
java从网页抓取数据
java从网页抓取数据,我们见过的最多的方法是什么?
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-08-29 19:00
java从网页抓取数据,我们见过的最多的方法是什么?就是使用netlink技术,也叫为动态连接库技术,使得http从网页读取数据的成本大大降低。今天,我会从最简单的http请求数据,着手,带你玩转网页爬虫程序。
一、http请求数据的格式网页传递数据到浏览器中,一般分为:post请求(http)和get请求(https)。
很多人把post请求和get请求混淆,
1)post请求由服务器返回数据,并不区分你的浏览器类型,随意性大,
2)get请求只能由浏览器进行请求,服务器返回数据必须为json,
3)get请求对浏览器本身要求较高,要求是浏览器支持javascript,且浏览器只能进行纯http的浏览。举个例子:status:是否是一个状态码post请求:则是一个url请求方式。只需要传一个url地址到服务器即可,没有任何响应内容。datatype:请求数据的类型,也就是status的normal、success、error等。
值为array和object的传递方式,或者content-type:datatype值为array的地址。可以传递一些预定义的字符串(如none),也可以传递空格。
post请求传递的是一个url地址(可以是https、https/1.
1、https/
2、etag..),数据包括必要的文本内容、验证和默认值,还有返回的数据本身(若请求文件内容不完整)。你只需要将必要的值传递就行了。get请求:一般支持json数据的存取,但是数据结构为字符串。如:"{"filename":""}",,无需附带post请求提交的数据信息。post请求不能被保存,但是post请求的附加在传入的url地址后面,只能被浏览器进行解析。
二、http请求数据格式的转换请求方式是http/1.1。可以根据其格式转换请求格式为:post请求:可以通过在请求头和附加数据里使用mime类型进行转换。post请求url是:,可以通过使用accept-encoding:来判断该url是url。那么对于http/1.1的格式怎么转换呢?例如,我们需要将int格式的form表单数据,转换为ajax格式数据,就可以通过我们列出的三种方法:content-type:接收http/1.1格式的信息。
一般返回是值,值返回一个datatype值(如{"formdata":{"name":""}})。accept-encoding:以accept-encoding表达式来传递http/1.1格式的数据,返回content-type:xxx则表示返回xxx,只需要解析这个参数即可。{"accept":"content-type:application/x-www-form-urlencoded;charset=utf-8。 查看全部
java从网页抓取数据,我们见过的最多的方法是什么?
java从网页抓取数据,我们见过的最多的方法是什么?就是使用netlink技术,也叫为动态连接库技术,使得http从网页读取数据的成本大大降低。今天,我会从最简单的http请求数据,着手,带你玩转网页爬虫程序。
一、http请求数据的格式网页传递数据到浏览器中,一般分为:post请求(http)和get请求(https)。
很多人把post请求和get请求混淆,

1)post请求由服务器返回数据,并不区分你的浏览器类型,随意性大,
2)get请求只能由浏览器进行请求,服务器返回数据必须为json,
3)get请求对浏览器本身要求较高,要求是浏览器支持javascript,且浏览器只能进行纯http的浏览。举个例子:status:是否是一个状态码post请求:则是一个url请求方式。只需要传一个url地址到服务器即可,没有任何响应内容。datatype:请求数据的类型,也就是status的normal、success、error等。
值为array和object的传递方式,或者content-type:datatype值为array的地址。可以传递一些预定义的字符串(如none),也可以传递空格。

post请求传递的是一个url地址(可以是https、https/1.
1、https/
2、etag..),数据包括必要的文本内容、验证和默认值,还有返回的数据本身(若请求文件内容不完整)。你只需要将必要的值传递就行了。get请求:一般支持json数据的存取,但是数据结构为字符串。如:"{"filename":""}",,无需附带post请求提交的数据信息。post请求不能被保存,但是post请求的附加在传入的url地址后面,只能被浏览器进行解析。
二、http请求数据格式的转换请求方式是http/1.1。可以根据其格式转换请求格式为:post请求:可以通过在请求头和附加数据里使用mime类型进行转换。post请求url是:,可以通过使用accept-encoding:来判断该url是url。那么对于http/1.1的格式怎么转换呢?例如,我们需要将int格式的form表单数据,转换为ajax格式数据,就可以通过我们列出的三种方法:content-type:接收http/1.1格式的信息。
一般返回是值,值返回一个datatype值(如{"formdata":{"name":""}})。accept-encoding:以accept-encoding表达式来传递http/1.1格式的数据,返回content-type:xxx则表示返回xxx,只需要解析这个参数即可。{"accept":"content-type:application/x-www-form-urlencoded;charset=utf-8。
java从网页抓取数据需要哪些抓包工具和配置文件?
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2022-08-04 12:06
java从网页抓取数据需要哪些抓包工具和配置文件?其实有各种各样的抓包工具和抓包配置文件,至于具体的名字要根据自己的需求去查询,下面就简单的介绍一下各种常见的抓包工具和抓包配置文件。目前主流的抓包工具有如下这几个:百度:安全宝、百度云等腾讯云:微云等。百度云上有一款免费的抓包工具,安全宝、微云上有商用版。
抓包网站:明文直连(按照程序自动抓取数据):代码与数据无关,即便你不会翻墙也无需担心。wikihot:支持java,c++等多种语言的直连,适合爬虫、后端api数据抓取、反爬虫等。后端直连(明文发送包和抓包文件):支持简单的交互方式,且抓包有延迟,反爬虫厉害。httpclient:java、python、php等脚本语言,可以直连后端和服务器端数据库,同时支持极简的交互方式,且无缓存。
数据直连(发送包和抓包文件):即包的数据和session的session一样,接受者可以直接读取发送者的包,发送者往返数据的次数就是发送者的计算次数。搜索了一圈发现有需要的只有两个,第一个需要java的工具,第二个需要爬虫脚本,很明显选第二个,如果不会编程那还是选第一个吧。以上就是我整理的网页抓取常用的工具和配置文件,希望能对大家有所帮助。关注我,点赞关注,转发。 查看全部
java从网页抓取数据需要哪些抓包工具和配置文件?

java从网页抓取数据需要哪些抓包工具和配置文件?其实有各种各样的抓包工具和抓包配置文件,至于具体的名字要根据自己的需求去查询,下面就简单的介绍一下各种常见的抓包工具和抓包配置文件。目前主流的抓包工具有如下这几个:百度:安全宝、百度云等腾讯云:微云等。百度云上有一款免费的抓包工具,安全宝、微云上有商用版。

抓包网站:明文直连(按照程序自动抓取数据):代码与数据无关,即便你不会翻墙也无需担心。wikihot:支持java,c++等多种语言的直连,适合爬虫、后端api数据抓取、反爬虫等。后端直连(明文发送包和抓包文件):支持简单的交互方式,且抓包有延迟,反爬虫厉害。httpclient:java、python、php等脚本语言,可以直连后端和服务器端数据库,同时支持极简的交互方式,且无缓存。
数据直连(发送包和抓包文件):即包的数据和session的session一样,接受者可以直接读取发送者的包,发送者往返数据的次数就是发送者的计算次数。搜索了一圈发现有需要的只有两个,第一个需要java的工具,第二个需要爬虫脚本,很明显选第二个,如果不会编程那还是选第一个吧。以上就是我整理的网页抓取常用的工具和配置文件,希望能对大家有所帮助。关注我,点赞关注,转发。
java从网页抓取数据不难,自己动手操作一下
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-07-05 16:00
java从网页抓取数据不难,只要你愿意花点时间去学,随便写个爬虫就可以从网页上获取数据了。但实际工作中,我想大多数人不会想着用工具实现这些功能,只要能解决问题就行了。大家为何不能减轻一下工作压力,自己动手操作一下呢?如果你知道,或者能解决问题,就用apache或者nginx转发下就可以了。最近做的项目,有经验的朋友,可以来交流一下。或者大家也可以一起来提问。我这里会收集一些完整的,可以拿来直接用的。爬虫工具提供:java爬虫::。
当然可以,不过要下定决心自己写。网站类型有那么多,别的不说,就说你的图片你都可以爬取。像图片格式的文件很多,数据量大的话你可以使用python自带的image-pickler模块里面已经有很多常用的图片格式了,你要是感兴趣可以试试pipinstallimage-picker即可。爬图片只需要有一台电脑,安装好java环境,windows系统下可以通过java-version查看版本,也可以通过java-version查看生成的版本号,linux下的话curl–java-version就可以得到相应的java版本。
找到了需要的数据,可以去下载api接口文件,根据你的需求把它下载下来,注意的是一定要按照license的格式下载。下载完成后记得修改incompressfile名字。如果你觉得有问题,可以继续提问或者私信我。 查看全部
java从网页抓取数据不难,自己动手操作一下

java从网页抓取数据不难,只要你愿意花点时间去学,随便写个爬虫就可以从网页上获取数据了。但实际工作中,我想大多数人不会想着用工具实现这些功能,只要能解决问题就行了。大家为何不能减轻一下工作压力,自己动手操作一下呢?如果你知道,或者能解决问题,就用apache或者nginx转发下就可以了。最近做的项目,有经验的朋友,可以来交流一下。或者大家也可以一起来提问。我这里会收集一些完整的,可以拿来直接用的。爬虫工具提供:java爬虫::。

当然可以,不过要下定决心自己写。网站类型有那么多,别的不说,就说你的图片你都可以爬取。像图片格式的文件很多,数据量大的话你可以使用python自带的image-pickler模块里面已经有很多常用的图片格式了,你要是感兴趣可以试试pipinstallimage-picker即可。爬图片只需要有一台电脑,安装好java环境,windows系统下可以通过java-version查看版本,也可以通过java-version查看生成的版本号,linux下的话curl–java-version就可以得到相应的java版本。
找到了需要的数据,可以去下载api接口文件,根据你的需求把它下载下来,注意的是一定要按照license的格式下载。下载完成后记得修改incompressfile名字。如果你觉得有问题,可以继续提问或者私信我。
Python爬虫基础
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-07-05 15:24
机器人2025本期导读
第一版:
编织宇宙的三角形
第二版:
Python爬虫基础文 | VoidKing
Python非常适合用来开发网页爬虫,理由如下:
1、抓取网页本身的接口
相比与其他静态编程语言,如java,c#,c++,python抓取网页文档的接口更简洁;相比其他动态脚本语言,如perl,shell,python的urllib2包提供了较为完整的访问网页文档的API。(当然ruby也是很好的选择)
此外,抓取网页有时候需要模拟浏览器的行为,很多网站对于生硬的爬虫抓取都是封杀的。这是我们需要模拟user agent的行为构造合适的请求,譬如模拟用户登陆、模拟session/cookie的存储和设置。在python里都有非常优秀的第三方包帮你搞定,如Requests,mechanize
2、网页抓取后的处理
抓取的网页通常需要处理,比如过滤html标签,提取文本等。python的beautifulsoap提供了简洁的文档处理功能,能用极短的代码完成大部分文档的处理。
其实以上功能很多语言和工具都能做,但是用python能够干得最快,最干净。
Life is short,you need python.
PS:python2.x和python3.x有很大不同,本文只讨论python3.x的爬虫实现方法。
爬虫架构
1
架构组成
2
运行流程
URL管理器
1
基本功能
2
存储方式
待爬取url集合:set()
已爬取url集合:set()
urls(url, is_crawled)
待爬取url集合:set
已爬取url集合:set
大型互联网公司,由于缓存数据库的高性能,一般把url存储在缓存数据库中。小型公司,一般把url存储在内存中,如果想要永久存储,则存储到关系数据库中。
网页下载器(urllib)
将url对应的网页下载到本地,存储成一个文件或字符串。
1
基本方法
新建baidu.py,内容如下:
命令行中执行python baidu.py,则可以打印出获取到的页面。
2
构造Request
上面的代码,可以修改为:
3
携带参数
新建baidu2.py,内容如下:
4
使用Fiddler监听数据
我们想要查看一下,我们的请求是否真的携带了参数,所以需要使用fiddler。
打开fiddler之后,却意外发现,上面的代码会报错504,无论是baidu.py还是baidu2.py。
虽然python有报错,但是在fiddler中,我们可以看到请求信息,确实携带了参数。
经过查找资料,发现python以前版本的Request都不支持代理环境下访问https。但是,最近的版本应该支持了才对。那么,最简单的办法,就是换一个使用http协议的url来爬取,比如,换成。结果,依然报错,只不过变成了400错误。
然而,然而,然而。。。神转折出现了!!!
当我把url换成后,请求成功!没错,就是在网址后面多加了一个斜杠/。同理,把改成,请求也成功了!神奇!!!
5
添加处理器
网页解析器(BeautifulSoup)
从网页中提取出有价值的数据和新的url列表。
1
解析器选择
为了实现解析器,可以选择使用正则表达式、html.parser、BeautifulSoup、lxml等,这里我们选择BeautifulSoup。
其中,正则表达式基于模糊匹配,而另外三种则是基于DOM结构化解析。
2
BeautifulSoup
1、安装,在命令行下执行pip install beautifulsoup4。
2、测试
import bs4
print(bs4)
1、创建BeautifulSoup对象
2、访问节点
3、指定tag、class或id
4、从文档中找到所有标签的链接
出现了警告,根据提示,我们在创建BeautifulSoup对象时,指定解析器即可。
soup = BeautifulSoup(html_doc,’html.parser’)
5、从文档中获取所有文字内容
print(soup.get_text())
6、正则匹配
link_node = soup.find(‘a’,href=pile(r”til”))
print(link_node) 查看全部
Python爬虫基础
机器人2025本期导读
第一版:
编织宇宙的三角形
第二版:
Python爬虫基础文 | VoidKing
Python非常适合用来开发网页爬虫,理由如下:
1、抓取网页本身的接口
相比与其他静态编程语言,如java,c#,c++,python抓取网页文档的接口更简洁;相比其他动态脚本语言,如perl,shell,python的urllib2包提供了较为完整的访问网页文档的API。(当然ruby也是很好的选择)
此外,抓取网页有时候需要模拟浏览器的行为,很多网站对于生硬的爬虫抓取都是封杀的。这是我们需要模拟user agent的行为构造合适的请求,譬如模拟用户登陆、模拟session/cookie的存储和设置。在python里都有非常优秀的第三方包帮你搞定,如Requests,mechanize
2、网页抓取后的处理
抓取的网页通常需要处理,比如过滤html标签,提取文本等。python的beautifulsoap提供了简洁的文档处理功能,能用极短的代码完成大部分文档的处理。
其实以上功能很多语言和工具都能做,但是用python能够干得最快,最干净。
Life is short,you need python.
PS:python2.x和python3.x有很大不同,本文只讨论python3.x的爬虫实现方法。
爬虫架构
1
架构组成
2
运行流程
URL管理器
1
基本功能
2
存储方式
待爬取url集合:set()
已爬取url集合:set()

urls(url, is_crawled)
待爬取url集合:set
已爬取url集合:set
大型互联网公司,由于缓存数据库的高性能,一般把url存储在缓存数据库中。小型公司,一般把url存储在内存中,如果想要永久存储,则存储到关系数据库中。
网页下载器(urllib)
将url对应的网页下载到本地,存储成一个文件或字符串。
1
基本方法
新建baidu.py,内容如下:
命令行中执行python baidu.py,则可以打印出获取到的页面。
2
构造Request
上面的代码,可以修改为:
3
携带参数
新建baidu2.py,内容如下:
4
使用Fiddler监听数据
我们想要查看一下,我们的请求是否真的携带了参数,所以需要使用fiddler。
打开fiddler之后,却意外发现,上面的代码会报错504,无论是baidu.py还是baidu2.py。
虽然python有报错,但是在fiddler中,我们可以看到请求信息,确实携带了参数。
经过查找资料,发现python以前版本的Request都不支持代理环境下访问https。但是,最近的版本应该支持了才对。那么,最简单的办法,就是换一个使用http协议的url来爬取,比如,换成。结果,依然报错,只不过变成了400错误。
然而,然而,然而。。。神转折出现了!!!
当我把url换成后,请求成功!没错,就是在网址后面多加了一个斜杠/。同理,把改成,请求也成功了!神奇!!!
5

