
文章采集api
汇总:爬取简书全站文章并生成 API(四)
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2020-11-23 12:04
简书
通过前面的介绍,可以说这个小项目已经基本完成。当然,剩下要做的就是代码重构,功能的不断改进和错误修复。最后,部署是联机的。如第一节所述,将有两种部署和联机方式。本节首先介绍第一种方法,使用nginx + uwsgi + django +超级用户进行环境部署。
nginx + uwsgi + django +环境部署主管
我使用Django已有一段时间了,但是它一直在本地进行测试并且尚未部署。我认为根据其他人博客的教程进行部署应该很容易,但是在阅读了十多个有关百度和Google的教程之后,部署仍然没有成功。我真的很失望。最后,在其他人的帮助下完成了部署,因此我进行了部署。该过程失败了,包括部署过程中遇到的许多问题。在安装之前,让我向大家介绍基本知识。
以下安装环境为CentOS7 x86_64 + python2.7.10 + Django1.9,CentOS 6也适用。
1.安装
首先,安装环境,除了nginx以外,其他两个可以通过pip安装:
# pip install django
# pip install uwsgi
可以使用yum直接安装nginx,有关编译和安装,请参阅编译和安装nginx。
# yum install nginx -y
创建Django应用程序。由于使用了nginx,因此最好将应用程序放置在nginx根目录中:
# django-admin startproject jianshu_api
# cd jianshu_api/
# django-admin startapp jianshu
然后在配置文件settings.py中设置要连接的数据库,将DEBUG = True更改为DEBUG = False,设置* ALLOWED_HOSTS = [''] **,并在末尾添加以下配置:
STATIC_ROOT = os.path.join(BASE_DIR, 'static')
然后运行并自动生成一个静态目录:
# python manage.py collectstatic
或直接将静态文件复制到相应目录:
# cp -r /root/.pyenv/versions/2.7.10/lib/python2.7/site-packages/rest_framework /usr/html/jianshu/static/
# cp -r /root/.pyenv/versions/2.7.10/lib/python2.7/site-packages/django/contrib/admin/static/* /usr/html/jianshu/static/
如果未正确设置,则在访问网站时无法加载相应的静态文件,如下所示:
无法加载静态文件
2.配置服务首先配置nginx:
server {
listen 8080;
#server_name jianshuapi ;
access_log /var/log/nginx/api.log;
# app 根目录
root /usr/html/jianshu;
index index.py index.htm;
location / {
# nginx 收到请求会就转发到 9001 端口
uwsgi_pass 127.0.0.1:9001;
include /etc/nginx/uwsgi_params;
}
#设定静态文件所在目录
location ^~ /static {
alias /usr/html/jianshu/static;
}
}
检查语法并重新启动:
# nginx -t
# nginx -s reload
配置uWSGi:
首先为uWSGI操作创建配置文件jianshu.ini:
# mkdir -p /etc/uwsgi && cd /etc/uwsgi
[uwsgi]
chdir = /usr/html/jianshu
socket = 127.0.0.1:9001
master = true
uid = root
wsgi-file = /usr/html/jianshu/jianshu_api/wsgi.py
processes = 2
threads = 4
chmod-socket = 666
chown-socket = root:nginx
vacuum = true
测试uWSGi是否可以正常工作:
# uwsgi /etc/uwsgi/jianshu.ini
然后在命令行中访问:8080 /:
api测试
现在您可以看到部署已成功。但是通常我们使用主管来管理
uwsgi和nginx,因此操作起来更加方便。
3.使用主管
有关主管的详细用法,请参阅:使用主管来管理流程。
首次安装主管:
# pip install supervisor
然后生成配置文件:
# echo_supervisord_conf > /etc/supervisord.conf
开始监督:
# supervisord
提供uwsgi配置文件,打开/etc/supervisord.conf并在底部添加:
[program:jianshu] ; 添加 uwsgi 的配置示例
command=/root/.pyenv/shims/uwsgi --ini /etc/uwsgi/jianshu.ini
directory=/usr/html/jianshu/
stdout_logfile=/var/log/supervisor/%(program_name)s_access.log
stderr_logfile=/var/log/supervisor/%(program_name)s_err.log
startsecs=10
stopwaitsecs=0
autostart=true
autorestart=true
[program:nginx] ;nginx 配置示例
directory=/
command=/usr/sbin/nginx -c /etc/nginx/nginx.conf
user=root
stdout_logfile=/var/log/supervisor/%(program_name)s_access.log
stderr_logfile=/var/log/supervisor/%(program_name)s_err.log
autostart=true
autorestart=true
startsecs=10
然后重新加载主管配置:
# supervisorctl reload
查看主管的状态:
# supervisorctl status
jianshu RUNNING pid 19466, uptime 0:07:08
nginx RUNNING pid 19490, uptime 0:07:05
再次访问api界面:8080/。
Jianshu API
-终于完成了部署,非常高兴,欢迎每个人使用该API,但不要随意使用它,毕竟服务器资源有限!
-下一节将介绍如何使用docker进行部署。 查看全部
抓取Jianshu整个网站文章并生成API(四)

简书
通过前面的介绍,可以说这个小项目已经基本完成。当然,剩下要做的就是代码重构,功能的不断改进和错误修复。最后,部署是联机的。如第一节所述,将有两种部署和联机方式。本节首先介绍第一种方法,使用nginx + uwsgi + django +超级用户进行环境部署。
nginx + uwsgi + django +环境部署主管
我使用Django已有一段时间了,但是它一直在本地进行测试并且尚未部署。我认为根据其他人博客的教程进行部署应该很容易,但是在阅读了十多个有关百度和Google的教程之后,部署仍然没有成功。我真的很失望。最后,在其他人的帮助下完成了部署,因此我进行了部署。该过程失败了,包括部署过程中遇到的许多问题。在安装之前,让我向大家介绍基本知识。
以下安装环境为CentOS7 x86_64 + python2.7.10 + Django1.9,CentOS 6也适用。
1.安装
首先,安装环境,除了nginx以外,其他两个可以通过pip安装:
# pip install django
# pip install uwsgi
可以使用yum直接安装nginx,有关编译和安装,请参阅编译和安装nginx。
# yum install nginx -y
创建Django应用程序。由于使用了nginx,因此最好将应用程序放置在nginx根目录中:
# django-admin startproject jianshu_api
# cd jianshu_api/
# django-admin startapp jianshu
然后在配置文件settings.py中设置要连接的数据库,将DEBUG = True更改为DEBUG = False,设置* ALLOWED_HOSTS = [''] **,并在末尾添加以下配置:
STATIC_ROOT = os.path.join(BASE_DIR, 'static')
然后运行并自动生成一个静态目录:
# python manage.py collectstatic
或直接将静态文件复制到相应目录:
# cp -r /root/.pyenv/versions/2.7.10/lib/python2.7/site-packages/rest_framework /usr/html/jianshu/static/
# cp -r /root/.pyenv/versions/2.7.10/lib/python2.7/site-packages/django/contrib/admin/static/* /usr/html/jianshu/static/
如果未正确设置,则在访问网站时无法加载相应的静态文件,如下所示:

无法加载静态文件
2.配置服务首先配置nginx:
server {
listen 8080;
#server_name jianshuapi ;
access_log /var/log/nginx/api.log;
# app 根目录
root /usr/html/jianshu;
index index.py index.htm;
location / {
# nginx 收到请求会就转发到 9001 端口
uwsgi_pass 127.0.0.1:9001;
include /etc/nginx/uwsgi_params;
}
#设定静态文件所在目录
location ^~ /static {
alias /usr/html/jianshu/static;
}
}
检查语法并重新启动:
# nginx -t
# nginx -s reload
配置uWSGi:
首先为uWSGI操作创建配置文件jianshu.ini:
# mkdir -p /etc/uwsgi && cd /etc/uwsgi
[uwsgi]
chdir = /usr/html/jianshu
socket = 127.0.0.1:9001
master = true
uid = root
wsgi-file = /usr/html/jianshu/jianshu_api/wsgi.py
processes = 2
threads = 4
chmod-socket = 666
chown-socket = root:nginx
vacuum = true
测试uWSGi是否可以正常工作:
# uwsgi /etc/uwsgi/jianshu.ini
然后在命令行中访问:8080 /:

api测试
现在您可以看到部署已成功。但是通常我们使用主管来管理
uwsgi和nginx,因此操作起来更加方便。
3.使用主管
有关主管的详细用法,请参阅:使用主管来管理流程。
首次安装主管:
# pip install supervisor
然后生成配置文件:
# echo_supervisord_conf > /etc/supervisord.conf
开始监督:
# supervisord
提供uwsgi配置文件,打开/etc/supervisord.conf并在底部添加:
[program:jianshu] ; 添加 uwsgi 的配置示例
command=/root/.pyenv/shims/uwsgi --ini /etc/uwsgi/jianshu.ini
directory=/usr/html/jianshu/
stdout_logfile=/var/log/supervisor/%(program_name)s_access.log
stderr_logfile=/var/log/supervisor/%(program_name)s_err.log
startsecs=10
stopwaitsecs=0
autostart=true
autorestart=true
[program:nginx] ;nginx 配置示例
directory=/
command=/usr/sbin/nginx -c /etc/nginx/nginx.conf
user=root
stdout_logfile=/var/log/supervisor/%(program_name)s_access.log
stderr_logfile=/var/log/supervisor/%(program_name)s_err.log
autostart=true
autorestart=true
startsecs=10
然后重新加载主管配置:
# supervisorctl reload
查看主管的状态:
# supervisorctl status
jianshu RUNNING pid 19466, uptime 0:07:08
nginx RUNNING pid 19490, uptime 0:07:05
再次访问api界面:8080/。

Jianshu API
-终于完成了部署,非常高兴,欢迎每个人使用该API,但不要随意使用它,毕竟服务器资源有限!
-下一节将介绍如何使用docker进行部署。
汇总:将ApiBoot Logging采集的日志上报到Admin
采集交流 • 优采云 发表了文章 • 0 个评论 • 335 次浏览 • 2020-09-17 08:11
每个请求的详细信息都可以通过ApiBoot Logging获得。在分布式部署模式下,请求可以通过多个服务。如果每个服务都独立保存请求日志信息,我们将无法做到。统一控制,日志数据库和业务数据库之间将存在不一致(可能使用多个数据源配置)。由于这个问题,ApiBoot Logging提供了Admin的概念,它将客户端采集连接到。每个日志都报告给Admin,并且Admin将分析并保存操作。
创建Logging Admin项目
ApiBoot Logging Admin可以汇总每个业务服务的请求日志(ApiBoot Logging),因此我们需要向Admin报告每个业务服务的日志采集,因此我们应该使用独立的部署方法。创建单独的服务以专门请求日志采集,然后将其保存。
初始化Logging Admin项目依赖项
使用想法创建一个SpringBoot项目,pom.xml配置文件中的依赖项如下:
org.springframework.boot
spring-boot-starter-web
org.minbox.framework
api-boot-starter-logging-admin
mysql
mysql-connector-java
com.zaxxer
HikariCP
org.minbox.framework
api-boot-starter-mybatis-enhance
我们需要将请求日志从采集保存到数据库,因此我们需要在项目中添加与数据库驱动程序和数据库连接池相关的依赖项。 ApiBoot Logging Admin通过DataSource操作数据,并依赖于ApiBoot MyBatis Enhance。您可以自动创建DataSource,摆脱手动创建的麻烦,并加入Spring IOC容器。
添加ApiBoot统一版本依赖项
org.minbox.framework
api-boot-dependencies
2.1.4.RELEASE
import
pom
最新版本的ApiBoot,请访问:: api-boot-dependencies以进行查询。
启用日志记录管理员
添加ApiBoot Logging Admin依赖项后,无法完全使用Admin功能。我们需要通过@EnableLoggingAdmin批注启用它。该批注将自动在Logging Admin中注册一些必需的类到Spring IOC,并将批注添加到条目类中,如下所示:
/**
* ApiBoot Logging Admin入口类
*/
@SpringBootApplication
@EnableLoggingAdmin
public class ApibootReportLogsByLoggingToAdminApplication {
public static void main(String[] args) {
SpringApplication.run(ApibootReportLogsByLoggingToAdminApplication.class, args);
}
}
配置日志数据源
application.yml配置文件中的数据源配置如下:
# 服务名称
spring:
application:
name: apiboot-report-logs-by-logging-to-admin
# 数据源相关配置
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test
username: root
password: 123456
type: com.zaxxer.hikari.HikariDataSource
# 服务端口号
server:
port: 8081
控制台将打印报告日志
ApiBoot Logging Admin可以控制是否通过配置文件在控制台上从采集打印请求日志信息,并在application.yml配置文件中添加以下内容:
api:
boot:
logging:
# Logging Admin相关配置
admin:
# 控制台显示采集的日志信息
show-console-report-log: true
注意:这不应与ApiBoot Logging提供的api.boot.logging.show-console-log配置混淆。
美化控制台打印的报告日志
api:
boot:
logging:
# Logging Admin相关配置
admin:
# 控制台输出时美化采集到的日志
format-console-log-json: true
注意:请勿在此处与api.boot.logging.format-console-log-json配置混淆。
初始化日志表结构
ApiBoot Logging Admin使用固定的表结构来存储请求日志和服务信息。表创建语句如下:
SET NAMES utf8mb4 ;
--
-- Table structure for table `logging_request_logs`
--
CREATE TABLE `logging_request_logs` (
`lrl_id` varchar(36) COLLATE utf8mb4_general_ci NOT NULL COMMENT '主键,UUID',
`lrl_service_detail_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '服务详情编号,关联logging_service_details主键',
`lrl_trace_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '链路ID',
`lrl_parent_span_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上级跨度ID',
`lrl_span_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '跨度ID',
`lrl_start_time` mediumtext COLLATE utf8mb4_general_ci COMMENT '请求开始时间',
`lrl_end_time` mediumtext COLLATE utf8mb4_general_ci COMMENT '请求结束时间',
`lrl_http_status` int(11) DEFAULT NULL COMMENT '请求响应状态码',
`lrl_request_body` longtext COLLATE utf8mb4_general_ci COMMENT '请求主体内容',
`lrl_request_headers` text COLLATE utf8mb4_general_ci COMMENT '请求头信息',
`lrl_request_ip` varchar(30) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '发起请求客户端的IP地址',
`lrl_request_method` varchar(10) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '请求方式',
`lrl_request_uri` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '请求路径',
`lrl_response_body` longtext COLLATE utf8mb4_general_ci COMMENT '响应内容',
`lrl_response_headers` text COLLATE utf8mb4_general_ci COMMENT '响应头信息',
`lrl_time_consuming` int(11) DEFAULT NULL COMMENT '请求耗时',
`lrl_create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '日志保存时间',
`lrl_request_params` text COLLATE utf8mb4_general_ci,
`lrl_exception_stack` text COLLATE utf8mb4_general_ci,
PRIMARY KEY (`lrl_id`),
KEY `logging_request_logs_LRL_SERVICE_DETAIL_ID_index` (`lrl_service_detail_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='请求日志信息表';
--
-- Table structure for table `logging_service_details`
--
CREATE TABLE `logging_service_details` (
`lsd_id` varchar(36) COLLATE utf8mb4_general_ci NOT NULL,
`lsd_service_id` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上报服务的ID,对应spring.application.name配置值',
`lsd_service_ip` varchar(50) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上报服务的IP地址',
`lsd_service_port` int(11) DEFAULT NULL COMMENT '上报服务的端口号',
`lsd_last_report_time` timestamp NULL DEFAULT NULL COMMENT '最后一次上报时间,每次上报更新',
`lsd_create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '首次上报时创建时间',
PRIMARY KEY (`lsd_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='上报日志的客户端服务详情';
到目前为止,ApiBoot Logging Admin已经准备就绪。接下来,我们需要修改业务服务,以将请求日志报告给Logging Admin。
将日志报告给指定的日志记录管理员
我们将修改使用ApiBoot Logging获取统一管理请求日志文章的源代码,并将Logging Admin的地址添加到application.yml中,如下所示:
api:
boot:
# ApiBoot Logging 日志组件配置
logging:
# 配置Logging Admin地址
admin:
server-address: 127.0.0.1:8081
api.boot.logging.admin-service-address的配置格式为:Ip:Port,我们只需要修改一个地方,所有其他任务都将在内部交付给ApiBoot Logging。
测试
我们以应用程序的形式启动ApiBoot Logging Admin和业务服务。
使用curl访问测试地址,如下所示:
~ curl http://localhost:8080/test\?name\=admin
你好:admin
我们检查ApiBoot Logging管理控制台日志,如下所示:
Receiving Service: 【apiboot-unified-manage-request-logs -> 127.0.0.1】, Request Log Report,Logging Content:[
{
"endTime":1571641723779,
"httpStatus":200,
"requestBody":"",
"requestHeaders":{
"server-region":"JiNan",
"host":"localhost:8080",
"user-agent":"curl/7.64.1",
"accept":"*/*"
},
"requestIp":"0:0:0:0:0:0:0:1",
"requestMethod":"GET",
"requestParam":"{\"name\":\"admin\"}",
"requestUri":"/test",
"responseBody":"你好:admin",
"responseHeaders":{},
"serviceId":"apiboot-unified-manage-request-logs",
"serviceIp":"127.0.0.1",
"servicePort":"8080",
"spanId":"95a73ca0-831b-45df-aa43-2b5887e8d98d",
"startTime":1571641723776,
"timeConsuming":3,
"traceId":"25a7de96-b3dd-48e5-9854-1a8069a4a681"
}
]
我们已经看到Logging Admin控制台打印的报告请求日志,并且尚不确定此请求的日志是否已保存到数据库中。接下来,我将使用命令行查看数据库的日志信息。
查看logging_service_details表中的数据
mysql> select * from logging_service_details\G;
*************************** 1. row ***************************
lsd_id: b069366a-25dc-41ec-8f09-242d81755cd0
lsd_service_id: apiboot-unified-manage-request-logs
lsd_service_ip: 10.180.98.112
lsd_service_port: 8080
lsd_last_report_time: 2019-10-21 02:14:26
lsd_create_time: 2019-10-21 15:14:26
logging_service_details存储报告请求日志的每个业务服务的基本信息。每个服务的基本信息将被缓存在Logging Admin内存中,以方便获取service_id来存储日志,并且唯一性是根据ip + port + service_id确定的。相同的服务仅保存一次。
查看logging_request_logs表中的数据
mysql> select * from logging_request_logs\G;
*************************** 1. row ***************************
lrl_id: c42761f6-b072-4744-8a17-d8e6097b85de
lrl_service_detail_id: b069366a-25dc-41ec-8f09-242d81755cd0
lrl_trace_id: 055329a0-cfc1-4606-baf0-4fb0cc905ba2
lrl_parent_span_id: NULL
lrl_span_id: aab83092-7749-4f88-8cb6-a949cc060197
lrl_start_time: 1571642065262
lrl_end_time: 1571642065286
lrl_http_status: 200
lrl_request_body:
lrl_request_headers: {"server-region":"JiNan","host":"localhost:8080","user-agent":"curl/7.64.1","accept":"*/*"}
lrl_request_ip: 0:0:0:0:0:0:0:1
lrl_request_method: GET
lrl_request_uri: /test
lrl_response_body: 你好:admin
lrl_response_headers: {}
lrl_time_consuming: 24
lrl_create_time: 2019-10-21 15:14:26
lrl_request_params: {"name":"admin"}
lrl_exception_stack: NULL
敲黑板画关键点
在本章中,我们集成了ApiBoot Logging Admin,将业务服务的每个请求日志报告给Logging Admin,先通过数据库保存请求日志,然后再通过其他方法,并通过spanId和traceId查看日志下属每个请求链接与消耗每个请求中时间最多的跨度的关系,以准确地优化服务性能。
作者的个人博客
使用开源框架ApiBoot帮助您成为Api接口服务架构师 查看全部
将ApiBoot日志记录采集的日志报告给管理员
每个请求的详细信息都可以通过ApiBoot Logging获得。在分布式部署模式下,请求可以通过多个服务。如果每个服务都独立保存请求日志信息,我们将无法做到。统一控制,日志数据库和业务数据库之间将存在不一致(可能使用多个数据源配置)。由于这个问题,ApiBoot Logging提供了Admin的概念,它将客户端采集连接到。每个日志都报告给Admin,并且Admin将分析并保存操作。
创建Logging Admin项目
ApiBoot Logging Admin可以汇总每个业务服务的请求日志(ApiBoot Logging),因此我们需要向Admin报告每个业务服务的日志采集,因此我们应该使用独立的部署方法。创建单独的服务以专门请求日志采集,然后将其保存。
初始化Logging Admin项目依赖项
使用想法创建一个SpringBoot项目,pom.xml配置文件中的依赖项如下:
org.springframework.boot
spring-boot-starter-web
org.minbox.framework
api-boot-starter-logging-admin
mysql
mysql-connector-java
com.zaxxer
HikariCP
org.minbox.framework
api-boot-starter-mybatis-enhance
我们需要将请求日志从采集保存到数据库,因此我们需要在项目中添加与数据库驱动程序和数据库连接池相关的依赖项。 ApiBoot Logging Admin通过DataSource操作数据,并依赖于ApiBoot MyBatis Enhance。您可以自动创建DataSource,摆脱手动创建的麻烦,并加入Spring IOC容器。
添加ApiBoot统一版本依赖项
org.minbox.framework
api-boot-dependencies
2.1.4.RELEASE
import
pom
最新版本的ApiBoot,请访问:: api-boot-dependencies以进行查询。
启用日志记录管理员
添加ApiBoot Logging Admin依赖项后,无法完全使用Admin功能。我们需要通过@EnableLoggingAdmin批注启用它。该批注将自动在Logging Admin中注册一些必需的类到Spring IOC,并将批注添加到条目类中,如下所示:
/**
* ApiBoot Logging Admin入口类
*/
@SpringBootApplication
@EnableLoggingAdmin
public class ApibootReportLogsByLoggingToAdminApplication {
public static void main(String[] args) {
SpringApplication.run(ApibootReportLogsByLoggingToAdminApplication.class, args);
}
}
配置日志数据源
application.yml配置文件中的数据源配置如下:
# 服务名称
spring:
application:
name: apiboot-report-logs-by-logging-to-admin
# 数据源相关配置
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test
username: root
password: 123456
type: com.zaxxer.hikari.HikariDataSource
# 服务端口号
server:
port: 8081
控制台将打印报告日志
ApiBoot Logging Admin可以控制是否通过配置文件在控制台上从采集打印请求日志信息,并在application.yml配置文件中添加以下内容:
api:
boot:
logging:
# Logging Admin相关配置
admin:
# 控制台显示采集的日志信息
show-console-report-log: true
注意:这不应与ApiBoot Logging提供的api.boot.logging.show-console-log配置混淆。
美化控制台打印的报告日志
api:
boot:
logging:
# Logging Admin相关配置
admin:
# 控制台输出时美化采集到的日志
format-console-log-json: true
注意:请勿在此处与api.boot.logging.format-console-log-json配置混淆。
初始化日志表结构
ApiBoot Logging Admin使用固定的表结构来存储请求日志和服务信息。表创建语句如下:
SET NAMES utf8mb4 ;
--
-- Table structure for table `logging_request_logs`
--
CREATE TABLE `logging_request_logs` (
`lrl_id` varchar(36) COLLATE utf8mb4_general_ci NOT NULL COMMENT '主键,UUID',
`lrl_service_detail_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '服务详情编号,关联logging_service_details主键',
`lrl_trace_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '链路ID',
`lrl_parent_span_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上级跨度ID',
`lrl_span_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '跨度ID',
`lrl_start_time` mediumtext COLLATE utf8mb4_general_ci COMMENT '请求开始时间',
`lrl_end_time` mediumtext COLLATE utf8mb4_general_ci COMMENT '请求结束时间',
`lrl_http_status` int(11) DEFAULT NULL COMMENT '请求响应状态码',
`lrl_request_body` longtext COLLATE utf8mb4_general_ci COMMENT '请求主体内容',
`lrl_request_headers` text COLLATE utf8mb4_general_ci COMMENT '请求头信息',
`lrl_request_ip` varchar(30) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '发起请求客户端的IP地址',
`lrl_request_method` varchar(10) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '请求方式',
`lrl_request_uri` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '请求路径',
`lrl_response_body` longtext COLLATE utf8mb4_general_ci COMMENT '响应内容',
`lrl_response_headers` text COLLATE utf8mb4_general_ci COMMENT '响应头信息',
`lrl_time_consuming` int(11) DEFAULT NULL COMMENT '请求耗时',
`lrl_create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '日志保存时间',
`lrl_request_params` text COLLATE utf8mb4_general_ci,
`lrl_exception_stack` text COLLATE utf8mb4_general_ci,
PRIMARY KEY (`lrl_id`),
KEY `logging_request_logs_LRL_SERVICE_DETAIL_ID_index` (`lrl_service_detail_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='请求日志信息表';
--
-- Table structure for table `logging_service_details`
--
CREATE TABLE `logging_service_details` (
`lsd_id` varchar(36) COLLATE utf8mb4_general_ci NOT NULL,
`lsd_service_id` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上报服务的ID,对应spring.application.name配置值',
`lsd_service_ip` varchar(50) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上报服务的IP地址',
`lsd_service_port` int(11) DEFAULT NULL COMMENT '上报服务的端口号',
`lsd_last_report_time` timestamp NULL DEFAULT NULL COMMENT '最后一次上报时间,每次上报更新',
`lsd_create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '首次上报时创建时间',
PRIMARY KEY (`lsd_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='上报日志的客户端服务详情';
到目前为止,ApiBoot Logging Admin已经准备就绪。接下来,我们需要修改业务服务,以将请求日志报告给Logging Admin。
将日志报告给指定的日志记录管理员
我们将修改使用ApiBoot Logging获取统一管理请求日志文章的源代码,并将Logging Admin的地址添加到application.yml中,如下所示:
api:
boot:
# ApiBoot Logging 日志组件配置
logging:
# 配置Logging Admin地址
admin:
server-address: 127.0.0.1:8081
api.boot.logging.admin-service-address的配置格式为:Ip:Port,我们只需要修改一个地方,所有其他任务都将在内部交付给ApiBoot Logging。
测试
我们以应用程序的形式启动ApiBoot Logging Admin和业务服务。
使用curl访问测试地址,如下所示:
~ curl http://localhost:8080/test\?name\=admin
你好:admin
我们检查ApiBoot Logging管理控制台日志,如下所示:
Receiving Service: 【apiboot-unified-manage-request-logs -> 127.0.0.1】, Request Log Report,Logging Content:[
{
"endTime":1571641723779,
"httpStatus":200,
"requestBody":"",
"requestHeaders":{
"server-region":"JiNan",
"host":"localhost:8080",
"user-agent":"curl/7.64.1",
"accept":"*/*"
},
"requestIp":"0:0:0:0:0:0:0:1",
"requestMethod":"GET",
"requestParam":"{\"name\":\"admin\"}",
"requestUri":"/test",
"responseBody":"你好:admin",
"responseHeaders":{},
"serviceId":"apiboot-unified-manage-request-logs",
"serviceIp":"127.0.0.1",
"servicePort":"8080",
"spanId":"95a73ca0-831b-45df-aa43-2b5887e8d98d",
"startTime":1571641723776,
"timeConsuming":3,
"traceId":"25a7de96-b3dd-48e5-9854-1a8069a4a681"
}
]
我们已经看到Logging Admin控制台打印的报告请求日志,并且尚不确定此请求的日志是否已保存到数据库中。接下来,我将使用命令行查看数据库的日志信息。
查看logging_service_details表中的数据
mysql> select * from logging_service_details\G;
*************************** 1. row ***************************
lsd_id: b069366a-25dc-41ec-8f09-242d81755cd0
lsd_service_id: apiboot-unified-manage-request-logs
lsd_service_ip: 10.180.98.112
lsd_service_port: 8080
lsd_last_report_time: 2019-10-21 02:14:26
lsd_create_time: 2019-10-21 15:14:26
logging_service_details存储报告请求日志的每个业务服务的基本信息。每个服务的基本信息将被缓存在Logging Admin内存中,以方便获取service_id来存储日志,并且唯一性是根据ip + port + service_id确定的。相同的服务仅保存一次。
查看logging_request_logs表中的数据
mysql> select * from logging_request_logs\G;
*************************** 1. row ***************************
lrl_id: c42761f6-b072-4744-8a17-d8e6097b85de
lrl_service_detail_id: b069366a-25dc-41ec-8f09-242d81755cd0
lrl_trace_id: 055329a0-cfc1-4606-baf0-4fb0cc905ba2
lrl_parent_span_id: NULL
lrl_span_id: aab83092-7749-4f88-8cb6-a949cc060197
lrl_start_time: 1571642065262
lrl_end_time: 1571642065286
lrl_http_status: 200
lrl_request_body:
lrl_request_headers: {"server-region":"JiNan","host":"localhost:8080","user-agent":"curl/7.64.1","accept":"*/*"}
lrl_request_ip: 0:0:0:0:0:0:0:1
lrl_request_method: GET
lrl_request_uri: /test
lrl_response_body: 你好:admin
lrl_response_headers: {}
lrl_time_consuming: 24
lrl_create_time: 2019-10-21 15:14:26
lrl_request_params: {"name":"admin"}
lrl_exception_stack: NULL
敲黑板画关键点
在本章中,我们集成了ApiBoot Logging Admin,将业务服务的每个请求日志报告给Logging Admin,先通过数据库保存请求日志,然后再通过其他方法,并通过spanId和traceId查看日志下属每个请求链接与消耗每个请求中时间最多的跨度的关系,以准确地优化服务性能。
作者的个人博客
使用开源框架ApiBoot帮助您成为Api接口服务架构师
解决方案:接入5118智能原创API教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 629 次浏览 • 2020-09-07 05:42
访问5118智能原创 API教程
优采云 采集支持调用5118一键式智能原创 API接口,处理采集数据标题和内容等;
提醒:第三方API访问功能需要优采云旗舰软件包支持使用,并且用户需要提供第三方接口帐户信息(即,用户需要注册第三方)界面,以及由第三方界面产生的所有费用,用户应承担);
详细使用步骤1. 5118智能原创 API接口配置I,API配置入口:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问权限] ==”单击[第三方API配置管理] ==“最后单击[+5118一键式智能原创 API]创建接口配置;
II。配置API接口信息:
[API-Key value]是要从5118背景中获取相应的Key值,请记住在填写后将其保存;
注意:5118将每次调用的最大长度限制为5000个字符(包括html代码),因此,当内容长度超过时,优采云将被分割并多次调用。此操作将增加api调用的次数,费用也会相应增加,这是用户需要承担的费用,使用前请务必注意! ! !
2.创建API处理规则
API处理规则,可以将其设置为调用API接口以处理哪些字段的内容;
I。 API处理规则条目:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问] ==”,进入[API处理规则管理]页面,最后单击[+添加API处理规则]以创建API处理规则;
II,API处理规则配置:
注意:当API处理1个字段时,API接口将被调用一次,因此建议不要添加不需要的字段!
3. API处理规则的用法
使用API处理规则的方式有两种:手动执行和自动执行:
I。手动执行API处理规则:
单击采集任务的[结果数据和发布]选项卡中的[SEO&API&翻译和其他工具]按钮==“选择[第三方API执行]列==”选择相应的API处理规则==“执行(数据范围有两种执行方法,根据发布状态批量执行和根据列表中选择的数据执行);
II。自动执行API处理规则:
启用API处理的自动执行。任务完成采集后,API处理将自动执行。通常,使用定时采集和自动发布功能很方便;
在任务的[自动化:发布和SEO和翻译]选项卡中,[自动执行第三方API配置] ==“选中[采集,自动执行API]选项==”选择要执行的API处理规则==“选择由API接口处理的数据范围(通常选择”要发布“,所有将导致所有数据被执行多次),最后单击保存;
4. API处理结果和发布,查看API接口处理结果:
API接口处理的内容将另存为新字段,例如:标题处理后的新字段:title_5118,以及内容处理后的新字段:content_5118,可以在[结果数据和发布]和数据预览界面。
温馨提示:API处理规则需要一段时间才能执行,执行后页面会自动刷新,并出现API接口处理后的新字段;
II。发布API接口的处理后内容:
发布文章之前,请在发布目标的第二步中修改映射字段,并在API接口处理之后将标题和内容更改为新的对应字段title_5118和content_5118;
提醒:如果无法在发布目标中选择新字段,请在此任务下复制或创建新的发布目标,然后可以在新发布目标中选择新字段。可以查看详细的教程;
5. 5118-API接口常见问题和解决方法I,如何将API处理规则和SEO规则一起使用?
系统默认对标题和内容字段执行SEO功能,需要将其修改为SEO规则中的title_5118和content_5118字段;
优采云导航:优采云 采集 优采云控制台如何使用优采云 SEO工具微信公众号文章 采集今天的标题采集 查看全部
访问5118智能原创 API教程
访问5118智能原创 API教程
优采云 采集支持调用5118一键式智能原创 API接口,处理采集数据标题和内容等;
提醒:第三方API访问功能需要优采云旗舰软件包支持使用,并且用户需要提供第三方接口帐户信息(即,用户需要注册第三方)界面,以及由第三方界面产生的所有费用,用户应承担);
详细使用步骤1. 5118智能原创 API接口配置I,API配置入口:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问权限] ==”单击[第三方API配置管理] ==“最后单击[+5118一键式智能原创 API]创建接口配置;

II。配置API接口信息:
[API-Key value]是要从5118背景中获取相应的Key值,请记住在填写后将其保存;
注意:5118将每次调用的最大长度限制为5000个字符(包括html代码),因此,当内容长度超过时,优采云将被分割并多次调用。此操作将增加api调用的次数,费用也会相应增加,这是用户需要承担的费用,使用前请务必注意! ! !


2.创建API处理规则
API处理规则,可以将其设置为调用API接口以处理哪些字段的内容;
I。 API处理规则条目:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问] ==”,进入[API处理规则管理]页面,最后单击[+添加API处理规则]以创建API处理规则;

II,API处理规则配置:

注意:当API处理1个字段时,API接口将被调用一次,因此建议不要添加不需要的字段!
3. API处理规则的用法
使用API处理规则的方式有两种:手动执行和自动执行:
I。手动执行API处理规则:
单击采集任务的[结果数据和发布]选项卡中的[SEO&API&翻译和其他工具]按钮==“选择[第三方API执行]列==”选择相应的API处理规则==“执行(数据范围有两种执行方法,根据发布状态批量执行和根据列表中选择的数据执行);

II。自动执行API处理规则:
启用API处理的自动执行。任务完成采集后,API处理将自动执行。通常,使用定时采集和自动发布功能很方便;
在任务的[自动化:发布和SEO和翻译]选项卡中,[自动执行第三方API配置] ==“选中[采集,自动执行API]选项==”选择要执行的API处理规则==“选择由API接口处理的数据范围(通常选择”要发布“,所有将导致所有数据被执行多次),最后单击保存;

4. API处理结果和发布,查看API接口处理结果:
API接口处理的内容将另存为新字段,例如:标题处理后的新字段:title_5118,以及内容处理后的新字段:content_5118,可以在[结果数据和发布]和数据预览界面。
温馨提示:API处理规则需要一段时间才能执行,执行后页面会自动刷新,并出现API接口处理后的新字段;


II。发布API接口的处理后内容:
发布文章之前,请在发布目标的第二步中修改映射字段,并在API接口处理之后将标题和内容更改为新的对应字段title_5118和content_5118;
提醒:如果无法在发布目标中选择新字段,请在此任务下复制或创建新的发布目标,然后可以在新发布目标中选择新字段。可以查看详细的教程;

5. 5118-API接口常见问题和解决方法I,如何将API处理规则和SEO规则一起使用?
系统默认对标题和内容字段执行SEO功能,需要将其修改为SEO规则中的title_5118和content_5118字段;

