
java从网页抓取数据
java从网页抓取数据( java多线程获取铃声的json数据()(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-04-02 18:24
java多线程获取铃声的json数据()(图)
)
java多线程抓取铃声官网的铃声数据
更新时间:2016-04-28 11:50:47 作者:bobo_ll
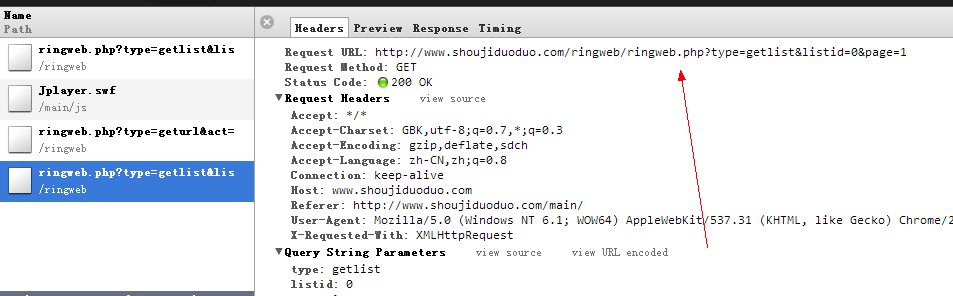
不难发现,通过改变listId和page,可以从服务端获取铃声的json数据。通过解析json数据可以看到有{"hasmore":1,"curpage":1}等指令,通过判断hasmore的值来决定是否取下一页。但是上面链接返回的json没有铃声的下载地址
我一直想练习java多线程来获取数据。
有一天我发现Ringtones()的官网有很多数据。
通过观察它们的前端来获取铃声数据的ajax
{类别 ID}&page={分页符页码}
不难发现,通过改变listId和page,可以从服务端获取铃声的json数据,通过解析json数据,
可以看到有{"hasmore":1,"curpage":1}这样的指令。通过判断hasmore的值,决定是否爬取下一页。
但是上面链接返回的json没有铃声的下载地址
你很快就会发现,点击页面上的“下载”,你会看到
通过以下请求,可以得到铃声的下载地址
{铃声ID}
因此,他们的数据很容易被窃取。于是我开始...
源代码已发布在 github 上。如果您对童鞋感兴趣,可以查看
github:
以上代码:
package me.yongbo.DuoduoRingRobot;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
import java.util.Iterator;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import com.google.gson.Gson;
import com.google.gson.JsonArray;
import com.google.gson.JsonElement;
import com.google.gson.JsonParser;
/* * @author yongbo_ * @created 2013/4/16 * * */
public class DuoduoRingRobotClient implements Runnable {
public static String GET_RINGINFO_URL = "http://www.shoujiduoduo.com/ri ... D%251$d&page=%2$d";
public static String GET_DOWN_URL = "http://www.shoujiduoduo.com/ri ... D%251$d";
public static String ERROR_MSG = "listId为 %1$d 的Robot发生错误,已自动停止。当前page为 %2$d";public static String STATUS_MSG = "开始抓取数据,当前listId: %1$d,当前page: %2$d";
public static String FILE_DIR = "E:/RingData/";public static String FILE_NAME = "listId=%1$d.txt";private boolean errorFlag = false;private int listId;private int page;
private int endPage = -1;private int hasMore = 1;
private DbHelper dbHelper;
/** * 构造函数 * @param listId 菜单ID * @param page 开始页码 * @param endPage 结束页码 * */
public DuoduoRingRobotClient(int listId, int beginPage, int endPage)
{this.listId = listId;this.page = beginPage;this.endPage = endPage;this.dbHelper = new DbHelper();}
/** * 构造函数 * @param listId 菜单ID * @param page 开始页码 * */
public DuoduoRingRobotClient(int listId, int page) {this(listId, page, -1);}
/** * 获取铃声 * */public void getRings() {String url = String.format(GET_RINGINFO_URL, listId, page);String responseStr = httpGet(url);hasMore = getHasmore(responseStr);
page = getNextPage(responseStr);
ringParse(responseStr.replaceAll("\\{\"hasmore\":[0-9]*,\"curpage\":[0-9]*\\},", "").replaceAll(",]", "]"));}/** * 发起http请求 * @param webUrl 请求连接地址 * */public String httpGet(String webUrl){URL url;URLConnection conn;StringBuilder sb = new StringBuilder();String resultStr = "";try {url = new URL(webUrl);conn = url.openConnection();conn.connect();InputStream is = conn.getInputStream();InputStreamReader isr = new InputStreamReader(is);BufferedReader bufReader = new BufferedReader(isr);String lineText;while ((lineText = bufReader.readLine()) != null) {sb.append(lineText);}resultStr = sb.toString();} catch (Exception e) {errorFlag = true;//将错误写入txtwriteToFile(String.format(ERROR_MSG, listId, page));}return resultStr;}/** * 将json字符串转化成Ring对象,并存入txt中 * @param json Json字符串 * */public void ringParse(String json) {Ring ring = null;JsonElement element = new JsonParser().parse(json);JsonArray array = element.getAsJsonArray();// 遍历数组Iterator it = array.iterator();
Gson gson = new Gson();while (it.hasNext() && !errorFlag) {JsonElement e = it.next();// JsonElement转换为JavaBean对象ring = gson.fromJson(e, Ring.class);ring.setDownUrl(getRingDownUrl(ring.getId()));if(isAvailableRing(ring)) {System.out.println(ring.toString());
//可选择写入数据库还是写入文本//writeToFile(ring.toString());writeToDatabase(ring);}}}
/** * 写入txt * @param data 字符串 * */public void writeToFile(String data)
{String path = FILE_DIR + String.format(FILE_NAME, listId);File dir = new File(FILE_DIR);File file = new File(path);FileWriter fw = null;if(!dir.exists()){dir.mkdirs();
}try {if(!file.exists()){file.createNewFile();}fw = new FileWriter(file, true);
fw.write(data);fw.write("\r\n");fw.flush();} catch (IOException e) {
// TODO Auto-generated catch blocke.printStackTrace();
}finally {try {if(fw != null){fw.close();}} catch (IOException e) {
// TODO Auto-generated catch blocke.printStackTrace();}}}/** * 写入数据库 * @param ring 一个Ring的实例 * */
public void writeToDatabase(Ring ring) {dbHelper.execute("addRing", ring);}
@Overridepublic void run() {while(hasMore == 1 && !errorFlag){if(endPage != -1){if(page > endPage) { break; }}System.out.println(String.format(STATUS_MSG, listId, page));
getRings();System.out.println(String.format("该页数据写入完成"));}System.out.println("ending...");}
private int getHasmore(String resultStr){Pattern p = Pattern.compile("\"hasmore\":([0-9]*),\"curpage\":([0-9]*)");
Matcher match = p.matcher(resultStr);
if (match.find()) { return Integer.parseInt(match.group(1));
} return 0;
}
private int getNextPage(String resultStr){Pattern p = Pattern.compile("\"hasmore\":([0-9]*),\"curpage\":([0-9]*)");Matcher match = p.matcher(resultStr);if (match.find()) {return Integer.parseInt(match.group(2));}return 0;}
/** * 判断当前Ring是否满足条件。当Ring的name大于50个字符或是duration为小数则不符合条件,将被剔除。 * @param ring 当前Ring对象实例 * */private boolean isAvailableRing(Ring ring){Pattern p = Pattern.compile("^[1-9][0-9]*$");
Matcher match = p.matcher(ring.getDuration());
if(!match.find()){return false;}if(ring.getName().length() > 50 || ring.getArtist().length() > 50 || ring.getDownUrl().length() == 0){return false;}return true;}
/** * 获取铃声的下载地址 * @param rid 铃声的id * */
public String getRingDownUrl(String rid){String url = String.format(GET_DOWN_URL, rid);
String responseStr = httpGet(url);return responseStr;}} 查看全部
java从网页抓取数据(
java多线程获取铃声的json数据()(图)
)
java多线程抓取铃声官网的铃声数据
更新时间:2016-04-28 11:50:47 作者:bobo_ll
不难发现,通过改变listId和page,可以从服务端获取铃声的json数据。通过解析json数据可以看到有{"hasmore":1,"curpage":1}等指令,通过判断hasmore的值来决定是否取下一页。但是上面链接返回的json没有铃声的下载地址
我一直想练习java多线程来获取数据。
有一天我发现Ringtones()的官网有很多数据。
通过观察它们的前端来获取铃声数据的ajax
{类别 ID}&page={分页符页码}
不难发现,通过改变listId和page,可以从服务端获取铃声的json数据,通过解析json数据,
可以看到有{"hasmore":1,"curpage":1}这样的指令。通过判断hasmore的值,决定是否爬取下一页。
但是上面链接返回的json没有铃声的下载地址
你很快就会发现,点击页面上的“下载”,你会看到
通过以下请求,可以得到铃声的下载地址
{铃声ID}

因此,他们的数据很容易被窃取。于是我开始...
源代码已发布在 github 上。如果您对童鞋感兴趣,可以查看
github:
以上代码:
package me.yongbo.DuoduoRingRobot;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
import java.util.Iterator;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import com.google.gson.Gson;
import com.google.gson.JsonArray;
import com.google.gson.JsonElement;
import com.google.gson.JsonParser;
/* * @author yongbo_ * @created 2013/4/16 * * */
public class DuoduoRingRobotClient implements Runnable {
public static String GET_RINGINFO_URL = "http://www.shoujiduoduo.com/ri ... D%251$d&page=%2$d";
public static String GET_DOWN_URL = "http://www.shoujiduoduo.com/ri ... D%251$d";
public static String ERROR_MSG = "listId为 %1$d 的Robot发生错误,已自动停止。当前page为 %2$d";public static String STATUS_MSG = "开始抓取数据,当前listId: %1$d,当前page: %2$d";
public static String FILE_DIR = "E:/RingData/";public static String FILE_NAME = "listId=%1$d.txt";private boolean errorFlag = false;private int listId;private int page;
private int endPage = -1;private int hasMore = 1;
private DbHelper dbHelper;
/** * 构造函数 * @param listId 菜单ID * @param page 开始页码 * @param endPage 结束页码 * */
public DuoduoRingRobotClient(int listId, int beginPage, int endPage)
{this.listId = listId;this.page = beginPage;this.endPage = endPage;this.dbHelper = new DbHelper();}
/** * 构造函数 * @param listId 菜单ID * @param page 开始页码 * */
public DuoduoRingRobotClient(int listId, int page) {this(listId, page, -1);}
/** * 获取铃声 * */public void getRings() {String url = String.format(GET_RINGINFO_URL, listId, page);String responseStr = httpGet(url);hasMore = getHasmore(responseStr);
page = getNextPage(responseStr);
ringParse(responseStr.replaceAll("\\{\"hasmore\":[0-9]*,\"curpage\":[0-9]*\\},", "").replaceAll(",]", "]"));}/** * 发起http请求 * @param webUrl 请求连接地址 * */public String httpGet(String webUrl){URL url;URLConnection conn;StringBuilder sb = new StringBuilder();String resultStr = "";try {url = new URL(webUrl);conn = url.openConnection();conn.connect();InputStream is = conn.getInputStream();InputStreamReader isr = new InputStreamReader(is);BufferedReader bufReader = new BufferedReader(isr);String lineText;while ((lineText = bufReader.readLine()) != null) {sb.append(lineText);}resultStr = sb.toString();} catch (Exception e) {errorFlag = true;//将错误写入txtwriteToFile(String.format(ERROR_MSG, listId, page));}return resultStr;}/** * 将json字符串转化成Ring对象,并存入txt中 * @param json Json字符串 * */public void ringParse(String json) {Ring ring = null;JsonElement element = new JsonParser().parse(json);JsonArray array = element.getAsJsonArray();// 遍历数组Iterator it = array.iterator();
Gson gson = new Gson();while (it.hasNext() && !errorFlag) {JsonElement e = it.next();// JsonElement转换为JavaBean对象ring = gson.fromJson(e, Ring.class);ring.setDownUrl(getRingDownUrl(ring.getId()));if(isAvailableRing(ring)) {System.out.println(ring.toString());
//可选择写入数据库还是写入文本//writeToFile(ring.toString());writeToDatabase(ring);}}}
/** * 写入txt * @param data 字符串 * */public void writeToFile(String data)
{String path = FILE_DIR + String.format(FILE_NAME, listId);File dir = new File(FILE_DIR);File file = new File(path);FileWriter fw = null;if(!dir.exists()){dir.mkdirs();
}try {if(!file.exists()){file.createNewFile();}fw = new FileWriter(file, true);
fw.write(data);fw.write("\r\n");fw.flush();} catch (IOException e) {
// TODO Auto-generated catch blocke.printStackTrace();
}finally {try {if(fw != null){fw.close();}} catch (IOException e) {
// TODO Auto-generated catch blocke.printStackTrace();}}}/** * 写入数据库 * @param ring 一个Ring的实例 * */
public void writeToDatabase(Ring ring) {dbHelper.execute("addRing", ring);}
@Overridepublic void run() {while(hasMore == 1 && !errorFlag){if(endPage != -1){if(page > endPage) { break; }}System.out.println(String.format(STATUS_MSG, listId, page));
getRings();System.out.println(String.format("该页数据写入完成"));}System.out.println("ending...");}
private int getHasmore(String resultStr){Pattern p = Pattern.compile("\"hasmore\":([0-9]*),\"curpage\":([0-9]*)");
Matcher match = p.matcher(resultStr);
if (match.find()) { return Integer.parseInt(match.group(1));
} return 0;
}
private int getNextPage(String resultStr){Pattern p = Pattern.compile("\"hasmore\":([0-9]*),\"curpage\":([0-9]*)");Matcher match = p.matcher(resultStr);if (match.find()) {return Integer.parseInt(match.group(2));}return 0;}
/** * 判断当前Ring是否满足条件。当Ring的name大于50个字符或是duration为小数则不符合条件,将被剔除。 * @param ring 当前Ring对象实例 * */private boolean isAvailableRing(Ring ring){Pattern p = Pattern.compile("^[1-9][0-9]*$");
Matcher match = p.matcher(ring.getDuration());
if(!match.find()){return false;}if(ring.getName().length() > 50 || ring.getArtist().length() > 50 || ring.getDownUrl().length() == 0){return false;}return true;}
/** * 获取铃声的下载地址 * @param rid 铃声的id * */
public String getRingDownUrl(String rid){String url = String.format(GET_DOWN_URL, rid);
String responseStr = httpGet(url);return responseStr;}}
java从网页抓取数据( 我个人网站一个页面为例(3.1)什么是Jsoup技术? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-04-01 20:15
我个人网站一个页面为例(3.1)什么是Jsoup技术?
)
(2.4)为了避免其他网站侵权问题,我们以我自己的一个页面网站为例(),我们把这个页面上的图片全部抓取.
(2.5) 可以看出这是一个get请求,返回一个Html页面。所以我们在HttpTool类中添加如下方法体:
/**
* 实现Get请求
* @param url 请求地址
* @return 页面内容
*/
public static String doGet(String url) {
return null;
}
(2.6)复制代码,添加get实现方法:
// 构建get请求
HttpGet get = new HttpGet(url);
// 创建客户端
CloseableHttpClient client = HttpClients.createDefault();
try {
// 客户端执行请求,获取响应
HttpResponse response = client.execute(get);
// 获取响应的页面内容
InputStream in = response.getEntity().getContent();
StringBuilder sb = new StringBuilder();
byte[]b = new byte[102400];
int length;
while ((length = in.read(b)) != -1) {
sb.append(new String(b, 0, length, "utf-8"));
}
// 返回页面内容
return sb.toString();
} catch (Exception e) {
e.printStackTrace();
return null;
}
(2.7)好的,网络请求相关的实现类我们已经写好了,接下来我们测试一下,我们在Test类的main方法中添加如下代码:
String html = HttpTool.doGet("http://www.zyqok.cn/material/index");
System.out.println(html);
(2.8)执行程序,查看结果,可以看到我们确实通过请求得到了网页的返回内容。
[3] Jsoup解析网页
在[2]的整个实现过程中,我们已经得到了网页返回的数据,但是我们要的是整个网页中的图片,而不是这种乱七八糟的网页数据,那我们该怎么办呢?很简单,接下来我们需要使用另一种技术——Jsoup。
(3.1)什么是Jsoup技术?
以下是度娘官方给出的解释:Jsoup是一个Java HTML解析器,可以直接解析一个URL地址和HTML文本内容。它提供了一个非常省力的API,用于通过DOM、CSS和类似jQuery的操作方法(取自百度)来获取和操作数据。
以下是我个人语言的简单总结: Jsoup技术用于处理各种html页面和xml数据。这里我们可以使用Jsoup来处理[2]中返回的html页面。
(3.2)添加Jsoup依赖
我们在 pom.xml 中添加以下依赖项:
org.jsoup
jsoup
1.11.3
(3.3) 当然,在使用Jsoup之前,我们需要对响应的HTML页面进行分析。分析的主要作用是:如何定位和过滤掉我们需要的数据?
我们将[2]中得到的页面响应复制到txt文本中,然后我们可以发现每张图片都收录在一个div中,并且该div有一个名为material-div的类。
(3.4)根据上面的分析:首先我们需要获取所有收录图片的div,所以我们修改main方法中的代码如下:
String html = HttpTool.doGet("http://www.zyqok.cn/material/index");
// 将 html 页面解析为 Document 对象
Document doc = Jsoup.parse(html);
// 获取所有包含 class = material-div 的 div 元素
Elements elements = doc.select("div.material-div");
for(Element div: elements){
System.out.println(div.toString());
}
注意:doc.select()括号内的参数为过滤条件,基本等价于jquery的过滤条件。所以,懂jquery的同学基本都能搞定过滤条件。当然,如果你不会写过滤条件也不要害怕。Jsoup 用户指南的副本,您不妨接受它(传送门:Jsoup 官方用户指南)。
(3.5)我们执行代码,继续将输出复制到文本中。
可以看到,这次只有图片相关的div元素,但这并不是我们想要的最终结果。我们最终的结果是得到所有的图片。
所以我们还需要继续分析:如何获取所有图片的链接和名称。
(3.6)由于每张图片所在的div元素的结构都是一样的,我们可以随机取一个div元素进行分析,所以可以取第一个div进行分析,结构为如下:
大树夕阳.jpg
2020-04-14 22:09:46
3.7)我们可以看到整个结构中只有一个img元素标签,所以我们可以把第一个img标签的src属性作为图片链接;同理,我们取第一个 font 元素的文本内容为图片名称。
(3.8)所以我们可以修改循环中的代码如下:
// 获取第1个 img 元素Element img = div.selectFirst("img");// 获取第1个 font 元素Element font = div.selectFirst("font");// 获取img元素src属性,即为图片链接String url = img.attr("src");// 获取name元素文本,即为图片名称String name = font.text();System.out.println(name + ": " + url);
(3.9)我们执行上面的代码,可以得到如下结果。
可以看到,这个页面上的所有图片地址和名字都已经被我们成功抓取了。
[4] 获取图片到本地
在步骤[3]中,我们得到的只是所有图片的链接,并且所有的图片都没有下载到我们的本地,那么接下来,我们需要把这张图片下载到我们的本地才算完整。
(4.1)既然要下载到本地,就先在本地找个地方存放这些图片。
例如:我将所有图片下载到D:\imgs(D盘的imgs文件夹)。
查看全部
java从网页抓取数据(
我个人网站一个页面为例(3.1)什么是Jsoup技术?
)
(2.4)为了避免其他网站侵权问题,我们以我自己的一个页面网站为例(),我们把这个页面上的图片全部抓取.
(2.5) 可以看出这是一个get请求,返回一个Html页面。所以我们在HttpTool类中添加如下方法体:
/**
* 实现Get请求
* @param url 请求地址
* @return 页面内容
*/
public static String doGet(String url) {
return null;
}
(2.6)复制代码,添加get实现方法:
// 构建get请求
HttpGet get = new HttpGet(url);
// 创建客户端
CloseableHttpClient client = HttpClients.createDefault();
try {
// 客户端执行请求,获取响应
HttpResponse response = client.execute(get);
// 获取响应的页面内容
InputStream in = response.getEntity().getContent();
StringBuilder sb = new StringBuilder();
byte[]b = new byte[102400];
int length;
while ((length = in.read(b)) != -1) {
sb.append(new String(b, 0, length, "utf-8"));
}
// 返回页面内容
return sb.toString();
} catch (Exception e) {
e.printStackTrace();
return null;
}
(2.7)好的,网络请求相关的实现类我们已经写好了,接下来我们测试一下,我们在Test类的main方法中添加如下代码:
String html = HttpTool.doGet("http://www.zyqok.cn/material/index";);
System.out.println(html);
(2.8)执行程序,查看结果,可以看到我们确实通过请求得到了网页的返回内容。
[3] Jsoup解析网页
在[2]的整个实现过程中,我们已经得到了网页返回的数据,但是我们要的是整个网页中的图片,而不是这种乱七八糟的网页数据,那我们该怎么办呢?很简单,接下来我们需要使用另一种技术——Jsoup。
(3.1)什么是Jsoup技术?
以下是度娘官方给出的解释:Jsoup是一个Java HTML解析器,可以直接解析一个URL地址和HTML文本内容。它提供了一个非常省力的API,用于通过DOM、CSS和类似jQuery的操作方法(取自百度)来获取和操作数据。
以下是我个人语言的简单总结: Jsoup技术用于处理各种html页面和xml数据。这里我们可以使用Jsoup来处理[2]中返回的html页面。
(3.2)添加Jsoup依赖
我们在 pom.xml 中添加以下依赖项:
org.jsoup
jsoup
1.11.3
(3.3) 当然,在使用Jsoup之前,我们需要对响应的HTML页面进行分析。分析的主要作用是:如何定位和过滤掉我们需要的数据?
我们将[2]中得到的页面响应复制到txt文本中,然后我们可以发现每张图片都收录在一个div中,并且该div有一个名为material-div的类。
(3.4)根据上面的分析:首先我们需要获取所有收录图片的div,所以我们修改main方法中的代码如下:
String html = HttpTool.doGet("http://www.zyqok.cn/material/index";);
// 将 html 页面解析为 Document 对象
Document doc = Jsoup.parse(html);
// 获取所有包含 class = material-div 的 div 元素
Elements elements = doc.select("div.material-div");
for(Element div: elements){
System.out.println(div.toString());
}
注意:doc.select()括号内的参数为过滤条件,基本等价于jquery的过滤条件。所以,懂jquery的同学基本都能搞定过滤条件。当然,如果你不会写过滤条件也不要害怕。Jsoup 用户指南的副本,您不妨接受它(传送门:Jsoup 官方用户指南)。
(3.5)我们执行代码,继续将输出复制到文本中。
可以看到,这次只有图片相关的div元素,但这并不是我们想要的最终结果。我们最终的结果是得到所有的图片。
所以我们还需要继续分析:如何获取所有图片的链接和名称。
(3.6)由于每张图片所在的div元素的结构都是一样的,我们可以随机取一个div元素进行分析,所以可以取第一个div进行分析,结构为如下:

大树夕阳.jpg
2020-04-14 22:09:46
3.7)我们可以看到整个结构中只有一个img元素标签,所以我们可以把第一个img标签的src属性作为图片链接;同理,我们取第一个 font 元素的文本内容为图片名称。
(3.8)所以我们可以修改循环中的代码如下:
// 获取第1个 img 元素Element img = div.selectFirst("img");// 获取第1个 font 元素Element font = div.selectFirst("font");// 获取img元素src属性,即为图片链接String url = img.attr("src");// 获取name元素文本,即为图片名称String name = font.text();System.out.println(name + ": " + url);
(3.9)我们执行上面的代码,可以得到如下结果。
可以看到,这个页面上的所有图片地址和名字都已经被我们成功抓取了。
[4] 获取图片到本地
在步骤[3]中,我们得到的只是所有图片的链接,并且所有的图片都没有下载到我们的本地,那么接下来,我们需要把这张图片下载到我们的本地才算完整。
(4.1)既然要下载到本地,就先在本地找个地方存放这些图片。
例如:我将所有图片下载到D:\imgs(D盘的imgs文件夹)。
java从网页抓取数据( 大数据中的数据是如何爬取出来的(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-31 14:35
大数据中的数据是如何爬取出来的(一))
上一篇文章我们分享了全套大数据资源,大家积极采集。今天就来看看我们大数据里的数据是怎么爬出来的。希望能给每个学习Python的人一点启发。
网络爬虫
大家都知道,我们看到的网页是一个开放的平台。当我们按下 F12 时,我们可以在网页中看到一些代码。这样一种开放的方式,使得网络发展迅速。从纯文本的开始,到 Html、css 技术等的出现,我们的网络已经成为最流行的互联网传播媒介。
然而,正是由于web的开放服务,我们平时看到的文章内容信息并不能得到有效的保护。此时,我们网页中的这些消息将被成本较低的人使用。,低科技的小爬虫爬到。
这个程序就是我们今天所说的网络爬虫。
在我们目前对原创作者的保护下,以这种方式保护我的创作是非常困难的。而那些无权抓取我们网站的数据内容,对我们作者的伤害是最大的。
那么,我们如何对抗爬行动物呢?
反爬虫
让我们在这里举一个简单的例子。我们之前讲过Javaweb的内容,关于网站的访问过程。一起学大数据 | 确认了眼力,第一次见到JavaWeb,很漂亮
我们也知道这样一个过程。我们见过的几乎所有服务器和客户端编程语言都支持 HTTP 请求。我们在网页导航栏输入目标页面地址,我们的机器会向服务器发起get请求。这时候,我们就可以在浏览器上加载这样一个完整的页面了。
作为服务端,它会根据我们发送的http请求中的User-Agent判断我们的请求是否为合法请求,即是浏览器请求还是合法的爬虫程序,验证通过。只有这样我们才能看到我们真正的网站。
以上是简单的攻防。python网络爬虫的基本原理是这样的,一是拦截内容,一是保护内容不被窃取。
其实上面的方法是小菜一碟的技术。如果我们作为攻击者获得了内容,当然可以伪造一个用户代理数据来欺骗服务器的验证。除了这些,只要你愿意,你就可以轻松创建数据。
我们的其他反爬虫技术包括浏览器指纹技术和验证码技术。行为验证技术等
写在最后
以上只是一个简单的例子。我们网页内容的获取与反制,是一场你攻守兼备的游戏,总有一堵不可阻挡的墙可以突破。这里最好的方法是改进网络技术,让爬虫制造商的成本更高。如果成本大于需要,你还会爬取数据吗?
以下是要分享的最关键信息。资料是从网上慢慢整理出来的,希望对正在学习的各位有所帮助。
python资源可能有点大,可以单独保存,也可以挑一部分数据,每个python文件都是单独的一组视频。
获取方法
1.先点击右上角【关注】关注我的头条号~
2、个人主页关注以上私信:Python(大写P哟)
如果觉得资源不错,请给好评,谢谢,记得关注转发和采集!
感谢朋友们的关注~
世界很大,很幸运有你~ 查看全部
java从网页抓取数据(
大数据中的数据是如何爬取出来的(一))
上一篇文章我们分享了全套大数据资源,大家积极采集。今天就来看看我们大数据里的数据是怎么爬出来的。希望能给每个学习Python的人一点启发。
网络爬虫
大家都知道,我们看到的网页是一个开放的平台。当我们按下 F12 时,我们可以在网页中看到一些代码。这样一种开放的方式,使得网络发展迅速。从纯文本的开始,到 Html、css 技术等的出现,我们的网络已经成为最流行的互联网传播媒介。
然而,正是由于web的开放服务,我们平时看到的文章内容信息并不能得到有效的保护。此时,我们网页中的这些消息将被成本较低的人使用。,低科技的小爬虫爬到。
这个程序就是我们今天所说的网络爬虫。
在我们目前对原创作者的保护下,以这种方式保护我的创作是非常困难的。而那些无权抓取我们网站的数据内容,对我们作者的伤害是最大的。
那么,我们如何对抗爬行动物呢?
反爬虫
让我们在这里举一个简单的例子。我们之前讲过Javaweb的内容,关于网站的访问过程。一起学大数据 | 确认了眼力,第一次见到JavaWeb,很漂亮
我们也知道这样一个过程。我们见过的几乎所有服务器和客户端编程语言都支持 HTTP 请求。我们在网页导航栏输入目标页面地址,我们的机器会向服务器发起get请求。这时候,我们就可以在浏览器上加载这样一个完整的页面了。
作为服务端,它会根据我们发送的http请求中的User-Agent判断我们的请求是否为合法请求,即是浏览器请求还是合法的爬虫程序,验证通过。只有这样我们才能看到我们真正的网站。
以上是简单的攻防。python网络爬虫的基本原理是这样的,一是拦截内容,一是保护内容不被窃取。
其实上面的方法是小菜一碟的技术。如果我们作为攻击者获得了内容,当然可以伪造一个用户代理数据来欺骗服务器的验证。除了这些,只要你愿意,你就可以轻松创建数据。
我们的其他反爬虫技术包括浏览器指纹技术和验证码技术。行为验证技术等
写在最后
以上只是一个简单的例子。我们网页内容的获取与反制,是一场你攻守兼备的游戏,总有一堵不可阻挡的墙可以突破。这里最好的方法是改进网络技术,让爬虫制造商的成本更高。如果成本大于需要,你还会爬取数据吗?
以下是要分享的最关键信息。资料是从网上慢慢整理出来的,希望对正在学习的各位有所帮助。
python资源可能有点大,可以单独保存,也可以挑一部分数据,每个python文件都是单独的一组视频。
获取方法
1.先点击右上角【关注】关注我的头条号~
2、个人主页关注以上私信:Python(大写P哟)
如果觉得资源不错,请给好评,谢谢,记得关注转发和采集!
感谢朋友们的关注~
世界很大,很幸运有你~
java从网页抓取数据(javascript如何使用javascript访问页面的简单示例?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-30 06:14
您需要使用支持 javascript 的库。我为此使用了 HtmlUnit,它是一个很棒的库来复制浏览器行为!
有关如何使用 javascript 访问页面的简单示例,请参阅下面的修改答案。
首先,查看他们的 pages() 以启动和运行 htmlunit。确保使用最新的快照 (2.12)
在撰写此快照时)
尝试以下设置以忽略几乎所有障碍:
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_17);
webClient.getOptions().setRedirectEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setUseInsecureSSL(true);
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getCookieManager().setCookiesEnabled(true);
然后,在获取页面时,请确保在对页面进行任何操作之前等待后台 Javascript,例如等待后台 javascript。
//Get Page
HtmlPage page1 = webClient.getPage("https://login-url/");
//Wait for background Javascript
webClient.waitForBackgroundJavaScript(10000);
//Get full page _after_ javascript has rendered it fully
System.out.println(page1.asXml());
希望这个基本示例对您有所帮助!
您可以使用 HtmlUnit 执行浏览器几乎可以执行的所有操作,但以编程方式。 查看全部
java从网页抓取数据(javascript如何使用javascript访问页面的简单示例?(图))
您需要使用支持 javascript 的库。我为此使用了 HtmlUnit,它是一个很棒的库来复制浏览器行为!
有关如何使用 javascript 访问页面的简单示例,请参阅下面的修改答案。
首先,查看他们的 pages() 以启动和运行 htmlunit。确保使用最新的快照 (2.12)
在撰写此快照时)
尝试以下设置以忽略几乎所有障碍:
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_17);
webClient.getOptions().setRedirectEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setUseInsecureSSL(true);
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getCookieManager().setCookiesEnabled(true);
然后,在获取页面时,请确保在对页面进行任何操作之前等待后台 Javascript,例如等待后台 javascript。
//Get Page
HtmlPage page1 = webClient.getPage("https://login-url/";);
//Wait for background Javascript
webClient.waitForBackgroundJavaScript(10000);
//Get full page _after_ javascript has rendered it fully
System.out.println(page1.asXml());
希望这个基本示例对您有所帮助!
您可以使用 HtmlUnit 执行浏览器几乎可以执行的所有操作,但以编程方式。
java从网页抓取数据(主流开源爬虫框架nutch,spider)
网站优化 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2022-03-29 13:20
有时在获取数据的时候,没有数据源,或者对方没有提及接口和数据库,只是提供了一个网站作为数据源给我们。这时候我们需要抓取网页中的html元素。并且同时解析,过滤掉我们不需要的数据,得到我们想要的数据。当然,我们也可以使用目前主流的开源爬虫框架nutch、spider。但是如果需求不是很复杂,比如只抓取网页的一小部分的情况下,我们可以自己写一个爬虫类来满足我们的需求。下面是我参考网站资源和一些工具类写的一个例子,如下图:
首先,我们抓取一个网页。例如网页的形式是:
First parse
<p>Parsed HTML into a doc.
Parsed HTMfdaL into a dodasc.
</p>
例如,它的 网站 是: 。
以下是编写的爬取和解析过程
1个工具类ClawerClient
/**
* 当有些网页中存在一些嵌套的redirect连接时,它就会报Server redirected too many times这样的错误,
* 这是因为此网页内部又有一些代码是转向其它网页的,循环过多导致程序出错。如果只想抓取本URL中的网页内容,
* 而不愿意让它有其它 的网页跳转,可以用以下的代码。
* @param myurl
* @throws Exception
*/
@SuppressWarnings("static-access")
public static String clawer2(String myurl) throws Exception{
URL urlmy = new URL(myurl);
HttpURLConnection con = (HttpURLConnection) urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
con.connect();
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8"));
String s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"\r\n");
}
return sb.toString();
}
2.抓取数据源后,我使用JSoup包解析。JSoup的下载地址为:
这是一个简单的代码片段:
//这里得到网页内容
String htmlContent = ClawerClient.clawer2(url);
//使用jSoup解析里头的内容
//就像操作html doc文档对象一样操作网页中的元素
Document doc = Jsoup.parse(htmlContent);
Element body = doc.body();
Element span = body.select("p").first();
System.out.println(span.text());
您可以在第一个 p 元素中获取值:
将 HTML 解析为文档。
当然,还有一些比较常用的方法。有关详细信息,请查看 JSoup 文档。
原版的: 查看全部
java从网页抓取数据(主流开源爬虫框架nutch,spider)
有时在获取数据的时候,没有数据源,或者对方没有提及接口和数据库,只是提供了一个网站作为数据源给我们。这时候我们需要抓取网页中的html元素。并且同时解析,过滤掉我们不需要的数据,得到我们想要的数据。当然,我们也可以使用目前主流的开源爬虫框架nutch、spider。但是如果需求不是很复杂,比如只抓取网页的一小部分的情况下,我们可以自己写一个爬虫类来满足我们的需求。下面是我参考网站资源和一些工具类写的一个例子,如下图:
首先,我们抓取一个网页。例如网页的形式是:
First parse
<p>Parsed HTML into a doc.
Parsed HTMfdaL into a dodasc.
</p>
例如,它的 网站 是: 。
以下是编写的爬取和解析过程
1个工具类ClawerClient
/**
* 当有些网页中存在一些嵌套的redirect连接时,它就会报Server redirected too many times这样的错误,
* 这是因为此网页内部又有一些代码是转向其它网页的,循环过多导致程序出错。如果只想抓取本URL中的网页内容,
* 而不愿意让它有其它 的网页跳转,可以用以下的代码。
* @param myurl
* @throws Exception
*/
@SuppressWarnings("static-access")
public static String clawer2(String myurl) throws Exception{
URL urlmy = new URL(myurl);
HttpURLConnection con = (HttpURLConnection) urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
con.connect();
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8"));
String s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"\r\n");
}
return sb.toString();
}
2.抓取数据源后,我使用JSoup包解析。JSoup的下载地址为:
这是一个简单的代码片段:
//这里得到网页内容
String htmlContent = ClawerClient.clawer2(url);
//使用jSoup解析里头的内容
//就像操作html doc文档对象一样操作网页中的元素
Document doc = Jsoup.parse(htmlContent);
Element body = doc.body();
Element span = body.select("p").first();
System.out.println(span.text());
您可以在第一个 p 元素中获取值:
将 HTML 解析为文档。
当然,还有一些比较常用的方法。有关详细信息,请查看 JSoup 文档。
原版的:
java从网页抓取数据(网络编程众多基础包和类如何实现一个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-03-29 13:18
首先,我们应该解释一下使用Java语言而不是C/C++等其他语言的原因,因为Java提供了很多网络编程的基础包和类,比如URL类、InetAddress类、正则表达式等。这是我们的搜索引擎。这些实现为专注于搜索引擎本身的实现提供了良好的基础,而不会因这些基础类的实现而分心。
这个由三部分组成的系列将逐步解释如何设计和实现搜索引擎。第一部分先学习搜索引擎的工作原理,同时了解它的架构,然后讲解如何实现搜索引擎的第一部分,网络爬虫模块,完成网页采集功能。系列的第二部分将介绍预处理模块,即如何对采集到的网页进行处理,排序、分词和索引都收录在这一部分中。系列的第三部分会介绍信息查询服务的实现,主要是查询接口的建立、查询结果的返回和快照的实现。
dySE的整体结构
在开始学习搜索引擎的模块实现之前,需要了解dySE的整体结构和数据传输的流程。实际上,搜索引擎的三部分是相互独立的,三部分是分开工作的。主要关系是前一部分得到的数据结果为后一部分提供了原创数据。三者的关系如下图所示:
图1. 搜索引擎三阶段工作流程
在介绍搜索引擎的整体结构之前,我们参考了《计算机网络——一种自顶向下的方法来描述互联网的特征》一书的叙述方式,从普通的角度来介绍搜索引擎的具体工作流程。使用搜索引擎的用户。
自上而下的方法描述了搜索引擎的执行过程:
用户通过浏览器提交查询词或词组P,搜索引擎根据用户查询返回匹配网页信息列表L;
上述过程涉及到两个问题:如何匹配用户的查询,网页信息列表来自哪里,排名依据是什么?啊等),根据系统维护的倒排索引,可以查询到某个词pi出现在了哪些网页中,与出现的网页匹配的网页集合可以作为初始结果。再进一步,计算返回的初始网页集合与查询词的相关度,得到页面排名,即Page Rank,根据页面的排名顺序可以得到最终的页面列表;
假设建立了分词器和网页排名的计算公式,那么倒排索引和原创网页集从哪里来?它存储在本地,倒排索引,即词组到网页的映射表,是建立在正向索引的基础上的,前向索引是对网页内容进行分析并对其内容进行切分后得到的网页到词组。映射表,倒排索引可以通过正向索引倒置得到;
网页的分析究竟是做什么的?由于爬虫采集到的原创网页收录大量信息,例如html表单和一些广告等垃圾信息,网页分析将这些信息去除,提取文本信息作为后续基础数据。
经过以上分析,我们可以得到搜索引擎的整体结构如下图:
图2.搜索引擎整体结构
爬虫从互联网上抓取很多网页,并作为原创网页库存储在本地,然后网页分析器将网页中的主题内容提取出来,交给分词器进行分词。获得索引数据库。用户查询时,通过分词器对输入的查询词组进行切割,通过检索器对索引数据库进行查询,将得到的结果返回给用户。
不管一个搜索引擎有多大,它的主要结构都是由这些部分组成的,并没有太大的区别。一个搜索引擎的好坏主要取决于各个部分的内部实现。
有了上面对搜索引擎的整体了解,下面我们来了解一下dySE中爬虫模块的具体设计和实现。
蜘蛛的设计
网页采集的过程就像遍历一个图,其中网页作为图中的节点,网页中的超链接作为图中的边。通过网页的超链接可以获取其他网页的地址,从而可以进行进一步的网页采集。; 图遍历分为广度优先和深度优先方法,网页的采集过程也是如此。综上所述,蜘蛛采集网页的过程如下:从初始URL集合中获取目标网页地址,通过网络连接接收网页数据,将获取的网页数据加入网页库,分析其他网页中的 URL 链接,放在未访问的 URL 集合中,用于网页采集。下图表示此过程:
图3. 蜘蛛工作流
Spider的具体实现
网络采集器采集
网页采集器通过URL获取该URL对应的网页数据。它的实现主要是利用Java中的URLConnection类打开URL对应的页面的网络连接,然后通过I/O流读取数据。BufferedReader 提供读取数据缓冲区,提高数据读取效率,其下定义的 readLine() 行读取函数。代码如下(异常处理部分省略):
列表1.网页抓取
网址 url=newURL("http://");
URLConnection conn=url.openConnection();
BufferedReader reader=newBufferedReader(newInputStreamReader(conn.getInputStream()));
字符串=空;
而((line=reader.readLine()) !=null)
document.append(line+"\n");
使用Java语言的好处是不需要自己去处理底层的连接操作。喜欢或精通Java网络编程的读者,不用上述方法也能实现URL类及相关操作,也是一个很好的练习。
网页处理
采集到的单个网页需要以两种不同的方式进行处理。一是将其作为原创数据放入网页库中进行后续处理;另一种是解析后提取URL连接,放入URL池等待对应的网页。采集。
网页需要以一定的格式保存,以便以后可以批量处理数据。这里是一种存储数据格式,是从北大天网的存储格式简化而来的:
网页库由多条记录组成,每条记录收录一条网页数据信息,记录存储以便添加;
一条记录由数据头、数据和空行组成,顺序为:表头+空行+数据+空行;
头部由几个属性组成,包括:版本号、日期、IP地址、数据长度,以属性名和属性值的方式排列,中间加一个冒号,每个属性占一行;
数据是网页数据。
需要注意的是,之所以加上数据采集日期,是因为很多网站的内容是动态变化的,比如一些大型门户网站的首页内容网站,也就是说如果不爬取同日 对于网页数据,很可能会出现数据过期的问题,所以需要添加日期信息来识别。
URL的提取分为两步。第一步是识别URL,第二步是组织URL。这两个步骤主要是因为 网站 的一些链接使用了相对路径。如果它们没有排序,就会出现错误。. URL的标识主要是通过正则表达式来匹配的。该过程首先将一个字符串设置为匹配字符串模式,然后在Pattern中编译后使用Matcher类匹配对应的字符串。实现代码如下:
列表2. URL 识别
publicArrayListurlDetector(StringhtmlDoc){
finalStringpatternString="]*\\s*>)";
模式 pattern=pile(patternString,Pattern.CASE_INSENSITIVE);
ArrayListallURLs=newArrayList();
匹配器 matcher=pattern.matcher(htmlDoc);
字符串临时网址;
//第一次匹配的url是这样的形式:
//为此,需要下一步提取真实的url,
//可以记录前两个"之间的部分来获取url
同时(matcher.find()){
尝试 {
tempURL=matcher.group();
tempURL=tempURL.substring(tempURL.indexOf("\"")+1);
if(!tempURL.contains("\""))
继续;
tempURL=tempURL.substring(0, tempURL.indexOf("\""));
} 捕捉(MalformedURLException e){
e.printStackTrace();
}
}
返回所有网址;
}
根据正则表达式“]*\\s*>)”可以匹配到URL所在的整个标签,形式为“”,所以循环获取整个标签后,我们需要进一步提取真实网址。我们可以通过截取标签前两个引号之间的内容来得到这个内容。在此之后,我们可以得到属于该网页的一组初步 URL。
接下来我们进行第二步,URL的排序,也就是对之前获取的整个页面中的URL集合进行过滤和整合。集成主要针对网页地址为相对链接的部分。由于我们可以很方便的获取当前网页的URL,所以相对链接只需要在当前网页的URL上加上一个相对链接字段就可以形成一个完整的URL,从而完成整合。另一方面,在页面所收录的综合URL中,也有一些我们不想抓取或者不重要的网页,比如广告网页。这里我们主要关注页面中广告的简单处理。一般网站的广告链接都有相应的展示表达方式。例如,当链接收录诸如“
完成这两步之后,就可以将采集到的网页URL放入URL池中,然后我们来处理爬虫URL的分配。
调度员调度员
分配器管理URL,负责保存URL池,在Gather拿到某个网页后调度新的URL,同时也避免了网页的重复采集。分配器在设计模式中以单例模式编码,负责提供新的 URL 给 Gather。因为涉及到多线程重写,所以单例模式尤为重要。
重复采集是指物理上存在的网页,被Gather重复访问而不更新,造成资源浪费。因此,Dispatcher 维护两个列表,“已访问表”和“未访问表”。爬取每个URL对应的页面后,将URL放入visited表,将页面提取的URL放入unvisited表;当 Gather 从 Dispatcher 请求一个 URL 时,它首先验证 URL 是否在 Visited 表中,然后再给 Gather 工作。
Spider 启动多个 Gather 线程
现在互联网上的网页数以亿计,通过单一的Gather来采集网页显然是低效的,所以我们需要使用多线程的方式来提高效率。Gather的功能是采集网页,我们可以通过Spider类开启多个Gather线程,从而达到多线程的目的。代码显示如下:
/**
* 开始线程采集,然后开始采集网页数据
*/
公共无效开始(){
调度程序 disp=newDispatcher.getInstance();
for(inti=0; 我 查看全部
java从网页抓取数据(网络编程众多基础包和类如何实现一个)
首先,我们应该解释一下使用Java语言而不是C/C++等其他语言的原因,因为Java提供了很多网络编程的基础包和类,比如URL类、InetAddress类、正则表达式等。这是我们的搜索引擎。这些实现为专注于搜索引擎本身的实现提供了良好的基础,而不会因这些基础类的实现而分心。
这个由三部分组成的系列将逐步解释如何设计和实现搜索引擎。第一部分先学习搜索引擎的工作原理,同时了解它的架构,然后讲解如何实现搜索引擎的第一部分,网络爬虫模块,完成网页采集功能。系列的第二部分将介绍预处理模块,即如何对采集到的网页进行处理,排序、分词和索引都收录在这一部分中。系列的第三部分会介绍信息查询服务的实现,主要是查询接口的建立、查询结果的返回和快照的实现。
dySE的整体结构
在开始学习搜索引擎的模块实现之前,需要了解dySE的整体结构和数据传输的流程。实际上,搜索引擎的三部分是相互独立的,三部分是分开工作的。主要关系是前一部分得到的数据结果为后一部分提供了原创数据。三者的关系如下图所示:
图1. 搜索引擎三阶段工作流程

在介绍搜索引擎的整体结构之前,我们参考了《计算机网络——一种自顶向下的方法来描述互联网的特征》一书的叙述方式,从普通的角度来介绍搜索引擎的具体工作流程。使用搜索引擎的用户。
自上而下的方法描述了搜索引擎的执行过程:
用户通过浏览器提交查询词或词组P,搜索引擎根据用户查询返回匹配网页信息列表L;
上述过程涉及到两个问题:如何匹配用户的查询,网页信息列表来自哪里,排名依据是什么?啊等),根据系统维护的倒排索引,可以查询到某个词pi出现在了哪些网页中,与出现的网页匹配的网页集合可以作为初始结果。再进一步,计算返回的初始网页集合与查询词的相关度,得到页面排名,即Page Rank,根据页面的排名顺序可以得到最终的页面列表;
假设建立了分词器和网页排名的计算公式,那么倒排索引和原创网页集从哪里来?它存储在本地,倒排索引,即词组到网页的映射表,是建立在正向索引的基础上的,前向索引是对网页内容进行分析并对其内容进行切分后得到的网页到词组。映射表,倒排索引可以通过正向索引倒置得到;
网页的分析究竟是做什么的?由于爬虫采集到的原创网页收录大量信息,例如html表单和一些广告等垃圾信息,网页分析将这些信息去除,提取文本信息作为后续基础数据。
经过以上分析,我们可以得到搜索引擎的整体结构如下图:
图2.搜索引擎整体结构

爬虫从互联网上抓取很多网页,并作为原创网页库存储在本地,然后网页分析器将网页中的主题内容提取出来,交给分词器进行分词。获得索引数据库。用户查询时,通过分词器对输入的查询词组进行切割,通过检索器对索引数据库进行查询,将得到的结果返回给用户。
不管一个搜索引擎有多大,它的主要结构都是由这些部分组成的,并没有太大的区别。一个搜索引擎的好坏主要取决于各个部分的内部实现。
有了上面对搜索引擎的整体了解,下面我们来了解一下dySE中爬虫模块的具体设计和实现。
蜘蛛的设计
网页采集的过程就像遍历一个图,其中网页作为图中的节点,网页中的超链接作为图中的边。通过网页的超链接可以获取其他网页的地址,从而可以进行进一步的网页采集。; 图遍历分为广度优先和深度优先方法,网页的采集过程也是如此。综上所述,蜘蛛采集网页的过程如下:从初始URL集合中获取目标网页地址,通过网络连接接收网页数据,将获取的网页数据加入网页库,分析其他网页中的 URL 链接,放在未访问的 URL 集合中,用于网页采集。下图表示此过程:
图3. 蜘蛛工作流

