
文章采集api
文章采集api(修改历史:本工具与2012-09-17发现一个bug且已修正)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-11-16 05:16
[大小=中等]
从2008年开始做网页数据采集,开始使用HTML Parser、NekoHTML、Jericho HTML Parser(用于解析html网页)、HtmlUtil(纯java版本的浏览器,带Http协议和Html解析功能,JS执行功能)等,带HttpClient(提供高效、最新、功能丰富的支持HTTP协议的客户端编程工具包,是一个HTTP协议相关的包,类似于我介绍的 API 中的 HtmlPage 类)。因为那些API采集[color=red]大量的多种格式的网页数据[/color]在配置上非常不灵活,比如DOM解析、Xpath等,导致配置复杂,所以从2009 3 我开始编写自己的 API 来获取和分析网页:网页。服务在公司' s 项目。通过预配置,经过采集10000多个数据源和多种网页数据呈现格式的测试和修正,于2010年9月形成了一个相对稳定的版本。
修改历史:
此工具在 2012-09-17 发现了一个错误,并已更正。今天从新包提交一个版本,之前的源码和jar包版本都会被删除。
1、源码包结构说明:基于com.hlxp.webpage包的启动说明:
(1)com.hlxp.webpage.app与采集的应用相关,可以独立运行,主要是与采集配合使用。
(2)com.hlxp.webpage.bean 采集中使用的一些无状态VO(值对象)
(3)com.hlxp.webpage.log包中收录日志类,主要打包jdk自带的日志对象;以及log4j的日志类。
(4)com.hlxp.webpage.util 包中收录一些特定的 采集 工具,它们使用 HtmlPage 和 HtmlUtil 类来完成特定的 采集,例如只有 采集 链接,或者只是采集img的链接。
(5)HtmlPage类是一个基础类,主要用于通过get和post获取网页,也支持参数的提交。
(6)HtmlUtil类是一个基础类,主要用于解析通过HtmlPage获取的网页,支持正则表达式分析、字符切割、HTML标记分析。
[颜色=红色]注意:[/color]
源码中没有示例程序,示例在每个解析类的main函数中。以后有时间我会写API帮助文档和示例程序。这些将发布在本博客的附件中。
有问题的朋友可以在本博客留言,我会和大家一起讨论。
2.API函数介绍
(1)可以或者普通网页和没有验证码的登录网页(需要登录的网页,需要手动登录,然后将cookie复制到程序中获取)
(2)可以解析HTML、XML、DTD等静态文本显示数据的网页。
(3)可以方便采集翻页,通过设置页面链接格式,自动生成或采集页面链接及其网页。
(4)HtmlPage.java 用于获取网页,HtmlUtil.java 用于解析网页的基本类。两个类的主要方法中有示例。
[/尺寸] 查看全部
文章采集api(修改历史:本工具与2012-09-17发现一个bug且已修正)
[大小=中等]
从2008年开始做网页数据采集,开始使用HTML Parser、NekoHTML、Jericho HTML Parser(用于解析html网页)、HtmlUtil(纯java版本的浏览器,带Http协议和Html解析功能,JS执行功能)等,带HttpClient(提供高效、最新、功能丰富的支持HTTP协议的客户端编程工具包,是一个HTTP协议相关的包,类似于我介绍的 API 中的 HtmlPage 类)。因为那些API采集[color=red]大量的多种格式的网页数据[/color]在配置上非常不灵活,比如DOM解析、Xpath等,导致配置复杂,所以从2009 3 我开始编写自己的 API 来获取和分析网页:网页。服务在公司' s 项目。通过预配置,经过采集10000多个数据源和多种网页数据呈现格式的测试和修正,于2010年9月形成了一个相对稳定的版本。
修改历史:
此工具在 2012-09-17 发现了一个错误,并已更正。今天从新包提交一个版本,之前的源码和jar包版本都会被删除。
1、源码包结构说明:基于com.hlxp.webpage包的启动说明:
(1)com.hlxp.webpage.app与采集的应用相关,可以独立运行,主要是与采集配合使用。
(2)com.hlxp.webpage.bean 采集中使用的一些无状态VO(值对象)
(3)com.hlxp.webpage.log包中收录日志类,主要打包jdk自带的日志对象;以及log4j的日志类。
(4)com.hlxp.webpage.util 包中收录一些特定的 采集 工具,它们使用 HtmlPage 和 HtmlUtil 类来完成特定的 采集,例如只有 采集 链接,或者只是采集img的链接。
(5)HtmlPage类是一个基础类,主要用于通过get和post获取网页,也支持参数的提交。
(6)HtmlUtil类是一个基础类,主要用于解析通过HtmlPage获取的网页,支持正则表达式分析、字符切割、HTML标记分析。
[颜色=红色]注意:[/color]
源码中没有示例程序,示例在每个解析类的main函数中。以后有时间我会写API帮助文档和示例程序。这些将发布在本博客的附件中。
有问题的朋友可以在本博客留言,我会和大家一起讨论。
2.API函数介绍
(1)可以或者普通网页和没有验证码的登录网页(需要登录的网页,需要手动登录,然后将cookie复制到程序中获取)
(2)可以解析HTML、XML、DTD等静态文本显示数据的网页。
(3)可以方便采集翻页,通过设置页面链接格式,自动生成或采集页面链接及其网页。
(4)HtmlPage.java 用于获取网页,HtmlUtil.java 用于解析网页的基本类。两个类的主要方法中有示例。
[/尺寸]
文章采集api(JSP众筹管理系统.5开发java语言设计系统源码特点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-11-15 12:11
一、 源码特点 JSP众筹管理系统是一个完整的网页设计系统,有助于理解JSP java编程语言。系统具有完整的源代码和数据库,系统主要采用B/S模式。发展。 二、功能介绍 前台主要功能:显示项目信息及项目周边相关信息 后台主要功能:(1)权限管理:添加、删除、修改、查看权限信息(2)用户管理:添加、删除、修改、查看用户信息(3)项目分类管理:添加、删除、修改、查看项目分类信息(4)项目管理:添加项目信息),删除、修改和查看(5)日志管理:添加、删除、修改和查看日志信息(6)项目支持管理:添加、删除、修改和查看项目支持信息(7)Project审核管理:添加、删除、修改和查看项目审核信息(8)报告管理:添加、删除、修改和查看报告信息(9)消息管理:对消息信息的添加、删除、修改和查看(8) 招生管理:添加、删除、修改和查看招生信息编队三、注意事项1、管理员账号:admin 密码:admin 数据库配置文件DBO.java2、开发环境为TOMCAT7.0,Myeclipse8.5,数据库为mysql,使用java语言开发。3、数据库文件名为jspfgongchou .mysql,系统名gongchou4、地址:xiangmu.jsp 查看全部
文章采集api(JSP众筹管理系统.5开发java语言设计系统源码特点)
一、 源码特点 JSP众筹管理系统是一个完整的网页设计系统,有助于理解JSP java编程语言。系统具有完整的源代码和数据库,系统主要采用B/S模式。发展。 二、功能介绍 前台主要功能:显示项目信息及项目周边相关信息 后台主要功能:(1)权限管理:添加、删除、修改、查看权限信息(2)用户管理:添加、删除、修改、查看用户信息(3)项目分类管理:添加、删除、修改、查看项目分类信息(4)项目管理:添加项目信息),删除、修改和查看(5)日志管理:添加、删除、修改和查看日志信息(6)项目支持管理:添加、删除、修改和查看项目支持信息(7)Project审核管理:添加、删除、修改和查看项目审核信息(8)报告管理:添加、删除、修改和查看报告信息(9)消息管理:对消息信息的添加、删除、修改和查看(8) 招生管理:添加、删除、修改和查看招生信息编队三、注意事项1、管理员账号:admin 密码:admin 数据库配置文件DBO.java2、开发环境为TOMCAT7.0,Myeclipse8.5,数据库为mysql,使用java语言开发。3、数据库文件名为jspfgongchou .mysql,系统名gongchou4、地址:xiangmu.jsp
文章采集api(MetricsAPI介绍Metrics-Server之前,必须要提一下API的概念)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-11-12 11:22
概述
从v1.8开始,可以通过Metrics API的形式获取资源使用监控。具体的组件是Metrics Server,用来替代之前的heapster。heapster 从 1.11 开始逐渐被废弃。
Metrics-Server 是集群核心监控数据的聚合器。从Kubernetes1.8开始,在kube-up.sh脚本创建的集群中默认部署为Deployment对象。如果是其他部署方式,则需要单独安装。, 或者咨询相应的云厂商。
指标 API
在介绍 Metrics-Server 之前,不得不提一下 Metrics API 的概念
与之前的监控采集方法(hepaster)相比,Metrics API是一个全新的思路。官方希望核心指标的监控稳定,版本可控,用户可以直接访问(比如使用kubectl top命令),或者集群中的控制器(比如HPA)使用,就像其他Kubernetes一样蜜蜂。
官方放弃heapster项目,是将核心资源监控当成一等公民,即通过api-server或client直接访问,如pod和service,而不是安装一个heapster,由heapster单独采集和管理。
假设我们为每个pod和节点采集10个指标,从k8s的1.6开始,支持5000个节点和每个节点30个pod,假设采集的粒度为每分钟一次,那么:
10 x 5000 x 30 / 60 = 25000 平均每分钟2万多个采集指标
因为k8s的api-server将所有数据持久化在etcd中,显然k8s本身无法处理采集的这种频率,而且这种监控数据变化很快,而且是临时数据,所以需要单独的组件来处理,k8s版本只是部分存储在内存中,因此metric-server的概念诞生了。
其实Hepaster已经暴露了API,但是Kubernetes的用户和其他组件必须通过master代理访问,而且Hepaster的接口不像api-server那样有完整的认证和客户端集成。这个api还在alpha阶段(8月18日),希望能达到GA阶段。以 api-server 风格编写:通用 apiserver
有了Metrics Server组件,采集已经到达需要的数据,暴露了api,但是因为api需要统一,如何将请求转发到api-server /apis/metrics请求到Metrics Server ? 解决方案即:kube-aggregator,在k8s的1.7中已经完成。Metrics Server 之前没有发布,在 kube-aggregator 的步骤中延迟了。
kube-aggregator(聚合api)主要提供:
详细设计文档:参考链接
metric api的使用:
喜欢:
http://127.0.0.1:8001/apis/met ... nodes
http://127.0.0.1:8001/apis/met ... odes/
http://127.0.0.1:8001/apis/met ... pods/
度量服务器
Metrics 服务器定期从 Kubelet 的 Summary API(类似于 /ap1/v1/nodes/nodename/stats/summary)获取指标信息采集。这些聚合后的数据会存储在内存中,并以metric-api的形式暴露出去。
Metrics server复用api-server库来实现自己的功能,比如认证、版本等,为了将数据存储在内存中,去掉默认的etcd存储,引入内存存储(即实现Storage接口)。因为是存储在内存中,所以监控数据不是持久化的,可以通过第三方存储进行扩展,与heapster一致。
Metrics服务器出现后,新的Kubernetes监控架构将如上图所示
官方地址:
用
如上所述,metric-server是一个扩展的apiserver,依赖kube-aggregator,所以需要在apiserver中开启相关参数。
--requestheader-client-ca-file=/etc/kubernetes/certs/proxy-ca.crt
--proxy-client-cert-file=/etc/kubernetes/certs/proxy.crt
--proxy-client-key-file=/etc/kubernetes/certs/proxy.key
--requestheader-allowed-names=aggregator
--requestheader-extra-headers-prefix=X-Remote-Extra-
--requestheader-group-headers=X-Remote-Group
--requestheader-username-headers=X-Remote-User
安装文件下载地址:1.8+,注意修改镜像地址为国内镜像
kubectl create -f metric-server/
安装成功后访问地址api地址为:
Metrics Server 的资源消耗会随着集群中 Pod 数量的不断增长而不断上升,因此需要
插件调整器垂直缩放这个容器。addon-resizer 根据集群中的节点数对 Metrics Server 进行线性扩展,以确保其能够提供完整的指标 API 服务。具体参考:链接
其他
基于 Metrics Server 的 HPA:参考链接
在kubernetes新的监控系统中,metrics-server属于Core metrics,提供API metrics.k8s.io,只提供Node和Pod的CPU和内存使用情况。Other Custom Metrics(自定义指标)由Prometheus等组件完成,后续文章会对自定义指标进行分析。
本文为容器监控实践系列文章,完整内容请看:container-monitor-book 查看全部
文章采集api(MetricsAPI介绍Metrics-Server之前,必须要提一下API的概念)
概述
从v1.8开始,可以通过Metrics API的形式获取资源使用监控。具体的组件是Metrics Server,用来替代之前的heapster。heapster 从 1.11 开始逐渐被废弃。
Metrics-Server 是集群核心监控数据的聚合器。从Kubernetes1.8开始,在kube-up.sh脚本创建的集群中默认部署为Deployment对象。如果是其他部署方式,则需要单独安装。, 或者咨询相应的云厂商。
指标 API
在介绍 Metrics-Server 之前,不得不提一下 Metrics API 的概念
与之前的监控采集方法(hepaster)相比,Metrics API是一个全新的思路。官方希望核心指标的监控稳定,版本可控,用户可以直接访问(比如使用kubectl top命令),或者集群中的控制器(比如HPA)使用,就像其他Kubernetes一样蜜蜂。
官方放弃heapster项目,是将核心资源监控当成一等公民,即通过api-server或client直接访问,如pod和service,而不是安装一个heapster,由heapster单独采集和管理。
假设我们为每个pod和节点采集10个指标,从k8s的1.6开始,支持5000个节点和每个节点30个pod,假设采集的粒度为每分钟一次,那么:
10 x 5000 x 30 / 60 = 25000 平均每分钟2万多个采集指标
因为k8s的api-server将所有数据持久化在etcd中,显然k8s本身无法处理采集的这种频率,而且这种监控数据变化很快,而且是临时数据,所以需要单独的组件来处理,k8s版本只是部分存储在内存中,因此metric-server的概念诞生了。
其实Hepaster已经暴露了API,但是Kubernetes的用户和其他组件必须通过master代理访问,而且Hepaster的接口不像api-server那样有完整的认证和客户端集成。这个api还在alpha阶段(8月18日),希望能达到GA阶段。以 api-server 风格编写:通用 apiserver
有了Metrics Server组件,采集已经到达需要的数据,暴露了api,但是因为api需要统一,如何将请求转发到api-server /apis/metrics请求到Metrics Server ? 解决方案即:kube-aggregator,在k8s的1.7中已经完成。Metrics Server 之前没有发布,在 kube-aggregator 的步骤中延迟了。
kube-aggregator(聚合api)主要提供:
详细设计文档:参考链接
metric api的使用:
喜欢:
http://127.0.0.1:8001/apis/met ... nodes
http://127.0.0.1:8001/apis/met ... odes/
http://127.0.0.1:8001/apis/met ... pods/
度量服务器
Metrics 服务器定期从 Kubelet 的 Summary API(类似于 /ap1/v1/nodes/nodename/stats/summary)获取指标信息采集。这些聚合后的数据会存储在内存中,并以metric-api的形式暴露出去。
Metrics server复用api-server库来实现自己的功能,比如认证、版本等,为了将数据存储在内存中,去掉默认的etcd存储,引入内存存储(即实现Storage接口)。因为是存储在内存中,所以监控数据不是持久化的,可以通过第三方存储进行扩展,与heapster一致。

Metrics服务器出现后,新的Kubernetes监控架构将如上图所示
官方地址:
用
如上所述,metric-server是一个扩展的apiserver,依赖kube-aggregator,所以需要在apiserver中开启相关参数。
--requestheader-client-ca-file=/etc/kubernetes/certs/proxy-ca.crt
--proxy-client-cert-file=/etc/kubernetes/certs/proxy.crt
--proxy-client-key-file=/etc/kubernetes/certs/proxy.key
--requestheader-allowed-names=aggregator
--requestheader-extra-headers-prefix=X-Remote-Extra-
--requestheader-group-headers=X-Remote-Group
--requestheader-username-headers=X-Remote-User
安装文件下载地址:1.8+,注意修改镜像地址为国内镜像
kubectl create -f metric-server/

安装成功后访问地址api地址为:

