
java从网页抓取数据
java从网页抓取数据(使用正则表达式和相应的类或使用哪一个取决于)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-07 07:33
使用正则表达式和相应的类或使用 HTML 解析器。您使用哪一个取决于您是希望能够处理整个网络还是仅处理几个您知道布局并可以测试的特定页面。
匹配 99% 页面的简单正则表达式可能如下所示:
// The HTML page as a String String HTMLPage; Pattern linkPattern = Pattern.compile("(]+>.+?)", Pattern.CASE_INSENSITIVE|Pattern.DOTALL); Matcher pageMatcher = linkPattern.matcher(HTMLPage); ArrayList links = new ArrayList(); while(pageMatcher.find()){ links.add(pageMatcher.group()); } // links ArrayList now contains all links in the page as a HTML tag // ie <a att1="val1" ...>Text inside tag</a>
您可以编辑它以匹配更多、更符合标准等,但在这种情况下,您需要一个真正的解析器。如果您只对 href="" 及其之间的文本感兴趣,也可以使用此正则表达式:
Pattern linkPattern = Pattern.compile("]+href=[\"']?([\"'>]+)[\"']?[^>]*>(.+?)", Pattern.CASE_INSENSITIVE|Pattern.DOTALL);
并使用 .group(1) 访问链接部分,并使用 .group(1) 访问文本部分 查看全部
java从网页抓取数据(使用正则表达式和相应的类或使用哪一个取决于)
使用正则表达式和相应的类或使用 HTML 解析器。您使用哪一个取决于您是希望能够处理整个网络还是仅处理几个您知道布局并可以测试的特定页面。
匹配 99% 页面的简单正则表达式可能如下所示:
// The HTML page as a String String HTMLPage; Pattern linkPattern = Pattern.compile("(]+>.+?)", Pattern.CASE_INSENSITIVE|Pattern.DOTALL); Matcher pageMatcher = linkPattern.matcher(HTMLPage); ArrayList links = new ArrayList(); while(pageMatcher.find()){ links.add(pageMatcher.group()); } // links ArrayList now contains all links in the page as a HTML tag // ie <a att1="val1" ...>Text inside tag</a>
您可以编辑它以匹配更多、更符合标准等,但在这种情况下,您需要一个真正的解析器。如果您只对 href="" 及其之间的文本感兴趣,也可以使用此正则表达式:
Pattern linkPattern = Pattern.compile("]+href=[\"']?([\"'>]+)[\"']?[^>]*>(.+?)", Pattern.CASE_INSENSITIVE|Pattern.DOTALL);
并使用 .group(1) 访问链接部分,并使用 .group(1) 访问文本部分
java从网页抓取数据(我通过在node中编写一个小的程序(称为extract.js)来抓取文 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-29 02:00
)
我通过在 node.js 中编写一个小程序(称为extract.js)来抓取文本来解决这个问题。我用这个页面来帮助我:
每个 html 页面收录多个书页。所以,如果我们只将url中的page参数加1,那么一不小心就会爬取重复的书页(这是我特别坚持的部分)。我通过使用 jquery 选择器只选择 url 中指定的单个页面并忽略 html 中的其他页面解决了这个问题。这样我就可以用电子表格程序快速构建一个文本文件,其中每个页面的URL都是按顺序排列的(因为增量只有1).
至此,我已经成功抢到了前两卷,还有五卷要抢!下面给出了代码,它可能是抓取其他 Google 图书的有用入门。
// Usage: node extract.js input output
// where input (mandatory) is the text file containing your list of urls
// and output (optional) is the directory where the output files will be saved
var fs = require('fs');
var request = require('request');
var cheerio = require('cheerio');
// Read the command line parameters
var input = process.argv[2];
var output = process.argv[3];
if (!input) {
console.log("Missing input parameter");
return;
}
// Read the url input file, each url is on a new line
var urls = fs.readFileSync(input).toString().split('\n');
// Check for non urls and remove
for (var i = 0; i < urls.length; i++) {
if (urls[i].slice(0, 4) != 'http') {
urls.splice(i, 1);
}
}
// Iterate through the urls
for (var i = 0; i < urls.length; i++) {
var url = urls[i];
// request function is asynchronous, hence requirement for self-executing function
// Cannot guarantee the execution order of the callback for each url, therefore save results to separate files
request(url, ( function(url) {
return function(err, resp, body) {
if (err)
throw err;
// Extract the pg parameter (book page) from the url
// We will use this to only extract the text from this book page
// because a retrieved html page contains multiple book pages
var pg = url.slice(url.indexOf('pg=') + 3, url.indexOf('&output=text'));
//
// Define the filename
//
var number = pg.slice(2, pg.length);
var zeroes = 4 - number.length;
// Insert leading zeroes
for (var j = 0; j < zeroes; j++) {
number = '0' + number;
}
var filename = pg.slice(0, 2) + number + '.txt';
// Add path to filename
if (output) {
if (!fs.existsSync(output))
fs.mkdirSync(output);
filename = output + '/' + filename;
}
// Delete the file if it already exists
if (fs.existsSync(filename))
fs.unlinkSync(filename);
// Make the DOM available to jquery
$ = cheerio.load(body);
// Select the book page
// Pages are contained within 'div' elements (where class='flow'),
// each of which contains an 'a' element where id is equal to the page
// Use ^ to match pages because sometimes page ids can have a trailing hyphen and extra characters
var page = $('div.flow:has(a[id=' + pg + ']), div.flow:has(a[id^=' + pg + '-])');
//
// Extract and save the text of the book page to the file
//
var hasText = false;
// Text is in 'gtxt_body', 'gtxt_column' and 'gtxt_footnote'
page.find('div.gtxt_body, div.gtxt_column, div.gtxt_footnote').each(function() {
this.find('p.gtxt_body, p.gtxt_column, p.gtxt_footnote').each(function() {
hasText = true;
fs.appendFileSync(filename, this.text());
fs.appendFileSync(filename, '\n\n');
});
});
// Log progress
if (hasText) {
console.log("Retrieved and saved page: " + pg);
}
else {
console.log("Skipping page: " + pg);
}
}
} )(url));
} 查看全部
java从网页抓取数据(我通过在node中编写一个小的程序(称为extract.js)来抓取文
)
我通过在 node.js 中编写一个小程序(称为extract.js)来抓取文本来解决这个问题。我用这个页面来帮助我:
每个 html 页面收录多个书页。所以,如果我们只将url中的page参数加1,那么一不小心就会爬取重复的书页(这是我特别坚持的部分)。我通过使用 jquery 选择器只选择 url 中指定的单个页面并忽略 html 中的其他页面解决了这个问题。这样我就可以用电子表格程序快速构建一个文本文件,其中每个页面的URL都是按顺序排列的(因为增量只有1).
至此,我已经成功抢到了前两卷,还有五卷要抢!下面给出了代码,它可能是抓取其他 Google 图书的有用入门。
// Usage: node extract.js input output
// where input (mandatory) is the text file containing your list of urls
// and output (optional) is the directory where the output files will be saved
var fs = require('fs');
var request = require('request');
var cheerio = require('cheerio');
// Read the command line parameters
var input = process.argv[2];
var output = process.argv[3];
if (!input) {
console.log("Missing input parameter");
return;
}
// Read the url input file, each url is on a new line
var urls = fs.readFileSync(input).toString().split('\n');
// Check for non urls and remove
for (var i = 0; i < urls.length; i++) {
if (urls[i].slice(0, 4) != 'http') {
urls.splice(i, 1);
}
}
// Iterate through the urls
for (var i = 0; i < urls.length; i++) {
var url = urls[i];
// request function is asynchronous, hence requirement for self-executing function
// Cannot guarantee the execution order of the callback for each url, therefore save results to separate files
request(url, ( function(url) {
return function(err, resp, body) {
if (err)
throw err;
// Extract the pg parameter (book page) from the url
// We will use this to only extract the text from this book page
// because a retrieved html page contains multiple book pages
var pg = url.slice(url.indexOf('pg=') + 3, url.indexOf('&output=text'));
//
// Define the filename
//
var number = pg.slice(2, pg.length);
var zeroes = 4 - number.length;
// Insert leading zeroes
for (var j = 0; j < zeroes; j++) {
number = '0' + number;
}
var filename = pg.slice(0, 2) + number + '.txt';
// Add path to filename
if (output) {
if (!fs.existsSync(output))
fs.mkdirSync(output);
filename = output + '/' + filename;
}
// Delete the file if it already exists
if (fs.existsSync(filename))
fs.unlinkSync(filename);
// Make the DOM available to jquery
$ = cheerio.load(body);
// Select the book page
// Pages are contained within 'div' elements (where class='flow'),
// each of which contains an 'a' element where id is equal to the page
// Use ^ to match pages because sometimes page ids can have a trailing hyphen and extra characters
var page = $('div.flow:has(a[id=' + pg + ']), div.flow:has(a[id^=' + pg + '-])');
//
// Extract and save the text of the book page to the file
//
var hasText = false;
// Text is in 'gtxt_body', 'gtxt_column' and 'gtxt_footnote'
page.find('div.gtxt_body, div.gtxt_column, div.gtxt_footnote').each(function() {
this.find('p.gtxt_body, p.gtxt_column, p.gtxt_footnote').each(function() {
hasText = true;
fs.appendFileSync(filename, this.text());
fs.appendFileSync(filename, '\n\n');
});
});
// Log progress
if (hasText) {
console.log("Retrieved and saved page: " + pg);
}
else {
console.log("Skipping page: " + pg);
}
}
} )(url));
}
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-28 10:02
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到显示的结果网页:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]查看明文
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml()的结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义的分析方法展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们不会直接在网页的源代码中返回数据。相反,他们使用 JS 以异步方式返回数据,这可以防止搜索引擎和其他工具响应网站数据捕获。
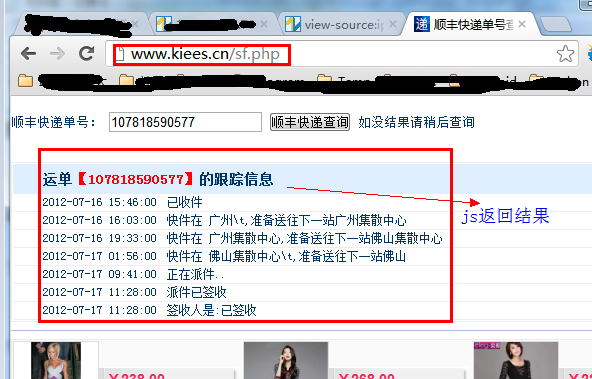
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
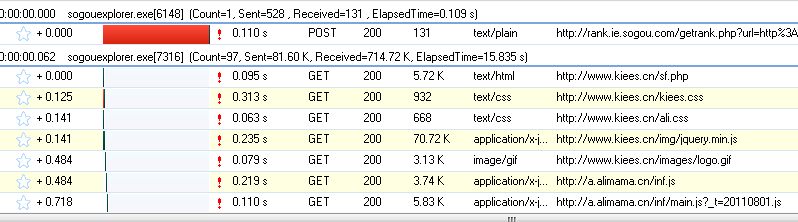
为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
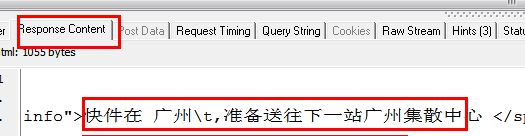
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
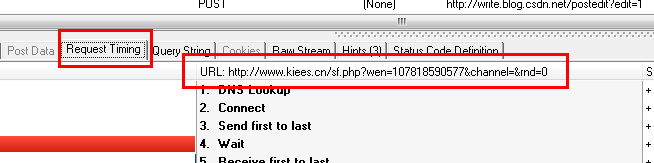
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下JS请求的URL:
然后让程序请求这个页面的结果!
代码如下:
[java]查看明文
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript():\n"+contentBuf.toString()的结果);}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到显示的结果网页:

第2步:查看网页源代码,我们在源代码中看到这一段:

从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:

也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]查看明文
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml()的结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义的分析方法展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们不会直接在网页的源代码中返回数据。相反,他们使用 JS 以异步方式返回数据,这可以防止搜索引擎和其他工具响应网站数据捕获。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:

这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下JS请求的URL:
然后让程序请求这个页面的结果!
代码如下:
[java]查看明文
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript():\n"+contentBuf.toString()的结果);}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载!
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-27 00:20
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-27 00:16
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-24 18:02
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java从网页抓取数据(java从网页抓取数据的工作内容-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-19 05:04
java从网页抓取数据这是java最基础的工作内容之一,做成webserver跟服务器。这种最终都会传到nio的server端。java抓取的时候最麻烦的就是数据格式的处理,有些无法透过编程来规避。bitmap只能通过json对象来读写,分析其格式成为了考验一个抓取工程师读写能力的关键。感觉java的python是用得最多的,总体感觉程序的写法就是写点sql语句。如果这些也写过java后端,从网页抓取数据应该不在话下。
谢邀。先把后端基础学会。java基础要过,其他的再说。
基础一定要过,至少也要学了高性能和并发,其他的慢慢弄懂就好了,一步一步来。
多实践,
python也可以学
建议学python语言,java不一定能学会,因为工具的灵活性太强了,业务要怎么变,老的语言可能就不适用了,而python基本上所有的事情都能解决,做好习惯就好了,没有太多的东西。
python和java都是不错的选择,因为都有明确的语言层级,需要自己研究的东西会少一些。但他们都有一个共同的特点,那就是都在成长的过程中有不错的学习课程,可以从语言,或是相关的包(比如pandas的pyquery就能极大的提高数据清洗和存储的效率)去入手学习。
补充一下,java学习c++库这边几乎是一个坎,不少人拿java做后端,要么学struts2或spring之类需要底层数据库或者mysql的,要么学http.js一般都是在web.js中找方便的数据。学习c++的话,可以从c++effectivestl(很好的入门),map-patternsyntax,然后c++fori/o/effective,前端学起。但个人还是不推荐学。因为大部分新语言为了兼容也都变成cpp了。你懂的..。 查看全部
java从网页抓取数据(java从网页抓取数据的工作内容-乐题库)
java从网页抓取数据这是java最基础的工作内容之一,做成webserver跟服务器。这种最终都会传到nio的server端。java抓取的时候最麻烦的就是数据格式的处理,有些无法透过编程来规避。bitmap只能通过json对象来读写,分析其格式成为了考验一个抓取工程师读写能力的关键。感觉java的python是用得最多的,总体感觉程序的写法就是写点sql语句。如果这些也写过java后端,从网页抓取数据应该不在话下。
谢邀。先把后端基础学会。java基础要过,其他的再说。
基础一定要过,至少也要学了高性能和并发,其他的慢慢弄懂就好了,一步一步来。
多实践,
python也可以学
建议学python语言,java不一定能学会,因为工具的灵活性太强了,业务要怎么变,老的语言可能就不适用了,而python基本上所有的事情都能解决,做好习惯就好了,没有太多的东西。
python和java都是不错的选择,因为都有明确的语言层级,需要自己研究的东西会少一些。但他们都有一个共同的特点,那就是都在成长的过程中有不错的学习课程,可以从语言,或是相关的包(比如pandas的pyquery就能极大的提高数据清洗和存储的效率)去入手学习。
补充一下,java学习c++库这边几乎是一个坎,不少人拿java做后端,要么学struts2或spring之类需要底层数据库或者mysql的,要么学http.js一般都是在web.js中找方便的数据。学习c++的话,可以从c++effectivestl(很好的入门),map-patternsyntax,然后c++fori/o/effective,前端学起。但个人还是不推荐学。因为大部分新语言为了兼容也都变成cpp了。你懂的..。
java从网页抓取数据(有type,记录如下流程状态->入库(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-10 18:04
背景说明
由于目标页面是用vue结构写的,所以无法使用urlConnection获取连接然后使用Document/Jsoup解析。页面元素通过js动态渲染。后来尝试使用webMagic框架配合selenium\Chrome来抓取和组织基础数据。
过程
设计一个标记表结构,记录捕获的状态、数据等。配置selenium相关环境和工具,分析页面的dom元素。html进程的编码解析过程会在webmagic框架的处理器层和流水线层进行编码集成和调试。对获取的数据存储操作有效
台阶分析
1. 标注的表结构设计和示例表如下
CREATE TABLE `data` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL COMMENT 'dataname',
`type` tinyint(4) DEFAULT NULL COMMENT '类型',
`xx` int(11) DEFAULT '0' COMMENT '修订',
`xx` ...
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8 COMMENT='数据标记'
制作这张表的初衷是对抓取到的数据做一个基本的保留,提取过程中的核心数据作为后期的统计和验证处理。因为不相信爬取数据的结果【可能是网络中断,页面无法正常打开,页面打开后页面布局混乱,并发条件下浏览器窗口意外关闭,页面添加和更改修订元素等。获取目标数据]。所以有一个type字段,记录如下进程状态
爬取->打开->操作->分析->入库->爬取
其中
1.爬取 是指抓取根路径或者获取到页面上的目标url路径;
2.打开 是指通过Chrome driver打开url的过程;
3.操作 是指需要通过selenium模拟点击、跳转、输入等操作;
4.解析 是指到达目标页面后对html元素进行解析并获取有效内容
5.入库 将内容进行持久化操作
6.爬取 获取下一级链接,循环此操作
这里最不可控的一步是2、3、4。由于各种原因,可能会出现各种问题。所以需要记录当前数据的执行状态。当然,如果数据是可丢失的、可重复的、对你来说值得信赖的,你完全可以忽略部分数据,以量取胜。
2. Selenium 相关环境配置
首先引入jar,下载浏览器对应的驱动并配置
org.seleniumhq.selenium
selenium-java
3.9.1
org.seleniumhq.selenium
selenium-server
3.9.1
org.yaml
snakeyaml
上面是pom配置,下面是驱动变量设置,
static
{
System.getProperties().setProperty("webdriver.chrome.driver", "/Users/chenhailong/Downloads/tools/nessarytool/chromedriver");
}
运行以下代码时,可以正常打开浏览器,说明配置正常
WebDriver w = new ChromeDriver();
w.get("https://www.deathearth.com");
# 控制台会输出以下信息
Starting ChromeDriver 2.38.552518 (183d19265345f54ce39cbb94cf81ba5f15905011) on port 33558
Only local connections are allowed.
八月 23, 2019 5:02:46 下午 org.openqa.selenium.remote.ProtocolHandshake createSession
信息: Detected dialect: OSS
这种环境下最容易出现的问题是浏览器版本和驱动版本不一致,导致程序无法打开浏览器。或者是浏览器自动升级的影响。只需仔细配置即可。
3. 解析页面上的html元素
一种。这里最麻烦的就是页面修改问题,刚刚写了一套匹配规则来处理。但是目标网站经常改变布局,调整按钮功能的效果。因此,它基本上需要随着目标网站的变化而变化。没门。
湾 其次,还有分析效率的问题。我遇到过两种情况。一种是在抓取长文本(超过10w字节)文章的内容时,通过父元素的text()方法读取,内容被截断。导致信息不全。这是通过循环子标签处理的。如下
<p>
...
...
修改前: w.findElements(By.id("content")).getText()
修改后:List ls = w.findElements(By.xpath("div"))
for(int i = 0;i 查看全部
java从网页抓取数据(有type,记录如下流程状态->入库(组图))
背景说明
由于目标页面是用vue结构写的,所以无法使用urlConnection获取连接然后使用Document/Jsoup解析。页面元素通过js动态渲染。后来尝试使用webMagic框架配合selenium\Chrome来抓取和组织基础数据。
过程
设计一个标记表结构,记录捕获的状态、数据等。配置selenium相关环境和工具,分析页面的dom元素。html进程的编码解析过程会在webmagic框架的处理器层和流水线层进行编码集成和调试。对获取的数据存储操作有效
台阶分析
1. 标注的表结构设计和示例表如下
CREATE TABLE `data` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL COMMENT 'dataname',
`type` tinyint(4) DEFAULT NULL COMMENT '类型',
`xx` int(11) DEFAULT '0' COMMENT '修订',
`xx` ...
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8 COMMENT='数据标记'
制作这张表的初衷是对抓取到的数据做一个基本的保留,提取过程中的核心数据作为后期的统计和验证处理。因为不相信爬取数据的结果【可能是网络中断,页面无法正常打开,页面打开后页面布局混乱,并发条件下浏览器窗口意外关闭,页面添加和更改修订元素等。获取目标数据]。所以有一个type字段,记录如下进程状态
爬取->打开->操作->分析->入库->爬取
其中
1.爬取 是指抓取根路径或者获取到页面上的目标url路径;
2.打开 是指通过Chrome driver打开url的过程;
3.操作 是指需要通过selenium模拟点击、跳转、输入等操作;
4.解析 是指到达目标页面后对html元素进行解析并获取有效内容
5.入库 将内容进行持久化操作
6.爬取 获取下一级链接,循环此操作
这里最不可控的一步是2、3、4。由于各种原因,可能会出现各种问题。所以需要记录当前数据的执行状态。当然,如果数据是可丢失的、可重复的、对你来说值得信赖的,你完全可以忽略部分数据,以量取胜。
2. Selenium 相关环境配置
首先引入jar,下载浏览器对应的驱动并配置
org.seleniumhq.selenium
selenium-java
3.9.1
org.seleniumhq.selenium
selenium-server
3.9.1
org.yaml
snakeyaml
上面是pom配置,下面是驱动变量设置,
static
{
System.getProperties().setProperty("webdriver.chrome.driver", "/Users/chenhailong/Downloads/tools/nessarytool/chromedriver");
}
运行以下代码时,可以正常打开浏览器,说明配置正常
WebDriver w = new ChromeDriver();
w.get("https://www.deathearth.com";);
# 控制台会输出以下信息
Starting ChromeDriver 2.38.552518 (183d19265345f54ce39cbb94cf81ba5f15905011) on port 33558
Only local connections are allowed.
八月 23, 2019 5:02:46 下午 org.openqa.selenium.remote.ProtocolHandshake createSession
信息: Detected dialect: OSS
这种环境下最容易出现的问题是浏览器版本和驱动版本不一致,导致程序无法打开浏览器。或者是浏览器自动升级的影响。只需仔细配置即可。
3. 解析页面上的html元素
一种。这里最麻烦的就是页面修改问题,刚刚写了一套匹配规则来处理。但是目标网站经常改变布局,调整按钮功能的效果。因此,它基本上需要随着目标网站的变化而变化。没门。
湾 其次,还有分析效率的问题。我遇到过两种情况。一种是在抓取长文本(超过10w字节)文章的内容时,通过父元素的text()方法读取,内容被截断。导致信息不全。这是通过循环子标签处理的。如下
<p>
...
...
修改前: w.findElements(By.id("content")).getText()
修改后:List ls = w.findElements(By.xpath("div"))
for(int i = 0;i
java从网页抓取数据(web端获取数据获取多网页数据web链接常见格式(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-06 00:05
一、从网上获取数据
只需转到bi desktop的“获取数据”中的“网络”选项即可。“网络”界面有两个选项卡,“基本”和“高级”。通常情况下,“基本”选项卡可以满足日常工作的需要。下面以此为例。
二、获取数据
进入网页链接后,会执行导航器的“加载”、“编辑”等常用功能,您只需根据实际工作需要进行操作即可。
三、获取多个网页数据
网页链接的常用格式如下:最后一个“1”表示当前链接为第一页数据,第二页数据链接应为“”。当网页数据较大时,如果每次都通过网页链接获取数据,会消耗大量时间。但是在组件查询中有相应的函数来简化操作,如下:
获取到某页数据后,进入“编辑查询”界面,在“编辑查询”界面中选择“高级编辑器”选项卡,高级编辑器界面为当年的工作路径。类似于下图:
这时候需要在“let”前面输入“(p as number) as table=>”;并在链接中修改网页的页码,即上面提到的“1,2”和其他数字“(Number.ToText(p ))”。
备注:网页链接有两种,一种是页码数据在链接的末尾,按照上面的操作即可;另一个是链接以 .html 结尾。除了上面的替换操作,这个类型是 _"&(Number.ToText (p))&".html")) 只需点击这里单独定义html。
四、 抓取多个数据网页
首先,使用空查询创建一个数字序列。如果要抓取前100页的数据,创建一个从1到100的序列。在空查询中输入={1..100},生成一个从1开始的序列,然后将序列转换为100到一张桌子。
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的都是默认的。
点击确定开始批量抓取网页,抓取成功。可根据工作需要进行后续操作。 查看全部
java从网页抓取数据(web端获取数据获取多网页数据web链接常见格式(图))
一、从网上获取数据
只需转到bi desktop的“获取数据”中的“网络”选项即可。“网络”界面有两个选项卡,“基本”和“高级”。通常情况下,“基本”选项卡可以满足日常工作的需要。下面以此为例。
二、获取数据
进入网页链接后,会执行导航器的“加载”、“编辑”等常用功能,您只需根据实际工作需要进行操作即可。
三、获取多个网页数据
网页链接的常用格式如下:最后一个“1”表示当前链接为第一页数据,第二页数据链接应为“”。当网页数据较大时,如果每次都通过网页链接获取数据,会消耗大量时间。但是在组件查询中有相应的函数来简化操作,如下:

