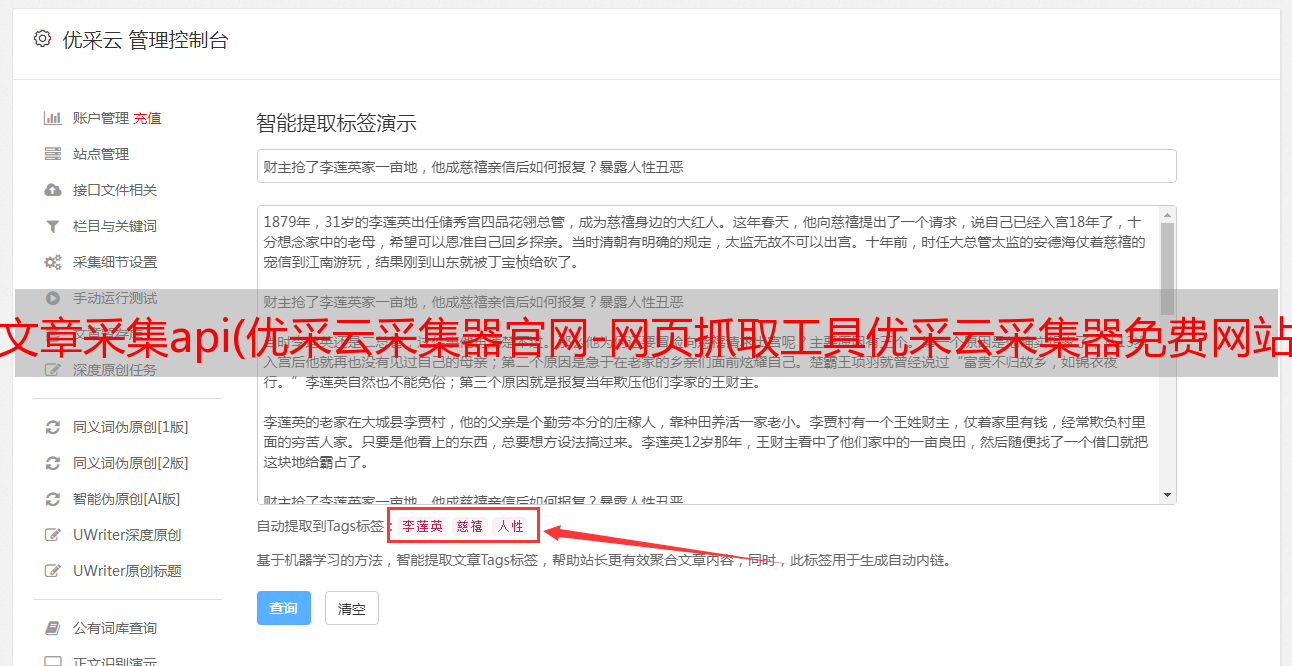
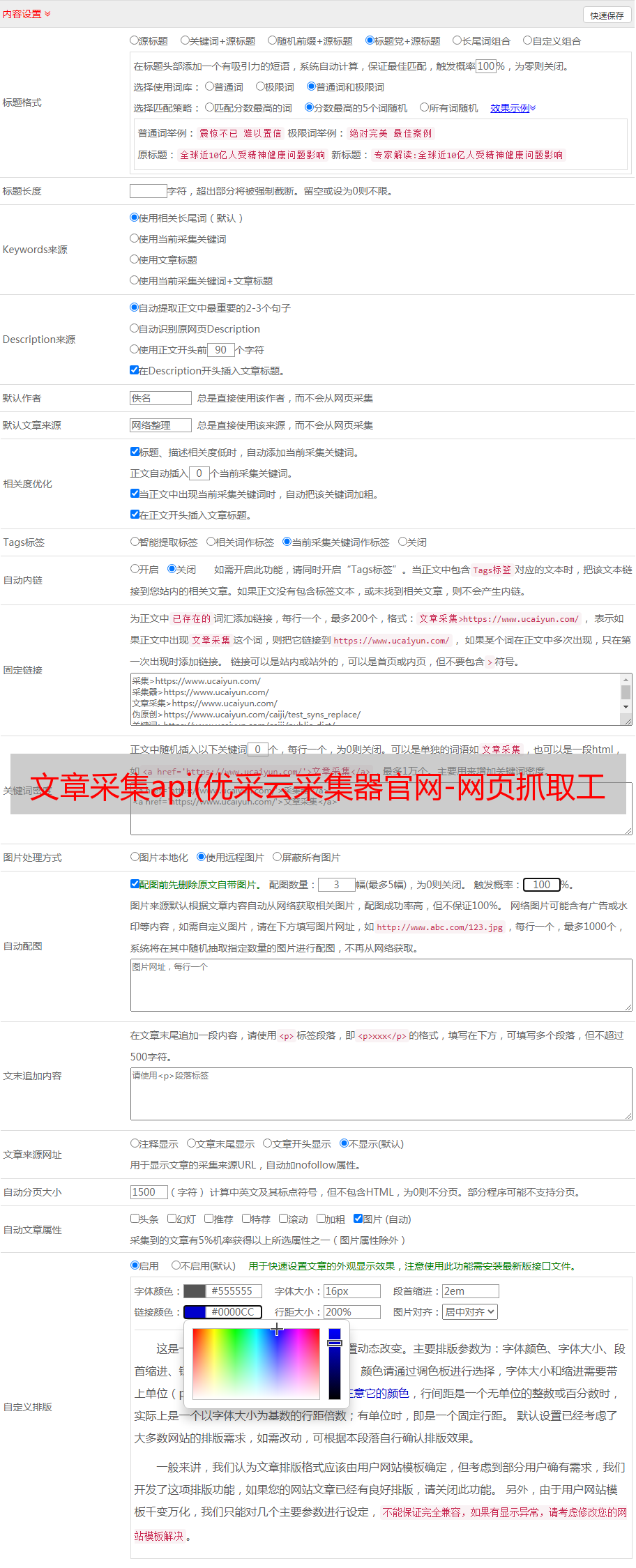
文章采集api(优采云采集器官网-网页抓取工具优采云采集器免费网站采集软件 )
优采云 发布时间: 2022-01-25 08:13文章采集api(优采云采集器官网-网页抓取工具优采云采集器免费网站采集软件
)
免责声明:本教程没有任何盈利目的,仅供学习使用,不会对网站的操作造成负担。请不要将其用于任何商业目的。
优采云简介
优采云采集器官网-网页抓取工具优采云采集器免费网站采集软件
优采云采集器,专业的互联网数据采集、处理、分析、挖掘软件,可以灵活快速的抓取网页上零散的数据信息,并通过一系列的分析处理,精准挖掘出来所需的数据。优采云采集器历经十二年的升级更新,积累了大量的用户和良好的口碑,是目前最受欢迎的网络数据采集软件。
简单来说,就是用软件来简化我们的爬取过程。整个过程无需编写代码即可实现爬虫逻辑。
示例爬取任务
需要爬取分页中的所有页面,并进一步爬取页面上所有有趣条目的二级URL
新任务 添加任务
URL采集规则 - URL 获取
URL采集规则-分页设置
分页规则主要设置在这里,也就是说不仅要抓取当前页面,还需要抓取所有页面。
内容采集规则
这里设置了将URL中的内容提取到前面的采集的规则,即每个商品详情页的内容
内容发布规则
用于指定如何处理采集发送的内容,这里设置为发送到一个api
单击 + 号以添加规则
新发布模块
这里指定要发送给api的参数,其中name为[Content 采集Rule]部分获取的信息,参数为规则名称。
您可以保存其他设置而不更改它们。
然后填写请求的主机
其他设置
以下是一些常用设置,可选。
查看爬取的数据
计划任务设置
这里可以指定任务重复运行的规则
发送通知
可以使用ios软件bark来接受通知,其内容就是爬取的规则。在这里,使用 Golang 简单地创建了一个新的 api。当软件爬取完成后,将信息发送到api【在内容发布规则中设置】,然后将消息发送到api。推送到ios
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
package main
import (
