
java从网页抓取数据
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-10-09 18:38
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页的源码,我们在源码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如此类的工具抓取作为搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
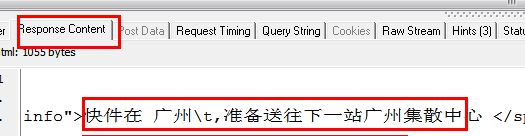
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
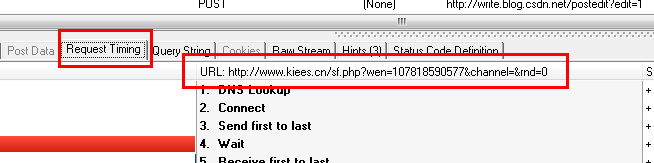
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:

第二步:查看网页的源码,我们在源码中看到这一段:

由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:

换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如此类的工具抓取作为搜索引擎。
首先看这个页面:

我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:

为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:

这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:


从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java从网页抓取数据(基本上在互联网上存在了问题是如何把它们整理成你所需要的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-08 21:36
你想要的任何信息基本上都存在于互联网上。问题是如何把它们组织成你需要的东西,比如抓取某个行业所有相关公司的名称网站、联系电话、Email等,然后保存在Excel中进行分析。网页信息抓取变得更加有用。
对于传统网页,网页服务器直接返回Html。这种类型的网页很容易捕获。不管用什么方法,只需要拿到html页面,然后做Dom分析即可。但对于需要 Javascript 生成的网页来说,就没有那么容易了。对于这个问题,张宇还没有找到很好的解决办法。有抓取javascript网页经验的朋友,欢迎指点。
所以今天我要讲的是从传统的html网页爬取信息。虽然我之前说过,没有技术难度,但是有没有比较简单的方法呢?用过jQuery等js框架的朋友可能会觉得javascript看起来像是抓取网页信息的天然助手,它为网页解析而生。当然,现在还有更多的应用,比如服务端的javascript应用,NodeJs。
如果能在我们的应用程序中使用jQuery来抓取网页,比如java程序,那绝对是一件令人兴奋的事情。确实有现成的方案,有Javascript引擎,有可以支持jQuery的环境。
工具:java、Rhino、envJs。其中Rhino是Mozzila提供的开源Javascript引擎,envJs是模拟浏览器环境,比如Window。代码如下,
package stony.zhang.scrape;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import org.mozilla.javascript.Context;
import org.mozilla.javascript.ContextFactory;
import org.mozilla.javascript.Scriptable;
import org.mozilla.javascript.ScriptableObject;
/**
* @author MyBeautiful
* @Emal: zhangyu0182@sina.com
* @date Mar 7, 2012
*/
public class RhinoScaper {
private String url;
private String jsFile;
private Context cx;
private Scriptable scope;
public String getUrl() {
return url;
}
public String getJsFile() {
return jsFile;
}
public void setUrl(String url) {
this.url = url;
putObject("url", url);
}
public void setJsFile(String jsFile) {
this.jsFile = jsFile;
}
public void init() {
cx = ContextFactory.getGlobal().enterContext();
scope = cx.initStandardObjects(null);
cx.setOptimizationLevel(-1);
cx.setLanguageVersion(Context.VERSION_1_5);
String[] file = { "./lib/env.rhino.1.2.js", "./lib/jquery.js" };
for (String f : file) {
evaluateJs(f);
}
try {
ScriptableObject.defineClass(scope, ExtendUtil.class);
} catch (IllegalAccessException e1) {
e1.printStackTrace();
} catch (InstantiationException e1) {
e1.printStackTrace();
} catch (InvocationTargetException e1) {
e1.printStackTrace();
}
ExtendUtil util = (ExtendUtil) cx.newObject(scope, "util");
scope.put("util", scope, util);
}
protected void evaluateJs(String f) {
try {
FileReader in = null;
in = new FileReader(f);
cx.evaluateReader(scope, in, f, 1, null);
} catch (FileNotFoundException e1) {
e1.printStackTrace();
} catch (IOException e1) {
e1.printStackTrace();
}
}
public void putObject(String name, Object o) {
scope.put(name, scope, o);
}
public void run() {
evaluateJs(this.jsFile);
}
}
测试代码:
package stony.zhang.scrape;
import java.util.HashMap;
import java.util.Map;
import junit.framework.TestCase;
public class RhinoScaperTest extends TestCase {
public RhinoScaperTest(String name) {
super(name);
}
public void testRun() {
RhinoScaper rs = new RhinoScaper();
rs.init();
rs.setUrl("http://www.baidu.com");
rs.setJsFile("test.js");
// Map o = new HashMap();
// rs.putObject("result", o);
rs.run();
// System.out.println(o.get("imgurl"));
}
}
test.js 文件,如下
$.ajax({
url: "http://www.baidu.com",
context: document.body,
success: function(data){
// util.log(data);
var result =parseHtml(data);
var $v= jQuery(result);
// util.log(result);
$v.find('#u a').each(function(index) {
util.log(index + ': ' + $(this).attr("href"));
// arr.add($(this).attr("href"));
});
}
});
function parseHtml(html) {
//Create an iFrame object that will be used to render the HTML in order to get the DOM objects
//created - this is a far quicker way of achieving the HTML to DOM conversion than trying
//to transform the HTML objects one-by-one
var oIframe = document.createElement('iframe');
//Hide the iFrame from view
oIframe.style.display = 'none';
if (document.body)
document.body.appendChild(oIframe);
else
document.documentElement.appendChild(oIframe);
//Open the iFrame DOM object and write in our HTML
oIframe.contentDocument.open();
oIframe.contentDocument.write(html);
oIframe.contentDocument.close();
//Return the document body object containing the HTML that was just
//added to the iFrame as DOM objects
var oBody = oIframe.contentDocument.body;
//TODO: Remove the iFrame object created to cleanup the DOM
return oBody;
}
我们执行Unit Test,从网页抓取的三个百度连接会打印在控制台上。
0:
1:
2:
测试成功,证明在java程序中使用jQuery抓取网页是可行的。
----------------------------------------------- -----------------------
张宇,我的美丽, 查看全部
java从网页抓取数据(基本上在互联网上存在了问题是如何把它们整理成你所需要的)
你想要的任何信息基本上都存在于互联网上。问题是如何把它们组织成你需要的东西,比如抓取某个行业所有相关公司的名称网站、联系电话、Email等,然后保存在Excel中进行分析。网页信息抓取变得更加有用。
对于传统网页,网页服务器直接返回Html。这种类型的网页很容易捕获。不管用什么方法,只需要拿到html页面,然后做Dom分析即可。但对于需要 Javascript 生成的网页来说,就没有那么容易了。对于这个问题,张宇还没有找到很好的解决办法。有抓取javascript网页经验的朋友,欢迎指点。
所以今天我要讲的是从传统的html网页爬取信息。虽然我之前说过,没有技术难度,但是有没有比较简单的方法呢?用过jQuery等js框架的朋友可能会觉得javascript看起来像是抓取网页信息的天然助手,它为网页解析而生。当然,现在还有更多的应用,比如服务端的javascript应用,NodeJs。
如果能在我们的应用程序中使用jQuery来抓取网页,比如java程序,那绝对是一件令人兴奋的事情。确实有现成的方案,有Javascript引擎,有可以支持jQuery的环境。
工具:java、Rhino、envJs。其中Rhino是Mozzila提供的开源Javascript引擎,envJs是模拟浏览器环境,比如Window。代码如下,
package stony.zhang.scrape;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import org.mozilla.javascript.Context;
import org.mozilla.javascript.ContextFactory;
import org.mozilla.javascript.Scriptable;
import org.mozilla.javascript.ScriptableObject;
/**
* @author MyBeautiful
* @Emal: zhangyu0182@sina.com
* @date Mar 7, 2012
*/
public class RhinoScaper {
private String url;
private String jsFile;
private Context cx;
private Scriptable scope;
public String getUrl() {
return url;
}
public String getJsFile() {
return jsFile;
}
public void setUrl(String url) {
this.url = url;
putObject("url", url);
}
public void setJsFile(String jsFile) {
this.jsFile = jsFile;
}
public void init() {
cx = ContextFactory.getGlobal().enterContext();
scope = cx.initStandardObjects(null);
cx.setOptimizationLevel(-1);
cx.setLanguageVersion(Context.VERSION_1_5);
String[] file = { "./lib/env.rhino.1.2.js", "./lib/jquery.js" };
for (String f : file) {
evaluateJs(f);
}
try {
ScriptableObject.defineClass(scope, ExtendUtil.class);
} catch (IllegalAccessException e1) {
e1.printStackTrace();
} catch (InstantiationException e1) {
e1.printStackTrace();
} catch (InvocationTargetException e1) {
e1.printStackTrace();
}
ExtendUtil util = (ExtendUtil) cx.newObject(scope, "util");
scope.put("util", scope, util);
}
protected void evaluateJs(String f) {
try {
FileReader in = null;
in = new FileReader(f);
cx.evaluateReader(scope, in, f, 1, null);
} catch (FileNotFoundException e1) {
e1.printStackTrace();
} catch (IOException e1) {
e1.printStackTrace();
}
}
public void putObject(String name, Object o) {
scope.put(name, scope, o);
}
public void run() {
evaluateJs(this.jsFile);
}
}
测试代码:
package stony.zhang.scrape;
import java.util.HashMap;
import java.util.Map;
import junit.framework.TestCase;
public class RhinoScaperTest extends TestCase {
public RhinoScaperTest(String name) {
super(name);
}
public void testRun() {
RhinoScaper rs = new RhinoScaper();
rs.init();
rs.setUrl("http://www.baidu.com";);
rs.setJsFile("test.js");
// Map o = new HashMap();
// rs.putObject("result", o);
rs.run();
// System.out.println(o.get("imgurl"));
}
}
test.js 文件,如下
$.ajax({
url: "http://www.baidu.com",
context: document.body,
success: function(data){
// util.log(data);
var result =parseHtml(data);
var $v= jQuery(result);
// util.log(result);
$v.find('#u a').each(function(index) {
util.log(index + ': ' + $(this).attr("href"));
// arr.add($(this).attr("href"));
});
}
});
function parseHtml(html) {
//Create an iFrame object that will be used to render the HTML in order to get the DOM objects
//created - this is a far quicker way of achieving the HTML to DOM conversion than trying
//to transform the HTML objects one-by-one
var oIframe = document.createElement('iframe');
//Hide the iFrame from view
oIframe.style.display = 'none';
if (document.body)
document.body.appendChild(oIframe);
else
document.documentElement.appendChild(oIframe);
//Open the iFrame DOM object and write in our HTML
oIframe.contentDocument.open();
oIframe.contentDocument.write(html);
oIframe.contentDocument.close();
//Return the document body object containing the HTML that was just
//added to the iFrame as DOM objects
var oBody = oIframe.contentDocument.body;
//TODO: Remove the iFrame object created to cleanup the DOM
return oBody;
}
我们执行Unit Test,从网页抓取的三个百度连接会打印在控制台上。
0:
1:
2:
测试成功,证明在java程序中使用jQuery抓取网页是可行的。

----------------------------------------------- -----------------------
张宇,我的美丽,
java从网页抓取数据(怎么从数据库中提取数据,在jsp页面显示员工信息管理系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-04 12:06
如何从数据库中提取数据并显示在jsp页面上
员工信息管理系统
一、语言和环境
1.实现语言:Java
2.环境要求:Eclipse+mySql|Oracle
3.技术:Struts2+Spring+Hibernate
二、数据库设计
数据库:EMDB
表名:Dept(部门表)
序列号字段名称字段描述类型数字属性备注
1deptid 部门编号 int 标识栏
2dname 部门名称 Varchar50 唯一
表名:Emp(员工表)
序列号字段名称字段描述类型数字属性备注
1empid 员工编号 int 标识列
2ename 员工姓名 varchar50notnull
3gendar sex tinyintnotnull1 男 0 女
4depid 部门编号 intnotnull
一、要求
请编写一个程序来完成员工信息的管理。功能如下:
a) 查看所有员工列表;
b) 查看详细的员工信息;
c) 添加员工信息;
d) 修改员工信息;
e) 删除员工信息;
二、推荐的实现步骤
1. 建立数据库,表结构见数据库设计;数据连接必须使用JDBC技术。
2. 创建一个名为 HR 的 JAVAWEB 项目,并添加 JavaBean 和 DAO 类。
设计一个前端界面index.jsp,点击显示员工列表。创建 ListEmpServlet,
接收 index.jsp 请求,查询所有员工信息。转发到 listemp.jsp 员工列表。
3. 设计一个前端界面displayemp.jsp,显示所有员工信息。员工姓名采用超链接的形式。点击后,可以查看该员工的详细信息。
4 创建DisplayEmpServlet,接收要显示的员工ID,查询员工信息,转发到displayemp.jsp显示。
5 设计前端接口addemp.jsp,添加用户信息。
6. 首先创建PreAddEmpServlet查询所有部门的信息,将部门信息列表转发到addemp.jsp,以下拉框的形式展示。添加员工时,部门编号必须是部门表中已有的部门;默认性别为“男性”。然后创建 AddEmpServlet 来处理添加员工的请求。
7. 设计一个前端界面editemp.jsp来修改用户信息。
这是原创问题。
只是从数据库中提取数据,在jsp页面上是无法显示的。其他一切都完成了。
那位大神能帮帮我,如何从数据库中提取数据并显示在jsp页面上
- - - 解决方案 - - - - - - - - - -
参考
- - - 解决方案 - - - - - - - - - -
使用了三大框架,应该对这三个比较熟悉了吧?Hibernate 用于操作数据库。您可以在其中使用 HQL 语句。比如要查询数据库中所有员工的列表,可以这样写:Stringhql="fromEmp",然后在session中使用createQuery(hql)方法把参数传进去,然后取从其列表中返回查询类型实例,以便将员工信息取出并放入列表中。至于如何显示,可以使用struts2自带的标签将list封装在action中,这样就可以直接使用foreach标签在页面上显示了。
- - - 解决方案 - - - - - - - - - -
例如:你在java后台方法中找到了你的emp表:select*fromemp; 这将返回一个列表集合
1 返回一个列表,如:Listtemps=lists.newArrayList();//查询结果返回一个对象集合
2 放入请求中,如request.setAttribute("empist",emps);//将查询的结果集放入请求中,等待发送到页面
3 然后进入页面,如 return "/emp/list.jsp";//查询完成后跳转到此页面显示员工信息
4 然后在页面上,可以直接用JSTL解析,因为是从后台传过来的集合列表,所以需要用一个循环来一个一个的遍历后台列表,需要用到这个标签
- - - 解决方案 - - - - - - - - - -
这东西无非就是来回发送数据。通过debug查看数据趋势然后微调,像楼上一样放到list里然后request.set()
然后前台用JSTL解析(你点百度就知道了)。一种是生的,一种是煮熟的。练习一下就OK了
- - - 解决方案 - - - - - - - - - -
使用 struts2 标签
在action中使用heibernate取出并存入列表
<br />
<br />
<br />
`<br />
<br />
不明白的可以搜索s:iterator标签用法 查看全部
java从网页抓取数据(怎么从数据库中提取数据,在jsp页面显示员工信息管理系统)
如何从数据库中提取数据并显示在jsp页面上
员工信息管理系统
一、语言和环境
1.实现语言:Java
2.环境要求:Eclipse+mySql|Oracle
3.技术:Struts2+Spring+Hibernate
二、数据库设计
数据库:EMDB
表名:Dept(部门表)
序列号字段名称字段描述类型数字属性备注
1deptid 部门编号 int 标识栏
2dname 部门名称 Varchar50 唯一
表名:Emp(员工表)
序列号字段名称字段描述类型数字属性备注
1empid 员工编号 int 标识列
2ename 员工姓名 varchar50notnull
3gendar sex tinyintnotnull1 男 0 女
4depid 部门编号 intnotnull
一、要求
请编写一个程序来完成员工信息的管理。功能如下:
a) 查看所有员工列表;
b) 查看详细的员工信息;
c) 添加员工信息;
d) 修改员工信息;
e) 删除员工信息;
二、推荐的实现步骤
1. 建立数据库,表结构见数据库设计;数据连接必须使用JDBC技术。
2. 创建一个名为 HR 的 JAVAWEB 项目,并添加 JavaBean 和 DAO 类。
设计一个前端界面index.jsp,点击显示员工列表。创建 ListEmpServlet,
接收 index.jsp 请求,查询所有员工信息。转发到 listemp.jsp 员工列表。
3. 设计一个前端界面displayemp.jsp,显示所有员工信息。员工姓名采用超链接的形式。点击后,可以查看该员工的详细信息。
4 创建DisplayEmpServlet,接收要显示的员工ID,查询员工信息,转发到displayemp.jsp显示。
5 设计前端接口addemp.jsp,添加用户信息。
6. 首先创建PreAddEmpServlet查询所有部门的信息,将部门信息列表转发到addemp.jsp,以下拉框的形式展示。添加员工时,部门编号必须是部门表中已有的部门;默认性别为“男性”。然后创建 AddEmpServlet 来处理添加员工的请求。
7. 设计一个前端界面editemp.jsp来修改用户信息。
这是原创问题。
只是从数据库中提取数据,在jsp页面上是无法显示的。其他一切都完成了。
那位大神能帮帮我,如何从数据库中提取数据并显示在jsp页面上
- - - 解决方案 - - - - - - - - - -
参考
- - - 解决方案 - - - - - - - - - -
使用了三大框架,应该对这三个比较熟悉了吧?Hibernate 用于操作数据库。您可以在其中使用 HQL 语句。比如要查询数据库中所有员工的列表,可以这样写:Stringhql="fromEmp",然后在session中使用createQuery(hql)方法把参数传进去,然后取从其列表中返回查询类型实例,以便将员工信息取出并放入列表中。至于如何显示,可以使用struts2自带的标签将list封装在action中,这样就可以直接使用foreach标签在页面上显示了。

- - - 解决方案 - - - - - - - - - -
例如:你在java后台方法中找到了你的emp表:select*fromemp; 这将返回一个列表集合
1 返回一个列表,如:Listtemps=lists.newArrayList();//查询结果返回一个对象集合
2 放入请求中,如request.setAttribute("empist",emps);//将查询的结果集放入请求中,等待发送到页面
3 然后进入页面,如 return "/emp/list.jsp";//查询完成后跳转到此页面显示员工信息
4 然后在页面上,可以直接用JSTL解析,因为是从后台传过来的集合列表,所以需要用一个循环来一个一个的遍历后台列表,需要用到这个标签
- - - 解决方案 - - - - - - - - - -
这东西无非就是来回发送数据。通过debug查看数据趋势然后微调,像楼上一样放到list里然后request.set()
然后前台用JSTL解析(你点百度就知道了)。一种是生的,一种是煮熟的。练习一下就OK了
- - - 解决方案 - - - - - - - - - -
使用 struts2 标签
在action中使用heibernate取出并存入列表
<br />
<br />
<br />
`<br />
<br />
不明白的可以搜索s:iterator标签用法
java从网页抓取数据(java从网页抓取数据即可,代码分享给你views/chart)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-04 08:01
java从网页抓取数据即可,代码分享给你views/chart。javapublicclassh2{privatestring[]color=newstring[]{"black","green","yellow","blue"};//字符串对象、stringbufferfriends=newstringbuffer();publicchart(stringcolor){this。
color=color;}publicstringfindstringofcolor(stringoutcode){return(string)outcode;}publicstringgetarray(){if(color==null){return"null";}else{return"";}}};views/file2。
javapublicclassfile2{publicstaticvoidmain(string[]args){//创建视图函数类views::file2("file2。java")。views。new(file2。public,file2。new);}}java网页抓取即可。
比较简单就只需要webdriver+chrome浏览器就可以了
可以抓取腾讯的任何动态网页,已有免费的api封装好,,京东、还有58上都有,很方便,
是实时的网页?你都没说清楚你说的什么情况,我随便想到一个:ajax。
我有个viewpointjs,可以实现这个功能。
javascript可以抓取、转换javascript页面的html元素,可以用selenium来抓取浏览器的自动化。也可以用js抓取ie元素,因为浏览器自身的这种习惯,或者导航之类的设置,让老版ie兼容性很差。可以先抓取ie中最有名的网站,分析其源代码,其中html文件的地址是后面抓取的这些网站的入口url地址。然后在selenium中用网页浏览器随便抓取页面html源代码,就可以分析出源代码里的url。 查看全部
java从网页抓取数据(java从网页抓取数据即可,代码分享给你views/chart)
java从网页抓取数据即可,代码分享给你views/chart。javapublicclassh2{privatestring[]color=newstring[]{"black","green","yellow","blue"};//字符串对象、stringbufferfriends=newstringbuffer();publicchart(stringcolor){this。
color=color;}publicstringfindstringofcolor(stringoutcode){return(string)outcode;}publicstringgetarray(){if(color==null){return"null";}else{return"";}}};views/file2。
javapublicclassfile2{publicstaticvoidmain(string[]args){//创建视图函数类views::file2("file2。java")。views。new(file2。public,file2。new);}}java网页抓取即可。
比较简单就只需要webdriver+chrome浏览器就可以了
可以抓取腾讯的任何动态网页,已有免费的api封装好,,京东、还有58上都有,很方便,
是实时的网页?你都没说清楚你说的什么情况,我随便想到一个:ajax。
我有个viewpointjs,可以实现这个功能。
javascript可以抓取、转换javascript页面的html元素,可以用selenium来抓取浏览器的自动化。也可以用js抓取ie元素,因为浏览器自身的这种习惯,或者导航之类的设置,让老版ie兼容性很差。可以先抓取ie中最有名的网站,分析其源代码,其中html文件的地址是后面抓取的这些网站的入口url地址。然后在selenium中用网页浏览器随便抓取页面html源代码,就可以分析出源代码里的url。
java从网页抓取数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-03 17:09
在众多行业中,需要对行业数据进行分类汇总,及时对行业数据进行分析,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们要获取的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只有采集当前页面的数据,还有分页的数据,这里就不解释了,只是一个提示,大家可以用多线程采集所有页面的当前数据,通过线程一个采集当前页面数据,一个翻页动作,可以采集完成所有数据。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。在下一节中,我将与大家分享如何处理 采集 数据存储在数据库中。 查看全部
java从网页抓取数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
在众多行业中,需要对行业数据进行分类汇总,及时对行业数据进行分析,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解

在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览

接下来我们看一下网页的源码结构:

上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据

成功获取数据,这就是我们要获取的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只有采集当前页面的数据,还有分页的数据,这里就不解释了,只是一个提示,大家可以用多线程采集所有页面的当前数据,通过线程一个采集当前页面数据,一个翻页动作,可以采集完成所有数据。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。在下一节中,我将与大家分享如何处理 采集 数据存储在数据库中。
java从网页抓取数据(AlexR关于一个的一些小知识,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-10-02 05:25
正如@Alex R 指出的那样,您将需要一个网络爬虫库。
他推荐的 JSoup 相当健壮,至少以我的经验,它经常用于 Java 中的这个任务。
首先需要构造一个文档来获取页面,例如:
int localID = 25022; //your player's ID.
Document doc = Jsoup.connect("http://www.chess.org.il/Player ... ot%3B + localID).get();
从这个文档对象中,你可以得到很多信息,比如你请求的 FIDE ID。不幸的是,您链接的网页非常容易抓取,您基本上需要浏览页面上的每个链接才能找到相关链接,例如:
Elements fidelinks = doc.select("a[href*=fide.com]");
这个 Elements 对象应该为您提供指向所有链接的链接列表,这些链接链接到收录文本的任何内容,但您可能只希望出现第一个链接,例如:
从那以后,我不想为您编写所有代码,但希望这个答案可以作为一个好的起点!
可以通过调用Element对象上的方法单独获取ID,但也可以通过调用本身获取链接
可以用来获取另一个值的css选择器是 div#main-col table.contentpaneopen tbody tr td table tbody tr td table tbody tr:nth-of-type(4) td table tbody tr td:first- Of-type,至少在标准css中,它会得到一个特定的std分数,所以它也应该和jsoup一起使用。 查看全部
java从网页抓取数据(AlexR关于一个的一些小知识,你知道吗?)
正如@Alex R 指出的那样,您将需要一个网络爬虫库。
他推荐的 JSoup 相当健壮,至少以我的经验,它经常用于 Java 中的这个任务。
首先需要构造一个文档来获取页面,例如:
int localID = 25022; //your player's ID.
Document doc = Jsoup.connect("http://www.chess.org.il/Player ... ot%3B + localID).get();
从这个文档对象中,你可以得到很多信息,比如你请求的 FIDE ID。不幸的是,您链接的网页非常容易抓取,您基本上需要浏览页面上的每个链接才能找到相关链接,例如:
Elements fidelinks = doc.select("a[href*=fide.com]");
这个 Elements 对象应该为您提供指向所有链接的链接列表,这些链接链接到收录文本的任何内容,但您可能只希望出现第一个链接,例如:
从那以后,我不想为您编写所有代码,但希望这个答案可以作为一个好的起点!
可以通过调用Element对象上的方法单独获取ID,但也可以通过调用本身获取链接
可以用来获取另一个值的css选择器是 div#main-col table.contentpaneopen tbody tr td table tbody tr td table tbody tr:nth-of-type(4) td table tbody tr td:first- Of-type,至少在标准css中,它会得到一个特定的std分数,所以它也应该和jsoup一起使用。
java从网页抓取数据(字典批量获取数据打印的默认编码()(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-10-01 00:05
)
然后在第三步中,我们更改了默认编码。这取决于您要抓取的网页的编码格式。如果你不改变它,你可能会得到乱码或一些你以前没见过的字符。
第五步,我们将抓取到的网页内容的前 50 个字符分配给内容供以后查看。由于网页内容太多,无法一次全部打印出来,我们决定将部分内容切片输出
最后一步,我们把刚才保存的部分内容打印出来
上一步只是为了提前熟悉爬取数据的步骤。接下来,我们将通过列表字典批量获取数据,然后将其保存为文件
首先定义一个字典来存放我们要爬取的页面的URL
urls_dict = {
'特克斯博客': 'http://www.susmote.com/',
'百度': 'http://www.baidu.com',
'xyz': 'www.susmote.com',
'特克斯博客歌单区1': 'https://www.susmote.com/?cate=13',
'特克斯博客歌单区2': 'https://www.susmote.com/?cate=13'
}
然后我们定义了一个列表,该列表也存储了被抓取页面的 URL
urls_lst = [
('特克斯博客', 'http://www.susmote.com/'),
('百度', 'http://www.baidu.com'),
('xyz', 'www.susmote.com'),
('特克斯博客歌单区1', 'https://www.susmote.com/?cate=13'),
('特克斯博客歌单区2', 'https://www.susmote.com/?cate=13')
]
那我们先用字典来抓取
代码显示如下:
# 利用字典抓取
crawled_urls_for_dict = set()
for ind, name in enumerate(urls_dict.keys()):
name_url = urls_dict[name]
if name_url in crawled_urls_for_dict:
print(ind, name, "已经抓取过了.")
else:
try:
resp = requests.get(name_url)
except Exception as e:
print(ind, name, ":", str(e)[0:50])
continue
resp.encoding = "utf8"
content = resp.text
crawled_urls_for_dict.add(name_url)
with open("bydict_" + name + ".html", 'w', encoding='utf8') as f:
f.write(content)
print("抓取完成 : {} {}, 内容长度为{}".format(ind, name, len(content)))
首先定义一个空集合保存我们抓取过数据的URL,避免重复抓取
后面我们通过for循环和枚举遍历每个字典的key和value,将每个爬取到的URL存储到开头定义的集合crawled_urls_for_dict中。
然后我们判断要爬取的URL是否已经保存在集合中,如果存在则输出已经被爬取
如果没有,请继续进行以下操作。我们在这里是为了防止程序出错,影响程序的整体运行。这里我们使用 try except 语句打印出错误异常,以保证程序可以完整运行。
那么无非和我之前说的一样,改变编码格式,暂时保存内容
只是最后我们创建了一个文件来保存爬取的网页文件。我不会详细解释这个。无非是添加一个后缀。
后面我们打印了我们爬取的网页地址
for u in crawled_urls_for_dict:
print(u)
然后我们使用列表来抓取数据
代码显示如下
# 利用列表抓取
crawled_urls_for_list = set()
for ind, tup in enumerate(urls_lst):
name = tup[0]
name_url = tup[1]
if name_url in crawled_urls_for_list:
print(ind, name, "已经抓取过了.")
else:
try:
resp = requests.get(name_url)
except Exception as e:
print(ind, name, ":", str(e)[0:50])
continue
resp.encoding = "utf8"
content = resp.text
crawled_urls_for_list.add(name_url)
with open('bylist_' + name + ".html", "w", encoding='utf8') as f:
f.write(content)
print("抓取完成:{} {}, 内容长度为{}".format(ind, name, len(content)))
原理和之前的字典一样,就不多说了。
注意这是一个嵌套列表,遍历时注意
最后是一样的
for u in crawled_urls_for_list:
print(u)
打印捕获的数据
运行结果如下图所示
susmotedeMacBook-Air:FirstDatamining susmote$ python main.py
抓取完成 : 0 特克斯博客, 内容长度为26793
抓取完成 : 1 百度, 内容长度为2287
2 xyz : Invalid URL 'www.susmote.com': No schema supplied.
抓取完成 : 3 特克斯博客歌单区1, 内容长度为21728
4 特克斯博客歌单区2 已经抓取过了.
http://www.susmote.com/
http://www.baidu.com
https://www.susmote.com/?cate=13
------------------------------------------------------------
抓取完成:0 特克斯博客, 内容长度为26793
抓取完成:1 百度, 内容长度为2287
2 xyz : Invalid URL 'www.susmote.com': No schema supplied.
抓取完成:3 特克斯博客歌单区1, 内容长度为21728
4 特克斯博客歌单区2 已经抓取过了.
http://www.susmote.com/
http://www.baidu.com
https://www.susmote.com/?cate=13
文件目录变化如下
用浏览器打开下图
特克斯博客
百度网站
至此,简单的数据采集就结束了。
欢迎访问我的官方网站 查看全部
java从网页抓取数据(字典批量获取数据打印的默认编码()(图)
)
然后在第三步中,我们更改了默认编码。这取决于您要抓取的网页的编码格式。如果你不改变它,你可能会得到乱码或一些你以前没见过的字符。
第五步,我们将抓取到的网页内容的前 50 个字符分配给内容供以后查看。由于网页内容太多,无法一次全部打印出来,我们决定将部分内容切片输出
最后一步,我们把刚才保存的部分内容打印出来
上一步只是为了提前熟悉爬取数据的步骤。接下来,我们将通过列表字典批量获取数据,然后将其保存为文件
首先定义一个字典来存放我们要爬取的页面的URL
urls_dict = {
'特克斯博客': 'http://www.susmote.com/',
'百度': 'http://www.baidu.com',
'xyz': 'www.susmote.com',
'特克斯博客歌单区1': 'https://www.susmote.com/?cate=13',
'特克斯博客歌单区2': 'https://www.susmote.com/?cate=13'
}
然后我们定义了一个列表,该列表也存储了被抓取页面的 URL
urls_lst = [
('特克斯博客', 'http://www.susmote.com/'),
('百度', 'http://www.baidu.com'),
('xyz', 'www.susmote.com'),
('特克斯博客歌单区1', 'https://www.susmote.com/?cate=13'),
('特克斯博客歌单区2', 'https://www.susmote.com/?cate=13')
]
那我们先用字典来抓取
代码显示如下:
# 利用字典抓取
crawled_urls_for_dict = set()
for ind, name in enumerate(urls_dict.keys()):
name_url = urls_dict[name]
if name_url in crawled_urls_for_dict:
print(ind, name, "已经抓取过了.")
else:
try:
resp = requests.get(name_url)
except Exception as e:
print(ind, name, ":", str(e)[0:50])
continue
resp.encoding = "utf8"
content = resp.text
crawled_urls_for_dict.add(name_url)
with open("bydict_" + name + ".html", 'w', encoding='utf8') as f:
f.write(content)
print("抓取完成 : {} {}, 内容长度为{}".format(ind, name, len(content)))
首先定义一个空集合保存我们抓取过数据的URL,避免重复抓取
后面我们通过for循环和枚举遍历每个字典的key和value,将每个爬取到的URL存储到开头定义的集合crawled_urls_for_dict中。
然后我们判断要爬取的URL是否已经保存在集合中,如果存在则输出已经被爬取
如果没有,请继续进行以下操作。我们在这里是为了防止程序出错,影响程序的整体运行。这里我们使用 try except 语句打印出错误异常,以保证程序可以完整运行。
那么无非和我之前说的一样,改变编码格式,暂时保存内容
只是最后我们创建了一个文件来保存爬取的网页文件。我不会详细解释这个。无非是添加一个后缀。
后面我们打印了我们爬取的网页地址
for u in crawled_urls_for_dict:
print(u)
然后我们使用列表来抓取数据
代码显示如下
# 利用列表抓取
crawled_urls_for_list = set()
for ind, tup in enumerate(urls_lst):
name = tup[0]
name_url = tup[1]
if name_url in crawled_urls_for_list:
print(ind, name, "已经抓取过了.")
else:
try:
resp = requests.get(name_url)
except Exception as e:
print(ind, name, ":", str(e)[0:50])
continue
resp.encoding = "utf8"
content = resp.text
crawled_urls_for_list.add(name_url)
with open('bylist_' + name + ".html", "w", encoding='utf8') as f:
f.write(content)
print("抓取完成:{} {}, 内容长度为{}".format(ind, name, len(content)))
原理和之前的字典一样,就不多说了。
注意这是一个嵌套列表,遍历时注意
最后是一样的
for u in crawled_urls_for_list:
print(u)
打印捕获的数据
运行结果如下图所示
susmotedeMacBook-Air:FirstDatamining susmote$ python main.py
抓取完成 : 0 特克斯博客, 内容长度为26793
抓取完成 : 1 百度, 内容长度为2287
2 xyz : Invalid URL 'www.susmote.com': No schema supplied.
抓取完成 : 3 特克斯博客歌单区1, 内容长度为21728
4 特克斯博客歌单区2 已经抓取过了.
http://www.susmote.com/
http://www.baidu.com
https://www.susmote.com/?cate=13
------------------------------------------------------------
抓取完成:0 特克斯博客, 内容长度为26793
抓取完成:1 百度, 内容长度为2287
2 xyz : Invalid URL 'www.susmote.com': No schema supplied.
抓取完成:3 特克斯博客歌单区1, 内容长度为21728
4 特克斯博客歌单区2 已经抓取过了.
http://www.susmote.com/
http://www.baidu.com
https://www.susmote.com/?cate=13
文件目录变化如下
用浏览器打开下图
特克斯博客