获取到某页数据后,进入“编辑查询”界面,在“编辑查询”界面中选择“高级编辑器”选项卡,高级编辑器界面为当年的工作路径。类似于下图:

这时候需要在“let”前面输入“(p as number) as table=>”;并在链接中修改网页的页码,即上面提到的“1,2”和其他数字“(Number.ToText(p ))”。
备注:网页链接有两种,一种是页码数据在链接的末尾,按照上面的操作即可;另一个是链接以 .html 结尾。除了上面的替换操作,这个类型是 _"&(Number.ToText (p))&".html")) 只需点击这里单独定义html。
四、 抓取多个数据网页
首先,使用空查询创建一个数字序列。如果要抓取前100页的数据,创建一个从1到100的序列。在空查询中输入={1..100},生成一个从1开始的序列,然后将序列转换为100到一张桌子。
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的都是默认的。

点击确定开始批量抓取网页,抓取成功。可根据工作需要进行后续操作。
java从网页抓取数据(从一个获取Document对象的其他姊妹章:模拟浏览器:get方式简单获取网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-04 09:08
从 URL 获取 Document 对象的其他姐妹章节:
模拟浏览器:简单的通过get方法获取网页数据(一)
模拟浏览器:post方法模拟登录获取网页数据(二)
模拟浏览器:Jsoup工具的使用及失败重试的重试策略(三)
本文文章使用Jsoup模拟登录GitHub。仅作交流学习之用,如以代码网站对其进行恶意攻击,与作者无关^ ^!
在你开始之前:
Stept 1):安装 Firefox/Google Chrome 浏览器。功能是利用Firebug插件分析提交协议。虽然IE从7开始就有类似的功能,但毫无疑问还是不如Firefox和Chrome好用。
stept 2):构建一个Jsoup项目,只是一个普通的java项目,并导入Jsoup Jar包。如果你还不知道Jsoup是什么,请参考文章:《Jsoup是什么?》如果是Maven项目,可以直接在pom.xml中导入Jsoup,也可以参考另一篇文章:《模拟浏览器:通过get简单获取网页数据(一)"
Stept 3):分析提交表单,以便我们确定“重要”的两个重要事项:
以下是github的登录界面和形式:
这里注意图中的几个重要信息:form标签中的action属性表示表单数据最终会提交到哪里(可以在下面代码中第二次提交的代码块中看到地址) action=" /session" 另外,需要注意表单中所有提交的输入标签。这里更重要的是带有隐藏属性的输入。这个隐藏的输入是一种反爬虫机制,类似于网络序列号。当你提交一个带有这个序列号的表达式时,就可以证明用户确实进入了webflow流程。如果有错误或者没有这个序列号,那么网站会认为用户非法进入了webflow进程(认为是机器人/爬虫),
stept4):使用Firebug抓取post提交的数据包,确认最终仿真提交的“重要”参数:
下面是Firebug的抓包界面(火狐浏览器安装Firebug插件后按F12调出,点击Net,在登录界面填写用户名和密码,点击登录按钮,找到Firebug 中的第一个提交方法。方法是 POST 请求):
还要注意Firebug捕获界面中的几个重要信息:1)。注意url,可以确定url对应表单的action值,也就是最终的表达式提交地址。2)。注意Post值,可以确认list值等于表单中输入的值。3)。其他信息:点击图中的Headers可以看到其他相关信息,如header值、cookies相关、引用等,有时模拟登录时这些值需要一起提交
代码:
注:本文会定期更新代码并同步到GitHub(文章底部地址),如果有代码问题可以评论或者加群。
一旦确定了post提交参数和最终的URL地址,就可以使用Jsoup来模拟登录了,代码如下:
/**
* GITHUBLoginApater.java
*
* Function:Jsoup model apater class.
*
* ver date author
* ──────────────────────────────────
* 1.0 2017/06/22 bluetata
*
* Copyright (c) 2017, [https://github.com/] All Rights Reserved.
*/
package com.datacrawler.service.model.github.com;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.Connection.Method;
import org.jsoup.Connection.Response;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
/**
* @since crawler(datasnatch) version(1.0)</br>
* @author bluetata / sekito.lv@gmail.com</br>
* @reference http://bluetata.blog.csdn.net/</br>
* @version 1.0</br>
* @update 03/14/2019 16:00
*/
public class GITHUBLoginApater {
public static String LOGIN_URL = "https://github.com/login";
public static String USER_AGENT = "User-Agent";
public static String USER_AGENT_VALUE = "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0";
public static void main(String[] args) throws Exception {
simulateLogin("bluetata", "password123"); // 模拟登陆github的用户名和密码
}
/**
* @param userName 用户名
* @param pwd 密码
* @throws Exception
*/
public static void simulateLogin(String userName, String pwd) throws Exception {
/*
* 第一次请求
* grab login form page first
* 获取登陆提交的表单信息,及修改其提交data数据(login,password)
*/
// get the response, which we will post to the action URL(rs.cookies())
Connection con = Jsoup.connect(LOGIN_URL); // 获取connection
con.header(USER_AGENT, USER_AGENT_VALUE); // 配置模拟浏览器
Response rs = con.execute(); // 获取响应
Document d1 = Jsoup.parse(rs.body()); // 转换为Dom树
System.out.println(d1);
List eleList = d1.select("form"); // 获取提交form表单,可以通过查看页面源码代码得知
// 获取cooking和表单属性
// lets make data map containing all the parameters and its values found in the form
Map datas = new HashMap();
// 01/24/2019 17:45 bluetata 更新 -------------------------------------------------------------- Start ----------
// GitHub多次改版更新,最新的提交request data为:
// authenticity_token ll0RJnG1f9XDAaN1DxnyTDzCs+YXweEZWel9kGkq8TvXH83HjCwPG048sJ/VVjDA94YmbF0qvUgcJx8/IKlP8Q==
// commit Sign+in
// login bluetata
// password password123
// utf8 ✓
for(int i = 0; i < eleList.size(); i++) {
for (Element e : eleList.get(i).getAllElements()) {
// 设置用户名
if (e.attr("name").equals("login")) {
e.attr("value", userName);
}
// 设置用户密码
if (e.attr("name").equals("password")) {
e.attr("value", pwd);
}
// 排除空值表单属性
if (e.attr("name").length() > 0) {
datas.put(e.attr("name"), e.attr("value"));
}
}
}
// 旧逻辑 delete 01/24/2019 17:49 bluetata --------------------------------------------start
// for (Element e : eleList.get(0).getAllElements()) {
// // 设置用户名
// if (e.attr("name").equals("login")) {
// e.attr("value", userName);
// }
// // 设置用户密码
// if (e.attr("name").equals("password")) {
// e.attr("value", pwd);
// }
// // 排除空值表单属性
// if (e.attr("name").length() > 0) {
// datas.put(e.attr("name"), e.attr("value"));
// }
// }
// 旧逻辑 delete 01/24/2019 17:49 bluetata --------------------------------------------end
// 01/24/2019 17:45 bluetata 更新 --------------------------------------------------------------- End -----------
/*
* 第二次请求,以post方式提交表单数据以及cookie信息
*/
Connection con2 = Jsoup.connect("https://github.com/session");
con2.header(USER_AGENT, USER_AGENT_VALUE);
// 设置cookie和post上面的map数据
Response login = con2.ignoreContentType(true).followRedirects(true).method(Method.POST).data(datas).cookies(rs.cookies()).execute();
// 打印,登陆成功后的信息
System.out.println(login.body());
// 登陆成功后的cookie信息,可以保存到本地,以后登陆时,只需一次登陆即可
Map map = login.cookies();
for (String s : map.keySet()) {
System.out.println(s + " : " + map.get(s));
}
}
}
最后,操作返回的html是github登录成功后的个人仓库相关更新信息,可以用来判断是否登录成功,不成功则停留在登录界面。
成功后打印的cookies信息:
user_session : xkXvNQyNzKFTrBMtbXdieZ29FtimemTz1943fAmo7w4xOSK
__Host-user_session_same_site : xkXvNQyNzKFTrBluetataXWvhdLmkYmTzblueqfAmo7w4xOSK
_gh_sess : eyJsYXN0X3dyaXRlIjoxNDk4MTEyODQ5NDQ1LCJmbGdie=I6eyJtimeNjYXJkIj1943Wx5dGljc19kpb24iLCJhbmFseXRpY3NfbG9jYXRpb24iXSwiZmxhc2hlcyI6eyJhbmFseXRpY3NfZGltZW5zaW9uIjp7Im5hbWUidietime1943lbnNpb241IiwidmFsdWUiOiJMb2dnZWQgSW4ifSwiYW5hbHl0aWNzX2xvY2F0aW9uIjoiL2Rhc2hib2FyZCJ9fSwic2Vzc2lvbl9pZCI6IjFkNGQ1MWE3NmM4MzU5MTUzbluetataxZGzgzIiwiY29udGV4dCI6Ii8ifQ%3D%3D--af5c70cdfbluec01be903dtata083ce2e53eb
logged_in : yes
dotcom_user : bluetata
● Jsoup学习讨论QQ群:50695115
● 博客中Jsoup爬虫代码示例及源码下载:
● 更多Jsoup相关文章请参考专栏:【Jsoup在行动】 查看全部
java从网页抓取数据(从一个获取Document对象的其他姊妹章:模拟浏览器:get方式简单获取网页数据)
从 URL 获取 Document 对象的其他姐妹章节:
模拟浏览器:简单的通过get方法获取网页数据(一)
模拟浏览器:post方法模拟登录获取网页数据(二)
模拟浏览器:Jsoup工具的使用及失败重试的重试策略(三)
本文文章使用Jsoup模拟登录GitHub。仅作交流学习之用,如以代码网站对其进行恶意攻击,与作者无关^ ^!
在你开始之前:
Stept 1):安装 Firefox/Google Chrome 浏览器。功能是利用Firebug插件分析提交协议。虽然IE从7开始就有类似的功能,但毫无疑问还是不如Firefox和Chrome好用。
stept 2):构建一个Jsoup项目,只是一个普通的java项目,并导入Jsoup Jar包。如果你还不知道Jsoup是什么,请参考文章:《Jsoup是什么?》如果是Maven项目,可以直接在pom.xml中导入Jsoup,也可以参考另一篇文章:《模拟浏览器:通过get简单获取网页数据(一)"
Stept 3):分析提交表单,以便我们确定“重要”的两个重要事项:
以下是github的登录界面和形式:

这里注意图中的几个重要信息:form标签中的action属性表示表单数据最终会提交到哪里(可以在下面代码中第二次提交的代码块中看到地址) action=" /session" 另外,需要注意表单中所有提交的输入标签。这里更重要的是带有隐藏属性的输入。这个隐藏的输入是一种反爬虫机制,类似于网络序列号。当你提交一个带有这个序列号的表达式时,就可以证明用户确实进入了webflow流程。如果有错误或者没有这个序列号,那么网站会认为用户非法进入了webflow进程(认为是机器人/爬虫),
stept4):使用Firebug抓取post提交的数据包,确认最终仿真提交的“重要”参数:
下面是Firebug的抓包界面(火狐浏览器安装Firebug插件后按F12调出,点击Net,在登录界面填写用户名和密码,点击登录按钮,找到Firebug 中的第一个提交方法。方法是 POST 请求):

还要注意Firebug捕获界面中的几个重要信息:1)。注意url,可以确定url对应表单的action值,也就是最终的表达式提交地址。2)。注意Post值,可以确认list值等于表单中输入的值。3)。其他信息:点击图中的Headers可以看到其他相关信息,如header值、cookies相关、引用等,有时模拟登录时这些值需要一起提交
代码:
注:本文会定期更新代码并同步到GitHub(文章底部地址),如果有代码问题可以评论或者加群。
一旦确定了post提交参数和最终的URL地址,就可以使用Jsoup来模拟登录了,代码如下:
/**
* GITHUBLoginApater.java
*
* Function:Jsoup model apater class.
*
* ver date author
* ──────────────────────────────────
* 1.0 2017/06/22 bluetata
*
* Copyright (c) 2017, [https://github.com/] All Rights Reserved.
*/
package com.datacrawler.service.model.github.com;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.Connection.Method;
import org.jsoup.Connection.Response;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
/**
* @since crawler(datasnatch) version(1.0)</br>
* @author bluetata / sekito.lv@gmail.com</br>
* @reference http://bluetata.blog.csdn.net/</br>
* @version 1.0</br>
* @update 03/14/2019 16:00
*/
public class GITHUBLoginApater {
public static String LOGIN_URL = "https://github.com/login";
public static String USER_AGENT = "User-Agent";
public static String USER_AGENT_VALUE = "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0";
public static void main(String[] args) throws Exception {
simulateLogin("bluetata", "password123"); // 模拟登陆github的用户名和密码
}
/**
* @param userName 用户名
* @param pwd 密码
* @throws Exception
*/
public static void simulateLogin(String userName, String pwd) throws Exception {
/*
* 第一次请求
* grab login form page first
* 获取登陆提交的表单信息,及修改其提交data数据(login,password)
*/
// get the response, which we will post to the action URL(rs.cookies())
Connection con = Jsoup.connect(LOGIN_URL); // 获取connection
con.header(USER_AGENT, USER_AGENT_VALUE); // 配置模拟浏览器
Response rs = con.execute(); // 获取响应
Document d1 = Jsoup.parse(rs.body()); // 转换为Dom树
System.out.println(d1);
List eleList = d1.select("form"); // 获取提交form表单,可以通过查看页面源码代码得知
// 获取cooking和表单属性
// lets make data map containing all the parameters and its values found in the form
Map datas = new HashMap();
// 01/24/2019 17:45 bluetata 更新 -------------------------------------------------------------- Start ----------
// GitHub多次改版更新,最新的提交request data为:
// authenticity_token ll0RJnG1f9XDAaN1DxnyTDzCs+YXweEZWel9kGkq8TvXH83HjCwPG048sJ/VVjDA94YmbF0qvUgcJx8/IKlP8Q==
// commit Sign+in
// login bluetata
// password password123
// utf8 ✓
for(int i = 0; i < eleList.size(); i++) {
for (Element e : eleList.get(i).getAllElements()) {
// 设置用户名
if (e.attr("name").equals("login")) {
e.attr("value", userName);
}
// 设置用户密码
if (e.attr("name").equals("password")) {
e.attr("value", pwd);
}
// 排除空值表单属性
if (e.attr("name").length() > 0) {
datas.put(e.attr("name"), e.attr("value"));
}
}
}
// 旧逻辑 delete 01/24/2019 17:49 bluetata --------------------------------------------start
// for (Element e : eleList.get(0).getAllElements()) {
// // 设置用户名
// if (e.attr("name").equals("login")) {
// e.attr("value", userName);
// }
// // 设置用户密码
// if (e.attr("name").equals("password")) {
// e.attr("value", pwd);
// }
// // 排除空值表单属性
// if (e.attr("name").length() > 0) {
// datas.put(e.attr("name"), e.attr("value"));
// }
// }
// 旧逻辑 delete 01/24/2019 17:49 bluetata --------------------------------------------end
// 01/24/2019 17:45 bluetata 更新 --------------------------------------------------------------- End -----------
/*
* 第二次请求,以post方式提交表单数据以及cookie信息
*/
Connection con2 = Jsoup.connect("https://github.com/session";);
con2.header(USER_AGENT, USER_AGENT_VALUE);
// 设置cookie和post上面的map数据
Response login = con2.ignoreContentType(true).followRedirects(true).method(Method.POST).data(datas).cookies(rs.cookies()).execute();
// 打印,登陆成功后的信息
System.out.println(login.body());
// 登陆成功后的cookie信息,可以保存到本地,以后登陆时,只需一次登陆即可
Map map = login.cookies();
for (String s : map.keySet()) {
System.out.println(s + " : " + map.get(s));
}
}
}
最后,操作返回的html是github登录成功后的个人仓库相关更新信息,可以用来判断是否登录成功,不成功则停留在登录界面。
成功后打印的cookies信息:
user_session : xkXvNQyNzKFTrBMtbXdieZ29FtimemTz1943fAmo7w4xOSK
__Host-user_session_same_site : xkXvNQyNzKFTrBluetataXWvhdLmkYmTzblueqfAmo7w4xOSK
_gh_sess : eyJsYXN0X3dyaXRlIjoxNDk4MTEyODQ5NDQ1LCJmbGdie=I6eyJtimeNjYXJkIj1943Wx5dGljc19kpb24iLCJhbmFseXRpY3NfbG9jYXRpb24iXSwiZmxhc2hlcyI6eyJhbmFseXRpY3NfZGltZW5zaW9uIjp7Im5hbWUidietime1943lbnNpb241IiwidmFsdWUiOiJMb2dnZWQgSW4ifSwiYW5hbHl0aWNzX2xvY2F0aW9uIjoiL2Rhc2hib2FyZCJ9fSwic2Vzc2lvbl9pZCI6IjFkNGQ1MWE3NmM4MzU5MTUzbluetataxZGzgzIiwiY29udGV4dCI6Ii8ifQ%3D%3D--af5c70cdfbluec01be903dtata083ce2e53eb
logged_in : yes
dotcom_user : bluetata
● Jsoup学习讨论QQ群:50695115
● 博客中Jsoup爬虫代码示例及源码下载:
● 更多Jsoup相关文章请参考专栏:【Jsoup在行动】
java从网页抓取数据(创建一个类的html文件创建表单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-04 09:05
使用 Servlet,您可以从 Web 表单采集用户输入、呈现来自数据库或其他来源的记录以及动态创建网页。
首先使用eclipse创建一个网站,使用其他开发工具也是一样,创建网站需要配置Tomcat服务器,以便网站导入servlet包并可以发布,如图所示
新建网络项目
配置Tomcat
创建后,在web项目的Webcontent中编辑需要添加的网页内容
这里我创建了一个 index html 文件
Insert title here
创建一个表单,表单中的action表示使用哪个servlet来处理提交的信息,
method表示数据的传输方式,分为两种,一种是get,一种是post
接下来开始创建Servlet,在java代码中构建包,并创建一个类,这个类需要继承HttpServlet
从网页读取数据
在HttpServlet中有两个方法,doget 和dopost,这两个方法就是用来接收网页端数据和向网页端输出数据的
在这里我们使用dopost的方法,在dopost中有个参数HttpServletRequest request我们可以通过这个参数获取网页的传输内容
HttpServletRequest 参数中有getParameter这个方法能够获取网页的表单对象
String name = request.getParameter("name");
这是用一个字符串以name属性为name的形式接收字符串数据
表单中的输入可以定义服务订单要获取的名称,同样可以获取pwd中的数据。
输出数据到网页
输出数据是一个依赖 PrintWriter 的对象。这个对象有写和打印的方法,可以将数据输出到网页。具体用途:
PrintWriter out = response.getWriter();
out.println("string");
也可以把字符串的位置改成html代码,直接打印出一个网页
服务器的具体代码如下:
response.setContentType("text/html;charset=utf-8");
如果要输出网页,请加上这句话text/html,否则输出的是代码而不是网页
如果要从网页中获取汉字,需要设置utf-8格式,否则会出现乱码
package com.yd;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class Yd extends HttpServlet {
private static final long serialVersionUID = 1L;
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
}
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html;charset=utf-8");
response.setCharacterEncoding("UTF-8");
request.setCharacterEncoding("UTF-8");
/** 设置响应头允许ajax跨域访问 **/
response.setHeader("Access-Control-Allow-Origin", "*");
/* 星号表示所有的异域请求都可以接受, */
response.setHeader("Access-Control-Allow-Methods", "GET,POST");
/**
* 接收json
*/
String name = request.getParameter("name");
String pwd = request.getParameter("pwd");
System.out.println(name);
System.out.println(pwd);
/**
* 返回json
*/
PrintWriter out = response.getWriter();
String title = "成果";
String docType = " \n";
out.println(
docType + "\n" + "" + title + "\n" + "\n"
+ "" + title + "\n" + "登陆成功\r\n" + "\r\n" + "");
out.close();
}
}
3、配置Web.Xml文件,
servlet 构建完成后,需要在 web.xml 中进行配置,这样 servlet 才能在网页和服务票证中找到
web.xml 文件也在 WebContent/Web-INF 中。如果没有,您需要手动创建一个。
web.xml 代码如下
My
index.html
index.htm
index.jsp
MyServlet
com.yd.MyServlet
MyServlet
/MyServlet
中的是与
中的对应的随便取什么名字都行,但是两个name需要一样
com.yd.MyServlet
这表示的是你要使用的Servlet所在的路径,需要写包名,
/MyServlet
其中的/MyServlet表示的是在网页中访问servlet时用到的URL地址,一定要加/ 名字随意
index.html
表示的是当只有前面部分的URL时访问的页面
例如你需要访问http://localhost/My/index.html时如果你在地址栏直接输入http://localhost/My则会直接访问你再这一项中设计的欢迎页面
至此,配置完成,只需要运行发布到Tomcat即可访问
从地址栏可以看到URL已经进入了Servlet,下面也可以读取输入框中的数据
需要提醒的是,html文件一定要放在WebContent下,而不是WebContent中的Web-INF下,否则会一直出错,一门血课。 . 使用jsp的原理类似,jsp本质上就是一个servlet
所以如果用jsp来设计,就不需要在xml文件中配置。你只需要在html中把表单中的action写成你自己的jsp文件,然后jsp和servlet就一样了。
代码如下:
Insert title here
jsp中的代码,
Insert title here
登陆成功
最后你会看到同样的效果,只不过地址栏中的servlet是用jsp文件编写的
html文件和jsp文件都需要写在WebContent下,而不是WebContent中的Web-INF下 查看全部
java从网页抓取数据(创建一个类的html文件创建表单)
使用 Servlet,您可以从 Web 表单采集用户输入、呈现来自数据库或其他来源的记录以及动态创建网页。
首先使用eclipse创建一个网站,使用其他开发工具也是一样,创建网站需要配置Tomcat服务器,以便网站导入servlet包并可以发布,如图所示
新建网络项目