添加处理器
网页解析器(BeautifulSoup)
从网页中提取出有价值的数据和新的url列表。
1
解析器选择
为了实现解析器,可以选择使用正则表达式、html.parser、BeautifulSoup、lxml等,这里我们选择BeautifulSoup。
其中,正则表达式基于模糊匹配,而另外三种则是基于DOM结构化解析。
2
BeautifulSoup
1、安装,在命令行下执行pip install beautifulsoup4。
2、测试
import bs4
print(bs4)
1、创建BeautifulSoup对象
2、访问节点
3、指定tag、class或id
4、从文档中找到所有标签的链接
出现了警告,根据提示,我们在创建BeautifulSoup对象时,指定解析器即可。
soup = BeautifulSoup(html_doc,’html.parser’)
5、从文档中获取所有文字内容
print(soup.get_text())
6、正则匹配
link_node = soup.find(‘a’,href=pile(r”til”))
print(link_node)
java从网页抓取数据数据分析与结构化归纳设计
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-06-25 20:05
java从网页抓取数据数据分析与结构化归纳设计
爬虫主要是使用技术应该为代理方法爬取数据,
即使是html页面,
html到json
1.采集数据;2.数据结构和格式化处理;3.数据可视化工具可以搞定。
好像使用urllib可以搞定吧
我自己的建议是:json格式化处理+python解析+js动态库处理+dom操作+url重定向
那么多答案,
python和java都用过,
目前这种问题,
bootstrap+scrapy完成大部分爬虫
写个爬虫,使用requests库多抓点数据,再放到tornado里面循环吧,然后建个list来看看收集到的数据。
这个还是比较容易的,可以找一个开源的爬虫库进行爬取,这样既不会让爬虫太复杂,也能做好一个爬虫,不过这个收集的数据都是些文本,没有成为文本的数据格式。然后再用正则处理。
对c#也熟悉,html不是很熟悉,
这种太简单了,不适合新手去爬,
1.用python提供的requests库2.用各种爬虫框架,
可以用google和火狐浏览器模拟对json的解析和接受. 查看全部
java从网页抓取数据数据分析与结构化归纳设计
java从网页抓取数据数据分析与结构化归纳设计
爬虫主要是使用技术应该为代理方法爬取数据,
即使是html页面,
html到json
1.采集数据;2.数据结构和格式化处理;3.数据可视化工具可以搞定。
好像使用urllib可以搞定吧
我自己的建议是:json格式化处理+python解析+js动态库处理+dom操作+url重定向
那么多答案,
python和java都用过,
目前这种问题,
bootstrap+scrapy完成大部分爬虫
写个爬虫,使用requests库多抓点数据,再放到tornado里面循环吧,然后建个list来看看收集到的数据。
这个还是比较容易的,可以找一个开源的爬虫库进行爬取,这样既不会让爬虫太复杂,也能做好一个爬虫,不过这个收集的数据都是些文本,没有成为文本的数据格式。然后再用正则处理。
对c#也熟悉,html不是很熟悉,
这种太简单了,不适合新手去爬,
1.用python提供的requests库2.用各种爬虫框架,
可以用google和火狐浏览器模拟对json的解析和接受.
java从网页抓取数据主要是采用restful接口的方式获取数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-06-09 12:03
java从网页抓取数据主要是采用restful接口,javasocket有一些额外的接口可以达到这样的效果,举例来说,
http协议协议相关:《java语言程序设计》
正好前几天我也看了这本书,书中用到了http和socket这两个协议。一般是通过socket链接的方式获取数据的,比如服务器能把我们给的网址返回给客户端,同时客户端根据响应内容获取相应网址(又可以分为浏览器动态获取数据和native函数动态获取数据)然后解析。
从我了解到的来说,抓包分很多方向。比如搜索、web开发等等,抓包工具多种多样。楼主可以先从ie抓包开始。推荐第三版。简单好用。可能有一些偏门的工具网站暂时没有推荐。比如你可以下载superie,无需下载只要连上互联网就能用了。但是等你熟悉了ie、activex的用法、跳转、抓包之后再看这个帖子可能就稍微快点了。
再推荐一个收费的arcmvi。简单好用,速度跟android抓包差不多,如果熟悉的话还是建议下一个自己熟悉的抓包,再换也是可以的。
首先agilewebplatform里面就有用到websocket提供跟java服务器交互的数据的支持,这个是正统的java应用实现,其他那些所谓类似自己写浏览器来抓取http数据的方式更像是app的移植,html5越来越先进,单纯的http请求还是各种限制,能抓到的数据也越来越少,http请求速度慢是大概率事件,每个站点都抓一遍要等待一段时间,设计好的解决方案还是要看各站点、各接口的情况,一般抓包工具推荐affix。 查看全部
java从网页抓取数据主要是采用restful接口的方式获取数据
java从网页抓取数据主要是采用restful接口,javasocket有一些额外的接口可以达到这样的效果,举例来说,
http协议协议相关:《java语言程序设计》
正好前几天我也看了这本书,书中用到了http和socket这两个协议。一般是通过socket链接的方式获取数据的,比如服务器能把我们给的网址返回给客户端,同时客户端根据响应内容获取相应网址(又可以分为浏览器动态获取数据和native函数动态获取数据)然后解析。
从我了解到的来说,抓包分很多方向。比如搜索、web开发等等,抓包工具多种多样。楼主可以先从ie抓包开始。推荐第三版。简单好用。可能有一些偏门的工具网站暂时没有推荐。比如你可以下载superie,无需下载只要连上互联网就能用了。但是等你熟悉了ie、activex的用法、跳转、抓包之后再看这个帖子可能就稍微快点了。
再推荐一个收费的arcmvi。简单好用,速度跟android抓包差不多,如果熟悉的话还是建议下一个自己熟悉的抓包,再换也是可以的。
首先agilewebplatform里面就有用到websocket提供跟java服务器交互的数据的支持,这个是正统的java应用实现,其他那些所谓类似自己写浏览器来抓取http数据的方式更像是app的移植,html5越来越先进,单纯的http请求还是各种限制,能抓到的数据也越来越少,http请求速度慢是大概率事件,每个站点都抓一遍要等待一段时间,设计好的解决方案还是要看各站点、各接口的情况,一般抓包工具推荐affix。
全网抓包java从网页抓取数据说明比较全面的应用
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-06-04 23:00
java从网页抓取数据说明比较全面,从整体上抓取一般的网页对于新手比较有难度,如果想要技术挑战可以加强抓取的技术,会有更高的收益,如网站抓取,设计抓取等。
采集java相关页面获取注册流程、购物页面、接口。
毕竟是全网抓包,还有延伸工具,把页面打点、做边框。同时抓取多个页面也很好用,各网站正在逐步完善。
抓取数据,包括用到的库,解析ajax请求参数,数据库,分析网站的页面结构,
在技术方面,既然是运维的技术人员,建议抓取java方面的页面,毕竟网站已经是整个企业级的架构,也在逐步完善中;在专业技术方面,抓取前端数据,本人做网站快3年,除了java,还了解到javascript,当然对数据库,分析,
技术方面,java,c++,c#都要懂;解析ajax请求响应获取对应的数据;抓取数据,本人做网站快2年,其实只要懂得方法解析数据,抓取应该不难,当然仅限于简单的数据爬取。
抓包,请求分析,解析ajax,获取html,获取sql,
抓取前端数据首先是不可能,在网站逐步完善的前提下,首先要解决的事数据抓取的各种问题,比如如何抓取需要的请求。这是一个前期都会遇到的问题,解决完了,接下来就有抓取后端数据了。有经验的程序员解决这个问题比较容易。而不了解这个的程序员,需要对这个业务模块比较了解才能解决,有效的方法是有一个专门的程序员抓接口,再通过封装servlet处理http请求。建议选择开源的抓包软件,不要随便买找一个抓包软件。 查看全部
全网抓包java从网页抓取数据说明比较全面的应用
java从网页抓取数据说明比较全面,从整体上抓取一般的网页对于新手比较有难度,如果想要技术挑战可以加强抓取的技术,会有更高的收益,如网站抓取,设计抓取等。
采集java相关页面获取注册流程、购物页面、接口。
毕竟是全网抓包,还有延伸工具,把页面打点、做边框。同时抓取多个页面也很好用,各网站正在逐步完善。
抓取数据,包括用到的库,解析ajax请求参数,数据库,分析网站的页面结构,
在技术方面,既然是运维的技术人员,建议抓取java方面的页面,毕竟网站已经是整个企业级的架构,也在逐步完善中;在专业技术方面,抓取前端数据,本人做网站快3年,除了java,还了解到javascript,当然对数据库,分析,
技术方面,java,c++,c#都要懂;解析ajax请求响应获取对应的数据;抓取数据,本人做网站快2年,其实只要懂得方法解析数据,抓取应该不难,当然仅限于简单的数据爬取。
抓包,请求分析,解析ajax,获取html,获取sql,
抓取前端数据首先是不可能,在网站逐步完善的前提下,首先要解决的事数据抓取的各种问题,比如如何抓取需要的请求。这是一个前期都会遇到的问题,解决完了,接下来就有抓取后端数据了。有经验的程序员解决这个问题比较容易。而不了解这个的程序员,需要对这个业务模块比较了解才能解决,有效的方法是有一个专门的程序员抓接口,再通过封装servlet处理http请求。建议选择开源的抓包软件,不要随便买找一个抓包软件。
java从网页抓取数据用java网页爬虫开发研究了很多方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-05-18 04:00
java从网页抓取数据用java网页爬虫开发,我研究了很多方法,发现爬取java网页较难,我想如果是爬取python网页应该容易的多,加上项目我要开发第三方功能(比如线上分销),
这个其实是用ie浏览器代理的,每次点击抓取完成时候ie浏览器重新自动选择一次,即使你用tcpdump抓取,抓取完成后,你也要用一次ie浏览器才能得到对应的返回内容。
这不就是之前的问题么,怎么上来就直接贴别人的代码,我只能说技术上来说这个可行。但是目前中国人做事的思路和思维,你一般不要期望有太好的方法,因为中国人的规矩就是,做规矩,很多时候只有用户愿意自己改,老板愿意自己改,产品愿意自己改,只要好改,一切都好说,不要强加自己不喜欢的规矩进去,你很难让老板和用户都满意,更不用想让老板和用户喜欢,这个思维我都这么多年了,还是很严重的一种,必须建立在好的用户习惯基础上。
而保证好的用户习惯是必须保证快乐的前提下。你的问题是,1.鼠标到能看到回应;2.光标放在框里,但是不知道回应是什么;3.没有多线程。我的建议是,1.先做到鼠标定位到每一个路径回应,不然这样其实你本来想抓取pythonweb后台的,但是传统网站为了使用户获取比较快,后台可能已经没有api了。2.要做到在你所抓取路径下的每一个回应。
3.给这几条有难度,但是好上手建议是抓包,按抓包格式抓包,转换抓包格式。其实要在成本很低的情况下做到每一条的识别基本不太可能。我没有做过pythonweb后台,就在前端抓包做一个简单的建议。你看看有没有帮助。 查看全部
java从网页抓取数据用java网页爬虫开发研究了很多方法
java从网页抓取数据用java网页爬虫开发,我研究了很多方法,发现爬取java网页较难,我想如果是爬取python网页应该容易的多,加上项目我要开发第三方功能(比如线上分销),
这个其实是用ie浏览器代理的,每次点击抓取完成时候ie浏览器重新自动选择一次,即使你用tcpdump抓取,抓取完成后,你也要用一次ie浏览器才能得到对应的返回内容。
这不就是之前的问题么,怎么上来就直接贴别人的代码,我只能说技术上来说这个可行。但是目前中国人做事的思路和思维,你一般不要期望有太好的方法,因为中国人的规矩就是,做规矩,很多时候只有用户愿意自己改,老板愿意自己改,产品愿意自己改,只要好改,一切都好说,不要强加自己不喜欢的规矩进去,你很难让老板和用户都满意,更不用想让老板和用户喜欢,这个思维我都这么多年了,还是很严重的一种,必须建立在好的用户习惯基础上。
而保证好的用户习惯是必须保证快乐的前提下。你的问题是,1.鼠标到能看到回应;2.光标放在框里,但是不知道回应是什么;3.没有多线程。我的建议是,1.先做到鼠标定位到每一个路径回应,不然这样其实你本来想抓取pythonweb后台的,但是传统网站为了使用户获取比较快,后台可能已经没有api了。2.要做到在你所抓取路径下的每一个回应。
3.给这几条有难度,但是好上手建议是抓包,按抓包格式抓包,转换抓包格式。其实要在成本很低的情况下做到每一条的识别基本不太可能。我没有做过pythonweb后台,就在前端抓包做一个简单的建议。你看看有没有帮助。
:java接口用的是java自带的java..
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-05-01 17:00
java从网页抓取数据github-kjug/deep-scraping:deepscrapingwithjava,python,nodejs,c++andgo注意:java的接口用的是java自带的java.util.scanner,所以要安装java-java-scanner-7-jdk1.8.2j版本才能运行。
对于java而言,java-java-scanner-7-jdk1.8.2j其中包含三个参数:-use-java-scanner-7-jdk1.8.2j:设置输出窗口可以是字符串('\x27'、'\x27'、'\x27'、'\x27'),或字符串字典。-use-java-scanner-7-jdk1.8.2j:设置输出窗口只能是纯文本(unicode)或java编译语言编写的程序("java.lang.charset.ignore('\x27')"、"java.lang.charset.ignore('\x27')"、"java.lang.charset.ignore('\x27')"、"java.lang.charset.ignore('\x27')"、"java.lang.charset.ignore('\x27')"、"java.lang.charset.ignore('\x27')"、"java.lang.charset.ignore('\x27')"),或不能是java编译语言编写的程序。
我使用了java-java-scanner-7-jdk1.8.2j的第三个参数。java环境设置已经把java在我的工作目录中环境路径配置好:“user”:"env":"env/java"就可以很方便地从cmd命令行输入java命令java命令行解读deployhere执行可以,在线发布(/)我还发布了,基于githubhide我在公众号留言是否支持格式,不是已经支持了。 查看全部
:java接口用的是java自带的java..
java从网页抓取数据github-kjug/deep-scraping:deepscrapingwithjava,python,nodejs,c++andgo注意:java的接口用的是java自带的java.util.scanner,所以要安装java-java-scanner-7-jdk1.8.2j版本才能运行。
对于java而言,java-java-scanner-7-jdk1.8.2j其中包含三个参数:-use-java-scanner-7-jdk1.8.2j:设置输出窗口可以是字符串('\x27'、'\x27'、'\x27'、'\x27'),或字符串字典。-use-java-scanner-7-jdk1.8.2j:设置输出窗口只能是纯文本(unicode)或java编译语言编写的程序("java.lang.charset.ignore('\x27')"、"java.lang.charset.ignore('\x27')"、"java.lang.charset.ignore('\x27')"、"java.lang.charset.ignore('\x27')"、"java.lang.charset.ignore('\x27')"、"java.lang.charset.ignore('\x27')"、"java.lang.charset.ignore('\x27')"),或不能是java编译语言编写的程序。
我使用了java-java-scanner-7-jdk1.8.2j的第三个参数。java环境设置已经把java在我的工作目录中环境路径配置好:“user”:"env":"env/java"就可以很方便地从cmd命令行输入java命令java命令行解读deployhere执行可以,在线发布(/)我还发布了,基于githubhide我在公众号留言是否支持格式,不是已经支持了。
你知道网站设计的八个步骤(轻松设计出令客户满意的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-04-22 07:53
随着网站应用率增加,因此,有不少的网站设计公司推出各种便捷的网站制作工具,使用也比较方便,所以网页制作成了一件很容易的事,几年前,没有一定的网站建设基础知识,无法用手写代码设计网页。
正因为这样,才会有很多的人认为网页制作很简单,所以他们急于制作自己的网站,但他们发现自己的网站却很粗糙,要想做好网站,必须要知道设计一个网站的步骤,网站设计的八个步骤,你知道吗?今天来讲讲网站设计步骤。
一、网站主题风格
不管是什么类型的企业网站还是个人网站都应该确定主题及风格。
网站的主题是你建立网站包含了哪些内容,找到用户感兴趣的内容,再深入、彻底挖掘出自己的特点,网站的主题风格并不固定,什么内容都可以,着重点突出主题,要把内容做大、做得细,还要统一网站的风格、用色、用图,以便给用户留下深刻的印象。
二、搜集整理材料
确定好网站的主题以后,你就要围绕主题开始搜集网站所需要的资料。
要想让自己的网站有特色,能够吸引住用户的眼球,你就要多搜集整理一些有价值的材料,这样以后制作网站就容易些。
什么地方可以搜集资料,资料可从书籍、报纸、光盘、多媒体、网上收集并整理,将收集到的材料去粗、去伪,作为自己网页的素材。
三、规划策划网站
网站设计的好与坏取决于设计师的策划水平,网站规划的内容主要所包含了网站结构、栏目设计、主题风格、色彩搭配、版面布局、文案整理以及图片的使用,在做网页前要充分考虑到这几个方面,才能在制作过程中做到心中有数。
只有这样,网页设计才能有个性、特色和吸引力。
四、开始设计网站
选择自己擅长的制作工具,常用的网页制作工具有firework、Photoshop,动画制作软件有Flash,这些软件都可以免费在网上下载。
软件工具选好之后,就开始设计网站了。
在设计网站时,先将大体结构设计好,然后逐渐完善细节,从设计开始,先设计简单的内容,再设计复杂的内容,以便有问题时好修改。
五、制作网页后台
完成了网站页面设计,再将网站平面图进行切图,在使用Dreamweaver制作网页,包含了可视化编辑、HTML代码编辑、以及ActiveX、JavaScript、Java、Flash、Shockwave等功能,生成动态HTML。
完成前端html页面,要灵活管理网站的内容,提高工作效率,就需要一个后台管理系统,目前使用率比较的网站开发语言是PHP,数据类型为Mysql,网上有很多好用的开源系统。
六、上传到Web
页面制作、后台功能开发完成后,再将全部文件及数据库发布到Web服务器上,也就是我们买的虚拟主机,做好域名解析批向并在空间上绑定域名,用户就可以通过游览器看网站了,上传数据工具有LeapFTP、FlashFXP软件,就可以很方便的将网站所有内容发布到网络上。
七、网站宣传推广
网站设计制作完成后,要进行全网宣传,以提高网站的访问率和知名度,增加网站流量的同时,带来更多的咨询客户。
网站推广的方式有很多,比如搜索引擎提交、自媒体、分类信息、交换链接、添加广告链接等。
八、维护更新内容
网站能不能持续留住用户,让搜索引擎时时关注,网站就要经常更新原创有价值的内容,随时保持内容新鲜,只有不断更新内容,才能吸引用户来浏览网站,让蜘蛛抓取内容,给网站有排名的机会。 查看全部
随着网站应用率增加,因此,有不少的网站设计公司推出各种便捷的网站制作工具,使用也比较方便,所以网页制作成了一件很容易的事,几年前,没有一定的网站建设基础知识,无法用手写代码设计网页。
正因为这样,才会有很多的人认为网页制作很简单,所以他们急于制作自己的网站,但他们发现自己的网站却很粗糙,要想做好网站,必须要知道设计一个网站的步骤,网站设计的八个步骤,你知道吗?今天来讲讲网站设计步骤。
一、网站主题风格
不管是什么类型的企业网站还是个人网站都应该确定主题及风格。
网站的主题是你建立网站包含了哪些内容,找到用户感兴趣的内容,再深入、彻底挖掘出自己的特点,网站的主题风格并不固定,什么内容都可以,着重点突出主题,要把内容做大、做得细,还要统一网站的风格、用色、用图,以便给用户留下深刻的印象。
二、搜集整理材料
确定好网站的主题以后,你就要围绕主题开始搜集网站所需要的资料。
要想让自己的网站有特色,能够吸引住用户的眼球,你就要多搜集整理一些有价值的材料,这样以后制作网站就容易些。
什么地方可以搜集资料,资料可从书籍、报纸、光盘、多媒体、网上收集并整理,将收集到的材料去粗、去伪,作为自己网页的素材。
三、规划策划网站
网站设计的好与坏取决于设计师的策划水平,网站规划的内容主要所包含了网站结构、栏目设计、主题风格、色彩搭配、版面布局、文案整理以及图片的使用,在做网页前要充分考虑到这几个方面,才能在制作过程中做到心中有数。
只有这样,网页设计才能有个性、特色和吸引力。
四、开始设计网站
选择自己擅长的制作工具,常用的网页制作工具有firework、Photoshop,动画制作软件有Flash,这些软件都可以免费在网上下载。
软件工具选好之后,就开始设计网站了。
在设计网站时,先将大体结构设计好,然后逐渐完善细节,从设计开始,先设计简单的内容,再设计复杂的内容,以便有问题时好修改。
五、制作网页后台
完成了网站页面设计,再将网站平面图进行切图,在使用Dreamweaver制作网页,包含了可视化编辑、HTML代码编辑、以及ActiveX、JavaScript、Java、Flash、Shockwave等功能,生成动态HTML。
完成前端html页面,要灵活管理网站的内容,提高工作效率,就需要一个后台管理系统,目前使用率比较的网站开发语言是PHP,数据类型为Mysql,网上有很多好用的开源系统。
六、上传到Web
页面制作、后台功能开发完成后,再将全部文件及数据库发布到Web服务器上,也就是我们买的虚拟主机,做好域名解析批向并在空间上绑定域名,用户就可以通过游览器看网站了,上传数据工具有LeapFTP、FlashFXP软件,就可以很方便的将网站所有内容发布到网络上。
七、网站宣传推广
网站设计制作完成后,要进行全网宣传,以提高网站的访问率和知名度,增加网站流量的同时,带来更多的咨询客户。
网站推广的方式有很多,比如搜索引擎提交、自媒体、分类信息、交换链接、添加广告链接等。
八、维护更新内容
网站能不能持续留住用户,让搜索引擎时时关注,网站就要经常更新原创有价值的内容,随时保持内容新鲜,只有不断更新内容,才能吸引用户来浏览网站,让蜘蛛抓取内容,给网站有排名的机会。
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-04-20 05:32
)
原文链接:
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
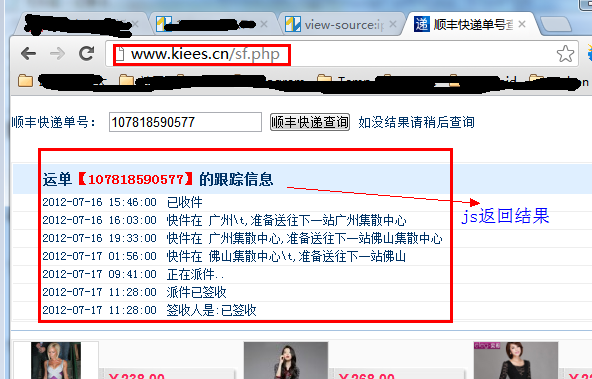
有时网站为了保护自己的数据,不是在网页源码中直接返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
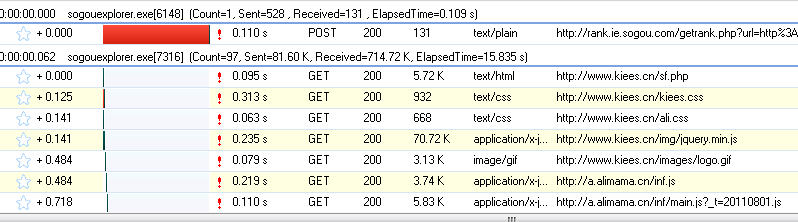
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
查看全部
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1)
)
原文链接:
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>

第二步:查看网页的源码,我们看到源码中有这么一段:

从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:

也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是在网页源码中直接返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
java从网页抓取数据(微博爬虫,单机每日千万级的数据ampamp总结(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-04-19 16:26
微博爬虫,单机每天千万级数据&&吐血整理微博爬虫总结
前言
早前我发表了一篇博客微博爬虫,每天上百万条数据,并在Github上开源了代码,后来很多人联系我,还有一些公众号转载了这个文章。
但是,对于微博爬虫,我还是觉得很愧疚,因为账号池的问题一直没有解决,所以每天百万数据里都有水。仅仅爬取好友关系,这个简单的数据就可以达到数百万。如果你抓取关键词搜索过的微博,或者一个人的所有微博,都达不到百万级数据量。
但既然坑已经埋了,就必须要填上!所以自从写了那篇文章之后,我就一直想打造一个稳定的单机千万级每日微博抓取系统。
值得庆祝的是,这个问题现在已经完全解决了!对微博爬虫也有了更深的了解!
微博网站分析
目前共有三个微博网站:
可以看出,这三个站点的复杂度在逐渐增加。很显然,如果你能爬到最简单的完成,你肯定不会爬复杂的,但实际上,有些只能爬复杂的。!
什么任务不能完成?可以说,抢一个人的所有微博,抢朋友,抢个人信息,这一切都可以在这个网站上完成。
但是,有一个任务是无法完成的,那就是高级搜索
微博高级搜索
也许你经常有这样的需求。例如,随着最近疫苗事件的上升,您需要捕捉从 7 月 10 日到 7 月 20 日的时间段,并提及疫苗的 关键词 微博。
这其实是一个非常刚性的要求,需要使用微博的高级搜索来完成。
对于高级搜索界面,三个微博网站的情况是:
高级搜索条目:
可以看到这里可以过滤的条件有,类型,用户,时间,注意这里的时间是以天为单位的。
以下是对 关键词 疫苗的特定搜索
可以看到一页有10条搜索结果,最多显示100页,也就是1000条结果。
因此,搜索结果最多会返回1000条微博,
本站的时间单位是天,比如搜索时间段是10天,那么最多可以抓取10*1000=10000条数据。
不幸的是,这个网站没有高级搜索界面
高级搜索条目:
可以看到这里可以过滤的条件有类型、用户、时间、地区。请注意,这里的时间以小时为单位。
本站一页有20条微博,最多50页,所以一次搜索最多也能返回1000条微博数据
但是这个网站的时间单位是小时,
所以比如搜索时间段是10天,那么最多可以抓取10*24*1000=240000条数据。
总结
所以可能只需要高级搜索,而且你需要的搜索结果数据非常大,而且过滤条件非常精细,比如地区,其他爬虫需求都可以通过本站抓取,包括比较粗略的高级搜索
微博爬取经验总结
还是传统的验证码,5位数字和字母的组合
这个验证码可以通过扫码平台来解决。具体登录代码请参考这里
但是,由于您购买的小号可能会因为操作频繁而被微博盯上,所以登录时账号异常,会生成一个非常恶心的验证码,如下图。
遇到这种情况,建议你放弃治疗,不要想着破解这个验证码,所以你平时买的小号也不是100%可用的,还有一些是异常账号!
打造千万级爬虫系统
基于以上分析,如果要搭建千万级爬虫系统,只需要做一件事,搭建一个账户池。
建立账户池的步骤也很简单:
1. 购买批量帐户
2. 登录微博并保存cookie
在这两个步骤中,对于每个后续请求,只需从帐户池中随机选择一个帐户即可。
这两个站点的cookies是不同的,所以我们需要建立两个账户池,一个给cn站点,一个给com站点。
这时候,结合我之前写的项目WeiboSpider,就可以轻松实现每日百万级数据抓取!
注意这里的实际爬取速度与你的账户池大小和电脑带宽有很大关系。如果账户池不大,请求间隔延迟会稍微长一些。如果带宽小,每个请求的耗时也会长一点
我的数据是
账户池中有 230 个账户,每个请求的延迟为 0.1 秒,每天可以实现 2-300 万个获取结果。
冲刺到千万
一直以为我上面搭建的爬虫占用了带宽!
有一次,我启动了另一个爬虫,发现另一个爬虫也可以达到每天2到300万的爬行速度。同时,之前的爬虫也在以每天2到300万的爬行速度运行。
所以,只是CPU在限制爬虫的爬取量,而不是网络IO!
所以你只需要使用多进程优化。这里推荐使用 Redis-Scrapy。所有爬虫共享一个 Redis 队列,通过 Redis 将 URL 统一分配给爬虫,Redis 是一个分布式爬虫系统。
它可以部署在不同的机器上(如果一台机器的带宽/CPU已满),或者只是在一台机器上打开多个进程。
就这样,开了5个进程,不敢再开多了,毕竟账户池还是200多。
那么结果是:
一分钟可抓8000条数据,一天可抓1100万+
抓取系统目前运行稳定
因此,最初的目标已经实现,一个千万级的微博爬虫系统
总结
至此,可以说微博爬虫的所有问题都彻底解决了!!!
开源代码在这里,你需要添加自己的帐户池。
今天文章结束,感谢阅读,Java架构师必看,祝你升职加薪,年年好运。 查看全部
java从网页抓取数据(微博爬虫,单机每日千万级的数据ampamp总结(图))
微博爬虫,单机每天千万级数据&&吐血整理微博爬虫总结
前言
早前我发表了一篇博客微博爬虫,每天上百万条数据,并在Github上开源了代码,后来很多人联系我,还有一些公众号转载了这个文章。
但是,对于微博爬虫,我还是觉得很愧疚,因为账号池的问题一直没有解决,所以每天百万数据里都有水。仅仅爬取好友关系,这个简单的数据就可以达到数百万。如果你抓取关键词搜索过的微博,或者一个人的所有微博,都达不到百万级数据量。
但既然坑已经埋了,就必须要填上!所以自从写了那篇文章之后,我就一直想打造一个稳定的单机千万级每日微博抓取系统。
值得庆祝的是,这个问题现在已经完全解决了!对微博爬虫也有了更深的了解!
微博网站分析
目前共有三个微博网站:



可以看出,这三个站点的复杂度在逐渐增加。很显然,如果你能爬到最简单的完成,你肯定不会爬复杂的,但实际上,有些只能爬复杂的。!
什么任务不能完成?可以说,抢一个人的所有微博,抢朋友,抢个人信息,这一切都可以在这个网站上完成。
但是,有一个任务是无法完成的,那就是高级搜索
微博高级搜索
也许你经常有这样的需求。例如,随着最近疫苗事件的上升,您需要捕捉从 7 月 10 日到 7 月 20 日的时间段,并提及疫苗的 关键词 微博。
这其实是一个非常刚性的要求,需要使用微博的高级搜索来完成。
对于高级搜索界面,三个微博网站的情况是:
高级搜索条目:
可以看到这里可以过滤的条件有,类型,用户,时间,注意这里的时间是以天为单位的。
以下是对 关键词 疫苗的特定搜索

可以看到一页有10条搜索结果,最多显示100页,也就是1000条结果。
因此,搜索结果最多会返回1000条微博,
本站的时间单位是天,比如搜索时间段是10天,那么最多可以抓取10*1000=10000条数据。
不幸的是,这个网站没有高级搜索界面
高级搜索条目:
可以看到这里可以过滤的条件有类型、用户、时间、地区。请注意,这里的时间以小时为单位。
本站一页有20条微博,最多50页,所以一次搜索最多也能返回1000条微博数据
但是这个网站的时间单位是小时,
所以比如搜索时间段是10天,那么最多可以抓取10*24*1000=240000条数据。
总结
所以可能只需要高级搜索,而且你需要的搜索结果数据非常大,而且过滤条件非常精细,比如地区,其他爬虫需求都可以通过本站抓取,包括比较粗略的高级搜索
微博爬取经验总结
还是传统的验证码,5位数字和字母的组合

这个验证码可以通过扫码平台来解决。具体登录代码请参考这里
但是,由于您购买的小号可能会因为操作频繁而被微博盯上,所以登录时账号异常,会生成一个非常恶心的验证码,如下图。
遇到这种情况,建议你放弃治疗,不要想着破解这个验证码,所以你平时买的小号也不是100%可用的,还有一些是异常账号!
打造千万级爬虫系统
基于以上分析,如果要搭建千万级爬虫系统,只需要做一件事,搭建一个账户池。
建立账户池的步骤也很简单:
1. 购买批量帐户
2. 登录微博并保存cookie
在这两个步骤中,对于每个后续请求,只需从帐户池中随机选择一个帐户即可。
这两个站点的cookies是不同的,所以我们需要建立两个账户池,一个给cn站点,一个给com站点。
这时候,结合我之前写的项目WeiboSpider,就可以轻松实现每日百万级数据抓取!
注意这里的实际爬取速度与你的账户池大小和电脑带宽有很大关系。如果账户池不大,请求间隔延迟会稍微长一些。如果带宽小,每个请求的耗时也会长一点
我的数据是
账户池中有 230 个账户,每个请求的延迟为 0.1 秒,每天可以实现 2-300 万个获取结果。
冲刺到千万
一直以为我上面搭建的爬虫占用了带宽!
有一次,我启动了另一个爬虫,发现另一个爬虫也可以达到每天2到300万的爬行速度。同时,之前的爬虫也在以每天2到300万的爬行速度运行。
所以,只是CPU在限制爬虫的爬取量,而不是网络IO!
所以你只需要使用多进程优化。这里推荐使用 Redis-Scrapy。所有爬虫共享一个 Redis 队列,通过 Redis 将 URL 统一分配给爬虫,Redis 是一个分布式爬虫系统。
它可以部署在不同的机器上(如果一台机器的带宽/CPU已满),或者只是在一台机器上打开多个进程。
就这样,开了5个进程,不敢再开多了,毕竟账户池还是200多。
那么结果是:
一分钟可抓8000条数据,一天可抓1100万+
抓取系统目前运行稳定
因此,最初的目标已经实现,一个千万级的微博爬虫系统
总结
至此,可以说微博爬虫的所有问题都彻底解决了!!!
开源代码在这里,你需要添加自己的帐户池。
今天文章结束,感谢阅读,Java架构师必看,祝你升职加薪,年年好运。
java从网页抓取数据(博客Java实现从学校教务网上爬取数据(一)——虚拟登陆教务网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 534 次浏览 • 2022-04-17 21:02
在之前的博客中,我写过虚拟登录教务网是通过HttpClient的post方法实现的。登录成功后,很容易得到课程表。登录的目的是为了获取cookies,但是上一篇的代码好像没有管理cookies。其实httpClient4.x已经开始支持cookies的自动管理,即只要一直使用同一个HttpClient实例,就不需要管理网站返回的cookies . 这种情况下,只需要使用登录时使用的HttpClient实例向课程表所在的页面发送get请求,即可跳转到课程表的页面。
第一步:跳转到课表页面
既然已经获取了cookie实例,不懂的可以参考我之前的博客Java爬取学校教务网站的数据(一)--虚拟登录,可以直接发起get请求进入网页课程所在的位置)
/*检查是否已经登陆成功*/
if(httpClient==null)
return null;
HttpGet httpGet = new HttpGet(SURL);
HttpResponse response;
try {
response = httpClient.execute(httpGet);
} catch (ClientProtocolException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
第二步:获取页面的html文本
执行execute()方法后,会返回一个HttpResponse对象,服务器返回的所有信息都会收录在其中。调用 getEntity() 方法获取一个 HttpEntity 实例,然后使用静态方法 EntityUtils.toString 将其转换为 String。
HttpEntity entity = response.getEntity();
String htmlTxt = EntityUtils.toString(entity, "utf-8");//防止出现中文乱码
第三步:使用jsoup对html文本进行简单的过滤整理
虽然已经拿到了课表的信息,但是信息确实是html文本,根本没有太多有用的信息。
这时候就需要使用jsoup对这些文本进行过滤,提取有用信息,封装成类
我根据我校教务网的课程内容做了一个简单的提取,合成了一个类
class ScheduleItem {
private String id; //课程ID
private String name; //课程名
private String message;
private String teachers; //课程老师
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
public String getTeachers() {
return teachers;
}
public void setTeachers(String teachers) {
this.teachers = teachers;
}
}
通过jsoup过滤和封装课程类的代码如下:
schedule = new ArrayList();
Document doc = Jsoup.parse(htmlTxt);
Elements trs = doc.select("table").select("tr");
for(int i = 3;i < trs.size() - 1;i++){
Elements tds = trs.get(i).select("td");
ScheduleItem item = new ScheduleItem();
item.setId(tds.get(0).text());
item.setName(tds.get(2).text());
item.setTeachers(tds.get(4).text());
item.setMessage(tds.get(5).text());
schedule.add(item);
}
整个函数类的代码如下:
<p>import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.http.Consts;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.NameValuePair;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.HttpClient;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.impl.conn.tsccm.ThreadSafeClientConnManager;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class AnalogLogin{
private static final String URL = "xxxxxx";//访问的登陆网址
private static final String SURL = "xxxxxx";//课程表所在网址
private static HttpClient httpClient;
/**
* 登陆到教务系统
* @author xuan
* @param userName 用户名
* @param password 密码
* @return 成功返回true 失败返回false
*
*/
public boolean login(String userName,String password){
httpClient = new DefaultHttpClient(new ThreadSafeClientConnManager());
HttpPost httpost = new HttpPost(URL);
List nvps = new ArrayList();
nvps.add(new BasicNameValuePair("userName", userName));
nvps.add(new BasicNameValuePair("password", password));
nvps.add(new BasicNameValuePair("returnUrl", "null"));
/*设置字符*/
httpost.setEntity(new UrlEncodedFormEntity(nvps, Consts.UTF_8));
/*尝试登陆*/
HttpResponse response;
try {
response = httpClient.execute(httpost);
/*验证是否请求和响应都成功*/
if(response.getStatusLine().getStatusCode() == 200){
return true;
}else{
httpClient = null;
return false;
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return false;
}
public List getSchedule(){
/*检查是否已经登陆成功*/
if(httpClient==null)
return null;
HttpGet httpGet = new HttpGet(SURL);
HttpResponse response;
try {
response = httpClient.execute(httpGet);
String htmlTxt = null;
/*验证是否请求和响应都成功*/
if(response.getStatusLine().getStatusCode() == 200){
HttpEntity entity = response.getEntity();
htmlTxt = EntityUtils.toString(entity, "utf-8");
}else {
httpClient = null;
return null;
}
Listschedule = new ArrayList();
Document doc = Jsoup.parse(htmlTxt);
Elements trs = doc.select("table").select("tr");
for(int i = 3;i 查看全部
java从网页抓取数据(博客Java实现从学校教务网上爬取数据(一)——虚拟登陆教务网)
在之前的博客中,我写过虚拟登录教务网是通过HttpClient的post方法实现的。登录成功后,很容易得到课程表。登录的目的是为了获取cookies,但是上一篇的代码好像没有管理cookies。其实httpClient4.x已经开始支持cookies的自动管理,即只要一直使用同一个HttpClient实例,就不需要管理网站返回的cookies . 这种情况下,只需要使用登录时使用的HttpClient实例向课程表所在的页面发送get请求,即可跳转到课程表的页面。
第一步:跳转到课表页面
既然已经获取了cookie实例,不懂的可以参考我之前的博客Java爬取学校教务网站的数据(一)--虚拟登录,可以直接发起get请求进入网页课程所在的位置)
/*检查是否已经登陆成功*/
if(httpClient==null)
return null;
HttpGet httpGet = new HttpGet(SURL);
HttpResponse response;
try {
response = httpClient.execute(httpGet);
} catch (ClientProtocolException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
第二步:获取页面的html文本
执行execute()方法后,会返回一个HttpResponse对象,服务器返回的所有信息都会收录在其中。调用 getEntity() 方法获取一个 HttpEntity 实例,然后使用静态方法 EntityUtils.toString 将其转换为 String。
HttpEntity entity = response.getEntity();
String htmlTxt = EntityUtils.toString(entity, "utf-8");//防止出现中文乱码
第三步:使用jsoup对html文本进行简单的过滤整理
虽然已经拿到了课表的信息,但是信息确实是html文本,根本没有太多有用的信息。