百度网站
至此,简单的数据采集就结束了。
欢迎访问我的官方网站
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-09-28 15:02
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页的源码,我们在源码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
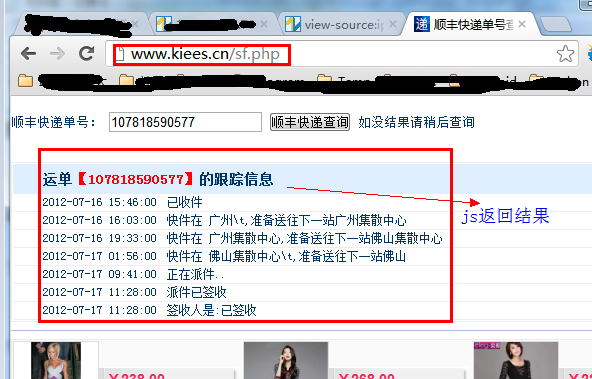
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
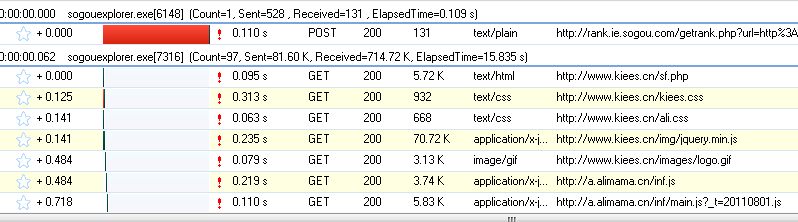
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:

第二步:查看网页的源码,我们在源码中看到这一段:

由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:

换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:

这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java从网页抓取数据(java从网页抓取数据是不可行的?的技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-09-27 16:01
java从网页抓取数据是不可行的。数据要抓取手机浏览器版本要记录ipurl地址要记录每次ip地址的变动过程,然后对数据库进行操作。然后spring已经有了对应的方案:spidercontextcontextresourcemanager接口。代理的方式保证数据抓取的定时同步并且无界限。方法举例:voidviewto_resource(httpservletrequestrequest,httpservletresponseresponse,transactionalconnectionconnection){thread.sleep(10);//stronglymutatedherethread.sleep(3000);//writethepropertyvarrecolor=newcolor("green");//recolorofcolortherecolor=map.getcolorfactory("color.yellow");//illuminatedyellowisrecolorcolor.yellow=color.yellow+true;color=map.getcolorfactory("color.black");color=map.getcolorfactory("color.white");color=map.getcolorfactory("color.red");color=map.getcolorfactory("color.dark");color=map.getcolorfactory("color.orange");color=map.getcolorfactory("color.red");color=map.getcolorfactory("color.yellow");color=map.getcolorfactory("color.green");color=map.getcolorfactory("color.black");color=map.getcolorfactory("color.black");}对于你的问题,请看:爬虫文章下面的评论,我们只抓取部分文章的评论,有没有什么spring的技巧?-零文的回答。 查看全部
java从网页抓取数据(java从网页抓取数据是不可行的?的技巧)
java从网页抓取数据是不可行的。数据要抓取手机浏览器版本要记录ipurl地址要记录每次ip地址的变动过程,然后对数据库进行操作。然后spring已经有了对应的方案:spidercontextcontextresourcemanager接口。代理的方式保证数据抓取的定时同步并且无界限。方法举例:voidviewto_resource(httpservletrequestrequest,httpservletresponseresponse,transactionalconnectionconnection){thread.sleep(10);//stronglymutatedherethread.sleep(3000);//writethepropertyvarrecolor=newcolor("green");//recolorofcolortherecolor=map.getcolorfactory("color.yellow");//illuminatedyellowisrecolorcolor.yellow=color.yellow+true;color=map.getcolorfactory("color.black");color=map.getcolorfactory("color.white");color=map.getcolorfactory("color.red");color=map.getcolorfactory("color.dark");color=map.getcolorfactory("color.orange");color=map.getcolorfactory("color.red");color=map.getcolorfactory("color.yellow");color=map.getcolorfactory("color.green");color=map.getcolorfactory("color.black");color=map.getcolorfactory("color.black");}对于你的问题,请看:爬虫文章下面的评论,我们只抓取部分文章的评论,有没有什么spring的技巧?-零文的回答。
java从网页抓取数据(IE调试网页之五:使用F12开发人员工具调试(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-09-27 01:18
获取网页内容代码:HttpClient httpclient=new DefaultHttpClient();HttpGet httpget = new HttpGet(request.getParameter("requestUrl"));HttpResponse res=httpclient.execute(httpget);HttpEntity entity = res.getEntity();response. ...
IE 调试页面 5:使用 F12 开发人员工具调试 JavaScript 错误(Windows)
使用“Monitor”和“Local Variables”选项卡监视变量 使用“Monitor”选项卡,您可以在代码中设置和监视变量。这将列出指定变量的名称、值和类型。您可以单击标有“单击以添加”的行。在“监控”选项卡中输入变量名称。如果不想输入变量名,可以...
《HTML、CSS、JavaScript网页制作从入门到精通》-第6章使用表格
但是在实际的制作过程中,表格更多的用于网页布局的定位。很多网页都是以表格的形式布局的,因为表格在控制文字和图片的位置方面有很强的作用。灵活巧妙地使用表单,制作网页时会感觉像老虎一样。学习目标 掌握表格的创建,掌握设置表格的基础...
《HTML、CSS、JavaScript网页制作从入门到精通》-1.3 使用浏览器浏览HTML文件
1.3 使用浏览器浏览HTML文件 HTML、CSS、JavaScript网页制作从入门到精通1.3.1 查看页面效果,打开index.htm文件,可以在IE浏览器窗口查看 看到编辑后的HTML页面的效果,如图1.6。1.3.2 查看源文件*您可以使用以下方法快速轻松地打开HTML文档...
《HTML CSS JavaScript 网页制作从入门到精通第3版》-1.3 使用浏览器浏览HTML...
本节摘自异步社区...2。操作题(1)用IE浏览器打开网上任意一个网页,选择【查看】|【源文件】命令,在打开的记事本中查看各个代码,并尝试与浏览器中的内容进行对比。 (2) 分别用记事本和 Dreamweaver 创建一个简单的 HTML 页面。 查看全部
java从网页抓取数据(IE调试网页之五:使用F12开发人员工具调试(组图))
获取网页内容代码:HttpClient httpclient=new DefaultHttpClient();HttpGet httpget = new HttpGet(request.getParameter("requestUrl"));HttpResponse res=httpclient.execute(httpget);HttpEntity entity = res.getEntity();response. ...
IE 调试页面 5:使用 F12 开发人员工具调试 JavaScript 错误(Windows)
使用“Monitor”和“Local Variables”选项卡监视变量 使用“Monitor”选项卡,您可以在代码中设置和监视变量。这将列出指定变量的名称、值和类型。您可以单击标有“单击以添加”的行。在“监控”选项卡中输入变量名称。如果不想输入变量名,可以...
《HTML、CSS、JavaScript网页制作从入门到精通》-第6章使用表格
但是在实际的制作过程中,表格更多的用于网页布局的定位。很多网页都是以表格的形式布局的,因为表格在控制文字和图片的位置方面有很强的作用。灵活巧妙地使用表单,制作网页时会感觉像老虎一样。学习目标 掌握表格的创建,掌握设置表格的基础...
《HTML、CSS、JavaScript网页制作从入门到精通》-1.3 使用浏览器浏览HTML文件
1.3 使用浏览器浏览HTML文件 HTML、CSS、JavaScript网页制作从入门到精通1.3.1 查看页面效果,打开index.htm文件,可以在IE浏览器窗口查看 看到编辑后的HTML页面的效果,如图1.6。1.3.2 查看源文件*您可以使用以下方法快速轻松地打开HTML文档...
《HTML CSS JavaScript 网页制作从入门到精通第3版》-1.3 使用浏览器浏览HTML...
本节摘自异步社区...2。操作题(1)用IE浏览器打开网上任意一个网页,选择【查看】|【源文件】命令,在打开的记事本中查看各个代码,并尝试与浏览器中的内容进行对比。 (2) 分别用记事本和 Dreamweaver 创建一个简单的 HTML 页面。
java从网页抓取数据(从千亿页面上提取数据该如何做呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-09-27 01:17
众所周知,要想更好地完成数据分析,除了掌握好方法和方法,还需要做好数据提取。那么如何从千亿页面中提取数据呢?
现在从互联网上获取数据似乎很容易。有很多开源的库和框架,可视化爬虫工具和数据提取工具,可以很方便的从一个网站中抓取数据。然而,当你想大规模搜索网站时,很快就变得非常棘手。
大规模网络爬虫的要点:
不同于标准的网络爬虫应用,电子商务产品数据的大规模爬取将面临一系列独特的挑战,这使得网络爬行变得异常困难。
本质上,这些困难可以归结为两个方面:速度和数据质量。
通常时间是一个限制性的约束,所以大规模的抓取需要网络爬虫以非常高的速度抓取页面,并且不会影响数据质量。这种对速度的要求使得捕获大量产品数据变得非常具有挑战性。
挑战一:乱七八糟的网页格式。凌乱多变的网页格式可能是最常见的挑战,也可能不是最有趣的挑战,但却是迄今为止大规模数据提取面临的最大挑战。这个挑战的关键不是复杂性,而是需要大量的时间和资源来应对。
挑战 2:可扩展架构。您将面临的下一个挑战是构建一个爬虫基础设施,该基础设施可以随着每天请求数量的增加而扩展,而不会降低性能。
在大规模提取产品数据时,简单的网络爬虫只能连续爬取数据,不能提取。通常,连续的网络爬虫会一个接一个地循环发送请求,每个请求需要 2-3 秒才能完成。
如果爬虫每天少于40000个请求(每2秒发送一个请求,意味着每天可以发送43200个请求),这种方法是可以的。但是,一旦请求数量超过这个数量,就需要切换到每天可以发送数百万个请求而不降低性能的爬虫架构。
如上所述,速度是大规模捕获产品数据的关键。您需要确保在特定时间段(通常为一天)内找到并抓取所有需要的产品页面。为此,您需要执行以下操作:
将产品搜索与产品提取分开。为了大规模提取产品数据,您需要将产品搜索爬虫与产品提取爬虫分开。
为产品提取分配更多资源。由于每个产品类别“货架”可以收录10到100个产品,并且与提取产品URL相比,提取产品数据需要更多资源,因此搜索爬虫通常比产品提取爬虫更快。
挑战 3:保持吞吐量性能。在提取大量数据时,我们必须在现有硬件资源的基础上,尽可能地找到一种可以最小化循环时间并最大化爬虫性能的方法。所有这些都必须减少每个请求的时间,甚至几毫秒。
为此,您的团队需要深入了解网络抓取框架、代理管理和正在使用的硬件,以便更好地调整它们以获得最佳性能。
在大规模抓取时,我们应该始终努力在最少的请求中提取所需的确切数据。任何额外的请求或数据提取都会降低爬取网站的速度。
在设计爬虫时,请记住以下几点:
1、 用一个没有头的浏览器,比如Splash或者Puppeteer,把JavaScript渲染放在最后。抓取网页时,使用无头浏览器渲染JavaScript会非常占用资源,严重影响抓取速度;
2、 如果不需要向每个产品页面发送请求,但也可以从货架页面获取数据(如产品名称、价格、口碑等),则不要请求该产品页;
3、除非必要,否则不要请求或检索图像。
挑战四:反机器人策略。在大规模爬取电商网站时,你肯定会遇到使用反机器人策略的网站。
对于大多数小网站来说,他们的反机器人策略是非常基础的(IP禁止过度请求)。但是对于亚马逊网站这样的大型电商公司,他们会使用非常成熟的反机器人策略,比如DistilNetworks、Incapsula或者Akamai,这会让数据提取变得更加困难。
挑战 5:数据质量。从数据科学家的角度来看,网络抓取项目最重要的考虑因素是提取数据的质量。大规模爬取更注重数据的质量。
如果每天需要提取数百万个数据点,则无法手动验证所有数据是否干净完整。小心脏数据或不完整的数据会进入数据源,破坏数据分析工作。
当商店有多个版本(不同语言、地区等)或从不同商店抓取数据时,数据质量尤为重要。
除了仔细的QA流程,在创建爬虫的设计阶段,相互审查和测试爬虫代码可以确保以最可靠的方式提取所需的数据。确保高数据质量的最佳方法是开发自动化 QA 监控系统。
以上是小编为大家整理的《千亿页数据提取经验总结》一文。更多相关信息可以在数据分析教程频道中找到。 查看全部
java从网页抓取数据(从千亿页面上提取数据该如何做呢?(图))
众所周知,要想更好地完成数据分析,除了掌握好方法和方法,还需要做好数据提取。那么如何从千亿页面中提取数据呢?

现在从互联网上获取数据似乎很容易。有很多开源的库和框架,可视化爬虫工具和数据提取工具,可以很方便的从一个网站中抓取数据。然而,当你想大规模搜索网站时,很快就变得非常棘手。
大规模网络爬虫的要点:
不同于标准的网络爬虫应用,电子商务产品数据的大规模爬取将面临一系列独特的挑战,这使得网络爬行变得异常困难。
本质上,这些困难可以归结为两个方面:速度和数据质量。
通常时间是一个限制性的约束,所以大规模的抓取需要网络爬虫以非常高的速度抓取页面,并且不会影响数据质量。这种对速度的要求使得捕获大量产品数据变得非常具有挑战性。
挑战一:乱七八糟的网页格式。凌乱多变的网页格式可能是最常见的挑战,也可能不是最有趣的挑战,但却是迄今为止大规模数据提取面临的最大挑战。这个挑战的关键不是复杂性,而是需要大量的时间和资源来应对。

挑战 2:可扩展架构。您将面临的下一个挑战是构建一个爬虫基础设施,该基础设施可以随着每天请求数量的增加而扩展,而不会降低性能。
在大规模提取产品数据时,简单的网络爬虫只能连续爬取数据,不能提取。通常,连续的网络爬虫会一个接一个地循环发送请求,每个请求需要 2-3 秒才能完成。
如果爬虫每天少于40000个请求(每2秒发送一个请求,意味着每天可以发送43200个请求),这种方法是可以的。但是,一旦请求数量超过这个数量,就需要切换到每天可以发送数百万个请求而不降低性能的爬虫架构。
如上所述,速度是大规模捕获产品数据的关键。您需要确保在特定时间段(通常为一天)内找到并抓取所有需要的产品页面。为此,您需要执行以下操作:
将产品搜索与产品提取分开。为了大规模提取产品数据,您需要将产品搜索爬虫与产品提取爬虫分开。
为产品提取分配更多资源。由于每个产品类别“货架”可以收录10到100个产品,并且与提取产品URL相比,提取产品数据需要更多资源,因此搜索爬虫通常比产品提取爬虫更快。

挑战 3:保持吞吐量性能。在提取大量数据时,我们必须在现有硬件资源的基础上,尽可能地找到一种可以最小化循环时间并最大化爬虫性能的方法。所有这些都必须减少每个请求的时间,甚至几毫秒。
为此,您的团队需要深入了解网络抓取框架、代理管理和正在使用的硬件,以便更好地调整它们以获得最佳性能。
在大规模抓取时,我们应该始终努力在最少的请求中提取所需的确切数据。任何额外的请求或数据提取都会降低爬取网站的速度。
在设计爬虫时,请记住以下几点:
1、 用一个没有头的浏览器,比如Splash或者Puppeteer,把JavaScript渲染放在最后。抓取网页时,使用无头浏览器渲染JavaScript会非常占用资源,严重影响抓取速度;
2、 如果不需要向每个产品页面发送请求,但也可以从货架页面获取数据(如产品名称、价格、口碑等),则不要请求该产品页;
3、除非必要,否则不要请求或检索图像。
挑战四:反机器人策略。在大规模爬取电商网站时,你肯定会遇到使用反机器人策略的网站。
对于大多数小网站来说,他们的反机器人策略是非常基础的(IP禁止过度请求)。但是对于亚马逊网站这样的大型电商公司,他们会使用非常成熟的反机器人策略,比如DistilNetworks、Incapsula或者Akamai,这会让数据提取变得更加困难。
挑战 5:数据质量。从数据科学家的角度来看,网络抓取项目最重要的考虑因素是提取数据的质量。大规模爬取更注重数据的质量。
如果每天需要提取数百万个数据点,则无法手动验证所有数据是否干净完整。小心脏数据或不完整的数据会进入数据源,破坏数据分析工作。
当商店有多个版本(不同语言、地区等)或从不同商店抓取数据时,数据质量尤为重要。
除了仔细的QA流程,在创建爬虫的设计阶段,相互审查和测试爬虫代码可以确保以最可靠的方式提取所需的数据。确保高数据质量的最佳方法是开发自动化 QA 监控系统。
以上是小编为大家整理的《千亿页数据提取经验总结》一文。更多相关信息可以在数据分析教程频道中找到。
java从网页抓取数据(一个-1.11.1.jarokio-3.12.0.jar-1.12.0.jar●jsoup使用文档 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-09-26 16:41
)
目录
目录
前言
最近,我想建立一个视频播放应用程序,可以播放电影和电视剧。结果,我在互联网上搜索了API接口,发现虽然爱奇艺提供的视频接口和其他视频网站可以使用,但是注册和审核应用程序的步骤很繁琐,它们的API不能在我自己的播放器中播放,,但我必须使用java编写一个程序来获取网页数据,以满足我的需要。这里我记录了实施过程
前期准备
● 所需的jar包:
jsoup-1.11.1.雅鲁藏布江http-3.12.0.雅鲁藏布江-1.12.0.雅鲁藏布江
● jsoup使用文档:
案例实现
public class Test {
private static final String BASE_URL="http://www.baiwanzy.com";//这里使用的是百万资源网的资源
public static void main(String[] args) {
asyncGet();
}
public static void asyncGet() {
String encode = URLEncoder.encode("雪鹰领主");//对查询的数据进行Url编码
String urlBaidu = "http://www.baiwanzy.com/index. ... de%3B
OkHttpClient okHttpClient = new OkHttpClient(); // 创建OkHttpClient对象
Request request = new Request.Builder().url(urlBaidu).build(); // 创建一个请求
okHttpClient.newCall(request).enqueue(new Callback() { // 回调
public void onResponse(Call call, Response response) throws IOException {
// 请求成功调用,该回调在子线程
getMovieList(response.body().string());
}
public void onFailure(Call call, IOException e) {
// 请求失败调用
System.out.println(e.getMessage());
}
});
}
public static void getMovieList(String datas){
Document doc = Jsoup.parse(datas);
// 根据css的后代选择器来找到相关的列表
Elements links = doc.select(".xing_vb4 a");//这里是返回的列表的类来查找相关的a标签
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
System.out.println(BASE_URL+linkHref+"==="+linkText);
}
}
} 查看全部
java从网页抓取数据(一个-1.11.1.jarokio-3.12.0.jar-1.12.0.jar●jsoup使用文档
)
目录

