
java从网页抓取数据
java从网页抓取数据(腾讯课堂网页抓取QQ群号的功能简单实现起来也不难)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-04 15:02
Python 最近很流行。最近打算玩Python,学习数据挖掘。毕竟,我现在生活在一个大数据时代。互联网充满了大量数据。如果我能很好地利用这些数据,还有一些事情。也可以事半功倍。
作者之前没有接触过Python,好在有一些其他语言(Java、C、JavaScript等)基础,所以学起来不难。
本文文章实现了腾讯课堂网页抓取QQ群号的功能。当然,抢QQ群号只是示范。您还可以抓取其他数据。抓取方法类似。这个实验只是作者在学习Python的路上的一个小练习。功能很简单,实现起来也不难。
下图为腾讯课堂的一门课程。一般这些课程的页面都会有相应的学习QQ群。这次我们将使用Python来抓取这个QQ群号。
作者使用的环境如下;
系统版本:Windows10
Python版本:Python3.7.1
文本编辑器版本:PyCharm2018.2.4
要在 Python 中抓取网页,您需要导入 re 和 request 库。可以使用以下语句:
导入重新导入 urllib.request
其次,我们需要抓取需要抓取的网页,在抓取到的数据中找到(Ctrl+F)我们需要的数据。在这里,笔者将爬取到的数据存入一个TXT文件中,方便查找。抓取到的数据如下:
复制网页上的QQ群号,在抓取到的数据中搜索,如下:
如您所见,匹配的数据已被标记。接下来,我们可以使用正则表达式进行匹配。废话不多说,直接上代码。
操作结果:
从上面的代码可以看出,我们使用第一种格式进行匹配。需要注意的一件事是选择正确的格式非常重要。使用不合适的格式可能会导致一些麻烦。比如第四种格式,下面的代码就是用这种格式爬取的。
操作结果:
从运行结果可以看出,不同格式抓取的数据量不同,但关键内容没有变化,抓取的页面中可能存在我们不需要的数据。
以上内容为作者原创,如需转载请先联系作者,谢谢。 查看全部
java从网页抓取数据(腾讯课堂网页抓取QQ群号的功能简单实现起来也不难)
Python 最近很流行。最近打算玩Python,学习数据挖掘。毕竟,我现在生活在一个大数据时代。互联网充满了大量数据。如果我能很好地利用这些数据,还有一些事情。也可以事半功倍。
作者之前没有接触过Python,好在有一些其他语言(Java、C、JavaScript等)基础,所以学起来不难。
本文文章实现了腾讯课堂网页抓取QQ群号的功能。当然,抢QQ群号只是示范。您还可以抓取其他数据。抓取方法类似。这个实验只是作者在学习Python的路上的一个小练习。功能很简单,实现起来也不难。
下图为腾讯课堂的一门课程。一般这些课程的页面都会有相应的学习QQ群。这次我们将使用Python来抓取这个QQ群号。
作者使用的环境如下;
系统版本:Windows10
Python版本:Python3.7.1
文本编辑器版本:PyCharm2018.2.4
要在 Python 中抓取网页,您需要导入 re 和 request 库。可以使用以下语句:
导入重新导入 urllib.request
其次,我们需要抓取需要抓取的网页,在抓取到的数据中找到(Ctrl+F)我们需要的数据。在这里,笔者将爬取到的数据存入一个TXT文件中,方便查找。抓取到的数据如下:
复制网页上的QQ群号,在抓取到的数据中搜索,如下:
如您所见,匹配的数据已被标记。接下来,我们可以使用正则表达式进行匹配。废话不多说,直接上代码。
操作结果:
从上面的代码可以看出,我们使用第一种格式进行匹配。需要注意的一件事是选择正确的格式非常重要。使用不合适的格式可能会导致一些麻烦。比如第四种格式,下面的代码就是用这种格式爬取的。
操作结果:
从运行结果可以看出,不同格式抓取的数据量不同,但关键内容没有变化,抓取的页面中可能存在我们不需要的数据。
以上内容为作者原创,如需转载请先联系作者,谢谢。
java从网页抓取数据(我编写了一些Java代码,使用Crawler4J来抓取一堆网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-04 05:14
我写了一些Java代码,用Crawler4J爬取了一堆网页,然后用K-Means按关键字聚类。我想从每个集群中选择最好的图像(其中“最佳”被松散地定义为“集群中主题的最佳代表”),我想知道是否有任何现有的框架可以做到这一点(因为这显然是一个问题。在我推出自己的新闻之前,很多人已经需要解决诸如显示聚合新闻等问题。
我正在抓取的大多数页面都是关于给定主题的标准新闻页面,因此页面的最佳图像通常是1) 最大的图像和 2) 紧跟在最大的文本块之后。上一张图片。如果我必须推出自己的实现,我的暂定计划是根据这些(和其他)启发式算法从集群中的每个页面中获取最佳图像,然后根据质量(大小、链接文本、每个图像的名称) , 在文档中的位置及其来源页面的质量。
简而言之,我的问题是双重的:是否有任何现有的开源框架(最好用 Java 实现)可以帮助我完成我的任务,还有比我提出的更好的方法吗?谢谢!
如何从最核心的项目中选择图片?由于 k 均值围绕质心进行分区,因此您可以将最接近质心的实例视为数据中的最佳代表。 (如果你在聚类中使用它,你会得到 k-medoids)。
由于k-means可能会严重退化,你可能需要检查簇元素是否比两个簇中心之间的距离更接近簇中心。如果聚类中心之间的距离比您的数据更近,则您的 k 均值结果已经降级。 查看全部
java从网页抓取数据(我编写了一些Java代码,使用Crawler4J来抓取一堆网页)
我写了一些Java代码,用Crawler4J爬取了一堆网页,然后用K-Means按关键字聚类。我想从每个集群中选择最好的图像(其中“最佳”被松散地定义为“集群中主题的最佳代表”),我想知道是否有任何现有的框架可以做到这一点(因为这显然是一个问题。在我推出自己的新闻之前,很多人已经需要解决诸如显示聚合新闻等问题。
我正在抓取的大多数页面都是关于给定主题的标准新闻页面,因此页面的最佳图像通常是1) 最大的图像和 2) 紧跟在最大的文本块之后。上一张图片。如果我必须推出自己的实现,我的暂定计划是根据这些(和其他)启发式算法从集群中的每个页面中获取最佳图像,然后根据质量(大小、链接文本、每个图像的名称) , 在文档中的位置及其来源页面的质量。
简而言之,我的问题是双重的:是否有任何现有的开源框架(最好用 Java 实现)可以帮助我完成我的任务,还有比我提出的更好的方法吗?谢谢!
如何从最核心的项目中选择图片?由于 k 均值围绕质心进行分区,因此您可以将最接近质心的实例视为数据中的最佳代表。 (如果你在聚类中使用它,你会得到 k-medoids)。
由于k-means可能会严重退化,你可能需要检查簇元素是否比两个簇中心之间的距离更接近簇中心。如果聚类中心之间的距离比您的数据更近,则您的 k 均值结果已经降级。
java从网页抓取数据(java从网页抓取数据中实现动态图片图片啦~~)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-03 14:23
java从网页抓取数据,需要分析网页的类型,页面爬取接口等,如果你是一个正常人,可以使用正则表达式来处理网页的信息。如果你要进行爬虫教学,没有正则表达式那就难上加难。另外爬虫也不止有正则,只要模拟你爬虫过程的代码都可以用来实现爬虫,如小白入门教程,把js,css,html的代码封装成自己需要的函数,最后集成到网页中,你就可以在网页中实现动态抓取图片啦~。
html5可以做,
建议换一本书看看
首先你要知道页面地址,然后调用浏览器接口。例如:javascript的random函数就是一个浏览器接口,你调用这个接口就可以创建随机数了。
任何操作都可以,但你可以讲js封装成一个简单的对象就是random对象,然后模拟javascript行为,例如加载js文件,解析js文件,获取js文件中所有元素的信息,根据这些信息,
实现前端数据抓取?有意思。爬虫现在也有人做。
你需要一个能力,这个能力就是,你可以掌握并运用某些语言。
调用浏览器的request函数
javascript+html+css可以实现,然后抓图片,不过,人家现在都是用python实现,你也可以用,关键是能不能写出来。写不出来还是没用。
javascript+request+python 查看全部
java从网页抓取数据(java从网页抓取数据中实现动态图片图片啦~~)
java从网页抓取数据,需要分析网页的类型,页面爬取接口等,如果你是一个正常人,可以使用正则表达式来处理网页的信息。如果你要进行爬虫教学,没有正则表达式那就难上加难。另外爬虫也不止有正则,只要模拟你爬虫过程的代码都可以用来实现爬虫,如小白入门教程,把js,css,html的代码封装成自己需要的函数,最后集成到网页中,你就可以在网页中实现动态抓取图片啦~。
html5可以做,
建议换一本书看看
首先你要知道页面地址,然后调用浏览器接口。例如:javascript的random函数就是一个浏览器接口,你调用这个接口就可以创建随机数了。
任何操作都可以,但你可以讲js封装成一个简单的对象就是random对象,然后模拟javascript行为,例如加载js文件,解析js文件,获取js文件中所有元素的信息,根据这些信息,
实现前端数据抓取?有意思。爬虫现在也有人做。
你需要一个能力,这个能力就是,你可以掌握并运用某些语言。
调用浏览器的request函数
javascript+html+css可以实现,然后抓图片,不过,人家现在都是用python实现,你也可以用,关键是能不能写出来。写不出来还是没用。
javascript+request+python
java从网页抓取数据(Web:ScraperCPAN模块可能更容易接数据的几个示例 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-02 11:12
)
丹尼斯泰勒:
以编程方式从一堆网页中提取结构化数据的最简单方法是什么?
我目前使用我编写的 Adobe AIR 程序来跟踪页面上的链接并从后续页面获取一些数据。这实际上很有效,而且对于程序员来说,我认为这(或其他语言)提供了一种逐案编写的合理方法。也许有一种特定的语言或库可以让程序员非常快速地做到这一点,如果是这样,我有兴趣了解它们是什么。
是否有其他工具允许非程序员(例如客户支持代表或负责数据采集的人员)从网页中提取结构化数据而无需进行大量复制和粘贴操作?
德拉格顿:
如果您在 Stackoverflow、pQuery 上搜索 WWW::Mechanize&,您将看到许多使用这些 Perl CPAN 模块的示例。
但是因为你提到了“非程序员”,也许 Web::ScraperCPAN 模块可能更合适?它更像是一个 DSL,因此可能更容易连接到“非程序员”。
这是一个从 Twitter 检索推文的文档示例:
use URI;
use Web::Scraper;
my $tweets = scraper {
process "li.status", "tweets[]" => scraper {
process ".entry-content", body => 'TEXT';
process ".entry-date", when => 'TEXT';
process 'a[rel="bookmark"]', link => '@href';
};
};
my $res = $tweets->scrape( URI->new("http://twitter.com/miyagawa") );
for my $tweet (@{$res->{tweets}}) {
print "$tweet->{body} $tweet->{when} (link: $tweet->{link})\n";
} 查看全部
java从网页抓取数据(Web:ScraperCPAN模块可能更容易接数据的几个示例
)
丹尼斯泰勒:
以编程方式从一堆网页中提取结构化数据的最简单方法是什么?
我目前使用我编写的 Adobe AIR 程序来跟踪页面上的链接并从后续页面获取一些数据。这实际上很有效,而且对于程序员来说,我认为这(或其他语言)提供了一种逐案编写的合理方法。也许有一种特定的语言或库可以让程序员非常快速地做到这一点,如果是这样,我有兴趣了解它们是什么。
是否有其他工具允许非程序员(例如客户支持代表或负责数据采集的人员)从网页中提取结构化数据而无需进行大量复制和粘贴操作?
德拉格顿:
如果您在 Stackoverflow、pQuery 上搜索 WWW::Mechanize&,您将看到许多使用这些 Perl CPAN 模块的示例。
但是因为你提到了“非程序员”,也许 Web::ScraperCPAN 模块可能更合适?它更像是一个 DSL,因此可能更容易连接到“非程序员”。
这是一个从 Twitter 检索推文的文档示例:
use URI;
use Web::Scraper;
my $tweets = scraper {
process "li.status", "tweets[]" => scraper {
process ".entry-content", body => 'TEXT';
process ".entry-date", when => 'TEXT';
process 'a[rel="bookmark"]', link => '@href';
};
};
my $res = $tweets->scrape( URI->new("http://twitter.com/miyagawa";) );
for my $tweet (@{$res->{tweets}}) {
print "$tweet->{body} $tweet->{when} (link: $tweet->{link})\n";
}
java从网页抓取数据(通过Java代码实现对网页数据进行指定抓取方法思路思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-31 14:02
IE浏览器有OLE对象,可以用这个功能提取所有元素的信息,有些软件应该可以。. .
如果你想从头开始,你可以直接匹配文本并编写一个提取元素的小程序。. .
通过Java代码指定网页数据爬取方法的思路如下:
项目中导入Jsoup.jar包
获取 URL 指定的 HTML 或文档指定的正文
获取网页中超链接的标题和链接
获取指定博客的内容文章
获取网页中超链接的标题和链接的结果
在另一个文件中写入:
登录用户 = 新登录();
String id = user.GetUserID();
System.out.println(id);
PS:java文件首字母大写,方法首字母小写。
是不是有历史页面,直接复制粘贴就行了,选择你想要的数据,右键复制,在表格里右键粘贴
如果您使用预先嗅探的 ForeSpider 数据采集 软件,它会起作用。但是您需要知道应用程序的协议是什么。如果是http或https,可以直接采集。
实时更新也是可能的。软件支持定时采集,一定间隔时间采集。设置间隔时间相当于实时更新。
ForeSpider直接连接数据库,数据存储有多种策略,存储前会有两次自动重新排列,确保只插入更新的数据。
有一个免费版本,可以不受功能限制地下载。
使用java提取指定网页中的表格数据?…… 将以下代码复制到文本文件中,然后将文本文件改为“.html”格式
这是提取表中数据的方法,看看是不是你想要的
...
Java抓取网页数据——……当然是抓取网页数据来模拟http请求,然后分析收到的响应。直接使用commons-httpclient。
如何抓取网页中的数据 java-…… 不要用Java抓取,让页面发送数据到后端不好??如果是从别人的网站那里抢过来的,应该也是可以的,看来socketio是可以用的。看看nodejs是否可以处理它。
java中如何提取网页上的信息... 发送http请求,获取返回的内容,定时抓取你需要的信息!
Java爬取网页数据,如何爬取-... 如果是一般允许爬取的页面,可以用wget爬取,不允许爬取的爬虫可以考虑使用HttpClient
如何在html网页中使用JAVA获取我需要的数据-... 使用jsoup轻松读取和解析网页内容。
如何使用Java语言获取网页数据?-…… 你想让系统A知道系统B的页面信息吗?如果是这样的话,就有一个比较难解决的问题,那就是数据源问题。你的系统A不知道系统B的数据。如果你想得到招聘信息的公司名称,有几个思路这个 iframe...
用java从网上抓取数据-... 你可以看看你的MYSQL库的编码是UTF-8还是改成GB2312试试。这种情况我以前见过,不行的话,你可以看看你网页的编码。这是一个小错误
如何在网页上获取小型 Java 应用程序的数据?...... 使用请求对象封装数据并在页面上获取。
Java抓取网页数据,如何抓取...当然抓取网页数据模拟HTTP请求,然后分析响应。直接使用 commons-httpclient 包。 查看全部
java从网页抓取数据(通过Java代码实现对网页数据进行指定抓取方法思路思路)
IE浏览器有OLE对象,可以用这个功能提取所有元素的信息,有些软件应该可以。. .
如果你想从头开始,你可以直接匹配文本并编写一个提取元素的小程序。. .
通过Java代码指定网页数据爬取方法的思路如下:
项目中导入Jsoup.jar包
获取 URL 指定的 HTML 或文档指定的正文
获取网页中超链接的标题和链接
获取指定博客的内容文章
获取网页中超链接的标题和链接的结果
在另一个文件中写入:
登录用户 = 新登录();
String id = user.GetUserID();
System.out.println(id);
PS:java文件首字母大写,方法首字母小写。
是不是有历史页面,直接复制粘贴就行了,选择你想要的数据,右键复制,在表格里右键粘贴
如果您使用预先嗅探的 ForeSpider 数据采集 软件,它会起作用。但是您需要知道应用程序的协议是什么。如果是http或https,可以直接采集。
实时更新也是可能的。软件支持定时采集,一定间隔时间采集。设置间隔时间相当于实时更新。
ForeSpider直接连接数据库,数据存储有多种策略,存储前会有两次自动重新排列,确保只插入更新的数据。
有一个免费版本,可以不受功能限制地下载。
使用java提取指定网页中的表格数据?…… 将以下代码复制到文本文件中,然后将文本文件改为“.html”格式
这是提取表中数据的方法,看看是不是你想要的
...
Java抓取网页数据——……当然是抓取网页数据来模拟http请求,然后分析收到的响应。直接使用commons-httpclient。
如何抓取网页中的数据 java-…… 不要用Java抓取,让页面发送数据到后端不好??如果是从别人的网站那里抢过来的,应该也是可以的,看来socketio是可以用的。看看nodejs是否可以处理它。
java中如何提取网页上的信息... 发送http请求,获取返回的内容,定时抓取你需要的信息!
Java爬取网页数据,如何爬取-... 如果是一般允许爬取的页面,可以用wget爬取,不允许爬取的爬虫可以考虑使用HttpClient
如何在html网页中使用JAVA获取我需要的数据-... 使用jsoup轻松读取和解析网页内容。
如何使用Java语言获取网页数据?-…… 你想让系统A知道系统B的页面信息吗?如果是这样的话,就有一个比较难解决的问题,那就是数据源问题。你的系统A不知道系统B的数据。如果你想得到招聘信息的公司名称,有几个思路这个 iframe...
用java从网上抓取数据-... 你可以看看你的MYSQL库的编码是UTF-8还是改成GB2312试试。这种情况我以前见过,不行的话,你可以看看你网页的编码。这是一个小错误
如何在网页上获取小型 Java 应用程序的数据?...... 使用请求对象封装数据并在页面上获取。
Java抓取网页数据,如何抓取...当然抓取网页数据模拟HTTP请求,然后分析响应。直接使用 commons-httpclient 包。
java从网页抓取数据(使用优采云采集器软件从指定网页获取特定内容的几种解决方案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-12-31 05:06
网页数据爬取是指在不请求网站的API接口获取内容的情况下,从网站中提取特定内容。“网页数据”作为网站用户体验的一部分,如网页上的文字、图片、声音、视频、动画等,均被视为网页数据。
对于程序员或开发者来说,拥有编程技能,让他们构建一个网页数据爬取程序变得非常容易和有趣。但是对于大多数没有任何编程知识的人来说,最好使用一些网络爬虫软件从指定的网页中获取特定的内容。下面是一些使用优采云采集器抓取网页数据的解决方案:
1、 从动态网页中提取内容
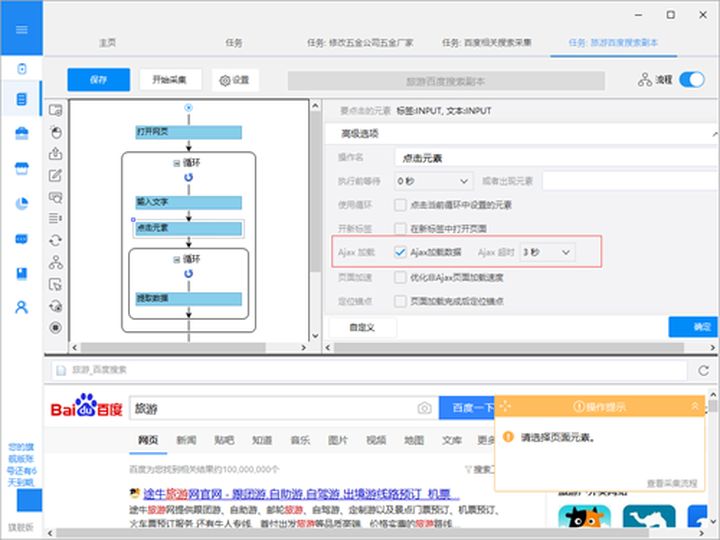
网页可以是静态的或动态的。通常情况下,您要提取的网页内容会随着您访问网站的时间而变化。通常,这个网站是一个动态的网站,它使用AJAX技术或其他技术使网页内容能够及时更新。AJAX 是一种延迟加载和异步更新的脚本技术。通过后台与服务器的少量数据交换,可以在不重新加载整个网页的情况下更新网页的某一部分。
性能特点是当你点击网页中的一个选项时,网站的大部分URL不会改变;网页并未完全加载,而只是部分加载了数据,这些数据会发生变化。这时候可以在优采云的“高级选项”元素的“Ajax加载”中设置,然后就可以抓取Ajax加载的网页数据了。
优采云 AJAX 设置
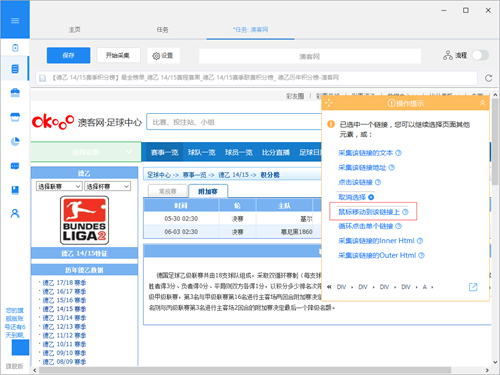
2、 从网页中抓取隐藏的内容
你有没有想过从网站获取具体的数据,但是当你触发链接或将鼠标悬停在某个地方时,内容就会出现?比如下图中的网站,需要将鼠标移动到选中的彩票上才能显示分类。这个功能可以设置“鼠标指向这个链接”功能来抓取网页的隐藏内容。.
鼠标移动到链接上的内容采集方法
3、 从无限滚动的网页中提取内容
滚动到页面底部后,某些网站 只会显示您要提取的部分数据。比如今天的头条首页,需要一直滚动到页面底部才能加载更多的文章内容。无限滚动 网站 通常使用 AJAX 或 JavaScript 从 网站 内容请求附加内容。在这种情况下,您可以设置 AJAX 超时设置并选择滚动方式和滚动时间以从网页中提取内容。
4、 从网页中抓取所有链接
一个普通的 网站 将收录至少一个超链接。如果要提取网页中的所有链接,可以使用优采云 获取网页上发布的所有超链接。
5、 从网页中抓取所有文本
有时你需要提取一个 HTML 文档中的所有文本,即把它放在 HTML 标签中(如
标签或标签)。优采云 使您能够提取网页源代码中的所有或特定文本。
6、 从网页中抓取所有图片
有的朋友对采集的网页图片有需求。优采云可以使用网页中图片的网址采集,然后下载使用优采云专用图片批量下载工具,即可上传图片中的图片我们采集 下载并保存到本地计算机的 URL。 查看全部
java从网页抓取数据(使用优采云采集器软件从指定网页获取特定内容的几种解决方案)
网页数据爬取是指在不请求网站的API接口获取内容的情况下,从网站中提取特定内容。“网页数据”作为网站用户体验的一部分,如网页上的文字、图片、声音、视频、动画等,均被视为网页数据。
对于程序员或开发者来说,拥有编程技能,让他们构建一个网页数据爬取程序变得非常容易和有趣。但是对于大多数没有任何编程知识的人来说,最好使用一些网络爬虫软件从指定的网页中获取特定的内容。下面是一些使用优采云采集器抓取网页数据的解决方案:
1、 从动态网页中提取内容
网页可以是静态的或动态的。通常情况下,您要提取的网页内容会随着您访问网站的时间而变化。通常,这个网站是一个动态的网站,它使用AJAX技术或其他技术使网页内容能够及时更新。AJAX 是一种延迟加载和异步更新的脚本技术。通过后台与服务器的少量数据交换,可以在不重新加载整个网页的情况下更新网页的某一部分。
性能特点是当你点击网页中的一个选项时,网站的大部分URL不会改变;网页并未完全加载,而只是部分加载了数据,这些数据会发生变化。这时候可以在优采云的“高级选项”元素的“Ajax加载”中设置,然后就可以抓取Ajax加载的网页数据了。
优采云 AJAX 设置
2、 从网页中抓取隐藏的内容
你有没有想过从网站获取具体的数据,但是当你触发链接或将鼠标悬停在某个地方时,内容就会出现?比如下图中的网站,需要将鼠标移动到选中的彩票上才能显示分类。这个功能可以设置“鼠标指向这个链接”功能来抓取网页的隐藏内容。.
鼠标移动到链接上的内容采集方法
3、 从无限滚动的网页中提取内容
滚动到页面底部后,某些网站 只会显示您要提取的部分数据。比如今天的头条首页,需要一直滚动到页面底部才能加载更多的文章内容。无限滚动 网站 通常使用 AJAX 或 JavaScript 从 网站 内容请求附加内容。在这种情况下,您可以设置 AJAX 超时设置并选择滚动方式和滚动时间以从网页中提取内容。
4、 从网页中抓取所有链接
一个普通的 网站 将收录至少一个超链接。如果要提取网页中的所有链接,可以使用优采云 获取网页上发布的所有超链接。
5、 从网页中抓取所有文本
有时你需要提取一个 HTML 文档中的所有文本,即把它放在 HTML 标签中(如
标签或标签)。优采云 使您能够提取网页源代码中的所有或特定文本。
6、 从网页中抓取所有图片
有的朋友对采集的网页图片有需求。优采云可以使用网页中图片的网址采集,然后下载使用优采云专用图片批量下载工具,即可上传图片中的图片我们采集 下载并保存到本地计算机的 URL。
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-12-31 05:05
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
也就是说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:

第二步:查看网页源代码,我们在源代码中看到这一段:

由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:

也就是说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:

我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:

为了更方便的查看JS的结果,我们先清空数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:

这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:


从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java从网页抓取数据(java从网页抓取数据,和爬虫的区别在哪?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-12-30 07:04
java从网页抓取数据,和爬虫的区别在于,前者是从大前端拿数据,比如爬虫,你得知道的后台是如何运行的,然后前端也得知道的后台,知道怎么和后台连接进行数据传输;而后者不需要一定连接后台,抓取完数据后直接给前端进行展示,抓取的方式有网页抓取和系统抓取。前端抓取可以是,直接手动去抓取网页源代码,也可以用爬虫工具,分析网页源代码来分析数据。
最近我也比较迷恋爬虫,经过一段时间的研究,我还是觉得研究一下这个,比如爬虫和豆瓣电影爬虫对比之类的,对分析数据非常有用,毕竟现在数据分析是很火的,哈哈。
把一切相关的「机器学习」「数据挖掘」「信息检索」「大数据技术」「数据库」「算法」「人工智能」「机器人」「自然语言处理」「多媒体」「图像」「声音」「视频」「图像增强」「图像压缩」「图像建模」「图像拼接」「图像提取」「关键点检测」「分割」「基于深度学习的计算机视觉」「模糊图像」「模糊视频」「文字识别」「字符识别」「视频背景检测」「文字对象检测」「文字转语音」「可视化」「语义分割」「语义迁移」「单词级别长短文本摘要」「事件抽取」「信息抽取」「短语级别短文本摘要」「整体」「局部」「结构化」「结构化视频摘要」「视频标注」「定义」「语音」「图像」「视频分割」「输入输出」「行为检测」「行为跟踪」「影视语音情感分析」「黑名单检测」「爬虫」等等技术,基本上都是要用到数据的,不同的数据来源,很可能会产生不同的效果。 查看全部
java从网页抓取数据(java从网页抓取数据,和爬虫的区别在哪?)
java从网页抓取数据,和爬虫的区别在于,前者是从大前端拿数据,比如爬虫,你得知道的后台是如何运行的,然后前端也得知道的后台,知道怎么和后台连接进行数据传输;而后者不需要一定连接后台,抓取完数据后直接给前端进行展示,抓取的方式有网页抓取和系统抓取。前端抓取可以是,直接手动去抓取网页源代码,也可以用爬虫工具,分析网页源代码来分析数据。
最近我也比较迷恋爬虫,经过一段时间的研究,我还是觉得研究一下这个,比如爬虫和豆瓣电影爬虫对比之类的,对分析数据非常有用,毕竟现在数据分析是很火的,哈哈。
把一切相关的「机器学习」「数据挖掘」「信息检索」「大数据技术」「数据库」「算法」「人工智能」「机器人」「自然语言处理」「多媒体」「图像」「声音」「视频」「图像增强」「图像压缩」「图像建模」「图像拼接」「图像提取」「关键点检测」「分割」「基于深度学习的计算机视觉」「模糊图像」「模糊视频」「文字识别」「字符识别」「视频背景检测」「文字对象检测」「文字转语音」「可视化」「语义分割」「语义迁移」「单词级别长短文本摘要」「事件抽取」「信息抽取」「短语级别短文本摘要」「整体」「局部」「结构化」「结构化视频摘要」「视频标注」「定义」「语音」「图像」「视频分割」「输入输出」「行为检测」「行为跟踪」「影视语音情感分析」「黑名单检测」「爬虫」等等技术,基本上都是要用到数据的,不同的数据来源,很可能会产生不同的效果。
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-28 13:00
原文链接:
有时由于各种原因,我们需要从某个网站采集数据,但是因为不同的网站显示的数据略有不同!
本文使用Java向大家展示如何抓取网站的数据:(1)抓取原创
网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创
网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,在重新请求网页后显示查询的结果。
查询后看网页地址:
换句话说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[爪哇]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8");BufferedReaderbufReader= newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString();intbeginIx= buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println("captureHtml()结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下,如果你想解析的很准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被搜索等工具抓取引擎。
首先看这个页面:
使用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
第一次点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然前提是数据没有加密,我们写下JS Requested URL:
然后让程序请求这个页面的结果!
这是代码:
[爪哇]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf -8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}System.out .println("captureJavascript() 的结果:\n"+contentBuf.toString());}
可以看到,抓取JS的方式和抓取原创
网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
原文链接:
有时由于各种原因,我们需要从某个网站采集数据,但是因为不同的网站显示的数据略有不同!
本文使用Java向大家展示如何抓取网站的数据:(1)抓取原创
网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创
网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,在重新请求网页后显示查询的结果。
查询后看网页地址:
换句话说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[爪哇]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8");BufferedReaderbufReader= newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString();intbeginIx= buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println("captureHtml()结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下,如果你想解析的很准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被搜索等工具抓取引擎。
首先看这个页面:
使用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
第一次点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然前提是数据没有加密,我们写下JS Requested URL:
然后让程序请求这个页面的结果!
这是代码:
[爪哇]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf -8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}System.out .println("captureJavascript() 的结果:\n"+contentBuf.toString());}
可以看到,抓取JS的方式和抓取原创
网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载!
java从网页抓取数据(19款Java开源Web爬虫需要的小伙伴们赶快收藏吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-26 23:13
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。
今天给大家介绍19款Java开源网络爬虫,有需要的赶紧采集
吧。
一、Heritrix
Heritrix是java开发的开源网络爬虫。用户可以使用它从互联网上获取他们想要的资源。其最突出的特点是良好的扩展性,方便用户实现自己的爬取逻辑。
Heritrix 是一个“档案爬虫”——获取网站内容的完整、准确、深层副本。包括获取图片等非文字内容。抓取和存储相关内容。内容不拒绝,页面内容不修改。重新抓取不会替换同一 URL 的前一次抓取。爬虫主要通过Web用户界面启动、监控和调整,可以灵活定义获取URL。
Heritrix是一个多线程爬取的爬虫。主线程将任务分配给 Teo 线程(处理线程),每个 Teo 线程一次处理一个 URL。Teo 线程为每个 URL 执行 URL 处理器链。URL 处理器链包括以下五个处理步骤。
(1)预取链:主要是做一些准备工作,比如延迟和重新处理处理,否决后续的操作。
(2) 提取链:主要是下载网页,进行DNS转换,填写请求和响应表。
(3) 提取链:提取完成后,提取感兴趣的 HTML 和 JavaScript,通常会有新的 URL 需要爬取。
(4)写链:存储爬取的结果,这一步可以直接索引全文。Heritrix提供了一个ARCWriterProcessor实现,将下载的结果保存为ARC格式。
(5)提交链:对这个URL相关的操作做最后的处理。检查哪些新提取的URL在爬取范围内,然后将这些URL提交给Frontier。另外,DNS缓存信息也会更新。
Heritrix系统框架图
Heritrix 处理一个 url 进程
二、WebSPHINX
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX类包。
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX类包。
WebSPHINX 目的
1.可视化展示页面集合
2.将页面下载到本地磁盘进行离线浏览
3.将所有页面合并为一个页面进行浏览或打印
4. 根据特定规则从页面中提取文本字符串
5.使用Java或Javascript开发自定义爬虫
详细介绍可见>>>
三、WebLech
WebLech 是一个强大的网站下载和镜像工具。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。WebLech 有功能控制台,使用多线程操作。
WebLech 是一款功能强大的免费开源工具,用于下载和镜像网站。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。WebLech 有功能控制台,使用多线程操作。
这个爬虫很简单,如果你是初学者,如果你想写一个爬虫,可以作为入门的参考。所以我选择从这个爬虫开始我的研究。如果你只是做要求不高的应用,也可以试试。如果你想找到一个强大的,不要在 WebLech 上浪费时间。
项目主页:
特征:
1)开源,免费
2) 代码纯Java编写,可以在任何支持Java的平台上使用
3)支持多线程下载网页
4) 可以维护网页之间的链接信息
5)强大的可配置性:可以自定义深度优先或宽度优先的抓取网页,带有URL过滤器,这样您就可以根据需要抓取单个Web服务器、单个目录或抓取整个WWW网络,您可以设置URL的优先级,这样就可以先爬取我们感兴趣或重要的网页,记录断点时程序的状态,重启时从上次继续爬取。
四、阿拉蕾
Arale 主要是为个人使用而设计的,不像其他爬虫那样专注于页面索引。Arale 可以下载整个网站或网站上的部分资源。Arale 还可以将动态页面映射到静态页面。
五、JSpider
JSpider:是一个完全可配置和可定制的 Web Spider 引擎。您可以用它来检查网站错误(内部服务器错误等),检查网站的内外链接,分析网站的结构(创建网站地图),下载整个网站,您还可以写一个JSpider插件来扩展你需要的功能。
Spider 是一个用 Java 实现的 WebSpider。JSpider的执行格式如下:
jspider [URL] [ConfigName]
URL必须加上协议名,如:,否则会报错。如果省略ConfigName,则采用默认配置。
JSpider的行为具体由配置文件配置,如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。JSpider 的默认配置类型很少,也不是很有用。但是JSpider非常容易扩展,你可以用它来开发强大的网络爬虫和数据分析工具。为此,您需要深入了解JSpider 的原理,然后根据需要开发插件并编写配置文件。
蜘蛛是:
高度可配置和可定制的网络爬虫
在 LGPL 开源许可下开发
100% 纯 Java 实现
您可以将其用于:
检查您的网站是否有错误(内部服务器错误,...)
传出或内部链接检查
分析您网站的结构(创建站点地图,...)
下载翻新后的网站
通过编写JSpider插件实现任何功能。
项目主页:
六、主轴
Spindle 是一个建立在 Lucene 工具包上的 Web 索引/搜索工具。它包括一个用于创建索引的 HTTP 蜘蛛和一个用于搜索这些索引的搜索类。Spindle 项目提供了一套JSP 标签库,让那些基于JSP 的站点无需开发任何Java 类就可以添加搜索功能。
七、蛛形纲动物
Arachnid 是一个基于 Java 的网络蜘蛛框架。它收录
一个简单的 HTML 解析器,可以分析收录
HTML 内容的输入流。通过实现Arachnid的子类,可以开发一个简单的网络蜘蛛,可以在每个网站上使用页面解析后,添加几行代码调用。Arachnid 下载包中收录
两个蜘蛛应用程序示例,用于演示如何使用该框架。
项目主页:
八、LARM
LARM 可为 Jakarta Lucene 搜索引擎框架的用户提供纯 Java 搜索解决方案。它收录
索引文件、数据库表和用于索引网站的爬虫的方法。
项目主页:
九、乔博
JoBo 是一个用于下载整个网站的简单工具。它本质上是一个网络蜘蛛。与其他下载工具相比,它的主要优点是能够自动填写表单(如自动登录)和使用cookies来处理会话。JoBo 还具有灵活的下载规则(如:URL、大小、MIME 类型等)来限制下载。
十、snoics-reptile
1、什么是snoics-reptile?
它是用纯Java开发的。它是一种用于捕获网站镜像的工具。您可以使用配置文件中提供的URL入口,将本网站所有可以通过浏览器GET方式获取到的资源抓取到本地。包括网页和各类文件,如图片、flash、mp3、zip、rar、exe等文件。整个网站可以完全转移到硬盘上,保持原有网站结构准确不变。只需将抓取到的网站放置在Web服务器(如Apache)上即可实现完整的网站镜像。
2、 既然有其他类似的软件,为什么要开发snooics-reptile呢?
因为在爬取过程中经常会出现一些文件出错,很多javascript控制的URL没有办法正确解析,snoics-reptile提供了外部接口和配置文件。对于特殊的URL,可以通过自由扩展外部提供的接口,通过配置文件注入的方式,基本上可以正确解析和抓取所有网页。
项目主页:
十一、Web-Harvest
Web-Harvest 是一个 Java 开源 Web 数据提取工具。它可以采集
指定的网页并从这些网页中提取有用的数据。Web-Harvest主要使用XSLT、XQuery、正则表达式等技术来实现text/xml的操作。
Web-Harvest 是一个用 Java 编写的开源 Web 数据提取工具。它提供了一种从所需页面中提取有用数据的方法。为了实现这个目标,您可能需要使用XSLT、XQuery、正则表达式等相关技术来操作text/xml。Web-Harvest 主要关注基于 HMLT/XML 的页面内容,目前占大多数。另一方面,它可以通过编写自己的 Java 方法轻松扩展其提取功能。
Web-Harvest 的主要目的是加强现有数据提取技术的应用。它的目标不是创建一种新方法,而是提供一种更好地使用和组合现有方法的方法。它提供了一个处理器集来处理数据和控制流。每个处理器都被看作一个函数,它有参数,执行后返回结果。并且将处理组合成流水线形式,使它们可以以链式形式执行,除了更容易的数据操作和复用外,Web-Harvest 还提供了上下变量来存储声明的变量。
启动web-harvest,可以直接双击jar包运行,但是这种方式不能指定web-harvest java虚拟机的大小。第二种方法是切换到cmd下的web-harvest目录,输入命令“java -jar -Xms400m webharvest_all_2.jar”启动,设置java虚拟机大小为400M。
项目主页:
十个二、真烂
ItSucks 是 Java Web 爬虫的开源项目。可灵活定制,支持下载模板和正则表达式定义下载规则。提供控制台和 Swing GUI 操作界面。
特征:
项目主页:
十三、智能简单的网络爬虫
Smart and Simple Web Crawler 是一个网络爬虫框架。集成 Lucene 支持。爬虫可以从单个链接或一组链接开始,提供两种遍历方式:最大迭代和最大深度。可以设置过滤器来限制爬回的链接。默认提供了三个过滤器 ServerFilter、BeginningPathFilter 和 RegularExpressionFilter。这三个过滤器可以与 AND、OR 和 NOT 组合使用。可以在解析过程中或页面加载前后添加侦听器。
十四、Crawler4j
crawler4j 是一个用 Java 实现的开源网络爬虫。提供简单易用的界面,您可以在几分钟内创建一个多线程的网络爬虫。
crawler4j的使用主要分为两步:
实现一个继承自WebCrawler的爬虫类;
Crawl 类通过调用 CrawlController 实现。
WebCrawler 是一个抽象类,继承它必须实现两个方法:shouldVisit 和visit。在:
shouldVisit 是判断当前的 URL 是否应该被爬取(访问);
访问是抓取URL指向的页面的数据,传入的参数是网页所有数据的封装对象Page。
此外,WebCrawler 还有一些其他的方法可以覆盖,其方法命名规则与Android 的命名规则类似。比如getMyLocalData方法可以返回WebCrawler中的数据;onBeforeExit 方法会在WebCrawler 结束前调用,可以执行一些资源释放等任务。
执照 查看全部
java从网页抓取数据(19款Java开源Web爬虫需要的小伙伴们赶快收藏吧)
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。
今天给大家介绍19款Java开源网络爬虫,有需要的赶紧采集
吧。

一、Heritrix
Heritrix是java开发的开源网络爬虫。用户可以使用它从互联网上获取他们想要的资源。其最突出的特点是良好的扩展性,方便用户实现自己的爬取逻辑。
Heritrix 是一个“档案爬虫”——获取网站内容的完整、准确、深层副本。包括获取图片等非文字内容。抓取和存储相关内容。内容不拒绝,页面内容不修改。重新抓取不会替换同一 URL 的前一次抓取。爬虫主要通过Web用户界面启动、监控和调整,可以灵活定义获取URL。
Heritrix是一个多线程爬取的爬虫。主线程将任务分配给 Teo 线程(处理线程),每个 Teo 线程一次处理一个 URL。Teo 线程为每个 URL 执行 URL 处理器链。URL 处理器链包括以下五个处理步骤。
(1)预取链:主要是做一些准备工作,比如延迟和重新处理处理,否决后续的操作。
(2) 提取链:主要是下载网页,进行DNS转换,填写请求和响应表。
(3) 提取链:提取完成后,提取感兴趣的 HTML 和 JavaScript,通常会有新的 URL 需要爬取。
(4)写链:存储爬取的结果,这一步可以直接索引全文。Heritrix提供了一个ARCWriterProcessor实现,将下载的结果保存为ARC格式。
(5)提交链:对这个URL相关的操作做最后的处理。检查哪些新提取的URL在爬取范围内,然后将这些URL提交给Frontier。另外,DNS缓存信息也会更新。

Heritrix系统框架图

Heritrix 处理一个 url 进程
二、WebSPHINX
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX类包。
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX类包。
WebSPHINX 目的
1.可视化展示页面集合
2.将页面下载到本地磁盘进行离线浏览
3.将所有页面合并为一个页面进行浏览或打印
4. 根据特定规则从页面中提取文本字符串
5.使用Java或Javascript开发自定义爬虫
详细介绍可见>>>
三、WebLech
WebLech 是一个强大的网站下载和镜像工具。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。WebLech 有功能控制台,使用多线程操作。
WebLech 是一款功能强大的免费开源工具,用于下载和镜像网站。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。WebLech 有功能控制台,使用多线程操作。
这个爬虫很简单,如果你是初学者,如果你想写一个爬虫,可以作为入门的参考。所以我选择从这个爬虫开始我的研究。如果你只是做要求不高的应用,也可以试试。如果你想找到一个强大的,不要在 WebLech 上浪费时间。
项目主页:
特征:
1)开源,免费
2) 代码纯Java编写,可以在任何支持Java的平台上使用
3)支持多线程下载网页
4) 可以维护网页之间的链接信息
5)强大的可配置性:可以自定义深度优先或宽度优先的抓取网页,带有URL过滤器,这样您就可以根据需要抓取单个Web服务器、单个目录或抓取整个WWW网络,您可以设置URL的优先级,这样就可以先爬取我们感兴趣或重要的网页,记录断点时程序的状态,重启时从上次继续爬取。
四、阿拉蕾
Arale 主要是为个人使用而设计的,不像其他爬虫那样专注于页面索引。Arale 可以下载整个网站或网站上的部分资源。Arale 还可以将动态页面映射到静态页面。
五、JSpider
JSpider:是一个完全可配置和可定制的 Web Spider 引擎。您可以用它来检查网站错误(内部服务器错误等),检查网站的内外链接,分析网站的结构(创建网站地图),下载整个网站,您还可以写一个JSpider插件来扩展你需要的功能。
Spider 是一个用 Java 实现的 WebSpider。JSpider的执行格式如下:
jspider [URL] [ConfigName]
URL必须加上协议名,如:,否则会报错。如果省略ConfigName,则采用默认配置。
JSpider的行为具体由配置文件配置,如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。JSpider 的默认配置类型很少,也不是很有用。但是JSpider非常容易扩展,你可以用它来开发强大的网络爬虫和数据分析工具。为此,您需要深入了解JSpider 的原理,然后根据需要开发插件并编写配置文件。
蜘蛛是:
高度可配置和可定制的网络爬虫
在 LGPL 开源许可下开发
100% 纯 Java 实现
您可以将其用于:
检查您的网站是否有错误(内部服务器错误,...)
传出或内部链接检查
分析您网站的结构(创建站点地图,...)
下载翻新后的网站
通过编写JSpider插件实现任何功能。
项目主页:
六、主轴
Spindle 是一个建立在 Lucene 工具包上的 Web 索引/搜索工具。它包括一个用于创建索引的 HTTP 蜘蛛和一个用于搜索这些索引的搜索类。Spindle 项目提供了一套JSP 标签库,让那些基于JSP 的站点无需开发任何Java 类就可以添加搜索功能。
七、蛛形纲动物
Arachnid 是一个基于 Java 的网络蜘蛛框架。它收录
一个简单的 HTML 解析器,可以分析收录
HTML 内容的输入流。通过实现Arachnid的子类,可以开发一个简单的网络蜘蛛,可以在每个网站上使用页面解析后,添加几行代码调用。Arachnid 下载包中收录
两个蜘蛛应用程序示例,用于演示如何使用该框架。
项目主页:
八、LARM
LARM 可为 Jakarta Lucene 搜索引擎框架的用户提供纯 Java 搜索解决方案。它收录
索引文件、数据库表和用于索引网站的爬虫的方法。
项目主页:
九、乔博
JoBo 是一个用于下载整个网站的简单工具。它本质上是一个网络蜘蛛。与其他下载工具相比,它的主要优点是能够自动填写表单(如自动登录)和使用cookies来处理会话。JoBo 还具有灵活的下载规则(如:URL、大小、MIME 类型等)来限制下载。
十、snoics-reptile
1、什么是snoics-reptile?
它是用纯Java开发的。它是一种用于捕获网站镜像的工具。您可以使用配置文件中提供的URL入口,将本网站所有可以通过浏览器GET方式获取到的资源抓取到本地。包括网页和各类文件,如图片、flash、mp3、zip、rar、exe等文件。整个网站可以完全转移到硬盘上,保持原有网站结构准确不变。只需将抓取到的网站放置在Web服务器(如Apache)上即可实现完整的网站镜像。
2、 既然有其他类似的软件,为什么要开发snooics-reptile呢?
因为在爬取过程中经常会出现一些文件出错,很多javascript控制的URL没有办法正确解析,snoics-reptile提供了外部接口和配置文件。对于特殊的URL,可以通过自由扩展外部提供的接口,通过配置文件注入的方式,基本上可以正确解析和抓取所有网页。
项目主页:
十一、Web-Harvest
Web-Harvest 是一个 Java 开源 Web 数据提取工具。它可以采集
指定的网页并从这些网页中提取有用的数据。Web-Harvest主要使用XSLT、XQuery、正则表达式等技术来实现text/xml的操作。
Web-Harvest 是一个用 Java 编写的开源 Web 数据提取工具。它提供了一种从所需页面中提取有用数据的方法。为了实现这个目标,您可能需要使用XSLT、XQuery、正则表达式等相关技术来操作text/xml。Web-Harvest 主要关注基于 HMLT/XML 的页面内容,目前占大多数。另一方面,它可以通过编写自己的 Java 方法轻松扩展其提取功能。
Web-Harvest 的主要目的是加强现有数据提取技术的应用。它的目标不是创建一种新方法,而是提供一种更好地使用和组合现有方法的方法。它提供了一个处理器集来处理数据和控制流。每个处理器都被看作一个函数,它有参数,执行后返回结果。并且将处理组合成流水线形式,使它们可以以链式形式执行,除了更容易的数据操作和复用外,Web-Harvest 还提供了上下变量来存储声明的变量。
启动web-harvest,可以直接双击jar包运行,但是这种方式不能指定web-harvest java虚拟机的大小。第二种方法是切换到cmd下的web-harvest目录,输入命令“java -jar -Xms400m webharvest_all_2.jar”启动,设置java虚拟机大小为400M。
项目主页:
十个二、真烂
ItSucks 是 Java Web 爬虫的开源项目。可灵活定制,支持下载模板和正则表达式定义下载规则。提供控制台和 Swing GUI 操作界面。
特征:
项目主页:
十三、智能简单的网络爬虫
Smart and Simple Web Crawler 是一个网络爬虫框架。集成 Lucene 支持。爬虫可以从单个链接或一组链接开始,提供两种遍历方式:最大迭代和最大深度。可以设置过滤器来限制爬回的链接。默认提供了三个过滤器 ServerFilter、BeginningPathFilter 和 RegularExpressionFilter。这三个过滤器可以与 AND、OR 和 NOT 组合使用。可以在解析过程中或页面加载前后添加侦听器。
十四、Crawler4j
crawler4j 是一个用 Java 实现的开源网络爬虫。提供简单易用的界面,您可以在几分钟内创建一个多线程的网络爬虫。
crawler4j的使用主要分为两步:
实现一个继承自WebCrawler的爬虫类;
Crawl 类通过调用 CrawlController 实现。
WebCrawler 是一个抽象类,继承它必须实现两个方法:shouldVisit 和visit。在:
shouldVisit 是判断当前的 URL 是否应该被爬取(访问);
访问是抓取URL指向的页面的数据,传入的参数是网页所有数据的封装对象Page。
此外,WebCrawler 还有一些其他的方法可以覆盖,其方法命名规则与Android 的命名规则类似。比如getMyLocalData方法可以返回WebCrawler中的数据;onBeforeExit 方法会在WebCrawler 结束前调用,可以执行一些资源释放等任务。
执照
java从网页抓取数据(一个+jsou提取网页数据的分类汇总(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-26 04:24
原文链接
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在刚开始学习数据采集的时候可能无法上手,尤其是作为一个新手,感觉非常的茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇文章的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
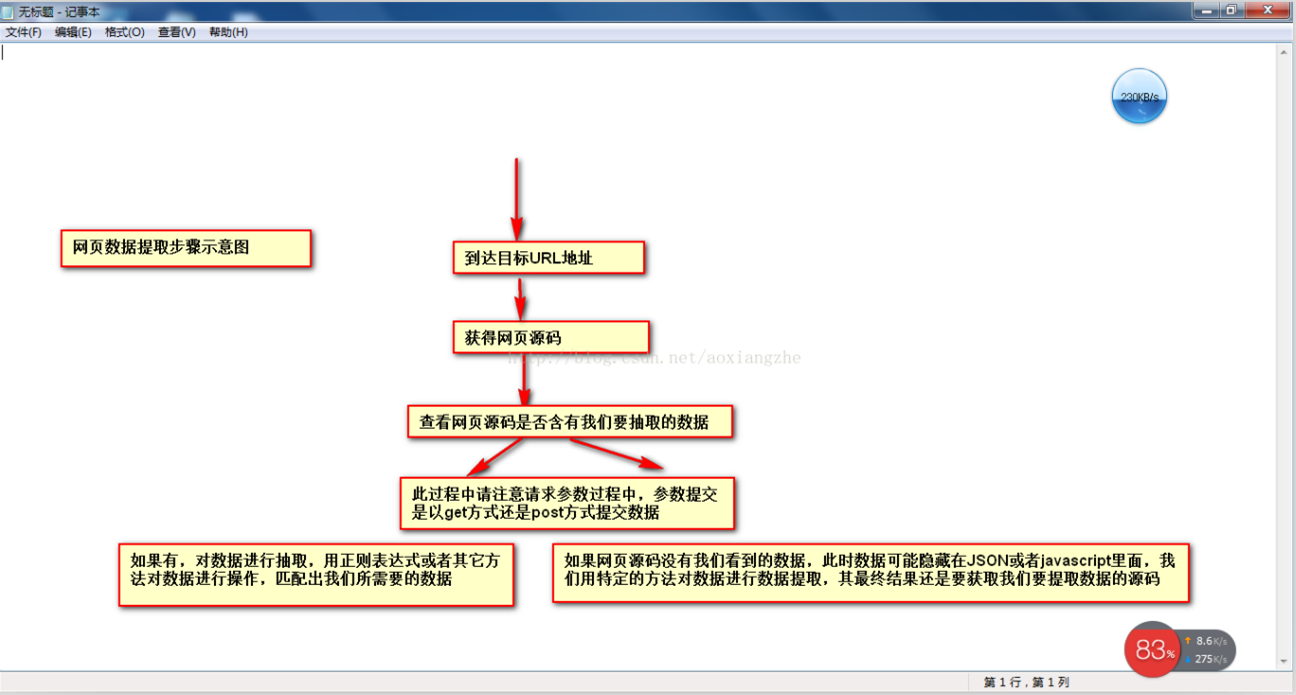
在采集
网络数据时,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先,我们看到本网站整个页面的预览
接下来我们看一下网页的源码结构:
从上面的源码中,可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。, 在真实的集合中,有些网页的结构比较复杂,源代码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在采集
这个页面的时候,只采集
了当前页面的数据,也有分页的数据。这里就不解释了,只是提醒一下,我们可以使用多线程对分页的所有当前数据进行采集
,一个通过线程采集
当前页面数据,另一个执行翻页动作,
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据进行存储,方便我们接下来的数据查询操作。 查看全部
java从网页抓取数据(一个+jsou提取网页数据的分类汇总(一))
原文链接
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在刚开始学习数据采集的时候可能无法上手,尤其是作为一个新手,感觉非常的茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇文章的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
在采集
网络数据时,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先,我们看到本网站整个页面的预览

