
java从网页抓取数据
java从网页抓取数据( 2018年Java实现的爬虫抓取图片并保存操作技巧汇总)
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-09-12 11:06
2018年Java实现的爬虫抓取图片并保存操作技巧汇总)
Java实现的抓取图片并保存的爬虫示例
更新时间:2018年8月31日09:47:10 作者:smilecjw
这次文章主要介绍了Java实现的爬虫抓取图片和保存操作,涉及Java对页面URL访问、获取、字符串匹配、文件下载等的相关操作技巧,有需要的朋友可以参考以下
本文介绍了一个用Java实现的爬虫抓取图片并保存的例子。分享给大家,供大家参考,如下:
这是我根据网上的一些资料写的第一个java爬虫程序
本来想弄个无聊的煎蛋图,但是网络返回码一直是503,所以改成网站
import java.io.BufferedReader;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网络爬虫取数据
*
* */
public class JianDan {
public static String GetUrl(String inUrl){
StringBuilder sb = new StringBuilder();
try {
URL url =new URL(inUrl);
BufferedReader reader =new BufferedReader(new InputStreamReader(url.openStream()));
String temp="";
while((temp=reader.readLine())!=null){
//System.out.println(temp);
sb.append(temp);
}
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
return sb.toString();
}
public static List GetMatcher(String str,String url){
List result = new ArrayList();
Pattern p =Pattern.compile(url);//获取网页地址
Matcher m =p.matcher(str);
while(m.find()){
//System.out.println(m.group(1));
result.add(m.group(1));
}
return result;
}
public static void main(String args[]){
String str=GetUrl("http://www.163.com");
List ouput =GetMatcher(str,"src=\"([\\w\\s./:]+?)\"");
for(String temp:ouput){
//System.out.println(ouput.get(0));
System.out.println(temp);
}
String aurl=ouput.get(0);
// 构造URL
URL url;
try {
url = new URL(aurl);
// 打开URL连接
URLConnection con = (URLConnection)url.openConnection();
// 得到URL的输入流
InputStream input = con.getInputStream();
// 设置数据缓冲
byte[] bs = new byte[1024 * 2];
// 读取到的数据长度
int len;
// 输出的文件流保存图片至本地
OutputStream os = new FileOutputStream("a.png");
while ((len = input.read(bs)) != -1) {
os.write(bs, 0, len);
}
os.close();
input.close();
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
运行输出:
对java相关内容感兴趣的读者可以查看本站主题:《Java网络编程技巧总结》、《Java Socket编程技巧总结》、《Java文件和目录操作技巧总结》、《Java》数据结构与算法教程》、《Java操作DOM节点技巧总结》和《Java缓存操作技巧总结》
希望这篇文章对你的java编程有所帮助。 查看全部
java从网页抓取数据(
2018年Java实现的爬虫抓取图片并保存操作技巧汇总)
Java实现的抓取图片并保存的爬虫示例
更新时间:2018年8月31日09:47:10 作者:smilecjw
这次文章主要介绍了Java实现的爬虫抓取图片和保存操作,涉及Java对页面URL访问、获取、字符串匹配、文件下载等的相关操作技巧,有需要的朋友可以参考以下
本文介绍了一个用Java实现的爬虫抓取图片并保存的例子。分享给大家,供大家参考,如下:
这是我根据网上的一些资料写的第一个java爬虫程序
本来想弄个无聊的煎蛋图,但是网络返回码一直是503,所以改成网站
import java.io.BufferedReader;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网络爬虫取数据
*
* */
public class JianDan {
public static String GetUrl(String inUrl){
StringBuilder sb = new StringBuilder();
try {
URL url =new URL(inUrl);
BufferedReader reader =new BufferedReader(new InputStreamReader(url.openStream()));
String temp="";
while((temp=reader.readLine())!=null){
//System.out.println(temp);
sb.append(temp);
}
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
return sb.toString();
}
public static List GetMatcher(String str,String url){
List result = new ArrayList();
Pattern p =Pattern.compile(url);//获取网页地址
Matcher m =p.matcher(str);
while(m.find()){
//System.out.println(m.group(1));
result.add(m.group(1));
}
return result;
}
public static void main(String args[]){
String str=GetUrl("http://www.163.com";);
List ouput =GetMatcher(str,"src=\"([\\w\\s./:]+?)\"");
for(String temp:ouput){
//System.out.println(ouput.get(0));
System.out.println(temp);
}
String aurl=ouput.get(0);
// 构造URL
URL url;
try {
url = new URL(aurl);
// 打开URL连接
URLConnection con = (URLConnection)url.openConnection();
// 得到URL的输入流
InputStream input = con.getInputStream();
// 设置数据缓冲
byte[] bs = new byte[1024 * 2];
// 读取到的数据长度
int len;
