
java从网页抓取数据
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-31 23:08
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java来给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页的源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
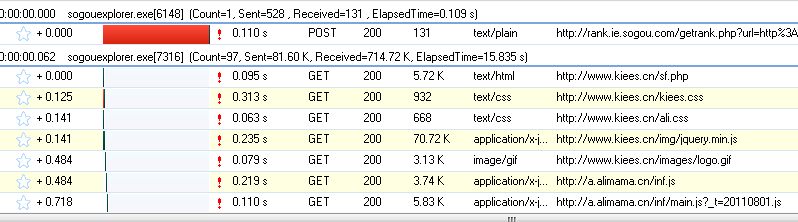
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
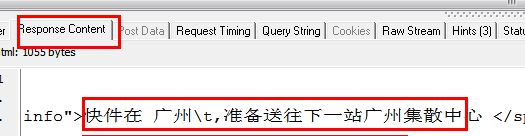
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
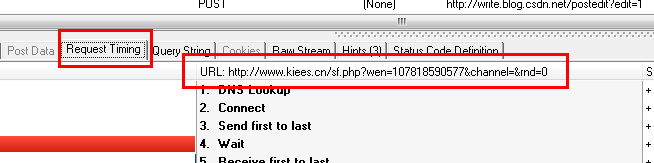
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java来给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:

第二步:查看网页的源码,我们看到源码中有这么一段:

由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:

也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页的源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:

第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:

为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:

这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:


从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据(用到抓取网页数据的功能:抓取数据功能详解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-31 17:14
经常用到爬取网页数据的功能。我在以前的工作中使用过它。今天我总结一下:
1、通过指定的URL抓取网页数据,获取页面信息,然后对带有DOM的页面进行NODE分析,处理原创的HTML数据。这样做的好处是处理某条数据的灵活性很高。 , 难点在于节算法需要优化。当页面的HTML信息较大时,算法不好,会影响处理效率。
2、htmlparser框架,对于HTML页面处理的数据结构,HtmlParser采用经典的Composite模式,通过RemarkNode、TextNode、TagNode、AbstractNode和Tag来描述HTML页面的各个元素。 Htmlparser基本可以满足垂直搜索引擎页面处理分析的需求,映射HTML标签,轻松获取标签中的HTMLCODE。
Htmlparser官方介绍:htmlparser是一个纯java编写的html解析库。它不依赖于其他java库文件,主要用于转换或提取html。它解析 html 的速度非常快而且没有错误。 htmlparser 的最新版本现在是 2.0。毫不夸张地说,htmlparser是目前最好的html解析分析工具。
3、nekohtml框架,nekohtml在容错和性能方面比htmlparser有更好的口碑(包括htmlunit也使用nekohtml),nokehtml类似于xml解析的原理,将html标签解析为dom,是的,它们对应于DOM树中的相应元素进行处理。
NekoHTML 官方介绍:NekoHTML 是Java 语言的HTML 扫描器和标签平衡器,它使程序能够解析HTML 文档并使用标准的XML 接口来访问其中的信息。此解析器能够扫描 HTML 文档并“修复”作者(人或机器)在编写 HTML 文档时所犯的许多常见错误。
NekoHTML 可以补充缺失的父元素,自动用结束标签关闭对应的元素,不匹配内联元素标签。 NekoHTML 是使用 XercesNativeInterface (XNI) 开发的,它是 Xerces2 实现的基础。 查看全部
java从网页抓取数据(用到抓取网页数据的功能:抓取数据功能详解)
经常用到爬取网页数据的功能。我在以前的工作中使用过它。今天我总结一下:
1、通过指定的URL抓取网页数据,获取页面信息,然后对带有DOM的页面进行NODE分析,处理原创的HTML数据。这样做的好处是处理某条数据的灵活性很高。 , 难点在于节算法需要优化。当页面的HTML信息较大时,算法不好,会影响处理效率。
2、htmlparser框架,对于HTML页面处理的数据结构,HtmlParser采用经典的Composite模式,通过RemarkNode、TextNode、TagNode、AbstractNode和Tag来描述HTML页面的各个元素。 Htmlparser基本可以满足垂直搜索引擎页面处理分析的需求,映射HTML标签,轻松获取标签中的HTMLCODE。
Htmlparser官方介绍:htmlparser是一个纯java编写的html解析库。它不依赖于其他java库文件,主要用于转换或提取html。它解析 html 的速度非常快而且没有错误。 htmlparser 的最新版本现在是 2.0。毫不夸张地说,htmlparser是目前最好的html解析分析工具。
3、nekohtml框架,nekohtml在容错和性能方面比htmlparser有更好的口碑(包括htmlunit也使用nekohtml),nokehtml类似于xml解析的原理,将html标签解析为dom,是的,它们对应于DOM树中的相应元素进行处理。
NekoHTML 官方介绍:NekoHTML 是Java 语言的HTML 扫描器和标签平衡器,它使程序能够解析HTML 文档并使用标准的XML 接口来访问其中的信息。此解析器能够扫描 HTML 文档并“修复”作者(人或机器)在编写 HTML 文档时所犯的许多常见错误。
NekoHTML 可以补充缺失的父元素,自动用结束标签关闭对应的元素,不匹配内联元素标签。 NekoHTML 是使用 XercesNativeInterface (XNI) 开发的,它是 Xerces2 实现的基础。
java从网页抓取数据( commons-io工具,获取页面或Json5)Jsoup工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-31 17:11
commons-io工具,获取页面或Json5)Jsoup工具)
4)commons-io 工具,获取页面或Json
5) Jsoup工具(一般用于html字段解析),获取页面,非Json返回格式]
完整代码:
package com.yeezhao.common.http;import java.io.BufferedReader;import java.io.InputStream;import java.io.InputStreamReader;import java.net.HttpURLConnection;import java.net.URL;import org.apache.commons.httpclient.HttpClient;import org.apache.commons.httpclient.HttpMethod;import org.apache.commons.httpclient.methods.GetMethod;import org.apache.commons.io.IOUtils;import org.jsoup.Jsoup;/**
* http工具对比
*
* @author Administrator -> junhong
*
* 2016年12月27日 */public class HttpFetchUtil {
/**
* 获取访问的状态码
* @param request
* @return
* @throws Exception */
public static int getResponseCode(String request) throws Exception {
URL url = new URL(request);
HttpURLConnection conn = (HttpURLConnection) url.openConnection(); return conn.getResponseCode();
} /**
* 1)JDK自带HTTP连接,获取页面或Json
* @param request
* @param charset
* @return
* @throws Exception */
public static String JDKFetch(String request, String charset) throws Exception {
URL url = new URL(request);
HttpURLConnection conn = (HttpURLConnection) url.openConnection(); //模拟浏览器参数
conn.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36"
+ " (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"); if (conn.getResponseCode() == HttpURLConnection.HTTP_OK) {
InputStream input = conn.getInputStream();
StringBuffer sb = new StringBuffer();
BufferedReader reader = new BufferedReader(new InputStreamReader(input, charset));
String s; while ((s = reader.readLine()) != null) {
sb.append(s + "\n");
}
input.close();
conn.disconnect(); return sb.toString();
} return "";
} /**
* 2) JDK自带URL连接,获取页面或Json
* @param request
* @param charset
* @return
* @throws Exception */
public static String URLFetch(String request, String charset) throws Exception {
URL url = new URL(request); return IOUtils.toString(url.openStream());
} /**
* 3)HttpClient Get工具,获取页面或Json
* @param url
* @param charset
* @return
* @throws Exception */
public static String httpClientFetch(String url, String charset) throws Exception { // GET
HttpClient httpClient = new HttpClient();
httpClient.getParams().setContentCharset(charset);
HttpMethod method = new GetMethod(url);
httpClient.executeMethod(method); return method.getResponseBodyAsString();
} /**
* 4)commons-io工具,获取页面或Json
* @param url
* @param charset
* @return
* @throws Exception */
public static String commonsIOFetch(String url, String charset) throws Exception { return IOUtils.toString(new URL(url), charset);
}
/**
* 5) Jsoup工具(通常用于html字段解析),获取页面,非Json返回格式
* @param url
* @return
* @throws Exception */
public static String jsoupFetch(String url) throws Exception { return Jsoup.parse(new URL(url), 2 * 1000).html();
}
}
测试代码:
附:相关jar依赖
...
org.jsoup
jsoup
1.7.3
commons-httpclient
commons-httpclient
3.1
commons-io
commons-io
2.4
...
后记:
在当前的数据时代,有“数据就是财富”的概念。因此,数据采集技术会不断的发展和更新,并在此基础上进一步扩展POST方式的采集方式,敬请期待!
以上就是Java实现http数据抓取的几种方式的详细内容。更多详情请关注宏旺互联网其他相关话题文章! 查看全部
java从网页抓取数据(
commons-io工具,获取页面或Json5)Jsoup工具)

4)commons-io 工具,获取页面或Json

5) Jsoup工具(一般用于html字段解析),获取页面,非Json返回格式]

完整代码:
package com.yeezhao.common.http;import java.io.BufferedReader;import java.io.InputStream;import java.io.InputStreamReader;import java.net.HttpURLConnection;import java.net.URL;import org.apache.commons.httpclient.HttpClient;import org.apache.commons.httpclient.HttpMethod;import org.apache.commons.httpclient.methods.GetMethod;import org.apache.commons.io.IOUtils;import org.jsoup.Jsoup;/**
* http工具对比
*
* @author Administrator -> junhong
*
* 2016年12月27日 */public class HttpFetchUtil {
/**
* 获取访问的状态码
* @param request
* @return
* @throws Exception */
public static int getResponseCode(String request) throws Exception {
URL url = new URL(request);
HttpURLConnection conn = (HttpURLConnection) url.openConnection(); return conn.getResponseCode();
} /**
* 1)JDK自带HTTP连接,获取页面或Json
* @param request
* @param charset
* @return
* @throws Exception */
public static String JDKFetch(String request, String charset) throws Exception {
URL url = new URL(request);
HttpURLConnection conn = (HttpURLConnection) url.openConnection(); //模拟浏览器参数
conn.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36"
+ " (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"); if (conn.getResponseCode() == HttpURLConnection.HTTP_OK) {
InputStream input = conn.getInputStream();
StringBuffer sb = new StringBuffer();
BufferedReader reader = new BufferedReader(new InputStreamReader(input, charset));
String s; while ((s = reader.readLine()) != null) {
sb.append(s + "\n");
}
input.close();
conn.disconnect(); return sb.toString();
} return "";
} /**
* 2) JDK自带URL连接,获取页面或Json
* @param request
* @param charset
* @return
* @throws Exception */
public static String URLFetch(String request, String charset) throws Exception {
URL url = new URL(request); return IOUtils.toString(url.openStream());
} /**
* 3)HttpClient Get工具,获取页面或Json
* @param url
* @param charset
* @return
* @throws Exception */
public static String httpClientFetch(String url, String charset) throws Exception { // GET
HttpClient httpClient = new HttpClient();
httpClient.getParams().setContentCharset(charset);
HttpMethod method = new GetMethod(url);
httpClient.executeMethod(method); return method.getResponseBodyAsString();
} /**
* 4)commons-io工具,获取页面或Json
* @param url
* @param charset
* @return
* @throws Exception */
public static String commonsIOFetch(String url, String charset) throws Exception { return IOUtils.toString(new URL(url), charset);
}
/**
* 5) Jsoup工具(通常用于html字段解析),获取页面,非Json返回格式
* @param url
* @return
* @throws Exception */
public static String jsoupFetch(String url) throws Exception { return Jsoup.parse(new URL(url), 2 * 1000).html();
}
}

测试代码:
附:相关jar依赖
...
org.jsoup
jsoup
1.7.3
commons-httpclient
commons-httpclient
3.1
commons-io
commons-io
2.4
...
后记:
在当前的数据时代,有“数据就是财富”的概念。因此,数据采集技术会不断的发展和更新,并在此基础上进一步扩展POST方式的采集方式,敬请期待!
以上就是Java实现http数据抓取的几种方式的详细内容。更多详情请关注宏旺互联网其他相关话题文章!
java从网页抓取数据(本文getNextUrl:Java代码更多的关于robot.txt的具体写法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-29 10:14
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。其基本结构如下图所示:
传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某个停止条件。对于垂直搜索,聚焦爬虫,即有针对性地爬取特定主题页面的爬虫更适合。
本文爬虫程序核心代码如下:
Java 代码
public void crawl() throws Throwable {
while (continueCrawling()) {
CrawlerUrl url = getNextUrl(); //获取待爬取队列中的下一个URL
if (url != null) {
printCrawlInfo();
String content = getContent(url); //获取URL的文本信息
//聚焦爬虫只爬取与主题内容相关的网页,这里采用正则匹配简单处理
if (isContentRelevant(content, this.regexpSearchPattern)) {
saveContent(url, content); //保存网页至本地
//获取网页内容中的链接,并放入待爬取队列中
Collection urlStrings = extractUrls(content, url);
addUrlsToUrlQueue(url, urlStrings);
} else {
System.out.println(url + " is not relevant ignoring ...");
}
//延时防止被对方屏蔽
Thread.sleep(this.delayBetweenUrls);
}
}
closeOutputStream();
}
整个函数由getNextUrl、getContent、isContentRelevant、extractUrls、addUrlsToUrlQueue等几个核心方法组成,下面将一一介绍。先看getNextUrl:
Java 代码
private CrawlerUrl getNextUrl() throws Throwable {
CrawlerUrl nextUrl = null;
while ((nextUrl == null) && (!urlQueue.isEmpty())) {
CrawlerUrl crawlerUrl = this.urlQueue.remove();
//doWeHavePermissionToVisit:是否有权限访问该URL,友好的爬虫会根据网站提供的"Robot.txt"中配置的规则进行爬取
//isUrlAlreadyVisited:URL是否访问过,大型的搜索引擎往往采用BloomFilter进行排重,这里简单使用HashMap
//isDepthAcceptable:是否达到指定的深度上限。爬虫一般采取广度优先的方式。一些网站会构建爬虫陷阱(自动生成一些无效链接使爬虫陷入死循环),采用深度限制加以避免
if (doWeHavePermissionToVisit(crawlerUrl)
&& (!isUrlAlreadyVisited(crawlerUrl))
&& isDepthAcceptable(crawlerUrl)) {
nextUrl = crawlerUrl;
// System.out.println("Next url to be visited is " + nextUrl);
}
}
return nextUrl;
}
更具体的robot.txt写法请参考以下文章:
getContent 内部使用 apache 的 httpclient 4.1 来获取网页内容。具体代码如下:
Java 代码
private String getContent(CrawlerUrl url) throws Throwable {
//HttpClient4.1的调用与之前的方式不同
HttpClient client = new DefaultHttpClient();
HttpGet httpGet = new HttpGet(url.getUrlString());
StringBuffer strBuf = new StringBuffer();
HttpResponse response = client.execute(httpGet);
if (HttpStatus.SC_OK == response.getStatusLine().getStatusCode()) {
HttpEntity entity = response.getEntity();
if (entity != null) {
BufferedReader reader = new BufferedReader(
new InputStreamReader(entity.getContent(), "UTF-8"));
String line = null;
if (entity.getContentLength() > 0) {
strBuf = new StringBuffer((int) entity.getContentLength());
while ((line = reader.readLine()) != null) {
strBuf.append(line);
}
}
}
if (entity != null) {
entity.consumeContent();
}
}
//将url标记为已访问
markUrlAsVisited(url);
return strBuf.toString();
}
对于垂直应用,数据准确性通常更为重要。聚焦爬虫的主要特点是它只采集与主题相关的数据,这就是 isContentRelevant 方法的作用。这里,可以使用分类预测技术,为了简单起见,改用正则匹配。其主要代码如下:
Java 代码
public static boolean isContentRelevant(String content,
Pattern regexpPattern) {
boolean retValue = false;
if (content != null) {
//是否符合正则表达式的条件
Matcher m = regexpPattern.matcher(content.toLowerCase());
retValue = m.find();
}
return retValue;
}
extractUrls 的主要作用是从网页中获取更多的 URL,包括内部链接和外部链接。代码如下:
Java 代码
public List extractUrls(String text, CrawlerUrl crawlerUrl) {
Map urlMap = new HashMap();
extractHttpUrls(urlMap, text);
extractRelativeUrls(urlMap, text, crawlerUrl);
return new ArrayList(urlMap.keySet());
}
//处理外部链接
private void extractHttpUrls(Map urlMap, String text) {
Matcher m = httpRegexp.matcher(text);
while (m.find()) {
String url = m.group();
String[] terms = url.split("a href=\"");
for (String term : terms) {
// System.out.println("Term = " + term);
if (term.startsWith("http")) {
int index = term.indexOf("\"");
if (index > 0) {
term = term.substring(0, index);
}
urlMap.put(term, term);
System.out.println("Hyperlink: " + term);
}
}
}
}
//处理内部链接
private void extractRelativeUrls(Map urlMap, String text,
CrawlerUrl crawlerUrl) {
Matcher m = relativeRegexp.matcher(text);
URL textURL = crawlerUrl.getURL();
String host = textURL.getHost();
while (m.find()) {
String url = m.group();
String[] terms = url.split("a href=\"");
for (String term : terms) {
if (term.startsWith("/")) {
int index = term.indexOf("\"");
if (index > 0) {
term = term.substring(0, index);
}
String s = "http://" + host + term;
urlMap.put(s, s);
System.out.println("Relative url: " + s);
}
}
}
}
这样就构建了一个简单的网络爬虫,可以用下面的程序进行测试:
Java 代码
public static void main(String[] args) {
try {
String url = "http://www.amazon.com";
Queue urlQueue = new LinkedList();
String regexp = "java";
urlQueue.add(new CrawlerUrl(url, 0));
NaiveCrawler crawler = new NaiveCrawler(urlQueue, 100, 5, 1000L,
regexp);
// boolean allowCrawl = crawler.areWeAllowedToVisit(url);
// System.out.println("Allowed to crawl: " + url + " " +
// allowCrawl);
crawler.crawl();
} catch (Throwable t) {
System.out.println(t.toString());
t.printStackTrace();
}
}
当然,你可以给它更高级的功能,比如多线程,更智能的对焦,用Lucene索引等等。对于更复杂的情况,你可以考虑使用一些开源的蜘蛛程序,比如Nutch或者Heritrix等,这超出了本文的范围。 查看全部
java从网页抓取数据(本文getNextUrl:Java代码更多的关于robot.txt的具体写法)
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。其基本结构如下图所示:

传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某个停止条件。对于垂直搜索,聚焦爬虫,即有针对性地爬取特定主题页面的爬虫更适合。
本文爬虫程序核心代码如下:
Java 代码
public void crawl() throws Throwable {
while (continueCrawling()) {
CrawlerUrl url = getNextUrl(); //获取待爬取队列中的下一个URL
if (url != null) {
printCrawlInfo();
String content = getContent(url); //获取URL的文本信息
//聚焦爬虫只爬取与主题内容相关的网页,这里采用正则匹配简单处理
if (isContentRelevant(content, this.regexpSearchPattern)) {
saveContent(url, content); //保存网页至本地
//获取网页内容中的链接,并放入待爬取队列中
Collection urlStrings = extractUrls(content, url);
addUrlsToUrlQueue(url, urlStrings);
} else {
System.out.println(url + " is not relevant ignoring ...");
}
//延时防止被对方屏蔽
Thread.sleep(this.delayBetweenUrls);
}
}
closeOutputStream();
}
整个函数由getNextUrl、getContent、isContentRelevant、extractUrls、addUrlsToUrlQueue等几个核心方法组成,下面将一一介绍。先看getNextUrl:
Java 代码
private CrawlerUrl getNextUrl() throws Throwable {
CrawlerUrl nextUrl = null;
while ((nextUrl == null) && (!urlQueue.isEmpty())) {
CrawlerUrl crawlerUrl = this.urlQueue.remove();
//doWeHavePermissionToVisit:是否有权限访问该URL,友好的爬虫会根据网站提供的"Robot.txt"中配置的规则进行爬取
//isUrlAlreadyVisited:URL是否访问过,大型的搜索引擎往往采用BloomFilter进行排重,这里简单使用HashMap
//isDepthAcceptable:是否达到指定的深度上限。爬虫一般采取广度优先的方式。一些网站会构建爬虫陷阱(自动生成一些无效链接使爬虫陷入死循环),采用深度限制加以避免
if (doWeHavePermissionToVisit(crawlerUrl)
&& (!isUrlAlreadyVisited(crawlerUrl))
&& isDepthAcceptable(crawlerUrl)) {
nextUrl = crawlerUrl;
// System.out.println("Next url to be visited is " + nextUrl);
}
}
return nextUrl;
}
更具体的robot.txt写法请参考以下文章:
getContent 内部使用 apache 的 httpclient 4.1 来获取网页内容。具体代码如下:
Java 代码
private String getContent(CrawlerUrl url) throws Throwable {
//HttpClient4.1的调用与之前的方式不同
HttpClient client = new DefaultHttpClient();
HttpGet httpGet = new HttpGet(url.getUrlString());
StringBuffer strBuf = new StringBuffer();
HttpResponse response = client.execute(httpGet);
if (HttpStatus.SC_OK == response.getStatusLine().getStatusCode()) {
HttpEntity entity = response.getEntity();
if (entity != null) {
BufferedReader reader = new BufferedReader(
new InputStreamReader(entity.getContent(), "UTF-8"));
String line = null;
if (entity.getContentLength() > 0) {
strBuf = new StringBuffer((int) entity.getContentLength());
while ((line = reader.readLine()) != null) {
strBuf.append(line);
}
}
}
if (entity != null) {
entity.consumeContent();
}
}
//将url标记为已访问
markUrlAsVisited(url);
return strBuf.toString();
}
对于垂直应用,数据准确性通常更为重要。聚焦爬虫的主要特点是它只采集与主题相关的数据,这就是 isContentRelevant 方法的作用。这里,可以使用分类预测技术,为了简单起见,改用正则匹配。其主要代码如下:
Java 代码
public static boolean isContentRelevant(String content,
Pattern regexpPattern) {
boolean retValue = false;
if (content != null) {
//是否符合正则表达式的条件
Matcher m = regexpPattern.matcher(content.toLowerCase());
retValue = m.find();
}
return retValue;
}
extractUrls 的主要作用是从网页中获取更多的 URL,包括内部链接和外部链接。代码如下:
Java 代码
public List extractUrls(String text, CrawlerUrl crawlerUrl) {
Map urlMap = new HashMap();
extractHttpUrls(urlMap, text);
extractRelativeUrls(urlMap, text, crawlerUrl);
return new ArrayList(urlMap.keySet());
}
//处理外部链接
private void extractHttpUrls(Map urlMap, String text) {
Matcher m = httpRegexp.matcher(text);
while (m.find()) {
String url = m.group();
String[] terms = url.split("a href=\"");
for (String term : terms) {
// System.out.println("Term = " + term);
if (term.startsWith("http")) {
int index = term.indexOf("\"");
if (index > 0) {
term = term.substring(0, index);
}
urlMap.put(term, term);
System.out.println("Hyperlink: " + term);
}
}
}
}
//处理内部链接
private void extractRelativeUrls(Map urlMap, String text,
CrawlerUrl crawlerUrl) {
Matcher m = relativeRegexp.matcher(text);
URL textURL = crawlerUrl.getURL();
String host = textURL.getHost();
while (m.find()) {
String url = m.group();
String[] terms = url.split("a href=\"");
for (String term : terms) {
if (term.startsWith("/")) {
int index = term.indexOf("\"");
if (index > 0) {
term = term.substring(0, index);
}
String s = "http://" + host + term;
urlMap.put(s, s);
System.out.println("Relative url: " + s);
}
}
}
}
这样就构建了一个简单的网络爬虫,可以用下面的程序进行测试:
Java 代码
public static void main(String[] args) {
try {
String url = "http://www.amazon.com";
Queue urlQueue = new LinkedList();
String regexp = "java";
urlQueue.add(new CrawlerUrl(url, 0));
NaiveCrawler crawler = new NaiveCrawler(urlQueue, 100, 5, 1000L,
regexp);
// boolean allowCrawl = crawler.areWeAllowedToVisit(url);
// System.out.println("Allowed to crawl: " + url + " " +
// allowCrawl);
crawler.crawl();
} catch (Throwable t) {
System.out.println(t.toString());
t.printStackTrace();
}
}
当然,你可以给它更高级的功能,比如多线程,更智能的对焦,用Lucene索引等等。对于更复杂的情况,你可以考虑使用一些开源的蜘蛛程序,比如Nutch或者Heritrix等,这超出了本文的范围。
java从网页抓取数据(网页信息提取文献总结-差异和对比零、基础知识结构化数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-29 10:13
【算法研究】Web信息抽取文献综述——差异与比较零,基础知识结构化数据2015_《数据库系统基础(第5版)》
存储在数据库中的信息称为结构化数据;XML 文档是模式信息与数据值混合的半结构化数据,而 HTML 中的网页是非结构化文档规范化
将格式错误的文档转换为格式良好的 HTML 文档。
一、审阅类型文章2002_《Web数据抽取工具简述》
伦达尔等人。建议通过区分用于为每种方法生成包装器的主要技术来区分结构化数据提取方法,例如基于 NLP 的方法、基于模型构建的方法等。
2006_《Web信息抽取系统综述》
C. Chang 等人。从提取任务的难易程度、使用的方法、自动化程度等方面对网页提取进行分类。
使用的技术(标记/编码方法、提取规则的类型、特征提取/机器学习)、自动化程度(有用户参与、无用户参与)(手动构建、监督、半监督、无监督)2012_“Web 数据挖掘”
兵等人。根据自动化程度对数据提取方法进行分类,将结构化数据提取方法分为手动、半自动和全自动方法。2013IEEE“从Web文档中提取区域的调查”
Sleiman 等人专注于区域提取器。描述区域提取器的发展并比较不同的区域提取器。2019_《基于层次分析法的Web数据提取方法比较研究》
描述从网页中提取数据的方法,详细描述每种方法,最后根据定义明确的精确标准比较所有方法。二、基于HTML页面代码的方法手动方法1997_《半结构化数据:TSIMMIS经验》
TSIMMIS 是最早提供手动构建 Web 包装器的框架之一,允许程序员输入一系列指令来确定应如何提取数据。
1998_ “WebOQL:重构文档、数据库和 Web”
半自动方法 2000_Snowball:从大型纯文本集合中提取关系
微软提出的一种从文本文档中提取有价值的结构化数据的方法,首先从用户那里获取少量训练样例作为种子元组生成提取模式,然后从文档集合中提取新的元组对,经过多次获取最终数据迭代。2007_《开放网络信息提取》
抽取范式是从语料库中构建的,不需要人工输入,自动发现可能的兴趣关系,实现了从Web中大规模数据抽取的无监督过程。2007_“深度网络的结构化数据注释”
解决如何为从 Web 数据库返回的 SRR 数据记录自动分配有意义的标签。
陆晔等。将数据单元对齐到不同的组中,使同一组中的数据具有相同的语义,然后为每个组从不同方面对它们进行注释,并聚合不同的注释以预测最终的注释标签。2013_《一种从深网精确提取实体数据的新方法》
根据 DeepWeb 的动态特性,Yu HT et al. 对网页资源进行预处理和规范化,结合XPath和Regexp,准确定位实体数据。缺点是不能泛化,需要在提取目标页面前定义正则表达式。2018_用户友好和可扩展的Web数据提取
Serrano T. Novella I. Holubová 等人提出了一种具有三个目标的新包装语言:(1)在受限环境中运行的能力,例如浏览器扩展,(2)可扩展性能以平衡交易-在命令集表达性和安全性之间关闭,以及(3) 处理能力,无需额外的程序来清理提取的数据。全自动方法 2001_“RoadRunner:从大型网站自动提取数据”》
RoadRunner 是一个完全自动化的包装器,它不依赖于任何用户交互,但需要一次处理至少两个或多个页面,因为算法的核心是基于一组给定的属于同一类的 HTML 示例页面并从提取数据。RoadRunner 使用一种称为 ACME 的匹配技术来查找两个页面中的共同结构(对齐相似的标签和折叠不同的标签)以从标签生成包装器。由于算法的比较机制,RoadRunner 还会收录一些噪声块。
三、基于DOM树的半自动文本识别方法2001_《Building Intelligent Web Applications Using Lightweight Wrappers》
W4F(万维网包装器工厂)是一个用于生成 Web 包装器的 Java 工具包。它提供了一种表达式语言,用于从 HTML 页面中提取 DOM 树结构,将提取的数据映射到 XML 或 Java 对象,并提供一些可视化工具,使打包过程更快、更容易。
2002_ “XWRAP:一个支持 XML 的 Web 信息源包装器构建系统”
XWRAP 是一种半自动的方法,它分析页面的 DOM 结构,使用组件库为 wrapper 程序提供基本的构建块,引导用户通过点击所需的组件来生成 wrapper 代码,XWRAP 还可以输出信息抽取规则。
叶节点融合相关算法
《基于DOM树和统计信息的Web内容信息提取》
全自动方法2001_《万维网全自动对象提取系统》
Omini 将网页解析成 DOM 树,然后使用子树提取算法定位收录感兴趣对象的最小子树,并使用对象提取算法定位正确的对象分隔符标签,从而有效分离对象。缺点是子树提取算法和对象分隔符提取算法都依赖于标签计数,数据库仅限于普通论文文章和书籍数据库网站,结构比较简单。
2003_《通过模式发现从半结构化网页中自动提取信息》
IEPAD(Automatic information extract from semi-structured Web pages by pattern discovery)是一种基于模式发现的方法。
2003_《挖掘网页中的数据记录》
MDR 方法基于两个观察和三个步骤:
两个观察
两个假设
该方法主要分为三个步骤
2005_《基于部分树对齐的Web数据提取》
DEPTA(即 MDR2)
主要流程
MDR2 挖掘数据区域(基于部分树对齐)
2017_《基于Web结构聚类的Web内容提取》
CECWS首先从同一个网站中提取了一组相似的页面,删除了内容相同的部分(噪声数据),然后提取了数据。
2018_《一种从单项页面中有效提取网络数据的新型对齐算法》
DCA 分治法专注于提取单项页面中的顺序对数。
本文的主要贡献是
四、基于视觉信息的数据提取2003-Vips:一种基于视觉的页面分割算法
蔡 D 等人。首先从DOM树中提取出所有合适的页面块,然后根据这些页面和段重构网页的语义结构。
2005-搜索引擎的全自动包装器生成
作者主要提出了ViNT的一种方法
对于搜索引擎的界面(如百度页面和谷歌界面),需要同一个搜索引擎下的多个页面。
2013-注释来自网络数据库的搜索结果
基于 ViNT 提取数据记录的 SRR,然后进行数据对齐以生成多类注释包装器。
2010-ViDE:一种基于视觉的深度网络数据提取方法
布局函数 (LF)
外观特征 (AFs)。这些函数捕获数据记录中的视觉函数。
内容函数 (CF)。这些特征暗示了数据记录中内容的规律性。
数据提取标准
数据提取过程
首先通过PFs特性,调整阈值对数据区域进行分框,过滤噪声块,判断噪声块位置是否左对齐,数据可视块,聚类块,数据块对齐
基于视觉的数据记录包装器 (f,l,d)
我们的方法包括四个主要步骤:可视块树构建、数据记录提取、数据项提取和可视化包装器生成。
2013_从深网可视化提取数据记录
4.3 基于机器学习的模式识别 从相似网页中提取对应模式的数据(从候选框中选择样本,将其坐标投影到最终的特征向量,然后使用softmax进行分类)4. 4 基于机器学习的本地化
《基于视觉信息处理的深度网络数据提取》
五、基于模板的文本识别
主要步骤是
六、基于语义标签的文本提取七、基于词库的信息提取 查看全部
java从网页抓取数据(网页信息提取文献总结-差异和对比零、基础知识结构化数据)
【算法研究】Web信息抽取文献综述——差异与比较零,基础知识结构化数据2015_《数据库系统基础(第5版)》
存储在数据库中的信息称为结构化数据;XML 文档是模式信息与数据值混合的半结构化数据,而 HTML 中的网页是非结构化文档规范化
将格式错误的文档转换为格式良好的 HTML 文档。
一、审阅类型文章2002_《Web数据抽取工具简述》
伦达尔等人。建议通过区分用于为每种方法生成包装器的主要技术来区分结构化数据提取方法,例如基于 NLP 的方法、基于模型构建的方法等。
2006_《Web信息抽取系统综述》
C. Chang 等人。从提取任务的难易程度、使用的方法、自动化程度等方面对网页提取进行分类。
使用的技术(标记/编码方法、提取规则的类型、特征提取/机器学习)、自动化程度(有用户参与、无用户参与)(手动构建、监督、半监督、无监督)2012_“Web 数据挖掘”
兵等人。根据自动化程度对数据提取方法进行分类,将结构化数据提取方法分为手动、半自动和全自动方法。2013IEEE“从Web文档中提取区域的调查”
Sleiman 等人专注于区域提取器。描述区域提取器的发展并比较不同的区域提取器。2019_《基于层次分析法的Web数据提取方法比较研究》
描述从网页中提取数据的方法,详细描述每种方法,最后根据定义明确的精确标准比较所有方法。二、基于HTML页面代码的方法手动方法1997_《半结构化数据:TSIMMIS经验》
TSIMMIS 是最早提供手动构建 Web 包装器的框架之一,允许程序员输入一系列指令来确定应如何提取数据。
1998_ “WebOQL:重构文档、数据库和 Web”
半自动方法 2000_Snowball:从大型纯文本集合中提取关系
微软提出的一种从文本文档中提取有价值的结构化数据的方法,首先从用户那里获取少量训练样例作为种子元组生成提取模式,然后从文档集合中提取新的元组对,经过多次获取最终数据迭代。2007_《开放网络信息提取》
抽取范式是从语料库中构建的,不需要人工输入,自动发现可能的兴趣关系,实现了从Web中大规模数据抽取的无监督过程。2007_“深度网络的结构化数据注释”
解决如何为从 Web 数据库返回的 SRR 数据记录自动分配有意义的标签。
陆晔等。将数据单元对齐到不同的组中,使同一组中的数据具有相同的语义,然后为每个组从不同方面对它们进行注释,并聚合不同的注释以预测最终的注释标签。2013_《一种从深网精确提取实体数据的新方法》
根据 DeepWeb 的动态特性,Yu HT et al. 对网页资源进行预处理和规范化,结合XPath和Regexp,准确定位实体数据。缺点是不能泛化,需要在提取目标页面前定义正则表达式。2018_用户友好和可扩展的Web数据提取
Serrano T. Novella I. Holubová 等人提出了一种具有三个目标的新包装语言:(1)在受限环境中运行的能力,例如浏览器扩展,(2)可扩展性能以平衡交易-在命令集表达性和安全性之间关闭,以及(3) 处理能力,无需额外的程序来清理提取的数据。全自动方法 2001_“RoadRunner:从大型网站自动提取数据”》
RoadRunner 是一个完全自动化的包装器,它不依赖于任何用户交互,但需要一次处理至少两个或多个页面,因为算法的核心是基于一组给定的属于同一类的 HTML 示例页面并从提取数据。RoadRunner 使用一种称为 ACME 的匹配技术来查找两个页面中的共同结构(对齐相似的标签和折叠不同的标签)以从标签生成包装器。由于算法的比较机制,RoadRunner 还会收录一些噪声块。
三、基于DOM树的半自动文本识别方法2001_《Building Intelligent Web Applications Using Lightweight Wrappers》
W4F(万维网包装器工厂)是一个用于生成 Web 包装器的 Java 工具包。它提供了一种表达式语言,用于从 HTML 页面中提取 DOM 树结构,将提取的数据映射到 XML 或 Java 对象,并提供一些可视化工具,使打包过程更快、更容易。
2002_ “XWRAP:一个支持 XML 的 Web 信息源包装器构建系统”
XWRAP 是一种半自动的方法,它分析页面的 DOM 结构,使用组件库为 wrapper 程序提供基本的构建块,引导用户通过点击所需的组件来生成 wrapper 代码,XWRAP 还可以输出信息抽取规则。
叶节点融合相关算法
《基于DOM树和统计信息的Web内容信息提取》
全自动方法2001_《万维网全自动对象提取系统》
Omini 将网页解析成 DOM 树,然后使用子树提取算法定位收录感兴趣对象的最小子树,并使用对象提取算法定位正确的对象分隔符标签,从而有效分离对象。缺点是子树提取算法和对象分隔符提取算法都依赖于标签计数,数据库仅限于普通论文文章和书籍数据库网站,结构比较简单。
2003_《通过模式发现从半结构化网页中自动提取信息》
IEPAD(Automatic information extract from semi-structured Web pages by pattern discovery)是一种基于模式发现的方法。
2003_《挖掘网页中的数据记录》
MDR 方法基于两个观察和三个步骤:
两个观察
两个假设
该方法主要分为三个步骤
2005_《基于部分树对齐的Web数据提取》
DEPTA(即 MDR2)
主要流程
MDR2 挖掘数据区域(基于部分树对齐)
2017_《基于Web结构聚类的Web内容提取》
CECWS首先从同一个网站中提取了一组相似的页面,删除了内容相同的部分(噪声数据),然后提取了数据。
2018_《一种从单项页面中有效提取网络数据的新型对齐算法》
DCA 分治法专注于提取单项页面中的顺序对数。
本文的主要贡献是
四、基于视觉信息的数据提取2003-Vips:一种基于视觉的页面分割算法
蔡 D 等人。首先从DOM树中提取出所有合适的页面块,然后根据这些页面和段重构网页的语义结构。
2005-搜索引擎的全自动包装器生成
作者主要提出了ViNT的一种方法
对于搜索引擎的界面(如百度页面和谷歌界面),需要同一个搜索引擎下的多个页面。
2013-注释来自网络数据库的搜索结果
基于 ViNT 提取数据记录的 SRR,然后进行数据对齐以生成多类注释包装器。
2010-ViDE:一种基于视觉的深度网络数据提取方法
布局函数 (LF)
外观特征 (AFs)。这些函数捕获数据记录中的视觉函数。
内容函数 (CF)。这些特征暗示了数据记录中内容的规律性。
数据提取标准
数据提取过程
首先通过PFs特性,调整阈值对数据区域进行分框,过滤噪声块,判断噪声块位置是否左对齐,数据可视块,聚类块,数据块对齐
基于视觉的数据记录包装器 (f,l,d)
我们的方法包括四个主要步骤:可视块树构建、数据记录提取、数据项提取和可视化包装器生成。
2013_从深网可视化提取数据记录
4.3 基于机器学习的模式识别 从相似网页中提取对应模式的数据(从候选框中选择样本,将其坐标投影到最终的特征向量,然后使用softmax进行分类)4. 4 基于机器学习的本地化
《基于视觉信息处理的深度网络数据提取》
五、基于模板的文本识别
主要步骤是
六、基于语义标签的文本提取七、基于词库的信息提取
java从网页抓取数据(网页获取速度和解析速度的主要功能有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-26 05:03
(4)支持代理服务器
(5)支持自动cookie管理等。
Java爬虫开发是应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
二、Jsoup
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
(1) 从 URL、文件或字符串解析 HTML
(2) 使用 DOM 或 CSS 选择器查找和检索数据
(3) 操作 HTML 元素、属性、文本
三、瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
四、硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
五、网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
芝麻HTTP可以为您提供海量的IP资源。我们保证资源的稳定性和可用性,在“互联网+”时代为您带来更好的体验。我们还可以根据您的要求为您提供优质的定制服务。助您不间断获取行业数据,赢在大数据时代。 查看全部
java从网页抓取数据(网页获取速度和解析速度的主要功能有哪些?)
(4)支持代理服务器
(5)支持自动cookie管理等。
Java爬虫开发是应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
二、Jsoup
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
(1) 从 URL、文件或字符串解析 HTML
(2) 使用 DOM 或 CSS 选择器查找和检索数据
(3) 操作 HTML 元素、属性、文本
三、瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
四、硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
五、网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
芝麻HTTP可以为您提供海量的IP资源。我们保证资源的稳定性和可用性,在“互联网+”时代为您带来更好的体验。我们还可以根据您的要求为您提供优质的定制服务。助您不间断获取行业数据,赢在大数据时代。
java从网页抓取数据(:java实现这个多线程的主要代码,用c#应该也是一样的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-25 21:29
)
任务详情:
有一个信息发布网站,会根据条件查询数据,分页展示,每页15条,每条信息是一个url链接。单击该链接将打开另一个页面,显示该项目的详细信息。
我们需要做的就是抓取每件作品的详细信息,并将其保存到数据库中。
一开始我制作了所有我抓取并保存到数据库中的程序。
运行完发现速度很慢,因为数据量比较大,大概有30万条详细信息需要抓取。
我只是觉得最好用多线程来实现这个,开15个线程,一次抓取一页的所有详细信息,不是很快吗?
后来加了多线程后,一次开了16个线程,比原来快多了,呵呵~!
因为这个项目是用java实现的,下面是java实现这个多线程的主要代码,在c#中应该是一样的!有兴趣的可以翻译成c#,厚厚的~
<p>import java.util.ArrayList;
public class Catcher
{
private static ArrayList threads= new ArrayList();//存储未处理URL
public static boolean isFinished=false;//是否已经把所有的链接存到threads了
public synchronized String getUrl()
{
if(threads.size()>0)
{
String tmp = String.valueOf(threads.get(0));
threads.remove(0);
return tmp;
}else
return null;
}
public void process(){
//处理预处理
//下面开10个线程等待处理
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
//进入翻页的处理
for(int j=0;j 查看全部
java从网页抓取数据(:java实现这个多线程的主要代码,用c#应该也是一样的
)
任务详情:
有一个信息发布网站,会根据条件查询数据,分页展示,每页15条,每条信息是一个url链接。单击该链接将打开另一个页面,显示该项目的详细信息。
我们需要做的就是抓取每件作品的详细信息,并将其保存到数据库中。
一开始我制作了所有我抓取并保存到数据库中的程序。
运行完发现速度很慢,因为数据量比较大,大概有30万条详细信息需要抓取。
我只是觉得最好用多线程来实现这个,开15个线程,一次抓取一页的所有详细信息,不是很快吗?
后来加了多线程后,一次开了16个线程,比原来快多了,呵呵~!
因为这个项目是用java实现的,下面是java实现这个多线程的主要代码,在c#中应该是一样的!有兴趣的可以翻译成c#,厚厚的~
<p>import java.util.ArrayList;
public class Catcher
{
private static ArrayList threads= new ArrayList();//存储未处理URL
public static boolean isFinished=false;//是否已经把所有的链接存到threads了
public synchronized String getUrl()
{
if(threads.size()>0)
{
String tmp = String.valueOf(threads.get(0));
threads.remove(0);
return tmp;
}else
return null;
}
public void process(){
//处理预处理
//下面开10个线程等待处理
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
//进入翻页的处理
for(int j=0;j
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-01-25 08:13
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页的源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页的源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据(哪些网页才是重要性高的呢?如何解决网页抓取乱码问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-24 11:14
)
相关话题
基于 Web 的数据传输方法的比较
22/5/201209:28:00
网站数据传输方式的选择影响网页的加载速度、服务请求响应时间等,因此网站数据传输方式的选择直接影响网站性能和用户体验。网页数据的高效安全传输是网站优化中需要考虑的重要问题之一,网页数据传输方式的选择在网站方面尤为重要优化。
中国病毒网页数量位居病毒网页前44%
2007 年 9 月 9 日 20:15:00
北京时间9月7日消息,据俄罗斯链接新闻网报道,全球领先的杀毒软件开发商9月6日表示,中美两国病毒网站数量居全球前两位,中国的病毒网站大幅下降。对8月份全球80亿网页进行分析,得出的结论是,中国病毒网页数量居全球之首,44.8%的网页
网页抓取优先策略
18/1/2008 11:30:00
网页爬取优先策略也称为“页面选择问题”(pageSelection),通常是尽可能先爬取重要的网页,以保证那些重要性高的网页得到尽可能多的照顾在有限的资源范围内。那么哪些页面最重要?如何量化重要性?
如何解决php网页抓取出现乱码问题
2012 年 4 月 9 日:03:36
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”转换编码;2、添加“curl_setopt($ch,CURLOPT_ENCODING,'gzip');” 选项; 3、在顶部添加标题代码。推荐
TAG页面数据和构图原理你要知道的三个最关键的点!点击进去看看!
6/8/202018:01:55
关于网站建设的优化,标签页起着关键的作用,所以大家对标签页的作用很熟悉,所以我来解释一下它的一些概念。其实一般来说,标签页是用来描述某个关键词的
搜索引擎如何抓取网页?
22/11/2011 09:50:00
搜索引擎在抓取大量原创网页时,会进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一致)未经任何修改)或“转载网页”。”(近副本,主题内容基本相同但可能有一些额外的编辑信息等,转载的页面也称为“近似镜像页面”)消除,链接分析和页面的重要性计算。
Nginx下更改网页地址后旧网页301重定向的代码
2018 年 2 月 3 日 01:09:49
总结:Nginx下更改网页地址后旧网页301重定向的代码
如何打开网页的源代码
2021 年 4 月 2 日 10:31:09
打开网页源代码的方法:先登录一个网站,在网页左侧空白处右击;然后点击inspect元素,再次右击网页左侧的空白处;最后,点击查看源文件。本文运行环境:Windows7系统,戴尔G3电脑
翻页式网络搜索引擎如何抓取
2013 年 7 月 11 日 10:53:00
Spider 系统的目标是发现和爬取 Internet 上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。@网站经验造成压力,也就是说蜘蛛不会爬取网站的所有页面。蜘蛛的爬取策略有很多,可以尽可能快速完整的找到资源链接,提高爬取效率。
使用网络抓取数据赚钱的 3 个想法
2/6/202012:01:26
文章目录使用自动程序花最少的钱在Airbnb上住最好的酒店捕获特定产品的价格数据,以最低的价格购买并捕获公共数据,在大时代将其可视化数据,如何有效获取数据 数据已成为业务决策的驱动力
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
Google 适当地将 POST 请求添加到 GET 以抓取网页内容
15/12/2011 13:58:00
近日,Google Blackboard 发布了一篇题为“GET、POST 和安全获取更多网络信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。在文章中提到,未来谷歌在读取网页内容时不仅会使用GET抓取,还会根据情况在抓取网页内容时增加POST请求方式,从而进一步提高谷歌搜索的准确率引擎。网页内容的判断。
如何系统地做好SEO-web抓取
14/5/202014:41:34
如果没有爬取,那么就没有页面的收录。如何获取或改进搜索引擎的爬取?
详细讲解php爬取网页内容的例子
6/8/202018:02:42
php爬取网页内容示例详解方法一:使用file_get_contents方法实现$url="";$html=file_ge
代码和内容优化和去噪以提高网页的信噪比
22/5/2012 13:58:00
网页的信噪比是指网页中的文本内容与生成这些文本所产生的html标签内容的比率。一般来说,一个网页的信噪比越高,我们的网页质量就越好。可以根据搜索引擎抓取网页的原理来解释:搜索引擎蜘蛛抓取网页时,会对网页进行去重,主要是去除网页的噪音,留下有用的信息。
查看全部
java从网页抓取数据(哪些网页才是重要性高的呢?如何解决网页抓取乱码问题
)
相关话题
基于 Web 的数据传输方法的比较
22/5/201209:28:00
网站数据传输方式的选择影响网页的加载速度、服务请求响应时间等,因此网站数据传输方式的选择直接影响网站性能和用户体验。网页数据的高效安全传输是网站优化中需要考虑的重要问题之一,网页数据传输方式的选择在网站方面尤为重要优化。