Metrics Server 的资源消耗会随着集群中 Pod 数量的不断增长而不断上升,因此需要
插件调整器垂直缩放这个容器。addon-resizer 根据集群中的节点数对 Metrics Server 进行线性扩展,以确保其能够提供完整的指标 API 服务。具体参考:链接
其他
基于 Metrics Server 的 HPA:参考链接
在kubernetes新的监控系统中,metrics-server属于Core metrics,提供API metrics.k8s.io,只提供Node和Pod的CPU和内存使用情况。Other Custom Metrics(自定义指标)由Prometheus等组件完成,后续文章会对自定义指标进行分析。
本文为容器监控实践系列文章,完整内容请看:container-monitor-book
文章采集api(创建LoggingAdmin项目ApiBootLogging项目依赖使用创建项目idea)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-11-09 19:03
通过 ApiBoot Logging 可以获得每个请求的详细信息。在分布式部署模式下,一个请求可能经过多个服务。如果每个服务独立保存请求日志信息,我们无法实现统一控制。, 并且会出现日志数据库和业务数据库不一致的情况(可能会使用多个数据源配置)。正是因为这个问题,ApiBoot Logging 提供了Admin的概念。一条日志上报给Admin,由Admin进行分析、存储等操作。
创建日志管理项目
由于ApiBoot Logging Admin可以汇总各个业务服务的请求日志(ApiBoot Logging),我们需要将各个业务服务的日志采集上报给Admin,所以我们应该使用独立的方式进行部署。创建一个服务,专门请求日志并保存。
初始化 Logging Admin 项目依赖项
使用idea创建一个SpringBoot项目,pom.xml配置文件中的依赖如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
org.springframework.boot
spring-boot-starter-web
org.minbox.framework
api-boot-starter-logging-admin
mysql
mysql-connector-java
com.zaxxer
HikariCP
org.minbox.framework
api-boot-starter-mybatis-enhance
我们需要将采集收到的请求日志保存到数据库中,所以需要在项目中添加数据库驱动和数据库连接池相关的依赖。ApiBoot Logging Admin 使用DataSource 通过ApiBoot MyBatis Enhance 的依赖来操作数据。自动创建DataSource,摆脱手动创建,加入Spring IOC容器。
添加 ApiBoot 统一版本依赖
1
2
3
4
5
6
7
8
9
10
11
12
org.minbox.framework
api-boot-dependencies
2.1.4.RELEASE
import
pom
最新版本的ApiBoot请访问::api-boot-dependencies查询。
启用日志管理
添加ApiBoot Logging Admin依赖后,无法完全使用Admin功能。我们需要通过@EnableLoggingAdmin 注释来启用它。这个注解会自动将Logging Admin中需要的一些类注册到Spring IOC,并在入口类中添加注解如下:
1
2
3
4
5
6
7
8
9
10
11
12
/**
* ApiBoot Logging Admin入口类
*/
@SpringBootApplication
@EnableLoggingAdmin
public class ApibootReportLogsByLoggingToAdminApplication {
public static void main(String[] args) {
SpringApplication.run(ApibootReportLogsByLoggingToAdminApplication.class, args);
}
}
配置日志数据源
application.yml配置文件中的数据源配置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# 服务名称
spring:
application:
name: apiboot-report-logs-by-logging-to-admin
# 数据源相关配置
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test
username: root
password: 123456
type: com.zaxxer.hikari.HikariDataSource
# 服务端口号
server:
port: 8081
控制台打印并报告日志
ApiBoot Logging Admin可以通过配置文件控制是否在控制台打印来自采集的请求日志信息,并在application.yml配置文件中添加如下内容:
1
2
3
4
5
6
7
api:
boot:
logging:
# Logging Admin相关配置
admin:
# 控制台显示采集的日志信息
show-console-report-log: true
注意:这不应与 ApiBoot Logging 提供的 api.boot.logging.show-console-log 配置混淆。
美化控制台打印的报告日志
1
2
3
4
5
6
7
api:
boot:
logging:
# Logging Admin相关配置
admin:
# 控制台输出时美化采集到的日志
format-console-log-json: true
注意:不要与这里的 api.boot.logging.format-console-log-json 配置混淆。
初始化日志表结构
ApiBoot Logging Admin 使用固定的表结构来存储请求日志和服务信息。建表语句如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
SET NAMES utf8mb4 ;
--
-- Table structure for table `logging_request_logs`
--
CREATE TABLE `logging_request_logs` (
`lrl_id` varchar(36) COLLATE utf8mb4_general_ci NOT NULL COMMENT '主键,UUID',
`lrl_service_detail_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '服务详情编号,关联logging_service_details主键',
`lrl_trace_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '链路ID',
`lrl_parent_span_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上级跨度ID',
`lrl_span_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '跨度ID',
`lrl_start_time` mediumtext COLLATE utf8mb4_general_ci COMMENT '请求开始时间',
`lrl_end_time` mediumtext COLLATE utf8mb4_general_ci COMMENT '请求结束时间',
`lrl_http_status` int(11) DEFAULT NULL COMMENT '请求响应状态码',
`lrl_request_body` longtext COLLATE utf8mb4_general_ci COMMENT '请求主体内容',
`lrl_request_headers` text COLLATE utf8mb4_general_ci COMMENT '请求头信息',
`lrl_request_ip` varchar(30) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '发起请求客户端的IP地址',
`lrl_request_method` varchar(10) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '请求方式',
`lrl_request_uri` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '请求路径',
`lrl_response_body` longtext COLLATE utf8mb4_general_ci COMMENT '响应内容',
`lrl_response_headers` text COLLATE utf8mb4_general_ci COMMENT '响应头信息',
`lrl_time_consuming` int(11) DEFAULT NULL COMMENT '请求耗时',
`lrl_create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '日志保存时间',
`lrl_request_params` text COLLATE utf8mb4_general_ci,
`lrl_exception_stack` text COLLATE utf8mb4_general_ci,
PRIMARY KEY (`lrl_id`),
KEY `logging_request_logs_LRL_SERVICE_DETAIL_ID_index` (`lrl_service_detail_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='请求日志信息表';
--
-- Table structure for table `logging_service_details`
--
CREATE TABLE `logging_service_details` (
`lsd_id` varchar(36) COLLATE utf8mb4_general_ci NOT NULL,
`lsd_service_id` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上报服务的ID,对应spring.application.name配置值',
`lsd_service_ip` varchar(50) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上报服务的IP地址',
`lsd_service_port` int(11) DEFAULT NULL COMMENT '上报服务的端口号',
`lsd_last_report_time` timestamp NULL DEFAULT NULL COMMENT '最后一次上报时间,每次上报更新',
`lsd_create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '首次上报时创建时间',
PRIMARY KEY (`lsd_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='上报日志的客户端服务详情';
到目前为止,ApiBoot Logging Admin 已经准备好了。接下来,我们需要修改业务服务,将请求日志上报给 Logging Admin。
向指定的日志管理员报告日志
我们将修改使用ApiBoot Logging统一管理请求日志文章的源码,并将Logging Admin的地址添加到application.yml中,如下图:
1
2
3
4
5
6
7
api:
boot:
# ApiBoot Logging 日志组件配置
logging:
# 配置Logging Admin地址
admin:
server-address: 127.0.0.1:8081
api.boot.logging.admin-service-address 的配置格式为:Ip:Port,我们只需要修改这一处,其他的所有任务内部交给ApiBoot Logging。
测试
我们以Application的形式启动ApiBoot Logging Admin和业务服务。
使用 curl 访问测试地址如下:
1
2
~ curl http://localhost:8080/test\?name\=admin
你好:admin
我们检查 ApiBoot Logging 管理控制台日志如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
Receiving Service: 【apiboot-unified-manage-request-logs -> 127.0.0.1】, Request Log Report,Logging Content:[
{
"endTime":1571641723779,
"httpStatus":200,
"requestBody":"",
"requestHeaders":{
"server-region":"JiNan",
"host":"localhost:8080",
"user-agent":"curl/7.64.1",
"accept":"*/*"
},
"requestIp":"0:0:0:0:0:0:0:1",
"requestMethod":"GET",
"requestParam":"{\"name\":\"admin\"}",
"requestUri":"/test",
"responseBody":"你好:admin",
"responseHeaders":{},
"serviceId":"apiboot-unified-manage-request-logs",
"serviceIp":"127.0.0.1",
"servicePort":"8080",
"spanId":"95a73ca0-831b-45df-aa43-2b5887e8d98d",
"startTime":1571641723776,
"timeConsuming":3,
"traceId":"25a7de96-b3dd-48e5-9854-1a8069a4a681"
}
]
我们已经看到Logging Admin控制台打印的报告请求日志,并不确定这个请求的日志是否已经保存到数据库中。接下来我使用命令行查看数据库的日志信息。
查看 logging_service_details 表中的数据
1
2
3
4
5
6
7
8
mysql> select * from logging_service_details\G;
*************************** 1. row ***************************
lsd_id: b069366a-25dc-41ec-8f09-242d81755cd0
lsd_service_id: apiboot-unified-manage-request-logs
lsd_service_ip: 10.180.98.112
lsd_service_port: 8080
lsd_last_report_time: 2019-10-21 02:14:26
lsd_create_time: 2019-10-21 15:14:26
logging_service_details 存储了每个上报请求日志的业务服务的基本信息。每个服务的基本信息都会缓存在Logging Admin内存中,方便获取service_id用于存储日志。唯一性根据ip+port+service_id确定,同一个service只保存一次。
查看 logging_request_logs 表中的数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
mysql> select * from logging_request_logs\G;
*************************** 1. row ***************************
lrl_id: c42761f6-b072-4744-8a17-d8e6097b85de
lrl_service_detail_id: b069366a-25dc-41ec-8f09-242d81755cd0
lrl_trace_id: 055329a0-cfc1-4606-baf0-4fb0cc905ba2
lrl_parent_span_id: NULL
lrl_span_id: aab83092-7749-4f88-8cb6-a949cc060197
lrl_start_time: 1571642065262
lrl_end_time: 1571642065286
lrl_http_status: 200
lrl_request_body:
lrl_request_headers: {"server-region":"JiNan","host":"localhost:8080","user-agent":"curl/7.64.1","accept":"*/*"}
lrl_request_ip: 0:0:0:0:0:0:0:1
lrl_request_method: GET
lrl_request_uri: /test
lrl_response_body: 你好:admin
lrl_response_headers: {}
lrl_time_consuming: 24
lrl_create_time: 2019-10-21 15:14:26
lrl_request_params: {"name":"admin"}
lrl_exception_stack: NULL
敲黑板画重点
本章我们集成了ApiBoot Logging Admin,将业务服务的每一个请求日志上报给Logging Admin,通过数据库保存请求日志,然后使用其他方法,可以通过spanId和traceId查看每一项的日志-从属关系请求链路和每个请求中消耗时间最多的跨度可以准确优化服务性能。
代码示例
如果你喜欢这篇文章文章,请为源码仓库点个Star,谢谢!!!
本文章示例源码可以通过以下方式获取,目录为apiboot-report-logs-by-logging-to-admin:
本文由恒宇少年-于启宇撰写,遵循CC4.0BY-SA版权协议。转载请注明文章出处。公众号转载请联系“微信” 查看全部
文章采集api(创建LoggingAdmin项目ApiBootLogging项目依赖使用创建项目idea)
通过 ApiBoot Logging 可以获得每个请求的详细信息。在分布式部署模式下,一个请求可能经过多个服务。如果每个服务独立保存请求日志信息,我们无法实现统一控制。, 并且会出现日志数据库和业务数据库不一致的情况(可能会使用多个数据源配置)。正是因为这个问题,ApiBoot Logging 提供了Admin的概念。一条日志上报给Admin,由Admin进行分析、存储等操作。
创建日志管理项目
由于ApiBoot Logging Admin可以汇总各个业务服务的请求日志(ApiBoot Logging),我们需要将各个业务服务的日志采集上报给Admin,所以我们应该使用独立的方式进行部署。创建一个服务,专门请求日志并保存。
初始化 Logging Admin 项目依赖项
使用idea创建一个SpringBoot项目,pom.xml配置文件中的依赖如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
org.springframework.boot
spring-boot-starter-web
org.minbox.framework
api-boot-starter-logging-admin
mysql
mysql-connector-java
com.zaxxer
HikariCP
org.minbox.framework
api-boot-starter-mybatis-enhance
我们需要将采集收到的请求日志保存到数据库中,所以需要在项目中添加数据库驱动和数据库连接池相关的依赖。ApiBoot Logging Admin 使用DataSource 通过ApiBoot MyBatis Enhance 的依赖来操作数据。自动创建DataSource,摆脱手动创建,加入Spring IOC容器。
添加 ApiBoot 统一版本依赖
1
2
3
4
5
6
7
8
9
10
11
12
org.minbox.framework
api-boot-dependencies
2.1.4.RELEASE
import
pom
最新版本的ApiBoot请访问::api-boot-dependencies查询。
启用日志管理
添加ApiBoot Logging Admin依赖后,无法完全使用Admin功能。我们需要通过@EnableLoggingAdmin 注释来启用它。这个注解会自动将Logging Admin中需要的一些类注册到Spring IOC,并在入口类中添加注解如下:
1
2
3
4
5
6
7
8
9
10
11
12
/**
* ApiBoot Logging Admin入口类
*/
@SpringBootApplication
@EnableLoggingAdmin
public class ApibootReportLogsByLoggingToAdminApplication {
public static void main(String[] args) {
SpringApplication.run(ApibootReportLogsByLoggingToAdminApplication.class, args);
}
}
配置日志数据源
application.yml配置文件中的数据源配置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# 服务名称
spring:
application:
name: apiboot-report-logs-by-logging-to-admin
# 数据源相关配置
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test
username: root
password: 123456
type: com.zaxxer.hikari.HikariDataSource
# 服务端口号
server:
port: 8081
控制台打印并报告日志
ApiBoot Logging Admin可以通过配置文件控制是否在控制台打印来自采集的请求日志信息,并在application.yml配置文件中添加如下内容:
1
2
3
4
5
6
7
api:
boot:
logging:
# Logging Admin相关配置
admin:
# 控制台显示采集的日志信息
show-console-report-log: true
注意:这不应与 ApiBoot Logging 提供的 api.boot.logging.show-console-log 配置混淆。
美化控制台打印的报告日志
1
2
3
4
5
6
7
api:
boot:
logging:
# Logging Admin相关配置
admin:
# 控制台输出时美化采集到的日志
format-console-log-json: true
注意:不要与这里的 api.boot.logging.format-console-log-json 配置混淆。
初始化日志表结构
ApiBoot Logging Admin 使用固定的表结构来存储请求日志和服务信息。建表语句如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
SET NAMES utf8mb4 ;
--
-- Table structure for table `logging_request_logs`
--
CREATE TABLE `logging_request_logs` (
`lrl_id` varchar(36) COLLATE utf8mb4_general_ci NOT NULL COMMENT '主键,UUID',
`lrl_service_detail_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '服务详情编号,关联logging_service_details主键',
`lrl_trace_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '链路ID',
`lrl_parent_span_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上级跨度ID',
`lrl_span_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '跨度ID',
`lrl_start_time` mediumtext COLLATE utf8mb4_general_ci COMMENT '请求开始时间',
`lrl_end_time` mediumtext COLLATE utf8mb4_general_ci COMMENT '请求结束时间',
`lrl_http_status` int(11) DEFAULT NULL COMMENT '请求响应状态码',
`lrl_request_body` longtext COLLATE utf8mb4_general_ci COMMENT '请求主体内容',
`lrl_request_headers` text COLLATE utf8mb4_general_ci COMMENT '请求头信息',
`lrl_request_ip` varchar(30) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '发起请求客户端的IP地址',
`lrl_request_method` varchar(10) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '请求方式',
`lrl_request_uri` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '请求路径',
`lrl_response_body` longtext COLLATE utf8mb4_general_ci COMMENT '响应内容',
`lrl_response_headers` text COLLATE utf8mb4_general_ci COMMENT '响应头信息',
`lrl_time_consuming` int(11) DEFAULT NULL COMMENT '请求耗时',
`lrl_create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '日志保存时间',
`lrl_request_params` text COLLATE utf8mb4_general_ci,
`lrl_exception_stack` text COLLATE utf8mb4_general_ci,
PRIMARY KEY (`lrl_id`),
KEY `logging_request_logs_LRL_SERVICE_DETAIL_ID_index` (`lrl_service_detail_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='请求日志信息表';
--
-- Table structure for table `logging_service_details`
--
CREATE TABLE `logging_service_details` (
`lsd_id` varchar(36) COLLATE utf8mb4_general_ci NOT NULL,
`lsd_service_id` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上报服务的ID,对应spring.application.name配置值',
`lsd_service_ip` varchar(50) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上报服务的IP地址',
`lsd_service_port` int(11) DEFAULT NULL COMMENT '上报服务的端口号',
`lsd_last_report_time` timestamp NULL DEFAULT NULL COMMENT '最后一次上报时间,每次上报更新',
`lsd_create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '首次上报时创建时间',
PRIMARY KEY (`lsd_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='上报日志的客户端服务详情';
到目前为止,ApiBoot Logging Admin 已经准备好了。接下来,我们需要修改业务服务,将请求日志上报给 Logging Admin。
向指定的日志管理员报告日志
我们将修改使用ApiBoot Logging统一管理请求日志文章的源码,并将Logging Admin的地址添加到application.yml中,如下图:
1
2
3
4
5
6
7
api:
boot:
# ApiBoot Logging 日志组件配置
logging:
# 配置Logging Admin地址
admin:
server-address: 127.0.0.1:8081
api.boot.logging.admin-service-address 的配置格式为:Ip:Port,我们只需要修改这一处,其他的所有任务内部交给ApiBoot Logging。
测试
我们以Application的形式启动ApiBoot Logging Admin和业务服务。
使用 curl 访问测试地址如下:
1
2
~ curl http://localhost:8080/test\?name\=admin
你好:admin
我们检查 ApiBoot Logging 管理控制台日志如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
Receiving Service: 【apiboot-unified-manage-request-logs -> 127.0.0.1】, Request Log Report,Logging Content:[
{
"endTime":1571641723779,
"httpStatus":200,
"requestBody":"",
"requestHeaders":{
"server-region":"JiNan",
"host":"localhost:8080",
"user-agent":"curl/7.64.1",
"accept":"*/*"
},
"requestIp":"0:0:0:0:0:0:0:1",
"requestMethod":"GET",
"requestParam":"{\"name\":\"admin\"}",
"requestUri":"/test",
"responseBody":"你好:admin",
"responseHeaders":{},
"serviceId":"apiboot-unified-manage-request-logs",
"serviceIp":"127.0.0.1",
"servicePort":"8080",
"spanId":"95a73ca0-831b-45df-aa43-2b5887e8d98d",
"startTime":1571641723776,
"timeConsuming":3,
"traceId":"25a7de96-b3dd-48e5-9854-1a8069a4a681"
}
]
我们已经看到Logging Admin控制台打印的报告请求日志,并不确定这个请求的日志是否已经保存到数据库中。接下来我使用命令行查看数据库的日志信息。
查看 logging_service_details 表中的数据
1
2
3
4
5
6
7
8
mysql> select * from logging_service_details\G;
*************************** 1. row ***************************
lsd_id: b069366a-25dc-41ec-8f09-242d81755cd0
lsd_service_id: apiboot-unified-manage-request-logs
lsd_service_ip: 10.180.98.112
lsd_service_port: 8080
lsd_last_report_time: 2019-10-21 02:14:26
lsd_create_time: 2019-10-21 15:14:26
logging_service_details 存储了每个上报请求日志的业务服务的基本信息。每个服务的基本信息都会缓存在Logging Admin内存中,方便获取service_id用于存储日志。唯一性根据ip+port+service_id确定,同一个service只保存一次。
查看 logging_request_logs 表中的数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
mysql> select * from logging_request_logs\G;
*************************** 1. row ***************************
lrl_id: c42761f6-b072-4744-8a17-d8e6097b85de
lrl_service_detail_id: b069366a-25dc-41ec-8f09-242d81755cd0
lrl_trace_id: 055329a0-cfc1-4606-baf0-4fb0cc905ba2
lrl_parent_span_id: NULL
lrl_span_id: aab83092-7749-4f88-8cb6-a949cc060197
lrl_start_time: 1571642065262
lrl_end_time: 1571642065286
lrl_http_status: 200
lrl_request_body:
lrl_request_headers: {"server-region":"JiNan","host":"localhost:8080","user-agent":"curl/7.64.1","accept":"*/*"}
lrl_request_ip: 0:0:0:0:0:0:0:1
lrl_request_method: GET
lrl_request_uri: /test
lrl_response_body: 你好:admin
lrl_response_headers: {}
lrl_time_consuming: 24
lrl_create_time: 2019-10-21 15:14:26
lrl_request_params: {"name":"admin"}
lrl_exception_stack: NULL
敲黑板画重点
本章我们集成了ApiBoot Logging Admin,将业务服务的每一个请求日志上报给Logging Admin,通过数据库保存请求日志,然后使用其他方法,可以通过spanId和traceId查看每一项的日志-从属关系请求链路和每个请求中消耗时间最多的跨度可以准确优化服务性能。
代码示例
如果你喜欢这篇文章文章,请为源码仓库点个Star,谢谢!!!
本文章示例源码可以通过以下方式获取,目录为apiboot-report-logs-by-logging-to-admin:
本文由恒宇少年-于启宇撰写,遵循CC4.0BY-SA版权协议。转载请注明文章出处。公众号转载请联系“微信”
文章采集api(基于API的微博信息采集系统设计与实现(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-11-09 19:02
基于API的微博信息采集系统设计与实现小结:微博已经成为网络信息的重要来源。本文分析了微博信息采集的相关方法和技术,提出了基于API的信息采集方法,进而设计了一个能够采集相关信息的信息采集系统在新浪微博上。实验测试表明,信息采集系统可以快速有效地采集新浪微博信息。关键词:新浪微博;微博界面;资料采集; C#语言中文图书馆分类号:TP315 文档识别码:A 文章 编号:1009-3044(2013)17-4005-04 微博[1],微博的简称,是一个信息共享平台, 基于用户关系的传播和获取。用户可以使用140字的WEB、WAP和各种客户端组件的个人社区左右文字更新信息,实现即时分享。中国互联网络信息中心《第31次中国互联网络发展状况统计报告》显示,截至2012年12月末,截至2012年12月末,中国微博用户数为3.09亿,比2011年末增加5873万,网民中微博用户占比比上年末提高6个百分点,达到54.7%[2]。随着微博网络的影响力的迅速扩张,政府部门、学校、知名企业、公众人物都开通了微博。在公众的参与下,微博已经成为一个强大的虚拟社会。微博已成为网络信息的重要来源。如何快速有效地使用采集微博信息已成为一项具有重要应用价值的研究。
1 研究方法和技术路线 国内微博用户以新浪微博为主,本文拟以新浪微博为例,设计研究方法和技术路线。通过对国内外科技文献和实际应用案例的分析,目前新浪微博的信息采集方法主要分为两类:一类是“模拟登录”、“网络爬虫”[3] ],以及“网页内容”“分析”[4]信息采集三种技术相结合的方法。二是基于新浪微博开放平台的API文档。开发者自己编写程序调用微博的API进行微博信息采集。对于第一种方法,难度比较高,研究技术复杂,尤其是“模拟登录”这一步。需要随时跟踪新浪微博的登录加密算法。新浪微博登录加密算法的变化会导致“网络爬虫”。“采集的失败最终导致微博信息缺失。同时,“网络爬虫”采集到达的网页需要进行“页面内容分析”,还有与基于API的数据采集相比,效率和性能差距明显。基于以上因素,本文拟采用第二种方法进行研究。基于新浪微博的微博信息采集系统开放平台API文档主要采用两种研究方法:文献分析法和实验测试法。文档分析方法:参考新浪微博开放平台的API文档,将这些API描述文档写成单独的接口文件。实验测试方法:在VS.NET2010平台[5]上,使用C/S模式开发程序调用接口类,采集微博返回的JOSN数据流,实现相关测试开发数据 采集 。
根据以上两种研究方法,设计本研究的技术路线:一是申请新浪微博开放平台App Key和App Secret。审核通过后,阅读理解API文档,将API文档描述写入API接口代码类(c#语言),然后进行OAuth2.0认证测试。认证通过后,可以获得Access Token,从而有权限调用API的各种功能接口,然后通过POST或GET调用API接口。最后返回JOSN数据流,最后解析这个数据流,保存为本地文本文件或数据库。详细技术路线如图1所示。 2研究内容设计微博信息采集系统功能结构如图2所示。系统分为七个部分,分别是:微博界面认证、微博用户登录、登录用户发微博、采集当前登录用户信息、采集其他用户信息、采集其他用户微博、采集学校信息、采集微博信息内容。1) 微博接口认证:访问大部分新浪微博API,如发布微博、获取私信等,都需要用户身份认证。目前新浪微博开放平台上的用户身份认证包括OAuth2.0和Basic Auth(仅用于应用开发者调试接口),新版接口也仅支持这两种方式[6] . 所以,系统设计开发的第一步是做微博界面鉴权功能。2) 微博用户登录:通过认证后,所有在新浪微博上注册的用户都可以通过本系统登录并发布微博。
3)采集登录用户信息:用户登录后,可以通过本系统查看自己的账号信息、自己的微博信息以及关注者的微博信息。4)采集 其他用户信息:这个功能主要是输入微博用户的昵称,可以采集获取昵称用户的账号信息,比如他有多少粉丝有,他关注哪些人,有多少人关注他,这个信息在微博采集中也是很有价值的。5)采集 其他用户的微博:此功能也使用微博用户的昵称来采集更改用户发送的所有微博信息。这个功能的目的是为了以后扩展为了自动采集 每隔一段时间将目标中多个微博用户的微博信息设置到本地进行数据内容分析。6)采集学校信息:该功能通过学校名称的模糊查询,获取学校微博账号ID、学校所在地区、学校类型信息。这是采集学校在微博上的影响力的基本数据。7)采集微博信息内容:您可以点击微博内容关键词查询,采集这条微博信息收录本关键词。但由于本次API接口调用需要高级权限,在系统完全发布前和新浪微博开放平台审核通过前,无法直接测试使用。3 主要功能的实现3. 1 微博界面认证功能 大部分新浪微博API访问都需要用户认证。本系统采用OAuth2.0设计微博界面认证功能,新浪微博认证流程如图3所示。
4 总结本文主要对微博信息采集的方法和技术进行了一系列的研究,然后设计开发了一个基于API的新浪微博信息采集系统,实现了微博的基础信息采集,在一定程度上解决了微博信息采集的自动化和采集结果数据格式的标准化。但是,目前本系统的微博信息采集方法只能输入单个“关键词”采集进行唯一匹配,没有批量多个“搜索词”采集,没有“话题型”微博信息采集功能,所以下一步的研究工作就是如何设计话题模型来优化系统。参考:[1]文锐.微博知乎[J].软件工程师, 2009 (12): 19-20. [2] 中国互联网络信息中心. 第31次中国互联网络发展统计报告[EB/OL]. (2013-01-1 5).http: ///hlwfzyj/hlwxzbg/hlwtjbg/201301/38508.htm. [3] 罗刚, 王振东. 自己手写的网络爬虫[M]. 北京:清华大学出版社, 2010. [4] 于满全, 陈铁瑞, 徐洪波. 基于块的网页信息解析器的研究与设计[J ]. 计算机应用, 2005, 25 (4):974-97 6. [5] Nick Randolph, David Gardner, Chris Anderson, et al.Professional Visual Studio 2010[M].Wrox, 2010. [6] 新浪微博开放平台.授权机制说明[EB] /OL]. (2013-01-19). 第31次中国互联网发展统计报告[EB/OL]。(2013-01-15).http: ///hlwfzyj/hlwxzbg/hlwtjbg/201301/38508.htm. [3] 罗刚, 王振东. 自己手写网页爬虫[M] . 北京: 清华大学出版社, 2010. [4] 于满全, 陈铁瑞, 徐洪波. 基于块的网页信息解析器的研究与设计[J]. 计算机应用, 2005, 25 (4):974-976. [5] Nick Randolph, David Gardner, Chris Anderson, et al.Professional Visual Studio 2010[M].Wrox, 2010. [6] 新浪微博开放平台。授权机制说明[EB/OL]. (2013-01-19). 第31次中国互联网发展统计报告[EB/OL]。(2013-01-15).http: ///hlwfzyj/hlwxzbg/hlwtjbg/201301/38508.htm. [3] 罗刚, 王振东. 自己手写网页爬虫[M] . 北京: 清华大学出版社, 2010. [4] 于满全, 陈铁瑞, 徐洪波. 基于块的网页信息解析器的研究与设计[J]. 计算机应用, 2005, 25 (4):974-976. [5] Nick Randolph, David Gardner, Chris Anderson, et al.Professional Visual Studio 2010[M].Wrox, 2010. [6] 新浪微博开放平台。授权机制说明[EB/OL]. (2013-01-19). 王振东。自己手写的网络爬虫[M]. 北京:清华大学出版社,2010. [4] 于曼全、陈铁瑞、徐洪波。基于块的网页信息解析器的研究与设计[J]. 计算机应用,2005, 25 (4):974-976. [5] Nick Randolph, David Gardner, Chris Anderson, et al.Professional Visual Studio 2010[M].Wrox, 2010. [6] 新浪微博开放平台. 授权机制解读[EB/OL]. (2013-01-19). 王振东。自己手写的网络爬虫[M]. 北京:清华大学出版社,2010. [4] 于曼泉、陈铁瑞、徐洪波。基于块的网页信息解析器的研究与设计[J]. 计算机应用,2005, 25 (4):974-976. [5] Nick Randolph, David Gardner, Chris Anderson, et al.Professional Visual Studio 2010[M].Wrox, 2010. [6] 新浪微博开放平台. 授权机制解读[EB/OL]. (2013-01-19). Professional Visual Studio 2010[M].Wrox,2010. [6] 新浪微博开放平台。授权机制说明[EB/OL]。(2013-01-19). Professional Visual Studio 2010[M].Wrox,2010. [6] 新浪微博开放平台。授权机制说明[EB/OL]。(2013-01-19). 查看全部
文章采集api(基于API的微博信息采集系统设计与实现(组图))
基于API的微博信息采集系统设计与实现小结:微博已经成为网络信息的重要来源。本文分析了微博信息采集的相关方法和技术,提出了基于API的信息采集方法,进而设计了一个能够采集相关信息的信息采集系统在新浪微博上。实验测试表明,信息采集系统可以快速有效地采集新浪微博信息。关键词:新浪微博;微博界面;资料采集; C#语言中文图书馆分类号:TP315 文档识别码:A 文章 编号:1009-3044(2013)17-4005-04 微博[1],微博的简称,是一个信息共享平台, 基于用户关系的传播和获取。用户可以使用140字的WEB、WAP和各种客户端组件的个人社区左右文字更新信息,实现即时分享。中国互联网络信息中心《第31次中国互联网络发展状况统计报告》显示,截至2012年12月末,截至2012年12月末,中国微博用户数为3.09亿,比2011年末增加5873万,网民中微博用户占比比上年末提高6个百分点,达到54.7%[2]。随着微博网络的影响力的迅速扩张,政府部门、学校、知名企业、公众人物都开通了微博。在公众的参与下,微博已经成为一个强大的虚拟社会。微博已成为网络信息的重要来源。如何快速有效地使用采集微博信息已成为一项具有重要应用价值的研究。
1 研究方法和技术路线 国内微博用户以新浪微博为主,本文拟以新浪微博为例,设计研究方法和技术路线。通过对国内外科技文献和实际应用案例的分析,目前新浪微博的信息采集方法主要分为两类:一类是“模拟登录”、“网络爬虫”[3] ],以及“网页内容”“分析”[4]信息采集三种技术相结合的方法。二是基于新浪微博开放平台的API文档。开发者自己编写程序调用微博的API进行微博信息采集。对于第一种方法,难度比较高,研究技术复杂,尤其是“模拟登录”这一步。需要随时跟踪新浪微博的登录加密算法。新浪微博登录加密算法的变化会导致“网络爬虫”。“采集的失败最终导致微博信息缺失。同时,“网络爬虫”采集到达的网页需要进行“页面内容分析”,还有与基于API的数据采集相比,效率和性能差距明显。基于以上因素,本文拟采用第二种方法进行研究。基于新浪微博的微博信息采集系统开放平台API文档主要采用两种研究方法:文献分析法和实验测试法。文档分析方法:参考新浪微博开放平台的API文档,将这些API描述文档写成单独的接口文件。实验测试方法:在VS.NET2010平台[5]上,使用C/S模式开发程序调用接口类,采集微博返回的JOSN数据流,实现相关测试开发数据 采集 。
根据以上两种研究方法,设计本研究的技术路线:一是申请新浪微博开放平台App Key和App Secret。审核通过后,阅读理解API文档,将API文档描述写入API接口代码类(c#语言),然后进行OAuth2.0认证测试。认证通过后,可以获得Access Token,从而有权限调用API的各种功能接口,然后通过POST或GET调用API接口。最后返回JOSN数据流,最后解析这个数据流,保存为本地文本文件或数据库。详细技术路线如图1所示。 2研究内容设计微博信息采集系统功能结构如图2所示。系统分为七个部分,分别是:微博界面认证、微博用户登录、登录用户发微博、采集当前登录用户信息、采集其他用户信息、采集其他用户微博、采集学校信息、采集微博信息内容。1) 微博接口认证:访问大部分新浪微博API,如发布微博、获取私信等,都需要用户身份认证。目前新浪微博开放平台上的用户身份认证包括OAuth2.0和Basic Auth(仅用于应用开发者调试接口),新版接口也仅支持这两种方式[6] . 所以,系统设计开发的第一步是做微博界面鉴权功能。2) 微博用户登录:通过认证后,所有在新浪微博上注册的用户都可以通过本系统登录并发布微博。
3)采集登录用户信息:用户登录后,可以通过本系统查看自己的账号信息、自己的微博信息以及关注者的微博信息。4)采集 其他用户信息:这个功能主要是输入微博用户的昵称,可以采集获取昵称用户的账号信息,比如他有多少粉丝有,他关注哪些人,有多少人关注他,这个信息在微博采集中也是很有价值的。5)采集 其他用户的微博:此功能也使用微博用户的昵称来采集更改用户发送的所有微博信息。这个功能的目的是为了以后扩展为了自动采集 每隔一段时间将目标中多个微博用户的微博信息设置到本地进行数据内容分析。6)采集学校信息:该功能通过学校名称的模糊查询,获取学校微博账号ID、学校所在地区、学校类型信息。这是采集学校在微博上的影响力的基本数据。7)采集微博信息内容:您可以点击微博内容关键词查询,采集这条微博信息收录本关键词。但由于本次API接口调用需要高级权限,在系统完全发布前和新浪微博开放平台审核通过前,无法直接测试使用。3 主要功能的实现3. 1 微博界面认证功能 大部分新浪微博API访问都需要用户认证。本系统采用OAuth2.0设计微博界面认证功能,新浪微博认证流程如图3所示。
4 总结本文主要对微博信息采集的方法和技术进行了一系列的研究,然后设计开发了一个基于API的新浪微博信息采集系统,实现了微博的基础信息采集,在一定程度上解决了微博信息采集的自动化和采集结果数据格式的标准化。但是,目前本系统的微博信息采集方法只能输入单个“关键词”采集进行唯一匹配,没有批量多个“搜索词”采集,没有“话题型”微博信息采集功能,所以下一步的研究工作就是如何设计话题模型来优化系统。参考:[1]文锐.微博知乎[J].软件工程师, 2009 (12): 19-20. [2] 中国互联网络信息中心. 第31次中国互联网络发展统计报告[EB/OL]. (2013-01-1 5).http: ///hlwfzyj/hlwxzbg/hlwtjbg/201301/38508.htm. [3] 罗刚, 王振东. 自己手写的网络爬虫[M]. 北京:清华大学出版社, 2010. [4] 于满全, 陈铁瑞, 徐洪波. 基于块的网页信息解析器的研究与设计[J ]. 计算机应用, 2005, 25 (4):974-97 6. [5] Nick Randolph, David Gardner, Chris Anderson, et al.Professional Visual Studio 2010[M].Wrox, 2010. [6] 新浪微博开放平台.授权机制说明[EB] /OL]. (2013-01-19). 第31次中国互联网发展统计报告[EB/OL]。(2013-01-15).http: ///hlwfzyj/hlwxzbg/hlwtjbg/201301/38508.htm. [3] 罗刚, 王振东. 自己手写网页爬虫[M] . 北京: 清华大学出版社, 2010. [4] 于满全, 陈铁瑞, 徐洪波. 基于块的网页信息解析器的研究与设计[J]. 计算机应用, 2005, 25 (4):974-976. [5] Nick Randolph, David Gardner, Chris Anderson, et al.Professional Visual Studio 2010[M].Wrox, 2010. [6] 新浪微博开放平台。授权机制说明[EB/OL]. (2013-01-19). 第31次中国互联网发展统计报告[EB/OL]。(2013-01-15).http: ///hlwfzyj/hlwxzbg/hlwtjbg/201301/38508.htm. [3] 罗刚, 王振东. 自己手写网页爬虫[M] . 北京: 清华大学出版社, 2010. [4] 于满全, 陈铁瑞, 徐洪波. 基于块的网页信息解析器的研究与设计[J]. 计算机应用, 2005, 25 (4):974-976. [5] Nick Randolph, David Gardner, Chris Anderson, et al.Professional Visual Studio 2010[M].Wrox, 2010. [6] 新浪微博开放平台。授权机制说明[EB/OL]. (2013-01-19). 王振东。自己手写的网络爬虫[M]. 北京:清华大学出版社,2010. [4] 于曼全、陈铁瑞、徐洪波。基于块的网页信息解析器的研究与设计[J]. 计算机应用,2005, 25 (4):974-976. [5] Nick Randolph, David Gardner, Chris Anderson, et al.Professional Visual Studio 2010[M].Wrox, 2010. [6] 新浪微博开放平台. 授权机制解读[EB/OL]. (2013-01-19). 王振东。自己手写的网络爬虫[M]. 北京:清华大学出版社,2010. [4] 于曼泉、陈铁瑞、徐洪波。基于块的网页信息解析器的研究与设计[J]. 计算机应用,2005, 25 (4):974-976. [5] Nick Randolph, David Gardner, Chris Anderson, et al.Professional Visual Studio 2010[M].Wrox, 2010. [6] 新浪微博开放平台. 授权机制解读[EB/OL]. (2013-01-19). Professional Visual Studio 2010[M].Wrox,2010. [6] 新浪微博开放平台。授权机制说明[EB/OL]。(2013-01-19). Professional Visual Studio 2010[M].Wrox,2010. [6] 新浪微博开放平台。授权机制说明[EB/OL]。(2013-01-19).
文章采集api(完美者()网站对功能性板块进行扩充,以期采集器智能分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-11-09 02:09
Perfect()网站基于软件下载,网站修订版扩展了功能部分,以解决用户在使用软件过程中遇到的所有问题。网站 新增“软件百科”、“甜蜜小贴士”等新频道,在软件使用全周期更好地为用户提供更专业的服务。
优采云采集器是一款高效的网页信息采集软件,一键采集网页数据,无论是静态网页还是动态网页都可以采集,支持99%的网站,内置大量网站采集模板,覆盖多个行业,提取成功后可另存为Excel表格,api数据库文件。
优采云采集器特点
一键提取数据
简单易学,通过可视化界面,鼠标点击即可采集数据
快速高效
内置一套高速浏览器内核,加上HTTP引擎模式,实现快速采集数据
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站
优采云采集器功能
向导模式
简单易用,轻松通过鼠标点击自动生成
脚本定期运行
可按计划定时运行,无需人工
原装高速核心
自主研发的浏览器内核速度快,远超对手
智能识别
可智能识别网页中的列表和表单结构(多选框下拉列表等)
广告拦截
自定义广告拦截模块,兼容AdblockPlus语法,可添加自定义规则
各种数据导出
支持 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等。
优采云采集器安装
1.到本站下载安装优采云采集器,打开安装程序,点击下一步继续安装
2.点击浏览选择安装位置
3.等一下
优采云采集器使用方法
第一步:输入采集 URL
打开软件,新建一个任务,输入需要采集的网站地址。
第二步:智能分析,全程自动提取数据
进入第二步后,优采云采集器自动对网页进行智能分析,从中提取列表数据。
第三步:将数据导出到表、数据库、网站等。
运行任务,将采集中的数据导出到Csv、Excel及各种数据库,支持api导出。
“技巧与妙计”栏目是全网软件使用技巧的集合或对软件使用过程中各种问题的解答。文章。专栏成立伊始,小编欢迎各位软件大神朋友踊跃投稿。该平台分享每个人的独特技能。
本站文章素材来自网络,文章作者姓名大部分缺失。为了让用户更容易阅读和使用,它们已被重新格式化并根据需要进行了部分调整。本站收录文章仅用于帮助用户解决实际问题。如有版权问题,请联系编辑修改或删除,谢谢合作。 查看全部
文章采集api(完美者()网站对功能性板块进行扩充,以期采集器智能分析)
Perfect()网站基于软件下载,网站修订版扩展了功能部分,以解决用户在使用软件过程中遇到的所有问题。网站 新增“软件百科”、“甜蜜小贴士”等新频道,在软件使用全周期更好地为用户提供更专业的服务。

优采云采集器是一款高效的网页信息采集软件,一键采集网页数据,无论是静态网页还是动态网页都可以采集,支持99%的网站,内置大量网站采集模板,覆盖多个行业,提取成功后可另存为Excel表格,api数据库文件。
优采云采集器特点
一键提取数据
简单易学,通过可视化界面,鼠标点击即可采集数据
快速高效
内置一套高速浏览器内核,加上HTTP引擎模式,实现快速采集数据
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站
优采云采集器功能
向导模式
简单易用,轻松通过鼠标点击自动生成
脚本定期运行
可按计划定时运行,无需人工
原装高速核心
自主研发的浏览器内核速度快,远超对手
智能识别
可智能识别网页中的列表和表单结构(多选框下拉列表等)
广告拦截
自定义广告拦截模块,兼容AdblockPlus语法,可添加自定义规则
各种数据导出
支持 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等。
优采云采集器安装
1.到本站下载安装优采云采集器,打开安装程序,点击下一步继续安装

2.点击浏览选择安装位置

3.等一下

优采云采集器使用方法
第一步:输入采集 URL
打开软件,新建一个任务,输入需要采集的网站地址。

第二步:智能分析,全程自动提取数据
进入第二步后,优采云采集器自动对网页进行智能分析,从中提取列表数据。

第三步:将数据导出到表、数据库、网站等。
运行任务,将采集中的数据导出到Csv、Excel及各种数据库,支持api导出。
“技巧与妙计”栏目是全网软件使用技巧的集合或对软件使用过程中各种问题的解答。文章。专栏成立伊始,小编欢迎各位软件大神朋友踊跃投稿。该平台分享每个人的独特技能。
本站文章素材来自网络,文章作者姓名大部分缺失。为了让用户更容易阅读和使用,它们已被重新格式化并根据需要进行了部分调整。本站收录文章仅用于帮助用户解决实际问题。如有版权问题,请联系编辑修改或删除,谢谢合作。
文章采集api(spring使用springcloud架构来做爬虫,历时二十多天,终于搞定)
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2021-11-08 10:15
前言
因公司业务需要,需要获取客户提供的微信公众号文章的历史记录,并每天更新。显然,300多个公众号无法每天手动检查,问题提交给IT团队。对于那些喜欢爬虫的人,我绝对想要他。之前做过搜狗的微信爬虫,之后一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过一系列文章分享项目经验,并提供源码供大家指正!
一、系统介绍
本系统是基于Java开发的。只需配置公众号或微信公众号,即可定时或实时(包括阅读、点赞、观看)抓拍微信公众号的文章。
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、RocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
Redis
演戏
提琴手
三、系统优缺点 系统优点
1、 配置公众号后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取;2、系统为分布式架构,高可用;3、RocketMq 消息队列解决Coupling,可以解决采集由于网络抖动导致的失败。3次消费不成功,会记录日志到mysql,保证文章的完整性;4、可以添加任意数量的微信ID提高采集的效率,抵抗反攀登限制;5、Redis在24小时内缓存每个微信账号的采集记录,防止账号被关闭;6、Nacos作为配置中心,可以通过热配置调整采集的频率 实时; 7、将采集接收到的数据存储在Solr集群中,提高检索速度;8、 将捕获返回的记录存储到MongoDB进行归档查看错误日志。
系统缺点:
1、通过真实手机真实账号采集留言,如果你需要大量公众号,需要有多个微信账号作为支持(如果当天账号达到上限,可以爬取微信官方平台消息,可通过接口获取);2、 不是发文就可以抓到的公众号。采集的时间由系统设置,消息有一定的滞后性(如果公众号不多的话,微信信号数量就足够了。通过增加采集频率优化)。
四、模块介绍
由于后面会添加管理系统和API调用功能,所以提前封装了一些功能。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis 模块:是
spring-boot-starter-data-redis第二个包暴露了打包好的Redis工具类和Redisson工具类。
RocketMQ-WS-启动器
RocketMQ 模块:是
Rocketmq-spring-boot-starter 的二次封装提供了消费重试和故障日志记录功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多种数据源,自定义注解实现数据源动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
电脑-wx-蜘蛛
PC端采集模块:收录PC端采集公众账号历史消息相关功能。
java-wx-蜘蛛
Java提取模块:收录Java程序提取文章内容相关的功能。
移动-wx-蜘蛛
模拟器采集模块:收录与模拟器或手机采集消息交互量相关的功能。
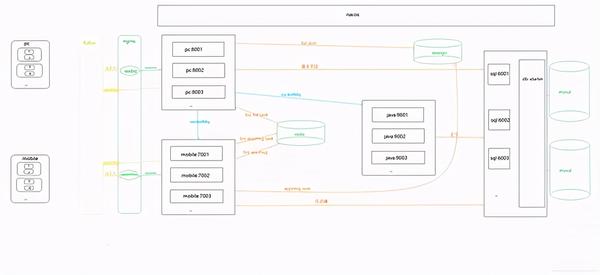
五、一般流程图
六、 在PC端和移动端运行截图
安慰
运行结束
总结
项目试运行中,微信搜狗临时链接永久链接问题已在项目开发中解决。希望能帮到被类似业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。我希望每个人都有自己的向日葵采集。如果你看到这个,你不把它给一个采集吗? 查看全部
文章采集api(spring使用springcloud架构来做爬虫,历时二十多天,终于搞定)
前言
因公司业务需要,需要获取客户提供的微信公众号文章的历史记录,并每天更新。显然,300多个公众号无法每天手动检查,问题提交给IT团队。对于那些喜欢爬虫的人,我绝对想要他。之前做过搜狗的微信爬虫,之后一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过一系列文章分享项目经验,并提供源码供大家指正!
一、系统介绍
本系统是基于Java开发的。只需配置公众号或微信公众号,即可定时或实时(包括阅读、点赞、观看)抓拍微信公众号的文章。
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、RocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
Redis
演戏
提琴手
三、系统优缺点 系统优点
1、 配置公众号后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取;2、系统为分布式架构,高可用;3、RocketMq 消息队列解决Coupling,可以解决采集由于网络抖动导致的失败。3次消费不成功,会记录日志到mysql,保证文章的完整性;4、可以添加任意数量的微信ID提高采集的效率,抵抗反攀登限制;5、Redis在24小时内缓存每个微信账号的采集记录,防止账号被关闭;6、Nacos作为配置中心,可以通过热配置调整采集的频率 实时; 7、将采集接收到的数据存储在Solr集群中,提高检索速度;8、 将捕获返回的记录存储到MongoDB进行归档查看错误日志。
系统缺点:
1、通过真实手机真实账号采集留言,如果你需要大量公众号,需要有多个微信账号作为支持(如果当天账号达到上限,可以爬取微信官方平台消息,可通过接口获取);2、 不是发文就可以抓到的公众号。采集的时间由系统设置,消息有一定的滞后性(如果公众号不多的话,微信信号数量就足够了。通过增加采集频率优化)。
四、模块介绍
由于后面会添加管理系统和API调用功能,所以提前封装了一些功能。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis 模块:是
spring-boot-starter-data-redis第二个包暴露了打包好的Redis工具类和Redisson工具类。
RocketMQ-WS-启动器
RocketMQ 模块:是
Rocketmq-spring-boot-starter 的二次封装提供了消费重试和故障日志记录功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多种数据源,自定义注解实现数据源动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
电脑-wx-蜘蛛
PC端采集模块:收录PC端采集公众账号历史消息相关功能。
java-wx-蜘蛛
Java提取模块:收录Java程序提取文章内容相关的功能。
移动-wx-蜘蛛
模拟器采集模块:收录与模拟器或手机采集消息交互量相关的功能。
五、一般流程图
六、 在PC端和移动端运行截图