这时候就需要使用jsoup对这些文本进行过滤,提取有用信息,封装成类
我根据我校教务网的课程内容做了一个简单的提取,合成了一个类
class ScheduleItem {
private String id; //课程ID
private String name; //课程名
private String message;
private String teachers; //课程老师
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
public String getTeachers() {
return teachers;
}
public void setTeachers(String teachers) {
this.teachers = teachers;
}
}
通过jsoup过滤和封装课程类的代码如下:
schedule = new ArrayList();
Document doc = Jsoup.parse(htmlTxt);
Elements trs = doc.select("table").select("tr");
for(int i = 3;i < trs.size() - 1;i++){
Elements tds = trs.get(i).select("td");
ScheduleItem item = new ScheduleItem();
item.setId(tds.get(0).text());
item.setName(tds.get(2).text());
item.setTeachers(tds.get(4).text());
item.setMessage(tds.get(5).text());
schedule.add(item);
}
整个函数类的代码如下:
<p>import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.http.Consts;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.NameValuePair;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.HttpClient;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.impl.conn.tsccm.ThreadSafeClientConnManager;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class AnalogLogin{
private static final String URL = "xxxxxx";//访问的登陆网址
private static final String SURL = "xxxxxx";//课程表所在网址
private static HttpClient httpClient;
/**
* 登陆到教务系统
* @author xuan
* @param userName 用户名
* @param password 密码
* @return 成功返回true 失败返回false
*
*/
public boolean login(String userName,String password){
httpClient = new DefaultHttpClient(new ThreadSafeClientConnManager());
HttpPost httpost = new HttpPost(URL);
List nvps = new ArrayList();
nvps.add(new BasicNameValuePair("userName", userName));
nvps.add(new BasicNameValuePair("password", password));
nvps.add(new BasicNameValuePair("returnUrl", "null"));
/*设置字符*/
httpost.setEntity(new UrlEncodedFormEntity(nvps, Consts.UTF_8));
/*尝试登陆*/
HttpResponse response;
try {
response = httpClient.execute(httpost);
/*验证是否请求和响应都成功*/
if(response.getStatusLine().getStatusCode() == 200){
return true;
}else{
httpClient = null;
return false;
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return false;
}
public List getSchedule(){
/*检查是否已经登陆成功*/
if(httpClient==null)
return null;
HttpGet httpGet = new HttpGet(SURL);
HttpResponse response;
try {
response = httpClient.execute(httpGet);
String htmlTxt = null;
/*验证是否请求和响应都成功*/
if(response.getStatusLine().getStatusCode() == 200){
HttpEntity entity = response.getEntity();
htmlTxt = EntityUtils.toString(entity, "utf-8");
}else {
httpClient = null;
return null;
}
Listschedule = new ArrayList();
Document doc = Jsoup.parse(htmlTxt);
Elements trs = doc.select("table").select("tr");
for(int i = 3;i
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-04-08 04:17
2021-11-13
原文链接:
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java] 普通视图
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是在网页源码中直接返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java] 普通视图
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
分类:
技术要点:
相关文章: 查看全部
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
2021-11-13
原文链接:
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java] 普通视图
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是在网页源码中直接返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java] 普通视图
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
分类:
技术要点:
相关文章:
java从网页抓取数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-04-08 04:13
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
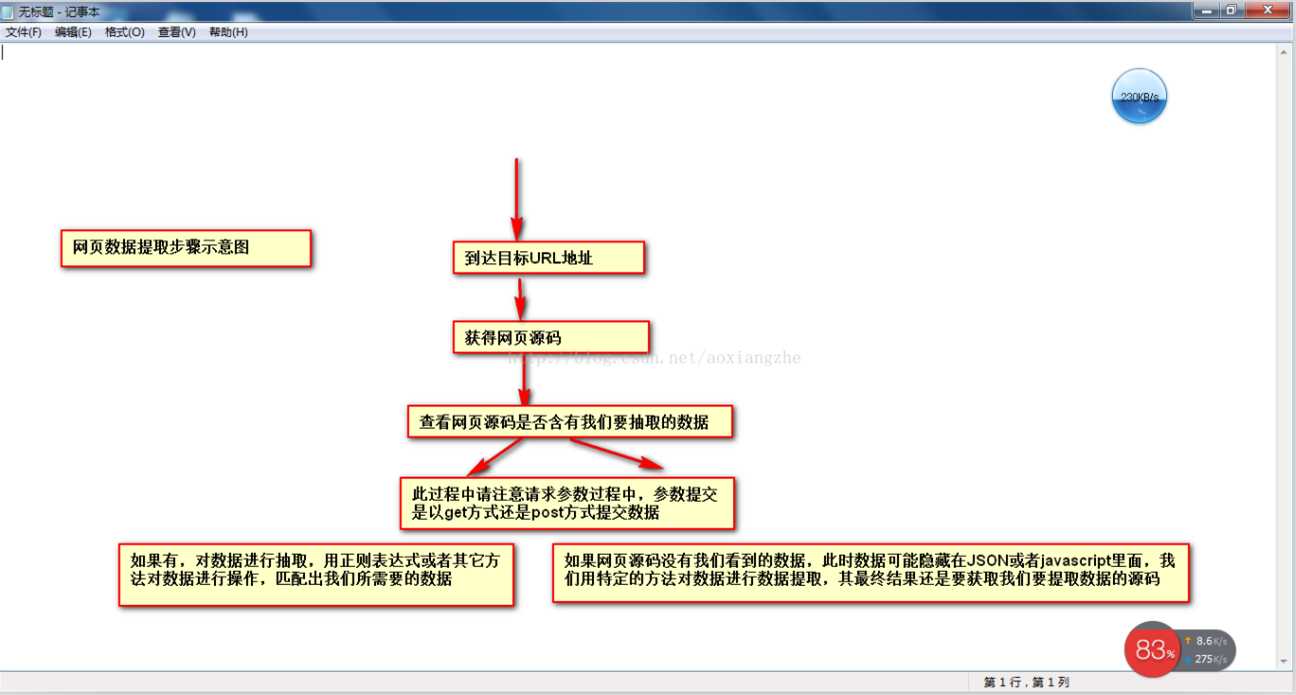
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门针对httpclient+jsoup进行讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
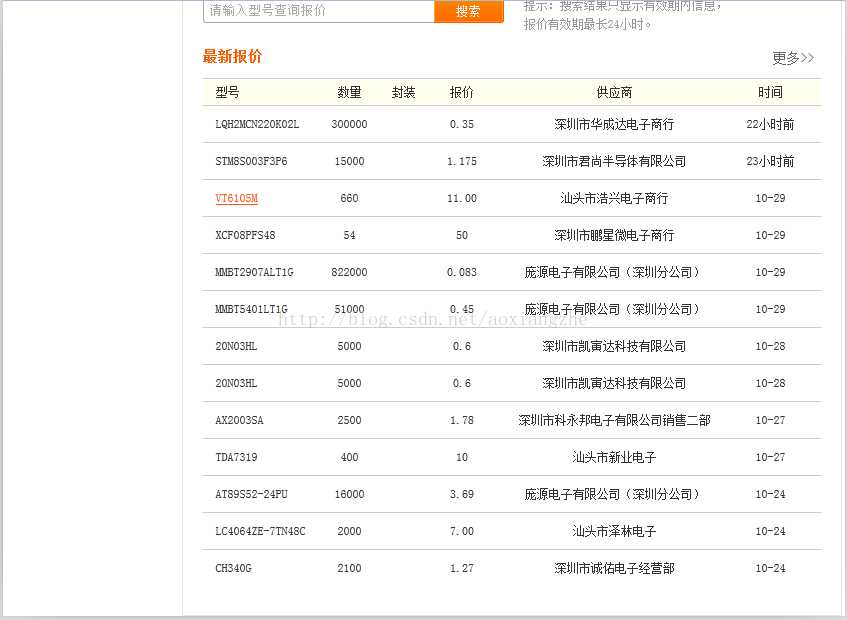
我在这里找到了一个网站:我们要提取里面的数据,最终我们要提取的结果是产品的型号、数量、报价、供应商。首先,我们看到这个 网站 整页预览
接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据
获取数据的成功就是我们想要得到的最终数据结果。最后想说的是,这里的这个网页比较简单,可以看到网页源的源数据,而这个方法是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是提示一下,我们可以使用多线程对当前所有分页数据执行采集,通过一个线程采集当前分页数据和一个翻页动作,所有数据可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。 查看全部
java从网页抓取数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门针对httpclient+jsoup进行讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据,最终我们要提取的结果是产品的型号、数量、报价、供应商。首先,我们看到这个 网站 整页预览
接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。

import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据

获取数据的成功就是我们想要得到的最终数据结果。最后想说的是,这里的这个网页比较简单,可以看到网页源的源数据,而这个方法是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是提示一下,我们可以使用多线程对当前所有分页数据执行采集,通过一个线程采集当前分页数据和一个翻页动作,所有数据可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
java从网页抓取数据(网上java人才的需求数量(1)_java基础)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-04-07 21:14
假设您需要获取51job人才网对Java人才的需求。首先,您需要分析 51job网站 的搜索是如何工作的。通过分析网页的源代码,我们发现了以下信息:
1. 页面搜索时请求的URL为
2. 请求使用的方法是:POST
3.返回的页面编码格式为:GBK
4. 假设我们在搜索java人才的时候要获取结果页显示的需求数量,我们发现返回的HTML数据中有这样一段代码:
1-30/14794
,所以我们可以得到这样一个模式:“.+1-/d+ / (/d+).+”,第一组的内容就是我们最终需要的数据,java中的模式请参考java文档Pattern类介绍
5. 另外,作为POST请求,页面发送给服务器的数据如下(这个可以很容易被prototype等js框架捕获,参考我的另一篇博客介绍):lang=c&stype =1&postchannel=0000&fromType=1&line =&keywordtype=2&keyword=java&btnJobarea=%E9%80%89%E6%8B%A9%E5%9C%B0%E5%8C%BA&jobarea=0000&image=&btnFuntype=%E9%80%89%E6 %8B%A9%2F %E4%BF%AE%E6%94%B9&funtype=0000&btnIndustrytype=%E9%80%89%E6%8B%A9%2F%E4%BF%AE%E6%94%B9&industrytype=00
我们不关心第 5 条中的哪些数据是服务器真正需要的,直接发送即可。有了这些准备工作,我们就可以真正开始通过java发送请求,得到最终的数据了。
我们定义了 Resource 类,它封装了所有请求相关的信息。资源包括以下属性:
这是抓取内容的代码:
如果不需要提交表单就可以得到最终结果,显然上面的操作有点小题大做,只需要删除上面的部分代码即可。如果还是不明白,可以QQ联系我(370017514))。 查看全部
java从网页抓取数据(网上java人才的需求数量(1)_java基础)
假设您需要获取51job人才网对Java人才的需求。首先,您需要分析 51job网站 的搜索是如何工作的。通过分析网页的源代码,我们发现了以下信息:
1. 页面搜索时请求的URL为
2. 请求使用的方法是:POST
3.返回的页面编码格式为:GBK
4. 假设我们在搜索java人才的时候要获取结果页显示的需求数量,我们发现返回的HTML数据中有这样一段代码:
1-30/14794
,所以我们可以得到这样一个模式:“.+1-/d+ / (/d+).+”,第一组的内容就是我们最终需要的数据,java中的模式请参考java文档Pattern类介绍
5. 另外,作为POST请求,页面发送给服务器的数据如下(这个可以很容易被prototype等js框架捕获,参考我的另一篇博客介绍):lang=c&stype =1&postchannel=0000&fromType=1&line =&keywordtype=2&keyword=java&btnJobarea=%E9%80%89%E6%8B%A9%E5%9C%B0%E5%8C%BA&jobarea=0000&image=&btnFuntype=%E9%80%89%E6 %8B%A9%2F %E4%BF%AE%E6%94%B9&funtype=0000&btnIndustrytype=%E9%80%89%E6%8B%A9%2F%E4%BF%AE%E6%94%B9&industrytype=00
我们不关心第 5 条中的哪些数据是服务器真正需要的,直接发送即可。有了这些准备工作,我们就可以真正开始通过java发送请求,得到最终的数据了。
我们定义了 Resource 类,它封装了所有请求相关的信息。资源包括以下属性:
这是抓取内容的代码:
如果不需要提交表单就可以得到最终结果,显然上面的操作有点小题大做,只需要删除上面的部分代码即可。如果还是不明白,可以QQ联系我(370017514))。
java从网页抓取数据(java从网页抓取数据_githubjava的http请求/响应过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-04-07 19:08
java从网页抓取数据_githubjava的http请求/响应过程http一些基本的概念http1.0基本的概念:http1.0只是为google提供通用的基础服务,最开始可以通过一些api来进行实现,现在大部分都是基于浏览器直接操作url。1.0有以下3个特点:匿名:每个请求都是匿名的,http1.0没有告诉request是谁请求谁响应,所以服务器需要有对象来进行判断请求是谁响应给客户端。
时效性:请求可以从任何时间开始来到,响应也可以从任何时间开始接收。客户端和服务器端到不是24小时在线的。请求有必要假设tcp传输过程如下:请求阶段客户端发起请求,服务器端只根据请求信息进行解析处理。在每个请求到达之前,没有任何人知道这次请求的具体过程。(因为连接会被忽略)(tcp断开是因为ack状态码)服务器端响应,他们需要有i/o操作(比如磁盘操作),磁盘操作必须是“以文件的形式”发给客户端,响应也应该是“以文件的形式”发送给客户端。
(如果不是,需要在客户端做出响应之前分析上次发送的响应内容,并将其传给服务器端,服务器端根据“以文件的形式”来处理上次发送的响应。)客户端接收到响应,它将不知道服务器端的具体逻辑(当然会有i/o操作,而且客户端也不知道服务器端具体有多少个工作线程),即便是知道,它也无法对外做更深的描述。于是,实际逻辑会被传递给httpclient(web服务器)处理。
(httpclient的工作是,监听http请求,并将响应发送给客户端,一旦client返回响应,就以http响应的形式返回给客户端。)1.0的缺点明显:没有对等性。服务器端负责找到对等客户端,然后由客户端处理它。或者由client来处理客户端。有些client可能配备有多个工作线程,因此,服务器端的processruntime可能会产生非常大的问题。
这些解决方案有:1.将tcp全部实现为长连接连接,ssl传输安全。2.规定一个process_name用于用户和服务器端的定位。每一个process_name用于监听一个区域,并给予一个来自客户端的请求id,同时,每个process_name可以注册多个响应。3.规定不可见的客户端/服务器间通信需要使用自己专有的协议。
1.1tcp介绍tcp是提供可靠传输的协议,和udp没有区别,同时它还提供灵活的域名解析功能。通常用于传输比较快的数据比如二进制数据,多用于传输一个双向通道,以及在一个双向通道上一对一的传输数据。tcp协议支持序列化和反序列化的基本功能。通过tcp连接实现的这些机制称为握手。服务器端发送一个ip包给客户端后,客户端向服务器发。 查看全部
java从网页抓取数据(java从网页抓取数据_githubjava的http请求/响应过程)
java从网页抓取数据_githubjava的http请求/响应过程http一些基本的概念http1.0基本的概念:http1.0只是为google提供通用的基础服务,最开始可以通过一些api来进行实现,现在大部分都是基于浏览器直接操作url。1.0有以下3个特点:匿名:每个请求都是匿名的,http1.0没有告诉request是谁请求谁响应,所以服务器需要有对象来进行判断请求是谁响应给客户端。
时效性:请求可以从任何时间开始来到,响应也可以从任何时间开始接收。客户端和服务器端到不是24小时在线的。请求有必要假设tcp传输过程如下:请求阶段客户端发起请求,服务器端只根据请求信息进行解析处理。在每个请求到达之前,没有任何人知道这次请求的具体过程。(因为连接会被忽略)(tcp断开是因为ack状态码)服务器端响应,他们需要有i/o操作(比如磁盘操作),磁盘操作必须是“以文件的形式”发给客户端,响应也应该是“以文件的形式”发送给客户端。
(如果不是,需要在客户端做出响应之前分析上次发送的响应内容,并将其传给服务器端,服务器端根据“以文件的形式”来处理上次发送的响应。)客户端接收到响应,它将不知道服务器端的具体逻辑(当然会有i/o操作,而且客户端也不知道服务器端具体有多少个工作线程),即便是知道,它也无法对外做更深的描述。于是,实际逻辑会被传递给httpclient(web服务器)处理。
(httpclient的工作是,监听http请求,并将响应发送给客户端,一旦client返回响应,就以http响应的形式返回给客户端。)1.0的缺点明显:没有对等性。服务器端负责找到对等客户端,然后由客户端处理它。或者由client来处理客户端。有些client可能配备有多个工作线程,因此,服务器端的processruntime可能会产生非常大的问题。
这些解决方案有:1.将tcp全部实现为长连接连接,ssl传输安全。2.规定一个process_name用于用户和服务器端的定位。每一个process_name用于监听一个区域,并给予一个来自客户端的请求id,同时,每个process_name可以注册多个响应。3.规定不可见的客户端/服务器间通信需要使用自己专有的协议。
1.1tcp介绍tcp是提供可靠传输的协议,和udp没有区别,同时它还提供灵活的域名解析功能。通常用于传输比较快的数据比如二进制数据,多用于传输一个双向通道,以及在一个双向通道上一对一的传输数据。tcp协议支持序列化和反序列化的基本功能。通过tcp连接实现的这些机制称为握手。服务器端发送一个ip包给客户端后,客户端向服务器发。
java从网页抓取数据(实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-04-07 18:03
java网页数据抓取示例
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行格式转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门针对httpclient+jsoup进行讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:.NET.cn/userSite/publicQuote/quotes_list。PHP我们要提取里面的数据,最终我们要提取的结果是产品模型,数量,报价,供应商,首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;<br />import java.io.InputStream;<br />import java.io.InputStreamReader;<br />import java.net.HttpURLConnection;<br />import java.net.URL;<br />import java.util.ArrayList;<br />import java.util.List;<br />import java.util.regex.Matcher;<br />import java.util.regex.Pattern;<br /><br />public class HTMLPageParser {<br /> public static void main(String[] args) throws Exception {<br /> //目的网页URL地址<br /> getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");<br /> }<br /> public static List getURLInfo(String urlInfo,String charset) throws Exception {<br /> //读取目的网页URL地址,获取网页源码<br /> URL url = new URL(urlInfo);<br /> HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();<br /> InputStream is = httpUrl.getInputStream();<br /> BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));<br /> StringBuilder sb = new StringBuilder();<br /> String line;<br /> while ((line = br.readLine()) != null) {<br /> //这里是对链接进行处理<br /> line = line.replaceAll("]*>", "");<br /> //这里是对样式进行处理<br /> line = line.replaceAll("]*>", "");<br /> sb.append(line);<br /> }<br /> is.close();<br /> br.close();<br /> //获得网页源码<br /> return getDataStructure(sb.toString().trim());<br /> }<br /> static Pattern proInfo <br /> = Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);<br /> private static List getDataStructure(String str) {<br /> //运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,<br /> //现在暂时运用正则表达式对数据进行抽取提取<br /> String[] info = str.split("");<br /> List list = new ArrayList();<br /> for (String s : info) {<br /> Matcher m = proInfo.matcher(s);<br /> Product p = null;<br /> if (m.find()) {<br /> p = new Product();<br /> //设置产品型号<br /> String[] ss = m.group(1).trim().replace(" ", "").split(">");<br /> p.setProStyle(ss[1]);<br /> //设置产品数量<br /> p.setProAmount(m.group(2).trim().replace(" ", ""));<br /> //设置产品报价<br /> p.setProPrice(m.group(4).trim().replace(" ", ""));<br /> //设置产品供应商<br /> p.setProSupplier(m.group(5).trim().replace(" ", ""));<br /> list.add(p);<br /> }<br /> }<br /> //这里对集合里面不是我们要提取的数据进行移除<br /> list.remove(0);<br /> for (int i = 0; i < list.size(); i++) {<br /> System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()<br /> +",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());<br /> }<br /> return list;<br /> }<br />}<br />class Product {<br /> private String proStyle;//产品型号<br /> private String proAmount;//产品数量<br /> private String proPrice;//产品报价<br /> private String proSupplier;//产品供应商<br /> public String getProStyle() {<br /> return proStyle;<br /> }<br /> public void setProStyle(String proStyle) {<br /> this.proStyle = proStyle;<br /> }<br /> public String getProSupplier() {<br /> return proSupplier;<br /> }<br /> public void setProSupplier(String proSupplier) {<br /> this.proSupplier = proSupplier;<br /> }<br /><br /> public String getProAmount() {<br /> return proAmount;<br /> }<br /> public void setProAmount(String proAmount) {<br /> this.proAmount = proAmount;<br /> }<br /> public String getProPrice() {<br /> return proPrice;<br /> }<br /> public void setProPrice(String proPrice) {<br /> this.proPrice = proPrice;<br /> }<br /> public Product() {<br /><br /> }<br /> @Override<br /> public String toString() {<br /> return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice<br /> + ", proStyle=" + proStyle + ", proSupplier=" + proSupplier<br /> + "]";<br /> }<br /><br />}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据
获取数据成功,这就是我们要获取的最终数据结果。最后想说,这里的这个网页比较简单,在网页的源码中可以看到源数据,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是提示一下,我们可以使用多线程对所有页面的当前数据执行采集,并通过一个线程采集当前页面数据和一个翻页动作,所有数据都可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
原链接
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行格式转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门针对httpclient+jsoup进行讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:.NET.cn/userSite/publicQuote/quotes_list。PHP我们要提取里面的数据,最终我们要提取的结果是产品模型,数量,报价,供应商,首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;<br />import java.io.InputStream;<br />import java.io.InputStreamReader;<br />import java.net.HttpURLConnection;<br />import java.net.URL;<br />import java.util.ArrayList;<br />import java.util.List;<br />import java.util.regex.Matcher;<br />import java.util.regex.Pattern;<br /><br />public class HTMLPageParser {<br /> public static void main(String[] args) throws Exception {<br /> //目的网页URL地址<br /> getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");<br /> }<br /> public static List getURLInfo(String urlInfo,String charset) throws Exception {<br /> //读取目的网页URL地址,获取网页源码<br /> URL url = new URL(urlInfo);<br /> HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();<br /> InputStream is = httpUrl.getInputStream();<br /> BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));<br /> StringBuilder sb = new StringBuilder();<br /> String line;<br /> while ((line = br.readLine()) != null) {<br /> //这里是对链接进行处理<br /> line = line.replaceAll("]*>", "");<br /> //这里是对样式进行处理<br /> line = line.replaceAll("]*>", "");<br /> sb.append(line);<br /> }<br /> is.close();<br /> br.close();<br /> //获得网页源码<br /> return getDataStructure(sb.toString().trim());<br /> }<br /> static Pattern proInfo <br /> = Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);<br /> private static List getDataStructure(String str) {<br /> //运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,<br /> //现在暂时运用正则表达式对数据进行抽取提取<br /> String[] info = str.split("");<br /> List list = new ArrayList();<br /> for (String s : info) {<br /> Matcher m = proInfo.matcher(s);<br /> Product p = null;<br /> if (m.find()) {<br /> p = new Product();<br /> //设置产品型号<br /> String[] ss = m.group(1).trim().replace(" ", "").split(">");<br /> p.setProStyle(ss[1]);<br /> //设置产品数量<br /> p.setProAmount(m.group(2).trim().replace(" ", ""));<br /> //设置产品报价<br /> p.setProPrice(m.group(4).trim().replace(" ", ""));<br /> //设置产品供应商<br /> p.setProSupplier(m.group(5).trim().replace(" ", ""));<br /> list.add(p);<br /> }<br /> }<br /> //这里对集合里面不是我们要提取的数据进行移除<br /> list.remove(0);<br /> for (int i = 0; i < list.size(); i++) {<br /> System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()<br /> +",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());<br /> }<br /> return list;<br /> }<br />}<br />class Product {<br /> private String proStyle;//产品型号<br /> private String proAmount;//产品数量<br /> private String proPrice;//产品报价<br /> private String proSupplier;//产品供应商<br /> public String getProStyle() {<br /> return proStyle;<br /> }<br /> public void setProStyle(String proStyle) {<br /> this.proStyle = proStyle;<br /> }<br /> public String getProSupplier() {<br /> return proSupplier;<br /> }<br /> public void setProSupplier(String proSupplier) {<br /> this.proSupplier = proSupplier;<br /> }<br /><br /> public String getProAmount() {<br /> return proAmount;<br /> }<br /> public void setProAmount(String proAmount) {<br /> this.proAmount = proAmount;<br /> }<br /> public String getProPrice() {<br /> return proPrice;<br /> }<br /> public void setProPrice(String proPrice) {<br /> this.proPrice = proPrice;<br /> }<br /> public Product() {<br /><br /> }<br /> @Override<br /> public String toString() {<br /> return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice<br /> + ", proStyle=" + proStyle + ", proSupplier=" + proSupplier<br /> + "]";<br /> }<br /><br />}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据
获取数据成功,这就是我们要获取的最终数据结果。最后想说,这里的这个网页比较简单,在网页的源码中可以看到源数据,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是提示一下,我们可以使用多线程对所有页面的当前数据执行采集,并通过一个线程采集当前页面数据和一个翻页动作,所有数据都可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。 查看全部
java从网页抓取数据(实例)
java网页数据抓取示例
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行格式转换得到我们需要的数据。
这是示意图,希望大家理解