中国病毒网页数量位居病毒网页前44%
2007 年 9 月 9 日 20:15:00
北京时间9月7日消息,据俄罗斯链接新闻网报道,全球领先的杀毒软件开发商9月6日表示,中美两国病毒网站数量居全球前两位,中国的病毒网站大幅下降。对8月份全球80亿网页进行分析,得出的结论是,中国病毒网页数量居全球之首,44.8%的网页
网页抓取优先策略
18/1/2008 11:30:00
网页爬取优先策略也称为“页面选择问题”(pageSelection),通常是尽可能先爬取重要的网页,以保证那些重要性高的网页得到尽可能多的照顾在有限的资源范围内。那么哪些页面最重要?如何量化重要性?
如何解决php网页抓取出现乱码问题
2012 年 4 月 9 日:03:36
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”转换编码;2、添加“curl_setopt($ch,CURLOPT_ENCODING,'gzip');” 选项; 3、在顶部添加标题代码。推荐
TAG页面数据和构图原理你要知道的三个最关键的点!点击进去看看!
6/8/202018:01:55
关于网站建设的优化,标签页起着关键的作用,所以大家对标签页的作用很熟悉,所以我来解释一下它的一些概念。其实一般来说,标签页是用来描述某个关键词的
搜索引擎如何抓取网页?
22/11/2011 09:50:00
搜索引擎在抓取大量原创网页时,会进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一致)未经任何修改)或“转载网页”。”(近副本,主题内容基本相同但可能有一些额外的编辑信息等,转载的页面也称为“近似镜像页面”)消除,链接分析和页面的重要性计算。
Nginx下更改网页地址后旧网页301重定向的代码
2018 年 2 月 3 日 01:09:49
总结:Nginx下更改网页地址后旧网页301重定向的代码
如何打开网页的源代码
2021 年 4 月 2 日 10:31:09
打开网页源代码的方法:先登录一个网站,在网页左侧空白处右击;然后点击inspect元素,再次右击网页左侧的空白处;最后,点击查看源文件。本文运行环境:Windows7系统,戴尔G3电脑
翻页式网络搜索引擎如何抓取
2013 年 7 月 11 日 10:53:00
Spider 系统的目标是发现和爬取 Internet 上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。@网站经验造成压力,也就是说蜘蛛不会爬取网站的所有页面。蜘蛛的爬取策略有很多,可以尽可能快速完整的找到资源链接,提高爬取效率。
使用网络抓取数据赚钱的 3 个想法
2/6/202012:01:26
文章目录使用自动程序花最少的钱在Airbnb上住最好的酒店捕获特定产品的价格数据,以最低的价格购买并捕获公共数据,在大时代将其可视化数据,如何有效获取数据 数据已成为业务决策的驱动力
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
Google 适当地将 POST 请求添加到 GET 以抓取网页内容
15/12/2011 13:58:00
近日,Google Blackboard 发布了一篇题为“GET、POST 和安全获取更多网络信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。在文章中提到,未来谷歌在读取网页内容时不仅会使用GET抓取,还会根据情况在抓取网页内容时增加POST请求方式,从而进一步提高谷歌搜索的准确率引擎。网页内容的判断。
如何系统地做好SEO-web抓取
14/5/202014:41:34
如果没有爬取,那么就没有页面的收录。如何获取或改进搜索引擎的爬取?
详细讲解php爬取网页内容的例子
6/8/202018:02:42
php爬取网页内容示例详解方法一:使用file_get_contents方法实现$url="";$html=file_ge
代码和内容优化和去噪以提高网页的信噪比
22/5/2012 13:58:00
网页的信噪比是指网页中的文本内容与生成这些文本所产生的html标签内容的比率。一般来说,一个网页的信噪比越高,我们的网页质量就越好。可以根据搜索引擎抓取网页的原理来解释:搜索引擎蜘蛛抓取网页时,会对网页进行去重,主要是去除网页的噪音,留下有用的信息。
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-24 07:10
原文链接:
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家演示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{ StringstrURL=""+ip; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8") ; BufferedReaderbufReader=newBufferedReader(输入);字符串线=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); } Stringbuf=contentBuf.toString() ; intbeginIx=buf.indexOf("查询结果["); intentIx=buf.indexOf("以上四项依次显示"); Stringresult=buf.substring(beginIx,endIx); System.out.println("captureHtml() 结果:\n"+result); }
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是直接在网页源码中返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即只需要访问JS请求的网页地址就可以获取数据,当然前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{ StringstrURL=""+postid +"&channel=&rnd=0"; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8"); BufferedReaderbufReader=newBufferedReader(输入);字符串线=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); } System.out.println("captureJavascript()的结果:\n"+contentBuf.toString()); }
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 【】 查看全部
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
原文链接:
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家演示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{ StringstrURL=""+ip; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8") ; BufferedReaderbufReader=newBufferedReader(输入);字符串线=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); } Stringbuf=contentBuf.toString() ; intbeginIx=buf.indexOf("查询结果["); intentIx=buf.indexOf("以上四项依次显示"); Stringresult=buf.substring(beginIx,endIx); System.out.println("captureHtml() 结果:\n"+result); }
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是直接在网页源码中返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即只需要访问JS请求的网页地址就可以获取数据,当然前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{ StringstrURL=""+postid +"&channel=&rnd=0"; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8"); BufferedReaderbufReader=newBufferedReader(输入);字符串线=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); } System.out.println("captureJavascript()的结果:\n"+contentBuf.toString()); }
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 【】
java从网页抓取数据(哪些网页才是重要性高的呢?如何让网页数据进行高效安全地传送 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-24 01:15
)
相关话题
基于 Web 的数据传输方法的比较
22/5/201209:28:00
网站数据传输方式的选择影响网页的加载速度、服务请求响应时间等,因此网站数据传输方式的选择直接影响网站性能和用户体验。网页数据的高效安全传输是网站优化中需要考虑的重要问题之一,网页数据传输方式的选择在网站方面尤为重要优化。
中国病毒网页数量位居病毒网页前44%
2007 年 9 月 9 日 20:15:00
北京时间9月7日消息,据俄罗斯链接新闻网报道,全球领先的杀毒软件开发商9月6日表示,中美两国病毒网站数量居全球前两位,中国的病毒网站大幅下降。对8月份全球80亿网页进行分析,得出的结论是,中国病毒网页数量居全球之首,44.8%的网页
网页抓取优先策略
18/1/2008 11:30:00
网页爬取优先策略也称为“页面选择问题”(pageSelection),通常是尽可能先爬取重要的网页,以保证那些重要性高的网页得到尽可能多的照顾在有限的资源范围内。那么哪些页面最重要?如何量化重要性?
TAG页面数据和构图原理你要知道的三个最关键的点!点击进去看看!
6/8/202018:01:55
关于网站建设的优化,标签页起着关键的作用,所以大家对标签页的作用很熟悉,所以我来解释一下它的一些概念。其实一般来说,标签页是用来描述某个关键词的
搜索引擎如何抓取网页?
22/11/2011 09:50:00
搜索引擎在抓取大量原创网页时,会进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一致)未经任何修改)或“转载网页”。”(近副本,主题内容基本相同但可能有一些额外的编辑信息等,转载的页面也称为“近似镜像页面”)消除,链接分析和页面的重要性计算。
翻页式网络搜索引擎如何抓取
2013 年 7 月 11 日 10:53:00
Spider 系统的目标是发现和爬取 Internet 上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。@网站经验造成压力,也就是说蜘蛛不会爬取网站的所有页面。蜘蛛的爬取策略有很多,可以尽可能快速完整的找到资源链接,提高爬取效率。
使用网络抓取数据赚钱的 3 个想法
2/6/202012:01:26
文章目录使用自动程序花最少的钱在Airbnb上住最好的酒店捕获特定产品的价格数据,以最低的价格购买并捕获公共数据,在大时代将其可视化数据,如何有效获取数据 数据已成为业务决策的驱动力
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是非常常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
Google 适当地将 POST 请求添加到 GET 以抓取网页内容
15/12/2011 13:58:00
近日,Google Blackboard 发布了一篇题为“GET、POST 和安全获取更多网络信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。在文章中提到,未来谷歌在读取网页内容时不仅会使用GET抓取,还会根据情况在抓取网页内容时增加POST请求方式,从而进一步提高谷歌搜索的准确率引擎。网页内容的判断。
如何系统地做好SEO-web抓取
14/5/202014:41:34
如果没有爬取,那么就没有页面的收录。如何获取或改进搜索引擎的爬取?
详细讲解php爬取网页内容的例子
6/8/202018:02:42
php爬取网页内容示例详解方法一:使用file_get_contents方法实现$url="";$html=file_ge
如何解决php网页抓取出现乱码问题
2012 年 4 月 9 日:03:36
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”转换编码;2、添加“curl_setopt($ch,CURLOPT_ENCODING,'gzip');” 选项; 3、在顶部添加标题代码。推荐
谷歌允许蜘蛛自动填写表单提交以抓取更多页面
2009 年 3 月 31 日 14:54:00
据外媒报道:美国搜索巨头谷歌最近开始在网络爬虫中实施一项新技术:他们可以让蜘蛛在某些网页中自动填写表单,并自动提交给服务器爬取反馈页面,以获取更多信息。关于这个 网站 的详细信息。
通过搜索引擎改进网络爬取、索引和排名的方法
2009 年 7 月 12 日 10:37:00
这是一个被许多 SEO 误解的重要概念。很久以前,搜索引擎爬虫(机器人)会递归地爬取某个网站(通过你提交的网站主页URL,然后爬取页面上找到的所有链接)指向该网页, 一次又一次)。
搜索引擎蜘蛛抓取网页的规律分析
27/8/2013 13:39:00
搜索引擎正面临着互联网上数以万亿计的网页。这么多网页如何高效爬取到本地镜像?这是网络爬虫的工作。我们也称它为网络蜘蛛,作为站长,我们每天都与它密切接触。
查看全部
java从网页抓取数据(哪些网页才是重要性高的呢?如何让网页数据进行高效安全地传送
)
相关话题
基于 Web 的数据传输方法的比较
22/5/201209:28:00
网站数据传输方式的选择影响网页的加载速度、服务请求响应时间等,因此网站数据传输方式的选择直接影响网站性能和用户体验。网页数据的高效安全传输是网站优化中需要考虑的重要问题之一,网页数据传输方式的选择在网站方面尤为重要优化。
中国病毒网页数量位居病毒网页前44%
2007 年 9 月 9 日 20:15:00
北京时间9月7日消息,据俄罗斯链接新闻网报道,全球领先的杀毒软件开发商9月6日表示,中美两国病毒网站数量居全球前两位,中国的病毒网站大幅下降。对8月份全球80亿网页进行分析,得出的结论是,中国病毒网页数量居全球之首,44.8%的网页
网页抓取优先策略
18/1/2008 11:30:00
网页爬取优先策略也称为“页面选择问题”(pageSelection),通常是尽可能先爬取重要的网页,以保证那些重要性高的网页得到尽可能多的照顾在有限的资源范围内。那么哪些页面最重要?如何量化重要性?
TAG页面数据和构图原理你要知道的三个最关键的点!点击进去看看!
6/8/202018:01:55
关于网站建设的优化,标签页起着关键的作用,所以大家对标签页的作用很熟悉,所以我来解释一下它的一些概念。其实一般来说,标签页是用来描述某个关键词的
搜索引擎如何抓取网页?
22/11/2011 09:50:00
搜索引擎在抓取大量原创网页时,会进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一致)未经任何修改)或“转载网页”。”(近副本,主题内容基本相同但可能有一些额外的编辑信息等,转载的页面也称为“近似镜像页面”)消除,链接分析和页面的重要性计算。
翻页式网络搜索引擎如何抓取
2013 年 7 月 11 日 10:53:00
Spider 系统的目标是发现和爬取 Internet 上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。@网站经验造成压力,也就是说蜘蛛不会爬取网站的所有页面。蜘蛛的爬取策略有很多,可以尽可能快速完整的找到资源链接,提高爬取效率。
使用网络抓取数据赚钱的 3 个想法
2/6/202012:01:26
文章目录使用自动程序花最少的钱在Airbnb上住最好的酒店捕获特定产品的价格数据,以最低的价格购买并捕获公共数据,在大时代将其可视化数据,如何有效获取数据 数据已成为业务决策的驱动力
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是非常常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
Google 适当地将 POST 请求添加到 GET 以抓取网页内容
15/12/2011 13:58:00
近日,Google Blackboard 发布了一篇题为“GET、POST 和安全获取更多网络信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。在文章中提到,未来谷歌在读取网页内容时不仅会使用GET抓取,还会根据情况在抓取网页内容时增加POST请求方式,从而进一步提高谷歌搜索的准确率引擎。网页内容的判断。
如何系统地做好SEO-web抓取
14/5/202014:41:34
如果没有爬取,那么就没有页面的收录。如何获取或改进搜索引擎的爬取?
详细讲解php爬取网页内容的例子
6/8/202018:02:42
php爬取网页内容示例详解方法一:使用file_get_contents方法实现$url="";$html=file_ge
如何解决php网页抓取出现乱码问题
2012 年 4 月 9 日:03:36
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”转换编码;2、添加“curl_setopt($ch,CURLOPT_ENCODING,'gzip');” 选项; 3、在顶部添加标题代码。推荐
谷歌允许蜘蛛自动填写表单提交以抓取更多页面
2009 年 3 月 31 日 14:54:00
据外媒报道:美国搜索巨头谷歌最近开始在网络爬虫中实施一项新技术:他们可以让蜘蛛在某些网页中自动填写表单,并自动提交给服务器爬取反馈页面,以获取更多信息。关于这个 网站 的详细信息。
通过搜索引擎改进网络爬取、索引和排名的方法
2009 年 7 月 12 日 10:37:00
这是一个被许多 SEO 误解的重要概念。很久以前,搜索引擎爬虫(机器人)会递归地爬取某个网站(通过你提交的网站主页URL,然后爬取页面上找到的所有链接)指向该网页, 一次又一次)。
搜索引擎蜘蛛抓取网页的规律分析
27/8/2013 13:39:00
搜索引擎正面临着互联网上数以万亿计的网页。这么多网页如何高效爬取到本地镜像?这是网络爬虫的工作。我们也称它为网络蜘蛛,作为站长,我们每天都与它密切接触。
java从网页抓取数据(新手网页爬虫selenium开发教程我学java是从哪里开始)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-20 15:03
java从网页抓取数据,一般要注意以下几点:数据量有多大?数据在哪里展示?交互性强吗?数据库设计是怎样的?等等...下面介绍一个简单的爬虫,先分析,后代码...1:首先分析网页数据,数据量没有想象中大,那么分析基本结构,首先抓取的是一段话,一个图标。作为一个新手我知道要找到段落,找到哪些词、标题、图片等2:数据展示首先分析html代码,属性,看到了段落特征,看到了标题。
2.1:是元标签2.2:是关键词2.3:数据排序一般都是按字母,大小写等多种方式排序2.4:字母与图标之间有空格4:代码点击后,进入java代码,先加载一个.java文件,然后是springmvc,加载相应的.py代码,然后是python函数。
这是为广大新手的网页爬虫selenium开发教程
我学的java是从哪里开始的??
--这个很简单一个http模拟就搞定了。抓包分析, 查看全部
java从网页抓取数据(新手网页爬虫selenium开发教程我学java是从哪里开始)
java从网页抓取数据,一般要注意以下几点:数据量有多大?数据在哪里展示?交互性强吗?数据库设计是怎样的?等等...下面介绍一个简单的爬虫,先分析,后代码...1:首先分析网页数据,数据量没有想象中大,那么分析基本结构,首先抓取的是一段话,一个图标。作为一个新手我知道要找到段落,找到哪些词、标题、图片等2:数据展示首先分析html代码,属性,看到了段落特征,看到了标题。
2.1:是元标签2.2:是关键词2.3:数据排序一般都是按字母,大小写等多种方式排序2.4:字母与图标之间有空格4:代码点击后,进入java代码,先加载一个.java文件,然后是springmvc,加载相应的.py代码,然后是python函数。
这是为广大新手的网页爬虫selenium开发教程
我学的java是从哪里开始的??
--这个很简单一个http模拟就搞定了。抓包分析,
java从网页抓取数据( 如何从网页上抓取有价值的东西?看懂了下面的程序(非常简单))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-16 06:01
如何从网页上抓取有价值的东西?看懂了下面的程序(非常简单))
java使用正则表达式提取网站titles
来自网页
如何从网页中抓取有价值的东西?理解了下面这个程序(很简单)之后,你就可以从网页中抓取任何你想抓取的信息(标题、内容、Email、价格等)了。
package catchhtml;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class GetHtmlTitle {
public GetHtmlTitle(String htmlUrl){
System.out.println("/n------------开始读取网页(" + htmlUrl + ")-----------");
String htmlSource = "";
htmlSource = getHtmlSource(htmlUrl);//获取htmlUrl网址网页的源码
System.out.println("------------读取网页(" + htmlUrl + ")结束-----------/n");
System.out.println("------------分析(" + htmlUrl + ")结果如下-----------/n");
String title = getTitle(htmlSource);
System.out.println("网站标题: " + title);
}
/**
* 根据网址返回网页的源码
* @param htmlUrl
* @return
*/
public String getHtmlSource(String htmlUrl){
URL url;
StringBuffer sb = new StringBuffer();
try{
url = new URL(htmlUrl);
BufferedReader in = new BufferedReader(new InputStreamReader(url.openStream(), "UTF-8"));//读取网页全部内容
String temp;
while ((temp = in.readLine()) != null)
{
sb.append(temp);
}
in.close();
}catch (MalformedURLException e) {
System.out.println("你输入的URL格式有问题!请仔细输入");
}catch (IOException e) {
e.printStackTrace();
}
return sb.toString();
}
/**
* 从html源码(字符串)中去掉标题
* @param htmlSource
* @return
*/
public String getTitle(String htmlSource){
List list = new ArrayList();
String title = "";
//Pattern pa = Pattern.compile(".*?", Pattern.CANON_EQ);也可以
Pattern pa = Pattern.compile(".*?");//源码中标题正则表达式
Matcher ma = pa.matcher(htmlSource);
while (ma.find())//寻找符合el的字串
{
list.add(ma.group());//将符合el的字串加入到list中
}
for (int i = 0; i < list.size(); i++)
{
title = title + list.get(i);
}
return outTag(title);
}
/**
* 去掉html源码中的标签
* @param s
* @return
*/
public String outTag(String s)
{
return s.replaceAll("", "");
}
public static void main(String[] args) {
String htmlUrl = "http://www.157buy.com";
new GetHtmlTitle(htmlUrl);
}
}
联系方式:【我的公司】(鑫臻科技)【技术咨询】【QQ】3396726884
购书京东链接***微信小程序商城开发实践*** | ***新媒体营销精髓:精准定位+爆款打造+巧妙运营+内容变现***
发表于@2015-07-28 15:04 肯新军阅读(5301)comments(0)edit 查看全部
java从网页抓取数据(
如何从网页上抓取有价值的东西?看懂了下面的程序(非常简单))
java使用正则表达式提取网站titles
来自网页
如何从网页中抓取有价值的东西?理解了下面这个程序(很简单)之后,你就可以从网页中抓取任何你想抓取的信息(标题、内容、Email、价格等)了。
package catchhtml;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class GetHtmlTitle {
public GetHtmlTitle(String htmlUrl){
System.out.println("/n------------开始读取网页(" + htmlUrl + ")-----------");
String htmlSource = "";
htmlSource = getHtmlSource(htmlUrl);//获取htmlUrl网址网页的源码
System.out.println("------------读取网页(" + htmlUrl + ")结束-----------/n");
System.out.println("------------分析(" + htmlUrl + ")结果如下-----------/n");
String title = getTitle(htmlSource);
System.out.println("网站标题: " + title);
}
/**
* 根据网址返回网页的源码
* @param htmlUrl
* @return
*/
public String getHtmlSource(String htmlUrl){
URL url;
StringBuffer sb = new StringBuffer();
try{
url = new URL(htmlUrl);
BufferedReader in = new BufferedReader(new InputStreamReader(url.openStream(), "UTF-8"));//读取网页全部内容
String temp;
while ((temp = in.readLine()) != null)
{
sb.append(temp);
}
in.close();
}catch (MalformedURLException e) {
System.out.println("你输入的URL格式有问题!请仔细输入");
}catch (IOException e) {
e.printStackTrace();
}
return sb.toString();
}
/**
* 从html源码(字符串)中去掉标题
* @param htmlSource
* @return
*/
public String getTitle(String htmlSource){
List list = new ArrayList();
String title = "";
//Pattern pa = Pattern.compile(".*?", Pattern.CANON_EQ);也可以
Pattern pa = Pattern.compile(".*?");//源码中标题正则表达式
Matcher ma = pa.matcher(htmlSource);
while (ma.find())//寻找符合el的字串
{
list.add(ma.group());//将符合el的字串加入到list中
}
for (int i = 0; i < list.size(); i++)
{
title = title + list.get(i);
}
return outTag(title);
}
/**
* 去掉html源码中的标签
* @param s
* @return
*/
public String outTag(String s)
{
return s.replaceAll("", "");
}
public static void main(String[] args) {
String htmlUrl = "http://www.157buy.com";
new GetHtmlTitle(htmlUrl);
}
}
联系方式:【我的公司】(鑫臻科技)【技术咨询】【QQ】3396726884
购书京东链接***微信小程序商城开发实践*** | ***新媒体营销精髓:精准定位+爆款打造+巧妙运营+内容变现***
发表于@2015-07-28 15:04 肯新军阅读(5301)comments(0)edit
java从网页抓取数据(怎样抓取站点的数据:(1)抓取原网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-15 11:17
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具抓取网站数据比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(怎样抓取站点的数据:(1)抓取原网页数据)
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:

第二步:查看网页的源码,我们看到源码中有这么一段:

由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:

也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具抓取网站数据比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:

这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据(百度和其他一些网站会公布一些公共API接口供调用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-13 19:26
百度和其他一些网站会发布一些公共API接口供调用,这里是如何使用Java获取url数据并读取数据。
URL url = new URL("http://api.baidu.com/[urlAddress]");
URLConnection uc = url.openConnection();
BufferedReader in = new BufferedReader(new InputStreamReader(uc.getInputStream(),"utf-8"));
//这段代码中需要指定获取内容的编码格式,默认为UTF-8。 然后数据就被存放在Buffer里面,你可以把Buffer看成一个水管,使用readline()读取水管里面传的数据(水滴)
String str =null;
while((str=in.readline())!=null){
System.out.print(str)}
}
如果api是json格式,那么当使用str=in.readline()获取数据时,会生成一组json数据。下面介绍如何阅读:
<p> //如果是数组格式,那么使用JSONArray,也可以使用JSONObject存JSON值。具体根据JSON对象内容格式吧。
JSONArray jsonArr = new JSONArray();
JSONArray data = JSONArray.fromObject(str);
for(int i=0;i 查看全部
java从网页抓取数据(百度和其他一些网站会公布一些公共API接口供调用)
百度和其他一些网站会发布一些公共API接口供调用,这里是如何使用Java获取url数据并读取数据。
URL url = new URL("http://api.baidu.com/[urlAddress]");
URLConnection uc = url.openConnection();
BufferedReader in = new BufferedReader(new InputStreamReader(uc.getInputStream(),"utf-8"));
//这段代码中需要指定获取内容的编码格式,默认为UTF-8。 然后数据就被存放在Buffer里面,你可以把Buffer看成一个水管,使用readline()读取水管里面传的数据(水滴)
String str =null;
while((str=in.readline())!=null){
System.out.print(str)}
}
如果api是json格式,那么当使用str=in.readline()获取数据时,会生成一组json数据。下面介绍如何阅读:
<p> //如果是数组格式,那么使用JSONArray,也可以使用JSONObject存JSON值。具体根据JSON对象内容格式吧。
JSONArray jsonArr = new JSONArray();
JSONArray data = JSONArray.fromObject(str);
for(int i=0;i
java从网页抓取数据(WebScraper就是以树插件使用生巧插件(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-10 03:12
安装
Web Scraper 是一个谷歌浏览器插件。访问官方网站并点击“安装”
它会自动跳转到 Chrome 的在线商店,点击“添加到 Chrome”。
如果无法访问Chrome的在线商店,请访问国产插件网站进行安装,如下:
浏览器插件下载中心
173应用网络
Chrome 网上应用店镜像
又一个英文下载网站
crx离线安装包下载
铬插件
ChromeFor 浏览器插件
利用
什么叫完美,新手可能很难理解,其实只需要记住一句话,一个网页的内容是一棵树,树的根是网站的url,从url 网站 到我们需要访问数据所在的元素(html元素),就是从根节点遍历到叶子节点的过程。这个过程很简单,就是直接去叶子节点,还有一个复杂的过程,就是用递归的思维来处理页面刷新的情况。
在这里,我只展示一些简单的,让您对 Web Scraper 有一个初步的了解。对于复杂的爬取,请访问官方文档,阅读视频和文档学习。
请记住,网页的内容是一棵树,因此您可以轻松了解该工具的工作原理。Web Scraper 以树的形式组织站点地图。以抓取知乎的热榜数据为例,一步步展示本插件的使用。
知乎热榜页面如下图:
root是页面的URL,也就是现在给这个root取个名字,叫知乎_hot(名字随意,方便识别),知乎_hot的子节点可以是video、science、digital、sports。这些子节点下的子节点就是我们要爬取的内容列表。
现在开始使用 Web Scraper:
第一步,打开谷歌浏览器的开发者工具,点击最右侧的Web Scraper菜单,如下图:
第二步是创建站点地图和选择器:
点击创建新站点地图->创建站点地图,在站点地图名称中输入知乎_hot,其中知乎_hot可以是任何名称以便于识别,只能是英文,然后填写Start Url:然后点击创建站点地图按钮完成创建,如下图所示:
点击Add new selector,添加一个选择器,即添加一个子节点:
然后会弹出一个框供我们填写选择器的相关信息。ID填写类别,类型选择元素点击。这时会出现两个选择器,一个是selector,代表要传递给category子节点的元素,另一个是Click选择器,代表要点击的元素。为了方便大家理解,请先选择Click选择器,再选择选择器,如下图:
点击选择器的选择:
选择器的选择:
选择完成后,勾选Mutiple爬取多类,点击保存选择器保存。
继续在category下添加Selector,即category_e,category_e接收到的元素就是category中选择器选中的元素,即div.HostList-list。category_e的配置如下图所示:
然后继续在category_e下添加三个Selector,分别是hot_no、title、hot_degree,如下图所示:
保存后点击Selector graph
您可以看到如下所示的树:
此时,我们的站点地图及其选择器已创建。
第三步是运行 Web Scraper。
单击菜单中的“刮擦”按钮
然后会要求你设置爬取的时间间隔,保持默认,如果网速慢可以适当延长:
单击开始抓取以运行 Web Scraper。此时Web Scraper会打开一个新的浏览器窗口,执行按钮点击操作,并将数据保存在浏览器的LocalStorage中。操作完成后,新窗口会自动关闭,点击下图中的刷新按钮:
可以看到抓取到的数据,如下图所示:
数据可以导出为 csv 文件,点击 Export data as CSV -> 立即下载
您可以下载 csv 文件:
是不是很方便?
如果还是不能成功爬取上面的数据,下面是我导出的sitemap信息,可以将这些文字复制到sitemap中,再试一次,对比一下看看有什么不同:
{"_id":"zhihu_hot","startUrl":["https://www.zhihu.com/hot"],"selectors":[{"id":"category","type":"SelectorElementClick","parentSelectors":["_root"],"selector":"div.HotList-list","multiple":true,"delay":2000,"clickElementSelector":"a.HotListNav-item","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType":"uniqueText"},{"id":"category_e","type":"SelectorElement","parentSelectors":["category"],"selector":"section","multiple":true,"delay":0},{"id":"hot_num","type":"SelectorText","parentSelectors":["category_e"],"selector":"div.HotItem-rank","multiple":false,"regex":"","delay":0},{"id":"title","type":"SelectorLink","parentSelectors":["category_e"],"selector":".HotItem-content a","multiple":false,"delay":0},{"id":"hot_degree","type":"SelectorText","parentSelectors":["category_e"],"selector":"div.HotItem-metrics","multiple":false,"regex":"","delay":0}]}
至于分页,或者无限加载,都可以轻松搞定。这种情况下的分类按钮相当于一种分页按钮。其他分页操作,官网有相应的视频教程。
的优点和缺点
优势:
Web Scraper 的优势在于无需学习编程即可抓取网页数据。
即使对于计算机专业人士来说,使用 Web Scraper 爬取一些网页的文本数据也比自己编写代码效率更高,可以节省大量的编码和调试时间。
依赖环境很简单,只需要谷歌浏览器和插件。
缺点:
仅支持文本数据采集,不能批量采集图片、短视频等多媒体数据。
不支持复杂的网页爬取,如采取反爬取措施,复杂的人机交互网页,Web Scraper无能为力。事实上,这种代码爬取也是相当困难的。
导出的数据不按爬取的顺序显示。如果要排序,需要导出Excel,然后排序。这也很容易克服。在数据分析之前,大部分数据都需要导出到 Excel 中。 查看全部
java从网页抓取数据(WebScraper就是以树插件使用生巧插件(图))
安装
Web Scraper 是一个谷歌浏览器插件。访问官方网站并点击“安装”

它会自动跳转到 Chrome 的在线商店,点击“添加到 Chrome”。
如果无法访问Chrome的在线商店,请访问国产插件网站进行安装,如下:
浏览器插件下载中心
173应用网络
Chrome 网上应用店镜像
又一个英文下载网站
crx离线安装包下载
铬插件
ChromeFor 浏览器插件
利用
什么叫完美,新手可能很难理解,其实只需要记住一句话,一个网页的内容是一棵树,树的根是网站的url,从url 网站 到我们需要访问数据所在的元素(html元素),就是从根节点遍历到叶子节点的过程。这个过程很简单,就是直接去叶子节点,还有一个复杂的过程,就是用递归的思维来处理页面刷新的情况。
在这里,我只展示一些简单的,让您对 Web Scraper 有一个初步的了解。对于复杂的爬取,请访问官方文档,阅读视频和文档学习。
请记住,网页的内容是一棵树,因此您可以轻松了解该工具的工作原理。Web Scraper 以树的形式组织站点地图。以抓取知乎的热榜数据为例,一步步展示本插件的使用。
知乎热榜页面如下图:

root是页面的URL,也就是现在给这个root取个名字,叫知乎_hot(名字随意,方便识别),知乎_hot的子节点可以是video、science、digital、sports。这些子节点下的子节点就是我们要爬取的内容列表。
现在开始使用 Web Scraper:
第一步,打开谷歌浏览器的开发者工具,点击最右侧的Web Scraper菜单,如下图:


第二步是创建站点地图和选择器:
点击创建新站点地图->创建站点地图,在站点地图名称中输入知乎_hot,其中知乎_hot可以是任何名称以便于识别,只能是英文,然后填写Start Url:然后点击创建站点地图按钮完成创建,如下图所示:
点击Add new selector,添加一个选择器,即添加一个子节点:
然后会弹出一个框供我们填写选择器的相关信息。ID填写类别,类型选择元素点击。这时会出现两个选择器,一个是selector,代表要传递给category子节点的元素,另一个是Click选择器,代表要点击的元素。为了方便大家理解,请先选择Click选择器,再选择选择器,如下图:
点击选择器的选择:
选择器的选择:
选择完成后,勾选Mutiple爬取多类,点击保存选择器保存。

继续在category下添加Selector,即category_e,category_e接收到的元素就是category中选择器选中的元素,即div.HostList-list。category_e的配置如下图所示:

然后继续在category_e下添加三个Selector,分别是hot_no、title、hot_degree,如下图所示:

保存后点击Selector graph
您可以看到如下所示的树:

此时,我们的站点地图及其选择器已创建。
第三步是运行 Web Scraper。
单击菜单中的“刮擦”按钮

然后会要求你设置爬取的时间间隔,保持默认,如果网速慢可以适当延长:

单击开始抓取以运行 Web Scraper。此时Web Scraper会打开一个新的浏览器窗口,执行按钮点击操作,并将数据保存在浏览器的LocalStorage中。操作完成后,新窗口会自动关闭,点击下图中的刷新按钮:

可以看到抓取到的数据,如下图所示:

数据可以导出为 csv 文件,点击 Export data as CSV -> 立即下载

您可以下载 csv 文件:

是不是很方便?
如果还是不能成功爬取上面的数据,下面是我导出的sitemap信息,可以将这些文字复制到sitemap中,再试一次,对比一下看看有什么不同:
{"_id":"zhihu_hot","startUrl":["https://www.zhihu.com/hot"],"selectors":[{"id":"category","type":"SelectorElementClick","parentSelectors":["_root"],"selector":"div.HotList-list","multiple":true,"delay":2000,"clickElementSelector":"a.HotListNav-item","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType":"uniqueText"},{"id":"category_e","type":"SelectorElement","parentSelectors":["category"],"selector":"section","multiple":true,"delay":0},{"id":"hot_num","type":"SelectorText","parentSelectors":["category_e"],"selector":"div.HotItem-rank","multiple":false,"regex":"","delay":0},{"id":"title","type":"SelectorLink","parentSelectors":["category_e"],"selector":".HotItem-content a","multiple":false,"delay":0},{"id":"hot_degree","type":"SelectorText","parentSelectors":["category_e"],"selector":"div.HotItem-metrics","multiple":false,"regex":"","delay":0}]}
至于分页,或者无限加载,都可以轻松搞定。这种情况下的分类按钮相当于一种分页按钮。其他分页操作,官网有相应的视频教程。
的优点和缺点
优势:
Web Scraper 的优势在于无需学习编程即可抓取网页数据。
即使对于计算机专业人士来说,使用 Web Scraper 爬取一些网页的文本数据也比自己编写代码效率更高,可以节省大量的编码和调试时间。
依赖环境很简单,只需要谷歌浏览器和插件。
缺点:
仅支持文本数据采集,不能批量采集图片、短视频等多媒体数据。
不支持复杂的网页爬取,如采取反爬取措施,复杂的人机交互网页,Web Scraper无能为力。事实上,这种代码爬取也是相当困难的。
导出的数据不按爬取的顺序显示。如果要排序,需要导出Excel,然后排序。这也很容易克服。在数据分析之前,大部分数据都需要导出到 Excel 中。
java从网页抓取数据(爬虫程序的开发比较简单程序程序开发程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-01-09 19:09
构建爬虫的一次旅行
最近需要从网上抓取很多资料,所以体验了爬虫程序的开发和部署,主要是学习一些实用工具的操作。本教程的开发要求是编写一个收录爬虫程序的Java项目,并且可以方便的在服务器端编译、部署和启动爬虫程序。1.爬虫程序的开发 爬虫程序的开发比较简单。下面是一个简单的例子。它的主要功能是爬取中国文学网新华词典中的所有汉字详情页,并保存到一个文件中。爬虫框架使用Crawl4j,优点是只需要配置爬虫框架的几个重要参数即可启动爬虫:(1) 爬虫的数据缓存目录;(2)爬虫的爬取Policy,包括是否跟随robots文件、请求之间的延迟、页面的最大深度、页数的控制等;(3)入口爬虫的地址;(4)爬虫遇到new页面的url,通过shouldVisit判断是否访问这个url;(5)爬虫访问(访问)那些url时的具体操作,比如as 将内容保存到文件 edu.uci.ics.crawler4j.url.WebURL;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.io.File; ** * 中国文学网的数据采集工具 页数等的控制;(3)爬虫的入口地址;(4)爬虫遇到new页面的url,通过shouldVisit判断是否访问这个url;(5)爬虫时的具体操作访问(访问)那些url,比如将内容保存到文件edu.uci.ics.crawler4j.url.WebURL;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.io.File;** * 中国文学网的数据采集工具 页数等的控制;(3)爬虫的入口地址;(4)爬虫遇到new页面的url,通过shouldVisit判断是否访问这个url;(5)爬虫时的具体操作访问(访问)那些url,比如将内容保存到文件edu.uci.ics.crawler4j.url.WebURL;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.io.File;** * 中国文学网的数据采集工具 导入 org.slf4j.LoggerFactory;导入java.io.File;** 中国文学网的数据采集工具 导入 org.slf4j.LoggerFactory;导入java.io.File;** 中国文学网的数据采集工具
449 查看全部
java从网页抓取数据(爬虫程序的开发比较简单程序程序开发程序)
构建爬虫的一次旅行
最近需要从网上抓取很多资料,所以体验了爬虫程序的开发和部署,主要是学习一些实用工具的操作。本教程的开发要求是编写一个收录爬虫程序的Java项目,并且可以方便的在服务器端编译、部署和启动爬虫程序。1.爬虫程序的开发 爬虫程序的开发比较简单。下面是一个简单的例子。它的主要功能是爬取中国文学网新华词典中的所有汉字详情页,并保存到一个文件中。爬虫框架使用Crawl4j,优点是只需要配置爬虫框架的几个重要参数即可启动爬虫:(1) 爬虫的数据缓存目录;(2)爬虫的爬取Policy,包括是否跟随robots文件、请求之间的延迟、页面的最大深度、页数的控制等;(3)入口爬虫的地址;(4)爬虫遇到new页面的url,通过shouldVisit判断是否访问这个url;(5)爬虫访问(访问)那些url时的具体操作,比如as 将内容保存到文件 edu.uci.ics.crawler4j.url.WebURL;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.io.File; ** * 中国文学网的数据采集工具 页数等的控制;(3)爬虫的入口地址;(4)爬虫遇到new页面的url,通过shouldVisit判断是否访问这个url;(5)爬虫时的具体操作访问(访问)那些url,比如将内容保存到文件edu.uci.ics.crawler4j.url.WebURL;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.io.File;** * 中国文学网的数据采集工具 页数等的控制;(3)爬虫的入口地址;(4)爬虫遇到new页面的url,通过shouldVisit判断是否访问这个url;(5)爬虫时的具体操作访问(访问)那些url,比如将内容保存到文件edu.uci.ics.crawler4j.url.WebURL;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.io.File;** * 中国文学网的数据采集工具 导入 org.slf4j.LoggerFactory;导入java.io.File;** 中国文学网的数据采集工具 导入 org.slf4j.LoggerFactory;导入java.io.File;** 中国文学网的数据采集工具
449
java从网页抓取数据(如何使用Java/Python访问网页和使用Python进行数据解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-09 19:05
前言:
网络爬虫看起来仍然很棒。但是,如果您考虑一下,或进行一些研究,您就会知道爬行动物并没有那么先进。最深刻的就是当我们的数据量很大的时候,也就是当我们的网络“图”中的循环越来越多的时候,如何解决。
这篇文章文章只是在这里起到一个引导的作用。本文主要讲解如何使用Java/Python访问网页并获取网页代码,Python模仿浏览器访问网页,使用Python进行数据分析。希望我们能从这篇文章开始,一步步揭开网络蜘蛛的神秘面纱。
参考:
1.《编写你自己的网络爬虫》
2.用python编写爬虫爬取csdn内容,完美解决403 Forbidden
运行效果图:
内容很多,我只选了一部分展示。
作者环境:
系统:Windows 7
CentOS 6.5
运行环境:JDK1.7
Python 2.6.6
IDE:EclipseRelease 4.2.0
PyCharm 4.5.1
数据库:MySQLVer 14.14 Distrib 5.1.73
开发过程:1.使用Java爬取页面
对于页面抓取我们使用Java来实现,当然你也可以使用其他语言来开发。但
下面以“博客园”首页为例,展示使用Java进行网页爬取的过程:
public class RetrivePageSimple {
private static HttpClient httpClient = new HttpClient();
// 设置代理服务器
static {
httpClient.getHostConfiguration().setProxy("58.220.2.132", 80);
}
public static boolean downloadPage(String path) throws HttpException,
IOException {
PostMethod postMethod = new PostMethod(path);
// 执行,返回状态码
int statusCode = httpClient.executeMethod(postMethod);
System.out.println(statusCode);
// 针对状态码进行处理 (简单起见,只处理返回值为200的状态码)
if (statusCode == HttpStatus.SC_OK) {
String a = postMethod.getResponseBodyAsString();
System.out.println(a);
return true;
}
return false;
}
public static void main(String[] args) {
try {
RetrivePageSimple.downloadPage("http://www.cnblogs.com/");
} catch (HttpException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
结果信息在这里不再显示,太多了。. . - -!
2.使用 Python 抓取页面
可能你会问我,为什么写成使用Java版的页面爬取,而这里又是一个Python?这是必要的。因为作者在开发这个demo之前没有考虑问题。当我们使用Java爬取网页到Python时,网页字符串太长无法作为参数传递。您可能认为保存文件是一个不错的选择,但是如果 html 文件过多怎么办?是的,在这里我们必须放弃这种累人的做法。
考虑到参数长度的限制,这里只给出Java端的页面地址,使用Python爬取网页。
以最简单的方式,我们通常使用这样的 Python 网页:
import urllib2
result = urllib2.urlopen('http://blog.csdn.net/mobile/index.html')
html = result.read()
print html
但是作者的代码使用的是CSDN博客频道的url。CSDN 过滤来自爬虫的访问。如下,我们会得到如下错误信息:
403,我被拒绝了。
3.使用模拟浏览器登录网站
如前所述,当我们访问一个带有保护措施的网页时,它会被拒绝。但是我们可以尝试使用我们自己的浏览器来访问它,它是可以访问的。
也就是说,如果我们能在 Python 中把自己模仿成一个浏览器,就可以访问这个网页。这是在 Python 中模仿浏览器的代码:
import random
import socket
import urllib2
import cookielib
ERROR = {
'0':'Can not open the url,checck you net',
'1':'Creat download dir error',
'2':'The image links is empty',
'3':'Download faild',
'4':'Build soup error,the html is empty',
'5':'Can not save the image to your disk',
}
class BrowserBase(object):
def __init__(self):
socket.setdefaulttimeout(20)
self._content = None
def speak(self, name, content):
print '[%s]%s' % (name, content)
def open_url(self, url):
"""
打开网页
"""
cookie_support= urllib2.HTTPCookieProcessor(cookielib.CookieJar())
self.opener = urllib2.build_opener(cookie_support,urllib2.HTTPHandler)
urllib2.install_opener(self.opener)
user_agents = [
'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11',
'Opera/9.25 (Windows NT 5.1; U; en)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 ",
]
agent = random.choice(user_agents)
self.opener.addheaders = [("User-agent", agent), ("Accept", "*/*"), ('Referer', 'http://www.google.com')]
try:
res = self.opener.open(url)
self._content = res.read()
# print self._content
except Exception, e:
self.speak(str(e)+url)
raise Exception
else:
return res
def get_html_content(self):
return self._content
def get_html_response(html):
spider = BrowserBase()
spider.open_url(html)
return spider.get_html_content()
以上代码可以正常获取返回值。下面我们来看看返回结果的解析过程。
4.数据分析
使用 Python 解析 Html 异常简单:
import HTMLParser
class ListWebParser(HTMLParser.HTMLParser):
def __init__(self):
HTMLParser.HTMLParser.__init__(self)
self.tagDIVFlag = False
self.tagDIVAFlag = False
self.tagH1Flag = False
self.tagSecondHrefFlag = False
self._name = None
self._address = None
def handle_starttag(self, tag, attrs):
if tag == 'div':
for name, value in attrs:
if name == 'class' and value == 'blog_list':
self.tagDIVFlag = True
if tag == 'h1':
if self.tagDIVFlag:
self.tagH1Flag = True
# print 'h1->', self.tagH1Flag
if tag == 'a':
#if self.tagDIVAFlag:
#print 'h1: ', self.tagH1Flag
if self.tagH1Flag:
for name, value in attrs:
if name == 'target' and value == '_blank':
self.tagDIVAFlag = True
if name == 'href':
if self.tagSecondHrefFlag:
print '网址:', value
self._address = value
self.tagSecondHrefFlag = True
# if name == 'href' and self.tagDIVAFlag:
# print '网址:', value
# self._address = value
def handle_endtag(self, tag):
if tag == 'div':
self.tagDIVFlag = False
if tag == 'h1':
self.tagH1Flag = False
# print 'false h1.'
if tag == 'a':
self.tagDIVAFlag = False
def handle_data(self, data):
if self.tagDIVAFlag:
print u"名称:", data.decode("utf-8")
如果你说你在网上找到的Html文件没有这个麻烦。我承认这一点,因为在正常情况下,我们解析一些简单的数据真的很简单。上面代码中的复杂逻辑是处理过滤。
说到过滤,我这里用了一个小技巧(当然,当更多的人使用它时,这不再只是一个技巧。但是,这种方法可以在以后的编码过程中进行参考)。我们通过标签的一些特殊属性(例如:id、class等)来锁定块。当我们开始block时,我们对应的flag会被标记为True,当我们退出block时,我们对应的flag会被标记为False。也许你认为这太麻烦了。其实,如果你仔细想想,你会发现它是有道理的。
预防措施:
1.当使用 Java 进行网页抓取时,我们使用代理服务器。这个代理服务器的主机和端口可以直接在网上免费查到。
2.你需要准备以下jar包并导入到你的Eclipse项目中:
3.修改MySQL默认编码为UTF-8
因为这里会有一些中文信息,所以我们需要转换MySQL的编码格式。
如果你是在Linux下编码,那么你可以参考:
转载于: 查看全部
java从网页抓取数据(如何使用Java/Python访问网页和使用Python进行数据解析)
前言:
网络爬虫看起来仍然很棒。但是,如果您考虑一下,或进行一些研究,您就会知道爬行动物并没有那么先进。最深刻的就是当我们的数据量很大的时候,也就是当我们的网络“图”中的循环越来越多的时候,如何解决。
这篇文章文章只是在这里起到一个引导的作用。本文主要讲解如何使用Java/Python访问网页并获取网页代码,Python模仿浏览器访问网页,使用Python进行数据分析。希望我们能从这篇文章开始,一步步揭开网络蜘蛛的神秘面纱。
参考:
1.《编写你自己的网络爬虫》
2.用python编写爬虫爬取csdn内容,完美解决403 Forbidden
运行效果图:
内容很多,我只选了一部分展示。
作者环境:
系统:Windows 7
CentOS 6.5
运行环境:JDK1.7
Python 2.6.6
IDE:EclipseRelease 4.2.0
PyCharm 4.5.1
数据库:MySQLVer 14.14 Distrib 5.1.73
开发过程:1.使用Java爬取页面
对于页面抓取我们使用Java来实现,当然你也可以使用其他语言来开发。但
下面以“博客园”首页为例,展示使用Java进行网页爬取的过程:
public class RetrivePageSimple {
private static HttpClient httpClient = new HttpClient();
// 设置代理服务器
static {
httpClient.getHostConfiguration().setProxy("58.220.2.132", 80);
}
public static boolean downloadPage(String path) throws HttpException,
IOException {
PostMethod postMethod = new PostMethod(path);
// 执行,返回状态码
int statusCode = httpClient.executeMethod(postMethod);
System.out.println(statusCode);
// 针对状态码进行处理 (简单起见,只处理返回值为200的状态码)
if (statusCode == HttpStatus.SC_OK) {
String a = postMethod.getResponseBodyAsString();
System.out.println(a);
return true;
}
return false;
}
public static void main(String[] args) {
try {
RetrivePageSimple.downloadPage("http://www.cnblogs.com/";);
} catch (HttpException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
结果信息在这里不再显示,太多了。. . - -!
2.使用 Python 抓取页面
可能你会问我,为什么写成使用Java版的页面爬取,而这里又是一个Python?这是必要的。因为作者在开发这个demo之前没有考虑问题。当我们使用Java爬取网页到Python时,网页字符串太长无法作为参数传递。您可能认为保存文件是一个不错的选择,但是如果 html 文件过多怎么办?是的,在这里我们必须放弃这种累人的做法。
考虑到参数长度的限制,这里只给出Java端的页面地址,使用Python爬取网页。
以最简单的方式,我们通常使用这样的 Python 网页:
import urllib2
result = urllib2.urlopen('http://blog.csdn.net/mobile/index.html')
html = result.read()
print html
但是作者的代码使用的是CSDN博客频道的url。CSDN 过滤来自爬虫的访问。如下,我们会得到如下错误信息:

403,我被拒绝了。
3.使用模拟浏览器登录网站
如前所述,当我们访问一个带有保护措施的网页时,它会被拒绝。但是我们可以尝试使用我们自己的浏览器来访问它,它是可以访问的。
也就是说,如果我们能在 Python 中把自己模仿成一个浏览器,就可以访问这个网页。这是在 Python 中模仿浏览器的代码:
import random
import socket
import urllib2
import cookielib
ERROR = {
'0':'Can not open the url,checck you net',
'1':'Creat download dir error',
'2':'The image links is empty',
'3':'Download faild',
'4':'Build soup error,the html is empty',
'5':'Can not save the image to your disk',
}
class BrowserBase(object):
def __init__(self):
socket.setdefaulttimeout(20)
self._content = None
def speak(self, name, content):
print '[%s]%s' % (name, content)
def open_url(self, url):
"""
打开网页
"""
cookie_support= urllib2.HTTPCookieProcessor(cookielib.CookieJar())
self.opener = urllib2.build_opener(cookie_support,urllib2.HTTPHandler)
urllib2.install_opener(self.opener)
user_agents = [
'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11',
'Opera/9.25 (Windows NT 5.1; U; en)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 ",
]
agent = random.choice(user_agents)
self.opener.addheaders = [("User-agent", agent), ("Accept", "*/*"), ('Referer', 'http://www.google.com')]
try:
res = self.opener.open(url)
self._content = res.read()
# print self._content
except Exception, e:
self.speak(str(e)+url)
raise Exception
else:
return res
def get_html_content(self):
return self._content
def get_html_response(html):
spider = BrowserBase()
spider.open_url(html)
return spider.get_html_content()
以上代码可以正常获取返回值。下面我们来看看返回结果的解析过程。
4.数据分析
使用 Python 解析 Html 异常简单:
import HTMLParser
class ListWebParser(HTMLParser.HTMLParser):
def __init__(self):
HTMLParser.HTMLParser.__init__(self)
self.tagDIVFlag = False
self.tagDIVAFlag = False
self.tagH1Flag = False
self.tagSecondHrefFlag = False
self._name = None
self._address = None
def handle_starttag(self, tag, attrs):
if tag == 'div':
for name, value in attrs:
if name == 'class' and value == 'blog_list':
self.tagDIVFlag = True
if tag == 'h1':
if self.tagDIVFlag:
self.tagH1Flag = True
# print 'h1->', self.tagH1Flag
if tag == 'a':
#if self.tagDIVAFlag:
#print 'h1: ', self.tagH1Flag
if self.tagH1Flag:
for name, value in attrs:
if name == 'target' and value == '_blank':
self.tagDIVAFlag = True
if name == 'href':
if self.tagSecondHrefFlag:
print '网址:', value
self._address = value
self.tagSecondHrefFlag = True
# if name == 'href' and self.tagDIVAFlag:
# print '网址:', value
# self._address = value
def handle_endtag(self, tag):
if tag == 'div':
self.tagDIVFlag = False
if tag == 'h1':
self.tagH1Flag = False
# print 'false h1.'
if tag == 'a':
self.tagDIVAFlag = False
def handle_data(self, data):
if self.tagDIVAFlag:
print u"名称:", data.decode("utf-8")
如果你说你在网上找到的Html文件没有这个麻烦。我承认这一点,因为在正常情况下,我们解析一些简单的数据真的很简单。上面代码中的复杂逻辑是处理过滤。
说到过滤,我这里用了一个小技巧(当然,当更多的人使用它时,这不再只是一个技巧。但是,这种方法可以在以后的编码过程中进行参考)。我们通过标签的一些特殊属性(例如:id、class等)来锁定块。当我们开始block时,我们对应的flag会被标记为True,当我们退出block时,我们对应的flag会被标记为False。也许你认为这太麻烦了。其实,如果你仔细想想,你会发现它是有道理的。
预防措施:
1.当使用 Java 进行网页抓取时,我们使用代理服务器。这个代理服务器的主机和端口可以直接在网上免费查到。
2.你需要准备以下jar包并导入到你的Eclipse项目中:
3.修改MySQL默认编码为UTF-8
因为这里会有一些中文信息,所以我们需要转换MySQL的编码格式。
如果你是在Linux下编码,那么你可以参考:
转载于:
java从网页抓取数据(本文某个站点对数据的显示方式略有不同演示怎样抓取站点的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-09 19:04
原文链接:
有时出于各种原因。我们需要从网站采集数据。但是因为不同的站点显示数据略有不同!
本文将使用Java来给大家展示如何抓取网站的数据:(1)抓取原创网页数据。(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页。然后输入IP:111.142.55.73,点击查询按钮。您可以在网页上看到显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出。再次请求网页后显示查询结果。
看看查询后的网页地址:
也就是说,我们只想访问表单的一个 URL。可以得到ip查询的结果,再看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?
IP=" + ip; URL url = new URL(strURL); HttpURLConnection httpConn = (HttpURLConnection) url.openConnection(); InputStreamReader input = new InputStreamReader(httpConn .getInputStream(), "utf-8"); BufferedReader bufReader = new BufferedReader(input); String line = ""; StringBuilder contentBuf = new StringBuilder(); while ((line = bufReader.readLine()) != null) { contentBuf.append(line); } String buf = contentBuf.toString( ); int beginIx = buf.indexOf("查询结果["); int endIx = buf.indexOf("以上四项依次显示"); String result = buf.substring(beginIx, endIx); System.out .println("captureHtml()的结果:\n" + result); }
使用 HttpURLConnection 连接到站点。使用bufReader保存网页返回的数据,然后通过自定义的分析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时,网站为了保护自己的数据,并不直接在网页源代码中返回数据,而是采用异步的方式。使用JS返回数据,可以避免搜索引擎等工具抓取网站数据。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7。点击查询按钮,查看 HTTP Analyzer 的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出。HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
既然如此。我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。我们记下 JS 请求的 URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?
wen=" + postid + "&channel=&rnd=0"; URL url = new URL(strURL); HttpURLConnection httpConn = (HttpURLConnection) url.openConnection(); InputStreamReader input = new InputStreamReader(httpConn .getInputStream(), "utf- 8"); BufferedReader bufReader = new BufferedReader(input); String line = ""; StringBuilder contentBuf = new StringBuilder(); while ((line = bufReader.readLine()) != null) { contentBuf.append(line); System.out.println("captureJavascript() 的结果:\n" + contentBuf.toString()); }
看见。抓取JS的方式和之前的代码抓取原创网页的方式一模一样。我们只是做了一个分析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这可以是需要帮助的小朋友,需要程序的源码,点此下载! 查看全部
java从网页抓取数据(本文某个站点对数据的显示方式略有不同演示怎样抓取站点的数据)
原文链接:
有时出于各种原因。我们需要从网站采集数据。但是因为不同的站点显示数据略有不同!
本文将使用Java来给大家展示如何抓取网站的数据:(1)抓取原创网页数据。(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页。然后输入IP:111.142.55.73,点击查询按钮。您可以在网页上看到显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出。再次请求网页后显示查询结果。
看看查询后的网页地址:
也就是说,我们只想访问表单的一个 URL。可以得到ip查询的结果,再看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?
IP=" + ip; URL url = new URL(strURL); HttpURLConnection httpConn = (HttpURLConnection) url.openConnection(); InputStreamReader input = new InputStreamReader(httpConn .getInputStream(), "utf-8"); BufferedReader bufReader = new BufferedReader(input); String line = ""; StringBuilder contentBuf = new StringBuilder(); while ((line = bufReader.readLine()) != null) { contentBuf.append(line); } String buf = contentBuf.toString( ); int beginIx = buf.indexOf("查询结果["); int endIx = buf.indexOf("以上四项依次显示"); String result = buf.substring(beginIx, endIx); System.out .println("captureHtml()的结果:\n" + result); }
使用 HttpURLConnection 连接到站点。使用bufReader保存网页返回的数据,然后通过自定义的分析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时,网站为了保护自己的数据,并不直接在网页源代码中返回数据,而是采用异步的方式。使用JS返回数据,可以避免搜索引擎等工具抓取网站数据。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7。点击查询按钮,查看 HTTP Analyzer 的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出。HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
既然如此。我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。我们记下 JS 请求的 URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?
wen=" + postid + "&channel=&rnd=0"; URL url = new URL(strURL); HttpURLConnection httpConn = (HttpURLConnection) url.openConnection(); InputStreamReader input = new InputStreamReader(httpConn .getInputStream(), "utf- 8"); BufferedReader bufReader = new BufferedReader(input); String line = ""; StringBuilder contentBuf = new StringBuilder(); while ((line = bufReader.readLine()) != null) { contentBuf.append(line); System.out.println("captureJavascript() 的结果:\n" + contentBuf.toString()); }
看见。抓取JS的方式和之前的代码抓取原创网页的方式一模一样。我们只是做了一个分析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这可以是需要帮助的小朋友,需要程序的源码,点此下载!
java从网页抓取数据(djangojava从网页抓取数据包括抓包后分析网页的方案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-05 02:00
java从网页抓取数据包括抓包后分析网页抓取数据还是比较简单的,只要你会抓包,简单的抓包技巧(可以去看前端可视化抓包数据)会写爬虫程序,你只要学会一点http/https/websocket代理工具就可以跑抓取数据了,数据量大情况下建议去抓网页从网页中读取数据,
泻药,好久没回答知乎上的问题了。这个问题想必是你没有抓取的人机交互数据吧。django有很多api,mongodb也有人机交互。方案1:直接用python写网页的开发人员工具库,如easyui或者bootstrap,通过ajax获取数据库数据,再通过python爬虫对数据进行分析。方案2:再购买bs3等bs文件,直接包装到python或者java中,然后可以通过java程序来处理。
顺便再分析分析网页的结构,数据,数据来源,再对数据进行处理。最后进行解析或者提交给程序进行解析。后两种,并不复杂,都是文件,文件里面都会写一些方法,需要的话通过加载对应的文件来操作,最难的就是数据库方面。
scrapy
django搭一个博客框架,爬爬行情、订单、二手车信息就足够了。
主要看你们的需求,问题是不是都这么问。你问你的导师,比如网页抓取产品一般收集新闻和php,django等redis有些集群来抓,也可以爬其他信息(这个你们得根据你们的需求, 查看全部
java从网页抓取数据(djangojava从网页抓取数据包括抓包后分析网页的方案)
java从网页抓取数据包括抓包后分析网页抓取数据还是比较简单的,只要你会抓包,简单的抓包技巧(可以去看前端可视化抓包数据)会写爬虫程序,你只要学会一点http/https/websocket代理工具就可以跑抓取数据了,数据量大情况下建议去抓网页从网页中读取数据,
泻药,好久没回答知乎上的问题了。这个问题想必是你没有抓取的人机交互数据吧。django有很多api,mongodb也有人机交互。方案1:直接用python写网页的开发人员工具库,如easyui或者bootstrap,通过ajax获取数据库数据,再通过python爬虫对数据进行分析。方案2:再购买bs3等bs文件,直接包装到python或者java中,然后可以通过java程序来处理。
顺便再分析分析网页的结构,数据,数据来源,再对数据进行处理。最后进行解析或者提交给程序进行解析。后两种,并不复杂,都是文件,文件里面都会写一些方法,需要的话通过加载对应的文件来操作,最难的就是数据库方面。
scrapy
django搭一个博客框架,爬爬行情、订单、二手车信息就足够了。
主要看你们的需求,问题是不是都这么问。你问你的导师,比如网页抓取产品一般收集新闻和php,django等redis有些集群来抓,也可以爬其他信息(这个你们得根据你们的需求,
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-31 23:08
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java来给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页的源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java来给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页的源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据(用到抓取网页数据的功能:抓取数据功能详解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-31 17:14
经常用到爬取网页数据的功能。我在以前的工作中使用过它。今天我总结一下:
1、通过指定的URL抓取网页数据,获取页面信息,然后对带有DOM的页面进行NODE分析,处理原创的HTML数据。这样做的好处是处理某条数据的灵活性很高。 , 难点在于节算法需要优化。当页面的HTML信息较大时,算法不好,会影响处理效率。
2、htmlparser框架,对于HTML页面处理的数据结构,HtmlParser采用经典的Composite模式,通过RemarkNode、TextNode、TagNode、AbstractNode和Tag来描述HTML页面的各个元素。 Htmlparser基本可以满足垂直搜索引擎页面处理分析的需求,映射HTML标签,轻松获取标签中的HTMLCODE。
Htmlparser官方介绍:htmlparser是一个纯java编写的html解析库。它不依赖于其他java库文件,主要用于转换或提取html。它解析 html 的速度非常快而且没有错误。 htmlparser 的最新版本现在是 2.0。毫不夸张地说,htmlparser是目前最好的html解析分析工具。
3、nekohtml框架,nekohtml在容错和性能方面比htmlparser有更好的口碑(包括htmlunit也使用nekohtml),nokehtml类似于xml解析的原理,将html标签解析为dom,是的,它们对应于DOM树中的相应元素进行处理。
NekoHTML 官方介绍:NekoHTML 是Java 语言的HTML 扫描器和标签平衡器,它使程序能够解析HTML 文档并使用标准的XML 接口来访问其中的信息。此解析器能够扫描 HTML 文档并“修复”作者(人或机器)在编写 HTML 文档时所犯的许多常见错误。
NekoHTML 可以补充缺失的父元素,自动用结束标签关闭对应的元素,不匹配内联元素标签。 NekoHTML 是使用 XercesNativeInterface (XNI) 开发的,它是 Xerces2 实现的基础。 查看全部
java从网页抓取数据(用到抓取网页数据的功能:抓取数据功能详解)
经常用到爬取网页数据的功能。我在以前的工作中使用过它。今天我总结一下:
1、通过指定的URL抓取网页数据,获取页面信息,然后对带有DOM的页面进行NODE分析,处理原创的HTML数据。这样做的好处是处理某条数据的灵活性很高。 , 难点在于节算法需要优化。当页面的HTML信息较大时,算法不好,会影响处理效率。
2、htmlparser框架,对于HTML页面处理的数据结构,HtmlParser采用经典的Composite模式,通过RemarkNode、TextNode、TagNode、AbstractNode和Tag来描述HTML页面的各个元素。 Htmlparser基本可以满足垂直搜索引擎页面处理分析的需求,映射HTML标签,轻松获取标签中的HTMLCODE。
Htmlparser官方介绍:htmlparser是一个纯java编写的html解析库。它不依赖于其他java库文件,主要用于转换或提取html。它解析 html 的速度非常快而且没有错误。 htmlparser 的最新版本现在是 2.0。毫不夸张地说,htmlparser是目前最好的html解析分析工具。
3、nekohtml框架,nekohtml在容错和性能方面比htmlparser有更好的口碑(包括htmlunit也使用nekohtml),nokehtml类似于xml解析的原理,将html标签解析为dom,是的,它们对应于DOM树中的相应元素进行处理。
NekoHTML 官方介绍:NekoHTML 是Java 语言的HTML 扫描器和标签平衡器,它使程序能够解析HTML 文档并使用标准的XML 接口来访问其中的信息。此解析器能够扫描 HTML 文档并“修复”作者(人或机器)在编写 HTML 文档时所犯的许多常见错误。
NekoHTML 可以补充缺失的父元素,自动用结束标签关闭对应的元素,不匹配内联元素标签。 NekoHTML 是使用 XercesNativeInterface (XNI) 开发的,它是 Xerces2 实现的基础。
java从网页抓取数据( commons-io工具,获取页面或Json5)Jsoup工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-31 17:11
commons-io工具,获取页面或Json5)Jsoup工具)
4)commons-io 工具,获取页面或Json
5) Jsoup工具(一般用于html字段解析),获取页面,非Json返回格式]
完整代码:
package com.yeezhao.common.http;import java.io.BufferedReader;import java.io.InputStream;import java.io.InputStreamReader;import java.net.HttpURLConnection;import java.net.URL;import org.apache.commons.httpclient.HttpClient;import org.apache.commons.httpclient.HttpMethod;import org.apache.commons.httpclient.methods.GetMethod;import org.apache.commons.io.IOUtils;import org.jsoup.Jsoup;/**
* http工具对比
*
* @author Administrator -> junhong
*
* 2016年12月27日 */public class HttpFetchUtil {
/**
* 获取访问的状态码
* @param request
* @return
* @throws Exception */
public static int getResponseCode(String request) throws Exception {
URL url = new URL(request);
HttpURLConnection conn = (HttpURLConnection) url.openConnection(); return conn.getResponseCode();
} /**
* 1)JDK自带HTTP连接,获取页面或Json
* @param request
* @param charset
* @return
* @throws Exception */
public static String JDKFetch(String request, String charset) throws Exception {
URL url = new URL(request);
HttpURLConnection conn = (HttpURLConnection) url.openConnection(); //模拟浏览器参数
conn.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36"
+ " (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"); if (conn.getResponseCode() == HttpURLConnection.HTTP_OK) {
InputStream input = conn.getInputStream();
StringBuffer sb = new StringBuffer();
BufferedReader reader = new BufferedReader(new InputStreamReader(input, charset));
String s; while ((s = reader.readLine()) != null) {
sb.append(s + "\n");
}
input.close();
conn.disconnect(); return sb.toString();
} return "";
} /**
* 2) JDK自带URL连接,获取页面或Json
* @param request
* @param charset
* @return
* @throws Exception */
public static String URLFetch(String request, String charset) throws Exception {
URL url = new URL(request); return IOUtils.toString(url.openStream());
} /**
* 3)HttpClient Get工具,获取页面或Json
* @param url
* @param charset
* @return
* @throws Exception */
public static String httpClientFetch(String url, String charset) throws Exception { // GET
HttpClient httpClient = new HttpClient();
httpClient.getParams().setContentCharset(charset);
HttpMethod method = new GetMethod(url);
httpClient.executeMethod(method); return method.getResponseBodyAsString();
} /**
* 4)commons-io工具,获取页面或Json
* @param url
* @param charset
* @return
* @throws Exception */
public static String commonsIOFetch(String url, String charset) throws Exception { return IOUtils.toString(new URL(url), charset);
}
/**
* 5) Jsoup工具(通常用于html字段解析),获取页面,非Json返回格式
* @param url
* @return
* @throws Exception */
public static String jsoupFetch(String url) throws Exception { return Jsoup.parse(new URL(url), 2 * 1000).html();
}
}
测试代码:
附:相关jar依赖
...
org.jsoup
jsoup
1.7.3
commons-httpclient
commons-httpclient
3.1
commons-io
commons-io
2.4
...
后记:
在当前的数据时代,有“数据就是财富”的概念。因此,数据采集技术会不断的发展和更新,并在此基础上进一步扩展POST方式的采集方式,敬请期待!
以上就是Java实现http数据抓取的几种方式的详细内容。更多详情请关注宏旺互联网其他相关话题文章! 查看全部
java从网页抓取数据(
commons-io工具,获取页面或Json5)Jsoup工具)
4)commons-io 工具,获取页面或Json
5) Jsoup工具(一般用于html字段解析),获取页面,非Json返回格式]
完整代码:
package com.yeezhao.common.http;import java.io.BufferedReader;import java.io.InputStream;import java.io.InputStreamReader;import java.net.HttpURLConnection;import java.net.URL;import org.apache.commons.httpclient.HttpClient;import org.apache.commons.httpclient.HttpMethod;import org.apache.commons.httpclient.methods.GetMethod;import org.apache.commons.io.IOUtils;import org.jsoup.Jsoup;/**
* http工具对比
*
* @author Administrator -> junhong
*
* 2016年12月27日 */public class HttpFetchUtil {
/**
* 获取访问的状态码
* @param request
* @return
* @throws Exception */
public static int getResponseCode(String request) throws Exception {
URL url = new URL(request);
HttpURLConnection conn = (HttpURLConnection) url.openConnection(); return conn.getResponseCode();
} /**
* 1)JDK自带HTTP连接,获取页面或Json
* @param request
* @param charset
* @return
* @throws Exception */
public static String JDKFetch(String request, String charset) throws Exception {
URL url = new URL(request);
HttpURLConnection conn = (HttpURLConnection) url.openConnection(); //模拟浏览器参数
conn.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36"
+ " (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"); if (conn.getResponseCode() == HttpURLConnection.HTTP_OK) {
InputStream input = conn.getInputStream();
StringBuffer sb = new StringBuffer();
BufferedReader reader = new BufferedReader(new InputStreamReader(input, charset));
String s; while ((s = reader.readLine()) != null) {
sb.append(s + "\n");
}
input.close();
conn.disconnect(); return sb.toString();
} return "";
} /**
* 2) JDK自带URL连接,获取页面或Json
* @param request
* @param charset
* @return
* @throws Exception */
public static String URLFetch(String request, String charset) throws Exception {
URL url = new URL(request); return IOUtils.toString(url.openStream());
} /**
* 3)HttpClient Get工具,获取页面或Json
* @param url
* @param charset
* @return
* @throws Exception */
public static String httpClientFetch(String url, String charset) throws Exception { // GET
HttpClient httpClient = new HttpClient();
httpClient.getParams().setContentCharset(charset);
HttpMethod method = new GetMethod(url);
httpClient.executeMethod(method); return method.getResponseBodyAsString();
} /**
* 4)commons-io工具,获取页面或Json
* @param url
* @param charset
* @return
* @throws Exception */
public static String commonsIOFetch(String url, String charset) throws Exception { return IOUtils.toString(new URL(url), charset);
}
/**
* 5) Jsoup工具(通常用于html字段解析),获取页面,非Json返回格式
* @param url
* @return
* @throws Exception */
public static String jsoupFetch(String url) throws Exception { return Jsoup.parse(new URL(url), 2 * 1000).html();
}
}
测试代码:
附:相关jar依赖
...
org.jsoup
jsoup
1.7.3
commons-httpclient
commons-httpclient
3.1
commons-io
commons-io
2.4
...
后记:
在当前的数据时代,有“数据就是财富”的概念。因此,数据采集技术会不断的发展和更新,并在此基础上进一步扩展POST方式的采集方式,敬请期待!
以上就是Java实现http数据抓取的几种方式的详细内容。更多详情请关注宏旺互联网其他相关话题文章!
java从网页抓取数据(本文getNextUrl:Java代码更多的关于robot.txt的具体写法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-29 10:14
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。其基本结构如下图所示:
传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某个停止条件。对于垂直搜索,聚焦爬虫,即有针对性地爬取特定主题页面的爬虫更适合。
本文爬虫程序核心代码如下:
Java 代码
public void crawl() throws Throwable {
while (continueCrawling()) {
CrawlerUrl url = getNextUrl(); //获取待爬取队列中的下一个URL
if (url != null) {
printCrawlInfo();
String content = getContent(url); //获取URL的文本信息
//聚焦爬虫只爬取与主题内容相关的网页,这里采用正则匹配简单处理
if (isContentRelevant(content, this.regexpSearchPattern)) {
saveContent(url, content); //保存网页至本地
//获取网页内容中的链接,并放入待爬取队列中
Collection urlStrings = extractUrls(content, url);
addUrlsToUrlQueue(url, urlStrings);
} else {
System.out.println(url + " is not relevant ignoring ...");
}
//延时防止被对方屏蔽
Thread.sleep(this.delayBetweenUrls);
}
}
closeOutputStream();
}
整个函数由getNextUrl、getContent、isContentRelevant、extractUrls、addUrlsToUrlQueue等几个核心方法组成,下面将一一介绍。先看getNextUrl:
Java 代码
private CrawlerUrl getNextUrl() throws Throwable {
CrawlerUrl nextUrl = null;
while ((nextUrl == null) && (!urlQueue.isEmpty())) {
CrawlerUrl crawlerUrl = this.urlQueue.remove();
//doWeHavePermissionToVisit:是否有权限访问该URL,友好的爬虫会根据网站提供的"Robot.txt"中配置的规则进行爬取
//isUrlAlreadyVisited:URL是否访问过,大型的搜索引擎往往采用BloomFilter进行排重,这里简单使用HashMap
//isDepthAcceptable:是否达到指定的深度上限。爬虫一般采取广度优先的方式。一些网站会构建爬虫陷阱(自动生成一些无效链接使爬虫陷入死循环),采用深度限制加以避免
if (doWeHavePermissionToVisit(crawlerUrl)
&& (!isUrlAlreadyVisited(crawlerUrl))
&& isDepthAcceptable(crawlerUrl)) {
nextUrl = crawlerUrl;
// System.out.println("Next url to be visited is " + nextUrl);
}
}
return nextUrl;
}
更具体的robot.txt写法请参考以下文章:
getContent 内部使用 apache 的 httpclient 4.1 来获取网页内容。具体代码如下:
Java 代码
private String getContent(CrawlerUrl url) throws Throwable {
//HttpClient4.1的调用与之前的方式不同
HttpClient client = new DefaultHttpClient();
HttpGet httpGet = new HttpGet(url.getUrlString());
StringBuffer strBuf = new StringBuffer();
HttpResponse response = client.execute(httpGet);
if (HttpStatus.SC_OK == response.getStatusLine().getStatusCode()) {
HttpEntity entity = response.getEntity();
if (entity != null) {
BufferedReader reader = new BufferedReader(
new InputStreamReader(entity.getContent(), "UTF-8"));
String line = null;
if (entity.getContentLength() > 0) {