// 输出的文件流保存图片至本地
OutputStream os = new FileOutputStream("a.png");
while ((len = input.read(bs)) != -1) {
os.write(bs, 0, len);
}
os.close();
input.close();
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
运行输出:

对java相关内容感兴趣的读者可以查看本站主题:《Java网络编程技巧总结》、《Java Socket编程技巧总结》、《Java文件和目录操作技巧总结》、《Java》数据结构与算法教程》、《Java操作DOM节点技巧总结》和《Java缓存操作技巧总结》
希望这篇文章对你的java编程有所帮助。
java从网页抓取数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 288 次浏览 • 2021-09-12 11:04
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到data采集的概念。 data采集的最终目标是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能无法上手,尤其是作为新手,感觉很茫然。所以,在这里分享一下自己的经验,希望能把技术分享给大家,如有不足之处还望指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长更多。
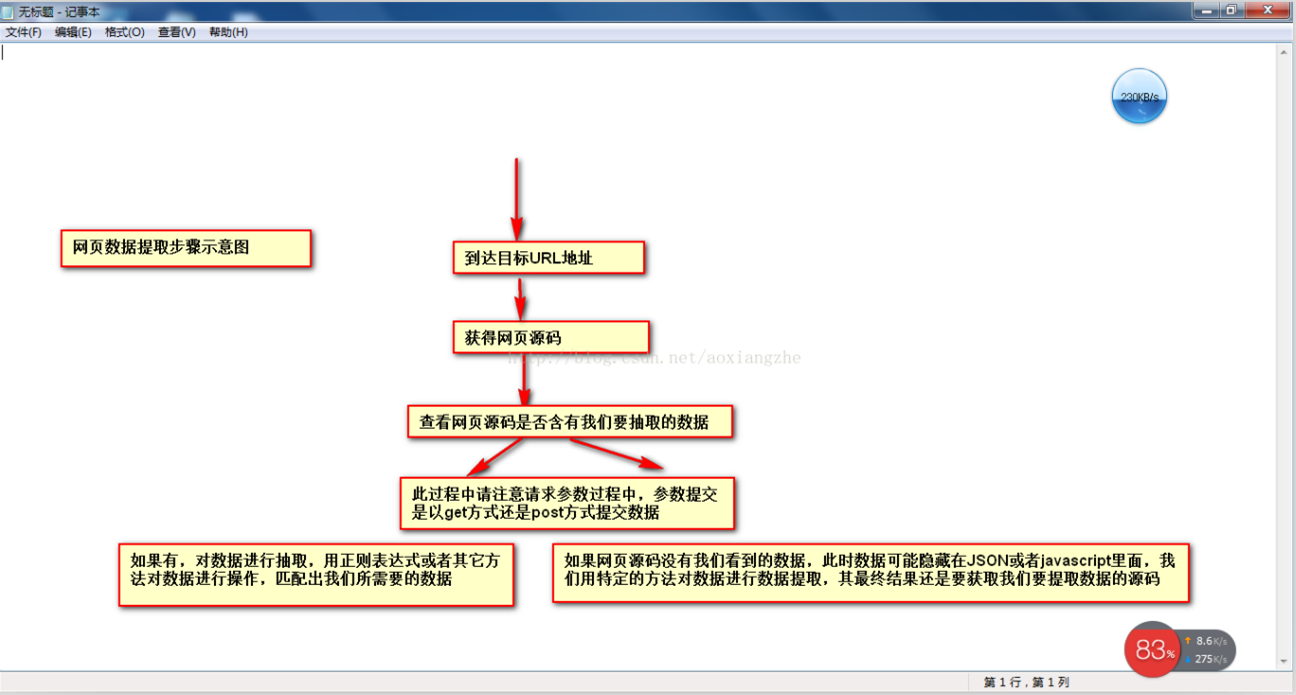
在网络数据采集的情况下,我们经常要经历这些大步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
了解了基本流程,我就用一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在这里,我暂时不解释httpclient。 +jsou提取网页数据的方法以后会在httpclient+jsoup上具体讲解。在这里,我们将首先说明如何使用正则表达式来提取数据。
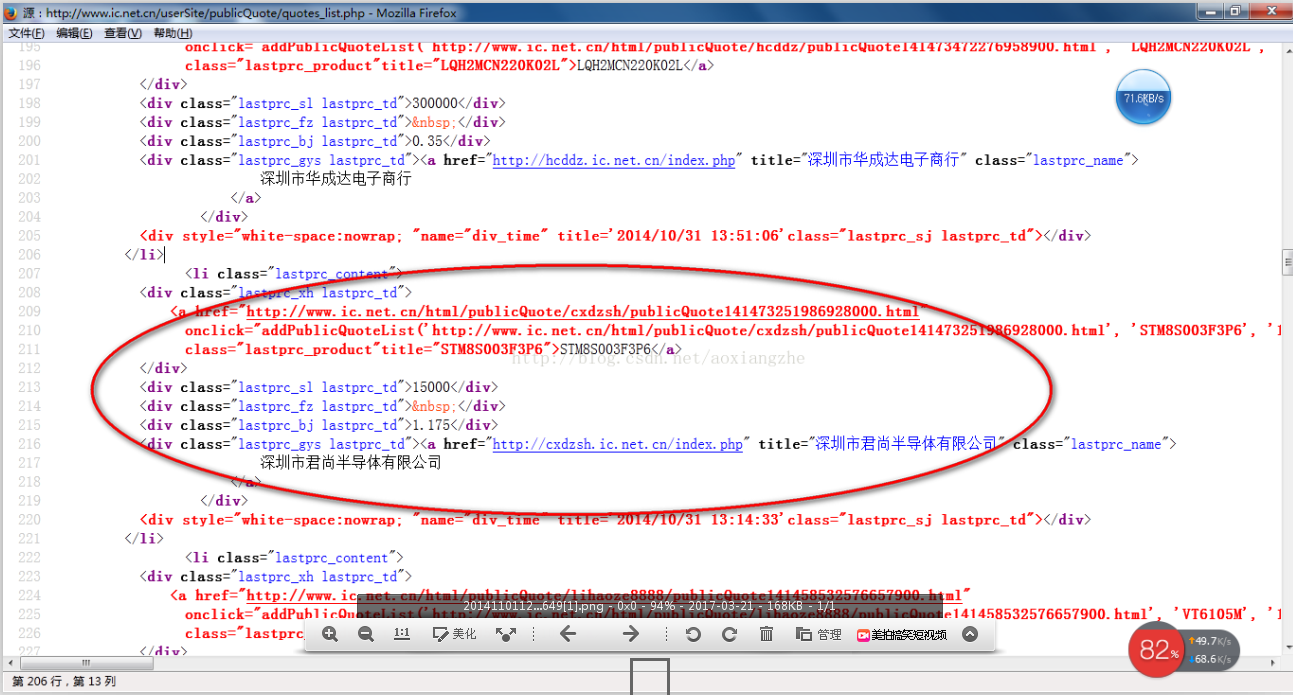
我在这里找到了一个网站:我们想提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站全页面预览
接下来我们看一下网页的源码结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好的,运行上面的程序,我们得到如下数据,也就是我们最终要获取的数据
数据获取成功,这就是我们要得到的最终数据结果,最后想说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是get方法提交数据的时候,采集真的是采集的时候,有的网页结构复杂,源码里可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在采集这个页面的时候,只有采集拿到了当前页面的数据,而且还有分页的数据。这个我就不解释了,只是一个提示,我们可以用多线程对所有分页的当前数据是采集,一个采集当前页面数据通过线程,另一个是翻页动作,你可以采集完成所有的数据。
我们匹配的数据可能在项目实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
转载于: 查看全部
java从网页抓取数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到data采集的概念。 data采集的最终目标是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能无法上手,尤其是作为新手,感觉很茫然。所以,在这里分享一下自己的经验,希望能把技术分享给大家,如有不足之处还望指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长更多。
在网络数据采集的情况下,我们经常要经历这些大步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
了解了基本流程,我就用一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在这里,我暂时不解释httpclient。 +jsou提取网页数据的方法以后会在httpclient+jsoup上具体讲解。在这里,我们将首先说明如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们想提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站全页面预览

接下来我们看一下网页的源码结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。

import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好的,运行上面的程序,我们得到如下数据,也就是我们最终要获取的数据

数据获取成功,这就是我们要得到的最终数据结果,最后想说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是get方法提交数据的时候,采集真的是采集的时候,有的网页结构复杂,源码里可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在采集这个页面的时候,只有采集拿到了当前页面的数据,而且还有分页的数据。这个我就不解释了,只是一个提示,我们可以用多线程对所有分页的当前数据是采集,一个采集当前页面数据通过线程,另一个是翻页动作,你可以采集完成所有的数据。
我们匹配的数据可能在项目实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
转载于:
java从网页抓取数据(30个最热门的大数据工具,你值得拥有!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 348 次浏览 • 2021-09-11 16:08
数据挖掘和数据分析的能力在当今时代非常重要。智能工具是您与竞争对手抗衡并增加公司业务优势的先决条件。我列出了 30 种最流行的大数据工具供您参考。
第 1 部分:Data采集tools
第 2 部分:开源数据工具
第 3 部分:数据可视化
第 4 部分:情绪分析
第 5 部分:开源数据库
第 1 部分:Data采集tools
1 .优采云
优采云 是一款免费、简单且直观的网络爬虫工具,无需编码即可从众多网站 中抓取数据。无论您是初学者还是经验丰富的技术人员或业务主管,它都能满足您的需求。为了降低使用难度,优采云为初学者准备了“网站简模板”,涵盖了市面上大部分主流的网站。使用简单的模板,用户无需配置任务即可采集data。简单的模板为采集小白树立信心,接下来就可以开始使用“高级模式”了,几分钟就可以捕捉海量数据。此外,您还可以设置定时云采集实时获取动态数据,并将数据导出到数据库或任何第三方平台。
2. 内容抓取器
Content Grabber 是一款支持智能抓取的网络爬虫软件。其程序运行环境可用于开发、测试和生产服务器。可以使用c#或VB.NET调试或编写脚本来控制爬虫程序。还支持在爬虫工具中添加第三方扩展插件。 Content Grabber 功能齐全,非常适合有技术基础的用户使用。
3.Import.io
Import.io 是一个基于网络的数据抓取工具。它于 2012 年首次在伦敦推出。现在 Import.io 已将其商业模式从 B2C 转变为 B2B。 2019年,Import.io收购Connotate,成为Web数据集成平台。凭借广泛的网络数据服务,Import.io 已成为业务分析的绝佳选择。
4.Parsehub