"github.com/gogf/gf/frame/g"
"github.com/gogf/gf/net/ghttp"
"github.com/gogf/gf/os/glog"
"github.com/gogf/gf/util/gconv"
"github.com/gogf/gf/util/grand"
)
type Info struct {
Url string `json:"url"`
Name string `json:"name"`
TaskType string `json:"task_type"`
}
func main() {
s := g.Server()
s.SetPort(8080)
_ = glog.SetConfigWithMap(g.Map{
"path": "log",
"level": "all",
"file": "{Y-m-d}.log",
"flags": glog.F_TIME_DATE | glog.F_TIME_MILLI | glog.F_FILE_LONG,
})
s.BindHandler("/send_info", func(r *ghttp.Request){
requestId := grand.Letters(16)
var info Info
if err := r.ParseForm(&info); err != nil {
glog.Error(requestId, err)
_ = r.Response.WriteJsonExit(nil)
}
glog.Info(requestId, info)
bark := "https://api.day.app/{xxxxxxxxxxxx}"
body := gconv.String(g.Map{
"device_key": "xxxxxxxxxxxxx",
"body": gconv.String(info),
"title": "商品信息",
"ext_params": g.Map{"url": info.Url},
})
glog.Info(requestId, body)
if _, err := g.Client().Post(bark, body); err != nil{
glog.Error(err)
}
})
s.Run()
}