安慰
运行结束
总结
项目试运行中,微信搜狗临时链接永久链接问题已在项目开发中解决。希望能帮到被类似业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。我希望每个人都有自己的向日葵采集。如果你看到这个,你不把它给一个采集吗?
文章采集api(INTERTIDTURBOAPIV1.0版提供公开信息数据开放平台对外接口 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-11-08 09:24
)
本次网站使用INTERTID TURBO API V1.0 版本提供开放信息数据开放平台的对外接口。通过对数据的编目、展示和管理,提供对数据的采集、采集、编辑和整理。、全生命周期管理和服务的编目、发布和更新,确保政府开放数据的机读性、原创性、及时性、公开性、真实性、完整性和安全性,并提供对外数据检索、展示和下载,并提供面向数据开发人员的数据访问 API。
本网站以数据签名权限的方式使用INTERTID TURBO API主动公开信息、咨询投诉、在线调查、舆情采集等方面的数据对接服务;同时,向公众提供非XML格式的公共信息API 提供此网站可共享的发布信息。
界面语言定义:
$.select(froms: from)(w: Query)(隐式排序:orders = null, l: limit =limit(-1), o: offest = offest(-1), maxDocs: Int = 10000)
字段类型:
字符串:字符类型。boolean: 布尔类型。number:数字类型。日期时间:时间类型。reader:流类型,流类型的字段类型store必须是storeno。bytes:字符数组,字符数组的字段类型存储为storeyes。
详情请参考政府数据查询服务统一开放平台,您可以致电网站索取详细的API文档。
查看全部
文章采集api(INTERTIDTURBOAPIV1.0版提供公开信息数据开放平台对外接口
)
本次网站使用INTERTID TURBO API V1.0 版本提供开放信息数据开放平台的对外接口。通过对数据的编目、展示和管理,提供对数据的采集、采集、编辑和整理。、全生命周期管理和服务的编目、发布和更新,确保政府开放数据的机读性、原创性、及时性、公开性、真实性、完整性和安全性,并提供对外数据检索、展示和下载,并提供面向数据开发人员的数据访问 API。
本网站以数据签名权限的方式使用INTERTID TURBO API主动公开信息、咨询投诉、在线调查、舆情采集等方面的数据对接服务;同时,向公众提供非XML格式的公共信息API 提供此网站可共享的发布信息。
界面语言定义:
$.select(froms: from)(w: Query)(隐式排序:orders = null, l: limit =limit(-1), o: offest = offest(-1), maxDocs: Int = 10000)
字段类型:
字符串:字符类型。boolean: 布尔类型。number:数字类型。日期时间:时间类型。reader:流类型,流类型的字段类型store必须是storeno。bytes:字符数组,字符数组的字段类型存储为storeyes。
详情请参考政府数据查询服务统一开放平台,您可以致电网站索取详细的API文档。

文章采集api(软件特色关于软件优采云采集器(SkyCaiji)功能特色10张壁纸)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-11-06 21:02
优采云采集器是一款免费的数据采集发布爬虫软件,用php+mysql开发,可以部署在云服务器上,几乎采集所有类型的网页,没有缝制对接各种cms建站程序,无需登录即可实时发布数据,全自动无需人工干预,是大数据和云时代最好的云爬虫软件网站数据自动化采集!软件特点 关于优采云采集器(天财记)软件,致力于网站数据自动化采集的发布,系统采用PHP+Mysql开发,可部署在云服务器上制作数据采集便捷、智能、云端,让您随时随地移动办公!数据采集支持多级、多页、分页< @采集,自定义采集规则(支持正则、XPATH、JSON等)准确匹配任何信息流,几乎采集所有类型的网页,大部分文章类型页面内容可实现内容发布智能识别,与各种cms建站程序无缝对接,实现免登录导入数据,支持自定义数据发布插件,或直接导入数据库,保存为Excel文件,生成API接口等自动化及云平台软件,实现定时定量自动采集发布,无需人工干预!内置云平台,用户可以分享和下载采集规则,发布供需信息,社区帮助,交流等。升级软件的使用方法可以直接在后台首页检测并点击升级,或者将压缩包上传到服务器解压覆盖就可以了!安装软件。将下载的软件上传到您的服务器。如果根目录下有站点,建议放在子目录下。解压后打开浏览器输入你的服务器域名或ip地址(存放在子目录时添加子目录名),进入安装界面点击“接受”,进入环境检测页面,一定要确保所有参数正确,否则使用过程中会出现错误,点击“下一步”进入数据安装界面填写数据库和创始人配置,点击“下一步” 最后安装完成,现在可以使用优采云采集器!具有 10 张壁纸,无需触摸板和鼠标即可操作内置时钟和日期小部件 3 种不同的时钟格式 5 种不同的日期格式 查看全部
文章采集api(软件特色关于软件优采云采集器(SkyCaiji)功能特色10张壁纸)
优采云采集器是一款免费的数据采集发布爬虫软件,用php+mysql开发,可以部署在云服务器上,几乎采集所有类型的网页,没有缝制对接各种cms建站程序,无需登录即可实时发布数据,全自动无需人工干预,是大数据和云时代最好的云爬虫软件网站数据自动化采集!软件特点 关于优采云采集器(天财记)软件,致力于网站数据自动化采集的发布,系统采用PHP+Mysql开发,可部署在云服务器上制作数据采集便捷、智能、云端,让您随时随地移动办公!数据采集支持多级、多页、分页< @采集,自定义采集规则(支持正则、XPATH、JSON等)准确匹配任何信息流,几乎采集所有类型的网页,大部分文章类型页面内容可实现内容发布智能识别,与各种cms建站程序无缝对接,实现免登录导入数据,支持自定义数据发布插件,或直接导入数据库,保存为Excel文件,生成API接口等自动化及云平台软件,实现定时定量自动采集发布,无需人工干预!内置云平台,用户可以分享和下载采集规则,发布供需信息,社区帮助,交流等。升级软件的使用方法可以直接在后台首页检测并点击升级,或者将压缩包上传到服务器解压覆盖就可以了!安装软件。将下载的软件上传到您的服务器。如果根目录下有站点,建议放在子目录下。解压后打开浏览器输入你的服务器域名或ip地址(存放在子目录时添加子目录名),进入安装界面点击“接受”,进入环境检测页面,一定要确保所有参数正确,否则使用过程中会出现错误,点击“下一步”进入数据安装界面填写数据库和创始人配置,点击“下一步” 最后安装完成,现在可以使用优采云采集器!具有 10 张壁纸,无需触摸板和鼠标即可操作内置时钟和日期小部件 3 种不同的时钟格式 5 种不同的日期格式
文章采集api( WebApi接口采集指标数据的配置实践操作(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 412 次浏览 • 2021-11-06 01:17
WebApi接口采集指标数据的配置实践操作(组图)
)
这个文章的主要目的是告诉你如何配置Prometheus,使其可以使用指定的Web Api接口采集指标数据。文章中使用的case是NGINX的采集配置,来自NGINX数据索引页的采集数据,设置了用户名和密码,所以这是文章@的副标题> 可能是nginx的prometheus 采集配置或者prometheus 采集 basic auth的nginx。
上图展示了配置完成后在Grafana中配置模板的效果。
用过Prometheus的朋友一定知道如何配置address:port服务。比如在采集某个Redis的信息时,配置可以这样写:
- job_name: 'redis'
static_configs:
- targets: ['11.22.33.58:6087']
复制代码
注意:以上情况假设Redis Exporter的地址和端口为11.22.33.58:6087。
这是最简单也是最广为人知的方法。但是如果要监控指定的Web API,就不能这样写了。如果你没有看到这个 文章,你可能会在搜索引擎中搜索这样的:
但是很遗憾,没有找到有效的信息(现在是2021年3月),基本上所有的坑都能找到。
条件假设
假设我们现在需要从带有地址...的接口采集相关的Prometheus监控指标,并且该接口使用basic auth(假设用户名为weishidong,密码为0099887kk)进行基本授权验证。
配置实践
如果填写之前看到的Prometheus配置,很可能这样写配置:
- job_name: 'web'
static_configs:
- targets: ['http://www.weishidong.com/status/format/prometheus']
basic_auth:
username: weishidong
password: 0099887kk
复制代码
保存配置文件,重启服务后,你会发现这种方式无法采集数据,太可怕了。
官方配置指南
刚才的手术实在是太可怕了。当我们遇到不明白的问题时,我们当然去官方文档-> Prometheus Configuration。建议从上到下阅读,但如果你赶时间,可以直接来这部分。官方示例如下(内容太多,这里只保留与本文相关的部分,建议大家阅读原文):
# The job name assigned to scraped metrics by default.
job_name:
# How frequently to scrape targets from this job.
[ scrape_interval: | default = ]
# Per-scrape timeout when scraping this job.
[ scrape_timeout: | default = ]
# The HTTP resource path on which to fetch metrics from targets.
[ metrics_path: | default = /metrics ]
# honor_labels controls how Prometheus handles conflicts between labels that are
# already present in scraped data and labels that Prometheus would attach
# server-side ("job" and "instance" labels, manually configured target
# labels, and labels generated by service discovery implementations).
#
# If honor_labels is set to "true", label conflicts are resolved by keeping label
# values from the scraped data and ignoring the conflicting server-side labels.
#
# If honor_labels is set to "false", label conflicts are resolved by renaming
# conflicting labels in the scraped data to "exported_" (for
# example "exported_instance", "exported_job") and then attaching server-side
# labels.
#
# Setting honor_labels to "true" is useful for use cases such as federation and
# scraping the Pushgateway, where all labels specified in the target should be
# preserved.
#
# Note that any globally configured "external_labels" are unaffected by this
# setting. In communication with external systems, they are always applied only
# when a time series does not have a given label yet and are ignored otherwise.
[ honor_labels: | default = false ]
# honor_timestamps controls whether Prometheus respects the timestamps present
# in scraped data.
#
# If honor_timestamps is set to "true", the timestamps of the metrics exposed
# by the target will be used.
#
# If honor_timestamps is set to "false", the timestamps of the metrics exposed
# by the target will be ignored.
[ honor_timestamps: | default = true ]
# Configures the protocol scheme used for requests.
[ scheme: | default = http ]
# Optional HTTP URL parameters.
params:
[ : [, ...] ]
# Sets the `Authorization` header on every scrape request with the
# configured username and password.
# password and password_file are mutually exclusive.
basic_auth:
[ username: ]
[ password: ]
[ password_file: ]
# Sets the `Authorization` header on every scrape request with
# the configured bearer token. It is mutually exclusive with `bearer_token_file`.
[ bearer_token: ]
# Sets the `Authorization` header on every scrape request with the bearer token
# read from the configured file. It is mutually exclusive with `bearer_token`.
[ bearer_token_file: ]
复制代码
如果仔细看,应该注意几个关键信息:metrics_path 和 basic_auth。其中,metrics_path用于指定HTTP类型指示符信息采集时的路由地址,默认值为/metrics;字段basic_auth用于授权验证,这里的password可以指定一个密码文件,而不是直接填写明文(一般来说,指定的密码文件的安全性稍高,明文)。
有效配置
根据官方文档的指引,我们可以快速推导出正确的配置写法:
- job_name: 'web'
metrics_path: /status/format/prometheus
static_configs:
- targets: ['www.weishidong.com']
basic_auth:
username: weishidong
password: 0099887kk
复制代码
需要注意的是这里的字不用填,因为Prometheus默认的Scheme是http。如果地址的scheme是https,我们需要根据文档指引添加scheme字段,对应的配置为:
- job_name: 'web'
metrics_path: /status/format/prometheus
static_configs:
- targets: ['www.weishidong.com']
scheme: https
basic_auth:
username: weishidong
password: 0099887kk
复制代码
配置完成后,Prometheus应该可以成功采集获取数据。用Grafana,可以看到开头给出的监控效果图。
查看全部
文章采集api(
WebApi接口采集指标数据的配置实践操作(组图)
)
这个文章的主要目的是告诉你如何配置Prometheus,使其可以使用指定的Web Api接口采集指标数据。文章中使用的case是NGINX的采集配置,来自NGINX数据索引页的采集数据,设置了用户名和密码,所以这是文章@的副标题> 可能是nginx的prometheus 采集配置或者prometheus 采集 basic auth的nginx。
上图展示了配置完成后在Grafana中配置模板的效果。
用过Prometheus的朋友一定知道如何配置address:port服务。比如在采集某个Redis的信息时,配置可以这样写:
- job_name: 'redis'
static_configs:
- targets: ['11.22.33.58:6087']
复制代码
注意:以上情况假设Redis Exporter的地址和端口为11.22.33.58:6087。
这是最简单也是最广为人知的方法。但是如果要监控指定的Web API,就不能这样写了。如果你没有看到这个 文章,你可能会在搜索引擎中搜索这样的:
但是很遗憾,没有找到有效的信息(现在是2021年3月),基本上所有的坑都能找到。
条件假设
假设我们现在需要从带有地址...的接口采集相关的Prometheus监控指标,并且该接口使用basic auth(假设用户名为weishidong,密码为0099887kk)进行基本授权验证。
配置实践
如果填写之前看到的Prometheus配置,很可能这样写配置:
- job_name: 'web'
static_configs:
- targets: ['http://www.weishidong.com/status/format/prometheus']
basic_auth:
username: weishidong
password: 0099887kk
复制代码
保存配置文件,重启服务后,你会发现这种方式无法采集数据,太可怕了。
官方配置指南
刚才的手术实在是太可怕了。当我们遇到不明白的问题时,我们当然去官方文档-> Prometheus Configuration。建议从上到下阅读,但如果你赶时间,可以直接来这部分。官方示例如下(内容太多,这里只保留与本文相关的部分,建议大家阅读原文):
# The job name assigned to scraped metrics by default.
job_name:
# How frequently to scrape targets from this job.
[ scrape_interval: | default = ]
# Per-scrape timeout when scraping this job.
[ scrape_timeout: | default = ]
# The HTTP resource path on which to fetch metrics from targets.
[ metrics_path: | default = /metrics ]
# honor_labels controls how Prometheus handles conflicts between labels that are
# already present in scraped data and labels that Prometheus would attach
# server-side ("job" and "instance" labels, manually configured target
# labels, and labels generated by service discovery implementations).
#
# If honor_labels is set to "true", label conflicts are resolved by keeping label
# values from the scraped data and ignoring the conflicting server-side labels.
#
# If honor_labels is set to "false", label conflicts are resolved by renaming
# conflicting labels in the scraped data to "exported_" (for
# example "exported_instance", "exported_job") and then attaching server-side
# labels.
#
# Setting honor_labels to "true" is useful for use cases such as federation and
# scraping the Pushgateway, where all labels specified in the target should be
# preserved.
#
# Note that any globally configured "external_labels" are unaffected by this
# setting. In communication with external systems, they are always applied only
# when a time series does not have a given label yet and are ignored otherwise.
[ honor_labels: | default = false ]
# honor_timestamps controls whether Prometheus respects the timestamps present
# in scraped data.
#
# If honor_timestamps is set to "true", the timestamps of the metrics exposed
# by the target will be used.
#
# If honor_timestamps is set to "false", the timestamps of the metrics exposed
# by the target will be ignored.
[ honor_timestamps: | default = true ]
# Configures the protocol scheme used for requests.
[ scheme: | default = http ]
# Optional HTTP URL parameters.
params:
[ : [, ...] ]
# Sets the `Authorization` header on every scrape request with the
# configured username and password.
# password and password_file are mutually exclusive.
basic_auth:
[ username: ]
[ password: ]
[ password_file: ]
# Sets the `Authorization` header on every scrape request with
# the configured bearer token. It is mutually exclusive with `bearer_token_file`.
[ bearer_token: ]
# Sets the `Authorization` header on every scrape request with the bearer token
# read from the configured file. It is mutually exclusive with `bearer_token`.
[ bearer_token_file: ]
复制代码
如果仔细看,应该注意几个关键信息:metrics_path 和 basic_auth。其中,metrics_path用于指定HTTP类型指示符信息采集时的路由地址,默认值为/metrics;字段basic_auth用于授权验证,这里的password可以指定一个密码文件,而不是直接填写明文(一般来说,指定的密码文件的安全性稍高,明文)。
有效配置
根据官方文档的指引,我们可以快速推导出正确的配置写法:
- job_name: 'web'
metrics_path: /status/format/prometheus
static_configs:
- targets: ['www.weishidong.com']
basic_auth:
username: weishidong
password: 0099887kk
复制代码
需要注意的是这里的字不用填,因为Prometheus默认的Scheme是http。如果地址的scheme是https,我们需要根据文档指引添加scheme字段,对应的配置为:
- job_name: 'web'
metrics_path: /status/format/prometheus
static_configs:
- targets: ['www.weishidong.com']
scheme: https
basic_auth:
username: weishidong
password: 0099887kk
复制代码
配置完成后,Prometheus应该可以成功采集获取数据。用Grafana,可以看到开头给出的监控效果图。
文章采集api( 大数据信息的收集和应用逐步普及,离不开网络爬虫来说 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-10-31 02:18
大数据信息的收集和应用逐步普及,离不开网络爬虫来说
)
数字时代,大数据信息的采集和应用逐渐普及,离不开网络爬虫的广泛应用。由于数据信息市场的不断扩大,需要大规模的网络爬虫来处理海量的数据信息采集。在这个过程中应该注意哪些问题?
1、 首先检查是否有API。API是网站提供官方数据信息的接口。
比如通过调用API采集数据信息,在网站允许的范围内采集数据,既没有道德法律风险,也没有故意设置网站的障碍;但是,API接口的访问受网站的控制,网站可用于计费和限制访问上限。二、 数据信息结构分析和数据信息存储。
2、网络爬虫需要明确显示需要哪些字段。
这些字段可以存在于网页上,也可以根据网页中的现有字段进行进一步计算。下面是如何生成表,如何连接多个表等等。需要注意的是,在确定字段链接时,不要只看网页的一小部分,因为一个网页可能缺少其他类型网页的字段。这可能是网站的问题,也可能是用户行为造成的,不同的是只有多浏览一些网页,才能全面提取关键字段。
对于大型网络爬虫,除了采集数据信息外,还必须存储其他重要的中间数据信息(如网页ID或url),避免每次都重新爬取id。
3、数据流分析。
如果要批量抓取页面,请查看其入口位置,该位置基于采集的范围。站点页面一般基于树状结构,可以以根节点为入口逐层进入。确定信息流的机制后,下一个单独的网页,然后将此模式复制到整个页面。
<p style="margin-top: 10px;margin-bottom: 10px;outline: 0px;max-width: 100%;min-height: 1em;letter-spacing: 0.544px;white-space: normal;border-width: 0px;border-style: initial;border-color: initial;-webkit-font-smoothing: antialiased;font-size: 18px;font-family: "Microsoft YaHei", Arial, Verdana, Tahoma, sans-serif;vertical-align: baseline;background-image: initial;background-position: initial;background-size: initial;background-repeat: initial;background-attachment: initial;background-origin: initial;background-clip: initial;line-height: 32px;color: rgb(85, 85, 85);text-align: start;box-sizing: border-box !important;overflow-wrap: break-word !important;">
搜索下方加老师微信<br data-filtered="filtered" style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;">
老师微信号:<strong style="outline: 0px;max-width: 100%;color: rgb(63, 63, 63);letter-spacing: 0.544px;box-sizing: border-box !important;overflow-wrap: break-word !important;">XTUOL1988【</strong>切记备注<strong style="outline: 0px;max-width: 100%;letter-spacing: 0.544px;box-sizing: border-box !important;overflow-wrap: break-word !important;">:学习Python</strong>】
领取Python web开发,Python爬虫,Python数据分析,人工智能等精品学习课程。带你从零基础系统性的学好Python!
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权
</p> 查看全部
文章采集api(
大数据信息的收集和应用逐步普及,离不开网络爬虫来说
)

数字时代,大数据信息的采集和应用逐渐普及,离不开网络爬虫的广泛应用。由于数据信息市场的不断扩大,需要大规模的网络爬虫来处理海量的数据信息采集。在这个过程中应该注意哪些问题?

1、 首先检查是否有API。API是网站提供官方数据信息的接口。
比如通过调用API采集数据信息,在网站允许的范围内采集数据,既没有道德法律风险,也没有故意设置网站的障碍;但是,API接口的访问受网站的控制,网站可用于计费和限制访问上限。二、 数据信息结构分析和数据信息存储。
2、网络爬虫需要明确显示需要哪些字段。
这些字段可以存在于网页上,也可以根据网页中的现有字段进行进一步计算。下面是如何生成表,如何连接多个表等等。需要注意的是,在确定字段链接时,不要只看网页的一小部分,因为一个网页可能缺少其他类型网页的字段。这可能是网站的问题,也可能是用户行为造成的,不同的是只有多浏览一些网页,才能全面提取关键字段。
对于大型网络爬虫,除了采集数据信息外,还必须存储其他重要的中间数据信息(如网页ID或url),避免每次都重新爬取id。
3、数据流分析。
如果要批量抓取页面,请查看其入口位置,该位置基于采集的范围。站点页面一般基于树状结构,可以以根节点为入口逐层进入。确定信息流的机制后,下一个单独的网页,然后将此模式复制到整个页面。
<p style="margin-top: 10px;margin-bottom: 10px;outline: 0px;max-width: 100%;min-height: 1em;letter-spacing: 0.544px;white-space: normal;border-width: 0px;border-style: initial;border-color: initial;-webkit-font-smoothing: antialiased;font-size: 18px;font-family: "Microsoft YaHei", Arial, Verdana, Tahoma, sans-serif;vertical-align: baseline;background-image: initial;background-position: initial;background-size: initial;background-repeat: initial;background-attachment: initial;background-origin: initial;background-clip: initial;line-height: 32px;color: rgb(85, 85, 85);text-align: start;box-sizing: border-box !important;overflow-wrap: break-word !important;">
搜索下方加老师微信<br data-filtered="filtered" style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;">
老师微信号:<strong style="outline: 0px;max-width: 100%;color: rgb(63, 63, 63);letter-spacing: 0.544px;box-sizing: border-box !important;overflow-wrap: break-word !important;">XTUOL1988【</strong>切记备注<strong style="outline: 0px;max-width: 100%;letter-spacing: 0.544px;box-sizing: border-box !important;overflow-wrap: break-word !important;">:学习Python</strong>】
领取Python web开发,Python爬虫,Python数据分析,人工智能等精品学习课程。带你从零基础系统性的学好Python!

*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权
 </p>
</p> 文章采集api(数据推送API的应用草料平台的3种推送方式(一) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-10-30 17:11
)
一、数据推送API应用
饲料平台的数据可以自动推送给您,您可以自己调用数据作为应用程序。目前不支持将数据从外部系统写入饲料。
应用一:制作实时数据报表
使用数据分析工具连接数据库,进行数据分析或报表制作,查看效果,制作教程
应用二:对接企业流程
通过在草料平台上实现扫码采集数据等功能,然后通过API与企业系统的进程对接,企业可以在保持原有系统的同时,以极低的成本应用草料功能,并检查影响
二、我们提供3种推送方式1、官方数据库
Forage 为您提供独立的云数据库来同步您的后端数据。之后,您可以使用数据分析软件连接到这个云数据库进行数据报告;或者编写程序主动调用数据连接其他系统。查看数据库字段说明
指示:
草料后台导航栏-数据API高级功能,选择官方数据库,填写信息,提交激活申请。以下是申请成功后得到的数据库示例:
类型:MySQL
主持人:
端口:3306
数据库名称:cli_202112111(示例)
用户名:cli_202112111(示例)
密码:ek82jk9e1kdi45(示例)
报告制作:
如需连接官方数据库并制作自定义报表,可查看报表制作教程
因为涉及到基础数据库(SQL)操作和BI工具操作,所以有一定的使用门槛。使用前请掌握基本操作能力。
2、自有数据库
Forage会将数据实时推送到您提供的企业数据库中(仅支持Mysql5.7版本),无需建表和开放公网访问权限。未来您可以自由读取数据,实现企业数据与信息的整合。查看数据字段说明
指示:
草料后台导航栏-数据API的高级功能,选择自己的数据库,填写自己的数据库主机、端口、账号等信息。
3、网络钩子
Forage 会将 JSON 格式的表单数据推送到您指定的 URL。该地址需要允许公共互联网访问。之后,您可以编写程序并使用接收到的数据与其他系统或进程进行交互。查看 Webhook 说明
指示:
草料后台导航栏-数据API的高级功能,选择Webhook,填写接收数据的URL地址并保存。
具体流程:
①首先准备一个可以从公网访问的接口地址,填写地址字段,例如(xxx部分为系统的域名或IP)
②配置后,每当在草料中生成新的表单数据时(如在表单中提交一条记录),都会向上述地址发出POST请求
查看全部
文章采集api(数据推送API的应用草料平台的3种推送方式(一)
)
一、数据推送API应用
饲料平台的数据可以自动推送给您,您可以自己调用数据作为应用程序。目前不支持将数据从外部系统写入饲料。
应用一:制作实时数据报表
使用数据分析工具连接数据库,进行数据分析或报表制作,查看效果,制作教程
应用二:对接企业流程
通过在草料平台上实现扫码采集数据等功能,然后通过API与企业系统的进程对接,企业可以在保持原有系统的同时,以极低的成本应用草料功能,并检查影响
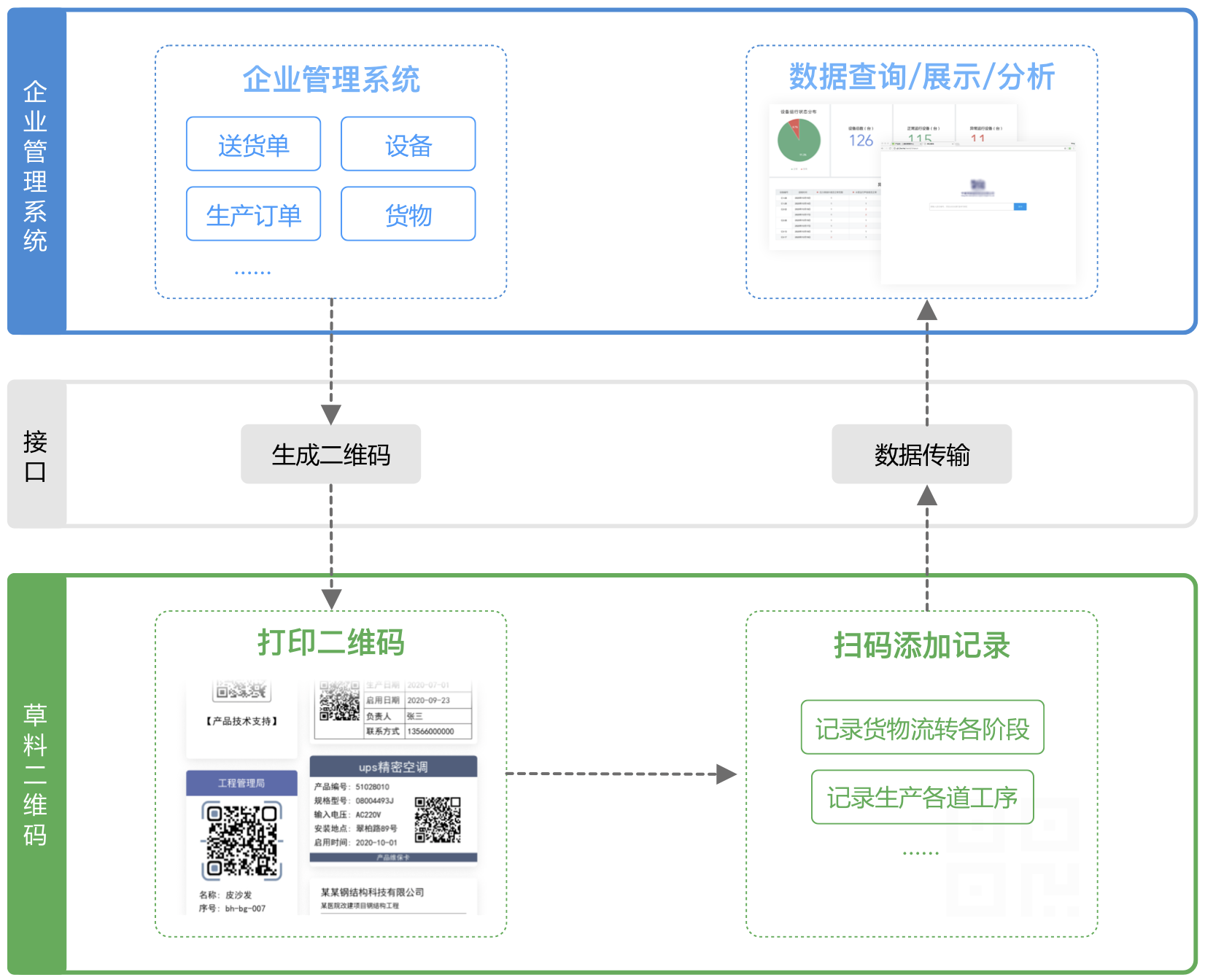
二、我们提供3种推送方式1、官方数据库
Forage 为您提供独立的云数据库来同步您的后端数据。之后,您可以使用数据分析软件连接到这个云数据库进行数据报告;或者编写程序主动调用数据连接其他系统。查看数据库字段说明
指示:
草料后台导航栏-数据API高级功能,选择官方数据库,填写信息,提交激活申请。以下是申请成功后得到的数据库示例:
类型:MySQL
主持人:
端口:3306
数据库名称:cli_202112111(示例)
用户名:cli_202112111(示例)
密码:ek82jk9e1kdi45(示例)
报告制作:
如需连接官方数据库并制作自定义报表,可查看报表制作教程
因为涉及到基础数据库(SQL)操作和BI工具操作,所以有一定的使用门槛。使用前请掌握基本操作能力。
2、自有数据库
Forage会将数据实时推送到您提供的企业数据库中(仅支持Mysql5.7版本),无需建表和开放公网访问权限。未来您可以自由读取数据,实现企业数据与信息的整合。查看数据字段说明
指示:
草料后台导航栏-数据API的高级功能,选择自己的数据库,填写自己的数据库主机、端口、账号等信息。

3、网络钩子
Forage 会将 JSON 格式的表单数据推送到您指定的 URL。该地址需要允许公共互联网访问。之后,您可以编写程序并使用接收到的数据与其他系统或进程进行交互。查看 Webhook 说明
指示:
草料后台导航栏-数据API的高级功能,选择Webhook,填写接收数据的URL地址并保存。
具体流程:
①首先准备一个可以从公网访问的接口地址,填写地址字段,例如(xxx部分为系统的域名或IP)
②配置后,每当在草料中生成新的表单数据时(如在表单中提交一条记录),都会向上述地址发出POST请求

文章采集api(越来越多企业开始做基于公众号平台的数据内容整合)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-29 06:16
越来越多的企业开始基于公众号平台或舆情分析或榜单排名进行数据内容整合。其中涉及的技术之一是公众号采集的数据,公众号数据只有集成到自己的平台后才能进行下一步。
公众号采集不仅技术门槛高,而且专业领域人才匮乏。自己组建团队,人工成本和时间成本都很高。市场上大多数公开可用的技术要么已经过时且无法获得,要么价格太高。
经过多年的技术沉淀,Power Data在公众号数据领域拥有完整的解决方案采集。用户只需提供微信ID号即可获取任意公众号的历史文章数据,包括阅读量、点赞、观看、评论等数据。只需一名工程师即可实现API接口的对接,进而完成数据集成。
电量数据可以提供分钟级的数据同步能力,这意味着在公众号发布后的几分钟内,电量数据就可以同步到用户自己的平台上。此外,它还根据用户需求提供多项个性化需求定制。
在我们服务的客户中,有很多行业标杆用户,包括36kr等新媒体。
Power Data的使命是全面提升客户价值,构建赋能能力,助力行业企业数字化转型。
欢迎联系我试用,加微信请备注“采集”
评论捕获文章 6 小时、12 小时、24 小时、48 小时后发布
有任何问题可以扫描二维码与我交流 查看全部
文章采集api(越来越多企业开始做基于公众号平台的数据内容整合)
越来越多的企业开始基于公众号平台或舆情分析或榜单排名进行数据内容整合。其中涉及的技术之一是公众号采集的数据,公众号数据只有集成到自己的平台后才能进行下一步。
公众号采集不仅技术门槛高,而且专业领域人才匮乏。自己组建团队,人工成本和时间成本都很高。市场上大多数公开可用的技术要么已经过时且无法获得,要么价格太高。

经过多年的技术沉淀,Power Data在公众号数据领域拥有完整的解决方案采集。用户只需提供微信ID号即可获取任意公众号的历史文章数据,包括阅读量、点赞、观看、评论等数据。只需一名工程师即可实现API接口的对接,进而完成数据集成。
电量数据可以提供分钟级的数据同步能力,这意味着在公众号发布后的几分钟内,电量数据就可以同步到用户自己的平台上。此外,它还根据用户需求提供多项个性化需求定制。

