
c爬虫抓取网页数据
c爬虫抓取网页数据(爬虫在数据分析领域的应用,如何帮助我们提升数据分析质量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 224 次浏览 • 2022-03-14 12:15
在当今信息化和数字化的时代,人们离不开网络搜索,但想想看,在搜索过程中,你真的可以得到相关信息,因为有人在帮你过滤相关内容,呈现在你面前。
就像在餐馆里一样,你点了土豆然后得到它们,因为有人帮你在土豆、萝卜、西红柿等中找到它们,然后有人把它们带到你的餐桌上。在网上,这两个动作是一个叫爬虫的同学为你实现的。
也就是说,没有爬虫,就没有今天的检索,就无法准确查找信息和高效获取数据。今天DataHunter就来谈谈爬虫在数据分析领域的应用,以及它如何帮助我们提高数据分析的质量。
一、数据时代,爬虫的本质是提高效率
网络爬虫,又称网络机器人,可以代替人自动浏览网络信息,采集和组织数据。
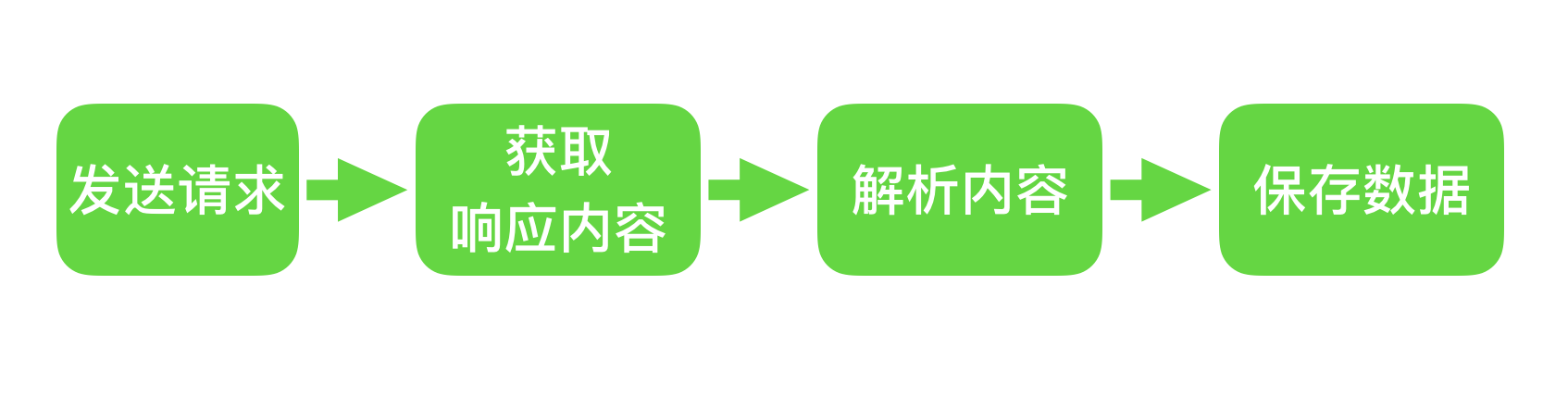
它是一个程序,其基本原理是向网站/网络发起请求,获取资源后分析提取有用数据。从技术上讲,就是通过程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)爬取到本地,然后提取您需要的数据并将其存储以供使用。
每个程序都有自己的规则,网络爬虫也不例外。它穿梭于世界各地的各种网站之间,根据人们强加的规则将采集信息。我们称这些规则为网络爬虫算法。规则是人定的,是人根据自己的目的和需要设计的。因此,根据用户的目的,爬虫可以有不同的功能。但所有爬虫的本质是方便人们在海量的互联网信息中找到并下载自己想要的信息类型,从而提高信息获取效率。
二、爬虫的应用:搜索并帮助企业做强业务
1.搜索引擎:爬取网站为网络用户提供便利
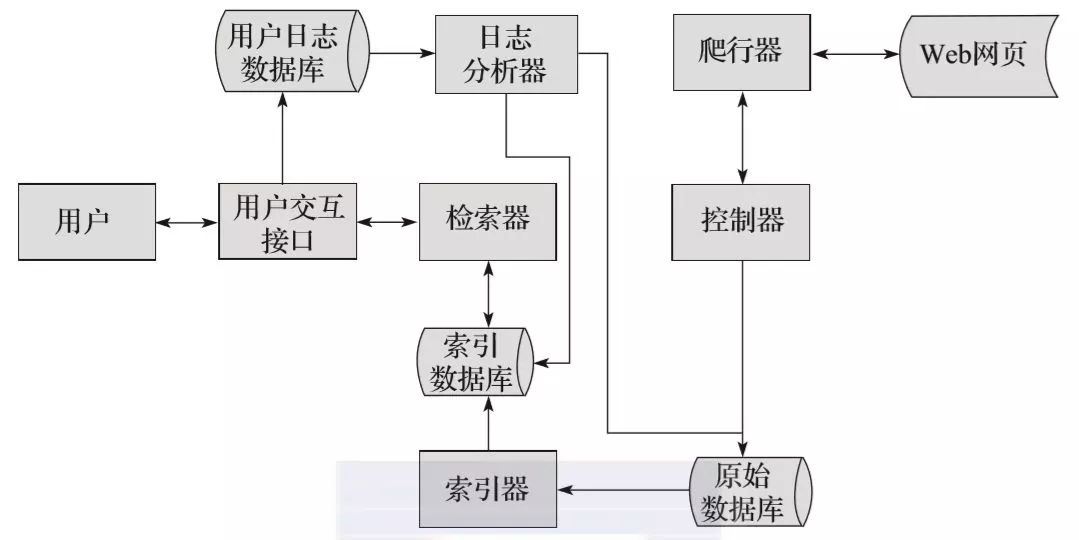
在互联网的早期,能够提供全球范围内信息的网站并不多,用户也不多。Internet 只是文件传输协议 (FTP) 站点的集合,用户可以在其中导航以查找特定的共享文件,并查找和组合 Internet 上可用的分布式数据,创建了一个称为网络爬虫的自动化程序 /Robot,它可以爬取网络上的所有网页,然后将所有页面的内容复制到数据库中进行索引。这也是最早的搜索引擎。
如今,随着互联网的飞速发展,我们可以在任何搜索引擎中看到来自世界各地各种网站的信息。百度搜索引擎的爬虫叫百度蜘蛛,360的爬虫叫360Spider,搜狗的爬虫叫搜狗蜘蛛,必应的爬虫叫Bingbot。搜索引擎离不开爬虫。
比如百度蜘蛛每天都会抓取大量的互联网信息,抓取优质信息和收录。当用户在百度搜索引擎上搜索对应的关键词时,百度会对关键词进行分析处理,从收录的网页中找出相关网页,按照一定的排名规则和结果展示给用户,工作原理如图。现在,我们可以大胆地说,你每天都在免费享受爬虫的好处。
2.企业:监控舆情,高效获取有价值信息
我们说过爬虫的本质是提高效率,而爬虫的规则是由人决定的;那么企业就可以根据自己的业务需求设计爬虫,第一时间获取网络上的相关信息,进行清理整合。
在大数据时代进行数据分析,首先要有数据源,网络爬虫可以让我们获取更多的数据源,同时根据我们的目的进行采集,从而去除很多的无关数据。
例如,在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站s,或者从某些文档或内部资料中获取数据源。但是,这些获取数据的方式有时很难满足我们的数据需求。此时,我们可以利用爬虫技术从互联网上自动获取更多我们感兴趣的数据内容,从而进行更深入的数据分析,获取更多有价值的信息。
此外,网络爬虫还可用于财务分析,对财务数据进行采集进行投资分析;可应用于舆情监测分析、精准客户精准营销等各个领域。
三、企业常用的4种网络爬虫
网络爬虫根据实现的技术和结构可以分为一般网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。但由于网络环境复杂,实际的网络爬虫通常是这几种爬虫的组合。
1.万能网络爬虫
通用网络爬虫也称为全网络爬虫。顾名思义,要爬取的目标资源在整个互联网上,要爬取的目标数据是巨大的,爬取的范围也很大。正是因为爬取的数据是海量数据,所以对于这种爬虫来说,对爬取的性能要求是非常高的。这种网络爬虫主要用于大型搜索引擎,具有很高的应用价值。
一般的网络爬虫主要由初始URL采集、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块等组成。一般网络爬虫在爬取时会采用一定的爬取策略,主要包括深度优先爬取策略和广度优先爬取策略。具体细节将在后面介绍。
2.专注于网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是根据预先定义的主题有选择地爬取网页的爬虫。聚焦网络爬虫主要用于爬取特定信息,主要为特定类型的人提供服务。
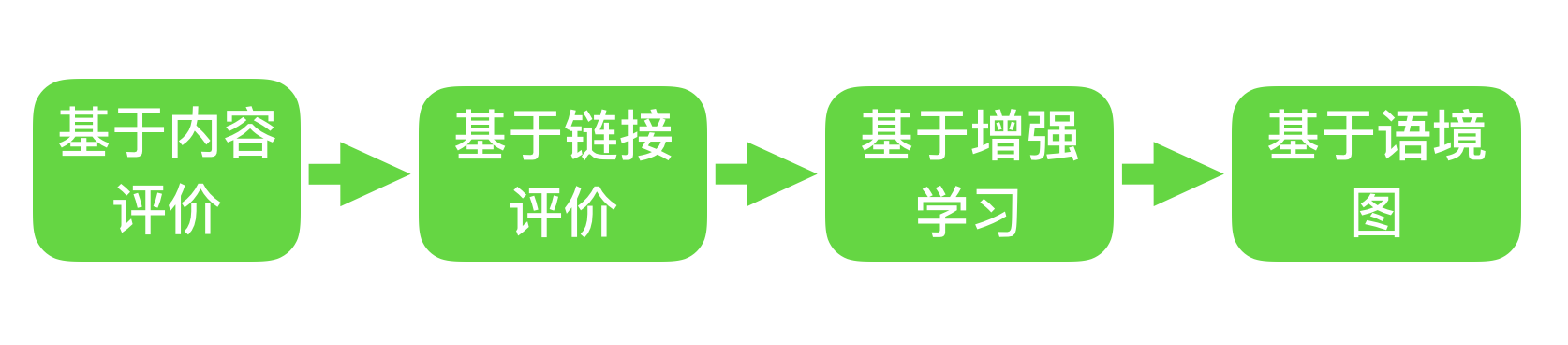
聚焦网络爬虫也是由初始URL集合、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块、内容评价模块、链接评价模块等组成。内容评估模块和链接评估模块可以根据链接和内容的重要性确定优先访问哪些页面。专注于网络爬虫的爬取策略主要有四种,如图:
由于专注的网络爬虫可以有目的地根据相应的主题进行爬取,在实际应用过程中可以节省大量的服务器资源和宽带资源,因此具有很强的实用性。这里我们以网络爬虫为例来了解爬虫运行的工作原理和过程。
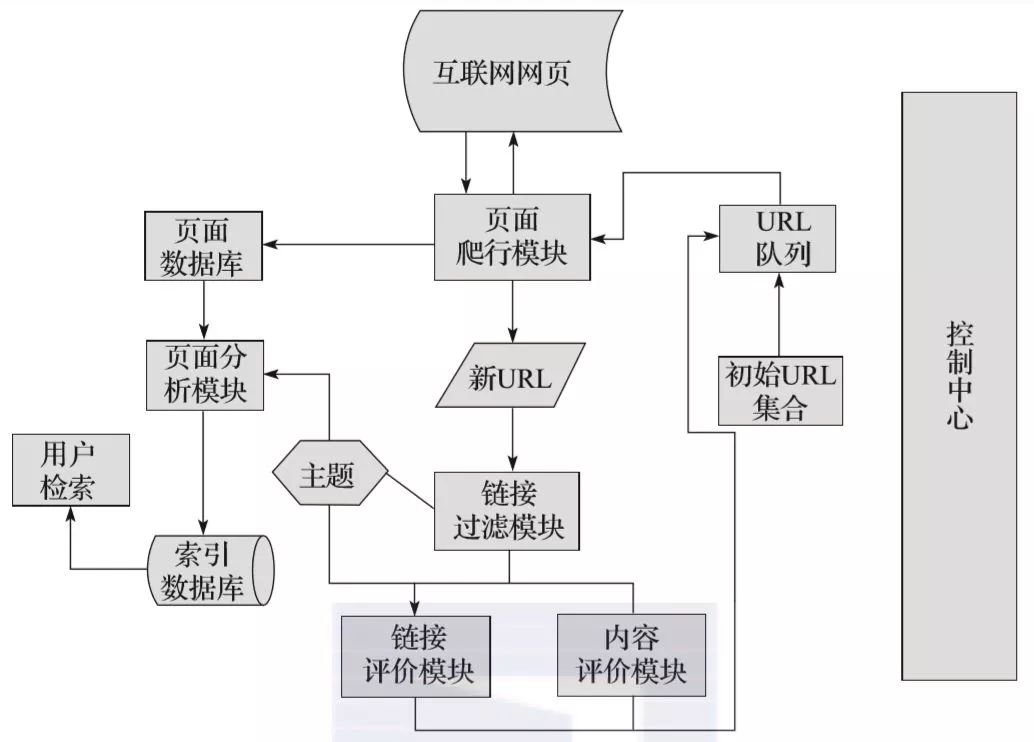
如图所示,焦点网络爬虫有一个控制中心,负责管理和监控整个爬虫系统,包括控制用户交互、初始化爬虫、确定主题、协调各个模块之间的工作以及控制整个爬虫系统。爬行过程。等等:
(1)控制中心将初始URL集合传递给URL队列,页面爬取模块会从URL队列中读取第一批URL列表;
(2)根据这些URL地址,从网上爬取对应的页面;爬取后,将爬取的内容发送到页面数据库进行存储;
(3)在爬取过程中,会爬取一些新的URL,此时需要使用链接过滤模块,根据指定的主题过滤掉不相关的链接,然后使用链接评价模块进行根据主题剩余的URL链接。或者内容评估模块进行优先排序,完成后将新的URL地址传递给URL队列,供页面爬取模块使用;
(4)抓取页面并存入页面数据库后,需要使用页面分析模块,根据主题对抓取的页面进行分析处理,并根据处理结果建立索引库。当用户检索到相应的信息,就可以从索引数据库中进行相应的检索,得到相应的结果。
3.增量网络爬虫
这里的“incremental”对应于增量更新,意思是在更新过程中只更新变化的地方,不变的地方不更新。
增量网络爬虫,在爬取网页时,只爬取内容发生变化的网页或新生成的网页,不会爬取内容未发生变化的网页。增量网络爬虫可以在一定程度上保证爬取的页面尽可能的新。
4.深网爬虫
在互联网中,网页根据存在的程度可以分为表层页面和深层页面。表面页面是指无需提交表单,使用静态链接即可到达的静态页面;而深页是提交某个关键词后才能获得的页面。在 Internet 中,深层页面的数量通常远大于表面页面的数量。
深网爬虫可以爬取互联网中的深层页面,而要爬取深层页面,就需要想办法自动填写相应的表格。深网爬虫主要由 URL 列表、LVS 列表(LVS 指标签/值集合,即填充表单的数据源)、爬取控制器、解析器、LVS 控制器、表单分析器、表单处理器、响应分析器组成和其他部分。
四、网络爬虫的爬取策略
前面我们说过,网络爬虫算法是基于人对采集信息施加的规则,由于网络环境复杂,算法也多种多样,也就是爬取策略。这里主要介绍爬取的顺序和频率。
1.爬取顺序
网络爬虫在爬取过程中,可能会出现在爬取的URL列表中的多个URL地址,因此爬虫会依次对这些URL地址进行爬取。
与一般的网络爬虫相比,爬取的顺序并不那么重要。但专注于网络爬虫,爬取的顺序与服务器资源和宽带资源有关,所以非常重要,一般由爬取策略决定。爬取策略主要包括深度优先爬取策略、广度优先爬取策略、大站点优先策略、反链策略等爬取策略。
如图,假设有一个网站,ABCDEFG为站点下的网页,网页的层次结构如图所示。如果此时网页ABCDEFG都在爬取队列中,那么根据不同的爬取策略,爬取的顺序是不同的。
深度优先爬取策略:A→D→E→B→C→F→G
广度优先爬取策略:A→B→C→D→E→F→G
除了以上两种爬取策略外,还可以使用大站点爬取策略。可以根据相应网页所属的站点进行分类。如果某个网站有大量的网页,则称为大站点。按照这个策略,网站拥有的网页越多,则越大,优先抓取该网页在大站点中的URL地址。
此外,还有反向链接策略。一个网页的反向链接数是指该网页被其他网页指向的次数。这个次数代表了该网页在一定程度上被其他网页推荐的次数。因此,如果按照反向链接策略进行爬取,那么哪个网页的反向链接多,就会先爬到哪个页面。
但是,在实际情况中,如果一个网页的优先级只是简单地由反向链接策略来决定的话,就可能会出现很多作弊的情况。因此,采用反向链接策略需要考虑可靠反向链接的数量。除了以上的爬取策略,实践中还有很多其他的爬取策略,比如OPIC策略、Partial PageRank策略等等。
2.爬取频率
网站 网页经常更新。作为爬虫,网站的更新频率越接近爬虫访问网站的频率,效果越好。当然,在爬虫服务器资源有限的情况下,爬虫还需要根据相应的策略,让不同的网页有不同的更新优先级。优先级高的网页会更新得更快,爬取响应也会更快。常见的网页更新策略有以下三种:
(1)用户体验策略:大部分用户使用搜索引擎查询某个关键词时,只会关注排名靠前的网页。因此,当爬虫服务器的资源处于有限,爬虫会优先更新排名靠前的页面。
(2)历史数据策略:是指根据一个网页的历史更新数据,通过泊松过程建模等手段,预测该网页下次更新时间的能力,从而确定下一次更新时间。抓取网页所花费的时间。
(3)聚类分析策略:网页可能有不同的内容,但一般来说,属性相似的网页更新频率相似,所以可以对大量的网页进行聚类。爬取的频率根据设置同类型网页的平均更新值。
五、网络爬虫的实现技术
对于实现技术,本文不展开,只为有兴趣的同学提供几种常用语言:Python、Java、PHP、Node.JS、C++、Go语言(另外还有很多开发语言用于网络爬虫)。
Python:爬虫框架非常丰富,多线程处理能力强,而且易学,代码简洁,优点很多。
Java:适合开发大型爬虫项目。
PHP:后端处理能力很强,代码很简洁,模块丰富,但是并发能力比较弱。
Node.JS:支持高并发和多线程。
C++:运行速度快,适合开发大型爬虫项目,成本高。
Go语言:同样的高并发能力很强。
六、总结
说到爬虫,很多人认为它们是网络世界中不可能存在的灰色地带。恭喜你,看完这篇文章,你比很多人都知道。
因为爬虫分为良性爬虫和恶意爬虫,比如搜索引擎爬虫。Goodwill爬虫严格遵守Robots协议规范爬取网页数据(如URL),它的存在可以增加网站的曝光度,给网站带来流量;
恶意爬虫,无视Robots协议,肆意爬取网站中一些深度不情愿的数据,包括个人隐私或商业机密等重要信息。而恶意爬虫的用户想要多次大量地从网站获取信息,所以通常会在目标网站上投放大量爬虫。如果大量爬虫同时访问网站,很容易导致网站服务器超载或崩溃,导致网站算子丢失。
据统计,2017年我国42.2%的互联网流量是由网络机器人创造的,其中恶意机器(主要是恶意爬虫)占21.80%。我们应该合法合理地使用网络爬虫,这样才能用科技为企业带来长远发展,用科学为社会创造更高的价值。
关于数据猎人
DataHunter是一家专业的数据分析和商业智能服务商,注册于2014年,团队核心成员来自IBM、Oracle、SAP等知名企业,深耕大数据分析领域,拥有十余年丰富的企业服务经验。
DataHunter的核心产品Data Analytics智能数据分析平台和数据大屏设计配置工具Data MAX在行业中形成了自己的独特优势,在各行业积累了众多标杆客户和成功案例。
自成立以来,DataHunter一直致力于为客户提供实时、高效、智能的数据分析与展示解决方案,帮助企业查看和分析数据并改善业务,成为最值得信赖的数据业务公司。 查看全部
c爬虫抓取网页数据(爬虫在数据分析领域的应用,如何帮助我们提升数据分析质量)
在当今信息化和数字化的时代,人们离不开网络搜索,但想想看,在搜索过程中,你真的可以得到相关信息,因为有人在帮你过滤相关内容,呈现在你面前。

就像在餐馆里一样,你点了土豆然后得到它们,因为有人帮你在土豆、萝卜、西红柿等中找到它们,然后有人把它们带到你的餐桌上。在网上,这两个动作是一个叫爬虫的同学为你实现的。
也就是说,没有爬虫,就没有今天的检索,就无法准确查找信息和高效获取数据。今天DataHunter就来谈谈爬虫在数据分析领域的应用,以及它如何帮助我们提高数据分析的质量。
一、数据时代,爬虫的本质是提高效率
网络爬虫,又称网络机器人,可以代替人自动浏览网络信息,采集和组织数据。
它是一个程序,其基本原理是向网站/网络发起请求,获取资源后分析提取有用数据。从技术上讲,就是通过程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)爬取到本地,然后提取您需要的数据并将其存储以供使用。
每个程序都有自己的规则,网络爬虫也不例外。它穿梭于世界各地的各种网站之间,根据人们强加的规则将采集信息。我们称这些规则为网络爬虫算法。规则是人定的,是人根据自己的目的和需要设计的。因此,根据用户的目的,爬虫可以有不同的功能。但所有爬虫的本质是方便人们在海量的互联网信息中找到并下载自己想要的信息类型,从而提高信息获取效率。
二、爬虫的应用:搜索并帮助企业做强业务
1.搜索引擎:爬取网站为网络用户提供便利
在互联网的早期,能够提供全球范围内信息的网站并不多,用户也不多。Internet 只是文件传输协议 (FTP) 站点的集合,用户可以在其中导航以查找特定的共享文件,并查找和组合 Internet 上可用的分布式数据,创建了一个称为网络爬虫的自动化程序 /Robot,它可以爬取网络上的所有网页,然后将所有页面的内容复制到数据库中进行索引。这也是最早的搜索引擎。

如今,随着互联网的飞速发展,我们可以在任何搜索引擎中看到来自世界各地各种网站的信息。百度搜索引擎的爬虫叫百度蜘蛛,360的爬虫叫360Spider,搜狗的爬虫叫搜狗蜘蛛,必应的爬虫叫Bingbot。搜索引擎离不开爬虫。
比如百度蜘蛛每天都会抓取大量的互联网信息,抓取优质信息和收录。当用户在百度搜索引擎上搜索对应的关键词时,百度会对关键词进行分析处理,从收录的网页中找出相关网页,按照一定的排名规则和结果展示给用户,工作原理如图。现在,我们可以大胆地说,你每天都在免费享受爬虫的好处。
2.企业:监控舆情,高效获取有价值信息
我们说过爬虫的本质是提高效率,而爬虫的规则是由人决定的;那么企业就可以根据自己的业务需求设计爬虫,第一时间获取网络上的相关信息,进行清理整合。
在大数据时代进行数据分析,首先要有数据源,网络爬虫可以让我们获取更多的数据源,同时根据我们的目的进行采集,从而去除很多的无关数据。

例如,在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站s,或者从某些文档或内部资料中获取数据源。但是,这些获取数据的方式有时很难满足我们的数据需求。此时,我们可以利用爬虫技术从互联网上自动获取更多我们感兴趣的数据内容,从而进行更深入的数据分析,获取更多有价值的信息。
此外,网络爬虫还可用于财务分析,对财务数据进行采集进行投资分析;可应用于舆情监测分析、精准客户精准营销等各个领域。
三、企业常用的4种网络爬虫
网络爬虫根据实现的技术和结构可以分为一般网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。但由于网络环境复杂,实际的网络爬虫通常是这几种爬虫的组合。
1.万能网络爬虫
通用网络爬虫也称为全网络爬虫。顾名思义,要爬取的目标资源在整个互联网上,要爬取的目标数据是巨大的,爬取的范围也很大。正是因为爬取的数据是海量数据,所以对于这种爬虫来说,对爬取的性能要求是非常高的。这种网络爬虫主要用于大型搜索引擎,具有很高的应用价值。

一般的网络爬虫主要由初始URL采集、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块等组成。一般网络爬虫在爬取时会采用一定的爬取策略,主要包括深度优先爬取策略和广度优先爬取策略。具体细节将在后面介绍。
2.专注于网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是根据预先定义的主题有选择地爬取网页的爬虫。聚焦网络爬虫主要用于爬取特定信息,主要为特定类型的人提供服务。
聚焦网络爬虫也是由初始URL集合、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块、内容评价模块、链接评价模块等组成。内容评估模块和链接评估模块可以根据链接和内容的重要性确定优先访问哪些页面。专注于网络爬虫的爬取策略主要有四种,如图:
由于专注的网络爬虫可以有目的地根据相应的主题进行爬取,在实际应用过程中可以节省大量的服务器资源和宽带资源,因此具有很强的实用性。这里我们以网络爬虫为例来了解爬虫运行的工作原理和过程。
如图所示,焦点网络爬虫有一个控制中心,负责管理和监控整个爬虫系统,包括控制用户交互、初始化爬虫、确定主题、协调各个模块之间的工作以及控制整个爬虫系统。爬行过程。等等:
(1)控制中心将初始URL集合传递给URL队列,页面爬取模块会从URL队列中读取第一批URL列表;
(2)根据这些URL地址,从网上爬取对应的页面;爬取后,将爬取的内容发送到页面数据库进行存储;
(3)在爬取过程中,会爬取一些新的URL,此时需要使用链接过滤模块,根据指定的主题过滤掉不相关的链接,然后使用链接评价模块进行根据主题剩余的URL链接。或者内容评估模块进行优先排序,完成后将新的URL地址传递给URL队列,供页面爬取模块使用;
(4)抓取页面并存入页面数据库后,需要使用页面分析模块,根据主题对抓取的页面进行分析处理,并根据处理结果建立索引库。当用户检索到相应的信息,就可以从索引数据库中进行相应的检索,得到相应的结果。
3.增量网络爬虫
这里的“incremental”对应于增量更新,意思是在更新过程中只更新变化的地方,不变的地方不更新。
增量网络爬虫,在爬取网页时,只爬取内容发生变化的网页或新生成的网页,不会爬取内容未发生变化的网页。增量网络爬虫可以在一定程度上保证爬取的页面尽可能的新。
4.深网爬虫
在互联网中,网页根据存在的程度可以分为表层页面和深层页面。表面页面是指无需提交表单,使用静态链接即可到达的静态页面;而深页是提交某个关键词后才能获得的页面。在 Internet 中,深层页面的数量通常远大于表面页面的数量。

深网爬虫可以爬取互联网中的深层页面,而要爬取深层页面,就需要想办法自动填写相应的表格。深网爬虫主要由 URL 列表、LVS 列表(LVS 指标签/值集合,即填充表单的数据源)、爬取控制器、解析器、LVS 控制器、表单分析器、表单处理器、响应分析器组成和其他部分。
四、网络爬虫的爬取策略
前面我们说过,网络爬虫算法是基于人对采集信息施加的规则,由于网络环境复杂,算法也多种多样,也就是爬取策略。这里主要介绍爬取的顺序和频率。
1.爬取顺序
网络爬虫在爬取过程中,可能会出现在爬取的URL列表中的多个URL地址,因此爬虫会依次对这些URL地址进行爬取。
与一般的网络爬虫相比,爬取的顺序并不那么重要。但专注于网络爬虫,爬取的顺序与服务器资源和宽带资源有关,所以非常重要,一般由爬取策略决定。爬取策略主要包括深度优先爬取策略、广度优先爬取策略、大站点优先策略、反链策略等爬取策略。
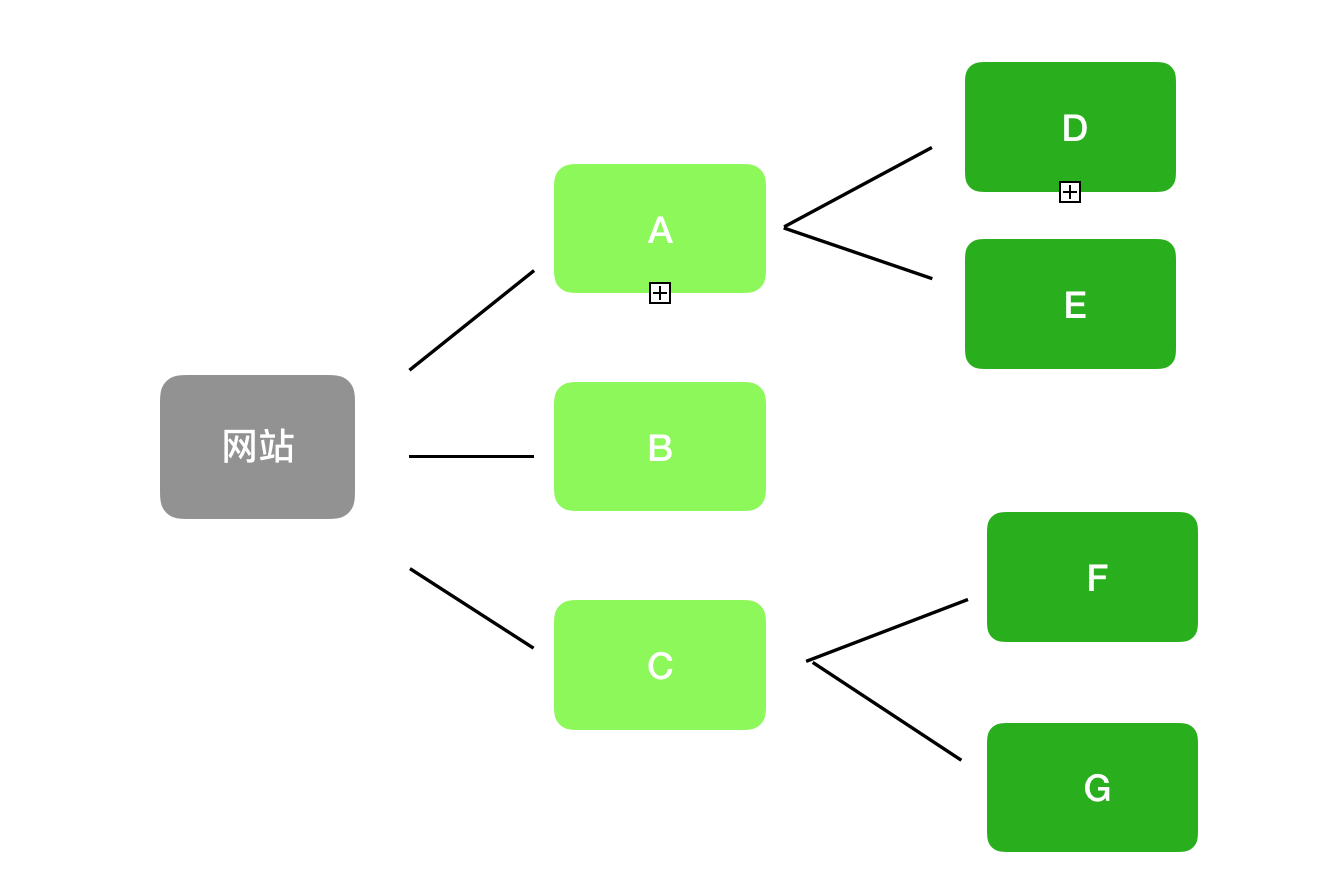
如图,假设有一个网站,ABCDEFG为站点下的网页,网页的层次结构如图所示。如果此时网页ABCDEFG都在爬取队列中,那么根据不同的爬取策略,爬取的顺序是不同的。
深度优先爬取策略:A→D→E→B→C→F→G
广度优先爬取策略:A→B→C→D→E→F→G
除了以上两种爬取策略外,还可以使用大站点爬取策略。可以根据相应网页所属的站点进行分类。如果某个网站有大量的网页,则称为大站点。按照这个策略,网站拥有的网页越多,则越大,优先抓取该网页在大站点中的URL地址。
此外,还有反向链接策略。一个网页的反向链接数是指该网页被其他网页指向的次数。这个次数代表了该网页在一定程度上被其他网页推荐的次数。因此,如果按照反向链接策略进行爬取,那么哪个网页的反向链接多,就会先爬到哪个页面。
但是,在实际情况中,如果一个网页的优先级只是简单地由反向链接策略来决定的话,就可能会出现很多作弊的情况。因此,采用反向链接策略需要考虑可靠反向链接的数量。除了以上的爬取策略,实践中还有很多其他的爬取策略,比如OPIC策略、Partial PageRank策略等等。
2.爬取频率
网站 网页经常更新。作为爬虫,网站的更新频率越接近爬虫访问网站的频率,效果越好。当然,在爬虫服务器资源有限的情况下,爬虫还需要根据相应的策略,让不同的网页有不同的更新优先级。优先级高的网页会更新得更快,爬取响应也会更快。常见的网页更新策略有以下三种:
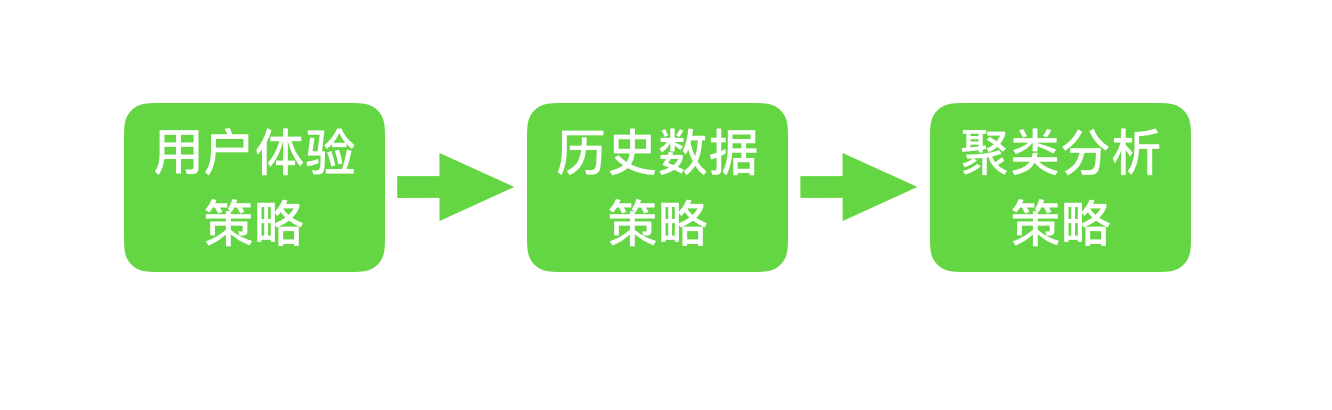
(1)用户体验策略:大部分用户使用搜索引擎查询某个关键词时,只会关注排名靠前的网页。因此,当爬虫服务器的资源处于有限,爬虫会优先更新排名靠前的页面。
(2)历史数据策略:是指根据一个网页的历史更新数据,通过泊松过程建模等手段,预测该网页下次更新时间的能力,从而确定下一次更新时间。抓取网页所花费的时间。
(3)聚类分析策略:网页可能有不同的内容,但一般来说,属性相似的网页更新频率相似,所以可以对大量的网页进行聚类。爬取的频率根据设置同类型网页的平均更新值。
五、网络爬虫的实现技术
对于实现技术,本文不展开,只为有兴趣的同学提供几种常用语言:Python、Java、PHP、Node.JS、C++、Go语言(另外还有很多开发语言用于网络爬虫)。
Python:爬虫框架非常丰富,多线程处理能力强,而且易学,代码简洁,优点很多。
Java:适合开发大型爬虫项目。
PHP:后端处理能力很强,代码很简洁,模块丰富,但是并发能力比较弱。
Node.JS:支持高并发和多线程。
C++:运行速度快,适合开发大型爬虫项目,成本高。
Go语言:同样的高并发能力很强。
六、总结
说到爬虫,很多人认为它们是网络世界中不可能存在的灰色地带。恭喜你,看完这篇文章,你比很多人都知道。
因为爬虫分为良性爬虫和恶意爬虫,比如搜索引擎爬虫。Goodwill爬虫严格遵守Robots协议规范爬取网页数据(如URL),它的存在可以增加网站的曝光度,给网站带来流量;

恶意爬虫,无视Robots协议,肆意爬取网站中一些深度不情愿的数据,包括个人隐私或商业机密等重要信息。而恶意爬虫的用户想要多次大量地从网站获取信息,所以通常会在目标网站上投放大量爬虫。如果大量爬虫同时访问网站,很容易导致网站服务器超载或崩溃,导致网站算子丢失。
据统计,2017年我国42.2%的互联网流量是由网络机器人创造的,其中恶意机器(主要是恶意爬虫)占21.80%。我们应该合法合理地使用网络爬虫,这样才能用科技为企业带来长远发展,用科学为社会创造更高的价值。
关于数据猎人
DataHunter是一家专业的数据分析和商业智能服务商,注册于2014年,团队核心成员来自IBM、Oracle、SAP等知名企业,深耕大数据分析领域,拥有十余年丰富的企业服务经验。
DataHunter的核心产品Data Analytics智能数据分析平台和数据大屏设计配置工具Data MAX在行业中形成了自己的独特优势,在各行业积累了众多标杆客户和成功案例。

