
java从网页抓取数据
java从网页抓取数据(Java语言连接数据库的技术及其设计原则(一)|数据库 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-27 08:07
)
相关话题
数据存储名称
2018 年 2 月 3 日 01:09:42
总结:查找数据库全局名:select*fromglobal_name;查找数据库实例名称:select*fromv$instance;查找数据库名称 selectnamefromv$database;
Java实现连接access数据库和读取数据的操作
19/11/202018:06:59
具体步骤如下:一、连接access数据库创建AccessDbUtil类,连接数据库importjava.sql.Connection;importjava.sql.DriverManager;/***获取Access连接**@authordof
数据库、数据库系统、数据库管理系统是什么关系
2021 年 11 月 1 日 21:03:47
数据库、数据库系统、数据库管理系统之间的关系是:数据库系统包括数据库和数据库管理系统。数据库系统是具有数据库的计算机系统,一般由数据库、数据库管理系统(及其开发工具)组成。
数据库设计原则
2018 年 4 月 3 日 01:12:52
数据库设计原则一、建立数据团队 大型数据库的数据元素很多,设计时需要成立专门的数据团队。由于数据库设计者不一定是用户,所以不可能在系统设计中充分考虑数据元素。数据库设计好后,往往很难找到需要的数据库表。因此,数据团队最好由熟悉业务的项目骨干组成。数据团队的作用不是设计数据库,而是在参考其他类似系统的基础上,通过需求分析提取系统的基本数据元素
Linux操作mysql数据库总结
2018 年 4 月 3 日 01:10:31
1、首先连接数据库所在机器2、使用“db”命令连接MySQL3、可以使用以下命令查看数据库信息,注意命令需要以“;”结尾:SHOWDATABASES/ /List MySQLServer 数据库。SHOWTABLES[FROMdb_name]//列表编号
与 MySQL 数据库的 JDBC 连接和示例
2018 年 4 月 3 日 01:14:06
DBC 是 Sun 开发的一种可以使用 Java 语言连接数据库的技术。一、JDBC基础知识 JDBC(JavaDataBaseConnectivity,java数据库连接)是用于执行SQL语句的Java API,可以提供对各种关系数据库的统一访问。它由一组用 Java 语言编写的类和接口组成。. JDBC 为数据库开发人员提供了一个标准 API,可在此基础上构建更高级的
关系数据库的特点和常用的关系数据库
29/4/202009:37:20
关系数据库是指使用“关系模型”来组织数据的数据库,它以“行和列”的形式存储数据,以便于用户理解。关系数据库是一系列称为表的行和列,一组表组成数据库。采用
数据库名、全局数据库名、SID区别及感受
2/3/2018 01:09:44
总结:数据库名、全局数据库名、SID区别及感受
详细讲解Oracle数据库中的各种名称和标识符
2018 年 2 月 3 日 01:10:26
在 ORACLE7、8 数据库中只有数据库名称(db_name)和数据库实例名称(instance_name)。在ORACLE8i中,9i出现了新的参数,即数据库域名(db_domain)、服务名(service_name)、操作系统环境变量(ORACLE_SID)。这些是存在于同一数据库中的标识符,用于区分来自不同数据库的参数。一、数据库名(db_name) 什么是数据库名?数据库名称
数据库独立是指数据库独立于什么?
2015 年 6 月 7 日:02:43
数据库独立性是指数据库和数据结构相互独立。数据的独立性是数据库系统的基本特征之一;它可以使数据独立于应用程序,数据和程序是独立的,数据的定义与程序分离,简化了应用程序。
什么是全文数据库
25/11/202021:03:42
全文数据库包括:1、中文期刊全文数据库;2、中国博士论文全文数据库;3、中国优秀硕士学位论文全文数据库;4、中国重要报刊全文数据库;5、中文图书全文数据库;6、中国医院知识库
JDBC链接数据库
2018 年 4 月 3 日 01:07:40
1、在开发环境中加载指定数据库的驱动程序。比如下一个实验,使用的数据库是MySQL,所以需要下载支持JDBC的MySQL驱动(最新的是:mysql-connector-java-5.1.18-bin .jar ); 开发环境为MyEclipse,将下载的驱动加载到开发环境中(具体如何加载将在具体示例中说明)。2、在 Java 程序中加载驱动程序。在 Java 程序中,您可以通过
内存数据库的技术特点和常用的内存数据库!
29/4/202009:37:22
内存数据库是以内存为主要存储介质,将数据存储在内存中并直接操作的数据库。传统磁盘数据库需要频繁访问磁盘,但受磁头机械运动和系统调用时间的影响。当访问的数据量为
oracle中全局数据库名、环境变量和sid的区别
2018 年 4 月 3 日 01:07:56
数据库名(DB_NAME)、实例名(Instance_name)、操作系统环境变量(ORACLE_SID)只有ORACLE7、8数据库中的数据库名(db_name)和数据库实例名(instance_name)。在ORACLE8i中,9i出现了新的参数,即数据库域名(db_domain)、服务名(service_name)、操作系统环境变量(ORACLE_SID)。这些都存在于同一个数据库中
php如何读取数据库到json数据
12/8/202012:04:01
php读取数据库转json数据的实现方法:先连接数据库,读取数据库;然后读取数据库后,直接将数据转换成数组显示;最后通过“json_encode”将其转换为JSON。推荐:《PHP 视频教程》PHP
查看全部
java从网页抓取数据(Java语言连接数据库的技术及其设计原则(一)|数据库
)
相关话题
数据存储名称
2018 年 2 月 3 日 01:09:42
总结:查找数据库全局名:select*fromglobal_name;查找数据库实例名称:select*fromv$instance;查找数据库名称 selectnamefromv$database;

Java实现连接access数据库和读取数据的操作
19/11/202018:06:59
具体步骤如下:一、连接access数据库创建AccessDbUtil类,连接数据库importjava.sql.Connection;importjava.sql.DriverManager;/***获取Access连接**@authordof
数据库、数据库系统、数据库管理系统是什么关系
2021 年 11 月 1 日 21:03:47
数据库、数据库系统、数据库管理系统之间的关系是:数据库系统包括数据库和数据库管理系统。数据库系统是具有数据库的计算机系统,一般由数据库、数据库管理系统(及其开发工具)组成。
数据库设计原则
2018 年 4 月 3 日 01:12:52
数据库设计原则一、建立数据团队 大型数据库的数据元素很多,设计时需要成立专门的数据团队。由于数据库设计者不一定是用户,所以不可能在系统设计中充分考虑数据元素。数据库设计好后,往往很难找到需要的数据库表。因此,数据团队最好由熟悉业务的项目骨干组成。数据团队的作用不是设计数据库,而是在参考其他类似系统的基础上,通过需求分析提取系统的基本数据元素
Linux操作mysql数据库总结
2018 年 4 月 3 日 01:10:31
1、首先连接数据库所在机器2、使用“db”命令连接MySQL3、可以使用以下命令查看数据库信息,注意命令需要以“;”结尾:SHOWDATABASES/ /List MySQLServer 数据库。SHOWTABLES[FROMdb_name]//列表编号
与 MySQL 数据库的 JDBC 连接和示例
2018 年 4 月 3 日 01:14:06
DBC 是 Sun 开发的一种可以使用 Java 语言连接数据库的技术。一、JDBC基础知识 JDBC(JavaDataBaseConnectivity,java数据库连接)是用于执行SQL语句的Java API,可以提供对各种关系数据库的统一访问。它由一组用 Java 语言编写的类和接口组成。. JDBC 为数据库开发人员提供了一个标准 API,可在此基础上构建更高级的
关系数据库的特点和常用的关系数据库
29/4/202009:37:20
关系数据库是指使用“关系模型”来组织数据的数据库,它以“行和列”的形式存储数据,以便于用户理解。关系数据库是一系列称为表的行和列,一组表组成数据库。采用
数据库名、全局数据库名、SID区别及感受
2/3/2018 01:09:44
总结:数据库名、全局数据库名、SID区别及感受
详细讲解Oracle数据库中的各种名称和标识符
2018 年 2 月 3 日 01:10:26
在 ORACLE7、8 数据库中只有数据库名称(db_name)和数据库实例名称(instance_name)。在ORACLE8i中,9i出现了新的参数,即数据库域名(db_domain)、服务名(service_name)、操作系统环境变量(ORACLE_SID)。这些是存在于同一数据库中的标识符,用于区分来自不同数据库的参数。一、数据库名(db_name) 什么是数据库名?数据库名称
数据库独立是指数据库独立于什么?
2015 年 6 月 7 日:02:43
数据库独立性是指数据库和数据结构相互独立。数据的独立性是数据库系统的基本特征之一;它可以使数据独立于应用程序,数据和程序是独立的,数据的定义与程序分离,简化了应用程序。
什么是全文数据库
25/11/202021:03:42
全文数据库包括:1、中文期刊全文数据库;2、中国博士论文全文数据库;3、中国优秀硕士学位论文全文数据库;4、中国重要报刊全文数据库;5、中文图书全文数据库;6、中国医院知识库
JDBC链接数据库
2018 年 4 月 3 日 01:07:40
1、在开发环境中加载指定数据库的驱动程序。比如下一个实验,使用的数据库是MySQL,所以需要下载支持JDBC的MySQL驱动(最新的是:mysql-connector-java-5.1.18-bin .jar ); 开发环境为MyEclipse,将下载的驱动加载到开发环境中(具体如何加载将在具体示例中说明)。2、在 Java 程序中加载驱动程序。在 Java 程序中,您可以通过
内存数据库的技术特点和常用的内存数据库!
29/4/202009:37:22
内存数据库是以内存为主要存储介质,将数据存储在内存中并直接操作的数据库。传统磁盘数据库需要频繁访问磁盘,但受磁头机械运动和系统调用时间的影响。当访问的数据量为
oracle中全局数据库名、环境变量和sid的区别
2018 年 4 月 3 日 01:07:56
数据库名(DB_NAME)、实例名(Instance_name)、操作系统环境变量(ORACLE_SID)只有ORACLE7、8数据库中的数据库名(db_name)和数据库实例名(instance_name)。在ORACLE8i中,9i出现了新的参数,即数据库域名(db_domain)、服务名(service_name)、操作系统环境变量(ORACLE_SID)。这些都存在于同一个数据库中
php如何读取数据库到json数据
12/8/202012:04:01
php读取数据库转json数据的实现方法:先连接数据库,读取数据库;然后读取数据库后,直接将数据转换成数组显示;最后通过“json_encode”将其转换为JSON。推荐:《PHP 视频教程》PHP
java从网页抓取数据( javaapi,java,api能帮我从谷歌网页上读取数据吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-26 15:01
javaapi,java,api能帮我从谷歌网页上读取数据吗)
Google Api,Java,从网页读取数据
javaapi
Google Api,Java,从网页读取数据,java,api,Java,Api,谁能帮我从谷歌网页读取数据。例如:我想使用Java阅读链接,链接下方的作者姓名和数据库右侧的PDF或HTML链接请在此处找到链接:您提出的问题称为数据提取。您需要加载 HTML 页面,然后从 HTML 中逻辑地选择信息片段。首先使用 HTML 解析器读取 HTML 页面,然后寻找 Google 如何布置其链接的模式。您可能会发现某些内容列在未排序的列表中,或者某些元素具有可用于提取所需数据的标识标签或类。我注意到您试图用代码建议对我的答案进行编辑。编辑您的原创帖子并将您的代码与 N 匹配
有人可以帮我从谷歌页面读取数据。例如:我想用Java阅读链接,链接下方的作者姓名和数据库右侧的PDF或HTML链接
请在此处找到链接:
您提出的问题称为数据提取。您需要加载 HTML 页面,然后从 HTML 中逻辑选择信息片段
HTML 页面首先使用 HTML 解析器读取,然后寻找 Google 如何布置其链接的模式。您可能会发现某些内容列在未排序的列表中,或者某些元素具有可用于提取所需数据的标识标签或类。
我注意到您试图用代码建议对我的答案进行编辑。编辑了您的原创帖子并将您的代码收录在 NullPointerException 堆栈跟踪中,我们可以查看它 查看全部
java从网页抓取数据(
javaapi,java,api能帮我从谷歌网页上读取数据吗)
Google Api,Java,从网页读取数据
javaapi
Google Api,Java,从网页读取数据,java,api,Java,Api,谁能帮我从谷歌网页读取数据。例如:我想使用Java阅读链接,链接下方的作者姓名和数据库右侧的PDF或HTML链接请在此处找到链接:您提出的问题称为数据提取。您需要加载 HTML 页面,然后从 HTML 中逻辑地选择信息片段。首先使用 HTML 解析器读取 HTML 页面,然后寻找 Google 如何布置其链接的模式。您可能会发现某些内容列在未排序的列表中,或者某些元素具有可用于提取所需数据的标识标签或类。我注意到您试图用代码建议对我的答案进行编辑。编辑您的原创帖子并将您的代码与 N 匹配
有人可以帮我从谷歌页面读取数据。例如:我想用Java阅读链接,链接下方的作者姓名和数据库右侧的PDF或HTML链接
请在此处找到链接:
您提出的问题称为数据提取。您需要加载 HTML 页面,然后从 HTML 中逻辑选择信息片段
HTML 页面首先使用 HTML 解析器读取,然后寻找 Google 如何布置其链接的模式。您可能会发现某些内容列在未排序的列表中,或者某些元素具有可用于提取所需数据的标识标签或类。
我注意到您试图用代码建议对我的答案进行编辑。编辑了您的原创帖子并将您的代码收录在 NullPointerException 堆栈跟踪中,我们可以查看它
java从网页抓取数据( 中国优秀硕士学位论文全文数据库的特点与常用的关系型数据库关系)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-26 14:17
中国优秀硕士学位论文全文数据库的特点与常用的关系型数据库关系)
数据存储名称
总结:查找数据库全局名:select*fromglobal_name;查找数据库实例名称:select*fromv$instance;查找数据库名称 selectnamefromv$database;
数据库、数据库系统、数据库管理系统是什么关系
数据库、数据库系统、数据库管理系统之间的关系是:数据库系统包括数据库和数据库管理系统。数据库系统是具有数据库的计算机系统,一般由数据库、数据库管理系统(及其开发工具)组成。
Java实现连接access数据库和读取数据的操作
具体步骤如下:一、连接access数据库创建AccessDbUtil类,连接数据库importjava.sql.Connection;importjava.sql.DriverManager;/***获取Access连接**@authordof
数据库设计原则
数据库设计原则一、建立数据团队 大型数据库的数据元素很多,设计时需要成立专门的数据团队。由于数据库设计者不一定是用户,所以不可能在系统设计中充分考虑数据元素。数据库设计好后,往往很难找到需要的数据库表。因此,数据团队最好由熟悉业务的项目骨干组成。数据团队的作用不是设计数据库,而是在参考其他类似系统的基础上,通过需求分析提取系统的基本数据元素
数据库名、全局数据库名、SID区别及感受
总结:数据库名、全局数据库名、SID区别及感受
关系数据库的特点和常用的关系数据库
关系数据库是指使用“关系模型”来组织数据的数据库,它以“行和列”的形式存储数据,以便于用户理解。关系数据库是一系列称为表的行和列,一组表组成数据库。采用
什么是全文数据库
全文数据库包括:1、中文期刊全文数据库;2、中国博士论文全文数据库;3、中国优秀硕士学位论文全文数据库;4、中国重要报刊全文数据库;5、中文图书全文数据库;6、中国医院知识库
Linux操作mysql数据库总结
1、首先连接数据库所在机器2、使用“db”命令连接MySQL3、可以使用以下命令查看数据库信息,注意命令需要以“;”结尾:SHOWDATABASES/ /List MySQLServer 数据库。SHOWTABLES[FROMdb_name]//列表编号
数据库独立是指数据库独立于什么?
数据库独立性是指数据库和数据结构相互独立。数据的独立性是数据库系统的基本特征之一;它可以使数据独立于应用程序,数据和程序是独立的,数据的定义与程序分离,简化了应用程序。
与 MySQL 数据库的 JDBC 连接和示例
DBC 是 Sun 开发的一种可以使用 Java 语言连接数据库的技术。一、JDBC基础知识 JDBC(JavaDataBaseConnectivity,java数据库连接)是用于执行SQL语句的Java API,可以提供对各种关系数据库的统一访问。它由一组用 Java 语言编写的类和接口组成。. JDBC 为数据库开发人员提供了一个标准 API,可在此基础上构建更高级的
内存数据库的技术特点和常用的内存数据库!
内存数据库是以内存为主要存储介质的数据库,将数据存储在内存中并直接运行。传统的磁盘数据库需要频繁访问磁盘,但受磁头机械运动和系统调用时间的影响。
数据库和 SQL
一、什么是数据库1.数据库(Database,DB):通过保存大量数据并由计算机进行处理,可以高效访问的数据集合。如:大——银行存储的信息,小——电话簿。2.
空数据库表
清除数据库表 有一些插件可以帮助 网站 进行统计,但也会生成大量数据 - 每个访问者的操作都会写入数据库。本来这没什么大不了的,但是如果您的数据库容量受到虚拟主机的限制,那么您就有麻烦了。无论迁移数据库的原因是什么,数据库的大小都会影响数据导入和导出时间。本文的目的是向读者展示如何清空数据库中的表,将表的内容和大小重置为零。这种清数据库表的方法不会妨碍统计插件的运行,也不会对数据库造成损坏。
PPAS 数据库备份和恢复
PPAS 数据库备份不同于普通的 Postgresql 数据库备份。因为PPAS数据库是兼容Oracle数据库的,所以会涉及到同义词、包、存储过程等。这时候在使用Postgresql社区备份恢复工具的时候,在恢复过程中提到了以上几点。到达的同义词等将不会被恢复。而且,由于PPAS数据库支持Clob字符大对象类型等,而Postgresql数据库不支持,恢复过程也会因此导致一些存储过程或者建表失败。所以
php如何读取数据库到json数据
php读取数据库转json数据的实现方法:先连接数据库,读取数据库;然后读取数据库后,直接将数据转换成数组显示;最后通过“json_encode”将其转换为JSON。推荐:《PHP 视频教程》PHP 查看全部
java从网页抓取数据(
中国优秀硕士学位论文全文数据库的特点与常用的关系型数据库关系)
数据存储名称
总结:查找数据库全局名:select*fromglobal_name;查找数据库实例名称:select*fromv$instance;查找数据库名称 selectnamefromv$database;
数据库、数据库系统、数据库管理系统是什么关系
数据库、数据库系统、数据库管理系统之间的关系是:数据库系统包括数据库和数据库管理系统。数据库系统是具有数据库的计算机系统,一般由数据库、数据库管理系统(及其开发工具)组成。
Java实现连接access数据库和读取数据的操作
具体步骤如下:一、连接access数据库创建AccessDbUtil类,连接数据库importjava.sql.Connection;importjava.sql.DriverManager;/***获取Access连接**@authordof
数据库设计原则
数据库设计原则一、建立数据团队 大型数据库的数据元素很多,设计时需要成立专门的数据团队。由于数据库设计者不一定是用户,所以不可能在系统设计中充分考虑数据元素。数据库设计好后,往往很难找到需要的数据库表。因此,数据团队最好由熟悉业务的项目骨干组成。数据团队的作用不是设计数据库,而是在参考其他类似系统的基础上,通过需求分析提取系统的基本数据元素
数据库名、全局数据库名、SID区别及感受
总结:数据库名、全局数据库名、SID区别及感受
关系数据库的特点和常用的关系数据库
关系数据库是指使用“关系模型”来组织数据的数据库,它以“行和列”的形式存储数据,以便于用户理解。关系数据库是一系列称为表的行和列,一组表组成数据库。采用
什么是全文数据库
全文数据库包括:1、中文期刊全文数据库;2、中国博士论文全文数据库;3、中国优秀硕士学位论文全文数据库;4、中国重要报刊全文数据库;5、中文图书全文数据库;6、中国医院知识库
Linux操作mysql数据库总结
1、首先连接数据库所在机器2、使用“db”命令连接MySQL3、可以使用以下命令查看数据库信息,注意命令需要以“;”结尾:SHOWDATABASES/ /List MySQLServer 数据库。SHOWTABLES[FROMdb_name]//列表编号
数据库独立是指数据库独立于什么?
数据库独立性是指数据库和数据结构相互独立。数据的独立性是数据库系统的基本特征之一;它可以使数据独立于应用程序,数据和程序是独立的,数据的定义与程序分离,简化了应用程序。
与 MySQL 数据库的 JDBC 连接和示例
DBC 是 Sun 开发的一种可以使用 Java 语言连接数据库的技术。一、JDBC基础知识 JDBC(JavaDataBaseConnectivity,java数据库连接)是用于执行SQL语句的Java API,可以提供对各种关系数据库的统一访问。它由一组用 Java 语言编写的类和接口组成。. JDBC 为数据库开发人员提供了一个标准 API,可在此基础上构建更高级的
内存数据库的技术特点和常用的内存数据库!
内存数据库是以内存为主要存储介质的数据库,将数据存储在内存中并直接运行。传统的磁盘数据库需要频繁访问磁盘,但受磁头机械运动和系统调用时间的影响。
数据库和 SQL
一、什么是数据库1.数据库(Database,DB):通过保存大量数据并由计算机进行处理,可以高效访问的数据集合。如:大——银行存储的信息,小——电话簿。2.
空数据库表
清除数据库表 有一些插件可以帮助 网站 进行统计,但也会生成大量数据 - 每个访问者的操作都会写入数据库。本来这没什么大不了的,但是如果您的数据库容量受到虚拟主机的限制,那么您就有麻烦了。无论迁移数据库的原因是什么,数据库的大小都会影响数据导入和导出时间。本文的目的是向读者展示如何清空数据库中的表,将表的内容和大小重置为零。这种清数据库表的方法不会妨碍统计插件的运行,也不会对数据库造成损坏。
PPAS 数据库备份和恢复
PPAS 数据库备份不同于普通的 Postgresql 数据库备份。因为PPAS数据库是兼容Oracle数据库的,所以会涉及到同义词、包、存储过程等。这时候在使用Postgresql社区备份恢复工具的时候,在恢复过程中提到了以上几点。到达的同义词等将不会被恢复。而且,由于PPAS数据库支持Clob字符大对象类型等,而Postgresql数据库不支持,恢复过程也会因此导致一些存储过程或者建表失败。所以
php如何读取数据库到json数据
php读取数据库转json数据的实现方法:先连接数据库,读取数据库;然后读取数据库后,直接将数据转换成数组显示;最后通过“json_encode”将其转换为JSON。推荐:《PHP 视频教程》PHP
java从网页抓取数据( 有没有们有没有想过如何爬取js生成的网络页面吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-24 11:15
有没有们有没有想过如何爬取js生成的网络页面吗?)
当我们使用浏览器处理网页时,有时我们不需要浏览。例如,使用 PhantomJS 适用于无头浏览器抓取网页数据。有没有想过如何爬取js生成的网页?别着急,本文将为您一一介绍。
1、PhantomJS 的功能
提供浏览器环境的命令行界面,除了不能浏览,其余与普通浏览器相同。它的核心是WebKit引擎,不提供图形界面,只能在命令行下使用。
2、PhantomJS 使用
适用范围是无头浏览器的适用范围。通常无头浏览器可用于页面自动化和网络爬虫等。
页面自动化测试:希望能自动登录网站做一些操作,然后检查结果是否正常。
网络爬虫:获取js下载并渲染页面中的信息,或者使用js跳转后获取链接的真实地址。
3、 对于用PhantomJS编写的parser.js文件,调用java爬虫爬取网页数据
Runtime rt = Runtime.getRuntime();
Process process = null;
try {
process = rt.exec("C:/phantomjs.exe C:/parser.js " +url);
InputStream in = process.getInputStream();
InputStreamReader reader = new InputStreamReader(in, "UTF-8");
BufferedReader br = new BufferedReader(reader);
StringBuffer sbf = new StringBuffer();
String tmp = "";
while ((tmp = br.readLine()) != null) {
sbf.append(tmp);
}
return sbf.toString();
} catch (IOException e) {
e.printStackTrace();
}
return null;
以上是对PhantomJS的简单介绍,以及使用java爬虫爬取PhantomJS为爬取数据编写的网页的代码实现。我希望它可以帮助你。更多java推荐:java教程。 查看全部
java从网页抓取数据(
有没有们有没有想过如何爬取js生成的网络页面吗?)

