
文章采集api
文章采集api(分布式事务为什么会使用分布式商城开发框架?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-04-17 22:18
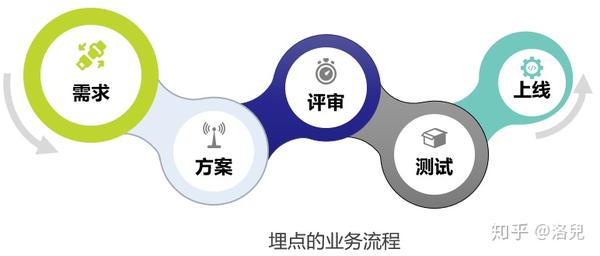
开始
自建商城设计之初,业务部就提出了两个要求:不倒塌,快速上线。
项目立项后,团队还没有完全装备好。在从其他团队招聘人员的同时,我们也在大力招聘。同时,我们的架构师也在搭建分布式商城开发框架,编写demo,让新生可以快速上手。
暴露问题
问题 1:分布式事务
为什么要使用分布式事务?
这暂时可以归结为快速上线,因为订单的生成会调用商品服务去扣库存,而使用分布式事务解决了跨服务调用导致的库存超卖问题,是性能消耗。
问题二:数据库压力
大促的时候有直接从业务数据库查询的实时统计,运营部小姐姐不断刷新,给界面造成很大压力,没有使用缓存,所以连接 SQL 查询条件需要时间。都是动态的,以至于无法使用DB层的缓存,每次请求都命中DB。
开发测试环境使用自建MySQL,生产环境使用PolarDB。来自阿里云官网:
我们主观上认为只要使用集群连接地址,就会自动进行读写分离,但实际上并没有。后来我们发现,如果我们在方法中显式指定一个只读事务,就会有请求去只读节点。
@Transactional(readOnly = true)
# 优化思路:
1)从SQL洞察和慢SQL中找出响应时间最长、频率最高的SQL;
2)结合代码,可以直接被缓存处理,而不是无法缓存的优化查询。结合阿里云提供的优化分析工具,可以调整指标;
3) 活动高峰期,禁止执行分析统计查询,暂时改代码已来不及。感谢AHAS(阿里云限流降级产品)的接口限流和SQL限流功能;
4)TP和AP分开,避免分析类直接查询到业务库(这个过程比较长)。
问题三:缓存压力
除了上面提到的分布式事务,我发现有同事用Keys写模糊查询Redis,直接导致Redis的CPU严重飙升。阿里云提供的 Redis 管理工具可以轻松检查慢查询。
另一个低级错误,我们认为它不应该是第一个,也不会是最后一个。最初,我们想设置一个 Key 的过期时间。结果我们少写了一个Unit参数,第三个改变了偏移量。
redisTemplate.opsForValue().set(key, value, offset)
# 为什么我们花了大约 10 分钟来解决?
1)惯性思维,没有找到review code;
2)当在错误日志中发现Redisson锁失败时,怀疑Redis已满;
3)我用阿里云的工具查大key的时候发现key很大,但是直接在网页上查值的时候只看到保存了一个字符。值好像是对的,但是大概过了2分钟左右,感觉不对劲,然后登录用redis-cli查看,傻眼了,里面全是0x00。
问题四:
商场开张当月有促销。由于瞬间进来的流量过大,小程序前端嵌入事件上报的接口连接数呈爆炸式增长。商城实时数据统计调用流量统计服务接口,但服务调用超时时间设置为60s,导致请求过多积压,CPU突然暴涨。
# 优化思路:
1)充分利用Nginx的并发处理能力,Lua脚本提供强大的处理能力,使用OpenResty接收来自Java的请求;
2)收到请求并做基础验证后,使用lua-resty-kafka模块异步发送到Kafka;
3)Kafka放到HDFS上后,Spark会离线计算日志数据;
4)后端接口独立部署,实时数据统计调用接口设置更短的超时时间;
经过上述改造,前端日志上报服务的单机处理能力由原来的1K增加了40K。丝般顺滑的体验真的很棒。
迭代
从当时的情况来看,为双十一活动调整代码优化基本上已经来不及了,距离活动还有不到两周的时间。就算改了,风险也很大。
1、压力测试
作为一个新推出的项目,数据量比较少。使用云服务搭建1:1压测环境相对容易。这个时间点,我们需要模拟真实场景来了解当前的系统性能。需要多少压力,需要多少台机器。
阿里云上有一个PTS压力测量工具,可以直接导入Jmeter脚本,使用非常方便。先说一下我们的使用步骤:
1)首先,根据近一个月的用户行为日志,找出用户的路径和每个行为的思考时间,并做了一个粗略的模型;
2)根据双十一活动的运行节奏,定义两个或三个场景;
3)使用ECS搭建Jmeter集群,内网对接口施加压力,以减少网络开销,允许向后端服务器发送请求;
4)观察服务器压力,调整应用内存分配,然后通过PolarDB的性能分析,找出存在性能瓶颈的SQL,尽可能优化;
5)将Jmeter脚本导入PTS,将数据库与ECS机器的云监控关联,设置思考时间等相关参数并施加压力,可以秒级动态调整压力,产生的压力测试报告是我们想要的结果,需要用于接下来的限流控制。
2、电流限制
上传的API与Restful风格的API不兼容,导致URL出现参数时多个URL没有合并在一起的情况。阿里云 AHAS 支持团队立即发布了 Fix 版本,并提供了新的 SentinelWebInterceptor 拦截器来清理 Restful 风格的 API 处理。; 在访问AHAS的应用模块进行限流时,也是使用SDK的访问方式。根据官网文档访问时,发现我们的微商城使用的是最新版本的Mybatis Plus版本。访问SQL限流分析时发现函数执行过程中出现ahas错误。将此情况报告给ahas钉钉团队的支持小组后,已经快凌晨1:00了 ahas团队及时响应,次日上午发布了兼容Mybatis Plus版本的SQL限流分析版本。对我们的微商城来说,进入新版本后,SQL分析和限流功能也可以正常使用了;在使用AHAS访问时,发现AHAS提供了CPU/Load的限流,为监控和保护服务器性能做了很好的保驾护航。当微商城服务器压力过大时,可以很好的保护服务器不被高并发压垮,保证服务的高可用。当服务器压力较大时,实现实时QPS日志上传的隔离,避免上传抢占服务器资源,并确保服务器在访问AHAS后能够保持良好的性能。未来
未来计划做:
1)按服务拆分Redis;
2)数据库读写分离,分库分表,TP/AP分离;
3)业务集中:建立业务中心,打通商品中心、库存中心、用户中心、交易中心; 查看全部
文章采集api(分布式事务为什么会使用分布式商城开发框架?(图))
开始
自建商城设计之初,业务部就提出了两个要求:不倒塌,快速上线。
项目立项后,团队还没有完全装备好。在从其他团队招聘人员的同时,我们也在大力招聘。同时,我们的架构师也在搭建分布式商城开发框架,编写demo,让新生可以快速上手。
暴露问题
问题 1:分布式事务
为什么要使用分布式事务?
这暂时可以归结为快速上线,因为订单的生成会调用商品服务去扣库存,而使用分布式事务解决了跨服务调用导致的库存超卖问题,是性能消耗。
问题二:数据库压力
大促的时候有直接从业务数据库查询的实时统计,运营部小姐姐不断刷新,给界面造成很大压力,没有使用缓存,所以连接 SQL 查询条件需要时间。都是动态的,以至于无法使用DB层的缓存,每次请求都命中DB。
开发测试环境使用自建MySQL,生产环境使用PolarDB。来自阿里云官网:
我们主观上认为只要使用集群连接地址,就会自动进行读写分离,但实际上并没有。后来我们发现,如果我们在方法中显式指定一个只读事务,就会有请求去只读节点。
@Transactional(readOnly = true)
# 优化思路:
1)从SQL洞察和慢SQL中找出响应时间最长、频率最高的SQL;
2)结合代码,可以直接被缓存处理,而不是无法缓存的优化查询。结合阿里云提供的优化分析工具,可以调整指标;
3) 活动高峰期,禁止执行分析统计查询,暂时改代码已来不及。感谢AHAS(阿里云限流降级产品)的接口限流和SQL限流功能;
4)TP和AP分开,避免分析类直接查询到业务库(这个过程比较长)。
问题三:缓存压力
除了上面提到的分布式事务,我发现有同事用Keys写模糊查询Redis,直接导致Redis的CPU严重飙升。阿里云提供的 Redis 管理工具可以轻松检查慢查询。
另一个低级错误,我们认为它不应该是第一个,也不会是最后一个。最初,我们想设置一个 Key 的过期时间。结果我们少写了一个Unit参数,第三个改变了偏移量。
redisTemplate.opsForValue().set(key, value, offset)
# 为什么我们花了大约 10 分钟来解决?
1)惯性思维,没有找到review code;
2)当在错误日志中发现Redisson锁失败时,怀疑Redis已满;
3)我用阿里云的工具查大key的时候发现key很大,但是直接在网页上查值的时候只看到保存了一个字符。值好像是对的,但是大概过了2分钟左右,感觉不对劲,然后登录用redis-cli查看,傻眼了,里面全是0x00。
问题四:
商场开张当月有促销。由于瞬间进来的流量过大,小程序前端嵌入事件上报的接口连接数呈爆炸式增长。商城实时数据统计调用流量统计服务接口,但服务调用超时时间设置为60s,导致请求过多积压,CPU突然暴涨。
# 优化思路:
1)充分利用Nginx的并发处理能力,Lua脚本提供强大的处理能力,使用OpenResty接收来自Java的请求;
2)收到请求并做基础验证后,使用lua-resty-kafka模块异步发送到Kafka;
3)Kafka放到HDFS上后,Spark会离线计算日志数据;
4)后端接口独立部署,实时数据统计调用接口设置更短的超时时间;
经过上述改造,前端日志上报服务的单机处理能力由原来的1K增加了40K。丝般顺滑的体验真的很棒。
迭代
从当时的情况来看,为双十一活动调整代码优化基本上已经来不及了,距离活动还有不到两周的时间。就算改了,风险也很大。
1、压力测试
作为一个新推出的项目,数据量比较少。使用云服务搭建1:1压测环境相对容易。这个时间点,我们需要模拟真实场景来了解当前的系统性能。需要多少压力,需要多少台机器。
阿里云上有一个PTS压力测量工具,可以直接导入Jmeter脚本,使用非常方便。先说一下我们的使用步骤:
1)首先,根据近一个月的用户行为日志,找出用户的路径和每个行为的思考时间,并做了一个粗略的模型;
2)根据双十一活动的运行节奏,定义两个或三个场景;
3)使用ECS搭建Jmeter集群,内网对接口施加压力,以减少网络开销,允许向后端服务器发送请求;
4)观察服务器压力,调整应用内存分配,然后通过PolarDB的性能分析,找出存在性能瓶颈的SQL,尽可能优化;
5)将Jmeter脚本导入PTS,将数据库与ECS机器的云监控关联,设置思考时间等相关参数并施加压力,可以秒级动态调整压力,产生的压力测试报告是我们想要的结果,需要用于接下来的限流控制。
2、电流限制
上传的API与Restful风格的API不兼容,导致URL出现参数时多个URL没有合并在一起的情况。阿里云 AHAS 支持团队立即发布了 Fix 版本,并提供了新的 SentinelWebInterceptor 拦截器来清理 Restful 风格的 API 处理。; 在访问AHAS的应用模块进行限流时,也是使用SDK的访问方式。根据官网文档访问时,发现我们的微商城使用的是最新版本的Mybatis Plus版本。访问SQL限流分析时发现函数执行过程中出现ahas错误。将此情况报告给ahas钉钉团队的支持小组后,已经快凌晨1:00了 ahas团队及时响应,次日上午发布了兼容Mybatis Plus版本的SQL限流分析版本。对我们的微商城来说,进入新版本后,SQL分析和限流功能也可以正常使用了;在使用AHAS访问时,发现AHAS提供了CPU/Load的限流,为监控和保护服务器性能做了很好的保驾护航。当微商城服务器压力过大时,可以很好的保护服务器不被高并发压垮,保证服务的高可用。当服务器压力较大时,实现实时QPS日志上传的隔离,避免上传抢占服务器资源,并确保服务器在访问AHAS后能够保持良好的性能。未来
未来计划做:
1)按服务拆分Redis;
2)数据库读写分离,分库分表,TP/AP分离;
3)业务集中:建立业务中心,打通商品中心、库存中心、用户中心、交易中心;
文章采集api(本节比较简单,有开发经验可以跳过。。(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-04-12 19:24
这部分比较简单,有开发经验的可以跳过。
使用 APIAPI 概述
百度百科对API的解释:API(Application Programming Interface,应用程序编程接口)是一些预定义的函数,目的是为应用程序和开发者提供基于某种软件或硬件访问一组例程的能力,而不需要访问源代码,或了解内部工作的细节。
表示这是接口,不管语言限制都可以调用。
API 通用规则
API 使用一套非常标准的规则来生成数据,并且生成的数据以非常标准的方式组织。
方法
有许多方法可以使用 HTTP 从 Web 服务器请求信息。这里有四种常用的方法: GET:从服务器获取数据的方法;POST:向服务器发送数据。比如提交表单到服务器处理的逻辑;PUT:主要用于更新一个对象或信息,一般很少用到;DELETE:从服务器中删除一个对象。
核实
API 不能随时或由任何人调用。为了保证服务器上的安全或减少资源等,我们会限制请求的方法或数量。通常,接口是经过验证的。一般的验证方法是令牌。该令牌一般在用户登录或注册时从服务器生成,然后交给用户。令牌可以是可变的或不可变的。除了在 URL 链接中传递 token 外,它还通过请求头中的 cookie 将用户信息传递给服务器。简单的例子:
token = ""
webRequest = urllib.request.Request("http://myapi.com", headers={"token":token})
html = urlopen(webRequest)
服务器响应
服务器响应的数据格式一般为 JSON 或 XML。目前 JSON 有很多原因,其中之一是 JSON 文件比完整的 XML 格式小;再加上网络技术的变化,后端语言越来越多,基本上所有接口都能实现。
API 调用的语法也存在差异,但也有既定的准则。例如,使用GET请求获取数据时,使用URL路径描述要获取的数据范围,查询参数可以作为过滤器或附加请求;还有很多API以文件路径(path)的形式指定API版本和数据格式。和其他财产;有些API以请求参数的形式指定数据格式和API版本:
市面上很多公司或者网站都有自己的公共接口,比如推特、谷歌等。
解析 JSON 数据
例如,我们使用 GET 来请求和查看返回的数据。返回为:
1
{"ip":"50.78.253.58","country_code":"US","country_name":"United States","region_code":"MA ","region_name":"Massachusetts","city":"Boston","zip_code":"02116","time_zone":"America/New_York","latitude":42.3496,"longitude ":-71.0746,"metro_code":506}
现在我们使用 Python 来解析。JSON 是 Python 的标准库,不需要额外安装。代码显示如下:
import json
from urllib.request import urlopen
def getCountry(ipAddress):
res = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
resJson = json.loads(res)
return resJson.get('country_code')
print(getCountry("22.18.53.22"))
Python 使用更灵活的方式将 JSON 转换为字典,将 JSON 数组转换为列表,以及将 JSON 字符串转换为 Python 字符串。 查看全部
文章采集api(本节比较简单,有开发经验可以跳过。。(组图))
这部分比较简单,有开发经验的可以跳过。
使用 APIAPI 概述
百度百科对API的解释:API(Application Programming Interface,应用程序编程接口)是一些预定义的函数,目的是为应用程序和开发者提供基于某种软件或硬件访问一组例程的能力,而不需要访问源代码,或了解内部工作的细节。
表示这是接口,不管语言限制都可以调用。
API 通用规则
API 使用一套非常标准的规则来生成数据,并且生成的数据以非常标准的方式组织。
方法
有许多方法可以使用 HTTP 从 Web 服务器请求信息。这里有四种常用的方法: GET:从服务器获取数据的方法;POST:向服务器发送数据。比如提交表单到服务器处理的逻辑;PUT:主要用于更新一个对象或信息,一般很少用到;DELETE:从服务器中删除一个对象。
核实
API 不能随时或由任何人调用。为了保证服务器上的安全或减少资源等,我们会限制请求的方法或数量。通常,接口是经过验证的。一般的验证方法是令牌。该令牌一般在用户登录或注册时从服务器生成,然后交给用户。令牌可以是可变的或不可变的。除了在 URL 链接中传递 token 外,它还通过请求头中的 cookie 将用户信息传递给服务器。简单的例子:
token = ""
webRequest = urllib.request.Request("http://myapi.com", headers={"token":token})
html = urlopen(webRequest)
服务器响应
服务器响应的数据格式一般为 JSON 或 XML。目前 JSON 有很多原因,其中之一是 JSON 文件比完整的 XML 格式小;再加上网络技术的变化,后端语言越来越多,基本上所有接口都能实现。
API 调用的语法也存在差异,但也有既定的准则。例如,使用GET请求获取数据时,使用URL路径描述要获取的数据范围,查询参数可以作为过滤器或附加请求;还有很多API以文件路径(path)的形式指定API版本和数据格式。和其他财产;有些API以请求参数的形式指定数据格式和API版本:
市面上很多公司或者网站都有自己的公共接口,比如推特、谷歌等。
解析 JSON 数据
例如,我们使用 GET 来请求和查看返回的数据。返回为:
1
{"ip":"50.78.253.58","country_code":"US","country_name":"United States","region_code":"MA ","region_name":"Massachusetts","city":"Boston","zip_code":"02116","time_zone":"America/New_York","latitude":42.3496,"longitude ":-71.0746,"metro_code":506}
现在我们使用 Python 来解析。JSON 是 Python 的标准库,不需要额外安装。代码显示如下:
import json
from urllib.request import urlopen
def getCountry(ipAddress):
res = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
resJson = json.loads(res)
return resJson.get('country_code')
print(getCountry("22.18.53.22"))
Python 使用更灵活的方式将 JSON 转换为字典,将 JSON 数组转换为列表,以及将 JSON 字符串转换为 Python 字符串。
文章采集api( PHP+fiddler抓包采集微信文章阅读数点效果总结)
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2022-04-12 10:10
PHP+fiddler抓包采集微信文章阅读数点效果总结)
2.截取这个接口转发到自己的服务器,点击rules-customize rules添加到OnBeforeRequest(正式请求前执行的函数)
if (oSession.fullUrl.Contains("mp.weixin.qq.com/mp/getappmsgext"))
{
oSession.oRequest["Host"]= 'ccc.aaa.com' ;
}
效果,可以看到这个接口已经转发了
3.服务器缓存key,代码以php为例
public function saveKey(Request $request)
{
$__biz = $request->param('__biz',0);
$data['uin'] = $request->param('uin',0);
$data['key'] = $request->param('key',0);
Cache::set($__biz,$data,30 * 60);
return 'ok';
}
4.提交文章链接查询API代码
public function getReadNum(Request $request)
{
$url = $request->param('url');
parse_str(parse_url($url)['query'], $param);
$__biz = $param['__biz'];
$key_data = Cache::get($__biz);
if (empty($key_data))
return 'no key';
$uin = $key_data['uin'];
$key = $key_data['key'bPfPBxaDBm];
$param['uin'] = $uin;
$param['key'] = $key;
$param['wxtoken'] = "777";
$wechat_url = "https://mp.weixin.qq.com/mp/getappmsgext?" . http_build_query($param);
//dump($wechat_url);
$data = array(
'is_only_read' => 1,
'is_temp_url' => 0,
'appmsg_type' => 9,
);
$res = $this->get_url($wechat_url,$data);
return $res;
}
function get_url($url,$data)
{
$ifpost = 1;//是否post请求
$datafields = $data;//post数据
$cookiefile = '';//cohttp://www.cppcns.comokie文件
$cookie = '';//cookie变量
$v = false;
//模拟http请求header头
$header = array("Connection: Keep-Alive","Accept: text/html, applicabPfPBxaDBmtion/xhtml+xml, */*", "Pragma: no-cache", "Accept-Language: zh-Hans-CN,zh-Hans;q=0.8,en-US;q=0.5,en;q=0.3","User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36 QBCore/4.0.1278.400 QQBrowser/9.0.2524.400 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2875.116 Safari/537.36 Nehttp://www.cppcns.comtType/WIFI MicroMessenger/7.0.5 WindowsWechat");
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, $v);
curl_setopt($ch, CURLOPT_HTTPHEADER, $header);
$ifpost && curl_setopt($ch, CURLOPT_POST, $ifpost);
$ifpost && curl_setopt($ch, CURLOPT_POSTFIELDS, $datafields);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
$cookie && curl_setopt($ch, CURLOPT_COOKIE, $cookie);//发送cookie变量
$cookiefile && curl_setopt($ch, CURLOPT_COOKIEFILE, $cookiefile);//发送cookie文件
$cookiefile && curl_setopt($ch, CURLOPT_COOKIEJAR, $cookiefile);//写入cookie到文件
curl_setopt($ch,CURLOPT_TIMEOUT,60); //允许执行的最长秒数
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
$ok = curl_exec($ch);
curl_close($ch);
unset($ch);
return $ok;
}
5.通知客户端重定向页面(这部分没写,看我的其他文字socket文章)
6.使用fiddler修改微信文章还有j脚本,
OnBeforeResponse(返回客户端前执行的方法)中,加上跳转到中间页面的代码
影响
总结
以上就是小编为大家介绍的PHP+fiddler抓包采集微信文章阅读量和点赞数,希望对你有所帮助。有什么问题请给我留言,小编会及时回复你的。我们还要感谢大家的支持网站!
如果您觉得本文对您有帮助,欢迎转载,请注明出处,谢谢!
本文标题:PHP+fiddler抓包采集微信文章阅读点赞数思路详解 查看全部
文章采集api(
PHP+fiddler抓包采集微信文章阅读数点效果总结)


2.截取这个接口转发到自己的服务器,点击rules-customize rules添加到OnBeforeRequest(正式请求前执行的函数)
if (oSession.fullUrl.Contains("mp.weixin.qq.com/mp/getappmsgext"))
{
oSession.oRequest["Host"]= 'ccc.aaa.com' ;
}

效果,可以看到这个接口已经转发了

3.服务器缓存key,代码以php为例
public function saveKey(Request $request)
{
$__biz = $request->param('__biz',0);
$data['uin'] = $request->param('uin',0);
$data['key'] = $request->param('key',0);
Cache::set($__biz,$data,30 * 60);
return 'ok';
}
4.提交文章链接查询API代码
public function getReadNum(Request $request)
{
$url = $request->param('url');
parse_str(parse_url($url)['query'], $param);
$__biz = $param['__biz'];
$key_data = Cache::get($__biz);
if (empty($key_data))
return 'no key';
$uin = $key_data['uin'];
$key = $key_data['key'bPfPBxaDBm];
$param['uin'] = $uin;
$param['key'] = $key;
$param['wxtoken'] = "777";
$wechat_url = "https://mp.weixin.qq.com/mp/getappmsgext?" . http_build_query($param);
//dump($wechat_url);
$data = array(
'is_only_read' => 1,
'is_temp_url' => 0,
'appmsg_type' => 9,
);
$res = $this->get_url($wechat_url,$data);
return $res;
}
function get_url($url,$data)
{
$ifpost = 1;//是否post请求
$datafields = $data;//post数据
$cookiefile = '';//cohttp://www.cppcns.comokie文件
$cookie = '';//cookie变量
$v = false;
//模拟http请求header头
$header = array("Connection: Keep-Alive","Accept: text/html, applicabPfPBxaDBmtion/xhtml+xml, */*", "Pragma: no-cache", "Accept-Language: zh-Hans-CN,zh-Hans;q=0.8,en-US;q=0.5,en;q=0.3","User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36 QBCore/4.0.1278.400 QQBrowser/9.0.2524.400 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2875.116 Safari/537.36 Nehttp://www.cppcns.comtType/WIFI MicroMessenger/7.0.5 WindowsWechat");
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, $v);
curl_setopt($ch, CURLOPT_HTTPHEADER, $header);
$ifpost && curl_setopt($ch, CURLOPT_POST, $ifpost);
$ifpost && curl_setopt($ch, CURLOPT_POSTFIELDS, $datafields);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
$cookie && curl_setopt($ch, CURLOPT_COOKIE, $cookie);//发送cookie变量
$cookiefile && curl_setopt($ch, CURLOPT_COOKIEFILE, $cookiefile);//发送cookie文件
$cookiefile && curl_setopt($ch, CURLOPT_COOKIEJAR, $cookiefile);//写入cookie到文件
curl_setopt($ch,CURLOPT_TIMEOUT,60); //允许执行的最长秒数
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
$ok = curl_exec($ch);
curl_close($ch);
unset($ch);
return $ok;
}
5.通知客户端重定向页面(这部分没写,看我的其他文字socket文章)
6.使用fiddler修改微信文章还有j脚本,
OnBeforeResponse(返回客户端前执行的方法)中,加上跳转到中间页面的代码
影响

总结
以上就是小编为大家介绍的PHP+fiddler抓包采集微信文章阅读量和点赞数,希望对你有所帮助。有什么问题请给我留言,小编会及时回复你的。我们还要感谢大家的支持网站!
如果您觉得本文对您有帮助,欢迎转载,请注明出处,谢谢!
本文标题:PHP+fiddler抓包采集微信文章阅读点赞数思路详解
文章采集api(数据埋点采集到底都是哪些事呢?的应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-04-12 10:01
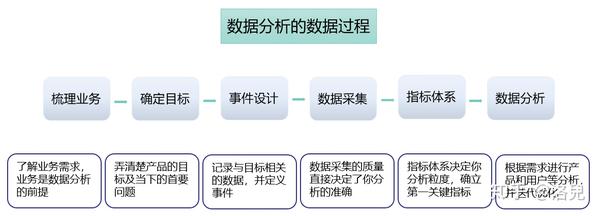
数据采集是数据分析的基础,跟踪是最重要的采集方法。那么数据埋点采集究竟是什么?我们主要从三个方面来看:什么是埋点,埋点如何设计,埋点的应用。
一、数据采集 和常见数据问题
1.1 数据采集
数据采集的方式有很多种,埋点采集是其中非常重要的一环。它是c端和b端产品的主要采集方式。数据采集,顾名思义采集对应的数据是整个数据流的起点,采集不完整,对与不对,直接决定数据的广度和质量并影响所有后续链接;在数据采集有效性和完整性较差的公司往往会发现其业务数据发生了重大变化。
数据处理通常包括以下五个步骤:
1.2常见数据问题
在大致了解了data采集及其结构之后,我们再来看看工作中遇到的问题,有多少与data采集链接有关
1、数据与背景差距较大,数据不准确——统计口径不同,埋点定义不同,采集方法带来误差
2、想用的时候,没有我要的数据——我没提数据采集要求,埋点不正确,不全
3、事件太多,意思不清楚——埋点设计的方式,埋点更新迭代的规则和维护
4、分析数据时不知道要看哪些数据和指标——数据的定义不明确,缺乏分析思路
我们需要根本原因的解决方案:将 采集 视为独立的研发业务,而不是产品开发的附属品
二、埋葬点是什么?
2.1 葬礼是什么
所谓埋点,是data采集领域的一个名词。它的学名应该叫事件追踪,对应的英文是Event Tracking,是指捕获、处理和发送特定用户行为或事件的相关技术和实现过程。数据埋点是数据分析师、数据产品经理和数据运营商,他们根据业务需求或产品需求,针对用户行为对应的每个事件开发埋点,并通过SDK上报埋点数据结果,并记录汇总数据。分析、推动产品优化和指导运营。
该过程伴随着规范。通过定义可以看出,具体的用户行为和事件是我们采集关注的焦点,也需要处理和发送相关的技术和实现流程;数据嵌入服务于产品,来自产品。,所以和产品息息相关,重点在于具体的实战过程,这关系到大家对底层数据的理解。
2.2 你为什么要埋头苦干?
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的质量直接影响数据质量、产品质量和运营质量。
1、数据驱动——Embedding将分析深度下钻到流量分布和流量层面,通过统计分析,对宏观指标进行深度分析,发现指标背后的问题,洞察用户行为与价值提升关联之间的潜力
2、产品优化——对于产品,用户在产品中做什么,在产品中停留的时间,有哪些异常需要注意。这些问题可以通过埋点来解决。
3、精细化运营-买点可以对产品全生命周期、不同来源的流量质量和分布、行为特征和人的关系等进行细化,洞察用户行为与商业价值提升之间的潜在关系。
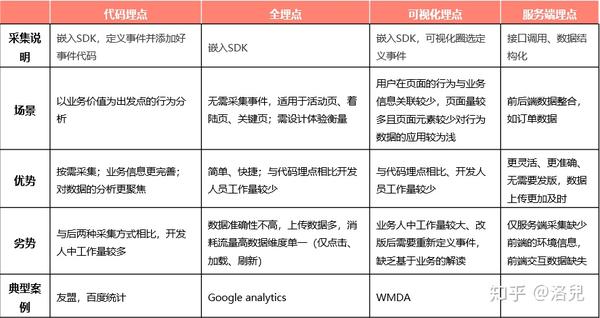
2.3种埋点方法
埋点方法有哪些?大多数公司目前使用客户端和服务器的组合
准确度:代码掩埋 > 视觉掩埋 > 完全掩埋
三、埋点架构与设计
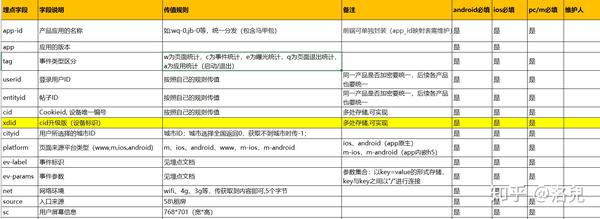
3.1埋点采集顶层设计
所谓顶层设计,就是想清楚怎么埋点,用什么方式埋点,上传机制是什么,怎么定义,怎么实现等等;我们遵循唯一性、可扩展性、一致性等,需要设计一些常用的字段和生成机制,比如:cid、idfa、idfv等。
用户识别:用户识别机制的混乱会导致两种结果:一是数据不准确,如UV数据不匹配;二是漏斗分析过程出现异常。因此,应该这样做:严格规范ID自身的识别机制;湾。跨平台用户识别
同构抽象:同构抽象包括事件抽象和属性抽象。事件抽象是浏览事件和点击事件的聚合;属性抽象,即结合大部分复用场景,增加源差异化
采集一致:采集一致包括两点:一是跨平台页面命名一致,二是按钮命名一致;制定嵌入点的过程就是对底层数据进行标准化的过程,所以一致性尤为重要,只有这样才能真正使用
渠道配置:渠道主要指推广渠道、落地页、网页推广页、APP推广页等,这个落地页的配置必须有统一的规范和标准
3.2埋点采集活动及物业设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变化的,哪些是业务行为,哪些是基本属性。基于基本的属性事件,我们认为属性一定是采集项,但是属性中的事件属性会根据不同的业务进行调整。因此,我们可以将埋点采集分为协议层和业务层Bury。
业务分解:梳理确认业务流程、操作路径和不同的细分场景,定义用户行为路径
分析指标:定义特定事件和核心业务指标所需的数据
事件设计:APP启动、退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.3 资料采集事件与属性设计
Ev 事件的命名也遵循一些规则。当相同类型的函数出现在不同的页面或位置时,根据函数名进行命名,并在ev参数中区分页面和位置。只有当按钮被点击时,它才会以按钮名称命名。
ev事件格式:ev分为ev标志和ev参数
规则:
在ev标识符和ev参数之间使用“#”(一级连接符);
在ev参数和ev参数之间使用“/”(二级连接符);
ev参数使用key=value的结构。当一个key对应多个value值时,value1和value2的连接为","(三级连接符);
当埋点只有ev标志,没有ev参数时,不需要#;
评论:
ev标识:作为埋点的唯一标识,用于区分埋点的位置和属性,不可变、不可修改;
ev参数:埋点需要返回的参数。ev参数的顺序是可变的,可以修改;
调整app嵌入点时,ev logo不变,仅修改以下嵌入点参数(更改参数值或添加参数类型)
一般埋点文档中收录的工作表名称和功能:
A. 暴露埋点汇总;
B、点击浏览埋点汇总;
C、故障埋点汇总:一般会记录埋点的故障版本或时间;
D、PC和M侧页面埋点对应的pageid;
E、各版本上线时间记录;
在埋点文档中,都收录了列名和函数:
3.4 基于埋点的数据统计
如何使用埋点统计找到埋藏的 ev 事件:
1. 指定埋点类型(点击/曝光/浏览)——过滤类型字段
2. 指定按钮子点所属的页面(页面或功能)-过滤功能模块字段
3. 指定跟踪事件的名称 - 过滤名称字段
4. 知道了ev标志,就可以直接用ev过滤了
如何根据ev事件查询统计:当点击查询按钮进行统计时,可以直接使用ev标志查询。有区别时,可以限制埋点参数的取值;因为ev参数的顺序不要求是可变的,查询统计的时候,不能根据参数的顺序来限制;
四、应用——数据流的基础
4.1 指标系统
系统化的指标可以整合不同的指标、不同的维度进行综合分析,可以更快的发现当前产品和业务流程中存在的问题。
4.2 可视化
人类解释图像信息比文本更有效。可视化对于数据分析非常重要。使用数据可视化可以揭示数据中固有的复杂关系。
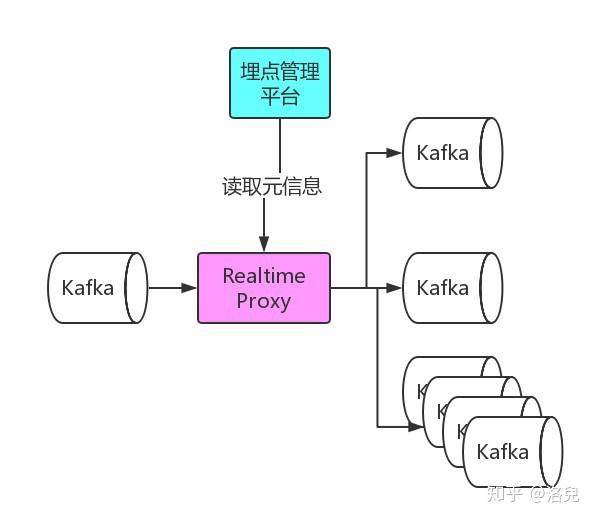
4.3 埋点元信息API提供
data采集 服务会将埋点到 Kafka 写入 Kafka。针对各个业务的实时数据消费需求,我们为各个业务提供单独的Kafka,流量分发模块会定时读取。取埋点管理平台提供的元信息,将流量实时分发到各个业务的Kafka。
数据采集就像设计一个产品,不应该过分,留有扩展的空间,但要不断思考有没有数据,是否完整、详细、稳定或快速。 查看全部
文章采集api(数据埋点采集到底都是哪些事呢?的应用)
数据采集是数据分析的基础,跟踪是最重要的采集方法。那么数据埋点采集究竟是什么?我们主要从三个方面来看:什么是埋点,埋点如何设计,埋点的应用。
一、数据采集 和常见数据问题
1.1 数据采集
数据采集的方式有很多种,埋点采集是其中非常重要的一环。它是c端和b端产品的主要采集方式。数据采集,顾名思义采集对应的数据是整个数据流的起点,采集不完整,对与不对,直接决定数据的广度和质量并影响所有后续链接;在数据采集有效性和完整性较差的公司往往会发现其业务数据发生了重大变化。
数据处理通常包括以下五个步骤:

1.2常见数据问题
在大致了解了data采集及其结构之后,我们再来看看工作中遇到的问题,有多少与data采集链接有关
1、数据与背景差距较大,数据不准确——统计口径不同,埋点定义不同,采集方法带来误差
2、想用的时候,没有我要的数据——我没提数据采集要求,埋点不正确,不全
3、事件太多,意思不清楚——埋点设计的方式,埋点更新迭代的规则和维护
4、分析数据时不知道要看哪些数据和指标——数据的定义不明确,缺乏分析思路
我们需要根本原因的解决方案:将 采集 视为独立的研发业务,而不是产品开发的附属品
二、埋葬点是什么?
2.1 葬礼是什么
所谓埋点,是data采集领域的一个名词。它的学名应该叫事件追踪,对应的英文是Event Tracking,是指捕获、处理和发送特定用户行为或事件的相关技术和实现过程。数据埋点是数据分析师、数据产品经理和数据运营商,他们根据业务需求或产品需求,针对用户行为对应的每个事件开发埋点,并通过SDK上报埋点数据结果,并记录汇总数据。分析、推动产品优化和指导运营。
该过程伴随着规范。通过定义可以看出,具体的用户行为和事件是我们采集关注的焦点,也需要处理和发送相关的技术和实现流程;数据嵌入服务于产品,来自产品。,所以和产品息息相关,重点在于具体的实战过程,这关系到大家对底层数据的理解。
2.2 你为什么要埋头苦干?
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的质量直接影响数据质量、产品质量和运营质量。
1、数据驱动——Embedding将分析深度下钻到流量分布和流量层面,通过统计分析,对宏观指标进行深度分析,发现指标背后的问题,洞察用户行为与价值提升关联之间的潜力
2、产品优化——对于产品,用户在产品中做什么,在产品中停留的时间,有哪些异常需要注意。这些问题可以通过埋点来解决。
3、精细化运营-买点可以对产品全生命周期、不同来源的流量质量和分布、行为特征和人的关系等进行细化,洞察用户行为与商业价值提升之间的潜在关系。
2.3种埋点方法
埋点方法有哪些?大多数公司目前使用客户端和服务器的组合
准确度:代码掩埋 > 视觉掩埋 > 完全掩埋
三、埋点架构与设计
3.1埋点采集顶层设计
所谓顶层设计,就是想清楚怎么埋点,用什么方式埋点,上传机制是什么,怎么定义,怎么实现等等;我们遵循唯一性、可扩展性、一致性等,需要设计一些常用的字段和生成机制,比如:cid、idfa、idfv等。
用户识别:用户识别机制的混乱会导致两种结果:一是数据不准确,如UV数据不匹配;二是漏斗分析过程出现异常。因此,应该这样做:严格规范ID自身的识别机制;湾。跨平台用户识别
同构抽象:同构抽象包括事件抽象和属性抽象。事件抽象是浏览事件和点击事件的聚合;属性抽象,即结合大部分复用场景,增加源差异化
采集一致:采集一致包括两点:一是跨平台页面命名一致,二是按钮命名一致;制定嵌入点的过程就是对底层数据进行标准化的过程,所以一致性尤为重要,只有这样才能真正使用
渠道配置:渠道主要指推广渠道、落地页、网页推广页、APP推广页等,这个落地页的配置必须有统一的规范和标准
3.2埋点采集活动及物业设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变化的,哪些是业务行为,哪些是基本属性。基于基本的属性事件,我们认为属性一定是采集项,但是属性中的事件属性会根据不同的业务进行调整。因此,我们可以将埋点采集分为协议层和业务层Bury。
业务分解:梳理确认业务流程、操作路径和不同的细分场景,定义用户行为路径
分析指标:定义特定事件和核心业务指标所需的数据
事件设计:APP启动、退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.3 资料采集事件与属性设计
Ev 事件的命名也遵循一些规则。当相同类型的函数出现在不同的页面或位置时,根据函数名进行命名,并在ev参数中区分页面和位置。只有当按钮被点击时,它才会以按钮名称命名。
ev事件格式:ev分为ev标志和ev参数
规则:
在ev标识符和ev参数之间使用“#”(一级连接符);
在ev参数和ev参数之间使用“/”(二级连接符);
ev参数使用key=value的结构。当一个key对应多个value值时,value1和value2的连接为","(三级连接符);
当埋点只有ev标志,没有ev参数时,不需要#;
评论:
ev标识:作为埋点的唯一标识,用于区分埋点的位置和属性,不可变、不可修改;
ev参数:埋点需要返回的参数。ev参数的顺序是可变的,可以修改;
调整app嵌入点时,ev logo不变,仅修改以下嵌入点参数(更改参数值或添加参数类型)
一般埋点文档中收录的工作表名称和功能:
A. 暴露埋点汇总;
B、点击浏览埋点汇总;
C、故障埋点汇总:一般会记录埋点的故障版本或时间;
D、PC和M侧页面埋点对应的pageid;
E、各版本上线时间记录;
在埋点文档中,都收录了列名和函数:

3.4 基于埋点的数据统计
如何使用埋点统计找到埋藏的 ev 事件:
1. 指定埋点类型(点击/曝光/浏览)——过滤类型字段
2. 指定按钮子点所属的页面(页面或功能)-过滤功能模块字段
3. 指定跟踪事件的名称 - 过滤名称字段
4. 知道了ev标志,就可以直接用ev过滤了
如何根据ev事件查询统计:当点击查询按钮进行统计时,可以直接使用ev标志查询。有区别时,可以限制埋点参数的取值;因为ev参数的顺序不要求是可变的,查询统计的时候,不能根据参数的顺序来限制;
四、应用——数据流的基础
4.1 指标系统
系统化的指标可以整合不同的指标、不同的维度进行综合分析,可以更快的发现当前产品和业务流程中存在的问题。
4.2 可视化
人类解释图像信息比文本更有效。可视化对于数据分析非常重要。使用数据可视化可以揭示数据中固有的复杂关系。
4.3 埋点元信息API提供
data采集 服务会将埋点到 Kafka 写入 Kafka。针对各个业务的实时数据消费需求,我们为各个业务提供单独的Kafka,流量分发模块会定时读取。取埋点管理平台提供的元信息,将流量实时分发到各个业务的Kafka。
数据采集就像设计一个产品,不应该过分,留有扩展的空间,但要不断思考有没有数据,是否完整、详细、稳定或快速。
文章采集api(数据埋点采集到底都是哪些事呢?的应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-04-11 15:43
数据采集是数据分析的基础,跟踪是最重要的采集方法。那么数据埋点采集究竟是什么?我们主要从三个方面来看:什么是埋点,埋点如何设计,埋点的应用。
一、数据采集 和常见数据问题
1.1 数据采集
数据采集的方式有很多种,埋点采集是其中非常重要的一环。它是c端和b端产品的主要采集方式。数据采集,顾名思义采集对应的数据是整个数据流的起点,采集不完整,对与不对,直接决定数据的广度和质量并影响所有后续链接;在数据采集有效性和完整性较差的公司往往会发现其业务数据发生了重大变化。
数据处理通常包括以下五个步骤:
1.2常见数据问题
在大致了解了data采集及其结构之后,我们再来看看工作中遇到的问题,有多少与data采集链接有关
1、数据与背景差距较大,数据不准确——统计口径不同,埋点定义不同,采集方法带来误差
2、想用的时候,没有我要的数据——我没提数据采集要求,埋点不正确,不全
3、事件太多,意思不清楚——埋点设计的方式,埋点更新迭代的规则和维护
4、分析数据时不知道要看哪些数据和指标——数据的定义不明确,缺乏分析思路
我们需要根本原因的解决方案:将 采集 视为独立的研发业务,而不是产品开发的附属品
二、埋葬点是什么?
2.1 葬礼是什么
所谓埋点,是data采集领域的一个名词。它的学名应该叫事件跟踪,对应的英文是Event Tracking,是指捕获、处理和发送特定用户行为或事件的相关技术和实现过程。数据埋点是数据分析师、数据产品经理和数据运营商,他们根据业务需求或产品需求,针对用户行为对应的每个事件开发埋点,并通过SDK上报埋点数据结果,并记录汇总数据。分析、推动产品优化和指导运营。
该过程伴随着规范。通过定义可以看出,具体的用户行为和事件是我们采集关注的焦点,也需要处理和发送相关的技术和实现流程;数据嵌入服务于产品,来自产品。,所以和产品息息相关,重点在于具体的实战过程,这关系到大家对底层数据的理解。
2.2 你为什么要埋头苦干?
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的质量直接影响数据质量、产品质量和运营质量。
1、数据驱动——Embedding将分析深度下钻到流量分布和流量层面,通过统计分析,对宏观指标进行深入分析,发现指标背后的问题,洞察用户行为与价值提升关联之间的潜力
2、产品优化——对于产品,用户在产品中做什么,在产品中停留的时间,有哪些异常需要注意。这些问题可以通过埋点来解决。
3、细化运营-买点可以实现产品全生命周期、不同来源的流量质量和分布、行为特征和人的关系,洞察用户行为与商业价值提升的潜在关系。
2.3种埋点方法
埋点方法有哪些?大多数公司目前使用客户端和服务器的组合
准确度:代码掩埋 > 视觉掩埋 > 完全掩埋
三、埋点架构与设计
3.1埋点采集顶层设计
所谓顶层设计,就是想清楚怎么埋点,用什么方式埋点,上传机制是什么,怎么定义,怎么实现等等;我们遵循唯一性、可扩展性、一致性等,需要设计一些常用的字段和生成机制,比如:cid、idfa、idfv等。
用户识别:用户识别机制的混乱会导致两种结果:一是数据不准确,如UV数据不匹配;二是漏斗分析过程出现异常。因此,应该这样做:严格规范ID自身的识别机制;湾。跨平台用户识别
同构抽象:同构抽象包括事件抽象和属性抽象。事件抽象是浏览事件和点击事件的聚合;属性抽象,即结合大部分复用场景,增加源差异化
采集一致:采集一致包括两点:一是跨平台页面命名一致,二是按钮命名一致;制定嵌入点的过程就是对底层数据进行标准化的过程,所以一致性尤为重要,只有这样才能真正使用
渠道配置:渠道主要指推广渠道、落地页、网页推广页、APP推广页等,这个落地页的配置必须有统一的规范和标准
3.2埋点采集活动及物业设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变化的,哪些是业务行为,哪些是基本属性。基于基本的属性事件,我们认为属性一定是采集项,但是属性中的事件属性会根据不同的业务进行调整。因此,我们可以将埋点采集分为协议层和业务层Bury。
业务分解:梳理确认业务流程、操作路径和不同的细分场景,定义用户行为路径
分析指标:定义特定事件和核心业务指标所需的数据
事件设计:APP启动、退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.3 资料采集事件与属性设计
Ev 事件的命名也遵循一些规则。当相同类型的函数出现在不同的页面或位置时,根据函数名进行命名,并在ev参数中区分页面和位置。只有当按钮被点击时,它才会以按钮名称命名。
ev事件格式:ev分为ev标志和ev参数
规则:
在ev标识符和ev参数之间使用“#”(一级连接符);
在ev参数和ev参数之间使用“/”(二级连接符);
ev参数使用key=value的结构。当一个key对应多个value值时,value1和value2的连接为","(三级连接符);
当埋点只有ev标志,没有ev参数时,不需要#;
评论:
ev标识:作为埋点的唯一标识,用于区分埋点的位置和属性,不可变、不可修改;
ev参数:埋点需要返回的参数。ev参数的顺序是可变的,可以修改;
调整app嵌入点时,ev logo不变,仅修改以下嵌入点参数(更改参数值或添加参数类型)
一般埋点文档中收录的工作表名称和功能:
A. 暴露埋点汇总;
B、点击浏览埋点汇总;
C、故障埋点汇总:一般会记录埋点的故障版本或时间;
D、PC和M侧页面埋点对应的pageid;
E、各版本上线时间记录;
在埋点文档中,都收录了列名和函数:
3.4 基于埋点的数据统计
如何使用埋点统计找到埋藏的 ev 事件:
1. 指定埋点类型(点击/曝光/浏览)——过滤类型字段
2. 指定按钮子点所属的页面(页面或功能)-过滤功能模块字段
3. 指定跟踪事件的名称 - 过滤名称字段
4. 知道了ev标志,就可以直接用ev过滤了
如何根据ev事件查询统计:当点击查询按钮进行统计时,可以直接使用ev标志查询。有区别时,可以限制埋点参数的取值;因为ev参数的顺序不要求是可变的,查询统计的时候,不能根据参数的顺序来限制;
四、应用——数据流的基础
4.1 指标系统
系统化的指标可以整合不同的指标、不同的维度进行综合分析,可以更快的发现当前产品和业务流程中存在的问题。
4.2 可视化
人类解释图像信息比文本更有效。可视化对于数据分析非常重要。使用数据可视化可以揭示数据中固有的复杂关系。
4.3 埋点元信息API提供
data采集服务会将采集收到的埋点写入Kafka。针对各个业务的实时数据消费需求,我们为各个业务提供单独的Kafka,流量分发模块会定时读取。取埋点管理平台提供的元信息,将流量实时分发到各个业务的Kafka。
数据采集就像设计一个产品,不应该过分,留有扩展的空间,但要不断思考有没有数据,是否完整、详细、稳定或快速。 查看全部
文章采集api(数据埋点采集到底都是哪些事呢?的应用)
数据采集是数据分析的基础,跟踪是最重要的采集方法。那么数据埋点采集究竟是什么?我们主要从三个方面来看:什么是埋点,埋点如何设计,埋点的应用。
一、数据采集 和常见数据问题
1.1 数据采集
数据采集的方式有很多种,埋点采集是其中非常重要的一环。它是c端和b端产品的主要采集方式。数据采集,顾名思义采集对应的数据是整个数据流的起点,采集不完整,对与不对,直接决定数据的广度和质量并影响所有后续链接;在数据采集有效性和完整性较差的公司往往会发现其业务数据发生了重大变化。
数据处理通常包括以下五个步骤:
1.2常见数据问题
在大致了解了data采集及其结构之后,我们再来看看工作中遇到的问题,有多少与data采集链接有关
1、数据与背景差距较大,数据不准确——统计口径不同,埋点定义不同,采集方法带来误差
2、想用的时候,没有我要的数据——我没提数据采集要求,埋点不正确,不全
3、事件太多,意思不清楚——埋点设计的方式,埋点更新迭代的规则和维护
4、分析数据时不知道要看哪些数据和指标——数据的定义不明确,缺乏分析思路
我们需要根本原因的解决方案:将 采集 视为独立的研发业务,而不是产品开发的附属品
二、埋葬点是什么?
2.1 葬礼是什么
所谓埋点,是data采集领域的一个名词。它的学名应该叫事件跟踪,对应的英文是Event Tracking,是指捕获、处理和发送特定用户行为或事件的相关技术和实现过程。数据埋点是数据分析师、数据产品经理和数据运营商,他们根据业务需求或产品需求,针对用户行为对应的每个事件开发埋点,并通过SDK上报埋点数据结果,并记录汇总数据。分析、推动产品优化和指导运营。
该过程伴随着规范。通过定义可以看出,具体的用户行为和事件是我们采集关注的焦点,也需要处理和发送相关的技术和实现流程;数据嵌入服务于产品,来自产品。,所以和产品息息相关,重点在于具体的实战过程,这关系到大家对底层数据的理解。
2.2 你为什么要埋头苦干?
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的质量直接影响数据质量、产品质量和运营质量。
1、数据驱动——Embedding将分析深度下钻到流量分布和流量层面,通过统计分析,对宏观指标进行深入分析,发现指标背后的问题,洞察用户行为与价值提升关联之间的潜力
2、产品优化——对于产品,用户在产品中做什么,在产品中停留的时间,有哪些异常需要注意。这些问题可以通过埋点来解决。
3、细化运营-买点可以实现产品全生命周期、不同来源的流量质量和分布、行为特征和人的关系,洞察用户行为与商业价值提升的潜在关系。
2.3种埋点方法
埋点方法有哪些?大多数公司目前使用客户端和服务器的组合
准确度:代码掩埋 > 视觉掩埋 > 完全掩埋
三、埋点架构与设计
3.1埋点采集顶层设计
所谓顶层设计,就是想清楚怎么埋点,用什么方式埋点,上传机制是什么,怎么定义,怎么实现等等;我们遵循唯一性、可扩展性、一致性等,需要设计一些常用的字段和生成机制,比如:cid、idfa、idfv等。
用户识别:用户识别机制的混乱会导致两种结果:一是数据不准确,如UV数据不匹配;二是漏斗分析过程出现异常。因此,应该这样做:严格规范ID自身的识别机制;湾。跨平台用户识别
同构抽象:同构抽象包括事件抽象和属性抽象。事件抽象是浏览事件和点击事件的聚合;属性抽象,即结合大部分复用场景,增加源差异化
采集一致:采集一致包括两点:一是跨平台页面命名一致,二是按钮命名一致;制定嵌入点的过程就是对底层数据进行标准化的过程,所以一致性尤为重要,只有这样才能真正使用
渠道配置:渠道主要指推广渠道、落地页、网页推广页、APP推广页等,这个落地页的配置必须有统一的规范和标准
3.2埋点采集活动及物业设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变化的,哪些是业务行为,哪些是基本属性。基于基本的属性事件,我们认为属性一定是采集项,但是属性中的事件属性会根据不同的业务进行调整。因此,我们可以将埋点采集分为协议层和业务层Bury。
业务分解:梳理确认业务流程、操作路径和不同的细分场景,定义用户行为路径
分析指标:定义特定事件和核心业务指标所需的数据
事件设计:APP启动、退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.3 资料采集事件与属性设计
Ev 事件的命名也遵循一些规则。当相同类型的函数出现在不同的页面或位置时,根据函数名进行命名,并在ev参数中区分页面和位置。只有当按钮被点击时,它才会以按钮名称命名。
ev事件格式:ev分为ev标志和ev参数
规则:
在ev标识符和ev参数之间使用“#”(一级连接符);
在ev参数和ev参数之间使用“/”(二级连接符);
ev参数使用key=value的结构。当一个key对应多个value值时,value1和value2的连接为","(三级连接符);
当埋点只有ev标志,没有ev参数时,不需要#;
评论:
ev标识:作为埋点的唯一标识,用于区分埋点的位置和属性,不可变、不可修改;
ev参数:埋点需要返回的参数。ev参数的顺序是可变的,可以修改;
调整app嵌入点时,ev logo不变,仅修改以下嵌入点参数(更改参数值或添加参数类型)
一般埋点文档中收录的工作表名称和功能:
A. 暴露埋点汇总;
B、点击浏览埋点汇总;
C、故障埋点汇总:一般会记录埋点的故障版本或时间;
D、PC和M侧页面埋点对应的pageid;
E、各版本上线时间记录;
在埋点文档中,都收录了列名和函数:
3.4 基于埋点的数据统计
如何使用埋点统计找到埋藏的 ev 事件:
1. 指定埋点类型(点击/曝光/浏览)——过滤类型字段
2. 指定按钮子点所属的页面(页面或功能)-过滤功能模块字段
3. 指定跟踪事件的名称 - 过滤名称字段
4. 知道了ev标志,就可以直接用ev过滤了
如何根据ev事件查询统计:当点击查询按钮进行统计时,可以直接使用ev标志查询。有区别时,可以限制埋点参数的取值;因为ev参数的顺序不要求是可变的,查询统计的时候,不能根据参数的顺序来限制;
四、应用——数据流的基础
4.1 指标系统
系统化的指标可以整合不同的指标、不同的维度进行综合分析,可以更快的发现当前产品和业务流程中存在的问题。
4.2 可视化
人类解释图像信息比文本更有效。可视化对于数据分析非常重要。使用数据可视化可以揭示数据中固有的复杂关系。
4.3 埋点元信息API提供
data采集服务会将采集收到的埋点写入Kafka。针对各个业务的实时数据消费需求,我们为各个业务提供单独的Kafka,流量分发模块会定时读取。取埋点管理平台提供的元信息,将流量实时分发到各个业务的Kafka。
数据采集就像设计一个产品,不应该过分,留有扩展的空间,但要不断思考有没有数据,是否完整、详细、稳定或快速。
文章采集api(数据具体的采集方案是什么?四种数据采集方法对比)
采集交流 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-04-09 21:07
根据企业在生产和管理过程中会产生的数据类型,提供链接标记、SDK和API三种采集方法,以及基于UTSE数据采集模型对用户的整个生命周期。
那么,数据的具体采集计划是什么?
四种数据采集方法对比
Data采集是通过埋点实现的。诸葛io提供了非常完善的数据访问解决方案,支持代码埋、全埋、可视埋、服务器埋等数据采集方式。
1.代码被埋没
说明:嵌入SDK定义事件和添加事件代码是一种常用的数据采集方法,主要包括网页和h5页面的JS嵌入、移动端的iOS和Android嵌入、微信小程序等。
优点:按需采集,业务信息更全,数据分析更专注,数据采集全面准确,便于后续深入分析。
缺点:需要研发人员配合,有一定的工作量。
2.全葬
说明:通过SDK自动采集页面所有可点击元素的操作数据,无需定义事件,适用于活动页面、登陆页面、关键页面的设计体验测量。
优点:更简单快捷,可以看到页面元素的点击量,更好的了解自己的产品特点。
缺点:采集的数据太多,只要是可点击的元素,就会是采集,上传数据很多,消耗流量很大。无法采集到更深层次的维度信息,比如事件的属性、用户的属性等。
3.可视化埋点
注意:视觉嵌入是基于完整嵌入的。技术同事整合后,业务同事需要圈出页面的元素,选中的元素会是采集。
优点:基于接口配置,无需开发,易于更新,快速生效。
缺点:自定义属性的支持范围比较有限;重构或页面更改时需要重新配置。
4.服务器埋点
描述:通过API对存储在服务器上的数据进行结构化处理,通过接口调用其他业务数据采集和集成,比如CRM等用户数据,对数据进行结构化处理,即适合拥有 采集 @采集 能力客户端的用户。
优点:服务端embedding更有针对性,数据更准确,减少编码embedding的发布过程,数据上传更及时。
缺点:用户的一些简单操作,比如点击按钮、切换模块,这些数据不能采集,用户行为不够完整。
总结:以上是诸葛io提供的四种data采集解决方案:code embedding、full embedding、visual embedding、server embedding,data采集目的是为了满足采集详细分析和操作然后执行需求。只有能够达到这个目标,才有可能选择一种或多种采集形式的组合。在企业业务中,选择哪种采集方式要根据企业自身的具体业务需求来决定。 查看全部
文章采集api(数据具体的采集方案是什么?四种数据采集方法对比)
根据企业在生产和管理过程中会产生的数据类型,提供链接标记、SDK和API三种采集方法,以及基于UTSE数据采集模型对用户的整个生命周期。
那么,数据的具体采集计划是什么?

四种数据采集方法对比
Data采集是通过埋点实现的。诸葛io提供了非常完善的数据访问解决方案,支持代码埋、全埋、可视埋、服务器埋等数据采集方式。
1.代码被埋没
说明:嵌入SDK定义事件和添加事件代码是一种常用的数据采集方法,主要包括网页和h5页面的JS嵌入、移动端的iOS和Android嵌入、微信小程序等。
优点:按需采集,业务信息更全,数据分析更专注,数据采集全面准确,便于后续深入分析。
缺点:需要研发人员配合,有一定的工作量。
2.全葬
说明:通过SDK自动采集页面所有可点击元素的操作数据,无需定义事件,适用于活动页面、登陆页面、关键页面的设计体验测量。
优点:更简单快捷,可以看到页面元素的点击量,更好的了解自己的产品特点。
缺点:采集的数据太多,只要是可点击的元素,就会是采集,上传数据很多,消耗流量很大。无法采集到更深层次的维度信息,比如事件的属性、用户的属性等。
3.可视化埋点
注意:视觉嵌入是基于完整嵌入的。技术同事整合后,业务同事需要圈出页面的元素,选中的元素会是采集。
优点:基于接口配置,无需开发,易于更新,快速生效。
缺点:自定义属性的支持范围比较有限;重构或页面更改时需要重新配置。
4.服务器埋点
描述:通过API对存储在服务器上的数据进行结构化处理,通过接口调用其他业务数据采集和集成,比如CRM等用户数据,对数据进行结构化处理,即适合拥有 采集 @采集 能力客户端的用户。
优点:服务端embedding更有针对性,数据更准确,减少编码embedding的发布过程,数据上传更及时。
缺点:用户的一些简单操作,比如点击按钮、切换模块,这些数据不能采集,用户行为不够完整。
总结:以上是诸葛io提供的四种data采集解决方案:code embedding、full embedding、visual embedding、server embedding,data采集目的是为了满足采集详细分析和操作然后执行需求。只有能够达到这个目标,才有可能选择一种或多种采集形式的组合。在企业业务中,选择哪种采集方式要根据企业自身的具体业务需求来决定。
文章采集api(七个步骤逐步介绍如何阅读API文档和测试?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-04-05 08:24
随着 API 在互联网时代变得越来越普遍,不仅程序员会使用它们,现在还需要产品经理或互联网运营商来调试和与 API 交互。阅读此 文章 您可能正在使用或开发 API,或两者兼而有之。因此,重要的是您不仅要知道如何编写,还要知道如何阅读 API 文档和测试。
什么是 API 文档?您还可以将 API 文档视为两方之间的服务协议。该文档概述了当第一方发送某种类型的请求时,第二方及其软件将如何响应。这些类型的请求(称为 API 调用)在文档中进行了描述,以便开发人员知道他们可以使用 API 做什么以及如何做。
好的 API 文档描述了它们的端点,解释了为什么应该使用它们,并提供了如何使用它们的非常具体的示例——所有这些都以对初学者和高级用户同样不言自明的方式进行。说明不清楚的 API 文档技术性太强,而且基于文本描述,因此并非所有用户都能正确使用。
下面,我们将通过七个步骤向您介绍如何编写好的 API 文档。
了解谁在使用您的 API
映射您的用户旅程
从一个基本的功能声明开始
添加代码示例
列出您的状态代码和错误消息
用白话编写和设计 API 文档
使 API 文档始终保持最新
1.了解谁在使用您的 API
与任何内容影响策略计划或 UI 设计过程一样,编写 API 文档的第一步是了解您的目标受众。这需要了解您的目标用户类型、您的内容需要为他们提供的有用价值以及它如何适应他们的实际场景。
在编写 API 文档时要记住两大类用户。一组用户是 API 文档的直接消费者,因此他们只需要查看教程和代码示例。该组主要是开发人员。另一组用户评估 API 功能、价格、速率限制、安全性等,以了解 API 如何与他们的业务需求和目标保持一致。该团队主要由 CTO 和产品经理以及一些开发人员组成。
您必须牢记这两个角色,以确保文档为每位读者提供良好的体验。
2.映射您的用户旅程
与任何产品一样,API 必须在买家旅程的每个阶段交付内容。这意味着文档应该解释 API 可以做什么(或解决),它提供的各种功能和端点,以及它与竞争对手的不同之处。
API 文档应该回答的一些基本问题是:
1.为什么要使用这个 API?
2.如何访问不同的工具和端点?
3.获得许可后的下一步是什么?
4.如何使用某些功能?
3.从一个基本的功能语句开始
每个 API 和功能都是独一无二的。例如,一些 API 可以将微博照片嵌入到电商平台的详情页中。一些 API 允许您通过 Bilibili Travel UP 大师访问数以千计的推荐酒店。网站 上甚至还有一个用于集成 Yoda 翻译器的 API。虽然每个 API 做的事情都不同,但每个 API 文档都应该涵盖一些基础知识。让我们看看下面的一些例子。
验证
由于认证对于保护 API 数据以及开发者和最终用户的数据安全非常重要,因此 API 通常有多种认证方案,因此 API 文档必须描述其每种认证方法,以便用户能够获得 Authorize 并正确使用 API。例如,YouTube 数据 API 支持两种类型的授权凭证。它的文档解释了如何使用 OAuth 2.0 以及如何获取 API 密钥,以便用户可以选择他们更熟悉的身份验证方法。
速率限制
与用户身份验证一样,速率限制有助于防止意外传输或 API 滥用。API 速率限制是您在给定时间内可以向 API 发送请求的次数。这些限制必须在 API 文档中明确说明,以便用户知道如何正确使用 API 及其功能。此信息最常在使用条款中找到。
使用条款
使用条款(或服务)是服务提供商与需要该服务的用户之间的法律协议。后者必须同意遵守这些条款才能使用服务。在 API 文档中,使用条款必须明确定义 API 使用者应如何理想地使用 API。这将有助于确保服务消费者充分利用 API 平台和功能。
内容变更日志
重要的是要让 API 使用者了解他们使用的 API 的任何减损。变更文档可以帮助他们正确维护应用程序并充分利用 API 平台的功能。案例:Twitter 的 API 文档收录对 Twitter 开发人员平台所做的所有更改的更改日志,包括新功能和产品。
4.添加代码示例
API 文档有两个主要目标:让开发人员尽可能轻松地使用 API,并让他们快速了解 API 的全部功能。实现这两个目标的一个好方法是为每个 API 端点提供代码示例。这样开发者就可以了解端点最关键的功能,从一些案例代码入手,然后直接在案例代码上调整参数,满足自己的实际需求和对接规范。
5.列出您的状态代码和错误消息
API 文档应清楚地概述用户在进行 API 调用时可能期望的状态代码和错误消息。理想情况下,每个响应都应附有简短描述,以便用户了解 API 何时成功调用、何时不成功,并能够解决他们遇到的任何错误。通常,此信息放置在其自己的页面上。这是 express 100API 文档中的一个示例。
6.用白话编写和设计 API 文档
如果您想以易于用户阅读和浏览的方式编写、构建和设计 API 文档。这意味着根据用户的使用场景和他们的需求来呈现和组织文档的内容信息。用户的使用场景是关于用户在何处、何时、为什么以及如何找到内容并与内容交互的一切。他们的需求还包括他们的目标、行为和期望。
最好的 API 文档是为完全不熟悉 API 的初学者和非常熟悉它的开发人员编写的。本文档需要尽可能避免过多的技术术语,并尽可能提供额外的上下文信息或文档的内部链接。它还需要提供诸如“入门”之类的内容以及新手用户需要的示例和教程,但更高级的用户可以跳过。
为了确保用户可以选择他们想要的东西,API 文档必须以导航的方式设计。最佳实践是使用页眉和侧边栏,以便用户无需上下滚动页面即可导航到文档的另一部分并提供搜索功能。其他设计考虑因素包括排版、配色方案和布局。三列布局被认为是收录大量代码示例的文档的理想选择。无衬线字体和对比色链接也是不错的设计选择。
7.使 API 文档保持最新
为了确保 API 消费者获得最佳体验并不断吸引新用户,API 提供者必须不时维护自己的 API 文档。过去,API 文档以 PDF 或静态网页的形式存在,导致文档更新困难。现在,有一些工具可以帮助您创建自动更新的动态和交互式文档。Redocly 和 SwaggerUI 是两个更常见的实际示例。
如何阅读 API 文档
如果你只是一个 API 消费者,而不是 API 服务提供者,那么你需要知道如何阅读 API 文档。尽管编写和阅读它的方法是相似的(寻找理由、尝试代码示例等),但它们并不完全相同。让我们仔细看看如何阅读 API 文档以了解特定 API 的可能性。
从文档概述开始
大多数 API 文档都会首先概述 API 的功能、如何连接它以及如何正确使用它。当然,您不需要了解概述的每个细节,但您应该大致了解它。
以Express 100的API文档为例,首先,Express 100的API文档解释了Express 100的API使用,使用的协议和语言,以及其认证方案。在左侧边栏的快速链接部分,您将找到指向其使用指南和速率限制、测试帐户、更改日志以及开始使用 API 所需的所有其他内容的重要链接。
了解有关功能的更多信息
了解 API 概览后,请浏览 API 参考文档,其中列出了 API 的所有函数(也称为方法)。在这一点上,没有必要彻底阅读或记住所有内容。相反,请仔细查看您特别感兴趣的函数。通过查看它的参数和示例,您可以了解是否可以成功使用 API 来完成您想做的确切事情。
例如,假设您想通过快递100的API实现如下物流查询功能: - 在电商网页/APP/小程序中,客户可以在订单详情中查看所购买产品的物流地图轨迹,向客户展示物流轨迹的文字信息
在此需求的驱动下,您可以导航到“接口文档”并查看其代码语言、参数、响应、错误消息等。
通读 API 文档教程
既然您知道是否可以使用 API 来实现您想要的,请查看教程。由于最好的 API 文档应该可以帮助用户快速入门,因此大多数文档将收录完成工作的详细教程。您应该至少通读一个教程,以了解需要仔细研究的详细程度和示例。想了解电商快递物流API的好处,这里有一篇文章文章《什么是电商API?这是它能给商家带来的12个运营好处》,里面介绍了它们的优势以及详细的缺点。如果你有兴趣,可以阅读它们,说不定你会发现意想不到的惊喜。
记录 API 信息变更
随着越来越多的公司提供 API 服务以形成高度集成的用户体验,了解如何编写和阅读 API 文档变得越来越有价值。在创建或评估 API 文档时,请确保您的 API 稳定且易于阅读和导航,并向开发人员和非开发人员清楚地传达您的 API 的价值。这确保技术用户可以快速正确地开始使用您的 API,并且同事确保他们可以与其他非技术同事一起使用它。 查看全部
文章采集api(七个步骤逐步介绍如何阅读API文档和测试?(组图))
随着 API 在互联网时代变得越来越普遍,不仅程序员会使用它们,现在还需要产品经理或互联网运营商来调试和与 API 交互。阅读此 文章 您可能正在使用或开发 API,或两者兼而有之。因此,重要的是您不仅要知道如何编写,还要知道如何阅读 API 文档和测试。
什么是 API 文档?您还可以将 API 文档视为两方之间的服务协议。该文档概述了当第一方发送某种类型的请求时,第二方及其软件将如何响应。这些类型的请求(称为 API 调用)在文档中进行了描述,以便开发人员知道他们可以使用 API 做什么以及如何做。
好的 API 文档描述了它们的端点,解释了为什么应该使用它们,并提供了如何使用它们的非常具体的示例——所有这些都以对初学者和高级用户同样不言自明的方式进行。说明不清楚的 API 文档技术性太强,而且基于文本描述,因此并非所有用户都能正确使用。
下面,我们将通过七个步骤向您介绍如何编写好的 API 文档。