自成立以来,DataHunter一直致力于为客户提供实时、高效、智能的数据分析与展示解决方案,帮助企业查看和分析数据并改善业务,成为最值得信赖的数据业务公司。
c爬虫抓取网页数据(利用cookie技术抓取网页静态数据这是什么?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-13 19:01
c爬虫抓取网页数据有很多种不同的方式,我用到的就有采集网页静态数据(爬虫)采集网页图片(webdatasnippet)采集网页视频数据采集网页音频数据采集网页视频采集网页图片采集网页文本采集返回的json数据采集cookie数据这种用javascrapy等方式都可以实现这个用的比较少,我们可以先思考用requests,selenium等各种库的用法和原理,一步步的调试实现。
但是采集网页静态数据用了再多的shell,模拟用户采集数据基本都失败了,gg有时候回头看看采集网页静态数据,小白用户可能会想,刚来知乎,肯定是要采集长得漂亮的妹子呀,那还要我来干嘛,偷懒呗。我这就是要教大家偷懒。这里我用到的javascrapy爬虫库。如何利用浏览器ua来识别浏览器,在采集完一个网页之后可以轻松的推断这个网页是否是正常浏览的,还可以实现转码的效果,省的再下一次下载数据了。
就好比我浏览某网站,一上来就浏览本站所有的大v的资料,不太好吧。利用cookie技术抓取网页静态数据这是什么?cookie技术就是用cookie在相应网站上存储一个数据,从而可以收集那些已经登录了的网站上数据,然后通过数据抓取框抓取所需数据,加密后再发回来,进一步传播给服务器。就好比有些网站,某些已经登录过的访客信息是有对应的。
再说到这个cookie技术,其实就是个社工库,看到这个名字,我能猜到你有一定的网络安全常识,我就不多说了,平时可以留意自己浏览网站的登录信息再补充一下,在很多网站上,输入一个用户名或者密码后,就可以获取他所有的所有浏览痕迹,过去有统计过,百度,豆瓣,美团等在百度被骚扰的用户是40w大家可以脑补一下。所以一个人的账号如果泄露出去,就会无孔不入。
我做为一个小白,也是很无奈的了,各位高手,各位大神就不要喷我了。哈哈哈(这种是最常见的一种套路,说到这里你可能会大吃一惊,那么如何隐藏自己的cookie?这个其实很简单,不管是任何的采集,只要是去掉数据,都可以按照通常的方式,只留一个,把输入的密码解出来,然后把解密的结果再返回来一个简单的后缀,去掉所有的https的字眼)手机渣排版还有很多需要补充的,慢慢跟上,预计写十篇,手机上传图不易,多多点赞啊。 查看全部
c爬虫抓取网页数据(利用cookie技术抓取网页静态数据这是什么?(组图))
c爬虫抓取网页数据有很多种不同的方式,我用到的就有采集网页静态数据(爬虫)采集网页图片(webdatasnippet)采集网页视频数据采集网页音频数据采集网页视频采集网页图片采集网页文本采集返回的json数据采集cookie数据这种用javascrapy等方式都可以实现这个用的比较少,我们可以先思考用requests,selenium等各种库的用法和原理,一步步的调试实现。
但是采集网页静态数据用了再多的shell,模拟用户采集数据基本都失败了,gg有时候回头看看采集网页静态数据,小白用户可能会想,刚来知乎,肯定是要采集长得漂亮的妹子呀,那还要我来干嘛,偷懒呗。我这就是要教大家偷懒。这里我用到的javascrapy爬虫库。如何利用浏览器ua来识别浏览器,在采集完一个网页之后可以轻松的推断这个网页是否是正常浏览的,还可以实现转码的效果,省的再下一次下载数据了。
就好比我浏览某网站,一上来就浏览本站所有的大v的资料,不太好吧。利用cookie技术抓取网页静态数据这是什么?cookie技术就是用cookie在相应网站上存储一个数据,从而可以收集那些已经登录了的网站上数据,然后通过数据抓取框抓取所需数据,加密后再发回来,进一步传播给服务器。就好比有些网站,某些已经登录过的访客信息是有对应的。
再说到这个cookie技术,其实就是个社工库,看到这个名字,我能猜到你有一定的网络安全常识,我就不多说了,平时可以留意自己浏览网站的登录信息再补充一下,在很多网站上,输入一个用户名或者密码后,就可以获取他所有的所有浏览痕迹,过去有统计过,百度,豆瓣,美团等在百度被骚扰的用户是40w大家可以脑补一下。所以一个人的账号如果泄露出去,就会无孔不入。
我做为一个小白,也是很无奈的了,各位高手,各位大神就不要喷我了。哈哈哈(这种是最常见的一种套路,说到这里你可能会大吃一惊,那么如何隐藏自己的cookie?这个其实很简单,不管是任何的采集,只要是去掉数据,都可以按照通常的方式,只留一个,把输入的密码解出来,然后把解密的结果再返回来一个简单的后缀,去掉所有的https的字眼)手机渣排版还有很多需要补充的,慢慢跟上,预计写十篇,手机上传图不易,多多点赞啊。
c爬虫抓取网页数据(HTTP请求头说明Allow服务器支持哪些请求方法(如GET、POST等))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-12 02:02
HTTP 请求标头提供有关请求、响应或其他发送实体的信息。 (直接搬菜鸟教程)
响应头描述
允许
服务器支持哪些请求方式(如GET、POST等)。
内容编码
文档的编码方法。 Content-Type 头指定的内容类型只有在解码后才能得到。使用 gzip 压缩文档可以显着减少 HTML 文档的下载时间。 Java 的 GZIPOutputStream 可以很方便地进行 gzip 压缩,但它只支持 Unix 上的 Netscape 和 Windows 上的 IE 4、IE 5。因此,servlet 应该通过查看 Accept-Encoding 标头(即 request.getHeader("Accept-Encoding"))来检查浏览器是否支持 gzip,对于支持 gzip 的浏览器返回 gzip 压缩的 HTML 页面,并返回正常其他浏览器页面的页面。
内容长度
表示内容长度。仅当浏览器使用持久 HTTP 连接时才需要此数据。如果要利用持久连接,可以将输出文档写入 ByteArrayOutputStream,完成后检查其大小,将该值放入 Content-Length 标头,最后通过 byteArrayStream.writeTo(response .getOutputStream()。
内容类型
指示以下文档属于哪种 MIME 类型。 Servlet 默认为 text/plain,但通常需要明确指定为 text/html。由于经常设置 Content-Type,HttpServletResponse 提供了专门的方法 setContentType。
日期
当前格林威治标准时间。可以用setDateHeader设置这个header,避免转换时间格式的麻烦。
过期
何时应将文档视为过期以不再缓存?
最后修改
上次修改文档的时间。客户端可以通过If-Modified-Since请求头提供日期,该请求将被视为条件GET,只返回修改时间晚于指定时间的文档,否则返回304(未修改)状态将被退回。 Last-Modified 也可以使用 setDateHeader 方法设置。
位置
指示客户端应该去哪里检索文档。 Location 通常不是直接设置的,而是通过 HttpServletResponse 的 sendRedirect 方法设置的,该方法也将状态码设置为 302。
刷新
表示浏览器刷新文档的时间(以秒为单位)。除了刷新当前文档,还可以使用 setHeader("Refresh", "5; URL=") 让浏览器读取指定页面。
注意这个功能通常是通过在HTML页面的HEAD区域设置来实现的,这是因为自动刷新或者重定向不是对于不会使用 CGI 或 servlet 的 HTML 编写器的人来说可能是非常重要的。不过对于servlet来说,直接设置Refresh header会更方便。
注意Refresh的意思是“刷新本页或N秒后访问指定页面”,而不是“每隔N秒刷新本页或访问指定页面”。因此,持续刷新需要每次发送一个Refresh头,发送204状态码可以阻止浏览器继续刷新,无论是使用Refresh头还是。
注意刷新头不是HTTP官方规范的一部分1.1,而是一个扩展,但是Netscape和IE都支持。
服务器
服务器名称。 Servlet一般不设置这个值,而是由Web服务器自己设置的。
设置-Cookie
设置与页面关联的cookie。 Servlet 不应使用 response.setHeader("Set-Cookie", ...),而应使用 HttpServletResponse 提供的专用方法 addCookie。请参阅下面关于 cookie 设置的讨论。
WWW-认证
客户端应该在 Authorization 标头中提供什么类型的授权信息?在收录 401(未授权)状态行的响应中需要此标头。例如 response.setHeader("WWW-Authenticate", "BASIC realm=\"executives\"")。
请注意,servlet 通常不处理此问题,而是允许 Web 服务器的专用机制来控制对受密码保护的页面(例如 .htaccess)的访问。
1.5 个 Cookie
指存储在用户本地终端上的一些数据(通常是加密的),用于识别用户身份和跟踪会话。
cookie 是存储在计算机浏览器目录中的文本文件。当浏览器运行时,它存储在 RAM 中以发挥作用(这种 cookie 称为会话 cookie)。一旦用户访问 网站 或服务器被注销,cookie 就可以存储在用户的本地硬盘上(这种 cookie 称为 Persistent Cookies)
1.6 认证
一般来说,爬虫在抓取和访问网页时,会通过HTTP请求中的User Agent字段告知自己的身份信息。
1.7 阿贾克斯
Ajax 代表“AsynchronousJavascriptAndXML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。 Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
因为Ajax技术,我们在爬取的时候,有时候会发现get()的结果并没有我们想要的内容,因为在加载页面的时候只有少量的数据交换,而我们得到了什么用爬虫只是第一次。 HTML,然后你需要在开发者工具中找到你想要的数据。等有例子再详细分析。
1.8 代理
在使用爬虫的过程中,难免会遇到带有反爬虫的网站。这时候,我们需要一个代理ip。
使用代理IP,我们可以先从代理获取代理网站,然后验证IP是否可用。 查看全部
c爬虫抓取网页数据(HTTP请求头说明Allow服务器支持哪些请求方法(如GET、POST等))
HTTP 请求标头提供有关请求、响应或其他发送实体的信息。 (直接搬菜鸟教程)
响应头描述
允许
服务器支持哪些请求方式(如GET、POST等)。
内容编码
文档的编码方法。 Content-Type 头指定的内容类型只有在解码后才能得到。使用 gzip 压缩文档可以显着减少 HTML 文档的下载时间。 Java 的 GZIPOutputStream 可以很方便地进行 gzip 压缩,但它只支持 Unix 上的 Netscape 和 Windows 上的 IE 4、IE 5。因此,servlet 应该通过查看 Accept-Encoding 标头(即 request.getHeader("Accept-Encoding"))来检查浏览器是否支持 gzip,对于支持 gzip 的浏览器返回 gzip 压缩的 HTML 页面,并返回正常其他浏览器页面的页面。
内容长度
表示内容长度。仅当浏览器使用持久 HTTP 连接时才需要此数据。如果要利用持久连接,可以将输出文档写入 ByteArrayOutputStream,完成后检查其大小,将该值放入 Content-Length 标头,最后通过 byteArrayStream.writeTo(response .getOutputStream()。
内容类型
指示以下文档属于哪种 MIME 类型。 Servlet 默认为 text/plain,但通常需要明确指定为 text/html。由于经常设置 Content-Type,HttpServletResponse 提供了专门的方法 setContentType。
日期
当前格林威治标准时间。可以用setDateHeader设置这个header,避免转换时间格式的麻烦。
过期
何时应将文档视为过期以不再缓存?
最后修改
上次修改文档的时间。客户端可以通过If-Modified-Since请求头提供日期,该请求将被视为条件GET,只返回修改时间晚于指定时间的文档,否则返回304(未修改)状态将被退回。 Last-Modified 也可以使用 setDateHeader 方法设置。
位置
指示客户端应该去哪里检索文档。 Location 通常不是直接设置的,而是通过 HttpServletResponse 的 sendRedirect 方法设置的,该方法也将状态码设置为 302。
刷新
表示浏览器刷新文档的时间(以秒为单位)。除了刷新当前文档,还可以使用 setHeader("Refresh", "5; URL=") 让浏览器读取指定页面。
注意这个功能通常是通过在HTML页面的HEAD区域设置来实现的,这是因为自动刷新或者重定向不是对于不会使用 CGI 或 servlet 的 HTML 编写器的人来说可能是非常重要的。不过对于servlet来说,直接设置Refresh header会更方便。
注意Refresh的意思是“刷新本页或N秒后访问指定页面”,而不是“每隔N秒刷新本页或访问指定页面”。因此,持续刷新需要每次发送一个Refresh头,发送204状态码可以阻止浏览器继续刷新,无论是使用Refresh头还是。
注意刷新头不是HTTP官方规范的一部分1.1,而是一个扩展,但是Netscape和IE都支持。
服务器
服务器名称。 Servlet一般不设置这个值,而是由Web服务器自己设置的。
设置-Cookie
设置与页面关联的cookie。 Servlet 不应使用 response.setHeader("Set-Cookie", ...),而应使用 HttpServletResponse 提供的专用方法 addCookie。请参阅下面关于 cookie 设置的讨论。
WWW-认证
客户端应该在 Authorization 标头中提供什么类型的授权信息?在收录 401(未授权)状态行的响应中需要此标头。例如 response.setHeader("WWW-Authenticate", "BASIC realm=\"executives\"")。
请注意,servlet 通常不处理此问题,而是允许 Web 服务器的专用机制来控制对受密码保护的页面(例如 .htaccess)的访问。
1.5 个 Cookie
指存储在用户本地终端上的一些数据(通常是加密的),用于识别用户身份和跟踪会话。
cookie 是存储在计算机浏览器目录中的文本文件。当浏览器运行时,它存储在 RAM 中以发挥作用(这种 cookie 称为会话 cookie)。一旦用户访问 网站 或服务器被注销,cookie 就可以存储在用户的本地硬盘上(这种 cookie 称为 Persistent Cookies)
1.6 认证
一般来说,爬虫在抓取和访问网页时,会通过HTTP请求中的User Agent字段告知自己的身份信息。
1.7 阿贾克斯
Ajax 代表“AsynchronousJavascriptAndXML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。 Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
因为Ajax技术,我们在爬取的时候,有时候会发现get()的结果并没有我们想要的内容,因为在加载页面的时候只有少量的数据交换,而我们得到了什么用爬虫只是第一次。 HTML,然后你需要在开发者工具中找到你想要的数据。等有例子再详细分析。
1.8 代理
在使用爬虫的过程中,难免会遇到带有反爬虫的网站。这时候,我们需要一个代理ip。
使用代理IP,我们可以先从代理获取代理网站,然后验证IP是否可用。
c爬虫抓取网页数据(南阳理工学院ACM题目信息获取源码我们知道浏览器查看网页时 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-12 02:00
)
南洋理工ACM专题信息
获取源代码
我们知道,浏览器在浏览网页时,首先会向服务器发送一个request请求,服务器会根据request请求做一些处理,生成一个response响应返回给浏览器,这个response收录我们需要的网页(或者数据,一般是静态的网站或者服务器端渲染就是直接返回网页),那么我们只需要模仿浏览器发送这个请求给服务器下载网页,而然后等待服务器发回响应。
1.引入第三方库
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
2.模拟浏览器
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
3. 爬网
r = requests.get(
f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
BeautifulSoup 网络分析
学习了request,了解了伪装技巧,终于可以爬到一些正常的web源码(html文档)了,但这离最后也是最重要的一步——筛选还差得很远。这个过程就像在沙子里淘金一样。没有合适的筛子,你就会错过有价值的东西,或者做无用的工作来筛掉无用的东西。
淘金者观察土壤并制作筛子。对应爬虫字段就是观察html,自定义过滤器。这里其实是一个简单的抓取 td 标签
1.初始化
soup = BeautifulSoup(r.text, 'html.parser')
2.抓取节点
td = soup.find_all('td')
subject = []
for t in td:
if t.string is not None:
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
保存文件
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
完整的源代码
URL链接中.htm前面的数字是相关的,所以可以通过循环爬取多页代码,找到爬取数据的位置,编写代码
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
subjects = []
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(
f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'html.parser')
td = soup.find_all('td')
subject = []
for t in td:
if t.string is not None:
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
运行结果:
查看全部
c爬虫抓取网页数据(南阳理工学院ACM题目信息获取源码我们知道浏览器查看网页时
)
南洋理工ACM专题信息

获取源代码
我们知道,浏览器在浏览网页时,首先会向服务器发送一个request请求,服务器会根据request请求做一些处理,生成一个response响应返回给浏览器,这个response收录我们需要的网页(或者数据,一般是静态的网站或者服务器端渲染就是直接返回网页),那么我们只需要模仿浏览器发送这个请求给服务器下载网页,而然后等待服务器发回响应。
1.引入第三方库
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
2.模拟浏览器
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
3. 爬网
r = requests.get(
f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
BeautifulSoup 网络分析
学习了request,了解了伪装技巧,终于可以爬到一些正常的web源码(html文档)了,但这离最后也是最重要的一步——筛选还差得很远。这个过程就像在沙子里淘金一样。没有合适的筛子,你就会错过有价值的东西,或者做无用的工作来筛掉无用的东西。
淘金者观察土壤并制作筛子。对应爬虫字段就是观察html,自定义过滤器。这里其实是一个简单的抓取 td 标签

1.初始化
soup = BeautifulSoup(r.text, 'html.parser')
2.抓取节点
td = soup.find_all('td')
subject = []
for t in td:
if t.string is not None:
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
保存文件
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
完整的源代码
URL链接中.htm前面的数字是相关的,所以可以通过循环爬取多页代码,找到爬取数据的位置,编写代码
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
subjects = []
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(
f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'html.parser')
td = soup.find_all('td')
subject = []
for t in td:
if t.string is not None:
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
运行结果:

c爬虫抓取网页数据(为什么说用Python开发爬虫更有优势?Java开发不行吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-03-10 00:14
为什么用Python开发爬虫更有优势?不能用Java开发?今天小编就为大家讲解一下!
C/C++
各种搜索引擎大多使用C/C++开发爬虫,可能是因为搜索引擎爬虫重要的是采集网站信息,对页面的解析要求不高。
Python
Python语言具有强大的网络功能,可以模拟登录和解析JavaScript。缺点是网页解析。Python 编写程序非常方便,特别是对于专注的爬虫。目标 网站 经常更改。使用Python根据目标的变化开发爬虫程序非常方便。
爪哇
Java有很多解析器,对网页的解析支持非常好。缺点是网络部分支持较差。
对于一般需求,Java 或 Python 都可以完成这项工作。如果需要模拟登录,选择Python对抗反爬虫比较方便。如果需要处理复杂的网页,解析网页内容生成结构化数据,或者需要精细解析网页内容,可以选择Java。
选择 Python 作为实现爬虫的语言的主要考虑因素是:
(1) 爬取网页本身的界面
与其他动态脚本语言(如Perl、Shell)相比,Python的urllib2包提供了更完善的访问web文档的API;与其他静态编程语言(如Java、C#、C++)相比,Python爬取网页文档。界面更简洁。
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这时候我们就需要模拟User Agent的行为来构造合适的请求,比如模拟用户登录,模拟Session/Cookie的存储和设置。Python 中有一些优秀的第三方包可以为你做这件事,例如 Requests 或 Mechanize。
(2) 爬取后处理
抓取的网页通常需要进行处理,例如过滤Html标签、提取文本等。Python的Beautiful Soup提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是Python可以做到最快最干净,就像那句“人生苦短,你需要Python”一样。
(3) 开发效率高
因为爬虫的具体代码要根据网站进行修改,而Python灵活的脚本语言特别适合这个任务。
(4) 快速入门
网上有很多Python教学资源,方便大家学习,有问题也很容易找到相关资料。此外,Python 对成熟的爬虫框架也有很强的支持,比如 Scrapy。返回搜狐,查看更多 查看全部
c爬虫抓取网页数据(为什么说用Python开发爬虫更有优势?Java开发不行吗?)
为什么用Python开发爬虫更有优势?不能用Java开发?今天小编就为大家讲解一下!

C/C++
各种搜索引擎大多使用C/C++开发爬虫,可能是因为搜索引擎爬虫重要的是采集网站信息,对页面的解析要求不高。
Python
Python语言具有强大的网络功能,可以模拟登录和解析JavaScript。缺点是网页解析。Python 编写程序非常方便,特别是对于专注的爬虫。目标 网站 经常更改。使用Python根据目标的变化开发爬虫程序非常方便。
爪哇
Java有很多解析器,对网页的解析支持非常好。缺点是网络部分支持较差。
对于一般需求,Java 或 Python 都可以完成这项工作。如果需要模拟登录,选择Python对抗反爬虫比较方便。如果需要处理复杂的网页,解析网页内容生成结构化数据,或者需要精细解析网页内容,可以选择Java。

选择 Python 作为实现爬虫的语言的主要考虑因素是:
(1) 爬取网页本身的界面
与其他动态脚本语言(如Perl、Shell)相比,Python的urllib2包提供了更完善的访问web文档的API;与其他静态编程语言(如Java、C#、C++)相比,Python爬取网页文档。界面更简洁。
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这时候我们就需要模拟User Agent的行为来构造合适的请求,比如模拟用户登录,模拟Session/Cookie的存储和设置。Python 中有一些优秀的第三方包可以为你做这件事,例如 Requests 或 Mechanize。
(2) 爬取后处理
抓取的网页通常需要进行处理,例如过滤Html标签、提取文本等。Python的Beautiful Soup提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是Python可以做到最快最干净,就像那句“人生苦短,你需要Python”一样。
(3) 开发效率高
因为爬虫的具体代码要根据网站进行修改,而Python灵活的脚本语言特别适合这个任务。
(4) 快速入门
网上有很多Python教学资源,方便大家学习,有问题也很容易找到相关资料。此外,Python 对成熟的爬虫框架也有很强的支持,比如 Scrapy。返回搜狐,查看更多
c爬虫抓取网页数据(查看更多写博客Python网络爬虫反爬源码分享--苏飞版)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-10 00:11
阿里云>云栖社区>主题图>C>c爬虫源码
推荐活动:
更多优惠>
当前话题:c网络爬虫源码加入采集
相关话题:
C网络爬虫源码相关博客看更多博文
Python网络爬虫反爬破解攻略实战
作者:薇薇8128 浏览评论:04年前
作者:薇薇,请注明出处。我们经常会写一些网络爬虫,想必大家都会有一种感觉,虽然写爬虫不难,但是反爬很难处理,因为大部分网站都有自己的反爬机制,所以我们将更加难以抓取这些数据。但是,对于每一种反爬机制,我们其实都会有相应的解决方案。作为一个爬虫,我们,
阅读全文
C#HttpHelper爬虫源码分享--苏飞版
作者:苏飞2071 浏览评论:03年前
简介C#HttpHelper实现了C#HttpWebRequest爬取时忽略编码、忽略证书、忽略cookie的功能,实现代理的功能。有了它,您可以发出 Get 和 Post 请求,并且可以轻松设置 cookie、证书、代理和编码。你不用担心这个问题,因为类会自动为你识别页面
阅读全文
Python网络爬虫抓取极品姐姐的视频并保存到文件
作者:keitwotest1060 浏览评论:04年前
项目描述 使用Python编写一个网络爬虫爬取Best Sister的视频并保存到文件中使用工具示例 Python2.7.X, pycharm 使用方法 创建视频爬取Best Sister in pycharm .py 文件,并在当前目录下创建video文件夹,用于存放采集到的视频文件,编写代码,运行
阅读全文
Java版网络爬虫基础(转)
作者:developerguy851 浏览评论:06年前
网络爬虫不仅可以爬取网站网页和图片,甚至可以实现抢票、网上购买、机票查询。这几天看了一些基础知识,记录下来。网页之间的关系可以看成一个大图,图的遍历可以分为深度优先和广度优先。网络爬虫采取的广度优先方式总结如下:2个数组,一个
阅读全文
C# 网络爬虫
作者:Street Corner Box 712 查看评论:05 年前
公司的编辑妹需要爬取网页的内容,让我帮我做一个简单的爬取工具。这是抓取网页的内容。看来这对大家来说并不难,不过这里有一些小改动,代码提供,请参考 1 private string GetHttpWebRequest(string url) 2 { 3 Ht
阅读全文
C#网络爬虫--多线程增强版
作者:街角盒饭 688 次浏览评论:05 年前
上次给公司的一个女生做爬虫,不是很精致。这次是在公司项目中使用的,所以做了一些改动。该函数添加了一个URL图片采集,下载,线程处理接口URL图片下载等。说说思路:总理在初始网站采集图片去获取初始网站的所有内容到初始网站 采集 链接并将 采集 的链接放入队列以继续 采集 图片
阅读全文
一篇文章文章教你使用Python网络爬虫爬取评论区百度贴吧图片和视频
作者:python进阶26人查看评论:01年前
[一、项目背景]百度贴吧是全球最大的中文交流平台。你是不是和我一样,有时候看到评论区的图片就想下载?或者观看视频并想下载?今天小编带大家通过搜索关键词,在评论区获取图片和视频。[二、项目目标]实现贴吧获取的图片或视频可以保存在
阅读全文
一篇文章文章教你用Python网络爬虫搞定差旅攻略
作者:python进阶13人查看评论:01年前
[一、项目背景] 趣游网提供原创实用的出境旅游指南、攻略、旅游社区和问答平台,以及智能旅游规划解决方案,以及签证、保险、机票、酒店在线预订、租车等增值服务。侨游“鼓励和帮助中国游客以自己的视角和方式体验世界”。今天就教大家如何获取侨友网的城市信息。
阅读全文 查看全部
c爬虫抓取网页数据(查看更多写博客Python网络爬虫反爬源码分享--苏飞版)
阿里云>云栖社区>主题图>C>c爬虫源码

推荐活动:
更多优惠>
当前话题:c网络爬虫源码加入采集
相关话题:
C网络爬虫源码相关博客看更多博文
Python网络爬虫反爬破解攻略实战


作者:薇薇8128 浏览评论:04年前
作者:薇薇,请注明出处。我们经常会写一些网络爬虫,想必大家都会有一种感觉,虽然写爬虫不难,但是反爬很难处理,因为大部分网站都有自己的反爬机制,所以我们将更加难以抓取这些数据。但是,对于每一种反爬机制,我们其实都会有相应的解决方案。作为一个爬虫,我们,
阅读全文
C#HttpHelper爬虫源码分享--苏飞版


作者:苏飞2071 浏览评论:03年前
简介C#HttpHelper实现了C#HttpWebRequest爬取时忽略编码、忽略证书、忽略cookie的功能,实现代理的功能。有了它,您可以发出 Get 和 Post 请求,并且可以轻松设置 cookie、证书、代理和编码。你不用担心这个问题,因为类会自动为你识别页面
阅读全文
Python网络爬虫抓取极品姐姐的视频并保存到文件


作者:keitwotest1060 浏览评论:04年前
项目描述 使用Python编写一个网络爬虫爬取Best Sister的视频并保存到文件中使用工具示例 Python2.7.X, pycharm 使用方法 创建视频爬取Best Sister in pycharm .py 文件,并在当前目录下创建video文件夹,用于存放采集到的视频文件,编写代码,运行
阅读全文
Java版网络爬虫基础(转)


作者:developerguy851 浏览评论:06年前
网络爬虫不仅可以爬取网站网页和图片,甚至可以实现抢票、网上购买、机票查询。这几天看了一些基础知识,记录下来。网页之间的关系可以看成一个大图,图的遍历可以分为深度优先和广度优先。网络爬虫采取的广度优先方式总结如下:2个数组,一个
阅读全文
C# 网络爬虫


作者:Street Corner Box 712 查看评论:05 年前
公司的编辑妹需要爬取网页的内容,让我帮我做一个简单的爬取工具。这是抓取网页的内容。看来这对大家来说并不难,不过这里有一些小改动,代码提供,请参考 1 private string GetHttpWebRequest(string url) 2 { 3 Ht
阅读全文
C#网络爬虫--多线程增强版

作者:街角盒饭 688 次浏览评论:05 年前
上次给公司的一个女生做爬虫,不是很精致。这次是在公司项目中使用的,所以做了一些改动。该函数添加了一个URL图片采集,下载,线程处理接口URL图片下载等。说说思路:总理在初始网站采集图片去获取初始网站的所有内容到初始网站 采集 链接并将 采集 的链接放入队列以继续 采集 图片
阅读全文
一篇文章文章教你使用Python网络爬虫爬取评论区百度贴吧图片和视频


作者:python进阶26人查看评论:01年前
[一、项目背景]百度贴吧是全球最大的中文交流平台。你是不是和我一样,有时候看到评论区的图片就想下载?或者观看视频并想下载?今天小编带大家通过搜索关键词,在评论区获取图片和视频。[二、项目目标]实现贴吧获取的图片或视频可以保存在
阅读全文
一篇文章文章教你用Python网络爬虫搞定差旅攻略
作者:python进阶13人查看评论:01年前
[一、项目背景] 趣游网提供原创实用的出境旅游指南、攻略、旅游社区和问答平台,以及智能旅游规划解决方案,以及签证、保险、机票、酒店在线预订、租车等增值服务。侨游“鼓励和帮助中国游客以自己的视角和方式体验世界”。今天就教大家如何获取侨友网的城市信息。
阅读全文
c爬虫抓取网页数据( 风中蹦迪03-0803:07阅读4网站SEO优化关注实战)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-09 20:14
风中蹦迪03-0803:07阅读4网站SEO优化关注实战)
随风起舞
03-08 03:07 阅读4 网站SEO优化
专注于
【网络爬虫学习】实战,爬取网页和贴吧数据
战斗一
抓取您想要的网页并将其保存到本地计算机。
首先我们简单分析下要编写的爬虫程序,可以分为以下三个部分:
理清逻辑后,我们就可以正式编写爬虫程序了。
导入所需模块
from urllib import request, parse
连接 URL 地址
定义 URL 变量并连接 url 地址。代码如下所示:
url = ‘http://www.baidu.com/s?wd={}‘
word = input(‘请输入想要搜索的内容:‘)
params = parse.quote(word)
full_url = url.format(params)
向 URL 发送请求
发送请求主要分为以下几个步骤:
代码如下所示:
# 重构请求头
headers = {
‘User-Agent‘:
‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0‘
}
# 创建请求对应
req = request.Request(url=full_url, headers=headers)
# 获取响应对象
res = request.urlopen(req)
# 获取响应内容
html = res.read().decode(‘utf-8‘)
另存为本地文件
将爬取的照片保存到本地,这里需要使用Python编程文件IO操作,代码如下:
filename = word + ‘.html‘
with open(filename, ‘w‘, encoding=‘utf-8‘) as f:
f.write(html)
完整的程序如下所示:
from urllib import request, parse
# 1.拼url地址
url = ‘http://www.baidu.com/s?wd={}‘
word = input(‘请输入想要搜索的内容:‘)
params = parse.quote(word)
full_url = url.format(params)
# 2.发请求保存到本地
# 重构请求头
headers = {
‘User-Agent‘:
‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0‘
}
# 创建请求对应
req = request.Request(url=full_url, headers=headers)
# 获取响应对象
res = request.urlopen(req)
# 获取响应内容
html = res.read().decode(‘utf-8‘)
# 3.保存文件至当前目录
filename = word + ‘.html‘
with open(filename, ‘w‘, encoding=‘utf-8‘) as f:
f.write(html)
尝试运行程序,进入RioTianの博客园,确认搜索,在当前工作目录下会找到“RioTianの博客园.html”文件。
函数式编程修饰符
Python函数式编程可以让程序的思路更清晰,更容易理解。接下来,利用函数式编程的思想,对上面的代码进行修改。
定义相应的函数,调用该函数执行爬虫程序。修改后的代码如下所示:
from urllib import request, parse
# 拼接URL地址
def get_url(word):
url = ‘http://www.baidu.com/s?{}‘
# 此处使用urlencode()进行编码
params = parse.urlencode({‘wd‘: word})
url = url.format(params)
return url
# 发请求,保存本地文件
def request_url(url, filename):
headers = {
‘User-Agent‘:
‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0‘
}
# 请求对象 + 响应对象 + 提取内容
req = request.Request(url=url, headers=headers)
res = request.urlopen(req)
html = res.read().decode(‘utf-8‘)
# 保存文件至本地
with open(filename, ‘w‘, encoding=‘utf-8‘) as f:
f.write(html)
# 主程序入口
if __name__ == ‘__main__‘:
word = input(‘请输入搜索内容:‘)
url = get_url(word)
filename = word + ‘.html‘
request_url(url, filename)
除了使用函数式编程,还可以使用面向对象的编程方式(实战二),后续内容会介绍。
第二幕
爬百度贴吧(Python爬虫,编程,只抓取贴吧的前5页。
确定页面类型
通过简单的分析,我们可以知道要爬取的页面是静态网页,分析方法很简单:打开百度贴吧,搜索“Python爬虫”,复制其中任意一条信息出现的页面,如“爬虫需要http代理”,然后右键选择查看源代码,在源代码页面使用Ctrl+F快捷键搜索刚刚复制的数据,如下图:
从上图可以看出,页面中的所有信息都收录在源页面中,不需要单独从数据库中加载数据,所以页面是静态页面。
找出 URL 变化的规律性
接下来,查找要抓取的页面的 URL 模式。搜索“Python爬虫”后,贴吧的首页网址如下:
https://tieba.baidu.com/f?ie=utf-8&kw=python爬虫&fr=search
点击第二页,其url信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=50
点击第三页,url信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=100
再次点击第一页,url信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=0
如果还是不能确定,可以继续多浏览几页。最后发现url有两个查询参数kw和pn,pn参数有规律是这样的:
第n页:pn=(n-1)*50
#参数params
pn=(page-1)*50
params={
‘kw‘:name,
‘pn‘:str(pn)
}
url地址可以简写为:
https://tieba.baidu.com/f?kw=python爬虫&pn=450
编写爬虫
爬虫程序以类的形式编写,在类下编写不同的功能函数。代码如下:
from urllib import request,parse
import time
import random
from ua_info import ua_list #使用自定义的ua池
#定义一个爬虫类
class TiebaSpider(object):
#初始化url属性
def __init__(self):
self.url=‘http://tieba.baidu.com/f?{}‘
# 1.请求函数,得到页面,传统三步
def get_html(self,url):
req=request.Request(url=url,headers={‘User-Agent‘:random.choice(ua_list)})
res=request.urlopen(req)
#windows会存在乱码问题,需要使用 gbk解码,并使用ignore忽略不能处理的字节
#linux不会存在上述问题,可以直接使用decode(‘utf-8‘)解码
html=res.read().decode("gbk","ignore")
return html
# 2.解析函数,此处代码暂时省略,还没介绍解析模块
def parse_html(self):
pass
# 3.保存文件函数
def save_html(self,filename,html):
with open(filename,‘w‘) as f:
f.write(html)
# 4.入口函数
def run(self):
name=input(‘输入贴吧名:‘)
begin=int(input(‘输入起始页:‘))
stop=int(input(‘输入终止页:‘))
# +1 操作保证能够取到整数
for page in range(begin,stop+1):
pn=(page-1)*50
params={
‘kw‘:name,
‘pn‘:str(pn)
}
#拼接URL地址
params=parse.urlencode(params)
url=self.url.format(params)
#发请求
html=self.get_html(url)
#定义路径
filename=‘{}-{}页.html‘.format(name,page)
self.save_html(filename,html)
#提示
print(‘第%d页抓取成功‘%page)
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
#以脚本的形式启动爬虫
if __name__==‘__main__‘:
start=time.time()
spider=TiebaSpider() #实例化一个对象spider
spider.run() #调用入口函数
end=time.time()
#查看程序执行时间
print(‘执行时间:%.2f‘%(end-start)) #爬虫执行时间
程序执行后,爬取的文件会保存到Pycharm的当前工作目录下,输出为:
输入贴吧名:python爬虫
输入起始页:1
输入终止页:2
第1页抓取成功
第2页抓取成功
执行时间:12.25
以面向对象的方式编写爬虫程序时,思路简单,逻辑清晰,非常容易理解。上述代码主要包括四个功能函数,分别负责不同的功能,总结如下:
1) 请求函数
request函数的最终结果是返回一个HTML对象,方便后续函数调用。
2) 分析函数
解析函数用于解析 HTML 页面。常见的解析模块有正则解析模块和bs4解析模块。通过分析页面,提取出需要的数据,在后续内容中会详细介绍。
3) 保存数据功能
该函数负责将采集到的数据保存到数据库,如MySQL、MongoDB等,或者保存为文件格式,如csv、txt、excel等。
4) 入口函数
入口函数作为整个爬虫程序的桥梁,通过调用不同的函数函数实现最终的数据抓取。入口函数的主要任务是组织数据,比如要搜索的贴吧的名字,编码url参数,拼接url地址,定义文件存储路径。
履带结构
用面向对象的方式编写爬虫程序时,逻辑结构是比较固定的,总结如下:
# 程序结构
class xxxSpider(object):
def __init__(self):
# 定义常用变量,比如url或计数变量等
def get_html(self):
# 获取响应内容函数,使用随机User-Agent
def parse_html(self):
# 使用正则表达式来解析页面,提取数据
def write_html(self):
# 将提取的数据按要求保存,csv、MySQL数据库等
def run(self):
# 主函数,用来控制整体逻辑
if __name__ == ‘__main__‘:
# 程序开始运行时间
spider = xxxSpider()
spider.run()
注意:掌握以上编程逻辑将有助于您后续的学习。
爬虫随机休眠
在入口函数代码中,收录以下代码:
# 每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
爬虫访问 网站 会非常快,这与正常的人类点击行为非常不符。因此,通过随机休眠,爬虫可以模仿人类点击网站,使得网站不容易察觉是爬虫访问网站,但这样做的代价是影响程序的执行效率。
焦点爬虫是一个执行效率低的程序,提高其性能是业界一直关注的问题。于是,高效的 Python 爬虫框架 Scrapy 应运而生。
原版的: 查看全部
c爬虫抓取网页数据(
风中蹦迪03-0803:07阅读4网站SEO优化关注实战)

