执行SEO功能,需要将其修改为SEO规则中的title_写作俱乐部和content_写作俱乐部字段;
优采云导航:优采云 采集优采云控制台如何使用优采云 SEO工具微信公众号文章采集今天的标题采集
技术文章:博易网API接口_免费接口源码_自动采集_php接口网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 329 次浏览 • 2021-01-16 09:01
本网站提供的“ Boyiwang API interface_free接口源代码_auto采集_php接口网站”资源来自Internet。版权纠纷与本网站无关,版权属于原创的所有者!它仅用于学习和研究目的,并且以上内容资源不得用于商业或非法目的。否则,用户应对所有后果负责。
1.本网站上的所有内容均从Internet采集并由网民上传,仅供您参考和学习。没有商业目的或商业用途。
2.如果您需要商业运作或其他商业活动,请购买正版许可证并合法使用。
3.如果您也有不错的源代码或教程,则可以将其发布在审阅区域中,并分享奖励和额外收入!
4.不能保证所有资源都是完整的和可用的,也不排除BUG或不完整的可能性。由于资源的特殊性,下载后将不会将其退回。
5.魔方资源网不提供任何技术支持和安装服务,请您自己评估。
6.如果存在无法下载,无效或带有广告的链接,请联系客服QQ:3420634106尽快为您处理!
7.本网站上的所有资源均不收费。用户只需要登录并登录即可获取相应的魔币,以交换学习和参考。所有会员费网站均用于网站运营和维护成本,与资源无关!
8.如果遇到加密的压缩包,则默认的解压缩密码为“或”,如果无法解压缩,请与管理员联系!
9.如果链接失败或侵犯版权,请首先与我们联系。点击这里给我发消息 查看全部
技术文章:博易网API接口_免费接口源码_自动采集_php接口网站
本网站提供的“ Boyiwang API interface_free接口源代码_auto采集_php接口网站”资源来自Internet。版权纠纷与本网站无关,版权属于原创的所有者!它仅用于学习和研究目的,并且以上内容资源不得用于商业或非法目的。否则,用户应对所有后果负责。
1.本网站上的所有内容均从Internet采集并由网民上传,仅供您参考和学习。没有商业目的或商业用途。
2.如果您需要商业运作或其他商业活动,请购买正版许可证并合法使用。
3.如果您也有不错的源代码或教程,则可以将其发布在审阅区域中,并分享奖励和额外收入!
4.不能保证所有资源都是完整的和可用的,也不排除BUG或不完整的可能性。由于资源的特殊性,下载后将不会将其退回。
5.魔方资源网不提供任何技术支持和安装服务,请您自己评估。
6.如果存在无法下载,无效或带有广告的链接,请联系客服QQ:3420634106尽快为您处理!
7.本网站上的所有资源均不收费。用户只需要登录并登录即可获取相应的魔币,以交换学习和参考。所有会员费网站均用于网站运营和维护成本,与资源无关!
8.如果遇到加密的压缩包,则默认的解压缩密码为“或”,如果无法解压缩,请与管理员联系!
9.如果链接失败或侵犯版权,请首先与我们联系。点击这里给我发消息
汇总:数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2021-01-13 11:10
数据采集
智能云采集器基于自行开发的分布式数据采集引擎,涵盖全球30,000网站平台和500个移动应用程序。各行各业的企业可以利用自身的优势和想象力,使用丰富多样的数据来开发自己的大数据应用程序。通过调用标准的Internet数据接口来完成数据采集的工作,颠覆了传统的Internet数据捕获方法,解决了数据清理麻烦,爬虫维护麻烦等问题
目前,每天超过500万家酒店的500万家互联网新闻文章,1500万个FB用户动态信息,1000万个微博帖子,5000万个商业数据信息以及1000万种房型都在不断更新,从而领先于世界数据采集能力
数据融合
在采集的过程中,大数据将在相同类型的不同平台上遇到数据结构的不一致。 99API智能数据融合,在采集过程中,根据采集平台的类型,选择合适的预定义数据结构进行适配,实现同类型平台的智能异构集成,规范数据结构,大大减少了底层数据,提高了客户清理数据的难度,促进了系统对接和开发人员程序对接
数据分析
通过Hadoop,Spark,TensorFlow和其他数据分析和挖掘框架,为大数据操作提供技术支持。实现数据统计分析,提供多种高级统计分析模型,可根据需要进行复杂的高级统计,并可以多层次,多角度显示数据,支持数据分析的可视化。基于独立知识产权的算法模型实现了文本挖掘的各种功能,包括Internet上非结构化文本数据的结构化处理,实体,关键词,主题,情感倾向和文章类别的智能提取。 ,准确率超过90%
数据管理