了解谁在使用您的 API
映射您的用户旅程
从一个基本的功能声明开始
添加代码示例
列出您的状态代码和错误消息
用白话编写和设计 API 文档
使 API 文档始终保持最新
1.了解谁在使用您的 API
与任何内容影响策略计划或 UI 设计过程一样,编写 API 文档的第一步是了解您的目标受众。这需要了解您的目标用户类型、您的内容需要为他们提供的有用价值以及它如何适应他们的实际场景。
在编写 API 文档时要记住两大类用户。一组用户是 API 文档的直接消费者,因此他们只需要查看教程和代码示例。该组主要是开发人员。另一组用户评估 API 功能、价格、速率限制、安全性等,以了解 API 如何与他们的业务需求和目标保持一致。该团队主要由 CTO 和产品经理以及一些开发人员组成。
您必须牢记这两个角色,以确保文档为每位读者提供良好的体验。
2.映射您的用户旅程
与任何产品一样,API 必须在买家旅程的每个阶段交付内容。这意味着文档应该解释 API 可以做什么(或解决),它提供的各种功能和端点,以及它与竞争对手的不同之处。
API 文档应该回答的一些基本问题是:
1.为什么要使用这个 API?
2.如何访问不同的工具和端点?
3.获得许可后的下一步是什么?
4.如何使用某些功能?
3.从一个基本的功能语句开始
每个 API 和功能都是独一无二的。例如,一些 API 可以将微博照片嵌入到电商平台的详情页中。一些 API 允许您通过 Bilibili Travel UP 大师访问数以千计的推荐酒店。网站 上甚至还有一个用于集成 Yoda 翻译器的 API。虽然每个 API 做的事情都不同,但每个 API 文档都应该涵盖一些基础知识。让我们看看下面的一些例子。
验证
由于认证对于保护 API 数据以及开发者和最终用户的数据安全非常重要,因此 API 通常有多种认证方案,因此 API 文档必须描述其每种认证方法,以便用户能够获得 Authorize 并正确使用 API。例如,YouTube 数据 API 支持两种类型的授权凭证。它的文档解释了如何使用 OAuth 2.0 以及如何获取 API 密钥,以便用户可以选择他们更熟悉的身份验证方法。
速率限制
与用户身份验证一样,速率限制有助于防止意外传输或 API 滥用。API 速率限制是您在给定时间内可以向 API 发送请求的次数。这些限制必须在 API 文档中明确说明,以便用户知道如何正确使用 API 及其功能。此信息最常在使用条款中找到。
使用条款
使用条款(或服务)是服务提供商与需要该服务的用户之间的法律协议。后者必须同意遵守这些条款才能使用服务。在 API 文档中,使用条款必须明确定义 API 使用者应如何理想地使用 API。这将有助于确保服务消费者充分利用 API 平台和功能。
内容变更日志
重要的是要让 API 使用者了解他们使用的 API 的任何减损。变更文档可以帮助他们正确维护应用程序并充分利用 API 平台的功能。案例:Twitter 的 API 文档收录对 Twitter 开发人员平台所做的所有更改的更改日志,包括新功能和产品。
4.添加代码示例
API 文档有两个主要目标:让开发人员尽可能轻松地使用 API,并让他们快速了解 API 的全部功能。实现这两个目标的一个好方法是为每个 API 端点提供代码示例。这样开发者就可以了解端点最关键的功能,从一些案例代码入手,然后直接在案例代码上调整参数,满足自己的实际需求和对接规范。
5.列出您的状态代码和错误消息
API 文档应清楚地概述用户在进行 API 调用时可能期望的状态代码和错误消息。理想情况下,每个响应都应附有简短描述,以便用户了解 API 何时成功调用、何时不成功,并能够解决他们遇到的任何错误。通常,此信息放置在其自己的页面上。这是 express 100API 文档中的一个示例。
6.用白话编写和设计 API 文档
如果您想以易于用户阅读和浏览的方式编写、构建和设计 API 文档。这意味着根据用户的使用场景和他们的需求来呈现和组织文档的内容信息。用户的使用场景是关于用户在何处、何时、为什么以及如何找到内容并与内容交互的一切。他们的需求还包括他们的目标、行为和期望。
最好的 API 文档是为完全不熟悉 API 的初学者和非常熟悉它的开发人员编写的。本文档需要尽可能避免过多的技术术语,并尽可能提供额外的上下文信息或文档的内部链接。它还需要提供诸如“入门”之类的内容以及新手用户需要的示例和教程,但更高级的用户可以跳过。
为了确保用户可以选择他们想要的东西,API 文档必须以导航的方式设计。最佳实践是使用页眉和侧边栏,以便用户无需上下滚动页面即可导航到文档的另一部分并提供搜索功能。其他设计考虑因素包括排版、配色方案和布局。三列布局被认为是收录大量代码示例的文档的理想选择。无衬线字体和对比色链接也是不错的设计选择。
7.使 API 文档保持最新
为了确保 API 消费者获得最佳体验并不断吸引新用户,API 提供者必须不时维护自己的 API 文档。过去,API 文档以 PDF 或静态网页的形式存在,导致文档更新困难。现在,有一些工具可以帮助您创建自动更新的动态和交互式文档。Redocly 和 SwaggerUI 是两个更常见的实际示例。
如何阅读 API 文档
如果你只是一个 API 消费者,而不是 API 服务提供者,那么你需要知道如何阅读 API 文档。尽管编写和阅读它的方法是相似的(寻找理由、尝试代码示例等),但它们并不完全相同。让我们仔细看看如何阅读 API 文档以了解特定 API 的可能性。
从文档概述开始
大多数 API 文档都会首先概述 API 的功能、如何连接它以及如何正确使用它。当然,您不需要了解概述的每个细节,但您应该大致了解它。
以Express 100的API文档为例,首先,Express 100的API文档解释了Express 100的API使用,使用的协议和语言,以及其认证方案。在左侧边栏的快速链接部分,您将找到指向其使用指南和速率限制、测试帐户、更改日志以及开始使用 API 所需的所有其他内容的重要链接。
了解有关功能的更多信息
了解 API 概览后,请浏览 API 参考文档,其中列出了 API 的所有函数(也称为方法)。在这一点上,没有必要彻底阅读或记住所有内容。相反,请仔细查看您特别感兴趣的函数。通过查看它的参数和示例,您可以了解是否可以成功使用 API 来完成您想做的确切事情。
例如,假设您想通过快递100的API实现如下物流查询功能: - 在电商网页/APP/小程序中,客户可以在订单详情中查看所购买产品的物流地图轨迹,向客户展示物流轨迹的文字信息
在此需求的驱动下,您可以导航到“接口文档”并查看其代码语言、参数、响应、错误消息等。
通读 API 文档教程
既然您知道是否可以使用 API 来实现您想要的,请查看教程。由于最好的 API 文档应该可以帮助用户快速入门,因此大多数文档将收录完成工作的详细教程。您应该至少通读一个教程,以了解需要仔细研究的详细程度和示例。想了解电商快递物流API的好处,这里有一篇文章文章《什么是电商API?这是它能给商家带来的12个运营好处》,里面介绍了它们的优势以及详细的缺点。如果你有兴趣,可以阅读它们,说不定你会发现意想不到的惊喜。
记录 API 信息变更
随着越来越多的公司提供 API 服务以形成高度集成的用户体验,了解如何编写和阅读 API 文档变得越来越有价值。在创建或评估 API 文档时,请确保您的 API 稳定且易于阅读和导航,并向开发人员和非开发人员清楚地传达您的 API 的价值。这确保技术用户可以快速正确地开始使用您的 API,并且同事确保他们可以与其他非技术同事一起使用它。
文章采集api(找到织梦后台目录下的文件/article_add.php)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-03-31 20:15
如果每次添加文章都得去百度站长平台手动提交收录资源,太麻烦了,
今天我们来一招dedecms5.7在文章发布时自动提交普通收录到百度API。
在织梦后台目录下找到文件dede/article_add.php(如果你改变了后台目录,请以实际路径为准)
找到以下代码(约 274 行):
已发布文章管理
$backurl
";
在下面添加:
//百度实时推送开始
$urls = array(
'https://www.nuegame.com'.$artUrl,
);
$api = 'http://data.zz.baidu.com/urls% ... 3B%3B
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => implode("\n", $urls),
CURLOPT_HTTPHEADER => array('Content-Type: text/plain'),
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
echo $result;
echo "提交到百度站长平台的URL地址".$urls[0];//百度实时推送结束
改成自己网站的地址,还有token,可以从百度站长平台获取。
保存文件并再次上传。
试试看添加文章时是否自动提交。当天的提交记录可在第三天后查看。 查看全部
文章采集api(找到织梦后台目录下的文件/article_add.php)
如果每次添加文章都得去百度站长平台手动提交收录资源,太麻烦了,
今天我们来一招dedecms5.7在文章发布时自动提交普通收录到百度API。
在织梦后台目录下找到文件dede/article_add.php(如果你改变了后台目录,请以实际路径为准)
找到以下代码(约 274 行):
已发布文章管理
$backurl
";
在下面添加:
//百度实时推送开始
$urls = array(
'https://www.nuegame.com'.$artUrl,
);
$api = 'http://data.zz.baidu.com/urls% ... 3B%3B
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => implode("\n", $urls),
CURLOPT_HTTPHEADER => array('Content-Type: text/plain'),
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
echo $result;
echo "提交到百度站长平台的URL地址".$urls[0];//百度实时推送结束
改成自己网站的地址,还有token,可以从百度站长平台获取。
保存文件并再次上传。
试试看添加文章时是否自动提交。当天的提交记录可在第三天后查看。
文章采集api(新建一个PHP文件请求API地址返回JSON格式的数据列表)
采集交流 • 优采云 发表了文章 • 0 个评论 • 406 次浏览 • 2022-03-31 20:14
大多数博客系统都是使用WordPress搭建的,而作为博客系统,我们可能需要在站外调用博客的文章,请求这个API接口,获取最新的文章列表,通常的做法就是就是新建一个PHP文件,接收几个参数,查询数据库,返回JSON格式的数据。
WordPress 插件非常强大,几乎可以完成我们需要的所有工作。有一个叫JSON API的插件,可以使用WordPress作为API接口,调用站点外的文章博客列表。
一个叫JSON API的WordPress插件正是我想要的,而且更全面,它可以返回最新的文章、类别、作者、文章详细信息,也就是说WordPress中几乎所有的东西都可以用它来获取JSON格式的数据,甚至可以通过传递JSON数据实现文章评论和用户注册。
有了这样的插件,关键是要有这样的API接口,不用费力就可以自己写API,但它有什么用呢?
比如我想做一个微信公众号,用户输入1,返回最新的文章列表,根据用户的输入返回不同的内容,这就需要请求API地址返回JSON格式的数据.
插件安装地址:
安装后使用方法如下(本文只介绍几种常用的,其他请参考插件文档):
隐式调用显示调用链友好调用
API返回的json数据如下:
{"id":1,
"slug":"hell-world",
"url":"http://localhost/wordpress/?p=1",
"title":"Hello world",
"title_plain":"Hello world!",
"content":"<p>Welcome to wordpress. this is your first post",
"date":"2015-06-12 12:25:36",
"modified":"2015-06-12 12:25:36",
"categories":[],
"tags":[]
}
如您所见,要返回的内容太多了,也许我们只需要最新列表中的标题和链接。
有很多参数可以选择,比如count就是返回文章的个数,请参考官方文档。
本文由作者提出问题发表,并由问题编辑。请注明出处和本文的链接。
除非另有说明,本网站上的 文章 是 原创 或翻译。欢迎任何形式的转载,但请务必注明出处,尊重他人的劳动。 查看全部
文章采集api(新建一个PHP文件请求API地址返回JSON格式的数据列表)
大多数博客系统都是使用WordPress搭建的,而作为博客系统,我们可能需要在站外调用博客的文章,请求这个API接口,获取最新的文章列表,通常的做法就是就是新建一个PHP文件,接收几个参数,查询数据库,返回JSON格式的数据。
WordPress 插件非常强大,几乎可以完成我们需要的所有工作。有一个叫JSON API的插件,可以使用WordPress作为API接口,调用站点外的文章博客列表。
一个叫JSON API的WordPress插件正是我想要的,而且更全面,它可以返回最新的文章、类别、作者、文章详细信息,也就是说WordPress中几乎所有的东西都可以用它来获取JSON格式的数据,甚至可以通过传递JSON数据实现文章评论和用户注册。
有了这样的插件,关键是要有这样的API接口,不用费力就可以自己写API,但它有什么用呢?
比如我想做一个微信公众号,用户输入1,返回最新的文章列表,根据用户的输入返回不同的内容,这就需要请求API地址返回JSON格式的数据.
插件安装地址:
安装后使用方法如下(本文只介绍几种常用的,其他请参考插件文档):
隐式调用显示调用链友好调用
API返回的json数据如下:
{"id":1,
"slug":"hell-world",
"url":"http://localhost/wordpress/?p=1",
"title":"Hello world",
"title_plain":"Hello world!",
"content":"<p>Welcome to wordpress. this is your first post",
"date":"2015-06-12 12:25:36",
"modified":"2015-06-12 12:25:36",
"categories":[],
"tags":[]
}
如您所见,要返回的内容太多了,也许我们只需要最新列表中的标题和链接。
有很多参数可以选择,比如count就是返回文章的个数,请参考官方文档。
本文由作者提出问题发表,并由问题编辑。请注明出处和本文的链接。
除非另有说明,本网站上的 文章 是 原创 或翻译。欢迎任何形式的转载,但请务必注明出处,尊重他人的劳动。
文章采集api(4.1API通用规则API用一套非常标准的规则生成数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-03-31 04:17
一般情况下,程序员可以使用HTPP协议向API发起请求,获取一定的信息,API会以XML或JSON格式返回服务器响应信息。
使用 API 通常不被视为网络数据采集,但实际上使用的许多技术(都发送 HTTP 请求)和结果(都获取信息)是相似的;两者经常有重叠的相容关系。
例如,结合 Wikipedia 编辑历史记录(其中收录编辑者的 IP 地址)和 IP 地址解析 API 以获取 Wikipedia 条目的编辑者的地理位置。
4.1 API 概述
谷歌 API
4.2 API 通用规则
API 使用一套非常标准的规则来生成数据,并且生成的数据以非常标准的方式组织。
四种方式:GET、POST、PUT、DELETE
验证:需要客户端验证
4.3 服务器响应
大多数反馈数据格式是 XML 和 JSON
过去,服务器端使用 PHP 和 .NET 等程序作为 API 的接收端。现在,服务器端也使用一些 JavaScript 框架作为 API 的发送和接收端,例如 Angular 或 Backbone。
接口调用:
4.4 回声巢穴
回声巢音乐资料网站
4.5 推特 API
点安装推特
from twitter import Twitter
t = Twitter(auth=OAuth(,,,))
pythonTweets = t.search.tweets(q = "#python")
print(pythonTweets)
鸣叫 4.6 个 Google API
无论您想使用哪种信息,包括语言翻译、地理位置、日历,甚至基因数据,Google 都提供 API。Google 还为其一些知名应用程序提供 API,例如 Gmail、YouTube 和 Blogger。
4.7 解析 JSON 数据
import json
from urllib.request import urlopen
def getCountry(ipAddress):
response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
responseJson = json.loads(response)
return responseJson.get("country_code")
print(getCountry("50.78.253.58"))
4.8 返回主题
将多个数据源组合成新的形式,或者使用 API 作为工具从新的角度解释数据采集。
先做一个采集维基百科的基础程序,找到编辑历史页面,然后在编辑历史中找出IP地址
# -*- coding: utf-8 -*-
from urllib.request import urlopen
from bs4 import BeautifulSoup
import datetime
import random
import re
import json
random.seed(datetime.datetime.now())
# https://en.wikipedia.org/wiki/Python_(programming_language)
def getLinks(articleUrl):
html = urlopen("http://en.wikipedia.org"+articleUrl)
bsObj = BeautifulSoup(html)
return bsObj.find("div",{"id":"bodyContent"}).findAll("a", href=re.compile("^(/wiki/)((?!:).)*$"))
def getHistoryIPs(pageUrl):
# 编辑历史页面URL链接格式是:
# https://en.wikipedia.org/w/index.php?title=Python_(programming_language)&action=history
pageUrl = pageUrl.replace("/wiki/", "")
historyUrl = "https://en.wikipedia.org/w/ind ... ot%3B
print("history url is: "+historyUrl)
html = urlopen(historyUrl)
bsObj = BeautifulSoup(html)
# 找出class属性是"mw-anonuserlink"的链接
# 它们用IP地址代替用户名
ipAddresses = bsObj.findAll("a", {"class":"mw-anonuserlink"})
addressList = set()
for ipAddress in ipAddresses:
addressList.add(ipAddress.get_text())
return addressList
links = getLinks("/wiki/Python_(programming_language)")
def getCountry(ipAddress):
try:
response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
except HTTPError:
return None
responseJson = json.loads(response)
return responseJson.get("country_code")
while (len(links) > 0):
for link in links:
print("-------------------")
historyIPs = getHistoryIPs(link.attrs["href"])
for historyIP in historyIPs:
#print(historyIP)
country = getCountry(historyIP)
if country is not None:
print(historyIP+" is from "+country)
newLink = links[random.randint(0, len(links)-1)].attrs["href"]
links = getLinks(newLink)
4.9 更多 API
Leonard Richardson、Mike Amundsen 和 Sam Ruby 的 RESTful Web APIs ( ) 为使用 Web APIs 提供了非常全面的理论和实践指南。此外,Mike Amundsen 的精彩视频教程 Designing APIs for the Web() 教您如何创建自己的 API。如果您想以方便的方式分享您的 采集 数据,他的视频非常有用 查看全部
文章采集api(4.1API通用规则API用一套非常标准的规则生成数据)
一般情况下,程序员可以使用HTPP协议向API发起请求,获取一定的信息,API会以XML或JSON格式返回服务器响应信息。
使用 API 通常不被视为网络数据采集,但实际上使用的许多技术(都发送 HTTP 请求)和结果(都获取信息)是相似的;两者经常有重叠的相容关系。
例如,结合 Wikipedia 编辑历史记录(其中收录编辑者的 IP 地址)和 IP 地址解析 API 以获取 Wikipedia 条目的编辑者的地理位置。
4.1 API 概述
谷歌 API
4.2 API 通用规则
API 使用一套非常标准的规则来生成数据,并且生成的数据以非常标准的方式组织。
四种方式:GET、POST、PUT、DELETE
验证:需要客户端验证
4.3 服务器响应
大多数反馈数据格式是 XML 和 JSON
过去,服务器端使用 PHP 和 .NET 等程序作为 API 的接收端。现在,服务器端也使用一些 JavaScript 框架作为 API 的发送和接收端,例如 Angular 或 Backbone。
接口调用:
4.4 回声巢穴
回声巢音乐资料网站
4.5 推特 API
点安装推特
from twitter import Twitter
t = Twitter(auth=OAuth(,,,))
pythonTweets = t.search.tweets(q = "#python")
print(pythonTweets)
鸣叫 4.6 个 Google API
无论您想使用哪种信息,包括语言翻译、地理位置、日历,甚至基因数据,Google 都提供 API。Google 还为其一些知名应用程序提供 API,例如 Gmail、YouTube 和 Blogger。
4.7 解析 JSON 数据
import json
from urllib.request import urlopen
def getCountry(ipAddress):
response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
responseJson = json.loads(response)
return responseJson.get("country_code")
print(getCountry("50.78.253.58"))
4.8 返回主题
将多个数据源组合成新的形式,或者使用 API 作为工具从新的角度解释数据采集。
先做一个采集维基百科的基础程序,找到编辑历史页面,然后在编辑历史中找出IP地址
# -*- coding: utf-8 -*-
from urllib.request import urlopen
from bs4 import BeautifulSoup
import datetime
import random
import re
import json
random.seed(datetime.datetime.now())
# https://en.wikipedia.org/wiki/Python_(programming_language)
def getLinks(articleUrl):
html = urlopen("http://en.wikipedia.org"+articleUrl)
bsObj = BeautifulSoup(html)
return bsObj.find("div",{"id":"bodyContent"}).findAll("a", href=re.compile("^(/wiki/)((?!:).)*$"))
def getHistoryIPs(pageUrl):
# 编辑历史页面URL链接格式是:
# https://en.wikipedia.org/w/index.php?title=Python_(programming_language)&action=history
pageUrl = pageUrl.replace("/wiki/", "")
historyUrl = "https://en.wikipedia.org/w/ind ... ot%3B
print("history url is: "+historyUrl)
html = urlopen(historyUrl)
bsObj = BeautifulSoup(html)
# 找出class属性是"mw-anonuserlink"的链接
# 它们用IP地址代替用户名
ipAddresses = bsObj.findAll("a", {"class":"mw-anonuserlink"})
addressList = set()
for ipAddress in ipAddresses:
addressList.add(ipAddress.get_text())
return addressList
links = getLinks("/wiki/Python_(programming_language)")
def getCountry(ipAddress):
try:
response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
except HTTPError:
return None
responseJson = json.loads(response)
return responseJson.get("country_code")
while (len(links) > 0):
for link in links:
print("-------------------")
historyIPs = getHistoryIPs(link.attrs["href"])
for historyIP in historyIPs:
#print(historyIP)
country = getCountry(historyIP)
if country is not None:
print(historyIP+" is from "+country)
newLink = links[random.randint(0, len(links)-1)].attrs["href"]
links = getLinks(newLink)
4.9 更多 API
Leonard Richardson、Mike Amundsen 和 Sam Ruby 的 RESTful Web APIs ( ) 为使用 Web APIs 提供了非常全面的理论和实践指南。此外,Mike Amundsen 的精彩视频教程 Designing APIs for the Web() 教您如何创建自己的 API。如果您想以方便的方式分享您的 采集 数据,他的视频非常有用
文章采集api(wellCMS前端基于BootStrap4.5、JQuery3.5.1的前端类库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-03-22 02:39
那么cms 是一个拥有大量数据的分布式架构。通过低成本解决网站负载和性能问题,cms可以实现高负载、高性能、高安全。Wellcms是一个亿级负载、开源、面向移动、轻量级、超快速响应能力的高负载cms。是大数据量和高并发访问的选择网站轻cms。wellcms是诞生于大数据时代的cms,wellcms是专为大数据量站点设计的高性能、高负载cms。
嗯cms前后台都可以在移动端操作,适配手机、平板、PC。还可以设置每个终端加载单独的模板,URL不变,插件机制非常方便。嗯cms首页自带API,可以通过JSON返回AJAX请求的数据,做APP和小程序无压力。采用静态语言编程风格,充分发挥PHP8 OPCache的威力。嗯cms前端是基于BootStrap4.5、JQuery3.5.1作为前端类库的,对第三方的依赖少-party 类库。后端基于PHP8数据库MySQL或MariaDB,缓存支持XCache、Yac、Redis、Memcached。
wellcms的架构是函数式MVC分层架构,AOP插件机制,分布式服务器设计,每张表可以创建单独的DB服务器组和Cache服务器组,方便部署和维护。cms安全性,参数类型严格过滤,SQL拼接严格转义,上传严格过滤,前后端权限分配,不用担心Webshell、SQL注入、XSS等问题。
不错的cms性能,1核/1G内存/SSD硬盘/OPcache/Yac,PHP8,MYSQL5.5可以承载1亿多数据,流畅打开每个页面,页面执行时间可以达到 0.00x 秒。好吧cms加载,从数据表设计、业务层排序,到代码实现,都是为了消耗硬件计算性能,在有限的环境下最大限度的发挥性能,在海量数据下更加突出。
wellcms的扩展使用hook插入,覆盖覆盖,零性能损失,强大简单,不影响编译。插件和模板完全分离,模板可以自由开发、安装和卸载。不错cms SEO优化,网站布局符合SEO标准,对搜索引擎友好,内置搜索引擎推送插件,实时蜘蛛抓取。URL短小精悍,模板适配PC手机。整个站点链接完整,SEO优化效果翻倍
wellcms支持多语言翻译自动转换,wellcms可以简繁英文转换,模板绑定,可以压缩全站代码,可以返回JSON数据,支持SSL , CDN, 最大支持 42 亿数据量。
wellcms的分离,除了php和htm文件外,整个站点的附件和文件都可以分离到云存储;多个DB主从读写分离,设置主从配置,自动读写分离,无需修改程序。而且cms是开源的,在MIT协议下发布,主程序开源免费,可以自由修改、商业化、衍生版本,不用担心任何风险,但必须提供原文件版权信息修改后保留。
嗯cms是基于XiunoPHP开发的,只有22张表,运行速度非常快,处理单个请求0.01秒级别,使缓存达到0.@级别>003 秒。wellcms支持多终端绑定模板,支持独立section绑定模板,支持前后端代码压缩,支持免登录存储,支持3种伪静态,支持数据库类型pdo_mysql和mysql ,支持数据库引擎MyISAM和InnoDB,支持SSL,支持CDN,支持各种NoSQL操作,支持附件分离,支持多DB主从读写分离。那么cms的分布式服务器设计,每张表可以创建单独的DB服务器组和CACHE服务器(组),单张表可承载亿级以上数据,方便部署和维护。它是二次开发非常好的基石。 查看全部
文章采集api(wellCMS前端基于BootStrap4.5、JQuery3.5.1的前端类库)
那么cms 是一个拥有大量数据的分布式架构。通过低成本解决网站负载和性能问题,cms可以实现高负载、高性能、高安全。Wellcms是一个亿级负载、开源、面向移动、轻量级、超快速响应能力的高负载cms。是大数据量和高并发访问的选择网站轻cms。wellcms是诞生于大数据时代的cms,wellcms是专为大数据量站点设计的高性能、高负载cms。
嗯cms前后台都可以在移动端操作,适配手机、平板、PC。还可以设置每个终端加载单独的模板,URL不变,插件机制非常方便。嗯cms首页自带API,可以通过JSON返回AJAX请求的数据,做APP和小程序无压力。采用静态语言编程风格,充分发挥PHP8 OPCache的威力。嗯cms前端是基于BootStrap4.5、JQuery3.5.1作为前端类库的,对第三方的依赖少-party 类库。后端基于PHP8数据库MySQL或MariaDB,缓存支持XCache、Yac、Redis、Memcached。
wellcms的架构是函数式MVC分层架构,AOP插件机制,分布式服务器设计,每张表可以创建单独的DB服务器组和Cache服务器组,方便部署和维护。cms安全性,参数类型严格过滤,SQL拼接严格转义,上传严格过滤,前后端权限分配,不用担心Webshell、SQL注入、XSS等问题。
不错的cms性能,1核/1G内存/SSD硬盘/OPcache/Yac,PHP8,MYSQL5.5可以承载1亿多数据,流畅打开每个页面,页面执行时间可以达到 0.00x 秒。好吧cms加载,从数据表设计、业务层排序,到代码实现,都是为了消耗硬件计算性能,在有限的环境下最大限度的发挥性能,在海量数据下更加突出。
wellcms的扩展使用hook插入,覆盖覆盖,零性能损失,强大简单,不影响编译。插件和模板完全分离,模板可以自由开发、安装和卸载。不错cms SEO优化,网站布局符合SEO标准,对搜索引擎友好,内置搜索引擎推送插件,实时蜘蛛抓取。URL短小精悍,模板适配PC手机。整个站点链接完整,SEO优化效果翻倍
wellcms支持多语言翻译自动转换,wellcms可以简繁英文转换,模板绑定,可以压缩全站代码,可以返回JSON数据,支持SSL , CDN, 最大支持 42 亿数据量。
wellcms的分离,除了php和htm文件外,整个站点的附件和文件都可以分离到云存储;多个DB主从读写分离,设置主从配置,自动读写分离,无需修改程序。而且cms是开源的,在MIT协议下发布,主程序开源免费,可以自由修改、商业化、衍生版本,不用担心任何风险,但必须提供原文件版权信息修改后保留。
嗯cms是基于XiunoPHP开发的,只有22张表,运行速度非常快,处理单个请求0.01秒级别,使缓存达到0.@级别>003 秒。wellcms支持多终端绑定模板,支持独立section绑定模板,支持前后端代码压缩,支持免登录存储,支持3种伪静态,支持数据库类型pdo_mysql和mysql ,支持数据库引擎MyISAM和InnoDB,支持SSL,支持CDN,支持各种NoSQL操作,支持附件分离,支持多DB主从读写分离。那么cms的分布式服务器设计,每张表可以创建单独的DB服务器组和CACHE服务器(组),单张表可承载亿级以上数据,方便部署和维护。它是二次开发非常好的基石。
文章采集api(数据埋点采集到底都是哪些事?(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2022-03-22 02:35
数据采集是数据分析的基础,跟踪是最重要的采集方法。那么数据埋点采集究竟是什么?我们主要从三个方面来看:什么是埋点,埋点如何设计,埋点的应用。
一、数据采集 和常见数据问题
1.数据采集
任何事情都必须有目的和目标,数据分析也不例外。在进行数据分析之前,我们需要思考为什么需要进行数据分析?您希望通过此次数据分析为您的业务解决哪些问题?
数据采集的方式有很多种,埋点采集是其中非常重要的一环。它是c端和b端产品的主要采集方式。Data采集 顾名思义就是采集对应的数据,是整个数据流的起点。采集的不完整性,对错,直接决定了数据的广度和质量,影响到后续的所有环节。在数据采集有效性和完整性较差的公司中,企业经常会发现数据发生了重大变化。
数据的处理通常包括以下5个步骤:
2.常见数据问题
在大致了解了data采集及其结构之后,我们再来看看工作中遇到的问题,有多少与data采集链接有关:
(1)数据与背景差距较大,数据不准确——统计口径不同,埋点定义不同,采集方法带来误差;
(2)想用的时候没有我要的数据——没提数据采集要求,埋点不正确,不全;
(3)事件太多,意思不清楚——埋点设计的方式,埋点更新迭代的规则和维护;
(4)分析数据的时候不知道要看哪些数据和指标——数据的定义不明确,缺乏分析思路
我们需要根本原因解决方案:将 采集 视为独立的研发业务,而不是产品开发的附属品。
二、埋葬点是什么?
1.葬礼是什么?
所谓埋点,是data采集领域的一个名词。它的学名应该叫事件追踪,对应的英文是Event Tracking,是指捕获、处理和发送特定用户行为或事件的相关技术和实现过程。
数据埋点是数据分析师、数据产品经理和数据运营商,他们根据业务需求或产品需求,针对用户行为对应的每个事件开发埋点,并通过SDK上报埋点数据结果,并记录汇总数据。分析、推动产品优化和指导运营。
该过程伴随着规范。通过定义可以看出,具体的用户行为和事件是我们采集关注的焦点,需要处理和发送相关的技术和实现流程;数据嵌入是为产品服务的,来源于产品。,所以和产品息息相关,重点在于具体的实战过程,这关系到大家对底层数据的理解。
2.你为什么要埋葬
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的质量直接影响数据质量、产品质量和运营质量。
(1)数据驱动-埋点将分析深度下钻到流量分布和流量层面,通过统计分析,对宏观指标进行深入分析,发现指标背后的问题,洞察用户行为与价值提升的关系 潜在关联
(2)产品优化——对于产品来说,用户在产品中做什么,在产品中停留的时间,有哪些异常需要注意。这些问题可以通过埋点来实现。
(3)精细化运营——买点可以实现产品全生命周期、不同来源的流量质量和分布、人群的行为特征和关系,洞察用户行为与商业价值提升的潜在关系。
3.如何埋点
埋点方法有哪些?大多数公司目前使用客户端和服务器的组合。
准确度:代码掩埋 > 视觉掩埋 > 完全掩埋
三、埋点架构与设计
1.埋点采集的顶层设计
所谓顶层设计,就是想清楚怎么埋点,用什么方式埋点,上传机制是什么,怎么定义,怎么实现等等;我们遵循唯一性、可扩展性、一致性等,需要设计一些常用的字段和生成机制,比如:cid、idfa、idfv等。
用户识别:用户识别机制的混乱会导致两个结果:一是数据不准确,比如UV数据不匹配;二是漏斗分析过程出现异常。因此,应该这样做:严格规范ID自身的识别机制;湾。跨平台用户识别。
同构抽象:同构抽象包括事件抽象和属性抽象。事件抽象是浏览事件和点击事件的聚合;属性抽象是大多数重用场景的组合,以增加源差异化。
采集一致:采集一致包括两点:一是跨平台页面的命名一致,二是按钮命名一致;制定埋点的过程本身就是对底层数据进行标准化的过程,所以一致性尤为重要,只有这样才能真正使用它。
渠道配置:渠道主要指推广渠道、落地页、网页推广页、APP推广页等,这个落地页的配置必须有统一的规范和标准
2.埋点采集活动与物业设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变化的,哪些是业务行为,哪些是基本属性。基于基本的属性事件,我们认为属性一定是采集项,但是属性中的事件属性会根据不同的业务进行调整。因此,我们可以将埋点采集分为协议层和业务层Bury。
业务分解:梳理确认业务流程、操作路径和不同的细分场景,定义用户行为路径
分析指标:定义特定事件和核心业务指标所需的数据
事件设计:APP启动、退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.数据采集事件和属性设计
Ev 事件的命名也遵循一些规则。当相同类型的函数出现在不同的页面或位置时,根据函数名进行命名,并在ev参数中区分页面和位置。只有当按钮被点击时,它才会以按钮名称命名。
ev事件格式:ev分为ev标志和ev参数
规则:
在 ev 标识符和 ev 参数之间使用“#”(一级连接符)
在 ev 参数和 ev 参数之间使用“/”(辅助连接器)
ev参数使用key=value的结构。当一个key对应多个value值时,value1和value2之间用“,”连接(三级连接符)
当埋点只有ev标志而没有ev参数时,不需要#。
评论:
ev identifier:作为埋点的唯一标识符,用来区分埋点的位置和属性。它是不可变的和不可修改的。
ev参数:埋点需要返回的参数,ev参数的顺序是可变的,可以修改)
调整app埋点时,ev logo不变,只修改以下埋点参数(参数值改变或参数类型增加)
一般埋点文档中收录的工作表名称和功能:
A. 暴露埋点汇总;
B、点击浏览埋点汇总;
C、故障埋点汇总:一般会记录埋点的故障版本或时间;
D、PC和M侧页面埋点对应的pageid;
E、各版本上线时间记录;
在埋点文档中,都收录了列名和函数:
4.基于埋点的数据统计
如何使用埋点统计找到埋藏的 ev 事件:
(1)明确埋点类型(点击/曝光/浏览)——过滤类型字段
(2)明确按钮嵌入所属的页面(页面或功能)-过滤功能模块字段
(3)指定跟踪事件的名称-过滤名称字段
(4)知道ev标志的可以直接用ev过滤
如何根据ev事件进行查询统计:当点击查询按钮进行统计时,可以直接使用ev标志进行查询。因为ev参数的顺序不要求是可变的,所以查询统计信息时不能限制参数的顺序。
四、应用——数据流的基础
1.指标系统
系统化的指标可以整合不同的指标、不同的维度进行综合分析,可以更快的发现当前产品和业务流程中存在的问题。
2.可视化
人类解释图像信息比文本更有效。可视化对于数据分析非常重要。使用数据可视化可以揭示数据中固有的复杂关系。
3.提供埋点元信息API
data采集服务会将采集收到的埋点写入Kafka。针对各个业务的实时数据消费需求,我们为各个业务提供单独的Kafka,流量分发模块会定时读取。取埋点管理平台提供的元信息,将流量实时分发到各个业务的Kafka。
Data采集 就像设计产品一样,不能过头。不仅要留有扩展的空间,还要时刻考虑有没有数据,是否完整,是否稳定,是否快。 查看全部
文章采集api(数据埋点采集到底都是哪些事?(一))
数据采集是数据分析的基础,跟踪是最重要的采集方法。那么数据埋点采集究竟是什么?我们主要从三个方面来看:什么是埋点,埋点如何设计,埋点的应用。
一、数据采集 和常见数据问题
1.数据采集
任何事情都必须有目的和目标,数据分析也不例外。在进行数据分析之前,我们需要思考为什么需要进行数据分析?您希望通过此次数据分析为您的业务解决哪些问题?
数据采集的方式有很多种,埋点采集是其中非常重要的一环。它是c端和b端产品的主要采集方式。Data采集 顾名思义就是采集对应的数据,是整个数据流的起点。采集的不完整性,对错,直接决定了数据的广度和质量,影响到后续的所有环节。在数据采集有效性和完整性较差的公司中,企业经常会发现数据发生了重大变化。
数据的处理通常包括以下5个步骤:
2.常见数据问题
在大致了解了data采集及其结构之后,我们再来看看工作中遇到的问题,有多少与data采集链接有关:
(1)数据与背景差距较大,数据不准确——统计口径不同,埋点定义不同,采集方法带来误差;
(2)想用的时候没有我要的数据——没提数据采集要求,埋点不正确,不全;
(3)事件太多,意思不清楚——埋点设计的方式,埋点更新迭代的规则和维护;
(4)分析数据的时候不知道要看哪些数据和指标——数据的定义不明确,缺乏分析思路
我们需要根本原因解决方案:将 采集 视为独立的研发业务,而不是产品开发的附属品。
二、埋葬点是什么?
1.葬礼是什么?
所谓埋点,是data采集领域的一个名词。它的学名应该叫事件追踪,对应的英文是Event Tracking,是指捕获、处理和发送特定用户行为或事件的相关技术和实现过程。
数据埋点是数据分析师、数据产品经理和数据运营商,他们根据业务需求或产品需求,针对用户行为对应的每个事件开发埋点,并通过SDK上报埋点数据结果,并记录汇总数据。分析、推动产品优化和指导运营。
该过程伴随着规范。通过定义可以看出,具体的用户行为和事件是我们采集关注的焦点,需要处理和发送相关的技术和实现流程;数据嵌入是为产品服务的,来源于产品。,所以和产品息息相关,重点在于具体的实战过程,这关系到大家对底层数据的理解。
2.你为什么要埋葬
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的质量直接影响数据质量、产品质量和运营质量。
(1)数据驱动-埋点将分析深度下钻到流量分布和流量层面,通过统计分析,对宏观指标进行深入分析,发现指标背后的问题,洞察用户行为与价值提升的关系 潜在关联
(2)产品优化——对于产品来说,用户在产品中做什么,在产品中停留的时间,有哪些异常需要注意。这些问题可以通过埋点来实现。
(3)精细化运营——买点可以实现产品全生命周期、不同来源的流量质量和分布、人群的行为特征和关系,洞察用户行为与商业价值提升的潜在关系。
3.如何埋点
埋点方法有哪些?大多数公司目前使用客户端和服务器的组合。
准确度:代码掩埋 > 视觉掩埋 > 完全掩埋
三、埋点架构与设计
1.埋点采集的顶层设计
所谓顶层设计,就是想清楚怎么埋点,用什么方式埋点,上传机制是什么,怎么定义,怎么实现等等;我们遵循唯一性、可扩展性、一致性等,需要设计一些常用的字段和生成机制,比如:cid、idfa、idfv等。
用户识别:用户识别机制的混乱会导致两个结果:一是数据不准确,比如UV数据不匹配;二是漏斗分析过程出现异常。因此,应该这样做:严格规范ID自身的识别机制;湾。跨平台用户识别。
同构抽象:同构抽象包括事件抽象和属性抽象。事件抽象是浏览事件和点击事件的聚合;属性抽象是大多数重用场景的组合,以增加源差异化。
采集一致:采集一致包括两点:一是跨平台页面的命名一致,二是按钮命名一致;制定埋点的过程本身就是对底层数据进行标准化的过程,所以一致性尤为重要,只有这样才能真正使用它。
渠道配置:渠道主要指推广渠道、落地页、网页推广页、APP推广页等,这个落地页的配置必须有统一的规范和标准
2.埋点采集活动与物业设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变化的,哪些是业务行为,哪些是基本属性。基于基本的属性事件,我们认为属性一定是采集项,但是属性中的事件属性会根据不同的业务进行调整。因此,我们可以将埋点采集分为协议层和业务层Bury。
业务分解:梳理确认业务流程、操作路径和不同的细分场景,定义用户行为路径
分析指标:定义特定事件和核心业务指标所需的数据
事件设计:APP启动、退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.数据采集事件和属性设计
Ev 事件的命名也遵循一些规则。当相同类型的函数出现在不同的页面或位置时,根据函数名进行命名,并在ev参数中区分页面和位置。只有当按钮被点击时,它才会以按钮名称命名。
ev事件格式:ev分为ev标志和ev参数
规则:
在 ev 标识符和 ev 参数之间使用“#”(一级连接符)
在 ev 参数和 ev 参数之间使用“/”(辅助连接器)
ev参数使用key=value的结构。当一个key对应多个value值时,value1和value2之间用“,”连接(三级连接符)
当埋点只有ev标志而没有ev参数时,不需要#。
评论:
ev identifier:作为埋点的唯一标识符,用来区分埋点的位置和属性。它是不可变的和不可修改的。
ev参数:埋点需要返回的参数,ev参数的顺序是可变的,可以修改)
调整app埋点时,ev logo不变,只修改以下埋点参数(参数值改变或参数类型增加)
一般埋点文档中收录的工作表名称和功能:
A. 暴露埋点汇总;
B、点击浏览埋点汇总;
C、故障埋点汇总:一般会记录埋点的故障版本或时间;
D、PC和M侧页面埋点对应的pageid;
E、各版本上线时间记录;
在埋点文档中,都收录了列名和函数:
4.基于埋点的数据统计
如何使用埋点统计找到埋藏的 ev 事件:
(1)明确埋点类型(点击/曝光/浏览)——过滤类型字段
(2)明确按钮嵌入所属的页面(页面或功能)-过滤功能模块字段
(3)指定跟踪事件的名称-过滤名称字段
(4)知道ev标志的可以直接用ev过滤
如何根据ev事件进行查询统计:当点击查询按钮进行统计时,可以直接使用ev标志进行查询。因为ev参数的顺序不要求是可变的,所以查询统计信息时不能限制参数的顺序。
四、应用——数据流的基础
1.指标系统
系统化的指标可以整合不同的指标、不同的维度进行综合分析,可以更快的发现当前产品和业务流程中存在的问题。
2.可视化
人类解释图像信息比文本更有效。可视化对于数据分析非常重要。使用数据可视化可以揭示数据中固有的复杂关系。
3.提供埋点元信息API
data采集服务会将采集收到的埋点写入Kafka。针对各个业务的实时数据消费需求,我们为各个业务提供单独的Kafka,流量分发模块会定时读取。取埋点管理平台提供的元信息,将流量实时分发到各个业务的Kafka。
Data采集 就像设计产品一样,不能过头。不仅要留有扩展的空间,还要时刻考虑有没有数据,是否完整,是否稳定,是否快。
文章采集api(优采云采集支持5118接口:5118一键智能换词API接口)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2022-03-12 19:10
优采云采集支持5118接口如下:
5118一键智能换字API接口
5118一键智能重写API接口
5118 智能标题生成 API
处理采集数据标题和内容、关键词、描述等,可以针对性配合优采云采集的SEO功能和5118智能换词API处理 原创 度数更高的 文章。@收录 和 网站 权重起着非常重要的作用。
访问和使用步骤 创建5118 API接口配置(所有接口通用) 创建API处理规则 API处理规则 使用API处理结果发布5118-API接口常见问题及解决方案
1. 创建5118 API接口配置(所有接口通用)
5118一键智能换字API接口,5118一键智能改写API接口:可用于处理采集的数据标题和内容;
5118智能标题生成API:可根据文章内容智能生成文章标题;
一、API配置入口:
点击控制台左侧列表中的【第三方服务配置】==点击【第三方内容API接入】==点击【第三方API配置管理】==点击创建对应接口配置:【5118_Intelligent】Word Change API]、【5118_Intelligent Rewriting API】、【5118_Intelligent Title Generation API】;
二、配置API接口信息:
【API-Key值】是从5118后端获取的一键智能换字API或5118一键智能改写API或5118智能标题生成API对应的key值,填写优采云;
设置锁字功能,首先开启核心字锁,填写的锁字在第三方原创api处理时不会被替换,多个字用|分隔,例如:word 1 | 字 2 | 词 3
2. 创建 API 处理规则
API处理规则,可以通过调用API接口设置处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==,点击【第三方内容API接入】==进入【API处理规则管理】页面,最后点击【添加】 API处理规则]创建API处理规则;
二、API处理规则配置:
三、5118智能标题生成API(可选,特殊接口使用说明)
5118智能标题生成API是根据文章的内容(content字段)智能生成文章标题,所以API处理规则中需要处理的字段要选择content字段根据内容生成标题。
3. API 处理规则使用
API处理规则有两种使用方式:手动执行和自动执行:
一、手动执行API处理规则:
在采集任务的【结果数据&发布】选项卡中,点击【SEO&API&翻译等工具】按钮==选择【第三方API执行】栏==选择对应的API处理规则= ="执行;
二、自动执行API处理规则:
启用 API 处理的自动执行。任务完成后采集会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡中,在【自动执行第三方API配置】==勾选【采集,自动执行API】选项===选择API处理rule for execution =="选择API接口处理的数据范围(一般选择'待释放',all会导致所有数据重复执行),最后点击保存;
4. API 处理结果并发布
一、查看API接口处理结果:
API接口处理的内容会生成API接口对应的新字段,如:
内容处理后添加的字段:
content_5118换字(对应5118一键智能换字API接口)
在【结果数据&发布】和数据预览界面都可以查看。
提示:执行 API 处理规则需要一段时间。执行后页面会自动刷新,出现API接口处理的新字段;
二、API接口处理后的内容发布
在发布文章之前,修改发布目标第二步的映射字段,重新选择标题和内容作为API接口处理后添加的对应字段。
例如,执行5118一键智能换词API后,选择title_5118换词和content_5118换词发布;
例如,执行5118智能标题生成API后,选择content_5118标题生成并发布;
提示:如果发布目标中无法选择新字段,请在任务下复制或新建发布目标,然后在新发布目标中选择新字段即可。详细教程请参考发布目标中不能选择的字段;
5. 5118-API接口常见问题及解决方法
一、API处理规则和SEO规则如何协同工作?
系统默认对title和content字段进行SEO功能,需要修改为SEO规则中对应的新字段,如title_5118换字、content_5118换字字段; 查看全部
文章采集api(优采云采集支持5118接口:5118一键智能换词API接口)
优采云采集支持5118接口如下:
5118一键智能换字API接口
5118一键智能重写API接口
5118 智能标题生成 API
处理采集数据标题和内容、关键词、描述等,可以针对性配合优采云采集的SEO功能和5118智能换词API处理 原创 度数更高的 文章。@收录 和 网站 权重起着非常重要的作用。
访问和使用步骤 创建5118 API接口配置(所有接口通用) 创建API处理规则 API处理规则 使用API处理结果发布5118-API接口常见问题及解决方案
1. 创建5118 API接口配置(所有接口通用)
5118一键智能换字API接口,5118一键智能改写API接口:可用于处理采集的数据标题和内容;
5118智能标题生成API:可根据文章内容智能生成文章标题;
一、API配置入口:
点击控制台左侧列表中的【第三方服务配置】==点击【第三方内容API接入】==点击【第三方API配置管理】==点击创建对应接口配置:【5118_Intelligent】Word Change API]、【5118_Intelligent Rewriting API】、【5118_Intelligent Title Generation API】;
二、配置API接口信息:
【API-Key值】是从5118后端获取的一键智能换字API或5118一键智能改写API或5118智能标题生成API对应的key值,填写优采云;
设置锁字功能,首先开启核心字锁,填写的锁字在第三方原创api处理时不会被替换,多个字用|分隔,例如:word 1 | 字 2 | 词 3
2. 创建 API 处理规则
API处理规则,可以通过调用API接口设置处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==,点击【第三方内容API接入】==进入【API处理规则管理】页面,最后点击【添加】 API处理规则]创建API处理规则;
二、API处理规则配置:
三、5118智能标题生成API(可选,特殊接口使用说明)
5118智能标题生成API是根据文章的内容(content字段)智能生成文章标题,所以API处理规则中需要处理的字段要选择content字段根据内容生成标题。
3. API 处理规则使用
API处理规则有两种使用方式:手动执行和自动执行:
一、手动执行API处理规则:
在采集任务的【结果数据&发布】选项卡中,点击【SEO&API&翻译等工具】按钮==选择【第三方API执行】栏==选择对应的API处理规则= ="执行;
二、自动执行API处理规则:
启用 API 处理的自动执行。任务完成后采集会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡中,在【自动执行第三方API配置】==勾选【采集,自动执行API】选项===选择API处理rule for execution =="选择API接口处理的数据范围(一般选择'待释放',all会导致所有数据重复执行),最后点击保存;
4. API 处理结果并发布
一、查看API接口处理结果:
API接口处理的内容会生成API接口对应的新字段,如:
内容处理后添加的字段:
content_5118换字(对应5118一键智能换字API接口)
在【结果数据&发布】和数据预览界面都可以查看。
提示:执行 API 处理规则需要一段时间。执行后页面会自动刷新,出现API接口处理的新字段;
二、API接口处理后的内容发布
在发布文章之前,修改发布目标第二步的映射字段,重新选择标题和内容作为API接口处理后添加的对应字段。
例如,执行5118一键智能换词API后,选择title_5118换词和content_5118换词发布;
例如,执行5118智能标题生成API后,选择content_5118标题生成并发布;
提示:如果发布目标中无法选择新字段,请在任务下复制或新建发布目标,然后在新发布目标中选择新字段即可。详细教程请参考发布目标中不能选择的字段;
5. 5118-API接口常见问题及解决方法
一、API处理规则和SEO规则如何协同工作?
系统默认对title和content字段进行SEO功能,需要修改为SEO规则中对应的新字段,如title_5118换字、content_5118换字字段;
文章采集api(为什么会有这个需求,某些时候我们需要把pillar数据存储在CMDB中 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2022-03-08 14:06
)
大部分时候,在使用pillar的时候,我们直接使用SLS文件来存储数据,但实际上pillar可以支持多种数据存储方式,比如:mysql、mongo、json等;这些可以在官网或者ext_piilar的code代码中看到;
pillar支持的数据存储模块列表地址:
要求:
我们来谈谈为什么会有这种需求。有时我们需要将柱子数据存储在CMDB中,或者从CMDB中拉取数据提供柱子使用。这时候在柱子下编辑SLS文件就有点不雅了。 ext_pillar 解决了这个问题,作为支柱数据映射和数据存储 (CMDB) 的枢纽。
最近写代码要发布,需要用到pillar data(一个版本号,平台提供代码url,代码打包推送到repo时,版本号更新为saltstack的pillar data call),刚好想到ext_pillar,OMS运维平台使用的是MySQL数据库,所以想直接使用这个模块;接触的时候有点难过,文档也很少~~ 找个翻译 文章 用的是MongoDB,想着再建个mongodb有点过分了;飞飞给我的建议是不要用MySQL,建议做一个Http API接口;
pillar 是一个很棒的工具,它不仅可以存储安全数据,还可以存储业务数据;使用ext_pillar连接CMDB系统,状态用于描述业务处理逻辑,真实数据取自CMDB;玩,这块绿肥和jacky是第一个意识到的,很有经验
说了这么多,再说说实现这个Http API的ext_pillar(没有CMDB)
1.实现后端数据->根据业务场景,设计满足业务的数据结构(dict),控制权在你手中,实现你想要的,关键积分符合你的业务
2.实现ext_pillar,可以访问http访问后端数据
3.配置salt master配置文件,重启master
4.支柱测试
实施:
1. 后端数据实现。
HTTP方式使用JSON数据,不仅可以生成json数据,还可以改变json数据;先来看看柱子数据映射SLS文件格式
hdworkers:
版本:2014102202
上面的数据格式转换成dict,{'hdworkers': {'ver': '2014102202'}},我只需要实现一个简单的版本号映射,你自己设计这么复杂的数据;把程序贴在Code下面(代码很烂,不要喷~)
# -*- coding: utf-8 -*-
import json
import os
class BuildJson(object):
'''
Build JSON data(base and minion_id etc..)
'''
def base_data(self,args):
'''
build base data
'''
info = {}
ret = dict(info,**args)
self.write_data('base',ret)
def build_data(self,id,args):
if not os.path.exists('/home/api/pillar/%s' % (id)):
with open('/home/api/pillar/base') as f:
obj = f.readlines()[0]
ret = eval(obj)
self.write_data(id,ret)
with open('/home/api/pillar/%s' % (id)) as f:
data = f.readlines()[0]
cov_data = eval(data)
if not cov_data.has_key(args.keys()[0]):
ret = dict(cov_data,**args)
self.write_data(id,ret)
else:
cov_data.update(args)
self.write_data(id,cov_data)
def write_data(self,file,ret):
f = open('/home/api/pillar/%s' % (file),'w+')
f.write(str(ret))
f.close()
#data = {'hdworkers':{'ver':'2014103105'}}
#bapi = BuildJson()
#bapi.base_data(数据)
#bapi.build_data('test-01',data)
生成基础数据,然后调用build_data(继承基础数据,同时更新数据),id上会有一些数据,但是基础不行~,所以上面是我写的评委自己玩,有好的可以反馈给我,我正在修改~
2.实现ext_pillar,可以通过http访问
因为是结合OMS平台,所以我对上面生成的文件在nginx中做了localtion设置,这样就可以通过http访问数据了;否则,ext_pillar 无法播放
我忽略了Nginx的配置过程,直接粘贴结果
查看全部
文章采集api(为什么会有这个需求,某些时候我们需要把pillar数据存储在CMDB中
)
大部分时候,在使用pillar的时候,我们直接使用SLS文件来存储数据,但实际上pillar可以支持多种数据存储方式,比如:mysql、mongo、json等;这些可以在官网或者ext_piilar的code代码中看到;
pillar支持的数据存储模块列表地址:
要求:
我们来谈谈为什么会有这种需求。有时我们需要将柱子数据存储在CMDB中,或者从CMDB中拉取数据提供柱子使用。这时候在柱子下编辑SLS文件就有点不雅了。 ext_pillar 解决了这个问题,作为支柱数据映射和数据存储 (CMDB) 的枢纽。
最近写代码要发布,需要用到pillar data(一个版本号,平台提供代码url,代码打包推送到repo时,版本号更新为saltstack的pillar data call),刚好想到ext_pillar,OMS运维平台使用的是MySQL数据库,所以想直接使用这个模块;接触的时候有点难过,文档也很少~~ 找个翻译 文章 用的是MongoDB,想着再建个mongodb有点过分了;飞飞给我的建议是不要用MySQL,建议做一个Http API接口;
pillar 是一个很棒的工具,它不仅可以存储安全数据,还可以存储业务数据;使用ext_pillar连接CMDB系统,状态用于描述业务处理逻辑,真实数据取自CMDB;玩,这块绿肥和jacky是第一个意识到的,很有经验
说了这么多,再说说实现这个Http API的ext_pillar(没有CMDB)
1.实现后端数据->根据业务场景,设计满足业务的数据结构(dict),控制权在你手中,实现你想要的,关键积分符合你的业务
2.实现ext_pillar,可以访问http访问后端数据
3.配置salt master配置文件,重启master
4.支柱测试
实施:
1. 后端数据实现。
HTTP方式使用JSON数据,不仅可以生成json数据,还可以改变json数据;先来看看柱子数据映射SLS文件格式
hdworkers:
版本:2014102202
上面的数据格式转换成dict,{'hdworkers': {'ver': '2014102202'}},我只需要实现一个简单的版本号映射,你自己设计这么复杂的数据;把程序贴在Code下面(代码很烂,不要喷~)
# -*- coding: utf-8 -*-
import json
import os
class BuildJson(object):
'''
Build JSON data(base and minion_id etc..)
'''
def base_data(self,args):
'''
build base data
'''
info = {}
ret = dict(info,**args)
self.write_data('base',ret)
def build_data(self,id,args):
if not os.path.exists('/home/api/pillar/%s' % (id)):
with open('/home/api/pillar/base') as f:
obj = f.readlines()[0]
ret = eval(obj)
self.write_data(id,ret)
with open('/home/api/pillar/%s' % (id)) as f:
data = f.readlines()[0]
cov_data = eval(data)
if not cov_data.has_key(args.keys()[0]):
ret = dict(cov_data,**args)
self.write_data(id,ret)
else:
cov_data.update(args)
self.write_data(id,cov_data)
def write_data(self,file,ret):
f = open('/home/api/pillar/%s' % (file),'w+')
f.write(str(ret))
f.close()
#data = {'hdworkers':{'ver':'2014103105'}}
#bapi = BuildJson()
#bapi.base_data(数据)
#bapi.build_data('test-01',data)
生成基础数据,然后调用build_data(继承基础数据,同时更新数据),id上会有一些数据,但是基础不行~,所以上面是我写的评委自己玩,有好的可以反馈给我,我正在修改~
2.实现ext_pillar,可以通过http访问
因为是结合OMS平台,所以我对上面生成的文件在nginx中做了localtion设置,这样就可以通过http访问数据了;否则,ext_pillar 无法播放
我忽略了Nginx的配置过程,直接粘贴结果

文章采集api(如何利用免费Dede采集插件让网站收录以及关键词排名?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-03-08 11:05
为什么要使用 Dede采集 插件?如何使用免费的 Dede采集 插件对 网站收录 和 关键词 进行排名。我们知道网站结构是seo优化过程中不可忽视的一个非常重要的环节。网站结构分为物理结构和逻辑结构。物理结构一般是指虚拟空间中的许多目录和文件。这种结构一般用户不能直接看到,逻辑结构主要是指网站上线后我们肉眼可以看到的网站界面中的链接关系。两者都是站长在优化过程中需要注意的重点。那么SEO网站结构优化有什么意义呢?
网站结构对我们的网站 优化真的那么重要吗?很多人都在问同样的问题。其实我们可以把我们网站想象成一栋房子,结构就是我们房子的布局,首页就是我们的客厅,搜索引擎就是来我们家参观的朋友。,当他来到你家时,他会先进入你家的客厅;通过客厅,您可以到达房子的每个房间,同样可以通过我们的首页搜索引擎到达我们的每个页面。为了方便起见,我们的网站最好的结构是三层,也就是说用户最多点击3次就可以到达他想到达的页面。这样做的目的是为了加快蜘蛛的爬行速度和蜘蛛的友好度。而且,
网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以利用Dede采集实现采集伪原创自动发布,主动推送给搜索引擎,增加搜索引擎的抓取频率,从而增加网站收录 和 关键词 排名。这个Dede采集不需要写规则,输入关键词就可以了采集。
一、免费Dede采集插件
免费Dede采集插件特点:
1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词。
2、支持多消息源:问答和各种消息源(可同时设置多个采集消息源采集/采集消息源稍后添加)
3、过滤其他促销信息
4、图片本地化/图片水印/图片第三方存储
5、文章交流+翻译(简体中文和繁体翻译+百度翻译+有道翻译+谷歌翻译+147翻译)
6、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、在所有平台上发布插件
全平台cms发布者的特点:
1、cms发布:目前市面上唯一支持Empirecms、易友、ZBLOG、dedecms、WordPress、PBoot、Applecms、迅锐cms、PHPcms、苹果cms、人人网cms、米拓cms、云游cms、小旋风站群 , THINKCMF, 建站ABC, 凡客cms, 一骑cms, 海洋cms, 飞飞cms, 本地发布, 搜外 等cms ,并同时进行批量管理和发布的工具
2、全网推送(百度/360/搜狗/神马)
3、伪原创(标题+内容)
4、替换图片防止侵权
5、强大的SEO功能(自动图片放置/插入内外链接/标题和文章前后插入内容/标题关键词与内容一致关键词/随机插入图片/随机属性添加页面原创度)
6、对应栏:对应文章可以发布对应栏/支持多栏发布
7、定期发布:可控发布间隔/每天发布总数
8、监控数据:直接监控已经发布、待发布的软件,是否为伪原创、发布状态、URL、程序、发布时间等。
还有一点大家要注意的是,我们的网站里面不能有死连接,网站里面的连接不能很乱,不要让网站看起来像迷宫是的,蜘蛛最讨厌的地方就是迷宫网站。因为这样的网站会浪费蜘蛛很多时间,会觉得额外的累赘,时间长了会减少蜘蛛爬行的数量,就像我们站在房子的客厅里,你想去到其中一个房间,然后你发现房子就像一个迷宫,需要很长时间才能找到你想去的房间。你想要这样的房子吗?你肯定不喜欢吧?蜘蛛也是如此。所以 网站 不需要添加太多的连接,
其实如果一个网站想要做好网站的优化,首先要做的就是要有一个好的网站结构。就像迷宫一样,设施齐全,没有人愿意住在那里。同理,我们的网站内容做的不错,但是找起来很麻烦,别说蜘蛛了,连用户都不愿意找。
对网站进行SEO优化时,主要分为站内优化和站外优化两部分。具体的优化内容可以分为很多部分。TDK选型部署如网站、关键词密度控制等现场优化,现场结构是否简单合理,目录层次是否过于复杂等,非现场优化比如网站外部链接的扩展、友好链接的交换等等,这些因素都是不容忽视的,任何一个领域的问题都可能导致网站整体不稳定。那么网站标签是如何进行SEO优化的呢?
alt标签的使用
很多人可能并不关心 网站alt 标签。该标签是为网站上的图片设置和部署的。想必大家都知道,搜索引擎蜘蛛无法顺利抓取网站上的图片。为了更好的识别图片,我们可以在图片后面加上图片的alt标签属性,在alt里面加上图片的详细信息或者网站关键词,这样就可以告诉蜘蛛图片内容,还可以累加网站关键词的权重和密度,有效提升网站关键词的排名和权重。
h1标签的用法和作用
说到网站的H1标签,可能有人会问,h1标签的意义何在,但我要告诉大家的是,网站的H1标签有很多功能,而h1是在一个页面中得到的权重最高的。当蜘蛛进入页面进行爬取时,第一个是标题,第二个是h1标签,所以后面我们可以在h1标签中部署网站的关键词。增加关键词的权重,为了突出网站的主题核心,所以在页面的h1标签中,不能随便部署词汇,网站的整体核心应该可以考虑,而 h1 标签在一个页面上只能出现一次。如果使用次数过多,将没有效果。这需要特别注意。
网站 标签的使用需要谨慎。如果使用不当,会直接导致网站降级,甚至K。标签优化是网站优化的好方法。比较重要,所以优化标签的时候不要操之过急,也不要过度优化问题。合理恰当地使用标签优化,可以增加网站的连接性,也可以增加用户粘性。,所以对网站标签的优化需要慎重。 查看全部
文章采集api(如何利用免费Dede采集插件让网站收录以及关键词排名?)
为什么要使用 Dede采集 插件?如何使用免费的 Dede采集 插件对 网站收录 和 关键词 进行排名。我们知道网站结构是seo优化过程中不可忽视的一个非常重要的环节。网站结构分为物理结构和逻辑结构。物理结构一般是指虚拟空间中的许多目录和文件。这种结构一般用户不能直接看到,逻辑结构主要是指网站上线后我们肉眼可以看到的网站界面中的链接关系。两者都是站长在优化过程中需要注意的重点。那么SEO网站结构优化有什么意义呢?