在我们服务的客户中,有很多行业标杆用户,包括36kr等新媒体。

Power Data的使命是全面提升客户价值,构建赋能能力,助力行业企业数字化转型。

欢迎联系我试用,加微信请备注“采集”
评论捕获文章 6 小时、12 小时、24 小时、48 小时后发布
有任何问题可以扫描二维码与我交流
文章采集api(优采云采集支持调用5118一键智能改写API接口(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-10-29 06:14
)
优采云采集支持调用5118一键智能重写API接口,处理采集数据标题和内容等,可以产生对搜索引擎更有吸引力的文章 ;
详细使用步骤如下:
1. 5118 一键智能换字API接口配置
一、API配置入口:
点击控制台左侧列表中的【第三方服务配置】 》点击【第三方内容API访问】 》点击【第三方API配置管理】》 最后点击【+5118一键智能原创API] 创建接口配置
二、配置API接口信息:
【API-Key值】从5118后台获取对应的5118一键智能重写APIKey值,填写优采云;
2. 创建 API 处理规则
API处理规则,可设置调用API接口处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】>点击【第三方内容API访问】>进入【API处理规则管理】页面,最后点击【添加API处理规则】创建API处理规则;
二、API处理规则配置:
规则名称:用户可以自己命名;
字段名:填写的字段名的内容将由API接口处理。默认为title和content字段,可以修改、添加或删除;(可以添加其他字段,点击添加内容字段,修改字段名称,但必须在【Detail Extractor】中已经定义,如作者、关键字、描述字段)
使用的API:选择已经设置好的API接口配置,执行时会调用该接口,可以从不同的API接口配置中选择多个字段。5118 一键智能改写;
处理顺序:执行顺序是按照数量从小到大执行;
3. API 处理规则使用
API处理规则的使用方式有两种:手动执行和自动执行:
手动执行:data采集后,在【Result Data & Release】中使用第三方API执行;
自动执行:自动化配置完成后,任务采集数据完成后,系统会自动执行指定的API处理规则,无需人工操作。
一、手动执行API处理规则:
在任务的【结果数据&发布】选项卡中,点击【SEO&API&翻译工具】按钮“选择【第三方API执行】列”选择对应的API处理规则“执行(数据范围有两个执行)方法,批处理根据发布状态执行并根据列表中选择的数据执行);
二、自动执行API处理规则:
启用 API 处理的自动执行。任务完成采集后,会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡,【自动执行第三方API配置】》勾选【采集,自动执行API】选项“选择要执行的API处理规则”选择API interface 处理数据的范围(一般选择“待释放”,all会导致所有数据被执行多次),最后点击save;
4. API处理结果及发布 一、查看API接口处理结果:
API接口处理的内容会生成API接口对应的新字段,例如:
标题处理后的新字段:
title_5118重写(对应5118一键智能重写API接口)
内容处理后的新字段:
content_5118 rewrite(对应5118一键智能重写API接口)
在【结果数据&发布】和数据预览界面均可查看。
提示:API 处理规则执行需要一段时间。执行后页面会自动刷新,出现API接口处理的新字段;
二、API接口处理后的内容发布
在发布文章之前,修改发布目标第二步的映射字段,在API接口处理后将title和content改为新的对应字段。
例如,执行5118一键智能改词API后,选择title_5118改词和content_5118改词发布;
5. 5118-API接口常见问题及解决方案 一、API处理规则和SEO规则如何搭配使用?
系统默认对title和content字段进行SEO功能,需要在SEO规则中修改对应新增的字段,如title_5118换词和content_5118换词字段;
查看全部
文章采集api(优采云采集支持调用5118一键智能改写API接口(组图)
)
优采云采集支持调用5118一键智能重写API接口,处理采集数据标题和内容等,可以产生对搜索引擎更有吸引力的文章 ;
详细使用步骤如下:
1. 5118 一键智能换字API接口配置
一、API配置入口:
点击控制台左侧列表中的【第三方服务配置】 》点击【第三方内容API访问】 》点击【第三方API配置管理】》 最后点击【+5118一键智能原创API] 创建接口配置

二、配置API接口信息:
【API-Key值】从5118后台获取对应的5118一键智能重写APIKey值,填写优采云;


2. 创建 API 处理规则
API处理规则,可设置调用API接口处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】>点击【第三方内容API访问】>进入【API处理规则管理】页面,最后点击【添加API处理规则】创建API处理规则;

二、API处理规则配置:

规则名称:用户可以自己命名;
字段名:填写的字段名的内容将由API接口处理。默认为title和content字段,可以修改、添加或删除;(可以添加其他字段,点击添加内容字段,修改字段名称,但必须在【Detail Extractor】中已经定义,如作者、关键字、描述字段)
使用的API:选择已经设置好的API接口配置,执行时会调用该接口,可以从不同的API接口配置中选择多个字段。5118 一键智能改写;
处理顺序:执行顺序是按照数量从小到大执行;
3. API 处理规则使用
API处理规则的使用方式有两种:手动执行和自动执行:
手动执行:data采集后,在【Result Data & Release】中使用第三方API执行;
自动执行:自动化配置完成后,任务采集数据完成后,系统会自动执行指定的API处理规则,无需人工操作。
一、手动执行API处理规则:
在任务的【结果数据&发布】选项卡中,点击【SEO&API&翻译工具】按钮“选择【第三方API执行】列”选择对应的API处理规则“执行(数据范围有两个执行)方法,批处理根据发布状态执行并根据列表中选择的数据执行);

二、自动执行API处理规则:

启用 API 处理的自动执行。任务完成采集后,会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡,【自动执行第三方API配置】》勾选【采集,自动执行API】选项“选择要执行的API处理规则”选择API interface 处理数据的范围(一般选择“待释放”,all会导致所有数据被执行多次),最后点击save;
4. API处理结果及发布 一、查看API接口处理结果:


API接口处理的内容会生成API接口对应的新字段,例如:
标题处理后的新字段:
title_5118重写(对应5118一键智能重写API接口)
内容处理后的新字段:
content_5118 rewrite(对应5118一键智能重写API接口)
在【结果数据&发布】和数据预览界面均可查看。
提示:API 处理规则执行需要一段时间。执行后页面会自动刷新,出现API接口处理的新字段;
二、API接口处理后的内容发布
在发布文章之前,修改发布目标第二步的映射字段,在API接口处理后将title和content改为新的对应字段。
例如,执行5118一键智能改词API后,选择title_5118改词和content_5118改词发布;

5. 5118-API接口常见问题及解决方案 一、API处理规则和SEO规则如何搭配使用?
系统默认对title和content字段进行SEO功能,需要在SEO规则中修改对应新增的字段,如title_5118换词和content_5118换词字段;

文章采集api(数据推送API的应用草料平台的3种推送方式(一) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-29 06:13
)
一、数据推送API应用
饲料平台的数据可以自动推送给您,您可以将数据作为应用程序自行调用。目前不支持将数据从外部系统写入饲料。
应用一:制作实时数据报表
使用数据分析工具连接数据库,进行数据分析或报表制作,查看效果,制作教程
应用二:对接企业流程
通过在草料平台上实现扫码采集数据等功能,然后通过API与企业系统的进程对接,企业可以在保持原有系统的同时,以极低的成本应用草料功能,并检查影响
二、我们提供3种推送方式1、官方数据库
Forage 为您提供独立的云数据库来同步您的后端数据。之后,您可以使用数据分析软件连接到这个云数据库进行数据报告;或者编写程序主动调用数据连接其他系统。查看数据库字段说明
指示:
草料后台导航栏-数据API高级功能,选择官方数据库,填写信息,提交激活申请。以下是申请成功后得到的数据库示例:
类型:MySQL
主持人:
端口:3306
数据库名称:cli_202112111(示例)
用户名:cli_202112111(示例)
密码:ek82jk9e1kdi45(示例)
报告制作:
如需连接官方数据库并制作自定义报表,可查看报表制作教程
因为涉及到基础数据库(SQL)操作和BI工具操作,所以有一定的使用门槛。使用前请掌握基本操作能力。
2、自有数据库
Forage会将数据实时推送到您提供的企业数据库中(仅支持Mysql5.7版本),无需建表和开放公网访问权限。后续可自由读取数据,实现企业数据与信息的整合。查看数据字段说明
指示:
草料后台导航栏-数据API的高级功能,选择自己的数据库,填写自己的数据库主机、端口、账号等信息。
3、网络钩子
Forage 会将 JSON 格式的表单数据推送到您指定的 URL。该地址需要允许公共互联网访问。之后,您可以编写程序并使用接收到的数据与其他系统或进程进行交互。查看 Webhook 说明
指示:
饲料后台导航栏-数据API的高级功能,选择Webhook,填写接收数据的URL地址并保存。
具体流程:
①首先准备一个可以从公网访问的接口地址,填写地址字段,例如(xxx部分为系统的域名或IP)
②配置后,每当在草料中生成新的表单数据时(如在表单中提交一条记录),都会向上述地址发出POST请求
查看全部
文章采集api(数据推送API的应用草料平台的3种推送方式(一)
)
一、数据推送API应用
饲料平台的数据可以自动推送给您,您可以将数据作为应用程序自行调用。目前不支持将数据从外部系统写入饲料。
应用一:制作实时数据报表
使用数据分析工具连接数据库,进行数据分析或报表制作,查看效果,制作教程

应用二:对接企业流程
通过在草料平台上实现扫码采集数据等功能,然后通过API与企业系统的进程对接,企业可以在保持原有系统的同时,以极低的成本应用草料功能,并检查影响

二、我们提供3种推送方式1、官方数据库
Forage 为您提供独立的云数据库来同步您的后端数据。之后,您可以使用数据分析软件连接到这个云数据库进行数据报告;或者编写程序主动调用数据连接其他系统。查看数据库字段说明
指示:
草料后台导航栏-数据API高级功能,选择官方数据库,填写信息,提交激活申请。以下是申请成功后得到的数据库示例:
类型:MySQL
主持人:
端口:3306
数据库名称:cli_202112111(示例)
用户名:cli_202112111(示例)
密码:ek82jk9e1kdi45(示例)
报告制作:
如需连接官方数据库并制作自定义报表,可查看报表制作教程
因为涉及到基础数据库(SQL)操作和BI工具操作,所以有一定的使用门槛。使用前请掌握基本操作能力。
2、自有数据库
Forage会将数据实时推送到您提供的企业数据库中(仅支持Mysql5.7版本),无需建表和开放公网访问权限。后续可自由读取数据,实现企业数据与信息的整合。查看数据字段说明
指示:
草料后台导航栏-数据API的高级功能,选择自己的数据库,填写自己的数据库主机、端口、账号等信息。

3、网络钩子
Forage 会将 JSON 格式的表单数据推送到您指定的 URL。该地址需要允许公共互联网访问。之后,您可以编写程序并使用接收到的数据与其他系统或进程进行交互。查看 Webhook 说明
指示:
饲料后台导航栏-数据API的高级功能,选择Webhook,填写接收数据的URL地址并保存。
具体流程:
①首先准备一个可以从公网访问的接口地址,填写地址字段,例如(xxx部分为系统的域名或IP)
②配置后,每当在草料中生成新的表单数据时(如在表单中提交一条记录),都会向上述地址发出POST请求


文章采集api(优采云采集支持调用写作社API接口,处理采集的数据标题和内容等 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-10-28 14:18
)
优采云采集 支持调用写代理API接口处理采集的数据标题和内容;
详细使用步骤如下:
1. 创建写代理API接口配置一、API配置入口:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》点击【第三方API配置管理】==》最后点击【写Club_Rewrite接口API】 ] 创建接口配置;
二、配置API接口信息:
购买代写API,请联系代写客服,告知在优采云采集平台使用。
【API key】请联系代写机构客服获取对应的API key,填写优采云;
注意:编写机构限制每次调用最多6000个字符(包括html代码),所以当内容长度超过时,优采云会被分割调用多次。这个操作会增加api调用次数,增加成本。会相应增加,这是用户需要承担的费用,使用前一定要注意!!!
2. 创建 API 处理规则
API处理规则,可设置调用API接口处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》进入【API处理规则管理】页面,最后点击【添加API】处理规则] 创建API处理规则;
二、API处理规则配置:
规则名称:用户可以自己命名;
字段名:填写的字段名的内容将由API接口处理。默认为title和content字段,可以修改、添加或删除;
使用的API:选择已经设置好的API接口配置,执行时会调用该接口,多个字段可以选择不同的API接口配置;
处理顺序:执行顺序是按照数量从小到大执行;
3. API 处理规则使用
API处理规则的使用方式有两种:手动执行和自动执行:
手动执行:data采集后,在【Result Data & Release】中使用第三方API执行;
自动执行:自动化配置完成后,任务采集数据完成后,系统会自动执行指定的API处理规则,无需人工操作。
一、手动执行API处理规则:
在任务的【结果数据&发布】选项卡中,点击【SEO&API&翻译工具】按钮==》选择【第三方API执行】栏==》选择对应的API处理规则==》执行(有两个执行数据范围的方法,根据发布状态批量执行,根据列表中选择的数据执行);
二、自动执行API处理规则:
启用 API 处理的自动执行。任务完成采集后,会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡中,【自动执行第三方API配置】==》勾选【采集,自动执行API】选项==》选择要执行的API处理规则==》选择API接口处理的数据范围(一般选择“待发布”,所有会导致所有数据被多次执行),最后点击保存;
4. API处理结果及发布 一、查看API接口处理结果:
API接口处理的内容会保存为一个新的字段,例如:
标题处理后新增字段:title_写社
内容处理后的新领域:content_写社
在【结果数据&发布】和数据预览界面均可查看。
提示:API处理规则执行需要一段时间,执行后页面会自动刷新,API接口处理的新字段会出现;
二、API接口处理后的内容发布
在发布文章之前,修改发布目标第二步的映射字段,通过API接口处理后将title和content改为新的对应字段title_writing club和content_writing club;
提示:如果无法在发布目标中选择新字段,请在此任务下复制或创建一个新的发布目标,然后您可以在新的发布目标中选择新字段。详细教程可以查看发布目标中不能选择的字段;
5. 编写Club-API接口常见问题及解决方法
一、API处理规则和SEO规则如何搭配使用?
系统默认对title和content字段进行SEO功能,需要在SEO规则中修改title_writing club和content_writing club字段;
查看全部
文章采集api(优采云采集支持调用写作社API接口,处理采集的数据标题和内容等
)
优采云采集 支持调用写代理API接口处理采集的数据标题和内容;
详细使用步骤如下:
1. 创建写代理API接口配置一、API配置入口:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》点击【第三方API配置管理】==》最后点击【写Club_Rewrite接口API】 ] 创建接口配置;

二、配置API接口信息:
购买代写API,请联系代写客服,告知在优采云采集平台使用。
【API key】请联系代写机构客服获取对应的API key,填写优采云;
注意:编写机构限制每次调用最多6000个字符(包括html代码),所以当内容长度超过时,优采云会被分割调用多次。这个操作会增加api调用次数,增加成本。会相应增加,这是用户需要承担的费用,使用前一定要注意!!!
2. 创建 API 处理规则
API处理规则,可设置调用API接口处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》进入【API处理规则管理】页面,最后点击【添加API】处理规则] 创建API处理规则;
二、API处理规则配置:
规则名称:用户可以自己命名;
字段名:填写的字段名的内容将由API接口处理。默认为title和content字段,可以修改、添加或删除;
使用的API:选择已经设置好的API接口配置,执行时会调用该接口,多个字段可以选择不同的API接口配置;
处理顺序:执行顺序是按照数量从小到大执行;
3. API 处理规则使用
API处理规则的使用方式有两种:手动执行和自动执行:
手动执行:data采集后,在【Result Data & Release】中使用第三方API执行;
自动执行:自动化配置完成后,任务采集数据完成后,系统会自动执行指定的API处理规则,无需人工操作。
一、手动执行API处理规则:
在任务的【结果数据&发布】选项卡中,点击【SEO&API&翻译工具】按钮==》选择【第三方API执行】栏==》选择对应的API处理规则==》执行(有两个执行数据范围的方法,根据发布状态批量执行,根据列表中选择的数据执行);
二、自动执行API处理规则:
启用 API 处理的自动执行。任务完成采集后,会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡中,【自动执行第三方API配置】==》勾选【采集,自动执行API】选项==》选择要执行的API处理规则==》选择API接口处理的数据范围(一般选择“待发布”,所有会导致所有数据被多次执行),最后点击保存;
4. API处理结果及发布 一、查看API接口处理结果:
API接口处理的内容会保存为一个新的字段,例如:
标题处理后新增字段:title_写社
内容处理后的新领域:content_写社
在【结果数据&发布】和数据预览界面均可查看。
提示:API处理规则执行需要一段时间,执行后页面会自动刷新,API接口处理的新字段会出现;
二、API接口处理后的内容发布
在发布文章之前,修改发布目标第二步的映射字段,通过API接口处理后将title和content改为新的对应字段title_writing club和content_writing club;
提示:如果无法在发布目标中选择新字段,请在此任务下复制或创建一个新的发布目标,然后您可以在新的发布目标中选择新字段。详细教程可以查看发布目标中不能选择的字段;
5. 编写Club-API接口常见问题及解决方法
一、API处理规则和SEO规则如何搭配使用?
系统默认对title和content字段进行SEO功能,需要在SEO规则中修改title_writing club和content_writing club字段;
文章采集api(批量采集“虎嗅”的文章到自己网站的应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-10-26 03:03
现在有这样一个需求:批量采集微信公众号文章给自己网站,批量采集“虎嗅”文章给自己网站 . 主要障碍之一是我们的网站中无法显示原创图片地址。
他们利用HTTP请求头中的referrer值,即请求的来源,来判断是否返回数据,以达到防盗的目的。一些直播源也使用这种方法来防止非法卖淫。我们需要知道的是,我们的网站通常会在发起http请求时自动将referrer设置为网站地址。
下面的方法主要是全局添加几个meta标签来设置默认的referrer值,以免请求原图数据时提供网站地址的来源,避免原网站反-leech设计,但是这部分依赖这个原理辅助统计的第三方推广链接非常不利,甚至可能会被判定为无效,导致无法获得佣金。
折中的方法是将微信公众号文章和采集分到一个单独的分类中,只有当网站在这个分类元标签下显示文章时才添加。
// 其它自定义代码加到此行下面
add_action('wp_head', 'guihet_referrer');// 前端添加 referrer 标签
add_action('admin_head', 'guihet_referrer');// 后台添加 referrer 标签
function guihet_referrer(){
$catsy = get_the_category();
$myCat = $catsy[0]->cat_ID;
if($myCat===22) //分类 ID 为 22 的..
{
echo'';
echo'';
echo'';
}
}
代码添加到WP主题模板下functions.php文件的最后,这里根据实际情况更改类别ID。 查看全部
文章采集api(批量采集“虎嗅”的文章到自己网站的应用)
现在有这样一个需求:批量采集微信公众号文章给自己网站,批量采集“虎嗅”文章给自己网站 . 主要障碍之一是我们的网站中无法显示原创图片地址。
他们利用HTTP请求头中的referrer值,即请求的来源,来判断是否返回数据,以达到防盗的目的。一些直播源也使用这种方法来防止非法卖淫。我们需要知道的是,我们的网站通常会在发起http请求时自动将referrer设置为网站地址。

下面的方法主要是全局添加几个meta标签来设置默认的referrer值,以免请求原图数据时提供网站地址的来源,避免原网站反-leech设计,但是这部分依赖这个原理辅助统计的第三方推广链接非常不利,甚至可能会被判定为无效,导致无法获得佣金。
折中的方法是将微信公众号文章和采集分到一个单独的分类中,只有当网站在这个分类元标签下显示文章时才添加。
// 其它自定义代码加到此行下面
add_action('wp_head', 'guihet_referrer');// 前端添加 referrer 标签
add_action('admin_head', 'guihet_referrer');// 后台添加 referrer 标签
function guihet_referrer(){
$catsy = get_the_category();
$myCat = $catsy[0]->cat_ID;
if($myCat===22) //分类 ID 为 22 的..
{
echo'';
echo'';
echo'';
}
}
代码添加到WP主题模板下functions.php文件的最后,这里根据实际情况更改类别ID。
文章采集api(数据推送API的应用草料平台的3种推送方式(一) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-10-24 01:00
)
一、数据推送API应用
饲料平台的数据可以自动推送给您,您可以自己调用数据作为应用程序。目前不支持将数据从外部系统写入饲料。
应用一:制作实时数据报表
使用数据分析工具连接数据库,进行数据分析或报表制作,查看效果,制作教程
应用二:对接企业流程
通过在草料平台上实现扫码采集数据等功能,然后通过API与企业系统的进程对接,企业可以在保持原有系统的同时,以极低的成本应用草料功能,并检查影响
二、我们提供3种推送方式1、官方数据库
Forage 为您提供独立的云数据库来同步您的后端数据。之后,您可以使用数据分析软件连接到这个云数据库进行数据报告;或者编写程序主动调用数据连接其他系统。查看数据库字段说明
指示:
草料后台导航栏-数据API高级功能,选择官方数据库,填写信息,提交激活申请。以下是申请成功后得到的数据库示例:
类型:MySQL
主持人:
端口:3306
数据库名称:cli_202112111(示例)
用户名:cli_202112111(示例)
密码:ek82jk9e1kdi45(示例)
报告制作:
如需连接官方数据库并制作自定义报表,可查看报表制作教程
因为涉及到基础数据库(SQL)操作和BI工具操作,所以有一定的使用门槛。使用前请掌握基本操作能力。
2、自有数据库
Forage会将数据实时推送到您提供的企业数据库中(仅支持Mysql5.7版本),无需建表和开放公网访问权限。后续可自由读取数据,实现企业数据与信息的整合。查看数据字段说明
指示:
草料后台导航栏-数据API的高级功能,选择自己的数据库,填写自己的数据库主机、端口、账号等信息。
3、网络钩子
Forage 会将 JSON 格式的表单数据推送到您指定的 URL。该地址需要允许公共互联网访问。之后,您可以编写程序并使用接收到的数据与其他系统或进程进行交互。查看 Webhook 说明
指示:
草料后台导航栏-数据API的高级功能,选择Webhook,填写接收数据的URL地址并保存。
具体流程:
①首先准备一个可以从公网访问的接口地址,填写地址字段,例如(xxx部分为系统的域名或IP)
②配置后,每当在草料中生成新的表单数据时(如在表单中提交一条记录),都会向上述地址发出POST请求
查看全部
文章采集api(数据推送API的应用草料平台的3种推送方式(一)
)
一、数据推送API应用
饲料平台的数据可以自动推送给您,您可以自己调用数据作为应用程序。目前不支持将数据从外部系统写入饲料。
应用一:制作实时数据报表
使用数据分析工具连接数据库,进行数据分析或报表制作,查看效果,制作教程
应用二:对接企业流程
通过在草料平台上实现扫码采集数据等功能,然后通过API与企业系统的进程对接,企业可以在保持原有系统的同时,以极低的成本应用草料功能,并检查影响
二、我们提供3种推送方式1、官方数据库
Forage 为您提供独立的云数据库来同步您的后端数据。之后,您可以使用数据分析软件连接到这个云数据库进行数据报告;或者编写程序主动调用数据连接其他系统。查看数据库字段说明
指示:
草料后台导航栏-数据API高级功能,选择官方数据库,填写信息,提交激活申请。以下是申请成功后得到的数据库示例:
类型:MySQL
主持人:
端口:3306
数据库名称:cli_202112111(示例)
用户名:cli_202112111(示例)
密码:ek82jk9e1kdi45(示例)
报告制作:
如需连接官方数据库并制作自定义报表,可查看报表制作教程
因为涉及到基础数据库(SQL)操作和BI工具操作,所以有一定的使用门槛。使用前请掌握基本操作能力。
2、自有数据库
Forage会将数据实时推送到您提供的企业数据库中(仅支持Mysql5.7版本),无需建表和开放公网访问权限。后续可自由读取数据,实现企业数据与信息的整合。查看数据字段说明
指示:
草料后台导航栏-数据API的高级功能,选择自己的数据库,填写自己的数据库主机、端口、账号等信息。
3、网络钩子
Forage 会将 JSON 格式的表单数据推送到您指定的 URL。该地址需要允许公共互联网访问。之后,您可以编写程序并使用接收到的数据与其他系统或进程进行交互。查看 Webhook 说明
指示:
草料后台导航栏-数据API的高级功能,选择Webhook,填写接收数据的URL地址并保存。
具体流程:
①首先准备一个可以从公网访问的接口地址,填写地址字段,例如(xxx部分为系统的域名或IP)
②配置后,每当在草料中生成新的表单数据时(如在表单中提交一条记录),都会向上述地址发出POST请求
文章采集api(php采集文章图片不显示的解决办法:1、根据关键字采集百度搜寻结果)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-10-22 21:10
今天PHP爱好者为大家带来php采集文章图片不显示的解决方法:1、根据关键字采集百度搜索结果; 2、@ >将采集中的html根据定义的域名进行批量转换。希望能帮到你。
本文运行环境:windows7系统,PHP7.版本1,DELL G3电脑
php采集文章图片不显示怎么办?
PHP CURL采集百度搜索结果图片不显示问题的解决方法
1.根据关键字采集百度搜索结果
根据关键字采集百度搜索结果,可以使用curl来实现,代码如下:
<p style="line-height: 2em; text-indent: 2em; text-align: left;"><br style="text-indent: 2em; text-align: left;"/></p>
输出后发现有些图片无法显示
2.采集显示后图片不显示原因分析
直接在百度搜索,页面可以显示图片。使用firebug查看图片路径,发现采集的图片域名与百度搜索的图片域名不同。
采集返回的图片域名
用于普通搜索的图像域
查看采集和正常搜索html,发现有域名转换js不一样
采集
<p style="line-height: 2em; text-indent: 2em; text-align: left;">var list = {<br style="text-indent: 2em; text-align: left;"/> "graph.baidu.com": "http://graph.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "t1.baidu.com":"http://t1.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "t2.baidu.com":"http://t2.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "t3.baidu.com":"http://t3.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "t10.baidu.com":"http://t10.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "t11.baidu.com":"http://t11.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "t12.baidu.com":"http://t12.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "i7.baidu.com":"http://i7.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "i8.baidu.com":"http://i8.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "i9.baidu.com":"http://i9.baidu.com",<br style="text-indent: 2em; text-align: left;"/>};<br style="text-indent: 2em; text-align: left;"/></p>
普通搜索
<p style="line-height: 2em; text-indent: 2em; text-align: left;">var list = {<br style="text-indent: 2em; text-align: left;"/> "graph.baidu.com": "https://sp0.baidu.com/-aYHfD0a2gU2pMbgoY3K",<br style="text-indent: 2em; text-align: left;"/> "t1.baidu.com":"https://ss0.baidu.com/6ON1bjeh1BF3odCf",<br style="text-indent: 2em; text-align: left;"/> "t2.baidu.com":"https://ss1.baidu.com/6OZ1bjeh1BF3odCf",<br style="text-indent: 2em; text-align: left;"/> "t3.baidu.com":"https://ss2.baidu.com/6OV1bjeh1BF3odCf",<br style="text-indent: 2em; text-align: left;"/> "t10.baidu.com":"https://ss0.baidu.com/6ONWsjip0QIZ8tyhnq",<br style="text-indent: 2em; text-align: left;"/> "t11.baidu.com":"https://ss1.baidu.com/6ONXsjip0QIZ8tyhnq",<br style="text-indent: 2em; text-align: left;"/> "t12.baidu.com":"https://ss2.baidu.com/6ONYsjip0QIZ8tyhnq",<br style="text-indent: 2em; text-align: left;"/> "i7.baidu.com":"https://ss0.baidu.com/73F1bjeh1BF3odCf",<br style="text-indent: 2em; text-align: left;"/> "i8.baidu.com":"https://ss0.baidu.com/73x1bjeh1BF3odCf",<br style="text-indent: 2em; text-align: left;"/> "i9.baidu.com":"https://ss0.baidu.com/73t1bjeh1BF3odCf",<br style="text-indent: 2em; text-align: left;"/>};<br style="text-indent: 2em; text-align: left;"/></p>
因此,根据源地址、IP、header等参数可以断定,如果是采集,百度会返回不同的js。
3.采集图片不显示后的解决方法
根据定义的域名批量传输采集中的html。
<p style="line-height: 2em; text-indent: 2em; text-align: left;"><br style="text-indent: 2em; text-align: left;"/></p>
添加域名转换后,所有图片均可正常显示。
以上是php采集文章的详细内容,图片没有说明怎么做。更多详情请关注其他相关php粉丝文章! 查看全部
文章采集api(php采集文章图片不显示的解决办法:1、根据关键字采集百度搜寻结果)
今天PHP爱好者为大家带来php采集文章图片不显示的解决方法:1、根据关键字采集百度搜索结果; 2、@ >将采集中的html根据定义的域名进行批量转换。希望能帮到你。

本文运行环境:windows7系统,PHP7.版本1,DELL G3电脑
php采集文章图片不显示怎么办?
PHP CURL采集百度搜索结果图片不显示问题的解决方法
1.根据关键字采集百度搜索结果
根据关键字采集百度搜索结果,可以使用curl来实现,代码如下:
<p style="line-height: 2em; text-indent: 2em; text-align: left;"><br style="text-indent: 2em; text-align: left;"/></p>
输出后发现有些图片无法显示
2.采集显示后图片不显示原因分析
直接在百度搜索,页面可以显示图片。使用firebug查看图片路径,发现采集的图片域名与百度搜索的图片域名不同。
采集返回的图片域名

用于普通搜索的图像域

查看采集和正常搜索html,发现有域名转换js不一样
采集
<p style="line-height: 2em; text-indent: 2em; text-align: left;">var list = {<br style="text-indent: 2em; text-align: left;"/> "graph.baidu.com": "http://graph.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "t1.baidu.com":"http://t1.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "t2.baidu.com":"http://t2.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "t3.baidu.com":"http://t3.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "t10.baidu.com":"http://t10.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "t11.baidu.com":"http://t11.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "t12.baidu.com":"http://t12.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "i7.baidu.com":"http://i7.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "i8.baidu.com":"http://i8.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "i9.baidu.com":"http://i9.baidu.com",<br style="text-indent: 2em; text-align: left;"/>};<br style="text-indent: 2em; text-align: left;"/></p>
普通搜索
<p style="line-height: 2em; text-indent: 2em; text-align: left;">var list = {<br style="text-indent: 2em; text-align: left;"/> "graph.baidu.com": "https://sp0.baidu.com/-aYHfD0a2gU2pMbgoY3K",<br style="text-indent: 2em; text-align: left;"/> "t1.baidu.com":"https://ss0.baidu.com/6ON1bjeh1BF3odCf",<br style="text-indent: 2em; text-align: left;"/> "t2.baidu.com":"https://ss1.baidu.com/6OZ1bjeh1BF3odCf",<br style="text-indent: 2em; text-align: left;"/> "t3.baidu.com":"https://ss2.baidu.com/6OV1bjeh1BF3odCf",<br style="text-indent: 2em; text-align: left;"/> "t10.baidu.com":"https://ss0.baidu.com/6ONWsjip0QIZ8tyhnq",<br style="text-indent: 2em; text-align: left;"/> "t11.baidu.com":"https://ss1.baidu.com/6ONXsjip0QIZ8tyhnq",<br style="text-indent: 2em; text-align: left;"/> "t12.baidu.com":"https://ss2.baidu.com/6ONYsjip0QIZ8tyhnq",<br style="text-indent: 2em; text-align: left;"/> "i7.baidu.com":"https://ss0.baidu.com/73F1bjeh1BF3odCf",<br style="text-indent: 2em; text-align: left;"/> "i8.baidu.com":"https://ss0.baidu.com/73x1bjeh1BF3odCf",<br style="text-indent: 2em; text-align: left;"/> "i9.baidu.com":"https://ss0.baidu.com/73t1bjeh1BF3odCf",<br style="text-indent: 2em; text-align: left;"/>};<br style="text-indent: 2em; text-align: left;"/></p>
因此,根据源地址、IP、header等参数可以断定,如果是采集,百度会返回不同的js。
3.采集图片不显示后的解决方法
根据定义的域名批量传输采集中的html。
<p style="line-height: 2em; text-indent: 2em; text-align: left;"><br style="text-indent: 2em; text-align: left;"/></p>
添加域名转换后,所有图片均可正常显示。
以上是php采集文章的详细内容,图片没有说明怎么做。更多详情请关注其他相关php粉丝文章!
文章采集api([搜一搜]智能写作神器减少脑力劳动,快速实现目标.)
采集交流 • 优采云 发表了文章 • 0 个评论 • 240 次浏览 • 2021-10-19 10:25
【搜一搜】智能写作是优秀自媒体人和SEOR必备的写作工具,减少脑力劳动,提高工作效率,快速达成目标。
如果你是第一次使用,【搜一搜】助你成为优秀的写作高手,一起来看看吧~
下面是几个新手需要知道的常用函数
一、找到登录网址
二、文章采集
三、原采集列表
四、伪原创列表
五、获取API
一、找到登录网址
1.在电脑上打开浏览器
2. 在地址栏中输入 URL/
3.注册账号,直接登录
二、文章采集
1、文章采集,打开界面,可以看到最上方的选项文章采集,点击进入关键词,你可以随便输入想表达 只需输入一两个字就可以自动生成专业的文章。
2.批量采集,批量采集可以一次搜索多个关键词,速度更快。
3.采集的结果,采集的结果是前两步提交的结果,处理状态和详细信息可以在这里查看。
三、原采集列表
在这里可以看到文章的出处和标题,也可以查看伪原创的内容和原文,方便修改。
四、伪原创列表
您可以使用伪原创直观的查看文章的相似度,更方便的修改文章的内容。
五、获取API
如果您有特殊需求,可以连接我们的API系统,连接您的网站系统,cms站群等。
那么今天给大家分享的5个实用技巧,你学会了吗?快点快点练习吧~
【体验地址】电脑登录,免费注册:/ 查看全部
文章采集api([搜一搜]智能写作神器减少脑力劳动,快速实现目标.)
【搜一搜】智能写作是优秀自媒体人和SEOR必备的写作工具,减少脑力劳动,提高工作效率,快速达成目标。