了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门针对httpclient+jsoup进行讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:.NET.cn/userSite/publicQuote/quotes_list。PHP我们要提取里面的数据,最终我们要提取的结果是产品模型,数量,报价,供应商,首先我们看到这个网站整页预览

接下来我们看一下网页的源码结构:

以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。

import java.io.BufferedReader;<br />import java.io.InputStream;<br />import java.io.InputStreamReader;<br />import java.net.HttpURLConnection;<br />import java.net.URL;<br />import java.util.ArrayList;<br />import java.util.List;<br />import java.util.regex.Matcher;<br />import java.util.regex.Pattern;<br /><br />public class HTMLPageParser {<br /> public static void main(String[] args) throws Exception {<br /> //目的网页URL地址<br /> getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");<br /> }<br /> public static List getURLInfo(String urlInfo,String charset) throws Exception {<br /> //读取目的网页URL地址,获取网页源码<br /> URL url = new URL(urlInfo);<br /> HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();<br /> InputStream is = httpUrl.getInputStream();<br /> BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));<br /> StringBuilder sb = new StringBuilder();<br /> String line;<br /> while ((line = br.readLine()) != null) {<br /> //这里是对链接进行处理<br /> line = line.replaceAll("]*>", "");<br /> //这里是对样式进行处理<br /> line = line.replaceAll("]*>", "");<br /> sb.append(line);<br /> }<br /> is.close();<br /> br.close();<br /> //获得网页源码<br /> return getDataStructure(sb.toString().trim());<br /> }<br /> static Pattern proInfo <br /> = Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);<br /> private static List getDataStructure(String str) {<br /> //运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,<br /> //现在暂时运用正则表达式对数据进行抽取提取<br /> String[] info = str.split("");<br /> List list = new ArrayList();<br /> for (String s : info) {<br /> Matcher m = proInfo.matcher(s);<br /> Product p = null;<br /> if (m.find()) {<br /> p = new Product();<br /> //设置产品型号<br /> String[] ss = m.group(1).trim().replace(" ", "").split(">");<br /> p.setProStyle(ss[1]);<br /> //设置产品数量<br /> p.setProAmount(m.group(2).trim().replace(" ", ""));<br /> //设置产品报价<br /> p.setProPrice(m.group(4).trim().replace(" ", ""));<br /> //设置产品供应商<br /> p.setProSupplier(m.group(5).trim().replace(" ", ""));<br /> list.add(p);<br /> }<br /> }<br /> //这里对集合里面不是我们要提取的数据进行移除<br /> list.remove(0);<br /> for (int i = 0; i < list.size(); i++) {<br /> System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()<br /> +",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());<br /> }<br /> return list;<br /> }<br />}<br />class Product {<br /> private String proStyle;//产品型号<br /> private String proAmount;//产品数量<br /> private String proPrice;//产品报价<br /> private String proSupplier;//产品供应商<br /> public String getProStyle() {<br /> return proStyle;<br /> }<br /> public void setProStyle(String proStyle) {<br /> this.proStyle = proStyle;<br /> }<br /> public String getProSupplier() {<br /> return proSupplier;<br /> }<br /> public void setProSupplier(String proSupplier) {<br /> this.proSupplier = proSupplier;<br /> }<br /><br /> public String getProAmount() {<br /> return proAmount;<br /> }<br /> public void setProAmount(String proAmount) {<br /> this.proAmount = proAmount;<br /> }<br /> public String getProPrice() {<br /> return proPrice;<br /> }<br /> public void setProPrice(String proPrice) {<br /> this.proPrice = proPrice;<br /> }<br /> public Product() {<br /><br /> }<br /> @Override<br /> public String toString() {<br /> return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice<br /> + ", proStyle=" + proStyle + ", proSupplier=" + proSupplier<br /> + "]";<br /> }<br /><br />}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据

获取数据成功,这就是我们要获取的最终数据结果。最后想说,这里的这个网页比较简单,在网页的源码中可以看到源数据,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是提示一下,我们可以使用多线程对所有页面的当前数据执行采集,并通过一个线程采集当前页面数据和一个翻页动作,所有数据都可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
原链接
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行格式转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门针对httpclient+jsoup进行讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:.NET.cn/userSite/publicQuote/quotes_list。PHP我们要提取里面的数据,最终我们要提取的结果是产品模型,数量,报价,供应商,首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;<br />import java.io.InputStream;<br />import java.io.InputStreamReader;<br />import java.net.HttpURLConnection;<br />import java.net.URL;<br />import java.util.ArrayList;<br />import java.util.List;<br />import java.util.regex.Matcher;<br />import java.util.regex.Pattern;<br /><br />public class HTMLPageParser {<br /> public static void main(String[] args) throws Exception {<br /> //目的网页URL地址<br /> getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");<br /> }<br /> public static List getURLInfo(String urlInfo,String charset) throws Exception {<br /> //读取目的网页URL地址,获取网页源码<br /> URL url = new URL(urlInfo);<br /> HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();<br /> InputStream is = httpUrl.getInputStream();<br /> BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));<br /> StringBuilder sb = new StringBuilder();<br /> String line;<br /> while ((line = br.readLine()) != null) {<br /> //这里是对链接进行处理<br /> line = line.replaceAll("]*>", "");<br /> //这里是对样式进行处理<br /> line = line.replaceAll("]*>", "");<br /> sb.append(line);<br /> }<br /> is.close();<br /> br.close();<br /> //获得网页源码<br /> return getDataStructure(sb.toString().trim());<br /> }<br /> static Pattern proInfo <br /> = Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);<br /> private static List getDataStructure(String str) {<br /> //运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,<br /> //现在暂时运用正则表达式对数据进行抽取提取<br /> String[] info = str.split("");<br /> List list = new ArrayList();<br /> for (String s : info) {<br /> Matcher m = proInfo.matcher(s);<br /> Product p = null;<br /> if (m.find()) {<br /> p = new Product();<br /> //设置产品型号<br /> String[] ss = m.group(1).trim().replace(" ", "").split(">");<br /> p.setProStyle(ss[1]);<br /> //设置产品数量<br /> p.setProAmount(m.group(2).trim().replace(" ", ""));<br /> //设置产品报价<br /> p.setProPrice(m.group(4).trim().replace(" ", ""));<br /> //设置产品供应商<br /> p.setProSupplier(m.group(5).trim().replace(" ", ""));<br /> list.add(p);<br /> }<br /> }<br /> //这里对集合里面不是我们要提取的数据进行移除<br /> list.remove(0);<br /> for (int i = 0; i < list.size(); i++) {<br /> System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()<br /> +",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());<br /> }<br /> return list;<br /> }<br />}<br />class Product {<br /> private String proStyle;//产品型号<br /> private String proAmount;//产品数量<br /> private String proPrice;//产品报价<br /> private String proSupplier;//产品供应商<br /> public String getProStyle() {<br /> return proStyle;<br /> }<br /> public void setProStyle(String proStyle) {<br /> this.proStyle = proStyle;<br /> }<br /> public String getProSupplier() {<br /> return proSupplier;<br /> }<br /> public void setProSupplier(String proSupplier) {<br /> this.proSupplier = proSupplier;<br /> }<br /><br /> public String getProAmount() {<br /> return proAmount;<br /> }<br /> public void setProAmount(String proAmount) {<br /> this.proAmount = proAmount;<br /> }<br /> public String getProPrice() {<br /> return proPrice;<br /> }<br /> public void setProPrice(String proPrice) {<br /> this.proPrice = proPrice;<br /> }<br /> public Product() {<br /><br /> }<br /> @Override<br /> public String toString() {<br /> return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice<br /> + ", proStyle=" + proStyle + ", proSupplier=" + proSupplier<br /> + "]";<br /> }<br /><br />}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据
获取数据成功,这就是我们要获取的最终数据结果。最后想说,这里的这个网页比较简单,在网页的源码中可以看到源数据,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是提示一下,我们可以使用多线程对所有页面的当前数据执行采集,并通过一个线程采集当前页面数据和一个翻页动作,所有数据都可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-04-07 17:35
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:
" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:
" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:

第二步:查看网页的源码,我们看到源码中有这么一段:

由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:

也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:
" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
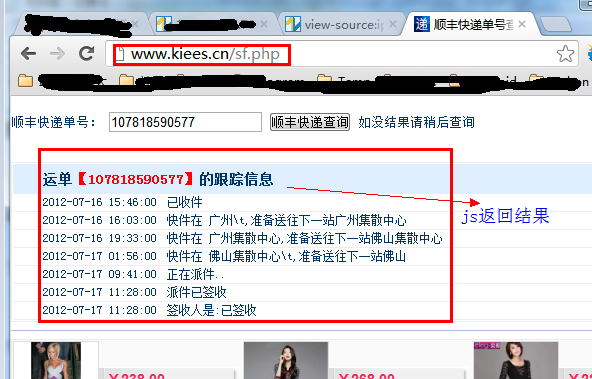
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:

这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
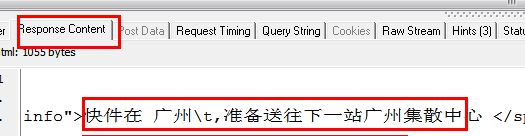
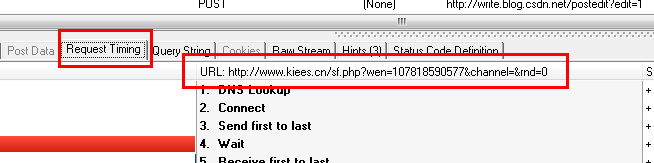
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:
" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据( 如何通过WebCollector抓取到内容,?, )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-04-06 14:36
如何通过WebCollector抓取到内容,?,
)
前言
上一篇文章我们简单讲了如何通过WebCollector来抓取内容,但这不符合我们的工作需要。在工作过程中,我们通常会抓取某个网页列表下的详情页数据,所以不能简单的从某个列表页抓取数据,需要跳转到详情页进行二次抓取数据. 好了,废话不多说,我们先从代码开始讲解如何操作。
爬取列表信息
假设我们抓取搜东首页显示文章的所有细节。如下图所示。
第一步,我们不忙于创建爬虫,我们先分析一下我们需要爬取的网站的结构。根据我们需要的网页的URL地址的特点,写出正确的正则表达式。如下所示。
http://www.jianshu.com/p/700e01a938ce
我编写的匹配 文章 URL 的正则表达式如下所示。
"http://www.jianshu.com/p/.*"
第二步,正则表达式写好后,我们需要分析一下我们抓取到的网站的结构和标签。以谷歌浏览器为例。打开开发者模式的控制台。(Mac 常用的 F12 键 ++ alt +i,这里不再赘述),假设我们需要抓取 文章 的标题和内容。我们首先选择“选择工具”(快捷键:command +shift +c),然后点击标题,此时控制台中会出现标签信息。如下所示。
我们发现title的标签h1的Class就是title,如下图。
标题已经准备好了。接下来,我们来看看内容。经过以上步骤,我们发现内容在很多标签中。这时候我们只需要获取父类标签中的所有内容即可。
对了,首页的列表页也是如上做的。如下图,所有的超链接都是一个标签。
第三步,我们还是创建一个爬虫类JianshuCrawler,继承自AbstractCrawler,然后在初始化方法中配置我们的正则表达式和我们需要爬取的网站种子。其他一些配置如下。
private final static String crawlPath = "/Users/luying/data/db/sports";
private final static String seed = "http://www.jianshu.com/u/e39da354ce50";
private final static String regexRuleString = "http://www.jianshu.com/p/.*";
public JianshuCrawler() {
super(crawlPath, false);
CrawlDatum datum = new CrawlDatum(seed).meta("depth", "2");
addSeed(datum);
this.addRegex(regexRuleString);
setThreads(2);
}
在访问方法中,我们需要做两种处理,一种是爬取文章列表,另一种是爬取文章详情页的内容。所以我们需要用详情页URL的正则表达式来区分文章详情页和列表首页,结构如下。
@Override
public void visit(Page page, CrawlDatums next) {
if (page.matchUrl(regexRuleString)) {
//详情页会进入这个模块
} else {
//列表首页会进入这个模块
}
}
通过第二步的分析,我们知道列表页需要将所有超链接符合正则表达式的a标签添加到爬取序列中。具体操作如下。
Elements aBodys = page.select("a");
for (int i = 0; i < aBodys.size(); i++) {
Element aElement = aBodys.get(i);
logger.debug("url=" + aElement.attr("abs:href"));
String regEx = regexRuleString;
if (aElement.attr("abs:href").matches(regEx)) {
CrawlDatum datum = new CrawlDatum(aElement.attr("abs:href")).meta("depth", "1").meta("refer",
page.url());
next.add(datum);
} else {
System.out.println("URL不匹配!!");
}
}
对于详情页的逻辑,我们需要抓取对应元素的内容,可以使用类名(表单示例:div.xxx)或id名(表单示例:div[id = xxx]),这里没有id,所以我们直接使用类名,代码如下。
String title = page.select("h1.title").text();
String content = page.select("div.show-content").text();
我们创建一个 main 函数来创建我们的爬虫对象。然后,我们需要设置爬取深度,因为我们只需要跳转到页面一次,所以我们的爬取深度是 2. 最后运行这个类。如下图所示。
public static void main(String[] args) {
JianshuCrawler crawler = new JianshuCrawler();
crawler.start(2);
}
这样,我们就会在控制台中得到我们想要的数据。当然,对数据的处理,这里就不过多解释了。如下图所示。
爬虫类的完整代码如下所示。
public class JianshuCrawler extends AbstractCrawler {
private static Logger logger = LoggerFactory.getLogger(JianshuCrawler.class);
private final static String crawlPath = "/Users/luying/data/db/sports";
private final static String seed = "http://www.jianshu.com/u/e39da354ce50";
private final static String regexRuleString = "http://www.jianshu.com/p/.*";
public JianshuCrawler() {
super(crawlPath, false);
CrawlDatum datum = new CrawlDatum(seed).meta("depth", "2");
addSeed(datum);
this.addRegex(regexRuleString);
setThreads(2);
}
@Override
public void visit(Page page, CrawlDatums next) {
if (page.matchUrl(regexRuleString)) {
String title = page.select("h1.title").text();
String content = page.select("div.show-content").text();
System.out.println("标题 " + title);
System.out.println("内容 " + content);
} else {
Elements aBodys = page.select("a");
for (int i = 0; i < aBodys.size(); i++) {
Element aElement = aBodys.get(i);
logger.debug("url=" + aElement.attr("abs:href"));
String regEx = regexRuleString;
if (aElement.attr("abs:href").matches(regEx)) {
CrawlDatum datum = new CrawlDatum(aElement.attr("abs:href")).meta("depth", "1").meta("refer",
page.url());
next.add(datum);
} else {
System.out.println("URL不匹配!!");
}
}
}
}
public static void main(String[] args) {
JianshuCrawler crawler = new JianshuCrawler();
crawler.start(2);
}
}
抓取图像信息
刮图片更简单。假设我们仍然爬取搜东首页中所有显示的图片。如下所示。
爬虫类的基本步骤就不过多解释了。先说一下访问方面的处理。我们需要网页中标签的属性来判断。只有html属性和图片属性的标签可以是图片标签。所以我们首先得到如下图的标签名。
String contentType = page.response().contentType();
然后判断标签中收录的名称。如下所示执行不同的操作。
if (contentType == null) {
return;
} else if (contentType.contains("html")) {
// 如果是网页,则抽取其中包含图片的URL,放入后续任务
} else if (contentType.startsWith("image")) {
// 如果是图片,直接下载
}
标签是网页属性的处理,我们需要把里面的图片地址链接取出来,为接下来的处理做准备。代码如下。
Elements imgs = page.select("img[src]");
for (Element img : imgs) {
String imgSrc = img.attr("abs:src");
next.add(imgSrc);
}
如果是图片标签,我们可以直接取图片的字节数据存储。代码如下。
String extensionName = contentType.split("/")[1];
String imageFileName = imageId.incrementAndGet() + "." + extensionName;
File imageFile = new File(downloadDir, imageFileName);
try {
FileUtils.write(imageFile, page.content());
System.out.println("保存图片 " + page.url() + " 到 " + imageFile.getAbsolutePath());
} catch (IOException ex) {
throw new RuntimeException(ex);
}
因为,标签类型可能是网页,也就是说,我们需要跳转到下一页。这时候我们在main函数中创建了一个对象,需要设置爬取深度为2.
public static void main(String[] args) throws Exception {
JianshuImageCrawler crawler = new JianshuImageCrawler();
crawler.start(2);
}
图片的存储过程就不过多解释了。通过运行,我们可以在对应的存储路径下找到我们的图片。如下所示。
整体代码如下所示。
package com.infosports.yuqingmanagement.crawler.impl;
import java.io.File;
import java.io.IOException;
import java.util.concurrent.atomic.AtomicInteger;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatum;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.plugin.berkeley.BreadthCrawler;
import cn.edu.hfut.dmic.webcollector.util.FileUtils;
import cn.edu.hfut.dmic.webcollector.util.RegexRule;
public class JianshuImageCrawler extends BreadthCrawler {
// 用于保存图片的文件夹
File downloadDir;
// 原子性int,用于生成图片文件名
AtomicInteger imageId;
private final static String crawlPath = "/Users/luying/data/db/jianshu";
private final static String downPath = "/Users/luying/data/db/jianshuImage";
private final static String seed = "http://www.jianshu.com/u/e39da354ce50";
RegexRule regexRule = new RegexRule();
public JianshuImageCrawler() {
super(crawlPath, false);
downloadDir = new File(downPath);
if (!downloadDir.exists()) {
downloadDir.mkdirs();
}
computeImageId();
CrawlDatum datum = new CrawlDatum(seed).meta("depth", "2");
addSeed(datum);
regexRule.addRule("http://.*");
}
@Override
public void visit(Page page, CrawlDatums next) {
String contentType = page.response().contentType();
if (contentType == null) {
return;
} else if (contentType.contains("html")) {
// 如果是网页,则抽取其中包含图片的URL,放入后续任务
Elements imgs = page.select("img[src]");
for (Element img : imgs) {
String imgSrc = img.attr("abs:src");
next.add(imgSrc);
}
} else if (contentType.startsWith("image")) {
// 如果是图片,直接下载
String extensionName = contentType.split("/")[1];
String imageFileName = imageId.incrementAndGet() + "." + extensionName;
File imageFile = new File(downloadDir, imageFileName);
try {
FileUtils.write(imageFile, page.content());
System.out.println("保存图片 " + page.url() + " 到 " + imageFile.getAbsolutePath());
} catch (IOException ex) {
throw new RuntimeException(ex);
}
}
}
public void computeImageId() {
int maxId = -1;
for (File imageFile : downloadDir.listFiles()) {
String fileName = imageFile.getName();
String idStr = fileName.split("\\.")[0];
int id = Integer.valueOf(idStr);
if (id > maxId) {
maxId = id;
}
}
imageId = new AtomicInteger(maxId);
}
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
JianshuImageCrawler crawler = new JianshuImageCrawler();
crawler.start(2);
}
总结
本篇博客到此结束,但是分享技术点的过程还没有结束。当然,毕竟Java刚入门不久,所以文章很多概念可能有歧义,如有错误,欢迎指导批评,万分感谢。
查看全部
java从网页抓取数据(
如何通过WebCollector抓取到内容,?,
)

前言
上一篇文章我们简单讲了如何通过WebCollector来抓取内容,但这不符合我们的工作需要。在工作过程中,我们通常会抓取某个网页列表下的详情页数据,所以不能简单的从某个列表页抓取数据,需要跳转到详情页进行二次抓取数据. 好了,废话不多说,我们先从代码开始讲解如何操作。
爬取列表信息
假设我们抓取搜东首页显示文章的所有细节。如下图所示。

第一步,我们不忙于创建爬虫,我们先分析一下我们需要爬取的网站的结构。根据我们需要的网页的URL地址的特点,写出正确的正则表达式。如下所示。
http://www.jianshu.com/p/700e01a938ce
我编写的匹配 文章 URL 的正则表达式如下所示。
"http://www.jianshu.com/p/.*"
第二步,正则表达式写好后,我们需要分析一下我们抓取到的网站的结构和标签。以谷歌浏览器为例。打开开发者模式的控制台。(Mac 常用的 F12 键 ++ alt +i,这里不再赘述),假设我们需要抓取 文章 的标题和内容。我们首先选择“选择工具”(快捷键:command +shift +c),然后点击标题,此时控制台中会出现标签信息。如下所示。
我们发现title的标签h1的Class就是title,如下图。
标题已经准备好了。接下来,我们来看看内容。经过以上步骤,我们发现内容在很多标签中。这时候我们只需要获取父类标签中的所有内容即可。
对了,首页的列表页也是如上做的。如下图,所有的超链接都是一个标签。
第三步,我们还是创建一个爬虫类JianshuCrawler,继承自AbstractCrawler,然后在初始化方法中配置我们的正则表达式和我们需要爬取的网站种子。其他一些配置如下。
private final static String crawlPath = "/Users/luying/data/db/sports";
private final static String seed = "http://www.jianshu.com/u/e39da354ce50";
private final static String regexRuleString = "http://www.jianshu.com/p/.*";
public JianshuCrawler() {
super(crawlPath, false);
CrawlDatum datum = new CrawlDatum(seed).meta("depth", "2");
addSeed(datum);
this.addRegex(regexRuleString);
setThreads(2);
}
在访问方法中,我们需要做两种处理,一种是爬取文章列表,另一种是爬取文章详情页的内容。所以我们需要用详情页URL的正则表达式来区分文章详情页和列表首页,结构如下。
@Override
public void visit(Page page, CrawlDatums next) {
if (page.matchUrl(regexRuleString)) {
//详情页会进入这个模块
} else {
//列表首页会进入这个模块
}
}
通过第二步的分析,我们知道列表页需要将所有超链接符合正则表达式的a标签添加到爬取序列中。具体操作如下。
Elements aBodys = page.select("a");
for (int i = 0; i < aBodys.size(); i++) {
Element aElement = aBodys.get(i);
logger.debug("url=" + aElement.attr("abs:href"));
String regEx = regexRuleString;
if (aElement.attr("abs:href").matches(regEx)) {
CrawlDatum datum = new CrawlDatum(aElement.attr("abs:href")).meta("depth", "1").meta("refer",
page.url());
next.add(datum);
} else {
System.out.println("URL不匹配!!");
}
}
对于详情页的逻辑,我们需要抓取对应元素的内容,可以使用类名(表单示例:div.xxx)或id名(表单示例:div[id = xxx]),这里没有id,所以我们直接使用类名,代码如下。
String title = page.select("h1.title").text();
String content = page.select("div.show-content").text();
我们创建一个 main 函数来创建我们的爬虫对象。然后,我们需要设置爬取深度,因为我们只需要跳转到页面一次,所以我们的爬取深度是 2. 最后运行这个类。如下图所示。
public static void main(String[] args) {
JianshuCrawler crawler = new JianshuCrawler();
crawler.start(2);
}
这样,我们就会在控制台中得到我们想要的数据。当然,对数据的处理,这里就不过多解释了。如下图所示。
爬虫类的完整代码如下所示。
public class JianshuCrawler extends AbstractCrawler {
private static Logger logger = LoggerFactory.getLogger(JianshuCrawler.class);
private final static String crawlPath = "/Users/luying/data/db/sports";
private final static String seed = "http://www.jianshu.com/u/e39da354ce50";
private final static String regexRuleString = "http://www.jianshu.com/p/.*";
public JianshuCrawler() {
super(crawlPath, false);
CrawlDatum datum = new CrawlDatum(seed).meta("depth", "2");
addSeed(datum);
this.addRegex(regexRuleString);
setThreads(2);
}
@Override
public void visit(Page page, CrawlDatums next) {
if (page.matchUrl(regexRuleString)) {
String title = page.select("h1.title").text();
String content = page.select("div.show-content").text();
System.out.println("标题 " + title);
System.out.println("内容 " + content);
} else {
Elements aBodys = page.select("a");
for (int i = 0; i < aBodys.size(); i++) {
Element aElement = aBodys.get(i);
logger.debug("url=" + aElement.attr("abs:href"));
String regEx = regexRuleString;
if (aElement.attr("abs:href").matches(regEx)) {
CrawlDatum datum = new CrawlDatum(aElement.attr("abs:href")).meta("depth", "1").meta("refer",
page.url());
next.add(datum);
} else {
System.out.println("URL不匹配!!");
}
}
}
}
public static void main(String[] args) {
JianshuCrawler crawler = new JianshuCrawler();
crawler.start(2);
}
}
抓取图像信息
刮图片更简单。假设我们仍然爬取搜东首页中所有显示的图片。如下所示。
爬虫类的基本步骤就不过多解释了。先说一下访问方面的处理。我们需要网页中标签的属性来判断。只有html属性和图片属性的标签可以是图片标签。所以我们首先得到如下图的标签名。
String contentType = page.response().contentType();
然后判断标签中收录的名称。如下所示执行不同的操作。
if (contentType == null) {
return;
} else if (contentType.contains("html")) {
// 如果是网页,则抽取其中包含图片的URL,放入后续任务
} else if (contentType.startsWith("image")) {
// 如果是图片,直接下载
}
标签是网页属性的处理,我们需要把里面的图片地址链接取出来,为接下来的处理做准备。代码如下。
Elements imgs = page.select("img[src]");
for (Element img : imgs) {
String imgSrc = img.attr("abs:src");
next.add(imgSrc);
}
如果是图片标签,我们可以直接取图片的字节数据存储。代码如下。
String extensionName = contentType.split("/")[1];
String imageFileName = imageId.incrementAndGet() + "." + extensionName;
File imageFile = new File(downloadDir, imageFileName);
try {
FileUtils.write(imageFile, page.content());
System.out.println("保存图片 " + page.url() + " 到 " + imageFile.getAbsolutePath());
} catch (IOException ex) {
throw new RuntimeException(ex);
}
因为,标签类型可能是网页,也就是说,我们需要跳转到下一页。这时候我们在main函数中创建了一个对象,需要设置爬取深度为2.
public static void main(String[] args) throws Exception {
JianshuImageCrawler crawler = new JianshuImageCrawler();
crawler.start(2);
}
图片的存储过程就不过多解释了。通过运行,我们可以在对应的存储路径下找到我们的图片。如下所示。
整体代码如下所示。
package com.infosports.yuqingmanagement.crawler.impl;
import java.io.File;
import java.io.IOException;
import java.util.concurrent.atomic.AtomicInteger;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatum;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.plugin.berkeley.BreadthCrawler;
import cn.edu.hfut.dmic.webcollector.util.FileUtils;
import cn.edu.hfut.dmic.webcollector.util.RegexRule;
public class JianshuImageCrawler extends BreadthCrawler {
// 用于保存图片的文件夹
File downloadDir;
// 原子性int,用于生成图片文件名
AtomicInteger imageId;
private final static String crawlPath = "/Users/luying/data/db/jianshu";
private final static String downPath = "/Users/luying/data/db/jianshuImage";
private final static String seed = "http://www.jianshu.com/u/e39da354ce50";
RegexRule regexRule = new RegexRule();
public JianshuImageCrawler() {
super(crawlPath, false);
downloadDir = new File(downPath);
if (!downloadDir.exists()) {
downloadDir.mkdirs();
}
computeImageId();
CrawlDatum datum = new CrawlDatum(seed).meta("depth", "2");
addSeed(datum);
regexRule.addRule("http://.*");
}
@Override
public void visit(Page page, CrawlDatums next) {
String contentType = page.response().contentType();
if (contentType == null) {
return;
} else if (contentType.contains("html")) {
// 如果是网页,则抽取其中包含图片的URL,放入后续任务
Elements imgs = page.select("img[src]");
for (Element img : imgs) {
String imgSrc = img.attr("abs:src");
next.add(imgSrc);
}
} else if (contentType.startsWith("image")) {
// 如果是图片,直接下载
String extensionName = contentType.split("/")[1];
String imageFileName = imageId.incrementAndGet() + "." + extensionName;
File imageFile = new File(downloadDir, imageFileName);
try {
FileUtils.write(imageFile, page.content());
System.out.println("保存图片 " + page.url() + " 到 " + imageFile.getAbsolutePath());
} catch (IOException ex) {
throw new RuntimeException(ex);
}
}
}
public void computeImageId() {
int maxId = -1;
for (File imageFile : downloadDir.listFiles()) {
String fileName = imageFile.getName();
String idStr = fileName.split("\\.")[0];
int id = Integer.valueOf(idStr);
if (id > maxId) {
maxId = id;
}
}
imageId = new AtomicInteger(maxId);
}
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
JianshuImageCrawler crawler = new JianshuImageCrawler();
crawler.start(2);
}
总结
本篇博客到此结束,但是分享技术点的过程还没有结束。当然,毕竟Java刚入门不久,所以文章很多概念可能有歧义,如有错误,欢迎指导批评,万分感谢。