优采云导航:优采云 采集 优采云控制台如何使用优采云 SEO工具微信公众号文章 采集今天的标题采集
解决方案:优采云采集器采集原理、流程介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 317 次浏览 • 2020-09-04 13:32
写作文章很无聊,但百度优化排名仍然与文章的积累密不可分,因此各种文章 采集器都占据了市场,今天SEO教程自学网站将向您优采云 采集器 采集的原理和过程。
什么是数据采集?我们可以理解,我们打开了网站并看到了一篇很好的文章文章,因此我们复制了文章的标题和内容,并将该文章文章转移到了我们的网站。我们的过程可以称为采集,它将对您网站上的其他人有用的信息转移到您自己的网站。
采集器正在执行此操作,但是整个过程由软件完成。我们可以理解,我们复制了文章的标题和内容。我们可以知道内容是什么,标题是什么,但是软件不知道,所以我们必须告诉软件如何选择它。这是编写规则的过程。复制之后,我们打开网站(例如发布论坛的地方),然后将其发布。对于软件,它是模仿我们的帖子,发布文章,如何发布,这就是数据发布的过程。
优采云 采集器是用于采集数据的软件。它是网络上功能最强大的采集器。它可以捕获您看到的几乎所有Web内容。
一、 优采云 采集器数据捕获原理:
优采云采集器如何抓取数据取决于您的规则。要获取网页的所有内容,您需要首先获取该网页的URL。这是URL。该程序根据规则获取列表页面,分析其中的URL,然后获取URL的Web内容。根据采集规则,分析下载的网页,分离标题内容和其他信息,然后保存。如果选择下载图像等网络资源,则程序将分析采集的数据,找到图像的下载地址,资源等,然后在本地下载。
二、 优采云 采集器数据发布原则:
采集数据后,默认情况下将其保存在本地。我们可以使用以下方法来处理数据。
1.什么也不要做。由于数据本身存储在数据库中(访问,db3,mysql,sqlserver),因此,如果仅查看数据,则可以使用相关软件将其打开。
2. 网站已发布到网站。该程序将模仿浏览器向您的网站发送数据,可以达到手动发布的效果。
3.直接转到数据库。您只需要编写一些SQL语句,程序就会根据您的SQL语句将数据导入数据库。
4.另存为本地文件。该程序将读取数据库中的数据,并以某种格式将其另存为本地sql或文本文件。
三、 优采云 采集器工作流程:
优采云 采集器分两步采集数据,一个是采集数据,另一个是发布数据。这两个过程可以分开。
1.采集数据,包括采集URL和采集内容。此过程是获取数据的过程。我们制定规则并处理采矿过程的内容。
2,发布内容是将数据发布到自己的论坛,cms的过程也是将数据作为现有过程执行。您可以使用WEB,数据库存储进行在线发布或另存为本地文件。
但我必须在此提醒大多数网站管理员,百度飓风算法2. 0的引入进一步提高了百度对采集这种现象的惩罚程度和惩罚范围。在经验丰富的时代,是否使用文章 采集器取决于您的想法! 查看全部
优采云 采集器 采集原理和过程介绍
写作文章很无聊,但百度优化排名仍然与文章的积累密不可分,因此各种文章 采集器都占据了市场,今天SEO教程自学网站将向您优采云 采集器 采集的原理和过程。
什么是数据采集?我们可以理解,我们打开了网站并看到了一篇很好的文章文章,因此我们复制了文章的标题和内容,并将该文章文章转移到了我们的网站。我们的过程可以称为采集,它将对您网站上的其他人有用的信息转移到您自己的网站。
采集器正在执行此操作,但是整个过程由软件完成。我们可以理解,我们复制了文章的标题和内容。我们可以知道内容是什么,标题是什么,但是软件不知道,所以我们必须告诉软件如何选择它。这是编写规则的过程。复制之后,我们打开网站(例如发布论坛的地方),然后将其发布。对于软件,它是模仿我们的帖子,发布文章,如何发布,这就是数据发布的过程。
优采云 采集器是用于采集数据的软件。它是网络上功能最强大的采集器。它可以捕获您看到的几乎所有Web内容。
一、 优采云 采集器数据捕获原理:
优采云采集器如何抓取数据取决于您的规则。要获取网页的所有内容,您需要首先获取该网页的URL。这是URL。该程序根据规则获取列表页面,分析其中的URL,然后获取URL的Web内容。根据采集规则,分析下载的网页,分离标题内容和其他信息,然后保存。如果选择下载图像等网络资源,则程序将分析采集的数据,找到图像的下载地址,资源等,然后在本地下载。
二、 优采云 采集器数据发布原则:
采集数据后,默认情况下将其保存在本地。我们可以使用以下方法来处理数据。
1.什么也不要做。由于数据本身存储在数据库中(访问,db3,mysql,sqlserver),因此,如果仅查看数据,则可以使用相关软件将其打开。
2. 网站已发布到网站。该程序将模仿浏览器向您的网站发送数据,可以达到手动发布的效果。
3.直接转到数据库。您只需要编写一些SQL语句,程序就会根据您的SQL语句将数据导入数据库。
4.另存为本地文件。该程序将读取数据库中的数据,并以某种格式将其另存为本地sql或文本文件。
三、 优采云 采集器工作流程:
优采云 采集器分两步采集数据,一个是采集数据,另一个是发布数据。这两个过程可以分开。
1.采集数据,包括采集URL和采集内容。此过程是获取数据的过程。我们制定规则并处理采矿过程的内容。
2,发布内容是将数据发布到自己的论坛,cms的过程也是将数据作为现有过程执行。您可以使用WEB,数据库存储进行在线发布或另存为本地文件。
但我必须在此提醒大多数网站管理员,百度飓风算法2. 0的引入进一步提高了百度对采集这种现象的惩罚程度和惩罚范围。在经验丰富的时代,是否使用文章 采集器取决于您的想法!
最佳实践:Python网络数据采集4:使用API
采集交流 • 优采云 发表了文章 • 0 个评论 • 408 次浏览 • 2020-09-01 06:09
通常情况下,程序员可以使用HTPP协议向API发起请求以获取某些信息,并且API将以XML或JSON格式返回服务器的响应信息.
通常,您不会考虑将API用作网络数据采集,但实际上,两者(都发送HTTP请求)和结果(都获取信息)所使用的许多技术都是相似的;两者通常是同一个关系.
例如,将Wikipedia编辑历史记录(与编辑者的IP地址)和IP地址解析API结合起来,以获取Wikipedia条目的编辑者的地理位置.
4.1 API概述
Google API
4.2 API通用规则
API使用非常标准的规则集来生成数据,并且所生成的数据以非常标准的方式进行组织.
四种方法: GET,POST,PUT,DELETE
验证: 需要客户验证
4.3服务器响应
大多数反馈数据格式是XML和JSON
过去,服务器使用PHP和.NET等程序作为API的接收器. 现在,服务器端还使用了一些JavaScript框架作为API的发送和接收端,例如Angular或Backbone.
API调用:
4.4回声巢
Echo Nest音乐数据网站
4.5 Twitter API
pip安装推特
from twitter import Twitter
t = Twitter(auth=OAuth(,,,))
pythonTweets = t.search.tweets(q = "#python")
print(pythonTweets)
发布推文4.6 Google API
无论您要处理哪种信息,包括语言翻译,地理位置,日历,甚至是遗传数据,Google都会提供API. Google还为其一些著名的应用程序提供API,例如Gmail,YouTube和Blogger.
4.7解析JSON数据
import json
from urllib.request import urlopen
def getCountry(ipAddress):
response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
responseJson = json.loads(response)
return responseJson.get("country_code")
print(getCountry("50.78.253.58"))
4.8返回主题
将多个数据源组合为新形式,或使用API作为工具从新的角度解释采集中的数据.
首先做一个采集 Wikipedia的基本程序,找到编辑历史记录页面,然后在编辑历史记录中找出IP地址
# -*- coding: utf-8 -*-
from urllib.request import urlopen
from bs4 import BeautifulSoup
import datetime
import random
import re
import json
random.seed(datetime.datetime.now())
# https://en.wikipedia.org/wiki/Python_(programming_language)
def getLinks(articleUrl):
html = urlopen("http://en.wikipedia.org"+articleUrl)
bsObj = BeautifulSoup(html)
return bsObj.find("div",{"id":"bodyContent"}).findAll("a", href=re.compile("^(/wiki/)((?!:).)*$"))
def getHistoryIPs(pageUrl):
# 编辑历史页面URL链接格式是:
# https://en.wikipedia.org/w/index.php?title=Python_(programming_language)&action=history
pageUrl = pageUrl.replace("/wiki/", "")
historyUrl = "https://en.wikipedia.org/w/ind ... ot%3B
print("history url is: "+historyUrl)
html = urlopen(historyUrl)
bsObj = BeautifulSoup(html)
# 找出class属性是"mw-anonuserlink"的链接
# 它们用IP地址代替用户名
ipAddresses = bsObj.findAll("a", {"class":"mw-anonuserlink"})
addressList = set()
for ipAddress in ipAddresses:
addressList.add(ipAddress.get_text())
return addressList
links = getLinks("/wiki/Python_(programming_language)")
def getCountry(ipAddress):
try:
response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
except HTTPError:
return None
responseJson = json.loads(response)
return responseJson.get("country_code")
while (len(links) > 0):
for link in links:
print("-------------------")
historyIPs = getHistoryIPs(link.attrs["href"])
for historyIP in historyIPs:
#print(historyIP)
country = getCountry(historyIP)
if country is not None:
print(historyIP+" is from "+country)
newLink = links[random.randint(0, len(links)-1)].attrs["href"]
links = getLinks(newLink)
4.9关于API的更多信息
Leonard Richardson,Mike Amundsen和Sam Ruby的RESTful Web API()为使用Web API提供了非常全面的理论和实践指导. 此外,Mike Amundsen的精彩视频教学课程“为Web()设计API”还可以教您创建自己的API. 如果您想方便地共享采集数据,那么他的视频非常有用 查看全部
Python网络数据采集 4: 使用API
通常情况下,程序员可以使用HTPP协议向API发起请求以获取某些信息,并且API将以XML或JSON格式返回服务器的响应信息.
通常,您不会考虑将API用作网络数据采集,但实际上,两者(都发送HTTP请求)和结果(都获取信息)所使用的许多技术都是相似的;两者通常是同一个关系.
例如,将Wikipedia编辑历史记录(与编辑者的IP地址)和IP地址解析API结合起来,以获取Wikipedia条目的编辑者的地理位置.
4.1 API概述
Google API
4.2 API通用规则
API使用非常标准的规则集来生成数据,并且所生成的数据以非常标准的方式进行组织.
四种方法: GET,POST,PUT,DELETE
验证: 需要客户验证
4.3服务器响应
大多数反馈数据格式是XML和JSON
过去,服务器使用PHP和.NET等程序作为API的接收器. 现在,服务器端还使用了一些JavaScript框架作为API的发送和接收端,例如Angular或Backbone.
API调用:
4.4回声巢
Echo Nest音乐数据网站
4.5 Twitter API
pip安装推特
from twitter import Twitter
t = Twitter(auth=OAuth(,,,))
pythonTweets = t.search.tweets(q = "#python")
print(pythonTweets)
发布推文4.6 Google API
无论您要处理哪种信息,包括语言翻译,地理位置,日历,甚至是遗传数据,Google都会提供API. Google还为其一些著名的应用程序提供API,例如Gmail,YouTube和Blogger.
4.7解析JSON数据
import json
from urllib.request import urlopen
def getCountry(ipAddress):
response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
responseJson = json.loads(response)
return responseJson.get("country_code")
print(getCountry("50.78.253.58"))
4.8返回主题
将多个数据源组合为新形式,或使用API作为工具从新的角度解释采集中的数据.
首先做一个采集 Wikipedia的基本程序,找到编辑历史记录页面,然后在编辑历史记录中找出IP地址
# -*- coding: utf-8 -*-
from urllib.request import urlopen
from bs4 import BeautifulSoup
import datetime
import random
import re
import json
random.seed(datetime.datetime.now())
# https://en.wikipedia.org/wiki/Python_(programming_language)
def getLinks(articleUrl):
html = urlopen("http://en.wikipedia.org"+articleUrl)
bsObj = BeautifulSoup(html)
return bsObj.find("div",{"id":"bodyContent"}).findAll("a", href=re.compile("^(/wiki/)((?!:).)*$"))
def getHistoryIPs(pageUrl):
# 编辑历史页面URL链接格式是:
# https://en.wikipedia.org/w/index.php?title=Python_(programming_language)&action=history
pageUrl = pageUrl.replace("/wiki/", "")
historyUrl = "https://en.wikipedia.org/w/ind ... ot%3B
print("history url is: "+historyUrl)
html = urlopen(historyUrl)
bsObj = BeautifulSoup(html)
# 找出class属性是"mw-anonuserlink"的链接
# 它们用IP地址代替用户名
ipAddresses = bsObj.findAll("a", {"class":"mw-anonuserlink"})
addressList = set()
for ipAddress in ipAddresses:
addressList.add(ipAddress.get_text())
return addressList
links = getLinks("/wiki/Python_(programming_language)")
def getCountry(ipAddress):
try:
response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
except HTTPError:
return None
responseJson = json.loads(response)
return responseJson.get("country_code")
while (len(links) > 0):
for link in links:
print("-------------------")
historyIPs = getHistoryIPs(link.attrs["href"])
for historyIP in historyIPs:
#print(historyIP)
country = getCountry(historyIP)
if country is not None:
print(historyIP+" is from "+country)
newLink = links[random.randint(0, len(links)-1)].attrs["href"]
links = getLinks(newLink)
4.9关于API的更多信息
Leonard Richardson,Mike Amundsen和Sam Ruby的RESTful Web API()为使用Web API提供了非常全面的理论和实践指导. 此外,Mike Amundsen的精彩视频教学课程“为Web()设计API”还可以教您创建自己的API. 如果您想方便地共享采集数据,那么他的视频非常有用
正式推出:QuicklibTrade A股行情采集API方案2.6正式发布
采集交流 • 优采云 发表了文章 • 0 个评论 • 620 次浏览 • 2020-08-31 01:19
/
/x/page/b0822umt6kk.html?pcsharecode=JjoaXqFW&sf=uri
版本升级说明
2.6版将采集数据字段从15增加到20
版本2.5进行了改进和发布
2.4版是大量个人使用的初始版本.
QuicklibTrade简介
QuicklibTrade是一个简单易用的A股程序交易程序,主要使用采集来获取股票软件客户(例如Big Wisdom,Straight Flush,Oriental Fortune,Tongdaxin)的数据,并提供多种接口. 支持直接调用公式编辑器的数据,大大简化了策略开发. 许多经典指标公式都可以直接使用.
关键是免费使用
QuicklibTrade市场数据采集视频教学
采集和API调用说明
/x/page/y0842b72xbh.html?pcsharecode=Y0h4qOSw&sf=uri
包括使用虚拟机采集市场的说明
/x/page/b0822umt6kk.html?pcsharecode=JjoaXqFW&sf=uri
QuicklibTrade免费A股Level2报价界面
/
注册
/register.html
下载
/mdapi.asp
其他相关问题,请浏览
/ comm / category / 20 /
在第一阶段中,仅发布市场信息采集和接口,而在第二阶段中,发布市场信息的交易接口和LAN网络接口
由于每个主机只能运行1个DataUpdate.exe,为了使用多个DataUpdate.exe通过LAN网络接口采集共享数据以加快更新速度,因此采用了虚拟机方法.
已提供虚拟机镜像网络磁盘下载,主要用于市场的LAN网络接口. 每个虚拟机可以打开1个Big Wisdom和DataUpdate.exe副本以加快数据更新
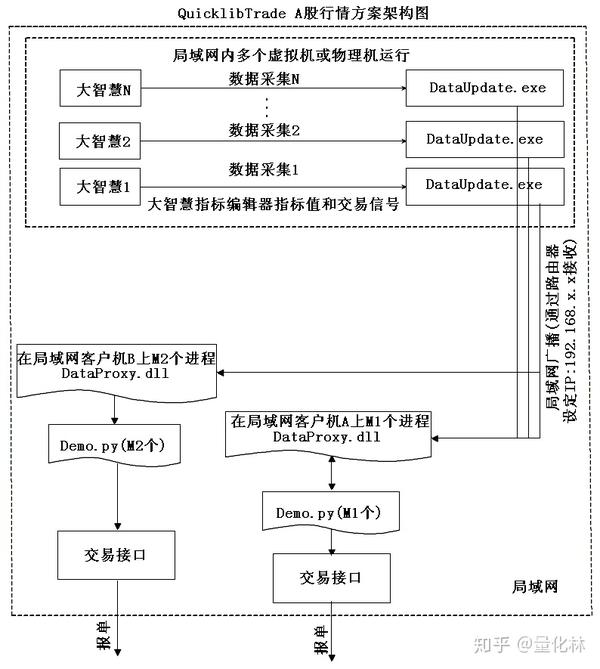
QuicklibTrade体系结构如下图所示:
它分为市场界面和交易界面. 本文仅说明市场界面. 交易界面计划于2019年初发布.
市场报价接口版本2.1的第一阶段支持明智的分界线模式,并且字体选择经典字体. 开始菜单保留冲洗,东方财富和通达信的数据采集方案菜单.
1)支持市场数据采集
2)支持指标数据采集
3)支持交易信号,可以使用Great Wisdom公式编辑器制定交易策略,使用特定的熟悉度来指示购买和出售,将指标加载到Great Wisdom列中,该界面可识别数据的价值,并直接判断通过界面确定交易的熟悉程度.
每次采集同时支持12个字段,这12个字段可以是报价,指标或交易信号.
**运行平台: ** Windows7,Windows78,Windows10,WindowsServer2008,WindowsServer2012,WindowsServer2016和其他版本
运行虚拟机的网络接口必须是64位操作系统
其他接口可用于32位和64位Windows操作系统.
**硬件配置: **请使用单屏显示,使用2个或更多屏幕会导致数据混乱
受支持的接口包括Python接口和C ++接口.
** Python接口: **可以由Python直接调用
从/mdapi.asp(即.py文件)下载的示例是Python2.7的示例,并且理论上支持Python3.x.
Python界面中.dll文件的理论适用于任何Python版本
** C ++接口: **支持所有支持调用DLL的语言,包括C ++,Java,C#,VB.NET,易用语言等.
第一期发行
(1)数据更新主程序
(2)A股CTP接口C ++接口(适用于运行DataUpdate的同一台计算机)
(3)A股CTP接口C ++接口演示期货CTP接口演示
(4)Dataupdate分布式程序等待发布,市场数据更新分布式程序
(5)适用于LAN的Python MSSQL接口,由多个DataUpdate采集共享
(6)Python Access接口适用于运行DataUpdate的同一台计算机
Python ShareMemory接口Python共享内存数据接口,适用于运行DataUpdate的同一台计算机
还提供了一个虚拟机环境,主要用于MSSQL数据库接口和将来的LocalNetwork接口(LAN网络数据接口)
第二期内容,新界面,版本2.2
(1)等待发布的Python LocalNetwork接口Python LAN共享数据接口(适用于LAN,同时采集多个DataUpdates)
(2)等待释放的C ++ LocalNetwork接口. Python LAN共享数据接口(适用于LAN,同时共享多个DataUpdate采集)
使用步骤(以大智慧为例):
1)下载Great Wisdom并安装Great Wisdom程序
付费版本有Level2版本和免费版本.
Great Wisdom的官方下载:
/detail/function_365.jsp?product=116
2)安装大智慧
安装Great Wisdom,安装完成,Great Wisdom在桌面上.
如果在虚拟机上运行,则由于路径较长,虚拟机可能无法直接安装. 安装物理机后,可以将C盘下的“ dzh365”目录复制.
将目录安装到虚拟机上以运行大智慧程序
3)注册并登录到大智慧
您也可以使用QQ和微信登录
4)进入大智慧股票排序模式
在上图中的Big Wisdom界面上单击红色按钮以输入“报价列表”
5)在标题栏中调出行和列分隔符
在大智慧中,我们使用分频器模式采集数据,因此我们需要调用分频器
右键单击并从列菜单中选择“列分隔符”和“行分隔符”
按从左到右的顺序操作标识的列,版本2.1为12列
您还可以为所有列和行设置分隔线.
设置完成后,如下图所示
6)在“大智慧”菜单中设置经典字体,不要更改字体大小和样式颜色
7)启动采集程序,采集程序将自动激活打开的Big Wisdom程序,并在第一行中标识数据,您可以手动检查标识的数据是否正确.
(如果识别错误,通常是由于未将字体设置为经典字体引起的,请确保使用经典字体再试一次)
从以下URL下载
解压缩后,运行DataUpdate.exe
8)如果通过手动观察识别的第一行中的数字是正确的,请按DdtaUpdate.exe程序的按钮以打开识别,然后Big Wisdom将自动在窗口的前面滚动并识别它.
可以通过API获取报价的股票代码的12个数据字段.
当前,只能识别数字,但是不能识别中文. 因此,无法识别“大智慧”中的“十亿”之类的汉字. 请不要识别不是纯数字的指标.
仔细检查黄色框中的数字是否正确识别. 如果它们是错误的,则可能是由于字体设置错误所致. 请重置字体,然后重试
如果正确,请激活DataUpdate.exe程序,然后单击按钮
DataUpdate.exe将自动最小化,并开始滚动窗口以进行识别
如果单击任务栏图标,则可以最大化DataUpdate.exe,并且识别将自动停止,或单击按钮停止.
打开C ++和Python API,您可以获得市场报价
C ++接口提供与期货CTP接口相同的方法,熟悉C ++和CTP的朋友可以更快地开始使用
1)共享内存接口和Access接口只能在运行DataUpdate.exe的计算机上运行
2)可以将MSSQL接口写入MSSQL数据库,其他PC主机调用MSSQL数据库以获取数据.
3)局域网数据接口(在2.2版之后发布)将发布到整个局域网. 局域网中的所有主机都可以通过API获取市场信息. 您还可以在多个主机上运行DataUpdate.exe
这样,数据更新速度将提高数倍.
在期货中开设一个帐户并绑定该帐户以自动激活DataUpdate.exe的功能
免费激活方法
1. 请按照以下步骤打开期货帐户并绑定期货帐户以激活
宏远期货是一家上市公司,隶属于深湾宏远
选择宏远期货进行网上开户,选择重庆销售部门作为营业部
推荐人填写: 上海良北信息技术有限公司
开设帐户的详细步骤:
2. 点激活
您也可以参考激活方法
用户注册| QuickLibTrade中国网站
“期货纪录片软件视频教学四集”
“酷交易者期货复制软件”
“以低佣金开设中国期货帐户”
“ mdshare财务数据接口包”
“ Python定量交易框架的性能评估”
python定量交易
“ Quicklib程序化交易框架”
Caffe深度学习框架
“定量社区”
Python人工智能算法库
<p>tushare,A股Level2数据,A股报价界面,A股Level2报价界面,TuShare,中国金融数据,期货历史交易记录下载,历史数据网络磁盘下载,A股,期货历史数据下载,东方财富选择,金融数据研究终端,iFinD,Go-Goal数据终端,Skysoft数据,新浪Level2报价,恒生数据,数据库金融数据(费用)以及深度分析API服务,Wind Wind,Tongdaxin免费数据,免费的历史数据 查看全部
QuicklibTrade A股市场采集API解决方案2.6正式发布
/

/x/page/b0822umt6kk.html?pcsharecode=JjoaXqFW&sf=uri

版本升级说明
2.6版将采集数据字段从15增加到20
版本2.5进行了改进和发布
2.4版是大量个人使用的初始版本.
QuicklibTrade简介
QuicklibTrade是一个简单易用的A股程序交易程序,主要使用采集来获取股票软件客户(例如Big Wisdom,Straight Flush,Oriental Fortune,Tongdaxin)的数据,并提供多种接口. 支持直接调用公式编辑器的数据,大大简化了策略开发. 许多经典指标公式都可以直接使用.
关键是免费使用
QuicklibTrade市场数据采集视频教学
采集和API调用说明
/x/page/y0842b72xbh.html?pcsharecode=Y0h4qOSw&sf=uri
包括使用虚拟机采集市场的说明
/x/page/b0822umt6kk.html?pcsharecode=JjoaXqFW&sf=uri
QuicklibTrade免费A股Level2报价界面
/
注册
/register.html
下载
/mdapi.asp
其他相关问题,请浏览
/ comm / category / 20 /
在第一阶段中,仅发布市场信息采集和接口,而在第二阶段中,发布市场信息的交易接口和LAN网络接口
由于每个主机只能运行1个DataUpdate.exe,为了使用多个DataUpdate.exe通过LAN网络接口采集共享数据以加快更新速度,因此采用了虚拟机方法.
已提供虚拟机镜像网络磁盘下载,主要用于市场的LAN网络接口. 每个虚拟机可以打开1个Big Wisdom和DataUpdate.exe副本以加快数据更新
QuicklibTrade体系结构如下图所示:
它分为市场界面和交易界面. 本文仅说明市场界面. 交易界面计划于2019年初发布.
市场报价接口版本2.1的第一阶段支持明智的分界线模式,并且字体选择经典字体. 开始菜单保留冲洗,东方财富和通达信的数据采集方案菜单.
1)支持市场数据采集
2)支持指标数据采集
3)支持交易信号,可以使用Great Wisdom公式编辑器制定交易策略,使用特定的熟悉度来指示购买和出售,将指标加载到Great Wisdom列中,该界面可识别数据的价值,并直接判断通过界面确定交易的熟悉程度.
每次采集同时支持12个字段,这12个字段可以是报价,指标或交易信号.
**运行平台: ** Windows7,Windows78,Windows10,WindowsServer2008,WindowsServer2012,WindowsServer2016和其他版本
运行虚拟机的网络接口必须是64位操作系统
其他接口可用于32位和64位Windows操作系统.
**硬件配置: **请使用单屏显示,使用2个或更多屏幕会导致数据混乱
受支持的接口包括Python接口和C ++接口.
** Python接口: **可以由Python直接调用
从/mdapi.asp(即.py文件)下载的示例是Python2.7的示例,并且理论上支持Python3.x.
Python界面中.dll文件的理论适用于任何Python版本
** C ++接口: **支持所有支持调用DLL的语言,包括C ++,Java,C#,VB.NET,易用语言等.
第一期发行
(1)数据更新主程序
(2)A股CTP接口C ++接口(适用于运行DataUpdate的同一台计算机)
(3)A股CTP接口C ++接口演示期货CTP接口演示
(4)Dataupdate分布式程序等待发布,市场数据更新分布式程序
(5)适用于LAN的Python MSSQL接口,由多个DataUpdate采集共享
(6)Python Access接口适用于运行DataUpdate的同一台计算机
Python ShareMemory接口Python共享内存数据接口,适用于运行DataUpdate的同一台计算机
还提供了一个虚拟机环境,主要用于MSSQL数据库接口和将来的LocalNetwork接口(LAN网络数据接口)
第二期内容,新界面,版本2.2
(1)等待发布的Python LocalNetwork接口Python LAN共享数据接口(适用于LAN,同时采集多个DataUpdates)
(2)等待释放的C ++ LocalNetwork接口. Python LAN共享数据接口(适用于LAN,同时共享多个DataUpdate采集)
使用步骤(以大智慧为例):
1)下载Great Wisdom并安装Great Wisdom程序
付费版本有Level2版本和免费版本.
Great Wisdom的官方下载:
/detail/function_365.jsp?product=116
2)安装大智慧
安装Great Wisdom,安装完成,Great Wisdom在桌面上.
如果在虚拟机上运行,则由于路径较长,虚拟机可能无法直接安装. 安装物理机后,可以将C盘下的“ dzh365”目录复制.

将目录安装到虚拟机上以运行大智慧程序
3)注册并登录到大智慧
您也可以使用QQ和微信登录
4)进入大智慧股票排序模式
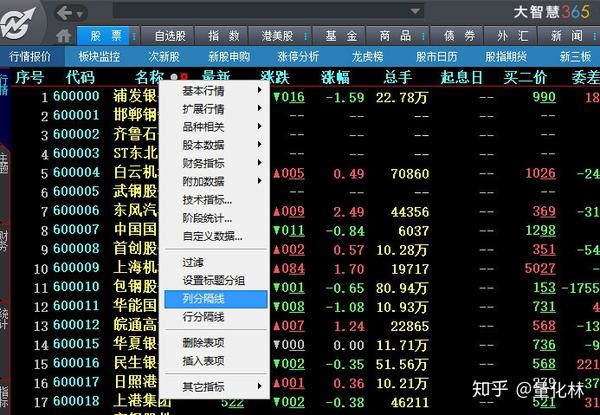
在上图中的Big Wisdom界面上单击红色按钮以输入“报价列表”
5)在标题栏中调出行和列分隔符
在大智慧中,我们使用分频器模式采集数据,因此我们需要调用分频器
右键单击并从列菜单中选择“列分隔符”和“行分隔符”
按从左到右的顺序操作标识的列,版本2.1为12列
您还可以为所有列和行设置分隔线.
设置完成后,如下图所示
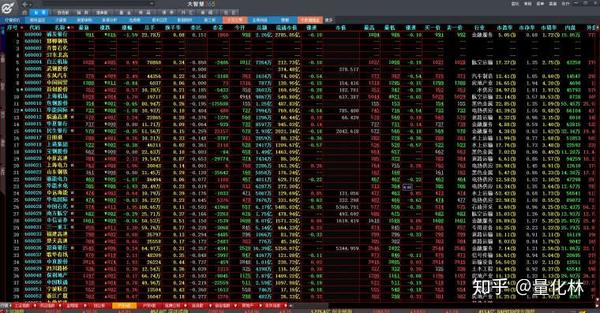
6)在“大智慧”菜单中设置经典字体,不要更改字体大小和样式颜色
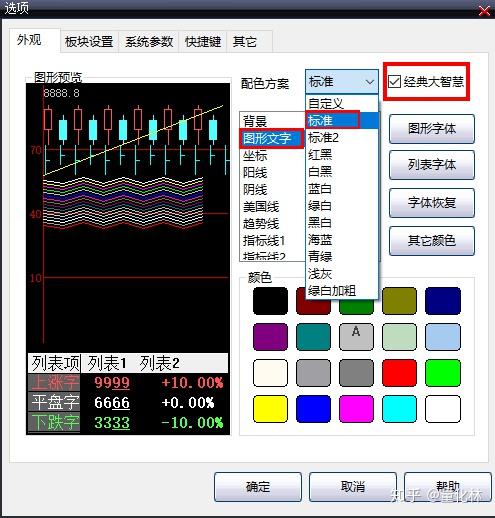
7)启动采集程序,采集程序将自动激活打开的Big Wisdom程序,并在第一行中标识数据,您可以手动检查标识的数据是否正确.
(如果识别错误,通常是由于未将字体设置为经典字体引起的,请确保使用经典字体再试一次)
从以下URL下载
解压缩后,运行DataUpdate.exe

8)如果通过手动观察识别的第一行中的数字是正确的,请按DdtaUpdate.exe程序的按钮以打开识别,然后Big Wisdom将自动在窗口的前面滚动并识别它.
可以通过API获取报价的股票代码的12个数据字段.
当前,只能识别数字,但是不能识别中文. 因此,无法识别“大智慧”中的“十亿”之类的汉字. 请不要识别不是纯数字的指标.
仔细检查黄色框中的数字是否正确识别. 如果它们是错误的,则可能是由于字体设置错误所致. 请重置字体,然后重试
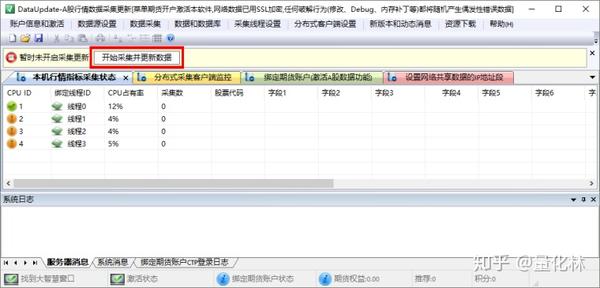
如果正确,请激活DataUpdate.exe程序,然后单击按钮
DataUpdate.exe将自动最小化,并开始滚动窗口以进行识别
如果单击任务栏图标,则可以最大化DataUpdate.exe,并且识别将自动停止,或单击按钮停止.
打开C ++和Python API,您可以获得市场报价
C ++接口提供与期货CTP接口相同的方法,熟悉C ++和CTP的朋友可以更快地开始使用
1)共享内存接口和Access接口只能在运行DataUpdate.exe的计算机上运行
2)可以将MSSQL接口写入MSSQL数据库,其他PC主机调用MSSQL数据库以获取数据.
3)局域网数据接口(在2.2版之后发布)将发布到整个局域网. 局域网中的所有主机都可以通过API获取市场信息. 您还可以在多个主机上运行DataUpdate.exe
这样,数据更新速度将提高数倍.
在期货中开设一个帐户并绑定该帐户以自动激活DataUpdate.exe的功能
免费激活方法
1. 请按照以下步骤打开期货帐户并绑定期货帐户以激活
宏远期货是一家上市公司,隶属于深湾宏远
选择宏远期货进行网上开户,选择重庆销售部门作为营业部
推荐人填写: 上海良北信息技术有限公司
开设帐户的详细步骤:
2. 点激活
您也可以参考激活方法
用户注册| QuickLibTrade中国网站

“期货纪录片软件视频教学四集”
“酷交易者期货复制软件”
“以低佣金开设中国期货帐户”
“ mdshare财务数据接口包”
“ Python定量交易框架的性能评估”
python定量交易
“ Quicklib程序化交易框架”
Caffe深度学习框架
“定量社区”
Python人工智能算法库
<p>tushare,A股Level2数据,A股报价界面,A股Level2报价界面,TuShare,中国金融数据,期货历史交易记录下载,历史数据网络磁盘下载,A股,期货历史数据下载,东方财富选择,金融数据研究终端,iFinD,Go-Goal数据终端,Skysoft数据,新浪Level2报价,恒生数据,数据库金融数据(费用)以及深度分析API服务,Wind Wind,Tongdaxin免费数据,免费的历史数据
一种基于网路爬虫和新浪API相结合的微博数据的采集方法与流程
采集交流 • 优采云 发表了文章 • 0 个评论 • 409 次浏览 • 2020-08-27 06:08
本发明涉及微博数据采集技术领域,特别是一种基于网路爬虫和新浪API 相结合的微博数据的采集方法。
背景技术:
对于微博中数据采集非常重要,这样也能为举办微博中社会安全 事件的探测提供重要的数据基础。目前,微博的数据采集方式主要有 两种:基于新浪API和针对新浪微博平台的网路爬虫。基于新浪API 的方案可以获取格式比较规范的数据,但是其调用次数有一定的限制, 无法进行大规模的数据爬取,并且有些信息难以获取到;基于网路爬 虫的方式其实可以获取大规模的数据,但是其页面的剖析处理过程比 较复杂,并且其爬取的数据格式不规范,噪声数据比较多。
技术实现要素:
本发明的目的是要解决现有技术中存在的不足,提供一种基于网路爬虫和 新浪API相结合的微博数据的采集方法。
为达到上述目的,本发明是根据以下技术方案施行的:
一种基于网路爬虫和新浪API相结合的微博数据的采集方法,包括以下步 骤:
Step1:基于新浪API从微博名人榜获取种子用户及其对应的粉丝用户和关 注用户,加入到种子列表;
Step2:将种子列表转换为种子URL,并判定种子用户列表是否为空,若为 空则步入Step4,否则步入Step3;
Step3:遍历种子列表,采用网路爬虫的方式,爬取种子用户的相关微博信 息、微博评论信息和用户个人信息,并将微博评论用户加入到种子列表中;
Step4:结束。
具体地,所述Step3包括:
获取种子列表中待爬取URL,并进行URL解析与信息获取,具体包括:获 取用户信息URL并步入相应页面爬取用户粉丝用户和关注用户以及爬取用户的 其他相关信息;获取用户微博URL并步入相应页面爬取微博转发点赞、评论用 户、爬取微博评论文本以及爬取微博其他相关信息;并将爬取的用户粉丝用户 和关注用户、用户的其他相关信息、微博转发点赞、评论用户、爬取微博评论 文本以及爬取微博其他相关建立相应的微博数据资源库;同时将爬取的用户粉 丝用户和关注用户、爬取的微博转发点赞、评论用户加入种子列表中。
与现有技术相比,本发明通过将新浪API和针对新浪微博平台的网路爬虫 相结合,既可以获取格式比较规范的微博数据,又能进行大规模的数据爬取, 并且爬取的数据格式愈发规范,噪声数据比较少,进而才能为举办微博中社会 安全风波的探测提供重要的数据基础。
附图说明
图1为本发明的流程图。
具体施行方法
下面结合具体施行例对本发明作进一步描述,在此发明的示意性施行例以 及说明拿来解释本发明,但并不作为对本发明的限定。
如图1所示,本施行例的一种基于网路爬虫和新浪API相结合的微博数据 的采集方法,包括以下步骤:
Step1:基于新浪API从微博名人榜获取种子用户及其对应的粉丝用户和关 注用户,加入到种子列表;
Step2:将种子列表转换为种子URL,并判定种子用户列表是否为空,若为 空则步入Step4,否则步入Step3;
Step3:遍历种子列表,采用网路爬虫的方式,爬取种子用户的相关微博信 息、微博评论信息和用户个人信息,并将微博评论用户加入到种子列表中,具 体步骤为:获取种子列表中待爬取URL,并进行URL解析与信息获取,具体包 括:获取用户信息URL并步入相应页面从微博数据资源库中爬取用户粉丝用户 和关注用户以及爬取用户的其他相关信息;获取用户微博URL并步入相应页面 从微博数据资源库中爬取微博转发点赞、评论用户、爬取微博评论文本以及爬 取微博其他相关信息;同时将爬取的用户粉丝用户和关注用户、爬取的微博转 发点赞、评论用户加入种子列表中。
Step4:结束。
根据本施行例的方式采集完微博数据后,就可以对采集到的微博文本数据 进行处理,清除其中的异常数据和噪音数据,实现数据格式的标准化,并建立 相应的微博资源库,进而才能为举办微博中社会安全风波的探测提供重要的数 据基础。
本发明的技术方案不限于上述具体施行例的限制,凡是按照本发明的技术 方案作出的技术变型,均落入本发明的保护范围之内。
当前第1页1&nbsp2&nbsp3&nbsp 查看全部
一种基于网路爬虫和新浪API相结合的微博数据的采集方法与流程