网站结构对我们的网站 优化真的那么重要吗?很多人都在问同样的问题。其实我们可以把我们网站想象成一栋房子,结构就是我们房子的布局,首页就是我们的客厅,搜索引擎就是来我们家参观的朋友。,当他来到你家时,他会先进入你家的客厅;通过客厅,您可以到达房子的每个房间,同样可以通过我们的首页搜索引擎到达我们的每个页面。为了方便起见,我们的网站最好的结构是三层,也就是说用户最多点击3次就可以到达他想到达的页面。这样做的目的是为了加快蜘蛛的爬行速度和蜘蛛的友好度。而且,

网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以利用Dede采集实现采集伪原创自动发布,主动推送给搜索引擎,增加搜索引擎的抓取频率,从而增加网站收录 和 关键词 排名。这个Dede采集不需要写规则,输入关键词就可以了采集。
一、免费Dede采集插件
免费Dede采集插件特点:
1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词。
2、支持多消息源:问答和各种消息源(可同时设置多个采集消息源采集/采集消息源稍后添加)
3、过滤其他促销信息
4、图片本地化/图片水印/图片第三方存储
5、文章交流+翻译(简体中文和繁体翻译+百度翻译+有道翻译+谷歌翻译+147翻译)
6、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、在所有平台上发布插件
全平台cms发布者的特点:
1、cms发布:目前市面上唯一支持Empirecms、易友、ZBLOG、dedecms、WordPress、PBoot、Applecms、迅锐cms、PHPcms、苹果cms、人人网cms、米拓cms、云游cms、小旋风站群 , THINKCMF, 建站ABC, 凡客cms, 一骑cms, 海洋cms, 飞飞cms, 本地发布, 搜外 等cms ,并同时进行批量管理和发布的工具
2、全网推送(百度/360/搜狗/神马)
3、伪原创(标题+内容)

4、替换图片防止侵权
5、强大的SEO功能(自动图片放置/插入内外链接/标题和文章前后插入内容/标题关键词与内容一致关键词/随机插入图片/随机属性添加页面原创度)
6、对应栏:对应文章可以发布对应栏/支持多栏发布
7、定期发布:可控发布间隔/每天发布总数
8、监控数据:直接监控已经发布、待发布的软件,是否为伪原创、发布状态、URL、程序、发布时间等。

还有一点大家要注意的是,我们的网站里面不能有死连接,网站里面的连接不能很乱,不要让网站看起来像迷宫是的,蜘蛛最讨厌的地方就是迷宫网站。因为这样的网站会浪费蜘蛛很多时间,会觉得额外的累赘,时间长了会减少蜘蛛爬行的数量,就像我们站在房子的客厅里,你想去到其中一个房间,然后你发现房子就像一个迷宫,需要很长时间才能找到你想去的房间。你想要这样的房子吗?你肯定不喜欢吧?蜘蛛也是如此。所以 网站 不需要添加太多的连接,
其实如果一个网站想要做好网站的优化,首先要做的就是要有一个好的网站结构。就像迷宫一样,设施齐全,没有人愿意住在那里。同理,我们的网站内容做的不错,但是找起来很麻烦,别说蜘蛛了,连用户都不愿意找。
对网站进行SEO优化时,主要分为站内优化和站外优化两部分。具体的优化内容可以分为很多部分。TDK选型部署如网站、关键词密度控制等现场优化,现场结构是否简单合理,目录层次是否过于复杂等,非现场优化比如网站外部链接的扩展、友好链接的交换等等,这些因素都是不容忽视的,任何一个领域的问题都可能导致网站整体不稳定。那么网站标签是如何进行SEO优化的呢?
alt标签的使用
很多人可能并不关心 网站alt 标签。该标签是为网站上的图片设置和部署的。想必大家都知道,搜索引擎蜘蛛无法顺利抓取网站上的图片。为了更好的识别图片,我们可以在图片后面加上图片的alt标签属性,在alt里面加上图片的详细信息或者网站关键词,这样就可以告诉蜘蛛图片内容,还可以累加网站关键词的权重和密度,有效提升网站关键词的排名和权重。

h1标签的用法和作用
说到网站的H1标签,可能有人会问,h1标签的意义何在,但我要告诉大家的是,网站的H1标签有很多功能,而h1是在一个页面中得到的权重最高的。当蜘蛛进入页面进行爬取时,第一个是标题,第二个是h1标签,所以后面我们可以在h1标签中部署网站的关键词。增加关键词的权重,为了突出网站的主题核心,所以在页面的h1标签中,不能随便部署词汇,网站的整体核心应该可以考虑,而 h1 标签在一个页面上只能出现一次。如果使用次数过多,将没有效果。这需要特别注意。
网站 标签的使用需要谨慎。如果使用不当,会直接导致网站降级,甚至K。标签优化是网站优化的好方法。比较重要,所以优化标签的时候不要操之过急,也不要过度优化问题。合理恰当地使用标签优化,可以增加网站的连接性,也可以增加用户粘性。,所以对网站标签的优化需要慎重。
文章采集api(..2、应用级参数(每个接入点有自己的参数))
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-03-08 05:02
趣头条采集接口接口地址:(注:接口支持https,更安全,但速度稍慢,你懂的。请根据自己的情况选择。) 支持格式:json 请求方式:HTTP协议,支持GET/POST 方法。二、请求参数/请求参数
对于非文件上传 POST,enctype=application/x-www-form-urlencoded。
在文件上传的POST中,enctype=multipart/form-data。
1、系统级参数(所有接入点都需要):
参数名称类型示例值必须描述
showapi_appidString100 是亿源app id
showapi_signString698d51a19d8a121ce581499d7b701668是为了验证用户的身份,保证参数不被中间人篡改,需要传递调用者的数字签名。可选,在url后面加上appid和secret
showapi_timestampString239 无客户端时间。
格式 yyyyMMddHHmmss,如 239
为了在一定程度上防止“重放攻击”,平台只接受10分钟内的请求。如果没有传递或传递空字符串,系统将不再检查该字段。
showapi_res_gzipString1 或 0 否 返回值是否被 gzip 压缩。值为1会压缩,其他值不会压缩。
...
2、应用级参数(每个接入点都有自己的参数,当前接入点的参数见下表):
参数名称类型默认值示例值必须描述
请求示例:String res=new ShowApiRequest("","my_appId","my_appSecret") .post();System.out.println(res);三、返回参数/返回参数
以 JSON 格式返回结果。
1、系统级参数(所有接入点返回的参数):
名称 类型 示例 值 描述
showapi_res_bodyString{"city":"Kunming","prov":"Yunnan"}消息体的JSON封装,所有应用级的返回参数都会嵌入到这个对象中。
showapi_res_codeint0 一元返回标志,0为成功,其他为失败。
0 成功
-1,系统调用错误
-2,调用次数或金额为0
-3,读取超时
-4、服务器返回数据解析错误
-5、后端服务器DNS解析错误
-6、服务不存在或不在线
-7,API创建者网关资源不足
-1000,系统维护
-1002,必须传递showapi_appid字段
-1003,必须通过showapi_sign字段
-1004,签名验证错误
-1005,showapi_timestamp 无效
-1006,app没有权限调用接口
-1007, 没有订购包裹
-1008,服务商关闭对你的通话权限
-1009,呼叫频率受限
-1010,找不到你的应用
-1011, 无效的子授权 app_child_id
-1012, 子授权已过期或过期
-1013,子授权ip受限
-1014,令牌权限无效
showapi_res_errorString 用户输入不正确!显示错误信息
showapi_res_idStringce135f6739294c63be0c021b76b6fbff这个请求id
...
2、应用级参数(系统级输出参数showapi_res_body字段中的json数据结构):
名称 类型 示例 值 描述
ret_codeNumber0
数据对象[]
- idNumber27
- titleString 为何史祥云不被视为宝儿祖母的人选?标题
- typeString 分类
- urlString文章地址
- descString 包办婚姻可能会影响结婚的决定,原因如下:1、当事人祥云和宝玉的感情愿望是一起长大的,大家只把两人当成兄弟姐妹,没想到男女之间的爱情。不过,据周汝昌先生调查,《红楼梦》中所谓的金玉福,是宝玉的玉石和石祥云的金子(锦旗的描述文章
- imgString 图像数组
- tagString"[\"娱乐\",\"明星\",\"八卦\"]",tag关键词数组
...
特别是工人","tag": "[]","img": "[\"\"]","type": "40","url": ""},{"id": "24" ,"time": "1519886219", "title_eng": "邓超对儿子和女儿的态度很不一样。最后一张图太暖心了!”,“desc”:“说邓超是女儿奴一点都不为过。近日,孙俪曝光了邓超和女儿小华。还有递一杯酒的照片,两人各拿一杯,画面十分恩爱。1519886219", "title_eng": "邓超对儿子和女儿的态度很不一样。最后一张图太暖心了!”,“desc”:“说邓超是女儿奴一点都不为过。近日,孙俪曝光了邓超和女儿小华。还有递一杯酒的照片,两人各拿一杯,画面十分恩爱。1519886219", "title_eng": "邓超对儿子和女儿的态度很不一样。最后一张图太暖心了!”,“desc”:“说邓超是女儿奴一点都不为过。近日,孙俪曝光了邓超和女儿小华。还有递一杯酒的照片,两人各拿一杯,画面十分恩爱。
网友纷纷回复:女儿真是爸爸前世的小情人,夫妻恩爱,孩子可爱,小姐姐是人生赢家!就在孙俪发这个","tag":"[\"邓超\",\"态度\",\"暖心\"]","img":"[\"\",\"\ " ,\"","type": "6","url": ""},{"id": "54","time": "1519886258","title": "靳东"娘-law”,12 影后称号,朱军拼命想娶她,如今62岁出家”,“desc”:“一提到杜十娘,你会想到谁?很多人认为应该是李嘉欣
房地产专家刘权解释:为什么现在买房越来越贵,买房越来越难?","desc": "日前,国家统计局发布了2018年1月70个大中城市商品房销售价格统计数据。
北京、天津、上海、南京、无锡、济南等13个城市新建住宅销售价格环比下降1.2%。深圳同比下降3.4%,福州同比下降2.7%,杭州","tag": "[]","img": "[ \"\"]","type" : "10","url": ""},{"id": "70","time": "1519885060","title": "狗走了 10 公里每天到镇上只是为了睡觉!原因让楼主心痛!","desc": "主人在镇上捡到一只流浪狗,带回自己的小村子养,但狗每天早上自己跑出去,晚上又回来。主人每天都对这只狗很好奇。你在干什么,所以这天主人跟着他的狗,发现狗居然跑回了镇上,然后","tag":"[\"奇葩\",\"轶事\",\"打猎\"]","img": "[\"\",\"\",\"","type": "3","url": ""},{"id": "74", “时间”:“1519886260”,“标题”:“国内不怕打,中国空军高调宣布歼20最佳搭档”,
","tag": "[\"军事事件\",\"热点事件\",\"科技事件\"]","img": "[\"\",\"\",\ "","type": "15","url": ""},{"id": "77","time": "1519885060","title": "女司机夜间驾驶导航,没想到导航给她指了一条水路!”,“desc”:“没想到当今社会连电子技术都开始骗人了。就像图中的司机,因为雾和极端的能见度,她看着导航。驱动器最终落入水中。
女司机还在专心看着导航往前走的时候,突然发现自己已经在水里开车了,“,tag”:“[\"轶事\",\"驾驶\",\"导航\"]","img": "[\"\",\"\",\"","type": "9","url": ""},{"id": "79" ,"time":"1519885060","title":"刘强东在手机上宠妻章泽天,网友:总比放过别的女人好","desc":"只有细心的网友才能发现刘强东有没有他那么爱老婆章泽天,刘强东在手机上宠老婆。
网友回应:总比把别的女人的照片当屏保好!今天章泽天和刘强东一起出席学校活动,随后刘强东手机壁纸曝光。仔细看其实很可爱","tag": "[\"娱乐",\"明星\",\"刘强东\",\"章泽天\"]","img": " [\"\",\"\",\"","type":"6","url":""},{"id":"81","time":"1519886862","title ”:“中共中央、国务院召开春节小组会议,习近平发表重要讲话”,“desc”:“ 查看全部
文章采集api(..2、应用级参数(每个接入点有自己的参数))
趣头条采集接口接口地址:(注:接口支持https,更安全,但速度稍慢,你懂的。请根据自己的情况选择。) 支持格式:json 请求方式:HTTP协议,支持GET/POST 方法。二、请求参数/请求参数
对于非文件上传 POST,enctype=application/x-www-form-urlencoded。
在文件上传的POST中,enctype=multipart/form-data。
1、系统级参数(所有接入点都需要):
参数名称类型示例值必须描述
showapi_appidString100 是亿源app id
showapi_signString698d51a19d8a121ce581499d7b701668是为了验证用户的身份,保证参数不被中间人篡改,需要传递调用者的数字签名。可选,在url后面加上appid和secret
showapi_timestampString239 无客户端时间。
格式 yyyyMMddHHmmss,如 239
为了在一定程度上防止“重放攻击”,平台只接受10分钟内的请求。如果没有传递或传递空字符串,系统将不再检查该字段。
showapi_res_gzipString1 或 0 否 返回值是否被 gzip 压缩。值为1会压缩,其他值不会压缩。
...
2、应用级参数(每个接入点都有自己的参数,当前接入点的参数见下表):
参数名称类型默认值示例值必须描述
请求示例:String res=new ShowApiRequest("","my_appId","my_appSecret") .post();System.out.println(res);三、返回参数/返回参数
以 JSON 格式返回结果。
1、系统级参数(所有接入点返回的参数):
名称 类型 示例 值 描述
showapi_res_bodyString{"city":"Kunming","prov":"Yunnan"}消息体的JSON封装,所有应用级的返回参数都会嵌入到这个对象中。
showapi_res_codeint0 一元返回标志,0为成功,其他为失败。
0 成功
-1,系统调用错误
-2,调用次数或金额为0
-3,读取超时
-4、服务器返回数据解析错误
-5、后端服务器DNS解析错误
-6、服务不存在或不在线
-7,API创建者网关资源不足
-1000,系统维护
-1002,必须传递showapi_appid字段
-1003,必须通过showapi_sign字段
-1004,签名验证错误
-1005,showapi_timestamp 无效
-1006,app没有权限调用接口
-1007, 没有订购包裹
-1008,服务商关闭对你的通话权限
-1009,呼叫频率受限
-1010,找不到你的应用
-1011, 无效的子授权 app_child_id
-1012, 子授权已过期或过期
-1013,子授权ip受限
-1014,令牌权限无效
showapi_res_errorString 用户输入不正确!显示错误信息
showapi_res_idStringce135f6739294c63be0c021b76b6fbff这个请求id
...
2、应用级参数(系统级输出参数showapi_res_body字段中的json数据结构):
名称 类型 示例 值 描述
ret_codeNumber0
数据对象[]
- idNumber27
- titleString 为何史祥云不被视为宝儿祖母的人选?标题
- typeString 分类
- urlString文章地址
- descString 包办婚姻可能会影响结婚的决定,原因如下:1、当事人祥云和宝玉的感情愿望是一起长大的,大家只把两人当成兄弟姐妹,没想到男女之间的爱情。不过,据周汝昌先生调查,《红楼梦》中所谓的金玉福,是宝玉的玉石和石祥云的金子(锦旗的描述文章
- imgString 图像数组
- tagString"[\"娱乐\",\"明星\",\"八卦\"]",tag关键词数组
...
特别是工人","tag": "[]","img": "[\"\"]","type": "40","url": ""},{"id": "24" ,"time": "1519886219", "title_eng": "邓超对儿子和女儿的态度很不一样。最后一张图太暖心了!”,“desc”:“说邓超是女儿奴一点都不为过。近日,孙俪曝光了邓超和女儿小华。还有递一杯酒的照片,两人各拿一杯,画面十分恩爱。1519886219", "title_eng": "邓超对儿子和女儿的态度很不一样。最后一张图太暖心了!”,“desc”:“说邓超是女儿奴一点都不为过。近日,孙俪曝光了邓超和女儿小华。还有递一杯酒的照片,两人各拿一杯,画面十分恩爱。1519886219", "title_eng": "邓超对儿子和女儿的态度很不一样。最后一张图太暖心了!”,“desc”:“说邓超是女儿奴一点都不为过。近日,孙俪曝光了邓超和女儿小华。还有递一杯酒的照片,两人各拿一杯,画面十分恩爱。
网友纷纷回复:女儿真是爸爸前世的小情人,夫妻恩爱,孩子可爱,小姐姐是人生赢家!就在孙俪发这个","tag":"[\"邓超\",\"态度\",\"暖心\"]","img":"[\"\",\"\ " ,\"","type": "6","url": ""},{"id": "54","time": "1519886258","title": "靳东"娘-law”,12 影后称号,朱军拼命想娶她,如今62岁出家”,“desc”:“一提到杜十娘,你会想到谁?很多人认为应该是李嘉欣
房地产专家刘权解释:为什么现在买房越来越贵,买房越来越难?","desc": "日前,国家统计局发布了2018年1月70个大中城市商品房销售价格统计数据。
北京、天津、上海、南京、无锡、济南等13个城市新建住宅销售价格环比下降1.2%。深圳同比下降3.4%,福州同比下降2.7%,杭州","tag": "[]","img": "[ \"\"]","type" : "10","url": ""},{"id": "70","time": "1519885060","title": "狗走了 10 公里每天到镇上只是为了睡觉!原因让楼主心痛!","desc": "主人在镇上捡到一只流浪狗,带回自己的小村子养,但狗每天早上自己跑出去,晚上又回来。主人每天都对这只狗很好奇。你在干什么,所以这天主人跟着他的狗,发现狗居然跑回了镇上,然后","tag":"[\"奇葩\",\"轶事\",\"打猎\"]","img": "[\"\",\"\",\"","type": "3","url": ""},{"id": "74", “时间”:“1519886260”,“标题”:“国内不怕打,中国空军高调宣布歼20最佳搭档”,
","tag": "[\"军事事件\",\"热点事件\",\"科技事件\"]","img": "[\"\",\"\",\ "","type": "15","url": ""},{"id": "77","time": "1519885060","title": "女司机夜间驾驶导航,没想到导航给她指了一条水路!”,“desc”:“没想到当今社会连电子技术都开始骗人了。就像图中的司机,因为雾和极端的能见度,她看着导航。驱动器最终落入水中。
女司机还在专心看着导航往前走的时候,突然发现自己已经在水里开车了,“,tag”:“[\"轶事\",\"驾驶\",\"导航\"]","img": "[\"\",\"\",\"","type": "9","url": ""},{"id": "79" ,"time":"1519885060","title":"刘强东在手机上宠妻章泽天,网友:总比放过别的女人好","desc":"只有细心的网友才能发现刘强东有没有他那么爱老婆章泽天,刘强东在手机上宠老婆。
网友回应:总比把别的女人的照片当屏保好!今天章泽天和刘强东一起出席学校活动,随后刘强东手机壁纸曝光。仔细看其实很可爱","tag": "[\"娱乐",\"明星\",\"刘强东\",\"章泽天\"]","img": " [\"\",\"\",\"","type":"6","url":""},{"id":"81","time":"1519886862","title ”:“中共中央、国务院召开春节小组会议,习近平发表重要讲话”,“desc”:“
文章采集api(API接口是什么?为什么我们需要实际上接口?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-03-05 14:05
对于很多产品新手或者求职者来说,API接口是产品和研发领域的一个专业名词,大家可能在文章或者PRD都接触过API接口的概念。
事实上,接口的应用已经非常广泛和成熟。这个概念主要活跃在公司内部各个系统之间的连接对接以及公司之间的合作场景中。如果你能仔细阅读这篇文章,相信你对API接口的理解会更深,甚至超过90%的新手和求职者。
本文目录:
API接口是什么?为什么我们需要API接口?API接口的核心一、什么是API接口?
让我们用一个常见的数学公式来理解API,比如y=x+2,当x=2时,y=4,对吧?
这时候我们调用y=x+2接口,x=2参数,y=4返回结果,那么这个接口的作用就是把我们输入的数字加2(注意:这里你可以发现接口本身有逻辑)。
以此类推,让我们理解一个常见的场景。比如有一个接口可以把经纬度转换成城市。当我输入55°的经纬度和88°的纬度时,界面会使用自己的逻辑运算,返回结果告诉我:杭州市。
这样就可以清楚的看懂百度百科的官方解释了。接口是预定义的功能逻辑。其他系统请求然后返回结果是一回事。
二、为什么我们需要一个 API 接口?
背景:我们的业务系统涉及到很多方面。如果我们想要一个公司或一个系统来完成所有的业务,那就太费力了,对吧?而如果其他系统或公司有更好的操作逻辑,我们在设计功能时可以考虑使用接口进行开发。
核心需求:利用现有接口可以降低开发成本,缩短开发成本。
例如:比如我是一个打车app,现在我需要在我的页面上显示地图功能。对于我们公司来说,新的地图功能太贵了。然后我们可以使用高德开放平台或者百度地图。打开平台,找到地图API,在这种情况下,我们只需要购买高德的服务,部署并调用高德地图API,就可以在我们的页面上快速启动地图功能。
三、API接口的核心
对于小白来说,第一次看 API 文档可能会让人迷惑——在哪里看,怎么看,摆在你面前的问题是什么。
其实对于产品经理来说,我们更应该关注的是这家公司能提供什么样的API接口服务。比如我知道高德可以提供地图API和规划路线的API。这样,我们就可以想到调用我们的设计函数和工作。他们的服务或参考。
因此,产品新手如果不了解,也无需过于担心。以后你也会对它有更深的理解,因为它理解起来并不复杂。以下是API接口的核心要点。所有的文档都离不开这五个核心。观点。
以下以微信开放平台为例进行说明。文末有各个开放平台的地址。有空的时候可以学习。好了,废话不多说,我们现在来搭建一个场景。
我们现在有一个APP,需要用户在购买时调用微信支付接口才能完成购买。请自动进入这个场景,把自己想象成一个产品经理。
1. 接口地址
现在,用户点击支付,我们需要告诉微信我们要打电话给你的收银员!但是在哪里说呢?这就需要接口地址,相当于把指定的数据传给微信链接。
链接地址不是我们所理解的页面。您可以将其理解为电话号码。新手应该改变这个概念。
至此,我们可以看到接口文档告诉我们链接如下,所以我们现在已经拨通了微信的号码。
2. 请求参数(消息)
我们现在需要告诉微信你要打电话给收银员,对吧?然后我们需要把它写下来。此时生成的消息称为消息,即你要告诉的界面内容是什么?相当于前面函数的输入 x=2。
一般来说,消息的格式和内容是根据接口文档指定的。以下是微信开放平台呼叫收银的消息要求。
我们先来看前两个参数。你现在正在和微信聊天。要不要先告诉微信,你是谁?这里的微信文档告诉你应该使用app ID+商户号来确定你的身份。那是什么意思?
比如你是商户,下面有a、b、c三个APP,那么微信需要知道你是哪个商户,下面哪个APP使用收银台。这个非常重要。微信应将收到的款项转到相应的账户和统计数据。
然后我们在消息中写下这两句话:
好吧,现在微信知道你是谁了,所以你得告诉微信你需要微信支付多少钱才能向你收费,对吧?这里定义了币种和总额,即收取什么币种,收取多少。
这里你看,币种一定要填,也就是说你也不能告诉微信支付是什么币种,因为他说默认是人民币。
好吧,让我们写两段
好了,现在微信知道你是谁,你要收多少钱,那么微信支付就会告诉你支付的结果,因为你要知道用户已经支付成功,才能继续发货、服务等。所以这里我们使用通知地址,就是告诉微信,等事情结束他会去哪里告诉你支付结果。然后我们写地址:
3. 返回结果
微信支付刚去收钱,现在他想在我们留下的通知地址告诉我们结果。结果不外乎两个:采集成功?收款失败?
(1)成功
很顺利,现在用户支付成功了,微信也把成功的消息告诉了我们,他也告诉了我们用户支付的一些信息。
那么这里就是收款成功后微信支付告诉我们的信息。
应用APPID,商户ID:告诉你我成功扣款的是哪个商户的APPID交易。
业务成果:成功或失败
(2)失败
在设计产品时,我们常常非常关心失败。当采集失败时,微信也会告诉你失败的原因。下面这张图很容易理解。失败的原因有很多。在设计的时候,我们经常去分析每一个失败的原因,设计每一个失败原因的页面和用户提示,以保证用户理解。
以上就是对API接口基本操作方式的理解。接下来我会继续更新API接口的一些更深入细致的关键元素,比如请求方法/签名/加解密等。
一个开放的平台供参考网站
微信支付:
高德平台开放平台:
本文由@islovesleeping原创 发表于每个人都是产品经理。未经许可禁止复制
题图来自Unsplash,基于CC0协议 查看全部
文章采集api(API接口是什么?为什么我们需要实际上接口?(图))
对于很多产品新手或者求职者来说,API接口是产品和研发领域的一个专业名词,大家可能在文章或者PRD都接触过API接口的概念。
事实上,接口的应用已经非常广泛和成熟。这个概念主要活跃在公司内部各个系统之间的连接对接以及公司之间的合作场景中。如果你能仔细阅读这篇文章,相信你对API接口的理解会更深,甚至超过90%的新手和求职者。
本文目录:
API接口是什么?为什么我们需要API接口?API接口的核心一、什么是API接口?
让我们用一个常见的数学公式来理解API,比如y=x+2,当x=2时,y=4,对吧?
这时候我们调用y=x+2接口,x=2参数,y=4返回结果,那么这个接口的作用就是把我们输入的数字加2(注意:这里你可以发现接口本身有逻辑)。
以此类推,让我们理解一个常见的场景。比如有一个接口可以把经纬度转换成城市。当我输入55°的经纬度和88°的纬度时,界面会使用自己的逻辑运算,返回结果告诉我:杭州市。
这样就可以清楚的看懂百度百科的官方解释了。接口是预定义的功能逻辑。其他系统请求然后返回结果是一回事。
二、为什么我们需要一个 API 接口?
背景:我们的业务系统涉及到很多方面。如果我们想要一个公司或一个系统来完成所有的业务,那就太费力了,对吧?而如果其他系统或公司有更好的操作逻辑,我们在设计功能时可以考虑使用接口进行开发。
核心需求:利用现有接口可以降低开发成本,缩短开发成本。
例如:比如我是一个打车app,现在我需要在我的页面上显示地图功能。对于我们公司来说,新的地图功能太贵了。然后我们可以使用高德开放平台或者百度地图。打开平台,找到地图API,在这种情况下,我们只需要购买高德的服务,部署并调用高德地图API,就可以在我们的页面上快速启动地图功能。
三、API接口的核心
对于小白来说,第一次看 API 文档可能会让人迷惑——在哪里看,怎么看,摆在你面前的问题是什么。
其实对于产品经理来说,我们更应该关注的是这家公司能提供什么样的API接口服务。比如我知道高德可以提供地图API和规划路线的API。这样,我们就可以想到调用我们的设计函数和工作。他们的服务或参考。
因此,产品新手如果不了解,也无需过于担心。以后你也会对它有更深的理解,因为它理解起来并不复杂。以下是API接口的核心要点。所有的文档都离不开这五个核心。观点。
以下以微信开放平台为例进行说明。文末有各个开放平台的地址。有空的时候可以学习。好了,废话不多说,我们现在来搭建一个场景。
我们现在有一个APP,需要用户在购买时调用微信支付接口才能完成购买。请自动进入这个场景,把自己想象成一个产品经理。
1. 接口地址
现在,用户点击支付,我们需要告诉微信我们要打电话给你的收银员!但是在哪里说呢?这就需要接口地址,相当于把指定的数据传给微信链接。
链接地址不是我们所理解的页面。您可以将其理解为电话号码。新手应该改变这个概念。
至此,我们可以看到接口文档告诉我们链接如下,所以我们现在已经拨通了微信的号码。
2. 请求参数(消息)
我们现在需要告诉微信你要打电话给收银员,对吧?然后我们需要把它写下来。此时生成的消息称为消息,即你要告诉的界面内容是什么?相当于前面函数的输入 x=2。
一般来说,消息的格式和内容是根据接口文档指定的。以下是微信开放平台呼叫收银的消息要求。
我们先来看前两个参数。你现在正在和微信聊天。要不要先告诉微信,你是谁?这里的微信文档告诉你应该使用app ID+商户号来确定你的身份。那是什么意思?
比如你是商户,下面有a、b、c三个APP,那么微信需要知道你是哪个商户,下面哪个APP使用收银台。这个非常重要。微信应将收到的款项转到相应的账户和统计数据。
然后我们在消息中写下这两句话:
好吧,现在微信知道你是谁了,所以你得告诉微信你需要微信支付多少钱才能向你收费,对吧?这里定义了币种和总额,即收取什么币种,收取多少。
这里你看,币种一定要填,也就是说你也不能告诉微信支付是什么币种,因为他说默认是人民币。
好吧,让我们写两段
好了,现在微信知道你是谁,你要收多少钱,那么微信支付就会告诉你支付的结果,因为你要知道用户已经支付成功,才能继续发货、服务等。所以这里我们使用通知地址,就是告诉微信,等事情结束他会去哪里告诉你支付结果。然后我们写地址:
3. 返回结果
微信支付刚去收钱,现在他想在我们留下的通知地址告诉我们结果。结果不外乎两个:采集成功?收款失败?
(1)成功
很顺利,现在用户支付成功了,微信也把成功的消息告诉了我们,他也告诉了我们用户支付的一些信息。
那么这里就是收款成功后微信支付告诉我们的信息。
应用APPID,商户ID:告诉你我成功扣款的是哪个商户的APPID交易。
业务成果:成功或失败
(2)失败
在设计产品时,我们常常非常关心失败。当采集失败时,微信也会告诉你失败的原因。下面这张图很容易理解。失败的原因有很多。在设计的时候,我们经常去分析每一个失败的原因,设计每一个失败原因的页面和用户提示,以保证用户理解。
以上就是对API接口基本操作方式的理解。接下来我会继续更新API接口的一些更深入细致的关键元素,比如请求方法/签名/加解密等。
一个开放的平台供参考网站
微信支付:
高德平台开放平台:
本文由@islovesleeping原创 发表于每个人都是产品经理。未经许可禁止复制
题图来自Unsplash,基于CC0协议
文章采集api(优采云采集支持调用优采云(小狗AI)API处理规则(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-03-03 13:11
)
优采云采集支持调用优采云(小狗AI)API接口,处理采集的数据标题和内容等;
温馨提示:第三方API接入功能需要用户提供第三方接口账号信息(即用户需要注册第三方接口,调用第三方接口产生的一切费用均需自行承担)由用户);
购买优采云 (Puppy AI) API,请先联系优采云 (Puppy AI) 客服并告知将用于优采云采集平台;
详细使用步骤
1.创建优采云API接口配置一、API配置入口:
点击控制台左侧列表中的【第三方服务配置】==点击【第三方内容API接入】==点击【第三方API配置管理】==最后点击【< @优采云API] 创建接口配置;
二、配置API接口信息:
购买优采云 (Puppy AI) API,请先联系优采云 (Puppy AI) 客服并告知将用于优采云采集平台。
【API key】是从优采云(Puppy AI)后台获取对应的API key,填入优采云;
注意:优采云限制每次调用最多6000个字符(包括html代码),所以当内容长度超过时,优采云会被拆分多次调用,会增加api调用次数,费用会相应增加,这是用户需要承担的费用,使用前一定要注意!!!!
2. 创建 API 处理规则
API处理规则,可以通过调用API接口设置处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==,点击【第三方内容API接入】==进入【API处理规则管理】页面,最后点击【+添加API处理规则]创建API处理规则;
二、API处理规则配置:
3. API 处理规则使用
API处理规则有两种使用方式:手动执行和自动执行:
一、手动执行API处理规则:
在采集任务的【结果数据&发布】选项卡中,点击【SEO&API&翻译等工具】按钮==选择【第三方API执行】栏==选择对应的API处理规则= ="执行(数据范围有两种执行方式,根据发布状态批量执行和根据列表中选择的数据执行);
二、自动执行API处理规则:
启用 API 处理的自动执行。任务完成后采集会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡【自动执行第三方API配置】==勾选【采集,自动执行API】选项==选择要执行的API处理规则= ="选择API接口处理的数据范围(一般选择'待发布',都将导致所有数据重复执行),最后点击保存;
4. API处理结果并发布一、查看API接口处理结果:
API接口处理的内容会保存为一个新的字段,如:标题处理后的新字段:`title_优采云`,内容处理后的新字段:`content_优采云`,在【结果数据&发布】和数据预览界面可以查看。
提示:执行 API 处理规则需要一段时间。执行完成后,页面会自动刷新,并出现API接口处理的新字段;
二、API接口处理后的内容发布
发布文章前,修改发布目标第二步的映射字段,重新选择标题和内容为对应字段`title_优采云`和`content_优采云`后面添加API接口处理;
提示:如果发布目标中无法选择新字段,请在任务下复制或新建发布目标,然后在新发布目标中选择新字段即可。详细教程请参考发布目标中不能选择的字段。
5. 优采云-API接口常见问题及解决方法一、API处理规则和SEO规则如何配合使用?
系统默认对title和content字段进行SEO功能,需要在SEO规则中修改为`title_优采云`和`content_优采云`字段;
查看全部
文章采集api(优采云采集支持调用优采云(小狗AI)API处理规则(组图)
)
优采云采集支持调用优采云(小狗AI)API接口,处理采集的数据标题和内容等;
温馨提示:第三方API接入功能需要用户提供第三方接口账号信息(即用户需要注册第三方接口,调用第三方接口产生的一切费用均需自行承担)由用户);
购买优采云 (Puppy AI) API,请先联系优采云 (Puppy AI) 客服并告知将用于优采云采集平台;
详细使用步骤
1.创建优采云API接口配置一、API配置入口:
点击控制台左侧列表中的【第三方服务配置】==点击【第三方内容API接入】==点击【第三方API配置管理】==最后点击【< @优采云API] 创建接口配置;

二、配置API接口信息:
购买优采云 (Puppy AI) API,请先联系优采云 (Puppy AI) 客服并告知将用于优采云采集平台。
【API key】是从优采云(Puppy AI)后台获取对应的API key,填入优采云;


注意:优采云限制每次调用最多6000个字符(包括html代码),所以当内容长度超过时,优采云会被拆分多次调用,会增加api调用次数,费用会相应增加,这是用户需要承担的费用,使用前一定要注意!!!!
2. 创建 API 处理规则
API处理规则,可以通过调用API接口设置处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==,点击【第三方内容API接入】==进入【API处理规则管理】页面,最后点击【+添加API处理规则]创建API处理规则;

二、API处理规则配置:

3. API 处理规则使用
API处理规则有两种使用方式:手动执行和自动执行:
一、手动执行API处理规则:
在采集任务的【结果数据&发布】选项卡中,点击【SEO&API&翻译等工具】按钮==选择【第三方API执行】栏==选择对应的API处理规则= ="执行(数据范围有两种执行方式,根据发布状态批量执行和根据列表中选择的数据执行);

二、自动执行API处理规则:

启用 API 处理的自动执行。任务完成后采集会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡【自动执行第三方API配置】==勾选【采集,自动执行API】选项==选择要执行的API处理规则= ="选择API接口处理的数据范围(一般选择'待发布',都将导致所有数据重复执行),最后点击保存;
4. API处理结果并发布一、查看API接口处理结果:
API接口处理的内容会保存为一个新的字段,如:标题处理后的新字段:`title_优采云`,内容处理后的新字段:`content_优采云`,在【结果数据&发布】和数据预览界面可以查看。
提示:执行 API 处理规则需要一段时间。执行完成后,页面会自动刷新,并出现API接口处理的新字段;


二、API接口处理后的内容发布
发布文章前,修改发布目标第二步的映射字段,重新选择标题和内容为对应字段`title_优采云`和`content_优采云`后面添加API接口处理;

提示:如果发布目标中无法选择新字段,请在任务下复制或新建发布目标,然后在新发布目标中选择新字段即可。详细教程请参考发布目标中不能选择的字段。
5. 优采云-API接口常见问题及解决方法一、API处理规则和SEO规则如何配合使用?
系统默认对title和content字段进行SEO功能,需要在SEO规则中修改为`title_优采云`和`content_优采云`字段;

文章采集api(APIPlatform可以快速的帮助我们创建操作文章的API接口)
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-03-03 13:08
API Platform 可以快速帮助我们创建 API。我们需要创建操作 文章 的 API 接口。我们打开 Post 类。在 Post 类之前,我们只需要添加一个注解 ApiResource。
#src/Entity/Post.php
/**
* @ORM\Entity(repositoryClass=PostRepository::class)
* @ORM\HasLifecycleCallbacks
*/
#[ApiResource]
class Post
{
// ...
}
我们打开配置目录。在config目录下,flex组件自动为我们添加了api_platform.yaml配置文件。我们打开配置文件,API Platform会自动检索Entity目录下的所有类,读取类之前的注解,然后根据注解设置生成API接口。
回到浏览器,我们刷新 Api 文档页面,API Platform 自动创建了 6 个接口来操作 文章 资源。前两个接口使用一个路径,后四个接口使用一个路径。这些接口使用相对统一的路径。但是同一个路径的接口,它们的方法是不一样的。
我们来看第一个接口,它使用 GET 方法来检索 文章 资源的集合。第二个接口使用 POST 方法创建 文章 资源。第三接口是操作单一资源的接口。GET 方法在这里用于检索 文章 资源。下面使用PUT方法,用于替换文章资源。第五个接口,该接口使用DELETE方法删除文章资源。最后一个使用 PATCH 方法,用于更新 文章 资源。
PUT 方法和 PATCH 方法都是对 文章 资源的修改,但是这两种方法之间存在一些差异。PUT 方法是对 文章 资源的整体替代。PATCH 方法是更新 文章 资源的一个或一些属性。这是 API 平台按照 REST 规范设计的一组 API。
它们有一个相对统一的路径,接口的方法也很重要。根据REST规范设计的接口具有相应的功能。这样,如果我们设计的界面被其他用户使用,其他用户可以快速上手。
我们可以直接在文档页面操作界面,我们看第三个界面,检索一篇文章文章。查看 文章 的列表,我们得到 ID 为 21 的 文章。单击,单击 Try it out 按钮,我们输入 id 参数。在这里输入21,点击后点击Execute。
curl库会发送一个get请求,请求地址为/api/posts/21,请求头有accept参数,接收到的响应格式为application/ld+json格式。在下一课中,我们将学习这种格式。
我们来看看响应的结果,响应码是400,有错误,还有循环引用。当我们得到某个文章数据时,我们也得到了文章的作者。回到项目,我们打开 User 类。在User类中,我们要获取当前作者的所有文章,然后再次获取文章。然后在文章中再次检索作者,所以有循环引用。我们在 User 类之前添加 API 注解,回到浏览器中,我们再次使用这个接口。
#src/Entity/User.php
/**
* @ORM\Entity(repositoryClass=UserRepository::class)
*/
#[ApiResource]
class User implements UserInterface, PasswordAuthenticatedUserInterface
{
// ...
}
这次我们看到当前的文章信息,作者属性没有展开,它得到一个字符串。在下一课中,我们将详细解释响应的结果格式。 查看全部
文章采集api(APIPlatform可以快速的帮助我们创建操作文章的API接口)
API Platform 可以快速帮助我们创建 API。我们需要创建操作 文章 的 API 接口。我们打开 Post 类。在 Post 类之前,我们只需要添加一个注解 ApiResource。
#src/Entity/Post.php
/**
* @ORM\Entity(repositoryClass=PostRepository::class)
* @ORM\HasLifecycleCallbacks
*/
#[ApiResource]
class Post
{
// ...
}
我们打开配置目录。在config目录下,flex组件自动为我们添加了api_platform.yaml配置文件。我们打开配置文件,API Platform会自动检索Entity目录下的所有类,读取类之前的注解,然后根据注解设置生成API接口。
回到浏览器,我们刷新 Api 文档页面,API Platform 自动创建了 6 个接口来操作 文章 资源。前两个接口使用一个路径,后四个接口使用一个路径。这些接口使用相对统一的路径。但是同一个路径的接口,它们的方法是不一样的。
我们来看第一个接口,它使用 GET 方法来检索 文章 资源的集合。第二个接口使用 POST 方法创建 文章 资源。第三接口是操作单一资源的接口。GET 方法在这里用于检索 文章 资源。下面使用PUT方法,用于替换文章资源。第五个接口,该接口使用DELETE方法删除文章资源。最后一个使用 PATCH 方法,用于更新 文章 资源。
PUT 方法和 PATCH 方法都是对 文章 资源的修改,但是这两种方法之间存在一些差异。PUT 方法是对 文章 资源的整体替代。PATCH 方法是更新 文章 资源的一个或一些属性。这是 API 平台按照 REST 规范设计的一组 API。
它们有一个相对统一的路径,接口的方法也很重要。根据REST规范设计的接口具有相应的功能。这样,如果我们设计的界面被其他用户使用,其他用户可以快速上手。
我们可以直接在文档页面操作界面,我们看第三个界面,检索一篇文章文章。查看 文章 的列表,我们得到 ID 为 21 的 文章。单击,单击 Try it out 按钮,我们输入 id 参数。在这里输入21,点击后点击Execute。
curl库会发送一个get请求,请求地址为/api/posts/21,请求头有accept参数,接收到的响应格式为application/ld+json格式。在下一课中,我们将学习这种格式。
我们来看看响应的结果,响应码是400,有错误,还有循环引用。当我们得到某个文章数据时,我们也得到了文章的作者。回到项目,我们打开 User 类。在User类中,我们要获取当前作者的所有文章,然后再次获取文章。然后在文章中再次检索作者,所以有循环引用。我们在 User 类之前添加 API 注解,回到浏览器中,我们再次使用这个接口。
#src/Entity/User.php
/**
* @ORM\Entity(repositoryClass=UserRepository::class)
*/
#[ApiResource]
class User implements UserInterface, PasswordAuthenticatedUserInterface
{
// ...
}
这次我们看到当前的文章信息,作者属性没有展开,它得到一个字符串。在下一课中,我们将详细解释响应的结果格式。
文章采集api(wordpress的内容算得上是优质内容吗?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-03-02 09:02
wordpress采集插件的使用,根据关键词采集对应的文章,哪些内容会被搜索索引判断为优质内容?这也是站长圈一直在讨论的问题。随着搜索引擎算法规则的不断升级和更新,判断优质内容的标准越来越高。那么什么样的内容才能算是优质内容呢?
wordpress采集插件的有效内容输出,首先,什么是有效内容输出,其实不管是新站长还是老站长,或多或少的时候都会为目的而创作内容的创建内容。如果没有搜索到你发布的内容,即使你的内容每天排名第一,没人看到你认为这个内容有意义吗?因此,有效的内容制作非常重要。
wordpress采集 插件生成的内容必须与标题一致。这里是网站生成的内容要和标题一致。下来,因为你的内容不符合用户的需求,用户不会长时间停留在这个页面,导致跳出率高,搜索引擎会认为这个内容是低质量的内容,所以产生的内容必须匹配标题和文本。无论标题是什么,内容都必须写出来。
wordpress采集插件选择的文章标题肯定是用户需要的,接下来就是创建内容了,网站创建的内容一定要解决用户的问题。做到以上两点,网站好的内容就会产生,但如果是优质的就不一定了,所以优质的内容必须满足以下条件。
网页的加载速度决定了它是否影响用户体验。用户很难访问您的 网站。网站首屏加载速度不能低于3秒。如果慢于 3 秒,就会被搜索引擎考虑。这是一个低质量的页面。如果你的内容真的是高质量的,但是因为网站加载速度的问题,被搜索引擎判断为低质量的内容,那不值得。
影响搜索引擎爬虫的爬取。在搜索引擎爬虫方面,由于你的网页打开速度慢,搜索引擎爬虫会爬取你的网站页面,但是很长时间没有加载,搜索引擎爬虫就会放弃这个页面. 其实,我们不妨换一种方式来思考这个问题。两个 网站 页面中的一个只需要 1 秒就可以爬取到,而另一个页面在 10 秒内不能爬取到。如果搜索引擎爬虫,哪个页面是爬虫收录?答案显然是爬取只需要 1 秒打开的 收录 页面。如果一个 网站 没有任何 收录,那么 关键词 的排名呢?
wordpress采集插件的内容文本是可读的,网站产生的内容是可读的,但是很难看懂。根据今天的搜索技术,这样的内容搜索引擎可以识别它。在 文章 的内容中,文字颜色可以设置为黑色或深灰色,但有些站长更喜欢将某些字体设置为浅灰色或类似于网页背景的颜色以用于其他用途。这是一个严重的问题。影响用户体验的行业也不算是优质内容。
有的站长将文章内容字体设置得太小或者段落间距太近,都会影响用户体验。想一想,如果用户看你的文章内容那么辛苦,而搜索引擎中类似的内容成千上万,那他为什么要看你的内容呢?他可以简单地关闭您的网页并查看其他网站 内容。 查看全部
文章采集api(wordpress的内容算得上是优质内容吗?(图))
wordpress采集插件的使用,根据关键词采集对应的文章,哪些内容会被搜索索引判断为优质内容?这也是站长圈一直在讨论的问题。随着搜索引擎算法规则的不断升级和更新,判断优质内容的标准越来越高。那么什么样的内容才能算是优质内容呢?

wordpress采集插件的有效内容输出,首先,什么是有效内容输出,其实不管是新站长还是老站长,或多或少的时候都会为目的而创作内容的创建内容。如果没有搜索到你发布的内容,即使你的内容每天排名第一,没人看到你认为这个内容有意义吗?因此,有效的内容制作非常重要。

wordpress采集 插件生成的内容必须与标题一致。这里是网站生成的内容要和标题一致。下来,因为你的内容不符合用户的需求,用户不会长时间停留在这个页面,导致跳出率高,搜索引擎会认为这个内容是低质量的内容,所以产生的内容必须匹配标题和文本。无论标题是什么,内容都必须写出来。

wordpress采集插件选择的文章标题肯定是用户需要的,接下来就是创建内容了,网站创建的内容一定要解决用户的问题。做到以上两点,网站好的内容就会产生,但如果是优质的就不一定了,所以优质的内容必须满足以下条件。