在当前流行的EFK(Elasticsearch,Filebeat,Kibana)的基础上,实现数据管理和监控,Internet大数据的分布式存储,提高容错性和并发性,并且适合于Internet异构大数据的集成,即将数据存储到统一JSON(JavaScript对象表示法)中。 JSON是一种标准化,轻量级且Internet通用的数据交换格式。同时实现了数据日志的可视化监控和7 * 24小时的数据监控 查看全部
汇总:数据采集
数据采集
智能云采集器基于自行开发的分布式数据采集引擎,涵盖全球30,000网站平台和500个移动应用程序。各行各业的企业可以利用自身的优势和想象力,使用丰富多样的数据来开发自己的大数据应用程序。通过调用标准的Internet数据接口来完成数据采集的工作,颠覆了传统的Internet数据捕获方法,解决了数据清理麻烦,爬虫维护麻烦等问题
目前,每天超过500万家酒店的500万家互联网新闻文章,1500万个FB用户动态信息,1000万个微博帖子,5000万个商业数据信息以及1000万种房型都在不断更新,从而领先于世界数据采集能力
数据融合
在采集的过程中,大数据将在相同类型的不同平台上遇到数据结构的不一致。 99API智能数据融合,在采集过程中,根据采集平台的类型,选择合适的预定义数据结构进行适配,实现同类型平台的智能异构集成,规范数据结构,大大减少了底层数据,提高了客户清理数据的难度,促进了系统对接和开发人员程序对接
数据分析
通过Hadoop,Spark,TensorFlow和其他数据分析和挖掘框架,为大数据操作提供技术支持。实现数据统计分析,提供多种高级统计分析模型,可根据需要进行复杂的高级统计,并可以多层次,多角度显示数据,支持数据分析的可视化。基于独立知识产权的算法模型实现了文本挖掘的各种功能,包括Internet上非结构化文本数据的结构化处理,实体,关键词,主题,情感倾向和文章类别的智能提取。 ,准确率超过90%
数据管理
在当前流行的EFK(Elasticsearch,Filebeat,Kibana)的基础上,实现数据管理和监控,Internet大数据的分布式存储,提高容错性和并发性,并且适合于Internet异构大数据的集成,即将数据存储到统一JSON(JavaScript对象表示法)中。 JSON是一种标准化,轻量级且Internet通用的数据交换格式。同时实现了数据日志的可视化监控和7 * 24小时的数据监控
解密:基于Python采集爬取微信公众号历史数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 589 次浏览 • 2020-12-27 10:12
基于Python抓取微信公众号的历史数据采集
更新时间:2020年11月27日09:22:47作者:Tempo父亲
本文文章主要介绍了基于Python 采集的微信公众号历史数据的抓取。本文介绍的示例代码非常详细。它对每个人的学习或工作都有一定的参考学习价值。需要它的朋友可以参考
Kun Zhipeng的技术人员将在本文中介绍一种通过操作微信应用程序采集模拟官方帐户的所有历史数据的方法。
通过数据包捕获分析,我们发现微信公众号的历史数据是通过HTTP协议加载的。相应的API接口如下图所示,它具有四个关键参数(__biz,appmsg_token,pass_ticket和Cookie)。
为了能够获得这四个参数,我们需要模拟App的操作,让其生成这些参数,然后捕获数据包。对于模拟的App操作,我们介绍了通过Python模拟Android App的方法(请参阅详细信息)。对于HTTP集成捕获,我们之前已经引入了Mitmproxy(请参阅详细信息)。
我们需要模拟微信的操作以完成以下步骤:
1.启动微信应用程序
2.点击“联系人”
3.点击“官方帐户”
4.单击官方帐户以采集
5.单击右上角的用户图片图标
6.单击“所有消息”
这时,我们可以从响应数据以及请求标头中的Cookie值中捕获__biz,appmsg_token和pass_ticket的三个关键参数。如下所示。
使用上述四个参数,我们可以构造一个API请求以获取历史记录文章列表,并通过调用API接口直接获取数据(无需模拟App操作)。核心参数如下。通过更改offset参数,您可以获得所有历史数据。
# Cookie
headers = {'Cookie': 'rewardsn=; wxtokenkey=777; wxuin=584068438; devicetype=android-19; version=26060736; lang=zh_CN; pass_ticket=Rr8cO5c2******3tKGqe7aVZzV9TupvrK+1uHHmHYQGL2WFdKIE; wap_sid2=COKhxu4KElxckFZQ3QzTHU4WThEUk0zcWdrZjhGcUdYdEVSV3Y1X2NPWHNUakRrd1ZzMnpLTERpdE5rbmxjSTg******dlRBcUNRazZpOGxTZUVEQUTgNQJVO'}
url = 'https://mp.weixin.qq.com/mp/profile_ext?'