如果你是第一次使用,【搜一搜】助你成为优秀的写作高手,一起来看看吧~
下面是几个新手需要知道的常用函数
一、找到登录网址
二、文章采集
三、原采集列表
四、伪原创列表
五、获取API
一、找到登录网址
1.在电脑上打开浏览器
2. 在地址栏中输入 URL/
3.注册账号,直接登录

二、文章采集
1、文章采集,打开界面,可以看到最上方的选项文章采集,点击进入关键词,你可以随便输入想表达 只需输入一两个字就可以自动生成专业的文章。
2.批量采集,批量采集可以一次搜索多个关键词,速度更快。
3.采集的结果,采集的结果是前两步提交的结果,处理状态和详细信息可以在这里查看。
三、原采集列表
在这里可以看到文章的出处和标题,也可以查看伪原创的内容和原文,方便修改。
四、伪原创列表
您可以使用伪原创直观的查看文章的相似度,更方便的修改文章的内容。
五、获取API
如果您有特殊需求,可以连接我们的API系统,连接您的网站系统,cms站群等。
那么今天给大家分享的5个实用技巧,你学会了吗?快点快点练习吧~
【体验地址】电脑登录,免费注册:/
文章采集api(修改历史:本工具与2012-09-17发现一个bug且已修正)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-11-16 05:16
[大小=中等]
从2008年开始做网页数据采集,开始使用HTML Parser、NekoHTML、Jericho HTML Parser(用于解析html网页)、HtmlUtil(纯java版本的浏览器,带Http协议和Html解析功能,JS执行功能)等,带HttpClient(提供高效、最新、功能丰富的支持HTTP协议的客户端编程工具包,是一个HTTP协议相关的包,类似于我介绍的 API 中的 HtmlPage 类)。因为那些API采集[color=red]大量的多种格式的网页数据[/color]在配置上非常不灵活,比如DOM解析、Xpath等,导致配置复杂,所以从2009 3 我开始编写自己的 API 来获取和分析网页:网页。服务在公司' s 项目。通过预配置,经过采集10000多个数据源和多种网页数据呈现格式的测试和修正,于2010年9月形成了一个相对稳定的版本。
修改历史:
此工具在 2012-09-17 发现了一个错误,并已更正。今天从新包提交一个版本,之前的源码和jar包版本都会被删除。
1、源码包结构说明:基于com.hlxp.webpage包的启动说明:
(1)com.hlxp.webpage.app与采集的应用相关,可以独立运行,主要是与采集配合使用。
(2)com.hlxp.webpage.bean 采集中使用的一些无状态VO(值对象)
(3)com.hlxp.webpage.log包中收录日志类,主要打包jdk自带的日志对象;以及log4j的日志类。
(4)com.hlxp.webpage.util 包中收录一些特定的 采集 工具,它们使用 HtmlPage 和 HtmlUtil 类来完成特定的 采集,例如只有 采集 链接,或者只是采集img的链接。
(5)HtmlPage类是一个基础类,主要用于通过get和post获取网页,也支持参数的提交。
(6)HtmlUtil类是一个基础类,主要用于解析通过HtmlPage获取的网页,支持正则表达式分析、字符切割、HTML标记分析。
[颜色=红色]注意:[/color]
源码中没有示例程序,示例在每个解析类的main函数中。以后有时间我会写API帮助文档和示例程序。这些将发布在本博客的附件中。
有问题的朋友可以在本博客留言,我会和大家一起讨论。
2.API函数介绍
(1)可以或者普通网页和没有验证码的登录网页(需要登录的网页,需要手动登录,然后将cookie复制到程序中获取)
(2)可以解析HTML、XML、DTD等静态文本显示数据的网页。
(3)可以方便采集翻页,通过设置页面链接格式,自动生成或采集页面链接及其网页。
(4)HtmlPage.java 用于获取网页,HtmlUtil.java 用于解析网页的基本类。两个类的主要方法中有示例。
[/尺寸] 查看全部
文章采集api(修改历史:本工具与2012-09-17发现一个bug且已修正)
[大小=中等]
从2008年开始做网页数据采集,开始使用HTML Parser、NekoHTML、Jericho HTML Parser(用于解析html网页)、HtmlUtil(纯java版本的浏览器,带Http协议和Html解析功能,JS执行功能)等,带HttpClient(提供高效、最新、功能丰富的支持HTTP协议的客户端编程工具包,是一个HTTP协议相关的包,类似于我介绍的 API 中的 HtmlPage 类)。因为那些API采集[color=red]大量的多种格式的网页数据[/color]在配置上非常不灵活,比如DOM解析、Xpath等,导致配置复杂,所以从2009 3 我开始编写自己的 API 来获取和分析网页:网页。服务在公司' s 项目。通过预配置,经过采集10000多个数据源和多种网页数据呈现格式的测试和修正,于2010年9月形成了一个相对稳定的版本。
修改历史:
此工具在 2012-09-17 发现了一个错误,并已更正。今天从新包提交一个版本,之前的源码和jar包版本都会被删除。
1、源码包结构说明:基于com.hlxp.webpage包的启动说明:
(1)com.hlxp.webpage.app与采集的应用相关,可以独立运行,主要是与采集配合使用。
(2)com.hlxp.webpage.bean 采集中使用的一些无状态VO(值对象)
(3)com.hlxp.webpage.log包中收录日志类,主要打包jdk自带的日志对象;以及log4j的日志类。
(4)com.hlxp.webpage.util 包中收录一些特定的 采集 工具,它们使用 HtmlPage 和 HtmlUtil 类来完成特定的 采集,例如只有 采集 链接,或者只是采集img的链接。
(5)HtmlPage类是一个基础类,主要用于通过get和post获取网页,也支持参数的提交。
(6)HtmlUtil类是一个基础类,主要用于解析通过HtmlPage获取的网页,支持正则表达式分析、字符切割、HTML标记分析。
[颜色=红色]注意:[/color]
源码中没有示例程序,示例在每个解析类的main函数中。以后有时间我会写API帮助文档和示例程序。这些将发布在本博客的附件中。
有问题的朋友可以在本博客留言,我会和大家一起讨论。
2.API函数介绍
(1)可以或者普通网页和没有验证码的登录网页(需要登录的网页,需要手动登录,然后将cookie复制到程序中获取)
(2)可以解析HTML、XML、DTD等静态文本显示数据的网页。
(3)可以方便采集翻页,通过设置页面链接格式,自动生成或采集页面链接及其网页。
(4)HtmlPage.java 用于获取网页,HtmlUtil.java 用于解析网页的基本类。两个类的主要方法中有示例。
[/尺寸]
文章采集api(JSP众筹管理系统.5开发java语言设计系统源码特点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-11-15 12:11
一、 源码特点 JSP众筹管理系统是一个完整的网页设计系统,有助于理解JSP java编程语言。系统具有完整的源代码和数据库,系统主要采用B/S模式。发展。 二、功能介绍 前台主要功能:显示项目信息及项目周边相关信息 后台主要功能:(1)权限管理:添加、删除、修改、查看权限信息(2)用户管理:添加、删除、修改、查看用户信息(3)项目分类管理:添加、删除、修改、查看项目分类信息(4)项目管理:添加项目信息),删除、修改和查看(5)日志管理:添加、删除、修改和查看日志信息(6)项目支持管理:添加、删除、修改和查看项目支持信息(7)Project审核管理:添加、删除、修改和查看项目审核信息(8)报告管理:添加、删除、修改和查看报告信息(9)消息管理:对消息信息的添加、删除、修改和查看(8) 招生管理:添加、删除、修改和查看招生信息编队三、注意事项1、管理员账号:admin 密码:admin 数据库配置文件DBO.java2、开发环境为TOMCAT7.0,Myeclipse8.5,数据库为mysql,使用java语言开发。3、数据库文件名为jspfgongchou .mysql,系统名gongchou4、地址:xiangmu.jsp 查看全部
文章采集api(JSP众筹管理系统.5开发java语言设计系统源码特点)
一、 源码特点 JSP众筹管理系统是一个完整的网页设计系统,有助于理解JSP java编程语言。系统具有完整的源代码和数据库,系统主要采用B/S模式。发展。 二、功能介绍 前台主要功能:显示项目信息及项目周边相关信息 后台主要功能:(1)权限管理:添加、删除、修改、查看权限信息(2)用户管理:添加、删除、修改、查看用户信息(3)项目分类管理:添加、删除、修改、查看项目分类信息(4)项目管理:添加项目信息),删除、修改和查看(5)日志管理:添加、删除、修改和查看日志信息(6)项目支持管理:添加、删除、修改和查看项目支持信息(7)Project审核管理:添加、删除、修改和查看项目审核信息(8)报告管理:添加、删除、修改和查看报告信息(9)消息管理:对消息信息的添加、删除、修改和查看(8) 招生管理:添加、删除、修改和查看招生信息编队三、注意事项1、管理员账号:admin 密码:admin 数据库配置文件DBO.java2、开发环境为TOMCAT7.0,Myeclipse8.5,数据库为mysql,使用java语言开发。3、数据库文件名为jspfgongchou .mysql,系统名gongchou4、地址:xiangmu.jsp
文章采集api(MetricsAPI介绍Metrics-Server之前,必须要提一下API的概念)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-11-12 11:22
概述
从v1.8开始,可以通过Metrics API的形式获取资源使用监控。具体的组件是Metrics Server,用来替代之前的heapster。heapster 从 1.11 开始逐渐被废弃。
Metrics-Server 是集群核心监控数据的聚合器。从Kubernetes1.8开始,在kube-up.sh脚本创建的集群中默认部署为Deployment对象。如果是其他部署方式,则需要单独安装。, 或者咨询相应的云厂商。
指标 API
在介绍 Metrics-Server 之前,不得不提一下 Metrics API 的概念
与之前的监控采集方法(hepaster)相比,Metrics API是一个全新的思路。官方希望核心指标的监控稳定,版本可控,用户可以直接访问(比如使用kubectl top命令),或者集群中的控制器(比如HPA)使用,就像其他Kubernetes一样蜜蜂。
官方放弃heapster项目,是将核心资源监控当成一等公民,即通过api-server或client直接访问,如pod和service,而不是安装一个heapster,由heapster单独采集和管理。
假设我们为每个pod和节点采集10个指标,从k8s的1.6开始,支持5000个节点和每个节点30个pod,假设采集的粒度为每分钟一次,那么:
10 x 5000 x 30 / 60 = 25000 平均每分钟2万多个采集指标
因为k8s的api-server将所有数据持久化在etcd中,显然k8s本身无法处理采集的这种频率,而且这种监控数据变化很快,而且是临时数据,所以需要单独的组件来处理,k8s版本只是部分存储在内存中,因此metric-server的概念诞生了。
其实Hepaster已经暴露了API,但是Kubernetes的用户和其他组件必须通过master代理访问,而且Hepaster的接口不像api-server那样有完整的认证和客户端集成。这个api还在alpha阶段(8月18日),希望能达到GA阶段。以 api-server 风格编写:通用 apiserver
有了Metrics Server组件,采集已经到达需要的数据,暴露了api,但是因为api需要统一,如何将请求转发到api-server /apis/metrics请求到Metrics Server ? 解决方案即:kube-aggregator,在k8s的1.7中已经完成。Metrics Server 之前没有发布,在 kube-aggregator 的步骤中延迟了。
kube-aggregator(聚合api)主要提供:
详细设计文档:参考链接
metric api的使用:
喜欢:
http://127.0.0.1:8001/apis/met ... nodes
http://127.0.0.1:8001/apis/met ... odes/
http://127.0.0.1:8001/apis/met ... pods/
度量服务器
Metrics 服务器定期从 Kubelet 的 Summary API(类似于 /ap1/v1/nodes/nodename/stats/summary)获取指标信息采集。这些聚合后的数据会存储在内存中,并以metric-api的形式暴露出去。
Metrics server复用api-server库来实现自己的功能,比如认证、版本等,为了将数据存储在内存中,去掉默认的etcd存储,引入内存存储(即实现Storage接口)。因为是存储在内存中,所以监控数据不是持久化的,可以通过第三方存储进行扩展,与heapster一致。
Metrics服务器出现后,新的Kubernetes监控架构将如上图所示
官方地址:
用
如上所述,metric-server是一个扩展的apiserver,依赖kube-aggregator,所以需要在apiserver中开启相关参数。
--requestheader-client-ca-file=/etc/kubernetes/certs/proxy-ca.crt
--proxy-client-cert-file=/etc/kubernetes/certs/proxy.crt
--proxy-client-key-file=/etc/kubernetes/certs/proxy.key
--requestheader-allowed-names=aggregator
--requestheader-extra-headers-prefix=X-Remote-Extra-
--requestheader-group-headers=X-Remote-Group
--requestheader-username-headers=X-Remote-User
安装文件下载地址:1.8+,注意修改镜像地址为国内镜像
kubectl create -f metric-server/
安装成功后访问地址api地址为:
Metrics Server 的资源消耗会随着集群中 Pod 数量的不断增长而不断上升,因此需要
插件调整器垂直缩放这个容器。addon-resizer 根据集群中的节点数对 Metrics Server 进行线性扩展,以确保其能够提供完整的指标 API 服务。具体参考:链接
其他
基于 Metrics Server 的 HPA:参考链接
在kubernetes新的监控系统中,metrics-server属于Core metrics,提供API metrics.k8s.io,只提供Node和Pod的CPU和内存使用情况。Other Custom Metrics(自定义指标)由Prometheus等组件完成,后续文章会对自定义指标进行分析。
本文为容器监控实践系列文章,完整内容请看:container-monitor-book 查看全部
文章采集api(MetricsAPI介绍Metrics-Server之前,必须要提一下API的概念)
概述
从v1.8开始,可以通过Metrics API的形式获取资源使用监控。具体的组件是Metrics Server,用来替代之前的heapster。heapster 从 1.11 开始逐渐被废弃。
Metrics-Server 是集群核心监控数据的聚合器。从Kubernetes1.8开始,在kube-up.sh脚本创建的集群中默认部署为Deployment对象。如果是其他部署方式,则需要单独安装。, 或者咨询相应的云厂商。
指标 API
在介绍 Metrics-Server 之前,不得不提一下 Metrics API 的概念
与之前的监控采集方法(hepaster)相比,Metrics API是一个全新的思路。官方希望核心指标的监控稳定,版本可控,用户可以直接访问(比如使用kubectl top命令),或者集群中的控制器(比如HPA)使用,就像其他Kubernetes一样蜜蜂。
官方放弃heapster项目,是将核心资源监控当成一等公民,即通过api-server或client直接访问,如pod和service,而不是安装一个heapster,由heapster单独采集和管理。
假设我们为每个pod和节点采集10个指标,从k8s的1.6开始,支持5000个节点和每个节点30个pod,假设采集的粒度为每分钟一次,那么:
10 x 5000 x 30 / 60 = 25000 平均每分钟2万多个采集指标
因为k8s的api-server将所有数据持久化在etcd中,显然k8s本身无法处理采集的这种频率,而且这种监控数据变化很快,而且是临时数据,所以需要单独的组件来处理,k8s版本只是部分存储在内存中,因此metric-server的概念诞生了。
其实Hepaster已经暴露了API,但是Kubernetes的用户和其他组件必须通过master代理访问,而且Hepaster的接口不像api-server那样有完整的认证和客户端集成。这个api还在alpha阶段(8月18日),希望能达到GA阶段。以 api-server 风格编写:通用 apiserver
有了Metrics Server组件,采集已经到达需要的数据,暴露了api,但是因为api需要统一,如何将请求转发到api-server /apis/metrics请求到Metrics Server ? 解决方案即:kube-aggregator,在k8s的1.7中已经完成。Metrics Server 之前没有发布,在 kube-aggregator 的步骤中延迟了。
kube-aggregator(聚合api)主要提供:
详细设计文档:参考链接
metric api的使用:
喜欢:
http://127.0.0.1:8001/apis/met ... nodes
http://127.0.0.1:8001/apis/met ... odes/
http://127.0.0.1:8001/apis/met ... pods/
度量服务器
Metrics 服务器定期从 Kubelet 的 Summary API(类似于 /ap1/v1/nodes/nodename/stats/summary)获取指标信息采集。这些聚合后的数据会存储在内存中,并以metric-api的形式暴露出去。
Metrics server复用api-server库来实现自己的功能,比如认证、版本等,为了将数据存储在内存中,去掉默认的etcd存储,引入内存存储(即实现Storage接口)。因为是存储在内存中,所以监控数据不是持久化的,可以通过第三方存储进行扩展,与heapster一致。
Metrics服务器出现后,新的Kubernetes监控架构将如上图所示
官方地址:
用
如上所述,metric-server是一个扩展的apiserver,依赖kube-aggregator,所以需要在apiserver中开启相关参数。
--requestheader-client-ca-file=/etc/kubernetes/certs/proxy-ca.crt
--proxy-client-cert-file=/etc/kubernetes/certs/proxy.crt
--proxy-client-key-file=/etc/kubernetes/certs/proxy.key
--requestheader-allowed-names=aggregator
--requestheader-extra-headers-prefix=X-Remote-Extra-
--requestheader-group-headers=X-Remote-Group
--requestheader-username-headers=X-Remote-User
安装文件下载地址:1.8+,注意修改镜像地址为国内镜像
kubectl create -f metric-server/
安装成功后访问地址api地址为:
Metrics Server 的资源消耗会随着集群中 Pod 数量的不断增长而不断上升,因此需要
插件调整器垂直缩放这个容器。addon-resizer 根据集群中的节点数对 Metrics Server 进行线性扩展,以确保其能够提供完整的指标 API 服务。具体参考:链接
其他
基于 Metrics Server 的 HPA:参考链接
在kubernetes新的监控系统中,metrics-server属于Core metrics,提供API metrics.k8s.io,只提供Node和Pod的CPU和内存使用情况。Other Custom Metrics(自定义指标)由Prometheus等组件完成,后续文章会对自定义指标进行分析。
本文为容器监控实践系列文章,完整内容请看:container-monitor-book
文章采集api(创建LoggingAdmin项目ApiBootLogging项目依赖使用创建项目idea)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-11-09 19:03
通过 ApiBoot Logging 可以获得每个请求的详细信息。在分布式部署模式下,一个请求可能经过多个服务。如果每个服务独立保存请求日志信息,我们无法实现统一控制。, 并且会出现日志数据库和业务数据库不一致的情况(可能会使用多个数据源配置)。正是因为这个问题,ApiBoot Logging 提供了Admin的概念。一条日志上报给Admin,由Admin进行分析、存储等操作。
创建日志管理项目
由于ApiBoot Logging Admin可以汇总各个业务服务的请求日志(ApiBoot Logging),我们需要将各个业务服务的日志采集上报给Admin,所以我们应该使用独立的方式进行部署。创建一个服务,专门请求日志并保存。
初始化 Logging Admin 项目依赖项
使用idea创建一个SpringBoot项目,pom.xml配置文件中的依赖如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
org.springframework.boot
spring-boot-starter-web
org.minbox.framework
api-boot-starter-logging-admin
mysql
mysql-connector-java
com.zaxxer
HikariCP
org.minbox.framework
api-boot-starter-mybatis-enhance
我们需要将采集收到的请求日志保存到数据库中,所以需要在项目中添加数据库驱动和数据库连接池相关的依赖。ApiBoot Logging Admin 使用DataSource 通过ApiBoot MyBatis Enhance 的依赖来操作数据。自动创建DataSource,摆脱手动创建,加入Spring IOC容器。
添加 ApiBoot 统一版本依赖
1
2
3
4
5
6
7
8
9
10
11
12
org.minbox.framework
api-boot-dependencies
2.1.4.RELEASE
import
pom
最新版本的ApiBoot请访问::api-boot-dependencies查询。
启用日志管理
添加ApiBoot Logging Admin依赖后,无法完全使用Admin功能。我们需要通过@EnableLoggingAdmin 注释来启用它。这个注解会自动将Logging Admin中需要的一些类注册到Spring IOC,并在入口类中添加注解如下:
1
2
3
4
5
6
7
8
9
10
11
12
/**
* ApiBoot Logging Admin入口类
*/
@SpringBootApplication
@EnableLoggingAdmin
public class ApibootReportLogsByLoggingToAdminApplication {
public static void main(String[] args) {
SpringApplication.run(ApibootReportLogsByLoggingToAdminApplication.class, args);
}
}
配置日志数据源
application.yml配置文件中的数据源配置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# 服务名称
spring:
application:
name: apiboot-report-logs-by-logging-to-admin
# 数据源相关配置
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test
username: root
password: 123456
type: com.zaxxer.hikari.HikariDataSource
# 服务端口号
server:
port: 8081
控制台打印并报告日志
ApiBoot Logging Admin可以通过配置文件控制是否在控制台打印来自采集的请求日志信息,并在application.yml配置文件中添加如下内容:
1
2
3
4
5
6
7
api:
boot:
logging:
# Logging Admin相关配置
admin:
# 控制台显示采集的日志信息
show-console-report-log: true
注意:这不应与 ApiBoot Logging 提供的 api.boot.logging.show-console-log 配置混淆。
美化控制台打印的报告日志
1
2
3
4
5
6
7
api:
boot:
logging:
# Logging Admin相关配置
admin:
# 控制台输出时美化采集到的日志
format-console-log-json: true
注意:不要与这里的 api.boot.logging.format-console-log-json 配置混淆。
初始化日志表结构
ApiBoot Logging Admin 使用固定的表结构来存储请求日志和服务信息。建表语句如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
SET NAMES utf8mb4 ;
--
-- Table structure for table `logging_request_logs`
--
CREATE TABLE `logging_request_logs` (
`lrl_id` varchar(36) COLLATE utf8mb4_general_ci NOT NULL COMMENT '主键,UUID',
`lrl_service_detail_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '服务详情编号,关联logging_service_details主键',
`lrl_trace_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '链路ID',
`lrl_parent_span_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上级跨度ID',
`lrl_span_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '跨度ID',
`lrl_start_time` mediumtext COLLATE utf8mb4_general_ci COMMENT '请求开始时间',
`lrl_end_time` mediumtext COLLATE utf8mb4_general_ci COMMENT '请求结束时间',
`lrl_http_status` int(11) DEFAULT NULL COMMENT '请求响应状态码',
`lrl_request_body` longtext COLLATE utf8mb4_general_ci COMMENT '请求主体内容',
`lrl_request_headers` text COLLATE utf8mb4_general_ci COMMENT '请求头信息',
`lrl_request_ip` varchar(30) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '发起请求客户端的IP地址',
`lrl_request_method` varchar(10) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '请求方式',
`lrl_request_uri` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '请求路径',
`lrl_response_body` longtext COLLATE utf8mb4_general_ci COMMENT '响应内容',
`lrl_response_headers` text COLLATE utf8mb4_general_ci COMMENT '响应头信息',
`lrl_time_consuming` int(11) DEFAULT NULL COMMENT '请求耗时',
`lrl_create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '日志保存时间',
`lrl_request_params` text COLLATE utf8mb4_general_ci,
`lrl_exception_stack` text COLLATE utf8mb4_general_ci,
PRIMARY KEY (`lrl_id`),
KEY `logging_request_logs_LRL_SERVICE_DETAIL_ID_index` (`lrl_service_detail_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='请求日志信息表';
--
-- Table structure for table `logging_service_details`
--
CREATE TABLE `logging_service_details` (
`lsd_id` varchar(36) COLLATE utf8mb4_general_ci NOT NULL,
`lsd_service_id` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上报服务的ID,对应spring.application.name配置值',
`lsd_service_ip` varchar(50) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上报服务的IP地址',
`lsd_service_port` int(11) DEFAULT NULL COMMENT '上报服务的端口号',
`lsd_last_report_time` timestamp NULL DEFAULT NULL COMMENT '最后一次上报时间,每次上报更新',
`lsd_create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '首次上报时创建时间',
PRIMARY KEY (`lsd_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='上报日志的客户端服务详情';
到目前为止,ApiBoot Logging Admin 已经准备好了。接下来,我们需要修改业务服务,将请求日志上报给 Logging Admin。
向指定的日志管理员报告日志
我们将修改使用ApiBoot Logging统一管理请求日志文章的源码,并将Logging Admin的地址添加到application.yml中,如下图:
1
2
3
4
5
6
7
api:
boot:
# ApiBoot Logging 日志组件配置
logging:
# 配置Logging Admin地址
admin:
server-address: 127.0.0.1:8081
api.boot.logging.admin-service-address 的配置格式为:Ip:Port,我们只需要修改这一处,其他的所有任务内部交给ApiBoot Logging。
测试
我们以Application的形式启动ApiBoot Logging Admin和业务服务。
使用 curl 访问测试地址如下:
1
2
~ curl http://localhost:8080/test\?name\=admin
你好:admin
我们检查 ApiBoot Logging 管理控制台日志如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
Receiving Service: 【apiboot-unified-manage-request-logs -> 127.0.0.1】, Request Log Report,Logging Content:[
{
"endTime":1571641723779,
"httpStatus":200,
"requestBody":"",
"requestHeaders":{
"server-region":"JiNan",
"host":"localhost:8080",
"user-agent":"curl/7.64.1",
"accept":"*/*"
},
"requestIp":"0:0:0:0:0:0:0:1",
"requestMethod":"GET",
"requestParam":"{\"name\":\"admin\"}",
"requestUri":"/test",
"responseBody":"你好:admin",
"responseHeaders":{},
"serviceId":"apiboot-unified-manage-request-logs",
"serviceIp":"127.0.0.1",
"servicePort":"8080",
"spanId":"95a73ca0-831b-45df-aa43-2b5887e8d98d",
"startTime":1571641723776,
"timeConsuming":3,
"traceId":"25a7de96-b3dd-48e5-9854-1a8069a4a681"
}
]
我们已经看到Logging Admin控制台打印的报告请求日志,并不确定这个请求的日志是否已经保存到数据库中。接下来我使用命令行查看数据库的日志信息。
查看 logging_service_details 表中的数据
1
2
3
4
5
6
7
8
mysql> select * from logging_service_details\G;
*************************** 1. row ***************************
lsd_id: b069366a-25dc-41ec-8f09-242d81755cd0
lsd_service_id: apiboot-unified-manage-request-logs
lsd_service_ip: 10.180.98.112
lsd_service_port: 8080
lsd_last_report_time: 2019-10-21 02:14:26
lsd_create_time: 2019-10-21 15:14:26
logging_service_details 存储了每个上报请求日志的业务服务的基本信息。每个服务的基本信息都会缓存在Logging Admin内存中,方便获取service_id用于存储日志。唯一性根据ip+port+service_id确定,同一个service只保存一次。
查看 logging_request_logs 表中的数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
mysql> select * from logging_request_logs\G;
*************************** 1. row ***************************
lrl_id: c42761f6-b072-4744-8a17-d8e6097b85de
lrl_service_detail_id: b069366a-25dc-41ec-8f09-242d81755cd0
lrl_trace_id: 055329a0-cfc1-4606-baf0-4fb0cc905ba2
lrl_parent_span_id: NULL
lrl_span_id: aab83092-7749-4f88-8cb6-a949cc060197
lrl_start_time: 1571642065262
lrl_end_time: 1571642065286
lrl_http_status: 200
lrl_request_body:
lrl_request_headers: {"server-region":"JiNan","host":"localhost:8080","user-agent":"curl/7.64.1","accept":"*/*"}
lrl_request_ip: 0:0:0:0:0:0:0:1
lrl_request_method: GET
lrl_request_uri: /test
lrl_response_body: 你好:admin
lrl_response_headers: {}
lrl_time_consuming: 24
lrl_create_time: 2019-10-21 15:14:26
lrl_request_params: {"name":"admin"}
lrl_exception_stack: NULL
敲黑板画重点
本章我们集成了ApiBoot Logging Admin,将业务服务的每一个请求日志上报给Logging Admin,通过数据库保存请求日志,然后使用其他方法,可以通过spanId和traceId查看每一项的日志-从属关系请求链路和每个请求中消耗时间最多的跨度可以准确优化服务性能。
代码示例
如果你喜欢这篇文章文章,请为源码仓库点个Star,谢谢!!!
本文章示例源码可以通过以下方式获取,目录为apiboot-report-logs-by-logging-to-admin:
本文由恒宇少年-于启宇撰写,遵循CC4.0BY-SA版权协议。转载请注明文章出处。公众号转载请联系“微信” 查看全部
文章采集api(创建LoggingAdmin项目ApiBootLogging项目依赖使用创建项目idea)
通过 ApiBoot Logging 可以获得每个请求的详细信息。在分布式部署模式下,一个请求可能经过多个服务。如果每个服务独立保存请求日志信息,我们无法实现统一控制。, 并且会出现日志数据库和业务数据库不一致的情况(可能会使用多个数据源配置)。正是因为这个问题,ApiBoot Logging 提供了Admin的概念。一条日志上报给Admin,由Admin进行分析、存储等操作。
创建日志管理项目
由于ApiBoot Logging Admin可以汇总各个业务服务的请求日志(ApiBoot Logging),我们需要将各个业务服务的日志采集上报给Admin,所以我们应该使用独立的方式进行部署。创建一个服务,专门请求日志并保存。
初始化 Logging Admin 项目依赖项
使用idea创建一个SpringBoot项目,pom.xml配置文件中的依赖如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
org.springframework.boot
spring-boot-starter-web
org.minbox.framework
api-boot-starter-logging-admin
mysql
mysql-connector-java
com.zaxxer
HikariCP
org.minbox.framework
api-boot-starter-mybatis-enhance
我们需要将采集收到的请求日志保存到数据库中,所以需要在项目中添加数据库驱动和数据库连接池相关的依赖。ApiBoot Logging Admin 使用DataSource 通过ApiBoot MyBatis Enhance 的依赖来操作数据。自动创建DataSource,摆脱手动创建,加入Spring IOC容器。
添加 ApiBoot 统一版本依赖
1
2
3
4
5
6
7
8
9
10
11
12
org.minbox.framework
api-boot-dependencies
2.1.4.RELEASE
import
pom
最新版本的ApiBoot请访问::api-boot-dependencies查询。
启用日志管理
添加ApiBoot Logging Admin依赖后,无法完全使用Admin功能。我们需要通过@EnableLoggingAdmin 注释来启用它。这个注解会自动将Logging Admin中需要的一些类注册到Spring IOC,并在入口类中添加注解如下:
1
2
3
4
5
6
7
8
9
10
11
12
/**
* ApiBoot Logging Admin入口类
*/
@SpringBootApplication
@EnableLoggingAdmin
public class ApibootReportLogsByLoggingToAdminApplication {
public static void main(String[] args) {
SpringApplication.run(ApibootReportLogsByLoggingToAdminApplication.class, args);
}
}
配置日志数据源
application.yml配置文件中的数据源配置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# 服务名称
spring:
application:
name: apiboot-report-logs-by-logging-to-admin
# 数据源相关配置
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test
username: root
password: 123456
type: com.zaxxer.hikari.HikariDataSource
# 服务端口号
server:
port: 8081
控制台打印并报告日志
ApiBoot Logging Admin可以通过配置文件控制是否在控制台打印来自采集的请求日志信息,并在application.yml配置文件中添加如下内容:
1
2
3
4
5
6
7
api:
boot:
logging:
# Logging Admin相关配置
admin:
# 控制台显示采集的日志信息
show-console-report-log: true