网页的加载速度决定了它是否影响用户体验。用户很难访问您的 网站。网站首屏加载速度不能低于3秒。如果慢于 3 秒,就会被搜索引擎考虑。这是一个低质量的页面。如果你的内容真的是高质量的,但是因为网站加载速度的问题,被搜索引擎判断为低质量的内容,那不值得。
影响搜索引擎爬虫的爬取。在搜索引擎爬虫方面,由于你的网页打开速度慢,搜索引擎爬虫会爬取你的网站页面,但是很长时间没有加载,搜索引擎爬虫就会放弃这个页面. 其实,我们不妨换一种方式来思考这个问题。两个 网站 页面中的一个只需要 1 秒就可以爬取到,而另一个页面在 10 秒内不能爬取到。如果搜索引擎爬虫,哪个页面是爬虫收录?答案显然是爬取只需要 1 秒打开的 收录 页面。如果一个 网站 没有任何 收录,那么 关键词 的排名呢?

wordpress采集插件的内容文本是可读的,网站产生的内容是可读的,但是很难看懂。根据今天的搜索技术,这样的内容搜索引擎可以识别它。在 文章 的内容中,文字颜色可以设置为黑色或深灰色,但有些站长更喜欢将某些字体设置为浅灰色或类似于网页背景的颜色以用于其他用途。这是一个严重的问题。影响用户体验的行业也不算是优质内容。
有的站长将文章内容字体设置得太小或者段落间距太近,都会影响用户体验。想一想,如果用户看你的文章内容那么辛苦,而搜索引擎中类似的内容成千上万,那他为什么要看你的内容呢?他可以简单地关闭您的网页并查看其他网站 内容。
文章采集api(分布式事务为什么会使用分布式商城开发框架?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-04-17 22:18
开始
自建商城设计之初,业务部就提出了两个要求:不倒塌,快速上线。
项目立项后,团队还没有完全装备好。在从其他团队招聘人员的同时,我们也在大力招聘。同时,我们的架构师也在搭建分布式商城开发框架,编写demo,让新生可以快速上手。
暴露问题
问题 1:分布式事务
为什么要使用分布式事务?
这暂时可以归结为快速上线,因为订单的生成会调用商品服务去扣库存,而使用分布式事务解决了跨服务调用导致的库存超卖问题,是性能消耗。
问题二:数据库压力
大促的时候有直接从业务数据库查询的实时统计,运营部小姐姐不断刷新,给界面造成很大压力,没有使用缓存,所以连接 SQL 查询条件需要时间。都是动态的,以至于无法使用DB层的缓存,每次请求都命中DB。
开发测试环境使用自建MySQL,生产环境使用PolarDB。来自阿里云官网:
我们主观上认为只要使用集群连接地址,就会自动进行读写分离,但实际上并没有。后来我们发现,如果我们在方法中显式指定一个只读事务,就会有请求去只读节点。
@Transactional(readOnly = true)
# 优化思路:
1)从SQL洞察和慢SQL中找出响应时间最长、频率最高的SQL;
2)结合代码,可以直接被缓存处理,而不是无法缓存的优化查询。结合阿里云提供的优化分析工具,可以调整指标;
3) 活动高峰期,禁止执行分析统计查询,暂时改代码已来不及。感谢AHAS(阿里云限流降级产品)的接口限流和SQL限流功能;
4)TP和AP分开,避免分析类直接查询到业务库(这个过程比较长)。
问题三:缓存压力
除了上面提到的分布式事务,我发现有同事用Keys写模糊查询Redis,直接导致Redis的CPU严重飙升。阿里云提供的 Redis 管理工具可以轻松检查慢查询。
另一个低级错误,我们认为它不应该是第一个,也不会是最后一个。最初,我们想设置一个 Key 的过期时间。结果我们少写了一个Unit参数,第三个改变了偏移量。
redisTemplate.opsForValue().set(key, value, offset)
# 为什么我们花了大约 10 分钟来解决?
1)惯性思维,没有找到review code;
2)当在错误日志中发现Redisson锁失败时,怀疑Redis已满;
3)我用阿里云的工具查大key的时候发现key很大,但是直接在网页上查值的时候只看到保存了一个字符。值好像是对的,但是大概过了2分钟左右,感觉不对劲,然后登录用redis-cli查看,傻眼了,里面全是0x00。
问题四:
商场开张当月有促销。由于瞬间进来的流量过大,小程序前端嵌入事件上报的接口连接数呈爆炸式增长。商城实时数据统计调用流量统计服务接口,但服务调用超时时间设置为60s,导致请求过多积压,CPU突然暴涨。
# 优化思路:
1)充分利用Nginx的并发处理能力,Lua脚本提供强大的处理能力,使用OpenResty接收来自Java的请求;
2)收到请求并做基础验证后,使用lua-resty-kafka模块异步发送到Kafka;
3)Kafka放到HDFS上后,Spark会离线计算日志数据;
4)后端接口独立部署,实时数据统计调用接口设置更短的超时时间;
经过上述改造,前端日志上报服务的单机处理能力由原来的1K增加了40K。丝般顺滑的体验真的很棒。
迭代
从当时的情况来看,为双十一活动调整代码优化基本上已经来不及了,距离活动还有不到两周的时间。就算改了,风险也很大。
1、压力测试
作为一个新推出的项目,数据量比较少。使用云服务搭建1:1压测环境相对容易。这个时间点,我们需要模拟真实场景来了解当前的系统性能。需要多少压力,需要多少台机器。
阿里云上有一个PTS压力测量工具,可以直接导入Jmeter脚本,使用非常方便。先说一下我们的使用步骤:
1)首先,根据近一个月的用户行为日志,找出用户的路径和每个行为的思考时间,并做了一个粗略的模型;
2)根据双十一活动的运行节奏,定义两个或三个场景;
3)使用ECS搭建Jmeter集群,内网对接口施加压力,以减少网络开销,允许向后端服务器发送请求;
4)观察服务器压力,调整应用内存分配,然后通过PolarDB的性能分析,找出存在性能瓶颈的SQL,尽可能优化;
5)将Jmeter脚本导入PTS,将数据库与ECS机器的云监控关联,设置思考时间等相关参数并施加压力,可以秒级动态调整压力,产生的压力测试报告是我们想要的结果,需要用于接下来的限流控制。
2、电流限制
上传的API与Restful风格的API不兼容,导致URL出现参数时多个URL没有合并在一起的情况。阿里云 AHAS 支持团队立即发布了 Fix 版本,并提供了新的 SentinelWebInterceptor 拦截器来清理 Restful 风格的 API 处理。; 在访问AHAS的应用模块进行限流时,也是使用SDK的访问方式。根据官网文档访问时,发现我们的微商城使用的是最新版本的Mybatis Plus版本。访问SQL限流分析时发现函数执行过程中出现ahas错误。将此情况报告给ahas钉钉团队的支持小组后,已经快凌晨1:00了 ahas团队及时响应,次日上午发布了兼容Mybatis Plus版本的SQL限流分析版本。对我们的微商城来说,进入新版本后,SQL分析和限流功能也可以正常使用了;在使用AHAS访问时,发现AHAS提供了CPU/Load的限流,为监控和保护服务器性能做了很好的保驾护航。当微商城服务器压力过大时,可以很好的保护服务器不被高并发压垮,保证服务的高可用。当服务器压力较大时,实现实时QPS日志上传的隔离,避免上传抢占服务器资源,并确保服务器在访问AHAS后能够保持良好的性能。未来
未来计划做:
1)按服务拆分Redis;
2)数据库读写分离,分库分表,TP/AP分离;
3)业务集中:建立业务中心,打通商品中心、库存中心、用户中心、交易中心; 查看全部
文章采集api(分布式事务为什么会使用分布式商城开发框架?(图))
开始
自建商城设计之初,业务部就提出了两个要求:不倒塌,快速上线。
项目立项后,团队还没有完全装备好。在从其他团队招聘人员的同时,我们也在大力招聘。同时,我们的架构师也在搭建分布式商城开发框架,编写demo,让新生可以快速上手。
暴露问题
问题 1:分布式事务
为什么要使用分布式事务?
这暂时可以归结为快速上线,因为订单的生成会调用商品服务去扣库存,而使用分布式事务解决了跨服务调用导致的库存超卖问题,是性能消耗。
问题二:数据库压力
大促的时候有直接从业务数据库查询的实时统计,运营部小姐姐不断刷新,给界面造成很大压力,没有使用缓存,所以连接 SQL 查询条件需要时间。都是动态的,以至于无法使用DB层的缓存,每次请求都命中DB。
开发测试环境使用自建MySQL,生产环境使用PolarDB。来自阿里云官网:
我们主观上认为只要使用集群连接地址,就会自动进行读写分离,但实际上并没有。后来我们发现,如果我们在方法中显式指定一个只读事务,就会有请求去只读节点。
@Transactional(readOnly = true)
# 优化思路:
1)从SQL洞察和慢SQL中找出响应时间最长、频率最高的SQL;
2)结合代码,可以直接被缓存处理,而不是无法缓存的优化查询。结合阿里云提供的优化分析工具,可以调整指标;
3) 活动高峰期,禁止执行分析统计查询,暂时改代码已来不及。感谢AHAS(阿里云限流降级产品)的接口限流和SQL限流功能;
4)TP和AP分开,避免分析类直接查询到业务库(这个过程比较长)。
问题三:缓存压力
除了上面提到的分布式事务,我发现有同事用Keys写模糊查询Redis,直接导致Redis的CPU严重飙升。阿里云提供的 Redis 管理工具可以轻松检查慢查询。
另一个低级错误,我们认为它不应该是第一个,也不会是最后一个。最初,我们想设置一个 Key 的过期时间。结果我们少写了一个Unit参数,第三个改变了偏移量。
redisTemplate.opsForValue().set(key, value, offset)
# 为什么我们花了大约 10 分钟来解决?
1)惯性思维,没有找到review code;
2)当在错误日志中发现Redisson锁失败时,怀疑Redis已满;
3)我用阿里云的工具查大key的时候发现key很大,但是直接在网页上查值的时候只看到保存了一个字符。值好像是对的,但是大概过了2分钟左右,感觉不对劲,然后登录用redis-cli查看,傻眼了,里面全是0x00。
问题四:
商场开张当月有促销。由于瞬间进来的流量过大,小程序前端嵌入事件上报的接口连接数呈爆炸式增长。商城实时数据统计调用流量统计服务接口,但服务调用超时时间设置为60s,导致请求过多积压,CPU突然暴涨。
# 优化思路:
1)充分利用Nginx的并发处理能力,Lua脚本提供强大的处理能力,使用OpenResty接收来自Java的请求;
2)收到请求并做基础验证后,使用lua-resty-kafka模块异步发送到Kafka;
3)Kafka放到HDFS上后,Spark会离线计算日志数据;
4)后端接口独立部署,实时数据统计调用接口设置更短的超时时间;
经过上述改造,前端日志上报服务的单机处理能力由原来的1K增加了40K。丝般顺滑的体验真的很棒。
迭代
从当时的情况来看,为双十一活动调整代码优化基本上已经来不及了,距离活动还有不到两周的时间。就算改了,风险也很大。
1、压力测试
作为一个新推出的项目,数据量比较少。使用云服务搭建1:1压测环境相对容易。这个时间点,我们需要模拟真实场景来了解当前的系统性能。需要多少压力,需要多少台机器。
阿里云上有一个PTS压力测量工具,可以直接导入Jmeter脚本,使用非常方便。先说一下我们的使用步骤:
1)首先,根据近一个月的用户行为日志,找出用户的路径和每个行为的思考时间,并做了一个粗略的模型;
2)根据双十一活动的运行节奏,定义两个或三个场景;
3)使用ECS搭建Jmeter集群,内网对接口施加压力,以减少网络开销,允许向后端服务器发送请求;
4)观察服务器压力,调整应用内存分配,然后通过PolarDB的性能分析,找出存在性能瓶颈的SQL,尽可能优化;
5)将Jmeter脚本导入PTS,将数据库与ECS机器的云监控关联,设置思考时间等相关参数并施加压力,可以秒级动态调整压力,产生的压力测试报告是我们想要的结果,需要用于接下来的限流控制。
2、电流限制
上传的API与Restful风格的API不兼容,导致URL出现参数时多个URL没有合并在一起的情况。阿里云 AHAS 支持团队立即发布了 Fix 版本,并提供了新的 SentinelWebInterceptor 拦截器来清理 Restful 风格的 API 处理。; 在访问AHAS的应用模块进行限流时,也是使用SDK的访问方式。根据官网文档访问时,发现我们的微商城使用的是最新版本的Mybatis Plus版本。访问SQL限流分析时发现函数执行过程中出现ahas错误。将此情况报告给ahas钉钉团队的支持小组后,已经快凌晨1:00了 ahas团队及时响应,次日上午发布了兼容Mybatis Plus版本的SQL限流分析版本。对我们的微商城来说,进入新版本后,SQL分析和限流功能也可以正常使用了;在使用AHAS访问时,发现AHAS提供了CPU/Load的限流,为监控和保护服务器性能做了很好的保驾护航。当微商城服务器压力过大时,可以很好的保护服务器不被高并发压垮,保证服务的高可用。当服务器压力较大时,实现实时QPS日志上传的隔离,避免上传抢占服务器资源,并确保服务器在访问AHAS后能够保持良好的性能。未来
未来计划做:
1)按服务拆分Redis;
2)数据库读写分离,分库分表,TP/AP分离;
3)业务集中:建立业务中心,打通商品中心、库存中心、用户中心、交易中心;
文章采集api(本节比较简单,有开发经验可以跳过。。(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-04-12 19:24
这部分比较简单,有开发经验的可以跳过。
使用 APIAPI 概述
百度百科对API的解释:API(Application Programming Interface,应用程序编程接口)是一些预定义的函数,目的是为应用程序和开发者提供基于某种软件或硬件访问一组例程的能力,而不需要访问源代码,或了解内部工作的细节。
表示这是接口,不管语言限制都可以调用。
API 通用规则
API 使用一套非常标准的规则来生成数据,并且生成的数据以非常标准的方式组织。
方法
有许多方法可以使用 HTTP 从 Web 服务器请求信息。这里有四种常用的方法: GET:从服务器获取数据的方法;POST:向服务器发送数据。比如提交表单到服务器处理的逻辑;PUT:主要用于更新一个对象或信息,一般很少用到;DELETE:从服务器中删除一个对象。
核实
API 不能随时或由任何人调用。为了保证服务器上的安全或减少资源等,我们会限制请求的方法或数量。通常,接口是经过验证的。一般的验证方法是令牌。该令牌一般在用户登录或注册时从服务器生成,然后交给用户。令牌可以是可变的或不可变的。除了在 URL 链接中传递 token 外,它还通过请求头中的 cookie 将用户信息传递给服务器。简单的例子:
token = ""
webRequest = urllib.request.Request("http://myapi.com", headers={"token":token})
html = urlopen(webRequest)
服务器响应
服务器响应的数据格式一般为 JSON 或 XML。目前 JSON 有很多原因,其中之一是 JSON 文件比完整的 XML 格式小;再加上网络技术的变化,后端语言越来越多,基本上所有接口都能实现。
API 调用的语法也存在差异,但也有既定的准则。例如,使用GET请求获取数据时,使用URL路径描述要获取的数据范围,查询参数可以作为过滤器或附加请求;还有很多API以文件路径(path)的形式指定API版本和数据格式。和其他财产;有些API以请求参数的形式指定数据格式和API版本:
市面上很多公司或者网站都有自己的公共接口,比如推特、谷歌等。
解析 JSON 数据
例如,我们使用 GET 来请求和查看返回的数据。返回为:
1
{"ip":"50.78.253.58","country_code":"US","country_name":"United States","region_code":"MA ","region_name":"Massachusetts","city":"Boston","zip_code":"02116","time_zone":"America/New_York","latitude":42.3496,"longitude ":-71.0746,"metro_code":506}
现在我们使用 Python 来解析。JSON 是 Python 的标准库,不需要额外安装。代码显示如下:
import json
from urllib.request import urlopen
def getCountry(ipAddress):
res = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
resJson = json.loads(res)
return resJson.get('country_code')
print(getCountry("22.18.53.22"))
Python 使用更灵活的方式将 JSON 转换为字典,将 JSON 数组转换为列表,以及将 JSON 字符串转换为 Python 字符串。 查看全部
文章采集api(本节比较简单,有开发经验可以跳过。。(组图))
这部分比较简单,有开发经验的可以跳过。
使用 APIAPI 概述
百度百科对API的解释:API(Application Programming Interface,应用程序编程接口)是一些预定义的函数,目的是为应用程序和开发者提供基于某种软件或硬件访问一组例程的能力,而不需要访问源代码,或了解内部工作的细节。
表示这是接口,不管语言限制都可以调用。
API 通用规则
API 使用一套非常标准的规则来生成数据,并且生成的数据以非常标准的方式组织。
方法
有许多方法可以使用 HTTP 从 Web 服务器请求信息。这里有四种常用的方法: GET:从服务器获取数据的方法;POST:向服务器发送数据。比如提交表单到服务器处理的逻辑;PUT:主要用于更新一个对象或信息,一般很少用到;DELETE:从服务器中删除一个对象。
核实
API 不能随时或由任何人调用。为了保证服务器上的安全或减少资源等,我们会限制请求的方法或数量。通常,接口是经过验证的。一般的验证方法是令牌。该令牌一般在用户登录或注册时从服务器生成,然后交给用户。令牌可以是可变的或不可变的。除了在 URL 链接中传递 token 外,它还通过请求头中的 cookie 将用户信息传递给服务器。简单的例子:
token = ""
webRequest = urllib.request.Request("http://myapi.com", headers={"token":token})
html = urlopen(webRequest)
服务器响应
服务器响应的数据格式一般为 JSON 或 XML。目前 JSON 有很多原因,其中之一是 JSON 文件比完整的 XML 格式小;再加上网络技术的变化,后端语言越来越多,基本上所有接口都能实现。
API 调用的语法也存在差异,但也有既定的准则。例如,使用GET请求获取数据时,使用URL路径描述要获取的数据范围,查询参数可以作为过滤器或附加请求;还有很多API以文件路径(path)的形式指定API版本和数据格式。和其他财产;有些API以请求参数的形式指定数据格式和API版本:
市面上很多公司或者网站都有自己的公共接口,比如推特、谷歌等。
解析 JSON 数据
例如,我们使用 GET 来请求和查看返回的数据。返回为:
1
{"ip":"50.78.253.58","country_code":"US","country_name":"United States","region_code":"MA ","region_name":"Massachusetts","city":"Boston","zip_code":"02116","time_zone":"America/New_York","latitude":42.3496,"longitude ":-71.0746,"metro_code":506}
现在我们使用 Python 来解析。JSON 是 Python 的标准库,不需要额外安装。代码显示如下:
import json
from urllib.request import urlopen
def getCountry(ipAddress):
res = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
resJson = json.loads(res)
return resJson.get('country_code')
print(getCountry("22.18.53.22"))
Python 使用更灵活的方式将 JSON 转换为字典,将 JSON 数组转换为列表,以及将 JSON 字符串转换为 Python 字符串。
文章采集api( PHP+fiddler抓包采集微信文章阅读数点效果总结)
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2022-04-12 10:10
PHP+fiddler抓包采集微信文章阅读数点效果总结)
2.截取这个接口转发到自己的服务器,点击rules-customize rules添加到OnBeforeRequest(正式请求前执行的函数)
if (oSession.fullUrl.Contains("mp.weixin.qq.com/mp/getappmsgext"))
{
oSession.oRequest["Host"]= 'ccc.aaa.com' ;
}
效果,可以看到这个接口已经转发了
3.服务器缓存key,代码以php为例
public function saveKey(Request $request)
{
$__biz = $request->param('__biz',0);
$data['uin'] = $request->param('uin',0);
$data['key'] = $request->param('key',0);
Cache::set($__biz,$data,30 * 60);
return 'ok';
}
4.提交文章链接查询API代码
public function getReadNum(Request $request)
{
$url = $request->param('url');
parse_str(parse_url($url)['query'], $param);
$__biz = $param['__biz'];
$key_data = Cache::get($__biz);
if (empty($key_data))
return 'no key';
$uin = $key_data['uin'];
$key = $key_data['key'bPfPBxaDBm];
$param['uin'] = $uin;
$param['key'] = $key;
$param['wxtoken'] = "777";
$wechat_url = "https://mp.weixin.qq.com/mp/getappmsgext?" . http_build_query($param);
//dump($wechat_url);
$data = array(
'is_only_read' => 1,
'is_temp_url' => 0,
'appmsg_type' => 9,
);
$res = $this->get_url($wechat_url,$data);
return $res;
}
function get_url($url,$data)
{
$ifpost = 1;//是否post请求
$datafields = $data;//post数据
$cookiefile = '';//cohttp://www.cppcns.comokie文件
$cookie = '';//cookie变量
$v = false;
//模拟http请求header头
$header = array("Connection: Keep-Alive","Accept: text/html, applicabPfPBxaDBmtion/xhtml+xml, */*", "Pragma: no-cache", "Accept-Language: zh-Hans-CN,zh-Hans;q=0.8,en-US;q=0.5,en;q=0.3","User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36 QBCore/4.0.1278.400 QQBrowser/9.0.2524.400 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2875.116 Safari/537.36 Nehttp://www.cppcns.comtType/WIFI MicroMessenger/7.0.5 WindowsWechat");
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, $v);
curl_setopt($ch, CURLOPT_HTTPHEADER, $header);
$ifpost && curl_setopt($ch, CURLOPT_POST, $ifpost);
$ifpost && curl_setopt($ch, CURLOPT_POSTFIELDS, $datafields);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
$cookie && curl_setopt($ch, CURLOPT_COOKIE, $cookie);//发送cookie变量
$cookiefile && curl_setopt($ch, CURLOPT_COOKIEFILE, $cookiefile);//发送cookie文件
$cookiefile && curl_setopt($ch, CURLOPT_COOKIEJAR, $cookiefile);//写入cookie到文件
curl_setopt($ch,CURLOPT_TIMEOUT,60); //允许执行的最长秒数
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
$ok = curl_exec($ch);
curl_close($ch);
unset($ch);
return $ok;
}
5.通知客户端重定向页面(这部分没写,看我的其他文字socket文章)
6.使用fiddler修改微信文章还有j脚本,
OnBeforeResponse(返回客户端前执行的方法)中,加上跳转到中间页面的代码
影响
总结
以上就是小编为大家介绍的PHP+fiddler抓包采集微信文章阅读量和点赞数,希望对你有所帮助。有什么问题请给我留言,小编会及时回复你的。我们还要感谢大家的支持网站!
如果您觉得本文对您有帮助,欢迎转载,请注明出处,谢谢!
本文标题:PHP+fiddler抓包采集微信文章阅读点赞数思路详解 查看全部
文章采集api(
PHP+fiddler抓包采集微信文章阅读数点效果总结)
2.截取这个接口转发到自己的服务器,点击rules-customize rules添加到OnBeforeRequest(正式请求前执行的函数)
if (oSession.fullUrl.Contains("mp.weixin.qq.com/mp/getappmsgext"))
{
oSession.oRequest["Host"]= 'ccc.aaa.com' ;
}
效果,可以看到这个接口已经转发了
3.服务器缓存key,代码以php为例
public function saveKey(Request $request)
{
$__biz = $request->param('__biz',0);
$data['uin'] = $request->param('uin',0);
$data['key'] = $request->param('key',0);
Cache::set($__biz,$data,30 * 60);
return 'ok';
}
4.提交文章链接查询API代码
public function getReadNum(Request $request)
{
$url = $request->param('url');
parse_str(parse_url($url)['query'], $param);
$__biz = $param['__biz'];
$key_data = Cache::get($__biz);
if (empty($key_data))
return 'no key';
$uin = $key_data['uin'];
$key = $key_data['key'bPfPBxaDBm];
$param['uin'] = $uin;
$param['key'] = $key;
$param['wxtoken'] = "777";
$wechat_url = "https://mp.weixin.qq.com/mp/getappmsgext?" . http_build_query($param);
//dump($wechat_url);
$data = array(
'is_only_read' => 1,
'is_temp_url' => 0,
'appmsg_type' => 9,
);
$res = $this->get_url($wechat_url,$data);
return $res;
}
function get_url($url,$data)
{
$ifpost = 1;//是否post请求
$datafields = $data;//post数据
$cookiefile = '';//cohttp://www.cppcns.comokie文件
$cookie = '';//cookie变量
$v = false;
//模拟http请求header头
$header = array("Connection: Keep-Alive","Accept: text/html, applicabPfPBxaDBmtion/xhtml+xml, */*", "Pragma: no-cache", "Accept-Language: zh-Hans-CN,zh-Hans;q=0.8,en-US;q=0.5,en;q=0.3","User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36 QBCore/4.0.1278.400 QQBrowser/9.0.2524.400 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2875.116 Safari/537.36 Nehttp://www.cppcns.comtType/WIFI MicroMessenger/7.0.5 WindowsWechat");
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, $v);
curl_setopt($ch, CURLOPT_HTTPHEADER, $header);
$ifpost && curl_setopt($ch, CURLOPT_POST, $ifpost);
$ifpost && curl_setopt($ch, CURLOPT_POSTFIELDS, $datafields);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
$cookie && curl_setopt($ch, CURLOPT_COOKIE, $cookie);//发送cookie变量
$cookiefile && curl_setopt($ch, CURLOPT_COOKIEFILE, $cookiefile);//发送cookie文件
$cookiefile && curl_setopt($ch, CURLOPT_COOKIEJAR, $cookiefile);//写入cookie到文件
curl_setopt($ch,CURLOPT_TIMEOUT,60); //允许执行的最长秒数
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
$ok = curl_exec($ch);
curl_close($ch);
unset($ch);
return $ok;
}
5.通知客户端重定向页面(这部分没写,看我的其他文字socket文章)
6.使用fiddler修改微信文章还有j脚本,
OnBeforeResponse(返回客户端前执行的方法)中,加上跳转到中间页面的代码
影响
总结
以上就是小编为大家介绍的PHP+fiddler抓包采集微信文章阅读量和点赞数,希望对你有所帮助。有什么问题请给我留言,小编会及时回复你的。我们还要感谢大家的支持网站!
如果您觉得本文对您有帮助,欢迎转载,请注明出处,谢谢!
本文标题:PHP+fiddler抓包采集微信文章阅读点赞数思路详解
文章采集api(数据埋点采集到底都是哪些事呢?的应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-04-12 10:01
数据采集是数据分析的基础,跟踪是最重要的采集方法。那么数据埋点采集究竟是什么?我们主要从三个方面来看:什么是埋点,埋点如何设计,埋点的应用。
一、数据采集 和常见数据问题
1.1 数据采集
数据采集的方式有很多种,埋点采集是其中非常重要的一环。它是c端和b端产品的主要采集方式。数据采集,顾名思义采集对应的数据是整个数据流的起点,采集不完整,对与不对,直接决定数据的广度和质量并影响所有后续链接;在数据采集有效性和完整性较差的公司往往会发现其业务数据发生了重大变化。
数据处理通常包括以下五个步骤:
1.2常见数据问题
在大致了解了data采集及其结构之后,我们再来看看工作中遇到的问题,有多少与data采集链接有关
1、数据与背景差距较大,数据不准确——统计口径不同,埋点定义不同,采集方法带来误差
2、想用的时候,没有我要的数据——我没提数据采集要求,埋点不正确,不全
3、事件太多,意思不清楚——埋点设计的方式,埋点更新迭代的规则和维护
4、分析数据时不知道要看哪些数据和指标——数据的定义不明确,缺乏分析思路
我们需要根本原因的解决方案:将 采集 视为独立的研发业务,而不是产品开发的附属品
二、埋葬点是什么?
2.1 葬礼是什么
所谓埋点,是data采集领域的一个名词。它的学名应该叫事件追踪,对应的英文是Event Tracking,是指捕获、处理和发送特定用户行为或事件的相关技术和实现过程。数据埋点是数据分析师、数据产品经理和数据运营商,他们根据业务需求或产品需求,针对用户行为对应的每个事件开发埋点,并通过SDK上报埋点数据结果,并记录汇总数据。分析、推动产品优化和指导运营。
该过程伴随着规范。通过定义可以看出,具体的用户行为和事件是我们采集关注的焦点,也需要处理和发送相关的技术和实现流程;数据嵌入服务于产品,来自产品。,所以和产品息息相关,重点在于具体的实战过程,这关系到大家对底层数据的理解。
2.2 你为什么要埋头苦干?
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的质量直接影响数据质量、产品质量和运营质量。
1、数据驱动——Embedding将分析深度下钻到流量分布和流量层面,通过统计分析,对宏观指标进行深度分析,发现指标背后的问题,洞察用户行为与价值提升关联之间的潜力
2、产品优化——对于产品,用户在产品中做什么,在产品中停留的时间,有哪些异常需要注意。这些问题可以通过埋点来解决。
3、精细化运营-买点可以对产品全生命周期、不同来源的流量质量和分布、行为特征和人的关系等进行细化,洞察用户行为与商业价值提升之间的潜在关系。
2.3种埋点方法
埋点方法有哪些?大多数公司目前使用客户端和服务器的组合
准确度:代码掩埋 > 视觉掩埋 > 完全掩埋
三、埋点架构与设计
3.1埋点采集顶层设计
所谓顶层设计,就是想清楚怎么埋点,用什么方式埋点,上传机制是什么,怎么定义,怎么实现等等;我们遵循唯一性、可扩展性、一致性等,需要设计一些常用的字段和生成机制,比如:cid、idfa、idfv等。
用户识别:用户识别机制的混乱会导致两种结果:一是数据不准确,如UV数据不匹配;二是漏斗分析过程出现异常。因此,应该这样做:严格规范ID自身的识别机制;湾。跨平台用户识别
同构抽象:同构抽象包括事件抽象和属性抽象。事件抽象是浏览事件和点击事件的聚合;属性抽象,即结合大部分复用场景,增加源差异化
采集一致:采集一致包括两点:一是跨平台页面命名一致,二是按钮命名一致;制定嵌入点的过程就是对底层数据进行标准化的过程,所以一致性尤为重要,只有这样才能真正使用
渠道配置:渠道主要指推广渠道、落地页、网页推广页、APP推广页等,这个落地页的配置必须有统一的规范和标准
3.2埋点采集活动及物业设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变化的,哪些是业务行为,哪些是基本属性。基于基本的属性事件,我们认为属性一定是采集项,但是属性中的事件属性会根据不同的业务进行调整。因此,我们可以将埋点采集分为协议层和业务层Bury。
业务分解:梳理确认业务流程、操作路径和不同的细分场景,定义用户行为路径
分析指标:定义特定事件和核心业务指标所需的数据
事件设计:APP启动、退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.3 资料采集事件与属性设计
Ev 事件的命名也遵循一些规则。当相同类型的函数出现在不同的页面或位置时,根据函数名进行命名,并在ev参数中区分页面和位置。只有当按钮被点击时,它才会以按钮名称命名。
ev事件格式:ev分为ev标志和ev参数
规则:
在ev标识符和ev参数之间使用“#”(一级连接符);
在ev参数和ev参数之间使用“/”(二级连接符);
ev参数使用key=value的结构。当一个key对应多个value值时,value1和value2的连接为","(三级连接符);
当埋点只有ev标志,没有ev参数时,不需要#;
评论:
ev标识:作为埋点的唯一标识,用于区分埋点的位置和属性,不可变、不可修改;
ev参数:埋点需要返回的参数。ev参数的顺序是可变的,可以修改;
调整app嵌入点时,ev logo不变,仅修改以下嵌入点参数(更改参数值或添加参数类型)
一般埋点文档中收录的工作表名称和功能:
A. 暴露埋点汇总;
B、点击浏览埋点汇总;
C、故障埋点汇总:一般会记录埋点的故障版本或时间;
D、PC和M侧页面埋点对应的pageid;
E、各版本上线时间记录;
在埋点文档中,都收录了列名和函数:
3.4 基于埋点的数据统计
如何使用埋点统计找到埋藏的 ev 事件:
1. 指定埋点类型(点击/曝光/浏览)——过滤类型字段
2. 指定按钮子点所属的页面(页面或功能)-过滤功能模块字段
3. 指定跟踪事件的名称 - 过滤名称字段
4. 知道了ev标志,就可以直接用ev过滤了
如何根据ev事件查询统计:当点击查询按钮进行统计时,可以直接使用ev标志查询。有区别时,可以限制埋点参数的取值;因为ev参数的顺序不要求是可变的,查询统计的时候,不能根据参数的顺序来限制;
四、应用——数据流的基础
4.1 指标系统
系统化的指标可以整合不同的指标、不同的维度进行综合分析,可以更快的发现当前产品和业务流程中存在的问题。
4.2 可视化
人类解释图像信息比文本更有效。可视化对于数据分析非常重要。使用数据可视化可以揭示数据中固有的复杂关系。
4.3 埋点元信息API提供
data采集 服务会将埋点到 Kafka 写入 Kafka。针对各个业务的实时数据消费需求,我们为各个业务提供单独的Kafka,流量分发模块会定时读取。取埋点管理平台提供的元信息,将流量实时分发到各个业务的Kafka。
数据采集就像设计一个产品,不应该过分,留有扩展的空间,但要不断思考有没有数据,是否完整、详细、稳定或快速。 查看全部
文章采集api(数据埋点采集到底都是哪些事呢?的应用)
数据采集是数据分析的基础,跟踪是最重要的采集方法。那么数据埋点采集究竟是什么?我们主要从三个方面来看:什么是埋点,埋点如何设计,埋点的应用。
一、数据采集 和常见数据问题
1.1 数据采集
数据采集的方式有很多种,埋点采集是其中非常重要的一环。它是c端和b端产品的主要采集方式。数据采集,顾名思义采集对应的数据是整个数据流的起点,采集不完整,对与不对,直接决定数据的广度和质量并影响所有后续链接;在数据采集有效性和完整性较差的公司往往会发现其业务数据发生了重大变化。
数据处理通常包括以下五个步骤:
1.2常见数据问题
在大致了解了data采集及其结构之后,我们再来看看工作中遇到的问题,有多少与data采集链接有关
1、数据与背景差距较大,数据不准确——统计口径不同,埋点定义不同,采集方法带来误差
2、想用的时候,没有我要的数据——我没提数据采集要求,埋点不正确,不全
3、事件太多,意思不清楚——埋点设计的方式,埋点更新迭代的规则和维护
4、分析数据时不知道要看哪些数据和指标——数据的定义不明确,缺乏分析思路
我们需要根本原因的解决方案:将 采集 视为独立的研发业务,而不是产品开发的附属品
二、埋葬点是什么?
2.1 葬礼是什么
所谓埋点,是data采集领域的一个名词。它的学名应该叫事件追踪,对应的英文是Event Tracking,是指捕获、处理和发送特定用户行为或事件的相关技术和实现过程。数据埋点是数据分析师、数据产品经理和数据运营商,他们根据业务需求或产品需求,针对用户行为对应的每个事件开发埋点,并通过SDK上报埋点数据结果,并记录汇总数据。分析、推动产品优化和指导运营。
该过程伴随着规范。通过定义可以看出,具体的用户行为和事件是我们采集关注的焦点,也需要处理和发送相关的技术和实现流程;数据嵌入服务于产品,来自产品。,所以和产品息息相关,重点在于具体的实战过程,这关系到大家对底层数据的理解。
2.2 你为什么要埋头苦干?
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的质量直接影响数据质量、产品质量和运营质量。
1、数据驱动——Embedding将分析深度下钻到流量分布和流量层面,通过统计分析,对宏观指标进行深度分析,发现指标背后的问题,洞察用户行为与价值提升关联之间的潜力
2、产品优化——对于产品,用户在产品中做什么,在产品中停留的时间,有哪些异常需要注意。这些问题可以通过埋点来解决。
3、精细化运营-买点可以对产品全生命周期、不同来源的流量质量和分布、行为特征和人的关系等进行细化,洞察用户行为与商业价值提升之间的潜在关系。
2.3种埋点方法
埋点方法有哪些?大多数公司目前使用客户端和服务器的组合
准确度:代码掩埋 > 视觉掩埋 > 完全掩埋
三、埋点架构与设计
3.1埋点采集顶层设计
所谓顶层设计,就是想清楚怎么埋点,用什么方式埋点,上传机制是什么,怎么定义,怎么实现等等;我们遵循唯一性、可扩展性、一致性等,需要设计一些常用的字段和生成机制,比如:cid、idfa、idfv等。
用户识别:用户识别机制的混乱会导致两种结果:一是数据不准确,如UV数据不匹配;二是漏斗分析过程出现异常。因此,应该这样做:严格规范ID自身的识别机制;湾。跨平台用户识别
同构抽象:同构抽象包括事件抽象和属性抽象。事件抽象是浏览事件和点击事件的聚合;属性抽象,即结合大部分复用场景,增加源差异化
采集一致:采集一致包括两点:一是跨平台页面命名一致,二是按钮命名一致;制定嵌入点的过程就是对底层数据进行标准化的过程,所以一致性尤为重要,只有这样才能真正使用
渠道配置:渠道主要指推广渠道、落地页、网页推广页、APP推广页等,这个落地页的配置必须有统一的规范和标准
3.2埋点采集活动及物业设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变化的,哪些是业务行为,哪些是基本属性。基于基本的属性事件,我们认为属性一定是采集项,但是属性中的事件属性会根据不同的业务进行调整。因此,我们可以将埋点采集分为协议层和业务层Bury。
业务分解:梳理确认业务流程、操作路径和不同的细分场景,定义用户行为路径
分析指标:定义特定事件和核心业务指标所需的数据
事件设计:APP启动、退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.3 资料采集事件与属性设计
Ev 事件的命名也遵循一些规则。当相同类型的函数出现在不同的页面或位置时,根据函数名进行命名,并在ev参数中区分页面和位置。只有当按钮被点击时,它才会以按钮名称命名。
ev事件格式:ev分为ev标志和ev参数
规则:
在ev标识符和ev参数之间使用“#”(一级连接符);
在ev参数和ev参数之间使用“/”(二级连接符);
ev参数使用key=value的结构。当一个key对应多个value值时,value1和value2的连接为","(三级连接符);
当埋点只有ev标志,没有ev参数时,不需要#;
评论:
ev标识:作为埋点的唯一标识,用于区分埋点的位置和属性,不可变、不可修改;
ev参数:埋点需要返回的参数。ev参数的顺序是可变的,可以修改;
调整app嵌入点时,ev logo不变,仅修改以下嵌入点参数(更改参数值或添加参数类型)
一般埋点文档中收录的工作表名称和功能:
A. 暴露埋点汇总;
B、点击浏览埋点汇总;
C、故障埋点汇总:一般会记录埋点的故障版本或时间;
D、PC和M侧页面埋点对应的pageid;
E、各版本上线时间记录;
在埋点文档中,都收录了列名和函数:
3.4 基于埋点的数据统计
如何使用埋点统计找到埋藏的 ev 事件:
1. 指定埋点类型(点击/曝光/浏览)——过滤类型字段
2. 指定按钮子点所属的页面(页面或功能)-过滤功能模块字段
3. 指定跟踪事件的名称 - 过滤名称字段
4. 知道了ev标志,就可以直接用ev过滤了
如何根据ev事件查询统计:当点击查询按钮进行统计时,可以直接使用ev标志查询。有区别时,可以限制埋点参数的取值;因为ev参数的顺序不要求是可变的,查询统计的时候,不能根据参数的顺序来限制;
四、应用——数据流的基础
4.1 指标系统
系统化的指标可以整合不同的指标、不同的维度进行综合分析,可以更快的发现当前产品和业务流程中存在的问题。
4.2 可视化
人类解释图像信息比文本更有效。可视化对于数据分析非常重要。使用数据可视化可以揭示数据中固有的复杂关系。
4.3 埋点元信息API提供
data采集 服务会将埋点到 Kafka 写入 Kafka。针对各个业务的实时数据消费需求,我们为各个业务提供单独的Kafka,流量分发模块会定时读取。取埋点管理平台提供的元信息,将流量实时分发到各个业务的Kafka。
数据采集就像设计一个产品,不应该过分,留有扩展的空间,但要不断思考有没有数据,是否完整、详细、稳定或快速。
文章采集api(数据埋点采集到底都是哪些事呢?的应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-04-11 15:43
数据采集是数据分析的基础,跟踪是最重要的采集方法。那么数据埋点采集究竟是什么?我们主要从三个方面来看:什么是埋点,埋点如何设计,埋点的应用。
一、数据采集 和常见数据问题
1.1 数据采集
数据采集的方式有很多种,埋点采集是其中非常重要的一环。它是c端和b端产品的主要采集方式。数据采集,顾名思义采集对应的数据是整个数据流的起点,采集不完整,对与不对,直接决定数据的广度和质量并影响所有后续链接;在数据采集有效性和完整性较差的公司往往会发现其业务数据发生了重大变化。
数据处理通常包括以下五个步骤:
1.2常见数据问题
在大致了解了data采集及其结构之后,我们再来看看工作中遇到的问题,有多少与data采集链接有关
1、数据与背景差距较大,数据不准确——统计口径不同,埋点定义不同,采集方法带来误差
2、想用的时候,没有我要的数据——我没提数据采集要求,埋点不正确,不全
3、事件太多,意思不清楚——埋点设计的方式,埋点更新迭代的规则和维护
4、分析数据时不知道要看哪些数据和指标——数据的定义不明确,缺乏分析思路
我们需要根本原因的解决方案:将 采集 视为独立的研发业务,而不是产品开发的附属品
二、埋葬点是什么?
2.1 葬礼是什么
所谓埋点,是data采集领域的一个名词。它的学名应该叫事件跟踪,对应的英文是Event Tracking,是指捕获、处理和发送特定用户行为或事件的相关技术和实现过程。数据埋点是数据分析师、数据产品经理和数据运营商,他们根据业务需求或产品需求,针对用户行为对应的每个事件开发埋点,并通过SDK上报埋点数据结果,并记录汇总数据。分析、推动产品优化和指导运营。
该过程伴随着规范。通过定义可以看出,具体的用户行为和事件是我们采集关注的焦点,也需要处理和发送相关的技术和实现流程;数据嵌入服务于产品,来自产品。,所以和产品息息相关,重点在于具体的实战过程,这关系到大家对底层数据的理解。
2.2 你为什么要埋头苦干?
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的质量直接影响数据质量、产品质量和运营质量。
1、数据驱动——Embedding将分析深度下钻到流量分布和流量层面,通过统计分析,对宏观指标进行深入分析,发现指标背后的问题,洞察用户行为与价值提升关联之间的潜力
2、产品优化——对于产品,用户在产品中做什么,在产品中停留的时间,有哪些异常需要注意。这些问题可以通过埋点来解决。
3、细化运营-买点可以实现产品全生命周期、不同来源的流量质量和分布、行为特征和人的关系,洞察用户行为与商业价值提升的潜在关系。
2.3种埋点方法
埋点方法有哪些?大多数公司目前使用客户端和服务器的组合
准确度:代码掩埋 > 视觉掩埋 > 完全掩埋
三、埋点架构与设计
3.1埋点采集顶层设计
所谓顶层设计,就是想清楚怎么埋点,用什么方式埋点,上传机制是什么,怎么定义,怎么实现等等;我们遵循唯一性、可扩展性、一致性等,需要设计一些常用的字段和生成机制,比如:cid、idfa、idfv等。
用户识别:用户识别机制的混乱会导致两种结果:一是数据不准确,如UV数据不匹配;二是漏斗分析过程出现异常。因此,应该这样做:严格规范ID自身的识别机制;湾。跨平台用户识别
同构抽象:同构抽象包括事件抽象和属性抽象。事件抽象是浏览事件和点击事件的聚合;属性抽象,即结合大部分复用场景,增加源差异化
