
c爬虫抓取网页数据
c爬虫抓取网页数据(Python爬虫如何获取JS生成的JS和网页内容和服务端?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-01-21 01:00
最近需要在一个网站中下载一批数据。但是输入一个查询,返回30000到40000个结果,每次只能导出500个,而且每次都要输入下载项的范围!就这样点击下载,我不要命了。所以我想自动化这个过程。
我的需求主要是两点:1.要求自动化程度高。最好有一个成熟的界面,直接模拟浏览器的鼠标和键盘动作,比如输入文本框、选择下拉列表、单选按钮、复选框、点击按钮等。2.效率不高。因为我想要的数据量比较少。3. python下的框架。因为我通常主要使用python。
对网站技术了解不多,对网站只有两个经验:自己开发了一个很简单的Android客户端,用python的scrapy框架写了一个爬虫自动爬取新闻. 所以了解客户端和服务器的一些基本交互方法,了解如何分析网页源代码,了解xpath语法。
当我第一次开始解决这个问题时,我什至不知道要搜索什么。知乎的这个文章提供了很多有用的信息:“Python爬虫如何获取JS生成的URL和网页内容?” 随之权衡了很多方法,最终选择了Selenium。主要优点是学习成本最小,代码实现速度快。缺点是爬取效率低。如果您想成为富有成效的朋友,您将不得不花一些时间学习更复杂的工具包。
网站技术
如果要自动爬取网页,需要了解一些基础知识,这样做会比较快。这里简单介绍一下相关知识。
1. 请求/响应
request 是客户端向服务器发出的请求。输入一个 URL 对应一个请求动作,这是最直观的。爬取静态网页的内容,只需要知道网址即可。但是,当前的许多网页都是动态的。指向或点击网页中的某些元素也会触发请求动作,从而使网页可以动态更新部分内容,而这些内容不能直接从静态网页中获取。这种技术叫做AJAX,但我对它了解不多。这里的问题是我们可能甚至不知道 URL 是什么,所以我们需要一些可以处理动态内容的高级接口。
response 是服务器返回给客户端的内容。如果要获取静态网页内容,直接从请求中获取即可。
2. 分析网页源码
如果我们想抓取网页上的某一部分信息,我们需要知道如何定位它。这里需要 HTML 和 XPATH 知识。不知道的可以去w3school在线教程:
查看网页的源代码,将鼠标指针指向网页的任意位置,或指向目标元素。右键单击并从下拉列表中选择“检查元素”。下面是我右键“百度”显示的网页源代码,是HTML格式的,我们可以看到对应的HTML代码。要提取它,我们可能需要 div//@[class="head_wrapper"]//input[@type="submit"] 的语句,它是 XPATH 语法,易于掌握。知道如何分析网页,我们更进一步。
3. 网页基本元素操作
前进、后退、刷新、打开新标签、输入网址等;
文本框输入、选择下拉列表、单选按钮、复选框、点击按钮等。
我这里只需要模拟这么多操作,可以参考对应的selenium接口。
4. Selenium 简介
底线:Selenium 是用于 Web 应用程序的自动化测试工具集。
很多话:Selenium 诞生于 2004 年,当时 ThoughtWorks 的 Jason Huggins 正在测试一个内部应用程序。作为一个聪明人,他意识到他的时间应该比手动测试每个更改更有价值。他开发了一个驱动页面交互的 Javascript 库,允许多个浏览器自动返回测试结果。该库最终成为 Selenium 的核心,它是 Selenium RC(远程控制)和 Selenium IDE 所有功能的基础。
实战练习1.分析数据采集过程
我的数据采集过程如下:
在A页输入查询语句,点击提交;浏览器自动打开新页面,跳转到新页面B,在文本框中输入下载项的范围;单击导出弹出一个弹出窗口,然后单击下拉列表,单选按钮,选取框进行一些选择,然后单击下载。然后浏览器开始下载文件。
页面 A
B页
2. 爬取过程 A. 安装 Selenium
Selenium 支持多种浏览器,我选择 google chrome。下载链接:。同时,当然要在python中安装selenium。从命令行输入 pip install senenium 进行安装。
B、配置环境变量
这一步需要将chromedriver的保存路径配置到操作系统的环境变量中,这样selenium才能找到chromedriver。windows下配置环境变量PATH,linux或者mac可以选择在.bash_rc中配置。配置方法很多,百度一下。
我用的是mac,不知道为什么配置不行!后来发现只有在代码中设置了才有效。
C. 核心代码(python)
# 设置下载路径,配置ChromeOptions的路径。
chromeoptions = webdriver.ChromeOptions()
首选项 = {'profile.default_content_settings.popups':0,'download.default_directory': query_dir}
chromeoptions.add_experimental_option('prefs', prefs)
# 设置环境变量并启动浏览器。
chromedriver = CHROMEDRIVER_DIR # 设置为你自己的路径
os.environ["webdriver.chrome.driver"] = chromedriver
驱动程序 = webdriver.Chrome(executable_path=chromedriver,chrome_options=chromeoptions)
# 设置不可见等待时间,因为点击网站后,可以返回一段时间的内容。如果不等待,就会报超时异常。
driver.implicitly_wait(IMPLICIT_WAIT_TIME)
# 请求页面A
司机.get("")
# 在页面A的两个文本框中输入并提交。
driver.find_element_by_name('D').clear()
driver.find_element_by_name('D').send_keys('mesz')
driver.find_element_by_name('SEARCH').clear()
driver.find_element_by_name('SEARCH').send_keys(str_search_query)
driver.find_element_by_name('ovid').click()
# 跳转到新窗口并关注该窗口。
current_window_handle = driver.current_window_handle
for hdl in driver.window_handles: # selenium 总是有两个句柄
如果 hdl != current_window_handle:
new_window_handle = hdl
driver.switch_to.window(new_window_handle)
driver.implicitly_wait(IMPLICIT_WAIT_TIME)
# 获取网页。首先获取返回的条目总数,然后提取文本框输入下载条目的范围,例如1-500。然后单击导出。
# 注意:等待页面加载完毕再计算下载次数
search_ret_num = WebDriverWait(驱动程序, EXPLICIT_WAIT_TIME, EXPLICIT_WAIT_INTERVAL).until(EC.presence_of_element_located((By.XPATH,'//*[@id="searchaid-numbers"]')))
search_ret_num =int(re.findall(r'\d+', search_ret_num.text.encode('utf-8'))[0])
list_range = chunks_by_element(范围(1, search_ret_num+1), DOWNLOAD_NUM_PER_TIME)
对于 list_range 中的项目:
download_range = driver.find_element_by_xpath('//*[@id="titles-display"]//input[@title="Range"]')
下载范围.clear()
download_range.send_keys('{}-{}'.format(item[0], item[-1]))
# 点击导出
export = driver.find_element_by_xpath('//*[@id="titles-display"]//input[@value="Export"]')
导出.click()
# 获取弹出窗口。进行一些设置。
driver.switch_to.alert
WebDriverWait(驱动程序, EXPLICIT_WAIT_TIME, EXPLICIT_WAIT_INTERVAL).until(EC.presence_of_element_located((By.XPATH,'//div[@id="export-citation-popup"]')))
# 设置下载文件的一些配置
export_to_options = driver.find_element_by_xpath('//select[@id="export-citation-export-to-options"]')
export_to_options.find_element_by_xpath('//option[@value="xml"]').click()# XML
# 设置引文内容电台
citation_options = driver.find_element_by_xpath('//ul[@id="export-citation-options"]')
citation_options.find_element_by_xpath('//input[@value="ALL"]').click()# 完整参考
# 设置收录复选框
citation_include = driver.find_element_by_xpath('//div[@id="export-citation-include"]')
ifcitation_include.find_element_by_xpath('//input[@name="externalResolverLink"]').is_selected():# 链接到外部解析器
citation_include.find_element_by_xpath('//input[@name="externalResolverLink"]').click()
ifcitation_include.find_element_by_xpath('//input[@name="jumpstartLink"]').is_selected():# 收录网址
citation_include.find_element_by_xpath('//input[@name="jumpstartLink"]').click()
ifcitation_include.find_element_by_xpath('//input[@name="saveStrategy"]').is_selected():# 搜索历史
citation_include.find_element_by_xpath('//input[@name="saveStrategy"]').click()
# 点击下载。
下载 = driver.find_element_by_xpath('//div[@class="export-citation-buttons"]')
下载.click()
最后:
sleep(30)#等待最后一个文件下载完成
# driver.implicitly_wait(30) # 不行!
driver.quit()
返回
3. 提示
A. 每次启动浏览器时,桌面上都会弹出一个浏览器。您可以清楚地看到自动化过程是怎样的。看来 selenium 真的为 Web 程序的自动化测试做好了准备。另外,在爬取过程中要注意保持屏幕打开。如果它进入睡眠或屏幕保护程序,也会抛出异常。
B、在模拟网页操作时,网页跳转是很常见的场景。所以要注意网页响应时间。Selenium 在继续执行代码之前不会等待网页响应完成,而是直接执行。两者应该是不同的过程。这里可以选择设置隐式等待和显式等待。在其他操作中,隐式等待起决定性作用,在WebDriverWait中..显式等待起主要作用,但需要注意的是,最长等待时间取决于两者中的较大者,如果隐式等待时间>显式等待时间,代码的最长等待时间等于隐式等待时间。
C. 设置下载路径时,一开始没有任何效果。怀疑是“download.default_directory”这个key写错了,于是通过查看网页源码找到了key,还是一样。问题出在其他地方。不过提醒了我以后在代码中使用字典进行相关配置的时候,看源码就能猜出来。
D.我以为至少需要两三天才能实现整个过程,因为我真的不明白。从头到尾完成这项研究只需不到一天的时间。大概是因为入手之前找了很久,反复比较之后,才找到了最得心应手的工具。
E. 整理完之后在github上搜了一圈,发现了一个神器。对于想要爬取大量内容的朋友,如果不想浪费时间过多学习web应用的底层知识,可以结合使用Selenium+scrapy。scrapy可以负责搜索网页,selenium负责处理每个网页上的内容,尤其是动态内容。下次如果我需要它,我打算使用这个想法!
F. 分享一句话。“关于爬虫,获取经验最快的方法是:学会写网站,你知道网站发送请求是什么,那么你就知道怎么爬网站了!” 很简单的。,但是这么简单的一句话却给了我很大的启发。之前太难了,一直卡在scrapy爬静态网页的水平。像 cookie 这样的技术也曾被阅读和遗忘过一次。现在看来是因为网站的整体流程还没有理清清楚。另一方面,我也害怕那些复杂的网站技术术语。其实只要在网上查查相关概念,就会慢慢打通。
G. 最后,完全不懂编程的人可以使用一些可视化爬虫工具。这里有一些介绍: 。懂编程又想提高效率的人需要参考其他工具。 查看全部
c爬虫抓取网页数据(Python爬虫如何获取JS生成的JS和网页内容和服务端?)
最近需要在一个网站中下载一批数据。但是输入一个查询,返回30000到40000个结果,每次只能导出500个,而且每次都要输入下载项的范围!就这样点击下载,我不要命了。所以我想自动化这个过程。
我的需求主要是两点:1.要求自动化程度高。最好有一个成熟的界面,直接模拟浏览器的鼠标和键盘动作,比如输入文本框、选择下拉列表、单选按钮、复选框、点击按钮等。2.效率不高。因为我想要的数据量比较少。3. python下的框架。因为我通常主要使用python。
对网站技术了解不多,对网站只有两个经验:自己开发了一个很简单的Android客户端,用python的scrapy框架写了一个爬虫自动爬取新闻. 所以了解客户端和服务器的一些基本交互方法,了解如何分析网页源代码,了解xpath语法。
当我第一次开始解决这个问题时,我什至不知道要搜索什么。知乎的这个文章提供了很多有用的信息:“Python爬虫如何获取JS生成的URL和网页内容?” 随之权衡了很多方法,最终选择了Selenium。主要优点是学习成本最小,代码实现速度快。缺点是爬取效率低。如果您想成为富有成效的朋友,您将不得不花一些时间学习更复杂的工具包。
网站技术
如果要自动爬取网页,需要了解一些基础知识,这样做会比较快。这里简单介绍一下相关知识。
1. 请求/响应
request 是客户端向服务器发出的请求。输入一个 URL 对应一个请求动作,这是最直观的。爬取静态网页的内容,只需要知道网址即可。但是,当前的许多网页都是动态的。指向或点击网页中的某些元素也会触发请求动作,从而使网页可以动态更新部分内容,而这些内容不能直接从静态网页中获取。这种技术叫做AJAX,但我对它了解不多。这里的问题是我们可能甚至不知道 URL 是什么,所以我们需要一些可以处理动态内容的高级接口。
response 是服务器返回给客户端的内容。如果要获取静态网页内容,直接从请求中获取即可。

2. 分析网页源码
如果我们想抓取网页上的某一部分信息,我们需要知道如何定位它。这里需要 HTML 和 XPATH 知识。不知道的可以去w3school在线教程:
查看网页的源代码,将鼠标指针指向网页的任意位置,或指向目标元素。右键单击并从下拉列表中选择“检查元素”。下面是我右键“百度”显示的网页源代码,是HTML格式的,我们可以看到对应的HTML代码。要提取它,我们可能需要 div//@[class="head_wrapper"]//input[@type="submit"] 的语句,它是 XPATH 语法,易于掌握。知道如何分析网页,我们更进一步。
3. 网页基本元素操作
前进、后退、刷新、打开新标签、输入网址等;
文本框输入、选择下拉列表、单选按钮、复选框、点击按钮等。
我这里只需要模拟这么多操作,可以参考对应的selenium接口。
4. Selenium 简介
底线:Selenium 是用于 Web 应用程序的自动化测试工具集。
很多话:Selenium 诞生于 2004 年,当时 ThoughtWorks 的 Jason Huggins 正在测试一个内部应用程序。作为一个聪明人,他意识到他的时间应该比手动测试每个更改更有价值。他开发了一个驱动页面交互的 Javascript 库,允许多个浏览器自动返回测试结果。该库最终成为 Selenium 的核心,它是 Selenium RC(远程控制)和 Selenium IDE 所有功能的基础。
实战练习1.分析数据采集过程
我的数据采集过程如下:
在A页输入查询语句,点击提交;浏览器自动打开新页面,跳转到新页面B,在文本框中输入下载项的范围;单击导出弹出一个弹出窗口,然后单击下拉列表,单选按钮,选取框进行一些选择,然后单击下载。然后浏览器开始下载文件。
页面 A
B页
2. 爬取过程 A. 安装 Selenium
Selenium 支持多种浏览器,我选择 google chrome。下载链接:。同时,当然要在python中安装selenium。从命令行输入 pip install senenium 进行安装。
B、配置环境变量
这一步需要将chromedriver的保存路径配置到操作系统的环境变量中,这样selenium才能找到chromedriver。windows下配置环境变量PATH,linux或者mac可以选择在.bash_rc中配置。配置方法很多,百度一下。
我用的是mac,不知道为什么配置不行!后来发现只有在代码中设置了才有效。
C. 核心代码(python)
# 设置下载路径,配置ChromeOptions的路径。
chromeoptions = webdriver.ChromeOptions()
首选项 = {'profile.default_content_settings.popups':0,'download.default_directory': query_dir}
chromeoptions.add_experimental_option('prefs', prefs)
# 设置环境变量并启动浏览器。
chromedriver = CHROMEDRIVER_DIR # 设置为你自己的路径
os.environ["webdriver.chrome.driver"] = chromedriver
驱动程序 = webdriver.Chrome(executable_path=chromedriver,chrome_options=chromeoptions)
# 设置不可见等待时间,因为点击网站后,可以返回一段时间的内容。如果不等待,就会报超时异常。
driver.implicitly_wait(IMPLICIT_WAIT_TIME)
# 请求页面A
司机.get("")
# 在页面A的两个文本框中输入并提交。
driver.find_element_by_name('D').clear()
driver.find_element_by_name('D').send_keys('mesz')
driver.find_element_by_name('SEARCH').clear()
driver.find_element_by_name('SEARCH').send_keys(str_search_query)
driver.find_element_by_name('ovid').click()
# 跳转到新窗口并关注该窗口。
current_window_handle = driver.current_window_handle
for hdl in driver.window_handles: # selenium 总是有两个句柄
如果 hdl != current_window_handle:
new_window_handle = hdl
driver.switch_to.window(new_window_handle)
driver.implicitly_wait(IMPLICIT_WAIT_TIME)
# 获取网页。首先获取返回的条目总数,然后提取文本框输入下载条目的范围,例如1-500。然后单击导出。
# 注意:等待页面加载完毕再计算下载次数
search_ret_num = WebDriverWait(驱动程序, EXPLICIT_WAIT_TIME, EXPLICIT_WAIT_INTERVAL).until(EC.presence_of_element_located((By.XPATH,'//*[@id="searchaid-numbers"]')))
search_ret_num =int(re.findall(r'\d+', search_ret_num.text.encode('utf-8'))[0])
list_range = chunks_by_element(范围(1, search_ret_num+1), DOWNLOAD_NUM_PER_TIME)
对于 list_range 中的项目:
download_range = driver.find_element_by_xpath('//*[@id="titles-display"]//input[@title="Range"]')
下载范围.clear()
download_range.send_keys('{}-{}'.format(item[0], item[-1]))
# 点击导出
export = driver.find_element_by_xpath('//*[@id="titles-display"]//input[@value="Export"]')
导出.click()
# 获取弹出窗口。进行一些设置。
driver.switch_to.alert
WebDriverWait(驱动程序, EXPLICIT_WAIT_TIME, EXPLICIT_WAIT_INTERVAL).until(EC.presence_of_element_located((By.XPATH,'//div[@id="export-citation-popup"]')))
# 设置下载文件的一些配置
export_to_options = driver.find_element_by_xpath('//select[@id="export-citation-export-to-options"]')
export_to_options.find_element_by_xpath('//option[@value="xml"]').click()# XML
# 设置引文内容电台
citation_options = driver.find_element_by_xpath('//ul[@id="export-citation-options"]')
citation_options.find_element_by_xpath('//input[@value="ALL"]').click()# 完整参考
# 设置收录复选框
citation_include = driver.find_element_by_xpath('//div[@id="export-citation-include"]')
ifcitation_include.find_element_by_xpath('//input[@name="externalResolverLink"]').is_selected():# 链接到外部解析器
citation_include.find_element_by_xpath('//input[@name="externalResolverLink"]').click()
ifcitation_include.find_element_by_xpath('//input[@name="jumpstartLink"]').is_selected():# 收录网址
citation_include.find_element_by_xpath('//input[@name="jumpstartLink"]').click()
ifcitation_include.find_element_by_xpath('//input[@name="saveStrategy"]').is_selected():# 搜索历史
citation_include.find_element_by_xpath('//input[@name="saveStrategy"]').click()
# 点击下载。
下载 = driver.find_element_by_xpath('//div[@class="export-citation-buttons"]')
下载.click()
最后:
sleep(30)#等待最后一个文件下载完成
# driver.implicitly_wait(30) # 不行!
driver.quit()
返回
3. 提示
A. 每次启动浏览器时,桌面上都会弹出一个浏览器。您可以清楚地看到自动化过程是怎样的。看来 selenium 真的为 Web 程序的自动化测试做好了准备。另外,在爬取过程中要注意保持屏幕打开。如果它进入睡眠或屏幕保护程序,也会抛出异常。
B、在模拟网页操作时,网页跳转是很常见的场景。所以要注意网页响应时间。Selenium 在继续执行代码之前不会等待网页响应完成,而是直接执行。两者应该是不同的过程。这里可以选择设置隐式等待和显式等待。在其他操作中,隐式等待起决定性作用,在WebDriverWait中..显式等待起主要作用,但需要注意的是,最长等待时间取决于两者中的较大者,如果隐式等待时间>显式等待时间,代码的最长等待时间等于隐式等待时间。
C. 设置下载路径时,一开始没有任何效果。怀疑是“download.default_directory”这个key写错了,于是通过查看网页源码找到了key,还是一样。问题出在其他地方。不过提醒了我以后在代码中使用字典进行相关配置的时候,看源码就能猜出来。
D.我以为至少需要两三天才能实现整个过程,因为我真的不明白。从头到尾完成这项研究只需不到一天的时间。大概是因为入手之前找了很久,反复比较之后,才找到了最得心应手的工具。
E. 整理完之后在github上搜了一圈,发现了一个神器。对于想要爬取大量内容的朋友,如果不想浪费时间过多学习web应用的底层知识,可以结合使用Selenium+scrapy。scrapy可以负责搜索网页,selenium负责处理每个网页上的内容,尤其是动态内容。下次如果我需要它,我打算使用这个想法!
F. 分享一句话。“关于爬虫,获取经验最快的方法是:学会写网站,你知道网站发送请求是什么,那么你就知道怎么爬网站了!” 很简单的。,但是这么简单的一句话却给了我很大的启发。之前太难了,一直卡在scrapy爬静态网页的水平。像 cookie 这样的技术也曾被阅读和遗忘过一次。现在看来是因为网站的整体流程还没有理清清楚。另一方面,我也害怕那些复杂的网站技术术语。其实只要在网上查查相关概念,就会慢慢打通。
G. 最后,完全不懂编程的人可以使用一些可视化爬虫工具。这里有一些介绍: 。懂编程又想提高效率的人需要参考其他工具。
c爬虫抓取网页数据(Python网络爬虫反爬破解策略实战作者(组图)作者)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-20 15:18
阿里云>云栖社区>主题图>C>c爬虫源码
推荐活动:
更多优惠>
当前话题:c网络爬虫源码加入采集
相关话题:
c网络爬虫源码相关博客看更多博文
C# 网络爬虫
作者:Street Corner Box 712 查看评论:05 年前
公司的编辑需要爬取网页的内容,让我帮我做一个简单的爬取工具。这是抓取网页的内容。看来这对大家来说并不难,不过这里有一些小的改动,代码提供,请参考 1 private string GetHttpWebRequest(string url) 2 { 3 Ht
阅读全文
C#HttpHelper爬虫源码分享--苏飞版
作者:苏飞2071 浏览评论:03年前
简介 C#HttpHelper实现了C#HttpWebRequest爬取时忽略编码、忽略证书、忽略cookie的功能,实现代理的功能。有了它,您可以发出 Get 和 Post 请求,并且可以轻松设置 cookie、证书、代理和编码。你不用担心这个问题,因为类会自动为你识别页面
阅读全文
Python网络爬虫反爬破解攻略实战
作者:薇薇8128 浏览评论:04年前
作者:薇薇,请注明出处。我们经常会写一些网络爬虫,想必大家都会有一种感觉,虽然写爬虫不难,但是反爬很难处理,因为大部分网站都有自己的反爬机制,所以我们将更加难以抓取这些数据。但是,对于每一种反爬机制,我们其实都会有相应的解决方案。作为一个爬虫,我们,
阅读全文
C#网络爬虫--多线程增强版
作者:街角盒饭 688 次浏览评论:05 年前
上次给公司的一个女生做爬虫,不是很精致。这次是用在公司的项目中,所以做了一些改动。该函数添加了一个URL图片采集,下载,线程处理接口URL图片下载等。说说思路:总理在初始网站采集图片去获取初始网站的所有内容到初始网站 采集 链接并将 采集 的链接放入队列以继续 采集 图片
阅读全文
Python网络爬虫抓取极品姐姐的视频并保存到文件
作者:keitwotest1060 浏览评论:04年前
项目描述 用Python写一个网络爬虫爬取Best Sister的视频并保存到文件中使用工具示例 Python2.7.X,pycharm如何使用创建视频爬取Best Sister in pycharm .py 文件,并在当前目录下创建video文件夹,用于存放采集到的视频文件,编写代码,运行
阅读全文
一篇文章文章教你用Python网络爬虫搞定差旅攻略
作者:python进阶13人查看评论:01年前
[一、项目背景] 趣游网提供原创实用的出境游指南、攻略、旅游社区和问答平台,以及智能旅游规划解决方案,以及签证、保险、机票、酒店在线预订、租车等增值服务。侨游“鼓励和帮助中国游客以自己的视角和方式体验世界”。今天就教大家如何获取侨友网的城市信息。
阅读全文
Java版网络爬虫基础(转)
作者:developerguy851 浏览评论:06年前
网络爬虫不仅可以爬取网站网页和图片,甚至可以实现抢票、网上购买、机票查询。这几天看了一些基础知识,记录下来。网页之间的关系可以看成一个大图,图的遍历可以分为深度优先和广度优先。网络爬虫采取的广度优先方式总结如下:2个数组,一个
阅读全文
一篇文章文章教你使用Python网络爬虫爬取评论区百度贴吧图片和视频
作者:python进阶26人查看评论:01年前
[一、项目背景]百度贴吧是全球最大的中文交流平台。你是不是和我一样,有时候看到评论区的图片就想下载?或者观看视频并想下载?今天小编带大家通过搜索关键词,在评论区获取图片和视频。[二、项目目标]实现贴吧获取的图片或视频将保存在
阅读全文 查看全部
c爬虫抓取网页数据(Python网络爬虫反爬破解策略实战作者(组图)作者)
阿里云>云栖社区>主题图>C>c爬虫源码

推荐活动:
更多优惠>
当前话题:c网络爬虫源码加入采集
相关话题:
c网络爬虫源码相关博客看更多博文
C# 网络爬虫


作者:Street Corner Box 712 查看评论:05 年前
公司的编辑需要爬取网页的内容,让我帮我做一个简单的爬取工具。这是抓取网页的内容。看来这对大家来说并不难,不过这里有一些小的改动,代码提供,请参考 1 private string GetHttpWebRequest(string url) 2 { 3 Ht
阅读全文
C#HttpHelper爬虫源码分享--苏飞版


作者:苏飞2071 浏览评论:03年前
简介 C#HttpHelper实现了C#HttpWebRequest爬取时忽略编码、忽略证书、忽略cookie的功能,实现代理的功能。有了它,您可以发出 Get 和 Post 请求,并且可以轻松设置 cookie、证书、代理和编码。你不用担心这个问题,因为类会自动为你识别页面
阅读全文
Python网络爬虫反爬破解攻略实战


作者:薇薇8128 浏览评论:04年前
作者:薇薇,请注明出处。我们经常会写一些网络爬虫,想必大家都会有一种感觉,虽然写爬虫不难,但是反爬很难处理,因为大部分网站都有自己的反爬机制,所以我们将更加难以抓取这些数据。但是,对于每一种反爬机制,我们其实都会有相应的解决方案。作为一个爬虫,我们,
阅读全文
C#网络爬虫--多线程增强版

作者:街角盒饭 688 次浏览评论:05 年前
上次给公司的一个女生做爬虫,不是很精致。这次是用在公司的项目中,所以做了一些改动。该函数添加了一个URL图片采集,下载,线程处理接口URL图片下载等。说说思路:总理在初始网站采集图片去获取初始网站的所有内容到初始网站 采集 链接并将 采集 的链接放入队列以继续 采集 图片
阅读全文
Python网络爬虫抓取极品姐姐的视频并保存到文件


作者:keitwotest1060 浏览评论:04年前
项目描述 用Python写一个网络爬虫爬取Best Sister的视频并保存到文件中使用工具示例 Python2.7.X,pycharm如何使用创建视频爬取Best Sister in pycharm .py 文件,并在当前目录下创建video文件夹,用于存放采集到的视频文件,编写代码,运行
阅读全文
一篇文章文章教你用Python网络爬虫搞定差旅攻略


作者:python进阶13人查看评论:01年前
[一、项目背景] 趣游网提供原创实用的出境游指南、攻略、旅游社区和问答平台,以及智能旅游规划解决方案,以及签证、保险、机票、酒店在线预订、租车等增值服务。侨游“鼓励和帮助中国游客以自己的视角和方式体验世界”。今天就教大家如何获取侨友网的城市信息。
阅读全文
Java版网络爬虫基础(转)

作者:developerguy851 浏览评论:06年前
网络爬虫不仅可以爬取网站网页和图片,甚至可以实现抢票、网上购买、机票查询。这几天看了一些基础知识,记录下来。网页之间的关系可以看成一个大图,图的遍历可以分为深度优先和广度优先。网络爬虫采取的广度优先方式总结如下:2个数组,一个
阅读全文
一篇文章文章教你使用Python网络爬虫爬取评论区百度贴吧图片和视频

作者:python进阶26人查看评论:01年前
[一、项目背景]百度贴吧是全球最大的中文交流平台。你是不是和我一样,有时候看到评论区的图片就想下载?或者观看视频并想下载?今天小编带大家通过搜索关键词,在评论区获取图片和视频。[二、项目目标]实现贴吧获取的图片或视频将保存在
阅读全文
c爬虫抓取网页数据(以文章首页爬取数据的首页方法数据类型及类型)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-01-16 16:01
c爬虫抓取网页数据,而且是从不同的,唯一的抓取途径。还可以做到自动翻页?还能直接或间接爬到某种信息?这些网站应该都是通过共享logo实现抓取的,使用flask-redis的interface进行封装。
cookie我是猜的,因为javascript只能获取某一特定浏览器上的数据。而这个功能在手机浏览器上,有更完美的封装。html5里的grid布局就可以覆盖.useragent。那么问题来了,抓取非ie浏览器不就得了。
什么是首页?网站的入口,无论是wap、flash还是http,都必须在“首页”上放置页面标签,而首页无非两种格式:网站首页和文章首页。文章首页只是网站中页面的补充,目的为使读者不至于从网站跳转而无法继续访问网站本身。下面的爬虫就是以文章首页爬取数据。为了编写方便,urllib.request、urllib.request.urlretrieve等同样用于这种场景,可以根据接口的数据结构灵活实现爬取json。
首页抓取方法数据类型1、地址2、标签名a标签:/useragent是tx在googleanalytics上面对当前我国互联网用户分析调研得出的pythonurlretrieve提供的接口。在python中常用。#headers头部urllib.request.headers.setretrieve("request_uri",url,verify=false)#声明请求头headers头部自定义urlurllib.request.headers.setretrieve("request_uri","",verify=false)#声明请求头urllib.request.headers.setretrieve("user-agent",tx.noagent.transform.alias_default)#声明请求头urllib.request.headers.setretrieve("data_string",tx.noagent.transform.text)#声明请求头urllib.request.headers.setretrieve("category","",verify=false)#声明请求头urllib.request.headers.setretrieve("category","",verify=false)urllib.request.headers.setretrieve("data_text",tx.noagent.transform.text)//网页简易使用urllib.request.headers.setretrieve("user-agent",tx.noagent.transform.text)urllib.request.headers.setretrieve("user-agent",tx.noagent.transform.text)//web浏览器根据url抓取元素urllib.request.headers.setretrieve("cookie",tx.noagent.cookie)python抓取cookie部分的代码importrequestsfrombs4importbeaut。 查看全部
c爬虫抓取网页数据(以文章首页爬取数据的首页方法数据类型及类型)
c爬虫抓取网页数据,而且是从不同的,唯一的抓取途径。还可以做到自动翻页?还能直接或间接爬到某种信息?这些网站应该都是通过共享logo实现抓取的,使用flask-redis的interface进行封装。
cookie我是猜的,因为javascript只能获取某一特定浏览器上的数据。而这个功能在手机浏览器上,有更完美的封装。html5里的grid布局就可以覆盖.useragent。那么问题来了,抓取非ie浏览器不就得了。
什么是首页?网站的入口,无论是wap、flash还是http,都必须在“首页”上放置页面标签,而首页无非两种格式:网站首页和文章首页。文章首页只是网站中页面的补充,目的为使读者不至于从网站跳转而无法继续访问网站本身。下面的爬虫就是以文章首页爬取数据。为了编写方便,urllib.request、urllib.request.urlretrieve等同样用于这种场景,可以根据接口的数据结构灵活实现爬取json。
首页抓取方法数据类型1、地址2、标签名a标签:/useragent是tx在googleanalytics上面对当前我国互联网用户分析调研得出的pythonurlretrieve提供的接口。在python中常用。#headers头部urllib.request.headers.setretrieve("request_uri",url,verify=false)#声明请求头headers头部自定义urlurllib.request.headers.setretrieve("request_uri","",verify=false)#声明请求头urllib.request.headers.setretrieve("user-agent",tx.noagent.transform.alias_default)#声明请求头urllib.request.headers.setretrieve("data_string",tx.noagent.transform.text)#声明请求头urllib.request.headers.setretrieve("category","",verify=false)#声明请求头urllib.request.headers.setretrieve("category","",verify=false)urllib.request.headers.setretrieve("data_text",tx.noagent.transform.text)//网页简易使用urllib.request.headers.setretrieve("user-agent",tx.noagent.transform.text)urllib.request.headers.setretrieve("user-agent",tx.noagent.transform.text)//web浏览器根据url抓取元素urllib.request.headers.setretrieve("cookie",tx.noagent.cookie)python抓取cookie部分的代码importrequestsfrombs4importbeaut。
c爬虫抓取网页数据(新手练习爬虫不过分吧?这篇爬虫实战教程,拿走不谢!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-14 09:13
最近暑假快到了,很多朋友都在找暑期实习吧?前几天,朋友的小弟暑假想找个实习来锻炼自己,但面对网上千篇一律的实习招聘信息,不知所措。然后我的朋友给我发了一条“请求帮助”的消息。得知大致情况后,我立即用爬虫爬取了练习网的信息,并将数据结果发送过去,分分钟解决了问题。请我吃饭会不会太过分了?
本爬虫实战教程不仅适合新手练习爬虫,也适合需要找实习资料的朋友!
希望看完这篇文章,能够清楚的知道整个爬虫流程,并且能够独立完成,二来可以通过自己的爬虫实战得到自己想要的信息。
好吧,事不宜迟,让我们开始吧!
内容主要分为两部分:
页面分析爬虫步骤详解
一、目标页面分析
首先,我们应该知道我们的爬虫目标是什么,对吧?俗话说,知己知彼,百战不殆。我们已经知道我们要爬的页面是“实习网”,所以我们首先要到实习网看看有什么数据。
实习网址:
页面如下:
比如我们要找的职位就是“品牌运营”职位的数据。因此,您可以直接在网页的搜索框中输入品牌运营。您会注意到网址已更改!
注:我们要抓取的页面是这个页面:品牌运营
在我们的爬取页面中,我们需要观察那里有哪些数据,一个页面中有几条数据。这点很重要,跟后面的代码编写有关,可以帮你检查页面上的所有信息是否都被爬取了。
此时,我们要注意的是,我们所在的页面是“一级页面”。在浏览过程中,我们随机点击一个帖子进入后,会显示“二级页面”。这时候你也会发现url又出现了。改变了。
比如我们点击一个品牌运营实践,二级页面会自动跳转到这个,生成一个新的链接。如图所示:
如何抓取页面上的信息?
在分析过程中,我们发现有的信息在一级页面,有的在二级页面。
在一级页面,我们可以得到什么信息?如图所示:
一共有五个有效数据:职位、公司名称、学历、薪水、地址
在二级页面中,我们来看看可以获得哪些有效数据、字段和刻度。如果觉得阶段很重要,也可以纳入爬虫的范围,但我个人认为这不影响实习。毕竟,它不是在寻找正式的工作。影响不会很大,但是招聘的实习生数量比较重要。这里没有显示新兵的数量,也无法在图片上显示。以后可以添加。
此时,我们一共需要抓取7个数据,加上“人数”,一共8个数据,就是我们爬虫最终的目标数据。
抓取“静态”网页
下面分析一下什么是静态网页,什么是动态网页。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
它们的区别在于静态网页中的数据是一劳永逸的,也就是说一次性给你。动态网页中的数据是随着页面的逐步加载而逐渐呈现出来的,也就是说,如果使用静态网页的爬虫技术,是无法获取其中所有数据的。
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是动态网站技术生成的网页,都可以称为动态网页。
点击“鼠标右键”,点击“查看网页源代码”,最终效果如图(部分截图):
这是最终反馈给您的数据。如果你发现你想要的数据都在里面,那么就可以说是静态页面,否则就认为是“动态页面”。
今天这里的案例是一个静态网页。
众所周知,在编写代码之前,我们必须知道我们使用哪些方法、库和模块来帮助您解析数据。常用的数据解析方法有:re正则表达式、xpath、beatifulsoup、pyquery等。
我们需要用到的是xpath解析方法来分析定位数据。
二、爬虫代码说明
导入相关库
爬取的第一步是考虑在爬取过程中需要哪些库。您必须知道python是一种依赖于许多库的语言。没有库的 Python 是不完整的。
import pandas as pd # 用于数据存储
import requests # 用于请求网页
import chardet # 用于修改编码
import re # 用于提取数据
from lxml import etree # 解析数据的库
import time # 可以粗糙模拟人为请求网页的速度
import warnings # 忽略代码运行时候的警告信息
warnings.filterwarnings("ignore")
2、请求一级页面的源码
url = 'https://www.shixi.com/search/index?key=品牌运营&districts=&education=0&full_opportunity=0&stage=0&practice_days=0&nature=0&trades=&lang=zh_cn'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
rqg = requests.get(url, headers=headers, verify=False) ①
rqg.encoding = chardet.detect(rqg.content)['encoding'] ②
html = etree.HTML(rqg.text)
这里要注意①和②两个地方。①处有两个参数,一个是headers,一个是verify。其中headers是一种防反爬的措施,它使浏览器认为爬虫不是爬虫,而是人们使用浏览器正常请求网页。verify 是忽略安全证书提示。某些网页会被视为不安全网页,并会提示您。只要记住这个参数。
在②处,我们已经获得了网页的源代码。但是由于网页源代码的编码方式和你电脑的解析方式,可能存在不一致,返回的结果会导致乱码。此时需要修改编码方式。chardet 库可以帮助您自动检测网页源代码的编码。(一个非常有用的三方库chardet检测文档编码)
3、解析一级页面中的信息
# 1. 公司名
company_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
company_list = [company_list[i].strip() for i in range(len(company_list)) if i % 2 != 0]
# 2. 岗位名
job_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
job_list = [job_list[i].strip() for i in range(len(job_list)) if i % 2 == 0]
# 3. 地址
address_list = html.xpath('//div[@class="job-pannel-two"]//a/text()')
# 4. 学历
degree_list = html.xpath('//div[@class="job-pannel-list"]//dd[@class="job-des"]/span/text()')
# 5. 薪资
salary_list = html.xpath('//div[@class="job-pannel-two"]//div[@class="company-info-des"]/text()')
salary_list = [i.strip() for i in salary_list]
# 获取二级页面的链接
deep_url_list = html.xpath('//div[@class="job-pannel-list"]//dt/a/@href')
x = "https://www.shixi.com"
deep_url_list = [x + i for i in deep_url_list]
此时,你可以看到,我直接采用xpath一个个去解析一级页面中的数据分析。在代码末尾,可以看到:我们获取到了二级页面的链接,为我们后面爬取二级页面中的信息,做准备。
解析二级页面网页中的信息
demand_list = []
area_list = []
scale_list = []
for deep_url in deep_url_list:
rqg = requests.get(deep_url, headers=headers, verify=False) ①
rqg.encoding = chardet.detect(rqg.content)['encoding'] ②
html = etree.HTML(rqg.text) ③
# 6. 招聘人数
demand = html.xpath('//div[@class="container-fluid"]//div[@class="intros"]/span[2]/text()')
# 7. 公司领域
area = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[1]/span/text()')
# 8. 公司规模
scale = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[2]/span/text()')
demand_list.append(demand)
area_list.append(area)
scale_list.append(scale)
需要注意的是,二级页面也是一个页面,在爬取里面的数据的时候需要请求这个页面。因此,①②③处的代码完全相同。
4、翻页操作
https://www.shixi.com/search/i ... e%3D1
https://www.shixi.com/search/i ... e%3D2
https://www.shixi.com/search/i ... e%3D3
随意复制几个不同页面的 URL 并观察差异。这里可以看出page参数后面的数字是不一样的,哪一页是数字,数字就是数字。
x = "https://www.shixi.com/search/index?key=数据分析&page="
url_list = [x + str(i) for i in range(1,61)]
由于我们已经爬取了60页的数据,所以这里构造了60个url,全部存放在url_list列表中。
现在来看整个代码,我不再用文字描述,直接在代码中写注释。
import pandas as pd
import requests
import chardet
import re
from lxml import etree
import time
import warnings
warnings.filterwarnings("ignore")
def get_CI(url):
# 请求获取一级页面的源代码
url = 'https://www.shixi.com/search/index?key=品牌运营&districts=&education=0&full_opportunity=0&stage=0&practice_days=0&nature=0&trades=&lang=zh_cn'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
rqg = requests.get(url, headers=headers, verify=False)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
# 获取一级页面中的信息:一共有5个信息。
# ①公司名
company_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
company_list = [company_list[i].strip() for i in range(len(company_list)) if i % 2 != 0]
#②岗位名
job_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
job_list = [job_list[i].strip() for i in range(len(job_list)) if i % 2 == 0]
#③地址
address_list = html.xpath('//div[@class="job-pannel-two"]//a/text()')
# ④ 学历
degree_list = html.xpath('//div[@class="job-pannel-list"]//dd[@class="job-des"]/span/text()')
# ⑤薪资
salary_list = html.xpath('//div[@class="job-pannel-two"]//div[@class="company-info-des"]/text()')
salary_list = [i.strip() for i in salary_list]
# ⑥获取二级页面的内容
deep_url_list = html.xpath('//div[@class="job-pannel-list"]//dt/a/@href')
x = "https://www.shixi.com"
deep_url_list = [x + i for i in deep_url_list]
demand_list = []
area_list = []
scale_list = []
# 获取二级页面中的信息:
for deep_url in deep_url_list:
rqg = requests.get(deep_url, headers=headers, verify=False)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
#① 需要几人
demand = html.xpath('//div[@class="container-fluid"]//div[@class="intros"]/span[2]/text()')
# ②公司领域
area = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[1]/span/text()')
# ③公司规模
scale = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[2]/span/text()')
demand_list.append(demand)
area_list.append(area)
scale_list.append(scale)
# ④ 将每个页面获取到的所有数据,存储到DataFrame中。
data = pd.DataFrame({'公司名':company_list,'岗位名':job_list,'地址':address_list,"学历":degree_list,
'薪资':salary_list,'岗位需求量':demand_list,'公司领域':area_list,'公司规模':scale_list})
return(data)
x = "https://www.shixi.com/search/index?key=数据分析&page="
url_list = [x + str(i) for i in range(1,61)]
res = pd.DataFrame(columns=['公司名','岗位名','地址',"学历",'薪资','岗位需求量','公司领域','公司规模'])
# 这里进行“翻页”操作
for url in url_list:
res0 = get_CI(url)
res = pd.concat([res,res0])
time.sleep(3)
# 保存数据
res.to_csv('aliang.csv',encoding='utf_8_sig')
这一套之后,爬虫的思路是不是瞬间清晰了?眼睛:我会的!手:我还是不会。多加练习。初学者不要急于求成,项目不多,但有技巧。看透一个比看十个要有效得多。
想要获取源码的朋友,点赞+评论,私聊~ 查看全部
c爬虫抓取网页数据(新手练习爬虫不过分吧?这篇爬虫实战教程,拿走不谢!)
最近暑假快到了,很多朋友都在找暑期实习吧?前几天,朋友的小弟暑假想找个实习来锻炼自己,但面对网上千篇一律的实习招聘信息,不知所措。然后我的朋友给我发了一条“请求帮助”的消息。得知大致情况后,我立即用爬虫爬取了练习网的信息,并将数据结果发送过去,分分钟解决了问题。请我吃饭会不会太过分了?
本爬虫实战教程不仅适合新手练习爬虫,也适合需要找实习资料的朋友!
希望看完这篇文章,能够清楚的知道整个爬虫流程,并且能够独立完成,二来可以通过自己的爬虫实战得到自己想要的信息。
好吧,事不宜迟,让我们开始吧!
内容主要分为两部分:
页面分析爬虫步骤详解
一、目标页面分析
首先,我们应该知道我们的爬虫目标是什么,对吧?俗话说,知己知彼,百战不殆。我们已经知道我们要爬的页面是“实习网”,所以我们首先要到实习网看看有什么数据。
实习网址:
页面如下:
比如我们要找的职位就是“品牌运营”职位的数据。因此,您可以直接在网页的搜索框中输入品牌运营。您会注意到网址已更改!
注:我们要抓取的页面是这个页面:品牌运营
在我们的爬取页面中,我们需要观察那里有哪些数据,一个页面中有几条数据。这点很重要,跟后面的代码编写有关,可以帮你检查页面上的所有信息是否都被爬取了。
此时,我们要注意的是,我们所在的页面是“一级页面”。在浏览过程中,我们随机点击一个帖子进入后,会显示“二级页面”。这时候你也会发现url又出现了。改变了。
比如我们点击一个品牌运营实践,二级页面会自动跳转到这个,生成一个新的链接。如图所示:
如何抓取页面上的信息?
在分析过程中,我们发现有的信息在一级页面,有的在二级页面。
在一级页面,我们可以得到什么信息?如图所示:
一共有五个有效数据:职位、公司名称、学历、薪水、地址
在二级页面中,我们来看看可以获得哪些有效数据、字段和刻度。如果觉得阶段很重要,也可以纳入爬虫的范围,但我个人认为这不影响实习。毕竟,它不是在寻找正式的工作。影响不会很大,但是招聘的实习生数量比较重要。这里没有显示新兵的数量,也无法在图片上显示。以后可以添加。
此时,我们一共需要抓取7个数据,加上“人数”,一共8个数据,就是我们爬虫最终的目标数据。
抓取“静态”网页
下面分析一下什么是静态网页,什么是动态网页。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
它们的区别在于静态网页中的数据是一劳永逸的,也就是说一次性给你。动态网页中的数据是随着页面的逐步加载而逐渐呈现出来的,也就是说,如果使用静态网页的爬虫技术,是无法获取其中所有数据的。
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是动态网站技术生成的网页,都可以称为动态网页。
点击“鼠标右键”,点击“查看网页源代码”,最终效果如图(部分截图):
这是最终反馈给您的数据。如果你发现你想要的数据都在里面,那么就可以说是静态页面,否则就认为是“动态页面”。
今天这里的案例是一个静态网页。
众所周知,在编写代码之前,我们必须知道我们使用哪些方法、库和模块来帮助您解析数据。常用的数据解析方法有:re正则表达式、xpath、beatifulsoup、pyquery等。
我们需要用到的是xpath解析方法来分析定位数据。
二、爬虫代码说明
导入相关库
爬取的第一步是考虑在爬取过程中需要哪些库。您必须知道python是一种依赖于许多库的语言。没有库的 Python 是不完整的。
import pandas as pd # 用于数据存储
import requests # 用于请求网页
import chardet # 用于修改编码
import re # 用于提取数据
from lxml import etree # 解析数据的库
import time # 可以粗糙模拟人为请求网页的速度
import warnings # 忽略代码运行时候的警告信息
warnings.filterwarnings("ignore")
2、请求一级页面的源码
url = 'https://www.shixi.com/search/index?key=品牌运营&districts=&education=0&full_opportunity=0&stage=0&practice_days=0&nature=0&trades=&lang=zh_cn'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
rqg = requests.get(url, headers=headers, verify=False) ①
rqg.encoding = chardet.detect(rqg.content)['encoding'] ②
html = etree.HTML(rqg.text)
这里要注意①和②两个地方。①处有两个参数,一个是headers,一个是verify。其中headers是一种防反爬的措施,它使浏览器认为爬虫不是爬虫,而是人们使用浏览器正常请求网页。verify 是忽略安全证书提示。某些网页会被视为不安全网页,并会提示您。只要记住这个参数。
在②处,我们已经获得了网页的源代码。但是由于网页源代码的编码方式和你电脑的解析方式,可能存在不一致,返回的结果会导致乱码。此时需要修改编码方式。chardet 库可以帮助您自动检测网页源代码的编码。(一个非常有用的三方库chardet检测文档编码)
3、解析一级页面中的信息
# 1. 公司名
company_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
company_list = [company_list[i].strip() for i in range(len(company_list)) if i % 2 != 0]
# 2. 岗位名
job_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
job_list = [job_list[i].strip() for i in range(len(job_list)) if i % 2 == 0]
# 3. 地址
address_list = html.xpath('//div[@class="job-pannel-two"]//a/text()')
# 4. 学历
degree_list = html.xpath('//div[@class="job-pannel-list"]//dd[@class="job-des"]/span/text()')
# 5. 薪资
salary_list = html.xpath('//div[@class="job-pannel-two"]//div[@class="company-info-des"]/text()')
salary_list = [i.strip() for i in salary_list]
# 获取二级页面的链接
deep_url_list = html.xpath('//div[@class="job-pannel-list"]//dt/a/@href')
x = "https://www.shixi.com"
deep_url_list = [x + i for i in deep_url_list]
此时,你可以看到,我直接采用xpath一个个去解析一级页面中的数据分析。在代码末尾,可以看到:我们获取到了二级页面的链接,为我们后面爬取二级页面中的信息,做准备。
解析二级页面网页中的信息
demand_list = []
area_list = []
scale_list = []
for deep_url in deep_url_list:
rqg = requests.get(deep_url, headers=headers, verify=False) ①
rqg.encoding = chardet.detect(rqg.content)['encoding'] ②
html = etree.HTML(rqg.text) ③
# 6. 招聘人数
demand = html.xpath('//div[@class="container-fluid"]//div[@class="intros"]/span[2]/text()')
# 7. 公司领域
area = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[1]/span/text()')
# 8. 公司规模
scale = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[2]/span/text()')
demand_list.append(demand)
area_list.append(area)
scale_list.append(scale)
需要注意的是,二级页面也是一个页面,在爬取里面的数据的时候需要请求这个页面。因此,①②③处的代码完全相同。
4、翻页操作
https://www.shixi.com/search/i ... e%3D1
https://www.shixi.com/search/i ... e%3D2
https://www.shixi.com/search/i ... e%3D3
随意复制几个不同页面的 URL 并观察差异。这里可以看出page参数后面的数字是不一样的,哪一页是数字,数字就是数字。
x = "https://www.shixi.com/search/index?key=数据分析&page="
url_list = [x + str(i) for i in range(1,61)]
由于我们已经爬取了60页的数据,所以这里构造了60个url,全部存放在url_list列表中。
现在来看整个代码,我不再用文字描述,直接在代码中写注释。
import pandas as pd
import requests
import chardet
import re
from lxml import etree
import time
import warnings
warnings.filterwarnings("ignore")
def get_CI(url):
# 请求获取一级页面的源代码
url = 'https://www.shixi.com/search/index?key=品牌运营&districts=&education=0&full_opportunity=0&stage=0&practice_days=0&nature=0&trades=&lang=zh_cn'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
rqg = requests.get(url, headers=headers, verify=False)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
# 获取一级页面中的信息:一共有5个信息。
# ①公司名
company_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
company_list = [company_list[i].strip() for i in range(len(company_list)) if i % 2 != 0]
#②岗位名
job_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
job_list = [job_list[i].strip() for i in range(len(job_list)) if i % 2 == 0]
#③地址
address_list = html.xpath('//div[@class="job-pannel-two"]//a/text()')
# ④ 学历
degree_list = html.xpath('//div[@class="job-pannel-list"]//dd[@class="job-des"]/span/text()')
# ⑤薪资
salary_list = html.xpath('//div[@class="job-pannel-two"]//div[@class="company-info-des"]/text()')
salary_list = [i.strip() for i in salary_list]
# ⑥获取二级页面的内容
deep_url_list = html.xpath('//div[@class="job-pannel-list"]//dt/a/@href')
x = "https://www.shixi.com"
deep_url_list = [x + i for i in deep_url_list]
demand_list = []
area_list = []
scale_list = []
# 获取二级页面中的信息:
for deep_url in deep_url_list:
rqg = requests.get(deep_url, headers=headers, verify=False)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
#① 需要几人
demand = html.xpath('//div[@class="container-fluid"]//div[@class="intros"]/span[2]/text()')
# ②公司领域
area = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[1]/span/text()')
# ③公司规模
scale = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[2]/span/text()')
demand_list.append(demand)
area_list.append(area)
scale_list.append(scale)
# ④ 将每个页面获取到的所有数据,存储到DataFrame中。
data = pd.DataFrame({'公司名':company_list,'岗位名':job_list,'地址':address_list,"学历":degree_list,
'薪资':salary_list,'岗位需求量':demand_list,'公司领域':area_list,'公司规模':scale_list})
return(data)
x = "https://www.shixi.com/search/index?key=数据分析&page="
url_list = [x + str(i) for i in range(1,61)]
res = pd.DataFrame(columns=['公司名','岗位名','地址',"学历",'薪资','岗位需求量','公司领域','公司规模'])
# 这里进行“翻页”操作
for url in url_list:
res0 = get_CI(url)
res = pd.concat([res,res0])
time.sleep(3)
# 保存数据
res.to_csv('aliang.csv',encoding='utf_8_sig')
这一套之后,爬虫的思路是不是瞬间清晰了?眼睛:我会的!手:我还是不会。多加练习。初学者不要急于求成,项目不多,但有技巧。看透一个比看十个要有效得多。
想要获取源码的朋友,点赞+评论,私聊~
c爬虫抓取网页数据(1.网络爬虫的基本概念网络蜘蛛,机器人都能够做到! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-01-13 21:28
)
1.网络爬虫基本概念
网络爬虫(也称为网络蜘蛛或机器人)是模拟客户端发送网络请求并接收请求响应的程序。它是一个按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做任何事情,原则上爬虫都能做到。
2.网络爬虫函数
网络爬虫可以手动替换很多东西,比如用作搜索引擎,或者爬取网站上的图片。比如有的朋友把一些网站上的所有图片都爬进去,集中在上面。可以进行投资分析。
有时候,可能有几个我们比较喜欢的新闻网站,每次浏览都单独打开这些新闻网站比较麻烦。这时候就可以用网络爬虫来爬取这多条新闻网站中的新闻信息,集中阅读。
有时候,我们在网上浏览信息的时候,会发现有很多广告。这时也可以利用爬虫来爬取相应网页上的信息,从而自动过滤掉这些广告,方便信息的阅读和使用。
有时候,我们需要做营销,所以如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以手动搜索互联网,但这会非常低效。这时候,我们可以通过爬虫设置相应的规则,自动采集从互联网上获取目标用户的联系方式,供我们营销使用。
有时候,我们想分析某个网站的用户信息,比如分析网站的用户活跃度、发言次数、热门文章等信息,如果我们没有网站@ >管理员,手动统计将是一个非常庞大的工程。此时,您可以使用爬虫轻松采集对这些数据进行进一步分析,并且所有的爬取操作都是自动进行的,我们只需要编写相应的爬虫并设计相应的爬虫即可。规则会做。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们以前需要手动访问互联网信息的操作现在可以通过爬虫实现自动化,从而更有效地使用互联网中的有效信息。.
3.安装第三方库
在爬取和解析数据之前,需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面输入pip install requests,回车安装。(注意连接网络)如下图
安装完成,如图
查看全部
c爬虫抓取网页数据(1.网络爬虫的基本概念网络蜘蛛,机器人都能够做到!
)
1.网络爬虫基本概念
网络爬虫(也称为网络蜘蛛或机器人)是模拟客户端发送网络请求并接收请求响应的程序。它是一个按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做任何事情,原则上爬虫都能做到。
2.网络爬虫函数