Parsehub 是一个基于网络的爬虫程序。支持使用AJax和JavaScripts技术的采集网页数据,也支持需要登录的采集网页数据。提供为期一周的免费试用窗口,供用户体验其功能。
5.Mozenda
Mozenda 是一款网页抓取软件,还为商业级数据抓取提供定制服务。它可以从云端和本地软件中抓取数据并进行数据托管。
部分2.开源数据工具
1. Knime
Knime 是一个分析平台。它可以帮助您发现商业洞察力和市场潜力。它为数据挖掘和机器学习提供了 Eclipse 平台和其他外部扩展。它为分析专业人员提供了超过 2k 个部署模块。
2.OpenRefine
OpenRefine(以前称为Google Refine)是处理杂乱数据的强大工具:它支持数据清理,支持数据从一种格式转换为另一种格式,并且可以通过网络服务和外部数据进行扩展。使用它的分组功能,您可以轻松地对网页上的杂乱数据进行标准化和规范化。
3. R-Programming
它是一种用于统计计算和图形的免费软件编程语言和软件环境。 R 语言在开发统计软件和数据分析的数据挖掘工作者中非常流行。近年来,它因其易用性和广泛的功能而受到了很多赞誉和欢迎。
除了数据挖掘,它还提供统计和图形技术、线性和非线性建模、经典统计检验、时间序列分析、分类、聚类等功能。
4.RapidMiner
与 KNIME 一样,RapidMiner 由可视化程序操作,可以手动操作、分析和建模。它通过开源平台、机器学习和模型部署来提高数据工作效率。统一的数据科学平台可以加速从数据准备到实现的分析工作流程,大大提高技术人员的工作效率,是最容易使用的预测分析软件之一。
5. Pentaho
它是一款出色的商业 BI 软件,可以帮助公司做出数据驱动的决策。该平台集成了本地数据库、Hadoop、NoSQL等数据源,您可以轻松使用它来分析和管理数据,进而从数据中获取价值。
6.Talend
它是一款开源集成软件,旨在将数据转化为洞察力。它提供各种服务和软件,包括云存储、企业应用程序集成、数据管理等。在大型社区的支持下,它允许所有 Talend 用户和成员从任何位置共享信息、经验和疑虑。
7.Weka
Weka 是一组用于数据挖掘任务的机器学习算法。这些算法可以直接应用于数据集,也可以从自己的JAVA代码中调用,也非常适合开发新的机器学习解决方案。它还具有可将数据科学世界转变为缺乏编程技能的专业人士的 GUI。
8.NodeXL
它是 Microsoft Excel 的开源软件包。作为一个附加的扩展,它没有数据集成服务和功能,它专注于社交网络分析。直观的网络和描述性关系使社交媒体分析变得容易。它是用于数据分析的最佳统计工具之一,包括高级网络指标、访问社交媒体网络数据导入器和自动化。
9.Gephi
Gephi 也是一个在 NetBeans 平台上用 Java 编写的开源网络分析和可视化软件包。想想你所看到的人与人之间的巨大联系网络。它们代表 LinkedIn 或 Facebook 上的社交关系。 Gephi 通过提供准确的计算为这一步提供了更准确的指标。
部分3.数据可视化工具
1.PowerBI
Microsoft PowerBI 提供本地和云服务。它最初是作为 Excel 插件推出的,PowerBI 很快因其强大的功能而广受欢迎。目前,它被认为是商业分析领域的软件领导者。提供数据可视化和双向功能,让用户能够以较低的成本轻松实现快速、明智的决策,用户可以协作共享定制化的仪表盘和交互式报表。
2.求解器
Solver 是一家专业的企业绩效管理(。Solver 致力于通过获取能够提高公司盈利能力的所有数据源,提供世界一流的财务报告、预算计划和财务分析。其软件 BI360 可用于云计算和本地部署,它侧重于四个关键分析领域,包括财务报告、预算、仪表板和数据仓库。
3.Qlik
Qlik 是一种自助式数据分析和可视化工具。它具有可视化仪表板,可简化数据分析并帮助公司快速做出业务决策。
4.Tableau Public
Tableau 是一种交互式数据可视化工具。与大多数需要编写脚本的可视化工具不同,Tableau 的简单性可以帮助新手降低使用难度。简单的拖拉操作,让数据分析轻松完成。他们还有“初学者入门工具包”和丰富的培训材料,可以帮助用户创建更多的分析报告。
5. Google 融合表
Fusion Table 是 Google 提供的数据管理平台。您可以将其用于数据采集、数据可视化和数据共享。它就像一个电子表格,但具有更强大和专业的功能。您可以通过在 CSV、KML 和电子表格中添加数据集来与同事共享数据。您还可以发布数据并将其嵌入到其他网络媒体资源中。
6. 信息图
Infogram 是一种直观的可视化工具,可帮助您创建精美的信息图表和报告。它提供了超过 35 个交互式图表和超过 500 个地图来帮助您可视化数据。除了各种图表,还有条形图、条形图、饼图或词云等,创新的信息图表给你留下深刻印象。
部分4.情感分析工具
1. HubSpot 的 ServiceHub
它是一个采集客户反馈和评论的客户反馈工具。该工具使用自然语言处理 (NLP) 来分析语言,区分其正面和负面含义,然后使用仪表板上的图形和图表将结果可视化。该工具支持将 HubSpot 的 ServiceHub 连接到 CRM 系统,这样您就可以将相应的结果与特定的人关联起来。例如,您可以筛选出满意度较低的客户,并及时提供优质服务,以提高客户保留率。
2. Semantria
Semantria 是一种可以从社交媒体渠道采集帖子、推文和评论的工具。它使用自然语言处理技术对文本进行解析,分析客户的正面和负面态度。通过这种方式,公司可以获取用户对产品或服务的真实看法,并提出更好的想法来改进您的产品和服务。
3.Trackur
Trackur是一个在线声誉管理工具,可以通过关注社交媒体网站来监控舆论。它会抓取大量网页,包括视频、博客、论坛和图片以搜索相关信息。您可以使用它来清理负面搜索引擎结果并建立和管理您的在线声誉。它是在线声誉和数字品牌管理方面的行业先驱。
4. SAS 情绪分析
SAS Sentiment Analysis 是一款非常强大的软件。网页文本分析最难的部分是拼写错误,SAS 可以轻松校对和聚类分析。通过自然语言处理、机器学习和语言规则的结合,SAS 可以帮助您分析最新趋势、最合适的商机,并从所有非结构化文本数据中提取真正有价值的信息。
5.Hootsuit Insight
这个工具可以分析评论、帖子、论坛、新闻网站以及超过50种语言的超过1000万个数据源平台。此外,它还可以对性别和位置进行分类。您可以为特定群体制定战略营销计划。您还可以获取实时数据并调查在线对话。
部分5.database
1.甲骨文
毫无疑问,Oracle 是开源数据库的领导者。功能众多,是企业的最佳选择。它还支持集成到不同平台。在 AWS 中易于设置,使其成为关系数据库的可靠选择。内置信用卡等隐私数据的高安全性技术使其不可替代。
2.PostgreSQL
它是仅次于 Oracle、MySQL 和 Microsoft SQL Server 的第四大流行数据库。由于其绝对可靠的稳定性,它可以处理高负载数据。
3.Airtable
是一款基于云服务器的数据库软件,具有丰富的数据表读取和信息展示功能。它还具有电子表格和内置日历,可轻松跟踪任务。它的入门模板易于使用,模板包括销售线索管理、错误跟踪和试用跟踪。
4. MariaDB
它是一个免费的开源数据库,用于数据存储、插入、修改和检索。此外,Maria 拥有强大的社区支持。社区成员非常活跃,积极分享信息和知识。
5.Improvado
Improvado 是一款专为营销人员设计的工具。它可以通过自动仪表盘和分析报告将所有数据实时整合到一个平台中。 Improvado 最适合希望将所有营销平台的数据整合到一个平台的营销分析领导者。
您可以选择在 Improvado 仪表板中查看数据,也可以将其导出到您选择的数据仓库或可视化工具,例如 Tableau、look ker、Excel 等。公司、机构和大学都喜欢使用改进是因为它为他们节省了数千小时的手动报告和数百万美元的营销预算。 查看全部
java从网页抓取数据(30个最热门的大数据工具,你值得拥有!)