采集一致:采集一致包括两点:一是跨平台页面命名一致,二是按钮命名一致;制定嵌入点的过程就是对底层数据进行标准化的过程,所以一致性尤为重要,只有这样才能真正使用
渠道配置:渠道主要指推广渠道、落地页、网页推广页、APP推广页等,这个落地页的配置必须有统一的规范和标准
3.2埋点采集活动及物业设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变化的,哪些是业务行为,哪些是基本属性。基于基本的属性事件,我们认为属性一定是采集项,但是属性中的事件属性会根据不同的业务进行调整。因此,我们可以将埋点采集分为协议层和业务层Bury。
业务分解:梳理确认业务流程、操作路径和不同的细分场景,定义用户行为路径
分析指标:定义特定事件和核心业务指标所需的数据
事件设计:APP启动、退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.3 资料采集事件与属性设计
Ev 事件的命名也遵循一些规则。当相同类型的函数出现在不同的页面或位置时,根据函数名进行命名,并在ev参数中区分页面和位置。只有当按钮被点击时,它才会以按钮名称命名。
ev事件格式:ev分为ev标志和ev参数
规则:
在ev标识符和ev参数之间使用“#”(一级连接符);
在ev参数和ev参数之间使用“/”(二级连接符);
ev参数使用key=value的结构。当一个key对应多个value值时,value1和value2的连接为","(三级连接符);
当埋点只有ev标志,没有ev参数时,不需要#;
评论:
ev标识:作为埋点的唯一标识,用于区分埋点的位置和属性,不可变、不可修改;
ev参数:埋点需要返回的参数。ev参数的顺序是可变的,可以修改;
调整app嵌入点时,ev logo不变,仅修改以下嵌入点参数(更改参数值或添加参数类型)
一般埋点文档中收录的工作表名称和功能:
A. 暴露埋点汇总;
B、点击浏览埋点汇总;
C、故障埋点汇总:一般会记录埋点的故障版本或时间;
D、PC和M侧页面埋点对应的pageid;
E、各版本上线时间记录;
在埋点文档中,都收录了列名和函数:
3.4 基于埋点的数据统计
如何使用埋点统计找到埋藏的 ev 事件:
1. 指定埋点类型(点击/曝光/浏览)——过滤类型字段
2. 指定按钮子点所属的页面(页面或功能)-过滤功能模块字段
3. 指定跟踪事件的名称 - 过滤名称字段
4. 知道了ev标志,就可以直接用ev过滤了
如何根据ev事件查询统计:当点击查询按钮进行统计时,可以直接使用ev标志查询。有区别时,可以限制埋点参数的取值;因为ev参数的顺序不要求是可变的,查询统计的时候,不能根据参数的顺序来限制;
四、应用——数据流的基础
4.1 指标系统
系统化的指标可以整合不同的指标、不同的维度进行综合分析,可以更快的发现当前产品和业务流程中存在的问题。
4.2 可视化
人类解释图像信息比文本更有效。可视化对于数据分析非常重要。使用数据可视化可以揭示数据中固有的复杂关系。
4.3 埋点元信息API提供
data采集服务会将采集收到的埋点写入Kafka。针对各个业务的实时数据消费需求,我们为各个业务提供单独的Kafka,流量分发模块会定时读取。取埋点管理平台提供的元信息,将流量实时分发到各个业务的Kafka。
数据采集就像设计一个产品,不应该过分,留有扩展的空间,但要不断思考有没有数据,是否完整、详细、稳定或快速。 查看全部
文章采集api(数据埋点采集到底都是哪些事呢?的应用)
数据采集是数据分析的基础,跟踪是最重要的采集方法。那么数据埋点采集究竟是什么?我们主要从三个方面来看:什么是埋点,埋点如何设计,埋点的应用。
一、数据采集 和常见数据问题
1.1 数据采集
数据采集的方式有很多种,埋点采集是其中非常重要的一环。它是c端和b端产品的主要采集方式。数据采集,顾名思义采集对应的数据是整个数据流的起点,采集不完整,对与不对,直接决定数据的广度和质量并影响所有后续链接;在数据采集有效性和完整性较差的公司往往会发现其业务数据发生了重大变化。
数据处理通常包括以下五个步骤:
1.2常见数据问题
在大致了解了data采集及其结构之后,我们再来看看工作中遇到的问题,有多少与data采集链接有关
1、数据与背景差距较大,数据不准确——统计口径不同,埋点定义不同,采集方法带来误差
2、想用的时候,没有我要的数据——我没提数据采集要求,埋点不正确,不全
3、事件太多,意思不清楚——埋点设计的方式,埋点更新迭代的规则和维护
4、分析数据时不知道要看哪些数据和指标——数据的定义不明确,缺乏分析思路
我们需要根本原因的解决方案:将 采集 视为独立的研发业务,而不是产品开发的附属品
二、埋葬点是什么?
2.1 葬礼是什么
所谓埋点,是data采集领域的一个名词。它的学名应该叫事件跟踪,对应的英文是Event Tracking,是指捕获、处理和发送特定用户行为或事件的相关技术和实现过程。数据埋点是数据分析师、数据产品经理和数据运营商,他们根据业务需求或产品需求,针对用户行为对应的每个事件开发埋点,并通过SDK上报埋点数据结果,并记录汇总数据。分析、推动产品优化和指导运营。
该过程伴随着规范。通过定义可以看出,具体的用户行为和事件是我们采集关注的焦点,也需要处理和发送相关的技术和实现流程;数据嵌入服务于产品,来自产品。,所以和产品息息相关,重点在于具体的实战过程,这关系到大家对底层数据的理解。
2.2 你为什么要埋头苦干?
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的质量直接影响数据质量、产品质量和运营质量。
1、数据驱动——Embedding将分析深度下钻到流量分布和流量层面,通过统计分析,对宏观指标进行深入分析,发现指标背后的问题,洞察用户行为与价值提升关联之间的潜力
2、产品优化——对于产品,用户在产品中做什么,在产品中停留的时间,有哪些异常需要注意。这些问题可以通过埋点来解决。
3、细化运营-买点可以实现产品全生命周期、不同来源的流量质量和分布、行为特征和人的关系,洞察用户行为与商业价值提升的潜在关系。
2.3种埋点方法
埋点方法有哪些?大多数公司目前使用客户端和服务器的组合
准确度:代码掩埋 > 视觉掩埋 > 完全掩埋
三、埋点架构与设计
3.1埋点采集顶层设计
所谓顶层设计,就是想清楚怎么埋点,用什么方式埋点,上传机制是什么,怎么定义,怎么实现等等;我们遵循唯一性、可扩展性、一致性等,需要设计一些常用的字段和生成机制,比如:cid、idfa、idfv等。
用户识别:用户识别机制的混乱会导致两种结果:一是数据不准确,如UV数据不匹配;二是漏斗分析过程出现异常。因此,应该这样做:严格规范ID自身的识别机制;湾。跨平台用户识别
同构抽象:同构抽象包括事件抽象和属性抽象。事件抽象是浏览事件和点击事件的聚合;属性抽象,即结合大部分复用场景,增加源差异化
采集一致:采集一致包括两点:一是跨平台页面命名一致,二是按钮命名一致;制定嵌入点的过程就是对底层数据进行标准化的过程,所以一致性尤为重要,只有这样才能真正使用
渠道配置:渠道主要指推广渠道、落地页、网页推广页、APP推广页等,这个落地页的配置必须有统一的规范和标准
3.2埋点采集活动及物业设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变化的,哪些是业务行为,哪些是基本属性。基于基本的属性事件,我们认为属性一定是采集项,但是属性中的事件属性会根据不同的业务进行调整。因此,我们可以将埋点采集分为协议层和业务层Bury。
业务分解:梳理确认业务流程、操作路径和不同的细分场景,定义用户行为路径
分析指标:定义特定事件和核心业务指标所需的数据
事件设计:APP启动、退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.3 资料采集事件与属性设计
Ev 事件的命名也遵循一些规则。当相同类型的函数出现在不同的页面或位置时,根据函数名进行命名,并在ev参数中区分页面和位置。只有当按钮被点击时,它才会以按钮名称命名。
ev事件格式:ev分为ev标志和ev参数
规则:
在ev标识符和ev参数之间使用“#”(一级连接符);
在ev参数和ev参数之间使用“/”(二级连接符);
ev参数使用key=value的结构。当一个key对应多个value值时,value1和value2的连接为","(三级连接符);
当埋点只有ev标志,没有ev参数时,不需要#;
评论:
ev标识:作为埋点的唯一标识,用于区分埋点的位置和属性,不可变、不可修改;
ev参数:埋点需要返回的参数。ev参数的顺序是可变的,可以修改;
调整app嵌入点时,ev logo不变,仅修改以下嵌入点参数(更改参数值或添加参数类型)
一般埋点文档中收录的工作表名称和功能:
A. 暴露埋点汇总;
B、点击浏览埋点汇总;
C、故障埋点汇总:一般会记录埋点的故障版本或时间;
D、PC和M侧页面埋点对应的pageid;
E、各版本上线时间记录;
在埋点文档中,都收录了列名和函数:
3.4 基于埋点的数据统计
如何使用埋点统计找到埋藏的 ev 事件:
1. 指定埋点类型(点击/曝光/浏览)——过滤类型字段
2. 指定按钮子点所属的页面(页面或功能)-过滤功能模块字段
3. 指定跟踪事件的名称 - 过滤名称字段
4. 知道了ev标志,就可以直接用ev过滤了
如何根据ev事件查询统计:当点击查询按钮进行统计时,可以直接使用ev标志查询。有区别时,可以限制埋点参数的取值;因为ev参数的顺序不要求是可变的,查询统计的时候,不能根据参数的顺序来限制;
四、应用——数据流的基础
4.1 指标系统
系统化的指标可以整合不同的指标、不同的维度进行综合分析,可以更快的发现当前产品和业务流程中存在的问题。
4.2 可视化
人类解释图像信息比文本更有效。可视化对于数据分析非常重要。使用数据可视化可以揭示数据中固有的复杂关系。
4.3 埋点元信息API提供
data采集服务会将采集收到的埋点写入Kafka。针对各个业务的实时数据消费需求,我们为各个业务提供单独的Kafka,流量分发模块会定时读取。取埋点管理平台提供的元信息,将流量实时分发到各个业务的Kafka。
数据采集就像设计一个产品,不应该过分,留有扩展的空间,但要不断思考有没有数据,是否完整、详细、稳定或快速。
文章采集api(数据具体的采集方案是什么?四种数据采集方法对比)
采集交流 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-04-09 21:07
根据企业在生产和管理过程中会产生的数据类型,提供链接标记、SDK和API三种采集方法,以及基于UTSE数据采集模型对用户的整个生命周期。
那么,数据的具体采集计划是什么?
四种数据采集方法对比
Data采集是通过埋点实现的。诸葛io提供了非常完善的数据访问解决方案,支持代码埋、全埋、可视埋、服务器埋等数据采集方式。
1.代码被埋没
说明:嵌入SDK定义事件和添加事件代码是一种常用的数据采集方法,主要包括网页和h5页面的JS嵌入、移动端的iOS和Android嵌入、微信小程序等。
优点:按需采集,业务信息更全,数据分析更专注,数据采集全面准确,便于后续深入分析。
缺点:需要研发人员配合,有一定的工作量。
2.全葬
说明:通过SDK自动采集页面所有可点击元素的操作数据,无需定义事件,适用于活动页面、登陆页面、关键页面的设计体验测量。
优点:更简单快捷,可以看到页面元素的点击量,更好的了解自己的产品特点。
缺点:采集的数据太多,只要是可点击的元素,就会是采集,上传数据很多,消耗流量很大。无法采集到更深层次的维度信息,比如事件的属性、用户的属性等。
3.可视化埋点
注意:视觉嵌入是基于完整嵌入的。技术同事整合后,业务同事需要圈出页面的元素,选中的元素会是采集。
优点:基于接口配置,无需开发,易于更新,快速生效。
缺点:自定义属性的支持范围比较有限;重构或页面更改时需要重新配置。
4.服务器埋点
描述:通过API对存储在服务器上的数据进行结构化处理,通过接口调用其他业务数据采集和集成,比如CRM等用户数据,对数据进行结构化处理,即适合拥有 采集 @采集 能力客户端的用户。
优点:服务端embedding更有针对性,数据更准确,减少编码embedding的发布过程,数据上传更及时。
缺点:用户的一些简单操作,比如点击按钮、切换模块,这些数据不能采集,用户行为不够完整。
总结:以上是诸葛io提供的四种data采集解决方案:code embedding、full embedding、visual embedding、server embedding,data采集目的是为了满足采集详细分析和操作然后执行需求。只有能够达到这个目标,才有可能选择一种或多种采集形式的组合。在企业业务中,选择哪种采集方式要根据企业自身的具体业务需求来决定。 查看全部
文章采集api(数据具体的采集方案是什么?四种数据采集方法对比)
根据企业在生产和管理过程中会产生的数据类型,提供链接标记、SDK和API三种采集方法,以及基于UTSE数据采集模型对用户的整个生命周期。
那么,数据的具体采集计划是什么?
四种数据采集方法对比
Data采集是通过埋点实现的。诸葛io提供了非常完善的数据访问解决方案,支持代码埋、全埋、可视埋、服务器埋等数据采集方式。
1.代码被埋没
说明:嵌入SDK定义事件和添加事件代码是一种常用的数据采集方法,主要包括网页和h5页面的JS嵌入、移动端的iOS和Android嵌入、微信小程序等。
优点:按需采集,业务信息更全,数据分析更专注,数据采集全面准确,便于后续深入分析。
缺点:需要研发人员配合,有一定的工作量。
2.全葬
说明:通过SDK自动采集页面所有可点击元素的操作数据,无需定义事件,适用于活动页面、登陆页面、关键页面的设计体验测量。
优点:更简单快捷,可以看到页面元素的点击量,更好的了解自己的产品特点。
缺点:采集的数据太多,只要是可点击的元素,就会是采集,上传数据很多,消耗流量很大。无法采集到更深层次的维度信息,比如事件的属性、用户的属性等。
3.可视化埋点
注意:视觉嵌入是基于完整嵌入的。技术同事整合后,业务同事需要圈出页面的元素,选中的元素会是采集。
优点:基于接口配置,无需开发,易于更新,快速生效。
缺点:自定义属性的支持范围比较有限;重构或页面更改时需要重新配置。
4.服务器埋点
描述:通过API对存储在服务器上的数据进行结构化处理,通过接口调用其他业务数据采集和集成,比如CRM等用户数据,对数据进行结构化处理,即适合拥有 采集 @采集 能力客户端的用户。
优点:服务端embedding更有针对性,数据更准确,减少编码embedding的发布过程,数据上传更及时。
缺点:用户的一些简单操作,比如点击按钮、切换模块,这些数据不能采集,用户行为不够完整。
总结:以上是诸葛io提供的四种data采集解决方案:code embedding、full embedding、visual embedding、server embedding,data采集目的是为了满足采集详细分析和操作然后执行需求。只有能够达到这个目标,才有可能选择一种或多种采集形式的组合。在企业业务中,选择哪种采集方式要根据企业自身的具体业务需求来决定。
文章采集api(七个步骤逐步介绍如何阅读API文档和测试?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-04-05 08:24
随着 API 在互联网时代变得越来越普遍,不仅程序员会使用它们,现在还需要产品经理或互联网运营商来调试和与 API 交互。阅读此 文章 您可能正在使用或开发 API,或两者兼而有之。因此,重要的是您不仅要知道如何编写,还要知道如何阅读 API 文档和测试。
什么是 API 文档?您还可以将 API 文档视为两方之间的服务协议。该文档概述了当第一方发送某种类型的请求时,第二方及其软件将如何响应。这些类型的请求(称为 API 调用)在文档中进行了描述,以便开发人员知道他们可以使用 API 做什么以及如何做。
好的 API 文档描述了它们的端点,解释了为什么应该使用它们,并提供了如何使用它们的非常具体的示例——所有这些都以对初学者和高级用户同样不言自明的方式进行。说明不清楚的 API 文档技术性太强,而且基于文本描述,因此并非所有用户都能正确使用。
下面,我们将通过七个步骤向您介绍如何编写好的 API 文档。
了解谁在使用您的 API
映射您的用户旅程
从一个基本的功能声明开始
添加代码示例
列出您的状态代码和错误消息
用白话编写和设计 API 文档
使 API 文档始终保持最新
1.了解谁在使用您的 API
与任何内容影响策略计划或 UI 设计过程一样,编写 API 文档的第一步是了解您的目标受众。这需要了解您的目标用户类型、您的内容需要为他们提供的有用价值以及它如何适应他们的实际场景。
在编写 API 文档时要记住两大类用户。一组用户是 API 文档的直接消费者,因此他们只需要查看教程和代码示例。该组主要是开发人员。另一组用户评估 API 功能、价格、速率限制、安全性等,以了解 API 如何与他们的业务需求和目标保持一致。该团队主要由 CTO 和产品经理以及一些开发人员组成。
您必须牢记这两个角色,以确保文档为每位读者提供良好的体验。
2.映射您的用户旅程
与任何产品一样,API 必须在买家旅程的每个阶段交付内容。这意味着文档应该解释 API 可以做什么(或解决),它提供的各种功能和端点,以及它与竞争对手的不同之处。
API 文档应该回答的一些基本问题是:
1.为什么要使用这个 API?
2.如何访问不同的工具和端点?
3.获得许可后的下一步是什么?
4.如何使用某些功能?
3.从一个基本的功能语句开始
每个 API 和功能都是独一无二的。例如,一些 API 可以将微博照片嵌入到电商平台的详情页中。一些 API 允许您通过 Bilibili Travel UP 大师访问数以千计的推荐酒店。网站 上甚至还有一个用于集成 Yoda 翻译器的 API。虽然每个 API 做的事情都不同,但每个 API 文档都应该涵盖一些基础知识。让我们看看下面的一些例子。
验证
由于认证对于保护 API 数据以及开发者和最终用户的数据安全非常重要,因此 API 通常有多种认证方案,因此 API 文档必须描述其每种认证方法,以便用户能够获得 Authorize 并正确使用 API。例如,YouTube 数据 API 支持两种类型的授权凭证。它的文档解释了如何使用 OAuth 2.0 以及如何获取 API 密钥,以便用户可以选择他们更熟悉的身份验证方法。
速率限制
与用户身份验证一样,速率限制有助于防止意外传输或 API 滥用。API 速率限制是您在给定时间内可以向 API 发送请求的次数。这些限制必须在 API 文档中明确说明,以便用户知道如何正确使用 API 及其功能。此信息最常在使用条款中找到。
使用条款
使用条款(或服务)是服务提供商与需要该服务的用户之间的法律协议。后者必须同意遵守这些条款才能使用服务。在 API 文档中,使用条款必须明确定义 API 使用者应如何理想地使用 API。这将有助于确保服务消费者充分利用 API 平台和功能。
内容变更日志
重要的是要让 API 使用者了解他们使用的 API 的任何减损。变更文档可以帮助他们正确维护应用程序并充分利用 API 平台的功能。案例:Twitter 的 API 文档收录对 Twitter 开发人员平台所做的所有更改的更改日志,包括新功能和产品。
4.添加代码示例
API 文档有两个主要目标:让开发人员尽可能轻松地使用 API,并让他们快速了解 API 的全部功能。实现这两个目标的一个好方法是为每个 API 端点提供代码示例。这样开发者就可以了解端点最关键的功能,从一些案例代码入手,然后直接在案例代码上调整参数,满足自己的实际需求和对接规范。
5.列出您的状态代码和错误消息
API 文档应清楚地概述用户在进行 API 调用时可能期望的状态代码和错误消息。理想情况下,每个响应都应附有简短描述,以便用户了解 API 何时成功调用、何时不成功,并能够解决他们遇到的任何错误。通常,此信息放置在其自己的页面上。这是 express 100API 文档中的一个示例。
6.用白话编写和设计 API 文档
如果您想以易于用户阅读和浏览的方式编写、构建和设计 API 文档。这意味着根据用户的使用场景和他们的需求来呈现和组织文档的内容信息。用户的使用场景是关于用户在何处、何时、为什么以及如何找到内容并与内容交互的一切。他们的需求还包括他们的目标、行为和期望。
最好的 API 文档是为完全不熟悉 API 的初学者和非常熟悉它的开发人员编写的。本文档需要尽可能避免过多的技术术语,并尽可能提供额外的上下文信息或文档的内部链接。它还需要提供诸如“入门”之类的内容以及新手用户需要的示例和教程,但更高级的用户可以跳过。
为了确保用户可以选择他们想要的东西,API 文档必须以导航的方式设计。最佳实践是使用页眉和侧边栏,以便用户无需上下滚动页面即可导航到文档的另一部分并提供搜索功能。其他设计考虑因素包括排版、配色方案和布局。三列布局被认为是收录大量代码示例的文档的理想选择。无衬线字体和对比色链接也是不错的设计选择。
7.使 API 文档保持最新
为了确保 API 消费者获得最佳体验并不断吸引新用户,API 提供者必须不时维护自己的 API 文档。过去,API 文档以 PDF 或静态网页的形式存在,导致文档更新困难。现在,有一些工具可以帮助您创建自动更新的动态和交互式文档。Redocly 和 SwaggerUI 是两个更常见的实际示例。
如何阅读 API 文档
如果你只是一个 API 消费者,而不是 API 服务提供者,那么你需要知道如何阅读 API 文档。尽管编写和阅读它的方法是相似的(寻找理由、尝试代码示例等),但它们并不完全相同。让我们仔细看看如何阅读 API 文档以了解特定 API 的可能性。
从文档概述开始
大多数 API 文档都会首先概述 API 的功能、如何连接它以及如何正确使用它。当然,您不需要了解概述的每个细节,但您应该大致了解它。
以Express 100的API文档为例,首先,Express 100的API文档解释了Express 100的API使用,使用的协议和语言,以及其认证方案。在左侧边栏的快速链接部分,您将找到指向其使用指南和速率限制、测试帐户、更改日志以及开始使用 API 所需的所有其他内容的重要链接。
了解有关功能的更多信息
了解 API 概览后,请浏览 API 参考文档,其中列出了 API 的所有函数(也称为方法)。在这一点上,没有必要彻底阅读或记住所有内容。相反,请仔细查看您特别感兴趣的函数。通过查看它的参数和示例,您可以了解是否可以成功使用 API 来完成您想做的确切事情。
例如,假设您想通过快递100的API实现如下物流查询功能: - 在电商网页/APP/小程序中,客户可以在订单详情中查看所购买产品的物流地图轨迹,向客户展示物流轨迹的文字信息
在此需求的驱动下,您可以导航到“接口文档”并查看其代码语言、参数、响应、错误消息等。
通读 API 文档教程
既然您知道是否可以使用 API 来实现您想要的,请查看教程。由于最好的 API 文档应该可以帮助用户快速入门,因此大多数文档将收录完成工作的详细教程。您应该至少通读一个教程,以了解需要仔细研究的详细程度和示例。想了解电商快递物流API的好处,这里有一篇文章文章《什么是电商API?这是它能给商家带来的12个运营好处》,里面介绍了它们的优势以及详细的缺点。如果你有兴趣,可以阅读它们,说不定你会发现意想不到的惊喜。
记录 API 信息变更
随着越来越多的公司提供 API 服务以形成高度集成的用户体验,了解如何编写和阅读 API 文档变得越来越有价值。在创建或评估 API 文档时,请确保您的 API 稳定且易于阅读和导航,并向开发人员和非开发人员清楚地传达您的 API 的价值。这确保技术用户可以快速正确地开始使用您的 API,并且同事确保他们可以与其他非技术同事一起使用它。 查看全部
文章采集api(七个步骤逐步介绍如何阅读API文档和测试?(组图))
随着 API 在互联网时代变得越来越普遍,不仅程序员会使用它们,现在还需要产品经理或互联网运营商来调试和与 API 交互。阅读此 文章 您可能正在使用或开发 API,或两者兼而有之。因此,重要的是您不仅要知道如何编写,还要知道如何阅读 API 文档和测试。
什么是 API 文档?您还可以将 API 文档视为两方之间的服务协议。该文档概述了当第一方发送某种类型的请求时,第二方及其软件将如何响应。这些类型的请求(称为 API 调用)在文档中进行了描述,以便开发人员知道他们可以使用 API 做什么以及如何做。
好的 API 文档描述了它们的端点,解释了为什么应该使用它们,并提供了如何使用它们的非常具体的示例——所有这些都以对初学者和高级用户同样不言自明的方式进行。说明不清楚的 API 文档技术性太强,而且基于文本描述,因此并非所有用户都能正确使用。
下面,我们将通过七个步骤向您介绍如何编写好的 API 文档。
了解谁在使用您的 API
映射您的用户旅程
从一个基本的功能声明开始
添加代码示例
列出您的状态代码和错误消息
用白话编写和设计 API 文档
使 API 文档始终保持最新
1.了解谁在使用您的 API
与任何内容影响策略计划或 UI 设计过程一样,编写 API 文档的第一步是了解您的目标受众。这需要了解您的目标用户类型、您的内容需要为他们提供的有用价值以及它如何适应他们的实际场景。
在编写 API 文档时要记住两大类用户。一组用户是 API 文档的直接消费者,因此他们只需要查看教程和代码示例。该组主要是开发人员。另一组用户评估 API 功能、价格、速率限制、安全性等,以了解 API 如何与他们的业务需求和目标保持一致。该团队主要由 CTO 和产品经理以及一些开发人员组成。
您必须牢记这两个角色,以确保文档为每位读者提供良好的体验。
2.映射您的用户旅程
与任何产品一样,API 必须在买家旅程的每个阶段交付内容。这意味着文档应该解释 API 可以做什么(或解决),它提供的各种功能和端点,以及它与竞争对手的不同之处。
API 文档应该回答的一些基本问题是:
1.为什么要使用这个 API?
2.如何访问不同的工具和端点?
3.获得许可后的下一步是什么?
4.如何使用某些功能?
3.从一个基本的功能语句开始
每个 API 和功能都是独一无二的。例如,一些 API 可以将微博照片嵌入到电商平台的详情页中。一些 API 允许您通过 Bilibili Travel UP 大师访问数以千计的推荐酒店。网站 上甚至还有一个用于集成 Yoda 翻译器的 API。虽然每个 API 做的事情都不同,但每个 API 文档都应该涵盖一些基础知识。让我们看看下面的一些例子。
验证
由于认证对于保护 API 数据以及开发者和最终用户的数据安全非常重要,因此 API 通常有多种认证方案,因此 API 文档必须描述其每种认证方法,以便用户能够获得 Authorize 并正确使用 API。例如,YouTube 数据 API 支持两种类型的授权凭证。它的文档解释了如何使用 OAuth 2.0 以及如何获取 API 密钥,以便用户可以选择他们更熟悉的身份验证方法。
速率限制
与用户身份验证一样,速率限制有助于防止意外传输或 API 滥用。API 速率限制是您在给定时间内可以向 API 发送请求的次数。这些限制必须在 API 文档中明确说明,以便用户知道如何正确使用 API 及其功能。此信息最常在使用条款中找到。
使用条款
使用条款(或服务)是服务提供商与需要该服务的用户之间的法律协议。后者必须同意遵守这些条款才能使用服务。在 API 文档中,使用条款必须明确定义 API 使用者应如何理想地使用 API。这将有助于确保服务消费者充分利用 API 平台和功能。
内容变更日志
重要的是要让 API 使用者了解他们使用的 API 的任何减损。变更文档可以帮助他们正确维护应用程序并充分利用 API 平台的功能。案例:Twitter 的 API 文档收录对 Twitter 开发人员平台所做的所有更改的更改日志,包括新功能和产品。
4.添加代码示例
API 文档有两个主要目标:让开发人员尽可能轻松地使用 API,并让他们快速了解 API 的全部功能。实现这两个目标的一个好方法是为每个 API 端点提供代码示例。这样开发者就可以了解端点最关键的功能,从一些案例代码入手,然后直接在案例代码上调整参数,满足自己的实际需求和对接规范。
5.列出您的状态代码和错误消息
API 文档应清楚地概述用户在进行 API 调用时可能期望的状态代码和错误消息。理想情况下,每个响应都应附有简短描述,以便用户了解 API 何时成功调用、何时不成功,并能够解决他们遇到的任何错误。通常,此信息放置在其自己的页面上。这是 express 100API 文档中的一个示例。
6.用白话编写和设计 API 文档
如果您想以易于用户阅读和浏览的方式编写、构建和设计 API 文档。这意味着根据用户的使用场景和他们的需求来呈现和组织文档的内容信息。用户的使用场景是关于用户在何处、何时、为什么以及如何找到内容并与内容交互的一切。他们的需求还包括他们的目标、行为和期望。
最好的 API 文档是为完全不熟悉 API 的初学者和非常熟悉它的开发人员编写的。本文档需要尽可能避免过多的技术术语,并尽可能提供额外的上下文信息或文档的内部链接。它还需要提供诸如“入门”之类的内容以及新手用户需要的示例和教程,但更高级的用户可以跳过。
为了确保用户可以选择他们想要的东西,API 文档必须以导航的方式设计。最佳实践是使用页眉和侧边栏,以便用户无需上下滚动页面即可导航到文档的另一部分并提供搜索功能。其他设计考虑因素包括排版、配色方案和布局。三列布局被认为是收录大量代码示例的文档的理想选择。无衬线字体和对比色链接也是不错的设计选择。
7.使 API 文档保持最新
为了确保 API 消费者获得最佳体验并不断吸引新用户,API 提供者必须不时维护自己的 API 文档。过去,API 文档以 PDF 或静态网页的形式存在,导致文档更新困难。现在,有一些工具可以帮助您创建自动更新的动态和交互式文档。Redocly 和 SwaggerUI 是两个更常见的实际示例。
如何阅读 API 文档
如果你只是一个 API 消费者,而不是 API 服务提供者,那么你需要知道如何阅读 API 文档。尽管编写和阅读它的方法是相似的(寻找理由、尝试代码示例等),但它们并不完全相同。让我们仔细看看如何阅读 API 文档以了解特定 API 的可能性。
从文档概述开始
大多数 API 文档都会首先概述 API 的功能、如何连接它以及如何正确使用它。当然,您不需要了解概述的每个细节,但您应该大致了解它。
以Express 100的API文档为例,首先,Express 100的API文档解释了Express 100的API使用,使用的协议和语言,以及其认证方案。在左侧边栏的快速链接部分,您将找到指向其使用指南和速率限制、测试帐户、更改日志以及开始使用 API 所需的所有其他内容的重要链接。
了解有关功能的更多信息
了解 API 概览后,请浏览 API 参考文档,其中列出了 API 的所有函数(也称为方法)。在这一点上,没有必要彻底阅读或记住所有内容。相反,请仔细查看您特别感兴趣的函数。通过查看它的参数和示例,您可以了解是否可以成功使用 API 来完成您想做的确切事情。
例如,假设您想通过快递100的API实现如下物流查询功能: - 在电商网页/APP/小程序中,客户可以在订单详情中查看所购买产品的物流地图轨迹,向客户展示物流轨迹的文字信息
在此需求的驱动下,您可以导航到“接口文档”并查看其代码语言、参数、响应、错误消息等。
通读 API 文档教程
既然您知道是否可以使用 API 来实现您想要的,请查看教程。由于最好的 API 文档应该可以帮助用户快速入门,因此大多数文档将收录完成工作的详细教程。您应该至少通读一个教程,以了解需要仔细研究的详细程度和示例。想了解电商快递物流API的好处,这里有一篇文章文章《什么是电商API?这是它能给商家带来的12个运营好处》,里面介绍了它们的优势以及详细的缺点。如果你有兴趣,可以阅读它们,说不定你会发现意想不到的惊喜。
记录 API 信息变更
随着越来越多的公司提供 API 服务以形成高度集成的用户体验,了解如何编写和阅读 API 文档变得越来越有价值。在创建或评估 API 文档时,请确保您的 API 稳定且易于阅读和导航,并向开发人员和非开发人员清楚地传达您的 API 的价值。这确保技术用户可以快速正确地开始使用您的 API,并且同事确保他们可以与其他非技术同事一起使用它。
文章采集api(找到织梦后台目录下的文件/article_add.php)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-03-31 20:15
如果每次添加文章都得去百度站长平台手动提交收录资源,太麻烦了,
今天我们来一招dedecms5.7在文章发布时自动提交普通收录到百度API。
在织梦后台目录下找到文件dede/article_add.php(如果你改变了后台目录,请以实际路径为准)
找到以下代码(约 274 行):
已发布文章管理
$backurl
";
在下面添加:
//百度实时推送开始
$urls = array(
'https://www.nuegame.com'.$artUrl,
);
$api = 'http://data.zz.baidu.com/urls% ... 3B%3B
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => implode("\n", $urls),
CURLOPT_HTTPHEADER => array('Content-Type: text/plain'),
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
echo $result;
echo "提交到百度站长平台的URL地址".$urls[0];//百度实时推送结束
改成自己网站的地址,还有token,可以从百度站长平台获取。
保存文件并再次上传。
试试看添加文章时是否自动提交。当天的提交记录可在第三天后查看。 查看全部
文章采集api(找到织梦后台目录下的文件/article_add.php)
如果每次添加文章都得去百度站长平台手动提交收录资源,太麻烦了,
今天我们来一招dedecms5.7在文章发布时自动提交普通收录到百度API。
在织梦后台目录下找到文件dede/article_add.php(如果你改变了后台目录,请以实际路径为准)
找到以下代码(约 274 行):
已发布文章管理
$backurl
";
在下面添加:
//百度实时推送开始
$urls = array(
'https://www.nuegame.com'.$artUrl,
);
$api = 'http://data.zz.baidu.com/urls% ... 3B%3B
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => implode("\n", $urls),
CURLOPT_HTTPHEADER => array('Content-Type: text/plain'),
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
echo $result;
echo "提交到百度站长平台的URL地址".$urls[0];//百度实时推送结束
改成自己网站的地址,还有token,可以从百度站长平台获取。
保存文件并再次上传。
试试看添加文章时是否自动提交。当天的提交记录可在第三天后查看。
文章采集api(新建一个PHP文件请求API地址返回JSON格式的数据列表)
采集交流 • 优采云 发表了文章 • 0 个评论 • 406 次浏览 • 2022-03-31 20:14
大多数博客系统都是使用WordPress搭建的,而作为博客系统,我们可能需要在站外调用博客的文章,请求这个API接口,获取最新的文章列表,通常的做法就是就是新建一个PHP文件,接收几个参数,查询数据库,返回JSON格式的数据。
WordPress 插件非常强大,几乎可以完成我们需要的所有工作。有一个叫JSON API的插件,可以使用WordPress作为API接口,调用站点外的文章博客列表。
一个叫JSON API的WordPress插件正是我想要的,而且更全面,它可以返回最新的文章、类别、作者、文章详细信息,也就是说WordPress中几乎所有的东西都可以用它来获取JSON格式的数据,甚至可以通过传递JSON数据实现文章评论和用户注册。
有了这样的插件,关键是要有这样的API接口,不用费力就可以自己写API,但它有什么用呢?
比如我想做一个微信公众号,用户输入1,返回最新的文章列表,根据用户的输入返回不同的内容,这就需要请求API地址返回JSON格式的数据.
插件安装地址:
安装后使用方法如下(本文只介绍几种常用的,其他请参考插件文档):
隐式调用显示调用链友好调用
API返回的json数据如下:
{"id":1,
"slug":"hell-world",
"url":"http://localhost/wordpress/?p=1",
"title":"Hello world",
"title_plain":"Hello world!",
"content":"<p>Welcome to wordpress. this is your first post",
"date":"2015-06-12 12:25:36",
"modified":"2015-06-12 12:25:36",
"categories":[],
"tags":[]
}
如您所见,要返回的内容太多了,也许我们只需要最新列表中的标题和链接。
有很多参数可以选择,比如count就是返回文章的个数,请参考官方文档。
本文由作者提出问题发表,并由问题编辑。请注明出处和本文的链接。
除非另有说明,本网站上的 文章 是 原创 或翻译。欢迎任何形式的转载,但请务必注明出处,尊重他人的劳动。 查看全部
文章采集api(新建一个PHP文件请求API地址返回JSON格式的数据列表)
大多数博客系统都是使用WordPress搭建的,而作为博客系统,我们可能需要在站外调用博客的文章,请求这个API接口,获取最新的文章列表,通常的做法就是就是新建一个PHP文件,接收几个参数,查询数据库,返回JSON格式的数据。
WordPress 插件非常强大,几乎可以完成我们需要的所有工作。有一个叫JSON API的插件,可以使用WordPress作为API接口,调用站点外的文章博客列表。
一个叫JSON API的WordPress插件正是我想要的,而且更全面,它可以返回最新的文章、类别、作者、文章详细信息,也就是说WordPress中几乎所有的东西都可以用它来获取JSON格式的数据,甚至可以通过传递JSON数据实现文章评论和用户注册。
有了这样的插件,关键是要有这样的API接口,不用费力就可以自己写API,但它有什么用呢?
比如我想做一个微信公众号,用户输入1,返回最新的文章列表,根据用户的输入返回不同的内容,这就需要请求API地址返回JSON格式的数据.
插件安装地址:
安装后使用方法如下(本文只介绍几种常用的,其他请参考插件文档):
隐式调用显示调用链友好调用
API返回的json数据如下:
{"id":1,
"slug":"hell-world",
"url":"http://localhost/wordpress/?p=1",
"title":"Hello world",
"title_plain":"Hello world!",
"content":"<p>Welcome to wordpress. this is your first post",
"date":"2015-06-12 12:25:36",
"modified":"2015-06-12 12:25:36",
"categories":[],
"tags":[]
}
如您所见,要返回的内容太多了,也许我们只需要最新列表中的标题和链接。
有很多参数可以选择,比如count就是返回文章的个数,请参考官方文档。
本文由作者提出问题发表,并由问题编辑。请注明出处和本文的链接。
除非另有说明,本网站上的 文章 是 原创 或翻译。欢迎任何形式的转载,但请务必注明出处,尊重他人的劳动。
文章采集api(4.1API通用规则API用一套非常标准的规则生成数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-03-31 04:17
一般情况下,程序员可以使用HTPP协议向API发起请求,获取一定的信息,API会以XML或JSON格式返回服务器响应信息。
使用 API 通常不被视为网络数据采集,但实际上使用的许多技术(都发送 HTTP 请求)和结果(都获取信息)是相似的;两者经常有重叠的相容关系。
例如,结合 Wikipedia 编辑历史记录(其中收录编辑者的 IP 地址)和 IP 地址解析 API 以获取 Wikipedia 条目的编辑者的地理位置。
4.1 API 概述
谷歌 API
4.2 API 通用规则
API 使用一套非常标准的规则来生成数据,并且生成的数据以非常标准的方式组织。
四种方式:GET、POST、PUT、DELETE
验证:需要客户端验证
4.3 服务器响应
大多数反馈数据格式是 XML 和 JSON
过去,服务器端使用 PHP 和 .NET 等程序作为 API 的接收端。现在,服务器端也使用一些 JavaScript 框架作为 API 的发送和接收端,例如 Angular 或 Backbone。
接口调用:
4.4 回声巢穴
回声巢音乐资料网站
4.5 推特 API
点安装推特
from twitter import Twitter
t = Twitter(auth=OAuth(,,,))
pythonTweets = t.search.tweets(q = "#python")
print(pythonTweets)
鸣叫 4.6 个 Google API
无论您想使用哪种信息,包括语言翻译、地理位置、日历,甚至基因数据,Google 都提供 API。Google 还为其一些知名应用程序提供 API,例如 Gmail、YouTube 和 Blogger。
4.7 解析 JSON 数据
import json
from urllib.request import urlopen
def getCountry(ipAddress):
response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
responseJson = json.loads(response)
return responseJson.get("country_code")
print(getCountry("50.78.253.58"))
4.8 返回主题
将多个数据源组合成新的形式,或者使用 API 作为工具从新的角度解释数据采集。
先做一个采集维基百科的基础程序,找到编辑历史页面,然后在编辑历史中找出IP地址
# -*- coding: utf-8 -*-
from urllib.request import urlopen
from bs4 import BeautifulSoup
import datetime
import random
import re
import json
random.seed(datetime.datetime.now())
# https://en.wikipedia.org/wiki/Python_(programming_language)
def getLinks(articleUrl):
html = urlopen("http://en.wikipedia.org"+articleUrl)
bsObj = BeautifulSoup(html)
return bsObj.find("div",{"id":"bodyContent"}).findAll("a", href=re.compile("^(/wiki/)((?!:).)*$"))
def getHistoryIPs(pageUrl):
# 编辑历史页面URL链接格式是:
# https://en.wikipedia.org/w/index.php?title=Python_(programming_language)&action=history
pageUrl = pageUrl.replace("/wiki/", "")
historyUrl = "https://en.wikipedia.org/w/ind ... ot%3B
print("history url is: "+historyUrl)
html = urlopen(historyUrl)
bsObj = BeautifulSoup(html)
# 找出class属性是"mw-anonuserlink"的链接
# 它们用IP地址代替用户名
ipAddresses = bsObj.findAll("a", {"class":"mw-anonuserlink"})
addressList = set()
for ipAddress in ipAddresses:
addressList.add(ipAddress.get_text())
return addressList
links = getLinks("/wiki/Python_(programming_language)")
def getCountry(ipAddress):
try:
response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
except HTTPError:
return None
responseJson = json.loads(response)
return responseJson.get("country_code")
while (len(links) > 0):
for link in links:
print("-------------------")
historyIPs = getHistoryIPs(link.attrs["href"])
for historyIP in historyIPs:
#print(historyIP)
country = getCountry(historyIP)
if country is not None:
print(historyIP+" is from "+country)
newLink = links[random.randint(0, len(links)-1)].attrs["href"]
links = getLinks(newLink)
4.9 更多 API
Leonard Richardson、Mike Amundsen 和 Sam Ruby 的 RESTful Web APIs ( ) 为使用 Web APIs 提供了非常全面的理论和实践指南。此外,Mike Amundsen 的精彩视频教程 Designing APIs for the Web() 教您如何创建自己的 API。如果您想以方便的方式分享您的 采集 数据,他的视频非常有用 查看全部
文章采集api(4.1API通用规则API用一套非常标准的规则生成数据)
一般情况下,程序员可以使用HTPP协议向API发起请求,获取一定的信息,API会以XML或JSON格式返回服务器响应信息。
使用 API 通常不被视为网络数据采集,但实际上使用的许多技术(都发送 HTTP 请求)和结果(都获取信息)是相似的;两者经常有重叠的相容关系。
例如,结合 Wikipedia 编辑历史记录(其中收录编辑者的 IP 地址)和 IP 地址解析 API 以获取 Wikipedia 条目的编辑者的地理位置。
4.1 API 概述
谷歌 API
4.2 API 通用规则
API 使用一套非常标准的规则来生成数据,并且生成的数据以非常标准的方式组织。
四种方式:GET、POST、PUT、DELETE
验证:需要客户端验证
4.3 服务器响应
大多数反馈数据格式是 XML 和 JSON
过去,服务器端使用 PHP 和 .NET 等程序作为 API 的接收端。现在,服务器端也使用一些 JavaScript 框架作为 API 的发送和接收端,例如 Angular 或 Backbone。
接口调用:
4.4 回声巢穴
回声巢音乐资料网站
4.5 推特 API
点安装推特
from twitter import Twitter
t = Twitter(auth=OAuth(,,,))
pythonTweets = t.search.tweets(q = "#python")
print(pythonTweets)
鸣叫 4.6 个 Google API
无论您想使用哪种信息,包括语言翻译、地理位置、日历,甚至基因数据,Google 都提供 API。Google 还为其一些知名应用程序提供 API,例如 Gmail、YouTube 和 Blogger。
4.7 解析 JSON 数据
import json
from urllib.request import urlopen
def getCountry(ipAddress):
response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
responseJson = json.loads(response)
return responseJson.get("country_code")
print(getCountry("50.78.253.58"))
4.8 返回主题
将多个数据源组合成新的形式,或者使用 API 作为工具从新的角度解释数据采集。
先做一个采集维基百科的基础程序,找到编辑历史页面,然后在编辑历史中找出IP地址
# -*- coding: utf-8 -*-
from urllib.request import urlopen
from bs4 import BeautifulSoup
import datetime
import random
import re
import json
random.seed(datetime.datetime.now())
# https://en.wikipedia.org/wiki/Python_(programming_language)
def getLinks(articleUrl):
html = urlopen("http://en.wikipedia.org"+articleUrl)
bsObj = BeautifulSoup(html)