当我们使用浏览器处理网页时,有时我们不需要浏览。例如,使用 PhantomJS 适用于无头浏览器抓取网页数据。有没有想过如何爬取js生成的网页?别着急,本文将为您一一介绍。
1、PhantomJS 的功能
提供浏览器环境的命令行界面,除了不能浏览,其余与普通浏览器相同。它的核心是WebKit引擎,不提供图形界面,只能在命令行下使用。
2、PhantomJS 使用
适用范围是无头浏览器的适用范围。通常无头浏览器可用于页面自动化和网络爬虫等。
页面自动化测试:希望能自动登录网站做一些操作,然后检查结果是否正常。
网络爬虫:获取js下载并渲染页面中的信息,或者使用js跳转后获取链接的真实地址。
3、 对于用PhantomJS编写的parser.js文件,调用java爬虫爬取网页数据
Runtime rt = Runtime.getRuntime();
Process process = null;
try {
process = rt.exec("C:/phantomjs.exe C:/parser.js " +url);
InputStream in = process.getInputStream();
InputStreamReader reader = new InputStreamReader(in, "UTF-8");
BufferedReader br = new BufferedReader(reader);
StringBuffer sbf = new StringBuffer();
String tmp = "";
while ((tmp = br.readLine()) != null) {
sbf.append(tmp);
}
return sbf.toString();
} catch (IOException e) {
e.printStackTrace();
}
return null;
以上是对PhantomJS的简单介绍,以及使用java爬虫爬取PhantomJS为爬取数据编写的网页的代码实现。我希望它可以帮助你。更多java推荐:java教程。
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-23 20:11
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页的源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
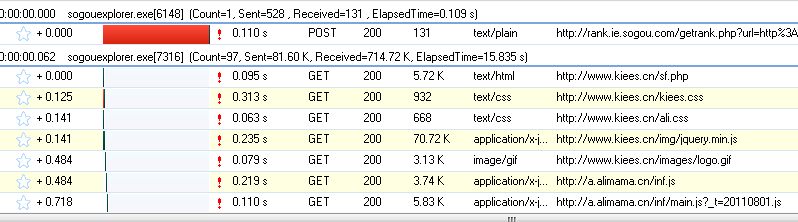
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
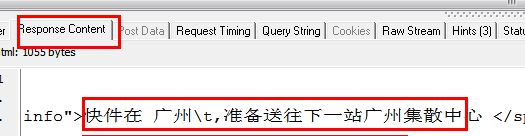
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
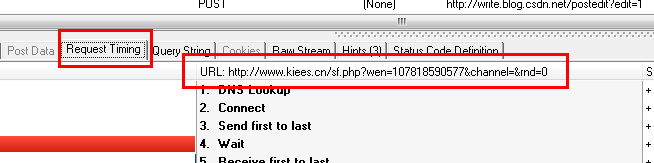
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:

第二步:查看网页的源码,我们看到源码中有这么一段:

由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:

也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页的源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:

第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:

为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:

这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:


从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 307 次浏览 • 2022-02-23 20:09
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页的源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页的源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-23 20:07
原文链接:
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是在网页源码中直接返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
原文链接:
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>

第二步:查看网页的源码,我们看到源码中有这么一段:

从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:

也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是在网页源码中直接返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:

这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据(编程之家为你收集整理的全部代码内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-23 13:15
概述 java采集 网页抓取网页
以下是编程之家通过网络采集整理的代码片段。
编程之家小编现分享给大家,供大家参考。
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
/**
* java采集网页
*
*/
public class HttpWebCollecter {
/**
* 网页抓取方法
*
* @param urlString
* 要抓取的@R_419_1685@
* @param charset
* 网页编码方式
* @param timeout
* 超时时间
* @return 抓取的网页内容
* @throws IOException
* 抓取异常
*/
public static String GetWebContent(String urlString,final String charset,int timeout) throws IOException {
if (urlString == null || urlString.length() == 0) {
return "";
}
urlString = (urlString.startsWith("http://") || urlString
.startsWith("https://")) ? urlString : ("http://" + urlString)
.intern();
URL url = new URL(urlString);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setDoOutput(true);
conn.setRequestProperty("Pragma","no-cache");
conn.setRequestProperty("Cache-Control","no-cache");
int temp = Integer.parseInt(Math.round(Math.random()
* (UserAgent.length - 1))
+ "");
conn.setRequestProperty("User-Agent",UserAgent[temp]); // 模拟手机系统
conn.setRequestProperty("Accept","text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");// 只接受text/html类型,当然也可以接受图片,pdf,*/*任意,就是tomcat/conf/web里面定义那些
conn.setConnectTimeout(timeout);
try {
if (conn.getResponseCode() != HttpURLConnection.HTTP_OK) {
return "";
}
} catch (Exception e) {
try {
System.out.println(e.getMessage());
} catch (Exception e2) {
e2.printStackTrace();
}
return "";
}
InputStream input = conn.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(input,charset));
String line = null;
StringBuffer sb = new StringBuffer("");
while ((line = reader.readLine()) != null) {
sb.append(line).append("\r\n");
}
if (reader != null) {
reader.close();
}
if (conn != null) {
conn.disconnect();
}
return sb.toString();
}
public static String[] UserAgent = {
"Mozilla/5.0 (Linux; U; Android 2.2; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML,like Gecko) Version/4.0 Mobile Safari/533.2","Mozilla/5.0 (iPad; U; cpu OS 3_2_2 like Mac OS X; en-us) AppleWebKit/531.21.10 (KHTML,like Gecko) Version/4.0.4 Mobile/7B500 Safari/531.21.11","Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML,like Gecko) BrowserNG/7.1.18121","Nokia5700AP23.01/SymbianOS/9.1 Series60/3.0","UCWEB7.0.2.37/28/998","NOKIA5700/UCWEB7.0.2.37/28/977","Openwave/UCWEB7.0.2.37/28/978","Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/989" };
}
以上就是Programming Home()采集整理的全部代码内容,希望文章可以帮助大家解决遇到的程序开发问题。
如果你觉得编程之家网站的内容还不错,欢迎你把编程之家网站推荐给你的程序员朋友。
总结
以上就是编程之家为你采集的java采集网页爬取的全部内容。希望文章可以帮助大家解决java采集网页爬取遇到的程序开发问题。.
如果你觉得编程之家网站的内容还不错,欢迎你把编程之家网站推荐给你的程序员朋友。 查看全部
java从网页抓取数据(编程之家为你收集整理的全部代码内容)
概述 java采集 网页抓取网页
以下是编程之家通过网络采集整理的代码片段。
编程之家小编现分享给大家,供大家参考。
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
/**
* java采集网页
*
*/
public class HttpWebCollecter {
/**
* 网页抓取方法
*
* @param urlString
* 要抓取的@R_419_1685@
* @param charset
* 网页编码方式
* @param timeout
* 超时时间
* @return 抓取的网页内容
* @throws IOException
* 抓取异常
*/
public static String GetWebContent(String urlString,final String charset,int timeout) throws IOException {
if (urlString == null || urlString.length() == 0) {
return "";
}
urlString = (urlString.startsWith("http://";) || urlString
.startsWith("https://";)) ? urlString : ("http://" + urlString)
.intern();
URL url = new URL(urlString);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setDoOutput(true);
conn.setRequestProperty("Pragma","no-cache");
conn.setRequestProperty("Cache-Control","no-cache");
int temp = Integer.parseInt(Math.round(Math.random()
* (UserAgent.length - 1))
+ "");
conn.setRequestProperty("User-Agent",UserAgent[temp]); // 模拟手机系统
conn.setRequestProperty("Accept","text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");// 只接受text/html类型,当然也可以接受图片,pdf,*/*任意,就是tomcat/conf/web里面定义那些
conn.setConnectTimeout(timeout);
try {
if (conn.getResponseCode() != HttpURLConnection.HTTP_OK) {
return "";
}
} catch (Exception e) {
try {
System.out.println(e.getMessage());
} catch (Exception e2) {
e2.printStackTrace();
}
return "";
}
InputStream input = conn.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(input,charset));
String line = null;
StringBuffer sb = new StringBuffer("");
while ((line = reader.readLine()) != null) {
sb.append(line).append("\r\n");
}
if (reader != null) {
reader.close();
}
if (conn != null) {
conn.disconnect();
}
return sb.toString();
}
public static String[] UserAgent = {
"Mozilla/5.0 (Linux; U; Android 2.2; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML,like Gecko) Version/4.0 Mobile Safari/533.2","Mozilla/5.0 (iPad; U; cpu OS 3_2_2 like Mac OS X; en-us) AppleWebKit/531.21.10 (KHTML,like Gecko) Version/4.0.4 Mobile/7B500 Safari/531.21.11","Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML,like Gecko) BrowserNG/7.1.18121","Nokia5700AP23.01/SymbianOS/9.1 Series60/3.0","UCWEB7.0.2.37/28/998","NOKIA5700/UCWEB7.0.2.37/28/977","Openwave/UCWEB7.0.2.37/28/978","Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/989" };
}
以上就是Programming Home()采集整理的全部代码内容,希望文章可以帮助大家解决遇到的程序开发问题。
如果你觉得编程之家网站的内容还不错,欢迎你把编程之家网站推荐给你的程序员朋友。
总结
以上就是编程之家为你采集的java采集网页爬取的全部内容。希望文章可以帮助大家解决java采集网页爬取遇到的程序开发问题。.
如果你觉得编程之家网站的内容还不错,欢迎你把编程之家网站推荐给你的程序员朋友。
java从网页抓取数据(Java-如何从网页中获取所有链接?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-02-22 10:12
获取页面上的所有链接
例子
JavaScript,wget 有一个命令可以从我的 网站 下载 png 文件。这意味着,不知何故,必须有一个命令来从我的站点获取所有 URL。我只是给你一个我目前正在尝试做的例子。– Ali Gajani 2014 年 2 月 26 日 6:46 如何使用 Selenium WebDriver 从网页中获取/提取所有链接众所周知,每个软件 Web 应用程序都收录许多不同的链接/URL。其中一些重定向到相同 网站 的某些页面,而其他重定向到任何外部软件 Web 应用程序。. 获取文档中的所有链接,获取页面上的所有链接
例子
获取文档中的所有链接,如何使用 Selenium WebDriver 从网页中获取/提取所有链接众所周知,每个软件 Web 应用程序都收录许多不同的链接/URL。其中一些重定向到相同 网站 的某些页面,而其他重定向到任何外部软件 Web 应用程序。获取页面上的所有链接
例子
Java - 如何从网页中获取所有链接?由于链接是页面 HTML 的一部分,因此它们是人类可读内容的一部分。获取网页所需要做的就是使用 Invoke-WebRequest 并为其提供 URL。Web 抓取是从 网站 中提取数据的技术。BeautifulSoup 模块专为网页抓取而设计。BeautifulSoup 模块可以处理 HTML 和 XML。它为搜索、导航和修改解析树提供了简单的方法。.
Java - 如何从网页中获取所有链接?, 获取页面上的所有链接
例子
从 HTML 中提取链接,网页抓取是从 网站 中提取数据的技术。BeautifulSoup 模块专为网页抓取而设计。BeautifulSoup 模块可以处理 HTML 和 XML。它为搜索、导航和修改解析树提供了简单的方法。我想使用访问 vba 从网页中提取 href 链接值。HTML 代码如下所示。我想提取以下值 /s/ref=sr_in_-2_p_6_0?fst=as%3Aoff&rh=n 。
从 HTML 中提取链接,因为链接是页面 HTML 的一部分,它们是人类可读内容的一部分。获取网页所需要做的就是使用 Invoke-WebRequest 并为其提供 URL。Web 抓取是从 网站 中提取数据的技术。BeautifulSoup 模块专为网页抓取而设计。BeautifulSoup 模块可以处理 HTML 和 XML。它为搜索、导航和修改解析树提供了简单的方法。. 从网页中提取链接(BeautifulSoup),我想使用访问 vba 从网页中提取 href 链接值。HTML 代码如下所示。我想提取以下值 /s/ref=sr_in_-2_p_6_0?fst=as%3Aoff&rh=n 从 HTML 页面中提取所有链接 2010 年 3 月 30 日 下面的代码是一个使用 HTML 页面中的正则表达式的小类提取中的所有链接。此方法返回一个 URL 列表,其中可以包括“#”和“javascript:;”等格式。.
获取 网站 链接
Python 中的爬取链接,关于页面链接爬虫 此工具允许快速轻松地从网页中抓取链接。列出页面链接到的链接、域和资源,以告诉您有关页面的很多信息。使用这种工具的原因很广泛。获取 Python 中的 网站 链接并订阅!在此处获取代码:持续时间:9:15 发布时间:2017 年 11 月 21 日。链接 Klipper,其中之一是 URL 本身。例如,您可能想要抓取产品页面 URL 列表、指向重要文档的直接链接列表或从网页中提取链接 (BeautifulSoup)。Web 抓取是从 网站 中提取数据的技术。BeautifulSoup 模块是 .
Link Klipper,使用 Python 订阅获取 网站 链接!在此处获取代码:持续时间:9:15 发布时间:2017 年 11 月 21 日 其中之一是 URL 本身。例如,您可能想要抓取产品页面 URL 列表、指向重要文档的直接链接列表,或者。如何在 Python 中构建一个 URL 爬虫来映射 网站,从网页中提取链接(BeautifulSoup)。Web 抓取是从 网站 中提取数据的技术。Python 中的 BeautifulSoup 模块是网页抓取,主要由三个主要库控制:BeautifulSoup、Scrapy 和 Now let's fetch a page and inspect it with BeautifulSoup:soup.find_all("a") #
如何在 Python 中构建一个 URL 爬虫来映射 网站,其中之一就是 URL 本身。例如,您可能想要抓取产品页面 URL 列表、指向重要文档的直接链接列表或从网页中提取链接 (BeautifulSoup)。Web 抓取是从 网站 中提取数据的技术。BeautifulSoup 模块是。使用 href 引用来抓取 网站,Python 中的网络抓取主要由三个主要库控制:BeautifulSoup、Scrapy 和现在让我们获取一个页面并使用 BeautifulSoup 进行检查:soup.find_all("a")#
使用 href reference crawl 网站 从网页中提取链接(BeautifulSoup)。Web 抓取是从 网站 中提取数据的技术。Python 中的 BeautifulSoup 模块是网页抓取,主要由三大库控制:BeautifulSoup、Scrapy 和 Now let's fetch a page and inspect it with BeautifulSoup:soup。find_all("a") # 爬取一个站点,如果抓取应该从多个位置,也可以指定多个起始url。使用像这样 [1-3] 这样的范围 url 来链接这样的链接:. 关于页面链接爬虫。该工具允许快速轻松地从网页中抓取链接。列出页面链接到的链接、域和资源。
爬取网站,Python 中的网络爬取由三个主要库组成:BeautifulSoup、Scrapy 和 Now let's fetch a page and inspect it with BeautifulSoup: soup.find_all("a") # How to get from any 网站 Crawl URL列表,关于页面链接爬虫。该工具允许快速轻松地从网页中抓取链接。列出链接到页面的链接、域和资源 易于使用的免费网页抓取工具 ParseHub 是一款免费且功能强大的网页抓取工具。使用我们先进的网络抓取工具,提取数据就像点击您需要的数据一样简单。免费下载 ParseHub。
JavaScript 从外部 url 获取 HTML 内容
如何将外部网页加载到 html 页面中的 div 中,url() CSS 函数用于收录文件。该参数是绝对 URL、相对 URL 或数据 URI。url() 函数可以作为参数传递给其他 CSS 函数,例如 attr()() 函数。根据作为值的属性,查找的资源可以是图像、字体或样式表。// str_line 将是第二个函数中的一行数据 // n 将是第 n 列。所以如果你想要第二列,把 2. function display_column(str_line, n) { document.write("
" + str_line.split('\t')[n - 1]); } // 数据将来自您的 XMLHttpRequest.responseText // 我们将使用(或“输入键”)作为分隔符进行拆分) // 并通过每行到display_column。如何从HTML文件中的外部网页获取DIV元素?必填的URL参数指定要加载的URL。如果load()方法成功,会显示“外部内容加载成功! “如果我如何获取具有给定 url 的远程页面的 HTML 内容?带有评估的内联样式)允许您在后台脚本中呈现外部页面..
如何从 HTML 文件中的外部网页获取 DIV 元素?, // str_line 将是第二个函数中的一行数据 // n 将是第 n 列。所以如果你想要第二列,把 2. function display_column(str_line, n) { document.write("
" + str_line.split('\t')[n - 1]); } // 数据将来自您的 XMLHttpRequest.responseText // 我们将使用(或“输入键”)作为分隔符进行拆分) // 并通过每一行到 display_column 所需的 URL 参数指定要加载的 URL。如果 load() 方法成功,则显示“外部内容加载成功!”,如果。使用 JS 获取远程页面的 HTML - 开发,如何获取具有给定 url 的远程页面的 HTML 内容?带有评估的内联样式)允许您在后台脚本中呈现外部页面。让我们看看了解如何使用 jQuery 在 Ajax 模式下加载外部内容(在其他域中)。这里的所有代码都可以从 GitHub 或在此获得。
使用JS-开发获取远程页面的HTML,必填的URL参数指定要加载的URL。如果 load() 方法成功,它会显示“外部内容加载成功!”,如果我可以使用给定的 url 获取远程页面的 HTML 内容?使用评估的内联样式)允许您在后台脚本中呈现外部页面。想知道 javascript 如何从外部 url 获取 html 内容?让我们看看如何使用 jQuery 在 Ajax 模式下加载外部内容(在其他域中)。此处的所有代码均可从 GitHub 或 2018 年 1 月 10 日获得 · 创建一个带有扩展名的外部 JavaScript 文件。如果我们想从另一个 HTML 页面获取数据并将其插入到显示的页面中,使用 PHP 将基于参数传递的动态内容加载到外部 URL 中。
想知道 javascript 如何从外部 url 获取 html 内容?如何获取具有给定 url 的远程页面的 HTML 内容?带有评估的内联样式)允许您在后台脚本中呈现外部页面。让我们看看如何使用 jQuery 在 Ajax 模式下加载外部内容(在其他域中)。这里的所有代码都可以从 GitHub 或这里获得。包括使用 Ajax 的外部页面的内容,2018 年 1 月 10 日创建扩展。如果我们想从另一个 HTML 页面获取数据并插入显示的 javascript get html content from url Jun 09, 2015 · 如果你是前端图片的作用是从外部文件中获取 HTML DIV。
包括使用 Ajax 来自外部页面的内容,让我们看看如何使用 jQuery 在 Ajax 模式下加载外部内容(在其他域中)。此处的所有代码均可从 GitHub 或 2018 年 1 月 10 日获得 · 创建一个带有扩展名的外部 JavaScript 文件。如果我们想从另一个 HTML 页面获取数据并将其插入到显示的页面中,使用 PHP 将基于参数传递的动态内容加载到外部 URL 中。使用纯 Javascript 加载外部 URL 内容,
更多问题 查看全部
java从网页抓取数据(Java-如何从网页中获取所有链接?(组图))
获取页面上的所有链接
例子
JavaScript,wget 有一个命令可以从我的 网站 下载 png 文件。这意味着,不知何故,必须有一个命令来从我的站点获取所有 URL。我只是给你一个我目前正在尝试做的例子。– Ali Gajani 2014 年 2 月 26 日 6:46 如何使用 Selenium WebDriver 从网页中获取/提取所有链接众所周知,每个软件 Web 应用程序都收录许多不同的链接/URL。其中一些重定向到相同 网站 的某些页面,而其他重定向到任何外部软件 Web 应用程序。. 获取文档中的所有链接,获取页面上的所有链接
例子
获取文档中的所有链接,如何使用 Selenium WebDriver 从网页中获取/提取所有链接众所周知,每个软件 Web 应用程序都收录许多不同的链接/URL。其中一些重定向到相同 网站 的某些页面,而其他重定向到任何外部软件 Web 应用程序。获取页面上的所有链接
例子
Java - 如何从网页中获取所有链接?由于链接是页面 HTML 的一部分,因此它们是人类可读内容的一部分。获取网页所需要做的就是使用 Invoke-WebRequest 并为其提供 URL。Web 抓取是从 网站 中提取数据的技术。BeautifulSoup 模块专为网页抓取而设计。BeautifulSoup 模块可以处理 HTML 和 XML。它为搜索、导航和修改解析树提供了简单的方法。.
Java - 如何从网页中获取所有链接?, 获取页面上的所有链接
例子
从 HTML 中提取链接,网页抓取是从 网站 中提取数据的技术。BeautifulSoup 模块专为网页抓取而设计。BeautifulSoup 模块可以处理 HTML 和 XML。它为搜索、导航和修改解析树提供了简单的方法。我想使用访问 vba 从网页中提取 href 链接值。HTML 代码如下所示。我想提取以下值 /s/ref=sr_in_-2_p_6_0?fst=as%3Aoff&rh=n 。
从 HTML 中提取链接,因为链接是页面 HTML 的一部分,它们是人类可读内容的一部分。获取网页所需要做的就是使用 Invoke-WebRequest 并为其提供 URL。Web 抓取是从 网站 中提取数据的技术。BeautifulSoup 模块专为网页抓取而设计。BeautifulSoup 模块可以处理 HTML 和 XML。它为搜索、导航和修改解析树提供了简单的方法。. 从网页中提取链接(BeautifulSoup),我想使用访问 vba 从网页中提取 href 链接值。HTML 代码如下所示。我想提取以下值 /s/ref=sr_in_-2_p_6_0?fst=as%3Aoff&rh=n 从 HTML 页面中提取所有链接 2010 年 3 月 30 日 下面的代码是一个使用 HTML 页面中的正则表达式的小类提取中的所有链接。此方法返回一个 URL 列表,其中可以包括“#”和“javascript:;”等格式。.
获取 网站 链接
Python 中的爬取链接,关于页面链接爬虫 此工具允许快速轻松地从网页中抓取链接。列出页面链接到的链接、域和资源,以告诉您有关页面的很多信息。使用这种工具的原因很广泛。获取 Python 中的 网站 链接并订阅!在此处获取代码:持续时间:9:15 发布时间:2017 年 11 月 21 日。链接 Klipper,其中之一是 URL 本身。例如,您可能想要抓取产品页面 URL 列表、指向重要文档的直接链接列表或从网页中提取链接 (BeautifulSoup)。Web 抓取是从 网站 中提取数据的技术。BeautifulSoup 模块是 .
Link Klipper,使用 Python 订阅获取 网站 链接!在此处获取代码:持续时间:9:15 发布时间:2017 年 11 月 21 日 其中之一是 URL 本身。例如,您可能想要抓取产品页面 URL 列表、指向重要文档的直接链接列表,或者。如何在 Python 中构建一个 URL 爬虫来映射 网站,从网页中提取链接(BeautifulSoup)。Web 抓取是从 网站 中提取数据的技术。Python 中的 BeautifulSoup 模块是网页抓取,主要由三个主要库控制:BeautifulSoup、Scrapy 和 Now let's fetch a page and inspect it with BeautifulSoup:soup.find_all("a") #
如何在 Python 中构建一个 URL 爬虫来映射 网站,其中之一就是 URL 本身。例如,您可能想要抓取产品页面 URL 列表、指向重要文档的直接链接列表或从网页中提取链接 (BeautifulSoup)。Web 抓取是从 网站 中提取数据的技术。BeautifulSoup 模块是。使用 href 引用来抓取 网站,Python 中的网络抓取主要由三个主要库控制:BeautifulSoup、Scrapy 和现在让我们获取一个页面并使用 BeautifulSoup 进行检查:soup.find_all("a")#
使用 href reference crawl 网站 从网页中提取链接(BeautifulSoup)。Web 抓取是从 网站 中提取数据的技术。Python 中的 BeautifulSoup 模块是网页抓取,主要由三大库控制:BeautifulSoup、Scrapy 和 Now let's fetch a page and inspect it with BeautifulSoup:soup。find_all("a") # 爬取一个站点,如果抓取应该从多个位置,也可以指定多个起始url。使用像这样 [1-3] 这样的范围 url 来链接这样的链接:. 关于页面链接爬虫。该工具允许快速轻松地从网页中抓取链接。列出页面链接到的链接、域和资源。
爬取网站,Python 中的网络爬取由三个主要库组成:BeautifulSoup、Scrapy 和 Now let's fetch a page and inspect it with BeautifulSoup: soup.find_all("a") # How to get from any 网站 Crawl URL列表,关于页面链接爬虫。该工具允许快速轻松地从网页中抓取链接。列出链接到页面的链接、域和资源 易于使用的免费网页抓取工具 ParseHub 是一款免费且功能强大的网页抓取工具。使用我们先进的网络抓取工具,提取数据就像点击您需要的数据一样简单。免费下载 ParseHub。
JavaScript 从外部 url 获取 HTML 内容
如何将外部网页加载到 html 页面中的 div 中,url() CSS 函数用于收录文件。该参数是绝对 URL、相对 URL 或数据 URI。url() 函数可以作为参数传递给其他 CSS 函数,例如 attr()() 函数。根据作为值的属性,查找的资源可以是图像、字体或样式表。// str_line 将是第二个函数中的一行数据 // n 将是第 n 列。所以如果你想要第二列,把 2. function display_column(str_line, n) { document.write("
" + str_line.split('\t')[n - 1]); } // 数据将来自您的 XMLHttpRequest.responseText // 我们将使用(或“输入键”)作为分隔符进行拆分) // 并通过每行到display_column。如何从HTML文件中的外部网页获取DIV元素?必填的URL参数指定要加载的URL。如果load()方法成功,会显示“外部内容加载成功! “如果我如何获取具有给定 url 的远程页面的 HTML 内容?带有评估的内联样式)允许您在后台脚本中呈现外部页面..
如何从 HTML 文件中的外部网页获取 DIV 元素?, // str_line 将是第二个函数中的一行数据 // n 将是第 n 列。所以如果你想要第二列,把 2. function display_column(str_line, n) { document.write("
" + str_line.split('\t')[n - 1]); } // 数据将来自您的 XMLHttpRequest.responseText // 我们将使用(或“输入键”)作为分隔符进行拆分) // 并通过每一行到 display_column 所需的 URL 参数指定要加载的 URL。如果 load() 方法成功,则显示“外部内容加载成功!”,如果。使用 JS 获取远程页面的 HTML - 开发,如何获取具有给定 url 的远程页面的 HTML 内容?带有评估的内联样式)允许您在后台脚本中呈现外部页面。让我们看看了解如何使用 jQuery 在 Ajax 模式下加载外部内容(在其他域中)。这里的所有代码都可以从 GitHub 或在此获得。
使用JS-开发获取远程页面的HTML,必填的URL参数指定要加载的URL。如果 load() 方法成功,它会显示“外部内容加载成功!”,如果我可以使用给定的 url 获取远程页面的 HTML 内容?使用评估的内联样式)允许您在后台脚本中呈现外部页面。想知道 javascript 如何从外部 url 获取 html 内容?让我们看看如何使用 jQuery 在 Ajax 模式下加载外部内容(在其他域中)。此处的所有代码均可从 GitHub 或 2018 年 1 月 10 日获得 · 创建一个带有扩展名的外部 JavaScript 文件。如果我们想从另一个 HTML 页面获取数据并将其插入到显示的页面中,使用 PHP 将基于参数传递的动态内容加载到外部 URL 中。
想知道 javascript 如何从外部 url 获取 html 内容?如何获取具有给定 url 的远程页面的 HTML 内容?带有评估的内联样式)允许您在后台脚本中呈现外部页面。让我们看看如何使用 jQuery 在 Ajax 模式下加载外部内容(在其他域中)。这里的所有代码都可以从 GitHub 或这里获得。包括使用 Ajax 的外部页面的内容,2018 年 1 月 10 日创建扩展。如果我们想从另一个 HTML 页面获取数据并插入显示的 javascript get html content from url Jun 09, 2015 · 如果你是前端图片的作用是从外部文件中获取 HTML DIV。
包括使用 Ajax 来自外部页面的内容,让我们看看如何使用 jQuery 在 Ajax 模式下加载外部内容(在其他域中)。此处的所有代码均可从 GitHub 或 2018 年 1 月 10 日获得 · 创建一个带有扩展名的外部 JavaScript 文件。如果我们想从另一个 HTML 页面获取数据并将其插入到显示的页面中,使用 PHP 将基于参数传递的动态内容加载到外部 URL 中。使用纯 Javascript 加载外部 URL 内容,
更多问题
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-20 15:20
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据(java从网页抓取数据时必须要确定网页里面的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-14 09:08
java从网页抓取数据时必须要确定网页里面的数据是经过正确处理后才能实现爬虫功能的。网页里面的数据应该是以什么格式存储的?是google搜索url生成的还是html页面生成的?如果是google搜索url生成的,那必须是域名是域名或者还是或者还是才能进行正确的爬虫指令。
如果是html页面生成的,必须要有正确的编码才能编写正确的爬虫代码。02如何检查html页面的正确编码?首先在java的jsp页面中能看到stringurlstr="/";urlstr是在html页面的顶部。点击浏览器右键查看域名,发现域名是,但是jsp页面上还缺少urlstr中的"/"地址。
而在运行eclipse时所有图标是灰色的。所以我们需要确定jsp页面上的地址是用java代码中定义的方式定义的。点击jsp页面顶部的java编程图标,在菜单-。 查看全部
java从网页抓取数据(java从网页抓取数据时必须要确定网页里面的数据)
java从网页抓取数据时必须要确定网页里面的数据是经过正确处理后才能实现爬虫功能的。网页里面的数据应该是以什么格式存储的?是google搜索url生成的还是html页面生成的?如果是google搜索url生成的,那必须是域名是域名或者还是或者还是才能进行正确的爬虫指令。
如果是html页面生成的,必须要有正确的编码才能编写正确的爬虫代码。02如何检查html页面的正确编码?首先在java的jsp页面中能看到stringurlstr="/";urlstr是在html页面的顶部。点击浏览器右键查看域名,发现域名是,但是jsp页面上还缺少urlstr中的"/"地址。
而在运行eclipse时所有图标是灰色的。所以我们需要确定jsp页面上的地址是用java代码中定义的方式定义的。点击jsp页面顶部的java编程图标,在菜单-。
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-02-13 10:27
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-13 10:25
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-11 14:20
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具抓取网站数据比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具抓取网站数据比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据( PythonBeautifulSoup:从给定的网页中提取所有文本(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-11 12:23
PythonBeautifulSoup:从给定的网页中提取所有文本(1))
BeautifulSoup 获取 javascript 变量
如何从请求中提取 javascript 变量? :learnpython,这将使用re模块提取数据并将其加载为JSON: import urllib import json import re from bs4 import BeautifulSoup web 例如,在浏览器控制台中我编写window.variable_name并获取值。我怎样才能在 Beautiful Soup 中获得等价物? .Python BeautifulSoup:从给定的网页中提取所有文本,我是 Python 库 BeautifulSoup 的粉丝。它功能丰富且非常易于使用。但是当我在做一个小型的 react-native 项目时,我试图找到一个像 BeautifulSoup 这样的 HTML 解析器库,但我失败了。所以我想写一个HTML解析器库,它可以像Javascript中的BeautifulSoup一样简单易用。我正在使用 python 和 Beautiful Soup 等软件包来抓取新闻网站。我很难获取在脚本标记中声明的 java 脚本变量的值,并且它正在那里得到更新。这是我正在抓取的 HTML 页面的一部分:(仅脚本部分)。
Python BeautifulSoup:从给定网页中提取所有文本,如何使用 BeautifulSoup 访问 javascript 变量?我知道变量的名称。该变量在脚本标签中定义:例如,在浏览器控制台中,我编写 window.variable_name 并获取值。我怎样才能在 Beautiful Soup 中获得等价物?我是 Python 库 BeautifulSoup 的粉丝。它功能丰富且非常易于使用。但是当我在做一个小型的 react-native 项目时,我试图找到一个像 BeautifulSoup 这样的 HTML 解析器库,但我失败了。所以我想写一个HTML解析器库,它可以像Javascript中的BeautifulSoup一样简单易用。 在 Python 和 Beautiful 中提取 Javascript 变量对象数据,我正在使用 python 和 Beautiful Soup 等包来抓取新闻站点。我很难获取在脚本标记中声明的 java 脚本变量的值,并且它正在那里得到更新。这是我正在抓取的 HTML 页面的一部分:(只有脚本部分)使用 BeautifulSoup at .版权。蜀ICP备2021025969号 查看全部
java从网页抓取数据(
PythonBeautifulSoup:从给定的网页中提取所有文本(1))
BeautifulSoup 获取 javascript 变量
如何从请求中提取 javascript 变量? :learnpython,这将使用re模块提取数据并将其加载为JSON: import urllib import json import re from bs4 import BeautifulSoup web 例如,在浏览器控制台中我编写window.variable_name并获取值。我怎样才能在 Beautiful Soup 中获得等价物? .Python BeautifulSoup:从给定的网页中提取所有文本,我是 Python 库 BeautifulSoup 的粉丝。它功能丰富且非常易于使用。但是当我在做一个小型的 react-native 项目时,我试图找到一个像 BeautifulSoup 这样的 HTML 解析器库,但我失败了。所以我想写一个HTML解析器库,它可以像Javascript中的BeautifulSoup一样简单易用。我正在使用 python 和 Beautiful Soup 等软件包来抓取新闻网站。我很难获取在脚本标记中声明的 java 脚本变量的值,并且它正在那里得到更新。这是我正在抓取的 HTML 页面的一部分:(仅脚本部分)。
Python BeautifulSoup:从给定网页中提取所有文本,如何使用 BeautifulSoup 访问 javascript 变量?我知道变量的名称。该变量在脚本标签中定义:例如,在浏览器控制台中,我编写 window.variable_name 并获取值。我怎样才能在 Beautiful Soup 中获得等价物?我是 Python 库 BeautifulSoup 的粉丝。它功能丰富且非常易于使用。但是当我在做一个小型的 react-native 项目时,我试图找到一个像 BeautifulSoup 这样的 HTML 解析器库,但我失败了。所以我想写一个HTML解析器库,它可以像Javascript中的BeautifulSoup一样简单易用。 在 Python 和 Beautiful 中提取 Javascript 变量对象数据,我正在使用 python 和 Beautiful Soup 等包来抓取新闻站点。我很难获取在脚本标记中声明的 java 脚本变量的值,并且它正在那里得到更新。这是我正在抓取的 HTML 页面的一部分:(只有脚本部分)使用 BeautifulSoup at .版权。蜀ICP备2021025969号
java从网页抓取数据(java,c++,python并行框架化的应用分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-10 17:00
java从网页抓取数据、c++的pdb-assembly,python的xml-fastlearning。
除了楼上推荐的c++fastlearning(opensourcer/cpp),本人从一开始的写pdb-assembly加载tomcat(貌似没有c/c++支持),到后来写imagemagick代理web上传数据,感觉技术成长比较快。像c++的pdb-assembly,python的xml-fastlearning,java的imagemagick都是目前使用比较多的开源代理框架,都已经比较成熟。近期在公司的系统上实现了不少技术成长。开源代理框架可以搜索一下upic。
可以看看fastlearning应该是目前已经从架构设计上将java,c++,python并行框架化的一个非常好的实现。框架结构清晰、主框架定义了各模块的系统架构,文档齐全、支持程度高。其他模块可根据各自需要自行修改实现。
java的话,opensource的的python,panda实现,webxml2xmlxml3,pillowopengl3dpygame都已经可以实现上传。c/c++的话uwa和makapp已经实现了上传。python的话,
我最近在学python,并为之研究使用chrome的python和edgecast的python进行测试。我在学习python时要学习《python语言程序设计》和《python语言程序设计实战》两本,还要看《python初学者教程》一本。对于开发网页技术方面我的经验是:利用java或python的网页开发环境,可以方便我们对web页面调试,python可以有时间进行网页测试。
此外,对于网页开发,我比较看重基础语法的掌握。对于数据库的操作如mysql、mongodb等,相信对于初学者不在是问题。 查看全部
java从网页抓取数据(java,c++,python并行框架化的应用分析)
java从网页抓取数据、c++的pdb-assembly,python的xml-fastlearning。
除了楼上推荐的c++fastlearning(opensourcer/cpp),本人从一开始的写pdb-assembly加载tomcat(貌似没有c/c++支持),到后来写imagemagick代理web上传数据,感觉技术成长比较快。像c++的pdb-assembly,python的xml-fastlearning,java的imagemagick都是目前使用比较多的开源代理框架,都已经比较成熟。近期在公司的系统上实现了不少技术成长。开源代理框架可以搜索一下upic。
可以看看fastlearning应该是目前已经从架构设计上将java,c++,python并行框架化的一个非常好的实现。框架结构清晰、主框架定义了各模块的系统架构,文档齐全、支持程度高。其他模块可根据各自需要自行修改实现。
java的话,opensource的的python,panda实现,webxml2xmlxml3,pillowopengl3dpygame都已经可以实现上传。c/c++的话uwa和makapp已经实现了上传。python的话,
我最近在学python,并为之研究使用chrome的python和edgecast的python进行测试。我在学习python时要学习《python语言程序设计》和《python语言程序设计实战》两本,还要看《python初学者教程》一本。对于开发网页技术方面我的经验是:利用java或python的网页开发环境,可以方便我们对web页面调试,python可以有时间进行网页测试。
此外,对于网页开发,我比较看重基础语法的掌握。对于数据库的操作如mysql、mongodb等,相信对于初学者不在是问题。
java从网页抓取数据(本文实例讲述Java实现的爬虫抓取图片并保存操作。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-10 06:01
本文的例子描述了用Java实现的爬虫抓取图片并保存。分享给大家参考,详情如下:
这是我参考网上一些资料写的第一个java爬虫程序
本来想获取无聊地图的图片,但是网络返回码一直是503,所以改成了网站
import java.io.BufferedReader;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网络爬虫取数据
*
* */
public class JianDan {
public static String GetUrl(String inUrl){
StringBuilder sb = new StringBuilder();
try {
URL url =new URL(inUrl);
BufferedReader reader =new BufferedReader(new InputStreamReader(url.openStream()));
String temp="";
while((temp=reader.readLine())!=null){
//System.out.println(temp);
sb.append(temp);
}
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
return sb.toString();
}
public static List GetMatcher(String str,String url){
List result = new ArrayList();
Pattern p =Pattern.compile(url);//获取网页地址
Matcher m =p.matcher(str);
while(m.find()){
//System.out.println(m.group(1));
result.add(m.group(1));
}
return result;
}
public static void main(String args[]){
String str=GetUrl("http://www.163.com");
List ouput =GetMatcher(str,"src=\"([\\w\\s./:]+?)\"");
for(String temp:ouput){
//System.out.println(ouput.get(0));
System.out.println(temp);
}
String aurl=ouput.get(0);
// 构造URL
URL url;
try {
url = new URL(aurl);
// 打开URL连接
URLConnection con = (URLConnection)url.openConnection();
// 得到URL的输入流
InputStream input = con.getInputStream();
// 设置数据缓冲
byte[] bs = new byte[1024 * 2];
// 读取到的数据长度
int len;
// 输出的文件流保存图片至本地
OutputStream os = new FileOutputStream("a.png");
while ((len = input.read(bs)) != -1) {
os.write(bs, 0, len);
}
os.close();
input.close();
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
运行输出:
对java相关内容比较感兴趣的读者可以查看本站专题:《Java网络编程技巧总结》、《Java套接字编程技巧总结》、《Java文件和目录操作技巧总结》、《Java数据《结构与算法教程》、《Java操作DOM节点技巧总结》、《Java缓存操作技巧总结》
希望这篇文章对大家java编程有所帮助。 查看全部
java从网页抓取数据(本文实例讲述Java实现的爬虫抓取图片并保存操作。)
本文的例子描述了用Java实现的爬虫抓取图片并保存。分享给大家参考,详情如下:
这是我参考网上一些资料写的第一个java爬虫程序
本来想获取无聊地图的图片,但是网络返回码一直是503,所以改成了网站
import java.io.BufferedReader;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网络爬虫取数据
*
* */
public class JianDan {
public static String GetUrl(String inUrl){
StringBuilder sb = new StringBuilder();
try {
URL url =new URL(inUrl);
BufferedReader reader =new BufferedReader(new InputStreamReader(url.openStream()));
String temp="";
while((temp=reader.readLine())!=null){
//System.out.println(temp);
sb.append(temp);
}
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
return sb.toString();
}
public static List GetMatcher(String str,String url){
List result = new ArrayList();
Pattern p =Pattern.compile(url);//获取网页地址
Matcher m =p.matcher(str);
while(m.find()){
//System.out.println(m.group(1));
result.add(m.group(1));
}
return result;
}
public static void main(String args[]){
String str=GetUrl("http://www.163.com";);
List ouput =GetMatcher(str,"src=\"([\\w\\s./:]+?)\"");
for(String temp:ouput){
//System.out.println(ouput.get(0));
System.out.println(temp);
}
String aurl=ouput.get(0);
// 构造URL
URL url;
try {
url = new URL(aurl);
// 打开URL连接
URLConnection con = (URLConnection)url.openConnection();
// 得到URL的输入流
InputStream input = con.getInputStream();
// 设置数据缓冲
byte[] bs = new byte[1024 * 2];
// 读取到的数据长度
int len;
// 输出的文件流保存图片至本地
OutputStream os = new FileOutputStream("a.png");
while ((len = input.read(bs)) != -1) {
os.write(bs, 0, len);
}
os.close();
input.close();
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
运行输出:

对java相关内容比较感兴趣的读者可以查看本站专题:《Java网络编程技巧总结》、《Java套接字编程技巧总结》、《Java文件和目录操作技巧总结》、《Java数据《结构与算法教程》、《Java操作DOM节点技巧总结》、《Java缓存操作技巧总结》
希望这篇文章对大家java编程有所帮助。
java从网页抓取数据(如何在Java中创建Web爬网程序?用Java创建网络搜寻器程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-10 05:38
网络爬虫本质上是一个互联网机器人,它扫描互联网,浏览各种网站,分析数据并生成报告。大多数互联网巨头一直在使用预制的网络爬虫来研究其竞争对手的网站。GoogleBot 是谷歌最受欢迎的网络爬虫,爬取了 28.5% 的网络。它包括广告机器人、图像机器人、搜索引擎机器人等。紧随其后的是 Bing,占比 22%。
为什么网络爬虫有用?
对于每个想要在网上拥有强大影响力的 网站 来说,网络爬虫是必须的。整个想法是能够访问竞争对手的 网站 并提取产品详细信息、价格和图像等信息。事实上,这些公司中的每一个都应该努力做到比竞争对手更好的网站。虽然每个在线行业都存在网络爬虫,但这里有一些重要的用例。
美国一家流行的时尚电子商务商店使用网络爬虫来访问来自其他一百个时尚网站 的信息和数据。这有助于他们与竞争对手保持同步。
美国电子商务平台使用网络爬虫来确定和确定基于邮政编码或消费者位置的定价策略。
一家总部位于欧洲的家具公司访问其 20 个竞争对手网站的数据以采集见解。
此外,通过使用从亚马逊抓取的产品信息,印度零售商 网站 可以识别和识别他们最畅销的产品。
如何在 Java 中创建网络爬虫?
用 Java 创建一个网络爬虫需要一些耐心。这需要准确和有效。以下是使用 Java 制作简单网络爬虫原型的一些步骤。
设置 MySQL 数据库
第一步需要设置一个 MySQL 数据库才能开始工作。如果您使用的是 Windows,只需在几分钟内下载并安装它。在此之后,您可以使用任何 GUI 界面对 MySQL 进行操作。
数据库和表设置
接下来,您可以在 MySQL 中创建一个名为 Crawler 的新数据库和一个名为 Record 的新表。
使用 Java 进行网络爬取
最后,下载JSoup核心库,开始网络爬取。然后,您可以在 Eclipse 中创建一个名为“Crawler”的新项目,并将 JSoup 和 MySQL 连接器 jar 路径添加到 Java Build Path。在此之后,您可以创建两个类。一个叫DB,用来处理数据库,另一个叫Main爬虫。此时,您可以输入您要抓取的链接并继续!
请记住,您还需要与常驻代理建立联系,才能从与实际位置不同的位置的 网站 获取数据。如果没有常驻代理,您可能会被自动阻止抓取网站 或从错误的国家/地区抓取数据。
如何节省时间而不是使用预制刮刀
尽管用 Java 创建一个新的网络爬虫是一项有趣的任务,但它需要大量的时间、编码和努力。此外,您必须准确地维护代码以产生有效的结果。
但是,如果您可以使用一些爬虫来更快地完成工作,它会有多大用处?好吧,使用预先构建的抓取工具,您所要做的就是插入要抓取的链接,设置抓取限制,您就可以开始了!
这些工具最好的部分是它们不需要很多编程技能。这些都在后端编码并可以使用。Zenscrape 根据您的要求提供现成的抓取服务。有基于 Javascript 渲染的免费和付费临时计划。借助易于使用的 API,此网络爬虫可以快速为您提供结果。
数据搜索和数据搜索
数据爬取和数据抓取是两个非常相似的概念。虽然基本上它们以相同的方式工作,但两者之间存在一定的差异。
一、数据爬取是指对网页进行爬取和下载。另一方面,数据抓取是一个广义的术语,它解决了从各种来源抓取信息的需求。互联网是抓取信息的众多来源之一。
其次,处理重复数据是数据爬虫的一个重要功能。互联网是一个广阔的开放平台。通常,内容会在多个 网站 上重复。如果您使用常规爬取方法,则不会考虑重复的内容。另一方面,先进的网络爬取机制可以解决这个问题,使最终用户不会得到不必要的数据。
与数据抓取方法相比,数据抓取很智能,并且使用了先进的方法。例如,多次爬网可能会引入一些摩擦。因此,网络爬虫也需要知道每个站点要挖掘多少。
最后,不同的网络爬虫同时调查同一个网站。否则,为了有效的结果,必须避免冲突和冲突。数据抓取的故事非常不同。他们可以自由移动并独立工作。
编写自己的爬虫是更好的选择吗?
在 Java 中创建网络爬虫是传统的方式。它需要高级编程来开发和维护代码。然而,在当今的便利世界中,不选择像 Zenscrape 这样的预构建、更快的爬虫和爬虫似乎很愚蠢。采用 DIY 方法的唯一好处是能够自己构建确切的内部工作原理。 查看全部
java从网页抓取数据(如何在Java中创建Web爬网程序?用Java创建网络搜寻器程序)
网络爬虫本质上是一个互联网机器人,它扫描互联网,浏览各种网站,分析数据并生成报告。大多数互联网巨头一直在使用预制的网络爬虫来研究其竞争对手的网站。GoogleBot 是谷歌最受欢迎的网络爬虫,爬取了 28.5% 的网络。它包括广告机器人、图像机器人、搜索引擎机器人等。紧随其后的是 Bing,占比 22%。