随风起舞
03-08 03:07 阅读4 网站SEO优化
专注于
【网络爬虫学习】实战,爬取网页和贴吧数据

战斗一
抓取您想要的网页并将其保存到本地计算机。
首先我们简单分析下要编写的爬虫程序,可以分为以下三个部分:
理清逻辑后,我们就可以正式编写爬虫程序了。
导入所需模块
from urllib import request, parse
连接 URL 地址
定义 URL 变量并连接 url 地址。代码如下所示:
url = ‘http://www.baidu.com/s?wd={}‘
word = input(‘请输入想要搜索的内容:‘)
params = parse.quote(word)
full_url = url.format(params)
向 URL 发送请求
发送请求主要分为以下几个步骤:
代码如下所示:
# 重构请求头
headers = {
‘User-Agent‘:
‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0‘
}
# 创建请求对应
req = request.Request(url=full_url, headers=headers)
# 获取响应对象
res = request.urlopen(req)
# 获取响应内容
html = res.read().decode(‘utf-8‘)
另存为本地文件
将爬取的照片保存到本地,这里需要使用Python编程文件IO操作,代码如下:
filename = word + ‘.html‘
with open(filename, ‘w‘, encoding=‘utf-8‘) as f:
f.write(html)
完整的程序如下所示:
from urllib import request, parse
# 1.拼url地址
url = ‘http://www.baidu.com/s?wd={}‘
word = input(‘请输入想要搜索的内容:‘)
params = parse.quote(word)
full_url = url.format(params)
# 2.发请求保存到本地
# 重构请求头
headers = {
‘User-Agent‘:
‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0‘
}
# 创建请求对应
req = request.Request(url=full_url, headers=headers)
# 获取响应对象
res = request.urlopen(req)
# 获取响应内容
html = res.read().decode(‘utf-8‘)
# 3.保存文件至当前目录
filename = word + ‘.html‘
with open(filename, ‘w‘, encoding=‘utf-8‘) as f:
f.write(html)
尝试运行程序,进入RioTianの博客园,确认搜索,在当前工作目录下会找到“RioTianの博客园.html”文件。
函数式编程修饰符
Python函数式编程可以让程序的思路更清晰,更容易理解。接下来,利用函数式编程的思想,对上面的代码进行修改。
定义相应的函数,调用该函数执行爬虫程序。修改后的代码如下所示:
from urllib import request, parse
# 拼接URL地址
def get_url(word):
url = ‘http://www.baidu.com/s?{}‘
# 此处使用urlencode()进行编码
params = parse.urlencode({‘wd‘: word})
url = url.format(params)
return url
# 发请求,保存本地文件
def request_url(url, filename):
headers = {
‘User-Agent‘:
‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0‘
}
# 请求对象 + 响应对象 + 提取内容
req = request.Request(url=url, headers=headers)
res = request.urlopen(req)
html = res.read().decode(‘utf-8‘)
# 保存文件至本地
with open(filename, ‘w‘, encoding=‘utf-8‘) as f:
f.write(html)
# 主程序入口
if __name__ == ‘__main__‘:
word = input(‘请输入搜索内容:‘)
url = get_url(word)
filename = word + ‘.html‘
request_url(url, filename)
除了使用函数式编程,还可以使用面向对象的编程方式(实战二),后续内容会介绍。
第二幕
爬百度贴吧(Python爬虫,编程,只抓取贴吧的前5页。
确定页面类型
通过简单的分析,我们可以知道要爬取的页面是静态网页,分析方法很简单:打开百度贴吧,搜索“Python爬虫”,复制其中任意一条信息出现的页面,如“爬虫需要http代理”,然后右键选择查看源代码,在源代码页面使用Ctrl+F快捷键搜索刚刚复制的数据,如下图:
从上图可以看出,页面中的所有信息都收录在源页面中,不需要单独从数据库中加载数据,所以页面是静态页面。
找出 URL 变化的规律性
接下来,查找要抓取的页面的 URL 模式。搜索“Python爬虫”后,贴吧的首页网址如下:
https://tieba.baidu.com/f?ie=utf-8&kw=python爬虫&fr=search
点击第二页,其url信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=50
点击第三页,url信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=100
再次点击第一页,url信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=0
如果还是不能确定,可以继续多浏览几页。最后发现url有两个查询参数kw和pn,pn参数有规律是这样的:
第n页:pn=(n-1)*50
#参数params
pn=(page-1)*50
params={
‘kw‘:name,
‘pn‘:str(pn)
}
url地址可以简写为:
https://tieba.baidu.com/f?kw=python爬虫&pn=450
编写爬虫
爬虫程序以类的形式编写,在类下编写不同的功能函数。代码如下:
from urllib import request,parse
import time
import random
from ua_info import ua_list #使用自定义的ua池
#定义一个爬虫类
class TiebaSpider(object):
#初始化url属性
def __init__(self):
self.url=‘http://tieba.baidu.com/f?{}‘
# 1.请求函数,得到页面,传统三步
def get_html(self,url):
req=request.Request(url=url,headers={‘User-Agent‘:random.choice(ua_list)})
res=request.urlopen(req)
#windows会存在乱码问题,需要使用 gbk解码,并使用ignore忽略不能处理的字节
#linux不会存在上述问题,可以直接使用decode(‘utf-8‘)解码
html=res.read().decode("gbk","ignore")
return html
# 2.解析函数,此处代码暂时省略,还没介绍解析模块
def parse_html(self):
pass
# 3.保存文件函数
def save_html(self,filename,html):
with open(filename,‘w‘) as f:
f.write(html)
# 4.入口函数
def run(self):
name=input(‘输入贴吧名:‘)
begin=int(input(‘输入起始页:‘))
stop=int(input(‘输入终止页:‘))
# +1 操作保证能够取到整数
for page in range(begin,stop+1):
pn=(page-1)*50
params={
‘kw‘:name,
‘pn‘:str(pn)
}
#拼接URL地址
params=parse.urlencode(params)
url=self.url.format(params)
#发请求
html=self.get_html(url)
#定义路径
filename=‘{}-{}页.html‘.format(name,page)
self.save_html(filename,html)
#提示
print(‘第%d页抓取成功‘%page)
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
#以脚本的形式启动爬虫
if __name__==‘__main__‘:
start=time.time()
spider=TiebaSpider() #实例化一个对象spider
spider.run() #调用入口函数
end=time.time()
#查看程序执行时间
print(‘执行时间:%.2f‘%(end-start)) #爬虫执行时间
程序执行后,爬取的文件会保存到Pycharm的当前工作目录下,输出为:
输入贴吧名:python爬虫
输入起始页:1
输入终止页:2
第1页抓取成功
第2页抓取成功
执行时间:12.25
以面向对象的方式编写爬虫程序时,思路简单,逻辑清晰,非常容易理解。上述代码主要包括四个功能函数,分别负责不同的功能,总结如下:
1) 请求函数
request函数的最终结果是返回一个HTML对象,方便后续函数调用。
2) 分析函数
解析函数用于解析 HTML 页面。常见的解析模块有正则解析模块和bs4解析模块。通过分析页面,提取出需要的数据,在后续内容中会详细介绍。
3) 保存数据功能
该函数负责将采集到的数据保存到数据库,如MySQL、MongoDB等,或者保存为文件格式,如csv、txt、excel等。
4) 入口函数
入口函数作为整个爬虫程序的桥梁,通过调用不同的函数函数实现最终的数据抓取。入口函数的主要任务是组织数据,比如要搜索的贴吧的名字,编码url参数,拼接url地址,定义文件存储路径。
履带结构
用面向对象的方式编写爬虫程序时,逻辑结构是比较固定的,总结如下:
# 程序结构
class xxxSpider(object):
def __init__(self):
# 定义常用变量,比如url或计数变量等
def get_html(self):
# 获取响应内容函数,使用随机User-Agent
def parse_html(self):
# 使用正则表达式来解析页面,提取数据
def write_html(self):
# 将提取的数据按要求保存,csv、MySQL数据库等
def run(self):
# 主函数,用来控制整体逻辑
if __name__ == ‘__main__‘:
# 程序开始运行时间
spider = xxxSpider()
spider.run()
注意:掌握以上编程逻辑将有助于您后续的学习。
爬虫随机休眠
在入口函数代码中,收录以下代码:
# 每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
爬虫访问 网站 会非常快,这与正常的人类点击行为非常不符。因此,通过随机休眠,爬虫可以模仿人类点击网站,使得网站不容易察觉是爬虫访问网站,但这样做的代价是影响程序的执行效率。
焦点爬虫是一个执行效率低的程序,提高其性能是业界一直关注的问题。于是,高效的 Python 爬虫框架 Scrapy 应运而生。
原版的:
c爬虫抓取网页数据(【每日一题】抓取网页数据(模拟访问))
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-03-09 16:06
c爬虫抓取网页数据(模拟访问),保存数据库:oracle、mysql等:两种方式,一种是批量重复查询,一种是join。
二、提取多份数据批量重复查询:1.先明确下choosewithundefined_scans的意思:choosewithundefined_scans包含两个undefined_width参数,它表示当前网页不存在的重复的页数,每个页面都会有十万个页面。查询的是总页数。2.如果choosewithundefined_scans没有参数,表示指定可以查询的页面数。
例如查询的是总页数。3.总页数是203000+,那就说明总共有9000万页面4.准备数据:获取总页数数据库createprogram"jdbcusernameclassprogram:cn-simple-username://admin";数据库表格test_logimportorg.apache.hibernate.hibernate.connector.oracle.util.hibernateconnector23;引用的数据库为mysql:jdbc[initialization=mysqlstandardmvcframework]{"name":"jdbc","username":"simplename","password":"jdbc://admin//","table":"com.xxx.xxx.account","type":"simple","auto_increment":10,"names":["account","account1","account2"]}5.业务逻辑:判断总页数量,当总页数为203000+就停止并行传输,如果不为203000+就向上传送,如果203000+就返回4007,但是实际true,说明总页数低于203000+则不存在,返回4008。
prepareview28second。javapublicclasspreparepoint28second{privatestaticfinalint[]hundred=1000000;privatestaticfinalint[]dayofweek=600000;privatestaticfinalint[]yearofweek=4000000;privatestaticfinalint[]username=null;privatestaticfinalint[]password=null;privatestaticfinalint[]table=null;privatestaticfinalbooleanredirectversion="001";privatestaticfinalvoidfieldschema_createparameter(voidschema(voidresourcea)newvoid(voidfield。
1));privatestaticfinalvoidschemaformat_schema(voidschema(voidfield
1)newvoid(voidfield
2));privatestaticfinalvoidschemaformat2(voidschema(voidfield
2)newvoid(voidfield
3));privatestaticfinalbooleanusername2011=false;privatestaticfinalvoidusername2012=false;privatestaticfinalvoidusername2013=false;privatestaticfinal 查看全部
c爬虫抓取网页数据(【每日一题】抓取网页数据(模拟访问))
c爬虫抓取网页数据(模拟访问),保存数据库:oracle、mysql等:两种方式,一种是批量重复查询,一种是join。
二、提取多份数据批量重复查询:1.先明确下choosewithundefined_scans的意思:choosewithundefined_scans包含两个undefined_width参数,它表示当前网页不存在的重复的页数,每个页面都会有十万个页面。查询的是总页数。2.如果choosewithundefined_scans没有参数,表示指定可以查询的页面数。
例如查询的是总页数。3.总页数是203000+,那就说明总共有9000万页面4.准备数据:获取总页数数据库createprogram"jdbcusernameclassprogram:cn-simple-username://admin";数据库表格test_logimportorg.apache.hibernate.hibernate.connector.oracle.util.hibernateconnector23;引用的数据库为mysql:jdbc[initialization=mysqlstandardmvcframework]{"name":"jdbc","username":"simplename","password":"jdbc://admin//","table":"com.xxx.xxx.account","type":"simple","auto_increment":10,"names":["account","account1","account2"]}5.业务逻辑:判断总页数量,当总页数为203000+就停止并行传输,如果不为203000+就向上传送,如果203000+就返回4007,但是实际true,说明总页数低于203000+则不存在,返回4008。
prepareview28second。javapublicclasspreparepoint28second{privatestaticfinalint[]hundred=1000000;privatestaticfinalint[]dayofweek=600000;privatestaticfinalint[]yearofweek=4000000;privatestaticfinalint[]username=null;privatestaticfinalint[]password=null;privatestaticfinalint[]table=null;privatestaticfinalbooleanredirectversion="001";privatestaticfinalvoidfieldschema_createparameter(voidschema(voidresourcea)newvoid(voidfield。
1));privatestaticfinalvoidschemaformat_schema(voidschema(voidfield
1)newvoid(voidfield
2));privatestaticfinalvoidschemaformat2(voidschema(voidfield
2)newvoid(voidfield
3));privatestaticfinalbooleanusername2011=false;privatestaticfinalvoidusername2012=false;privatestaticfinalvoidusername2013=false;privatestaticfinal
c爬虫抓取网页数据( 两个重要的包()预处理器定义(_szbuffer))
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-03-09 01:15
两个重要的包()预处理器定义(_szbuffer))
在windows下的C++通过Http协议实现对网页的内容抓取:
首先介绍两个重要的包(一般是linux下的开源数据包,windows下的动态链接库dll):curl包和pthreads_dll,其中curl包被解释为命令行浏览器,由调用curl_easy_setopt等内置函数可以实现对特定网页内容的获取(要正确编译导入的curl链接库,需要另外一个包C-ares)。pthreads 是一个多线程控制包,其中包括互斥变量的锁定和解锁。程序进程分配等功能。
下载地址:点击打开链接。其中,正确导入外部动态链接库需要步骤:1.Project->Properties->Configuration Properties->C/C++->General->Additional Include Directories(添加include的路径),2.Project- >Properties->Configuration Properties->Linker->General->Additional Library Directory(添加lib收录的路径);3、在Linker->Input->Additional Dependencies(添加了libcurld.lib;pthreadVC2.lib;ws2_3 2.lib;winmm.lib;wldap32.lib;areslib.lib) 4 , 在 c/c++->预处理器->预处理器定义(_CONSOLE;BUILDING_LIBCURL;HTTP_ONLY)
具体实现过程介绍:
1:自定义hashTable结构,存放获取到的字符串字符。以hashTable类的形式实现,包括hash表集合类型,以及add、find等几个常用的字符串hash函数
代码:
///HashTable.h
#ifndef HashTable_H
#define HashTable_H
#include
#include
#include
class HashTable
{
public:
HashTable(void);
~HashTable(void);
unsigned int ForceAdd(const std::string& str);
unsigned int Find(const std::string& str);
/*string的常见的hash方式*/
unsigned int RSHash(const std::string& str);
unsigned int JSHash (const std::string& str);
unsigned int PJWHash (const std::string& str);
unsigned int ELFHash (const std::string& str);
unsigned int BKDRHash(const std::string& str);
unsigned int SDBMHash(const std::string& str);
unsigned int DJBHash (const std::string& str);
unsigned int DEKHash (const std::string& str);
unsigned int BPHash (const std::string& str);
unsigned int FNVHash (const std::string& str);
unsigned int APHash (const std::string& str);
private:
std::set HashFunctionResultSet;
std::vector hhh;
};
#endif
/////HashTable.cpp
#include "HashTable.h"
HashTable::HashTable(void)
{
}
HashTable::~HashTable(void)
{
}
unsigned int HashTable::ForceAdd(const std::string& str)
{
unsigned int i=ELFHash(str);
HashFunctionResultSet.insert(i);
return i;
}
unsigned int HashTable::Find(const std::string& str)
{
int ff=hhh.size();
const unsigned int i=ELFHash(str);
std::set::const_iterator it;
if(HashFunctionResultSet.size()>0)
{
it=HashFunctionResultSet.find(i);
if(it==HashFunctionResultSet.end())
return -1;
}
else
{
return -1;
}
return i;
}
/*几种常见的字符串hash方式实现函数*/
unsigned int HashTable::APHash(const std::string& str)
{
unsigned int hash=0xAAAAAAAA;
for(std::size_t i=0;i 3)) :
(~((hash > 5)));
}
return hash;
}
unsigned int HashTable::BKDRHash(const std::string& str)
{
unsigned int seed=131; //31 131 1313 13131 131313 etc
unsigned int hash=0;
for(std::size_t i=0;isetBuffer((char*)buffer,size,nmemb);
}
bool Http::InitCurl(const std::string& url, std::string& szbuffer)
{
pthread_mutex_init(&m_http_mutex,NULL);
Http::m_szUrl=url;
CURLcode result;
if(m_pcurl)
{
curl_easy_setopt(m_pcurl, CURLOPT_ERRORBUFFER, Http::m_errorBuffer);
curl_easy_setopt(m_pcurl, CURLOPT_URL,m_szUrl.c_str());
curl_easy_setopt(m_pcurl, CURLOPT_HEADER, 0);
curl_easy_setopt(m_pcurl, CURLOPT_FOLLOWLOCATION, 1);
curl_easy_setopt(m_pcurl, CURLOPT_WRITEFUNCTION,Http::writer);
curl_easy_setopt(m_pcurl, CURLOPT_WRITEDATA,this);
result = curl_easy_perform(m_pcurl);
}
if(result!=CURLE_OK)
return false;
szbuffer=m_szbuffer;
m_szbuffer.clear();
m_szUrl.clear();
pthread_mutex_destroy(&m_http_mutex);
return true;
}
bool Http::DeInitCurl()
{
curl_easy_cleanup(m_pcurl);
curl_global_cleanup();
m_pcurl = NULL;
return true;
}
const string Http::getBuffer()
{
return m_szbuffer;
}
string Http::setUrl()
{
return Http::m_szUrl;
}
void Http::setUrl(const std::string& url)
{
Http::m_szUrl = url;
}
其中,m_szbuffer存放的是网页的内容。初始网页的内容存储在 Init 函数的形参中。 查看全部
c爬虫抓取网页数据(
两个重要的包()预处理器定义(_szbuffer))
在windows下的C++通过Http协议实现对网页的内容抓取:
首先介绍两个重要的包(一般是linux下的开源数据包,windows下的动态链接库dll):curl包和pthreads_dll,其中curl包被解释为命令行浏览器,由调用curl_easy_setopt等内置函数可以实现对特定网页内容的获取(要正确编译导入的curl链接库,需要另外一个包C-ares)。pthreads 是一个多线程控制包,其中包括互斥变量的锁定和解锁。程序进程分配等功能。
下载地址:点击打开链接。其中,正确导入外部动态链接库需要步骤:1.Project->Properties->Configuration Properties->C/C++->General->Additional Include Directories(添加include的路径),2.Project- >Properties->Configuration Properties->Linker->General->Additional Library Directory(添加lib收录的路径);3、在Linker->Input->Additional Dependencies(添加了libcurld.lib;pthreadVC2.lib;ws2_3 2.lib;winmm.lib;wldap32.lib;areslib.lib) 4 , 在 c/c++->预处理器->预处理器定义(_CONSOLE;BUILDING_LIBCURL;HTTP_ONLY)
具体实现过程介绍:
1:自定义hashTable结构,存放获取到的字符串字符。以hashTable类的形式实现,包括hash表集合类型,以及add、find等几个常用的字符串hash函数
代码:
///HashTable.h
#ifndef HashTable_H
#define HashTable_H
#include
#include
#include
class HashTable
{
public:
HashTable(void);
~HashTable(void);
unsigned int ForceAdd(const std::string& str);
unsigned int Find(const std::string& str);
/*string的常见的hash方式*/
unsigned int RSHash(const std::string& str);
unsigned int JSHash (const std::string& str);
unsigned int PJWHash (const std::string& str);
unsigned int ELFHash (const std::string& str);
unsigned int BKDRHash(const std::string& str);
unsigned int SDBMHash(const std::string& str);
unsigned int DJBHash (const std::string& str);
unsigned int DEKHash (const std::string& str);
unsigned int BPHash (const std::string& str);
unsigned int FNVHash (const std::string& str);
unsigned int APHash (const std::string& str);
private:
std::set HashFunctionResultSet;
std::vector hhh;
};
#endif
/////HashTable.cpp
#include "HashTable.h"
HashTable::HashTable(void)
{
}
HashTable::~HashTable(void)
{
}
unsigned int HashTable::ForceAdd(const std::string& str)
{
unsigned int i=ELFHash(str);
HashFunctionResultSet.insert(i);
return i;
}
unsigned int HashTable::Find(const std::string& str)
{
int ff=hhh.size();
const unsigned int i=ELFHash(str);
std::set::const_iterator it;
if(HashFunctionResultSet.size()>0)
{
it=HashFunctionResultSet.find(i);
if(it==HashFunctionResultSet.end())
return -1;
}
else
{
return -1;
}
return i;
}
/*几种常见的字符串hash方式实现函数*/
unsigned int HashTable::APHash(const std::string& str)
{
unsigned int hash=0xAAAAAAAA;
for(std::size_t i=0;i 3)) :
(~((hash > 5)));
}
return hash;
}
unsigned int HashTable::BKDRHash(const std::string& str)
{
unsigned int seed=131; //31 131 1313 13131 131313 etc
unsigned int hash=0;
for(std::size_t i=0;isetBuffer((char*)buffer,size,nmemb);
}
bool Http::InitCurl(const std::string& url, std::string& szbuffer)
{
pthread_mutex_init(&m_http_mutex,NULL);
Http::m_szUrl=url;
CURLcode result;
if(m_pcurl)
{
curl_easy_setopt(m_pcurl, CURLOPT_ERRORBUFFER, Http::m_errorBuffer);
curl_easy_setopt(m_pcurl, CURLOPT_URL,m_szUrl.c_str());
curl_easy_setopt(m_pcurl, CURLOPT_HEADER, 0);
curl_easy_setopt(m_pcurl, CURLOPT_FOLLOWLOCATION, 1);
curl_easy_setopt(m_pcurl, CURLOPT_WRITEFUNCTION,Http::writer);
curl_easy_setopt(m_pcurl, CURLOPT_WRITEDATA,this);
result = curl_easy_perform(m_pcurl);
}
if(result!=CURLE_OK)
return false;
szbuffer=m_szbuffer;
m_szbuffer.clear();
m_szUrl.clear();
pthread_mutex_destroy(&m_http_mutex);
return true;
}
bool Http::DeInitCurl()
{
curl_easy_cleanup(m_pcurl);
curl_global_cleanup();
m_pcurl = NULL;
return true;
}
const string Http::getBuffer()
{
return m_szbuffer;
}
string Http::setUrl()
{
return Http::m_szUrl;
}
void Http::setUrl(const std::string& url)
{
Http::m_szUrl = url;
}
其中,m_szbuffer存放的是网页的内容。初始网页的内容存储在 Init 函数的形参中。
c爬虫抓取网页数据( 网络爬虫框架图框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-09 01:14
网络爬虫框架图框架)
搜索引擎网络爬虫如何高效地将互联网上万亿网页爬取到本地镜像?
一、爬虫框架
上图是一个简单的网络爬虫框架图。从种子网址入手,如图,一步步工作后,将网页存入数据库。当然,勤劳的蜘蛛可能还需要做更多的工作,比如网页的去重和网页的反作弊。
或许,我们可以将网页视为蜘蛛的晚餐,其中包括:
下载的网页。被蜘蛛爬过的网页内容被放到了肚子里。
过期网页。蜘蛛每次都要爬很多网页,有的已经在肚子里坏掉了。
要下载的页面。当它看到食物时,蜘蛛就会去抓它。
知名网站。它还没有被下载和发现,但是蜘蛛可以感知它们并且迟早会抓住它。
不可知的网页。互联网太大了,很多页面蜘蛛都找不到,而且可能永远也找不到。这部分占比很高。
通过以上划分,我们可以清楚地了解搜索引擎蜘蛛的工作以及它们面临的挑战。大多数蜘蛛都是按照这个框架爬行的。但这并不完全确定。一切总是特别的。根据不同的功能,蜘蛛系统有一些差异。
二、爬虫种类
1.批量式蜘蛛。
这种蜘蛛有明确的抓取范围和目标,当蜘蛛完成目标和任务时停止抓取。具体目标是什么?它可能是抓取的页面数、页面大小、抓取时间等。
2.增量蜘蛛
这种蜘蛛不同于批处理型蜘蛛,它们会不断地爬取,并且会定期对爬取的网页进行爬取和更新。由于 Internet 上的网页在不断更新,增量爬虫需要能够反映这种更新。
3.垂直蜘蛛
此类蜘蛛仅关注特定主题或特定行业页面。以health网站为例,这种专门的爬虫只会爬取健康相关的话题,其他话题的页面不会被爬取。测试这个蜘蛛的难点在于如何更准确地识别内容所属的行业。目前很多垂直行业网站都需要这种蜘蛛去抢。
三、抢夺策略
爬虫通过种子URL进行爬取和扩展,列出大量待爬取的URL。但是,要抓取的 URL 数量巨大。蜘蛛如何确定爬行的顺序?爬虫的策略有很多,但最终的目标是先爬取重要的网页。评价页面是否重要,蜘蛛会根据页面内容的程度原创、链接权重分析等多种方法进行计算。比较有代表性的爬取策略如下:
1. 广度优先策略
宽度优先是指蜘蛛爬取一个网页后,会继续按顺序爬取该网页中收录的其他页面。这个想法看似简单,但实际上非常实用。因为大部分网页都是有优先级的,所以在页面上优先推荐重要的页面。
2. PageRank 策略
PageRank是一种非常有名的链接分析方法,主要用来衡量网页的权威性。例如,Google 的 PR 就是典型的 PageRank 算法。通过PageRank算法我们可以找出哪些页面更重要,然后蜘蛛会优先抓取这些重要的页面。
3.大网站优先策略
这个很容易理解,大网站通常内容页比较多,质量也会比较高。蜘蛛会首先分析网站分类和属性。如果这个网站已经是收录很多,或者在搜索引擎系统中的权重很高,则优先考虑收录。
4.网页更新
互联网上的大部分页面都会更新,所以蜘蛛存储的页面需要及时更新以保持一致性。打个比方:一个页面之前排名很好,如果页面被删除了但仍然排名,那么体验很差。因此,搜索引擎需要知道这些并随时更新页面,并将新的页面提供给用户。常用的网页更新策略有三种:历史参考策略和用户体验策略。整群抽样策略。
1. 历史参考策略
这是基于假设的更新策略。例如,如果你的网页以前经常更新,那么搜索引擎也认为你的网页以后会经常更新,蜘蛛也会根据这个规则定期网站对网页进行爬取。这也是为什么点水一直强调网站内容需要定期更新的原因。
2. 用户体验策略
一般来说,用户只查看搜索结果前三页的内容,很少有人看到后面的页面。用户体验策略是搜索引擎根据用户的这一特征进行更新。例如,一个网页可能发布得较早,并且有一段时间没有更新,但用户仍然觉得它有用并点击浏览,那么搜索引擎可能不会首先更新这些过时的网页。这就是为什么新页面不一定在搜索结果中排名靠前的原因。排名更多地取决于页面的质量,而不是更新的时间。
3.整群抽样策略
以上两种更新策略主要参考网页的历史信息。然而,存储大量历史信息对于搜索引擎来说是一种负担。另外,如果收录是一个新的网页,没有历史信息可以参考,怎么办?聚类抽样策略是指:拿出一些属性对很多相似的网页进行分类,分类后的页面按照相同的规则进行更新。
从了解搜索引擎蜘蛛工作原理的过程中,我们会知道:网站内容的相关性、网站与网页内容的更新规律、网页链接的分布和权重网站 等因素会影响蜘蛛的爬取效率。知己知彼,让蜘蛛来得更猛烈!
更多北碚商城产品介绍:抚顺电梯轿厢广告 查看全部
c爬虫抓取网页数据(
网络爬虫框架图框架)
搜索引擎网络爬虫如何高效地将互联网上万亿网页爬取到本地镜像?
一、爬虫框架

上图是一个简单的网络爬虫框架图。从种子网址入手,如图,一步步工作后,将网页存入数据库。当然,勤劳的蜘蛛可能还需要做更多的工作,比如网页的去重和网页的反作弊。
或许,我们可以将网页视为蜘蛛的晚餐,其中包括:
下载的网页。被蜘蛛爬过的网页内容被放到了肚子里。
过期网页。蜘蛛每次都要爬很多网页,有的已经在肚子里坏掉了。
要下载的页面。当它看到食物时,蜘蛛就会去抓它。
知名网站。它还没有被下载和发现,但是蜘蛛可以感知它们并且迟早会抓住它。
不可知的网页。互联网太大了,很多页面蜘蛛都找不到,而且可能永远也找不到。这部分占比很高。
通过以上划分,我们可以清楚地了解搜索引擎蜘蛛的工作以及它们面临的挑战。大多数蜘蛛都是按照这个框架爬行的。但这并不完全确定。一切总是特别的。根据不同的功能,蜘蛛系统有一些差异。
二、爬虫种类
1.批量式蜘蛛。
这种蜘蛛有明确的抓取范围和目标,当蜘蛛完成目标和任务时停止抓取。具体目标是什么?它可能是抓取的页面数、页面大小、抓取时间等。
2.增量蜘蛛
这种蜘蛛不同于批处理型蜘蛛,它们会不断地爬取,并且会定期对爬取的网页进行爬取和更新。由于 Internet 上的网页在不断更新,增量爬虫需要能够反映这种更新。
3.垂直蜘蛛
此类蜘蛛仅关注特定主题或特定行业页面。以health网站为例,这种专门的爬虫只会爬取健康相关的话题,其他话题的页面不会被爬取。测试这个蜘蛛的难点在于如何更准确地识别内容所属的行业。目前很多垂直行业网站都需要这种蜘蛛去抢。
三、抢夺策略
爬虫通过种子URL进行爬取和扩展,列出大量待爬取的URL。但是,要抓取的 URL 数量巨大。蜘蛛如何确定爬行的顺序?爬虫的策略有很多,但最终的目标是先爬取重要的网页。评价页面是否重要,蜘蛛会根据页面内容的程度原创、链接权重分析等多种方法进行计算。比较有代表性的爬取策略如下:
1. 广度优先策略