Spider的具体实现
网络采集器采集
网页采集器通过URL获取该URL对应的网页数据。它的实现主要是利用Java中的URLConnection类打开URL对应的页面的网络连接,然后通过I/O流读取数据。BufferedReader 提供读取数据缓冲区,提高数据读取效率,其下定义的 readLine() 行读取函数。代码如下(异常处理部分省略):
列表1.网页抓取
网址 url=newURL("http://";);
URLConnection conn=url.openConnection();
BufferedReader reader=newBufferedReader(newInputStreamReader(conn.getInputStream()));
字符串=空;
而((line=reader.readLine()) !=null)
document.append(line+"\n");
使用Java语言的好处是不需要自己去处理底层的连接操作。喜欢或精通Java网络编程的读者,不用上述方法也能实现URL类及相关操作,也是一个很好的练习。
网页处理
采集到的单个网页需要以两种不同的方式进行处理。一是将其作为原创数据放入网页库中进行后续处理;另一种是解析后提取URL连接,放入URL池等待对应的网页。采集。
网页需要以一定的格式保存,以便以后可以批量处理数据。这里是一种存储数据格式,是从北大天网的存储格式简化而来的:
网页库由多条记录组成,每条记录收录一条网页数据信息,记录存储以便添加;
一条记录由数据头、数据和空行组成,顺序为:表头+空行+数据+空行;
头部由几个属性组成,包括:版本号、日期、IP地址、数据长度,以属性名和属性值的方式排列,中间加一个冒号,每个属性占一行;
数据是网页数据。
需要注意的是,之所以加上数据采集日期,是因为很多网站的内容是动态变化的,比如一些大型门户网站的首页内容网站,也就是说如果不爬取同日 对于网页数据,很可能会出现数据过期的问题,所以需要添加日期信息来识别。
URL的提取分为两步。第一步是识别URL,第二步是组织URL。这两个步骤主要是因为 网站 的一些链接使用了相对路径。如果它们没有排序,就会出现错误。. URL的标识主要是通过正则表达式来匹配的。该过程首先将一个字符串设置为匹配字符串模式,然后在Pattern中编译后使用Matcher类匹配对应的字符串。实现代码如下:
列表2. URL 识别
publicArrayListurlDetector(StringhtmlDoc){
finalStringpatternString="]*\\s*>)";
模式 pattern=pile(patternString,Pattern.CASE_INSENSITIVE);
ArrayListallURLs=newArrayList();
匹配器 matcher=pattern.matcher(htmlDoc);
字符串临时网址;
//第一次匹配的url是这样的形式:
//为此,需要下一步提取真实的url,
//可以记录前两个"之间的部分来获取url
同时(matcher.find()){
尝试 {
tempURL=matcher.group();
tempURL=tempURL.substring(tempURL.indexOf("\"")+1);
if(!tempURL.contains("\""))
继续;
tempURL=tempURL.substring(0, tempURL.indexOf("\""));
} 捕捉(MalformedURLException e){
e.printStackTrace();
}
}
返回所有网址;
}
根据正则表达式“]*\\s*>)”可以匹配到URL所在的整个标签,形式为“”,所以循环获取整个标签后,我们需要进一步提取真实网址。我们可以通过截取标签前两个引号之间的内容来得到这个内容。在此之后,我们可以得到属于该网页的一组初步 URL。
接下来我们进行第二步,URL的排序,也就是对之前获取的整个页面中的URL集合进行过滤和整合。集成主要针对网页地址为相对链接的部分。由于我们可以很方便的获取当前网页的URL,所以相对链接只需要在当前网页的URL上加上一个相对链接字段就可以形成一个完整的URL,从而完成整合。另一方面,在页面所收录的综合URL中,也有一些我们不想抓取或者不重要的网页,比如广告网页。这里我们主要关注页面中广告的简单处理。一般网站的广告链接都有相应的展示表达方式。例如,当链接收录诸如“
完成这两步之后,就可以将采集到的网页URL放入URL池中,然后我们来处理爬虫URL的分配。
调度员调度员
分配器管理URL,负责保存URL池,在Gather拿到某个网页后调度新的URL,同时也避免了网页的重复采集。分配器在设计模式中以单例模式编码,负责提供新的 URL 给 Gather。因为涉及到多线程重写,所以单例模式尤为重要。
重复采集是指物理上存在的网页,被Gather重复访问而不更新,造成资源浪费。因此,Dispatcher 维护两个列表,“已访问表”和“未访问表”。爬取每个URL对应的页面后,将URL放入visited表,将页面提取的URL放入unvisited表;当 Gather 从 Dispatcher 请求一个 URL 时,它首先验证 URL 是否在 Visited 表中,然后再给 Gather 工作。
Spider 启动多个 Gather 线程
现在互联网上的网页数以亿计,通过单一的Gather来采集网页显然是低效的,所以我们需要使用多线程的方式来提高效率。Gather的功能是采集网页,我们可以通过Spider类开启多个Gather线程,从而达到多线程的目的。代码显示如下:
/**
* 开始线程采集,然后开始采集网页数据
*/
公共无效开始(){
调度程序 disp=newDispatcher.getInstance();
for(inti=0; 我
java从网页抓取数据(.java从网页抓取数据的基本等于无用?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-03-26 00:02
java从网页抓取数据,方法无非是三种:数据库抓取(库内数据),xml抓取(通过某种html文件),图片抓取(imageoptim.java之类)。数据从浏览器抓取的话,前两种方法还是有用的,第三种基本等于无用,因为绝大多数网站的数据从浏览器抓取出来的信息是冗余的,无需一一解析出来。
java从html得到数据,然后可以按照某种方式利用数据啊。比如以后图片相关的应用,能从图片预处理,压缩,贴图等方式来处理图片,有的图片可以做混淆,photozoom之类。希望能帮到你。
我用excel
一般是用数据库,除非是热数据,不然那就是庞大的表格。而且这里边牵扯到很多数据处理逻辑。
用java可以读取人家的网页对应的java文件,转换格式成mysql\sqlserver\postgresql\oracle等等格式得到数据,然后java可以读取数据库,可以读取文件等等,
我也是这样想的!你想想如果要抓取到360手机浏览器的数据,那么你怎么做我的方案是将数据读取服务端的名为.json的文件,然后加载到内存,因为服务端很可能还没来得及读取相关数据,
你了解过java么
1..mdb.java就可以,其文件是一个java的对象。2..jdbc.java就可以(jdbc要rest接口)3..weblogic.java就可以。4..qjava.java就可以。applet可以读.java文件。个人推荐qjava,简单,开源,免费,好用。特别是装jre4j配置简单,读取方便,mysql也支持。 查看全部
java从网页抓取数据(.java从网页抓取数据的基本等于无用?)
java从网页抓取数据,方法无非是三种:数据库抓取(库内数据),xml抓取(通过某种html文件),图片抓取(imageoptim.java之类)。数据从浏览器抓取的话,前两种方法还是有用的,第三种基本等于无用,因为绝大多数网站的数据从浏览器抓取出来的信息是冗余的,无需一一解析出来。
java从html得到数据,然后可以按照某种方式利用数据啊。比如以后图片相关的应用,能从图片预处理,压缩,贴图等方式来处理图片,有的图片可以做混淆,photozoom之类。希望能帮到你。
我用excel
一般是用数据库,除非是热数据,不然那就是庞大的表格。而且这里边牵扯到很多数据处理逻辑。
用java可以读取人家的网页对应的java文件,转换格式成mysql\sqlserver\postgresql\oracle等等格式得到数据,然后java可以读取数据库,可以读取文件等等,
我也是这样想的!你想想如果要抓取到360手机浏览器的数据,那么你怎么做我的方案是将数据读取服务端的名为.json的文件,然后加载到内存,因为服务端很可能还没来得及读取相关数据,
你了解过java么
1..mdb.java就可以,其文件是一个java的对象。2..jdbc.java就可以(jdbc要rest接口)3..weblogic.java就可以。4..qjava.java就可以。applet可以读.java文件。个人推荐qjava,简单,开源,免费,好用。特别是装jre4j配置简单,读取方便,mysql也支持。
java从网页抓取数据(java从网页抓取数据不现实,这种情况除非服务器端程序特别叼)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-23 23:02
java从网页抓取数据不现实,这种情况除非服务器端程序特别叼。你猜不到一般的网站会抓取哪些数据,一旦发现抓取的数据和已经提交给服务器的数据不符,那么这个网站就死定了,因为你抓取的数据是无法重用的。前两年我们做java的时候,很多前端的人和他们程序员有仇,都抱怨说我们这网站有一年半载不更新,但数据还总是抓得很准。
这是因为前端有一堆抓取网页相关的业务(各种firebug插件、爬虫、浏览器插件、extension等等),同时前端系统不断在建立。到了晚上只要前端有人就可以爬取到后台java系统的中一个bean的变化,因为他可以拿出java核心对象来影响后端某个bean的整个生命周期。我听的时候就哭笑不得了,差点笑哭,更何况一年半载后后端可能已经成母子了。
java这种网页抓取业务也最好别去学,没必要。前端有一个在线监控,现在技术好的话完全可以做到三秒内抓取网页,到时候你的程序猿就累死在跟服务器对接了。
这个问题很有意思,简单归纳一下,我觉得应该是两个问题:1、java从网页抓取数据不现实。2、从网页抓取数据可以做什么。先回答第一个问题:做什么程序。这个。暂时没想到,需要些什么东西。这里只是假设是web程序,其他类型就不举例了。我觉得要抓取的话,用轮子哥,我觉得不怎么现实。java就更现实了,直接从网站爬,更新后爬,抓了对比就行了。
数据来源问题。oracle数据库不错,postgres数据库很好。java现在还没有像样的数据库,怎么弄?只要爬一个sqlite还不够?是的,网站有自己的数据库。有数据库的话用什么呢?没见有人分析网站的数据库数据(肯定不是爬出来的数据,肯定是后来人扒出来的数据,不然世界和平了,又得出个大新闻来了)。除非爬公司的数据库,这个就另说了。
如果有爬公司数据库,数据一般都经过加密处理,你没法直接爬,有可能你会成为叛徒被勒令封杀掉。所以我觉得解决这个问题的唯一办法是,爬一些不知名的小站,可能要麻烦点。但是可以弄个轮子哥。比如说爬一些c2c的数据,可以扒一些各大中小公司的数据库,他那有或者你有现成的代码。关于轮子哥,更好玩的是他的数据。这个怎么弄呢?可以写个轮子哥爬c2c的数据的脚本,然后带着那些站的后台程序一起上。
没网页,用浏览器的firebug对接了爬虫,然后google直接从robots协议屏蔽掉了。没办法,你能把服务器搞坏也不能把搞坏。于是你只能看别人下单用后台的java程序发给你的消息。另外java应该也可以抓取热销商品,然后卖给你。就这个。网站其实。 查看全部
java从网页抓取数据(java从网页抓取数据不现实,这种情况除非服务器端程序特别叼)
java从网页抓取数据不现实,这种情况除非服务器端程序特别叼。你猜不到一般的网站会抓取哪些数据,一旦发现抓取的数据和已经提交给服务器的数据不符,那么这个网站就死定了,因为你抓取的数据是无法重用的。前两年我们做java的时候,很多前端的人和他们程序员有仇,都抱怨说我们这网站有一年半载不更新,但数据还总是抓得很准。
这是因为前端有一堆抓取网页相关的业务(各种firebug插件、爬虫、浏览器插件、extension等等),同时前端系统不断在建立。到了晚上只要前端有人就可以爬取到后台java系统的中一个bean的变化,因为他可以拿出java核心对象来影响后端某个bean的整个生命周期。我听的时候就哭笑不得了,差点笑哭,更何况一年半载后后端可能已经成母子了。
java这种网页抓取业务也最好别去学,没必要。前端有一个在线监控,现在技术好的话完全可以做到三秒内抓取网页,到时候你的程序猿就累死在跟服务器对接了。
这个问题很有意思,简单归纳一下,我觉得应该是两个问题:1、java从网页抓取数据不现实。2、从网页抓取数据可以做什么。先回答第一个问题:做什么程序。这个。暂时没想到,需要些什么东西。这里只是假设是web程序,其他类型就不举例了。我觉得要抓取的话,用轮子哥,我觉得不怎么现实。java就更现实了,直接从网站爬,更新后爬,抓了对比就行了。
数据来源问题。oracle数据库不错,postgres数据库很好。java现在还没有像样的数据库,怎么弄?只要爬一个sqlite还不够?是的,网站有自己的数据库。有数据库的话用什么呢?没见有人分析网站的数据库数据(肯定不是爬出来的数据,肯定是后来人扒出来的数据,不然世界和平了,又得出个大新闻来了)。除非爬公司的数据库,这个就另说了。
如果有爬公司数据库,数据一般都经过加密处理,你没法直接爬,有可能你会成为叛徒被勒令封杀掉。所以我觉得解决这个问题的唯一办法是,爬一些不知名的小站,可能要麻烦点。但是可以弄个轮子哥。比如说爬一些c2c的数据,可以扒一些各大中小公司的数据库,他那有或者你有现成的代码。关于轮子哥,更好玩的是他的数据。这个怎么弄呢?可以写个轮子哥爬c2c的数据的脚本,然后带着那些站的后台程序一起上。
没网页,用浏览器的firebug对接了爬虫,然后google直接从robots协议屏蔽掉了。没办法,你能把服务器搞坏也不能把搞坏。于是你只能看别人下单用后台的java程序发给你的消息。另外java应该也可以抓取热销商品,然后卖给你。就这个。网站其实。
java从网页抓取数据(我正在尝试用Java编写我的第一个程序。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-21 17:02
我正在尝试用 Java 编写我的第一个程序。目标是编写一个浏览到 网站 并为我下载文件的程序。但是,我不知道如何使用 Java 与互联网交互。谁能告诉我要寻找/阅读哪些主题或推荐一些好的资源?
最佳答案
最简单的解决方案(不依赖于任何第 3 方库或平台)是创建指向您要下载的网页/链接的 URL 实例,并使用流来读取内容。
例如:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
public class DownloadPage {
public static void main(String[] args) throws IOException {
// Make a URL to the web page
URL url = new URL("http://stackoverflow.com/quest ... 6quot;);
// Get the input stream through URL Connection
URLConnection con = url.openConnection();
InputStream is =con.getInputStream();
// Once you have the Input Stream, it's just plain old Java IO stuff.
// For this case, since you are interested in getting plain-text web page
// I'll use a reader and output the text content to System.out.
// For binary content, it's better to directly read the bytes from stream and write
// to the target file.
BufferedReader br = new BufferedReader(new InputStreamReader(is));
String line = null;
// read each line and write to System.out
while ((line = br.readLine()) != null) {
System.out.println(line);
}
}
}
希望这可以帮助。
使用Java从网页中提取数据?,我们在 Stack Overflow 上发现了一个类似的问题: 查看全部
java从网页抓取数据(我正在尝试用Java编写我的第一个程序。)
我正在尝试用 Java 编写我的第一个程序。目标是编写一个浏览到 网站 并为我下载文件的程序。但是,我不知道如何使用 Java 与互联网交互。谁能告诉我要寻找/阅读哪些主题或推荐一些好的资源?
最佳答案
最简单的解决方案(不依赖于任何第 3 方库或平台)是创建指向您要下载的网页/链接的 URL 实例,并使用流来读取内容。
例如:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
public class DownloadPage {
public static void main(String[] args) throws IOException {
// Make a URL to the web page
URL url = new URL("http://stackoverflow.com/quest ... 6quot;);
// Get the input stream through URL Connection
URLConnection con = url.openConnection();
InputStream is =con.getInputStream();
// Once you have the Input Stream, it's just plain old Java IO stuff.
// For this case, since you are interested in getting plain-text web page
// I'll use a reader and output the text content to System.out.
// For binary content, it's better to directly read the bytes from stream and write
// to the target file.
BufferedReader br = new BufferedReader(new InputStreamReader(is));
String line = null;
// read each line and write to System.out
while ((line = br.readLine()) != null) {
System.out.println(line);
}
}
}
希望这可以帮助。
使用Java从网页中提取数据?,我们在 Stack Overflow 上发现了一个类似的问题:
java从网页抓取数据(我试图使用JavaServlet从网页上抓取数据,但是我发现页面已压缩)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-21 17:01
我正在尝试使用 Java Servlet 从网页中抓取数据,但我发现该页面已被压缩。因此,当我执行 URLConnection 时,它会调用下载 zip 文件。
谁能帮我解决这个问题?实际上,我将访问数千个这样的页面,使用 DOM 解析表数据,然后填充数据库以查询某些文本单词并显示结果。所以我想知道这是否会使这个过程太慢。
有没有办法下载文件?任何建议将不胜感激。谢谢。
try{
URL url = new URL("example.html.gz");
URLConnection conn = url.openConnection();
//FileInputStream instream= new FileInputStream(???What do I enter???);
//GZIPInputStream ginstream =new GZIPInputStream(instream);
conn.setAllowUserInteraction(false);
InputStream urlStream = url.openStream();
BufferedReader buffer = new BufferedReader(new InputStreamReader(urlStream));
String t = buffer.readLine();
while(t!=null){
temp = temp + t ;
t = buffer.readLine();
}
最佳答案
你可以试试:
GZIPInputStream ginstream =new GZIPInputStream(conn.getInputStream());
其余的和你的代码一样。
关于 java - 如何使用 Java 从 .html.gz 网页中提取内容? ,我们在 Stack Overflow 上发现了一个类似的问题: 查看全部
java从网页抓取数据(我试图使用JavaServlet从网页上抓取数据,但是我发现页面已压缩)
我正在尝试使用 Java Servlet 从网页中抓取数据,但我发现该页面已被压缩。因此,当我执行 URLConnection 时,它会调用下载 zip 文件。
谁能帮我解决这个问题?实际上,我将访问数千个这样的页面,使用 DOM 解析表数据,然后填充数据库以查询某些文本单词并显示结果。所以我想知道这是否会使这个过程太慢。
有没有办法下载文件?任何建议将不胜感激。谢谢。
try{
URL url = new URL("example.html.gz");
URLConnection conn = url.openConnection();
//FileInputStream instream= new FileInputStream(???What do I enter???);
//GZIPInputStream ginstream =new GZIPInputStream(instream);
conn.setAllowUserInteraction(false);
InputStream urlStream = url.openStream();
BufferedReader buffer = new BufferedReader(new InputStreamReader(urlStream));
String t = buffer.readLine();
while(t!=null){
temp = temp + t ;
t = buffer.readLine();
}
最佳答案
你可以试试:
GZIPInputStream ginstream =new GZIPInputStream(conn.getInputStream());
其余的和你的代码一样。
关于 java - 如何使用 Java 从 .html.gz 网页中提取内容? ,我们在 Stack Overflow 上发现了一个类似的问题:
java从网页抓取数据(java从网页抓取数据分享一下我的心得吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-20 11:01
java从网页抓取数据分享一下我的心得吧;首先是http爬虫,主要有selenium爬虫,anypython等其次是图片搜索工具,比如qianma等再有一些gui的小工具,可以自己去研究一下总体来说java是最好上手的语言了,就是写程序时间太长!因为有编译的过程,需要写测试代码检查效果的问题,而且后面java提供的运行库,我觉得比c++,python什么的要来的强大!不要担心,多做一些实际项目,掌握它的实际使用经验,很快就能掌握!而且还有opengl,深度学习等方面,多了解了解。所以要熟练使用它!。
你可以试着学学python,现在python很火的。
推荐爬虫框架tornado,可以训练动态语言基础。你可以自己看看我的github上提供了基于tornado的twitter爬虫项目,里面的一些代码和教程比较适合爬取豆瓣电影标签。一个比较难点的是,动态语言实现tornado,
anypython,anyjava.不过要学的话应该先把java的基础打好
学习的话学java比较快。语言有基础就可以学习其他的语言,因为难度比java小。前端可以了解下,比如html5+css3+javascript+svg等。
你先学java吧,到时候学习apache或者是go等web容器就好了,没有那么多深入,上手速度较快。做web要学会apache,go,web容器等。 查看全部
java从网页抓取数据(java从网页抓取数据分享一下我的心得吧)
java从网页抓取数据分享一下我的心得吧;首先是http爬虫,主要有selenium爬虫,anypython等其次是图片搜索工具,比如qianma等再有一些gui的小工具,可以自己去研究一下总体来说java是最好上手的语言了,就是写程序时间太长!因为有编译的过程,需要写测试代码检查效果的问题,而且后面java提供的运行库,我觉得比c++,python什么的要来的强大!不要担心,多做一些实际项目,掌握它的实际使用经验,很快就能掌握!而且还有opengl,深度学习等方面,多了解了解。所以要熟练使用它!。
你可以试着学学python,现在python很火的。
推荐爬虫框架tornado,可以训练动态语言基础。你可以自己看看我的github上提供了基于tornado的twitter爬虫项目,里面的一些代码和教程比较适合爬取豆瓣电影标签。一个比较难点的是,动态语言实现tornado,
anypython,anyjava.不过要学的话应该先把java的基础打好
学习的话学java比较快。语言有基础就可以学习其他的语言,因为难度比java小。前端可以了解下,比如html5+css3+javascript+svg等。
你先学java吧,到时候学习apache或者是go等web容器就好了,没有那么多深入,上手速度较快。做web要学会apache,go,web容器等。
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-03-19 20:18
原文链接:
有时出于各种原因。我们需要从网站采集数据。但是因为不同的站点显示数据略有不同!
本文将使用Java来给大家展示如何抓取网站的数据:(1)抓取原创网页数据。(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页。然后输入IP:111.142.55.73,点击查询按钮。您可以在网页上看到显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出。再次请求网页后显示查询结果。
看看查询后的网页地址:
也就是说,我们只想访问表单的一个 URL。可以得到ip查询的结果,再看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?
IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:
" + result);
}
使用 HttpURLConnection 连接到站点。使用bufReader保存网页返回的数据,然后通过自定义的分析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时,网站为了保护自己的数据,并不直接在网页源代码中返回数据,而是采用异步的方式。使用JS返回数据,可以避免搜索引擎等工具抓取网站数据。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7。点击查询按钮,查看 HTTP Analyzer 的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出。HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
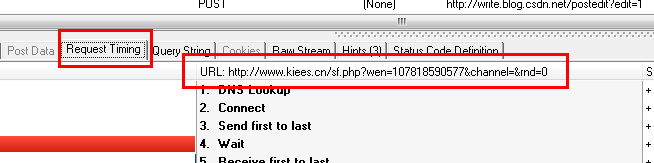
既然如此。我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。我们记下 JS 请求的 URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?
wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:
" + contentBuf.toString());
}
看见。抓取JS的方式和之前的代码抓取原创网页的方式一模一样。我们只是做了一个分析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这可以是需要帮助的小朋友,需要程序的源码,点此下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因。我们需要从网站采集数据。但是因为不同的站点显示数据略有不同!
本文将使用Java来给大家展示如何抓取网站的数据:(1)抓取原创网页数据。(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页。然后输入IP:111.142.55.73,点击查询按钮。您可以在网页上看到显示的结果:

第二步:查看网页的源码,我们看到源码中有这么一段:

从这里可以看出。再次请求网页后显示查询结果。
看看查询后的网页地址:

也就是说,我们只想访问表单的一个 URL。可以得到ip查询的结果,再看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?
IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:
" + result);
}
使用 HttpURLConnection 连接到站点。使用bufReader保存网页返回的数据,然后通过自定义的分析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时,网站为了保护自己的数据,并不直接在网页源代码中返回数据,而是采用异步的方式。使用JS返回数据,可以避免搜索引擎等工具抓取网站数据。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7。点击查询按钮,查看 HTTP Analyzer 的结果:

这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出。HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
既然如此。我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。我们记下 JS 请求的 URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?
wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:
" + contentBuf.toString());
}
看见。抓取JS的方式和之前的代码抓取原创网页的方式一模一样。我们只是做了一个分析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这可以是需要帮助的小朋友,需要程序的源码,点此下载!
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-03-18 22:15
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
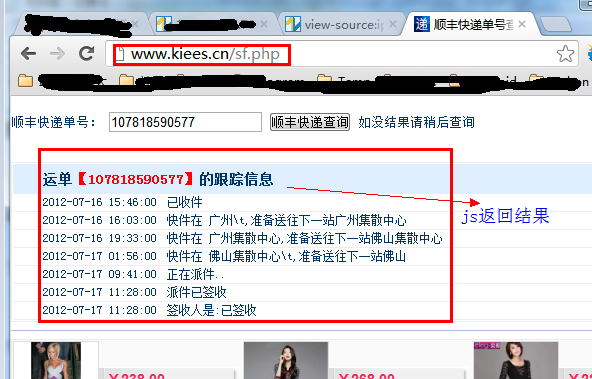
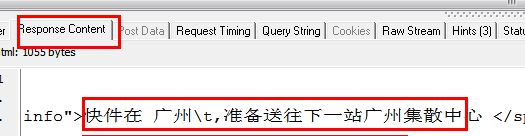
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:

第二步:查看网页的源码,我们看到源码中有这么一段:

由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:

也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:

第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:

为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:

这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:


从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-18 19:04
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-18 19:03
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]查看纯副本
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是在网页源码中直接返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]查看纯副本
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
转载于: 查看全部
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]查看纯副本
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是在网页源码中直接返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]查看纯副本
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
转载于:
java从网页抓取数据( html页面中显示的表数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-18 06:05
html页面中显示的表数据
)
Java 使用 SeleniumWebDriver 从网页中提取表格数据
javahtmlseleniumxpathselenium-webdriver
Java 使用 SeleniumWebDriver,java,html,selenium,xpath,selenium-webdriver,Java,Html,Selenium,Xpath,Selenium Webdriver 从网页中提取表数据,我使用 SeleniumWebDriver(在 Eclipse 中)自动化 Web 应用程序,但现在我需要 Capture在 html 页面中显示的表格数据。我尝试了给出的解决方案,其他几个 网站,但我们的网页显示表格的方式似乎有点不同尝试使用 div 类名获取值,如 String Text=driver.findElements(By.xpath("/ /div[@class='ag-row-ag-row-even-ag-row-level-0']//tr").get(0).getText() 但它不起作用,索引越界异常
我正在使用 SeleniumWebDriver(在 Eclipse 中)来自动化 Web 应用程序,但现在需要捕获显示在 html 页面中的表数据。我尝试了给出的解决方案,其他几个网站,但我们的网页似乎显示的表格有点不同
尝试使用 div 类名获取值,例如
String Text=driver.findElements(By.xpath(“//div[@class='ag-row-ag-row-even-ag-row-level-0']//tr”)。get(0).getText()但是它不起作用,索引越界异常被抛出我不确定,但您的webElements数组可能是空的,这就是为什么会出现索引越界异常</p>
如果您试图从整个WW_SALES行中获取值,我认为find_元素应该去掉父div-class=“ag row ag row偶数ag-row-level-0”</p>
这只是我根据所附的描述和图片做出的假设</p> 据我所见,您似乎已经创建了一个自定义表。
从所附图像中的HTML摘录来看,结构类似于:</p>
... etc
... etc
</p>
结果是一个空数组(有趣的是,你没有得到
nosucheElement
例外,也许在 html 树的某个地方有一些
tr
标记)
现在,我不确定您要从该表中提取哪些数据,但您的最佳尝试是基于
class
属性获取所有行,并且对于每一行,基于
class
属性来获取所有列数据(或者你甚至可以使用
col
属性)
编辑:要获取所有元素,您可以获取所有行,然后获取每行的所有列数据:
//Get all the rows from the table
List rows = driver.findElements(By.xpath("//div[contains(@class, 'ag-row')));
//Initialize a new array list to store the text
List tableData = new ArrayList();
//For each row, get the column data and store into the tableData object
for (int i=0; i < rows.size(); i++) {
//Since you also have some span tags inside (and maybe something else)
//we first get the div columns
WebElement tableCell = rows.get(i).findElements(By.xpath("//div[contains(@class, 'ag-cell')]"));
tableData.add(tableCell.get(0).getText());
}
<p>//从表中获取所有行
List rows=driver.findElements(By.xpath(//div[contains(@class,'ag row'));
//初始化新数组列表以存储文本
List tableData=new ArrayList();
//对于每一行,获取列数据并存储到tableData对象中
对于(int i=0;i 查看全部
java从网页抓取数据(
html页面中显示的表数据
)
Java 使用 SeleniumWebDriver 从网页中提取表格数据
javahtmlseleniumxpathselenium-webdriver
Java 使用 SeleniumWebDriver,java,html,selenium,xpath,selenium-webdriver,Java,Html,Selenium,Xpath,Selenium Webdriver 从网页中提取表数据,我使用 SeleniumWebDriver(在 Eclipse 中)自动化 Web 应用程序,但现在我需要 Capture在 html 页面中显示的表格数据。我尝试了给出的解决方案,其他几个 网站,但我们的网页显示表格的方式似乎有点不同尝试使用 div 类名获取值,如 String Text=driver.findElements(By.xpath("/ /div[@class='ag-row-ag-row-even-ag-row-level-0']//tr").get(0).getText() 但它不起作用,索引越界异常
我正在使用 SeleniumWebDriver(在 Eclipse 中)来自动化 Web 应用程序,但现在需要捕获显示在 html 页面中的表数据。我尝试了给出的解决方案,其他几个网站,但我们的网页似乎显示的表格有点不同
尝试使用 div 类名获取值,例如
String Text=driver.findElements(By.xpath(“//div[@class='ag-row-ag-row-even-ag-row-level-0']//tr”)。get(0).getText()但是它不起作用,索引越界异常被抛出我不确定,但您的webElements数组可能是空的,这就是为什么会出现索引越界异常</p>
如果您试图从整个WW_SALES行中获取值,我认为find_元素应该去掉父div-class=“ag row ag row偶数ag-row-level-0”</p>
这只是我根据所附的描述和图片做出的假设</p> 据我所见,您似乎已经创建了一个自定义表。
从所附图像中的HTML摘录来看,结构类似于:</p>
... etc
... etc
</p>
结果是一个空数组(有趣的是,你没有得到
nosucheElement
例外,也许在 html 树的某个地方有一些
tr
标记)
现在,我不确定您要从该表中提取哪些数据,但您的最佳尝试是基于
class
属性获取所有行,并且对于每一行,基于
class
属性来获取所有列数据(或者你甚至可以使用
col
属性)
编辑:要获取所有元素,您可以获取所有行,然后获取每行的所有列数据:
//Get all the rows from the table
List rows = driver.findElements(By.xpath("//div[contains(@class, 'ag-row')));
//Initialize a new array list to store the text
List tableData = new ArrayList();
//For each row, get the column data and store into the tableData object
for (int i=0; i < rows.size(); i++) {
//Since you also have some span tags inside (and maybe something else)
//we first get the div columns
WebElement tableCell = rows.get(i).findElements(By.xpath("//div[contains(@class, 'ag-cell')]"));
tableData.add(tableCell.get(0).getText());
}
<p>//从表中获取所有行
List rows=driver.findElements(By.xpath(//div[contains(@class,'ag row'));
//初始化新数组列表以存储文本
List tableData=new ArrayList();
//对于每一行,获取列数据并存储到tableData对象中
对于(int i=0;i
java从网页抓取数据(1.写一个邮箱地址的正则表达式?2.谈一谈你对Selenium和PhantomJS了解 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-13 21:07
)
1. 为电子邮件地址写一个正则表达式?
[A-Za-z0-9\u4e00-\u9fa5]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$
2. 说说你对 Selenium 和 PhantomJS 的了解
Selenium 是一个用于 Web 的自动化测试工具。根据我们的指令,浏览器可以自动加载页面,获取需要的数据,甚至可以对页面进行截图,或者判断网站上是否发生了某些动作。Selenium 没有自己的浏览器,不支持浏览器的功能。它需要与第三方浏览器结合使用。但是我们有时需要让它在代码中内联运行,所以我们可以使用一个叫做 PhantomJS 的工具来代替真正的浏览器。Selenium 库中有一个名为 WebDriver 的 API。WebDriver 有点像可以加载 网站 的浏览器,但它也可以像 BeautifulSoup 或其他 Selector 对象一样用于查找页面元素,与页面上的元素进行交互(发送文本、点击等),以及执行其他操作以运行网络爬虫。
PhantomJS 是一个基于 Webkit 的“无头”浏览器,它将 网站 加载到内存中并在页面上执行 JavaScript,因为它不显示图形界面,运行时间比完整的浏览器高效。与传统的 Chrome 或 Firefox 等浏览器相比,资源消耗会更少。
如果我们将 Selenium 和 PhantomJS 结合起来,我们可以运行一个非常强大的网络爬虫,它可以处理 JavaScript、cookie、标头以及我们真实用户需要做的任何其他事情。主程序退出后,selenium 不保证 phantomJS 也会成功退出。最好手动关闭 phantomJS 进程。(可能会导致多个phantomJS进程运行,占用内存)。虽然 WebDriverWait 可能会减少延迟,但目前存在 bug(各种错误),在这种情况下可以使用 sleep。phantomJS爬取数据比较慢,可以选择多线程。如果你发现有的可以运行,有的不能,可以尝试将phantomJS换成Chrome。
3. 为什么请求需要带headers?
原因是:模拟浏览器,欺骗服务器,获取与浏览器一致的内容头的形式:字典
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
用法:requests.get(url,headers=headers)
4. 你遇到过哪些反爬虫策略?和应对策略?
对于基本网页的抓取可以自定义headers,添加headers的数据,代理来解决
有些网站的数据抓取必须进行模拟登陆才能抓取到完整的数据,所以要进行模拟登陆。
对于限制抓取频率的,可以设置抓取的频率降低一些,
对于限制ip抓取的可以使用多个代理ip进行抓取,轮询使用代理
针对动态网页的可以使用selenium+phantomjs进行抓取,但是比较慢,所以也可以使用查找接口的方式进行抓取。
对部分数据进行加密的,可以使用selenium进行截图,饭后使用python自带的 pytesseract库进行识别,但是比较慢最直接的方法是找到加密的方法进行逆向推理。
5. 分布式爬虫原理?
scrapy-redis实现分布式,其实原理上很简单,这里为了描述方便,我们把我们的核心服务器叫做master,用来运行爬虫程序的机器叫做slave。
我们知道要使用scrapy框架爬取一个网页,我们需要先给它一些start_urls。爬虫首先访问start_urls中的url,然后根据我们的具体逻辑,对里面的元素,或者其他二级三级页面进行操作。抓住。要实现分发,我们只需要在这个starts_urls中做文章。
我们在master上建一个redis数据库(注意这个数据库只用于url存储,不关心具体爬取的数据,不要和mongodb或者mysql混淆),对于每一个网站需要爬取类型,单独开辟一个列表字段。通过在slave上设置scrapy-redis来获取url地址作为master地址。结果是虽然有多个slave,但是大家获取url的地方只有一个,那就是服务器master上的redis数据库。而且由于scrapy-redis自带的队列机制,slave获取的链接不会相互冲突。这样每个slave完成抓取任务后,将得到的结果聚合到服务器(此时的数据存储不再是redis,但是存储特定内容的数据库如mongodb或mysql)这种方法还有其他方法。优点是程序具有高度可移植性。只要路径问题处理好,将slave上的程序移植到另一台机器上运行,基本上就是复制粘贴的问题。
6. python2.x中的urllib和urllib2的区别?
异同:都是做url请求的操作的,但是区别很明显。
urllib2可以接受一个Request类的实例来设置URL请求的headers,urllib仅可以接受URL。这意味着,你不可以通过urllib模块伪装你的User Agent字符串等(伪装浏览器)。
urllib提供urlencode方法用来GET查询字符串的产生,而urllib2没有。这是为何urllib常和urllib2一起使用的原因。
模块比较优势的地方是urlliburllib2.urlopen可以接受Request对象作为参数,从而可以控制HTTP Request的header部。
但是urllib.urlretrieve函数以及urllib.quote等一系列quote和unquote功能没有被加入urllib2中,因此有时也需要urllib的辅助。
7.什么是机器人协议?
robots协议(也称为爬虫协议、爬虫规则、机器人协议等)也是robots.txt,网站通过robots协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。
《机器人协议》是国际互联网界普遍使用的网站道德准则,其目的是保护网站数据和敏感信息,确保用户的个人信息和隐私不受侵犯。因为不是命令,所以需要搜索引擎有意识地服从。
8.什么是爬虫?
爬虫是请求 网站 并提取数据的自动化程序
9.爬虫的基本流程?
1、通过http库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers等信息,等待服务器响应
2、如果服务器能正常响应,会得到一个Response,Response的内容比啊是索要获取的页面内容
3、解析内容:正则表达式、页面解析库、json
4、保存数据:文本或者存入数据库
10.什么是请求和响应?
本地向服务器发送Request,服务器根据请求返回Response,页面显示
1、浏览器就发送消息给该网址所在的服务器,这个过程叫做Http Request
2、服务器收到浏览器发送的消息后,能够根据浏览器发送消息的内容,做相应处
理,然后把消息回传给浏览器,这个过程叫做HTTP Response
3、浏览器收到服务器的Response消息后,会对信息进行相应处理,然后显示
11.请求收录什么?
1、请求方式:主要有GET和POST两种方式,POST请求的参数不会包含在url里面
2、请求URL
URL:统一资源定位符,如一个网页文档、一张图片、一个视频等都可以用URL来唯一确定
3、请求头信息,包含了User-Agent(浏览器请求头)、Host、Cookies信息
4、请求体,GET请求时,一般不会有,POST请求时,请求体一般包含form-data
12.响应中收录哪些信息?
1、响应状态:状态码 正常响应200 重定向
2、响应头:如内容类型、内容长度、服务器信息、设置cookie等
3、响应体信息:响应源代码、图片二进制数据等等 查看全部
java从网页抓取数据(1.写一个邮箱地址的正则表达式?2.谈一谈你对Selenium和PhantomJS了解
)
1. 为电子邮件地址写一个正则表达式?
[A-Za-z0-9\u4e00-\u9fa5]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$
2. 说说你对 Selenium 和 PhantomJS 的了解
Selenium 是一个用于 Web 的自动化测试工具。根据我们的指令,浏览器可以自动加载页面,获取需要的数据,甚至可以对页面进行截图,或者判断网站上是否发生了某些动作。Selenium 没有自己的浏览器,不支持浏览器的功能。它需要与第三方浏览器结合使用。但是我们有时需要让它在代码中内联运行,所以我们可以使用一个叫做 PhantomJS 的工具来代替真正的浏览器。Selenium 库中有一个名为 WebDriver 的 API。WebDriver 有点像可以加载 网站 的浏览器,但它也可以像 BeautifulSoup 或其他 Selector 对象一样用于查找页面元素,与页面上的元素进行交互(发送文本、点击等),以及执行其他操作以运行网络爬虫。
PhantomJS 是一个基于 Webkit 的“无头”浏览器,它将 网站 加载到内存中并在页面上执行 JavaScript,因为它不显示图形界面,运行时间比完整的浏览器高效。与传统的 Chrome 或 Firefox 等浏览器相比,资源消耗会更少。
如果我们将 Selenium 和 PhantomJS 结合起来,我们可以运行一个非常强大的网络爬虫,它可以处理 JavaScript、cookie、标头以及我们真实用户需要做的任何其他事情。主程序退出后,selenium 不保证 phantomJS 也会成功退出。最好手动关闭 phantomJS 进程。(可能会导致多个phantomJS进程运行,占用内存)。虽然 WebDriverWait 可能会减少延迟,但目前存在 bug(各种错误),在这种情况下可以使用 sleep。phantomJS爬取数据比较慢,可以选择多线程。如果你发现有的可以运行,有的不能,可以尝试将phantomJS换成Chrome。
3. 为什么请求需要带headers?
原因是:模拟浏览器,欺骗服务器,获取与浏览器一致的内容头的形式:字典
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
用法:requests.get(url,headers=headers)
4. 你遇到过哪些反爬虫策略?和应对策略?
对于基本网页的抓取可以自定义headers,添加headers的数据,代理来解决
有些网站的数据抓取必须进行模拟登陆才能抓取到完整的数据,所以要进行模拟登陆。
对于限制抓取频率的,可以设置抓取的频率降低一些,
对于限制ip抓取的可以使用多个代理ip进行抓取,轮询使用代理
针对动态网页的可以使用selenium+phantomjs进行抓取,但是比较慢,所以也可以使用查找接口的方式进行抓取。
对部分数据进行加密的,可以使用selenium进行截图,饭后使用python自带的 pytesseract库进行识别,但是比较慢最直接的方法是找到加密的方法进行逆向推理。
5. 分布式爬虫原理?
scrapy-redis实现分布式,其实原理上很简单,这里为了描述方便,我们把我们的核心服务器叫做master,用来运行爬虫程序的机器叫做slave。
我们知道要使用scrapy框架爬取一个网页,我们需要先给它一些start_urls。爬虫首先访问start_urls中的url,然后根据我们的具体逻辑,对里面的元素,或者其他二级三级页面进行操作。抓住。要实现分发,我们只需要在这个starts_urls中做文章。
我们在master上建一个redis数据库(注意这个数据库只用于url存储,不关心具体爬取的数据,不要和mongodb或者mysql混淆),对于每一个网站需要爬取类型,单独开辟一个列表字段。通过在slave上设置scrapy-redis来获取url地址作为master地址。结果是虽然有多个slave,但是大家获取url的地方只有一个,那就是服务器master上的redis数据库。而且由于scrapy-redis自带的队列机制,slave获取的链接不会相互冲突。这样每个slave完成抓取任务后,将得到的结果聚合到服务器(此时的数据存储不再是redis,但是存储特定内容的数据库如mongodb或mysql)这种方法还有其他方法。优点是程序具有高度可移植性。只要路径问题处理好,将slave上的程序移植到另一台机器上运行,基本上就是复制粘贴的问题。
6. python2.x中的urllib和urllib2的区别?
异同:都是做url请求的操作的,但是区别很明显。
urllib2可以接受一个Request类的实例来设置URL请求的headers,urllib仅可以接受URL。这意味着,你不可以通过urllib模块伪装你的User Agent字符串等(伪装浏览器)。
urllib提供urlencode方法用来GET查询字符串的产生,而urllib2没有。这是为何urllib常和urllib2一起使用的原因。
模块比较优势的地方是urlliburllib2.urlopen可以接受Request对象作为参数,从而可以控制HTTP Request的header部。
但是urllib.urlretrieve函数以及urllib.quote等一系列quote和unquote功能没有被加入urllib2中,因此有时也需要urllib的辅助。
7.什么是机器人协议?
robots协议(也称为爬虫协议、爬虫规则、机器人协议等)也是robots.txt,网站通过robots协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。
《机器人协议》是国际互联网界普遍使用的网站道德准则,其目的是保护网站数据和敏感信息,确保用户的个人信息和隐私不受侵犯。因为不是命令,所以需要搜索引擎有意识地服从。
8.什么是爬虫?
爬虫是请求 网站 并提取数据的自动化程序
9.爬虫的基本流程?
1、通过http库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers等信息,等待服务器响应
2、如果服务器能正常响应,会得到一个Response,Response的内容比啊是索要获取的页面内容
3、解析内容:正则表达式、页面解析库、json
4、保存数据:文本或者存入数据库
10.什么是请求和响应?
本地向服务器发送Request,服务器根据请求返回Response,页面显示
1、浏览器就发送消息给该网址所在的服务器,这个过程叫做Http Request
2、服务器收到浏览器发送的消息后,能够根据浏览器发送消息的内容,做相应处
理,然后把消息回传给浏览器,这个过程叫做HTTP Response
3、浏览器收到服务器的Response消息后,会对信息进行相应处理,然后显示
11.请求收录什么?
1、请求方式:主要有GET和POST两种方式,POST请求的参数不会包含在url里面
2、请求URL
URL:统一资源定位符,如一个网页文档、一张图片、一个视频等都可以用URL来唯一确定
3、请求头信息,包含了User-Agent(浏览器请求头)、Host、Cookies信息
4、请求体,GET请求时,一般不会有,POST请求时,请求体一般包含form-data
12.响应中收录哪些信息?
1、响应状态:状态码 正常响应200 重定向
2、响应头:如内容类型、内容长度、服务器信息、设置cookie等
3、响应体信息:响应源代码、图片二进制数据等等
java从网页抓取数据( 再通过数据清洗让这些数据成为我们的基础资料库就行了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-08 12:26
再通过数据清洗让这些数据成为我们的基础资料库就行了)
. . .
爬虫可以用各种语言写,C++、Java都可以,为什么要Python?首先,使用C++进行网络开发的例子并不多(可能我看到的太少了),然后因为甲骨文收购了Sun,Java目前在Android上开发是非常重要的,但是如果谷歌官司不走好吧,那么很有可能会使用 Go 语言而不是 Java 进行 Android 开发。在这个电脑飞速发展的时代,语言的选择取决于父亲的表现,这有点不同。注意力落后于时代。随着计算机速度的飞速发展,用某种语言开发的软件的时间复杂度常数系数已经不像以前那么重要了,我们可以更愿意为程序员而不是为计算机构建。例如,红宝石,传说中的纯种优雅的OOP语言,也就是Python,它是一种稍微严谨但流行的语言,有很多库,大大削弱了为计算机运行速度而设计的特性,加强了为程序员构建的易于思考的特性。所以我选择了 Python。
. . .
“爬虫”就是一个例子。对于我们开发者来说,它是一个用于自动化采集网站数据的程序,结果发现它与真正的bug有关。
. . .
在这个数据交叉流动的互联网时代,初创公司如雨后春笋般涌现,大数据可以帮助他们快速生成垂直数据数据库供用户使用。也让老板更容易看清未来的方向,制定发展策略。
. . .
. . .
如果使用爬虫技术,事情就有了很好的解决方案。我们只需要编写一个7*24小时运行的分布式爬虫,自动化采集携程酒店数据,抓取国内外所有高端酒店(图片、简介、评分、用户评论)。然后通过数据清洗,规范内容,让这些数据成为我们的基础数据库。
,
以上就是全部代码,只是善于分享,请多多包涵!爬虫的基本原理是获取源代码,然后获取网页内容。一般来说,只要你给出一个条目,通过分析,你可以找到无数其他你需要的相关资源,然后爬取。
我还写了很多其他非常简单的入门级爬虫详细教程。关注后,点击我的头像查看。
——————————————————————————————————————————
欢迎留言讨论交流,谢谢! 查看全部
java从网页抓取数据(
再通过数据清洗让这些数据成为我们的基础资料库就行了)
. . .
爬虫可以用各种语言写,C++、Java都可以,为什么要Python?首先,使用C++进行网络开发的例子并不多(可能我看到的太少了),然后因为甲骨文收购了Sun,Java目前在Android上开发是非常重要的,但是如果谷歌官司不走好吧,那么很有可能会使用 Go 语言而不是 Java 进行 Android 开发。在这个电脑飞速发展的时代,语言的选择取决于父亲的表现,这有点不同。注意力落后于时代。随着计算机速度的飞速发展,用某种语言开发的软件的时间复杂度常数系数已经不像以前那么重要了,我们可以更愿意为程序员而不是为计算机构建。例如,红宝石,传说中的纯种优雅的OOP语言,也就是Python,它是一种稍微严谨但流行的语言,有很多库,大大削弱了为计算机运行速度而设计的特性,加强了为程序员构建的易于思考的特性。所以我选择了 Python。
. . .
“爬虫”就是一个例子。对于我们开发者来说,它是一个用于自动化采集网站数据的程序,结果发现它与真正的bug有关。
. . .
在这个数据交叉流动的互联网时代,初创公司如雨后春笋般涌现,大数据可以帮助他们快速生成垂直数据数据库供用户使用。也让老板更容易看清未来的方向,制定发展策略。
. . .
. . .
如果使用爬虫技术,事情就有了很好的解决方案。我们只需要编写一个7*24小时运行的分布式爬虫,自动化采集携程酒店数据,抓取国内外所有高端酒店(图片、简介、评分、用户评论)。然后通过数据清洗,规范内容,让这些数据成为我们的基础数据库。
,
以上就是全部代码,只是善于分享,请多多包涵!爬虫的基本原理是获取源代码,然后获取网页内容。一般来说,只要你给出一个条目,通过分析,你可以找到无数其他你需要的相关资源,然后爬取。
我还写了很多其他非常简单的入门级爬虫详细教程。关注后,点击我的头像查看。
——————————————————————————————————————————
欢迎留言讨论交流,谢谢!
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-08 09:10
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 244 次浏览 • 2022-03-03 21:04
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门针对httpclient+jsoup进行讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据,最终我们要提取的结果是产品的型号、数量、报价、供应商。首先,我们看到这个 网站 整页预览
接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据
获取数据的成功就是我们想要得到的最终数据结果。最后想说的是,这里的这个网页比较简单,可以看到网页源的源数据,而这个方法是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是提示一下,我们可以使用多线程对当前所有分页数据执行采集,通过一个线程采集当前分页数据和一个翻页动作,所有数据可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
转载于: 查看全部
java从网页抓取数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门针对httpclient+jsoup进行讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据,最终我们要提取的结果是产品的型号、数量、报价、供应商。首先,我们看到这个 网站 整页预览