data = {}
data['is_ok'] = '1'
data['count'] = '10'
data['wxtoken'] = ''
data['f'] = 'json'
data['scene'] = '124'
data['uin'] = '777'
data['key'] = '777'
data['offset'] = '0'
data['action'] = 'getmsg'
data['x5'] = '0'
# 下面三个参数需要替换
# https://mp.weixin.qq.com/mp/pr ... Dhome应答数据里会暴漏这三个参数
data['__biz'] = 'MjM5MzQyOTM1OQ=='
data['appmsg_token'] = '993_V8%2BEmfVD7g%2FvMZ****4DNUJNFkg~~'
data['pass_ticket'] = 'Rr8cO5c23ZngeQHRGy8E7gv*****pvrK+1uHHmHYQGL2WFdKIE'
url = url + urllib.urlencode(data)
以“数字工厂”的微信公众号为例,采集过程操作的截图如下:
输出结果的屏幕截图如下:
以上是本文的全部内容,希望对大家的学习有所帮助,并希望您能更多地支持Scripthome。 查看全部
解密:基于Python采集爬取微信公众号历史数据
基于Python抓取微信公众号的历史数据采集
更新时间:2020年11月27日09:22:47作者:Tempo父亲
本文文章主要介绍了基于Python 采集的微信公众号历史数据的抓取。本文介绍的示例代码非常详细。它对每个人的学习或工作都有一定的参考学习价值。需要它的朋友可以参考
Kun Zhipeng的技术人员将在本文中介绍一种通过操作微信应用程序采集模拟官方帐户的所有历史数据的方法。
通过数据包捕获分析,我们发现微信公众号的历史数据是通过HTTP协议加载的。相应的API接口如下图所示,它具有四个关键参数(__biz,appmsg_token,pass_ticket和Cookie)。
为了能够获得这四个参数,我们需要模拟App的操作,让其生成这些参数,然后捕获数据包。对于模拟的App操作,我们介绍了通过Python模拟Android App的方法(请参阅详细信息)。对于HTTP集成捕获,我们之前已经引入了Mitmproxy(请参阅详细信息)。
我们需要模拟微信的操作以完成以下步骤:
1.启动微信应用程序
2.点击“联系人”
3.点击“官方帐户”
4.单击官方帐户以采集
5.单击右上角的用户图片图标
6.单击“所有消息”
这时,我们可以从响应数据以及请求标头中的Cookie值中捕获__biz,appmsg_token和pass_ticket的三个关键参数。如下所示。
使用上述四个参数,我们可以构造一个API请求以获取历史记录文章列表,并通过调用API接口直接获取数据(无需模拟App操作)。核心参数如下。通过更改offset参数,您可以获得所有历史数据。
# Cookie
headers = {'Cookie': 'rewardsn=; wxtokenkey=777; wxuin=584068438; devicetype=android-19; version=26060736; lang=zh_CN; pass_ticket=Rr8cO5c2******3tKGqe7aVZzV9TupvrK+1uHHmHYQGL2WFdKIE; wap_sid2=COKhxu4KElxckFZQ3QzTHU4WThEUk0zcWdrZjhGcUdYdEVSV3Y1X2NPWHNUakRrd1ZzMnpLTERpdE5rbmxjSTg******dlRBcUNRazZpOGxTZUVEQUTgNQJVO'}
url = 'https://mp.weixin.qq.com/mp/profile_ext?'