目录
前言
最近,我想建立一个视频播放应用程序,可以播放电影和电视剧。结果,我在互联网上搜索了API接口,发现虽然爱奇艺提供的视频接口和其他视频网站可以使用,但是注册和审核应用程序的步骤很繁琐,它们的API不能在我自己的播放器中播放,,但我必须使用java编写一个程序来获取网页数据,以满足我的需要。这里我记录了实施过程
前期准备
● 所需的jar包:
jsoup-1.11.1.雅鲁藏布江http-3.12.0.雅鲁藏布江-1.12.0.雅鲁藏布江
● jsoup使用文档:
案例实现
public class Test {
private static final String BASE_URL="http://www.baiwanzy.com";//这里使用的是百万资源网的资源
public static void main(String[] args) {
asyncGet();
}
public static void asyncGet() {
String encode = URLEncoder.encode("雪鹰领主");//对查询的数据进行Url编码
String urlBaidu = "http://www.baiwanzy.com/index. ... de%3B
OkHttpClient okHttpClient = new OkHttpClient(); // 创建OkHttpClient对象
Request request = new Request.Builder().url(urlBaidu).build(); // 创建一个请求
okHttpClient.newCall(request).enqueue(new Callback() { // 回调
public void onResponse(Call call, Response response) throws IOException {
// 请求成功调用,该回调在子线程
getMovieList(response.body().string());
}
public void onFailure(Call call, IOException e) {
// 请求失败调用
System.out.println(e.getMessage());
}
});
}
public static void getMovieList(String datas){
Document doc = Jsoup.parse(datas);
// 根据css的后代选择器来找到相关的列表
Elements links = doc.select(".xing_vb4 a");//这里是返回的列表的类来查找相关的a标签
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
System.out.println(BASE_URL+linkHref+"==="+linkText);
}
}
}
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-09-26 14:06
原创链接:
有时由于各种原因,我们需要一些采集数据,但由于不同网站
本文使用Java向您展示如何抓取网站的数据:(1)抓取原创网页的数据;(2)抓取网页JavaScript返回的数据
一、抓取原创页面
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此网页,输入IP:111.142.55.73,然后单击查询按钮查看网页上显示的结果:
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
[爪哇]
publicvoidcaptureHtml(Stringip)通过异常{StringstrURL=“”+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferer=newBufferedReader(input);Stringline=“;StringBuildercontentBuf=newStringBuilder();而(((line=bufrader.Readline())!=null){contentbuf.Append(line);}stringbuf=contentbuf.Tostring();intbeginix=buf.Indexof(“查询结果[”);intendix=buf.Indexof(“上述四项依次显示”);stringresult=buf.Substring(beginix,endix);system.Out.Println(“capturehtml的结果:”“n”+结果);]
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111.142.55.73==>;1871591241==>;福建省漳州移动
二、在网页上抓取JavaScript返回的结果
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这可以避免搜索引擎和其他工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
[爪哇]
publicvoidcaptureJavascript(Stringpostid)通过异常{StringstrURL=“”+postid+”&;channel=&;rnd=0;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferReader=NewBuffereder(input);Stringline=”“stringbuildercontentbuf=newstringbuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}system.Out.Println(“capturejavascript()的结果:\n”+contentbuf.Tostring());”
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载 查看全部
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
原创链接:
有时由于各种原因,我们需要一些采集数据,但由于不同网站
本文使用Java向您展示如何抓取网站的数据:(1)抓取原创网页的数据;(2)抓取网页JavaScript返回的数据
一、抓取原创页面
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此网页,输入IP:111.142.55.73,然后单击查询按钮查看网页上显示的结果:
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
[爪哇]
publicvoidcaptureHtml(Stringip)通过异常{StringstrURL=“”+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferer=newBufferedReader(input);Stringline=“;StringBuildercontentBuf=newStringBuilder();而(((line=bufrader.Readline())!=null){contentbuf.Append(line);}stringbuf=contentbuf.Tostring();intbeginix=buf.Indexof(“查询结果[”);intendix=buf.Indexof(“上述四项依次显示”);stringresult=buf.Substring(beginix,endix);system.Out.Println(“capturehtml的结果:”“n”+结果);]
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111.142.55.73==>;1871591241==>;福建省漳州移动
二、在网页上抓取JavaScript返回的结果
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这可以避免搜索引擎和其他工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
[爪哇]
publicvoidcaptureJavascript(Stringpostid)通过异常{StringstrURL=“”+postid+”&;channel=&;rnd=0;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferReader=NewBuffereder(input);Stringline=”“stringbuildercontentbuf=newstringbuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}system.Out.Println(“capturejavascript()的结果:\n”+contentbuf.Tostring());”
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载
java从网页抓取数据(怎样抓取站点的数据:(1)抓取原网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-09-23 07:21
说明链接:
有时,由于各种原因,我们必须采集某个站点的数据,但由于不同的网站与数据显示略有不同!
本文使用Java来演示如何抓取网站的数据:( 1)抓取原创网页数据;(2)抓取Web JavaScript返回的数据。
一、 grab原创网页。
此示例我们将从顶部抓取IP查询的结果:
第一步:打开此页面,然后输入IP:11 1. 14 2. 5. 73,单击“查询”按钮,您可以看到Web显示的结果:
步骤2:查看Web源代码,我们在源代码中看到这样的段落:
可以从这里看出,查询的结果再次在另一个请求之后再次显示。
查询后查看Web地址:
也就是说,我们只需访问这样一个URL的形式,您可以获得IP查询的结果,代码旁边:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpUrlConnection连接站点保存Bufreader返回的数据,然后通过解决您自己的定义来显示结果。
我只是一个偶然的解决方案。如果要解决它,则需要重新处理它。
解析结果,例如:
capturehtml()结果:
查询结果[1]:11 1. 14 2. 5 5. 73 ==&gt; &gt; 1871591241 ==&gt; &gt;福建省漳州移动
二、 crawler页面javascript返回的结果。
有时该网站是保护自己的数据,也不会直接将数据直接放在Web源代码中,但使用异步方式,用JS返回数据,这避免了搜索引擎和其他工具来捕获网站数据。 。
首先查看此页面:
以第一种方式查看网页的源代码,但没有Waybill的跟踪信息,因为它通过JS获取结果。
但有时我们必须得到JS的数据,我该怎么做?
我们必须使用工具:HTTP分析仪,此工具可以拦截HTTP的互动内容,我们通过此工具实现了我们的目标。
单击startButton后,它开始收听网页的交互行为。
我们打开页面:您可以看到HTTP分析仪列出所有请求数据和结果:
对于JS的结果更方便,让我们先将数据输入数据,然后在网页上输入快递号码:7,单击“查询”按钮,然后查看HTTP分析器的结果:
这是点击查询按钮,HTTP分析仪的结果,我们继续查看:
从上面的两个图表可以看出,HTTP分析器可以拦截JS返回的数据并在响应内容中显示,并且可以同时看到JS请求的网页地址。
在这种情况下,我们只想分析HTTP分析仪的结果,然后模拟JS的行为来获取数据,即我们只想访问JS的Web地址,当然,数据未加密我们将写下URL:
js请求。
然后让程序请求此页面的结果!
以下是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
参见它,抓住js模式和捕获原创网页的代码,我们只有一个分析js的过程。
以下是程序运行的结果:
capturejavascript()结果:
Waybill [7]跟踪信息
这些数据是JS返回的结果,我们的目的是达到的!
我希望这篇文章有点帮助所需的朋友,请点击这里下载! 查看全部
java从网页抓取数据(怎样抓取站点的数据:(1)抓取原网页数据)
说明链接:
有时,由于各种原因,我们必须采集某个站点的数据,但由于不同的网站与数据显示略有不同!
本文使用Java来演示如何抓取网站的数据:( 1)抓取原创网页数据;(2)抓取Web JavaScript返回的数据。
一、 grab原创网页。
此示例我们将从顶部抓取IP查询的结果:
第一步:打开此页面,然后输入IP:11 1. 14 2. 5. 73,单击“查询”按钮,您可以看到Web显示的结果:
步骤2:查看Web源代码,我们在源代码中看到这样的段落:
可以从这里看出,查询的结果再次在另一个请求之后再次显示。
查询后查看Web地址:
也就是说,我们只需访问这样一个URL的形式,您可以获得IP查询的结果,代码旁边:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpUrlConnection连接站点保存Bufreader返回的数据,然后通过解决您自己的定义来显示结果。
我只是一个偶然的解决方案。如果要解决它,则需要重新处理它。
解析结果,例如:
capturehtml()结果:
查询结果[1]:11 1. 14 2. 5 5. 73 ==&gt; &gt; 1871591241 ==&gt; &gt;福建省漳州移动
二、 crawler页面javascript返回的结果。
有时该网站是保护自己的数据,也不会直接将数据直接放在Web源代码中,但使用异步方式,用JS返回数据,这避免了搜索引擎和其他工具来捕获网站数据。 。
首先查看此页面:
以第一种方式查看网页的源代码,但没有Waybill的跟踪信息,因为它通过JS获取结果。
但有时我们必须得到JS的数据,我该怎么做?
我们必须使用工具:HTTP分析仪,此工具可以拦截HTTP的互动内容,我们通过此工具实现了我们的目标。
单击startButton后,它开始收听网页的交互行为。
我们打开页面:您可以看到HTTP分析仪列出所有请求数据和结果:
对于JS的结果更方便,让我们先将数据输入数据,然后在网页上输入快递号码:7,单击“查询”按钮,然后查看HTTP分析器的结果:
这是点击查询按钮,HTTP分析仪的结果,我们继续查看:
从上面的两个图表可以看出,HTTP分析器可以拦截JS返回的数据并在响应内容中显示,并且可以同时看到JS请求的网页地址。
在这种情况下,我们只想分析HTTP分析仪的结果,然后模拟JS的行为来获取数据,即我们只想访问JS的Web地址,当然,数据未加密我们将写下URL:
js请求。
然后让程序请求此页面的结果!
以下是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
参见它,抓住js模式和捕获原创网页的代码,我们只有一个分析js的过程。
以下是程序运行的结果:
capturejavascript()结果:
Waybill [7]跟踪信息
这些数据是JS返回的结果,我们的目的是达到的!
我希望这篇文章有点帮助所需的朋友,请点击这里下载!
java从网页抓取数据(使用Python网络爬虫首先需要了解一下什么是HTTP的请求与响应)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-09-21 19:01
使用Python网络爬虫首先需要了解一下什么是HTTP,因为这个跟Python爬虫的基本原理息息相关。而正是围绕着这些底层逻辑,Python爬虫才能一步步地往下进行。
HTTP全称是Hyper Text Transfer Protocol,中文叫超文本传输协议,用于从网络传输超文本数据到本地浏览器的传送协议,也是因特网上应用最为广泛的一种网络传输协议。
请求与响应
当我们从浏览器输入URL回车之后,浏览器就会向网站所在的服务器发送一个请求,服务器收到请求后对其进行解析和处理,然后返回浏览器对应的响应,响应里收录了页面的源代码等内容,经过浏览器的解析之后便呈现出我们在浏览器上看到的内容。这整个过程就是HTTP的请求与响应。
请求方法常见的请求方法有两种:GET和POST。二者的主要区别在于GET请求的内容会体现在URL里,POST请求则体现在表单形式里,所以当涉及一些敏感或私密的信息时,如用户名和密码,我们用POST请求来进行信息的传递。
响应状态码请求完之后,客户端会收到服务器返回的响应状态,常见的响应状态码有200(服务器正常响应)、404(页面未找到)、500(服务器内部发生错误)等。
2.网页
在爬虫时,我们通过响应得到的网页源代码、JSON数据等来提取需要的信息数据,所以我们需要了解一下网页的基础结构。一个网页基本由以下三部分组成:
HTML,全称Hyper Text Marked Language,中文叫超文本标记语言,用来表述网页以呈现出内容,如文字,图片,视频等,相当于网页的骨架。
JavaScript,简称JS,是一种脚本语言,能够给页面增加实时、动态、交互的功能,相当于网页的肌肉。
CSS,全称Cascading Style Sheets,中文叫层叠样式表,对网页页面进行布局和装饰,使页面变得美观、优雅,相当于网页的皮肤。
3.基本原理
Python爬虫的基本原理其实是围绕着HTTP和网页结构展开的:首先是请求网页,接着是解析和提取信息,最后是存储信息。
1) 请求
Python经常用来请求的第三方库有requests、selenium,内置的库也可以用urllib。
requests是用Python编写的,基于urllib,采用Apache2 Licensed开源协议的HTTP库。相比urllib库,requests库更加方便,可以节约我们大量工作,所以我们倾向于使用requests来请求网页。
selenium是一个用于web应用程序的自动化测试工具,它可以驱动浏览器执行特定的动作,如输入、点击、下拉等,就像真正的用户在操作一样,在爬虫中常用来解决JavaScript渲染问题。selenium可以支持多种浏览器,如Chrome,Firefox,Edge等。在通过selenium使用这些浏览器之前,需要配置好相关的浏览器驱动:
ChromeDriver:Chrome浏览器驱动
GeckoDriver:Firefox浏览器驱动
PhantomJS:无界面、可脚本编程的WebKit浏览器引擎
2)解析和提取
Python用来解析和提取信息的第三方库有BeautifulSoup、lxml、pyquery等。
每个库可以用不同的方法来提取数据:
BeautifulSoup:方法选择器find()和find_all()或CSS选择器
lxml:XPath
pyquery:CSS选择器
此外,还可以用正则表达式来提取自己想要的信息,有了它,字符串检索、替换和匹配都不在话下。
3)存储
将数据提取出之后就是对数据进行存储了。最简单的可以将数据保存为文本文件,如TXT文本、CSV文件、Excel文件、JSON文件等,也可以保存为二进制数据,如图片、音频、视频等,还可以保存到数据库中,如关系型数据库MySQL,非关系型数据库MongoDB、Redis等。
若是将数据存储为CSV文件、Excel文件和JSON文件则需要用到csv库、openpyxl库和json库。
4.静态网页爬取
了解完爬虫基本原理之后就可以爬取网页了,其中静态网页是最容易操作的。
对静态网页进行爬取,我们可以选择requests进行请求,得到网页源代码,接着使用BeautifulSoup进行解析和提取,最后选择合适的存储方法。
5.动态网页爬取
有时候在使用requests爬取网页的时候,会发现抓取的内容和浏览器显示的不一样,在浏览器里能看到要爬取的内容,但是爬取完之后的结果却没有,这就与网页是静态的还是动态的有关了。
静态网页是相对于动态网页而言,是指没有后台数据库、不含程序和不可交互的网页。而动态网页则是基本的html语法规范与Java、VB、VC等高级程序设计语言、数据库编程等多种技术的融合,以期实现对网站内容和风格的高效、动态和交互式的管理的网页。
二者的区别在于:
静态网页随着html代码的生成,页面的内容和显示效果基本上不会发生变化了——除非修改页面代码。
动态网页的页面代码虽然没有变,但是显示的内容却可以随着时间、环境或者数据库操作的结果而发生改变。
1)Ajax
Ajax不是一门编程语言,而是利用JavaScript在不重新加载整个页面的情况下可以与服务器交换数据并更新部分网页内容的技术。
因为使用Ajax技术的网页里的信息是通过JavaScript脚本语言动态生成的,所以使用requests-BeautifulSoup的静态页面的爬取方法是抓不到数据的,我们可以通过以下两种方法爬取Ajax数据:
通过查找浏览器开发者工具里的Network-XHR/JS栏找到储存着数据的动态页面,使用requests请求网页,再将得到的数据使用json()方法进行转化就可以提取了。
使用selenium指挥浏览器,直接对数据进行抓取(或者通过selenium获取到渲染完整的网页源代码,再使用BeautifulSoup进行解析和提取数据)。
2)Cookie和Session
Cookie是网站为了辨别用户身份进行Session跟踪而储存在用户本地终端上的数据(通常经过加密),由用户客户端计算机暂时或永久保存。
Session称为“会话”,存储着特定用户会话所需的属性及配置信息。
很多情况下,页面的更多信息需要登陆才能查看,所以在面对这类网页时,需要先模拟登陆后才可以对网页作进一步爬取。当我们模拟登陆时,客户端会生成Cookie并发送给服务器。因为Cookie保存着SessionID信息,所以服务器就可以根据Cookie判断出对应的SessionID,进而找到会话。如果当前的会话是有效的,那么服务器就会判断用户已经登陆并返回请求的页面信息,这样就可以对网页作进一步爬取了。
6.APP爬取
除了web端,Python还可以爬取APP数据,不过这需要用到抓包工具,比如Fiddler。
相比web端而言,APP的数据爬取其实更容易,反爬虫也没那么强,返回的数据类型大多数为json。
7.多协程
当我们在做爬虫项目的时候,如果需要爬取的数据非常多,因为程序是一行行依次执行的,所以爬取的速度就会非常慢。而多协程就能解决这一个问题。
使用多协程,我们就可以同时执行多个任务。实际上,使用多协程时,如果一个任务在执行的过程中遇到等待,那它就会先去执行其它的任务,当等待结束,再回来继续执行之前的那个任务。因为这个过程切换得非常迅速,所以看上去像多个任务被同时执行一样,用计算机里的概念来解释的话,这其实就是异步。
我们可以使用gevent库来实现多协程,使用Queue()创建队列,spawn()创建任务,最后joinall()执行任务。
8.爬虫框架
在遇到比较大型的需求时,为了方便管理及拓展,我们可以使用爬虫框架实现数据爬取。
有了爬虫框架之后,我们就不必一个个地去组建爬虫的整个流程,只需要关心爬虫的核心逻辑部分即可,这样就大大提高了开发效率,节省了很多时间。爬虫框架有很多个,如Scrapy、PySpider等。
9.分布式爬虫
使用爬虫框架已经大大提高了开发效率,不过这些框架都是在同一台主机上运行的,如果能多台主机协同爬取,那么爬取效率就会更近一步提高。将多台主机组合起来,共同完成一个爬取任务,这就是分布式爬虫。
10.反爬虫机制与应对方法
为了防止爬虫开发者过度爬取造成网站的负担或者进行恶意的数据抓取,很多网站会设置反爬虫机制。所以当我们在对网站进行数据抓取的时候,可以查看一下网站的robots.txt了解一下网站允许爬取什么,不允许爬取什么。
常见的爬虫机制有以下4种:
①请求头验证:请求头验证是最常见的反爬虫机制,很多网站会对Headers里的user-agent进行检测,一部分网站还会检测origin和referer。应对这类反爬虫机制可以在爬虫中添加请求头headers,将浏览器里对应的值以字典的形式添加进去即可。
②Cookie限制:有些网站会用Cookie跟踪你的访问过程,如果发现爬虫的异常行为就会中断该爬虫的访问。应对Cookie限制类的反爬虫,一般可以通过先取得该网站的Cookie,再把Cookie发送给服务器即可,可以手动添加或者使用Session机制。不过,针对部分网站需要用户浏览页面时才能产生Cookie的情况,比如点击按钮,可以使用selenium-PhantomJS来请求网页并获取Cookie。
③IP访问频率限制:一些网站会通过检测用户行为来判断同一IP是否在短时间内多次请求页面,如果这个频率超过了某个阈值,网站通常会对爬虫进行提示并要求输入验证码,或者直接封掉IP拒绝服务。针对这种情况,可以使用IP代理的方法来绕过反爬虫,如代理池维护、付费代理、ADSL拨号代理等。
④验证码限制:很多网站在登陆的时候需要输入验证码,常见的有:图形验证码、极验滑动验证码、点触验证码和宫格验证码。
图形验证码:需要用到OCR技术,使用Python的第三方库tesserocr可以做到这一点。
极验滑动验证码:需要使用selenium来完成模拟人的行为的方式来验证。
点触验证码:需要在使用selenium的基础上借助第三方验证码服务平台来解决。
宫格验证码:需要使用selenium和模板匹配的方法。
验证码类型 查看全部
java从网页抓取数据(使用Python网络爬虫首先需要了解一下什么是HTTP的请求与响应)
使用Python网络爬虫首先需要了解一下什么是HTTP,因为这个跟Python爬虫的基本原理息息相关。而正是围绕着这些底层逻辑,Python爬虫才能一步步地往下进行。
HTTP全称是Hyper Text Transfer Protocol,中文叫超文本传输协议,用于从网络传输超文本数据到本地浏览器的传送协议,也是因特网上应用最为广泛的一种网络传输协议。
请求与响应
当我们从浏览器输入URL回车之后,浏览器就会向网站所在的服务器发送一个请求,服务器收到请求后对其进行解析和处理,然后返回浏览器对应的响应,响应里收录了页面的源代码等内容,经过浏览器的解析之后便呈现出我们在浏览器上看到的内容。这整个过程就是HTTP的请求与响应。
请求方法常见的请求方法有两种:GET和POST。二者的主要区别在于GET请求的内容会体现在URL里,POST请求则体现在表单形式里,所以当涉及一些敏感或私密的信息时,如用户名和密码,我们用POST请求来进行信息的传递。
响应状态码请求完之后,客户端会收到服务器返回的响应状态,常见的响应状态码有200(服务器正常响应)、404(页面未找到)、500(服务器内部发生错误)等。
2.网页
在爬虫时,我们通过响应得到的网页源代码、JSON数据等来提取需要的信息数据,所以我们需要了解一下网页的基础结构。一个网页基本由以下三部分组成:
HTML,全称Hyper Text Marked Language,中文叫超文本标记语言,用来表述网页以呈现出内容,如文字,图片,视频等,相当于网页的骨架。
JavaScript,简称JS,是一种脚本语言,能够给页面增加实时、动态、交互的功能,相当于网页的肌肉。
CSS,全称Cascading Style Sheets,中文叫层叠样式表,对网页页面进行布局和装饰,使页面变得美观、优雅,相当于网页的皮肤。
3.基本原理
Python爬虫的基本原理其实是围绕着HTTP和网页结构展开的:首先是请求网页,接着是解析和提取信息,最后是存储信息。
1) 请求
Python经常用来请求的第三方库有requests、selenium,内置的库也可以用urllib。
requests是用Python编写的,基于urllib,采用Apache2 Licensed开源协议的HTTP库。相比urllib库,requests库更加方便,可以节约我们大量工作,所以我们倾向于使用requests来请求网页。
selenium是一个用于web应用程序的自动化测试工具,它可以驱动浏览器执行特定的动作,如输入、点击、下拉等,就像真正的用户在操作一样,在爬虫中常用来解决JavaScript渲染问题。selenium可以支持多种浏览器,如Chrome,Firefox,Edge等。在通过selenium使用这些浏览器之前,需要配置好相关的浏览器驱动:
ChromeDriver:Chrome浏览器驱动
GeckoDriver:Firefox浏览器驱动
PhantomJS:无界面、可脚本编程的WebKit浏览器引擎
2)解析和提取
Python用来解析和提取信息的第三方库有BeautifulSoup、lxml、pyquery等。
每个库可以用不同的方法来提取数据:
BeautifulSoup:方法选择器find()和find_all()或CSS选择器
lxml:XPath
pyquery:CSS选择器
此外,还可以用正则表达式来提取自己想要的信息,有了它,字符串检索、替换和匹配都不在话下。
3)存储
将数据提取出之后就是对数据进行存储了。最简单的可以将数据保存为文本文件,如TXT文本、CSV文件、Excel文件、JSON文件等,也可以保存为二进制数据,如图片、音频、视频等,还可以保存到数据库中,如关系型数据库MySQL,非关系型数据库MongoDB、Redis等。
若是将数据存储为CSV文件、Excel文件和JSON文件则需要用到csv库、openpyxl库和json库。
4.静态网页爬取
了解完爬虫基本原理之后就可以爬取网页了,其中静态网页是最容易操作的。
对静态网页进行爬取,我们可以选择requests进行请求,得到网页源代码,接着使用BeautifulSoup进行解析和提取,最后选择合适的存储方法。
5.动态网页爬取
有时候在使用requests爬取网页的时候,会发现抓取的内容和浏览器显示的不一样,在浏览器里能看到要爬取的内容,但是爬取完之后的结果却没有,这就与网页是静态的还是动态的有关了。
静态网页是相对于动态网页而言,是指没有后台数据库、不含程序和不可交互的网页。而动态网页则是基本的html语法规范与Java、VB、VC等高级程序设计语言、数据库编程等多种技术的融合,以期实现对网站内容和风格的高效、动态和交互式的管理的网页。
二者的区别在于:
静态网页随着html代码的生成,页面的内容和显示效果基本上不会发生变化了——除非修改页面代码。
动态网页的页面代码虽然没有变,但是显示的内容却可以随着时间、环境或者数据库操作的结果而发生改变。
1)Ajax
Ajax不是一门编程语言,而是利用JavaScript在不重新加载整个页面的情况下可以与服务器交换数据并更新部分网页内容的技术。
因为使用Ajax技术的网页里的信息是通过JavaScript脚本语言动态生成的,所以使用requests-BeautifulSoup的静态页面的爬取方法是抓不到数据的,我们可以通过以下两种方法爬取Ajax数据:
通过查找浏览器开发者工具里的Network-XHR/JS栏找到储存着数据的动态页面,使用requests请求网页,再将得到的数据使用json()方法进行转化就可以提取了。
使用selenium指挥浏览器,直接对数据进行抓取(或者通过selenium获取到渲染完整的网页源代码,再使用BeautifulSoup进行解析和提取数据)。
2)Cookie和Session
Cookie是网站为了辨别用户身份进行Session跟踪而储存在用户本地终端上的数据(通常经过加密),由用户客户端计算机暂时或永久保存。
Session称为“会话”,存储着特定用户会话所需的属性及配置信息。
很多情况下,页面的更多信息需要登陆才能查看,所以在面对这类网页时,需要先模拟登陆后才可以对网页作进一步爬取。当我们模拟登陆时,客户端会生成Cookie并发送给服务器。因为Cookie保存着SessionID信息,所以服务器就可以根据Cookie判断出对应的SessionID,进而找到会话。如果当前的会话是有效的,那么服务器就会判断用户已经登陆并返回请求的页面信息,这样就可以对网页作进一步爬取了。
6.APP爬取
除了web端,Python还可以爬取APP数据,不过这需要用到抓包工具,比如Fiddler。
相比web端而言,APP的数据爬取其实更容易,反爬虫也没那么强,返回的数据类型大多数为json。
7.多协程
当我们在做爬虫项目的时候,如果需要爬取的数据非常多,因为程序是一行行依次执行的,所以爬取的速度就会非常慢。而多协程就能解决这一个问题。
使用多协程,我们就可以同时执行多个任务。实际上,使用多协程时,如果一个任务在执行的过程中遇到等待,那它就会先去执行其它的任务,当等待结束,再回来继续执行之前的那个任务。因为这个过程切换得非常迅速,所以看上去像多个任务被同时执行一样,用计算机里的概念来解释的话,这其实就是异步。
我们可以使用gevent库来实现多协程,使用Queue()创建队列,spawn()创建任务,最后joinall()执行任务。
8.爬虫框架
在遇到比较大型的需求时,为了方便管理及拓展,我们可以使用爬虫框架实现数据爬取。
有了爬虫框架之后,我们就不必一个个地去组建爬虫的整个流程,只需要关心爬虫的核心逻辑部分即可,这样就大大提高了开发效率,节省了很多时间。爬虫框架有很多个,如Scrapy、PySpider等。
9.分布式爬虫
使用爬虫框架已经大大提高了开发效率,不过这些框架都是在同一台主机上运行的,如果能多台主机协同爬取,那么爬取效率就会更近一步提高。将多台主机组合起来,共同完成一个爬取任务,这就是分布式爬虫。
10.反爬虫机制与应对方法
为了防止爬虫开发者过度爬取造成网站的负担或者进行恶意的数据抓取,很多网站会设置反爬虫机制。所以当我们在对网站进行数据抓取的时候,可以查看一下网站的robots.txt了解一下网站允许爬取什么,不允许爬取什么。
常见的爬虫机制有以下4种:
①请求头验证:请求头验证是最常见的反爬虫机制,很多网站会对Headers里的user-agent进行检测,一部分网站还会检测origin和referer。应对这类反爬虫机制可以在爬虫中添加请求头headers,将浏览器里对应的值以字典的形式添加进去即可。
②Cookie限制:有些网站会用Cookie跟踪你的访问过程,如果发现爬虫的异常行为就会中断该爬虫的访问。应对Cookie限制类的反爬虫,一般可以通过先取得该网站的Cookie,再把Cookie发送给服务器即可,可以手动添加或者使用Session机制。不过,针对部分网站需要用户浏览页面时才能产生Cookie的情况,比如点击按钮,可以使用selenium-PhantomJS来请求网页并获取Cookie。
③IP访问频率限制:一些网站会通过检测用户行为来判断同一IP是否在短时间内多次请求页面,如果这个频率超过了某个阈值,网站通常会对爬虫进行提示并要求输入验证码,或者直接封掉IP拒绝服务。针对这种情况,可以使用IP代理的方法来绕过反爬虫,如代理池维护、付费代理、ADSL拨号代理等。
④验证码限制:很多网站在登陆的时候需要输入验证码,常见的有:图形验证码、极验滑动验证码、点触验证码和宫格验证码。
图形验证码:需要用到OCR技术,使用Python的第三方库tesserocr可以做到这一点。
极验滑动验证码:需要使用selenium来完成模拟人的行为的方式来验证。
点触验证码:需要在使用selenium的基础上借助第三方验证码服务平台来解决。
宫格验证码:需要使用selenium和模板匹配的方法。

验证码类型
java从网页抓取数据(怎样抓取站点的数据:(1)抓取原网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-09-21 18:19
原创链接:
有时,由于各种原因,我们需要采集一个站点的数据,但不同站点的数据显示方式略有不同
本文使用Java向您展示如何抓取站点的数据:(1)grab原创网页的数据;(2)grab网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:
第二步:检查网页源代码。我们可以看到源代码中有一段:
从这里可以看出,再次请求网页后会显示查询结果
我们来看看查询后的网址:
换言之,我们只能通过访问这样的网站才能得到IP查询的结果。接下来,请看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到站点,使用bufreader保存网页返回的数据,然后通过自定义解析方法显示结果
这里我只是随便分析一下。如果我想准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时候,为了保护自己的数据,网站不直接在网页源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:
第一种方法用于查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但是有时候我们非常需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
在第一次单击startbutton之后,它开始监视web页面的交互
当我们打开网页时,可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了便于查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们只需要分析HTTP analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址来获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两个豌豆一样,抓取JS的方法与原创网页完全相同。我们只是做了一个分析JS的过程
以下是该计划的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
我希望这篇文章能对有需要的朋友有所帮助。如果你需要程序源代码,请点击这里下载 查看全部
java从网页抓取数据(怎样抓取站点的数据:(1)抓取原网页数据)
原创链接:
有时,由于各种原因,我们需要采集一个站点的数据,但不同站点的数据显示方式略有不同
本文使用Java向您展示如何抓取站点的数据:(1)grab原创网页的数据;(2)grab网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:
第二步:检查网页源代码。我们可以看到源代码中有一段:
从这里可以看出,再次请求网页后会显示查询结果
我们来看看查询后的网址:
换言之,我们只能通过访问这样的网站才能得到IP查询的结果。接下来,请看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到站点,使用bufreader保存网页返回的数据,然后通过自定义解析方法显示结果
这里我只是随便分析一下。如果我想准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时候,为了保护自己的数据,网站不直接在网页源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:
第一种方法用于查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但是有时候我们非常需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
在第一次单击startbutton之后,它开始监视web页面的交互
当我们打开网页时,可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了便于查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们只需要分析HTTP analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址来获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两个豌豆一样,抓取JS的方法与原创网页完全相同。我们只是做了一个分析JS的过程
以下是该计划的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
我希望这篇文章能对有需要的朋友有所帮助。如果你需要程序源代码,请点击这里下载
java从网页抓取数据(什么是网页抓取?Web搜集如何工作?最可靠的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-09-21 18:16
什么是网络爬行
简言之,网络爬网允许您从网站提取数据,以便将其保存在计算机上的文件中,以便稍后在电子表格中访问。通常,您只能查看下载的网页,而不能提取数据。是的,其中一些可以手动复制,但此方法耗时且不可扩展。Web爬网从选定的页面提取可靠的数据,因此该过程完全自动化。接收到的数据可用于以后的商业智能。换句话说,人们可以处理任何类型的数据,因为到目前为止,web非常适合捕获大量数据和不同的数据类型。图像、文本、电子邮件甚至电话号码都将被提取出来,以满足您的业务需求。对于某些项目,可能需要特定数据,如财务数据、房地产数据、评论、价格或竞争对手数据。也可以使用网页捕获工具快速轻松地提取。但最重要的是,提取的数据最终将以您选择的格式获得。它可以是纯文本、JSON或CSV
网络采集是如何运作的
当然,提取数据的方法有很多,但下面是最简单、最可靠的方法。操作模式如下所示
1.request-response
任何网络爬虫(也称为“爬虫”)的第一步是从目标网站请求请求特定URL的内容。以HTML格式获取请求的信息。请记住,html是用于在网页上显示所有文本信息的文件类型
2.解析和提取
Html是一种结构简单明了的标记语言。解析适用于任何计算机语言,将代码视为一堆文本。它在内存中产生一种计算机可以理解和使用的结构。为了简单起见,我们可以说HTML解析需要HTML代码并提取相关信息——标题、段落、标题。链接和格式(如粗体文本)。因此,您只需要一个正则表达式来定义正则语言,这样正则表达式引擎就可以为该特定语言生成解析器。因此,模式匹配和文本提取是可能的
3.下载资料
最后一步-以您选择的格式(CSV、JSON或数据库)下载并保存数据。在它变得可访问之后,可以在其他程序中检索和实现它。换句话说,爬网不仅使您能够提取数据,还可以将其存储在本地中央数据库或电子表格中,并在以后需要时使用
网络搜索的先进技术
如今,计算机视觉技术和机器学习技术已经被用来从图像中识别和刮取数据,这与人类所能做的相似。所有的工作都很简单。机器系统学习有自己的分类,并被分配一个所谓的信心分数。它是统计可能性的度量。因此,如果认为分类是正确的,则意味着它非常接近训练数据中识别的模式。如果置信度得分过低,系统将启动新的搜索查询,以选择最可能收录先前请求的数据的文本堆。系统尝试从新文本中删除相关数据,并将原创数据中的数据与接收到的结果进行核对后。如果信心分数仍然过低,它将继续处理下一个拉取的文本
网络爬网的用途是什么
使用网络爬网的方法有很多,几乎可以在每个已知领域实现。然而,让我们仔细看看我们认为对于网络爬行
最有效的一些领域。
价格监测
竞争性定价是电子商务的主要策略。在这里取得成功的唯一方法是始终跟踪竞争对手及其定价策略。解析的数据可以帮助您定义自己的定价策略。它比手动比较和分析快得多。在价格监控方面,网络爬虫非常有效
领先一步
营销对于任何企业都是必不可少的。为了使营销策略成功,不仅需要获得相关方的联系信息,还需要联系他们。这是潜在客户开发的本质。网页爬行可以改进该过程并使其更高效。潜在客户是加速营销活动的第一件事。为了吸引目标受众,您可能需要大量数据,如电话号码、电子邮件等。当然,不可能在网络上的数千网站上手动采集数据。但是网络爬虫对你很有帮助!它提取数据。这一过程不仅准确、快速,而且只需要一小部分时间。收到的数据可以轻松集成到您的销售工具中
竞争分析
竞争一直是任何企业的血肉之躯,但今天,了解竞争对手是非常重要的。它使我们能够更有效地了解它们的优缺点、策略和评估风险。当然,只有大量的相关数据才有可能。网络爬行在这方面也有帮助。任何战略都是从分析开始的。但如何处理各地的数据呢?有时你甚至无法手动访问它。如果很难手动完成,请使用网页爬网。这为您提供了几乎立即开始工作所需的数据。这里的优势是——抓取工具的速度越快,竞争分析就越好
提取图像和产品描述
当客户进入任何电子商务网站时,他首先看到的是视觉内容,如图片和视频。但是你如何在一夜之间创造出所有数量的产品描述和图片呢?用网页抓取它。因此,当你想到开始一个新的电子商务网站想法时,你会遇到内容问题——图片描述等。雇佣某人从头开始复制、粘贴或编写内容的旧方法可能会奏效,但可能不会永远持续下去。请改用网络爬网并查看结果。换句话说,网络爬行让你的电子商务网站所有者的生活更轻松
爬行软件合法吗
网络爬虫软件是处理数据的——从技术上讲,它是一个数据提取的过程。但如果它受到法律或版权的保护呢?自然产生的第一个问题是“它合法吗”?这个问题很难解决。到目前为止,即使是在各个层面,也没有明确的意见。以下是需要考虑的几点:
1、公共数据可以不受任何限制地丢弃。但是,如果您输入私人数据,可能会给您带来麻烦
2、出于商业目的滥用或使用个人数据是侵犯隐私的最佳方式,因此请避免使用它
3、删除受版权保护的数据是非法和不道德的
4、为了安全起见,请遵守robots.txt的要求和服务条款(TOS)
5、您也可以使用API抓取
6、将爬坡速度视为10-15秒。否则,可能会阻止您继续进行下一步
7、如果你想确保安全,请不要频繁访问服务器,也不要以攻击性的方式处理网络爬网
网络搜索面临的挑战
Web爬行在某些方面具有挑战性,尽管它通常相对简单。您可能遇到的主要挑战如下所示:
1.频繁的结构变化
在你设置刮板之前,大型游戏不会开始。换句话说,设置工具是第一步,因此您将面临一些意想不到的挑战:
所有网站都在不断更新其用户界面和功能。这意味着网站结构在不断变化。就爬虫而言,只要记住现有结构,任何更改都可能破坏您的计划。当相应地更改搜索者时,此问题将得到解决。因此,为了获得完整的相关数据,应在结构发生变化后立即不断更换刮板
2.蜜罐陷阱
请记住,所有收录敏感数据的网站都会采取预防措施,以这种方式保护数据。它们被称为蜜罐。这意味着您的所有网络爬网工作都可能被阻止。请试着找出这次出了什么问题。蜜罐是可供爬虫访问的链接,但已开发用于检测爬虫并防止它们提取数据。在大多数情况下,它们是CSS样式设置为display:none的链接。另一种隐藏它们的方法是将它们从可见区域中移除或使它们具有背景色。当您的搜索者被“捕获”时,IP将被标记,甚至被阻止。深层目录树是检测搜索者的另一种方法。因此,必须限制检索的页面数或遍历深度
3.scrapper技巧
scraper技术的发展与web技术一样快,因为有很多数据不应该共享,这是很好的。然而,如果不牢记这一点,它最终可能会被阻止。以下是您应该知道的最基本要点的简短列表:
网站越大,保护数据和定义爬虫就越好。例如,LinkedIn、StubHub和CrunchBase使用了强大的反爬网技术
对于这种网站,可以通过使用动态编码算法和IP阻塞机制来防止漫游访问来实现
显然,这是一个巨大的挑战——应该避免阻塞,因此解决方案在各个方面都成为一个耗时且相当昂贵的项目
4.数据质量
获取数据只是要达到的目的之一。为了有效地工作,数据应该是干净和准确的。换言之,如果数据不完整或有很多错误,它是无用的。从业务的角度来看,数据质量是主要的标准,到一天结束时,您需要准备好数据以供使用
<p> 查看全部
java从网页抓取数据(什么是网页抓取?Web搜集如何工作?最可靠的方法)
什么是网络爬行
简言之,网络爬网允许您从网站提取数据,以便将其保存在计算机上的文件中,以便稍后在电子表格中访问。通常,您只能查看下载的网页,而不能提取数据。是的,其中一些可以手动复制,但此方法耗时且不可扩展。Web爬网从选定的页面提取可靠的数据,因此该过程完全自动化。接收到的数据可用于以后的商业智能。换句话说,人们可以处理任何类型的数据,因为到目前为止,web非常适合捕获大量数据和不同的数据类型。图像、文本、电子邮件甚至电话号码都将被提取出来,以满足您的业务需求。对于某些项目,可能需要特定数据,如财务数据、房地产数据、评论、价格或竞争对手数据。也可以使用网页捕获工具快速轻松地提取。但最重要的是,提取的数据最终将以您选择的格式获得。它可以是纯文本、JSON或CSV
网络采集是如何运作的
当然,提取数据的方法有很多,但下面是最简单、最可靠的方法。操作模式如下所示