接下来我们看一下网页的源码结构:
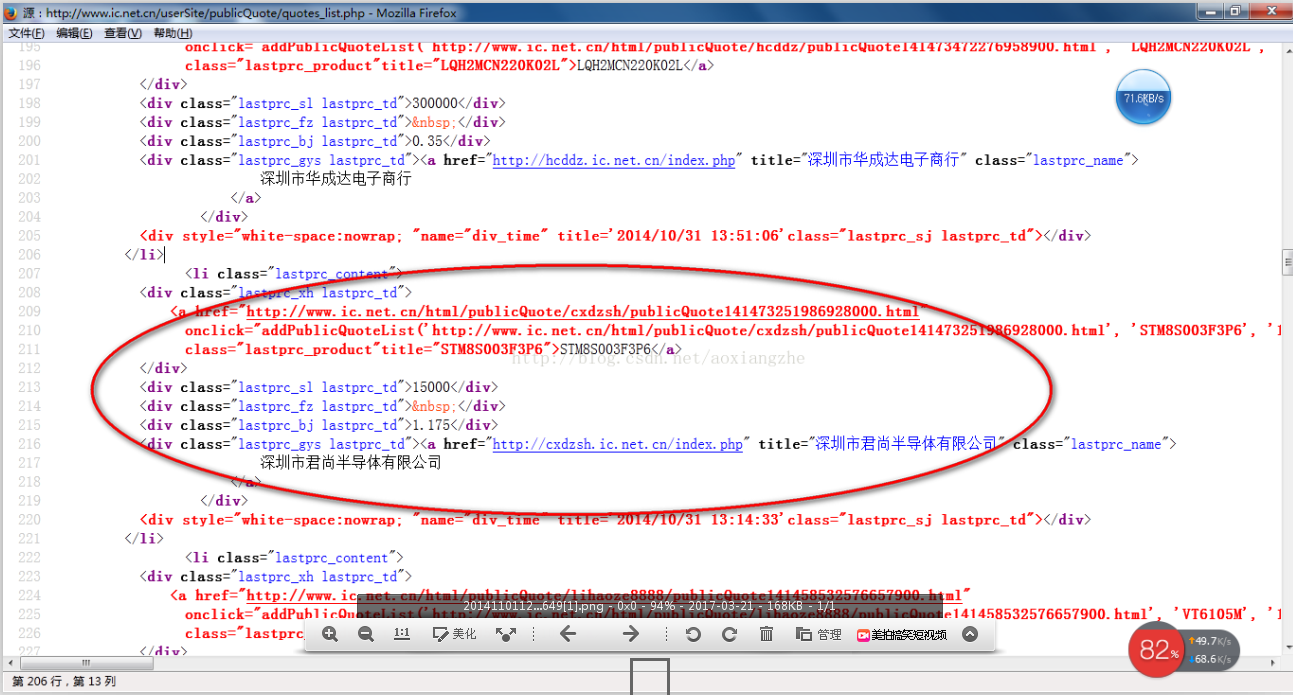
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据