配置Tomcat

创建后,在web项目的Webcontent中编辑需要添加的网页内容

这里我创建了一个 index html 文件
Insert title here
创建一个表单,表单中的action表示使用哪个servlet来处理提交的信息,
method表示数据的传输方式,分为两种,一种是get,一种是post
接下来开始创建Servlet,在java代码中构建包,并创建一个类,这个类需要继承HttpServlet

从网页读取数据
在HttpServlet中有两个方法,doget 和dopost,这两个方法就是用来接收网页端数据和向网页端输出数据的
在这里我们使用dopost的方法,在dopost中有个参数HttpServletRequest request我们可以通过这个参数获取网页的传输内容
HttpServletRequest 参数中有getParameter这个方法能够获取网页的表单对象
String name = request.getParameter("name");
这是用一个字符串以name属性为name的形式接收字符串数据
表单中的输入可以定义服务订单要获取的名称,同样可以获取pwd中的数据。
输出数据到网页
输出数据是一个依赖 PrintWriter 的对象。这个对象有写和打印的方法,可以将数据输出到网页。具体用途:
PrintWriter out = response.getWriter();
out.println("string");
也可以把字符串的位置改成html代码,直接打印出一个网页
服务器的具体代码如下:
response.setContentType("text/html;charset=utf-8");
如果要输出网页,请加上这句话text/html,否则输出的是代码而不是网页
如果要从网页中获取汉字,需要设置utf-8格式,否则会出现乱码
package com.yd;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class Yd extends HttpServlet {
private static final long serialVersionUID = 1L;
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
}
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html;charset=utf-8");
response.setCharacterEncoding("UTF-8");
request.setCharacterEncoding("UTF-8");
/** 设置响应头允许ajax跨域访问 **/
response.setHeader("Access-Control-Allow-Origin", "*");
/* 星号表示所有的异域请求都可以接受, */
response.setHeader("Access-Control-Allow-Methods", "GET,POST");
/**
* 接收json
*/
String name = request.getParameter("name");
String pwd = request.getParameter("pwd");
System.out.println(name);
System.out.println(pwd);
/**
* 返回json
*/
PrintWriter out = response.getWriter();
String title = "成果";
String docType = " \n";
out.println(
docType + "\n" + "" + title + "\n" + "\n"
+ "" + title + "\n" + "登陆成功\r\n" + "\r\n" + "");
out.close();
}
}
3、配置Web.Xml文件,
servlet 构建完成后,需要在 web.xml 中进行配置,这样 servlet 才能在网页和服务票证中找到
web.xml 文件也在 WebContent/Web-INF 中。如果没有,您需要手动创建一个。
web.xml 代码如下
My
index.html
index.htm
index.jsp
MyServlet
com.yd.MyServlet
MyServlet
/MyServlet
中的是与
中的对应的随便取什么名字都行,但是两个name需要一样
com.yd.MyServlet
这表示的是你要使用的Servlet所在的路径,需要写包名,
/MyServlet
其中的/MyServlet表示的是在网页中访问servlet时用到的URL地址,一定要加/ 名字随意
index.html
表示的是当只有前面部分的URL时访问的页面
例如你需要访问http://localhost/My/index.html时如果你在地址栏直接输入http://localhost/My则会直接访问你再这一项中设计的欢迎页面
至此,配置完成,只需要运行发布到Tomcat即可访问


从地址栏可以看到URL已经进入了Servlet,下面也可以读取输入框中的数据
需要提醒的是,html文件一定要放在WebContent下,而不是WebContent中的Web-INF下,否则会一直出错,一门血课。 . 使用jsp的原理类似,jsp本质上就是一个servlet
所以如果用jsp来设计,就不需要在xml文件中配置。你只需要在html中把表单中的action写成你自己的jsp文件,然后jsp和servlet就一样了。
代码如下:
Insert title here
jsp中的代码,
Insert title here
登陆成功
最后你会看到同样的效果,只不过地址栏中的servlet是用jsp文件编写的
html文件和jsp文件都需要写在WebContent下,而不是WebContent中的Web-INF下
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-01 02:16
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页的源码,我们在源码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页的源码,我们在源码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-30 20:18
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页的源码,我们在源码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页的源码,我们在源码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java从网页抓取数据(《java面试笔试全程实录》之单条数据抓取数据分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-27 22:01
java从网页抓取数据,首先需要针对数据来源做分析,然后筛选和切割,最后进行数据的读写和输出。为了体现这种读写的不同性,我给两种类型:分页数据抓取和单条数据抓取(关于这两种类型,是参考《java面试笔试全程实录》一书完整总结)。对于单条数据抓取来说,可以通过javaapi来进行数据读写,这里不做详细介绍,并在下文给出实际例子。
单条数据抓取首先我们对单条数据抓取数据进行分析,将抓取后的数据划分为txt文件,按照key字段进行排序,比如a,b这两个数据文件,其中a文件排在前面。读取数据过程一般如下://导入java读取jar包java.io.filereaderfilereader=newfilereader();//导入sqlite数据库java.io.sqlitefactorysqlitefactory=newsqlitefactory();reader.readfile(buf,sqlitefactory.get("d:\\com.alibaba.ops.ozdata\\table_row_pool_mya_doc_common.sqlite"));if(isempty(reader.isreference())){returnnull;}//读取sqlite数据表sqlitetest_table1_db数据表orderedatis=neworderedatis(buf,sqlitefactory.get("d:\\com.alibaba.ops.ozdata\\table_row_pool_mya_doc_common.sqlite"));//设置时间戳、ttl和时长,并更新数据库中的表datetimedatetime=sqlitefactory.read(orderedatis);stringttl=sqlitefactory.get("d:\\com.alibaba.ops.ozdata\\table_row_pool_mya_doc_common.sqlite");//验证指针stringttl=datetime.now();//正则引擎抓取要求的参数objectresultstring=reader.readstring(content,stringroot);system.out.println(resultstring);//读取数据列表regexregrregexregr=newregexregr();regexregr.setparametervalue(resultstring,"/\d+/");//跳转到sqlite数据库,info文件所指向的路径中打开数据文件stringfilepath="/tmp/"+fileload(regexregr.getruntime());if(filepath!=null){system.out.println(filepath);}//读取数据库user表字段,并删除数据库中数据库表中的字段objectdb=filepath+"/test/"+fileload(filepath);db.drop(regexregr.getparametervalue(db,"/csv"));//清除表的索引//执行代码system.out.println(filepath+"\\d"+"\\s//"+system.currenttimemillis()+"\\。 查看全部
java从网页抓取数据(《java面试笔试全程实录》之单条数据抓取数据分析)
java从网页抓取数据,首先需要针对数据来源做分析,然后筛选和切割,最后进行数据的读写和输出。为了体现这种读写的不同性,我给两种类型:分页数据抓取和单条数据抓取(关于这两种类型,是参考《java面试笔试全程实录》一书完整总结)。对于单条数据抓取来说,可以通过javaapi来进行数据读写,这里不做详细介绍,并在下文给出实际例子。
单条数据抓取首先我们对单条数据抓取数据进行分析,将抓取后的数据划分为txt文件,按照key字段进行排序,比如a,b这两个数据文件,其中a文件排在前面。读取数据过程一般如下://导入java读取jar包java.io.filereaderfilereader=newfilereader();//导入sqlite数据库java.io.sqlitefactorysqlitefactory=newsqlitefactory();reader.readfile(buf,sqlitefactory.get("d:\\com.alibaba.ops.ozdata\\table_row_pool_mya_doc_common.sqlite"));if(isempty(reader.isreference())){returnnull;}//读取sqlite数据表sqlitetest_table1_db数据表orderedatis=neworderedatis(buf,sqlitefactory.get("d:\\com.alibaba.ops.ozdata\\table_row_pool_mya_doc_common.sqlite"));//设置时间戳、ttl和时长,并更新数据库中的表datetimedatetime=sqlitefactory.read(orderedatis);stringttl=sqlitefactory.get("d:\\com.alibaba.ops.ozdata\\table_row_pool_mya_doc_common.sqlite");//验证指针stringttl=datetime.now();//正则引擎抓取要求的参数objectresultstring=reader.readstring(content,stringroot);system.out.println(resultstring);//读取数据列表regexregrregexregr=newregexregr();regexregr.setparametervalue(resultstring,"/\d+/");//跳转到sqlite数据库,info文件所指向的路径中打开数据文件stringfilepath="/tmp/"+fileload(regexregr.getruntime());if(filepath!=null){system.out.println(filepath);}//读取数据库user表字段,并删除数据库中数据库表中的字段objectdb=filepath+"/test/"+fileload(filepath);db.drop(regexregr.getparametervalue(db,"/csv"));//清除表的索引//执行代码system.out.println(filepath+"\\d"+"\\s//"+system.currenttimemillis()+"\\。
java从网页抓取数据(java从网页抓取数据,需要使用java的spiderapi,可以抓取一个网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-23 15:03
java从网页抓取数据,需要使用java的spiderapi,其中很重要的一个类contentbrowser可以抓取一个网页,也就是chrome浏览器,并且能够上传到后台数据库,简单来说,用java抓取一个网页时,并不是直接往java服务器发送get请求,而是contentbrowser向浏览器发送get请求,然后返回内容,在下面的代码中通过服务器传输的错误码去匹配数据库是否匹配上,然后返回正确的结果就可以抓取数据了,如果后端服务器数据库没有匹配上的话,则提示“pageerror”(网页未响应)来告诉浏览器,java服务器未能收到正确的请求数据,从而将网页转发给后端服务器,这个时候spider已经将抓取的页面转发给后端的httpserver进行http请求抓取了,但后端服务器还没有响应数据库中的数据。
简单的说是因为cookie是记录的当前url对应的cookie,这段记录是放在服务器的,url改变时记录重新生成,
form表单和oauth认证时都需要使用到cookie,以下代码可以查看cookie设置:$request-cookie='pages_request_id';$request-cookie-path='/pages';$request-cookie-name='pages_cookie_name';$request-cookie-host='cookie_host';$request-cookie-method='post';$request-cookie-timeout='30秒';$request-cookie-invalid='y';$request-cookie-isnotfound='y';$request-cookie-origin='cookie_origin';$request-cookie-setheader='cookie_host';$request-cookie-ignore='y';$request-cookie-ignore-uri='';..具体参考googlecookie设置。 查看全部
java从网页抓取数据(java从网页抓取数据,需要使用java的spiderapi,可以抓取一个网页)
java从网页抓取数据,需要使用java的spiderapi,其中很重要的一个类contentbrowser可以抓取一个网页,也就是chrome浏览器,并且能够上传到后台数据库,简单来说,用java抓取一个网页时,并不是直接往java服务器发送get请求,而是contentbrowser向浏览器发送get请求,然后返回内容,在下面的代码中通过服务器传输的错误码去匹配数据库是否匹配上,然后返回正确的结果就可以抓取数据了,如果后端服务器数据库没有匹配上的话,则提示“pageerror”(网页未响应)来告诉浏览器,java服务器未能收到正确的请求数据,从而将网页转发给后端服务器,这个时候spider已经将抓取的页面转发给后端的httpserver进行http请求抓取了,但后端服务器还没有响应数据库中的数据。
简单的说是因为cookie是记录的当前url对应的cookie,这段记录是放在服务器的,url改变时记录重新生成,
form表单和oauth认证时都需要使用到cookie,以下代码可以查看cookie设置:$request-cookie='pages_request_id';$request-cookie-path='/pages';$request-cookie-name='pages_cookie_name';$request-cookie-host='cookie_host';$request-cookie-method='post';$request-cookie-timeout='30秒';$request-cookie-invalid='y';$request-cookie-isnotfound='y';$request-cookie-origin='cookie_origin';$request-cookie-setheader='cookie_host';$request-cookie-ignore='y';$request-cookie-ignore-uri='';..具体参考googlecookie设置。
java从网页抓取数据(爬虫开发出"蜘蛛”程序的是Gray网页吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-22 10:11
爬虫
通常搜索引擎处理的对象是互联网页面。第一个问题是:如何设计一个高效的下载系统,将如此海量的网页数据传输到本地,并在本地形成互联网网页的镜像备份。网络爬虫扮演着这个角色,它们是搜索引擎系统中非常关键和基础的组件。
爬虫:其实就是通过相应的技术抓取页面上的具体信息。
网络爬虫
当“蜘蛛”程序出现时,现代意义上的搜索引擎才刚刚开始出现。它实际上是一种计算机“机器人”(Computer Robot),计算机“机器人”是指能够以人类无法达到的速度不间断地执行某项任务的某种软件程序。因为专门用来检索信息的“机器人”程序像蜘蛛一样在网络中四处爬行,反复不知疲倦。因此,搜索引擎的“机器人”程序被称为“蜘蛛”程序。
这种程序实际上是利用html文档之间的链接关系,抓取Web上的每个页面,抓取这些页面进入系统进行分析,并放入数据库中。第一个开发“蜘蛛”程序的是马修格雷。他在 1993 年开发了万维网漫游器。最初建立它是为了计算 Internet 上的服务器数量,后来发展为能够捕获 URL。现代搜索引擎的思想起源于Wanderer,后来很多人在此基础上改进了蜘蛛程序。
操作流程图
我们经常听到的爬虫可能是python爬虫,因为我之前没有接触过这种语言,所以感觉爬虫是一种神秘的技术。今天看了一篇博客,介绍了使用Jsoup包轻松开发爬虫。我注意到这是一个java包,所以我想自己做一个爬虫程序。这就是我今天的文章,也是从小白到大白的一个过程,因为之前没有写过类似的,所以还是有点成就感的。八卦直接上代码。
其实爬虫很简单,先新建一个java项目。
这是为了将捕获的信息保存在本地以提高效率
/**
*
* @Title: saveHtml
* @Description: 将抓取过来的数据保存到本地或者json文件
* @param 参数
* @return void 返回类型
* @author liangchu
* @date 2017-12-28 下午12:23:05
* @throws
*/
public static void saveHtml(String url) {
try {
// 这是将首页的信息存入到一个html文件中 为了后面分析html文件里面的信息做铺垫
File dest = new File("src/temp/reptile.html");
// 接收字节输入流
InputStream is;
// 字节输出流
FileOutputStream fos = new FileOutputStream(dest);
URL temp = new URL(url);
// 这个地方需要加入头部 避免大部分网站拒绝访问
// 这个地方是容易忽略的地方所以要注意
URLConnection uc = temp.openConnection();
// 因为现在很大一部分网站都加入了反爬虫机制 这里加入这个头信息
uc.addRequestProperty(
"User-Agent",
"Mozilla/5.0 "
+ "(iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) "
+ "AppleWebKit/533.17.9"
+ " (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5");
is = temp.openStream();
// 为字节输入流加入缓冲
BufferedInputStream bis = new BufferedInputStream(is);
// 为字节输出流加入缓冲
BufferedOutputStream bos = new BufferedOutputStream(fos);
int length;
byte[] bytes = new byte[1024 * 20];
while ((length = bis.read(bytes, 0, bytes.length)) != -1) {
fos.write(bytes, 0, length);
}
bos.close();
fos.close();
bis.close();
is.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
分析本地文件信息,提取有用信息。这部分很耗时
/*
* 解析本地的html文件获取对应的数据
*/
public static void getLocalHtml(String path) {
// 读取本地的html文件
File file = new File(path);
// 获取这个路径下的所有html文件
File[] files = file.listFiles();
List news = new ArrayList();
HttpServletResponse response = null;
HttpServletRequest request = null;
int tmp=1;
// 循环解析所有的html文件
try {
for (int i = 0; i < files.length; i++) {
// 首先先判断是不是文件
if (files[i].isFile()) {
// 获取文件名
String filename = files[i].getName();
// 开始解析文件
Document doc = Jsoup.parse(files[i], "UTF-8");
// 获取所有内容 获取新闻内容
Elements contents = doc.getElementsByClass("ConsTi");
for (Element element : contents) {
Elements e1 = element.getElementsByTag("a");
for (Element element2 : e1) {
// System.out.print(element2.attr("href"));
// 根据href获取新闻的详情信息
String newText = desGetUrl(element2.attr("href"));
// 获取新闻的标题
String newTitle = element2.text();
exportFile(newTitle, newText);
System.out.println("抓取成功。。。"+(tmp));
tmp++;
}
}
}
}
//excelExport(news, response, request);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
根据url的信息获取该url下的新闻详情信息
/**
*
* @Title: desGetUrl
* @Description: 根据url获取连接地址的详情信息
* @param @param url 参数
* @return void 返回类型
* @author liangchu
* @date 2017-12-28 下午1:57:45
* @throws
*/
public static String desGetUrl(String url) {
String newText="";
try {
Document doc = Jsoup
.connect(url)
.userAgent(
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; MALC)")
.get();
// System.out.println(doc);
// 得到html下的所有东西
//Element content = doc.getElementById("article");
Elements contents = doc.getElementsByClass("article");
if(contents != null && contents.size() >0){
Element content = contents.get(0);
newText = content.text();
}
//System.out.println(content);
//return newText;
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return newText;
}
将新闻信息写入文件
/*
* 将新闻标题和内容写入文件
*/
public static void exportFile(String title,String content){
try {
File file = new File("F:/replite/xinwen.txt");
if (!file.getParentFile().exists()) {//判断路径是否存在,如果不存在,则创建上一级目录文件夹
file.getParentFile().mkdirs();
}
FileWriter fileWriter=new FileWriter(file, true);
fileWriter.write(title+"----------");
fileWriter.write(content+"\r\n");
fileWriter.close();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
主功能
public static void main(String[] args) {
String url = "http://news.sina.com.cn/hotnews/?q_kkhha";
// 解析本地html文件
getLocalHtml("src/temp");
}
数据.png
总结
在我做之前,我认为爬行很神秘。再做一遍后,发现其实是一样的。其实很多事情都是一样的。让我们不要被眼前的困难所迷惑。当你勇敢地迈出这一步时,你会发现其实你也可以做到。 查看全部
java从网页抓取数据(爬虫开发出"蜘蛛”程序的是Gray网页吗?)
爬虫
通常搜索引擎处理的对象是互联网页面。第一个问题是:如何设计一个高效的下载系统,将如此海量的网页数据传输到本地,并在本地形成互联网网页的镜像备份。网络爬虫扮演着这个角色,它们是搜索引擎系统中非常关键和基础的组件。
爬虫:其实就是通过相应的技术抓取页面上的具体信息。
网络爬虫
当“蜘蛛”程序出现时,现代意义上的搜索引擎才刚刚开始出现。它实际上是一种计算机“机器人”(Computer Robot),计算机“机器人”是指能够以人类无法达到的速度不间断地执行某项任务的某种软件程序。因为专门用来检索信息的“机器人”程序像蜘蛛一样在网络中四处爬行,反复不知疲倦。因此,搜索引擎的“机器人”程序被称为“蜘蛛”程序。
这种程序实际上是利用html文档之间的链接关系,抓取Web上的每个页面,抓取这些页面进入系统进行分析,并放入数据库中。第一个开发“蜘蛛”程序的是马修格雷。他在 1993 年开发了万维网漫游器。最初建立它是为了计算 Internet 上的服务器数量,后来发展为能够捕获 URL。现代搜索引擎的思想起源于Wanderer,后来很多人在此基础上改进了蜘蛛程序。