1.request-response
任何网络爬虫(也称为“爬虫”)的第一步是从目标网站请求请求特定URL的内容。以HTML格式获取请求的信息。请记住,html是用于在网页上显示所有文本信息的文件类型
2.解析和提取
Html是一种结构简单明了的标记语言。解析适用于任何计算机语言,将代码视为一堆文本。它在内存中产生一种计算机可以理解和使用的结构。为了简单起见,我们可以说HTML解析需要HTML代码并提取相关信息——标题、段落、标题。链接和格式(如粗体文本)。因此,您只需要一个正则表达式来定义正则语言,这样正则表达式引擎就可以为该特定语言生成解析器。因此,模式匹配和文本提取是可能的
3.下载资料
最后一步-以您选择的格式(CSV、JSON或数据库)下载并保存数据。在它变得可访问之后,可以在其他程序中检索和实现它。换句话说,爬网不仅使您能够提取数据,还可以将其存储在本地中央数据库或电子表格中,并在以后需要时使用
网络搜索的先进技术

如今,计算机视觉技术和机器学习技术已经被用来从图像中识别和刮取数据,这与人类所能做的相似。所有的工作都很简单。机器系统学习有自己的分类,并被分配一个所谓的信心分数。它是统计可能性的度量。因此,如果认为分类是正确的,则意味着它非常接近训练数据中识别的模式。如果置信度得分过低,系统将启动新的搜索查询,以选择最可能收录先前请求的数据的文本堆。系统尝试从新文本中删除相关数据,并将原创数据中的数据与接收到的结果进行核对后。如果信心分数仍然过低,它将继续处理下一个拉取的文本
网络爬网的用途是什么

使用网络爬网的方法有很多,几乎可以在每个已知领域实现。然而,让我们仔细看看我们认为对于网络爬行
最有效的一些领域。
价格监测
竞争性定价是电子商务的主要策略。在这里取得成功的唯一方法是始终跟踪竞争对手及其定价策略。解析的数据可以帮助您定义自己的定价策略。它比手动比较和分析快得多。在价格监控方面,网络爬虫非常有效
领先一步
营销对于任何企业都是必不可少的。为了使营销策略成功,不仅需要获得相关方的联系信息,还需要联系他们。这是潜在客户开发的本质。网页爬行可以改进该过程并使其更高效。潜在客户是加速营销活动的第一件事。为了吸引目标受众,您可能需要大量数据,如电话号码、电子邮件等。当然,不可能在网络上的数千网站上手动采集数据。但是网络爬虫对你很有帮助!它提取数据。这一过程不仅准确、快速,而且只需要一小部分时间。收到的数据可以轻松集成到您的销售工具中
竞争分析
竞争一直是任何企业的血肉之躯,但今天,了解竞争对手是非常重要的。它使我们能够更有效地了解它们的优缺点、策略和评估风险。当然,只有大量的相关数据才有可能。网络爬行在这方面也有帮助。任何战略都是从分析开始的。但如何处理各地的数据呢?有时你甚至无法手动访问它。如果很难手动完成,请使用网页爬网。这为您提供了几乎立即开始工作所需的数据。这里的优势是——抓取工具的速度越快,竞争分析就越好
提取图像和产品描述
当客户进入任何电子商务网站时,他首先看到的是视觉内容,如图片和视频。但是你如何在一夜之间创造出所有数量的产品描述和图片呢?用网页抓取它。因此,当你想到开始一个新的电子商务网站想法时,你会遇到内容问题——图片描述等。雇佣某人从头开始复制、粘贴或编写内容的旧方法可能会奏效,但可能不会永远持续下去。请改用网络爬网并查看结果。换句话说,网络爬行让你的电子商务网站所有者的生活更轻松
爬行软件合法吗
网络爬虫软件是处理数据的——从技术上讲,它是一个数据提取的过程。但如果它受到法律或版权的保护呢?自然产生的第一个问题是“它合法吗”?这个问题很难解决。到目前为止,即使是在各个层面,也没有明确的意见。以下是需要考虑的几点:
1、公共数据可以不受任何限制地丢弃。但是,如果您输入私人数据,可能会给您带来麻烦
2、出于商业目的滥用或使用个人数据是侵犯隐私的最佳方式,因此请避免使用它
3、删除受版权保护的数据是非法和不道德的
4、为了安全起见,请遵守robots.txt的要求和服务条款(TOS)
5、您也可以使用API抓取
6、将爬坡速度视为10-15秒。否则,可能会阻止您继续进行下一步
7、如果你想确保安全,请不要频繁访问服务器,也不要以攻击性的方式处理网络爬网
网络搜索面临的挑战

Web爬行在某些方面具有挑战性,尽管它通常相对简单。您可能遇到的主要挑战如下所示:
1.频繁的结构变化
在你设置刮板之前,大型游戏不会开始。换句话说,设置工具是第一步,因此您将面临一些意想不到的挑战:
所有网站都在不断更新其用户界面和功能。这意味着网站结构在不断变化。就爬虫而言,只要记住现有结构,任何更改都可能破坏您的计划。当相应地更改搜索者时,此问题将得到解决。因此,为了获得完整的相关数据,应在结构发生变化后立即不断更换刮板
2.蜜罐陷阱
请记住,所有收录敏感数据的网站都会采取预防措施,以这种方式保护数据。它们被称为蜜罐。这意味着您的所有网络爬网工作都可能被阻止。请试着找出这次出了什么问题。蜜罐是可供爬虫访问的链接,但已开发用于检测爬虫并防止它们提取数据。在大多数情况下,它们是CSS样式设置为display:none的链接。另一种隐藏它们的方法是将它们从可见区域中移除或使它们具有背景色。当您的搜索者被“捕获”时,IP将被标记,甚至被阻止。深层目录树是检测搜索者的另一种方法。因此,必须限制检索的页面数或遍历深度
3.scrapper技巧
scraper技术的发展与web技术一样快,因为有很多数据不应该共享,这是很好的。然而,如果不牢记这一点,它最终可能会被阻止。以下是您应该知道的最基本要点的简短列表:
网站越大,保护数据和定义爬虫就越好。例如,LinkedIn、StubHub和CrunchBase使用了强大的反爬网技术
对于这种网站,可以通过使用动态编码算法和IP阻塞机制来防止漫游访问来实现
显然,这是一个巨大的挑战——应该避免阻塞,因此解决方案在各个方面都成为一个耗时且相当昂贵的项目
4.数据质量
获取数据只是要达到的目的之一。为了有效地工作,数据应该是干净和准确的。换言之,如果数据不完整或有很多错误,它是无用的。从业务的角度来看,数据质量是主要的标准,到一天结束时,您需要准备好数据以供使用
<p>
java从网页抓取数据(如何使用Java/Python访问网页和使用Python进行数据解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-09-21 18:14
前言:
网络爬虫看起来仍然很神奇。然而,如果你想一想或者做一些研究,你就会知道爬行动物并没有那么先进。深刻的是,当我们有大量的数据时,即当我们的网络“图”中有越来越多的循环时,我们应该如何解决它
此物品文章仅用于吸引翡翠。本文主要介绍如何使用Java/Python访问web页面并获取web页面代码,Python模仿浏览器访问web页面,并使用Python分析数据。我希望我们能从这篇文章开始,一步一步地解决蜘蛛网神秘的一面
参考:
1.“编写自己的网络爬虫”
2.使用Python编写爬虫程序,爬升CSDN内容,完美解决403问题
运行效果图:
有很多内容。我只选择了一些来显示
作者环境:
系统:Windows7
CentOS6.5
操作环境:JDK1.7
Python2.6.6
IDE:EclipseRelease@k282.0
PyCharm4.5.1
数据库:mysqlver14.14 Distrib@k311.73
开发过程:1.使用java抓取页面
对于页面捕获,我们使用java来实现它。当然,您可以使用其他语言来开发它。但是
以“博客公园”主页为例,展示了使用Java捕获网页的过程:
public class RetrivePageSimple {
private static HttpClient httpClient = new HttpClient();
// 设置代理服务器
static {
httpClient.getHostConfiguration().setProxy("58.220.2.132", 80);
}
public static boolean downloadPage(String path) throws HttpException,
IOException {
PostMethod postMethod = new PostMethod(path);
// 执行,返回状态码
int statusCode = httpClient.executeMethod(postMethod);
System.out.println(statusCode);
// 针对状态码进行处理 (简单起见,只处理返回值为200的状态码)
if (statusCode == HttpStatus.SC_OK) {
String a = postMethod.getResponseBodyAsString();
System.out.println(a);
return true;
}
return false;
}
public static void main(String[] args) {
try {
RetrivePageSimple.downloadPage("http://www.cnblogs.com/");
} catch (HttpException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
结果信息不会显示在这里,太多--
2.grab页面使用Python
您可能会问我,为什么要使用Java版本的页面捕获,而在这里要编写python?这是必要的。因为作者在开发这个演示之前没有考虑问题。当我们使用java将网页抓取到python时,网页字符串太长,无法作为参数传递。您可能认为保存文件是一个不错的选择。如果HTML文件太多怎么办?是的,我们必须放弃这种累人的练习
考虑到参数长度的限制,我们只在Java端给出页面地址,并使用python抓取网页
最简单的方法是,我们通常使用Python网页,如下所示:
import urllib2
result = urllib2.urlopen('http://blog.csdn.net/mobile/index.html')
html = result.read()
print html
然而,作者的代码中使用了CSDN博客频道的URL。CSDN过滤爬虫的访问。我们将收到以下错误消息:
我被拒绝了
3.使用模拟浏览器登录网站
如前所述,当我们访问受保护的网页时,我们将被拒绝。但是,我们可以尝试使用自己的浏览器来访问它
换句话说,如果我们可以模仿Python中的浏览器,我们就可以访问这个网页。下面是Python模仿浏览器的代码:
import random
import socket
import urllib2
import cookielib
ERROR = {
'0':'Can not open the url,checck you net',
'1':'Creat download dir error',
'2':'The image links is empty',
'3':'Download faild',
'4':'Build soup error,the html is empty',
'5':'Can not save the image to your disk',
}
class BrowserBase(object):
def __init__(self):
socket.setdefaulttimeout(20)
self._content = None
def speak(self, name, content):
print '[%s]%s' % (name, content)
def open_url(self, url):
"""
打开网页
"""
cookie_support= urllib2.HTTPCookieProcessor(cookielib.CookieJar())
self.opener = urllib2.build_opener(cookie_support,urllib2.HTTPHandler)
urllib2.install_opener(self.opener)
user_agents = [
'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11',
'Opera/9.25 (Windows NT 5.1; U; en)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 ",
]
agent = random.choice(user_agents)
self.opener.addheaders = [("User-agent", agent), ("Accept", "*/*"), ('Referer', 'http://www.google.com')]
try:
res = self.opener.open(url)
self._content = res.read()
# print self._content
except Exception, e:
self.speak(str(e)+url)
raise Exception
else:
return res
def get_html_content(self):
return self._content
def get_html_response(html):
spider = BrowserBase()
spider.open_url(html)
return spider.get_html_content()
上述代码通常可以获取返回值。让我们看一下返回结果
的解析过程。
4.数据分析
使用Python解析html非常简单:
import HTMLParser
class ListWebParser(HTMLParser.HTMLParser):
def __init__(self):
HTMLParser.HTMLParser.__init__(self)
self.tagDIVFlag = False
self.tagDIVAFlag = False
self.tagH1Flag = False
self.tagSecondHrefFlag = False
self._name = None
self._address = None
def handle_starttag(self, tag, attrs):
if tag == 'div':
for name, value in attrs:
if name == 'class' and value == 'blog_list':
self.tagDIVFlag = True
if tag == 'h1':
if self.tagDIVFlag:
self.tagH1Flag = True
# print 'h1->', self.tagH1Flag
if tag == 'a':
#if self.tagDIVAFlag:
#print 'h1: ', self.tagH1Flag
if self.tagH1Flag:
for name, value in attrs:
if name == 'target' and value == '_blank':
self.tagDIVAFlag = True
if name == 'href':
if self.tagSecondHrefFlag:
print '网址:', value
self._address = value
self.tagSecondHrefFlag = True
# if name == 'href' and self.tagDIVAFlag:
# print '网址:', value
# self._address = value
def handle_endtag(self, tag):
if tag == 'div':
self.tagDIVFlag = False
if tag == 'h1':
self.tagH1Flag = False
# print 'false h1.'
if tag == 'a':
self.tagDIVAFlag = False
def handle_data(self, data):
if self.tagDIVAFlag:
print u"名称:", data.decode("utf-8")
如果你说你在互联网上找到的HTML文件没有这个问题。我承认这一点,因为在正常情况下,解析一些简单的数据对我们来说非常容易。上面代码中的复杂逻辑处理过滤
说到筛选,我在这里使用了一个小技巧(当然,当更多的人使用它时,它不再只是一个技巧,但这种方法可以在未来的编码过程中作为参考)。我们通过标记的一些特殊属性(如ID、class等)锁定块。当我们启动块时,相应的标志位将被标记为true。当我们退出块时,相应的标志位将被标记为false。也许你觉得太麻烦了。事实上,如果你仔细想想,你就会知道这是有道理的
注意事项:
1.当使用java抓取页面时,我们使用代理服务器。此代理服务器的主机和端口可以直接在Internet上免费找到
2.您需要准备以下jar包并将其导入eclipse项目:
3.将Mysql的默认代码修改为UTF-8
这里会有一些中文信息,所以我们需要转换MySQL的编码格式
如果您是在Linux下编码,可以参考: 查看全部
java从网页抓取数据(如何使用Java/Python访问网页和使用Python进行数据解析)
前言:
网络爬虫看起来仍然很神奇。然而,如果你想一想或者做一些研究,你就会知道爬行动物并没有那么先进。深刻的是,当我们有大量的数据时,即当我们的网络“图”中有越来越多的循环时,我们应该如何解决它
此物品文章仅用于吸引翡翠。本文主要介绍如何使用Java/Python访问web页面并获取web页面代码,Python模仿浏览器访问web页面,并使用Python分析数据。我希望我们能从这篇文章开始,一步一步地解决蜘蛛网神秘的一面
参考:
1.“编写自己的网络爬虫”
2.使用Python编写爬虫程序,爬升CSDN内容,完美解决403问题
运行效果图:

有很多内容。我只选择了一些来显示
作者环境:
系统:Windows7
CentOS6.5
操作环境:JDK1.7
Python2.6.6
IDE:EclipseRelease@k282.0
PyCharm4.5.1
数据库:mysqlver14.14 Distrib@k311.73
开发过程:1.使用java抓取页面
对于页面捕获,我们使用java来实现它。当然,您可以使用其他语言来开发它。但是
以“博客公园”主页为例,展示了使用Java捕获网页的过程:
public class RetrivePageSimple {
private static HttpClient httpClient = new HttpClient();
// 设置代理服务器
static {
httpClient.getHostConfiguration().setProxy("58.220.2.132", 80);
}
public static boolean downloadPage(String path) throws HttpException,
IOException {
PostMethod postMethod = new PostMethod(path);
// 执行,返回状态码
int statusCode = httpClient.executeMethod(postMethod);
System.out.println(statusCode);
// 针对状态码进行处理 (简单起见,只处理返回值为200的状态码)
if (statusCode == HttpStatus.SC_OK) {
String a = postMethod.getResponseBodyAsString();
System.out.println(a);
return true;
}
return false;
}
public static void main(String[] args) {
try {
RetrivePageSimple.downloadPage("http://www.cnblogs.com/";);
} catch (HttpException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
结果信息不会显示在这里,太多--
2.grab页面使用Python
您可能会问我,为什么要使用Java版本的页面捕获,而在这里要编写python?这是必要的。因为作者在开发这个演示之前没有考虑问题。当我们使用java将网页抓取到python时,网页字符串太长,无法作为参数传递。您可能认为保存文件是一个不错的选择。如果HTML文件太多怎么办?是的,我们必须放弃这种累人的练习
考虑到参数长度的限制,我们只在Java端给出页面地址,并使用python抓取网页
最简单的方法是,我们通常使用Python网页,如下所示:
import urllib2
result = urllib2.urlopen('http://blog.csdn.net/mobile/index.html')
html = result.read()
print html
然而,作者的代码中使用了CSDN博客频道的URL。CSDN过滤爬虫的访问。我们将收到以下错误消息:

我被拒绝了
3.使用模拟浏览器登录网站
如前所述,当我们访问受保护的网页时,我们将被拒绝。但是,我们可以尝试使用自己的浏览器来访问它
换句话说,如果我们可以模仿Python中的浏览器,我们就可以访问这个网页。下面是Python模仿浏览器的代码:
import random
import socket
import urllib2
import cookielib
ERROR = {
'0':'Can not open the url,checck you net',
'1':'Creat download dir error',
'2':'The image links is empty',
'3':'Download faild',
'4':'Build soup error,the html is empty',
'5':'Can not save the image to your disk',
}
class BrowserBase(object):
def __init__(self):
socket.setdefaulttimeout(20)
self._content = None
def speak(self, name, content):
print '[%s]%s' % (name, content)
def open_url(self, url):
"""
打开网页
"""
cookie_support= urllib2.HTTPCookieProcessor(cookielib.CookieJar())
self.opener = urllib2.build_opener(cookie_support,urllib2.HTTPHandler)
urllib2.install_opener(self.opener)
user_agents = [
'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11',
'Opera/9.25 (Windows NT 5.1; U; en)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 ",
]
agent = random.choice(user_agents)
self.opener.addheaders = [("User-agent", agent), ("Accept", "*/*"), ('Referer', 'http://www.google.com')]
try:
res = self.opener.open(url)
self._content = res.read()
# print self._content
except Exception, e:
self.speak(str(e)+url)
raise Exception
else:
return res
def get_html_content(self):
return self._content
def get_html_response(html):
spider = BrowserBase()
spider.open_url(html)
return spider.get_html_content()
上述代码通常可以获取返回值。让我们看一下返回结果
的解析过程。
4.数据分析
使用Python解析html非常简单:
import HTMLParser
class ListWebParser(HTMLParser.HTMLParser):
def __init__(self):
HTMLParser.HTMLParser.__init__(self)
self.tagDIVFlag = False
self.tagDIVAFlag = False
self.tagH1Flag = False
self.tagSecondHrefFlag = False
self._name = None
self._address = None
def handle_starttag(self, tag, attrs):
if tag == 'div':
for name, value in attrs:
if name == 'class' and value == 'blog_list':
self.tagDIVFlag = True
if tag == 'h1':
if self.tagDIVFlag:
self.tagH1Flag = True
# print 'h1->', self.tagH1Flag
if tag == 'a':
#if self.tagDIVAFlag:
#print 'h1: ', self.tagH1Flag
if self.tagH1Flag:
for name, value in attrs:
if name == 'target' and value == '_blank':
self.tagDIVAFlag = True
if name == 'href':
if self.tagSecondHrefFlag:
print '网址:', value
self._address = value
self.tagSecondHrefFlag = True
# if name == 'href' and self.tagDIVAFlag:
# print '网址:', value
# self._address = value
def handle_endtag(self, tag):
if tag == 'div':
self.tagDIVFlag = False
if tag == 'h1':
self.tagH1Flag = False
# print 'false h1.'
if tag == 'a':
self.tagDIVAFlag = False
def handle_data(self, data):
if self.tagDIVAFlag:
print u"名称:", data.decode("utf-8")
如果你说你在互联网上找到的HTML文件没有这个问题。我承认这一点,因为在正常情况下,解析一些简单的数据对我们来说非常容易。上面代码中的复杂逻辑处理过滤
说到筛选,我在这里使用了一个小技巧(当然,当更多的人使用它时,它不再只是一个技巧,但这种方法可以在未来的编码过程中作为参考)。我们通过标记的一些特殊属性(如ID、class等)锁定块。当我们启动块时,相应的标志位将被标记为true。当我们退出块时,相应的标志位将被标记为false。也许你觉得太麻烦了。事实上,如果你仔细想想,你就会知道这是有道理的
注意事项:
1.当使用java抓取页面时,我们使用代理服务器。此代理服务器的主机和端口可以直接在Internet上免费找到
2.您需要准备以下jar包并将其导入eclipse项目:

3.将Mysql的默认代码修改为UTF-8
这里会有一些中文信息,所以我们需要转换MySQL的编码格式
如果您是在Linux下编码,可以参考:
java从网页抓取数据(java脚本_doPostBack和onclick事件(一)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-09-18 06:17
__DoPostBack和onclick事件:
当您检查与选择主contentdiv列(例如longterme)相关联的HTML时,您可以看到与每个bar item_uudopostback函数的onclick事件相关联的java脚本
请注意所讨论的HTML:
请参阅上面的链接:
该函数采用以下两个参数:EventTarget-它收录导致回发的控件的ID。Eventargument-收录与控件关联的任何其他数据。在任何页面中,都会自动声明两个隐藏字段:_u事件目标和_u事件参数。会检查何时将页面发回服务器_uu事件目标和_uu事件参数值,以便确定哪些控件导致页面发回以及必须处理哪些事件
tldr
在ASP的“旧”时代,通常必须有一个表单来捕获用户输入,然后创建其他页面来接受这些输入(get或post)、验证、执行操作等。使用,您可以在服务器上声明接受上述参数的控件,并在检查值后发回同一页面
第一个参数告诉您哪个控件被触发,第二个参数提供附加信息,在这种情况下,它决定返回哪个选项卡信息
从上面可以看出,tabaction是一个控件,它后面的数字对应于感兴趣的标记。例如,2是长期的(0-指数)
在VBA中,我们可以通过多种方式执行此JS函数,但我将使用:
.document.parentWindow.execScript "__doPostBack('EVENTTARGET', 'EVENTARGUMENT')"
这就变成了:
.document.parentWindow.execScript "__doPostBack('TabAction', '2')"
我将其重写为接受eventargument作为常量选项uchoose,因此您可以通过更改顶部的值来检索不同的选项卡
函数执行后,还有一点时间刷新页面,然后通过ID捕获表:
Set hTable = .document.getElementById("ctl00_ctl00_MainContent_Layout_1MainContent_gridResult")
然后,表格沿行和列循环(列是沿每行长度的表格单元格)
第页的示例:
代码输出示例:
完整代码:
Option Explicit
Public Sub GetTable()
Dim IE As New InternetExplorer
Const OPTION_CHOSEN As Long = 2 '0 Aperçu; 1 Court terme; 2 Long terme; 3 Portefeuille; 4 Frais & Détails
Application.ScreenUpdating = True
With IE
.Visible = True
.navigate "http://www.morningstar.fr/fr/f ... ot%3B
While .readyState < 4: DoEvents: Wend
.document.parentWindow.execScript "__doPostBack('TabAction', ' " & OPTION_CHOSEN & "')"
Do While .Busy = True Or .readyState 4: DoEvents: Loop
Dim hTable As HTMLTable, tRow As HTMLTableRow, tCell As HTMLTableCell
Set hTable = .document.getElementById("ctl00_ctl00_MainContent_Layout_1MainContent_gridResult")
Dim c As Long, r As Long
With ActiveSheet
For Each tRow In hTable.Rows
For Each tCell In tRow.Cells
c = c + 1: .Cells(r + 1, c) = tCell.innerText
Next tCell
c = 0: r = r + 1
Next tRow
.Columns("A:A").Delete
.UsedRange.Columns.AutoFit
End With
.Quit
End With
Application.ScreenUpdating = True
End Sub
参考资料(VBE>;工具>;参考资料): 查看全部
java从网页抓取数据(java脚本_doPostBack和onclick事件(一)(图))
__DoPostBack和onclick事件:
当您检查与选择主contentdiv列(例如longterme)相关联的HTML时,您可以看到与每个bar item_uudopostback函数的onclick事件相关联的java脚本
请注意所讨论的HTML:

请参阅上面的链接:
该函数采用以下两个参数:EventTarget-它收录导致回发的控件的ID。Eventargument-收录与控件关联的任何其他数据。在任何页面中,都会自动声明两个隐藏字段:_u事件目标和_u事件参数。会检查何时将页面发回服务器_uu事件目标和_uu事件参数值,以便确定哪些控件导致页面发回以及必须处理哪些事件
tldr
在ASP的“旧”时代,通常必须有一个表单来捕获用户输入,然后创建其他页面来接受这些输入(get或post)、验证、执行操作等。使用,您可以在服务器上声明接受上述参数的控件,并在检查值后发回同一页面
第一个参数告诉您哪个控件被触发,第二个参数提供附加信息,在这种情况下,它决定返回哪个选项卡信息
从上面可以看出,tabaction是一个控件,它后面的数字对应于感兴趣的标记。例如,2是长期的(0-指数)
在VBA中,我们可以通过多种方式执行此JS函数,但我将使用:
.document.parentWindow.execScript "__doPostBack('EVENTTARGET', 'EVENTARGUMENT')"
这就变成了:
.document.parentWindow.execScript "__doPostBack('TabAction', '2')"
我将其重写为接受eventargument作为常量选项uchoose,因此您可以通过更改顶部的值来检索不同的选项卡
函数执行后,还有一点时间刷新页面,然后通过ID捕获表:
Set hTable = .document.getElementById("ctl00_ctl00_MainContent_Layout_1MainContent_gridResult")
然后,表格沿行和列循环(列是沿每行长度的表格单元格)
第页的示例:

代码输出示例:

完整代码:
Option Explicit
Public Sub GetTable()
Dim IE As New InternetExplorer
Const OPTION_CHOSEN As Long = 2 '0 Aperçu; 1 Court terme; 2 Long terme; 3 Portefeuille; 4 Frais & Détails
Application.ScreenUpdating = True
With IE
.Visible = True
.navigate "http://www.morningstar.fr/fr/f ... ot%3B
While .readyState < 4: DoEvents: Wend
.document.parentWindow.execScript "__doPostBack('TabAction', ' " & OPTION_CHOSEN & "')"
Do While .Busy = True Or .readyState 4: DoEvents: Loop
Dim hTable As HTMLTable, tRow As HTMLTableRow, tCell As HTMLTableCell
Set hTable = .document.getElementById("ctl00_ctl00_MainContent_Layout_1MainContent_gridResult")
Dim c As Long, r As Long
With ActiveSheet
For Each tRow In hTable.Rows
For Each tCell In tRow.Cells
c = c + 1: .Cells(r + 1, c) = tCell.innerText
Next tCell
c = 0: r = r + 1
Next tRow
.Columns("A:A").Delete
.UsedRange.Columns.AutoFit
End With
.Quit
End With
Application.ScreenUpdating = True
End Sub
参考资料(VBE>;工具>;参考资料):
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-14 18:09
原文链接:
有时由于各种原因,我们需要采集一些网站的数据,但是由于网站不同,数据的显示方式略有不同!
本文用Java来告诉你如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml()的结果:\n"+result);}
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不会直接在网页的源代码中返回数据。而是使用JS异步返回数据,避免搜索引擎等工具响应网站数据的爬行。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript():\n"+contentBuf.toString()的结果);}
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
原文链接:
有时由于各种原因,我们需要采集一些网站的数据,但是由于网站不同,数据的显示方式略有不同!
本文用Java来告诉你如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml()的结果:\n"+result);}
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不会直接在网页的源代码中返回数据。而是使用JS异步返回数据,避免搜索引擎等工具响应网站数据的爬行。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript():\n"+contentBuf.toString()的结果);}
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载!
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-10-09 18:38
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页的源码,我们在源码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如此类的工具抓取作为搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页的源码,我们在源码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如此类的工具抓取作为搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java从网页抓取数据(基本上在互联网上存在了问题是如何把它们整理成你所需要的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-08 21:36
你想要的任何信息基本上都存在于互联网上。问题是如何把它们组织成你需要的东西,比如抓取某个行业所有相关公司的名称网站、联系电话、Email等,然后保存在Excel中进行分析。网页信息抓取变得更加有用。
对于传统网页,网页服务器直接返回Html。这种类型的网页很容易捕获。不管用什么方法,只需要拿到html页面,然后做Dom分析即可。但对于需要 Javascript 生成的网页来说,就没有那么容易了。对于这个问题,张宇还没有找到很好的解决办法。有抓取javascript网页经验的朋友,欢迎指点。
所以今天我要讲的是从传统的html网页爬取信息。虽然我之前说过,没有技术难度,但是有没有比较简单的方法呢?用过jQuery等js框架的朋友可能会觉得javascript看起来像是抓取网页信息的天然助手,它为网页解析而生。当然,现在还有更多的应用,比如服务端的javascript应用,NodeJs。
如果能在我们的应用程序中使用jQuery来抓取网页,比如java程序,那绝对是一件令人兴奋的事情。确实有现成的方案,有Javascript引擎,有可以支持jQuery的环境。
工具:java、Rhino、envJs。其中Rhino是Mozzila提供的开源Javascript引擎,envJs是模拟浏览器环境,比如Window。代码如下,
package stony.zhang.scrape;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import org.mozilla.javascript.Context;
import org.mozilla.javascript.ContextFactory;
import org.mozilla.javascript.Scriptable;
import org.mozilla.javascript.ScriptableObject;
/**
* @author MyBeautiful
* @Emal: zhangyu0182@sina.com
* @date Mar 7, 2012
*/
public class RhinoScaper {
private String url;
private String jsFile;
private Context cx;
private Scriptable scope;
public String getUrl() {
return url;
}
public String getJsFile() {
return jsFile;
}
public void setUrl(String url) {
this.url = url;
putObject("url", url);
}
public void setJsFile(String jsFile) {
this.jsFile = jsFile;
}
public void init() {
cx = ContextFactory.getGlobal().enterContext();
scope = cx.initStandardObjects(null);
cx.setOptimizationLevel(-1);
cx.setLanguageVersion(Context.VERSION_1_5);
String[] file = { "./lib/env.rhino.1.2.js", "./lib/jquery.js" };
for (String f : file) {
evaluateJs(f);
}
try {
ScriptableObject.defineClass(scope, ExtendUtil.class);
} catch (IllegalAccessException e1) {
e1.printStackTrace();
} catch (InstantiationException e1) {
e1.printStackTrace();
} catch (InvocationTargetException e1) {
e1.printStackTrace();
}
ExtendUtil util = (ExtendUtil) cx.newObject(scope, "util");
scope.put("util", scope, util);
}
protected void evaluateJs(String f) {
try {
FileReader in = null;
in = new FileReader(f);
cx.evaluateReader(scope, in, f, 1, null);
} catch (FileNotFoundException e1) {
e1.printStackTrace();
} catch (IOException e1) {
e1.printStackTrace();
}
}
public void putObject(String name, Object o) {
scope.put(name, scope, o);
}
public void run() {
evaluateJs(this.jsFile);
}
}
测试代码:
package stony.zhang.scrape;
import java.util.HashMap;
import java.util.Map;
import junit.framework.TestCase;
public class RhinoScaperTest extends TestCase {
public RhinoScaperTest(String name) {
super(name);
}
public void testRun() {
RhinoScaper rs = new RhinoScaper();
rs.init();
rs.setUrl("http://www.baidu.com");
rs.setJsFile("test.js");
// Map o = new HashMap();
// rs.putObject("result", o);
rs.run();
// System.out.println(o.get("imgurl"));
}
}
test.js 文件,如下
$.ajax({
url: "http://www.baidu.com",
context: document.body,
success: function(data){
// util.log(data);
var result =parseHtml(data);
var $v= jQuery(result);
// util.log(result);
$v.find('#u a').each(function(index) {
util.log(index + ': ' + $(this).attr("href"));
// arr.add($(this).attr("href"));
});
}
});
function parseHtml(html) {
//Create an iFrame object that will be used to render the HTML in order to get the DOM objects
//created - this is a far quicker way of achieving the HTML to DOM conversion than trying
//to transform the HTML objects one-by-one
var oIframe = document.createElement('iframe');
//Hide the iFrame from view
oIframe.style.display = 'none';
if (document.body)
document.body.appendChild(oIframe);
else
document.documentElement.appendChild(oIframe);
//Open the iFrame DOM object and write in our HTML
oIframe.contentDocument.open();
oIframe.contentDocument.write(html);
oIframe.contentDocument.close();
//Return the document body object containing the HTML that was just
//added to the iFrame as DOM objects
var oBody = oIframe.contentDocument.body;
//TODO: Remove the iFrame object created to cleanup the DOM
return oBody;
}
我们执行Unit Test,从网页抓取的三个百度连接会打印在控制台上。
0:
1:
2:
测试成功,证明在java程序中使用jQuery抓取网页是可行的。
----------------------------------------------- -----------------------
张宇,我的美丽, 查看全部
java从网页抓取数据(基本上在互联网上存在了问题是如何把它们整理成你所需要的)
你想要的任何信息基本上都存在于互联网上。问题是如何把它们组织成你需要的东西,比如抓取某个行业所有相关公司的名称网站、联系电话、Email等,然后保存在Excel中进行分析。网页信息抓取变得更加有用。
对于传统网页,网页服务器直接返回Html。这种类型的网页很容易捕获。不管用什么方法,只需要拿到html页面,然后做Dom分析即可。但对于需要 Javascript 生成的网页来说,就没有那么容易了。对于这个问题,张宇还没有找到很好的解决办法。有抓取javascript网页经验的朋友,欢迎指点。
所以今天我要讲的是从传统的html网页爬取信息。虽然我之前说过,没有技术难度,但是有没有比较简单的方法呢?用过jQuery等js框架的朋友可能会觉得javascript看起来像是抓取网页信息的天然助手,它为网页解析而生。当然,现在还有更多的应用,比如服务端的javascript应用,NodeJs。
如果能在我们的应用程序中使用jQuery来抓取网页,比如java程序,那绝对是一件令人兴奋的事情。确实有现成的方案,有Javascript引擎,有可以支持jQuery的环境。
工具:java、Rhino、envJs。其中Rhino是Mozzila提供的开源Javascript引擎,envJs是模拟浏览器环境,比如Window。代码如下,
package stony.zhang.scrape;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import org.mozilla.javascript.Context;
import org.mozilla.javascript.ContextFactory;
import org.mozilla.javascript.Scriptable;
import org.mozilla.javascript.ScriptableObject;
/**
* @author MyBeautiful
* @Emal: zhangyu0182@sina.com
* @date Mar 7, 2012
*/
public class RhinoScaper {
private String url;
private String jsFile;
private Context cx;
private Scriptable scope;
public String getUrl() {
return url;
}
public String getJsFile() {
return jsFile;
}
public void setUrl(String url) {
this.url = url;
putObject("url", url);
}
public void setJsFile(String jsFile) {
this.jsFile = jsFile;
}
public void init() {
cx = ContextFactory.getGlobal().enterContext();
scope = cx.initStandardObjects(null);
cx.setOptimizationLevel(-1);
cx.setLanguageVersion(Context.VERSION_1_5);
String[] file = { "./lib/env.rhino.1.2.js", "./lib/jquery.js" };
for (String f : file) {
evaluateJs(f);
}
try {
ScriptableObject.defineClass(scope, ExtendUtil.class);
} catch (IllegalAccessException e1) {
e1.printStackTrace();
} catch (InstantiationException e1) {
e1.printStackTrace();
} catch (InvocationTargetException e1) {
e1.printStackTrace();
}
ExtendUtil util = (ExtendUtil) cx.newObject(scope, "util");
scope.put("util", scope, util);
}
protected void evaluateJs(String f) {
try {
FileReader in = null;
in = new FileReader(f);
cx.evaluateReader(scope, in, f, 1, null);
} catch (FileNotFoundException e1) {
e1.printStackTrace();
} catch (IOException e1) {
e1.printStackTrace();
}
}
public void putObject(String name, Object o) {
scope.put(name, scope, o);
}
public void run() {
evaluateJs(this.jsFile);
}
}
测试代码:
package stony.zhang.scrape;
import java.util.HashMap;
import java.util.Map;
import junit.framework.TestCase;
public class RhinoScaperTest extends TestCase {
public RhinoScaperTest(String name) {
super(name);
}
public void testRun() {
RhinoScaper rs = new RhinoScaper();
rs.init();
rs.setUrl("http://www.baidu.com";);
rs.setJsFile("test.js");
// Map o = new HashMap();
// rs.putObject("result", o);
rs.run();
// System.out.println(o.get("imgurl"));
}
}
test.js 文件,如下
$.ajax({
url: "http://www.baidu.com",
context: document.body,
success: function(data){
// util.log(data);
var result =parseHtml(data);
var $v= jQuery(result);
// util.log(result);
$v.find('#u a').each(function(index) {
util.log(index + ': ' + $(this).attr("href"));
// arr.add($(this).attr("href"));
});
}
});
function parseHtml(html) {
//Create an iFrame object that will be used to render the HTML in order to get the DOM objects
//created - this is a far quicker way of achieving the HTML to DOM conversion than trying
//to transform the HTML objects one-by-one
var oIframe = document.createElement('iframe');
//Hide the iFrame from view
oIframe.style.display = 'none';
if (document.body)
document.body.appendChild(oIframe);
else
document.documentElement.appendChild(oIframe);
//Open the iFrame DOM object and write in our HTML
oIframe.contentDocument.open();
oIframe.contentDocument.write(html);
oIframe.contentDocument.close();
//Return the document body object containing the HTML that was just
//added to the iFrame as DOM objects
var oBody = oIframe.contentDocument.body;
//TODO: Remove the iFrame object created to cleanup the DOM
return oBody;
}
我们执行Unit Test,从网页抓取的三个百度连接会打印在控制台上。
0:
1:
2:
测试成功,证明在java程序中使用jQuery抓取网页是可行的。
----------------------------------------------- -----------------------
张宇,我的美丽,
java从网页抓取数据(怎么从数据库中提取数据,在jsp页面显示员工信息管理系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-04 12:06
如何从数据库中提取数据并显示在jsp页面上
员工信息管理系统
一、语言和环境
1.实现语言:Java
2.环境要求:Eclipse+mySql|Oracle
3.技术:Struts2+Spring+Hibernate
二、数据库设计
数据库:EMDB
表名:Dept(部门表)
序列号字段名称字段描述类型数字属性备注
1deptid 部门编号 int 标识栏
2dname 部门名称 Varchar50 唯一
表名:Emp(员工表)
序列号字段名称字段描述类型数字属性备注
1empid 员工编号 int 标识列
2ename 员工姓名 varchar50notnull
3gendar sex tinyintnotnull1 男 0 女
4depid 部门编号 intnotnull
一、要求
请编写一个程序来完成员工信息的管理。功能如下:
a) 查看所有员工列表;
b) 查看详细的员工信息;
c) 添加员工信息;
d) 修改员工信息;
e) 删除员工信息;
二、推荐的实现步骤
1. 建立数据库,表结构见数据库设计;数据连接必须使用JDBC技术。
2. 创建一个名为 HR 的 JAVAWEB 项目,并添加 JavaBean 和 DAO 类。
设计一个前端界面index.jsp,点击显示员工列表。创建 ListEmpServlet,
接收 index.jsp 请求,查询所有员工信息。转发到 listemp.jsp 员工列表。
3. 设计一个前端界面displayemp.jsp,显示所有员工信息。员工姓名采用超链接的形式。点击后,可以查看该员工的详细信息。
4 创建DisplayEmpServlet,接收要显示的员工ID,查询员工信息,转发到displayemp.jsp显示。
5 设计前端接口addemp.jsp,添加用户信息。
6. 首先创建PreAddEmpServlet查询所有部门的信息,将部门信息列表转发到addemp.jsp,以下拉框的形式展示。添加员工时,部门编号必须是部门表中已有的部门;默认性别为“男性”。然后创建 AddEmpServlet 来处理添加员工的请求。
7. 设计一个前端界面editemp.jsp来修改用户信息。
这是原创问题。
只是从数据库中提取数据,在jsp页面上是无法显示的。其他一切都完成了。
那位大神能帮帮我,如何从数据库中提取数据并显示在jsp页面上
- - - 解决方案 - - - - - - - - - -
参考
- - - 解决方案 - - - - - - - - - -
使用了三大框架,应该对这三个比较熟悉了吧?Hibernate 用于操作数据库。您可以在其中使用 HQL 语句。比如要查询数据库中所有员工的列表,可以这样写:Stringhql="fromEmp",然后在session中使用createQuery(hql)方法把参数传进去,然后取从其列表中返回查询类型实例,以便将员工信息取出并放入列表中。至于如何显示,可以使用struts2自带的标签将list封装在action中,这样就可以直接使用foreach标签在页面上显示了。
- - - 解决方案 - - - - - - - - - -
例如:你在java后台方法中找到了你的emp表:select*fromemp; 这将返回一个列表集合
1 返回一个列表,如:Listtemps=lists.newArrayList();//查询结果返回一个对象集合
2 放入请求中,如request.setAttribute("empist",emps);//将查询的结果集放入请求中,等待发送到页面
3 然后进入页面,如 return "/emp/list.jsp";//查询完成后跳转到此页面显示员工信息
4 然后在页面上,可以直接用JSTL解析,因为是从后台传过来的集合列表,所以需要用一个循环来一个一个的遍历后台列表,需要用到这个标签
- - - 解决方案 - - - - - - - - - -
这东西无非就是来回发送数据。通过debug查看数据趋势然后微调,像楼上一样放到list里然后request.set()
然后前台用JSTL解析(你点百度就知道了)。一种是生的,一种是煮熟的。练习一下就OK了
- - - 解决方案 - - - - - - - - - -
使用 struts2 标签
在action中使用heibernate取出并存入列表
<br />
<br />
<br />
`<br />
<br />
不明白的可以搜索s:iterator标签用法 查看全部
java从网页抓取数据(怎么从数据库中提取数据,在jsp页面显示员工信息管理系统)
如何从数据库中提取数据并显示在jsp页面上
员工信息管理系统
一、语言和环境
1.实现语言:Java
2.环境要求:Eclipse+mySql|Oracle
3.技术:Struts2+Spring+Hibernate
二、数据库设计
数据库:EMDB
表名:Dept(部门表)
序列号字段名称字段描述类型数字属性备注
1deptid 部门编号 int 标识栏
2dname 部门名称 Varchar50 唯一
表名:Emp(员工表)
序列号字段名称字段描述类型数字属性备注
1empid 员工编号 int 标识列
2ename 员工姓名 varchar50notnull
3gendar sex tinyintnotnull1 男 0 女
4depid 部门编号 intnotnull
一、要求
请编写一个程序来完成员工信息的管理。功能如下:
a) 查看所有员工列表;
b) 查看详细的员工信息;
c) 添加员工信息;
d) 修改员工信息;
e) 删除员工信息;
二、推荐的实现步骤
1. 建立数据库,表结构见数据库设计;数据连接必须使用JDBC技术。
2. 创建一个名为 HR 的 JAVAWEB 项目,并添加 JavaBean 和 DAO 类。
设计一个前端界面index.jsp,点击显示员工列表。创建 ListEmpServlet,
接收 index.jsp 请求,查询所有员工信息。转发到 listemp.jsp 员工列表。
3. 设计一个前端界面displayemp.jsp,显示所有员工信息。员工姓名采用超链接的形式。点击后,可以查看该员工的详细信息。
4 创建DisplayEmpServlet,接收要显示的员工ID,查询员工信息,转发到displayemp.jsp显示。
5 设计前端接口addemp.jsp,添加用户信息。
6. 首先创建PreAddEmpServlet查询所有部门的信息,将部门信息列表转发到addemp.jsp,以下拉框的形式展示。添加员工时,部门编号必须是部门表中已有的部门;默认性别为“男性”。然后创建 AddEmpServlet 来处理添加员工的请求。
7. 设计一个前端界面editemp.jsp来修改用户信息。
这是原创问题。
只是从数据库中提取数据,在jsp页面上是无法显示的。其他一切都完成了。
那位大神能帮帮我,如何从数据库中提取数据并显示在jsp页面上
- - - 解决方案 - - - - - - - - - -
参考
- - - 解决方案 - - - - - - - - - -
使用了三大框架,应该对这三个比较熟悉了吧?Hibernate 用于操作数据库。您可以在其中使用 HQL 语句。比如要查询数据库中所有员工的列表,可以这样写:Stringhql="fromEmp",然后在session中使用createQuery(hql)方法把参数传进去,然后取从其列表中返回查询类型实例,以便将员工信息取出并放入列表中。至于如何显示,可以使用struts2自带的标签将list封装在action中,这样就可以直接使用foreach标签在页面上显示了。
- - - 解决方案 - - - - - - - - - -
例如:你在java后台方法中找到了你的emp表:select*fromemp; 这将返回一个列表集合
1 返回一个列表,如:Listtemps=lists.newArrayList();//查询结果返回一个对象集合
2 放入请求中,如request.setAttribute("empist",emps);//将查询的结果集放入请求中,等待发送到页面
3 然后进入页面,如 return "/emp/list.jsp";//查询完成后跳转到此页面显示员工信息
4 然后在页面上,可以直接用JSTL解析,因为是从后台传过来的集合列表,所以需要用一个循环来一个一个的遍历后台列表,需要用到这个标签
- - - 解决方案 - - - - - - - - - -
这东西无非就是来回发送数据。通过debug查看数据趋势然后微调,像楼上一样放到list里然后request.set()
然后前台用JSTL解析(你点百度就知道了)。一种是生的,一种是煮熟的。练习一下就OK了
- - - 解决方案 - - - - - - - - - -
使用 struts2 标签
在action中使用heibernate取出并存入列表
<br />
<br />
<br />
`<br />
<br />
不明白的可以搜索s:iterator标签用法
java从网页抓取数据(java从网页抓取数据即可,代码分享给你views/chart)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-04 08:01
java从网页抓取数据即可,代码分享给你views/chart。javapublicclassh2{privatestring[]color=newstring[]{"black","green","yellow","blue"};//字符串对象、stringbufferfriends=newstringbuffer();publicchart(stringcolor){this。
color=color;}publicstringfindstringofcolor(stringoutcode){return(string)outcode;}publicstringgetarray(){if(color==null){return"null";}else{return"";}}};views/file2。
javapublicclassfile2{publicstaticvoidmain(string[]args){//创建视图函数类views::file2("file2。java")。views。new(file2。public,file2。new);}}java网页抓取即可。
比较简单就只需要webdriver+chrome浏览器就可以了
可以抓取腾讯的任何动态网页,已有免费的api封装好,,京东、还有58上都有,很方便,
是实时的网页?你都没说清楚你说的什么情况,我随便想到一个:ajax。
我有个viewpointjs,可以实现这个功能。
javascript可以抓取、转换javascript页面的html元素,可以用selenium来抓取浏览器的自动化。也可以用js抓取ie元素,因为浏览器自身的这种习惯,或者导航之类的设置,让老版ie兼容性很差。可以先抓取ie中最有名的网站,分析其源代码,其中html文件的地址是后面抓取的这些网站的入口url地址。然后在selenium中用网页浏览器随便抓取页面html源代码,就可以分析出源代码里的url。 查看全部
java从网页抓取数据(java从网页抓取数据即可,代码分享给你views/chart)
java从网页抓取数据即可,代码分享给你views/chart。javapublicclassh2{privatestring[]color=newstring[]{"black","green","yellow","blue"};//字符串对象、stringbufferfriends=newstringbuffer();publicchart(stringcolor){this。
color=color;}publicstringfindstringofcolor(stringoutcode){return(string)outcode;}publicstringgetarray(){if(color==null){return"null";}else{return"";}}};views/file2。
javapublicclassfile2{publicstaticvoidmain(string[]args){//创建视图函数类views::file2("file2。java")。views。new(file2。public,file2。new);}}java网页抓取即可。
比较简单就只需要webdriver+chrome浏览器就可以了
可以抓取腾讯的任何动态网页,已有免费的api封装好,,京东、还有58上都有,很方便,
是实时的网页?你都没说清楚你说的什么情况,我随便想到一个:ajax。
我有个viewpointjs,可以实现这个功能。
javascript可以抓取、转换javascript页面的html元素,可以用selenium来抓取浏览器的自动化。也可以用js抓取ie元素,因为浏览器自身的这种习惯,或者导航之类的设置,让老版ie兼容性很差。可以先抓取ie中最有名的网站,分析其源代码,其中html文件的地址是后面抓取的这些网站的入口url地址。然后在selenium中用网页浏览器随便抓取页面html源代码,就可以分析出源代码里的url。
java从网页抓取数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-03 17:09
在众多行业中,需要对行业数据进行分类汇总,及时对行业数据进行分析,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们要获取的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只有采集当前页面的数据,还有分页的数据,这里就不解释了,只是一个提示,大家可以用多线程采集所有页面的当前数据,通过线程一个采集当前页面数据,一个翻页动作,可以采集完成所有数据。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。在下一节中,我将与大家分享如何处理 采集 数据存储在数据库中。 查看全部
java从网页抓取数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
在众多行业中,需要对行业数据进行分类汇总,及时对行业数据进行分析,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们要获取的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只有采集当前页面的数据,还有分页的数据,这里就不解释了,只是一个提示,大家可以用多线程采集所有页面的当前数据,通过线程一个采集当前页面数据,一个翻页动作,可以采集完成所有数据。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。在下一节中,我将与大家分享如何处理 采集 数据存储在数据库中。
java从网页抓取数据(AlexR关于一个的一些小知识,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-10-02 05:25
正如@Alex R 指出的那样,您将需要一个网络爬虫库。
他推荐的 JSoup 相当健壮,至少以我的经验,它经常用于 Java 中的这个任务。
首先需要构造一个文档来获取页面,例如:
int localID = 25022; //your player's ID.
Document doc = Jsoup.connect("http://www.chess.org.il/Player ... ot%3B + localID).get();
从这个文档对象中,你可以得到很多信息,比如你请求的 FIDE ID。不幸的是,您链接的网页非常容易抓取,您基本上需要浏览页面上的每个链接才能找到相关链接,例如:
Elements fidelinks = doc.select("a[href*=fide.com]");
这个 Elements 对象应该为您提供指向所有链接的链接列表,这些链接链接到收录文本的任何内容,但您可能只希望出现第一个链接,例如:
从那以后,我不想为您编写所有代码,但希望这个答案可以作为一个好的起点!
可以通过调用Element对象上的方法单独获取ID,但也可以通过调用本身获取链接
可以用来获取另一个值的css选择器是 div#main-col table.contentpaneopen tbody tr td table tbody tr td table tbody tr:nth-of-type(4) td table tbody tr td:first- Of-type,至少在标准css中,它会得到一个特定的std分数,所以它也应该和jsoup一起使用。 查看全部
java从网页抓取数据(AlexR关于一个的一些小知识,你知道吗?)
正如@Alex R 指出的那样,您将需要一个网络爬虫库。
他推荐的 JSoup 相当健壮,至少以我的经验,它经常用于 Java 中的这个任务。
首先需要构造一个文档来获取页面,例如:
int localID = 25022; //your player's ID.