注意:这不应与 ApiBoot Logging 提供的 api.boot.logging.show-console-log 配置混淆。
美化控制台打印的报告日志
1
2
3
4
5
6
7
api:
boot:
logging:
# Logging Admin相关配置
admin:
# 控制台输出时美化采集到的日志
format-console-log-json: true
注意:不要与这里的 api.boot.logging.format-console-log-json 配置混淆。
初始化日志表结构
ApiBoot Logging Admin 使用固定的表结构来存储请求日志和服务信息。建表语句如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
SET NAMES utf8mb4 ;
--
-- Table structure for table `logging_request_logs`
--
CREATE TABLE `logging_request_logs` (
`lrl_id` varchar(36) COLLATE utf8mb4_general_ci NOT NULL COMMENT '主键,UUID',
`lrl_service_detail_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '服务详情编号,关联logging_service_details主键',
`lrl_trace_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '链路ID',
`lrl_parent_span_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上级跨度ID',
`lrl_span_id` varchar(36) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '跨度ID',
`lrl_start_time` mediumtext COLLATE utf8mb4_general_ci COMMENT '请求开始时间',
`lrl_end_time` mediumtext COLLATE utf8mb4_general_ci COMMENT '请求结束时间',
`lrl_http_status` int(11) DEFAULT NULL COMMENT '请求响应状态码',
`lrl_request_body` longtext COLLATE utf8mb4_general_ci COMMENT '请求主体内容',
`lrl_request_headers` text COLLATE utf8mb4_general_ci COMMENT '请求头信息',
`lrl_request_ip` varchar(30) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '发起请求客户端的IP地址',
`lrl_request_method` varchar(10) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '请求方式',
`lrl_request_uri` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '请求路径',
`lrl_response_body` longtext COLLATE utf8mb4_general_ci COMMENT '响应内容',
`lrl_response_headers` text COLLATE utf8mb4_general_ci COMMENT '响应头信息',
`lrl_time_consuming` int(11) DEFAULT NULL COMMENT '请求耗时',
`lrl_create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '日志保存时间',
`lrl_request_params` text COLLATE utf8mb4_general_ci,
`lrl_exception_stack` text COLLATE utf8mb4_general_ci,
PRIMARY KEY (`lrl_id`),
KEY `logging_request_logs_LRL_SERVICE_DETAIL_ID_index` (`lrl_service_detail_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='请求日志信息表';
--
-- Table structure for table `logging_service_details`
--
CREATE TABLE `logging_service_details` (
`lsd_id` varchar(36) COLLATE utf8mb4_general_ci NOT NULL,
`lsd_service_id` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上报服务的ID,对应spring.application.name配置值',
`lsd_service_ip` varchar(50) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '上报服务的IP地址',
`lsd_service_port` int(11) DEFAULT NULL COMMENT '上报服务的端口号',
`lsd_last_report_time` timestamp NULL DEFAULT NULL COMMENT '最后一次上报时间,每次上报更新',
`lsd_create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '首次上报时创建时间',
PRIMARY KEY (`lsd_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='上报日志的客户端服务详情';
到目前为止,ApiBoot Logging Admin 已经准备好了。接下来,我们需要修改业务服务,将请求日志上报给 Logging Admin。
向指定的日志管理员报告日志
我们将修改使用ApiBoot Logging统一管理请求日志文章的源码,并将Logging Admin的地址添加到application.yml中,如下图:
1
2
3
4
5
6
7
api:
boot:
# ApiBoot Logging 日志组件配置
logging:
# 配置Logging Admin地址
admin:
server-address: 127.0.0.1:8081
api.boot.logging.admin-service-address 的配置格式为:Ip:Port,我们只需要修改这一处,其他的所有任务内部交给ApiBoot Logging。
测试
我们以Application的形式启动ApiBoot Logging Admin和业务服务。
使用 curl 访问测试地址如下:
1
2
~ curl http://localhost:8080/test\?name\=admin
你好:admin
我们检查 ApiBoot Logging 管理控制台日志如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
Receiving Service: 【apiboot-unified-manage-request-logs -> 127.0.0.1】, Request Log Report,Logging Content:[
{
"endTime":1571641723779,
"httpStatus":200,
"requestBody":"",
"requestHeaders":{
"server-region":"JiNan",
"host":"localhost:8080",
"user-agent":"curl/7.64.1",
"accept":"*/*"
},
"requestIp":"0:0:0:0:0:0:0:1",
"requestMethod":"GET",
"requestParam":"{\"name\":\"admin\"}",
"requestUri":"/test",
"responseBody":"你好:admin",
"responseHeaders":{},
"serviceId":"apiboot-unified-manage-request-logs",
"serviceIp":"127.0.0.1",
"servicePort":"8080",
"spanId":"95a73ca0-831b-45df-aa43-2b5887e8d98d",
"startTime":1571641723776,
"timeConsuming":3,
"traceId":"25a7de96-b3dd-48e5-9854-1a8069a4a681"
}
]
我们已经看到Logging Admin控制台打印的报告请求日志,并不确定这个请求的日志是否已经保存到数据库中。接下来我使用命令行查看数据库的日志信息。
查看 logging_service_details 表中的数据
1
2
3
4
5
6
7
8
mysql> select * from logging_service_details\G;
*************************** 1. row ***************************
lsd_id: b069366a-25dc-41ec-8f09-242d81755cd0
lsd_service_id: apiboot-unified-manage-request-logs
lsd_service_ip: 10.180.98.112
lsd_service_port: 8080
lsd_last_report_time: 2019-10-21 02:14:26
lsd_create_time: 2019-10-21 15:14:26
logging_service_details 存储了每个上报请求日志的业务服务的基本信息。每个服务的基本信息都会缓存在Logging Admin内存中,方便获取service_id用于存储日志。唯一性根据ip+port+service_id确定,同一个service只保存一次。
查看 logging_request_logs 表中的数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
mysql> select * from logging_request_logs\G;
*************************** 1. row ***************************
lrl_id: c42761f6-b072-4744-8a17-d8e6097b85de
lrl_service_detail_id: b069366a-25dc-41ec-8f09-242d81755cd0
lrl_trace_id: 055329a0-cfc1-4606-baf0-4fb0cc905ba2
lrl_parent_span_id: NULL
lrl_span_id: aab83092-7749-4f88-8cb6-a949cc060197
lrl_start_time: 1571642065262
lrl_end_time: 1571642065286
lrl_http_status: 200
lrl_request_body:
lrl_request_headers: {"server-region":"JiNan","host":"localhost:8080","user-agent":"curl/7.64.1","accept":"*/*"}
lrl_request_ip: 0:0:0:0:0:0:0:1
lrl_request_method: GET
lrl_request_uri: /test
lrl_response_body: 你好:admin
lrl_response_headers: {}
lrl_time_consuming: 24
lrl_create_time: 2019-10-21 15:14:26
lrl_request_params: {"name":"admin"}
lrl_exception_stack: NULL
敲黑板画重点
本章我们集成了ApiBoot Logging Admin,将业务服务的每一个请求日志上报给Logging Admin,通过数据库保存请求日志,然后使用其他方法,可以通过spanId和traceId查看每一项的日志-从属关系请求链路和每个请求中消耗时间最多的跨度可以准确优化服务性能。
代码示例
如果你喜欢这篇文章文章,请为源码仓库点个Star,谢谢!!!
本文章示例源码可以通过以下方式获取,目录为apiboot-report-logs-by-logging-to-admin:
本文由恒宇少年-于启宇撰写,遵循CC4.0BY-SA版权协议。转载请注明文章出处。公众号转载请联系“微信”
文章采集api(基于API的微博信息采集系统设计与实现(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-11-09 19:02
基于API的微博信息采集系统设计与实现小结:微博已经成为网络信息的重要来源。本文分析了微博信息采集的相关方法和技术,提出了基于API的信息采集方法,进而设计了一个能够采集相关信息的信息采集系统在新浪微博上。实验测试表明,信息采集系统可以快速有效地采集新浪微博信息。关键词:新浪微博;微博界面;资料采集; C#语言中文图书馆分类号:TP315 文档识别码:A 文章 编号:1009-3044(2013)17-4005-04 微博[1],微博的简称,是一个信息共享平台, 基于用户关系的传播和获取。用户可以使用140字的WEB、WAP和各种客户端组件的个人社区左右文字更新信息,实现即时分享。中国互联网络信息中心《第31次中国互联网络发展状况统计报告》显示,截至2012年12月末,截至2012年12月末,中国微博用户数为3.09亿,比2011年末增加5873万,网民中微博用户占比比上年末提高6个百分点,达到54.7%[2]。随着微博网络的影响力的迅速扩张,政府部门、学校、知名企业、公众人物都开通了微博。在公众的参与下,微博已经成为一个强大的虚拟社会。微博已成为网络信息的重要来源。如何快速有效地使用采集微博信息已成为一项具有重要应用价值的研究。
1 研究方法和技术路线 国内微博用户以新浪微博为主,本文拟以新浪微博为例,设计研究方法和技术路线。通过对国内外科技文献和实际应用案例的分析,目前新浪微博的信息采集方法主要分为两类:一类是“模拟登录”、“网络爬虫”[3] ],以及“网页内容”“分析”[4]信息采集三种技术相结合的方法。二是基于新浪微博开放平台的API文档。开发者自己编写程序调用微博的API进行微博信息采集。对于第一种方法,难度比较高,研究技术复杂,尤其是“模拟登录”这一步。需要随时跟踪新浪微博的登录加密算法。新浪微博登录加密算法的变化会导致“网络爬虫”。“采集的失败最终导致微博信息缺失。同时,“网络爬虫”采集到达的网页需要进行“页面内容分析”,还有与基于API的数据采集相比,效率和性能差距明显。基于以上因素,本文拟采用第二种方法进行研究。基于新浪微博的微博信息采集系统开放平台API文档主要采用两种研究方法:文献分析法和实验测试法。文档分析方法:参考新浪微博开放平台的API文档,将这些API描述文档写成单独的接口文件。实验测试方法:在VS.NET2010平台[5]上,使用C/S模式开发程序调用接口类,采集微博返回的JOSN数据流,实现相关测试开发数据 采集 。
根据以上两种研究方法,设计本研究的技术路线:一是申请新浪微博开放平台App Key和App Secret。审核通过后,阅读理解API文档,将API文档描述写入API接口代码类(c#语言),然后进行OAuth2.0认证测试。认证通过后,可以获得Access Token,从而有权限调用API的各种功能接口,然后通过POST或GET调用API接口。最后返回JOSN数据流,最后解析这个数据流,保存为本地文本文件或数据库。详细技术路线如图1所示。 2研究内容设计微博信息采集系统功能结构如图2所示。系统分为七个部分,分别是:微博界面认证、微博用户登录、登录用户发微博、采集当前登录用户信息、采集其他用户信息、采集其他用户微博、采集学校信息、采集微博信息内容。1) 微博接口认证:访问大部分新浪微博API,如发布微博、获取私信等,都需要用户身份认证。目前新浪微博开放平台上的用户身份认证包括OAuth2.0和Basic Auth(仅用于应用开发者调试接口),新版接口也仅支持这两种方式[6] . 所以,系统设计开发的第一步是做微博界面鉴权功能。2) 微博用户登录:通过认证后,所有在新浪微博上注册的用户都可以通过本系统登录并发布微博。
3)采集登录用户信息:用户登录后,可以通过本系统查看自己的账号信息、自己的微博信息以及关注者的微博信息。4)采集 其他用户信息:这个功能主要是输入微博用户的昵称,可以采集获取昵称用户的账号信息,比如他有多少粉丝有,他关注哪些人,有多少人关注他,这个信息在微博采集中也是很有价值的。5)采集 其他用户的微博:此功能也使用微博用户的昵称来采集更改用户发送的所有微博信息。这个功能的目的是为了以后扩展为了自动采集 每隔一段时间将目标中多个微博用户的微博信息设置到本地进行数据内容分析。6)采集学校信息:该功能通过学校名称的模糊查询,获取学校微博账号ID、学校所在地区、学校类型信息。这是采集学校在微博上的影响力的基本数据。7)采集微博信息内容:您可以点击微博内容关键词查询,采集这条微博信息收录本关键词。但由于本次API接口调用需要高级权限,在系统完全发布前和新浪微博开放平台审核通过前,无法直接测试使用。3 主要功能的实现3. 1 微博界面认证功能 大部分新浪微博API访问都需要用户认证。本系统采用OAuth2.0设计微博界面认证功能,新浪微博认证流程如图3所示。
4 总结本文主要对微博信息采集的方法和技术进行了一系列的研究,然后设计开发了一个基于API的新浪微博信息采集系统,实现了微博的基础信息采集,在一定程度上解决了微博信息采集的自动化和采集结果数据格式的标准化。但是,目前本系统的微博信息采集方法只能输入单个“关键词”采集进行唯一匹配,没有批量多个“搜索词”采集,没有“话题型”微博信息采集功能,所以下一步的研究工作就是如何设计话题模型来优化系统。参考:[1]文锐.微博知乎[J].软件工程师, 2009 (12): 19-20. [2] 中国互联网络信息中心. 第31次中国互联网络发展统计报告[EB/OL]. (2013-01-1 5).http: ///hlwfzyj/hlwxzbg/hlwtjbg/201301/38508.htm. [3] 罗刚, 王振东. 自己手写的网络爬虫[M]. 北京:清华大学出版社, 2010. [4] 于满全, 陈铁瑞, 徐洪波. 基于块的网页信息解析器的研究与设计[J ]. 计算机应用, 2005, 25 (4):974-97 6. [5] Nick Randolph, David Gardner, Chris Anderson, et al.Professional Visual Studio 2010[M].Wrox, 2010. [6] 新浪微博开放平台.授权机制说明[EB] /OL]. (2013-01-19). 第31次中国互联网发展统计报告[EB/OL]。(2013-01-15).http: ///hlwfzyj/hlwxzbg/hlwtjbg/201301/38508.htm. [3] 罗刚, 王振东. 自己手写网页爬虫[M] . 北京: 清华大学出版社, 2010. [4] 于满全, 陈铁瑞, 徐洪波. 基于块的网页信息解析器的研究与设计[J]. 计算机应用, 2005, 25 (4):974-976. [5] Nick Randolph, David Gardner, Chris Anderson, et al.Professional Visual Studio 2010[M].Wrox, 2010. [6] 新浪微博开放平台。授权机制说明[EB/OL]. (2013-01-19). 第31次中国互联网发展统计报告[EB/OL]。(2013-01-15).http: ///hlwfzyj/hlwxzbg/hlwtjbg/201301/38508.htm. [3] 罗刚, 王振东. 自己手写网页爬虫[M] . 北京: 清华大学出版社, 2010. [4] 于满全, 陈铁瑞, 徐洪波. 基于块的网页信息解析器的研究与设计[J]. 计算机应用, 2005, 25 (4):974-976. [5] Nick Randolph, David Gardner, Chris Anderson, et al.Professional Visual Studio 2010[M].Wrox, 2010. [6] 新浪微博开放平台。授权机制说明[EB/OL]. (2013-01-19). 王振东。自己手写的网络爬虫[M]. 北京:清华大学出版社,2010. [4] 于曼全、陈铁瑞、徐洪波。基于块的网页信息解析器的研究与设计[J]. 计算机应用,2005, 25 (4):974-976. [5] Nick Randolph, David Gardner, Chris Anderson, et al.Professional Visual Studio 2010[M].Wrox, 2010. [6] 新浪微博开放平台. 授权机制解读[EB/OL]. (2013-01-19). 王振东。自己手写的网络爬虫[M]. 北京:清华大学出版社,2010. [4] 于曼泉、陈铁瑞、徐洪波。基于块的网页信息解析器的研究与设计[J]. 计算机应用,2005, 25 (4):974-976. [5] Nick Randolph, David Gardner, Chris Anderson, et al.Professional Visual Studio 2010[M].Wrox, 2010. [6] 新浪微博开放平台. 授权机制解读[EB/OL]. (2013-01-19). Professional Visual Studio 2010[M].Wrox,2010. [6] 新浪微博开放平台。授权机制说明[EB/OL]。(2013-01-19). Professional Visual Studio 2010[M].Wrox,2010. [6] 新浪微博开放平台。授权机制说明[EB/OL]。(2013-01-19). 查看全部
文章采集api(基于API的微博信息采集系统设计与实现(组图))
基于API的微博信息采集系统设计与实现小结:微博已经成为网络信息的重要来源。本文分析了微博信息采集的相关方法和技术,提出了基于API的信息采集方法,进而设计了一个能够采集相关信息的信息采集系统在新浪微博上。实验测试表明,信息采集系统可以快速有效地采集新浪微博信息。关键词:新浪微博;微博界面;资料采集; C#语言中文图书馆分类号:TP315 文档识别码:A 文章 编号:1009-3044(2013)17-4005-04 微博[1],微博的简称,是一个信息共享平台, 基于用户关系的传播和获取。用户可以使用140字的WEB、WAP和各种客户端组件的个人社区左右文字更新信息,实现即时分享。中国互联网络信息中心《第31次中国互联网络发展状况统计报告》显示,截至2012年12月末,截至2012年12月末,中国微博用户数为3.09亿,比2011年末增加5873万,网民中微博用户占比比上年末提高6个百分点,达到54.7%[2]。随着微博网络的影响力的迅速扩张,政府部门、学校、知名企业、公众人物都开通了微博。在公众的参与下,微博已经成为一个强大的虚拟社会。微博已成为网络信息的重要来源。如何快速有效地使用采集微博信息已成为一项具有重要应用价值的研究。
1 研究方法和技术路线 国内微博用户以新浪微博为主,本文拟以新浪微博为例,设计研究方法和技术路线。通过对国内外科技文献和实际应用案例的分析,目前新浪微博的信息采集方法主要分为两类:一类是“模拟登录”、“网络爬虫”[3] ],以及“网页内容”“分析”[4]信息采集三种技术相结合的方法。二是基于新浪微博开放平台的API文档。开发者自己编写程序调用微博的API进行微博信息采集。对于第一种方法,难度比较高,研究技术复杂,尤其是“模拟登录”这一步。需要随时跟踪新浪微博的登录加密算法。新浪微博登录加密算法的变化会导致“网络爬虫”。“采集的失败最终导致微博信息缺失。同时,“网络爬虫”采集到达的网页需要进行“页面内容分析”,还有与基于API的数据采集相比,效率和性能差距明显。基于以上因素,本文拟采用第二种方法进行研究。基于新浪微博的微博信息采集系统开放平台API文档主要采用两种研究方法:文献分析法和实验测试法。文档分析方法:参考新浪微博开放平台的API文档,将这些API描述文档写成单独的接口文件。实验测试方法:在VS.NET2010平台[5]上,使用C/S模式开发程序调用接口类,采集微博返回的JOSN数据流,实现相关测试开发数据 采集 。
根据以上两种研究方法,设计本研究的技术路线:一是申请新浪微博开放平台App Key和App Secret。审核通过后,阅读理解API文档,将API文档描述写入API接口代码类(c#语言),然后进行OAuth2.0认证测试。认证通过后,可以获得Access Token,从而有权限调用API的各种功能接口,然后通过POST或GET调用API接口。最后返回JOSN数据流,最后解析这个数据流,保存为本地文本文件或数据库。详细技术路线如图1所示。 2研究内容设计微博信息采集系统功能结构如图2所示。系统分为七个部分,分别是:微博界面认证、微博用户登录、登录用户发微博、采集当前登录用户信息、采集其他用户信息、采集其他用户微博、采集学校信息、采集微博信息内容。1) 微博接口认证:访问大部分新浪微博API,如发布微博、获取私信等,都需要用户身份认证。目前新浪微博开放平台上的用户身份认证包括OAuth2.0和Basic Auth(仅用于应用开发者调试接口),新版接口也仅支持这两种方式[6] . 所以,系统设计开发的第一步是做微博界面鉴权功能。2) 微博用户登录:通过认证后,所有在新浪微博上注册的用户都可以通过本系统登录并发布微博。
3)采集登录用户信息:用户登录后,可以通过本系统查看自己的账号信息、自己的微博信息以及关注者的微博信息。4)采集 其他用户信息:这个功能主要是输入微博用户的昵称,可以采集获取昵称用户的账号信息,比如他有多少粉丝有,他关注哪些人,有多少人关注他,这个信息在微博采集中也是很有价值的。5)采集 其他用户的微博:此功能也使用微博用户的昵称来采集更改用户发送的所有微博信息。这个功能的目的是为了以后扩展为了自动采集 每隔一段时间将目标中多个微博用户的微博信息设置到本地进行数据内容分析。6)采集学校信息:该功能通过学校名称的模糊查询,获取学校微博账号ID、学校所在地区、学校类型信息。这是采集学校在微博上的影响力的基本数据。7)采集微博信息内容:您可以点击微博内容关键词查询,采集这条微博信息收录本关键词。但由于本次API接口调用需要高级权限,在系统完全发布前和新浪微博开放平台审核通过前,无法直接测试使用。3 主要功能的实现3. 1 微博界面认证功能 大部分新浪微博API访问都需要用户认证。本系统采用OAuth2.0设计微博界面认证功能,新浪微博认证流程如图3所示。
4 总结本文主要对微博信息采集的方法和技术进行了一系列的研究,然后设计开发了一个基于API的新浪微博信息采集系统,实现了微博的基础信息采集,在一定程度上解决了微博信息采集的自动化和采集结果数据格式的标准化。但是,目前本系统的微博信息采集方法只能输入单个“关键词”采集进行唯一匹配,没有批量多个“搜索词”采集,没有“话题型”微博信息采集功能,所以下一步的研究工作就是如何设计话题模型来优化系统。参考:[1]文锐.微博知乎[J].软件工程师, 2009 (12): 19-20. [2] 中国互联网络信息中心. 第31次中国互联网络发展统计报告[EB/OL]. (2013-01-1 5).http: ///hlwfzyj/hlwxzbg/hlwtjbg/201301/38508.htm. [3] 罗刚, 王振东. 自己手写的网络爬虫[M]. 北京:清华大学出版社, 2010. [4] 于满全, 陈铁瑞, 徐洪波. 基于块的网页信息解析器的研究与设计[J ]. 计算机应用, 2005, 25 (4):974-97 6. [5] Nick Randolph, David Gardner, Chris Anderson, et al.Professional Visual Studio 2010[M].Wrox, 2010. [6] 新浪微博开放平台.授权机制说明[EB] /OL]. (2013-01-19). 第31次中国互联网发展统计报告[EB/OL]。(2013-01-15).http: ///hlwfzyj/hlwxzbg/hlwtjbg/201301/38508.htm. [3] 罗刚, 王振东. 自己手写网页爬虫[M] . 北京: 清华大学出版社, 2010. [4] 于满全, 陈铁瑞, 徐洪波. 基于块的网页信息解析器的研究与设计[J]. 计算机应用, 2005, 25 (4):974-976. [5] Nick Randolph, David Gardner, Chris Anderson, et al.Professional Visual Studio 2010[M].Wrox, 2010. [6] 新浪微博开放平台。授权机制说明[EB/OL]. (2013-01-19). 第31次中国互联网发展统计报告[EB/OL]。(2013-01-15).http: ///hlwfzyj/hlwxzbg/hlwtjbg/201301/38508.htm. [3] 罗刚, 王振东. 自己手写网页爬虫[M] . 北京: 清华大学出版社, 2010. [4] 于满全, 陈铁瑞, 徐洪波. 基于块的网页信息解析器的研究与设计[J]. 计算机应用, 2005, 25 (4):974-976. [5] Nick Randolph, David Gardner, Chris Anderson, et al.Professional Visual Studio 2010[M].Wrox, 2010. [6] 新浪微博开放平台。授权机制说明[EB/OL]. (2013-01-19). 王振东。自己手写的网络爬虫[M]. 北京:清华大学出版社,2010. [4] 于曼全、陈铁瑞、徐洪波。基于块的网页信息解析器的研究与设计[J]. 计算机应用,2005, 25 (4):974-976. [5] Nick Randolph, David Gardner, Chris Anderson, et al.Professional Visual Studio 2010[M].Wrox, 2010. [6] 新浪微博开放平台. 授权机制解读[EB/OL]. (2013-01-19). 王振东。自己手写的网络爬虫[M]. 北京:清华大学出版社,2010. [4] 于曼泉、陈铁瑞、徐洪波。基于块的网页信息解析器的研究与设计[J]. 计算机应用,2005, 25 (4):974-976. [5] Nick Randolph, David Gardner, Chris Anderson, et al.Professional Visual Studio 2010[M].Wrox, 2010. [6] 新浪微博开放平台. 授权机制解读[EB/OL]. (2013-01-19). Professional Visual Studio 2010[M].Wrox,2010. [6] 新浪微博开放平台。授权机制说明[EB/OL]。(2013-01-19). Professional Visual Studio 2010[M].Wrox,2010. [6] 新浪微博开放平台。授权机制说明[EB/OL]。(2013-01-19).
文章采集api(完美者()网站对功能性板块进行扩充,以期采集器智能分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-11-09 02:09
Perfect()网站基于软件下载,网站修订版扩展了功能部分,以解决用户在使用软件过程中遇到的所有问题。网站 新增“软件百科”、“甜蜜小贴士”等新频道,在软件使用全周期更好地为用户提供更专业的服务。
优采云采集器是一款高效的网页信息采集软件,一键采集网页数据,无论是静态网页还是动态网页都可以采集,支持99%的网站,内置大量网站采集模板,覆盖多个行业,提取成功后可另存为Excel表格,api数据库文件。
优采云采集器特点
一键提取数据
简单易学,通过可视化界面,鼠标点击即可采集数据
快速高效
内置一套高速浏览器内核,加上HTTP引擎模式,实现快速采集数据
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站
优采云采集器功能
向导模式
简单易用,轻松通过鼠标点击自动生成
脚本定期运行
可按计划定时运行,无需人工
原装高速核心
自主研发的浏览器内核速度快,远超对手
智能识别
可智能识别网页中的列表和表单结构(多选框下拉列表等)
广告拦截
自定义广告拦截模块,兼容AdblockPlus语法,可添加自定义规则
各种数据导出
支持 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等。
优采云采集器安装
1.到本站下载安装优采云采集器,打开安装程序,点击下一步继续安装
2.点击浏览选择安装位置
3.等一下
优采云采集器使用方法
第一步:输入采集 URL
打开软件,新建一个任务,输入需要采集的网站地址。
第二步:智能分析,全程自动提取数据
进入第二步后,优采云采集器自动对网页进行智能分析,从中提取列表数据。
第三步:将数据导出到表、数据库、网站等。
运行任务,将采集中的数据导出到Csv、Excel及各种数据库,支持api导出。
“技巧与妙计”栏目是全网软件使用技巧的集合或对软件使用过程中各种问题的解答。文章。专栏成立伊始,小编欢迎各位软件大神朋友踊跃投稿。该平台分享每个人的独特技能。
本站文章素材来自网络,文章作者姓名大部分缺失。为了让用户更容易阅读和使用,它们已被重新格式化并根据需要进行了部分调整。本站收录文章仅用于帮助用户解决实际问题。如有版权问题,请联系编辑修改或删除,谢谢合作。 查看全部
文章采集api(完美者()网站对功能性板块进行扩充,以期采集器智能分析)
Perfect()网站基于软件下载,网站修订版扩展了功能部分,以解决用户在使用软件过程中遇到的所有问题。网站 新增“软件百科”、“甜蜜小贴士”等新频道,在软件使用全周期更好地为用户提供更专业的服务。
优采云采集器是一款高效的网页信息采集软件,一键采集网页数据,无论是静态网页还是动态网页都可以采集,支持99%的网站,内置大量网站采集模板,覆盖多个行业,提取成功后可另存为Excel表格,api数据库文件。
优采云采集器特点
一键提取数据
简单易学,通过可视化界面,鼠标点击即可采集数据
快速高效
内置一套高速浏览器内核,加上HTTP引擎模式,实现快速采集数据
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站
优采云采集器功能
向导模式
简单易用,轻松通过鼠标点击自动生成
脚本定期运行
可按计划定时运行,无需人工
原装高速核心
自主研发的浏览器内核速度快,远超对手
智能识别
可智能识别网页中的列表和表单结构(多选框下拉列表等)
广告拦截
自定义广告拦截模块,兼容AdblockPlus语法,可添加自定义规则
各种数据导出
支持 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等。
优采云采集器安装
1.到本站下载安装优采云采集器,打开安装程序,点击下一步继续安装
2.点击浏览选择安装位置
3.等一下
优采云采集器使用方法
第一步:输入采集 URL
打开软件,新建一个任务,输入需要采集的网站地址。
第二步:智能分析,全程自动提取数据
进入第二步后,优采云采集器自动对网页进行智能分析,从中提取列表数据。
第三步:将数据导出到表、数据库、网站等。
运行任务,将采集中的数据导出到Csv、Excel及各种数据库,支持api导出。
“技巧与妙计”栏目是全网软件使用技巧的集合或对软件使用过程中各种问题的解答。文章。专栏成立伊始,小编欢迎各位软件大神朋友踊跃投稿。该平台分享每个人的独特技能。
本站文章素材来自网络,文章作者姓名大部分缺失。为了让用户更容易阅读和使用,它们已被重新格式化并根据需要进行了部分调整。本站收录文章仅用于帮助用户解决实际问题。如有版权问题,请联系编辑修改或删除,谢谢合作。
文章采集api(spring使用springcloud架构来做爬虫,历时二十多天,终于搞定)
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2021-11-08 10:15
前言
因公司业务需要,需要获取客户提供的微信公众号文章的历史记录,并每天更新。显然,300多个公众号无法每天手动检查,问题提交给IT团队。对于那些喜欢爬虫的人,我绝对想要他。之前做过搜狗的微信爬虫,之后一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过一系列文章分享项目经验,并提供源码供大家指正!
一、系统介绍
本系统是基于Java开发的。只需配置公众号或微信公众号,即可定时或实时(包括阅读、点赞、观看)抓拍微信公众号的文章。
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、RocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
Redis
演戏
提琴手
三、系统优缺点 系统优点
1、 配置公众号后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取;2、系统为分布式架构,高可用;3、RocketMq 消息队列解决Coupling,可以解决采集由于网络抖动导致的失败。3次消费不成功,会记录日志到mysql,保证文章的完整性;4、可以添加任意数量的微信ID提高采集的效率,抵抗反攀登限制;5、Redis在24小时内缓存每个微信账号的采集记录,防止账号被关闭;6、Nacos作为配置中心,可以通过热配置调整采集的频率 实时; 7、将采集接收到的数据存储在Solr集群中,提高检索速度;8、 将捕获返回的记录存储到MongoDB进行归档查看错误日志。
系统缺点:
1、通过真实手机真实账号采集留言,如果你需要大量公众号,需要有多个微信账号作为支持(如果当天账号达到上限,可以爬取微信官方平台消息,可通过接口获取);2、 不是发文就可以抓到的公众号。采集的时间由系统设置,消息有一定的滞后性(如果公众号不多的话,微信信号数量就足够了。通过增加采集频率优化)。
四、模块介绍
由于后面会添加管理系统和API调用功能,所以提前封装了一些功能。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis 模块:是
spring-boot-starter-data-redis第二个包暴露了打包好的Redis工具类和Redisson工具类。
RocketMQ-WS-启动器
RocketMQ 模块:是
Rocketmq-spring-boot-starter 的二次封装提供了消费重试和故障日志记录功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多种数据源,自定义注解实现数据源动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
电脑-wx-蜘蛛
PC端采集模块:收录PC端采集公众账号历史消息相关功能。
java-wx-蜘蛛
Java提取模块:收录Java程序提取文章内容相关的功能。
移动-wx-蜘蛛
模拟器采集模块:收录与模拟器或手机采集消息交互量相关的功能。
五、一般流程图
六、 在PC端和移动端运行截图
安慰
运行结束
总结
项目试运行中,微信搜狗临时链接永久链接问题已在项目开发中解决。希望能帮到被类似业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。我希望每个人都有自己的向日葵采集。如果你看到这个,你不把它给一个采集吗? 查看全部
文章采集api(spring使用springcloud架构来做爬虫,历时二十多天,终于搞定)
前言
因公司业务需要,需要获取客户提供的微信公众号文章的历史记录,并每天更新。显然,300多个公众号无法每天手动检查,问题提交给IT团队。对于那些喜欢爬虫的人,我绝对想要他。之前做过搜狗的微信爬虫,之后一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过一系列文章分享项目经验,并提供源码供大家指正!
一、系统介绍
本系统是基于Java开发的。只需配置公众号或微信公众号,即可定时或实时(包括阅读、点赞、观看)抓拍微信公众号的文章。
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、RocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
Redis
演戏
提琴手
三、系统优缺点 系统优点
1、 配置公众号后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取;2、系统为分布式架构,高可用;3、RocketMq 消息队列解决Coupling,可以解决采集由于网络抖动导致的失败。3次消费不成功,会记录日志到mysql,保证文章的完整性;4、可以添加任意数量的微信ID提高采集的效率,抵抗反攀登限制;5、Redis在24小时内缓存每个微信账号的采集记录,防止账号被关闭;6、Nacos作为配置中心,可以通过热配置调整采集的频率 实时; 7、将采集接收到的数据存储在Solr集群中,提高检索速度;8、 将捕获返回的记录存储到MongoDB进行归档查看错误日志。
系统缺点:
1、通过真实手机真实账号采集留言,如果你需要大量公众号,需要有多个微信账号作为支持(如果当天账号达到上限,可以爬取微信官方平台消息,可通过接口获取);2、 不是发文就可以抓到的公众号。采集的时间由系统设置,消息有一定的滞后性(如果公众号不多的话,微信信号数量就足够了。通过增加采集频率优化)。
四、模块介绍
由于后面会添加管理系统和API调用功能,所以提前封装了一些功能。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis 模块:是
spring-boot-starter-data-redis第二个包暴露了打包好的Redis工具类和Redisson工具类。
RocketMQ-WS-启动器
RocketMQ 模块:是
Rocketmq-spring-boot-starter 的二次封装提供了消费重试和故障日志记录功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多种数据源,自定义注解实现数据源动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
电脑-wx-蜘蛛
PC端采集模块:收录PC端采集公众账号历史消息相关功能。
java-wx-蜘蛛
Java提取模块:收录Java程序提取文章内容相关的功能。
移动-wx-蜘蛛