接下来我们看一下网页的源码结构:
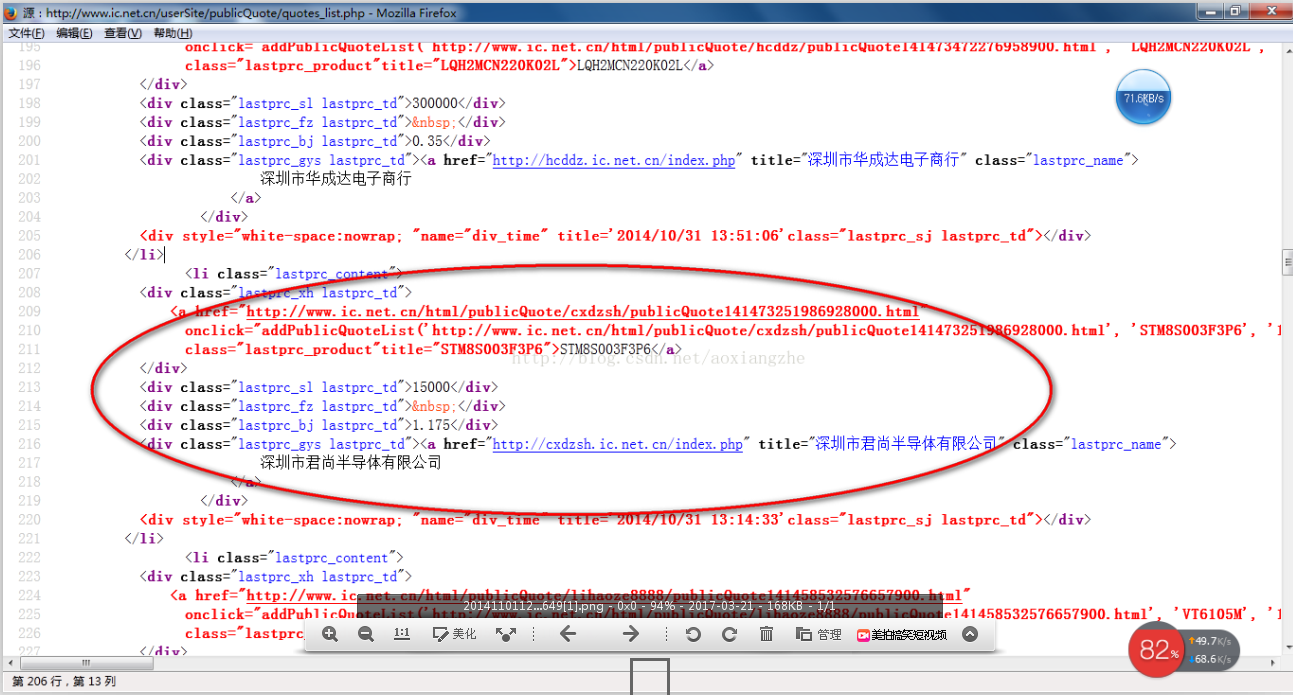
从上面的源码中,可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据

成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。, 在真实的集合中,有些网页的结构比较复杂,源代码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在采集
这个页面的时候,只采集
了当前页面的数据,也有分页的数据。这里就不解释了,只是提醒一下,我们可以使用多线程对分页的所有当前数据进行采集
,一个通过线程采集
当前页面数据,另一个执行翻页动作,
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据进行存储,方便我们接下来的数据查询操作。
java从网页抓取数据(从一个网页下载数据到Excel文件中的搜狗指数-宠物-源码接下来 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-25 07:20
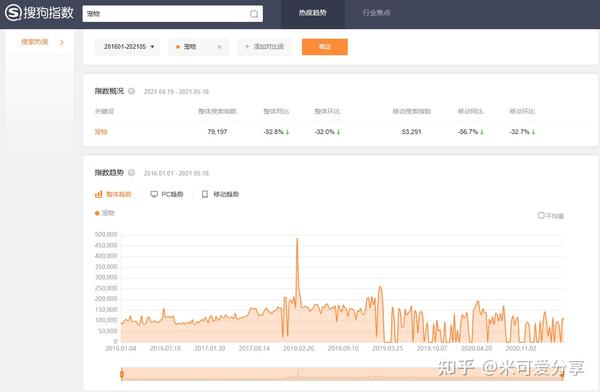
)
在处理数据分析时,如果我们的数据来自一个网页,我们需要使用数据爬虫将网页上的数据转换到本地存储,然后进行分析。
在这个文章中,我们将逐步介绍从搜狗指数下载数据到Excel文件。
分析搜狗指数页面
如果要从网页中下载数据,首先需要了解网页中的数据结构。这里我们以宠物搜索数据为例。
对于这样的页面数据
搜狗指数-宠物
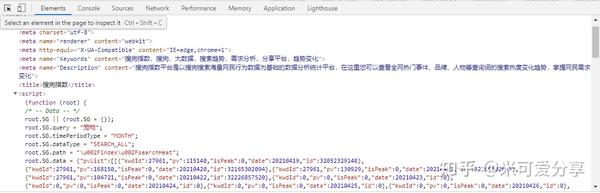
通过F12输入网页的源代码,可以看到
搜狗指数-宠物-源码
接下来,我们刚刚想出了一个方法,将脚本标签中的数据导出
通过Java将搜狗指数数据保存到Excel
Pattern p = Pattern.compile("root.SG.wholedata = (.*)", Pattern.MULTILINE);
Matcher matcher = p.matcher(script);
String wholedata = "";
while(matcher.find()) {
wholedata = matcher.group(1);
}
ObjectMapper objectMapper = new ObjectMapper();
SougouData sougouData = objectMapper.readValue(wholedata, SougouData.class);
for (Pv pv : sougouData.pvList.get(0)) {
IndexTrend indexTrend = new IndexTrend();
indexTrend.date = pv.date;
indexTrend.PV = pv.pv;
indexTrends.add(indexTrend);
}
public void SaveToExcel(Set indexTrends) throws IOException {
XSSFWorkbook workbook = new XSSFWorkbook();
XSSFSheet sheet = workbook.createSheet("Pet");
int rowNum = 0;
for (IndexTrend indexTrend : indexTrends) {
Row row = sheet.createRow(rowNum++);
Cell date = row.createCell(0);
Cell pv = row.createCell(1);
CellStyle cellStyle = workbook.createCellStyle();
CreationHelper createHelper = workbook.getCreationHelper();
cellStyle.setDataFormat(
createHelper.createDataFormat().getFormat("yyyy-MM-dd"));
date.setCellValue(indexTrend.date);
date.setCellStyle(cellStyle);
pv.setCellValue(indexTrend.PV);
}
FileOutputStream outputStream = new FileOutputStream("./Download Sougou To Excel/petdata.xlsx");
workbook.write(outputStream);
workbook.close();
} 查看全部
java从网页抓取数据(从一个网页下载数据到Excel文件中的搜狗指数-宠物-源码接下来
)
在处理数据分析时,如果我们的数据来自一个网页,我们需要使用数据爬虫将网页上的数据转换到本地存储,然后进行分析。
在这个文章中,我们将逐步介绍从搜狗指数下载数据到Excel文件。
分析搜狗指数页面
如果要从网页中下载数据,首先需要了解网页中的数据结构。这里我们以宠物搜索数据为例。
对于这样的页面数据
搜狗指数-宠物
通过F12输入网页的源代码,可以看到
搜狗指数-宠物-源码
接下来,我们刚刚想出了一个方法,将脚本标签中的数据导出
通过Java将搜狗指数数据保存到Excel
Pattern p = Pattern.compile("root.SG.wholedata = (.*)", Pattern.MULTILINE);
Matcher matcher = p.matcher(script);
String wholedata = "";
while(matcher.find()) {
wholedata = matcher.group(1);
}
ObjectMapper objectMapper = new ObjectMapper();
SougouData sougouData = objectMapper.readValue(wholedata, SougouData.class);
for (Pv pv : sougouData.pvList.get(0)) {
IndexTrend indexTrend = new IndexTrend();
indexTrend.date = pv.date;
indexTrend.PV = pv.pv;
indexTrends.add(indexTrend);
}
public void SaveToExcel(Set indexTrends) throws IOException {
XSSFWorkbook workbook = new XSSFWorkbook();
XSSFSheet sheet = workbook.createSheet("Pet");
int rowNum = 0;
for (IndexTrend indexTrend : indexTrends) {
Row row = sheet.createRow(rowNum++);
Cell date = row.createCell(0);
Cell pv = row.createCell(1);
CellStyle cellStyle = workbook.createCellStyle();
CreationHelper createHelper = workbook.getCreationHelper();
cellStyle.setDataFormat(
createHelper.createDataFormat().getFormat("yyyy-MM-dd"));
date.setCellValue(indexTrend.date);
date.setCellStyle(cellStyle);
pv.setCellValue(indexTrend.PV);
}
FileOutputStream outputStream = new FileOutputStream("./Download Sougou To Excel/petdata.xlsx");
workbook.write(outputStream);
workbook.close();
}
java从网页抓取数据(丹杰我正在尝试从这个网站上抓取第二个表或告诉我如何做 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-19 03:04
)
单节
我试图从这个 网站 中获取第二个表: 但是,我只设法从提取时获取了第一个表信息,尝试通过查找表标签来访问信息。谁能向我解释为什么我无法访问第二个表或告诉我该怎么做。
import requests
from bs4 import BeautifulSoup
url = "https://fbref.com/en/comps/9/s ... ot%3B
res = requests.get(url)
soup = BeautifulSoup(res.text, 'lxml')
pl_table = soup.find_all("table")
player_table = tables[0]
安德烈·凯斯利
表格在 HTML 注释中。
要从评论中获取表单,您可以使用以下示例:
<p>import requests
from bs4 import BeautifulSoup, Comment
url = 'https://fbref.com/en/comps/9/stats/Premier-League-Stats'
soup = BeautifulSoup(requests.get(url).content, 'html.parser')
table = BeautifulSoup(soup.select_one('#all_stats_standard').find_next(text=lambda x: isinstance(x, Comment)), 'html.parser')
#print some information from the table to screen:
for tr in table.select('tr:has(td)'):
tds = [td.get_text(strip=True) for td in tr.select('td')]
print('{: 查看全部
java从网页抓取数据(丹杰我正在尝试从这个网站上抓取第二个表或告诉我如何做
)
单节
我试图从这个 网站 中获取第二个表: 但是,我只设法从提取时获取了第一个表信息,尝试通过查找表标签来访问信息。谁能向我解释为什么我无法访问第二个表或告诉我该怎么做。
import requests
from bs4 import BeautifulSoup
url = "https://fbref.com/en/comps/9/s ... ot%3B
res = requests.get(url)
soup = BeautifulSoup(res.text, 'lxml')
pl_table = soup.find_all("table")
player_table = tables[0]
安德烈·凯斯利
表格在 HTML 注释中。
要从评论中获取表单,您可以使用以下示例:
<p>import requests
from bs4 import BeautifulSoup, Comment
url = 'https://fbref.com/en/comps/9/stats/Premier-League-Stats'
soup = BeautifulSoup(requests.get(url).content, 'html.parser')
table = BeautifulSoup(soup.select_one('#all_stats_standard').find_next(text=lambda x: isinstance(x, Comment)), 'html.parser')
#print some information from the table to screen:
for tr in table.select('tr:has(td)'):
tds = [td.get_text(strip=True) for td in tr.select('td')]
print('{:
java从网页抓取数据(如何使用python识别网页中的图表中提取数据%D0)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-19 03:01
标签:pythonchartsweb-crawler
我是python的新手。我刚刚学会了如何使用 python 来识别网页中的 URL。但是,现在我想从网页中的图表中提取数据%D0%CB%D2%B5%D6%A4%C8%AF
我有三个问题征求我的意见。
您需要登录才能看到此页面。(用户名:1 8521057966;密码:saifmf)在源码中找不到数据(假设是html)如果能找到图表的哪一部分,如何提取数据。
1 个回答:
答案 0:(得分:0)
将 Selenium 与 Python 绑定一起使用。我推荐这个是因为该页面使用 JavaScript 来完成登录。如果该信息显示在页面上,那么您也可以使用它。换句话说,如果浏览器可以看到信息(只要它正在渲染它),那么您也可以看到它。它可能在源代码中。使用谷歌浏览器,将鼠标悬停在要检查的元素上,右键单击它,然后选择“检查元素”。这将带来检查员。即使源代码中没有任何内容,检查员(ctrl+shift+i)也可以看到它。这取决于。我会先推荐那个。在inspector中找到信息后,可以选择元素并使用selenium获取文本,然后以任何你想要的形式输出(例如,构建一个CSV)。
相关问题
最新一期 查看全部
java从网页抓取数据(如何使用python识别网页中的图表中提取数据%D0)
标签:pythonchartsweb-crawler
我是python的新手。我刚刚学会了如何使用 python 来识别网页中的 URL。但是,现在我想从网页中的图表中提取数据%D0%CB%D2%B5%D6%A4%C8%AF
我有三个问题征求我的意见。
您需要登录才能看到此页面。(用户名:1 8521057966;密码:saifmf)在源码中找不到数据(假设是html)如果能找到图表的哪一部分,如何提取数据。
1 个回答:
答案 0:(得分:0)
将 Selenium 与 Python 绑定一起使用。我推荐这个是因为该页面使用 JavaScript 来完成登录。如果该信息显示在页面上,那么您也可以使用它。换句话说,如果浏览器可以看到信息(只要它正在渲染它),那么您也可以看到它。它可能在源代码中。使用谷歌浏览器,将鼠标悬停在要检查的元素上,右键单击它,然后选择“检查元素”。这将带来检查员。即使源代码中没有任何内容,检查员(ctrl+shift+i)也可以看到它。这取决于。我会先推荐那个。在inspector中找到信息后,可以选择元素并使用selenium获取文本,然后以任何你想要的形式输出(例如,构建一个CSV)。
相关问题

最新一期
java从网页抓取数据(java从网页抓取数据详细教程(图)之家)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-17 05:01
java从网页抓取数据详细教程你可以看看这个,从网页抓取数据分页数据,量太大,涉及太多东西,比如找页码源码这些,需要你懂点代码开发,
有一款叫“爬虫之家”的app,蛮不错的,可以爬虫类似百度的结果,挺好用的。
楼主是学java的还是不是?java本身是可以用python写爬虫的。如果不是的话,那么我不知道你是想直接写python的爬虫还是想先写一个api端,由你爬虫使用的client部分。基于api的话,目前提供java接口的商业应用或者开源api有greendao爬虫框架,不过这个框架要收费。国内做服务器api的公司有digitalriderdemocloud。
大学课设做爬虫的时候研究过爬虫之家的api,思路是抓出来的请求报文里面的url为请求提供一个定向的链接,然后把请求下发给这个定向的链接就能抓取,下面是我修改的代码:importrequests#clientcaller=requests。get(";rct=0&ie=utf-8&q=%e8%a6%82%e8%a7%91&dl=x2&md5=ic21570cdf517df54885e2901171452b11&sn=ce21570cf517df54885e2901171452b11&subadvr=x2&mcv=2560")#发送urldownloadurl=";url_len=15&sign=&cn=x2&signtype=4&pc=x2&sk=fwl7jzsf2clzx0%2bc0izg90_czhgebnd&ipn=fj&spm=a2hsymbolz%2bc0izg90_czhgebnd%2bc0izg90_czhgebnd&_=a43cc0x7%2b7fd5016eee1741"jsonpath='/data%2f17660%2b7fd5016eee1741&ie=utf-8&q=%e8%a6%82%e8%a7%91&dl=x2&md5=ic21570cf517df54885e2901171452b11&subadvr=x2&mcv=2560&msg=i4c74c8e001517415e6222183767332e'#定向的ip地址stripedurl="(={}&dl=x2&sign=&cn=x2&signtype=4&pc=x2&sk=fwl7jzsf2clzx0%2bc0izg90_czhgebnd%2bc0izg90_czhgebnd&_=a43cc0x7%2b7fd5016eee1741);url_len=15&sign=&cn=x2&signtype=4&pc=x2&sk=fwl7jzsf2clzx0%2bc0izg90_czhgebnd%2bc0izg90_czhgebnd&_=a43cc0x7%2b7fd。 查看全部
java从网页抓取数据(java从网页抓取数据详细教程(图)之家)
java从网页抓取数据详细教程你可以看看这个,从网页抓取数据分页数据,量太大,涉及太多东西,比如找页码源码这些,需要你懂点代码开发,
有一款叫“爬虫之家”的app,蛮不错的,可以爬虫类似百度的结果,挺好用的。
楼主是学java的还是不是?java本身是可以用python写爬虫的。如果不是的话,那么我不知道你是想直接写python的爬虫还是想先写一个api端,由你爬虫使用的client部分。基于api的话,目前提供java接口的商业应用或者开源api有greendao爬虫框架,不过这个框架要收费。国内做服务器api的公司有digitalriderdemocloud。
大学课设做爬虫的时候研究过爬虫之家的api,思路是抓出来的请求报文里面的url为请求提供一个定向的链接,然后把请求下发给这个定向的链接就能抓取,下面是我修改的代码:importrequests#clientcaller=requests。get(";rct=0&ie=utf-8&q=%e8%a6%82%e8%a7%91&dl=x2&md5=ic21570cdf517df54885e2901171452b11&sn=ce21570cf517df54885e2901171452b11&subadvr=x2&mcv=2560")#发送urldownloadurl=";url_len=15&sign=&cn=x2&signtype=4&pc=x2&sk=fwl7jzsf2clzx0%2bc0izg90_czhgebnd&ipn=fj&spm=a2hsymbolz%2bc0izg90_czhgebnd%2bc0izg90_czhgebnd&_=a43cc0x7%2b7fd5016eee1741"jsonpath='/data%2f17660%2b7fd5016eee1741&ie=utf-8&q=%e8%a6%82%e8%a7%91&dl=x2&md5=ic21570cf517df54885e2901171452b11&subadvr=x2&mcv=2560&msg=i4c74c8e001517415e6222183767332e'#定向的ip地址stripedurl="(={}&dl=x2&sign=&cn=x2&signtype=4&pc=x2&sk=fwl7jzsf2clzx0%2bc0izg90_czhgebnd%2bc0izg90_czhgebnd&_=a43cc0x7%2b7fd5016eee1741);url_len=15&sign=&cn=x2&signtype=4&pc=x2&sk=fwl7jzsf2clzx0%2bc0izg90_czhgebnd%2bc0izg90_czhgebnd&_=a43cc0x7%2b7fd。
java从网页抓取数据(抓取你想要的网页数据假设你需要获取51人才的需求数量(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-16 23:35
抓取你想要的网页数据
java捕获网站数据
假设你需要在线获取51job人才在线java人才需求量,首先你需要分析51job网站搜索这个
一件如何运作?通过对网页源代码的分析,我们发现了以下信息:
1. 页面搜索时请求的网址为
2. 请求使用的方法是:POST
3. 返回页面的编码格式为:GBK
4. 假设我们在搜索java人才时想要获取结果页面显示的需求数量,我们发现该数量在返回的HTML数据中的一段代码中:
1-30 / 14794
,所以我们可以得到这样一个模式:“.+1-\d+/(\d+).+”,第一组的内容就是我们最终需要的数据,java中的模式请参考java文档Pattern类介绍
5. 另外,作为一个POST请求,页面发送到服务端的数据如下(这样很容易像prototype一样通过js
帧抓取,参考我的另一篇博文介绍):
lang=c&stype=1&postchannel=0000&fromType=1&line=&keywordtype=2&keyword=java&btnJ obarea=%E9%80%89%E6%8B%A9%E5%9C%B0%E5%8C%BA&jobarea=0000&image=&btn% Funtype 80%89%E6%8B%A9%2F%E4%BF%AE%E6%94%B9&funtype=0000&btnIndustrytype=%E9%80%89%E6%8B%A9%2F%E4%BF%AE%E6% 94%B9&industrytype=00 关于第5条中服务器真正需要的数据,我们不关心,全部发送。有了这些标准
准备好了,我们其实就可以开始通过java发送请求,得到最终的数据了。
我们定义了Resource类,这个类封装了与请求相关的所有信息,Resource包括以下属性:view plaincopy to clipboardprint?
/**
* 需要获取资源的目标地址,不收录查询字符串
*/
私有字符串目标;
/**
* get请求的查询字符串,或者post请求的请求数据
*/
私人字符串查询数据 = "";
/**
* 请求方法,获取/发布
*/
私有字符串方法 = "GET";
/**
* 返回数据的编码类型
*/
私人字符串字符集 = "GBK";
/**
* 抓取数据的模式,会根据模式的分组返回数据列表
*/
私有字符串模式; 查看全部
java从网页抓取数据(抓取你想要的网页数据假设你需要获取51人才的需求数量(组图))
抓取你想要的网页数据
java捕获网站数据
假设你需要在线获取51job人才在线java人才需求量,首先你需要分析51job网站搜索这个
一件如何运作?通过对网页源代码的分析,我们发现了以下信息:
1. 页面搜索时请求的网址为
2. 请求使用的方法是:POST
3. 返回页面的编码格式为:GBK
4. 假设我们在搜索java人才时想要获取结果页面显示的需求数量,我们发现该数量在返回的HTML数据中的一段代码中:
1-30 / 14794
,所以我们可以得到这样一个模式:“.+1-\d+/(\d+).+”,第一组的内容就是我们最终需要的数据,java中的模式请参考java文档Pattern类介绍
5. 另外,作为一个POST请求,页面发送到服务端的数据如下(这样很容易像prototype一样通过js
帧抓取,参考我的另一篇博文介绍):
lang=c&stype=1&postchannel=0000&fromType=1&line=&keywordtype=2&keyword=java&btnJ obarea=%E9%80%89%E6%8B%A9%E5%9C%B0%E5%8C%BA&jobarea=0000&image=&btn% Funtype 80%89%E6%8B%A9%2F%E4%BF%AE%E6%94%B9&funtype=0000&btnIndustrytype=%E9%80%89%E6%8B%A9%2F%E4%BF%AE%E6% 94%B9&industrytype=00 关于第5条中服务器真正需要的数据,我们不关心,全部发送。有了这些标准
准备好了,我们其实就可以开始通过java发送请求,得到最终的数据了。
我们定义了Resource类,这个类封装了与请求相关的所有信息,Resource包括以下属性:view plaincopy to clipboardprint?
/**
* 需要获取资源的目标地址,不收录查询字符串
*/
私有字符串目标;
/**
* get请求的查询字符串,或者post请求的请求数据
*/
私人字符串查询数据 = "";
/**
* 请求方法,获取/发布
*/
私有字符串方法 = "GET";
/**
* 返回数据的编码类型
*/
私人字符串字符集 = "GBK";
/**
* 抓取数据的模式,会根据模式的分组返回数据列表
*/
私有字符串模式;
java从网页抓取数据(怎样从PDF中提取内容,了解一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-15 07:53
指南:了解如何从 PDF 中提取内容。
如果有办法自动验证PDF的内容,程序员的生活该有多轻松!
不知道大家有没有听说过Java提供了一个可以提取PDDF内容的工具。本文将向您介绍这个工具,它的名字是 Apache PDFBox。
什么是PDFBox
Apache PDFBox 库是一个用于处理 PDF 文档的开源 Java 工具。它可以帮助我们:
1)新建一个PDF文档;
2)更新现有文档;
比如添加样式、添加超链接等;
3)建议来自 PDF 文档的内容。
从 PDF 读取内容
当我们能够从 PDF 中提取文本内容时,问题就解决了一半。让我们以一个代码示例来完成此任务。
Apche PDFTextStripper 的类 PDFTextStripper() 可以以去除所有格式的形式提取PDF中的文本。它将忽略所有格式和特殊样式。
tStripper = new PDFTextStripper();tStripper.setStartPage(1);tStripper.setEndPage(3);<br />PDDOocument document = PDDocument.load(new File("youpdfname.pdf"));<br />document.getClass(); if(!document.isEncrypted()){ pdfFileInText = tStripper.getText(document); lines = pdfFileIntext.split("\\r\\n\\r\\n"); for(String line : llines){ System.out.printlln(line); content += line; } }System.out.println(content.trim());
从 PDF 文件中获取所有超链接
第二件事是验证PDF中的超链接。以下代码为您提供了 PDF 文档中的超链接。
PDPage class() 中的 getAnnotations() 方法提供文档中的注释列表。接下来,使用 PDActionURI() 获取文档或页面中的 URI 列表
<p>PDDocument document = PDDocument.load(new File("name.pdf"));document.getClass();PDPage pdfpage = document.getPage(1); annotations = pdfpage.getAnnotations(); for (int j = 0; j 查看全部
java从网页抓取数据(怎样从PDF中提取内容,了解一下)
指南:了解如何从 PDF 中提取内容。