获取数据的成功就是我们想要得到的最终数据结果。最后想说的是,这里的这个网页比较简单,可以看到网页源的源数据,而这个方法是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是提示一下,我们可以使用多线程对当前所有分页数据执行采集,通过一个线程采集当前分页数据和一个翻页动作,所有数据可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
转载于:
java从网页抓取数据( java多线程获取铃声的json数据()(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-04-02 18:24
java多线程获取铃声的json数据()(图)
)
java多线程抓取铃声官网的铃声数据
更新时间:2016-04-28 11:50:47 作者:bobo_ll
不难发现,通过改变listId和page,可以从服务端获取铃声的json数据。通过解析json数据可以看到有{"hasmore":1,"curpage":1}等指令,通过判断hasmore的值来决定是否取下一页。但是上面链接返回的json没有铃声的下载地址
我一直想练习java多线程来获取数据。
有一天我发现Ringtones()的官网有很多数据。
通过观察它们的前端来获取铃声数据的ajax
{类别 ID}&page={分页符页码}
不难发现,通过改变listId和page,可以从服务端获取铃声的json数据,通过解析json数据,
可以看到有{"hasmore":1,"curpage":1}这样的指令。通过判断hasmore的值,决定是否爬取下一页。
但是上面链接返回的json没有铃声的下载地址
你很快就会发现,点击页面上的“下载”,你会看到
通过以下请求,可以得到铃声的下载地址
{铃声ID}
因此,他们的数据很容易被窃取。于是我开始...
源代码已发布在 github 上。如果您对童鞋感兴趣,可以查看
github:
以上代码:
package me.yongbo.DuoduoRingRobot;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
import java.util.Iterator;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import com.google.gson.Gson;
import com.google.gson.JsonArray;
import com.google.gson.JsonElement;
import com.google.gson.JsonParser;
/* * @author yongbo_ * @created 2013/4/16 * * */
public class DuoduoRingRobotClient implements Runnable {
public static String GET_RINGINFO_URL = "http://www.shoujiduoduo.com/ri ... D%251$d&page=%2$d";
public static String GET_DOWN_URL = "http://www.shoujiduoduo.com/ri ... D%251$d";
public static String ERROR_MSG = "listId为 %1$d 的Robot发生错误,已自动停止。当前page为 %2$d";public static String STATUS_MSG = "开始抓取数据,当前listId: %1$d,当前page: %2$d";
public static String FILE_DIR = "E:/RingData/";public static String FILE_NAME = "listId=%1$d.txt";private boolean errorFlag = false;private int listId;private int page;
private int endPage = -1;private int hasMore = 1;
private DbHelper dbHelper;
/** * 构造函数 * @param listId 菜单ID * @param page 开始页码 * @param endPage 结束页码 * */
public DuoduoRingRobotClient(int listId, int beginPage, int endPage)
{this.listId = listId;this.page = beginPage;this.endPage = endPage;this.dbHelper = new DbHelper();}
/** * 构造函数 * @param listId 菜单ID * @param page 开始页码 * */
public DuoduoRingRobotClient(int listId, int page) {this(listId, page, -1);}
/** * 获取铃声 * */public void getRings() {String url = String.format(GET_RINGINFO_URL, listId, page);String responseStr = httpGet(url);hasMore = getHasmore(responseStr);
page = getNextPage(responseStr);
ringParse(responseStr.replaceAll("\\{\"hasmore\":[0-9]*,\"curpage\":[0-9]*\\},", "").replaceAll(",]", "]"));}/** * 发起http请求 * @param webUrl 请求连接地址 * */public String httpGet(String webUrl){URL url;URLConnection conn;StringBuilder sb = new StringBuilder();String resultStr = "";try {url = new URL(webUrl);conn = url.openConnection();conn.connect();InputStream is = conn.getInputStream();InputStreamReader isr = new InputStreamReader(is);BufferedReader bufReader = new BufferedReader(isr);String lineText;while ((lineText = bufReader.readLine()) != null) {sb.append(lineText);}resultStr = sb.toString();} catch (Exception e) {errorFlag = true;//将错误写入txtwriteToFile(String.format(ERROR_MSG, listId, page));}return resultStr;}/** * 将json字符串转化成Ring对象,并存入txt中 * @param json Json字符串 * */public void ringParse(String json) {Ring ring = null;JsonElement element = new JsonParser().parse(json);JsonArray array = element.getAsJsonArray();// 遍历数组Iterator it = array.iterator();
Gson gson = new Gson();while (it.hasNext() && !errorFlag) {JsonElement e = it.next();// JsonElement转换为JavaBean对象ring = gson.fromJson(e, Ring.class);ring.setDownUrl(getRingDownUrl(ring.getId()));if(isAvailableRing(ring)) {System.out.println(ring.toString());
//可选择写入数据库还是写入文本//writeToFile(ring.toString());writeToDatabase(ring);}}}
/** * 写入txt * @param data 字符串 * */public void writeToFile(String data)
{String path = FILE_DIR + String.format(FILE_NAME, listId);File dir = new File(FILE_DIR);File file = new File(path);FileWriter fw = null;if(!dir.exists()){dir.mkdirs();
}try {if(!file.exists()){file.createNewFile();}fw = new FileWriter(file, true);
fw.write(data);fw.write("\r\n");fw.flush();} catch (IOException e) {
// TODO Auto-generated catch blocke.printStackTrace();
}finally {try {if(fw != null){fw.close();}} catch (IOException e) {
// TODO Auto-generated catch blocke.printStackTrace();}}}/** * 写入数据库 * @param ring 一个Ring的实例 * */
public void writeToDatabase(Ring ring) {dbHelper.execute("addRing", ring);}
@Overridepublic void run() {while(hasMore == 1 && !errorFlag){if(endPage != -1){if(page > endPage) { break; }}System.out.println(String.format(STATUS_MSG, listId, page));
getRings();System.out.println(String.format("该页数据写入完成"));}System.out.println("ending...");}
private int getHasmore(String resultStr){Pattern p = Pattern.compile("\"hasmore\":([0-9]*),\"curpage\":([0-9]*)");
Matcher match = p.matcher(resultStr);
if (match.find()) { return Integer.parseInt(match.group(1));
} return 0;
}
private int getNextPage(String resultStr){Pattern p = Pattern.compile("\"hasmore\":([0-9]*),\"curpage\":([0-9]*)");Matcher match = p.matcher(resultStr);if (match.find()) {return Integer.parseInt(match.group(2));}return 0;}
/** * 判断当前Ring是否满足条件。当Ring的name大于50个字符或是duration为小数则不符合条件,将被剔除。 * @param ring 当前Ring对象实例 * */private boolean isAvailableRing(Ring ring){Pattern p = Pattern.compile("^[1-9][0-9]*$");
Matcher match = p.matcher(ring.getDuration());
if(!match.find()){return false;}if(ring.getName().length() > 50 || ring.getArtist().length() > 50 || ring.getDownUrl().length() == 0){return false;}return true;}
/** * 获取铃声的下载地址 * @param rid 铃声的id * */
public String getRingDownUrl(String rid){String url = String.format(GET_DOWN_URL, rid);
String responseStr = httpGet(url);return responseStr;}} 查看全部
java从网页抓取数据(
java多线程获取铃声的json数据()(图)
)
java多线程抓取铃声官网的铃声数据
更新时间:2016-04-28 11:50:47 作者:bobo_ll
不难发现,通过改变listId和page,可以从服务端获取铃声的json数据。通过解析json数据可以看到有{"hasmore":1,"curpage":1}等指令,通过判断hasmore的值来决定是否取下一页。但是上面链接返回的json没有铃声的下载地址
我一直想练习java多线程来获取数据。
有一天我发现Ringtones()的官网有很多数据。
通过观察它们的前端来获取铃声数据的ajax
{类别 ID}&page={分页符页码}
不难发现,通过改变listId和page,可以从服务端获取铃声的json数据,通过解析json数据,
可以看到有{"hasmore":1,"curpage":1}这样的指令。通过判断hasmore的值,决定是否爬取下一页。
但是上面链接返回的json没有铃声的下载地址
你很快就会发现,点击页面上的“下载”,你会看到
通过以下请求,可以得到铃声的下载地址
{铃声ID}
因此,他们的数据很容易被窃取。于是我开始...
源代码已发布在 github 上。如果您对童鞋感兴趣,可以查看
github:
以上代码:
package me.yongbo.DuoduoRingRobot;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
import java.util.Iterator;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import com.google.gson.Gson;
import com.google.gson.JsonArray;
import com.google.gson.JsonElement;
import com.google.gson.JsonParser;
/* * @author yongbo_ * @created 2013/4/16 * * */
public class DuoduoRingRobotClient implements Runnable {
public static String GET_RINGINFO_URL = "http://www.shoujiduoduo.com/ri ... D%251$d&page=%2$d";
public static String GET_DOWN_URL = "http://www.shoujiduoduo.com/ri ... D%251$d";
public static String ERROR_MSG = "listId为 %1$d 的Robot发生错误,已自动停止。当前page为 %2$d";public static String STATUS_MSG = "开始抓取数据,当前listId: %1$d,当前page: %2$d";
public static String FILE_DIR = "E:/RingData/";public static String FILE_NAME = "listId=%1$d.txt";private boolean errorFlag = false;private int listId;private int page;
private int endPage = -1;private int hasMore = 1;
private DbHelper dbHelper;
/** * 构造函数 * @param listId 菜单ID * @param page 开始页码 * @param endPage 结束页码 * */
public DuoduoRingRobotClient(int listId, int beginPage, int endPage)
{this.listId = listId;this.page = beginPage;this.endPage = endPage;this.dbHelper = new DbHelper();}
/** * 构造函数 * @param listId 菜单ID * @param page 开始页码 * */
public DuoduoRingRobotClient(int listId, int page) {this(listId, page, -1);}
/** * 获取铃声 * */public void getRings() {String url = String.format(GET_RINGINFO_URL, listId, page);String responseStr = httpGet(url);hasMore = getHasmore(responseStr);
page = getNextPage(responseStr);
ringParse(responseStr.replaceAll("\\{\"hasmore\":[0-9]*,\"curpage\":[0-9]*\\},", "").replaceAll(",]", "]"));}/** * 发起http请求 * @param webUrl 请求连接地址 * */public String httpGet(String webUrl){URL url;URLConnection conn;StringBuilder sb = new StringBuilder();String resultStr = "";try {url = new URL(webUrl);conn = url.openConnection();conn.connect();InputStream is = conn.getInputStream();InputStreamReader isr = new InputStreamReader(is);BufferedReader bufReader = new BufferedReader(isr);String lineText;while ((lineText = bufReader.readLine()) != null) {sb.append(lineText);}resultStr = sb.toString();} catch (Exception e) {errorFlag = true;//将错误写入txtwriteToFile(String.format(ERROR_MSG, listId, page));}return resultStr;}/** * 将json字符串转化成Ring对象,并存入txt中 * @param json Json字符串 * */public void ringParse(String json) {Ring ring = null;JsonElement element = new JsonParser().parse(json);JsonArray array = element.getAsJsonArray();// 遍历数组Iterator it = array.iterator();
Gson gson = new Gson();while (it.hasNext() && !errorFlag) {JsonElement e = it.next();// JsonElement转换为JavaBean对象ring = gson.fromJson(e, Ring.class);ring.setDownUrl(getRingDownUrl(ring.getId()));if(isAvailableRing(ring)) {System.out.println(ring.toString());
//可选择写入数据库还是写入文本//writeToFile(ring.toString());writeToDatabase(ring);}}}
/** * 写入txt * @param data 字符串 * */public void writeToFile(String data)
{String path = FILE_DIR + String.format(FILE_NAME, listId);File dir = new File(FILE_DIR);File file = new File(path);FileWriter fw = null;if(!dir.exists()){dir.mkdirs();
}try {if(!file.exists()){file.createNewFile();}fw = new FileWriter(file, true);
fw.write(data);fw.write("\r\n");fw.flush();} catch (IOException e) {
// TODO Auto-generated catch blocke.printStackTrace();
}finally {try {if(fw != null){fw.close();}} catch (IOException e) {
// TODO Auto-generated catch blocke.printStackTrace();}}}/** * 写入数据库 * @param ring 一个Ring的实例 * */
public void writeToDatabase(Ring ring) {dbHelper.execute("addRing", ring);}
@Overridepublic void run() {while(hasMore == 1 && !errorFlag){if(endPage != -1){if(page > endPage) { break; }}System.out.println(String.format(STATUS_MSG, listId, page));
getRings();System.out.println(String.format("该页数据写入完成"));}System.out.println("ending...");}
private int getHasmore(String resultStr){Pattern p = Pattern.compile("\"hasmore\":([0-9]*),\"curpage\":([0-9]*)");
Matcher match = p.matcher(resultStr);
if (match.find()) { return Integer.parseInt(match.group(1));
} return 0;
}
private int getNextPage(String resultStr){Pattern p = Pattern.compile("\"hasmore\":([0-9]*),\"curpage\":([0-9]*)");Matcher match = p.matcher(resultStr);if (match.find()) {return Integer.parseInt(match.group(2));}return 0;}
/** * 判断当前Ring是否满足条件。当Ring的name大于50个字符或是duration为小数则不符合条件,将被剔除。 * @param ring 当前Ring对象实例 * */private boolean isAvailableRing(Ring ring){Pattern p = Pattern.compile("^[1-9][0-9]*$");
Matcher match = p.matcher(ring.getDuration());
if(!match.find()){return false;}if(ring.getName().length() > 50 || ring.getArtist().length() > 50 || ring.getDownUrl().length() == 0){return false;}return true;}
/** * 获取铃声的下载地址 * @param rid 铃声的id * */
public String getRingDownUrl(String rid){String url = String.format(GET_DOWN_URL, rid);
String responseStr = httpGet(url);return responseStr;}}
java从网页抓取数据( 我个人网站一个页面为例(3.1)什么是Jsoup技术? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-04-01 20:15
我个人网站一个页面为例(3.1)什么是Jsoup技术?
)
(2.4)为了避免其他网站侵权问题,我们以我自己的一个页面网站为例(),我们把这个页面上的图片全部抓取.
(2.5) 可以看出这是一个get请求,返回一个Html页面。所以我们在HttpTool类中添加如下方法体:
/**
* 实现Get请求
* @param url 请求地址
* @return 页面内容
*/
public static String doGet(String url) {
return null;
}
(2.6)复制代码,添加get实现方法:
// 构建get请求
HttpGet get = new HttpGet(url);
// 创建客户端
CloseableHttpClient client = HttpClients.createDefault();
try {
// 客户端执行请求,获取响应
HttpResponse response = client.execute(get);
// 获取响应的页面内容
InputStream in = response.getEntity().getContent();
StringBuilder sb = new StringBuilder();
byte[]b = new byte[102400];
int length;
while ((length = in.read(b)) != -1) {
sb.append(new String(b, 0, length, "utf-8"));
}
// 返回页面内容
return sb.toString();
} catch (Exception e) {
e.printStackTrace();
return null;
}
(2.7)好的,网络请求相关的实现类我们已经写好了,接下来我们测试一下,我们在Test类的main方法中添加如下代码:
String html = HttpTool.doGet("http://www.zyqok.cn/material/index");
System.out.println(html);
(2.8)执行程序,查看结果,可以看到我们确实通过请求得到了网页的返回内容。
[3] Jsoup解析网页
在[2]的整个实现过程中,我们已经得到了网页返回的数据,但是我们要的是整个网页中的图片,而不是这种乱七八糟的网页数据,那我们该怎么办呢?很简单,接下来我们需要使用另一种技术——Jsoup。
(3.1)什么是Jsoup技术?
以下是度娘官方给出的解释:Jsoup是一个Java HTML解析器,可以直接解析一个URL地址和HTML文本内容。它提供了一个非常省力的API,用于通过DOM、CSS和类似jQuery的操作方法(取自百度)来获取和操作数据。
以下是我个人语言的简单总结: Jsoup技术用于处理各种html页面和xml数据。这里我们可以使用Jsoup来处理[2]中返回的html页面。
(3.2)添加Jsoup依赖
我们在 pom.xml 中添加以下依赖项:
org.jsoup
jsoup
1.11.3
(3.3) 当然,在使用Jsoup之前,我们需要对响应的HTML页面进行分析。分析的主要作用是:如何定位和过滤掉我们需要的数据?
我们将[2]中得到的页面响应复制到txt文本中,然后我们可以发现每张图片都收录在一个div中,并且该div有一个名为material-div的类。
(3.4)根据上面的分析:首先我们需要获取所有收录图片的div,所以我们修改main方法中的代码如下:
String html = HttpTool.doGet("http://www.zyqok.cn/material/index");
// 将 html 页面解析为 Document 对象
Document doc = Jsoup.parse(html);
// 获取所有包含 class = material-div 的 div 元素
Elements elements = doc.select("div.material-div");
for(Element div: elements){
System.out.println(div.toString());
}
注意:doc.select()括号内的参数为过滤条件,基本等价于jquery的过滤条件。所以,懂jquery的同学基本都能搞定过滤条件。当然,如果你不会写过滤条件也不要害怕。Jsoup 用户指南的副本,您不妨接受它(传送门:Jsoup 官方用户指南)。
(3.5)我们执行代码,继续将输出复制到文本中。
可以看到,这次只有图片相关的div元素,但这并不是我们想要的最终结果。我们最终的结果是得到所有的图片。
所以我们还需要继续分析:如何获取所有图片的链接和名称。
(3.6)由于每张图片所在的div元素的结构都是一样的,我们可以随机取一个div元素进行分析,所以可以取第一个div进行分析,结构为如下:
大树夕阳.jpg
2020-04-14 22:09:46
3.7)我们可以看到整个结构中只有一个img元素标签,所以我们可以把第一个img标签的src属性作为图片链接;同理,我们取第一个 font 元素的文本内容为图片名称。
(3.8)所以我们可以修改循环中的代码如下:
// 获取第1个 img 元素Element img = div.selectFirst("img");// 获取第1个 font 元素Element font = div.selectFirst("font");// 获取img元素src属性,即为图片链接String url = img.attr("src");// 获取name元素文本,即为图片名称String name = font.text();System.out.println(name + ": " + url);
(3.9)我们执行上面的代码,可以得到如下结果。
可以看到,这个页面上的所有图片地址和名字都已经被我们成功抓取了。
[4] 获取图片到本地
在步骤[3]中,我们得到的只是所有图片的链接,并且所有的图片都没有下载到我们的本地,那么接下来,我们需要把这张图片下载到我们的本地才算完整。
(4.1)既然要下载到本地,就先在本地找个地方存放这些图片。
例如:我将所有图片下载到D:\imgs(D盘的imgs文件夹)。
查看全部
java从网页抓取数据(
我个人网站一个页面为例(3.1)什么是Jsoup技术?
)
(2.4)为了避免其他网站侵权问题,我们以我自己的一个页面网站为例(),我们把这个页面上的图片全部抓取.
(2.5) 可以看出这是一个get请求,返回一个Html页面。所以我们在HttpTool类中添加如下方法体:
/**
* 实现Get请求
* @param url 请求地址
* @return 页面内容
*/
public static String doGet(String url) {
return null;
}
(2.6)复制代码,添加get实现方法:
// 构建get请求
HttpGet get = new HttpGet(url);
// 创建客户端
CloseableHttpClient client = HttpClients.createDefault();
try {
// 客户端执行请求,获取响应
HttpResponse response = client.execute(get);
// 获取响应的页面内容
InputStream in = response.getEntity().getContent();
StringBuilder sb = new StringBuilder();
byte[]b = new byte[102400];
int length;
while ((length = in.read(b)) != -1) {
sb.append(new String(b, 0, length, "utf-8"));
}
// 返回页面内容
return sb.toString();
} catch (Exception e) {
e.printStackTrace();
return null;
}
(2.7)好的,网络请求相关的实现类我们已经写好了,接下来我们测试一下,我们在Test类的main方法中添加如下代码:
String html = HttpTool.doGet("http://www.zyqok.cn/material/index";);
System.out.println(html);
(2.8)执行程序,查看结果,可以看到我们确实通过请求得到了网页的返回内容。
[3] Jsoup解析网页
在[2]的整个实现过程中,我们已经得到了网页返回的数据,但是我们要的是整个网页中的图片,而不是这种乱七八糟的网页数据,那我们该怎么办呢?很简单,接下来我们需要使用另一种技术——Jsoup。
(3.1)什么是Jsoup技术?
以下是度娘官方给出的解释:Jsoup是一个Java HTML解析器,可以直接解析一个URL地址和HTML文本内容。它提供了一个非常省力的API,用于通过DOM、CSS和类似jQuery的操作方法(取自百度)来获取和操作数据。
以下是我个人语言的简单总结: Jsoup技术用于处理各种html页面和xml数据。这里我们可以使用Jsoup来处理[2]中返回的html页面。
(3.2)添加Jsoup依赖
我们在 pom.xml 中添加以下依赖项:
org.jsoup
jsoup
1.11.3
(3.3) 当然,在使用Jsoup之前,我们需要对响应的HTML页面进行分析。分析的主要作用是:如何定位和过滤掉我们需要的数据?
我们将[2]中得到的页面响应复制到txt文本中,然后我们可以发现每张图片都收录在一个div中,并且该div有一个名为material-div的类。
(3.4)根据上面的分析:首先我们需要获取所有收录图片的div,所以我们修改main方法中的代码如下:
String html = HttpTool.doGet("http://www.zyqok.cn/material/index";);
// 将 html 页面解析为 Document 对象
Document doc = Jsoup.parse(html);
// 获取所有包含 class = material-div 的 div 元素
Elements elements = doc.select("div.material-div");
for(Element div: elements){
System.out.println(div.toString());
}
注意:doc.select()括号内的参数为过滤条件,基本等价于jquery的过滤条件。所以,懂jquery的同学基本都能搞定过滤条件。当然,如果你不会写过滤条件也不要害怕。Jsoup 用户指南的副本,您不妨接受它(传送门:Jsoup 官方用户指南)。
(3.5)我们执行代码,继续将输出复制到文本中。
可以看到,这次只有图片相关的div元素,但这并不是我们想要的最终结果。我们最终的结果是得到所有的图片。
所以我们还需要继续分析:如何获取所有图片的链接和名称。
(3.6)由于每张图片所在的div元素的结构都是一样的,我们可以随机取一个div元素进行分析,所以可以取第一个div进行分析,结构为如下:
大树夕阳.jpg
2020-04-14 22:09:46
3.7)我们可以看到整个结构中只有一个img元素标签,所以我们可以把第一个img标签的src属性作为图片链接;同理,我们取第一个 font 元素的文本内容为图片名称。
(3.8)所以我们可以修改循环中的代码如下:
// 获取第1个 img 元素Element img = div.selectFirst("img");// 获取第1个 font 元素Element font = div.selectFirst("font");// 获取img元素src属性,即为图片链接String url = img.attr("src");// 获取name元素文本,即为图片名称String name = font.text();System.out.println(name + ": " + url);
(3.9)我们执行上面的代码,可以得到如下结果。
可以看到,这个页面上的所有图片地址和名字都已经被我们成功抓取了。
[4] 获取图片到本地
在步骤[3]中,我们得到的只是所有图片的链接,并且所有的图片都没有下载到我们的本地,那么接下来,我们需要把这张图片下载到我们的本地才算完整。
(4.1)既然要下载到本地,就先在本地找个地方存放这些图片。
例如:我将所有图片下载到D:\imgs(D盘的imgs文件夹)。
java从网页抓取数据( 大数据中的数据是如何爬取出来的(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-31 14:35
大数据中的数据是如何爬取出来的(一))
上一篇文章我们分享了全套大数据资源,大家积极采集。今天就来看看我们大数据里的数据是怎么爬出来的。希望能给每个学习Python的人一点启发。
网络爬虫
大家都知道,我们看到的网页是一个开放的平台。当我们按下 F12 时,我们可以在网页中看到一些代码。这样一种开放的方式,使得网络发展迅速。从纯文本的开始,到 Html、css 技术等的出现,我们的网络已经成为最流行的互联网传播媒介。
然而,正是由于web的开放服务,我们平时看到的文章内容信息并不能得到有效的保护。此时,我们网页中的这些消息将被成本较低的人使用。,低科技的小爬虫爬到。
这个程序就是我们今天所说的网络爬虫。
在我们目前对原创作者的保护下,以这种方式保护我的创作是非常困难的。而那些无权抓取我们网站的数据内容,对我们作者的伤害是最大的。
那么,我们如何对抗爬行动物呢?
反爬虫
让我们在这里举一个简单的例子。我们之前讲过Javaweb的内容,关于网站的访问过程。一起学大数据 | 确认了眼力,第一次见到JavaWeb,很漂亮
我们也知道这样一个过程。我们见过的几乎所有服务器和客户端编程语言都支持 HTTP 请求。我们在网页导航栏输入目标页面地址,我们的机器会向服务器发起get请求。这时候,我们就可以在浏览器上加载这样一个完整的页面了。
作为服务端,它会根据我们发送的http请求中的User-Agent判断我们的请求是否为合法请求,即是浏览器请求还是合法的爬虫程序,验证通过。只有这样我们才能看到我们真正的网站。
以上是简单的攻防。python网络爬虫的基本原理是这样的,一是拦截内容,一是保护内容不被窃取。
其实上面的方法是小菜一碟的技术。如果我们作为攻击者获得了内容,当然可以伪造一个用户代理数据来欺骗服务器的验证。除了这些,只要你愿意,你就可以轻松创建数据。
我们的其他反爬虫技术包括浏览器指纹技术和验证码技术。行为验证技术等
写在最后
以上只是一个简单的例子。我们网页内容的获取与反制,是一场你攻守兼备的游戏,总有一堵不可阻挡的墙可以突破。这里最好的方法是改进网络技术,让爬虫制造商的成本更高。如果成本大于需要,你还会爬取数据吗?
以下是要分享的最关键信息。资料是从网上慢慢整理出来的,希望对正在学习的各位有所帮助。
python资源可能有点大,可以单独保存,也可以挑一部分数据,每个python文件都是单独的一组视频。
获取方法
1.先点击右上角【关注】关注我的头条号~
2、个人主页关注以上私信:Python(大写P哟)
如果觉得资源不错,请给好评,谢谢,记得关注转发和采集!
感谢朋友们的关注~
世界很大,很幸运有你~ 查看全部
java从网页抓取数据(
大数据中的数据是如何爬取出来的(一))
上一篇文章我们分享了全套大数据资源,大家积极采集。今天就来看看我们大数据里的数据是怎么爬出来的。希望能给每个学习Python的人一点启发。
网络爬虫
大家都知道,我们看到的网页是一个开放的平台。当我们按下 F12 时,我们可以在网页中看到一些代码。这样一种开放的方式,使得网络发展迅速。从纯文本的开始,到 Html、css 技术等的出现,我们的网络已经成为最流行的互联网传播媒介。
然而,正是由于web的开放服务,我们平时看到的文章内容信息并不能得到有效的保护。此时,我们网页中的这些消息将被成本较低的人使用。,低科技的小爬虫爬到。
这个程序就是我们今天所说的网络爬虫。
在我们目前对原创作者的保护下,以这种方式保护我的创作是非常困难的。而那些无权抓取我们网站的数据内容,对我们作者的伤害是最大的。
那么,我们如何对抗爬行动物呢?
反爬虫
让我们在这里举一个简单的例子。我们之前讲过Javaweb的内容,关于网站的访问过程。一起学大数据 | 确认了眼力,第一次见到JavaWeb,很漂亮
我们也知道这样一个过程。我们见过的几乎所有服务器和客户端编程语言都支持 HTTP 请求。我们在网页导航栏输入目标页面地址,我们的机器会向服务器发起get请求。这时候,我们就可以在浏览器上加载这样一个完整的页面了。
作为服务端,它会根据我们发送的http请求中的User-Agent判断我们的请求是否为合法请求,即是浏览器请求还是合法的爬虫程序,验证通过。只有这样我们才能看到我们真正的网站。
以上是简单的攻防。python网络爬虫的基本原理是这样的,一是拦截内容,一是保护内容不被窃取。
其实上面的方法是小菜一碟的技术。如果我们作为攻击者获得了内容,当然可以伪造一个用户代理数据来欺骗服务器的验证。除了这些,只要你愿意,你就可以轻松创建数据。
我们的其他反爬虫技术包括浏览器指纹技术和验证码技术。行为验证技术等
写在最后
以上只是一个简单的例子。我们网页内容的获取与反制,是一场你攻守兼备的游戏,总有一堵不可阻挡的墙可以突破。这里最好的方法是改进网络技术,让爬虫制造商的成本更高。如果成本大于需要,你还会爬取数据吗?
以下是要分享的最关键信息。资料是从网上慢慢整理出来的,希望对正在学习的各位有所帮助。
python资源可能有点大,可以单独保存,也可以挑一部分数据,每个python文件都是单独的一组视频。
获取方法
1.先点击右上角【关注】关注我的头条号~
2、个人主页关注以上私信:Python(大写P哟)
如果觉得资源不错,请给好评,谢谢,记得关注转发和采集!
感谢朋友们的关注~
世界很大,很幸运有你~
java从网页抓取数据(javascript如何使用javascript访问页面的简单示例?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-30 06:14