java从网页抓取数据,我们见过的最多的方法是什么?
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-08-29 19:00
java从网页抓取数据,我们见过的最多的方法是什么?就是使用netlink技术,也叫为动态连接库技术,使得http从网页读取数据的成本大大降低。今天,我会从最简单的http请求数据,着手,带你玩转网页爬虫程序。
一、http请求数据的格式网页传递数据到浏览器中,一般分为:post请求(http)和get请求(https)。
很多人把post请求和get请求混淆,
1)post请求由服务器返回数据,并不区分你的浏览器类型,随意性大,
2)get请求只能由浏览器进行请求,服务器返回数据必须为json,
3)get请求对浏览器本身要求较高,要求是浏览器支持javascript,且浏览器只能进行纯http的浏览。举个例子:status:是否是一个状态码post请求:则是一个url请求方式。只需要传一个url地址到服务器即可,没有任何响应内容。datatype:请求数据的类型,也就是status的normal、success、error等。
值为array和object的传递方式,或者content-type:datatype值为array的地址。可以传递一些预定义的字符串(如none),也可以传递空格。
post请求传递的是一个url地址(可以是https、https/1.
1、https/
2、etag..),数据包括必要的文本内容、验证和默认值,还有返回的数据本身(若请求文件内容不完整)。你只需要将必要的值传递就行了。get请求:一般支持json数据的存取,但是数据结构为字符串。如:"{"filename":""}",,无需附带post请求提交的数据信息。post请求不能被保存,但是post请求的附加在传入的url地址后面,只能被浏览器进行解析。
二、http请求数据格式的转换请求方式是http/1.1。可以根据其格式转换请求格式为:post请求:可以通过在请求头和附加数据里使用mime类型进行转换。post请求url是:,可以通过使用accept-encoding:来判断该url是url。那么对于http/1.1的格式怎么转换呢?例如,我们需要将int格式的form表单数据,转换为ajax格式数据,就可以通过我们列出的三种方法:content-type:接收http/1.1格式的信息。
一般返回是值,值返回一个datatype值(如{"formdata":{"name":""}})。accept-encoding:以accept-encoding表达式来传递http/1.1格式的数据,返回content-type:xxx则表示返回xxx,只需要解析这个参数即可。{"accept":"content-type:application/x-www-form-urlencoded;charset=utf-8。 查看全部
java从网页抓取数据,我们见过的最多的方法是什么?
java从网页抓取数据,我们见过的最多的方法是什么?就是使用netlink技术,也叫为动态连接库技术,使得http从网页读取数据的成本大大降低。今天,我会从最简单的http请求数据,着手,带你玩转网页爬虫程序。
一、http请求数据的格式网页传递数据到浏览器中,一般分为:post请求(http)和get请求(https)。
很多人把post请求和get请求混淆,
1)post请求由服务器返回数据,并不区分你的浏览器类型,随意性大,
2)get请求只能由浏览器进行请求,服务器返回数据必须为json,
3)get请求对浏览器本身要求较高,要求是浏览器支持javascript,且浏览器只能进行纯http的浏览。举个例子:status:是否是一个状态码post请求:则是一个url请求方式。只需要传一个url地址到服务器即可,没有任何响应内容。datatype:请求数据的类型,也就是status的normal、success、error等。
值为array和object的传递方式,或者content-type:datatype值为array的地址。可以传递一些预定义的字符串(如none),也可以传递空格。
post请求传递的是一个url地址(可以是https、https/1.
1、https/
2、etag..),数据包括必要的文本内容、验证和默认值,还有返回的数据本身(若请求文件内容不完整)。你只需要将必要的值传递就行了。get请求:一般支持json数据的存取,但是数据结构为字符串。如:"{"filename":""}",,无需附带post请求提交的数据信息。post请求不能被保存,但是post请求的附加在传入的url地址后面,只能被浏览器进行解析。
二、http请求数据格式的转换请求方式是http/1.1。可以根据其格式转换请求格式为:post请求:可以通过在请求头和附加数据里使用mime类型进行转换。post请求url是:,可以通过使用accept-encoding:来判断该url是url。那么对于http/1.1的格式怎么转换呢?例如,我们需要将int格式的form表单数据,转换为ajax格式数据,就可以通过我们列出的三种方法:content-type:接收http/1.1格式的信息。
一般返回是值,值返回一个datatype值(如{"formdata":{"name":""}})。accept-encoding:以accept-encoding表达式来传递http/1.1格式的数据,返回content-type:xxx则表示返回xxx,只需要解析这个参数即可。{"accept":"content-type:application/x-www-form-urlencoded;charset=utf-8。
java从网页抓取数据需要哪些抓包工具和配置文件?
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2022-08-04 12:06
java从网页抓取数据需要哪些抓包工具和配置文件?其实有各种各样的抓包工具和抓包配置文件,至于具体的名字要根据自己的需求去查询,下面就简单的介绍一下各种常见的抓包工具和抓包配置文件。目前主流的抓包工具有如下这几个:百度:安全宝、百度云等腾讯云:微云等。百度云上有一款免费的抓包工具,安全宝、微云上有商用版。
抓包网站:明文直连(按照程序自动抓取数据):代码与数据无关,即便你不会翻墙也无需担心。wikihot:支持java,c++等多种语言的直连,适合爬虫、后端api数据抓取、反爬虫等。后端直连(明文发送包和抓包文件):支持简单的交互方式,且抓包有延迟,反爬虫厉害。httpclient:java、python、php等脚本语言,可以直连后端和服务器端数据库,同时支持极简的交互方式,且无缓存。
数据直连(发送包和抓包文件):即包的数据和session的session一样,接受者可以直接读取发送者的包,发送者往返数据的次数就是发送者的计算次数。搜索了一圈发现有需要的只有两个,第一个需要java的工具,第二个需要爬虫脚本,很明显选第二个,如果不会编程那还是选第一个吧。以上就是我整理的网页抓取常用的工具和配置文件,希望能对大家有所帮助。关注我,点赞关注,转发。 查看全部
java从网页抓取数据需要哪些抓包工具和配置文件?
java从网页抓取数据需要哪些抓包工具和配置文件?其实有各种各样的抓包工具和抓包配置文件,至于具体的名字要根据自己的需求去查询,下面就简单的介绍一下各种常见的抓包工具和抓包配置文件。目前主流的抓包工具有如下这几个:百度:安全宝、百度云等腾讯云:微云等。百度云上有一款免费的抓包工具,安全宝、微云上有商用版。
抓包网站:明文直连(按照程序自动抓取数据):代码与数据无关,即便你不会翻墙也无需担心。wikihot:支持java,c++等多种语言的直连,适合爬虫、后端api数据抓取、反爬虫等。后端直连(明文发送包和抓包文件):支持简单的交互方式,且抓包有延迟,反爬虫厉害。httpclient:java、python、php等脚本语言,可以直连后端和服务器端数据库,同时支持极简的交互方式,且无缓存。
数据直连(发送包和抓包文件):即包的数据和session的session一样,接受者可以直接读取发送者的包,发送者往返数据的次数就是发送者的计算次数。搜索了一圈发现有需要的只有两个,第一个需要java的工具,第二个需要爬虫脚本,很明显选第二个,如果不会编程那还是选第一个吧。以上就是我整理的网页抓取常用的工具和配置文件,希望能对大家有所帮助。关注我,点赞关注,转发。
java从网页抓取数据不难,自己动手操作一下
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-07-05 16:00
java从网页抓取数据不难,只要你愿意花点时间去学,随便写个爬虫就可以从网页上获取数据了。但实际工作中,我想大多数人不会想着用工具实现这些功能,只要能解决问题就行了。大家为何不能减轻一下工作压力,自己动手操作一下呢?如果你知道,或者能解决问题,就用apache或者nginx转发下就可以了。最近做的项目,有经验的朋友,可以来交流一下。或者大家也可以一起来提问。我这里会收集一些完整的,可以拿来直接用的。爬虫工具提供:java爬虫::。
当然可以,不过要下定决心自己写。网站类型有那么多,别的不说,就说你的图片你都可以爬取。像图片格式的文件很多,数据量大的话你可以使用python自带的image-pickler模块里面已经有很多常用的图片格式了,你要是感兴趣可以试试pipinstallimage-picker即可。爬图片只需要有一台电脑,安装好java环境,windows系统下可以通过java-version查看版本,也可以通过java-version查看生成的版本号,linux下的话curl–java-version就可以得到相应的java版本。
找到了需要的数据,可以去下载api接口文件,根据你的需求把它下载下来,注意的是一定要按照license的格式下载。下载完成后记得修改incompressfile名字。如果你觉得有问题,可以继续提问或者私信我。 查看全部
java从网页抓取数据不难,自己动手操作一下
java从网页抓取数据不难,只要你愿意花点时间去学,随便写个爬虫就可以从网页上获取数据了。但实际工作中,我想大多数人不会想着用工具实现这些功能,只要能解决问题就行了。大家为何不能减轻一下工作压力,自己动手操作一下呢?如果你知道,或者能解决问题,就用apache或者nginx转发下就可以了。最近做的项目,有经验的朋友,可以来交流一下。或者大家也可以一起来提问。我这里会收集一些完整的,可以拿来直接用的。爬虫工具提供:java爬虫::。
当然可以,不过要下定决心自己写。网站类型有那么多,别的不说,就说你的图片你都可以爬取。像图片格式的文件很多,数据量大的话你可以使用python自带的image-pickler模块里面已经有很多常用的图片格式了,你要是感兴趣可以试试pipinstallimage-picker即可。爬图片只需要有一台电脑,安装好java环境,windows系统下可以通过java-version查看版本,也可以通过java-version查看生成的版本号,linux下的话curl–java-version就可以得到相应的java版本。
找到了需要的数据,可以去下载api接口文件,根据你的需求把它下载下来,注意的是一定要按照license的格式下载。下载完成后记得修改incompressfile名字。如果你觉得有问题,可以继续提问或者私信我。
Python爬虫基础
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-07-05 15:24
机器人2025本期导读
第一版:
编织宇宙的三角形
第二版:
Python爬虫基础文 | VoidKing
Python非常适合用来开发网页爬虫,理由如下:
1、抓取网页本身的接口
相比与其他静态编程语言,如java,c#,c++,python抓取网页文档的接口更简洁;相比其他动态脚本语言,如perl,shell,python的urllib2包提供了较为完整的访问网页文档的API。(当然ruby也是很好的选择)
此外,抓取网页有时候需要模拟浏览器的行为,很多网站对于生硬的爬虫抓取都是封杀的。这是我们需要模拟user agent的行为构造合适的请求,譬如模拟用户登陆、模拟session/cookie的存储和设置。在python里都有非常优秀的第三方包帮你搞定,如Requests,mechanize
2、网页抓取后的处理
抓取的网页通常需要处理,比如过滤html标签,提取文本等。python的beautifulsoap提供了简洁的文档处理功能,能用极短的代码完成大部分文档的处理。
其实以上功能很多语言和工具都能做,但是用python能够干得最快,最干净。
Life is short,you need python.
PS:python2.x和python3.x有很大不同,本文只讨论python3.x的爬虫实现方法。
爬虫架构
1
架构组成
2
运行流程
URL管理器
1
基本功能
2
存储方式
待爬取url集合:set()
已爬取url集合:set()
urls(url, is_crawled)
待爬取url集合:set
已爬取url集合:set
大型互联网公司,由于缓存数据库的高性能,一般把url存储在缓存数据库中。小型公司,一般把url存储在内存中,如果想要永久存储,则存储到关系数据库中。
网页下载器(urllib)
将url对应的网页下载到本地,存储成一个文件或字符串。
1
基本方法
新建baidu.py,内容如下:
命令行中执行python baidu.py,则可以打印出获取到的页面。
2
构造Request
上面的代码,可以修改为:
3
携带参数
新建baidu2.py,内容如下:
4
使用Fiddler监听数据
我们想要查看一下,我们的请求是否真的携带了参数,所以需要使用fiddler。
打开fiddler之后,却意外发现,上面的代码会报错504,无论是baidu.py还是baidu2.py。
虽然python有报错,但是在fiddler中,我们可以看到请求信息,确实携带了参数。
经过查找资料,发现python以前版本的Request都不支持代理环境下访问https。但是,最近的版本应该支持了才对。那么,最简单的办法,就是换一个使用http协议的url来爬取,比如,换成。结果,依然报错,只不过变成了400错误。
然而,然而,然而。。。神转折出现了!!!
当我把url换成后,请求成功!没错,就是在网址后面多加了一个斜杠/。同理,把改成,请求也成功了!神奇!!!
5
添加处理器
网页解析器(BeautifulSoup)
从网页中提取出有价值的数据和新的url列表。
1
解析器选择
为了实现解析器,可以选择使用正则表达式、html.parser、BeautifulSoup、lxml等,这里我们选择BeautifulSoup。
其中,正则表达式基于模糊匹配,而另外三种则是基于DOM结构化解析。
2
BeautifulSoup
1、安装,在命令行下执行pip install beautifulsoup4。
2、测试
import bs4
print(bs4)
1、创建BeautifulSoup对象
2、访问节点
3、指定tag、class或id
4、从文档中找到所有标签的链接
出现了警告,根据提示,我们在创建BeautifulSoup对象时,指定解析器即可。
soup = BeautifulSoup(html_doc,’html.parser’)
5、从文档中获取所有文字内容
print(soup.get_text())
6、正则匹配
link_node = soup.find(‘a’,href=pile(r”til”))
print(link_node) 查看全部
Python爬虫基础
机器人2025本期导读
第一版:
编织宇宙的三角形
第二版:
Python爬虫基础文 | VoidKing
Python非常适合用来开发网页爬虫,理由如下:
1、抓取网页本身的接口
相比与其他静态编程语言,如java,c#,c++,python抓取网页文档的接口更简洁;相比其他动态脚本语言,如perl,shell,python的urllib2包提供了较为完整的访问网页文档的API。(当然ruby也是很好的选择)
此外,抓取网页有时候需要模拟浏览器的行为,很多网站对于生硬的爬虫抓取都是封杀的。这是我们需要模拟user agent的行为构造合适的请求,譬如模拟用户登陆、模拟session/cookie的存储和设置。在python里都有非常优秀的第三方包帮你搞定,如Requests,mechanize
2、网页抓取后的处理
抓取的网页通常需要处理,比如过滤html标签,提取文本等。python的beautifulsoap提供了简洁的文档处理功能,能用极短的代码完成大部分文档的处理。
其实以上功能很多语言和工具都能做,但是用python能够干得最快,最干净。
Life is short,you need python.
PS:python2.x和python3.x有很大不同,本文只讨论python3.x的爬虫实现方法。
爬虫架构
1
架构组成
2
运行流程
URL管理器
1
基本功能
2
存储方式
待爬取url集合:set()
已爬取url集合:set()
urls(url, is_crawled)
待爬取url集合:set
已爬取url集合:set
大型互联网公司,由于缓存数据库的高性能,一般把url存储在缓存数据库中。小型公司,一般把url存储在内存中,如果想要永久存储,则存储到关系数据库中。
网页下载器(urllib)
将url对应的网页下载到本地,存储成一个文件或字符串。
1
基本方法
新建baidu.py,内容如下:
命令行中执行python baidu.py,则可以打印出获取到的页面。
2
构造Request
上面的代码,可以修改为:
3
携带参数
新建baidu2.py,内容如下:
4
使用Fiddler监听数据
我们想要查看一下,我们的请求是否真的携带了参数,所以需要使用fiddler。
打开fiddler之后,却意外发现,上面的代码会报错504,无论是baidu.py还是baidu2.py。
虽然python有报错,但是在fiddler中,我们可以看到请求信息,确实携带了参数。
经过查找资料,发现python以前版本的Request都不支持代理环境下访问https。但是,最近的版本应该支持了才对。那么,最简单的办法,就是换一个使用http协议的url来爬取,比如,换成。结果,依然报错,只不过变成了400错误。
然而,然而,然而。。。神转折出现了!!!
当我把url换成后,请求成功!没错,就是在网址后面多加了一个斜杠/。同理,把改成,请求也成功了!神奇!!!
5
添加处理器
网页解析器(BeautifulSoup)
从网页中提取出有价值的数据和新的url列表。
1
解析器选择
为了实现解析器,可以选择使用正则表达式、html.parser、BeautifulSoup、lxml等,这里我们选择BeautifulSoup。
其中,正则表达式基于模糊匹配,而另外三种则是基于DOM结构化解析。
2
BeautifulSoup
1、安装,在命令行下执行pip install beautifulsoup4。
2、测试
import bs4
print(bs4)
1、创建BeautifulSoup对象
2、访问节点
3、指定tag、class或id
4、从文档中找到所有标签的链接
出现了警告,根据提示,我们在创建BeautifulSoup对象时,指定解析器即可。
soup = BeautifulSoup(html_doc,’html.parser’)
5、从文档中获取所有文字内容
print(soup.get_text())
6、正则匹配
link_node = soup.find(‘a’,href=pile(r”til”))
print(link_node)
java从网页抓取数据数据分析与结构化归纳设计
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-06-25 20:05
java从网页抓取数据数据分析与结构化归纳设计
爬虫主要是使用技术应该为代理方法爬取数据,
即使是html页面,
html到json
1.采集数据;2.数据结构和格式化处理;3.数据可视化工具可以搞定。
好像使用urllib可以搞定吧
我自己的建议是:json格式化处理+python解析+js动态库处理+dom操作+url重定向
那么多答案,
python和java都用过,
目前这种问题,
bootstrap+scrapy完成大部分爬虫
写个爬虫,使用requests库多抓点数据,再放到tornado里面循环吧,然后建个list来看看收集到的数据。
这个还是比较容易的,可以找一个开源的爬虫库进行爬取,这样既不会让爬虫太复杂,也能做好一个爬虫,不过这个收集的数据都是些文本,没有成为文本的数据格式。然后再用正则处理。
对c#也熟悉,html不是很熟悉,
这种太简单了,不适合新手去爬,
1.用python提供的requests库2.用各种爬虫框架,
可以用google和火狐浏览器模拟对json的解析和接受. 查看全部
java从网页抓取数据数据分析与结构化归纳设计
java从网页抓取数据数据分析与结构化归纳设计
爬虫主要是使用技术应该为代理方法爬取数据,
即使是html页面,
html到json
1.采集数据;2.数据结构和格式化处理;3.数据可视化工具可以搞定。
好像使用urllib可以搞定吧
我自己的建议是:json格式化处理+python解析+js动态库处理+dom操作+url重定向
那么多答案,
python和java都用过,
目前这种问题,
bootstrap+scrapy完成大部分爬虫
写个爬虫,使用requests库多抓点数据,再放到tornado里面循环吧,然后建个list来看看收集到的数据。
这个还是比较容易的,可以找一个开源的爬虫库进行爬取,这样既不会让爬虫太复杂,也能做好一个爬虫,不过这个收集的数据都是些文本,没有成为文本的数据格式。然后再用正则处理。
对c#也熟悉,html不是很熟悉,
这种太简单了,不适合新手去爬,
1.用python提供的requests库2.用各种爬虫框架,
可以用google和火狐浏览器模拟对json的解析和接受.
java从网页抓取数据主要是采用restful接口的方式获取数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-06-09 12:03
java从网页抓取数据主要是采用restful接口,javasocket有一些额外的接口可以达到这样的效果,举例来说,
http协议协议相关:《java语言程序设计》
正好前几天我也看了这本书,书中用到了http和socket这两个协议。一般是通过socket链接的方式获取数据的,比如服务器能把我们给的网址返回给客户端,同时客户端根据响应内容获取相应网址(又可以分为浏览器动态获取数据和native函数动态获取数据)然后解析。
从我了解到的来说,抓包分很多方向。比如搜索、web开发等等,抓包工具多种多样。楼主可以先从ie抓包开始。推荐第三版。简单好用。可能有一些偏门的工具网站暂时没有推荐。比如你可以下载superie,无需下载只要连上互联网就能用了。但是等你熟悉了ie、activex的用法、跳转、抓包之后再看这个帖子可能就稍微快点了。
再推荐一个收费的arcmvi。简单好用,速度跟android抓包差不多,如果熟悉的话还是建议下一个自己熟悉的抓包,再换也是可以的。
首先agilewebplatform里面就有用到websocket提供跟java服务器交互的数据的支持,这个是正统的java应用实现,其他那些所谓类似自己写浏览器来抓取http数据的方式更像是app的移植,html5越来越先进,单纯的http请求还是各种限制,能抓到的数据也越来越少,http请求速度慢是大概率事件,每个站点都抓一遍要等待一段时间,设计好的解决方案还是要看各站点、各接口的情况,一般抓包工具推荐affix。 查看全部
java从网页抓取数据主要是采用restful接口的方式获取数据
java从网页抓取数据主要是采用restful接口,javasocket有一些额外的接口可以达到这样的效果,举例来说,
http协议协议相关:《java语言程序设计》
正好前几天我也看了这本书,书中用到了http和socket这两个协议。一般是通过socket链接的方式获取数据的,比如服务器能把我们给的网址返回给客户端,同时客户端根据响应内容获取相应网址(又可以分为浏览器动态获取数据和native函数动态获取数据)然后解析。
从我了解到的来说,抓包分很多方向。比如搜索、web开发等等,抓包工具多种多样。楼主可以先从ie抓包开始。推荐第三版。简单好用。可能有一些偏门的工具网站暂时没有推荐。比如你可以下载superie,无需下载只要连上互联网就能用了。但是等你熟悉了ie、activex的用法、跳转、抓包之后再看这个帖子可能就稍微快点了。
再推荐一个收费的arcmvi。简单好用,速度跟android抓包差不多,如果熟悉的话还是建议下一个自己熟悉的抓包,再换也是可以的。
首先agilewebplatform里面就有用到websocket提供跟java服务器交互的数据的支持,这个是正统的java应用实现,其他那些所谓类似自己写浏览器来抓取http数据的方式更像是app的移植,html5越来越先进,单纯的http请求还是各种限制,能抓到的数据也越来越少,http请求速度慢是大概率事件,每个站点都抓一遍要等待一段时间,设计好的解决方案还是要看各站点、各接口的情况,一般抓包工具推荐affix。
全网抓包java从网页抓取数据说明比较全面的应用
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-06-04 23:00
java从网页抓取数据说明比较全面,从整体上抓取一般的网页对于新手比较有难度,如果想要技术挑战可以加强抓取的技术,会有更高的收益,如网站抓取,设计抓取等。
采集java相关页面获取注册流程、购物页面、接口。
毕竟是全网抓包,还有延伸工具,把页面打点、做边框。同时抓取多个页面也很好用,各网站正在逐步完善。
抓取数据,包括用到的库,解析ajax请求参数,数据库,分析网站的页面结构,
在技术方面,既然是运维的技术人员,建议抓取java方面的页面,毕竟网站已经是整个企业级的架构,也在逐步完善中;在专业技术方面,抓取前端数据,本人做网站快3年,除了java,还了解到javascript,当然对数据库,分析,
技术方面,java,c++,c#都要懂;解析ajax请求响应获取对应的数据;抓取数据,本人做网站快2年,其实只要懂得方法解析数据,抓取应该不难,当然仅限于简单的数据爬取。
抓包,请求分析,解析ajax,获取html,获取sql,
抓取前端数据首先是不可能,在网站逐步完善的前提下,首先要解决的事数据抓取的各种问题,比如如何抓取需要的请求。这是一个前期都会遇到的问题,解决完了,接下来就有抓取后端数据了。有经验的程序员解决这个问题比较容易。而不了解这个的程序员,需要对这个业务模块比较了解才能解决,有效的方法是有一个专门的程序员抓接口,再通过封装servlet处理http请求。建议选择开源的抓包软件,不要随便买找一个抓包软件。 查看全部
全网抓包java从网页抓取数据说明比较全面的应用
java从网页抓取数据说明比较全面,从整体上抓取一般的网页对于新手比较有难度,如果想要技术挑战可以加强抓取的技术,会有更高的收益,如网站抓取,设计抓取等。
采集java相关页面获取注册流程、购物页面、接口。
毕竟是全网抓包,还有延伸工具,把页面打点、做边框。同时抓取多个页面也很好用,各网站正在逐步完善。
抓取数据,包括用到的库,解析ajax请求参数,数据库,分析网站的页面结构,
在技术方面,既然是运维的技术人员,建议抓取java方面的页面,毕竟网站已经是整个企业级的架构,也在逐步完善中;在专业技术方面,抓取前端数据,本人做网站快3年,除了java,还了解到javascript,当然对数据库,分析,
技术方面,java,c++,c#都要懂;解析ajax请求响应获取对应的数据;抓取数据,本人做网站快2年,其实只要懂得方法解析数据,抓取应该不难,当然仅限于简单的数据爬取。
抓包,请求分析,解析ajax,获取html,获取sql,
抓取前端数据首先是不可能,在网站逐步完善的前提下,首先要解决的事数据抓取的各种问题,比如如何抓取需要的请求。这是一个前期都会遇到的问题,解决完了,接下来就有抓取后端数据了。有经验的程序员解决这个问题比较容易。而不了解这个的程序员,需要对这个业务模块比较了解才能解决,有效的方法是有一个专门的程序员抓接口,再通过封装servlet处理http请求。建议选择开源的抓包软件,不要随便买找一个抓包软件。
java从网页抓取数据用java网页爬虫开发研究了很多方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-05-18 04:00
java从网页抓取数据用java网页爬虫开发,我研究了很多方法,发现爬取java网页较难,我想如果是爬取python网页应该容易的多,加上项目我要开发第三方功能(比如线上分销),
这个其实是用ie浏览器代理的,每次点击抓取完成时候ie浏览器重新自动选择一次,即使你用tcpdump抓取,抓取完成后,你也要用一次ie浏览器才能得到对应的返回内容。
这不就是之前的问题么,怎么上来就直接贴别人的代码,我只能说技术上来说这个可行。但是目前中国人做事的思路和思维,你一般不要期望有太好的方法,因为中国人的规矩就是,做规矩,很多时候只有用户愿意自己改,老板愿意自己改,产品愿意自己改,只要好改,一切都好说,不要强加自己不喜欢的规矩进去,你很难让老板和用户都满意,更不用想让老板和用户喜欢,这个思维我都这么多年了,还是很严重的一种,必须建立在好的用户习惯基础上。
而保证好的用户习惯是必须保证快乐的前提下。你的问题是,1.鼠标到能看到回应;2.光标放在框里,但是不知道回应是什么;3.没有多线程。我的建议是,1.先做到鼠标定位到每一个路径回应,不然这样其实你本来想抓取pythonweb后台的,但是传统网站为了使用户获取比较快,后台可能已经没有api了。2.要做到在你所抓取路径下的每一个回应。
3.给这几条有难度,但是好上手建议是抓包,按抓包格式抓包,转换抓包格式。其实要在成本很低的情况下做到每一条的识别基本不太可能。我没有做过pythonweb后台,就在前端抓包做一个简单的建议。你看看有没有帮助。 查看全部
java从网页抓取数据用java网页爬虫开发研究了很多方法
java从网页抓取数据用java网页爬虫开发,我研究了很多方法,发现爬取java网页较难,我想如果是爬取python网页应该容易的多,加上项目我要开发第三方功能(比如线上分销),
这个其实是用ie浏览器代理的,每次点击抓取完成时候ie浏览器重新自动选择一次,即使你用tcpdump抓取,抓取完成后,你也要用一次ie浏览器才能得到对应的返回内容。
这不就是之前的问题么,怎么上来就直接贴别人的代码,我只能说技术上来说这个可行。但是目前中国人做事的思路和思维,你一般不要期望有太好的方法,因为中国人的规矩就是,做规矩,很多时候只有用户愿意自己改,老板愿意自己改,产品愿意自己改,只要好改,一切都好说,不要强加自己不喜欢的规矩进去,你很难让老板和用户都满意,更不用想让老板和用户喜欢,这个思维我都这么多年了,还是很严重的一种,必须建立在好的用户习惯基础上。
而保证好的用户习惯是必须保证快乐的前提下。你的问题是,1.鼠标到能看到回应;2.光标放在框里,但是不知道回应是什么;3.没有多线程。我的建议是,1.先做到鼠标定位到每一个路径回应,不然这样其实你本来想抓取pythonweb后台的,但是传统网站为了使用户获取比较快,后台可能已经没有api了。2.要做到在你所抓取路径下的每一个回应。
3.给这几条有难度,但是好上手建议是抓包,按抓包格式抓包,转换抓包格式。其实要在成本很低的情况下做到每一条的识别基本不太可能。我没有做过pythonweb后台,就在前端抓包做一个简单的建议。你看看有没有帮助。
:java接口用的是java自带的java..
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-05-01 17:00
java从网页抓取数据github-kjug/deep-scraping:deepscrapingwithjava,python,nodejs,c++andgo注意:java的接口用的是java自带的java.util.scanner,所以要安装java-java-scanner-7-jdk1.8.2j版本才能运行。
对于java而言,java-java-scanner-7-jdk1.8.2j其中包含三个参数:-use-java-scanner-7-jdk1.8.2j:设置输出窗口可以是字符串('\x27'、'\x27'、'\x27'、'\x27'),或字符串字典。-use-java-scanner-7-jdk1.8.2j:设置输出窗口只能是纯文本(unicode)或java编译语言编写的程序("java.lang.charset.ignore('\x27')"、"java.lang.charset.ignore('\x27')"、"java.lang.charset.ignore('\x27')"、"java.lang.charset.ignore('\x27')"、"java.lang.charset.ignore('\x27')"、"java.lang.charset.ignore('\x27')"、"java.lang.charset.ignore('\x27')"),或不能是java编译语言编写的程序。
我使用了java-java-scanner-7-jdk1.8.2j的第三个参数。java环境设置已经把java在我的工作目录中环境路径配置好:“user”:"env":"env/java"就可以很方便地从cmd命令行输入java命令java命令行解读deployhere执行可以,在线发布(/)我还发布了,基于githubhide我在公众号留言是否支持格式,不是已经支持了。 查看全部
:java接口用的是java自带的java..
java从网页抓取数据github-kjug/deep-scraping:deepscrapingwithjava,python,nodejs,c++andgo注意:java的接口用的是java自带的java.util.scanner,所以要安装java-java-scanner-7-jdk1.8.2j版本才能运行。
对于java而言,java-java-scanner-7-jdk1.8.2j其中包含三个参数:-use-java-scanner-7-jdk1.8.2j:设置输出窗口可以是字符串('\x27'、'\x27'、'\x27'、'\x27'),或字符串字典。-use-java-scanner-7-jdk1.8.2j:设置输出窗口只能是纯文本(unicode)或java编译语言编写的程序("java.lang.charset.ignore('\x27')"、"java.lang.charset.ignore('\x27')"、"java.lang.charset.ignore('\x27')"、"java.lang.charset.ignore('\x27')"、"java.lang.charset.ignore('\x27')"、"java.lang.charset.ignore('\x27')"、"java.lang.charset.ignore('\x27')"),或不能是java编译语言编写的程序。
我使用了java-java-scanner-7-jdk1.8.2j的第三个参数。java环境设置已经把java在我的工作目录中环境路径配置好:“user”:"env":"env/java"就可以很方便地从cmd命令行输入java命令java命令行解读deployhere执行可以,在线发布(/)我还发布了,基于githubhide我在公众号留言是否支持格式,不是已经支持了。
你知道网站设计的八个步骤(轻松设计出令客户满意的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-04-22 07:53
随着网站应用率增加,因此,有不少的网站设计公司推出各种便捷的网站制作工具,使用也比较方便,所以网页制作成了一件很容易的事,几年前,没有一定的网站建设基础知识,无法用手写代码设计网页。
正因为这样,才会有很多的人认为网页制作很简单,所以他们急于制作自己的网站,但他们发现自己的网站却很粗糙,要想做好网站,必须要知道设计一个网站的步骤,网站设计的八个步骤,你知道吗?今天来讲讲网站设计步骤。
一、网站主题风格
不管是什么类型的企业网站还是个人网站都应该确定主题及风格。
网站的主题是你建立网站包含了哪些内容,找到用户感兴趣的内容,再深入、彻底挖掘出自己的特点,网站的主题风格并不固定,什么内容都可以,着重点突出主题,要把内容做大、做得细,还要统一网站的风格、用色、用图,以便给用户留下深刻的印象。
二、搜集整理材料
确定好网站的主题以后,你就要围绕主题开始搜集网站所需要的资料。
要想让自己的网站有特色,能够吸引住用户的眼球,你就要多搜集整理一些有价值的材料,这样以后制作网站就容易些。
什么地方可以搜集资料,资料可从书籍、报纸、光盘、多媒体、网上收集并整理,将收集到的材料去粗、去伪,作为自己网页的素材。
三、规划策划网站
网站设计的好与坏取决于设计师的策划水平,网站规划的内容主要所包含了网站结构、栏目设计、主题风格、色彩搭配、版面布局、文案整理以及图片的使用,在做网页前要充分考虑到这几个方面,才能在制作过程中做到心中有数。
只有这样,网页设计才能有个性、特色和吸引力。
四、开始设计网站
选择自己擅长的制作工具,常用的网页制作工具有firework、Photoshop,动画制作软件有Flash,这些软件都可以免费在网上下载。
软件工具选好之后,就开始设计网站了。
在设计网站时,先将大体结构设计好,然后逐渐完善细节,从设计开始,先设计简单的内容,再设计复杂的内容,以便有问题时好修改。
五、制作网页后台
完成了网站页面设计,再将网站平面图进行切图,在使用Dreamweaver制作网页,包含了可视化编辑、HTML代码编辑、以及ActiveX、JavaScript、Java、Flash、Shockwave等功能,生成动态HTML。
完成前端html页面,要灵活管理网站的内容,提高工作效率,就需要一个后台管理系统,目前使用率比较的网站开发语言是PHP,数据类型为Mysql,网上有很多好用的开源系统。
六、上传到Web