data = {}
data['is_ok'] = '1'
data['count'] = '10'
data['wxtoken'] = ''
data['f'] = 'json'
data['scene'] = '124'
data['uin'] = '777'
data['key'] = '777'
data['offset'] = '0'
data['action'] = 'getmsg'
data['x5'] = '0'
# 下面三个参数需要替换
# https://mp.weixin.qq.com/mp/pr ... Dhome应答数据里会暴漏这三个参数
data['__biz'] = 'MjM5MzQyOTM1OQ=='
data['appmsg_token'] = '993_V8%2BEmfVD7g%2FvMZ****4DNUJNFkg~~'
data['pass_ticket'] = 'Rr8cO5c23ZngeQHRGy8E7gv*****pvrK+1uHHmHYQGL2WFdKIE'
url = url + urllib.urlencode(data)
以“数字工厂”的微信公众号为例,采集过程操作的截图如下:
输出结果的屏幕截图如下:
以上是本文的全部内容,希望对大家的学习有所帮助,并希望您能更多地支持Scripthome。
干货教程:优采云采集接入写作社API详细教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 305 次浏览 • 2020-12-20 09:13
优采云采集支持调用书写机构API接口来处理采集等的数据标题和内容;
详细步骤如下:
1.创建书写代理商API接口配置I,API配置入口:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问权限] ==”单击[第三方API配置管理] ==“最后,单击[Writing Club_Rewrite接口API]创建接口配置;
II。配置API接口信息:
要购买写作机构的API,请联系写作机构的客户服务并告知其已在优采云采集平台上使用。
[API密钥],请联系写作机构的客户服务部门以获取相应的API密钥,并填写优采云;
注意:写作机构将每次调用的最大长度限制为6000个字符(包括html代码),因此,如果内容长度超出限制,则优采云将被分割并多次调用。此操作将增加api调用的次数和成本,也将相应增加。这是用户需要承担的费用。使用前请小心! ! !
2.创建API处理规则
API处理规则,可以将其设置为调用API接口以处理哪些字段的内容;
I。 API处理规则条目:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问] ==”,进入[API处理规则管理]页面,最后单击[添加API处理规则]创建API处理规则;
II,API处理规则配置:
规则名称:用户可以自己命名;
字段名称:填充的字段名称的内容将由API接口处理。默认为标题和内容字段,可以对其进行修改,添加或删除;
使用的API:选择已设置的API接口配置,执行时将调用该接口,并且可以为多个字段选择不同的API接口配置;
处理顺序:执行顺序是按从小到大的顺序执行的;
3.API处理规则的用法
使用API处理规则的方式有两种:手动执行和自动执行:
手动执行:在采集数据之后,使用第三方API在[结果数据和发布]中执行;
自动执行:配置自动化后,完成任务采集数据后,系统将自动执行指定的API处理规则,而无需人工操作。
I。手动执行API处理规则:
在采集任务的[结果数据和发布]选项卡中单击[SEO&API&翻译和其他工具]按钮==“选择[第三方API执行]列==”选择相应的API处理规则==“执行(数据范围有两种执行方法,根据发布状态批量执行和根据列表中选择的数据执行);
II。自动执行API处理规则:
启用API处理的自动执行。任务完成采集后,API处理将自动执行。定时采集和自动发布功能通常很方便;
在任务的[自动化:发布和SEO和翻译]选项卡中,[自动执行第三方API配置] ==“选中[采集,自动执行API]选项==”选择要执行的API处理规则==“选择由API接口处理的数据范围(通常选择”要发布“,所有将导致所有数据被多次执行),最后单击保存;
4.API处理结果和发布,查看API接口处理结果:
API接口处理的内容将另存为新字段,例如:
在标题处理后添加新字段:title_写作俱乐部
在内容处理后添加新字段:content_ Writing club
可以在[结果数据和发布]和数据预览界面中查看它。
提醒:API处理规则需要一段时间才能执行。执行后,页面将自动刷新,并显示由API界面处理的新字段;
II,API接口处理后的内容发布
发布文章之前,请在发布目标的第二步中修改映射字段,并在经过API接口处理后将标题和内容更改为新的对应字段title_写作俱乐部和content_写作俱乐部;
提醒:如果无法在发布目标中选择新字段,请在此任务下复制或创建新的发布目标,然后可以在新发布目标中选择新字段。对于详细的教程,您可以查看发布目标无法选择的字段;
5.编写Club-API接口常见问题和解决方法
I。如何同时使用API处理规则和SEO规则?