您需要使用支持 javascript 的库。我为此使用了 HtmlUnit,它是一个很棒的库来复制浏览器行为!
有关如何使用 javascript 访问页面的简单示例,请参阅下面的修改答案。
首先,查看他们的 pages() 以启动和运行 htmlunit。确保使用最新的快照 (2.12)
在撰写此快照时)
尝试以下设置以忽略几乎所有障碍:
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_17);
webClient.getOptions().setRedirectEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setUseInsecureSSL(true);
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getCookieManager().setCookiesEnabled(true);
然后,在获取页面时,请确保在对页面进行任何操作之前等待后台 Javascript,例如等待后台 javascript。
//Get Page
HtmlPage page1 = webClient.getPage("https://login-url/");
//Wait for background Javascript
webClient.waitForBackgroundJavaScript(10000);
//Get full page _after_ javascript has rendered it fully
System.out.println(page1.asXml());
希望这个基本示例对您有所帮助!
您可以使用 HtmlUnit 执行浏览器几乎可以执行的所有操作,但以编程方式。 查看全部
java从网页抓取数据(javascript如何使用javascript访问页面的简单示例?(图))
您需要使用支持 javascript 的库。我为此使用了 HtmlUnit,它是一个很棒的库来复制浏览器行为!
有关如何使用 javascript 访问页面的简单示例,请参阅下面的修改答案。
首先,查看他们的 pages() 以启动和运行 htmlunit。确保使用最新的快照 (2.12)
在撰写此快照时)
尝试以下设置以忽略几乎所有障碍:
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_17);
webClient.getOptions().setRedirectEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setUseInsecureSSL(true);
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getCookieManager().setCookiesEnabled(true);
然后,在获取页面时,请确保在对页面进行任何操作之前等待后台 Javascript,例如等待后台 javascript。
//Get Page
HtmlPage page1 = webClient.getPage("https://login-url/";);
//Wait for background Javascript
webClient.waitForBackgroundJavaScript(10000);
//Get full page _after_ javascript has rendered it fully
System.out.println(page1.asXml());
希望这个基本示例对您有所帮助!
您可以使用 HtmlUnit 执行浏览器几乎可以执行的所有操作,但以编程方式。
java从网页抓取数据(主流开源爬虫框架nutch,spider)
网站优化 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2022-03-29 13:20
有时在获取数据的时候,没有数据源,或者对方没有提及接口和数据库,只是提供了一个网站作为数据源给我们。这时候我们需要抓取网页中的html元素。并且同时解析,过滤掉我们不需要的数据,得到我们想要的数据。当然,我们也可以使用目前主流的开源爬虫框架nutch、spider。但是如果需求不是很复杂,比如只抓取网页的一小部分的情况下,我们可以自己写一个爬虫类来满足我们的需求。下面是我参考网站资源和一些工具类写的一个例子,如下图:
首先,我们抓取一个网页。例如网页的形式是:
First parse
<p>Parsed HTML into a doc.
Parsed HTMfdaL into a dodasc.
</p>
例如,它的 网站 是: 。
以下是编写的爬取和解析过程
1个工具类ClawerClient
/**
* 当有些网页中存在一些嵌套的redirect连接时,它就会报Server redirected too many times这样的错误,
* 这是因为此网页内部又有一些代码是转向其它网页的,循环过多导致程序出错。如果只想抓取本URL中的网页内容,
* 而不愿意让它有其它 的网页跳转,可以用以下的代码。
* @param myurl
* @throws Exception
*/
@SuppressWarnings("static-access")
public static String clawer2(String myurl) throws Exception{
URL urlmy = new URL(myurl);
HttpURLConnection con = (HttpURLConnection) urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
con.connect();
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8"));
String s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"\r\n");
}
return sb.toString();
}
2.抓取数据源后,我使用JSoup包解析。JSoup的下载地址为:
这是一个简单的代码片段:
//这里得到网页内容
String htmlContent = ClawerClient.clawer2(url);
//使用jSoup解析里头的内容
//就像操作html doc文档对象一样操作网页中的元素
Document doc = Jsoup.parse(htmlContent);
Element body = doc.body();
Element span = body.select("p").first();
System.out.println(span.text());
您可以在第一个 p 元素中获取值:
将 HTML 解析为文档。
当然,还有一些比较常用的方法。有关详细信息,请查看 JSoup 文档。
原版的: 查看全部
java从网页抓取数据(主流开源爬虫框架nutch,spider)
有时在获取数据的时候,没有数据源,或者对方没有提及接口和数据库,只是提供了一个网站作为数据源给我们。这时候我们需要抓取网页中的html元素。并且同时解析,过滤掉我们不需要的数据,得到我们想要的数据。当然,我们也可以使用目前主流的开源爬虫框架nutch、spider。但是如果需求不是很复杂,比如只抓取网页的一小部分的情况下,我们可以自己写一个爬虫类来满足我们的需求。下面是我参考网站资源和一些工具类写的一个例子,如下图:
首先,我们抓取一个网页。例如网页的形式是:
First parse
<p>Parsed HTML into a doc.
Parsed HTMfdaL into a dodasc.
</p>
例如,它的 网站 是: 。
以下是编写的爬取和解析过程
1个工具类ClawerClient
/**
* 当有些网页中存在一些嵌套的redirect连接时,它就会报Server redirected too many times这样的错误,
* 这是因为此网页内部又有一些代码是转向其它网页的,循环过多导致程序出错。如果只想抓取本URL中的网页内容,
* 而不愿意让它有其它 的网页跳转,可以用以下的代码。
* @param myurl
* @throws Exception
*/
@SuppressWarnings("static-access")
public static String clawer2(String myurl) throws Exception{
URL urlmy = new URL(myurl);
HttpURLConnection con = (HttpURLConnection) urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
con.connect();
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8"));
String s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"\r\n");
}
return sb.toString();
}
2.抓取数据源后,我使用JSoup包解析。JSoup的下载地址为:
这是一个简单的代码片段:
//这里得到网页内容
String htmlContent = ClawerClient.clawer2(url);
//使用jSoup解析里头的内容
//就像操作html doc文档对象一样操作网页中的元素
Document doc = Jsoup.parse(htmlContent);
Element body = doc.body();
Element span = body.select("p").first();
System.out.println(span.text());
您可以在第一个 p 元素中获取值:
将 HTML 解析为文档。
当然,还有一些比较常用的方法。有关详细信息,请查看 JSoup 文档。
原版的:
java从网页抓取数据(网络编程众多基础包和类如何实现一个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-03-29 13:18
首先,我们应该解释一下使用Java语言而不是C/C++等其他语言的原因,因为Java提供了很多网络编程的基础包和类,比如URL类、InetAddress类、正则表达式等。这是我们的搜索引擎。这些实现为专注于搜索引擎本身的实现提供了良好的基础,而不会因这些基础类的实现而分心。
这个由三部分组成的系列将逐步解释如何设计和实现搜索引擎。第一部分先学习搜索引擎的工作原理,同时了解它的架构,然后讲解如何实现搜索引擎的第一部分,网络爬虫模块,完成网页采集功能。系列的第二部分将介绍预处理模块,即如何对采集到的网页进行处理,排序、分词和索引都收录在这一部分中。系列的第三部分会介绍信息查询服务的实现,主要是查询接口的建立、查询结果的返回和快照的实现。
dySE的整体结构
在开始学习搜索引擎的模块实现之前,需要了解dySE的整体结构和数据传输的流程。实际上,搜索引擎的三部分是相互独立的,三部分是分开工作的。主要关系是前一部分得到的数据结果为后一部分提供了原创数据。三者的关系如下图所示:
图1. 搜索引擎三阶段工作流程
在介绍搜索引擎的整体结构之前,我们参考了《计算机网络——一种自顶向下的方法来描述互联网的特征》一书的叙述方式,从普通的角度来介绍搜索引擎的具体工作流程。使用搜索引擎的用户。
自上而下的方法描述了搜索引擎的执行过程:
用户通过浏览器提交查询词或词组P,搜索引擎根据用户查询返回匹配网页信息列表L;
上述过程涉及到两个问题:如何匹配用户的查询,网页信息列表来自哪里,排名依据是什么?啊等),根据系统维护的倒排索引,可以查询到某个词pi出现在了哪些网页中,与出现的网页匹配的网页集合可以作为初始结果。再进一步,计算返回的初始网页集合与查询词的相关度,得到页面排名,即Page Rank,根据页面的排名顺序可以得到最终的页面列表;
假设建立了分词器和网页排名的计算公式,那么倒排索引和原创网页集从哪里来?它存储在本地,倒排索引,即词组到网页的映射表,是建立在正向索引的基础上的,前向索引是对网页内容进行分析并对其内容进行切分后得到的网页到词组。映射表,倒排索引可以通过正向索引倒置得到;
网页的分析究竟是做什么的?由于爬虫采集到的原创网页收录大量信息,例如html表单和一些广告等垃圾信息,网页分析将这些信息去除,提取文本信息作为后续基础数据。
经过以上分析,我们可以得到搜索引擎的整体结构如下图:
图2.搜索引擎整体结构
爬虫从互联网上抓取很多网页,并作为原创网页库存储在本地,然后网页分析器将网页中的主题内容提取出来,交给分词器进行分词。获得索引数据库。用户查询时,通过分词器对输入的查询词组进行切割,通过检索器对索引数据库进行查询,将得到的结果返回给用户。
不管一个搜索引擎有多大,它的主要结构都是由这些部分组成的,并没有太大的区别。一个搜索引擎的好坏主要取决于各个部分的内部实现。
有了上面对搜索引擎的整体了解,下面我们来了解一下dySE中爬虫模块的具体设计和实现。
蜘蛛的设计
网页采集的过程就像遍历一个图,其中网页作为图中的节点,网页中的超链接作为图中的边。通过网页的超链接可以获取其他网页的地址,从而可以进行进一步的网页采集。; 图遍历分为广度优先和深度优先方法,网页的采集过程也是如此。综上所述,蜘蛛采集网页的过程如下:从初始URL集合中获取目标网页地址,通过网络连接接收网页数据,将获取的网页数据加入网页库,分析其他网页中的 URL 链接,放在未访问的 URL 集合中,用于网页采集。下图表示此过程:
图3. 蜘蛛工作流
Spider的具体实现
网络采集器采集
网页采集器通过URL获取该URL对应的网页数据。它的实现主要是利用Java中的URLConnection类打开URL对应的页面的网络连接,然后通过I/O流读取数据。BufferedReader 提供读取数据缓冲区,提高数据读取效率,其下定义的 readLine() 行读取函数。代码如下(异常处理部分省略):
列表1.网页抓取
网址 url=newURL("http://");
URLConnection conn=url.openConnection();
BufferedReader reader=newBufferedReader(newInputStreamReader(conn.getInputStream()));
字符串=空;
而((line=reader.readLine()) !=null)
document.append(line+"\n");
使用Java语言的好处是不需要自己去处理底层的连接操作。喜欢或精通Java网络编程的读者,不用上述方法也能实现URL类及相关操作,也是一个很好的练习。
网页处理
采集到的单个网页需要以两种不同的方式进行处理。一是将其作为原创数据放入网页库中进行后续处理;另一种是解析后提取URL连接,放入URL池等待对应的网页。采集。
网页需要以一定的格式保存,以便以后可以批量处理数据。这里是一种存储数据格式,是从北大天网的存储格式简化而来的:
网页库由多条记录组成,每条记录收录一条网页数据信息,记录存储以便添加;
一条记录由数据头、数据和空行组成,顺序为:表头+空行+数据+空行;
头部由几个属性组成,包括:版本号、日期、IP地址、数据长度,以属性名和属性值的方式排列,中间加一个冒号,每个属性占一行;
数据是网页数据。
需要注意的是,之所以加上数据采集日期,是因为很多网站的内容是动态变化的,比如一些大型门户网站的首页内容网站,也就是说如果不爬取同日 对于网页数据,很可能会出现数据过期的问题,所以需要添加日期信息来识别。
URL的提取分为两步。第一步是识别URL,第二步是组织URL。这两个步骤主要是因为 网站 的一些链接使用了相对路径。如果它们没有排序,就会出现错误。. URL的标识主要是通过正则表达式来匹配的。该过程首先将一个字符串设置为匹配字符串模式,然后在Pattern中编译后使用Matcher类匹配对应的字符串。实现代码如下:
列表2. URL 识别
publicArrayListurlDetector(StringhtmlDoc){
finalStringpatternString="]*\\s*>)";
模式 pattern=pile(patternString,Pattern.CASE_INSENSITIVE);
ArrayListallURLs=newArrayList();
匹配器 matcher=pattern.matcher(htmlDoc);
字符串临时网址;
//第一次匹配的url是这样的形式:
//为此,需要下一步提取真实的url,
//可以记录前两个"之间的部分来获取url
同时(matcher.find()){
尝试 {
tempURL=matcher.group();
tempURL=tempURL.substring(tempURL.indexOf("\"")+1);
if(!tempURL.contains("\""))
继续;
tempURL=tempURL.substring(0, tempURL.indexOf("\""));
} 捕捉(MalformedURLException e){
e.printStackTrace();
}
}
返回所有网址;
}
根据正则表达式“]*\\s*>)”可以匹配到URL所在的整个标签,形式为“”,所以循环获取整个标签后,我们需要进一步提取真实网址。我们可以通过截取标签前两个引号之间的内容来得到这个内容。在此之后,我们可以得到属于该网页的一组初步 URL。
接下来我们进行第二步,URL的排序,也就是对之前获取的整个页面中的URL集合进行过滤和整合。集成主要针对网页地址为相对链接的部分。由于我们可以很方便的获取当前网页的URL,所以相对链接只需要在当前网页的URL上加上一个相对链接字段就可以形成一个完整的URL,从而完成整合。另一方面,在页面所收录的综合URL中,也有一些我们不想抓取或者不重要的网页,比如广告网页。这里我们主要关注页面中广告的简单处理。一般网站的广告链接都有相应的展示表达方式。例如,当链接收录诸如“
完成这两步之后,就可以将采集到的网页URL放入URL池中,然后我们来处理爬虫URL的分配。
调度员调度员
分配器管理URL,负责保存URL池,在Gather拿到某个网页后调度新的URL,同时也避免了网页的重复采集。分配器在设计模式中以单例模式编码,负责提供新的 URL 给 Gather。因为涉及到多线程重写,所以单例模式尤为重要。
重复采集是指物理上存在的网页,被Gather重复访问而不更新,造成资源浪费。因此,Dispatcher 维护两个列表,“已访问表”和“未访问表”。爬取每个URL对应的页面后,将URL放入visited表,将页面提取的URL放入unvisited表;当 Gather 从 Dispatcher 请求一个 URL 时,它首先验证 URL 是否在 Visited 表中,然后再给 Gather 工作。
Spider 启动多个 Gather 线程
现在互联网上的网页数以亿计,通过单一的Gather来采集网页显然是低效的,所以我们需要使用多线程的方式来提高效率。Gather的功能是采集网页,我们可以通过Spider类开启多个Gather线程,从而达到多线程的目的。代码显示如下:
/**
* 开始线程采集,然后开始采集网页数据
*/
公共无效开始(){
调度程序 disp=newDispatcher.getInstance();
for(inti=0; 我 查看全部
java从网页抓取数据(网络编程众多基础包和类如何实现一个)
首先,我们应该解释一下使用Java语言而不是C/C++等其他语言的原因,因为Java提供了很多网络编程的基础包和类,比如URL类、InetAddress类、正则表达式等。这是我们的搜索引擎。这些实现为专注于搜索引擎本身的实现提供了良好的基础,而不会因这些基础类的实现而分心。
这个由三部分组成的系列将逐步解释如何设计和实现搜索引擎。第一部分先学习搜索引擎的工作原理,同时了解它的架构,然后讲解如何实现搜索引擎的第一部分,网络爬虫模块,完成网页采集功能。系列的第二部分将介绍预处理模块,即如何对采集到的网页进行处理,排序、分词和索引都收录在这一部分中。系列的第三部分会介绍信息查询服务的实现,主要是查询接口的建立、查询结果的返回和快照的实现。
dySE的整体结构
在开始学习搜索引擎的模块实现之前,需要了解dySE的整体结构和数据传输的流程。实际上,搜索引擎的三部分是相互独立的,三部分是分开工作的。主要关系是前一部分得到的数据结果为后一部分提供了原创数据。三者的关系如下图所示:
图1. 搜索引擎三阶段工作流程
在介绍搜索引擎的整体结构之前,我们参考了《计算机网络——一种自顶向下的方法来描述互联网的特征》一书的叙述方式,从普通的角度来介绍搜索引擎的具体工作流程。使用搜索引擎的用户。
自上而下的方法描述了搜索引擎的执行过程:
用户通过浏览器提交查询词或词组P,搜索引擎根据用户查询返回匹配网页信息列表L;
上述过程涉及到两个问题:如何匹配用户的查询,网页信息列表来自哪里,排名依据是什么?啊等),根据系统维护的倒排索引,可以查询到某个词pi出现在了哪些网页中,与出现的网页匹配的网页集合可以作为初始结果。再进一步,计算返回的初始网页集合与查询词的相关度,得到页面排名,即Page Rank,根据页面的排名顺序可以得到最终的页面列表;
假设建立了分词器和网页排名的计算公式,那么倒排索引和原创网页集从哪里来?它存储在本地,倒排索引,即词组到网页的映射表,是建立在正向索引的基础上的,前向索引是对网页内容进行分析并对其内容进行切分后得到的网页到词组。映射表,倒排索引可以通过正向索引倒置得到;
网页的分析究竟是做什么的?由于爬虫采集到的原创网页收录大量信息,例如html表单和一些广告等垃圾信息,网页分析将这些信息去除,提取文本信息作为后续基础数据。
经过以上分析,我们可以得到搜索引擎的整体结构如下图:
图2.搜索引擎整体结构
爬虫从互联网上抓取很多网页,并作为原创网页库存储在本地,然后网页分析器将网页中的主题内容提取出来,交给分词器进行分词。获得索引数据库。用户查询时,通过分词器对输入的查询词组进行切割,通过检索器对索引数据库进行查询,将得到的结果返回给用户。
不管一个搜索引擎有多大,它的主要结构都是由这些部分组成的,并没有太大的区别。一个搜索引擎的好坏主要取决于各个部分的内部实现。
有了上面对搜索引擎的整体了解,下面我们来了解一下dySE中爬虫模块的具体设计和实现。
蜘蛛的设计
网页采集的过程就像遍历一个图,其中网页作为图中的节点,网页中的超链接作为图中的边。通过网页的超链接可以获取其他网页的地址,从而可以进行进一步的网页采集。; 图遍历分为广度优先和深度优先方法,网页的采集过程也是如此。综上所述,蜘蛛采集网页的过程如下:从初始URL集合中获取目标网页地址,通过网络连接接收网页数据,将获取的网页数据加入网页库,分析其他网页中的 URL 链接,放在未访问的 URL 集合中,用于网页采集。下图表示此过程:
图3. 蜘蛛工作流
Spider的具体实现
网络采集器采集
网页采集器通过URL获取该URL对应的网页数据。它的实现主要是利用Java中的URLConnection类打开URL对应的页面的网络连接,然后通过I/O流读取数据。BufferedReader 提供读取数据缓冲区,提高数据读取效率,其下定义的 readLine() 行读取函数。代码如下(异常处理部分省略):
列表1.网页抓取
网址 url=newURL("http://";);
URLConnection conn=url.openConnection();
BufferedReader reader=newBufferedReader(newInputStreamReader(conn.getInputStream()));
字符串=空;
而((line=reader.readLine()) !=null)
document.append(line+"\n");
使用Java语言的好处是不需要自己去处理底层的连接操作。喜欢或精通Java网络编程的读者,不用上述方法也能实现URL类及相关操作,也是一个很好的练习。
网页处理
采集到的单个网页需要以两种不同的方式进行处理。一是将其作为原创数据放入网页库中进行后续处理;另一种是解析后提取URL连接,放入URL池等待对应的网页。采集。
网页需要以一定的格式保存,以便以后可以批量处理数据。这里是一种存储数据格式,是从北大天网的存储格式简化而来的:
网页库由多条记录组成,每条记录收录一条网页数据信息,记录存储以便添加;
一条记录由数据头、数据和空行组成,顺序为:表头+空行+数据+空行;
头部由几个属性组成,包括:版本号、日期、IP地址、数据长度,以属性名和属性值的方式排列,中间加一个冒号,每个属性占一行;
数据是网页数据。
需要注意的是,之所以加上数据采集日期,是因为很多网站的内容是动态变化的,比如一些大型门户网站的首页内容网站,也就是说如果不爬取同日 对于网页数据,很可能会出现数据过期的问题,所以需要添加日期信息来识别。
URL的提取分为两步。第一步是识别URL,第二步是组织URL。这两个步骤主要是因为 网站 的一些链接使用了相对路径。如果它们没有排序,就会出现错误。. URL的标识主要是通过正则表达式来匹配的。该过程首先将一个字符串设置为匹配字符串模式,然后在Pattern中编译后使用Matcher类匹配对应的字符串。实现代码如下:
列表2. URL 识别
publicArrayListurlDetector(StringhtmlDoc){
finalStringpatternString="]*\\s*>)";
模式 pattern=pile(patternString,Pattern.CASE_INSENSITIVE);
ArrayListallURLs=newArrayList();
匹配器 matcher=pattern.matcher(htmlDoc);
字符串临时网址;
//第一次匹配的url是这样的形式:
//为此,需要下一步提取真实的url,
//可以记录前两个"之间的部分来获取url
同时(matcher.find()){
尝试 {
tempURL=matcher.group();
tempURL=tempURL.substring(tempURL.indexOf("\"")+1);
if(!tempURL.contains("\""))
继续;
tempURL=tempURL.substring(0, tempURL.indexOf("\""));
} 捕捉(MalformedURLException e){
e.printStackTrace();
}
}
返回所有网址;
}
根据正则表达式“]*\\s*>)”可以匹配到URL所在的整个标签,形式为“”,所以循环获取整个标签后,我们需要进一步提取真实网址。我们可以通过截取标签前两个引号之间的内容来得到这个内容。在此之后,我们可以得到属于该网页的一组初步 URL。
接下来我们进行第二步,URL的排序,也就是对之前获取的整个页面中的URL集合进行过滤和整合。集成主要针对网页地址为相对链接的部分。由于我们可以很方便的获取当前网页的URL,所以相对链接只需要在当前网页的URL上加上一个相对链接字段就可以形成一个完整的URL,从而完成整合。另一方面,在页面所收录的综合URL中,也有一些我们不想抓取或者不重要的网页,比如广告网页。这里我们主要关注页面中广告的简单处理。一般网站的广告链接都有相应的展示表达方式。例如,当链接收录诸如“
完成这两步之后,就可以将采集到的网页URL放入URL池中,然后我们来处理爬虫URL的分配。
调度员调度员
分配器管理URL,负责保存URL池,在Gather拿到某个网页后调度新的URL,同时也避免了网页的重复采集。分配器在设计模式中以单例模式编码,负责提供新的 URL 给 Gather。因为涉及到多线程重写,所以单例模式尤为重要。
重复采集是指物理上存在的网页,被Gather重复访问而不更新,造成资源浪费。因此,Dispatcher 维护两个列表,“已访问表”和“未访问表”。爬取每个URL对应的页面后,将URL放入visited表,将页面提取的URL放入unvisited表;当 Gather 从 Dispatcher 请求一个 URL 时,它首先验证 URL 是否在 Visited 表中,然后再给 Gather 工作。
Spider 启动多个 Gather 线程
现在互联网上的网页数以亿计,通过单一的Gather来采集网页显然是低效的,所以我们需要使用多线程的方式来提高效率。Gather的功能是采集网页,我们可以通过Spider类开启多个Gather线程,从而达到多线程的目的。代码显示如下:
/**
* 开始线程采集,然后开始采集网页数据
*/
公共无效开始(){
调度程序 disp=newDispatcher.getInstance();
for(inti=0; 我
java从网页抓取数据(.java从网页抓取数据的基本等于无用?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-03-26 00:02
java从网页抓取数据,方法无非是三种:数据库抓取(库内数据),xml抓取(通过某种html文件),图片抓取(imageoptim.java之类)。数据从浏览器抓取的话,前两种方法还是有用的,第三种基本等于无用,因为绝大多数网站的数据从浏览器抓取出来的信息是冗余的,无需一一解析出来。
java从html得到数据,然后可以按照某种方式利用数据啊。比如以后图片相关的应用,能从图片预处理,压缩,贴图等方式来处理图片,有的图片可以做混淆,photozoom之类。希望能帮到你。
我用excel
一般是用数据库,除非是热数据,不然那就是庞大的表格。而且这里边牵扯到很多数据处理逻辑。
用java可以读取人家的网页对应的java文件,转换格式成mysql\sqlserver\postgresql\oracle等等格式得到数据,然后java可以读取数据库,可以读取文件等等,
我也是这样想的!你想想如果要抓取到360手机浏览器的数据,那么你怎么做我的方案是将数据读取服务端的名为.json的文件,然后加载到内存,因为服务端很可能还没来得及读取相关数据,
你了解过java么
1..mdb.java就可以,其文件是一个java的对象。2..jdbc.java就可以(jdbc要rest接口)3..weblogic.java就可以。4..qjava.java就可以。applet可以读.java文件。个人推荐qjava,简单,开源,免费,好用。特别是装jre4j配置简单,读取方便,mysql也支持。 查看全部
java从网页抓取数据(.java从网页抓取数据的基本等于无用?)
java从网页抓取数据,方法无非是三种:数据库抓取(库内数据),xml抓取(通过某种html文件),图片抓取(imageoptim.java之类)。数据从浏览器抓取的话,前两种方法还是有用的,第三种基本等于无用,因为绝大多数网站的数据从浏览器抓取出来的信息是冗余的,无需一一解析出来。
java从html得到数据,然后可以按照某种方式利用数据啊。比如以后图片相关的应用,能从图片预处理,压缩,贴图等方式来处理图片,有的图片可以做混淆,photozoom之类。希望能帮到你。
我用excel
一般是用数据库,除非是热数据,不然那就是庞大的表格。而且这里边牵扯到很多数据处理逻辑。
用java可以读取人家的网页对应的java文件,转换格式成mysql\sqlserver\postgresql\oracle等等格式得到数据,然后java可以读取数据库,可以读取文件等等,
我也是这样想的!你想想如果要抓取到360手机浏览器的数据,那么你怎么做我的方案是将数据读取服务端的名为.json的文件,然后加载到内存,因为服务端很可能还没来得及读取相关数据,
你了解过java么
1..mdb.java就可以,其文件是一个java的对象。2..jdbc.java就可以(jdbc要rest接口)3..weblogic.java就可以。4..qjava.java就可以。applet可以读.java文件。个人推荐qjava,简单,开源,免费,好用。特别是装jre4j配置简单,读取方便,mysql也支持。
java从网页抓取数据(java从网页抓取数据不现实,这种情况除非服务器端程序特别叼)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-23 23:02
java从网页抓取数据不现实,这种情况除非服务器端程序特别叼。你猜不到一般的网站会抓取哪些数据,一旦发现抓取的数据和已经提交给服务器的数据不符,那么这个网站就死定了,因为你抓取的数据是无法重用的。前两年我们做java的时候,很多前端的人和他们程序员有仇,都抱怨说我们这网站有一年半载不更新,但数据还总是抓得很准。
这是因为前端有一堆抓取网页相关的业务(各种firebug插件、爬虫、浏览器插件、extension等等),同时前端系统不断在建立。到了晚上只要前端有人就可以爬取到后台java系统的中一个bean的变化,因为他可以拿出java核心对象来影响后端某个bean的整个生命周期。我听的时候就哭笑不得了,差点笑哭,更何况一年半载后后端可能已经成母子了。
java这种网页抓取业务也最好别去学,没必要。前端有一个在线监控,现在技术好的话完全可以做到三秒内抓取网页,到时候你的程序猿就累死在跟服务器对接了。
这个问题很有意思,简单归纳一下,我觉得应该是两个问题:1、java从网页抓取数据不现实。2、从网页抓取数据可以做什么。先回答第一个问题:做什么程序。这个。暂时没想到,需要些什么东西。这里只是假设是web程序,其他类型就不举例了。我觉得要抓取的话,用轮子哥,我觉得不怎么现实。java就更现实了,直接从网站爬,更新后爬,抓了对比就行了。
数据来源问题。oracle数据库不错,postgres数据库很好。java现在还没有像样的数据库,怎么弄?只要爬一个sqlite还不够?是的,网站有自己的数据库。有数据库的话用什么呢?没见有人分析网站的数据库数据(肯定不是爬出来的数据,肯定是后来人扒出来的数据,不然世界和平了,又得出个大新闻来了)。除非爬公司的数据库,这个就另说了。
如果有爬公司数据库,数据一般都经过加密处理,你没法直接爬,有可能你会成为叛徒被勒令封杀掉。所以我觉得解决这个问题的唯一办法是,爬一些不知名的小站,可能要麻烦点。但是可以弄个轮子哥。比如说爬一些c2c的数据,可以扒一些各大中小公司的数据库,他那有或者你有现成的代码。关于轮子哥,更好玩的是他的数据。这个怎么弄呢?可以写个轮子哥爬c2c的数据的脚本,然后带着那些站的后台程序一起上。
没网页,用浏览器的firebug对接了爬虫,然后google直接从robots协议屏蔽掉了。没办法,你能把服务器搞坏也不能把搞坏。于是你只能看别人下单用后台的java程序发给你的消息。另外java应该也可以抓取热销商品,然后卖给你。就这个。网站其实。 查看全部
java从网页抓取数据(java从网页抓取数据不现实,这种情况除非服务器端程序特别叼)
java从网页抓取数据不现实,这种情况除非服务器端程序特别叼。你猜不到一般的网站会抓取哪些数据,一旦发现抓取的数据和已经提交给服务器的数据不符,那么这个网站就死定了,因为你抓取的数据是无法重用的。前两年我们做java的时候,很多前端的人和他们程序员有仇,都抱怨说我们这网站有一年半载不更新,但数据还总是抓得很准。
这是因为前端有一堆抓取网页相关的业务(各种firebug插件、爬虫、浏览器插件、extension等等),同时前端系统不断在建立。到了晚上只要前端有人就可以爬取到后台java系统的中一个bean的变化,因为他可以拿出java核心对象来影响后端某个bean的整个生命周期。我听的时候就哭笑不得了,差点笑哭,更何况一年半载后后端可能已经成母子了。
java这种网页抓取业务也最好别去学,没必要。前端有一个在线监控,现在技术好的话完全可以做到三秒内抓取网页,到时候你的程序猿就累死在跟服务器对接了。
这个问题很有意思,简单归纳一下,我觉得应该是两个问题:1、java从网页抓取数据不现实。2、从网页抓取数据可以做什么。先回答第一个问题:做什么程序。这个。暂时没想到,需要些什么东西。这里只是假设是web程序,其他类型就不举例了。我觉得要抓取的话,用轮子哥,我觉得不怎么现实。java就更现实了,直接从网站爬,更新后爬,抓了对比就行了。
数据来源问题。oracle数据库不错,postgres数据库很好。java现在还没有像样的数据库,怎么弄?只要爬一个sqlite还不够?是的,网站有自己的数据库。有数据库的话用什么呢?没见有人分析网站的数据库数据(肯定不是爬出来的数据,肯定是后来人扒出来的数据,不然世界和平了,又得出个大新闻来了)。除非爬公司的数据库,这个就另说了。
如果有爬公司数据库,数据一般都经过加密处理,你没法直接爬,有可能你会成为叛徒被勒令封杀掉。所以我觉得解决这个问题的唯一办法是,爬一些不知名的小站,可能要麻烦点。但是可以弄个轮子哥。比如说爬一些c2c的数据,可以扒一些各大中小公司的数据库,他那有或者你有现成的代码。关于轮子哥,更好玩的是他的数据。这个怎么弄呢?可以写个轮子哥爬c2c的数据的脚本,然后带着那些站的后台程序一起上。
没网页,用浏览器的firebug对接了爬虫,然后google直接从robots协议屏蔽掉了。没办法,你能把服务器搞坏也不能把搞坏。于是你只能看别人下单用后台的java程序发给你的消息。另外java应该也可以抓取热销商品,然后卖给你。就这个。网站其实。
java从网页抓取数据(我正在尝试用Java编写我的第一个程序。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-21 17:02
我正在尝试用 Java 编写我的第一个程序。目标是编写一个浏览到 网站 并为我下载文件的程序。但是,我不知道如何使用 Java 与互联网交互。谁能告诉我要寻找/阅读哪些主题或推荐一些好的资源?
最佳答案
最简单的解决方案(不依赖于任何第 3 方库或平台)是创建指向您要下载的网页/链接的 URL 实例,并使用流来读取内容。
例如:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
public class DownloadPage {
public static void main(String[] args) throws IOException {
// Make a URL to the web page
URL url = new URL("http://stackoverflow.com/quest ... 6quot;);
// Get the input stream through URL Connection
URLConnection con = url.openConnection();
InputStream is =con.getInputStream();
// Once you have the Input Stream, it's just plain old Java IO stuff.
// For this case, since you are interested in getting plain-text web page
// I'll use a reader and output the text content to System.out.
// For binary content, it's better to directly read the bytes from stream and write
// to the target file.
BufferedReader br = new BufferedReader(new InputStreamReader(is));
String line = null;
// read each line and write to System.out
while ((line = br.readLine()) != null) {
System.out.println(line);
}
}
}
希望这可以帮助。
使用Java从网页中提取数据?,我们在 Stack Overflow 上发现了一个类似的问题: 查看全部
java从网页抓取数据(我正在尝试用Java编写我的第一个程序。)
我正在尝试用 Java 编写我的第一个程序。目标是编写一个浏览到 网站 并为我下载文件的程序。但是,我不知道如何使用 Java 与互联网交互。谁能告诉我要寻找/阅读哪些主题或推荐一些好的资源?
最佳答案
最简单的解决方案(不依赖于任何第 3 方库或平台)是创建指向您要下载的网页/链接的 URL 实例,并使用流来读取内容。
例如:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
public class DownloadPage {
public static void main(String[] args) throws IOException {
// Make a URL to the web page
URL url = new URL("http://stackoverflow.com/quest ... 6quot;);
// Get the input stream through URL Connection
URLConnection con = url.openConnection();
InputStream is =con.getInputStream();
// Once you have the Input Stream, it's just plain old Java IO stuff.
// For this case, since you are interested in getting plain-text web page
// I'll use a reader and output the text content to System.out.
// For binary content, it's better to directly read the bytes from stream and write
// to the target file.
BufferedReader br = new BufferedReader(new InputStreamReader(is));
String line = null;
// read each line and write to System.out
while ((line = br.readLine()) != null) {
System.out.println(line);
}
}
}
希望这可以帮助。
使用Java从网页中提取数据?,我们在 Stack Overflow 上发现了一个类似的问题:
java从网页抓取数据(我试图使用JavaServlet从网页上抓取数据,但是我发现页面已压缩)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-21 17:01
我正在尝试使用 Java Servlet 从网页中抓取数据,但我发现该页面已被压缩。因此,当我执行 URLConnection 时,它会调用下载 zip 文件。
谁能帮我解决这个问题?实际上,我将访问数千个这样的页面,使用 DOM 解析表数据,然后填充数据库以查询某些文本单词并显示结果。所以我想知道这是否会使这个过程太慢。
有没有办法下载文件?任何建议将不胜感激。谢谢。
try{
URL url = new URL("example.html.gz");
URLConnection conn = url.openConnection();
//FileInputStream instream= new FileInputStream(???What do I enter???);
//GZIPInputStream ginstream =new GZIPInputStream(instream);