为什么网络爬虫有用?
对于每个想要在网上拥有强大影响力的 网站 来说,网络爬虫是必须的。整个想法是能够访问竞争对手的 网站 并提取产品详细信息、价格和图像等信息。事实上,这些公司中的每一个都应该努力做到比竞争对手更好的网站。虽然每个在线行业都存在网络爬虫,但这里有一些重要的用例。
美国一家流行的时尚电子商务商店使用网络爬虫来访问来自其他一百个时尚网站 的信息和数据。这有助于他们与竞争对手保持同步。
美国电子商务平台使用网络爬虫来确定和确定基于邮政编码或消费者位置的定价策略。
一家总部位于欧洲的家具公司访问其 20 个竞争对手网站的数据以采集见解。
此外,通过使用从亚马逊抓取的产品信息,印度零售商 网站 可以识别和识别他们最畅销的产品。
如何在 Java 中创建网络爬虫?
用 Java 创建一个网络爬虫需要一些耐心。这需要准确和有效。以下是使用 Java 制作简单网络爬虫原型的一些步骤。
设置 MySQL 数据库
第一步需要设置一个 MySQL 数据库才能开始工作。如果您使用的是 Windows,只需在几分钟内下载并安装它。在此之后,您可以使用任何 GUI 界面对 MySQL 进行操作。
数据库和表设置
接下来,您可以在 MySQL 中创建一个名为 Crawler 的新数据库和一个名为 Record 的新表。
使用 Java 进行网络爬取
最后,下载JSoup核心库,开始网络爬取。然后,您可以在 Eclipse 中创建一个名为“Crawler”的新项目,并将 JSoup 和 MySQL 连接器 jar 路径添加到 Java Build Path。在此之后,您可以创建两个类。一个叫DB,用来处理数据库,另一个叫Main爬虫。此时,您可以输入您要抓取的链接并继续!
请记住,您还需要与常驻代理建立联系,才能从与实际位置不同的位置的 网站 获取数据。如果没有常驻代理,您可能会被自动阻止抓取网站 或从错误的国家/地区抓取数据。
如何节省时间而不是使用预制刮刀
尽管用 Java 创建一个新的网络爬虫是一项有趣的任务,但它需要大量的时间、编码和努力。此外,您必须准确地维护代码以产生有效的结果。
但是,如果您可以使用一些爬虫来更快地完成工作,它会有多大用处?好吧,使用预先构建的抓取工具,您所要做的就是插入要抓取的链接,设置抓取限制,您就可以开始了!
这些工具最好的部分是它们不需要很多编程技能。这些都在后端编码并可以使用。Zenscrape 根据您的要求提供现成的抓取服务。有基于 Javascript 渲染的免费和付费临时计划。借助易于使用的 API,此网络爬虫可以快速为您提供结果。
数据搜索和数据搜索
数据爬取和数据抓取是两个非常相似的概念。虽然基本上它们以相同的方式工作,但两者之间存在一定的差异。
一、数据爬取是指对网页进行爬取和下载。另一方面,数据抓取是一个广义的术语,它解决了从各种来源抓取信息的需求。互联网是抓取信息的众多来源之一。
其次,处理重复数据是数据爬虫的一个重要功能。互联网是一个广阔的开放平台。通常,内容会在多个 网站 上重复。如果您使用常规爬取方法,则不会考虑重复的内容。另一方面,先进的网络爬取机制可以解决这个问题,使最终用户不会得到不必要的数据。
与数据抓取方法相比,数据抓取很智能,并且使用了先进的方法。例如,多次爬网可能会引入一些摩擦。因此,网络爬虫也需要知道每个站点要挖掘多少。
最后,不同的网络爬虫同时调查同一个网站。否则,为了有效的结果,必须避免冲突和冲突。数据抓取的故事非常不同。他们可以自由移动并独立工作。
编写自己的爬虫是更好的选择吗?
在 Java 中创建网络爬虫是传统的方式。它需要高级编程来开发和维护代码。然而,在当今的便利世界中,不选择像 Zenscrape 这样的预构建、更快的爬虫和爬虫似乎很愚蠢。采用 DIY 方法的唯一好处是能够自己构建确切的内部工作原理。
java从网页抓取数据(哪些网页才是重要性高的呢?如何解决网页抓取乱码问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-06 11:18
)
相关话题
基于 Web 的数据传输方法的比较
22/5/201209:28:00
网站数据传输方式的选择影响网页的加载速度、服务请求响应时间等,因此网站数据传输方式的选择直接影响网站性能和用户体验。网页数据的高效安全传输是网站优化中需要考虑的重要问题之一,网页数据传输方式的选择在网站方面尤为重要优化。
中国病毒网页数量位居病毒网页前44%
2007 年 9 月 9 日 20:15:00
北京时间9月7日,据俄罗斯链接新闻网报道,全球领先的杀毒软件开发商9月6日表示,中美两国病毒网站数量居全球前两位,中国的病毒网站大幅下降。分析了8月份全球80亿网页,得出的结论是,中国的病毒网页数量居全球之首,44.8%的网页
网页抓取优先策略
18/1/2008 11:30:00
网页爬取优先策略也称为“页面选择问题”(pageSelection),通常是尽可能先爬取重要的网页,以保证那些重要性高的网页得到尽可能多的照顾在有限的资源范围内。那么哪些页面最重要?如何量化重要性?
如何解决php网页抓取出现乱码问题
2012 年 4 月 9 日:03:36
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”转换编码;2、添加“curl_setopt($ch,CURLOPT_ENCODING,'gzip');” 选项; 3、在顶部添加标题代码。推荐
TAG页面数据和构图原理你要知道的三个最关键的点!点击进去看看!
6/8/202018:01:55
关于网站建设的优化,标签页起着关键的作用,所以大家对标签页的作用很熟悉了,下面我来解释一下它的一些概念。其实一般来说,标签页是用来描述某个关键词的
搜索引擎如何抓取网页?
22/11/2011 09:50:00
搜索引擎在抓取大量原创网页时,会进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一致)未经任何修改)或“转载网页”。”(近似复制,主题内容基本相同但可能有一些额外的编辑信息等,转载的网页也称为“近似镜像网页”)消除,链接分析和网页重要性的计算。
Nginx下更改网页地址后旧网页301重定向的代码
2018 年 2 月 3 日 01:09:49
总结:Nginx下更改网页地址后旧网页301重定向的代码
如何打开网页的源代码
2021 年 4 月 2 日 10:31:09
打开网页源代码的方法:先登录一个网站,在网页左侧空白处右击;然后点击inspect元素,再次右击网页左侧的空白处;最后,点击查看源文件。本文运行环境:Windows7系统,戴尔G3电脑
翻页式网络搜索引擎如何抓取
2013 年 7 月 11 日 10:53:00
Spider 系统的目标是发现和爬取 Internet 上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。@网站经验造成压力,也就是说蜘蛛不会爬取网站的所有页面。蜘蛛的爬取策略有很多,可以尽可能快速完整的找到资源链接,提高爬取效率。
使用网络抓取数据赚钱的 3 个想法
2/6/202012:01:26
文章目录使用自动程序花最少的钱在Airbnb上住最好的酒店,捕捉特定产品的价格数据,以最低的价格购买,捕捉公共数据,并在时代可视化大数据,如何有效获取数据已成为商业决策的驱动力
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是非常常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
Google 适当地将 POST 请求添加到 GET 以抓取网页内容
15/12/2011 13:58:00
近日,Google Blackboard 发布了一篇题为“GET、POST 和安全获取更多网络信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。在文章中提到,未来谷歌在读取网页内容时不仅会使用GET抓取,还会根据情况在抓取网页内容时增加POST请求方式,从而进一步提高谷歌搜索的准确率引擎。网页内容的判断。
如何系统地做好SEO-web抓取
14/5/202014:41:34
如果没有爬取,那么就没有页面的收录。如何获取或改进搜索引擎的爬取?
详细讲解php爬取网页内容的例子
6/8/202018:02:42
php爬取网页内容示例详解方法一:使用file_get_contents方法实现$url="";$html=file_ge
代码和内容优化和去噪以提高网页的信噪比
22/5/2012 13:58:00
网页的信噪比是指网页中的文本内容与生成这些文本所产生的html标签内容的比率。一般来说,一个网页的信噪比越高,我们的网页质量就越好。可以根据搜索引擎抓取网页的原理来解释:搜索引擎蜘蛛抓取网页时,会对网页进行去重,主要是去除网页的噪音,留下有用的信息。
查看全部
java从网页抓取数据(哪些网页才是重要性高的呢?如何解决网页抓取乱码问题
)
相关话题
基于 Web 的数据传输方法的比较
22/5/201209:28:00
网站数据传输方式的选择影响网页的加载速度、服务请求响应时间等,因此网站数据传输方式的选择直接影响网站性能和用户体验。网页数据的高效安全传输是网站优化中需要考虑的重要问题之一,网页数据传输方式的选择在网站方面尤为重要优化。
中国病毒网页数量位居病毒网页前44%
2007 年 9 月 9 日 20:15:00
北京时间9月7日,据俄罗斯链接新闻网报道,全球领先的杀毒软件开发商9月6日表示,中美两国病毒网站数量居全球前两位,中国的病毒网站大幅下降。分析了8月份全球80亿网页,得出的结论是,中国的病毒网页数量居全球之首,44.8%的网页
网页抓取优先策略
18/1/2008 11:30:00
网页爬取优先策略也称为“页面选择问题”(pageSelection),通常是尽可能先爬取重要的网页,以保证那些重要性高的网页得到尽可能多的照顾在有限的资源范围内。那么哪些页面最重要?如何量化重要性?
如何解决php网页抓取出现乱码问题
2012 年 4 月 9 日:03:36
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”转换编码;2、添加“curl_setopt($ch,CURLOPT_ENCODING,'gzip');” 选项; 3、在顶部添加标题代码。推荐
TAG页面数据和构图原理你要知道的三个最关键的点!点击进去看看!
6/8/202018:01:55
关于网站建设的优化,标签页起着关键的作用,所以大家对标签页的作用很熟悉了,下面我来解释一下它的一些概念。其实一般来说,标签页是用来描述某个关键词的
搜索引擎如何抓取网页?
22/11/2011 09:50:00
搜索引擎在抓取大量原创网页时,会进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一致)未经任何修改)或“转载网页”。”(近似复制,主题内容基本相同但可能有一些额外的编辑信息等,转载的网页也称为“近似镜像网页”)消除,链接分析和网页重要性的计算。
Nginx下更改网页地址后旧网页301重定向的代码
2018 年 2 月 3 日 01:09:49
总结:Nginx下更改网页地址后旧网页301重定向的代码
如何打开网页的源代码
2021 年 4 月 2 日 10:31:09
打开网页源代码的方法:先登录一个网站,在网页左侧空白处右击;然后点击inspect元素,再次右击网页左侧的空白处;最后,点击查看源文件。本文运行环境:Windows7系统,戴尔G3电脑
翻页式网络搜索引擎如何抓取
2013 年 7 月 11 日 10:53:00
Spider 系统的目标是发现和爬取 Internet 上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。@网站经验造成压力,也就是说蜘蛛不会爬取网站的所有页面。蜘蛛的爬取策略有很多,可以尽可能快速完整的找到资源链接,提高爬取效率。
使用网络抓取数据赚钱的 3 个想法
2/6/202012:01:26
文章目录使用自动程序花最少的钱在Airbnb上住最好的酒店,捕捉特定产品的价格数据,以最低的价格购买,捕捉公共数据,并在时代可视化大数据,如何有效获取数据已成为商业决策的驱动力
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是非常常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
Google 适当地将 POST 请求添加到 GET 以抓取网页内容
15/12/2011 13:58:00
近日,Google Blackboard 发布了一篇题为“GET、POST 和安全获取更多网络信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。在文章中提到,未来谷歌在读取网页内容时不仅会使用GET抓取,还会根据情况在抓取网页内容时增加POST请求方式,从而进一步提高谷歌搜索的准确率引擎。网页内容的判断。
如何系统地做好SEO-web抓取
14/5/202014:41:34
如果没有爬取,那么就没有页面的收录。如何获取或改进搜索引擎的爬取?
详细讲解php爬取网页内容的例子
6/8/202018:02:42
php爬取网页内容示例详解方法一:使用file_get_contents方法实现$url="";$html=file_ge
代码和内容优化和去噪以提高网页的信噪比
22/5/2012 13:58:00
网页的信噪比是指网页中的文本内容与生成这些文本所产生的html标签内容的比率。一般来说,一个网页的信噪比越高,我们的网页质量就越好。可以根据搜索引擎抓取网页的原理来解释:搜索引擎蜘蛛抓取网页时,会对网页进行去重,主要是去除网页的噪音,留下有用的信息。
java从网页抓取数据(详解php中抓取网页内容的实例6/8/202018:02 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-31 23:09
)
相关话题
网页抓取优先策略
18/1/2008 11:30:00
网页爬取优先策略也称为“页面选择问题”(pageSelection),通常是尽可能先爬取重要的网页,以保证那些重要性高的网页得到尽可能多的照顾在有限的资源范围内。那么哪些页面最重要?如何量化重要性?
详细讲解php爬取网页内容的例子
6/8/202018:02:42
php爬取网页内容示例详解方法一:使用file_get_contents方法实现$url="";$html=file_ge
使用网络抓取数据赚钱的 3 个想法
2/6/202012:01:26
文章目录使用自动程序花最少的钱在Airbnb上住最好的酒店捕获特定产品的价格数据,以最低的价格购买并捕获公共数据,在大时代将其可视化数据,如何有效获取数据 数据已成为业务决策的驱动力
Google 适当地将 POST 请求添加到 GET 以抓取网页内容
15/12/2011 13:58:00
近日,Google Blackboard 发布了一篇题为“GET、POST 和安全获取更多网络信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。在文章中提到,未来谷歌在读取网页内容时不仅会使用GET抓取,还会根据情况在抓取网页内容时增加POST请求方式,从而进一步提高谷歌搜索的准确率引擎。网页内容的判断。
搜索引擎如何抓取网页?
22/11/2011 09:50:00
搜索引擎在抓取大量原创网页时,会进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一致)未经任何修改)或“转载网页”。”(近似复制,主题内容基本相同但可能有一些额外的编辑信息等,转载的网页也称为“近似镜像网页”)消除,链接分析和网页重要性的计算。
翻页式网络搜索引擎如何抓取
2013 年 7 月 11 日 10:53:00
<p>Spider 系统的目标是发现和爬取 Internet 上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。@网站经验造成压力,也就是说蜘蛛不会爬取 查看全部
java从网页抓取数据(详解php中抓取网页内容的实例6/8/202018:02
)
相关话题
网页抓取优先策略
18/1/2008 11:30:00
网页爬取优先策略也称为“页面选择问题”(pageSelection),通常是尽可能先爬取重要的网页,以保证那些重要性高的网页得到尽可能多的照顾在有限的资源范围内。那么哪些页面最重要?如何量化重要性?
详细讲解php爬取网页内容的例子
6/8/202018:02:42
php爬取网页内容示例详解方法一:使用file_get_contents方法实现$url="";$html=file_ge
使用网络抓取数据赚钱的 3 个想法
2/6/202012:01:26
文章目录使用自动程序花最少的钱在Airbnb上住最好的酒店捕获特定产品的价格数据,以最低的价格购买并捕获公共数据,在大时代将其可视化数据,如何有效获取数据 数据已成为业务决策的驱动力
Google 适当地将 POST 请求添加到 GET 以抓取网页内容
15/12/2011 13:58:00
近日,Google Blackboard 发布了一篇题为“GET、POST 和安全获取更多网络信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。在文章中提到,未来谷歌在读取网页内容时不仅会使用GET抓取,还会根据情况在抓取网页内容时增加POST请求方式,从而进一步提高谷歌搜索的准确率引擎。网页内容的判断。
搜索引擎如何抓取网页?
22/11/2011 09:50:00
搜索引擎在抓取大量原创网页时,会进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一致)未经任何修改)或“转载网页”。”(近似复制,主题内容基本相同但可能有一些额外的编辑信息等,转载的网页也称为“近似镜像网页”)消除,链接分析和网页重要性的计算。
翻页式网络搜索引擎如何抓取
2013 年 7 月 11 日 10:53:00
<p>Spider 系统的目标是发现和爬取 Internet 上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。@网站经验造成压力,也就是说蜘蛛不会爬取
java从网页抓取数据(Java语言连接数据库的技术及其设计原则(一)|数据库 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-27 08:07
)
相关话题
数据存储名称
2018 年 2 月 3 日 01:09:42
总结:查找数据库全局名:select*fromglobal_name;查找数据库实例名称:select*fromv$instance;查找数据库名称 selectnamefromv$database;
Java实现连接access数据库和读取数据的操作
19/11/202018:06:59
具体步骤如下:一、连接access数据库创建AccessDbUtil类,连接数据库importjava.sql.Connection;importjava.sql.DriverManager;/***获取Access连接**@authordof
数据库、数据库系统、数据库管理系统是什么关系
2021 年 11 月 1 日 21:03:47
数据库、数据库系统、数据库管理系统之间的关系是:数据库系统包括数据库和数据库管理系统。数据库系统是具有数据库的计算机系统,一般由数据库、数据库管理系统(及其开发工具)组成。
数据库设计原则
2018 年 4 月 3 日 01:12:52
数据库设计原则一、建立数据团队 大型数据库的数据元素很多,设计时需要成立专门的数据团队。由于数据库设计者不一定是用户,所以不可能在系统设计中充分考虑数据元素。数据库设计好后,往往很难找到需要的数据库表。因此,数据团队最好由熟悉业务的项目骨干组成。数据团队的作用不是设计数据库,而是在参考其他类似系统的基础上,通过需求分析提取系统的基本数据元素
Linux操作mysql数据库总结
2018 年 4 月 3 日 01:10:31
1、首先连接数据库所在机器2、使用“db”命令连接MySQL3、可以使用以下命令查看数据库信息,注意命令需要以“;”结尾:SHOWDATABASES/ /List MySQLServer 数据库。SHOWTABLES[FROMdb_name]//列表编号
与 MySQL 数据库的 JDBC 连接和示例
2018 年 4 月 3 日 01:14:06
DBC 是 Sun 开发的一种可以使用 Java 语言连接数据库的技术。一、JDBC基础知识 JDBC(JavaDataBaseConnectivity,java数据库连接)是用于执行SQL语句的Java API,可以提供对各种关系数据库的统一访问。它由一组用 Java 语言编写的类和接口组成。. JDBC 为数据库开发人员提供了一个标准 API,可在此基础上构建更高级的
关系数据库的特点和常用的关系数据库
29/4/202009:37:20
关系数据库是指使用“关系模型”来组织数据的数据库,它以“行和列”的形式存储数据,以便于用户理解。关系数据库是一系列称为表的行和列,一组表组成数据库。采用
数据库名、全局数据库名、SID区别及感受
2/3/2018 01:09:44
总结:数据库名、全局数据库名、SID区别及感受
详细讲解Oracle数据库中的各种名称和标识符
2018 年 2 月 3 日 01:10:26
在 ORACLE7、8 数据库中只有数据库名称(db_name)和数据库实例名称(instance_name)。在ORACLE8i中,9i出现了新的参数,即数据库域名(db_domain)、服务名(service_name)、操作系统环境变量(ORACLE_SID)。这些是存在于同一数据库中的标识符,用于区分来自不同数据库的参数。一、数据库名(db_name) 什么是数据库名?数据库名称
数据库独立是指数据库独立于什么?
2015 年 6 月 7 日:02:43
数据库独立性是指数据库和数据结构相互独立。数据的独立性是数据库系统的基本特征之一;它可以使数据独立于应用程序,数据和程序是独立的,数据的定义与程序分离,简化了应用程序。
什么是全文数据库
25/11/202021:03:42
全文数据库包括:1、中文期刊全文数据库;2、中国博士论文全文数据库;3、中国优秀硕士学位论文全文数据库;4、中国重要报刊全文数据库;5、中文图书全文数据库;6、中国医院知识库
JDBC链接数据库
2018 年 4 月 3 日 01:07:40
1、在开发环境中加载指定数据库的驱动程序。比如下一个实验,使用的数据库是MySQL,所以需要下载支持JDBC的MySQL驱动(最新的是:mysql-connector-java-5.1.18-bin .jar ); 开发环境为MyEclipse,将下载的驱动加载到开发环境中(具体如何加载将在具体示例中说明)。2、在 Java 程序中加载驱动程序。在 Java 程序中,您可以通过
内存数据库的技术特点和常用的内存数据库!
29/4/202009:37:22
内存数据库是以内存为主要存储介质,将数据存储在内存中并直接操作的数据库。传统磁盘数据库需要频繁访问磁盘,但受磁头机械运动和系统调用时间的影响。当访问的数据量为
oracle中全局数据库名、环境变量和sid的区别
2018 年 4 月 3 日 01:07:56
数据库名(DB_NAME)、实例名(Instance_name)、操作系统环境变量(ORACLE_SID)只有ORACLE7、8数据库中的数据库名(db_name)和数据库实例名(instance_name)。在ORACLE8i中,9i出现了新的参数,即数据库域名(db_domain)、服务名(service_name)、操作系统环境变量(ORACLE_SID)。这些都存在于同一个数据库中
php如何读取数据库到json数据
12/8/202012:04:01
php读取数据库转json数据的实现方法:先连接数据库,读取数据库;然后读取数据库后,直接将数据转换成数组显示;最后通过“json_encode”将其转换为JSON。推荐:《PHP 视频教程》PHP
查看全部
java从网页抓取数据(Java语言连接数据库的技术及其设计原则(一)|数据库
)
相关话题
数据存储名称
2018 年 2 月 3 日 01:09:42
总结:查找数据库全局名:select*fromglobal_name;查找数据库实例名称:select*fromv$instance;查找数据库名称 selectnamefromv$database;
Java实现连接access数据库和读取数据的操作
19/11/202018:06:59
具体步骤如下:一、连接access数据库创建AccessDbUtil类,连接数据库importjava.sql.Connection;importjava.sql.DriverManager;/***获取Access连接**@authordof
数据库、数据库系统、数据库管理系统是什么关系
2021 年 11 月 1 日 21:03:47
数据库、数据库系统、数据库管理系统之间的关系是:数据库系统包括数据库和数据库管理系统。数据库系统是具有数据库的计算机系统,一般由数据库、数据库管理系统(及其开发工具)组成。
数据库设计原则
2018 年 4 月 3 日 01:12:52
数据库设计原则一、建立数据团队 大型数据库的数据元素很多,设计时需要成立专门的数据团队。由于数据库设计者不一定是用户,所以不可能在系统设计中充分考虑数据元素。数据库设计好后,往往很难找到需要的数据库表。因此,数据团队最好由熟悉业务的项目骨干组成。数据团队的作用不是设计数据库,而是在参考其他类似系统的基础上,通过需求分析提取系统的基本数据元素
Linux操作mysql数据库总结
2018 年 4 月 3 日 01:10:31
1、首先连接数据库所在机器2、使用“db”命令连接MySQL3、可以使用以下命令查看数据库信息,注意命令需要以“;”结尾:SHOWDATABASES/ /List MySQLServer 数据库。SHOWTABLES[FROMdb_name]//列表编号
与 MySQL 数据库的 JDBC 连接和示例
2018 年 4 月 3 日 01:14:06
DBC 是 Sun 开发的一种可以使用 Java 语言连接数据库的技术。一、JDBC基础知识 JDBC(JavaDataBaseConnectivity,java数据库连接)是用于执行SQL语句的Java API,可以提供对各种关系数据库的统一访问。它由一组用 Java 语言编写的类和接口组成。. JDBC 为数据库开发人员提供了一个标准 API,可在此基础上构建更高级的
关系数据库的特点和常用的关系数据库
29/4/202009:37:20
关系数据库是指使用“关系模型”来组织数据的数据库,它以“行和列”的形式存储数据,以便于用户理解。关系数据库是一系列称为表的行和列,一组表组成数据库。采用
数据库名、全局数据库名、SID区别及感受
2/3/2018 01:09:44
总结:数据库名、全局数据库名、SID区别及感受
详细讲解Oracle数据库中的各种名称和标识符
2018 年 2 月 3 日 01:10:26
在 ORACLE7、8 数据库中只有数据库名称(db_name)和数据库实例名称(instance_name)。在ORACLE8i中,9i出现了新的参数,即数据库域名(db_domain)、服务名(service_name)、操作系统环境变量(ORACLE_SID)。这些是存在于同一数据库中的标识符,用于区分来自不同数据库的参数。一、数据库名(db_name) 什么是数据库名?数据库名称
数据库独立是指数据库独立于什么?
2015 年 6 月 7 日:02:43
数据库独立性是指数据库和数据结构相互独立。数据的独立性是数据库系统的基本特征之一;它可以使数据独立于应用程序,数据和程序是独立的,数据的定义与程序分离,简化了应用程序。
什么是全文数据库
25/11/202021:03:42
全文数据库包括:1、中文期刊全文数据库;2、中国博士论文全文数据库;3、中国优秀硕士学位论文全文数据库;4、中国重要报刊全文数据库;5、中文图书全文数据库;6、中国医院知识库
JDBC链接数据库
2018 年 4 月 3 日 01:07:40
1、在开发环境中加载指定数据库的驱动程序。比如下一个实验,使用的数据库是MySQL,所以需要下载支持JDBC的MySQL驱动(最新的是:mysql-connector-java-5.1.18-bin .jar ); 开发环境为MyEclipse,将下载的驱动加载到开发环境中(具体如何加载将在具体示例中说明)。2、在 Java 程序中加载驱动程序。在 Java 程序中,您可以通过
内存数据库的技术特点和常用的内存数据库!
29/4/202009:37:22
内存数据库是以内存为主要存储介质,将数据存储在内存中并直接操作的数据库。传统磁盘数据库需要频繁访问磁盘,但受磁头机械运动和系统调用时间的影响。当访问的数据量为
oracle中全局数据库名、环境变量和sid的区别
2018 年 4 月 3 日 01:07:56
数据库名(DB_NAME)、实例名(Instance_name)、操作系统环境变量(ORACLE_SID)只有ORACLE7、8数据库中的数据库名(db_name)和数据库实例名(instance_name)。在ORACLE8i中,9i出现了新的参数,即数据库域名(db_domain)、服务名(service_name)、操作系统环境变量(ORACLE_SID)。这些都存在于同一个数据库中
php如何读取数据库到json数据
12/8/202012:04:01
php读取数据库转json数据的实现方法:先连接数据库,读取数据库;然后读取数据库后,直接将数据转换成数组显示;最后通过“json_encode”将其转换为JSON。推荐:《PHP 视频教程》PHP
java从网页抓取数据( javaapi,java,api能帮我从谷歌网页上读取数据吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-26 15:01
javaapi,java,api能帮我从谷歌网页上读取数据吗)
Google Api,Java,从网页读取数据
javaapi
Google Api,Java,从网页读取数据,java,api,Java,Api,谁能帮我从谷歌网页读取数据。例如:我想使用Java阅读链接,链接下方的作者姓名和数据库右侧的PDF或HTML链接请在此处找到链接:您提出的问题称为数据提取。您需要加载 HTML 页面,然后从 HTML 中逻辑地选择信息片段。首先使用 HTML 解析器读取 HTML 页面,然后寻找 Google 如何布置其链接的模式。您可能会发现某些内容列在未排序的列表中,或者某些元素具有可用于提取所需数据的标识标签或类。我注意到您试图用代码建议对我的答案进行编辑。编辑您的原创帖子并将您的代码与 N 匹配
有人可以帮我从谷歌页面读取数据。例如:我想用Java阅读链接,链接下方的作者姓名和数据库右侧的PDF或HTML链接
请在此处找到链接:
您提出的问题称为数据提取。您需要加载 HTML 页面,然后从 HTML 中逻辑选择信息片段
HTML 页面首先使用 HTML 解析器读取,然后寻找 Google 如何布置其链接的模式。您可能会发现某些内容列在未排序的列表中,或者某些元素具有可用于提取所需数据的标识标签或类。