模拟器采集模块:收录与模拟器或手机采集消息交互量相关的功能。
五、一般流程图
六、 在PC端和移动端运行截图
安慰
运行结束
总结
项目试运行中,微信搜狗临时链接永久链接问题已在项目开发中解决。希望能帮到被类似业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。我希望每个人都有自己的向日葵采集。如果你看到这个,你不把它给一个采集吗?
文章采集api(INTERTIDTURBOAPIV1.0版提供公开信息数据开放平台对外接口 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-11-08 09:24
)
本次网站使用INTERTID TURBO API V1.0 版本提供开放信息数据开放平台的对外接口。通过对数据的编目、展示和管理,提供对数据的采集、采集、编辑和整理。、全生命周期管理和服务的编目、发布和更新,确保政府开放数据的机读性、原创性、及时性、公开性、真实性、完整性和安全性,并提供对外数据检索、展示和下载,并提供面向数据开发人员的数据访问 API。
本网站以数据签名权限的方式使用INTERTID TURBO API主动公开信息、咨询投诉、在线调查、舆情采集等方面的数据对接服务;同时,向公众提供非XML格式的公共信息API 提供此网站可共享的发布信息。
界面语言定义:
$.select(froms: from)(w: Query)(隐式排序:orders = null, l: limit =limit(-1), o: offest = offest(-1), maxDocs: Int = 10000)
字段类型:
字符串:字符类型。boolean: 布尔类型。number:数字类型。日期时间:时间类型。reader:流类型,流类型的字段类型store必须是storeno。bytes:字符数组,字符数组的字段类型存储为storeyes。
详情请参考政府数据查询服务统一开放平台,您可以致电网站索取详细的API文档。
查看全部
文章采集api(INTERTIDTURBOAPIV1.0版提供公开信息数据开放平台对外接口
)
本次网站使用INTERTID TURBO API V1.0 版本提供开放信息数据开放平台的对外接口。通过对数据的编目、展示和管理,提供对数据的采集、采集、编辑和整理。、全生命周期管理和服务的编目、发布和更新,确保政府开放数据的机读性、原创性、及时性、公开性、真实性、完整性和安全性,并提供对外数据检索、展示和下载,并提供面向数据开发人员的数据访问 API。
本网站以数据签名权限的方式使用INTERTID TURBO API主动公开信息、咨询投诉、在线调查、舆情采集等方面的数据对接服务;同时,向公众提供非XML格式的公共信息API 提供此网站可共享的发布信息。
界面语言定义:
$.select(froms: from)(w: Query)(隐式排序:orders = null, l: limit =limit(-1), o: offest = offest(-1), maxDocs: Int = 10000)
字段类型:
字符串:字符类型。boolean: 布尔类型。number:数字类型。日期时间:时间类型。reader:流类型,流类型的字段类型store必须是storeno。bytes:字符数组,字符数组的字段类型存储为storeyes。
详情请参考政府数据查询服务统一开放平台,您可以致电网站索取详细的API文档。
文章采集api(软件特色关于软件优采云采集器(SkyCaiji)功能特色10张壁纸)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-11-06 21:02
优采云采集器是一款免费的数据采集发布爬虫软件,用php+mysql开发,可以部署在云服务器上,几乎采集所有类型的网页,没有缝制对接各种cms建站程序,无需登录即可实时发布数据,全自动无需人工干预,是大数据和云时代最好的云爬虫软件网站数据自动化采集!软件特点 关于优采云采集器(天财记)软件,致力于网站数据自动化采集的发布,系统采用PHP+Mysql开发,可部署在云服务器上制作数据采集便捷、智能、云端,让您随时随地移动办公!数据采集支持多级、多页、分页< @采集,自定义采集规则(支持正则、XPATH、JSON等)准确匹配任何信息流,几乎采集所有类型的网页,大部分文章类型页面内容可实现内容发布智能识别,与各种cms建站程序无缝对接,实现免登录导入数据,支持自定义数据发布插件,或直接导入数据库,保存为Excel文件,生成API接口等自动化及云平台软件,实现定时定量自动采集发布,无需人工干预!内置云平台,用户可以分享和下载采集规则,发布供需信息,社区帮助,交流等。升级软件的使用方法可以直接在后台首页检测并点击升级,或者将压缩包上传到服务器解压覆盖就可以了!安装软件。将下载的软件上传到您的服务器。如果根目录下有站点,建议放在子目录下。解压后打开浏览器输入你的服务器域名或ip地址(存放在子目录时添加子目录名),进入安装界面点击“接受”,进入环境检测页面,一定要确保所有参数正确,否则使用过程中会出现错误,点击“下一步”进入数据安装界面填写数据库和创始人配置,点击“下一步” 最后安装完成,现在可以使用优采云采集器!具有 10 张壁纸,无需触摸板和鼠标即可操作内置时钟和日期小部件 3 种不同的时钟格式 5 种不同的日期格式 查看全部
文章采集api(软件特色关于软件优采云采集器(SkyCaiji)功能特色10张壁纸)
优采云采集器是一款免费的数据采集发布爬虫软件,用php+mysql开发,可以部署在云服务器上,几乎采集所有类型的网页,没有缝制对接各种cms建站程序,无需登录即可实时发布数据,全自动无需人工干预,是大数据和云时代最好的云爬虫软件网站数据自动化采集!软件特点 关于优采云采集器(天财记)软件,致力于网站数据自动化采集的发布,系统采用PHP+Mysql开发,可部署在云服务器上制作数据采集便捷、智能、云端,让您随时随地移动办公!数据采集支持多级、多页、分页< @采集,自定义采集规则(支持正则、XPATH、JSON等)准确匹配任何信息流,几乎采集所有类型的网页,大部分文章类型页面内容可实现内容发布智能识别,与各种cms建站程序无缝对接,实现免登录导入数据,支持自定义数据发布插件,或直接导入数据库,保存为Excel文件,生成API接口等自动化及云平台软件,实现定时定量自动采集发布,无需人工干预!内置云平台,用户可以分享和下载采集规则,发布供需信息,社区帮助,交流等。升级软件的使用方法可以直接在后台首页检测并点击升级,或者将压缩包上传到服务器解压覆盖就可以了!安装软件。将下载的软件上传到您的服务器。如果根目录下有站点,建议放在子目录下。解压后打开浏览器输入你的服务器域名或ip地址(存放在子目录时添加子目录名),进入安装界面点击“接受”,进入环境检测页面,一定要确保所有参数正确,否则使用过程中会出现错误,点击“下一步”进入数据安装界面填写数据库和创始人配置,点击“下一步” 最后安装完成,现在可以使用优采云采集器!具有 10 张壁纸,无需触摸板和鼠标即可操作内置时钟和日期小部件 3 种不同的时钟格式 5 种不同的日期格式
文章采集api( WebApi接口采集指标数据的配置实践操作(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 412 次浏览 • 2021-11-06 01:17
WebApi接口采集指标数据的配置实践操作(组图)
)
这个文章的主要目的是告诉你如何配置Prometheus,使其可以使用指定的Web Api接口采集指标数据。文章中使用的case是NGINX的采集配置,来自NGINX数据索引页的采集数据,设置了用户名和密码,所以这是文章@的副标题> 可能是nginx的prometheus 采集配置或者prometheus 采集 basic auth的nginx。
上图展示了配置完成后在Grafana中配置模板的效果。
用过Prometheus的朋友一定知道如何配置address:port服务。比如在采集某个Redis的信息时,配置可以这样写:
- job_name: 'redis'
static_configs:
- targets: ['11.22.33.58:6087']
复制代码
注意:以上情况假设Redis Exporter的地址和端口为11.22.33.58:6087。
这是最简单也是最广为人知的方法。但是如果要监控指定的Web API,就不能这样写了。如果你没有看到这个 文章,你可能会在搜索引擎中搜索这样的:
但是很遗憾,没有找到有效的信息(现在是2021年3月),基本上所有的坑都能找到。
条件假设
假设我们现在需要从带有地址...的接口采集相关的Prometheus监控指标,并且该接口使用basic auth(假设用户名为weishidong,密码为0099887kk)进行基本授权验证。
配置实践
如果填写之前看到的Prometheus配置,很可能这样写配置:
- job_name: 'web'
static_configs:
- targets: ['http://www.weishidong.com/status/format/prometheus']
basic_auth:
username: weishidong
password: 0099887kk
复制代码
保存配置文件,重启服务后,你会发现这种方式无法采集数据,太可怕了。
官方配置指南
刚才的手术实在是太可怕了。当我们遇到不明白的问题时,我们当然去官方文档-> Prometheus Configuration。建议从上到下阅读,但如果你赶时间,可以直接来这部分。官方示例如下(内容太多,这里只保留与本文相关的部分,建议大家阅读原文):
# The job name assigned to scraped metrics by default.
job_name:
# How frequently to scrape targets from this job.
[ scrape_interval: | default = ]
# Per-scrape timeout when scraping this job.
[ scrape_timeout: | default = ]
# The HTTP resource path on which to fetch metrics from targets.
[ metrics_path: | default = /metrics ]
# honor_labels controls how Prometheus handles conflicts between labels that are
# already present in scraped data and labels that Prometheus would attach
# server-side ("job" and "instance" labels, manually configured target
# labels, and labels generated by service discovery implementations).
#
# If honor_labels is set to "true", label conflicts are resolved by keeping label
# values from the scraped data and ignoring the conflicting server-side labels.
#
# If honor_labels is set to "false", label conflicts are resolved by renaming
# conflicting labels in the scraped data to "exported_" (for
# example "exported_instance", "exported_job") and then attaching server-side
# labels.
#
# Setting honor_labels to "true" is useful for use cases such as federation and
# scraping the Pushgateway, where all labels specified in the target should be
# preserved.
#
# Note that any globally configured "external_labels" are unaffected by this
# setting. In communication with external systems, they are always applied only
# when a time series does not have a given label yet and are ignored otherwise.
[ honor_labels: | default = false ]
# honor_timestamps controls whether Prometheus respects the timestamps present
# in scraped data.
#
# If honor_timestamps is set to "true", the timestamps of the metrics exposed
# by the target will be used.
#
# If honor_timestamps is set to "false", the timestamps of the metrics exposed
# by the target will be ignored.
[ honor_timestamps: | default = true ]
# Configures the protocol scheme used for requests.
[ scheme: | default = http ]
# Optional HTTP URL parameters.
params:
[ : [, ...] ]
# Sets the `Authorization` header on every scrape request with the
# configured username and password.
# password and password_file are mutually exclusive.
basic_auth:
[ username: ]
[ password: ]
[ password_file: ]
# Sets the `Authorization` header on every scrape request with
# the configured bearer token. It is mutually exclusive with `bearer_token_file`.
[ bearer_token: ]
# Sets the `Authorization` header on every scrape request with the bearer token
# read from the configured file. It is mutually exclusive with `bearer_token`.
[ bearer_token_file: ]
复制代码
如果仔细看,应该注意几个关键信息:metrics_path 和 basic_auth。其中,metrics_path用于指定HTTP类型指示符信息采集时的路由地址,默认值为/metrics;字段basic_auth用于授权验证,这里的password可以指定一个密码文件,而不是直接填写明文(一般来说,指定的密码文件的安全性稍高,明文)。
有效配置
根据官方文档的指引,我们可以快速推导出正确的配置写法:
- job_name: 'web'
metrics_path: /status/format/prometheus
static_configs:
- targets: ['www.weishidong.com']
basic_auth:
username: weishidong
password: 0099887kk
复制代码
需要注意的是这里的字不用填,因为Prometheus默认的Scheme是http。如果地址的scheme是https,我们需要根据文档指引添加scheme字段,对应的配置为:
- job_name: 'web'
metrics_path: /status/format/prometheus
static_configs:
- targets: ['www.weishidong.com']
scheme: https
basic_auth:
username: weishidong
password: 0099887kk
复制代码
配置完成后,Prometheus应该可以成功采集获取数据。用Grafana,可以看到开头给出的监控效果图。
查看全部
文章采集api(
WebApi接口采集指标数据的配置实践操作(组图)
)
这个文章的主要目的是告诉你如何配置Prometheus,使其可以使用指定的Web Api接口采集指标数据。文章中使用的case是NGINX的采集配置,来自NGINX数据索引页的采集数据,设置了用户名和密码,所以这是文章@的副标题> 可能是nginx的prometheus 采集配置或者prometheus 采集 basic auth的nginx。
上图展示了配置完成后在Grafana中配置模板的效果。
用过Prometheus的朋友一定知道如何配置address:port服务。比如在采集某个Redis的信息时,配置可以这样写:
- job_name: 'redis'
static_configs:
- targets: ['11.22.33.58:6087']
复制代码
注意:以上情况假设Redis Exporter的地址和端口为11.22.33.58:6087。
这是最简单也是最广为人知的方法。但是如果要监控指定的Web API,就不能这样写了。如果你没有看到这个 文章,你可能会在搜索引擎中搜索这样的:
但是很遗憾,没有找到有效的信息(现在是2021年3月),基本上所有的坑都能找到。
条件假设
假设我们现在需要从带有地址...的接口采集相关的Prometheus监控指标,并且该接口使用basic auth(假设用户名为weishidong,密码为0099887kk)进行基本授权验证。
配置实践
如果填写之前看到的Prometheus配置,很可能这样写配置:
- job_name: 'web'
static_configs:
- targets: ['http://www.weishidong.com/status/format/prometheus']
basic_auth:
username: weishidong
password: 0099887kk
复制代码
保存配置文件,重启服务后,你会发现这种方式无法采集数据,太可怕了。
官方配置指南
刚才的手术实在是太可怕了。当我们遇到不明白的问题时,我们当然去官方文档-> Prometheus Configuration。建议从上到下阅读,但如果你赶时间,可以直接来这部分。官方示例如下(内容太多,这里只保留与本文相关的部分,建议大家阅读原文):
# The job name assigned to scraped metrics by default.
job_name:
# How frequently to scrape targets from this job.
[ scrape_interval: | default = ]
# Per-scrape timeout when scraping this job.
[ scrape_timeout: | default = ]
# The HTTP resource path on which to fetch metrics from targets.
[ metrics_path: | default = /metrics ]
# honor_labels controls how Prometheus handles conflicts between labels that are
# already present in scraped data and labels that Prometheus would attach
# server-side ("job" and "instance" labels, manually configured target
# labels, and labels generated by service discovery implementations).
#
# If honor_labels is set to "true", label conflicts are resolved by keeping label
# values from the scraped data and ignoring the conflicting server-side labels.
#
# If honor_labels is set to "false", label conflicts are resolved by renaming
# conflicting labels in the scraped data to "exported_" (for
# example "exported_instance", "exported_job") and then attaching server-side
# labels.
#
# Setting honor_labels to "true" is useful for use cases such as federation and
# scraping the Pushgateway, where all labels specified in the target should be
# preserved.
#
# Note that any globally configured "external_labels" are unaffected by this
# setting. In communication with external systems, they are always applied only
# when a time series does not have a given label yet and are ignored otherwise.
[ honor_labels: | default = false ]
# honor_timestamps controls whether Prometheus respects the timestamps present
# in scraped data.
#
# If honor_timestamps is set to "true", the timestamps of the metrics exposed
# by the target will be used.
#
# If honor_timestamps is set to "false", the timestamps of the metrics exposed
# by the target will be ignored.
[ honor_timestamps: | default = true ]
# Configures the protocol scheme used for requests.
[ scheme: | default = http ]
# Optional HTTP URL parameters.
params:
[ : [, ...] ]
# Sets the `Authorization` header on every scrape request with the
# configured username and password.
# password and password_file are mutually exclusive.
basic_auth:
[ username: ]
[ password: ]
[ password_file: ]
# Sets the `Authorization` header on every scrape request with
# the configured bearer token. It is mutually exclusive with `bearer_token_file`.
[ bearer_token: ]
# Sets the `Authorization` header on every scrape request with the bearer token
# read from the configured file. It is mutually exclusive with `bearer_token`.
[ bearer_token_file: ]
复制代码
如果仔细看,应该注意几个关键信息:metrics_path 和 basic_auth。其中,metrics_path用于指定HTTP类型指示符信息采集时的路由地址,默认值为/metrics;字段basic_auth用于授权验证,这里的password可以指定一个密码文件,而不是直接填写明文(一般来说,指定的密码文件的安全性稍高,明文)。
有效配置
根据官方文档的指引,我们可以快速推导出正确的配置写法:
- job_name: 'web'
metrics_path: /status/format/prometheus
static_configs:
- targets: ['www.weishidong.com']
basic_auth:
username: weishidong
password: 0099887kk
复制代码
需要注意的是这里的字不用填,因为Prometheus默认的Scheme是http。如果地址的scheme是https,我们需要根据文档指引添加scheme字段,对应的配置为:
- job_name: 'web'
metrics_path: /status/format/prometheus
static_configs:
- targets: ['www.weishidong.com']
scheme: https
basic_auth:
username: weishidong
password: 0099887kk
复制代码
配置完成后,Prometheus应该可以成功采集获取数据。用Grafana,可以看到开头给出的监控效果图。
文章采集api( 大数据信息的收集和应用逐步普及,离不开网络爬虫来说 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-10-31 02:18
大数据信息的收集和应用逐步普及,离不开网络爬虫来说
)
数字时代,大数据信息的采集和应用逐渐普及,离不开网络爬虫的广泛应用。由于数据信息市场的不断扩大,需要大规模的网络爬虫来处理海量的数据信息采集。在这个过程中应该注意哪些问题?
1、 首先检查是否有API。API是网站提供官方数据信息的接口。
比如通过调用API采集数据信息,在网站允许的范围内采集数据,既没有道德法律风险,也没有故意设置网站的障碍;但是,API接口的访问受网站的控制,网站可用于计费和限制访问上限。二、 数据信息结构分析和数据信息存储。
2、网络爬虫需要明确显示需要哪些字段。
这些字段可以存在于网页上,也可以根据网页中的现有字段进行进一步计算。下面是如何生成表,如何连接多个表等等。需要注意的是,在确定字段链接时,不要只看网页的一小部分,因为一个网页可能缺少其他类型网页的字段。这可能是网站的问题,也可能是用户行为造成的,不同的是只有多浏览一些网页,才能全面提取关键字段。
对于大型网络爬虫,除了采集数据信息外,还必须存储其他重要的中间数据信息(如网页ID或url),避免每次都重新爬取id。
3、数据流分析。
如果要批量抓取页面,请查看其入口位置,该位置基于采集的范围。站点页面一般基于树状结构,可以以根节点为入口逐层进入。确定信息流的机制后,下一个单独的网页,然后将此模式复制到整个页面。
<p style="margin-top: 10px;margin-bottom: 10px;outline: 0px;max-width: 100%;min-height: 1em;letter-spacing: 0.544px;white-space: normal;border-width: 0px;border-style: initial;border-color: initial;-webkit-font-smoothing: antialiased;font-size: 18px;font-family: "Microsoft YaHei", Arial, Verdana, Tahoma, sans-serif;vertical-align: baseline;background-image: initial;background-position: initial;background-size: initial;background-repeat: initial;background-attachment: initial;background-origin: initial;background-clip: initial;line-height: 32px;color: rgb(85, 85, 85);text-align: start;box-sizing: border-box !important;overflow-wrap: break-word !important;">
搜索下方加老师微信<br data-filtered="filtered" style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;">
老师微信号:<strong style="outline: 0px;max-width: 100%;color: rgb(63, 63, 63);letter-spacing: 0.544px;box-sizing: border-box !important;overflow-wrap: break-word !important;">XTUOL1988【</strong>切记备注<strong style="outline: 0px;max-width: 100%;letter-spacing: 0.544px;box-sizing: border-box !important;overflow-wrap: break-word !important;">:学习Python</strong>】
领取Python web开发,Python爬虫,Python数据分析,人工智能等精品学习课程。带你从零基础系统性的学好Python!
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权
</p> 查看全部
文章采集api(
大数据信息的收集和应用逐步普及,离不开网络爬虫来说
)
数字时代,大数据信息的采集和应用逐渐普及,离不开网络爬虫的广泛应用。由于数据信息市场的不断扩大,需要大规模的网络爬虫来处理海量的数据信息采集。在这个过程中应该注意哪些问题?
1、 首先检查是否有API。API是网站提供官方数据信息的接口。
比如通过调用API采集数据信息,在网站允许的范围内采集数据,既没有道德法律风险,也没有故意设置网站的障碍;但是,API接口的访问受网站的控制,网站可用于计费和限制访问上限。二、 数据信息结构分析和数据信息存储。
2、网络爬虫需要明确显示需要哪些字段。
这些字段可以存在于网页上,也可以根据网页中的现有字段进行进一步计算。下面是如何生成表,如何连接多个表等等。需要注意的是,在确定字段链接时,不要只看网页的一小部分,因为一个网页可能缺少其他类型网页的字段。这可能是网站的问题,也可能是用户行为造成的,不同的是只有多浏览一些网页,才能全面提取关键字段。
对于大型网络爬虫,除了采集数据信息外,还必须存储其他重要的中间数据信息(如网页ID或url),避免每次都重新爬取id。
3、数据流分析。
如果要批量抓取页面,请查看其入口位置,该位置基于采集的范围。站点页面一般基于树状结构,可以以根节点为入口逐层进入。确定信息流的机制后,下一个单独的网页,然后将此模式复制到整个页面。
<p style="margin-top: 10px;margin-bottom: 10px;outline: 0px;max-width: 100%;min-height: 1em;letter-spacing: 0.544px;white-space: normal;border-width: 0px;border-style: initial;border-color: initial;-webkit-font-smoothing: antialiased;font-size: 18px;font-family: "Microsoft YaHei", Arial, Verdana, Tahoma, sans-serif;vertical-align: baseline;background-image: initial;background-position: initial;background-size: initial;background-repeat: initial;background-attachment: initial;background-origin: initial;background-clip: initial;line-height: 32px;color: rgb(85, 85, 85);text-align: start;box-sizing: border-box !important;overflow-wrap: break-word !important;">
搜索下方加老师微信<br data-filtered="filtered" style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;">
老师微信号:<strong style="outline: 0px;max-width: 100%;color: rgb(63, 63, 63);letter-spacing: 0.544px;box-sizing: border-box !important;overflow-wrap: break-word !important;">XTUOL1988【</strong>切记备注<strong style="outline: 0px;max-width: 100%;letter-spacing: 0.544px;box-sizing: border-box !important;overflow-wrap: break-word !important;">:学习Python</strong>】
领取Python web开发,Python爬虫,Python数据分析,人工智能等精品学习课程。带你从零基础系统性的学好Python!
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权
</p> 文章采集api(数据推送API的应用草料平台的3种推送方式(一) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-10-30 17:11
)
一、数据推送API应用
饲料平台的数据可以自动推送给您,您可以自己调用数据作为应用程序。目前不支持将数据从外部系统写入饲料。
应用一:制作实时数据报表
使用数据分析工具连接数据库,进行数据分析或报表制作,查看效果,制作教程
应用二:对接企业流程
通过在草料平台上实现扫码采集数据等功能,然后通过API与企业系统的进程对接,企业可以在保持原有系统的同时,以极低的成本应用草料功能,并检查影响
二、我们提供3种推送方式1、官方数据库
Forage 为您提供独立的云数据库来同步您的后端数据。之后,您可以使用数据分析软件连接到这个云数据库进行数据报告;或者编写程序主动调用数据连接其他系统。查看数据库字段说明
指示:
草料后台导航栏-数据API高级功能,选择官方数据库,填写信息,提交激活申请。以下是申请成功后得到的数据库示例:
类型:MySQL
主持人:
端口:3306
数据库名称:cli_202112111(示例)
用户名:cli_202112111(示例)
密码:ek82jk9e1kdi45(示例)
报告制作:
如需连接官方数据库并制作自定义报表,可查看报表制作教程
因为涉及到基础数据库(SQL)操作和BI工具操作,所以有一定的使用门槛。使用前请掌握基本操作能力。
2、自有数据库
Forage会将数据实时推送到您提供的企业数据库中(仅支持Mysql5.7版本),无需建表和开放公网访问权限。未来您可以自由读取数据,实现企业数据与信息的整合。查看数据字段说明
指示:
草料后台导航栏-数据API的高级功能,选择自己的数据库,填写自己的数据库主机、端口、账号等信息。
3、网络钩子
Forage 会将 JSON 格式的表单数据推送到您指定的 URL。该地址需要允许公共互联网访问。之后,您可以编写程序并使用接收到的数据与其他系统或进程进行交互。查看 Webhook 说明
指示:
草料后台导航栏-数据API的高级功能,选择Webhook,填写接收数据的URL地址并保存。
具体流程:
①首先准备一个可以从公网访问的接口地址,填写地址字段,例如(xxx部分为系统的域名或IP)
②配置后,每当在草料中生成新的表单数据时(如在表单中提交一条记录),都会向上述地址发出POST请求
查看全部
文章采集api(数据推送API的应用草料平台的3种推送方式(一)
)
一、数据推送API应用
饲料平台的数据可以自动推送给您,您可以自己调用数据作为应用程序。目前不支持将数据从外部系统写入饲料。
应用一:制作实时数据报表
使用数据分析工具连接数据库,进行数据分析或报表制作,查看效果,制作教程
应用二:对接企业流程
通过在草料平台上实现扫码采集数据等功能,然后通过API与企业系统的进程对接,企业可以在保持原有系统的同时,以极低的成本应用草料功能,并检查影响
二、我们提供3种推送方式1、官方数据库
Forage 为您提供独立的云数据库来同步您的后端数据。之后,您可以使用数据分析软件连接到这个云数据库进行数据报告;或者编写程序主动调用数据连接其他系统。查看数据库字段说明
指示:
草料后台导航栏-数据API高级功能,选择官方数据库,填写信息,提交激活申请。以下是申请成功后得到的数据库示例:
类型:MySQL
主持人:
端口:3306
数据库名称:cli_202112111(示例)
用户名:cli_202112111(示例)
密码:ek82jk9e1kdi45(示例)
报告制作:
如需连接官方数据库并制作自定义报表,可查看报表制作教程
因为涉及到基础数据库(SQL)操作和BI工具操作,所以有一定的使用门槛。使用前请掌握基本操作能力。
2、自有数据库
Forage会将数据实时推送到您提供的企业数据库中(仅支持Mysql5.7版本),无需建表和开放公网访问权限。未来您可以自由读取数据,实现企业数据与信息的整合。查看数据字段说明
指示:
草料后台导航栏-数据API的高级功能,选择自己的数据库,填写自己的数据库主机、端口、账号等信息。
3、网络钩子
Forage 会将 JSON 格式的表单数据推送到您指定的 URL。该地址需要允许公共互联网访问。之后,您可以编写程序并使用接收到的数据与其他系统或进程进行交互。查看 Webhook 说明
指示:
草料后台导航栏-数据API的高级功能,选择Webhook,填写接收数据的URL地址并保存。
具体流程:
①首先准备一个可以从公网访问的接口地址,填写地址字段,例如(xxx部分为系统的域名或IP)
②配置后,每当在草料中生成新的表单数据时(如在表单中提交一条记录),都会向上述地址发出POST请求
文章采集api(越来越多企业开始做基于公众号平台的数据内容整合)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-29 06:16
越来越多的企业开始基于公众号平台或舆情分析或榜单排名进行数据内容整合。其中涉及的技术之一是公众号采集的数据,公众号数据只有集成到自己的平台后才能进行下一步。
公众号采集不仅技术门槛高,而且专业领域人才匮乏。自己组建团队,人工成本和时间成本都很高。市场上大多数公开可用的技术要么已经过时且无法获得,要么价格太高。
经过多年的技术沉淀,Power Data在公众号数据领域拥有完整的解决方案采集。用户只需提供微信ID号即可获取任意公众号的历史文章数据,包括阅读量、点赞、观看、评论等数据。只需一名工程师即可实现API接口的对接,进而完成数据集成。
电量数据可以提供分钟级的数据同步能力,这意味着在公众号发布后的几分钟内,电量数据就可以同步到用户自己的平台上。此外,它还根据用户需求提供多项个性化需求定制。
在我们服务的客户中,有很多行业标杆用户,包括36kr等新媒体。
Power Data的使命是全面提升客户价值,构建赋能能力,助力行业企业数字化转型。
欢迎联系我试用,加微信请备注“采集”
评论捕获文章 6 小时、12 小时、24 小时、48 小时后发布
有任何问题可以扫描二维码与我交流 查看全部
文章采集api(越来越多企业开始做基于公众号平台的数据内容整合)
越来越多的企业开始基于公众号平台或舆情分析或榜单排名进行数据内容整合。其中涉及的技术之一是公众号采集的数据,公众号数据只有集成到自己的平台后才能进行下一步。
公众号采集不仅技术门槛高,而且专业领域人才匮乏。自己组建团队,人工成本和时间成本都很高。市场上大多数公开可用的技术要么已经过时且无法获得,要么价格太高。
经过多年的技术沉淀,Power Data在公众号数据领域拥有完整的解决方案采集。用户只需提供微信ID号即可获取任意公众号的历史文章数据,包括阅读量、点赞、观看、评论等数据。只需一名工程师即可实现API接口的对接,进而完成数据集成。
电量数据可以提供分钟级的数据同步能力,这意味着在公众号发布后的几分钟内,电量数据就可以同步到用户自己的平台上。此外,它还根据用户需求提供多项个性化需求定制。
在我们服务的客户中,有很多行业标杆用户,包括36kr等新媒体。
Power Data的使命是全面提升客户价值,构建赋能能力,助力行业企业数字化转型。
欢迎联系我试用,加微信请备注“采集”
评论捕获文章 6 小时、12 小时、24 小时、48 小时后发布
有任何问题可以扫描二维码与我交流
文章采集api(优采云采集支持调用5118一键智能改写API接口(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-10-29 06:14
)
优采云采集支持调用5118一键智能重写API接口,处理采集数据标题和内容等,可以产生对搜索引擎更有吸引力的文章 ;
详细使用步骤如下:
1. 5118 一键智能换字API接口配置
一、API配置入口:
点击控制台左侧列表中的【第三方服务配置】 》点击【第三方内容API访问】 》点击【第三方API配置管理】》 最后点击【+5118一键智能原创API] 创建接口配置
二、配置API接口信息:
【API-Key值】从5118后台获取对应的5118一键智能重写APIKey值,填写优采云;
2. 创建 API 处理规则
API处理规则,可设置调用API接口处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】>点击【第三方内容API访问】>进入【API处理规则管理】页面,最后点击【添加API处理规则】创建API处理规则;