Document doc = Jsoup.connect("http://www.chess.org.il/Player ... ot%3B + localID).get();
从这个文档对象中,你可以得到很多信息,比如你请求的 FIDE ID。不幸的是,您链接的网页非常容易抓取,您基本上需要浏览页面上的每个链接才能找到相关链接,例如:
Elements fidelinks = doc.select("a[href*=fide.com]");
这个 Elements 对象应该为您提供指向所有链接的链接列表,这些链接链接到收录文本的任何内容,但您可能只希望出现第一个链接,例如:
从那以后,我不想为您编写所有代码,但希望这个答案可以作为一个好的起点!
可以通过调用Element对象上的方法单独获取ID,但也可以通过调用本身获取链接
可以用来获取另一个值的css选择器是 div#main-col table.contentpaneopen tbody tr td table tbody tr td table tbody tr:nth-of-type(4) td table tbody tr td:first- Of-type,至少在标准css中,它会得到一个特定的std分数,所以它也应该和jsoup一起使用。
java从网页抓取数据(字典批量获取数据打印的默认编码()(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-10-01 00:05
)
然后在第三步中,我们更改了默认编码。这取决于您要抓取的网页的编码格式。如果你不改变它,你可能会得到乱码或一些你以前没见过的字符。
第五步,我们将抓取到的网页内容的前 50 个字符分配给内容供以后查看。由于网页内容太多,无法一次全部打印出来,我们决定将部分内容切片输出
最后一步,我们把刚才保存的部分内容打印出来
上一步只是为了提前熟悉爬取数据的步骤。接下来,我们将通过列表字典批量获取数据,然后将其保存为文件
首先定义一个字典来存放我们要爬取的页面的URL
urls_dict = {
'特克斯博客': 'http://www.susmote.com/',
'百度': 'http://www.baidu.com',
'xyz': 'www.susmote.com',
'特克斯博客歌单区1': 'https://www.susmote.com/?cate=13',
'特克斯博客歌单区2': 'https://www.susmote.com/?cate=13'
}
然后我们定义了一个列表,该列表也存储了被抓取页面的 URL
urls_lst = [
('特克斯博客', 'http://www.susmote.com/'),
('百度', 'http://www.baidu.com'),
('xyz', 'www.susmote.com'),
('特克斯博客歌单区1', 'https://www.susmote.com/?cate=13'),
('特克斯博客歌单区2', 'https://www.susmote.com/?cate=13')
]
那我们先用字典来抓取
代码显示如下:
# 利用字典抓取
crawled_urls_for_dict = set()
for ind, name in enumerate(urls_dict.keys()):
name_url = urls_dict[name]
if name_url in crawled_urls_for_dict:
print(ind, name, "已经抓取过了.")
else:
try:
resp = requests.get(name_url)
except Exception as e:
print(ind, name, ":", str(e)[0:50])
continue
resp.encoding = "utf8"
content = resp.text
crawled_urls_for_dict.add(name_url)
with open("bydict_" + name + ".html", 'w', encoding='utf8') as f:
f.write(content)
print("抓取完成 : {} {}, 内容长度为{}".format(ind, name, len(content)))
首先定义一个空集合保存我们抓取过数据的URL,避免重复抓取
后面我们通过for循环和枚举遍历每个字典的key和value,将每个爬取到的URL存储到开头定义的集合crawled_urls_for_dict中。
然后我们判断要爬取的URL是否已经保存在集合中,如果存在则输出已经被爬取
如果没有,请继续进行以下操作。我们在这里是为了防止程序出错,影响程序的整体运行。这里我们使用 try except 语句打印出错误异常,以保证程序可以完整运行。
那么无非和我之前说的一样,改变编码格式,暂时保存内容
只是最后我们创建了一个文件来保存爬取的网页文件。我不会详细解释这个。无非是添加一个后缀。
后面我们打印了我们爬取的网页地址
for u in crawled_urls_for_dict:
print(u)
然后我们使用列表来抓取数据
代码显示如下
# 利用列表抓取
crawled_urls_for_list = set()
for ind, tup in enumerate(urls_lst):
name = tup[0]
name_url = tup[1]
if name_url in crawled_urls_for_list:
print(ind, name, "已经抓取过了.")
else:
try:
resp = requests.get(name_url)
except Exception as e:
print(ind, name, ":", str(e)[0:50])
continue
resp.encoding = "utf8"
content = resp.text
crawled_urls_for_list.add(name_url)
with open('bylist_' + name + ".html", "w", encoding='utf8') as f:
f.write(content)
print("抓取完成:{} {}, 内容长度为{}".format(ind, name, len(content)))
原理和之前的字典一样,就不多说了。
注意这是一个嵌套列表,遍历时注意
最后是一样的
for u in crawled_urls_for_list:
print(u)
打印捕获的数据
运行结果如下图所示
susmotedeMacBook-Air:FirstDatamining susmote$ python main.py
抓取完成 : 0 特克斯博客, 内容长度为26793
抓取完成 : 1 百度, 内容长度为2287
2 xyz : Invalid URL 'www.susmote.com': No schema supplied.
抓取完成 : 3 特克斯博客歌单区1, 内容长度为21728
4 特克斯博客歌单区2 已经抓取过了.
http://www.susmote.com/
http://www.baidu.com
https://www.susmote.com/?cate=13
------------------------------------------------------------
抓取完成:0 特克斯博客, 内容长度为26793
抓取完成:1 百度, 内容长度为2287
2 xyz : Invalid URL 'www.susmote.com': No schema supplied.
抓取完成:3 特克斯博客歌单区1, 内容长度为21728
4 特克斯博客歌单区2 已经抓取过了.
http://www.susmote.com/
http://www.baidu.com
https://www.susmote.com/?cate=13
文件目录变化如下
用浏览器打开下图
特克斯博客
百度网站
至此,简单的数据采集就结束了。
欢迎访问我的官方网站 查看全部
java从网页抓取数据(字典批量获取数据打印的默认编码()(图)
)
然后在第三步中,我们更改了默认编码。这取决于您要抓取的网页的编码格式。如果你不改变它,你可能会得到乱码或一些你以前没见过的字符。
第五步,我们将抓取到的网页内容的前 50 个字符分配给内容供以后查看。由于网页内容太多,无法一次全部打印出来,我们决定将部分内容切片输出
最后一步,我们把刚才保存的部分内容打印出来
上一步只是为了提前熟悉爬取数据的步骤。接下来,我们将通过列表字典批量获取数据,然后将其保存为文件
首先定义一个字典来存放我们要爬取的页面的URL
urls_dict = {
'特克斯博客': 'http://www.susmote.com/',
'百度': 'http://www.baidu.com',
'xyz': 'www.susmote.com',
'特克斯博客歌单区1': 'https://www.susmote.com/?cate=13',
'特克斯博客歌单区2': 'https://www.susmote.com/?cate=13'
}
然后我们定义了一个列表,该列表也存储了被抓取页面的 URL
urls_lst = [
('特克斯博客', 'http://www.susmote.com/'),
('百度', 'http://www.baidu.com'),
('xyz', 'www.susmote.com'),
('特克斯博客歌单区1', 'https://www.susmote.com/?cate=13'),
('特克斯博客歌单区2', 'https://www.susmote.com/?cate=13')
]
那我们先用字典来抓取
代码显示如下:
# 利用字典抓取
crawled_urls_for_dict = set()
for ind, name in enumerate(urls_dict.keys()):
name_url = urls_dict[name]
if name_url in crawled_urls_for_dict:
print(ind, name, "已经抓取过了.")
else:
try:
resp = requests.get(name_url)
except Exception as e:
print(ind, name, ":", str(e)[0:50])
continue
resp.encoding = "utf8"
content = resp.text
crawled_urls_for_dict.add(name_url)
with open("bydict_" + name + ".html", 'w', encoding='utf8') as f:
f.write(content)
print("抓取完成 : {} {}, 内容长度为{}".format(ind, name, len(content)))
首先定义一个空集合保存我们抓取过数据的URL,避免重复抓取
后面我们通过for循环和枚举遍历每个字典的key和value,将每个爬取到的URL存储到开头定义的集合crawled_urls_for_dict中。
然后我们判断要爬取的URL是否已经保存在集合中,如果存在则输出已经被爬取
如果没有,请继续进行以下操作。我们在这里是为了防止程序出错,影响程序的整体运行。这里我们使用 try except 语句打印出错误异常,以保证程序可以完整运行。
那么无非和我之前说的一样,改变编码格式,暂时保存内容
只是最后我们创建了一个文件来保存爬取的网页文件。我不会详细解释这个。无非是添加一个后缀。
后面我们打印了我们爬取的网页地址
for u in crawled_urls_for_dict:
print(u)
然后我们使用列表来抓取数据
代码显示如下
# 利用列表抓取
crawled_urls_for_list = set()
for ind, tup in enumerate(urls_lst):
name = tup[0]
name_url = tup[1]
if name_url in crawled_urls_for_list:
print(ind, name, "已经抓取过了.")
else:
try:
resp = requests.get(name_url)
except Exception as e:
print(ind, name, ":", str(e)[0:50])
continue
resp.encoding = "utf8"
content = resp.text
crawled_urls_for_list.add(name_url)
with open('bylist_' + name + ".html", "w", encoding='utf8') as f:
f.write(content)
print("抓取完成:{} {}, 内容长度为{}".format(ind, name, len(content)))
原理和之前的字典一样,就不多说了。
注意这是一个嵌套列表,遍历时注意
最后是一样的
for u in crawled_urls_for_list:
print(u)
打印捕获的数据
运行结果如下图所示
susmotedeMacBook-Air:FirstDatamining susmote$ python main.py
抓取完成 : 0 特克斯博客, 内容长度为26793
抓取完成 : 1 百度, 内容长度为2287
2 xyz : Invalid URL 'www.susmote.com': No schema supplied.
抓取完成 : 3 特克斯博客歌单区1, 内容长度为21728
4 特克斯博客歌单区2 已经抓取过了.
http://www.susmote.com/
http://www.baidu.com
https://www.susmote.com/?cate=13
------------------------------------------------------------
抓取完成:0 特克斯博客, 内容长度为26793
抓取完成:1 百度, 内容长度为2287
2 xyz : Invalid URL 'www.susmote.com': No schema supplied.
抓取完成:3 特克斯博客歌单区1, 内容长度为21728
4 特克斯博客歌单区2 已经抓取过了.
http://www.susmote.com/
http://www.baidu.com
https://www.susmote.com/?cate=13
文件目录变化如下
用浏览器打开下图
特克斯博客
百度网站
至此,简单的数据采集就结束了。
欢迎访问我的官方网站
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-09-28 15:02
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页的源码,我们在源码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页的源码,我们在源码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java从网页抓取数据(java从网页抓取数据是不可行的?的技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-09-27 16:01
java从网页抓取数据是不可行的。数据要抓取手机浏览器版本要记录ipurl地址要记录每次ip地址的变动过程,然后对数据库进行操作。然后spring已经有了对应的方案:spidercontextcontextresourcemanager接口。代理的方式保证数据抓取的定时同步并且无界限。方法举例:voidviewto_resource(httpservletrequestrequest,httpservletresponseresponse,transactionalconnectionconnection){thread.sleep(10);//stronglymutatedherethread.sleep(3000);//writethepropertyvarrecolor=newcolor("green");//recolorofcolortherecolor=map.getcolorfactory("color.yellow");//illuminatedyellowisrecolorcolor.yellow=color.yellow+true;color=map.getcolorfactory("color.black");color=map.getcolorfactory("color.white");color=map.getcolorfactory("color.red");color=map.getcolorfactory("color.dark");color=map.getcolorfactory("color.orange");color=map.getcolorfactory("color.red");color=map.getcolorfactory("color.yellow");color=map.getcolorfactory("color.green");color=map.getcolorfactory("color.black");color=map.getcolorfactory("color.black");}对于你的问题,请看:爬虫文章下面的评论,我们只抓取部分文章的评论,有没有什么spring的技巧?-零文的回答。 查看全部
java从网页抓取数据(java从网页抓取数据是不可行的?的技巧)
java从网页抓取数据是不可行的。数据要抓取手机浏览器版本要记录ipurl地址要记录每次ip地址的变动过程,然后对数据库进行操作。然后spring已经有了对应的方案:spidercontextcontextresourcemanager接口。代理的方式保证数据抓取的定时同步并且无界限。方法举例:voidviewto_resource(httpservletrequestrequest,httpservletresponseresponse,transactionalconnectionconnection){thread.sleep(10);//stronglymutatedherethread.sleep(3000);//writethepropertyvarrecolor=newcolor("green");//recolorofcolortherecolor=map.getcolorfactory("color.yellow");//illuminatedyellowisrecolorcolor.yellow=color.yellow+true;color=map.getcolorfactory("color.black");color=map.getcolorfactory("color.white");color=map.getcolorfactory("color.red");color=map.getcolorfactory("color.dark");color=map.getcolorfactory("color.orange");color=map.getcolorfactory("color.red");color=map.getcolorfactory("color.yellow");color=map.getcolorfactory("color.green");color=map.getcolorfactory("color.black");color=map.getcolorfactory("color.black");}对于你的问题,请看:爬虫文章下面的评论,我们只抓取部分文章的评论,有没有什么spring的技巧?-零文的回答。
java从网页抓取数据(IE调试网页之五:使用F12开发人员工具调试(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-09-27 01:18
获取网页内容代码:HttpClient httpclient=new DefaultHttpClient();HttpGet httpget = new HttpGet(request.getParameter("requestUrl"));HttpResponse res=httpclient.execute(httpget);HttpEntity entity = res.getEntity();response. ...
IE 调试页面 5:使用 F12 开发人员工具调试 JavaScript 错误(Windows)
使用“Monitor”和“Local Variables”选项卡监视变量 使用“Monitor”选项卡,您可以在代码中设置和监视变量。这将列出指定变量的名称、值和类型。您可以单击标有“单击以添加”的行。在“监控”选项卡中输入变量名称。如果不想输入变量名,可以...
《HTML、CSS、JavaScript网页制作从入门到精通》-第6章使用表格
但是在实际的制作过程中,表格更多的用于网页布局的定位。很多网页都是以表格的形式布局的,因为表格在控制文字和图片的位置方面有很强的作用。灵活巧妙地使用表单,制作网页时会感觉像老虎一样。学习目标 掌握表格的创建,掌握设置表格的基础...
《HTML、CSS、JavaScript网页制作从入门到精通》-1.3 使用浏览器浏览HTML文件
1.3 使用浏览器浏览HTML文件 HTML、CSS、JavaScript网页制作从入门到精通1.3.1 查看页面效果,打开index.htm文件,可以在IE浏览器窗口查看 看到编辑后的HTML页面的效果,如图1.6。1.3.2 查看源文件*您可以使用以下方法快速轻松地打开HTML文档...
《HTML CSS JavaScript 网页制作从入门到精通第3版》-1.3 使用浏览器浏览HTML...
本节摘自异步社区...2。操作题(1)用IE浏览器打开网上任意一个网页,选择【查看】|【源文件】命令,在打开的记事本中查看各个代码,并尝试与浏览器中的内容进行对比。 (2) 分别用记事本和 Dreamweaver 创建一个简单的 HTML 页面。 查看全部
java从网页抓取数据(IE调试网页之五:使用F12开发人员工具调试(组图))
获取网页内容代码:HttpClient httpclient=new DefaultHttpClient();HttpGet httpget = new HttpGet(request.getParameter("requestUrl"));HttpResponse res=httpclient.execute(httpget);HttpEntity entity = res.getEntity();response. ...
IE 调试页面 5:使用 F12 开发人员工具调试 JavaScript 错误(Windows)
使用“Monitor”和“Local Variables”选项卡监视变量 使用“Monitor”选项卡,您可以在代码中设置和监视变量。这将列出指定变量的名称、值和类型。您可以单击标有“单击以添加”的行。在“监控”选项卡中输入变量名称。如果不想输入变量名,可以...
《HTML、CSS、JavaScript网页制作从入门到精通》-第6章使用表格
但是在实际的制作过程中,表格更多的用于网页布局的定位。很多网页都是以表格的形式布局的,因为表格在控制文字和图片的位置方面有很强的作用。灵活巧妙地使用表单,制作网页时会感觉像老虎一样。学习目标 掌握表格的创建,掌握设置表格的基础...
《HTML、CSS、JavaScript网页制作从入门到精通》-1.3 使用浏览器浏览HTML文件
1.3 使用浏览器浏览HTML文件 HTML、CSS、JavaScript网页制作从入门到精通1.3.1 查看页面效果,打开index.htm文件,可以在IE浏览器窗口查看 看到编辑后的HTML页面的效果,如图1.6。1.3.2 查看源文件*您可以使用以下方法快速轻松地打开HTML文档...
《HTML CSS JavaScript 网页制作从入门到精通第3版》-1.3 使用浏览器浏览HTML...
本节摘自异步社区...2。操作题(1)用IE浏览器打开网上任意一个网页,选择【查看】|【源文件】命令,在打开的记事本中查看各个代码,并尝试与浏览器中的内容进行对比。 (2) 分别用记事本和 Dreamweaver 创建一个简单的 HTML 页面。
java从网页抓取数据(从千亿页面上提取数据该如何做呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-09-27 01:17
众所周知,要想更好地完成数据分析,除了掌握好方法和方法,还需要做好数据提取。那么如何从千亿页面中提取数据呢?
现在从互联网上获取数据似乎很容易。有很多开源的库和框架,可视化爬虫工具和数据提取工具,可以很方便的从一个网站中抓取数据。然而,当你想大规模搜索网站时,很快就变得非常棘手。
大规模网络爬虫的要点:
不同于标准的网络爬虫应用,电子商务产品数据的大规模爬取将面临一系列独特的挑战,这使得网络爬行变得异常困难。
本质上,这些困难可以归结为两个方面:速度和数据质量。
通常时间是一个限制性的约束,所以大规模的抓取需要网络爬虫以非常高的速度抓取页面,并且不会影响数据质量。这种对速度的要求使得捕获大量产品数据变得非常具有挑战性。
挑战一:乱七八糟的网页格式。凌乱多变的网页格式可能是最常见的挑战,也可能不是最有趣的挑战,但却是迄今为止大规模数据提取面临的最大挑战。这个挑战的关键不是复杂性,而是需要大量的时间和资源来应对。
挑战 2:可扩展架构。您将面临的下一个挑战是构建一个爬虫基础设施,该基础设施可以随着每天请求数量的增加而扩展,而不会降低性能。
在大规模提取产品数据时,简单的网络爬虫只能连续爬取数据,不能提取。通常,连续的网络爬虫会一个接一个地循环发送请求,每个请求需要 2-3 秒才能完成。
如果爬虫每天少于40000个请求(每2秒发送一个请求,意味着每天可以发送43200个请求),这种方法是可以的。但是,一旦请求数量超过这个数量,就需要切换到每天可以发送数百万个请求而不降低性能的爬虫架构。
如上所述,速度是大规模捕获产品数据的关键。您需要确保在特定时间段(通常为一天)内找到并抓取所有需要的产品页面。为此,您需要执行以下操作:
将产品搜索与产品提取分开。为了大规模提取产品数据,您需要将产品搜索爬虫与产品提取爬虫分开。
为产品提取分配更多资源。由于每个产品类别“货架”可以收录10到100个产品,并且与提取产品URL相比,提取产品数据需要更多资源,因此搜索爬虫通常比产品提取爬虫更快。
挑战 3:保持吞吐量性能。在提取大量数据时,我们必须在现有硬件资源的基础上,尽可能地找到一种可以最小化循环时间并最大化爬虫性能的方法。所有这些都必须减少每个请求的时间,甚至几毫秒。
为此,您的团队需要深入了解网络抓取框架、代理管理和正在使用的硬件,以便更好地调整它们以获得最佳性能。
在大规模抓取时,我们应该始终努力在最少的请求中提取所需的确切数据。任何额外的请求或数据提取都会降低爬取网站的速度。
在设计爬虫时,请记住以下几点:
1、 用一个没有头的浏览器,比如Splash或者Puppeteer,把JavaScript渲染放在最后。抓取网页时,使用无头浏览器渲染JavaScript会非常占用资源,严重影响抓取速度;
2、 如果不需要向每个产品页面发送请求,但也可以从货架页面获取数据(如产品名称、价格、口碑等),则不要请求该产品页;
3、除非必要,否则不要请求或检索图像。
挑战四:反机器人策略。在大规模爬取电商网站时,你肯定会遇到使用反机器人策略的网站。
对于大多数小网站来说,他们的反机器人策略是非常基础的(IP禁止过度请求)。但是对于亚马逊网站这样的大型电商公司,他们会使用非常成熟的反机器人策略,比如DistilNetworks、Incapsula或者Akamai,这会让数据提取变得更加困难。
挑战 5:数据质量。从数据科学家的角度来看,网络抓取项目最重要的考虑因素是提取数据的质量。大规模爬取更注重数据的质量。
如果每天需要提取数百万个数据点,则无法手动验证所有数据是否干净完整。小心脏数据或不完整的数据会进入数据源,破坏数据分析工作。
当商店有多个版本(不同语言、地区等)或从不同商店抓取数据时,数据质量尤为重要。
除了仔细的QA流程,在创建爬虫的设计阶段,相互审查和测试爬虫代码可以确保以最可靠的方式提取所需的数据。确保高数据质量的最佳方法是开发自动化 QA 监控系统。
以上是小编为大家整理的《千亿页数据提取经验总结》一文。更多相关信息可以在数据分析教程频道中找到。 查看全部
java从网页抓取数据(从千亿页面上提取数据该如何做呢?(图))
众所周知,要想更好地完成数据分析,除了掌握好方法和方法,还需要做好数据提取。那么如何从千亿页面中提取数据呢?
现在从互联网上获取数据似乎很容易。有很多开源的库和框架,可视化爬虫工具和数据提取工具,可以很方便的从一个网站中抓取数据。然而,当你想大规模搜索网站时,很快就变得非常棘手。
大规模网络爬虫的要点:
不同于标准的网络爬虫应用,电子商务产品数据的大规模爬取将面临一系列独特的挑战,这使得网络爬行变得异常困难。
本质上,这些困难可以归结为两个方面:速度和数据质量。
通常时间是一个限制性的约束,所以大规模的抓取需要网络爬虫以非常高的速度抓取页面,并且不会影响数据质量。这种对速度的要求使得捕获大量产品数据变得非常具有挑战性。
挑战一:乱七八糟的网页格式。凌乱多变的网页格式可能是最常见的挑战,也可能不是最有趣的挑战,但却是迄今为止大规模数据提取面临的最大挑战。这个挑战的关键不是复杂性,而是需要大量的时间和资源来应对。
挑战 2:可扩展架构。您将面临的下一个挑战是构建一个爬虫基础设施,该基础设施可以随着每天请求数量的增加而扩展,而不会降低性能。
在大规模提取产品数据时,简单的网络爬虫只能连续爬取数据,不能提取。通常,连续的网络爬虫会一个接一个地循环发送请求,每个请求需要 2-3 秒才能完成。
如果爬虫每天少于40000个请求(每2秒发送一个请求,意味着每天可以发送43200个请求),这种方法是可以的。但是,一旦请求数量超过这个数量,就需要切换到每天可以发送数百万个请求而不降低性能的爬虫架构。
如上所述,速度是大规模捕获产品数据的关键。您需要确保在特定时间段(通常为一天)内找到并抓取所有需要的产品页面。为此,您需要执行以下操作:
将产品搜索与产品提取分开。为了大规模提取产品数据,您需要将产品搜索爬虫与产品提取爬虫分开。
为产品提取分配更多资源。由于每个产品类别“货架”可以收录10到100个产品,并且与提取产品URL相比,提取产品数据需要更多资源,因此搜索爬虫通常比产品提取爬虫更快。
挑战 3:保持吞吐量性能。在提取大量数据时,我们必须在现有硬件资源的基础上,尽可能地找到一种可以最小化循环时间并最大化爬虫性能的方法。所有这些都必须减少每个请求的时间,甚至几毫秒。
为此,您的团队需要深入了解网络抓取框架、代理管理和正在使用的硬件,以便更好地调整它们以获得最佳性能。
在大规模抓取时,我们应该始终努力在最少的请求中提取所需的确切数据。任何额外的请求或数据提取都会降低爬取网站的速度。
在设计爬虫时,请记住以下几点:
1、 用一个没有头的浏览器,比如Splash或者Puppeteer,把JavaScript渲染放在最后。抓取网页时,使用无头浏览器渲染JavaScript会非常占用资源,严重影响抓取速度;
2、 如果不需要向每个产品页面发送请求,但也可以从货架页面获取数据(如产品名称、价格、口碑等),则不要请求该产品页;
3、除非必要,否则不要请求或检索图像。
挑战四:反机器人策略。在大规模爬取电商网站时,你肯定会遇到使用反机器人策略的网站。
对于大多数小网站来说,他们的反机器人策略是非常基础的(IP禁止过度请求)。但是对于亚马逊网站这样的大型电商公司,他们会使用非常成熟的反机器人策略,比如DistilNetworks、Incapsula或者Akamai,这会让数据提取变得更加困难。
挑战 5:数据质量。从数据科学家的角度来看,网络抓取项目最重要的考虑因素是提取数据的质量。大规模爬取更注重数据的质量。
如果每天需要提取数百万个数据点,则无法手动验证所有数据是否干净完整。小心脏数据或不完整的数据会进入数据源,破坏数据分析工作。
当商店有多个版本(不同语言、地区等)或从不同商店抓取数据时,数据质量尤为重要。
除了仔细的QA流程,在创建爬虫的设计阶段,相互审查和测试爬虫代码可以确保以最可靠的方式提取所需的数据。确保高数据质量的最佳方法是开发自动化 QA 监控系统。
以上是小编为大家整理的《千亿页数据提取经验总结》一文。更多相关信息可以在数据分析教程频道中找到。
java从网页抓取数据(一个-1.11.1.jarokio-3.12.0.jar-1.12.0.jar●jsoup使用文档 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-09-26 16:41
)
目录
目录
前言
最近,我想建立一个视频播放应用程序,可以播放电影和电视剧。结果,我在互联网上搜索了API接口,发现虽然爱奇艺提供的视频接口和其他视频网站可以使用,但是注册和审核应用程序的步骤很繁琐,它们的API不能在我自己的播放器中播放,,但我必须使用java编写一个程序来获取网页数据,以满足我的需要。这里我记录了实施过程
前期准备
● 所需的jar包:
jsoup-1.11.1.雅鲁藏布江http-3.12.0.雅鲁藏布江-1.12.0.雅鲁藏布江
● jsoup使用文档:
案例实现
public class Test {
private static final String BASE_URL="http://www.baiwanzy.com";//这里使用的是百万资源网的资源
public static void main(String[] args) {
asyncGet();
}
public static void asyncGet() {
String encode = URLEncoder.encode("雪鹰领主");//对查询的数据进行Url编码
String urlBaidu = "http://www.baiwanzy.com/index. ... de%3B
OkHttpClient okHttpClient = new OkHttpClient(); // 创建OkHttpClient对象
Request request = new Request.Builder().url(urlBaidu).build(); // 创建一个请求
okHttpClient.newCall(request).enqueue(new Callback() { // 回调
public void onResponse(Call call, Response response) throws IOException {
// 请求成功调用,该回调在子线程
getMovieList(response.body().string());
}
public void onFailure(Call call, IOException e) {
// 请求失败调用
System.out.println(e.getMessage());
}
});
}
public static void getMovieList(String datas){
Document doc = Jsoup.parse(datas);
// 根据css的后代选择器来找到相关的列表
Elements links = doc.select(".xing_vb4 a");//这里是返回的列表的类来查找相关的a标签
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
System.out.println(BASE_URL+linkHref+"==="+linkText);
}
}
} 查看全部
java从网页抓取数据(一个-1.11.1.jarokio-3.12.0.jar-1.12.0.jar●jsoup使用文档
)
目录
目录
前言
最近,我想建立一个视频播放应用程序,可以播放电影和电视剧。结果,我在互联网上搜索了API接口,发现虽然爱奇艺提供的视频接口和其他视频网站可以使用,但是注册和审核应用程序的步骤很繁琐,它们的API不能在我自己的播放器中播放,,但我必须使用java编写一个程序来获取网页数据,以满足我的需要。这里我记录了实施过程
前期准备
● 所需的jar包:
jsoup-1.11.1.雅鲁藏布江http-3.12.0.雅鲁藏布江-1.12.0.雅鲁藏布江
● jsoup使用文档:
案例实现
public class Test {
private static final String BASE_URL="http://www.baiwanzy.com";//这里使用的是百万资源网的资源
public static void main(String[] args) {
asyncGet();
}
public static void asyncGet() {
String encode = URLEncoder.encode("雪鹰领主");//对查询的数据进行Url编码
String urlBaidu = "http://www.baiwanzy.com/index. ... de%3B
OkHttpClient okHttpClient = new OkHttpClient(); // 创建OkHttpClient对象
Request request = new Request.Builder().url(urlBaidu).build(); // 创建一个请求
okHttpClient.newCall(request).enqueue(new Callback() { // 回调
public void onResponse(Call call, Response response) throws IOException {
// 请求成功调用,该回调在子线程
getMovieList(response.body().string());
}
public void onFailure(Call call, IOException e) {
// 请求失败调用
System.out.println(e.getMessage());
}
});
}
public static void getMovieList(String datas){
Document doc = Jsoup.parse(datas);
// 根据css的后代选择器来找到相关的列表
Elements links = doc.select(".xing_vb4 a");//这里是返回的列表的类来查找相关的a标签
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
System.out.println(BASE_URL+linkHref+"==="+linkText);
}
}
}
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-09-26 14:06
原创链接:
有时由于各种原因,我们需要一些采集数据,但由于不同网站
本文使用Java向您展示如何抓取网站的数据:(1)抓取原创网页的数据;(2)抓取网页JavaScript返回的数据
一、抓取原创页面
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此网页,输入IP:111.142.55.73,然后单击查询按钮查看网页上显示的结果:
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
[爪哇]
publicvoidcaptureHtml(Stringip)通过异常{StringstrURL=“”+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferer=newBufferedReader(input);Stringline=“;StringBuildercontentBuf=newStringBuilder();而(((line=bufrader.Readline())!=null){contentbuf.Append(line);}stringbuf=contentbuf.Tostring();intbeginix=buf.Indexof(“查询结果[”);intendix=buf.Indexof(“上述四项依次显示”);stringresult=buf.Substring(beginix,endix);system.Out.Println(“capturehtml的结果:”“n”+结果);]
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111.142.55.73==>;1871591241==>;福建省漳州移动
二、在网页上抓取JavaScript返回的结果
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这可以避免搜索引擎和其他工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