宽度优先是指蜘蛛爬取一个网页后,会继续按顺序爬取该网页中收录的其他页面。这个想法看似简单,但实际上非常实用。因为大部分网页都是有优先级的,所以在页面上优先推荐重要的页面。
2. PageRank 策略
PageRank是一种非常有名的链接分析方法,主要用来衡量网页的权威性。例如,Google 的 PR 就是典型的 PageRank 算法。通过PageRank算法我们可以找出哪些页面更重要,然后蜘蛛会优先抓取这些重要的页面。
3.大网站优先策略
这个很容易理解,大网站通常内容页比较多,质量也会比较高。蜘蛛会首先分析网站分类和属性。如果这个网站已经是收录很多,或者在搜索引擎系统中的权重很高,则优先考虑收录。
4.网页更新
互联网上的大部分页面都会更新,所以蜘蛛存储的页面需要及时更新以保持一致性。打个比方:一个页面之前排名很好,如果页面被删除了但仍然排名,那么体验很差。因此,搜索引擎需要知道这些并随时更新页面,并将新的页面提供给用户。常用的网页更新策略有三种:历史参考策略和用户体验策略。整群抽样策略。
1. 历史参考策略
这是基于假设的更新策略。例如,如果你的网页以前经常更新,那么搜索引擎也认为你的网页以后会经常更新,蜘蛛也会根据这个规则定期网站对网页进行爬取。这也是为什么点水一直强调网站内容需要定期更新的原因。
2. 用户体验策略
一般来说,用户只查看搜索结果前三页的内容,很少有人看到后面的页面。用户体验策略是搜索引擎根据用户的这一特征进行更新。例如,一个网页可能发布得较早,并且有一段时间没有更新,但用户仍然觉得它有用并点击浏览,那么搜索引擎可能不会首先更新这些过时的网页。这就是为什么新页面不一定在搜索结果中排名靠前的原因。排名更多地取决于页面的质量,而不是更新的时间。
3.整群抽样策略
以上两种更新策略主要参考网页的历史信息。然而,存储大量历史信息对于搜索引擎来说是一种负担。另外,如果收录是一个新的网页,没有历史信息可以参考,怎么办?聚类抽样策略是指:拿出一些属性对很多相似的网页进行分类,分类后的页面按照相同的规则进行更新。
从了解搜索引擎蜘蛛工作原理的过程中,我们会知道:网站内容的相关性、网站与网页内容的更新规律、网页链接的分布和权重网站 等因素会影响蜘蛛的爬取效率。知己知彼,让蜘蛛来得更猛烈!
更多北碚商城产品介绍:抚顺电梯轿厢广告
c爬虫抓取网页数据( Scraoy入门实例一—Scrapy介绍与安装ampamp的安装)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-09 01:12
Scraoy入门实例一—Scrapy介绍与安装ampamp的安装)
Scraoy入门示例1-Scrapy介绍与安装&PyCharm安装&项目实战
一、Scrapy 的安装
1.Scrapy介绍
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。
2.Scrapy 安装
建议使用 Anaconda 安装 Scrapy
Anaconda 是一个开源包和环境管理神器。Anaconda 包括 180 多个科学包及其依赖项,包括 conda 和 Python。从官网下载安装Anaconda(个人版),根据自己的系统选择下载,安装,选择next继续安装,Install for选项选择Just for me,选择安装位置,等待安装完成。
安装完成后,打开命令行,输入conda install scrapy,根据提示按Y,即可下载所有Scrapy及其依赖包,从而完成安装。
注意:使用命令行安装scrapy包时,会出现下载超时问题,即下载失败。我们可以通过修改scrapy包的镜像文件来提高scrapy包的下载速度。你可以参考博客:
这时候测试Scrapy是否安装成功:在命令行窗口输入scrapy,回车。如果出现如下界面,则表示安装成功:
二、安装 PyCharm
1.PyCharm介绍
PyCharm 是一个 Python IDE,拥有一套完整的工具,可以帮助用户在使用 Python 语言进行开发时提高效率,例如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试和版本控制。此外,IDE 还提供高级功能以支持 Django 框架下的专业 Web 开发。
2.PyCharm 安装
进入PyCharm官网,直接点击DownLoad下载,左边是专业版,右边是社区版,社区版免费,专业版免费试用。
如果我们之前没有下载过Python解释器,可以在等待安装的同时下载Python解释器,进入Python官网,根据系统和版本下载对应的压缩包。安装完成后,在环境变量 Path 中配置 Python 解释器的安装路径。你可以参考博客:
三、Scrapy 抓豆瓣项目在行动
前提条件:如果要在 PyCharm 中使用 Scrapy,首先必须在 PyCharm 中安装支持的 Scrapy 包。流程如下,点击文件>>设置... 两个包,如果点击的时候看到一个Scrapy包,那么就不需要安装了,继续下一步。
如果没有Scrapy包,点击“+”,搜索Scrapy包,点击Install Package进行安装
等待安装完成。
1.新项目
打开新安装的PyCharm,使用软件终端中的pycharm工具,如果找不到PyCharm终端在哪里,就是左下角的Terminal。
输入命令:scrapy startproject douban 这是使用命令行新建爬虫项目,如下图,图中项目名称为pythonProject
然后在命令行输入命令:cd douban进入生成项目的根目录
然后在终端继续输入命令:scrapy genspider douban_spider 生成douban_spider爬虫文件。
此时的项目结构如下图所示:
2.明确目标
我们要练习的 网站 是:
假设,我们获取 top250 电影的序列号、电影名称、介绍、星级、评论数、电影描述选项
至此,我们在 items.py 文件中定义抓取的数据项,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.接下来,我们需要创建爬虫并存储爬取的内容
在douban_spider.py爬虫文件中编写具体的逻辑代码,如下:
# -*- coding: utf-8 -*-
import scrapy
from ..items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
name = "douban_spider"
# 允许的域名
allowed_domains = ["movie.douban.com"]
# 入口URL
start_urls = ["https://movie.douban.com/top250"]
def parse(self, response):
movie_list = response.xpath("//div[@class="article"]//ol[@class="grid_view"]/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item["serial_number"] = i_item.xpath(".//div[@class="item"]//em/text()").extract_first()
douban_item["movie_name"] = i_item.xpath(".//div[@class="info"]//div[@class="hd"]/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class="info"]//div[@class="bd"]/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item["introduce"] = content_s
douban_item["star"] = i_item.xpath(".//span[@class="rating_num"]/text()").extract_first()
douban_item["evaluate"] = i_item.xpath(".//div[@class="star"]//span[4]/text()").extract_first()
douban_item["describe"] = i_item.xpath(".//p[@class="quote"]/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class="next"]/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
这个时候不需要运行这个python文件,因为我们不单独使用,所以不需要运行,允许报错。import引入的问题,主目录的绝对路径和相对路径,原因是我们使用的是相对路径“..items”,对相关内容感兴趣的同学可以去网上找一下此类问题的解释.
4.存储内容
将爬取的内容存储为 json 或 csv 格式的文件
在命令行输入:scrapy crawl douban_spider -o test.json 或者 scrapy crawl douban_spider -o test.csv
将爬取的数据存储在 json 文件或 csv 文件中。
执行爬取命令后,当鼠标聚焦到项目面板时,会显示生成的 json 文件或 csv 文件。打开json或者csv文件后,如果里面什么都没有,那么我们需要做进一步的修改,修改代理USER_AGENT的内容,
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.8 Safari/537.36"
如果存储在json文件中,所有内容都会以十六进制形式显示,可以通过相应的方法进行转码。这里就不多解释了,如下图所示:
并且存储在csv文件中,它会直接显示我们要爬取的所有内容,如下图:
至此,我们就完成了网站具体内容的爬取。接下来,我们需要对爬取的数据进行处理。
分界线 —————————————————————————————————————————————- 分界线
Scraoy 入门示例 2 - 使用管道实现
在本次实战中,需要重新创建项目或者安装scrapy包。参考上面的内容,新建项目的方法也参考上面的内容,这里不再赘述。
项目目录结构如下图所示:
一、流水线介绍
当我们通过Spider爬取数据,通过Item采集数据时,我们需要对数据做一些处理,因为我们爬取的数据不一定是我们想要的最终数据,可能还需要对数据进行清洗和验证。数据有效性。Scripy 中的 Pipeline 组件用于数据处理。Pipeline 组件是一个收录特定接口的类。它通常只负责一项功能的数据处理。在一个项目中可以同时启用多个管道。
二、在items.py中定义你要抓取的数据
首先打开一个新的pycharm项目,通过终端新建一个项目教程,在item中定义你要抓取的数据,比如电影名,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、定义 pipeline.py 文件
每个 item 管道组件都是一个独立的 pyhton 类,必须实现 process_item(self, item, spider) 方法。每个item管道组件都需要调用这个方法。该方法必须返回一个带有数据的dict,或者一个item对象,或者抛出一个DropItem异常,并且被丢弃的item不会被后续管道组件处理。定义的 pipelines.py 代码如下所示:
# Define your item pipelines here
#
# Don"t forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/lat ... .html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class TutorialPipeline(object):
def process_item(self, item, spider):
return item
import time
class DoubanmoviePipeline(object):
def process_item(self, item, spider):
now = time.strftime("%Y-%m-%d", time.localtime())
fileName = "douban" + now + ".txt"
with open(fileName, "a", encoding="utf-8") as fp:
fp.write(item["moiveName"][0]+"")
return item
四、配置设置.py
由于这次使用的是管道,所以我们需要在settings.py中打开管道通道注释,并在其中添加一条新记录,如下图所示:
五、写爬虫文件
在tutorial/spiders目录下创建quotes_spider.py文件,目录结构如下,编写初步代码:
quote_spider.py 代码如下:
import scrapy
from items import DoubanmovieItem
class QuotesSpider(scrapy.Spider):
name = "doubanSpider"
allowed_domains = ["douban.com"]
start_urls = ["http://movie.douban.com/cinema/nowplaying",
"http://movie.douban.com/cinema ... ot%3B]
def parse(self, response):
print("--" * 20 )
#print(response.body)
print("==" * 20 )
subSelector = response.xpath("//li[@class="stitle"]")
items = []
for sub in subSelector:
#print(sub.xpath("normalize-space(./a/text())").extract())
print(sub)
item = DoubanmovieItem()
item["moiveName"] = sub.xpath("normalize-space(./a/text())").extract()
items.append(item)
print(items)
return items
六、从启动文件运行
在豆瓣文件目录下新建启动文件douban_spider_run.py(文件名可取不同),运行文件查看结果。编写代码如下:
from scrapy import cmdline
cmdline.execute("scrapy crawl doubanSpider".split())
最后,处理后的爬取数据如下图(部分)所示:
最后,希望大家在写代码的时候可以小心,不要马虎。实验的时候写了方法DoubanmovieItem作为DobanmovieItem引入,导致整个程序失败,而且PyCharm也没有告诉我哪里错了,我到处找问题的解决方法也没找到。最后查了很多遍,都是在生成方法的时候才发现的,所以一定要小心。该错误如下图所示。提示找不到DobanmovieItem模块。它可能告诉我错误的地方。因为懒得找,找了很久。希望大家多多注意!
至此,使用Scrapy抓取网页内容,并对抓取到的内容进行清理和处理的实验已经完成。要求熟悉并使用此过程中的代码和操作,不要在网上搜索和消化。吸收它并记住它,这是学习知识的真正方法,而不仅仅是画一个勺子。
本文地址:H5W3 » python爬虫示例:使用Scrapy爬取网页采集数据 查看全部
c爬虫抓取网页数据(
Scraoy入门实例一—Scrapy介绍与安装ampamp的安装)
 https://www.h5w3.com/wp-conten ... 3.jpg 150w" />
https://www.h5w3.com/wp-conten ... 3.jpg 150w" />Scraoy入门示例1-Scrapy介绍与安装&PyCharm安装&项目实战
一、Scrapy 的安装
1.Scrapy介绍
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。
2.Scrapy 安装
建议使用 Anaconda 安装 Scrapy
Anaconda 是一个开源包和环境管理神器。Anaconda 包括 180 多个科学包及其依赖项,包括 conda 和 Python。从官网下载安装Anaconda(个人版),根据自己的系统选择下载,安装,选择next继续安装,Install for选项选择Just for me,选择安装位置,等待安装完成。
安装完成后,打开命令行,输入conda install scrapy,根据提示按Y,即可下载所有Scrapy及其依赖包,从而完成安装。
注意:使用命令行安装scrapy包时,会出现下载超时问题,即下载失败。我们可以通过修改scrapy包的镜像文件来提高scrapy包的下载速度。你可以参考博客:
这时候测试Scrapy是否安装成功:在命令行窗口输入scrapy,回车。如果出现如下界面,则表示安装成功:
 https://www.h5w3.com/wp-conten ... 9.png 150w" />
https://www.h5w3.com/wp-conten ... 9.png 150w" />二、安装 PyCharm
1.PyCharm介绍
PyCharm 是一个 Python IDE,拥有一套完整的工具,可以帮助用户在使用 Python 语言进行开发时提高效率,例如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试和版本控制。此外,IDE 还提供高级功能以支持 Django 框架下的专业 Web 开发。
2.PyCharm 安装
进入PyCharm官网,直接点击DownLoad下载,左边是专业版,右边是社区版,社区版免费,专业版免费试用。
如果我们之前没有下载过Python解释器,可以在等待安装的同时下载Python解释器,进入Python官网,根据系统和版本下载对应的压缩包。安装完成后,在环境变量 Path 中配置 Python 解释器的安装路径。你可以参考博客:
三、Scrapy 抓豆瓣项目在行动
前提条件:如果要在 PyCharm 中使用 Scrapy,首先必须在 PyCharm 中安装支持的 Scrapy 包。流程如下,点击文件>>设置... 两个包,如果点击的时候看到一个Scrapy包,那么就不需要安装了,继续下一步。
 https://www.h5w3.com/wp-conten ... 7.png 150w" />
https://www.h5w3.com/wp-conten ... 7.png 150w" />如果没有Scrapy包,点击“+”,搜索Scrapy包,点击Install Package进行安装
 https://www.h5w3.com/wp-conten ... 1.png 150w" />
https://www.h5w3.com/wp-conten ... 1.png 150w" />等待安装完成。
1.新项目
打开新安装的PyCharm,使用软件终端中的pycharm工具,如果找不到PyCharm终端在哪里,就是左下角的Terminal。
输入命令:scrapy startproject douban 这是使用命令行新建爬虫项目,如下图,图中项目名称为pythonProject
 https://www.h5w3.com/wp-conten ... 0.png 150w" />
https://www.h5w3.com/wp-conten ... 0.png 150w" />然后在命令行输入命令:cd douban进入生成项目的根目录
然后在终端继续输入命令:scrapy genspider douban_spider 生成douban_spider爬虫文件。
此时的项目结构如下图所示:
 https://www.h5w3.com/wp-conten ... 0.png 136w" />
https://www.h5w3.com/wp-conten ... 0.png 136w" />2.明确目标
我们要练习的 网站 是:
假设,我们获取 top250 电影的序列号、电影名称、介绍、星级、评论数、电影描述选项
至此,我们在 items.py 文件中定义抓取的数据项,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.接下来,我们需要创建爬虫并存储爬取的内容
在douban_spider.py爬虫文件中编写具体的逻辑代码,如下:
# -*- coding: utf-8 -*-
import scrapy
from ..items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
name = "douban_spider"
# 允许的域名
allowed_domains = ["movie.douban.com"]
# 入口URL
start_urls = ["https://movie.douban.com/top250"]
def parse(self, response):
movie_list = response.xpath("//div[@class="article"]//ol[@class="grid_view"]/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item["serial_number"] = i_item.xpath(".//div[@class="item"]//em/text()").extract_first()
douban_item["movie_name"] = i_item.xpath(".//div[@class="info"]//div[@class="hd"]/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class="info"]//div[@class="bd"]/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item["introduce"] = content_s
douban_item["star"] = i_item.xpath(".//span[@class="rating_num"]/text()").extract_first()
douban_item["evaluate"] = i_item.xpath(".//div[@class="star"]//span[4]/text()").extract_first()
douban_item["describe"] = i_item.xpath(".//p[@class="quote"]/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class="next"]/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
这个时候不需要运行这个python文件,因为我们不单独使用,所以不需要运行,允许报错。import引入的问题,主目录的绝对路径和相对路径,原因是我们使用的是相对路径“..items”,对相关内容感兴趣的同学可以去网上找一下此类问题的解释.
4.存储内容
将爬取的内容存储为 json 或 csv 格式的文件
在命令行输入:scrapy crawl douban_spider -o test.json 或者 scrapy crawl douban_spider -o test.csv
将爬取的数据存储在 json 文件或 csv 文件中。
执行爬取命令后,当鼠标聚焦到项目面板时,会显示生成的 json 文件或 csv 文件。打开json或者csv文件后,如果里面什么都没有,那么我们需要做进一步的修改,修改代理USER_AGENT的内容,
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.8 Safari/537.36"
 https://www.h5w3.com/wp-conten ... 4.png 150w" />
https://www.h5w3.com/wp-conten ... 4.png 150w" />如果存储在json文件中,所有内容都会以十六进制形式显示,可以通过相应的方法进行转码。这里就不多解释了,如下图所示:
 https://www.h5w3.com/wp-conten ... 4.png 150w" />
https://www.h5w3.com/wp-conten ... 4.png 150w" />并且存储在csv文件中,它会直接显示我们要爬取的所有内容,如下图:
 https://www.h5w3.com/wp-conten ... 9.png 150w" />
https://www.h5w3.com/wp-conten ... 9.png 150w" />至此,我们就完成了网站具体内容的爬取。接下来,我们需要对爬取的数据进行处理。
分界线 —————————————————————————————————————————————- 分界线
Scraoy 入门示例 2 - 使用管道实现
在本次实战中,需要重新创建项目或者安装scrapy包。参考上面的内容,新建项目的方法也参考上面的内容,这里不再赘述。
项目目录结构如下图所示:
 https://www.h5w3.com/wp-conten ... 0.png 78w" />
https://www.h5w3.com/wp-conten ... 0.png 78w" />一、流水线介绍
当我们通过Spider爬取数据,通过Item采集数据时,我们需要对数据做一些处理,因为我们爬取的数据不一定是我们想要的最终数据,可能还需要对数据进行清洗和验证。数据有效性。Scripy 中的 Pipeline 组件用于数据处理。Pipeline 组件是一个收录特定接口的类。它通常只负责一项功能的数据处理。在一个项目中可以同时启用多个管道。
二、在items.py中定义你要抓取的数据
首先打开一个新的pycharm项目,通过终端新建一个项目教程,在item中定义你要抓取的数据,比如电影名,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、定义 pipeline.py 文件
每个 item 管道组件都是一个独立的 pyhton 类,必须实现 process_item(self, item, spider) 方法。每个item管道组件都需要调用这个方法。该方法必须返回一个带有数据的dict,或者一个item对象,或者抛出一个DropItem异常,并且被丢弃的item不会被后续管道组件处理。定义的 pipelines.py 代码如下所示:
# Define your item pipelines here
#
# Don"t forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/lat ... .html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class TutorialPipeline(object):
def process_item(self, item, spider):
return item
import time
class DoubanmoviePipeline(object):
def process_item(self, item, spider):
now = time.strftime("%Y-%m-%d", time.localtime())
fileName = "douban" + now + ".txt"
with open(fileName, "a", encoding="utf-8") as fp:
fp.write(item["moiveName"][0]+"")
return item
四、配置设置.py
由于这次使用的是管道,所以我们需要在settings.py中打开管道通道注释,并在其中添加一条新记录,如下图所示:
 https://www.h5w3.com/wp-conten ... 2.png 150w" />
https://www.h5w3.com/wp-conten ... 2.png 150w" />五、写爬虫文件
在tutorial/spiders目录下创建quotes_spider.py文件,目录结构如下,编写初步代码:
 https://www.h5w3.com/wp-conten ... 0.png 93w" />
https://www.h5w3.com/wp-conten ... 0.png 93w" />quote_spider.py 代码如下:
import scrapy
from items import DoubanmovieItem
class QuotesSpider(scrapy.Spider):
name = "doubanSpider"
allowed_domains = ["douban.com"]
start_urls = ["http://movie.douban.com/cinema/nowplaying",
"http://movie.douban.com/cinema ... ot%3B]
def parse(self, response):
print("--" * 20 )
#print(response.body)
print("==" * 20 )
subSelector = response.xpath("//li[@class="stitle"]")
items = []
for sub in subSelector:
#print(sub.xpath("normalize-space(./a/text())").extract())
print(sub)
item = DoubanmovieItem()
item["moiveName"] = sub.xpath("normalize-space(./a/text())").extract()
items.append(item)
print(items)
return items
六、从启动文件运行
在豆瓣文件目录下新建启动文件douban_spider_run.py(文件名可取不同),运行文件查看结果。编写代码如下:
from scrapy import cmdline
cmdline.execute("scrapy crawl doubanSpider".split())
最后,处理后的爬取数据如下图(部分)所示:
 https://www.h5w3.com/wp-conten ... 7.png 150w" />
https://www.h5w3.com/wp-conten ... 7.png 150w" />最后,希望大家在写代码的时候可以小心,不要马虎。实验的时候写了方法DoubanmovieItem作为DobanmovieItem引入,导致整个程序失败,而且PyCharm也没有告诉我哪里错了,我到处找问题的解决方法也没找到。最后查了很多遍,都是在生成方法的时候才发现的,所以一定要小心。该错误如下图所示。提示找不到DobanmovieItem模块。它可能告诉我错误的地方。因为懒得找,找了很久。希望大家多多注意!
 https://www.h5w3.com/wp-conten ... 5.png 150w" />
https://www.h5w3.com/wp-conten ... 5.png 150w" />至此,使用Scrapy抓取网页内容,并对抓取到的内容进行清理和处理的实验已经完成。要求熟悉并使用此过程中的代码和操作,不要在网上搜索和消化。吸收它并记住它,这是学习知识的真正方法,而不仅仅是画一个勺子。
本文地址:H5W3 » python爬虫示例:使用Scrapy爬取网页采集数据
c爬虫抓取网页数据(开始定位,也即这两个写法在XML包中都是适用的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-07 22:07
开始定位,即
div[@class='first']/a/text()
这两种写法都适用于 XML 包。
由于不是主要内容,更多关于HTML的知识这里不再赘述。详细的可以自己学习HTML和CSS相关知识,是爬虫的基础。
我们通常使用chrome浏览器右键->查看源代码,或者右键要查看的内容->检查,然后会看到如下界面:
这时候如果我们在Khaled Hosseini那一行右键,可以右键->复制->选择器或者Xpath直接复制对应的层次定位。需要注意的是,我们还需要将复制的定位代码替换成XML包可以识别的格式。例如,属性值使用单引号,“//”表示该类型的所有节点等。
下面重点介绍XML中常见的节点定位方法和代码,可以作为参考:
<p>getNodeSet(doc,'/bookstore/book[1]')
# 选取属于 bookstore 子元素的最后一个 book 元素。
getNodeSet(doc,'/bookstore/book[last()]')
# 选取最前面的两个属于 bookstore 元素的子元素的 book 元素
getNodeSet(doc,'/bookstore/book[position() 查看全部
c爬虫抓取网页数据(开始定位,也即这两个写法在XML包中都是适用的)
开始定位,即
div[@class='first']/a/text()
这两种写法都适用于 XML 包。
由于不是主要内容,更多关于HTML的知识这里不再赘述。详细的可以自己学习HTML和CSS相关知识,是爬虫的基础。
我们通常使用chrome浏览器右键->查看源代码,或者右键要查看的内容->检查,然后会看到如下界面:
这时候如果我们在Khaled Hosseini那一行右键,可以右键->复制->选择器或者Xpath直接复制对应的层次定位。需要注意的是,我们还需要将复制的定位代码替换成XML包可以识别的格式。例如,属性值使用单引号,“//”表示该类型的所有节点等。
下面重点介绍XML中常见的节点定位方法和代码,可以作为参考:
<p>getNodeSet(doc,'/bookstore/book[1]')
# 选取属于 bookstore 子元素的最后一个 book 元素。
getNodeSet(doc,'/bookstore/book[last()]')
# 选取最前面的两个属于 bookstore 元素的子元素的 book 元素
getNodeSet(doc,'/bookstore/book[position()
c爬虫抓取网页数据(:网络爬虫;Python;MySQL;正则表达式;)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-03-06 05:20
吴永聪
摘要: 近年来,随着互联网的发展,如何有效地从互联网上获取所需信息已成为众多互联网公司竞争研究的新方向。从互联网获取数据最常用的方法是网络爬虫。网络爬虫,也称为网络蜘蛛和网络机器人,是一种根据特定规则和给定 URL 自动采集互联网数据和信息的程序。文章讨论了网络爬虫实现过程中的主要问题:如何使用python模拟登录、如何使用正则表达式匹配字符串获取信息、如何使用mysql存储数据等,并实现一个使用 python 的网络爬虫系统。
关键词:网络爬虫;Python; MySQL;常用表达
CLC 编号:TP311.11 文号:A文章编号:1006-8228 (2019)08-94-03
摘要:近年来,随着互联网的发展,如何有效地从互联网上获取所需的信息成为众多互联网公司争相研究的新方向,而最常见的从互联网上获取数据的手段是网络爬虫。网络爬虫也称为网络蜘蛛或网络机器人,它是根据给定的 URL 和特定规则自动采集互联网数据和信息的程序。本文讨论了网络爬虫实现中的主要问题,如如何使用Python模拟登录、如何使用正则表达式匹配字符串获取信息以及如何使用MySQL存储数据等。最后通过对Python语言的研究,实现了一个基于Python的网络爬虫程序系统。
关键词:网络爬虫;Python; MySQL;正则表达式
0 前言
在网络信息和数据爆炸式增长的时代,尽管互联网信息技术飞速发展,但仍然难以从如此海量的信息数据中找到真正有用的信息。于是,谷歌、百度、雅虎等搜索引擎应运而生。搜索引擎可以根据用户输入的关键字检索互联网上的网页,为用户查找与关键字相关或收录关键字的信息。网络爬虫作为搜索引擎的重要组成部分,在信息检索过程中发挥着重要作用。因此,网络爬虫的研究对搜索引擎的发展具有重要意义。对于编写网络爬虫,python有其独特的优势。比如python中有很多爬虫框架,使得网络爬虫爬取数据的效率更高。同时,Python 是一种面向对象的解释型高级编程语言。它的语法比其他高级编程语言更简单、更容易阅读和理解。因此,使用 Python 实现网络爬虫是一个不错的选择。
1 网络爬虫概述
1.1 网络爬虫原理
网络爬虫,又称网络蜘蛛、网络机器人,主要用于采集互联网上的各种资源。它是搜索引擎的重要组成部分,是一种自动提取 Internet 上特定页面内容的程序。通用搜索引擎网络爬虫工作流程[1]:①将种子URL放入等待URL队列;② 将等待URL从等待URL队列中取出,进行读取URL、DNS解析、网页下载等操作;③ 下载 将下载的网页放入下载的网页库;④ 将下载的网页网址放入抓取的网址队列中;爬行循环。
爬虫的工作流程:①通过URL抓取页面代码;② 通过正则匹配获取页面的有用数据或页面上有用的URL;③ 对获取的数据进行处理或通过获取的新URL进入下一轮爬取循环。
1.2 网络爬虫的分类
网络爬虫大致可以分为一般网络爬虫和专注网络爬虫[2]。
通用网络爬虫,又称全网爬虫,从一个或多个初始URL开始,获取初始页面的代码,同时从页面中提取相关URL放入队列中直到满足程序停止条件。与一般网络爬虫相比,聚焦网络爬虫的工作流程更为复杂。它需要提前通过一定的网页分析算法过滤掉一些与主题无关的URL,以保证剩余的URL在一定程度上与主题相关。放入等待抓取的 URL 队列。然后根据搜索策略,从队列中选择下一步要爬取的URL,重复上述操作,直到满足程序的停止条件。专注的网络爬虫可以爬取与主题更相关的信息。例如,为了快速获取微博中的数据,我们可以利用聚焦爬虫技术开发微博数据抓取工具[3-5]。在当今大数据时代,专注爬虫可以大海捞针,从网络数据的海洋中找到人们需要的信息,过滤掉那些“垃圾数据”(广告信息等与检索主题无关的数据) )。
2 蟒蛇
Python的作者是荷兰人Guido von Rossum。1982 年,Guido 获得了阿姆斯特丹大学的数学和计算硕士学位[6]。相比现在,在他那个年代,个人电脑的频率和内存都非常低,导致电脑的配置偏低。为了让程序在 PC 上运行,所有编译器都在其核心进行了优化,因为如果不进行优化,更大的数组可能会填满内存。Guido 想要编写一种全面、易于学习、易于使用和可扩展的新语言。1989 年,Guido 开始为 Python 语言编写编译器。
3 系统分析
本系统是一个基于Python的网络爬虫系统,用于登录并爬取豆瓣上的相册、日记、话题、评论等一些动态数据信息。并且可以将关键字查询到的动态信息数据存入数据库,将部分数据存入数据库,存入本地txt文件,同时可以将相册动态中的图片下载到本地,还记录专辑信息,在每一页上。操作完成后,可以翻页,选择页面继续操作。因此系统应满足以下要求。
(1)可以通过验证码验证模拟登录豆瓣。即不需要通过浏览器登录,输入用户名、密码和验证即可登录豆瓣。控制台中的代码。
(2)登录成功后可以抓取豆瓣首页的代码。即通过登录成功后的cookie,可以访问游客无法访问的页面,抓取页面代码.
(3)可以从页面代码中提取出需要的信息,即需要通过正则表达式匹配等方法从抓取的页面中获取有用的数据信息。
(4)可以实现翻页和分页功能。即访问网站的动态页面时,可以通过在控制台输入具体内容进行翻页或者输入页码选择页面,然后抓取其他页面。
(5)实现关键字查询的功能,爬取找到的数据并存入数据库表中。即在爬取页面获取数据后,在控制台输入关键字即可爬取获取需要的信息。
(6)可以将爬取的图片的url下载到本地,图片的详细信息可以保存在本地txt[12]。也就是说,不仅要下载图片到本地,还有图片的主题信息、图片的用户、图片的具体网址等信息都保存在txt文件中。
(7) 将日记等动态信息存储在不同的本地文件中。即针对抓取到的不同数据信息,采用不同的存储方式和存储路径。
(8)在登录成功的情况下,可以进入个人中心,将当前用户关注的用户信息存储在数据库表中。这些信息可能包括用户id、昵称、主页url、个性化签名等
以上是本课程对爬虫系统的一些基本要求,据此可以明确系统的功能。因为这个系统注重网络信息资源的爬取,所以在用户交互方面可能不是很美观。本系统没有编写界面,所有操作都在Eclipse控制台中进行。例如:在控制台输入用户名、密码和验证码登录,登录成功后的页面选择,页面选择后的数据爬取等。
但是系统运行后爬取的数据可以在数据所在的本地txt文件或数据库中查看。因此,测试系统是否真的可以爬取数据,可以通过观察本地txt文件内容的变化或者数据库表中记录的变化来验证。
该爬虫系统包括模拟登录、页面爬取、信息爬取、数据存储等主要功能。其中,页面爬取包括翻页爬取、页面选择爬取、个人页面爬取;信息爬取包括动态爬取和跟随用户爬取;数据存储包括写入文件、下载到本地和存储数据库,如图1所示。
自动爬取 Internet 信息的程序称为爬虫。它主要由爬虫调度器、URL管理器、网页下载器和网页解析器组成。
(1)爬虫调度器:程序的入口点,主要负责爬虫程序的控制。
⑵ 网址管理器:
① 为要爬取的集合添加新的URL;
②判断要添加的URL是否已经存在;
③ 判断是否还有待爬取的URL,将待爬取集合中的URL移动到爬取集合中。
URL存储方式:Python内存是set()集合、关系数据库、缓存数据库。
(3)网页下载器:根据URL获取网页内容,通过urllib2和request实现。
⑷网页解析器:从网页中提取有价值的数据。实现方式包括正则表达式、html.parser、BeautifulSoup、lxml。
4。结论
爬虫是一种自动下载网页的程序。它根据给定的爬取目标有选择地访问万维网上的网页及其相关链接,以获取所需的信息。
本文中,爬虫旨在爬取与特定主题内容相关的网页,为面向主题的用户查询准备数据资源,实现网页数据的抓取和分析。
参考:
[1] 曾小虎. 基于主题的微博网络爬虫研究[D]. 武汉理工大学, 2014.
[2] 周丽珠,林玲.爬虫技术研究综述[J]. 计算机应用,2005. 25 (9): 1965-1969
[3] 周中华,张惠然,谢江。Python中的新浪微博数据爬虫[J]. 计算机应用,2014.34 (11): 3131-3134
[4] 刘晶晶. 面向微博的网络爬虫研究与实现[D]. 复旦大学,2012.
[5] 王静,朱可,王斌强。基于信息数据分析的微博研究综述[J]. 计算机应用, 2012. 32 (7): 2027-2029, 2037.@ >
[6](挪威)Magnus Lie Hetland。思伟,曾俊伟,谭英华,译。Python基础教程[M].人民邮电出版社,2014. 查看全部
c爬虫抓取网页数据(:网络爬虫;Python;MySQL;正则表达式;)
吴永聪