网络爬虫可以手动替换很多东西,比如用作搜索引擎,或者爬取网站上的图片。比如有的朋友把一些网站上的所有图片都爬进去,集中在上面。可以进行投资分析。
有时候,可能有几个我们比较喜欢的新闻网站,每次浏览都单独打开这些新闻网站比较麻烦。这时候就可以用网络爬虫来爬取这多条新闻网站中的新闻信息,集中阅读。
有时候,我们在网上浏览信息的时候,会发现有很多广告。这时也可以利用爬虫来爬取相应网页上的信息,从而自动过滤掉这些广告,方便信息的阅读和使用。
有时候,我们需要做营销,所以如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以手动搜索互联网,但这会非常低效。这时候,我们可以通过爬虫设置相应的规则,自动采集从互联网上获取目标用户的联系方式,供我们营销使用。
有时候,我们想分析某个网站的用户信息,比如分析网站的用户活跃度、发言次数、热门文章等信息,如果我们没有网站@ >管理员,手动统计将是一个非常庞大的工程。此时,您可以使用爬虫轻松采集对这些数据进行进一步分析,并且所有的爬取操作都是自动进行的,我们只需要编写相应的爬虫并设计相应的爬虫即可。规则会做。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们以前需要手动访问互联网信息的操作现在可以通过爬虫实现自动化,从而更有效地使用互联网中的有效信息。.
3.安装第三方库
在爬取和解析数据之前,需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面输入pip install requests,回车安装。(注意连接网络)如下图

安装完成,如图

c爬虫抓取网页数据(头条搜索爬虫暴力抓取网站内容直接瘫痪百度也没有这么折腾)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-13 21:25
近日,一位站长在网上发帖抱怨字节跳动为了快速发展搜索业务,派出爬虫暴力抓取网站内容。@>业主造成了很大的损失和麻烦,严重影响了网站的正常用户访问。
站长说,今年7月突然发现公司的网站不能频繁打开,网页加载极慢,有时甚至直接瘫痪。经过一系列排查,在服务器日志中发现了bytespider爬虫的踪迹。爬虫的爬取频率每天几百万次,最高的是几千万次。服务器带宽负载飙升至 100%,爬虫在爬取时完全不遵循 网站 robots 协议。
站长顺着爬虫的IP地址查询,确认该爬虫是字节跳动搜索爬虫。
另外,我还从CSDN、V2EX等技术论坛了解到,字节跳动开始搜索后,其实网上一直有站长抱怨头条搜索爬虫爬得太猛,被字节跳动搜索爬虫。这不是个例,很多小网站他们都没有放过。
一些网站小站长抱怨:字节跳动的爬虫“一上午就向网站发出46万个请求”,网站瘫痪了,百度也没有那么麻烦!
最后,站长说,对于像我们这样做SEO的人来说,主要目标是希望自己的首页网站能够在主流搜索引擎的搜索结果中排名靠前。360、收录等搜索引擎的标准爬取很受欢迎,但是今日头条搜索爬虫的疯狂爬取内容网站完全瘫痪,不仅没有给网站带来流量也影响正常用户访问,不是很“特殊”。
但字节跳动对此的回应是,“网络报道不实,目前今日头条搜索有反馈机制。网站由于爬虫受到影响,可以通过邮件反馈直接处理。” 明是不准备正面回应的。
因此,从头条搜索爬虫暴力爬取网站的内容来看,雷哥个人认为字节跳动进军全网搜索,搅动搜索市场是好事,但为了快速崛起,让他的爬虫到处乱爬,刚好有问题,大网站服务器配置高,技术人员多,但是很多小网站受不了字节的折腾- 完全击败搜索爬虫。
搜索引擎的索引数据是一点一点积累的。百度和搜狗.360经历了这么多年的发展和积累,才走到了今天。今日头条搜索疯狂爬取内容。远离! 查看全部
c爬虫抓取网页数据(头条搜索爬虫暴力抓取网站内容直接瘫痪百度也没有这么折腾)
近日,一位站长在网上发帖抱怨字节跳动为了快速发展搜索业务,派出爬虫暴力抓取网站内容。@>业主造成了很大的损失和麻烦,严重影响了网站的正常用户访问。
站长说,今年7月突然发现公司的网站不能频繁打开,网页加载极慢,有时甚至直接瘫痪。经过一系列排查,在服务器日志中发现了bytespider爬虫的踪迹。爬虫的爬取频率每天几百万次,最高的是几千万次。服务器带宽负载飙升至 100%,爬虫在爬取时完全不遵循 网站 robots 协议。
站长顺着爬虫的IP地址查询,确认该爬虫是字节跳动搜索爬虫。
另外,我还从CSDN、V2EX等技术论坛了解到,字节跳动开始搜索后,其实网上一直有站长抱怨头条搜索爬虫爬得太猛,被字节跳动搜索爬虫。这不是个例,很多小网站他们都没有放过。
一些网站小站长抱怨:字节跳动的爬虫“一上午就向网站发出46万个请求”,网站瘫痪了,百度也没有那么麻烦!
最后,站长说,对于像我们这样做SEO的人来说,主要目标是希望自己的首页网站能够在主流搜索引擎的搜索结果中排名靠前。360、收录等搜索引擎的标准爬取很受欢迎,但是今日头条搜索爬虫的疯狂爬取内容网站完全瘫痪,不仅没有给网站带来流量也影响正常用户访问,不是很“特殊”。
但字节跳动对此的回应是,“网络报道不实,目前今日头条搜索有反馈机制。网站由于爬虫受到影响,可以通过邮件反馈直接处理。” 明是不准备正面回应的。
因此,从头条搜索爬虫暴力爬取网站的内容来看,雷哥个人认为字节跳动进军全网搜索,搅动搜索市场是好事,但为了快速崛起,让他的爬虫到处乱爬,刚好有问题,大网站服务器配置高,技术人员多,但是很多小网站受不了字节的折腾- 完全击败搜索爬虫。
搜索引擎的索引数据是一点一点积累的。百度和搜狗.360经历了这么多年的发展和积累,才走到了今天。今日头条搜索疯狂爬取内容。远离!
c爬虫抓取网页数据(入门文章数据库入门指南系列(一)·#11·cdalogic/cdablog)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-13 02:01
c爬虫抓取网页数据redis-spider批量下载百度、新浪、凤凰、搜狐网站所有热门话题内容elasticsearch-parser全文搜索工具elasticsearch-dnspod解析页面数据blogger搜索各大人气博客
真羡慕你年纪轻轻不急不慢,就开始学计算机技术。计算机是真正可以学到一辈子的东西。上面这些我告诉你,一年之后肯定比30岁有技术有资本的人。
在计算机领域,
希望你可以学习一下数据库相关的知识,如nosql或者mongodb,这些都是你大数据开发基础中必不可少的组成。你可以从学习数据库开始入手,或者sql开始入手,
netframework不过呢,看书理论性太强,光理论书就够你看几年了。还是老老实实看视频吧。
刚好昨天刚写了一个数据库管理员界面,希望对你有所帮助,
推荐一本数据库管理员的入门手册,
我写了一篇入门文章数据库入门指南系列(一)·issue#11·cdalogic/cdablog,
1.推荐《这个网站是数据库(databasemanagementtechniquesandtools)》,应该是hadoop之前经典书籍。2.再推荐《数据库系统概念(databasesystems)》3.又来个《数据库系统概念导论(databasesystems)》4.还有一本《数据库管理系统(databasemanagementsystems)》。 查看全部
c爬虫抓取网页数据(入门文章数据库入门指南系列(一)·#11·cdalogic/cdablog)
c爬虫抓取网页数据redis-spider批量下载百度、新浪、凤凰、搜狐网站所有热门话题内容elasticsearch-parser全文搜索工具elasticsearch-dnspod解析页面数据blogger搜索各大人气博客
真羡慕你年纪轻轻不急不慢,就开始学计算机技术。计算机是真正可以学到一辈子的东西。上面这些我告诉你,一年之后肯定比30岁有技术有资本的人。
在计算机领域,
希望你可以学习一下数据库相关的知识,如nosql或者mongodb,这些都是你大数据开发基础中必不可少的组成。你可以从学习数据库开始入手,或者sql开始入手,
netframework不过呢,看书理论性太强,光理论书就够你看几年了。还是老老实实看视频吧。
刚好昨天刚写了一个数据库管理员界面,希望对你有所帮助,
推荐一本数据库管理员的入门手册,
我写了一篇入门文章数据库入门指南系列(一)·issue#11·cdalogic/cdablog,
1.推荐《这个网站是数据库(databasemanagementtechniquesandtools)》,应该是hadoop之前经典书籍。2.再推荐《数据库系统概念(databasesystems)》3.又来个《数据库系统概念导论(databasesystems)》4.还有一本《数据库管理系统(databasemanagementsystems)》。
c爬虫抓取网页数据(产品经理网站结构比较简单的翻太慢错的方法有哪些)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-12 08:09
再次重申:我不是程序员,也没有涉及代码。当页面被修改时,我只涉及复制和粘贴。
要去给朋友圈添点专业气息,需要添加一些新的微信ID;
在哪里可以找到专业的微信账号?
想着大家都是产品经理,我看到传播者在文章下的评论里留下微信,但是每个文章的翻译太慢了,也许你可以用一个工具把所有的评论发到抓住它进行过滤。
网站结构比较简单,这个应该是简单的抓取,到最后会发现自己错了。
以下简称人人为产品经理网站;
上一篇文章中已经详细介绍了常规爬取的过程,重复部分本文不再赘述;
思考过程:如果有需求,找到需求对应的信息,找到信息对应的位置,找到位置对应的工具,找到工具对应的功能或技能。
一:换算法,使用更准确的方法;
上一篇文章介绍了一种生成链接的方法,大家准备用同样的方法再做一遍;
然后遇到第一个难点:大家的链接结构不统一,比如:/pmd/1660079.html、/pd/1659496.html、/ai/1648500.html等.;
总共有10多个类别,最大数量为1,660,079,超过160万。如果每个类别产生超过160万个链接,去链接审核工具进行审核,可能需要十天以上的时间来审核链接;
这种方法是行不通的,需要一个新的方法:网站提供了一个方便的通道——列表页,通过它可以获得整个列表的链接。
使用这种方法,从十几天,这个步骤可以缩短到几个小时。
二:确定约束条件,根据约束条件改进流程
在得到链接之前,我做了一个计算,有几万条文章,而文章下的评论就更多了;
该工具的数据导出限制为 10,000 条。这次真的要花钱升级吗?
又想到一句话:带枷锁跳舞,不带枷锁跳舞不是技巧,带枷锁跳舞是技巧。
最近一直在思考一个基本的二元关系问题:A和B之间有多少条路径?
对初步思考的回答:A和B之间至少有两条路径:AB和BA。
这说明了这样一个事实,即两件事之间必须有两条路径,并且除了常规路径之外至少还有一条其他路径。
把这个结论应用到限定条件上,那么解决问题的路径至少有两条:
1:常规路径:需求(自身)不变,(环境)极限扩大,极限适应需求;
2:反向路径:限制(环境)不变,压缩(自己)需求,使需求适应限制;
第二条反向路径为解决问题带来了新的视角,为流程演化建立了新的理论基础。
原来的流程是:
获取链接—>导出链接(限制出现1)—>重新导入—>评论抓取—>导出评论(限制出现2)—>本地过滤。
第一个改进:重新定义需求,细化获取环节:
其实第二阶段需要的不是任何文章,而是带注释的文章(没有注释就不用抢注释了),在初始条件上加上细化条件提前过滤,一下子把链接数减少了三分之一。
新流程:获取精确链接—>导出链接(限制1)的位置—>重新导入—>评论捕获—>导出评论(限制2)的位置—>本地过滤。
第二次改进:将新的认识应用到大局中,在第二阶段增加细化条件;
不是所有的评论都要被抓,而是收录公众号或微信账号的评论。
新流程:获取精准链接—>导出链接(限制1)的位置—>重新导入—>准确抓取评论—>导出评论(限制2)的位置—>本地过滤。
第三次改进:合并和推进流程
我在中间去了一次洗手间,洗手间做得很好。在其中,我想到了两个过程。为什么要把这两个进程分开?
这两个阶段是一个连续的过程,如果这些过程可以合并,第一阶段的限制就会消失。
这说明除了适应约束之外,还可以选择合理地调整流程以消除或跳过约束。
将两个流程合二为一后,新流程:获取精准链接—>准确抓取评论—>导出评论(限制位置2)—>本地过滤。
由于重新定义了两阶段要求,最终出口数据中只剩下有意义的部分。
这个改进过程也让我发现了一个优化的关键点:在设计过程时,结合约束,用约束激发深度优化。
最终得到了我想要的数据,结果发现约束不是敌人,约束是持续创新的重要条件。
这一发现也为创新开辟了一种新的思维方式:自我强加的限制,没有限制创造限制。就像这个文章,本来是不打算写的,但是我给自己设计了一个新的限制:把事情做完,从实践到总结,就完成了。
在过滤数据时,我有点气馁。评论数据是非结构化的,很难快速过滤此类数据。这也让我有了一个新的发现:数据的价值取决于结构的程度。结构化数据很少。既然如此,与其捕获杂乱无章的数据,事后对其进行结构化,不如在初始设计中建立结构化的数据捕获过程。
结束了吗?确实是时候结束了,本来预定的数据已经拿到了;
但这并没有结束,甚至真正的困难才刚刚开始,所以这是一个意外。
三:抢公众号,重新整理全站内容;
一边抓着上面的微信,一边也隔出了一部分公众号,很少。如果能得到更多的公众号,或许可以做一个专门的页面来提供一个服务,也就是集成即服务。该方法的效果很差,需要更高效的采集方法;
我想还有一个地方也会放公众号,每个文章底部的作者介绍部分:
如果能够获取大量数据,就可以形成公众账户矩阵。据我所知,没有这样的信息库,信息集中对用户也很有价值;
准备开始抓取,遇到了第一个难点:文章内容很多,如何定位要抓取的对象?
定位要抓拍的物体有一个窍门:分析物体的特征,尤其是独特的特征,通过独特的特征准确识别;比如这次要抓的对象是一个公众号,而这三个词在文章中也经常出现,但是出现在文章中的时候一般不会跟a : 符号,仅在作者介绍时才收录,这是关键特性。
第一个改进:多角度观察数据,增加要捕获的数据类型;
这是一个非常偶然的想法。我想着数据可能可以供官方参考,然后又想到了大家官方需要的数据格式。然后我想到了一个新的需求场景:如果提供给用户,用户面对的是数据。数据应该如何使用?
三个角色:我、用户和人人官方。每个角色需要不同的数据并使用不同的方法。比如我只需要公众号,用户需要更多数据。用户将希望执行一些过滤,以便他们可以找到适合您自己的公共帐户。
第二个改进:增加辅助判断条件;
在爬取中,我们遇到了一个问题:如果没有符合设定条件的数据,数据就会留空。这类数据需要丢弃(否则会占用导出索引)。为了丢弃数据,必须对数据进行处理。判断,进行判断,数据不能为空;
这里有一个矛盾或冲突:需要删除空数据,但只能删除非空数据;终于找到了一个办法:给所有数据加上一个固定的前缀——delete,这样无论数据是否为空,最终都不会为空;
比如两条数据:一条数据为空,需要删除,加上前缀后,数据变为:delete;数据B数据不为空,加前缀后数据变为删除+原创数据;要确定哪些数据只收录删除,您可以丢弃,因为只有空数据将只收录添加的前缀。
这种方法是excel中的一个技巧:当数据本身难以判断时,加一列辅助判断,让具有相同特征的选项转化为易于识别的数据;如A/A/B/B/C/D,需要确定哪些重复项单独列出。因为A/B不同,无法实现排序。这时候可以添加一个单独的辅助判断列,将重复项转换为1,不重复项转换为0,然后对新列进行排序。
在最后一页,我也使用了这个技巧,通过在未认证的前面加上前缀A,让未认证的在排序的时候总是排成一行。
第三项改进:增加精准判断条件;
由于我不是程序员,对程序了解不多,无法准确判断代码的含义,这就带来了一个问题:不知道代码是否能完全达到目的,同时处理一些边缘情况;
在第一次数据捕获后,我们发现了这样一种情况:当数据中收录-等符号时,捕获会被中断。很多公众号都收录-符号,结果只抓到一半,比如lmh-china,只会抓lmh。
这是一个超出我能力的改进,所以我准备手动修改,但是接近1000个公众号,效率太低,如果你能改进爬取过程并修复这个问题,那么你可以重新爬取再次使用正确的数据,我决定试一试。
最终,我添加了结束条件(正则表达式),必须遇到,或者。会结束,遇到其他符号也不会结束。
这并不意味着我可以编写代码。该工具提供了一个工具来帮助生成正则表达式。然后我在互联网上搜索答案以找到可能的答案,并不断尝试成功。
PS:写这篇文章的时候,又查了一遍资料,发现上次修改没有生效,还是老流程。我必须确认未来的重要步骤,以确认我在做正确的事情。
改进之四:进行下一步,从实际场景中观察数据;
抓数据的时候想,可能需要一个地方放数据,这样方便查看,一张简单的表就够了,还需要排序,这样就可以根据自己的需要进行排序了;
找了几个插件,最后选择了一个简单的页面,经过测试,符合我的要求;
这次提前操作数据让我决定再次添加一个数据类型,添加一个经过认证的数据类型。人人网网站拥有各类认证。添加新的排序字段对用户有好处,可以让我排除官方用户,排除官方用户意味着排除非贡献者的公共账户。
这些官方发布的文章中的公众号是官方转载的来源,也很有价值;它们可以制成单独的页面。
改进之五:试用公共CDN地址查找bug;
由于所有网页都使用开源程序,我可以将本地的css和js改成免费的CDN地址,速度更快,节省带宽;国内外有一些服务为开源程序提供免费CDN,如/,合理节省使用成本;
在不断测试的过程中,突然发现了一个致命的bug:排序错误,这个bug一下子让我陷入了深渊。如果存在此错误,那么对用户最有意义的功能将失败:
我没有修复错误的能力,但我想到了一些可能性。作为一个开源程序,按理说这样明显的排序bug肯定会被修复。页面使用的版本比较旧。这是原因吗?
我去CDN找了最新版本,页面直接崩溃了;回去找了个中间版本,bug修复了,原来是程序版本问题。
这个修订过程教会了我一个反向精益思想:从后到前改进,提前验证整个过程,如果可能的话,把整个过程,特别是还没有达到的过程,并努力做到在少量数据的支持下。实际场景模拟,去模拟场景看看,这个模拟有利于整个过程的改进,场景中的思维可以反馈到整个过程的改进。
改进之六:增加公众号查询;
看了几个公众号,发现很多公众号已经不存在或者没有更新。如果能提供一个新的筛选维度,让用户可以直接看到公众号的更新,这个数据会更有价值;
我知道搜狗搜索提供了微信搜外,我开始尝试爬取搜狗搜索,但是搜狗搜索的反爬虫规则太严格了。
这个想法失败了,但我可以提供一个折衷方案:点击直接查询;
检查搜狗搜索的链接规则后,生成所有公众号对应的查询链接。
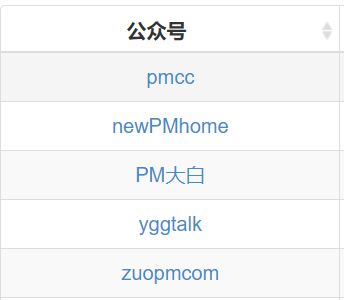
最终页面如下所示:
您可以在页面内搜索并按列排序。
我将页面上传到服务器,页面地址:open.skyfollowsnow.pro/special/woshipm-author/。
您可以在此处查看本次抓取中使用的工具和知识:open.skyfollowsnow.pro/?thread-55.htm。
第七项改进:统一修改位置;
将文件上传到服务器后,我犯了一个明显的错误:在服务器中修改文档,很多修改必须在本地,于是出现了一个新问题:有些东西是在服务器上修改的,有些东西是在本地修改的,文件两端不一致;
虽小,但也是很实用的一课:统一修改位置,避免协作时起点不一致。
其他:
在本次爬取中,使用了两种新的方法来解决两个问题:
1:解决json数据中a标签不被解析的问题;
作者ID和空格链接本来是两列,但是我以为可以合并,但是一旦合并就会报错,然后我以为我看到了一个用\符号隔开的程序”,于是试了一下,确实如此。
2:解决excel列过多时合并容易出错的问题;
最后合并成需要的数据时,需要合并的项很多,很容易发现顺序不对。为了一次性看到所有列的选项,我使用了一个新工具:桌面纹理工具 Snipaste,这也是我之前见过的。程序使用的工具正好解决了这个问题:
平时看到新事物的时候要有点好奇,需要的时候可能会想到。 查看全部
c爬虫抓取网页数据(产品经理网站结构比较简单的翻太慢错的方法有哪些)
再次重申:我不是程序员,也没有涉及代码。当页面被修改时,我只涉及复制和粘贴。
要去给朋友圈添点专业气息,需要添加一些新的微信ID;
在哪里可以找到专业的微信账号?
想着大家都是产品经理,我看到传播者在文章下的评论里留下微信,但是每个文章的翻译太慢了,也许你可以用一个工具把所有的评论发到抓住它进行过滤。
网站结构比较简单,这个应该是简单的抓取,到最后会发现自己错了。
以下简称人人为产品经理网站;
上一篇文章中已经详细介绍了常规爬取的过程,重复部分本文不再赘述;
思考过程:如果有需求,找到需求对应的信息,找到信息对应的位置,找到位置对应的工具,找到工具对应的功能或技能。
一:换算法,使用更准确的方法;
上一篇文章介绍了一种生成链接的方法,大家准备用同样的方法再做一遍;
然后遇到第一个难点:大家的链接结构不统一,比如:/pmd/1660079.html、/pd/1659496.html、/ai/1648500.html等.;
总共有10多个类别,最大数量为1,660,079,超过160万。如果每个类别产生超过160万个链接,去链接审核工具进行审核,可能需要十天以上的时间来审核链接;
这种方法是行不通的,需要一个新的方法:网站提供了一个方便的通道——列表页,通过它可以获得整个列表的链接。
使用这种方法,从十几天,这个步骤可以缩短到几个小时。
二:确定约束条件,根据约束条件改进流程
在得到链接之前,我做了一个计算,有几万条文章,而文章下的评论就更多了;
该工具的数据导出限制为 10,000 条。这次真的要花钱升级吗?
又想到一句话:带枷锁跳舞,不带枷锁跳舞不是技巧,带枷锁跳舞是技巧。
最近一直在思考一个基本的二元关系问题:A和B之间有多少条路径?
对初步思考的回答:A和B之间至少有两条路径:AB和BA。
这说明了这样一个事实,即两件事之间必须有两条路径,并且除了常规路径之外至少还有一条其他路径。
把这个结论应用到限定条件上,那么解决问题的路径至少有两条:
1:常规路径:需求(自身)不变,(环境)极限扩大,极限适应需求;
2:反向路径:限制(环境)不变,压缩(自己)需求,使需求适应限制;
第二条反向路径为解决问题带来了新的视角,为流程演化建立了新的理论基础。
原来的流程是:
获取链接—>导出链接(限制出现1)—>重新导入—>评论抓取—>导出评论(限制出现2)—>本地过滤。
第一个改进:重新定义需求,细化获取环节:
其实第二阶段需要的不是任何文章,而是带注释的文章(没有注释就不用抢注释了),在初始条件上加上细化条件提前过滤,一下子把链接数减少了三分之一。
新流程:获取精确链接—>导出链接(限制1)的位置—>重新导入—>评论捕获—>导出评论(限制2)的位置—>本地过滤。
第二次改进:将新的认识应用到大局中,在第二阶段增加细化条件;
不是所有的评论都要被抓,而是收录公众号或微信账号的评论。
新流程:获取精准链接—>导出链接(限制1)的位置—>重新导入—>准确抓取评论—>导出评论(限制2)的位置—>本地过滤。
第三次改进:合并和推进流程
我在中间去了一次洗手间,洗手间做得很好。在其中,我想到了两个过程。为什么要把这两个进程分开?
这两个阶段是一个连续的过程,如果这些过程可以合并,第一阶段的限制就会消失。
这说明除了适应约束之外,还可以选择合理地调整流程以消除或跳过约束。
将两个流程合二为一后,新流程:获取精准链接—>准确抓取评论—>导出评论(限制位置2)—>本地过滤。
由于重新定义了两阶段要求,最终出口数据中只剩下有意义的部分。
这个改进过程也让我发现了一个优化的关键点:在设计过程时,结合约束,用约束激发深度优化。
最终得到了我想要的数据,结果发现约束不是敌人,约束是持续创新的重要条件。
这一发现也为创新开辟了一种新的思维方式:自我强加的限制,没有限制创造限制。就像这个文章,本来是不打算写的,但是我给自己设计了一个新的限制:把事情做完,从实践到总结,就完成了。
在过滤数据时,我有点气馁。评论数据是非结构化的,很难快速过滤此类数据。这也让我有了一个新的发现:数据的价值取决于结构的程度。结构化数据很少。既然如此,与其捕获杂乱无章的数据,事后对其进行结构化,不如在初始设计中建立结构化的数据捕获过程。

结束了吗?确实是时候结束了,本来预定的数据已经拿到了;
但这并没有结束,甚至真正的困难才刚刚开始,所以这是一个意外。
三:抢公众号,重新整理全站内容;
一边抓着上面的微信,一边也隔出了一部分公众号,很少。如果能得到更多的公众号,或许可以做一个专门的页面来提供一个服务,也就是集成即服务。该方法的效果很差,需要更高效的采集方法;
我想还有一个地方也会放公众号,每个文章底部的作者介绍部分:

如果能够获取大量数据,就可以形成公众账户矩阵。据我所知,没有这样的信息库,信息集中对用户也很有价值;
准备开始抓取,遇到了第一个难点:文章内容很多,如何定位要抓取的对象?
定位要抓拍的物体有一个窍门:分析物体的特征,尤其是独特的特征,通过独特的特征准确识别;比如这次要抓的对象是一个公众号,而这三个词在文章中也经常出现,但是出现在文章中的时候一般不会跟a : 符号,仅在作者介绍时才收录,这是关键特性。
第一个改进:多角度观察数据,增加要捕获的数据类型;
这是一个非常偶然的想法。我想着数据可能可以供官方参考,然后又想到了大家官方需要的数据格式。然后我想到了一个新的需求场景:如果提供给用户,用户面对的是数据。数据应该如何使用?
三个角色:我、用户和人人官方。每个角色需要不同的数据并使用不同的方法。比如我只需要公众号,用户需要更多数据。用户将希望执行一些过滤,以便他们可以找到适合您自己的公共帐户。
第二个改进:增加辅助判断条件;
在爬取中,我们遇到了一个问题:如果没有符合设定条件的数据,数据就会留空。这类数据需要丢弃(否则会占用导出索引)。为了丢弃数据,必须对数据进行处理。判断,进行判断,数据不能为空;
这里有一个矛盾或冲突:需要删除空数据,但只能删除非空数据;终于找到了一个办法:给所有数据加上一个固定的前缀——delete,这样无论数据是否为空,最终都不会为空;
比如两条数据:一条数据为空,需要删除,加上前缀后,数据变为:delete;数据B数据不为空,加前缀后数据变为删除+原创数据;要确定哪些数据只收录删除,您可以丢弃,因为只有空数据将只收录添加的前缀。
这种方法是excel中的一个技巧:当数据本身难以判断时,加一列辅助判断,让具有相同特征的选项转化为易于识别的数据;如A/A/B/B/C/D,需要确定哪些重复项单独列出。因为A/B不同,无法实现排序。这时候可以添加一个单独的辅助判断列,将重复项转换为1,不重复项转换为0,然后对新列进行排序。
在最后一页,我也使用了这个技巧,通过在未认证的前面加上前缀A,让未认证的在排序的时候总是排成一行。
第三项改进:增加精准判断条件;
由于我不是程序员,对程序了解不多,无法准确判断代码的含义,这就带来了一个问题:不知道代码是否能完全达到目的,同时处理一些边缘情况;
在第一次数据捕获后,我们发现了这样一种情况:当数据中收录-等符号时,捕获会被中断。很多公众号都收录-符号,结果只抓到一半,比如lmh-china,只会抓lmh。
这是一个超出我能力的改进,所以我准备手动修改,但是接近1000个公众号,效率太低,如果你能改进爬取过程并修复这个问题,那么你可以重新爬取再次使用正确的数据,我决定试一试。
最终,我添加了结束条件(正则表达式),必须遇到,或者。会结束,遇到其他符号也不会结束。
这并不意味着我可以编写代码。该工具提供了一个工具来帮助生成正则表达式。然后我在互联网上搜索答案以找到可能的答案,并不断尝试成功。
PS:写这篇文章的时候,又查了一遍资料,发现上次修改没有生效,还是老流程。我必须确认未来的重要步骤,以确认我在做正确的事情。
改进之四:进行下一步,从实际场景中观察数据;
抓数据的时候想,可能需要一个地方放数据,这样方便查看,一张简单的表就够了,还需要排序,这样就可以根据自己的需要进行排序了;
找了几个插件,最后选择了一个简单的页面,经过测试,符合我的要求;
这次提前操作数据让我决定再次添加一个数据类型,添加一个经过认证的数据类型。人人网网站拥有各类认证。添加新的排序字段对用户有好处,可以让我排除官方用户,排除官方用户意味着排除非贡献者的公共账户。
这些官方发布的文章中的公众号是官方转载的来源,也很有价值;它们可以制成单独的页面。
改进之五:试用公共CDN地址查找bug;
由于所有网页都使用开源程序,我可以将本地的css和js改成免费的CDN地址,速度更快,节省带宽;国内外有一些服务为开源程序提供免费CDN,如/,合理节省使用成本;
在不断测试的过程中,突然发现了一个致命的bug:排序错误,这个bug一下子让我陷入了深渊。如果存在此错误,那么对用户最有意义的功能将失败:
我没有修复错误的能力,但我想到了一些可能性。作为一个开源程序,按理说这样明显的排序bug肯定会被修复。页面使用的版本比较旧。这是原因吗?
我去CDN找了最新版本,页面直接崩溃了;回去找了个中间版本,bug修复了,原来是程序版本问题。
这个修订过程教会了我一个反向精益思想:从后到前改进,提前验证整个过程,如果可能的话,把整个过程,特别是还没有达到的过程,并努力做到在少量数据的支持下。实际场景模拟,去模拟场景看看,这个模拟有利于整个过程的改进,场景中的思维可以反馈到整个过程的改进。
改进之六:增加公众号查询;
看了几个公众号,发现很多公众号已经不存在或者没有更新。如果能提供一个新的筛选维度,让用户可以直接看到公众号的更新,这个数据会更有价值;
我知道搜狗搜索提供了微信搜外,我开始尝试爬取搜狗搜索,但是搜狗搜索的反爬虫规则太严格了。
这个想法失败了,但我可以提供一个折衷方案:点击直接查询;
检查搜狗搜索的链接规则后,生成所有公众号对应的查询链接。
最终页面如下所示:
您可以在页面内搜索并按列排序。
我将页面上传到服务器,页面地址:open.skyfollowsnow.pro/special/woshipm-author/。
您可以在此处查看本次抓取中使用的工具和知识:open.skyfollowsnow.pro/?thread-55.htm。
第七项改进:统一修改位置;
将文件上传到服务器后,我犯了一个明显的错误:在服务器中修改文档,很多修改必须在本地,于是出现了一个新问题:有些东西是在服务器上修改的,有些东西是在本地修改的,文件两端不一致;
虽小,但也是很实用的一课:统一修改位置,避免协作时起点不一致。
其他:
在本次爬取中,使用了两种新的方法来解决两个问题:
1:解决json数据中a标签不被解析的问题;
作者ID和空格链接本来是两列,但是我以为可以合并,但是一旦合并就会报错,然后我以为我看到了一个用\符号隔开的程序”,于是试了一下,确实如此。
2:解决excel列过多时合并容易出错的问题;
最后合并成需要的数据时,需要合并的项很多,很容易发现顺序不对。为了一次性看到所有列的选项,我使用了一个新工具:桌面纹理工具 Snipaste,这也是我之前见过的。程序使用的工具正好解决了这个问题:
平时看到新事物的时候要有点好奇,需要的时候可能会想到。
c爬虫抓取网页数据(如何轻松定制一个网络爬虫的总体架构环境?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-12 04:14
万维网的大量信息、股票报价、电影评论、市场价格趋势主题以及几乎所有内容都可以通过单击按钮找到。在分析数据的过程中,发现很多SAS用户对网络很感兴趣,但是你获取这些数据的SAS环境呢?有很多方法,例如设计自己的网络爬虫或利用 SAS %TMFILTER 文本挖掘的 SAS 数据步骤中的代码。在本文中,我们将回顾网络爬虫的一般架构。我们将讨论将 网站 信息导入 SAS 的方法,并在内部查看来自名为 SAS Search 的实验项目的实验代码管道。我们还将提供有关如何轻松自定义网络爬虫以满足个人需求以及如何将特定数据导入 SAS Miner 的建议。介绍:互联网已成为有用的信息来源。通常是网络上的数据,我们想在SAS内部使用,所以我们需要想办法获取这些数据。最好的方法是使用网络爬虫。SAS 提供了几种从 Web 爬取和提取信息的方法。您可以使用基本 SAS 数据步骤中的代码,或 SAS Text Miner 的 %TMFILTER 宏。虽然目前不可用,但 SAS Search Pipeline 将是一个强大的网络爬虫产品,并为网络爬虫提供更多工具。每种方法都有其优点和缺点,因此根据您想要实现的抓取,最好对其进行审查。SAS 提供了几种从 Web 爬取和提取信息的方法。您可以使用基本 SAS 数据步骤中的代码,或 SAS Text Miner 的 %TMFILTER 宏。虽然目前不可用,但 SAS Search Pipeline 将是一个强大的网络爬虫产品,并为网络爬虫提供更多工具。每种方法都有其优点和缺点,因此根据您想要实现的抓取,最好对其进行审查。SAS 提供了几种从 Web 爬取和提取信息的方法。您可以使用基本 SAS 数据步骤中的代码,或 SAS Text Miner 的 %TMFILTER 宏。虽然目前不可用,但 SAS Search Pipeline 将是一个强大的网络爬虫产品,并为网络爬虫提供更多工具。每种方法都有其优点和缺点,因此根据您想要实现的抓取,最好对其进行审查。
首先,了解网络爬虫的工作原理很重要。在继续之前,您应该熟悉数据步骤代码、宏和 SAS 过程 PROC SQL。网络爬虫概述:网络爬虫是一个程序,具有一个或多个起始地址作为“种子 URL”,它下载与这些 URL 关联的网页,提取网页中收录的任何超链接,并以递归方式继续这些超链接标识下载网页。从概念上讲,网络爬虫很简单。网络爬虫有四个职责: 1. 从候选者中选择一个 URL。2. 下载相关的 Web 3. 提取网页中的 URL(超链接)。4. 补充了未遇到的URLs候选集方法1:WEB SAS数据步爬虫中的代码首先创建了一个网站网络爬虫将启动的URL列表。数据工作.links_to_crawl;长度 url $256 inputurl 数据线;运行 为确保我们不会多次抓取同一个 URL,已使用该链接创建了数据抓取。当 web 数据集一开始是空的,但是一个 网站 URL 将被添加到数据集爬虫完成对 网站 的爬取。数据work.links_crawled;网址长度 256 美元;跑; 现在我们开始爬行!此代码需要我们的 work.links_to_crawl 数据集的第一个 URL。
在第一个观察“_N_Formula 1”中,URL 被放入一个名为 next_url 的宏变量中,所有剩余的 URL 都被放回我们的种子 URL 数据集中,以使其在未来的迭代中可用。nexturl 关闭 %letnext_url datawork.links_to_crawl; 设置 work.links_to_crawl;callymput("next_url", url); 否则输出;跑; 现在,从互联网上下载网址。创建一个文件名 _nexturl。我们让 SAS 知道这是一个 URL,并且可以找到 AT&next_url,这是我们的宏变量,其中收录我们从 work.links_to_crawl 数据集中提取的 URL。filename_nexturl url "&next_url" 创建一个对文件名的 URL 引用,它决定了放置我们下载文件的位置。创建另一个引用文件名的条目,称为 htmlfilm,并将从 url_file.html 采集的信息放在那里。
查找更多 urls datawork._urls(keep=url); 长度 url $256 filehtmlfile; infile _nexturl 长度=len;输入文本 $varying2000. len; 放文字;起始长度(文本);使用正则表达式 网站 URL 来帮助搜索。文本字符串的正则表达式匹配方法,例如单词、单词或字符模式。SAS 已经提供了许多强大的字符串功能。但是,正则表达式通常提供了一种更简洁的方式来处理和匹配文本。做;保留patternID; pattern '/href=”([^"]+)”/i';patternID prxparse(pattern);end 首先观察到,创建 patternID 将使整个数据步骤保持运行。要查找的模式是:“/href= "([^"]+)"/i'"., 表示我们在寻找字符串 "HREF purpose" 表示使用不区分大小写的方法来匹配我们的正则表达式。
PRXNEXT 有五个参数:我们要查找的正则表达式,开始查找正则表达式的开始位置,停止正则表达式的结束位置,字符串中一旦找到的位置,以及字符串的长度,如果找到的位置将如果未找到字符串,则为 0。PRXNEXT 还更改了 start 参数,以便在找到最后一个匹配项后重新开始搜索。调用 prxnext(patternID, start, stop, text, position, length); 代码中的循环,显示在 网站 上的所有链接的文本。do while (position substr(text,position+6, length-7); output; call prxnext(patternID, start, stop, text, position, length); end; run; 如果代码找到一个 URL,它will 检索在第一个引号之后开始的 URL 的唯一部分。例如,如果代码找到 href="",那么它应该保存。使用 substr 从 URL 的其余部分中删除前 6 个字符和最后一个字符 work._urls 数据集的输出。现在,我们插入 URL 代码只是为了跟踪抓取到我们已经拥有的名为 work.links_crawled 的数据集,并确保我们不再浏览那里。
currentlink urls我们已经爬取了datawork._old_link;网址“&next_url”;运行;proc append base=work.links_crawled data=work._old_link force;跑; 确保: 1. 我们还没有抓取它们,也就是说 URL 不在 work.links_crawled 中)。2.我们没有排队的url进行爬取(即url不在work.links_to_crawl只添加url我们已经爬过queuedup procsql noprint;创建表work._append selecturl from work._urls where url (selecturl from work.links_crawled) (selecturl from work .links_to_crawl); quit; 然后,我们添加尚未被爬取的 URL,尚未排队 work.links_to_crawl addnew links procappend base=work.links_to_crawl data=work._append force; run; 查看全部
c爬虫抓取网页数据(如何轻松定制一个网络爬虫的总体架构环境?)
万维网的大量信息、股票报价、电影评论、市场价格趋势主题以及几乎所有内容都可以通过单击按钮找到。在分析数据的过程中,发现很多SAS用户对网络很感兴趣,但是你获取这些数据的SAS环境呢?有很多方法,例如设计自己的网络爬虫或利用 SAS %TMFILTER 文本挖掘的 SAS 数据步骤中的代码。在本文中,我们将回顾网络爬虫的一般架构。我们将讨论将 网站 信息导入 SAS 的方法,并在内部查看来自名为 SAS Search 的实验项目的实验代码管道。我们还将提供有关如何轻松自定义网络爬虫以满足个人需求以及如何将特定数据导入 SAS Miner 的建议。介绍:互联网已成为有用的信息来源。通常是网络上的数据,我们想在SAS内部使用,所以我们需要想办法获取这些数据。最好的方法是使用网络爬虫。SAS 提供了几种从 Web 爬取和提取信息的方法。您可以使用基本 SAS 数据步骤中的代码,或 SAS Text Miner 的 %TMFILTER 宏。虽然目前不可用,但 SAS Search Pipeline 将是一个强大的网络爬虫产品,并为网络爬虫提供更多工具。每种方法都有其优点和缺点,因此根据您想要实现的抓取,最好对其进行审查。SAS 提供了几种从 Web 爬取和提取信息的方法。您可以使用基本 SAS 数据步骤中的代码,或 SAS Text Miner 的 %TMFILTER 宏。虽然目前不可用,但 SAS Search Pipeline 将是一个强大的网络爬虫产品,并为网络爬虫提供更多工具。每种方法都有其优点和缺点,因此根据您想要实现的抓取,最好对其进行审查。SAS 提供了几种从 Web 爬取和提取信息的方法。您可以使用基本 SAS 数据步骤中的代码,或 SAS Text Miner 的 %TMFILTER 宏。虽然目前不可用,但 SAS Search Pipeline 将是一个强大的网络爬虫产品,并为网络爬虫提供更多工具。每种方法都有其优点和缺点,因此根据您想要实现的抓取,最好对其进行审查。
首先,了解网络爬虫的工作原理很重要。在继续之前,您应该熟悉数据步骤代码、宏和 SAS 过程 PROC SQL。网络爬虫概述:网络爬虫是一个程序,具有一个或多个起始地址作为“种子 URL”,它下载与这些 URL 关联的网页,提取网页中收录的任何超链接,并以递归方式继续这些超链接标识下载网页。从概念上讲,网络爬虫很简单。网络爬虫有四个职责: 1. 从候选者中选择一个 URL。2. 下载相关的 Web 3. 提取网页中的 URL(超链接)。4. 补充了未遇到的URLs候选集方法1:WEB SAS数据步爬虫中的代码首先创建了一个网站网络爬虫将启动的URL列表。数据工作.links_to_crawl;长度 url $256 inputurl 数据线;运行 为确保我们不会多次抓取同一个 URL,已使用该链接创建了数据抓取。当 web 数据集一开始是空的,但是一个 网站 URL 将被添加到数据集爬虫完成对 网站 的爬取。数据work.links_crawled;网址长度 256 美元;跑; 现在我们开始爬行!此代码需要我们的 work.links_to_crawl 数据集的第一个 URL。
在第一个观察“_N_Formula 1”中,URL 被放入一个名为 next_url 的宏变量中,所有剩余的 URL 都被放回我们的种子 URL 数据集中,以使其在未来的迭代中可用。nexturl 关闭 %letnext_url datawork.links_to_crawl; 设置 work.links_to_crawl;callymput("next_url", url); 否则输出;跑; 现在,从互联网上下载网址。创建一个文件名 _nexturl。我们让 SAS 知道这是一个 URL,并且可以找到 AT&next_url,这是我们的宏变量,其中收录我们从 work.links_to_crawl 数据集中提取的 URL。filename_nexturl url "&next_url" 创建一个对文件名的 URL 引用,它决定了放置我们下载文件的位置。创建另一个引用文件名的条目,称为 htmlfilm,并将从 url_file.html 采集的信息放在那里。
查找更多 urls datawork._urls(keep=url); 长度 url $256 filehtmlfile; infile _nexturl 长度=len;输入文本 $varying2000. len; 放文字;起始长度(文本);使用正则表达式 网站 URL 来帮助搜索。文本字符串的正则表达式匹配方法,例如单词、单词或字符模式。SAS 已经提供了许多强大的字符串功能。但是,正则表达式通常提供了一种更简洁的方式来处理和匹配文本。做;保留patternID; pattern '/href=”([^"]+)”/i';patternID prxparse(pattern);end 首先观察到,创建 patternID 将使整个数据步骤保持运行。要查找的模式是:“/href= "([^"]+)"/i'"., 表示我们在寻找字符串 "HREF purpose" 表示使用不区分大小写的方法来匹配我们的正则表达式。
PRXNEXT 有五个参数:我们要查找的正则表达式,开始查找正则表达式的开始位置,停止正则表达式的结束位置,字符串中一旦找到的位置,以及字符串的长度,如果找到的位置将如果未找到字符串,则为 0。PRXNEXT 还更改了 start 参数,以便在找到最后一个匹配项后重新开始搜索。调用 prxnext(patternID, start, stop, text, position, length); 代码中的循环,显示在 网站 上的所有链接的文本。do while (position substr(text,position+6, length-7); output; call prxnext(patternID, start, stop, text, position, length); end; run; 如果代码找到一个 URL,它will 检索在第一个引号之后开始的 URL 的唯一部分。例如,如果代码找到 href="",那么它应该保存。使用 substr 从 URL 的其余部分中删除前 6 个字符和最后一个字符 work._urls 数据集的输出。现在,我们插入 URL 代码只是为了跟踪抓取到我们已经拥有的名为 work.links_crawled 的数据集,并确保我们不再浏览那里。
currentlink urls我们已经爬取了datawork._old_link;网址“&next_url”;运行;proc append base=work.links_crawled data=work._old_link force;跑; 确保: 1. 我们还没有抓取它们,也就是说 URL 不在 work.links_crawled 中)。2.我们没有排队的url进行爬取(即url不在work.links_to_crawl只添加url我们已经爬过queuedup procsql noprint;创建表work._append selecturl from work._urls where url (selecturl from work.links_crawled) (selecturl from work .links_to_crawl); quit; 然后,我们添加尚未被爬取的 URL,尚未排队 work.links_to_crawl addnew links procappend base=work.links_to_crawl data=work._append force; run;
c爬虫抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-10 16:06
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1. 正则表达式
如果您是正则表达式的新手,或者需要一些提示,请查看正则表达式 HOWTO 以获得完整的介绍。
当我们使用正则表达式抓取国家/地区数据时,我们首先尝试匹配元素的内容,如下所示:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从以上结果可以看出,标签用于多个国家属性。要隔离 area 属性,我们只需选择其中的第二个元素,如下所示:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然这个方案现在可用,但如果页面发生变化,它很可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们也可以添加它的父元素。由于元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来好一点,但是网页更新还有很多其他的方式也会让这个正则表达式不令人满意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。下面是一个尝试支持这些可能性的改进版本。
>>> re.findall('.*?(.*?)',html)['244,820 square kilometres']
虽然这个正则表达式更容易适应未来的变化,但它也存在构造困难、可读性差的问题。此外,还有一些细微的布局更改可能会使此正则表达式无法令人满意,例如为标签添加标题属性。
从这个例子可以看出,正则表达式为我们提供了一种抓取数据的捷径,但是这种方法过于脆弱,在页面更新后容易出现问题。好在还有一些更好的解决方案,后面会介绍。
2. 靓汤
Beautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装其最新版本(需要先安装pip,请自行百度):
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个汤文档。由于大多数网页不是格式良好的 HTML,Beautiful Soup 需要确定它们的实际格式。例如,在下面这个简单网页的清单中,存在属性值和未闭合标签周围缺少引号的问题。
Area
Population
如果 Population 列表项被解析为 Area 列表项的子项,而不是两个并排的列表项,我们在抓取时会得到错误的结果。让我们看看Beautiful Soup是如何处理它的。
>>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup 能够正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注意:由于不同版本的Python内置库的容错能力存在差异,处理结果可能与上述不同。详情请参阅: 。想知道所有的方法和参数,可以参考 Beautiful Soup 的官方文档
以下是使用此方法提取样本国家地区数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
此代码虽然比正则表达式代码更复杂,但更易于构建和理解。此外,布局中的一些小变化,例如额外的空白和制表符属性,我们不再需要担心它了。
3. Lxml
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。模块用C语言编写,解析速度比Beautiful Soup快,但安装过程比较复杂。最新安装说明可以参考。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将可能无效的 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同样,lxml 正确解析属性周围缺少的引号并关闭标签,但模块不会添加和标签。
解析输入后,是时候选择元素了。此时,lxml 有几种不同的方法,例如 XPath 选择器和 Beautiful Soup 之类的 find() 方法。但是,我们将来会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重用。此外,一些有 jQuery 选择器经验的读者会更熟悉它。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到ID为places_area__row的表格行元素,然后选择类为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 在
Lxml 已经实现了大部分 CSS3 属性,其不支持的功能可以在: .
注意:lxml 的内部实现实际上将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能比较
在下面的代码中,每个爬虫会执行1000次,每次执行都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com ... %2339;).read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 *line 代码中调用了 re.purge() 方法。默认情况下,正则表达式会缓存搜索结果,公平起见,我们需要使用这种方法来清除缓存。
这是在我的计算机上运行脚本的结果:
由于硬件条件的不同,不同计算机的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,Beautiful Soup 在爬取我们的示例网页时比其他两种方法慢 7 倍以上。事实上,这个结果是意料之中的,因为 lxml 和正则表达式模块是用 C 编写的,而 Beautiful Soup 是用纯 Python 编写的。一个有趣的事实是 lxml 的性能与正则表达式差不多。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当爬取同一个网页的多个特征时,这个初始解析的开销会减少,lxml会更有竞争力,所以lxml是一个强大的模块。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用难度 安装难度
正则表达式
快的
困难
简单(内置模块)
美丽的汤
慢的
简单的
简单(纯 Python)
lxml
快的
简单的
比较困难
如果您的爬虫的瓶颈是下载页面,而不是提取数据,那么使用较慢的方法(如 Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,除了可以避免解析整个网页的开销,如果只需要抓取少量数据并想避免额外的依赖,那么正则表达式可能更适合. 但是,总的来说,lxml 是抓取数据的最佳选择,因为它不仅速度更快,功能更强大,而正则表达式和 Beautiful Soup 仅在某些场景下才有用。 查看全部
c爬虫抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1. 正则表达式
如果您是正则表达式的新手,或者需要一些提示,请查看正则表达式 HOWTO 以获得完整的介绍。
当我们使用正则表达式抓取国家/地区数据时,我们首先尝试匹配元素的内容,如下所示:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从以上结果可以看出,标签用于多个国家属性。要隔离 area 属性,我们只需选择其中的第二个元素,如下所示:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然这个方案现在可用,但如果页面发生变化,它很可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们也可以添加它的父元素。由于元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来好一点,但是网页更新还有很多其他的方式也会让这个正则表达式不令人满意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。下面是一个尝试支持这些可能性的改进版本。
>>> re.findall('.*?(.*?)',html)['244,820 square kilometres']
虽然这个正则表达式更容易适应未来的变化,但它也存在构造困难、可读性差的问题。此外,还有一些细微的布局更改可能会使此正则表达式无法令人满意,例如为标签添加标题属性。
从这个例子可以看出,正则表达式为我们提供了一种抓取数据的捷径,但是这种方法过于脆弱,在页面更新后容易出现问题。好在还有一些更好的解决方案,后面会介绍。
2. 靓汤
Beautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装其最新版本(需要先安装pip,请自行百度):
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个汤文档。由于大多数网页不是格式良好的 HTML,Beautiful Soup 需要确定它们的实际格式。例如,在下面这个简单网页的清单中,存在属性值和未闭合标签周围缺少引号的问题。
Area
Population
如果 Population 列表项被解析为 Area 列表项的子项,而不是两个并排的列表项,我们在抓取时会得到错误的结果。让我们看看Beautiful Soup是如何处理它的。
>>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup 能够正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注意:由于不同版本的Python内置库的容错能力存在差异,处理结果可能与上述不同。详情请参阅: 。想知道所有的方法和参数,可以参考 Beautiful Soup 的官方文档
以下是使用此方法提取样本国家地区数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
此代码虽然比正则表达式代码更复杂,但更易于构建和理解。此外,布局中的一些小变化,例如额外的空白和制表符属性,我们不再需要担心它了。
3. Lxml
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。模块用C语言编写,解析速度比Beautiful Soup快,但安装过程比较复杂。最新安装说明可以参考。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将可能无效的 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同样,lxml 正确解析属性周围缺少的引号并关闭标签,但模块不会添加和标签。
解析输入后,是时候选择元素了。此时,lxml 有几种不同的方法,例如 XPath 选择器和 Beautiful Soup 之类的 find() 方法。但是,我们将来会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重用。此外,一些有 jQuery 选择器经验的读者会更熟悉它。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到ID为places_area__row的表格行元素,然后选择类为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 在
Lxml 已经实现了大部分 CSS3 属性,其不支持的功能可以在: .
注意:lxml 的内部实现实际上将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能比较
在下面的代码中,每个爬虫会执行1000次,每次执行都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com ... %2339;).read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 *line 代码中调用了 re.purge() 方法。默认情况下,正则表达式会缓存搜索结果,公平起见,我们需要使用这种方法来清除缓存。
这是在我的计算机上运行脚本的结果:

由于硬件条件的不同,不同计算机的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,Beautiful Soup 在爬取我们的示例网页时比其他两种方法慢 7 倍以上。事实上,这个结果是意料之中的,因为 lxml 和正则表达式模块是用 C 编写的,而 Beautiful Soup 是用纯 Python 编写的。一个有趣的事实是 lxml 的性能与正则表达式差不多。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当爬取同一个网页的多个特征时,这个初始解析的开销会减少,lxml会更有竞争力,所以lxml是一个强大的模块。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用难度 安装难度
正则表达式
快的
困难
简单(内置模块)
美丽的汤
慢的
简单的
简单(纯 Python)
lxml
快的
简单的
比较困难
如果您的爬虫的瓶颈是下载页面,而不是提取数据,那么使用较慢的方法(如 Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,除了可以避免解析整个网页的开销,如果只需要抓取少量数据并想避免额外的依赖,那么正则表达式可能更适合. 但是,总的来说,lxml 是抓取数据的最佳选择,因为它不仅速度更快,功能更强大,而正则表达式和 Beautiful Soup 仅在某些场景下才有用。
c爬虫抓取网页数据(爬取的人物画像(数据的实时性)难点打赏礼物)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-09 10:13
后台抓取某直播平台信息和普通网站直播平台数据有热门主播在线数,经常,热门直播的送礼情况(粉丝头像) 送礼难度人像httpswss(实时数据),需要模拟匿名用户的访问。一个直播的wss数据网站是一个大二进制数据头的js代码。您需要先模拟匿名登录才能获取二进制数据。然后分析网站的js代码进行分析。找到工具chrome developer tool,选择f12 ws,你只能看到帧在移动和我们两个不认识的二进制。Wireshark,遗憾的是,我报了很大的希望,但是通过websocket找不到,我马上分析了一下。我想我不知道如何拦截它。稍后我会研究如何使用它。看到有人说直接搜索websocket就可以看到。. 但是通过websocket过滤器我真的找不到我想要的数据。除非通过ip.addr ip.src 等charles,意外发现。名副其实,查尔斯。虽然一开始不太好用,但总算搞定了,下面详细说说怎么用。首先激活charles工具 一开始不太好用,终于搞定了,下面详细说说怎么用。首先激活charles工具 一开始不太好用,终于搞定了,下面详细说说怎么用。首先激活charles工具
// Charles Proxy License
// 适用于Charles任意版本的注册码,谁还会想要使用破解版呢。
// Charles 4.2目前是最新版,可用。
Registered Name: https://zhile.io
License Key: 48891cf209c6d32bf4
安装 ssl 证书支持
help->SSL proxying->install charles root certificate
下面这篇文章说的非常好
https://www.cnblogs.com/ceshij ... .html
设置代理,和上面的文章一样,但是我推荐使用*:443查看结果。在浏览器上访问你要访问的网站普通https网页。您已经可以看到背面的内容。同样wss的爬取也出来了,只是具体的二进制数据。还是需要你自己分析
目前可以抓到数据,下一步就是对二进制数据进行分析解析,得到有价值的数据。
原创文章,版权所有,禁止抄袭,违者必究!!!请注明出处!!!技术需求请联系。 查看全部
c爬虫抓取网页数据(爬取的人物画像(数据的实时性)难点打赏礼物)
后台抓取某直播平台信息和普通网站直播平台数据有热门主播在线数,经常,热门直播的送礼情况(粉丝头像) 送礼难度人像httpswss(实时数据),需要模拟匿名用户的访问。一个直播的wss数据网站是一个大二进制数据头的js代码。您需要先模拟匿名登录才能获取二进制数据。然后分析网站的js代码进行分析。找到工具chrome developer tool,选择f12 ws,你只能看到帧在移动和我们两个不认识的二进制。Wireshark,遗憾的是,我报了很大的希望,但是通过websocket找不到,我马上分析了一下。我想我不知道如何拦截它。稍后我会研究如何使用它。看到有人说直接搜索websocket就可以看到。. 但是通过websocket过滤器我真的找不到我想要的数据。除非通过ip.addr ip.src 等charles,意外发现。名副其实,查尔斯。虽然一开始不太好用,但总算搞定了,下面详细说说怎么用。首先激活charles工具 一开始不太好用,终于搞定了,下面详细说说怎么用。首先激活charles工具 一开始不太好用,终于搞定了,下面详细说说怎么用。首先激活charles工具
// Charles Proxy License
// 适用于Charles任意版本的注册码,谁还会想要使用破解版呢。
// Charles 4.2目前是最新版,可用。
Registered Name: https://zhile.io
License Key: 48891cf209c6d32bf4
安装 ssl 证书支持
help->SSL proxying->install charles root certificate
下面这篇文章说的非常好
https://www.cnblogs.com/ceshij ... .html
设置代理,和上面的文章一样,但是我推荐使用*:443查看结果。在浏览器上访问你要访问的网站普通https网页。您已经可以看到背面的内容。同样wss的爬取也出来了,只是具体的二进制数据。还是需要你自己分析


目前可以抓到数据,下一步就是对二进制数据进行分析解析,得到有价值的数据。
原创文章,版权所有,禁止抄袭,违者必究!!!请注明出处!!!技术需求请联系。
c爬虫抓取网页数据(talkischeap,showmethecodeshowthe )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-09 10:10
)
谈话很便宜,给我看代码:
#coding=utf-8
import sys
from scrapy.spider import BaseSpider
from scrapy.selector import Selector
from scrapy.contrib.spiders import CrawlSpider,Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
import json
reload(sys)
sys.setdefaultencoding('utf8')
class DmozSpider(BaseSpider):
name = "dmoz"
allowed_domains=[""]
start_urls=["http://www.jjkjj.gov.cn/"]
def parse(self,response):
filename = response.url.split("/")[-2]
titles=[] titles.extend(response.selector.xpath('//div[@class ="Work_News_line"]/a/text()').extract())
open(filename,'w').write(json.dumps(titles, encoding="gb2312", ensure_ascii=False))
我们来分析一下代码:
from scrapy.spider import BaseSpider
这是基于单页的爬取,所以使用BaseSpider,基于链接跳转的爬虫可以看第二篇文章
name = "dmoz"
allowed_domains=[""]
start_urls=["http://www.jjkjj.gov.cn/"]
start_urls是主域名,
所以 allowed_domain 设置为空
def parse(self,response):
filename = response.url.split("/")[-2]
titles=[] titles.extend(response.selector.xpath('//div[@class ="Work_News_line"]/a/text()').extract())
这个markdown编辑器的缩进有问题,titles.extend... 这行要和上一行保持一样的缩进,否则会报错
Python 运行时错误,引发 notImplementedError
遇到此类错误,检查缩进,一般可以解决
接下来看xpath表达式,
具体含义是:找到class属性为“Work_News_line”的div,以及它下面label的值
extract()函数 返回一个unicode字符串,该字符串为XPath选择器返回的数据
xpath的使用有几点需要注意
上面第二篇文章中,xpath的使用方式是:
sel=Selector(response) item=DoubanmoiveItem() item['name']=sel.xpath('//[@id="content"]/h1/span[1]/text()').extract()
新版本的scrapy不建议这样做
所以我把它改成了上面的
接下来是最头疼的中文显示问题
在shell中查看xpath查询结果:
一堆Unicode字符,其实这也算是捕获成功了,但是基本不可用,还是需要转成中文的。
感觉scrapy,甚至python,在字符集上都不是很好,
再看上面的代码:
titles=[] titles.extend(response.selector.xpath('//div[@class ="Work_News_line"]/a/text()').extract())
这里声明了一个列表。每次查询到一个值,就将其放入列表中,然后列表需要转换成字符串写入文件。
python本身提供了str()方法可以将任意对象转换成字符串,但是不支持中文,转换后的字符串还是unicode编码的。
详情见此贴:str字符串转换
一种解决方法是使用python自带的json模块
open(filename,'w').write(json.dumps(titles, encoding="gb2312", ensure_ascii=False))
没关系
我们将捕获的数据写入文件,我们来看看结果:
查看全部
c爬虫抓取网页数据(talkischeap,showmethecodeshowthe
)
谈话很便宜,给我看代码:
#coding=utf-8
import sys
from scrapy.spider import BaseSpider
from scrapy.selector import Selector
from scrapy.contrib.spiders import CrawlSpider,Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
import json
reload(sys)
sys.setdefaultencoding('utf8')
class DmozSpider(BaseSpider):
name = "dmoz"
allowed_domains=[""]
start_urls=["http://www.jjkjj.gov.cn/"]
def parse(self,response):
filename = response.url.split("/")[-2]
titles=[] titles.extend(response.selector.xpath('//div[@class ="Work_News_line"]/a/text()').extract())
open(filename,'w').write(json.dumps(titles, encoding="gb2312", ensure_ascii=False))
我们来分析一下代码:
from scrapy.spider import BaseSpider
这是基于单页的爬取,所以使用BaseSpider,基于链接跳转的爬虫可以看第二篇文章
name = "dmoz"
allowed_domains=[""]
start_urls=["http://www.jjkjj.gov.cn/"]
start_urls是主域名,
所以 allowed_domain 设置为空
def parse(self,response):
filename = response.url.split("/")[-2]
titles=[] titles.extend(response.selector.xpath('//div[@class ="Work_News_line"]/a/text()').extract())
这个markdown编辑器的缩进有问题,titles.extend... 这行要和上一行保持一样的缩进,否则会报错
Python 运行时错误,引发 notImplementedError
遇到此类错误,检查缩进,一般可以解决
接下来看xpath表达式,
具体含义是:找到class属性为“Work_News_line”的div,以及它下面label的值
extract()函数 返回一个unicode字符串,该字符串为XPath选择器返回的数据
xpath的使用有几点需要注意
上面第二篇文章中,xpath的使用方式是:
sel=Selector(response) item=DoubanmoiveItem() item['name']=sel.xpath('//[@id="content"]/h1/span[1]/text()').extract()
新版本的scrapy不建议这样做

所以我把它改成了上面的
接下来是最头疼的中文显示问题
在shell中查看xpath查询结果:
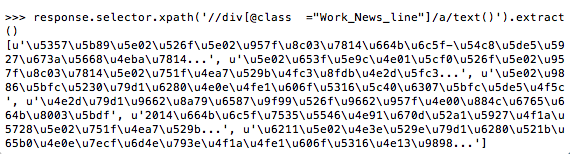
一堆Unicode字符,其实这也算是捕获成功了,但是基本不可用,还是需要转成中文的。
感觉scrapy,甚至python,在字符集上都不是很好,
再看上面的代码:
titles=[] titles.extend(response.selector.xpath('//div[@class ="Work_News_line"]/a/text()').extract())
这里声明了一个列表。每次查询到一个值,就将其放入列表中,然后列表需要转换成字符串写入文件。
python本身提供了str()方法可以将任意对象转换成字符串,但是不支持中文,转换后的字符串还是unicode编码的。
详情见此贴:str字符串转换
一种解决方法是使用python自带的json模块
open(filename,'w').write(json.dumps(titles, encoding="gb2312", ensure_ascii=False))
没关系
我们将捕获的数据写入文件,我们来看看结果:
c爬虫抓取网页数据(WEBCRAWLER网络爬虫实训项目1WEBCRAWLER网络爬虫实训项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-08 00:16
WEBCRAWLER 网络爬虫培训项目1 WEBCRAWLER 网络爬虫培训项目文档版本:1.0.0.1 作者:Dane IT Training Group C++教学研发部作者:Min Wei 定稿日期:11月,星期五20, 2015 WEBCRAWLER 网络爬虫培训项目21. 项目概述 互联网产品种类繁多,以产品为导向,以营销为导向,以技术为导向,但掌握技术的互联网产品占比较高。更小。搜索引擎是目前互联网产品中技术最先进的产品,如果不是唯一的,至少也是其中之一。经过十多年的发展,搜索引擎已经成为互联网的重要门户之一。Twitter联合创始人埃文威廉姆斯提出“
WEBCRAWLER网络爬虫训练项目3这样海量的数据如何获取、存储和计算?如何快速响应用户查询?如何让搜索结果尽可能满足用户对信息的需求?这些都是搜索引擎设计者必须面对的技术挑战。下图展示了一个通用搜索引擎的基本结构。商业级搜索引擎通常由许多独立的模块组成。每个模块只负责搜索引擎的部分功能,相互配合形成一个完整的搜索引擎:搜索引擎的信息源来自网页,整个“网络爬虫”的信息“互联网”在本地获取,由于网页上的大部分内容完全相同或几乎重复,“网页去重”模块会检测到并删除重复的内容。之后,搜索引擎将解析网页,提取网页的主要内容,以及指向该网页中收录的其他页面的所谓超链接。为了加快用户查询的响应速度,通过“倒排索引”的高效查询数据结构保存网页内容,同时保存网页之间的链接关系。之所以保存链接关系,是因为在网页的相关性排名阶段,这个关系是可用的。页面的相对重要性可以通过“链接分析”来判断,这对于为用户提供准确的搜索结果非常有帮助。由于网页数量众多,搜索引擎不仅需要保存网页的原创信息,还需要保存一些中间处理结果。使用单台计算机或少量计算机显然是不现实的。
谷歌等商业搜索引擎提供商为此开发了一套完整的云存储和云计算平台,利用数以万计的普通PCWEBCRAWLER网络爬虫训练项目4,构建了海量信息作为搜索的可靠存储和计算架构引擎及其相关应用的基础支持。优秀的云存储和云计算平台已成为大型商业搜索引擎的核心竞争力。以上就是搜索引擎获取和存储海量网页相关信息的方式。由于这些功能不需要实时计算,可以看作是搜索引擎的后端计算系统。搜索引擎的首要目标当然是为用户提供准确、全面的搜索结果。因此,实时响应用户查询并提供准确结果构成了搜索引擎的前端计算系统。搜索引擎收到用户的查询请求后,首先需要对查询词进行分析,并通过与用户信息的结合,正确推断出用户的真实搜索意图。之后,首先查看“缓存系统”维护的缓存。搜索引擎的缓存存储了不同的搜索意图及其对应的搜索结果。如果在缓存中找到满足用户需求的信息,则直接将搜索结果返回给用户。这不仅节省了重复计算的资源消耗,同时也加快了整个搜索过程的响应速度。而如果缓存中没有找到满足用户需求的信息,则需要使用“页面排序”,根据用户的搜索意图实时计算哪些网页满足用户需求,并将输出排序为搜索结果。
网页排名最重要的两个参考因素是“内容相似度”,即哪些网页与用户的搜索意图密切相关;另一个是网页重要性,即哪些网页质量好或相对重要。这通常可以从“链接分析”的结果中获得。结合以上两种考虑,前端系统将网页进行排序,作为搜索的最终结果。除了上述功能模块外,搜索引擎的“反作弊”模块近年来也越来越受到关注。搜索引擎作为网民上网的入口,对网络流量的引导和分流至关重要,甚至可以说起到了举足轻重的作用。因此,各种“作弊” 方法逐渐流行起来。各种方法被用来将网页的搜索排名提升到与网页质量不相称的位置,这将严重影响用户的搜索体验。因此,如何自动发现作弊网页并给予相应的惩罚,成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页数量已达数百万,因此搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 各种方法被用来将网页的搜索排名提升到与网页质量不相称的位置,这将严重影响用户的搜索体验。因此,如何自动发现作弊网页并给予相应的惩罚,成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页数量已达数百万,因此搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 各种方法被用来将网页的搜索排名提升到与网页质量不相称的位置,这将严重影响用户的搜索体验。因此,如何自动发现作弊网页并给予相应的惩罚,成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页数量已达数百万,因此搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 如何自动发现作弊网页并给予相应的惩罚已经成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页数量已达数百万,因此搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 如何自动发现作弊网页并给予相应的惩罚已经成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页数量已达数百万,因此搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 查看全部
c爬虫抓取网页数据(WEBCRAWLER网络爬虫实训项目1WEBCRAWLER网络爬虫实训项目)
WEBCRAWLER 网络爬虫培训项目1 WEBCRAWLER 网络爬虫培训项目文档版本:1.0.0.1 作者:Dane IT Training Group C++教学研发部作者:Min Wei 定稿日期:11月,星期五20, 2015 WEBCRAWLER 网络爬虫培训项目21. 项目概述 互联网产品种类繁多,以产品为导向,以营销为导向,以技术为导向,但掌握技术的互联网产品占比较高。更小。搜索引擎是目前互联网产品中技术最先进的产品,如果不是唯一的,至少也是其中之一。经过十多年的发展,搜索引擎已经成为互联网的重要门户之一。Twitter联合创始人埃文威廉姆斯提出“
WEBCRAWLER网络爬虫训练项目3这样海量的数据如何获取、存储和计算?如何快速响应用户查询?如何让搜索结果尽可能满足用户对信息的需求?这些都是搜索引擎设计者必须面对的技术挑战。下图展示了一个通用搜索引擎的基本结构。商业级搜索引擎通常由许多独立的模块组成。每个模块只负责搜索引擎的部分功能,相互配合形成一个完整的搜索引擎:搜索引擎的信息源来自网页,整个“网络爬虫”的信息“互联网”在本地获取,由于网页上的大部分内容完全相同或几乎重复,“网页去重”模块会检测到并删除重复的内容。之后,搜索引擎将解析网页,提取网页的主要内容,以及指向该网页中收录的其他页面的所谓超链接。为了加快用户查询的响应速度,通过“倒排索引”的高效查询数据结构保存网页内容,同时保存网页之间的链接关系。之所以保存链接关系,是因为在网页的相关性排名阶段,这个关系是可用的。页面的相对重要性可以通过“链接分析”来判断,这对于为用户提供准确的搜索结果非常有帮助。由于网页数量众多,搜索引擎不仅需要保存网页的原创信息,还需要保存一些中间处理结果。使用单台计算机或少量计算机显然是不现实的。
谷歌等商业搜索引擎提供商为此开发了一套完整的云存储和云计算平台,利用数以万计的普通PCWEBCRAWLER网络爬虫训练项目4,构建了海量信息作为搜索的可靠存储和计算架构引擎及其相关应用的基础支持。优秀的云存储和云计算平台已成为大型商业搜索引擎的核心竞争力。以上就是搜索引擎获取和存储海量网页相关信息的方式。由于这些功能不需要实时计算,可以看作是搜索引擎的后端计算系统。搜索引擎的首要目标当然是为用户提供准确、全面的搜索结果。因此,实时响应用户查询并提供准确结果构成了搜索引擎的前端计算系统。搜索引擎收到用户的查询请求后,首先需要对查询词进行分析,并通过与用户信息的结合,正确推断出用户的真实搜索意图。之后,首先查看“缓存系统”维护的缓存。搜索引擎的缓存存储了不同的搜索意图及其对应的搜索结果。如果在缓存中找到满足用户需求的信息,则直接将搜索结果返回给用户。这不仅节省了重复计算的资源消耗,同时也加快了整个搜索过程的响应速度。而如果缓存中没有找到满足用户需求的信息,则需要使用“页面排序”,根据用户的搜索意图实时计算哪些网页满足用户需求,并将输出排序为搜索结果。
网页排名最重要的两个参考因素是“内容相似度”,即哪些网页与用户的搜索意图密切相关;另一个是网页重要性,即哪些网页质量好或相对重要。这通常可以从“链接分析”的结果中获得。结合以上两种考虑,前端系统将网页进行排序,作为搜索的最终结果。除了上述功能模块外,搜索引擎的“反作弊”模块近年来也越来越受到关注。搜索引擎作为网民上网的入口,对网络流量的引导和分流至关重要,甚至可以说起到了举足轻重的作用。因此,各种“作弊” 方法逐渐流行起来。各种方法被用来将网页的搜索排名提升到与网页质量不相称的位置,这将严重影响用户的搜索体验。因此,如何自动发现作弊网页并给予相应的惩罚,成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页数量已达数百万,因此搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 各种方法被用来将网页的搜索排名提升到与网页质量不相称的位置,这将严重影响用户的搜索体验。因此,如何自动发现作弊网页并给予相应的惩罚,成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页数量已达数百万,因此搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 各种方法被用来将网页的搜索排名提升到与网页质量不相称的位置,这将严重影响用户的搜索体验。因此,如何自动发现作弊网页并给予相应的惩罚,成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页数量已达数百万,因此搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 如何自动发现作弊网页并给予相应的惩罚已经成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页数量已达数百万,因此搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 如何自动发现作弊网页并给予相应的惩罚已经成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页数量已达数百万,因此搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联
c爬虫抓取网页数据(具有一定的参考价值安装mysql需要屏蔽掉相关代码:抓取网页数据格式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-07 19:14
本文文章主要介绍python2.7,详细实现爬虫网页数据。有一定的参考价值,感兴趣的朋友可以参考
最近刚学了Python,做了一个简单的爬虫。作为一个简单的demo,希望对我这样的初学者有所帮助。
代码使用python制作的爬虫2.7抓取51job上的职位名称、公司名称、工资、发布时间等。
直接上代码。代码中的注释相当清楚。如果没有安装mysql,需要屏蔽相关代码:
#!/usr/bin/python # -*- coding: UTF-8 -*- from bs4 import BeautifulSoup import urllib import urllib2 import codecs import re import time import logging import MySQLdb class Jobs(object): # 初始化 """docstring for Jobs""" def __init__(self): super(Jobs, self).__init__() logging.basicConfig(level=logging.DEBUG, format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s') #数据库的操作,没有mysql可以做屏蔽 self.db = MySQLdb.connect('127.0.0.1','root','rootroot','MySQL_Test',charset='utf8') self.cursor = self.db.cursor() #log日志的显示 self.logger = logging.getLogger("sjk") self.logger.setLevel(level=logging.DEBUG) formatter = logging.Formatter( '%(asctime)s - %(name)s - %(levelname)s - %(message)s') handler = logging.FileHandler('log.txt') handler.setFormatter(formatter) handler.setLevel(logging.DEBUG) self.logger.addHandler(handler) self.logger.info('初始化完成') # 模拟请求数据 def jobshtml(self, key, page='1'): try: self.logger.info('开始请求第' + page + '页') #网页url searchurl = "https://search.51job.com/list/040000,000000,0000,00,9,99,{key},2,{page}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=" user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:59.0) Gecko/20100101 Firefox/59.0' #设置请求头 header = {'User-Agent': user_agent, 'Host': 'search.51job.com', 'Referer': 'https://www.51job.com/'} #拼接url finalUrl = searchurl.format(key=key, page=page) request = urllib2.Request(finalUrl, headers=header) response = urllib2.urlopen(request) #等待网页加载完成 time.sleep(3) #gbk格式解码 info = response.read().decode('gbk') self.logger.info('请求网页网页') self.decodeHtml(info=info, key=key, page=page) except urllib2.HTTPError as e: print e.reason # 解析网页数据 def decodeHtml(self, info, key, page): self.logger.info('开始解析网页数据') #BeautifulSoup 解析网页 soup = BeautifulSoup(info, 'html.parser') #找到class = t1 t2 t3 t4 t5 的标签数据 ps = soup.find_all(attrs={"class": re.compile(r'^t[1-5].*')}) #打开txt文件 a+ 代表追加 f = codecs.open(key + '.txt', 'a+', 'UTF-8') #清除之前的数据信息 f.truncate() f.write('\n------------' + page + '--------------\n') count = 1 arr = [] #做一些字符串的处理,形成数据格式 iOS开发工程师 有限公司 深圳-南山区 0.9-1.6万/月 05-16 for pi in ps: spe = " " finalstr = pi.getText().strip() arr.append(finalstr) if count % 5 == 0: #每一条数据插入数据库,如果没有安装mysql 可以将当前行注释掉 self.connectMySQL(arr=arr) arr = [] spe = "\n" writestr = finalstr + spe count += 1 f.write(writestr) f.close() self.logger.info('解析完成') #数据库操作 没有安装mysql 可以屏蔽掉 def connectMySQL(self,arr): work=arr[0] company=arr[1] place=arr[2] salary=arr[3] time=arr[4] query = "select * from Jobs_tab where \ company_name='%s' and work_name='%s' and work_place='%s' \ and salary='%s' and time='%s'" %(company,work,place,salary,time) self.cursor.execute(query) queryresult = self.cursor.fetchall() #数据库中不存在就插入数据 存在就可以更新数据 不过我这边没有写 if len(queryresult) > 0: sql = "insert into Jobs_tab(work_name,company_name,work_place,salary\ ,time) values('%s','%s','%s','%s','%s')" %(work,company,place,salary,time) try: self.cursor.execute(sql) self.db.commit() except Exception as e: self.logger.info('写入数据库失败') #模拟登陆 # def login(self): # data = {'action':'save','isread':'on','loginname':'18086514327','password':'kui4131sjk'} # 开始抓取 主函数 def run(self, key): # 只要前5页的数据 key代表搜索工做类型 这边我是用的ios page是页数 for x in xrange(1, 6): self.jobshtml(key=key, page=str(x)) self.logger.info('写入数据库完成') self.db.close() if __name__ == '__main__': Jobs().run(key='iOS')
这种方式抓取的网页数据格式如下:
以上是python2.7实现抓取网页数据的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
c爬虫抓取网页数据(具有一定的参考价值安装mysql需要屏蔽掉相关代码:抓取网页数据格式)
本文文章主要介绍python2.7,详细实现爬虫网页数据。有一定的参考价值,感兴趣的朋友可以参考
最近刚学了Python,做了一个简单的爬虫。作为一个简单的demo,希望对我这样的初学者有所帮助。
代码使用python制作的爬虫2.7抓取51job上的职位名称、公司名称、工资、发布时间等。
直接上代码。代码中的注释相当清楚。如果没有安装mysql,需要屏蔽相关代码:
#!/usr/bin/python # -*- coding: UTF-8 -*- from bs4 import BeautifulSoup import urllib import urllib2 import codecs import re import time import logging import MySQLdb class Jobs(object): # 初始化 """docstring for Jobs""" def __init__(self): super(Jobs, self).__init__() logging.basicConfig(level=logging.DEBUG, format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s') #数据库的操作,没有mysql可以做屏蔽 self.db = MySQLdb.connect('127.0.0.1','root','rootroot','MySQL_Test',charset='utf8') self.cursor = self.db.cursor() #log日志的显示 self.logger = logging.getLogger("sjk") self.logger.setLevel(level=logging.DEBUG) formatter = logging.Formatter( '%(asctime)s - %(name)s - %(levelname)s - %(message)s') handler = logging.FileHandler('log.txt') handler.setFormatter(formatter) handler.setLevel(logging.DEBUG) self.logger.addHandler(handler) self.logger.info('初始化完成') # 模拟请求数据 def jobshtml(self, key, page='1'): try: self.logger.info('开始请求第' + page + '页') #网页url searchurl = "https://search.51job.com/list/040000,000000,0000,00,9,99,{key},2,{page}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=" user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:59.0) Gecko/20100101 Firefox/59.0' #设置请求头 header = {'User-Agent': user_agent, 'Host': 'search.51job.com', 'Referer': 'https://www.51job.com/'} #拼接url finalUrl = searchurl.format(key=key, page=page) request = urllib2.Request(finalUrl, headers=header) response = urllib2.urlopen(request) #等待网页加载完成 time.sleep(3) #gbk格式解码 info = response.read().decode('gbk') self.logger.info('请求网页网页') self.decodeHtml(info=info, key=key, page=page) except urllib2.HTTPError as e: print e.reason # 解析网页数据 def decodeHtml(self, info, key, page): self.logger.info('开始解析网页数据') #BeautifulSoup 解析网页 soup = BeautifulSoup(info, 'html.parser') #找到class = t1 t2 t3 t4 t5 的标签数据 ps = soup.find_all(attrs={"class": re.compile(r'^t[1-5].*')}) #打开txt文件 a+ 代表追加 f = codecs.open(key + '.txt', 'a+', 'UTF-8') #清除之前的数据信息 f.truncate() f.write('\n------------' + page + '--------------\n') count = 1 arr = [] #做一些字符串的处理,形成数据格式 iOS开发工程师 有限公司 深圳-南山区 0.9-1.6万/月 05-16 for pi in ps: spe = " " finalstr = pi.getText().strip() arr.append(finalstr) if count % 5 == 0: #每一条数据插入数据库,如果没有安装mysql 可以将当前行注释掉 self.connectMySQL(arr=arr) arr = [] spe = "\n" writestr = finalstr + spe count += 1 f.write(writestr) f.close() self.logger.info('解析完成') #数据库操作 没有安装mysql 可以屏蔽掉 def connectMySQL(self,arr): work=arr[0] company=arr[1] place=arr[2] salary=arr[3] time=arr[4] query = "select * from Jobs_tab where \ company_name='%s' and work_name='%s' and work_place='%s' \ and salary='%s' and time='%s'" %(company,work,place,salary,time) self.cursor.execute(query) queryresult = self.cursor.fetchall() #数据库中不存在就插入数据 存在就可以更新数据 不过我这边没有写 if len(queryresult) > 0: sql = "insert into Jobs_tab(work_name,company_name,work_place,salary\ ,time) values('%s','%s','%s','%s','%s')" %(work,company,place,salary,time) try: self.cursor.execute(sql) self.db.commit() except Exception as e: self.logger.info('写入数据库失败') #模拟登陆 # def login(self): # data = {'action':'save','isread':'on','loginname':'18086514327','password':'kui4131sjk'} # 开始抓取 主函数 def run(self, key): # 只要前5页的数据 key代表搜索工做类型 这边我是用的ios page是页数 for x in xrange(1, 6): self.jobshtml(key=key, page=str(x)) self.logger.info('写入数据库完成') self.db.close() if __name__ == '__main__': Jobs().run(key='iOS')
这种方式抓取的网页数据格式如下:

以上是python2.7实现抓取网页数据的详细内容。更多详情请关注其他相关html中文网站文章!
c爬虫抓取网页数据(待URL队列中的URL以什么样的顺序排列算法的思想 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-07 00:03
)
遍历策略是爬虫的核心问题。在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL的顺序也是一个很重要的问题,因为它涉及到先爬取那个页面,再爬到哪个页面来确定这些URL的顺序,这就是爬取策略爬虫。主要有以下几种策略:
1.深度优先遍历策略:
深度优先遍历测试是指网络爬虫会从起始页开始,逐个跟踪每一个链接。处理完该行的链接后,会转到下一个起始页,继续跟踪该链接。我们用下图为例:
走过的路径是:AFG EHI BCD
但是,我们在做爬虫的时候,深度优先策略可能并不是所有情况都适用。如果深度优先误入无限分支(深度无限),则无法找到目标节点。
二、广度优先遍历策略:
广度优先策略是根据树的级别进行搜索。如果在这一层没有完成搜索,则不会进入下一层搜索。即先完成一层搜索,再进行下一层,也称为分层处理。我们也以上图为例:
遍历路径为:第一次遍历:ABCDEF,第二次遍历:GH,第三次遍历:I
然而,广度优先遍历策略是一种盲目搜索。它没有考虑结果的可能位置,会彻底搜索整个图像,因此效率低。但是,如果您想覆盖尽可能多的网页,广度优先搜索方法是更好的选择。
三、部分PageRank策略:
PageRank算法的思想:对于下载的网页,连同要爬取的URL队列的URL,组成一个网页集,计算每个页面的PageRank值(PageRank算法参考:PageRank算法-从原理到实现),计算完成后,根据页面级别的值排列待爬取队列中的URL,依次爬取URL页面。
如果每次都爬一个新的页面,重新计算出来的PageRank值显然效率太低了。折中是保存足够的网页来计算一次。
下图是web级策略的示意图:
为每下载 3 个网页设置一个新的 PageRank 计算。此时,本地已经下载了3个网页{1,2,3}。这三个网页中收录的链接指向{4,5,6},即要爬取的URL队列。如何确定下载顺序?
把这6个网页组成一个新的集合,计算这个集合的PageRank值,这样4、5、6就会得到各自对应的页面排名值,从大到小排序,就可以得到假设的顺序下载顺序为5,4,6,当下载55页时,提取链接指向第8页,此时临时分配PageRank值为8。如果该值大于 4 和 6 的 PageRank,则将首先下载第 8 页,依此类推。循环,即不完全页面级策略的计算思想形成。
四、OPIC策略策略(在线页面重要性计算):
基本思想:在算法开始之前,给所有页面相同的初始现金(cash)。下载一个页面P后,将P的现金分配给所有从P解析出来的链接,并清空P的现金。所有要爬取的URL队列中的页面按照现金的数量进行排序。
与PageRank不同的是:PageRank每次都需要迭代计算,而OPIC策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。
五、各大站优先策略:
策略:以网站为单位选择网页的重要性。对于URL队列中待抓取的网页,根据自己的网站进行分类。如果哪个网站等待下载的页面最多,先下载这些链接,本质思路倾向于优先下载大的网站。因为大 网站 往往收录更多页面。鉴于大型网站往往是知名公司的内容,而且他们的网页一般都是高质量的,这个想法很简单,但是有一定的依据。实验表明,该算法的效果也应该略优于宽度优先遍历策略。
花生代理动态IP更改软件可实现全国城市IP自动切换,千万级动态IP池,支持过滤,支持电脑手机多终端使用,数万条随机拨号线路, 24小时不间断提供动态IP。
查看全部
c爬虫抓取网页数据(待URL队列中的URL以什么样的顺序排列算法的思想
)
遍历策略是爬虫的核心问题。在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL的顺序也是一个很重要的问题,因为它涉及到先爬取那个页面,再爬到哪个页面来确定这些URL的顺序,这就是爬取策略爬虫。主要有以下几种策略:
1.深度优先遍历策略:
深度优先遍历测试是指网络爬虫会从起始页开始,逐个跟踪每一个链接。处理完该行的链接后,会转到下一个起始页,继续跟踪该链接。我们用下图为例:
走过的路径是:AFG EHI BCD
但是,我们在做爬虫的时候,深度优先策略可能并不是所有情况都适用。如果深度优先误入无限分支(深度无限),则无法找到目标节点。
二、广度优先遍历策略:
广度优先策略是根据树的级别进行搜索。如果在这一层没有完成搜索,则不会进入下一层搜索。即先完成一层搜索,再进行下一层,也称为分层处理。我们也以上图为例:
遍历路径为:第一次遍历:ABCDEF,第二次遍历:GH,第三次遍历:I
然而,广度优先遍历策略是一种盲目搜索。它没有考虑结果的可能位置,会彻底搜索整个图像,因此效率低。但是,如果您想覆盖尽可能多的网页,广度优先搜索方法是更好的选择。
三、部分PageRank策略:
PageRank算法的思想:对于下载的网页,连同要爬取的URL队列的URL,组成一个网页集,计算每个页面的PageRank值(PageRank算法参考:PageRank算法-从原理到实现),计算完成后,根据页面级别的值排列待爬取队列中的URL,依次爬取URL页面。
如果每次都爬一个新的页面,重新计算出来的PageRank值显然效率太低了。折中是保存足够的网页来计算一次。
下图是web级策略的示意图:
为每下载 3 个网页设置一个新的 PageRank 计算。此时,本地已经下载了3个网页{1,2,3}。这三个网页中收录的链接指向{4,5,6},即要爬取的URL队列。如何确定下载顺序?
把这6个网页组成一个新的集合,计算这个集合的PageRank值,这样4、5、6就会得到各自对应的页面排名值,从大到小排序,就可以得到假设的顺序下载顺序为5,4,6,当下载55页时,提取链接指向第8页,此时临时分配PageRank值为8。如果该值大于 4 和 6 的 PageRank,则将首先下载第 8 页,依此类推。循环,即不完全页面级策略的计算思想形成。
四、OPIC策略策略(在线页面重要性计算):
基本思想:在算法开始之前,给所有页面相同的初始现金(cash)。下载一个页面P后,将P的现金分配给所有从P解析出来的链接,并清空P的现金。所有要爬取的URL队列中的页面按照现金的数量进行排序。
与PageRank不同的是:PageRank每次都需要迭代计算,而OPIC策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。
五、各大站优先策略:
策略:以网站为单位选择网页的重要性。对于URL队列中待抓取的网页,根据自己的网站进行分类。如果哪个网站等待下载的页面最多,先下载这些链接,本质思路倾向于优先下载大的网站。因为大 网站 往往收录更多页面。鉴于大型网站往往是知名公司的内容,而且他们的网页一般都是高质量的,这个想法很简单,但是有一定的依据。实验表明,该算法的效果也应该略优于宽度优先遍历策略。
花生代理动态IP更改软件可实现全国城市IP自动切换,千万级动态IP池,支持过滤,支持电脑手机多终端使用,数万条随机拨号线路, 24小时不间断提供动态IP。

c爬虫抓取网页数据( 循环来实现所有网页的爬取总结(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-06 17:16
循环来实现所有网页的爬取总结(图))
public static List ParseLink(string html)
{
List res = new List();
var doc = new HtmlDocument();
doc.LoadHtml(html);
var linkNodes = doc.DocumentNode.SelectNodes("//a[@href]");
foreach (var linkNode in linkNodes)
{
string link = linkNode.GetAttributeValue("href", "");
if (link.StartsWith("/lishi/beijing/month"))
{
res.Add(link);
}
}
return res;
}
到目前为止,我们已经解析出网站上所有收录过去时间段的链接。接下来,我们需要分析每个链接对应的特定网页的结构,从中获取天气信息。
分析天气网页的结构
上一个链接是站点链接。上一节分析了特定天气网页对应的链接集合,例如。
现在我们需要从这个页面分析天气,就像解析站点结构中的目标链接一样,在浏览器中观察Html代码,发现天气的目标内容在一个表格中,所以我们只需要选择节点,因为一个节点代表某一天的天气(天气状况、温度和风向)。
public static void ParseDailyWeather(string html)
{
var doc = new HtmlDocument();
doc.LoadHtml(html);
var rows = doc.DocumentNode.SelectNodes("//tr");
StringBuilder sb = new StringBuilder();
rows.RemoveAt(0);
foreach (var row in rows)
{
var cols = row.SelectNodes("td");
foreach (var col in cols)
{
string temp = col.InnerText.Replace("\r\n", "").Replace(" ", "").Trim();
sb.Append(temp + ",");
}
sb.Append("\r\n");
}
FileStream fs = new FileStream("output.csv", FileMode.Append, FileAccess.Write);
StreamWriter sw = new StreamWriter(fs, Encoding.GetEncoding("gbk"));
sw.WriteLine(sb);
sw.Close();
fs.Close();
}
最后,为了实现对网站的爬取,需要一个循环来实现对所有网页的爬取
public static void ParseWebsite(string url)
{
string html = Weather.GetHtml(url);
var links = Weather.ParseLink(html);
foreach (var link in links)
{
url = "http://www.tianqihoubao.com" + link;
html = Weather.GetHtml(url);
Weather.ParseDailyWeather(html);
}
}
总结
静态网页的爬取比较简单,可以分为以下几个步骤 查看全部
c爬虫抓取网页数据(
循环来实现所有网页的爬取总结(图))
public static List ParseLink(string html)
{
List res = new List();
var doc = new HtmlDocument();
doc.LoadHtml(html);
var linkNodes = doc.DocumentNode.SelectNodes("//a[@href]");
foreach (var linkNode in linkNodes)
{
string link = linkNode.GetAttributeValue("href", "");
if (link.StartsWith("/lishi/beijing/month"))
{
res.Add(link);
}
}
return res;
}
到目前为止,我们已经解析出网站上所有收录过去时间段的链接。接下来,我们需要分析每个链接对应的特定网页的结构,从中获取天气信息。
分析天气网页的结构
上一个链接是站点链接。上一节分析了特定天气网页对应的链接集合,例如。

现在我们需要从这个页面分析天气,就像解析站点结构中的目标链接一样,在浏览器中观察Html代码,发现天气的目标内容在一个表格中,所以我们只需要选择节点,因为一个节点代表某一天的天气(天气状况、温度和风向)。

public static void ParseDailyWeather(string html)
{
var doc = new HtmlDocument();
doc.LoadHtml(html);
var rows = doc.DocumentNode.SelectNodes("//tr");
StringBuilder sb = new StringBuilder();
rows.RemoveAt(0);
foreach (var row in rows)
{
var cols = row.SelectNodes("td");
foreach (var col in cols)
{
string temp = col.InnerText.Replace("\r\n", "").Replace(" ", "").Trim();
sb.Append(temp + ",");
}
sb.Append("\r\n");
}
FileStream fs = new FileStream("output.csv", FileMode.Append, FileAccess.Write);
StreamWriter sw = new StreamWriter(fs, Encoding.GetEncoding("gbk"));
sw.WriteLine(sb);
sw.Close();
fs.Close();
}
最后,为了实现对网站的爬取,需要一个循环来实现对所有网页的爬取
public static void ParseWebsite(string url)
{
string html = Weather.GetHtml(url);
var links = Weather.ParseLink(html);
foreach (var link in links)
{
url = "http://www.tianqihoubao.com" + link;
html = Weather.GetHtml(url);
Weather.ParseDailyWeather(html);
}
}
总结
静态网页的爬取比较简单,可以分为以下几个步骤
c爬虫抓取网页数据(一下新建项目(Project)文件的作用和作用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-04 02:18
网络爬虫是在互联网上爬取数据的程序,用它来爬取特定网页的 HTML 数据。虽然我们使用一些库来开发爬虫程序,但是使用框架可以大大提高效率,缩短开发时间。 Scrapy是用Python编写的,轻量级,简单轻便,使用起来非常方便。使用Scrapy可以很方便的完成在线数据采集的工作,它已经为我们完成了很多工作,不需要花大力气去开发。
首先,我们必须回答一个问题。
问:网站安装到爬虫需要几步?
答案很简单,四步:
新建项目(Project):新建一个爬虫项目
清除目标(Items):清除你要爬取的目标
制作蜘蛛:制作蜘蛛并开始抓取网页
存储内容(管道):设计管道来存储抓取的内容
好了,基本流程确定了,接下来就是一步步完成了。
1.新建项目(Project)
在空目录下按住Shift键右键,选择“在此处打开命令窗口”,输入命令:
代码如下:
scrapy startproject 教程
其中,tutorial 为项目名称。
可以看到会创建一个tutorial文件夹,目录结构如下:
代码如下:
教程/
scrapy.cfg
教程/
__init__.py
items.py
pipelines.py
settings.py
蜘蛛/
__init__.py
...
简单介绍一下各个文件的作用:
scrapy.cfg:项目配置文件
tutorial/:项目的Python模块,代码会从这里引用
tutorial/items.py:项目的items文件
tutorial/pipelines.py:项目的流水线文件
tutorial/settings.py:项目设置文件
tutorial/spiders/:蜘蛛存放的目录
2.明确目标(Item)
在 Scrapy 中,items 是用于加载爬取内容的容器,有点像 Python 中的 Dic,它是一个字典,但提供了一些额外的保护以减少错误。
一般来说item可以用scrapy.item.Item类创建,scrapy.item.Field对象用来定义属性(可以理解为类似于ORM的映射关系)。
接下来,我们开始构建项目模型。
首先,我们想要的是:
姓名(姓名)
链接(网址)
说明
修改tutorial目录下的items.py文件,在原来的类之后添加我们自己的类。
因为我们要抓取网站的内容,所以可以命名为DmozItem:
代码如下:
# 在此处定义已抓取项目的模型
#
# 查看文档:
#
从scrapy.item导入项目,字段
class TutorialItem(Item):
# 在此处定义您的项目的字段,例如:
# name = Field()
通过
类 DmozItem(Item):
title = Field()
link = Field()
desc = Field()
乍一看可能有点难以理解,但定义这些项目会让您在使用其他组件时了解您的项目是什么。
Item 可以简单理解为一个封装的类对象。
3.制作蜘蛛(Spider)
做一个爬虫,一般有两个步骤:先爬后取。
也就是说,首先你需要获取整个网页的所有内容,然后取出对你有用的部分。
3.1 次攀爬
Spider 是用户编写的一个类,用于从域(或域组)中获取信息。
它们定义了用于下载的 URL 列表、跟踪链接的方案以及解析 Web 内容以提取项目的方法。
要创建蜘蛛,您必须使用scrapy.spider.BaseSpider 创建一个子类并确定三个必需属性:
name:爬虫的标识名,必须是唯一的。您必须在不同的爬虫中定义不同的名称。
start_urls:抓取的 URL 列表。爬虫从这里开始抓取数据,所以第一次下载数据会从这些url开始。其他子 URL 将从这些起始 URL 继承。
parse():解析方法,调用时将每个URL返回的Response对象作为唯一参数传入,负责解析匹配捕获的数据(解析为item),跟踪更多的URL。
<p>这里可以参考宽度爬虫教程中提到的思路帮助理解,教程传输:【Java】知乎下巴第五集:使用HttpClient工具包和宽度爬虫。 查看全部
c爬虫抓取网页数据(一下新建项目(Project)文件的作用和作用)
网络爬虫是在互联网上爬取数据的程序,用它来爬取特定网页的 HTML 数据。虽然我们使用一些库来开发爬虫程序,但是使用框架可以大大提高效率,缩短开发时间。 Scrapy是用Python编写的,轻量级,简单轻便,使用起来非常方便。使用Scrapy可以很方便的完成在线数据采集的工作,它已经为我们完成了很多工作,不需要花大力气去开发。
首先,我们必须回答一个问题。
问:网站安装到爬虫需要几步?
答案很简单,四步:
新建项目(Project):新建一个爬虫项目
清除目标(Items):清除你要爬取的目标
制作蜘蛛:制作蜘蛛并开始抓取网页
存储内容(管道):设计管道来存储抓取的内容
好了,基本流程确定了,接下来就是一步步完成了。
1.新建项目(Project)
在空目录下按住Shift键右键,选择“在此处打开命令窗口”,输入命令:
代码如下:
scrapy startproject 教程
其中,tutorial 为项目名称。
可以看到会创建一个tutorial文件夹,目录结构如下:
代码如下:
教程/
scrapy.cfg
教程/
__init__.py
items.py
pipelines.py
settings.py
蜘蛛/
__init__.py
...
简单介绍一下各个文件的作用:
scrapy.cfg:项目配置文件
tutorial/:项目的Python模块,代码会从这里引用
tutorial/items.py:项目的items文件
tutorial/pipelines.py:项目的流水线文件
tutorial/settings.py:项目设置文件
tutorial/spiders/:蜘蛛存放的目录
2.明确目标(Item)
在 Scrapy 中,items 是用于加载爬取内容的容器,有点像 Python 中的 Dic,它是一个字典,但提供了一些额外的保护以减少错误。
一般来说item可以用scrapy.item.Item类创建,scrapy.item.Field对象用来定义属性(可以理解为类似于ORM的映射关系)。
接下来,我们开始构建项目模型。
首先,我们想要的是:
姓名(姓名)
链接(网址)
说明
修改tutorial目录下的items.py文件,在原来的类之后添加我们自己的类。
因为我们要抓取网站的内容,所以可以命名为DmozItem:
代码如下:
# 在此处定义已抓取项目的模型
#
# 查看文档:
#
从scrapy.item导入项目,字段
class TutorialItem(Item):
# 在此处定义您的项目的字段,例如:
# name = Field()
通过
类 DmozItem(Item):
title = Field()
link = Field()
desc = Field()
乍一看可能有点难以理解,但定义这些项目会让您在使用其他组件时了解您的项目是什么。
Item 可以简单理解为一个封装的类对象。
3.制作蜘蛛(Spider)
做一个爬虫,一般有两个步骤:先爬后取。
也就是说,首先你需要获取整个网页的所有内容,然后取出对你有用的部分。
3.1 次攀爬
Spider 是用户编写的一个类,用于从域(或域组)中获取信息。
它们定义了用于下载的 URL 列表、跟踪链接的方案以及解析 Web 内容以提取项目的方法。
要创建蜘蛛,您必须使用scrapy.spider.BaseSpider 创建一个子类并确定三个必需属性:
name:爬虫的标识名,必须是唯一的。您必须在不同的爬虫中定义不同的名称。
start_urls:抓取的 URL 列表。爬虫从这里开始抓取数据,所以第一次下载数据会从这些url开始。其他子 URL 将从这些起始 URL 继承。
parse():解析方法,调用时将每个URL返回的Response对象作为唯一参数传入,负责解析匹配捕获的数据(解析为item),跟踪更多的URL。
<p>这里可以参考宽度爬虫教程中提到的思路帮助理解,教程传输:【Java】知乎下巴第五集:使用HttpClient工具包和宽度爬虫。
c爬虫抓取网页数据(网络爬虫提取出该网页中的新一轮URL的抓取环路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-01-03 21:17
一般我们要抓取一个网站的所有网址,先传递起始网址,然后通过网络爬虫提取网页中的所有网址链接,然后进行每一个网址抓取的提取,在每个网页中提取新一轮的 URL,依此类推。总体感觉是从上到下爬取网页中的链接。理论上,您可以抓取整个网站上的所有链接。但问题来了。 网站 中的网页链接有循环。
比如在网站的首页,我们可以看到首页的链接,然后我们也可能在子页面中看到首页的链接,可能会有对应的子子-页面。该链接指向主页。按照我们之前的逻辑,抓取每个网页中的所有链接,然后继续抓取所有链接。以首页为例。我们爬行的第一件事就是它。然后子页面里面有一个到首页的链接,子子页面也有一个到首页的链接。进行这种爬取会导致网页的重复爬取。其他的根本就没有抓取网页的机会,无法想象~~解决这个问题不难。这时候就需要用到网络爬虫中一个很重要的知识点,就是网页去重。
先介绍一个简单的思路,也是一个常用的思路。我们将抓取到的网页放到一个列表中。以首页为例。抓取主页后,将主页放入列表中。那么当我们抓取子页面的时候,如果再次触摸首页,并且首页已经被抓取了。这时候可以跳过首页,继续爬取其他网页,避免重复爬取首页。这样在爬取整个站点的时候就不会出现循环了。路。以这个思路为出发点,将访问过的URL保存在数据库中,当获取到下一个URL时,到数据库中查看该URL是否被访问过。虽然数据库有缓存,但是在数据库中查询每个URL时,效率会下降的很快,所以这个策略用的不多,但是是最简单的方法。
第二种方法是将访问过的URL保存在集合中。这种方式获取URL的速度非常快,基本不用查询。但是这种方法有一个缺点。保存集合中的URL实际上是将其保存在内存中。当 URL 数据量较大(如 1 亿)时,内存压力会增加。对于小型爬虫,这种方法是非常可取的,但对于大型网络爬虫来说,这种方法很难实现。
第三种方式是对md5中的字符进行编码,md5编码可以将字符缩减为固定长度。一般来说,md5编码的长度在128bit左右,约等于16byte。在缩减之前,假设一个URL占用的内存大小为50字节,1字节等于2字节,相当于100字节。可以看出,经过md5编码后,节省了大量的内存空间。通过md5,可以将任意长度的URL压缩成相同长度的md5字符串,不会有重复,可以达到去重的效果。这样,在很大程度上节省了内存。 scrapy框架采用的方法与md5方法有些类似。因此,一般情况下,即使URL的量级达到亿级,scrapy占用的内存也比set方法高。少很多。
第四种方式是使用位图方法进一步压缩字符。这种方法的意思是在计算机中申请8位,即8位,每一位用0或1表示,是计算机中的最小单位。如果8位组成一个字节,一位代表一个URL,为什么一位可以确定一个URL?因为我们可以对一个 URL 执行哈希函数,然后将其映射到位。例如,假设我们有8个URL,对应8位,然后通过位上的0和1的状态,就可以表明这个URL是否存在,这种方法可以进一步压缩内存。
但是位图方法有一个非常大的缺点,就是它的冲突会非常高,因为使用了同一个hash函数,很有可能将两个不同的URL或者多个不同的URL映射到一个位置。其实这个hash方法也是set方法的一个实现原理。它对 URL 执行函数计算,然后将其映射到位的位置。因此,这种方法可以大大压缩内存。简单计算一下,还是用1亿个URL来计算,相当于1亿比特。通过计算,相当于1250万字节。除以1024之后,大约是12207KB,也就是大约12MB的空间。在实际过程中,内存占用可能会大于12MB,但即便如此,与前三种方法相比,这种方法又大大减少了内存占用的空间。但同时,与此方法冲突的可能性非常高,因此此方法不是很适用。那么有没有办法进一步优化位图,这是一种重内存压缩的方法,以减少冲突的可能性?答案是肯定的,是第五种方式。
第五种方法是bloomfilter,改进位图。它可以通过多个散列函数减少冲突的可能性。这样一来,一方面不仅可以减少位图方法的内存,另一方面,同时也起到了减少冲突的作用。关于bloomfilter的原理和实现,后期我一定会介绍给大家的。今天就让大家有个简单的了解。 Bloomfilter适用于大型网络爬虫,尤其是数量级超大的时候。布隆过滤器方法可以事半功倍。也经常与分布式爬虫配合,达到爬取的目的。
我是来为大家介绍爬网过程中去重策略的五种方法的。如果你不明白,你应该知道它。在科普下,问题不大。希望对朋友的学习有所帮助。 . 查看全部
c爬虫抓取网页数据(网络爬虫提取出该网页中的新一轮URL的抓取环路)
一般我们要抓取一个网站的所有网址,先传递起始网址,然后通过网络爬虫提取网页中的所有网址链接,然后进行每一个网址抓取的提取,在每个网页中提取新一轮的 URL,依此类推。总体感觉是从上到下爬取网页中的链接。理论上,您可以抓取整个网站上的所有链接。但问题来了。 网站 中的网页链接有循环。
比如在网站的首页,我们可以看到首页的链接,然后我们也可能在子页面中看到首页的链接,可能会有对应的子子-页面。该链接指向主页。按照我们之前的逻辑,抓取每个网页中的所有链接,然后继续抓取所有链接。以首页为例。我们爬行的第一件事就是它。然后子页面里面有一个到首页的链接,子子页面也有一个到首页的链接。进行这种爬取会导致网页的重复爬取。其他的根本就没有抓取网页的机会,无法想象~~解决这个问题不难。这时候就需要用到网络爬虫中一个很重要的知识点,就是网页去重。

先介绍一个简单的思路,也是一个常用的思路。我们将抓取到的网页放到一个列表中。以首页为例。抓取主页后,将主页放入列表中。那么当我们抓取子页面的时候,如果再次触摸首页,并且首页已经被抓取了。这时候可以跳过首页,继续爬取其他网页,避免重复爬取首页。这样在爬取整个站点的时候就不会出现循环了。路。以这个思路为出发点,将访问过的URL保存在数据库中,当获取到下一个URL时,到数据库中查看该URL是否被访问过。虽然数据库有缓存,但是在数据库中查询每个URL时,效率会下降的很快,所以这个策略用的不多,但是是最简单的方法。

第二种方法是将访问过的URL保存在集合中。这种方式获取URL的速度非常快,基本不用查询。但是这种方法有一个缺点。保存集合中的URL实际上是将其保存在内存中。当 URL 数据量较大(如 1 亿)时,内存压力会增加。对于小型爬虫,这种方法是非常可取的,但对于大型网络爬虫来说,这种方法很难实现。

第三种方式是对md5中的字符进行编码,md5编码可以将字符缩减为固定长度。一般来说,md5编码的长度在128bit左右,约等于16byte。在缩减之前,假设一个URL占用的内存大小为50字节,1字节等于2字节,相当于100字节。可以看出,经过md5编码后,节省了大量的内存空间。通过md5,可以将任意长度的URL压缩成相同长度的md5字符串,不会有重复,可以达到去重的效果。这样,在很大程度上节省了内存。 scrapy框架采用的方法与md5方法有些类似。因此,一般情况下,即使URL的量级达到亿级,scrapy占用的内存也比set方法高。少很多。

第四种方式是使用位图方法进一步压缩字符。这种方法的意思是在计算机中申请8位,即8位,每一位用0或1表示,是计算机中的最小单位。如果8位组成一个字节,一位代表一个URL,为什么一位可以确定一个URL?因为我们可以对一个 URL 执行哈希函数,然后将其映射到位。例如,假设我们有8个URL,对应8位,然后通过位上的0和1的状态,就可以表明这个URL是否存在,这种方法可以进一步压缩内存。
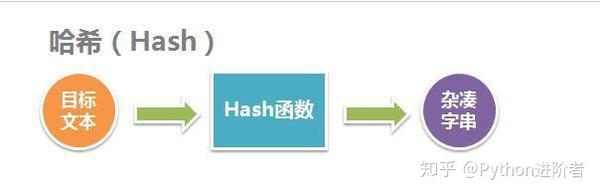
但是位图方法有一个非常大的缺点,就是它的冲突会非常高,因为使用了同一个hash函数,很有可能将两个不同的URL或者多个不同的URL映射到一个位置。其实这个hash方法也是set方法的一个实现原理。它对 URL 执行函数计算,然后将其映射到位的位置。因此,这种方法可以大大压缩内存。简单计算一下,还是用1亿个URL来计算,相当于1亿比特。通过计算,相当于1250万字节。除以1024之后,大约是12207KB,也就是大约12MB的空间。在实际过程中,内存占用可能会大于12MB,但即便如此,与前三种方法相比,这种方法又大大减少了内存占用的空间。但同时,与此方法冲突的可能性非常高,因此此方法不是很适用。那么有没有办法进一步优化位图,这是一种重内存压缩的方法,以减少冲突的可能性?答案是肯定的,是第五种方式。

第五种方法是bloomfilter,改进位图。它可以通过多个散列函数减少冲突的可能性。这样一来,一方面不仅可以减少位图方法的内存,另一方面,同时也起到了减少冲突的作用。关于bloomfilter的原理和实现,后期我一定会介绍给大家的。今天就让大家有个简单的了解。 Bloomfilter适用于大型网络爬虫,尤其是数量级超大的时候。布隆过滤器方法可以事半功倍。也经常与分布式爬虫配合,达到爬取的目的。
我是来为大家介绍爬网过程中去重策略的五种方法的。如果你不明白,你应该知道它。在科普下,问题不大。希望对朋友的学习有所帮助。 .
c爬虫抓取网页数据(这请我吃一顿饭不过分吧?这篇爬虫实战教程,不仅适合新手练习爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-01 12:21
暑假已经开始很久了,但是还有很多朋友没有找到暑期实习?前几天,我朋友的弟弟想在暑假找一份实习来锻炼自己,但面对网上成千上万的实习招聘信息,简直让人望而生畏。然后我的朋友给我发了一条“帮助”信息。了解了大致情况后,我立即用爬虫爬取了实习网的信息,并贴出了数据结果。问题在几分钟内得到解决。请我吃饭会不会过分?
本爬虫实战教程不仅适合新手练习爬虫,也适合需要找实习信息的朋友!
希望看完这篇文章后,能够清楚的了解整个爬虫流程,能够独立完成。其次,可以通过自己的爬虫实战获取自己想要的信息。
好了,话不多说,开始吧!
内容主要分为三部分:
1、页面分析
2、爬虫步骤详解
一、目标页面分析
首先我们要知道我们的爬虫目标是什么?俗话说,知己知彼,百战不殆。我们已经知道我们要爬取的页面是“实习网”,所以我们首先要去实习网看看里面有什么数据。
实习网址:
页面如下:
比如我们要找的职位是“品牌运营”职位的数据。因此,直接在网页的搜索框中输入品牌操作即可。你会发现url变了!
注意:我们要抓取的页面是这个页面:品牌运营
在我们的抓取页面中,我们需要观察有哪些数据,一个页面中有几条数据。这一点很重要,关系到后续的代码编写,可以帮助你检查页面上的信息是否全部被抓取。
此时需要注意的是,我们所在的页面是“一级页面”。在浏览过程中,我们点击任意一个帖子进入,就会显示“二级页面”。这时候你也会发现url又变了。
比如我们点击一个品牌运营实习,二级页面会自动跳转到这个,并且会生成一个新的链接。如图:
应该在页面上抓取哪些信息?
我们在分析中发现,有的信息在一级页面,有的在二级页面。
在一级页面上我们可以得到什么样的信息?如图:
一共有五个有效数据:职位、公司名称、学历、薪水、地址
在二级页面中,我们来看看可以获取哪些有效数据、字段和比例。如果你觉得阶段很重要,也可以把它包括在爬虫的范围内,不过我个人认为这不影响实习,毕竟不是找正式工作不会有很大影响。相反,招聘的实习生人数更为重要。新兵人数这里没有显示,无法在图片上显示,以后可以添加。
这里,我们需要抓取一共7条数据,加上“人数”一共8条数据,就是我们爬虫最终的目标数据。
抓取“静态”网页
这里分析一下什么是静态网页,什么是动态网页。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。
它们的区别在于:静态网页中的数据是一劳永逸的,也就是说一次性全部给你。动态网页中的数据是随着页面的逐步加载而逐渐呈现的,即静态网页的爬虫技术无法获取其中的所有数据。
值得强调的是,不要将动态网页与动态页面内容混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果无关。动态网页也可以是纯文本内容,也可以收录各种动画内容。这些只是网页的细节。内容的呈现形式,无论网页是否有动态效果,只要是使用动态网站技术生成的网页,都可以称为动态网页。
点击“鼠标右键”,点击“查看网页源代码”,最终效果如图(部分截图):
这是最终反馈给你的数据。如果你发现你想要的所有数据都在里面,你可以说它是一个静态页面。如果不是,则将其视为“动态页面”。
今天的案例是一个静态网页。
大家都知道,在编写代码之前,我们首先要知道我们将使用哪些方法、库和模块来帮助您解析数据。常用的解析数据的方法有:re正则表达式、xpath、beatifulsoup、pyquery等
我们需要使用的是xpath分析方法来分析定位数据。
二、爬虫代码说明1、导入相关库
爬虫的第一步是考虑在爬虫过程中需要哪些库。你要知道python是一种依赖很多库的语言。没有库的 Python 是不完整的。
import pandas as pd # 用于数据存储
import requests # 用于请求网页
import chardet # 用于修改编码
import re # 用于提取数据
from lxml import etree # 解析数据的库
import time # 可以粗糙模拟人为请求网页的速度
import warnings # 忽略代码运行时候的警告信息
warnings.filterwarnings("ignore")
2、请求一级页面源码
url = 'https://www.shixi.com/search/index?key=品牌运营&districts=&education=0&full_opportunity=0&stage=0&practice_days=0&nature=0&trades=&lang=zh_cn'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
rqg = requests.get(url, headers=headers, verify=False) ①
rqg.encoding = chardet.detect(rqg.content)['encoding'] ②
html = etree.HTML(rqg.text)
这里要注意两个地方①②。 ①处有两个参数,一个是headers,一个是verify。其中,headers是一种反乱码措施,使浏览器认为爬虫不是爬虫,而是人们在正常使用浏览器请求网页。验证是忽略安全证书提示。某些网页将被视为不安全并会提示您。记住这个参数就行了。
在②处,我们已经获得了网页的源代码。但是由于网页源代码的编码方式和您电脑的解析方式,可能会出现不一致的情况,返回结果会造成乱码。此时需要修改编码方式,chardet库可以帮你自动检测网页源代码的编码方式。 (一个非常有用的检测文档编码的三方库chardet)
3、解析一级页面网页中的信息
# 1. 公司名
company_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
company_list = [company_list[i].strip() for i in range(len(company_list)) if i % 2 != 0]
# 2. 岗位名
job_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
job_list = [job_list[i].strip() for i in range(len(job_list)) if i % 2 == 0]
# 3. 地址
address_list = html.xpath('//div[@class="job-pannel-two"]//a/text()')
# 4. 学历
degree_list = html.xpath('//div[@class="job-pannel-list"]//dd[@class="job-des"]/span/text()')
# 5. 薪资
salary_list = html.xpath('//div[@class="job-pannel-two"]//div[@class="company-info-des"]/text()')
salary_list = [i.strip() for i in salary_list]
4、获取二级页面的链接
deep_url_list = html.xpath('//div[@class="job-pannel-list"]//dt/a/@href')
x = "https://www.shixi.com"
deep_url_list = [x + i for i in deep_url_list]
这时候可以看到我直接用xpath对一级页面中的数据分析进行了分析。代码最后可以看到:我们已经获取到了二级页面的链接,为我们后续抓取二级页面的信息做准备。
分析二级页面网页中的信息
需求列表 = []
area_list = []
scale_list = []
对于 deep_url_list 中的 deep_url:
rqg = requests.get(deep_url, headers=headers, verify=False) ①
rqg.encoding = chardet.detect(rqg.content)['encoding'] ②
html = etree.HTML(rqg.text) ③
# 6. 招聘人数
demand = html.xpath('//div[@class="container-fluid"]//div[@class="intros"]/span[2]/text()')
# 7. 公司领域
area = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[1]/span/text()')
# 8. 公司规模
scale = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[2]/span/text()')
demand_list.append(demand)
area_list.append(area)
scale_list.append(scale)
需要注意的是,二级页面也是一个页面,爬取其中的数据时需要请求该页面。因此,①②③处的代码完全相同。
5、翻页操作
随意复制几个不同页面的URL,观察差异。这里可以看到page参数后面的数字不同,是第一页,数字就是数字。
x = "https://www.shixi.com/search/index?key=数据分析&page="
url_list = [x + str(i) for i in range(1,21)]
由于我们抓取了 20 页数据,这里构造了 20 个 URL,它们都存在于 url_list 列表中。
现在让我们看一下整个代码。不再用文字描述,直接在代码中写注释。
import pandas as pd
import requests
import chardet
import re
from lxml import etree
import time
import warnings
warnings.filterwarnings("ignore")
def get_CI(url):
# 请求获取一级页面的源代码
url = 'https://www.shixi.com/search/index?key=品牌运营&districts=&education=0&full_opportunity=0&stage=0&practice_days=0&nature=0&trades=&lang=zh_cn'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
rqg = requests.get(url, headers=headers, verify=False)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
# 获取一级页面中的信息:一共有5个信息。
# ①公司名
company_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
company_list = [company_list[i].strip() for i in range(len(company_list)) if i % 2 != 0]
#②岗位名
job_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
job_list = [job_list[i].strip() for i in range(len(job_list)) if i % 2 == 0]
#③地址
address_list = html.xpath('//div[@class="job-pannel-two"]//a/text()')
# ④ 学历
degree_list = html.xpath('//div[@class="job-pannel-list"]//dd[@class="job-des"]/span/text()')
# ⑤薪资
salary_list = html.xpath('//div[@class="job-pannel-two"]//div[@class="company-info-des"]/text()')
salary_list = [i.strip() for i in salary_list]
# ⑥获取二级页面的内容
deep_url_list = html.xpath('//div[@class="job-pannel-list"]//dt/a/@href')
x = "https://www.shixi.com"
deep_url_list = [x + i for i in deep_url_list]
demand_list = []
area_list = []
scale_list = []
# 获取二级页面中的信息:
for deep_url in deep_url_list:
rqg = requests.get(deep_url, headers=headers, verify=False)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
#① 需要几人
demand = html.xpath('//div[@class="container-fluid"]//div[@class="intros"]/span[2]/text()')
# ②公司领域
area = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[1]/span/text()')
# ③公司规模
scale = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[2]/span/text()')
demand_list.append(demand)
area_list.append(area)
scale_list.append(scale)
# ④ 将每个页面获取到的所有数据,存储到DataFrame中。
data = pd.DataFrame({'公司名':company_list,'岗位名':job_list,'地址':address_list,"学历":degree_list,
'薪资':salary_list,'岗位需求量':demand_list,'公司领域':area_list,'公司规模':scale_list})
return(data)
x = "https://www.shixi.com/search/index?key=数据分析&page="
url_list = [x + str(i) for i in range(1,61)]
res = pd.DataFrame(columns=['公司名','岗位名','地址',"学历",'薪资','岗位需求量','公司领域','公司规模'])
# 这里进行“翻页”操作
for url in url_list:
res0 = get_CI(url)
res = pd.concat([res,res0])
time.sleep(3)
# 保存数据
res.to_csv('aliang.csv',encoding='utf_8_sig')
有了这样的一套,爬虫的思路会不会瞬间清晰?眼睛:我会的!手:我还是不会。多练。初学者不要急于求成,项目不多,但要精髓。吃一个比看十个更有效。
来自: 查看全部
c爬虫抓取网页数据(这请我吃一顿饭不过分吧?这篇爬虫实战教程,不仅适合新手练习爬虫)
暑假已经开始很久了,但是还有很多朋友没有找到暑期实习?前几天,我朋友的弟弟想在暑假找一份实习来锻炼自己,但面对网上成千上万的实习招聘信息,简直让人望而生畏。然后我的朋友给我发了一条“帮助”信息。了解了大致情况后,我立即用爬虫爬取了实习网的信息,并贴出了数据结果。问题在几分钟内得到解决。请我吃饭会不会过分?