本发明涉及微博数据采集技术领域,特别是一种基于网路爬虫和新浪API 相结合的微博数据的采集方法。
背景技术:
对于微博中数据采集非常重要,这样也能为举办微博中社会安全 事件的探测提供重要的数据基础。目前,微博的数据采集方式主要有 两种:基于新浪API和针对新浪微博平台的网路爬虫。基于新浪API 的方案可以获取格式比较规范的数据,但是其调用次数有一定的限制, 无法进行大规模的数据爬取,并且有些信息难以获取到;基于网路爬 虫的方式其实可以获取大规模的数据,但是其页面的剖析处理过程比 较复杂,并且其爬取的数据格式不规范,噪声数据比较多。
技术实现要素:
本发明的目的是要解决现有技术中存在的不足,提供一种基于网路爬虫和 新浪API相结合的微博数据的采集方法。
为达到上述目的,本发明是根据以下技术方案施行的:
一种基于网路爬虫和新浪API相结合的微博数据的采集方法,包括以下步 骤:
Step1:基于新浪API从微博名人榜获取种子用户及其对应的粉丝用户和关 注用户,加入到种子列表;
Step2:将种子列表转换为种子URL,并判定种子用户列表是否为空,若为 空则步入Step4,否则步入Step3;
Step3:遍历种子列表,采用网路爬虫的方式,爬取种子用户的相关微博信 息、微博评论信息和用户个人信息,并将微博评论用户加入到种子列表中;
Step4:结束。
具体地,所述Step3包括:
获取种子列表中待爬取URL,并进行URL解析与信息获取,具体包括:获 取用户信息URL并步入相应页面爬取用户粉丝用户和关注用户以及爬取用户的 其他相关信息;获取用户微博URL并步入相应页面爬取微博转发点赞、评论用 户、爬取微博评论文本以及爬取微博其他相关信息;并将爬取的用户粉丝用户 和关注用户、用户的其他相关信息、微博转发点赞、评论用户、爬取微博评论 文本以及爬取微博其他相关建立相应的微博数据资源库;同时将爬取的用户粉 丝用户和关注用户、爬取的微博转发点赞、评论用户加入种子列表中。
与现有技术相比,本发明通过将新浪API和针对新浪微博平台的网路爬虫 相结合,既可以获取格式比较规范的微博数据,又能进行大规模的数据爬取, 并且爬取的数据格式愈发规范,噪声数据比较少,进而才能为举办微博中社会 安全风波的探测提供重要的数据基础。
附图说明
图1为本发明的流程图。
具体施行方法
下面结合具体施行例对本发明作进一步描述,在此发明的示意性施行例以 及说明拿来解释本发明,但并不作为对本发明的限定。
如图1所示,本施行例的一种基于网路爬虫和新浪API相结合的微博数据 的采集方法,包括以下步骤:
Step1:基于新浪API从微博名人榜获取种子用户及其对应的粉丝用户和关 注用户,加入到种子列表;
Step2:将种子列表转换为种子URL,并判定种子用户列表是否为空,若为 空则步入Step4,否则步入Step3;
Step3:遍历种子列表,采用网路爬虫的方式,爬取种子用户的相关微博信 息、微博评论信息和用户个人信息,并将微博评论用户加入到种子列表中,具 体步骤为:获取种子列表中待爬取URL,并进行URL解析与信息获取,具体包 括:获取用户信息URL并步入相应页面从微博数据资源库中爬取用户粉丝用户 和关注用户以及爬取用户的其他相关信息;获取用户微博URL并步入相应页面 从微博数据资源库中爬取微博转发点赞、评论用户、爬取微博评论文本以及爬 取微博其他相关信息;同时将爬取的用户粉丝用户和关注用户、爬取的微博转 发点赞、评论用户加入种子列表中。
Step4:结束。
根据本施行例的方式采集完微博数据后,就可以对采集到的微博文本数据 进行处理,清除其中的异常数据和噪音数据,实现数据格式的标准化,并建立 相应的微博资源库,进而才能为举办微博中社会安全风波的探测提供重要的数 据基础。
本发明的技术方案不限于上述具体施行例的限制,凡是按照本发明的技术 方案作出的技术变型,均落入本发明的保护范围之内。
当前第1页1&nbsp2&nbsp3&nbsp
用Python挖掘Twitter数据:数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 402 次浏览 • 2020-08-26 04:59
这是一系列使用Python专门用于Twitter数据挖掘的文章中的第一篇。在第一部份中,我们将见到通过不同的方法来进行Twitter的数据搜集。一旦我们构建好了一个数据集,在接下来的环节中,我们就将会讨论一些有趣的数据应用。
注册应用
为了才能访问Twitter数据编程,我们须要创建一个与Twitter的API交互的应用程序。
第一步是注册一个你的应用程序。值得注意的是,您须要将您的浏览器转入,登录到Twitter(如果您仍未登陆),并注册一个新的应用程序。您如今可以为您的应用程序选择一个名称和说明(例如“挖掘演示”或类似)。您将收到一个消费者秘钥和消费者密码:这些都是应用程序设置,应一直保密。在您的应用程序的配置页面,你也可以要求获取一个访问令牌和访问令牌的密码。类似于消费者秘钥,这些字符串也必须保密:他们提供的应用程序是代表您的账户访问到Twitter。默认权限是只读的,这是我们在案例中须要的,但假如你决定改变您的许可,在应用中提供修改功能,你就必须再获得一个新的访问令牌。
重要提示:使用Twitter的API时有速度限制,或者你想要提供一个可下载的数据集也会有限制,请参见: >
您可以使用 Twitter提供的REST APIs与她们的服务进行交互。那里还有一群基于Python的顾客,我们可以重复循环使用。尤其Tweepy是其中最有趣和最直白的一个,所以我们一起把它安装上去:
更新:Tweepy发布的3.4.0版本在Python3上出现了一些问题,目前被绑定在GitHub上还不能进行使用,因此在新的版本下来之前,我们仍然使用3.3.0版本。
更多的更新:Tweepy发布的3.5.0版本早已可以使用,似乎解决了上述提及的在Python3上的问题。
为了授权我们的应用程序以代表我们访问Twitter,我们须要使用OAuth的界面:
现在的API变量是我们为可以在Twitter上执行的大多数操作的入口点。
例如,我们可以看见我们自己的时间表(或者我们的Twitter主页):
Tweepy提供方便的光标插口,对不同类型的对象进行迭代。在前面的事例中我们用10来限制我们正在阅读的tweets的数目,但是其实也许我们是可以访问更多的。状态变量是Status() class的一个实例,是访问数据时一个漂亮的包装。Twitter API的JSON响应在_json属性(带有前导顿号)上是可用的,它不是纯JSON字符串,而是一个字典。
所以前面的代码可以被重新写入去处理/存储JSON:
如果我们想要一个所有用户的名单?来这里:
那么我们所有的tweets的列表呢? 也很简单:
通过这些方法,我们可以很容易地搜集tweets(以及更多),并将它们储存为原创的JSON格式,可以很方便的根据我们的储存格式将其转换为不同的数据模型(很多NoSQL技术提供一些批量导出功能)。
process_or_store()功能是您的自定义施行占位符。最简单的形式就是你可以只复印出JSON,每行一个tweet:
流
如果我们要“保持联接”,并搜集所有关于特定风波将会出现的tweets,流API就是我们所须要的。我们须要扩充StreamListener()来定义我们处理输入数据的形式。一个用#python hashtag搜集了所有新的tweet的事例:
根据不同的搜索词,我们可以在几分钟之内搜集到成千上万的tweet。世界性覆盖的现场活动尤其这么(世界杯、超级杯、奥斯卡颁奖典礼等),所以保持关注JSON文件,看看它下降的速率是多么的快,并审视你的测试可能须要多少tweet。以上脚本将把每位tweet保存在新的行中,所以你可以从Unix shell中使用wc-l python.json命令来了解到你搜集了多少tweet。
你可以在下边的要点中见到Twitter的API流的一个最小工作示例:
twitter_stream_downloader.py
总结
我们早已介绍了tweepy作为通过Python访问Twitter数据的一个相当简单的工具。我们可以按照明晰的“tweet”项目目标搜集一些不同类型的数据。
一旦我们搜集了一些数据,在剖析应用方面的就可以进行展开了。在接下来的内容中,我们将讨论部份问题。
简介:Marco Bonzanini是美国纽约的一个数据科学家。活跃于PyData社区的他喜欢从事文本剖析和数据挖掘的应用工作。他是“用Python把握社会化媒体挖掘”( 2016月7月出版)的作者。
原文>>
文章来源36大数据, ,微信号dashuju36 ,36大数据是一个专注大数据创业、大数据技术与剖析、大数据商业与应用的网站。分享大数据的干货教程和大数据应用案例,提供大数据剖析工具和资料下载,解决大数据产业链上的创业、技术、分析、商业、应用等问题,为大数据产业链上的公司和数据行业从业人员提供支持与服务。
via:shumeng
End. 查看全部
用Python挖掘Twitter数据:数据采集
这是一系列使用Python专门用于Twitter数据挖掘的文章中的第一篇。在第一部份中,我们将见到通过不同的方法来进行Twitter的数据搜集。一旦我们构建好了一个数据集,在接下来的环节中,我们就将会讨论一些有趣的数据应用。
注册应用
为了才能访问Twitter数据编程,我们须要创建一个与Twitter的API交互的应用程序。
第一步是注册一个你的应用程序。值得注意的是,您须要将您的浏览器转入,登录到Twitter(如果您仍未登陆),并注册一个新的应用程序。您如今可以为您的应用程序选择一个名称和说明(例如“挖掘演示”或类似)。您将收到一个消费者秘钥和消费者密码:这些都是应用程序设置,应一直保密。在您的应用程序的配置页面,你也可以要求获取一个访问令牌和访问令牌的密码。类似于消费者秘钥,这些字符串也必须保密:他们提供的应用程序是代表您的账户访问到Twitter。默认权限是只读的,这是我们在案例中须要的,但假如你决定改变您的许可,在应用中提供修改功能,你就必须再获得一个新的访问令牌。
重要提示:使用Twitter的API时有速度限制,或者你想要提供一个可下载的数据集也会有限制,请参见: >
您可以使用 Twitter提供的REST APIs与她们的服务进行交互。那里还有一群基于Python的顾客,我们可以重复循环使用。尤其Tweepy是其中最有趣和最直白的一个,所以我们一起把它安装上去:
更新:Tweepy发布的3.4.0版本在Python3上出现了一些问题,目前被绑定在GitHub上还不能进行使用,因此在新的版本下来之前,我们仍然使用3.3.0版本。
更多的更新:Tweepy发布的3.5.0版本早已可以使用,似乎解决了上述提及的在Python3上的问题。
为了授权我们的应用程序以代表我们访问Twitter,我们须要使用OAuth的界面:
现在的API变量是我们为可以在Twitter上执行的大多数操作的入口点。
例如,我们可以看见我们自己的时间表(或者我们的Twitter主页):
Tweepy提供方便的光标插口,对不同类型的对象进行迭代。在前面的事例中我们用10来限制我们正在阅读的tweets的数目,但是其实也许我们是可以访问更多的。状态变量是Status() class的一个实例,是访问数据时一个漂亮的包装。Twitter API的JSON响应在_json属性(带有前导顿号)上是可用的,它不是纯JSON字符串,而是一个字典。
所以前面的代码可以被重新写入去处理/存储JSON:
如果我们想要一个所有用户的名单?来这里:
那么我们所有的tweets的列表呢? 也很简单:
通过这些方法,我们可以很容易地搜集tweets(以及更多),并将它们储存为原创的JSON格式,可以很方便的根据我们的储存格式将其转换为不同的数据模型(很多NoSQL技术提供一些批量导出功能)。
process_or_store()功能是您的自定义施行占位符。最简单的形式就是你可以只复印出JSON,每行一个tweet:
流
如果我们要“保持联接”,并搜集所有关于特定风波将会出现的tweets,流API就是我们所须要的。我们须要扩充StreamListener()来定义我们处理输入数据的形式。一个用#python hashtag搜集了所有新的tweet的事例:
根据不同的搜索词,我们可以在几分钟之内搜集到成千上万的tweet。世界性覆盖的现场活动尤其这么(世界杯、超级杯、奥斯卡颁奖典礼等),所以保持关注JSON文件,看看它下降的速率是多么的快,并审视你的测试可能须要多少tweet。以上脚本将把每位tweet保存在新的行中,所以你可以从Unix shell中使用wc-l python.json命令来了解到你搜集了多少tweet。
你可以在下边的要点中见到Twitter的API流的一个最小工作示例:
twitter_stream_downloader.py
总结
我们早已介绍了tweepy作为通过Python访问Twitter数据的一个相当简单的工具。我们可以按照明晰的“tweet”项目目标搜集一些不同类型的数据。
一旦我们搜集了一些数据,在剖析应用方面的就可以进行展开了。在接下来的内容中,我们将讨论部份问题。
简介:Marco Bonzanini是美国纽约的一个数据科学家。活跃于PyData社区的他喜欢从事文本剖析和数据挖掘的应用工作。他是“用Python把握社会化媒体挖掘”( 2016月7月出版)的作者。
原文>>
文章来源36大数据, ,微信号dashuju36 ,36大数据是一个专注大数据创业、大数据技术与剖析、大数据商业与应用的网站。分享大数据的干货教程和大数据应用案例,提供大数据剖析工具和资料下载,解决大数据产业链上的创业、技术、分析、商业、应用等问题,为大数据产业链上的公司和数据行业从业人员提供支持与服务。
via:shumeng
End.
优采云采集怎样获取数据API链接 优采云采集获取数据API链接的方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 327 次浏览 • 2020-08-26 04:28
今天给你们带来优采云采集怎样获取数据API链接,优采云采集获取数据API链接的方式,让您轻松解决问题。
优采云采集如何获取数据API链接
具体方式如下:
1
java、cs、php示例代码点击下载
这个教程为你们讲解数据API的使用
注:只有在有效期内的旗舰版用户才可以使用数据API
如何获取数据API链接?
1.打开任务配置界面,如下图:
2
2.点下一步,直到最后一步,选择生成数据导入API接口,如下图:
3
3.点击后将会有一个弹出窗口,从弹出窗口上复制API链接,并可查看API示例:
4
最终的API链接格式是:{开始时间}&to={结束时间},key由系统手动生成,请勿更改!最终使用的时侯须要将{开始时间}和{结束时间}替换为想要获取数据的时间区间(采集时间),如:/SkieerDataAPI/GetData?key=key&from=2014-11-11 12:00&to=2014-11-11 13:00,时间区间最长为一个小时(总数据量不少于1000条,多于1000条的请用 )。pageindex是页脚,pageSize是那页显示的数据量 如pageindex=3&pageSize=100的意义为恳求第三页的数据,每页根据100条数据进行界定。
5
如何使用数据API?
数据API返回的是XML格式的数据,您的程序可定时的通过API获取指定时间段云采集的数据,API返回数据的格式如下图: 查看全部
优采云采集怎样获取数据API链接 优采云采集获取数据API链接的方式
今天给你们带来优采云采集怎样获取数据API链接,优采云采集获取数据API链接的方式,让您轻松解决问题。
优采云采集如何获取数据API链接
具体方式如下:
1
java、cs、php示例代码点击下载
这个教程为你们讲解数据API的使用
注:只有在有效期内的旗舰版用户才可以使用数据API
如何获取数据API链接?
1.打开任务配置界面,如下图:

2
2.点下一步,直到最后一步,选择生成数据导入API接口,如下图:

3
3.点击后将会有一个弹出窗口,从弹出窗口上复制API链接,并可查看API示例:

4
最终的API链接格式是:{开始时间}&to={结束时间},key由系统手动生成,请勿更改!最终使用的时侯须要将{开始时间}和{结束时间}替换为想要获取数据的时间区间(采集时间),如:/SkieerDataAPI/GetData?key=key&from=2014-11-11 12:00&to=2014-11-11 13:00,时间区间最长为一个小时(总数据量不少于1000条,多于1000条的请用 )。pageindex是页脚,pageSize是那页显示的数据量 如pageindex=3&pageSize=100的意义为恳求第三页的数据,每页根据100条数据进行界定。
5
如何使用数据API?
数据API返回的是XML格式的数据,您的程序可定时的通过API获取指定时间段云采集的数据,API返回数据的格式如下图:
爬虫数据采集技术趋势—智能化解析
采集交流 • 优采云 发表了文章 • 0 个评论 • 416 次浏览 • 2020-08-26 04:21
用一句话概括爬虫工程师的工作内容,就是We Structure the World's Knowledge。
爬虫工作内容
互联网作为人类历史最大的知识库房,是没有充分结构化的。目前互联网仅仅是一些文本等多媒体数据的聚合,内容似乎十分有价值,但是程序是难以使用这些没有结构化的数据。
在2006年左右,有专家提出的web3.0,语义互联网,知识共享。虽然现今开放API,SOA概念越来越普及,真正语义上的互联网的时代虽然还十分遥远。因此爬虫仍然是最重要的手段,一端不断解析,聚合互联网上的数据,另外一端向各种各样的的应用输送数据。
现有爬虫开发技术存在问题
从急聘市场岗位需求可以看出,近年来对爬虫工程师需求越来越强烈。
个人判定缘由有两个:
信息聚合是互联网公司的基本需求。
数据时代到来,对数据更强烈的需求。
下面是我整理的部份靠爬虫聚合信息的创业公司,按照时间次序排序:
最后5种类型,几乎2014年都是开始。很多金融场景相关应用开始出现,这就对准确度和可靠性提出了更高的要求。但现有的爬虫开发技术能够满足高可靠,大规模,高效率开发需求呢?
从软件工程角度来看,一件事情若果未能评估,那就难以管理。爬虫开发常常是被吐槽的诱因之一,就是工作量往往难以评估。一般的软件项目的开发过程随着时间推动,工作量会渐渐降低,也是你们常常说的烧尽疗效。
而爬虫开发生命周期如下图:
爬虫开发主要有两个方面内容:下载网页,解析网页。解析网页大约抢占开发工作的80%左右。
下载网页功能的开发工作,会涉及IP限制,验证码等问题,这样问题都是可以预期的。同时,随着现今优秀的爬虫框架和云服务器的普及,问题解决上去会更轻松。
编写解析代码,虽然有一些基本工具chrome,firecdebug可以使用,但仍然须要人工剖析,编写解析规则。无论是使用xpath,正则表达式,css selector,都不能减轻这一部分的工作量。
大量重复性工作会导致以下两个问题:
即使同类型的网页看起来99%是一样,也须要编撰独立的爬虫。这都会给人这样一种感觉——爬虫开发大部分的工作内容是重复的。
数据源网页改版,几乎整个爬虫项目须要重做。重做的工作量几乎是100%,爬虫工程师心里常常是一万只矮马跑过。现在好多征信数据采集公司的合作伙伴,当数据源网站改版,常常须要一至两天能够修补爬虫,很明显这些可靠性是难以满足金融场景须要。
智能化解析
这是一张新浪新闻的图片。
可以发觉,视觉上很容易了解到,新闻所报导的风波的标题,发表时间和正文。自然也会想到,能否通过一些机器学习的算法达到手动解析的目的?这样就不用人工编撰解析额,减少重复劳动。在2008年开始,就要研究机构发表了相关论文。
~deepay/mywww/papers/www08-segments.pdf
/en-us/um/people/znie/p048.special.nie.pdf
也就是在2008有一家相关的创业公司,在斯坦福大学孵化。
DiffBot智能化数据采集公司
总部坐落加洲的Diffbot创立于2008年,创始人Mike Tung,是哈佛结业研究生。Diffbot是通过人工智能技术,让“机器”识别网页内容,抓取关键内容,并输出软件可以直接辨识的结构化数据。其创始人兼首席执行官Mike Tung表示,“Diffbot如今做的,相当于人类在浏览网页文章时所做的事情,找出页面中最核心的相关信息。”目前Diffbot早已发布了头版API和文章API,还有产品API。服务的顾客包括三星、eBay、思科、美国在线等。
Diffbot的理念就是通过“视觉机器人”来扫描和辨识不同的网页类型(主要是非结构化的数据),再将这种丰富的数据源用于其他应用。Mike Tung表示:“我们在获取页面然后会对其进行剖析,然后通过成熟先进的技术进行结构化处理。”之前我提及的we structure the world's knowledge,就是该公司提出的理念。
Diffbot在基于智能采集的基础上,又开发出好多数据产品,比如知识图谱,智能商业BI。在2016腾讯与硅谷风投机构Felicis Ventures领投了人工智能创业公司Diffbot 1000万美元的A轮融资,很多互联网大鳄开始发觉这家公司的价值。
算法实践
通过智能方法来解析网页须要两个步骤:
基于视觉上的网页分割,将网页分割几个视觉块。
通过机器学习训练的方法来判定各个视觉块的类型,是标题,还是正文。其中主要流程和通常机器须要流程没哪些区别。这就不详尽解释。使用到使用的开源框架有:scikit-learn,phantomjs
Scikit-Learn机器学习库早已十分成熟,很容易上手。
phantomjs,是一个headless webkit渲染引擎。做爬虫开发的朋友应当十分须要。
网页分割算法
从Diffbot初期发布的文章来看,是通过图象处理的方法来切割视觉块。使用到的算法有,边界检测,文字辨识等算法。但这些方法估算量偏大,复杂度很高。
另外一种实现方法是基于Dom树结构,导出所需的视觉特点。
聚合时侯需用的特点变量。主要考虑视觉相关的诱因有元素在页面上的位置,宽度和高度,Dom的层次。
有一点须要注意的是,现在网页好多是动态生成。需要依靠phantomjs工具来进行动态网页渲染。
聚类算法可以选用的DBSCAN,DBSCAN算法优点是愈发密度来界定,比起K-mean算法的优点,是处理任意形状的聚合。
具体的实现方法可以参考下边博文:
分类算法
在第一步处理后,网页上的标签,会被界定分若干类,需要判定标签的类型,是否是标题,正文,广告,导航之类。需要整理出类似下边的,训练矩阵。
整个学习过程与通常的机器学习训练过程没有区别。由于数据样本规模不大,分类算法基本算法采取。分类算法可以选用朴素贝叶斯,或者SVM。
总结和展望
本文介绍的方法比较简略,一般来说解析模型只能针对特定的网路训练解析模型,比如新闻,电商产品页。所以不同类型的网页,所须要的特点变量有较大差异。针对不同特征类型数据,需要你们自己花时间去探求和实践。
随着数据时代和智能化时代到来,爬虫作为重要的数据来源,自身须要一些技术提高来适应时代的要求,这也就对爬虫工程师提出更高的要求。
本文作者:李国建(点融黑手党),现就职于点融网成都团队Data Team,喜欢研究各类机器学习,爬虫,自动化交易相关的技术。 查看全部
爬虫数据采集技术趋势—智能化解析
用一句话概括爬虫工程师的工作内容,就是We Structure the World's Knowledge。
爬虫工作内容
互联网作为人类历史最大的知识库房,是没有充分结构化的。目前互联网仅仅是一些文本等多媒体数据的聚合,内容似乎十分有价值,但是程序是难以使用这些没有结构化的数据。
在2006年左右,有专家提出的web3.0,语义互联网,知识共享。虽然现今开放API,SOA概念越来越普及,真正语义上的互联网的时代虽然还十分遥远。因此爬虫仍然是最重要的手段,一端不断解析,聚合互联网上的数据,另外一端向各种各样的的应用输送数据。
现有爬虫开发技术存在问题
从急聘市场岗位需求可以看出,近年来对爬虫工程师需求越来越强烈。
个人判定缘由有两个:
信息聚合是互联网公司的基本需求。
数据时代到来,对数据更强烈的需求。
下面是我整理的部份靠爬虫聚合信息的创业公司,按照时间次序排序:
最后5种类型,几乎2014年都是开始。很多金融场景相关应用开始出现,这就对准确度和可靠性提出了更高的要求。但现有的爬虫开发技术能够满足高可靠,大规模,高效率开发需求呢?
从软件工程角度来看,一件事情若果未能评估,那就难以管理。爬虫开发常常是被吐槽的诱因之一,就是工作量往往难以评估。一般的软件项目的开发过程随着时间推动,工作量会渐渐降低,也是你们常常说的烧尽疗效。
而爬虫开发生命周期如下图:
爬虫开发主要有两个方面内容:下载网页,解析网页。解析网页大约抢占开发工作的80%左右。
下载网页功能的开发工作,会涉及IP限制,验证码等问题,这样问题都是可以预期的。同时,随着现今优秀的爬虫框架和云服务器的普及,问题解决上去会更轻松。
编写解析代码,虽然有一些基本工具chrome,firecdebug可以使用,但仍然须要人工剖析,编写解析规则。无论是使用xpath,正则表达式,css selector,都不能减轻这一部分的工作量。
大量重复性工作会导致以下两个问题:
即使同类型的网页看起来99%是一样,也须要编撰独立的爬虫。这都会给人这样一种感觉——爬虫开发大部分的工作内容是重复的。
数据源网页改版,几乎整个爬虫项目须要重做。重做的工作量几乎是100%,爬虫工程师心里常常是一万只矮马跑过。现在好多征信数据采集公司的合作伙伴,当数据源网站改版,常常须要一至两天能够修补爬虫,很明显这些可靠性是难以满足金融场景须要。
智能化解析
这是一张新浪新闻的图片。
可以发觉,视觉上很容易了解到,新闻所报导的风波的标题,发表时间和正文。自然也会想到,能否通过一些机器学习的算法达到手动解析的目的?这样就不用人工编撰解析额,减少重复劳动。在2008年开始,就要研究机构发表了相关论文。
~deepay/mywww/papers/www08-segments.pdf
/en-us/um/people/znie/p048.special.nie.pdf
也就是在2008有一家相关的创业公司,在斯坦福大学孵化。
DiffBot智能化数据采集公司
总部坐落加洲的Diffbot创立于2008年,创始人Mike Tung,是哈佛结业研究生。Diffbot是通过人工智能技术,让“机器”识别网页内容,抓取关键内容,并输出软件可以直接辨识的结构化数据。其创始人兼首席执行官Mike Tung表示,“Diffbot如今做的,相当于人类在浏览网页文章时所做的事情,找出页面中最核心的相关信息。”目前Diffbot早已发布了头版API和文章API,还有产品API。服务的顾客包括三星、eBay、思科、美国在线等。
Diffbot的理念就是通过“视觉机器人”来扫描和辨识不同的网页类型(主要是非结构化的数据),再将这种丰富的数据源用于其他应用。Mike Tung表示:“我们在获取页面然后会对其进行剖析,然后通过成熟先进的技术进行结构化处理。”之前我提及的we structure the world's knowledge,就是该公司提出的理念。
Diffbot在基于智能采集的基础上,又开发出好多数据产品,比如知识图谱,智能商业BI。在2016腾讯与硅谷风投机构Felicis Ventures领投了人工智能创业公司Diffbot 1000万美元的A轮融资,很多互联网大鳄开始发觉这家公司的价值。
算法实践
通过智能方法来解析网页须要两个步骤:
基于视觉上的网页分割,将网页分割几个视觉块。
通过机器学习训练的方法来判定各个视觉块的类型,是标题,还是正文。其中主要流程和通常机器须要流程没哪些区别。这就不详尽解释。使用到使用的开源框架有:scikit-learn,phantomjs
Scikit-Learn机器学习库早已十分成熟,很容易上手。
phantomjs,是一个headless webkit渲染引擎。做爬虫开发的朋友应当十分须要。
网页分割算法
从Diffbot初期发布的文章来看,是通过图象处理的方法来切割视觉块。使用到的算法有,边界检测,文字辨识等算法。但这些方法估算量偏大,复杂度很高。
另外一种实现方法是基于Dom树结构,导出所需的视觉特点。
聚合时侯需用的特点变量。主要考虑视觉相关的诱因有元素在页面上的位置,宽度和高度,Dom的层次。
有一点须要注意的是,现在网页好多是动态生成。需要依靠phantomjs工具来进行动态网页渲染。
聚类算法可以选用的DBSCAN,DBSCAN算法优点是愈发密度来界定,比起K-mean算法的优点,是处理任意形状的聚合。
具体的实现方法可以参考下边博文:
分类算法
在第一步处理后,网页上的标签,会被界定分若干类,需要判定标签的类型,是否是标题,正文,广告,导航之类。需要整理出类似下边的,训练矩阵。
整个学习过程与通常的机器学习训练过程没有区别。由于数据样本规模不大,分类算法基本算法采取。分类算法可以选用朴素贝叶斯,或者SVM。
总结和展望
本文介绍的方法比较简略,一般来说解析模型只能针对特定的网路训练解析模型,比如新闻,电商产品页。所以不同类型的网页,所须要的特点变量有较大差异。针对不同特征类型数据,需要你们自己花时间去探求和实践。
随着数据时代和智能化时代到来,爬虫作为重要的数据来源,自身须要一些技术提高来适应时代的要求,这也就对爬虫工程师提出更高的要求。
本文作者:李国建(点融黑手党),现就职于点融网成都团队Data Team,喜欢研究各类机器学习,爬虫,自动化交易相关的技术。
Python爬虫:十分钟实现从数据抓取到数据API提供
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2020-08-26 01:31
欢迎点击右上角关注小编,除了分享技术文章之外还有好多福利,私信学习资料可以发放包括不限于Python实战演练、PDF电子文档、面试集锦、学习资料等。
依旧先从爬虫的基本概念说起,你去做爬虫做数据抓取,第一件事想必是去查看目标网站是否有api。有且可以使用的话,皆大欢喜。
假如目标网站自身不提供api,但明天你心情不好就想用api来抓数据,那如何办。有个长者说,没api创造api也要上,所以,那就创造api吧~
关于Toapi
很多时侯你须要经历抓取数据->存储数据->构建API的基本步骤,然后在去定时更新数据。然而你的目的并不是想去学习搭建稳定可靠手动更新的API服务,你只是想用这个网站的数据而已。Toapi就是因此实现,可以自动化的完成前述任务,达到使用网站实时数据的目的。
先看效果图 (这个网站是没有api的哟)手机点进去可能没有数据,用pc端浏览器就好。
如你所见,Toapi会使数据弄成一块面包,你只须要将它切出来喝了(虽然英文的显示是unicode)。那么话不多说,看代码。
满打满算10行代码吧,你就可以实现数据的api,心动不如行动还不给我打钱,啊呸,不好意思,串场了。下面还是解释下里面的代码。希望对你有帮助。
对了对了,你写那些代码不用十分钟吧,不要算我标题党。
安装:pip install toapi 查看全部
Python爬虫:十分钟实现从数据抓取到数据API提供
欢迎点击右上角关注小编,除了分享技术文章之外还有好多福利,私信学习资料可以发放包括不限于Python实战演练、PDF电子文档、面试集锦、学习资料等。
依旧先从爬虫的基本概念说起,你去做爬虫做数据抓取,第一件事想必是去查看目标网站是否有api。有且可以使用的话,皆大欢喜。
假如目标网站自身不提供api,但明天你心情不好就想用api来抓数据,那如何办。有个长者说,没api创造api也要上,所以,那就创造api吧~
关于Toapi
很多时侯你须要经历抓取数据->存储数据->构建API的基本步骤,然后在去定时更新数据。然而你的目的并不是想去学习搭建稳定可靠手动更新的API服务,你只是想用这个网站的数据而已。Toapi就是因此实现,可以自动化的完成前述任务,达到使用网站实时数据的目的。
先看效果图 (这个网站是没有api的哟)手机点进去可能没有数据,用pc端浏览器就好。
如你所见,Toapi会使数据弄成一块面包,你只须要将它切出来喝了(虽然英文的显示是unicode)。那么话不多说,看代码。
满打满算10行代码吧,你就可以实现数据的api,心动不如行动还不给我打钱,啊呸,不好意思,串场了。下面还是解释下里面的代码。希望对你有帮助。
对了对了,你写那些代码不用十分钟吧,不要算我标题党。
安装:pip install toapi
第 7 篇:文章详情的 API 接口
采集交流 • 优采云 发表了文章 • 0 个评论 • 359 次浏览 • 2020-08-26 00:36
作者:HelloGitHub-追梦人物
一旦我们使用了视图集,并实现了 HTTP 请求对应的 action 方法(对应规则的说明见 使用视图集简化代码),将其在路由器中注册后,django-restframework 自动会手动为我们生成对应的 API 接口。
目前为止,我们只实现了 GET 请求对应的 action——list 方法,因此路由器只为我们生成了一个 API,这个 API 返回文章资源列表。GET 请求还可以用于获取单个资源,对应的 action 为 retrieve,因此,只要我们在视图集中实现 retrieve 方法的逻辑,就可以直接生成获取单篇文章资源的 API 接口。
贴心的是,django-rest-framework 已经帮我们把 retrieve 的逻辑在 mixins.RetrieveModelMixin 里写好了,直接混进视图集即可:
现在,路由会手动降低一个 /posts/:pk/ 的 URL 模式,其中 pk 为文章的 id。访问此 API 接口可以获得指定文章 id 的资源。
实际上,实现各个 action 逻辑的混进类都十分简单,以 RetrieveModelMixin 为例,我们来瞧瞧它的源码:
retrieve 方法首先调用 get_object 方法获取需序列化的对象。get_object 方法一般情况下根据以下两点来筛选出单个资源对象:
get_queryset 方法(或者 queryset 属性,get_queryset 方法返回的值优先)返回的资源列表对象。lookup_field 属性指定的资源筛选数组(默认为 pk)。django-rest-framework 以该数组的值从 get_queryset 返回的资源列表中筛选出单个资源对象。lookup_field 字段的值将从恳求的 URL 中捕获,所以你听到文章接口的 url 模式为 /posts/:pk/,假设将 lookup_field 指定为 title,则 url 模式为 /posts/:title/,此时将按照文章标题获取单篇文章资源。文章详情 Serializer
现在,假设我们要获取 id 为 1 的文章资源,访问获取单篇文章资源的 API 接口 :10000/api/posts/1/,得到如下的返回结果:
可以看见好多我们须要在详情页中展示的数组值并没有返回,比如文章正文(body)。原因是视图集中指定的文章序列化器为 PostListSerializer,这个序列化器被用于序列化文章列表。因为展示文章列表数据时,有些数组用不上,所以出于性能考虑,只序列化了部份数组。
显然,我们须要给文章详情写一个新的序列化器了:
详情序列化器和列表序列化器几乎一样,只是在 fields 中指定了更多须要序列化的数组。
同时注意,为了序列化文章的标签 tags,我们新增了一个 TagSerializer,由于文章可能有多个标签,因为 tags 是一个列表,要序列化一个列表资源,需要将序列化器参数 many 的值指定为 True。
动态 Serializer
现在新的序列化器写好了,可是在那里指定呢?视图集中 serializer_class 属性早已被指定为了 PostListSerializer,那 PostRetrieveSerializer 应该指定在哪呢?
类似于视图集类的 queryset 属性和 get_queryset 方法的关系, serializer_class 属性的值也可以通过 get_serializer_class 方法返回的值覆盖,因此我们可以按照不同的 action 动作来动态指定对应的序列化器。
那么怎样在视图集中分辨不同的 action 动作呢?视图集有一个 action 属性,专门拿来记录当前恳求对应的动作。对应关系如下:
HTTP 请求对应 action 属性的值GETlist(资源列表)/ retrieve(单个资源)PUTupdatePATCHpartial_updateDELETEdestory
因此,我们在视图集中重画 get_serializer_class 方法,写入我们自己的逻辑,就可以按照不同恳求,分别获取相应的序列化器了:
后续对于其他动作,可以再加 elif 判断,不过若果动作变多了,就会有很多的 if 判断。更好的做好是,给视图集加一个属性,用于配置 action 和 serializer_class 的对应关系,通过查表法查找 action 应该使用的序列化器。
现在,再次访问单篇文章 API 接口,可以看见返回了愈加详尽的博客文章数据了:
『讲解开源项目系列』——让对开源项目感兴趣的人不再惧怕、让开源项目的发起者不再孤单。跟着我们的文章,你会发觉编程的乐趣、使用和发觉参与开源项目这么简单。欢迎留言联系我们、加入我们,让更多人爱上开源、贡献开源~ 查看全部
第 7 篇:文章详情的 API 接口
作者:HelloGitHub-追梦人物
一旦我们使用了视图集,并实现了 HTTP 请求对应的 action 方法(对应规则的说明见 使用视图集简化代码),将其在路由器中注册后,django-restframework 自动会手动为我们生成对应的 API 接口。
目前为止,我们只实现了 GET 请求对应的 action——list 方法,因此路由器只为我们生成了一个 API,这个 API 返回文章资源列表。GET 请求还可以用于获取单个资源,对应的 action 为 retrieve,因此,只要我们在视图集中实现 retrieve 方法的逻辑,就可以直接生成获取单篇文章资源的 API 接口。
贴心的是,django-rest-framework 已经帮我们把 retrieve 的逻辑在 mixins.RetrieveModelMixin 里写好了,直接混进视图集即可:
现在,路由会手动降低一个 /posts/:pk/ 的 URL 模式,其中 pk 为文章的 id。访问此 API 接口可以获得指定文章 id 的资源。
实际上,实现各个 action 逻辑的混进类都十分简单,以 RetrieveModelMixin 为例,我们来瞧瞧它的源码:
retrieve 方法首先调用 get_object 方法获取需序列化的对象。get_object 方法一般情况下根据以下两点来筛选出单个资源对象:
get_queryset 方法(或者 queryset 属性,get_queryset 方法返回的值优先)返回的资源列表对象。lookup_field 属性指定的资源筛选数组(默认为 pk)。django-rest-framework 以该数组的值从 get_queryset 返回的资源列表中筛选出单个资源对象。lookup_field 字段的值将从恳求的 URL 中捕获,所以你听到文章接口的 url 模式为 /posts/:pk/,假设将 lookup_field 指定为 title,则 url 模式为 /posts/:title/,此时将按照文章标题获取单篇文章资源。文章详情 Serializer
现在,假设我们要获取 id 为 1 的文章资源,访问获取单篇文章资源的 API 接口 :10000/api/posts/1/,得到如下的返回结果:
可以看见好多我们须要在详情页中展示的数组值并没有返回,比如文章正文(body)。原因是视图集中指定的文章序列化器为 PostListSerializer,这个序列化器被用于序列化文章列表。因为展示文章列表数据时,有些数组用不上,所以出于性能考虑,只序列化了部份数组。
显然,我们须要给文章详情写一个新的序列化器了:
详情序列化器和列表序列化器几乎一样,只是在 fields 中指定了更多须要序列化的数组。
同时注意,为了序列化文章的标签 tags,我们新增了一个 TagSerializer,由于文章可能有多个标签,因为 tags 是一个列表,要序列化一个列表资源,需要将序列化器参数 many 的值指定为 True。
动态 Serializer
现在新的序列化器写好了,可是在那里指定呢?视图集中 serializer_class 属性早已被指定为了 PostListSerializer,那 PostRetrieveSerializer 应该指定在哪呢?
类似于视图集类的 queryset 属性和 get_queryset 方法的关系, serializer_class 属性的值也可以通过 get_serializer_class 方法返回的值覆盖,因此我们可以按照不同的 action 动作来动态指定对应的序列化器。
那么怎样在视图集中分辨不同的 action 动作呢?视图集有一个 action 属性,专门拿来记录当前恳求对应的动作。对应关系如下:
HTTP 请求对应 action 属性的值GETlist(资源列表)/ retrieve(单个资源)PUTupdatePATCHpartial_updateDELETEdestory
因此,我们在视图集中重画 get_serializer_class 方法,写入我们自己的逻辑,就可以按照不同恳求,分别获取相应的序列化器了:
后续对于其他动作,可以再加 elif 判断,不过若果动作变多了,就会有很多的 if 判断。更好的做好是,给视图集加一个属性,用于配置 action 和 serializer_class 的对应关系,通过查表法查找 action 应该使用的序列化器。
现在,再次访问单篇文章 API 接口,可以看见返回了愈加详尽的博客文章数据了:
『讲解开源项目系列』——让对开源项目感兴趣的人不再惧怕、让开源项目的发起者不再孤单。跟着我们的文章,你会发觉编程的乐趣、使用和发觉参与开源项目这么简单。欢迎留言联系我们、加入我们,让更多人爱上开源、贡献开源~
教你三步爬取后端优质文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2020-08-25 22:36
打开官网,(F12) 打开开发者模式查看network 选项,咱们可以看见获取文章接口的api如下:
打开开发者模式,我们太轻松的找到获取文章的插口,这就好办了,说实话后端开发,只要有了插口,那就等于有了一切,我们可以恣意的 coding 了~
第二步
创建服务器文件 app.js ,通过superagent 模块发送恳求获取文章数据。
app.js 是我们服务端代码,这里通过服务端发送恳求获取爬虫所要的数据保存出来。
// 定义一个函数,用来获取首页前端文章信息
function getInfo () {
// 利用superagent 模块发送请求,获取前20篇文章。注意请求头的设置和POST请求体数据(请求参数)
superagent.post('https://web-api..im/query').send(params).set('X-Agent', 'Juejin/Web').end((err, res) => {
if (err) {
return console.log(err)
}
// 保存所有文章信息
const array1 = JSON.parse(res.text).data.articleFeed.items.edges
const num = JSON.parse(res.text).data.articleFeed.items.pageInfo.endCursor
// 筛选出点赞数大于 50 的文章
result = array1.filter(item => {
return item.node.likeCount > 50
})
params.variables.after = num.toString()
// 再次发送请求获取另外的20篇文章
superagent.post('https://web-api..im/query').send(params).set('X-Agent', 'Juejin/Web').end((err, res) => {
if (err) {
return console.log(err)
}
const array2 = JSON.parse(res.text).data.articleFeed.items.edges
const result2 = array2.filter(item => {
return item.node.likeCount > 50
})
result2.forEach(item => {
result.push(item)
})
})
})
}
// 调用一次获取数据
getInfo()
// 设置定时器,规定10分钟更新一此数据
setInterval(() => {
getInfo()
}, 10*1000*60)
复制代码
这里要注意插口那儿须要设置恳求头的 X-Agent 属性,一定要在 superagent 发送 post 请求时侯带上,否则会出错,另外就是固定的恳求参数 params,这个可以仿造官网来写。
第三步
模板引擎渲染数据,发送结果到浏览器渲染
这一步须要利用模板引擎渲染 HTML 页面,把从第二步领到的结果渲染到页面中,最终返回给浏览器渲染。
app.js 代码:
// 监听路由
app.get('/', (req, res, next) => {
res.render('index.html', {
result
})
})
// 绑定端口,启动服务
app.listen(3000, () => {
console.log('running...')
})
复制代码
模板 index.html 代码 :
{{each result}}
{{$value.node.title}}
{{$value.node.likeCount}}
{{/each}}
复制代码
写在前面
如果你须要项目的源码可以在GitHub对应库房的 node学习demo案例 文件夹下查找, 谢谢! 查看全部
教你三步爬取后端优质文章
打开官网,(F12) 打开开发者模式查看network 选项,咱们可以看见获取文章接口的api如下:
打开开发者模式,我们太轻松的找到获取文章的插口,这就好办了,说实话后端开发,只要有了插口,那就等于有了一切,我们可以恣意的 coding 了~
第二步
创建服务器文件 app.js ,通过superagent 模块发送恳求获取文章数据。
app.js 是我们服务端代码,这里通过服务端发送恳求获取爬虫所要的数据保存出来。
// 定义一个函数,用来获取首页前端文章信息
function getInfo () {
// 利用superagent 模块发送请求,获取前20篇文章。注意请求头的设置和POST请求体数据(请求参数)
superagent.post('https://web-api..im/query').send(params).set('X-Agent', 'Juejin/Web').end((err, res) => {
if (err) {
return console.log(err)
}
// 保存所有文章信息
const array1 = JSON.parse(res.text).data.articleFeed.items.edges
const num = JSON.parse(res.text).data.articleFeed.items.pageInfo.endCursor
// 筛选出点赞数大于 50 的文章
result = array1.filter(item => {
return item.node.likeCount > 50
})
params.variables.after = num.toString()
// 再次发送请求获取另外的20篇文章
superagent.post('https://web-api..im/query').send(params).set('X-Agent', 'Juejin/Web').end((err, res) => {
if (err) {
return console.log(err)
}
const array2 = JSON.parse(res.text).data.articleFeed.items.edges
const result2 = array2.filter(item => {
return item.node.likeCount > 50
})
result2.forEach(item => {
result.push(item)
})
})
})
}
// 调用一次获取数据
getInfo()
// 设置定时器,规定10分钟更新一此数据
setInterval(() => {
getInfo()
}, 10*1000*60)
复制代码
这里要注意插口那儿须要设置恳求头的 X-Agent 属性,一定要在 superagent 发送 post 请求时侯带上,否则会出错,另外就是固定的恳求参数 params,这个可以仿造官网来写。
第三步
模板引擎渲染数据,发送结果到浏览器渲染
这一步须要利用模板引擎渲染 HTML 页面,把从第二步领到的结果渲染到页面中,最终返回给浏览器渲染。
app.js 代码:
// 监听路由
app.get('/', (req, res, next) => {
res.render('index.html', {
result
})
})
// 绑定端口,启动服务
app.listen(3000, () => {
console.log('running...')
})
复制代码
模板 index.html 代码 :
{{each result}}
{{$value.node.title}}