strBuf = new StringBuffer((int) entity.getContentLength());
while ((line = reader.readLine()) != null) {
strBuf.append(line);
}
}
}
if (entity != null) {
entity.consumeContent();
}
}
//将url标记为已访问
markUrlAsVisited(url);
return strBuf.toString();
}
对于垂直应用,数据准确性通常更为重要。聚焦爬虫的主要特点是它只采集与主题相关的数据,这就是 isContentRelevant 方法的作用。这里,可以使用分类预测技术,为了简单起见,改用正则匹配。其主要代码如下:
Java 代码
public static boolean isContentRelevant(String content,
Pattern regexpPattern) {
boolean retValue = false;
if (content != null) {
//是否符合正则表达式的条件
Matcher m = regexpPattern.matcher(content.toLowerCase());
retValue = m.find();
}
return retValue;
}
extractUrls 的主要作用是从网页中获取更多的 URL,包括内部链接和外部链接。代码如下:
Java 代码
public List extractUrls(String text, CrawlerUrl crawlerUrl) {
Map urlMap = new HashMap();
extractHttpUrls(urlMap, text);
extractRelativeUrls(urlMap, text, crawlerUrl);
return new ArrayList(urlMap.keySet());
}
//处理外部链接
private void extractHttpUrls(Map urlMap, String text) {
Matcher m = httpRegexp.matcher(text);
while (m.find()) {
String url = m.group();
String[] terms = url.split("a href=\"");
for (String term : terms) {
// System.out.println("Term = " + term);
if (term.startsWith("http")) {
int index = term.indexOf("\"");
if (index > 0) {
term = term.substring(0, index);
}
urlMap.put(term, term);
System.out.println("Hyperlink: " + term);
}
}
}
}
//处理内部链接
private void extractRelativeUrls(Map urlMap, String text,
CrawlerUrl crawlerUrl) {
Matcher m = relativeRegexp.matcher(text);
URL textURL = crawlerUrl.getURL();
String host = textURL.getHost();
while (m.find()) {
String url = m.group();
String[] terms = url.split("a href=\"");
for (String term : terms) {
if (term.startsWith("/")) {
int index = term.indexOf("\"");
if (index > 0) {
term = term.substring(0, index);
}
String s = "http://" + host + term;
urlMap.put(s, s);
System.out.println("Relative url: " + s);
}
}
}
}
这样就构建了一个简单的网络爬虫,可以用下面的程序进行测试:
Java 代码
public static void main(String[] args) {
try {
String url = "http://www.amazon.com";
Queue urlQueue = new LinkedList();
String regexp = "java";
urlQueue.add(new CrawlerUrl(url, 0));
NaiveCrawler crawler = new NaiveCrawler(urlQueue, 100, 5, 1000L,
regexp);
// boolean allowCrawl = crawler.areWeAllowedToVisit(url);
// System.out.println("Allowed to crawl: " + url + " " +
// allowCrawl);
crawler.crawl();
} catch (Throwable t) {
System.out.println(t.toString());
t.printStackTrace();
}
}
当然,你可以给它更高级的功能,比如多线程,更智能的对焦,用Lucene索引等等。对于更复杂的情况,你可以考虑使用一些开源的蜘蛛程序,比如Nutch或者Heritrix等,这超出了本文的范围。 查看全部
java从网页抓取数据(本文getNextUrl:Java代码更多的关于robot.txt的具体写法)
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。其基本结构如下图所示:
传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某个停止条件。对于垂直搜索,聚焦爬虫,即有针对性地爬取特定主题页面的爬虫更适合。
本文爬虫程序核心代码如下:
Java 代码
public void crawl() throws Throwable {
while (continueCrawling()) {
CrawlerUrl url = getNextUrl(); //获取待爬取队列中的下一个URL
if (url != null) {
printCrawlInfo();
String content = getContent(url); //获取URL的文本信息
//聚焦爬虫只爬取与主题内容相关的网页,这里采用正则匹配简单处理
if (isContentRelevant(content, this.regexpSearchPattern)) {
saveContent(url, content); //保存网页至本地
//获取网页内容中的链接,并放入待爬取队列中
Collection urlStrings = extractUrls(content, url);
addUrlsToUrlQueue(url, urlStrings);
} else {
System.out.println(url + " is not relevant ignoring ...");
}
//延时防止被对方屏蔽
Thread.sleep(this.delayBetweenUrls);
}
}
closeOutputStream();
}
整个函数由getNextUrl、getContent、isContentRelevant、extractUrls、addUrlsToUrlQueue等几个核心方法组成,下面将一一介绍。先看getNextUrl:
Java 代码
private CrawlerUrl getNextUrl() throws Throwable {
CrawlerUrl nextUrl = null;
while ((nextUrl == null) && (!urlQueue.isEmpty())) {
CrawlerUrl crawlerUrl = this.urlQueue.remove();
//doWeHavePermissionToVisit:是否有权限访问该URL,友好的爬虫会根据网站提供的"Robot.txt"中配置的规则进行爬取
//isUrlAlreadyVisited:URL是否访问过,大型的搜索引擎往往采用BloomFilter进行排重,这里简单使用HashMap
//isDepthAcceptable:是否达到指定的深度上限。爬虫一般采取广度优先的方式。一些网站会构建爬虫陷阱(自动生成一些无效链接使爬虫陷入死循环),采用深度限制加以避免
if (doWeHavePermissionToVisit(crawlerUrl)
&& (!isUrlAlreadyVisited(crawlerUrl))
&& isDepthAcceptable(crawlerUrl)) {
nextUrl = crawlerUrl;
// System.out.println("Next url to be visited is " + nextUrl);
}
}
return nextUrl;
}
更具体的robot.txt写法请参考以下文章:
getContent 内部使用 apache 的 httpclient 4.1 来获取网页内容。具体代码如下:
Java 代码
private String getContent(CrawlerUrl url) throws Throwable {
//HttpClient4.1的调用与之前的方式不同
HttpClient client = new DefaultHttpClient();
HttpGet httpGet = new HttpGet(url.getUrlString());
StringBuffer strBuf = new StringBuffer();
HttpResponse response = client.execute(httpGet);
if (HttpStatus.SC_OK == response.getStatusLine().getStatusCode()) {
HttpEntity entity = response.getEntity();
if (entity != null) {
BufferedReader reader = new BufferedReader(
new InputStreamReader(entity.getContent(), "UTF-8"));
String line = null;
if (entity.getContentLength() > 0) {
strBuf = new StringBuffer((int) entity.getContentLength());
while ((line = reader.readLine()) != null) {
strBuf.append(line);
}
}
}
if (entity != null) {
entity.consumeContent();
}
}
//将url标记为已访问
markUrlAsVisited(url);
return strBuf.toString();
}
对于垂直应用,数据准确性通常更为重要。聚焦爬虫的主要特点是它只采集与主题相关的数据,这就是 isContentRelevant 方法的作用。这里,可以使用分类预测技术,为了简单起见,改用正则匹配。其主要代码如下:
Java 代码
public static boolean isContentRelevant(String content,
Pattern regexpPattern) {
boolean retValue = false;
if (content != null) {
//是否符合正则表达式的条件
Matcher m = regexpPattern.matcher(content.toLowerCase());
retValue = m.find();
}
return retValue;
}
extractUrls 的主要作用是从网页中获取更多的 URL,包括内部链接和外部链接。代码如下:
Java 代码
public List extractUrls(String text, CrawlerUrl crawlerUrl) {
Map urlMap = new HashMap();
extractHttpUrls(urlMap, text);
extractRelativeUrls(urlMap, text, crawlerUrl);
return new ArrayList(urlMap.keySet());
}
//处理外部链接
private void extractHttpUrls(Map urlMap, String text) {
Matcher m = httpRegexp.matcher(text);
while (m.find()) {
String url = m.group();
String[] terms = url.split("a href=\"");
for (String term : terms) {
// System.out.println("Term = " + term);
if (term.startsWith("http")) {
int index = term.indexOf("\"");
if (index > 0) {
term = term.substring(0, index);
}
urlMap.put(term, term);
System.out.println("Hyperlink: " + term);
}
}
}
}
//处理内部链接
private void extractRelativeUrls(Map urlMap, String text,
CrawlerUrl crawlerUrl) {
Matcher m = relativeRegexp.matcher(text);
URL textURL = crawlerUrl.getURL();
String host = textURL.getHost();
while (m.find()) {
String url = m.group();
String[] terms = url.split("a href=\"");
for (String term : terms) {
if (term.startsWith("/")) {
int index = term.indexOf("\"");
if (index > 0) {
term = term.substring(0, index);
}
String s = "http://" + host + term;
urlMap.put(s, s);
System.out.println("Relative url: " + s);
}
}
}
}
这样就构建了一个简单的网络爬虫,可以用下面的程序进行测试:
Java 代码
public static void main(String[] args) {
try {
String url = "http://www.amazon.com";
Queue urlQueue = new LinkedList();
String regexp = "java";
urlQueue.add(new CrawlerUrl(url, 0));
NaiveCrawler crawler = new NaiveCrawler(urlQueue, 100, 5, 1000L,
regexp);
// boolean allowCrawl = crawler.areWeAllowedToVisit(url);
// System.out.println("Allowed to crawl: " + url + " " +
// allowCrawl);
crawler.crawl();
} catch (Throwable t) {
System.out.println(t.toString());
t.printStackTrace();
}
}
当然,你可以给它更高级的功能,比如多线程,更智能的对焦,用Lucene索引等等。对于更复杂的情况,你可以考虑使用一些开源的蜘蛛程序,比如Nutch或者Heritrix等,这超出了本文的范围。
java从网页抓取数据(网页信息提取文献总结-差异和对比零、基础知识结构化数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-29 10:13
【算法研究】Web信息抽取文献综述——差异与比较零,基础知识结构化数据2015_《数据库系统基础(第5版)》
存储在数据库中的信息称为结构化数据;XML 文档是模式信息与数据值混合的半结构化数据,而 HTML 中的网页是非结构化文档规范化
将格式错误的文档转换为格式良好的 HTML 文档。
一、审阅类型文章2002_《Web数据抽取工具简述》
伦达尔等人。建议通过区分用于为每种方法生成包装器的主要技术来区分结构化数据提取方法,例如基于 NLP 的方法、基于模型构建的方法等。
2006_《Web信息抽取系统综述》
C. Chang 等人。从提取任务的难易程度、使用的方法、自动化程度等方面对网页提取进行分类。
使用的技术(标记/编码方法、提取规则的类型、特征提取/机器学习)、自动化程度(有用户参与、无用户参与)(手动构建、监督、半监督、无监督)2012_“Web 数据挖掘”
兵等人。根据自动化程度对数据提取方法进行分类,将结构化数据提取方法分为手动、半自动和全自动方法。2013IEEE“从Web文档中提取区域的调查”
Sleiman 等人专注于区域提取器。描述区域提取器的发展并比较不同的区域提取器。2019_《基于层次分析法的Web数据提取方法比较研究》
描述从网页中提取数据的方法,详细描述每种方法,最后根据定义明确的精确标准比较所有方法。二、基于HTML页面代码的方法手动方法1997_《半结构化数据:TSIMMIS经验》
TSIMMIS 是最早提供手动构建 Web 包装器的框架之一,允许程序员输入一系列指令来确定应如何提取数据。
1998_ “WebOQL:重构文档、数据库和 Web”
半自动方法 2000_Snowball:从大型纯文本集合中提取关系
微软提出的一种从文本文档中提取有价值的结构化数据的方法,首先从用户那里获取少量训练样例作为种子元组生成提取模式,然后从文档集合中提取新的元组对,经过多次获取最终数据迭代。2007_《开放网络信息提取》
抽取范式是从语料库中构建的,不需要人工输入,自动发现可能的兴趣关系,实现了从Web中大规模数据抽取的无监督过程。2007_“深度网络的结构化数据注释”
解决如何为从 Web 数据库返回的 SRR 数据记录自动分配有意义的标签。
陆晔等。将数据单元对齐到不同的组中,使同一组中的数据具有相同的语义,然后为每个组从不同方面对它们进行注释,并聚合不同的注释以预测最终的注释标签。2013_《一种从深网精确提取实体数据的新方法》
根据 DeepWeb 的动态特性,Yu HT et al. 对网页资源进行预处理和规范化,结合XPath和Regexp,准确定位实体数据。缺点是不能泛化,需要在提取目标页面前定义正则表达式。2018_用户友好和可扩展的Web数据提取
Serrano T. Novella I. Holubová 等人提出了一种具有三个目标的新包装语言:(1)在受限环境中运行的能力,例如浏览器扩展,(2)可扩展性能以平衡交易-在命令集表达性和安全性之间关闭,以及(3) 处理能力,无需额外的程序来清理提取的数据。全自动方法 2001_“RoadRunner:从大型网站自动提取数据”》
RoadRunner 是一个完全自动化的包装器,它不依赖于任何用户交互,但需要一次处理至少两个或多个页面,因为算法的核心是基于一组给定的属于同一类的 HTML 示例页面并从提取数据。RoadRunner 使用一种称为 ACME 的匹配技术来查找两个页面中的共同结构(对齐相似的标签和折叠不同的标签)以从标签生成包装器。由于算法的比较机制,RoadRunner 还会收录一些噪声块。
三、基于DOM树的半自动文本识别方法2001_《Building Intelligent Web Applications Using Lightweight Wrappers》
W4F(万维网包装器工厂)是一个用于生成 Web 包装器的 Java 工具包。它提供了一种表达式语言,用于从 HTML 页面中提取 DOM 树结构,将提取的数据映射到 XML 或 Java 对象,并提供一些可视化工具,使打包过程更快、更容易。
2002_ “XWRAP:一个支持 XML 的 Web 信息源包装器构建系统”
XWRAP 是一种半自动的方法,它分析页面的 DOM 结构,使用组件库为 wrapper 程序提供基本的构建块,引导用户通过点击所需的组件来生成 wrapper 代码,XWRAP 还可以输出信息抽取规则。
叶节点融合相关算法
《基于DOM树和统计信息的Web内容信息提取》
全自动方法2001_《万维网全自动对象提取系统》
Omini 将网页解析成 DOM 树,然后使用子树提取算法定位收录感兴趣对象的最小子树,并使用对象提取算法定位正确的对象分隔符标签,从而有效分离对象。缺点是子树提取算法和对象分隔符提取算法都依赖于标签计数,数据库仅限于普通论文文章和书籍数据库网站,结构比较简单。
2003_《通过模式发现从半结构化网页中自动提取信息》
IEPAD(Automatic information extract from semi-structured Web pages by pattern discovery)是一种基于模式发现的方法。
2003_《挖掘网页中的数据记录》
MDR 方法基于两个观察和三个步骤:
两个观察
两个假设
该方法主要分为三个步骤
2005_《基于部分树对齐的Web数据提取》
DEPTA(即 MDR2)
主要流程
MDR2 挖掘数据区域(基于部分树对齐)
2017_《基于Web结构聚类的Web内容提取》
CECWS首先从同一个网站中提取了一组相似的页面,删除了内容相同的部分(噪声数据),然后提取了数据。
2018_《一种从单项页面中有效提取网络数据的新型对齐算法》
DCA 分治法专注于提取单项页面中的顺序对数。
本文的主要贡献是
四、基于视觉信息的数据提取2003-Vips:一种基于视觉的页面分割算法
蔡 D 等人。首先从DOM树中提取出所有合适的页面块,然后根据这些页面和段重构网页的语义结构。
2005-搜索引擎的全自动包装器生成
作者主要提出了ViNT的一种方法
对于搜索引擎的界面(如百度页面和谷歌界面),需要同一个搜索引擎下的多个页面。
2013-注释来自网络数据库的搜索结果
基于 ViNT 提取数据记录的 SRR,然后进行数据对齐以生成多类注释包装器。
2010-ViDE:一种基于视觉的深度网络数据提取方法
布局函数 (LF)
外观特征 (AFs)。这些函数捕获数据记录中的视觉函数。
内容函数 (CF)。这些特征暗示了数据记录中内容的规律性。
数据提取标准
数据提取过程
首先通过PFs特性,调整阈值对数据区域进行分框,过滤噪声块,判断噪声块位置是否左对齐,数据可视块,聚类块,数据块对齐
基于视觉的数据记录包装器 (f,l,d)
我们的方法包括四个主要步骤:可视块树构建、数据记录提取、数据项提取和可视化包装器生成。
2013_从深网可视化提取数据记录
4.3 基于机器学习的模式识别 从相似网页中提取对应模式的数据(从候选框中选择样本,将其坐标投影到最终的特征向量,然后使用softmax进行分类)4. 4 基于机器学习的本地化
《基于视觉信息处理的深度网络数据提取》
五、基于模板的文本识别
主要步骤是
六、基于语义标签的文本提取七、基于词库的信息提取 查看全部
java从网页抓取数据(网页信息提取文献总结-差异和对比零、基础知识结构化数据)
【算法研究】Web信息抽取文献综述——差异与比较零,基础知识结构化数据2015_《数据库系统基础(第5版)》
存储在数据库中的信息称为结构化数据;XML 文档是模式信息与数据值混合的半结构化数据,而 HTML 中的网页是非结构化文档规范化
将格式错误的文档转换为格式良好的 HTML 文档。
一、审阅类型文章2002_《Web数据抽取工具简述》
伦达尔等人。建议通过区分用于为每种方法生成包装器的主要技术来区分结构化数据提取方法,例如基于 NLP 的方法、基于模型构建的方法等。
2006_《Web信息抽取系统综述》
C. Chang 等人。从提取任务的难易程度、使用的方法、自动化程度等方面对网页提取进行分类。
使用的技术(标记/编码方法、提取规则的类型、特征提取/机器学习)、自动化程度(有用户参与、无用户参与)(手动构建、监督、半监督、无监督)2012_“Web 数据挖掘”
兵等人。根据自动化程度对数据提取方法进行分类,将结构化数据提取方法分为手动、半自动和全自动方法。2013IEEE“从Web文档中提取区域的调查”
Sleiman 等人专注于区域提取器。描述区域提取器的发展并比较不同的区域提取器。2019_《基于层次分析法的Web数据提取方法比较研究》
描述从网页中提取数据的方法,详细描述每种方法,最后根据定义明确的精确标准比较所有方法。二、基于HTML页面代码的方法手动方法1997_《半结构化数据:TSIMMIS经验》
TSIMMIS 是最早提供手动构建 Web 包装器的框架之一,允许程序员输入一系列指令来确定应如何提取数据。
1998_ “WebOQL:重构文档、数据库和 Web”
半自动方法 2000_Snowball:从大型纯文本集合中提取关系
微软提出的一种从文本文档中提取有价值的结构化数据的方法,首先从用户那里获取少量训练样例作为种子元组生成提取模式,然后从文档集合中提取新的元组对,经过多次获取最终数据迭代。2007_《开放网络信息提取》
抽取范式是从语料库中构建的,不需要人工输入,自动发现可能的兴趣关系,实现了从Web中大规模数据抽取的无监督过程。2007_“深度网络的结构化数据注释”
解决如何为从 Web 数据库返回的 SRR 数据记录自动分配有意义的标签。
陆晔等。将数据单元对齐到不同的组中,使同一组中的数据具有相同的语义,然后为每个组从不同方面对它们进行注释,并聚合不同的注释以预测最终的注释标签。2013_《一种从深网精确提取实体数据的新方法》
根据 DeepWeb 的动态特性,Yu HT et al. 对网页资源进行预处理和规范化,结合XPath和Regexp,准确定位实体数据。缺点是不能泛化,需要在提取目标页面前定义正则表达式。2018_用户友好和可扩展的Web数据提取
Serrano T. Novella I. Holubová 等人提出了一种具有三个目标的新包装语言:(1)在受限环境中运行的能力,例如浏览器扩展,(2)可扩展性能以平衡交易-在命令集表达性和安全性之间关闭,以及(3) 处理能力,无需额外的程序来清理提取的数据。全自动方法 2001_“RoadRunner:从大型网站自动提取数据”》
RoadRunner 是一个完全自动化的包装器,它不依赖于任何用户交互,但需要一次处理至少两个或多个页面,因为算法的核心是基于一组给定的属于同一类的 HTML 示例页面并从提取数据。RoadRunner 使用一种称为 ACME 的匹配技术来查找两个页面中的共同结构(对齐相似的标签和折叠不同的标签)以从标签生成包装器。由于算法的比较机制,RoadRunner 还会收录一些噪声块。
三、基于DOM树的半自动文本识别方法2001_《Building Intelligent Web Applications Using Lightweight Wrappers》
W4F(万维网包装器工厂)是一个用于生成 Web 包装器的 Java 工具包。它提供了一种表达式语言,用于从 HTML 页面中提取 DOM 树结构,将提取的数据映射到 XML 或 Java 对象,并提供一些可视化工具,使打包过程更快、更容易。
2002_ “XWRAP:一个支持 XML 的 Web 信息源包装器构建系统”
XWRAP 是一种半自动的方法,它分析页面的 DOM 结构,使用组件库为 wrapper 程序提供基本的构建块,引导用户通过点击所需的组件来生成 wrapper 代码,XWRAP 还可以输出信息抽取规则。
叶节点融合相关算法
《基于DOM树和统计信息的Web内容信息提取》
全自动方法2001_《万维网全自动对象提取系统》
Omini 将网页解析成 DOM 树,然后使用子树提取算法定位收录感兴趣对象的最小子树,并使用对象提取算法定位正确的对象分隔符标签,从而有效分离对象。缺点是子树提取算法和对象分隔符提取算法都依赖于标签计数,数据库仅限于普通论文文章和书籍数据库网站,结构比较简单。
2003_《通过模式发现从半结构化网页中自动提取信息》
IEPAD(Automatic information extract from semi-structured Web pages by pattern discovery)是一种基于模式发现的方法。
2003_《挖掘网页中的数据记录》
MDR 方法基于两个观察和三个步骤:
两个观察
两个假设
该方法主要分为三个步骤
2005_《基于部分树对齐的Web数据提取》
DEPTA(即 MDR2)
主要流程
MDR2 挖掘数据区域(基于部分树对齐)
2017_《基于Web结构聚类的Web内容提取》
CECWS首先从同一个网站中提取了一组相似的页面,删除了内容相同的部分(噪声数据),然后提取了数据。
2018_《一种从单项页面中有效提取网络数据的新型对齐算法》
DCA 分治法专注于提取单项页面中的顺序对数。
本文的主要贡献是
四、基于视觉信息的数据提取2003-Vips:一种基于视觉的页面分割算法
蔡 D 等人。首先从DOM树中提取出所有合适的页面块,然后根据这些页面和段重构网页的语义结构。
2005-搜索引擎的全自动包装器生成
作者主要提出了ViNT的一种方法
对于搜索引擎的界面(如百度页面和谷歌界面),需要同一个搜索引擎下的多个页面。
2013-注释来自网络数据库的搜索结果
基于 ViNT 提取数据记录的 SRR,然后进行数据对齐以生成多类注释包装器。
2010-ViDE:一种基于视觉的深度网络数据提取方法
布局函数 (LF)
外观特征 (AFs)。这些函数捕获数据记录中的视觉函数。
内容函数 (CF)。这些特征暗示了数据记录中内容的规律性。
数据提取标准
数据提取过程
首先通过PFs特性,调整阈值对数据区域进行分框,过滤噪声块,判断噪声块位置是否左对齐,数据可视块,聚类块,数据块对齐
基于视觉的数据记录包装器 (f,l,d)
我们的方法包括四个主要步骤:可视块树构建、数据记录提取、数据项提取和可视化包装器生成。
2013_从深网可视化提取数据记录
4.3 基于机器学习的模式识别 从相似网页中提取对应模式的数据(从候选框中选择样本,将其坐标投影到最终的特征向量,然后使用softmax进行分类)4. 4 基于机器学习的本地化
《基于视觉信息处理的深度网络数据提取》
五、基于模板的文本识别
主要步骤是
六、基于语义标签的文本提取七、基于词库的信息提取
java从网页抓取数据(网页获取速度和解析速度的主要功能有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-26 05:03
(4)支持代理服务器
(5)支持自动cookie管理等。
Java爬虫开发是应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
二、Jsoup
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
(1) 从 URL、文件或字符串解析 HTML
(2) 使用 DOM 或 CSS 选择器查找和检索数据
(3) 操作 HTML 元素、属性、文本
三、瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
四、硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
五、网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
芝麻HTTP可以为您提供海量的IP资源。我们保证资源的稳定性和可用性,在“互联网+”时代为您带来更好的体验。我们还可以根据您的要求为您提供优质的定制服务。助您不间断获取行业数据,赢在大数据时代。 查看全部
java从网页抓取数据(网页获取速度和解析速度的主要功能有哪些?)
(4)支持代理服务器
(5)支持自动cookie管理等。
Java爬虫开发是应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
二、Jsoup
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
(1) 从 URL、文件或字符串解析 HTML
(2) 使用 DOM 或 CSS 选择器查找和检索数据
(3) 操作 HTML 元素、属性、文本
三、瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
四、硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
五、网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
芝麻HTTP可以为您提供海量的IP资源。我们保证资源的稳定性和可用性,在“互联网+”时代为您带来更好的体验。我们还可以根据您的要求为您提供优质的定制服务。助您不间断获取行业数据,赢在大数据时代。
java从网页抓取数据(:java实现这个多线程的主要代码,用c#应该也是一样的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-25 21:29
)
任务详情:
有一个信息发布网站,会根据条件查询数据,分页展示,每页15条,每条信息是一个url链接。单击该链接将打开另一个页面,显示该项目的详细信息。
我们需要做的就是抓取每件作品的详细信息,并将其保存到数据库中。
一开始我制作了所有我抓取并保存到数据库中的程序。
运行完发现速度很慢,因为数据量比较大,大概有30万条详细信息需要抓取。
我只是觉得最好用多线程来实现这个,开15个线程,一次抓取一页的所有详细信息,不是很快吗?
后来加了多线程后,一次开了16个线程,比原来快多了,呵呵~!
因为这个项目是用java实现的,下面是java实现这个多线程的主要代码,在c#中应该是一样的!有兴趣的可以翻译成c#,厚厚的~
<p>import java.util.ArrayList;
public class Catcher
{
private static ArrayList threads= new ArrayList();//存储未处理URL
public static boolean isFinished=false;//是否已经把所有的链接存到threads了
public synchronized String getUrl()
{
if(threads.size()>0)
{
String tmp = String.valueOf(threads.get(0));
threads.remove(0);
return tmp;
}else
return null;
}
public void process(){
//处理预处理
//下面开10个线程等待处理
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
//进入翻页的处理
for(int j=0;j 查看全部
java从网页抓取数据(:java实现这个多线程的主要代码,用c#应该也是一样的
)
任务详情:
有一个信息发布网站,会根据条件查询数据,分页展示,每页15条,每条信息是一个url链接。单击该链接将打开另一个页面,显示该项目的详细信息。
我们需要做的就是抓取每件作品的详细信息,并将其保存到数据库中。
一开始我制作了所有我抓取并保存到数据库中的程序。
运行完发现速度很慢,因为数据量比较大,大概有30万条详细信息需要抓取。
我只是觉得最好用多线程来实现这个,开15个线程,一次抓取一页的所有详细信息,不是很快吗?
后来加了多线程后,一次开了16个线程,比原来快多了,呵呵~!
因为这个项目是用java实现的,下面是java实现这个多线程的主要代码,在c#中应该是一样的!有兴趣的可以翻译成c#,厚厚的~
<p>import java.util.ArrayList;
public class Catcher
{
private static ArrayList threads= new ArrayList();//存储未处理URL
public static boolean isFinished=false;//是否已经把所有的链接存到threads了
public synchronized String getUrl()
{
if(threads.size()>0)
{
String tmp = String.valueOf(threads.get(0));
threads.remove(0);
return tmp;
}else
return null;
}
public void process(){
//处理预处理
//下面开10个线程等待处理
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
new Thread(new Processer(this)).start();
//进入翻页的处理
for(int j=0;j
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-01-25 08:13
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页的源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页的源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据(哪些网页才是重要性高的呢?如何解决网页抓取乱码问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-24 11:14
)
相关话题
基于 Web 的数据传输方法的比较
22/5/201209:28:00
网站数据传输方式的选择影响网页的加载速度、服务请求响应时间等,因此网站数据传输方式的选择直接影响网站性能和用户体验。网页数据的高效安全传输是网站优化中需要考虑的重要问题之一,网页数据传输方式的选择在网站方面尤为重要优化。
中国病毒网页数量位居病毒网页前44%
2007 年 9 月 9 日 20:15:00
北京时间9月7日消息,据俄罗斯链接新闻网报道,全球领先的杀毒软件开发商9月6日表示,中美两国病毒网站数量居全球前两位,中国的病毒网站大幅下降。对8月份全球80亿网页进行分析,得出的结论是,中国病毒网页数量居全球之首,44.8%的网页
网页抓取优先策略
18/1/2008 11:30:00
网页爬取优先策略也称为“页面选择问题”(pageSelection),通常是尽可能先爬取重要的网页,以保证那些重要性高的网页得到尽可能多的照顾在有限的资源范围内。那么哪些页面最重要?如何量化重要性?
如何解决php网页抓取出现乱码问题
2012 年 4 月 9 日:03:36
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”转换编码;2、添加“curl_setopt($ch,CURLOPT_ENCODING,'gzip');” 选项; 3、在顶部添加标题代码。推荐
TAG页面数据和构图原理你要知道的三个最关键的点!点击进去看看!
6/8/202018:01:55
关于网站建设的优化,标签页起着关键的作用,所以大家对标签页的作用很熟悉,所以我来解释一下它的一些概念。其实一般来说,标签页是用来描述某个关键词的
搜索引擎如何抓取网页?
22/11/2011 09:50:00
搜索引擎在抓取大量原创网页时,会进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一致)未经任何修改)或“转载网页”。”(近副本,主题内容基本相同但可能有一些额外的编辑信息等,转载的页面也称为“近似镜像页面”)消除,链接分析和页面的重要性计算。
Nginx下更改网页地址后旧网页301重定向的代码
2018 年 2 月 3 日 01:09:49
总结:Nginx下更改网页地址后旧网页301重定向的代码
如何打开网页的源代码
2021 年 4 月 2 日 10:31:09
打开网页源代码的方法:先登录一个网站,在网页左侧空白处右击;然后点击inspect元素,再次右击网页左侧的空白处;最后,点击查看源文件。本文运行环境:Windows7系统,戴尔G3电脑
翻页式网络搜索引擎如何抓取
2013 年 7 月 11 日 10:53:00
Spider 系统的目标是发现和爬取 Internet 上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。@网站经验造成压力,也就是说蜘蛛不会爬取网站的所有页面。蜘蛛的爬取策略有很多,可以尽可能快速完整的找到资源链接,提高爬取效率。
使用网络抓取数据赚钱的 3 个想法
2/6/202012:01:26
文章目录使用自动程序花最少的钱在Airbnb上住最好的酒店捕获特定产品的价格数据,以最低的价格购买并捕获公共数据,在大时代将其可视化数据,如何有效获取数据 数据已成为业务决策的驱动力
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
Google 适当地将 POST 请求添加到 GET 以抓取网页内容
15/12/2011 13:58:00
近日,Google Blackboard 发布了一篇题为“GET、POST 和安全获取更多网络信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。在文章中提到,未来谷歌在读取网页内容时不仅会使用GET抓取,还会根据情况在抓取网页内容时增加POST请求方式,从而进一步提高谷歌搜索的准确率引擎。网页内容的判断。
如何系统地做好SEO-web抓取
14/5/202014:41:34
如果没有爬取,那么就没有页面的收录。如何获取或改进搜索引擎的爬取?
详细讲解php爬取网页内容的例子
6/8/202018:02:42
php爬取网页内容示例详解方法一:使用file_get_contents方法实现$url="";$html=file_ge
代码和内容优化和去噪以提高网页的信噪比
22/5/2012 13:58:00
网页的信噪比是指网页中的文本内容与生成这些文本所产生的html标签内容的比率。一般来说,一个网页的信噪比越高,我们的网页质量就越好。可以根据搜索引擎抓取网页的原理来解释:搜索引擎蜘蛛抓取网页时,会对网页进行去重,主要是去除网页的噪音,留下有用的信息。
查看全部
java从网页抓取数据(哪些网页才是重要性高的呢?如何解决网页抓取乱码问题
)
相关话题
基于 Web 的数据传输方法的比较
22/5/201209:28:00
网站数据传输方式的选择影响网页的加载速度、服务请求响应时间等,因此网站数据传输方式的选择直接影响网站性能和用户体验。网页数据的高效安全传输是网站优化中需要考虑的重要问题之一,网页数据传输方式的选择在网站方面尤为重要优化。
中国病毒网页数量位居病毒网页前44%
2007 年 9 月 9 日 20:15:00
北京时间9月7日消息,据俄罗斯链接新闻网报道,全球领先的杀毒软件开发商9月6日表示,中美两国病毒网站数量居全球前两位,中国的病毒网站大幅下降。对8月份全球80亿网页进行分析,得出的结论是,中国病毒网页数量居全球之首,44.8%的网页
网页抓取优先策略
18/1/2008 11:30:00