[爪哇]
publicvoidcaptureJavascript(Stringpostid)通过异常{StringstrURL=“”+postid+”&;channel=&;rnd=0;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferReader=NewBuffereder(input);Stringline=”“stringbuildercontentbuf=newstringbuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}system.Out.Println(“capturejavascript()的结果:\n”+contentbuf.Tostring());”
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载 查看全部
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
原创链接:
有时由于各种原因,我们需要一些采集数据,但由于不同网站
本文使用Java向您展示如何抓取网站的数据:(1)抓取原创网页的数据;(2)抓取网页JavaScript返回的数据
一、抓取原创页面
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此网页,输入IP:111.142.55.73,然后单击查询按钮查看网页上显示的结果:
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
[爪哇]
publicvoidcaptureHtml(Stringip)通过异常{StringstrURL=“”+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferer=newBufferedReader(input);Stringline=“;StringBuildercontentBuf=newStringBuilder();而(((line=bufrader.Readline())!=null){contentbuf.Append(line);}stringbuf=contentbuf.Tostring();intbeginix=buf.Indexof(“查询结果[”);intendix=buf.Indexof(“上述四项依次显示”);stringresult=buf.Substring(beginix,endix);system.Out.Println(“capturehtml的结果:”“n”+结果);]
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111.142.55.73==>;1871591241==>;福建省漳州移动
二、在网页上抓取JavaScript返回的结果
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这可以避免搜索引擎和其他工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
[爪哇]
publicvoidcaptureJavascript(Stringpostid)通过异常{StringstrURL=“”+postid+”&;channel=&;rnd=0;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferReader=NewBuffereder(input);Stringline=”“stringbuildercontentbuf=newstringbuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}system.Out.Println(“capturejavascript()的结果:\n”+contentbuf.Tostring());”
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载
java从网页抓取数据(怎样抓取站点的数据:(1)抓取原网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-09-23 07:21
说明链接:
有时,由于各种原因,我们必须采集某个站点的数据,但由于不同的网站与数据显示略有不同!
本文使用Java来演示如何抓取网站的数据:( 1)抓取原创网页数据;(2)抓取Web JavaScript返回的数据。
一、 grab原创网页。
此示例我们将从顶部抓取IP查询的结果:
第一步:打开此页面,然后输入IP:11 1. 14 2. 5. 73,单击“查询”按钮,您可以看到Web显示的结果:
步骤2:查看Web源代码,我们在源代码中看到这样的段落:
可以从这里看出,查询的结果再次在另一个请求之后再次显示。
查询后查看Web地址:
也就是说,我们只需访问这样一个URL的形式,您可以获得IP查询的结果,代码旁边:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpUrlConnection连接站点保存Bufreader返回的数据,然后通过解决您自己的定义来显示结果。
我只是一个偶然的解决方案。如果要解决它,则需要重新处理它。
解析结果,例如:
capturehtml()结果:
查询结果[1]:11 1. 14 2. 5 5. 73 ==&gt; &gt; 1871591241 ==&gt; &gt;福建省漳州移动
二、 crawler页面javascript返回的结果。
有时该网站是保护自己的数据,也不会直接将数据直接放在Web源代码中,但使用异步方式,用JS返回数据,这避免了搜索引擎和其他工具来捕获网站数据。 。
首先查看此页面:
以第一种方式查看网页的源代码,但没有Waybill的跟踪信息,因为它通过JS获取结果。
但有时我们必须得到JS的数据,我该怎么做?
我们必须使用工具:HTTP分析仪,此工具可以拦截HTTP的互动内容,我们通过此工具实现了我们的目标。
单击startButton后,它开始收听网页的交互行为。
我们打开页面:您可以看到HTTP分析仪列出所有请求数据和结果:
对于JS的结果更方便,让我们先将数据输入数据,然后在网页上输入快递号码:7,单击“查询”按钮,然后查看HTTP分析器的结果:
这是点击查询按钮,HTTP分析仪的结果,我们继续查看:
从上面的两个图表可以看出,HTTP分析器可以拦截JS返回的数据并在响应内容中显示,并且可以同时看到JS请求的网页地址。
在这种情况下,我们只想分析HTTP分析仪的结果,然后模拟JS的行为来获取数据,即我们只想访问JS的Web地址,当然,数据未加密我们将写下URL:
js请求。
然后让程序请求此页面的结果!
以下是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
参见它,抓住js模式和捕获原创网页的代码,我们只有一个分析js的过程。
以下是程序运行的结果:
capturejavascript()结果:
Waybill [7]跟踪信息
这些数据是JS返回的结果,我们的目的是达到的!
我希望这篇文章有点帮助所需的朋友,请点击这里下载! 查看全部
java从网页抓取数据(怎样抓取站点的数据:(1)抓取原网页数据)
说明链接:
有时,由于各种原因,我们必须采集某个站点的数据,但由于不同的网站与数据显示略有不同!
本文使用Java来演示如何抓取网站的数据:( 1)抓取原创网页数据;(2)抓取Web JavaScript返回的数据。
一、 grab原创网页。
此示例我们将从顶部抓取IP查询的结果:
第一步:打开此页面,然后输入IP:11 1. 14 2. 5. 73,单击“查询”按钮,您可以看到Web显示的结果:
步骤2:查看Web源代码,我们在源代码中看到这样的段落:
可以从这里看出,查询的结果再次在另一个请求之后再次显示。
查询后查看Web地址:
也就是说,我们只需访问这样一个URL的形式,您可以获得IP查询的结果,代码旁边:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpUrlConnection连接站点保存Bufreader返回的数据,然后通过解决您自己的定义来显示结果。
我只是一个偶然的解决方案。如果要解决它,则需要重新处理它。
解析结果,例如:
capturehtml()结果:
查询结果[1]:11 1. 14 2. 5 5. 73 ==&gt; &gt; 1871591241 ==&gt; &gt;福建省漳州移动
二、 crawler页面javascript返回的结果。
有时该网站是保护自己的数据,也不会直接将数据直接放在Web源代码中,但使用异步方式,用JS返回数据,这避免了搜索引擎和其他工具来捕获网站数据。 。
首先查看此页面:
以第一种方式查看网页的源代码,但没有Waybill的跟踪信息,因为它通过JS获取结果。
但有时我们必须得到JS的数据,我该怎么做?
我们必须使用工具:HTTP分析仪,此工具可以拦截HTTP的互动内容,我们通过此工具实现了我们的目标。
单击startButton后,它开始收听网页的交互行为。
我们打开页面:您可以看到HTTP分析仪列出所有请求数据和结果:
对于JS的结果更方便,让我们先将数据输入数据,然后在网页上输入快递号码:7,单击“查询”按钮,然后查看HTTP分析器的结果:
这是点击查询按钮,HTTP分析仪的结果,我们继续查看:
从上面的两个图表可以看出,HTTP分析器可以拦截JS返回的数据并在响应内容中显示,并且可以同时看到JS请求的网页地址。
在这种情况下,我们只想分析HTTP分析仪的结果,然后模拟JS的行为来获取数据,即我们只想访问JS的Web地址,当然,数据未加密我们将写下URL:
js请求。
然后让程序请求此页面的结果!
以下是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
参见它,抓住js模式和捕获原创网页的代码,我们只有一个分析js的过程。
以下是程序运行的结果:
capturejavascript()结果:
Waybill [7]跟踪信息
这些数据是JS返回的结果,我们的目的是达到的!
我希望这篇文章有点帮助所需的朋友,请点击这里下载!
java从网页抓取数据(使用Python网络爬虫首先需要了解一下什么是HTTP的请求与响应)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-09-21 19:01
使用Python网络爬虫首先需要了解一下什么是HTTP,因为这个跟Python爬虫的基本原理息息相关。而正是围绕着这些底层逻辑,Python爬虫才能一步步地往下进行。
HTTP全称是Hyper Text Transfer Protocol,中文叫超文本传输协议,用于从网络传输超文本数据到本地浏览器的传送协议,也是因特网上应用最为广泛的一种网络传输协议。
请求与响应
当我们从浏览器输入URL回车之后,浏览器就会向网站所在的服务器发送一个请求,服务器收到请求后对其进行解析和处理,然后返回浏览器对应的响应,响应里收录了页面的源代码等内容,经过浏览器的解析之后便呈现出我们在浏览器上看到的内容。这整个过程就是HTTP的请求与响应。
请求方法常见的请求方法有两种:GET和POST。二者的主要区别在于GET请求的内容会体现在URL里,POST请求则体现在表单形式里,所以当涉及一些敏感或私密的信息时,如用户名和密码,我们用POST请求来进行信息的传递。
响应状态码请求完之后,客户端会收到服务器返回的响应状态,常见的响应状态码有200(服务器正常响应)、404(页面未找到)、500(服务器内部发生错误)等。
2.网页
在爬虫时,我们通过响应得到的网页源代码、JSON数据等来提取需要的信息数据,所以我们需要了解一下网页的基础结构。一个网页基本由以下三部分组成:
HTML,全称Hyper Text Marked Language,中文叫超文本标记语言,用来表述网页以呈现出内容,如文字,图片,视频等,相当于网页的骨架。
JavaScript,简称JS,是一种脚本语言,能够给页面增加实时、动态、交互的功能,相当于网页的肌肉。
CSS,全称Cascading Style Sheets,中文叫层叠样式表,对网页页面进行布局和装饰,使页面变得美观、优雅,相当于网页的皮肤。
3.基本原理
Python爬虫的基本原理其实是围绕着HTTP和网页结构展开的:首先是请求网页,接着是解析和提取信息,最后是存储信息。
1) 请求
Python经常用来请求的第三方库有requests、selenium,内置的库也可以用urllib。
requests是用Python编写的,基于urllib,采用Apache2 Licensed开源协议的HTTP库。相比urllib库,requests库更加方便,可以节约我们大量工作,所以我们倾向于使用requests来请求网页。
selenium是一个用于web应用程序的自动化测试工具,它可以驱动浏览器执行特定的动作,如输入、点击、下拉等,就像真正的用户在操作一样,在爬虫中常用来解决JavaScript渲染问题。selenium可以支持多种浏览器,如Chrome,Firefox,Edge等。在通过selenium使用这些浏览器之前,需要配置好相关的浏览器驱动:
ChromeDriver:Chrome浏览器驱动
GeckoDriver:Firefox浏览器驱动
PhantomJS:无界面、可脚本编程的WebKit浏览器引擎
2)解析和提取
Python用来解析和提取信息的第三方库有BeautifulSoup、lxml、pyquery等。
每个库可以用不同的方法来提取数据:
BeautifulSoup:方法选择器find()和find_all()或CSS选择器
lxml:XPath
pyquery:CSS选择器
此外,还可以用正则表达式来提取自己想要的信息,有了它,字符串检索、替换和匹配都不在话下。
3)存储
将数据提取出之后就是对数据进行存储了。最简单的可以将数据保存为文本文件,如TXT文本、CSV文件、Excel文件、JSON文件等,也可以保存为二进制数据,如图片、音频、视频等,还可以保存到数据库中,如关系型数据库MySQL,非关系型数据库MongoDB、Redis等。
若是将数据存储为CSV文件、Excel文件和JSON文件则需要用到csv库、openpyxl库和json库。
4.静态网页爬取
了解完爬虫基本原理之后就可以爬取网页了,其中静态网页是最容易操作的。
对静态网页进行爬取,我们可以选择requests进行请求,得到网页源代码,接着使用BeautifulSoup进行解析和提取,最后选择合适的存储方法。
5.动态网页爬取
有时候在使用requests爬取网页的时候,会发现抓取的内容和浏览器显示的不一样,在浏览器里能看到要爬取的内容,但是爬取完之后的结果却没有,这就与网页是静态的还是动态的有关了。
静态网页是相对于动态网页而言,是指没有后台数据库、不含程序和不可交互的网页。而动态网页则是基本的html语法规范与Java、VB、VC等高级程序设计语言、数据库编程等多种技术的融合,以期实现对网站内容和风格的高效、动态和交互式的管理的网页。
二者的区别在于:
静态网页随着html代码的生成,页面的内容和显示效果基本上不会发生变化了——除非修改页面代码。
动态网页的页面代码虽然没有变,但是显示的内容却可以随着时间、环境或者数据库操作的结果而发生改变。
1)Ajax
Ajax不是一门编程语言,而是利用JavaScript在不重新加载整个页面的情况下可以与服务器交换数据并更新部分网页内容的技术。
因为使用Ajax技术的网页里的信息是通过JavaScript脚本语言动态生成的,所以使用requests-BeautifulSoup的静态页面的爬取方法是抓不到数据的,我们可以通过以下两种方法爬取Ajax数据:
通过查找浏览器开发者工具里的Network-XHR/JS栏找到储存着数据的动态页面,使用requests请求网页,再将得到的数据使用json()方法进行转化就可以提取了。
使用selenium指挥浏览器,直接对数据进行抓取(或者通过selenium获取到渲染完整的网页源代码,再使用BeautifulSoup进行解析和提取数据)。
2)Cookie和Session
Cookie是网站为了辨别用户身份进行Session跟踪而储存在用户本地终端上的数据(通常经过加密),由用户客户端计算机暂时或永久保存。
Session称为“会话”,存储着特定用户会话所需的属性及配置信息。
很多情况下,页面的更多信息需要登陆才能查看,所以在面对这类网页时,需要先模拟登陆后才可以对网页作进一步爬取。当我们模拟登陆时,客户端会生成Cookie并发送给服务器。因为Cookie保存着SessionID信息,所以服务器就可以根据Cookie判断出对应的SessionID,进而找到会话。如果当前的会话是有效的,那么服务器就会判断用户已经登陆并返回请求的页面信息,这样就可以对网页作进一步爬取了。
6.APP爬取
除了web端,Python还可以爬取APP数据,不过这需要用到抓包工具,比如Fiddler。
相比web端而言,APP的数据爬取其实更容易,反爬虫也没那么强,返回的数据类型大多数为json。
7.多协程
当我们在做爬虫项目的时候,如果需要爬取的数据非常多,因为程序是一行行依次执行的,所以爬取的速度就会非常慢。而多协程就能解决这一个问题。
使用多协程,我们就可以同时执行多个任务。实际上,使用多协程时,如果一个任务在执行的过程中遇到等待,那它就会先去执行其它的任务,当等待结束,再回来继续执行之前的那个任务。因为这个过程切换得非常迅速,所以看上去像多个任务被同时执行一样,用计算机里的概念来解释的话,这其实就是异步。
我们可以使用gevent库来实现多协程,使用Queue()创建队列,spawn()创建任务,最后joinall()执行任务。
8.爬虫框架
在遇到比较大型的需求时,为了方便管理及拓展,我们可以使用爬虫框架实现数据爬取。
有了爬虫框架之后,我们就不必一个个地去组建爬虫的整个流程,只需要关心爬虫的核心逻辑部分即可,这样就大大提高了开发效率,节省了很多时间。爬虫框架有很多个,如Scrapy、PySpider等。
9.分布式爬虫
使用爬虫框架已经大大提高了开发效率,不过这些框架都是在同一台主机上运行的,如果能多台主机协同爬取,那么爬取效率就会更近一步提高。将多台主机组合起来,共同完成一个爬取任务,这就是分布式爬虫。
10.反爬虫机制与应对方法
为了防止爬虫开发者过度爬取造成网站的负担或者进行恶意的数据抓取,很多网站会设置反爬虫机制。所以当我们在对网站进行数据抓取的时候,可以查看一下网站的robots.txt了解一下网站允许爬取什么,不允许爬取什么。
常见的爬虫机制有以下4种:
①请求头验证:请求头验证是最常见的反爬虫机制,很多网站会对Headers里的user-agent进行检测,一部分网站还会检测origin和referer。应对这类反爬虫机制可以在爬虫中添加请求头headers,将浏览器里对应的值以字典的形式添加进去即可。
②Cookie限制:有些网站会用Cookie跟踪你的访问过程,如果发现爬虫的异常行为就会中断该爬虫的访问。应对Cookie限制类的反爬虫,一般可以通过先取得该网站的Cookie,再把Cookie发送给服务器即可,可以手动添加或者使用Session机制。不过,针对部分网站需要用户浏览页面时才能产生Cookie的情况,比如点击按钮,可以使用selenium-PhantomJS来请求网页并获取Cookie。
③IP访问频率限制:一些网站会通过检测用户行为来判断同一IP是否在短时间内多次请求页面,如果这个频率超过了某个阈值,网站通常会对爬虫进行提示并要求输入验证码,或者直接封掉IP拒绝服务。针对这种情况,可以使用IP代理的方法来绕过反爬虫,如代理池维护、付费代理、ADSL拨号代理等。
④验证码限制:很多网站在登陆的时候需要输入验证码,常见的有:图形验证码、极验滑动验证码、点触验证码和宫格验证码。
图形验证码:需要用到OCR技术,使用Python的第三方库tesserocr可以做到这一点。
极验滑动验证码:需要使用selenium来完成模拟人的行为的方式来验证。
点触验证码:需要在使用selenium的基础上借助第三方验证码服务平台来解决。
宫格验证码:需要使用selenium和模板匹配的方法。
验证码类型 查看全部
java从网页抓取数据(使用Python网络爬虫首先需要了解一下什么是HTTP的请求与响应)
使用Python网络爬虫首先需要了解一下什么是HTTP,因为这个跟Python爬虫的基本原理息息相关。而正是围绕着这些底层逻辑,Python爬虫才能一步步地往下进行。
HTTP全称是Hyper Text Transfer Protocol,中文叫超文本传输协议,用于从网络传输超文本数据到本地浏览器的传送协议,也是因特网上应用最为广泛的一种网络传输协议。
请求与响应
当我们从浏览器输入URL回车之后,浏览器就会向网站所在的服务器发送一个请求,服务器收到请求后对其进行解析和处理,然后返回浏览器对应的响应,响应里收录了页面的源代码等内容,经过浏览器的解析之后便呈现出我们在浏览器上看到的内容。这整个过程就是HTTP的请求与响应。
请求方法常见的请求方法有两种:GET和POST。二者的主要区别在于GET请求的内容会体现在URL里,POST请求则体现在表单形式里,所以当涉及一些敏感或私密的信息时,如用户名和密码,我们用POST请求来进行信息的传递。
响应状态码请求完之后,客户端会收到服务器返回的响应状态,常见的响应状态码有200(服务器正常响应)、404(页面未找到)、500(服务器内部发生错误)等。
2.网页
在爬虫时,我们通过响应得到的网页源代码、JSON数据等来提取需要的信息数据,所以我们需要了解一下网页的基础结构。一个网页基本由以下三部分组成:
HTML,全称Hyper Text Marked Language,中文叫超文本标记语言,用来表述网页以呈现出内容,如文字,图片,视频等,相当于网页的骨架。
JavaScript,简称JS,是一种脚本语言,能够给页面增加实时、动态、交互的功能,相当于网页的肌肉。
CSS,全称Cascading Style Sheets,中文叫层叠样式表,对网页页面进行布局和装饰,使页面变得美观、优雅,相当于网页的皮肤。
3.基本原理
Python爬虫的基本原理其实是围绕着HTTP和网页结构展开的:首先是请求网页,接着是解析和提取信息,最后是存储信息。
1) 请求
Python经常用来请求的第三方库有requests、selenium,内置的库也可以用urllib。
requests是用Python编写的,基于urllib,采用Apache2 Licensed开源协议的HTTP库。相比urllib库,requests库更加方便,可以节约我们大量工作,所以我们倾向于使用requests来请求网页。
selenium是一个用于web应用程序的自动化测试工具,它可以驱动浏览器执行特定的动作,如输入、点击、下拉等,就像真正的用户在操作一样,在爬虫中常用来解决JavaScript渲染问题。selenium可以支持多种浏览器,如Chrome,Firefox,Edge等。在通过selenium使用这些浏览器之前,需要配置好相关的浏览器驱动:
ChromeDriver:Chrome浏览器驱动
GeckoDriver:Firefox浏览器驱动
PhantomJS:无界面、可脚本编程的WebKit浏览器引擎
2)解析和提取
Python用来解析和提取信息的第三方库有BeautifulSoup、lxml、pyquery等。
每个库可以用不同的方法来提取数据:
BeautifulSoup:方法选择器find()和find_all()或CSS选择器
lxml:XPath
pyquery:CSS选择器
此外,还可以用正则表达式来提取自己想要的信息,有了它,字符串检索、替换和匹配都不在话下。
3)存储
将数据提取出之后就是对数据进行存储了。最简单的可以将数据保存为文本文件,如TXT文本、CSV文件、Excel文件、JSON文件等,也可以保存为二进制数据,如图片、音频、视频等,还可以保存到数据库中,如关系型数据库MySQL,非关系型数据库MongoDB、Redis等。
若是将数据存储为CSV文件、Excel文件和JSON文件则需要用到csv库、openpyxl库和json库。
4.静态网页爬取
了解完爬虫基本原理之后就可以爬取网页了,其中静态网页是最容易操作的。
对静态网页进行爬取,我们可以选择requests进行请求,得到网页源代码,接着使用BeautifulSoup进行解析和提取,最后选择合适的存储方法。
5.动态网页爬取
有时候在使用requests爬取网页的时候,会发现抓取的内容和浏览器显示的不一样,在浏览器里能看到要爬取的内容,但是爬取完之后的结果却没有,这就与网页是静态的还是动态的有关了。
静态网页是相对于动态网页而言,是指没有后台数据库、不含程序和不可交互的网页。而动态网页则是基本的html语法规范与Java、VB、VC等高级程序设计语言、数据库编程等多种技术的融合,以期实现对网站内容和风格的高效、动态和交互式的管理的网页。
二者的区别在于:
静态网页随着html代码的生成,页面的内容和显示效果基本上不会发生变化了——除非修改页面代码。
动态网页的页面代码虽然没有变,但是显示的内容却可以随着时间、环境或者数据库操作的结果而发生改变。
1)Ajax
Ajax不是一门编程语言,而是利用JavaScript在不重新加载整个页面的情况下可以与服务器交换数据并更新部分网页内容的技术。
因为使用Ajax技术的网页里的信息是通过JavaScript脚本语言动态生成的,所以使用requests-BeautifulSoup的静态页面的爬取方法是抓不到数据的,我们可以通过以下两种方法爬取Ajax数据:
通过查找浏览器开发者工具里的Network-XHR/JS栏找到储存着数据的动态页面,使用requests请求网页,再将得到的数据使用json()方法进行转化就可以提取了。
使用selenium指挥浏览器,直接对数据进行抓取(或者通过selenium获取到渲染完整的网页源代码,再使用BeautifulSoup进行解析和提取数据)。
2)Cookie和Session
Cookie是网站为了辨别用户身份进行Session跟踪而储存在用户本地终端上的数据(通常经过加密),由用户客户端计算机暂时或永久保存。
Session称为“会话”,存储着特定用户会话所需的属性及配置信息。
很多情况下,页面的更多信息需要登陆才能查看,所以在面对这类网页时,需要先模拟登陆后才可以对网页作进一步爬取。当我们模拟登陆时,客户端会生成Cookie并发送给服务器。因为Cookie保存着SessionID信息,所以服务器就可以根据Cookie判断出对应的SessionID,进而找到会话。如果当前的会话是有效的,那么服务器就会判断用户已经登陆并返回请求的页面信息,这样就可以对网页作进一步爬取了。
6.APP爬取
除了web端,Python还可以爬取APP数据,不过这需要用到抓包工具,比如Fiddler。
相比web端而言,APP的数据爬取其实更容易,反爬虫也没那么强,返回的数据类型大多数为json。
7.多协程
当我们在做爬虫项目的时候,如果需要爬取的数据非常多,因为程序是一行行依次执行的,所以爬取的速度就会非常慢。而多协程就能解决这一个问题。
使用多协程,我们就可以同时执行多个任务。实际上,使用多协程时,如果一个任务在执行的过程中遇到等待,那它就会先去执行其它的任务,当等待结束,再回来继续执行之前的那个任务。因为这个过程切换得非常迅速,所以看上去像多个任务被同时执行一样,用计算机里的概念来解释的话,这其实就是异步。
我们可以使用gevent库来实现多协程,使用Queue()创建队列,spawn()创建任务,最后joinall()执行任务。
8.爬虫框架
在遇到比较大型的需求时,为了方便管理及拓展,我们可以使用爬虫框架实现数据爬取。
有了爬虫框架之后,我们就不必一个个地去组建爬虫的整个流程,只需要关心爬虫的核心逻辑部分即可,这样就大大提高了开发效率,节省了很多时间。爬虫框架有很多个,如Scrapy、PySpider等。
9.分布式爬虫
使用爬虫框架已经大大提高了开发效率,不过这些框架都是在同一台主机上运行的,如果能多台主机协同爬取,那么爬取效率就会更近一步提高。将多台主机组合起来,共同完成一个爬取任务,这就是分布式爬虫。
10.反爬虫机制与应对方法
为了防止爬虫开发者过度爬取造成网站的负担或者进行恶意的数据抓取,很多网站会设置反爬虫机制。所以当我们在对网站进行数据抓取的时候,可以查看一下网站的robots.txt了解一下网站允许爬取什么,不允许爬取什么。
常见的爬虫机制有以下4种:
①请求头验证:请求头验证是最常见的反爬虫机制,很多网站会对Headers里的user-agent进行检测,一部分网站还会检测origin和referer。应对这类反爬虫机制可以在爬虫中添加请求头headers,将浏览器里对应的值以字典的形式添加进去即可。
②Cookie限制:有些网站会用Cookie跟踪你的访问过程,如果发现爬虫的异常行为就会中断该爬虫的访问。应对Cookie限制类的反爬虫,一般可以通过先取得该网站的Cookie,再把Cookie发送给服务器即可,可以手动添加或者使用Session机制。不过,针对部分网站需要用户浏览页面时才能产生Cookie的情况,比如点击按钮,可以使用selenium-PhantomJS来请求网页并获取Cookie。
③IP访问频率限制:一些网站会通过检测用户行为来判断同一IP是否在短时间内多次请求页面,如果这个频率超过了某个阈值,网站通常会对爬虫进行提示并要求输入验证码,或者直接封掉IP拒绝服务。针对这种情况,可以使用IP代理的方法来绕过反爬虫,如代理池维护、付费代理、ADSL拨号代理等。
④验证码限制:很多网站在登陆的时候需要输入验证码,常见的有:图形验证码、极验滑动验证码、点触验证码和宫格验证码。
图形验证码:需要用到OCR技术,使用Python的第三方库tesserocr可以做到这一点。
极验滑动验证码:需要使用selenium来完成模拟人的行为的方式来验证。
点触验证码:需要在使用selenium的基础上借助第三方验证码服务平台来解决。
宫格验证码:需要使用selenium和模板匹配的方法。
验证码类型
java从网页抓取数据(怎样抓取站点的数据:(1)抓取原网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-09-21 18:19
原创链接:
有时,由于各种原因,我们需要采集一个站点的数据,但不同站点的数据显示方式略有不同
本文使用Java向您展示如何抓取站点的数据:(1)grab原创网页的数据;(2)grab网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:
第二步:检查网页源代码。我们可以看到源代码中有一段:
从这里可以看出,再次请求网页后会显示查询结果
我们来看看查询后的网址:
换言之,我们只能通过访问这样的网站才能得到IP查询的结果。接下来,请看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到站点,使用bufreader保存网页返回的数据,然后通过自定义解析方法显示结果
这里我只是随便分析一下。如果我想准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时候,为了保护自己的数据,网站不直接在网页源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:
第一种方法用于查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但是有时候我们非常需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
在第一次单击startbutton之后,它开始监视web页面的交互
当我们打开网页时,可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了便于查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们只需要分析HTTP analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址来获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两个豌豆一样,抓取JS的方法与原创网页完全相同。我们只是做了一个分析JS的过程
以下是该计划的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
我希望这篇文章能对有需要的朋友有所帮助。如果你需要程序源代码,请点击这里下载 查看全部
java从网页抓取数据(怎样抓取站点的数据:(1)抓取原网页数据)
原创链接:
有时,由于各种原因,我们需要采集一个站点的数据,但不同站点的数据显示方式略有不同
本文使用Java向您展示如何抓取站点的数据:(1)grab原创网页的数据;(2)grab网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:
第二步:检查网页源代码。我们可以看到源代码中有一段:
从这里可以看出,再次请求网页后会显示查询结果
我们来看看查询后的网址:
换言之,我们只能通过访问这样的网站才能得到IP查询的结果。接下来,请看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到站点,使用bufreader保存网页返回的数据,然后通过自定义解析方法显示结果
这里我只是随便分析一下。如果我想准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时候,为了保护自己的数据,网站不直接在网页源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:
第一种方法用于查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但是有时候我们非常需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
在第一次单击startbutton之后,它开始监视web页面的交互
当我们打开网页时,可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了便于查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们只需要分析HTTP analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址来获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两个豌豆一样,抓取JS的方法与原创网页完全相同。我们只是做了一个分析JS的过程
以下是该计划的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
我希望这篇文章能对有需要的朋友有所帮助。如果你需要程序源代码,请点击这里下载
java从网页抓取数据(什么是网页抓取?Web搜集如何工作?最可靠的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-09-21 18:16
什么是网络爬行
简言之,网络爬网允许您从网站提取数据,以便将其保存在计算机上的文件中,以便稍后在电子表格中访问。通常,您只能查看下载的网页,而不能提取数据。是的,其中一些可以手动复制,但此方法耗时且不可扩展。Web爬网从选定的页面提取可靠的数据,因此该过程完全自动化。接收到的数据可用于以后的商业智能。换句话说,人们可以处理任何类型的数据,因为到目前为止,web非常适合捕获大量数据和不同的数据类型。图像、文本、电子邮件甚至电话号码都将被提取出来,以满足您的业务需求。对于某些项目,可能需要特定数据,如财务数据、房地产数据、评论、价格或竞争对手数据。也可以使用网页捕获工具快速轻松地提取。但最重要的是,提取的数据最终将以您选择的格式获得。它可以是纯文本、JSON或CSV
网络采集是如何运作的
当然,提取数据的方法有很多,但下面是最简单、最可靠的方法。操作模式如下所示
1.request-response
任何网络爬虫(也称为“爬虫”)的第一步是从目标网站请求请求特定URL的内容。以HTML格式获取请求的信息。请记住,html是用于在网页上显示所有文本信息的文件类型
2.解析和提取
Html是一种结构简单明了的标记语言。解析适用于任何计算机语言,将代码视为一堆文本。它在内存中产生一种计算机可以理解和使用的结构。为了简单起见,我们可以说HTML解析需要HTML代码并提取相关信息——标题、段落、标题。链接和格式(如粗体文本)。因此,您只需要一个正则表达式来定义正则语言,这样正则表达式引擎就可以为该特定语言生成解析器。因此,模式匹配和文本提取是可能的
3.下载资料
最后一步-以您选择的格式(CSV、JSON或数据库)下载并保存数据。在它变得可访问之后,可以在其他程序中检索和实现它。换句话说,爬网不仅使您能够提取数据,还可以将其存储在本地中央数据库或电子表格中,并在以后需要时使用
网络搜索的先进技术
如今,计算机视觉技术和机器学习技术已经被用来从图像中识别和刮取数据,这与人类所能做的相似。所有的工作都很简单。机器系统学习有自己的分类,并被分配一个所谓的信心分数。它是统计可能性的度量。因此,如果认为分类是正确的,则意味着它非常接近训练数据中识别的模式。如果置信度得分过低,系统将启动新的搜索查询,以选择最可能收录先前请求的数据的文本堆。系统尝试从新文本中删除相关数据,并将原创数据中的数据与接收到的结果进行核对后。如果信心分数仍然过低,它将继续处理下一个拉取的文本
网络爬网的用途是什么
使用网络爬网的方法有很多,几乎可以在每个已知领域实现。然而,让我们仔细看看我们认为对于网络爬行
最有效的一些领域。
价格监测
竞争性定价是电子商务的主要策略。在这里取得成功的唯一方法是始终跟踪竞争对手及其定价策略。解析的数据可以帮助您定义自己的定价策略。它比手动比较和分析快得多。在价格监控方面,网络爬虫非常有效
领先一步
营销对于任何企业都是必不可少的。为了使营销策略成功,不仅需要获得相关方的联系信息,还需要联系他们。这是潜在客户开发的本质。网页爬行可以改进该过程并使其更高效。潜在客户是加速营销活动的第一件事。为了吸引目标受众,您可能需要大量数据,如电话号码、电子邮件等。当然,不可能在网络上的数千网站上手动采集数据。但是网络爬虫对你很有帮助!它提取数据。这一过程不仅准确、快速,而且只需要一小部分时间。收到的数据可以轻松集成到您的销售工具中
竞争分析
竞争一直是任何企业的血肉之躯,但今天,了解竞争对手是非常重要的。它使我们能够更有效地了解它们的优缺点、策略和评估风险。当然,只有大量的相关数据才有可能。网络爬行在这方面也有帮助。任何战略都是从分析开始的。但如何处理各地的数据呢?有时你甚至无法手动访问它。如果很难手动完成,请使用网页爬网。这为您提供了几乎立即开始工作所需的数据。这里的优势是——抓取工具的速度越快,竞争分析就越好
提取图像和产品描述
当客户进入任何电子商务网站时,他首先看到的是视觉内容,如图片和视频。但是你如何在一夜之间创造出所有数量的产品描述和图片呢?用网页抓取它。因此,当你想到开始一个新的电子商务网站想法时,你会遇到内容问题——图片描述等。雇佣某人从头开始复制、粘贴或编写内容的旧方法可能会奏效,但可能不会永远持续下去。请改用网络爬网并查看结果。换句话说,网络爬行让你的电子商务网站所有者的生活更轻松
爬行软件合法吗
网络爬虫软件是处理数据的——从技术上讲,它是一个数据提取的过程。但如果它受到法律或版权的保护呢?自然产生的第一个问题是“它合法吗”?这个问题很难解决。到目前为止,即使是在各个层面,也没有明确的意见。以下是需要考虑的几点:
1、公共数据可以不受任何限制地丢弃。但是,如果您输入私人数据,可能会给您带来麻烦
2、出于商业目的滥用或使用个人数据是侵犯隐私的最佳方式,因此请避免使用它
3、删除受版权保护的数据是非法和不道德的
4、为了安全起见,请遵守robots.txt的要求和服务条款(TOS)
5、您也可以使用API抓取
6、将爬坡速度视为10-15秒。否则,可能会阻止您继续进行下一步
7、如果你想确保安全,请不要频繁访问服务器,也不要以攻击性的方式处理网络爬网
网络搜索面临的挑战
Web爬行在某些方面具有挑战性,尽管它通常相对简单。您可能遇到的主要挑战如下所示:
1.频繁的结构变化
在你设置刮板之前,大型游戏不会开始。换句话说,设置工具是第一步,因此您将面临一些意想不到的挑战:
所有网站都在不断更新其用户界面和功能。这意味着网站结构在不断变化。就爬虫而言,只要记住现有结构,任何更改都可能破坏您的计划。当相应地更改搜索者时,此问题将得到解决。因此,为了获得完整的相关数据,应在结构发生变化后立即不断更换刮板
2.蜜罐陷阱