操作流程图
我们经常听到的爬虫可能是python爬虫,因为我之前没有接触过这种语言,所以感觉爬虫是一种神秘的技术。今天看了一篇博客,介绍了使用Jsoup包轻松开发爬虫。我注意到这是一个java包,所以我想自己做一个爬虫程序。这就是我今天的文章,也是从小白到大白的一个过程,因为之前没有写过类似的,所以还是有点成就感的。八卦直接上代码。
其实爬虫很简单,先新建一个java项目。
这是为了将捕获的信息保存在本地以提高效率
/**
*
* @Title: saveHtml
* @Description: 将抓取过来的数据保存到本地或者json文件
* @param 参数
* @return void 返回类型
* @author liangchu
* @date 2017-12-28 下午12:23:05
* @throws
*/
public static void saveHtml(String url) {
try {
// 这是将首页的信息存入到一个html文件中 为了后面分析html文件里面的信息做铺垫
File dest = new File("src/temp/reptile.html");
// 接收字节输入流
InputStream is;
// 字节输出流
FileOutputStream fos = new FileOutputStream(dest);
URL temp = new URL(url);
// 这个地方需要加入头部 避免大部分网站拒绝访问
// 这个地方是容易忽略的地方所以要注意
URLConnection uc = temp.openConnection();
// 因为现在很大一部分网站都加入了反爬虫机制 这里加入这个头信息
uc.addRequestProperty(
"User-Agent",
"Mozilla/5.0 "
+ "(iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) "
+ "AppleWebKit/533.17.9"
+ " (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5");
is = temp.openStream();
// 为字节输入流加入缓冲
BufferedInputStream bis = new BufferedInputStream(is);
// 为字节输出流加入缓冲
BufferedOutputStream bos = new BufferedOutputStream(fos);
int length;
byte[] bytes = new byte[1024 * 20];
while ((length = bis.read(bytes, 0, bytes.length)) != -1) {
fos.write(bytes, 0, length);
}
bos.close();
fos.close();
bis.close();
is.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
分析本地文件信息,提取有用信息。这部分很耗时
/*
* 解析本地的html文件获取对应的数据
*/
public static void getLocalHtml(String path) {
// 读取本地的html文件
File file = new File(path);
// 获取这个路径下的所有html文件
File[] files = file.listFiles();
List news = new ArrayList();
HttpServletResponse response = null;
HttpServletRequest request = null;
int tmp=1;
// 循环解析所有的html文件
try {
for (int i = 0; i < files.length; i++) {
// 首先先判断是不是文件
if (files[i].isFile()) {
// 获取文件名
String filename = files[i].getName();
// 开始解析文件
Document doc = Jsoup.parse(files[i], "UTF-8");
// 获取所有内容 获取新闻内容
Elements contents = doc.getElementsByClass("ConsTi");
for (Element element : contents) {
Elements e1 = element.getElementsByTag("a");
for (Element element2 : e1) {
// System.out.print(element2.attr("href"));
// 根据href获取新闻的详情信息
String newText = desGetUrl(element2.attr("href"));
// 获取新闻的标题
String newTitle = element2.text();
exportFile(newTitle, newText);
System.out.println("抓取成功。。。"+(tmp));
tmp++;
}
}
}
}
//excelExport(news, response, request);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
根据url的信息获取该url下的新闻详情信息
/**
*
* @Title: desGetUrl
* @Description: 根据url获取连接地址的详情信息
* @param @param url 参数
* @return void 返回类型
* @author liangchu
* @date 2017-12-28 下午1:57:45
* @throws
*/
public static String desGetUrl(String url) {
String newText="";
try {
Document doc = Jsoup
.connect(url)
.userAgent(
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; MALC)")
.get();
// System.out.println(doc);
// 得到html下的所有东西
//Element content = doc.getElementById("article");
Elements contents = doc.getElementsByClass("article");
if(contents != null && contents.size() >0){
Element content = contents.get(0);
newText = content.text();
}
//System.out.println(content);
//return newText;
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return newText;
}
将新闻信息写入文件
/*
* 将新闻标题和内容写入文件
*/
public static void exportFile(String title,String content){
try {
File file = new File("F:/replite/xinwen.txt");
if (!file.getParentFile().exists()) {//判断路径是否存在,如果不存在,则创建上一级目录文件夹
file.getParentFile().mkdirs();
}
FileWriter fileWriter=new FileWriter(file, true);
fileWriter.write(title+"----------");
fileWriter.write(content+"\r\n");
fileWriter.close();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
主功能
public static void main(String[] args) {
String url = "http://news.sina.com.cn/hotnews/?q_kkhha";
// 解析本地html文件
getLocalHtml("src/temp");
}

数据.png
总结
在我做之前,我认为爬行很神秘。再做一遍后,发现其实是一样的。其实很多事情都是一样的。让我们不要被眼前的困难所迷惑。当你勇敢地迈出这一步时,你会发现其实你也可以做到。
java从网页抓取数据(机器IE加密证书加密的解决方案方法及安装方法分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-20 15:04
1、 用户登录数据采集 用户登录
采集银行或其他企业数据首先需要用户登录。使用java语言的url方式获取登录url或者使用java开源工具HTTPClient模拟登录。使用的插件有IE的httpwotch工具和FireFox的Firebug工具和cookie。插件获取post密码地址或获取URL请求的密码地址。
2、 采集 用户密码登录难点及其验证码和证书解决办法
a) 对于普通用户登录,只需查看用户登录信息并从中获取POST的值即可模拟post数据登录并抓取相关数据
b) post提交,发现前端js做了md5加密,或者其他aes和des加密,查看网站项目js源码看是什么类型的加密方式,使用它的解密方法得到一般的aes加密密钥会保存在客户端,所以需要一定的时间才能找到它的加密密钥来模拟登录。有的加密与用js做的加密有关,有的使用开发加密,但其他语言的加密就不一样了。Rhino JavaScript引擎技术模拟js获取加密密钥,然后登录。
c) 对于证书加密方案,首先要打开一个网站,找到证书,选择查看证书,然后在详细信息中选择copy to file,选择der to compile binary x.509 to导出cer证书,将证书转换为c密钥的形式,windows中有一个keytool工具。使用该命令以加密的keystore文件格式导出key文件,然后使用httpclient的keyStore工具获取keystore登录keystore密码并使用sslsocketfactory注册密钥来达到keystore登录的目的。
d) 第三方服务器认证服务器密钥登录方式的解决方案。一直登录。通过firebug的url检测查看url访问路径,采集分析dom数据,查看html代码是否有变化。获取url获取数据,继续模拟登录,直到访问数据成功,一般这个比较耗时。
e) 本机IE加密证书及数据采集程序需安装相关插件。有些网站为了限制某台机器的登录,需要按照用户登录方式模拟登录,模拟登录时下载证书,模拟访问证书路径,模拟下载后访问的页面证书,最后他可能会生成一个密钥。密钥可以每天生成。可以每天模拟一次,然后根据用户的post数据模拟登录并提交key。
f) 对于有验证码破解的登录方式,使用程序将图片调整为灰度,使用谷歌开源项目tesseract-ocr查看验证码。对于一些难以破解的验证码,就得想办法搭建字典学习库了。采集一些程序验证码来学习破解(注意*必须用c语言写接口和左http服务谷歌开源tesseract-ocr使用的c语言),也可以自己写算法实现验证码的破解。
g) U-key登录方式的破解,看这个U-KEY里面存放的是什么类型的key,有的是用证书制作的密钥,有的是非对称加密密钥。不同的密钥有不同的解决方案,可以破解。密钥作为模拟器使用,也可以破解加密狗复制到其他加密狗使用。
3、数据采集页面数据分析分页及日常数据抓取相关注意事项
a) 对于普通页面的分页数据分析,一般规则是url中的参数会存在于html页面中。对于一些有搜索的,先用SQL注入测试一下是否可以一次直接暴露所有数据。如果是普通的直接url,提交对应的页面。
b) 对于某些aspx类型的网站数据抓取,一般aspx网站很多人会使用一些制作精良的dll文件,其中很多都会有session功能,即访问第二个一页数据,他会读取相关页面中隐藏的数据,输入一页数据,每一页的数据都不一样,只是模拟爬行。
c) 其他一些页面数据的抓取,有些是Ajax返回的数据,前台无法解析。捕获此类数据的最佳方式是直接用 java 解析 json 数据。找json可能很费劲。
d) 对于一些横竖分页数据的爬取,只能横向切换爬取,然后垂直爬取所有分页数据。一些横向数据的post参数可以自己定义,可以抓到数据。
4、 数据分析与清洗数据
对于一些数据清洗,可以使用Jsoup、xpath、regex进行数据分析和分析。有些数据需要一些算法来获取数据,可以通过二次数据页面分析方法获取数据。(针对不同的数据选择不同的解决方案)
5、 用户限制和ip限制的解决方案
对于用户受限的数据抓取程序,只能通过时间间隔来掌握网站的频率抓取数据,解决用户登录问题。对于多用户登录和ip查看程序抓取数据,也可以申请多个账号进行抓取。ip限制取的方法可以冒充谷歌IP取数据,使用ADSL拨号方式取数据。这需要很长时间。其他方式可以购买代理ip和高保真代理数据抓取。
6、 下载和编码注意事项
对于普通爬虫,一般使用url的数据流下载相关文档解析word和excel,一般使用POI来达到效果。对于pdf,一般使用PDFParser来分析。有的会造成乱码,大部分是InputStream等造成的。一般用utf-8\gbk请求时,检查请求的头信息,相应修改代码。一些 网站 需要使用字节。为了解决乱码。有些下载需要修改请求头信息才能下载。
对于一些定制化的数据采集,只能编写定制的采集方案,统一种子中心分发下载,实现分布式数据采集。(注*部分网站不能使用分布式数据采集)。 查看全部
java从网页抓取数据(机器IE加密证书加密的解决方案方法及安装方法分析)
1、 用户登录数据采集 用户登录
采集银行或其他企业数据首先需要用户登录。使用java语言的url方式获取登录url或者使用java开源工具HTTPClient模拟登录。使用的插件有IE的httpwotch工具和FireFox的Firebug工具和cookie。插件获取post密码地址或获取URL请求的密码地址。
2、 采集 用户密码登录难点及其验证码和证书解决办法
a) 对于普通用户登录,只需查看用户登录信息并从中获取POST的值即可模拟post数据登录并抓取相关数据
b) post提交,发现前端js做了md5加密,或者其他aes和des加密,查看网站项目js源码看是什么类型的加密方式,使用它的解密方法得到一般的aes加密密钥会保存在客户端,所以需要一定的时间才能找到它的加密密钥来模拟登录。有的加密与用js做的加密有关,有的使用开发加密,但其他语言的加密就不一样了。Rhino JavaScript引擎技术模拟js获取加密密钥,然后登录。
c) 对于证书加密方案,首先要打开一个网站,找到证书,选择查看证书,然后在详细信息中选择copy to file,选择der to compile binary x.509 to导出cer证书,将证书转换为c密钥的形式,windows中有一个keytool工具。使用该命令以加密的keystore文件格式导出key文件,然后使用httpclient的keyStore工具获取keystore登录keystore密码并使用sslsocketfactory注册密钥来达到keystore登录的目的。
d) 第三方服务器认证服务器密钥登录方式的解决方案。一直登录。通过firebug的url检测查看url访问路径,采集分析dom数据,查看html代码是否有变化。获取url获取数据,继续模拟登录,直到访问数据成功,一般这个比较耗时。
e) 本机IE加密证书及数据采集程序需安装相关插件。有些网站为了限制某台机器的登录,需要按照用户登录方式模拟登录,模拟登录时下载证书,模拟访问证书路径,模拟下载后访问的页面证书,最后他可能会生成一个密钥。密钥可以每天生成。可以每天模拟一次,然后根据用户的post数据模拟登录并提交key。
f) 对于有验证码破解的登录方式,使用程序将图片调整为灰度,使用谷歌开源项目tesseract-ocr查看验证码。对于一些难以破解的验证码,就得想办法搭建字典学习库了。采集一些程序验证码来学习破解(注意*必须用c语言写接口和左http服务谷歌开源tesseract-ocr使用的c语言),也可以自己写算法实现验证码的破解。
g) U-key登录方式的破解,看这个U-KEY里面存放的是什么类型的key,有的是用证书制作的密钥,有的是非对称加密密钥。不同的密钥有不同的解决方案,可以破解。密钥作为模拟器使用,也可以破解加密狗复制到其他加密狗使用。
3、数据采集页面数据分析分页及日常数据抓取相关注意事项
a) 对于普通页面的分页数据分析,一般规则是url中的参数会存在于html页面中。对于一些有搜索的,先用SQL注入测试一下是否可以一次直接暴露所有数据。如果是普通的直接url,提交对应的页面。
b) 对于某些aspx类型的网站数据抓取,一般aspx网站很多人会使用一些制作精良的dll文件,其中很多都会有session功能,即访问第二个一页数据,他会读取相关页面中隐藏的数据,输入一页数据,每一页的数据都不一样,只是模拟爬行。
c) 其他一些页面数据的抓取,有些是Ajax返回的数据,前台无法解析。捕获此类数据的最佳方式是直接用 java 解析 json 数据。找json可能很费劲。
d) 对于一些横竖分页数据的爬取,只能横向切换爬取,然后垂直爬取所有分页数据。一些横向数据的post参数可以自己定义,可以抓到数据。
4、 数据分析与清洗数据
对于一些数据清洗,可以使用Jsoup、xpath、regex进行数据分析和分析。有些数据需要一些算法来获取数据,可以通过二次数据页面分析方法获取数据。(针对不同的数据选择不同的解决方案)
5、 用户限制和ip限制的解决方案
对于用户受限的数据抓取程序,只能通过时间间隔来掌握网站的频率抓取数据,解决用户登录问题。对于多用户登录和ip查看程序抓取数据,也可以申请多个账号进行抓取。ip限制取的方法可以冒充谷歌IP取数据,使用ADSL拨号方式取数据。这需要很长时间。其他方式可以购买代理ip和高保真代理数据抓取。
6、 下载和编码注意事项
对于普通爬虫,一般使用url的数据流下载相关文档解析word和excel,一般使用POI来达到效果。对于pdf,一般使用PDFParser来分析。有的会造成乱码,大部分是InputStream等造成的。一般用utf-8\gbk请求时,检查请求的头信息,相应修改代码。一些 网站 需要使用字节。为了解决乱码。有些下载需要修改请求头信息才能下载。
对于一些定制化的数据采集,只能编写定制的采集方案,统一种子中心分发下载,实现分布式数据采集。(注*部分网站不能使用分布式数据采集)。
java从网页抓取数据( 本文介绍java网络几个常用框架及框架介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-19 11:12
本文介绍java网络几个常用框架及框架介绍)
爬虫是每个程序员都必须掌握的技能。与python爬虫的广泛应用相比,java爬虫也有着不可缺少的优势。Java爬虫现在也相当成熟。Python爬虫中的框架支持爬虫任务的进度,Java爬虫的框架也是如此。每个框架都扮演着不同的角色。本文介绍几个java网络常用的框架:Nutch、Crawler4j、WebMagic、WebCollecto。
1、Nutch:为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。
2、Crawler4j:是一款开源的Java爬虫网络爬虫,代码相当轻量,可以实现多线程爬取,上手难度低。
3、WebMagic:是一个简单灵活的Java爬虫框架。WebMagic 的结构分为四大组件:Downloader、pageProcessor、Scheduler、pipeline,它们以spliter 进行组织。这四个组件分别对应爬虫生命周期中的下载、处理、管理和持久化功能。
4、WebCollector:致力于维护一个稳定可扩展的爬虫内核,方便开发者进行灵活的二次开发。内核扩展性强,用户可以基于内核开发自己的爬虫。Jsoup 集成在源代码中,用于准确的网页分析。
以上就是对java网络爬虫的简单介绍,希望对大家有所帮助~更多java学习推荐:java教程。 查看全部
java从网页抓取数据(
本文介绍java网络几个常用框架及框架介绍)

爬虫是每个程序员都必须掌握的技能。与python爬虫的广泛应用相比,java爬虫也有着不可缺少的优势。Java爬虫现在也相当成熟。Python爬虫中的框架支持爬虫任务的进度,Java爬虫的框架也是如此。每个框架都扮演着不同的角色。本文介绍几个java网络常用的框架:Nutch、Crawler4j、WebMagic、WebCollecto。
1、Nutch:为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。
2、Crawler4j:是一款开源的Java爬虫网络爬虫,代码相当轻量,可以实现多线程爬取,上手难度低。
3、WebMagic:是一个简单灵活的Java爬虫框架。WebMagic 的结构分为四大组件:Downloader、pageProcessor、Scheduler、pipeline,它们以spliter 进行组织。这四个组件分别对应爬虫生命周期中的下载、处理、管理和持久化功能。
4、WebCollector:致力于维护一个稳定可扩展的爬虫内核,方便开发者进行灵活的二次开发。内核扩展性强,用户可以基于内核开发自己的爬虫。Jsoup 集成在源代码中,用于准确的网页分析。
以上就是对java网络爬虫的简单介绍,希望对大家有所帮助~更多java学习推荐:java教程。
java从网页抓取数据(本节书摘来自华章社区《Clojure数据分析秘笈》(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-10-13 00:34
本节摘自华章社区《Clojure数据分析秘诀》一书第1章,1.8节从web表中抓取数据,作者(美国)Eric Rochester,更多章节可访问查看官方云栖社区“华章社区”账号
1.8 从网页表格中抓取数据
数据在互联网上无处不在。不幸的是,互联网上的许多数据并不容易获得。这些数据深埋在表格、文章 或深度嵌套的标签中。网页抓取是一项令人讨厌的物理任务,但它通常是提取此数据进行分析的唯一方法。此方法描述了如何加载网页并挖掘其内容以检索数据。
这可以使用 Enlive 库 () 来完成。该库使用基于 CSS 选择器的领域特定语言 (DSL) 来定位网页中的元素。这个库也可以用于模板。在本例中,仅使用它从网页中检索数据。
1.8.1 准备工作
首先需要在项目的依赖中添加Enlive:
故意删除文件的其他内容并使用表格的布局。
1.8.2 具体实现
由于任务有点复杂,这里把每一步的工作写成一个函数。
现在,选择所有标题单元格,从中提取文本,将每个单元格转换为 关键词,然后将整个序列加载到向量中。获取数据集的头部:
应该注意的是,这里显示的代码是多次试验和错误的结果。截屏过程是这样的。通常我会下载并保存页面,这样我就不需要不断地向 Web 服务器发送请求。然后启动REPL并解析其中的网页。可以通过浏览器的“查看源代码”功能查看网页和HTML,还可以在REPL解释器中交互查看网页中的数据。由于它的方便,我可以在工作过程中不断地在REPL解释器和文本编辑器中复制和粘贴代码。这种工作流程和环境使屏幕捕获变得容易,这是一项艰巨的任务,即使一切正常也需要精细操作。 查看全部
java从网页抓取数据(本节书摘来自华章社区《Clojure数据分析秘笈》(图))
本节摘自华章社区《Clojure数据分析秘诀》一书第1章,1.8节从web表中抓取数据,作者(美国)Eric Rochester,更多章节可访问查看官方云栖社区“华章社区”账号
1.8 从网页表格中抓取数据
数据在互联网上无处不在。不幸的是,互联网上的许多数据并不容易获得。这些数据深埋在表格、文章 或深度嵌套的标签中。网页抓取是一项令人讨厌的物理任务,但它通常是提取此数据进行分析的唯一方法。此方法描述了如何加载网页并挖掘其内容以检索数据。
这可以使用 Enlive 库 () 来完成。该库使用基于 CSS 选择器的领域特定语言 (DSL) 来定位网页中的元素。这个库也可以用于模板。在本例中,仅使用它从网页中检索数据。
1.8.1 准备工作
首先需要在项目的依赖中添加Enlive:
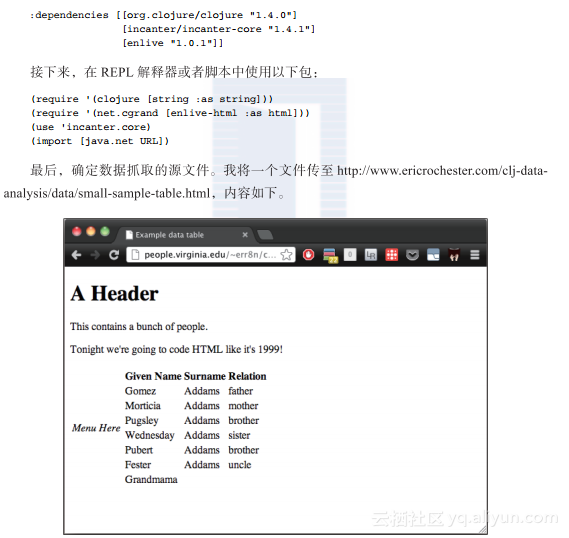
故意删除文件的其他内容并使用表格的布局。
1.8.2 具体实现
由于任务有点复杂,这里把每一步的工作写成一个函数。