我注意到您试图用代码建议对我的答案进行编辑。编辑了您的原创帖子并将您的代码收录在 NullPointerException 堆栈跟踪中,我们可以查看它 查看全部
java从网页抓取数据(
javaapi,java,api能帮我从谷歌网页上读取数据吗)
Google Api,Java,从网页读取数据
javaapi
Google Api,Java,从网页读取数据,java,api,Java,Api,谁能帮我从谷歌网页读取数据。例如:我想使用Java阅读链接,链接下方的作者姓名和数据库右侧的PDF或HTML链接请在此处找到链接:您提出的问题称为数据提取。您需要加载 HTML 页面,然后从 HTML 中逻辑地选择信息片段。首先使用 HTML 解析器读取 HTML 页面,然后寻找 Google 如何布置其链接的模式。您可能会发现某些内容列在未排序的列表中,或者某些元素具有可用于提取所需数据的标识标签或类。我注意到您试图用代码建议对我的答案进行编辑。编辑您的原创帖子并将您的代码与 N 匹配
有人可以帮我从谷歌页面读取数据。例如:我想用Java阅读链接,链接下方的作者姓名和数据库右侧的PDF或HTML链接
请在此处找到链接:
您提出的问题称为数据提取。您需要加载 HTML 页面,然后从 HTML 中逻辑选择信息片段
HTML 页面首先使用 HTML 解析器读取,然后寻找 Google 如何布置其链接的模式。您可能会发现某些内容列在未排序的列表中,或者某些元素具有可用于提取所需数据的标识标签或类。
我注意到您试图用代码建议对我的答案进行编辑。编辑了您的原创帖子并将您的代码收录在 NullPointerException 堆栈跟踪中,我们可以查看它
java从网页抓取数据( 中国优秀硕士学位论文全文数据库的特点与常用的关系型数据库关系)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-26 14:17
中国优秀硕士学位论文全文数据库的特点与常用的关系型数据库关系)
数据存储名称
总结:查找数据库全局名:select*fromglobal_name;查找数据库实例名称:select*fromv$instance;查找数据库名称 selectnamefromv$database;
数据库、数据库系统、数据库管理系统是什么关系
数据库、数据库系统、数据库管理系统之间的关系是:数据库系统包括数据库和数据库管理系统。数据库系统是具有数据库的计算机系统,一般由数据库、数据库管理系统(及其开发工具)组成。
Java实现连接access数据库和读取数据的操作
具体步骤如下:一、连接access数据库创建AccessDbUtil类,连接数据库importjava.sql.Connection;importjava.sql.DriverManager;/***获取Access连接**@authordof
数据库设计原则
数据库设计原则一、建立数据团队 大型数据库的数据元素很多,设计时需要成立专门的数据团队。由于数据库设计者不一定是用户,所以不可能在系统设计中充分考虑数据元素。数据库设计好后,往往很难找到需要的数据库表。因此,数据团队最好由熟悉业务的项目骨干组成。数据团队的作用不是设计数据库,而是在参考其他类似系统的基础上,通过需求分析提取系统的基本数据元素
数据库名、全局数据库名、SID区别及感受
总结:数据库名、全局数据库名、SID区别及感受
关系数据库的特点和常用的关系数据库
关系数据库是指使用“关系模型”来组织数据的数据库,它以“行和列”的形式存储数据,以便于用户理解。关系数据库是一系列称为表的行和列,一组表组成数据库。采用
什么是全文数据库
全文数据库包括:1、中文期刊全文数据库;2、中国博士论文全文数据库;3、中国优秀硕士学位论文全文数据库;4、中国重要报刊全文数据库;5、中文图书全文数据库;6、中国医院知识库
Linux操作mysql数据库总结
1、首先连接数据库所在机器2、使用“db”命令连接MySQL3、可以使用以下命令查看数据库信息,注意命令需要以“;”结尾:SHOWDATABASES/ /List MySQLServer 数据库。SHOWTABLES[FROMdb_name]//列表编号
数据库独立是指数据库独立于什么?
数据库独立性是指数据库和数据结构相互独立。数据的独立性是数据库系统的基本特征之一;它可以使数据独立于应用程序,数据和程序是独立的,数据的定义与程序分离,简化了应用程序。
与 MySQL 数据库的 JDBC 连接和示例
DBC 是 Sun 开发的一种可以使用 Java 语言连接数据库的技术。一、JDBC基础知识 JDBC(JavaDataBaseConnectivity,java数据库连接)是用于执行SQL语句的Java API,可以提供对各种关系数据库的统一访问。它由一组用 Java 语言编写的类和接口组成。. JDBC 为数据库开发人员提供了一个标准 API,可在此基础上构建更高级的
内存数据库的技术特点和常用的内存数据库!
内存数据库是以内存为主要存储介质的数据库,将数据存储在内存中并直接运行。传统的磁盘数据库需要频繁访问磁盘,但受磁头机械运动和系统调用时间的影响。
数据库和 SQL
一、什么是数据库1.数据库(Database,DB):通过保存大量数据并由计算机进行处理,可以高效访问的数据集合。如:大——银行存储的信息,小——电话簿。2.
空数据库表
清除数据库表 有一些插件可以帮助 网站 进行统计,但也会生成大量数据 - 每个访问者的操作都会写入数据库。本来这没什么大不了的,但是如果您的数据库容量受到虚拟主机的限制,那么您就有麻烦了。无论迁移数据库的原因是什么,数据库的大小都会影响数据导入和导出时间。本文的目的是向读者展示如何清空数据库中的表,将表的内容和大小重置为零。这种清数据库表的方法不会妨碍统计插件的运行,也不会对数据库造成损坏。
PPAS 数据库备份和恢复
PPAS 数据库备份不同于普通的 Postgresql 数据库备份。因为PPAS数据库是兼容Oracle数据库的,所以会涉及到同义词、包、存储过程等。这时候在使用Postgresql社区备份恢复工具的时候,在恢复过程中提到了以上几点。到达的同义词等将不会被恢复。而且,由于PPAS数据库支持Clob字符大对象类型等,而Postgresql数据库不支持,恢复过程也会因此导致一些存储过程或者建表失败。所以
php如何读取数据库到json数据
php读取数据库转json数据的实现方法:先连接数据库,读取数据库;然后读取数据库后,直接将数据转换成数组显示;最后通过“json_encode”将其转换为JSON。推荐:《PHP 视频教程》PHP 查看全部
java从网页抓取数据(
中国优秀硕士学位论文全文数据库的特点与常用的关系型数据库关系)
数据存储名称
总结:查找数据库全局名:select*fromglobal_name;查找数据库实例名称:select*fromv$instance;查找数据库名称 selectnamefromv$database;
数据库、数据库系统、数据库管理系统是什么关系
数据库、数据库系统、数据库管理系统之间的关系是:数据库系统包括数据库和数据库管理系统。数据库系统是具有数据库的计算机系统,一般由数据库、数据库管理系统(及其开发工具)组成。
Java实现连接access数据库和读取数据的操作
具体步骤如下:一、连接access数据库创建AccessDbUtil类,连接数据库importjava.sql.Connection;importjava.sql.DriverManager;/***获取Access连接**@authordof
数据库设计原则
数据库设计原则一、建立数据团队 大型数据库的数据元素很多,设计时需要成立专门的数据团队。由于数据库设计者不一定是用户,所以不可能在系统设计中充分考虑数据元素。数据库设计好后,往往很难找到需要的数据库表。因此,数据团队最好由熟悉业务的项目骨干组成。数据团队的作用不是设计数据库,而是在参考其他类似系统的基础上,通过需求分析提取系统的基本数据元素
数据库名、全局数据库名、SID区别及感受
总结:数据库名、全局数据库名、SID区别及感受
关系数据库的特点和常用的关系数据库
关系数据库是指使用“关系模型”来组织数据的数据库,它以“行和列”的形式存储数据,以便于用户理解。关系数据库是一系列称为表的行和列,一组表组成数据库。采用
什么是全文数据库
全文数据库包括:1、中文期刊全文数据库;2、中国博士论文全文数据库;3、中国优秀硕士学位论文全文数据库;4、中国重要报刊全文数据库;5、中文图书全文数据库;6、中国医院知识库
Linux操作mysql数据库总结
1、首先连接数据库所在机器2、使用“db”命令连接MySQL3、可以使用以下命令查看数据库信息,注意命令需要以“;”结尾:SHOWDATABASES/ /List MySQLServer 数据库。SHOWTABLES[FROMdb_name]//列表编号
数据库独立是指数据库独立于什么?
数据库独立性是指数据库和数据结构相互独立。数据的独立性是数据库系统的基本特征之一;它可以使数据独立于应用程序,数据和程序是独立的,数据的定义与程序分离,简化了应用程序。
与 MySQL 数据库的 JDBC 连接和示例
DBC 是 Sun 开发的一种可以使用 Java 语言连接数据库的技术。一、JDBC基础知识 JDBC(JavaDataBaseConnectivity,java数据库连接)是用于执行SQL语句的Java API,可以提供对各种关系数据库的统一访问。它由一组用 Java 语言编写的类和接口组成。. JDBC 为数据库开发人员提供了一个标准 API,可在此基础上构建更高级的
内存数据库的技术特点和常用的内存数据库!
内存数据库是以内存为主要存储介质的数据库,将数据存储在内存中并直接运行。传统的磁盘数据库需要频繁访问磁盘,但受磁头机械运动和系统调用时间的影响。
数据库和 SQL
一、什么是数据库1.数据库(Database,DB):通过保存大量数据并由计算机进行处理,可以高效访问的数据集合。如:大——银行存储的信息,小——电话簿。2.
空数据库表
清除数据库表 有一些插件可以帮助 网站 进行统计,但也会生成大量数据 - 每个访问者的操作都会写入数据库。本来这没什么大不了的,但是如果您的数据库容量受到虚拟主机的限制,那么您就有麻烦了。无论迁移数据库的原因是什么,数据库的大小都会影响数据导入和导出时间。本文的目的是向读者展示如何清空数据库中的表,将表的内容和大小重置为零。这种清数据库表的方法不会妨碍统计插件的运行,也不会对数据库造成损坏。
PPAS 数据库备份和恢复
PPAS 数据库备份不同于普通的 Postgresql 数据库备份。因为PPAS数据库是兼容Oracle数据库的,所以会涉及到同义词、包、存储过程等。这时候在使用Postgresql社区备份恢复工具的时候,在恢复过程中提到了以上几点。到达的同义词等将不会被恢复。而且,由于PPAS数据库支持Clob字符大对象类型等,而Postgresql数据库不支持,恢复过程也会因此导致一些存储过程或者建表失败。所以
php如何读取数据库到json数据
php读取数据库转json数据的实现方法:先连接数据库,读取数据库;然后读取数据库后,直接将数据转换成数组显示;最后通过“json_encode”将其转换为JSON。推荐:《PHP 视频教程》PHP
java从网页抓取数据( 有没有们有没有想过如何爬取js生成的网络页面吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-24 11:15
有没有们有没有想过如何爬取js生成的网络页面吗?)
当我们使用浏览器处理网页时,有时我们不需要浏览。例如,使用 PhantomJS 适用于无头浏览器抓取网页数据。有没有想过如何爬取js生成的网页?别着急,本文将为您一一介绍。
1、PhantomJS 的功能
提供浏览器环境的命令行界面,除了不能浏览,其余与普通浏览器相同。它的核心是WebKit引擎,不提供图形界面,只能在命令行下使用。
2、PhantomJS 使用
适用范围是无头浏览器的适用范围。通常无头浏览器可用于页面自动化和网络爬虫等。
页面自动化测试:希望能自动登录网站做一些操作,然后检查结果是否正常。
网络爬虫:获取js下载并渲染页面中的信息,或者使用js跳转后获取链接的真实地址。
3、 对于用PhantomJS编写的parser.js文件,调用java爬虫爬取网页数据
Runtime rt = Runtime.getRuntime();
Process process = null;
try {
process = rt.exec("C:/phantomjs.exe C:/parser.js " +url);
InputStream in = process.getInputStream();
InputStreamReader reader = new InputStreamReader(in, "UTF-8");
BufferedReader br = new BufferedReader(reader);
StringBuffer sbf = new StringBuffer();
String tmp = "";
while ((tmp = br.readLine()) != null) {
sbf.append(tmp);
}
return sbf.toString();
} catch (IOException e) {
e.printStackTrace();
}
return null;
以上是对PhantomJS的简单介绍,以及使用java爬虫爬取PhantomJS为爬取数据编写的网页的代码实现。我希望它可以帮助你。更多java推荐:java教程。 查看全部
java从网页抓取数据(
有没有们有没有想过如何爬取js生成的网络页面吗?)
当我们使用浏览器处理网页时,有时我们不需要浏览。例如,使用 PhantomJS 适用于无头浏览器抓取网页数据。有没有想过如何爬取js生成的网页?别着急,本文将为您一一介绍。
1、PhantomJS 的功能
提供浏览器环境的命令行界面,除了不能浏览,其余与普通浏览器相同。它的核心是WebKit引擎,不提供图形界面,只能在命令行下使用。
2、PhantomJS 使用
适用范围是无头浏览器的适用范围。通常无头浏览器可用于页面自动化和网络爬虫等。
页面自动化测试:希望能自动登录网站做一些操作,然后检查结果是否正常。
网络爬虫:获取js下载并渲染页面中的信息,或者使用js跳转后获取链接的真实地址。
3、 对于用PhantomJS编写的parser.js文件,调用java爬虫爬取网页数据
Runtime rt = Runtime.getRuntime();
Process process = null;
try {
process = rt.exec("C:/phantomjs.exe C:/parser.js " +url);
InputStream in = process.getInputStream();
InputStreamReader reader = new InputStreamReader(in, "UTF-8");
BufferedReader br = new BufferedReader(reader);
StringBuffer sbf = new StringBuffer();
String tmp = "";
while ((tmp = br.readLine()) != null) {
sbf.append(tmp);
}
return sbf.toString();
} catch (IOException e) {
e.printStackTrace();
}
return null;
以上是对PhantomJS的简单介绍,以及使用java爬虫爬取PhantomJS为爬取数据编写的网页的代码实现。我希望它可以帮助你。更多java推荐:java教程。
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-23 20:11
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页的源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页的源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 307 次浏览 • 2022-02-23 20:09
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页的源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页的源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-23 20:07
原文链接:
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是在网页源码中直接返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
原文链接:
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是在网页源码中直接返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据(编程之家为你收集整理的全部代码内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-23 13:15
概述 java采集 网页抓取网页
以下是编程之家通过网络采集整理的代码片段。
编程之家小编现分享给大家,供大家参考。
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
/**
* java采集网页
*
*/
public class HttpWebCollecter {
/**
* 网页抓取方法
*
* @param urlString
* 要抓取的@R_419_1685@
* @param charset
* 网页编码方式
* @param timeout
* 超时时间
* @return 抓取的网页内容
* @throws IOException
* 抓取异常
*/
public static String GetWebContent(String urlString,final String charset,int timeout) throws IOException {
if (urlString == null || urlString.length() == 0) {
return "";
}
urlString = (urlString.startsWith("http://") || urlString
.startsWith("https://")) ? urlString : ("http://" + urlString)
.intern();
URL url = new URL(urlString);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setDoOutput(true);
conn.setRequestProperty("Pragma","no-cache");
conn.setRequestProperty("Cache-Control","no-cache");
int temp = Integer.parseInt(Math.round(Math.random()
* (UserAgent.length - 1))
+ "");
conn.setRequestProperty("User-Agent",UserAgent[temp]); // 模拟手机系统
conn.setRequestProperty("Accept","text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");// 只接受text/html类型,当然也可以接受图片,pdf,*/*任意,就是tomcat/conf/web里面定义那些
conn.setConnectTimeout(timeout);
try {
if (conn.getResponseCode() != HttpURLConnection.HTTP_OK) {
return "";
}
} catch (Exception e) {
try {
System.out.println(e.getMessage());
} catch (Exception e2) {
e2.printStackTrace();
}
return "";
}
InputStream input = conn.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(input,charset));
String line = null;
StringBuffer sb = new StringBuffer("");
while ((line = reader.readLine()) != null) {
sb.append(line).append("\r\n");
}
if (reader != null) {
reader.close();
}
if (conn != null) {
conn.disconnect();
}
return sb.toString();
}
public static String[] UserAgent = {
"Mozilla/5.0 (Linux; U; Android 2.2; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML,like Gecko) Version/4.0 Mobile Safari/533.2","Mozilla/5.0 (iPad; U; cpu OS 3_2_2 like Mac OS X; en-us) AppleWebKit/531.21.10 (KHTML,like Gecko) Version/4.0.4 Mobile/7B500 Safari/531.21.11","Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML,like Gecko) BrowserNG/7.1.18121","Nokia5700AP23.01/SymbianOS/9.1 Series60/3.0","UCWEB7.0.2.37/28/998","NOKIA5700/UCWEB7.0.2.37/28/977","Openwave/UCWEB7.0.2.37/28/978","Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/989" };
}
以上就是Programming Home()采集整理的全部代码内容,希望文章可以帮助大家解决遇到的程序开发问题。
如果你觉得编程之家网站的内容还不错,欢迎你把编程之家网站推荐给你的程序员朋友。
总结
以上就是编程之家为你采集的java采集网页爬取的全部内容。希望文章可以帮助大家解决java采集网页爬取遇到的程序开发问题。.
如果你觉得编程之家网站的内容还不错,欢迎你把编程之家网站推荐给你的程序员朋友。 查看全部
java从网页抓取数据(编程之家为你收集整理的全部代码内容)
概述 java采集 网页抓取网页
以下是编程之家通过网络采集整理的代码片段。
编程之家小编现分享给大家,供大家参考。
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
/**
* java采集网页
*
*/
public class HttpWebCollecter {
/**
* 网页抓取方法
*
* @param urlString
* 要抓取的@R_419_1685@
* @param charset
* 网页编码方式
* @param timeout
* 超时时间
* @return 抓取的网页内容
* @throws IOException
* 抓取异常
*/
public static String GetWebContent(String urlString,final String charset,int timeout) throws IOException {
if (urlString == null || urlString.length() == 0) {
return "";
}
urlString = (urlString.startsWith("http://";) || urlString
.startsWith("https://";)) ? urlString : ("http://" + urlString)
.intern();
URL url = new URL(urlString);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setDoOutput(true);
conn.setRequestProperty("Pragma","no-cache");
conn.setRequestProperty("Cache-Control","no-cache");
int temp = Integer.parseInt(Math.round(Math.random()
* (UserAgent.length - 1))
+ "");
conn.setRequestProperty("User-Agent",UserAgent[temp]); // 模拟手机系统
conn.setRequestProperty("Accept","text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");// 只接受text/html类型,当然也可以接受图片,pdf,*/*任意,就是tomcat/conf/web里面定义那些
conn.setConnectTimeout(timeout);
try {
if (conn.getResponseCode() != HttpURLConnection.HTTP_OK) {
return "";
}
} catch (Exception e) {
try {
System.out.println(e.getMessage());
} catch (Exception e2) {
e2.printStackTrace();
}
return "";
}
InputStream input = conn.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(input,charset));
String line = null;
StringBuffer sb = new StringBuffer("");
while ((line = reader.readLine()) != null) {
sb.append(line).append("\r\n");
}
if (reader != null) {
reader.close();
}
if (conn != null) {
conn.disconnect();
}
return sb.toString();
}
public static String[] UserAgent = {
"Mozilla/5.0 (Linux; U; Android 2.2; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML,like Gecko) Version/4.0 Mobile Safari/533.2","Mozilla/5.0 (iPad; U; cpu OS 3_2_2 like Mac OS X; en-us) AppleWebKit/531.21.10 (KHTML,like Gecko) Version/4.0.4 Mobile/7B500 Safari/531.21.11","Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML,like Gecko) BrowserNG/7.1.18121","Nokia5700AP23.01/SymbianOS/9.1 Series60/3.0","UCWEB7.0.2.37/28/998","NOKIA5700/UCWEB7.0.2.37/28/977","Openwave/UCWEB7.0.2.37/28/978","Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/989" };
}
以上就是Programming Home()采集整理的全部代码内容,希望文章可以帮助大家解决遇到的程序开发问题。
如果你觉得编程之家网站的内容还不错,欢迎你把编程之家网站推荐给你的程序员朋友。
总结
以上就是编程之家为你采集的java采集网页爬取的全部内容。希望文章可以帮助大家解决java采集网页爬取遇到的程序开发问题。.
如果你觉得编程之家网站的内容还不错,欢迎你把编程之家网站推荐给你的程序员朋友。
java从网页抓取数据(Java-如何从网页中获取所有链接?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-02-22 10:12
获取页面上的所有链接
例子
JavaScript,wget 有一个命令可以从我的 网站 下载 png 文件。这意味着,不知何故,必须有一个命令来从我的站点获取所有 URL。我只是给你一个我目前正在尝试做的例子。– Ali Gajani 2014 年 2 月 26 日 6:46 如何使用 Selenium WebDriver 从网页中获取/提取所有链接众所周知,每个软件 Web 应用程序都收录许多不同的链接/URL。其中一些重定向到相同 网站 的某些页面,而其他重定向到任何外部软件 Web 应用程序。. 获取文档中的所有链接,获取页面上的所有链接
例子
获取文档中的所有链接,如何使用 Selenium WebDriver 从网页中获取/提取所有链接众所周知,每个软件 Web 应用程序都收录许多不同的链接/URL。其中一些重定向到相同 网站 的某些页面,而其他重定向到任何外部软件 Web 应用程序。获取页面上的所有链接
例子
Java - 如何从网页中获取所有链接?由于链接是页面 HTML 的一部分,因此它们是人类可读内容的一部分。获取网页所需要做的就是使用 Invoke-WebRequest 并为其提供 URL。Web 抓取是从 网站 中提取数据的技术。BeautifulSoup 模块专为网页抓取而设计。BeautifulSoup 模块可以处理 HTML 和 XML。它为搜索、导航和修改解析树提供了简单的方法。.
Java - 如何从网页中获取所有链接?, 获取页面上的所有链接
例子
从 HTML 中提取链接,网页抓取是从 网站 中提取数据的技术。BeautifulSoup 模块专为网页抓取而设计。BeautifulSoup 模块可以处理 HTML 和 XML。它为搜索、导航和修改解析树提供了简单的方法。我想使用访问 vba 从网页中提取 href 链接值。HTML 代码如下所示。我想提取以下值 /s/ref=sr_in_-2_p_6_0?fst=as%3Aoff&rh=n 。