数据挖掘和数据分析的能力在当今时代非常重要。智能工具是您与竞争对手抗衡并增加公司业务优势的先决条件。我列出了 30 种最流行的大数据工具供您参考。
第 1 部分:Data采集tools
第 2 部分:开源数据工具
第 3 部分:数据可视化
第 4 部分:情绪分析
第 5 部分:开源数据库
第 1 部分:Data采集tools
1 .优采云

优采云 是一款免费、简单且直观的网络爬虫工具,无需编码即可从众多网站 中抓取数据。无论您是初学者还是经验丰富的技术人员或业务主管,它都能满足您的需求。为了降低使用难度,优采云为初学者准备了“网站简模板”,涵盖了市面上大部分主流的网站。使用简单的模板,用户无需配置任务即可采集data。简单的模板为采集小白树立信心,接下来就可以开始使用“高级模式”了,几分钟就可以捕捉海量数据。此外,您还可以设置定时云采集实时获取动态数据,并将数据导出到数据库或任何第三方平台。
2. 内容抓取器
Content Grabber 是一款支持智能抓取的网络爬虫软件。其程序运行环境可用于开发、测试和生产服务器。可以使用c#或VB.NET调试或编写脚本来控制爬虫程序。还支持在爬虫工具中添加第三方扩展插件。 Content Grabber 功能齐全,非常适合有技术基础的用户使用。
3.Import.io
Import.io 是一个基于网络的数据抓取工具。它于 2012 年首次在伦敦推出。现在 Import.io 已将其商业模式从 B2C 转变为 B2B。 2019年,Import.io收购Connotate,成为Web数据集成平台。凭借广泛的网络数据服务,Import.io 已成为业务分析的绝佳选择。
4.Parsehub
Parsehub 是一个基于网络的爬虫程序。支持使用AJax和JavaScripts技术的采集网页数据,也支持需要登录的采集网页数据。提供为期一周的免费试用窗口,供用户体验其功能。
5.Mozenda
Mozenda 是一款网页抓取软件,还为商业级数据抓取提供定制服务。它可以从云端和本地软件中抓取数据并进行数据托管。
部分2.开源数据工具
1. Knime
Knime 是一个分析平台。它可以帮助您发现商业洞察力和市场潜力。它为数据挖掘和机器学习提供了 Eclipse 平台和其他外部扩展。它为分析专业人员提供了超过 2k 个部署模块。
2.OpenRefine
OpenRefine(以前称为Google Refine)是处理杂乱数据的强大工具:它支持数据清理,支持数据从一种格式转换为另一种格式,并且可以通过网络服务和外部数据进行扩展。使用它的分组功能,您可以轻松地对网页上的杂乱数据进行标准化和规范化。
3. R-Programming
它是一种用于统计计算和图形的免费软件编程语言和软件环境。 R 语言在开发统计软件和数据分析的数据挖掘工作者中非常流行。近年来,它因其易用性和广泛的功能而受到了很多赞誉和欢迎。
除了数据挖掘,它还提供统计和图形技术、线性和非线性建模、经典统计检验、时间序列分析、分类、聚类等功能。
4.RapidMiner
与 KNIME 一样,RapidMiner 由可视化程序操作,可以手动操作、分析和建模。它通过开源平台、机器学习和模型部署来提高数据工作效率。统一的数据科学平台可以加速从数据准备到实现的分析工作流程,大大提高技术人员的工作效率,是最容易使用的预测分析软件之一。
5. Pentaho
它是一款出色的商业 BI 软件,可以帮助公司做出数据驱动的决策。该平台集成了本地数据库、Hadoop、NoSQL等数据源,您可以轻松使用它来分析和管理数据,进而从数据中获取价值。

6.Talend
它是一款开源集成软件,旨在将数据转化为洞察力。它提供各种服务和软件,包括云存储、企业应用程序集成、数据管理等。在大型社区的支持下,它允许所有 Talend 用户和成员从任何位置共享信息、经验和疑虑。
7.Weka
Weka 是一组用于数据挖掘任务的机器学习算法。这些算法可以直接应用于数据集,也可以从自己的JAVA代码中调用,也非常适合开发新的机器学习解决方案。它还具有可将数据科学世界转变为缺乏编程技能的专业人士的 GUI。
8.NodeXL
它是 Microsoft Excel 的开源软件包。作为一个附加的扩展,它没有数据集成服务和功能,它专注于社交网络分析。直观的网络和描述性关系使社交媒体分析变得容易。它是用于数据分析的最佳统计工具之一,包括高级网络指标、访问社交媒体网络数据导入器和自动化。
9.Gephi
Gephi 也是一个在 NetBeans 平台上用 Java 编写的开源网络分析和可视化软件包。想想你所看到的人与人之间的巨大联系网络。它们代表 LinkedIn 或 Facebook 上的社交关系。 Gephi 通过提供准确的计算为这一步提供了更准确的指标。
部分3.数据可视化工具
1.PowerBI
Microsoft PowerBI 提供本地和云服务。它最初是作为 Excel 插件推出的,PowerBI 很快因其强大的功能而广受欢迎。目前,它被认为是商业分析领域的软件领导者。提供数据可视化和双向功能,让用户能够以较低的成本轻松实现快速、明智的决策,用户可以协作共享定制化的仪表盘和交互式报表。
2.求解器
Solver 是一家专业的企业绩效管理(。Solver 致力于通过获取能够提高公司盈利能力的所有数据源,提供世界一流的财务报告、预算计划和财务分析。其软件 BI360 可用于云计算和本地部署,它侧重于四个关键分析领域,包括财务报告、预算、仪表板和数据仓库。
3.Qlik
Qlik 是一种自助式数据分析和可视化工具。它具有可视化仪表板,可简化数据分析并帮助公司快速做出业务决策。
4.Tableau Public
Tableau 是一种交互式数据可视化工具。与大多数需要编写脚本的可视化工具不同,Tableau 的简单性可以帮助新手降低使用难度。简单的拖拉操作,让数据分析轻松完成。他们还有“初学者入门工具包”和丰富的培训材料,可以帮助用户创建更多的分析报告。
5. Google 融合表
Fusion Table 是 Google 提供的数据管理平台。您可以将其用于数据采集、数据可视化和数据共享。它就像一个电子表格,但具有更强大和专业的功能。您可以通过在 CSV、KML 和电子表格中添加数据集来与同事共享数据。您还可以发布数据并将其嵌入到其他网络媒体资源中。
6. 信息图
Infogram 是一种直观的可视化工具,可帮助您创建精美的信息图表和报告。它提供了超过 35 个交互式图表和超过 500 个地图来帮助您可视化数据。除了各种图表,还有条形图、条形图、饼图或词云等,创新的信息图表给你留下深刻印象。
部分4.情感分析工具
1. HubSpot 的 ServiceHub
它是一个采集客户反馈和评论的客户反馈工具。该工具使用自然语言处理 (NLP) 来分析语言,区分其正面和负面含义,然后使用仪表板上的图形和图表将结果可视化。该工具支持将 HubSpot 的 ServiceHub 连接到 CRM 系统,这样您就可以将相应的结果与特定的人关联起来。例如,您可以筛选出满意度较低的客户,并及时提供优质服务,以提高客户保留率。
2. Semantria
Semantria 是一种可以从社交媒体渠道采集帖子、推文和评论的工具。它使用自然语言处理技术对文本进行解析,分析客户的正面和负面态度。通过这种方式,公司可以获取用户对产品或服务的真实看法,并提出更好的想法来改进您的产品和服务。
3.Trackur
Trackur是一个在线声誉管理工具,可以通过关注社交媒体网站来监控舆论。它会抓取大量网页,包括视频、博客、论坛和图片以搜索相关信息。您可以使用它来清理负面搜索引擎结果并建立和管理您的在线声誉。它是在线声誉和数字品牌管理方面的行业先驱。
4. SAS 情绪分析
SAS Sentiment Analysis 是一款非常强大的软件。网页文本分析最难的部分是拼写错误,SAS 可以轻松校对和聚类分析。通过自然语言处理、机器学习和语言规则的结合,SAS 可以帮助您分析最新趋势、最合适的商机,并从所有非结构化文本数据中提取真正有价值的信息。
5.Hootsuit Insight
这个工具可以分析评论、帖子、论坛、新闻网站以及超过50种语言的超过1000万个数据源平台。此外,它还可以对性别和位置进行分类。您可以为特定群体制定战略营销计划。您还可以获取实时数据并调查在线对话。
部分5.database
1.甲骨文
毫无疑问,Oracle 是开源数据库的领导者。功能众多,是企业的最佳选择。它还支持集成到不同平台。在 AWS 中易于设置,使其成为关系数据库的可靠选择。内置信用卡等隐私数据的高安全性技术使其不可替代。
2.PostgreSQL
它是仅次于 Oracle、MySQL 和 Microsoft SQL Server 的第四大流行数据库。由于其绝对可靠的稳定性,它可以处理高负载数据。
3.Airtable
是一款基于云服务器的数据库软件,具有丰富的数据表读取和信息展示功能。它还具有电子表格和内置日历,可轻松跟踪任务。它的入门模板易于使用,模板包括销售线索管理、错误跟踪和试用跟踪。
4. MariaDB
它是一个免费的开源数据库,用于数据存储、插入、修改和检索。此外,Maria 拥有强大的社区支持。社区成员非常活跃,积极分享信息和知识。
5.Improvado
Improvado 是一款专为营销人员设计的工具。它可以通过自动仪表盘和分析报告将所有数据实时整合到一个平台中。 Improvado 最适合希望将所有营销平台的数据整合到一个平台的营销分析领导者。
您可以选择在 Improvado 仪表板中查看数据,也可以将其导出到您选择的数据仓库或可视化工具,例如 Tableau、look ker、Excel 等。公司、机构和大学都喜欢使用改进是因为它为他们节省了数千小时的手动报告和数百万美元的营销预算。
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2021-09-11 16:07
原文链接:
有时,出于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,再次请求一个网页后,查询的结果就显示出来了。
查询后看网页地址:
也就是说,我们只需要访问这种网址就可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、抓取网页的JavaScript返回的结果。
有时,网站为了保护自己的数据,不会直接在网页源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据的爬取通过搜索引擎等工具。 .