{{$value.node.likeCount}}
{{/each}}
复制代码
写在前面
如果你须要项目的源码可以在GitHub对应库房的 node学习demo案例 文件夹下查找, 谢谢!
API数据提取
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2020-08-25 22:35
GET
POST
PUT
DELETE
GET 就是你在浏览器中输入网址浏览网站所做的事情;POST基本就是当你填写表单或递交信息到网路服务器的前端程序时所做的事情;PUT 在网站交互过程中不常用,但是在API 里面有时会用到;PUT 请求拿来更新一个对象或信息。其实,很多API 在更新信息的时侯都是用POST恳求取代PUT 请求。究竟是创建一个新实体还是更新一个旧实体,通常要看API 请求本身是怎样构筑的。不过,掌握二者的差别还是有用处的,用 API的时侯你常常会碰到PUT 请求;DELETE用于删掉一个对象。例如,如果我们向发出一个DELETE恳求,就会删掉ID号是23的用户。DELETE方式在公共API 里面不常用,它们主要用于创建信息,不能随意使一个用户去删除数据库的信息。
在恳求验证方面,有些API 不需要验证操作(就是说任何人都可以使用API,不需要注册)。有些API 要求顾客验证是为了估算API 调用的费用,或者是提供了包年的服务。有些验证是为了“限制”用户使用API(限制每秒钟、每小时或每晚API 调用的次数),或者是限制一部分用户对某种信息或某类API 的访问。
通常API 验证的方式都是用类似令牌(token)的方法调用,每次API 调用就会把令牌传递到服务器上。这种令牌要么是用户注册的时侯分配给用户,要么就是在用户调用的时侯
才提供,可能是常年固定的值,也可能是频繁变化的,通过服务器对用户名和密码的组合处理后生成。令牌不仅在URL链接中传递,还会通过恳求头里的cookie 把用户信息传递给服务器。
在服务器响应方面,API 有一个重要的特点是它们会反馈格式友好的数据。大多数反馈的数据格式都是XML和JSON 。这几年,JSON 比XML更受欢迎,主要有两个缘由。首先,JSON 文件比完整的XML格式小。如
如下边的XML数据用了98个字符:
RyanMitchellKludgist
同样的JSON 格式数据:
{"user":{"firstname":"Ryan","lastname":"Mitchell","username":"Kludgist"}}
只要用73个字符,比叙述同样内容的XML文件要小36% 。
JSON 格式比XML更受欢迎的另一个缘由是网路技术的改变。过去,服务器端用PHP
和.NET 这些程序作为API 的接收端。现在,服务器端也会用一些JavaScript 框架作为API
的发送和接收端,像Angular或Backbone 等。虽然服务器端的技术难以预测它们将要收到
的数据格式,但是象Backbone 之类的JavaScript 库处理JSON 比处理XML要更简单。
解析JSON数据
调用API,多数服务器会返回JSON格式的数据。Python中通过json库的loads()函数可以把json格式的字符串转换为python对象。
如获取地理位置信息的百度地图API恳求响应
>>> import requests
>>> import json
>>>
>>> par={'address':'北京','key':'cb649a25c1f81c1451adbeca73623251'}
>>>
>>> r=requests.get('',par)
>>> r.text
'{"status":"1","info":"OK","infocode":"10000","count":"1","geocodes":[{"formatted_address":"北京市","country":"中国","province":"北京市","citycode":"010","city":"北京市","district":[],"township":[],"neighborhood":{"name":[],"type":[]},"building":{"name":[],"type":[]},"adcode":"110000","street":[],"number":[],"location":"116.407526,39.904030","level":"省"}]}'
>>>
>>> json_data=json.loads(r.text) #转换为python对象
>>> json_data
{'status': '1', 'info': 'OK', 'infocode': '10000', 'count': '1', 'geocodes': [{'formatted_address': '北京市', 'country': '中国', 'province': '北京市', 'citycode': '010', 'city': '北京市', 'district': [], 'township': [], 'neighborhood': {'name': [], 'type': []}, 'building': {'name': [], 'type': []}, 'adcode': '110000', 'street': [], 'number': [], 'location': '116.407526,39.904030', 'level': '省'}]}
>>>
取北京市的经纬度如下
>>> json_data['geocodes'][0]['location']
'116.407526,39.904030'
>>> 查看全部
API数据提取
GET
POST
PUT
DELETE
GET 就是你在浏览器中输入网址浏览网站所做的事情;POST基本就是当你填写表单或递交信息到网路服务器的前端程序时所做的事情;PUT 在网站交互过程中不常用,但是在API 里面有时会用到;PUT 请求拿来更新一个对象或信息。其实,很多API 在更新信息的时侯都是用POST恳求取代PUT 请求。究竟是创建一个新实体还是更新一个旧实体,通常要看API 请求本身是怎样构筑的。不过,掌握二者的差别还是有用处的,用 API的时侯你常常会碰到PUT 请求;DELETE用于删掉一个对象。例如,如果我们向发出一个DELETE恳求,就会删掉ID号是23的用户。DELETE方式在公共API 里面不常用,它们主要用于创建信息,不能随意使一个用户去删除数据库的信息。
在恳求验证方面,有些API 不需要验证操作(就是说任何人都可以使用API,不需要注册)。有些API 要求顾客验证是为了估算API 调用的费用,或者是提供了包年的服务。有些验证是为了“限制”用户使用API(限制每秒钟、每小时或每晚API 调用的次数),或者是限制一部分用户对某种信息或某类API 的访问。
通常API 验证的方式都是用类似令牌(token)的方法调用,每次API 调用就会把令牌传递到服务器上。这种令牌要么是用户注册的时侯分配给用户,要么就是在用户调用的时侯
才提供,可能是常年固定的值,也可能是频繁变化的,通过服务器对用户名和密码的组合处理后生成。令牌不仅在URL链接中传递,还会通过恳求头里的cookie 把用户信息传递给服务器。
在服务器响应方面,API 有一个重要的特点是它们会反馈格式友好的数据。大多数反馈的数据格式都是XML和JSON 。这几年,JSON 比XML更受欢迎,主要有两个缘由。首先,JSON 文件比完整的XML格式小。如
如下边的XML数据用了98个字符:
RyanMitchellKludgist
同样的JSON 格式数据:
{"user":{"firstname":"Ryan","lastname":"Mitchell","username":"Kludgist"}}
只要用73个字符,比叙述同样内容的XML文件要小36% 。
JSON 格式比XML更受欢迎的另一个缘由是网路技术的改变。过去,服务器端用PHP
和.NET 这些程序作为API 的接收端。现在,服务器端也会用一些JavaScript 框架作为API
的发送和接收端,像Angular或Backbone 等。虽然服务器端的技术难以预测它们将要收到
的数据格式,但是象Backbone 之类的JavaScript 库处理JSON 比处理XML要更简单。
解析JSON数据
调用API,多数服务器会返回JSON格式的数据。Python中通过json库的loads()函数可以把json格式的字符串转换为python对象。
如获取地理位置信息的百度地图API恳求响应
>>> import requests
>>> import json
>>>
>>> par={'address':'北京','key':'cb649a25c1f81c1451adbeca73623251'}
>>>
>>> r=requests.get('',par)
>>> r.text
'{"status":"1","info":"OK","infocode":"10000","count":"1","geocodes":[{"formatted_address":"北京市","country":"中国","province":"北京市","citycode":"010","city":"北京市","district":[],"township":[],"neighborhood":{"name":[],"type":[]},"building":{"name":[],"type":[]},"adcode":"110000","street":[],"number":[],"location":"116.407526,39.904030","level":"省"}]}'
>>>
>>> json_data=json.loads(r.text) #转换为python对象
>>> json_data
{'status': '1', 'info': 'OK', 'infocode': '10000', 'count': '1', 'geocodes': [{'formatted_address': '北京市', 'country': '中国', 'province': '北京市', 'citycode': '010', 'city': '北京市', 'district': [], 'township': [], 'neighborhood': {'name': [], 'type': []}, 'building': {'name': [], 'type': []}, 'adcode': '110000', 'street': [], 'number': [], 'location': '116.407526,39.904030', 'level': '省'}]}
>>>
取北京市的经纬度如下
>>> json_data['geocodes'][0]['location']
'116.407526,39.904030'
>>>
文章采集api Python CMDB开发
采集交流 • 优采云 发表了文章 • 0 个评论 • 334 次浏览 • 2020-08-24 18:44
运维自动化路线:
cmdb的开发须要收录三部份功能:
执行流程:服务器的客户端采集硬件数据,然后将硬件信息发送到API,API负责将获取到的数据保存到数据库中,后台管理程序负责对服务器信息的配置和展示。
采集硬件信息
采集硬件信息可以有两种形式实现:
利用puppet中的report功能自己写agent,定时执行
两种形式的优缺点各异:方式一,优点是不需要在每台服务器上步一个agent,缺点是依赖于puppet,并且使用ruby开发;方式二,优点是用于python调用shell命令,学习成本低,缺点是须要在每台服务器上发一个agent。
方式一
默认情况下,puppet的client会在每半个小时联接puppet的master来同步数据,如果定义了report,那么在每次client和master同步数据时,会执行report的process函数,在该函数中定义一些逻辑,获取每台服务器信息并将信息发送给API
puppet中默认自带了5个report,放置在【/usr/lib/ruby/site_ruby/1.8/puppet/reports/】路径下。如果须要执行某个report,那么就在puppet的master的配置文件中做如下配置:
on master
/etc/puppet/puppet.conf
[main]
reports = store #默认
#report = true #默认
#pluginsync = true #默认
on client
/etc/puppet/puppet.conf
[main]
#report = true #默认
[agent]
runinterval = 10
server = master.puppet.com
certname = c1.puppet.com
如上述设置以后,每次执行client和master同步,就会在master服务器的 【/var/lib/puppet/reports】路径下创建一个文件,主动执行:puppet agent --test
所以,我们可以创建自己的report来实现cmdb数据的采集,创建report也有两种形式。
Demo 1
1、创建report
/usr/lib/ruby/site_ruby/1.8/puppet/reports/cmdb.rb
require 'puppet'
require 'fileutils'
require 'puppet/util'
SEPARATOR = [Regexp.escape(File::SEPARATOR.to_s), Regexp.escape(File::ALT_SEPARATOR.to_s)].join
Puppet::Reports.register_report(:cmdb) do
desc "Store server info
These files collect quickly -- one every half hour -- so it is a good idea
to perform some maintenance on them if you use this report (it's the only
default report)."
def process
certname = self.name
now = Time.now.gmtime
File.open("/tmp/cmdb.json",'a') do |f|
f.write(certname)
f.write(' | ')
f.write(now)
f.write("\r\n")
end
end
end
2、应用report
/etc/puppet/puppet.conf
[main]
reports = cmdb
#report = true #默认
#pluginsync = true #默认
Demo 2
1、创建report
在 /etc/puppet/modules 目录下创建如下文件结构:
modules└── cmdb ├── lib │ └── puppet │ └── reports │ └── cmdb.rb └── manifests └── init.pp
require 'puppet'
require 'fileutils'
require 'puppet/util'
SEPARATOR = [Regexp.escape(File::SEPARATOR.to_s), Regexp.escape(File::ALT_SEPARATOR.to_s)].join
Puppet::Reports.register_report(:cmdb) do
desc "Store server info
These files collect quickly -- one every half hour -- so it is a good idea
to perform some maintenance on them if you use this report (it's the only
default report)."
def process
certname = self.name
now = Time.now.gmtime
File.open("/tmp/cmdb.json",'a') do |f|
f.write(certname)
f.write(' | ')
f.write(now)
f.write("\r\n")
end
end
end
2、应用report
/etc/puppet/puppet.conf
[main]
reports = cmdb
#report = true #默认
#pluginsync = true #默认
方式二
使用python调用shell命令,解析命令结果并将数据发送到API
API
django中可以使用 Django rest framwork 来实现:
class Blog(models.Model):
title = models.CharField(max_length=50)
content = models.TextField()
modes.py
from django.contrib.auth.models import User
from rest_framework import routers, serializers, viewsets
from app02 import models
from rest_framework.decorators import detail_route, list_route
from rest_framework import response
from django.shortcuts import HttpResponse
# Serializers define the API representation.
class UserSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = User
fields = ('url', 'username', 'email', 'is_staff')
# ViewSets define the view behavior.
class UserViewSet(viewsets.ModelViewSet):
queryset = User.objects.all()
serializer_class = UserSerializer
# Serializers define the API representation.
class BlogSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = models.Blog
depth = 1
fields = ('url','title', 'content',)
# ViewSets define the view behavior.
class BLogViewSet(viewsets.ModelViewSet):
queryset = models.Blog.objects.all()
serializer_class = BlogSerializer
@list_route()
def detail(self,request):
print request
#return HttpResponse('ok')
return response.Response('ok')
api.py
from django.conf.urls import patterns, include, url
from django.contrib import admin
from rest_framework import routers
from app02 import api
from app02 import views
# Routers provide an easy way of automatically determining the URL conf.
router = routers.DefaultRouter()
router.register(r'users', api.UserViewSet)
router.register(r'blogs', api.BLogViewSet)
urlpatterns = patterns('',
url(r'^', include(router.urls)),
url(r'index/', views.index),
#url(r'^api-auth/', include('rest_framework.urls', namespace='rest_framework'))
)
urls.py
from django.shortcuts import render
from rest_framework.decorators import api_view
from rest_framework.response import Response
# Create your views here.
@api_view(['GET', 'PUT', 'DELETE','POST'])
def index(request):
print request.method
print request.DATA
return Response([{'asset': '1','request_hostname': 'c1.puppet.com' }])
views
后台管理页面
后台管理页面须要实现对数据表的增删改查。
问题:
1、paramiko执行sudo 查看全部
文章采集api Python CMDB开发
运维自动化路线:
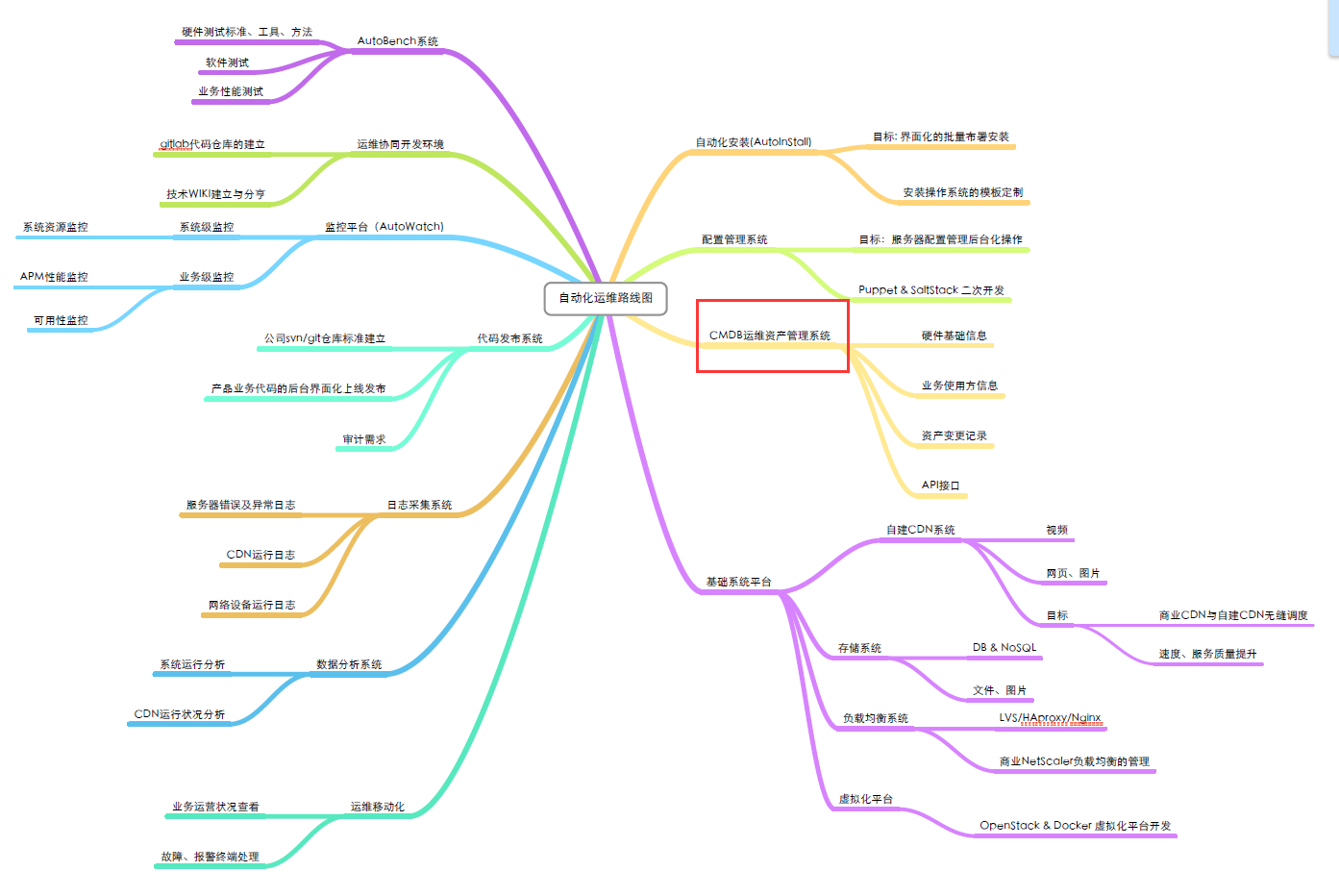
cmdb的开发须要收录三部份功能:
执行流程:服务器的客户端采集硬件数据,然后将硬件信息发送到API,API负责将获取到的数据保存到数据库中,后台管理程序负责对服务器信息的配置和展示。
采集硬件信息
采集硬件信息可以有两种形式实现:
利用puppet中的report功能自己写agent,定时执行
两种形式的优缺点各异:方式一,优点是不需要在每台服务器上步一个agent,缺点是依赖于puppet,并且使用ruby开发;方式二,优点是用于python调用shell命令,学习成本低,缺点是须要在每台服务器上发一个agent。
方式一
默认情况下,puppet的client会在每半个小时联接puppet的master来同步数据,如果定义了report,那么在每次client和master同步数据时,会执行report的process函数,在该函数中定义一些逻辑,获取每台服务器信息并将信息发送给API
puppet中默认自带了5个report,放置在【/usr/lib/ruby/site_ruby/1.8/puppet/reports/】路径下。如果须要执行某个report,那么就在puppet的master的配置文件中做如下配置:
on master
/etc/puppet/puppet.conf
[main]
reports = store #默认
#report = true #默认
#pluginsync = true #默认
on client
/etc/puppet/puppet.conf
[main]
#report = true #默认
[agent]
runinterval = 10
server = master.puppet.com
certname = c1.puppet.com
如上述设置以后,每次执行client和master同步,就会在master服务器的 【/var/lib/puppet/reports】路径下创建一个文件,主动执行:puppet agent --test
所以,我们可以创建自己的report来实现cmdb数据的采集,创建report也有两种形式。
Demo 1
1、创建report
/usr/lib/ruby/site_ruby/1.8/puppet/reports/cmdb.rb
require 'puppet'
require 'fileutils'
require 'puppet/util'
SEPARATOR = [Regexp.escape(File::SEPARATOR.to_s), Regexp.escape(File::ALT_SEPARATOR.to_s)].join
Puppet::Reports.register_report(:cmdb) do
desc "Store server info
These files collect quickly -- one every half hour -- so it is a good idea
to perform some maintenance on them if you use this report (it's the only
default report)."
def process
certname = self.name
now = Time.now.gmtime
File.open("/tmp/cmdb.json",'a') do |f|
f.write(certname)
f.write(' | ')
f.write(now)
f.write("\r\n")
end
end
end
2、应用report
/etc/puppet/puppet.conf
[main]
reports = cmdb
#report = true #默认
#pluginsync = true #默认
Demo 2
1、创建report
在 /etc/puppet/modules 目录下创建如下文件结构:
modules└── cmdb ├── lib │ └── puppet │ └── reports │ └── cmdb.rb └── manifests └── init.pp
require 'puppet'
require 'fileutils'
require 'puppet/util'
SEPARATOR = [Regexp.escape(File::SEPARATOR.to_s), Regexp.escape(File::ALT_SEPARATOR.to_s)].join
Puppet::Reports.register_report(:cmdb) do
desc "Store server info
These files collect quickly -- one every half hour -- so it is a good idea
to perform some maintenance on them if you use this report (it's the only
default report)."
def process
certname = self.name
now = Time.now.gmtime
File.open("/tmp/cmdb.json",'a') do |f|
f.write(certname)
f.write(' | ')
f.write(now)
f.write("\r\n")
end
end
end
2、应用report
/etc/puppet/puppet.conf
[main]
reports = cmdb
#report = true #默认
#pluginsync = true #默认
方式二
使用python调用shell命令,解析命令结果并将数据发送到API
API
django中可以使用 Django rest framwork 来实现:


class Blog(models.Model):
title = models.CharField(max_length=50)
content = models.TextField()
modes.py
from django.contrib.auth.models import User
from rest_framework import routers, serializers, viewsets
from app02 import models
from rest_framework.decorators import detail_route, list_route
from rest_framework import response
from django.shortcuts import HttpResponse
# Serializers define the API representation.
class UserSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = User
fields = ('url', 'username', 'email', 'is_staff')
# ViewSets define the view behavior.
class UserViewSet(viewsets.ModelViewSet):
queryset = User.objects.all()
serializer_class = UserSerializer
# Serializers define the API representation.
class BlogSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = models.Blog
depth = 1
fields = ('url','title', 'content',)
# ViewSets define the view behavior.
class BLogViewSet(viewsets.ModelViewSet):
queryset = models.Blog.objects.all()
serializer_class = BlogSerializer
@list_route()
def detail(self,request):
print request
#return HttpResponse('ok')
return response.Response('ok')
api.py
from django.conf.urls import patterns, include, url
from django.contrib import admin
from rest_framework import routers
from app02 import api
from app02 import views
# Routers provide an easy way of automatically determining the URL conf.
router = routers.DefaultRouter()
router.register(r'users', api.UserViewSet)
router.register(r'blogs', api.BLogViewSet)
urlpatterns = patterns('',
url(r'^', include(router.urls)),
url(r'index/', views.index),
#url(r'^api-auth/', include('rest_framework.urls', namespace='rest_framework'))
)
urls.py
from django.shortcuts import render
from rest_framework.decorators import api_view
from rest_framework.response import Response
# Create your views here.
@api_view(['GET', 'PUT', 'DELETE','POST'])
def index(request):
print request.method
print request.DATA
return Response([{'asset': '1','request_hostname': 'c1.puppet.com' }])
views
后台管理页面
后台管理页面须要实现对数据表的增删改查。
问题:
1、paramiko执行sudo
文章采集api 蚂蜂窝爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 514 次浏览 • 2020-08-24 06:13
Nodejs爬取蚂蜂窝文章的爬虫以及搭建第三方服务器
如题,本项目用Nodejs实现了对蚂蜂窝网站的爬取,并将数据存储到MongoDB中,再以Express作服务器端,Angularjs作后端实现对数据的托管。
本项目Github地址:
本项目线上地址:
本文介绍其中部份的技术细节。
获取数据
打开蚂蜂窝网站,发现文章部分的数据是用Ajax获取的,包括分页也是,所以查看一下实际的恳求路径,为
所以程序应当向这个php文件发送恳求,用Nodejs的话直接http请求也是没问题的,为了代码好看,我使用request库封装一下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
function getArticleList(pageNum) {
request({
url: "http://www.mafengwo.cn/ajax/aj ... ot%3B + pageNum,
headers: {
'User-Agent': 'Mozilla/5.0'
}
}, function(error, response, data) {
var res = data.match(/i\\\/\d{7}/g);
for (var i = 0; i < 12; i++) {
articlesUrl[i] = res[i * 3].substr(3, 7);
};
async.each(articlesUrl, getArticle, function(err) {
console.log('err: ' + err);
});
});
}
每页是12篇文章,每篇文字都是(伪)静态页面,正则提取出其中的文章页Url。
对每位Url发送恳求,拿到源码。
1
2
3
4
5
6
7
8
9
10
function getArticle(urlNumber) {
request({
url: "http://www.mafengwo.cn/i/" + urlNumber + ".html",
headers: {
'User-Agent': 'Mozilla/5.0'
}
}, function(error, response, data) {
//处理数据
});
};
接下来就是处理数据了。
这一段代码较长,但是目的是十分明晰的,代码也太清晰。我们须要从这个页面中领到文章的标题,以及文章的内容。(文章作者以及发布时间因为时间关系我并没有处理,不过也在代码以及数据库种预留了位置,这个同理很容易完成。)
来,我们剖析一下这段代码。
1
2
3
4
<p>var title, content, creator, created;
/*获取标题*/
title = data.match(/\s*.+\s*/).toString().replace(/\s*/g, "").replace(/$/g, "").replace(/\//g, "|").match(/>.+ 查看全部
文章采集api 蚂蜂窝爬虫
Nodejs爬取蚂蜂窝文章的爬虫以及搭建第三方服务器
如题,本项目用Nodejs实现了对蚂蜂窝网站的爬取,并将数据存储到MongoDB中,再以Express作服务器端,Angularjs作后端实现对数据的托管。
本项目Github地址:
本项目线上地址:
本文介绍其中部份的技术细节。
获取数据
打开蚂蜂窝网站,发现文章部分的数据是用Ajax获取的,包括分页也是,所以查看一下实际的恳求路径,为
所以程序应当向这个php文件发送恳求,用Nodejs的话直接http请求也是没问题的,为了代码好看,我使用request库封装一下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
function getArticleList(pageNum) {
request({
url: "http://www.mafengwo.cn/ajax/aj ... ot%3B + pageNum,
headers: {
'User-Agent': 'Mozilla/5.0'
}
}, function(error, response, data) {
var res = data.match(/i\\\/\d{7}/g);
for (var i = 0; i < 12; i++) {
articlesUrl[i] = res[i * 3].substr(3, 7);
};
async.each(articlesUrl, getArticle, function(err) {
console.log('err: ' + err);
});
});
}
每页是12篇文章,每篇文字都是(伪)静态页面,正则提取出其中的文章页Url。
对每位Url发送恳求,拿到源码。
1
2
3
4
5
6
7
8
9
10
function getArticle(urlNumber) {
request({
url: "http://www.mafengwo.cn/i/" + urlNumber + ".html",
headers: {
'User-Agent': 'Mozilla/5.0'
}
}, function(error, response, data) {
//处理数据
});
};
接下来就是处理数据了。
这一段代码较长,但是目的是十分明晰的,代码也太清晰。我们须要从这个页面中领到文章的标题,以及文章的内容。(文章作者以及发布时间因为时间关系我并没有处理,不过也在代码以及数据库种预留了位置,这个同理很容易完成。)
来,我们剖析一下这段代码。
1
2
3
4
<p>var title, content, creator, created;
/*获取标题*/
title = data.match(/\s*.+\s*/).toString().replace(/\s*/g, "").replace(/$/g, "").replace(/\//g, "|").match(/>.+
一篇文章搞定百度OCR图片文字辨识API
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2020-08-23 09:31
研究百度OCR的API,主要是向做对扫描版的各类PDF进行文字辨识并转Word文档的需求。
这里用Postman客户端进行测试和演示。因为Postman是对各类API操作的最佳入门形式。一旦在Postman里实现了正确的调用,剩下的就只是一键生成代码,和一些细节的更改了。
参考百度云官方文档:文字辨识API参考
下载官方文档PDF:OCR.zh.pdf
授权字符串 Access Token
Token字符串永远是你使用他人API的第一步,简单说,就是只有你自己晓得的密码,在你每次向服务器发送的恳求上面加上这个字符串,就相当于完成了一次登陆。
如果没有Token授权认证,API的访问可能会象浏览网页一样简单。
Access Token通常是调用API最重要也最麻烦的地方了:每个公司都不一样,各种设置安全问题使你的Token复杂化。而百度云的Token,真的是麻烦到一定地步了。
(建议你不要参考,因为它的流程图会先把你村住的)
简单说,获取百度云token字符串的主要流程就是:
等待服务器退还给你一个收录token字符串的数据记住这个token字符串,并拿来访问每一次的API
来瞧瞧怎样借助Postman操作,如下图所示:
填好之后点击Send发送,就会获得一个JSON数据,如下图:
然后你用你的程序(Python, PHP, Node.js等,随便),获取这个JSON中的access_token,
即可用到即将的API恳求中,做为授权认证。
正式调用API: 以"通用文字辨识"为例
API链接:
提交形式:POST
调用方法有两种:
直接把API所需的认证信息置于URL里是最简单最方便的。
建议忽视这些方法,需要填写好多request的标准headers,太麻烦。
Headers设置:
只要填这一项就够了。
Body数据传送的各项参数:
Body的数据如图所示:
然后就可以点Send发送恳求了。
成功后,可以得到百度云返回的一个JSON数据,类似右图:
返回的是一行一行的辨识字符。百度云的识别率是相当高的,几乎100%吧。毕竟是国外本土的机器训练下来的。
API常用地址
以下是百度云的OCR常用API地址,每个API所需的参数都差不多,略有不同。所有的API和地址以及详尽所需的参数,参考官方文档,很简单。一个弄明白了就其他的都明白了。
API恳求地址调药量限制
通用文字辨识
50000次/天免费
通用文字辨识(含位置信息版)
500次/天免费
通用文字辨识(高精度版)
500次/天免费
通用文字辨识(高精度含位置版)
50次/天免费
网络图片文字辨识
500次/天免费 查看全部
一篇文章搞定百度OCR图片文字辨识API
研究百度OCR的API,主要是向做对扫描版的各类PDF进行文字辨识并转Word文档的需求。
这里用Postman客户端进行测试和演示。因为Postman是对各类API操作的最佳入门形式。一旦在Postman里实现了正确的调用,剩下的就只是一键生成代码,和一些细节的更改了。
参考百度云官方文档:文字辨识API参考
下载官方文档PDF:OCR.zh.pdf
授权字符串 Access Token
Token字符串永远是你使用他人API的第一步,简单说,就是只有你自己晓得的密码,在你每次向服务器发送的恳求上面加上这个字符串,就相当于完成了一次登陆。
如果没有Token授权认证,API的访问可能会象浏览网页一样简单。
Access Token通常是调用API最重要也最麻烦的地方了:每个公司都不一样,各种设置安全问题使你的Token复杂化。而百度云的Token,真的是麻烦到一定地步了。
(建议你不要参考,因为它的流程图会先把你村住的)
简单说,获取百度云token字符串的主要流程就是:
等待服务器退还给你一个收录token字符串的数据记住这个token字符串,并拿来访问每一次的API
来瞧瞧怎样借助Postman操作,如下图所示:

填好之后点击Send发送,就会获得一个JSON数据,如下图:

然后你用你的程序(Python, PHP, Node.js等,随便),获取这个JSON中的access_token,
即可用到即将的API恳求中,做为授权认证。
正式调用API: 以"通用文字辨识"为例
API链接:
提交形式:POST
调用方法有两种:
直接把API所需的认证信息置于URL里是最简单最方便的。
建议忽视这些方法,需要填写好多request的标准headers,太麻烦。
Headers设置:
只要填这一项就够了。
Body数据传送的各项参数:
Body的数据如图所示:

然后就可以点Send发送恳求了。
成功后,可以得到百度云返回的一个JSON数据,类似右图:

返回的是一行一行的辨识字符。百度云的识别率是相当高的,几乎100%吧。毕竟是国外本土的机器训练下来的。
API常用地址
以下是百度云的OCR常用API地址,每个API所需的参数都差不多,略有不同。所有的API和地址以及详尽所需的参数,参考官方文档,很简单。一个弄明白了就其他的都明白了。
API恳求地址调药量限制
通用文字辨识
50000次/天免费
通用文字辨识(含位置信息版)
500次/天免费
通用文字辨识(高精度版)
500次/天免费
通用文字辨识(高精度含位置版)
50次/天免费
网络图片文字辨识
500次/天免费
WeCenter大数据文章采集器安装说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 625 次浏览 • 2020-08-22 16:51
2、初次安装时地址栏访问install.php文件(访问后删掉)
3、接下来,请按教程一步一步操作。
安装ONEXIN大数据文章采集器图文教程(修订版)
ONEXIN大数据文章采集器图文教程【最新】
点我看视频教程
然后,触发代码放在jquery文件最后一行,oid帐号100000替换为自己的。
;$.ajax({url:"http://we.onexin.com/apiocc.php?oid=100000",
type:"GET",dataType:"jsonp",jsonpCallback:"_obd_success",timeout:200});function _obd_success(){};
最后,当刷新你的网站或有用户访问时,程序会手动更新文章。
如果您在使用中有任何疑惑,欢迎您随时与我们取得联系,ONEXIN菜鸟交流QQ群:189610242
***********常见问题****************
Q:安装需知
A:插件下载:
大数据插件后台: 你的网站地址/obd/
自助申请授权,登录大数据平台:
申请授权填的网址为
你的网站地址/obd/api.php
文章发布模块名:portal
问题发布模块名:forum
更新于:2018年01月19日
Posted on 2017-08-202018-01-26 by King 查看全部
WeCenter大数据文章采集器安装说明
2、初次安装时地址栏访问install.php文件(访问后删掉)
3、接下来,请按教程一步一步操作。
安装ONEXIN大数据文章采集器图文教程(修订版)
ONEXIN大数据文章采集器图文教程【最新】

点我看视频教程
然后,触发代码放在jquery文件最后一行,oid帐号100000替换为自己的。
;$.ajax({url:"http://we.onexin.com/apiocc.php?oid=100000",
type:"GET",dataType:"jsonp",jsonpCallback:"_obd_success",timeout:200});function _obd_success(){};
最后,当刷新你的网站或有用户访问时,程序会手动更新文章。
如果您在使用中有任何疑惑,欢迎您随时与我们取得联系,ONEXIN菜鸟交流QQ群:189610242
***********常见问题****************
Q:安装需知
A:插件下载:
大数据插件后台: 你的网站地址/obd/
自助申请授权,登录大数据平台:
申请授权填的网址为
你的网站地址/obd/api.php
文章发布模块名:portal
问题发布模块名:forum
更新于:2018年01月19日
Posted on 2017-08-202018-01-26 by King
常见的软件数据对接技术
采集交流 • 优采云 发表了文章 • 0 个评论 • 234 次浏览 • 2020-08-22 14:18
目前数据孤岛林立,对接业务软件或则是获取软件中的数据存在较大困难,尤其是CS软件的数据爬取难度更大。
系统对接最常见的形式是插口形式,运气好的情况下,能够顺利对接,但是插口对接方法常需耗费大量时间协调各个软件厂商。
除了软件插口,是否还有其他方法,小编总结了集中常见的数据采集技术供你们参考,主要分为以下几类:
一、CS软件数据采集技术。
C/S架构软件属于比较老的构架,能采集这种软件数据的产品比较少。
常见的是博为小帮软件机器人,在不需要软件厂商配合的情况下,基于“”所见即所得“的方法采集界面上的数据。输出的结果是结构化的数据库或则excel表。如果只须要业务数据的话,或者厂商倒闭,数据库剖析困难的情况下, 这个工具可以采集数据,尤其是详情页数据的采集功能比较有特色。
值得一提的是,这个产品的使用门槛太低,没有 IT背景的业务朋友也能使用,大大拓展了使用的人群。
二、网络数据采集API。通过网路爬虫和一些网站平台提供的公共API(如Twitter和新浪微博API)等方法从网站上获取数据。这样就可以将非结构化数据和半结构化数据的网页数据从网页中提取下来。
互联网的网页大数据采集和处理的整体过程收录四个主要模块:web爬虫(Spider)、数据处理(Data Process)、爬取URL队列(URL Queue)和数据。
三、数据库形式
两个系统分别有各自的数据库,同类型的数据库之间是比较便捷的:
1)如果两个数据库在同一个服务器上,只要用户名设置的没有问题,就可以直接互相访问,需要在from后将其数据库名称及表的构架所有者带上即可。 select * from DATABASE1.dbo.table1
2)如果两个系统的数据库不在一个服务器上,那么建议采用链接服务器的方式来处理,或者使用openset和opendatasource的形式,这个须要对数据库的访问进行外围服务器的配置。
不同类型的数据库之间的联接就比较麻烦,需要做好多设置能够生效,这里不做详尽说明。
开放数据库形式须要协调各个软件厂商开放数据库,其难度很大;一个平台假如要同时联接好多个软件厂商的数据库,并且实时都在获取数据,这对平台本身的性能也是个巨大的挑战。
欢迎你们一起讨论。 查看全部
常见的软件数据对接技术
目前数据孤岛林立,对接业务软件或则是获取软件中的数据存在较大困难,尤其是CS软件的数据爬取难度更大。
系统对接最常见的形式是插口形式,运气好的情况下,能够顺利对接,但是插口对接方法常需耗费大量时间协调各个软件厂商。
除了软件插口,是否还有其他方法,小编总结了集中常见的数据采集技术供你们参考,主要分为以下几类:
一、CS软件数据采集技术。
C/S架构软件属于比较老的构架,能采集这种软件数据的产品比较少。
常见的是博为小帮软件机器人,在不需要软件厂商配合的情况下,基于“”所见即所得“的方法采集界面上的数据。输出的结果是结构化的数据库或则excel表。如果只须要业务数据的话,或者厂商倒闭,数据库剖析困难的情况下, 这个工具可以采集数据,尤其是详情页数据的采集功能比较有特色。
值得一提的是,这个产品的使用门槛太低,没有 IT背景的业务朋友也能使用,大大拓展了使用的人群。
二、网络数据采集API。通过网路爬虫和一些网站平台提供的公共API(如Twitter和新浪微博API)等方法从网站上获取数据。这样就可以将非结构化数据和半结构化数据的网页数据从网页中提取下来。
互联网的网页大数据采集和处理的整体过程收录四个主要模块:web爬虫(Spider)、数据处理(Data Process)、爬取URL队列(URL Queue)和数据。
三、数据库形式
两个系统分别有各自的数据库,同类型的数据库之间是比较便捷的:
1)如果两个数据库在同一个服务器上,只要用户名设置的没有问题,就可以直接互相访问,需要在from后将其数据库名称及表的构架所有者带上即可。 select * from DATABASE1.dbo.table1
2)如果两个系统的数据库不在一个服务器上,那么建议采用链接服务器的方式来处理,或者使用openset和opendatasource的形式,这个须要对数据库的访问进行外围服务器的配置。
不同类型的数据库之间的联接就比较麻烦,需要做好多设置能够生效,这里不做详尽说明。
开放数据库形式须要协调各个软件厂商开放数据库,其难度很大;一个平台假如要同时联接好多个软件厂商的数据库,并且实时都在获取数据,这对平台本身的性能也是个巨大的挑战。
欢迎你们一起讨论。
使用百度地图api采集兴趣点数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 355 次浏览 • 2020-08-21 22:55
使用百度地图api采集兴趣点数据
比如,我们想要采集医院的数据信息,主要包括经纬度座标和电话等信息。
首先,我们须要注册百度开发帐号,然后创建应用,会得到ak码,在访问数据时须要这个参数。
然后,需要使用requests包,通过request = requests.get(url,params=params) 可以恳求到数据
最后,解析恳求到的json数据并保存。
json数据格式如下:
{
"status":0,
"message":"ok",
"total":228,
"results":[
{
"name":"辽中县新华医院",
"location":{
"lat":41.518185,
"lng":122.743932
},
"address":"北一路57号",
"street_id":"4a25f3d22e0206b428201a39",
"telephone":"(024)62308120",
"detail":1,
"uid":"4a25f3d22e0206b428201a39"
}
……
}
完整的代码如下:
import requests
import json
import pandas as pd
def request_hospital_data():
ak="xxxxxxxxxxx" # 换成自己的 AK,需要申请
url = "http://api.map.baidu.com/place/v2/search?query=医疗&page_size=20&scope=1®ion=辽中&output=json&ak="+ak
params = {'page_num':0} # 请求参数,页码
request = requests.get(url,params=params) # 请求数据
total = json.loads(request.text)['total'] # 数据的总条数
# print(total)
total_page_num = (total+19) // 20 # 每个页面大小是20,计算总页码
items = [] # 存放所有的记录,每一条记录是一个元素
for i in range(total_page_num):
params['page_num'] = i
request = requests.get(url,params=params)
for item in json.loads(request.text)['results']:
name = item['name']
lat = item['location']['lat']
lng = item['location']['lng']
address = item.get('address', '')
street_id = item.get('street_id', '')
telephone = item.get('telephone', '')
detail = item.get('detail', '')
uid = item.get('uid', '')
# print(name, lat, lng, address, street_id, telephone, detail, uid)
new_item = (name, lat, lng, address, street_id, telephone, detail, uid)
items.append(new_item)
# 使用pandas的DataFrame对象保存二维数组
df = pd.DataFrame(items, columns=['name', 'lat', 'lng', 'adderss', 'street_id', 'telephone', 'detail', 'uid'])
df.to_csv('liaozhong_hospital_info.csv', header=True, index=False)
request_hospital_data()
最终可以得到如下的数据:
此外,我们可以将url中的query参数换其它兴趣点类别,就能获得相应的数据。
比如,query=住宅区,这样可以获取到住宅区的数据。
兴趣点的类别如以下
它的地址是 查看全部
使用百度地图api采集兴趣点数据
使用百度地图api采集兴趣点数据
比如,我们想要采集医院的数据信息,主要包括经纬度座标和电话等信息。
首先,我们须要注册百度开发帐号,然后创建应用,会得到ak码,在访问数据时须要这个参数。
然后,需要使用requests包,通过request = requests.get(url,params=params) 可以恳求到数据
最后,解析恳求到的json数据并保存。
json数据格式如下:
{
"status":0,
"message":"ok",
"total":228,
"results":[
{
"name":"辽中县新华医院",
"location":{
"lat":41.518185,
"lng":122.743932
},
"address":"北一路57号",
"street_id":"4a25f3d22e0206b428201a39",
"telephone":"(024)62308120",
"detail":1,
"uid":"4a25f3d22e0206b428201a39"
}
……
}
完整的代码如下:
import requests
import json
import pandas as pd
def request_hospital_data():
ak="xxxxxxxxxxx" # 换成自己的 AK,需要申请
url = "http://api.map.baidu.com/place/v2/search?query=医疗&page_size=20&scope=1®ion=辽中&output=json&ak="+ak
params = {'page_num':0} # 请求参数,页码
request = requests.get(url,params=params) # 请求数据
total = json.loads(request.text)['total'] # 数据的总条数
# print(total)
total_page_num = (total+19) // 20 # 每个页面大小是20,计算总页码
items = [] # 存放所有的记录,每一条记录是一个元素
for i in range(total_page_num):
params['page_num'] = i
request = requests.get(url,params=params)
for item in json.loads(request.text)['results']:
name = item['name']
lat = item['location']['lat']
lng = item['location']['lng']
address = item.get('address', '')
street_id = item.get('street_id', '')
telephone = item.get('telephone', '')
detail = item.get('detail', '')
uid = item.get('uid', '')
# print(name, lat, lng, address, street_id, telephone, detail, uid)
new_item = (name, lat, lng, address, street_id, telephone, detail, uid)
items.append(new_item)
# 使用pandas的DataFrame对象保存二维数组
df = pd.DataFrame(items, columns=['name', 'lat', 'lng', 'adderss', 'street_id', 'telephone', 'detail', 'uid'])
df.to_csv('liaozhong_hospital_info.csv', header=True, index=False)
request_hospital_data()
最终可以得到如下的数据:

此外,我们可以将url中的query参数换其它兴趣点类别,就能获得相应的数据。
比如,query=住宅区,这样可以获取到住宅区的数据。
兴趣点的类别如以下

它的地址是
汇总:爬取简书全站文章并生成 API(四)
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2020-11-23 12:04
简书
通过前面的介绍,可以说这个小项目已经基本完成。当然,剩下要做的就是代码重构,功能的不断改进和错误修复。最后,部署是联机的。如第一节所述,将有两种部署和联机方式。本节首先介绍第一种方法,使用nginx + uwsgi + django +超级用户进行环境部署。
nginx + uwsgi + django +环境部署主管
我使用Django已有一段时间了,但是它一直在本地进行测试并且尚未部署。我认为根据其他人博客的教程进行部署应该很容易,但是在阅读了十多个有关百度和Google的教程之后,部署仍然没有成功。我真的很失望。最后,在其他人的帮助下完成了部署,因此我进行了部署。该过程失败了,包括部署过程中遇到的许多问题。在安装之前,让我向大家介绍基本知识。
以下安装环境为CentOS7 x86_64 + python2.7.10 + Django1.9,CentOS 6也适用。
1.安装
首先,安装环境,除了nginx以外,其他两个可以通过pip安装:
# pip install django
# pip install uwsgi
可以使用yum直接安装nginx,有关编译和安装,请参阅编译和安装nginx。
# yum install nginx -y
创建Django应用程序。由于使用了nginx,因此最好将应用程序放置在nginx根目录中:
# django-admin startproject jianshu_api
# cd jianshu_api/
# django-admin startapp jianshu
然后在配置文件settings.py中设置要连接的数据库,将DEBUG = True更改为DEBUG = False,设置* ALLOWED_HOSTS = [''] **,并在末尾添加以下配置:
STATIC_ROOT = os.path.join(BASE_DIR, 'static')
然后运行并自动生成一个静态目录:
# python manage.py collectstatic
或直接将静态文件复制到相应目录:
# cp -r /root/.pyenv/versions/2.7.10/lib/python2.7/site-packages/rest_framework /usr/html/jianshu/static/
# cp -r /root/.pyenv/versions/2.7.10/lib/python2.7/site-packages/django/contrib/admin/static/* /usr/html/jianshu/static/
如果未正确设置,则在访问网站时无法加载相应的静态文件,如下所示:
无法加载静态文件
2.配置服务首先配置nginx:
server {
listen 8080;
#server_name jianshuapi ;
access_log /var/log/nginx/api.log;
# app 根目录
root /usr/html/jianshu;
index index.py index.htm;
location / {
# nginx 收到请求会就转发到 9001 端口
uwsgi_pass 127.0.0.1:9001;
include /etc/nginx/uwsgi_params;
}
#设定静态文件所在目录
location ^~ /static {
alias /usr/html/jianshu/static;
}
}
检查语法并重新启动:
# nginx -t
# nginx -s reload
配置uWSGi:
首先为uWSGI操作创建配置文件jianshu.ini:
# mkdir -p /etc/uwsgi && cd /etc/uwsgi
[uwsgi]
chdir = /usr/html/jianshu
socket = 127.0.0.1:9001
master = true
uid = root
wsgi-file = /usr/html/jianshu/jianshu_api/wsgi.py
processes = 2
threads = 4
chmod-socket = 666
chown-socket = root:nginx
vacuum = true
测试uWSGi是否可以正常工作:
# uwsgi /etc/uwsgi/jianshu.ini
然后在命令行中访问:8080 /:
api测试
现在您可以看到部署已成功。但是通常我们使用主管来管理
uwsgi和nginx,因此操作起来更加方便。
3.使用主管
有关主管的详细用法,请参阅:使用主管来管理流程。
首次安装主管:
# pip install supervisor
然后生成配置文件:
# echo_supervisord_conf > /etc/supervisord.conf
开始监督:
# supervisord
提供uwsgi配置文件,打开/etc/supervisord.conf并在底部添加:
[program:jianshu] ; 添加 uwsgi 的配置示例
command=/root/.pyenv/shims/uwsgi --ini /etc/uwsgi/jianshu.ini
directory=/usr/html/jianshu/
stdout_logfile=/var/log/supervisor/%(program_name)s_access.log
stderr_logfile=/var/log/supervisor/%(program_name)s_err.log
startsecs=10
stopwaitsecs=0
autostart=true
autorestart=true
[program:nginx] ;nginx 配置示例
directory=/
command=/usr/sbin/nginx -c /etc/nginx/nginx.conf
user=root
stdout_logfile=/var/log/supervisor/%(program_name)s_access.log
stderr_logfile=/var/log/supervisor/%(program_name)s_err.log
autostart=true
autorestart=true
startsecs=10
然后重新加载主管配置:
# supervisorctl reload
查看主管的状态:
# supervisorctl status
jianshu RUNNING pid 19466, uptime 0:07:08
nginx RUNNING pid 19490, uptime 0:07:05
再次访问api界面:8080/。
Jianshu API
-终于完成了部署,非常高兴,欢迎每个人使用该API,但不要随意使用它,毕竟服务器资源有限!
-下一节将介绍如何使用docker进行部署。 查看全部
抓取Jianshu整个网站文章并生成API(四)
简书
通过前面的介绍,可以说这个小项目已经基本完成。当然,剩下要做的就是代码重构,功能的不断改进和错误修复。最后,部署是联机的。如第一节所述,将有两种部署和联机方式。本节首先介绍第一种方法,使用nginx + uwsgi + django +超级用户进行环境部署。
nginx + uwsgi + django +环境部署主管
我使用Django已有一段时间了,但是它一直在本地进行测试并且尚未部署。我认为根据其他人博客的教程进行部署应该很容易,但是在阅读了十多个有关百度和Google的教程之后,部署仍然没有成功。我真的很失望。最后,在其他人的帮助下完成了部署,因此我进行了部署。该过程失败了,包括部署过程中遇到的许多问题。在安装之前,让我向大家介绍基本知识。
以下安装环境为CentOS7 x86_64 + python2.7.10 + Django1.9,CentOS 6也适用。
1.安装
首先,安装环境,除了nginx以外,其他两个可以通过pip安装:
# pip install django
# pip install uwsgi
可以使用yum直接安装nginx,有关编译和安装,请参阅编译和安装nginx。
# yum install nginx -y
创建Django应用程序。由于使用了nginx,因此最好将应用程序放置在nginx根目录中:
# django-admin startproject jianshu_api
# cd jianshu_api/
# django-admin startapp jianshu
然后在配置文件settings.py中设置要连接的数据库,将DEBUG = True更改为DEBUG = False,设置* ALLOWED_HOSTS = [''] **,并在末尾添加以下配置:
STATIC_ROOT = os.path.join(BASE_DIR, 'static')
然后运行并自动生成一个静态目录:
# python manage.py collectstatic
或直接将静态文件复制到相应目录:
# cp -r /root/.pyenv/versions/2.7.10/lib/python2.7/site-packages/rest_framework /usr/html/jianshu/static/
# cp -r /root/.pyenv/versions/2.7.10/lib/python2.7/site-packages/django/contrib/admin/static/* /usr/html/jianshu/static/
如果未正确设置,则在访问网站时无法加载相应的静态文件,如下所示:
无法加载静态文件
2.配置服务首先配置nginx:
server {
listen 8080;
#server_name jianshuapi ;
access_log /var/log/nginx/api.log;
# app 根目录
root /usr/html/jianshu;
index index.py index.htm;
location / {
# nginx 收到请求会就转发到 9001 端口
uwsgi_pass 127.0.0.1:9001;
include /etc/nginx/uwsgi_params;
}
#设定静态文件所在目录
location ^~ /static {
alias /usr/html/jianshu/static;
}
}
检查语法并重新启动:
# nginx -t
# nginx -s reload
配置uWSGi:
首先为uWSGI操作创建配置文件jianshu.ini:
# mkdir -p /etc/uwsgi && cd /etc/uwsgi
[uwsgi]
chdir = /usr/html/jianshu
socket = 127.0.0.1:9001
master = true
uid = root
wsgi-file = /usr/html/jianshu/jianshu_api/wsgi.py
processes = 2
threads = 4
chmod-socket = 666
chown-socket = root:nginx
vacuum = true
测试uWSGi是否可以正常工作:
# uwsgi /etc/uwsgi/jianshu.ini
然后在命令行中访问:8080 /:
api测试
现在您可以看到部署已成功。但是通常我们使用主管来管理
uwsgi和nginx,因此操作起来更加方便。
3.使用主管
有关主管的详细用法,请参阅:使用主管来管理流程。
首次安装主管:
# pip install supervisor
然后生成配置文件:
# echo_supervisord_conf > /etc/supervisord.conf
开始监督:
# supervisord
提供uwsgi配置文件,打开/etc/supervisord.conf并在底部添加:
[program:jianshu] ; 添加 uwsgi 的配置示例
command=/root/.pyenv/shims/uwsgi --ini /etc/uwsgi/jianshu.ini
directory=/usr/html/jianshu/
stdout_logfile=/var/log/supervisor/%(program_name)s_access.log
stderr_logfile=/var/log/supervisor/%(program_name)s_err.log
startsecs=10
stopwaitsecs=0
autostart=true
autorestart=true
[program:nginx] ;nginx 配置示例
directory=/
command=/usr/sbin/nginx -c /etc/nginx/nginx.conf
user=root
stdout_logfile=/var/log/supervisor/%(program_name)s_access.log
stderr_logfile=/var/log/supervisor/%(program_name)s_err.log
autostart=true
autorestart=true
startsecs=10
然后重新加载主管配置:
# supervisorctl reload
查看主管的状态:
# supervisorctl status
jianshu RUNNING pid 19466, uptime 0:07:08
nginx RUNNING pid 19490, uptime 0:07:05
再次访问api界面:8080/。
Jianshu API
-终于完成了部署,非常高兴,欢迎每个人使用该API,但不要随意使用它,毕竟服务器资源有限!
-下一节将介绍如何使用docker进行部署。
汇总:将ApiBoot Logging采集的日志上报到Admin
采集交流 • 优采云 发表了文章 • 0 个评论 • 335 次浏览 • 2020-09-17 08:11
每个请求的详细信息都可以通过ApiBoot Logging获得。在分布式部署模式下,请求可以通过多个服务。如果每个服务都独立保存请求日志信息,我们将无法做到。统一控制,日志数据库和业务数据库之间将存在不一致(可能使用多个数据源配置)。由于这个问题,ApiBoot Logging提供了Admin的概念,它将客户端采集连接到。每个日志都报告给Admin,并且Admin将分析并保存操作。
创建Logging Admin项目
ApiBoot Logging Admin可以汇总每个业务服务的请求日志(ApiBoot Logging),因此我们需要向Admin报告每个业务服务的日志采集,因此我们应该使用独立的部署方法。创建单独的服务以专门请求日志采集,然后将其保存。
初始化Logging Admin项目依赖项
使用想法创建一个SpringBoot项目,pom.xml配置文件中的依赖项如下:
org.springframework.boot
spring-boot-starter-web
org.minbox.framework
api-boot-starter-logging-admin
mysql
mysql-connector-java
com.zaxxer
HikariCP
org.minbox.framework
api-boot-starter-mybatis-enhance
我们需要将请求日志从采集保存到数据库,因此我们需要在项目中添加与数据库驱动程序和数据库连接池相关的依赖项。 ApiBoot Logging Admin通过DataSource操作数据,并依赖于ApiBoot MyBatis Enhance。您可以自动创建DataSource,摆脱手动创建的麻烦,并加入Spring IOC容器。
添加ApiBoot统一版本依赖项
org.minbox.framework
api-boot-dependencies
2.1.4.RELEASE
import
pom
最新版本的ApiBoot,请访问:: api-boot-dependencies以进行查询。
启用日志记录管理员
添加ApiBoot Logging Admin依赖项后,无法完全使用Admin功能。我们需要通过@EnableLoggingAdmin批注启用它。该批注将自动在Logging Admin中注册一些必需的类到Spring IOC,并将批注添加到条目类中,如下所示:
/**
* ApiBoot Logging Admin入口类
*/
@SpringBootApplication
@EnableLoggingAdmin
public class ApibootReportLogsByLoggingToAdminApplication {
public static void main(String[] args) {
SpringApplication.run(ApibootReportLogsByLoggingToAdminApplication.class, args);
}
}
配置日志数据源
application.yml配置文件中的数据源配置如下:
# 服务名称
spring:
application:
name: apiboot-report-logs-by-logging-to-admin
# 数据源相关配置
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test
username: root
password: 123456
type: com.zaxxer.hikari.HikariDataSource
# 服务端口号
server:
port: 8081
控制台将打印报告日志
ApiBoot Logging Admin可以控制是否通过配置文件在控制台上从采集打印请求日志信息,并在application.yml配置文件中添加以下内容:
api:
boot:
logging:
# Logging Admin相关配置
admin:
# 控制台显示采集的日志信息
show-console-report-log: true
注意:这不应与ApiBoot Logging提供的api.boot.logging.show-console-log配置混淆。
美化控制台打印的报告日志
api:
boot:
logging:
# Logging Admin相关配置
admin:
# 控制台输出时美化采集到的日志
format-console-log-json: true
注意:请勿在此处与api.boot.logging.format-console-log-json配置混淆。
初始化日志表结构
ApiBoot Logging Admin使用固定的表结构来存储请求日志和服务信息。表创建语句如下:
SET NAMES utf8mb4 ;
--
-- Table structure for table `logging_request_logs`
--
CREATE TABLE `logging_request_logs` (
`lrl_id` varchar(36) COLLATE utf8mb4_general_ci NOT NULL COMMENT '主键,UUID',
`lrl_service_detail_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '服务详情编号,关联logging_service_details主键',
`lrl_trace_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '链路ID',
`lrl_parent_span_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上级跨度ID',
`lrl_span_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '跨度ID',
`lrl_start_time` mediumtext COLLATE utf8mb4_general_ci COMMENT '请求开始时间',
`lrl_end_time` mediumtext COLLATE utf8mb4_general_ci COMMENT '请求结束时间',
`lrl_http_status` int(11) DEFAULT NULL COMMENT '请求响应状态码',
`lrl_request_body` longtext COLLATE utf8mb4_general_ci COMMENT '请求主体内容',
`lrl_request_headers` text COLLATE utf8mb4_general_ci COMMENT '请求头信息',
`lrl_request_ip` varchar(30) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '发起请求客户端的IP地址',
`lrl_request_method` varchar(10) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '请求方式',
`lrl_request_uri` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '请求路径',
`lrl_response_body` longtext COLLATE utf8mb4_general_ci COMMENT '响应内容',
`lrl_response_headers` text COLLATE utf8mb4_general_ci COMMENT '响应头信息',
`lrl_time_consuming` int(11) DEFAULT NULL COMMENT '请求耗时',
`lrl_create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '日志保存时间',
`lrl_request_params` text COLLATE utf8mb4_general_ci,
`lrl_exception_stack` text COLLATE utf8mb4_general_ci,
PRIMARY KEY (`lrl_id`),
KEY `logging_request_logs_LRL_SERVICE_DETAIL_ID_index` (`lrl_service_detail_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='请求日志信息表';
--
-- Table structure for table `logging_service_details`
--
CREATE TABLE `logging_service_details` (
`lsd_id` varchar(36) COLLATE utf8mb4_general_ci NOT NULL,
`lsd_service_id` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上报服务的ID,对应spring.application.name配置值',
`lsd_service_ip` varchar(50) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上报服务的IP地址',
`lsd_service_port` int(11) DEFAULT NULL COMMENT '上报服务的端口号',
`lsd_last_report_time` timestamp NULL DEFAULT NULL COMMENT '最后一次上报时间,每次上报更新',
`lsd_create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '首次上报时创建时间',
PRIMARY KEY (`lsd_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='上报日志的客户端服务详情';
到目前为止,ApiBoot Logging Admin已经准备就绪。接下来,我们需要修改业务服务,以将请求日志报告给Logging Admin。
将日志报告给指定的日志记录管理员
我们将修改使用ApiBoot Logging获取统一管理请求日志文章的源代码,并将Logging Admin的地址添加到application.yml中,如下所示:
api:
boot:
# ApiBoot Logging 日志组件配置
logging:
# 配置Logging Admin地址
admin:
server-address: 127.0.0.1:8081
api.boot.logging.admin-service-address的配置格式为:Ip:Port,我们只需要修改一个地方,所有其他任务都将在内部交付给ApiBoot Logging。
测试
我们以应用程序的形式启动ApiBoot Logging Admin和业务服务。
使用curl访问测试地址,如下所示:
~ curl http://localhost:8080/test\?name\=admin
你好:admin
我们检查ApiBoot Logging管理控制台日志,如下所示:
Receiving Service: 【apiboot-unified-manage-request-logs -> 127.0.0.1】, Request Log Report,Logging Content:[
{
"endTime":1571641723779,
"httpStatus":200,
"requestBody":"",
"requestHeaders":{
"server-region":"JiNan",
"host":"localhost:8080",
"user-agent":"curl/7.64.1",
"accept":"*/*"
},
"requestIp":"0:0:0:0:0:0:0:1",
"requestMethod":"GET",
"requestParam":"{\"name\":\"admin\"}",
"requestUri":"/test",
"responseBody":"你好:admin",
"responseHeaders":{},
"serviceId":"apiboot-unified-manage-request-logs",
"serviceIp":"127.0.0.1",
"servicePort":"8080",
"spanId":"95a73ca0-831b-45df-aa43-2b5887e8d98d",
"startTime":1571641723776,
"timeConsuming":3,
"traceId":"25a7de96-b3dd-48e5-9854-1a8069a4a681"
}
]
我们已经看到Logging Admin控制台打印的报告请求日志,并且尚不确定此请求的日志是否已保存到数据库中。接下来,我将使用命令行查看数据库的日志信息。
查看logging_service_details表中的数据
mysql> select * from logging_service_details\G;
*************************** 1. row ***************************
lsd_id: b069366a-25dc-41ec-8f09-242d81755cd0
lsd_service_id: apiboot-unified-manage-request-logs
lsd_service_ip: 10.180.98.112
lsd_service_port: 8080
lsd_last_report_time: 2019-10-21 02:14:26
lsd_create_time: 2019-10-21 15:14:26
logging_service_details存储报告请求日志的每个业务服务的基本信息。每个服务的基本信息将被缓存在Logging Admin内存中,以方便获取service_id来存储日志,并且唯一性是根据ip + port + service_id确定的。相同的服务仅保存一次。
查看logging_request_logs表中的数据
mysql> select * from logging_request_logs\G;
*************************** 1. row ***************************
lrl_id: c42761f6-b072-4744-8a17-d8e6097b85de
lrl_service_detail_id: b069366a-25dc-41ec-8f09-242d81755cd0
lrl_trace_id: 055329a0-cfc1-4606-baf0-4fb0cc905ba2
lrl_parent_span_id: NULL
lrl_span_id: aab83092-7749-4f88-8cb6-a949cc060197
lrl_start_time: 1571642065262
lrl_end_time: 1571642065286
lrl_http_status: 200
lrl_request_body:
lrl_request_headers: {"server-region":"JiNan","host":"localhost:8080","user-agent":"curl/7.64.1","accept":"*/*"}
lrl_request_ip: 0:0:0:0:0:0:0:1
lrl_request_method: GET
lrl_request_uri: /test
lrl_response_body: 你好:admin
lrl_response_headers: {}
lrl_time_consuming: 24
lrl_create_time: 2019-10-21 15:14:26
lrl_request_params: {"name":"admin"}
lrl_exception_stack: NULL
敲黑板画关键点
在本章中,我们集成了ApiBoot Logging Admin,将业务服务的每个请求日志报告给Logging Admin,先通过数据库保存请求日志,然后再通过其他方法,并通过spanId和traceId查看日志下属每个请求链接与消耗每个请求中时间最多的跨度的关系,以准确地优化服务性能。
作者的个人博客
使用开源框架ApiBoot帮助您成为Api接口服务架构师 查看全部
将ApiBoot日志记录采集的日志报告给管理员
每个请求的详细信息都可以通过ApiBoot Logging获得。在分布式部署模式下,请求可以通过多个服务。如果每个服务都独立保存请求日志信息,我们将无法做到。统一控制,日志数据库和业务数据库之间将存在不一致(可能使用多个数据源配置)。由于这个问题,ApiBoot Logging提供了Admin的概念,它将客户端采集连接到。每个日志都报告给Admin,并且Admin将分析并保存操作。
创建Logging Admin项目
ApiBoot Logging Admin可以汇总每个业务服务的请求日志(ApiBoot Logging),因此我们需要向Admin报告每个业务服务的日志采集,因此我们应该使用独立的部署方法。创建单独的服务以专门请求日志采集,然后将其保存。
初始化Logging Admin项目依赖项
使用想法创建一个SpringBoot项目,pom.xml配置文件中的依赖项如下:
org.springframework.boot
spring-boot-starter-web
org.minbox.framework
api-boot-starter-logging-admin
mysql
mysql-connector-java
com.zaxxer
HikariCP
org.minbox.framework
api-boot-starter-mybatis-enhance
我们需要将请求日志从采集保存到数据库,因此我们需要在项目中添加与数据库驱动程序和数据库连接池相关的依赖项。 ApiBoot Logging Admin通过DataSource操作数据,并依赖于ApiBoot MyBatis Enhance。您可以自动创建DataSource,摆脱手动创建的麻烦,并加入Spring IOC容器。
添加ApiBoot统一版本依赖项
org.minbox.framework
api-boot-dependencies
2.1.4.RELEASE
import
pom
最新版本的ApiBoot,请访问:: api-boot-dependencies以进行查询。
启用日志记录管理员
添加ApiBoot Logging Admin依赖项后,无法完全使用Admin功能。我们需要通过@EnableLoggingAdmin批注启用它。该批注将自动在Logging Admin中注册一些必需的类到Spring IOC,并将批注添加到条目类中,如下所示:
/**
* ApiBoot Logging Admin入口类
*/
@SpringBootApplication
@EnableLoggingAdmin
public class ApibootReportLogsByLoggingToAdminApplication {
public static void main(String[] args) {
SpringApplication.run(ApibootReportLogsByLoggingToAdminApplication.class, args);
}
}
配置日志数据源
application.yml配置文件中的数据源配置如下:
# 服务名称
spring:
application:
name: apiboot-report-logs-by-logging-to-admin
# 数据源相关配置
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test
username: root
password: 123456
type: com.zaxxer.hikari.HikariDataSource
# 服务端口号
server:
port: 8081
控制台将打印报告日志
ApiBoot Logging Admin可以控制是否通过配置文件在控制台上从采集打印请求日志信息,并在application.yml配置文件中添加以下内容:
api:
boot:
logging:
# Logging Admin相关配置
admin:
# 控制台显示采集的日志信息
show-console-report-log: true
注意:这不应与ApiBoot Logging提供的api.boot.logging.show-console-log配置混淆。
美化控制台打印的报告日志
api:
boot:
logging:
# Logging Admin相关配置
admin:
# 控制台输出时美化采集到的日志
format-console-log-json: true
注意:请勿在此处与api.boot.logging.format-console-log-json配置混淆。
初始化日志表结构
ApiBoot Logging Admin使用固定的表结构来存储请求日志和服务信息。表创建语句如下:
SET NAMES utf8mb4 ;
--
-- Table structure for table `logging_request_logs`
--
CREATE TABLE `logging_request_logs` (
`lrl_id` varchar(36) COLLATE utf8mb4_general_ci NOT NULL COMMENT '主键,UUID',
`lrl_service_detail_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '服务详情编号,关联logging_service_details主键',
`lrl_trace_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '链路ID',
`lrl_parent_span_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上级跨度ID',
`lrl_span_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '跨度ID',
`lrl_start_time` mediumtext COLLATE utf8mb4_general_ci COMMENT '请求开始时间',
`lrl_end_time` mediumtext COLLATE utf8mb4_general_ci COMMENT '请求结束时间',
`lrl_http_status` int(11) DEFAULT NULL COMMENT '请求响应状态码',
`lrl_request_body` longtext COLLATE utf8mb4_general_ci COMMENT '请求主体内容',
`lrl_request_headers` text COLLATE utf8mb4_general_ci COMMENT '请求头信息',
`lrl_request_ip` varchar(30) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '发起请求客户端的IP地址',
`lrl_request_method` varchar(10) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '请求方式',
`lrl_request_uri` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '请求路径',
`lrl_response_body` longtext COLLATE utf8mb4_general_ci COMMENT '响应内容',
`lrl_response_headers` text COLLATE utf8mb4_general_ci COMMENT '响应头信息',
`lrl_time_consuming` int(11) DEFAULT NULL COMMENT '请求耗时',
`lrl_create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '日志保存时间',
`lrl_request_params` text COLLATE utf8mb4_general_ci,
`lrl_exception_stack` text COLLATE utf8mb4_general_ci,
PRIMARY KEY (`lrl_id`),
KEY `logging_request_logs_LRL_SERVICE_DETAIL_ID_index` (`lrl_service_detail_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='请求日志信息表';
--
-- Table structure for table `logging_service_details`
--
CREATE TABLE `logging_service_details` (
`lsd_id` varchar(36) COLLATE utf8mb4_general_ci NOT NULL,
`lsd_service_id` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上报服务的ID,对应spring.application.name配置值',
`lsd_service_ip` varchar(50) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上报服务的IP地址',
`lsd_service_port` int(11) DEFAULT NULL COMMENT '上报服务的端口号',
`lsd_last_report_time` timestamp NULL DEFAULT NULL COMMENT '最后一次上报时间,每次上报更新',
`lsd_create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '首次上报时创建时间',
PRIMARY KEY (`lsd_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='上报日志的客户端服务详情';
到目前为止,ApiBoot Logging Admin已经准备就绪。接下来,我们需要修改业务服务,以将请求日志报告给Logging Admin。
将日志报告给指定的日志记录管理员
我们将修改使用ApiBoot Logging获取统一管理请求日志文章的源代码,并将Logging Admin的地址添加到application.yml中,如下所示:
api:
boot:
# ApiBoot Logging 日志组件配置
logging:
# 配置Logging Admin地址
admin:
server-address: 127.0.0.1:8081
api.boot.logging.admin-service-address的配置格式为:Ip:Port,我们只需要修改一个地方,所有其他任务都将在内部交付给ApiBoot Logging。
测试
我们以应用程序的形式启动ApiBoot Logging Admin和业务服务。
使用curl访问测试地址,如下所示:
~ curl http://localhost:8080/test\?name\=admin
你好:admin
我们检查ApiBoot Logging管理控制台日志,如下所示:
Receiving Service: 【apiboot-unified-manage-request-logs -> 127.0.0.1】, Request Log Report,Logging Content:[
{
"endTime":1571641723779,
"httpStatus":200,
"requestBody":"",
"requestHeaders":{
"server-region":"JiNan",
"host":"localhost:8080",
"user-agent":"curl/7.64.1",
"accept":"*/*"
},
"requestIp":"0:0:0:0:0:0:0:1",
"requestMethod":"GET",
"requestParam":"{\"name\":\"admin\"}",
"requestUri":"/test",
"responseBody":"你好:admin",
"responseHeaders":{},
"serviceId":"apiboot-unified-manage-request-logs",
"serviceIp":"127.0.0.1",
"servicePort":"8080",
"spanId":"95a73ca0-831b-45df-aa43-2b5887e8d98d",
"startTime":1571641723776,
"timeConsuming":3,
"traceId":"25a7de96-b3dd-48e5-9854-1a8069a4a681"
}
]
我们已经看到Logging Admin控制台打印的报告请求日志,并且尚不确定此请求的日志是否已保存到数据库中。接下来,我将使用命令行查看数据库的日志信息。
查看logging_service_details表中的数据
mysql> select * from logging_service_details\G;
*************************** 1. row ***************************
lsd_id: b069366a-25dc-41ec-8f09-242d81755cd0
lsd_service_id: apiboot-unified-manage-request-logs
lsd_service_ip: 10.180.98.112
lsd_service_port: 8080
lsd_last_report_time: 2019-10-21 02:14:26
lsd_create_time: 2019-10-21 15:14:26
logging_service_details存储报告请求日志的每个业务服务的基本信息。每个服务的基本信息将被缓存在Logging Admin内存中,以方便获取service_id来存储日志,并且唯一性是根据ip + port + service_id确定的。相同的服务仅保存一次。
查看logging_request_logs表中的数据
mysql> select * from logging_request_logs\G;
*************************** 1. row ***************************
lrl_id: c42761f6-b072-4744-8a17-d8e6097b85de
lrl_service_detail_id: b069366a-25dc-41ec-8f09-242d81755cd0
lrl_trace_id: 055329a0-cfc1-4606-baf0-4fb0cc905ba2
lrl_parent_span_id: NULL
lrl_span_id: aab83092-7749-4f88-8cb6-a949cc060197
lrl_start_time: 1571642065262
lrl_end_time: 1571642065286
lrl_http_status: 200
lrl_request_body:
lrl_request_headers: {"server-region":"JiNan","host":"localhost:8080","user-agent":"curl/7.64.1","accept":"*/*"}
lrl_request_ip: 0:0:0:0:0:0:0:1
lrl_request_method: GET
lrl_request_uri: /test
lrl_response_body: 你好:admin
lrl_response_headers: {}
lrl_time_consuming: 24
lrl_create_time: 2019-10-21 15:14:26
lrl_request_params: {"name":"admin"}
lrl_exception_stack: NULL
敲黑板画关键点
在本章中,我们集成了ApiBoot Logging Admin,将业务服务的每个请求日志报告给Logging Admin,先通过数据库保存请求日志,然后再通过其他方法,并通过spanId和traceId查看日志下属每个请求链接与消耗每个请求中时间最多的跨度的关系,以准确地优化服务性能。
作者的个人博客
使用开源框架ApiBoot帮助您成为Api接口服务架构师
解决方案:接入5118智能原创API教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 629 次浏览 • 2020-09-07 05:42
访问5118智能原创 API教程
优采云 采集支持调用5118一键式智能原创 API接口,处理采集数据标题和内容等;
提醒:第三方API访问功能需要优采云旗舰软件包支持使用,并且用户需要提供第三方接口帐户信息(即,用户需要注册第三方)界面,以及由第三方界面产生的所有费用,用户应承担);
详细使用步骤1. 5118智能原创 API接口配置I,API配置入口:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问权限] ==”单击[第三方API配置管理] ==“最后单击[+5118一键式智能原创 API]创建接口配置;
II。配置API接口信息:
[API-Key value]是要从5118背景中获取相应的Key值,请记住在填写后将其保存;
注意:5118将每次调用的最大长度限制为5000个字符(包括html代码),因此,当内容长度超过时,优采云将被分割并多次调用。此操作将增加api调用的次数,费用也会相应增加,这是用户需要承担的费用,使用前请务必注意! ! !
2.创建API处理规则
API处理规则,可以将其设置为调用API接口以处理哪些字段的内容;
I。 API处理规则条目:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问] ==”,进入[API处理规则管理]页面,最后单击[+添加API处理规则]以创建API处理规则;
II,API处理规则配置:
注意:当API处理1个字段时,API接口将被调用一次,因此建议不要添加不需要的字段!
3. API处理规则的用法
使用API处理规则的方式有两种:手动执行和自动执行:
I。手动执行API处理规则:
单击采集任务的[结果数据和发布]选项卡中的[SEO&API&翻译和其他工具]按钮==“选择[第三方API执行]列==”选择相应的API处理规则==“执行(数据范围有两种执行方法,根据发布状态批量执行和根据列表中选择的数据执行);
II。自动执行API处理规则:
启用API处理的自动执行。任务完成采集后,API处理将自动执行。通常,使用定时采集和自动发布功能很方便;
在任务的[自动化:发布和SEO和翻译]选项卡中,[自动执行第三方API配置] ==“选中[采集,自动执行API]选项==”选择要执行的API处理规则==“选择由API接口处理的数据范围(通常选择”要发布“,所有将导致所有数据被执行多次),最后单击保存;
4. API处理结果和发布,查看API接口处理结果:
API接口处理的内容将另存为新字段,例如:标题处理后的新字段:title_5118,以及内容处理后的新字段:content_5118,可以在[结果数据和发布]和数据预览界面。
温馨提示:API处理规则需要一段时间才能执行,执行后页面会自动刷新,并出现API接口处理后的新字段;
II。发布API接口的处理后内容:
发布文章之前,请在发布目标的第二步中修改映射字段,并在API接口处理之后将标题和内容更改为新的对应字段title_5118和content_5118;
提醒:如果无法在发布目标中选择新字段,请在此任务下复制或创建新的发布目标,然后可以在新发布目标中选择新字段。可以查看详细的教程;