从 HTML 中提取链接,因为链接是页面 HTML 的一部分,它们是人类可读内容的一部分。获取网页所需要做的就是使用 Invoke-WebRequest 并为其提供 URL。Web 抓取是从 网站 中提取数据的技术。BeautifulSoup 模块专为网页抓取而设计。BeautifulSoup 模块可以处理 HTML 和 XML。它为搜索、导航和修改解析树提供了简单的方法。. 从网页中提取链接(BeautifulSoup),我想使用访问 vba 从网页中提取 href 链接值。HTML 代码如下所示。我想提取以下值 /s/ref=sr_in_-2_p_6_0?fst=as%3Aoff&rh=n 从 HTML 页面中提取所有链接 2010 年 3 月 30 日 下面的代码是一个使用 HTML 页面中的正则表达式的小类提取中的所有链接。此方法返回一个 URL 列表,其中可以包括“#”和“javascript:;”等格式。.
获取 网站 链接
Python 中的爬取链接,关于页面链接爬虫 此工具允许快速轻松地从网页中抓取链接。列出页面链接到的链接、域和资源,以告诉您有关页面的很多信息。使用这种工具的原因很广泛。获取 Python 中的 网站 链接并订阅!在此处获取代码:持续时间:9:15 发布时间:2017 年 11 月 21 日。链接 Klipper,其中之一是 URL 本身。例如,您可能想要抓取产品页面 URL 列表、指向重要文档的直接链接列表或从网页中提取链接 (BeautifulSoup)。Web 抓取是从 网站 中提取数据的技术。BeautifulSoup 模块是 .
Link Klipper,使用 Python 订阅获取 网站 链接!在此处获取代码:持续时间:9:15 发布时间:2017 年 11 月 21 日 其中之一是 URL 本身。例如,您可能想要抓取产品页面 URL 列表、指向重要文档的直接链接列表,或者。如何在 Python 中构建一个 URL 爬虫来映射 网站,从网页中提取链接(BeautifulSoup)。Web 抓取是从 网站 中提取数据的技术。Python 中的 BeautifulSoup 模块是网页抓取,主要由三个主要库控制:BeautifulSoup、Scrapy 和 Now let's fetch a page and inspect it with BeautifulSoup:soup.find_all("a") #
如何在 Python 中构建一个 URL 爬虫来映射 网站,其中之一就是 URL 本身。例如,您可能想要抓取产品页面 URL 列表、指向重要文档的直接链接列表或从网页中提取链接 (BeautifulSoup)。Web 抓取是从 网站 中提取数据的技术。BeautifulSoup 模块是。使用 href 引用来抓取 网站,Python 中的网络抓取主要由三个主要库控制:BeautifulSoup、Scrapy 和现在让我们获取一个页面并使用 BeautifulSoup 进行检查:soup.find_all("a")#
使用 href reference crawl 网站 从网页中提取链接(BeautifulSoup)。Web 抓取是从 网站 中提取数据的技术。Python 中的 BeautifulSoup 模块是网页抓取,主要由三大库控制:BeautifulSoup、Scrapy 和 Now let's fetch a page and inspect it with BeautifulSoup:soup。find_all("a") # 爬取一个站点,如果抓取应该从多个位置,也可以指定多个起始url。使用像这样 [1-3] 这样的范围 url 来链接这样的链接:. 关于页面链接爬虫。该工具允许快速轻松地从网页中抓取链接。列出页面链接到的链接、域和资源。
爬取网站,Python 中的网络爬取由三个主要库组成:BeautifulSoup、Scrapy 和 Now let's fetch a page and inspect it with BeautifulSoup: soup.find_all("a") # How to get from any 网站 Crawl URL列表,关于页面链接爬虫。该工具允许快速轻松地从网页中抓取链接。列出链接到页面的链接、域和资源 易于使用的免费网页抓取工具 ParseHub 是一款免费且功能强大的网页抓取工具。使用我们先进的网络抓取工具,提取数据就像点击您需要的数据一样简单。免费下载 ParseHub。
JavaScript 从外部 url 获取 HTML 内容
如何将外部网页加载到 html 页面中的 div 中,url() CSS 函数用于收录文件。该参数是绝对 URL、相对 URL 或数据 URI。url() 函数可以作为参数传递给其他 CSS 函数,例如 attr()() 函数。根据作为值的属性,查找的资源可以是图像、字体或样式表。// str_line 将是第二个函数中的一行数据 // n 将是第 n 列。所以如果你想要第二列,把 2. function display_column(str_line, n) { document.write("
" + str_line.split('\t')[n - 1]); } // 数据将来自您的 XMLHttpRequest.responseText // 我们将使用(或“输入键”)作为分隔符进行拆分) // 并通过每行到display_column。如何从HTML文件中的外部网页获取DIV元素?必填的URL参数指定要加载的URL。如果load()方法成功,会显示“外部内容加载成功! “如果我如何获取具有给定 url 的远程页面的 HTML 内容?带有评估的内联样式)允许您在后台脚本中呈现外部页面..
如何从 HTML 文件中的外部网页获取 DIV 元素?, // str_line 将是第二个函数中的一行数据 // n 将是第 n 列。所以如果你想要第二列,把 2. function display_column(str_line, n) { document.write("
" + str_line.split('\t')[n - 1]); } // 数据将来自您的 XMLHttpRequest.responseText // 我们将使用(或“输入键”)作为分隔符进行拆分) // 并通过每一行到 display_column 所需的 URL 参数指定要加载的 URL。如果 load() 方法成功,则显示“外部内容加载成功!”,如果。使用 JS 获取远程页面的 HTML - 开发,如何获取具有给定 url 的远程页面的 HTML 内容?带有评估的内联样式)允许您在后台脚本中呈现外部页面。让我们看看了解如何使用 jQuery 在 Ajax 模式下加载外部内容(在其他域中)。这里的所有代码都可以从 GitHub 或在此获得。
使用JS-开发获取远程页面的HTML,必填的URL参数指定要加载的URL。如果 load() 方法成功,它会显示“外部内容加载成功!”,如果我可以使用给定的 url 获取远程页面的 HTML 内容?使用评估的内联样式)允许您在后台脚本中呈现外部页面。想知道 javascript 如何从外部 url 获取 html 内容?让我们看看如何使用 jQuery 在 Ajax 模式下加载外部内容(在其他域中)。此处的所有代码均可从 GitHub 或 2018 年 1 月 10 日获得 · 创建一个带有扩展名的外部 JavaScript 文件。如果我们想从另一个 HTML 页面获取数据并将其插入到显示的页面中,使用 PHP 将基于参数传递的动态内容加载到外部 URL 中。
想知道 javascript 如何从外部 url 获取 html 内容?如何获取具有给定 url 的远程页面的 HTML 内容?带有评估的内联样式)允许您在后台脚本中呈现外部页面。让我们看看如何使用 jQuery 在 Ajax 模式下加载外部内容(在其他域中)。这里的所有代码都可以从 GitHub 或这里获得。包括使用 Ajax 的外部页面的内容,2018 年 1 月 10 日创建扩展。如果我们想从另一个 HTML 页面获取数据并插入显示的 javascript get html content from url Jun 09, 2015 · 如果你是前端图片的作用是从外部文件中获取 HTML DIV。
包括使用 Ajax 来自外部页面的内容,让我们看看如何使用 jQuery 在 Ajax 模式下加载外部内容(在其他域中)。此处的所有代码均可从 GitHub 或 2018 年 1 月 10 日获得 · 创建一个带有扩展名的外部 JavaScript 文件。如果我们想从另一个 HTML 页面获取数据并将其插入到显示的页面中,使用 PHP 将基于参数传递的动态内容加载到外部 URL 中。使用纯 Javascript 加载外部 URL 内容,
更多问题 查看全部
java从网页抓取数据(Java-如何从网页中获取所有链接?(组图))
获取页面上的所有链接
例子
JavaScript,wget 有一个命令可以从我的 网站 下载 png 文件。这意味着,不知何故,必须有一个命令来从我的站点获取所有 URL。我只是给你一个我目前正在尝试做的例子。– Ali Gajani 2014 年 2 月 26 日 6:46 如何使用 Selenium WebDriver 从网页中获取/提取所有链接众所周知,每个软件 Web 应用程序都收录许多不同的链接/URL。其中一些重定向到相同 网站 的某些页面,而其他重定向到任何外部软件 Web 应用程序。. 获取文档中的所有链接,获取页面上的所有链接
例子
获取文档中的所有链接,如何使用 Selenium WebDriver 从网页中获取/提取所有链接众所周知,每个软件 Web 应用程序都收录许多不同的链接/URL。其中一些重定向到相同 网站 的某些页面,而其他重定向到任何外部软件 Web 应用程序。获取页面上的所有链接
例子
Java - 如何从网页中获取所有链接?由于链接是页面 HTML 的一部分,因此它们是人类可读内容的一部分。获取网页所需要做的就是使用 Invoke-WebRequest 并为其提供 URL。Web 抓取是从 网站 中提取数据的技术。BeautifulSoup 模块专为网页抓取而设计。BeautifulSoup 模块可以处理 HTML 和 XML。它为搜索、导航和修改解析树提供了简单的方法。.
Java - 如何从网页中获取所有链接?, 获取页面上的所有链接
例子
从 HTML 中提取链接,网页抓取是从 网站 中提取数据的技术。BeautifulSoup 模块专为网页抓取而设计。BeautifulSoup 模块可以处理 HTML 和 XML。它为搜索、导航和修改解析树提供了简单的方法。我想使用访问 vba 从网页中提取 href 链接值。HTML 代码如下所示。我想提取以下值 /s/ref=sr_in_-2_p_6_0?fst=as%3Aoff&rh=n 。
从 HTML 中提取链接,因为链接是页面 HTML 的一部分,它们是人类可读内容的一部分。获取网页所需要做的就是使用 Invoke-WebRequest 并为其提供 URL。Web 抓取是从 网站 中提取数据的技术。BeautifulSoup 模块专为网页抓取而设计。BeautifulSoup 模块可以处理 HTML 和 XML。它为搜索、导航和修改解析树提供了简单的方法。. 从网页中提取链接(BeautifulSoup),我想使用访问 vba 从网页中提取 href 链接值。HTML 代码如下所示。我想提取以下值 /s/ref=sr_in_-2_p_6_0?fst=as%3Aoff&rh=n 从 HTML 页面中提取所有链接 2010 年 3 月 30 日 下面的代码是一个使用 HTML 页面中的正则表达式的小类提取中的所有链接。此方法返回一个 URL 列表,其中可以包括“#”和“javascript:;”等格式。.
获取 网站 链接
Python 中的爬取链接,关于页面链接爬虫 此工具允许快速轻松地从网页中抓取链接。列出页面链接到的链接、域和资源,以告诉您有关页面的很多信息。使用这种工具的原因很广泛。获取 Python 中的 网站 链接并订阅!在此处获取代码:持续时间:9:15 发布时间:2017 年 11 月 21 日。链接 Klipper,其中之一是 URL 本身。例如,您可能想要抓取产品页面 URL 列表、指向重要文档的直接链接列表或从网页中提取链接 (BeautifulSoup)。Web 抓取是从 网站 中提取数据的技术。BeautifulSoup 模块是 .
Link Klipper,使用 Python 订阅获取 网站 链接!在此处获取代码:持续时间:9:15 发布时间:2017 年 11 月 21 日 其中之一是 URL 本身。例如,您可能想要抓取产品页面 URL 列表、指向重要文档的直接链接列表,或者。如何在 Python 中构建一个 URL 爬虫来映射 网站,从网页中提取链接(BeautifulSoup)。Web 抓取是从 网站 中提取数据的技术。Python 中的 BeautifulSoup 模块是网页抓取,主要由三个主要库控制:BeautifulSoup、Scrapy 和 Now let's fetch a page and inspect it with BeautifulSoup:soup.find_all("a") #
如何在 Python 中构建一个 URL 爬虫来映射 网站,其中之一就是 URL 本身。例如,您可能想要抓取产品页面 URL 列表、指向重要文档的直接链接列表或从网页中提取链接 (BeautifulSoup)。Web 抓取是从 网站 中提取数据的技术。BeautifulSoup 模块是。使用 href 引用来抓取 网站,Python 中的网络抓取主要由三个主要库控制:BeautifulSoup、Scrapy 和现在让我们获取一个页面并使用 BeautifulSoup 进行检查:soup.find_all("a")#
使用 href reference crawl 网站 从网页中提取链接(BeautifulSoup)。Web 抓取是从 网站 中提取数据的技术。Python 中的 BeautifulSoup 模块是网页抓取,主要由三大库控制:BeautifulSoup、Scrapy 和 Now let's fetch a page and inspect it with BeautifulSoup:soup。find_all("a") # 爬取一个站点,如果抓取应该从多个位置,也可以指定多个起始url。使用像这样 [1-3] 这样的范围 url 来链接这样的链接:. 关于页面链接爬虫。该工具允许快速轻松地从网页中抓取链接。列出页面链接到的链接、域和资源。
爬取网站,Python 中的网络爬取由三个主要库组成:BeautifulSoup、Scrapy 和 Now let's fetch a page and inspect it with BeautifulSoup: soup.find_all("a") # How to get from any 网站 Crawl URL列表,关于页面链接爬虫。该工具允许快速轻松地从网页中抓取链接。列出链接到页面的链接、域和资源 易于使用的免费网页抓取工具 ParseHub 是一款免费且功能强大的网页抓取工具。使用我们先进的网络抓取工具,提取数据就像点击您需要的数据一样简单。免费下载 ParseHub。
JavaScript 从外部 url 获取 HTML 内容
如何将外部网页加载到 html 页面中的 div 中,url() CSS 函数用于收录文件。该参数是绝对 URL、相对 URL 或数据 URI。url() 函数可以作为参数传递给其他 CSS 函数,例如 attr()() 函数。根据作为值的属性,查找的资源可以是图像、字体或样式表。// str_line 将是第二个函数中的一行数据 // n 将是第 n 列。所以如果你想要第二列,把 2. function display_column(str_line, n) { document.write("
" + str_line.split('\t')[n - 1]); } // 数据将来自您的 XMLHttpRequest.responseText // 我们将使用(或“输入键”)作为分隔符进行拆分) // 并通过每行到display_column。如何从HTML文件中的外部网页获取DIV元素?必填的URL参数指定要加载的URL。如果load()方法成功,会显示“外部内容加载成功! “如果我如何获取具有给定 url 的远程页面的 HTML 内容?带有评估的内联样式)允许您在后台脚本中呈现外部页面..
如何从 HTML 文件中的外部网页获取 DIV 元素?, // str_line 将是第二个函数中的一行数据 // n 将是第 n 列。所以如果你想要第二列,把 2. function display_column(str_line, n) { document.write("
" + str_line.split('\t')[n - 1]); } // 数据将来自您的 XMLHttpRequest.responseText // 我们将使用(或“输入键”)作为分隔符进行拆分) // 并通过每一行到 display_column 所需的 URL 参数指定要加载的 URL。如果 load() 方法成功,则显示“外部内容加载成功!”,如果。使用 JS 获取远程页面的 HTML - 开发,如何获取具有给定 url 的远程页面的 HTML 内容?带有评估的内联样式)允许您在后台脚本中呈现外部页面。让我们看看了解如何使用 jQuery 在 Ajax 模式下加载外部内容(在其他域中)。这里的所有代码都可以从 GitHub 或在此获得。
使用JS-开发获取远程页面的HTML,必填的URL参数指定要加载的URL。如果 load() 方法成功,它会显示“外部内容加载成功!”,如果我可以使用给定的 url 获取远程页面的 HTML 内容?使用评估的内联样式)允许您在后台脚本中呈现外部页面。想知道 javascript 如何从外部 url 获取 html 内容?让我们看看如何使用 jQuery 在 Ajax 模式下加载外部内容(在其他域中)。此处的所有代码均可从 GitHub 或 2018 年 1 月 10 日获得 · 创建一个带有扩展名的外部 JavaScript 文件。如果我们想从另一个 HTML 页面获取数据并将其插入到显示的页面中,使用 PHP 将基于参数传递的动态内容加载到外部 URL 中。
想知道 javascript 如何从外部 url 获取 html 内容?如何获取具有给定 url 的远程页面的 HTML 内容?带有评估的内联样式)允许您在后台脚本中呈现外部页面。让我们看看如何使用 jQuery 在 Ajax 模式下加载外部内容(在其他域中)。这里的所有代码都可以从 GitHub 或这里获得。包括使用 Ajax 的外部页面的内容,2018 年 1 月 10 日创建扩展。如果我们想从另一个 HTML 页面获取数据并插入显示的 javascript get html content from url Jun 09, 2015 · 如果你是前端图片的作用是从外部文件中获取 HTML DIV。
包括使用 Ajax 来自外部页面的内容,让我们看看如何使用 jQuery 在 Ajax 模式下加载外部内容(在其他域中)。此处的所有代码均可从 GitHub 或 2018 年 1 月 10 日获得 · 创建一个带有扩展名的外部 JavaScript 文件。如果我们想从另一个 HTML 页面获取数据并将其插入到显示的页面中,使用 PHP 将基于参数传递的动态内容加载到外部 URL 中。使用纯 Javascript 加载外部 URL 内容,
更多问题
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-20 15:20
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据(java从网页抓取数据时必须要确定网页里面的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-14 09:08
java从网页抓取数据时必须要确定网页里面的数据是经过正确处理后才能实现爬虫功能的。网页里面的数据应该是以什么格式存储的?是google搜索url生成的还是html页面生成的?如果是google搜索url生成的,那必须是域名是域名或者还是或者还是才能进行正确的爬虫指令。
如果是html页面生成的,必须要有正确的编码才能编写正确的爬虫代码。02如何检查html页面的正确编码?首先在java的jsp页面中能看到stringurlstr="/";urlstr是在html页面的顶部。点击浏览器右键查看域名,发现域名是,但是jsp页面上还缺少urlstr中的"/"地址。
而在运行eclipse时所有图标是灰色的。所以我们需要确定jsp页面上的地址是用java代码中定义的方式定义的。点击jsp页面顶部的java编程图标,在菜单-。 查看全部
java从网页抓取数据(java从网页抓取数据时必须要确定网页里面的数据)
java从网页抓取数据时必须要确定网页里面的数据是经过正确处理后才能实现爬虫功能的。网页里面的数据应该是以什么格式存储的?是google搜索url生成的还是html页面生成的?如果是google搜索url生成的,那必须是域名是域名或者还是或者还是才能进行正确的爬虫指令。
如果是html页面生成的,必须要有正确的编码才能编写正确的爬虫代码。02如何检查html页面的正确编码?首先在java的jsp页面中能看到stringurlstr="/";urlstr是在html页面的顶部。点击浏览器右键查看域名,发现域名是,但是jsp页面上还缺少urlstr中的"/"地址。
而在运行eclipse时所有图标是灰色的。所以我们需要确定jsp页面上的地址是用java代码中定义的方式定义的。点击jsp页面顶部的java编程图标,在菜单-。
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-02-13 10:27
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-13 10:25
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-11 14:20
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具抓取网站数据比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具抓取网站数据比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java从网页抓取数据( PythonBeautifulSoup:从给定的网页中提取所有文本(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-11 12:23
PythonBeautifulSoup:从给定的网页中提取所有文本(1))
BeautifulSoup 获取 javascript 变量
如何从请求中提取 javascript 变量? :learnpython,这将使用re模块提取数据并将其加载为JSON: import urllib import json import re from bs4 import BeautifulSoup web 例如,在浏览器控制台中我编写window.variable_name并获取值。我怎样才能在 Beautiful Soup 中获得等价物? .Python BeautifulSoup:从给定的网页中提取所有文本,我是 Python 库 BeautifulSoup 的粉丝。它功能丰富且非常易于使用。但是当我在做一个小型的 react-native 项目时,我试图找到一个像 BeautifulSoup 这样的 HTML 解析器库,但我失败了。所以我想写一个HTML解析器库,它可以像Javascript中的BeautifulSoup一样简单易用。我正在使用 python 和 Beautiful Soup 等软件包来抓取新闻网站。我很难获取在脚本标记中声明的 java 脚本变量的值,并且它正在那里得到更新。这是我正在抓取的 HTML 页面的一部分:(仅脚本部分)。
Python BeautifulSoup:从给定网页中提取所有文本,如何使用 BeautifulSoup 访问 javascript 变量?我知道变量的名称。该变量在脚本标签中定义:例如,在浏览器控制台中,我编写 window.variable_name 并获取值。我怎样才能在 Beautiful Soup 中获得等价物?我是 Python 库 BeautifulSoup 的粉丝。它功能丰富且非常易于使用。但是当我在做一个小型的 react-native 项目时,我试图找到一个像 BeautifulSoup 这样的 HTML 解析器库,但我失败了。所以我想写一个HTML解析器库,它可以像Javascript中的BeautifulSoup一样简单易用。 在 Python 和 Beautiful 中提取 Javascript 变量对象数据,我正在使用 python 和 Beautiful Soup 等包来抓取新闻站点。我很难获取在脚本标记中声明的 java 脚本变量的值,并且它正在那里得到更新。这是我正在抓取的 HTML 页面的一部分:(只有脚本部分)使用 BeautifulSoup at .版权。蜀ICP备2021025969号 查看全部
java从网页抓取数据(
PythonBeautifulSoup:从给定的网页中提取所有文本(1))
BeautifulSoup 获取 javascript 变量
如何从请求中提取 javascript 变量? :learnpython,这将使用re模块提取数据并将其加载为JSON: import urllib import json import re from bs4 import BeautifulSoup web 例如,在浏览器控制台中我编写window.variable_name并获取值。我怎样才能在 Beautiful Soup 中获得等价物? .Python BeautifulSoup:从给定的网页中提取所有文本,我是 Python 库 BeautifulSoup 的粉丝。它功能丰富且非常易于使用。但是当我在做一个小型的 react-native 项目时,我试图找到一个像 BeautifulSoup 这样的 HTML 解析器库,但我失败了。所以我想写一个HTML解析器库,它可以像Javascript中的BeautifulSoup一样简单易用。我正在使用 python 和 Beautiful Soup 等软件包来抓取新闻网站。我很难获取在脚本标记中声明的 java 脚本变量的值,并且它正在那里得到更新。这是我正在抓取的 HTML 页面的一部分:(仅脚本部分)。
Python BeautifulSoup:从给定网页中提取所有文本,如何使用 BeautifulSoup 访问 javascript 变量?我知道变量的名称。该变量在脚本标签中定义:例如,在浏览器控制台中,我编写 window.variable_name 并获取值。我怎样才能在 Beautiful Soup 中获得等价物?我是 Python 库 BeautifulSoup 的粉丝。它功能丰富且非常易于使用。但是当我在做一个小型的 react-native 项目时,我试图找到一个像 BeautifulSoup 这样的 HTML 解析器库,但我失败了。所以我想写一个HTML解析器库,它可以像Javascript中的BeautifulSoup一样简单易用。 在 Python 和 Beautiful 中提取 Javascript 变量对象数据,我正在使用 python 和 Beautiful Soup 等包来抓取新闻站点。我很难获取在脚本标记中声明的 java 脚本变量的值,并且它正在那里得到更新。这是我正在抓取的 HTML 页面的一部分:(只有脚本部分)使用 BeautifulSoup at .版权。蜀ICP备2021025969号
java从网页抓取数据(java,c++,python并行框架化的应用分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-10 17:00
java从网页抓取数据、c++的pdb-assembly,python的xml-fastlearning。
除了楼上推荐的c++fastlearning(opensourcer/cpp),本人从一开始的写pdb-assembly加载tomcat(貌似没有c/c++支持),到后来写imagemagick代理web上传数据,感觉技术成长比较快。像c++的pdb-assembly,python的xml-fastlearning,java的imagemagick都是目前使用比较多的开源代理框架,都已经比较成熟。近期在公司的系统上实现了不少技术成长。开源代理框架可以搜索一下upic。
可以看看fastlearning应该是目前已经从架构设计上将java,c++,python并行框架化的一个非常好的实现。框架结构清晰、主框架定义了各模块的系统架构,文档齐全、支持程度高。其他模块可根据各自需要自行修改实现。
java的话,opensource的的python,panda实现,webxml2xmlxml3,pillowopengl3dpygame都已经可以实现上传。c/c++的话uwa和makapp已经实现了上传。python的话,
我最近在学python,并为之研究使用chrome的python和edgecast的python进行测试。我在学习python时要学习《python语言程序设计》和《python语言程序设计实战》两本,还要看《python初学者教程》一本。对于开发网页技术方面我的经验是:利用java或python的网页开发环境,可以方便我们对web页面调试,python可以有时间进行网页测试。
此外,对于网页开发,我比较看重基础语法的掌握。对于数据库的操作如mysql、mongodb等,相信对于初学者不在是问题。 查看全部
java从网页抓取数据(java,c++,python并行框架化的应用分析)
java从网页抓取数据、c++的pdb-assembly,python的xml-fastlearning。
除了楼上推荐的c++fastlearning(opensourcer/cpp),本人从一开始的写pdb-assembly加载tomcat(貌似没有c/c++支持),到后来写imagemagick代理web上传数据,感觉技术成长比较快。像c++的pdb-assembly,python的xml-fastlearning,java的imagemagick都是目前使用比较多的开源代理框架,都已经比较成熟。近期在公司的系统上实现了不少技术成长。开源代理框架可以搜索一下upic。
可以看看fastlearning应该是目前已经从架构设计上将java,c++,python并行框架化的一个非常好的实现。框架结构清晰、主框架定义了各模块的系统架构,文档齐全、支持程度高。其他模块可根据各自需要自行修改实现。
java的话,opensource的的python,panda实现,webxml2xmlxml3,pillowopengl3dpygame都已经可以实现上传。c/c++的话uwa和makapp已经实现了上传。python的话,
我最近在学python,并为之研究使用chrome的python和edgecast的python进行测试。我在学习python时要学习《python语言程序设计》和《python语言程序设计实战》两本,还要看《python初学者教程》一本。对于开发网页技术方面我的经验是:利用java或python的网页开发环境,可以方便我们对web页面调试,python可以有时间进行网页测试。