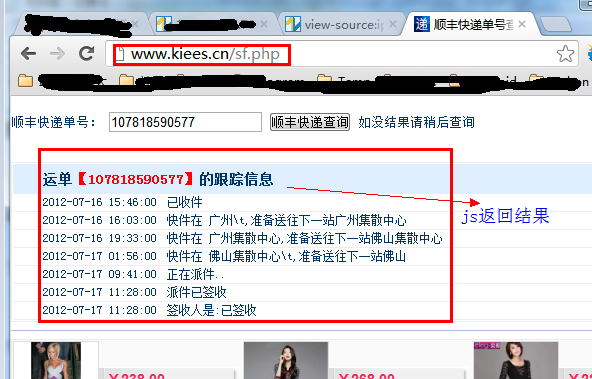
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候该怎么办?
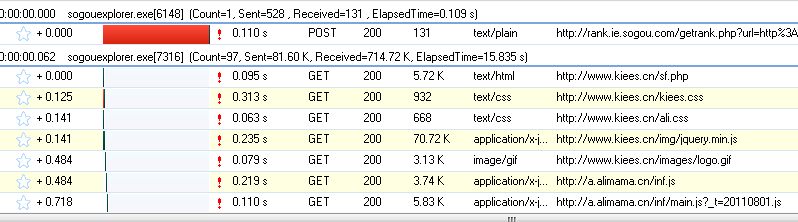
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后输入tracking number:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
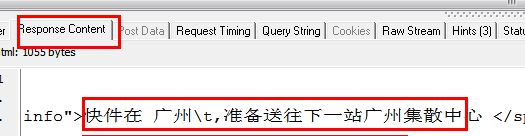
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据当然,前提是数据没有加密对,我们写下JS请求的URL:
然后让程序请求这个页面的结果!
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时,出于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:

第2步:查看网页源代码,我们在源代码中看到这一段:

从这里可以看出,再次请求一个网页后,查询的结果就显示出来了。
查询后看网页地址:

也就是说,我们只需要访问这种网址就可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、抓取网页的JavaScript返回的结果。
有时,网站为了保护自己的数据,不会直接在网页源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据的爬取通过搜索引擎等工具。 .
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后输入tracking number:7,点击查询按钮,然后查看HTTP Analyzer的结果:

这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据当然,前提是数据没有加密对,我们写下JS请求的URL:
然后让程序请求这个页面的结果!
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-09 15:29
有时由于各种原因,我们需要采集一些网站的数据,但由于网站不同,显示数据的方式略有不同!
本文用Java来告诉你如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页返回的数据。
一、抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml()的结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时候网站为了保护自己的数据,不会直接在网页的源代码中返回数据。而是使用JS异步返回数据,避免搜索引擎等工具响应网站数据的爬行。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript():\n"+contentBuf.toString()的结果);}
看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
有时由于各种原因,我们需要采集一些网站的数据,但由于网站不同,显示数据的方式略有不同!
本文用Java来告诉你如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页返回的数据。
一、抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml()的结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时候网站为了保护自己的数据,不会直接在网页的源代码中返回数据。而是使用JS异步返回数据,避免搜索引擎等工具响应网站数据的爬行。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript():\n"+contentBuf.toString()的结果);}
看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载!
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-09 11:03
原文链接:
有时,出于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,再次请求一个网页后,查询的结果就显示出来了。
查询后看网页地址:
也就是说,我们只需要访问这种网址就可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、抓取网页的JavaScript返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据。而是采用异步方式用JS返回数据,可以避免网站数据被搜索引擎等工具抓取。 .
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后输入tracking number:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据当然,前提是数据没有加密对,我们写下JS请求的URL:
然后让程序请求这个页面的结果!
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时,出于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,再次请求一个网页后,查询的结果就显示出来了。
查询后看网页地址:
也就是说,我们只需要访问这种网址就可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、抓取网页的JavaScript返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据。而是采用异步方式用JS返回数据,可以避免网站数据被搜索引擎等工具抓取。 .
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后输入tracking number:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据当然,前提是数据没有加密对,我们写下JS请求的URL:
然后让程序请求这个页面的结果!
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java从网页抓取数据( 2018年Java实现的爬虫抓取图片并保存操作技巧汇总)
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-09-12 11:06
2018年Java实现的爬虫抓取图片并保存操作技巧汇总)
Java实现的抓取图片并保存的爬虫示例
更新时间:2018年8月31日09:47:10 作者:smilecjw
这次文章主要介绍了Java实现的爬虫抓取图片和保存操作,涉及Java对页面URL访问、获取、字符串匹配、文件下载等的相关操作技巧,有需要的朋友可以参考以下
本文介绍了一个用Java实现的爬虫抓取图片并保存的例子。分享给大家,供大家参考,如下:
这是我根据网上的一些资料写的第一个java爬虫程序
本来想弄个无聊的煎蛋图,但是网络返回码一直是503,所以改成网站
import java.io.BufferedReader;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网络爬虫取数据
*
* */
public class JianDan {
public static String GetUrl(String inUrl){
StringBuilder sb = new StringBuilder();
try {
URL url =new URL(inUrl);
BufferedReader reader =new BufferedReader(new InputStreamReader(url.openStream()));
String temp="";
while((temp=reader.readLine())!=null){
//System.out.println(temp);
sb.append(temp);
}
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
return sb.toString();
}
public static List GetMatcher(String str,String url){
List result = new ArrayList();
Pattern p =Pattern.compile(url);//获取网页地址
Matcher m =p.matcher(str);
while(m.find()){
//System.out.println(m.group(1));
result.add(m.group(1));
}
return result;
}
public static void main(String args[]){
String str=GetUrl("http://www.163.com");
List ouput =GetMatcher(str,"src=\"([\\w\\s./:]+?)\"");
for(String temp:ouput){
//System.out.println(ouput.get(0));
System.out.println(temp);
}
String aurl=ouput.get(0);
// 构造URL
URL url;
try {
url = new URL(aurl);
// 打开URL连接
URLConnection con = (URLConnection)url.openConnection();
// 得到URL的输入流
InputStream input = con.getInputStream();
// 设置数据缓冲
byte[] bs = new byte[1024 * 2];
// 读取到的数据长度
int len;
// 输出的文件流保存图片至本地
OutputStream os = new FileOutputStream("a.png");
while ((len = input.read(bs)) != -1) {
os.write(bs, 0, len);
}
os.close();
input.close();
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
运行输出:
对java相关内容感兴趣的读者可以查看本站主题:《Java网络编程技巧总结》、《Java Socket编程技巧总结》、《Java文件和目录操作技巧总结》、《Java》数据结构与算法教程》、《Java操作DOM节点技巧总结》和《Java缓存操作技巧总结》
希望这篇文章对你的java编程有所帮助。 查看全部
java从网页抓取数据(
2018年Java实现的爬虫抓取图片并保存操作技巧汇总)
Java实现的抓取图片并保存的爬虫示例
更新时间:2018年8月31日09:47:10 作者:smilecjw
这次文章主要介绍了Java实现的爬虫抓取图片和保存操作,涉及Java对页面URL访问、获取、字符串匹配、文件下载等的相关操作技巧,有需要的朋友可以参考以下