系统默认对标题和内容字段执行SEO功能,需要将其修改为SEO规则中的title_写作俱乐部和content_写作俱乐部字段;
查看全部
干货教程:优采云采集接入写作社API详细教程
优采云采集支持调用书写机构API接口来处理采集等的数据标题和内容;
详细步骤如下:
1.创建书写代理商API接口配置I,API配置入口:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问权限] ==”单击[第三方API配置管理] ==“最后,单击[Writing Club_Rewrite接口API]创建接口配置;
II。配置API接口信息:
要购买写作机构的API,请联系写作机构的客户服务并告知其已在优采云采集平台上使用。
[API密钥],请联系写作机构的客户服务部门以获取相应的API密钥,并填写优采云;
注意:写作机构将每次调用的最大长度限制为6000个字符(包括html代码),因此,如果内容长度超出限制,则优采云将被分割并多次调用。此操作将增加api调用的次数和成本,也将相应增加。这是用户需要承担的费用。使用前请小心! ! !
2.创建API处理规则
API处理规则,可以将其设置为调用API接口以处理哪些字段的内容;
I。 API处理规则条目:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问] ==”,进入[API处理规则管理]页面,最后单击[添加API处理规则]创建API处理规则;
II,API处理规则配置:
规则名称:用户可以自己命名;
字段名称:填充的字段名称的内容将由API接口处理。默认为标题和内容字段,可以对其进行修改,添加或删除;
使用的API:选择已设置的API接口配置,执行时将调用该接口,并且可以为多个字段选择不同的API接口配置;
处理顺序:执行顺序是按从小到大的顺序执行的;
3.API处理规则的用法
使用API处理规则的方式有两种:手动执行和自动执行:
手动执行:在采集数据之后,使用第三方API在[结果数据和发布]中执行;
自动执行:配置自动化后,完成任务采集数据后,系统将自动执行指定的API处理规则,而无需人工操作。
I。手动执行API处理规则:
在采集任务的[结果数据和发布]选项卡中单击[SEO&API&翻译和其他工具]按钮==“选择[第三方API执行]列==”选择相应的API处理规则==“执行(数据范围有两种执行方法,根据发布状态批量执行和根据列表中选择的数据执行);
II。自动执行API处理规则:
启用API处理的自动执行。任务完成采集后,API处理将自动执行。定时采集和自动发布功能通常很方便;
在任务的[自动化:发布和SEO和翻译]选项卡中,[自动执行第三方API配置] ==“选中[采集,自动执行API]选项==”选择要执行的API处理规则==“选择由API接口处理的数据范围(通常选择”要发布“,所有将导致所有数据被多次执行),最后单击保存;
4.API处理结果和发布,查看API接口处理结果:
API接口处理的内容将另存为新字段,例如:
在标题处理后添加新字段:title_写作俱乐部
在内容处理后添加新字段:content_ Writing club
可以在[结果数据和发布]和数据预览界面中查看它。
提醒:API处理规则需要一段时间才能执行。执行后,页面将自动刷新,并显示由API界面处理的新字段;
II,API接口处理后的内容发布
发布文章之前,请在发布目标的第二步中修改映射字段,并在经过API接口处理后将标题和内容更改为新的对应字段title_写作俱乐部和content_写作俱乐部;
提醒:如果无法在发布目标中选择新字段,请在此任务下复制或创建新的发布目标,然后可以在新发布目标中选择新字段。对于详细的教程,您可以查看发布目标无法选择的字段;
5.编写Club-API接口常见问题和解决方法
I。如何同时使用API处理规则和SEO规则?