return bsObj.find("div",{"id":"bodyContent"}).findAll("a", href=re.compile("^(/wiki/)((?!:).)*$"))
def getHistoryIPs(pageUrl):
# 编辑历史页面URL链接格式是:
# https://en.wikipedia.org/w/index.php?title=Python_(programming_language)&action=history
pageUrl = pageUrl.replace("/wiki/", "")
historyUrl = "https://en.wikipedia.org/w/ind ... ot%3B
print("history url is: "+historyUrl)
html = urlopen(historyUrl)
bsObj = BeautifulSoup(html)
# 找出class属性是"mw-anonuserlink"的链接
# 它们用IP地址代替用户名
ipAddresses = bsObj.findAll("a", {"class":"mw-anonuserlink"})
addressList = set()
for ipAddress in ipAddresses:
addressList.add(ipAddress.get_text())
return addressList
links = getLinks("/wiki/Python_(programming_language)")
def getCountry(ipAddress):
try:
response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
except HTTPError:
return None
responseJson = json.loads(response)
return responseJson.get("country_code")
while (len(links) > 0):
for link in links:
print("-------------------")
historyIPs = getHistoryIPs(link.attrs["href"])
for historyIP in historyIPs:
#print(historyIP)
country = getCountry(historyIP)
if country is not None:
print(historyIP+" is from "+country)
newLink = links[random.randint(0, len(links)-1)].attrs["href"]
links = getLinks(newLink)
4.9 更多 API
Leonard Richardson、Mike Amundsen 和 Sam Ruby 的 RESTful Web APIs ( ) 为使用 Web APIs 提供了非常全面的理论和实践指南。此外,Mike Amundsen 的精彩视频教程 Designing APIs for the Web() 教您如何创建自己的 API。如果您想以方便的方式分享您的 采集 数据,他的视频非常有用
文章采集api(wellCMS前端基于BootStrap4.5、JQuery3.5.1的前端类库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-03-22 02:39
那么cms 是一个拥有大量数据的分布式架构。通过低成本解决网站负载和性能问题,cms可以实现高负载、高性能、高安全。Wellcms是一个亿级负载、开源、面向移动、轻量级、超快速响应能力的高负载cms。是大数据量和高并发访问的选择网站轻cms。wellcms是诞生于大数据时代的cms,wellcms是专为大数据量站点设计的高性能、高负载cms。
嗯cms前后台都可以在移动端操作,适配手机、平板、PC。还可以设置每个终端加载单独的模板,URL不变,插件机制非常方便。嗯cms首页自带API,可以通过JSON返回AJAX请求的数据,做APP和小程序无压力。采用静态语言编程风格,充分发挥PHP8 OPCache的威力。嗯cms前端是基于BootStrap4.5、JQuery3.5.1作为前端类库的,对第三方的依赖少-party 类库。后端基于PHP8数据库MySQL或MariaDB,缓存支持XCache、Yac、Redis、Memcached。
wellcms的架构是函数式MVC分层架构,AOP插件机制,分布式服务器设计,每张表可以创建单独的DB服务器组和Cache服务器组,方便部署和维护。cms安全性,参数类型严格过滤,SQL拼接严格转义,上传严格过滤,前后端权限分配,不用担心Webshell、SQL注入、XSS等问题。
不错的cms性能,1核/1G内存/SSD硬盘/OPcache/Yac,PHP8,MYSQL5.5可以承载1亿多数据,流畅打开每个页面,页面执行时间可以达到 0.00x 秒。好吧cms加载,从数据表设计、业务层排序,到代码实现,都是为了消耗硬件计算性能,在有限的环境下最大限度的发挥性能,在海量数据下更加突出。
wellcms的扩展使用hook插入,覆盖覆盖,零性能损失,强大简单,不影响编译。插件和模板完全分离,模板可以自由开发、安装和卸载。不错cms SEO优化,网站布局符合SEO标准,对搜索引擎友好,内置搜索引擎推送插件,实时蜘蛛抓取。URL短小精悍,模板适配PC手机。整个站点链接完整,SEO优化效果翻倍
wellcms支持多语言翻译自动转换,wellcms可以简繁英文转换,模板绑定,可以压缩全站代码,可以返回JSON数据,支持SSL , CDN, 最大支持 42 亿数据量。
wellcms的分离,除了php和htm文件外,整个站点的附件和文件都可以分离到云存储;多个DB主从读写分离,设置主从配置,自动读写分离,无需修改程序。而且cms是开源的,在MIT协议下发布,主程序开源免费,可以自由修改、商业化、衍生版本,不用担心任何风险,但必须提供原文件版权信息修改后保留。
嗯cms是基于XiunoPHP开发的,只有22张表,运行速度非常快,处理单个请求0.01秒级别,使缓存达到0.@级别>003 秒。wellcms支持多终端绑定模板,支持独立section绑定模板,支持前后端代码压缩,支持免登录存储,支持3种伪静态,支持数据库类型pdo_mysql和mysql ,支持数据库引擎MyISAM和InnoDB,支持SSL,支持CDN,支持各种NoSQL操作,支持附件分离,支持多DB主从读写分离。那么cms的分布式服务器设计,每张表可以创建单独的DB服务器组和CACHE服务器(组),单张表可承载亿级以上数据,方便部署和维护。它是二次开发非常好的基石。 查看全部
文章采集api(wellCMS前端基于BootStrap4.5、JQuery3.5.1的前端类库)
那么cms 是一个拥有大量数据的分布式架构。通过低成本解决网站负载和性能问题,cms可以实现高负载、高性能、高安全。Wellcms是一个亿级负载、开源、面向移动、轻量级、超快速响应能力的高负载cms。是大数据量和高并发访问的选择网站轻cms。wellcms是诞生于大数据时代的cms,wellcms是专为大数据量站点设计的高性能、高负载cms。
嗯cms前后台都可以在移动端操作,适配手机、平板、PC。还可以设置每个终端加载单独的模板,URL不变,插件机制非常方便。嗯cms首页自带API,可以通过JSON返回AJAX请求的数据,做APP和小程序无压力。采用静态语言编程风格,充分发挥PHP8 OPCache的威力。嗯cms前端是基于BootStrap4.5、JQuery3.5.1作为前端类库的,对第三方的依赖少-party 类库。后端基于PHP8数据库MySQL或MariaDB,缓存支持XCache、Yac、Redis、Memcached。
wellcms的架构是函数式MVC分层架构,AOP插件机制,分布式服务器设计,每张表可以创建单独的DB服务器组和Cache服务器组,方便部署和维护。cms安全性,参数类型严格过滤,SQL拼接严格转义,上传严格过滤,前后端权限分配,不用担心Webshell、SQL注入、XSS等问题。
不错的cms性能,1核/1G内存/SSD硬盘/OPcache/Yac,PHP8,MYSQL5.5可以承载1亿多数据,流畅打开每个页面,页面执行时间可以达到 0.00x 秒。好吧cms加载,从数据表设计、业务层排序,到代码实现,都是为了消耗硬件计算性能,在有限的环境下最大限度的发挥性能,在海量数据下更加突出。
wellcms的扩展使用hook插入,覆盖覆盖,零性能损失,强大简单,不影响编译。插件和模板完全分离,模板可以自由开发、安装和卸载。不错cms SEO优化,网站布局符合SEO标准,对搜索引擎友好,内置搜索引擎推送插件,实时蜘蛛抓取。URL短小精悍,模板适配PC手机。整个站点链接完整,SEO优化效果翻倍
wellcms支持多语言翻译自动转换,wellcms可以简繁英文转换,模板绑定,可以压缩全站代码,可以返回JSON数据,支持SSL , CDN, 最大支持 42 亿数据量。
wellcms的分离,除了php和htm文件外,整个站点的附件和文件都可以分离到云存储;多个DB主从读写分离,设置主从配置,自动读写分离,无需修改程序。而且cms是开源的,在MIT协议下发布,主程序开源免费,可以自由修改、商业化、衍生版本,不用担心任何风险,但必须提供原文件版权信息修改后保留。
嗯cms是基于XiunoPHP开发的,只有22张表,运行速度非常快,处理单个请求0.01秒级别,使缓存达到0.@级别>003 秒。wellcms支持多终端绑定模板,支持独立section绑定模板,支持前后端代码压缩,支持免登录存储,支持3种伪静态,支持数据库类型pdo_mysql和mysql ,支持数据库引擎MyISAM和InnoDB,支持SSL,支持CDN,支持各种NoSQL操作,支持附件分离,支持多DB主从读写分离。那么cms的分布式服务器设计,每张表可以创建单独的DB服务器组和CACHE服务器(组),单张表可承载亿级以上数据,方便部署和维护。它是二次开发非常好的基石。
文章采集api(数据埋点采集到底都是哪些事?(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2022-03-22 02:35
数据采集是数据分析的基础,跟踪是最重要的采集方法。那么数据埋点采集究竟是什么?我们主要从三个方面来看:什么是埋点,埋点如何设计,埋点的应用。
一、数据采集 和常见数据问题
1.数据采集
任何事情都必须有目的和目标,数据分析也不例外。在进行数据分析之前,我们需要思考为什么需要进行数据分析?您希望通过此次数据分析为您的业务解决哪些问题?
数据采集的方式有很多种,埋点采集是其中非常重要的一环。它是c端和b端产品的主要采集方式。Data采集 顾名思义就是采集对应的数据,是整个数据流的起点。采集的不完整性,对错,直接决定了数据的广度和质量,影响到后续的所有环节。在数据采集有效性和完整性较差的公司中,企业经常会发现数据发生了重大变化。
数据的处理通常包括以下5个步骤:
2.常见数据问题
在大致了解了data采集及其结构之后,我们再来看看工作中遇到的问题,有多少与data采集链接有关:
(1)数据与背景差距较大,数据不准确——统计口径不同,埋点定义不同,采集方法带来误差;
(2)想用的时候没有我要的数据——没提数据采集要求,埋点不正确,不全;
(3)事件太多,意思不清楚——埋点设计的方式,埋点更新迭代的规则和维护;
(4)分析数据的时候不知道要看哪些数据和指标——数据的定义不明确,缺乏分析思路
我们需要根本原因解决方案:将 采集 视为独立的研发业务,而不是产品开发的附属品。
二、埋葬点是什么?
1.葬礼是什么?
所谓埋点,是data采集领域的一个名词。它的学名应该叫事件追踪,对应的英文是Event Tracking,是指捕获、处理和发送特定用户行为或事件的相关技术和实现过程。
数据埋点是数据分析师、数据产品经理和数据运营商,他们根据业务需求或产品需求,针对用户行为对应的每个事件开发埋点,并通过SDK上报埋点数据结果,并记录汇总数据。分析、推动产品优化和指导运营。
该过程伴随着规范。通过定义可以看出,具体的用户行为和事件是我们采集关注的焦点,需要处理和发送相关的技术和实现流程;数据嵌入是为产品服务的,来源于产品。,所以和产品息息相关,重点在于具体的实战过程,这关系到大家对底层数据的理解。
2.你为什么要埋葬
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的质量直接影响数据质量、产品质量和运营质量。
(1)数据驱动-埋点将分析深度下钻到流量分布和流量层面,通过统计分析,对宏观指标进行深入分析,发现指标背后的问题,洞察用户行为与价值提升的关系 潜在关联
(2)产品优化——对于产品来说,用户在产品中做什么,在产品中停留的时间,有哪些异常需要注意。这些问题可以通过埋点来实现。
(3)精细化运营——买点可以实现产品全生命周期、不同来源的流量质量和分布、人群的行为特征和关系,洞察用户行为与商业价值提升的潜在关系。
3.如何埋点
埋点方法有哪些?大多数公司目前使用客户端和服务器的组合。
准确度:代码掩埋 > 视觉掩埋 > 完全掩埋
三、埋点架构与设计
1.埋点采集的顶层设计
所谓顶层设计,就是想清楚怎么埋点,用什么方式埋点,上传机制是什么,怎么定义,怎么实现等等;我们遵循唯一性、可扩展性、一致性等,需要设计一些常用的字段和生成机制,比如:cid、idfa、idfv等。
用户识别:用户识别机制的混乱会导致两个结果:一是数据不准确,比如UV数据不匹配;二是漏斗分析过程出现异常。因此,应该这样做:严格规范ID自身的识别机制;湾。跨平台用户识别。
同构抽象:同构抽象包括事件抽象和属性抽象。事件抽象是浏览事件和点击事件的聚合;属性抽象是大多数重用场景的组合,以增加源差异化。
采集一致:采集一致包括两点:一是跨平台页面的命名一致,二是按钮命名一致;制定埋点的过程本身就是对底层数据进行标准化的过程,所以一致性尤为重要,只有这样才能真正使用它。
渠道配置:渠道主要指推广渠道、落地页、网页推广页、APP推广页等,这个落地页的配置必须有统一的规范和标准
2.埋点采集活动与物业设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变化的,哪些是业务行为,哪些是基本属性。基于基本的属性事件,我们认为属性一定是采集项,但是属性中的事件属性会根据不同的业务进行调整。因此,我们可以将埋点采集分为协议层和业务层Bury。
业务分解:梳理确认业务流程、操作路径和不同的细分场景,定义用户行为路径
分析指标:定义特定事件和核心业务指标所需的数据
事件设计:APP启动、退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.数据采集事件和属性设计
Ev 事件的命名也遵循一些规则。当相同类型的函数出现在不同的页面或位置时,根据函数名进行命名,并在ev参数中区分页面和位置。只有当按钮被点击时,它才会以按钮名称命名。
ev事件格式:ev分为ev标志和ev参数
规则:
在 ev 标识符和 ev 参数之间使用“#”(一级连接符)
在 ev 参数和 ev 参数之间使用“/”(辅助连接器)
ev参数使用key=value的结构。当一个key对应多个value值时,value1和value2之间用“,”连接(三级连接符)
当埋点只有ev标志而没有ev参数时,不需要#。
评论:
ev identifier:作为埋点的唯一标识符,用来区分埋点的位置和属性。它是不可变的和不可修改的。
ev参数:埋点需要返回的参数,ev参数的顺序是可变的,可以修改)
调整app埋点时,ev logo不变,只修改以下埋点参数(参数值改变或参数类型增加)
一般埋点文档中收录的工作表名称和功能:
A. 暴露埋点汇总;
B、点击浏览埋点汇总;
C、故障埋点汇总:一般会记录埋点的故障版本或时间;
D、PC和M侧页面埋点对应的pageid;
E、各版本上线时间记录;
在埋点文档中,都收录了列名和函数:
4.基于埋点的数据统计
如何使用埋点统计找到埋藏的 ev 事件:
(1)明确埋点类型(点击/曝光/浏览)——过滤类型字段
(2)明确按钮嵌入所属的页面(页面或功能)-过滤功能模块字段
(3)指定跟踪事件的名称-过滤名称字段
(4)知道ev标志的可以直接用ev过滤
如何根据ev事件进行查询统计:当点击查询按钮进行统计时,可以直接使用ev标志进行查询。因为ev参数的顺序不要求是可变的,所以查询统计信息时不能限制参数的顺序。
四、应用——数据流的基础
1.指标系统
系统化的指标可以整合不同的指标、不同的维度进行综合分析,可以更快的发现当前产品和业务流程中存在的问题。
2.可视化
人类解释图像信息比文本更有效。可视化对于数据分析非常重要。使用数据可视化可以揭示数据中固有的复杂关系。
3.提供埋点元信息API
data采集服务会将采集收到的埋点写入Kafka。针对各个业务的实时数据消费需求,我们为各个业务提供单独的Kafka,流量分发模块会定时读取。取埋点管理平台提供的元信息,将流量实时分发到各个业务的Kafka。
Data采集 就像设计产品一样,不能过头。不仅要留有扩展的空间,还要时刻考虑有没有数据,是否完整,是否稳定,是否快。 查看全部
文章采集api(数据埋点采集到底都是哪些事?(一))
数据采集是数据分析的基础,跟踪是最重要的采集方法。那么数据埋点采集究竟是什么?我们主要从三个方面来看:什么是埋点,埋点如何设计,埋点的应用。
一、数据采集 和常见数据问题
1.数据采集
任何事情都必须有目的和目标,数据分析也不例外。在进行数据分析之前,我们需要思考为什么需要进行数据分析?您希望通过此次数据分析为您的业务解决哪些问题?
数据采集的方式有很多种,埋点采集是其中非常重要的一环。它是c端和b端产品的主要采集方式。Data采集 顾名思义就是采集对应的数据,是整个数据流的起点。采集的不完整性,对错,直接决定了数据的广度和质量,影响到后续的所有环节。在数据采集有效性和完整性较差的公司中,企业经常会发现数据发生了重大变化。
数据的处理通常包括以下5个步骤:
2.常见数据问题
在大致了解了data采集及其结构之后,我们再来看看工作中遇到的问题,有多少与data采集链接有关:
(1)数据与背景差距较大,数据不准确——统计口径不同,埋点定义不同,采集方法带来误差;
(2)想用的时候没有我要的数据——没提数据采集要求,埋点不正确,不全;
(3)事件太多,意思不清楚——埋点设计的方式,埋点更新迭代的规则和维护;
(4)分析数据的时候不知道要看哪些数据和指标——数据的定义不明确,缺乏分析思路
我们需要根本原因解决方案:将 采集 视为独立的研发业务,而不是产品开发的附属品。
二、埋葬点是什么?
1.葬礼是什么?
所谓埋点,是data采集领域的一个名词。它的学名应该叫事件追踪,对应的英文是Event Tracking,是指捕获、处理和发送特定用户行为或事件的相关技术和实现过程。
数据埋点是数据分析师、数据产品经理和数据运营商,他们根据业务需求或产品需求,针对用户行为对应的每个事件开发埋点,并通过SDK上报埋点数据结果,并记录汇总数据。分析、推动产品优化和指导运营。
该过程伴随着规范。通过定义可以看出,具体的用户行为和事件是我们采集关注的焦点,需要处理和发送相关的技术和实现流程;数据嵌入是为产品服务的,来源于产品。,所以和产品息息相关,重点在于具体的实战过程,这关系到大家对底层数据的理解。
2.你为什么要埋葬
埋点的目的是对产品进行全方位的持续跟踪,通过数据分析不断引导和优化产品。数据埋点的质量直接影响数据质量、产品质量和运营质量。
(1)数据驱动-埋点将分析深度下钻到流量分布和流量层面,通过统计分析,对宏观指标进行深入分析,发现指标背后的问题,洞察用户行为与价值提升的关系 潜在关联
(2)产品优化——对于产品来说,用户在产品中做什么,在产品中停留的时间,有哪些异常需要注意。这些问题可以通过埋点来实现。
(3)精细化运营——买点可以实现产品全生命周期、不同来源的流量质量和分布、人群的行为特征和关系,洞察用户行为与商业价值提升的潜在关系。
3.如何埋点
埋点方法有哪些?大多数公司目前使用客户端和服务器的组合。
准确度:代码掩埋 > 视觉掩埋 > 完全掩埋
三、埋点架构与设计
1.埋点采集的顶层设计
所谓顶层设计,就是想清楚怎么埋点,用什么方式埋点,上传机制是什么,怎么定义,怎么实现等等;我们遵循唯一性、可扩展性、一致性等,需要设计一些常用的字段和生成机制,比如:cid、idfa、idfv等。
用户识别:用户识别机制的混乱会导致两个结果:一是数据不准确,比如UV数据不匹配;二是漏斗分析过程出现异常。因此,应该这样做:严格规范ID自身的识别机制;湾。跨平台用户识别。
同构抽象:同构抽象包括事件抽象和属性抽象。事件抽象是浏览事件和点击事件的聚合;属性抽象是大多数重用场景的组合,以增加源差异化。
采集一致:采集一致包括两点:一是跨平台页面的命名一致,二是按钮命名一致;制定埋点的过程本身就是对底层数据进行标准化的过程,所以一致性尤为重要,只有这样才能真正使用它。
渠道配置:渠道主要指推广渠道、落地页、网页推广页、APP推广页等,这个落地页的配置必须有统一的规范和标准
2.埋点采集活动与物业设计
在设计属性和事件时,我们需要知道哪些是经常变化的,哪些是不变化的,哪些是业务行为,哪些是基本属性。基于基本的属性事件,我们认为属性一定是采集项,但是属性中的事件属性会根据不同的业务进行调整。因此,我们可以将埋点采集分为协议层和业务层Bury。
业务分解:梳理确认业务流程、操作路径和不同的细分场景,定义用户行为路径
分析指标:定义特定事件和核心业务指标所需的数据
事件设计:APP启动、退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.数据采集事件和属性设计
Ev 事件的命名也遵循一些规则。当相同类型的函数出现在不同的页面或位置时,根据函数名进行命名,并在ev参数中区分页面和位置。只有当按钮被点击时,它才会以按钮名称命名。
ev事件格式:ev分为ev标志和ev参数
规则:
在 ev 标识符和 ev 参数之间使用“#”(一级连接符)
在 ev 参数和 ev 参数之间使用“/”(辅助连接器)
ev参数使用key=value的结构。当一个key对应多个value值时,value1和value2之间用“,”连接(三级连接符)
当埋点只有ev标志而没有ev参数时,不需要#。
评论:
ev identifier:作为埋点的唯一标识符,用来区分埋点的位置和属性。它是不可变的和不可修改的。
ev参数:埋点需要返回的参数,ev参数的顺序是可变的,可以修改)
调整app埋点时,ev logo不变,只修改以下埋点参数(参数值改变或参数类型增加)
一般埋点文档中收录的工作表名称和功能:
A. 暴露埋点汇总;
B、点击浏览埋点汇总;
C、故障埋点汇总:一般会记录埋点的故障版本或时间;
D、PC和M侧页面埋点对应的pageid;
E、各版本上线时间记录;
在埋点文档中,都收录了列名和函数:
4.基于埋点的数据统计
如何使用埋点统计找到埋藏的 ev 事件:
(1)明确埋点类型(点击/曝光/浏览)——过滤类型字段
(2)明确按钮嵌入所属的页面(页面或功能)-过滤功能模块字段
(3)指定跟踪事件的名称-过滤名称字段
(4)知道ev标志的可以直接用ev过滤
如何根据ev事件进行查询统计:当点击查询按钮进行统计时,可以直接使用ev标志进行查询。因为ev参数的顺序不要求是可变的,所以查询统计信息时不能限制参数的顺序。
四、应用——数据流的基础
1.指标系统
系统化的指标可以整合不同的指标、不同的维度进行综合分析,可以更快的发现当前产品和业务流程中存在的问题。
2.可视化
人类解释图像信息比文本更有效。可视化对于数据分析非常重要。使用数据可视化可以揭示数据中固有的复杂关系。
3.提供埋点元信息API
data采集服务会将采集收到的埋点写入Kafka。针对各个业务的实时数据消费需求,我们为各个业务提供单独的Kafka,流量分发模块会定时读取。取埋点管理平台提供的元信息,将流量实时分发到各个业务的Kafka。
Data采集 就像设计产品一样,不能过头。不仅要留有扩展的空间,还要时刻考虑有没有数据,是否完整,是否稳定,是否快。
文章采集api(优采云采集支持5118接口:5118一键智能换词API接口)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2022-03-12 19:10
优采云采集支持5118接口如下:
5118一键智能换字API接口
5118一键智能重写API接口
5118 智能标题生成 API
处理采集数据标题和内容、关键词、描述等,可以针对性配合优采云采集的SEO功能和5118智能换词API处理 原创 度数更高的 文章。@收录 和 网站 权重起着非常重要的作用。
访问和使用步骤 创建5118 API接口配置(所有接口通用) 创建API处理规则 API处理规则 使用API处理结果发布5118-API接口常见问题及解决方案
1. 创建5118 API接口配置(所有接口通用)
5118一键智能换字API接口,5118一键智能改写API接口:可用于处理采集的数据标题和内容;
5118智能标题生成API:可根据文章内容智能生成文章标题;
一、API配置入口:
点击控制台左侧列表中的【第三方服务配置】==点击【第三方内容API接入】==点击【第三方API配置管理】==点击创建对应接口配置:【5118_Intelligent】Word Change API]、【5118_Intelligent Rewriting API】、【5118_Intelligent Title Generation API】;
二、配置API接口信息:
【API-Key值】是从5118后端获取的一键智能换字API或5118一键智能改写API或5118智能标题生成API对应的key值,填写优采云;
设置锁字功能,首先开启核心字锁,填写的锁字在第三方原创api处理时不会被替换,多个字用|分隔,例如:word 1 | 字 2 | 词 3
2. 创建 API 处理规则
API处理规则,可以通过调用API接口设置处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==,点击【第三方内容API接入】==进入【API处理规则管理】页面,最后点击【添加】 API处理规则]创建API处理规则;
二、API处理规则配置:
三、5118智能标题生成API(可选,特殊接口使用说明)
5118智能标题生成API是根据文章的内容(content字段)智能生成文章标题,所以API处理规则中需要处理的字段要选择content字段根据内容生成标题。
3. API 处理规则使用
API处理规则有两种使用方式:手动执行和自动执行:
一、手动执行API处理规则:
在采集任务的【结果数据&发布】选项卡中,点击【SEO&API&翻译等工具】按钮==选择【第三方API执行】栏==选择对应的API处理规则= ="执行;
二、自动执行API处理规则:
启用 API 处理的自动执行。任务完成后采集会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡中,在【自动执行第三方API配置】==勾选【采集,自动执行API】选项===选择API处理rule for execution =="选择API接口处理的数据范围(一般选择'待释放',all会导致所有数据重复执行),最后点击保存;
4. API 处理结果并发布
一、查看API接口处理结果:
API接口处理的内容会生成API接口对应的新字段,如:
内容处理后添加的字段:
content_5118换字(对应5118一键智能换字API接口)
在【结果数据&发布】和数据预览界面都可以查看。
提示:执行 API 处理规则需要一段时间。执行后页面会自动刷新,出现API接口处理的新字段;
二、API接口处理后的内容发布
在发布文章之前,修改发布目标第二步的映射字段,重新选择标题和内容作为API接口处理后添加的对应字段。
例如,执行5118一键智能换词API后,选择title_5118换词和content_5118换词发布;
例如,执行5118智能标题生成API后,选择content_5118标题生成并发布;
提示:如果发布目标中无法选择新字段,请在任务下复制或新建发布目标,然后在新发布目标中选择新字段即可。详细教程请参考发布目标中不能选择的字段;
5. 5118-API接口常见问题及解决方法
一、API处理规则和SEO规则如何协同工作?
系统默认对title和content字段进行SEO功能,需要修改为SEO规则中对应的新字段,如title_5118换字、content_5118换字字段; 查看全部
文章采集api(优采云采集支持5118接口:5118一键智能换词API接口)
优采云采集支持5118接口如下:
5118一键智能换字API接口
5118一键智能重写API接口
5118 智能标题生成 API
处理采集数据标题和内容、关键词、描述等,可以针对性配合优采云采集的SEO功能和5118智能换词API处理 原创 度数更高的 文章。@收录 和 网站 权重起着非常重要的作用。
访问和使用步骤 创建5118 API接口配置(所有接口通用) 创建API处理规则 API处理规则 使用API处理结果发布5118-API接口常见问题及解决方案
1. 创建5118 API接口配置(所有接口通用)
5118一键智能换字API接口,5118一键智能改写API接口:可用于处理采集的数据标题和内容;
5118智能标题生成API:可根据文章内容智能生成文章标题;
一、API配置入口:
点击控制台左侧列表中的【第三方服务配置】==点击【第三方内容API接入】==点击【第三方API配置管理】==点击创建对应接口配置:【5118_Intelligent】Word Change API]、【5118_Intelligent Rewriting API】、【5118_Intelligent Title Generation API】;
二、配置API接口信息:
【API-Key值】是从5118后端获取的一键智能换字API或5118一键智能改写API或5118智能标题生成API对应的key值,填写优采云;
设置锁字功能,首先开启核心字锁,填写的锁字在第三方原创api处理时不会被替换,多个字用|分隔,例如:word 1 | 字 2 | 词 3
2. 创建 API 处理规则
API处理规则,可以通过调用API接口设置处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==,点击【第三方内容API接入】==进入【API处理规则管理】页面,最后点击【添加】 API处理规则]创建API处理规则;
二、API处理规则配置:
三、5118智能标题生成API(可选,特殊接口使用说明)
5118智能标题生成API是根据文章的内容(content字段)智能生成文章标题,所以API处理规则中需要处理的字段要选择content字段根据内容生成标题。
3. API 处理规则使用
API处理规则有两种使用方式:手动执行和自动执行:
一、手动执行API处理规则:
在采集任务的【结果数据&发布】选项卡中,点击【SEO&API&翻译等工具】按钮==选择【第三方API执行】栏==选择对应的API处理规则= ="执行;
二、自动执行API处理规则:
启用 API 处理的自动执行。任务完成后采集会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡中,在【自动执行第三方API配置】==勾选【采集,自动执行API】选项===选择API处理rule for execution =="选择API接口处理的数据范围(一般选择'待释放',all会导致所有数据重复执行),最后点击保存;
4. API 处理结果并发布
一、查看API接口处理结果:
API接口处理的内容会生成API接口对应的新字段,如:
内容处理后添加的字段:
content_5118换字(对应5118一键智能换字API接口)
在【结果数据&发布】和数据预览界面都可以查看。
提示:执行 API 处理规则需要一段时间。执行后页面会自动刷新,出现API接口处理的新字段;
二、API接口处理后的内容发布
在发布文章之前,修改发布目标第二步的映射字段,重新选择标题和内容作为API接口处理后添加的对应字段。
例如,执行5118一键智能换词API后,选择title_5118换词和content_5118换词发布;
例如,执行5118智能标题生成API后,选择content_5118标题生成并发布;
提示:如果发布目标中无法选择新字段,请在任务下复制或新建发布目标,然后在新发布目标中选择新字段即可。详细教程请参考发布目标中不能选择的字段;
5. 5118-API接口常见问题及解决方法
一、API处理规则和SEO规则如何协同工作?
系统默认对title和content字段进行SEO功能,需要修改为SEO规则中对应的新字段,如title_5118换字、content_5118换字字段;
文章采集api(为什么会有这个需求,某些时候我们需要把pillar数据存储在CMDB中 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2022-03-08 14:06
)
大部分时候,在使用pillar的时候,我们直接使用SLS文件来存储数据,但实际上pillar可以支持多种数据存储方式,比如:mysql、mongo、json等;这些可以在官网或者ext_piilar的code代码中看到;
pillar支持的数据存储模块列表地址:
要求:
我们来谈谈为什么会有这种需求。有时我们需要将柱子数据存储在CMDB中,或者从CMDB中拉取数据提供柱子使用。这时候在柱子下编辑SLS文件就有点不雅了。 ext_pillar 解决了这个问题,作为支柱数据映射和数据存储 (CMDB) 的枢纽。
最近写代码要发布,需要用到pillar data(一个版本号,平台提供代码url,代码打包推送到repo时,版本号更新为saltstack的pillar data call),刚好想到ext_pillar,OMS运维平台使用的是MySQL数据库,所以想直接使用这个模块;接触的时候有点难过,文档也很少~~ 找个翻译 文章 用的是MongoDB,想着再建个mongodb有点过分了;飞飞给我的建议是不要用MySQL,建议做一个Http API接口;
pillar 是一个很棒的工具,它不仅可以存储安全数据,还可以存储业务数据;使用ext_pillar连接CMDB系统,状态用于描述业务处理逻辑,真实数据取自CMDB;玩,这块绿肥和jacky是第一个意识到的,很有经验
说了这么多,再说说实现这个Http API的ext_pillar(没有CMDB)
1.实现后端数据->根据业务场景,设计满足业务的数据结构(dict),控制权在你手中,实现你想要的,关键积分符合你的业务
2.实现ext_pillar,可以访问http访问后端数据
3.配置salt master配置文件,重启master
4.支柱测试
实施:
1. 后端数据实现。
HTTP方式使用JSON数据,不仅可以生成json数据,还可以改变json数据;先来看看柱子数据映射SLS文件格式
hdworkers:
版本:2014102202
上面的数据格式转换成dict,{'hdworkers': {'ver': '2014102202'}},我只需要实现一个简单的版本号映射,你自己设计这么复杂的数据;把程序贴在Code下面(代码很烂,不要喷~)
# -*- coding: utf-8 -*-
import json
import os
class BuildJson(object):
'''
Build JSON data(base and minion_id etc..)
'''
def base_data(self,args):
'''
build base data
'''
info = {}
ret = dict(info,**args)
self.write_data('base',ret)
def build_data(self,id,args):
if not os.path.exists('/home/api/pillar/%s' % (id)):
with open('/home/api/pillar/base') as f:
obj = f.readlines()[0]
ret = eval(obj)
self.write_data(id,ret)
with open('/home/api/pillar/%s' % (id)) as f:
data = f.readlines()[0]
cov_data = eval(data)
if not cov_data.has_key(args.keys()[0]):
ret = dict(cov_data,**args)
self.write_data(id,ret)
else:
cov_data.update(args)
self.write_data(id,cov_data)
def write_data(self,file,ret):
f = open('/home/api/pillar/%s' % (file),'w+')
f.write(str(ret))
f.close()
#data = {'hdworkers':{'ver':'2014103105'}}
#bapi = BuildJson()
#bapi.base_data(数据)
#bapi.build_data('test-01',data)
生成基础数据,然后调用build_data(继承基础数据,同时更新数据),id上会有一些数据,但是基础不行~,所以上面是我写的评委自己玩,有好的可以反馈给我,我正在修改~
2.实现ext_pillar,可以通过http访问
因为是结合OMS平台,所以我对上面生成的文件在nginx中做了localtion设置,这样就可以通过http访问数据了;否则,ext_pillar 无法播放
我忽略了Nginx的配置过程,直接粘贴结果
查看全部
文章采集api(为什么会有这个需求,某些时候我们需要把pillar数据存储在CMDB中
)
大部分时候,在使用pillar的时候,我们直接使用SLS文件来存储数据,但实际上pillar可以支持多种数据存储方式,比如:mysql、mongo、json等;这些可以在官网或者ext_piilar的code代码中看到;
pillar支持的数据存储模块列表地址:
要求:
我们来谈谈为什么会有这种需求。有时我们需要将柱子数据存储在CMDB中,或者从CMDB中拉取数据提供柱子使用。这时候在柱子下编辑SLS文件就有点不雅了。 ext_pillar 解决了这个问题,作为支柱数据映射和数据存储 (CMDB) 的枢纽。
最近写代码要发布,需要用到pillar data(一个版本号,平台提供代码url,代码打包推送到repo时,版本号更新为saltstack的pillar data call),刚好想到ext_pillar,OMS运维平台使用的是MySQL数据库,所以想直接使用这个模块;接触的时候有点难过,文档也很少~~ 找个翻译 文章 用的是MongoDB,想着再建个mongodb有点过分了;飞飞给我的建议是不要用MySQL,建议做一个Http API接口;
pillar 是一个很棒的工具,它不仅可以存储安全数据,还可以存储业务数据;使用ext_pillar连接CMDB系统,状态用于描述业务处理逻辑,真实数据取自CMDB;玩,这块绿肥和jacky是第一个意识到的,很有经验
说了这么多,再说说实现这个Http API的ext_pillar(没有CMDB)
1.实现后端数据->根据业务场景,设计满足业务的数据结构(dict),控制权在你手中,实现你想要的,关键积分符合你的业务
2.实现ext_pillar,可以访问http访问后端数据
3.配置salt master配置文件,重启master
4.支柱测试
实施:
1. 后端数据实现。
HTTP方式使用JSON数据,不仅可以生成json数据,还可以改变json数据;先来看看柱子数据映射SLS文件格式
hdworkers:
版本:2014102202
上面的数据格式转换成dict,{'hdworkers': {'ver': '2014102202'}},我只需要实现一个简单的版本号映射,你自己设计这么复杂的数据;把程序贴在Code下面(代码很烂,不要喷~)
# -*- coding: utf-8 -*-
import json
import os
class BuildJson(object):
'''
Build JSON data(base and minion_id etc..)
'''
def base_data(self,args):
'''
build base data
'''
info = {}
ret = dict(info,**args)
self.write_data('base',ret)
def build_data(self,id,args):
if not os.path.exists('/home/api/pillar/%s' % (id)):
with open('/home/api/pillar/base') as f:
obj = f.readlines()[0]
ret = eval(obj)
self.write_data(id,ret)
with open('/home/api/pillar/%s' % (id)) as f:
data = f.readlines()[0]
cov_data = eval(data)
if not cov_data.has_key(args.keys()[0]):
ret = dict(cov_data,**args)
self.write_data(id,ret)
else:
cov_data.update(args)
self.write_data(id,cov_data)
def write_data(self,file,ret):
f = open('/home/api/pillar/%s' % (file),'w+')
f.write(str(ret))
f.close()
#data = {'hdworkers':{'ver':'2014103105'}}
#bapi = BuildJson()
#bapi.base_data(数据)
#bapi.build_data('test-01',data)
生成基础数据,然后调用build_data(继承基础数据,同时更新数据),id上会有一些数据,但是基础不行~,所以上面是我写的评委自己玩,有好的可以反馈给我,我正在修改~
2.实现ext_pillar,可以通过http访问
因为是结合OMS平台,所以我对上面生成的文件在nginx中做了localtion设置,这样就可以通过http访问数据了;否则,ext_pillar 无法播放
我忽略了Nginx的配置过程,直接粘贴结果
文章采集api(如何利用免费Dede采集插件让网站收录以及关键词排名?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-03-08 11:05
为什么要使用 Dede采集 插件?如何使用免费的 Dede采集 插件对 网站收录 和 关键词 进行排名。我们知道网站结构是seo优化过程中不可忽视的一个非常重要的环节。网站结构分为物理结构和逻辑结构。物理结构一般是指虚拟空间中的许多目录和文件。这种结构一般用户不能直接看到,逻辑结构主要是指网站上线后我们肉眼可以看到的网站界面中的链接关系。两者都是站长在优化过程中需要注意的重点。那么SEO网站结构优化有什么意义呢?
网站结构对我们的网站 优化真的那么重要吗?很多人都在问同样的问题。其实我们可以把我们网站想象成一栋房子,结构就是我们房子的布局,首页就是我们的客厅,搜索引擎就是来我们家参观的朋友。,当他来到你家时,他会先进入你家的客厅;通过客厅,您可以到达房子的每个房间,同样可以通过我们的首页搜索引擎到达我们的每个页面。为了方便起见,我们的网站最好的结构是三层,也就是说用户最多点击3次就可以到达他想到达的页面。这样做的目的是为了加快蜘蛛的爬行速度和蜘蛛的友好度。而且,
网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以利用Dede采集实现采集伪原创自动发布,主动推送给搜索引擎,增加搜索引擎的抓取频率,从而增加网站收录 和 关键词 排名。这个Dede采集不需要写规则,输入关键词就可以了采集。
一、免费Dede采集插件
免费Dede采集插件特点:
1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词。
2、支持多消息源:问答和各种消息源(可同时设置多个采集消息源采集/采集消息源稍后添加)
3、过滤其他促销信息
4、图片本地化/图片水印/图片第三方存储
5、文章交流+翻译(简体中文和繁体翻译+百度翻译+有道翻译+谷歌翻译+147翻译)
6、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、在所有平台上发布插件
全平台cms发布者的特点:
1、cms发布:目前市面上唯一支持Empirecms、易友、ZBLOG、dedecms、WordPress、PBoot、Applecms、迅锐cms、PHPcms、苹果cms、人人网cms、米拓cms、云游cms、小旋风站群 , THINKCMF, 建站ABC, 凡客cms, 一骑cms, 海洋cms, 飞飞cms, 本地发布, 搜外 等cms ,并同时进行批量管理和发布的工具
2、全网推送(百度/360/搜狗/神马)
3、伪原创(标题+内容)
4、替换图片防止侵权
5、强大的SEO功能(自动图片放置/插入内外链接/标题和文章前后插入内容/标题关键词与内容一致关键词/随机插入图片/随机属性添加页面原创度)
6、对应栏:对应文章可以发布对应栏/支持多栏发布
7、定期发布:可控发布间隔/每天发布总数
8、监控数据:直接监控已经发布、待发布的软件,是否为伪原创、发布状态、URL、程序、发布时间等。
还有一点大家要注意的是,我们的网站里面不能有死连接,网站里面的连接不能很乱,不要让网站看起来像迷宫是的,蜘蛛最讨厌的地方就是迷宫网站。因为这样的网站会浪费蜘蛛很多时间,会觉得额外的累赘,时间长了会减少蜘蛛爬行的数量,就像我们站在房子的客厅里,你想去到其中一个房间,然后你发现房子就像一个迷宫,需要很长时间才能找到你想去的房间。你想要这样的房子吗?你肯定不喜欢吧?蜘蛛也是如此。所以 网站 不需要添加太多的连接,
其实如果一个网站想要做好网站的优化,首先要做的就是要有一个好的网站结构。就像迷宫一样,设施齐全,没有人愿意住在那里。同理,我们的网站内容做的不错,但是找起来很麻烦,别说蜘蛛了,连用户都不愿意找。
对网站进行SEO优化时,主要分为站内优化和站外优化两部分。具体的优化内容可以分为很多部分。TDK选型部署如网站、关键词密度控制等现场优化,现场结构是否简单合理,目录层次是否过于复杂等,非现场优化比如网站外部链接的扩展、友好链接的交换等等,这些因素都是不容忽视的,任何一个领域的问题都可能导致网站整体不稳定。那么网站标签是如何进行SEO优化的呢?
alt标签的使用
很多人可能并不关心 网站alt 标签。该标签是为网站上的图片设置和部署的。想必大家都知道,搜索引擎蜘蛛无法顺利抓取网站上的图片。为了更好的识别图片,我们可以在图片后面加上图片的alt标签属性,在alt里面加上图片的详细信息或者网站关键词,这样就可以告诉蜘蛛图片内容,还可以累加网站关键词的权重和密度,有效提升网站关键词的排名和权重。
h1标签的用法和作用
说到网站的H1标签,可能有人会问,h1标签的意义何在,但我要告诉大家的是,网站的H1标签有很多功能,而h1是在一个页面中得到的权重最高的。当蜘蛛进入页面进行爬取时,第一个是标题,第二个是h1标签,所以后面我们可以在h1标签中部署网站的关键词。增加关键词的权重,为了突出网站的主题核心,所以在页面的h1标签中,不能随便部署词汇,网站的整体核心应该可以考虑,而 h1 标签在一个页面上只能出现一次。如果使用次数过多,将没有效果。这需要特别注意。
网站 标签的使用需要谨慎。如果使用不当,会直接导致网站降级,甚至K。标签优化是网站优化的好方法。比较重要,所以优化标签的时候不要操之过急,也不要过度优化问题。合理恰当地使用标签优化,可以增加网站的连接性,也可以增加用户粘性。,所以对网站标签的优化需要慎重。 查看全部
文章采集api(如何利用免费Dede采集插件让网站收录以及关键词排名?)
为什么要使用 Dede采集 插件?如何使用免费的 Dede采集 插件对 网站收录 和 关键词 进行排名。我们知道网站结构是seo优化过程中不可忽视的一个非常重要的环节。网站结构分为物理结构和逻辑结构。物理结构一般是指虚拟空间中的许多目录和文件。这种结构一般用户不能直接看到,逻辑结构主要是指网站上线后我们肉眼可以看到的网站界面中的链接关系。两者都是站长在优化过程中需要注意的重点。那么SEO网站结构优化有什么意义呢?
网站结构对我们的网站 优化真的那么重要吗?很多人都在问同样的问题。其实我们可以把我们网站想象成一栋房子,结构就是我们房子的布局,首页就是我们的客厅,搜索引擎就是来我们家参观的朋友。,当他来到你家时,他会先进入你家的客厅;通过客厅,您可以到达房子的每个房间,同样可以通过我们的首页搜索引擎到达我们的每个页面。为了方便起见,我们的网站最好的结构是三层,也就是说用户最多点击3次就可以到达他想到达的页面。这样做的目的是为了加快蜘蛛的爬行速度和蜘蛛的友好度。而且,
网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以利用Dede采集实现采集伪原创自动发布,主动推送给搜索引擎,增加搜索引擎的抓取频率,从而增加网站收录 和 关键词 排名。这个Dede采集不需要写规则,输入关键词就可以了采集。
一、免费Dede采集插件
免费Dede采集插件特点:
1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词。
2、支持多消息源:问答和各种消息源(可同时设置多个采集消息源采集/采集消息源稍后添加)
3、过滤其他促销信息
4、图片本地化/图片水印/图片第三方存储
5、文章交流+翻译(简体中文和繁体翻译+百度翻译+有道翻译+谷歌翻译+147翻译)