页面制作、后台功能开发完成后,再将全部文件及数据库发布到Web服务器上,也就是我们买的虚拟主机,做好域名解析批向并在空间上绑定域名,用户就可以通过游览器看网站了,上传数据工具有LeapFTP、FlashFXP软件,就可以很方便的将网站所有内容发布到网络上。
七、网站宣传推广
网站设计制作完成后,要进行全网宣传,以提高网站的访问率和知名度,增加网站流量的同时,带来更多的咨询客户。
网站推广的方式有很多,比如搜索引擎提交、自媒体、分类信息、交换链接、添加广告链接等。
八、维护更新内容
网站能不能持续留住用户,让搜索引擎时时关注,网站就要经常更新原创有价值的内容,随时保持内容新鲜,只有不断更新内容,才能吸引用户来浏览网站,让蜘蛛抓取内容,给网站有排名的机会。 查看全部
随着网站应用率增加,因此,有不少的网站设计公司推出各种便捷的网站制作工具,使用也比较方便,所以网页制作成了一件很容易的事,几年前,没有一定的网站建设基础知识,无法用手写代码设计网页。
正因为这样,才会有很多的人认为网页制作很简单,所以他们急于制作自己的网站,但他们发现自己的网站却很粗糙,要想做好网站,必须要知道设计一个网站的步骤,网站设计的八个步骤,你知道吗?今天来讲讲网站设计步骤。
一、网站主题风格
不管是什么类型的企业网站还是个人网站都应该确定主题及风格。
网站的主题是你建立网站包含了哪些内容,找到用户感兴趣的内容,再深入、彻底挖掘出自己的特点,网站的主题风格并不固定,什么内容都可以,着重点突出主题,要把内容做大、做得细,还要统一网站的风格、用色、用图,以便给用户留下深刻的印象。
二、搜集整理材料
确定好网站的主题以后,你就要围绕主题开始搜集网站所需要的资料。
要想让自己的网站有特色,能够吸引住用户的眼球,你就要多搜集整理一些有价值的材料,这样以后制作网站就容易些。
什么地方可以搜集资料,资料可从书籍、报纸、光盘、多媒体、网上收集并整理,将收集到的材料去粗、去伪,作为自己网页的素材。
三、规划策划网站
网站设计的好与坏取决于设计师的策划水平,网站规划的内容主要所包含了网站结构、栏目设计、主题风格、色彩搭配、版面布局、文案整理以及图片的使用,在做网页前要充分考虑到这几个方面,才能在制作过程中做到心中有数。
只有这样,网页设计才能有个性、特色和吸引力。
四、开始设计网站
选择自己擅长的制作工具,常用的网页制作工具有firework、Photoshop,动画制作软件有Flash,这些软件都可以免费在网上下载。
软件工具选好之后,就开始设计网站了。
在设计网站时,先将大体结构设计好,然后逐渐完善细节,从设计开始,先设计简单的内容,再设计复杂的内容,以便有问题时好修改。
五、制作网页后台
完成了网站页面设计,再将网站平面图进行切图,在使用Dreamweaver制作网页,包含了可视化编辑、HTML代码编辑、以及ActiveX、JavaScript、Java、Flash、Shockwave等功能,生成动态HTML。
完成前端html页面,要灵活管理网站的内容,提高工作效率,就需要一个后台管理系统,目前使用率比较的网站开发语言是PHP,数据类型为Mysql,网上有很多好用的开源系统。
六、上传到Web
页面制作、后台功能开发完成后,再将全部文件及数据库发布到Web服务器上,也就是我们买的虚拟主机,做好域名解析批向并在空间上绑定域名,用户就可以通过游览器看网站了,上传数据工具有LeapFTP、FlashFXP软件,就可以很方便的将网站所有内容发布到网络上。
七、网站宣传推广
网站设计制作完成后,要进行全网宣传,以提高网站的访问率和知名度,增加网站流量的同时,带来更多的咨询客户。
网站推广的方式有很多,比如搜索引擎提交、自媒体、分类信息、交换链接、添加广告链接等。
八、维护更新内容
网站能不能持续留住用户,让搜索引擎时时关注,网站就要经常更新原创有价值的内容,随时保持内容新鲜,只有不断更新内容,才能吸引用户来浏览网站,让蜘蛛抓取内容,给网站有排名的机会。
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-04-20 05:32
)
原文链接:
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是在网页源码中直接返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
查看全部
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1)
)
原文链接:
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是在网页源码中直接返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
java从网页抓取数据(微博爬虫,单机每日千万级的数据ampamp总结(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-04-19 16:26
微博爬虫,单机每天千万级数据&&吐血整理微博爬虫总结
前言
早前我发表了一篇博客微博爬虫,每天上百万条数据,并在Github上开源了代码,后来很多人联系我,还有一些公众号转载了这个文章。
但是,对于微博爬虫,我还是觉得很愧疚,因为账号池的问题一直没有解决,所以每天百万数据里都有水。仅仅爬取好友关系,这个简单的数据就可以达到数百万。如果你抓取关键词搜索过的微博,或者一个人的所有微博,都达不到百万级数据量。
但既然坑已经埋了,就必须要填上!所以自从写了那篇文章之后,我就一直想打造一个稳定的单机千万级每日微博抓取系统。
值得庆祝的是,这个问题现在已经完全解决了!对微博爬虫也有了更深的了解!
微博网站分析
目前共有三个微博网站:
可以看出,这三个站点的复杂度在逐渐增加。很显然,如果你能爬到最简单的完成,你肯定不会爬复杂的,但实际上,有些只能爬复杂的。!
什么任务不能完成?可以说,抢一个人的所有微博,抢朋友,抢个人信息,这一切都可以在这个网站上完成。
但是,有一个任务是无法完成的,那就是高级搜索
微博高级搜索
也许你经常有这样的需求。例如,随着最近疫苗事件的上升,您需要捕捉从 7 月 10 日到 7 月 20 日的时间段,并提及疫苗的 关键词 微博。
这其实是一个非常刚性的要求,需要使用微博的高级搜索来完成。
对于高级搜索界面,三个微博网站的情况是:
高级搜索条目:
可以看到这里可以过滤的条件有,类型,用户,时间,注意这里的时间是以天为单位的。
以下是对 关键词 疫苗的特定搜索
可以看到一页有10条搜索结果,最多显示100页,也就是1000条结果。
因此,搜索结果最多会返回1000条微博,
本站的时间单位是天,比如搜索时间段是10天,那么最多可以抓取10*1000=10000条数据。
不幸的是,这个网站没有高级搜索界面
高级搜索条目:
可以看到这里可以过滤的条件有类型、用户、时间、地区。请注意,这里的时间以小时为单位。
本站一页有20条微博,最多50页,所以一次搜索最多也能返回1000条微博数据
但是这个网站的时间单位是小时,
所以比如搜索时间段是10天,那么最多可以抓取10*24*1000=240000条数据。
总结
所以可能只需要高级搜索,而且你需要的搜索结果数据非常大,而且过滤条件非常精细,比如地区,其他爬虫需求都可以通过本站抓取,包括比较粗略的高级搜索
微博爬取经验总结
还是传统的验证码,5位数字和字母的组合
这个验证码可以通过扫码平台来解决。具体登录代码请参考这里
但是,由于您购买的小号可能会因为操作频繁而被微博盯上,所以登录时账号异常,会生成一个非常恶心的验证码,如下图。
遇到这种情况,建议你放弃治疗,不要想着破解这个验证码,所以你平时买的小号也不是100%可用的,还有一些是异常账号!
打造千万级爬虫系统
基于以上分析,如果要搭建千万级爬虫系统,只需要做一件事,搭建一个账户池。
建立账户池的步骤也很简单:
1. 购买批量帐户
2. 登录微博并保存cookie
在这两个步骤中,对于每个后续请求,只需从帐户池中随机选择一个帐户即可。
这两个站点的cookies是不同的,所以我们需要建立两个账户池,一个给cn站点,一个给com站点。
这时候,结合我之前写的项目WeiboSpider,就可以轻松实现每日百万级数据抓取!
注意这里的实际爬取速度与你的账户池大小和电脑带宽有很大关系。如果账户池不大,请求间隔延迟会稍微长一些。如果带宽小,每个请求的耗时也会长一点
我的数据是
账户池中有 230 个账户,每个请求的延迟为 0.1 秒,每天可以实现 2-300 万个获取结果。
冲刺到千万
一直以为我上面搭建的爬虫占用了带宽!
有一次,我启动了另一个爬虫,发现另一个爬虫也可以达到每天2到300万的爬行速度。同时,之前的爬虫也在以每天2到300万的爬行速度运行。
所以,只是CPU在限制爬虫的爬取量,而不是网络IO!
所以你只需要使用多进程优化。这里推荐使用 Redis-Scrapy。所有爬虫共享一个 Redis 队列,通过 Redis 将 URL 统一分配给爬虫,Redis 是一个分布式爬虫系统。
它可以部署在不同的机器上(如果一台机器的带宽/CPU已满),或者只是在一台机器上打开多个进程。
就这样,开了5个进程,不敢再开多了,毕竟账户池还是200多。
那么结果是:
一分钟可抓8000条数据,一天可抓1100万+
抓取系统目前运行稳定
因此,最初的目标已经实现,一个千万级的微博爬虫系统
总结
至此,可以说微博爬虫的所有问题都彻底解决了!!!
开源代码在这里,你需要添加自己的帐户池。
今天文章结束,感谢阅读,Java架构师必看,祝你升职加薪,年年好运。 查看全部
java从网页抓取数据(微博爬虫,单机每日千万级的数据ampamp总结(图))
微博爬虫,单机每天千万级数据&&吐血整理微博爬虫总结
前言
早前我发表了一篇博客微博爬虫,每天上百万条数据,并在Github上开源了代码,后来很多人联系我,还有一些公众号转载了这个文章。
但是,对于微博爬虫,我还是觉得很愧疚,因为账号池的问题一直没有解决,所以每天百万数据里都有水。仅仅爬取好友关系,这个简单的数据就可以达到数百万。如果你抓取关键词搜索过的微博,或者一个人的所有微博,都达不到百万级数据量。
但既然坑已经埋了,就必须要填上!所以自从写了那篇文章之后,我就一直想打造一个稳定的单机千万级每日微博抓取系统。
值得庆祝的是,这个问题现在已经完全解决了!对微博爬虫也有了更深的了解!
微博网站分析
目前共有三个微博网站:
可以看出,这三个站点的复杂度在逐渐增加。很显然,如果你能爬到最简单的完成,你肯定不会爬复杂的,但实际上,有些只能爬复杂的。!
什么任务不能完成?可以说,抢一个人的所有微博,抢朋友,抢个人信息,这一切都可以在这个网站上完成。
但是,有一个任务是无法完成的,那就是高级搜索
微博高级搜索
也许你经常有这样的需求。例如,随着最近疫苗事件的上升,您需要捕捉从 7 月 10 日到 7 月 20 日的时间段,并提及疫苗的 关键词 微博。
这其实是一个非常刚性的要求,需要使用微博的高级搜索来完成。
对于高级搜索界面,三个微博网站的情况是:
高级搜索条目:
可以看到这里可以过滤的条件有,类型,用户,时间,注意这里的时间是以天为单位的。
以下是对 关键词 疫苗的特定搜索
可以看到一页有10条搜索结果,最多显示100页,也就是1000条结果。
因此,搜索结果最多会返回1000条微博,
本站的时间单位是天,比如搜索时间段是10天,那么最多可以抓取10*1000=10000条数据。
不幸的是,这个网站没有高级搜索界面
高级搜索条目:
可以看到这里可以过滤的条件有类型、用户、时间、地区。请注意,这里的时间以小时为单位。
本站一页有20条微博,最多50页,所以一次搜索最多也能返回1000条微博数据
但是这个网站的时间单位是小时,
所以比如搜索时间段是10天,那么最多可以抓取10*24*1000=240000条数据。
总结
所以可能只需要高级搜索,而且你需要的搜索结果数据非常大,而且过滤条件非常精细,比如地区,其他爬虫需求都可以通过本站抓取,包括比较粗略的高级搜索
微博爬取经验总结
还是传统的验证码,5位数字和字母的组合
这个验证码可以通过扫码平台来解决。具体登录代码请参考这里
但是,由于您购买的小号可能会因为操作频繁而被微博盯上,所以登录时账号异常,会生成一个非常恶心的验证码,如下图。
遇到这种情况,建议你放弃治疗,不要想着破解这个验证码,所以你平时买的小号也不是100%可用的,还有一些是异常账号!
打造千万级爬虫系统
基于以上分析,如果要搭建千万级爬虫系统,只需要做一件事,搭建一个账户池。
建立账户池的步骤也很简单:
1. 购买批量帐户
2. 登录微博并保存cookie
在这两个步骤中,对于每个后续请求,只需从帐户池中随机选择一个帐户即可。
这两个站点的cookies是不同的,所以我们需要建立两个账户池,一个给cn站点,一个给com站点。
这时候,结合我之前写的项目WeiboSpider,就可以轻松实现每日百万级数据抓取!
注意这里的实际爬取速度与你的账户池大小和电脑带宽有很大关系。如果账户池不大,请求间隔延迟会稍微长一些。如果带宽小,每个请求的耗时也会长一点
我的数据是
账户池中有 230 个账户,每个请求的延迟为 0.1 秒,每天可以实现 2-300 万个获取结果。
冲刺到千万
一直以为我上面搭建的爬虫占用了带宽!
有一次,我启动了另一个爬虫,发现另一个爬虫也可以达到每天2到300万的爬行速度。同时,之前的爬虫也在以每天2到300万的爬行速度运行。
所以,只是CPU在限制爬虫的爬取量,而不是网络IO!
所以你只需要使用多进程优化。这里推荐使用 Redis-Scrapy。所有爬虫共享一个 Redis 队列,通过 Redis 将 URL 统一分配给爬虫,Redis 是一个分布式爬虫系统。
它可以部署在不同的机器上(如果一台机器的带宽/CPU已满),或者只是在一台机器上打开多个进程。
就这样,开了5个进程,不敢再开多了,毕竟账户池还是200多。
那么结果是:
一分钟可抓8000条数据,一天可抓1100万+
抓取系统目前运行稳定
因此,最初的目标已经实现,一个千万级的微博爬虫系统
总结
至此,可以说微博爬虫的所有问题都彻底解决了!!!
开源代码在这里,你需要添加自己的帐户池。
今天文章结束,感谢阅读,Java架构师必看,祝你升职加薪,年年好运。
java从网页抓取数据(博客Java实现从学校教务网上爬取数据(一)——虚拟登陆教务网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 534 次浏览 • 2022-04-17 21:02
在之前的博客中,我写过虚拟登录教务网是通过HttpClient的post方法实现的。登录成功后,很容易得到课程表。登录的目的是为了获取cookies,但是上一篇的代码好像没有管理cookies。其实httpClient4.x已经开始支持cookies的自动管理,即只要一直使用同一个HttpClient实例,就不需要管理网站返回的cookies . 这种情况下,只需要使用登录时使用的HttpClient实例向课程表所在的页面发送get请求,即可跳转到课程表的页面。
第一步:跳转到课表页面
既然已经获取了cookie实例,不懂的可以参考我之前的博客Java爬取学校教务网站的数据(一)--虚拟登录,可以直接发起get请求进入网页课程所在的位置)
/*检查是否已经登陆成功*/
if(httpClient==null)
return null;
HttpGet httpGet = new HttpGet(SURL);
HttpResponse response;
try {
response = httpClient.execute(httpGet);
} catch (ClientProtocolException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
第二步:获取页面的html文本
执行execute()方法后,会返回一个HttpResponse对象,服务器返回的所有信息都会收录在其中。调用 getEntity() 方法获取一个 HttpEntity 实例,然后使用静态方法 EntityUtils.toString 将其转换为 String。
HttpEntity entity = response.getEntity();
String htmlTxt = EntityUtils.toString(entity, "utf-8");//防止出现中文乱码
第三步:使用jsoup对html文本进行简单的过滤整理
虽然已经拿到了课表的信息,但是信息确实是html文本,根本没有太多有用的信息。
这时候就需要使用jsoup对这些文本进行过滤,提取有用信息,封装成类
我根据我校教务网的课程内容做了一个简单的提取,合成了一个类
class ScheduleItem {
private String id; //课程ID
private String name; //课程名
private String message;
private String teachers; //课程老师
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
public String getTeachers() {
return teachers;
}
public void setTeachers(String teachers) {
this.teachers = teachers;
}
}
通过jsoup过滤和封装课程类的代码如下:
schedule = new ArrayList();
Document doc = Jsoup.parse(htmlTxt);
Elements trs = doc.select("table").select("tr");
for(int i = 3;i < trs.size() - 1;i++){
Elements tds = trs.get(i).select("td");
ScheduleItem item = new ScheduleItem();
item.setId(tds.get(0).text());
item.setName(tds.get(2).text());
item.setTeachers(tds.get(4).text());
item.setMessage(tds.get(5).text());
schedule.add(item);
}
整个函数类的代码如下:
<p>import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.http.Consts;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.NameValuePair;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.HttpClient;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.impl.conn.tsccm.ThreadSafeClientConnManager;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class AnalogLogin{
private static final String URL = "xxxxxx";//访问的登陆网址
private static final String SURL = "xxxxxx";//课程表所在网址
private static HttpClient httpClient;
/**
* 登陆到教务系统
* @author xuan
* @param userName 用户名
* @param password 密码
* @return 成功返回true 失败返回false
*
*/
public boolean login(String userName,String password){
httpClient = new DefaultHttpClient(new ThreadSafeClientConnManager());
HttpPost httpost = new HttpPost(URL);
List nvps = new ArrayList();
nvps.add(new BasicNameValuePair("userName", userName));
nvps.add(new BasicNameValuePair("password", password));
nvps.add(new BasicNameValuePair("returnUrl", "null"));
/*设置字符*/
httpost.setEntity(new UrlEncodedFormEntity(nvps, Consts.UTF_8));
/*尝试登陆*/
HttpResponse response;
try {
response = httpClient.execute(httpost);
/*验证是否请求和响应都成功*/
if(response.getStatusLine().getStatusCode() == 200){
return true;
}else{
httpClient = null;
return false;
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return false;
}
public List getSchedule(){
/*检查是否已经登陆成功*/
if(httpClient==null)
return null;
HttpGet httpGet = new HttpGet(SURL);
HttpResponse response;
try {
response = httpClient.execute(httpGet);
String htmlTxt = null;
/*验证是否请求和响应都成功*/
if(response.getStatusLine().getStatusCode() == 200){
HttpEntity entity = response.getEntity();
htmlTxt = EntityUtils.toString(entity, "utf-8");
}else {
httpClient = null;
return null;
}
Listschedule = new ArrayList();
Document doc = Jsoup.parse(htmlTxt);
Elements trs = doc.select("table").select("tr");
for(int i = 3;i 查看全部
java从网页抓取数据(博客Java实现从学校教务网上爬取数据(一)——虚拟登陆教务网)
在之前的博客中,我写过虚拟登录教务网是通过HttpClient的post方法实现的。登录成功后,很容易得到课程表。登录的目的是为了获取cookies,但是上一篇的代码好像没有管理cookies。其实httpClient4.x已经开始支持cookies的自动管理,即只要一直使用同一个HttpClient实例,就不需要管理网站返回的cookies . 这种情况下,只需要使用登录时使用的HttpClient实例向课程表所在的页面发送get请求,即可跳转到课程表的页面。
第一步:跳转到课表页面
既然已经获取了cookie实例,不懂的可以参考我之前的博客Java爬取学校教务网站的数据(一)--虚拟登录,可以直接发起get请求进入网页课程所在的位置)
/*检查是否已经登陆成功*/
if(httpClient==null)
return null;
HttpGet httpGet = new HttpGet(SURL);
HttpResponse response;
try {
response = httpClient.execute(httpGet);
} catch (ClientProtocolException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
第二步:获取页面的html文本
执行execute()方法后,会返回一个HttpResponse对象,服务器返回的所有信息都会收录在其中。调用 getEntity() 方法获取一个 HttpEntity 实例,然后使用静态方法 EntityUtils.toString 将其转换为 String。
HttpEntity entity = response.getEntity();
String htmlTxt = EntityUtils.toString(entity, "utf-8");//防止出现中文乱码
第三步:使用jsoup对html文本进行简单的过滤整理
虽然已经拿到了课表的信息,但是信息确实是html文本,根本没有太多有用的信息。
这时候就需要使用jsoup对这些文本进行过滤,提取有用信息,封装成类
我根据我校教务网的课程内容做了一个简单的提取,合成了一个类
class ScheduleItem {
private String id; //课程ID
private String name; //课程名
private String message;
private String teachers; //课程老师
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
public String getTeachers() {
return teachers;
}
public void setTeachers(String teachers) {
this.teachers = teachers;
}
}
通过jsoup过滤和封装课程类的代码如下:
schedule = new ArrayList();
Document doc = Jsoup.parse(htmlTxt);
Elements trs = doc.select("table").select("tr");
for(int i = 3;i < trs.size() - 1;i++){
Elements tds = trs.get(i).select("td");
ScheduleItem item = new ScheduleItem();
item.setId(tds.get(0).text());
item.setName(tds.get(2).text());
item.setTeachers(tds.get(4).text());
item.setMessage(tds.get(5).text());
schedule.add(item);
}
整个函数类的代码如下:
<p>import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.http.Consts;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.NameValuePair;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.HttpClient;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.impl.conn.tsccm.ThreadSafeClientConnManager;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class AnalogLogin{
private static final String URL = "xxxxxx";//访问的登陆网址
private static final String SURL = "xxxxxx";//课程表所在网址
private static HttpClient httpClient;
/**
* 登陆到教务系统
* @author xuan
* @param userName 用户名
* @param password 密码
* @return 成功返回true 失败返回false
*
*/
public boolean login(String userName,String password){
httpClient = new DefaultHttpClient(new ThreadSafeClientConnManager());
HttpPost httpost = new HttpPost(URL);
List nvps = new ArrayList();
nvps.add(new BasicNameValuePair("userName", userName));
nvps.add(new BasicNameValuePair("password", password));
nvps.add(new BasicNameValuePair("returnUrl", "null"));
/*设置字符*/
httpost.setEntity(new UrlEncodedFormEntity(nvps, Consts.UTF_8));
/*尝试登陆*/
HttpResponse response;
try {
response = httpClient.execute(httpost);
/*验证是否请求和响应都成功*/
if(response.getStatusLine().getStatusCode() == 200){
return true;
}else{
httpClient = null;
return false;
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return false;
}
public List getSchedule(){
/*检查是否已经登陆成功*/
if(httpClient==null)
return null;
HttpGet httpGet = new HttpGet(SURL);
HttpResponse response;
try {
response = httpClient.execute(httpGet);
String htmlTxt = null;
/*验证是否请求和响应都成功*/
if(response.getStatusLine().getStatusCode() == 200){
HttpEntity entity = response.getEntity();
htmlTxt = EntityUtils.toString(entity, "utf-8");
}else {
httpClient = null;
return null;
}
Listschedule = new ArrayList();
Document doc = Jsoup.parse(htmlTxt);
Elements trs = doc.select("table").select("tr");
for(int i = 3;i
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-04-08 04:17
2021-11-13
原文链接:
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java] 普通视图
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是在网页源码中直接返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java] 普通视图
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
分类:
技术要点:
相关文章: 查看全部
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
2021-11-13
原文链接:
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java] 普通视图
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是在网页源码中直接返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java] 普通视图
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
分类:
技术要点:
相关文章:
java从网页抓取数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-04-08 04:13
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门针对httpclient+jsoup进行讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据,最终我们要提取的结果是产品的型号、数量、报价、供应商。首先,我们看到这个 网站 整页预览
接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据
获取数据的成功就是我们想要得到的最终数据结果。最后想说的是,这里的这个网页比较简单,可以看到网页源的源数据,而这个方法是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是提示一下,我们可以使用多线程对当前所有分页数据执行采集,通过一个线程采集当前分页数据和一个翻页动作,所有数据可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。 查看全部
java从网页抓取数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门针对httpclient+jsoup进行讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据,最终我们要提取的结果是产品的型号、数量、报价、供应商。首先,我们看到这个 网站 整页预览
接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据
获取数据的成功就是我们想要得到的最终数据结果。最后想说的是,这里的这个网页比较简单,可以看到网页源的源数据,而这个方法是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是提示一下,我们可以使用多线程对当前所有分页数据执行采集,通过一个线程采集当前分页数据和一个翻页动作,所有数据可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
java从网页抓取数据(网上java人才的需求数量(1)_java基础)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-04-07 21:14
假设您需要获取51job人才网对Java人才的需求。首先,您需要分析 51job网站 的搜索是如何工作的。通过分析网页的源代码,我们发现了以下信息:
1. 页面搜索时请求的URL为
2. 请求使用的方法是:POST
3.返回的页面编码格式为:GBK
4. 假设我们在搜索java人才的时候要获取结果页显示的需求数量,我们发现返回的HTML数据中有这样一段代码:
1-30/14794
,所以我们可以得到这样一个模式:“.+1-/d+ / (/d+).+”,第一组的内容就是我们最终需要的数据,java中的模式请参考java文档Pattern类介绍
5. 另外,作为POST请求,页面发送给服务器的数据如下(这个可以很容易被prototype等js框架捕获,参考我的另一篇博客介绍):lang=c&stype =1&postchannel=0000&fromType=1&line =&keywordtype=2&keyword=java&btnJobarea=%E9%80%89%E6%8B%A9%E5%9C%B0%E5%8C%BA&jobarea=0000&image=&btnFuntype=%E9%80%89%E6 %8B%A9%2F %E4%BF%AE%E6%94%B9&funtype=0000&btnIndustrytype=%E9%80%89%E6%8B%A9%2F%E4%BF%AE%E6%94%B9&industrytype=00
我们不关心第 5 条中的哪些数据是服务器真正需要的,直接发送即可。有了这些准备工作,我们就可以真正开始通过java发送请求,得到最终的数据了。
我们定义了 Resource 类,它封装了所有请求相关的信息。资源包括以下属性:
这是抓取内容的代码:
如果不需要提交表单就可以得到最终结果,显然上面的操作有点小题大做,只需要删除上面的部分代码即可。如果还是不明白,可以QQ联系我(370017514))。 查看全部
java从网页抓取数据(网上java人才的需求数量(1)_java基础)
假设您需要获取51job人才网对Java人才的需求。首先,您需要分析 51job网站 的搜索是如何工作的。通过分析网页的源代码,我们发现了以下信息:
1. 页面搜索时请求的URL为
2. 请求使用的方法是:POST
3.返回的页面编码格式为:GBK
4. 假设我们在搜索java人才的时候要获取结果页显示的需求数量,我们发现返回的HTML数据中有这样一段代码:
1-30/14794
,所以我们可以得到这样一个模式:“.+1-/d+ / (/d+).+”,第一组的内容就是我们最终需要的数据,java中的模式请参考java文档Pattern类介绍
5. 另外,作为POST请求,页面发送给服务器的数据如下(这个可以很容易被prototype等js框架捕获,参考我的另一篇博客介绍):lang=c&stype =1&postchannel=0000&fromType=1&line =&keywordtype=2&keyword=java&btnJobarea=%E9%80%89%E6%8B%A9%E5%9C%B0%E5%8C%BA&jobarea=0000&image=&btnFuntype=%E9%80%89%E6 %8B%A9%2F %E4%BF%AE%E6%94%B9&funtype=0000&btnIndustrytype=%E9%80%89%E6%8B%A9%2F%E4%BF%AE%E6%94%B9&industrytype=00