如果有办法自动验证PDF的内容,程序员的生活该有多轻松!
不知道大家有没有听说过Java提供了一个可以提取PDDF内容的工具。本文将向您介绍这个工具,它的名字是 Apache PDFBox。
什么是PDFBox
Apache PDFBox 库是一个用于处理 PDF 文档的开源 Java 工具。它可以帮助我们:
1)新建一个PDF文档;
2)更新现有文档;
比如添加样式、添加超链接等;
3)建议来自 PDF 文档的内容。
从 PDF 读取内容
当我们能够从 PDF 中提取文本内容时,问题就解决了一半。让我们以一个代码示例来完成此任务。
Apche PDFTextStripper 的类 PDFTextStripper() 可以以去除所有格式的形式提取PDF中的文本。它将忽略所有格式和特殊样式。
tStripper = new PDFTextStripper();tStripper.setStartPage(1);tStripper.setEndPage(3);<br />PDDOocument document = PDDocument.load(new File("youpdfname.pdf"));<br />document.getClass(); if(!document.isEncrypted()){ pdfFileInText = tStripper.getText(document); lines = pdfFileIntext.split("\\r\\n\\r\\n"); for(String line : llines){ System.out.printlln(line); content += line; } }System.out.println(content.trim());
从 PDF 文件中获取所有超链接
第二件事是验证PDF中的超链接。以下代码为您提供了 PDF 文档中的超链接。
PDPage class() 中的 getAnnotations() 方法提供文档中的注释列表。接下来,使用 PDActionURI() 获取文档或页面中的 URI 列表
<p>PDDocument document = PDDocument.load(new File("name.pdf"));document.getClass();PDPage pdfpage = document.getPage(1); annotations = pdfpage.getAnnotations(); for (int j = 0; j
java从网页抓取数据(一个+jsou提取网页数据的分类汇总(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-12 18:13
原文链接
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候,可能都无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇文章的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
从上面的源码中,可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只是采集拿到了当前页面的数据,也有分页的数据。这里就不解释了,只是一个提示,我们可以使用多线程采集所有页面的当前数据,通过线程一个采集当前页面数据,和一个翻页动作,可以< @采集
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据进行存储,方便我们接下来的数据查询操作。
转载于: 查看全部
java从网页抓取数据(一个+jsou提取网页数据的分类汇总(一))
原文链接
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候,可能都无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇文章的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
从上面的源码中,可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只是采集拿到了当前页面的数据,也有分页的数据。这里就不解释了,只是一个提示,我们可以使用多线程采集所有页面的当前数据,通过线程一个采集当前页面数据,和一个翻页动作,可以< @采集
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据进行存储,方便我们接下来的数据查询操作。
转载于:
java从网页抓取数据(Java六级540多分的水平,大家见谅!(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-10 03:30
翻译Java开源爬虫框架crawler4j文档花了两个小时。因为这几天一直在学习Java爬虫的知识,突然觉得英语可能会阻碍很多人学习的动力。这个爬虫框架,所以决定翻译一下。第六关540多点还请见谅。每个句子都是根据您自己的理解翻译的。尤其是快速入门那部分的源代码。这里是:
爬虫4j
crawler4j 是一个开源的 Java 爬虫网络爬虫,提供了一个简单的网络爬虫接口。使用它,您可以在几分钟内设置一个多线程网络爬虫。
使用Maven下载和安装内容列表
要使用最新版本的 crawler4j,请在您的 pom.xml 中使用以下代码片段
edu.uci.ics
crawler4j
4.3
快照
您可以添加以下内容以使用下一个快照版本
onebeartoe
onebeartoe
https://repository-onebeartoe. ... shot/
edu.uci.ics
crawler4j
4.4-SNAPSHOT
如果没有Maven
从4.3版本开始,如果你需要一个收录所有依赖的jar包。您需要自己构建它。克隆 repo 并运行
$ mvn package -Pfatjar
你会发现target/文件夹中有一个crawler4j-XY-with-dependencies.jar。
使用摇篮
请在 build.gradle 文件中收录以下依赖项以使用 crawler4j
compile group: 'edu.uci.ics', name: 'crawler4j', version: '4.3'
另外在build.gradle中添加如下repository url获取依赖[sleepycat]()
maven {
url "https://repo.boundlessgeo.com/main/"
}
快速开始
您需要创建一个扩展 WebCrawler 的爬虫类。此类确定应抓取哪些 URL 并处理下载的页面。下面是一个示例实现:
public class MyCrawler extends WebCrawler {
/**
* 正则表达式匹配指定的后缀文件
*/
private final static Pattern FILTERS = Pattern.compile(".*(\\.(css|js|gif|jpg" + "|png|mp3|mp4|zip|gz))$");
/**
* 这个方法主要是决定哪些url我们需要抓取,返回true表示是我们需要的,返回false表示不是我们需要的Url
* 第一个参数referringPage封装了当前爬取的页面信息 第二个参数url封装了当前爬取的页面url信息
* 在这个例子中,我们指定爬虫忽略具有css,js,git,...扩展名的url,只接受以“http://www.ics.uci.edu/”开头的url。
* 在这种情况下,我们不需要referringPage参数来做出决定。
*/
@Override
public boolean shouldVisit(Page referringPage, WebURL url) {
String href = url.getURL().toLowerCase();// 得到小写的url
return !FILTERS.matcher(href).matches() // 正则匹配,过滤掉我们不需要的后缀文件
&& href.startsWith("http://www.ics.uci.edu/");// 只接受以“http://www.ics.uci.edu/”开头的url
}
/**
* 当一个页面被提取并准备好被你的程序处理时,这个函数被调用。
*/
@Override
public void visit(Page page) {
String url = page.getWebURL().getURL();// 获取url
System.out.println("URL: " + url);
if (page.getParseData() instanceof HtmlParseData) {// 判断是否是html数据
HtmlParseData htmlParseData = (HtmlParseData) page.getParseData();//// 强制类型转换,获取html数据对象
String text = htmlParseData.getText();//获取页面纯文本(无html标签)
String html = htmlParseData.getHtml();//获取页面Html
Set links = htmlParseData.getOutgoingUrls();// 获取页面输出链接
System.out.println("纯文本长度: " + text.length());
System.out.println("html长度: " + html.length());
System.out.println("链接个数 " + links.size());
}
}
}
从上面的代码可以看出,主要有两个方法需要覆盖
您还应该实现一个控制器类,该类指定爬取的种子、爬取的数据应存储在哪个文件夹中以及并发线程数:
public class Controller {
public static void main(String[] args) throws Exception {
String crawlStorageFolder = "E:/crawler";// 定义爬虫数据存储位置
int numberOfCrawlers = 7;// 定义了7个爬虫,也就是7个线程
CrawlConfig config = new CrawlConfig();// 定义爬虫配置
config.setCrawlStorageFolder(crawlStorageFolder);// 设置爬虫文件存储位置
/*
* 实例化爬虫控制器。
*/
PageFetcher pageFetcher = new PageFetcher(config);// 实例化页面获取器
RobotstxtConfig robotstxtConfig = new RobotstxtConfig();// 实例化爬虫机器人配置
// 实例化爬虫机器人对目标服务器的配置,每个网站都有一个robots.txt文件
// 规定了该网站哪些页面可以爬,哪些页面禁止爬,该类是对robots.txt规范的实现
RobotstxtServer robotstxtServer = new RobotstxtServer(robotstxtConfig, pageFetcher);
// 实例化爬虫控制器
CrawlController controller = new CrawlController(config, pageFetcher, robotstxtServer);
/*
* 对于每次抓取,您需要添加一些种子网址。 这些是抓取的第一个URL,然后抓取工具开始跟随这些页面中的链接
*/
controller.addSeed("http://www.ics.uci.edu/~lopes/");
controller.addSeed("http://www.ics.uci.edu/~welling/");
controller.addSeed("http://www.ics.uci.edu/");
/**
* 启动爬虫,爬虫从此刻开始执行爬虫任务,根据以上配置
*/
controller.start(MyCrawler.class, numberOfCrawlers);
}
}
结果(eclipse+Marven 测试):
使用工厂
使用工厂可以轻松地将 crawler4j 集成到 IoC 环境(如 Spring、Guice)或将信息或协作者传递给每个“WebCrawler”实例。
public class CsiCrawlerCrawlerControllerFactory implements CrawlController.WebCrawlerFactory {
Map metadata;
SqlRepository repository;
public CsiCrawlerCrawlerControllerFactory(Map metadata, SqlRepository repository) {
this.metadata = metadata;
this.repository = repository;
}
@Override
public WebCrawler newInstance() {
return new MyCrawler(metadata, repository);
}
}
要使用工厂,你只需要在 CrawlController 中调用正确的方法(如果你在 Spring 或 Guice,你可能想使用 startNonBlocking):
MyCrawlerFactory factory = new MyCrawlerFactory(metadata, repository);
controller.startNonBlocking(factory, numberOfCrawlers);
更多示例配置细节
控制器类具有 CrawlConfig 类型的必需参数
此类的实例可用于配置 crawler4j。以下部分描述了配置的一些细节。
爬行深度
默认情况下,抓取深度没有限制。但是你可以限制爬行的深度。例如,假设您有一个种子页面“A”,链接到“B”,链接到“C”,链接到“D”。所以,我们有以下链接结构:
A -> B -> C -> D
因为“A”是种子页面,它的深度为0.,“B”的深度为1,以此类推。可以设置crawler4j 抓取的网页深度限制。例如,如果将此限制设置为 2,则不会抓取页面“D”。要设置您可以使用的最大深度:
crawlConfig.setMaxDepthOfCrawling(maxDepthOfCrawling);
启用 SSL
只需启用 SSL:
CrawlConfig config = new CrawlConfig();
config.setIncludeHttpsPages(true);
要抓取的最大页面数
虽然默认情况下对抓取的页面数量没有限制,但您可以为此设置一个限制:
crawlConfig.setMaxPagesToFetch(maxPagesToFetch);
启用二进制内容抓取
默认情况下,抓取二进制内容(即图像、音频等)是关闭的。您必须启用它才能抓取这些文件:
crawlConfig.setIncludeBinaryContentInCrawling(true);
有关更多详细信息,请参阅此处的示例。
文明问题(礼貌爬行)
crawler4j 的设计非常高效,可以非常快速地抓取域名
(例如,它已经能够每秒抓取 200 个维基百科页面)。但现在我反对爬取 网站,因为这会给服务器带来巨大的负担(他们可能会阻止你!),
从 1.3 版本开始,crawler4j 默认会在请求之间等待至少 200 毫秒。
但是,可以调整此参数:
crawlConfig.setPolitenessDelay(politenessDelay);
演戏
你的爬行应该在代理后面运行吗?如果是这样,您可以使用:
crawlConfig.setProxyHost("proxyserver.example.com");
crawlConfig.setProxyPort(8080);
如果您的代理还需要认证:
crawlConfig.setProxyUsername(username);
crawlConfig.setProxyPassword(password);
可恢复抓取
有时需要长时间运行爬虫。搜索者可能会意外终止。在这种情况下,可能需要恢复爬行。您可以使用以下设置恢复先前停止/崩溃的爬网:
crawlConfig.setResumableCrawling(true);
但是,您应该注意它可能会使爬行速度稍微变慢。
用户代理字符串
用户代理字符串用于将您的爬虫表示为 Web 服务器。
请参阅此处了解更多详情。默认情况下,crawler4j 使用以下用户代理字符串:
"crawler4j (https://github.com/yasserg/crawler4j/)"
但是,您可以覆盖它:
crawlConfig.setUserAgentString(userAgentString);
执照 查看全部
java从网页抓取数据(Java六级540多分的水平,大家见谅!(组图))
翻译Java开源爬虫框架crawler4j文档花了两个小时。因为这几天一直在学习Java爬虫的知识,突然觉得英语可能会阻碍很多人学习的动力。这个爬虫框架,所以决定翻译一下。第六关540多点还请见谅。每个句子都是根据您自己的理解翻译的。尤其是快速入门那部分的源代码。这里是:
爬虫4j
crawler4j 是一个开源的 Java 爬虫网络爬虫,提供了一个简单的网络爬虫接口。使用它,您可以在几分钟内设置一个多线程网络爬虫。
使用Maven下载和安装内容列表
要使用最新版本的 crawler4j,请在您的 pom.xml 中使用以下代码片段
edu.uci.ics
crawler4j
4.3
快照
您可以添加以下内容以使用下一个快照版本
onebeartoe
onebeartoe
https://repository-onebeartoe. ... shot/
edu.uci.ics
crawler4j
4.4-SNAPSHOT
如果没有Maven
从4.3版本开始,如果你需要一个收录所有依赖的jar包。您需要自己构建它。克隆 repo 并运行
$ mvn package -Pfatjar
你会发现target/文件夹中有一个crawler4j-XY-with-dependencies.jar。
使用摇篮
请在 build.gradle 文件中收录以下依赖项以使用 crawler4j
compile group: 'edu.uci.ics', name: 'crawler4j', version: '4.3'
另外在build.gradle中添加如下repository url获取依赖[sleepycat]()
maven {
url "https://repo.boundlessgeo.com/main/"
}
快速开始
您需要创建一个扩展 WebCrawler 的爬虫类。此类确定应抓取哪些 URL 并处理下载的页面。下面是一个示例实现:
public class MyCrawler extends WebCrawler {
/**
* 正则表达式匹配指定的后缀文件
*/
private final static Pattern FILTERS = Pattern.compile(".*(\\.(css|js|gif|jpg" + "|png|mp3|mp4|zip|gz))$");
/**
* 这个方法主要是决定哪些url我们需要抓取,返回true表示是我们需要的,返回false表示不是我们需要的Url
* 第一个参数referringPage封装了当前爬取的页面信息 第二个参数url封装了当前爬取的页面url信息
* 在这个例子中,我们指定爬虫忽略具有css,js,git,...扩展名的url,只接受以“http://www.ics.uci.edu/”开头的url。
* 在这种情况下,我们不需要referringPage参数来做出决定。
*/
@Override
public boolean shouldVisit(Page referringPage, WebURL url) {
String href = url.getURL().toLowerCase();// 得到小写的url
return !FILTERS.matcher(href).matches() // 正则匹配,过滤掉我们不需要的后缀文件
&& href.startsWith("http://www.ics.uci.edu/";);// 只接受以“http://www.ics.uci.edu/”开头的url
}
/**
* 当一个页面被提取并准备好被你的程序处理时,这个函数被调用。
*/
@Override
public void visit(Page page) {
String url = page.getWebURL().getURL();// 获取url
System.out.println("URL: " + url);
if (page.getParseData() instanceof HtmlParseData) {// 判断是否是html数据
HtmlParseData htmlParseData = (HtmlParseData) page.getParseData();//// 强制类型转换,获取html数据对象
String text = htmlParseData.getText();//获取页面纯文本(无html标签)
String html = htmlParseData.getHtml();//获取页面Html
Set links = htmlParseData.getOutgoingUrls();// 获取页面输出链接
System.out.println("纯文本长度: " + text.length());
System.out.println("html长度: " + html.length());
System.out.println("链接个数 " + links.size());
}
}
}
从上面的代码可以看出,主要有两个方法需要覆盖
您还应该实现一个控制器类,该类指定爬取的种子、爬取的数据应存储在哪个文件夹中以及并发线程数:
public class Controller {
public static void main(String[] args) throws Exception {
String crawlStorageFolder = "E:/crawler";// 定义爬虫数据存储位置
int numberOfCrawlers = 7;// 定义了7个爬虫,也就是7个线程
CrawlConfig config = new CrawlConfig();// 定义爬虫配置
config.setCrawlStorageFolder(crawlStorageFolder);// 设置爬虫文件存储位置
/*
* 实例化爬虫控制器。
*/
PageFetcher pageFetcher = new PageFetcher(config);// 实例化页面获取器
RobotstxtConfig robotstxtConfig = new RobotstxtConfig();// 实例化爬虫机器人配置
// 实例化爬虫机器人对目标服务器的配置,每个网站都有一个robots.txt文件
// 规定了该网站哪些页面可以爬,哪些页面禁止爬,该类是对robots.txt规范的实现
RobotstxtServer robotstxtServer = new RobotstxtServer(robotstxtConfig, pageFetcher);
// 实例化爬虫控制器
CrawlController controller = new CrawlController(config, pageFetcher, robotstxtServer);
/*
* 对于每次抓取,您需要添加一些种子网址。 这些是抓取的第一个URL,然后抓取工具开始跟随这些页面中的链接
*/
controller.addSeed("http://www.ics.uci.edu/~lopes/";);
controller.addSeed("http://www.ics.uci.edu/~welling/";);
controller.addSeed("http://www.ics.uci.edu/";);
/**
* 启动爬虫,爬虫从此刻开始执行爬虫任务,根据以上配置
*/
controller.start(MyCrawler.class, numberOfCrawlers);
}
}
结果(eclipse+Marven 测试):