请记住,所有收录敏感数据的网站都会采取预防措施,以这种方式保护数据。它们被称为蜜罐。这意味着您的所有网络爬网工作都可能被阻止。请试着找出这次出了什么问题。蜜罐是可供爬虫访问的链接,但已开发用于检测爬虫并防止它们提取数据。在大多数情况下,它们是CSS样式设置为display:none的链接。另一种隐藏它们的方法是将它们从可见区域中移除或使它们具有背景色。当您的搜索者被“捕获”时,IP将被标记,甚至被阻止。深层目录树是检测搜索者的另一种方法。因此,必须限制检索的页面数或遍历深度
3.scrapper技巧
scraper技术的发展与web技术一样快,因为有很多数据不应该共享,这是很好的。然而,如果不牢记这一点,它最终可能会被阻止。以下是您应该知道的最基本要点的简短列表:
网站越大,保护数据和定义爬虫就越好。例如,LinkedIn、StubHub和CrunchBase使用了强大的反爬网技术
对于这种网站,可以通过使用动态编码算法和IP阻塞机制来防止漫游访问来实现
显然,这是一个巨大的挑战——应该避免阻塞,因此解决方案在各个方面都成为一个耗时且相当昂贵的项目
4.数据质量
获取数据只是要达到的目的之一。为了有效地工作,数据应该是干净和准确的。换言之,如果数据不完整或有很多错误,它是无用的。从业务的角度来看,数据质量是主要的标准,到一天结束时,您需要准备好数据以供使用
<p> 查看全部
java从网页抓取数据(什么是网页抓取?Web搜集如何工作?最可靠的方法)
什么是网络爬行
简言之,网络爬网允许您从网站提取数据,以便将其保存在计算机上的文件中,以便稍后在电子表格中访问。通常,您只能查看下载的网页,而不能提取数据。是的,其中一些可以手动复制,但此方法耗时且不可扩展。Web爬网从选定的页面提取可靠的数据,因此该过程完全自动化。接收到的数据可用于以后的商业智能。换句话说,人们可以处理任何类型的数据,因为到目前为止,web非常适合捕获大量数据和不同的数据类型。图像、文本、电子邮件甚至电话号码都将被提取出来,以满足您的业务需求。对于某些项目,可能需要特定数据,如财务数据、房地产数据、评论、价格或竞争对手数据。也可以使用网页捕获工具快速轻松地提取。但最重要的是,提取的数据最终将以您选择的格式获得。它可以是纯文本、JSON或CSV
网络采集是如何运作的
当然,提取数据的方法有很多,但下面是最简单、最可靠的方法。操作模式如下所示
1.request-response
任何网络爬虫(也称为“爬虫”)的第一步是从目标网站请求请求特定URL的内容。以HTML格式获取请求的信息。请记住,html是用于在网页上显示所有文本信息的文件类型
2.解析和提取
Html是一种结构简单明了的标记语言。解析适用于任何计算机语言,将代码视为一堆文本。它在内存中产生一种计算机可以理解和使用的结构。为了简单起见,我们可以说HTML解析需要HTML代码并提取相关信息——标题、段落、标题。链接和格式(如粗体文本)。因此,您只需要一个正则表达式来定义正则语言,这样正则表达式引擎就可以为该特定语言生成解析器。因此,模式匹配和文本提取是可能的
3.下载资料
最后一步-以您选择的格式(CSV、JSON或数据库)下载并保存数据。在它变得可访问之后,可以在其他程序中检索和实现它。换句话说,爬网不仅使您能够提取数据,还可以将其存储在本地中央数据库或电子表格中,并在以后需要时使用
网络搜索的先进技术
如今,计算机视觉技术和机器学习技术已经被用来从图像中识别和刮取数据,这与人类所能做的相似。所有的工作都很简单。机器系统学习有自己的分类,并被分配一个所谓的信心分数。它是统计可能性的度量。因此,如果认为分类是正确的,则意味着它非常接近训练数据中识别的模式。如果置信度得分过低,系统将启动新的搜索查询,以选择最可能收录先前请求的数据的文本堆。系统尝试从新文本中删除相关数据,并将原创数据中的数据与接收到的结果进行核对后。如果信心分数仍然过低,它将继续处理下一个拉取的文本
网络爬网的用途是什么
使用网络爬网的方法有很多,几乎可以在每个已知领域实现。然而,让我们仔细看看我们认为对于网络爬行
最有效的一些领域。
价格监测
竞争性定价是电子商务的主要策略。在这里取得成功的唯一方法是始终跟踪竞争对手及其定价策略。解析的数据可以帮助您定义自己的定价策略。它比手动比较和分析快得多。在价格监控方面,网络爬虫非常有效
领先一步
营销对于任何企业都是必不可少的。为了使营销策略成功,不仅需要获得相关方的联系信息,还需要联系他们。这是潜在客户开发的本质。网页爬行可以改进该过程并使其更高效。潜在客户是加速营销活动的第一件事。为了吸引目标受众,您可能需要大量数据,如电话号码、电子邮件等。当然,不可能在网络上的数千网站上手动采集数据。但是网络爬虫对你很有帮助!它提取数据。这一过程不仅准确、快速,而且只需要一小部分时间。收到的数据可以轻松集成到您的销售工具中
竞争分析
竞争一直是任何企业的血肉之躯,但今天,了解竞争对手是非常重要的。它使我们能够更有效地了解它们的优缺点、策略和评估风险。当然,只有大量的相关数据才有可能。网络爬行在这方面也有帮助。任何战略都是从分析开始的。但如何处理各地的数据呢?有时你甚至无法手动访问它。如果很难手动完成,请使用网页爬网。这为您提供了几乎立即开始工作所需的数据。这里的优势是——抓取工具的速度越快,竞争分析就越好
提取图像和产品描述
当客户进入任何电子商务网站时,他首先看到的是视觉内容,如图片和视频。但是你如何在一夜之间创造出所有数量的产品描述和图片呢?用网页抓取它。因此,当你想到开始一个新的电子商务网站想法时,你会遇到内容问题——图片描述等。雇佣某人从头开始复制、粘贴或编写内容的旧方法可能会奏效,但可能不会永远持续下去。请改用网络爬网并查看结果。换句话说,网络爬行让你的电子商务网站所有者的生活更轻松
爬行软件合法吗
网络爬虫软件是处理数据的——从技术上讲,它是一个数据提取的过程。但如果它受到法律或版权的保护呢?自然产生的第一个问题是“它合法吗”?这个问题很难解决。到目前为止,即使是在各个层面,也没有明确的意见。以下是需要考虑的几点:
1、公共数据可以不受任何限制地丢弃。但是,如果您输入私人数据,可能会给您带来麻烦
2、出于商业目的滥用或使用个人数据是侵犯隐私的最佳方式,因此请避免使用它
3、删除受版权保护的数据是非法和不道德的
4、为了安全起见,请遵守robots.txt的要求和服务条款(TOS)
5、您也可以使用API抓取
6、将爬坡速度视为10-15秒。否则,可能会阻止您继续进行下一步
7、如果你想确保安全,请不要频繁访问服务器,也不要以攻击性的方式处理网络爬网
网络搜索面临的挑战
Web爬行在某些方面具有挑战性,尽管它通常相对简单。您可能遇到的主要挑战如下所示:
1.频繁的结构变化
在你设置刮板之前,大型游戏不会开始。换句话说,设置工具是第一步,因此您将面临一些意想不到的挑战:
所有网站都在不断更新其用户界面和功能。这意味着网站结构在不断变化。就爬虫而言,只要记住现有结构,任何更改都可能破坏您的计划。当相应地更改搜索者时,此问题将得到解决。因此,为了获得完整的相关数据,应在结构发生变化后立即不断更换刮板
2.蜜罐陷阱
请记住,所有收录敏感数据的网站都会采取预防措施,以这种方式保护数据。它们被称为蜜罐。这意味着您的所有网络爬网工作都可能被阻止。请试着找出这次出了什么问题。蜜罐是可供爬虫访问的链接,但已开发用于检测爬虫并防止它们提取数据。在大多数情况下,它们是CSS样式设置为display:none的链接。另一种隐藏它们的方法是将它们从可见区域中移除或使它们具有背景色。当您的搜索者被“捕获”时,IP将被标记,甚至被阻止。深层目录树是检测搜索者的另一种方法。因此,必须限制检索的页面数或遍历深度
3.scrapper技巧
scraper技术的发展与web技术一样快,因为有很多数据不应该共享,这是很好的。然而,如果不牢记这一点,它最终可能会被阻止。以下是您应该知道的最基本要点的简短列表:
网站越大,保护数据和定义爬虫就越好。例如,LinkedIn、StubHub和CrunchBase使用了强大的反爬网技术
对于这种网站,可以通过使用动态编码算法和IP阻塞机制来防止漫游访问来实现
显然,这是一个巨大的挑战——应该避免阻塞,因此解决方案在各个方面都成为一个耗时且相当昂贵的项目
4.数据质量
获取数据只是要达到的目的之一。为了有效地工作,数据应该是干净和准确的。换言之,如果数据不完整或有很多错误,它是无用的。从业务的角度来看,数据质量是主要的标准,到一天结束时,您需要准备好数据以供使用
<p>
java从网页抓取数据(如何使用Java/Python访问网页和使用Python进行数据解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-09-21 18:14
前言:
网络爬虫看起来仍然很神奇。然而,如果你想一想或者做一些研究,你就会知道爬行动物并没有那么先进。深刻的是,当我们有大量的数据时,即当我们的网络“图”中有越来越多的循环时,我们应该如何解决它
此物品文章仅用于吸引翡翠。本文主要介绍如何使用Java/Python访问web页面并获取web页面代码,Python模仿浏览器访问web页面,并使用Python分析数据。我希望我们能从这篇文章开始,一步一步地解决蜘蛛网神秘的一面
参考:
1.“编写自己的网络爬虫”
2.使用Python编写爬虫程序,爬升CSDN内容,完美解决403问题
运行效果图:
有很多内容。我只选择了一些来显示
作者环境:
系统:Windows7
CentOS6.5
操作环境:JDK1.7
Python2.6.6
IDE:EclipseRelease@k282.0
PyCharm4.5.1
数据库:mysqlver14.14 Distrib@k311.73
开发过程:1.使用java抓取页面
对于页面捕获,我们使用java来实现它。当然,您可以使用其他语言来开发它。但是
以“博客公园”主页为例,展示了使用Java捕获网页的过程:
public class RetrivePageSimple {
private static HttpClient httpClient = new HttpClient();
// 设置代理服务器
static {
httpClient.getHostConfiguration().setProxy("58.220.2.132", 80);
}
public static boolean downloadPage(String path) throws HttpException,
IOException {
PostMethod postMethod = new PostMethod(path);
// 执行,返回状态码
int statusCode = httpClient.executeMethod(postMethod);
System.out.println(statusCode);
// 针对状态码进行处理 (简单起见,只处理返回值为200的状态码)
if (statusCode == HttpStatus.SC_OK) {
String a = postMethod.getResponseBodyAsString();
System.out.println(a);
return true;
}
return false;
}
public static void main(String[] args) {
try {
RetrivePageSimple.downloadPage("http://www.cnblogs.com/");
} catch (HttpException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
结果信息不会显示在这里,太多--
2.grab页面使用Python
您可能会问我,为什么要使用Java版本的页面捕获,而在这里要编写python?这是必要的。因为作者在开发这个演示之前没有考虑问题。当我们使用java将网页抓取到python时,网页字符串太长,无法作为参数传递。您可能认为保存文件是一个不错的选择。如果HTML文件太多怎么办?是的,我们必须放弃这种累人的练习
考虑到参数长度的限制,我们只在Java端给出页面地址,并使用python抓取网页
最简单的方法是,我们通常使用Python网页,如下所示:
import urllib2
result = urllib2.urlopen('http://blog.csdn.net/mobile/index.html')
html = result.read()
print html
然而,作者的代码中使用了CSDN博客频道的URL。CSDN过滤爬虫的访问。我们将收到以下错误消息:
我被拒绝了
3.使用模拟浏览器登录网站
如前所述,当我们访问受保护的网页时,我们将被拒绝。但是,我们可以尝试使用自己的浏览器来访问它
换句话说,如果我们可以模仿Python中的浏览器,我们就可以访问这个网页。下面是Python模仿浏览器的代码:
import random
import socket
import urllib2
import cookielib
ERROR = {
'0':'Can not open the url,checck you net',
'1':'Creat download dir error',
'2':'The image links is empty',
'3':'Download faild',
'4':'Build soup error,the html is empty',
'5':'Can not save the image to your disk',
}
class BrowserBase(object):
def __init__(self):
socket.setdefaulttimeout(20)
self._content = None
def speak(self, name, content):
print '[%s]%s' % (name, content)
def open_url(self, url):
"""
打开网页
"""
cookie_support= urllib2.HTTPCookieProcessor(cookielib.CookieJar())
self.opener = urllib2.build_opener(cookie_support,urllib2.HTTPHandler)
urllib2.install_opener(self.opener)
user_agents = [
'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11',
'Opera/9.25 (Windows NT 5.1; U; en)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 ",
]
agent = random.choice(user_agents)
self.opener.addheaders = [("User-agent", agent), ("Accept", "*/*"), ('Referer', 'http://www.google.com')]
try:
res = self.opener.open(url)
self._content = res.read()
# print self._content
except Exception, e:
self.speak(str(e)+url)
raise Exception
else:
return res
def get_html_content(self):
return self._content
def get_html_response(html):
spider = BrowserBase()
spider.open_url(html)
return spider.get_html_content()
上述代码通常可以获取返回值。让我们看一下返回结果
的解析过程。
4.数据分析
使用Python解析html非常简单:
import HTMLParser
class ListWebParser(HTMLParser.HTMLParser):
def __init__(self):
HTMLParser.HTMLParser.__init__(self)
self.tagDIVFlag = False
self.tagDIVAFlag = False
self.tagH1Flag = False
self.tagSecondHrefFlag = False
self._name = None
self._address = None
def handle_starttag(self, tag, attrs):
if tag == 'div':
for name, value in attrs:
if name == 'class' and value == 'blog_list':
self.tagDIVFlag = True
if tag == 'h1':
if self.tagDIVFlag:
self.tagH1Flag = True
# print 'h1->', self.tagH1Flag
if tag == 'a':
#if self.tagDIVAFlag:
#print 'h1: ', self.tagH1Flag
if self.tagH1Flag:
for name, value in attrs:
if name == 'target' and value == '_blank':
self.tagDIVAFlag = True
if name == 'href':
if self.tagSecondHrefFlag:
print '网址:', value
self._address = value
self.tagSecondHrefFlag = True
# if name == 'href' and self.tagDIVAFlag:
# print '网址:', value
# self._address = value
def handle_endtag(self, tag):
if tag == 'div':
self.tagDIVFlag = False
if tag == 'h1':
self.tagH1Flag = False
# print 'false h1.'
if tag == 'a':
self.tagDIVAFlag = False
def handle_data(self, data):
if self.tagDIVAFlag:
print u"名称:", data.decode("utf-8")
如果你说你在互联网上找到的HTML文件没有这个问题。我承认这一点,因为在正常情况下,解析一些简单的数据对我们来说非常容易。上面代码中的复杂逻辑处理过滤
说到筛选,我在这里使用了一个小技巧(当然,当更多的人使用它时,它不再只是一个技巧,但这种方法可以在未来的编码过程中作为参考)。我们通过标记的一些特殊属性(如ID、class等)锁定块。当我们启动块时,相应的标志位将被标记为true。当我们退出块时,相应的标志位将被标记为false。也许你觉得太麻烦了。事实上,如果你仔细想想,你就会知道这是有道理的
注意事项:
1.当使用java抓取页面时,我们使用代理服务器。此代理服务器的主机和端口可以直接在Internet上免费找到
2.您需要准备以下jar包并将其导入eclipse项目:
3.将Mysql的默认代码修改为UTF-8
这里会有一些中文信息,所以我们需要转换MySQL的编码格式
如果您是在Linux下编码,可以参考: 查看全部
java从网页抓取数据(如何使用Java/Python访问网页和使用Python进行数据解析)
前言:
网络爬虫看起来仍然很神奇。然而,如果你想一想或者做一些研究,你就会知道爬行动物并没有那么先进。深刻的是,当我们有大量的数据时,即当我们的网络“图”中有越来越多的循环时,我们应该如何解决它
此物品文章仅用于吸引翡翠。本文主要介绍如何使用Java/Python访问web页面并获取web页面代码,Python模仿浏览器访问web页面,并使用Python分析数据。我希望我们能从这篇文章开始,一步一步地解决蜘蛛网神秘的一面
参考:
1.“编写自己的网络爬虫”
2.使用Python编写爬虫程序,爬升CSDN内容,完美解决403问题
运行效果图:
有很多内容。我只选择了一些来显示
作者环境:
系统:Windows7
CentOS6.5
操作环境:JDK1.7
Python2.6.6
IDE:EclipseRelease@k282.0
PyCharm4.5.1
数据库:mysqlver14.14 Distrib@k311.73
开发过程:1.使用java抓取页面
对于页面捕获,我们使用java来实现它。当然,您可以使用其他语言来开发它。但是
以“博客公园”主页为例,展示了使用Java捕获网页的过程:
public class RetrivePageSimple {
private static HttpClient httpClient = new HttpClient();
// 设置代理服务器
static {
httpClient.getHostConfiguration().setProxy("58.220.2.132", 80);
}
public static boolean downloadPage(String path) throws HttpException,
IOException {
PostMethod postMethod = new PostMethod(path);
// 执行,返回状态码
int statusCode = httpClient.executeMethod(postMethod);
System.out.println(statusCode);
// 针对状态码进行处理 (简单起见,只处理返回值为200的状态码)
if (statusCode == HttpStatus.SC_OK) {
String a = postMethod.getResponseBodyAsString();
System.out.println(a);
return true;
}
return false;
}
public static void main(String[] args) {
try {
RetrivePageSimple.downloadPage("http://www.cnblogs.com/";);
} catch (HttpException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
结果信息不会显示在这里,太多--
2.grab页面使用Python
您可能会问我,为什么要使用Java版本的页面捕获,而在这里要编写python?这是必要的。因为作者在开发这个演示之前没有考虑问题。当我们使用java将网页抓取到python时,网页字符串太长,无法作为参数传递。您可能认为保存文件是一个不错的选择。如果HTML文件太多怎么办?是的,我们必须放弃这种累人的练习
考虑到参数长度的限制,我们只在Java端给出页面地址,并使用python抓取网页
最简单的方法是,我们通常使用Python网页,如下所示:
import urllib2
result = urllib2.urlopen('http://blog.csdn.net/mobile/index.html')
html = result.read()
print html
然而,作者的代码中使用了CSDN博客频道的URL。CSDN过滤爬虫的访问。我们将收到以下错误消息:
我被拒绝了
3.使用模拟浏览器登录网站
如前所述,当我们访问受保护的网页时,我们将被拒绝。但是,我们可以尝试使用自己的浏览器来访问它
换句话说,如果我们可以模仿Python中的浏览器,我们就可以访问这个网页。下面是Python模仿浏览器的代码:
import random
import socket
import urllib2
import cookielib
ERROR = {
'0':'Can not open the url,checck you net',
'1':'Creat download dir error',
'2':'The image links is empty',
'3':'Download faild',
'4':'Build soup error,the html is empty',
'5':'Can not save the image to your disk',
}
class BrowserBase(object):
def __init__(self):
socket.setdefaulttimeout(20)
self._content = None
def speak(self, name, content):
print '[%s]%s' % (name, content)
def open_url(self, url):
"""
打开网页
"""
cookie_support= urllib2.HTTPCookieProcessor(cookielib.CookieJar())
self.opener = urllib2.build_opener(cookie_support,urllib2.HTTPHandler)
urllib2.install_opener(self.opener)
user_agents = [
'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11',
'Opera/9.25 (Windows NT 5.1; U; en)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 ",
]
agent = random.choice(user_agents)
self.opener.addheaders = [("User-agent", agent), ("Accept", "*/*"), ('Referer', 'http://www.google.com')]
try:
res = self.opener.open(url)
self._content = res.read()
# print self._content
except Exception, e:
self.speak(str(e)+url)
raise Exception
else:
return res
def get_html_content(self):
return self._content
def get_html_response(html):
spider = BrowserBase()
spider.open_url(html)
return spider.get_html_content()
上述代码通常可以获取返回值。让我们看一下返回结果
的解析过程。
4.数据分析
使用Python解析html非常简单:
import HTMLParser
class ListWebParser(HTMLParser.HTMLParser):
def __init__(self):
HTMLParser.HTMLParser.__init__(self)
self.tagDIVFlag = False
self.tagDIVAFlag = False
self.tagH1Flag = False
self.tagSecondHrefFlag = False
self._name = None
self._address = None
def handle_starttag(self, tag, attrs):
if tag == 'div':
for name, value in attrs:
if name == 'class' and value == 'blog_list':
self.tagDIVFlag = True
if tag == 'h1':
if self.tagDIVFlag:
self.tagH1Flag = True
# print 'h1->', self.tagH1Flag
if tag == 'a':
#if self.tagDIVAFlag:
#print 'h1: ', self.tagH1Flag
if self.tagH1Flag:
for name, value in attrs:
if name == 'target' and value == '_blank':
self.tagDIVAFlag = True
if name == 'href':
if self.tagSecondHrefFlag:
print '网址:', value
self._address = value
self.tagSecondHrefFlag = True
# if name == 'href' and self.tagDIVAFlag:
# print '网址:', value
# self._address = value
def handle_endtag(self, tag):
if tag == 'div':
self.tagDIVFlag = False
if tag == 'h1':
self.tagH1Flag = False
# print 'false h1.'
if tag == 'a':
self.tagDIVAFlag = False
def handle_data(self, data):
if self.tagDIVAFlag:
print u"名称:", data.decode("utf-8")
如果你说你在互联网上找到的HTML文件没有这个问题。我承认这一点,因为在正常情况下,解析一些简单的数据对我们来说非常容易。上面代码中的复杂逻辑处理过滤
说到筛选,我在这里使用了一个小技巧(当然,当更多的人使用它时,它不再只是一个技巧,但这种方法可以在未来的编码过程中作为参考)。我们通过标记的一些特殊属性(如ID、class等)锁定块。当我们启动块时,相应的标志位将被标记为true。当我们退出块时,相应的标志位将被标记为false。也许你觉得太麻烦了。事实上,如果你仔细想想,你就会知道这是有道理的
注意事项:
1.当使用java抓取页面时,我们使用代理服务器。此代理服务器的主机和端口可以直接在Internet上免费找到
2.您需要准备以下jar包并将其导入eclipse项目:
3.将Mysql的默认代码修改为UTF-8
这里会有一些中文信息,所以我们需要转换MySQL的编码格式
如果您是在Linux下编码,可以参考:
java从网页抓取数据(java脚本_doPostBack和onclick事件(一)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-09-18 06:17
__DoPostBack和onclick事件:
当您检查与选择主contentdiv列(例如longterme)相关联的HTML时,您可以看到与每个bar item_uudopostback函数的onclick事件相关联的java脚本
请注意所讨论的HTML:
请参阅上面的链接:
该函数采用以下两个参数:EventTarget-它收录导致回发的控件的ID。Eventargument-收录与控件关联的任何其他数据。在任何页面中,都会自动声明两个隐藏字段:_u事件目标和_u事件参数。会检查何时将页面发回服务器_uu事件目标和_uu事件参数值,以便确定哪些控件导致页面发回以及必须处理哪些事件
tldr
在ASP的“旧”时代,通常必须有一个表单来捕获用户输入,然后创建其他页面来接受这些输入(get或post)、验证、执行操作等。使用,您可以在服务器上声明接受上述参数的控件,并在检查值后发回同一页面
第一个参数告诉您哪个控件被触发,第二个参数提供附加信息,在这种情况下,它决定返回哪个选项卡信息
从上面可以看出,tabaction是一个控件,它后面的数字对应于感兴趣的标记。例如,2是长期的(0-指数)
在VBA中,我们可以通过多种方式执行此JS函数,但我将使用:
.document.parentWindow.execScript "__doPostBack('EVENTTARGET', 'EVENTARGUMENT')"
这就变成了:
.document.parentWindow.execScript "__doPostBack('TabAction', '2')"
我将其重写为接受eventargument作为常量选项uchoose,因此您可以通过更改顶部的值来检索不同的选项卡
函数执行后,还有一点时间刷新页面,然后通过ID捕获表:
Set hTable = .document.getElementById("ctl00_ctl00_MainContent_Layout_1MainContent_gridResult")
然后,表格沿行和列循环(列是沿每行长度的表格单元格)
第页的示例:
代码输出示例:
完整代码:
Option Explicit
Public Sub GetTable()
Dim IE As New InternetExplorer
Const OPTION_CHOSEN As Long = 2 '0 Aperçu; 1 Court terme; 2 Long terme; 3 Portefeuille; 4 Frais & Détails
Application.ScreenUpdating = True
With IE
.Visible = True
.navigate "http://www.morningstar.fr/fr/f ... ot%3B
While .readyState < 4: DoEvents: Wend
.document.parentWindow.execScript "__doPostBack('TabAction', ' " & OPTION_CHOSEN & "')"
Do While .Busy = True Or .readyState 4: DoEvents: Loop
Dim hTable As HTMLTable, tRow As HTMLTableRow, tCell As HTMLTableCell
Set hTable = .document.getElementById("ctl00_ctl00_MainContent_Layout_1MainContent_gridResult")
Dim c As Long, r As Long
With ActiveSheet
For Each tRow In hTable.Rows
For Each tCell In tRow.Cells
c = c + 1: .Cells(r + 1, c) = tCell.innerText
Next tCell
c = 0: r = r + 1
Next tRow
.Columns("A:A").Delete
.UsedRange.Columns.AutoFit
End With
.Quit
End With
Application.ScreenUpdating = True
End Sub
参考资料(VBE>;工具>;参考资料): 查看全部
java从网页抓取数据(java脚本_doPostBack和onclick事件(一)(图))
__DoPostBack和onclick事件:
当您检查与选择主contentdiv列(例如longterme)相关联的HTML时,您可以看到与每个bar item_uudopostback函数的onclick事件相关联的java脚本
请注意所讨论的HTML:
请参阅上面的链接:
该函数采用以下两个参数:EventTarget-它收录导致回发的控件的ID。Eventargument-收录与控件关联的任何其他数据。在任何页面中,都会自动声明两个隐藏字段:_u事件目标和_u事件参数。会检查何时将页面发回服务器_uu事件目标和_uu事件参数值,以便确定哪些控件导致页面发回以及必须处理哪些事件
tldr
在ASP的“旧”时代,通常必须有一个表单来捕获用户输入,然后创建其他页面来接受这些输入(get或post)、验证、执行操作等。使用,您可以在服务器上声明接受上述参数的控件,并在检查值后发回同一页面
第一个参数告诉您哪个控件被触发,第二个参数提供附加信息,在这种情况下,它决定返回哪个选项卡信息
从上面可以看出,tabaction是一个控件,它后面的数字对应于感兴趣的标记。例如,2是长期的(0-指数)
在VBA中,我们可以通过多种方式执行此JS函数,但我将使用:
.document.parentWindow.execScript "__doPostBack('EVENTTARGET', 'EVENTARGUMENT')"
这就变成了:
.document.parentWindow.execScript "__doPostBack('TabAction', '2')"
我将其重写为接受eventargument作为常量选项uchoose,因此您可以通过更改顶部的值来检索不同的选项卡
函数执行后,还有一点时间刷新页面,然后通过ID捕获表:
Set hTable = .document.getElementById("ctl00_ctl00_MainContent_Layout_1MainContent_gridResult")
然后,表格沿行和列循环(列是沿每行长度的表格单元格)
第页的示例:
代码输出示例:
完整代码:
Option Explicit
Public Sub GetTable()
Dim IE As New InternetExplorer
Const OPTION_CHOSEN As Long = 2 '0 Aperçu; 1 Court terme; 2 Long terme; 3 Portefeuille; 4 Frais & Détails
Application.ScreenUpdating = True
With IE
.Visible = True
.navigate "http://www.morningstar.fr/fr/f ... ot%3B
While .readyState < 4: DoEvents: Wend
.document.parentWindow.execScript "__doPostBack('TabAction', ' " & OPTION_CHOSEN & "')"
Do While .Busy = True Or .readyState 4: DoEvents: Loop
Dim hTable As HTMLTable, tRow As HTMLTableRow, tCell As HTMLTableCell
Set hTable = .document.getElementById("ctl00_ctl00_MainContent_Layout_1MainContent_gridResult")
Dim c As Long, r As Long
With ActiveSheet
For Each tRow In hTable.Rows
For Each tCell In tRow.Cells
c = c + 1: .Cells(r + 1, c) = tCell.innerText
Next tCell
c = 0: r = r + 1
Next tRow
.Columns("A:A").Delete
.UsedRange.Columns.AutoFit
End With
.Quit
End With
Application.ScreenUpdating = True
End Sub
参考资料(VBE>;工具>;参考资料):
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-14 18:09
原文链接:
有时由于各种原因,我们需要采集一些网站的数据,但是由于网站不同,数据的显示方式略有不同!
本文用Java来告诉你如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml()的结果:\n"+result);}
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不会直接在网页的源代码中返回数据。而是使用JS异步返回数据,避免搜索引擎等工具响应网站数据的爬行。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript():\n"+contentBuf.toString()的结果);}
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
原文链接:
有时由于各种原因,我们需要采集一些网站的数据,但是由于网站不同,数据的显示方式略有不同!
本文用Java来告诉你如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml()的结果:\n"+result);}
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不会直接在网页的源代码中返回数据。而是使用JS异步返回数据,避免搜索引擎等工具响应网站数据的爬行。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript():\n"+contentBuf.toString()的结果);}
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载!