系统默认对标题和内容字段执行SEO功能,需要将其修改为SEO规则中的title_写作俱乐部和content_写作俱乐部字段;
解决方案:优采云采集接入写作社API详细教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 290 次浏览 • 2020-12-19 10:19
优采云采集支持调用书写机构API接口来处理采集,关键词,描述等的数据标题和内容。可以通过优采云采集的SEO功能来定位]和写作机构API来处理原创程度更高的文章,这对于增加文章的收录和网站的权重具有非常重要的作用。
详细的使用步骤
1.创建书写代理商API接口配置
I。 API配置入口:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问权限] ==”单击[第三方API配置管理] ==“最后,单击[Writing Club_Rewrite接口API]创建接口配置;
II。配置API接口信息:
要购买写作机构的API,请联系写作机构的客户服务并告知其已在优采云采集平台上使用。
[API密钥],请联系写作机构的客户服务部门以获取相应的API密钥,并填写优采云;
2.创建API处理规则
API处理规则,可以将其设置为调用API接口以处理哪些字段的内容;
I。 API处理规则条目:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问] ==”,进入[API处理规则管理]页面,最后单击[添加API处理规则]创建API处理规则;
II,API处理规则配置:
3.API处理规则的用法
使用API处理规则的方式有两种:手动执行和自动执行:
I。手动执行API处理规则:
在采集任务的[结果数据和发布]选项卡中单击[SEO&API&翻译和其他工具]按钮==“选择[第三方API执行]列==”选择相应的API处理规则==“执行(数据范围有两种执行方法,根据发布状态批量执行和根据列表中选择的数据执行);
II。自动执行API处理规则:
启用API处理的自动执行。任务完成采集后,API处理将自动执行。定时采集和自动发布功能通常很方便;
在任务的[自动化:发布和SEO和翻译]选项卡中,[自动执行第三方API配置] ==“选中[采集,自动执行API]选项==”选择要执行的API处理规则==“选择由API接口处理的数据范围(通常选择”要发布“,所有将导致所有数据被多次执行),最后单击保存;
4.API处理结果和发布
I。查看API接口处理的结果:
API接口处理的内容将另存为新字段,例如:
可以在[结果数据和发布]和数据预览界面中查看它。
提醒:API处理规则需要一段时间才能执行。执行后,页面将自动刷新,并显示由API界面处理的新字段;
II,API接口处理后的内容发布
发布文章之前,请在发布目标的第二步中修改映射字段,并在经过API接口处理后将标题和内容更改为新的对应字段title_写作俱乐部和content_写作俱乐部;
提醒:如果无法在发布目标中选择新字段,请在此任务下复制或创建新的发布目标,然后可以在新发布目标中选择新字段。可以查看详细的教程;
5.编写Club-API接口常见问题和解决方法
I。如何同时使用API处理规则和SEO规则?
系统默认对标题和内容字段执行SEO功能,需要将其修改为SEO规则中的title_写作俱乐部和content_写作俱乐部字段;
查看全部
解决方案:优采云采集接入写作社API详细教程
优采云采集支持调用书写机构API接口来处理采集,关键词,描述等的数据标题和内容。可以通过优采云采集的SEO功能来定位]和写作机构API来处理原创程度更高的文章,这对于增加文章的收录和网站的权重具有非常重要的作用。
详细的使用步骤
1.创建书写代理商API接口配置
I。 API配置入口:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问权限] ==”单击[第三方API配置管理] ==“最后,单击[Writing Club_Rewrite接口API]创建接口配置;
II。配置API接口信息:
要购买写作机构的API,请联系写作机构的客户服务并告知其已在优采云采集平台上使用。
[API密钥],请联系写作机构的客户服务部门以获取相应的API密钥,并填写优采云;
2.创建API处理规则
API处理规则,可以将其设置为调用API接口以处理哪些字段的内容;
I。 API处理规则条目:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问] ==”,进入[API处理规则管理]页面,最后单击[添加API处理规则]创建API处理规则;
II,API处理规则配置:
3.API处理规则的用法
使用API处理规则的方式有两种:手动执行和自动执行:
I。手动执行API处理规则:
在采集任务的[结果数据和发布]选项卡中单击[SEO&API&翻译和其他工具]按钮==“选择[第三方API执行]列==”选择相应的API处理规则==“执行(数据范围有两种执行方法,根据发布状态批量执行和根据列表中选择的数据执行);
II。自动执行API处理规则:
启用API处理的自动执行。任务完成采集后,API处理将自动执行。定时采集和自动发布功能通常很方便;
在任务的[自动化:发布和SEO和翻译]选项卡中,[自动执行第三方API配置] ==“选中[采集,自动执行API]选项==”选择要执行的API处理规则==“选择由API接口处理的数据范围(通常选择”要发布“,所有将导致所有数据被多次执行),最后单击保存;
4.API处理结果和发布
I。查看API接口处理的结果:
API接口处理的内容将另存为新字段,例如:
可以在[结果数据和发布]和数据预览界面中查看它。
提醒:API处理规则需要一段时间才能执行。执行后,页面将自动刷新,并显示由API界面处理的新字段;
II,API接口处理后的内容发布
发布文章之前,请在发布目标的第二步中修改映射字段,并在经过API接口处理后将标题和内容更改为新的对应字段title_写作俱乐部和content_写作俱乐部;
提醒:如果无法在发布目标中选择新字段,请在此任务下复制或创建新的发布目标,然后可以在新发布目标中选择新字段。可以查看详细的教程;
5.编写Club-API接口常见问题和解决方法
I。如何同时使用API处理规则和SEO规则?
系统默认对标题和内容字段执行SEO功能,需要将其修改为SEO规则中的title_写作俱乐部和content_写作俱乐部字段;