使用工厂
使用工厂可以轻松地将 crawler4j 集成到 IoC 环境(如 Spring、Guice)或将信息或协作者传递给每个“WebCrawler”实例。
public class CsiCrawlerCrawlerControllerFactory implements CrawlController.WebCrawlerFactory {
Map metadata;
SqlRepository repository;
public CsiCrawlerCrawlerControllerFactory(Map metadata, SqlRepository repository) {
this.metadata = metadata;
this.repository = repository;
}
@Override
public WebCrawler newInstance() {
return new MyCrawler(metadata, repository);
}
}
要使用工厂,你只需要在 CrawlController 中调用正确的方法(如果你在 Spring 或 Guice,你可能想使用 startNonBlocking):
MyCrawlerFactory factory = new MyCrawlerFactory(metadata, repository);
controller.startNonBlocking(factory, numberOfCrawlers);
更多示例配置细节
控制器类具有 CrawlConfig 类型的必需参数
此类的实例可用于配置 crawler4j。以下部分描述了配置的一些细节。
爬行深度
默认情况下,抓取深度没有限制。但是你可以限制爬行的深度。例如,假设您有一个种子页面“A”,链接到“B”,链接到“C”,链接到“D”。所以,我们有以下链接结构:
A -> B -> C -> D
因为“A”是种子页面,它的深度为0.,“B”的深度为1,以此类推。可以设置crawler4j 抓取的网页深度限制。例如,如果将此限制设置为 2,则不会抓取页面“D”。要设置您可以使用的最大深度:
crawlConfig.setMaxDepthOfCrawling(maxDepthOfCrawling);
启用 SSL
只需启用 SSL:
CrawlConfig config = new CrawlConfig();
config.setIncludeHttpsPages(true);
要抓取的最大页面数
虽然默认情况下对抓取的页面数量没有限制,但您可以为此设置一个限制:
crawlConfig.setMaxPagesToFetch(maxPagesToFetch);
启用二进制内容抓取
默认情况下,抓取二进制内容(即图像、音频等)是关闭的。您必须启用它才能抓取这些文件:
crawlConfig.setIncludeBinaryContentInCrawling(true);
有关更多详细信息,请参阅此处的示例。
文明问题(礼貌爬行)
crawler4j 的设计非常高效,可以非常快速地抓取域名
(例如,它已经能够每秒抓取 200 个维基百科页面)。但现在我反对爬取 网站,因为这会给服务器带来巨大的负担(他们可能会阻止你!),
从 1.3 版本开始,crawler4j 默认会在请求之间等待至少 200 毫秒。
但是,可以调整此参数:
crawlConfig.setPolitenessDelay(politenessDelay);
演戏
你的爬行应该在代理后面运行吗?如果是这样,您可以使用:
crawlConfig.setProxyHost("proxyserver.example.com");
crawlConfig.setProxyPort(8080);
如果您的代理还需要认证:
crawlConfig.setProxyUsername(username);
crawlConfig.setProxyPassword(password);
可恢复抓取
有时需要长时间运行爬虫。搜索者可能会意外终止。在这种情况下,可能需要恢复爬行。您可以使用以下设置恢复先前停止/崩溃的爬网:
crawlConfig.setResumableCrawling(true);
但是,您应该注意它可能会使爬行速度稍微变慢。
用户代理字符串
用户代理字符串用于将您的爬虫表示为 Web 服务器。
请参阅此处了解更多详情。默认情况下,crawler4j 使用以下用户代理字符串:
"crawler4j (https://github.com/yasserg/crawler4j/)"
但是,您可以覆盖它:
crawlConfig.setUserAgentString(userAgentString);
执照
java从网页抓取数据(java从网页抓取数据是个好想法,难道不是代码实现么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-12-07 13:31
java从网页抓取数据是个好想法,但是如果你要做到网页本身的数据可抓取就不是那么容易了。网页本身的数据抓取,难道不是代码实现么?并且实现起来,算法也非常复杂。除非,你网页已经做好了,你一下子能够把网页上的每个文字都抓取下来,把它分词后重新命名抓取数据。但是这里要考虑的问题,就是抓取程序要和真正的浏览器兼容,并且实现的话还要做网页加密以避免web2.0的各种隐私问题。除非真的可以一步登录对应的网页,现在绝大多数的网站做不到。理论上那就可以抓取了。
个人觉得不可能,目前浏览器都是原生渲染的,本身对于网页内容来说已经足够接近原生情况了,如果他给你爬取网页上的内容,那等于你把网页内容重新实现一遍,那其实无论浏览器做成多好,到了加载页面那一步,你的浏览器就会蒙逼,因为它已经没有办法响应网页上更新的内容了,所以我觉得想实现这个功能不现实。
比一比lol和dota
个人认为有难度
前两年火爆起来的ar技术如果ar做出点儿违和感谁不会觉得奇怪,个人猜想其实也许制造业也想过在消费者脑海中实现购物的场景。举例,如果能同时让消费者觉得门口有一块布在非节假日时空荡荡的存在,而节假日时是热闹非凡,这么想能不觉得哪里有点儿奇怪吗?不能控制流量而靠服务实现网络推广,普通消费者肯定接受不了这个,除非消费者的行为是预设路径的,好像地铁的线路查询,汽车的车牌查询。 查看全部
java从网页抓取数据(java从网页抓取数据是个好想法,难道不是代码实现么?)
java从网页抓取数据是个好想法,但是如果你要做到网页本身的数据可抓取就不是那么容易了。网页本身的数据抓取,难道不是代码实现么?并且实现起来,算法也非常复杂。除非,你网页已经做好了,你一下子能够把网页上的每个文字都抓取下来,把它分词后重新命名抓取数据。但是这里要考虑的问题,就是抓取程序要和真正的浏览器兼容,并且实现的话还要做网页加密以避免web2.0的各种隐私问题。除非真的可以一步登录对应的网页,现在绝大多数的网站做不到。理论上那就可以抓取了。
个人觉得不可能,目前浏览器都是原生渲染的,本身对于网页内容来说已经足够接近原生情况了,如果他给你爬取网页上的内容,那等于你把网页内容重新实现一遍,那其实无论浏览器做成多好,到了加载页面那一步,你的浏览器就会蒙逼,因为它已经没有办法响应网页上更新的内容了,所以我觉得想实现这个功能不现实。
比一比lol和dota
个人认为有难度
前两年火爆起来的ar技术如果ar做出点儿违和感谁不会觉得奇怪,个人猜想其实也许制造业也想过在消费者脑海中实现购物的场景。举例,如果能同时让消费者觉得门口有一块布在非节假日时空荡荡的存在,而节假日时是热闹非凡,这么想能不觉得哪里有点儿奇怪吗?不能控制流量而靠服务实现网络推广,普通消费者肯定接受不了这个,除非消费者的行为是预设路径的,好像地铁的线路查询,汽车的车牌查询。
java从网页抓取数据(腾讯课堂网页抓取QQ群号的功能简单实现起来也不难)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-04 15:02
Python 最近很流行。最近打算玩Python,学习数据挖掘。毕竟,我现在生活在一个大数据时代。互联网充满了大量数据。如果我能很好地利用这些数据,还有一些事情。也可以事半功倍。
作者之前没有接触过Python,好在有一些其他语言(Java、C、JavaScript等)基础,所以学起来不难。
本文文章实现了腾讯课堂网页抓取QQ群号的功能。当然,抢QQ群号只是示范。您还可以抓取其他数据。抓取方法类似。这个实验只是作者在学习Python的路上的一个小练习。功能很简单,实现起来也不难。
下图为腾讯课堂的一门课程。一般这些课程的页面都会有相应的学习QQ群。这次我们将使用Python来抓取这个QQ群号。
作者使用的环境如下;
系统版本:Windows10
Python版本:Python3.7.1
文本编辑器版本:PyCharm2018.2.4
要在 Python 中抓取网页,您需要导入 re 和 request 库。可以使用以下语句:
导入重新导入 urllib.request
其次,我们需要抓取需要抓取的网页,在抓取到的数据中找到(Ctrl+F)我们需要的数据。在这里,笔者将爬取到的数据存入一个TXT文件中,方便查找。抓取到的数据如下:
复制网页上的QQ群号,在抓取到的数据中搜索,如下:
如您所见,匹配的数据已被标记。接下来,我们可以使用正则表达式进行匹配。废话不多说,直接上代码。
操作结果:
从上面的代码可以看出,我们使用第一种格式进行匹配。需要注意的一件事是选择正确的格式非常重要。使用不合适的格式可能会导致一些麻烦。比如第四种格式,下面的代码就是用这种格式爬取的。
操作结果:
从运行结果可以看出,不同格式抓取的数据量不同,但关键内容没有变化,抓取的页面中可能存在我们不需要的数据。
以上内容为作者原创,如需转载请先联系作者,谢谢。 查看全部
java从网页抓取数据(腾讯课堂网页抓取QQ群号的功能简单实现起来也不难)
Python 最近很流行。最近打算玩Python,学习数据挖掘。毕竟,我现在生活在一个大数据时代。互联网充满了大量数据。如果我能很好地利用这些数据,还有一些事情。也可以事半功倍。
作者之前没有接触过Python,好在有一些其他语言(Java、C、JavaScript等)基础,所以学起来不难。
本文文章实现了腾讯课堂网页抓取QQ群号的功能。当然,抢QQ群号只是示范。您还可以抓取其他数据。抓取方法类似。这个实验只是作者在学习Python的路上的一个小练习。功能很简单,实现起来也不难。
下图为腾讯课堂的一门课程。一般这些课程的页面都会有相应的学习QQ群。这次我们将使用Python来抓取这个QQ群号。
作者使用的环境如下;
系统版本:Windows10
Python版本:Python3.7.1
文本编辑器版本:PyCharm2018.2.4
要在 Python 中抓取网页,您需要导入 re 和 request 库。可以使用以下语句:
导入重新导入 urllib.request
其次,我们需要抓取需要抓取的网页,在抓取到的数据中找到(Ctrl+F)我们需要的数据。在这里,笔者将爬取到的数据存入一个TXT文件中,方便查找。抓取到的数据如下:
复制网页上的QQ群号,在抓取到的数据中搜索,如下:
如您所见,匹配的数据已被标记。接下来,我们可以使用正则表达式进行匹配。废话不多说,直接上代码。
操作结果:
从上面的代码可以看出,我们使用第一种格式进行匹配。需要注意的一件事是选择正确的格式非常重要。使用不合适的格式可能会导致一些麻烦。比如第四种格式,下面的代码就是用这种格式爬取的。
操作结果:
从运行结果可以看出,不同格式抓取的数据量不同,但关键内容没有变化,抓取的页面中可能存在我们不需要的数据。
以上内容为作者原创,如需转载请先联系作者,谢谢。
java从网页抓取数据(我编写了一些Java代码,使用Crawler4J来抓取一堆网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-04 05:14
我写了一些Java代码,用Crawler4J爬取了一堆网页,然后用K-Means按关键字聚类。我想从每个集群中选择最好的图像(其中“最佳”被松散地定义为“集群中主题的最佳代表”),我想知道是否有任何现有的框架可以做到这一点(因为这显然是一个问题。在我推出自己的新闻之前,很多人已经需要解决诸如显示聚合新闻等问题。
我正在抓取的大多数页面都是关于给定主题的标准新闻页面,因此页面的最佳图像通常是1) 最大的图像和 2) 紧跟在最大的文本块之后。上一张图片。如果我必须推出自己的实现,我的暂定计划是根据这些(和其他)启发式算法从集群中的每个页面中获取最佳图像,然后根据质量(大小、链接文本、每个图像的名称) , 在文档中的位置及其来源页面的质量。
简而言之,我的问题是双重的:是否有任何现有的开源框架(最好用 Java 实现)可以帮助我完成我的任务,还有比我提出的更好的方法吗?谢谢!
如何从最核心的项目中选择图片?由于 k 均值围绕质心进行分区,因此您可以将最接近质心的实例视为数据中的最佳代表。 (如果你在聚类中使用它,你会得到 k-medoids)。
由于k-means可能会严重退化,你可能需要检查簇元素是否比两个簇中心之间的距离更接近簇中心。如果聚类中心之间的距离比您的数据更近,则您的 k 均值结果已经降级。 查看全部
java从网页抓取数据(我编写了一些Java代码,使用Crawler4J来抓取一堆网页)
我写了一些Java代码,用Crawler4J爬取了一堆网页,然后用K-Means按关键字聚类。我想从每个集群中选择最好的图像(其中“最佳”被松散地定义为“集群中主题的最佳代表”),我想知道是否有任何现有的框架可以做到这一点(因为这显然是一个问题。在我推出自己的新闻之前,很多人已经需要解决诸如显示聚合新闻等问题。
我正在抓取的大多数页面都是关于给定主题的标准新闻页面,因此页面的最佳图像通常是1) 最大的图像和 2) 紧跟在最大的文本块之后。上一张图片。如果我必须推出自己的实现,我的暂定计划是根据这些(和其他)启发式算法从集群中的每个页面中获取最佳图像,然后根据质量(大小、链接文本、每个图像的名称) , 在文档中的位置及其来源页面的质量。
简而言之,我的问题是双重的:是否有任何现有的开源框架(最好用 Java 实现)可以帮助我完成我的任务,还有比我提出的更好的方法吗?谢谢!
如何从最核心的项目中选择图片?由于 k 均值围绕质心进行分区,因此您可以将最接近质心的实例视为数据中的最佳代表。 (如果你在聚类中使用它,你会得到 k-medoids)。
由于k-means可能会严重退化,你可能需要检查簇元素是否比两个簇中心之间的距离更接近簇中心。如果聚类中心之间的距离比您的数据更近,则您的 k 均值结果已经降级。
java从网页抓取数据(java从网页抓取数据中实现动态图片图片啦~~)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-03 14:23
java从网页抓取数据,需要分析网页的类型,页面爬取接口等,如果你是一个正常人,可以使用正则表达式来处理网页的信息。如果你要进行爬虫教学,没有正则表达式那就难上加难。另外爬虫也不止有正则,只要模拟你爬虫过程的代码都可以用来实现爬虫,如小白入门教程,把js,css,html的代码封装成自己需要的函数,最后集成到网页中,你就可以在网页中实现动态抓取图片啦~。
html5可以做,
建议换一本书看看
首先你要知道页面地址,然后调用浏览器接口。例如:javascript的random函数就是一个浏览器接口,你调用这个接口就可以创建随机数了。
任何操作都可以,但你可以讲js封装成一个简单的对象就是random对象,然后模拟javascript行为,例如加载js文件,解析js文件,获取js文件中所有元素的信息,根据这些信息,
实现前端数据抓取?有意思。爬虫现在也有人做。
你需要一个能力,这个能力就是,你可以掌握并运用某些语言。
调用浏览器的request函数
javascript+html+css可以实现,然后抓图片,不过,人家现在都是用python实现,你也可以用,关键是能不能写出来。写不出来还是没用。
javascript+request+python 查看全部
java从网页抓取数据(java从网页抓取数据中实现动态图片图片啦~~)
java从网页抓取数据,需要分析网页的类型,页面爬取接口等,如果你是一个正常人,可以使用正则表达式来处理网页的信息。如果你要进行爬虫教学,没有正则表达式那就难上加难。另外爬虫也不止有正则,只要模拟你爬虫过程的代码都可以用来实现爬虫,如小白入门教程,把js,css,html的代码封装成自己需要的函数,最后集成到网页中,你就可以在网页中实现动态抓取图片啦~。
html5可以做,
建议换一本书看看
首先你要知道页面地址,然后调用浏览器接口。例如:javascript的random函数就是一个浏览器接口,你调用这个接口就可以创建随机数了。
任何操作都可以,但你可以讲js封装成一个简单的对象就是random对象,然后模拟javascript行为,例如加载js文件,解析js文件,获取js文件中所有元素的信息,根据这些信息,
实现前端数据抓取?有意思。爬虫现在也有人做。
你需要一个能力,这个能力就是,你可以掌握并运用某些语言。
调用浏览器的request函数
javascript+html+css可以实现,然后抓图片,不过,人家现在都是用python实现,你也可以用,关键是能不能写出来。写不出来还是没用。
javascript+request+python
java从网页抓取数据(Web:ScraperCPAN模块可能更容易接数据的几个示例 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-02 11:12
)
丹尼斯泰勒:
以编程方式从一堆网页中提取结构化数据的最简单方法是什么?
我目前使用我编写的 Adobe AIR 程序来跟踪页面上的链接并从后续页面获取一些数据。这实际上很有效,而且对于程序员来说,我认为这(或其他语言)提供了一种逐案编写的合理方法。也许有一种特定的语言或库可以让程序员非常快速地做到这一点,如果是这样,我有兴趣了解它们是什么。
是否有其他工具允许非程序员(例如客户支持代表或负责数据采集的人员)从网页中提取结构化数据而无需进行大量复制和粘贴操作?
德拉格顿:
如果您在 Stackoverflow、pQuery 上搜索 WWW::Mechanize&,您将看到许多使用这些 Perl CPAN 模块的示例。
但是因为你提到了“非程序员”,也许 Web::ScraperCPAN 模块可能更合适?它更像是一个 DSL,因此可能更容易连接到“非程序员”。
这是一个从 Twitter 检索推文的文档示例:
use URI;
use Web::Scraper;
my $tweets = scraper {
process "li.status", "tweets[]" => scraper {
process ".entry-content", body => 'TEXT';
process ".entry-date", when => 'TEXT';
process 'a[rel="bookmark"]', link => '@href';
};
};
my $res = $tweets->scrape( URI->new("http://twitter.com/miyagawa") );
for my $tweet (@{$res->{tweets}}) {
print "$tweet->{body} $tweet->{when} (link: $tweet->{link})\n";
} 查看全部
java从网页抓取数据(Web:ScraperCPAN模块可能更容易接数据的几个示例
)
丹尼斯泰勒:
以编程方式从一堆网页中提取结构化数据的最简单方法是什么?
我目前使用我编写的 Adobe AIR 程序来跟踪页面上的链接并从后续页面获取一些数据。这实际上很有效,而且对于程序员来说,我认为这(或其他语言)提供了一种逐案编写的合理方法。也许有一种特定的语言或库可以让程序员非常快速地做到这一点,如果是这样,我有兴趣了解它们是什么。
是否有其他工具允许非程序员(例如客户支持代表或负责数据采集的人员)从网页中提取结构化数据而无需进行大量复制和粘贴操作?
德拉格顿:
如果您在 Stackoverflow、pQuery 上搜索 WWW::Mechanize&,您将看到许多使用这些 Perl CPAN 模块的示例。
但是因为你提到了“非程序员”,也许 Web::ScraperCPAN 模块可能更合适?它更像是一个 DSL,因此可能更容易连接到“非程序员”。
这是一个从 Twitter 检索推文的文档示例:
use URI;
use Web::Scraper;
my $tweets = scraper {
process "li.status", "tweets[]" => scraper {
process ".entry-content", body => 'TEXT';
process ".entry-date", when => 'TEXT';
process 'a[rel="bookmark"]', link => '@href';
};
};
my $res = $tweets->scrape( URI->new("http://twitter.com/miyagawa";) );
for my $tweet (@{$res->{tweets}}) {
print "$tweet->{body} $tweet->{when} (link: $tweet->{link})\n";
}
java从网页抓取数据(通过Java代码实现对网页数据进行指定抓取方法思路思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-31 14:02
IE浏览器有OLE对象,可以用这个功能提取所有元素的信息,有些软件应该可以。. .
如果你想从头开始,你可以直接匹配文本并编写一个提取元素的小程序。. .
通过Java代码指定网页数据爬取方法的思路如下:
项目中导入Jsoup.jar包
获取 URL 指定的 HTML 或文档指定的正文
获取网页中超链接的标题和链接
获取指定博客的内容文章
获取网页中超链接的标题和链接的结果
在另一个文件中写入:
登录用户 = 新登录();
String id = user.GetUserID();
System.out.println(id);
PS:java文件首字母大写,方法首字母小写。
是不是有历史页面,直接复制粘贴就行了,选择你想要的数据,右键复制,在表格里右键粘贴
如果您使用预先嗅探的 ForeSpider 数据采集 软件,它会起作用。但是您需要知道应用程序的协议是什么。如果是http或https,可以直接采集。
实时更新也是可能的。软件支持定时采集,一定间隔时间采集。设置间隔时间相当于实时更新。
ForeSpider直接连接数据库,数据存储有多种策略,存储前会有两次自动重新排列,确保只插入更新的数据。
有一个免费版本,可以不受功能限制地下载。
使用java提取指定网页中的表格数据?…… 将以下代码复制到文本文件中,然后将文本文件改为“.html”格式
这是提取表中数据的方法,看看是不是你想要的
...
Java抓取网页数据——……当然是抓取网页数据来模拟http请求,然后分析收到的响应。直接使用commons-httpclient。
如何抓取网页中的数据 java-…… 不要用Java抓取,让页面发送数据到后端不好??如果是从别人的网站那里抢过来的,应该也是可以的,看来socketio是可以用的。看看nodejs是否可以处理它。
java中如何提取网页上的信息... 发送http请求,获取返回的内容,定时抓取你需要的信息!
Java爬取网页数据,如何爬取-... 如果是一般允许爬取的页面,可以用wget爬取,不允许爬取的爬虫可以考虑使用HttpClient
如何在html网页中使用JAVA获取我需要的数据-... 使用jsoup轻松读取和解析网页内容。
如何使用Java语言获取网页数据?-…… 你想让系统A知道系统B的页面信息吗?如果是这样的话,就有一个比较难解决的问题,那就是数据源问题。你的系统A不知道系统B的数据。如果你想得到招聘信息的公司名称,有几个思路这个 iframe...
用java从网上抓取数据-... 你可以看看你的MYSQL库的编码是UTF-8还是改成GB2312试试。这种情况我以前见过,不行的话,你可以看看你网页的编码。这是一个小错误
如何在网页上获取小型 Java 应用程序的数据?...... 使用请求对象封装数据并在页面上获取。
Java抓取网页数据,如何抓取...当然抓取网页数据模拟HTTP请求,然后分析响应。直接使用 commons-httpclient 包。 查看全部
java从网页抓取数据(通过Java代码实现对网页数据进行指定抓取方法思路思路)
IE浏览器有OLE对象,可以用这个功能提取所有元素的信息,有些软件应该可以。. .
如果你想从头开始,你可以直接匹配文本并编写一个提取元素的小程序。. .
通过Java代码指定网页数据爬取方法的思路如下:
项目中导入Jsoup.jar包
获取 URL 指定的 HTML 或文档指定的正文
获取网页中超链接的标题和链接
获取指定博客的内容文章
获取网页中超链接的标题和链接的结果
在另一个文件中写入:
登录用户 = 新登录();
String id = user.GetUserID();
System.out.println(id);
PS:java文件首字母大写,方法首字母小写。
是不是有历史页面,直接复制粘贴就行了,选择你想要的数据,右键复制,在表格里右键粘贴
如果您使用预先嗅探的 ForeSpider 数据采集 软件,它会起作用。但是您需要知道应用程序的协议是什么。如果是http或https,可以直接采集。
实时更新也是可能的。软件支持定时采集,一定间隔时间采集。设置间隔时间相当于实时更新。
ForeSpider直接连接数据库,数据存储有多种策略,存储前会有两次自动重新排列,确保只插入更新的数据。
有一个免费版本,可以不受功能限制地下载。
使用java提取指定网页中的表格数据?…… 将以下代码复制到文本文件中,然后将文本文件改为“.html”格式
这是提取表中数据的方法,看看是不是你想要的
...
Java抓取网页数据——……当然是抓取网页数据来模拟http请求,然后分析收到的响应。直接使用commons-httpclient。
如何抓取网页中的数据 java-…… 不要用Java抓取,让页面发送数据到后端不好??如果是从别人的网站那里抢过来的,应该也是可以的,看来socketio是可以用的。看看nodejs是否可以处理它。
java中如何提取网页上的信息... 发送http请求,获取返回的内容,定时抓取你需要的信息!
Java爬取网页数据,如何爬取-... 如果是一般允许爬取的页面,可以用wget爬取,不允许爬取的爬虫可以考虑使用HttpClient
如何在html网页中使用JAVA获取我需要的数据-... 使用jsoup轻松读取和解析网页内容。
如何使用Java语言获取网页数据?-…… 你想让系统A知道系统B的页面信息吗?如果是这样的话,就有一个比较难解决的问题,那就是数据源问题。你的系统A不知道系统B的数据。如果你想得到招聘信息的公司名称,有几个思路这个 iframe...
用java从网上抓取数据-... 你可以看看你的MYSQL库的编码是UTF-8还是改成GB2312试试。这种情况我以前见过,不行的话,你可以看看你网页的编码。这是一个小错误
如何在网页上获取小型 Java 应用程序的数据?...... 使用请求对象封装数据并在页面上获取。
Java抓取网页数据,如何抓取...当然抓取网页数据模拟HTTP请求,然后分析响应。直接使用 commons-httpclient 包。
java从网页抓取数据(使用优采云采集器软件从指定网页获取特定内容的几种解决方案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-12-31 05:06
网页数据爬取是指在不请求网站的API接口获取内容的情况下,从网站中提取特定内容。“网页数据”作为网站用户体验的一部分,如网页上的文字、图片、声音、视频、动画等,均被视为网页数据。
对于程序员或开发者来说,拥有编程技能,让他们构建一个网页数据爬取程序变得非常容易和有趣。但是对于大多数没有任何编程知识的人来说,最好使用一些网络爬虫软件从指定的网页中获取特定的内容。下面是一些使用优采云采集器抓取网页数据的解决方案:
1、 从动态网页中提取内容
网页可以是静态的或动态的。通常情况下,您要提取的网页内容会随着您访问网站的时间而变化。通常,这个网站是一个动态的网站,它使用AJAX技术或其他技术使网页内容能够及时更新。AJAX 是一种延迟加载和异步更新的脚本技术。通过后台与服务器的少量数据交换,可以在不重新加载整个网页的情况下更新网页的某一部分。
性能特点是当你点击网页中的一个选项时,网站的大部分URL不会改变;网页并未完全加载,而只是部分加载了数据,这些数据会发生变化。这时候可以在优采云的“高级选项”元素的“Ajax加载”中设置,然后就可以抓取Ajax加载的网页数据了。
优采云 AJAX 设置
2、 从网页中抓取隐藏的内容
你有没有想过从网站获取具体的数据,但是当你触发链接或将鼠标悬停在某个地方时,内容就会出现?比如下图中的网站,需要将鼠标移动到选中的彩票上才能显示分类。这个功能可以设置“鼠标指向这个链接”功能来抓取网页的隐藏内容。.
鼠标移动到链接上的内容采集方法
3、 从无限滚动的网页中提取内容
滚动到页面底部后,某些网站 只会显示您要提取的部分数据。比如今天的头条首页,需要一直滚动到页面底部才能加载更多的文章内容。无限滚动 网站 通常使用 AJAX 或 JavaScript 从 网站 内容请求附加内容。在这种情况下,您可以设置 AJAX 超时设置并选择滚动方式和滚动时间以从网页中提取内容。
4、 从网页中抓取所有链接
一个普通的 网站 将收录至少一个超链接。如果要提取网页中的所有链接,可以使用优采云 获取网页上发布的所有超链接。
5、 从网页中抓取所有文本
有时你需要提取一个 HTML 文档中的所有文本,即把它放在 HTML 标签中(如
标签或标签)。优采云 使您能够提取网页源代码中的所有或特定文本。
6、 从网页中抓取所有图片
有的朋友对采集的网页图片有需求。优采云可以使用网页中图片的网址采集,然后下载使用优采云专用图片批量下载工具,即可上传图片中的图片我们采集 下载并保存到本地计算机的 URL。 查看全部
java从网页抓取数据(使用优采云采集器软件从指定网页获取特定内容的几种解决方案)
网页数据爬取是指在不请求网站的API接口获取内容的情况下,从网站中提取特定内容。“网页数据”作为网站用户体验的一部分,如网页上的文字、图片、声音、视频、动画等,均被视为网页数据。
对于程序员或开发者来说,拥有编程技能,让他们构建一个网页数据爬取程序变得非常容易和有趣。但是对于大多数没有任何编程知识的人来说,最好使用一些网络爬虫软件从指定的网页中获取特定的内容。下面是一些使用优采云采集器抓取网页数据的解决方案:
1、 从动态网页中提取内容
网页可以是静态的或动态的。通常情况下,您要提取的网页内容会随着您访问网站的时间而变化。通常,这个网站是一个动态的网站,它使用AJAX技术或其他技术使网页内容能够及时更新。AJAX 是一种延迟加载和异步更新的脚本技术。通过后台与服务器的少量数据交换,可以在不重新加载整个网页的情况下更新网页的某一部分。
性能特点是当你点击网页中的一个选项时,网站的大部分URL不会改变;网页并未完全加载,而只是部分加载了数据,这些数据会发生变化。这时候可以在优采云的“高级选项”元素的“Ajax加载”中设置,然后就可以抓取Ajax加载的网页数据了。