本文介绍了一个用Java实现的爬虫抓取图片并保存的例子。分享给大家,供大家参考,如下:
这是我根据网上的一些资料写的第一个java爬虫程序
本来想弄个无聊的煎蛋图,但是网络返回码一直是503,所以改成网站
import java.io.BufferedReader;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网络爬虫取数据
*
* */
public class JianDan {
public static String GetUrl(String inUrl){
StringBuilder sb = new StringBuilder();
try {
URL url =new URL(inUrl);
BufferedReader reader =new BufferedReader(new InputStreamReader(url.openStream()));
String temp="";
while((temp=reader.readLine())!=null){
//System.out.println(temp);
sb.append(temp);
}
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
return sb.toString();
}
public static List GetMatcher(String str,String url){
List result = new ArrayList();
Pattern p =Pattern.compile(url);//获取网页地址
Matcher m =p.matcher(str);
while(m.find()){
//System.out.println(m.group(1));
result.add(m.group(1));
}
return result;
}
public static void main(String args[]){
String str=GetUrl("http://www.163.com";);
List ouput =GetMatcher(str,"src=\"([\\w\\s./:]+?)\"");
for(String temp:ouput){
//System.out.println(ouput.get(0));
System.out.println(temp);
}
String aurl=ouput.get(0);
// 构造URL
URL url;
try {
url = new URL(aurl);
// 打开URL连接
URLConnection con = (URLConnection)url.openConnection();
// 得到URL的输入流
InputStream input = con.getInputStream();
// 设置数据缓冲
byte[] bs = new byte[1024 * 2];
// 读取到的数据长度
int len;
// 输出的文件流保存图片至本地
OutputStream os = new FileOutputStream("a.png");
while ((len = input.read(bs)) != -1) {
os.write(bs, 0, len);
}
os.close();
input.close();
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
运行输出:
对java相关内容感兴趣的读者可以查看本站主题:《Java网络编程技巧总结》、《Java Socket编程技巧总结》、《Java文件和目录操作技巧总结》、《Java》数据结构与算法教程》、《Java操作DOM节点技巧总结》和《Java缓存操作技巧总结》
希望这篇文章对你的java编程有所帮助。
java从网页抓取数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 288 次浏览 • 2021-09-12 11:04
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到data采集的概念。 data采集的最终目标是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能无法上手,尤其是作为新手,感觉很茫然。所以,在这里分享一下自己的经验,希望能把技术分享给大家,如有不足之处还望指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长更多。
在网络数据采集的情况下,我们经常要经历这些大步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
了解了基本流程,我就用一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在这里,我暂时不解释httpclient。 +jsou提取网页数据的方法以后会在httpclient+jsoup上具体讲解。在这里,我们将首先说明如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们想提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站全页面预览
接下来我们看一下网页的源码结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好的,运行上面的程序,我们得到如下数据,也就是我们最终要获取的数据
数据获取成功,这就是我们要得到的最终数据结果,最后想说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是get方法提交数据的时候,采集真的是采集的时候,有的网页结构复杂,源码里可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在采集这个页面的时候,只有采集拿到了当前页面的数据,而且还有分页的数据。这个我就不解释了,只是一个提示,我们可以用多线程对所有分页的当前数据是采集,一个采集当前页面数据通过线程,另一个是翻页动作,你可以采集完成所有的数据。
我们匹配的数据可能在项目实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
转载于: 查看全部
java从网页抓取数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到data采集的概念。 data采集的最终目标是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能无法上手,尤其是作为新手,感觉很茫然。所以,在这里分享一下自己的经验,希望能把技术分享给大家,如有不足之处还望指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长更多。
在网络数据采集的情况下,我们经常要经历这些大步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
了解了基本流程,我就用一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在这里,我暂时不解释httpclient。 +jsou提取网页数据的方法以后会在httpclient+jsoup上具体讲解。在这里,我们将首先说明如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们想提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站全页面预览
接下来我们看一下网页的源码结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好的,运行上面的程序,我们得到如下数据,也就是我们最终要获取的数据
数据获取成功,这就是我们要得到的最终数据结果,最后想说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是get方法提交数据的时候,采集真的是采集的时候,有的网页结构复杂,源码里可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在采集这个页面的时候,只有采集拿到了当前页面的数据,而且还有分页的数据。这个我就不解释了,只是一个提示,我们可以用多线程对所有分页的当前数据是采集,一个采集当前页面数据通过线程,另一个是翻页动作,你可以采集完成所有的数据。
我们匹配的数据可能在项目实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
转载于:
java从网页抓取数据(30个最热门的大数据工具,你值得拥有!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 348 次浏览 • 2021-09-11 16:08
数据挖掘和数据分析的能力在当今时代非常重要。智能工具是您与竞争对手抗衡并增加公司业务优势的先决条件。我列出了 30 种最流行的大数据工具供您参考。
第 1 部分:Data采集tools
第 2 部分:开源数据工具
第 3 部分:数据可视化
第 4 部分:情绪分析
第 5 部分:开源数据库
第 1 部分:Data采集tools
1 .优采云
优采云 是一款免费、简单且直观的网络爬虫工具,无需编码即可从众多网站 中抓取数据。无论您是初学者还是经验丰富的技术人员或业务主管,它都能满足您的需求。为了降低使用难度,优采云为初学者准备了“网站简模板”,涵盖了市面上大部分主流的网站。使用简单的模板,用户无需配置任务即可采集data。简单的模板为采集小白树立信心,接下来就可以开始使用“高级模式”了,几分钟就可以捕捉海量数据。此外,您还可以设置定时云采集实时获取动态数据,并将数据导出到数据库或任何第三方平台。
2. 内容抓取器
Content Grabber 是一款支持智能抓取的网络爬虫软件。其程序运行环境可用于开发、测试和生产服务器。可以使用c#或VB.NET调试或编写脚本来控制爬虫程序。还支持在爬虫工具中添加第三方扩展插件。 Content Grabber 功能齐全,非常适合有技术基础的用户使用。
3.Import.io
Import.io 是一个基于网络的数据抓取工具。它于 2012 年首次在伦敦推出。现在 Import.io 已将其商业模式从 B2C 转变为 B2B。 2019年,Import.io收购Connotate,成为Web数据集成平台。凭借广泛的网络数据服务,Import.io 已成为业务分析的绝佳选择。
4.Parsehub
Parsehub 是一个基于网络的爬虫程序。支持使用AJax和JavaScripts技术的采集网页数据,也支持需要登录的采集网页数据。提供为期一周的免费试用窗口,供用户体验其功能。
5.Mozenda
Mozenda 是一款网页抓取软件,还为商业级数据抓取提供定制服务。它可以从云端和本地软件中抓取数据并进行数据托管。
部分2.开源数据工具
1. Knime
Knime 是一个分析平台。它可以帮助您发现商业洞察力和市场潜力。它为数据挖掘和机器学习提供了 Eclipse 平台和其他外部扩展。它为分析专业人员提供了超过 2k 个部署模块。
2.OpenRefine
OpenRefine(以前称为Google Refine)是处理杂乱数据的强大工具:它支持数据清理,支持数据从一种格式转换为另一种格式,并且可以通过网络服务和外部数据进行扩展。使用它的分组功能,您可以轻松地对网页上的杂乱数据进行标准化和规范化。
3. R-Programming