二、API处理规则配置:
规则名称:用户可以自己命名;
字段名:填写的字段名的内容将由API接口处理。默认为title和content字段,可以修改、添加或删除;(可以添加其他字段,点击添加内容字段,修改字段名称,但必须在【Detail Extractor】中已经定义,如作者、关键字、描述字段)
使用的API:选择已经设置好的API接口配置,执行时会调用该接口,可以从不同的API接口配置中选择多个字段。5118 一键智能改写;
处理顺序:执行顺序是按照数量从小到大执行;
3. API 处理规则使用
API处理规则的使用方式有两种:手动执行和自动执行:
手动执行:data采集后,在【Result Data & Release】中使用第三方API执行;
自动执行:自动化配置完成后,任务采集数据完成后,系统会自动执行指定的API处理规则,无需人工操作。
一、手动执行API处理规则:
在任务的【结果数据&发布】选项卡中,点击【SEO&API&翻译工具】按钮“选择【第三方API执行】列”选择对应的API处理规则“执行(数据范围有两个执行)方法,批处理根据发布状态执行并根据列表中选择的数据执行);
二、自动执行API处理规则:
启用 API 处理的自动执行。任务完成采集后,会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡,【自动执行第三方API配置】》勾选【采集,自动执行API】选项“选择要执行的API处理规则”选择API interface 处理数据的范围(一般选择“待释放”,all会导致所有数据被执行多次),最后点击save;
4. API处理结果及发布 一、查看API接口处理结果:
API接口处理的内容会生成API接口对应的新字段,例如:
标题处理后的新字段:
title_5118重写(对应5118一键智能重写API接口)
内容处理后的新字段:
content_5118 rewrite(对应5118一键智能重写API接口)
在【结果数据&发布】和数据预览界面均可查看。
提示:API 处理规则执行需要一段时间。执行后页面会自动刷新,出现API接口处理的新字段;
二、API接口处理后的内容发布
在发布文章之前,修改发布目标第二步的映射字段,在API接口处理后将title和content改为新的对应字段。
例如,执行5118一键智能改词API后,选择title_5118改词和content_5118改词发布;
5. 5118-API接口常见问题及解决方案 一、API处理规则和SEO规则如何搭配使用?
系统默认对title和content字段进行SEO功能,需要在SEO规则中修改对应新增的字段,如title_5118换词和content_5118换词字段;
查看全部
文章采集api(优采云采集支持调用5118一键智能改写API接口(组图)
)
优采云采集支持调用5118一键智能重写API接口,处理采集数据标题和内容等,可以产生对搜索引擎更有吸引力的文章 ;
详细使用步骤如下:
1. 5118 一键智能换字API接口配置
一、API配置入口:
点击控制台左侧列表中的【第三方服务配置】 》点击【第三方内容API访问】 》点击【第三方API配置管理】》 最后点击【+5118一键智能原创API] 创建接口配置
二、配置API接口信息:
【API-Key值】从5118后台获取对应的5118一键智能重写APIKey值,填写优采云;
2. 创建 API 处理规则
API处理规则,可设置调用API接口处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】>点击【第三方内容API访问】>进入【API处理规则管理】页面,最后点击【添加API处理规则】创建API处理规则;
二、API处理规则配置:
规则名称:用户可以自己命名;
字段名:填写的字段名的内容将由API接口处理。默认为title和content字段,可以修改、添加或删除;(可以添加其他字段,点击添加内容字段,修改字段名称,但必须在【Detail Extractor】中已经定义,如作者、关键字、描述字段)
使用的API:选择已经设置好的API接口配置,执行时会调用该接口,可以从不同的API接口配置中选择多个字段。5118 一键智能改写;
处理顺序:执行顺序是按照数量从小到大执行;
3. API 处理规则使用
API处理规则的使用方式有两种:手动执行和自动执行:
手动执行:data采集后,在【Result Data & Release】中使用第三方API执行;
自动执行:自动化配置完成后,任务采集数据完成后,系统会自动执行指定的API处理规则,无需人工操作。
一、手动执行API处理规则:
在任务的【结果数据&发布】选项卡中,点击【SEO&API&翻译工具】按钮“选择【第三方API执行】列”选择对应的API处理规则“执行(数据范围有两个执行)方法,批处理根据发布状态执行并根据列表中选择的数据执行);
二、自动执行API处理规则:
启用 API 处理的自动执行。任务完成采集后,会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡,【自动执行第三方API配置】》勾选【采集,自动执行API】选项“选择要执行的API处理规则”选择API interface 处理数据的范围(一般选择“待释放”,all会导致所有数据被执行多次),最后点击save;
4. API处理结果及发布 一、查看API接口处理结果:
API接口处理的内容会生成API接口对应的新字段,例如:
标题处理后的新字段:
title_5118重写(对应5118一键智能重写API接口)
内容处理后的新字段:
content_5118 rewrite(对应5118一键智能重写API接口)
在【结果数据&发布】和数据预览界面均可查看。
提示:API 处理规则执行需要一段时间。执行后页面会自动刷新,出现API接口处理的新字段;
二、API接口处理后的内容发布
在发布文章之前,修改发布目标第二步的映射字段,在API接口处理后将title和content改为新的对应字段。
例如,执行5118一键智能改词API后,选择title_5118改词和content_5118改词发布;
5. 5118-API接口常见问题及解决方案 一、API处理规则和SEO规则如何搭配使用?
系统默认对title和content字段进行SEO功能,需要在SEO规则中修改对应新增的字段,如title_5118换词和content_5118换词字段;
文章采集api(数据推送API的应用草料平台的3种推送方式(一) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-29 06:13
)
一、数据推送API应用
饲料平台的数据可以自动推送给您,您可以将数据作为应用程序自行调用。目前不支持将数据从外部系统写入饲料。
应用一:制作实时数据报表
使用数据分析工具连接数据库,进行数据分析或报表制作,查看效果,制作教程
应用二:对接企业流程
通过在草料平台上实现扫码采集数据等功能,然后通过API与企业系统的进程对接,企业可以在保持原有系统的同时,以极低的成本应用草料功能,并检查影响
二、我们提供3种推送方式1、官方数据库
Forage 为您提供独立的云数据库来同步您的后端数据。之后,您可以使用数据分析软件连接到这个云数据库进行数据报告;或者编写程序主动调用数据连接其他系统。查看数据库字段说明
指示:
草料后台导航栏-数据API高级功能,选择官方数据库,填写信息,提交激活申请。以下是申请成功后得到的数据库示例:
类型:MySQL
主持人:
端口:3306
数据库名称:cli_202112111(示例)
用户名:cli_202112111(示例)
密码:ek82jk9e1kdi45(示例)
报告制作:
如需连接官方数据库并制作自定义报表,可查看报表制作教程
因为涉及到基础数据库(SQL)操作和BI工具操作,所以有一定的使用门槛。使用前请掌握基本操作能力。
2、自有数据库
Forage会将数据实时推送到您提供的企业数据库中(仅支持Mysql5.7版本),无需建表和开放公网访问权限。后续可自由读取数据,实现企业数据与信息的整合。查看数据字段说明
指示:
草料后台导航栏-数据API的高级功能,选择自己的数据库,填写自己的数据库主机、端口、账号等信息。
3、网络钩子
Forage 会将 JSON 格式的表单数据推送到您指定的 URL。该地址需要允许公共互联网访问。之后,您可以编写程序并使用接收到的数据与其他系统或进程进行交互。查看 Webhook 说明
指示:
饲料后台导航栏-数据API的高级功能,选择Webhook,填写接收数据的URL地址并保存。
具体流程:
①首先准备一个可以从公网访问的接口地址,填写地址字段,例如(xxx部分为系统的域名或IP)
②配置后,每当在草料中生成新的表单数据时(如在表单中提交一条记录),都会向上述地址发出POST请求
查看全部
文章采集api(数据推送API的应用草料平台的3种推送方式(一)
)
一、数据推送API应用
饲料平台的数据可以自动推送给您,您可以将数据作为应用程序自行调用。目前不支持将数据从外部系统写入饲料。
应用一:制作实时数据报表
使用数据分析工具连接数据库,进行数据分析或报表制作,查看效果,制作教程
应用二:对接企业流程
通过在草料平台上实现扫码采集数据等功能,然后通过API与企业系统的进程对接,企业可以在保持原有系统的同时,以极低的成本应用草料功能,并检查影响
二、我们提供3种推送方式1、官方数据库
Forage 为您提供独立的云数据库来同步您的后端数据。之后,您可以使用数据分析软件连接到这个云数据库进行数据报告;或者编写程序主动调用数据连接其他系统。查看数据库字段说明
指示:
草料后台导航栏-数据API高级功能,选择官方数据库,填写信息,提交激活申请。以下是申请成功后得到的数据库示例:
类型:MySQL
主持人:
端口:3306
数据库名称:cli_202112111(示例)
用户名:cli_202112111(示例)
密码:ek82jk9e1kdi45(示例)
报告制作:
如需连接官方数据库并制作自定义报表,可查看报表制作教程
因为涉及到基础数据库(SQL)操作和BI工具操作,所以有一定的使用门槛。使用前请掌握基本操作能力。
2、自有数据库
Forage会将数据实时推送到您提供的企业数据库中(仅支持Mysql5.7版本),无需建表和开放公网访问权限。后续可自由读取数据,实现企业数据与信息的整合。查看数据字段说明
指示:
草料后台导航栏-数据API的高级功能,选择自己的数据库,填写自己的数据库主机、端口、账号等信息。
3、网络钩子
Forage 会将 JSON 格式的表单数据推送到您指定的 URL。该地址需要允许公共互联网访问。之后,您可以编写程序并使用接收到的数据与其他系统或进程进行交互。查看 Webhook 说明
指示:
饲料后台导航栏-数据API的高级功能,选择Webhook,填写接收数据的URL地址并保存。
具体流程:
①首先准备一个可以从公网访问的接口地址,填写地址字段,例如(xxx部分为系统的域名或IP)
②配置后,每当在草料中生成新的表单数据时(如在表单中提交一条记录),都会向上述地址发出POST请求
文章采集api(优采云采集支持调用写作社API接口,处理采集的数据标题和内容等 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-10-28 14:18
)
优采云采集 支持调用写代理API接口处理采集的数据标题和内容;
详细使用步骤如下:
1. 创建写代理API接口配置一、API配置入口:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》点击【第三方API配置管理】==》最后点击【写Club_Rewrite接口API】 ] 创建接口配置;
二、配置API接口信息:
购买代写API,请联系代写客服,告知在优采云采集平台使用。
【API key】请联系代写机构客服获取对应的API key,填写优采云;
注意:编写机构限制每次调用最多6000个字符(包括html代码),所以当内容长度超过时,优采云会被分割调用多次。这个操作会增加api调用次数,增加成本。会相应增加,这是用户需要承担的费用,使用前一定要注意!!!
2. 创建 API 处理规则
API处理规则,可设置调用API接口处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》进入【API处理规则管理】页面,最后点击【添加API】处理规则] 创建API处理规则;
二、API处理规则配置:
规则名称:用户可以自己命名;
字段名:填写的字段名的内容将由API接口处理。默认为title和content字段,可以修改、添加或删除;
使用的API:选择已经设置好的API接口配置,执行时会调用该接口,多个字段可以选择不同的API接口配置;
处理顺序:执行顺序是按照数量从小到大执行;
3. API 处理规则使用
API处理规则的使用方式有两种:手动执行和自动执行:
手动执行:data采集后,在【Result Data & Release】中使用第三方API执行;
自动执行:自动化配置完成后,任务采集数据完成后,系统会自动执行指定的API处理规则,无需人工操作。
一、手动执行API处理规则:
在任务的【结果数据&发布】选项卡中,点击【SEO&API&翻译工具】按钮==》选择【第三方API执行】栏==》选择对应的API处理规则==》执行(有两个执行数据范围的方法,根据发布状态批量执行,根据列表中选择的数据执行);
二、自动执行API处理规则:
启用 API 处理的自动执行。任务完成采集后,会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡中,【自动执行第三方API配置】==》勾选【采集,自动执行API】选项==》选择要执行的API处理规则==》选择API接口处理的数据范围(一般选择“待发布”,所有会导致所有数据被多次执行),最后点击保存;
4. API处理结果及发布 一、查看API接口处理结果:
API接口处理的内容会保存为一个新的字段,例如:
标题处理后新增字段:title_写社
内容处理后的新领域:content_写社
在【结果数据&发布】和数据预览界面均可查看。
提示:API处理规则执行需要一段时间,执行后页面会自动刷新,API接口处理的新字段会出现;
二、API接口处理后的内容发布
在发布文章之前,修改发布目标第二步的映射字段,通过API接口处理后将title和content改为新的对应字段title_writing club和content_writing club;
提示:如果无法在发布目标中选择新字段,请在此任务下复制或创建一个新的发布目标,然后您可以在新的发布目标中选择新字段。详细教程可以查看发布目标中不能选择的字段;
5. 编写Club-API接口常见问题及解决方法
一、API处理规则和SEO规则如何搭配使用?
系统默认对title和content字段进行SEO功能,需要在SEO规则中修改title_writing club和content_writing club字段;
查看全部
文章采集api(优采云采集支持调用写作社API接口,处理采集的数据标题和内容等
)
优采云采集 支持调用写代理API接口处理采集的数据标题和内容;
详细使用步骤如下:
1. 创建写代理API接口配置一、API配置入口:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》点击【第三方API配置管理】==》最后点击【写Club_Rewrite接口API】 ] 创建接口配置;
二、配置API接口信息:
购买代写API,请联系代写客服,告知在优采云采集平台使用。
【API key】请联系代写机构客服获取对应的API key,填写优采云;
注意:编写机构限制每次调用最多6000个字符(包括html代码),所以当内容长度超过时,优采云会被分割调用多次。这个操作会增加api调用次数,增加成本。会相应增加,这是用户需要承担的费用,使用前一定要注意!!!
2. 创建 API 处理规则
API处理规则,可设置调用API接口处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》进入【API处理规则管理】页面,最后点击【添加API】处理规则] 创建API处理规则;
二、API处理规则配置:
规则名称:用户可以自己命名;
字段名:填写的字段名的内容将由API接口处理。默认为title和content字段,可以修改、添加或删除;
使用的API:选择已经设置好的API接口配置,执行时会调用该接口,多个字段可以选择不同的API接口配置;
处理顺序:执行顺序是按照数量从小到大执行;
3. API 处理规则使用
API处理规则的使用方式有两种:手动执行和自动执行:
手动执行:data采集后,在【Result Data & Release】中使用第三方API执行;
自动执行:自动化配置完成后,任务采集数据完成后,系统会自动执行指定的API处理规则,无需人工操作。
一、手动执行API处理规则:
在任务的【结果数据&发布】选项卡中,点击【SEO&API&翻译工具】按钮==》选择【第三方API执行】栏==》选择对应的API处理规则==》执行(有两个执行数据范围的方法,根据发布状态批量执行,根据列表中选择的数据执行);
二、自动执行API处理规则:
启用 API 处理的自动执行。任务完成采集后,会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡中,【自动执行第三方API配置】==》勾选【采集,自动执行API】选项==》选择要执行的API处理规则==》选择API接口处理的数据范围(一般选择“待发布”,所有会导致所有数据被多次执行),最后点击保存;
4. API处理结果及发布 一、查看API接口处理结果:
API接口处理的内容会保存为一个新的字段,例如:
标题处理后新增字段:title_写社
内容处理后的新领域:content_写社
在【结果数据&发布】和数据预览界面均可查看。
提示:API处理规则执行需要一段时间,执行后页面会自动刷新,API接口处理的新字段会出现;
二、API接口处理后的内容发布
在发布文章之前,修改发布目标第二步的映射字段,通过API接口处理后将title和content改为新的对应字段title_writing club和content_writing club;
提示:如果无法在发布目标中选择新字段,请在此任务下复制或创建一个新的发布目标,然后您可以在新的发布目标中选择新字段。详细教程可以查看发布目标中不能选择的字段;
5. 编写Club-API接口常见问题及解决方法
一、API处理规则和SEO规则如何搭配使用?
系统默认对title和content字段进行SEO功能,需要在SEO规则中修改title_writing club和content_writing club字段;
文章采集api(批量采集“虎嗅”的文章到自己网站的应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-10-26 03:03
现在有这样一个需求:批量采集微信公众号文章给自己网站,批量采集“虎嗅”文章给自己网站 . 主要障碍之一是我们的网站中无法显示原创图片地址。
他们利用HTTP请求头中的referrer值,即请求的来源,来判断是否返回数据,以达到防盗的目的。一些直播源也使用这种方法来防止非法卖淫。我们需要知道的是,我们的网站通常会在发起http请求时自动将referrer设置为网站地址。
下面的方法主要是全局添加几个meta标签来设置默认的referrer值,以免请求原图数据时提供网站地址的来源,避免原网站反-leech设计,但是这部分依赖这个原理辅助统计的第三方推广链接非常不利,甚至可能会被判定为无效,导致无法获得佣金。
折中的方法是将微信公众号文章和采集分到一个单独的分类中,只有当网站在这个分类元标签下显示文章时才添加。
// 其它自定义代码加到此行下面
add_action('wp_head', 'guihet_referrer');// 前端添加 referrer 标签
add_action('admin_head', 'guihet_referrer');// 后台添加 referrer 标签
function guihet_referrer(){
$catsy = get_the_category();
$myCat = $catsy[0]->cat_ID;
if($myCat===22) //分类 ID 为 22 的..
{
echo'';
echo'';
echo'';
}
}
代码添加到WP主题模板下functions.php文件的最后,这里根据实际情况更改类别ID。 查看全部
文章采集api(批量采集“虎嗅”的文章到自己网站的应用)
现在有这样一个需求:批量采集微信公众号文章给自己网站,批量采集“虎嗅”文章给自己网站 . 主要障碍之一是我们的网站中无法显示原创图片地址。
他们利用HTTP请求头中的referrer值,即请求的来源,来判断是否返回数据,以达到防盗的目的。一些直播源也使用这种方法来防止非法卖淫。我们需要知道的是,我们的网站通常会在发起http请求时自动将referrer设置为网站地址。
下面的方法主要是全局添加几个meta标签来设置默认的referrer值,以免请求原图数据时提供网站地址的来源,避免原网站反-leech设计,但是这部分依赖这个原理辅助统计的第三方推广链接非常不利,甚至可能会被判定为无效,导致无法获得佣金。
折中的方法是将微信公众号文章和采集分到一个单独的分类中,只有当网站在这个分类元标签下显示文章时才添加。
// 其它自定义代码加到此行下面
add_action('wp_head', 'guihet_referrer');// 前端添加 referrer 标签
add_action('admin_head', 'guihet_referrer');// 后台添加 referrer 标签
function guihet_referrer(){
$catsy = get_the_category();
$myCat = $catsy[0]->cat_ID;
if($myCat===22) //分类 ID 为 22 的..
{
echo'';
echo'';
echo'';
}
}
代码添加到WP主题模板下functions.php文件的最后,这里根据实际情况更改类别ID。
文章采集api(数据推送API的应用草料平台的3种推送方式(一) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-10-24 01:00
)
一、数据推送API应用
饲料平台的数据可以自动推送给您,您可以自己调用数据作为应用程序。目前不支持将数据从外部系统写入饲料。
应用一:制作实时数据报表
使用数据分析工具连接数据库,进行数据分析或报表制作,查看效果,制作教程
应用二:对接企业流程
通过在草料平台上实现扫码采集数据等功能,然后通过API与企业系统的进程对接,企业可以在保持原有系统的同时,以极低的成本应用草料功能,并检查影响
二、我们提供3种推送方式1、官方数据库
Forage 为您提供独立的云数据库来同步您的后端数据。之后,您可以使用数据分析软件连接到这个云数据库进行数据报告;或者编写程序主动调用数据连接其他系统。查看数据库字段说明
指示:
草料后台导航栏-数据API高级功能,选择官方数据库,填写信息,提交激活申请。以下是申请成功后得到的数据库示例:
类型:MySQL
主持人:
端口:3306
数据库名称:cli_202112111(示例)
用户名:cli_202112111(示例)
密码:ek82jk9e1kdi45(示例)
报告制作:
如需连接官方数据库并制作自定义报表,可查看报表制作教程
因为涉及到基础数据库(SQL)操作和BI工具操作,所以有一定的使用门槛。使用前请掌握基本操作能力。
2、自有数据库
Forage会将数据实时推送到您提供的企业数据库中(仅支持Mysql5.7版本),无需建表和开放公网访问权限。后续可自由读取数据,实现企业数据与信息的整合。查看数据字段说明
指示:
草料后台导航栏-数据API的高级功能,选择自己的数据库,填写自己的数据库主机、端口、账号等信息。
3、网络钩子
Forage 会将 JSON 格式的表单数据推送到您指定的 URL。该地址需要允许公共互联网访问。之后,您可以编写程序并使用接收到的数据与其他系统或进程进行交互。查看 Webhook 说明
指示:
草料后台导航栏-数据API的高级功能,选择Webhook,填写接收数据的URL地址并保存。
具体流程:
①首先准备一个可以从公网访问的接口地址,填写地址字段,例如(xxx部分为系统的域名或IP)
②配置后,每当在草料中生成新的表单数据时(如在表单中提交一条记录),都会向上述地址发出POST请求
查看全部
文章采集api(数据推送API的应用草料平台的3种推送方式(一)
)
一、数据推送API应用
饲料平台的数据可以自动推送给您,您可以自己调用数据作为应用程序。目前不支持将数据从外部系统写入饲料。
应用一:制作实时数据报表
使用数据分析工具连接数据库,进行数据分析或报表制作,查看效果,制作教程
应用二:对接企业流程
通过在草料平台上实现扫码采集数据等功能,然后通过API与企业系统的进程对接,企业可以在保持原有系统的同时,以极低的成本应用草料功能,并检查影响
二、我们提供3种推送方式1、官方数据库
Forage 为您提供独立的云数据库来同步您的后端数据。之后,您可以使用数据分析软件连接到这个云数据库进行数据报告;或者编写程序主动调用数据连接其他系统。查看数据库字段说明
指示:
草料后台导航栏-数据API高级功能,选择官方数据库,填写信息,提交激活申请。以下是申请成功后得到的数据库示例:
类型:MySQL
主持人:
端口:3306
数据库名称:cli_202112111(示例)
用户名:cli_202112111(示例)
密码:ek82jk9e1kdi45(示例)
报告制作:
如需连接官方数据库并制作自定义报表,可查看报表制作教程
因为涉及到基础数据库(SQL)操作和BI工具操作,所以有一定的使用门槛。使用前请掌握基本操作能力。
2、自有数据库
Forage会将数据实时推送到您提供的企业数据库中(仅支持Mysql5.7版本),无需建表和开放公网访问权限。后续可自由读取数据,实现企业数据与信息的整合。查看数据字段说明
指示:
草料后台导航栏-数据API的高级功能,选择自己的数据库,填写自己的数据库主机、端口、账号等信息。
3、网络钩子
Forage 会将 JSON 格式的表单数据推送到您指定的 URL。该地址需要允许公共互联网访问。之后,您可以编写程序并使用接收到的数据与其他系统或进程进行交互。查看 Webhook 说明
指示:
草料后台导航栏-数据API的高级功能,选择Webhook,填写接收数据的URL地址并保存。
具体流程:
①首先准备一个可以从公网访问的接口地址,填写地址字段,例如(xxx部分为系统的域名或IP)
②配置后,每当在草料中生成新的表单数据时(如在表单中提交一条记录),都会向上述地址发出POST请求
文章采集api(php采集文章图片不显示的解决办法:1、根据关键字采集百度搜寻结果)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-10-22 21:10
今天PHP爱好者为大家带来php采集文章图片不显示的解决方法:1、根据关键字采集百度搜索结果; 2、@ >将采集中的html根据定义的域名进行批量转换。希望能帮到你。
本文运行环境:windows7系统,PHP7.版本1,DELL G3电脑
php采集文章图片不显示怎么办?
PHP CURL采集百度搜索结果图片不显示问题的解决方法
1.根据关键字采集百度搜索结果
根据关键字采集百度搜索结果,可以使用curl来实现,代码如下:
<p style="line-height: 2em; text-indent: 2em; text-align: left;"><br style="text-indent: 2em; text-align: left;"/></p>
输出后发现有些图片无法显示
2.采集显示后图片不显示原因分析
直接在百度搜索,页面可以显示图片。使用firebug查看图片路径,发现采集的图片域名与百度搜索的图片域名不同。
采集返回的图片域名
用于普通搜索的图像域
查看采集和正常搜索html,发现有域名转换js不一样
采集
<p style="line-height: 2em; text-indent: 2em; text-align: left;">var list = {<br style="text-indent: 2em; text-align: left;"/> "graph.baidu.com": "http://graph.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "t1.baidu.com":"http://t1.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "t2.baidu.com":"http://t2.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "t3.baidu.com":"http://t3.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "t10.baidu.com":"http://t10.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "t11.baidu.com":"http://t11.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "t12.baidu.com":"http://t12.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "i7.baidu.com":"http://i7.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "i8.baidu.com":"http://i8.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "i9.baidu.com":"http://i9.baidu.com",<br style="text-indent: 2em; text-align: left;"/>};<br style="text-indent: 2em; text-align: left;"/></p>
普通搜索
<p style="line-height: 2em; text-indent: 2em; text-align: left;">var list = {<br style="text-indent: 2em; text-align: left;"/> "graph.baidu.com": "https://sp0.baidu.com/-aYHfD0a2gU2pMbgoY3K",<br style="text-indent: 2em; text-align: left;"/> "t1.baidu.com":"https://ss0.baidu.com/6ON1bjeh1BF3odCf",<br style="text-indent: 2em; text-align: left;"/> "t2.baidu.com":"https://ss1.baidu.com/6OZ1bjeh1BF3odCf",<br style="text-indent: 2em; text-align: left;"/> "t3.baidu.com":"https://ss2.baidu.com/6OV1bjeh1BF3odCf",<br style="text-indent: 2em; text-align: left;"/> "t10.baidu.com":"https://ss0.baidu.com/6ONWsjip0QIZ8tyhnq",<br style="text-indent: 2em; text-align: left;"/> "t11.baidu.com":"https://ss1.baidu.com/6ONXsjip0QIZ8tyhnq",<br style="text-indent: 2em; text-align: left;"/> "t12.baidu.com":"https://ss2.baidu.com/6ONYsjip0QIZ8tyhnq",<br style="text-indent: 2em; text-align: left;"/> "i7.baidu.com":"https://ss0.baidu.com/73F1bjeh1BF3odCf",<br style="text-indent: 2em; text-align: left;"/> "i8.baidu.com":"https://ss0.baidu.com/73x1bjeh1BF3odCf",<br style="text-indent: 2em; text-align: left;"/> "i9.baidu.com":"https://ss0.baidu.com/73t1bjeh1BF3odCf",<br style="text-indent: 2em; text-align: left;"/>};<br style="text-indent: 2em; text-align: left;"/></p>
因此,根据源地址、IP、header等参数可以断定,如果是采集,百度会返回不同的js。
3.采集图片不显示后的解决方法
根据定义的域名批量传输采集中的html。
<p style="line-height: 2em; text-indent: 2em; text-align: left;"><br style="text-indent: 2em; text-align: left;"/></p>
添加域名转换后,所有图片均可正常显示。
以上是php采集文章的详细内容,图片没有说明怎么做。更多详情请关注其他相关php粉丝文章! 查看全部
文章采集api(php采集文章图片不显示的解决办法:1、根据关键字采集百度搜寻结果)
今天PHP爱好者为大家带来php采集文章图片不显示的解决方法:1、根据关键字采集百度搜索结果; 2、@ >将采集中的html根据定义的域名进行批量转换。希望能帮到你。
本文运行环境:windows7系统,PHP7.版本1,DELL G3电脑
php采集文章图片不显示怎么办?
PHP CURL采集百度搜索结果图片不显示问题的解决方法
1.根据关键字采集百度搜索结果
根据关键字采集百度搜索结果,可以使用curl来实现,代码如下:
<p style="line-height: 2em; text-indent: 2em; text-align: left;"><br style="text-indent: 2em; text-align: left;"/></p>
输出后发现有些图片无法显示
2.采集显示后图片不显示原因分析
直接在百度搜索,页面可以显示图片。使用firebug查看图片路径,发现采集的图片域名与百度搜索的图片域名不同。
采集返回的图片域名
用于普通搜索的图像域
查看采集和正常搜索html,发现有域名转换js不一样
采集
<p style="line-height: 2em; text-indent: 2em; text-align: left;">var list = {<br style="text-indent: 2em; text-align: left;"/> "graph.baidu.com": "http://graph.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "t1.baidu.com":"http://t1.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "t2.baidu.com":"http://t2.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "t3.baidu.com":"http://t3.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "t10.baidu.com":"http://t10.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "t11.baidu.com":"http://t11.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "t12.baidu.com":"http://t12.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "i7.baidu.com":"http://i7.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "i8.baidu.com":"http://i8.baidu.com",<br style="text-indent: 2em; text-align: left;"/> "i9.baidu.com":"http://i9.baidu.com",<br style="text-indent: 2em; text-align: left;"/>};<br style="text-indent: 2em; text-align: left;"/></p>
普通搜索
<p style="line-height: 2em; text-indent: 2em; text-align: left;">var list = {<br style="text-indent: 2em; text-align: left;"/> "graph.baidu.com": "https://sp0.baidu.com/-aYHfD0a2gU2pMbgoY3K",<br style="text-indent: 2em; text-align: left;"/> "t1.baidu.com":"https://ss0.baidu.com/6ON1bjeh1BF3odCf",<br style="text-indent: 2em; text-align: left;"/> "t2.baidu.com":"https://ss1.baidu.com/6OZ1bjeh1BF3odCf",<br style="text-indent: 2em; text-align: left;"/> "t3.baidu.com":"https://ss2.baidu.com/6OV1bjeh1BF3odCf",<br style="text-indent: 2em; text-align: left;"/> "t10.baidu.com":"https://ss0.baidu.com/6ONWsjip0QIZ8tyhnq",<br style="text-indent: 2em; text-align: left;"/> "t11.baidu.com":"https://ss1.baidu.com/6ONXsjip0QIZ8tyhnq",<br style="text-indent: 2em; text-align: left;"/> "t12.baidu.com":"https://ss2.baidu.com/6ONYsjip0QIZ8tyhnq",<br style="text-indent: 2em; text-align: left;"/> "i7.baidu.com":"https://ss0.baidu.com/73F1bjeh1BF3odCf",<br style="text-indent: 2em; text-align: left;"/> "i8.baidu.com":"https://ss0.baidu.com/73x1bjeh1BF3odCf",<br style="text-indent: 2em; text-align: left;"/> "i9.baidu.com":"https://ss0.baidu.com/73t1bjeh1BF3odCf",<br style="text-indent: 2em; text-align: left;"/>};<br style="text-indent: 2em; text-align: left;"/></p>
因此,根据源地址、IP、header等参数可以断定,如果是采集,百度会返回不同的js。
3.采集图片不显示后的解决方法
根据定义的域名批量传输采集中的html。
<p style="line-height: 2em; text-indent: 2em; text-align: left;"><br style="text-indent: 2em; text-align: left;"/></p>
添加域名转换后,所有图片均可正常显示。
以上是php采集文章的详细内容,图片没有说明怎么做。更多详情请关注其他相关php粉丝文章!
文章采集api([搜一搜]智能写作神器减少脑力劳动,快速实现目标.)
采集交流 • 优采云 发表了文章 • 0 个评论 • 240 次浏览 • 2021-10-19 10:25
【搜一搜】智能写作是优秀自媒体人和SEOR必备的写作工具,减少脑力劳动,提高工作效率,快速达成目标。
如果你是第一次使用,【搜一搜】助你成为优秀的写作高手,一起来看看吧~
下面是几个新手需要知道的常用函数
一、找到登录网址
二、文章采集
三、原采集列表
四、伪原创列表
五、获取API
一、找到登录网址
1.在电脑上打开浏览器
2. 在地址栏中输入 URL/
3.注册账号,直接登录
二、文章采集
1、文章采集,打开界面,可以看到最上方的选项文章采集,点击进入关键词,你可以随便输入想表达 只需输入一两个字就可以自动生成专业的文章。
2.批量采集,批量采集可以一次搜索多个关键词,速度更快。
3.采集的结果,采集的结果是前两步提交的结果,处理状态和详细信息可以在这里查看。
三、原采集列表
在这里可以看到文章的出处和标题,也可以查看伪原创的内容和原文,方便修改。
四、伪原创列表
您可以使用伪原创直观的查看文章的相似度,更方便的修改文章的内容。
五、获取API
如果您有特殊需求,可以连接我们的API系统,连接您的网站系统,cms站群等。
那么今天给大家分享的5个实用技巧,你学会了吗?快点快点练习吧~
【体验地址】电脑登录,免费注册:/ 查看全部
文章采集api([搜一搜]智能写作神器减少脑力劳动,快速实现目标.)
【搜一搜】智能写作是优秀自媒体人和SEOR必备的写作工具,减少脑力劳动,提高工作效率,快速达成目标。
如果你是第一次使用,【搜一搜】助你成为优秀的写作高手,一起来看看吧~
下面是几个新手需要知道的常用函数
一、找到登录网址
二、文章采集
三、原采集列表
四、伪原创列表
五、获取API
一、找到登录网址
1.在电脑上打开浏览器
2. 在地址栏中输入 URL/
3.注册账号,直接登录
二、文章采集
1、文章采集,打开界面,可以看到最上方的选项文章采集,点击进入关键词,你可以随便输入想表达 只需输入一两个字就可以自动生成专业的文章。
2.批量采集,批量采集可以一次搜索多个关键词,速度更快。
3.采集的结果,采集的结果是前两步提交的结果,处理状态和详细信息可以在这里查看。
三、原采集列表
在这里可以看到文章的出处和标题,也可以查看伪原创的内容和原文,方便修改。
四、伪原创列表
您可以使用伪原创直观的查看文章的相似度,更方便的修改文章的内容。
五、获取API
如果您有特殊需求,可以连接我们的API系统,连接您的网站系统,cms站群等。
那么今天给大家分享的5个实用技巧,你学会了吗?快点快点练习吧~
【体验地址】电脑登录,免费注册:/