6、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、在所有平台上发布插件
全平台cms发布者的特点:
1、cms发布:目前市面上唯一支持Empirecms、易友、ZBLOG、dedecms、WordPress、PBoot、Applecms、迅锐cms、PHPcms、苹果cms、人人网cms、米拓cms、云游cms、小旋风站群 , THINKCMF, 建站ABC, 凡客cms, 一骑cms, 海洋cms, 飞飞cms, 本地发布, 搜外 等cms ,并同时进行批量管理和发布的工具
2、全网推送(百度/360/搜狗/神马)
3、伪原创(标题+内容)
4、替换图片防止侵权
5、强大的SEO功能(自动图片放置/插入内外链接/标题和文章前后插入内容/标题关键词与内容一致关键词/随机插入图片/随机属性添加页面原创度)
6、对应栏:对应文章可以发布对应栏/支持多栏发布
7、定期发布:可控发布间隔/每天发布总数
8、监控数据:直接监控已经发布、待发布的软件,是否为伪原创、发布状态、URL、程序、发布时间等。
还有一点大家要注意的是,我们的网站里面不能有死连接,网站里面的连接不能很乱,不要让网站看起来像迷宫是的,蜘蛛最讨厌的地方就是迷宫网站。因为这样的网站会浪费蜘蛛很多时间,会觉得额外的累赘,时间长了会减少蜘蛛爬行的数量,就像我们站在房子的客厅里,你想去到其中一个房间,然后你发现房子就像一个迷宫,需要很长时间才能找到你想去的房间。你想要这样的房子吗?你肯定不喜欢吧?蜘蛛也是如此。所以 网站 不需要添加太多的连接,
其实如果一个网站想要做好网站的优化,首先要做的就是要有一个好的网站结构。就像迷宫一样,设施齐全,没有人愿意住在那里。同理,我们的网站内容做的不错,但是找起来很麻烦,别说蜘蛛了,连用户都不愿意找。
对网站进行SEO优化时,主要分为站内优化和站外优化两部分。具体的优化内容可以分为很多部分。TDK选型部署如网站、关键词密度控制等现场优化,现场结构是否简单合理,目录层次是否过于复杂等,非现场优化比如网站外部链接的扩展、友好链接的交换等等,这些因素都是不容忽视的,任何一个领域的问题都可能导致网站整体不稳定。那么网站标签是如何进行SEO优化的呢?
alt标签的使用
很多人可能并不关心 网站alt 标签。该标签是为网站上的图片设置和部署的。想必大家都知道,搜索引擎蜘蛛无法顺利抓取网站上的图片。为了更好的识别图片,我们可以在图片后面加上图片的alt标签属性,在alt里面加上图片的详细信息或者网站关键词,这样就可以告诉蜘蛛图片内容,还可以累加网站关键词的权重和密度,有效提升网站关键词的排名和权重。
h1标签的用法和作用
说到网站的H1标签,可能有人会问,h1标签的意义何在,但我要告诉大家的是,网站的H1标签有很多功能,而h1是在一个页面中得到的权重最高的。当蜘蛛进入页面进行爬取时,第一个是标题,第二个是h1标签,所以后面我们可以在h1标签中部署网站的关键词。增加关键词的权重,为了突出网站的主题核心,所以在页面的h1标签中,不能随便部署词汇,网站的整体核心应该可以考虑,而 h1 标签在一个页面上只能出现一次。如果使用次数过多,将没有效果。这需要特别注意。
网站 标签的使用需要谨慎。如果使用不当,会直接导致网站降级,甚至K。标签优化是网站优化的好方法。比较重要,所以优化标签的时候不要操之过急,也不要过度优化问题。合理恰当地使用标签优化,可以增加网站的连接性,也可以增加用户粘性。,所以对网站标签的优化需要慎重。
文章采集api(..2、应用级参数(每个接入点有自己的参数))
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-03-08 05:02
趣头条采集接口接口地址:(注:接口支持https,更安全,但速度稍慢,你懂的。请根据自己的情况选择。) 支持格式:json 请求方式:HTTP协议,支持GET/POST 方法。二、请求参数/请求参数
对于非文件上传 POST,enctype=application/x-www-form-urlencoded。
在文件上传的POST中,enctype=multipart/form-data。
1、系统级参数(所有接入点都需要):
参数名称类型示例值必须描述
showapi_appidString100 是亿源app id
showapi_signString698d51a19d8a121ce581499d7b701668是为了验证用户的身份,保证参数不被中间人篡改,需要传递调用者的数字签名。可选,在url后面加上appid和secret
showapi_timestampString239 无客户端时间。
格式 yyyyMMddHHmmss,如 239
为了在一定程度上防止“重放攻击”,平台只接受10分钟内的请求。如果没有传递或传递空字符串,系统将不再检查该字段。
showapi_res_gzipString1 或 0 否 返回值是否被 gzip 压缩。值为1会压缩,其他值不会压缩。
...
2、应用级参数(每个接入点都有自己的参数,当前接入点的参数见下表):
参数名称类型默认值示例值必须描述
请求示例:String res=new ShowApiRequest("","my_appId","my_appSecret") .post();System.out.println(res);三、返回参数/返回参数
以 JSON 格式返回结果。
1、系统级参数(所有接入点返回的参数):
名称 类型 示例 值 描述
showapi_res_bodyString{"city":"Kunming","prov":"Yunnan"}消息体的JSON封装,所有应用级的返回参数都会嵌入到这个对象中。
showapi_res_codeint0 一元返回标志,0为成功,其他为失败。
0 成功
-1,系统调用错误
-2,调用次数或金额为0
-3,读取超时
-4、服务器返回数据解析错误
-5、后端服务器DNS解析错误
-6、服务不存在或不在线
-7,API创建者网关资源不足
-1000,系统维护
-1002,必须传递showapi_appid字段
-1003,必须通过showapi_sign字段
-1004,签名验证错误
-1005,showapi_timestamp 无效
-1006,app没有权限调用接口
-1007, 没有订购包裹
-1008,服务商关闭对你的通话权限
-1009,呼叫频率受限
-1010,找不到你的应用
-1011, 无效的子授权 app_child_id
-1012, 子授权已过期或过期
-1013,子授权ip受限
-1014,令牌权限无效
showapi_res_errorString 用户输入不正确!显示错误信息
showapi_res_idStringce135f6739294c63be0c021b76b6fbff这个请求id
...
2、应用级参数(系统级输出参数showapi_res_body字段中的json数据结构):
名称 类型 示例 值 描述
ret_codeNumber0
数据对象[]
- idNumber27
- titleString 为何史祥云不被视为宝儿祖母的人选?标题
- typeString 分类
- urlString文章地址
- descString 包办婚姻可能会影响结婚的决定,原因如下:1、当事人祥云和宝玉的感情愿望是一起长大的,大家只把两人当成兄弟姐妹,没想到男女之间的爱情。不过,据周汝昌先生调查,《红楼梦》中所谓的金玉福,是宝玉的玉石和石祥云的金子(锦旗的描述文章
- imgString 图像数组
- tagString"[\"娱乐\",\"明星\",\"八卦\"]",tag关键词数组
...
特别是工人","tag": "[]","img": "[\"\"]","type": "40","url": ""},{"id": "24" ,"time": "1519886219", "title_eng": "邓超对儿子和女儿的态度很不一样。最后一张图太暖心了!”,“desc”:“说邓超是女儿奴一点都不为过。近日,孙俪曝光了邓超和女儿小华。还有递一杯酒的照片,两人各拿一杯,画面十分恩爱。1519886219", "title_eng": "邓超对儿子和女儿的态度很不一样。最后一张图太暖心了!”,“desc”:“说邓超是女儿奴一点都不为过。近日,孙俪曝光了邓超和女儿小华。还有递一杯酒的照片,两人各拿一杯,画面十分恩爱。1519886219", "title_eng": "邓超对儿子和女儿的态度很不一样。最后一张图太暖心了!”,“desc”:“说邓超是女儿奴一点都不为过。近日,孙俪曝光了邓超和女儿小华。还有递一杯酒的照片,两人各拿一杯,画面十分恩爱。
网友纷纷回复:女儿真是爸爸前世的小情人,夫妻恩爱,孩子可爱,小姐姐是人生赢家!就在孙俪发这个","tag":"[\"邓超\",\"态度\",\"暖心\"]","img":"[\"\",\"\ " ,\"","type": "6","url": ""},{"id": "54","time": "1519886258","title": "靳东"娘-law”,12 影后称号,朱军拼命想娶她,如今62岁出家”,“desc”:“一提到杜十娘,你会想到谁?很多人认为应该是李嘉欣
房地产专家刘权解释:为什么现在买房越来越贵,买房越来越难?","desc": "日前,国家统计局发布了2018年1月70个大中城市商品房销售价格统计数据。
北京、天津、上海、南京、无锡、济南等13个城市新建住宅销售价格环比下降1.2%。深圳同比下降3.4%,福州同比下降2.7%,杭州","tag": "[]","img": "[ \"\"]","type" : "10","url": ""},{"id": "70","time": "1519885060","title": "狗走了 10 公里每天到镇上只是为了睡觉!原因让楼主心痛!","desc": "主人在镇上捡到一只流浪狗,带回自己的小村子养,但狗每天早上自己跑出去,晚上又回来。主人每天都对这只狗很好奇。你在干什么,所以这天主人跟着他的狗,发现狗居然跑回了镇上,然后","tag":"[\"奇葩\",\"轶事\",\"打猎\"]","img": "[\"\",\"\",\"","type": "3","url": ""},{"id": "74", “时间”:“1519886260”,“标题”:“国内不怕打,中国空军高调宣布歼20最佳搭档”,
","tag": "[\"军事事件\",\"热点事件\",\"科技事件\"]","img": "[\"\",\"\",\ "","type": "15","url": ""},{"id": "77","time": "1519885060","title": "女司机夜间驾驶导航,没想到导航给她指了一条水路!”,“desc”:“没想到当今社会连电子技术都开始骗人了。就像图中的司机,因为雾和极端的能见度,她看着导航。驱动器最终落入水中。
女司机还在专心看着导航往前走的时候,突然发现自己已经在水里开车了,“,tag”:“[\"轶事\",\"驾驶\",\"导航\"]","img": "[\"\",\"\",\"","type": "9","url": ""},{"id": "79" ,"time":"1519885060","title":"刘强东在手机上宠妻章泽天,网友:总比放过别的女人好","desc":"只有细心的网友才能发现刘强东有没有他那么爱老婆章泽天,刘强东在手机上宠老婆。
网友回应:总比把别的女人的照片当屏保好!今天章泽天和刘强东一起出席学校活动,随后刘强东手机壁纸曝光。仔细看其实很可爱","tag": "[\"娱乐",\"明星\",\"刘强东\",\"章泽天\"]","img": " [\"\",\"\",\"","type":"6","url":""},{"id":"81","time":"1519886862","title ”:“中共中央、国务院召开春节小组会议,习近平发表重要讲话”,“desc”:“ 查看全部
文章采集api(..2、应用级参数(每个接入点有自己的参数))
趣头条采集接口接口地址:(注:接口支持https,更安全,但速度稍慢,你懂的。请根据自己的情况选择。) 支持格式:json 请求方式:HTTP协议,支持GET/POST 方法。二、请求参数/请求参数
对于非文件上传 POST,enctype=application/x-www-form-urlencoded。
在文件上传的POST中,enctype=multipart/form-data。
1、系统级参数(所有接入点都需要):
参数名称类型示例值必须描述
showapi_appidString100 是亿源app id
showapi_signString698d51a19d8a121ce581499d7b701668是为了验证用户的身份,保证参数不被中间人篡改,需要传递调用者的数字签名。可选,在url后面加上appid和secret
showapi_timestampString239 无客户端时间。
格式 yyyyMMddHHmmss,如 239
为了在一定程度上防止“重放攻击”,平台只接受10分钟内的请求。如果没有传递或传递空字符串,系统将不再检查该字段。
showapi_res_gzipString1 或 0 否 返回值是否被 gzip 压缩。值为1会压缩,其他值不会压缩。
...
2、应用级参数(每个接入点都有自己的参数,当前接入点的参数见下表):
参数名称类型默认值示例值必须描述
请求示例:String res=new ShowApiRequest("","my_appId","my_appSecret") .post();System.out.println(res);三、返回参数/返回参数
以 JSON 格式返回结果。
1、系统级参数(所有接入点返回的参数):
名称 类型 示例 值 描述
showapi_res_bodyString{"city":"Kunming","prov":"Yunnan"}消息体的JSON封装,所有应用级的返回参数都会嵌入到这个对象中。
showapi_res_codeint0 一元返回标志,0为成功,其他为失败。
0 成功
-1,系统调用错误
-2,调用次数或金额为0
-3,读取超时
-4、服务器返回数据解析错误
-5、后端服务器DNS解析错误
-6、服务不存在或不在线
-7,API创建者网关资源不足
-1000,系统维护
-1002,必须传递showapi_appid字段
-1003,必须通过showapi_sign字段
-1004,签名验证错误
-1005,showapi_timestamp 无效
-1006,app没有权限调用接口
-1007, 没有订购包裹
-1008,服务商关闭对你的通话权限
-1009,呼叫频率受限
-1010,找不到你的应用
-1011, 无效的子授权 app_child_id
-1012, 子授权已过期或过期
-1013,子授权ip受限
-1014,令牌权限无效
showapi_res_errorString 用户输入不正确!显示错误信息
showapi_res_idStringce135f6739294c63be0c021b76b6fbff这个请求id
...
2、应用级参数(系统级输出参数showapi_res_body字段中的json数据结构):
名称 类型 示例 值 描述
ret_codeNumber0
数据对象[]
- idNumber27
- titleString 为何史祥云不被视为宝儿祖母的人选?标题
- typeString 分类
- urlString文章地址
- descString 包办婚姻可能会影响结婚的决定,原因如下:1、当事人祥云和宝玉的感情愿望是一起长大的,大家只把两人当成兄弟姐妹,没想到男女之间的爱情。不过,据周汝昌先生调查,《红楼梦》中所谓的金玉福,是宝玉的玉石和石祥云的金子(锦旗的描述文章
- imgString 图像数组
- tagString"[\"娱乐\",\"明星\",\"八卦\"]",tag关键词数组
...
特别是工人","tag": "[]","img": "[\"\"]","type": "40","url": ""},{"id": "24" ,"time": "1519886219", "title_eng": "邓超对儿子和女儿的态度很不一样。最后一张图太暖心了!”,“desc”:“说邓超是女儿奴一点都不为过。近日,孙俪曝光了邓超和女儿小华。还有递一杯酒的照片,两人各拿一杯,画面十分恩爱。1519886219", "title_eng": "邓超对儿子和女儿的态度很不一样。最后一张图太暖心了!”,“desc”:“说邓超是女儿奴一点都不为过。近日,孙俪曝光了邓超和女儿小华。还有递一杯酒的照片,两人各拿一杯,画面十分恩爱。1519886219", "title_eng": "邓超对儿子和女儿的态度很不一样。最后一张图太暖心了!”,“desc”:“说邓超是女儿奴一点都不为过。近日,孙俪曝光了邓超和女儿小华。还有递一杯酒的照片,两人各拿一杯,画面十分恩爱。
网友纷纷回复:女儿真是爸爸前世的小情人,夫妻恩爱,孩子可爱,小姐姐是人生赢家!就在孙俪发这个","tag":"[\"邓超\",\"态度\",\"暖心\"]","img":"[\"\",\"\ " ,\"","type": "6","url": ""},{"id": "54","time": "1519886258","title": "靳东"娘-law”,12 影后称号,朱军拼命想娶她,如今62岁出家”,“desc”:“一提到杜十娘,你会想到谁?很多人认为应该是李嘉欣
房地产专家刘权解释:为什么现在买房越来越贵,买房越来越难?","desc": "日前,国家统计局发布了2018年1月70个大中城市商品房销售价格统计数据。
北京、天津、上海、南京、无锡、济南等13个城市新建住宅销售价格环比下降1.2%。深圳同比下降3.4%,福州同比下降2.7%,杭州","tag": "[]","img": "[ \"\"]","type" : "10","url": ""},{"id": "70","time": "1519885060","title": "狗走了 10 公里每天到镇上只是为了睡觉!原因让楼主心痛!","desc": "主人在镇上捡到一只流浪狗,带回自己的小村子养,但狗每天早上自己跑出去,晚上又回来。主人每天都对这只狗很好奇。你在干什么,所以这天主人跟着他的狗,发现狗居然跑回了镇上,然后","tag":"[\"奇葩\",\"轶事\",\"打猎\"]","img": "[\"\",\"\",\"","type": "3","url": ""},{"id": "74", “时间”:“1519886260”,“标题”:“国内不怕打,中国空军高调宣布歼20最佳搭档”,
","tag": "[\"军事事件\",\"热点事件\",\"科技事件\"]","img": "[\"\",\"\",\ "","type": "15","url": ""},{"id": "77","time": "1519885060","title": "女司机夜间驾驶导航,没想到导航给她指了一条水路!”,“desc”:“没想到当今社会连电子技术都开始骗人了。就像图中的司机,因为雾和极端的能见度,她看着导航。驱动器最终落入水中。
女司机还在专心看着导航往前走的时候,突然发现自己已经在水里开车了,“,tag”:“[\"轶事\",\"驾驶\",\"导航\"]","img": "[\"\",\"\",\"","type": "9","url": ""},{"id": "79" ,"time":"1519885060","title":"刘强东在手机上宠妻章泽天,网友:总比放过别的女人好","desc":"只有细心的网友才能发现刘强东有没有他那么爱老婆章泽天,刘强东在手机上宠老婆。
网友回应:总比把别的女人的照片当屏保好!今天章泽天和刘强东一起出席学校活动,随后刘强东手机壁纸曝光。仔细看其实很可爱","tag": "[\"娱乐",\"明星\",\"刘强东\",\"章泽天\"]","img": " [\"\",\"\",\"","type":"6","url":""},{"id":"81","time":"1519886862","title ”:“中共中央、国务院召开春节小组会议,习近平发表重要讲话”,“desc”:“
文章采集api(API接口是什么?为什么我们需要实际上接口?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-03-05 14:05
对于很多产品新手或者求职者来说,API接口是产品和研发领域的一个专业名词,大家可能在文章或者PRD都接触过API接口的概念。
事实上,接口的应用已经非常广泛和成熟。这个概念主要活跃在公司内部各个系统之间的连接对接以及公司之间的合作场景中。如果你能仔细阅读这篇文章,相信你对API接口的理解会更深,甚至超过90%的新手和求职者。
本文目录:
API接口是什么?为什么我们需要API接口?API接口的核心一、什么是API接口?
让我们用一个常见的数学公式来理解API,比如y=x+2,当x=2时,y=4,对吧?
这时候我们调用y=x+2接口,x=2参数,y=4返回结果,那么这个接口的作用就是把我们输入的数字加2(注意:这里你可以发现接口本身有逻辑)。
以此类推,让我们理解一个常见的场景。比如有一个接口可以把经纬度转换成城市。当我输入55°的经纬度和88°的纬度时,界面会使用自己的逻辑运算,返回结果告诉我:杭州市。
这样就可以清楚的看懂百度百科的官方解释了。接口是预定义的功能逻辑。其他系统请求然后返回结果是一回事。
二、为什么我们需要一个 API 接口?
背景:我们的业务系统涉及到很多方面。如果我们想要一个公司或一个系统来完成所有的业务,那就太费力了,对吧?而如果其他系统或公司有更好的操作逻辑,我们在设计功能时可以考虑使用接口进行开发。
核心需求:利用现有接口可以降低开发成本,缩短开发成本。
例如:比如我是一个打车app,现在我需要在我的页面上显示地图功能。对于我们公司来说,新的地图功能太贵了。然后我们可以使用高德开放平台或者百度地图。打开平台,找到地图API,在这种情况下,我们只需要购买高德的服务,部署并调用高德地图API,就可以在我们的页面上快速启动地图功能。
三、API接口的核心
对于小白来说,第一次看 API 文档可能会让人迷惑——在哪里看,怎么看,摆在你面前的问题是什么。
其实对于产品经理来说,我们更应该关注的是这家公司能提供什么样的API接口服务。比如我知道高德可以提供地图API和规划路线的API。这样,我们就可以想到调用我们的设计函数和工作。他们的服务或参考。
因此,产品新手如果不了解,也无需过于担心。以后你也会对它有更深的理解,因为它理解起来并不复杂。以下是API接口的核心要点。所有的文档都离不开这五个核心。观点。
以下以微信开放平台为例进行说明。文末有各个开放平台的地址。有空的时候可以学习。好了,废话不多说,我们现在来搭建一个场景。
我们现在有一个APP,需要用户在购买时调用微信支付接口才能完成购买。请自动进入这个场景,把自己想象成一个产品经理。
1. 接口地址
现在,用户点击支付,我们需要告诉微信我们要打电话给你的收银员!但是在哪里说呢?这就需要接口地址,相当于把指定的数据传给微信链接。
链接地址不是我们所理解的页面。您可以将其理解为电话号码。新手应该改变这个概念。
至此,我们可以看到接口文档告诉我们链接如下,所以我们现在已经拨通了微信的号码。
2. 请求参数(消息)
我们现在需要告诉微信你要打电话给收银员,对吧?然后我们需要把它写下来。此时生成的消息称为消息,即你要告诉的界面内容是什么?相当于前面函数的输入 x=2。
一般来说,消息的格式和内容是根据接口文档指定的。以下是微信开放平台呼叫收银的消息要求。
我们先来看前两个参数。你现在正在和微信聊天。要不要先告诉微信,你是谁?这里的微信文档告诉你应该使用app ID+商户号来确定你的身份。那是什么意思?
比如你是商户,下面有a、b、c三个APP,那么微信需要知道你是哪个商户,下面哪个APP使用收银台。这个非常重要。微信应将收到的款项转到相应的账户和统计数据。
然后我们在消息中写下这两句话:
好吧,现在微信知道你是谁了,所以你得告诉微信你需要微信支付多少钱才能向你收费,对吧?这里定义了币种和总额,即收取什么币种,收取多少。
这里你看,币种一定要填,也就是说你也不能告诉微信支付是什么币种,因为他说默认是人民币。
好吧,让我们写两段
好了,现在微信知道你是谁,你要收多少钱,那么微信支付就会告诉你支付的结果,因为你要知道用户已经支付成功,才能继续发货、服务等。所以这里我们使用通知地址,就是告诉微信,等事情结束他会去哪里告诉你支付结果。然后我们写地址:
3. 返回结果
微信支付刚去收钱,现在他想在我们留下的通知地址告诉我们结果。结果不外乎两个:采集成功?收款失败?
(1)成功
很顺利,现在用户支付成功了,微信也把成功的消息告诉了我们,他也告诉了我们用户支付的一些信息。
那么这里就是收款成功后微信支付告诉我们的信息。
应用APPID,商户ID:告诉你我成功扣款的是哪个商户的APPID交易。
业务成果:成功或失败
(2)失败
在设计产品时,我们常常非常关心失败。当采集失败时,微信也会告诉你失败的原因。下面这张图很容易理解。失败的原因有很多。在设计的时候,我们经常去分析每一个失败的原因,设计每一个失败原因的页面和用户提示,以保证用户理解。
以上就是对API接口基本操作方式的理解。接下来我会继续更新API接口的一些更深入细致的关键元素,比如请求方法/签名/加解密等。
一个开放的平台供参考网站
微信支付:
高德平台开放平台:
本文由@islovesleeping原创 发表于每个人都是产品经理。未经许可禁止复制
题图来自Unsplash,基于CC0协议 查看全部
文章采集api(API接口是什么?为什么我们需要实际上接口?(图))
对于很多产品新手或者求职者来说,API接口是产品和研发领域的一个专业名词,大家可能在文章或者PRD都接触过API接口的概念。
事实上,接口的应用已经非常广泛和成熟。这个概念主要活跃在公司内部各个系统之间的连接对接以及公司之间的合作场景中。如果你能仔细阅读这篇文章,相信你对API接口的理解会更深,甚至超过90%的新手和求职者。
本文目录:
API接口是什么?为什么我们需要API接口?API接口的核心一、什么是API接口?
让我们用一个常见的数学公式来理解API,比如y=x+2,当x=2时,y=4,对吧?
这时候我们调用y=x+2接口,x=2参数,y=4返回结果,那么这个接口的作用就是把我们输入的数字加2(注意:这里你可以发现接口本身有逻辑)。
以此类推,让我们理解一个常见的场景。比如有一个接口可以把经纬度转换成城市。当我输入55°的经纬度和88°的纬度时,界面会使用自己的逻辑运算,返回结果告诉我:杭州市。
这样就可以清楚的看懂百度百科的官方解释了。接口是预定义的功能逻辑。其他系统请求然后返回结果是一回事。
二、为什么我们需要一个 API 接口?
背景:我们的业务系统涉及到很多方面。如果我们想要一个公司或一个系统来完成所有的业务,那就太费力了,对吧?而如果其他系统或公司有更好的操作逻辑,我们在设计功能时可以考虑使用接口进行开发。
核心需求:利用现有接口可以降低开发成本,缩短开发成本。
例如:比如我是一个打车app,现在我需要在我的页面上显示地图功能。对于我们公司来说,新的地图功能太贵了。然后我们可以使用高德开放平台或者百度地图。打开平台,找到地图API,在这种情况下,我们只需要购买高德的服务,部署并调用高德地图API,就可以在我们的页面上快速启动地图功能。
三、API接口的核心
对于小白来说,第一次看 API 文档可能会让人迷惑——在哪里看,怎么看,摆在你面前的问题是什么。
其实对于产品经理来说,我们更应该关注的是这家公司能提供什么样的API接口服务。比如我知道高德可以提供地图API和规划路线的API。这样,我们就可以想到调用我们的设计函数和工作。他们的服务或参考。
因此,产品新手如果不了解,也无需过于担心。以后你也会对它有更深的理解,因为它理解起来并不复杂。以下是API接口的核心要点。所有的文档都离不开这五个核心。观点。
以下以微信开放平台为例进行说明。文末有各个开放平台的地址。有空的时候可以学习。好了,废话不多说,我们现在来搭建一个场景。
我们现在有一个APP,需要用户在购买时调用微信支付接口才能完成购买。请自动进入这个场景,把自己想象成一个产品经理。
1. 接口地址
现在,用户点击支付,我们需要告诉微信我们要打电话给你的收银员!但是在哪里说呢?这就需要接口地址,相当于把指定的数据传给微信链接。
链接地址不是我们所理解的页面。您可以将其理解为电话号码。新手应该改变这个概念。
至此,我们可以看到接口文档告诉我们链接如下,所以我们现在已经拨通了微信的号码。
2. 请求参数(消息)
我们现在需要告诉微信你要打电话给收银员,对吧?然后我们需要把它写下来。此时生成的消息称为消息,即你要告诉的界面内容是什么?相当于前面函数的输入 x=2。
一般来说,消息的格式和内容是根据接口文档指定的。以下是微信开放平台呼叫收银的消息要求。
我们先来看前两个参数。你现在正在和微信聊天。要不要先告诉微信,你是谁?这里的微信文档告诉你应该使用app ID+商户号来确定你的身份。那是什么意思?
比如你是商户,下面有a、b、c三个APP,那么微信需要知道你是哪个商户,下面哪个APP使用收银台。这个非常重要。微信应将收到的款项转到相应的账户和统计数据。
然后我们在消息中写下这两句话:
好吧,现在微信知道你是谁了,所以你得告诉微信你需要微信支付多少钱才能向你收费,对吧?这里定义了币种和总额,即收取什么币种,收取多少。
这里你看,币种一定要填,也就是说你也不能告诉微信支付是什么币种,因为他说默认是人民币。
好吧,让我们写两段
好了,现在微信知道你是谁,你要收多少钱,那么微信支付就会告诉你支付的结果,因为你要知道用户已经支付成功,才能继续发货、服务等。所以这里我们使用通知地址,就是告诉微信,等事情结束他会去哪里告诉你支付结果。然后我们写地址:
3. 返回结果
微信支付刚去收钱,现在他想在我们留下的通知地址告诉我们结果。结果不外乎两个:采集成功?收款失败?
(1)成功
很顺利,现在用户支付成功了,微信也把成功的消息告诉了我们,他也告诉了我们用户支付的一些信息。
那么这里就是收款成功后微信支付告诉我们的信息。
应用APPID,商户ID:告诉你我成功扣款的是哪个商户的APPID交易。
业务成果:成功或失败
(2)失败
在设计产品时,我们常常非常关心失败。当采集失败时,微信也会告诉你失败的原因。下面这张图很容易理解。失败的原因有很多。在设计的时候,我们经常去分析每一个失败的原因,设计每一个失败原因的页面和用户提示,以保证用户理解。
以上就是对API接口基本操作方式的理解。接下来我会继续更新API接口的一些更深入细致的关键元素,比如请求方法/签名/加解密等。
一个开放的平台供参考网站
微信支付:
高德平台开放平台:
本文由@islovesleeping原创 发表于每个人都是产品经理。未经许可禁止复制
题图来自Unsplash,基于CC0协议
文章采集api(优采云采集支持调用优采云(小狗AI)API处理规则(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-03-03 13:11
)
优采云采集支持调用优采云(小狗AI)API接口,处理采集的数据标题和内容等;
温馨提示:第三方API接入功能需要用户提供第三方接口账号信息(即用户需要注册第三方接口,调用第三方接口产生的一切费用均需自行承担)由用户);
购买优采云 (Puppy AI) API,请先联系优采云 (Puppy AI) 客服并告知将用于优采云采集平台;
详细使用步骤
1.创建优采云API接口配置一、API配置入口:
点击控制台左侧列表中的【第三方服务配置】==点击【第三方内容API接入】==点击【第三方API配置管理】==最后点击【< @优采云API] 创建接口配置;
二、配置API接口信息:
购买优采云 (Puppy AI) API,请先联系优采云 (Puppy AI) 客服并告知将用于优采云采集平台。
【API key】是从优采云(Puppy AI)后台获取对应的API key,填入优采云;
注意:优采云限制每次调用最多6000个字符(包括html代码),所以当内容长度超过时,优采云会被拆分多次调用,会增加api调用次数,费用会相应增加,这是用户需要承担的费用,使用前一定要注意!!!!
2. 创建 API 处理规则
API处理规则,可以通过调用API接口设置处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==,点击【第三方内容API接入】==进入【API处理规则管理】页面,最后点击【+添加API处理规则]创建API处理规则;
二、API处理规则配置:
3. API 处理规则使用
API处理规则有两种使用方式:手动执行和自动执行:
一、手动执行API处理规则:
在采集任务的【结果数据&发布】选项卡中,点击【SEO&API&翻译等工具】按钮==选择【第三方API执行】栏==选择对应的API处理规则= ="执行(数据范围有两种执行方式,根据发布状态批量执行和根据列表中选择的数据执行);
二、自动执行API处理规则:
启用 API 处理的自动执行。任务完成后采集会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡【自动执行第三方API配置】==勾选【采集,自动执行API】选项==选择要执行的API处理规则= ="选择API接口处理的数据范围(一般选择'待发布',都将导致所有数据重复执行),最后点击保存;
4. API处理结果并发布一、查看API接口处理结果:
API接口处理的内容会保存为一个新的字段,如:标题处理后的新字段:`title_优采云`,内容处理后的新字段:`content_优采云`,在【结果数据&发布】和数据预览界面可以查看。
提示:执行 API 处理规则需要一段时间。执行完成后,页面会自动刷新,并出现API接口处理的新字段;
二、API接口处理后的内容发布
发布文章前,修改发布目标第二步的映射字段,重新选择标题和内容为对应字段`title_优采云`和`content_优采云`后面添加API接口处理;
提示:如果发布目标中无法选择新字段,请在任务下复制或新建发布目标,然后在新发布目标中选择新字段即可。详细教程请参考发布目标中不能选择的字段。
5. 优采云-API接口常见问题及解决方法一、API处理规则和SEO规则如何配合使用?
系统默认对title和content字段进行SEO功能,需要在SEO规则中修改为`title_优采云`和`content_优采云`字段;
查看全部
文章采集api(优采云采集支持调用优采云(小狗AI)API处理规则(组图)
)
优采云采集支持调用优采云(小狗AI)API接口,处理采集的数据标题和内容等;
温馨提示:第三方API接入功能需要用户提供第三方接口账号信息(即用户需要注册第三方接口,调用第三方接口产生的一切费用均需自行承担)由用户);
购买优采云 (Puppy AI) API,请先联系优采云 (Puppy AI) 客服并告知将用于优采云采集平台;
详细使用步骤
1.创建优采云API接口配置一、API配置入口:
点击控制台左侧列表中的【第三方服务配置】==点击【第三方内容API接入】==点击【第三方API配置管理】==最后点击【< @优采云API] 创建接口配置;
二、配置API接口信息:
购买优采云 (Puppy AI) API,请先联系优采云 (Puppy AI) 客服并告知将用于优采云采集平台。
【API key】是从优采云(Puppy AI)后台获取对应的API key,填入优采云;
注意:优采云限制每次调用最多6000个字符(包括html代码),所以当内容长度超过时,优采云会被拆分多次调用,会增加api调用次数,费用会相应增加,这是用户需要承担的费用,使用前一定要注意!!!!
2. 创建 API 处理规则
API处理规则,可以通过调用API接口设置处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==,点击【第三方内容API接入】==进入【API处理规则管理】页面,最后点击【+添加API处理规则]创建API处理规则;
二、API处理规则配置:
3. API 处理规则使用
API处理规则有两种使用方式:手动执行和自动执行:
一、手动执行API处理规则:
在采集任务的【结果数据&发布】选项卡中,点击【SEO&API&翻译等工具】按钮==选择【第三方API执行】栏==选择对应的API处理规则= ="执行(数据范围有两种执行方式,根据发布状态批量执行和根据列表中选择的数据执行);
二、自动执行API处理规则:
启用 API 处理的自动执行。任务完成后采集会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡【自动执行第三方API配置】==勾选【采集,自动执行API】选项==选择要执行的API处理规则= ="选择API接口处理的数据范围(一般选择'待发布',都将导致所有数据重复执行),最后点击保存;
4. API处理结果并发布一、查看API接口处理结果:
API接口处理的内容会保存为一个新的字段,如:标题处理后的新字段:`title_优采云`,内容处理后的新字段:`content_优采云`,在【结果数据&发布】和数据预览界面可以查看。
提示:执行 API 处理规则需要一段时间。执行完成后,页面会自动刷新,并出现API接口处理的新字段;
二、API接口处理后的内容发布
发布文章前,修改发布目标第二步的映射字段,重新选择标题和内容为对应字段`title_优采云`和`content_优采云`后面添加API接口处理;
提示:如果发布目标中无法选择新字段,请在任务下复制或新建发布目标,然后在新发布目标中选择新字段即可。详细教程请参考发布目标中不能选择的字段。
5. 优采云-API接口常见问题及解决方法一、API处理规则和SEO规则如何配合使用?
系统默认对title和content字段进行SEO功能,需要在SEO规则中修改为`title_优采云`和`content_优采云`字段;
文章采集api(APIPlatform可以快速的帮助我们创建操作文章的API接口)
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-03-03 13:08
API Platform 可以快速帮助我们创建 API。我们需要创建操作 文章 的 API 接口。我们打开 Post 类。在 Post 类之前,我们只需要添加一个注解 ApiResource。
#src/Entity/Post.php
/**
* @ORM\Entity(repositoryClass=PostRepository::class)
* @ORM\HasLifecycleCallbacks
*/
#[ApiResource]
class Post
{
// ...
}
我们打开配置目录。在config目录下,flex组件自动为我们添加了api_platform.yaml配置文件。我们打开配置文件,API Platform会自动检索Entity目录下的所有类,读取类之前的注解,然后根据注解设置生成API接口。
回到浏览器,我们刷新 Api 文档页面,API Platform 自动创建了 6 个接口来操作 文章 资源。前两个接口使用一个路径,后四个接口使用一个路径。这些接口使用相对统一的路径。但是同一个路径的接口,它们的方法是不一样的。
我们来看第一个接口,它使用 GET 方法来检索 文章 资源的集合。第二个接口使用 POST 方法创建 文章 资源。第三接口是操作单一资源的接口。GET 方法在这里用于检索 文章 资源。下面使用PUT方法,用于替换文章资源。第五个接口,该接口使用DELETE方法删除文章资源。最后一个使用 PATCH 方法,用于更新 文章 资源。
PUT 方法和 PATCH 方法都是对 文章 资源的修改,但是这两种方法之间存在一些差异。PUT 方法是对 文章 资源的整体替代。PATCH 方法是更新 文章 资源的一个或一些属性。这是 API 平台按照 REST 规范设计的一组 API。
它们有一个相对统一的路径,接口的方法也很重要。根据REST规范设计的接口具有相应的功能。这样,如果我们设计的界面被其他用户使用,其他用户可以快速上手。
我们可以直接在文档页面操作界面,我们看第三个界面,检索一篇文章文章。查看 文章 的列表,我们得到 ID 为 21 的 文章。单击,单击 Try it out 按钮,我们输入 id 参数。在这里输入21,点击后点击Execute。
curl库会发送一个get请求,请求地址为/api/posts/21,请求头有accept参数,接收到的响应格式为application/ld+json格式。在下一课中,我们将学习这种格式。
我们来看看响应的结果,响应码是400,有错误,还有循环引用。当我们得到某个文章数据时,我们也得到了文章的作者。回到项目,我们打开 User 类。在User类中,我们要获取当前作者的所有文章,然后再次获取文章。然后在文章中再次检索作者,所以有循环引用。我们在 User 类之前添加 API 注解,回到浏览器中,我们再次使用这个接口。
#src/Entity/User.php
/**
* @ORM\Entity(repositoryClass=UserRepository::class)
*/
#[ApiResource]
class User implements UserInterface, PasswordAuthenticatedUserInterface
{
// ...
}
这次我们看到当前的文章信息,作者属性没有展开,它得到一个字符串。在下一课中,我们将详细解释响应的结果格式。 查看全部
文章采集api(APIPlatform可以快速的帮助我们创建操作文章的API接口)
API Platform 可以快速帮助我们创建 API。我们需要创建操作 文章 的 API 接口。我们打开 Post 类。在 Post 类之前,我们只需要添加一个注解 ApiResource。
#src/Entity/Post.php
/**
* @ORM\Entity(repositoryClass=PostRepository::class)
* @ORM\HasLifecycleCallbacks
*/
#[ApiResource]
class Post
{
// ...
}
我们打开配置目录。在config目录下,flex组件自动为我们添加了api_platform.yaml配置文件。我们打开配置文件,API Platform会自动检索Entity目录下的所有类,读取类之前的注解,然后根据注解设置生成API接口。
回到浏览器,我们刷新 Api 文档页面,API Platform 自动创建了 6 个接口来操作 文章 资源。前两个接口使用一个路径,后四个接口使用一个路径。这些接口使用相对统一的路径。但是同一个路径的接口,它们的方法是不一样的。
我们来看第一个接口,它使用 GET 方法来检索 文章 资源的集合。第二个接口使用 POST 方法创建 文章 资源。第三接口是操作单一资源的接口。GET 方法在这里用于检索 文章 资源。下面使用PUT方法,用于替换文章资源。第五个接口,该接口使用DELETE方法删除文章资源。最后一个使用 PATCH 方法,用于更新 文章 资源。
PUT 方法和 PATCH 方法都是对 文章 资源的修改,但是这两种方法之间存在一些差异。PUT 方法是对 文章 资源的整体替代。PATCH 方法是更新 文章 资源的一个或一些属性。这是 API 平台按照 REST 规范设计的一组 API。
它们有一个相对统一的路径,接口的方法也很重要。根据REST规范设计的接口具有相应的功能。这样,如果我们设计的界面被其他用户使用,其他用户可以快速上手。
我们可以直接在文档页面操作界面,我们看第三个界面,检索一篇文章文章。查看 文章 的列表,我们得到 ID 为 21 的 文章。单击,单击 Try it out 按钮,我们输入 id 参数。在这里输入21,点击后点击Execute。
curl库会发送一个get请求,请求地址为/api/posts/21,请求头有accept参数,接收到的响应格式为application/ld+json格式。在下一课中,我们将学习这种格式。
我们来看看响应的结果,响应码是400,有错误,还有循环引用。当我们得到某个文章数据时,我们也得到了文章的作者。回到项目,我们打开 User 类。在User类中,我们要获取当前作者的所有文章,然后再次获取文章。然后在文章中再次检索作者,所以有循环引用。我们在 User 类之前添加 API 注解,回到浏览器中,我们再次使用这个接口。
#src/Entity/User.php
/**
* @ORM\Entity(repositoryClass=UserRepository::class)
*/
#[ApiResource]
class User implements UserInterface, PasswordAuthenticatedUserInterface
{
// ...
}
这次我们看到当前的文章信息,作者属性没有展开,它得到一个字符串。在下一课中,我们将详细解释响应的结果格式。
文章采集api(wordpress的内容算得上是优质内容吗?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-03-02 09:02
wordpress采集插件的使用,根据关键词采集对应的文章,哪些内容会被搜索索引判断为优质内容?这也是站长圈一直在讨论的问题。随着搜索引擎算法规则的不断升级和更新,判断优质内容的标准越来越高。那么什么样的内容才能算是优质内容呢?
wordpress采集插件的有效内容输出,首先,什么是有效内容输出,其实不管是新站长还是老站长,或多或少的时候都会为目的而创作内容的创建内容。如果没有搜索到你发布的内容,即使你的内容每天排名第一,没人看到你认为这个内容有意义吗?因此,有效的内容制作非常重要。
wordpress采集 插件生成的内容必须与标题一致。这里是网站生成的内容要和标题一致。下来,因为你的内容不符合用户的需求,用户不会长时间停留在这个页面,导致跳出率高,搜索引擎会认为这个内容是低质量的内容,所以产生的内容必须匹配标题和文本。无论标题是什么,内容都必须写出来。
wordpress采集插件选择的文章标题肯定是用户需要的,接下来就是创建内容了,网站创建的内容一定要解决用户的问题。做到以上两点,网站好的内容就会产生,但如果是优质的就不一定了,所以优质的内容必须满足以下条件。
网页的加载速度决定了它是否影响用户体验。用户很难访问您的 网站。网站首屏加载速度不能低于3秒。如果慢于 3 秒,就会被搜索引擎考虑。这是一个低质量的页面。如果你的内容真的是高质量的,但是因为网站加载速度的问题,被搜索引擎判断为低质量的内容,那不值得。
影响搜索引擎爬虫的爬取。在搜索引擎爬虫方面,由于你的网页打开速度慢,搜索引擎爬虫会爬取你的网站页面,但是很长时间没有加载,搜索引擎爬虫就会放弃这个页面. 其实,我们不妨换一种方式来思考这个问题。两个 网站 页面中的一个只需要 1 秒就可以爬取到,而另一个页面在 10 秒内不能爬取到。如果搜索引擎爬虫,哪个页面是爬虫收录?答案显然是爬取只需要 1 秒打开的 收录 页面。如果一个 网站 没有任何 收录,那么 关键词 的排名呢?
wordpress采集插件的内容文本是可读的,网站产生的内容是可读的,但是很难看懂。根据今天的搜索技术,这样的内容搜索引擎可以识别它。在 文章 的内容中,文字颜色可以设置为黑色或深灰色,但有些站长更喜欢将某些字体设置为浅灰色或类似于网页背景的颜色以用于其他用途。这是一个严重的问题。影响用户体验的行业也不算是优质内容。
有的站长将文章内容字体设置得太小或者段落间距太近,都会影响用户体验。想一想,如果用户看你的文章内容那么辛苦,而搜索引擎中类似的内容成千上万,那他为什么要看你的内容呢?他可以简单地关闭您的网页并查看其他网站 内容。 查看全部
文章采集api(wordpress的内容算得上是优质内容吗?(图))
wordpress采集插件的使用,根据关键词采集对应的文章,哪些内容会被搜索索引判断为优质内容?这也是站长圈一直在讨论的问题。随着搜索引擎算法规则的不断升级和更新,判断优质内容的标准越来越高。那么什么样的内容才能算是优质内容呢?
wordpress采集插件的有效内容输出,首先,什么是有效内容输出,其实不管是新站长还是老站长,或多或少的时候都会为目的而创作内容的创建内容。如果没有搜索到你发布的内容,即使你的内容每天排名第一,没人看到你认为这个内容有意义吗?因此,有效的内容制作非常重要。
wordpress采集 插件生成的内容必须与标题一致。这里是网站生成的内容要和标题一致。下来,因为你的内容不符合用户的需求,用户不会长时间停留在这个页面,导致跳出率高,搜索引擎会认为这个内容是低质量的内容,所以产生的内容必须匹配标题和文本。无论标题是什么,内容都必须写出来。
wordpress采集插件选择的文章标题肯定是用户需要的,接下来就是创建内容了,网站创建的内容一定要解决用户的问题。做到以上两点,网站好的内容就会产生,但如果是优质的就不一定了,所以优质的内容必须满足以下条件。
网页的加载速度决定了它是否影响用户体验。用户很难访问您的 网站。网站首屏加载速度不能低于3秒。如果慢于 3 秒,就会被搜索引擎考虑。这是一个低质量的页面。如果你的内容真的是高质量的,但是因为网站加载速度的问题,被搜索引擎判断为低质量的内容,那不值得。
影响搜索引擎爬虫的爬取。在搜索引擎爬虫方面,由于你的网页打开速度慢,搜索引擎爬虫会爬取你的网站页面,但是很长时间没有加载,搜索引擎爬虫就会放弃这个页面. 其实,我们不妨换一种方式来思考这个问题。两个 网站 页面中的一个只需要 1 秒就可以爬取到,而另一个页面在 10 秒内不能爬取到。如果搜索引擎爬虫,哪个页面是爬虫收录?答案显然是爬取只需要 1 秒打开的 收录 页面。如果一个 网站 没有任何 收录,那么 关键词 的排名呢?
wordpress采集插件的内容文本是可读的,网站产生的内容是可读的,但是很难看懂。根据今天的搜索技术,这样的内容搜索引擎可以识别它。在 文章 的内容中,文字颜色可以设置为黑色或深灰色,但有些站长更喜欢将某些字体设置为浅灰色或类似于网页背景的颜色以用于其他用途。这是一个严重的问题。影响用户体验的行业也不算是优质内容。
有的站长将文章内容字体设置得太小或者段落间距太近,都会影响用户体验。想一想,如果用户看你的文章内容那么辛苦,而搜索引擎中类似的内容成千上万,那他为什么要看你的内容呢?他可以简单地关闭您的网页并查看其他网站 内容。