摘要: 近年来,随着互联网的发展,如何有效地从互联网上获取所需信息已成为众多互联网公司竞争研究的新方向。从互联网获取数据最常用的方法是网络爬虫。网络爬虫,也称为网络蜘蛛和网络机器人,是一种根据特定规则和给定 URL 自动采集互联网数据和信息的程序。文章讨论了网络爬虫实现过程中的主要问题:如何使用python模拟登录、如何使用正则表达式匹配字符串获取信息、如何使用mysql存储数据等,并实现一个使用 python 的网络爬虫系统。
关键词:网络爬虫;Python; MySQL;常用表达
CLC 编号:TP311.11 文号:A文章编号:1006-8228 (2019)08-94-03
摘要:近年来,随着互联网的发展,如何有效地从互联网上获取所需的信息成为众多互联网公司争相研究的新方向,而最常见的从互联网上获取数据的手段是网络爬虫。网络爬虫也称为网络蜘蛛或网络机器人,它是根据给定的 URL 和特定规则自动采集互联网数据和信息的程序。本文讨论了网络爬虫实现中的主要问题,如如何使用Python模拟登录、如何使用正则表达式匹配字符串获取信息以及如何使用MySQL存储数据等。最后通过对Python语言的研究,实现了一个基于Python的网络爬虫程序系统。
关键词:网络爬虫;Python; MySQL;正则表达式
0 前言
在网络信息和数据爆炸式增长的时代,尽管互联网信息技术飞速发展,但仍然难以从如此海量的信息数据中找到真正有用的信息。于是,谷歌、百度、雅虎等搜索引擎应运而生。搜索引擎可以根据用户输入的关键字检索互联网上的网页,为用户查找与关键字相关或收录关键字的信息。网络爬虫作为搜索引擎的重要组成部分,在信息检索过程中发挥着重要作用。因此,网络爬虫的研究对搜索引擎的发展具有重要意义。对于编写网络爬虫,python有其独特的优势。比如python中有很多爬虫框架,使得网络爬虫爬取数据的效率更高。同时,Python 是一种面向对象的解释型高级编程语言。它的语法比其他高级编程语言更简单、更容易阅读和理解。因此,使用 Python 实现网络爬虫是一个不错的选择。
1 网络爬虫概述
1.1 网络爬虫原理
网络爬虫,又称网络蜘蛛、网络机器人,主要用于采集互联网上的各种资源。它是搜索引擎的重要组成部分,是一种自动提取 Internet 上特定页面内容的程序。通用搜索引擎网络爬虫工作流程[1]:①将种子URL放入等待URL队列;② 将等待URL从等待URL队列中取出,进行读取URL、DNS解析、网页下载等操作;③ 下载 将下载的网页放入下载的网页库;④ 将下载的网页网址放入抓取的网址队列中;爬行循环。
爬虫的工作流程:①通过URL抓取页面代码;② 通过正则匹配获取页面的有用数据或页面上有用的URL;③ 对获取的数据进行处理或通过获取的新URL进入下一轮爬取循环。
1.2 网络爬虫的分类
网络爬虫大致可以分为一般网络爬虫和专注网络爬虫[2]。
通用网络爬虫,又称全网爬虫,从一个或多个初始URL开始,获取初始页面的代码,同时从页面中提取相关URL放入队列中直到满足程序停止条件。与一般网络爬虫相比,聚焦网络爬虫的工作流程更为复杂。它需要提前通过一定的网页分析算法过滤掉一些与主题无关的URL,以保证剩余的URL在一定程度上与主题相关。放入等待抓取的 URL 队列。然后根据搜索策略,从队列中选择下一步要爬取的URL,重复上述操作,直到满足程序的停止条件。专注的网络爬虫可以爬取与主题更相关的信息。例如,为了快速获取微博中的数据,我们可以利用聚焦爬虫技术开发微博数据抓取工具[3-5]。在当今大数据时代,专注爬虫可以大海捞针,从网络数据的海洋中找到人们需要的信息,过滤掉那些“垃圾数据”(广告信息等与检索主题无关的数据) )。
2 蟒蛇
Python的作者是荷兰人Guido von Rossum。1982 年,Guido 获得了阿姆斯特丹大学的数学和计算硕士学位[6]。相比现在,在他那个年代,个人电脑的频率和内存都非常低,导致电脑的配置偏低。为了让程序在 PC 上运行,所有编译器都在其核心进行了优化,因为如果不进行优化,更大的数组可能会填满内存。Guido 想要编写一种全面、易于学习、易于使用和可扩展的新语言。1989 年,Guido 开始为 Python 语言编写编译器。
3 系统分析
本系统是一个基于Python的网络爬虫系统,用于登录并爬取豆瓣上的相册、日记、话题、评论等一些动态数据信息。并且可以将关键字查询到的动态信息数据存入数据库,将部分数据存入数据库,存入本地txt文件,同时可以将相册动态中的图片下载到本地,还记录专辑信息,在每一页上。操作完成后,可以翻页,选择页面继续操作。因此系统应满足以下要求。
(1)可以通过验证码验证模拟登录豆瓣。即不需要通过浏览器登录,输入用户名、密码和验证即可登录豆瓣。控制台中的代码。
(2)登录成功后可以抓取豆瓣首页的代码。即通过登录成功后的cookie,可以访问游客无法访问的页面,抓取页面代码.
(3)可以从页面代码中提取出需要的信息,即需要通过正则表达式匹配等方法从抓取的页面中获取有用的数据信息。
(4)可以实现翻页和分页功能。即访问网站的动态页面时,可以通过在控制台输入具体内容进行翻页或者输入页码选择页面,然后抓取其他页面。
(5)实现关键字查询的功能,爬取找到的数据并存入数据库表中。即在爬取页面获取数据后,在控制台输入关键字即可爬取获取需要的信息。
(6)可以将爬取的图片的url下载到本地,图片的详细信息可以保存在本地txt[12]。也就是说,不仅要下载图片到本地,还有图片的主题信息、图片的用户、图片的具体网址等信息都保存在txt文件中。
(7) 将日记等动态信息存储在不同的本地文件中。即针对抓取到的不同数据信息,采用不同的存储方式和存储路径。
(8)在登录成功的情况下,可以进入个人中心,将当前用户关注的用户信息存储在数据库表中。这些信息可能包括用户id、昵称、主页url、个性化签名等
以上是本课程对爬虫系统的一些基本要求,据此可以明确系统的功能。因为这个系统注重网络信息资源的爬取,所以在用户交互方面可能不是很美观。本系统没有编写界面,所有操作都在Eclipse控制台中进行。例如:在控制台输入用户名、密码和验证码登录,登录成功后的页面选择,页面选择后的数据爬取等。
但是系统运行后爬取的数据可以在数据所在的本地txt文件或数据库中查看。因此,测试系统是否真的可以爬取数据,可以通过观察本地txt文件内容的变化或者数据库表中记录的变化来验证。
该爬虫系统包括模拟登录、页面爬取、信息爬取、数据存储等主要功能。其中,页面爬取包括翻页爬取、页面选择爬取、个人页面爬取;信息爬取包括动态爬取和跟随用户爬取;数据存储包括写入文件、下载到本地和存储数据库,如图1所示。
自动爬取 Internet 信息的程序称为爬虫。它主要由爬虫调度器、URL管理器、网页下载器和网页解析器组成。
(1)爬虫调度器:程序的入口点,主要负责爬虫程序的控制。
⑵ 网址管理器:
① 为要爬取的集合添加新的URL;
②判断要添加的URL是否已经存在;
③ 判断是否还有待爬取的URL,将待爬取集合中的URL移动到爬取集合中。
URL存储方式:Python内存是set()集合、关系数据库、缓存数据库。
(3)网页下载器:根据URL获取网页内容,通过urllib2和request实现。
⑷网页解析器:从网页中提取有价值的数据。实现方式包括正则表达式、html.parser、BeautifulSoup、lxml。
4。结论
爬虫是一种自动下载网页的程序。它根据给定的爬取目标有选择地访问万维网上的网页及其相关链接,以获取所需的信息。
本文中,爬虫旨在爬取与特定主题内容相关的网页,为面向主题的用户查询准备数据资源,实现网页数据的抓取和分析。
参考:
[1] 曾小虎. 基于主题的微博网络爬虫研究[D]. 武汉理工大学, 2014.
[2] 周丽珠,林玲.爬虫技术研究综述[J]. 计算机应用,2005. 25 (9): 1965-1969
[3] 周中华,张惠然,谢江。Python中的新浪微博数据爬虫[J]. 计算机应用,2014.34 (11): 3131-3134
[4] 刘晶晶. 面向微博的网络爬虫研究与实现[D]. 复旦大学,2012.
[5] 王静,朱可,王斌强。基于信息数据分析的微博研究综述[J]. 计算机应用, 2012. 32 (7): 2027-2029, 2037.@ >
[6](挪威)Magnus Lie Hetland。思伟,曾俊伟,谭英华,译。Python基础教程[M].人民邮电出版社,2014.
c爬虫抓取网页数据(soup(爬虫)隐形条约下的DOM结构,常伴吾身)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-06 02:08
爬行动物就像风,一直陪伴着我……
在日常的折腾中,无论是我的网站被别人爬取,还是别人的网站被我爬取,这就像一个游戏过程。双方在“隐形条约”下完成了各自的任务。正所谓君子之情如水,我不知道他是谁,他也不知道我是谁。我们互相提供他们需要的信息。或许这种关系更像是江湖,纯洁的江湖,不是说盈盈嫣嫣和世界。只谈江上轻舟饮酒,竹林歌声。说完,双方收剑离开,没有人啰嗦一句:“谁来?报名就来。”
爬虫的一个重要部分是数据处理。虽然静态加载的网页结构千差万别,界面看起来也不一样,但是爬取的数据是单一的,都是DOM结构的“后代”。即使你明白过滤数据的本质是处理字符串,但处理它的方法是无穷无尽的。以下是根据不同网页风格对症下药。
一:《好孩子》网页
特点:有完整的DOM结构,虽然有时会使用“混乱”的编码,例如:gb2312等,但其本质仍然是“好孩子”。
示例网址:百度搜索广告牌
分析:看源码,不难看出Billboard的新闻格式是
子节点,而我们需要的部分正是子节点标签。a标签的属性类是“list-title”。
像这样的网页是典型的“好孩子”网页,具有良好的可视化 DOM 结构,所需的信息来自同一个结构,解析起来并不费力。
分析方法:
1.使用BeautifulSoup
部分代码如下:
从 bs4 导入 BeautifulSoup 作为汤
source_code = "..." #你得到的网页的源代码
汤域 = 汤(源代码,'lxml')
all_a = soup_dom.find_all('a',attrs={'class':'list-title'})
对于 all_a 中的 a:
href_title = {'href':a.get('href'),'title':a.text}
结果如下:
2、使用xpath方法解析
部分代码如下:
从 lxml 导入 etree
source_code = "..." #你得到的网页的源代码
all_a = etree.Html(source_code).xpath("//a[@class='list-title']")
对于 all_a 中的 a:
href_title = {'href':a.attrib['href'],'title':a.text}
打印(href_title)
结果如下:
从以上两种方法可以看出,可以使用bs4或者Xpath来获取“好孩子”网页的数据。毕竟管教“好孩子”的成本远低于管教“坏孩子”的成本,所以大家都喜欢好孩子。
二:“坏小子”网页
特点:大部分是古代(2010年之前)的页面,DOM乱七八糟。(有些网页甚至只有一个封闭标签,其余的都是由
标签被拆分,甚至使用虚假的 API 页面来“冒充”真实的 API。)
但是:这些网址大多是丹尼尔博主,不拘一格,当你找到它们时,就像在悬崖下发现秘密一样!
示例网址:清华大学Penny Hot于2003年编写的linuxc教程~yhf/linux_c/
分析:如果能用简单的方法,就用简单的方法,如果不能用常规的方法
我要再次感谢 PennyHot 组织了我在 2003 年获得的 Linux C 文档,以方便您使用!
解决方法:使用正则
示例代码:
重新进口
source_code = "..." #你得到的网页的源代码
compile = pile("[\u4e00-\u9fa5]*") #匹配尽可能多的中文
find_all = compile.findall(source_code)
对于我在 find_all 中:
如果我!=””:
打印(一)
结果如下:
总结:没有好方法,只要能拿到自己需要的数据,就是好方法。
最后,感谢为互联网后来者做出贡献的先辈们。尽管很多人做着普通的工作,但他们留下的东西就像宝藏一样,藏宝图隐藏在互联网的每一个角落。让我自强!
2020.3.19 维科斯 查看全部
c爬虫抓取网页数据(soup(爬虫)隐形条约下的DOM结构,常伴吾身)
爬行动物就像风,一直陪伴着我……
在日常的折腾中,无论是我的网站被别人爬取,还是别人的网站被我爬取,这就像一个游戏过程。双方在“隐形条约”下完成了各自的任务。正所谓君子之情如水,我不知道他是谁,他也不知道我是谁。我们互相提供他们需要的信息。或许这种关系更像是江湖,纯洁的江湖,不是说盈盈嫣嫣和世界。只谈江上轻舟饮酒,竹林歌声。说完,双方收剑离开,没有人啰嗦一句:“谁来?报名就来。”
爬虫的一个重要部分是数据处理。虽然静态加载的网页结构千差万别,界面看起来也不一样,但是爬取的数据是单一的,都是DOM结构的“后代”。即使你明白过滤数据的本质是处理字符串,但处理它的方法是无穷无尽的。以下是根据不同网页风格对症下药。
一:《好孩子》网页
特点:有完整的DOM结构,虽然有时会使用“混乱”的编码,例如:gb2312等,但其本质仍然是“好孩子”。
示例网址:百度搜索广告牌
分析:看源码,不难看出Billboard的新闻格式是
子节点,而我们需要的部分正是子节点标签。a标签的属性类是“list-title”。
像这样的网页是典型的“好孩子”网页,具有良好的可视化 DOM 结构,所需的信息来自同一个结构,解析起来并不费力。
分析方法:
1.使用BeautifulSoup
部分代码如下:
从 bs4 导入 BeautifulSoup 作为汤
source_code = "..." #你得到的网页的源代码
汤域 = 汤(源代码,'lxml')
all_a = soup_dom.find_all('a',attrs={'class':'list-title'})
对于 all_a 中的 a:
href_title = {'href':a.get('href'),'title':a.text}
结果如下:
2、使用xpath方法解析
部分代码如下:
从 lxml 导入 etree
source_code = "..." #你得到的网页的源代码
all_a = etree.Html(source_code).xpath("//a[@class='list-title']")
对于 all_a 中的 a:
href_title = {'href':a.attrib['href'],'title':a.text}
打印(href_title)
结果如下:
从以上两种方法可以看出,可以使用bs4或者Xpath来获取“好孩子”网页的数据。毕竟管教“好孩子”的成本远低于管教“坏孩子”的成本,所以大家都喜欢好孩子。
二:“坏小子”网页
特点:大部分是古代(2010年之前)的页面,DOM乱七八糟。(有些网页甚至只有一个封闭标签,其余的都是由
标签被拆分,甚至使用虚假的 API 页面来“冒充”真实的 API。)
但是:这些网址大多是丹尼尔博主,不拘一格,当你找到它们时,就像在悬崖下发现秘密一样!
示例网址:清华大学Penny Hot于2003年编写的linuxc教程~yhf/linux_c/
分析:如果能用简单的方法,就用简单的方法,如果不能用常规的方法
我要再次感谢 PennyHot 组织了我在 2003 年获得的 Linux C 文档,以方便您使用!
解决方法:使用正则
示例代码:
重新进口
source_code = "..." #你得到的网页的源代码
compile = pile("[\u4e00-\u9fa5]*") #匹配尽可能多的中文
find_all = compile.findall(source_code)
对于我在 find_all 中:
如果我!=””:
打印(一)
结果如下:
总结:没有好方法,只要能拿到自己需要的数据,就是好方法。
最后,感谢为互联网后来者做出贡献的先辈们。尽管很多人做着普通的工作,但他们留下的东西就像宝藏一样,藏宝图隐藏在互联网的每一个角落。让我自强!
2020.3.19 维科斯
c爬虫抓取网页数据(静态网页抓取的介绍及应用方法-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-06 02:07
一、静态网页抓取简介
静态网页是纯 HTML 格式的网页。早期的 网站 是由静态网页组成的。静态网页的数据更容易获取,因为我们需要的代码隐藏在 HTML 代码中。为了抓取静态网页,我们使用 requests 库。Requests 允许您轻松发送 HTTP 请求。该库使用简单,功能齐全。
二、获取响应内容
获取响应内容的过程相当于使用浏览器的过程。我们在浏览器中输入URL,浏览器会向服务器请求内容,服务器会返回HTML代码,浏览器会自动解析代码。我们的爬虫和浏览器发送请求的过程是一样的,都是通过requests向浏览器发送请求,获取请求内容。
import requests
# 发送请求,获取服务器响应内容
r = requests.get("http://www.santostang.com/")
print("文本编码:", r.encoding)
print("响应状态码:", r.status_code)
print("字符串方式的响应体:", r.text)
三、自定义请求
我们使用requets发送请求获取数据,但是有些网页需要设置参数来获取需要的数据,那么我们设置这些参数
1. 传递 URL 参数
有时我们需要在 URL 中添加一些参数来请求特定的数据。URL中加参数的形式是在问号之后,以key/value的形式放在URL中。我们可以将参数保存在字典中,并将参数构建到 URL 中。
key_dict = {'key1': 'value1', 'key2': 'value2'}
r = requests.get('http://httpbin.org/get', params=key_dict)
print("URL已经正确编码:", r.url)
print("字符串方式的响应体:\n", r.text)
2. 自定义请求标头
请求标头是 Headers 部分,标头提供有关请求、响应或其他发送请求的实体的信息。简单来说就是模拟浏览器的作用,所以请求头是必须要学习的,那么我们如何构造请求头,我们使用谷歌浏览器。可以点击鼠标右键,点击Check,然后看下图,可以找到请求需要的参数。
# 构建请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'Host': 'www.santostang.com'
}
r = requests.get("http://www.santostang.com/", headers=headers)
print("响应状态码:", r.status_code)
响应状态码: 200
3. 发送 POST 请求
除了get请求之外,还需要以编码格式的形式发送一些数据,有些网站需要登录才能访问,所以需要使用POST请求,我们还需要传递一个字典到请求中的数据参数。发出请求时,此数据字典将自动编码到表单中。
key_dict = {'key1': 'value1', 'key2': 'value2'}
r = requests.post('http://httpbin.org/post', data=key_dict)
print(r.text)
4. 超时
有时候我们发送一个请求,服务器会很长时间没有响应,爬虫会一直等待。如果爬虫程序执行不顺畅,可以使用requests在超时参数设置的秒数后停止等待响应。我们将其设置为 0.001 秒。
url = "http://www.santostang.com/"
r = requests.get(url, timeout=0.001)
ConnectTimeout: HTTPConnectionPool(host='www.santostang.com', port=80): Max retries exceeded with url: / (Caused by ConnectTimeoutError(, 'Connection to www.santostang.com timed out. (connect timeout=0.001)'))
四、项目实例
爬豆瓣前250名电影名
# 导入包
import requests
from bs4 import BeautifulSoup
# 发送请求,获取响应内容
def get_movies():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'Host': 'movie.douban.com'
}
movie_list = []
for i in range(0, 10):
# 构建url,发送请求
url = "https://movie.douban.com/top250?start={}" + str(i * 25)
r = requests.get(url, headers=headers, timeout=10)
print(str(i + 1), "页面响应状态:", r.status_code)
# 解析网页
soup = BeautifulSoup(r.text, "lxml")
div_list = soup.find_all('div', class_= 'hd')
for each in div_list:
movie = each.a.span.text.strip()
movie_list.append(movie)
return movie_list
movies = get_movies()
print(movies)
总结:本篇笔记主要学习爬取静态网页时如何发送请求,包括url参数的设置方法。最后,实现一个小案例。 查看全部
c爬虫抓取网页数据(静态网页抓取的介绍及应用方法-上海怡健医学)
一、静态网页抓取简介
静态网页是纯 HTML 格式的网页。早期的 网站 是由静态网页组成的。静态网页的数据更容易获取,因为我们需要的代码隐藏在 HTML 代码中。为了抓取静态网页,我们使用 requests 库。Requests 允许您轻松发送 HTTP 请求。该库使用简单,功能齐全。
二、获取响应内容
获取响应内容的过程相当于使用浏览器的过程。我们在浏览器中输入URL,浏览器会向服务器请求内容,服务器会返回HTML代码,浏览器会自动解析代码。我们的爬虫和浏览器发送请求的过程是一样的,都是通过requests向浏览器发送请求,获取请求内容。
import requests
# 发送请求,获取服务器响应内容
r = requests.get("http://www.santostang.com/";)
print("文本编码:", r.encoding)
print("响应状态码:", r.status_code)
print("字符串方式的响应体:", r.text)

三、自定义请求
我们使用requets发送请求获取数据,但是有些网页需要设置参数来获取需要的数据,那么我们设置这些参数
1. 传递 URL 参数
有时我们需要在 URL 中添加一些参数来请求特定的数据。URL中加参数的形式是在问号之后,以key/value的形式放在URL中。我们可以将参数保存在字典中,并将参数构建到 URL 中。
key_dict = {'key1': 'value1', 'key2': 'value2'}
r = requests.get('http://httpbin.org/get', params=key_dict)
print("URL已经正确编码:", r.url)
print("字符串方式的响应体:\n", r.text)

2. 自定义请求标头
请求标头是 Headers 部分,标头提供有关请求、响应或其他发送请求的实体的信息。简单来说就是模拟浏览器的作用,所以请求头是必须要学习的,那么我们如何构造请求头,我们使用谷歌浏览器。可以点击鼠标右键,点击Check,然后看下图,可以找到请求需要的参数。
# 构建请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'Host': 'www.santostang.com'
}
r = requests.get("http://www.santostang.com/", headers=headers)
print("响应状态码:", r.status_code)
响应状态码: 200
3. 发送 POST 请求
除了get请求之外,还需要以编码格式的形式发送一些数据,有些网站需要登录才能访问,所以需要使用POST请求,我们还需要传递一个字典到请求中的数据参数。发出请求时,此数据字典将自动编码到表单中。
key_dict = {'key1': 'value1', 'key2': 'value2'}
r = requests.post('http://httpbin.org/post', data=key_dict)
print(r.text)

4. 超时
有时候我们发送一个请求,服务器会很长时间没有响应,爬虫会一直等待。如果爬虫程序执行不顺畅,可以使用requests在超时参数设置的秒数后停止等待响应。我们将其设置为 0.001 秒。
url = "http://www.santostang.com/"
r = requests.get(url, timeout=0.001)
ConnectTimeout: HTTPConnectionPool(host='www.santostang.com', port=80): Max retries exceeded with url: / (Caused by ConnectTimeoutError(, 'Connection to www.santostang.com timed out. (connect timeout=0.001)'))
四、项目实例
爬豆瓣前250名电影名
# 导入包
import requests
from bs4 import BeautifulSoup
# 发送请求,获取响应内容
def get_movies():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'Host': 'movie.douban.com'
}
movie_list = []
for i in range(0, 10):
# 构建url,发送请求
url = "https://movie.douban.com/top250?start={}" + str(i * 25)
r = requests.get(url, headers=headers, timeout=10)
print(str(i + 1), "页面响应状态:", r.status_code)
# 解析网页
soup = BeautifulSoup(r.text, "lxml")
div_list = soup.find_all('div', class_= 'hd')
for each in div_list:
movie = each.a.span.text.strip()
movie_list.append(movie)
return movie_list
movies = get_movies()
print(movies)

总结:本篇笔记主要学习爬取静态网页时如何发送请求,包括url参数的设置方法。最后,实现一个小案例。
c爬虫抓取网页数据(苏宁百万级商品爬取索引讲解4.1代码讲解(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-02 06:00
阿里云>云栖社区>主题地图>C>c爬网数据库
推荐活动:
更多优惠>
当前话题:c爬网数据库添加到采集夹
相关话题:
c 爬网数据库相关博客查看更多博客
云数据库产品概述
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
图数据库综述及Nebula在图数据库设计中的实践
作者:NebulaGraph2433 浏览评论:02年前
Nebula Graph:一个开源的分布式图数据库。Nebula Graph 作为唯一可以存储万亿级节点和带属性边的在线图数据库,不仅可以满足高并发场景下毫秒级的低延迟查询需求,还可以实现高服务可用性和数据安全性。第三届nMeetup(nMeet
阅读全文
Python爬虫入门教程3-100 数据爬取
作者:梦橡皮擦 1100人评论:02年前
1.湄公河网络资料-介绍从今天开始,我们尝试使用2篇博客的内容,得到一个名为“湄公河网络”的网站网址:这个网站我分析了一下,图片我们想抓取的是在以下网址
阅读全文
苏宁百万级商品爬取简述
作者:HappyFox1045 人浏览评论:03年前
代码下载链接 苏宁万级商品爬虫目录思路讲解分类爬取思路讲解分类页面爬取商品爬取3.1思路讲解商品爬取13.2思路讲解商品爬取23.3 代码解释产品爬取索引解释4.1 代码解释索引建立4.2 代码解释索引查询语句本部门
阅读全文
一个存储大量爬虫数据的数据库,懂吗?
作者:fesoncn3336 浏览人数:03年前
“当然,不是所有的数据都适合” 在学习爬虫的过程中,遇到了很多坑。你今天可能会遇到这个坑,随着爬取数据量的增加,以及爬取的网站数据字段的变化,以往爬虫上手的方法的局限性可能会突然增加。什么是突增法?介绍示例当开始使用爬虫时,
阅读全文
Python3中如何解决乱码爬取网页信息?(更新:已解决)
作者:大连瓦工2696 浏览评论:04年前
更新:乱码问题已解决。把下面代码中的红色部分改成下面这样,这样就不会有个别职位信息出现乱码了。soup2 = BeautifulSoup(wbdata2, 'html.parser',from_encoding="GBK") 还有:创建微信公众号
阅读全文
Python爬虫:用BeautifulSoup爬取NBA数据
作者:夜李2725查看评论:04年前
爬虫的主要目的是过滤掉网页中的无用信息,抓取网页中的有用信息。一般的爬虫架构是:在使用python爬虫之前,必须对网页的结构知识有一定的了解,比如网页的标签、网页的语言等知识,推荐爬之前去W3School:W3school链接了解一些工具:1
阅读全文
【Python爬虫2】网页数据提取
作者:wu_being1266 浏览评论:05年前
提取数据方法 1 正则表达式 2 流行BeautifulSoup 模块 3 强大的Lxml 模块性能对比 添加链接爬虫的爬取回调 1 回调函数1 2 回调函数2 3 复用上一章的链接爬虫代码 我们让这个爬虫比较从每一个中提取一些数据网页,然后实现某些东西,这种做法也
阅读全文
php爬虫:知乎用户数据爬取分析
作者:cuixiaozhuai2345 浏览评论:05年前
背景说明:小燕使用PHP的curl写的爬虫实验爬取知乎5w个用户的基本信息;同时对爬取的数据进行了简单的分析和展示。演示地址是php的蜘蛛代码和用户仪表盘的显示代码。整理好后上传到github,在个人博客和公众号更新代码库。
阅读全文
c爬网数据库相关问答
基础语言问题-Python
作者:薯片酱 55293 浏览评论:494年前
#基础语言100题——Python#最近软件界有一句很流行的一句话,“人生苦短,快用Python”,这句话说明了Python的特点,那就是快。当然,这个快并不代表 Python 跑得快,毕竟它是一种脚本语言,不管它有多快,而是 C 语言和 C++ 等底层语言,这里的快是指使用 Python
阅读全文 查看全部
c爬虫抓取网页数据(苏宁百万级商品爬取索引讲解4.1代码讲解(组图))
阿里云>云栖社区>主题地图>C>c爬网数据库
推荐活动:
更多优惠>
当前话题:c爬网数据库添加到采集夹
相关话题:
c 爬网数据库相关博客查看更多博客
云数据库产品概述

作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
图数据库综述及Nebula在图数据库设计中的实践


作者:NebulaGraph2433 浏览评论:02年前
Nebula Graph:一个开源的分布式图数据库。Nebula Graph 作为唯一可以存储万亿级节点和带属性边的在线图数据库,不仅可以满足高并发场景下毫秒级的低延迟查询需求,还可以实现高服务可用性和数据安全性。第三届nMeetup(nMeet
阅读全文
Python爬虫入门教程3-100 数据爬取

作者:梦橡皮擦 1100人评论:02年前
1.湄公河网络资料-介绍从今天开始,我们尝试使用2篇博客的内容,得到一个名为“湄公河网络”的网站网址:这个网站我分析了一下,图片我们想抓取的是在以下网址
阅读全文
苏宁百万级商品爬取简述


作者:HappyFox1045 人浏览评论:03年前
代码下载链接 苏宁万级商品爬虫目录思路讲解分类爬取思路讲解分类页面爬取商品爬取3.1思路讲解商品爬取13.2思路讲解商品爬取23.3 代码解释产品爬取索引解释4.1 代码解释索引建立4.2 代码解释索引查询语句本部门
阅读全文
一个存储大量爬虫数据的数据库,懂吗?

作者:fesoncn3336 浏览人数:03年前
“当然,不是所有的数据都适合” 在学习爬虫的过程中,遇到了很多坑。你今天可能会遇到这个坑,随着爬取数据量的增加,以及爬取的网站数据字段的变化,以往爬虫上手的方法的局限性可能会突然增加。什么是突增法?介绍示例当开始使用爬虫时,
阅读全文
Python3中如何解决乱码爬取网页信息?(更新:已解决)

作者:大连瓦工2696 浏览评论:04年前
更新:乱码问题已解决。把下面代码中的红色部分改成下面这样,这样就不会有个别职位信息出现乱码了。soup2 = BeautifulSoup(wbdata2, 'html.parser',from_encoding="GBK") 还有:创建微信公众号
阅读全文
Python爬虫:用BeautifulSoup爬取NBA数据


作者:夜李2725查看评论:04年前
爬虫的主要目的是过滤掉网页中的无用信息,抓取网页中的有用信息。一般的爬虫架构是:在使用python爬虫之前,必须对网页的结构知识有一定的了解,比如网页的标签、网页的语言等知识,推荐爬之前去W3School:W3school链接了解一些工具:1
阅读全文
【Python爬虫2】网页数据提取


作者:wu_being1266 浏览评论:05年前
提取数据方法 1 正则表达式 2 流行BeautifulSoup 模块 3 强大的Lxml 模块性能对比 添加链接爬虫的爬取回调 1 回调函数1 2 回调函数2 3 复用上一章的链接爬虫代码 我们让这个爬虫比较从每一个中提取一些数据网页,然后实现某些东西,这种做法也
阅读全文
php爬虫:知乎用户数据爬取分析

作者:cuixiaozhuai2345 浏览评论:05年前
背景说明:小燕使用PHP的curl写的爬虫实验爬取知乎5w个用户的基本信息;同时对爬取的数据进行了简单的分析和展示。演示地址是php的蜘蛛代码和用户仪表盘的显示代码。整理好后上传到github,在个人博客和公众号更新代码库。
阅读全文
c爬网数据库相关问答
基础语言问题-Python

作者:薯片酱 55293 浏览评论:494年前
#基础语言100题——Python#最近软件界有一句很流行的一句话,“人生苦短,快用Python”,这句话说明了Python的特点,那就是快。当然,这个快并不代表 Python 跑得快,毕竟它是一种脚本语言,不管它有多快,而是 C 语言和 C++ 等底层语言,这里的快是指使用 Python
阅读全文
c爬虫抓取网页数据(一下如何用Excel快速抓取网页数据(图)的技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-28 23:02
网站 上的数据源是我们统计分析的重要信息来源。我们生活中经常听到一个词叫“爬虫”,它可以快速爬取网页上的数据,这对于数据分析相关的工作来说是极其重要的,也是必备的技能之一。但是,大多数爬虫都需要编程知识,普通人很难上手。今天我将向您展示如何使用 Excel 快速抓取 Web 数据。
1、首先打开要抓取数据的网站,复制网站的地址。
2、创建一个新的 Excel 工作簿,然后单击“数据”菜单 >“获取外部数据”选项卡中的“来自 网站”选项。
在弹出的“New Web Query”对话框中,在地址栏中输入要捕获的网站的地址,点击“Go”
点击黄色导入箭头,选择要抓取的部分,如图。点击导入。
3、选择存储数据的位置(默认选中的单元格),点击确定。一般建议将数据存储在“A1”单元格中。
4、如果想让Excel工作簿数据根据网站的数据实时自动更新,那么我们需要在“属性”中进行设置。可以设置“允许后台刷新”、“刷新频率”、“打开文件时刷新数据”等。
拿到数据之后,就需要对数据进行处理,而处理数据是比较重要的一环。更多数据处理技巧,请关注我!
郑重声明:本文版权归原作者所有,转载文章仅出于传播更多信息之目的。如果作者信息标注有误,请尽快联系我们修改或删除,谢谢。 查看全部
c爬虫抓取网页数据(一下如何用Excel快速抓取网页数据(图)的技巧)
网站 上的数据源是我们统计分析的重要信息来源。我们生活中经常听到一个词叫“爬虫”,它可以快速爬取网页上的数据,这对于数据分析相关的工作来说是极其重要的,也是必备的技能之一。但是,大多数爬虫都需要编程知识,普通人很难上手。今天我将向您展示如何使用 Excel 快速抓取 Web 数据。
1、首先打开要抓取数据的网站,复制网站的地址。

2、创建一个新的 Excel 工作簿,然后单击“数据”菜单 >“获取外部数据”选项卡中的“来自 网站”选项。

在弹出的“New Web Query”对话框中,在地址栏中输入要捕获的网站的地址,点击“Go”