它是一种用于统计计算和图形的免费软件编程语言和软件环境。 R 语言在开发统计软件和数据分析的数据挖掘工作者中非常流行。近年来,它因其易用性和广泛的功能而受到了很多赞誉和欢迎。
除了数据挖掘,它还提供统计和图形技术、线性和非线性建模、经典统计检验、时间序列分析、分类、聚类等功能。
4.RapidMiner
与 KNIME 一样,RapidMiner 由可视化程序操作,可以手动操作、分析和建模。它通过开源平台、机器学习和模型部署来提高数据工作效率。统一的数据科学平台可以加速从数据准备到实现的分析工作流程,大大提高技术人员的工作效率,是最容易使用的预测分析软件之一。
5. Pentaho
它是一款出色的商业 BI 软件,可以帮助公司做出数据驱动的决策。该平台集成了本地数据库、Hadoop、NoSQL等数据源,您可以轻松使用它来分析和管理数据,进而从数据中获取价值。
6.Talend
它是一款开源集成软件,旨在将数据转化为洞察力。它提供各种服务和软件,包括云存储、企业应用程序集成、数据管理等。在大型社区的支持下,它允许所有 Talend 用户和成员从任何位置共享信息、经验和疑虑。
7.Weka
Weka 是一组用于数据挖掘任务的机器学习算法。这些算法可以直接应用于数据集,也可以从自己的JAVA代码中调用,也非常适合开发新的机器学习解决方案。它还具有可将数据科学世界转变为缺乏编程技能的专业人士的 GUI。
8.NodeXL
它是 Microsoft Excel 的开源软件包。作为一个附加的扩展,它没有数据集成服务和功能,它专注于社交网络分析。直观的网络和描述性关系使社交媒体分析变得容易。它是用于数据分析的最佳统计工具之一,包括高级网络指标、访问社交媒体网络数据导入器和自动化。
9.Gephi
Gephi 也是一个在 NetBeans 平台上用 Java 编写的开源网络分析和可视化软件包。想想你所看到的人与人之间的巨大联系网络。它们代表 LinkedIn 或 Facebook 上的社交关系。 Gephi 通过提供准确的计算为这一步提供了更准确的指标。
部分3.数据可视化工具
1.PowerBI
Microsoft PowerBI 提供本地和云服务。它最初是作为 Excel 插件推出的,PowerBI 很快因其强大的功能而广受欢迎。目前,它被认为是商业分析领域的软件领导者。提供数据可视化和双向功能,让用户能够以较低的成本轻松实现快速、明智的决策,用户可以协作共享定制化的仪表盘和交互式报表。
2.求解器
Solver 是一家专业的企业绩效管理(。Solver 致力于通过获取能够提高公司盈利能力的所有数据源,提供世界一流的财务报告、预算计划和财务分析。其软件 BI360 可用于云计算和本地部署,它侧重于四个关键分析领域,包括财务报告、预算、仪表板和数据仓库。
3.Qlik
Qlik 是一种自助式数据分析和可视化工具。它具有可视化仪表板,可简化数据分析并帮助公司快速做出业务决策。
4.Tableau Public
Tableau 是一种交互式数据可视化工具。与大多数需要编写脚本的可视化工具不同,Tableau 的简单性可以帮助新手降低使用难度。简单的拖拉操作,让数据分析轻松完成。他们还有“初学者入门工具包”和丰富的培训材料,可以帮助用户创建更多的分析报告。
5. Google 融合表
Fusion Table 是 Google 提供的数据管理平台。您可以将其用于数据采集、数据可视化和数据共享。它就像一个电子表格,但具有更强大和专业的功能。您可以通过在 CSV、KML 和电子表格中添加数据集来与同事共享数据。您还可以发布数据并将其嵌入到其他网络媒体资源中。
6. 信息图
Infogram 是一种直观的可视化工具,可帮助您创建精美的信息图表和报告。它提供了超过 35 个交互式图表和超过 500 个地图来帮助您可视化数据。除了各种图表,还有条形图、条形图、饼图或词云等,创新的信息图表给你留下深刻印象。
部分4.情感分析工具
1. HubSpot 的 ServiceHub
它是一个采集客户反馈和评论的客户反馈工具。该工具使用自然语言处理 (NLP) 来分析语言,区分其正面和负面含义,然后使用仪表板上的图形和图表将结果可视化。该工具支持将 HubSpot 的 ServiceHub 连接到 CRM 系统,这样您就可以将相应的结果与特定的人关联起来。例如,您可以筛选出满意度较低的客户,并及时提供优质服务,以提高客户保留率。
2. Semantria
Semantria 是一种可以从社交媒体渠道采集帖子、推文和评论的工具。它使用自然语言处理技术对文本进行解析,分析客户的正面和负面态度。通过这种方式,公司可以获取用户对产品或服务的真实看法,并提出更好的想法来改进您的产品和服务。
3.Trackur
Trackur是一个在线声誉管理工具,可以通过关注社交媒体网站来监控舆论。它会抓取大量网页,包括视频、博客、论坛和图片以搜索相关信息。您可以使用它来清理负面搜索引擎结果并建立和管理您的在线声誉。它是在线声誉和数字品牌管理方面的行业先驱。
4. SAS 情绪分析
SAS Sentiment Analysis 是一款非常强大的软件。网页文本分析最难的部分是拼写错误,SAS 可以轻松校对和聚类分析。通过自然语言处理、机器学习和语言规则的结合,SAS 可以帮助您分析最新趋势、最合适的商机,并从所有非结构化文本数据中提取真正有价值的信息。
5.Hootsuit Insight
这个工具可以分析评论、帖子、论坛、新闻网站以及超过50种语言的超过1000万个数据源平台。此外,它还可以对性别和位置进行分类。您可以为特定群体制定战略营销计划。您还可以获取实时数据并调查在线对话。
部分5.database
1.甲骨文
毫无疑问,Oracle 是开源数据库的领导者。功能众多,是企业的最佳选择。它还支持集成到不同平台。在 AWS 中易于设置,使其成为关系数据库的可靠选择。内置信用卡等隐私数据的高安全性技术使其不可替代。
2.PostgreSQL
它是仅次于 Oracle、MySQL 和 Microsoft SQL Server 的第四大流行数据库。由于其绝对可靠的稳定性,它可以处理高负载数据。
3.Airtable
是一款基于云服务器的数据库软件,具有丰富的数据表读取和信息展示功能。它还具有电子表格和内置日历,可轻松跟踪任务。它的入门模板易于使用,模板包括销售线索管理、错误跟踪和试用跟踪。
4. MariaDB
它是一个免费的开源数据库,用于数据存储、插入、修改和检索。此外,Maria 拥有强大的社区支持。社区成员非常活跃,积极分享信息和知识。
5.Improvado
Improvado 是一款专为营销人员设计的工具。它可以通过自动仪表盘和分析报告将所有数据实时整合到一个平台中。 Improvado 最适合希望将所有营销平台的数据整合到一个平台的营销分析领导者。
您可以选择在 Improvado 仪表板中查看数据,也可以将其导出到您选择的数据仓库或可视化工具,例如 Tableau、look ker、Excel 等。公司、机构和大学都喜欢使用改进是因为它为他们节省了数千小时的手动报告和数百万美元的营销预算。 查看全部
java从网页抓取数据(30个最热门的大数据工具,你值得拥有!)
数据挖掘和数据分析的能力在当今时代非常重要。智能工具是您与竞争对手抗衡并增加公司业务优势的先决条件。我列出了 30 种最流行的大数据工具供您参考。
第 1 部分:Data采集tools
第 2 部分:开源数据工具
第 3 部分:数据可视化
第 4 部分:情绪分析
第 5 部分:开源数据库
第 1 部分:Data采集tools
1 .优采云
优采云 是一款免费、简单且直观的网络爬虫工具,无需编码即可从众多网站 中抓取数据。无论您是初学者还是经验丰富的技术人员或业务主管,它都能满足您的需求。为了降低使用难度,优采云为初学者准备了“网站简模板”,涵盖了市面上大部分主流的网站。使用简单的模板,用户无需配置任务即可采集data。简单的模板为采集小白树立信心,接下来就可以开始使用“高级模式”了,几分钟就可以捕捉海量数据。此外,您还可以设置定时云采集实时获取动态数据,并将数据导出到数据库或任何第三方平台。
2. 内容抓取器
Content Grabber 是一款支持智能抓取的网络爬虫软件。其程序运行环境可用于开发、测试和生产服务器。可以使用c#或VB.NET调试或编写脚本来控制爬虫程序。还支持在爬虫工具中添加第三方扩展插件。 Content Grabber 功能齐全,非常适合有技术基础的用户使用。
3.Import.io
Import.io 是一个基于网络的数据抓取工具。它于 2012 年首次在伦敦推出。现在 Import.io 已将其商业模式从 B2C 转变为 B2B。 2019年,Import.io收购Connotate,成为Web数据集成平台。凭借广泛的网络数据服务,Import.io 已成为业务分析的绝佳选择。
4.Parsehub
Parsehub 是一个基于网络的爬虫程序。支持使用AJax和JavaScripts技术的采集网页数据,也支持需要登录的采集网页数据。提供为期一周的免费试用窗口,供用户体验其功能。
5.Mozenda
Mozenda 是一款网页抓取软件,还为商业级数据抓取提供定制服务。它可以从云端和本地软件中抓取数据并进行数据托管。
部分2.开源数据工具
1. Knime
Knime 是一个分析平台。它可以帮助您发现商业洞察力和市场潜力。它为数据挖掘和机器学习提供了 Eclipse 平台和其他外部扩展。它为分析专业人员提供了超过 2k 个部署模块。
2.OpenRefine
OpenRefine(以前称为Google Refine)是处理杂乱数据的强大工具:它支持数据清理,支持数据从一种格式转换为另一种格式,并且可以通过网络服务和外部数据进行扩展。使用它的分组功能,您可以轻松地对网页上的杂乱数据进行标准化和规范化。
3. R-Programming
它是一种用于统计计算和图形的免费软件编程语言和软件环境。 R 语言在开发统计软件和数据分析的数据挖掘工作者中非常流行。近年来,它因其易用性和广泛的功能而受到了很多赞誉和欢迎。
除了数据挖掘,它还提供统计和图形技术、线性和非线性建模、经典统计检验、时间序列分析、分类、聚类等功能。
4.RapidMiner
与 KNIME 一样,RapidMiner 由可视化程序操作,可以手动操作、分析和建模。它通过开源平台、机器学习和模型部署来提高数据工作效率。统一的数据科学平台可以加速从数据准备到实现的分析工作流程,大大提高技术人员的工作效率,是最容易使用的预测分析软件之一。
5. Pentaho
它是一款出色的商业 BI 软件,可以帮助公司做出数据驱动的决策。该平台集成了本地数据库、Hadoop、NoSQL等数据源,您可以轻松使用它来分析和管理数据,进而从数据中获取价值。
6.Talend
它是一款开源集成软件,旨在将数据转化为洞察力。它提供各种服务和软件,包括云存储、企业应用程序集成、数据管理等。在大型社区的支持下,它允许所有 Talend 用户和成员从任何位置共享信息、经验和疑虑。
7.Weka
Weka 是一组用于数据挖掘任务的机器学习算法。这些算法可以直接应用于数据集,也可以从自己的JAVA代码中调用,也非常适合开发新的机器学习解决方案。它还具有可将数据科学世界转变为缺乏编程技能的专业人士的 GUI。
8.NodeXL
它是 Microsoft Excel 的开源软件包。作为一个附加的扩展,它没有数据集成服务和功能,它专注于社交网络分析。直观的网络和描述性关系使社交媒体分析变得容易。它是用于数据分析的最佳统计工具之一,包括高级网络指标、访问社交媒体网络数据导入器和自动化。
9.Gephi
Gephi 也是一个在 NetBeans 平台上用 Java 编写的开源网络分析和可视化软件包。想想你所看到的人与人之间的巨大联系网络。它们代表 LinkedIn 或 Facebook 上的社交关系。 Gephi 通过提供准确的计算为这一步提供了更准确的指标。
部分3.数据可视化工具
1.PowerBI