5. 5118-API接口常见问题和解决方法I,如何将API处理规则和SEO规则一起使用?
系统默认对标题和内容字段执行SEO功能,需要将其修改为SEO规则中的title_5118和content_5118字段;
优采云导航:优采云 采集 优采云控制台如何使用优采云 SEO工具微信公众号文章 采集今天的标题采集 查看全部
访问5118智能原创 API教程
访问5118智能原创 API教程
优采云 采集支持调用5118一键式智能原创 API接口,处理采集数据标题和内容等;
提醒:第三方API访问功能需要优采云旗舰软件包支持使用,并且用户需要提供第三方接口帐户信息(即,用户需要注册第三方)界面,以及由第三方界面产生的所有费用,用户应承担);
详细使用步骤1. 5118智能原创 API接口配置I,API配置入口:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问权限] ==”单击[第三方API配置管理] ==“最后单击[+5118一键式智能原创 API]创建接口配置;
II。配置API接口信息:
[API-Key value]是要从5118背景中获取相应的Key值,请记住在填写后将其保存;
注意:5118将每次调用的最大长度限制为5000个字符(包括html代码),因此,当内容长度超过时,优采云将被分割并多次调用。此操作将增加api调用的次数,费用也会相应增加,这是用户需要承担的费用,使用前请务必注意! ! !
2.创建API处理规则
API处理规则,可以将其设置为调用API接口以处理哪些字段的内容;
I。 API处理规则条目:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问] ==”,进入[API处理规则管理]页面,最后单击[+添加API处理规则]以创建API处理规则;
II,API处理规则配置:
注意:当API处理1个字段时,API接口将被调用一次,因此建议不要添加不需要的字段!
3. API处理规则的用法
使用API处理规则的方式有两种:手动执行和自动执行:
I。手动执行API处理规则:
单击采集任务的[结果数据和发布]选项卡中的[SEO&API&翻译和其他工具]按钮==“选择[第三方API执行]列==”选择相应的API处理规则==“执行(数据范围有两种执行方法,根据发布状态批量执行和根据列表中选择的数据执行);
II。自动执行API处理规则:
启用API处理的自动执行。任务完成采集后,API处理将自动执行。通常,使用定时采集和自动发布功能很方便;
在任务的[自动化:发布和SEO和翻译]选项卡中,[自动执行第三方API配置] ==“选中[采集,自动执行API]选项==”选择要执行的API处理规则==“选择由API接口处理的数据范围(通常选择”要发布“,所有将导致所有数据被执行多次),最后单击保存;
4. API处理结果和发布,查看API接口处理结果:
API接口处理的内容将另存为新字段,例如:标题处理后的新字段:title_5118,以及内容处理后的新字段:content_5118,可以在[结果数据和发布]和数据预览界面。
温馨提示:API处理规则需要一段时间才能执行,执行后页面会自动刷新,并出现API接口处理后的新字段;
II。发布API接口的处理后内容:
发布文章之前,请在发布目标的第二步中修改映射字段,并在API接口处理之后将标题和内容更改为新的对应字段title_5118和content_5118;
提醒:如果无法在发布目标中选择新字段,请在此任务下复制或创建新的发布目标,然后可以在新发布目标中选择新字段。可以查看详细的教程;
5. 5118-API接口常见问题和解决方法I,如何将API处理规则和SEO规则一起使用?
系统默认对标题和内容字段执行SEO功能,需要将其修改为SEO规则中的title_5118和content_5118字段;
优采云导航:优采云 采集 优采云控制台如何使用优采云 SEO工具微信公众号文章 采集今天的标题采集
解决方案:优采云采集器采集原理、流程介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 317 次浏览 • 2020-09-04 13:32
写作文章很无聊,但百度优化排名仍然与文章的积累密不可分,因此各种文章 采集器都占据了市场,今天SEO教程自学网站将向您优采云 采集器 采集的原理和过程。
什么是数据采集?我们可以理解,我们打开了网站并看到了一篇很好的文章文章,因此我们复制了文章的标题和内容,并将该文章文章转移到了我们的网站。我们的过程可以称为采集,它将对您网站上的其他人有用的信息转移到您自己的网站。
采集器正在执行此操作,但是整个过程由软件完成。我们可以理解,我们复制了文章的标题和内容。我们可以知道内容是什么,标题是什么,但是软件不知道,所以我们必须告诉软件如何选择它。这是编写规则的过程。复制之后,我们打开网站(例如发布论坛的地方),然后将其发布。对于软件,它是模仿我们的帖子,发布文章,如何发布,这就是数据发布的过程。
优采云 采集器是用于采集数据的软件。它是网络上功能最强大的采集器。它可以捕获您看到的几乎所有Web内容。
一、 优采云 采集器数据捕获原理:
优采云采集器如何抓取数据取决于您的规则。要获取网页的所有内容,您需要首先获取该网页的URL。这是URL。该程序根据规则获取列表页面,分析其中的URL,然后获取URL的Web内容。根据采集规则,分析下载的网页,分离标题内容和其他信息,然后保存。如果选择下载图像等网络资源,则程序将分析采集的数据,找到图像的下载地址,资源等,然后在本地下载。
二、 优采云 采集器数据发布原则:
采集数据后,默认情况下将其保存在本地。我们可以使用以下方法来处理数据。
1.什么也不要做。由于数据本身存储在数据库中(访问,db3,mysql,sqlserver),因此,如果仅查看数据,则可以使用相关软件将其打开。
2. 网站已发布到网站。该程序将模仿浏览器向您的网站发送数据,可以达到手动发布的效果。
3.直接转到数据库。您只需要编写一些SQL语句,程序就会根据您的SQL语句将数据导入数据库。
4.另存为本地文件。该程序将读取数据库中的数据,并以某种格式将其另存为本地sql或文本文件。
三、 优采云 采集器工作流程:
优采云 采集器分两步采集数据,一个是采集数据,另一个是发布数据。这两个过程可以分开。
1.采集数据,包括采集URL和采集内容。此过程是获取数据的过程。我们制定规则并处理采矿过程的内容。
2,发布内容是将数据发布到自己的论坛,cms的过程也是将数据作为现有过程执行。您可以使用WEB,数据库存储进行在线发布或另存为本地文件。
但我必须在此提醒大多数网站管理员,百度飓风算法2. 0的引入进一步提高了百度对采集这种现象的惩罚程度和惩罚范围。在经验丰富的时代,是否使用文章 采集器取决于您的想法! 查看全部
优采云 采集器 采集原理和过程介绍
写作文章很无聊,但百度优化排名仍然与文章的积累密不可分,因此各种文章 采集器都占据了市场,今天SEO教程自学网站将向您优采云 采集器 采集的原理和过程。
什么是数据采集?我们可以理解,我们打开了网站并看到了一篇很好的文章文章,因此我们复制了文章的标题和内容,并将该文章文章转移到了我们的网站。我们的过程可以称为采集,它将对您网站上的其他人有用的信息转移到您自己的网站。
采集器正在执行此操作,但是整个过程由软件完成。我们可以理解,我们复制了文章的标题和内容。我们可以知道内容是什么,标题是什么,但是软件不知道,所以我们必须告诉软件如何选择它。这是编写规则的过程。复制之后,我们打开网站(例如发布论坛的地方),然后将其发布。对于软件,它是模仿我们的帖子,发布文章,如何发布,这就是数据发布的过程。
优采云 采集器是用于采集数据的软件。它是网络上功能最强大的采集器。它可以捕获您看到的几乎所有Web内容。
一、 优采云 采集器数据捕获原理:
优采云采集器如何抓取数据取决于您的规则。要获取网页的所有内容,您需要首先获取该网页的URL。这是URL。该程序根据规则获取列表页面,分析其中的URL,然后获取URL的Web内容。根据采集规则,分析下载的网页,分离标题内容和其他信息,然后保存。如果选择下载图像等网络资源,则程序将分析采集的数据,找到图像的下载地址,资源等,然后在本地下载。
二、 优采云 采集器数据发布原则:
采集数据后,默认情况下将其保存在本地。我们可以使用以下方法来处理数据。
1.什么也不要做。由于数据本身存储在数据库中(访问,db3,mysql,sqlserver),因此,如果仅查看数据,则可以使用相关软件将其打开。
2. 网站已发布到网站。该程序将模仿浏览器向您的网站发送数据,可以达到手动发布的效果。
3.直接转到数据库。您只需要编写一些SQL语句,程序就会根据您的SQL语句将数据导入数据库。
4.另存为本地文件。该程序将读取数据库中的数据,并以某种格式将其另存为本地sql或文本文件。
三、 优采云 采集器工作流程:
优采云 采集器分两步采集数据,一个是采集数据,另一个是发布数据。这两个过程可以分开。
1.采集数据,包括采集URL和采集内容。此过程是获取数据的过程。我们制定规则并处理采矿过程的内容。
2,发布内容是将数据发布到自己的论坛,cms的过程也是将数据作为现有过程执行。您可以使用WEB,数据库存储进行在线发布或另存为本地文件。
但我必须在此提醒大多数网站管理员,百度飓风算法2. 0的引入进一步提高了百度对采集这种现象的惩罚程度和惩罚范围。在经验丰富的时代,是否使用文章 采集器取决于您的想法!
最佳实践:Python网络数据采集4:使用API
采集交流 • 优采云 发表了文章 • 0 个评论 • 408 次浏览 • 2020-09-01 06:09
通常情况下,程序员可以使用HTPP协议向API发起请求以获取某些信息,并且API将以XML或JSON格式返回服务器的响应信息.
通常,您不会考虑将API用作网络数据采集,但实际上,两者(都发送HTTP请求)和结果(都获取信息)所使用的许多技术都是相似的;两者通常是同一个关系.
例如,将Wikipedia编辑历史记录(与编辑者的IP地址)和IP地址解析API结合起来,以获取Wikipedia条目的编辑者的地理位置.
4.1 API概述
Google API
4.2 API通用规则
API使用非常标准的规则集来生成数据,并且所生成的数据以非常标准的方式进行组织.
四种方法: GET,POST,PUT,DELETE
验证: 需要客户验证
4.3服务器响应
大多数反馈数据格式是XML和JSON
过去,服务器使用PHP和.NET等程序作为API的接收器. 现在,服务器端还使用了一些JavaScript框架作为API的发送和接收端,例如Angular或Backbone.
API调用:
4.4回声巢
Echo Nest音乐数据网站
4.5 Twitter API
pip安装推特
from twitter import Twitter
t = Twitter(auth=OAuth(,,,))
pythonTweets = t.search.tweets(q = "#python")
print(pythonTweets)
发布推文4.6 Google API
无论您要处理哪种信息,包括语言翻译,地理位置,日历,甚至是遗传数据,Google都会提供API. Google还为其一些著名的应用程序提供API,例如Gmail,YouTube和Blogger.
4.7解析JSON数据
import json
from urllib.request import urlopen
def getCountry(ipAddress):
response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
responseJson = json.loads(response)
return responseJson.get("country_code")
print(getCountry("50.78.253.58"))
4.8返回主题
将多个数据源组合为新形式,或使用API作为工具从新的角度解释采集中的数据.
首先做一个采集 Wikipedia的基本程序,找到编辑历史记录页面,然后在编辑历史记录中找出IP地址
# -*- coding: utf-8 -*-
from urllib.request import urlopen
from bs4 import BeautifulSoup
import datetime
import random
import re
import json
random.seed(datetime.datetime.now())
# https://en.wikipedia.org/wiki/Python_(programming_language)
def getLinks(articleUrl):
html = urlopen("http://en.wikipedia.org"+articleUrl)
bsObj = BeautifulSoup(html)
return bsObj.find("div",{"id":"bodyContent"}).findAll("a", href=re.compile("^(/wiki/)((?!:).)*$"))
def getHistoryIPs(pageUrl):
# 编辑历史页面URL链接格式是:
# https://en.wikipedia.org/w/index.php?title=Python_(programming_language)&action=history
pageUrl = pageUrl.replace("/wiki/", "")
historyUrl = "https://en.wikipedia.org/w/ind ... ot%3B
print("history url is: "+historyUrl)
html = urlopen(historyUrl)
bsObj = BeautifulSoup(html)
# 找出class属性是"mw-anonuserlink"的链接
# 它们用IP地址代替用户名
ipAddresses = bsObj.findAll("a", {"class":"mw-anonuserlink"})
addressList = set()
for ipAddress in ipAddresses:
addressList.add(ipAddress.get_text())
return addressList
links = getLinks("/wiki/Python_(programming_language)")
def getCountry(ipAddress):
try:
response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
except HTTPError:
return None
responseJson = json.loads(response)
return responseJson.get("country_code")
while (len(links) > 0):
for link in links:
print("-------------------")
historyIPs = getHistoryIPs(link.attrs["href"])
for historyIP in historyIPs:
#print(historyIP)
country = getCountry(historyIP)
if country is not None:
print(historyIP+" is from "+country)
newLink = links[random.randint(0, len(links)-1)].attrs["href"]
links = getLinks(newLink)
4.9关于API的更多信息
Leonard Richardson,Mike Amundsen和Sam Ruby的RESTful Web API()为使用Web API提供了非常全面的理论和实践指导. 此外,Mike Amundsen的精彩视频教学课程“为Web()设计API”还可以教您创建自己的API. 如果您想方便地共享采集数据,那么他的视频非常有用 查看全部
Python网络数据采集 4: 使用API
通常情况下,程序员可以使用HTPP协议向API发起请求以获取某些信息,并且API将以XML或JSON格式返回服务器的响应信息.
通常,您不会考虑将API用作网络数据采集,但实际上,两者(都发送HTTP请求)和结果(都获取信息)所使用的许多技术都是相似的;两者通常是同一个关系.
例如,将Wikipedia编辑历史记录(与编辑者的IP地址)和IP地址解析API结合起来,以获取Wikipedia条目的编辑者的地理位置.
4.1 API概述
Google API
4.2 API通用规则
API使用非常标准的规则集来生成数据,并且所生成的数据以非常标准的方式进行组织.
四种方法: GET,POST,PUT,DELETE
验证: 需要客户验证
4.3服务器响应
大多数反馈数据格式是XML和JSON
过去,服务器使用PHP和.NET等程序作为API的接收器. 现在,服务器端还使用了一些JavaScript框架作为API的发送和接收端,例如Angular或Backbone.
API调用:
4.4回声巢
Echo Nest音乐数据网站
4.5 Twitter API
pip安装推特
from twitter import Twitter
t = Twitter(auth=OAuth(,,,))
pythonTweets = t.search.tweets(q = "#python")
print(pythonTweets)
发布推文4.6 Google API
无论您要处理哪种信息,包括语言翻译,地理位置,日历,甚至是遗传数据,Google都会提供API. Google还为其一些著名的应用程序提供API,例如Gmail,YouTube和Blogger.
4.7解析JSON数据
import json
from urllib.request import urlopen
def getCountry(ipAddress):
response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
responseJson = json.loads(response)
return responseJson.get("country_code")
print(getCountry("50.78.253.58"))
4.8返回主题
将多个数据源组合为新形式,或使用API作为工具从新的角度解释采集中的数据.
首先做一个采集 Wikipedia的基本程序,找到编辑历史记录页面,然后在编辑历史记录中找出IP地址
# -*- coding: utf-8 -*-
from urllib.request import urlopen
from bs4 import BeautifulSoup
import datetime
import random
import re
import json
random.seed(datetime.datetime.now())
# https://en.wikipedia.org/wiki/Python_(programming_language)
def getLinks(articleUrl):
html = urlopen("http://en.wikipedia.org"+articleUrl)
bsObj = BeautifulSoup(html)
return bsObj.find("div",{"id":"bodyContent"}).findAll("a", href=re.compile("^(/wiki/)((?!:).)*$"))
def getHistoryIPs(pageUrl):
# 编辑历史页面URL链接格式是:
# https://en.wikipedia.org/w/index.php?title=Python_(programming_language)&action=history
pageUrl = pageUrl.replace("/wiki/", "")
historyUrl = "https://en.wikipedia.org/w/ind ... ot%3B
print("history url is: "+historyUrl)
html = urlopen(historyUrl)
bsObj = BeautifulSoup(html)
# 找出class属性是"mw-anonuserlink"的链接
# 它们用IP地址代替用户名
ipAddresses = bsObj.findAll("a", {"class":"mw-anonuserlink"})
addressList = set()
for ipAddress in ipAddresses:
addressList.add(ipAddress.get_text())
return addressList
links = getLinks("/wiki/Python_(programming_language)")
def getCountry(ipAddress):
try:
response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
except HTTPError:
return None
responseJson = json.loads(response)
return responseJson.get("country_code")
while (len(links) > 0):
for link in links:
print("-------------------")
historyIPs = getHistoryIPs(link.attrs["href"])
for historyIP in historyIPs:
#print(historyIP)
country = getCountry(historyIP)
if country is not None:
print(historyIP+" is from "+country)
newLink = links[random.randint(0, len(links)-1)].attrs["href"]
links = getLinks(newLink)
4.9关于API的更多信息
Leonard Richardson,Mike Amundsen和Sam Ruby的RESTful Web API()为使用Web API提供了非常全面的理论和实践指导. 此外,Mike Amundsen的精彩视频教学课程“为Web()设计API”还可以教您创建自己的API. 如果您想方便地共享采集数据,那么他的视频非常有用
正式推出:QuicklibTrade A股行情采集API方案2.6正式发布
采集交流 • 优采云 发表了文章 • 0 个评论 • 620 次浏览 • 2020-08-31 01:19
/
/x/page/b0822umt6kk.html?pcsharecode=JjoaXqFW&sf=uri
版本升级说明
2.6版将采集数据字段从15增加到20
版本2.5进行了改进和发布
2.4版是大量个人使用的初始版本.
QuicklibTrade简介
QuicklibTrade是一个简单易用的A股程序交易程序,主要使用采集来获取股票软件客户(例如Big Wisdom,Straight Flush,Oriental Fortune,Tongdaxin)的数据,并提供多种接口. 支持直接调用公式编辑器的数据,大大简化了策略开发. 许多经典指标公式都可以直接使用.
关键是免费使用
QuicklibTrade市场数据采集视频教学
采集和API调用说明
/x/page/y0842b72xbh.html?pcsharecode=Y0h4qOSw&sf=uri
包括使用虚拟机采集市场的说明
/x/page/b0822umt6kk.html?pcsharecode=JjoaXqFW&sf=uri
QuicklibTrade免费A股Level2报价界面
/
注册
/register.html
下载
/mdapi.asp
其他相关问题,请浏览
/ comm / category / 20 /
在第一阶段中,仅发布市场信息采集和接口,而在第二阶段中,发布市场信息的交易接口和LAN网络接口
由于每个主机只能运行1个DataUpdate.exe,为了使用多个DataUpdate.exe通过LAN网络接口采集共享数据以加快更新速度,因此采用了虚拟机方法.
已提供虚拟机镜像网络磁盘下载,主要用于市场的LAN网络接口. 每个虚拟机可以打开1个Big Wisdom和DataUpdate.exe副本以加快数据更新
QuicklibTrade体系结构如下图所示:
它分为市场界面和交易界面. 本文仅说明市场界面. 交易界面计划于2019年初发布.
市场报价接口版本2.1的第一阶段支持明智的分界线模式,并且字体选择经典字体. 开始菜单保留冲洗,东方财富和通达信的数据采集方案菜单.
1)支持市场数据采集
2)支持指标数据采集
3)支持交易信号,可以使用Great Wisdom公式编辑器制定交易策略,使用特定的熟悉度来指示购买和出售,将指标加载到Great Wisdom列中,该界面可识别数据的价值,并直接判断通过界面确定交易的熟悉程度.
每次采集同时支持12个字段,这12个字段可以是报价,指标或交易信号.
**运行平台: ** Windows7,Windows78,Windows10,WindowsServer2008,WindowsServer2012,WindowsServer2016和其他版本
运行虚拟机的网络接口必须是64位操作系统
其他接口可用于32位和64位Windows操作系统.
**硬件配置: **请使用单屏显示,使用2个或更多屏幕会导致数据混乱
受支持的接口包括Python接口和C ++接口.
** Python接口: **可以由Python直接调用
从/mdapi.asp(即.py文件)下载的示例是Python2.7的示例,并且理论上支持Python3.x.
Python界面中.dll文件的理论适用于任何Python版本
** C ++接口: **支持所有支持调用DLL的语言,包括C ++,Java,C#,VB.NET,易用语言等.
第一期发行
(1)数据更新主程序
(2)A股CTP接口C ++接口(适用于运行DataUpdate的同一台计算机)
(3)A股CTP接口C ++接口演示期货CTP接口演示
(4)Dataupdate分布式程序等待发布,市场数据更新分布式程序
(5)适用于LAN的Python MSSQL接口,由多个DataUpdate采集共享
(6)Python Access接口适用于运行DataUpdate的同一台计算机
Python ShareMemory接口Python共享内存数据接口,适用于运行DataUpdate的同一台计算机
还提供了一个虚拟机环境,主要用于MSSQL数据库接口和将来的LocalNetwork接口(LAN网络数据接口)
第二期内容,新界面,版本2.2
(1)等待发布的Python LocalNetwork接口Python LAN共享数据接口(适用于LAN,同时采集多个DataUpdates)
(2)等待释放的C ++ LocalNetwork接口. Python LAN共享数据接口(适用于LAN,同时共享多个DataUpdate采集)
使用步骤(以大智慧为例):
1)下载Great Wisdom并安装Great Wisdom程序
付费版本有Level2版本和免费版本.
Great Wisdom的官方下载:
/detail/function_365.jsp?product=116
2)安装大智慧
安装Great Wisdom,安装完成,Great Wisdom在桌面上.
如果在虚拟机上运行,则由于路径较长,虚拟机可能无法直接安装. 安装物理机后,可以将C盘下的“ dzh365”目录复制.
将目录安装到虚拟机上以运行大智慧程序
3)注册并登录到大智慧
您也可以使用QQ和微信登录
4)进入大智慧股票排序模式
在上图中的Big Wisdom界面上单击红色按钮以输入“报价列表”
5)在标题栏中调出行和列分隔符
在大智慧中,我们使用分频器模式采集数据,因此我们需要调用分频器
右键单击并从列菜单中选择“列分隔符”和“行分隔符”
按从左到右的顺序操作标识的列,版本2.1为12列
您还可以为所有列和行设置分隔线.
设置完成后,如下图所示
6)在“大智慧”菜单中设置经典字体,不要更改字体大小和样式颜色
7)启动采集程序,采集程序将自动激活打开的Big Wisdom程序,并在第一行中标识数据,您可以手动检查标识的数据是否正确.
(如果识别错误,通常是由于未将字体设置为经典字体引起的,请确保使用经典字体再试一次)
从以下URL下载
解压缩后,运行DataUpdate.exe
8)如果通过手动观察识别的第一行中的数字是正确的,请按DdtaUpdate.exe程序的按钮以打开识别,然后Big Wisdom将自动在窗口的前面滚动并识别它.
可以通过API获取报价的股票代码的12个数据字段.
当前,只能识别数字,但是不能识别中文. 因此,无法识别“大智慧”中的“十亿”之类的汉字. 请不要识别不是纯数字的指标.
仔细检查黄色框中的数字是否正确识别. 如果它们是错误的,则可能是由于字体设置错误所致. 请重置字体,然后重试
如果正确,请激活DataUpdate.exe程序,然后单击按钮
DataUpdate.exe将自动最小化,并开始滚动窗口以进行识别
如果单击任务栏图标,则可以最大化DataUpdate.exe,并且识别将自动停止,或单击按钮停止.
打开C ++和Python API,您可以获得市场报价
C ++接口提供与期货CTP接口相同的方法,熟悉C ++和CTP的朋友可以更快地开始使用
1)共享内存接口和Access接口只能在运行DataUpdate.exe的计算机上运行
2)可以将MSSQL接口写入MSSQL数据库,其他PC主机调用MSSQL数据库以获取数据.
3)局域网数据接口(在2.2版之后发布)将发布到整个局域网. 局域网中的所有主机都可以通过API获取市场信息. 您还可以在多个主机上运行DataUpdate.exe
这样,数据更新速度将提高数倍.
在期货中开设一个帐户并绑定该帐户以自动激活DataUpdate.exe的功能
免费激活方法
1. 请按照以下步骤打开期货帐户并绑定期货帐户以激活
宏远期货是一家上市公司,隶属于深湾宏远
选择宏远期货进行网上开户,选择重庆销售部门作为营业部
推荐人填写: 上海良北信息技术有限公司
开设帐户的详细步骤:
2. 点激活
您也可以参考激活方法
用户注册| QuickLibTrade中国网站
“期货纪录片软件视频教学四集”
“酷交易者期货复制软件”
“以低佣金开设中国期货帐户”
“ mdshare财务数据接口包”
“ Python定量交易框架的性能评估”
python定量交易
“ Quicklib程序化交易框架”
Caffe深度学习框架
“定量社区”
Python人工智能算法库
<p>tushare,A股Level2数据,A股报价界面,A股Level2报价界面,TuShare,中国金融数据,期货历史交易记录下载,历史数据网络磁盘下载,A股,期货历史数据下载,东方财富选择,金融数据研究终端,iFinD,Go-Goal数据终端,Skysoft数据,新浪Level2报价,恒生数据,数据库金融数据(费用)以及深度分析API服务,Wind Wind,Tongdaxin免费数据,免费的历史数据 查看全部
QuicklibTrade A股市场采集API解决方案2.6正式发布
/
/x/page/b0822umt6kk.html?pcsharecode=JjoaXqFW&sf=uri
版本升级说明
2.6版将采集数据字段从15增加到20
版本2.5进行了改进和发布
2.4版是大量个人使用的初始版本.
QuicklibTrade简介
QuicklibTrade是一个简单易用的A股程序交易程序,主要使用采集来获取股票软件客户(例如Big Wisdom,Straight Flush,Oriental Fortune,Tongdaxin)的数据,并提供多种接口. 支持直接调用公式编辑器的数据,大大简化了策略开发. 许多经典指标公式都可以直接使用.
关键是免费使用
QuicklibTrade市场数据采集视频教学
采集和API调用说明
/x/page/y0842b72xbh.html?pcsharecode=Y0h4qOSw&sf=uri
包括使用虚拟机采集市场的说明
/x/page/b0822umt6kk.html?pcsharecode=JjoaXqFW&sf=uri
QuicklibTrade免费A股Level2报价界面
/
注册
/register.html
下载
/mdapi.asp
其他相关问题,请浏览
/ comm / category / 20 /
在第一阶段中,仅发布市场信息采集和接口,而在第二阶段中,发布市场信息的交易接口和LAN网络接口
由于每个主机只能运行1个DataUpdate.exe,为了使用多个DataUpdate.exe通过LAN网络接口采集共享数据以加快更新速度,因此采用了虚拟机方法.
已提供虚拟机镜像网络磁盘下载,主要用于市场的LAN网络接口. 每个虚拟机可以打开1个Big Wisdom和DataUpdate.exe副本以加快数据更新
QuicklibTrade体系结构如下图所示:
它分为市场界面和交易界面. 本文仅说明市场界面. 交易界面计划于2019年初发布.
市场报价接口版本2.1的第一阶段支持明智的分界线模式,并且字体选择经典字体. 开始菜单保留冲洗,东方财富和通达信的数据采集方案菜单.
1)支持市场数据采集
2)支持指标数据采集
3)支持交易信号,可以使用Great Wisdom公式编辑器制定交易策略,使用特定的熟悉度来指示购买和出售,将指标加载到Great Wisdom列中,该界面可识别数据的价值,并直接判断通过界面确定交易的熟悉程度.
每次采集同时支持12个字段,这12个字段可以是报价,指标或交易信号.
**运行平台: ** Windows7,Windows78,Windows10,WindowsServer2008,WindowsServer2012,WindowsServer2016和其他版本
运行虚拟机的网络接口必须是64位操作系统
其他接口可用于32位和64位Windows操作系统.
**硬件配置: **请使用单屏显示,使用2个或更多屏幕会导致数据混乱
受支持的接口包括Python接口和C ++接口.
** Python接口: **可以由Python直接调用
从/mdapi.asp(即.py文件)下载的示例是Python2.7的示例,并且理论上支持Python3.x.
Python界面中.dll文件的理论适用于任何Python版本
** C ++接口: **支持所有支持调用DLL的语言,包括C ++,Java,C#,VB.NET,易用语言等.
第一期发行
(1)数据更新主程序
(2)A股CTP接口C ++接口(适用于运行DataUpdate的同一台计算机)
(3)A股CTP接口C ++接口演示期货CTP接口演示
(4)Dataupdate分布式程序等待发布,市场数据更新分布式程序
(5)适用于LAN的Python MSSQL接口,由多个DataUpdate采集共享
(6)Python Access接口适用于运行DataUpdate的同一台计算机
Python ShareMemory接口Python共享内存数据接口,适用于运行DataUpdate的同一台计算机
还提供了一个虚拟机环境,主要用于MSSQL数据库接口和将来的LocalNetwork接口(LAN网络数据接口)
第二期内容,新界面,版本2.2
(1)等待发布的Python LocalNetwork接口Python LAN共享数据接口(适用于LAN,同时采集多个DataUpdates)
(2)等待释放的C ++ LocalNetwork接口. Python LAN共享数据接口(适用于LAN,同时共享多个DataUpdate采集)
使用步骤(以大智慧为例):
1)下载Great Wisdom并安装Great Wisdom程序
付费版本有Level2版本和免费版本.
Great Wisdom的官方下载:
/detail/function_365.jsp?product=116
2)安装大智慧
安装Great Wisdom,安装完成,Great Wisdom在桌面上.
如果在虚拟机上运行,则由于路径较长,虚拟机可能无法直接安装. 安装物理机后,可以将C盘下的“ dzh365”目录复制.
将目录安装到虚拟机上以运行大智慧程序
3)注册并登录到大智慧
您也可以使用QQ和微信登录
4)进入大智慧股票排序模式
在上图中的Big Wisdom界面上单击红色按钮以输入“报价列表”
5)在标题栏中调出行和列分隔符
在大智慧中,我们使用分频器模式采集数据,因此我们需要调用分频器
右键单击并从列菜单中选择“列分隔符”和“行分隔符”
按从左到右的顺序操作标识的列,版本2.1为12列
您还可以为所有列和行设置分隔线.
设置完成后,如下图所示
6)在“大智慧”菜单中设置经典字体,不要更改字体大小和样式颜色
7)启动采集程序,采集程序将自动激活打开的Big Wisdom程序,并在第一行中标识数据,您可以手动检查标识的数据是否正确.
(如果识别错误,通常是由于未将字体设置为经典字体引起的,请确保使用经典字体再试一次)
从以下URL下载
解压缩后,运行DataUpdate.exe
8)如果通过手动观察识别的第一行中的数字是正确的,请按DdtaUpdate.exe程序的按钮以打开识别,然后Big Wisdom将自动在窗口的前面滚动并识别它.
可以通过API获取报价的股票代码的12个数据字段.
当前,只能识别数字,但是不能识别中文. 因此,无法识别“大智慧”中的“十亿”之类的汉字. 请不要识别不是纯数字的指标.
仔细检查黄色框中的数字是否正确识别. 如果它们是错误的,则可能是由于字体设置错误所致. 请重置字体,然后重试
如果正确,请激活DataUpdate.exe程序,然后单击按钮
DataUpdate.exe将自动最小化,并开始滚动窗口以进行识别
如果单击任务栏图标,则可以最大化DataUpdate.exe,并且识别将自动停止,或单击按钮停止.
打开C ++和Python API,您可以获得市场报价
C ++接口提供与期货CTP接口相同的方法,熟悉C ++和CTP的朋友可以更快地开始使用
1)共享内存接口和Access接口只能在运行DataUpdate.exe的计算机上运行
2)可以将MSSQL接口写入MSSQL数据库,其他PC主机调用MSSQL数据库以获取数据.
3)局域网数据接口(在2.2版之后发布)将发布到整个局域网. 局域网中的所有主机都可以通过API获取市场信息. 您还可以在多个主机上运行DataUpdate.exe
这样,数据更新速度将提高数倍.
在期货中开设一个帐户并绑定该帐户以自动激活DataUpdate.exe的功能
免费激活方法
1. 请按照以下步骤打开期货帐户并绑定期货帐户以激活
宏远期货是一家上市公司,隶属于深湾宏远
选择宏远期货进行网上开户,选择重庆销售部门作为营业部
推荐人填写: 上海良北信息技术有限公司
开设帐户的详细步骤:
2. 点激活
您也可以参考激活方法
用户注册| QuickLibTrade中国网站
“期货纪录片软件视频教学四集”
“酷交易者期货复制软件”
“以低佣金开设中国期货帐户”
“ mdshare财务数据接口包”
“ Python定量交易框架的性能评估”
python定量交易
“ Quicklib程序化交易框架”
Caffe深度学习框架
“定量社区”
Python人工智能算法库
<p>tushare,A股Level2数据,A股报价界面,A股Level2报价界面,TuShare,中国金融数据,期货历史交易记录下载,历史数据网络磁盘下载,A股,期货历史数据下载,东方财富选择,金融数据研究终端,iFinD,Go-Goal数据终端,Skysoft数据,新浪Level2报价,恒生数据,数据库金融数据(费用)以及深度分析API服务,Wind Wind,Tongdaxin免费数据,免费的历史数据
一种基于网路爬虫和新浪API相结合的微博数据的采集方法与流程
采集交流 • 优采云 发表了文章 • 0 个评论 • 409 次浏览 • 2020-08-27 06:08
本发明涉及微博数据采集技术领域,特别是一种基于网路爬虫和新浪API 相结合的微博数据的采集方法。
背景技术:
对于微博中数据采集非常重要,这样也能为举办微博中社会安全 事件的探测提供重要的数据基础。目前,微博的数据采集方式主要有 两种:基于新浪API和针对新浪微博平台的网路爬虫。基于新浪API 的方案可以获取格式比较规范的数据,但是其调用次数有一定的限制, 无法进行大规模的数据爬取,并且有些信息难以获取到;基于网路爬 虫的方式其实可以获取大规模的数据,但是其页面的剖析处理过程比 较复杂,并且其爬取的数据格式不规范,噪声数据比较多。
技术实现要素:
本发明的目的是要解决现有技术中存在的不足,提供一种基于网路爬虫和 新浪API相结合的微博数据的采集方法。
为达到上述目的,本发明是根据以下技术方案施行的:
一种基于网路爬虫和新浪API相结合的微博数据的采集方法,包括以下步 骤:
Step1:基于新浪API从微博名人榜获取种子用户及其对应的粉丝用户和关 注用户,加入到种子列表;
Step2:将种子列表转换为种子URL,并判定种子用户列表是否为空,若为 空则步入Step4,否则步入Step3;
Step3:遍历种子列表,采用网路爬虫的方式,爬取种子用户的相关微博信 息、微博评论信息和用户个人信息,并将微博评论用户加入到种子列表中;
Step4:结束。
具体地,所述Step3包括:
获取种子列表中待爬取URL,并进行URL解析与信息获取,具体包括:获 取用户信息URL并步入相应页面爬取用户粉丝用户和关注用户以及爬取用户的 其他相关信息;获取用户微博URL并步入相应页面爬取微博转发点赞、评论用 户、爬取微博评论文本以及爬取微博其他相关信息;并将爬取的用户粉丝用户 和关注用户、用户的其他相关信息、微博转发点赞、评论用户、爬取微博评论 文本以及爬取微博其他相关建立相应的微博数据资源库;同时将爬取的用户粉 丝用户和关注用户、爬取的微博转发点赞、评论用户加入种子列表中。
与现有技术相比,本发明通过将新浪API和针对新浪微博平台的网路爬虫 相结合,既可以获取格式比较规范的微博数据,又能进行大规模的数据爬取, 并且爬取的数据格式愈发规范,噪声数据比较少,进而才能为举办微博中社会 安全风波的探测提供重要的数据基础。
附图说明
图1为本发明的流程图。
具体施行方法
下面结合具体施行例对本发明作进一步描述,在此发明的示意性施行例以 及说明拿来解释本发明,但并不作为对本发明的限定。
如图1所示,本施行例的一种基于网路爬虫和新浪API相结合的微博数据 的采集方法,包括以下步骤:
Step1:基于新浪API从微博名人榜获取种子用户及其对应的粉丝用户和关 注用户,加入到种子列表;
Step2:将种子列表转换为种子URL,并判定种子用户列表是否为空,若为 空则步入Step4,否则步入Step3;
Step3:遍历种子列表,采用网路爬虫的方式,爬取种子用户的相关微博信 息、微博评论信息和用户个人信息,并将微博评论用户加入到种子列表中,具 体步骤为:获取种子列表中待爬取URL,并进行URL解析与信息获取,具体包 括:获取用户信息URL并步入相应页面从微博数据资源库中爬取用户粉丝用户 和关注用户以及爬取用户的其他相关信息;获取用户微博URL并步入相应页面 从微博数据资源库中爬取微博转发点赞、评论用户、爬取微博评论文本以及爬 取微博其他相关信息;同时将爬取的用户粉丝用户和关注用户、爬取的微博转 发点赞、评论用户加入种子列表中。
Step4:结束。
根据本施行例的方式采集完微博数据后,就可以对采集到的微博文本数据 进行处理,清除其中的异常数据和噪音数据,实现数据格式的标准化,并建立 相应的微博资源库,进而才能为举办微博中社会安全风波的探测提供重要的数 据基础。
本发明的技术方案不限于上述具体施行例的限制,凡是按照本发明的技术 方案作出的技术变型,均落入本发明的保护范围之内。
当前第1页1&nbsp2&nbsp3&nbsp 查看全部
一种基于网路爬虫和新浪API相结合的微博数据的采集方法与流程
本发明涉及微博数据采集技术领域,特别是一种基于网路爬虫和新浪API 相结合的微博数据的采集方法。
背景技术:
对于微博中数据采集非常重要,这样也能为举办微博中社会安全 事件的探测提供重要的数据基础。目前,微博的数据采集方式主要有 两种:基于新浪API和针对新浪微博平台的网路爬虫。基于新浪API 的方案可以获取格式比较规范的数据,但是其调用次数有一定的限制, 无法进行大规模的数据爬取,并且有些信息难以获取到;基于网路爬 虫的方式其实可以获取大规模的数据,但是其页面的剖析处理过程比 较复杂,并且其爬取的数据格式不规范,噪声数据比较多。
技术实现要素:
本发明的目的是要解决现有技术中存在的不足,提供一种基于网路爬虫和 新浪API相结合的微博数据的采集方法。
为达到上述目的,本发明是根据以下技术方案施行的:
一种基于网路爬虫和新浪API相结合的微博数据的采集方法,包括以下步 骤:
Step1:基于新浪API从微博名人榜获取种子用户及其对应的粉丝用户和关 注用户,加入到种子列表;
Step2:将种子列表转换为种子URL,并判定种子用户列表是否为空,若为 空则步入Step4,否则步入Step3;
Step3:遍历种子列表,采用网路爬虫的方式,爬取种子用户的相关微博信 息、微博评论信息和用户个人信息,并将微博评论用户加入到种子列表中;
Step4:结束。
具体地,所述Step3包括:
获取种子列表中待爬取URL,并进行URL解析与信息获取,具体包括:获 取用户信息URL并步入相应页面爬取用户粉丝用户和关注用户以及爬取用户的 其他相关信息;获取用户微博URL并步入相应页面爬取微博转发点赞、评论用 户、爬取微博评论文本以及爬取微博其他相关信息;并将爬取的用户粉丝用户 和关注用户、用户的其他相关信息、微博转发点赞、评论用户、爬取微博评论 文本以及爬取微博其他相关建立相应的微博数据资源库;同时将爬取的用户粉 丝用户和关注用户、爬取的微博转发点赞、评论用户加入种子列表中。
与现有技术相比,本发明通过将新浪API和针对新浪微博平台的网路爬虫 相结合,既可以获取格式比较规范的微博数据,又能进行大规模的数据爬取, 并且爬取的数据格式愈发规范,噪声数据比较少,进而才能为举办微博中社会 安全风波的探测提供重要的数据基础。
附图说明
图1为本发明的流程图。
具体施行方法
下面结合具体施行例对本发明作进一步描述,在此发明的示意性施行例以 及说明拿来解释本发明,但并不作为对本发明的限定。
如图1所示,本施行例的一种基于网路爬虫和新浪API相结合的微博数据 的采集方法,包括以下步骤:
Step1:基于新浪API从微博名人榜获取种子用户及其对应的粉丝用户和关 注用户,加入到种子列表;
Step2:将种子列表转换为种子URL,并判定种子用户列表是否为空,若为 空则步入Step4,否则步入Step3;
Step3:遍历种子列表,采用网路爬虫的方式,爬取种子用户的相关微博信 息、微博评论信息和用户个人信息,并将微博评论用户加入到种子列表中,具 体步骤为:获取种子列表中待爬取URL,并进行URL解析与信息获取,具体包 括:获取用户信息URL并步入相应页面从微博数据资源库中爬取用户粉丝用户 和关注用户以及爬取用户的其他相关信息;获取用户微博URL并步入相应页面 从微博数据资源库中爬取微博转发点赞、评论用户、爬取微博评论文本以及爬 取微博其他相关信息;同时将爬取的用户粉丝用户和关注用户、爬取的微博转 发点赞、评论用户加入种子列表中。
Step4:结束。
根据本施行例的方式采集完微博数据后,就可以对采集到的微博文本数据 进行处理,清除其中的异常数据和噪音数据,实现数据格式的标准化,并建立 相应的微博资源库,进而才能为举办微博中社会安全风波的探测提供重要的数 据基础。
本发明的技术方案不限于上述具体施行例的限制,凡是按照本发明的技术 方案作出的技术变型,均落入本发明的保护范围之内。
当前第1页1&nbsp2&nbsp3&nbsp
用Python挖掘Twitter数据:数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 402 次浏览 • 2020-08-26 04:59
这是一系列使用Python专门用于Twitter数据挖掘的文章中的第一篇。在第一部份中,我们将见到通过不同的方法来进行Twitter的数据搜集。一旦我们构建好了一个数据集,在接下来的环节中,我们就将会讨论一些有趣的数据应用。
注册应用
为了才能访问Twitter数据编程,我们须要创建一个与Twitter的API交互的应用程序。
第一步是注册一个你的应用程序。值得注意的是,您须要将您的浏览器转入,登录到Twitter(如果您仍未登陆),并注册一个新的应用程序。您如今可以为您的应用程序选择一个名称和说明(例如“挖掘演示”或类似)。您将收到一个消费者秘钥和消费者密码:这些都是应用程序设置,应一直保密。在您的应用程序的配置页面,你也可以要求获取一个访问令牌和访问令牌的密码。类似于消费者秘钥,这些字符串也必须保密:他们提供的应用程序是代表您的账户访问到Twitter。默认权限是只读的,这是我们在案例中须要的,但假如你决定改变您的许可,在应用中提供修改功能,你就必须再获得一个新的访问令牌。
重要提示:使用Twitter的API时有速度限制,或者你想要提供一个可下载的数据集也会有限制,请参见: >
您可以使用 Twitter提供的REST APIs与她们的服务进行交互。那里还有一群基于Python的顾客,我们可以重复循环使用。尤其Tweepy是其中最有趣和最直白的一个,所以我们一起把它安装上去:
更新:Tweepy发布的3.4.0版本在Python3上出现了一些问题,目前被绑定在GitHub上还不能进行使用,因此在新的版本下来之前,我们仍然使用3.3.0版本。
更多的更新:Tweepy发布的3.5.0版本早已可以使用,似乎解决了上述提及的在Python3上的问题。
为了授权我们的应用程序以代表我们访问Twitter,我们须要使用OAuth的界面:
现在的API变量是我们为可以在Twitter上执行的大多数操作的入口点。
例如,我们可以看见我们自己的时间表(或者我们的Twitter主页):
Tweepy提供方便的光标插口,对不同类型的对象进行迭代。在前面的事例中我们用10来限制我们正在阅读的tweets的数目,但是其实也许我们是可以访问更多的。状态变量是Status() class的一个实例,是访问数据时一个漂亮的包装。Twitter API的JSON响应在_json属性(带有前导顿号)上是可用的,它不是纯JSON字符串,而是一个字典。
所以前面的代码可以被重新写入去处理/存储JSON:
如果我们想要一个所有用户的名单?来这里:
那么我们所有的tweets的列表呢? 也很简单:
通过这些方法,我们可以很容易地搜集tweets(以及更多),并将它们储存为原创的JSON格式,可以很方便的根据我们的储存格式将其转换为不同的数据模型(很多NoSQL技术提供一些批量导出功能)。
process_or_store()功能是您的自定义施行占位符。最简单的形式就是你可以只复印出JSON,每行一个tweet:
流
如果我们要“保持联接”,并搜集所有关于特定风波将会出现的tweets,流API就是我们所须要的。我们须要扩充StreamListener()来定义我们处理输入数据的形式。一个用#python hashtag搜集了所有新的tweet的事例:
根据不同的搜索词,我们可以在几分钟之内搜集到成千上万的tweet。世界性覆盖的现场活动尤其这么(世界杯、超级杯、奥斯卡颁奖典礼等),所以保持关注JSON文件,看看它下降的速率是多么的快,并审视你的测试可能须要多少tweet。以上脚本将把每位tweet保存在新的行中,所以你可以从Unix shell中使用wc-l python.json命令来了解到你搜集了多少tweet。
你可以在下边的要点中见到Twitter的API流的一个最小工作示例:
twitter_stream_downloader.py
总结
我们早已介绍了tweepy作为通过Python访问Twitter数据的一个相当简单的工具。我们可以按照明晰的“tweet”项目目标搜集一些不同类型的数据。
一旦我们搜集了一些数据,在剖析应用方面的就可以进行展开了。在接下来的内容中,我们将讨论部份问题。
简介:Marco Bonzanini是美国纽约的一个数据科学家。活跃于PyData社区的他喜欢从事文本剖析和数据挖掘的应用工作。他是“用Python把握社会化媒体挖掘”( 2016月7月出版)的作者。
原文>>
文章来源36大数据, ,微信号dashuju36 ,36大数据是一个专注大数据创业、大数据技术与剖析、大数据商业与应用的网站。分享大数据的干货教程和大数据应用案例,提供大数据剖析工具和资料下载,解决大数据产业链上的创业、技术、分析、商业、应用等问题,为大数据产业链上的公司和数据行业从业人员提供支持与服务。
via:shumeng
End. 查看全部
用Python挖掘Twitter数据:数据采集
这是一系列使用Python专门用于Twitter数据挖掘的文章中的第一篇。在第一部份中,我们将见到通过不同的方法来进行Twitter的数据搜集。一旦我们构建好了一个数据集,在接下来的环节中,我们就将会讨论一些有趣的数据应用。
注册应用
为了才能访问Twitter数据编程,我们须要创建一个与Twitter的API交互的应用程序。
第一步是注册一个你的应用程序。值得注意的是,您须要将您的浏览器转入,登录到Twitter(如果您仍未登陆),并注册一个新的应用程序。您如今可以为您的应用程序选择一个名称和说明(例如“挖掘演示”或类似)。您将收到一个消费者秘钥和消费者密码:这些都是应用程序设置,应一直保密。在您的应用程序的配置页面,你也可以要求获取一个访问令牌和访问令牌的密码。类似于消费者秘钥,这些字符串也必须保密:他们提供的应用程序是代表您的账户访问到Twitter。默认权限是只读的,这是我们在案例中须要的,但假如你决定改变您的许可,在应用中提供修改功能,你就必须再获得一个新的访问令牌。
重要提示:使用Twitter的API时有速度限制,或者你想要提供一个可下载的数据集也会有限制,请参见: >
您可以使用 Twitter提供的REST APIs与她们的服务进行交互。那里还有一群基于Python的顾客,我们可以重复循环使用。尤其Tweepy是其中最有趣和最直白的一个,所以我们一起把它安装上去:
更新:Tweepy发布的3.4.0版本在Python3上出现了一些问题,目前被绑定在GitHub上还不能进行使用,因此在新的版本下来之前,我们仍然使用3.3.0版本。
更多的更新:Tweepy发布的3.5.0版本早已可以使用,似乎解决了上述提及的在Python3上的问题。
为了授权我们的应用程序以代表我们访问Twitter,我们须要使用OAuth的界面:
现在的API变量是我们为可以在Twitter上执行的大多数操作的入口点。
例如,我们可以看见我们自己的时间表(或者我们的Twitter主页):
Tweepy提供方便的光标插口,对不同类型的对象进行迭代。在前面的事例中我们用10来限制我们正在阅读的tweets的数目,但是其实也许我们是可以访问更多的。状态变量是Status() class的一个实例,是访问数据时一个漂亮的包装。Twitter API的JSON响应在_json属性(带有前导顿号)上是可用的,它不是纯JSON字符串,而是一个字典。
所以前面的代码可以被重新写入去处理/存储JSON:
如果我们想要一个所有用户的名单?来这里:
那么我们所有的tweets的列表呢? 也很简单:
通过这些方法,我们可以很容易地搜集tweets(以及更多),并将它们储存为原创的JSON格式,可以很方便的根据我们的储存格式将其转换为不同的数据模型(很多NoSQL技术提供一些批量导出功能)。
process_or_store()功能是您的自定义施行占位符。最简单的形式就是你可以只复印出JSON,每行一个tweet:
流
如果我们要“保持联接”,并搜集所有关于特定风波将会出现的tweets,流API就是我们所须要的。我们须要扩充StreamListener()来定义我们处理输入数据的形式。一个用#python hashtag搜集了所有新的tweet的事例:
根据不同的搜索词,我们可以在几分钟之内搜集到成千上万的tweet。世界性覆盖的现场活动尤其这么(世界杯、超级杯、奥斯卡颁奖典礼等),所以保持关注JSON文件,看看它下降的速率是多么的快,并审视你的测试可能须要多少tweet。以上脚本将把每位tweet保存在新的行中,所以你可以从Unix shell中使用wc-l python.json命令来了解到你搜集了多少tweet。
你可以在下边的要点中见到Twitter的API流的一个最小工作示例:
twitter_stream_downloader.py
总结
我们早已介绍了tweepy作为通过Python访问Twitter数据的一个相当简单的工具。我们可以按照明晰的“tweet”项目目标搜集一些不同类型的数据。
一旦我们搜集了一些数据,在剖析应用方面的就可以进行展开了。在接下来的内容中,我们将讨论部份问题。
简介:Marco Bonzanini是美国纽约的一个数据科学家。活跃于PyData社区的他喜欢从事文本剖析和数据挖掘的应用工作。他是“用Python把握社会化媒体挖掘”( 2016月7月出版)的作者。
原文>>
文章来源36大数据, ,微信号dashuju36 ,36大数据是一个专注大数据创业、大数据技术与剖析、大数据商业与应用的网站。分享大数据的干货教程和大数据应用案例,提供大数据剖析工具和资料下载,解决大数据产业链上的创业、技术、分析、商业、应用等问题,为大数据产业链上的公司和数据行业从业人员提供支持与服务。
via:shumeng
End.
优采云采集怎样获取数据API链接 优采云采集获取数据API链接的方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 327 次浏览 • 2020-08-26 04:28
今天给你们带来优采云采集怎样获取数据API链接,优采云采集获取数据API链接的方式,让您轻松解决问题。
优采云采集如何获取数据API链接
具体方式如下:
1
java、cs、php示例代码点击下载
这个教程为你们讲解数据API的使用
注:只有在有效期内的旗舰版用户才可以使用数据API
如何获取数据API链接?
1.打开任务配置界面,如下图:
2
2.点下一步,直到最后一步,选择生成数据导入API接口,如下图:
3
3.点击后将会有一个弹出窗口,从弹出窗口上复制API链接,并可查看API示例:
4
最终的API链接格式是:{开始时间}&to={结束时间},key由系统手动生成,请勿更改!最终使用的时侯须要将{开始时间}和{结束时间}替换为想要获取数据的时间区间(采集时间),如:/SkieerDataAPI/GetData?key=key&from=2014-11-11 12:00&to=2014-11-11 13:00,时间区间最长为一个小时(总数据量不少于1000条,多于1000条的请用 )。pageindex是页脚,pageSize是那页显示的数据量 如pageindex=3&pageSize=100的意义为恳求第三页的数据,每页根据100条数据进行界定。
5
如何使用数据API?
数据API返回的是XML格式的数据,您的程序可定时的通过API获取指定时间段云采集的数据,API返回数据的格式如下图: 查看全部
优采云采集怎样获取数据API链接 优采云采集获取数据API链接的方式
今天给你们带来优采云采集怎样获取数据API链接,优采云采集获取数据API链接的方式,让您轻松解决问题。
优采云采集如何获取数据API链接
具体方式如下:
1
java、cs、php示例代码点击下载
这个教程为你们讲解数据API的使用
注:只有在有效期内的旗舰版用户才可以使用数据API
如何获取数据API链接?
1.打开任务配置界面,如下图:
2
2.点下一步,直到最后一步,选择生成数据导入API接口,如下图:
3
3.点击后将会有一个弹出窗口,从弹出窗口上复制API链接,并可查看API示例:
4
最终的API链接格式是:{开始时间}&to={结束时间},key由系统手动生成,请勿更改!最终使用的时侯须要将{开始时间}和{结束时间}替换为想要获取数据的时间区间(采集时间),如:/SkieerDataAPI/GetData?key=key&from=2014-11-11 12:00&to=2014-11-11 13:00,时间区间最长为一个小时(总数据量不少于1000条,多于1000条的请用 )。pageindex是页脚,pageSize是那页显示的数据量 如pageindex=3&pageSize=100的意义为恳求第三页的数据,每页根据100条数据进行界定。
5
如何使用数据API?
数据API返回的是XML格式的数据,您的程序可定时的通过API获取指定时间段云采集的数据,API返回数据的格式如下图:
爬虫数据采集技术趋势—智能化解析
采集交流 • 优采云 发表了文章 • 0 个评论 • 416 次浏览 • 2020-08-26 04:21
用一句话概括爬虫工程师的工作内容,就是We Structure the World's Knowledge。
爬虫工作内容
互联网作为人类历史最大的知识库房,是没有充分结构化的。目前互联网仅仅是一些文本等多媒体数据的聚合,内容似乎十分有价值,但是程序是难以使用这些没有结构化的数据。
在2006年左右,有专家提出的web3.0,语义互联网,知识共享。虽然现今开放API,SOA概念越来越普及,真正语义上的互联网的时代虽然还十分遥远。因此爬虫仍然是最重要的手段,一端不断解析,聚合互联网上的数据,另外一端向各种各样的的应用输送数据。
现有爬虫开发技术存在问题
从急聘市场岗位需求可以看出,近年来对爬虫工程师需求越来越强烈。
个人判定缘由有两个:
信息聚合是互联网公司的基本需求。
数据时代到来,对数据更强烈的需求。
下面是我整理的部份靠爬虫聚合信息的创业公司,按照时间次序排序:
最后5种类型,几乎2014年都是开始。很多金融场景相关应用开始出现,这就对准确度和可靠性提出了更高的要求。但现有的爬虫开发技术能够满足高可靠,大规模,高效率开发需求呢?
从软件工程角度来看,一件事情若果未能评估,那就难以管理。爬虫开发常常是被吐槽的诱因之一,就是工作量往往难以评估。一般的软件项目的开发过程随着时间推动,工作量会渐渐降低,也是你们常常说的烧尽疗效。
而爬虫开发生命周期如下图:
爬虫开发主要有两个方面内容:下载网页,解析网页。解析网页大约抢占开发工作的80%左右。
下载网页功能的开发工作,会涉及IP限制,验证码等问题,这样问题都是可以预期的。同时,随着现今优秀的爬虫框架和云服务器的普及,问题解决上去会更轻松。
编写解析代码,虽然有一些基本工具chrome,firecdebug可以使用,但仍然须要人工剖析,编写解析规则。无论是使用xpath,正则表达式,css selector,都不能减轻这一部分的工作量。
大量重复性工作会导致以下两个问题:
即使同类型的网页看起来99%是一样,也须要编撰独立的爬虫。这都会给人这样一种感觉——爬虫开发大部分的工作内容是重复的。
数据源网页改版,几乎整个爬虫项目须要重做。重做的工作量几乎是100%,爬虫工程师心里常常是一万只矮马跑过。现在好多征信数据采集公司的合作伙伴,当数据源网站改版,常常须要一至两天能够修补爬虫,很明显这些可靠性是难以满足金融场景须要。
智能化解析
这是一张新浪新闻的图片。
可以发觉,视觉上很容易了解到,新闻所报导的风波的标题,发表时间和正文。自然也会想到,能否通过一些机器学习的算法达到手动解析的目的?这样就不用人工编撰解析额,减少重复劳动。在2008年开始,就要研究机构发表了相关论文。
~deepay/mywww/papers/www08-segments.pdf
/en-us/um/people/znie/p048.special.nie.pdf
也就是在2008有一家相关的创业公司,在斯坦福大学孵化。
DiffBot智能化数据采集公司
总部坐落加洲的Diffbot创立于2008年,创始人Mike Tung,是哈佛结业研究生。Diffbot是通过人工智能技术,让“机器”识别网页内容,抓取关键内容,并输出软件可以直接辨识的结构化数据。其创始人兼首席执行官Mike Tung表示,“Diffbot如今做的,相当于人类在浏览网页文章时所做的事情,找出页面中最核心的相关信息。”目前Diffbot早已发布了头版API和文章API,还有产品API。服务的顾客包括三星、eBay、思科、美国在线等。
Diffbot的理念就是通过“视觉机器人”来扫描和辨识不同的网页类型(主要是非结构化的数据),再将这种丰富的数据源用于其他应用。Mike Tung表示:“我们在获取页面然后会对其进行剖析,然后通过成熟先进的技术进行结构化处理。”之前我提及的we structure the world's knowledge,就是该公司提出的理念。
Diffbot在基于智能采集的基础上,又开发出好多数据产品,比如知识图谱,智能商业BI。在2016腾讯与硅谷风投机构Felicis Ventures领投了人工智能创业公司Diffbot 1000万美元的A轮融资,很多互联网大鳄开始发觉这家公司的价值。
算法实践
通过智能方法来解析网页须要两个步骤:
基于视觉上的网页分割,将网页分割几个视觉块。
通过机器学习训练的方法来判定各个视觉块的类型,是标题,还是正文。其中主要流程和通常机器须要流程没哪些区别。这就不详尽解释。使用到使用的开源框架有:scikit-learn,phantomjs
Scikit-Learn机器学习库早已十分成熟,很容易上手。
phantomjs,是一个headless webkit渲染引擎。做爬虫开发的朋友应当十分须要。
网页分割算法
从Diffbot初期发布的文章来看,是通过图象处理的方法来切割视觉块。使用到的算法有,边界检测,文字辨识等算法。但这些方法估算量偏大,复杂度很高。
另外一种实现方法是基于Dom树结构,导出所需的视觉特点。
聚合时侯需用的特点变量。主要考虑视觉相关的诱因有元素在页面上的位置,宽度和高度,Dom的层次。
有一点须要注意的是,现在网页好多是动态生成。需要依靠phantomjs工具来进行动态网页渲染。
聚类算法可以选用的DBSCAN,DBSCAN算法优点是愈发密度来界定,比起K-mean算法的优点,是处理任意形状的聚合。
具体的实现方法可以参考下边博文:
分类算法
在第一步处理后,网页上的标签,会被界定分若干类,需要判定标签的类型,是否是标题,正文,广告,导航之类。需要整理出类似下边的,训练矩阵。
整个学习过程与通常的机器学习训练过程没有区别。由于数据样本规模不大,分类算法基本算法采取。分类算法可以选用朴素贝叶斯,或者SVM。
总结和展望
本文介绍的方法比较简略,一般来说解析模型只能针对特定的网路训练解析模型,比如新闻,电商产品页。所以不同类型的网页,所须要的特点变量有较大差异。针对不同特征类型数据,需要你们自己花时间去探求和实践。
随着数据时代和智能化时代到来,爬虫作为重要的数据来源,自身须要一些技术提高来适应时代的要求,这也就对爬虫工程师提出更高的要求。
本文作者:李国建(点融黑手党),现就职于点融网成都团队Data Team,喜欢研究各类机器学习,爬虫,自动化交易相关的技术。 查看全部
爬虫数据采集技术趋势—智能化解析
用一句话概括爬虫工程师的工作内容,就是We Structure the World's Knowledge。
爬虫工作内容
互联网作为人类历史最大的知识库房,是没有充分结构化的。目前互联网仅仅是一些文本等多媒体数据的聚合,内容似乎十分有价值,但是程序是难以使用这些没有结构化的数据。
在2006年左右,有专家提出的web3.0,语义互联网,知识共享。虽然现今开放API,SOA概念越来越普及,真正语义上的互联网的时代虽然还十分遥远。因此爬虫仍然是最重要的手段,一端不断解析,聚合互联网上的数据,另外一端向各种各样的的应用输送数据。
现有爬虫开发技术存在问题
从急聘市场岗位需求可以看出,近年来对爬虫工程师需求越来越强烈。
个人判定缘由有两个:
信息聚合是互联网公司的基本需求。
数据时代到来,对数据更强烈的需求。
下面是我整理的部份靠爬虫聚合信息的创业公司,按照时间次序排序:
最后5种类型,几乎2014年都是开始。很多金融场景相关应用开始出现,这就对准确度和可靠性提出了更高的要求。但现有的爬虫开发技术能够满足高可靠,大规模,高效率开发需求呢?
从软件工程角度来看,一件事情若果未能评估,那就难以管理。爬虫开发常常是被吐槽的诱因之一,就是工作量往往难以评估。一般的软件项目的开发过程随着时间推动,工作量会渐渐降低,也是你们常常说的烧尽疗效。
而爬虫开发生命周期如下图:
爬虫开发主要有两个方面内容:下载网页,解析网页。解析网页大约抢占开发工作的80%左右。
下载网页功能的开发工作,会涉及IP限制,验证码等问题,这样问题都是可以预期的。同时,随着现今优秀的爬虫框架和云服务器的普及,问题解决上去会更轻松。
编写解析代码,虽然有一些基本工具chrome,firecdebug可以使用,但仍然须要人工剖析,编写解析规则。无论是使用xpath,正则表达式,css selector,都不能减轻这一部分的工作量。
大量重复性工作会导致以下两个问题:
即使同类型的网页看起来99%是一样,也须要编撰独立的爬虫。这都会给人这样一种感觉——爬虫开发大部分的工作内容是重复的。
数据源网页改版,几乎整个爬虫项目须要重做。重做的工作量几乎是100%,爬虫工程师心里常常是一万只矮马跑过。现在好多征信数据采集公司的合作伙伴,当数据源网站改版,常常须要一至两天能够修补爬虫,很明显这些可靠性是难以满足金融场景须要。
智能化解析
这是一张新浪新闻的图片。
可以发觉,视觉上很容易了解到,新闻所报导的风波的标题,发表时间和正文。自然也会想到,能否通过一些机器学习的算法达到手动解析的目的?这样就不用人工编撰解析额,减少重复劳动。在2008年开始,就要研究机构发表了相关论文。
~deepay/mywww/papers/www08-segments.pdf
/en-us/um/people/znie/p048.special.nie.pdf
也就是在2008有一家相关的创业公司,在斯坦福大学孵化。
DiffBot智能化数据采集公司
总部坐落加洲的Diffbot创立于2008年,创始人Mike Tung,是哈佛结业研究生。Diffbot是通过人工智能技术,让“机器”识别网页内容,抓取关键内容,并输出软件可以直接辨识的结构化数据。其创始人兼首席执行官Mike Tung表示,“Diffbot如今做的,相当于人类在浏览网页文章时所做的事情,找出页面中最核心的相关信息。”目前Diffbot早已发布了头版API和文章API,还有产品API。服务的顾客包括三星、eBay、思科、美国在线等。
Diffbot的理念就是通过“视觉机器人”来扫描和辨识不同的网页类型(主要是非结构化的数据),再将这种丰富的数据源用于其他应用。Mike Tung表示:“我们在获取页面然后会对其进行剖析,然后通过成熟先进的技术进行结构化处理。”之前我提及的we structure the world's knowledge,就是该公司提出的理念。
Diffbot在基于智能采集的基础上,又开发出好多数据产品,比如知识图谱,智能商业BI。在2016腾讯与硅谷风投机构Felicis Ventures领投了人工智能创业公司Diffbot 1000万美元的A轮融资,很多互联网大鳄开始发觉这家公司的价值。
算法实践
通过智能方法来解析网页须要两个步骤:
基于视觉上的网页分割,将网页分割几个视觉块。
通过机器学习训练的方法来判定各个视觉块的类型,是标题,还是正文。其中主要流程和通常机器须要流程没哪些区别。这就不详尽解释。使用到使用的开源框架有:scikit-learn,phantomjs
Scikit-Learn机器学习库早已十分成熟,很容易上手。
phantomjs,是一个headless webkit渲染引擎。做爬虫开发的朋友应当十分须要。
网页分割算法
从Diffbot初期发布的文章来看,是通过图象处理的方法来切割视觉块。使用到的算法有,边界检测,文字辨识等算法。但这些方法估算量偏大,复杂度很高。
另外一种实现方法是基于Dom树结构,导出所需的视觉特点。
聚合时侯需用的特点变量。主要考虑视觉相关的诱因有元素在页面上的位置,宽度和高度,Dom的层次。
有一点须要注意的是,现在网页好多是动态生成。需要依靠phantomjs工具来进行动态网页渲染。
聚类算法可以选用的DBSCAN,DBSCAN算法优点是愈发密度来界定,比起K-mean算法的优点,是处理任意形状的聚合。
具体的实现方法可以参考下边博文:
分类算法
在第一步处理后,网页上的标签,会被界定分若干类,需要判定标签的类型,是否是标题,正文,广告,导航之类。需要整理出类似下边的,训练矩阵。
整个学习过程与通常的机器学习训练过程没有区别。由于数据样本规模不大,分类算法基本算法采取。分类算法可以选用朴素贝叶斯,或者SVM。
总结和展望
本文介绍的方法比较简略,一般来说解析模型只能针对特定的网路训练解析模型,比如新闻,电商产品页。所以不同类型的网页,所须要的特点变量有较大差异。针对不同特征类型数据,需要你们自己花时间去探求和实践。
随着数据时代和智能化时代到来,爬虫作为重要的数据来源,自身须要一些技术提高来适应时代的要求,这也就对爬虫工程师提出更高的要求。
本文作者:李国建(点融黑手党),现就职于点融网成都团队Data Team,喜欢研究各类机器学习,爬虫,自动化交易相关的技术。
Python爬虫:十分钟实现从数据抓取到数据API提供
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2020-08-26 01:31
欢迎点击右上角关注小编,除了分享技术文章之外还有好多福利,私信学习资料可以发放包括不限于Python实战演练、PDF电子文档、面试集锦、学习资料等。
依旧先从爬虫的基本概念说起,你去做爬虫做数据抓取,第一件事想必是去查看目标网站是否有api。有且可以使用的话,皆大欢喜。
假如目标网站自身不提供api,但明天你心情不好就想用api来抓数据,那如何办。有个长者说,没api创造api也要上,所以,那就创造api吧~
关于Toapi
很多时侯你须要经历抓取数据->存储数据->构建API的基本步骤,然后在去定时更新数据。然而你的目的并不是想去学习搭建稳定可靠手动更新的API服务,你只是想用这个网站的数据而已。Toapi就是因此实现,可以自动化的完成前述任务,达到使用网站实时数据的目的。
先看效果图 (这个网站是没有api的哟)手机点进去可能没有数据,用pc端浏览器就好。
如你所见,Toapi会使数据弄成一块面包,你只须要将它切出来喝了(虽然英文的显示是unicode)。那么话不多说,看代码。
满打满算10行代码吧,你就可以实现数据的api,心动不如行动还不给我打钱,啊呸,不好意思,串场了。下面还是解释下里面的代码。希望对你有帮助。
对了对了,你写那些代码不用十分钟吧,不要算我标题党。
安装:pip install toapi 查看全部
Python爬虫:十分钟实现从数据抓取到数据API提供
欢迎点击右上角关注小编,除了分享技术文章之外还有好多福利,私信学习资料可以发放包括不限于Python实战演练、PDF电子文档、面试集锦、学习资料等。
依旧先从爬虫的基本概念说起,你去做爬虫做数据抓取,第一件事想必是去查看目标网站是否有api。有且可以使用的话,皆大欢喜。
假如目标网站自身不提供api,但明天你心情不好就想用api来抓数据,那如何办。有个长者说,没api创造api也要上,所以,那就创造api吧~
关于Toapi
很多时侯你须要经历抓取数据->存储数据->构建API的基本步骤,然后在去定时更新数据。然而你的目的并不是想去学习搭建稳定可靠手动更新的API服务,你只是想用这个网站的数据而已。Toapi就是因此实现,可以自动化的完成前述任务,达到使用网站实时数据的目的。
先看效果图 (这个网站是没有api的哟)手机点进去可能没有数据,用pc端浏览器就好。
如你所见,Toapi会使数据弄成一块面包,你只须要将它切出来喝了(虽然英文的显示是unicode)。那么话不多说,看代码。
满打满算10行代码吧,你就可以实现数据的api,心动不如行动还不给我打钱,啊呸,不好意思,串场了。下面还是解释下里面的代码。希望对你有帮助。
对了对了,你写那些代码不用十分钟吧,不要算我标题党。
安装:pip install toapi
第 7 篇:文章详情的 API 接口
采集交流 • 优采云 发表了文章 • 0 个评论 • 359 次浏览 • 2020-08-26 00:36
作者:HelloGitHub-追梦人物
一旦我们使用了视图集,并实现了 HTTP 请求对应的 action 方法(对应规则的说明见 使用视图集简化代码),将其在路由器中注册后,django-restframework 自动会手动为我们生成对应的 API 接口。
目前为止,我们只实现了 GET 请求对应的 action——list 方法,因此路由器只为我们生成了一个 API,这个 API 返回文章资源列表。GET 请求还可以用于获取单个资源,对应的 action 为 retrieve,因此,只要我们在视图集中实现 retrieve 方法的逻辑,就可以直接生成获取单篇文章资源的 API 接口。
贴心的是,django-rest-framework 已经帮我们把 retrieve 的逻辑在 mixins.RetrieveModelMixin 里写好了,直接混进视图集即可:
现在,路由会手动降低一个 /posts/:pk/ 的 URL 模式,其中 pk 为文章的 id。访问此 API 接口可以获得指定文章 id 的资源。
实际上,实现各个 action 逻辑的混进类都十分简单,以 RetrieveModelMixin 为例,我们来瞧瞧它的源码:
retrieve 方法首先调用 get_object 方法获取需序列化的对象。get_object 方法一般情况下根据以下两点来筛选出单个资源对象:
get_queryset 方法(或者 queryset 属性,get_queryset 方法返回的值优先)返回的资源列表对象。lookup_field 属性指定的资源筛选数组(默认为 pk)。django-rest-framework 以该数组的值从 get_queryset 返回的资源列表中筛选出单个资源对象。lookup_field 字段的值将从恳求的 URL 中捕获,所以你听到文章接口的 url 模式为 /posts/:pk/,假设将 lookup_field 指定为 title,则 url 模式为 /posts/:title/,此时将按照文章标题获取单篇文章资源。文章详情 Serializer
现在,假设我们要获取 id 为 1 的文章资源,访问获取单篇文章资源的 API 接口 :10000/api/posts/1/,得到如下的返回结果:
可以看见好多我们须要在详情页中展示的数组值并没有返回,比如文章正文(body)。原因是视图集中指定的文章序列化器为 PostListSerializer,这个序列化器被用于序列化文章列表。因为展示文章列表数据时,有些数组用不上,所以出于性能考虑,只序列化了部份数组。
显然,我们须要给文章详情写一个新的序列化器了:
详情序列化器和列表序列化器几乎一样,只是在 fields 中指定了更多须要序列化的数组。
同时注意,为了序列化文章的标签 tags,我们新增了一个 TagSerializer,由于文章可能有多个标签,因为 tags 是一个列表,要序列化一个列表资源,需要将序列化器参数 many 的值指定为 True。
动态 Serializer
现在新的序列化器写好了,可是在那里指定呢?视图集中 serializer_class 属性早已被指定为了 PostListSerializer,那 PostRetrieveSerializer 应该指定在哪呢?
类似于视图集类的 queryset 属性和 get_queryset 方法的关系, serializer_class 属性的值也可以通过 get_serializer_class 方法返回的值覆盖,因此我们可以按照不同的 action 动作来动态指定对应的序列化器。
那么怎样在视图集中分辨不同的 action 动作呢?视图集有一个 action 属性,专门拿来记录当前恳求对应的动作。对应关系如下:
HTTP 请求对应 action 属性的值GETlist(资源列表)/ retrieve(单个资源)PUTupdatePATCHpartial_updateDELETEdestory
因此,我们在视图集中重画 get_serializer_class 方法,写入我们自己的逻辑,就可以按照不同恳求,分别获取相应的序列化器了:
后续对于其他动作,可以再加 elif 判断,不过若果动作变多了,就会有很多的 if 判断。更好的做好是,给视图集加一个属性,用于配置 action 和 serializer_class 的对应关系,通过查表法查找 action 应该使用的序列化器。
现在,再次访问单篇文章 API 接口,可以看见返回了愈加详尽的博客文章数据了:
『讲解开源项目系列』——让对开源项目感兴趣的人不再惧怕、让开源项目的发起者不再孤单。跟着我们的文章,你会发觉编程的乐趣、使用和发觉参与开源项目这么简单。欢迎留言联系我们、加入我们,让更多人爱上开源、贡献开源~ 查看全部
第 7 篇:文章详情的 API 接口
作者:HelloGitHub-追梦人物
一旦我们使用了视图集,并实现了 HTTP 请求对应的 action 方法(对应规则的说明见 使用视图集简化代码),将其在路由器中注册后,django-restframework 自动会手动为我们生成对应的 API 接口。
目前为止,我们只实现了 GET 请求对应的 action——list 方法,因此路由器只为我们生成了一个 API,这个 API 返回文章资源列表。GET 请求还可以用于获取单个资源,对应的 action 为 retrieve,因此,只要我们在视图集中实现 retrieve 方法的逻辑,就可以直接生成获取单篇文章资源的 API 接口。
贴心的是,django-rest-framework 已经帮我们把 retrieve 的逻辑在 mixins.RetrieveModelMixin 里写好了,直接混进视图集即可:
现在,路由会手动降低一个 /posts/:pk/ 的 URL 模式,其中 pk 为文章的 id。访问此 API 接口可以获得指定文章 id 的资源。
实际上,实现各个 action 逻辑的混进类都十分简单,以 RetrieveModelMixin 为例,我们来瞧瞧它的源码:
retrieve 方法首先调用 get_object 方法获取需序列化的对象。get_object 方法一般情况下根据以下两点来筛选出单个资源对象:
get_queryset 方法(或者 queryset 属性,get_queryset 方法返回的值优先)返回的资源列表对象。lookup_field 属性指定的资源筛选数组(默认为 pk)。django-rest-framework 以该数组的值从 get_queryset 返回的资源列表中筛选出单个资源对象。lookup_field 字段的值将从恳求的 URL 中捕获,所以你听到文章接口的 url 模式为 /posts/:pk/,假设将 lookup_field 指定为 title,则 url 模式为 /posts/:title/,此时将按照文章标题获取单篇文章资源。文章详情 Serializer
现在,假设我们要获取 id 为 1 的文章资源,访问获取单篇文章资源的 API 接口 :10000/api/posts/1/,得到如下的返回结果:
可以看见好多我们须要在详情页中展示的数组值并没有返回,比如文章正文(body)。原因是视图集中指定的文章序列化器为 PostListSerializer,这个序列化器被用于序列化文章列表。因为展示文章列表数据时,有些数组用不上,所以出于性能考虑,只序列化了部份数组。
显然,我们须要给文章详情写一个新的序列化器了:
详情序列化器和列表序列化器几乎一样,只是在 fields 中指定了更多须要序列化的数组。
同时注意,为了序列化文章的标签 tags,我们新增了一个 TagSerializer,由于文章可能有多个标签,因为 tags 是一个列表,要序列化一个列表资源,需要将序列化器参数 many 的值指定为 True。
动态 Serializer
现在新的序列化器写好了,可是在那里指定呢?视图集中 serializer_class 属性早已被指定为了 PostListSerializer,那 PostRetrieveSerializer 应该指定在哪呢?
类似于视图集类的 queryset 属性和 get_queryset 方法的关系, serializer_class 属性的值也可以通过 get_serializer_class 方法返回的值覆盖,因此我们可以按照不同的 action 动作来动态指定对应的序列化器。
那么怎样在视图集中分辨不同的 action 动作呢?视图集有一个 action 属性,专门拿来记录当前恳求对应的动作。对应关系如下:
HTTP 请求对应 action 属性的值GETlist(资源列表)/ retrieve(单个资源)PUTupdatePATCHpartial_updateDELETEdestory
因此,我们在视图集中重画 get_serializer_class 方法,写入我们自己的逻辑,就可以按照不同恳求,分别获取相应的序列化器了:
后续对于其他动作,可以再加 elif 判断,不过若果动作变多了,就会有很多的 if 判断。更好的做好是,给视图集加一个属性,用于配置 action 和 serializer_class 的对应关系,通过查表法查找 action 应该使用的序列化器。
现在,再次访问单篇文章 API 接口,可以看见返回了愈加详尽的博客文章数据了:
『讲解开源项目系列』——让对开源项目感兴趣的人不再惧怕、让开源项目的发起者不再孤单。跟着我们的文章,你会发觉编程的乐趣、使用和发觉参与开源项目这么简单。欢迎留言联系我们、加入我们,让更多人爱上开源、贡献开源~
教你三步爬取后端优质文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2020-08-25 22:36
打开官网,(F12) 打开开发者模式查看network 选项,咱们可以看见获取文章接口的api如下:
打开开发者模式,我们太轻松的找到获取文章的插口,这就好办了,说实话后端开发,只要有了插口,那就等于有了一切,我们可以恣意的 coding 了~
第二步
创建服务器文件 app.js ,通过superagent 模块发送恳求获取文章数据。
app.js 是我们服务端代码,这里通过服务端发送恳求获取爬虫所要的数据保存出来。
// 定义一个函数,用来获取首页前端文章信息
function getInfo () {
// 利用superagent 模块发送请求,获取前20篇文章。注意请求头的设置和POST请求体数据(请求参数)
superagent.post('https://web-api..im/query').send(params).set('X-Agent', 'Juejin/Web').end((err, res) => {
if (err) {
return console.log(err)
}
// 保存所有文章信息
const array1 = JSON.parse(res.text).data.articleFeed.items.edges
const num = JSON.parse(res.text).data.articleFeed.items.pageInfo.endCursor
// 筛选出点赞数大于 50 的文章
result = array1.filter(item => {
return item.node.likeCount > 50
})
params.variables.after = num.toString()
// 再次发送请求获取另外的20篇文章
superagent.post('https://web-api..im/query').send(params).set('X-Agent', 'Juejin/Web').end((err, res) => {
if (err) {
return console.log(err)
}
const array2 = JSON.parse(res.text).data.articleFeed.items.edges
const result2 = array2.filter(item => {
return item.node.likeCount > 50
})
result2.forEach(item => {
result.push(item)
})
})
})
}
// 调用一次获取数据
getInfo()
// 设置定时器,规定10分钟更新一此数据
setInterval(() => {
getInfo()
}, 10*1000*60)
复制代码
这里要注意插口那儿须要设置恳求头的 X-Agent 属性,一定要在 superagent 发送 post 请求时侯带上,否则会出错,另外就是固定的恳求参数 params,这个可以仿造官网来写。
第三步
模板引擎渲染数据,发送结果到浏览器渲染
这一步须要利用模板引擎渲染 HTML 页面,把从第二步领到的结果渲染到页面中,最终返回给浏览器渲染。
app.js 代码:
// 监听路由
app.get('/', (req, res, next) => {
res.render('index.html', {
result
})
})
// 绑定端口,启动服务
app.listen(3000, () => {
console.log('running...')
})
复制代码
模板 index.html 代码 :
{{each result}}
{{$value.node.title}}
{{$value.node.likeCount}}
{{/each}}
复制代码
写在前面
如果你须要项目的源码可以在GitHub对应库房的 node学习demo案例 文件夹下查找, 谢谢! 查看全部
教你三步爬取后端优质文章
打开官网,(F12) 打开开发者模式查看network 选项,咱们可以看见获取文章接口的api如下:
打开开发者模式,我们太轻松的找到获取文章的插口,这就好办了,说实话后端开发,只要有了插口,那就等于有了一切,我们可以恣意的 coding 了~
第二步
创建服务器文件 app.js ,通过superagent 模块发送恳求获取文章数据。
app.js 是我们服务端代码,这里通过服务端发送恳求获取爬虫所要的数据保存出来。
// 定义一个函数,用来获取首页前端文章信息
function getInfo () {
// 利用superagent 模块发送请求,获取前20篇文章。注意请求头的设置和POST请求体数据(请求参数)
superagent.post('https://web-api..im/query').send(params).set('X-Agent', 'Juejin/Web').end((err, res) => {
if (err) {
return console.log(err)
}
// 保存所有文章信息
const array1 = JSON.parse(res.text).data.articleFeed.items.edges
const num = JSON.parse(res.text).data.articleFeed.items.pageInfo.endCursor
// 筛选出点赞数大于 50 的文章
result = array1.filter(item => {
return item.node.likeCount > 50
})
params.variables.after = num.toString()
// 再次发送请求获取另外的20篇文章
superagent.post('https://web-api..im/query').send(params).set('X-Agent', 'Juejin/Web').end((err, res) => {
if (err) {
return console.log(err)
}
const array2 = JSON.parse(res.text).data.articleFeed.items.edges
const result2 = array2.filter(item => {
return item.node.likeCount > 50
})
result2.forEach(item => {
result.push(item)
})
})
})
}
// 调用一次获取数据
getInfo()
// 设置定时器,规定10分钟更新一此数据
setInterval(() => {
getInfo()
}, 10*1000*60)
复制代码
这里要注意插口那儿须要设置恳求头的 X-Agent 属性,一定要在 superagent 发送 post 请求时侯带上,否则会出错,另外就是固定的恳求参数 params,这个可以仿造官网来写。
第三步
模板引擎渲染数据,发送结果到浏览器渲染
这一步须要利用模板引擎渲染 HTML 页面,把从第二步领到的结果渲染到页面中,最终返回给浏览器渲染。
app.js 代码:
// 监听路由
app.get('/', (req, res, next) => {
res.render('index.html', {
result
})
})
// 绑定端口,启动服务
app.listen(3000, () => {
console.log('running...')
})
复制代码
模板 index.html 代码 :
{{each result}}
{{$value.node.title}}
{{$value.node.likeCount}}
{{/each}}
复制代码
写在前面
如果你须要项目的源码可以在GitHub对应库房的 node学习demo案例 文件夹下查找, 谢谢!
API数据提取
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2020-08-25 22:35
GET
POST
PUT
DELETE
GET 就是你在浏览器中输入网址浏览网站所做的事情;POST基本就是当你填写表单或递交信息到网路服务器的前端程序时所做的事情;PUT 在网站交互过程中不常用,但是在API 里面有时会用到;PUT 请求拿来更新一个对象或信息。其实,很多API 在更新信息的时侯都是用POST恳求取代PUT 请求。究竟是创建一个新实体还是更新一个旧实体,通常要看API 请求本身是怎样构筑的。不过,掌握二者的差别还是有用处的,用 API的时侯你常常会碰到PUT 请求;DELETE用于删掉一个对象。例如,如果我们向发出一个DELETE恳求,就会删掉ID号是23的用户。DELETE方式在公共API 里面不常用,它们主要用于创建信息,不能随意使一个用户去删除数据库的信息。
在恳求验证方面,有些API 不需要验证操作(就是说任何人都可以使用API,不需要注册)。有些API 要求顾客验证是为了估算API 调用的费用,或者是提供了包年的服务。有些验证是为了“限制”用户使用API(限制每秒钟、每小时或每晚API 调用的次数),或者是限制一部分用户对某种信息或某类API 的访问。
通常API 验证的方式都是用类似令牌(token)的方法调用,每次API 调用就会把令牌传递到服务器上。这种令牌要么是用户注册的时侯分配给用户,要么就是在用户调用的时侯
才提供,可能是常年固定的值,也可能是频繁变化的,通过服务器对用户名和密码的组合处理后生成。令牌不仅在URL链接中传递,还会通过恳求头里的cookie 把用户信息传递给服务器。
在服务器响应方面,API 有一个重要的特点是它们会反馈格式友好的数据。大多数反馈的数据格式都是XML和JSON 。这几年,JSON 比XML更受欢迎,主要有两个缘由。首先,JSON 文件比完整的XML格式小。如
如下边的XML数据用了98个字符:
RyanMitchellKludgist
同样的JSON 格式数据:
{"user":{"firstname":"Ryan","lastname":"Mitchell","username":"Kludgist"}}
只要用73个字符,比叙述同样内容的XML文件要小36% 。
JSON 格式比XML更受欢迎的另一个缘由是网路技术的改变。过去,服务器端用PHP
和.NET 这些程序作为API 的接收端。现在,服务器端也会用一些JavaScript 框架作为API
的发送和接收端,像Angular或Backbone 等。虽然服务器端的技术难以预测它们将要收到
的数据格式,但是象Backbone 之类的JavaScript 库处理JSON 比处理XML要更简单。
解析JSON数据
调用API,多数服务器会返回JSON格式的数据。Python中通过json库的loads()函数可以把json格式的字符串转换为python对象。
如获取地理位置信息的百度地图API恳求响应
>>> import requests
>>> import json
>>>
>>> par={'address':'北京','key':'cb649a25c1f81c1451adbeca73623251'}
>>>
>>> r=requests.get('',par)
>>> r.text
'{"status":"1","info":"OK","infocode":"10000","count":"1","geocodes":[{"formatted_address":"北京市","country":"中国","province":"北京市","citycode":"010","city":"北京市","district":[],"township":[],"neighborhood":{"name":[],"type":[]},"building":{"name":[],"type":[]},"adcode":"110000","street":[],"number":[],"location":"116.407526,39.904030","level":"省"}]}'
>>>
>>> json_data=json.loads(r.text) #转换为python对象
>>> json_data
{'status': '1', 'info': 'OK', 'infocode': '10000', 'count': '1', 'geocodes': [{'formatted_address': '北京市', 'country': '中国', 'province': '北京市', 'citycode': '010', 'city': '北京市', 'district': [], 'township': [], 'neighborhood': {'name': [], 'type': []}, 'building': {'name': [], 'type': []}, 'adcode': '110000', 'street': [], 'number': [], 'location': '116.407526,39.904030', 'level': '省'}]}
>>>
取北京市的经纬度如下
>>> json_data['geocodes'][0]['location']
'116.407526,39.904030'
>>> 查看全部
API数据提取
GET
POST
PUT
DELETE
GET 就是你在浏览器中输入网址浏览网站所做的事情;POST基本就是当你填写表单或递交信息到网路服务器的前端程序时所做的事情;PUT 在网站交互过程中不常用,但是在API 里面有时会用到;PUT 请求拿来更新一个对象或信息。其实,很多API 在更新信息的时侯都是用POST恳求取代PUT 请求。究竟是创建一个新实体还是更新一个旧实体,通常要看API 请求本身是怎样构筑的。不过,掌握二者的差别还是有用处的,用 API的时侯你常常会碰到PUT 请求;DELETE用于删掉一个对象。例如,如果我们向发出一个DELETE恳求,就会删掉ID号是23的用户。DELETE方式在公共API 里面不常用,它们主要用于创建信息,不能随意使一个用户去删除数据库的信息。
在恳求验证方面,有些API 不需要验证操作(就是说任何人都可以使用API,不需要注册)。有些API 要求顾客验证是为了估算API 调用的费用,或者是提供了包年的服务。有些验证是为了“限制”用户使用API(限制每秒钟、每小时或每晚API 调用的次数),或者是限制一部分用户对某种信息或某类API 的访问。
通常API 验证的方式都是用类似令牌(token)的方法调用,每次API 调用就会把令牌传递到服务器上。这种令牌要么是用户注册的时侯分配给用户,要么就是在用户调用的时侯
才提供,可能是常年固定的值,也可能是频繁变化的,通过服务器对用户名和密码的组合处理后生成。令牌不仅在URL链接中传递,还会通过恳求头里的cookie 把用户信息传递给服务器。
在服务器响应方面,API 有一个重要的特点是它们会反馈格式友好的数据。大多数反馈的数据格式都是XML和JSON 。这几年,JSON 比XML更受欢迎,主要有两个缘由。首先,JSON 文件比完整的XML格式小。如
如下边的XML数据用了98个字符:
RyanMitchellKludgist
同样的JSON 格式数据:
{"user":{"firstname":"Ryan","lastname":"Mitchell","username":"Kludgist"}}
只要用73个字符,比叙述同样内容的XML文件要小36% 。
JSON 格式比XML更受欢迎的另一个缘由是网路技术的改变。过去,服务器端用PHP
和.NET 这些程序作为API 的接收端。现在,服务器端也会用一些JavaScript 框架作为API
的发送和接收端,像Angular或Backbone 等。虽然服务器端的技术难以预测它们将要收到
的数据格式,但是象Backbone 之类的JavaScript 库处理JSON 比处理XML要更简单。
解析JSON数据
调用API,多数服务器会返回JSON格式的数据。Python中通过json库的loads()函数可以把json格式的字符串转换为python对象。
如获取地理位置信息的百度地图API恳求响应
>>> import requests
>>> import json