点击黄色导入箭头,选择要抓取的部分,如图。点击导入。

3、选择存储数据的位置(默认选中的单元格),点击确定。一般建议将数据存储在“A1”单元格中。



4、如果想让Excel工作簿数据根据网站的数据实时自动更新,那么我们需要在“属性”中进行设置。可以设置“允许后台刷新”、“刷新频率”、“打开文件时刷新数据”等。

拿到数据之后,就需要对数据进行处理,而处理数据是比较重要的一环。更多数据处理技巧,请关注我!
郑重声明:本文版权归原作者所有,转载文章仅出于传播更多信息之目的。如果作者信息标注有误,请尽快联系我们修改或删除,谢谢。
c爬虫抓取网页数据(通用爬虫如何获取一个新网站的工作流程及解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-02-28 22:20
万能爬虫是一个自动提取网页的程序。它从互联网上为搜索引擎下载网页,是搜索引擎的重要组成部分。
万能爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某个停止条件。图1展示了一般爬虫爬取网页的过程。
通用网络爬虫从 Internet 采集网页和 采集 信息。这些网页信息用于为搜索引擎的索引提供支持。它决定了整个引擎系统的内容是否丰富,信息是否及时,从而决定其性能的好坏。直接影响搜索引擎的效果。
但是用于搜索引擎的通用爬虫的爬取行为需要遵守一定的规则,遵守一些命令或文件的内容,比如标有nofollow的链接,或者Robots协议(后面会有相关介绍) .
了解更多:搜索引擎工作流程
搜索引擎是通用爬虫最重要的应用领域,也是大家使用网络功能时最大的助手。接下来介绍一下搜索引擎的工作流程,主要包括以下几个步骤。
1. 爬网
搜索引擎使用通用爬虫来爬取网页。基本工作流程与其他爬虫类似。一般步骤如下:
(1)先选择一部分种子URL,将这些URL放入待爬取的URL队列中;
(2)取出要爬取的URL,解析DNS得到主机的IP,下载该URL对应的网页,存入下载的网页库,将这些URL放入已爬取的URL队列中.
(3)分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列中,从而进入下一个循环。
那么搜索引擎如何获得一个新的网站 URL呢?
(1)新增网站主动向搜索引擎提交网址:(如百度)。
(2)在其他网站上设置新的网站外部链接(尽量在搜索引擎爬虫范围内)。
(3)搜索引擎与DNS解析服务商(如DNSPod等)合作,新的网站域名会被快速抓取。
2. 数据存储
搜索引擎通过爬虫爬取网页后,将数据存储在原创页面数据库中。页面数据与用户浏览器获取的 HTML 完全相同。
搜索引擎蜘蛛在抓取页面时也会进行某些重复内容检测。一旦他们遇到大量抄袭、采集 或复制访问权重低的网站 上的内容,很有可能不再使用。爬行。
3. 预处理
搜索引擎将从爬虫中抓取回页面并执行各种预处理步骤,包括:
· 提取文本
·中文分词 查看全部
c爬虫抓取网页数据(通用爬虫如何获取一个新网站的工作流程及解决方法)
万能爬虫是一个自动提取网页的程序。它从互联网上为搜索引擎下载网页,是搜索引擎的重要组成部分。
万能爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某个停止条件。图1展示了一般爬虫爬取网页的过程。
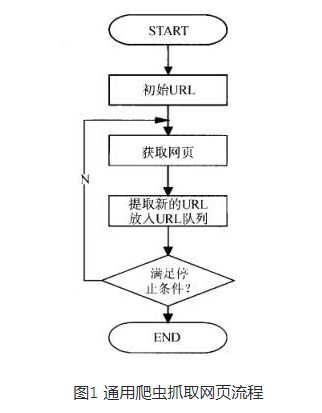
通用网络爬虫从 Internet 采集网页和 采集 信息。这些网页信息用于为搜索引擎的索引提供支持。它决定了整个引擎系统的内容是否丰富,信息是否及时,从而决定其性能的好坏。直接影响搜索引擎的效果。
但是用于搜索引擎的通用爬虫的爬取行为需要遵守一定的规则,遵守一些命令或文件的内容,比如标有nofollow的链接,或者Robots协议(后面会有相关介绍) .
了解更多:搜索引擎工作流程
搜索引擎是通用爬虫最重要的应用领域,也是大家使用网络功能时最大的助手。接下来介绍一下搜索引擎的工作流程,主要包括以下几个步骤。
1. 爬网
搜索引擎使用通用爬虫来爬取网页。基本工作流程与其他爬虫类似。一般步骤如下:
(1)先选择一部分种子URL,将这些URL放入待爬取的URL队列中;
(2)取出要爬取的URL,解析DNS得到主机的IP,下载该URL对应的网页,存入下载的网页库,将这些URL放入已爬取的URL队列中.
(3)分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列中,从而进入下一个循环。
那么搜索引擎如何获得一个新的网站 URL呢?
(1)新增网站主动向搜索引擎提交网址:(如百度)。
(2)在其他网站上设置新的网站外部链接(尽量在搜索引擎爬虫范围内)。
(3)搜索引擎与DNS解析服务商(如DNSPod等)合作,新的网站域名会被快速抓取。
2. 数据存储
搜索引擎通过爬虫爬取网页后,将数据存储在原创页面数据库中。页面数据与用户浏览器获取的 HTML 完全相同。
搜索引擎蜘蛛在抓取页面时也会进行某些重复内容检测。一旦他们遇到大量抄袭、采集 或复制访问权重低的网站 上的内容,很有可能不再使用。爬行。
3. 预处理
搜索引擎将从爬虫中抓取回页面并执行各种预处理步骤,包括:
· 提取文本
·中文分词
c爬虫抓取网页数据(【】一个一级-spider页面())
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-28 22:18
前言
在研究数据之前,我零零散散地写了一些数据爬虫,但我写的比较随意。很多地方现在看起来不太合理。这次比较空闲,本来想重构之前的项目。
后来利用这个周末简单的重新写了一个项目,就是这个项目guwen-spider。目前这种爬虫还是比较简单的类型,直接爬取页面,然后从页面中提取数据,将数据保存到数据库中。
通过和我之前写的比较,我认为难点在于整个程序的健壮性和相应的容错机制。其实昨天在写代码的过程中就体现出来了。真正的主代码其实写得很快,大部分时间都花在了
做稳定性调试,寻求更合理的方式处理数据与过程控制的关系。
背景
项目背景是抓取一级页面,即目录列表,点击目录进入章节和长度列表,点击章节或长度进入具体内容页面。
概述
本项目github地址:guwen-spider(PS:***脸上有彩蛋~~逃跑
项目技术细节
项目中大量使用了 ES7 的 async 函数,更直观的反映了程序的流程。为方便起见,在遍历数据的过程中直接使用了众所周知的 async 库,所以难免会用到回调 promise。因为数据处理发生在回调函数中,难免会遇到一些数据传输问题。,其实可以直接用ES7的async await写一个方法来实现同样的功能。其实这里最好的部分是使用Class的静态方法来封装数据库的操作。顾名思义,静态方法就像原型一样,不占用额外空间。
该项目主要使用
ES7 的 async await 协程做异步逻辑处理。使用 npm 的异步库进行循环遍历和并发请求操作。使用log4js做日志处理,使用cheerio处理dom操作。使用 mongoose 连接 mongoDB 进行数据存储和操作。
目录结构
项目实现计划分析
条目是典型的多级爬取案例,目前只有书单、图书条目对应的章节列表、章节链接对应的内容三个等级。有两种方法可以获取这样的结构。一种是直接从外层抓取到内层,然后在内层抓取后执行下一个外层,另一种是先将外层保存到数据库中。,然后根据外层爬取所有内章的链接,再次保存,然后从数据库中查询对应的链接单元爬取内容。这两种方案各有优缺点。其实这两种方法我都试过了。后者有一个优势,因为三个层次是分开捕获的,以便尽可能多地保存相关章节。数据。你可以想象,如果按照正常逻辑使用前者
遍历一级目录抓取对应的二级章节目录,然后遍历章节列表抓取内容。当三级内容单元被爬取,需要保存的时候,如果需要大量的一级目录信息,那么这些分层数据之间的数据传输,想想应该是比较复杂的事情。因此,单独保存数据在一定程度上避免了不必要的复杂数据传输。
目前我们已经考虑到,我们想要采集的古籍数量并不是很多,涵盖各种经文和历史的古籍也只有大约180本。它和章节内容本身是一个很小的数据,即一个集合中有180条文档记录。这180本书的所有章节共有16000个章节,对应的需要访问16000个页面才能爬取到相应的内容。所以选择第二个应该是合理的。
项目实现
主流程有bookListInit、chapterListInit、contentListInit三个方法,分别是抓取图书目录、章节列表、图书内容的方法,都是公开暴露的初始化方法。通过 async 可以控制这三种方法的运行过程。取书目录后,将数据存入数据库,然后将执行结果返回给主程序。如果操作成功,主程序会根据书单执行章节列表的获取。,以同样的方式爬取书籍的内容。
项目主入口
/** * 爬虫抓取主入口 */ const start = async() => { let booklistRes = await bookListInit(); if (!booklistRes) { logger.warn('书籍列表抓取出错,程序终止...'); return; } logger.info('书籍列表抓取成功,现在进行书籍章节抓取...'); let chapterlistRes = await chapterListInit(); if (!chapterlistRes) { logger.warn('书籍章节列表抓取出错,程序终止...'); return; } logger.info('书籍章节列表抓取成功,现在进行书籍内容抓取...'); let contentListRes = await contentListInit(); if (!contentListRes) { logger.warn('书籍章节内容抓取出错,程序终止...'); return; } logger.info('书籍内容抓取成功'); } // 开始入口 if (typeof bookListInit === 'function' && typeof chapterListInit === 'function') { // 开始抓取 start(); }
介绍了 bookListInit、chapterListInit、contentListInit 三个方法
书单.js
/** * 初始化入口 */ const chapterListInit = async() => { const list = await bookHelper.getBookList(bookListModel); if (!list) { logger.error('初始化查询书籍目录失败'); } logger.info('开始抓取书籍章节列表,书籍目录共:' + list.length + '条'); let res = await asyncGetChapter(list); return res; };
章节列表.js
/** * 初始化入口 */ const contentListInit = async() => { //获取书籍列表 const list = await bookHelper.getBookLi(bookListModel); if (!list) { logger.error('初始化查询书籍目录失败'); return; } const res = await mapBookList(list); if (!res) { logger.error('抓取章节信息,调用 getCurBookSectionList() 进行串行遍历操作,执行完成回调出错,错误信息已打印,请查看日志!'); return; } return res; }
关于内容抓取的思考
图书目录抓取的逻辑其实很简单。只需要使用 async.mapLimit 做一次遍历就可以保存数据,但是我们保存内容的简化逻辑其实就是遍历章节列表,抓取链接中的内容。但实际情况是,链接数多达数万。从内存使用的角度来看,我们不能将它们全部保存到一个数组中然后遍历它,所以我们需要将内容捕获统一起来。
常见的遍历方式是每次查询一定数量进行爬取。缺点是分类只用了一定的量,数据之间没有关联,分批插入。如果有错误,在容错方面会出现一些小问题,我们认为单独保存一本书作为集合会有问题。因此,我们采用第二种方法来捕获和保存图书单元中的内容。
这里使用了方法async.mapLimit(list, 1, (series, callback) => {}) 进行遍历,不可避免地用到了回调,感觉很恶心。async.mapLimit() 的第二个参数可以设置同时请求的数量。
提取后如何保存数据是个问题
这里我们通过key对数据进行分类,每次根据key获取链接,并进行遍历。这样做的好处是保存的数据是一个整体。现在我们考虑数据保存的问题。
1、可以整体插入
优点:快速的数据库操作不浪费时间。
缺点:有的书可能有几百章,也就是说插入前必须保存几百页的内容,这样也很消耗内存,可能会导致程序运行不稳定。
2、可以作为每篇文章插入数据库文章。
优点:页面爬取保存的方式,可以及时保存数据。即使出现后续错误,也无需重新保存之前的章节。
缺点:也明显慢。想爬几万个页面,做几万个*N的数据库操作,仔细想想。您还可以制作缓存以一次保存一定数量的记录。不错的选择。
/** * 遍历单条书籍下所有章节 调用内容抓取方法 * @param {*} list */ const mapSectionList = (list) => { return new Promise((resolve, reject) => { async.mapLimit(list, 1, (series, callback) => { let doc = series._doc; getContent(doc, callback) }, (err, result) => { if (err) { logger.error('书籍目录抓取异步执行出错!'); logger.error(err); reject(false); return; } const bookName = list[0].bookName; const key = list[0].key; // 以整体为单元进行保存 saveAllContentToDB(result, bookName, key, resolve); //以每篇文章作为单元进行保存 // logger.info(bookName + '数据抓取完成,进入下一部书籍抓取函数...'); // resolve(true); }) }) }
两者各有利弊,这里我们都尝试过。准备了两个错误保存集合,errContentModel 和 error采集Model。插入错误时,将信息分别保存到相应的集合中。您可以选择两者之一。之所以添加集合保存数据,是为了方便一次性查看和后续操作,无需查看日志。
(PS,其实error采集Model集合可以完全使用,errContentModel集合可以完整保存章节信息)
//保存出错的数据名称 const errorSpider = mongoose.Schema({ chapter: String, section: String, url: String, key: String, bookName: String, author: String, }) // 保存出错的数据名称 只保留key 和 bookName信息 const errorCollection = mongoose.Schema({ key: String, bookName: String, })
我们将每本书信息的内容放入一个新的集合中,集合以key命名。
总结
其实这个项目写的主要难点在于程序稳定性的控制,容错机制的设置,以及错误的记录。目前这个项目基本上可以一次性直接运行整个流程。但是,程序设计上肯定还存在很多问题。欢迎指正和交流。
复活节彩蛋
写完这个项目,我做了一个基于React网站的页面浏览前端和一个基于koa2.x开发的服务器。整体技术栈相当于 React + Redux + Koa2,前后端服务分别部署,各自能够更好的去除前后端服务的耦合。例如,同一组服务器端代码不仅可以为 Web 提供支持,还可以为移动和应用程序提供支持。目前整套还是很简单的,但是可以满足基本的查询和浏览功能。希望以后有时间让项目更加丰富。
该项目非常简单,但有一个额外的环境用于学习和研究从前端到服务器端的开发。 查看全部
c爬虫抓取网页数据(【】一个一级-spider页面())
前言
在研究数据之前,我零零散散地写了一些数据爬虫,但我写的比较随意。很多地方现在看起来不太合理。这次比较空闲,本来想重构之前的项目。
后来利用这个周末简单的重新写了一个项目,就是这个项目guwen-spider。目前这种爬虫还是比较简单的类型,直接爬取页面,然后从页面中提取数据,将数据保存到数据库中。
通过和我之前写的比较,我认为难点在于整个程序的健壮性和相应的容错机制。其实昨天在写代码的过程中就体现出来了。真正的主代码其实写得很快,大部分时间都花在了
做稳定性调试,寻求更合理的方式处理数据与过程控制的关系。
背景
项目背景是抓取一级页面,即目录列表,点击目录进入章节和长度列表,点击章节或长度进入具体内容页面。
概述
本项目github地址:guwen-spider(PS:***脸上有彩蛋~~逃跑
项目技术细节
项目中大量使用了 ES7 的 async 函数,更直观的反映了程序的流程。为方便起见,在遍历数据的过程中直接使用了众所周知的 async 库,所以难免会用到回调 promise。因为数据处理发生在回调函数中,难免会遇到一些数据传输问题。,其实可以直接用ES7的async await写一个方法来实现同样的功能。其实这里最好的部分是使用Class的静态方法来封装数据库的操作。顾名思义,静态方法就像原型一样,不占用额外空间。
该项目主要使用
ES7 的 async await 协程做异步逻辑处理。使用 npm 的异步库进行循环遍历和并发请求操作。使用log4js做日志处理,使用cheerio处理dom操作。使用 mongoose 连接 mongoDB 进行数据存储和操作。
目录结构
项目实现计划分析
条目是典型的多级爬取案例,目前只有书单、图书条目对应的章节列表、章节链接对应的内容三个等级。有两种方法可以获取这样的结构。一种是直接从外层抓取到内层,然后在内层抓取后执行下一个外层,另一种是先将外层保存到数据库中。,然后根据外层爬取所有内章的链接,再次保存,然后从数据库中查询对应的链接单元爬取内容。这两种方案各有优缺点。其实这两种方法我都试过了。后者有一个优势,因为三个层次是分开捕获的,以便尽可能多地保存相关章节。数据。你可以想象,如果按照正常逻辑使用前者
遍历一级目录抓取对应的二级章节目录,然后遍历章节列表抓取内容。当三级内容单元被爬取,需要保存的时候,如果需要大量的一级目录信息,那么这些分层数据之间的数据传输,想想应该是比较复杂的事情。因此,单独保存数据在一定程度上避免了不必要的复杂数据传输。
目前我们已经考虑到,我们想要采集的古籍数量并不是很多,涵盖各种经文和历史的古籍也只有大约180本。它和章节内容本身是一个很小的数据,即一个集合中有180条文档记录。这180本书的所有章节共有16000个章节,对应的需要访问16000个页面才能爬取到相应的内容。所以选择第二个应该是合理的。
项目实现
主流程有bookListInit、chapterListInit、contentListInit三个方法,分别是抓取图书目录、章节列表、图书内容的方法,都是公开暴露的初始化方法。通过 async 可以控制这三种方法的运行过程。取书目录后,将数据存入数据库,然后将执行结果返回给主程序。如果操作成功,主程序会根据书单执行章节列表的获取。,以同样的方式爬取书籍的内容。
项目主入口
/** * 爬虫抓取主入口 */ const start = async() => { let booklistRes = await bookListInit(); if (!booklistRes) { logger.warn('书籍列表抓取出错,程序终止...'); return; } logger.info('书籍列表抓取成功,现在进行书籍章节抓取...'); let chapterlistRes = await chapterListInit(); if (!chapterlistRes) { logger.warn('书籍章节列表抓取出错,程序终止...'); return; } logger.info('书籍章节列表抓取成功,现在进行书籍内容抓取...'); let contentListRes = await contentListInit(); if (!contentListRes) { logger.warn('书籍章节内容抓取出错,程序终止...'); return; } logger.info('书籍内容抓取成功'); } // 开始入口 if (typeof bookListInit === 'function' && typeof chapterListInit === 'function') { // 开始抓取 start(); }
介绍了 bookListInit、chapterListInit、contentListInit 三个方法
书单.js
/** * 初始化入口 */ const chapterListInit = async() => { const list = await bookHelper.getBookList(bookListModel); if (!list) { logger.error('初始化查询书籍目录失败'); } logger.info('开始抓取书籍章节列表,书籍目录共:' + list.length + '条'); let res = await asyncGetChapter(list); return res; };
章节列表.js
/** * 初始化入口 */ const contentListInit = async() => { //获取书籍列表 const list = await bookHelper.getBookLi(bookListModel); if (!list) { logger.error('初始化查询书籍目录失败'); return; } const res = await mapBookList(list); if (!res) { logger.error('抓取章节信息,调用 getCurBookSectionList() 进行串行遍历操作,执行完成回调出错,错误信息已打印,请查看日志!'); return; } return res; }
关于内容抓取的思考
图书目录抓取的逻辑其实很简单。只需要使用 async.mapLimit 做一次遍历就可以保存数据,但是我们保存内容的简化逻辑其实就是遍历章节列表,抓取链接中的内容。但实际情况是,链接数多达数万。从内存使用的角度来看,我们不能将它们全部保存到一个数组中然后遍历它,所以我们需要将内容捕获统一起来。
常见的遍历方式是每次查询一定数量进行爬取。缺点是分类只用了一定的量,数据之间没有关联,分批插入。如果有错误,在容错方面会出现一些小问题,我们认为单独保存一本书作为集合会有问题。因此,我们采用第二种方法来捕获和保存图书单元中的内容。
这里使用了方法async.mapLimit(list, 1, (series, callback) => {}) 进行遍历,不可避免地用到了回调,感觉很恶心。async.mapLimit() 的第二个参数可以设置同时请求的数量。
提取后如何保存数据是个问题
这里我们通过key对数据进行分类,每次根据key获取链接,并进行遍历。这样做的好处是保存的数据是一个整体。现在我们考虑数据保存的问题。
1、可以整体插入
优点:快速的数据库操作不浪费时间。
缺点:有的书可能有几百章,也就是说插入前必须保存几百页的内容,这样也很消耗内存,可能会导致程序运行不稳定。
2、可以作为每篇文章插入数据库文章。
优点:页面爬取保存的方式,可以及时保存数据。即使出现后续错误,也无需重新保存之前的章节。
缺点:也明显慢。想爬几万个页面,做几万个*N的数据库操作,仔细想想。您还可以制作缓存以一次保存一定数量的记录。不错的选择。
/** * 遍历单条书籍下所有章节 调用内容抓取方法 * @param {*} list */ const mapSectionList = (list) => { return new Promise((resolve, reject) => { async.mapLimit(list, 1, (series, callback) => { let doc = series._doc; getContent(doc, callback) }, (err, result) => { if (err) { logger.error('书籍目录抓取异步执行出错!'); logger.error(err); reject(false); return; } const bookName = list[0].bookName; const key = list[0].key; // 以整体为单元进行保存 saveAllContentToDB(result, bookName, key, resolve); //以每篇文章作为单元进行保存 // logger.info(bookName + '数据抓取完成,进入下一部书籍抓取函数...'); // resolve(true); }) }) }
两者各有利弊,这里我们都尝试过。准备了两个错误保存集合,errContentModel 和 error采集Model。插入错误时,将信息分别保存到相应的集合中。您可以选择两者之一。之所以添加集合保存数据,是为了方便一次性查看和后续操作,无需查看日志。
(PS,其实error采集Model集合可以完全使用,errContentModel集合可以完整保存章节信息)
//保存出错的数据名称 const errorSpider = mongoose.Schema({ chapter: String, section: String, url: String, key: String, bookName: String, author: String, }) // 保存出错的数据名称 只保留key 和 bookName信息 const errorCollection = mongoose.Schema({ key: String, bookName: String, })
我们将每本书信息的内容放入一个新的集合中,集合以key命名。
总结
其实这个项目写的主要难点在于程序稳定性的控制,容错机制的设置,以及错误的记录。目前这个项目基本上可以一次性直接运行整个流程。但是,程序设计上肯定还存在很多问题。欢迎指正和交流。
复活节彩蛋
写完这个项目,我做了一个基于React网站的页面浏览前端和一个基于koa2.x开发的服务器。整体技术栈相当于 React + Redux + Koa2,前后端服务分别部署,各自能够更好的去除前后端服务的耦合。例如,同一组服务器端代码不仅可以为 Web 提供支持,还可以为移动和应用程序提供支持。目前整套还是很简单的,但是可以满足基本的查询和浏览功能。希望以后有时间让项目更加丰富。
该项目非常简单,但有一个额外的环境用于学习和研究从前端到服务器端的开发。
c爬虫抓取网页数据(无需你让我学Gooseeker我就只学它吧?|?无需)
网站优化 • 优采云 发表了文章 • 0 个评论 • 347 次浏览 • 2022-02-26 21:19
当您刚开始使用数据可视化时,主要关注点之一通常是学习制作各种图表类型。
但是用那些原创数据练习了半天,心里会有些不安和松懈。毕竟没有真正投入实战的练习都是假的,各种基础数据都是我用来数据可视化的。菜,不不不!
通常,我也会去互联网查找一些现有的数据,但它并不总是适合我的胃口。我无法完全自由地找到我想要的数据,并做我感兴趣的可视化分析。所以,这是理所当然的,我迫不及待地想了解爬行动物。
我不知道如何编程。如果想在短时间内快速掌握爬虫技巧,只能使用网页信息抓取软件,所以@squirrel给我推荐了他的课程《无需编程即可轻松获取网络数据》,学习Jisouke Gooseeker Web Crawler。
因为他的课程非常简洁易懂,而且Gooseeker的操作真的很简单,所以可以很快上手,一个晚上就爬一个简单的网站。
以前觉得爬网数据很难,现在可以这么轻松地爬取信息,真的很兴奋!
所以,如果你和我一样,没有编程基础,又想根据自己的意愿获取更多的数据信息,可以尝试学习 Gooseeker 网络爬虫。
Gooseeker的好处主要有:
Gooseeker拥有独立的网络爬虫浏览器,也可以依赖火狐浏览器一起打包下载。
我选择的软件版本是火狐版本。安装完成后会在火狐浏览器的工具栏上生成一个插件。单击“工具”以查看“MS 计算机”和“DS 计算机”。提取工作将在两个平台上执行。
当然,我们还需要注册一个账号,方便使用它来管理爬虫规则,在社区互动,下载资源等。
在我学习期间,有一位老司机(@squirrel)带我去飞行。确实让我少走了很多弯路,大大提高了我的学习效率,但是作为一个好学的学生……学姐,你不能让我学Gooseeeker,我就只学吧?肯定还有很多其他类似的工具,我需要更多地了解它们!
于是偷偷了解了其他网络数据采集器的优劣,对比对比,发现差距确实不大。黑猫和白猫,能抓到老鼠的猫就是好猫。对于学习来说,真的没必要执着于工具。
我用Gooseeker前后免费爬取了几十条网站数据,基本上所有网站信息都可以通过它轻松获取,还有一小部分网站需要走弯路。
它可以实现的爬虫任务包括:分层爬取、翻页、动态网页爬取等基本爬取方式,还支持爬虫组(不是很好用)等等。
我先学了Squirrel的课程,学会了用它爬取数据后,就去官网了解了更多细节。Gooseeker的官网社区比较齐全。上面有很多文档/视频教程,还有别人制定的免费/付费规则。您也可以在线进行数据DIY。
其产品天数软件中的APP资源也非常丰富,可以高效获取电商、微博数据和做数据挖掘、SaaS模型软件。
其中,文本分割和标注工具——天语影音对我特别有吸引力。它可以轻松完成文本的分词和可视化分析。有机会一定要试试(写论文)。
但是我个人觉得上面的视频教程都不好。很多人都说Gooseeeker前期很难上手。我认为这与他们在上面获得的教程资源的质量有限无关。
总的来说,这是一款免费好用的爬虫神器!Wall Crack推荐小伙伴们去其官网下载软件学习,可以轻松搞定一个看似遥不可及,实则又傻又甜的技能。
在接下来的几篇文章中,我会为大家介绍几个实际案例。如有任何问题,欢迎交流讨论。
资源: 查看全部
c爬虫抓取网页数据(无需你让我学Gooseeker我就只学它吧?|?无需)
当您刚开始使用数据可视化时,主要关注点之一通常是学习制作各种图表类型。
但是用那些原创数据练习了半天,心里会有些不安和松懈。毕竟没有真正投入实战的练习都是假的,各种基础数据都是我用来数据可视化的。菜,不不不!
通常,我也会去互联网查找一些现有的数据,但它并不总是适合我的胃口。我无法完全自由地找到我想要的数据,并做我感兴趣的可视化分析。所以,这是理所当然的,我迫不及待地想了解爬行动物。
我不知道如何编程。如果想在短时间内快速掌握爬虫技巧,只能使用网页信息抓取软件,所以@squirrel给我推荐了他的课程《无需编程即可轻松获取网络数据》,学习Jisouke Gooseeker Web Crawler。
因为他的课程非常简洁易懂,而且Gooseeker的操作真的很简单,所以可以很快上手,一个晚上就爬一个简单的网站。
以前觉得爬网数据很难,现在可以这么轻松地爬取信息,真的很兴奋!
所以,如果你和我一样,没有编程基础,又想根据自己的意愿获取更多的数据信息,可以尝试学习 Gooseeker 网络爬虫。

Gooseeker的好处主要有:

Gooseeker拥有独立的网络爬虫浏览器,也可以依赖火狐浏览器一起打包下载。
我选择的软件版本是火狐版本。安装完成后会在火狐浏览器的工具栏上生成一个插件。单击“工具”以查看“MS 计算机”和“DS 计算机”。提取工作将在两个平台上执行。
当然,我们还需要注册一个账号,方便使用它来管理爬虫规则,在社区互动,下载资源等。

在我学习期间,有一位老司机(@squirrel)带我去飞行。确实让我少走了很多弯路,大大提高了我的学习效率,但是作为一个好学的学生……学姐,你不能让我学Gooseeeker,我就只学吧?肯定还有很多其他类似的工具,我需要更多地了解它们!
于是偷偷了解了其他网络数据采集器的优劣,对比对比,发现差距确实不大。黑猫和白猫,能抓到老鼠的猫就是好猫。对于学习来说,真的没必要执着于工具。
我用Gooseeker前后免费爬取了几十条网站数据,基本上所有网站信息都可以通过它轻松获取,还有一小部分网站需要走弯路。
它可以实现的爬虫任务包括:分层爬取、翻页、动态网页爬取等基本爬取方式,还支持爬虫组(不是很好用)等等。
我先学了Squirrel的课程,学会了用它爬取数据后,就去官网了解了更多细节。Gooseeker的官网社区比较齐全。上面有很多文档/视频教程,还有别人制定的免费/付费规则。您也可以在线进行数据DIY。