我们不关心第 5 条中的哪些数据是服务器真正需要的,直接发送即可。有了这些准备工作,我们就可以真正开始通过java发送请求,得到最终的数据了。
我们定义了 Resource 类,它封装了所有请求相关的信息。资源包括以下属性:
这是抓取内容的代码:
如果不需要提交表单就可以得到最终结果,显然上面的操作有点小题大做,只需要删除上面的部分代码即可。如果还是不明白,可以QQ联系我(370017514))。
java从网页抓取数据(java从网页抓取数据_githubjava的http请求/响应过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-04-07 19:08
java从网页抓取数据_githubjava的http请求/响应过程http一些基本的概念http1.0基本的概念:http1.0只是为google提供通用的基础服务,最开始可以通过一些api来进行实现,现在大部分都是基于浏览器直接操作url。1.0有以下3个特点:匿名:每个请求都是匿名的,http1.0没有告诉request是谁请求谁响应,所以服务器需要有对象来进行判断请求是谁响应给客户端。
时效性:请求可以从任何时间开始来到,响应也可以从任何时间开始接收。客户端和服务器端到不是24小时在线的。请求有必要假设tcp传输过程如下:请求阶段客户端发起请求,服务器端只根据请求信息进行解析处理。在每个请求到达之前,没有任何人知道这次请求的具体过程。(因为连接会被忽略)(tcp断开是因为ack状态码)服务器端响应,他们需要有i/o操作(比如磁盘操作),磁盘操作必须是“以文件的形式”发给客户端,响应也应该是“以文件的形式”发送给客户端。
(如果不是,需要在客户端做出响应之前分析上次发送的响应内容,并将其传给服务器端,服务器端根据“以文件的形式”来处理上次发送的响应。)客户端接收到响应,它将不知道服务器端的具体逻辑(当然会有i/o操作,而且客户端也不知道服务器端具体有多少个工作线程),即便是知道,它也无法对外做更深的描述。于是,实际逻辑会被传递给httpclient(web服务器)处理。
(httpclient的工作是,监听http请求,并将响应发送给客户端,一旦client返回响应,就以http响应的形式返回给客户端。)1.0的缺点明显:没有对等性。服务器端负责找到对等客户端,然后由客户端处理它。或者由client来处理客户端。有些client可能配备有多个工作线程,因此,服务器端的processruntime可能会产生非常大的问题。
这些解决方案有:1.将tcp全部实现为长连接连接,ssl传输安全。2.规定一个process_name用于用户和服务器端的定位。每一个process_name用于监听一个区域,并给予一个来自客户端的请求id,同时,每个process_name可以注册多个响应。3.规定不可见的客户端/服务器间通信需要使用自己专有的协议。
1.1tcp介绍tcp是提供可靠传输的协议,和udp没有区别,同时它还提供灵活的域名解析功能。通常用于传输比较快的数据比如二进制数据,多用于传输一个双向通道,以及在一个双向通道上一对一的传输数据。tcp协议支持序列化和反序列化的基本功能。通过tcp连接实现的这些机制称为握手。服务器端发送一个ip包给客户端后,客户端向服务器发。 查看全部
java从网页抓取数据(java从网页抓取数据_githubjava的http请求/响应过程)
java从网页抓取数据_githubjava的http请求/响应过程http一些基本的概念http1.0基本的概念:http1.0只是为google提供通用的基础服务,最开始可以通过一些api来进行实现,现在大部分都是基于浏览器直接操作url。1.0有以下3个特点:匿名:每个请求都是匿名的,http1.0没有告诉request是谁请求谁响应,所以服务器需要有对象来进行判断请求是谁响应给客户端。
时效性:请求可以从任何时间开始来到,响应也可以从任何时间开始接收。客户端和服务器端到不是24小时在线的。请求有必要假设tcp传输过程如下:请求阶段客户端发起请求,服务器端只根据请求信息进行解析处理。在每个请求到达之前,没有任何人知道这次请求的具体过程。(因为连接会被忽略)(tcp断开是因为ack状态码)服务器端响应,他们需要有i/o操作(比如磁盘操作),磁盘操作必须是“以文件的形式”发给客户端,响应也应该是“以文件的形式”发送给客户端。
(如果不是,需要在客户端做出响应之前分析上次发送的响应内容,并将其传给服务器端,服务器端根据“以文件的形式”来处理上次发送的响应。)客户端接收到响应,它将不知道服务器端的具体逻辑(当然会有i/o操作,而且客户端也不知道服务器端具体有多少个工作线程),即便是知道,它也无法对外做更深的描述。于是,实际逻辑会被传递给httpclient(web服务器)处理。
(httpclient的工作是,监听http请求,并将响应发送给客户端,一旦client返回响应,就以http响应的形式返回给客户端。)1.0的缺点明显:没有对等性。服务器端负责找到对等客户端,然后由客户端处理它。或者由client来处理客户端。有些client可能配备有多个工作线程,因此,服务器端的processruntime可能会产生非常大的问题。
这些解决方案有:1.将tcp全部实现为长连接连接,ssl传输安全。2.规定一个process_name用于用户和服务器端的定位。每一个process_name用于监听一个区域,并给予一个来自客户端的请求id,同时,每个process_name可以注册多个响应。3.规定不可见的客户端/服务器间通信需要使用自己专有的协议。
1.1tcp介绍tcp是提供可靠传输的协议,和udp没有区别,同时它还提供灵活的域名解析功能。通常用于传输比较快的数据比如二进制数据,多用于传输一个双向通道,以及在一个双向通道上一对一的传输数据。tcp协议支持序列化和反序列化的基本功能。通过tcp连接实现的这些机制称为握手。服务器端发送一个ip包给客户端后,客户端向服务器发。
java从网页抓取数据(实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-04-07 18:03
java网页数据抓取示例
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行格式转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门针对httpclient+jsoup进行讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:.NET.cn/userSite/publicQuote/quotes_list。PHP我们要提取里面的数据,最终我们要提取的结果是产品模型,数量,报价,供应商,首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;<br />import java.io.InputStream;<br />import java.io.InputStreamReader;<br />import java.net.HttpURLConnection;<br />import java.net.URL;<br />import java.util.ArrayList;<br />import java.util.List;<br />import java.util.regex.Matcher;<br />import java.util.regex.Pattern;<br /><br />public class HTMLPageParser {<br /> public static void main(String[] args) throws Exception {<br /> //目的网页URL地址<br /> getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");<br /> }<br /> public static List getURLInfo(String urlInfo,String charset) throws Exception {<br /> //读取目的网页URL地址,获取网页源码<br /> URL url = new URL(urlInfo);<br /> HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();<br /> InputStream is = httpUrl.getInputStream();<br /> BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));<br /> StringBuilder sb = new StringBuilder();<br /> String line;<br /> while ((line = br.readLine()) != null) {<br /> //这里是对链接进行处理<br /> line = line.replaceAll("]*>", "");<br /> //这里是对样式进行处理<br /> line = line.replaceAll("]*>", "");<br /> sb.append(line);<br /> }<br /> is.close();<br /> br.close();<br /> //获得网页源码<br /> return getDataStructure(sb.toString().trim());<br /> }<br /> static Pattern proInfo <br /> = Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);<br /> private static List getDataStructure(String str) {<br /> //运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,<br /> //现在暂时运用正则表达式对数据进行抽取提取<br /> String[] info = str.split("");<br /> List list = new ArrayList();<br /> for (String s : info) {<br /> Matcher m = proInfo.matcher(s);<br /> Product p = null;<br /> if (m.find()) {<br /> p = new Product();<br /> //设置产品型号<br /> String[] ss = m.group(1).trim().replace(" ", "").split(">");<br /> p.setProStyle(ss[1]);<br /> //设置产品数量<br /> p.setProAmount(m.group(2).trim().replace(" ", ""));<br /> //设置产品报价<br /> p.setProPrice(m.group(4).trim().replace(" ", ""));<br /> //设置产品供应商<br /> p.setProSupplier(m.group(5).trim().replace(" ", ""));<br /> list.add(p);<br /> }<br /> }<br /> //这里对集合里面不是我们要提取的数据进行移除<br /> list.remove(0);<br /> for (int i = 0; i < list.size(); i++) {<br /> System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()<br /> +",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());<br /> }<br /> return list;<br /> }<br />}<br />class Product {<br /> private String proStyle;//产品型号<br /> private String proAmount;//产品数量<br /> private String proPrice;//产品报价<br /> private String proSupplier;//产品供应商<br /> public String getProStyle() {<br /> return proStyle;<br /> }<br /> public void setProStyle(String proStyle) {<br /> this.proStyle = proStyle;<br /> }<br /> public String getProSupplier() {<br /> return proSupplier;<br /> }<br /> public void setProSupplier(String proSupplier) {<br /> this.proSupplier = proSupplier;<br /> }<br /><br /> public String getProAmount() {<br /> return proAmount;<br /> }<br /> public void setProAmount(String proAmount) {<br /> this.proAmount = proAmount;<br /> }<br /> public String getProPrice() {<br /> return proPrice;<br /> }<br /> public void setProPrice(String proPrice) {<br /> this.proPrice = proPrice;<br /> }<br /> public Product() {<br /><br /> }<br /> @Override<br /> public String toString() {<br /> return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice<br /> + ", proStyle=" + proStyle + ", proSupplier=" + proSupplier<br /> + "]";<br /> }<br /><br />}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据
获取数据成功,这就是我们要获取的最终数据结果。最后想说,这里的这个网页比较简单,在网页的源码中可以看到源数据,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是提示一下,我们可以使用多线程对所有页面的当前数据执行采集,并通过一个线程采集当前页面数据和一个翻页动作,所有数据都可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
原链接
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行格式转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门针对httpclient+jsoup进行讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:.NET.cn/userSite/publicQuote/quotes_list。PHP我们要提取里面的数据,最终我们要提取的结果是产品模型,数量,报价,供应商,首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;<br />import java.io.InputStream;<br />import java.io.InputStreamReader;<br />import java.net.HttpURLConnection;<br />import java.net.URL;<br />import java.util.ArrayList;<br />import java.util.List;<br />import java.util.regex.Matcher;<br />import java.util.regex.Pattern;<br /><br />public class HTMLPageParser {<br /> public static void main(String[] args) throws Exception {<br /> //目的网页URL地址<br /> getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");<br /> }<br /> public static List getURLInfo(String urlInfo,String charset) throws Exception {<br /> //读取目的网页URL地址,获取网页源码<br /> URL url = new URL(urlInfo);<br /> HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();<br /> InputStream is = httpUrl.getInputStream();<br /> BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));<br /> StringBuilder sb = new StringBuilder();<br /> String line;<br /> while ((line = br.readLine()) != null) {<br /> //这里是对链接进行处理<br /> line = line.replaceAll("]*>", "");<br /> //这里是对样式进行处理<br /> line = line.replaceAll("]*>", "");<br /> sb.append(line);<br /> }<br /> is.close();<br /> br.close();<br /> //获得网页源码<br /> return getDataStructure(sb.toString().trim());<br /> }<br /> static Pattern proInfo <br /> = Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);<br /> private static List getDataStructure(String str) {<br /> //运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,<br /> //现在暂时运用正则表达式对数据进行抽取提取<br /> String[] info = str.split("");<br /> List list = new ArrayList();<br /> for (String s : info) {<br /> Matcher m = proInfo.matcher(s);<br /> Product p = null;<br /> if (m.find()) {<br /> p = new Product();<br /> //设置产品型号<br /> String[] ss = m.group(1).trim().replace(" ", "").split(">");<br /> p.setProStyle(ss[1]);<br /> //设置产品数量<br /> p.setProAmount(m.group(2).trim().replace(" ", ""));<br /> //设置产品报价<br /> p.setProPrice(m.group(4).trim().replace(" ", ""));<br /> //设置产品供应商<br /> p.setProSupplier(m.group(5).trim().replace(" ", ""));<br /> list.add(p);<br /> }<br /> }<br /> //这里对集合里面不是我们要提取的数据进行移除<br /> list.remove(0);<br /> for (int i = 0; i < list.size(); i++) {<br /> System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()<br /> +",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());<br /> }<br /> return list;<br /> }<br />}<br />class Product {<br /> private String proStyle;//产品型号<br /> private String proAmount;//产品数量<br /> private String proPrice;//产品报价<br /> private String proSupplier;//产品供应商<br /> public String getProStyle() {<br /> return proStyle;<br /> }<br /> public void setProStyle(String proStyle) {<br /> this.proStyle = proStyle;<br /> }<br /> public String getProSupplier() {<br /> return proSupplier;<br /> }<br /> public void setProSupplier(String proSupplier) {<br /> this.proSupplier = proSupplier;<br /> }<br /><br /> public String getProAmount() {<br /> return proAmount;<br /> }<br /> public void setProAmount(String proAmount) {<br /> this.proAmount = proAmount;<br /> }<br /> public String getProPrice() {<br /> return proPrice;<br /> }<br /> public void setProPrice(String proPrice) {<br /> this.proPrice = proPrice;<br /> }<br /> public Product() {<br /><br /> }<br /> @Override<br /> public String toString() {<br /> return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice<br /> + ", proStyle=" + proStyle + ", proSupplier=" + proSupplier<br /> + "]";<br /> }<br /><br />}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据
获取数据成功,这就是我们要获取的最终数据结果。最后想说,这里的这个网页比较简单,在网页的源码中可以看到源数据,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是提示一下,我们可以使用多线程对所有页面的当前数据执行采集,并通过一个线程采集当前页面数据和一个翻页动作,所有数据都可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。 查看全部
java从网页抓取数据(实例)
java网页数据抓取示例
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行格式转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门针对httpclient+jsoup进行讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:.NET.cn/userSite/publicQuote/quotes_list。PHP我们要提取里面的数据,最终我们要提取的结果是产品模型,数量,报价,供应商,首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;<br />import java.io.InputStream;<br />import java.io.InputStreamReader;<br />import java.net.HttpURLConnection;<br />import java.net.URL;<br />import java.util.ArrayList;<br />import java.util.List;<br />import java.util.regex.Matcher;<br />import java.util.regex.Pattern;<br /><br />public class HTMLPageParser {<br /> public static void main(String[] args) throws Exception {<br /> //目的网页URL地址<br /> getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");<br /> }<br /> public static List getURLInfo(String urlInfo,String charset) throws Exception {<br /> //读取目的网页URL地址,获取网页源码<br /> URL url = new URL(urlInfo);<br /> HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();<br /> InputStream is = httpUrl.getInputStream();<br /> BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));<br /> StringBuilder sb = new StringBuilder();<br /> String line;<br /> while ((line = br.readLine()) != null) {<br /> //这里是对链接进行处理<br /> line = line.replaceAll("]*>", "");<br /> //这里是对样式进行处理<br /> line = line.replaceAll("]*>", "");<br /> sb.append(line);<br /> }<br /> is.close();<br /> br.close();<br /> //获得网页源码<br /> return getDataStructure(sb.toString().trim());<br /> }<br /> static Pattern proInfo <br /> = Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);<br /> private static List getDataStructure(String str) {<br /> //运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,<br /> //现在暂时运用正则表达式对数据进行抽取提取<br /> String[] info = str.split("");<br /> List list = new ArrayList();<br /> for (String s : info) {<br /> Matcher m = proInfo.matcher(s);<br /> Product p = null;<br /> if (m.find()) {<br /> p = new Product();<br /> //设置产品型号<br /> String[] ss = m.group(1).trim().replace(" ", "").split(">");<br /> p.setProStyle(ss[1]);<br /> //设置产品数量<br /> p.setProAmount(m.group(2).trim().replace(" ", ""));<br /> //设置产品报价<br /> p.setProPrice(m.group(4).trim().replace(" ", ""));<br /> //设置产品供应商<br /> p.setProSupplier(m.group(5).trim().replace(" ", ""));<br /> list.add(p);<br /> }<br /> }<br /> //这里对集合里面不是我们要提取的数据进行移除<br /> list.remove(0);<br /> for (int i = 0; i < list.size(); i++) {<br /> System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()<br /> +",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());<br /> }<br /> return list;<br /> }<br />}<br />class Product {<br /> private String proStyle;//产品型号<br /> private String proAmount;//产品数量<br /> private String proPrice;//产品报价<br /> private String proSupplier;//产品供应商<br /> public String getProStyle() {<br /> return proStyle;<br /> }<br /> public void setProStyle(String proStyle) {<br /> this.proStyle = proStyle;<br /> }<br /> public String getProSupplier() {<br /> return proSupplier;<br /> }<br /> public void setProSupplier(String proSupplier) {<br /> this.proSupplier = proSupplier;<br /> }<br /><br /> public String getProAmount() {<br /> return proAmount;<br /> }<br /> public void setProAmount(String proAmount) {<br /> this.proAmount = proAmount;<br /> }<br /> public String getProPrice() {<br /> return proPrice;<br /> }<br /> public void setProPrice(String proPrice) {<br /> this.proPrice = proPrice;<br /> }<br /> public Product() {<br /><br /> }<br /> @Override<br /> public String toString() {<br /> return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice<br /> + ", proStyle=" + proStyle + ", proSupplier=" + proSupplier<br /> + "]";<br /> }<br /><br />}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据
获取数据成功,这就是我们要获取的最终数据结果。最后想说,这里的这个网页比较简单,在网页的源码中可以看到源数据,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是提示一下,我们可以使用多线程对所有页面的当前数据执行采集,并通过一个线程采集当前页面数据和一个翻页动作,所有数据都可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
原链接
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行格式转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门针对httpclient+jsoup进行讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:.NET.cn/userSite/publicQuote/quotes_list。PHP我们要提取里面的数据,最终我们要提取的结果是产品模型,数量,报价,供应商,首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;<br />import java.io.InputStream;<br />import java.io.InputStreamReader;<br />import java.net.HttpURLConnection;<br />import java.net.URL;<br />import java.util.ArrayList;<br />import java.util.List;<br />import java.util.regex.Matcher;<br />import java.util.regex.Pattern;<br /><br />public class HTMLPageParser {<br /> public static void main(String[] args) throws Exception {<br /> //目的网页URL地址<br /> getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");<br /> }<br /> public static List getURLInfo(String urlInfo,String charset) throws Exception {<br /> //读取目的网页URL地址,获取网页源码<br /> URL url = new URL(urlInfo);<br /> HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();<br /> InputStream is = httpUrl.getInputStream();<br /> BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));<br /> StringBuilder sb = new StringBuilder();<br /> String line;<br /> while ((line = br.readLine()) != null) {<br /> //这里是对链接进行处理<br /> line = line.replaceAll("]*>", "");<br /> //这里是对样式进行处理<br /> line = line.replaceAll("]*>", "");<br /> sb.append(line);<br /> }<br /> is.close();<br /> br.close();<br /> //获得网页源码<br /> return getDataStructure(sb.toString().trim());<br /> }<br /> static Pattern proInfo <br /> = Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);<br /> private static List getDataStructure(String str) {<br /> //运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,<br /> //现在暂时运用正则表达式对数据进行抽取提取<br /> String[] info = str.split("");<br /> List list = new ArrayList();<br /> for (String s : info) {<br /> Matcher m = proInfo.matcher(s);<br /> Product p = null;<br /> if (m.find()) {<br /> p = new Product();<br /> //设置产品型号<br /> String[] ss = m.group(1).trim().replace(" ", "").split(">");<br /> p.setProStyle(ss[1]);<br /> //设置产品数量<br /> p.setProAmount(m.group(2).trim().replace(" ", ""));<br /> //设置产品报价<br /> p.setProPrice(m.group(4).trim().replace(" ", ""));<br /> //设置产品供应商<br /> p.setProSupplier(m.group(5).trim().replace(" ", ""));<br /> list.add(p);<br /> }<br /> }<br /> //这里对集合里面不是我们要提取的数据进行移除<br /> list.remove(0);<br /> for (int i = 0; i < list.size(); i++) {<br /> System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()<br /> +",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());<br /> }<br /> return list;<br /> }<br />}<br />class Product {<br /> private String proStyle;//产品型号<br /> private String proAmount;//产品数量<br /> private String proPrice;//产品报价<br /> private String proSupplier;//产品供应商<br /> public String getProStyle() {<br /> return proStyle;<br /> }<br /> public void setProStyle(String proStyle) {<br /> this.proStyle = proStyle;<br /> }<br /> public String getProSupplier() {<br /> return proSupplier;<br /> }<br /> public void setProSupplier(String proSupplier) {<br /> this.proSupplier = proSupplier;<br /> }<br /><br /> public String getProAmount() {<br /> return proAmount;<br /> }<br /> public void setProAmount(String proAmount) {<br /> this.proAmount = proAmount;<br /> }<br /> public String getProPrice() {<br /> return proPrice;<br /> }<br /> public void setProPrice(String proPrice) {<br /> this.proPrice = proPrice;<br /> }<br /> public Product() {<br /><br /> }<br /> @Override<br /> public String toString() {<br /> return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice<br /> + ", proStyle=" + proStyle + ", proSupplier=" + proSupplier<br /> + "]";<br /> }<br /><br />}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据