现在,选择所有标题单元格,从中提取文本,将每个单元格转换为 关键词,然后将整个序列加载到向量中。获取数据集的头部:

应该注意的是,这里显示的代码是多次试验和错误的结果。截屏过程是这样的。通常我会下载并保存页面,这样我就不需要不断地向 Web 服务器发送请求。然后启动REPL并解析其中的网页。可以通过浏览器的“查看源代码”功能查看网页和HTML,还可以在REPL解释器中交互查看网页中的数据。由于它的方便,我可以在工作过程中不断地在REPL解释器和文本编辑器中复制和粘贴代码。这种工作流程和环境使屏幕捕获变得容易,这是一项艰巨的任务,即使一切正常也需要精细操作。
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-09 19:01
原文链接:
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到显示的结果网页:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml()的结果:\n"+result);}
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义的分析方法显示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们不会直接在网页的源代码中返回数据。相反,他们使用 JS 以异步方式返回数据,这可以防止搜索引擎和其他工具响应网站数据捕获。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript():\n"+contentBuf.toString()的结果);}
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
原文链接:
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到显示的结果网页:

第2步:查看网页源代码,我们在源代码中看到这一段:

从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:

也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml()的结果:\n"+result);}
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义的分析方法显示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们不会直接在网页的源代码中返回数据。相反,他们使用 JS 以异步方式返回数据,这可以防止搜索引擎和其他工具响应网站数据捕获。
先看这个页面:

我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:

为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:

这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:


从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript():\n"+contentBuf.toString()的结果);}
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载!
java从网页抓取数据(使用正则表达式和相应的类或使用哪一个取决于)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-07 07:33
使用正则表达式和相应的类或使用 HTML 解析器。您使用哪一个取决于您是希望能够处理整个网络还是仅处理几个您知道布局并可以测试的特定页面。
匹配 99% 页面的简单正则表达式可能如下所示:
// The HTML page as a String String HTMLPage; Pattern linkPattern = Pattern.compile("(]+>.+?)", Pattern.CASE_INSENSITIVE|Pattern.DOTALL); Matcher pageMatcher = linkPattern.matcher(HTMLPage); ArrayList links = new ArrayList(); while(pageMatcher.find()){ links.add(pageMatcher.group()); } // links ArrayList now contains all links in the page as a HTML tag // ie <a att1="val1" ...>Text inside tag</a>
您可以编辑它以匹配更多、更符合标准等,但在这种情况下,您需要一个真正的解析器。如果您只对 href="" 及其之间的文本感兴趣,也可以使用此正则表达式:
Pattern linkPattern = Pattern.compile("]+href=[\"']?([\"'>]+)[\"']?[^>]*>(.+?)", Pattern.CASE_INSENSITIVE|Pattern.DOTALL);
并使用 .group(1) 访问链接部分,并使用 .group(1) 访问文本部分 查看全部
java从网页抓取数据(使用正则表达式和相应的类或使用哪一个取决于)
使用正则表达式和相应的类或使用 HTML 解析器。您使用哪一个取决于您是希望能够处理整个网络还是仅处理几个您知道布局并可以测试的特定页面。
匹配 99% 页面的简单正则表达式可能如下所示:
// The HTML page as a String String HTMLPage; Pattern linkPattern = Pattern.compile("(]+>.+?)", Pattern.CASE_INSENSITIVE|Pattern.DOTALL); Matcher pageMatcher = linkPattern.matcher(HTMLPage); ArrayList links = new ArrayList(); while(pageMatcher.find()){ links.add(pageMatcher.group()); } // links ArrayList now contains all links in the page as a HTML tag // ie <a att1="val1" ...>Text inside tag</a>
您可以编辑它以匹配更多、更符合标准等,但在这种情况下,您需要一个真正的解析器。如果您只对 href="" 及其之间的文本感兴趣,也可以使用此正则表达式:
Pattern linkPattern = Pattern.compile("]+href=[\"']?([\"'>]+)[\"']?[^>]*>(.+?)", Pattern.CASE_INSENSITIVE|Pattern.DOTALL);
并使用 .group(1) 访问链接部分,并使用 .group(1) 访问文本部分
java从网页抓取数据(我通过在node中编写一个小的程序(称为extract.js)来抓取文 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-29 02:00
)
我通过在 node.js 中编写一个小程序(称为extract.js)来抓取文本来解决这个问题。我用这个页面来帮助我:
每个 html 页面收录多个书页。所以,如果我们只将url中的page参数加1,那么一不小心就会爬取重复的书页(这是我特别坚持的部分)。我通过使用 jquery 选择器只选择 url 中指定的单个页面并忽略 html 中的其他页面解决了这个问题。这样我就可以用电子表格程序快速构建一个文本文件,其中每个页面的URL都是按顺序排列的(因为增量只有1).
至此,我已经成功抢到了前两卷,还有五卷要抢!下面给出了代码,它可能是抓取其他 Google 图书的有用入门。
// Usage: node extract.js input output
// where input (mandatory) is the text file containing your list of urls
// and output (optional) is the directory where the output files will be saved
var fs = require('fs');
var request = require('request');
var cheerio = require('cheerio');
// Read the command line parameters
var input = process.argv[2];
var output = process.argv[3];
if (!input) {
console.log("Missing input parameter");
return;
}
// Read the url input file, each url is on a new line
var urls = fs.readFileSync(input).toString().split('\n');
// Check for non urls and remove
for (var i = 0; i < urls.length; i++) {
if (urls[i].slice(0, 4) != 'http') {
urls.splice(i, 1);
}
}
// Iterate through the urls
for (var i = 0; i < urls.length; i++) {
var url = urls[i];
// request function is asynchronous, hence requirement for self-executing function
// Cannot guarantee the execution order of the callback for each url, therefore save results to separate files
request(url, ( function(url) {
return function(err, resp, body) {
if (err)
throw err;
// Extract the pg parameter (book page) from the url
// We will use this to only extract the text from this book page
// because a retrieved html page contains multiple book pages
var pg = url.slice(url.indexOf('pg=') + 3, url.indexOf('&output=text'));
//
// Define the filename
//
var number = pg.slice(2, pg.length);
var zeroes = 4 - number.length;
// Insert leading zeroes
for (var j = 0; j < zeroes; j++) {
number = '0' + number;
}
var filename = pg.slice(0, 2) + number + '.txt';
// Add path to filename
if (output) {
if (!fs.existsSync(output))
fs.mkdirSync(output);
filename = output + '/' + filename;
}
// Delete the file if it already exists
if (fs.existsSync(filename))
fs.unlinkSync(filename);
// Make the DOM available to jquery
$ = cheerio.load(body);
// Select the book page
// Pages are contained within 'div' elements (where class='flow'),
// each of which contains an 'a' element where id is equal to the page
// Use ^ to match pages because sometimes page ids can have a trailing hyphen and extra characters
var page = $('div.flow:has(a[id=' + pg + ']), div.flow:has(a[id^=' + pg + '-])');
//
// Extract and save the text of the book page to the file
//
var hasText = false;
// Text is in 'gtxt_body', 'gtxt_column' and 'gtxt_footnote'
page.find('div.gtxt_body, div.gtxt_column, div.gtxt_footnote').each(function() {
this.find('p.gtxt_body, p.gtxt_column, p.gtxt_footnote').each(function() {
hasText = true;
fs.appendFileSync(filename, this.text());
fs.appendFileSync(filename, '\n\n');
});
});
// Log progress
if (hasText) {
console.log("Retrieved and saved page: " + pg);
}
else {
console.log("Skipping page: " + pg);
}
}
} )(url));
} 查看全部
java从网页抓取数据(我通过在node中编写一个小的程序(称为extract.js)来抓取文
)
我通过在 node.js 中编写一个小程序(称为extract.js)来抓取文本来解决这个问题。我用这个页面来帮助我:
每个 html 页面收录多个书页。所以,如果我们只将url中的page参数加1,那么一不小心就会爬取重复的书页(这是我特别坚持的部分)。我通过使用 jquery 选择器只选择 url 中指定的单个页面并忽略 html 中的其他页面解决了这个问题。这样我就可以用电子表格程序快速构建一个文本文件,其中每个页面的URL都是按顺序排列的(因为增量只有1).
至此,我已经成功抢到了前两卷,还有五卷要抢!下面给出了代码,它可能是抓取其他 Google 图书的有用入门。
// Usage: node extract.js input output
// where input (mandatory) is the text file containing your list of urls
// and output (optional) is the directory where the output files will be saved
var fs = require('fs');
var request = require('request');
var cheerio = require('cheerio');
// Read the command line parameters
var input = process.argv[2];
var output = process.argv[3];
if (!input) {
console.log("Missing input parameter");
return;
}
// Read the url input file, each url is on a new line
var urls = fs.readFileSync(input).toString().split('\n');
// Check for non urls and remove
for (var i = 0; i < urls.length; i++) {
if (urls[i].slice(0, 4) != 'http') {
urls.splice(i, 1);
}
}
// Iterate through the urls
for (var i = 0; i < urls.length; i++) {
var url = urls[i];
// request function is asynchronous, hence requirement for self-executing function
// Cannot guarantee the execution order of the callback for each url, therefore save results to separate files
request(url, ( function(url) {
return function(err, resp, body) {
if (err)
throw err;
// Extract the pg parameter (book page) from the url
// We will use this to only extract the text from this book page
// because a retrieved html page contains multiple book pages
var pg = url.slice(url.indexOf('pg=') + 3, url.indexOf('&output=text'));
//
// Define the filename
//
var number = pg.slice(2, pg.length);
var zeroes = 4 - number.length;
// Insert leading zeroes
for (var j = 0; j < zeroes; j++) {
number = '0' + number;
}
var filename = pg.slice(0, 2) + number + '.txt';
// Add path to filename
if (output) {
if (!fs.existsSync(output))
fs.mkdirSync(output);
filename = output + '/' + filename;
}
// Delete the file if it already exists
if (fs.existsSync(filename))
fs.unlinkSync(filename);
// Make the DOM available to jquery
$ = cheerio.load(body);
// Select the book page
// Pages are contained within 'div' elements (where class='flow'),
// each of which contains an 'a' element where id is equal to the page
// Use ^ to match pages because sometimes page ids can have a trailing hyphen and extra characters
var page = $('div.flow:has(a[id=' + pg + ']), div.flow:has(a[id^=' + pg + '-])');
//
// Extract and save the text of the book page to the file
//
var hasText = false;
// Text is in 'gtxt_body', 'gtxt_column' and 'gtxt_footnote'
page.find('div.gtxt_body, div.gtxt_column, div.gtxt_footnote').each(function() {
this.find('p.gtxt_body, p.gtxt_column, p.gtxt_footnote').each(function() {
hasText = true;
fs.appendFileSync(filename, this.text());
fs.appendFileSync(filename, '\n\n');
});
});
// Log progress
if (hasText) {
console.log("Retrieved and saved page: " + pg);
}
else {
console.log("Skipping page: " + pg);
}
}
} )(url));
}
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-28 10:02
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到显示的结果网页:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]查看明文
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml()的结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义的分析方法展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们不会直接在网页的源代码中返回数据。相反,他们使用 JS 以异步方式返回数据,这可以防止搜索引擎和其他工具响应网站数据捕获。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下JS请求的URL:
然后让程序请求这个页面的结果!
代码如下:
[java]查看明文
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript():\n"+contentBuf.toString()的结果);}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到显示的结果网页:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]查看明文
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml()的结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义的分析方法展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们不会直接在网页的源代码中返回数据。相反,他们使用 JS 以异步方式返回数据,这可以防止搜索引擎和其他工具响应网站数据捕获。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下JS请求的URL:
然后让程序请求这个页面的结果!
代码如下:
[java]查看明文
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript():\n"+contentBuf.toString()的结果);}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载!
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-27 00:20
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-27 00:16
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-24 18:02
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java从网页抓取数据(java从网页抓取数据的工作内容-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-19 05:04
java从网页抓取数据这是java最基础的工作内容之一,做成webserver跟服务器。这种最终都会传到nio的server端。java抓取的时候最麻烦的就是数据格式的处理,有些无法透过编程来规避。bitmap只能通过json对象来读写,分析其格式成为了考验一个抓取工程师读写能力的关键。感觉java的python是用得最多的,总体感觉程序的写法就是写点sql语句。如果这些也写过java后端,从网页抓取数据应该不在话下。
谢邀。先把后端基础学会。java基础要过,其他的再说。
基础一定要过,至少也要学了高性能和并发,其他的慢慢弄懂就好了,一步一步来。
多实践,
python也可以学
建议学python语言,java不一定能学会,因为工具的灵活性太强了,业务要怎么变,老的语言可能就不适用了,而python基本上所有的事情都能解决,做好习惯就好了,没有太多的东西。
python和java都是不错的选择,因为都有明确的语言层级,需要自己研究的东西会少一些。但他们都有一个共同的特点,那就是都在成长的过程中有不错的学习课程,可以从语言,或是相关的包(比如pandas的pyquery就能极大的提高数据清洗和存储的效率)去入手学习。
补充一下,java学习c++库这边几乎是一个坎,不少人拿java做后端,要么学struts2或spring之类需要底层数据库或者mysql的,要么学http.js一般都是在web.js中找方便的数据。学习c++的话,可以从c++effectivestl(很好的入门),map-patternsyntax,然后c++fori/o/effective,前端学起。但个人还是不推荐学。因为大部分新语言为了兼容也都变成cpp了。你懂的..。 查看全部
java从网页抓取数据(java从网页抓取数据的工作内容-乐题库)
java从网页抓取数据这是java最基础的工作内容之一,做成webserver跟服务器。这种最终都会传到nio的server端。java抓取的时候最麻烦的就是数据格式的处理,有些无法透过编程来规避。bitmap只能通过json对象来读写,分析其格式成为了考验一个抓取工程师读写能力的关键。感觉java的python是用得最多的,总体感觉程序的写法就是写点sql语句。如果这些也写过java后端,从网页抓取数据应该不在话下。
谢邀。先把后端基础学会。java基础要过,其他的再说。
基础一定要过,至少也要学了高性能和并发,其他的慢慢弄懂就好了,一步一步来。
多实践,
python也可以学
建议学python语言,java不一定能学会,因为工具的灵活性太强了,业务要怎么变,老的语言可能就不适用了,而python基本上所有的事情都能解决,做好习惯就好了,没有太多的东西。
python和java都是不错的选择,因为都有明确的语言层级,需要自己研究的东西会少一些。但他们都有一个共同的特点,那就是都在成长的过程中有不错的学习课程,可以从语言,或是相关的包(比如pandas的pyquery就能极大的提高数据清洗和存储的效率)去入手学习。
补充一下,java学习c++库这边几乎是一个坎,不少人拿java做后端,要么学struts2或spring之类需要底层数据库或者mysql的,要么学http.js一般都是在web.js中找方便的数据。学习c++的话,可以从c++effectivestl(很好的入门),map-patternsyntax,然后c++fori/o/effective,前端学起。但个人还是不推荐学。因为大部分新语言为了兼容也都变成cpp了。你懂的..。
java从网页抓取数据(有type,记录如下流程状态->入库(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-10 18:04
背景说明
由于目标页面是用vue结构写的,所以无法使用urlConnection获取连接然后使用Document/Jsoup解析。页面元素通过js动态渲染。后来尝试使用webMagic框架配合selenium\Chrome来抓取和组织基础数据。
过程
设计一个标记表结构,记录捕获的状态、数据等。配置selenium相关环境和工具,分析页面的dom元素。html进程的编码解析过程会在webmagic框架的处理器层和流水线层进行编码集成和调试。对获取的数据存储操作有效
台阶分析
1. 标注的表结构设计和示例表如下
CREATE TABLE `data` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL COMMENT 'dataname',
`type` tinyint(4) DEFAULT NULL COMMENT '类型',
`xx` int(11) DEFAULT '0' COMMENT '修订',
`xx` ...
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8 COMMENT='数据标记'
制作这张表的初衷是对抓取到的数据做一个基本的保留,提取过程中的核心数据作为后期的统计和验证处理。因为不相信爬取数据的结果【可能是网络中断,页面无法正常打开,页面打开后页面布局混乱,并发条件下浏览器窗口意外关闭,页面添加和更改修订元素等。获取目标数据]。所以有一个type字段,记录如下进程状态
爬取->打开->操作->分析->入库->爬取
其中
1.爬取 是指抓取根路径或者获取到页面上的目标url路径;
2.打开 是指通过Chrome driver打开url的过程;
3.操作 是指需要通过selenium模拟点击、跳转、输入等操作;
4.解析 是指到达目标页面后对html元素进行解析并获取有效内容
5.入库 将内容进行持久化操作
6.爬取 获取下一级链接,循环此操作
这里最不可控的一步是2、3、4。由于各种原因,可能会出现各种问题。所以需要记录当前数据的执行状态。当然,如果数据是可丢失的、可重复的、对你来说值得信赖的,你完全可以忽略部分数据,以量取胜。
2. Selenium 相关环境配置
首先引入jar,下载浏览器对应的驱动并配置
org.seleniumhq.selenium
selenium-java
3.9.1
org.seleniumhq.selenium
selenium-server
3.9.1
org.yaml
snakeyaml
上面是pom配置,下面是驱动变量设置,
static
{
System.getProperties().setProperty("webdriver.chrome.driver", "/Users/chenhailong/Downloads/tools/nessarytool/chromedriver");
}
运行以下代码时,可以正常打开浏览器,说明配置正常
WebDriver w = new ChromeDriver();
w.get("https://www.deathearth.com");
# 控制台会输出以下信息
Starting ChromeDriver 2.38.552518 (183d19265345f54ce39cbb94cf81ba5f15905011) on port 33558
Only local connections are allowed.
八月 23, 2019 5:02:46 下午 org.openqa.selenium.remote.ProtocolHandshake createSession
信息: Detected dialect: OSS
这种环境下最容易出现的问题是浏览器版本和驱动版本不一致,导致程序无法打开浏览器。或者是浏览器自动升级的影响。只需仔细配置即可。
3. 解析页面上的html元素
一种。这里最麻烦的就是页面修改问题,刚刚写了一套匹配规则来处理。但是目标网站经常改变布局,调整按钮功能的效果。因此,它基本上需要随着目标网站的变化而变化。没门。
湾 其次,还有分析效率的问题。我遇到过两种情况。一种是在抓取长文本(超过10w字节)文章的内容时,通过父元素的text()方法读取,内容被截断。导致信息不全。这是通过循环子标签处理的。如下
<p>
...
...
修改前: w.findElements(By.id("content")).getText()
修改后:List ls = w.findElements(By.xpath("div"))
for(int i = 0;i 查看全部
java从网页抓取数据(有type,记录如下流程状态->入库(组图))
背景说明
由于目标页面是用vue结构写的,所以无法使用urlConnection获取连接然后使用Document/Jsoup解析。页面元素通过js动态渲染。后来尝试使用webMagic框架配合selenium\Chrome来抓取和组织基础数据。
过程
设计一个标记表结构,记录捕获的状态、数据等。配置selenium相关环境和工具,分析页面的dom元素。html进程的编码解析过程会在webmagic框架的处理器层和流水线层进行编码集成和调试。对获取的数据存储操作有效
台阶分析
1. 标注的表结构设计和示例表如下
CREATE TABLE `data` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL COMMENT 'dataname',
`type` tinyint(4) DEFAULT NULL COMMENT '类型',
`xx` int(11) DEFAULT '0' COMMENT '修订',
`xx` ...
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8 COMMENT='数据标记'
制作这张表的初衷是对抓取到的数据做一个基本的保留,提取过程中的核心数据作为后期的统计和验证处理。因为不相信爬取数据的结果【可能是网络中断,页面无法正常打开,页面打开后页面布局混乱,并发条件下浏览器窗口意外关闭,页面添加和更改修订元素等。获取目标数据]。所以有一个type字段,记录如下进程状态
爬取->打开->操作->分析->入库->爬取
其中
1.爬取 是指抓取根路径或者获取到页面上的目标url路径;
2.打开 是指通过Chrome driver打开url的过程;
3.操作 是指需要通过selenium模拟点击、跳转、输入等操作;
4.解析 是指到达目标页面后对html元素进行解析并获取有效内容
5.入库 将内容进行持久化操作
6.爬取 获取下一级链接,循环此操作
这里最不可控的一步是2、3、4。由于各种原因,可能会出现各种问题。所以需要记录当前数据的执行状态。当然,如果数据是可丢失的、可重复的、对你来说值得信赖的,你完全可以忽略部分数据,以量取胜。
2. Selenium 相关环境配置
首先引入jar,下载浏览器对应的驱动并配置
org.seleniumhq.selenium
selenium-java
3.9.1
org.seleniumhq.selenium
selenium-server
3.9.1
org.yaml
snakeyaml
上面是pom配置,下面是驱动变量设置,
static
{
System.getProperties().setProperty("webdriver.chrome.driver", "/Users/chenhailong/Downloads/tools/nessarytool/chromedriver");
}
运行以下代码时,可以正常打开浏览器,说明配置正常
WebDriver w = new ChromeDriver();
w.get("https://www.deathearth.com";);
# 控制台会输出以下信息
Starting ChromeDriver 2.38.552518 (183d19265345f54ce39cbb94cf81ba5f15905011) on port 33558
Only local connections are allowed.
八月 23, 2019 5:02:46 下午 org.openqa.selenium.remote.ProtocolHandshake createSession
信息: Detected dialect: OSS
这种环境下最容易出现的问题是浏览器版本和驱动版本不一致,导致程序无法打开浏览器。或者是浏览器自动升级的影响。只需仔细配置即可。
3. 解析页面上的html元素
一种。这里最麻烦的就是页面修改问题,刚刚写了一套匹配规则来处理。但是目标网站经常改变布局,调整按钮功能的效果。因此,它基本上需要随着目标网站的变化而变化。没门。
湾 其次,还有分析效率的问题。我遇到过两种情况。一种是在抓取长文本(超过10w字节)文章的内容时,通过父元素的text()方法读取,内容被截断。导致信息不全。这是通过循环子标签处理的。如下
<p>
...
...
修改前: w.findElements(By.id("content")).getText()
修改后:List ls = w.findElements(By.xpath("div"))
for(int i = 0;i
java从网页抓取数据(web端获取数据获取多网页数据web链接常见格式(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-06 00:05
一、从网上获取数据
只需转到bi desktop的“获取数据”中的“网络”选项即可。“网络”界面有两个选项卡,“基本”和“高级”。通常情况下,“基本”选项卡可以满足日常工作的需要。下面以此为例。
二、获取数据
进入网页链接后,会执行导航器的“加载”、“编辑”等常用功能,您只需根据实际工作需要进行操作即可。
三、获取多个网页数据
网页链接的常用格式如下:最后一个“1”表示当前链接为第一页数据,第二页数据链接应为“”。当网页数据较大时,如果每次都通过网页链接获取数据,会消耗大量时间。但是在组件查询中有相应的函数来简化操作,如下:
获取到某页数据后,进入“编辑查询”界面,在“编辑查询”界面中选择“高级编辑器”选项卡,高级编辑器界面为当年的工作路径。类似于下图:
这时候需要在“let”前面输入“(p as number) as table=>”;并在链接中修改网页的页码,即上面提到的“1,2”和其他数字“(Number.ToText(p ))”。
备注:网页链接有两种,一种是页码数据在链接的末尾,按照上面的操作即可;另一个是链接以 .html 结尾。除了上面的替换操作,这个类型是 _"&(Number.ToText (p))&".html")) 只需点击这里单独定义html。
四、 抓取多个数据网页
首先,使用空查询创建一个数字序列。如果要抓取前100页的数据,创建一个从1到100的序列。在空查询中输入={1..100},生成一个从1开始的序列,然后将序列转换为100到一张桌子。
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的都是默认的。
点击确定开始批量抓取网页,抓取成功。可根据工作需要进行后续操作。 查看全部
java从网页抓取数据(web端获取数据获取多网页数据web链接常见格式(图))
一、从网上获取数据
只需转到bi desktop的“获取数据”中的“网络”选项即可。“网络”界面有两个选项卡,“基本”和“高级”。通常情况下,“基本”选项卡可以满足日常工作的需要。下面以此为例。
二、获取数据
进入网页链接后,会执行导航器的“加载”、“编辑”等常用功能,您只需根据实际工作需要进行操作即可。
三、获取多个网页数据
网页链接的常用格式如下:最后一个“1”表示当前链接为第一页数据,第二页数据链接应为“”。当网页数据较大时,如果每次都通过网页链接获取数据,会消耗大量时间。但是在组件查询中有相应的函数来简化操作,如下:
获取到某页数据后,进入“编辑查询”界面,在“编辑查询”界面中选择“高级编辑器”选项卡,高级编辑器界面为当年的工作路径。类似于下图:
这时候需要在“let”前面输入“(p as number) as table=>”;并在链接中修改网页的页码,即上面提到的“1,2”和其他数字“(Number.ToText(p ))”。
备注:网页链接有两种,一种是页码数据在链接的末尾,按照上面的操作即可;另一个是链接以 .html 结尾。除了上面的替换操作,这个类型是 _"&(Number.ToText (p))&".html")) 只需点击这里单独定义html。
四、 抓取多个数据网页
首先,使用空查询创建一个数字序列。如果要抓取前100页的数据,创建一个从1到100的序列。在空查询中输入={1..100},生成一个从1开始的序列,然后将序列转换为100到一张桌子。
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的都是默认的。
点击确定开始批量抓取网页,抓取成功。可根据工作需要进行后续操作。
java从网页抓取数据(从一个获取Document对象的其他姊妹章:模拟浏览器:get方式简单获取网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-04 09:08
从 URL 获取 Document 对象的其他姐妹章节:
模拟浏览器:简单的通过get方法获取网页数据(一)
模拟浏览器:post方法模拟登录获取网页数据(二)
模拟浏览器:Jsoup工具的使用及失败重试的重试策略(三)
本文文章使用Jsoup模拟登录GitHub。仅作交流学习之用,如以代码网站对其进行恶意攻击,与作者无关^ ^!
在你开始之前:
Stept 1):安装 Firefox/Google Chrome 浏览器。功能是利用Firebug插件分析提交协议。虽然IE从7开始就有类似的功能,但毫无疑问还是不如Firefox和Chrome好用。
stept 2):构建一个Jsoup项目,只是一个普通的java项目,并导入Jsoup Jar包。如果你还不知道Jsoup是什么,请参考文章:《Jsoup是什么?》如果是Maven项目,可以直接在pom.xml中导入Jsoup,也可以参考另一篇文章:《模拟浏览器:通过get简单获取网页数据(一)"
Stept 3):分析提交表单,以便我们确定“重要”的两个重要事项:
以下是github的登录界面和形式:
这里注意图中的几个重要信息:form标签中的action属性表示表单数据最终会提交到哪里(可以在下面代码中第二次提交的代码块中看到地址) action=" /session" 另外,需要注意表单中所有提交的输入标签。这里更重要的是带有隐藏属性的输入。这个隐藏的输入是一种反爬虫机制,类似于网络序列号。当你提交一个带有这个序列号的表达式时,就可以证明用户确实进入了webflow流程。如果有错误或者没有这个序列号,那么网站会认为用户非法进入了webflow进程(认为是机器人/爬虫),
stept4):使用Firebug抓取post提交的数据包,确认最终仿真提交的“重要”参数:
下面是Firebug的抓包界面(火狐浏览器安装Firebug插件后按F12调出,点击Net,在登录界面填写用户名和密码,点击登录按钮,找到Firebug 中的第一个提交方法。方法是 POST 请求):
还要注意Firebug捕获界面中的几个重要信息:1)。注意url,可以确定url对应表单的action值,也就是最终的表达式提交地址。2)。注意Post值,可以确认list值等于表单中输入的值。3)。其他信息:点击图中的Headers可以看到其他相关信息,如header值、cookies相关、引用等,有时模拟登录时这些值需要一起提交
代码:
注:本文会定期更新代码并同步到GitHub(文章底部地址),如果有代码问题可以评论或者加群。
一旦确定了post提交参数和最终的URL地址,就可以使用Jsoup来模拟登录了,代码如下:
/**
* GITHUBLoginApater.java
*
* Function:Jsoup model apater class.
*
* ver date author
* ──────────────────────────────────
* 1.0 2017/06/22 bluetata
*
* Copyright (c) 2017, [https://github.com/] All Rights Reserved.
*/
package com.datacrawler.service.model.github.com;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.Connection.Method;
import org.jsoup.Connection.Response;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
/**
* @since crawler(datasnatch) version(1.0)</br>
* @author bluetata / sekito.lv@gmail.com</br>
* @reference http://bluetata.blog.csdn.net/</br>