网页爬取优先策略也称为“页面选择问题”(pageSelection),通常是尽可能先爬取重要的网页,以保证那些重要性高的网页得到尽可能多的照顾在有限的资源范围内。那么哪些页面最重要?如何量化重要性?
如何解决php网页抓取出现乱码问题
2012 年 4 月 9 日:03:36
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”转换编码;2、添加“curl_setopt($ch,CURLOPT_ENCODING,'gzip');” 选项; 3、在顶部添加标题代码。推荐
TAG页面数据和构图原理你要知道的三个最关键的点!点击进去看看!
6/8/202018:01:55
关于网站建设的优化,标签页起着关键的作用,所以大家对标签页的作用很熟悉,所以我来解释一下它的一些概念。其实一般来说,标签页是用来描述某个关键词的
搜索引擎如何抓取网页?
22/11/2011 09:50:00
搜索引擎在抓取大量原创网页时,会进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一致)未经任何修改)或“转载网页”。”(近副本,主题内容基本相同但可能有一些额外的编辑信息等,转载的页面也称为“近似镜像页面”)消除,链接分析和页面的重要性计算。
Nginx下更改网页地址后旧网页301重定向的代码
2018 年 2 月 3 日 01:09:49
总结:Nginx下更改网页地址后旧网页301重定向的代码
如何打开网页的源代码
2021 年 4 月 2 日 10:31:09
打开网页源代码的方法:先登录一个网站,在网页左侧空白处右击;然后点击inspect元素,再次右击网页左侧的空白处;最后,点击查看源文件。本文运行环境:Windows7系统,戴尔G3电脑
翻页式网络搜索引擎如何抓取
2013 年 7 月 11 日 10:53:00
Spider 系统的目标是发现和爬取 Internet 上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。@网站经验造成压力,也就是说蜘蛛不会爬取网站的所有页面。蜘蛛的爬取策略有很多,可以尽可能快速完整的找到资源链接,提高爬取效率。
使用网络抓取数据赚钱的 3 个想法
2/6/202012:01:26
文章目录使用自动程序花最少的钱在Airbnb上住最好的酒店捕获特定产品的价格数据,以最低的价格购买并捕获公共数据,在大时代将其可视化数据,如何有效获取数据 数据已成为业务决策的驱动力
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
Google 适当地将 POST 请求添加到 GET 以抓取网页内容
15/12/2011 13:58:00
近日,Google Blackboard 发布了一篇题为“GET、POST 和安全获取更多网络信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。在文章中提到,未来谷歌在读取网页内容时不仅会使用GET抓取,还会根据情况在抓取网页内容时增加POST请求方式,从而进一步提高谷歌搜索的准确率引擎。网页内容的判断。
如何系统地做好SEO-web抓取
14/5/202014:41:34
如果没有爬取,那么就没有页面的收录。如何获取或改进搜索引擎的爬取?
详细讲解php爬取网页内容的例子
6/8/202018:02:42
php爬取网页内容示例详解方法一:使用file_get_contents方法实现$url="";$html=file_ge
代码和内容优化和去噪以提高网页的信噪比
22/5/2012 13:58:00
网页的信噪比是指网页中的文本内容与生成这些文本所产生的html标签内容的比率。一般来说,一个网页的信噪比越高,我们的网页质量就越好。可以根据搜索引擎抓取网页的原理来解释:搜索引擎蜘蛛抓取网页时,会对网页进行去重,主要是去除网页的噪音,留下有用的信息。
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-24 07:10
原文链接:
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家演示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{ StringstrURL=""+ip; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8") ; BufferedReaderbufReader=newBufferedReader(输入);字符串线=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); } Stringbuf=contentBuf.toString() ; intbeginIx=buf.indexOf("查询结果["); intentIx=buf.indexOf("以上四项依次显示"); Stringresult=buf.substring(beginIx,endIx); System.out.println("captureHtml() 结果:\n"+result); }
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是直接在网页源码中返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即只需要访问JS请求的网页地址就可以获取数据,当然前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{ StringstrURL=""+postid +"&channel=&rnd=0"; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8"); BufferedReaderbufReader=newBufferedReader(输入);字符串线=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); } System.out.println("captureJavascript()的结果:\n"+contentBuf.toString()); }
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 【】 查看全部
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
原文链接:
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家演示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{ StringstrURL=""+ip; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8") ; BufferedReaderbufReader=newBufferedReader(输入);字符串线=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); } Stringbuf=contentBuf.toString() ; intbeginIx=buf.indexOf("查询结果["); intentIx=buf.indexOf("以上四项依次显示"); Stringresult=buf.substring(beginIx,endIx); System.out.println("captureHtml() 结果:\n"+result); }
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是直接在网页源码中返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即只需要访问JS请求的网页地址就可以获取数据,当然前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{ StringstrURL=""+postid +"&channel=&rnd=0"; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8"); BufferedReaderbufReader=newBufferedReader(输入);字符串线=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); } System.out.println("captureJavascript()的结果:\n"+contentBuf.toString()); }
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 【】
java从网页抓取数据(哪些网页才是重要性高的呢?如何让网页数据进行高效安全地传送 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-24 01:15
)
相关话题
基于 Web 的数据传输方法的比较
22/5/201209:28:00
网站数据传输方式的选择影响网页的加载速度、服务请求响应时间等,因此网站数据传输方式的选择直接影响网站性能和用户体验。网页数据的高效安全传输是网站优化中需要考虑的重要问题之一,网页数据传输方式的选择在网站方面尤为重要优化。
中国病毒网页数量位居病毒网页前44%
2007 年 9 月 9 日 20:15:00
北京时间9月7日消息,据俄罗斯链接新闻网报道,全球领先的杀毒软件开发商9月6日表示,中美两国病毒网站数量居全球前两位,中国的病毒网站大幅下降。对8月份全球80亿网页进行分析,得出的结论是,中国病毒网页数量居全球之首,44.8%的网页
网页抓取优先策略
18/1/2008 11:30:00
网页爬取优先策略也称为“页面选择问题”(pageSelection),通常是尽可能先爬取重要的网页,以保证那些重要性高的网页得到尽可能多的照顾在有限的资源范围内。那么哪些页面最重要?如何量化重要性?
TAG页面数据和构图原理你要知道的三个最关键的点!点击进去看看!
6/8/202018:01:55
关于网站建设的优化,标签页起着关键的作用,所以大家对标签页的作用很熟悉,所以我来解释一下它的一些概念。其实一般来说,标签页是用来描述某个关键词的
搜索引擎如何抓取网页?
22/11/2011 09:50:00
搜索引擎在抓取大量原创网页时,会进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一致)未经任何修改)或“转载网页”。”(近副本,主题内容基本相同但可能有一些额外的编辑信息等,转载的页面也称为“近似镜像页面”)消除,链接分析和页面的重要性计算。
翻页式网络搜索引擎如何抓取
2013 年 7 月 11 日 10:53:00
Spider 系统的目标是发现和爬取 Internet 上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。@网站经验造成压力,也就是说蜘蛛不会爬取网站的所有页面。蜘蛛的爬取策略有很多,可以尽可能快速完整的找到资源链接,提高爬取效率。
使用网络抓取数据赚钱的 3 个想法
2/6/202012:01:26
文章目录使用自动程序花最少的钱在Airbnb上住最好的酒店捕获特定产品的价格数据,以最低的价格购买并捕获公共数据,在大时代将其可视化数据,如何有效获取数据 数据已成为业务决策的驱动力
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是非常常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
Google 适当地将 POST 请求添加到 GET 以抓取网页内容
15/12/2011 13:58:00
近日,Google Blackboard 发布了一篇题为“GET、POST 和安全获取更多网络信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。在文章中提到,未来谷歌在读取网页内容时不仅会使用GET抓取,还会根据情况在抓取网页内容时增加POST请求方式,从而进一步提高谷歌搜索的准确率引擎。网页内容的判断。
如何系统地做好SEO-web抓取
14/5/202014:41:34
如果没有爬取,那么就没有页面的收录。如何获取或改进搜索引擎的爬取?
详细讲解php爬取网页内容的例子
6/8/202018:02:42
php爬取网页内容示例详解方法一:使用file_get_contents方法实现$url="";$html=file_ge
如何解决php网页抓取出现乱码问题
2012 年 4 月 9 日:03:36
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”转换编码;2、添加“curl_setopt($ch,CURLOPT_ENCODING,'gzip');” 选项; 3、在顶部添加标题代码。推荐
谷歌允许蜘蛛自动填写表单提交以抓取更多页面
2009 年 3 月 31 日 14:54:00
据外媒报道:美国搜索巨头谷歌最近开始在网络爬虫中实施一项新技术:他们可以让蜘蛛在某些网页中自动填写表单,并自动提交给服务器爬取反馈页面,以获取更多信息。关于这个 网站 的详细信息。
通过搜索引擎改进网络爬取、索引和排名的方法
2009 年 7 月 12 日 10:37:00
这是一个被许多 SEO 误解的重要概念。很久以前,搜索引擎爬虫(机器人)会递归地爬取某个网站(通过你提交的网站主页URL,然后爬取页面上找到的所有链接)指向该网页, 一次又一次)。
搜索引擎蜘蛛抓取网页的规律分析
27/8/2013 13:39:00
搜索引擎正面临着互联网上数以万亿计的网页。这么多网页如何高效爬取到本地镜像?这是网络爬虫的工作。我们也称它为网络蜘蛛,作为站长,我们每天都与它密切接触。
查看全部
java从网页抓取数据(哪些网页才是重要性高的呢?如何让网页数据进行高效安全地传送
)
相关话题
基于 Web 的数据传输方法的比较
22/5/201209:28:00
网站数据传输方式的选择影响网页的加载速度、服务请求响应时间等,因此网站数据传输方式的选择直接影响网站性能和用户体验。网页数据的高效安全传输是网站优化中需要考虑的重要问题之一,网页数据传输方式的选择在网站方面尤为重要优化。
中国病毒网页数量位居病毒网页前44%
2007 年 9 月 9 日 20:15:00
北京时间9月7日消息,据俄罗斯链接新闻网报道,全球领先的杀毒软件开发商9月6日表示,中美两国病毒网站数量居全球前两位,中国的病毒网站大幅下降。对8月份全球80亿网页进行分析,得出的结论是,中国病毒网页数量居全球之首,44.8%的网页
网页抓取优先策略
18/1/2008 11:30:00
网页爬取优先策略也称为“页面选择问题”(pageSelection),通常是尽可能先爬取重要的网页,以保证那些重要性高的网页得到尽可能多的照顾在有限的资源范围内。那么哪些页面最重要?如何量化重要性?
TAG页面数据和构图原理你要知道的三个最关键的点!点击进去看看!
6/8/202018:01:55
关于网站建设的优化,标签页起着关键的作用,所以大家对标签页的作用很熟悉,所以我来解释一下它的一些概念。其实一般来说,标签页是用来描述某个关键词的
搜索引擎如何抓取网页?
22/11/2011 09:50:00
搜索引擎在抓取大量原创网页时,会进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一致)未经任何修改)或“转载网页”。”(近副本,主题内容基本相同但可能有一些额外的编辑信息等,转载的页面也称为“近似镜像页面”)消除,链接分析和页面的重要性计算。
翻页式网络搜索引擎如何抓取
2013 年 7 月 11 日 10:53:00
Spider 系统的目标是发现和爬取 Internet 上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。@网站经验造成压力,也就是说蜘蛛不会爬取网站的所有页面。蜘蛛的爬取策略有很多,可以尽可能快速完整的找到资源链接,提高爬取效率。
使用网络抓取数据赚钱的 3 个想法
2/6/202012:01:26
文章目录使用自动程序花最少的钱在Airbnb上住最好的酒店捕获特定产品的价格数据,以最低的价格购买并捕获公共数据,在大时代将其可视化数据,如何有效获取数据 数据已成为业务决策的驱动力
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是非常常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
Google 适当地将 POST 请求添加到 GET 以抓取网页内容
15/12/2011 13:58:00
近日,Google Blackboard 发布了一篇题为“GET、POST 和安全获取更多网络信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。在文章中提到,未来谷歌在读取网页内容时不仅会使用GET抓取,还会根据情况在抓取网页内容时增加POST请求方式,从而进一步提高谷歌搜索的准确率引擎。网页内容的判断。
如何系统地做好SEO-web抓取
14/5/202014:41:34
如果没有爬取,那么就没有页面的收录。如何获取或改进搜索引擎的爬取?
详细讲解php爬取网页内容的例子
6/8/202018:02:42
php爬取网页内容示例详解方法一:使用file_get_contents方法实现$url="";$html=file_ge
如何解决php网页抓取出现乱码问题
2012 年 4 月 9 日:03:36
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”转换编码;2、添加“curl_setopt($ch,CURLOPT_ENCODING,'gzip');” 选项; 3、在顶部添加标题代码。推荐
谷歌允许蜘蛛自动填写表单提交以抓取更多页面
2009 年 3 月 31 日 14:54:00
据外媒报道:美国搜索巨头谷歌最近开始在网络爬虫中实施一项新技术:他们可以让蜘蛛在某些网页中自动填写表单,并自动提交给服务器爬取反馈页面,以获取更多信息。关于这个 网站 的详细信息。
通过搜索引擎改进网络爬取、索引和排名的方法
2009 年 7 月 12 日 10:37:00
这是一个被许多 SEO 误解的重要概念。很久以前,搜索引擎爬虫(机器人)会递归地爬取某个网站(通过你提交的网站主页URL,然后爬取页面上找到的所有链接)指向该网页, 一次又一次)。
搜索引擎蜘蛛抓取网页的规律分析
27/8/2013 13:39:00
搜索引擎正面临着互联网上数以万亿计的网页。这么多网页如何高效爬取到本地镜像?这是网络爬虫的工作。我们也称它为网络蜘蛛,作为站长,我们每天都与它密切接触。
java从网页抓取数据(新手网页爬虫selenium开发教程我学java是从哪里开始)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-20 15:03
java从网页抓取数据,一般要注意以下几点:数据量有多大?数据在哪里展示?交互性强吗?数据库设计是怎样的?等等...下面介绍一个简单的爬虫,先分析,后代码...1:首先分析网页数据,数据量没有想象中大,那么分析基本结构,首先抓取的是一段话,一个图标。作为一个新手我知道要找到段落,找到哪些词、标题、图片等2:数据展示首先分析html代码,属性,看到了段落特征,看到了标题。
2.1:是元标签2.2:是关键词2.3:数据排序一般都是按字母,大小写等多种方式排序2.4:字母与图标之间有空格4:代码点击后,进入java代码,先加载一个.java文件,然后是springmvc,加载相应的.py代码,然后是python函数。
这是为广大新手的网页爬虫selenium开发教程
我学的java是从哪里开始的??
--这个很简单一个http模拟就搞定了。抓包分析, 查看全部
java从网页抓取数据(新手网页爬虫selenium开发教程我学java是从哪里开始)
java从网页抓取数据,一般要注意以下几点:数据量有多大?数据在哪里展示?交互性强吗?数据库设计是怎样的?等等...下面介绍一个简单的爬虫,先分析,后代码...1:首先分析网页数据,数据量没有想象中大,那么分析基本结构,首先抓取的是一段话,一个图标。作为一个新手我知道要找到段落,找到哪些词、标题、图片等2:数据展示首先分析html代码,属性,看到了段落特征,看到了标题。
2.1:是元标签2.2:是关键词2.3:数据排序一般都是按字母,大小写等多种方式排序2.4:字母与图标之间有空格4:代码点击后,进入java代码,先加载一个.java文件,然后是springmvc,加载相应的.py代码,然后是python函数。
这是为广大新手的网页爬虫selenium开发教程
我学的java是从哪里开始的??
--这个很简单一个http模拟就搞定了。抓包分析,
java从网页抓取数据( 如何从网页上抓取有价值的东西?看懂了下面的程序(非常简单))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-16 06:01
如何从网页上抓取有价值的东西?看懂了下面的程序(非常简单))
java使用正则表达式提取网站titles
来自网页
如何从网页中抓取有价值的东西?理解了下面这个程序(很简单)之后,你就可以从网页中抓取任何你想抓取的信息(标题、内容、Email、价格等)了。
package catchhtml;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class GetHtmlTitle {
public GetHtmlTitle(String htmlUrl){
System.out.println("/n------------开始读取网页(" + htmlUrl + ")-----------");
String htmlSource = "";
htmlSource = getHtmlSource(htmlUrl);//获取htmlUrl网址网页的源码
System.out.println("------------读取网页(" + htmlUrl + ")结束-----------/n");
System.out.println("------------分析(" + htmlUrl + ")结果如下-----------/n");
String title = getTitle(htmlSource);
System.out.println("网站标题: " + title);
}
/**
* 根据网址返回网页的源码
* @param htmlUrl
* @return
*/
public String getHtmlSource(String htmlUrl){
URL url;
StringBuffer sb = new StringBuffer();
try{
url = new URL(htmlUrl);
BufferedReader in = new BufferedReader(new InputStreamReader(url.openStream(), "UTF-8"));//读取网页全部内容
String temp;
while ((temp = in.readLine()) != null)
{
sb.append(temp);
}
in.close();
}catch (MalformedURLException e) {
System.out.println("你输入的URL格式有问题!请仔细输入");
}catch (IOException e) {
e.printStackTrace();
}
return sb.toString();
}
/**
* 从html源码(字符串)中去掉标题
* @param htmlSource
* @return
*/
public String getTitle(String htmlSource){
List list = new ArrayList();
String title = "";
//Pattern pa = Pattern.compile(".*?", Pattern.CANON_EQ);也可以
Pattern pa = Pattern.compile(".*?");//源码中标题正则表达式
Matcher ma = pa.matcher(htmlSource);
while (ma.find())//寻找符合el的字串
{
list.add(ma.group());//将符合el的字串加入到list中
}
for (int i = 0; i < list.size(); i++)
{
title = title + list.get(i);
}
return outTag(title);
}
/**
* 去掉html源码中的标签
* @param s
* @return
*/
public String outTag(String s)
{
return s.replaceAll("", "");
}
public static void main(String[] args) {
String htmlUrl = "http://www.157buy.com";
new GetHtmlTitle(htmlUrl);
}
}
联系方式:【我的公司】(鑫臻科技)【技术咨询】【QQ】3396726884
购书京东链接***微信小程序商城开发实践*** | ***新媒体营销精髓:精准定位+爆款打造+巧妙运营+内容变现***
发表于@2015-07-28 15:04 肯新军阅读(5301)comments(0)edit 查看全部
java从网页抓取数据(
如何从网页上抓取有价值的东西?看懂了下面的程序(非常简单))
java使用正则表达式提取网站titles
来自网页
如何从网页中抓取有价值的东西?理解了下面这个程序(很简单)之后,你就可以从网页中抓取任何你想抓取的信息(标题、内容、Email、价格等)了。
package catchhtml;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class GetHtmlTitle {
public GetHtmlTitle(String htmlUrl){
System.out.println("/n------------开始读取网页(" + htmlUrl + ")-----------");
String htmlSource = "";
htmlSource = getHtmlSource(htmlUrl);//获取htmlUrl网址网页的源码
System.out.println("------------读取网页(" + htmlUrl + ")结束-----------/n");
System.out.println("------------分析(" + htmlUrl + ")结果如下-----------/n");
String title = getTitle(htmlSource);
System.out.println("网站标题: " + title);
}
/**
* 根据网址返回网页的源码
* @param htmlUrl
* @return
*/
public String getHtmlSource(String htmlUrl){
URL url;
StringBuffer sb = new StringBuffer();
try{
url = new URL(htmlUrl);
BufferedReader in = new BufferedReader(new InputStreamReader(url.openStream(), "UTF-8"));//读取网页全部内容
String temp;
while ((temp = in.readLine()) != null)
{
sb.append(temp);
}
in.close();
}catch (MalformedURLException e) {
System.out.println("你输入的URL格式有问题!请仔细输入");
}catch (IOException e) {
e.printStackTrace();
}
return sb.toString();
}
/**
* 从html源码(字符串)中去掉标题
* @param htmlSource
* @return
*/
public String getTitle(String htmlSource){
List list = new ArrayList();
String title = "";
//Pattern pa = Pattern.compile(".*?", Pattern.CANON_EQ);也可以
Pattern pa = Pattern.compile(".*?");//源码中标题正则表达式
Matcher ma = pa.matcher(htmlSource);
while (ma.find())//寻找符合el的字串
{
list.add(ma.group());//将符合el的字串加入到list中
}
for (int i = 0; i < list.size(); i++)
{
title = title + list.get(i);
}
return outTag(title);
}
/**
* 去掉html源码中的标签
* @param s
* @return
*/
public String outTag(String s)
{
return s.replaceAll("", "");
}
public static void main(String[] args) {
String htmlUrl = "http://www.157buy.com";
new GetHtmlTitle(htmlUrl);
}
}
联系方式:【我的公司】(鑫臻科技)【技术咨询】【QQ】3396726884
购书京东链接***微信小程序商城开发实践*** | ***新媒体营销精髓:精准定位+爆款打造+巧妙运营+内容变现***
发表于@2015-07-28 15:04 肯新军阅读(5301)comments(0)edit
java从网页抓取数据(怎样抓取站点的数据:(1)抓取原网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-15 11:17
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具抓取网站数据比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(怎样抓取站点的数据:(1)抓取原网页数据)
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具抓取网站数据比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据(百度和其他一些网站会公布一些公共API接口供调用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-13 19:26
百度和其他一些网站会发布一些公共API接口供调用,这里是如何使用Java获取url数据并读取数据。
URL url = new URL("http://api.baidu.com/[urlAddress]");
URLConnection uc = url.openConnection();
BufferedReader in = new BufferedReader(new InputStreamReader(uc.getInputStream(),"utf-8"));
//这段代码中需要指定获取内容的编码格式,默认为UTF-8。 然后数据就被存放在Buffer里面,你可以把Buffer看成一个水管,使用readline()读取水管里面传的数据(水滴)
String str =null;
while((str=in.readline())!=null){
System.out.print(str)}
}
如果api是json格式,那么当使用str=in.readline()获取数据时,会生成一组json数据。下面介绍如何阅读:
<p> //如果是数组格式,那么使用JSONArray,也可以使用JSONObject存JSON值。具体根据JSON对象内容格式吧。
JSONArray jsonArr = new JSONArray();
JSONArray data = JSONArray.fromObject(str);
for(int i=0;i 查看全部
java从网页抓取数据(百度和其他一些网站会公布一些公共API接口供调用)
百度和其他一些网站会发布一些公共API接口供调用,这里是如何使用Java获取url数据并读取数据。
URL url = new URL("http://api.baidu.com/[urlAddress]");
URLConnection uc = url.openConnection();
BufferedReader in = new BufferedReader(new InputStreamReader(uc.getInputStream(),"utf-8"));
//这段代码中需要指定获取内容的编码格式,默认为UTF-8。 然后数据就被存放在Buffer里面,你可以把Buffer看成一个水管,使用readline()读取水管里面传的数据(水滴)
String str =null;
while((str=in.readline())!=null){
System.out.print(str)}
}
如果api是json格式,那么当使用str=in.readline()获取数据时,会生成一组json数据。下面介绍如何阅读:
<p> //如果是数组格式,那么使用JSONArray,也可以使用JSONObject存JSON值。具体根据JSON对象内容格式吧。
JSONArray jsonArr = new JSONArray();
JSONArray data = JSONArray.fromObject(str);
for(int i=0;i
java从网页抓取数据(WebScraper就是以树插件使用生巧插件(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-10 03:12
安装
Web Scraper 是一个谷歌浏览器插件。访问官方网站并点击“安装”
它会自动跳转到 Chrome 的在线商店,点击“添加到 Chrome”。
如果无法访问Chrome的在线商店,请访问国产插件网站进行安装,如下:
浏览器插件下载中心
173应用网络
Chrome 网上应用店镜像
又一个英文下载网站
crx离线安装包下载
铬插件
ChromeFor 浏览器插件
利用
什么叫完美,新手可能很难理解,其实只需要记住一句话,一个网页的内容是一棵树,树的根是网站的url,从url 网站 到我们需要访问数据所在的元素(html元素),就是从根节点遍历到叶子节点的过程。这个过程很简单,就是直接去叶子节点,还有一个复杂的过程,就是用递归的思维来处理页面刷新的情况。
在这里,我只展示一些简单的,让您对 Web Scraper 有一个初步的了解。对于复杂的爬取,请访问官方文档,阅读视频和文档学习。
请记住,网页的内容是一棵树,因此您可以轻松了解该工具的工作原理。Web Scraper 以树的形式组织站点地图。以抓取知乎的热榜数据为例,一步步展示本插件的使用。
知乎热榜页面如下图:
root是页面的URL,也就是现在给这个root取个名字,叫知乎_hot(名字随意,方便识别),知乎_hot的子节点可以是video、science、digital、sports。这些子节点下的子节点就是我们要爬取的内容列表。
现在开始使用 Web Scraper:
第一步,打开谷歌浏览器的开发者工具,点击最右侧的Web Scraper菜单,如下图:
第二步是创建站点地图和选择器:
点击创建新站点地图->创建站点地图,在站点地图名称中输入知乎_hot,其中知乎_hot可以是任何名称以便于识别,只能是英文,然后填写Start Url:然后点击创建站点地图按钮完成创建,如下图所示:
点击Add new selector,添加一个选择器,即添加一个子节点:
然后会弹出一个框供我们填写选择器的相关信息。ID填写类别,类型选择元素点击。这时会出现两个选择器,一个是selector,代表要传递给category子节点的元素,另一个是Click选择器,代表要点击的元素。为了方便大家理解,请先选择Click选择器,再选择选择器,如下图:
点击选择器的选择:
选择器的选择:
选择完成后,勾选Mutiple爬取多类,点击保存选择器保存。
继续在category下添加Selector,即category_e,category_e接收到的元素就是category中选择器选中的元素,即div.HostList-list。category_e的配置如下图所示:
然后继续在category_e下添加三个Selector,分别是hot_no、title、hot_degree,如下图所示:
保存后点击Selector graph
您可以看到如下所示的树:
此时,我们的站点地图及其选择器已创建。
第三步是运行 Web Scraper。
单击菜单中的“刮擦”按钮
然后会要求你设置爬取的时间间隔,保持默认,如果网速慢可以适当延长:
单击开始抓取以运行 Web Scraper。此时Web Scraper会打开一个新的浏览器窗口,执行按钮点击操作,并将数据保存在浏览器的LocalStorage中。操作完成后,新窗口会自动关闭,点击下图中的刷新按钮:
可以看到抓取到的数据,如下图所示:
数据可以导出为 csv 文件,点击 Export data as CSV -> 立即下载
您可以下载 csv 文件:
是不是很方便?
如果还是不能成功爬取上面的数据,下面是我导出的sitemap信息,可以将这些文字复制到sitemap中,再试一次,对比一下看看有什么不同:
{"_id":"zhihu_hot","startUrl":["https://www.zhihu.com/hot"],"selectors":[{"id":"category","type":"SelectorElementClick","parentSelectors":["_root"],"selector":"div.HotList-list","multiple":true,"delay":2000,"clickElementSelector":"a.HotListNav-item","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType":"uniqueText"},{"id":"category_e","type":"SelectorElement","parentSelectors":["category"],"selector":"section","multiple":true,"delay":0},{"id":"hot_num","type":"SelectorText","parentSelectors":["category_e"],"selector":"div.HotItem-rank","multiple":false,"regex":"","delay":0},{"id":"title","type":"SelectorLink","parentSelectors":["category_e"],"selector":".HotItem-content a","multiple":false,"delay":0},{"id":"hot_degree","type":"SelectorText","parentSelectors":["category_e"],"selector":"div.HotItem-metrics","multiple":false,"regex":"","delay":0}]}
至于分页,或者无限加载,都可以轻松搞定。这种情况下的分类按钮相当于一种分页按钮。其他分页操作,官网有相应的视频教程。
的优点和缺点
优势:
Web Scraper 的优势在于无需学习编程即可抓取网页数据。
即使对于计算机专业人士来说,使用 Web Scraper 爬取一些网页的文本数据也比自己编写代码效率更高,可以节省大量的编码和调试时间。
依赖环境很简单,只需要谷歌浏览器和插件。
缺点:
仅支持文本数据采集,不能批量采集图片、短视频等多媒体数据。
不支持复杂的网页爬取,如采取反爬取措施,复杂的人机交互网页,Web Scraper无能为力。事实上,这种代码爬取也是相当困难的。
导出的数据不按爬取的顺序显示。如果要排序,需要导出Excel,然后排序。这也很容易克服。在数据分析之前,大部分数据都需要导出到 Excel 中。 查看全部
java从网页抓取数据(WebScraper就是以树插件使用生巧插件(图))
安装
Web Scraper 是一个谷歌浏览器插件。访问官方网站并点击“安装”
它会自动跳转到 Chrome 的在线商店,点击“添加到 Chrome”。
如果无法访问Chrome的在线商店,请访问国产插件网站进行安装,如下:
浏览器插件下载中心
173应用网络
Chrome 网上应用店镜像
又一个英文下载网站
crx离线安装包下载
铬插件
ChromeFor 浏览器插件
利用
什么叫完美,新手可能很难理解,其实只需要记住一句话,一个网页的内容是一棵树,树的根是网站的url,从url 网站 到我们需要访问数据所在的元素(html元素),就是从根节点遍历到叶子节点的过程。这个过程很简单,就是直接去叶子节点,还有一个复杂的过程,就是用递归的思维来处理页面刷新的情况。
在这里,我只展示一些简单的,让您对 Web Scraper 有一个初步的了解。对于复杂的爬取,请访问官方文档,阅读视频和文档学习。
请记住,网页的内容是一棵树,因此您可以轻松了解该工具的工作原理。Web Scraper 以树的形式组织站点地图。以抓取知乎的热榜数据为例,一步步展示本插件的使用。
知乎热榜页面如下图:
root是页面的URL,也就是现在给这个root取个名字,叫知乎_hot(名字随意,方便识别),知乎_hot的子节点可以是video、science、digital、sports。这些子节点下的子节点就是我们要爬取的内容列表。
现在开始使用 Web Scraper:
第一步,打开谷歌浏览器的开发者工具,点击最右侧的Web Scraper菜单,如下图:
第二步是创建站点地图和选择器:
点击创建新站点地图->创建站点地图,在站点地图名称中输入知乎_hot,其中知乎_hot可以是任何名称以便于识别,只能是英文,然后填写Start Url:然后点击创建站点地图按钮完成创建,如下图所示:
点击Add new selector,添加一个选择器,即添加一个子节点:
然后会弹出一个框供我们填写选择器的相关信息。ID填写类别,类型选择元素点击。这时会出现两个选择器,一个是selector,代表要传递给category子节点的元素,另一个是Click选择器,代表要点击的元素。为了方便大家理解,请先选择Click选择器,再选择选择器,如下图:
点击选择器的选择:
选择器的选择:
选择完成后,勾选Mutiple爬取多类,点击保存选择器保存。
继续在category下添加Selector,即category_e,category_e接收到的元素就是category中选择器选中的元素,即div.HostList-list。category_e的配置如下图所示:
然后继续在category_e下添加三个Selector,分别是hot_no、title、hot_degree,如下图所示:
保存后点击Selector graph
您可以看到如下所示的树:
此时,我们的站点地图及其选择器已创建。
第三步是运行 Web Scraper。
单击菜单中的“刮擦”按钮
然后会要求你设置爬取的时间间隔,保持默认,如果网速慢可以适当延长:
单击开始抓取以运行 Web Scraper。此时Web Scraper会打开一个新的浏览器窗口,执行按钮点击操作,并将数据保存在浏览器的LocalStorage中。操作完成后,新窗口会自动关闭,点击下图中的刷新按钮:
可以看到抓取到的数据,如下图所示:
数据可以导出为 csv 文件,点击 Export data as CSV -> 立即下载
您可以下载 csv 文件:
是不是很方便?
如果还是不能成功爬取上面的数据,下面是我导出的sitemap信息,可以将这些文字复制到sitemap中,再试一次,对比一下看看有什么不同:
{"_id":"zhihu_hot","startUrl":["https://www.zhihu.com/hot"],"selectors":[{"id":"category","type":"SelectorElementClick","parentSelectors":["_root"],"selector":"div.HotList-list","multiple":true,"delay":2000,"clickElementSelector":"a.HotListNav-item","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType":"uniqueText"},{"id":"category_e","type":"SelectorElement","parentSelectors":["category"],"selector":"section","multiple":true,"delay":0},{"id":"hot_num","type":"SelectorText","parentSelectors":["category_e"],"selector":"div.HotItem-rank","multiple":false,"regex":"","delay":0},{"id":"title","type":"SelectorLink","parentSelectors":["category_e"],"selector":".HotItem-content a","multiple":false,"delay":0},{"id":"hot_degree","type":"SelectorText","parentSelectors":["category_e"],"selector":"div.HotItem-metrics","multiple":false,"regex":"","delay":0}]}
至于分页,或者无限加载,都可以轻松搞定。这种情况下的分类按钮相当于一种分页按钮。其他分页操作,官网有相应的视频教程。
的优点和缺点
优势:
Web Scraper 的优势在于无需学习编程即可抓取网页数据。
即使对于计算机专业人士来说,使用 Web Scraper 爬取一些网页的文本数据也比自己编写代码效率更高,可以节省大量的编码和调试时间。
依赖环境很简单,只需要谷歌浏览器和插件。
缺点:
仅支持文本数据采集,不能批量采集图片、短视频等多媒体数据。
不支持复杂的网页爬取,如采取反爬取措施,复杂的人机交互网页,Web Scraper无能为力。事实上,这种代码爬取也是相当困难的。
导出的数据不按爬取的顺序显示。如果要排序,需要导出Excel,然后排序。这也很容易克服。在数据分析之前,大部分数据都需要导出到 Excel 中。
java从网页抓取数据(爬虫程序的开发比较简单程序程序开发程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-01-09 19:09
构建爬虫的一次旅行
最近需要从网上抓取很多资料,所以体验了爬虫程序的开发和部署,主要是学习一些实用工具的操作。本教程的开发要求是编写一个收录爬虫程序的Java项目,并且可以方便的在服务器端编译、部署和启动爬虫程序。1.爬虫程序的开发 爬虫程序的开发比较简单。下面是一个简单的例子。它的主要功能是爬取中国文学网新华词典中的所有汉字详情页,并保存到一个文件中。爬虫框架使用Crawl4j,优点是只需要配置爬虫框架的几个重要参数即可启动爬虫:(1) 爬虫的数据缓存目录;(2)爬虫的爬取Policy,包括是否跟随robots文件、请求之间的延迟、页面的最大深度、页数的控制等;(3)入口爬虫的地址;(4)爬虫遇到new页面的url,通过shouldVisit判断是否访问这个url;(5)爬虫访问(访问)那些url时的具体操作,比如as 将内容保存到文件 edu.uci.ics.crawler4j.url.WebURL;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.io.File; ** * 中国文学网的数据采集工具 页数等的控制;(3)爬虫的入口地址;(4)爬虫遇到new页面的url,通过shouldVisit判断是否访问这个url;(5)爬虫时的具体操作访问(访问)那些url,比如将内容保存到文件edu.uci.ics.crawler4j.url.WebURL;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.io.File;** * 中国文学网的数据采集工具 页数等的控制;(3)爬虫的入口地址;(4)爬虫遇到new页面的url,通过shouldVisit判断是否访问这个url;(5)爬虫时的具体操作访问(访问)那些url,比如将内容保存到文件edu.uci.ics.crawler4j.url.WebURL;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.io.File;** * 中国文学网的数据采集工具 导入 org.slf4j.LoggerFactory;导入java.io.File;** 中国文学网的数据采集工具 导入 org.slf4j.LoggerFactory;导入java.io.File;** 中国文学网的数据采集工具
449 查看全部
java从网页抓取数据(爬虫程序的开发比较简单程序程序开发程序)
构建爬虫的一次旅行
最近需要从网上抓取很多资料,所以体验了爬虫程序的开发和部署,主要是学习一些实用工具的操作。本教程的开发要求是编写一个收录爬虫程序的Java项目,并且可以方便的在服务器端编译、部署和启动爬虫程序。1.爬虫程序的开发 爬虫程序的开发比较简单。下面是一个简单的例子。它的主要功能是爬取中国文学网新华词典中的所有汉字详情页,并保存到一个文件中。爬虫框架使用Crawl4j,优点是只需要配置爬虫框架的几个重要参数即可启动爬虫:(1) 爬虫的数据缓存目录;(2)爬虫的爬取Policy,包括是否跟随robots文件、请求之间的延迟、页面的最大深度、页数的控制等;(3)入口爬虫的地址;(4)爬虫遇到new页面的url,通过shouldVisit判断是否访问这个url;(5)爬虫访问(访问)那些url时的具体操作,比如as 将内容保存到文件 edu.uci.ics.crawler4j.url.WebURL;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.io.File; ** * 中国文学网的数据采集工具 页数等的控制;(3)爬虫的入口地址;(4)爬虫遇到new页面的url,通过shouldVisit判断是否访问这个url;(5)爬虫时的具体操作访问(访问)那些url,比如将内容保存到文件edu.uci.ics.crawler4j.url.WebURL;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.io.File;** * 中国文学网的数据采集工具 页数等的控制;(3)爬虫的入口地址;(4)爬虫遇到new页面的url,通过shouldVisit判断是否访问这个url;(5)爬虫时的具体操作访问(访问)那些url,比如将内容保存到文件edu.uci.ics.crawler4j.url.WebURL;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.io.File;** * 中国文学网的数据采集工具 导入 org.slf4j.LoggerFactory;导入java.io.File;** 中国文学网的数据采集工具 导入 org.slf4j.LoggerFactory;导入java.io.File;** 中国文学网的数据采集工具
449
java从网页抓取数据(如何使用Java/Python访问网页和使用Python进行数据解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-09 19:05
前言:
网络爬虫看起来仍然很棒。但是,如果您考虑一下,或进行一些研究,您就会知道爬行动物并没有那么先进。最深刻的就是当我们的数据量很大的时候,也就是当我们的网络“图”中的循环越来越多的时候,如何解决。
这篇文章文章只是在这里起到一个引导的作用。本文主要讲解如何使用Java/Python访问网页并获取网页代码,Python模仿浏览器访问网页,使用Python进行数据分析。希望我们能从这篇文章开始,一步步揭开网络蜘蛛的神秘面纱。
参考:
1.《编写你自己的网络爬虫》
2.用python编写爬虫爬取csdn内容,完美解决403 Forbidden
运行效果图:
内容很多,我只选了一部分展示。
作者环境:
系统:Windows 7
CentOS 6.5
运行环境:JDK1.7
Python 2.6.6
IDE:EclipseRelease 4.2.0
PyCharm 4.5.1
数据库:MySQLVer 14.14 Distrib 5.1.73
开发过程:1.使用Java爬取页面
对于页面抓取我们使用Java来实现,当然你也可以使用其他语言来开发。但
下面以“博客园”首页为例,展示使用Java进行网页爬取的过程:
public class RetrivePageSimple {
private static HttpClient httpClient = new HttpClient();
// 设置代理服务器
static {
httpClient.getHostConfiguration().setProxy("58.220.2.132", 80);
}
public static boolean downloadPage(String path) throws HttpException,
IOException {
PostMethod postMethod = new PostMethod(path);
// 执行,返回状态码
int statusCode = httpClient.executeMethod(postMethod);
System.out.println(statusCode);
// 针对状态码进行处理 (简单起见,只处理返回值为200的状态码)
if (statusCode == HttpStatus.SC_OK) {
String a = postMethod.getResponseBodyAsString();
System.out.println(a);
return true;
}
return false;
}
public static void main(String[] args) {
try {
RetrivePageSimple.downloadPage("http://www.cnblogs.com/");
} catch (HttpException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
结果信息在这里不再显示,太多了。. . - -!
2.使用 Python 抓取页面
可能你会问我,为什么写成使用Java版的页面爬取,而这里又是一个Python?这是必要的。因为作者在开发这个demo之前没有考虑问题。当我们使用Java爬取网页到Python时,网页字符串太长无法作为参数传递。您可能认为保存文件是一个不错的选择,但是如果 html 文件过多怎么办?是的,在这里我们必须放弃这种累人的做法。
考虑到参数长度的限制,这里只给出Java端的页面地址,使用Python爬取网页。
以最简单的方式,我们通常使用这样的 Python 网页:
import urllib2
result = urllib2.urlopen('http://blog.csdn.net/mobile/index.html')
html = result.read()
print html
但是作者的代码使用的是CSDN博客频道的url。CSDN 过滤来自爬虫的访问。如下,我们会得到如下错误信息:
403,我被拒绝了。
3.使用模拟浏览器登录网站
如前所述,当我们访问一个带有保护措施的网页时,它会被拒绝。但是我们可以尝试使用我们自己的浏览器来访问它,它是可以访问的。
也就是说,如果我们能在 Python 中把自己模仿成一个浏览器,就可以访问这个网页。这是在 Python 中模仿浏览器的代码:
import random
import socket
import urllib2
import cookielib
ERROR = {
'0':'Can not open the url,checck you net',
'1':'Creat download dir error',
'2':'The image links is empty',
'3':'Download faild',
'4':'Build soup error,the html is empty',
'5':'Can not save the image to your disk',
}
class BrowserBase(object):
def __init__(self):
socket.setdefaulttimeout(20)
self._content = None
def speak(self, name, content):
print '[%s]%s' % (name, content)
def open_url(self, url):
"""
打开网页
"""
cookie_support= urllib2.HTTPCookieProcessor(cookielib.CookieJar())
self.opener = urllib2.build_opener(cookie_support,urllib2.HTTPHandler)
urllib2.install_opener(self.opener)
user_agents = [
'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11',
'Opera/9.25 (Windows NT 5.1; U; en)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 ",
]
agent = random.choice(user_agents)
self.opener.addheaders = [("User-agent", agent), ("Accept", "*/*"), ('Referer', 'http://www.google.com')]
try:
res = self.opener.open(url)
self._content = res.read()
# print self._content
except Exception, e:
self.speak(str(e)+url)
raise Exception
else:
return res
def get_html_content(self):
return self._content
def get_html_response(html):
spider = BrowserBase()
spider.open_url(html)
return spider.get_html_content()
以上代码可以正常获取返回值。下面我们来看看返回结果的解析过程。
4.数据分析
使用 Python 解析 Html 异常简单:
import HTMLParser
class ListWebParser(HTMLParser.HTMLParser):
def __init__(self):
HTMLParser.HTMLParser.__init__(self)
self.tagDIVFlag = False
self.tagDIVAFlag = False
self.tagH1Flag = False
self.tagSecondHrefFlag = False
self._name = None
self._address = None
def handle_starttag(self, tag, attrs):
if tag == 'div':
for name, value in attrs:
if name == 'class' and value == 'blog_list':
self.tagDIVFlag = True
if tag == 'h1':
if self.tagDIVFlag:
self.tagH1Flag = True
# print 'h1->', self.tagH1Flag
if tag == 'a':
#if self.tagDIVAFlag:
#print 'h1: ', self.tagH1Flag
if self.tagH1Flag:
for name, value in attrs:
if name == 'target' and value == '_blank':
self.tagDIVAFlag = True
if name == 'href':
if self.tagSecondHrefFlag:
print '网址:', value
self._address = value
self.tagSecondHrefFlag = True
# if name == 'href' and self.tagDIVAFlag:
# print '网址:', value
# self._address = value
def handle_endtag(self, tag):
if tag == 'div':
self.tagDIVFlag = False
if tag == 'h1':
self.tagH1Flag = False
# print 'false h1.'
if tag == 'a':
self.tagDIVAFlag = False
def handle_data(self, data):
if self.tagDIVAFlag:
print u"名称:", data.decode("utf-8")
如果你说你在网上找到的Html文件没有这个麻烦。我承认这一点,因为在正常情况下,我们解析一些简单的数据真的很简单。上面代码中的复杂逻辑是处理过滤。
说到过滤,我这里用了一个小技巧(当然,当更多的人使用它时,这不再只是一个技巧。但是,这种方法可以在以后的编码过程中进行参考)。我们通过标签的一些特殊属性(例如:id、class等)来锁定块。当我们开始block时,我们对应的flag会被标记为True,当我们退出block时,我们对应的flag会被标记为False。也许你认为这太麻烦了。其实,如果你仔细想想,你会发现它是有道理的。
预防措施:
1.当使用 Java 进行网页抓取时,我们使用代理服务器。这个代理服务器的主机和端口可以直接在网上免费查到。
2.你需要准备以下jar包并导入到你的Eclipse项目中:
3.修改MySQL默认编码为UTF-8
因为这里会有一些中文信息,所以我们需要转换MySQL的编码格式。
如果你是在Linux下编码,那么你可以参考:
转载于: 查看全部
java从网页抓取数据(如何使用Java/Python访问网页和使用Python进行数据解析)
前言:
网络爬虫看起来仍然很棒。但是,如果您考虑一下,或进行一些研究,您就会知道爬行动物并没有那么先进。最深刻的就是当我们的数据量很大的时候,也就是当我们的网络“图”中的循环越来越多的时候,如何解决。
这篇文章文章只是在这里起到一个引导的作用。本文主要讲解如何使用Java/Python访问网页并获取网页代码,Python模仿浏览器访问网页,使用Python进行数据分析。希望我们能从这篇文章开始,一步步揭开网络蜘蛛的神秘面纱。
参考:
1.《编写你自己的网络爬虫》
2.用python编写爬虫爬取csdn内容,完美解决403 Forbidden
运行效果图:
内容很多,我只选了一部分展示。
作者环境:
系统:Windows 7
CentOS 6.5
运行环境:JDK1.7
Python 2.6.6
IDE:EclipseRelease 4.2.0
PyCharm 4.5.1
数据库:MySQLVer 14.14 Distrib 5.1.73
开发过程:1.使用Java爬取页面
对于页面抓取我们使用Java来实现,当然你也可以使用其他语言来开发。但
下面以“博客园”首页为例,展示使用Java进行网页爬取的过程:
public class RetrivePageSimple {
private static HttpClient httpClient = new HttpClient();
// 设置代理服务器
static {
httpClient.getHostConfiguration().setProxy("58.220.2.132", 80);
}
public static boolean downloadPage(String path) throws HttpException,
IOException {
PostMethod postMethod = new PostMethod(path);
// 执行,返回状态码
int statusCode = httpClient.executeMethod(postMethod);
System.out.println(statusCode);
// 针对状态码进行处理 (简单起见,只处理返回值为200的状态码)
if (statusCode == HttpStatus.SC_OK) {
String a = postMethod.getResponseBodyAsString();
System.out.println(a);
return true;
}
return false;
}
public static void main(String[] args) {
try {
RetrivePageSimple.downloadPage("http://www.cnblogs.com/";);
} catch (HttpException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
结果信息在这里不再显示,太多了。. . - -!
2.使用 Python 抓取页面
可能你会问我,为什么写成使用Java版的页面爬取,而这里又是一个Python?这是必要的。因为作者在开发这个demo之前没有考虑问题。当我们使用Java爬取网页到Python时,网页字符串太长无法作为参数传递。您可能认为保存文件是一个不错的选择,但是如果 html 文件过多怎么办?是的,在这里我们必须放弃这种累人的做法。
考虑到参数长度的限制,这里只给出Java端的页面地址,使用Python爬取网页。
以最简单的方式,我们通常使用这样的 Python 网页:
import urllib2
result = urllib2.urlopen('http://blog.csdn.net/mobile/index.html')
html = result.read()
print html
但是作者的代码使用的是CSDN博客频道的url。CSDN 过滤来自爬虫的访问。如下,我们会得到如下错误信息:
403,我被拒绝了。
3.使用模拟浏览器登录网站
如前所述,当我们访问一个带有保护措施的网页时,它会被拒绝。但是我们可以尝试使用我们自己的浏览器来访问它,它是可以访问的。
也就是说,如果我们能在 Python 中把自己模仿成一个浏览器,就可以访问这个网页。这是在 Python 中模仿浏览器的代码:
import random
import socket
import urllib2
import cookielib
ERROR = {
'0':'Can not open the url,checck you net',
'1':'Creat download dir error',
'2':'The image links is empty',
'3':'Download faild',
'4':'Build soup error,the html is empty',
'5':'Can not save the image to your disk',
}
class BrowserBase(object):
def __init__(self):
socket.setdefaulttimeout(20)
self._content = None
def speak(self, name, content):
print '[%s]%s' % (name, content)
def open_url(self, url):
"""
打开网页
"""
cookie_support= urllib2.HTTPCookieProcessor(cookielib.CookieJar())
self.opener = urllib2.build_opener(cookie_support,urllib2.HTTPHandler)
urllib2.install_opener(self.opener)
user_agents = [
'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11',
'Opera/9.25 (Windows NT 5.1; U; en)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 ",
]
agent = random.choice(user_agents)
self.opener.addheaders = [("User-agent", agent), ("Accept", "*/*"), ('Referer', 'http://www.google.com')]
try:
res = self.opener.open(url)
self._content = res.read()
# print self._content
except Exception, e:
self.speak(str(e)+url)
raise Exception
else:
return res
def get_html_content(self):
return self._content
def get_html_response(html):
spider = BrowserBase()
spider.open_url(html)
return spider.get_html_content()
以上代码可以正常获取返回值。下面我们来看看返回结果的解析过程。
4.数据分析
使用 Python 解析 Html 异常简单:
import HTMLParser
class ListWebParser(HTMLParser.HTMLParser):
def __init__(self):
HTMLParser.HTMLParser.__init__(self)
self.tagDIVFlag = False
self.tagDIVAFlag = False
self.tagH1Flag = False
self.tagSecondHrefFlag = False
self._name = None
self._address = None
def handle_starttag(self, tag, attrs):
if tag == 'div':
for name, value in attrs:
if name == 'class' and value == 'blog_list':
self.tagDIVFlag = True
if tag == 'h1':
if self.tagDIVFlag:
self.tagH1Flag = True
# print 'h1->', self.tagH1Flag
if tag == 'a':
#if self.tagDIVAFlag:
#print 'h1: ', self.tagH1Flag
if self.tagH1Flag:
for name, value in attrs:
if name == 'target' and value == '_blank':
self.tagDIVAFlag = True
if name == 'href':
if self.tagSecondHrefFlag:
print '网址:', value
self._address = value
self.tagSecondHrefFlag = True
# if name == 'href' and self.tagDIVAFlag:
# print '网址:', value
# self._address = value
def handle_endtag(self, tag):
if tag == 'div':
self.tagDIVFlag = False
if tag == 'h1':
self.tagH1Flag = False
# print 'false h1.'
if tag == 'a':
self.tagDIVAFlag = False
def handle_data(self, data):
if self.tagDIVAFlag:
print u"名称:", data.decode("utf-8")
如果你说你在网上找到的Html文件没有这个麻烦。我承认这一点,因为在正常情况下,我们解析一些简单的数据真的很简单。上面代码中的复杂逻辑是处理过滤。
说到过滤,我这里用了一个小技巧(当然,当更多的人使用它时,这不再只是一个技巧。但是,这种方法可以在以后的编码过程中进行参考)。我们通过标签的一些特殊属性(例如:id、class等)来锁定块。当我们开始block时,我们对应的flag会被标记为True,当我们退出block时,我们对应的flag会被标记为False。也许你认为这太麻烦了。其实,如果你仔细想想,你会发现它是有道理的。
预防措施:
1.当使用 Java 进行网页抓取时,我们使用代理服务器。这个代理服务器的主机和端口可以直接在网上免费查到。
2.你需要准备以下jar包并导入到你的Eclipse项目中:
3.修改MySQL默认编码为UTF-8
因为这里会有一些中文信息,所以我们需要转换MySQL的编码格式。
如果你是在Linux下编码,那么你可以参考:
转载于:
java从网页抓取数据(本文某个站点对数据的显示方式略有不同演示怎样抓取站点的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-09 19:04
原文链接:
有时出于各种原因。我们需要从网站采集数据。但是因为不同的站点显示数据略有不同!
本文将使用Java来给大家展示如何抓取网站的数据:(1)抓取原创网页数据。(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页。然后输入IP:111.142.55.73,点击查询按钮。您可以在网页上看到显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出。再次请求网页后显示查询结果。
看看查询后的网页地址:
也就是说,我们只想访问表单的一个 URL。可以得到ip查询的结果,再看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?
IP=" + ip; URL url = new URL(strURL); HttpURLConnection httpConn = (HttpURLConnection) url.openConnection(); InputStreamReader input = new InputStreamReader(httpConn .getInputStream(), "utf-8"); BufferedReader bufReader = new BufferedReader(input); String line = ""; StringBuilder contentBuf = new StringBuilder(); while ((line = bufReader.readLine()) != null) { contentBuf.append(line); } String buf = contentBuf.toString( ); int beginIx = buf.indexOf("查询结果["); int endIx = buf.indexOf("以上四项依次显示"); String result = buf.substring(beginIx, endIx); System.out .println("captureHtml()的结果:\n" + result); }
使用 HttpURLConnection 连接到站点。使用bufReader保存网页返回的数据,然后通过自定义的分析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时,网站为了保护自己的数据,并不直接在网页源代码中返回数据,而是采用异步的方式。使用JS返回数据,可以避免搜索引擎等工具抓取网站数据。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7。点击查询按钮,查看 HTTP Analyzer 的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出。HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
既然如此。我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。我们记下 JS 请求的 URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?
wen=" + postid + "&channel=&rnd=0"; URL url = new URL(strURL); HttpURLConnection httpConn = (HttpURLConnection) url.openConnection(); InputStreamReader input = new InputStreamReader(httpConn .getInputStream(), "utf- 8"); BufferedReader bufReader = new BufferedReader(input); String line = ""; StringBuilder contentBuf = new StringBuilder(); while ((line = bufReader.readLine()) != null) { contentBuf.append(line); System.out.println("captureJavascript() 的结果:\n" + contentBuf.toString()); }
看见。抓取JS的方式和之前的代码抓取原创网页的方式一模一样。我们只是做了一个分析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这可以是需要帮助的小朋友,需要程序的源码,点此下载! 查看全部
java从网页抓取数据(本文某个站点对数据的显示方式略有不同演示怎样抓取站点的数据)
原文链接:
有时出于各种原因。我们需要从网站采集数据。但是因为不同的站点显示数据略有不同!
本文将使用Java来给大家展示如何抓取网站的数据:(1)抓取原创网页数据。(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页。然后输入IP:111.142.55.73,点击查询按钮。您可以在网页上看到显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出。再次请求网页后显示查询结果。
看看查询后的网页地址:
也就是说,我们只想访问表单的一个 URL。可以得到ip查询的结果,再看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?
IP=" + ip; URL url = new URL(strURL); HttpURLConnection httpConn = (HttpURLConnection) url.openConnection(); InputStreamReader input = new InputStreamReader(httpConn .getInputStream(), "utf-8"); BufferedReader bufReader = new BufferedReader(input); String line = ""; StringBuilder contentBuf = new StringBuilder(); while ((line = bufReader.readLine()) != null) { contentBuf.append(line); } String buf = contentBuf.toString( ); int beginIx = buf.indexOf("查询结果["); int endIx = buf.indexOf("以上四项依次显示"); String result = buf.substring(beginIx, endIx); System.out .println("captureHtml()的结果:\n" + result); }
使用 HttpURLConnection 连接到站点。使用bufReader保存网页返回的数据,然后通过自定义的分析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时,网站为了保护自己的数据,并不直接在网页源代码中返回数据,而是采用异步的方式。使用JS返回数据,可以避免搜索引擎等工具抓取网站数据。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7。点击查询按钮,查看 HTTP Analyzer 的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出。HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
既然如此。我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。我们记下 JS 请求的 URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?
wen=" + postid + "&channel=&rnd=0"; URL url = new URL(strURL); HttpURLConnection httpConn = (HttpURLConnection) url.openConnection(); InputStreamReader input = new InputStreamReader(httpConn .getInputStream(), "utf- 8"); BufferedReader bufReader = new BufferedReader(input); String line = ""; StringBuilder contentBuf = new StringBuilder(); while ((line = bufReader.readLine()) != null) { contentBuf.append(line); System.out.println("captureJavascript() 的结果:\n" + contentBuf.toString()); }
看见。抓取JS的方式和之前的代码抓取原创网页的方式一模一样。我们只是做了一个分析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这可以是需要帮助的小朋友,需要程序的源码,点此下载!
java从网页抓取数据(djangojava从网页抓取数据包括抓包后分析网页的方案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-05 02:00
java从网页抓取数据包括抓包后分析网页抓取数据还是比较简单的,只要你会抓包,简单的抓包技巧(可以去看前端可视化抓包数据)会写爬虫程序,你只要学会一点http/https/websocket代理工具就可以跑抓取数据了,数据量大情况下建议去抓网页从网页中读取数据,
泻药,好久没回答知乎上的问题了。这个问题想必是你没有抓取的人机交互数据吧。django有很多api,mongodb也有人机交互。方案1:直接用python写网页的开发人员工具库,如easyui或者bootstrap,通过ajax获取数据库数据,再通过python爬虫对数据进行分析。方案2:再购买bs3等bs文件,直接包装到python或者java中,然后可以通过java程序来处理。
顺便再分析分析网页的结构,数据,数据来源,再对数据进行处理。最后进行解析或者提交给程序进行解析。后两种,并不复杂,都是文件,文件里面都会写一些方法,需要的话通过加载对应的文件来操作,最难的就是数据库方面。
scrapy
django搭一个博客框架,爬爬行情、订单、二手车信息就足够了。
主要看你们的需求,问题是不是都这么问。你问你的导师,比如网页抓取产品一般收集新闻和php,django等redis有些集群来抓,也可以爬其他信息(这个你们得根据你们的需求, 查看全部
java从网页抓取数据(djangojava从网页抓取数据包括抓包后分析网页的方案)
java从网页抓取数据包括抓包后分析网页抓取数据还是比较简单的,只要你会抓包,简单的抓包技巧(可以去看前端可视化抓包数据)会写爬虫程序,你只要学会一点http/https/websocket代理工具就可以跑抓取数据了,数据量大情况下建议去抓网页从网页中读取数据,
泻药,好久没回答知乎上的问题了。这个问题想必是你没有抓取的人机交互数据吧。django有很多api,mongodb也有人机交互。方案1:直接用python写网页的开发人员工具库,如easyui或者bootstrap,通过ajax获取数据库数据,再通过python爬虫对数据进行分析。方案2:再购买bs3等bs文件,直接包装到python或者java中,然后可以通过java程序来处理。
顺便再分析分析网页的结构,数据,数据来源,再对数据进行处理。最后进行解析或者提交给程序进行解析。后两种,并不复杂,都是文件,文件里面都会写一些方法,需要的话通过加载对应的文件来操作,最难的就是数据库方面。
scrapy
django搭一个博客框架,爬爬行情、订单、二手车信息就足够了。
主要看你们的需求,问题是不是都这么问。你问你的导师,比如网页抓取产品一般收集新闻和php,django等redis有些集群来抓,也可以爬其他信息(这个你们得根据你们的需求,