获取数据成功,这就是我们要获取的最终数据结果。最后想说,这里的这个网页比较简单,在网页的源码中可以看到源数据,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是提示一下,我们可以使用多线程对所有页面的当前数据执行采集,并通过一个线程采集当前页面数据和一个翻页动作,所有数据都可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-04-07 17:35
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:
" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:
" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:
" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:
" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据( 如何通过WebCollector抓取到内容,?, )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-04-06 14:36
如何通过WebCollector抓取到内容,?,
)
前言
上一篇文章我们简单讲了如何通过WebCollector来抓取内容,但这不符合我们的工作需要。在工作过程中,我们通常会抓取某个网页列表下的详情页数据,所以不能简单的从某个列表页抓取数据,需要跳转到详情页进行二次抓取数据. 好了,废话不多说,我们先从代码开始讲解如何操作。
爬取列表信息
假设我们抓取搜东首页显示文章的所有细节。如下图所示。
第一步,我们不忙于创建爬虫,我们先分析一下我们需要爬取的网站的结构。根据我们需要的网页的URL地址的特点,写出正确的正则表达式。如下所示。
http://www.jianshu.com/p/700e01a938ce
我编写的匹配 文章 URL 的正则表达式如下所示。
"http://www.jianshu.com/p/.*"
第二步,正则表达式写好后,我们需要分析一下我们抓取到的网站的结构和标签。以谷歌浏览器为例。打开开发者模式的控制台。(Mac 常用的 F12 键 ++ alt +i,这里不再赘述),假设我们需要抓取 文章 的标题和内容。我们首先选择“选择工具”(快捷键:command +shift +c),然后点击标题,此时控制台中会出现标签信息。如下所示。
我们发现title的标签h1的Class就是title,如下图。
标题已经准备好了。接下来,我们来看看内容。经过以上步骤,我们发现内容在很多标签中。这时候我们只需要获取父类标签中的所有内容即可。
对了,首页的列表页也是如上做的。如下图,所有的超链接都是一个标签。
第三步,我们还是创建一个爬虫类JianshuCrawler,继承自AbstractCrawler,然后在初始化方法中配置我们的正则表达式和我们需要爬取的网站种子。其他一些配置如下。
private final static String crawlPath = "/Users/luying/data/db/sports";
private final static String seed = "http://www.jianshu.com/u/e39da354ce50";
private final static String regexRuleString = "http://www.jianshu.com/p/.*";
public JianshuCrawler() {
super(crawlPath, false);
CrawlDatum datum = new CrawlDatum(seed).meta("depth", "2");
addSeed(datum);
this.addRegex(regexRuleString);
setThreads(2);
}
在访问方法中,我们需要做两种处理,一种是爬取文章列表,另一种是爬取文章详情页的内容。所以我们需要用详情页URL的正则表达式来区分文章详情页和列表首页,结构如下。
@Override
public void visit(Page page, CrawlDatums next) {
if (page.matchUrl(regexRuleString)) {
//详情页会进入这个模块
} else {
//列表首页会进入这个模块
}
}
通过第二步的分析,我们知道列表页需要将所有超链接符合正则表达式的a标签添加到爬取序列中。具体操作如下。
Elements aBodys = page.select("a");
for (int i = 0; i < aBodys.size(); i++) {
Element aElement = aBodys.get(i);
logger.debug("url=" + aElement.attr("abs:href"));
String regEx = regexRuleString;
if (aElement.attr("abs:href").matches(regEx)) {
CrawlDatum datum = new CrawlDatum(aElement.attr("abs:href")).meta("depth", "1").meta("refer",
page.url());
next.add(datum);
} else {
System.out.println("URL不匹配!!");
}
}
对于详情页的逻辑,我们需要抓取对应元素的内容,可以使用类名(表单示例:div.xxx)或id名(表单示例:div[id = xxx]),这里没有id,所以我们直接使用类名,代码如下。
String title = page.select("h1.title").text();
String content = page.select("div.show-content").text();
我们创建一个 main 函数来创建我们的爬虫对象。然后,我们需要设置爬取深度,因为我们只需要跳转到页面一次,所以我们的爬取深度是 2. 最后运行这个类。如下图所示。
public static void main(String[] args) {
JianshuCrawler crawler = new JianshuCrawler();
crawler.start(2);
}
这样,我们就会在控制台中得到我们想要的数据。当然,对数据的处理,这里就不过多解释了。如下图所示。
爬虫类的完整代码如下所示。
public class JianshuCrawler extends AbstractCrawler {
private static Logger logger = LoggerFactory.getLogger(JianshuCrawler.class);
private final static String crawlPath = "/Users/luying/data/db/sports";
private final static String seed = "http://www.jianshu.com/u/e39da354ce50";
private final static String regexRuleString = "http://www.jianshu.com/p/.*";
public JianshuCrawler() {
super(crawlPath, false);
CrawlDatum datum = new CrawlDatum(seed).meta("depth", "2");
addSeed(datum);
this.addRegex(regexRuleString);
setThreads(2);
}
@Override
public void visit(Page page, CrawlDatums next) {
if (page.matchUrl(regexRuleString)) {
String title = page.select("h1.title").text();
String content = page.select("div.show-content").text();
System.out.println("标题 " + title);
System.out.println("内容 " + content);
} else {
Elements aBodys = page.select("a");
for (int i = 0; i < aBodys.size(); i++) {
Element aElement = aBodys.get(i);
logger.debug("url=" + aElement.attr("abs:href"));
String regEx = regexRuleString;
if (aElement.attr("abs:href").matches(regEx)) {
CrawlDatum datum = new CrawlDatum(aElement.attr("abs:href")).meta("depth", "1").meta("refer",
page.url());
next.add(datum);
} else {
System.out.println("URL不匹配!!");
}
}
}
}
public static void main(String[] args) {
JianshuCrawler crawler = new JianshuCrawler();
crawler.start(2);
}
}
抓取图像信息
刮图片更简单。假设我们仍然爬取搜东首页中所有显示的图片。如下所示。
爬虫类的基本步骤就不过多解释了。先说一下访问方面的处理。我们需要网页中标签的属性来判断。只有html属性和图片属性的标签可以是图片标签。所以我们首先得到如下图的标签名。
String contentType = page.response().contentType();
然后判断标签中收录的名称。如下所示执行不同的操作。
if (contentType == null) {
return;
} else if (contentType.contains("html")) {
// 如果是网页,则抽取其中包含图片的URL,放入后续任务
} else if (contentType.startsWith("image")) {
// 如果是图片,直接下载
}
标签是网页属性的处理,我们需要把里面的图片地址链接取出来,为接下来的处理做准备。代码如下。
Elements imgs = page.select("img[src]");
for (Element img : imgs) {
String imgSrc = img.attr("abs:src");
next.add(imgSrc);
}
如果是图片标签,我们可以直接取图片的字节数据存储。代码如下。
String extensionName = contentType.split("/")[1];
String imageFileName = imageId.incrementAndGet() + "." + extensionName;
File imageFile = new File(downloadDir, imageFileName);
try {
FileUtils.write(imageFile, page.content());
System.out.println("保存图片 " + page.url() + " 到 " + imageFile.getAbsolutePath());
} catch (IOException ex) {
throw new RuntimeException(ex);
}
因为,标签类型可能是网页,也就是说,我们需要跳转到下一页。这时候我们在main函数中创建了一个对象,需要设置爬取深度为2.
public static void main(String[] args) throws Exception {
JianshuImageCrawler crawler = new JianshuImageCrawler();
crawler.start(2);
}
图片的存储过程就不过多解释了。通过运行,我们可以在对应的存储路径下找到我们的图片。如下所示。
整体代码如下所示。
package com.infosports.yuqingmanagement.crawler.impl;
import java.io.File;
import java.io.IOException;
import java.util.concurrent.atomic.AtomicInteger;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatum;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.plugin.berkeley.BreadthCrawler;
import cn.edu.hfut.dmic.webcollector.util.FileUtils;
import cn.edu.hfut.dmic.webcollector.util.RegexRule;
public class JianshuImageCrawler extends BreadthCrawler {
// 用于保存图片的文件夹
File downloadDir;
// 原子性int,用于生成图片文件名
AtomicInteger imageId;
private final static String crawlPath = "/Users/luying/data/db/jianshu";
private final static String downPath = "/Users/luying/data/db/jianshuImage";
private final static String seed = "http://www.jianshu.com/u/e39da354ce50";
RegexRule regexRule = new RegexRule();
public JianshuImageCrawler() {
super(crawlPath, false);
downloadDir = new File(downPath);
if (!downloadDir.exists()) {
downloadDir.mkdirs();
}
computeImageId();
CrawlDatum datum = new CrawlDatum(seed).meta("depth", "2");
addSeed(datum);
regexRule.addRule("http://.*");
}
@Override
public void visit(Page page, CrawlDatums next) {
String contentType = page.response().contentType();
if (contentType == null) {
return;
} else if (contentType.contains("html")) {
// 如果是网页,则抽取其中包含图片的URL,放入后续任务
Elements imgs = page.select("img[src]");
for (Element img : imgs) {
String imgSrc = img.attr("abs:src");
next.add(imgSrc);
}
} else if (contentType.startsWith("image")) {
// 如果是图片,直接下载
String extensionName = contentType.split("/")[1];
String imageFileName = imageId.incrementAndGet() + "." + extensionName;
File imageFile = new File(downloadDir, imageFileName);
try {
FileUtils.write(imageFile, page.content());
System.out.println("保存图片 " + page.url() + " 到 " + imageFile.getAbsolutePath());
} catch (IOException ex) {
throw new RuntimeException(ex);
}
}
}
public void computeImageId() {
int maxId = -1;
for (File imageFile : downloadDir.listFiles()) {
String fileName = imageFile.getName();
String idStr = fileName.split("\\.")[0];
int id = Integer.valueOf(idStr);
if (id > maxId) {
maxId = id;
}
}
imageId = new AtomicInteger(maxId);
}
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
JianshuImageCrawler crawler = new JianshuImageCrawler();
crawler.start(2);
}
总结
本篇博客到此结束,但是分享技术点的过程还没有结束。当然,毕竟Java刚入门不久,所以文章很多概念可能有歧义,如有错误,欢迎指导批评,万分感谢。
查看全部
java从网页抓取数据(
如何通过WebCollector抓取到内容,?,
)
前言
上一篇文章我们简单讲了如何通过WebCollector来抓取内容,但这不符合我们的工作需要。在工作过程中,我们通常会抓取某个网页列表下的详情页数据,所以不能简单的从某个列表页抓取数据,需要跳转到详情页进行二次抓取数据. 好了,废话不多说,我们先从代码开始讲解如何操作。
爬取列表信息
假设我们抓取搜东首页显示文章的所有细节。如下图所示。
第一步,我们不忙于创建爬虫,我们先分析一下我们需要爬取的网站的结构。根据我们需要的网页的URL地址的特点,写出正确的正则表达式。如下所示。
http://www.jianshu.com/p/700e01a938ce
我编写的匹配 文章 URL 的正则表达式如下所示。
"http://www.jianshu.com/p/.*"
第二步,正则表达式写好后,我们需要分析一下我们抓取到的网站的结构和标签。以谷歌浏览器为例。打开开发者模式的控制台。(Mac 常用的 F12 键 ++ alt +i,这里不再赘述),假设我们需要抓取 文章 的标题和内容。我们首先选择“选择工具”(快捷键:command +shift +c),然后点击标题,此时控制台中会出现标签信息。如下所示。
我们发现title的标签h1的Class就是title,如下图。
标题已经准备好了。接下来,我们来看看内容。经过以上步骤,我们发现内容在很多标签中。这时候我们只需要获取父类标签中的所有内容即可。
对了,首页的列表页也是如上做的。如下图,所有的超链接都是一个标签。
第三步,我们还是创建一个爬虫类JianshuCrawler,继承自AbstractCrawler,然后在初始化方法中配置我们的正则表达式和我们需要爬取的网站种子。其他一些配置如下。
private final static String crawlPath = "/Users/luying/data/db/sports";
private final static String seed = "http://www.jianshu.com/u/e39da354ce50";
private final static String regexRuleString = "http://www.jianshu.com/p/.*";
public JianshuCrawler() {
super(crawlPath, false);
CrawlDatum datum = new CrawlDatum(seed).meta("depth", "2");
addSeed(datum);
this.addRegex(regexRuleString);
setThreads(2);
}
在访问方法中,我们需要做两种处理,一种是爬取文章列表,另一种是爬取文章详情页的内容。所以我们需要用详情页URL的正则表达式来区分文章详情页和列表首页,结构如下。
@Override
public void visit(Page page, CrawlDatums next) {
if (page.matchUrl(regexRuleString)) {
//详情页会进入这个模块
} else {
//列表首页会进入这个模块
}
}
通过第二步的分析,我们知道列表页需要将所有超链接符合正则表达式的a标签添加到爬取序列中。具体操作如下。
Elements aBodys = page.select("a");
for (int i = 0; i < aBodys.size(); i++) {
Element aElement = aBodys.get(i);
logger.debug("url=" + aElement.attr("abs:href"));
String regEx = regexRuleString;
if (aElement.attr("abs:href").matches(regEx)) {
CrawlDatum datum = new CrawlDatum(aElement.attr("abs:href")).meta("depth", "1").meta("refer",
page.url());
next.add(datum);
} else {
System.out.println("URL不匹配!!");
}
}
对于详情页的逻辑,我们需要抓取对应元素的内容,可以使用类名(表单示例:div.xxx)或id名(表单示例:div[id = xxx]),这里没有id,所以我们直接使用类名,代码如下。
String title = page.select("h1.title").text();
String content = page.select("div.show-content").text();
我们创建一个 main 函数来创建我们的爬虫对象。然后,我们需要设置爬取深度,因为我们只需要跳转到页面一次,所以我们的爬取深度是 2. 最后运行这个类。如下图所示。
public static void main(String[] args) {
JianshuCrawler crawler = new JianshuCrawler();
crawler.start(2);
}
这样,我们就会在控制台中得到我们想要的数据。当然,对数据的处理,这里就不过多解释了。如下图所示。
爬虫类的完整代码如下所示。
public class JianshuCrawler extends AbstractCrawler {
private static Logger logger = LoggerFactory.getLogger(JianshuCrawler.class);
private final static String crawlPath = "/Users/luying/data/db/sports";
private final static String seed = "http://www.jianshu.com/u/e39da354ce50";
private final static String regexRuleString = "http://www.jianshu.com/p/.*";
public JianshuCrawler() {
super(crawlPath, false);
CrawlDatum datum = new CrawlDatum(seed).meta("depth", "2");
addSeed(datum);
this.addRegex(regexRuleString);
setThreads(2);
}
@Override
public void visit(Page page, CrawlDatums next) {
if (page.matchUrl(regexRuleString)) {
String title = page.select("h1.title").text();
String content = page.select("div.show-content").text();
System.out.println("标题 " + title);
System.out.println("内容 " + content);
} else {
Elements aBodys = page.select("a");
for (int i = 0; i < aBodys.size(); i++) {
Element aElement = aBodys.get(i);
logger.debug("url=" + aElement.attr("abs:href"));
String regEx = regexRuleString;
if (aElement.attr("abs:href").matches(regEx)) {
CrawlDatum datum = new CrawlDatum(aElement.attr("abs:href")).meta("depth", "1").meta("refer",
page.url());
next.add(datum);
} else {
System.out.println("URL不匹配!!");
}
}
}
}
public static void main(String[] args) {
JianshuCrawler crawler = new JianshuCrawler();
crawler.start(2);
}
}
抓取图像信息
刮图片更简单。假设我们仍然爬取搜东首页中所有显示的图片。如下所示。
爬虫类的基本步骤就不过多解释了。先说一下访问方面的处理。我们需要网页中标签的属性来判断。只有html属性和图片属性的标签可以是图片标签。所以我们首先得到如下图的标签名。
String contentType = page.response().contentType();
然后判断标签中收录的名称。如下所示执行不同的操作。
if (contentType == null) {
return;
} else if (contentType.contains("html")) {
// 如果是网页,则抽取其中包含图片的URL,放入后续任务
} else if (contentType.startsWith("image")) {
// 如果是图片,直接下载
}
标签是网页属性的处理,我们需要把里面的图片地址链接取出来,为接下来的处理做准备。代码如下。
Elements imgs = page.select("img[src]");
for (Element img : imgs) {
String imgSrc = img.attr("abs:src");
next.add(imgSrc);
}
如果是图片标签,我们可以直接取图片的字节数据存储。代码如下。
String extensionName = contentType.split("/")[1];
String imageFileName = imageId.incrementAndGet() + "." + extensionName;
File imageFile = new File(downloadDir, imageFileName);
try {
FileUtils.write(imageFile, page.content());
System.out.println("保存图片 " + page.url() + " 到 " + imageFile.getAbsolutePath());
} catch (IOException ex) {
throw new RuntimeException(ex);
}
因为,标签类型可能是网页,也就是说,我们需要跳转到下一页。这时候我们在main函数中创建了一个对象,需要设置爬取深度为2.
public static void main(String[] args) throws Exception {
JianshuImageCrawler crawler = new JianshuImageCrawler();
crawler.start(2);
}
图片的存储过程就不过多解释了。通过运行,我们可以在对应的存储路径下找到我们的图片。如下所示。
整体代码如下所示。
package com.infosports.yuqingmanagement.crawler.impl;
import java.io.File;
import java.io.IOException;
import java.util.concurrent.atomic.AtomicInteger;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatum;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.plugin.berkeley.BreadthCrawler;
import cn.edu.hfut.dmic.webcollector.util.FileUtils;
import cn.edu.hfut.dmic.webcollector.util.RegexRule;
public class JianshuImageCrawler extends BreadthCrawler {
// 用于保存图片的文件夹
File downloadDir;
// 原子性int,用于生成图片文件名
AtomicInteger imageId;
private final static String crawlPath = "/Users/luying/data/db/jianshu";
private final static String downPath = "/Users/luying/data/db/jianshuImage";
private final static String seed = "http://www.jianshu.com/u/e39da354ce50";
RegexRule regexRule = new RegexRule();
public JianshuImageCrawler() {
super(crawlPath, false);
downloadDir = new File(downPath);
if (!downloadDir.exists()) {
downloadDir.mkdirs();
}
computeImageId();
CrawlDatum datum = new CrawlDatum(seed).meta("depth", "2");
addSeed(datum);
regexRule.addRule("http://.*");
}
@Override
public void visit(Page page, CrawlDatums next) {
String contentType = page.response().contentType();
if (contentType == null) {
return;
} else if (contentType.contains("html")) {
// 如果是网页,则抽取其中包含图片的URL,放入后续任务
Elements imgs = page.select("img[src]");
for (Element img : imgs) {
String imgSrc = img.attr("abs:src");
next.add(imgSrc);
}
} else if (contentType.startsWith("image")) {
// 如果是图片,直接下载
String extensionName = contentType.split("/")[1];
String imageFileName = imageId.incrementAndGet() + "." + extensionName;
File imageFile = new File(downloadDir, imageFileName);
try {
FileUtils.write(imageFile, page.content());
System.out.println("保存图片 " + page.url() + " 到 " + imageFile.getAbsolutePath());
} catch (IOException ex) {
throw new RuntimeException(ex);
}
}
}
public void computeImageId() {
int maxId = -1;
for (File imageFile : downloadDir.listFiles()) {
String fileName = imageFile.getName();
String idStr = fileName.split("\\.")[0];
int id = Integer.valueOf(idStr);
if (id > maxId) {
maxId = id;
}
}
imageId = new AtomicInteger(maxId);
}
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
JianshuImageCrawler crawler = new JianshuImageCrawler();
crawler.start(2);
}
总结
本篇博客到此结束,但是分享技术点的过程还没有结束。当然,毕竟Java刚入门不久,所以文章很多概念可能有歧义,如有错误,欢迎指导批评,万分感谢。