本爬虫实战教程不仅适合新手练习爬虫,也适合需要找实习信息的朋友!
希望看完这篇文章后,能够清楚的了解整个爬虫流程,能够独立完成。其次,可以通过自己的爬虫实战获取自己想要的信息。
好了,话不多说,开始吧!
内容主要分为三部分:
1、页面分析
2、爬虫步骤详解
一、目标页面分析
首先我们要知道我们的爬虫目标是什么?俗话说,知己知彼,百战不殆。我们已经知道我们要爬取的页面是“实习网”,所以我们首先要去实习网看看里面有什么数据。
实习网址:
页面如下:
比如我们要找的职位是“品牌运营”职位的数据。因此,直接在网页的搜索框中输入品牌操作即可。你会发现url变了!
注意:我们要抓取的页面是这个页面:品牌运营
在我们的抓取页面中,我们需要观察有哪些数据,一个页面中有几条数据。这一点很重要,关系到后续的代码编写,可以帮助你检查页面上的信息是否全部被抓取。
此时需要注意的是,我们所在的页面是“一级页面”。在浏览过程中,我们点击任意一个帖子进入,就会显示“二级页面”。这时候你也会发现url又变了。
比如我们点击一个品牌运营实习,二级页面会自动跳转到这个,并且会生成一个新的链接。如图:
应该在页面上抓取哪些信息?
我们在分析中发现,有的信息在一级页面,有的在二级页面。
在一级页面上我们可以得到什么样的信息?如图:
一共有五个有效数据:职位、公司名称、学历、薪水、地址
在二级页面中,我们来看看可以获取哪些有效数据、字段和比例。如果你觉得阶段很重要,也可以把它包括在爬虫的范围内,不过我个人认为这不影响实习,毕竟不是找正式工作不会有很大影响。相反,招聘的实习生人数更为重要。新兵人数这里没有显示,无法在图片上显示,以后可以添加。
这里,我们需要抓取一共7条数据,加上“人数”一共8条数据,就是我们爬虫最终的目标数据。
抓取“静态”网页
这里分析一下什么是静态网页,什么是动态网页。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。
它们的区别在于:静态网页中的数据是一劳永逸的,也就是说一次性全部给你。动态网页中的数据是随着页面的逐步加载而逐渐呈现的,即静态网页的爬虫技术无法获取其中的所有数据。
值得强调的是,不要将动态网页与动态页面内容混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果无关。动态网页也可以是纯文本内容,也可以收录各种动画内容。这些只是网页的细节。内容的呈现形式,无论网页是否有动态效果,只要是使用动态网站技术生成的网页,都可以称为动态网页。
点击“鼠标右键”,点击“查看网页源代码”,最终效果如图(部分截图):
这是最终反馈给你的数据。如果你发现你想要的所有数据都在里面,你可以说它是一个静态页面。如果不是,则将其视为“动态页面”。
今天的案例是一个静态网页。
大家都知道,在编写代码之前,我们首先要知道我们将使用哪些方法、库和模块来帮助您解析数据。常用的解析数据的方法有:re正则表达式、xpath、beatifulsoup、pyquery等
我们需要使用的是xpath分析方法来分析定位数据。
二、爬虫代码说明1、导入相关库
爬虫的第一步是考虑在爬虫过程中需要哪些库。你要知道python是一种依赖很多库的语言。没有库的 Python 是不完整的。
import pandas as pd # 用于数据存储
import requests # 用于请求网页
import chardet # 用于修改编码
import re # 用于提取数据
from lxml import etree # 解析数据的库
import time # 可以粗糙模拟人为请求网页的速度
import warnings # 忽略代码运行时候的警告信息
warnings.filterwarnings("ignore")
2、请求一级页面源码
url = 'https://www.shixi.com/search/index?key=品牌运营&districts=&education=0&full_opportunity=0&stage=0&practice_days=0&nature=0&trades=&lang=zh_cn'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
rqg = requests.get(url, headers=headers, verify=False) ①
rqg.encoding = chardet.detect(rqg.content)['encoding'] ②
html = etree.HTML(rqg.text)
这里要注意两个地方①②。 ①处有两个参数,一个是headers,一个是verify。其中,headers是一种反乱码措施,使浏览器认为爬虫不是爬虫,而是人们在正常使用浏览器请求网页。验证是忽略安全证书提示。某些网页将被视为不安全并会提示您。记住这个参数就行了。
在②处,我们已经获得了网页的源代码。但是由于网页源代码的编码方式和您电脑的解析方式,可能会出现不一致的情况,返回结果会造成乱码。此时需要修改编码方式,chardet库可以帮你自动检测网页源代码的编码方式。 (一个非常有用的检测文档编码的三方库chardet)
3、解析一级页面网页中的信息
# 1. 公司名
company_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
company_list = [company_list[i].strip() for i in range(len(company_list)) if i % 2 != 0]
# 2. 岗位名
job_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
job_list = [job_list[i].strip() for i in range(len(job_list)) if i % 2 == 0]
# 3. 地址
address_list = html.xpath('//div[@class="job-pannel-two"]//a/text()')
# 4. 学历
degree_list = html.xpath('//div[@class="job-pannel-list"]//dd[@class="job-des"]/span/text()')
# 5. 薪资
salary_list = html.xpath('//div[@class="job-pannel-two"]//div[@class="company-info-des"]/text()')
salary_list = [i.strip() for i in salary_list]
4、获取二级页面的链接
deep_url_list = html.xpath('//div[@class="job-pannel-list"]//dt/a/@href')
x = "https://www.shixi.com"
deep_url_list = [x + i for i in deep_url_list]
这时候可以看到我直接用xpath对一级页面中的数据分析进行了分析。代码最后可以看到:我们已经获取到了二级页面的链接,为我们后续抓取二级页面的信息做准备。
分析二级页面网页中的信息
需求列表 = []
area_list = []
scale_list = []
对于 deep_url_list 中的 deep_url:
rqg = requests.get(deep_url, headers=headers, verify=False) ①
rqg.encoding = chardet.detect(rqg.content)['encoding'] ②
html = etree.HTML(rqg.text) ③
# 6. 招聘人数
demand = html.xpath('//div[@class="container-fluid"]//div[@class="intros"]/span[2]/text()')
# 7. 公司领域
area = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[1]/span/text()')
# 8. 公司规模
scale = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[2]/span/text()')
demand_list.append(demand)
area_list.append(area)
scale_list.append(scale)
需要注意的是,二级页面也是一个页面,爬取其中的数据时需要请求该页面。因此,①②③处的代码完全相同。
5、翻页操作
随意复制几个不同页面的URL,观察差异。这里可以看到page参数后面的数字不同,是第一页,数字就是数字。
x = "https://www.shixi.com/search/index?key=数据分析&page="
url_list = [x + str(i) for i in range(1,21)]
由于我们抓取了 20 页数据,这里构造了 20 个 URL,它们都存在于 url_list 列表中。
现在让我们看一下整个代码。不再用文字描述,直接在代码中写注释。
import pandas as pd
import requests
import chardet
import re
from lxml import etree
import time
import warnings
warnings.filterwarnings("ignore")
def get_CI(url):
# 请求获取一级页面的源代码
url = 'https://www.shixi.com/search/index?key=品牌运营&districts=&education=0&full_opportunity=0&stage=0&practice_days=0&nature=0&trades=&lang=zh_cn'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
rqg = requests.get(url, headers=headers, verify=False)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
# 获取一级页面中的信息:一共有5个信息。
# ①公司名
company_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
company_list = [company_list[i].strip() for i in range(len(company_list)) if i % 2 != 0]
#②岗位名
job_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
job_list = [job_list[i].strip() for i in range(len(job_list)) if i % 2 == 0]
#③地址
address_list = html.xpath('//div[@class="job-pannel-two"]//a/text()')
# ④ 学历
degree_list = html.xpath('//div[@class="job-pannel-list"]//dd[@class="job-des"]/span/text()')
# ⑤薪资
salary_list = html.xpath('//div[@class="job-pannel-two"]//div[@class="company-info-des"]/text()')
salary_list = [i.strip() for i in salary_list]
# ⑥获取二级页面的内容
deep_url_list = html.xpath('//div[@class="job-pannel-list"]//dt/a/@href')
x = "https://www.shixi.com"
deep_url_list = [x + i for i in deep_url_list]
demand_list = []
area_list = []
scale_list = []
# 获取二级页面中的信息:
for deep_url in deep_url_list:
rqg = requests.get(deep_url, headers=headers, verify=False)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
#① 需要几人
demand = html.xpath('//div[@class="container-fluid"]//div[@class="intros"]/span[2]/text()')
# ②公司领域
area = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[1]/span/text()')
# ③公司规模
scale = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[2]/span/text()')
demand_list.append(demand)
area_list.append(area)
scale_list.append(scale)
# ④ 将每个页面获取到的所有数据,存储到DataFrame中。
data = pd.DataFrame({'公司名':company_list,'岗位名':job_list,'地址':address_list,"学历":degree_list,
'薪资':salary_list,'岗位需求量':demand_list,'公司领域':area_list,'公司规模':scale_list})
return(data)
x = "https://www.shixi.com/search/index?key=数据分析&page="
url_list = [x + str(i) for i in range(1,61)]
res = pd.DataFrame(columns=['公司名','岗位名','地址',"学历",'薪资','岗位需求量','公司领域','公司规模'])
# 这里进行“翻页”操作
for url in url_list:
res0 = get_CI(url)
res = pd.concat([res,res0])
time.sleep(3)
# 保存数据
res.to_csv('aliang.csv',encoding='utf_8_sig')
有了这样的一套,爬虫的思路会不会瞬间清晰?眼睛:我会的!手:我还是不会。多练。初学者不要急于求成,项目不多,但要精髓。吃一个比看十个更有效。
来自:
c爬虫抓取网页数据(基于Python爬虫技术简单易用的特点,利用python语言编写爬虫程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-31 13:29
摘要:基于Python爬虫技术简单易用的特点,采用python语言编写爬虫程序,对广电总局电视剧电子政务平台的电视剧记录数据进行爬取。此外,还对抓取的电视剧记录数据进行了统计分析,得出了相关结论。
关键词:Python;爬虫;数据分析
中文图书馆分类号:TP311.11 文献识别码:A 文章 编号:1007-9416 (2017)09-0035-02
1 爬虫技术介绍
网络爬虫是一种通过既定规则自动抓取网络信息的计算机程序。爬虫的目的是将目标网页数据下载到本地进行后续的数据分析。爬虫技术的兴起源于海量网络数据的可用性。通过爬虫技术,我们可以轻松获取网络数据,通过数据分析得出有价值的结论。
Python语言简单易用,现成的爬虫框架和工具包降低了使用门槛。正则表达式的具体使用,使得数据采集工作生动有趣。
2 案例分析
2.1 网页描述
目标数据是历年全国电视剧拍摄的记录数据。数据来源于广电总局电视剧电子政务平台公开信息,如图1所示。 具体网址:“http:
// /tims/site/views/applications.shanty? 应用名称=注释”。
我们需要爬取历年来每个月的记录公开信息列表数据,如图2所示,并进行汇总分析。
2.2 爬虫程序的设计与实现
首先,我们使用 BeautifulSoup 解析器来解析 URL 的文本信息。在分析了网页的 HTML 文本和页面规则后,我们制定了以下步骤来捕获目标数据。
①抓取第一页码和最后页码后,循环抓取列表页信息; 查看全部
c爬虫抓取网页数据(基于Python爬虫技术简单易用的特点,利用python语言编写爬虫程序)
摘要:基于Python爬虫技术简单易用的特点,采用python语言编写爬虫程序,对广电总局电视剧电子政务平台的电视剧记录数据进行爬取。此外,还对抓取的电视剧记录数据进行了统计分析,得出了相关结论。
关键词:Python;爬虫;数据分析
中文图书馆分类号:TP311.11 文献识别码:A 文章 编号:1007-9416 (2017)09-0035-02
1 爬虫技术介绍
网络爬虫是一种通过既定规则自动抓取网络信息的计算机程序。爬虫的目的是将目标网页数据下载到本地进行后续的数据分析。爬虫技术的兴起源于海量网络数据的可用性。通过爬虫技术,我们可以轻松获取网络数据,通过数据分析得出有价值的结论。
Python语言简单易用,现成的爬虫框架和工具包降低了使用门槛。正则表达式的具体使用,使得数据采集工作生动有趣。
2 案例分析
2.1 网页描述
目标数据是历年全国电视剧拍摄的记录数据。数据来源于广电总局电视剧电子政务平台公开信息,如图1所示。 具体网址:“http:
// /tims/site/views/applications.shanty? 应用名称=注释”。
我们需要爬取历年来每个月的记录公开信息列表数据,如图2所示,并进行汇总分析。
2.2 爬虫程序的设计与实现
首先,我们使用 BeautifulSoup 解析器来解析 URL 的文本信息。在分析了网页的 HTML 文本和页面规则后,我们制定了以下步骤来捕获目标数据。
①抓取第一页码和最后页码后,循环抓取列表页信息;
c爬虫抓取网页数据(Python爬虫如何获取JS生成的JS和网页内容和服务端?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-01-21 01:00
最近需要在一个网站中下载一批数据。但是输入一个查询,返回30000到40000个结果,每次只能导出500个,而且每次都要输入下载项的范围!就这样点击下载,我不要命了。所以我想自动化这个过程。
我的需求主要是两点:1.要求自动化程度高。最好有一个成熟的界面,直接模拟浏览器的鼠标和键盘动作,比如输入文本框、选择下拉列表、单选按钮、复选框、点击按钮等。2.效率不高。因为我想要的数据量比较少。3. python下的框架。因为我通常主要使用python。
对网站技术了解不多,对网站只有两个经验:自己开发了一个很简单的Android客户端,用python的scrapy框架写了一个爬虫自动爬取新闻. 所以了解客户端和服务器的一些基本交互方法,了解如何分析网页源代码,了解xpath语法。
当我第一次开始解决这个问题时,我什至不知道要搜索什么。知乎的这个文章提供了很多有用的信息:“Python爬虫如何获取JS生成的URL和网页内容?” 随之权衡了很多方法,最终选择了Selenium。主要优点是学习成本最小,代码实现速度快。缺点是爬取效率低。如果您想成为富有成效的朋友,您将不得不花一些时间学习更复杂的工具包。
网站技术
如果要自动爬取网页,需要了解一些基础知识,这样做会比较快。这里简单介绍一下相关知识。
1. 请求/响应
request 是客户端向服务器发出的请求。输入一个 URL 对应一个请求动作,这是最直观的。爬取静态网页的内容,只需要知道网址即可。但是,当前的许多网页都是动态的。指向或点击网页中的某些元素也会触发请求动作,从而使网页可以动态更新部分内容,而这些内容不能直接从静态网页中获取。这种技术叫做AJAX,但我对它了解不多。这里的问题是我们可能甚至不知道 URL 是什么,所以我们需要一些可以处理动态内容的高级接口。
response 是服务器返回给客户端的内容。如果要获取静态网页内容,直接从请求中获取即可。
2. 分析网页源码
如果我们想抓取网页上的某一部分信息,我们需要知道如何定位它。这里需要 HTML 和 XPATH 知识。不知道的可以去w3school在线教程:
查看网页的源代码,将鼠标指针指向网页的任意位置,或指向目标元素。右键单击并从下拉列表中选择“检查元素”。下面是我右键“百度”显示的网页源代码,是HTML格式的,我们可以看到对应的HTML代码。要提取它,我们可能需要 div//@[class="head_wrapper"]//input[@type="submit"] 的语句,它是 XPATH 语法,易于掌握。知道如何分析网页,我们更进一步。
3. 网页基本元素操作
前进、后退、刷新、打开新标签、输入网址等;
文本框输入、选择下拉列表、单选按钮、复选框、点击按钮等。
我这里只需要模拟这么多操作,可以参考对应的selenium接口。
4. Selenium 简介
底线:Selenium 是用于 Web 应用程序的自动化测试工具集。
很多话:Selenium 诞生于 2004 年,当时 ThoughtWorks 的 Jason Huggins 正在测试一个内部应用程序。作为一个聪明人,他意识到他的时间应该比手动测试每个更改更有价值。他开发了一个驱动页面交互的 Javascript 库,允许多个浏览器自动返回测试结果。该库最终成为 Selenium 的核心,它是 Selenium RC(远程控制)和 Selenium IDE 所有功能的基础。
实战练习1.分析数据采集过程
我的数据采集过程如下:
在A页输入查询语句,点击提交;浏览器自动打开新页面,跳转到新页面B,在文本框中输入下载项的范围;单击导出弹出一个弹出窗口,然后单击下拉列表,单选按钮,选取框进行一些选择,然后单击下载。然后浏览器开始下载文件。
页面 A
B页
2. 爬取过程 A. 安装 Selenium
Selenium 支持多种浏览器,我选择 google chrome。下载链接:。同时,当然要在python中安装selenium。从命令行输入 pip install senenium 进行安装。
B、配置环境变量
这一步需要将chromedriver的保存路径配置到操作系统的环境变量中,这样selenium才能找到chromedriver。windows下配置环境变量PATH,linux或者mac可以选择在.bash_rc中配置。配置方法很多,百度一下。
我用的是mac,不知道为什么配置不行!后来发现只有在代码中设置了才有效。
C. 核心代码(python)
# 设置下载路径,配置ChromeOptions的路径。
chromeoptions = webdriver.ChromeOptions()
首选项 = {'profile.default_content_settings.popups':0,'download.default_directory': query_dir}
chromeoptions.add_experimental_option('prefs', prefs)
# 设置环境变量并启动浏览器。
chromedriver = CHROMEDRIVER_DIR # 设置为你自己的路径
os.environ["webdriver.chrome.driver"] = chromedriver
驱动程序 = webdriver.Chrome(executable_path=chromedriver,chrome_options=chromeoptions)
# 设置不可见等待时间,因为点击网站后,可以返回一段时间的内容。如果不等待,就会报超时异常。
driver.implicitly_wait(IMPLICIT_WAIT_TIME)
# 请求页面A
司机.get("")
# 在页面A的两个文本框中输入并提交。
driver.find_element_by_name('D').clear()
driver.find_element_by_name('D').send_keys('mesz')
driver.find_element_by_name('SEARCH').clear()
driver.find_element_by_name('SEARCH').send_keys(str_search_query)
driver.find_element_by_name('ovid').click()
# 跳转到新窗口并关注该窗口。
current_window_handle = driver.current_window_handle
for hdl in driver.window_handles: # selenium 总是有两个句柄
如果 hdl != current_window_handle:
new_window_handle = hdl
driver.switch_to.window(new_window_handle)
driver.implicitly_wait(IMPLICIT_WAIT_TIME)
# 获取网页。首先获取返回的条目总数,然后提取文本框输入下载条目的范围,例如1-500。然后单击导出。
# 注意:等待页面加载完毕再计算下载次数
search_ret_num = WebDriverWait(驱动程序, EXPLICIT_WAIT_TIME, EXPLICIT_WAIT_INTERVAL).until(EC.presence_of_element_located((By.XPATH,'//*[@id="searchaid-numbers"]')))
search_ret_num =int(re.findall(r'\d+', search_ret_num.text.encode('utf-8'))[0])
list_range = chunks_by_element(范围(1, search_ret_num+1), DOWNLOAD_NUM_PER_TIME)
对于 list_range 中的项目:
download_range = driver.find_element_by_xpath('//*[@id="titles-display"]//input[@title="Range"]')
下载范围.clear()
download_range.send_keys('{}-{}'.format(item[0], item[-1]))
# 点击导出
export = driver.find_element_by_xpath('//*[@id="titles-display"]//input[@value="Export"]')
导出.click()
# 获取弹出窗口。进行一些设置。
driver.switch_to.alert
WebDriverWait(驱动程序, EXPLICIT_WAIT_TIME, EXPLICIT_WAIT_INTERVAL).until(EC.presence_of_element_located((By.XPATH,'//div[@id="export-citation-popup"]')))
# 设置下载文件的一些配置
export_to_options = driver.find_element_by_xpath('//select[@id="export-citation-export-to-options"]')
export_to_options.find_element_by_xpath('//option[@value="xml"]').click()# XML
# 设置引文内容电台
citation_options = driver.find_element_by_xpath('//ul[@id="export-citation-options"]')
citation_options.find_element_by_xpath('//input[@value="ALL"]').click()# 完整参考
# 设置收录复选框
citation_include = driver.find_element_by_xpath('//div[@id="export-citation-include"]')
ifcitation_include.find_element_by_xpath('//input[@name="externalResolverLink"]').is_selected():# 链接到外部解析器
citation_include.find_element_by_xpath('//input[@name="externalResolverLink"]').click()
ifcitation_include.find_element_by_xpath('//input[@name="jumpstartLink"]').is_selected():# 收录网址
citation_include.find_element_by_xpath('//input[@name="jumpstartLink"]').click()
ifcitation_include.find_element_by_xpath('//input[@name="saveStrategy"]').is_selected():# 搜索历史
citation_include.find_element_by_xpath('//input[@name="saveStrategy"]').click()
# 点击下载。
下载 = driver.find_element_by_xpath('//div[@class="export-citation-buttons"]')
下载.click()
最后:
sleep(30)#等待最后一个文件下载完成
# driver.implicitly_wait(30) # 不行!
driver.quit()
返回
3. 提示
A. 每次启动浏览器时,桌面上都会弹出一个浏览器。您可以清楚地看到自动化过程是怎样的。看来 selenium 真的为 Web 程序的自动化测试做好了准备。另外,在爬取过程中要注意保持屏幕打开。如果它进入睡眠或屏幕保护程序,也会抛出异常。
B、在模拟网页操作时,网页跳转是很常见的场景。所以要注意网页响应时间。Selenium 在继续执行代码之前不会等待网页响应完成,而是直接执行。两者应该是不同的过程。这里可以选择设置隐式等待和显式等待。在其他操作中,隐式等待起决定性作用,在WebDriverWait中..显式等待起主要作用,但需要注意的是,最长等待时间取决于两者中的较大者,如果隐式等待时间>显式等待时间,代码的最长等待时间等于隐式等待时间。
C. 设置下载路径时,一开始没有任何效果。怀疑是“download.default_directory”这个key写错了,于是通过查看网页源码找到了key,还是一样。问题出在其他地方。不过提醒了我以后在代码中使用字典进行相关配置的时候,看源码就能猜出来。
D.我以为至少需要两三天才能实现整个过程,因为我真的不明白。从头到尾完成这项研究只需不到一天的时间。大概是因为入手之前找了很久,反复比较之后,才找到了最得心应手的工具。
E. 整理完之后在github上搜了一圈,发现了一个神器。对于想要爬取大量内容的朋友,如果不想浪费时间过多学习web应用的底层知识,可以结合使用Selenium+scrapy。scrapy可以负责搜索网页,selenium负责处理每个网页上的内容,尤其是动态内容。下次如果我需要它,我打算使用这个想法!
F. 分享一句话。“关于爬虫,获取经验最快的方法是:学会写网站,你知道网站发送请求是什么,那么你就知道怎么爬网站了!” 很简单的。,但是这么简单的一句话却给了我很大的启发。之前太难了,一直卡在scrapy爬静态网页的水平。像 cookie 这样的技术也曾被阅读和遗忘过一次。现在看来是因为网站的整体流程还没有理清清楚。另一方面,我也害怕那些复杂的网站技术术语。其实只要在网上查查相关概念,就会慢慢打通。
G. 最后,完全不懂编程的人可以使用一些可视化爬虫工具。这里有一些介绍: 。懂编程又想提高效率的人需要参考其他工具。 查看全部
c爬虫抓取网页数据(Python爬虫如何获取JS生成的JS和网页内容和服务端?)
最近需要在一个网站中下载一批数据。但是输入一个查询,返回30000到40000个结果,每次只能导出500个,而且每次都要输入下载项的范围!就这样点击下载,我不要命了。所以我想自动化这个过程。
我的需求主要是两点:1.要求自动化程度高。最好有一个成熟的界面,直接模拟浏览器的鼠标和键盘动作,比如输入文本框、选择下拉列表、单选按钮、复选框、点击按钮等。2.效率不高。因为我想要的数据量比较少。3. python下的框架。因为我通常主要使用python。
对网站技术了解不多,对网站只有两个经验:自己开发了一个很简单的Android客户端,用python的scrapy框架写了一个爬虫自动爬取新闻. 所以了解客户端和服务器的一些基本交互方法,了解如何分析网页源代码,了解xpath语法。
当我第一次开始解决这个问题时,我什至不知道要搜索什么。知乎的这个文章提供了很多有用的信息:“Python爬虫如何获取JS生成的URL和网页内容?” 随之权衡了很多方法,最终选择了Selenium。主要优点是学习成本最小,代码实现速度快。缺点是爬取效率低。如果您想成为富有成效的朋友,您将不得不花一些时间学习更复杂的工具包。
网站技术
如果要自动爬取网页,需要了解一些基础知识,这样做会比较快。这里简单介绍一下相关知识。
1. 请求/响应
request 是客户端向服务器发出的请求。输入一个 URL 对应一个请求动作,这是最直观的。爬取静态网页的内容,只需要知道网址即可。但是,当前的许多网页都是动态的。指向或点击网页中的某些元素也会触发请求动作,从而使网页可以动态更新部分内容,而这些内容不能直接从静态网页中获取。这种技术叫做AJAX,但我对它了解不多。这里的问题是我们可能甚至不知道 URL 是什么,所以我们需要一些可以处理动态内容的高级接口。
response 是服务器返回给客户端的内容。如果要获取静态网页内容,直接从请求中获取即可。
2. 分析网页源码
如果我们想抓取网页上的某一部分信息,我们需要知道如何定位它。这里需要 HTML 和 XPATH 知识。不知道的可以去w3school在线教程:
查看网页的源代码,将鼠标指针指向网页的任意位置,或指向目标元素。右键单击并从下拉列表中选择“检查元素”。下面是我右键“百度”显示的网页源代码,是HTML格式的,我们可以看到对应的HTML代码。要提取它,我们可能需要 div//@[class="head_wrapper"]//input[@type="submit"] 的语句,它是 XPATH 语法,易于掌握。知道如何分析网页,我们更进一步。
3. 网页基本元素操作
前进、后退、刷新、打开新标签、输入网址等;
文本框输入、选择下拉列表、单选按钮、复选框、点击按钮等。
我这里只需要模拟这么多操作,可以参考对应的selenium接口。
4. Selenium 简介
底线:Selenium 是用于 Web 应用程序的自动化测试工具集。
很多话:Selenium 诞生于 2004 年,当时 ThoughtWorks 的 Jason Huggins 正在测试一个内部应用程序。作为一个聪明人,他意识到他的时间应该比手动测试每个更改更有价值。他开发了一个驱动页面交互的 Javascript 库,允许多个浏览器自动返回测试结果。该库最终成为 Selenium 的核心,它是 Selenium RC(远程控制)和 Selenium IDE 所有功能的基础。
实战练习1.分析数据采集过程
我的数据采集过程如下:
在A页输入查询语句,点击提交;浏览器自动打开新页面,跳转到新页面B,在文本框中输入下载项的范围;单击导出弹出一个弹出窗口,然后单击下拉列表,单选按钮,选取框进行一些选择,然后单击下载。然后浏览器开始下载文件。
页面 A
B页
2. 爬取过程 A. 安装 Selenium
Selenium 支持多种浏览器,我选择 google chrome。下载链接:。同时,当然要在python中安装selenium。从命令行输入 pip install senenium 进行安装。
B、配置环境变量
这一步需要将chromedriver的保存路径配置到操作系统的环境变量中,这样selenium才能找到chromedriver。windows下配置环境变量PATH,linux或者mac可以选择在.bash_rc中配置。配置方法很多,百度一下。
我用的是mac,不知道为什么配置不行!后来发现只有在代码中设置了才有效。
C. 核心代码(python)
# 设置下载路径,配置ChromeOptions的路径。
chromeoptions = webdriver.ChromeOptions()
首选项 = {'profile.default_content_settings.popups':0,'download.default_directory': query_dir}
chromeoptions.add_experimental_option('prefs', prefs)
# 设置环境变量并启动浏览器。
chromedriver = CHROMEDRIVER_DIR # 设置为你自己的路径
os.environ["webdriver.chrome.driver"] = chromedriver
驱动程序 = webdriver.Chrome(executable_path=chromedriver,chrome_options=chromeoptions)
# 设置不可见等待时间,因为点击网站后,可以返回一段时间的内容。如果不等待,就会报超时异常。
driver.implicitly_wait(IMPLICIT_WAIT_TIME)
# 请求页面A
司机.get("")
# 在页面A的两个文本框中输入并提交。
driver.find_element_by_name('D').clear()
driver.find_element_by_name('D').send_keys('mesz')
driver.find_element_by_name('SEARCH').clear()
driver.find_element_by_name('SEARCH').send_keys(str_search_query)
driver.find_element_by_name('ovid').click()
# 跳转到新窗口并关注该窗口。
current_window_handle = driver.current_window_handle
for hdl in driver.window_handles: # selenium 总是有两个句柄
如果 hdl != current_window_handle:
new_window_handle = hdl
driver.switch_to.window(new_window_handle)
driver.implicitly_wait(IMPLICIT_WAIT_TIME)
# 获取网页。首先获取返回的条目总数,然后提取文本框输入下载条目的范围,例如1-500。然后单击导出。
# 注意:等待页面加载完毕再计算下载次数
search_ret_num = WebDriverWait(驱动程序, EXPLICIT_WAIT_TIME, EXPLICIT_WAIT_INTERVAL).until(EC.presence_of_element_located((By.XPATH,'//*[@id="searchaid-numbers"]')))
search_ret_num =int(re.findall(r'\d+', search_ret_num.text.encode('utf-8'))[0])
list_range = chunks_by_element(范围(1, search_ret_num+1), DOWNLOAD_NUM_PER_TIME)
对于 list_range 中的项目:
download_range = driver.find_element_by_xpath('//*[@id="titles-display"]//input[@title="Range"]')
下载范围.clear()
download_range.send_keys('{}-{}'.format(item[0], item[-1]))
# 点击导出
export = driver.find_element_by_xpath('//*[@id="titles-display"]//input[@value="Export"]')
导出.click()
# 获取弹出窗口。进行一些设置。
driver.switch_to.alert
WebDriverWait(驱动程序, EXPLICIT_WAIT_TIME, EXPLICIT_WAIT_INTERVAL).until(EC.presence_of_element_located((By.XPATH,'//div[@id="export-citation-popup"]')))
# 设置下载文件的一些配置
export_to_options = driver.find_element_by_xpath('//select[@id="export-citation-export-to-options"]')
export_to_options.find_element_by_xpath('//option[@value="xml"]').click()# XML
# 设置引文内容电台
citation_options = driver.find_element_by_xpath('//ul[@id="export-citation-options"]')
citation_options.find_element_by_xpath('//input[@value="ALL"]').click()# 完整参考
# 设置收录复选框
citation_include = driver.find_element_by_xpath('//div[@id="export-citation-include"]')
ifcitation_include.find_element_by_xpath('//input[@name="externalResolverLink"]').is_selected():# 链接到外部解析器
citation_include.find_element_by_xpath('//input[@name="externalResolverLink"]').click()
ifcitation_include.find_element_by_xpath('//input[@name="jumpstartLink"]').is_selected():# 收录网址
citation_include.find_element_by_xpath('//input[@name="jumpstartLink"]').click()
ifcitation_include.find_element_by_xpath('//input[@name="saveStrategy"]').is_selected():# 搜索历史
citation_include.find_element_by_xpath('//input[@name="saveStrategy"]').click()
# 点击下载。
下载 = driver.find_element_by_xpath('//div[@class="export-citation-buttons"]')
下载.click()
最后:
sleep(30)#等待最后一个文件下载完成
# driver.implicitly_wait(30) # 不行!
driver.quit()
返回
3. 提示
A. 每次启动浏览器时,桌面上都会弹出一个浏览器。您可以清楚地看到自动化过程是怎样的。看来 selenium 真的为 Web 程序的自动化测试做好了准备。另外,在爬取过程中要注意保持屏幕打开。如果它进入睡眠或屏幕保护程序,也会抛出异常。
B、在模拟网页操作时,网页跳转是很常见的场景。所以要注意网页响应时间。Selenium 在继续执行代码之前不会等待网页响应完成,而是直接执行。两者应该是不同的过程。这里可以选择设置隐式等待和显式等待。在其他操作中,隐式等待起决定性作用,在WebDriverWait中..显式等待起主要作用,但需要注意的是,最长等待时间取决于两者中的较大者,如果隐式等待时间>显式等待时间,代码的最长等待时间等于隐式等待时间。
C. 设置下载路径时,一开始没有任何效果。怀疑是“download.default_directory”这个key写错了,于是通过查看网页源码找到了key,还是一样。问题出在其他地方。不过提醒了我以后在代码中使用字典进行相关配置的时候,看源码就能猜出来。
D.我以为至少需要两三天才能实现整个过程,因为我真的不明白。从头到尾完成这项研究只需不到一天的时间。大概是因为入手之前找了很久,反复比较之后,才找到了最得心应手的工具。
E. 整理完之后在github上搜了一圈,发现了一个神器。对于想要爬取大量内容的朋友,如果不想浪费时间过多学习web应用的底层知识,可以结合使用Selenium+scrapy。scrapy可以负责搜索网页,selenium负责处理每个网页上的内容,尤其是动态内容。下次如果我需要它,我打算使用这个想法!
F. 分享一句话。“关于爬虫,获取经验最快的方法是:学会写网站,你知道网站发送请求是什么,那么你就知道怎么爬网站了!” 很简单的。,但是这么简单的一句话却给了我很大的启发。之前太难了,一直卡在scrapy爬静态网页的水平。像 cookie 这样的技术也曾被阅读和遗忘过一次。现在看来是因为网站的整体流程还没有理清清楚。另一方面,我也害怕那些复杂的网站技术术语。其实只要在网上查查相关概念,就会慢慢打通。
G. 最后,完全不懂编程的人可以使用一些可视化爬虫工具。这里有一些介绍: 。懂编程又想提高效率的人需要参考其他工具。
c爬虫抓取网页数据(Python网络爬虫反爬破解策略实战作者(组图)作者)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-20 15:18
阿里云>云栖社区>主题图>C>c爬虫源码
推荐活动:
更多优惠>
当前话题:c网络爬虫源码加入采集
相关话题:
c网络爬虫源码相关博客看更多博文
C# 网络爬虫
作者:Street Corner Box 712 查看评论:05 年前
公司的编辑需要爬取网页的内容,让我帮我做一个简单的爬取工具。这是抓取网页的内容。看来这对大家来说并不难,不过这里有一些小的改动,代码提供,请参考 1 private string GetHttpWebRequest(string url) 2 { 3 Ht
阅读全文
C#HttpHelper爬虫源码分享--苏飞版
作者:苏飞2071 浏览评论:03年前
简介 C#HttpHelper实现了C#HttpWebRequest爬取时忽略编码、忽略证书、忽略cookie的功能,实现代理的功能。有了它,您可以发出 Get 和 Post 请求,并且可以轻松设置 cookie、证书、代理和编码。你不用担心这个问题,因为类会自动为你识别页面
阅读全文
Python网络爬虫反爬破解攻略实战
作者:薇薇8128 浏览评论:04年前
作者:薇薇,请注明出处。我们经常会写一些网络爬虫,想必大家都会有一种感觉,虽然写爬虫不难,但是反爬很难处理,因为大部分网站都有自己的反爬机制,所以我们将更加难以抓取这些数据。但是,对于每一种反爬机制,我们其实都会有相应的解决方案。作为一个爬虫,我们,
阅读全文
C#网络爬虫--多线程增强版
作者:街角盒饭 688 次浏览评论:05 年前
上次给公司的一个女生做爬虫,不是很精致。这次是用在公司的项目中,所以做了一些改动。该函数添加了一个URL图片采集,下载,线程处理接口URL图片下载等。说说思路:总理在初始网站采集图片去获取初始网站的所有内容到初始网站 采集 链接并将 采集 的链接放入队列以继续 采集 图片
阅读全文
Python网络爬虫抓取极品姐姐的视频并保存到文件
作者:keitwotest1060 浏览评论:04年前
项目描述 用Python写一个网络爬虫爬取Best Sister的视频并保存到文件中使用工具示例 Python2.7.X,pycharm如何使用创建视频爬取Best Sister in pycharm .py 文件,并在当前目录下创建video文件夹,用于存放采集到的视频文件,编写代码,运行
阅读全文
一篇文章文章教你用Python网络爬虫搞定差旅攻略
作者:python进阶13人查看评论:01年前
[一、项目背景] 趣游网提供原创实用的出境游指南、攻略、旅游社区和问答平台,以及智能旅游规划解决方案,以及签证、保险、机票、酒店在线预订、租车等增值服务。侨游“鼓励和帮助中国游客以自己的视角和方式体验世界”。今天就教大家如何获取侨友网的城市信息。
阅读全文
Java版网络爬虫基础(转)
作者:developerguy851 浏览评论:06年前
网络爬虫不仅可以爬取网站网页和图片,甚至可以实现抢票、网上购买、机票查询。这几天看了一些基础知识,记录下来。网页之间的关系可以看成一个大图,图的遍历可以分为深度优先和广度优先。网络爬虫采取的广度优先方式总结如下:2个数组,一个
阅读全文
一篇文章文章教你使用Python网络爬虫爬取评论区百度贴吧图片和视频
作者:python进阶26人查看评论:01年前
[一、项目背景]百度贴吧是全球最大的中文交流平台。你是不是和我一样,有时候看到评论区的图片就想下载?或者观看视频并想下载?今天小编带大家通过搜索关键词,在评论区获取图片和视频。[二、项目目标]实现贴吧获取的图片或视频将保存在
阅读全文 查看全部
c爬虫抓取网页数据(Python网络爬虫反爬破解策略实战作者(组图)作者)
阿里云>云栖社区>主题图>C>c爬虫源码
推荐活动:
更多优惠>
当前话题:c网络爬虫源码加入采集
相关话题:
c网络爬虫源码相关博客看更多博文
C# 网络爬虫
作者:Street Corner Box 712 查看评论:05 年前
公司的编辑需要爬取网页的内容,让我帮我做一个简单的爬取工具。这是抓取网页的内容。看来这对大家来说并不难,不过这里有一些小的改动,代码提供,请参考 1 private string GetHttpWebRequest(string url) 2 { 3 Ht
阅读全文
C#HttpHelper爬虫源码分享--苏飞版
作者:苏飞2071 浏览评论:03年前
简介 C#HttpHelper实现了C#HttpWebRequest爬取时忽略编码、忽略证书、忽略cookie的功能,实现代理的功能。有了它,您可以发出 Get 和 Post 请求,并且可以轻松设置 cookie、证书、代理和编码。你不用担心这个问题,因为类会自动为你识别页面
阅读全文
Python网络爬虫反爬破解攻略实战
作者:薇薇8128 浏览评论:04年前
作者:薇薇,请注明出处。我们经常会写一些网络爬虫,想必大家都会有一种感觉,虽然写爬虫不难,但是反爬很难处理,因为大部分网站都有自己的反爬机制,所以我们将更加难以抓取这些数据。但是,对于每一种反爬机制,我们其实都会有相应的解决方案。作为一个爬虫,我们,
阅读全文
C#网络爬虫--多线程增强版
作者:街角盒饭 688 次浏览评论:05 年前
上次给公司的一个女生做爬虫,不是很精致。这次是用在公司的项目中,所以做了一些改动。该函数添加了一个URL图片采集,下载,线程处理接口URL图片下载等。说说思路:总理在初始网站采集图片去获取初始网站的所有内容到初始网站 采集 链接并将 采集 的链接放入队列以继续 采集 图片
阅读全文
Python网络爬虫抓取极品姐姐的视频并保存到文件
作者:keitwotest1060 浏览评论:04年前
项目描述 用Python写一个网络爬虫爬取Best Sister的视频并保存到文件中使用工具示例 Python2.7.X,pycharm如何使用创建视频爬取Best Sister in pycharm .py 文件,并在当前目录下创建video文件夹,用于存放采集到的视频文件,编写代码,运行
阅读全文
一篇文章文章教你用Python网络爬虫搞定差旅攻略
作者:python进阶13人查看评论:01年前
[一、项目背景] 趣游网提供原创实用的出境游指南、攻略、旅游社区和问答平台,以及智能旅游规划解决方案,以及签证、保险、机票、酒店在线预订、租车等增值服务。侨游“鼓励和帮助中国游客以自己的视角和方式体验世界”。今天就教大家如何获取侨友网的城市信息。
阅读全文
Java版网络爬虫基础(转)
作者:developerguy851 浏览评论:06年前
网络爬虫不仅可以爬取网站网页和图片,甚至可以实现抢票、网上购买、机票查询。这几天看了一些基础知识,记录下来。网页之间的关系可以看成一个大图,图的遍历可以分为深度优先和广度优先。网络爬虫采取的广度优先方式总结如下:2个数组,一个
阅读全文
一篇文章文章教你使用Python网络爬虫爬取评论区百度贴吧图片和视频
作者:python进阶26人查看评论:01年前
[一、项目背景]百度贴吧是全球最大的中文交流平台。你是不是和我一样,有时候看到评论区的图片就想下载?或者观看视频并想下载?今天小编带大家通过搜索关键词,在评论区获取图片和视频。[二、项目目标]实现贴吧获取的图片或视频将保存在
阅读全文
c爬虫抓取网页数据(以文章首页爬取数据的首页方法数据类型及类型)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-01-16 16:01
c爬虫抓取网页数据,而且是从不同的,唯一的抓取途径。还可以做到自动翻页?还能直接或间接爬到某种信息?这些网站应该都是通过共享logo实现抓取的,使用flask-redis的interface进行封装。
cookie我是猜的,因为javascript只能获取某一特定浏览器上的数据。而这个功能在手机浏览器上,有更完美的封装。html5里的grid布局就可以覆盖.useragent。那么问题来了,抓取非ie浏览器不就得了。
什么是首页?网站的入口,无论是wap、flash还是http,都必须在“首页”上放置页面标签,而首页无非两种格式:网站首页和文章首页。文章首页只是网站中页面的补充,目的为使读者不至于从网站跳转而无法继续访问网站本身。下面的爬虫就是以文章首页爬取数据。为了编写方便,urllib.request、urllib.request.urlretrieve等同样用于这种场景,可以根据接口的数据结构灵活实现爬取json。
首页抓取方法数据类型1、地址2、标签名a标签:/useragent是tx在googleanalytics上面对当前我国互联网用户分析调研得出的pythonurlretrieve提供的接口。在python中常用。#headers头部urllib.request.headers.setretrieve("request_uri",url,verify=false)#声明请求头headers头部自定义urlurllib.request.headers.setretrieve("request_uri","",verify=false)#声明请求头urllib.request.headers.setretrieve("user-agent",tx.noagent.transform.alias_default)#声明请求头urllib.request.headers.setretrieve("data_string",tx.noagent.transform.text)#声明请求头urllib.request.headers.setretrieve("category","",verify=false)#声明请求头urllib.request.headers.setretrieve("category","",verify=false)urllib.request.headers.setretrieve("data_text",tx.noagent.transform.text)//网页简易使用urllib.request.headers.setretrieve("user-agent",tx.noagent.transform.text)urllib.request.headers.setretrieve("user-agent",tx.noagent.transform.text)//web浏览器根据url抓取元素urllib.request.headers.setretrieve("cookie",tx.noagent.cookie)python抓取cookie部分的代码importrequestsfrombs4importbeaut。 查看全部
c爬虫抓取网页数据(以文章首页爬取数据的首页方法数据类型及类型)
c爬虫抓取网页数据,而且是从不同的,唯一的抓取途径。还可以做到自动翻页?还能直接或间接爬到某种信息?这些网站应该都是通过共享logo实现抓取的,使用flask-redis的interface进行封装。
cookie我是猜的,因为javascript只能获取某一特定浏览器上的数据。而这个功能在手机浏览器上,有更完美的封装。html5里的grid布局就可以覆盖.useragent。那么问题来了,抓取非ie浏览器不就得了。
什么是首页?网站的入口,无论是wap、flash还是http,都必须在“首页”上放置页面标签,而首页无非两种格式:网站首页和文章首页。文章首页只是网站中页面的补充,目的为使读者不至于从网站跳转而无法继续访问网站本身。下面的爬虫就是以文章首页爬取数据。为了编写方便,urllib.request、urllib.request.urlretrieve等同样用于这种场景,可以根据接口的数据结构灵活实现爬取json。
首页抓取方法数据类型1、地址2、标签名a标签:/useragent是tx在googleanalytics上面对当前我国互联网用户分析调研得出的pythonurlretrieve提供的接口。在python中常用。#headers头部urllib.request.headers.setretrieve("request_uri",url,verify=false)#声明请求头headers头部自定义urlurllib.request.headers.setretrieve("request_uri","",verify=false)#声明请求头urllib.request.headers.setretrieve("user-agent",tx.noagent.transform.alias_default)#声明请求头urllib.request.headers.setretrieve("data_string",tx.noagent.transform.text)#声明请求头urllib.request.headers.setretrieve("category","",verify=false)#声明请求头urllib.request.headers.setretrieve("category","",verify=false)urllib.request.headers.setretrieve("data_text",tx.noagent.transform.text)//网页简易使用urllib.request.headers.setretrieve("user-agent",tx.noagent.transform.text)urllib.request.headers.setretrieve("user-agent",tx.noagent.transform.text)//web浏览器根据url抓取元素urllib.request.headers.setretrieve("cookie",tx.noagent.cookie)python抓取cookie部分的代码importrequestsfrombs4importbeaut。
c爬虫抓取网页数据(新手练习爬虫不过分吧?这篇爬虫实战教程,拿走不谢!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-14 09:13
最近暑假快到了,很多朋友都在找暑期实习吧?前几天,朋友的小弟暑假想找个实习来锻炼自己,但面对网上千篇一律的实习招聘信息,不知所措。然后我的朋友给我发了一条“请求帮助”的消息。得知大致情况后,我立即用爬虫爬取了练习网的信息,并将数据结果发送过去,分分钟解决了问题。请我吃饭会不会太过分了?
本爬虫实战教程不仅适合新手练习爬虫,也适合需要找实习资料的朋友!
希望看完这篇文章,能够清楚的知道整个爬虫流程,并且能够独立完成,二来可以通过自己的爬虫实战得到自己想要的信息。
好吧,事不宜迟,让我们开始吧!
内容主要分为两部分:
页面分析爬虫步骤详解
一、目标页面分析
首先,我们应该知道我们的爬虫目标是什么,对吧?俗话说,知己知彼,百战不殆。我们已经知道我们要爬的页面是“实习网”,所以我们首先要到实习网看看有什么数据。
实习网址:
页面如下:
比如我们要找的职位就是“品牌运营”职位的数据。因此,您可以直接在网页的搜索框中输入品牌运营。您会注意到网址已更改!
注:我们要抓取的页面是这个页面:品牌运营
在我们的爬取页面中,我们需要观察那里有哪些数据,一个页面中有几条数据。这点很重要,跟后面的代码编写有关,可以帮你检查页面上的所有信息是否都被爬取了。
此时,我们要注意的是,我们所在的页面是“一级页面”。在浏览过程中,我们随机点击一个帖子进入后,会显示“二级页面”。这时候你也会发现url又出现了。改变了。
比如我们点击一个品牌运营实践,二级页面会自动跳转到这个,生成一个新的链接。如图所示:
如何抓取页面上的信息?
在分析过程中,我们发现有的信息在一级页面,有的在二级页面。
在一级页面,我们可以得到什么信息?如图所示:
一共有五个有效数据:职位、公司名称、学历、薪水、地址
在二级页面中,我们来看看可以获得哪些有效数据、字段和刻度。如果觉得阶段很重要,也可以纳入爬虫的范围,但我个人认为这不影响实习。毕竟,它不是在寻找正式的工作。影响不会很大,但是招聘的实习生数量比较重要。这里没有显示新兵的数量,也无法在图片上显示。以后可以添加。
此时,我们一共需要抓取7个数据,加上“人数”,一共8个数据,就是我们爬虫最终的目标数据。
抓取“静态”网页
下面分析一下什么是静态网页,什么是动态网页。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
它们的区别在于静态网页中的数据是一劳永逸的,也就是说一次性给你。动态网页中的数据是随着页面的逐步加载而逐渐呈现出来的,也就是说,如果使用静态网页的爬虫技术,是无法获取其中所有数据的。
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是动态网站技术生成的网页,都可以称为动态网页。
点击“鼠标右键”,点击“查看网页源代码”,最终效果如图(部分截图):
这是最终反馈给您的数据。如果你发现你想要的数据都在里面,那么就可以说是静态页面,否则就认为是“动态页面”。
今天这里的案例是一个静态网页。
众所周知,在编写代码之前,我们必须知道我们使用哪些方法、库和模块来帮助您解析数据。常用的数据解析方法有:re正则表达式、xpath、beatifulsoup、pyquery等。
我们需要用到的是xpath解析方法来分析定位数据。
二、爬虫代码说明
导入相关库
爬取的第一步是考虑在爬取过程中需要哪些库。您必须知道python是一种依赖于许多库的语言。没有库的 Python 是不完整的。
import pandas as pd # 用于数据存储
import requests # 用于请求网页
import chardet # 用于修改编码
import re # 用于提取数据
from lxml import etree # 解析数据的库
import time # 可以粗糙模拟人为请求网页的速度
import warnings # 忽略代码运行时候的警告信息
warnings.filterwarnings("ignore")
2、请求一级页面的源码
url = 'https://www.shixi.com/search/index?key=品牌运营&districts=&education=0&full_opportunity=0&stage=0&practice_days=0&nature=0&trades=&lang=zh_cn'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
rqg = requests.get(url, headers=headers, verify=False) ①
rqg.encoding = chardet.detect(rqg.content)['encoding'] ②
html = etree.HTML(rqg.text)
这里要注意①和②两个地方。①处有两个参数,一个是headers,一个是verify。其中headers是一种防反爬的措施,它使浏览器认为爬虫不是爬虫,而是人们使用浏览器正常请求网页。verify 是忽略安全证书提示。某些网页会被视为不安全网页,并会提示您。只要记住这个参数。