优采云 AJAX 设置
2、 从网页中抓取隐藏的内容
你有没有想过从网站获取具体的数据,但是当你触发链接或将鼠标悬停在某个地方时,内容就会出现?比如下图中的网站,需要将鼠标移动到选中的彩票上才能显示分类。这个功能可以设置“鼠标指向这个链接”功能来抓取网页的隐藏内容。.
鼠标移动到链接上的内容采集方法
3、 从无限滚动的网页中提取内容
滚动到页面底部后,某些网站 只会显示您要提取的部分数据。比如今天的头条首页,需要一直滚动到页面底部才能加载更多的文章内容。无限滚动 网站 通常使用 AJAX 或 JavaScript 从 网站 内容请求附加内容。在这种情况下,您可以设置 AJAX 超时设置并选择滚动方式和滚动时间以从网页中提取内容。
4、 从网页中抓取所有链接
一个普通的 网站 将收录至少一个超链接。如果要提取网页中的所有链接,可以使用优采云 获取网页上发布的所有超链接。
5、 从网页中抓取所有文本
有时你需要提取一个 HTML 文档中的所有文本,即把它放在 HTML 标签中(如
标签或标签)。优采云 使您能够提取网页源代码中的所有或特定文本。
6、 从网页中抓取所有图片
有的朋友对采集的网页图片有需求。优采云可以使用网页中图片的网址采集,然后下载使用优采云专用图片批量下载工具,即可上传图片中的图片我们采集 下载并保存到本地计算机的 URL。
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-12-31 05:05
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
也就是说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
也就是说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java从网页抓取数据(java从网页抓取数据,和爬虫的区别在哪?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-12-30 07:04
java从网页抓取数据,和爬虫的区别在于,前者是从大前端拿数据,比如爬虫,你得知道的后台是如何运行的,然后前端也得知道的后台,知道怎么和后台连接进行数据传输;而后者不需要一定连接后台,抓取完数据后直接给前端进行展示,抓取的方式有网页抓取和系统抓取。前端抓取可以是,直接手动去抓取网页源代码,也可以用爬虫工具,分析网页源代码来分析数据。
最近我也比较迷恋爬虫,经过一段时间的研究,我还是觉得研究一下这个,比如爬虫和豆瓣电影爬虫对比之类的,对分析数据非常有用,毕竟现在数据分析是很火的,哈哈。
把一切相关的「机器学习」「数据挖掘」「信息检索」「大数据技术」「数据库」「算法」「人工智能」「机器人」「自然语言处理」「多媒体」「图像」「声音」「视频」「图像增强」「图像压缩」「图像建模」「图像拼接」「图像提取」「关键点检测」「分割」「基于深度学习的计算机视觉」「模糊图像」「模糊视频」「文字识别」「字符识别」「视频背景检测」「文字对象检测」「文字转语音」「可视化」「语义分割」「语义迁移」「单词级别长短文本摘要」「事件抽取」「信息抽取」「短语级别短文本摘要」「整体」「局部」「结构化」「结构化视频摘要」「视频标注」「定义」「语音」「图像」「视频分割」「输入输出」「行为检测」「行为跟踪」「影视语音情感分析」「黑名单检测」「爬虫」等等技术,基本上都是要用到数据的,不同的数据来源,很可能会产生不同的效果。 查看全部
java从网页抓取数据(java从网页抓取数据,和爬虫的区别在哪?)
java从网页抓取数据,和爬虫的区别在于,前者是从大前端拿数据,比如爬虫,你得知道的后台是如何运行的,然后前端也得知道的后台,知道怎么和后台连接进行数据传输;而后者不需要一定连接后台,抓取完数据后直接给前端进行展示,抓取的方式有网页抓取和系统抓取。前端抓取可以是,直接手动去抓取网页源代码,也可以用爬虫工具,分析网页源代码来分析数据。
最近我也比较迷恋爬虫,经过一段时间的研究,我还是觉得研究一下这个,比如爬虫和豆瓣电影爬虫对比之类的,对分析数据非常有用,毕竟现在数据分析是很火的,哈哈。
把一切相关的「机器学习」「数据挖掘」「信息检索」「大数据技术」「数据库」「算法」「人工智能」「机器人」「自然语言处理」「多媒体」「图像」「声音」「视频」「图像增强」「图像压缩」「图像建模」「图像拼接」「图像提取」「关键点检测」「分割」「基于深度学习的计算机视觉」「模糊图像」「模糊视频」「文字识别」「字符识别」「视频背景检测」「文字对象检测」「文字转语音」「可视化」「语义分割」「语义迁移」「单词级别长短文本摘要」「事件抽取」「信息抽取」「短语级别短文本摘要」「整体」「局部」「结构化」「结构化视频摘要」「视频标注」「定义」「语音」「图像」「视频分割」「输入输出」「行为检测」「行为跟踪」「影视语音情感分析」「黑名单检测」「爬虫」等等技术,基本上都是要用到数据的,不同的数据来源,很可能会产生不同的效果。
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-28 13:00
原文链接:
有时由于各种原因,我们需要从某个网站采集数据,但是因为不同的网站显示的数据略有不同!
本文使用Java向大家展示如何抓取网站的数据:(1)抓取原创
网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创
网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,在重新请求网页后显示查询的结果。
查询后看网页地址:
换句话说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[爪哇]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8");BufferedReaderbufReader= newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString();intbeginIx= buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println("captureHtml()结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下,如果你想解析的很准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被搜索等工具抓取引擎。
首先看这个页面:
使用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
第一次点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然前提是数据没有加密,我们写下JS Requested URL:
然后让程序请求这个页面的结果!
这是代码:
[爪哇]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf -8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}System.out .println("captureJavascript() 的结果:\n"+contentBuf.toString());}
可以看到,抓取JS的方式和抓取原创
网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
原文链接:
有时由于各种原因,我们需要从某个网站采集数据,但是因为不同的网站显示的数据略有不同!
本文使用Java向大家展示如何抓取网站的数据:(1)抓取原创
网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创
网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,在重新请求网页后显示查询的结果。
查询后看网页地址:
换句话说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[爪哇]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8");BufferedReaderbufReader= newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString();intbeginIx= buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println("captureHtml()结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下,如果你想解析的很准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被搜索等工具抓取引擎。
首先看这个页面:
使用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
第一次点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然前提是数据没有加密,我们写下JS Requested URL:
然后让程序请求这个页面的结果!
这是代码:
[爪哇]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf -8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}System.out .println("captureJavascript() 的结果:\n"+contentBuf.toString());}
可以看到,抓取JS的方式和抓取原创
网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载!
java从网页抓取数据(19款Java开源Web爬虫需要的小伙伴们赶快收藏吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-26 23:13
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。
今天给大家介绍19款Java开源网络爬虫,有需要的赶紧采集
吧。
一、Heritrix
Heritrix是java开发的开源网络爬虫。用户可以使用它从互联网上获取他们想要的资源。其最突出的特点是良好的扩展性,方便用户实现自己的爬取逻辑。
Heritrix 是一个“档案爬虫”——获取网站内容的完整、准确、深层副本。包括获取图片等非文字内容。抓取和存储相关内容。内容不拒绝,页面内容不修改。重新抓取不会替换同一 URL 的前一次抓取。爬虫主要通过Web用户界面启动、监控和调整,可以灵活定义获取URL。
Heritrix是一个多线程爬取的爬虫。主线程将任务分配给 Teo 线程(处理线程),每个 Teo 线程一次处理一个 URL。Teo 线程为每个 URL 执行 URL 处理器链。URL 处理器链包括以下五个处理步骤。
(1)预取链:主要是做一些准备工作,比如延迟和重新处理处理,否决后续的操作。
(2) 提取链:主要是下载网页,进行DNS转换,填写请求和响应表。
(3) 提取链:提取完成后,提取感兴趣的 HTML 和 JavaScript,通常会有新的 URL 需要爬取。
(4)写链:存储爬取的结果,这一步可以直接索引全文。Heritrix提供了一个ARCWriterProcessor实现,将下载的结果保存为ARC格式。
(5)提交链:对这个URL相关的操作做最后的处理。检查哪些新提取的URL在爬取范围内,然后将这些URL提交给Frontier。另外,DNS缓存信息也会更新。
Heritrix系统框架图
Heritrix 处理一个 url 进程
二、WebSPHINX
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX类包。
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX类包。
WebSPHINX 目的
1.可视化展示页面集合
2.将页面下载到本地磁盘进行离线浏览
3.将所有页面合并为一个页面进行浏览或打印
4. 根据特定规则从页面中提取文本字符串
5.使用Java或Javascript开发自定义爬虫
详细介绍可见>>>
三、WebLech
WebLech 是一个强大的网站下载和镜像工具。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。WebLech 有功能控制台,使用多线程操作。
WebLech 是一款功能强大的免费开源工具,用于下载和镜像网站。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。WebLech 有功能控制台,使用多线程操作。
这个爬虫很简单,如果你是初学者,如果你想写一个爬虫,可以作为入门的参考。所以我选择从这个爬虫开始我的研究。如果你只是做要求不高的应用,也可以试试。如果你想找到一个强大的,不要在 WebLech 上浪费时间。
项目主页:
特征:
1)开源,免费
2) 代码纯Java编写,可以在任何支持Java的平台上使用
3)支持多线程下载网页
4) 可以维护网页之间的链接信息
5)强大的可配置性:可以自定义深度优先或宽度优先的抓取网页,带有URL过滤器,这样您就可以根据需要抓取单个Web服务器、单个目录或抓取整个WWW网络,您可以设置URL的优先级,这样就可以先爬取我们感兴趣或重要的网页,记录断点时程序的状态,重启时从上次继续爬取。
四、阿拉蕾
Arale 主要是为个人使用而设计的,不像其他爬虫那样专注于页面索引。Arale 可以下载整个网站或网站上的部分资源。Arale 还可以将动态页面映射到静态页面。
五、JSpider
JSpider:是一个完全可配置和可定制的 Web Spider 引擎。您可以用它来检查网站错误(内部服务器错误等),检查网站的内外链接,分析网站的结构(创建网站地图),下载整个网站,您还可以写一个JSpider插件来扩展你需要的功能。
Spider 是一个用 Java 实现的 WebSpider。JSpider的执行格式如下:
jspider [URL] [ConfigName]
URL必须加上协议名,如:,否则会报错。如果省略ConfigName,则采用默认配置。
JSpider的行为具体由配置文件配置,如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。JSpider 的默认配置类型很少,也不是很有用。但是JSpider非常容易扩展,你可以用它来开发强大的网络爬虫和数据分析工具。为此,您需要深入了解JSpider 的原理,然后根据需要开发插件并编写配置文件。
蜘蛛是:
高度可配置和可定制的网络爬虫
在 LGPL 开源许可下开发
100% 纯 Java 实现
您可以将其用于:
检查您的网站是否有错误(内部服务器错误,...)
传出或内部链接检查
分析您网站的结构(创建站点地图,...)
下载翻新后的网站
通过编写JSpider插件实现任何功能。
项目主页:
六、主轴
Spindle 是一个建立在 Lucene 工具包上的 Web 索引/搜索工具。它包括一个用于创建索引的 HTTP 蜘蛛和一个用于搜索这些索引的搜索类。Spindle 项目提供了一套JSP 标签库,让那些基于JSP 的站点无需开发任何Java 类就可以添加搜索功能。
七、蛛形纲动物
Arachnid 是一个基于 Java 的网络蜘蛛框架。它收录
一个简单的 HTML 解析器,可以分析收录
HTML 内容的输入流。通过实现Arachnid的子类,可以开发一个简单的网络蜘蛛,可以在每个网站上使用页面解析后,添加几行代码调用。Arachnid 下载包中收录
两个蜘蛛应用程序示例,用于演示如何使用该框架。
项目主页:
八、LARM
LARM 可为 Jakarta Lucene 搜索引擎框架的用户提供纯 Java 搜索解决方案。它收录
索引文件、数据库表和用于索引网站的爬虫的方法。
项目主页:
九、乔博
JoBo 是一个用于下载整个网站的简单工具。它本质上是一个网络蜘蛛。与其他下载工具相比,它的主要优点是能够自动填写表单(如自动登录)和使用cookies来处理会话。JoBo 还具有灵活的下载规则(如:URL、大小、MIME 类型等)来限制下载。
十、snoics-reptile
1、什么是snoics-reptile?
它是用纯Java开发的。它是一种用于捕获网站镜像的工具。您可以使用配置文件中提供的URL入口,将本网站所有可以通过浏览器GET方式获取到的资源抓取到本地。包括网页和各类文件,如图片、flash、mp3、zip、rar、exe等文件。整个网站可以完全转移到硬盘上,保持原有网站结构准确不变。只需将抓取到的网站放置在Web服务器(如Apache)上即可实现完整的网站镜像。
2、 既然有其他类似的软件,为什么要开发snooics-reptile呢?
因为在爬取过程中经常会出现一些文件出错,很多javascript控制的URL没有办法正确解析,snoics-reptile提供了外部接口和配置文件。对于特殊的URL,可以通过自由扩展外部提供的接口,通过配置文件注入的方式,基本上可以正确解析和抓取所有网页。
项目主页:
十一、Web-Harvest
Web-Harvest 是一个 Java 开源 Web 数据提取工具。它可以采集
指定的网页并从这些网页中提取有用的数据。Web-Harvest主要使用XSLT、XQuery、正则表达式等技术来实现text/xml的操作。
Web-Harvest 是一个用 Java 编写的开源 Web 数据提取工具。它提供了一种从所需页面中提取有用数据的方法。为了实现这个目标,您可能需要使用XSLT、XQuery、正则表达式等相关技术来操作text/xml。Web-Harvest 主要关注基于 HMLT/XML 的页面内容,目前占大多数。另一方面,它可以通过编写自己的 Java 方法轻松扩展其提取功能。
Web-Harvest 的主要目的是加强现有数据提取技术的应用。它的目标不是创建一种新方法,而是提供一种更好地使用和组合现有方法的方法。它提供了一个处理器集来处理数据和控制流。每个处理器都被看作一个函数,它有参数,执行后返回结果。并且将处理组合成流水线形式,使它们可以以链式形式执行,除了更容易的数据操作和复用外,Web-Harvest 还提供了上下变量来存储声明的变量。
启动web-harvest,可以直接双击jar包运行,但是这种方式不能指定web-harvest java虚拟机的大小。第二种方法是切换到cmd下的web-harvest目录,输入命令“java -jar -Xms400m webharvest_all_2.jar”启动,设置java虚拟机大小为400M。
项目主页:
十个二、真烂
ItSucks 是 Java Web 爬虫的开源项目。可灵活定制,支持下载模板和正则表达式定义下载规则。提供控制台和 Swing GUI 操作界面。
特征:
项目主页:
十三、智能简单的网络爬虫
Smart and Simple Web Crawler 是一个网络爬虫框架。集成 Lucene 支持。爬虫可以从单个链接或一组链接开始,提供两种遍历方式:最大迭代和最大深度。可以设置过滤器来限制爬回的链接。默认提供了三个过滤器 ServerFilter、BeginningPathFilter 和 RegularExpressionFilter。这三个过滤器可以与 AND、OR 和 NOT 组合使用。可以在解析过程中或页面加载前后添加侦听器。
十四、Crawler4j
crawler4j 是一个用 Java 实现的开源网络爬虫。提供简单易用的界面,您可以在几分钟内创建一个多线程的网络爬虫。
crawler4j的使用主要分为两步:
实现一个继承自WebCrawler的爬虫类;
Crawl 类通过调用 CrawlController 实现。
WebCrawler 是一个抽象类,继承它必须实现两个方法:shouldVisit 和visit。在:
shouldVisit 是判断当前的 URL 是否应该被爬取(访问);
访问是抓取URL指向的页面的数据,传入的参数是网页所有数据的封装对象Page。
此外,WebCrawler 还有一些其他的方法可以覆盖,其方法命名规则与Android 的命名规则类似。比如getMyLocalData方法可以返回WebCrawler中的数据;onBeforeExit 方法会在WebCrawler 结束前调用,可以执行一些资源释放等任务。
执照 查看全部
java从网页抓取数据(19款Java开源Web爬虫需要的小伙伴们赶快收藏吧)
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。
今天给大家介绍19款Java开源网络爬虫,有需要的赶紧采集
吧。
一、Heritrix
Heritrix是java开发的开源网络爬虫。用户可以使用它从互联网上获取他们想要的资源。其最突出的特点是良好的扩展性,方便用户实现自己的爬取逻辑。
Heritrix 是一个“档案爬虫”——获取网站内容的完整、准确、深层副本。包括获取图片等非文字内容。抓取和存储相关内容。内容不拒绝,页面内容不修改。重新抓取不会替换同一 URL 的前一次抓取。爬虫主要通过Web用户界面启动、监控和调整,可以灵活定义获取URL。
Heritrix是一个多线程爬取的爬虫。主线程将任务分配给 Teo 线程(处理线程),每个 Teo 线程一次处理一个 URL。Teo 线程为每个 URL 执行 URL 处理器链。URL 处理器链包括以下五个处理步骤。
(1)预取链:主要是做一些准备工作,比如延迟和重新处理处理,否决后续的操作。
(2) 提取链:主要是下载网页,进行DNS转换,填写请求和响应表。
(3) 提取链:提取完成后,提取感兴趣的 HTML 和 JavaScript,通常会有新的 URL 需要爬取。
(4)写链:存储爬取的结果,这一步可以直接索引全文。Heritrix提供了一个ARCWriterProcessor实现,将下载的结果保存为ARC格式。
(5)提交链:对这个URL相关的操作做最后的处理。检查哪些新提取的URL在爬取范围内,然后将这些URL提交给Frontier。另外,DNS缓存信息也会更新。
Heritrix系统框架图
Heritrix 处理一个 url 进程
二、WebSPHINX
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX类包。
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX类包。
WebSPHINX 目的
1.可视化展示页面集合
2.将页面下载到本地磁盘进行离线浏览
3.将所有页面合并为一个页面进行浏览或打印
4. 根据特定规则从页面中提取文本字符串
5.使用Java或Javascript开发自定义爬虫
详细介绍可见>>>
三、WebLech
WebLech 是一个强大的网站下载和镜像工具。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。WebLech 有功能控制台,使用多线程操作。
WebLech 是一款功能强大的免费开源工具,用于下载和镜像网站。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。WebLech 有功能控制台,使用多线程操作。
这个爬虫很简单,如果你是初学者,如果你想写一个爬虫,可以作为入门的参考。所以我选择从这个爬虫开始我的研究。如果你只是做要求不高的应用,也可以试试。如果你想找到一个强大的,不要在 WebLech 上浪费时间。
项目主页:
特征:
1)开源,免费
2) 代码纯Java编写,可以在任何支持Java的平台上使用
3)支持多线程下载网页
4) 可以维护网页之间的链接信息
5)强大的可配置性:可以自定义深度优先或宽度优先的抓取网页,带有URL过滤器,这样您就可以根据需要抓取单个Web服务器、单个目录或抓取整个WWW网络,您可以设置URL的优先级,这样就可以先爬取我们感兴趣或重要的网页,记录断点时程序的状态,重启时从上次继续爬取。
四、阿拉蕾
Arale 主要是为个人使用而设计的,不像其他爬虫那样专注于页面索引。Arale 可以下载整个网站或网站上的部分资源。Arale 还可以将动态页面映射到静态页面。
五、JSpider
JSpider:是一个完全可配置和可定制的 Web Spider 引擎。您可以用它来检查网站错误(内部服务器错误等),检查网站的内外链接,分析网站的结构(创建网站地图),下载整个网站,您还可以写一个JSpider插件来扩展你需要的功能。
Spider 是一个用 Java 实现的 WebSpider。JSpider的执行格式如下:
jspider [URL] [ConfigName]
URL必须加上协议名,如:,否则会报错。如果省略ConfigName,则采用默认配置。
JSpider的行为具体由配置文件配置,如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。JSpider 的默认配置类型很少,也不是很有用。但是JSpider非常容易扩展,你可以用它来开发强大的网络爬虫和数据分析工具。为此,您需要深入了解JSpider 的原理,然后根据需要开发插件并编写配置文件。
蜘蛛是:
高度可配置和可定制的网络爬虫
在 LGPL 开源许可下开发
100% 纯 Java 实现
您可以将其用于:
检查您的网站是否有错误(内部服务器错误,...)
传出或内部链接检查
分析您网站的结构(创建站点地图,...)
下载翻新后的网站
通过编写JSpider插件实现任何功能。
项目主页:
六、主轴
Spindle 是一个建立在 Lucene 工具包上的 Web 索引/搜索工具。它包括一个用于创建索引的 HTTP 蜘蛛和一个用于搜索这些索引的搜索类。Spindle 项目提供了一套JSP 标签库,让那些基于JSP 的站点无需开发任何Java 类就可以添加搜索功能。
七、蛛形纲动物
Arachnid 是一个基于 Java 的网络蜘蛛框架。它收录
一个简单的 HTML 解析器,可以分析收录
HTML 内容的输入流。通过实现Arachnid的子类,可以开发一个简单的网络蜘蛛,可以在每个网站上使用页面解析后,添加几行代码调用。Arachnid 下载包中收录
两个蜘蛛应用程序示例,用于演示如何使用该框架。
项目主页:
八、LARM
LARM 可为 Jakarta Lucene 搜索引擎框架的用户提供纯 Java 搜索解决方案。它收录
索引文件、数据库表和用于索引网站的爬虫的方法。
项目主页:
九、乔博
JoBo 是一个用于下载整个网站的简单工具。它本质上是一个网络蜘蛛。与其他下载工具相比,它的主要优点是能够自动填写表单(如自动登录)和使用cookies来处理会话。JoBo 还具有灵活的下载规则(如:URL、大小、MIME 类型等)来限制下载。
十、snoics-reptile
1、什么是snoics-reptile?
它是用纯Java开发的。它是一种用于捕获网站镜像的工具。您可以使用配置文件中提供的URL入口,将本网站所有可以通过浏览器GET方式获取到的资源抓取到本地。包括网页和各类文件,如图片、flash、mp3、zip、rar、exe等文件。整个网站可以完全转移到硬盘上,保持原有网站结构准确不变。只需将抓取到的网站放置在Web服务器(如Apache)上即可实现完整的网站镜像。
2、 既然有其他类似的软件,为什么要开发snooics-reptile呢?
因为在爬取过程中经常会出现一些文件出错,很多javascript控制的URL没有办法正确解析,snoics-reptile提供了外部接口和配置文件。对于特殊的URL,可以通过自由扩展外部提供的接口,通过配置文件注入的方式,基本上可以正确解析和抓取所有网页。
项目主页:
十一、Web-Harvest
Web-Harvest 是一个 Java 开源 Web 数据提取工具。它可以采集
指定的网页并从这些网页中提取有用的数据。Web-Harvest主要使用XSLT、XQuery、正则表达式等技术来实现text/xml的操作。
Web-Harvest 是一个用 Java 编写的开源 Web 数据提取工具。它提供了一种从所需页面中提取有用数据的方法。为了实现这个目标,您可能需要使用XSLT、XQuery、正则表达式等相关技术来操作text/xml。Web-Harvest 主要关注基于 HMLT/XML 的页面内容,目前占大多数。另一方面,它可以通过编写自己的 Java 方法轻松扩展其提取功能。
Web-Harvest 的主要目的是加强现有数据提取技术的应用。它的目标不是创建一种新方法,而是提供一种更好地使用和组合现有方法的方法。它提供了一个处理器集来处理数据和控制流。每个处理器都被看作一个函数,它有参数,执行后返回结果。并且将处理组合成流水线形式,使它们可以以链式形式执行,除了更容易的数据操作和复用外,Web-Harvest 还提供了上下变量来存储声明的变量。
启动web-harvest,可以直接双击jar包运行,但是这种方式不能指定web-harvest java虚拟机的大小。第二种方法是切换到cmd下的web-harvest目录,输入命令“java -jar -Xms400m webharvest_all_2.jar”启动,设置java虚拟机大小为400M。
项目主页:
十个二、真烂
ItSucks 是 Java Web 爬虫的开源项目。可灵活定制,支持下载模板和正则表达式定义下载规则。提供控制台和 Swing GUI 操作界面。
特征:
项目主页:
十三、智能简单的网络爬虫
Smart and Simple Web Crawler 是一个网络爬虫框架。集成 Lucene 支持。爬虫可以从单个链接或一组链接开始,提供两种遍历方式:最大迭代和最大深度。可以设置过滤器来限制爬回的链接。默认提供了三个过滤器 ServerFilter、BeginningPathFilter 和 RegularExpressionFilter。这三个过滤器可以与 AND、OR 和 NOT 组合使用。可以在解析过程中或页面加载前后添加侦听器。
十四、Crawler4j
crawler4j 是一个用 Java 实现的开源网络爬虫。提供简单易用的界面,您可以在几分钟内创建一个多线程的网络爬虫。
crawler4j的使用主要分为两步:
实现一个继承自WebCrawler的爬虫类;
Crawl 类通过调用 CrawlController 实现。
WebCrawler 是一个抽象类,继承它必须实现两个方法:shouldVisit 和visit。在:
shouldVisit 是判断当前的 URL 是否应该被爬取(访问);
访问是抓取URL指向的页面的数据,传入的参数是网页所有数据的封装对象Page。
此外,WebCrawler 还有一些其他的方法可以覆盖,其方法命名规则与Android 的命名规则类似。比如getMyLocalData方法可以返回WebCrawler中的数据;onBeforeExit 方法会在WebCrawler 结束前调用,可以执行一些资源释放等任务。
执照
java从网页抓取数据(一个+jsou提取网页数据的分类汇总(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-26 04:24