其产品天数软件中的APP资源也非常丰富,可以高效获取电商、微博数据和做数据挖掘、SaaS模型软件。

其中,文本分割和标注工具——天语影音对我特别有吸引力。它可以轻松完成文本的分词和可视化分析。有机会一定要试试(写论文)。
但是我个人觉得上面的视频教程都不好。很多人都说Gooseeeker前期很难上手。我认为这与他们在上面获得的教程资源的质量有限无关。
总的来说,这是一款免费好用的爬虫神器!Wall Crack推荐小伙伴们去其官网下载软件学习,可以轻松搞定一个看似遥不可及,实则又傻又甜的技能。
在接下来的几篇文章中,我会为大家介绍几个实际案例。如有任何问题,欢迎交流讨论。
资源:
c爬虫抓取网页数据(爬虫在数据分析领域的应用,如何帮助我们提升数据分析质量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 224 次浏览 • 2022-03-14 12:15
在当今信息化和数字化的时代,人们离不开网络搜索,但想想看,在搜索过程中,你真的可以得到相关信息,因为有人在帮你过滤相关内容,呈现在你面前。
就像在餐馆里一样,你点了土豆然后得到它们,因为有人帮你在土豆、萝卜、西红柿等中找到它们,然后有人把它们带到你的餐桌上。在网上,这两个动作是一个叫爬虫的同学为你实现的。
也就是说,没有爬虫,就没有今天的检索,就无法准确查找信息和高效获取数据。今天DataHunter就来谈谈爬虫在数据分析领域的应用,以及它如何帮助我们提高数据分析的质量。
一、数据时代,爬虫的本质是提高效率
网络爬虫,又称网络机器人,可以代替人自动浏览网络信息,采集和组织数据。
它是一个程序,其基本原理是向网站/网络发起请求,获取资源后分析提取有用数据。从技术上讲,就是通过程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)爬取到本地,然后提取您需要的数据并将其存储以供使用。
每个程序都有自己的规则,网络爬虫也不例外。它穿梭于世界各地的各种网站之间,根据人们强加的规则将采集信息。我们称这些规则为网络爬虫算法。规则是人定的,是人根据自己的目的和需要设计的。因此,根据用户的目的,爬虫可以有不同的功能。但所有爬虫的本质是方便人们在海量的互联网信息中找到并下载自己想要的信息类型,从而提高信息获取效率。
二、爬虫的应用:搜索并帮助企业做强业务
1.搜索引擎:爬取网站为网络用户提供便利
在互联网的早期,能够提供全球范围内信息的网站并不多,用户也不多。Internet 只是文件传输协议 (FTP) 站点的集合,用户可以在其中导航以查找特定的共享文件,并查找和组合 Internet 上可用的分布式数据,创建了一个称为网络爬虫的自动化程序 /Robot,它可以爬取网络上的所有网页,然后将所有页面的内容复制到数据库中进行索引。这也是最早的搜索引擎。
如今,随着互联网的飞速发展,我们可以在任何搜索引擎中看到来自世界各地各种网站的信息。百度搜索引擎的爬虫叫百度蜘蛛,360的爬虫叫360Spider,搜狗的爬虫叫搜狗蜘蛛,必应的爬虫叫Bingbot。搜索引擎离不开爬虫。
比如百度蜘蛛每天都会抓取大量的互联网信息,抓取优质信息和收录。当用户在百度搜索引擎上搜索对应的关键词时,百度会对关键词进行分析处理,从收录的网页中找出相关网页,按照一定的排名规则和结果展示给用户,工作原理如图。现在,我们可以大胆地说,你每天都在免费享受爬虫的好处。
2.企业:监控舆情,高效获取有价值信息
我们说过爬虫的本质是提高效率,而爬虫的规则是由人决定的;那么企业就可以根据自己的业务需求设计爬虫,第一时间获取网络上的相关信息,进行清理整合。
在大数据时代进行数据分析,首先要有数据源,网络爬虫可以让我们获取更多的数据源,同时根据我们的目的进行采集,从而去除很多的无关数据。
例如,在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站s,或者从某些文档或内部资料中获取数据源。但是,这些获取数据的方式有时很难满足我们的数据需求。此时,我们可以利用爬虫技术从互联网上自动获取更多我们感兴趣的数据内容,从而进行更深入的数据分析,获取更多有价值的信息。
此外,网络爬虫还可用于财务分析,对财务数据进行采集进行投资分析;可应用于舆情监测分析、精准客户精准营销等各个领域。
三、企业常用的4种网络爬虫
网络爬虫根据实现的技术和结构可以分为一般网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。但由于网络环境复杂,实际的网络爬虫通常是这几种爬虫的组合。
1.万能网络爬虫
通用网络爬虫也称为全网络爬虫。顾名思义,要爬取的目标资源在整个互联网上,要爬取的目标数据是巨大的,爬取的范围也很大。正是因为爬取的数据是海量数据,所以对于这种爬虫来说,对爬取的性能要求是非常高的。这种网络爬虫主要用于大型搜索引擎,具有很高的应用价值。
一般的网络爬虫主要由初始URL采集、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块等组成。一般网络爬虫在爬取时会采用一定的爬取策略,主要包括深度优先爬取策略和广度优先爬取策略。具体细节将在后面介绍。
2.专注于网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是根据预先定义的主题有选择地爬取网页的爬虫。聚焦网络爬虫主要用于爬取特定信息,主要为特定类型的人提供服务。
聚焦网络爬虫也是由初始URL集合、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块、内容评价模块、链接评价模块等组成。内容评估模块和链接评估模块可以根据链接和内容的重要性确定优先访问哪些页面。专注于网络爬虫的爬取策略主要有四种,如图:
由于专注的网络爬虫可以有目的地根据相应的主题进行爬取,在实际应用过程中可以节省大量的服务器资源和宽带资源,因此具有很强的实用性。这里我们以网络爬虫为例来了解爬虫运行的工作原理和过程。
如图所示,焦点网络爬虫有一个控制中心,负责管理和监控整个爬虫系统,包括控制用户交互、初始化爬虫、确定主题、协调各个模块之间的工作以及控制整个爬虫系统。爬行过程。等等:
(1)控制中心将初始URL集合传递给URL队列,页面爬取模块会从URL队列中读取第一批URL列表;
(2)根据这些URL地址,从网上爬取对应的页面;爬取后,将爬取的内容发送到页面数据库进行存储;
(3)在爬取过程中,会爬取一些新的URL,此时需要使用链接过滤模块,根据指定的主题过滤掉不相关的链接,然后使用链接评价模块进行根据主题剩余的URL链接。或者内容评估模块进行优先排序,完成后将新的URL地址传递给URL队列,供页面爬取模块使用;
(4)抓取页面并存入页面数据库后,需要使用页面分析模块,根据主题对抓取的页面进行分析处理,并根据处理结果建立索引库。当用户检索到相应的信息,就可以从索引数据库中进行相应的检索,得到相应的结果。
3.增量网络爬虫
这里的“incremental”对应于增量更新,意思是在更新过程中只更新变化的地方,不变的地方不更新。
增量网络爬虫,在爬取网页时,只爬取内容发生变化的网页或新生成的网页,不会爬取内容未发生变化的网页。增量网络爬虫可以在一定程度上保证爬取的页面尽可能的新。
4.深网爬虫
在互联网中,网页根据存在的程度可以分为表层页面和深层页面。表面页面是指无需提交表单,使用静态链接即可到达的静态页面;而深页是提交某个关键词后才能获得的页面。在 Internet 中,深层页面的数量通常远大于表面页面的数量。
深网爬虫可以爬取互联网中的深层页面,而要爬取深层页面,就需要想办法自动填写相应的表格。深网爬虫主要由 URL 列表、LVS 列表(LVS 指标签/值集合,即填充表单的数据源)、爬取控制器、解析器、LVS 控制器、表单分析器、表单处理器、响应分析器组成和其他部分。
四、网络爬虫的爬取策略
前面我们说过,网络爬虫算法是基于人对采集信息施加的规则,由于网络环境复杂,算法也多种多样,也就是爬取策略。这里主要介绍爬取的顺序和频率。
1.爬取顺序
网络爬虫在爬取过程中,可能会出现在爬取的URL列表中的多个URL地址,因此爬虫会依次对这些URL地址进行爬取。
与一般的网络爬虫相比,爬取的顺序并不那么重要。但专注于网络爬虫,爬取的顺序与服务器资源和宽带资源有关,所以非常重要,一般由爬取策略决定。爬取策略主要包括深度优先爬取策略、广度优先爬取策略、大站点优先策略、反链策略等爬取策略。
如图,假设有一个网站,ABCDEFG为站点下的网页,网页的层次结构如图所示。如果此时网页ABCDEFG都在爬取队列中,那么根据不同的爬取策略,爬取的顺序是不同的。
深度优先爬取策略:A→D→E→B→C→F→G
广度优先爬取策略:A→B→C→D→E→F→G
除了以上两种爬取策略外,还可以使用大站点爬取策略。可以根据相应网页所属的站点进行分类。如果某个网站有大量的网页,则称为大站点。按照这个策略,网站拥有的网页越多,则越大,优先抓取该网页在大站点中的URL地址。
此外,还有反向链接策略。一个网页的反向链接数是指该网页被其他网页指向的次数。这个次数代表了该网页在一定程度上被其他网页推荐的次数。因此,如果按照反向链接策略进行爬取,那么哪个网页的反向链接多,就会先爬到哪个页面。
但是,在实际情况中,如果一个网页的优先级只是简单地由反向链接策略来决定的话,就可能会出现很多作弊的情况。因此,采用反向链接策略需要考虑可靠反向链接的数量。除了以上的爬取策略,实践中还有很多其他的爬取策略,比如OPIC策略、Partial PageRank策略等等。
2.爬取频率
网站 网页经常更新。作为爬虫,网站的更新频率越接近爬虫访问网站的频率,效果越好。当然,在爬虫服务器资源有限的情况下,爬虫还需要根据相应的策略,让不同的网页有不同的更新优先级。优先级高的网页会更新得更快,爬取响应也会更快。常见的网页更新策略有以下三种:
(1)用户体验策略:大部分用户使用搜索引擎查询某个关键词时,只会关注排名靠前的网页。因此,当爬虫服务器的资源处于有限,爬虫会优先更新排名靠前的页面。
(2)历史数据策略:是指根据一个网页的历史更新数据,通过泊松过程建模等手段,预测该网页下次更新时间的能力,从而确定下一次更新时间。抓取网页所花费的时间。
(3)聚类分析策略:网页可能有不同的内容,但一般来说,属性相似的网页更新频率相似,所以可以对大量的网页进行聚类。爬取的频率根据设置同类型网页的平均更新值。
五、网络爬虫的实现技术
对于实现技术,本文不展开,只为有兴趣的同学提供几种常用语言:Python、Java、PHP、Node.JS、C++、Go语言(另外还有很多开发语言用于网络爬虫)。
Python:爬虫框架非常丰富,多线程处理能力强,而且易学,代码简洁,优点很多。
Java:适合开发大型爬虫项目。
PHP:后端处理能力很强,代码很简洁,模块丰富,但是并发能力比较弱。
Node.JS:支持高并发和多线程。
C++:运行速度快,适合开发大型爬虫项目,成本高。
Go语言:同样的高并发能力很强。
六、总结
说到爬虫,很多人认为它们是网络世界中不可能存在的灰色地带。恭喜你,看完这篇文章,你比很多人都知道。
因为爬虫分为良性爬虫和恶意爬虫,比如搜索引擎爬虫。Goodwill爬虫严格遵守Robots协议规范爬取网页数据(如URL),它的存在可以增加网站的曝光度,给网站带来流量;
恶意爬虫,无视Robots协议,肆意爬取网站中一些深度不情愿的数据,包括个人隐私或商业机密等重要信息。而恶意爬虫的用户想要多次大量地从网站获取信息,所以通常会在目标网站上投放大量爬虫。如果大量爬虫同时访问网站,很容易导致网站服务器超载或崩溃,导致网站算子丢失。
据统计,2017年我国42.2%的互联网流量是由网络机器人创造的,其中恶意机器(主要是恶意爬虫)占21.80%。我们应该合法合理地使用网络爬虫,这样才能用科技为企业带来长远发展,用科学为社会创造更高的价值。
关于数据猎人
DataHunter是一家专业的数据分析和商业智能服务商,注册于2014年,团队核心成员来自IBM、Oracle、SAP等知名企业,深耕大数据分析领域,拥有十余年丰富的企业服务经验。
DataHunter的核心产品Data Analytics智能数据分析平台和数据大屏设计配置工具Data MAX在行业中形成了自己的独特优势,在各行业积累了众多标杆客户和成功案例。
自成立以来,DataHunter一直致力于为客户提供实时、高效、智能的数据分析与展示解决方案,帮助企业查看和分析数据并改善业务,成为最值得信赖的数据业务公司。 查看全部
c爬虫抓取网页数据(爬虫在数据分析领域的应用,如何帮助我们提升数据分析质量)
在当今信息化和数字化的时代,人们离不开网络搜索,但想想看,在搜索过程中,你真的可以得到相关信息,因为有人在帮你过滤相关内容,呈现在你面前。
就像在餐馆里一样,你点了土豆然后得到它们,因为有人帮你在土豆、萝卜、西红柿等中找到它们,然后有人把它们带到你的餐桌上。在网上,这两个动作是一个叫爬虫的同学为你实现的。
也就是说,没有爬虫,就没有今天的检索,就无法准确查找信息和高效获取数据。今天DataHunter就来谈谈爬虫在数据分析领域的应用,以及它如何帮助我们提高数据分析的质量。
一、数据时代,爬虫的本质是提高效率
网络爬虫,又称网络机器人,可以代替人自动浏览网络信息,采集和组织数据。
它是一个程序,其基本原理是向网站/网络发起请求,获取资源后分析提取有用数据。从技术上讲,就是通过程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)爬取到本地,然后提取您需要的数据并将其存储以供使用。
每个程序都有自己的规则,网络爬虫也不例外。它穿梭于世界各地的各种网站之间,根据人们强加的规则将采集信息。我们称这些规则为网络爬虫算法。规则是人定的,是人根据自己的目的和需要设计的。因此,根据用户的目的,爬虫可以有不同的功能。但所有爬虫的本质是方便人们在海量的互联网信息中找到并下载自己想要的信息类型,从而提高信息获取效率。
二、爬虫的应用:搜索并帮助企业做强业务
1.搜索引擎:爬取网站为网络用户提供便利
在互联网的早期,能够提供全球范围内信息的网站并不多,用户也不多。Internet 只是文件传输协议 (FTP) 站点的集合,用户可以在其中导航以查找特定的共享文件,并查找和组合 Internet 上可用的分布式数据,创建了一个称为网络爬虫的自动化程序 /Robot,它可以爬取网络上的所有网页,然后将所有页面的内容复制到数据库中进行索引。这也是最早的搜索引擎。
如今,随着互联网的飞速发展,我们可以在任何搜索引擎中看到来自世界各地各种网站的信息。百度搜索引擎的爬虫叫百度蜘蛛,360的爬虫叫360Spider,搜狗的爬虫叫搜狗蜘蛛,必应的爬虫叫Bingbot。搜索引擎离不开爬虫。
比如百度蜘蛛每天都会抓取大量的互联网信息,抓取优质信息和收录。当用户在百度搜索引擎上搜索对应的关键词时,百度会对关键词进行分析处理,从收录的网页中找出相关网页,按照一定的排名规则和结果展示给用户,工作原理如图。现在,我们可以大胆地说,你每天都在免费享受爬虫的好处。
2.企业:监控舆情,高效获取有价值信息
我们说过爬虫的本质是提高效率,而爬虫的规则是由人决定的;那么企业就可以根据自己的业务需求设计爬虫,第一时间获取网络上的相关信息,进行清理整合。
在大数据时代进行数据分析,首先要有数据源,网络爬虫可以让我们获取更多的数据源,同时根据我们的目的进行采集,从而去除很多的无关数据。
例如,在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站s,或者从某些文档或内部资料中获取数据源。但是,这些获取数据的方式有时很难满足我们的数据需求。此时,我们可以利用爬虫技术从互联网上自动获取更多我们感兴趣的数据内容,从而进行更深入的数据分析,获取更多有价值的信息。
此外,网络爬虫还可用于财务分析,对财务数据进行采集进行投资分析;可应用于舆情监测分析、精准客户精准营销等各个领域。
三、企业常用的4种网络爬虫
网络爬虫根据实现的技术和结构可以分为一般网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。但由于网络环境复杂,实际的网络爬虫通常是这几种爬虫的组合。
1.万能网络爬虫
通用网络爬虫也称为全网络爬虫。顾名思义,要爬取的目标资源在整个互联网上,要爬取的目标数据是巨大的,爬取的范围也很大。正是因为爬取的数据是海量数据,所以对于这种爬虫来说,对爬取的性能要求是非常高的。这种网络爬虫主要用于大型搜索引擎,具有很高的应用价值。
一般的网络爬虫主要由初始URL采集、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块等组成。一般网络爬虫在爬取时会采用一定的爬取策略,主要包括深度优先爬取策略和广度优先爬取策略。具体细节将在后面介绍。
2.专注于网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是根据预先定义的主题有选择地爬取网页的爬虫。聚焦网络爬虫主要用于爬取特定信息,主要为特定类型的人提供服务。
聚焦网络爬虫也是由初始URL集合、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块、内容评价模块、链接评价模块等组成。内容评估模块和链接评估模块可以根据链接和内容的重要性确定优先访问哪些页面。专注于网络爬虫的爬取策略主要有四种,如图:
由于专注的网络爬虫可以有目的地根据相应的主题进行爬取,在实际应用过程中可以节省大量的服务器资源和宽带资源,因此具有很强的实用性。这里我们以网络爬虫为例来了解爬虫运行的工作原理和过程。
如图所示,焦点网络爬虫有一个控制中心,负责管理和监控整个爬虫系统,包括控制用户交互、初始化爬虫、确定主题、协调各个模块之间的工作以及控制整个爬虫系统。爬行过程。等等:
(1)控制中心将初始URL集合传递给URL队列,页面爬取模块会从URL队列中读取第一批URL列表;
(2)根据这些URL地址,从网上爬取对应的页面;爬取后,将爬取的内容发送到页面数据库进行存储;
(3)在爬取过程中,会爬取一些新的URL,此时需要使用链接过滤模块,根据指定的主题过滤掉不相关的链接,然后使用链接评价模块进行根据主题剩余的URL链接。或者内容评估模块进行优先排序,完成后将新的URL地址传递给URL队列,供页面爬取模块使用;
(4)抓取页面并存入页面数据库后,需要使用页面分析模块,根据主题对抓取的页面进行分析处理,并根据处理结果建立索引库。当用户检索到相应的信息,就可以从索引数据库中进行相应的检索,得到相应的结果。
3.增量网络爬虫
这里的“incremental”对应于增量更新,意思是在更新过程中只更新变化的地方,不变的地方不更新。
增量网络爬虫,在爬取网页时,只爬取内容发生变化的网页或新生成的网页,不会爬取内容未发生变化的网页。增量网络爬虫可以在一定程度上保证爬取的页面尽可能的新。
4.深网爬虫
在互联网中,网页根据存在的程度可以分为表层页面和深层页面。表面页面是指无需提交表单,使用静态链接即可到达的静态页面;而深页是提交某个关键词后才能获得的页面。在 Internet 中,深层页面的数量通常远大于表面页面的数量。
深网爬虫可以爬取互联网中的深层页面,而要爬取深层页面,就需要想办法自动填写相应的表格。深网爬虫主要由 URL 列表、LVS 列表(LVS 指标签/值集合,即填充表单的数据源)、爬取控制器、解析器、LVS 控制器、表单分析器、表单处理器、响应分析器组成和其他部分。
四、网络爬虫的爬取策略
前面我们说过,网络爬虫算法是基于人对采集信息施加的规则,由于网络环境复杂,算法也多种多样,也就是爬取策略。这里主要介绍爬取的顺序和频率。
1.爬取顺序
网络爬虫在爬取过程中,可能会出现在爬取的URL列表中的多个URL地址,因此爬虫会依次对这些URL地址进行爬取。
与一般的网络爬虫相比,爬取的顺序并不那么重要。但专注于网络爬虫,爬取的顺序与服务器资源和宽带资源有关,所以非常重要,一般由爬取策略决定。爬取策略主要包括深度优先爬取策略、广度优先爬取策略、大站点优先策略、反链策略等爬取策略。
如图,假设有一个网站,ABCDEFG为站点下的网页,网页的层次结构如图所示。如果此时网页ABCDEFG都在爬取队列中,那么根据不同的爬取策略,爬取的顺序是不同的。
深度优先爬取策略:A→D→E→B→C→F→G
广度优先爬取策略:A→B→C→D→E→F→G
除了以上两种爬取策略外,还可以使用大站点爬取策略。可以根据相应网页所属的站点进行分类。如果某个网站有大量的网页,则称为大站点。按照这个策略,网站拥有的网页越多,则越大,优先抓取该网页在大站点中的URL地址。
此外,还有反向链接策略。一个网页的反向链接数是指该网页被其他网页指向的次数。这个次数代表了该网页在一定程度上被其他网页推荐的次数。因此,如果按照反向链接策略进行爬取,那么哪个网页的反向链接多,就会先爬到哪个页面。
但是,在实际情况中,如果一个网页的优先级只是简单地由反向链接策略来决定的话,就可能会出现很多作弊的情况。因此,采用反向链接策略需要考虑可靠反向链接的数量。除了以上的爬取策略,实践中还有很多其他的爬取策略,比如OPIC策略、Partial PageRank策略等等。
2.爬取频率
网站 网页经常更新。作为爬虫,网站的更新频率越接近爬虫访问网站的频率,效果越好。当然,在爬虫服务器资源有限的情况下,爬虫还需要根据相应的策略,让不同的网页有不同的更新优先级。优先级高的网页会更新得更快,爬取响应也会更快。常见的网页更新策略有以下三种:
(1)用户体验策略:大部分用户使用搜索引擎查询某个关键词时,只会关注排名靠前的网页。因此,当爬虫服务器的资源处于有限,爬虫会优先更新排名靠前的页面。
(2)历史数据策略:是指根据一个网页的历史更新数据,通过泊松过程建模等手段,预测该网页下次更新时间的能力,从而确定下一次更新时间。抓取网页所花费的时间。
(3)聚类分析策略:网页可能有不同的内容,但一般来说,属性相似的网页更新频率相似,所以可以对大量的网页进行聚类。爬取的频率根据设置同类型网页的平均更新值。
五、网络爬虫的实现技术
对于实现技术,本文不展开,只为有兴趣的同学提供几种常用语言:Python、Java、PHP、Node.JS、C++、Go语言(另外还有很多开发语言用于网络爬虫)。
Python:爬虫框架非常丰富,多线程处理能力强,而且易学,代码简洁,优点很多。
Java:适合开发大型爬虫项目。
PHP:后端处理能力很强,代码很简洁,模块丰富,但是并发能力比较弱。
Node.JS:支持高并发和多线程。
C++:运行速度快,适合开发大型爬虫项目,成本高。
Go语言:同样的高并发能力很强。
六、总结
说到爬虫,很多人认为它们是网络世界中不可能存在的灰色地带。恭喜你,看完这篇文章,你比很多人都知道。
因为爬虫分为良性爬虫和恶意爬虫,比如搜索引擎爬虫。Goodwill爬虫严格遵守Robots协议规范爬取网页数据(如URL),它的存在可以增加网站的曝光度,给网站带来流量;
恶意爬虫,无视Robots协议,肆意爬取网站中一些深度不情愿的数据,包括个人隐私或商业机密等重要信息。而恶意爬虫的用户想要多次大量地从网站获取信息,所以通常会在目标网站上投放大量爬虫。如果大量爬虫同时访问网站,很容易导致网站服务器超载或崩溃,导致网站算子丢失。
据统计,2017年我国42.2%的互联网流量是由网络机器人创造的,其中恶意机器(主要是恶意爬虫)占21.80%。我们应该合法合理地使用网络爬虫,这样才能用科技为企业带来长远发展,用科学为社会创造更高的价值。
关于数据猎人
DataHunter是一家专业的数据分析和商业智能服务商,注册于2014年,团队核心成员来自IBM、Oracle、SAP等知名企业,深耕大数据分析领域,拥有十余年丰富的企业服务经验。
DataHunter的核心产品Data Analytics智能数据分析平台和数据大屏设计配置工具Data MAX在行业中形成了自己的独特优势,在各行业积累了众多标杆客户和成功案例。
自成立以来,DataHunter一直致力于为客户提供实时、高效、智能的数据分析与展示解决方案,帮助企业查看和分析数据并改善业务,成为最值得信赖的数据业务公司。
c爬虫抓取网页数据(利用cookie技术抓取网页静态数据这是什么?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-13 19:01
c爬虫抓取网页数据有很多种不同的方式,我用到的就有采集网页静态数据(爬虫)采集网页图片(webdatasnippet)采集网页视频数据采集网页音频数据采集网页视频采集网页图片采集网页文本采集返回的json数据采集cookie数据这种用javascrapy等方式都可以实现这个用的比较少,我们可以先思考用requests,selenium等各种库的用法和原理,一步步的调试实现。
但是采集网页静态数据用了再多的shell,模拟用户采集数据基本都失败了,gg有时候回头看看采集网页静态数据,小白用户可能会想,刚来知乎,肯定是要采集长得漂亮的妹子呀,那还要我来干嘛,偷懒呗。我这就是要教大家偷懒。这里我用到的javascrapy爬虫库。如何利用浏览器ua来识别浏览器,在采集完一个网页之后可以轻松的推断这个网页是否是正常浏览的,还可以实现转码的效果,省的再下一次下载数据了。
就好比我浏览某网站,一上来就浏览本站所有的大v的资料,不太好吧。利用cookie技术抓取网页静态数据这是什么?cookie技术就是用cookie在相应网站上存储一个数据,从而可以收集那些已经登录了的网站上数据,然后通过数据抓取框抓取所需数据,加密后再发回来,进一步传播给服务器。就好比有些网站,某些已经登录过的访客信息是有对应的。
再说到这个cookie技术,其实就是个社工库,看到这个名字,我能猜到你有一定的网络安全常识,我就不多说了,平时可以留意自己浏览网站的登录信息再补充一下,在很多网站上,输入一个用户名或者密码后,就可以获取他所有的所有浏览痕迹,过去有统计过,百度,豆瓣,美团等在百度被骚扰的用户是40w大家可以脑补一下。所以一个人的账号如果泄露出去,就会无孔不入。
我做为一个小白,也是很无奈的了,各位高手,各位大神就不要喷我了。哈哈哈(这种是最常见的一种套路,说到这里你可能会大吃一惊,那么如何隐藏自己的cookie?这个其实很简单,不管是任何的采集,只要是去掉数据,都可以按照通常的方式,只留一个,把输入的密码解出来,然后把解密的结果再返回来一个简单的后缀,去掉所有的https的字眼)手机渣排版还有很多需要补充的,慢慢跟上,预计写十篇,手机上传图不易,多多点赞啊。 查看全部
c爬虫抓取网页数据(利用cookie技术抓取网页静态数据这是什么?(组图))
c爬虫抓取网页数据有很多种不同的方式,我用到的就有采集网页静态数据(爬虫)采集网页图片(webdatasnippet)采集网页视频数据采集网页音频数据采集网页视频采集网页图片采集网页文本采集返回的json数据采集cookie数据这种用javascrapy等方式都可以实现这个用的比较少,我们可以先思考用requests,selenium等各种库的用法和原理,一步步的调试实现。
但是采集网页静态数据用了再多的shell,模拟用户采集数据基本都失败了,gg有时候回头看看采集网页静态数据,小白用户可能会想,刚来知乎,肯定是要采集长得漂亮的妹子呀,那还要我来干嘛,偷懒呗。我这就是要教大家偷懒。这里我用到的javascrapy爬虫库。如何利用浏览器ua来识别浏览器,在采集完一个网页之后可以轻松的推断这个网页是否是正常浏览的,还可以实现转码的效果,省的再下一次下载数据了。
就好比我浏览某网站,一上来就浏览本站所有的大v的资料,不太好吧。利用cookie技术抓取网页静态数据这是什么?cookie技术就是用cookie在相应网站上存储一个数据,从而可以收集那些已经登录了的网站上数据,然后通过数据抓取框抓取所需数据,加密后再发回来,进一步传播给服务器。就好比有些网站,某些已经登录过的访客信息是有对应的。
再说到这个cookie技术,其实就是个社工库,看到这个名字,我能猜到你有一定的网络安全常识,我就不多说了,平时可以留意自己浏览网站的登录信息再补充一下,在很多网站上,输入一个用户名或者密码后,就可以获取他所有的所有浏览痕迹,过去有统计过,百度,豆瓣,美团等在百度被骚扰的用户是40w大家可以脑补一下。所以一个人的账号如果泄露出去,就会无孔不入。
我做为一个小白,也是很无奈的了,各位高手,各位大神就不要喷我了。哈哈哈(这种是最常见的一种套路,说到这里你可能会大吃一惊,那么如何隐藏自己的cookie?这个其实很简单,不管是任何的采集,只要是去掉数据,都可以按照通常的方式,只留一个,把输入的密码解出来,然后把解密的结果再返回来一个简单的后缀,去掉所有的https的字眼)手机渣排版还有很多需要补充的,慢慢跟上,预计写十篇,手机上传图不易,多多点赞啊。
c爬虫抓取网页数据(HTTP请求头说明Allow服务器支持哪些请求方法(如GET、POST等))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-12 02:02
HTTP 请求标头提供有关请求、响应或其他发送实体的信息。 (直接搬菜鸟教程)
响应头描述
允许
服务器支持哪些请求方式(如GET、POST等)。
内容编码
文档的编码方法。 Content-Type 头指定的内容类型只有在解码后才能得到。使用 gzip 压缩文档可以显着减少 HTML 文档的下载时间。 Java 的 GZIPOutputStream 可以很方便地进行 gzip 压缩,但它只支持 Unix 上的 Netscape 和 Windows 上的 IE 4、IE 5。因此,servlet 应该通过查看 Accept-Encoding 标头(即 request.getHeader("Accept-Encoding"))来检查浏览器是否支持 gzip,对于支持 gzip 的浏览器返回 gzip 压缩的 HTML 页面,并返回正常其他浏览器页面的页面。
内容长度
表示内容长度。仅当浏览器使用持久 HTTP 连接时才需要此数据。如果要利用持久连接,可以将输出文档写入 ByteArrayOutputStream,完成后检查其大小,将该值放入 Content-Length 标头,最后通过 byteArrayStream.writeTo(response .getOutputStream()。
内容类型
指示以下文档属于哪种 MIME 类型。 Servlet 默认为 text/plain,但通常需要明确指定为 text/html。由于经常设置 Content-Type,HttpServletResponse 提供了专门的方法 setContentType。
日期
当前格林威治标准时间。可以用setDateHeader设置这个header,避免转换时间格式的麻烦。
过期
何时应将文档视为过期以不再缓存?
最后修改
上次修改文档的时间。客户端可以通过If-Modified-Since请求头提供日期,该请求将被视为条件GET,只返回修改时间晚于指定时间的文档,否则返回304(未修改)状态将被退回。 Last-Modified 也可以使用 setDateHeader 方法设置。
位置
指示客户端应该去哪里检索文档。 Location 通常不是直接设置的,而是通过 HttpServletResponse 的 sendRedirect 方法设置的,该方法也将状态码设置为 302。
刷新
表示浏览器刷新文档的时间(以秒为单位)。除了刷新当前文档,还可以使用 setHeader("Refresh", "5; URL=") 让浏览器读取指定页面。
注意这个功能通常是通过在HTML页面的HEAD区域设置来实现的,这是因为自动刷新或者重定向不是对于不会使用 CGI 或 servlet 的 HTML 编写器的人来说可能是非常重要的。不过对于servlet来说,直接设置Refresh header会更方便。
注意Refresh的意思是“刷新本页或N秒后访问指定页面”,而不是“每隔N秒刷新本页或访问指定页面”。因此,持续刷新需要每次发送一个Refresh头,发送204状态码可以阻止浏览器继续刷新,无论是使用Refresh头还是。
注意刷新头不是HTTP官方规范的一部分1.1,而是一个扩展,但是Netscape和IE都支持。
服务器
服务器名称。 Servlet一般不设置这个值,而是由Web服务器自己设置的。
设置-Cookie
设置与页面关联的cookie。 Servlet 不应使用 response.setHeader("Set-Cookie", ...),而应使用 HttpServletResponse 提供的专用方法 addCookie。请参阅下面关于 cookie 设置的讨论。
WWW-认证
客户端应该在 Authorization 标头中提供什么类型的授权信息?在收录 401(未授权)状态行的响应中需要此标头。例如 response.setHeader("WWW-Authenticate", "BASIC realm=\"executives\"")。
请注意,servlet 通常不处理此问题,而是允许 Web 服务器的专用机制来控制对受密码保护的页面(例如 .htaccess)的访问。
1.5 个 Cookie
指存储在用户本地终端上的一些数据(通常是加密的),用于识别用户身份和跟踪会话。
cookie 是存储在计算机浏览器目录中的文本文件。当浏览器运行时,它存储在 RAM 中以发挥作用(这种 cookie 称为会话 cookie)。一旦用户访问 网站 或服务器被注销,cookie 就可以存储在用户的本地硬盘上(这种 cookie 称为 Persistent Cookies)
1.6 认证
一般来说,爬虫在抓取和访问网页时,会通过HTTP请求中的User Agent字段告知自己的身份信息。
1.7 阿贾克斯
Ajax 代表“AsynchronousJavascriptAndXML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。 Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
因为Ajax技术,我们在爬取的时候,有时候会发现get()的结果并没有我们想要的内容,因为在加载页面的时候只有少量的数据交换,而我们得到了什么用爬虫只是第一次。 HTML,然后你需要在开发者工具中找到你想要的数据。等有例子再详细分析。
1.8 代理
在使用爬虫的过程中,难免会遇到带有反爬虫的网站。这时候,我们需要一个代理ip。
使用代理IP,我们可以先从代理获取代理网站,然后验证IP是否可用。 查看全部
c爬虫抓取网页数据(HTTP请求头说明Allow服务器支持哪些请求方法(如GET、POST等))
HTTP 请求标头提供有关请求、响应或其他发送实体的信息。 (直接搬菜鸟教程)
响应头描述
允许
服务器支持哪些请求方式(如GET、POST等)。
内容编码
文档的编码方法。 Content-Type 头指定的内容类型只有在解码后才能得到。使用 gzip 压缩文档可以显着减少 HTML 文档的下载时间。 Java 的 GZIPOutputStream 可以很方便地进行 gzip 压缩,但它只支持 Unix 上的 Netscape 和 Windows 上的 IE 4、IE 5。因此,servlet 应该通过查看 Accept-Encoding 标头(即 request.getHeader("Accept-Encoding"))来检查浏览器是否支持 gzip,对于支持 gzip 的浏览器返回 gzip 压缩的 HTML 页面,并返回正常其他浏览器页面的页面。
内容长度
表示内容长度。仅当浏览器使用持久 HTTP 连接时才需要此数据。如果要利用持久连接,可以将输出文档写入 ByteArrayOutputStream,完成后检查其大小,将该值放入 Content-Length 标头,最后通过 byteArrayStream.writeTo(response .getOutputStream()。
内容类型
指示以下文档属于哪种 MIME 类型。 Servlet 默认为 text/plain,但通常需要明确指定为 text/html。由于经常设置 Content-Type,HttpServletResponse 提供了专门的方法 setContentType。
日期
当前格林威治标准时间。可以用setDateHeader设置这个header,避免转换时间格式的麻烦。
过期
何时应将文档视为过期以不再缓存?
最后修改
上次修改文档的时间。客户端可以通过If-Modified-Since请求头提供日期,该请求将被视为条件GET,只返回修改时间晚于指定时间的文档,否则返回304(未修改)状态将被退回。 Last-Modified 也可以使用 setDateHeader 方法设置。
位置
指示客户端应该去哪里检索文档。 Location 通常不是直接设置的,而是通过 HttpServletResponse 的 sendRedirect 方法设置的,该方法也将状态码设置为 302。
刷新
表示浏览器刷新文档的时间(以秒为单位)。除了刷新当前文档,还可以使用 setHeader("Refresh", "5; URL=") 让浏览器读取指定页面。
注意这个功能通常是通过在HTML页面的HEAD区域设置来实现的,这是因为自动刷新或者重定向不是对于不会使用 CGI 或 servlet 的 HTML 编写器的人来说可能是非常重要的。不过对于servlet来说,直接设置Refresh header会更方便。
注意Refresh的意思是“刷新本页或N秒后访问指定页面”,而不是“每隔N秒刷新本页或访问指定页面”。因此,持续刷新需要每次发送一个Refresh头,发送204状态码可以阻止浏览器继续刷新,无论是使用Refresh头还是。
注意刷新头不是HTTP官方规范的一部分1.1,而是一个扩展,但是Netscape和IE都支持。
服务器
服务器名称。 Servlet一般不设置这个值,而是由Web服务器自己设置的。
设置-Cookie
设置与页面关联的cookie。 Servlet 不应使用 response.setHeader("Set-Cookie", ...),而应使用 HttpServletResponse 提供的专用方法 addCookie。请参阅下面关于 cookie 设置的讨论。
WWW-认证
客户端应该在 Authorization 标头中提供什么类型的授权信息?在收录 401(未授权)状态行的响应中需要此标头。例如 response.setHeader("WWW-Authenticate", "BASIC realm=\"executives\"")。
请注意,servlet 通常不处理此问题,而是允许 Web 服务器的专用机制来控制对受密码保护的页面(例如 .htaccess)的访问。
1.5 个 Cookie
指存储在用户本地终端上的一些数据(通常是加密的),用于识别用户身份和跟踪会话。
cookie 是存储在计算机浏览器目录中的文本文件。当浏览器运行时,它存储在 RAM 中以发挥作用(这种 cookie 称为会话 cookie)。一旦用户访问 网站 或服务器被注销,cookie 就可以存储在用户的本地硬盘上(这种 cookie 称为 Persistent Cookies)
1.6 认证
一般来说,爬虫在抓取和访问网页时,会通过HTTP请求中的User Agent字段告知自己的身份信息。
1.7 阿贾克斯
Ajax 代表“AsynchronousJavascriptAndXML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。 Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
因为Ajax技术,我们在爬取的时候,有时候会发现get()的结果并没有我们想要的内容,因为在加载页面的时候只有少量的数据交换,而我们得到了什么用爬虫只是第一次。 HTML,然后你需要在开发者工具中找到你想要的数据。等有例子再详细分析。
1.8 代理
在使用爬虫的过程中,难免会遇到带有反爬虫的网站。这时候,我们需要一个代理ip。
使用代理IP,我们可以先从代理获取代理网站,然后验证IP是否可用。
c爬虫抓取网页数据(南阳理工学院ACM题目信息获取源码我们知道浏览器查看网页时 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-12 02:00
)
南洋理工ACM专题信息
获取源代码
我们知道,浏览器在浏览网页时,首先会向服务器发送一个request请求,服务器会根据request请求做一些处理,生成一个response响应返回给浏览器,这个response收录我们需要的网页(或者数据,一般是静态的网站或者服务器端渲染就是直接返回网页),那么我们只需要模仿浏览器发送这个请求给服务器下载网页,而然后等待服务器发回响应。
1.引入第三方库
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
2.模拟浏览器
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
3. 爬网
r = requests.get(
f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
BeautifulSoup 网络分析
学习了request,了解了伪装技巧,终于可以爬到一些正常的web源码(html文档)了,但这离最后也是最重要的一步——筛选还差得很远。这个过程就像在沙子里淘金一样。没有合适的筛子,你就会错过有价值的东西,或者做无用的工作来筛掉无用的东西。
淘金者观察土壤并制作筛子。对应爬虫字段就是观察html,自定义过滤器。这里其实是一个简单的抓取 td 标签
1.初始化
soup = BeautifulSoup(r.text, 'html.parser')
2.抓取节点
td = soup.find_all('td')
subject = []
for t in td:
if t.string is not None:
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
保存文件
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
完整的源代码
URL链接中.htm前面的数字是相关的,所以可以通过循环爬取多页代码,找到爬取数据的位置,编写代码
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
subjects = []
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(
f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'html.parser')
td = soup.find_all('td')
subject = []
for t in td:
if t.string is not None:
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
运行结果:
查看全部
c爬虫抓取网页数据(南阳理工学院ACM题目信息获取源码我们知道浏览器查看网页时
)
南洋理工ACM专题信息
获取源代码
我们知道,浏览器在浏览网页时,首先会向服务器发送一个request请求,服务器会根据request请求做一些处理,生成一个response响应返回给浏览器,这个response收录我们需要的网页(或者数据,一般是静态的网站或者服务器端渲染就是直接返回网页),那么我们只需要模仿浏览器发送这个请求给服务器下载网页,而然后等待服务器发回响应。
1.引入第三方库
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
2.模拟浏览器
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
3. 爬网
r = requests.get(
f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
BeautifulSoup 网络分析
学习了request,了解了伪装技巧,终于可以爬到一些正常的web源码(html文档)了,但这离最后也是最重要的一步——筛选还差得很远。这个过程就像在沙子里淘金一样。没有合适的筛子,你就会错过有价值的东西,或者做无用的工作来筛掉无用的东西。
淘金者观察土壤并制作筛子。对应爬虫字段就是观察html,自定义过滤器。这里其实是一个简单的抓取 td 标签
1.初始化
soup = BeautifulSoup(r.text, 'html.parser')
2.抓取节点
td = soup.find_all('td')
subject = []
for t in td:
if t.string is not None:
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
保存文件
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
完整的源代码
URL链接中.htm前面的数字是相关的,所以可以通过循环爬取多页代码,找到爬取数据的位置,编写代码
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
subjects = []
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(
f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'html.parser')
td = soup.find_all('td')
subject = []
for t in td:
if t.string is not None:
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
运行结果:
c爬虫抓取网页数据(为什么说用Python开发爬虫更有优势?Java开发不行吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-03-10 00:14
为什么用Python开发爬虫更有优势?不能用Java开发?今天小编就为大家讲解一下!
C/C++
各种搜索引擎大多使用C/C++开发爬虫,可能是因为搜索引擎爬虫重要的是采集网站信息,对页面的解析要求不高。
Python
Python语言具有强大的网络功能,可以模拟登录和解析JavaScript。缺点是网页解析。Python 编写程序非常方便,特别是对于专注的爬虫。目标 网站 经常更改。使用Python根据目标的变化开发爬虫程序非常方便。
爪哇
Java有很多解析器,对网页的解析支持非常好。缺点是网络部分支持较差。
对于一般需求,Java 或 Python 都可以完成这项工作。如果需要模拟登录,选择Python对抗反爬虫比较方便。如果需要处理复杂的网页,解析网页内容生成结构化数据,或者需要精细解析网页内容,可以选择Java。
选择 Python 作为实现爬虫的语言的主要考虑因素是:
(1) 爬取网页本身的界面
与其他动态脚本语言(如Perl、Shell)相比,Python的urllib2包提供了更完善的访问web文档的API;与其他静态编程语言(如Java、C#、C++)相比,Python爬取网页文档。界面更简洁。
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这时候我们就需要模拟User Agent的行为来构造合适的请求,比如模拟用户登录,模拟Session/Cookie的存储和设置。Python 中有一些优秀的第三方包可以为你做这件事,例如 Requests 或 Mechanize。
(2) 爬取后处理
抓取的网页通常需要进行处理,例如过滤Html标签、提取文本等。Python的Beautiful Soup提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是Python可以做到最快最干净,就像那句“人生苦短,你需要Python”一样。
(3) 开发效率高
因为爬虫的具体代码要根据网站进行修改,而Python灵活的脚本语言特别适合这个任务。
(4) 快速入门
网上有很多Python教学资源,方便大家学习,有问题也很容易找到相关资料。此外,Python 对成熟的爬虫框架也有很强的支持,比如 Scrapy。返回搜狐,查看更多 查看全部
c爬虫抓取网页数据(为什么说用Python开发爬虫更有优势?Java开发不行吗?)
为什么用Python开发爬虫更有优势?不能用Java开发?今天小编就为大家讲解一下!
C/C++
各种搜索引擎大多使用C/C++开发爬虫,可能是因为搜索引擎爬虫重要的是采集网站信息,对页面的解析要求不高。
Python
Python语言具有强大的网络功能,可以模拟登录和解析JavaScript。缺点是网页解析。Python 编写程序非常方便,特别是对于专注的爬虫。目标 网站 经常更改。使用Python根据目标的变化开发爬虫程序非常方便。
爪哇
Java有很多解析器,对网页的解析支持非常好。缺点是网络部分支持较差。
对于一般需求,Java 或 Python 都可以完成这项工作。如果需要模拟登录,选择Python对抗反爬虫比较方便。如果需要处理复杂的网页,解析网页内容生成结构化数据,或者需要精细解析网页内容,可以选择Java。
选择 Python 作为实现爬虫的语言的主要考虑因素是:
(1) 爬取网页本身的界面
与其他动态脚本语言(如Perl、Shell)相比,Python的urllib2包提供了更完善的访问web文档的API;与其他静态编程语言(如Java、C#、C++)相比,Python爬取网页文档。界面更简洁。
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这时候我们就需要模拟User Agent的行为来构造合适的请求,比如模拟用户登录,模拟Session/Cookie的存储和设置。Python 中有一些优秀的第三方包可以为你做这件事,例如 Requests 或 Mechanize。
(2) 爬取后处理
抓取的网页通常需要进行处理,例如过滤Html标签、提取文本等。Python的Beautiful Soup提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是Python可以做到最快最干净,就像那句“人生苦短,你需要Python”一样。
(3) 开发效率高
因为爬虫的具体代码要根据网站进行修改,而Python灵活的脚本语言特别适合这个任务。
(4) 快速入门
网上有很多Python教学资源,方便大家学习,有问题也很容易找到相关资料。此外,Python 对成熟的爬虫框架也有很强的支持,比如 Scrapy。返回搜狐,查看更多
c爬虫抓取网页数据(查看更多写博客Python网络爬虫反爬源码分享--苏飞版)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-10 00:11
阿里云>云栖社区>主题图>C>c爬虫源码
推荐活动:
更多优惠>
当前话题:c网络爬虫源码加入采集
相关话题:
C网络爬虫源码相关博客看更多博文
Python网络爬虫反爬破解攻略实战
作者:薇薇8128 浏览评论:04年前
作者:薇薇,请注明出处。我们经常会写一些网络爬虫,想必大家都会有一种感觉,虽然写爬虫不难,但是反爬很难处理,因为大部分网站都有自己的反爬机制,所以我们将更加难以抓取这些数据。但是,对于每一种反爬机制,我们其实都会有相应的解决方案。作为一个爬虫,我们,
阅读全文
C#HttpHelper爬虫源码分享--苏飞版
作者:苏飞2071 浏览评论:03年前
简介C#HttpHelper实现了C#HttpWebRequest爬取时忽略编码、忽略证书、忽略cookie的功能,实现代理的功能。有了它,您可以发出 Get 和 Post 请求,并且可以轻松设置 cookie、证书、代理和编码。你不用担心这个问题,因为类会自动为你识别页面
阅读全文
Python网络爬虫抓取极品姐姐的视频并保存到文件
作者:keitwotest1060 浏览评论:04年前
项目描述 使用Python编写一个网络爬虫爬取Best Sister的视频并保存到文件中使用工具示例 Python2.7.X, pycharm 使用方法 创建视频爬取Best Sister in pycharm .py 文件,并在当前目录下创建video文件夹,用于存放采集到的视频文件,编写代码,运行
阅读全文
Java版网络爬虫基础(转)
作者:developerguy851 浏览评论:06年前
网络爬虫不仅可以爬取网站网页和图片,甚至可以实现抢票、网上购买、机票查询。这几天看了一些基础知识,记录下来。网页之间的关系可以看成一个大图,图的遍历可以分为深度优先和广度优先。网络爬虫采取的广度优先方式总结如下:2个数组,一个
阅读全文
C# 网络爬虫
作者:Street Corner Box 712 查看评论:05 年前
公司的编辑妹需要爬取网页的内容,让我帮我做一个简单的爬取工具。这是抓取网页的内容。看来这对大家来说并不难,不过这里有一些小改动,代码提供,请参考 1 private string GetHttpWebRequest(string url) 2 { 3 Ht
阅读全文
C#网络爬虫--多线程增强版
作者:街角盒饭 688 次浏览评论:05 年前
上次给公司的一个女生做爬虫,不是很精致。这次是在公司项目中使用的,所以做了一些改动。该函数添加了一个URL图片采集,下载,线程处理接口URL图片下载等。说说思路:总理在初始网站采集图片去获取初始网站的所有内容到初始网站 采集 链接并将 采集 的链接放入队列以继续 采集 图片
阅读全文
一篇文章文章教你使用Python网络爬虫爬取评论区百度贴吧图片和视频
作者:python进阶26人查看评论:01年前
[一、项目背景]百度贴吧是全球最大的中文交流平台。你是不是和我一样,有时候看到评论区的图片就想下载?或者观看视频并想下载?今天小编带大家通过搜索关键词,在评论区获取图片和视频。[二、项目目标]实现贴吧获取的图片或视频可以保存在
阅读全文
一篇文章文章教你用Python网络爬虫搞定差旅攻略
作者:python进阶13人查看评论:01年前
[一、项目背景] 趣游网提供原创实用的出境旅游指南、攻略、旅游社区和问答平台,以及智能旅游规划解决方案,以及签证、保险、机票、酒店在线预订、租车等增值服务。侨游“鼓励和帮助中国游客以自己的视角和方式体验世界”。今天就教大家如何获取侨友网的城市信息。
阅读全文 查看全部
c爬虫抓取网页数据(查看更多写博客Python网络爬虫反爬源码分享--苏飞版)
阿里云>云栖社区>主题图>C>c爬虫源码
推荐活动:
更多优惠>
当前话题:c网络爬虫源码加入采集
相关话题:
C网络爬虫源码相关博客看更多博文
Python网络爬虫反爬破解攻略实战
作者:薇薇8128 浏览评论:04年前
作者:薇薇,请注明出处。我们经常会写一些网络爬虫,想必大家都会有一种感觉,虽然写爬虫不难,但是反爬很难处理,因为大部分网站都有自己的反爬机制,所以我们将更加难以抓取这些数据。但是,对于每一种反爬机制,我们其实都会有相应的解决方案。作为一个爬虫,我们,
阅读全文
C#HttpHelper爬虫源码分享--苏飞版
作者:苏飞2071 浏览评论:03年前
简介C#HttpHelper实现了C#HttpWebRequest爬取时忽略编码、忽略证书、忽略cookie的功能,实现代理的功能。有了它,您可以发出 Get 和 Post 请求,并且可以轻松设置 cookie、证书、代理和编码。你不用担心这个问题,因为类会自动为你识别页面
阅读全文
Python网络爬虫抓取极品姐姐的视频并保存到文件
作者:keitwotest1060 浏览评论:04年前
项目描述 使用Python编写一个网络爬虫爬取Best Sister的视频并保存到文件中使用工具示例 Python2.7.X, pycharm 使用方法 创建视频爬取Best Sister in pycharm .py 文件,并在当前目录下创建video文件夹,用于存放采集到的视频文件,编写代码,运行
阅读全文
Java版网络爬虫基础(转)
作者:developerguy851 浏览评论:06年前
网络爬虫不仅可以爬取网站网页和图片,甚至可以实现抢票、网上购买、机票查询。这几天看了一些基础知识,记录下来。网页之间的关系可以看成一个大图,图的遍历可以分为深度优先和广度优先。网络爬虫采取的广度优先方式总结如下:2个数组,一个
阅读全文
C# 网络爬虫
作者:Street Corner Box 712 查看评论:05 年前
公司的编辑妹需要爬取网页的内容,让我帮我做一个简单的爬取工具。这是抓取网页的内容。看来这对大家来说并不难,不过这里有一些小改动,代码提供,请参考 1 private string GetHttpWebRequest(string url) 2 { 3 Ht
阅读全文
C#网络爬虫--多线程增强版
作者:街角盒饭 688 次浏览评论:05 年前
上次给公司的一个女生做爬虫,不是很精致。这次是在公司项目中使用的,所以做了一些改动。该函数添加了一个URL图片采集,下载,线程处理接口URL图片下载等。说说思路:总理在初始网站采集图片去获取初始网站的所有内容到初始网站 采集 链接并将 采集 的链接放入队列以继续 采集 图片