此外,对于网页开发,我比较看重基础语法的掌握。对于数据库的操作如mysql、mongodb等,相信对于初学者不在是问题。
java从网页抓取数据(本文实例讲述Java实现的爬虫抓取图片并保存操作。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-10 06:01
本文的例子描述了用Java实现的爬虫抓取图片并保存。分享给大家参考,详情如下:
这是我参考网上一些资料写的第一个java爬虫程序
本来想获取无聊地图的图片,但是网络返回码一直是503,所以改成了网站
import java.io.BufferedReader;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网络爬虫取数据
*
* */
public class JianDan {
public static String GetUrl(String inUrl){
StringBuilder sb = new StringBuilder();
try {
URL url =new URL(inUrl);
BufferedReader reader =new BufferedReader(new InputStreamReader(url.openStream()));
String temp="";
while((temp=reader.readLine())!=null){
//System.out.println(temp);
sb.append(temp);
}
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
return sb.toString();
}
public static List GetMatcher(String str,String url){
List result = new ArrayList();
Pattern p =Pattern.compile(url);//获取网页地址
Matcher m =p.matcher(str);
while(m.find()){
//System.out.println(m.group(1));
result.add(m.group(1));
}
return result;
}
public static void main(String args[]){
String str=GetUrl("http://www.163.com");
List ouput =GetMatcher(str,"src=\"([\\w\\s./:]+?)\"");
for(String temp:ouput){
//System.out.println(ouput.get(0));
System.out.println(temp);
}
String aurl=ouput.get(0);
// 构造URL
URL url;
try {
url = new URL(aurl);
// 打开URL连接
URLConnection con = (URLConnection)url.openConnection();
// 得到URL的输入流
InputStream input = con.getInputStream();
// 设置数据缓冲
byte[] bs = new byte[1024 * 2];
// 读取到的数据长度
int len;
// 输出的文件流保存图片至本地
OutputStream os = new FileOutputStream("a.png");
while ((len = input.read(bs)) != -1) {
os.write(bs, 0, len);
}
os.close();
input.close();
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
运行输出:
对java相关内容比较感兴趣的读者可以查看本站专题:《Java网络编程技巧总结》、《Java套接字编程技巧总结》、《Java文件和目录操作技巧总结》、《Java数据《结构与算法教程》、《Java操作DOM节点技巧总结》、《Java缓存操作技巧总结》
希望这篇文章对大家java编程有所帮助。 查看全部
java从网页抓取数据(本文实例讲述Java实现的爬虫抓取图片并保存操作。)
本文的例子描述了用Java实现的爬虫抓取图片并保存。分享给大家参考,详情如下:
这是我参考网上一些资料写的第一个java爬虫程序
本来想获取无聊地图的图片,但是网络返回码一直是503,所以改成了网站
import java.io.BufferedReader;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网络爬虫取数据
*
* */
public class JianDan {
public static String GetUrl(String inUrl){
StringBuilder sb = new StringBuilder();
try {
URL url =new URL(inUrl);
BufferedReader reader =new BufferedReader(new InputStreamReader(url.openStream()));
String temp="";
while((temp=reader.readLine())!=null){
//System.out.println(temp);
sb.append(temp);
}
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
return sb.toString();
}
public static List GetMatcher(String str,String url){
List result = new ArrayList();
Pattern p =Pattern.compile(url);//获取网页地址
Matcher m =p.matcher(str);
while(m.find()){
//System.out.println(m.group(1));
result.add(m.group(1));
}
return result;
}
public static void main(String args[]){
String str=GetUrl("http://www.163.com";);
List ouput =GetMatcher(str,"src=\"([\\w\\s./:]+?)\"");
for(String temp:ouput){
//System.out.println(ouput.get(0));
System.out.println(temp);
}
String aurl=ouput.get(0);
// 构造URL
URL url;
try {
url = new URL(aurl);
// 打开URL连接
URLConnection con = (URLConnection)url.openConnection();
// 得到URL的输入流
InputStream input = con.getInputStream();
// 设置数据缓冲
byte[] bs = new byte[1024 * 2];
// 读取到的数据长度
int len;
// 输出的文件流保存图片至本地
OutputStream os = new FileOutputStream("a.png");
while ((len = input.read(bs)) != -1) {
os.write(bs, 0, len);
}
os.close();
input.close();
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
运行输出:
对java相关内容比较感兴趣的读者可以查看本站专题:《Java网络编程技巧总结》、《Java套接字编程技巧总结》、《Java文件和目录操作技巧总结》、《Java数据《结构与算法教程》、《Java操作DOM节点技巧总结》、《Java缓存操作技巧总结》
希望这篇文章对大家java编程有所帮助。
java从网页抓取数据(如何在Java中创建Web爬网程序?用Java创建网络搜寻器程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-10 05:38
网络爬虫本质上是一个互联网机器人,它扫描互联网,浏览各种网站,分析数据并生成报告。大多数互联网巨头一直在使用预制的网络爬虫来研究其竞争对手的网站。GoogleBot 是谷歌最受欢迎的网络爬虫,爬取了 28.5% 的网络。它包括广告机器人、图像机器人、搜索引擎机器人等。紧随其后的是 Bing,占比 22%。
为什么网络爬虫有用?
对于每个想要在网上拥有强大影响力的 网站 来说,网络爬虫是必须的。整个想法是能够访问竞争对手的 网站 并提取产品详细信息、价格和图像等信息。事实上,这些公司中的每一个都应该努力做到比竞争对手更好的网站。虽然每个在线行业都存在网络爬虫,但这里有一些重要的用例。
美国一家流行的时尚电子商务商店使用网络爬虫来访问来自其他一百个时尚网站 的信息和数据。这有助于他们与竞争对手保持同步。
美国电子商务平台使用网络爬虫来确定和确定基于邮政编码或消费者位置的定价策略。
一家总部位于欧洲的家具公司访问其 20 个竞争对手网站的数据以采集见解。
此外,通过使用从亚马逊抓取的产品信息,印度零售商 网站 可以识别和识别他们最畅销的产品。
如何在 Java 中创建网络爬虫?
用 Java 创建一个网络爬虫需要一些耐心。这需要准确和有效。以下是使用 Java 制作简单网络爬虫原型的一些步骤。
设置 MySQL 数据库
第一步需要设置一个 MySQL 数据库才能开始工作。如果您使用的是 Windows,只需在几分钟内下载并安装它。在此之后,您可以使用任何 GUI 界面对 MySQL 进行操作。
数据库和表设置
接下来,您可以在 MySQL 中创建一个名为 Crawler 的新数据库和一个名为 Record 的新表。
使用 Java 进行网络爬取
最后,下载JSoup核心库,开始网络爬取。然后,您可以在 Eclipse 中创建一个名为“Crawler”的新项目,并将 JSoup 和 MySQL 连接器 jar 路径添加到 Java Build Path。在此之后,您可以创建两个类。一个叫DB,用来处理数据库,另一个叫Main爬虫。此时,您可以输入您要抓取的链接并继续!
请记住,您还需要与常驻代理建立联系,才能从与实际位置不同的位置的 网站 获取数据。如果没有常驻代理,您可能会被自动阻止抓取网站 或从错误的国家/地区抓取数据。
如何节省时间而不是使用预制刮刀
尽管用 Java 创建一个新的网络爬虫是一项有趣的任务,但它需要大量的时间、编码和努力。此外,您必须准确地维护代码以产生有效的结果。
但是,如果您可以使用一些爬虫来更快地完成工作,它会有多大用处?好吧,使用预先构建的抓取工具,您所要做的就是插入要抓取的链接,设置抓取限制,您就可以开始了!
这些工具最好的部分是它们不需要很多编程技能。这些都在后端编码并可以使用。Zenscrape 根据您的要求提供现成的抓取服务。有基于 Javascript 渲染的免费和付费临时计划。借助易于使用的 API,此网络爬虫可以快速为您提供结果。
数据搜索和数据搜索
数据爬取和数据抓取是两个非常相似的概念。虽然基本上它们以相同的方式工作,但两者之间存在一定的差异。
一、数据爬取是指对网页进行爬取和下载。另一方面,数据抓取是一个广义的术语,它解决了从各种来源抓取信息的需求。互联网是抓取信息的众多来源之一。
其次,处理重复数据是数据爬虫的一个重要功能。互联网是一个广阔的开放平台。通常,内容会在多个 网站 上重复。如果您使用常规爬取方法,则不会考虑重复的内容。另一方面,先进的网络爬取机制可以解决这个问题,使最终用户不会得到不必要的数据。
与数据抓取方法相比,数据抓取很智能,并且使用了先进的方法。例如,多次爬网可能会引入一些摩擦。因此,网络爬虫也需要知道每个站点要挖掘多少。
最后,不同的网络爬虫同时调查同一个网站。否则,为了有效的结果,必须避免冲突和冲突。数据抓取的故事非常不同。他们可以自由移动并独立工作。
编写自己的爬虫是更好的选择吗?
在 Java 中创建网络爬虫是传统的方式。它需要高级编程来开发和维护代码。然而,在当今的便利世界中,不选择像 Zenscrape 这样的预构建、更快的爬虫和爬虫似乎很愚蠢。采用 DIY 方法的唯一好处是能够自己构建确切的内部工作原理。 查看全部
java从网页抓取数据(如何在Java中创建Web爬网程序?用Java创建网络搜寻器程序)
网络爬虫本质上是一个互联网机器人,它扫描互联网,浏览各种网站,分析数据并生成报告。大多数互联网巨头一直在使用预制的网络爬虫来研究其竞争对手的网站。GoogleBot 是谷歌最受欢迎的网络爬虫,爬取了 28.5% 的网络。它包括广告机器人、图像机器人、搜索引擎机器人等。紧随其后的是 Bing,占比 22%。
为什么网络爬虫有用?
对于每个想要在网上拥有强大影响力的 网站 来说,网络爬虫是必须的。整个想法是能够访问竞争对手的 网站 并提取产品详细信息、价格和图像等信息。事实上,这些公司中的每一个都应该努力做到比竞争对手更好的网站。虽然每个在线行业都存在网络爬虫,但这里有一些重要的用例。
美国一家流行的时尚电子商务商店使用网络爬虫来访问来自其他一百个时尚网站 的信息和数据。这有助于他们与竞争对手保持同步。
美国电子商务平台使用网络爬虫来确定和确定基于邮政编码或消费者位置的定价策略。
一家总部位于欧洲的家具公司访问其 20 个竞争对手网站的数据以采集见解。
此外,通过使用从亚马逊抓取的产品信息,印度零售商 网站 可以识别和识别他们最畅销的产品。
如何在 Java 中创建网络爬虫?
用 Java 创建一个网络爬虫需要一些耐心。这需要准确和有效。以下是使用 Java 制作简单网络爬虫原型的一些步骤。
设置 MySQL 数据库
第一步需要设置一个 MySQL 数据库才能开始工作。如果您使用的是 Windows,只需在几分钟内下载并安装它。在此之后,您可以使用任何 GUI 界面对 MySQL 进行操作。
数据库和表设置
接下来,您可以在 MySQL 中创建一个名为 Crawler 的新数据库和一个名为 Record 的新表。
使用 Java 进行网络爬取
最后,下载JSoup核心库,开始网络爬取。然后,您可以在 Eclipse 中创建一个名为“Crawler”的新项目,并将 JSoup 和 MySQL 连接器 jar 路径添加到 Java Build Path。在此之后,您可以创建两个类。一个叫DB,用来处理数据库,另一个叫Main爬虫。此时,您可以输入您要抓取的链接并继续!
请记住,您还需要与常驻代理建立联系,才能从与实际位置不同的位置的 网站 获取数据。如果没有常驻代理,您可能会被自动阻止抓取网站 或从错误的国家/地区抓取数据。
如何节省时间而不是使用预制刮刀
尽管用 Java 创建一个新的网络爬虫是一项有趣的任务,但它需要大量的时间、编码和努力。此外,您必须准确地维护代码以产生有效的结果。
但是,如果您可以使用一些爬虫来更快地完成工作,它会有多大用处?好吧,使用预先构建的抓取工具,您所要做的就是插入要抓取的链接,设置抓取限制,您就可以开始了!
这些工具最好的部分是它们不需要很多编程技能。这些都在后端编码并可以使用。Zenscrape 根据您的要求提供现成的抓取服务。有基于 Javascript 渲染的免费和付费临时计划。借助易于使用的 API,此网络爬虫可以快速为您提供结果。
数据搜索和数据搜索
数据爬取和数据抓取是两个非常相似的概念。虽然基本上它们以相同的方式工作,但两者之间存在一定的差异。
一、数据爬取是指对网页进行爬取和下载。另一方面,数据抓取是一个广义的术语,它解决了从各种来源抓取信息的需求。互联网是抓取信息的众多来源之一。
其次,处理重复数据是数据爬虫的一个重要功能。互联网是一个广阔的开放平台。通常,内容会在多个 网站 上重复。如果您使用常规爬取方法,则不会考虑重复的内容。另一方面,先进的网络爬取机制可以解决这个问题,使最终用户不会得到不必要的数据。
与数据抓取方法相比,数据抓取很智能,并且使用了先进的方法。例如,多次爬网可能会引入一些摩擦。因此,网络爬虫也需要知道每个站点要挖掘多少。
最后,不同的网络爬虫同时调查同一个网站。否则,为了有效的结果,必须避免冲突和冲突。数据抓取的故事非常不同。他们可以自由移动并独立工作。
编写自己的爬虫是更好的选择吗?
在 Java 中创建网络爬虫是传统的方式。它需要高级编程来开发和维护代码。然而,在当今的便利世界中,不选择像 Zenscrape 这样的预构建、更快的爬虫和爬虫似乎很愚蠢。采用 DIY 方法的唯一好处是能够自己构建确切的内部工作原理。
java从网页抓取数据(哪些网页才是重要性高的呢?如何解决网页抓取乱码问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-06 11:18
)
相关话题
基于 Web 的数据传输方法的比较
22/5/201209:28:00
网站数据传输方式的选择影响网页的加载速度、服务请求响应时间等,因此网站数据传输方式的选择直接影响网站性能和用户体验。网页数据的高效安全传输是网站优化中需要考虑的重要问题之一,网页数据传输方式的选择在网站方面尤为重要优化。
中国病毒网页数量位居病毒网页前44%
2007 年 9 月 9 日 20:15:00
北京时间9月7日,据俄罗斯链接新闻网报道,全球领先的杀毒软件开发商9月6日表示,中美两国病毒网站数量居全球前两位,中国的病毒网站大幅下降。分析了8月份全球80亿网页,得出的结论是,中国的病毒网页数量居全球之首,44.8%的网页
网页抓取优先策略
18/1/2008 11:30:00
网页爬取优先策略也称为“页面选择问题”(pageSelection),通常是尽可能先爬取重要的网页,以保证那些重要性高的网页得到尽可能多的照顾在有限的资源范围内。那么哪些页面最重要?如何量化重要性?
如何解决php网页抓取出现乱码问题
2012 年 4 月 9 日:03:36
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”转换编码;2、添加“curl_setopt($ch,CURLOPT_ENCODING,'gzip');” 选项; 3、在顶部添加标题代码。推荐
TAG页面数据和构图原理你要知道的三个最关键的点!点击进去看看!
6/8/202018:01:55
关于网站建设的优化,标签页起着关键的作用,所以大家对标签页的作用很熟悉了,下面我来解释一下它的一些概念。其实一般来说,标签页是用来描述某个关键词的
搜索引擎如何抓取网页?
22/11/2011 09:50:00
搜索引擎在抓取大量原创网页时,会进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一致)未经任何修改)或“转载网页”。”(近似复制,主题内容基本相同但可能有一些额外的编辑信息等,转载的网页也称为“近似镜像网页”)消除,链接分析和网页重要性的计算。
Nginx下更改网页地址后旧网页301重定向的代码
2018 年 2 月 3 日 01:09:49
总结:Nginx下更改网页地址后旧网页301重定向的代码
如何打开网页的源代码
2021 年 4 月 2 日 10:31:09
打开网页源代码的方法:先登录一个网站,在网页左侧空白处右击;然后点击inspect元素,再次右击网页左侧的空白处;最后,点击查看源文件。本文运行环境:Windows7系统,戴尔G3电脑
翻页式网络搜索引擎如何抓取
2013 年 7 月 11 日 10:53:00
Spider 系统的目标是发现和爬取 Internet 上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。@网站经验造成压力,也就是说蜘蛛不会爬取网站的所有页面。蜘蛛的爬取策略有很多,可以尽可能快速完整的找到资源链接,提高爬取效率。
使用网络抓取数据赚钱的 3 个想法
2/6/202012:01:26
文章目录使用自动程序花最少的钱在Airbnb上住最好的酒店,捕捉特定产品的价格数据,以最低的价格购买,捕捉公共数据,并在时代可视化大数据,如何有效获取数据已成为商业决策的驱动力
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是非常常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
Google 适当地将 POST 请求添加到 GET 以抓取网页内容
15/12/2011 13:58:00
近日,Google Blackboard 发布了一篇题为“GET、POST 和安全获取更多网络信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。在文章中提到,未来谷歌在读取网页内容时不仅会使用GET抓取,还会根据情况在抓取网页内容时增加POST请求方式,从而进一步提高谷歌搜索的准确率引擎。网页内容的判断。
如何系统地做好SEO-web抓取
14/5/202014:41:34
如果没有爬取,那么就没有页面的收录。如何获取或改进搜索引擎的爬取?
详细讲解php爬取网页内容的例子
6/8/202018:02:42
php爬取网页内容示例详解方法一:使用file_get_contents方法实现$url="";$html=file_ge
代码和内容优化和去噪以提高网页的信噪比
22/5/2012 13:58:00
网页的信噪比是指网页中的文本内容与生成这些文本所产生的html标签内容的比率。一般来说,一个网页的信噪比越高,我们的网页质量就越好。可以根据搜索引擎抓取网页的原理来解释:搜索引擎蜘蛛抓取网页时,会对网页进行去重,主要是去除网页的噪音,留下有用的信息。
查看全部
java从网页抓取数据(哪些网页才是重要性高的呢?如何解决网页抓取乱码问题
)
相关话题
基于 Web 的数据传输方法的比较
22/5/201209:28:00
网站数据传输方式的选择影响网页的加载速度、服务请求响应时间等,因此网站数据传输方式的选择直接影响网站性能和用户体验。网页数据的高效安全传输是网站优化中需要考虑的重要问题之一,网页数据传输方式的选择在网站方面尤为重要优化。
中国病毒网页数量位居病毒网页前44%
2007 年 9 月 9 日 20:15:00
北京时间9月7日,据俄罗斯链接新闻网报道,全球领先的杀毒软件开发商9月6日表示,中美两国病毒网站数量居全球前两位,中国的病毒网站大幅下降。分析了8月份全球80亿网页,得出的结论是,中国的病毒网页数量居全球之首,44.8%的网页
网页抓取优先策略
18/1/2008 11:30:00
网页爬取优先策略也称为“页面选择问题”(pageSelection),通常是尽可能先爬取重要的网页,以保证那些重要性高的网页得到尽可能多的照顾在有限的资源范围内。那么哪些页面最重要?如何量化重要性?
如何解决php网页抓取出现乱码问题
2012 年 4 月 9 日:03:36
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”转换编码;2、添加“curl_setopt($ch,CURLOPT_ENCODING,'gzip');” 选项; 3、在顶部添加标题代码。推荐
TAG页面数据和构图原理你要知道的三个最关键的点!点击进去看看!
6/8/202018:01:55
关于网站建设的优化,标签页起着关键的作用,所以大家对标签页的作用很熟悉了,下面我来解释一下它的一些概念。其实一般来说,标签页是用来描述某个关键词的
搜索引擎如何抓取网页?
22/11/2011 09:50:00
搜索引擎在抓取大量原创网页时,会进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一致)未经任何修改)或“转载网页”。”(近似复制,主题内容基本相同但可能有一些额外的编辑信息等,转载的网页也称为“近似镜像网页”)消除,链接分析和网页重要性的计算。
Nginx下更改网页地址后旧网页301重定向的代码
2018 年 2 月 3 日 01:09:49
总结:Nginx下更改网页地址后旧网页301重定向的代码
如何打开网页的源代码
2021 年 4 月 2 日 10:31:09
打开网页源代码的方法:先登录一个网站,在网页左侧空白处右击;然后点击inspect元素,再次右击网页左侧的空白处;最后,点击查看源文件。本文运行环境:Windows7系统,戴尔G3电脑
翻页式网络搜索引擎如何抓取
2013 年 7 月 11 日 10:53:00
Spider 系统的目标是发现和爬取 Internet 上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。@网站经验造成压力,也就是说蜘蛛不会爬取网站的所有页面。蜘蛛的爬取策略有很多,可以尽可能快速完整的找到资源链接,提高爬取效率。
使用网络抓取数据赚钱的 3 个想法
2/6/202012:01:26
文章目录使用自动程序花最少的钱在Airbnb上住最好的酒店,捕捉特定产品的价格数据,以最低的价格购买,捕捉公共数据,并在时代可视化大数据,如何有效获取数据已成为商业决策的驱动力
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是非常常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
Google 适当地将 POST 请求添加到 GET 以抓取网页内容
15/12/2011 13:58:00
近日,Google Blackboard 发布了一篇题为“GET、POST 和安全获取更多网络信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。在文章中提到,未来谷歌在读取网页内容时不仅会使用GET抓取,还会根据情况在抓取网页内容时增加POST请求方式,从而进一步提高谷歌搜索的准确率引擎。网页内容的判断。
如何系统地做好SEO-web抓取
14/5/202014:41:34
如果没有爬取,那么就没有页面的收录。如何获取或改进搜索引擎的爬取?
详细讲解php爬取网页内容的例子
6/8/202018:02:42
php爬取网页内容示例详解方法一:使用file_get_contents方法实现$url="";$html=file_ge
代码和内容优化和去噪以提高网页的信噪比
22/5/2012 13:58:00
网页的信噪比是指网页中的文本内容与生成这些文本所产生的html标签内容的比率。一般来说,一个网页的信噪比越高,我们的网页质量就越好。可以根据搜索引擎抓取网页的原理来解释:搜索引擎蜘蛛抓取网页时,会对网页进行去重,主要是去除网页的噪音,留下有用的信息。
java从网页抓取数据(详解php中抓取网页内容的实例6/8/202018:02 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-31 23:09
)
相关话题
网页抓取优先策略
18/1/2008 11:30:00
网页爬取优先策略也称为“页面选择问题”(pageSelection),通常是尽可能先爬取重要的网页,以保证那些重要性高的网页得到尽可能多的照顾在有限的资源范围内。那么哪些页面最重要?如何量化重要性?
详细讲解php爬取网页内容的例子
6/8/202018:02:42
php爬取网页内容示例详解方法一:使用file_get_contents方法实现$url="";$html=file_ge
使用网络抓取数据赚钱的 3 个想法
2/6/202012:01:26
文章目录使用自动程序花最少的钱在Airbnb上住最好的酒店捕获特定产品的价格数据,以最低的价格购买并捕获公共数据,在大时代将其可视化数据,如何有效获取数据 数据已成为业务决策的驱动力
Google 适当地将 POST 请求添加到 GET 以抓取网页内容
15/12/2011 13:58:00
近日,Google Blackboard 发布了一篇题为“GET、POST 和安全获取更多网络信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。在文章中提到,未来谷歌在读取网页内容时不仅会使用GET抓取,还会根据情况在抓取网页内容时增加POST请求方式,从而进一步提高谷歌搜索的准确率引擎。网页内容的判断。
搜索引擎如何抓取网页?
22/11/2011 09:50:00
搜索引擎在抓取大量原创网页时,会进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一致)未经任何修改)或“转载网页”。”(近似复制,主题内容基本相同但可能有一些额外的编辑信息等,转载的网页也称为“近似镜像网页”)消除,链接分析和网页重要性的计算。
翻页式网络搜索引擎如何抓取
2013 年 7 月 11 日 10:53:00
<p>Spider 系统的目标是发现和爬取 Internet 上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。@网站经验造成压力,也就是说蜘蛛不会爬取 查看全部
java从网页抓取数据(详解php中抓取网页内容的实例6/8/202018:02
)
相关话题
网页抓取优先策略
18/1/2008 11:30:00
网页爬取优先策略也称为“页面选择问题”(pageSelection),通常是尽可能先爬取重要的网页,以保证那些重要性高的网页得到尽可能多的照顾在有限的资源范围内。那么哪些页面最重要?如何量化重要性?
详细讲解php爬取网页内容的例子
6/8/202018:02:42
php爬取网页内容示例详解方法一:使用file_get_contents方法实现$url="";$html=file_ge
使用网络抓取数据赚钱的 3 个想法
2/6/202012:01:26
文章目录使用自动程序花最少的钱在Airbnb上住最好的酒店捕获特定产品的价格数据,以最低的价格购买并捕获公共数据,在大时代将其可视化数据,如何有效获取数据 数据已成为业务决策的驱动力
Google 适当地将 POST 请求添加到 GET 以抓取网页内容
15/12/2011 13:58:00
近日,Google Blackboard 发布了一篇题为“GET、POST 和安全获取更多网络信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。在文章中提到,未来谷歌在读取网页内容时不仅会使用GET抓取,还会根据情况在抓取网页内容时增加POST请求方式,从而进一步提高谷歌搜索的准确率引擎。网页内容的判断。
搜索引擎如何抓取网页?
22/11/2011 09:50:00
搜索引擎在抓取大量原创网页时,会进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一致)未经任何修改)或“转载网页”。”(近似复制,主题内容基本相同但可能有一些额外的编辑信息等,转载的网页也称为“近似镜像网页”)消除,链接分析和网页重要性的计算。
翻页式网络搜索引擎如何抓取
2013 年 7 月 11 日 10:53:00
<p>Spider 系统的目标是发现和爬取 Internet 上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。@网站经验造成压力,也就是说蜘蛛不会爬取