在②处,我们已经获得了网页的源代码。但是由于网页源代码的编码方式和你电脑的解析方式,可能存在不一致,返回的结果会导致乱码。此时需要修改编码方式。chardet 库可以帮助您自动检测网页源代码的编码。(一个非常有用的三方库chardet检测文档编码)
3、解析一级页面中的信息
# 1. 公司名
company_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
company_list = [company_list[i].strip() for i in range(len(company_list)) if i % 2 != 0]
# 2. 岗位名
job_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
job_list = [job_list[i].strip() for i in range(len(job_list)) if i % 2 == 0]
# 3. 地址
address_list = html.xpath('//div[@class="job-pannel-two"]//a/text()')
# 4. 学历
degree_list = html.xpath('//div[@class="job-pannel-list"]//dd[@class="job-des"]/span/text()')
# 5. 薪资
salary_list = html.xpath('//div[@class="job-pannel-two"]//div[@class="company-info-des"]/text()')
salary_list = [i.strip() for i in salary_list]
# 获取二级页面的链接
deep_url_list = html.xpath('//div[@class="job-pannel-list"]//dt/a/@href')
x = "https://www.shixi.com"
deep_url_list = [x + i for i in deep_url_list]
此时,你可以看到,我直接采用xpath一个个去解析一级页面中的数据分析。在代码末尾,可以看到:我们获取到了二级页面的链接,为我们后面爬取二级页面中的信息,做准备。
解析二级页面网页中的信息
demand_list = []
area_list = []
scale_list = []
for deep_url in deep_url_list:
rqg = requests.get(deep_url, headers=headers, verify=False) ①
rqg.encoding = chardet.detect(rqg.content)['encoding'] ②
html = etree.HTML(rqg.text) ③
# 6. 招聘人数
demand = html.xpath('//div[@class="container-fluid"]//div[@class="intros"]/span[2]/text()')
# 7. 公司领域
area = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[1]/span/text()')
# 8. 公司规模
scale = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[2]/span/text()')
demand_list.append(demand)
area_list.append(area)
scale_list.append(scale)
需要注意的是,二级页面也是一个页面,在爬取里面的数据的时候需要请求这个页面。因此,①②③处的代码完全相同。
4、翻页操作
https://www.shixi.com/search/i ... e%3D1
https://www.shixi.com/search/i ... e%3D2
https://www.shixi.com/search/i ... e%3D3
随意复制几个不同页面的 URL 并观察差异。这里可以看出page参数后面的数字是不一样的,哪一页是数字,数字就是数字。
x = "https://www.shixi.com/search/index?key=数据分析&page="
url_list = [x + str(i) for i in range(1,61)]
由于我们已经爬取了60页的数据,所以这里构造了60个url,全部存放在url_list列表中。
现在来看整个代码,我不再用文字描述,直接在代码中写注释。
import pandas as pd
import requests
import chardet
import re
from lxml import etree
import time
import warnings
warnings.filterwarnings("ignore")
def get_CI(url):
# 请求获取一级页面的源代码
url = 'https://www.shixi.com/search/index?key=品牌运营&districts=&education=0&full_opportunity=0&stage=0&practice_days=0&nature=0&trades=&lang=zh_cn'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
rqg = requests.get(url, headers=headers, verify=False)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
# 获取一级页面中的信息:一共有5个信息。
# ①公司名
company_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
company_list = [company_list[i].strip() for i in range(len(company_list)) if i % 2 != 0]
#②岗位名
job_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
job_list = [job_list[i].strip() for i in range(len(job_list)) if i % 2 == 0]
#③地址
address_list = html.xpath('//div[@class="job-pannel-two"]//a/text()')
# ④ 学历
degree_list = html.xpath('//div[@class="job-pannel-list"]//dd[@class="job-des"]/span/text()')
# ⑤薪资
salary_list = html.xpath('//div[@class="job-pannel-two"]//div[@class="company-info-des"]/text()')
salary_list = [i.strip() for i in salary_list]
# ⑥获取二级页面的内容
deep_url_list = html.xpath('//div[@class="job-pannel-list"]//dt/a/@href')
x = "https://www.shixi.com"
deep_url_list = [x + i for i in deep_url_list]
demand_list = []
area_list = []
scale_list = []
# 获取二级页面中的信息:
for deep_url in deep_url_list:
rqg = requests.get(deep_url, headers=headers, verify=False)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
#① 需要几人
demand = html.xpath('//div[@class="container-fluid"]//div[@class="intros"]/span[2]/text()')
# ②公司领域
area = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[1]/span/text()')
# ③公司规模
scale = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[2]/span/text()')
demand_list.append(demand)
area_list.append(area)
scale_list.append(scale)
# ④ 将每个页面获取到的所有数据,存储到DataFrame中。
data = pd.DataFrame({'公司名':company_list,'岗位名':job_list,'地址':address_list,"学历":degree_list,
'薪资':salary_list,'岗位需求量':demand_list,'公司领域':area_list,'公司规模':scale_list})
return(data)
x = "https://www.shixi.com/search/index?key=数据分析&page="
url_list = [x + str(i) for i in range(1,61)]
res = pd.DataFrame(columns=['公司名','岗位名','地址',"学历",'薪资','岗位需求量','公司领域','公司规模'])
# 这里进行“翻页”操作
for url in url_list:
res0 = get_CI(url)
res = pd.concat([res,res0])
time.sleep(3)
# 保存数据
res.to_csv('aliang.csv',encoding='utf_8_sig')
这一套之后,爬虫的思路是不是瞬间清晰了?眼睛:我会的!手:我还是不会。多加练习。初学者不要急于求成,项目不多,但有技巧。看透一个比看十个要有效得多。
想要获取源码的朋友,点赞+评论,私聊~ 查看全部
c爬虫抓取网页数据(新手练习爬虫不过分吧?这篇爬虫实战教程,拿走不谢!)
最近暑假快到了,很多朋友都在找暑期实习吧?前几天,朋友的小弟暑假想找个实习来锻炼自己,但面对网上千篇一律的实习招聘信息,不知所措。然后我的朋友给我发了一条“请求帮助”的消息。得知大致情况后,我立即用爬虫爬取了练习网的信息,并将数据结果发送过去,分分钟解决了问题。请我吃饭会不会太过分了?
本爬虫实战教程不仅适合新手练习爬虫,也适合需要找实习资料的朋友!
希望看完这篇文章,能够清楚的知道整个爬虫流程,并且能够独立完成,二来可以通过自己的爬虫实战得到自己想要的信息。
好吧,事不宜迟,让我们开始吧!
内容主要分为两部分:
页面分析爬虫步骤详解
一、目标页面分析
首先,我们应该知道我们的爬虫目标是什么,对吧?俗话说,知己知彼,百战不殆。我们已经知道我们要爬的页面是“实习网”,所以我们首先要到实习网看看有什么数据。
实习网址:
页面如下:
比如我们要找的职位就是“品牌运营”职位的数据。因此,您可以直接在网页的搜索框中输入品牌运营。您会注意到网址已更改!
注:我们要抓取的页面是这个页面:品牌运营
在我们的爬取页面中,我们需要观察那里有哪些数据,一个页面中有几条数据。这点很重要,跟后面的代码编写有关,可以帮你检查页面上的所有信息是否都被爬取了。
此时,我们要注意的是,我们所在的页面是“一级页面”。在浏览过程中,我们随机点击一个帖子进入后,会显示“二级页面”。这时候你也会发现url又出现了。改变了。
比如我们点击一个品牌运营实践,二级页面会自动跳转到这个,生成一个新的链接。如图所示:
如何抓取页面上的信息?
在分析过程中,我们发现有的信息在一级页面,有的在二级页面。
在一级页面,我们可以得到什么信息?如图所示:
一共有五个有效数据:职位、公司名称、学历、薪水、地址
在二级页面中,我们来看看可以获得哪些有效数据、字段和刻度。如果觉得阶段很重要,也可以纳入爬虫的范围,但我个人认为这不影响实习。毕竟,它不是在寻找正式的工作。影响不会很大,但是招聘的实习生数量比较重要。这里没有显示新兵的数量,也无法在图片上显示。以后可以添加。
此时,我们一共需要抓取7个数据,加上“人数”,一共8个数据,就是我们爬虫最终的目标数据。
抓取“静态”网页
下面分析一下什么是静态网页,什么是动态网页。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
它们的区别在于静态网页中的数据是一劳永逸的,也就是说一次性给你。动态网页中的数据是随着页面的逐步加载而逐渐呈现出来的,也就是说,如果使用静态网页的爬虫技术,是无法获取其中所有数据的。
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是动态网站技术生成的网页,都可以称为动态网页。
点击“鼠标右键”,点击“查看网页源代码”,最终效果如图(部分截图):
这是最终反馈给您的数据。如果你发现你想要的数据都在里面,那么就可以说是静态页面,否则就认为是“动态页面”。
今天这里的案例是一个静态网页。
众所周知,在编写代码之前,我们必须知道我们使用哪些方法、库和模块来帮助您解析数据。常用的数据解析方法有:re正则表达式、xpath、beatifulsoup、pyquery等。
我们需要用到的是xpath解析方法来分析定位数据。
二、爬虫代码说明
导入相关库
爬取的第一步是考虑在爬取过程中需要哪些库。您必须知道python是一种依赖于许多库的语言。没有库的 Python 是不完整的。
import pandas as pd # 用于数据存储
import requests # 用于请求网页
import chardet # 用于修改编码
import re # 用于提取数据
from lxml import etree # 解析数据的库
import time # 可以粗糙模拟人为请求网页的速度
import warnings # 忽略代码运行时候的警告信息
warnings.filterwarnings("ignore")
2、请求一级页面的源码
url = 'https://www.shixi.com/search/index?key=品牌运营&districts=&education=0&full_opportunity=0&stage=0&practice_days=0&nature=0&trades=&lang=zh_cn'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
rqg = requests.get(url, headers=headers, verify=False) ①
rqg.encoding = chardet.detect(rqg.content)['encoding'] ②
html = etree.HTML(rqg.text)
这里要注意①和②两个地方。①处有两个参数,一个是headers,一个是verify。其中headers是一种防反爬的措施,它使浏览器认为爬虫不是爬虫,而是人们使用浏览器正常请求网页。verify 是忽略安全证书提示。某些网页会被视为不安全网页,并会提示您。只要记住这个参数。
在②处,我们已经获得了网页的源代码。但是由于网页源代码的编码方式和你电脑的解析方式,可能存在不一致,返回的结果会导致乱码。此时需要修改编码方式。chardet 库可以帮助您自动检测网页源代码的编码。(一个非常有用的三方库chardet检测文档编码)
3、解析一级页面中的信息
# 1. 公司名
company_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
company_list = [company_list[i].strip() for i in range(len(company_list)) if i % 2 != 0]
# 2. 岗位名
job_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
job_list = [job_list[i].strip() for i in range(len(job_list)) if i % 2 == 0]
# 3. 地址
address_list = html.xpath('//div[@class="job-pannel-two"]//a/text()')
# 4. 学历
degree_list = html.xpath('//div[@class="job-pannel-list"]//dd[@class="job-des"]/span/text()')
# 5. 薪资
salary_list = html.xpath('//div[@class="job-pannel-two"]//div[@class="company-info-des"]/text()')
salary_list = [i.strip() for i in salary_list]
# 获取二级页面的链接
deep_url_list = html.xpath('//div[@class="job-pannel-list"]//dt/a/@href')
x = "https://www.shixi.com"
deep_url_list = [x + i for i in deep_url_list]
此时,你可以看到,我直接采用xpath一个个去解析一级页面中的数据分析。在代码末尾,可以看到:我们获取到了二级页面的链接,为我们后面爬取二级页面中的信息,做准备。
解析二级页面网页中的信息
demand_list = []
area_list = []
scale_list = []
for deep_url in deep_url_list:
rqg = requests.get(deep_url, headers=headers, verify=False) ①
rqg.encoding = chardet.detect(rqg.content)['encoding'] ②
html = etree.HTML(rqg.text) ③
# 6. 招聘人数
demand = html.xpath('//div[@class="container-fluid"]//div[@class="intros"]/span[2]/text()')
# 7. 公司领域
area = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[1]/span/text()')
# 8. 公司规模
scale = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[2]/span/text()')
demand_list.append(demand)
area_list.append(area)
scale_list.append(scale)
需要注意的是,二级页面也是一个页面,在爬取里面的数据的时候需要请求这个页面。因此,①②③处的代码完全相同。
4、翻页操作
https://www.shixi.com/search/i ... e%3D1
https://www.shixi.com/search/i ... e%3D2
https://www.shixi.com/search/i ... e%3D3
随意复制几个不同页面的 URL 并观察差异。这里可以看出page参数后面的数字是不一样的,哪一页是数字,数字就是数字。
x = "https://www.shixi.com/search/index?key=数据分析&page="
url_list = [x + str(i) for i in range(1,61)]
由于我们已经爬取了60页的数据,所以这里构造了60个url,全部存放在url_list列表中。
现在来看整个代码,我不再用文字描述,直接在代码中写注释。
import pandas as pd
import requests
import chardet
import re
from lxml import etree
import time
import warnings
warnings.filterwarnings("ignore")
def get_CI(url):
# 请求获取一级页面的源代码
url = 'https://www.shixi.com/search/index?key=品牌运营&districts=&education=0&full_opportunity=0&stage=0&practice_days=0&nature=0&trades=&lang=zh_cn'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
rqg = requests.get(url, headers=headers, verify=False)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
# 获取一级页面中的信息:一共有5个信息。
# ①公司名
company_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
company_list = [company_list[i].strip() for i in range(len(company_list)) if i % 2 != 0]
#②岗位名
job_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
job_list = [job_list[i].strip() for i in range(len(job_list)) if i % 2 == 0]
#③地址
address_list = html.xpath('//div[@class="job-pannel-two"]//a/text()')
# ④ 学历
degree_list = html.xpath('//div[@class="job-pannel-list"]//dd[@class="job-des"]/span/text()')
# ⑤薪资
salary_list = html.xpath('//div[@class="job-pannel-two"]//div[@class="company-info-des"]/text()')
salary_list = [i.strip() for i in salary_list]
# ⑥获取二级页面的内容
deep_url_list = html.xpath('//div[@class="job-pannel-list"]//dt/a/@href')
x = "https://www.shixi.com"
deep_url_list = [x + i for i in deep_url_list]
demand_list = []
area_list = []
scale_list = []
# 获取二级页面中的信息:
for deep_url in deep_url_list:
rqg = requests.get(deep_url, headers=headers, verify=False)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
#① 需要几人
demand = html.xpath('//div[@class="container-fluid"]//div[@class="intros"]/span[2]/text()')
# ②公司领域
area = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[1]/span/text()')
# ③公司规模
scale = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[2]/span/text()')
demand_list.append(demand)
area_list.append(area)
scale_list.append(scale)
# ④ 将每个页面获取到的所有数据,存储到DataFrame中。
data = pd.DataFrame({'公司名':company_list,'岗位名':job_list,'地址':address_list,"学历":degree_list,
'薪资':salary_list,'岗位需求量':demand_list,'公司领域':area_list,'公司规模':scale_list})
return(data)
x = "https://www.shixi.com/search/index?key=数据分析&page="
url_list = [x + str(i) for i in range(1,61)]
res = pd.DataFrame(columns=['公司名','岗位名','地址',"学历",'薪资','岗位需求量','公司领域','公司规模'])
# 这里进行“翻页”操作
for url in url_list:
res0 = get_CI(url)
res = pd.concat([res,res0])
time.sleep(3)
# 保存数据
res.to_csv('aliang.csv',encoding='utf_8_sig')
这一套之后,爬虫的思路是不是瞬间清晰了?眼睛:我会的!手:我还是不会。多加练习。初学者不要急于求成,项目不多,但有技巧。看透一个比看十个要有效得多。
想要获取源码的朋友,点赞+评论,私聊~
c爬虫抓取网页数据(1.网络爬虫的基本概念网络蜘蛛,机器人都能够做到! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-01-13 21:28
)
1.网络爬虫基本概念
网络爬虫(也称为网络蜘蛛或机器人)是模拟客户端发送网络请求并接收请求响应的程序。它是一个按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做任何事情,原则上爬虫都能做到。
2.网络爬虫函数
网络爬虫可以手动替换很多东西,比如用作搜索引擎,或者爬取网站上的图片。比如有的朋友把一些网站上的所有图片都爬进去,集中在上面。可以进行投资分析。
有时候,可能有几个我们比较喜欢的新闻网站,每次浏览都单独打开这些新闻网站比较麻烦。这时候就可以用网络爬虫来爬取这多条新闻网站中的新闻信息,集中阅读。
有时候,我们在网上浏览信息的时候,会发现有很多广告。这时也可以利用爬虫来爬取相应网页上的信息,从而自动过滤掉这些广告,方便信息的阅读和使用。
有时候,我们需要做营销,所以如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以手动搜索互联网,但这会非常低效。这时候,我们可以通过爬虫设置相应的规则,自动采集从互联网上获取目标用户的联系方式,供我们营销使用。
有时候,我们想分析某个网站的用户信息,比如分析网站的用户活跃度、发言次数、热门文章等信息,如果我们没有网站@ >管理员,手动统计将是一个非常庞大的工程。此时,您可以使用爬虫轻松采集对这些数据进行进一步分析,并且所有的爬取操作都是自动进行的,我们只需要编写相应的爬虫并设计相应的爬虫即可。规则会做。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们以前需要手动访问互联网信息的操作现在可以通过爬虫实现自动化,从而更有效地使用互联网中的有效信息。.
3.安装第三方库
在爬取和解析数据之前,需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面输入pip install requests,回车安装。(注意连接网络)如下图
安装完成,如图
查看全部
c爬虫抓取网页数据(1.网络爬虫的基本概念网络蜘蛛,机器人都能够做到!
)
1.网络爬虫基本概念
网络爬虫(也称为网络蜘蛛或机器人)是模拟客户端发送网络请求并接收请求响应的程序。它是一个按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做任何事情,原则上爬虫都能做到。
2.网络爬虫函数
网络爬虫可以手动替换很多东西,比如用作搜索引擎,或者爬取网站上的图片。比如有的朋友把一些网站上的所有图片都爬进去,集中在上面。可以进行投资分析。
有时候,可能有几个我们比较喜欢的新闻网站,每次浏览都单独打开这些新闻网站比较麻烦。这时候就可以用网络爬虫来爬取这多条新闻网站中的新闻信息,集中阅读。
有时候,我们在网上浏览信息的时候,会发现有很多广告。这时也可以利用爬虫来爬取相应网页上的信息,从而自动过滤掉这些广告,方便信息的阅读和使用。
有时候,我们需要做营销,所以如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以手动搜索互联网,但这会非常低效。这时候,我们可以通过爬虫设置相应的规则,自动采集从互联网上获取目标用户的联系方式,供我们营销使用。
有时候,我们想分析某个网站的用户信息,比如分析网站的用户活跃度、发言次数、热门文章等信息,如果我们没有网站@ >管理员,手动统计将是一个非常庞大的工程。此时,您可以使用爬虫轻松采集对这些数据进行进一步分析,并且所有的爬取操作都是自动进行的,我们只需要编写相应的爬虫并设计相应的爬虫即可。规则会做。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们以前需要手动访问互联网信息的操作现在可以通过爬虫实现自动化,从而更有效地使用互联网中的有效信息。.
3.安装第三方库
在爬取和解析数据之前,需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面输入pip install requests,回车安装。(注意连接网络)如下图
安装完成,如图
c爬虫抓取网页数据(头条搜索爬虫暴力抓取网站内容直接瘫痪百度也没有这么折腾)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-13 21:25
近日,一位站长在网上发帖抱怨字节跳动为了快速发展搜索业务,派出爬虫暴力抓取网站内容。@>业主造成了很大的损失和麻烦,严重影响了网站的正常用户访问。
站长说,今年7月突然发现公司的网站不能频繁打开,网页加载极慢,有时甚至直接瘫痪。经过一系列排查,在服务器日志中发现了bytespider爬虫的踪迹。爬虫的爬取频率每天几百万次,最高的是几千万次。服务器带宽负载飙升至 100%,爬虫在爬取时完全不遵循 网站 robots 协议。
站长顺着爬虫的IP地址查询,确认该爬虫是字节跳动搜索爬虫。
另外,我还从CSDN、V2EX等技术论坛了解到,字节跳动开始搜索后,其实网上一直有站长抱怨头条搜索爬虫爬得太猛,被字节跳动搜索爬虫。这不是个例,很多小网站他们都没有放过。
一些网站小站长抱怨:字节跳动的爬虫“一上午就向网站发出46万个请求”,网站瘫痪了,百度也没有那么麻烦!
最后,站长说,对于像我们这样做SEO的人来说,主要目标是希望自己的首页网站能够在主流搜索引擎的搜索结果中排名靠前。360、收录等搜索引擎的标准爬取很受欢迎,但是今日头条搜索爬虫的疯狂爬取内容网站完全瘫痪,不仅没有给网站带来流量也影响正常用户访问,不是很“特殊”。
但字节跳动对此的回应是,“网络报道不实,目前今日头条搜索有反馈机制。网站由于爬虫受到影响,可以通过邮件反馈直接处理。” 明是不准备正面回应的。
因此,从头条搜索爬虫暴力爬取网站的内容来看,雷哥个人认为字节跳动进军全网搜索,搅动搜索市场是好事,但为了快速崛起,让他的爬虫到处乱爬,刚好有问题,大网站服务器配置高,技术人员多,但是很多小网站受不了字节的折腾- 完全击败搜索爬虫。
搜索引擎的索引数据是一点一点积累的。百度和搜狗.360经历了这么多年的发展和积累,才走到了今天。今日头条搜索疯狂爬取内容。远离! 查看全部
c爬虫抓取网页数据(头条搜索爬虫暴力抓取网站内容直接瘫痪百度也没有这么折腾)
近日,一位站长在网上发帖抱怨字节跳动为了快速发展搜索业务,派出爬虫暴力抓取网站内容。@>业主造成了很大的损失和麻烦,严重影响了网站的正常用户访问。
站长说,今年7月突然发现公司的网站不能频繁打开,网页加载极慢,有时甚至直接瘫痪。经过一系列排查,在服务器日志中发现了bytespider爬虫的踪迹。爬虫的爬取频率每天几百万次,最高的是几千万次。服务器带宽负载飙升至 100%,爬虫在爬取时完全不遵循 网站 robots 协议。
站长顺着爬虫的IP地址查询,确认该爬虫是字节跳动搜索爬虫。
另外,我还从CSDN、V2EX等技术论坛了解到,字节跳动开始搜索后,其实网上一直有站长抱怨头条搜索爬虫爬得太猛,被字节跳动搜索爬虫。这不是个例,很多小网站他们都没有放过。
一些网站小站长抱怨:字节跳动的爬虫“一上午就向网站发出46万个请求”,网站瘫痪了,百度也没有那么麻烦!
最后,站长说,对于像我们这样做SEO的人来说,主要目标是希望自己的首页网站能够在主流搜索引擎的搜索结果中排名靠前。360、收录等搜索引擎的标准爬取很受欢迎,但是今日头条搜索爬虫的疯狂爬取内容网站完全瘫痪,不仅没有给网站带来流量也影响正常用户访问,不是很“特殊”。
但字节跳动对此的回应是,“网络报道不实,目前今日头条搜索有反馈机制。网站由于爬虫受到影响,可以通过邮件反馈直接处理。” 明是不准备正面回应的。
因此,从头条搜索爬虫暴力爬取网站的内容来看,雷哥个人认为字节跳动进军全网搜索,搅动搜索市场是好事,但为了快速崛起,让他的爬虫到处乱爬,刚好有问题,大网站服务器配置高,技术人员多,但是很多小网站受不了字节的折腾- 完全击败搜索爬虫。
搜索引擎的索引数据是一点一点积累的。百度和搜狗.360经历了这么多年的发展和积累,才走到了今天。今日头条搜索疯狂爬取内容。远离!
c爬虫抓取网页数据(入门文章数据库入门指南系列(一)·#11·cdalogic/cdablog)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-13 02:01
c爬虫抓取网页数据redis-spider批量下载百度、新浪、凤凰、搜狐网站所有热门话题内容elasticsearch-parser全文搜索工具elasticsearch-dnspod解析页面数据blogger搜索各大人气博客
真羡慕你年纪轻轻不急不慢,就开始学计算机技术。计算机是真正可以学到一辈子的东西。上面这些我告诉你,一年之后肯定比30岁有技术有资本的人。
在计算机领域,
希望你可以学习一下数据库相关的知识,如nosql或者mongodb,这些都是你大数据开发基础中必不可少的组成。你可以从学习数据库开始入手,或者sql开始入手,
netframework不过呢,看书理论性太强,光理论书就够你看几年了。还是老老实实看视频吧。
刚好昨天刚写了一个数据库管理员界面,希望对你有所帮助,
推荐一本数据库管理员的入门手册,
我写了一篇入门文章数据库入门指南系列(一)·issue#11·cdalogic/cdablog,
1.推荐《这个网站是数据库(databasemanagementtechniquesandtools)》,应该是hadoop之前经典书籍。2.再推荐《数据库系统概念(databasesystems)》3.又来个《数据库系统概念导论(databasesystems)》4.还有一本《数据库管理系统(databasemanagementsystems)》。 查看全部
c爬虫抓取网页数据(入门文章数据库入门指南系列(一)·#11·cdalogic/cdablog)
c爬虫抓取网页数据redis-spider批量下载百度、新浪、凤凰、搜狐网站所有热门话题内容elasticsearch-parser全文搜索工具elasticsearch-dnspod解析页面数据blogger搜索各大人气博客
真羡慕你年纪轻轻不急不慢,就开始学计算机技术。计算机是真正可以学到一辈子的东西。上面这些我告诉你,一年之后肯定比30岁有技术有资本的人。
在计算机领域,
希望你可以学习一下数据库相关的知识,如nosql或者mongodb,这些都是你大数据开发基础中必不可少的组成。你可以从学习数据库开始入手,或者sql开始入手,
netframework不过呢,看书理论性太强,光理论书就够你看几年了。还是老老实实看视频吧。
刚好昨天刚写了一个数据库管理员界面,希望对你有所帮助,
推荐一本数据库管理员的入门手册,
我写了一篇入门文章数据库入门指南系列(一)·issue#11·cdalogic/cdablog,
1.推荐《这个网站是数据库(databasemanagementtechniquesandtools)》,应该是hadoop之前经典书籍。2.再推荐《数据库系统概念(databasesystems)》3.又来个《数据库系统概念导论(databasesystems)》4.还有一本《数据库管理系统(databasemanagementsystems)》。
c爬虫抓取网页数据(产品经理网站结构比较简单的翻太慢错的方法有哪些)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-12 08:09
再次重申:我不是程序员,也没有涉及代码。当页面被修改时,我只涉及复制和粘贴。
要去给朋友圈添点专业气息,需要添加一些新的微信ID;
在哪里可以找到专业的微信账号?
想着大家都是产品经理,我看到传播者在文章下的评论里留下微信,但是每个文章的翻译太慢了,也许你可以用一个工具把所有的评论发到抓住它进行过滤。
网站结构比较简单,这个应该是简单的抓取,到最后会发现自己错了。
以下简称人人为产品经理网站;
上一篇文章中已经详细介绍了常规爬取的过程,重复部分本文不再赘述;
思考过程:如果有需求,找到需求对应的信息,找到信息对应的位置,找到位置对应的工具,找到工具对应的功能或技能。
一:换算法,使用更准确的方法;
上一篇文章介绍了一种生成链接的方法,大家准备用同样的方法再做一遍;
然后遇到第一个难点:大家的链接结构不统一,比如:/pmd/1660079.html、/pd/1659496.html、/ai/1648500.html等.;
总共有10多个类别,最大数量为1,660,079,超过160万。如果每个类别产生超过160万个链接,去链接审核工具进行审核,可能需要十天以上的时间来审核链接;
这种方法是行不通的,需要一个新的方法:网站提供了一个方便的通道——列表页,通过它可以获得整个列表的链接。
使用这种方法,从十几天,这个步骤可以缩短到几个小时。
二:确定约束条件,根据约束条件改进流程
在得到链接之前,我做了一个计算,有几万条文章,而文章下的评论就更多了;
该工具的数据导出限制为 10,000 条。这次真的要花钱升级吗?
又想到一句话:带枷锁跳舞,不带枷锁跳舞不是技巧,带枷锁跳舞是技巧。
最近一直在思考一个基本的二元关系问题:A和B之间有多少条路径?
对初步思考的回答:A和B之间至少有两条路径:AB和BA。
这说明了这样一个事实,即两件事之间必须有两条路径,并且除了常规路径之外至少还有一条其他路径。
把这个结论应用到限定条件上,那么解决问题的路径至少有两条:
1:常规路径:需求(自身)不变,(环境)极限扩大,极限适应需求;
2:反向路径:限制(环境)不变,压缩(自己)需求,使需求适应限制;
第二条反向路径为解决问题带来了新的视角,为流程演化建立了新的理论基础。
原来的流程是:
获取链接—>导出链接(限制出现1)—>重新导入—>评论抓取—>导出评论(限制出现2)—>本地过滤。
第一个改进:重新定义需求,细化获取环节:
其实第二阶段需要的不是任何文章,而是带注释的文章(没有注释就不用抢注释了),在初始条件上加上细化条件提前过滤,一下子把链接数减少了三分之一。
新流程:获取精确链接—>导出链接(限制1)的位置—>重新导入—>评论捕获—>导出评论(限制2)的位置—>本地过滤。
第二次改进:将新的认识应用到大局中,在第二阶段增加细化条件;
不是所有的评论都要被抓,而是收录公众号或微信账号的评论。
新流程:获取精准链接—>导出链接(限制1)的位置—>重新导入—>准确抓取评论—>导出评论(限制2)的位置—>本地过滤。
第三次改进:合并和推进流程
我在中间去了一次洗手间,洗手间做得很好。在其中,我想到了两个过程。为什么要把这两个进程分开?
这两个阶段是一个连续的过程,如果这些过程可以合并,第一阶段的限制就会消失。
这说明除了适应约束之外,还可以选择合理地调整流程以消除或跳过约束。
将两个流程合二为一后,新流程:获取精准链接—>准确抓取评论—>导出评论(限制位置2)—>本地过滤。
由于重新定义了两阶段要求,最终出口数据中只剩下有意义的部分。
这个改进过程也让我发现了一个优化的关键点:在设计过程时,结合约束,用约束激发深度优化。
最终得到了我想要的数据,结果发现约束不是敌人,约束是持续创新的重要条件。
这一发现也为创新开辟了一种新的思维方式:自我强加的限制,没有限制创造限制。就像这个文章,本来是不打算写的,但是我给自己设计了一个新的限制:把事情做完,从实践到总结,就完成了。
在过滤数据时,我有点气馁。评论数据是非结构化的,很难快速过滤此类数据。这也让我有了一个新的发现:数据的价值取决于结构的程度。结构化数据很少。既然如此,与其捕获杂乱无章的数据,事后对其进行结构化,不如在初始设计中建立结构化的数据捕获过程。
结束了吗?确实是时候结束了,本来预定的数据已经拿到了;
但这并没有结束,甚至真正的困难才刚刚开始,所以这是一个意外。
三:抢公众号,重新整理全站内容;
一边抓着上面的微信,一边也隔出了一部分公众号,很少。如果能得到更多的公众号,或许可以做一个专门的页面来提供一个服务,也就是集成即服务。该方法的效果很差,需要更高效的采集方法;
我想还有一个地方也会放公众号,每个文章底部的作者介绍部分:
如果能够获取大量数据,就可以形成公众账户矩阵。据我所知,没有这样的信息库,信息集中对用户也很有价值;
准备开始抓取,遇到了第一个难点:文章内容很多,如何定位要抓取的对象?
定位要抓拍的物体有一个窍门:分析物体的特征,尤其是独特的特征,通过独特的特征准确识别;比如这次要抓的对象是一个公众号,而这三个词在文章中也经常出现,但是出现在文章中的时候一般不会跟a : 符号,仅在作者介绍时才收录,这是关键特性。
第一个改进:多角度观察数据,增加要捕获的数据类型;
这是一个非常偶然的想法。我想着数据可能可以供官方参考,然后又想到了大家官方需要的数据格式。然后我想到了一个新的需求场景:如果提供给用户,用户面对的是数据。数据应该如何使用?
三个角色:我、用户和人人官方。每个角色需要不同的数据并使用不同的方法。比如我只需要公众号,用户需要更多数据。用户将希望执行一些过滤,以便他们可以找到适合您自己的公共帐户。
第二个改进:增加辅助判断条件;
在爬取中,我们遇到了一个问题:如果没有符合设定条件的数据,数据就会留空。这类数据需要丢弃(否则会占用导出索引)。为了丢弃数据,必须对数据进行处理。判断,进行判断,数据不能为空;
这里有一个矛盾或冲突:需要删除空数据,但只能删除非空数据;终于找到了一个办法:给所有数据加上一个固定的前缀——delete,这样无论数据是否为空,最终都不会为空;
比如两条数据:一条数据为空,需要删除,加上前缀后,数据变为:delete;数据B数据不为空,加前缀后数据变为删除+原创数据;要确定哪些数据只收录删除,您可以丢弃,因为只有空数据将只收录添加的前缀。
这种方法是excel中的一个技巧:当数据本身难以判断时,加一列辅助判断,让具有相同特征的选项转化为易于识别的数据;如A/A/B/B/C/D,需要确定哪些重复项单独列出。因为A/B不同,无法实现排序。这时候可以添加一个单独的辅助判断列,将重复项转换为1,不重复项转换为0,然后对新列进行排序。
在最后一页,我也使用了这个技巧,通过在未认证的前面加上前缀A,让未认证的在排序的时候总是排成一行。
第三项改进:增加精准判断条件;
由于我不是程序员,对程序了解不多,无法准确判断代码的含义,这就带来了一个问题:不知道代码是否能完全达到目的,同时处理一些边缘情况;
在第一次数据捕获后,我们发现了这样一种情况:当数据中收录-等符号时,捕获会被中断。很多公众号都收录-符号,结果只抓到一半,比如lmh-china,只会抓lmh。
这是一个超出我能力的改进,所以我准备手动修改,但是接近1000个公众号,效率太低,如果你能改进爬取过程并修复这个问题,那么你可以重新爬取再次使用正确的数据,我决定试一试。
最终,我添加了结束条件(正则表达式),必须遇到,或者。会结束,遇到其他符号也不会结束。
这并不意味着我可以编写代码。该工具提供了一个工具来帮助生成正则表达式。然后我在互联网上搜索答案以找到可能的答案,并不断尝试成功。
PS:写这篇文章的时候,又查了一遍资料,发现上次修改没有生效,还是老流程。我必须确认未来的重要步骤,以确认我在做正确的事情。
改进之四:进行下一步,从实际场景中观察数据;
抓数据的时候想,可能需要一个地方放数据,这样方便查看,一张简单的表就够了,还需要排序,这样就可以根据自己的需要进行排序了;
找了几个插件,最后选择了一个简单的页面,经过测试,符合我的要求;
这次提前操作数据让我决定再次添加一个数据类型,添加一个经过认证的数据类型。人人网网站拥有各类认证。添加新的排序字段对用户有好处,可以让我排除官方用户,排除官方用户意味着排除非贡献者的公共账户。
这些官方发布的文章中的公众号是官方转载的来源,也很有价值;它们可以制成单独的页面。
改进之五:试用公共CDN地址查找bug;
由于所有网页都使用开源程序,我可以将本地的css和js改成免费的CDN地址,速度更快,节省带宽;国内外有一些服务为开源程序提供免费CDN,如/,合理节省使用成本;
在不断测试的过程中,突然发现了一个致命的bug:排序错误,这个bug一下子让我陷入了深渊。如果存在此错误,那么对用户最有意义的功能将失败:
我没有修复错误的能力,但我想到了一些可能性。作为一个开源程序,按理说这样明显的排序bug肯定会被修复。页面使用的版本比较旧。这是原因吗?
我去CDN找了最新版本,页面直接崩溃了;回去找了个中间版本,bug修复了,原来是程序版本问题。
这个修订过程教会了我一个反向精益思想:从后到前改进,提前验证整个过程,如果可能的话,把整个过程,特别是还没有达到的过程,并努力做到在少量数据的支持下。实际场景模拟,去模拟场景看看,这个模拟有利于整个过程的改进,场景中的思维可以反馈到整个过程的改进。
改进之六:增加公众号查询;
看了几个公众号,发现很多公众号已经不存在或者没有更新。如果能提供一个新的筛选维度,让用户可以直接看到公众号的更新,这个数据会更有价值;
我知道搜狗搜索提供了微信搜外,我开始尝试爬取搜狗搜索,但是搜狗搜索的反爬虫规则太严格了。
这个想法失败了,但我可以提供一个折衷方案:点击直接查询;
检查搜狗搜索的链接规则后,生成所有公众号对应的查询链接。
最终页面如下所示:
您可以在页面内搜索并按列排序。
我将页面上传到服务器,页面地址:open.skyfollowsnow.pro/special/woshipm-author/。
您可以在此处查看本次抓取中使用的工具和知识:open.skyfollowsnow.pro/?thread-55.htm。
第七项改进:统一修改位置;
将文件上传到服务器后,我犯了一个明显的错误:在服务器中修改文档,很多修改必须在本地,于是出现了一个新问题:有些东西是在服务器上修改的,有些东西是在本地修改的,文件两端不一致;
虽小,但也是很实用的一课:统一修改位置,避免协作时起点不一致。
其他:
在本次爬取中,使用了两种新的方法来解决两个问题:
1:解决json数据中a标签不被解析的问题;
作者ID和空格链接本来是两列,但是我以为可以合并,但是一旦合并就会报错,然后我以为我看到了一个用\符号隔开的程序”,于是试了一下,确实如此。
2:解决excel列过多时合并容易出错的问题;
最后合并成需要的数据时,需要合并的项很多,很容易发现顺序不对。为了一次性看到所有列的选项,我使用了一个新工具:桌面纹理工具 Snipaste,这也是我之前见过的。程序使用的工具正好解决了这个问题:
平时看到新事物的时候要有点好奇,需要的时候可能会想到。 查看全部
c爬虫抓取网页数据(产品经理网站结构比较简单的翻太慢错的方法有哪些)
再次重申:我不是程序员,也没有涉及代码。当页面被修改时,我只涉及复制和粘贴。
要去给朋友圈添点专业气息,需要添加一些新的微信ID;
在哪里可以找到专业的微信账号?
想着大家都是产品经理,我看到传播者在文章下的评论里留下微信,但是每个文章的翻译太慢了,也许你可以用一个工具把所有的评论发到抓住它进行过滤。
网站结构比较简单,这个应该是简单的抓取,到最后会发现自己错了。
以下简称人人为产品经理网站;
上一篇文章中已经详细介绍了常规爬取的过程,重复部分本文不再赘述;
思考过程:如果有需求,找到需求对应的信息,找到信息对应的位置,找到位置对应的工具,找到工具对应的功能或技能。
一:换算法,使用更准确的方法;
上一篇文章介绍了一种生成链接的方法,大家准备用同样的方法再做一遍;
然后遇到第一个难点:大家的链接结构不统一,比如:/pmd/1660079.html、/pd/1659496.html、/ai/1648500.html等.;
总共有10多个类别,最大数量为1,660,079,超过160万。如果每个类别产生超过160万个链接,去链接审核工具进行审核,可能需要十天以上的时间来审核链接;
这种方法是行不通的,需要一个新的方法:网站提供了一个方便的通道——列表页,通过它可以获得整个列表的链接。
使用这种方法,从十几天,这个步骤可以缩短到几个小时。
二:确定约束条件,根据约束条件改进流程
在得到链接之前,我做了一个计算,有几万条文章,而文章下的评论就更多了;
该工具的数据导出限制为 10,000 条。这次真的要花钱升级吗?
又想到一句话:带枷锁跳舞,不带枷锁跳舞不是技巧,带枷锁跳舞是技巧。
最近一直在思考一个基本的二元关系问题:A和B之间有多少条路径?
对初步思考的回答:A和B之间至少有两条路径:AB和BA。
这说明了这样一个事实,即两件事之间必须有两条路径,并且除了常规路径之外至少还有一条其他路径。
把这个结论应用到限定条件上,那么解决问题的路径至少有两条:
1:常规路径:需求(自身)不变,(环境)极限扩大,极限适应需求;
2:反向路径:限制(环境)不变,压缩(自己)需求,使需求适应限制;
第二条反向路径为解决问题带来了新的视角,为流程演化建立了新的理论基础。
原来的流程是:
获取链接—>导出链接(限制出现1)—>重新导入—>评论抓取—>导出评论(限制出现2)—>本地过滤。
第一个改进:重新定义需求,细化获取环节:
其实第二阶段需要的不是任何文章,而是带注释的文章(没有注释就不用抢注释了),在初始条件上加上细化条件提前过滤,一下子把链接数减少了三分之一。
新流程:获取精确链接—>导出链接(限制1)的位置—>重新导入—>评论捕获—>导出评论(限制2)的位置—>本地过滤。
第二次改进:将新的认识应用到大局中,在第二阶段增加细化条件;
不是所有的评论都要被抓,而是收录公众号或微信账号的评论。
新流程:获取精准链接—>导出链接(限制1)的位置—>重新导入—>准确抓取评论—>导出评论(限制2)的位置—>本地过滤。
第三次改进:合并和推进流程
我在中间去了一次洗手间,洗手间做得很好。在其中,我想到了两个过程。为什么要把这两个进程分开?
这两个阶段是一个连续的过程,如果这些过程可以合并,第一阶段的限制就会消失。
这说明除了适应约束之外,还可以选择合理地调整流程以消除或跳过约束。
将两个流程合二为一后,新流程:获取精准链接—>准确抓取评论—>导出评论(限制位置2)—>本地过滤。
由于重新定义了两阶段要求,最终出口数据中只剩下有意义的部分。
这个改进过程也让我发现了一个优化的关键点:在设计过程时,结合约束,用约束激发深度优化。
最终得到了我想要的数据,结果发现约束不是敌人,约束是持续创新的重要条件。
这一发现也为创新开辟了一种新的思维方式:自我强加的限制,没有限制创造限制。就像这个文章,本来是不打算写的,但是我给自己设计了一个新的限制:把事情做完,从实践到总结,就完成了。
在过滤数据时,我有点气馁。评论数据是非结构化的,很难快速过滤此类数据。这也让我有了一个新的发现:数据的价值取决于结构的程度。结构化数据很少。既然如此,与其捕获杂乱无章的数据,事后对其进行结构化,不如在初始设计中建立结构化的数据捕获过程。
结束了吗?确实是时候结束了,本来预定的数据已经拿到了;
但这并没有结束,甚至真正的困难才刚刚开始,所以这是一个意外。
三:抢公众号,重新整理全站内容;
一边抓着上面的微信,一边也隔出了一部分公众号,很少。如果能得到更多的公众号,或许可以做一个专门的页面来提供一个服务,也就是集成即服务。该方法的效果很差,需要更高效的采集方法;
我想还有一个地方也会放公众号,每个文章底部的作者介绍部分:
如果能够获取大量数据,就可以形成公众账户矩阵。据我所知,没有这样的信息库,信息集中对用户也很有价值;
准备开始抓取,遇到了第一个难点:文章内容很多,如何定位要抓取的对象?
定位要抓拍的物体有一个窍门:分析物体的特征,尤其是独特的特征,通过独特的特征准确识别;比如这次要抓的对象是一个公众号,而这三个词在文章中也经常出现,但是出现在文章中的时候一般不会跟a : 符号,仅在作者介绍时才收录,这是关键特性。
第一个改进:多角度观察数据,增加要捕获的数据类型;
这是一个非常偶然的想法。我想着数据可能可以供官方参考,然后又想到了大家官方需要的数据格式。然后我想到了一个新的需求场景:如果提供给用户,用户面对的是数据。数据应该如何使用?
三个角色:我、用户和人人官方。每个角色需要不同的数据并使用不同的方法。比如我只需要公众号,用户需要更多数据。用户将希望执行一些过滤,以便他们可以找到适合您自己的公共帐户。
第二个改进:增加辅助判断条件;
在爬取中,我们遇到了一个问题:如果没有符合设定条件的数据,数据就会留空。这类数据需要丢弃(否则会占用导出索引)。为了丢弃数据,必须对数据进行处理。判断,进行判断,数据不能为空;
这里有一个矛盾或冲突:需要删除空数据,但只能删除非空数据;终于找到了一个办法:给所有数据加上一个固定的前缀——delete,这样无论数据是否为空,最终都不会为空;
比如两条数据:一条数据为空,需要删除,加上前缀后,数据变为:delete;数据B数据不为空,加前缀后数据变为删除+原创数据;要确定哪些数据只收录删除,您可以丢弃,因为只有空数据将只收录添加的前缀。
这种方法是excel中的一个技巧:当数据本身难以判断时,加一列辅助判断,让具有相同特征的选项转化为易于识别的数据;如A/A/B/B/C/D,需要确定哪些重复项单独列出。因为A/B不同,无法实现排序。这时候可以添加一个单独的辅助判断列,将重复项转换为1,不重复项转换为0,然后对新列进行排序。
在最后一页,我也使用了这个技巧,通过在未认证的前面加上前缀A,让未认证的在排序的时候总是排成一行。
第三项改进:增加精准判断条件;
由于我不是程序员,对程序了解不多,无法准确判断代码的含义,这就带来了一个问题:不知道代码是否能完全达到目的,同时处理一些边缘情况;
在第一次数据捕获后,我们发现了这样一种情况:当数据中收录-等符号时,捕获会被中断。很多公众号都收录-符号,结果只抓到一半,比如lmh-china,只会抓lmh。
这是一个超出我能力的改进,所以我准备手动修改,但是接近1000个公众号,效率太低,如果你能改进爬取过程并修复这个问题,那么你可以重新爬取再次使用正确的数据,我决定试一试。
最终,我添加了结束条件(正则表达式),必须遇到,或者。会结束,遇到其他符号也不会结束。
这并不意味着我可以编写代码。该工具提供了一个工具来帮助生成正则表达式。然后我在互联网上搜索答案以找到可能的答案,并不断尝试成功。
PS:写这篇文章的时候,又查了一遍资料,发现上次修改没有生效,还是老流程。我必须确认未来的重要步骤,以确认我在做正确的事情。
改进之四:进行下一步,从实际场景中观察数据;
抓数据的时候想,可能需要一个地方放数据,这样方便查看,一张简单的表就够了,还需要排序,这样就可以根据自己的需要进行排序了;
找了几个插件,最后选择了一个简单的页面,经过测试,符合我的要求;
这次提前操作数据让我决定再次添加一个数据类型,添加一个经过认证的数据类型。人人网网站拥有各类认证。添加新的排序字段对用户有好处,可以让我排除官方用户,排除官方用户意味着排除非贡献者的公共账户。
这些官方发布的文章中的公众号是官方转载的来源,也很有价值;它们可以制成单独的页面。
改进之五:试用公共CDN地址查找bug;
由于所有网页都使用开源程序,我可以将本地的css和js改成免费的CDN地址,速度更快,节省带宽;国内外有一些服务为开源程序提供免费CDN,如/,合理节省使用成本;
在不断测试的过程中,突然发现了一个致命的bug:排序错误,这个bug一下子让我陷入了深渊。如果存在此错误,那么对用户最有意义的功能将失败:
我没有修复错误的能力,但我想到了一些可能性。作为一个开源程序,按理说这样明显的排序bug肯定会被修复。页面使用的版本比较旧。这是原因吗?
我去CDN找了最新版本,页面直接崩溃了;回去找了个中间版本,bug修复了,原来是程序版本问题。
这个修订过程教会了我一个反向精益思想:从后到前改进,提前验证整个过程,如果可能的话,把整个过程,特别是还没有达到的过程,并努力做到在少量数据的支持下。实际场景模拟,去模拟场景看看,这个模拟有利于整个过程的改进,场景中的思维可以反馈到整个过程的改进。
改进之六:增加公众号查询;
看了几个公众号,发现很多公众号已经不存在或者没有更新。如果能提供一个新的筛选维度,让用户可以直接看到公众号的更新,这个数据会更有价值;
我知道搜狗搜索提供了微信搜外,我开始尝试爬取搜狗搜索,但是搜狗搜索的反爬虫规则太严格了。
这个想法失败了,但我可以提供一个折衷方案:点击直接查询;
检查搜狗搜索的链接规则后,生成所有公众号对应的查询链接。
最终页面如下所示:
您可以在页面内搜索并按列排序。
我将页面上传到服务器,页面地址:open.skyfollowsnow.pro/special/woshipm-author/。
您可以在此处查看本次抓取中使用的工具和知识:open.skyfollowsnow.pro/?thread-55.htm。
第七项改进:统一修改位置;
将文件上传到服务器后,我犯了一个明显的错误:在服务器中修改文档,很多修改必须在本地,于是出现了一个新问题:有些东西是在服务器上修改的,有些东西是在本地修改的,文件两端不一致;
虽小,但也是很实用的一课:统一修改位置,避免协作时起点不一致。
其他:
在本次爬取中,使用了两种新的方法来解决两个问题:
1:解决json数据中a标签不被解析的问题;
作者ID和空格链接本来是两列,但是我以为可以合并,但是一旦合并就会报错,然后我以为我看到了一个用\符号隔开的程序”,于是试了一下,确实如此。
2:解决excel列过多时合并容易出错的问题;
最后合并成需要的数据时,需要合并的项很多,很容易发现顺序不对。为了一次性看到所有列的选项,我使用了一个新工具:桌面纹理工具 Snipaste,这也是我之前见过的。程序使用的工具正好解决了这个问题:
平时看到新事物的时候要有点好奇,需要的时候可能会想到。
c爬虫抓取网页数据(如何轻松定制一个网络爬虫的总体架构环境?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-12 04:14
万维网的大量信息、股票报价、电影评论、市场价格趋势主题以及几乎所有内容都可以通过单击按钮找到。在分析数据的过程中,发现很多SAS用户对网络很感兴趣,但是你获取这些数据的SAS环境呢?有很多方法,例如设计自己的网络爬虫或利用 SAS %TMFILTER 文本挖掘的 SAS 数据步骤中的代码。在本文中,我们将回顾网络爬虫的一般架构。我们将讨论将 网站 信息导入 SAS 的方法,并在内部查看来自名为 SAS Search 的实验项目的实验代码管道。我们还将提供有关如何轻松自定义网络爬虫以满足个人需求以及如何将特定数据导入 SAS Miner 的建议。介绍:互联网已成为有用的信息来源。通常是网络上的数据,我们想在SAS内部使用,所以我们需要想办法获取这些数据。最好的方法是使用网络爬虫。SAS 提供了几种从 Web 爬取和提取信息的方法。您可以使用基本 SAS 数据步骤中的代码,或 SAS Text Miner 的 %TMFILTER 宏。虽然目前不可用,但 SAS Search Pipeline 将是一个强大的网络爬虫产品,并为网络爬虫提供更多工具。每种方法都有其优点和缺点,因此根据您想要实现的抓取,最好对其进行审查。SAS 提供了几种从 Web 爬取和提取信息的方法。您可以使用基本 SAS 数据步骤中的代码,或 SAS Text Miner 的 %TMFILTER 宏。虽然目前不可用,但 SAS Search Pipeline 将是一个强大的网络爬虫产品,并为网络爬虫提供更多工具。每种方法都有其优点和缺点,因此根据您想要实现的抓取,最好对其进行审查。SAS 提供了几种从 Web 爬取和提取信息的方法。您可以使用基本 SAS 数据步骤中的代码,或 SAS Text Miner 的 %TMFILTER 宏。虽然目前不可用,但 SAS Search Pipeline 将是一个强大的网络爬虫产品,并为网络爬虫提供更多工具。每种方法都有其优点和缺点,因此根据您想要实现的抓取,最好对其进行审查。
首先,了解网络爬虫的工作原理很重要。在继续之前,您应该熟悉数据步骤代码、宏和 SAS 过程 PROC SQL。网络爬虫概述:网络爬虫是一个程序,具有一个或多个起始地址作为“种子 URL”,它下载与这些 URL 关联的网页,提取网页中收录的任何超链接,并以递归方式继续这些超链接标识下载网页。从概念上讲,网络爬虫很简单。网络爬虫有四个职责: 1. 从候选者中选择一个 URL。2. 下载相关的 Web 3. 提取网页中的 URL(超链接)。4. 补充了未遇到的URLs候选集方法1:WEB SAS数据步爬虫中的代码首先创建了一个网站网络爬虫将启动的URL列表。数据工作.links_to_crawl;长度 url $256 inputurl 数据线;运行 为确保我们不会多次抓取同一个 URL,已使用该链接创建了数据抓取。当 web 数据集一开始是空的,但是一个 网站 URL 将被添加到数据集爬虫完成对 网站 的爬取。数据work.links_crawled;网址长度 256 美元;跑; 现在我们开始爬行!此代码需要我们的 work.links_to_crawl 数据集的第一个 URL。
在第一个观察“_N_Formula 1”中,URL 被放入一个名为 next_url 的宏变量中,所有剩余的 URL 都被放回我们的种子 URL 数据集中,以使其在未来的迭代中可用。nexturl 关闭 %letnext_url datawork.links_to_crawl; 设置 work.links_to_crawl;callymput("next_url", url); 否则输出;跑; 现在,从互联网上下载网址。创建一个文件名 _nexturl。我们让 SAS 知道这是一个 URL,并且可以找到 AT&next_url,这是我们的宏变量,其中收录我们从 work.links_to_crawl 数据集中提取的 URL。filename_nexturl url "&next_url" 创建一个对文件名的 URL 引用,它决定了放置我们下载文件的位置。创建另一个引用文件名的条目,称为 htmlfilm,并将从 url_file.html 采集的信息放在那里。
查找更多 urls datawork._urls(keep=url); 长度 url $256 filehtmlfile; infile _nexturl 长度=len;输入文本 $varying2000. len; 放文字;起始长度(文本);使用正则表达式 网站 URL 来帮助搜索。文本字符串的正则表达式匹配方法,例如单词、单词或字符模式。SAS 已经提供了许多强大的字符串功能。但是,正则表达式通常提供了一种更简洁的方式来处理和匹配文本。做;保留patternID; pattern '/href=”([^"]+)”/i';patternID prxparse(pattern);end 首先观察到,创建 patternID 将使整个数据步骤保持运行。要查找的模式是:“/href= "([^"]+)"/i'"., 表示我们在寻找字符串 "HREF purpose" 表示使用不区分大小写的方法来匹配我们的正则表达式。
PRXNEXT 有五个参数:我们要查找的正则表达式,开始查找正则表达式的开始位置,停止正则表达式的结束位置,字符串中一旦找到的位置,以及字符串的长度,如果找到的位置将如果未找到字符串,则为 0。PRXNEXT 还更改了 start 参数,以便在找到最后一个匹配项后重新开始搜索。调用 prxnext(patternID, start, stop, text, position, length); 代码中的循环,显示在 网站 上的所有链接的文本。do while (position substr(text,position+6, length-7); output; call prxnext(patternID, start, stop, text, position, length); end; run; 如果代码找到一个 URL,它will 检索在第一个引号之后开始的 URL 的唯一部分。例如,如果代码找到 href="",那么它应该保存。使用 substr 从 URL 的其余部分中删除前 6 个字符和最后一个字符 work._urls 数据集的输出。现在,我们插入 URL 代码只是为了跟踪抓取到我们已经拥有的名为 work.links_crawled 的数据集,并确保我们不再浏览那里。
currentlink urls我们已经爬取了datawork._old_link;网址“&next_url”;运行;proc append base=work.links_crawled data=work._old_link force;跑; 确保: 1. 我们还没有抓取它们,也就是说 URL 不在 work.links_crawled 中)。2.我们没有排队的url进行爬取(即url不在work.links_to_crawl只添加url我们已经爬过queuedup procsql noprint;创建表work._append selecturl from work._urls where url (selecturl from work.links_crawled) (selecturl from work .links_to_crawl); quit; 然后,我们添加尚未被爬取的 URL,尚未排队 work.links_to_crawl addnew links procappend base=work.links_to_crawl data=work._append force; run; 查看全部
c爬虫抓取网页数据(如何轻松定制一个网络爬虫的总体架构环境?)
万维网的大量信息、股票报价、电影评论、市场价格趋势主题以及几乎所有内容都可以通过单击按钮找到。在分析数据的过程中,发现很多SAS用户对网络很感兴趣,但是你获取这些数据的SAS环境呢?有很多方法,例如设计自己的网络爬虫或利用 SAS %TMFILTER 文本挖掘的 SAS 数据步骤中的代码。在本文中,我们将回顾网络爬虫的一般架构。我们将讨论将 网站 信息导入 SAS 的方法,并在内部查看来自名为 SAS Search 的实验项目的实验代码管道。我们还将提供有关如何轻松自定义网络爬虫以满足个人需求以及如何将特定数据导入 SAS Miner 的建议。介绍:互联网已成为有用的信息来源。通常是网络上的数据,我们想在SAS内部使用,所以我们需要想办法获取这些数据。最好的方法是使用网络爬虫。SAS 提供了几种从 Web 爬取和提取信息的方法。您可以使用基本 SAS 数据步骤中的代码,或 SAS Text Miner 的 %TMFILTER 宏。虽然目前不可用,但 SAS Search Pipeline 将是一个强大的网络爬虫产品,并为网络爬虫提供更多工具。每种方法都有其优点和缺点,因此根据您想要实现的抓取,最好对其进行审查。SAS 提供了几种从 Web 爬取和提取信息的方法。您可以使用基本 SAS 数据步骤中的代码,或 SAS Text Miner 的 %TMFILTER 宏。虽然目前不可用,但 SAS Search Pipeline 将是一个强大的网络爬虫产品,并为网络爬虫提供更多工具。每种方法都有其优点和缺点,因此根据您想要实现的抓取,最好对其进行审查。SAS 提供了几种从 Web 爬取和提取信息的方法。您可以使用基本 SAS 数据步骤中的代码,或 SAS Text Miner 的 %TMFILTER 宏。虽然目前不可用,但 SAS Search Pipeline 将是一个强大的网络爬虫产品,并为网络爬虫提供更多工具。每种方法都有其优点和缺点,因此根据您想要实现的抓取,最好对其进行审查。
首先,了解网络爬虫的工作原理很重要。在继续之前,您应该熟悉数据步骤代码、宏和 SAS 过程 PROC SQL。网络爬虫概述:网络爬虫是一个程序,具有一个或多个起始地址作为“种子 URL”,它下载与这些 URL 关联的网页,提取网页中收录的任何超链接,并以递归方式继续这些超链接标识下载网页。从概念上讲,网络爬虫很简单。网络爬虫有四个职责: 1. 从候选者中选择一个 URL。2. 下载相关的 Web 3. 提取网页中的 URL(超链接)。4. 补充了未遇到的URLs候选集方法1:WEB SAS数据步爬虫中的代码首先创建了一个网站网络爬虫将启动的URL列表。数据工作.links_to_crawl;长度 url $256 inputurl 数据线;运行 为确保我们不会多次抓取同一个 URL,已使用该链接创建了数据抓取。当 web 数据集一开始是空的,但是一个 网站 URL 将被添加到数据集爬虫完成对 网站 的爬取。数据work.links_crawled;网址长度 256 美元;跑; 现在我们开始爬行!此代码需要我们的 work.links_to_crawl 数据集的第一个 URL。
在第一个观察“_N_Formula 1”中,URL 被放入一个名为 next_url 的宏变量中,所有剩余的 URL 都被放回我们的种子 URL 数据集中,以使其在未来的迭代中可用。nexturl 关闭 %letnext_url datawork.links_to_crawl; 设置 work.links_to_crawl;callymput("next_url", url); 否则输出;跑; 现在,从互联网上下载网址。创建一个文件名 _nexturl。我们让 SAS 知道这是一个 URL,并且可以找到 AT&next_url,这是我们的宏变量,其中收录我们从 work.links_to_crawl 数据集中提取的 URL。filename_nexturl url "&next_url" 创建一个对文件名的 URL 引用,它决定了放置我们下载文件的位置。创建另一个引用文件名的条目,称为 htmlfilm,并将从 url_file.html 采集的信息放在那里。
查找更多 urls datawork._urls(keep=url); 长度 url $256 filehtmlfile; infile _nexturl 长度=len;输入文本 $varying2000. len; 放文字;起始长度(文本);使用正则表达式 网站 URL 来帮助搜索。文本字符串的正则表达式匹配方法,例如单词、单词或字符模式。SAS 已经提供了许多强大的字符串功能。但是,正则表达式通常提供了一种更简洁的方式来处理和匹配文本。做;保留patternID; pattern '/href=”([^"]+)”/i';patternID prxparse(pattern);end 首先观察到,创建 patternID 将使整个数据步骤保持运行。要查找的模式是:“/href= "([^"]+)"/i'"., 表示我们在寻找字符串 "HREF purpose" 表示使用不区分大小写的方法来匹配我们的正则表达式。
PRXNEXT 有五个参数:我们要查找的正则表达式,开始查找正则表达式的开始位置,停止正则表达式的结束位置,字符串中一旦找到的位置,以及字符串的长度,如果找到的位置将如果未找到字符串,则为 0。PRXNEXT 还更改了 start 参数,以便在找到最后一个匹配项后重新开始搜索。调用 prxnext(patternID, start, stop, text, position, length); 代码中的循环,显示在 网站 上的所有链接的文本。do while (position substr(text,position+6, length-7); output; call prxnext(patternID, start, stop, text, position, length); end; run; 如果代码找到一个 URL,它will 检索在第一个引号之后开始的 URL 的唯一部分。例如,如果代码找到 href="",那么它应该保存。使用 substr 从 URL 的其余部分中删除前 6 个字符和最后一个字符 work._urls 数据集的输出。现在,我们插入 URL 代码只是为了跟踪抓取到我们已经拥有的名为 work.links_crawled 的数据集,并确保我们不再浏览那里。
currentlink urls我们已经爬取了datawork._old_link;网址“&next_url”;运行;proc append base=work.links_crawled data=work._old_link force;跑; 确保: 1. 我们还没有抓取它们,也就是说 URL 不在 work.links_crawled 中)。2.我们没有排队的url进行爬取(即url不在work.links_to_crawl只添加url我们已经爬过queuedup procsql noprint;创建表work._append selecturl from work._urls where url (selecturl from work.links_crawled) (selecturl from work .links_to_crawl); quit; 然后,我们添加尚未被爬取的 URL,尚未排队 work.links_to_crawl addnew links procappend base=work.links_to_crawl data=work._append force; run;
c爬虫抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-10 16:06
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1. 正则表达式
如果您是正则表达式的新手,或者需要一些提示,请查看正则表达式 HOWTO 以获得完整的介绍。
当我们使用正则表达式抓取国家/地区数据时,我们首先尝试匹配元素的内容,如下所示:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从以上结果可以看出,标签用于多个国家属性。要隔离 area 属性,我们只需选择其中的第二个元素,如下所示:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然这个方案现在可用,但如果页面发生变化,它很可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们也可以添加它的父元素。由于元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来好一点,但是网页更新还有很多其他的方式也会让这个正则表达式不令人满意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。下面是一个尝试支持这些可能性的改进版本。
>>> re.findall('.*?(.*?)',html)['244,820 square kilometres']
虽然这个正则表达式更容易适应未来的变化,但它也存在构造困难、可读性差的问题。此外,还有一些细微的布局更改可能会使此正则表达式无法令人满意,例如为标签添加标题属性。
从这个例子可以看出,正则表达式为我们提供了一种抓取数据的捷径,但是这种方法过于脆弱,在页面更新后容易出现问题。好在还有一些更好的解决方案,后面会介绍。
2. 靓汤
Beautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装其最新版本(需要先安装pip,请自行百度):
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个汤文档。由于大多数网页不是格式良好的 HTML,Beautiful Soup 需要确定它们的实际格式。例如,在下面这个简单网页的清单中,存在属性值和未闭合标签周围缺少引号的问题。
Area
Population
如果 Population 列表项被解析为 Area 列表项的子项,而不是两个并排的列表项,我们在抓取时会得到错误的结果。让我们看看Beautiful Soup是如何处理它的。
>>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup 能够正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注意:由于不同版本的Python内置库的容错能力存在差异,处理结果可能与上述不同。详情请参阅: 。想知道所有的方法和参数,可以参考 Beautiful Soup 的官方文档
以下是使用此方法提取样本国家地区数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
此代码虽然比正则表达式代码更复杂,但更易于构建和理解。此外,布局中的一些小变化,例如额外的空白和制表符属性,我们不再需要担心它了。
3. Lxml
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。模块用C语言编写,解析速度比Beautiful Soup快,但安装过程比较复杂。最新安装说明可以参考。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将可能无效的 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同样,lxml 正确解析属性周围缺少的引号并关闭标签,但模块不会添加和标签。
解析输入后,是时候选择元素了。此时,lxml 有几种不同的方法,例如 XPath 选择器和 Beautiful Soup 之类的 find() 方法。但是,我们将来会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重用。此外,一些有 jQuery 选择器经验的读者会更熟悉它。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到ID为places_area__row的表格行元素,然后选择类为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 在
Lxml 已经实现了大部分 CSS3 属性,其不支持的功能可以在: .
注意:lxml 的内部实现实际上将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能比较
在下面的代码中,每个爬虫会执行1000次,每次执行都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com ... %2339;).read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 *line 代码中调用了 re.purge() 方法。默认情况下,正则表达式会缓存搜索结果,公平起见,我们需要使用这种方法来清除缓存。
这是在我的计算机上运行脚本的结果:
由于硬件条件的不同,不同计算机的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,Beautiful Soup 在爬取我们的示例网页时比其他两种方法慢 7 倍以上。事实上,这个结果是意料之中的,因为 lxml 和正则表达式模块是用 C 编写的,而 Beautiful Soup 是用纯 Python 编写的。一个有趣的事实是 lxml 的性能与正则表达式差不多。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当爬取同一个网页的多个特征时,这个初始解析的开销会减少,lxml会更有竞争力,所以lxml是一个强大的模块。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用难度 安装难度
正则表达式
快的
困难
简单(内置模块)
美丽的汤
慢的
简单的
简单(纯 Python)
lxml
快的
简单的
比较困难
如果您的爬虫的瓶颈是下载页面,而不是提取数据,那么使用较慢的方法(如 Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,除了可以避免解析整个网页的开销,如果只需要抓取少量数据并想避免额外的依赖,那么正则表达式可能更适合. 但是,总的来说,lxml 是抓取数据的最佳选择,因为它不仅速度更快,功能更强大,而正则表达式和 Beautiful Soup 仅在某些场景下才有用。 查看全部
c爬虫抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1. 正则表达式
如果您是正则表达式的新手,或者需要一些提示,请查看正则表达式 HOWTO 以获得完整的介绍。
当我们使用正则表达式抓取国家/地区数据时,我们首先尝试匹配元素的内容,如下所示:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从以上结果可以看出,标签用于多个国家属性。要隔离 area 属性,我们只需选择其中的第二个元素,如下所示:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然这个方案现在可用,但如果页面发生变化,它很可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们也可以添加它的父元素。由于元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来好一点,但是网页更新还有很多其他的方式也会让这个正则表达式不令人满意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。下面是一个尝试支持这些可能性的改进版本。
>>> re.findall('.*?(.*?)',html)['244,820 square kilometres']
虽然这个正则表达式更容易适应未来的变化,但它也存在构造困难、可读性差的问题。此外,还有一些细微的布局更改可能会使此正则表达式无法令人满意,例如为标签添加标题属性。
从这个例子可以看出,正则表达式为我们提供了一种抓取数据的捷径,但是这种方法过于脆弱,在页面更新后容易出现问题。好在还有一些更好的解决方案,后面会介绍。
2. 靓汤
Beautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装其最新版本(需要先安装pip,请自行百度):
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个汤文档。由于大多数网页不是格式良好的 HTML,Beautiful Soup 需要确定它们的实际格式。例如,在下面这个简单网页的清单中,存在属性值和未闭合标签周围缺少引号的问题。
Area
Population
如果 Population 列表项被解析为 Area 列表项的子项,而不是两个并排的列表项,我们在抓取时会得到错误的结果。让我们看看Beautiful Soup是如何处理它的。
>>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup 能够正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注意:由于不同版本的Python内置库的容错能力存在差异,处理结果可能与上述不同。详情请参阅: 。想知道所有的方法和参数,可以参考 Beautiful Soup 的官方文档
以下是使用此方法提取样本国家地区数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
此代码虽然比正则表达式代码更复杂,但更易于构建和理解。此外,布局中的一些小变化,例如额外的空白和制表符属性,我们不再需要担心它了。
3. Lxml
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。模块用C语言编写,解析速度比Beautiful Soup快,但安装过程比较复杂。最新安装说明可以参考。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将可能无效的 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同样,lxml 正确解析属性周围缺少的引号并关闭标签,但模块不会添加和标签。
解析输入后,是时候选择元素了。此时,lxml 有几种不同的方法,例如 XPath 选择器和 Beautiful Soup 之类的 find() 方法。但是,我们将来会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重用。此外,一些有 jQuery 选择器经验的读者会更熟悉它。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到ID为places_area__row的表格行元素,然后选择类为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 在
Lxml 已经实现了大部分 CSS3 属性,其不支持的功能可以在: .
注意:lxml 的内部实现实际上将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能比较
在下面的代码中,每个爬虫会执行1000次,每次执行都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com ... %2339;).read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 *line 代码中调用了 re.purge() 方法。默认情况下,正则表达式会缓存搜索结果,公平起见,我们需要使用这种方法来清除缓存。
这是在我的计算机上运行脚本的结果:
由于硬件条件的不同,不同计算机的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,Beautiful Soup 在爬取我们的示例网页时比其他两种方法慢 7 倍以上。事实上,这个结果是意料之中的,因为 lxml 和正则表达式模块是用 C 编写的,而 Beautiful Soup 是用纯 Python 编写的。一个有趣的事实是 lxml 的性能与正则表达式差不多。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当爬取同一个网页的多个特征时,这个初始解析的开销会减少,lxml会更有竞争力,所以lxml是一个强大的模块。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用难度 安装难度
正则表达式
快的
困难
简单(内置模块)
美丽的汤
慢的
简单的
简单(纯 Python)
lxml
快的
简单的
比较困难
如果您的爬虫的瓶颈是下载页面,而不是提取数据,那么使用较慢的方法(如 Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,除了可以避免解析整个网页的开销,如果只需要抓取少量数据并想避免额外的依赖,那么正则表达式可能更适合. 但是,总的来说,lxml 是抓取数据的最佳选择,因为它不仅速度更快,功能更强大,而正则表达式和 Beautiful Soup 仅在某些场景下才有用。
c爬虫抓取网页数据(爬取的人物画像(数据的实时性)难点打赏礼物)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-09 10:13
后台抓取某直播平台信息和普通网站直播平台数据有热门主播在线数,经常,热门直播的送礼情况(粉丝头像) 送礼难度人像httpswss(实时数据),需要模拟匿名用户的访问。一个直播的wss数据网站是一个大二进制数据头的js代码。您需要先模拟匿名登录才能获取二进制数据。然后分析网站的js代码进行分析。找到工具chrome developer tool,选择f12 ws,你只能看到帧在移动和我们两个不认识的二进制。Wireshark,遗憾的是,我报了很大的希望,但是通过websocket找不到,我马上分析了一下。我想我不知道如何拦截它。稍后我会研究如何使用它。看到有人说直接搜索websocket就可以看到。. 但是通过websocket过滤器我真的找不到我想要的数据。除非通过ip.addr ip.src 等charles,意外发现。名副其实,查尔斯。虽然一开始不太好用,但总算搞定了,下面详细说说怎么用。首先激活charles工具 一开始不太好用,终于搞定了,下面详细说说怎么用。首先激活charles工具 一开始不太好用,终于搞定了,下面详细说说怎么用。首先激活charles工具
// Charles Proxy License
// 适用于Charles任意版本的注册码,谁还会想要使用破解版呢。
// Charles 4.2目前是最新版,可用。
Registered Name: https://zhile.io
License Key: 48891cf209c6d32bf4
安装 ssl 证书支持
help->SSL proxying->install charles root certificate
下面这篇文章说的非常好
https://www.cnblogs.com/ceshij ... .html
设置代理,和上面的文章一样,但是我推荐使用*:443查看结果。在浏览器上访问你要访问的网站普通https网页。您已经可以看到背面的内容。同样wss的爬取也出来了,只是具体的二进制数据。还是需要你自己分析
目前可以抓到数据,下一步就是对二进制数据进行分析解析,得到有价值的数据。
原创文章,版权所有,禁止抄袭,违者必究!!!请注明出处!!!技术需求请联系。 查看全部
c爬虫抓取网页数据(爬取的人物画像(数据的实时性)难点打赏礼物)
后台抓取某直播平台信息和普通网站直播平台数据有热门主播在线数,经常,热门直播的送礼情况(粉丝头像) 送礼难度人像httpswss(实时数据),需要模拟匿名用户的访问。一个直播的wss数据网站是一个大二进制数据头的js代码。您需要先模拟匿名登录才能获取二进制数据。然后分析网站的js代码进行分析。找到工具chrome developer tool,选择f12 ws,你只能看到帧在移动和我们两个不认识的二进制。Wireshark,遗憾的是,我报了很大的希望,但是通过websocket找不到,我马上分析了一下。我想我不知道如何拦截它。稍后我会研究如何使用它。看到有人说直接搜索websocket就可以看到。. 但是通过websocket过滤器我真的找不到我想要的数据。除非通过ip.addr ip.src 等charles,意外发现。名副其实,查尔斯。虽然一开始不太好用,但总算搞定了,下面详细说说怎么用。首先激活charles工具 一开始不太好用,终于搞定了,下面详细说说怎么用。首先激活charles工具 一开始不太好用,终于搞定了,下面详细说说怎么用。首先激活charles工具
// Charles Proxy License
// 适用于Charles任意版本的注册码,谁还会想要使用破解版呢。
// Charles 4.2目前是最新版,可用。
Registered Name: https://zhile.io
License Key: 48891cf209c6d32bf4
安装 ssl 证书支持
help->SSL proxying->install charles root certificate
下面这篇文章说的非常好
https://www.cnblogs.com/ceshij ... .html
设置代理,和上面的文章一样,但是我推荐使用*:443查看结果。在浏览器上访问你要访问的网站普通https网页。您已经可以看到背面的内容。同样wss的爬取也出来了,只是具体的二进制数据。还是需要你自己分析
目前可以抓到数据,下一步就是对二进制数据进行分析解析,得到有价值的数据。
原创文章,版权所有,禁止抄袭,违者必究!!!请注明出处!!!技术需求请联系。
c爬虫抓取网页数据(talkischeap,showmethecodeshowthe )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-09 10:10
)
谈话很便宜,给我看代码:
#coding=utf-8
import sys
from scrapy.spider import BaseSpider
from scrapy.selector import Selector
from scrapy.contrib.spiders import CrawlSpider,Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
import json
reload(sys)
sys.setdefaultencoding('utf8')
class DmozSpider(BaseSpider):
name = "dmoz"
allowed_domains=[""]
start_urls=["http://www.jjkjj.gov.cn/"]
def parse(self,response):
filename = response.url.split("/")[-2]
titles=[] titles.extend(response.selector.xpath('//div[@class ="Work_News_line"]/a/text()').extract())
open(filename,'w').write(json.dumps(titles, encoding="gb2312", ensure_ascii=False))
我们来分析一下代码:
from scrapy.spider import BaseSpider
这是基于单页的爬取,所以使用BaseSpider,基于链接跳转的爬虫可以看第二篇文章
name = "dmoz"
allowed_domains=[""]
start_urls=["http://www.jjkjj.gov.cn/"]
start_urls是主域名,
所以 allowed_domain 设置为空
def parse(self,response):
filename = response.url.split("/")[-2]
titles=[] titles.extend(response.selector.xpath('//div[@class ="Work_News_line"]/a/text()').extract())
这个markdown编辑器的缩进有问题,titles.extend... 这行要和上一行保持一样的缩进,否则会报错
Python 运行时错误,引发 notImplementedError
遇到此类错误,检查缩进,一般可以解决
接下来看xpath表达式,
具体含义是:找到class属性为“Work_News_line”的div,以及它下面label的值
extract()函数 返回一个unicode字符串,该字符串为XPath选择器返回的数据
xpath的使用有几点需要注意
上面第二篇文章中,xpath的使用方式是:
sel=Selector(response) item=DoubanmoiveItem() item['name']=sel.xpath('//[@id="content"]/h1/span[1]/text()').extract()
新版本的scrapy不建议这样做
所以我把它改成了上面的
接下来是最头疼的中文显示问题
在shell中查看xpath查询结果:
一堆Unicode字符,其实这也算是捕获成功了,但是基本不可用,还是需要转成中文的。
感觉scrapy,甚至python,在字符集上都不是很好,
再看上面的代码:
titles=[] titles.extend(response.selector.xpath('//div[@class ="Work_News_line"]/a/text()').extract())
这里声明了一个列表。每次查询到一个值,就将其放入列表中,然后列表需要转换成字符串写入文件。
python本身提供了str()方法可以将任意对象转换成字符串,但是不支持中文,转换后的字符串还是unicode编码的。
详情见此贴:str字符串转换
一种解决方法是使用python自带的json模块
open(filename,'w').write(json.dumps(titles, encoding="gb2312", ensure_ascii=False))
没关系
我们将捕获的数据写入文件,我们来看看结果:
查看全部
c爬虫抓取网页数据(talkischeap,showmethecodeshowthe
)
谈话很便宜,给我看代码:
#coding=utf-8
import sys
from scrapy.spider import BaseSpider
from scrapy.selector import Selector
from scrapy.contrib.spiders import CrawlSpider,Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
import json
reload(sys)
sys.setdefaultencoding('utf8')
class DmozSpider(BaseSpider):
name = "dmoz"
allowed_domains=[""]
start_urls=["http://www.jjkjj.gov.cn/"]
def parse(self,response):
filename = response.url.split("/")[-2]
titles=[] titles.extend(response.selector.xpath('//div[@class ="Work_News_line"]/a/text()').extract())
open(filename,'w').write(json.dumps(titles, encoding="gb2312", ensure_ascii=False))
我们来分析一下代码:
from scrapy.spider import BaseSpider
这是基于单页的爬取,所以使用BaseSpider,基于链接跳转的爬虫可以看第二篇文章
name = "dmoz"
allowed_domains=[""]
start_urls=["http://www.jjkjj.gov.cn/"]
start_urls是主域名,
所以 allowed_domain 设置为空
def parse(self,response):
filename = response.url.split("/")[-2]
titles=[] titles.extend(response.selector.xpath('//div[@class ="Work_News_line"]/a/text()').extract())
这个markdown编辑器的缩进有问题,titles.extend... 这行要和上一行保持一样的缩进,否则会报错
Python 运行时错误,引发 notImplementedError
遇到此类错误,检查缩进,一般可以解决
接下来看xpath表达式,
具体含义是:找到class属性为“Work_News_line”的div,以及它下面label的值
extract()函数 返回一个unicode字符串,该字符串为XPath选择器返回的数据
xpath的使用有几点需要注意
上面第二篇文章中,xpath的使用方式是:
sel=Selector(response) item=DoubanmoiveItem() item['name']=sel.xpath('//[@id="content"]/h1/span[1]/text()').extract()
新版本的scrapy不建议这样做
所以我把它改成了上面的
接下来是最头疼的中文显示问题
在shell中查看xpath查询结果:
一堆Unicode字符,其实这也算是捕获成功了,但是基本不可用,还是需要转成中文的。
感觉scrapy,甚至python,在字符集上都不是很好,
再看上面的代码:
titles=[] titles.extend(response.selector.xpath('//div[@class ="Work_News_line"]/a/text()').extract())
这里声明了一个列表。每次查询到一个值,就将其放入列表中,然后列表需要转换成字符串写入文件。
python本身提供了str()方法可以将任意对象转换成字符串,但是不支持中文,转换后的字符串还是unicode编码的。
详情见此贴:str字符串转换
一种解决方法是使用python自带的json模块
open(filename,'w').write(json.dumps(titles, encoding="gb2312", ensure_ascii=False))
没关系
我们将捕获的数据写入文件,我们来看看结果:
c爬虫抓取网页数据(WEBCRAWLER网络爬虫实训项目1WEBCRAWLER网络爬虫实训项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-08 00:16
WEBCRAWLER 网络爬虫培训项目1 WEBCRAWLER 网络爬虫培训项目文档版本:1.0.0.1 作者:Dane IT Training Group C++教学研发部作者:Min Wei 定稿日期:11月,星期五20, 2015 WEBCRAWLER 网络爬虫培训项目21. 项目概述 互联网产品种类繁多,以产品为导向,以营销为导向,以技术为导向,但掌握技术的互联网产品占比较高。更小。搜索引擎是目前互联网产品中技术最先进的产品,如果不是唯一的,至少也是其中之一。经过十多年的发展,搜索引擎已经成为互联网的重要门户之一。Twitter联合创始人埃文威廉姆斯提出“
WEBCRAWLER网络爬虫训练项目3这样海量的数据如何获取、存储和计算?如何快速响应用户查询?如何让搜索结果尽可能满足用户对信息的需求?这些都是搜索引擎设计者必须面对的技术挑战。下图展示了一个通用搜索引擎的基本结构。商业级搜索引擎通常由许多独立的模块组成。每个模块只负责搜索引擎的部分功能,相互配合形成一个完整的搜索引擎:搜索引擎的信息源来自网页,整个“网络爬虫”的信息“互联网”在本地获取,由于网页上的大部分内容完全相同或几乎重复,“网页去重”模块会检测到并删除重复的内容。之后,搜索引擎将解析网页,提取网页的主要内容,以及指向该网页中收录的其他页面的所谓超链接。为了加快用户查询的响应速度,通过“倒排索引”的高效查询数据结构保存网页内容,同时保存网页之间的链接关系。之所以保存链接关系,是因为在网页的相关性排名阶段,这个关系是可用的。页面的相对重要性可以通过“链接分析”来判断,这对于为用户提供准确的搜索结果非常有帮助。由于网页数量众多,搜索引擎不仅需要保存网页的原创信息,还需要保存一些中间处理结果。使用单台计算机或少量计算机显然是不现实的。
谷歌等商业搜索引擎提供商为此开发了一套完整的云存储和云计算平台,利用数以万计的普通PCWEBCRAWLER网络爬虫训练项目4,构建了海量信息作为搜索的可靠存储和计算架构引擎及其相关应用的基础支持。优秀的云存储和云计算平台已成为大型商业搜索引擎的核心竞争力。以上就是搜索引擎获取和存储海量网页相关信息的方式。由于这些功能不需要实时计算,可以看作是搜索引擎的后端计算系统。搜索引擎的首要目标当然是为用户提供准确、全面的搜索结果。因此,实时响应用户查询并提供准确结果构成了搜索引擎的前端计算系统。搜索引擎收到用户的查询请求后,首先需要对查询词进行分析,并通过与用户信息的结合,正确推断出用户的真实搜索意图。之后,首先查看“缓存系统”维护的缓存。搜索引擎的缓存存储了不同的搜索意图及其对应的搜索结果。如果在缓存中找到满足用户需求的信息,则直接将搜索结果返回给用户。这不仅节省了重复计算的资源消耗,同时也加快了整个搜索过程的响应速度。而如果缓存中没有找到满足用户需求的信息,则需要使用“页面排序”,根据用户的搜索意图实时计算哪些网页满足用户需求,并将输出排序为搜索结果。
网页排名最重要的两个参考因素是“内容相似度”,即哪些网页与用户的搜索意图密切相关;另一个是网页重要性,即哪些网页质量好或相对重要。这通常可以从“链接分析”的结果中获得。结合以上两种考虑,前端系统将网页进行排序,作为搜索的最终结果。除了上述功能模块外,搜索引擎的“反作弊”模块近年来也越来越受到关注。搜索引擎作为网民上网的入口,对网络流量的引导和分流至关重要,甚至可以说起到了举足轻重的作用。因此,各种“作弊” 方法逐渐流行起来。各种方法被用来将网页的搜索排名提升到与网页质量不相称的位置,这将严重影响用户的搜索体验。因此,如何自动发现作弊网页并给予相应的惩罚,成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页数量已达数百万,因此搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 各种方法被用来将网页的搜索排名提升到与网页质量不相称的位置,这将严重影响用户的搜索体验。因此,如何自动发现作弊网页并给予相应的惩罚,成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页数量已达数百万,因此搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 各种方法被用来将网页的搜索排名提升到与网页质量不相称的位置,这将严重影响用户的搜索体验。因此,如何自动发现作弊网页并给予相应的惩罚,成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页数量已达数百万,因此搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 如何自动发现作弊网页并给予相应的惩罚已经成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页数量已达数百万,因此搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 如何自动发现作弊网页并给予相应的惩罚已经成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页数量已达数百万,因此搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 查看全部
c爬虫抓取网页数据(WEBCRAWLER网络爬虫实训项目1WEBCRAWLER网络爬虫实训项目)
WEBCRAWLER 网络爬虫培训项目1 WEBCRAWLER 网络爬虫培训项目文档版本:1.0.0.1 作者:Dane IT Training Group C++教学研发部作者:Min Wei 定稿日期:11月,星期五20, 2015 WEBCRAWLER 网络爬虫培训项目21. 项目概述 互联网产品种类繁多,以产品为导向,以营销为导向,以技术为导向,但掌握技术的互联网产品占比较高。更小。搜索引擎是目前互联网产品中技术最先进的产品,如果不是唯一的,至少也是其中之一。经过十多年的发展,搜索引擎已经成为互联网的重要门户之一。Twitter联合创始人埃文威廉姆斯提出“
WEBCRAWLER网络爬虫训练项目3这样海量的数据如何获取、存储和计算?如何快速响应用户查询?如何让搜索结果尽可能满足用户对信息的需求?这些都是搜索引擎设计者必须面对的技术挑战。下图展示了一个通用搜索引擎的基本结构。商业级搜索引擎通常由许多独立的模块组成。每个模块只负责搜索引擎的部分功能,相互配合形成一个完整的搜索引擎:搜索引擎的信息源来自网页,整个“网络爬虫”的信息“互联网”在本地获取,由于网页上的大部分内容完全相同或几乎重复,“网页去重”模块会检测到并删除重复的内容。之后,搜索引擎将解析网页,提取网页的主要内容,以及指向该网页中收录的其他页面的所谓超链接。为了加快用户查询的响应速度,通过“倒排索引”的高效查询数据结构保存网页内容,同时保存网页之间的链接关系。之所以保存链接关系,是因为在网页的相关性排名阶段,这个关系是可用的。页面的相对重要性可以通过“链接分析”来判断,这对于为用户提供准确的搜索结果非常有帮助。由于网页数量众多,搜索引擎不仅需要保存网页的原创信息,还需要保存一些中间处理结果。使用单台计算机或少量计算机显然是不现实的。
谷歌等商业搜索引擎提供商为此开发了一套完整的云存储和云计算平台,利用数以万计的普通PCWEBCRAWLER网络爬虫训练项目4,构建了海量信息作为搜索的可靠存储和计算架构引擎及其相关应用的基础支持。优秀的云存储和云计算平台已成为大型商业搜索引擎的核心竞争力。以上就是搜索引擎获取和存储海量网页相关信息的方式。由于这些功能不需要实时计算,可以看作是搜索引擎的后端计算系统。搜索引擎的首要目标当然是为用户提供准确、全面的搜索结果。因此,实时响应用户查询并提供准确结果构成了搜索引擎的前端计算系统。搜索引擎收到用户的查询请求后,首先需要对查询词进行分析,并通过与用户信息的结合,正确推断出用户的真实搜索意图。之后,首先查看“缓存系统”维护的缓存。搜索引擎的缓存存储了不同的搜索意图及其对应的搜索结果。如果在缓存中找到满足用户需求的信息,则直接将搜索结果返回给用户。这不仅节省了重复计算的资源消耗,同时也加快了整个搜索过程的响应速度。而如果缓存中没有找到满足用户需求的信息,则需要使用“页面排序”,根据用户的搜索意图实时计算哪些网页满足用户需求,并将输出排序为搜索结果。
网页排名最重要的两个参考因素是“内容相似度”,即哪些网页与用户的搜索意图密切相关;另一个是网页重要性,即哪些网页质量好或相对重要。这通常可以从“链接分析”的结果中获得。结合以上两种考虑,前端系统将网页进行排序,作为搜索的最终结果。除了上述功能模块外,搜索引擎的“反作弊”模块近年来也越来越受到关注。搜索引擎作为网民上网的入口,对网络流量的引导和分流至关重要,甚至可以说起到了举足轻重的作用。因此,各种“作弊” 方法逐渐流行起来。各种方法被用来将网页的搜索排名提升到与网页质量不相称的位置,这将严重影响用户的搜索体验。因此,如何自动发现作弊网页并给予相应的惩罚,成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页数量已达数百万,因此搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 各种方法被用来将网页的搜索排名提升到与网页质量不相称的位置,这将严重影响用户的搜索体验。因此,如何自动发现作弊网页并给予相应的惩罚,成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页数量已达数百万,因此搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 各种方法被用来将网页的搜索排名提升到与网页质量不相称的位置,这将严重影响用户的搜索体验。因此,如何自动发现作弊网页并给予相应的惩罚,成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页数量已达数百万,因此搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 如何自动发现作弊网页并给予相应的惩罚已经成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页数量已达数百万,因此搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 如何自动发现作弊网页并给予相应的惩罚已经成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页数量已达数百万,因此搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联
c爬虫抓取网页数据(具有一定的参考价值安装mysql需要屏蔽掉相关代码:抓取网页数据格式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-07 19:14
本文文章主要介绍python2.7,详细实现爬虫网页数据。有一定的参考价值,感兴趣的朋友可以参考
最近刚学了Python,做了一个简单的爬虫。作为一个简单的demo,希望对我这样的初学者有所帮助。
代码使用python制作的爬虫2.7抓取51job上的职位名称、公司名称、工资、发布时间等。
直接上代码。代码中的注释相当清楚。如果没有安装mysql,需要屏蔽相关代码:
#!/usr/bin/python # -*- coding: UTF-8 -*- from bs4 import BeautifulSoup import urllib import urllib2 import codecs import re import time import logging import MySQLdb class Jobs(object): # 初始化 """docstring for Jobs""" def __init__(self): super(Jobs, self).__init__() logging.basicConfig(level=logging.DEBUG, format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s') #数据库的操作,没有mysql可以做屏蔽 self.db = MySQLdb.connect('127.0.0.1','root','rootroot','MySQL_Test',charset='utf8') self.cursor = self.db.cursor() #log日志的显示 self.logger = logging.getLogger("sjk") self.logger.setLevel(level=logging.DEBUG) formatter = logging.Formatter( '%(asctime)s - %(name)s - %(levelname)s - %(message)s') handler = logging.FileHandler('log.txt') handler.setFormatter(formatter) handler.setLevel(logging.DEBUG) self.logger.addHandler(handler) self.logger.info('初始化完成') # 模拟请求数据 def jobshtml(self, key, page='1'): try: self.logger.info('开始请求第' + page + '页') #网页url searchurl = "https://search.51job.com/list/040000,000000,0000,00,9,99,{key},2,{page}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=" user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:59.0) Gecko/20100101 Firefox/59.0' #设置请求头 header = {'User-Agent': user_agent, 'Host': 'search.51job.com', 'Referer': 'https://www.51job.com/'} #拼接url finalUrl = searchurl.format(key=key, page=page) request = urllib2.Request(finalUrl, headers=header) response = urllib2.urlopen(request) #等待网页加载完成 time.sleep(3) #gbk格式解码 info = response.read().decode('gbk') self.logger.info('请求网页网页') self.decodeHtml(info=info, key=key, page=page) except urllib2.HTTPError as e: print e.reason # 解析网页数据 def decodeHtml(self, info, key, page): self.logger.info('开始解析网页数据') #BeautifulSoup 解析网页 soup = BeautifulSoup(info, 'html.parser') #找到class = t1 t2 t3 t4 t5 的标签数据 ps = soup.find_all(attrs={"class": re.compile(r'^t[1-5].*')}) #打开txt文件 a+ 代表追加 f = codecs.open(key + '.txt', 'a+', 'UTF-8') #清除之前的数据信息 f.truncate() f.write('\n------------' + page + '--------------\n') count = 1 arr = [] #做一些字符串的处理,形成数据格式 iOS开发工程师 有限公司 深圳-南山区 0.9-1.6万/月 05-16 for pi in ps: spe = " " finalstr = pi.getText().strip() arr.append(finalstr) if count % 5 == 0: #每一条数据插入数据库,如果没有安装mysql 可以将当前行注释掉 self.connectMySQL(arr=arr) arr = [] spe = "\n" writestr = finalstr + spe count += 1 f.write(writestr) f.close() self.logger.info('解析完成') #数据库操作 没有安装mysql 可以屏蔽掉 def connectMySQL(self,arr): work=arr[0] company=arr[1] place=arr[2] salary=arr[3] time=arr[4] query = "select * from Jobs_tab where \ company_name='%s' and work_name='%s' and work_place='%s' \ and salary='%s' and time='%s'" %(company,work,place,salary,time) self.cursor.execute(query) queryresult = self.cursor.fetchall() #数据库中不存在就插入数据 存在就可以更新数据 不过我这边没有写 if len(queryresult) > 0: sql = "insert into Jobs_tab(work_name,company_name,work_place,salary\ ,time) values('%s','%s','%s','%s','%s')" %(work,company,place,salary,time) try: self.cursor.execute(sql) self.db.commit() except Exception as e: self.logger.info('写入数据库失败') #模拟登陆 # def login(self): # data = {'action':'save','isread':'on','loginname':'18086514327','password':'kui4131sjk'} # 开始抓取 主函数 def run(self, key): # 只要前5页的数据 key代表搜索工做类型 这边我是用的ios page是页数 for x in xrange(1, 6): self.jobshtml(key=key, page=str(x)) self.logger.info('写入数据库完成') self.db.close() if __name__ == '__main__': Jobs().run(key='iOS')
这种方式抓取的网页数据格式如下:
以上是python2.7实现抓取网页数据的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
c爬虫抓取网页数据(具有一定的参考价值安装mysql需要屏蔽掉相关代码:抓取网页数据格式)
本文文章主要介绍python2.7,详细实现爬虫网页数据。有一定的参考价值,感兴趣的朋友可以参考
最近刚学了Python,做了一个简单的爬虫。作为一个简单的demo,希望对我这样的初学者有所帮助。
代码使用python制作的爬虫2.7抓取51job上的职位名称、公司名称、工资、发布时间等。
直接上代码。代码中的注释相当清楚。如果没有安装mysql,需要屏蔽相关代码:
#!/usr/bin/python # -*- coding: UTF-8 -*- from bs4 import BeautifulSoup import urllib import urllib2 import codecs import re import time import logging import MySQLdb class Jobs(object): # 初始化 """docstring for Jobs""" def __init__(self): super(Jobs, self).__init__() logging.basicConfig(level=logging.DEBUG, format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s') #数据库的操作,没有mysql可以做屏蔽 self.db = MySQLdb.connect('127.0.0.1','root','rootroot','MySQL_Test',charset='utf8') self.cursor = self.db.cursor() #log日志的显示 self.logger = logging.getLogger("sjk") self.logger.setLevel(level=logging.DEBUG) formatter = logging.Formatter( '%(asctime)s - %(name)s - %(levelname)s - %(message)s') handler = logging.FileHandler('log.txt') handler.setFormatter(formatter) handler.setLevel(logging.DEBUG) self.logger.addHandler(handler) self.logger.info('初始化完成') # 模拟请求数据 def jobshtml(self, key, page='1'): try: self.logger.info('开始请求第' + page + '页') #网页url searchurl = "https://search.51job.com/list/040000,000000,0000,00,9,99,{key},2,{page}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=" user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:59.0) Gecko/20100101 Firefox/59.0' #设置请求头 header = {'User-Agent': user_agent, 'Host': 'search.51job.com', 'Referer': 'https://www.51job.com/'} #拼接url finalUrl = searchurl.format(key=key, page=page) request = urllib2.Request(finalUrl, headers=header) response = urllib2.urlopen(request) #等待网页加载完成 time.sleep(3) #gbk格式解码 info = response.read().decode('gbk') self.logger.info('请求网页网页') self.decodeHtml(info=info, key=key, page=page) except urllib2.HTTPError as e: print e.reason # 解析网页数据 def decodeHtml(self, info, key, page): self.logger.info('开始解析网页数据') #BeautifulSoup 解析网页 soup = BeautifulSoup(info, 'html.parser') #找到class = t1 t2 t3 t4 t5 的标签数据 ps = soup.find_all(attrs={"class": re.compile(r'^t[1-5].*')}) #打开txt文件 a+ 代表追加 f = codecs.open(key + '.txt', 'a+', 'UTF-8') #清除之前的数据信息 f.truncate() f.write('\n------------' + page + '--------------\n') count = 1 arr = [] #做一些字符串的处理,形成数据格式 iOS开发工程师 有限公司 深圳-南山区 0.9-1.6万/月 05-16 for pi in ps: spe = " " finalstr = pi.getText().strip() arr.append(finalstr) if count % 5 == 0: #每一条数据插入数据库,如果没有安装mysql 可以将当前行注释掉 self.connectMySQL(arr=arr) arr = [] spe = "\n" writestr = finalstr + spe count += 1 f.write(writestr) f.close() self.logger.info('解析完成') #数据库操作 没有安装mysql 可以屏蔽掉 def connectMySQL(self,arr): work=arr[0] company=arr[1] place=arr[2] salary=arr[3] time=arr[4] query = "select * from Jobs_tab where \ company_name='%s' and work_name='%s' and work_place='%s' \ and salary='%s' and time='%s'" %(company,work,place,salary,time) self.cursor.execute(query) queryresult = self.cursor.fetchall() #数据库中不存在就插入数据 存在就可以更新数据 不过我这边没有写 if len(queryresult) > 0: sql = "insert into Jobs_tab(work_name,company_name,work_place,salary\ ,time) values('%s','%s','%s','%s','%s')" %(work,company,place,salary,time) try: self.cursor.execute(sql) self.db.commit() except Exception as e: self.logger.info('写入数据库失败') #模拟登陆 # def login(self): # data = {'action':'save','isread':'on','loginname':'18086514327','password':'kui4131sjk'} # 开始抓取 主函数 def run(self, key): # 只要前5页的数据 key代表搜索工做类型 这边我是用的ios page是页数 for x in xrange(1, 6): self.jobshtml(key=key, page=str(x)) self.logger.info('写入数据库完成') self.db.close() if __name__ == '__main__': Jobs().run(key='iOS')
这种方式抓取的网页数据格式如下:
以上是python2.7实现抓取网页数据的详细内容。更多详情请关注其他相关html中文网站文章!
c爬虫抓取网页数据(待URL队列中的URL以什么样的顺序排列算法的思想 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-07 00:03
)