* @version 1.0</br>
* @update 03/14/2019 16:00
*/
public class GITHUBLoginApater {
public static String LOGIN_URL = "https://github.com/login";
public static String USER_AGENT = "User-Agent";
public static String USER_AGENT_VALUE = "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0";
public static void main(String[] args) throws Exception {
simulateLogin("bluetata", "password123"); // 模拟登陆github的用户名和密码
}
/**
* @param userName 用户名
* @param pwd 密码
* @throws Exception
*/
public static void simulateLogin(String userName, String pwd) throws Exception {
/*
* 第一次请求
* grab login form page first
* 获取登陆提交的表单信息,及修改其提交data数据(login,password)
*/
// get the response, which we will post to the action URL(rs.cookies())
Connection con = Jsoup.connect(LOGIN_URL); // 获取connection
con.header(USER_AGENT, USER_AGENT_VALUE); // 配置模拟浏览器
Response rs = con.execute(); // 获取响应
Document d1 = Jsoup.parse(rs.body()); // 转换为Dom树
System.out.println(d1);
List eleList = d1.select("form"); // 获取提交form表单,可以通过查看页面源码代码得知
// 获取cooking和表单属性
// lets make data map containing all the parameters and its values found in the form
Map datas = new HashMap();
// 01/24/2019 17:45 bluetata 更新 -------------------------------------------------------------- Start ----------
// GitHub多次改版更新,最新的提交request data为:
// authenticity_token ll0RJnG1f9XDAaN1DxnyTDzCs+YXweEZWel9kGkq8TvXH83HjCwPG048sJ/VVjDA94YmbF0qvUgcJx8/IKlP8Q==
// commit Sign+in
// login bluetata
// password password123
// utf8 ✓
for(int i = 0; i < eleList.size(); i++) {
for (Element e : eleList.get(i).getAllElements()) {
// 设置用户名
if (e.attr("name").equals("login")) {
e.attr("value", userName);
}
// 设置用户密码
if (e.attr("name").equals("password")) {
e.attr("value", pwd);
}
// 排除空值表单属性
if (e.attr("name").length() > 0) {
datas.put(e.attr("name"), e.attr("value"));
}
}
}
// 旧逻辑 delete 01/24/2019 17:49 bluetata --------------------------------------------start
// for (Element e : eleList.get(0).getAllElements()) {
// // 设置用户名
// if (e.attr("name").equals("login")) {
// e.attr("value", userName);
// }
// // 设置用户密码
// if (e.attr("name").equals("password")) {
// e.attr("value", pwd);
// }
// // 排除空值表单属性
// if (e.attr("name").length() > 0) {
// datas.put(e.attr("name"), e.attr("value"));
// }
// }
// 旧逻辑 delete 01/24/2019 17:49 bluetata --------------------------------------------end
// 01/24/2019 17:45 bluetata 更新 --------------------------------------------------------------- End -----------
/*
* 第二次请求,以post方式提交表单数据以及cookie信息
*/
Connection con2 = Jsoup.connect("https://github.com/session");
con2.header(USER_AGENT, USER_AGENT_VALUE);
// 设置cookie和post上面的map数据
Response login = con2.ignoreContentType(true).followRedirects(true).method(Method.POST).data(datas).cookies(rs.cookies()).execute();
// 打印,登陆成功后的信息
System.out.println(login.body());
// 登陆成功后的cookie信息,可以保存到本地,以后登陆时,只需一次登陆即可
Map map = login.cookies();
for (String s : map.keySet()) {
System.out.println(s + " : " + map.get(s));
}
}
}
最后,操作返回的html是github登录成功后的个人仓库相关更新信息,可以用来判断是否登录成功,不成功则停留在登录界面。
成功后打印的cookies信息:
user_session : xkXvNQyNzKFTrBMtbXdieZ29FtimemTz1943fAmo7w4xOSK
__Host-user_session_same_site : xkXvNQyNzKFTrBluetataXWvhdLmkYmTzblueqfAmo7w4xOSK
_gh_sess : eyJsYXN0X3dyaXRlIjoxNDk4MTEyODQ5NDQ1LCJmbGdie=I6eyJtimeNjYXJkIj1943Wx5dGljc19kpb24iLCJhbmFseXRpY3NfbG9jYXRpb24iXSwiZmxhc2hlcyI6eyJhbmFseXRpY3NfZGltZW5zaW9uIjp7Im5hbWUidietime1943lbnNpb241IiwidmFsdWUiOiJMb2dnZWQgSW4ifSwiYW5hbHl0aWNzX2xvY2F0aW9uIjoiL2Rhc2hib2FyZCJ9fSwic2Vzc2lvbl9pZCI6IjFkNGQ1MWE3NmM4MzU5MTUzbluetataxZGzgzIiwiY29udGV4dCI6Ii8ifQ%3D%3D--af5c70cdfbluec01be903dtata083ce2e53eb
logged_in : yes
dotcom_user : bluetata
● Jsoup学习讨论QQ群:50695115
● 博客中Jsoup爬虫代码示例及源码下载:
● 更多Jsoup相关文章请参考专栏:【Jsoup在行动】 查看全部
java从网页抓取数据(从一个获取Document对象的其他姊妹章:模拟浏览器:get方式简单获取网页数据)
从 URL 获取 Document 对象的其他姐妹章节:
模拟浏览器:简单的通过get方法获取网页数据(一)
模拟浏览器:post方法模拟登录获取网页数据(二)
模拟浏览器:Jsoup工具的使用及失败重试的重试策略(三)
本文文章使用Jsoup模拟登录GitHub。仅作交流学习之用,如以代码网站对其进行恶意攻击,与作者无关^ ^!
在你开始之前:
Stept 1):安装 Firefox/Google Chrome 浏览器。功能是利用Firebug插件分析提交协议。虽然IE从7开始就有类似的功能,但毫无疑问还是不如Firefox和Chrome好用。
stept 2):构建一个Jsoup项目,只是一个普通的java项目,并导入Jsoup Jar包。如果你还不知道Jsoup是什么,请参考文章:《Jsoup是什么?》如果是Maven项目,可以直接在pom.xml中导入Jsoup,也可以参考另一篇文章:《模拟浏览器:通过get简单获取网页数据(一)"
Stept 3):分析提交表单,以便我们确定“重要”的两个重要事项:
以下是github的登录界面和形式:
这里注意图中的几个重要信息:form标签中的action属性表示表单数据最终会提交到哪里(可以在下面代码中第二次提交的代码块中看到地址) action=" /session" 另外,需要注意表单中所有提交的输入标签。这里更重要的是带有隐藏属性的输入。这个隐藏的输入是一种反爬虫机制,类似于网络序列号。当你提交一个带有这个序列号的表达式时,就可以证明用户确实进入了webflow流程。如果有错误或者没有这个序列号,那么网站会认为用户非法进入了webflow进程(认为是机器人/爬虫),
stept4):使用Firebug抓取post提交的数据包,确认最终仿真提交的“重要”参数:
下面是Firebug的抓包界面(火狐浏览器安装Firebug插件后按F12调出,点击Net,在登录界面填写用户名和密码,点击登录按钮,找到Firebug 中的第一个提交方法。方法是 POST 请求):
还要注意Firebug捕获界面中的几个重要信息:1)。注意url,可以确定url对应表单的action值,也就是最终的表达式提交地址。2)。注意Post值,可以确认list值等于表单中输入的值。3)。其他信息:点击图中的Headers可以看到其他相关信息,如header值、cookies相关、引用等,有时模拟登录时这些值需要一起提交
代码:
注:本文会定期更新代码并同步到GitHub(文章底部地址),如果有代码问题可以评论或者加群。
一旦确定了post提交参数和最终的URL地址,就可以使用Jsoup来模拟登录了,代码如下:
/**
* GITHUBLoginApater.java
*
* Function:Jsoup model apater class.
*
* ver date author
* ──────────────────────────────────
* 1.0 2017/06/22 bluetata
*
* Copyright (c) 2017, [https://github.com/] All Rights Reserved.
*/
package com.datacrawler.service.model.github.com;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.Connection.Method;
import org.jsoup.Connection.Response;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
/**
* @since crawler(datasnatch) version(1.0)</br>
* @author bluetata / sekito.lv@gmail.com</br>
* @reference http://bluetata.blog.csdn.net/</br>
* @version 1.0</br>
* @update 03/14/2019 16:00
*/
public class GITHUBLoginApater {
public static String LOGIN_URL = "https://github.com/login";
public static String USER_AGENT = "User-Agent";
public static String USER_AGENT_VALUE = "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0";
public static void main(String[] args) throws Exception {
simulateLogin("bluetata", "password123"); // 模拟登陆github的用户名和密码
}
/**
* @param userName 用户名
* @param pwd 密码
* @throws Exception
*/
public static void simulateLogin(String userName, String pwd) throws Exception {
/*
* 第一次请求
* grab login form page first
* 获取登陆提交的表单信息,及修改其提交data数据(login,password)
*/
// get the response, which we will post to the action URL(rs.cookies())
Connection con = Jsoup.connect(LOGIN_URL); // 获取connection
con.header(USER_AGENT, USER_AGENT_VALUE); // 配置模拟浏览器
Response rs = con.execute(); // 获取响应
Document d1 = Jsoup.parse(rs.body()); // 转换为Dom树
System.out.println(d1);
List eleList = d1.select("form"); // 获取提交form表单,可以通过查看页面源码代码得知
// 获取cooking和表单属性
// lets make data map containing all the parameters and its values found in the form
Map datas = new HashMap();
// 01/24/2019 17:45 bluetata 更新 -------------------------------------------------------------- Start ----------
// GitHub多次改版更新,最新的提交request data为:
// authenticity_token ll0RJnG1f9XDAaN1DxnyTDzCs+YXweEZWel9kGkq8TvXH83HjCwPG048sJ/VVjDA94YmbF0qvUgcJx8/IKlP8Q==
// commit Sign+in
// login bluetata
// password password123
// utf8 ✓
for(int i = 0; i < eleList.size(); i++) {
for (Element e : eleList.get(i).getAllElements()) {
// 设置用户名
if (e.attr("name").equals("login")) {
e.attr("value", userName);
}
// 设置用户密码
if (e.attr("name").equals("password")) {
e.attr("value", pwd);
}
// 排除空值表单属性
if (e.attr("name").length() > 0) {
datas.put(e.attr("name"), e.attr("value"));
}
}
}
// 旧逻辑 delete 01/24/2019 17:49 bluetata --------------------------------------------start
// for (Element e : eleList.get(0).getAllElements()) {
// // 设置用户名
// if (e.attr("name").equals("login")) {
// e.attr("value", userName);
// }
// // 设置用户密码
// if (e.attr("name").equals("password")) {
// e.attr("value", pwd);
// }
// // 排除空值表单属性
// if (e.attr("name").length() > 0) {
// datas.put(e.attr("name"), e.attr("value"));
// }
// }
// 旧逻辑 delete 01/24/2019 17:49 bluetata --------------------------------------------end
// 01/24/2019 17:45 bluetata 更新 --------------------------------------------------------------- End -----------
/*
* 第二次请求,以post方式提交表单数据以及cookie信息
*/
Connection con2 = Jsoup.connect("https://github.com/session";);
con2.header(USER_AGENT, USER_AGENT_VALUE);
// 设置cookie和post上面的map数据
Response login = con2.ignoreContentType(true).followRedirects(true).method(Method.POST).data(datas).cookies(rs.cookies()).execute();
// 打印,登陆成功后的信息
System.out.println(login.body());
// 登陆成功后的cookie信息,可以保存到本地,以后登陆时,只需一次登陆即可
Map map = login.cookies();
for (String s : map.keySet()) {
System.out.println(s + " : " + map.get(s));
}
}
}
最后,操作返回的html是github登录成功后的个人仓库相关更新信息,可以用来判断是否登录成功,不成功则停留在登录界面。
成功后打印的cookies信息:
user_session : xkXvNQyNzKFTrBMtbXdieZ29FtimemTz1943fAmo7w4xOSK
__Host-user_session_same_site : xkXvNQyNzKFTrBluetataXWvhdLmkYmTzblueqfAmo7w4xOSK
_gh_sess : eyJsYXN0X3dyaXRlIjoxNDk4MTEyODQ5NDQ1LCJmbGdie=I6eyJtimeNjYXJkIj1943Wx5dGljc19kpb24iLCJhbmFseXRpY3NfbG9jYXRpb24iXSwiZmxhc2hlcyI6eyJhbmFseXRpY3NfZGltZW5zaW9uIjp7Im5hbWUidietime1943lbnNpb241IiwidmFsdWUiOiJMb2dnZWQgSW4ifSwiYW5hbHl0aWNzX2xvY2F0aW9uIjoiL2Rhc2hib2FyZCJ9fSwic2Vzc2lvbl9pZCI6IjFkNGQ1MWE3NmM4MzU5MTUzbluetataxZGzgzIiwiY29udGV4dCI6Ii8ifQ%3D%3D--af5c70cdfbluec01be903dtata083ce2e53eb
logged_in : yes
dotcom_user : bluetata
● Jsoup学习讨论QQ群:50695115
● 博客中Jsoup爬虫代码示例及源码下载:
● 更多Jsoup相关文章请参考专栏:【Jsoup在行动】
java从网页抓取数据(创建一个类的html文件创建表单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-04 09:05
使用 Servlet,您可以从 Web 表单采集用户输入、呈现来自数据库或其他来源的记录以及动态创建网页。
首先使用eclipse创建一个网站,使用其他开发工具也是一样,创建网站需要配置Tomcat服务器,以便网站导入servlet包并可以发布,如图所示
新建网络项目
配置Tomcat
创建后,在web项目的Webcontent中编辑需要添加的网页内容
这里我创建了一个 index html 文件
Insert title here
创建一个表单,表单中的action表示使用哪个servlet来处理提交的信息,
method表示数据的传输方式,分为两种,一种是get,一种是post
接下来开始创建Servlet,在java代码中构建包,并创建一个类,这个类需要继承HttpServlet
从网页读取数据
在HttpServlet中有两个方法,doget 和dopost,这两个方法就是用来接收网页端数据和向网页端输出数据的
在这里我们使用dopost的方法,在dopost中有个参数HttpServletRequest request我们可以通过这个参数获取网页的传输内容
HttpServletRequest 参数中有getParameter这个方法能够获取网页的表单对象
String name = request.getParameter("name");
这是用一个字符串以name属性为name的形式接收字符串数据
表单中的输入可以定义服务订单要获取的名称,同样可以获取pwd中的数据。
输出数据到网页
输出数据是一个依赖 PrintWriter 的对象。这个对象有写和打印的方法,可以将数据输出到网页。具体用途:
PrintWriter out = response.getWriter();
out.println("string");
也可以把字符串的位置改成html代码,直接打印出一个网页
服务器的具体代码如下:
response.setContentType("text/html;charset=utf-8");
如果要输出网页,请加上这句话text/html,否则输出的是代码而不是网页
如果要从网页中获取汉字,需要设置utf-8格式,否则会出现乱码
package com.yd;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class Yd extends HttpServlet {
private static final long serialVersionUID = 1L;
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
}
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html;charset=utf-8");
response.setCharacterEncoding("UTF-8");
request.setCharacterEncoding("UTF-8");
/** 设置响应头允许ajax跨域访问 **/
response.setHeader("Access-Control-Allow-Origin", "*");
/* 星号表示所有的异域请求都可以接受, */
response.setHeader("Access-Control-Allow-Methods", "GET,POST");
/**
* 接收json
*/
String name = request.getParameter("name");
String pwd = request.getParameter("pwd");
System.out.println(name);
System.out.println(pwd);
/**
* 返回json
*/
PrintWriter out = response.getWriter();
String title = "成果";
String docType = " \n";
out.println(
docType + "\n" + "" + title + "\n" + "\n"
+ "" + title + "\n" + "登陆成功\r\n" + "\r\n" + "");
out.close();
}
}
3、配置Web.Xml文件,
servlet 构建完成后,需要在 web.xml 中进行配置,这样 servlet 才能在网页和服务票证中找到
web.xml 文件也在 WebContent/Web-INF 中。如果没有,您需要手动创建一个。
web.xml 代码如下
My
index.html
index.htm
index.jsp
MyServlet
com.yd.MyServlet
MyServlet
/MyServlet
中的是与
中的对应的随便取什么名字都行,但是两个name需要一样
com.yd.MyServlet
这表示的是你要使用的Servlet所在的路径,需要写包名,
/MyServlet
其中的/MyServlet表示的是在网页中访问servlet时用到的URL地址,一定要加/ 名字随意
index.html
表示的是当只有前面部分的URL时访问的页面
例如你需要访问http://localhost/My/index.html时如果你在地址栏直接输入http://localhost/My则会直接访问你再这一项中设计的欢迎页面
至此,配置完成,只需要运行发布到Tomcat即可访问
从地址栏可以看到URL已经进入了Servlet,下面也可以读取输入框中的数据
需要提醒的是,html文件一定要放在WebContent下,而不是WebContent中的Web-INF下,否则会一直出错,一门血课。 . 使用jsp的原理类似,jsp本质上就是一个servlet
所以如果用jsp来设计,就不需要在xml文件中配置。你只需要在html中把表单中的action写成你自己的jsp文件,然后jsp和servlet就一样了。
代码如下:
Insert title here
jsp中的代码,
Insert title here
登陆成功
最后你会看到同样的效果,只不过地址栏中的servlet是用jsp文件编写的
html文件和jsp文件都需要写在WebContent下,而不是WebContent中的Web-INF下 查看全部
java从网页抓取数据(创建一个类的html文件创建表单)
使用 Servlet,您可以从 Web 表单采集用户输入、呈现来自数据库或其他来源的记录以及动态创建网页。
首先使用eclipse创建一个网站,使用其他开发工具也是一样,创建网站需要配置Tomcat服务器,以便网站导入servlet包并可以发布,如图所示
新建网络项目
配置Tomcat
创建后,在web项目的Webcontent中编辑需要添加的网页内容
这里我创建了一个 index html 文件
Insert title here
创建一个表单,表单中的action表示使用哪个servlet来处理提交的信息,
method表示数据的传输方式,分为两种,一种是get,一种是post
接下来开始创建Servlet,在java代码中构建包,并创建一个类,这个类需要继承HttpServlet
从网页读取数据
在HttpServlet中有两个方法,doget 和dopost,这两个方法就是用来接收网页端数据和向网页端输出数据的
在这里我们使用dopost的方法,在dopost中有个参数HttpServletRequest request我们可以通过这个参数获取网页的传输内容
HttpServletRequest 参数中有getParameter这个方法能够获取网页的表单对象
String name = request.getParameter("name");
这是用一个字符串以name属性为name的形式接收字符串数据
表单中的输入可以定义服务订单要获取的名称,同样可以获取pwd中的数据。
输出数据到网页
输出数据是一个依赖 PrintWriter 的对象。这个对象有写和打印的方法,可以将数据输出到网页。具体用途:
PrintWriter out = response.getWriter();
out.println("string");
也可以把字符串的位置改成html代码,直接打印出一个网页
服务器的具体代码如下:
response.setContentType("text/html;charset=utf-8");
如果要输出网页,请加上这句话text/html,否则输出的是代码而不是网页
如果要从网页中获取汉字,需要设置utf-8格式,否则会出现乱码
package com.yd;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class Yd extends HttpServlet {
private static final long serialVersionUID = 1L;
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
}
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html;charset=utf-8");
response.setCharacterEncoding("UTF-8");
request.setCharacterEncoding("UTF-8");
/** 设置响应头允许ajax跨域访问 **/
response.setHeader("Access-Control-Allow-Origin", "*");
/* 星号表示所有的异域请求都可以接受, */
response.setHeader("Access-Control-Allow-Methods", "GET,POST");
/**
* 接收json
*/
String name = request.getParameter("name");
String pwd = request.getParameter("pwd");
System.out.println(name);
System.out.println(pwd);
/**
* 返回json
*/
PrintWriter out = response.getWriter();
String title = "成果";
String docType = " \n";
out.println(
docType + "\n" + "" + title + "\n" + "\n"
+ "" + title + "\n" + "登陆成功\r\n" + "\r\n" + "");
out.close();
}
}
3、配置Web.Xml文件,
servlet 构建完成后,需要在 web.xml 中进行配置,这样 servlet 才能在网页和服务票证中找到
web.xml 文件也在 WebContent/Web-INF 中。如果没有,您需要手动创建一个。
web.xml 代码如下
My
index.html
index.htm
index.jsp
MyServlet
com.yd.MyServlet
MyServlet
/MyServlet
中的是与
中的对应的随便取什么名字都行,但是两个name需要一样
com.yd.MyServlet
这表示的是你要使用的Servlet所在的路径,需要写包名,
/MyServlet
其中的/MyServlet表示的是在网页中访问servlet时用到的URL地址,一定要加/ 名字随意
index.html
表示的是当只有前面部分的URL时访问的页面
例如你需要访问http://localhost/My/index.html时如果你在地址栏直接输入http://localhost/My则会直接访问你再这一项中设计的欢迎页面
至此,配置完成,只需要运行发布到Tomcat即可访问
从地址栏可以看到URL已经进入了Servlet,下面也可以读取输入框中的数据
需要提醒的是,html文件一定要放在WebContent下,而不是WebContent中的Web-INF下,否则会一直出错,一门血课。 . 使用jsp的原理类似,jsp本质上就是一个servlet
所以如果用jsp来设计,就不需要在xml文件中配置。你只需要在html中把表单中的action写成你自己的jsp文件,然后jsp和servlet就一样了。
代码如下:
Insert title here
jsp中的代码,
Insert title here
登陆成功
最后你会看到同样的效果,只不过地址栏中的servlet是用jsp文件编写的
html文件和jsp文件都需要写在WebContent下,而不是WebContent中的Web-INF下
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-01 02:16
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页的源码,我们在源码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页的源码,我们在源码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-30 20:18
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页的源码,我们在源码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页的源码,我们在源码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java从网页抓取数据(《java面试笔试全程实录》之单条数据抓取数据分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-27 22:01
java从网页抓取数据,首先需要针对数据来源做分析,然后筛选和切割,最后进行数据的读写和输出。为了体现这种读写的不同性,我给两种类型:分页数据抓取和单条数据抓取(关于这两种类型,是参考《java面试笔试全程实录》一书完整总结)。对于单条数据抓取来说,可以通过javaapi来进行数据读写,这里不做详细介绍,并在下文给出实际例子。
单条数据抓取首先我们对单条数据抓取数据进行分析,将抓取后的数据划分为txt文件,按照key字段进行排序,比如a,b这两个数据文件,其中a文件排在前面。读取数据过程一般如下://导入java读取jar包java.io.filereaderfilereader=newfilereader();//导入sqlite数据库java.io.sqlitefactorysqlitefactory=newsqlitefactory();reader.readfile(buf,sqlitefactory.get("d:\\com.alibaba.ops.ozdata\\table_row_pool_mya_doc_common.sqlite"));if(isempty(reader.isreference())){returnnull;}//读取sqlite数据表sqlitetest_table1_db数据表orderedatis=neworderedatis(buf,sqlitefactory.get("d:\\com.alibaba.ops.ozdata\\table_row_pool_mya_doc_common.sqlite"));//设置时间戳、ttl和时长,并更新数据库中的表datetimedatetime=sqlitefactory.read(orderedatis);stringttl=sqlitefactory.get("d:\\com.alibaba.ops.ozdata\\table_row_pool_mya_doc_common.sqlite");//验证指针stringttl=datetime.now();//正则引擎抓取要求的参数objectresultstring=reader.readstring(content,stringroot);system.out.println(resultstring);//读取数据列表regexregrregexregr=newregexregr();regexregr.setparametervalue(resultstring,"/\d+/");//跳转到sqlite数据库,info文件所指向的路径中打开数据文件stringfilepath="/tmp/"+fileload(regexregr.getruntime());if(filepath!=null){system.out.println(filepath);}//读取数据库user表字段,并删除数据库中数据库表中的字段objectdb=filepath+"/test/"+fileload(filepath);db.drop(regexregr.getparametervalue(db,"/csv"));//清除表的索引//执行代码system.out.println(filepath+"\\d"+"\\s//"+system.currenttimemillis()+"\\。 查看全部
java从网页抓取数据(《java面试笔试全程实录》之单条数据抓取数据分析)
java从网页抓取数据,首先需要针对数据来源做分析,然后筛选和切割,最后进行数据的读写和输出。为了体现这种读写的不同性,我给两种类型:分页数据抓取和单条数据抓取(关于这两种类型,是参考《java面试笔试全程实录》一书完整总结)。对于单条数据抓取来说,可以通过javaapi来进行数据读写,这里不做详细介绍,并在下文给出实际例子。
单条数据抓取首先我们对单条数据抓取数据进行分析,将抓取后的数据划分为txt文件,按照key字段进行排序,比如a,b这两个数据文件,其中a文件排在前面。读取数据过程一般如下://导入java读取jar包java.io.filereaderfilereader=newfilereader();//导入sqlite数据库java.io.sqlitefactorysqlitefactory=newsqlitefactory();reader.readfile(buf,sqlitefactory.get("d:\\com.alibaba.ops.ozdata\\table_row_pool_mya_doc_common.sqlite"));if(isempty(reader.isreference())){returnnull;}//读取sqlite数据表sqlitetest_table1_db数据表orderedatis=neworderedatis(buf,sqlitefactory.get("d:\\com.alibaba.ops.ozdata\\table_row_pool_mya_doc_common.sqlite"));//设置时间戳、ttl和时长,并更新数据库中的表datetimedatetime=sqlitefactory.read(orderedatis);stringttl=sqlitefactory.get("d:\\com.alibaba.ops.ozdata\\table_row_pool_mya_doc_common.sqlite");//验证指针stringttl=datetime.now();//正则引擎抓取要求的参数objectresultstring=reader.readstring(content,stringroot);system.out.println(resultstring);//读取数据列表regexregrregexregr=newregexregr();regexregr.setparametervalue(resultstring,"/\d+/");//跳转到sqlite数据库,info文件所指向的路径中打开数据文件stringfilepath="/tmp/"+fileload(regexregr.getruntime());if(filepath!=null){system.out.println(filepath);}//读取数据库user表字段,并删除数据库中数据库表中的字段objectdb=filepath+"/test/"+fileload(filepath);db.drop(regexregr.getparametervalue(db,"/csv"));//清除表的索引//执行代码system.out.println(filepath+"\\d"+"\\s//"+system.currenttimemillis()+"\\。
java从网页抓取数据(java从网页抓取数据,需要使用java的spiderapi,可以抓取一个网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-23 15:03
java从网页抓取数据,需要使用java的spiderapi,其中很重要的一个类contentbrowser可以抓取一个网页,也就是chrome浏览器,并且能够上传到后台数据库,简单来说,用java抓取一个网页时,并不是直接往java服务器发送get请求,而是contentbrowser向浏览器发送get请求,然后返回内容,在下面的代码中通过服务器传输的错误码去匹配数据库是否匹配上,然后返回正确的结果就可以抓取数据了,如果后端服务器数据库没有匹配上的话,则提示“pageerror”(网页未响应)来告诉浏览器,java服务器未能收到正确的请求数据,从而将网页转发给后端服务器,这个时候spider已经将抓取的页面转发给后端的httpserver进行http请求抓取了,但后端服务器还没有响应数据库中的数据。