conn.setAllowUserInteraction(false);
InputStream urlStream = url.openStream();
BufferedReader buffer = new BufferedReader(new InputStreamReader(urlStream));
String t = buffer.readLine();
while(t!=null){
temp = temp + t ;
t = buffer.readLine();
}
最佳答案
你可以试试:
GZIPInputStream ginstream =new GZIPInputStream(conn.getInputStream());
其余的和你的代码一样。
关于 java - 如何使用 Java 从 .html.gz 网页中提取内容? ,我们在 Stack Overflow 上发现了一个类似的问题: 查看全部
java从网页抓取数据(我试图使用JavaServlet从网页上抓取数据,但是我发现页面已压缩)
我正在尝试使用 Java Servlet 从网页中抓取数据,但我发现该页面已被压缩。因此,当我执行 URLConnection 时,它会调用下载 zip 文件。
谁能帮我解决这个问题?实际上,我将访问数千个这样的页面,使用 DOM 解析表数据,然后填充数据库以查询某些文本单词并显示结果。所以我想知道这是否会使这个过程太慢。
有没有办法下载文件?任何建议将不胜感激。谢谢。
try{
URL url = new URL("example.html.gz");
URLConnection conn = url.openConnection();
//FileInputStream instream= new FileInputStream(???What do I enter???);
//GZIPInputStream ginstream =new GZIPInputStream(instream);
conn.setAllowUserInteraction(false);
InputStream urlStream = url.openStream();
BufferedReader buffer = new BufferedReader(new InputStreamReader(urlStream));
String t = buffer.readLine();
while(t!=null){
temp = temp + t ;
t = buffer.readLine();
}
最佳答案
你可以试试:
GZIPInputStream ginstream =new GZIPInputStream(conn.getInputStream());
其余的和你的代码一样。
关于 java - 如何使用 Java 从 .html.gz 网页中提取内容? ,我们在 Stack Overflow 上发现了一个类似的问题:
java从网页抓取数据(java从网页抓取数据分享一下我的心得吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-20 11:01
java从网页抓取数据分享一下我的心得吧;首先是http爬虫,主要有selenium爬虫,anypython等其次是图片搜索工具,比如qianma等再有一些gui的小工具,可以自己去研究一下总体来说java是最好上手的语言了,就是写程序时间太长!因为有编译的过程,需要写测试代码检查效果的问题,而且后面java提供的运行库,我觉得比c++,python什么的要来的强大!不要担心,多做一些实际项目,掌握它的实际使用经验,很快就能掌握!而且还有opengl,深度学习等方面,多了解了解。所以要熟练使用它!。
你可以试着学学python,现在python很火的。
推荐爬虫框架tornado,可以训练动态语言基础。你可以自己看看我的github上提供了基于tornado的twitter爬虫项目,里面的一些代码和教程比较适合爬取豆瓣电影标签。一个比较难点的是,动态语言实现tornado,
anypython,anyjava.不过要学的话应该先把java的基础打好
学习的话学java比较快。语言有基础就可以学习其他的语言,因为难度比java小。前端可以了解下,比如html5+css3+javascript+svg等。
你先学java吧,到时候学习apache或者是go等web容器就好了,没有那么多深入,上手速度较快。做web要学会apache,go,web容器等。 查看全部
java从网页抓取数据(java从网页抓取数据分享一下我的心得吧)
java从网页抓取数据分享一下我的心得吧;首先是http爬虫,主要有selenium爬虫,anypython等其次是图片搜索工具,比如qianma等再有一些gui的小工具,可以自己去研究一下总体来说java是最好上手的语言了,就是写程序时间太长!因为有编译的过程,需要写测试代码检查效果的问题,而且后面java提供的运行库,我觉得比c++,python什么的要来的强大!不要担心,多做一些实际项目,掌握它的实际使用经验,很快就能掌握!而且还有opengl,深度学习等方面,多了解了解。所以要熟练使用它!。
你可以试着学学python,现在python很火的。
推荐爬虫框架tornado,可以训练动态语言基础。你可以自己看看我的github上提供了基于tornado的twitter爬虫项目,里面的一些代码和教程比较适合爬取豆瓣电影标签。一个比较难点的是,动态语言实现tornado,
anypython,anyjava.不过要学的话应该先把java的基础打好
学习的话学java比较快。语言有基础就可以学习其他的语言,因为难度比java小。前端可以了解下,比如html5+css3+javascript+svg等。
你先学java吧,到时候学习apache或者是go等web容器就好了,没有那么多深入,上手速度较快。做web要学会apache,go,web容器等。
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-03-19 20:18
原文链接:
有时出于各种原因。我们需要从网站采集数据。但是因为不同的站点显示数据略有不同!
本文将使用Java来给大家展示如何抓取网站的数据:(1)抓取原创网页数据。(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页。然后输入IP:111.142.55.73,点击查询按钮。您可以在网页上看到显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出。再次请求网页后显示查询结果。
看看查询后的网页地址:
也就是说,我们只想访问表单的一个 URL。可以得到ip查询的结果,再看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?
IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:
" + result);
}
使用 HttpURLConnection 连接到站点。使用bufReader保存网页返回的数据,然后通过自定义的分析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时,网站为了保护自己的数据,并不直接在网页源代码中返回数据,而是采用异步的方式。使用JS返回数据,可以避免搜索引擎等工具抓取网站数据。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7。点击查询按钮,查看 HTTP Analyzer 的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出。HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
既然如此。我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。我们记下 JS 请求的 URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?
wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:
" + contentBuf.toString());
}
看见。抓取JS的方式和之前的代码抓取原创网页的方式一模一样。我们只是做了一个分析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这可以是需要帮助的小朋友,需要程序的源码,点此下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因。我们需要从网站采集数据。但是因为不同的站点显示数据略有不同!
本文将使用Java来给大家展示如何抓取网站的数据:(1)抓取原创网页数据。(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页。然后输入IP:111.142.55.73,点击查询按钮。您可以在网页上看到显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出。再次请求网页后显示查询结果。
看看查询后的网页地址:
也就是说,我们只想访问表单的一个 URL。可以得到ip查询的结果,再看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?
IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:
" + result);
}
使用 HttpURLConnection 连接到站点。使用bufReader保存网页返回的数据,然后通过自定义的分析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时,网站为了保护自己的数据,并不直接在网页源代码中返回数据,而是采用异步的方式。使用JS返回数据,可以避免搜索引擎等工具抓取网站数据。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7。点击查询按钮,查看 HTTP Analyzer 的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出。HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
既然如此。我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。我们记下 JS 请求的 URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?
wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:
" + contentBuf.toString());
}
看见。抓取JS的方式和之前的代码抓取原创网页的方式一模一样。我们只是做了一个分析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这可以是需要帮助的小朋友,需要程序的源码,点此下载!
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-03-18 22:15
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-18 19:04
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-18 19:03
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]查看纯副本
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是在网页源码中直接返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]查看纯副本
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
转载于: 查看全部
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]查看纯副本
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是在网页源码中直接返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]查看纯副本
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
转载于:
java从网页抓取数据( html页面中显示的表数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-18 06:05
html页面中显示的表数据
)
Java 使用 SeleniumWebDriver 从网页中提取表格数据
javahtmlseleniumxpathselenium-webdriver
Java 使用 SeleniumWebDriver,java,html,selenium,xpath,selenium-webdriver,Java,Html,Selenium,Xpath,Selenium Webdriver 从网页中提取表数据,我使用 SeleniumWebDriver(在 Eclipse 中)自动化 Web 应用程序,但现在我需要 Capture在 html 页面中显示的表格数据。我尝试了给出的解决方案,其他几个 网站,但我们的网页显示表格的方式似乎有点不同尝试使用 div 类名获取值,如 String Text=driver.findElements(By.xpath("/ /div[@class='ag-row-ag-row-even-ag-row-level-0']//tr").get(0).getText() 但它不起作用,索引越界异常
我正在使用 SeleniumWebDriver(在 Eclipse 中)来自动化 Web 应用程序,但现在需要捕获显示在 html 页面中的表数据。我尝试了给出的解决方案,其他几个网站,但我们的网页似乎显示的表格有点不同
尝试使用 div 类名获取值,例如
String Text=driver.findElements(By.xpath(“//div[@class='ag-row-ag-row-even-ag-row-level-0']//tr”)。get(0).getText()但是它不起作用,索引越界异常被抛出我不确定,但您的webElements数组可能是空的,这就是为什么会出现索引越界异常</p>
如果您试图从整个WW_SALES行中获取值,我认为find_元素应该去掉父div-class=“ag row ag row偶数ag-row-level-0”</p>
这只是我根据所附的描述和图片做出的假设</p> 据我所见,您似乎已经创建了一个自定义表。
从所附图像中的HTML摘录来看,结构类似于:</p>
... etc
... etc
</p>
结果是一个空数组(有趣的是,你没有得到
nosucheElement
例外,也许在 html 树的某个地方有一些
tr
标记)
现在,我不确定您要从该表中提取哪些数据,但您的最佳尝试是基于
class
属性获取所有行,并且对于每一行,基于
class
属性来获取所有列数据(或者你甚至可以使用
col
属性)
编辑:要获取所有元素,您可以获取所有行,然后获取每行的所有列数据:
//Get all the rows from the table
List rows = driver.findElements(By.xpath("//div[contains(@class, 'ag-row')));
//Initialize a new array list to store the text
List tableData = new ArrayList();
//For each row, get the column data and store into the tableData object
for (int i=0; i < rows.size(); i++) {
//Since you also have some span tags inside (and maybe something else)
//we first get the div columns
WebElement tableCell = rows.get(i).findElements(By.xpath("//div[contains(@class, 'ag-cell')]"));
tableData.add(tableCell.get(0).getText());
}
<p>//从表中获取所有行
List rows=driver.findElements(By.xpath(//div[contains(@class,'ag row'));
//初始化新数组列表以存储文本
List tableData=new ArrayList();
//对于每一行,获取列数据并存储到tableData对象中
对于(int i=0;i 查看全部
java从网页抓取数据(
html页面中显示的表数据
)
Java 使用 SeleniumWebDriver 从网页中提取表格数据
javahtmlseleniumxpathselenium-webdriver
Java 使用 SeleniumWebDriver,java,html,selenium,xpath,selenium-webdriver,Java,Html,Selenium,Xpath,Selenium Webdriver 从网页中提取表数据,我使用 SeleniumWebDriver(在 Eclipse 中)自动化 Web 应用程序,但现在我需要 Capture在 html 页面中显示的表格数据。我尝试了给出的解决方案,其他几个 网站,但我们的网页显示表格的方式似乎有点不同尝试使用 div 类名获取值,如 String Text=driver.findElements(By.xpath("/ /div[@class='ag-row-ag-row-even-ag-row-level-0']//tr").get(0).getText() 但它不起作用,索引越界异常
我正在使用 SeleniumWebDriver(在 Eclipse 中)来自动化 Web 应用程序,但现在需要捕获显示在 html 页面中的表数据。我尝试了给出的解决方案,其他几个网站,但我们的网页似乎显示的表格有点不同
尝试使用 div 类名获取值,例如
String Text=driver.findElements(By.xpath(“//div[@class='ag-row-ag-row-even-ag-row-level-0']//tr”)。get(0).getText()但是它不起作用,索引越界异常被抛出我不确定,但您的webElements数组可能是空的,这就是为什么会出现索引越界异常</p>
如果您试图从整个WW_SALES行中获取值,我认为find_元素应该去掉父div-class=“ag row ag row偶数ag-row-level-0”</p>
这只是我根据所附的描述和图片做出的假设</p> 据我所见,您似乎已经创建了一个自定义表。
从所附图像中的HTML摘录来看,结构类似于:</p>
... etc
... etc
</p>
结果是一个空数组(有趣的是,你没有得到
nosucheElement
例外,也许在 html 树的某个地方有一些
tr
标记)
现在,我不确定您要从该表中提取哪些数据,但您的最佳尝试是基于
class
属性获取所有行,并且对于每一行,基于
class
属性来获取所有列数据(或者你甚至可以使用
col
属性)
编辑:要获取所有元素,您可以获取所有行,然后获取每行的所有列数据:
//Get all the rows from the table
List rows = driver.findElements(By.xpath("//div[contains(@class, 'ag-row')));
//Initialize a new array list to store the text
List tableData = new ArrayList();
//For each row, get the column data and store into the tableData object
for (int i=0; i < rows.size(); i++) {
//Since you also have some span tags inside (and maybe something else)
//we first get the div columns
WebElement tableCell = rows.get(i).findElements(By.xpath("//div[contains(@class, 'ag-cell')]"));
tableData.add(tableCell.get(0).getText());
}
<p>//从表中获取所有行
List rows=driver.findElements(By.xpath(//div[contains(@class,'ag row'));
//初始化新数组列表以存储文本
List tableData=new ArrayList();
//对于每一行,获取列数据并存储到tableData对象中
对于(int i=0;i
java从网页抓取数据(1.写一个邮箱地址的正则表达式?2.谈一谈你对Selenium和PhantomJS了解 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-13 21:07
)
1. 为电子邮件地址写一个正则表达式?
[A-Za-z0-9\u4e00-\u9fa5]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$
2. 说说你对 Selenium 和 PhantomJS 的了解
Selenium 是一个用于 Web 的自动化测试工具。根据我们的指令,浏览器可以自动加载页面,获取需要的数据,甚至可以对页面进行截图,或者判断网站上是否发生了某些动作。Selenium 没有自己的浏览器,不支持浏览器的功能。它需要与第三方浏览器结合使用。但是我们有时需要让它在代码中内联运行,所以我们可以使用一个叫做 PhantomJS 的工具来代替真正的浏览器。Selenium 库中有一个名为 WebDriver 的 API。WebDriver 有点像可以加载 网站 的浏览器,但它也可以像 BeautifulSoup 或其他 Selector 对象一样用于查找页面元素,与页面上的元素进行交互(发送文本、点击等),以及执行其他操作以运行网络爬虫。
PhantomJS 是一个基于 Webkit 的“无头”浏览器,它将 网站 加载到内存中并在页面上执行 JavaScript,因为它不显示图形界面,运行时间比完整的浏览器高效。与传统的 Chrome 或 Firefox 等浏览器相比,资源消耗会更少。
如果我们将 Selenium 和 PhantomJS 结合起来,我们可以运行一个非常强大的网络爬虫,它可以处理 JavaScript、cookie、标头以及我们真实用户需要做的任何其他事情。主程序退出后,selenium 不保证 phantomJS 也会成功退出。最好手动关闭 phantomJS 进程。(可能会导致多个phantomJS进程运行,占用内存)。虽然 WebDriverWait 可能会减少延迟,但目前存在 bug(各种错误),在这种情况下可以使用 sleep。phantomJS爬取数据比较慢,可以选择多线程。如果你发现有的可以运行,有的不能,可以尝试将phantomJS换成Chrome。
3. 为什么请求需要带headers?
原因是:模拟浏览器,欺骗服务器,获取与浏览器一致的内容头的形式:字典
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
用法:requests.get(url,headers=headers)
4. 你遇到过哪些反爬虫策略?和应对策略?
对于基本网页的抓取可以自定义headers,添加headers的数据,代理来解决
有些网站的数据抓取必须进行模拟登陆才能抓取到完整的数据,所以要进行模拟登陆。
对于限制抓取频率的,可以设置抓取的频率降低一些,
对于限制ip抓取的可以使用多个代理ip进行抓取,轮询使用代理
针对动态网页的可以使用selenium+phantomjs进行抓取,但是比较慢,所以也可以使用查找接口的方式进行抓取。
对部分数据进行加密的,可以使用selenium进行截图,饭后使用python自带的 pytesseract库进行识别,但是比较慢最直接的方法是找到加密的方法进行逆向推理。
5. 分布式爬虫原理?
scrapy-redis实现分布式,其实原理上很简单,这里为了描述方便,我们把我们的核心服务器叫做master,用来运行爬虫程序的机器叫做slave。
我们知道要使用scrapy框架爬取一个网页,我们需要先给它一些start_urls。爬虫首先访问start_urls中的url,然后根据我们的具体逻辑,对里面的元素,或者其他二级三级页面进行操作。抓住。要实现分发,我们只需要在这个starts_urls中做文章。
我们在master上建一个redis数据库(注意这个数据库只用于url存储,不关心具体爬取的数据,不要和mongodb或者mysql混淆),对于每一个网站需要爬取类型,单独开辟一个列表字段。通过在slave上设置scrapy-redis来获取url地址作为master地址。结果是虽然有多个slave,但是大家获取url的地方只有一个,那就是服务器master上的redis数据库。而且由于scrapy-redis自带的队列机制,slave获取的链接不会相互冲突。这样每个slave完成抓取任务后,将得到的结果聚合到服务器(此时的数据存储不再是redis,但是存储特定内容的数据库如mongodb或mysql)这种方法还有其他方法。优点是程序具有高度可移植性。只要路径问题处理好,将slave上的程序移植到另一台机器上运行,基本上就是复制粘贴的问题。
6. python2.x中的urllib和urllib2的区别?
异同:都是做url请求的操作的,但是区别很明显。
urllib2可以接受一个Request类的实例来设置URL请求的headers,urllib仅可以接受URL。这意味着,你不可以通过urllib模块伪装你的User Agent字符串等(伪装浏览器)。
urllib提供urlencode方法用来GET查询字符串的产生,而urllib2没有。这是为何urllib常和urllib2一起使用的原因。
模块比较优势的地方是urlliburllib2.urlopen可以接受Request对象作为参数,从而可以控制HTTP Request的header部。
但是urllib.urlretrieve函数以及urllib.quote等一系列quote和unquote功能没有被加入urllib2中,因此有时也需要urllib的辅助。
7.什么是机器人协议?
robots协议(也称为爬虫协议、爬虫规则、机器人协议等)也是robots.txt,网站通过robots协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。
《机器人协议》是国际互联网界普遍使用的网站道德准则,其目的是保护网站数据和敏感信息,确保用户的个人信息和隐私不受侵犯。因为不是命令,所以需要搜索引擎有意识地服从。
8.什么是爬虫?
爬虫是请求 网站 并提取数据的自动化程序
9.爬虫的基本流程?
1、通过http库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers等信息,等待服务器响应
2、如果服务器能正常响应,会得到一个Response,Response的内容比啊是索要获取的页面内容
3、解析内容:正则表达式、页面解析库、json
4、保存数据:文本或者存入数据库
10.什么是请求和响应?
本地向服务器发送Request,服务器根据请求返回Response,页面显示
1、浏览器就发送消息给该网址所在的服务器,这个过程叫做Http Request
2、服务器收到浏览器发送的消息后,能够根据浏览器发送消息的内容,做相应处
理,然后把消息回传给浏览器,这个过程叫做HTTP Response
3、浏览器收到服务器的Response消息后,会对信息进行相应处理,然后显示
11.请求收录什么?
1、请求方式:主要有GET和POST两种方式,POST请求的参数不会包含在url里面
2、请求URL
URL:统一资源定位符,如一个网页文档、一张图片、一个视频等都可以用URL来唯一确定
3、请求头信息,包含了User-Agent(浏览器请求头)、Host、Cookies信息
4、请求体,GET请求时,一般不会有,POST请求时,请求体一般包含form-data
12.响应中收录哪些信息?
1、响应状态:状态码 正常响应200 重定向
2、响应头:如内容类型、内容长度、服务器信息、设置cookie等
3、响应体信息:响应源代码、图片二进制数据等等 查看全部
java从网页抓取数据(1.写一个邮箱地址的正则表达式?2.谈一谈你对Selenium和PhantomJS了解
)
1. 为电子邮件地址写一个正则表达式?
[A-Za-z0-9\u4e00-\u9fa5]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$
2. 说说你对 Selenium 和 PhantomJS 的了解
Selenium 是一个用于 Web 的自动化测试工具。根据我们的指令,浏览器可以自动加载页面,获取需要的数据,甚至可以对页面进行截图,或者判断网站上是否发生了某些动作。Selenium 没有自己的浏览器,不支持浏览器的功能。它需要与第三方浏览器结合使用。但是我们有时需要让它在代码中内联运行,所以我们可以使用一个叫做 PhantomJS 的工具来代替真正的浏览器。Selenium 库中有一个名为 WebDriver 的 API。WebDriver 有点像可以加载 网站 的浏览器,但它也可以像 BeautifulSoup 或其他 Selector 对象一样用于查找页面元素,与页面上的元素进行交互(发送文本、点击等),以及执行其他操作以运行网络爬虫。
PhantomJS 是一个基于 Webkit 的“无头”浏览器,它将 网站 加载到内存中并在页面上执行 JavaScript,因为它不显示图形界面,运行时间比完整的浏览器高效。与传统的 Chrome 或 Firefox 等浏览器相比,资源消耗会更少。
如果我们将 Selenium 和 PhantomJS 结合起来,我们可以运行一个非常强大的网络爬虫,它可以处理 JavaScript、cookie、标头以及我们真实用户需要做的任何其他事情。主程序退出后,selenium 不保证 phantomJS 也会成功退出。最好手动关闭 phantomJS 进程。(可能会导致多个phantomJS进程运行,占用内存)。虽然 WebDriverWait 可能会减少延迟,但目前存在 bug(各种错误),在这种情况下可以使用 sleep。phantomJS爬取数据比较慢,可以选择多线程。如果你发现有的可以运行,有的不能,可以尝试将phantomJS换成Chrome。
3. 为什么请求需要带headers?
原因是:模拟浏览器,欺骗服务器,获取与浏览器一致的内容头的形式:字典
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
用法:requests.get(url,headers=headers)
4. 你遇到过哪些反爬虫策略?和应对策略?
对于基本网页的抓取可以自定义headers,添加headers的数据,代理来解决
有些网站的数据抓取必须进行模拟登陆才能抓取到完整的数据,所以要进行模拟登陆。
对于限制抓取频率的,可以设置抓取的频率降低一些,
对于限制ip抓取的可以使用多个代理ip进行抓取,轮询使用代理
针对动态网页的可以使用selenium+phantomjs进行抓取,但是比较慢,所以也可以使用查找接口的方式进行抓取。
对部分数据进行加密的,可以使用selenium进行截图,饭后使用python自带的 pytesseract库进行识别,但是比较慢最直接的方法是找到加密的方法进行逆向推理。
5. 分布式爬虫原理?
scrapy-redis实现分布式,其实原理上很简单,这里为了描述方便,我们把我们的核心服务器叫做master,用来运行爬虫程序的机器叫做slave。
我们知道要使用scrapy框架爬取一个网页,我们需要先给它一些start_urls。爬虫首先访问start_urls中的url,然后根据我们的具体逻辑,对里面的元素,或者其他二级三级页面进行操作。抓住。要实现分发,我们只需要在这个starts_urls中做文章。
我们在master上建一个redis数据库(注意这个数据库只用于url存储,不关心具体爬取的数据,不要和mongodb或者mysql混淆),对于每一个网站需要爬取类型,单独开辟一个列表字段。通过在slave上设置scrapy-redis来获取url地址作为master地址。结果是虽然有多个slave,但是大家获取url的地方只有一个,那就是服务器master上的redis数据库。而且由于scrapy-redis自带的队列机制,slave获取的链接不会相互冲突。这样每个slave完成抓取任务后,将得到的结果聚合到服务器(此时的数据存储不再是redis,但是存储特定内容的数据库如mongodb或mysql)这种方法还有其他方法。优点是程序具有高度可移植性。只要路径问题处理好,将slave上的程序移植到另一台机器上运行,基本上就是复制粘贴的问题。
6. python2.x中的urllib和urllib2的区别?
异同:都是做url请求的操作的,但是区别很明显。
urllib2可以接受一个Request类的实例来设置URL请求的headers,urllib仅可以接受URL。这意味着,你不可以通过urllib模块伪装你的User Agent字符串等(伪装浏览器)。
urllib提供urlencode方法用来GET查询字符串的产生,而urllib2没有。这是为何urllib常和urllib2一起使用的原因。
模块比较优势的地方是urlliburllib2.urlopen可以接受Request对象作为参数,从而可以控制HTTP Request的header部。
但是urllib.urlretrieve函数以及urllib.quote等一系列quote和unquote功能没有被加入urllib2中,因此有时也需要urllib的辅助。
7.什么是机器人协议?
robots协议(也称为爬虫协议、爬虫规则、机器人协议等)也是robots.txt,网站通过robots协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。
《机器人协议》是国际互联网界普遍使用的网站道德准则,其目的是保护网站数据和敏感信息,确保用户的个人信息和隐私不受侵犯。因为不是命令,所以需要搜索引擎有意识地服从。
8.什么是爬虫?
爬虫是请求 网站 并提取数据的自动化程序
9.爬虫的基本流程?
1、通过http库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers等信息,等待服务器响应
2、如果服务器能正常响应,会得到一个Response,Response的内容比啊是索要获取的页面内容
3、解析内容:正则表达式、页面解析库、json
4、保存数据:文本或者存入数据库
10.什么是请求和响应?
本地向服务器发送Request,服务器根据请求返回Response,页面显示
1、浏览器就发送消息给该网址所在的服务器,这个过程叫做Http Request
2、服务器收到浏览器发送的消息后,能够根据浏览器发送消息的内容,做相应处
理,然后把消息回传给浏览器,这个过程叫做HTTP Response
3、浏览器收到服务器的Response消息后,会对信息进行相应处理,然后显示
11.请求收录什么?
1、请求方式:主要有GET和POST两种方式,POST请求的参数不会包含在url里面
2、请求URL
URL:统一资源定位符,如一个网页文档、一张图片、一个视频等都可以用URL来唯一确定
3、请求头信息,包含了User-Agent(浏览器请求头)、Host、Cookies信息
4、请求体,GET请求时,一般不会有,POST请求时,请求体一般包含form-data
12.响应中收录哪些信息?
1、响应状态:状态码 正常响应200 重定向
2、响应头:如内容类型、内容长度、服务器信息、设置cookie等
3、响应体信息:响应源代码、图片二进制数据等等
java从网页抓取数据( 再通过数据清洗让这些数据成为我们的基础资料库就行了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-08 12:26
再通过数据清洗让这些数据成为我们的基础资料库就行了)
. . .
爬虫可以用各种语言写,C++、Java都可以,为什么要Python?首先,使用C++进行网络开发的例子并不多(可能我看到的太少了),然后因为甲骨文收购了Sun,Java目前在Android上开发是非常重要的,但是如果谷歌官司不走好吧,那么很有可能会使用 Go 语言而不是 Java 进行 Android 开发。在这个电脑飞速发展的时代,语言的选择取决于父亲的表现,这有点不同。注意力落后于时代。随着计算机速度的飞速发展,用某种语言开发的软件的时间复杂度常数系数已经不像以前那么重要了,我们可以更愿意为程序员而不是为计算机构建。例如,红宝石,传说中的纯种优雅的OOP语言,也就是Python,它是一种稍微严谨但流行的语言,有很多库,大大削弱了为计算机运行速度而设计的特性,加强了为程序员构建的易于思考的特性。所以我选择了 Python。
. . .
“爬虫”就是一个例子。对于我们开发者来说,它是一个用于自动化采集网站数据的程序,结果发现它与真正的bug有关。
. . .
在这个数据交叉流动的互联网时代,初创公司如雨后春笋般涌现,大数据可以帮助他们快速生成垂直数据数据库供用户使用。也让老板更容易看清未来的方向,制定发展策略。
. . .
. . .
如果使用爬虫技术,事情就有了很好的解决方案。我们只需要编写一个7*24小时运行的分布式爬虫,自动化采集携程酒店数据,抓取国内外所有高端酒店(图片、简介、评分、用户评论)。然后通过数据清洗,规范内容,让这些数据成为我们的基础数据库。
,
以上就是全部代码,只是善于分享,请多多包涵!爬虫的基本原理是获取源代码,然后获取网页内容。一般来说,只要你给出一个条目,通过分析,你可以找到无数其他你需要的相关资源,然后爬取。
我还写了很多其他非常简单的入门级爬虫详细教程。关注后,点击我的头像查看。
——————————————————————————————————————————
欢迎留言讨论交流,谢谢! 查看全部
java从网页抓取数据(
再通过数据清洗让这些数据成为我们的基础资料库就行了)
. . .
爬虫可以用各种语言写,C++、Java都可以,为什么要Python?首先,使用C++进行网络开发的例子并不多(可能我看到的太少了),然后因为甲骨文收购了Sun,Java目前在Android上开发是非常重要的,但是如果谷歌官司不走好吧,那么很有可能会使用 Go 语言而不是 Java 进行 Android 开发。在这个电脑飞速发展的时代,语言的选择取决于父亲的表现,这有点不同。注意力落后于时代。随着计算机速度的飞速发展,用某种语言开发的软件的时间复杂度常数系数已经不像以前那么重要了,我们可以更愿意为程序员而不是为计算机构建。例如,红宝石,传说中的纯种优雅的OOP语言,也就是Python,它是一种稍微严谨但流行的语言,有很多库,大大削弱了为计算机运行速度而设计的特性,加强了为程序员构建的易于思考的特性。所以我选择了 Python。
. . .
“爬虫”就是一个例子。对于我们开发者来说,它是一个用于自动化采集网站数据的程序,结果发现它与真正的bug有关。
. . .
在这个数据交叉流动的互联网时代,初创公司如雨后春笋般涌现,大数据可以帮助他们快速生成垂直数据数据库供用户使用。也让老板更容易看清未来的方向,制定发展策略。
. . .
. . .
如果使用爬虫技术,事情就有了很好的解决方案。我们只需要编写一个7*24小时运行的分布式爬虫,自动化采集携程酒店数据,抓取国内外所有高端酒店(图片、简介、评分、用户评论)。然后通过数据清洗,规范内容,让这些数据成为我们的基础数据库。
,
以上就是全部代码,只是善于分享,请多多包涵!爬虫的基本原理是获取源代码,然后获取网页内容。一般来说,只要你给出一个条目,通过分析,你可以找到无数其他你需要的相关资源,然后爬取。
我还写了很多其他非常简单的入门级爬虫详细教程。关注后,点击我的头像查看。
——————————————————————————————————————————
欢迎留言讨论交流,谢谢!
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-08 09:10
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 244 次浏览 • 2022-03-03 21:04
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门针对httpclient+jsoup进行讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据,最终我们要提取的结果是产品的型号、数量、报价、供应商。首先,我们看到这个 网站 整页预览
接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据
获取数据的成功就是我们想要得到的最终数据结果。最后想说的是,这里的这个网页比较简单,可以看到网页源的源数据,而这个方法是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是提示一下,我们可以使用多线程对当前所有分页数据执行采集,通过一个线程采集当前分页数据和一个翻页动作,所有数据可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
转载于: 查看全部
java从网页抓取数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门针对httpclient+jsoup进行讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据,最终我们要提取的结果是产品的型号、数量、报价、供应商。首先,我们看到这个 网站 整页预览
接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据
获取数据的成功就是我们想要得到的最终数据结果。最后想说的是,这里的这个网页比较简单,可以看到网页源的源数据,而这个方法是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是提示一下,我们可以使用多线程对当前所有分页数据执行采集,通过一个线程采集当前分页数据和一个翻页动作,所有数据可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
转载于:

