c爬虫抓取网页数据(产品经理网站结构比较简单的翻太慢错的方法有哪些)
优采云 发布时间: 2022-01-12 08:09c爬虫抓取网页数据(产品经理网站结构比较简单的翻太慢错的方法有哪些)
再次重申:我不是程序员,也没有涉及代码。当页面被修改时,我只涉及复制和粘贴。
要去给朋友圈添点专业气息,需要添加一些新的微信ID;
在哪里可以找到专业的微信账号?
想着大家都是产品经理,我看到传播者在文章下的评论里留下微信,但是每个文章的翻译太慢了,也许你可以用一个工具把所有的评论发到抓住它进行过滤。
网站结构比较简单,这个应该是简单的抓取,到最后会发现自己错了。
以下简称人人为产品经理网站;
上一篇文章中已经详细介绍了常规爬取的过程,重复部分本文不再赘述;
思考过程:如果有需求,找到需求对应的信息,找到信息对应的位置,找到位置对应的工具,找到工具对应的功能或技能。
一:换算法,使用更准确的方法;
上一篇文章介绍了一种生成链接的方法,大家准备用同样的方法再做一遍;
然后遇到第一个难点:大家的链接结构不统一,比如:/pmd/1660079.html、/pd/1659496.html、/ai/1648500.html等.;
总共有10多个类别,最大数量为1,660,079,超过160万。如果每个类别产生超过160万个链接,去链接审核工具进行审核,可能需要十天以上的时间来审核链接;
这种方法是行不通的,需要一个新的方法:网站提供了一个方便的通道——列表页,通过它可以获得整个列表的链接。
使用这种方法,从十几天,这个步骤可以缩短到几个小时。
二:确定约束条件,根据约束条件改进流程
在得到链接之前,我做了一个计算,有几万条文章,而文章下的评论就更多了;
该工具的数据导出限制为 10,000 条。这次真的要花钱升级吗?
又想到一句话:带枷锁跳舞,不带枷锁跳舞不是技巧,带枷锁跳舞是技巧。
最近一直在思考一个基本的二元关系问题:A和B之间有多少条路径?
对初步思考的回答:A和B之间至少有两条路径:AB和BA。
这说明了这样一个事实,即两件事之间必须有两条路径,并且除了常规路径之外至少还有一条其他路径。
把这个结论应用到限定条件上,那么解决问题的路径至少有两条:
1:常规路径:需求(自身)不变,(环境)极限扩大,极限适应需求;
2:反向路径:限制(环境)不变,压缩(自己)需求,使需求适应限制;
第二条反向路径为解决问题带来了新的视角,为流程演化建立了新的理论基础。
原来的流程是:
获取链接—>导出链接(限制出现1)—>重新导入—>评论抓取—>导出评论(限制出现2)—>本地过滤。
第一个改进:重新定义需求,细化获取环节:
其实第二阶段需要的不是任何文章,而是带注释的文章(没有注释就不用抢注释了),在初始条件上加上细化条件提前过滤,一下子把链接数减少了三分之一。
新流程:获取精确链接—>导出链接(限制1)的位置—>重新导入—>评论捕获—>导出评论(限制2)的位置—>本地过滤。
第二次改进:将新的认识应用到大局中,在第二阶段增加细化条件;
不是所有的评论都要被抓,而是收录公众号或微信账号的评论。
新流程:获取精准链接—>导出链接(限制1)的位置—>重新导入—>准确抓取评论—>导出评论(限制2)的位置—>本地过滤。
第三次改进:合并和推进流程
我在中间去了一次洗手间,洗手间做得很好。在其中,我想到了两个过程。为什么要把这两个进程分开?
这两个阶段是一个连续的过程,如果这些过程可以合并,第一阶段的限制就会消失。
这说明除了适应约束之外,还可以选择合理地调整流程以消除或跳过约束。
将两个流程合二为一后,新流程:获取精准链接—>准确抓取评论—>导出评论(限制位置2)—>本地过滤。
由于重新定义了两阶段要求,最终出口数据中只剩下有意义的部分。
这个改进过程也让我发现了一个优化的关键点:在设计过程时,结合约束,用约束激发深度优化。
最终得到了我想要的数据,结果发现约束不是敌人,约束是持续创新的重要条件。
这一发现也为创新开辟了一种新的思维方式:自我强加的限制,没有限制创造限制。就像这个文章,本来是不打算写的,但是我给自己设计了一个新的限制:把事情做完,从实践到总结,就完成了。
在过滤数据时,我有点气馁。评论数据是非结构化的,很难快速过滤此类数据。这也让我有了一个新的发现:数据的价值取决于结构的程度。结构化数据很少。既然如此,与其捕获杂乱无章的数据,事后对其进行结构化,不如在初始设计中建立结构化的数据捕获过程。
结束了吗?确实是时候结束了,本来预定的数据已经拿到了;
但这并没有结束,甚至真正的困难才刚刚开始,所以这是一个意外。
三:抢公众号,重新整理全站内容;
一边抓着上面的微信,一边也隔出了一部分公众号,很少。如果能得到更多的公众号,或许可以做一个专门的页面来提供一个服务,也就是集成即服务。该方法的效果很差,需要更高效的采集方法;
我想还有一个地方也会放公众号,每个文章底部的作者介绍部分:
如果能够获取大量数据,就可以形成公众账户矩阵。据我所知,没有这样的信息库,信息集中对用户也很有价值;
准备开始抓取,遇到了第一个难点:文章内容很多,如何定位要抓取的对象?
定位要抓拍的物体有一个窍门:分析物体的特征,尤其是独特的特征,通过独特的特征准确识别;比如这次要抓的对象是一个公众号,而这三个词在文章中也经常出现,但是出现在文章中的时候一般不会跟a : 符号,仅在作者介绍时才收录,这是关键特性。
第一个改进:多角度观察数据,增加要捕获的数据类型;
这是一个非常偶然的想法。我想着数据可能可以供官方参考,然后又想到了大家官方需要的数据格式。然后我想到了一个新的需求场景:如果提供给用户,用户面对的是数据。数据应该如何使用?
三个角色:我、用户和人人官方。每个角色需要不同的数据并使用不同的方法。比如我只需要公众号,用户需要更多数据。用户将希望执行一些过滤,以便他们可以找到适合您自己的公共帐户。

第二个改进:增加辅助判断条件;
在爬取中,我们遇到了一个问题:如果没有符合设定条件的数据,数据就会留空。这类数据需要丢弃(否则会占用导出索引)。为了丢弃数据,必须对数据进行处理。判断,进行判断,数据不能为空;
这里有一个矛盾或冲突:需要删除空数据,但只能删除非空数据;终于找到了一个办法:给所有数据加上一个固定的前缀——delete,这样无论数据是否为空,最终都不会为空;
比如两条数据:一条数据为空,需要删除,加上前缀后,数据变为:delete;数据B数据不为空,加前缀后数据变为删除+原创数据;要确定哪些数据只收录删除,您可以丢弃,因为只有空数据将只收录添加的前缀。
这种方法是excel中的一个技巧:当数据本身难以判断时,加一列辅助判断,让具有相同特征的选项转化为易于识别的数据;如A/A/B/B/C/D,需要确定哪些重复项单独列出。因为A/B不同,无法实现排序。这时候可以添加一个单独的辅助判断列,将重复项转换为1,不重复项转换为0,然后对新列进行排序。
在最后一页,我也使用了这个技巧,通过在未认证的前面加上前缀A,让未认证的在排序的时候总是排成一行。
第三项改进:增加精准判断条件;
由于我不是程序员,对程序了解不多,无法准确判断代码的含义,这就带来了一个问题:不知道代码是否能完全达到目的,同时处理一些边缘情况;
在第一次数据捕获后,我们发现了这样一种情况:当数据中收录-等符号时,捕获会被中断。很多公众号都收录-符号,结果只抓到一半,比如lmh-china,只会抓lmh。
这是一个超出我能力的改进,所以我准备手动修改,但是接近1000个公众号,效率太低,如果你能改进爬取过程并修复这个问题,那么你可以重新爬取再次使用正确的数据,我决定试一试。
最终,我添加了结束条件(正则表达式),必须遇到,或者。会结束,遇到其他符号也不会结束。
这并不意味着我可以编写代码。该工具提供了一个工具来帮助生成正则表达式。然后我在互联网上搜索答案以找到可能的答案,并不断尝试成功。
PS:写这篇文章的时候,又查了一遍资料,发现上次修改没有生效,还是老流程。我必须确认未来的重要步骤,以确认我在做正确的事情。
改进之四:进行下一步,从实际场景中观察数据;
抓数据的时候想,可能需要一个地方放数据,这样方便查看,一张简单的表就够了,还需要排序,这样就可以根据自己的需要进行排序了;
找了几个插件,最后选择了一个简单的页面,经过测试,符合我的要求;
这次提前操作数据让我决定再次添加一个数据类型,添加一个经过认证的数据类型。人人网网站拥有各类认证。添加新的排序字段对用户有好处,可以让我排除官方用户,排除官方用户意味着排除非贡献者的公共账户。
这些官方发布的文章中的公众号是官方转载的来源,也很有价值;它们可以制成单独的页面。
改进之五:试用公共CDN地址查找bug;
由于所有网页都使用开源程序,我可以将本地的css和js改成免费的CDN地址,速度更快,节省带宽;*敏*感*词*有一些服务为开源程序提供免费CDN,如/,合理节省使用成本;
在不断测试的过程中,突然发现了一个致命的bug:排序错误,这个bug一下子让我陷入了深渊。如果存在此错误,那么对用户最有意义的功能将失败:
我没有修复错误的能力,但我想到了一些可能性。作为一个开源程序,按理说这样明显的排序bug肯定会被修复。页面使用的版本比较旧。这是原因吗?
我去CDN找了最新版本,页面直接崩溃了;回去找了个中间版本,bug修复了,原来是程序版本问题。
这个修订过程教会了我一个反向精益思想:从后到前改进,提前验证整个过程,如果可能的话,把整个过程,特别是还没有达到的过程,并努力做到在少量数据的支持下。实际场景模拟,去模拟场景看看,这个模拟有利于整个过程的改进,场景中的思维可以反馈到整个过程的改进。
改进之六:增加公众号查询;
看了几个公众号,发现很多公众号已经不存在或者没有更新。如果能提供一个新的筛选维度,让用户可以直接看到公众号的更新,这个数据会更有价值;
我知道搜狗搜索提供了微信搜外,我开始尝试爬取搜狗搜索,但是搜狗搜索的反爬虫规则太严格了。
这个想法失败了,但我可以提供一个折衷方案:点击直接查询;
检查搜狗搜索的链接规则后,生成所有公众号对应的查询链接。
最终页面如下所示:
您可以在页面内搜索并按列排序。
我将页面上传到服务器,页面地址:open.skyfollowsnow.pro/special/woshipm-author/。
您可以在此处查看本次抓取中使用的工具和知识:open.skyfollowsnow.pro/?thread-55.htm。
第七项改进:统一修改位置;
将文件上传到服务器后,我犯了一个明显的错误:在服务器中修改文档,很多修改必须在本地,于是出现了一个新问题:有些东西是在服务器上修改的,有些东西是在本地修改的,文件两端不一致;
虽小,但也是很实用的一课:统一修改位置,避免协作时起点不一致。
其他:
在本次爬取中,使用了两种新的方法来解决两个问题:
1:解决json数据中a标签不被解析的问题;
作者ID和空格链接本来是两列,但是我以为可以合并,但是一旦合并就会报错,然后我以为我看到了一个用\符号隔开的程序”,于是试了一下,确实如此。
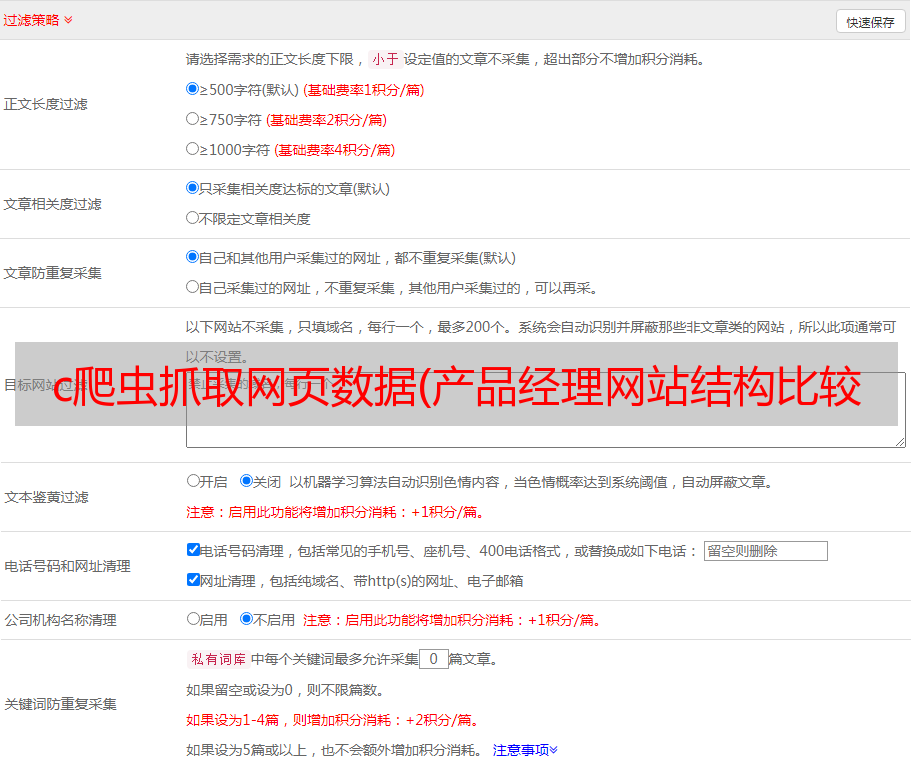
2:解决excel列过多时合并容易出错的问题;
最后合并成需要的数据时,需要合并的项很多,很容易发现顺序不对。为了一次性看到所有列的选项,我使用了一个新工具:桌面纹理工具 Snipaste,这也是我之前见过的。程序使用的工具正好解决了这个问题:
平时看到新事物的时候要有点好奇,需要的时候可能会想到。