简单的说是因为cookie是记录的当前url对应的cookie,这段记录是放在服务器的,url改变时记录重新生成,
form表单和oauth认证时都需要使用到cookie,以下代码可以查看cookie设置:$request-cookie='pages_request_id';$request-cookie-path='/pages';$request-cookie-name='pages_cookie_name';$request-cookie-host='cookie_host';$request-cookie-method='post';$request-cookie-timeout='30秒';$request-cookie-invalid='y';$request-cookie-isnotfound='y';$request-cookie-origin='cookie_origin';$request-cookie-setheader='cookie_host';$request-cookie-ignore='y';$request-cookie-ignore-uri='';..具体参考googlecookie设置。 查看全部
java从网页抓取数据(java从网页抓取数据,需要使用java的spiderapi,可以抓取一个网页)
java从网页抓取数据,需要使用java的spiderapi,其中很重要的一个类contentbrowser可以抓取一个网页,也就是chrome浏览器,并且能够上传到后台数据库,简单来说,用java抓取一个网页时,并不是直接往java服务器发送get请求,而是contentbrowser向浏览器发送get请求,然后返回内容,在下面的代码中通过服务器传输的错误码去匹配数据库是否匹配上,然后返回正确的结果就可以抓取数据了,如果后端服务器数据库没有匹配上的话,则提示“pageerror”(网页未响应)来告诉浏览器,java服务器未能收到正确的请求数据,从而将网页转发给后端服务器,这个时候spider已经将抓取的页面转发给后端的httpserver进行http请求抓取了,但后端服务器还没有响应数据库中的数据。
简单的说是因为cookie是记录的当前url对应的cookie,这段记录是放在服务器的,url改变时记录重新生成,
form表单和oauth认证时都需要使用到cookie,以下代码可以查看cookie设置:$request-cookie='pages_request_id';$request-cookie-path='/pages';$request-cookie-name='pages_cookie_name';$request-cookie-host='cookie_host';$request-cookie-method='post';$request-cookie-timeout='30秒';$request-cookie-invalid='y';$request-cookie-isnotfound='y';$request-cookie-origin='cookie_origin';$request-cookie-setheader='cookie_host';$request-cookie-ignore='y';$request-cookie-ignore-uri='';..具体参考googlecookie设置。
java从网页抓取数据(爬虫开发出"蜘蛛”程序的是Gray网页吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-22 10:11
爬虫
通常搜索引擎处理的对象是互联网页面。第一个问题是:如何设计一个高效的下载系统,将如此海量的网页数据传输到本地,并在本地形成互联网网页的镜像备份。网络爬虫扮演着这个角色,它们是搜索引擎系统中非常关键和基础的组件。
爬虫:其实就是通过相应的技术抓取页面上的具体信息。
网络爬虫
当“蜘蛛”程序出现时,现代意义上的搜索引擎才刚刚开始出现。它实际上是一种计算机“机器人”(Computer Robot),计算机“机器人”是指能够以人类无法达到的速度不间断地执行某项任务的某种软件程序。因为专门用来检索信息的“机器人”程序像蜘蛛一样在网络中四处爬行,反复不知疲倦。因此,搜索引擎的“机器人”程序被称为“蜘蛛”程序。
这种程序实际上是利用html文档之间的链接关系,抓取Web上的每个页面,抓取这些页面进入系统进行分析,并放入数据库中。第一个开发“蜘蛛”程序的是马修格雷。他在 1993 年开发了万维网漫游器。最初建立它是为了计算 Internet 上的服务器数量,后来发展为能够捕获 URL。现代搜索引擎的思想起源于Wanderer,后来很多人在此基础上改进了蜘蛛程序。
操作流程图
我们经常听到的爬虫可能是python爬虫,因为我之前没有接触过这种语言,所以感觉爬虫是一种神秘的技术。今天看了一篇博客,介绍了使用Jsoup包轻松开发爬虫。我注意到这是一个java包,所以我想自己做一个爬虫程序。这就是我今天的文章,也是从小白到大白的一个过程,因为之前没有写过类似的,所以还是有点成就感的。八卦直接上代码。
其实爬虫很简单,先新建一个java项目。
这是为了将捕获的信息保存在本地以提高效率
/**
*
* @Title: saveHtml
* @Description: 将抓取过来的数据保存到本地或者json文件
* @param 参数
* @return void 返回类型
* @author liangchu
* @date 2017-12-28 下午12:23:05
* @throws
*/
public static void saveHtml(String url) {
try {
// 这是将首页的信息存入到一个html文件中 为了后面分析html文件里面的信息做铺垫
File dest = new File("src/temp/reptile.html");
// 接收字节输入流
InputStream is;
// 字节输出流
FileOutputStream fos = new FileOutputStream(dest);
URL temp = new URL(url);
// 这个地方需要加入头部 避免大部分网站拒绝访问
// 这个地方是容易忽略的地方所以要注意
URLConnection uc = temp.openConnection();
// 因为现在很大一部分网站都加入了反爬虫机制 这里加入这个头信息
uc.addRequestProperty(
"User-Agent",
"Mozilla/5.0 "
+ "(iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) "
+ "AppleWebKit/533.17.9"
+ " (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5");
is = temp.openStream();
// 为字节输入流加入缓冲
BufferedInputStream bis = new BufferedInputStream(is);
// 为字节输出流加入缓冲
BufferedOutputStream bos = new BufferedOutputStream(fos);
int length;
byte[] bytes = new byte[1024 * 20];
while ((length = bis.read(bytes, 0, bytes.length)) != -1) {
fos.write(bytes, 0, length);
}
bos.close();
fos.close();
bis.close();
is.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
分析本地文件信息,提取有用信息。这部分很耗时
/*
* 解析本地的html文件获取对应的数据
*/
public static void getLocalHtml(String path) {
// 读取本地的html文件
File file = new File(path);
// 获取这个路径下的所有html文件
File[] files = file.listFiles();
List news = new ArrayList();
HttpServletResponse response = null;
HttpServletRequest request = null;
int tmp=1;
// 循环解析所有的html文件
try {
for (int i = 0; i < files.length; i++) {
// 首先先判断是不是文件
if (files[i].isFile()) {
// 获取文件名
String filename = files[i].getName();
// 开始解析文件
Document doc = Jsoup.parse(files[i], "UTF-8");
// 获取所有内容 获取新闻内容
Elements contents = doc.getElementsByClass("ConsTi");
for (Element element : contents) {
Elements e1 = element.getElementsByTag("a");
for (Element element2 : e1) {
// System.out.print(element2.attr("href"));
// 根据href获取新闻的详情信息
String newText = desGetUrl(element2.attr("href"));
// 获取新闻的标题
String newTitle = element2.text();
exportFile(newTitle, newText);
System.out.println("抓取成功。。。"+(tmp));
tmp++;
}
}
}
}
//excelExport(news, response, request);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
根据url的信息获取该url下的新闻详情信息
/**
*
* @Title: desGetUrl
* @Description: 根据url获取连接地址的详情信息
* @param @param url 参数
* @return void 返回类型
* @author liangchu
* @date 2017-12-28 下午1:57:45
* @throws
*/
public static String desGetUrl(String url) {
String newText="";
try {
Document doc = Jsoup
.connect(url)
.userAgent(
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; MALC)")
.get();
// System.out.println(doc);
// 得到html下的所有东西
//Element content = doc.getElementById("article");
Elements contents = doc.getElementsByClass("article");
if(contents != null && contents.size() >0){
Element content = contents.get(0);
newText = content.text();
}
//System.out.println(content);
//return newText;
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return newText;
}
将新闻信息写入文件
/*
* 将新闻标题和内容写入文件
*/
public static void exportFile(String title,String content){
try {
File file = new File("F:/replite/xinwen.txt");
if (!file.getParentFile().exists()) {//判断路径是否存在,如果不存在,则创建上一级目录文件夹
file.getParentFile().mkdirs();
}
FileWriter fileWriter=new FileWriter(file, true);
fileWriter.write(title+"----------");
fileWriter.write(content+"\r\n");
fileWriter.close();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
主功能
public static void main(String[] args) {
String url = "http://news.sina.com.cn/hotnews/?q_kkhha";
// 解析本地html文件
getLocalHtml("src/temp");
}
数据.png
总结
在我做之前,我认为爬行很神秘。再做一遍后,发现其实是一样的。其实很多事情都是一样的。让我们不要被眼前的困难所迷惑。当你勇敢地迈出这一步时,你会发现其实你也可以做到。 查看全部
java从网页抓取数据(爬虫开发出"蜘蛛”程序的是Gray网页吗?)
爬虫
通常搜索引擎处理的对象是互联网页面。第一个问题是:如何设计一个高效的下载系统,将如此海量的网页数据传输到本地,并在本地形成互联网网页的镜像备份。网络爬虫扮演着这个角色,它们是搜索引擎系统中非常关键和基础的组件。
爬虫:其实就是通过相应的技术抓取页面上的具体信息。
网络爬虫
当“蜘蛛”程序出现时,现代意义上的搜索引擎才刚刚开始出现。它实际上是一种计算机“机器人”(Computer Robot),计算机“机器人”是指能够以人类无法达到的速度不间断地执行某项任务的某种软件程序。因为专门用来检索信息的“机器人”程序像蜘蛛一样在网络中四处爬行,反复不知疲倦。因此,搜索引擎的“机器人”程序被称为“蜘蛛”程序。
这种程序实际上是利用html文档之间的链接关系,抓取Web上的每个页面,抓取这些页面进入系统进行分析,并放入数据库中。第一个开发“蜘蛛”程序的是马修格雷。他在 1993 年开发了万维网漫游器。最初建立它是为了计算 Internet 上的服务器数量,后来发展为能够捕获 URL。现代搜索引擎的思想起源于Wanderer,后来很多人在此基础上改进了蜘蛛程序。
操作流程图
我们经常听到的爬虫可能是python爬虫,因为我之前没有接触过这种语言,所以感觉爬虫是一种神秘的技术。今天看了一篇博客,介绍了使用Jsoup包轻松开发爬虫。我注意到这是一个java包,所以我想自己做一个爬虫程序。这就是我今天的文章,也是从小白到大白的一个过程,因为之前没有写过类似的,所以还是有点成就感的。八卦直接上代码。
其实爬虫很简单,先新建一个java项目。
这是为了将捕获的信息保存在本地以提高效率
/**
*
* @Title: saveHtml
* @Description: 将抓取过来的数据保存到本地或者json文件
* @param 参数
* @return void 返回类型
* @author liangchu
* @date 2017-12-28 下午12:23:05
* @throws
*/
public static void saveHtml(String url) {
try {
// 这是将首页的信息存入到一个html文件中 为了后面分析html文件里面的信息做铺垫
File dest = new File("src/temp/reptile.html");
// 接收字节输入流
InputStream is;
// 字节输出流
FileOutputStream fos = new FileOutputStream(dest);
URL temp = new URL(url);
// 这个地方需要加入头部 避免大部分网站拒绝访问
// 这个地方是容易忽略的地方所以要注意
URLConnection uc = temp.openConnection();
// 因为现在很大一部分网站都加入了反爬虫机制 这里加入这个头信息
uc.addRequestProperty(
"User-Agent",
"Mozilla/5.0 "
+ "(iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) "
+ "AppleWebKit/533.17.9"
+ " (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5");
is = temp.openStream();
// 为字节输入流加入缓冲
BufferedInputStream bis = new BufferedInputStream(is);
// 为字节输出流加入缓冲
BufferedOutputStream bos = new BufferedOutputStream(fos);
int length;
byte[] bytes = new byte[1024 * 20];
while ((length = bis.read(bytes, 0, bytes.length)) != -1) {
fos.write(bytes, 0, length);
}
bos.close();
fos.close();
bis.close();
is.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
分析本地文件信息,提取有用信息。这部分很耗时
/*
* 解析本地的html文件获取对应的数据
*/
public static void getLocalHtml(String path) {
// 读取本地的html文件
File file = new File(path);
// 获取这个路径下的所有html文件
File[] files = file.listFiles();
List news = new ArrayList();
HttpServletResponse response = null;
HttpServletRequest request = null;
int tmp=1;
// 循环解析所有的html文件
try {
for (int i = 0; i < files.length; i++) {
// 首先先判断是不是文件
if (files[i].isFile()) {
// 获取文件名
String filename = files[i].getName();
// 开始解析文件
Document doc = Jsoup.parse(files[i], "UTF-8");
// 获取所有内容 获取新闻内容
Elements contents = doc.getElementsByClass("ConsTi");
for (Element element : contents) {
Elements e1 = element.getElementsByTag("a");
for (Element element2 : e1) {
// System.out.print(element2.attr("href"));
// 根据href获取新闻的详情信息
String newText = desGetUrl(element2.attr("href"));
// 获取新闻的标题
String newTitle = element2.text();
exportFile(newTitle, newText);
System.out.println("抓取成功。。。"+(tmp));
tmp++;
}
}
}
}
//excelExport(news, response, request);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
根据url的信息获取该url下的新闻详情信息
/**
*
* @Title: desGetUrl
* @Description: 根据url获取连接地址的详情信息
* @param @param url 参数
* @return void 返回类型
* @author liangchu
* @date 2017-12-28 下午1:57:45
* @throws
*/
public static String desGetUrl(String url) {
String newText="";
try {
Document doc = Jsoup
.connect(url)
.userAgent(
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; MALC)")
.get();
// System.out.println(doc);
// 得到html下的所有东西
//Element content = doc.getElementById("article");
Elements contents = doc.getElementsByClass("article");
if(contents != null && contents.size() >0){
Element content = contents.get(0);
newText = content.text();
}
//System.out.println(content);
//return newText;
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return newText;
}
将新闻信息写入文件
/*
* 将新闻标题和内容写入文件
*/
public static void exportFile(String title,String content){
try {
File file = new File("F:/replite/xinwen.txt");
if (!file.getParentFile().exists()) {//判断路径是否存在,如果不存在,则创建上一级目录文件夹
file.getParentFile().mkdirs();
}
FileWriter fileWriter=new FileWriter(file, true);
fileWriter.write(title+"----------");
fileWriter.write(content+"\r\n");
fileWriter.close();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
主功能
public static void main(String[] args) {
String url = "http://news.sina.com.cn/hotnews/?q_kkhha";
// 解析本地html文件
getLocalHtml("src/temp");
}
数据.png
总结
在我做之前,我认为爬行很神秘。再做一遍后,发现其实是一样的。其实很多事情都是一样的。让我们不要被眼前的困难所迷惑。当你勇敢地迈出这一步时,你会发现其实你也可以做到。
java从网页抓取数据(机器IE加密证书加密的解决方案方法及安装方法分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-20 15:04
1、 用户登录数据采集 用户登录
采集银行或其他企业数据首先需要用户登录。使用java语言的url方式获取登录url或者使用java开源工具HTTPClient模拟登录。使用的插件有IE的httpwotch工具和FireFox的Firebug工具和cookie。插件获取post密码地址或获取URL请求的密码地址。
2、 采集 用户密码登录难点及其验证码和证书解决办法
a) 对于普通用户登录,只需查看用户登录信息并从中获取POST的值即可模拟post数据登录并抓取相关数据
b) post提交,发现前端js做了md5加密,或者其他aes和des加密,查看网站项目js源码看是什么类型的加密方式,使用它的解密方法得到一般的aes加密密钥会保存在客户端,所以需要一定的时间才能找到它的加密密钥来模拟登录。有的加密与用js做的加密有关,有的使用开发加密,但其他语言的加密就不一样了。Rhino JavaScript引擎技术模拟js获取加密密钥,然后登录。
c) 对于证书加密方案,首先要打开一个网站,找到证书,选择查看证书,然后在详细信息中选择copy to file,选择der to compile binary x.509 to导出cer证书,将证书转换为c密钥的形式,windows中有一个keytool工具。使用该命令以加密的keystore文件格式导出key文件,然后使用httpclient的keyStore工具获取keystore登录keystore密码并使用sslsocketfactory注册密钥来达到keystore登录的目的。
d) 第三方服务器认证服务器密钥登录方式的解决方案。一直登录。通过firebug的url检测查看url访问路径,采集分析dom数据,查看html代码是否有变化。获取url获取数据,继续模拟登录,直到访问数据成功,一般这个比较耗时。
e) 本机IE加密证书及数据采集程序需安装相关插件。有些网站为了限制某台机器的登录,需要按照用户登录方式模拟登录,模拟登录时下载证书,模拟访问证书路径,模拟下载后访问的页面证书,最后他可能会生成一个密钥。密钥可以每天生成。可以每天模拟一次,然后根据用户的post数据模拟登录并提交key。
f) 对于有验证码破解的登录方式,使用程序将图片调整为灰度,使用谷歌开源项目tesseract-ocr查看验证码。对于一些难以破解的验证码,就得想办法搭建字典学习库了。采集一些程序验证码来学习破解(注意*必须用c语言写接口和左http服务谷歌开源tesseract-ocr使用的c语言),也可以自己写算法实现验证码的破解。
g) U-key登录方式的破解,看这个U-KEY里面存放的是什么类型的key,有的是用证书制作的密钥,有的是非对称加密密钥。不同的密钥有不同的解决方案,可以破解。密钥作为模拟器使用,也可以破解加密狗复制到其他加密狗使用。
3、数据采集页面数据分析分页及日常数据抓取相关注意事项
a) 对于普通页面的分页数据分析,一般规则是url中的参数会存在于html页面中。对于一些有搜索的,先用SQL注入测试一下是否可以一次直接暴露所有数据。如果是普通的直接url,提交对应的页面。
b) 对于某些aspx类型的网站数据抓取,一般aspx网站很多人会使用一些制作精良的dll文件,其中很多都会有session功能,即访问第二个一页数据,他会读取相关页面中隐藏的数据,输入一页数据,每一页的数据都不一样,只是模拟爬行。
c) 其他一些页面数据的抓取,有些是Ajax返回的数据,前台无法解析。捕获此类数据的最佳方式是直接用 java 解析 json 数据。找json可能很费劲。
d) 对于一些横竖分页数据的爬取,只能横向切换爬取,然后垂直爬取所有分页数据。一些横向数据的post参数可以自己定义,可以抓到数据。
4、 数据分析与清洗数据
对于一些数据清洗,可以使用Jsoup、xpath、regex进行数据分析和分析。有些数据需要一些算法来获取数据,可以通过二次数据页面分析方法获取数据。(针对不同的数据选择不同的解决方案)
5、 用户限制和ip限制的解决方案
对于用户受限的数据抓取程序,只能通过时间间隔来掌握网站的频率抓取数据,解决用户登录问题。对于多用户登录和ip查看程序抓取数据,也可以申请多个账号进行抓取。ip限制取的方法可以冒充谷歌IP取数据,使用ADSL拨号方式取数据。这需要很长时间。其他方式可以购买代理ip和高保真代理数据抓取。
6、 下载和编码注意事项
对于普通爬虫,一般使用url的数据流下载相关文档解析word和excel,一般使用POI来达到效果。对于pdf,一般使用PDFParser来分析。有的会造成乱码,大部分是InputStream等造成的。一般用utf-8\gbk请求时,检查请求的头信息,相应修改代码。一些 网站 需要使用字节。为了解决乱码。有些下载需要修改请求头信息才能下载。
对于一些定制化的数据采集,只能编写定制的采集方案,统一种子中心分发下载,实现分布式数据采集。(注*部分网站不能使用分布式数据采集)。 查看全部
java从网页抓取数据(机器IE加密证书加密的解决方案方法及安装方法分析)
1、 用户登录数据采集 用户登录
采集银行或其他企业数据首先需要用户登录。使用java语言的url方式获取登录url或者使用java开源工具HTTPClient模拟登录。使用的插件有IE的httpwotch工具和FireFox的Firebug工具和cookie。插件获取post密码地址或获取URL请求的密码地址。
2、 采集 用户密码登录难点及其验证码和证书解决办法
a) 对于普通用户登录,只需查看用户登录信息并从中获取POST的值即可模拟post数据登录并抓取相关数据
b) post提交,发现前端js做了md5加密,或者其他aes和des加密,查看网站项目js源码看是什么类型的加密方式,使用它的解密方法得到一般的aes加密密钥会保存在客户端,所以需要一定的时间才能找到它的加密密钥来模拟登录。有的加密与用js做的加密有关,有的使用开发加密,但其他语言的加密就不一样了。Rhino JavaScript引擎技术模拟js获取加密密钥,然后登录。
c) 对于证书加密方案,首先要打开一个网站,找到证书,选择查看证书,然后在详细信息中选择copy to file,选择der to compile binary x.509 to导出cer证书,将证书转换为c密钥的形式,windows中有一个keytool工具。使用该命令以加密的keystore文件格式导出key文件,然后使用httpclient的keyStore工具获取keystore登录keystore密码并使用sslsocketfactory注册密钥来达到keystore登录的目的。
d) 第三方服务器认证服务器密钥登录方式的解决方案。一直登录。通过firebug的url检测查看url访问路径,采集分析dom数据,查看html代码是否有变化。获取url获取数据,继续模拟登录,直到访问数据成功,一般这个比较耗时。
e) 本机IE加密证书及数据采集程序需安装相关插件。有些网站为了限制某台机器的登录,需要按照用户登录方式模拟登录,模拟登录时下载证书,模拟访问证书路径,模拟下载后访问的页面证书,最后他可能会生成一个密钥。密钥可以每天生成。可以每天模拟一次,然后根据用户的post数据模拟登录并提交key。
f) 对于有验证码破解的登录方式,使用程序将图片调整为灰度,使用谷歌开源项目tesseract-ocr查看验证码。对于一些难以破解的验证码,就得想办法搭建字典学习库了。采集一些程序验证码来学习破解(注意*必须用c语言写接口和左http服务谷歌开源tesseract-ocr使用的c语言),也可以自己写算法实现验证码的破解。
g) U-key登录方式的破解,看这个U-KEY里面存放的是什么类型的key,有的是用证书制作的密钥,有的是非对称加密密钥。不同的密钥有不同的解决方案,可以破解。密钥作为模拟器使用,也可以破解加密狗复制到其他加密狗使用。
3、数据采集页面数据分析分页及日常数据抓取相关注意事项
a) 对于普通页面的分页数据分析,一般规则是url中的参数会存在于html页面中。对于一些有搜索的,先用SQL注入测试一下是否可以一次直接暴露所有数据。如果是普通的直接url,提交对应的页面。
b) 对于某些aspx类型的网站数据抓取,一般aspx网站很多人会使用一些制作精良的dll文件,其中很多都会有session功能,即访问第二个一页数据,他会读取相关页面中隐藏的数据,输入一页数据,每一页的数据都不一样,只是模拟爬行。
c) 其他一些页面数据的抓取,有些是Ajax返回的数据,前台无法解析。捕获此类数据的最佳方式是直接用 java 解析 json 数据。找json可能很费劲。
d) 对于一些横竖分页数据的爬取,只能横向切换爬取,然后垂直爬取所有分页数据。一些横向数据的post参数可以自己定义,可以抓到数据。
4、 数据分析与清洗数据
对于一些数据清洗,可以使用Jsoup、xpath、regex进行数据分析和分析。有些数据需要一些算法来获取数据,可以通过二次数据页面分析方法获取数据。(针对不同的数据选择不同的解决方案)
5、 用户限制和ip限制的解决方案
对于用户受限的数据抓取程序,只能通过时间间隔来掌握网站的频率抓取数据,解决用户登录问题。对于多用户登录和ip查看程序抓取数据,也可以申请多个账号进行抓取。ip限制取的方法可以冒充谷歌IP取数据,使用ADSL拨号方式取数据。这需要很长时间。其他方式可以购买代理ip和高保真代理数据抓取。
6、 下载和编码注意事项
对于普通爬虫,一般使用url的数据流下载相关文档解析word和excel,一般使用POI来达到效果。对于pdf,一般使用PDFParser来分析。有的会造成乱码,大部分是InputStream等造成的。一般用utf-8\gbk请求时,检查请求的头信息,相应修改代码。一些 网站 需要使用字节。为了解决乱码。有些下载需要修改请求头信息才能下载。
对于一些定制化的数据采集,只能编写定制的采集方案,统一种子中心分发下载,实现分布式数据采集。(注*部分网站不能使用分布式数据采集)。
java从网页抓取数据( 本文介绍java网络几个常用框架及框架介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-19 11:12
本文介绍java网络几个常用框架及框架介绍)
爬虫是每个程序员都必须掌握的技能。与python爬虫的广泛应用相比,java爬虫也有着不可缺少的优势。Java爬虫现在也相当成熟。Python爬虫中的框架支持爬虫任务的进度,Java爬虫的框架也是如此。每个框架都扮演着不同的角色。本文介绍几个java网络常用的框架:Nutch、Crawler4j、WebMagic、WebCollecto。
1、Nutch:为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。
2、Crawler4j:是一款开源的Java爬虫网络爬虫,代码相当轻量,可以实现多线程爬取,上手难度低。
3、WebMagic:是一个简单灵活的Java爬虫框架。WebMagic 的结构分为四大组件:Downloader、pageProcessor、Scheduler、pipeline,它们以spliter 进行组织。这四个组件分别对应爬虫生命周期中的下载、处理、管理和持久化功能。
4、WebCollector:致力于维护一个稳定可扩展的爬虫内核,方便开发者进行灵活的二次开发。内核扩展性强,用户可以基于内核开发自己的爬虫。Jsoup 集成在源代码中,用于准确的网页分析。
以上就是对java网络爬虫的简单介绍,希望对大家有所帮助~更多java学习推荐:java教程。 查看全部
java从网页抓取数据(
本文介绍java网络几个常用框架及框架介绍)
爬虫是每个程序员都必须掌握的技能。与python爬虫的广泛应用相比,java爬虫也有着不可缺少的优势。Java爬虫现在也相当成熟。Python爬虫中的框架支持爬虫任务的进度,Java爬虫的框架也是如此。每个框架都扮演着不同的角色。本文介绍几个java网络常用的框架:Nutch、Crawler4j、WebMagic、WebCollecto。
1、Nutch:为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。
2、Crawler4j:是一款开源的Java爬虫网络爬虫,代码相当轻量,可以实现多线程爬取,上手难度低。
3、WebMagic:是一个简单灵活的Java爬虫框架。WebMagic 的结构分为四大组件:Downloader、pageProcessor、Scheduler、pipeline,它们以spliter 进行组织。这四个组件分别对应爬虫生命周期中的下载、处理、管理和持久化功能。
4、WebCollector:致力于维护一个稳定可扩展的爬虫内核,方便开发者进行灵活的二次开发。内核扩展性强,用户可以基于内核开发自己的爬虫。Jsoup 集成在源代码中,用于准确的网页分析。
以上就是对java网络爬虫的简单介绍,希望对大家有所帮助~更多java学习推荐:java教程。
java从网页抓取数据(本节书摘来自华章社区《Clojure数据分析秘笈》(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-10-13 00:34
本节摘自华章社区《Clojure数据分析秘诀》一书第1章,1.8节从web表中抓取数据,作者(美国)Eric Rochester,更多章节可访问查看官方云栖社区“华章社区”账号
1.8 从网页表格中抓取数据
数据在互联网上无处不在。不幸的是,互联网上的许多数据并不容易获得。这些数据深埋在表格、文章 或深度嵌套的标签中。网页抓取是一项令人讨厌的物理任务,但它通常是提取此数据进行分析的唯一方法。此方法描述了如何加载网页并挖掘其内容以检索数据。
这可以使用 Enlive 库 () 来完成。该库使用基于 CSS 选择器的领域特定语言 (DSL) 来定位网页中的元素。这个库也可以用于模板。在本例中,仅使用它从网页中检索数据。
1.8.1 准备工作
首先需要在项目的依赖中添加Enlive:
故意删除文件的其他内容并使用表格的布局。
1.8.2 具体实现
由于任务有点复杂,这里把每一步的工作写成一个函数。
现在,选择所有标题单元格,从中提取文本,将每个单元格转换为 关键词,然后将整个序列加载到向量中。获取数据集的头部:
应该注意的是,这里显示的代码是多次试验和错误的结果。截屏过程是这样的。通常我会下载并保存页面,这样我就不需要不断地向 Web 服务器发送请求。然后启动REPL并解析其中的网页。可以通过浏览器的“查看源代码”功能查看网页和HTML,还可以在REPL解释器中交互查看网页中的数据。由于它的方便,我可以在工作过程中不断地在REPL解释器和文本编辑器中复制和粘贴代码。这种工作流程和环境使屏幕捕获变得容易,这是一项艰巨的任务,即使一切正常也需要精细操作。 查看全部
java从网页抓取数据(本节书摘来自华章社区《Clojure数据分析秘笈》(图))
本节摘自华章社区《Clojure数据分析秘诀》一书第1章,1.8节从web表中抓取数据,作者(美国)Eric Rochester,更多章节可访问查看官方云栖社区“华章社区”账号
1.8 从网页表格中抓取数据
数据在互联网上无处不在。不幸的是,互联网上的许多数据并不容易获得。这些数据深埋在表格、文章 或深度嵌套的标签中。网页抓取是一项令人讨厌的物理任务,但它通常是提取此数据进行分析的唯一方法。此方法描述了如何加载网页并挖掘其内容以检索数据。
这可以使用 Enlive 库 () 来完成。该库使用基于 CSS 选择器的领域特定语言 (DSL) 来定位网页中的元素。这个库也可以用于模板。在本例中,仅使用它从网页中检索数据。
1.8.1 准备工作
首先需要在项目的依赖中添加Enlive:
故意删除文件的其他内容并使用表格的布局。
1.8.2 具体实现
由于任务有点复杂,这里把每一步的工作写成一个函数。
现在,选择所有标题单元格,从中提取文本,将每个单元格转换为 关键词,然后将整个序列加载到向量中。获取数据集的头部:
应该注意的是,这里显示的代码是多次试验和错误的结果。截屏过程是这样的。通常我会下载并保存页面,这样我就不需要不断地向 Web 服务器发送请求。然后启动REPL并解析其中的网页。可以通过浏览器的“查看源代码”功能查看网页和HTML,还可以在REPL解释器中交互查看网页中的数据。由于它的方便,我可以在工作过程中不断地在REPL解释器和文本编辑器中复制和粘贴代码。这种工作流程和环境使屏幕捕获变得容易,这是一项艰巨的任务,即使一切正常也需要精细操作。
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-09 19:01
原文链接:
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到显示的结果网页:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml()的结果:\n"+result);}
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义的分析方法显示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们不会直接在网页的源代码中返回数据。相反,他们使用 JS 以异步方式返回数据,这可以防止搜索引擎和其他工具响应网站数据捕获。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript():\n"+contentBuf.toString()的结果);}
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载! 查看全部
java从网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
原文链接:
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到显示的结果网页:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml()的结果:\n"+result);}
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义的分析方法显示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们不会直接在网页的源代码中返回数据。相反,他们使用 JS 以异步方式返回数据,这可以防止搜索引擎和其他工具响应网站数据捕获。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript():\n"+contentBuf.toString()的结果);}
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载!