>>>
>>> par={'address':'北京','key':'cb649a25c1f81c1451adbeca73623251'}
>>>
>>> r=requests.get('',par)
>>> r.text
'{"status":"1","info":"OK","infocode":"10000","count":"1","geocodes":[{"formatted_address":"北京市","country":"中国","province":"北京市","citycode":"010","city":"北京市","district":[],"township":[],"neighborhood":{"name":[],"type":[]},"building":{"name":[],"type":[]},"adcode":"110000","street":[],"number":[],"location":"116.407526,39.904030","level":"省"}]}'
>>>
>>> json_data=json.loads(r.text) #转换为python对象
>>> json_data
{'status': '1', 'info': 'OK', 'infocode': '10000', 'count': '1', 'geocodes': [{'formatted_address': '北京市', 'country': '中国', 'province': '北京市', 'citycode': '010', 'city': '北京市', 'district': [], 'township': [], 'neighborhood': {'name': [], 'type': []}, 'building': {'name': [], 'type': []}, 'adcode': '110000', 'street': [], 'number': [], 'location': '116.407526,39.904030', 'level': '省'}]}
>>>
取北京市的经纬度如下
>>> json_data['geocodes'][0]['location']
'116.407526,39.904030'
>>>
文章采集api Python CMDB开发
采集交流 • 优采云 发表了文章 • 0 个评论 • 334 次浏览 • 2020-08-24 18:44
运维自动化路线:
cmdb的开发须要收录三部份功能:
执行流程:服务器的客户端采集硬件数据,然后将硬件信息发送到API,API负责将获取到的数据保存到数据库中,后台管理程序负责对服务器信息的配置和展示。
采集硬件信息
采集硬件信息可以有两种形式实现:
利用puppet中的report功能自己写agent,定时执行
两种形式的优缺点各异:方式一,优点是不需要在每台服务器上步一个agent,缺点是依赖于puppet,并且使用ruby开发;方式二,优点是用于python调用shell命令,学习成本低,缺点是须要在每台服务器上发一个agent。
方式一
默认情况下,puppet的client会在每半个小时联接puppet的master来同步数据,如果定义了report,那么在每次client和master同步数据时,会执行report的process函数,在该函数中定义一些逻辑,获取每台服务器信息并将信息发送给API
puppet中默认自带了5个report,放置在【/usr/lib/ruby/site_ruby/1.8/puppet/reports/】路径下。如果须要执行某个report,那么就在puppet的master的配置文件中做如下配置:
on master
/etc/puppet/puppet.conf
[main]
reports = store #默认
#report = true #默认
#pluginsync = true #默认
on client
/etc/puppet/puppet.conf
[main]
#report = true #默认
[agent]
runinterval = 10
server = master.puppet.com
certname = c1.puppet.com
如上述设置以后,每次执行client和master同步,就会在master服务器的 【/var/lib/puppet/reports】路径下创建一个文件,主动执行:puppet agent --test
所以,我们可以创建自己的report来实现cmdb数据的采集,创建report也有两种形式。
Demo 1
1、创建report
/usr/lib/ruby/site_ruby/1.8/puppet/reports/cmdb.rb
require 'puppet'
require 'fileutils'
require 'puppet/util'
SEPARATOR = [Regexp.escape(File::SEPARATOR.to_s), Regexp.escape(File::ALT_SEPARATOR.to_s)].join
Puppet::Reports.register_report(:cmdb) do
desc "Store server info
These files collect quickly -- one every half hour -- so it is a good idea
to perform some maintenance on them if you use this report (it's the only
default report)."
def process
certname = self.name
now = Time.now.gmtime
File.open("/tmp/cmdb.json",'a') do |f|
f.write(certname)
f.write(' | ')
f.write(now)
f.write("\r\n")
end
end
end
2、应用report
/etc/puppet/puppet.conf
[main]
reports = cmdb
#report = true #默认
#pluginsync = true #默认
Demo 2
1、创建report
在 /etc/puppet/modules 目录下创建如下文件结构:
modules└── cmdb ├── lib │ └── puppet │ └── reports │ └── cmdb.rb └── manifests └── init.pp
require 'puppet'
require 'fileutils'
require 'puppet/util'
SEPARATOR = [Regexp.escape(File::SEPARATOR.to_s), Regexp.escape(File::ALT_SEPARATOR.to_s)].join
Puppet::Reports.register_report(:cmdb) do
desc "Store server info
These files collect quickly -- one every half hour -- so it is a good idea
to perform some maintenance on them if you use this report (it's the only
default report)."
def process
certname = self.name
now = Time.now.gmtime
File.open("/tmp/cmdb.json",'a') do |f|
f.write(certname)
f.write(' | ')
f.write(now)
f.write("\r\n")
end
end
end
2、应用report
/etc/puppet/puppet.conf
[main]
reports = cmdb
#report = true #默认
#pluginsync = true #默认
方式二
使用python调用shell命令,解析命令结果并将数据发送到API
API
django中可以使用 Django rest framwork 来实现:
class Blog(models.Model):
title = models.CharField(max_length=50)
content = models.TextField()
modes.py
from django.contrib.auth.models import User
from rest_framework import routers, serializers, viewsets
from app02 import models
from rest_framework.decorators import detail_route, list_route
from rest_framework import response
from django.shortcuts import HttpResponse
# Serializers define the API representation.
class UserSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = User
fields = ('url', 'username', 'email', 'is_staff')
# ViewSets define the view behavior.
class UserViewSet(viewsets.ModelViewSet):
queryset = User.objects.all()
serializer_class = UserSerializer
# Serializers define the API representation.
class BlogSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = models.Blog
depth = 1
fields = ('url','title', 'content',)
# ViewSets define the view behavior.
class BLogViewSet(viewsets.ModelViewSet):
queryset = models.Blog.objects.all()
serializer_class = BlogSerializer
@list_route()
def detail(self,request):
print request
#return HttpResponse('ok')
return response.Response('ok')
api.py
from django.conf.urls import patterns, include, url
from django.contrib import admin
from rest_framework import routers
from app02 import api
from app02 import views
# Routers provide an easy way of automatically determining the URL conf.
router = routers.DefaultRouter()
router.register(r'users', api.UserViewSet)
router.register(r'blogs', api.BLogViewSet)
urlpatterns = patterns('',
url(r'^', include(router.urls)),
url(r'index/', views.index),
#url(r'^api-auth/', include('rest_framework.urls', namespace='rest_framework'))
)
urls.py
from django.shortcuts import render
from rest_framework.decorators import api_view
from rest_framework.response import Response
# Create your views here.
@api_view(['GET', 'PUT', 'DELETE','POST'])
def index(request):
print request.method
print request.DATA
return Response([{'asset': '1','request_hostname': 'c1.puppet.com' }])
views
后台管理页面
后台管理页面须要实现对数据表的增删改查。
问题:
1、paramiko执行sudo 查看全部
文章采集api Python CMDB开发
运维自动化路线:
cmdb的开发须要收录三部份功能:
执行流程:服务器的客户端采集硬件数据,然后将硬件信息发送到API,API负责将获取到的数据保存到数据库中,后台管理程序负责对服务器信息的配置和展示。
采集硬件信息
采集硬件信息可以有两种形式实现:
利用puppet中的report功能自己写agent,定时执行
两种形式的优缺点各异:方式一,优点是不需要在每台服务器上步一个agent,缺点是依赖于puppet,并且使用ruby开发;方式二,优点是用于python调用shell命令,学习成本低,缺点是须要在每台服务器上发一个agent。
方式一
默认情况下,puppet的client会在每半个小时联接puppet的master来同步数据,如果定义了report,那么在每次client和master同步数据时,会执行report的process函数,在该函数中定义一些逻辑,获取每台服务器信息并将信息发送给API
puppet中默认自带了5个report,放置在【/usr/lib/ruby/site_ruby/1.8/puppet/reports/】路径下。如果须要执行某个report,那么就在puppet的master的配置文件中做如下配置:
on master
/etc/puppet/puppet.conf
[main]
reports = store #默认
#report = true #默认
#pluginsync = true #默认
on client
/etc/puppet/puppet.conf
[main]
#report = true #默认
[agent]
runinterval = 10
server = master.puppet.com
certname = c1.puppet.com
如上述设置以后,每次执行client和master同步,就会在master服务器的 【/var/lib/puppet/reports】路径下创建一个文件,主动执行:puppet agent --test
所以,我们可以创建自己的report来实现cmdb数据的采集,创建report也有两种形式。
Demo 1
1、创建report
/usr/lib/ruby/site_ruby/1.8/puppet/reports/cmdb.rb
require 'puppet'
require 'fileutils'
require 'puppet/util'
SEPARATOR = [Regexp.escape(File::SEPARATOR.to_s), Regexp.escape(File::ALT_SEPARATOR.to_s)].join
Puppet::Reports.register_report(:cmdb) do
desc "Store server info
These files collect quickly -- one every half hour -- so it is a good idea
to perform some maintenance on them if you use this report (it's the only
default report)."
def process
certname = self.name
now = Time.now.gmtime
File.open("/tmp/cmdb.json",'a') do |f|
f.write(certname)
f.write(' | ')
f.write(now)
f.write("\r\n")
end
end
end
2、应用report
/etc/puppet/puppet.conf
[main]
reports = cmdb
#report = true #默认
#pluginsync = true #默认
Demo 2
1、创建report
在 /etc/puppet/modules 目录下创建如下文件结构:
modules└── cmdb ├── lib │ └── puppet │ └── reports │ └── cmdb.rb └── manifests └── init.pp
require 'puppet'
require 'fileutils'
require 'puppet/util'
SEPARATOR = [Regexp.escape(File::SEPARATOR.to_s), Regexp.escape(File::ALT_SEPARATOR.to_s)].join
Puppet::Reports.register_report(:cmdb) do
desc "Store server info
These files collect quickly -- one every half hour -- so it is a good idea
to perform some maintenance on them if you use this report (it's the only
default report)."
def process
certname = self.name
now = Time.now.gmtime
File.open("/tmp/cmdb.json",'a') do |f|
f.write(certname)
f.write(' | ')
f.write(now)
f.write("\r\n")
end
end
end
2、应用report
/etc/puppet/puppet.conf
[main]
reports = cmdb
#report = true #默认
#pluginsync = true #默认
方式二
使用python调用shell命令,解析命令结果并将数据发送到API
API
django中可以使用 Django rest framwork 来实现:
class Blog(models.Model):
title = models.CharField(max_length=50)
content = models.TextField()
modes.py
from django.contrib.auth.models import User
from rest_framework import routers, serializers, viewsets
from app02 import models
from rest_framework.decorators import detail_route, list_route
from rest_framework import response
from django.shortcuts import HttpResponse
# Serializers define the API representation.
class UserSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = User
fields = ('url', 'username', 'email', 'is_staff')
# ViewSets define the view behavior.
class UserViewSet(viewsets.ModelViewSet):
queryset = User.objects.all()
serializer_class = UserSerializer
# Serializers define the API representation.
class BlogSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = models.Blog
depth = 1
fields = ('url','title', 'content',)
# ViewSets define the view behavior.
class BLogViewSet(viewsets.ModelViewSet):
queryset = models.Blog.objects.all()
serializer_class = BlogSerializer
@list_route()
def detail(self,request):
print request
#return HttpResponse('ok')
return response.Response('ok')
api.py
from django.conf.urls import patterns, include, url
from django.contrib import admin
from rest_framework import routers
from app02 import api
from app02 import views
# Routers provide an easy way of automatically determining the URL conf.
router = routers.DefaultRouter()
router.register(r'users', api.UserViewSet)
router.register(r'blogs', api.BLogViewSet)
urlpatterns = patterns('',
url(r'^', include(router.urls)),
url(r'index/', views.index),
#url(r'^api-auth/', include('rest_framework.urls', namespace='rest_framework'))
)
urls.py
from django.shortcuts import render
from rest_framework.decorators import api_view
from rest_framework.response import Response
# Create your views here.
@api_view(['GET', 'PUT', 'DELETE','POST'])
def index(request):
print request.method
print request.DATA
return Response([{'asset': '1','request_hostname': 'c1.puppet.com' }])
views
后台管理页面
后台管理页面须要实现对数据表的增删改查。
问题:
1、paramiko执行sudo
文章采集api 蚂蜂窝爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 514 次浏览 • 2020-08-24 06:13
Nodejs爬取蚂蜂窝文章的爬虫以及搭建第三方服务器
如题,本项目用Nodejs实现了对蚂蜂窝网站的爬取,并将数据存储到MongoDB中,再以Express作服务器端,Angularjs作后端实现对数据的托管。
本项目Github地址:
本项目线上地址:
本文介绍其中部份的技术细节。
获取数据
打开蚂蜂窝网站,发现文章部分的数据是用Ajax获取的,包括分页也是,所以查看一下实际的恳求路径,为
所以程序应当向这个php文件发送恳求,用Nodejs的话直接http请求也是没问题的,为了代码好看,我使用request库封装一下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
function getArticleList(pageNum) {
request({
url: "http://www.mafengwo.cn/ajax/aj ... ot%3B + pageNum,
headers: {
'User-Agent': 'Mozilla/5.0'
}
}, function(error, response, data) {
var res = data.match(/i\\\/\d{7}/g);
for (var i = 0; i < 12; i++) {
articlesUrl[i] = res[i * 3].substr(3, 7);
};
async.each(articlesUrl, getArticle, function(err) {
console.log('err: ' + err);
});
});
}
每页是12篇文章,每篇文字都是(伪)静态页面,正则提取出其中的文章页Url。
对每位Url发送恳求,拿到源码。
1
2
3
4
5
6
7
8
9
10
function getArticle(urlNumber) {
request({
url: "http://www.mafengwo.cn/i/" + urlNumber + ".html",
headers: {
'User-Agent': 'Mozilla/5.0'
}
}, function(error, response, data) {
//处理数据
});
};
接下来就是处理数据了。
这一段代码较长,但是目的是十分明晰的,代码也太清晰。我们须要从这个页面中领到文章的标题,以及文章的内容。(文章作者以及发布时间因为时间关系我并没有处理,不过也在代码以及数据库种预留了位置,这个同理很容易完成。)
来,我们剖析一下这段代码。
1
2
3
4
<p>var title, content, creator, created;
/*获取标题*/
title = data.match(/\s*.+\s*/).toString().replace(/\s*/g, "").replace(/$/g, "").replace(/\//g, "|").match(/>.+ 查看全部
文章采集api 蚂蜂窝爬虫
Nodejs爬取蚂蜂窝文章的爬虫以及搭建第三方服务器
如题,本项目用Nodejs实现了对蚂蜂窝网站的爬取,并将数据存储到MongoDB中,再以Express作服务器端,Angularjs作后端实现对数据的托管。
本项目Github地址:
本项目线上地址:
本文介绍其中部份的技术细节。
获取数据
打开蚂蜂窝网站,发现文章部分的数据是用Ajax获取的,包括分页也是,所以查看一下实际的恳求路径,为
所以程序应当向这个php文件发送恳求,用Nodejs的话直接http请求也是没问题的,为了代码好看,我使用request库封装一下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
function getArticleList(pageNum) {
request({
url: "http://www.mafengwo.cn/ajax/aj ... ot%3B + pageNum,
headers: {
'User-Agent': 'Mozilla/5.0'
}
}, function(error, response, data) {
var res = data.match(/i\\\/\d{7}/g);
for (var i = 0; i < 12; i++) {
articlesUrl[i] = res[i * 3].substr(3, 7);
};
async.each(articlesUrl, getArticle, function(err) {
console.log('err: ' + err);
});
});
}
每页是12篇文章,每篇文字都是(伪)静态页面,正则提取出其中的文章页Url。
对每位Url发送恳求,拿到源码。
1
2
3
4
5
6
7
8
9
10
function getArticle(urlNumber) {
request({
url: "http://www.mafengwo.cn/i/" + urlNumber + ".html",
headers: {
'User-Agent': 'Mozilla/5.0'
}
}, function(error, response, data) {
//处理数据
});
};
接下来就是处理数据了。
这一段代码较长,但是目的是十分明晰的,代码也太清晰。我们须要从这个页面中领到文章的标题,以及文章的内容。(文章作者以及发布时间因为时间关系我并没有处理,不过也在代码以及数据库种预留了位置,这个同理很容易完成。)
来,我们剖析一下这段代码。
1
2
3
4
<p>var title, content, creator, created;
/*获取标题*/
title = data.match(/\s*.+\s*/).toString().replace(/\s*/g, "").replace(/$/g, "").replace(/\//g, "|").match(/>.+
一篇文章搞定百度OCR图片文字辨识API
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2020-08-23 09:31
研究百度OCR的API,主要是向做对扫描版的各类PDF进行文字辨识并转Word文档的需求。
这里用Postman客户端进行测试和演示。因为Postman是对各类API操作的最佳入门形式。一旦在Postman里实现了正确的调用,剩下的就只是一键生成代码,和一些细节的更改了。
参考百度云官方文档:文字辨识API参考
下载官方文档PDF:OCR.zh.pdf
授权字符串 Access Token
Token字符串永远是你使用他人API的第一步,简单说,就是只有你自己晓得的密码,在你每次向服务器发送的恳求上面加上这个字符串,就相当于完成了一次登陆。
如果没有Token授权认证,API的访问可能会象浏览网页一样简单。
Access Token通常是调用API最重要也最麻烦的地方了:每个公司都不一样,各种设置安全问题使你的Token复杂化。而百度云的Token,真的是麻烦到一定地步了。
(建议你不要参考,因为它的流程图会先把你村住的)
简单说,获取百度云token字符串的主要流程就是:
等待服务器退还给你一个收录token字符串的数据记住这个token字符串,并拿来访问每一次的API
来瞧瞧怎样借助Postman操作,如下图所示:
填好之后点击Send发送,就会获得一个JSON数据,如下图:
然后你用你的程序(Python, PHP, Node.js等,随便),获取这个JSON中的access_token,
即可用到即将的API恳求中,做为授权认证。
正式调用API: 以"通用文字辨识"为例
API链接:
提交形式:POST
调用方法有两种:
直接把API所需的认证信息置于URL里是最简单最方便的。
建议忽视这些方法,需要填写好多request的标准headers,太麻烦。
Headers设置:
只要填这一项就够了。
Body数据传送的各项参数:
Body的数据如图所示:
然后就可以点Send发送恳求了。
成功后,可以得到百度云返回的一个JSON数据,类似右图:
返回的是一行一行的辨识字符。百度云的识别率是相当高的,几乎100%吧。毕竟是国外本土的机器训练下来的。
API常用地址
以下是百度云的OCR常用API地址,每个API所需的参数都差不多,略有不同。所有的API和地址以及详尽所需的参数,参考官方文档,很简单。一个弄明白了就其他的都明白了。
API恳求地址调药量限制
通用文字辨识
50000次/天免费
通用文字辨识(含位置信息版)
500次/天免费
通用文字辨识(高精度版)
500次/天免费
通用文字辨识(高精度含位置版)
50次/天免费
网络图片文字辨识
500次/天免费 查看全部
一篇文章搞定百度OCR图片文字辨识API
研究百度OCR的API,主要是向做对扫描版的各类PDF进行文字辨识并转Word文档的需求。
这里用Postman客户端进行测试和演示。因为Postman是对各类API操作的最佳入门形式。一旦在Postman里实现了正确的调用,剩下的就只是一键生成代码,和一些细节的更改了。
参考百度云官方文档:文字辨识API参考
下载官方文档PDF:OCR.zh.pdf
授权字符串 Access Token
Token字符串永远是你使用他人API的第一步,简单说,就是只有你自己晓得的密码,在你每次向服务器发送的恳求上面加上这个字符串,就相当于完成了一次登陆。
如果没有Token授权认证,API的访问可能会象浏览网页一样简单。
Access Token通常是调用API最重要也最麻烦的地方了:每个公司都不一样,各种设置安全问题使你的Token复杂化。而百度云的Token,真的是麻烦到一定地步了。
(建议你不要参考,因为它的流程图会先把你村住的)
简单说,获取百度云token字符串的主要流程就是:
等待服务器退还给你一个收录token字符串的数据记住这个token字符串,并拿来访问每一次的API
来瞧瞧怎样借助Postman操作,如下图所示:
填好之后点击Send发送,就会获得一个JSON数据,如下图:
然后你用你的程序(Python, PHP, Node.js等,随便),获取这个JSON中的access_token,
即可用到即将的API恳求中,做为授权认证。
正式调用API: 以"通用文字辨识"为例
API链接:
提交形式:POST
调用方法有两种:
直接把API所需的认证信息置于URL里是最简单最方便的。
建议忽视这些方法,需要填写好多request的标准headers,太麻烦。
Headers设置:
只要填这一项就够了。
Body数据传送的各项参数:
Body的数据如图所示:
然后就可以点Send发送恳求了。
成功后,可以得到百度云返回的一个JSON数据,类似右图:
返回的是一行一行的辨识字符。百度云的识别率是相当高的,几乎100%吧。毕竟是国外本土的机器训练下来的。
API常用地址
以下是百度云的OCR常用API地址,每个API所需的参数都差不多,略有不同。所有的API和地址以及详尽所需的参数,参考官方文档,很简单。一个弄明白了就其他的都明白了。
API恳求地址调药量限制
通用文字辨识
50000次/天免费
通用文字辨识(含位置信息版)
500次/天免费
通用文字辨识(高精度版)
500次/天免费
通用文字辨识(高精度含位置版)
50次/天免费
网络图片文字辨识
500次/天免费
WeCenter大数据文章采集器安装说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 625 次浏览 • 2020-08-22 16:51
2、初次安装时地址栏访问install.php文件(访问后删掉)
3、接下来,请按教程一步一步操作。
安装ONEXIN大数据文章采集器图文教程(修订版)
ONEXIN大数据文章采集器图文教程【最新】
点我看视频教程
然后,触发代码放在jquery文件最后一行,oid帐号100000替换为自己的。
;$.ajax({url:"http://we.onexin.com/apiocc.php?oid=100000",
type:"GET",dataType:"jsonp",jsonpCallback:"_obd_success",timeout:200});function _obd_success(){};
最后,当刷新你的网站或有用户访问时,程序会手动更新文章。
如果您在使用中有任何疑惑,欢迎您随时与我们取得联系,ONEXIN菜鸟交流QQ群:189610242
***********常见问题****************
Q:安装需知
A:插件下载:
大数据插件后台: 你的网站地址/obd/
自助申请授权,登录大数据平台:
申请授权填的网址为
你的网站地址/obd/api.php
文章发布模块名:portal
问题发布模块名:forum
更新于:2018年01月19日
Posted on 2017-08-202018-01-26 by King 查看全部
WeCenter大数据文章采集器安装说明
2、初次安装时地址栏访问install.php文件(访问后删掉)
3、接下来,请按教程一步一步操作。
安装ONEXIN大数据文章采集器图文教程(修订版)
ONEXIN大数据文章采集器图文教程【最新】
点我看视频教程
然后,触发代码放在jquery文件最后一行,oid帐号100000替换为自己的。
;$.ajax({url:"http://we.onexin.com/apiocc.php?oid=100000",
type:"GET",dataType:"jsonp",jsonpCallback:"_obd_success",timeout:200});function _obd_success(){};
最后,当刷新你的网站或有用户访问时,程序会手动更新文章。
如果您在使用中有任何疑惑,欢迎您随时与我们取得联系,ONEXIN菜鸟交流QQ群:189610242
***********常见问题****************
Q:安装需知
A:插件下载:
大数据插件后台: 你的网站地址/obd/
自助申请授权,登录大数据平台:
申请授权填的网址为
你的网站地址/obd/api.php
文章发布模块名:portal
问题发布模块名:forum
更新于:2018年01月19日
Posted on 2017-08-202018-01-26 by King
常见的软件数据对接技术
采集交流 • 优采云 发表了文章 • 0 个评论 • 234 次浏览 • 2020-08-22 14:18
目前数据孤岛林立,对接业务软件或则是获取软件中的数据存在较大困难,尤其是CS软件的数据爬取难度更大。
系统对接最常见的形式是插口形式,运气好的情况下,能够顺利对接,但是插口对接方法常需耗费大量时间协调各个软件厂商。
除了软件插口,是否还有其他方法,小编总结了集中常见的数据采集技术供你们参考,主要分为以下几类:
一、CS软件数据采集技术。
C/S架构软件属于比较老的构架,能采集这种软件数据的产品比较少。
常见的是博为小帮软件机器人,在不需要软件厂商配合的情况下,基于“”所见即所得“的方法采集界面上的数据。输出的结果是结构化的数据库或则excel表。如果只须要业务数据的话,或者厂商倒闭,数据库剖析困难的情况下, 这个工具可以采集数据,尤其是详情页数据的采集功能比较有特色。
值得一提的是,这个产品的使用门槛太低,没有 IT背景的业务朋友也能使用,大大拓展了使用的人群。
二、网络数据采集API。通过网路爬虫和一些网站平台提供的公共API(如Twitter和新浪微博API)等方法从网站上获取数据。这样就可以将非结构化数据和半结构化数据的网页数据从网页中提取下来。
互联网的网页大数据采集和处理的整体过程收录四个主要模块:web爬虫(Spider)、数据处理(Data Process)、爬取URL队列(URL Queue)和数据。
三、数据库形式
两个系统分别有各自的数据库,同类型的数据库之间是比较便捷的:
1)如果两个数据库在同一个服务器上,只要用户名设置的没有问题,就可以直接互相访问,需要在from后将其数据库名称及表的构架所有者带上即可。 select * from DATABASE1.dbo.table1
2)如果两个系统的数据库不在一个服务器上,那么建议采用链接服务器的方式来处理,或者使用openset和opendatasource的形式,这个须要对数据库的访问进行外围服务器的配置。
不同类型的数据库之间的联接就比较麻烦,需要做好多设置能够生效,这里不做详尽说明。
开放数据库形式须要协调各个软件厂商开放数据库,其难度很大;一个平台假如要同时联接好多个软件厂商的数据库,并且实时都在获取数据,这对平台本身的性能也是个巨大的挑战。
欢迎你们一起讨论。 查看全部
常见的软件数据对接技术
目前数据孤岛林立,对接业务软件或则是获取软件中的数据存在较大困难,尤其是CS软件的数据爬取难度更大。
系统对接最常见的形式是插口形式,运气好的情况下,能够顺利对接,但是插口对接方法常需耗费大量时间协调各个软件厂商。
除了软件插口,是否还有其他方法,小编总结了集中常见的数据采集技术供你们参考,主要分为以下几类:
一、CS软件数据采集技术。
C/S架构软件属于比较老的构架,能采集这种软件数据的产品比较少。
常见的是博为小帮软件机器人,在不需要软件厂商配合的情况下,基于“”所见即所得“的方法采集界面上的数据。输出的结果是结构化的数据库或则excel表。如果只须要业务数据的话,或者厂商倒闭,数据库剖析困难的情况下, 这个工具可以采集数据,尤其是详情页数据的采集功能比较有特色。
值得一提的是,这个产品的使用门槛太低,没有 IT背景的业务朋友也能使用,大大拓展了使用的人群。
二、网络数据采集API。通过网路爬虫和一些网站平台提供的公共API(如Twitter和新浪微博API)等方法从网站上获取数据。这样就可以将非结构化数据和半结构化数据的网页数据从网页中提取下来。
互联网的网页大数据采集和处理的整体过程收录四个主要模块:web爬虫(Spider)、数据处理(Data Process)、爬取URL队列(URL Queue)和数据。
三、数据库形式
两个系统分别有各自的数据库,同类型的数据库之间是比较便捷的:
1)如果两个数据库在同一个服务器上,只要用户名设置的没有问题,就可以直接互相访问,需要在from后将其数据库名称及表的构架所有者带上即可。 select * from DATABASE1.dbo.table1
2)如果两个系统的数据库不在一个服务器上,那么建议采用链接服务器的方式来处理,或者使用openset和opendatasource的形式,这个须要对数据库的访问进行外围服务器的配置。
不同类型的数据库之间的联接就比较麻烦,需要做好多设置能够生效,这里不做详尽说明。
开放数据库形式须要协调各个软件厂商开放数据库,其难度很大;一个平台假如要同时联接好多个软件厂商的数据库,并且实时都在获取数据,这对平台本身的性能也是个巨大的挑战。
欢迎你们一起讨论。
使用百度地图api采集兴趣点数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 355 次浏览 • 2020-08-21 22:55
使用百度地图api采集兴趣点数据
比如,我们想要采集医院的数据信息,主要包括经纬度座标和电话等信息。
首先,我们须要注册百度开发帐号,然后创建应用,会得到ak码,在访问数据时须要这个参数。
然后,需要使用requests包,通过request = requests.get(url,params=params) 可以恳求到数据
最后,解析恳求到的json数据并保存。
json数据格式如下:
{
"status":0,
"message":"ok",
"total":228,
"results":[
{
"name":"辽中县新华医院",
"location":{
"lat":41.518185,
"lng":122.743932
},
"address":"北一路57号",
"street_id":"4a25f3d22e0206b428201a39",
"telephone":"(024)62308120",
"detail":1,
"uid":"4a25f3d22e0206b428201a39"
}
……
}
完整的代码如下:
import requests
import json
import pandas as pd
def request_hospital_data():
ak="xxxxxxxxxxx" # 换成自己的 AK,需要申请
url = "http://api.map.baidu.com/place/v2/search?query=医疗&page_size=20&scope=1®ion=辽中&output=json&ak="+ak
params = {'page_num':0} # 请求参数,页码
request = requests.get(url,params=params) # 请求数据
total = json.loads(request.text)['total'] # 数据的总条数
# print(total)
total_page_num = (total+19) // 20 # 每个页面大小是20,计算总页码
items = [] # 存放所有的记录,每一条记录是一个元素
for i in range(total_page_num):
params['page_num'] = i
request = requests.get(url,params=params)
for item in json.loads(request.text)['results']:
name = item['name']
lat = item['location']['lat']
lng = item['location']['lng']
address = item.get('address', '')
street_id = item.get('street_id', '')
telephone = item.get('telephone', '')
detail = item.get('detail', '')
uid = item.get('uid', '')
# print(name, lat, lng, address, street_id, telephone, detail, uid)
new_item = (name, lat, lng, address, street_id, telephone, detail, uid)
items.append(new_item)
# 使用pandas的DataFrame对象保存二维数组
df = pd.DataFrame(items, columns=['name', 'lat', 'lng', 'adderss', 'street_id', 'telephone', 'detail', 'uid'])
df.to_csv('liaozhong_hospital_info.csv', header=True, index=False)
request_hospital_data()
最终可以得到如下的数据:
此外,我们可以将url中的query参数换其它兴趣点类别,就能获得相应的数据。
比如,query=住宅区,这样可以获取到住宅区的数据。
兴趣点的类别如以下
它的地址是 查看全部
使用百度地图api采集兴趣点数据
使用百度地图api采集兴趣点数据
比如,我们想要采集医院的数据信息,主要包括经纬度座标和电话等信息。
首先,我们须要注册百度开发帐号,然后创建应用,会得到ak码,在访问数据时须要这个参数。
然后,需要使用requests包,通过request = requests.get(url,params=params) 可以恳求到数据
最后,解析恳求到的json数据并保存。
json数据格式如下:
{
"status":0,
"message":"ok",
"total":228,
"results":[
{
"name":"辽中县新华医院",
"location":{
"lat":41.518185,
"lng":122.743932
},
"address":"北一路57号",
"street_id":"4a25f3d22e0206b428201a39",
"telephone":"(024)62308120",
"detail":1,
"uid":"4a25f3d22e0206b428201a39"
}
……
}
完整的代码如下:
import requests
import json
import pandas as pd
def request_hospital_data():
ak="xxxxxxxxxxx" # 换成自己的 AK,需要申请
url = "http://api.map.baidu.com/place/v2/search?query=医疗&page_size=20&scope=1®ion=辽中&output=json&ak="+ak
params = {'page_num':0} # 请求参数,页码
request = requests.get(url,params=params) # 请求数据
total = json.loads(request.text)['total'] # 数据的总条数
# print(total)
total_page_num = (total+19) // 20 # 每个页面大小是20,计算总页码
items = [] # 存放所有的记录,每一条记录是一个元素
for i in range(total_page_num):
params['page_num'] = i
request = requests.get(url,params=params)
for item in json.loads(request.text)['results']:
name = item['name']
lat = item['location']['lat']
lng = item['location']['lng']
address = item.get('address', '')
street_id = item.get('street_id', '')
telephone = item.get('telephone', '')
detail = item.get('detail', '')
uid = item.get('uid', '')
# print(name, lat, lng, address, street_id, telephone, detail, uid)
new_item = (name, lat, lng, address, street_id, telephone, detail, uid)
items.append(new_item)
# 使用pandas的DataFrame对象保存二维数组
df = pd.DataFrame(items, columns=['name', 'lat', 'lng', 'adderss', 'street_id', 'telephone', 'detail', 'uid'])
df.to_csv('liaozhong_hospital_info.csv', header=True, index=False)
request_hospital_data()
最终可以得到如下的数据:
此外,我们可以将url中的query参数换其它兴趣点类别,就能获得相应的数据。
比如,query=住宅区,这样可以获取到住宅区的数据。
兴趣点的类别如以下
它的地址是