遍历策略是爬虫的核心问题。在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL的顺序也是一个很重要的问题,因为它涉及到先爬取那个页面,再爬到哪个页面来确定这些URL的顺序,这就是爬取策略爬虫。主要有以下几种策略:
1.深度优先遍历策略:
深度优先遍历测试是指网络爬虫会从起始页开始,逐个跟踪每一个链接。处理完该行的链接后,会转到下一个起始页,继续跟踪该链接。我们用下图为例:
走过的路径是:AFG EHI BCD
但是,我们在做爬虫的时候,深度优先策略可能并不是所有情况都适用。如果深度优先误入无限分支(深度无限),则无法找到目标节点。
二、广度优先遍历策略:
广度优先策略是根据树的级别进行搜索。如果在这一层没有完成搜索,则不会进入下一层搜索。即先完成一层搜索,再进行下一层,也称为分层处理。我们也以上图为例:
遍历路径为:第一次遍历:ABCDEF,第二次遍历:GH,第三次遍历:I
然而,广度优先遍历策略是一种盲目搜索。它没有考虑结果的可能位置,会彻底搜索整个图像,因此效率低。但是,如果您想覆盖尽可能多的网页,广度优先搜索方法是更好的选择。
三、部分PageRank策略:
PageRank算法的思想:对于下载的网页,连同要爬取的URL队列的URL,组成一个网页集,计算每个页面的PageRank值(PageRank算法参考:PageRank算法-从原理到实现),计算完成后,根据页面级别的值排列待爬取队列中的URL,依次爬取URL页面。
如果每次都爬一个新的页面,重新计算出来的PageRank值显然效率太低了。折中是保存足够的网页来计算一次。
下图是web级策略的示意图:
为每下载 3 个网页设置一个新的 PageRank 计算。此时,本地已经下载了3个网页{1,2,3}。这三个网页中收录的链接指向{4,5,6},即要爬取的URL队列。如何确定下载顺序?
把这6个网页组成一个新的集合,计算这个集合的PageRank值,这样4、5、6就会得到各自对应的页面排名值,从大到小排序,就可以得到假设的顺序下载顺序为5,4,6,当下载55页时,提取链接指向第8页,此时临时分配PageRank值为8。如果该值大于 4 和 6 的 PageRank,则将首先下载第 8 页,依此类推。循环,即不完全页面级策略的计算思想形成。
四、OPIC策略策略(在线页面重要性计算):
基本思想:在算法开始之前,给所有页面相同的初始现金(cash)。下载一个页面P后,将P的现金分配给所有从P解析出来的链接,并清空P的现金。所有要爬取的URL队列中的页面按照现金的数量进行排序。
与PageRank不同的是:PageRank每次都需要迭代计算,而OPIC策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。
五、各大站优先策略:
策略:以网站为单位选择网页的重要性。对于URL队列中待抓取的网页,根据自己的网站进行分类。如果哪个网站等待下载的页面最多,先下载这些链接,本质思路倾向于优先下载大的网站。因为大 网站 往往收录更多页面。鉴于大型网站往往是知名公司的内容,而且他们的网页一般都是高质量的,这个想法很简单,但是有一定的依据。实验表明,该算法的效果也应该略优于宽度优先遍历策略。
花生代理动态IP更改软件可实现全国城市IP自动切换,千万级动态IP池,支持过滤,支持电脑手机多终端使用,数万条随机拨号线路, 24小时不间断提供动态IP。
查看全部
c爬虫抓取网页数据(待URL队列中的URL以什么样的顺序排列算法的思想
)
遍历策略是爬虫的核心问题。在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL的顺序也是一个很重要的问题,因为它涉及到先爬取那个页面,再爬到哪个页面来确定这些URL的顺序,这就是爬取策略爬虫。主要有以下几种策略:
1.深度优先遍历策略:
深度优先遍历测试是指网络爬虫会从起始页开始,逐个跟踪每一个链接。处理完该行的链接后,会转到下一个起始页,继续跟踪该链接。我们用下图为例:
走过的路径是:AFG EHI BCD
但是,我们在做爬虫的时候,深度优先策略可能并不是所有情况都适用。如果深度优先误入无限分支(深度无限),则无法找到目标节点。
二、广度优先遍历策略:
广度优先策略是根据树的级别进行搜索。如果在这一层没有完成搜索,则不会进入下一层搜索。即先完成一层搜索,再进行下一层,也称为分层处理。我们也以上图为例:
遍历路径为:第一次遍历:ABCDEF,第二次遍历:GH,第三次遍历:I
然而,广度优先遍历策略是一种盲目搜索。它没有考虑结果的可能位置,会彻底搜索整个图像,因此效率低。但是,如果您想覆盖尽可能多的网页,广度优先搜索方法是更好的选择。
三、部分PageRank策略:
PageRank算法的思想:对于下载的网页,连同要爬取的URL队列的URL,组成一个网页集,计算每个页面的PageRank值(PageRank算法参考:PageRank算法-从原理到实现),计算完成后,根据页面级别的值排列待爬取队列中的URL,依次爬取URL页面。
如果每次都爬一个新的页面,重新计算出来的PageRank值显然效率太低了。折中是保存足够的网页来计算一次。
下图是web级策略的示意图:
为每下载 3 个网页设置一个新的 PageRank 计算。此时,本地已经下载了3个网页{1,2,3}。这三个网页中收录的链接指向{4,5,6},即要爬取的URL队列。如何确定下载顺序?
把这6个网页组成一个新的集合,计算这个集合的PageRank值,这样4、5、6就会得到各自对应的页面排名值,从大到小排序,就可以得到假设的顺序下载顺序为5,4,6,当下载55页时,提取链接指向第8页,此时临时分配PageRank值为8。如果该值大于 4 和 6 的 PageRank,则将首先下载第 8 页,依此类推。循环,即不完全页面级策略的计算思想形成。
四、OPIC策略策略(在线页面重要性计算):
基本思想:在算法开始之前,给所有页面相同的初始现金(cash)。下载一个页面P后,将P的现金分配给所有从P解析出来的链接,并清空P的现金。所有要爬取的URL队列中的页面按照现金的数量进行排序。
与PageRank不同的是:PageRank每次都需要迭代计算,而OPIC策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。
五、各大站优先策略:
策略:以网站为单位选择网页的重要性。对于URL队列中待抓取的网页,根据自己的网站进行分类。如果哪个网站等待下载的页面最多,先下载这些链接,本质思路倾向于优先下载大的网站。因为大 网站 往往收录更多页面。鉴于大型网站往往是知名公司的内容,而且他们的网页一般都是高质量的,这个想法很简单,但是有一定的依据。实验表明,该算法的效果也应该略优于宽度优先遍历策略。
花生代理动态IP更改软件可实现全国城市IP自动切换,千万级动态IP池,支持过滤,支持电脑手机多终端使用,数万条随机拨号线路, 24小时不间断提供动态IP。
c爬虫抓取网页数据( 循环来实现所有网页的爬取总结(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-06 17:16
循环来实现所有网页的爬取总结(图))
public static List ParseLink(string html)
{
List res = new List();
var doc = new HtmlDocument();
doc.LoadHtml(html);
var linkNodes = doc.DocumentNode.SelectNodes("//a[@href]");
foreach (var linkNode in linkNodes)
{
string link = linkNode.GetAttributeValue("href", "");
if (link.StartsWith("/lishi/beijing/month"))
{
res.Add(link);
}
}
return res;
}
到目前为止,我们已经解析出网站上所有收录过去时间段的链接。接下来,我们需要分析每个链接对应的特定网页的结构,从中获取天气信息。
分析天气网页的结构
上一个链接是站点链接。上一节分析了特定天气网页对应的链接集合,例如。
现在我们需要从这个页面分析天气,就像解析站点结构中的目标链接一样,在浏览器中观察Html代码,发现天气的目标内容在一个表格中,所以我们只需要选择节点,因为一个节点代表某一天的天气(天气状况、温度和风向)。
public static void ParseDailyWeather(string html)
{
var doc = new HtmlDocument();
doc.LoadHtml(html);
var rows = doc.DocumentNode.SelectNodes("//tr");
StringBuilder sb = new StringBuilder();
rows.RemoveAt(0);
foreach (var row in rows)
{
var cols = row.SelectNodes("td");
foreach (var col in cols)
{
string temp = col.InnerText.Replace("\r\n", "").Replace(" ", "").Trim();
sb.Append(temp + ",");
}
sb.Append("\r\n");
}
FileStream fs = new FileStream("output.csv", FileMode.Append, FileAccess.Write);
StreamWriter sw = new StreamWriter(fs, Encoding.GetEncoding("gbk"));
sw.WriteLine(sb);
sw.Close();
fs.Close();
}
最后,为了实现对网站的爬取,需要一个循环来实现对所有网页的爬取
public static void ParseWebsite(string url)
{
string html = Weather.GetHtml(url);
var links = Weather.ParseLink(html);
foreach (var link in links)
{
url = "http://www.tianqihoubao.com" + link;
html = Weather.GetHtml(url);
Weather.ParseDailyWeather(html);
}
}
总结
静态网页的爬取比较简单,可以分为以下几个步骤 查看全部
c爬虫抓取网页数据(
循环来实现所有网页的爬取总结(图))
public static List ParseLink(string html)
{
List res = new List();
var doc = new HtmlDocument();
doc.LoadHtml(html);
var linkNodes = doc.DocumentNode.SelectNodes("//a[@href]");
foreach (var linkNode in linkNodes)
{
string link = linkNode.GetAttributeValue("href", "");
if (link.StartsWith("/lishi/beijing/month"))
{
res.Add(link);
}
}
return res;
}
到目前为止,我们已经解析出网站上所有收录过去时间段的链接。接下来,我们需要分析每个链接对应的特定网页的结构,从中获取天气信息。
分析天气网页的结构
上一个链接是站点链接。上一节分析了特定天气网页对应的链接集合,例如。
现在我们需要从这个页面分析天气,就像解析站点结构中的目标链接一样,在浏览器中观察Html代码,发现天气的目标内容在一个表格中,所以我们只需要选择节点,因为一个节点代表某一天的天气(天气状况、温度和风向)。
public static void ParseDailyWeather(string html)
{
var doc = new HtmlDocument();
doc.LoadHtml(html);
var rows = doc.DocumentNode.SelectNodes("//tr");
StringBuilder sb = new StringBuilder();
rows.RemoveAt(0);
foreach (var row in rows)
{
var cols = row.SelectNodes("td");
foreach (var col in cols)
{
string temp = col.InnerText.Replace("\r\n", "").Replace(" ", "").Trim();
sb.Append(temp + ",");
}
sb.Append("\r\n");
}
FileStream fs = new FileStream("output.csv", FileMode.Append, FileAccess.Write);
StreamWriter sw = new StreamWriter(fs, Encoding.GetEncoding("gbk"));
sw.WriteLine(sb);
sw.Close();
fs.Close();
}
最后,为了实现对网站的爬取,需要一个循环来实现对所有网页的爬取
public static void ParseWebsite(string url)
{
string html = Weather.GetHtml(url);
var links = Weather.ParseLink(html);
foreach (var link in links)
{
url = "http://www.tianqihoubao.com" + link;
html = Weather.GetHtml(url);
Weather.ParseDailyWeather(html);
}
}
总结
静态网页的爬取比较简单,可以分为以下几个步骤
c爬虫抓取网页数据(一下新建项目(Project)文件的作用和作用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-04 02:18
网络爬虫是在互联网上爬取数据的程序,用它来爬取特定网页的 HTML 数据。虽然我们使用一些库来开发爬虫程序,但是使用框架可以大大提高效率,缩短开发时间。 Scrapy是用Python编写的,轻量级,简单轻便,使用起来非常方便。使用Scrapy可以很方便的完成在线数据采集的工作,它已经为我们完成了很多工作,不需要花大力气去开发。
首先,我们必须回答一个问题。
问:网站安装到爬虫需要几步?
答案很简单,四步:
新建项目(Project):新建一个爬虫项目
清除目标(Items):清除你要爬取的目标
制作蜘蛛:制作蜘蛛并开始抓取网页
存储内容(管道):设计管道来存储抓取的内容
好了,基本流程确定了,接下来就是一步步完成了。
1.新建项目(Project)
在空目录下按住Shift键右键,选择“在此处打开命令窗口”,输入命令:
代码如下:
scrapy startproject 教程
其中,tutorial 为项目名称。
可以看到会创建一个tutorial文件夹,目录结构如下:
代码如下:
教程/
scrapy.cfg
教程/
__init__.py
items.py
pipelines.py
settings.py
蜘蛛/
__init__.py
...
简单介绍一下各个文件的作用:
scrapy.cfg:项目配置文件
tutorial/:项目的Python模块,代码会从这里引用
tutorial/items.py:项目的items文件
tutorial/pipelines.py:项目的流水线文件
tutorial/settings.py:项目设置文件
tutorial/spiders/:蜘蛛存放的目录
2.明确目标(Item)
在 Scrapy 中,items 是用于加载爬取内容的容器,有点像 Python 中的 Dic,它是一个字典,但提供了一些额外的保护以减少错误。
一般来说item可以用scrapy.item.Item类创建,scrapy.item.Field对象用来定义属性(可以理解为类似于ORM的映射关系)。
接下来,我们开始构建项目模型。
首先,我们想要的是:
姓名(姓名)
链接(网址)
说明
修改tutorial目录下的items.py文件,在原来的类之后添加我们自己的类。
因为我们要抓取网站的内容,所以可以命名为DmozItem:
代码如下:
# 在此处定义已抓取项目的模型
#
# 查看文档:
#
从scrapy.item导入项目,字段
class TutorialItem(Item):
# 在此处定义您的项目的字段,例如:
# name = Field()
通过
类 DmozItem(Item):
title = Field()
link = Field()
desc = Field()
乍一看可能有点难以理解,但定义这些项目会让您在使用其他组件时了解您的项目是什么。
Item 可以简单理解为一个封装的类对象。
3.制作蜘蛛(Spider)
做一个爬虫,一般有两个步骤:先爬后取。
也就是说,首先你需要获取整个网页的所有内容,然后取出对你有用的部分。
3.1 次攀爬
Spider 是用户编写的一个类,用于从域(或域组)中获取信息。
它们定义了用于下载的 URL 列表、跟踪链接的方案以及解析 Web 内容以提取项目的方法。
要创建蜘蛛,您必须使用scrapy.spider.BaseSpider 创建一个子类并确定三个必需属性:
name:爬虫的标识名,必须是唯一的。您必须在不同的爬虫中定义不同的名称。
start_urls:抓取的 URL 列表。爬虫从这里开始抓取数据,所以第一次下载数据会从这些url开始。其他子 URL 将从这些起始 URL 继承。
parse():解析方法,调用时将每个URL返回的Response对象作为唯一参数传入,负责解析匹配捕获的数据(解析为item),跟踪更多的URL。
<p>这里可以参考宽度爬虫教程中提到的思路帮助理解,教程传输:【Java】知乎下巴第五集:使用HttpClient工具包和宽度爬虫。 查看全部
c爬虫抓取网页数据(一下新建项目(Project)文件的作用和作用)
网络爬虫是在互联网上爬取数据的程序,用它来爬取特定网页的 HTML 数据。虽然我们使用一些库来开发爬虫程序,但是使用框架可以大大提高效率,缩短开发时间。 Scrapy是用Python编写的,轻量级,简单轻便,使用起来非常方便。使用Scrapy可以很方便的完成在线数据采集的工作,它已经为我们完成了很多工作,不需要花大力气去开发。
首先,我们必须回答一个问题。
问:网站安装到爬虫需要几步?
答案很简单,四步:
新建项目(Project):新建一个爬虫项目
清除目标(Items):清除你要爬取的目标
制作蜘蛛:制作蜘蛛并开始抓取网页
存储内容(管道):设计管道来存储抓取的内容
好了,基本流程确定了,接下来就是一步步完成了。
1.新建项目(Project)
在空目录下按住Shift键右键,选择“在此处打开命令窗口”,输入命令:
代码如下:
scrapy startproject 教程
其中,tutorial 为项目名称。
可以看到会创建一个tutorial文件夹,目录结构如下:
代码如下:
教程/
scrapy.cfg
教程/
__init__.py
items.py
pipelines.py
settings.py
蜘蛛/
__init__.py
...
简单介绍一下各个文件的作用:
scrapy.cfg:项目配置文件
tutorial/:项目的Python模块,代码会从这里引用
tutorial/items.py:项目的items文件
tutorial/pipelines.py:项目的流水线文件
tutorial/settings.py:项目设置文件
tutorial/spiders/:蜘蛛存放的目录
2.明确目标(Item)
在 Scrapy 中,items 是用于加载爬取内容的容器,有点像 Python 中的 Dic,它是一个字典,但提供了一些额外的保护以减少错误。
一般来说item可以用scrapy.item.Item类创建,scrapy.item.Field对象用来定义属性(可以理解为类似于ORM的映射关系)。
接下来,我们开始构建项目模型。
首先,我们想要的是:
姓名(姓名)
链接(网址)
说明
修改tutorial目录下的items.py文件,在原来的类之后添加我们自己的类。
因为我们要抓取网站的内容,所以可以命名为DmozItem:
代码如下:
# 在此处定义已抓取项目的模型
#
# 查看文档:
#
从scrapy.item导入项目,字段
class TutorialItem(Item):
# 在此处定义您的项目的字段,例如:
# name = Field()
通过
类 DmozItem(Item):
title = Field()
link = Field()
desc = Field()
乍一看可能有点难以理解,但定义这些项目会让您在使用其他组件时了解您的项目是什么。
Item 可以简单理解为一个封装的类对象。
3.制作蜘蛛(Spider)
做一个爬虫,一般有两个步骤:先爬后取。
也就是说,首先你需要获取整个网页的所有内容,然后取出对你有用的部分。
3.1 次攀爬
Spider 是用户编写的一个类,用于从域(或域组)中获取信息。
它们定义了用于下载的 URL 列表、跟踪链接的方案以及解析 Web 内容以提取项目的方法。
要创建蜘蛛,您必须使用scrapy.spider.BaseSpider 创建一个子类并确定三个必需属性:
name:爬虫的标识名,必须是唯一的。您必须在不同的爬虫中定义不同的名称。
start_urls:抓取的 URL 列表。爬虫从这里开始抓取数据,所以第一次下载数据会从这些url开始。其他子 URL 将从这些起始 URL 继承。
parse():解析方法,调用时将每个URL返回的Response对象作为唯一参数传入,负责解析匹配捕获的数据(解析为item),跟踪更多的URL。
<p>这里可以参考宽度爬虫教程中提到的思路帮助理解,教程传输:【Java】知乎下巴第五集:使用HttpClient工具包和宽度爬虫。
c爬虫抓取网页数据(网络爬虫提取出该网页中的新一轮URL的抓取环路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-01-03 21:17
一般我们要抓取一个网站的所有网址,先传递起始网址,然后通过网络爬虫提取网页中的所有网址链接,然后进行每一个网址抓取的提取,在每个网页中提取新一轮的 URL,依此类推。总体感觉是从上到下爬取网页中的链接。理论上,您可以抓取整个网站上的所有链接。但问题来了。 网站 中的网页链接有循环。
比如在网站的首页,我们可以看到首页的链接,然后我们也可能在子页面中看到首页的链接,可能会有对应的子子-页面。该链接指向主页。按照我们之前的逻辑,抓取每个网页中的所有链接,然后继续抓取所有链接。以首页为例。我们爬行的第一件事就是它。然后子页面里面有一个到首页的链接,子子页面也有一个到首页的链接。进行这种爬取会导致网页的重复爬取。其他的根本就没有抓取网页的机会,无法想象~~解决这个问题不难。这时候就需要用到网络爬虫中一个很重要的知识点,就是网页去重。
先介绍一个简单的思路,也是一个常用的思路。我们将抓取到的网页放到一个列表中。以首页为例。抓取主页后,将主页放入列表中。那么当我们抓取子页面的时候,如果再次触摸首页,并且首页已经被抓取了。这时候可以跳过首页,继续爬取其他网页,避免重复爬取首页。这样在爬取整个站点的时候就不会出现循环了。路。以这个思路为出发点,将访问过的URL保存在数据库中,当获取到下一个URL时,到数据库中查看该URL是否被访问过。虽然数据库有缓存,但是在数据库中查询每个URL时,效率会下降的很快,所以这个策略用的不多,但是是最简单的方法。
第二种方法是将访问过的URL保存在集合中。这种方式获取URL的速度非常快,基本不用查询。但是这种方法有一个缺点。保存集合中的URL实际上是将其保存在内存中。当 URL 数据量较大(如 1 亿)时,内存压力会增加。对于小型爬虫,这种方法是非常可取的,但对于大型网络爬虫来说,这种方法很难实现。
第三种方式是对md5中的字符进行编码,md5编码可以将字符缩减为固定长度。一般来说,md5编码的长度在128bit左右,约等于16byte。在缩减之前,假设一个URL占用的内存大小为50字节,1字节等于2字节,相当于100字节。可以看出,经过md5编码后,节省了大量的内存空间。通过md5,可以将任意长度的URL压缩成相同长度的md5字符串,不会有重复,可以达到去重的效果。这样,在很大程度上节省了内存。 scrapy框架采用的方法与md5方法有些类似。因此,一般情况下,即使URL的量级达到亿级,scrapy占用的内存也比set方法高。少很多。
第四种方式是使用位图方法进一步压缩字符。这种方法的意思是在计算机中申请8位,即8位,每一位用0或1表示,是计算机中的最小单位。如果8位组成一个字节,一位代表一个URL,为什么一位可以确定一个URL?因为我们可以对一个 URL 执行哈希函数,然后将其映射到位。例如,假设我们有8个URL,对应8位,然后通过位上的0和1的状态,就可以表明这个URL是否存在,这种方法可以进一步压缩内存。
但是位图方法有一个非常大的缺点,就是它的冲突会非常高,因为使用了同一个hash函数,很有可能将两个不同的URL或者多个不同的URL映射到一个位置。其实这个hash方法也是set方法的一个实现原理。它对 URL 执行函数计算,然后将其映射到位的位置。因此,这种方法可以大大压缩内存。简单计算一下,还是用1亿个URL来计算,相当于1亿比特。通过计算,相当于1250万字节。除以1024之后,大约是12207KB,也就是大约12MB的空间。在实际过程中,内存占用可能会大于12MB,但即便如此,与前三种方法相比,这种方法又大大减少了内存占用的空间。但同时,与此方法冲突的可能性非常高,因此此方法不是很适用。那么有没有办法进一步优化位图,这是一种重内存压缩的方法,以减少冲突的可能性?答案是肯定的,是第五种方式。
第五种方法是bloomfilter,改进位图。它可以通过多个散列函数减少冲突的可能性。这样一来,一方面不仅可以减少位图方法的内存,另一方面,同时也起到了减少冲突的作用。关于bloomfilter的原理和实现,后期我一定会介绍给大家的。今天就让大家有个简单的了解。 Bloomfilter适用于大型网络爬虫,尤其是数量级超大的时候。布隆过滤器方法可以事半功倍。也经常与分布式爬虫配合,达到爬取的目的。
我是来为大家介绍爬网过程中去重策略的五种方法的。如果你不明白,你应该知道它。在科普下,问题不大。希望对朋友的学习有所帮助。 . 查看全部
c爬虫抓取网页数据(网络爬虫提取出该网页中的新一轮URL的抓取环路)
一般我们要抓取一个网站的所有网址,先传递起始网址,然后通过网络爬虫提取网页中的所有网址链接,然后进行每一个网址抓取的提取,在每个网页中提取新一轮的 URL,依此类推。总体感觉是从上到下爬取网页中的链接。理论上,您可以抓取整个网站上的所有链接。但问题来了。 网站 中的网页链接有循环。
比如在网站的首页,我们可以看到首页的链接,然后我们也可能在子页面中看到首页的链接,可能会有对应的子子-页面。该链接指向主页。按照我们之前的逻辑,抓取每个网页中的所有链接,然后继续抓取所有链接。以首页为例。我们爬行的第一件事就是它。然后子页面里面有一个到首页的链接,子子页面也有一个到首页的链接。进行这种爬取会导致网页的重复爬取。其他的根本就没有抓取网页的机会,无法想象~~解决这个问题不难。这时候就需要用到网络爬虫中一个很重要的知识点,就是网页去重。
先介绍一个简单的思路,也是一个常用的思路。我们将抓取到的网页放到一个列表中。以首页为例。抓取主页后,将主页放入列表中。那么当我们抓取子页面的时候,如果再次触摸首页,并且首页已经被抓取了。这时候可以跳过首页,继续爬取其他网页,避免重复爬取首页。这样在爬取整个站点的时候就不会出现循环了。路。以这个思路为出发点,将访问过的URL保存在数据库中,当获取到下一个URL时,到数据库中查看该URL是否被访问过。虽然数据库有缓存,但是在数据库中查询每个URL时,效率会下降的很快,所以这个策略用的不多,但是是最简单的方法。
第二种方法是将访问过的URL保存在集合中。这种方式获取URL的速度非常快,基本不用查询。但是这种方法有一个缺点。保存集合中的URL实际上是将其保存在内存中。当 URL 数据量较大(如 1 亿)时,内存压力会增加。对于小型爬虫,这种方法是非常可取的,但对于大型网络爬虫来说,这种方法很难实现。
第三种方式是对md5中的字符进行编码,md5编码可以将字符缩减为固定长度。一般来说,md5编码的长度在128bit左右,约等于16byte。在缩减之前,假设一个URL占用的内存大小为50字节,1字节等于2字节,相当于100字节。可以看出,经过md5编码后,节省了大量的内存空间。通过md5,可以将任意长度的URL压缩成相同长度的md5字符串,不会有重复,可以达到去重的效果。这样,在很大程度上节省了内存。 scrapy框架采用的方法与md5方法有些类似。因此,一般情况下,即使URL的量级达到亿级,scrapy占用的内存也比set方法高。少很多。
第四种方式是使用位图方法进一步压缩字符。这种方法的意思是在计算机中申请8位,即8位,每一位用0或1表示,是计算机中的最小单位。如果8位组成一个字节,一位代表一个URL,为什么一位可以确定一个URL?因为我们可以对一个 URL 执行哈希函数,然后将其映射到位。例如,假设我们有8个URL,对应8位,然后通过位上的0和1的状态,就可以表明这个URL是否存在,这种方法可以进一步压缩内存。
但是位图方法有一个非常大的缺点,就是它的冲突会非常高,因为使用了同一个hash函数,很有可能将两个不同的URL或者多个不同的URL映射到一个位置。其实这个hash方法也是set方法的一个实现原理。它对 URL 执行函数计算,然后将其映射到位的位置。因此,这种方法可以大大压缩内存。简单计算一下,还是用1亿个URL来计算,相当于1亿比特。通过计算,相当于1250万字节。除以1024之后,大约是12207KB,也就是大约12MB的空间。在实际过程中,内存占用可能会大于12MB,但即便如此,与前三种方法相比,这种方法又大大减少了内存占用的空间。但同时,与此方法冲突的可能性非常高,因此此方法不是很适用。那么有没有办法进一步优化位图,这是一种重内存压缩的方法,以减少冲突的可能性?答案是肯定的,是第五种方式。
第五种方法是bloomfilter,改进位图。它可以通过多个散列函数减少冲突的可能性。这样一来,一方面不仅可以减少位图方法的内存,另一方面,同时也起到了减少冲突的作用。关于bloomfilter的原理和实现,后期我一定会介绍给大家的。今天就让大家有个简单的了解。 Bloomfilter适用于大型网络爬虫,尤其是数量级超大的时候。布隆过滤器方法可以事半功倍。也经常与分布式爬虫配合,达到爬取的目的。
我是来为大家介绍爬网过程中去重策略的五种方法的。如果你不明白,你应该知道它。在科普下,问题不大。希望对朋友的学习有所帮助。 .
c爬虫抓取网页数据(这请我吃一顿饭不过分吧?这篇爬虫实战教程,不仅适合新手练习爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-01 12:21
暑假已经开始很久了,但是还有很多朋友没有找到暑期实习?前几天,我朋友的弟弟想在暑假找一份实习来锻炼自己,但面对网上成千上万的实习招聘信息,简直让人望而生畏。然后我的朋友给我发了一条“帮助”信息。了解了大致情况后,我立即用爬虫爬取了实习网的信息,并贴出了数据结果。问题在几分钟内得到解决。请我吃饭会不会过分?
本爬虫实战教程不仅适合新手练习爬虫,也适合需要找实习信息的朋友!
希望看完这篇文章后,能够清楚的了解整个爬虫流程,能够独立完成。其次,可以通过自己的爬虫实战获取自己想要的信息。
好了,话不多说,开始吧!
内容主要分为三部分:
1、页面分析
2、爬虫步骤详解
一、目标页面分析
首先我们要知道我们的爬虫目标是什么?俗话说,知己知彼,百战不殆。我们已经知道我们要爬取的页面是“实习网”,所以我们首先要去实习网看看里面有什么数据。
实习网址:
页面如下:
比如我们要找的职位是“品牌运营”职位的数据。因此,直接在网页的搜索框中输入品牌操作即可。你会发现url变了!
注意:我们要抓取的页面是这个页面:品牌运营
在我们的抓取页面中,我们需要观察有哪些数据,一个页面中有几条数据。这一点很重要,关系到后续的代码编写,可以帮助你检查页面上的信息是否全部被抓取。
此时需要注意的是,我们所在的页面是“一级页面”。在浏览过程中,我们点击任意一个帖子进入,就会显示“二级页面”。这时候你也会发现url又变了。
比如我们点击一个品牌运营实习,二级页面会自动跳转到这个,并且会生成一个新的链接。如图:
应该在页面上抓取哪些信息?
我们在分析中发现,有的信息在一级页面,有的在二级页面。
在一级页面上我们可以得到什么样的信息?如图:
一共有五个有效数据:职位、公司名称、学历、薪水、地址
在二级页面中,我们来看看可以获取哪些有效数据、字段和比例。如果你觉得阶段很重要,也可以把它包括在爬虫的范围内,不过我个人认为这不影响实习,毕竟不是找正式工作不会有很大影响。相反,招聘的实习生人数更为重要。新兵人数这里没有显示,无法在图片上显示,以后可以添加。
这里,我们需要抓取一共7条数据,加上“人数”一共8条数据,就是我们爬虫最终的目标数据。
抓取“静态”网页
这里分析一下什么是静态网页,什么是动态网页。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。
它们的区别在于:静态网页中的数据是一劳永逸的,也就是说一次性全部给你。动态网页中的数据是随着页面的逐步加载而逐渐呈现的,即静态网页的爬虫技术无法获取其中的所有数据。
值得强调的是,不要将动态网页与动态页面内容混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果无关。动态网页也可以是纯文本内容,也可以收录各种动画内容。这些只是网页的细节。内容的呈现形式,无论网页是否有动态效果,只要是使用动态网站技术生成的网页,都可以称为动态网页。
点击“鼠标右键”,点击“查看网页源代码”,最终效果如图(部分截图):
这是最终反馈给你的数据。如果你发现你想要的所有数据都在里面,你可以说它是一个静态页面。如果不是,则将其视为“动态页面”。
今天的案例是一个静态网页。
大家都知道,在编写代码之前,我们首先要知道我们将使用哪些方法、库和模块来帮助您解析数据。常用的解析数据的方法有:re正则表达式、xpath、beatifulsoup、pyquery等
我们需要使用的是xpath分析方法来分析定位数据。
二、爬虫代码说明1、导入相关库
爬虫的第一步是考虑在爬虫过程中需要哪些库。你要知道python是一种依赖很多库的语言。没有库的 Python 是不完整的。
import pandas as pd # 用于数据存储
import requests # 用于请求网页
import chardet # 用于修改编码
import re # 用于提取数据
from lxml import etree # 解析数据的库
import time # 可以粗糙模拟人为请求网页的速度
import warnings # 忽略代码运行时候的警告信息
warnings.filterwarnings("ignore")
2、请求一级页面源码
url = 'https://www.shixi.com/search/index?key=品牌运营&districts=&education=0&full_opportunity=0&stage=0&practice_days=0&nature=0&trades=&lang=zh_cn'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
rqg = requests.get(url, headers=headers, verify=False) ①
rqg.encoding = chardet.detect(rqg.content)['encoding'] ②
html = etree.HTML(rqg.text)
这里要注意两个地方①②。 ①处有两个参数,一个是headers,一个是verify。其中,headers是一种反乱码措施,使浏览器认为爬虫不是爬虫,而是人们在正常使用浏览器请求网页。验证是忽略安全证书提示。某些网页将被视为不安全并会提示您。记住这个参数就行了。
在②处,我们已经获得了网页的源代码。但是由于网页源代码的编码方式和您电脑的解析方式,可能会出现不一致的情况,返回结果会造成乱码。此时需要修改编码方式,chardet库可以帮你自动检测网页源代码的编码方式。 (一个非常有用的检测文档编码的三方库chardet)
3、解析一级页面网页中的信息
# 1. 公司名
company_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
company_list = [company_list[i].strip() for i in range(len(company_list)) if i % 2 != 0]
# 2. 岗位名
job_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
job_list = [job_list[i].strip() for i in range(len(job_list)) if i % 2 == 0]
# 3. 地址
address_list = html.xpath('//div[@class="job-pannel-two"]//a/text()')
# 4. 学历
degree_list = html.xpath('//div[@class="job-pannel-list"]//dd[@class="job-des"]/span/text()')
# 5. 薪资
salary_list = html.xpath('//div[@class="job-pannel-two"]//div[@class="company-info-des"]/text()')
salary_list = [i.strip() for i in salary_list]
4、获取二级页面的链接
deep_url_list = html.xpath('//div[@class="job-pannel-list"]//dt/a/@href')
x = "https://www.shixi.com"
deep_url_list = [x + i for i in deep_url_list]
这时候可以看到我直接用xpath对一级页面中的数据分析进行了分析。代码最后可以看到:我们已经获取到了二级页面的链接,为我们后续抓取二级页面的信息做准备。
分析二级页面网页中的信息
需求列表 = []
area_list = []
scale_list = []
对于 deep_url_list 中的 deep_url:
rqg = requests.get(deep_url, headers=headers, verify=False) ①
rqg.encoding = chardet.detect(rqg.content)['encoding'] ②
html = etree.HTML(rqg.text) ③
# 6. 招聘人数
demand = html.xpath('//div[@class="container-fluid"]//div[@class="intros"]/span[2]/text()')
# 7. 公司领域
area = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[1]/span/text()')
# 8. 公司规模
scale = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[2]/span/text()')
demand_list.append(demand)
area_list.append(area)
scale_list.append(scale)
需要注意的是,二级页面也是一个页面,爬取其中的数据时需要请求该页面。因此,①②③处的代码完全相同。
5、翻页操作
随意复制几个不同页面的URL,观察差异。这里可以看到page参数后面的数字不同,是第一页,数字就是数字。
x = "https://www.shixi.com/search/index?key=数据分析&page="
url_list = [x + str(i) for i in range(1,21)]
由于我们抓取了 20 页数据,这里构造了 20 个 URL,它们都存在于 url_list 列表中。
现在让我们看一下整个代码。不再用文字描述,直接在代码中写注释。
import pandas as pd
import requests
import chardet
import re
from lxml import etree
import time
import warnings
warnings.filterwarnings("ignore")
def get_CI(url):
# 请求获取一级页面的源代码
url = 'https://www.shixi.com/search/index?key=品牌运营&districts=&education=0&full_opportunity=0&stage=0&practice_days=0&nature=0&trades=&lang=zh_cn'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
rqg = requests.get(url, headers=headers, verify=False)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
# 获取一级页面中的信息:一共有5个信息。
# ①公司名
company_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
company_list = [company_list[i].strip() for i in range(len(company_list)) if i % 2 != 0]
#②岗位名
job_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
job_list = [job_list[i].strip() for i in range(len(job_list)) if i % 2 == 0]
#③地址
address_list = html.xpath('//div[@class="job-pannel-two"]//a/text()')
# ④ 学历
degree_list = html.xpath('//div[@class="job-pannel-list"]//dd[@class="job-des"]/span/text()')
# ⑤薪资
salary_list = html.xpath('//div[@class="job-pannel-two"]//div[@class="company-info-des"]/text()')
salary_list = [i.strip() for i in salary_list]
# ⑥获取二级页面的内容
deep_url_list = html.xpath('//div[@class="job-pannel-list"]//dt/a/@href')
x = "https://www.shixi.com"
deep_url_list = [x + i for i in deep_url_list]
demand_list = []
area_list = []
scale_list = []
# 获取二级页面中的信息:
for deep_url in deep_url_list:
rqg = requests.get(deep_url, headers=headers, verify=False)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
#① 需要几人
demand = html.xpath('//div[@class="container-fluid"]//div[@class="intros"]/span[2]/text()')
# ②公司领域
area = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[1]/span/text()')
# ③公司规模
scale = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[2]/span/text()')
demand_list.append(demand)
area_list.append(area)
scale_list.append(scale)
# ④ 将每个页面获取到的所有数据,存储到DataFrame中。
data = pd.DataFrame({'公司名':company_list,'岗位名':job_list,'地址':address_list,"学历":degree_list,
'薪资':salary_list,'岗位需求量':demand_list,'公司领域':area_list,'公司规模':scale_list})
return(data)
x = "https://www.shixi.com/search/index?key=数据分析&page="
url_list = [x + str(i) for i in range(1,61)]
res = pd.DataFrame(columns=['公司名','岗位名','地址',"学历",'薪资','岗位需求量','公司领域','公司规模'])
# 这里进行“翻页”操作
for url in url_list:
res0 = get_CI(url)
res = pd.concat([res,res0])
time.sleep(3)
# 保存数据
res.to_csv('aliang.csv',encoding='utf_8_sig')
有了这样的一套,爬虫的思路会不会瞬间清晰?眼睛:我会的!手:我还是不会。多练。初学者不要急于求成,项目不多,但要精髓。吃一个比看十个更有效。
来自: 查看全部
c爬虫抓取网页数据(这请我吃一顿饭不过分吧?这篇爬虫实战教程,不仅适合新手练习爬虫)
暑假已经开始很久了,但是还有很多朋友没有找到暑期实习?前几天,我朋友的弟弟想在暑假找一份实习来锻炼自己,但面对网上成千上万的实习招聘信息,简直让人望而生畏。然后我的朋友给我发了一条“帮助”信息。了解了大致情况后,我立即用爬虫爬取了实习网的信息,并贴出了数据结果。问题在几分钟内得到解决。请我吃饭会不会过分?
本爬虫实战教程不仅适合新手练习爬虫,也适合需要找实习信息的朋友!
希望看完这篇文章后,能够清楚的了解整个爬虫流程,能够独立完成。其次,可以通过自己的爬虫实战获取自己想要的信息。
好了,话不多说,开始吧!
内容主要分为三部分:
1、页面分析
2、爬虫步骤详解
一、目标页面分析
首先我们要知道我们的爬虫目标是什么?俗话说,知己知彼,百战不殆。我们已经知道我们要爬取的页面是“实习网”,所以我们首先要去实习网看看里面有什么数据。
实习网址:
页面如下:
比如我们要找的职位是“品牌运营”职位的数据。因此,直接在网页的搜索框中输入品牌操作即可。你会发现url变了!
注意:我们要抓取的页面是这个页面:品牌运营
在我们的抓取页面中,我们需要观察有哪些数据,一个页面中有几条数据。这一点很重要,关系到后续的代码编写,可以帮助你检查页面上的信息是否全部被抓取。
此时需要注意的是,我们所在的页面是“一级页面”。在浏览过程中,我们点击任意一个帖子进入,就会显示“二级页面”。这时候你也会发现url又变了。
比如我们点击一个品牌运营实习,二级页面会自动跳转到这个,并且会生成一个新的链接。如图:
应该在页面上抓取哪些信息?
我们在分析中发现,有的信息在一级页面,有的在二级页面。
在一级页面上我们可以得到什么样的信息?如图:
一共有五个有效数据:职位、公司名称、学历、薪水、地址
在二级页面中,我们来看看可以获取哪些有效数据、字段和比例。如果你觉得阶段很重要,也可以把它包括在爬虫的范围内,不过我个人认为这不影响实习,毕竟不是找正式工作不会有很大影响。相反,招聘的实习生人数更为重要。新兵人数这里没有显示,无法在图片上显示,以后可以添加。
这里,我们需要抓取一共7条数据,加上“人数”一共8条数据,就是我们爬虫最终的目标数据。
抓取“静态”网页
这里分析一下什么是静态网页,什么是动态网页。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。
它们的区别在于:静态网页中的数据是一劳永逸的,也就是说一次性全部给你。动态网页中的数据是随着页面的逐步加载而逐渐呈现的,即静态网页的爬虫技术无法获取其中的所有数据。
值得强调的是,不要将动态网页与动态页面内容混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果无关。动态网页也可以是纯文本内容,也可以收录各种动画内容。这些只是网页的细节。内容的呈现形式,无论网页是否有动态效果,只要是使用动态网站技术生成的网页,都可以称为动态网页。
点击“鼠标右键”,点击“查看网页源代码”,最终效果如图(部分截图):
这是最终反馈给你的数据。如果你发现你想要的所有数据都在里面,你可以说它是一个静态页面。如果不是,则将其视为“动态页面”。
今天的案例是一个静态网页。
大家都知道,在编写代码之前,我们首先要知道我们将使用哪些方法、库和模块来帮助您解析数据。常用的解析数据的方法有:re正则表达式、xpath、beatifulsoup、pyquery等
我们需要使用的是xpath分析方法来分析定位数据。
二、爬虫代码说明1、导入相关库
爬虫的第一步是考虑在爬虫过程中需要哪些库。你要知道python是一种依赖很多库的语言。没有库的 Python 是不完整的。
import pandas as pd # 用于数据存储
import requests # 用于请求网页
import chardet # 用于修改编码
import re # 用于提取数据
from lxml import etree # 解析数据的库
import time # 可以粗糙模拟人为请求网页的速度
import warnings # 忽略代码运行时候的警告信息
warnings.filterwarnings("ignore")
2、请求一级页面源码
url = 'https://www.shixi.com/search/index?key=品牌运营&districts=&education=0&full_opportunity=0&stage=0&practice_days=0&nature=0&trades=&lang=zh_cn'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
rqg = requests.get(url, headers=headers, verify=False) ①
rqg.encoding = chardet.detect(rqg.content)['encoding'] ②
html = etree.HTML(rqg.text)
这里要注意两个地方①②。 ①处有两个参数,一个是headers,一个是verify。其中,headers是一种反乱码措施,使浏览器认为爬虫不是爬虫,而是人们在正常使用浏览器请求网页。验证是忽略安全证书提示。某些网页将被视为不安全并会提示您。记住这个参数就行了。
在②处,我们已经获得了网页的源代码。但是由于网页源代码的编码方式和您电脑的解析方式,可能会出现不一致的情况,返回结果会造成乱码。此时需要修改编码方式,chardet库可以帮你自动检测网页源代码的编码方式。 (一个非常有用的检测文档编码的三方库chardet)
3、解析一级页面网页中的信息
# 1. 公司名
company_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
company_list = [company_list[i].strip() for i in range(len(company_list)) if i % 2 != 0]
# 2. 岗位名
job_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
job_list = [job_list[i].strip() for i in range(len(job_list)) if i % 2 == 0]
# 3. 地址
address_list = html.xpath('//div[@class="job-pannel-two"]//a/text()')
# 4. 学历
degree_list = html.xpath('//div[@class="job-pannel-list"]//dd[@class="job-des"]/span/text()')
# 5. 薪资
salary_list = html.xpath('//div[@class="job-pannel-two"]//div[@class="company-info-des"]/text()')
salary_list = [i.strip() for i in salary_list]
4、获取二级页面的链接
deep_url_list = html.xpath('//div[@class="job-pannel-list"]//dt/a/@href')
x = "https://www.shixi.com"
deep_url_list = [x + i for i in deep_url_list]
这时候可以看到我直接用xpath对一级页面中的数据分析进行了分析。代码最后可以看到:我们已经获取到了二级页面的链接,为我们后续抓取二级页面的信息做准备。
分析二级页面网页中的信息
需求列表 = []
area_list = []
scale_list = []
对于 deep_url_list 中的 deep_url:
rqg = requests.get(deep_url, headers=headers, verify=False) ①
rqg.encoding = chardet.detect(rqg.content)['encoding'] ②
html = etree.HTML(rqg.text) ③
# 6. 招聘人数
demand = html.xpath('//div[@class="container-fluid"]//div[@class="intros"]/span[2]/text()')
# 7. 公司领域
area = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[1]/span/text()')
# 8. 公司规模
scale = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[2]/span/text()')
demand_list.append(demand)
area_list.append(area)
scale_list.append(scale)
需要注意的是,二级页面也是一个页面,爬取其中的数据时需要请求该页面。因此,①②③处的代码完全相同。
5、翻页操作
随意复制几个不同页面的URL,观察差异。这里可以看到page参数后面的数字不同,是第一页,数字就是数字。
x = "https://www.shixi.com/search/index?key=数据分析&page="
url_list = [x + str(i) for i in range(1,21)]
由于我们抓取了 20 页数据,这里构造了 20 个 URL,它们都存在于 url_list 列表中。
现在让我们看一下整个代码。不再用文字描述,直接在代码中写注释。
import pandas as pd
import requests
import chardet
import re
from lxml import etree
import time
import warnings
warnings.filterwarnings("ignore")
def get_CI(url):
# 请求获取一级页面的源代码
url = 'https://www.shixi.com/search/index?key=品牌运营&districts=&education=0&full_opportunity=0&stage=0&practice_days=0&nature=0&trades=&lang=zh_cn'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
rqg = requests.get(url, headers=headers, verify=False)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
# 获取一级页面中的信息:一共有5个信息。
# ①公司名
company_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
company_list = [company_list[i].strip() for i in range(len(company_list)) if i % 2 != 0]
#②岗位名
job_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
job_list = [job_list[i].strip() for i in range(len(job_list)) if i % 2 == 0]
#③地址
address_list = html.xpath('//div[@class="job-pannel-two"]//a/text()')
# ④ 学历
degree_list = html.xpath('//div[@class="job-pannel-list"]//dd[@class="job-des"]/span/text()')
# ⑤薪资
salary_list = html.xpath('//div[@class="job-pannel-two"]//div[@class="company-info-des"]/text()')
salary_list = [i.strip() for i in salary_list]
# ⑥获取二级页面的内容
deep_url_list = html.xpath('//div[@class="job-pannel-list"]//dt/a/@href')
x = "https://www.shixi.com"
deep_url_list = [x + i for i in deep_url_list]
demand_list = []
area_list = []
scale_list = []
# 获取二级页面中的信息:
for deep_url in deep_url_list:
rqg = requests.get(deep_url, headers=headers, verify=False)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
#① 需要几人
demand = html.xpath('//div[@class="container-fluid"]//div[@class="intros"]/span[2]/text()')
# ②公司领域
area = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[1]/span/text()')
# ③公司规模
scale = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[2]/span/text()')
demand_list.append(demand)
area_list.append(area)
scale_list.append(scale)
# ④ 将每个页面获取到的所有数据,存储到DataFrame中。
data = pd.DataFrame({'公司名':company_list,'岗位名':job_list,'地址':address_list,"学历":degree_list,
'薪资':salary_list,'岗位需求量':demand_list,'公司领域':area_list,'公司规模':scale_list})
return(data)
x = "https://www.shixi.com/search/index?key=数据分析&page="
url_list = [x + str(i) for i in range(1,61)]
res = pd.DataFrame(columns=['公司名','岗位名','地址',"学历",'薪资','岗位需求量','公司领域','公司规模'])
# 这里进行“翻页”操作
for url in url_list:
res0 = get_CI(url)
res = pd.concat([res,res0])
time.sleep(3)
# 保存数据
res.to_csv('aliang.csv',encoding='utf_8_sig')
有了这样的一套,爬虫的思路会不会瞬间清晰?眼睛:我会的!手:我还是不会。多练。初学者不要急于求成,项目不多,但要精髓。吃一个比看十个更有效。
来自:
c爬虫抓取网页数据(基于Python爬虫技术简单易用的特点,利用python语言编写爬虫程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-31 13:29
摘要:基于Python爬虫技术简单易用的特点,采用python语言编写爬虫程序,对广电总局电视剧电子政务平台的电视剧记录数据进行爬取。此外,还对抓取的电视剧记录数据进行了统计分析,得出了相关结论。
关键词:Python;爬虫;数据分析
中文图书馆分类号:TP311.11 文献识别码:A 文章 编号:1007-9416 (2017)09-0035-02
1 爬虫技术介绍
网络爬虫是一种通过既定规则自动抓取网络信息的计算机程序。爬虫的目的是将目标网页数据下载到本地进行后续的数据分析。爬虫技术的兴起源于海量网络数据的可用性。通过爬虫技术,我们可以轻松获取网络数据,通过数据分析得出有价值的结论。
Python语言简单易用,现成的爬虫框架和工具包降低了使用门槛。正则表达式的具体使用,使得数据采集工作生动有趣。
2 案例分析
2.1 网页描述
目标数据是历年全国电视剧拍摄的记录数据。数据来源于广电总局电视剧电子政务平台公开信息,如图1所示。 具体网址:“http:
// /tims/site/views/applications.shanty? 应用名称=注释”。
我们需要爬取历年来每个月的记录公开信息列表数据,如图2所示,并进行汇总分析。
2.2 爬虫程序的设计与实现
首先,我们使用 BeautifulSoup 解析器来解析 URL 的文本信息。在分析了网页的 HTML 文本和页面规则后,我们制定了以下步骤来捕获目标数据。
①抓取第一页码和最后页码后,循环抓取列表页信息; 查看全部
c爬虫抓取网页数据(基于Python爬虫技术简单易用的特点,利用python语言编写爬虫程序)
摘要:基于Python爬虫技术简单易用的特点,采用python语言编写爬虫程序,对广电总局电视剧电子政务平台的电视剧记录数据进行爬取。此外,还对抓取的电视剧记录数据进行了统计分析,得出了相关结论。
关键词:Python;爬虫;数据分析
中文图书馆分类号:TP311.11 文献识别码:A 文章 编号:1007-9416 (2017)09-0035-02
1 爬虫技术介绍
网络爬虫是一种通过既定规则自动抓取网络信息的计算机程序。爬虫的目的是将目标网页数据下载到本地进行后续的数据分析。爬虫技术的兴起源于海量网络数据的可用性。通过爬虫技术,我们可以轻松获取网络数据,通过数据分析得出有价值的结论。
Python语言简单易用,现成的爬虫框架和工具包降低了使用门槛。正则表达式的具体使用,使得数据采集工作生动有趣。
2 案例分析
2.1 网页描述
目标数据是历年全国电视剧拍摄的记录数据。数据来源于广电总局电视剧电子政务平台公开信息,如图1所示。 具体网址:“http:
// /tims/site/views/applications.shanty? 应用名称=注释”。
我们需要爬取历年来每个月的记录公开信息列表数据,如图2所示,并进行汇总分析。
2.2 爬虫程序的设计与实现
首先,我们使用 BeautifulSoup 解析器来解析 URL 的文本信息。在分析了网页的 HTML 文本和页面规则后,我们制定了以下步骤来捕获目标数据。
①抓取第一页码和最后页码后,循环抓取列表页信息;