原文链接
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在刚开始学习数据采集的时候可能无法上手,尤其是作为一个新手,感觉非常的茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇文章的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
在采集
网络数据时,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先,我们看到本网站整个页面的预览
接下来我们看一下网页的源码结构:
从上面的源码中,可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。, 在真实的集合中,有些网页的结构比较复杂,源代码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在采集
这个页面的时候,只采集
了当前页面的数据,也有分页的数据。这里就不解释了,只是提醒一下,我们可以使用多线程对分页的所有当前数据进行采集
,一个通过线程采集
当前页面数据,另一个执行翻页动作,
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据进行存储,方便我们接下来的数据查询操作。 查看全部
java从网页抓取数据(一个+jsou提取网页数据的分类汇总(一))
原文链接
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在刚开始学习数据采集的时候可能无法上手,尤其是作为一个新手,感觉非常的茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇文章的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
在采集
网络数据时,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先,我们看到本网站整个页面的预览
接下来我们看一下网页的源码结构:
从上面的源码中,可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。, 在真实的集合中,有些网页的结构比较复杂,源代码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在采集
这个页面的时候,只采集
了当前页面的数据,也有分页的数据。这里就不解释了,只是提醒一下,我们可以使用多线程对分页的所有当前数据进行采集
,一个通过线程采集
当前页面数据,另一个执行翻页动作,
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据进行存储,方便我们接下来的数据查询操作。
java从网页抓取数据(从一个网页下载数据到Excel文件中的搜狗指数-宠物-源码接下来 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-25 07:20
)
在处理数据分析时,如果我们的数据来自一个网页,我们需要使用数据爬虫将网页上的数据转换到本地存储,然后进行分析。
在这个文章中,我们将逐步介绍从搜狗指数下载数据到Excel文件。
分析搜狗指数页面
如果要从网页中下载数据,首先需要了解网页中的数据结构。这里我们以宠物搜索数据为例。
对于这样的页面数据
搜狗指数-宠物
通过F12输入网页的源代码,可以看到
搜狗指数-宠物-源码
接下来,我们刚刚想出了一个方法,将脚本标签中的数据导出
通过Java将搜狗指数数据保存到Excel
Pattern p = Pattern.compile("root.SG.wholedata = (.*)", Pattern.MULTILINE);
Matcher matcher = p.matcher(script);
String wholedata = "";
while(matcher.find()) {
wholedata = matcher.group(1);
}
ObjectMapper objectMapper = new ObjectMapper();
SougouData sougouData = objectMapper.readValue(wholedata, SougouData.class);
for (Pv pv : sougouData.pvList.get(0)) {
IndexTrend indexTrend = new IndexTrend();
indexTrend.date = pv.date;
indexTrend.PV = pv.pv;
indexTrends.add(indexTrend);
}
public void SaveToExcel(Set indexTrends) throws IOException {
XSSFWorkbook workbook = new XSSFWorkbook();
XSSFSheet sheet = workbook.createSheet("Pet");
int rowNum = 0;
for (IndexTrend indexTrend : indexTrends) {
Row row = sheet.createRow(rowNum++);
Cell date = row.createCell(0);
Cell pv = row.createCell(1);
CellStyle cellStyle = workbook.createCellStyle();
CreationHelper createHelper = workbook.getCreationHelper();
cellStyle.setDataFormat(
createHelper.createDataFormat().getFormat("yyyy-MM-dd"));
date.setCellValue(indexTrend.date);
date.setCellStyle(cellStyle);
pv.setCellValue(indexTrend.PV);
}
FileOutputStream outputStream = new FileOutputStream("./Download Sougou To Excel/petdata.xlsx");
workbook.write(outputStream);
workbook.close();
} 查看全部
java从网页抓取数据(从一个网页下载数据到Excel文件中的搜狗指数-宠物-源码接下来
)
在处理数据分析时,如果我们的数据来自一个网页,我们需要使用数据爬虫将网页上的数据转换到本地存储,然后进行分析。
在这个文章中,我们将逐步介绍从搜狗指数下载数据到Excel文件。
分析搜狗指数页面
如果要从网页中下载数据,首先需要了解网页中的数据结构。这里我们以宠物搜索数据为例。
对于这样的页面数据
搜狗指数-宠物
通过F12输入网页的源代码,可以看到
搜狗指数-宠物-源码
接下来,我们刚刚想出了一个方法,将脚本标签中的数据导出
通过Java将搜狗指数数据保存到Excel
Pattern p = Pattern.compile("root.SG.wholedata = (.*)", Pattern.MULTILINE);
Matcher matcher = p.matcher(script);
String wholedata = "";
while(matcher.find()) {
wholedata = matcher.group(1);
}
ObjectMapper objectMapper = new ObjectMapper();
SougouData sougouData = objectMapper.readValue(wholedata, SougouData.class);
for (Pv pv : sougouData.pvList.get(0)) {
IndexTrend indexTrend = new IndexTrend();
indexTrend.date = pv.date;
indexTrend.PV = pv.pv;
indexTrends.add(indexTrend);
}
public void SaveToExcel(Set indexTrends) throws IOException {
XSSFWorkbook workbook = new XSSFWorkbook();
XSSFSheet sheet = workbook.createSheet("Pet");
int rowNum = 0;
for (IndexTrend indexTrend : indexTrends) {
Row row = sheet.createRow(rowNum++);
Cell date = row.createCell(0);
Cell pv = row.createCell(1);
CellStyle cellStyle = workbook.createCellStyle();
CreationHelper createHelper = workbook.getCreationHelper();
cellStyle.setDataFormat(
createHelper.createDataFormat().getFormat("yyyy-MM-dd"));
date.setCellValue(indexTrend.date);
date.setCellStyle(cellStyle);
pv.setCellValue(indexTrend.PV);
}
FileOutputStream outputStream = new FileOutputStream("./Download Sougou To Excel/petdata.xlsx");
workbook.write(outputStream);
workbook.close();
}
java从网页抓取数据(丹杰我正在尝试从这个网站上抓取第二个表或告诉我如何做 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-19 03:04
)
单节
我试图从这个 网站 中获取第二个表: 但是,我只设法从提取时获取了第一个表信息,尝试通过查找表标签来访问信息。谁能向我解释为什么我无法访问第二个表或告诉我该怎么做。
import requests
from bs4 import BeautifulSoup
url = "https://fbref.com/en/comps/9/s ... ot%3B
res = requests.get(url)
soup = BeautifulSoup(res.text, 'lxml')
pl_table = soup.find_all("table")
player_table = tables[0]
安德烈·凯斯利
表格在 HTML 注释中。
要从评论中获取表单,您可以使用以下示例:
<p>import requests
from bs4 import BeautifulSoup, Comment
url = 'https://fbref.com/en/comps/9/stats/Premier-League-Stats'
soup = BeautifulSoup(requests.get(url).content, 'html.parser')
table = BeautifulSoup(soup.select_one('#all_stats_standard').find_next(text=lambda x: isinstance(x, Comment)), 'html.parser')
#print some information from the table to screen:
for tr in table.select('tr:has(td)'):
tds = [td.get_text(strip=True) for td in tr.select('td')]
print('{: 查看全部
java从网页抓取数据(丹杰我正在尝试从这个网站上抓取第二个表或告诉我如何做
)
单节
我试图从这个 网站 中获取第二个表: 但是,我只设法从提取时获取了第一个表信息,尝试通过查找表标签来访问信息。谁能向我解释为什么我无法访问第二个表或告诉我该怎么做。
import requests
from bs4 import BeautifulSoup
url = "https://fbref.com/en/comps/9/s ... ot%3B
res = requests.get(url)
soup = BeautifulSoup(res.text, 'lxml')
pl_table = soup.find_all("table")
player_table = tables[0]
安德烈·凯斯利
表格在 HTML 注释中。
要从评论中获取表单,您可以使用以下示例:
<p>import requests
from bs4 import BeautifulSoup, Comment
url = 'https://fbref.com/en/comps/9/stats/Premier-League-Stats'
soup = BeautifulSoup(requests.get(url).content, 'html.parser')
table = BeautifulSoup(soup.select_one('#all_stats_standard').find_next(text=lambda x: isinstance(x, Comment)), 'html.parser')
#print some information from the table to screen:
for tr in table.select('tr:has(td)'):
tds = [td.get_text(strip=True) for td in tr.select('td')]
print('{:
java从网页抓取数据(如何使用python识别网页中的图表中提取数据%D0)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-19 03:01
标签:pythonchartsweb-crawler
我是python的新手。我刚刚学会了如何使用 python 来识别网页中的 URL。但是,现在我想从网页中的图表中提取数据%D0%CB%D2%B5%D6%A4%C8%AF
我有三个问题征求我的意见。
您需要登录才能看到此页面。(用户名:1 8521057966;密码:saifmf)在源码中找不到数据(假设是html)如果能找到图表的哪一部分,如何提取数据。
1 个回答:
答案 0:(得分:0)
将 Selenium 与 Python 绑定一起使用。我推荐这个是因为该页面使用 JavaScript 来完成登录。如果该信息显示在页面上,那么您也可以使用它。换句话说,如果浏览器可以看到信息(只要它正在渲染它),那么您也可以看到它。它可能在源代码中。使用谷歌浏览器,将鼠标悬停在要检查的元素上,右键单击它,然后选择“检查元素”。这将带来检查员。即使源代码中没有任何内容,检查员(ctrl+shift+i)也可以看到它。这取决于。我会先推荐那个。在inspector中找到信息后,可以选择元素并使用selenium获取文本,然后以任何你想要的形式输出(例如,构建一个CSV)。
相关问题
最新一期 查看全部
java从网页抓取数据(如何使用python识别网页中的图表中提取数据%D0)
标签:pythonchartsweb-crawler
我是python的新手。我刚刚学会了如何使用 python 来识别网页中的 URL。但是,现在我想从网页中的图表中提取数据%D0%CB%D2%B5%D6%A4%C8%AF
我有三个问题征求我的意见。
您需要登录才能看到此页面。(用户名:1 8521057966;密码:saifmf)在源码中找不到数据(假设是html)如果能找到图表的哪一部分,如何提取数据。
1 个回答:
答案 0:(得分:0)
将 Selenium 与 Python 绑定一起使用。我推荐这个是因为该页面使用 JavaScript 来完成登录。如果该信息显示在页面上,那么您也可以使用它。换句话说,如果浏览器可以看到信息(只要它正在渲染它),那么您也可以看到它。它可能在源代码中。使用谷歌浏览器,将鼠标悬停在要检查的元素上,右键单击它,然后选择“检查元素”。这将带来检查员。即使源代码中没有任何内容,检查员(ctrl+shift+i)也可以看到它。这取决于。我会先推荐那个。在inspector中找到信息后,可以选择元素并使用selenium获取文本,然后以任何你想要的形式输出(例如,构建一个CSV)。
相关问题
最新一期
java从网页抓取数据(java从网页抓取数据详细教程(图)之家)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-17 05:01
java从网页抓取数据详细教程你可以看看这个,从网页抓取数据分页数据,量太大,涉及太多东西,比如找页码源码这些,需要你懂点代码开发,
有一款叫“爬虫之家”的app,蛮不错的,可以爬虫类似百度的结果,挺好用的。
楼主是学java的还是不是?java本身是可以用python写爬虫的。如果不是的话,那么我不知道你是想直接写python的爬虫还是想先写一个api端,由你爬虫使用的client部分。基于api的话,目前提供java接口的商业应用或者开源api有greendao爬虫框架,不过这个框架要收费。国内做服务器api的公司有digitalriderdemocloud。
大学课设做爬虫的时候研究过爬虫之家的api,思路是抓出来的请求报文里面的url为请求提供一个定向的链接,然后把请求下发给这个定向的链接就能抓取,下面是我修改的代码:importrequests#clientcaller=requests。get(";rct=0&ie=utf-8&q=%e8%a6%82%e8%a7%91&dl=x2&md5=ic21570cdf517df54885e2901171452b11&sn=ce21570cf517df54885e2901171452b11&subadvr=x2&mcv=2560")#发送urldownloadurl=";url_len=15&sign=&cn=x2&signtype=4&pc=x2&sk=fwl7jzsf2clzx0%2bc0izg90_czhgebnd&ipn=fj&spm=a2hsymbolz%2bc0izg90_czhgebnd%2bc0izg90_czhgebnd&_=a43cc0x7%2b7fd5016eee1741"jsonpath='/data%2f17660%2b7fd5016eee1741&ie=utf-8&q=%e8%a6%82%e8%a7%91&dl=x2&md5=ic21570cf517df54885e2901171452b11&subadvr=x2&mcv=2560&msg=i4c74c8e001517415e6222183767332e'#定向的ip地址stripedurl="(={}&dl=x2&sign=&cn=x2&signtype=4&pc=x2&sk=fwl7jzsf2clzx0%2bc0izg90_czhgebnd%2bc0izg90_czhgebnd&_=a43cc0x7%2b7fd5016eee1741);url_len=15&sign=&cn=x2&signtype=4&pc=x2&sk=fwl7jzsf2clzx0%2bc0izg90_czhgebnd%2bc0izg90_czhgebnd&_=a43cc0x7%2b7fd。 查看全部
java从网页抓取数据(java从网页抓取数据详细教程(图)之家)
java从网页抓取数据详细教程你可以看看这个,从网页抓取数据分页数据,量太大,涉及太多东西,比如找页码源码这些,需要你懂点代码开发,
有一款叫“爬虫之家”的app,蛮不错的,可以爬虫类似百度的结果,挺好用的。
楼主是学java的还是不是?java本身是可以用python写爬虫的。如果不是的话,那么我不知道你是想直接写python的爬虫还是想先写一个api端,由你爬虫使用的client部分。基于api的话,目前提供java接口的商业应用或者开源api有greendao爬虫框架,不过这个框架要收费。国内做服务器api的公司有digitalriderdemocloud。
大学课设做爬虫的时候研究过爬虫之家的api,思路是抓出来的请求报文里面的url为请求提供一个定向的链接,然后把请求下发给这个定向的链接就能抓取,下面是我修改的代码:importrequests#clientcaller=requests。get(";rct=0&ie=utf-8&q=%e8%a6%82%e8%a7%91&dl=x2&md5=ic21570cdf517df54885e2901171452b11&sn=ce21570cf517df54885e2901171452b11&subadvr=x2&mcv=2560")#发送urldownloadurl=";url_len=15&sign=&cn=x2&signtype=4&pc=x2&sk=fwl7jzsf2clzx0%2bc0izg90_czhgebnd&ipn=fj&spm=a2hsymbolz%2bc0izg90_czhgebnd%2bc0izg90_czhgebnd&_=a43cc0x7%2b7fd5016eee1741"jsonpath='/data%2f17660%2b7fd5016eee1741&ie=utf-8&q=%e8%a6%82%e8%a7%91&dl=x2&md5=ic21570cf517df54885e2901171452b11&subadvr=x2&mcv=2560&msg=i4c74c8e001517415e6222183767332e'#定向的ip地址stripedurl="(={}&dl=x2&sign=&cn=x2&signtype=4&pc=x2&sk=fwl7jzsf2clzx0%2bc0izg90_czhgebnd%2bc0izg90_czhgebnd&_=a43cc0x7%2b7fd5016eee1741);url_len=15&sign=&cn=x2&signtype=4&pc=x2&sk=fwl7jzsf2clzx0%2bc0izg90_czhgebnd%2bc0izg90_czhgebnd&_=a43cc0x7%2b7fd。
java从网页抓取数据(抓取你想要的网页数据假设你需要获取51人才的需求数量(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-16 23:35
抓取你想要的网页数据
java捕获网站数据
假设你需要在线获取51job人才在线java人才需求量,首先你需要分析51job网站搜索这个
一件如何运作?通过对网页源代码的分析,我们发现了以下信息:
1. 页面搜索时请求的网址为
2. 请求使用的方法是:POST
3. 返回页面的编码格式为:GBK
4. 假设我们在搜索java人才时想要获取结果页面显示的需求数量,我们发现该数量在返回的HTML数据中的一段代码中:
1-30 / 14794
,所以我们可以得到这样一个模式:“.+1-\d+/(\d+).+”,第一组的内容就是我们最终需要的数据,java中的模式请参考java文档Pattern类介绍
5. 另外,作为一个POST请求,页面发送到服务端的数据如下(这样很容易像prototype一样通过js
帧抓取,参考我的另一篇博文介绍):
lang=c&stype=1&postchannel=0000&fromType=1&line=&keywordtype=2&keyword=java&btnJ obarea=%E9%80%89%E6%8B%A9%E5%9C%B0%E5%8C%BA&jobarea=0000&image=&btn% Funtype 80%89%E6%8B%A9%2F%E4%BF%AE%E6%94%B9&funtype=0000&btnIndustrytype=%E9%80%89%E6%8B%A9%2F%E4%BF%AE%E6% 94%B9&industrytype=00 关于第5条中服务器真正需要的数据,我们不关心,全部发送。有了这些标准
准备好了,我们其实就可以开始通过java发送请求,得到最终的数据了。
我们定义了Resource类,这个类封装了与请求相关的所有信息,Resource包括以下属性:view plaincopy to clipboardprint?
/**
* 需要获取资源的目标地址,不收录查询字符串
*/
私有字符串目标;
/**
* get请求的查询字符串,或者post请求的请求数据
*/
私人字符串查询数据 = "";
/**
* 请求方法,获取/发布
*/
私有字符串方法 = "GET";
/**
* 返回数据的编码类型
*/
私人字符串字符集 = "GBK";
/**
* 抓取数据的模式,会根据模式的分组返回数据列表
*/
私有字符串模式; 查看全部
java从网页抓取数据(抓取你想要的网页数据假设你需要获取51人才的需求数量(组图))
抓取你想要的网页数据
java捕获网站数据
假设你需要在线获取51job人才在线java人才需求量,首先你需要分析51job网站搜索这个
一件如何运作?通过对网页源代码的分析,我们发现了以下信息:
1. 页面搜索时请求的网址为
2. 请求使用的方法是:POST
3. 返回页面的编码格式为:GBK
4. 假设我们在搜索java人才时想要获取结果页面显示的需求数量,我们发现该数量在返回的HTML数据中的一段代码中:
1-30 / 14794
,所以我们可以得到这样一个模式:“.+1-\d+/(\d+).+”,第一组的内容就是我们最终需要的数据,java中的模式请参考java文档Pattern类介绍
5. 另外,作为一个POST请求,页面发送到服务端的数据如下(这样很容易像prototype一样通过js
帧抓取,参考我的另一篇博文介绍):
lang=c&stype=1&postchannel=0000&fromType=1&line=&keywordtype=2&keyword=java&btnJ obarea=%E9%80%89%E6%8B%A9%E5%9C%B0%E5%8C%BA&jobarea=0000&image=&btn% Funtype 80%89%E6%8B%A9%2F%E4%BF%AE%E6%94%B9&funtype=0000&btnIndustrytype=%E9%80%89%E6%8B%A9%2F%E4%BF%AE%E6% 94%B9&industrytype=00 关于第5条中服务器真正需要的数据,我们不关心,全部发送。有了这些标准
准备好了,我们其实就可以开始通过java发送请求,得到最终的数据了。
我们定义了Resource类,这个类封装了与请求相关的所有信息,Resource包括以下属性:view plaincopy to clipboardprint?
/**
* 需要获取资源的目标地址,不收录查询字符串
*/
私有字符串目标;
/**
* get请求的查询字符串,或者post请求的请求数据
*/
私人字符串查询数据 = "";
/**
* 请求方法,获取/发布
*/
私有字符串方法 = "GET";
/**
* 返回数据的编码类型
*/
私人字符串字符集 = "GBK";
/**
* 抓取数据的模式,会根据模式的分组返回数据列表
*/
私有字符串模式;
java从网页抓取数据(怎样从PDF中提取内容,了解一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-15 07:53
指南:了解如何从 PDF 中提取内容。
如果有办法自动验证PDF的内容,程序员的生活该有多轻松!
不知道大家有没有听说过Java提供了一个可以提取PDDF内容的工具。本文将向您介绍这个工具,它的名字是 Apache PDFBox。
什么是PDFBox
Apache PDFBox 库是一个用于处理 PDF 文档的开源 Java 工具。它可以帮助我们:
1)新建一个PDF文档;
2)更新现有文档;
比如添加样式、添加超链接等;
3)建议来自 PDF 文档的内容。
从 PDF 读取内容
当我们能够从 PDF 中提取文本内容时,问题就解决了一半。让我们以一个代码示例来完成此任务。
Apche PDFTextStripper 的类 PDFTextStripper() 可以以去除所有格式的形式提取PDF中的文本。它将忽略所有格式和特殊样式。
tStripper = new PDFTextStripper();tStripper.setStartPage(1);tStripper.setEndPage(3);<br />PDDOocument document = PDDocument.load(new File("youpdfname.pdf"));<br />document.getClass(); if(!document.isEncrypted()){ pdfFileInText = tStripper.getText(document); lines = pdfFileIntext.split("\\r\\n\\r\\n"); for(String line : llines){ System.out.printlln(line); content += line; } }System.out.println(content.trim());
从 PDF 文件中获取所有超链接
第二件事是验证PDF中的超链接。以下代码为您提供了 PDF 文档中的超链接。
PDPage class() 中的 getAnnotations() 方法提供文档中的注释列表。接下来,使用 PDActionURI() 获取文档或页面中的 URI 列表
<p>PDDocument document = PDDocument.load(new File("name.pdf"));document.getClass();PDPage pdfpage = document.getPage(1); annotations = pdfpage.getAnnotations(); for (int j = 0; j 查看全部
java从网页抓取数据(怎样从PDF中提取内容,了解一下)
指南:了解如何从 PDF 中提取内容。
如果有办法自动验证PDF的内容,程序员的生活该有多轻松!
不知道大家有没有听说过Java提供了一个可以提取PDDF内容的工具。本文将向您介绍这个工具,它的名字是 Apache PDFBox。
什么是PDFBox
Apache PDFBox 库是一个用于处理 PDF 文档的开源 Java 工具。它可以帮助我们:
1)新建一个PDF文档;
2)更新现有文档;
比如添加样式、添加超链接等;
3)建议来自 PDF 文档的内容。
从 PDF 读取内容
当我们能够从 PDF 中提取文本内容时,问题就解决了一半。让我们以一个代码示例来完成此任务。
Apche PDFTextStripper 的类 PDFTextStripper() 可以以去除所有格式的形式提取PDF中的文本。它将忽略所有格式和特殊样式。