Microsoft PowerBI 提供本地和云服务。它最初是作为 Excel 插件推出的,PowerBI 很快因其强大的功能而广受欢迎。目前,它被认为是商业分析领域的软件领导者。提供数据可视化和双向功能,让用户能够以较低的成本轻松实现快速、明智的决策,用户可以协作共享定制化的仪表盘和交互式报表。
2.求解器
Solver 是一家专业的企业绩效管理(。Solver 致力于通过获取能够提高公司盈利能力的所有数据源,提供世界一流的财务报告、预算计划和财务分析。其软件 BI360 可用于云计算和本地部署,它侧重于四个关键分析领域,包括财务报告、预算、仪表板和数据仓库。
3.Qlik
Qlik 是一种自助式数据分析和可视化工具。它具有可视化仪表板,可简化数据分析并帮助公司快速做出业务决策。
4.Tableau Public
Tableau 是一种交互式数据可视化工具。与大多数需要编写脚本的可视化工具不同,Tableau 的简单性可以帮助新手降低使用难度。简单的拖拉操作,让数据分析轻松完成。他们还有“初学者入门工具包”和丰富的培训材料,可以帮助用户创建更多的分析报告。
5. Google 融合表
Fusion Table 是 Google 提供的数据管理平台。您可以将其用于数据采集、数据可视化和数据共享。它就像一个电子表格,但具有更强大和专业的功能。您可以通过在 CSV、KML 和电子表格中添加数据集来与同事共享数据。您还可以发布数据并将其嵌入到其他网络媒体资源中。
6. 信息图
Infogram 是一种直观的可视化工具,可帮助您创建精美的信息图表和报告。它提供了超过 35 个交互式图表和超过 500 个地图来帮助您可视化数据。除了各种图表,还有条形图、条形图、饼图或词云等,创新的信息图表给你留下深刻印象。
部分4.情感分析工具
1. HubSpot 的 ServiceHub
它是一个采集客户反馈和评论的客户反馈工具。该工具使用自然语言处理 (NLP) 来分析语言,区分其正面和负面含义,然后使用仪表板上的图形和图表将结果可视化。该工具支持将 HubSpot 的 ServiceHub 连接到 CRM 系统,这样您就可以将相应的结果与特定的人关联起来。例如,您可以筛选出满意度较低的客户,并及时提供优质服务,以提高客户保留率。
2. Semantria
Semantria 是一种可以从社交媒体渠道采集帖子、推文和评论的工具。它使用自然语言处理技术对文本进行解析,分析客户的正面和负面态度。通过这种方式,公司可以获取用户对产品或服务的真实看法,并提出更好的想法来改进您的产品和服务。
3.Trackur
Trackur是一个在线声誉管理工具,可以通过关注社交媒体网站来监控舆论。它会抓取大量网页,包括视频、博客、论坛和图片以搜索相关信息。您可以使用它来清理负面搜索引擎结果并建立和管理您的在线声誉。它是在线声誉和数字品牌管理方面的行业先驱。
4. SAS 情绪分析
SAS Sentiment Analysis 是一款非常强大的软件。网页文本分析最难的部分是拼写错误,SAS 可以轻松校对和聚类分析。通过自然语言处理、机器学习和语言规则的结合,SAS 可以帮助您分析最新趋势、最合适的商机,并从所有非结构化文本数据中提取真正有价值的信息。
5.Hootsuit Insight
这个工具可以分析评论、帖子、论坛、新闻网站以及超过50种语言的超过1000万个数据源平台。此外,它还可以对性别和位置进行分类。您可以为特定群体制定战略营销计划。您还可以获取实时数据并调查在线对话。
部分5.database
1.甲骨文
毫无疑问,Oracle 是开源数据库的领导者。功能众多,是企业的最佳选择。它还支持集成到不同平台。在 AWS 中易于设置,使其成为关系数据库的可靠选择。内置信用卡等隐私数据的高安全性技术使其不可替代。
2.PostgreSQL
它是仅次于 Oracle、MySQL 和 Microsoft SQL Server 的第四大流行数据库。由于其绝对可靠的稳定性,它可以处理高负载数据。
3.Airtable
是一款基于云服务器的数据库软件,具有丰富的数据表读取和信息展示功能。它还具有电子表格和内置日历,可轻松跟踪任务。它的入门模板易于使用,模板包括销售线索管理、错误跟踪和试用跟踪。
4. MariaDB
它是一个免费的开源数据库,用于数据存储、插入、修改和检索。此外,Maria 拥有强大的社区支持。社区成员非常活跃,积极分享信息和知识。
5.Improvado
Improvado 是一款专为营销人员设计的工具。它可以通过自动仪表盘和分析报告将所有数据实时整合到一个平台中。 Improvado 最适合希望将所有营销平台的数据整合到一个平台的营销分析领导者。
您可以选择在 Improvado 仪表板中查看数据,也可以将其导出到您选择的数据仓库或可视化工具,例如 Tableau、look ker、Excel 等。公司、机构和大学都喜欢使用改进是因为它为他们节省了数千小时的手动报告和数百万美元的营销预算。
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2021-09-11 16:07
原文链接:
有时,出于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,再次请求一个网页后,查询的结果就显示出来了。
查询后看网页地址:
也就是说,我们只需要访问这种网址就可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、抓取网页的JavaScript返回的结果。
有时,网站为了保护自己的数据,不会直接在网页源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据的爬取通过搜索引擎等工具。 .
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后输入tracking number:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据当然,前提是数据没有加密对,我们写下JS请求的URL:
然后让程序请求这个页面的结果!
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时,出于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,再次请求一个网页后,查询的结果就显示出来了。
查询后看网页地址:
也就是说,我们只需要访问这种网址就可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、抓取网页的JavaScript返回的结果。
有时,网站为了保护自己的数据,不会直接在网页源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据的爬取通过搜索引擎等工具。 .
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后输入tracking number:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据当然,前提是数据没有加密对,我们写下JS请求的URL:
然后让程序请求这个页面的结果!
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-09 15:29
有时由于各种原因,我们需要采集一些网站的数据,但由于网站不同,显示数据的方式略有不同!
本文用Java来告诉你如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页返回的数据。
一、抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml()的结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时候网站为了保护自己的数据,不会直接在网页的源代码中返回数据。而是使用JS异步返回数据,避免搜索引擎等工具响应网站数据的爬行。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript():\n"+contentBuf.toString()的结果);}
看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
有时由于各种原因,我们需要采集一些网站的数据,但由于网站不同,显示数据的方式略有不同!
本文用Java来告诉你如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页返回的数据。
一、抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml()的结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时候网站为了保护自己的数据,不会直接在网页的源代码中返回数据。而是使用JS异步返回数据,避免搜索引擎等工具响应网站数据的爬行。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript():\n"+contentBuf.toString()的结果);}
看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载!
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-09 11:03
原文链接:
有时,出于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,再次请求一个网页后,查询的结果就显示出来了。
查询后看网页地址:
也就是说,我们只需要访问这种网址就可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、抓取网页的JavaScript返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据。而是采用异步方式用JS返回数据,可以避免网站数据被搜索引擎等工具抓取。 .
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后输入tracking number:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据当然,前提是数据没有加密对,我们写下JS请求的URL:
然后让程序请求这个页面的结果!
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时,出于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,再次请求一个网页后,查询的结果就显示出来了。
查询后看网页地址:
也就是说,我们只需要访问这种网址就可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、抓取网页的JavaScript返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据。而是采用异步方式用JS返回数据,可以避免网站数据被搜索引擎等工具抓取。 .
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后输入tracking number:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据当然,前提是数据没有加密对,我们写下JS请求的URL:
然后让程序请求这个页面的结果!
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!