tStripper = new PDFTextStripper();tStripper.setStartPage(1);tStripper.setEndPage(3);<br />PDDOocument document = PDDocument.load(new File("youpdfname.pdf"));<br />document.getClass(); if(!document.isEncrypted()){ pdfFileInText = tStripper.getText(document); lines = pdfFileIntext.split("\\r\\n\\r\\n"); for(String line : llines){ System.out.printlln(line); content += line; } }System.out.println(content.trim());
从 PDF 文件中获取所有超链接
第二件事是验证PDF中的超链接。以下代码为您提供了 PDF 文档中的超链接。
PDPage class() 中的 getAnnotations() 方法提供文档中的注释列表。接下来,使用 PDActionURI() 获取文档或页面中的 URI 列表
<p>PDDocument document = PDDocument.load(new File("name.pdf"));document.getClass();PDPage pdfpage = document.getPage(1); annotations = pdfpage.getAnnotations(); for (int j = 0; j
java从网页抓取数据(一个+jsou提取网页数据的分类汇总(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-12 18:13
原文链接
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候,可能都无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇文章的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
从上面的源码中,可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只是采集拿到了当前页面的数据,也有分页的数据。这里就不解释了,只是一个提示,我们可以使用多线程采集所有页面的当前数据,通过线程一个采集当前页面数据,和一个翻页动作,可以< @采集
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据进行存储,方便我们接下来的数据查询操作。
转载于: 查看全部
java从网页抓取数据(一个+jsou提取网页数据的分类汇总(一))
原文链接
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候,可能都无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇文章的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
从上面的源码中,可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只是采集拿到了当前页面的数据,也有分页的数据。这里就不解释了,只是一个提示,我们可以使用多线程采集所有页面的当前数据,通过线程一个采集当前页面数据,和一个翻页动作,可以< @采集
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据进行存储,方便我们接下来的数据查询操作。
转载于:
java从网页抓取数据(Java六级540多分的水平,大家见谅!(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-10 03:30
翻译Java开源爬虫框架crawler4j文档花了两个小时。因为这几天一直在学习Java爬虫的知识,突然觉得英语可能会阻碍很多人学习的动力。这个爬虫框架,所以决定翻译一下。第六关540多点还请见谅。每个句子都是根据您自己的理解翻译的。尤其是快速入门那部分的源代码。这里是:
爬虫4j
crawler4j 是一个开源的 Java 爬虫网络爬虫,提供了一个简单的网络爬虫接口。使用它,您可以在几分钟内设置一个多线程网络爬虫。
使用Maven下载和安装内容列表
要使用最新版本的 crawler4j,请在您的 pom.xml 中使用以下代码片段
edu.uci.ics
crawler4j
4.3
快照
您可以添加以下内容以使用下一个快照版本
onebeartoe
onebeartoe
https://repository-onebeartoe. ... shot/
edu.uci.ics
crawler4j
4.4-SNAPSHOT
如果没有Maven
从4.3版本开始,如果你需要一个收录所有依赖的jar包。您需要自己构建它。克隆 repo 并运行
$ mvn package -Pfatjar
你会发现target/文件夹中有一个crawler4j-XY-with-dependencies.jar。
使用摇篮
请在 build.gradle 文件中收录以下依赖项以使用 crawler4j
compile group: 'edu.uci.ics', name: 'crawler4j', version: '4.3'
另外在build.gradle中添加如下repository url获取依赖[sleepycat]()
maven {
url "https://repo.boundlessgeo.com/main/"
}
快速开始
您需要创建一个扩展 WebCrawler 的爬虫类。此类确定应抓取哪些 URL 并处理下载的页面。下面是一个示例实现:
public class MyCrawler extends WebCrawler {
/**
* 正则表达式匹配指定的后缀文件
*/
private final static Pattern FILTERS = Pattern.compile(".*(\\.(css|js|gif|jpg" + "|png|mp3|mp4|zip|gz))$");
/**
* 这个方法主要是决定哪些url我们需要抓取,返回true表示是我们需要的,返回false表示不是我们需要的Url
* 第一个参数referringPage封装了当前爬取的页面信息 第二个参数url封装了当前爬取的页面url信息
* 在这个例子中,我们指定爬虫忽略具有css,js,git,...扩展名的url,只接受以“http://www.ics.uci.edu/”开头的url。
* 在这种情况下,我们不需要referringPage参数来做出决定。
*/
@Override
public boolean shouldVisit(Page referringPage, WebURL url) {
String href = url.getURL().toLowerCase();// 得到小写的url
return !FILTERS.matcher(href).matches() // 正则匹配,过滤掉我们不需要的后缀文件
&& href.startsWith("http://www.ics.uci.edu/");// 只接受以“http://www.ics.uci.edu/”开头的url
}
/**
* 当一个页面被提取并准备好被你的程序处理时,这个函数被调用。
*/
@Override
public void visit(Page page) {
String url = page.getWebURL().getURL();// 获取url
System.out.println("URL: " + url);
if (page.getParseData() instanceof HtmlParseData) {// 判断是否是html数据
HtmlParseData htmlParseData = (HtmlParseData) page.getParseData();//// 强制类型转换,获取html数据对象
String text = htmlParseData.getText();//获取页面纯文本(无html标签)
String html = htmlParseData.getHtml();//获取页面Html
Set links = htmlParseData.getOutgoingUrls();// 获取页面输出链接
System.out.println("纯文本长度: " + text.length());
System.out.println("html长度: " + html.length());
System.out.println("链接个数 " + links.size());
}
}
}
从上面的代码可以看出,主要有两个方法需要覆盖
您还应该实现一个控制器类,该类指定爬取的种子、爬取的数据应存储在哪个文件夹中以及并发线程数:
public class Controller {
public static void main(String[] args) throws Exception {
String crawlStorageFolder = "E:/crawler";// 定义爬虫数据存储位置
int numberOfCrawlers = 7;// 定义了7个爬虫,也就是7个线程
CrawlConfig config = new CrawlConfig();// 定义爬虫配置
config.setCrawlStorageFolder(crawlStorageFolder);// 设置爬虫文件存储位置
/*
* 实例化爬虫控制器。
*/
PageFetcher pageFetcher = new PageFetcher(config);// 实例化页面获取器
RobotstxtConfig robotstxtConfig = new RobotstxtConfig();// 实例化爬虫机器人配置
// 实例化爬虫机器人对目标服务器的配置,每个网站都有一个robots.txt文件
// 规定了该网站哪些页面可以爬,哪些页面禁止爬,该类是对robots.txt规范的实现
RobotstxtServer robotstxtServer = new RobotstxtServer(robotstxtConfig, pageFetcher);
// 实例化爬虫控制器
CrawlController controller = new CrawlController(config, pageFetcher, robotstxtServer);
/*
* 对于每次抓取,您需要添加一些种子网址。 这些是抓取的第一个URL,然后抓取工具开始跟随这些页面中的链接
*/
controller.addSeed("http://www.ics.uci.edu/~lopes/");
controller.addSeed("http://www.ics.uci.edu/~welling/");
controller.addSeed("http://www.ics.uci.edu/");
/**
* 启动爬虫,爬虫从此刻开始执行爬虫任务,根据以上配置
*/
controller.start(MyCrawler.class, numberOfCrawlers);
}
}
结果(eclipse+Marven 测试):
使用工厂
使用工厂可以轻松地将 crawler4j 集成到 IoC 环境(如 Spring、Guice)或将信息或协作者传递给每个“WebCrawler”实例。
public class CsiCrawlerCrawlerControllerFactory implements CrawlController.WebCrawlerFactory {
Map metadata;
SqlRepository repository;
public CsiCrawlerCrawlerControllerFactory(Map metadata, SqlRepository repository) {
this.metadata = metadata;
this.repository = repository;
}
@Override
public WebCrawler newInstance() {
return new MyCrawler(metadata, repository);
}
}
要使用工厂,你只需要在 CrawlController 中调用正确的方法(如果你在 Spring 或 Guice,你可能想使用 startNonBlocking):
MyCrawlerFactory factory = new MyCrawlerFactory(metadata, repository);
controller.startNonBlocking(factory, numberOfCrawlers);
更多示例配置细节
控制器类具有 CrawlConfig 类型的必需参数
此类的实例可用于配置 crawler4j。以下部分描述了配置的一些细节。
爬行深度
默认情况下,抓取深度没有限制。但是你可以限制爬行的深度。例如,假设您有一个种子页面“A”,链接到“B”,链接到“C”,链接到“D”。所以,我们有以下链接结构:
A -> B -> C -> D
因为“A”是种子页面,它的深度为0.,“B”的深度为1,以此类推。可以设置crawler4j 抓取的网页深度限制。例如,如果将此限制设置为 2,则不会抓取页面“D”。要设置您可以使用的最大深度:
crawlConfig.setMaxDepthOfCrawling(maxDepthOfCrawling);
启用 SSL
只需启用 SSL:
CrawlConfig config = new CrawlConfig();
config.setIncludeHttpsPages(true);
要抓取的最大页面数
虽然默认情况下对抓取的页面数量没有限制,但您可以为此设置一个限制:
crawlConfig.setMaxPagesToFetch(maxPagesToFetch);
启用二进制内容抓取
默认情况下,抓取二进制内容(即图像、音频等)是关闭的。您必须启用它才能抓取这些文件:
crawlConfig.setIncludeBinaryContentInCrawling(true);
有关更多详细信息,请参阅此处的示例。
文明问题(礼貌爬行)
crawler4j 的设计非常高效,可以非常快速地抓取域名
(例如,它已经能够每秒抓取 200 个维基百科页面)。但现在我反对爬取 网站,因为这会给服务器带来巨大的负担(他们可能会阻止你!),
从 1.3 版本开始,crawler4j 默认会在请求之间等待至少 200 毫秒。
但是,可以调整此参数:
crawlConfig.setPolitenessDelay(politenessDelay);
演戏
你的爬行应该在代理后面运行吗?如果是这样,您可以使用:
crawlConfig.setProxyHost("proxyserver.example.com");
crawlConfig.setProxyPort(8080);
如果您的代理还需要认证:
crawlConfig.setProxyUsername(username);
crawlConfig.setProxyPassword(password);
可恢复抓取
有时需要长时间运行爬虫。搜索者可能会意外终止。在这种情况下,可能需要恢复爬行。您可以使用以下设置恢复先前停止/崩溃的爬网:
crawlConfig.setResumableCrawling(true);
但是,您应该注意它可能会使爬行速度稍微变慢。
用户代理字符串
用户代理字符串用于将您的爬虫表示为 Web 服务器。
请参阅此处了解更多详情。默认情况下,crawler4j 使用以下用户代理字符串:
"crawler4j (https://github.com/yasserg/crawler4j/)"
但是,您可以覆盖它:
crawlConfig.setUserAgentString(userAgentString);
执照 查看全部
java从网页抓取数据(Java六级540多分的水平,大家见谅!(组图))
翻译Java开源爬虫框架crawler4j文档花了两个小时。因为这几天一直在学习Java爬虫的知识,突然觉得英语可能会阻碍很多人学习的动力。这个爬虫框架,所以决定翻译一下。第六关540多点还请见谅。每个句子都是根据您自己的理解翻译的。尤其是快速入门那部分的源代码。这里是:
爬虫4j
crawler4j 是一个开源的 Java 爬虫网络爬虫,提供了一个简单的网络爬虫接口。使用它,您可以在几分钟内设置一个多线程网络爬虫。
使用Maven下载和安装内容列表
要使用最新版本的 crawler4j,请在您的 pom.xml 中使用以下代码片段
edu.uci.ics
crawler4j
4.3
快照
您可以添加以下内容以使用下一个快照版本
onebeartoe
onebeartoe
https://repository-onebeartoe. ... shot/
edu.uci.ics
crawler4j
4.4-SNAPSHOT
如果没有Maven
从4.3版本开始,如果你需要一个收录所有依赖的jar包。您需要自己构建它。克隆 repo 并运行
$ mvn package -Pfatjar
你会发现target/文件夹中有一个crawler4j-XY-with-dependencies.jar。
使用摇篮
请在 build.gradle 文件中收录以下依赖项以使用 crawler4j
compile group: 'edu.uci.ics', name: 'crawler4j', version: '4.3'
另外在build.gradle中添加如下repository url获取依赖[sleepycat]()
maven {
url "https://repo.boundlessgeo.com/main/"
}
快速开始
您需要创建一个扩展 WebCrawler 的爬虫类。此类确定应抓取哪些 URL 并处理下载的页面。下面是一个示例实现:
public class MyCrawler extends WebCrawler {
/**
* 正则表达式匹配指定的后缀文件
*/
private final static Pattern FILTERS = Pattern.compile(".*(\\.(css|js|gif|jpg" + "|png|mp3|mp4|zip|gz))$");
/**
* 这个方法主要是决定哪些url我们需要抓取,返回true表示是我们需要的,返回false表示不是我们需要的Url
* 第一个参数referringPage封装了当前爬取的页面信息 第二个参数url封装了当前爬取的页面url信息
* 在这个例子中,我们指定爬虫忽略具有css,js,git,...扩展名的url,只接受以“http://www.ics.uci.edu/”开头的url。
* 在这种情况下,我们不需要referringPage参数来做出决定。
*/
@Override
public boolean shouldVisit(Page referringPage, WebURL url) {
String href = url.getURL().toLowerCase();// 得到小写的url
return !FILTERS.matcher(href).matches() // 正则匹配,过滤掉我们不需要的后缀文件
&& href.startsWith("http://www.ics.uci.edu/";);// 只接受以“http://www.ics.uci.edu/”开头的url
}
/**
* 当一个页面被提取并准备好被你的程序处理时,这个函数被调用。
*/
@Override
public void visit(Page page) {
String url = page.getWebURL().getURL();// 获取url
System.out.println("URL: " + url);
if (page.getParseData() instanceof HtmlParseData) {// 判断是否是html数据
HtmlParseData htmlParseData = (HtmlParseData) page.getParseData();//// 强制类型转换,获取html数据对象
String text = htmlParseData.getText();//获取页面纯文本(无html标签)
String html = htmlParseData.getHtml();//获取页面Html
Set links = htmlParseData.getOutgoingUrls();// 获取页面输出链接
System.out.println("纯文本长度: " + text.length());
System.out.println("html长度: " + html.length());
System.out.println("链接个数 " + links.size());
}
}
}
从上面的代码可以看出,主要有两个方法需要覆盖
您还应该实现一个控制器类,该类指定爬取的种子、爬取的数据应存储在哪个文件夹中以及并发线程数:
public class Controller {
public static void main(String[] args) throws Exception {
String crawlStorageFolder = "E:/crawler";// 定义爬虫数据存储位置
int numberOfCrawlers = 7;// 定义了7个爬虫,也就是7个线程
CrawlConfig config = new CrawlConfig();// 定义爬虫配置
config.setCrawlStorageFolder(crawlStorageFolder);// 设置爬虫文件存储位置
/*
* 实例化爬虫控制器。
*/
PageFetcher pageFetcher = new PageFetcher(config);// 实例化页面获取器
RobotstxtConfig robotstxtConfig = new RobotstxtConfig();// 实例化爬虫机器人配置
// 实例化爬虫机器人对目标服务器的配置,每个网站都有一个robots.txt文件
// 规定了该网站哪些页面可以爬,哪些页面禁止爬,该类是对robots.txt规范的实现
RobotstxtServer robotstxtServer = new RobotstxtServer(robotstxtConfig, pageFetcher);
// 实例化爬虫控制器
CrawlController controller = new CrawlController(config, pageFetcher, robotstxtServer);
/*
* 对于每次抓取,您需要添加一些种子网址。 这些是抓取的第一个URL,然后抓取工具开始跟随这些页面中的链接
*/
controller.addSeed("http://www.ics.uci.edu/~lopes/";);
controller.addSeed("http://www.ics.uci.edu/~welling/";);
controller.addSeed("http://www.ics.uci.edu/";);
/**
* 启动爬虫,爬虫从此刻开始执行爬虫任务,根据以上配置
*/
controller.start(MyCrawler.class, numberOfCrawlers);
}
}
结果(eclipse+Marven 测试):
使用工厂
使用工厂可以轻松地将 crawler4j 集成到 IoC 环境(如 Spring、Guice)或将信息或协作者传递给每个“WebCrawler”实例。
public class CsiCrawlerCrawlerControllerFactory implements CrawlController.WebCrawlerFactory {
Map metadata;
SqlRepository repository;
public CsiCrawlerCrawlerControllerFactory(Map metadata, SqlRepository repository) {
this.metadata = metadata;
this.repository = repository;
}
@Override
public WebCrawler newInstance() {
return new MyCrawler(metadata, repository);
}
}
要使用工厂,你只需要在 CrawlController 中调用正确的方法(如果你在 Spring 或 Guice,你可能想使用 startNonBlocking):
MyCrawlerFactory factory = new MyCrawlerFactory(metadata, repository);
controller.startNonBlocking(factory, numberOfCrawlers);
更多示例配置细节
控制器类具有 CrawlConfig 类型的必需参数
此类的实例可用于配置 crawler4j。以下部分描述了配置的一些细节。
爬行深度
默认情况下,抓取深度没有限制。但是你可以限制爬行的深度。例如,假设您有一个种子页面“A”,链接到“B”,链接到“C”,链接到“D”。所以,我们有以下链接结构:
A -> B -> C -> D
因为“A”是种子页面,它的深度为0.,“B”的深度为1,以此类推。可以设置crawler4j 抓取的网页深度限制。例如,如果将此限制设置为 2,则不会抓取页面“D”。要设置您可以使用的最大深度:
crawlConfig.setMaxDepthOfCrawling(maxDepthOfCrawling);
启用 SSL
只需启用 SSL:
CrawlConfig config = new CrawlConfig();
config.setIncludeHttpsPages(true);
要抓取的最大页面数
虽然默认情况下对抓取的页面数量没有限制,但您可以为此设置一个限制:
crawlConfig.setMaxPagesToFetch(maxPagesToFetch);
启用二进制内容抓取
默认情况下,抓取二进制内容(即图像、音频等)是关闭的。您必须启用它才能抓取这些文件:
crawlConfig.setIncludeBinaryContentInCrawling(true);
有关更多详细信息,请参阅此处的示例。
文明问题(礼貌爬行)
crawler4j 的设计非常高效,可以非常快速地抓取域名
(例如,它已经能够每秒抓取 200 个维基百科页面)。但现在我反对爬取 网站,因为这会给服务器带来巨大的负担(他们可能会阻止你!),
从 1.3 版本开始,crawler4j 默认会在请求之间等待至少 200 毫秒。
但是,可以调整此参数:
crawlConfig.setPolitenessDelay(politenessDelay);
演戏
你的爬行应该在代理后面运行吗?如果是这样,您可以使用:
crawlConfig.setProxyHost("proxyserver.example.com");
crawlConfig.setProxyPort(8080);
如果您的代理还需要认证:
crawlConfig.setProxyUsername(username);
crawlConfig.setProxyPassword(password);
可恢复抓取
有时需要长时间运行爬虫。搜索者可能会意外终止。在这种情况下,可能需要恢复爬行。您可以使用以下设置恢复先前停止/崩溃的爬网:
crawlConfig.setResumableCrawling(true);
但是,您应该注意它可能会使爬行速度稍微变慢。
用户代理字符串
用户代理字符串用于将您的爬虫表示为 Web 服务器。
请参阅此处了解更多详情。默认情况下,crawler4j 使用以下用户代理字符串:
"crawler4j (https://github.com/yasserg/crawler4j/)"
但是,您可以覆盖它:
crawlConfig.setUserAgentString(userAgentString);
执照
java从网页抓取数据(java从网页抓取数据是个好想法,难道不是代码实现么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-12-07 13:31
java从网页抓取数据是个好想法,但是如果你要做到网页本身的数据可抓取就不是那么容易了。网页本身的数据抓取,难道不是代码实现么?并且实现起来,算法也非常复杂。除非,你网页已经做好了,你一下子能够把网页上的每个文字都抓取下来,把它分词后重新命名抓取数据。但是这里要考虑的问题,就是抓取程序要和真正的浏览器兼容,并且实现的话还要做网页加密以避免web2.0的各种隐私问题。除非真的可以一步登录对应的网页,现在绝大多数的网站做不到。理论上那就可以抓取了。
个人觉得不可能,目前浏览器都是原生渲染的,本身对于网页内容来说已经足够接近原生情况了,如果他给你爬取网页上的内容,那等于你把网页内容重新实现一遍,那其实无论浏览器做成多好,到了加载页面那一步,你的浏览器就会蒙逼,因为它已经没有办法响应网页上更新的内容了,所以我觉得想实现这个功能不现实。
比一比lol和dota
个人认为有难度
前两年火爆起来的ar技术如果ar做出点儿违和感谁不会觉得奇怪,个人猜想其实也许制造业也想过在消费者脑海中实现购物的场景。举例,如果能同时让消费者觉得门口有一块布在非节假日时空荡荡的存在,而节假日时是热闹非凡,这么想能不觉得哪里有点儿奇怪吗?不能控制流量而靠服务实现网络推广,普通消费者肯定接受不了这个,除非消费者的行为是预设路径的,好像地铁的线路查询,汽车的车牌查询。 查看全部
java从网页抓取数据(java从网页抓取数据是个好想法,难道不是代码实现么?)
java从网页抓取数据是个好想法,但是如果你要做到网页本身的数据可抓取就不是那么容易了。网页本身的数据抓取,难道不是代码实现么?并且实现起来,算法也非常复杂。除非,你网页已经做好了,你一下子能够把网页上的每个文字都抓取下来,把它分词后重新命名抓取数据。但是这里要考虑的问题,就是抓取程序要和真正的浏览器兼容,并且实现的话还要做网页加密以避免web2.0的各种隐私问题。除非真的可以一步登录对应的网页,现在绝大多数的网站做不到。理论上那就可以抓取了。
个人觉得不可能,目前浏览器都是原生渲染的,本身对于网页内容来说已经足够接近原生情况了,如果他给你爬取网页上的内容,那等于你把网页内容重新实现一遍,那其实无论浏览器做成多好,到了加载页面那一步,你的浏览器就会蒙逼,因为它已经没有办法响应网页上更新的内容了,所以我觉得想实现这个功能不现实。
比一比lol和dota
个人认为有难度
前两年火爆起来的ar技术如果ar做出点儿违和感谁不会觉得奇怪,个人猜想其实也许制造业也想过在消费者脑海中实现购物的场景。举例,如果能同时让消费者觉得门口有一块布在非节假日时空荡荡的存在,而节假日时是热闹非凡,这么想能不觉得哪里有点儿奇怪吗?不能控制流量而靠服务实现网络推广,普通消费者肯定接受不了这个,除非消费者的行为是预设路径的,好像地铁的线路查询,汽车的车牌查询。