阅读全文
一篇文章文章教你使用Python网络爬虫爬取评论区百度贴吧图片和视频
作者:python进阶26人查看评论:01年前
[一、项目背景]百度贴吧是全球最大的中文交流平台。你是不是和我一样,有时候看到评论区的图片就想下载?或者观看视频并想下载?今天小编带大家通过搜索关键词,在评论区获取图片和视频。[二、项目目标]实现贴吧获取的图片或视频可以保存在
阅读全文
一篇文章文章教你用Python网络爬虫搞定差旅攻略
作者:python进阶13人查看评论:01年前
[一、项目背景] 趣游网提供原创实用的出境旅游指南、攻略、旅游社区和问答平台,以及智能旅游规划解决方案,以及签证、保险、机票、酒店在线预订、租车等增值服务。侨游“鼓励和帮助中国游客以自己的视角和方式体验世界”。今天就教大家如何获取侨友网的城市信息。
阅读全文
c爬虫抓取网页数据( 风中蹦迪03-0803:07阅读4网站SEO优化关注实战)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-09 20:14
风中蹦迪03-0803:07阅读4网站SEO优化关注实战)
随风起舞
03-08 03:07 阅读4 网站SEO优化
专注于
【网络爬虫学习】实战,爬取网页和贴吧数据
战斗一
抓取您想要的网页并将其保存到本地计算机。
首先我们简单分析下要编写的爬虫程序,可以分为以下三个部分:
理清逻辑后,我们就可以正式编写爬虫程序了。
导入所需模块
from urllib import request, parse
连接 URL 地址
定义 URL 变量并连接 url 地址。代码如下所示:
url = ‘http://www.baidu.com/s?wd={}‘
word = input(‘请输入想要搜索的内容:‘)
params = parse.quote(word)
full_url = url.format(params)
向 URL 发送请求
发送请求主要分为以下几个步骤:
代码如下所示:
# 重构请求头
headers = {
‘User-Agent‘:
‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0‘
}
# 创建请求对应
req = request.Request(url=full_url, headers=headers)
# 获取响应对象
res = request.urlopen(req)
# 获取响应内容
html = res.read().decode(‘utf-8‘)
另存为本地文件
将爬取的照片保存到本地,这里需要使用Python编程文件IO操作,代码如下:
filename = word + ‘.html‘
with open(filename, ‘w‘, encoding=‘utf-8‘) as f:
f.write(html)
完整的程序如下所示:
from urllib import request, parse
# 1.拼url地址
url = ‘http://www.baidu.com/s?wd={}‘
word = input(‘请输入想要搜索的内容:‘)
params = parse.quote(word)
full_url = url.format(params)
# 2.发请求保存到本地
# 重构请求头
headers = {
‘User-Agent‘:
‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0‘
}
# 创建请求对应
req = request.Request(url=full_url, headers=headers)
# 获取响应对象
res = request.urlopen(req)
# 获取响应内容
html = res.read().decode(‘utf-8‘)
# 3.保存文件至当前目录
filename = word + ‘.html‘
with open(filename, ‘w‘, encoding=‘utf-8‘) as f:
f.write(html)
尝试运行程序,进入RioTianの博客园,确认搜索,在当前工作目录下会找到“RioTianの博客园.html”文件。
函数式编程修饰符
Python函数式编程可以让程序的思路更清晰,更容易理解。接下来,利用函数式编程的思想,对上面的代码进行修改。
定义相应的函数,调用该函数执行爬虫程序。修改后的代码如下所示:
from urllib import request, parse
# 拼接URL地址
def get_url(word):
url = ‘http://www.baidu.com/s?{}‘
# 此处使用urlencode()进行编码
params = parse.urlencode({‘wd‘: word})
url = url.format(params)
return url
# 发请求,保存本地文件
def request_url(url, filename):
headers = {
‘User-Agent‘:
‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0‘
}
# 请求对象 + 响应对象 + 提取内容
req = request.Request(url=url, headers=headers)
res = request.urlopen(req)
html = res.read().decode(‘utf-8‘)
# 保存文件至本地
with open(filename, ‘w‘, encoding=‘utf-8‘) as f:
f.write(html)
# 主程序入口
if __name__ == ‘__main__‘:
word = input(‘请输入搜索内容:‘)
url = get_url(word)
filename = word + ‘.html‘
request_url(url, filename)
除了使用函数式编程,还可以使用面向对象的编程方式(实战二),后续内容会介绍。
第二幕
爬百度贴吧(Python爬虫,编程,只抓取贴吧的前5页。
确定页面类型
通过简单的分析,我们可以知道要爬取的页面是静态网页,分析方法很简单:打开百度贴吧,搜索“Python爬虫”,复制其中任意一条信息出现的页面,如“爬虫需要http代理”,然后右键选择查看源代码,在源代码页面使用Ctrl+F快捷键搜索刚刚复制的数据,如下图:
从上图可以看出,页面中的所有信息都收录在源页面中,不需要单独从数据库中加载数据,所以页面是静态页面。
找出 URL 变化的规律性
接下来,查找要抓取的页面的 URL 模式。搜索“Python爬虫”后,贴吧的首页网址如下:
https://tieba.baidu.com/f?ie=utf-8&kw=python爬虫&fr=search
点击第二页,其url信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=50
点击第三页,url信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=100
再次点击第一页,url信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=0
如果还是不能确定,可以继续多浏览几页。最后发现url有两个查询参数kw和pn,pn参数有规律是这样的:
第n页:pn=(n-1)*50
#参数params
pn=(page-1)*50
params={
‘kw‘:name,
‘pn‘:str(pn)
}
url地址可以简写为:
https://tieba.baidu.com/f?kw=python爬虫&pn=450
编写爬虫
爬虫程序以类的形式编写,在类下编写不同的功能函数。代码如下:
from urllib import request,parse
import time
import random
from ua_info import ua_list #使用自定义的ua池
#定义一个爬虫类
class TiebaSpider(object):
#初始化url属性
def __init__(self):
self.url=‘http://tieba.baidu.com/f?{}‘
# 1.请求函数,得到页面,传统三步
def get_html(self,url):
req=request.Request(url=url,headers={‘User-Agent‘:random.choice(ua_list)})
res=request.urlopen(req)
#windows会存在乱码问题,需要使用 gbk解码,并使用ignore忽略不能处理的字节
#linux不会存在上述问题,可以直接使用decode(‘utf-8‘)解码
html=res.read().decode("gbk","ignore")
return html
# 2.解析函数,此处代码暂时省略,还没介绍解析模块
def parse_html(self):
pass
# 3.保存文件函数
def save_html(self,filename,html):
with open(filename,‘w‘) as f:
f.write(html)
# 4.入口函数
def run(self):
name=input(‘输入贴吧名:‘)
begin=int(input(‘输入起始页:‘))
stop=int(input(‘输入终止页:‘))
# +1 操作保证能够取到整数
for page in range(begin,stop+1):
pn=(page-1)*50
params={
‘kw‘:name,
‘pn‘:str(pn)
}
#拼接URL地址
params=parse.urlencode(params)
url=self.url.format(params)
#发请求
html=self.get_html(url)
#定义路径
filename=‘{}-{}页.html‘.format(name,page)
self.save_html(filename,html)
#提示
print(‘第%d页抓取成功‘%page)
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
#以脚本的形式启动爬虫
if __name__==‘__main__‘:
start=time.time()
spider=TiebaSpider() #实例化一个对象spider
spider.run() #调用入口函数
end=time.time()
#查看程序执行时间
print(‘执行时间:%.2f‘%(end-start)) #爬虫执行时间
程序执行后,爬取的文件会保存到Pycharm的当前工作目录下,输出为:
输入贴吧名:python爬虫
输入起始页:1
输入终止页:2
第1页抓取成功
第2页抓取成功
执行时间:12.25
以面向对象的方式编写爬虫程序时,思路简单,逻辑清晰,非常容易理解。上述代码主要包括四个功能函数,分别负责不同的功能,总结如下:
1) 请求函数
request函数的最终结果是返回一个HTML对象,方便后续函数调用。
2) 分析函数
解析函数用于解析 HTML 页面。常见的解析模块有正则解析模块和bs4解析模块。通过分析页面,提取出需要的数据,在后续内容中会详细介绍。
3) 保存数据功能
该函数负责将采集到的数据保存到数据库,如MySQL、MongoDB等,或者保存为文件格式,如csv、txt、excel等。
4) 入口函数
入口函数作为整个爬虫程序的桥梁,通过调用不同的函数函数实现最终的数据抓取。入口函数的主要任务是组织数据,比如要搜索的贴吧的名字,编码url参数,拼接url地址,定义文件存储路径。
履带结构
用面向对象的方式编写爬虫程序时,逻辑结构是比较固定的,总结如下:
# 程序结构
class xxxSpider(object):
def __init__(self):
# 定义常用变量,比如url或计数变量等
def get_html(self):
# 获取响应内容函数,使用随机User-Agent
def parse_html(self):
# 使用正则表达式来解析页面,提取数据
def write_html(self):
# 将提取的数据按要求保存,csv、MySQL数据库等
def run(self):
# 主函数,用来控制整体逻辑
if __name__ == ‘__main__‘:
# 程序开始运行时间
spider = xxxSpider()
spider.run()
注意:掌握以上编程逻辑将有助于您后续的学习。
爬虫随机休眠
在入口函数代码中,收录以下代码:
# 每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
爬虫访问 网站 会非常快,这与正常的人类点击行为非常不符。因此,通过随机休眠,爬虫可以模仿人类点击网站,使得网站不容易察觉是爬虫访问网站,但这样做的代价是影响程序的执行效率。
焦点爬虫是一个执行效率低的程序,提高其性能是业界一直关注的问题。于是,高效的 Python 爬虫框架 Scrapy 应运而生。
原版的: 查看全部
c爬虫抓取网页数据(
风中蹦迪03-0803:07阅读4网站SEO优化关注实战)
随风起舞
03-08 03:07 阅读4 网站SEO优化
专注于
【网络爬虫学习】实战,爬取网页和贴吧数据
战斗一
抓取您想要的网页并将其保存到本地计算机。
首先我们简单分析下要编写的爬虫程序,可以分为以下三个部分:
理清逻辑后,我们就可以正式编写爬虫程序了。
导入所需模块
from urllib import request, parse
连接 URL 地址
定义 URL 变量并连接 url 地址。代码如下所示:
url = ‘http://www.baidu.com/s?wd={}‘
word = input(‘请输入想要搜索的内容:‘)
params = parse.quote(word)
full_url = url.format(params)
向 URL 发送请求
发送请求主要分为以下几个步骤:
代码如下所示:
# 重构请求头
headers = {
‘User-Agent‘:
‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0‘
}
# 创建请求对应
req = request.Request(url=full_url, headers=headers)
# 获取响应对象
res = request.urlopen(req)
# 获取响应内容
html = res.read().decode(‘utf-8‘)
另存为本地文件
将爬取的照片保存到本地,这里需要使用Python编程文件IO操作,代码如下:
filename = word + ‘.html‘
with open(filename, ‘w‘, encoding=‘utf-8‘) as f:
f.write(html)
完整的程序如下所示:
from urllib import request, parse
# 1.拼url地址
url = ‘http://www.baidu.com/s?wd={}‘
word = input(‘请输入想要搜索的内容:‘)
params = parse.quote(word)
full_url = url.format(params)
# 2.发请求保存到本地
# 重构请求头
headers = {
‘User-Agent‘:
‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0‘
}
# 创建请求对应
req = request.Request(url=full_url, headers=headers)
# 获取响应对象
res = request.urlopen(req)
# 获取响应内容
html = res.read().decode(‘utf-8‘)
# 3.保存文件至当前目录
filename = word + ‘.html‘
with open(filename, ‘w‘, encoding=‘utf-8‘) as f:
f.write(html)
尝试运行程序,进入RioTianの博客园,确认搜索,在当前工作目录下会找到“RioTianの博客园.html”文件。
函数式编程修饰符
Python函数式编程可以让程序的思路更清晰,更容易理解。接下来,利用函数式编程的思想,对上面的代码进行修改。
定义相应的函数,调用该函数执行爬虫程序。修改后的代码如下所示:
from urllib import request, parse
# 拼接URL地址
def get_url(word):
url = ‘http://www.baidu.com/s?{}‘
# 此处使用urlencode()进行编码
params = parse.urlencode({‘wd‘: word})
url = url.format(params)
return url
# 发请求,保存本地文件
def request_url(url, filename):
headers = {
‘User-Agent‘:
‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0‘
}
# 请求对象 + 响应对象 + 提取内容
req = request.Request(url=url, headers=headers)
res = request.urlopen(req)
html = res.read().decode(‘utf-8‘)
# 保存文件至本地
with open(filename, ‘w‘, encoding=‘utf-8‘) as f:
f.write(html)
# 主程序入口
if __name__ == ‘__main__‘:
word = input(‘请输入搜索内容:‘)
url = get_url(word)
filename = word + ‘.html‘
request_url(url, filename)
除了使用函数式编程,还可以使用面向对象的编程方式(实战二),后续内容会介绍。
第二幕
爬百度贴吧(Python爬虫,编程,只抓取贴吧的前5页。
确定页面类型
通过简单的分析,我们可以知道要爬取的页面是静态网页,分析方法很简单:打开百度贴吧,搜索“Python爬虫”,复制其中任意一条信息出现的页面,如“爬虫需要http代理”,然后右键选择查看源代码,在源代码页面使用Ctrl+F快捷键搜索刚刚复制的数据,如下图:
从上图可以看出,页面中的所有信息都收录在源页面中,不需要单独从数据库中加载数据,所以页面是静态页面。
找出 URL 变化的规律性
接下来,查找要抓取的页面的 URL 模式。搜索“Python爬虫”后,贴吧的首页网址如下:
https://tieba.baidu.com/f?ie=utf-8&kw=python爬虫&fr=search
点击第二页,其url信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=50
点击第三页,url信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=100
再次点击第一页,url信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=0
如果还是不能确定,可以继续多浏览几页。最后发现url有两个查询参数kw和pn,pn参数有规律是这样的:
第n页:pn=(n-1)*50
#参数params
pn=(page-1)*50
params={
‘kw‘:name,
‘pn‘:str(pn)
}
url地址可以简写为:
https://tieba.baidu.com/f?kw=python爬虫&pn=450
编写爬虫
爬虫程序以类的形式编写,在类下编写不同的功能函数。代码如下:
from urllib import request,parse
import time
import random
from ua_info import ua_list #使用自定义的ua池
#定义一个爬虫类
class TiebaSpider(object):
#初始化url属性
def __init__(self):
self.url=‘http://tieba.baidu.com/f?{}‘
# 1.请求函数,得到页面,传统三步
def get_html(self,url):
req=request.Request(url=url,headers={‘User-Agent‘:random.choice(ua_list)})
res=request.urlopen(req)
#windows会存在乱码问题,需要使用 gbk解码,并使用ignore忽略不能处理的字节
#linux不会存在上述问题,可以直接使用decode(‘utf-8‘)解码
html=res.read().decode("gbk","ignore")
return html
# 2.解析函数,此处代码暂时省略,还没介绍解析模块
def parse_html(self):
pass
# 3.保存文件函数
def save_html(self,filename,html):
with open(filename,‘w‘) as f:
f.write(html)
# 4.入口函数
def run(self):
name=input(‘输入贴吧名:‘)
begin=int(input(‘输入起始页:‘))
stop=int(input(‘输入终止页:‘))
# +1 操作保证能够取到整数
for page in range(begin,stop+1):
pn=(page-1)*50
params={
‘kw‘:name,
‘pn‘:str(pn)
}
#拼接URL地址
params=parse.urlencode(params)
url=self.url.format(params)
#发请求
html=self.get_html(url)
#定义路径
filename=‘{}-{}页.html‘.format(name,page)
self.save_html(filename,html)
#提示
print(‘第%d页抓取成功‘%page)
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
#以脚本的形式启动爬虫
if __name__==‘__main__‘:
start=time.time()
spider=TiebaSpider() #实例化一个对象spider
spider.run() #调用入口函数
end=time.time()
#查看程序执行时间
print(‘执行时间:%.2f‘%(end-start)) #爬虫执行时间
程序执行后,爬取的文件会保存到Pycharm的当前工作目录下,输出为:
输入贴吧名:python爬虫
输入起始页:1
输入终止页:2
第1页抓取成功
第2页抓取成功
执行时间:12.25
以面向对象的方式编写爬虫程序时,思路简单,逻辑清晰,非常容易理解。上述代码主要包括四个功能函数,分别负责不同的功能,总结如下:
1) 请求函数
request函数的最终结果是返回一个HTML对象,方便后续函数调用。
2) 分析函数
解析函数用于解析 HTML 页面。常见的解析模块有正则解析模块和bs4解析模块。通过分析页面,提取出需要的数据,在后续内容中会详细介绍。
3) 保存数据功能
该函数负责将采集到的数据保存到数据库,如MySQL、MongoDB等,或者保存为文件格式,如csv、txt、excel等。
4) 入口函数
入口函数作为整个爬虫程序的桥梁,通过调用不同的函数函数实现最终的数据抓取。入口函数的主要任务是组织数据,比如要搜索的贴吧的名字,编码url参数,拼接url地址,定义文件存储路径。
履带结构
用面向对象的方式编写爬虫程序时,逻辑结构是比较固定的,总结如下:
# 程序结构
class xxxSpider(object):
def __init__(self):
# 定义常用变量,比如url或计数变量等
def get_html(self):
# 获取响应内容函数,使用随机User-Agent
def parse_html(self):
# 使用正则表达式来解析页面,提取数据
def write_html(self):
# 将提取的数据按要求保存,csv、MySQL数据库等
def run(self):
# 主函数,用来控制整体逻辑
if __name__ == ‘__main__‘:
# 程序开始运行时间
spider = xxxSpider()
spider.run()
注意:掌握以上编程逻辑将有助于您后续的学习。
爬虫随机休眠
在入口函数代码中,收录以下代码:
# 每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
爬虫访问 网站 会非常快,这与正常的人类点击行为非常不符。因此,通过随机休眠,爬虫可以模仿人类点击网站,使得网站不容易察觉是爬虫访问网站,但这样做的代价是影响程序的执行效率。
焦点爬虫是一个执行效率低的程序,提高其性能是业界一直关注的问题。于是,高效的 Python 爬虫框架 Scrapy 应运而生。
原版的:
c爬虫抓取网页数据(【每日一题】抓取网页数据(模拟访问))
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-03-09 16:06
c爬虫抓取网页数据(模拟访问),保存数据库:oracle、mysql等:两种方式,一种是批量重复查询,一种是join。
二、提取多份数据批量重复查询:1.先明确下choosewithundefined_scans的意思:choosewithundefined_scans包含两个undefined_width参数,它表示当前网页不存在的重复的页数,每个页面都会有十万个页面。查询的是总页数。2.如果choosewithundefined_scans没有参数,表示指定可以查询的页面数。
例如查询的是总页数。3.总页数是203000+,那就说明总共有9000万页面4.准备数据:获取总页数数据库createprogram"jdbcusernameclassprogram:cn-simple-username://admin";数据库表格test_logimportorg.apache.hibernate.hibernate.connector.oracle.util.hibernateconnector23;引用的数据库为mysql:jdbc[initialization=mysqlstandardmvcframework]{"name":"jdbc","username":"simplename","password":"jdbc://admin//","table":"com.xxx.xxx.account","type":"simple","auto_increment":10,"names":["account","account1","account2"]}5.业务逻辑:判断总页数量,当总页数为203000+就停止并行传输,如果不为203000+就向上传送,如果203000+就返回4007,但是实际true,说明总页数低于203000+则不存在,返回4008。
prepareview28second。javapublicclasspreparepoint28second{privatestaticfinalint[]hundred=1000000;privatestaticfinalint[]dayofweek=600000;privatestaticfinalint[]yearofweek=4000000;privatestaticfinalint[]username=null;privatestaticfinalint[]password=null;privatestaticfinalint[]table=null;privatestaticfinalbooleanredirectversion="001";privatestaticfinalvoidfieldschema_createparameter(voidschema(voidresourcea)newvoid(voidfield。
1));privatestaticfinalvoidschemaformat_schema(voidschema(voidfield
1)newvoid(voidfield
2));privatestaticfinalvoidschemaformat2(voidschema(voidfield
2)newvoid(voidfield
3));privatestaticfinalbooleanusername2011=false;privatestaticfinalvoidusername2012=false;privatestaticfinalvoidusername2013=false;privatestaticfinal 查看全部
c爬虫抓取网页数据(【每日一题】抓取网页数据(模拟访问))
c爬虫抓取网页数据(模拟访问),保存数据库:oracle、mysql等:两种方式,一种是批量重复查询,一种是join。
二、提取多份数据批量重复查询:1.先明确下choosewithundefined_scans的意思:choosewithundefined_scans包含两个undefined_width参数,它表示当前网页不存在的重复的页数,每个页面都会有十万个页面。查询的是总页数。2.如果choosewithundefined_scans没有参数,表示指定可以查询的页面数。
例如查询的是总页数。3.总页数是203000+,那就说明总共有9000万页面4.准备数据:获取总页数数据库createprogram"jdbcusernameclassprogram:cn-simple-username://admin";数据库表格test_logimportorg.apache.hibernate.hibernate.connector.oracle.util.hibernateconnector23;引用的数据库为mysql:jdbc[initialization=mysqlstandardmvcframework]{"name":"jdbc","username":"simplename","password":"jdbc://admin//","table":"com.xxx.xxx.account","type":"simple","auto_increment":10,"names":["account","account1","account2"]}5.业务逻辑:判断总页数量,当总页数为203000+就停止并行传输,如果不为203000+就向上传送,如果203000+就返回4007,但是实际true,说明总页数低于203000+则不存在,返回4008。
prepareview28second。javapublicclasspreparepoint28second{privatestaticfinalint[]hundred=1000000;privatestaticfinalint[]dayofweek=600000;privatestaticfinalint[]yearofweek=4000000;privatestaticfinalint[]username=null;privatestaticfinalint[]password=null;privatestaticfinalint[]table=null;privatestaticfinalbooleanredirectversion="001";privatestaticfinalvoidfieldschema_createparameter(voidschema(voidresourcea)newvoid(voidfield。
1));privatestaticfinalvoidschemaformat_schema(voidschema(voidfield
1)newvoid(voidfield
2));privatestaticfinalvoidschemaformat2(voidschema(voidfield
2)newvoid(voidfield
3));privatestaticfinalbooleanusername2011=false;privatestaticfinalvoidusername2012=false;privatestaticfinalvoidusername2013=false;privatestaticfinal
c爬虫抓取网页数据( 两个重要的包()预处理器定义(_szbuffer))
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-03-09 01:15
两个重要的包()预处理器定义(_szbuffer))
在windows下的C++通过Http协议实现对网页的内容抓取:
首先介绍两个重要的包(一般是linux下的开源数据包,windows下的动态链接库dll):curl包和pthreads_dll,其中curl包被解释为命令行浏览器,由调用curl_easy_setopt等内置函数可以实现对特定网页内容的获取(要正确编译导入的curl链接库,需要另外一个包C-ares)。pthreads 是一个多线程控制包,其中包括互斥变量的锁定和解锁。程序进程分配等功能。
下载地址:点击打开链接。其中,正确导入外部动态链接库需要步骤:1.Project->Properties->Configuration Properties->C/C++->General->Additional Include Directories(添加include的路径),2.Project- >Properties->Configuration Properties->Linker->General->Additional Library Directory(添加lib收录的路径);3、在Linker->Input->Additional Dependencies(添加了libcurld.lib;pthreadVC2.lib;ws2_3 2.lib;winmm.lib;wldap32.lib;areslib.lib) 4 , 在 c/c++->预处理器->预处理器定义(_CONSOLE;BUILDING_LIBCURL;HTTP_ONLY)
具体实现过程介绍:
1:自定义hashTable结构,存放获取到的字符串字符。以hashTable类的形式实现,包括hash表集合类型,以及add、find等几个常用的字符串hash函数
代码:
///HashTable.h
#ifndef HashTable_H
#define HashTable_H
#include
#include
#include
class HashTable
{
public:
HashTable(void);
~HashTable(void);
unsigned int ForceAdd(const std::string& str);
unsigned int Find(const std::string& str);
/*string的常见的hash方式*/
unsigned int RSHash(const std::string& str);
unsigned int JSHash (const std::string& str);
unsigned int PJWHash (const std::string& str);
unsigned int ELFHash (const std::string& str);
unsigned int BKDRHash(const std::string& str);
unsigned int SDBMHash(const std::string& str);
unsigned int DJBHash (const std::string& str);
unsigned int DEKHash (const std::string& str);
unsigned int BPHash (const std::string& str);
unsigned int FNVHash (const std::string& str);
unsigned int APHash (const std::string& str);
private:
std::set HashFunctionResultSet;
std::vector hhh;
};
#endif
/////HashTable.cpp
#include "HashTable.h"
HashTable::HashTable(void)
{
}
HashTable::~HashTable(void)
{
}
unsigned int HashTable::ForceAdd(const std::string& str)
{
unsigned int i=ELFHash(str);
HashFunctionResultSet.insert(i);
return i;
}
unsigned int HashTable::Find(const std::string& str)
{
int ff=hhh.size();
const unsigned int i=ELFHash(str);
std::set::const_iterator it;
if(HashFunctionResultSet.size()>0)
{
it=HashFunctionResultSet.find(i);
if(it==HashFunctionResultSet.end())
return -1;
}
else
{
return -1;
}
return i;
}
/*几种常见的字符串hash方式实现函数*/
unsigned int HashTable::APHash(const std::string& str)
{
unsigned int hash=0xAAAAAAAA;
for(std::size_t i=0;i 3)) :
(~((hash > 5)));
}
return hash;
}
unsigned int HashTable::BKDRHash(const std::string& str)
{
unsigned int seed=131; //31 131 1313 13131 131313 etc
unsigned int hash=0;
for(std::size_t i=0;isetBuffer((char*)buffer,size,nmemb);
}
bool Http::InitCurl(const std::string& url, std::string& szbuffer)
{
pthread_mutex_init(&m_http_mutex,NULL);
Http::m_szUrl=url;
CURLcode result;
if(m_pcurl)
{
curl_easy_setopt(m_pcurl, CURLOPT_ERRORBUFFER, Http::m_errorBuffer);
curl_easy_setopt(m_pcurl, CURLOPT_URL,m_szUrl.c_str());
curl_easy_setopt(m_pcurl, CURLOPT_HEADER, 0);
curl_easy_setopt(m_pcurl, CURLOPT_FOLLOWLOCATION, 1);
curl_easy_setopt(m_pcurl, CURLOPT_WRITEFUNCTION,Http::writer);
curl_easy_setopt(m_pcurl, CURLOPT_WRITEDATA,this);
result = curl_easy_perform(m_pcurl);
}
if(result!=CURLE_OK)
return false;
szbuffer=m_szbuffer;
m_szbuffer.clear();
m_szUrl.clear();
pthread_mutex_destroy(&m_http_mutex);
return true;
}
bool Http::DeInitCurl()
{
curl_easy_cleanup(m_pcurl);
curl_global_cleanup();
m_pcurl = NULL;
return true;
}
const string Http::getBuffer()
{
return m_szbuffer;
}
string Http::setUrl()
{
return Http::m_szUrl;
}
void Http::setUrl(const std::string& url)
{
Http::m_szUrl = url;
}
其中,m_szbuffer存放的是网页的内容。初始网页的内容存储在 Init 函数的形参中。 查看全部
c爬虫抓取网页数据(
两个重要的包()预处理器定义(_szbuffer))
在windows下的C++通过Http协议实现对网页的内容抓取:
首先介绍两个重要的包(一般是linux下的开源数据包,windows下的动态链接库dll):curl包和pthreads_dll,其中curl包被解释为命令行浏览器,由调用curl_easy_setopt等内置函数可以实现对特定网页内容的获取(要正确编译导入的curl链接库,需要另外一个包C-ares)。pthreads 是一个多线程控制包,其中包括互斥变量的锁定和解锁。程序进程分配等功能。
下载地址:点击打开链接。其中,正确导入外部动态链接库需要步骤:1.Project->Properties->Configuration Properties->C/C++->General->Additional Include Directories(添加include的路径),2.Project- >Properties->Configuration Properties->Linker->General->Additional Library Directory(添加lib收录的路径);3、在Linker->Input->Additional Dependencies(添加了libcurld.lib;pthreadVC2.lib;ws2_3 2.lib;winmm.lib;wldap32.lib;areslib.lib) 4 , 在 c/c++->预处理器->预处理器定义(_CONSOLE;BUILDING_LIBCURL;HTTP_ONLY)
具体实现过程介绍:
1:自定义hashTable结构,存放获取到的字符串字符。以hashTable类的形式实现,包括hash表集合类型,以及add、find等几个常用的字符串hash函数
代码:
///HashTable.h
#ifndef HashTable_H
#define HashTable_H
#include
#include
#include
class HashTable
{
public:
HashTable(void);
~HashTable(void);
unsigned int ForceAdd(const std::string& str);
unsigned int Find(const std::string& str);
/*string的常见的hash方式*/
unsigned int RSHash(const std::string& str);
unsigned int JSHash (const std::string& str);
unsigned int PJWHash (const std::string& str);
unsigned int ELFHash (const std::string& str);
unsigned int BKDRHash(const std::string& str);
unsigned int SDBMHash(const std::string& str);
unsigned int DJBHash (const std::string& str);
unsigned int DEKHash (const std::string& str);
unsigned int BPHash (const std::string& str);
unsigned int FNVHash (const std::string& str);
unsigned int APHash (const std::string& str);
private:
std::set HashFunctionResultSet;
std::vector hhh;
};
#endif
/////HashTable.cpp
#include "HashTable.h"
HashTable::HashTable(void)
{
}
HashTable::~HashTable(void)
{
}
unsigned int HashTable::ForceAdd(const std::string& str)
{
unsigned int i=ELFHash(str);
HashFunctionResultSet.insert(i);
return i;
}
unsigned int HashTable::Find(const std::string& str)
{
int ff=hhh.size();
const unsigned int i=ELFHash(str);
std::set::const_iterator it;
if(HashFunctionResultSet.size()>0)
{
it=HashFunctionResultSet.find(i);
if(it==HashFunctionResultSet.end())
return -1;
}
else
{
return -1;
}
return i;
}
/*几种常见的字符串hash方式实现函数*/
unsigned int HashTable::APHash(const std::string& str)
{
unsigned int hash=0xAAAAAAAA;
for(std::size_t i=0;i 3)) :
(~((hash > 5)));
}
return hash;
}
unsigned int HashTable::BKDRHash(const std::string& str)
{
unsigned int seed=131; //31 131 1313 13131 131313 etc
unsigned int hash=0;
for(std::size_t i=0;isetBuffer((char*)buffer,size,nmemb);
}
bool Http::InitCurl(const std::string& url, std::string& szbuffer)
{
pthread_mutex_init(&m_http_mutex,NULL);
Http::m_szUrl=url;
CURLcode result;
if(m_pcurl)
{
curl_easy_setopt(m_pcurl, CURLOPT_ERRORBUFFER, Http::m_errorBuffer);
curl_easy_setopt(m_pcurl, CURLOPT_URL,m_szUrl.c_str());
curl_easy_setopt(m_pcurl, CURLOPT_HEADER, 0);
curl_easy_setopt(m_pcurl, CURLOPT_FOLLOWLOCATION, 1);
curl_easy_setopt(m_pcurl, CURLOPT_WRITEFUNCTION,Http::writer);
curl_easy_setopt(m_pcurl, CURLOPT_WRITEDATA,this);
result = curl_easy_perform(m_pcurl);
}
if(result!=CURLE_OK)
return false;
szbuffer=m_szbuffer;
m_szbuffer.clear();
m_szUrl.clear();
pthread_mutex_destroy(&m_http_mutex);
return true;
}
bool Http::DeInitCurl()
{
curl_easy_cleanup(m_pcurl);
curl_global_cleanup();
m_pcurl = NULL;
return true;
}
const string Http::getBuffer()
{
return m_szbuffer;
}
string Http::setUrl()
{
return Http::m_szUrl;
}
void Http::setUrl(const std::string& url)
{
Http::m_szUrl = url;
}
其中,m_szbuffer存放的是网页的内容。初始网页的内容存储在 Init 函数的形参中。
c爬虫抓取网页数据( 网络爬虫框架图框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-09 01:14
网络爬虫框架图框架)
搜索引擎网络爬虫如何高效地将互联网上万亿网页爬取到本地镜像?
一、爬虫框架
上图是一个简单的网络爬虫框架图。从种子网址入手,如图,一步步工作后,将网页存入数据库。当然,勤劳的蜘蛛可能还需要做更多的工作,比如网页的去重和网页的反作弊。
或许,我们可以将网页视为蜘蛛的晚餐,其中包括:
下载的网页。被蜘蛛爬过的网页内容被放到了肚子里。
过期网页。蜘蛛每次都要爬很多网页,有的已经在肚子里坏掉了。
要下载的页面。当它看到食物时,蜘蛛就会去抓它。
知名网站。它还没有被下载和发现,但是蜘蛛可以感知它们并且迟早会抓住它。
不可知的网页。互联网太大了,很多页面蜘蛛都找不到,而且可能永远也找不到。这部分占比很高。
通过以上划分,我们可以清楚地了解搜索引擎蜘蛛的工作以及它们面临的挑战。大多数蜘蛛都是按照这个框架爬行的。但这并不完全确定。一切总是特别的。根据不同的功能,蜘蛛系统有一些差异。
二、爬虫种类
1.批量式蜘蛛。
这种蜘蛛有明确的抓取范围和目标,当蜘蛛完成目标和任务时停止抓取。具体目标是什么?它可能是抓取的页面数、页面大小、抓取时间等。
2.增量蜘蛛
这种蜘蛛不同于批处理型蜘蛛,它们会不断地爬取,并且会定期对爬取的网页进行爬取和更新。由于 Internet 上的网页在不断更新,增量爬虫需要能够反映这种更新。
3.垂直蜘蛛
此类蜘蛛仅关注特定主题或特定行业页面。以health网站为例,这种专门的爬虫只会爬取健康相关的话题,其他话题的页面不会被爬取。测试这个蜘蛛的难点在于如何更准确地识别内容所属的行业。目前很多垂直行业网站都需要这种蜘蛛去抢。
三、抢夺策略
爬虫通过种子URL进行爬取和扩展,列出大量待爬取的URL。但是,要抓取的 URL 数量巨大。蜘蛛如何确定爬行的顺序?爬虫的策略有很多,但最终的目标是先爬取重要的网页。评价页面是否重要,蜘蛛会根据页面内容的程度原创、链接权重分析等多种方法进行计算。比较有代表性的爬取策略如下:
1. 广度优先策略
宽度优先是指蜘蛛爬取一个网页后,会继续按顺序爬取该网页中收录的其他页面。这个想法看似简单,但实际上非常实用。因为大部分网页都是有优先级的,所以在页面上优先推荐重要的页面。
2. PageRank 策略
PageRank是一种非常有名的链接分析方法,主要用来衡量网页的权威性。例如,Google 的 PR 就是典型的 PageRank 算法。通过PageRank算法我们可以找出哪些页面更重要,然后蜘蛛会优先抓取这些重要的页面。
3.大网站优先策略
这个很容易理解,大网站通常内容页比较多,质量也会比较高。蜘蛛会首先分析网站分类和属性。如果这个网站已经是收录很多,或者在搜索引擎系统中的权重很高,则优先考虑收录。
4.网页更新
互联网上的大部分页面都会更新,所以蜘蛛存储的页面需要及时更新以保持一致性。打个比方:一个页面之前排名很好,如果页面被删除了但仍然排名,那么体验很差。因此,搜索引擎需要知道这些并随时更新页面,并将新的页面提供给用户。常用的网页更新策略有三种:历史参考策略和用户体验策略。整群抽样策略。
1. 历史参考策略
这是基于假设的更新策略。例如,如果你的网页以前经常更新,那么搜索引擎也认为你的网页以后会经常更新,蜘蛛也会根据这个规则定期网站对网页进行爬取。这也是为什么点水一直强调网站内容需要定期更新的原因。
2. 用户体验策略
一般来说,用户只查看搜索结果前三页的内容,很少有人看到后面的页面。用户体验策略是搜索引擎根据用户的这一特征进行更新。例如,一个网页可能发布得较早,并且有一段时间没有更新,但用户仍然觉得它有用并点击浏览,那么搜索引擎可能不会首先更新这些过时的网页。这就是为什么新页面不一定在搜索结果中排名靠前的原因。排名更多地取决于页面的质量,而不是更新的时间。
3.整群抽样策略
以上两种更新策略主要参考网页的历史信息。然而,存储大量历史信息对于搜索引擎来说是一种负担。另外,如果收录是一个新的网页,没有历史信息可以参考,怎么办?聚类抽样策略是指:拿出一些属性对很多相似的网页进行分类,分类后的页面按照相同的规则进行更新。
从了解搜索引擎蜘蛛工作原理的过程中,我们会知道:网站内容的相关性、网站与网页内容的更新规律、网页链接的分布和权重网站 等因素会影响蜘蛛的爬取效率。知己知彼,让蜘蛛来得更猛烈!
更多北碚商城产品介绍:抚顺电梯轿厢广告 查看全部
c爬虫抓取网页数据(
网络爬虫框架图框架)
搜索引擎网络爬虫如何高效地将互联网上万亿网页爬取到本地镜像?
一、爬虫框架
上图是一个简单的网络爬虫框架图。从种子网址入手,如图,一步步工作后,将网页存入数据库。当然,勤劳的蜘蛛可能还需要做更多的工作,比如网页的去重和网页的反作弊。
或许,我们可以将网页视为蜘蛛的晚餐,其中包括:
下载的网页。被蜘蛛爬过的网页内容被放到了肚子里。
过期网页。蜘蛛每次都要爬很多网页,有的已经在肚子里坏掉了。
要下载的页面。当它看到食物时,蜘蛛就会去抓它。
知名网站。它还没有被下载和发现,但是蜘蛛可以感知它们并且迟早会抓住它。
不可知的网页。互联网太大了,很多页面蜘蛛都找不到,而且可能永远也找不到。这部分占比很高。
通过以上划分,我们可以清楚地了解搜索引擎蜘蛛的工作以及它们面临的挑战。大多数蜘蛛都是按照这个框架爬行的。但这并不完全确定。一切总是特别的。根据不同的功能,蜘蛛系统有一些差异。
二、爬虫种类
1.批量式蜘蛛。
这种蜘蛛有明确的抓取范围和目标,当蜘蛛完成目标和任务时停止抓取。具体目标是什么?它可能是抓取的页面数、页面大小、抓取时间等。
2.增量蜘蛛
这种蜘蛛不同于批处理型蜘蛛,它们会不断地爬取,并且会定期对爬取的网页进行爬取和更新。由于 Internet 上的网页在不断更新,增量爬虫需要能够反映这种更新。
3.垂直蜘蛛
此类蜘蛛仅关注特定主题或特定行业页面。以health网站为例,这种专门的爬虫只会爬取健康相关的话题,其他话题的页面不会被爬取。测试这个蜘蛛的难点在于如何更准确地识别内容所属的行业。目前很多垂直行业网站都需要这种蜘蛛去抢。
三、抢夺策略
爬虫通过种子URL进行爬取和扩展,列出大量待爬取的URL。但是,要抓取的 URL 数量巨大。蜘蛛如何确定爬行的顺序?爬虫的策略有很多,但最终的目标是先爬取重要的网页。评价页面是否重要,蜘蛛会根据页面内容的程度原创、链接权重分析等多种方法进行计算。比较有代表性的爬取策略如下:
1. 广度优先策略
宽度优先是指蜘蛛爬取一个网页后,会继续按顺序爬取该网页中收录的其他页面。这个想法看似简单,但实际上非常实用。因为大部分网页都是有优先级的,所以在页面上优先推荐重要的页面。
2. PageRank 策略
PageRank是一种非常有名的链接分析方法,主要用来衡量网页的权威性。例如,Google 的 PR 就是典型的 PageRank 算法。通过PageRank算法我们可以找出哪些页面更重要,然后蜘蛛会优先抓取这些重要的页面。
3.大网站优先策略
这个很容易理解,大网站通常内容页比较多,质量也会比较高。蜘蛛会首先分析网站分类和属性。如果这个网站已经是收录很多,或者在搜索引擎系统中的权重很高,则优先考虑收录。
4.网页更新
互联网上的大部分页面都会更新,所以蜘蛛存储的页面需要及时更新以保持一致性。打个比方:一个页面之前排名很好,如果页面被删除了但仍然排名,那么体验很差。因此,搜索引擎需要知道这些并随时更新页面,并将新的页面提供给用户。常用的网页更新策略有三种:历史参考策略和用户体验策略。整群抽样策略。
1. 历史参考策略
这是基于假设的更新策略。例如,如果你的网页以前经常更新,那么搜索引擎也认为你的网页以后会经常更新,蜘蛛也会根据这个规则定期网站对网页进行爬取。这也是为什么点水一直强调网站内容需要定期更新的原因。
2. 用户体验策略
一般来说,用户只查看搜索结果前三页的内容,很少有人看到后面的页面。用户体验策略是搜索引擎根据用户的这一特征进行更新。例如,一个网页可能发布得较早,并且有一段时间没有更新,但用户仍然觉得它有用并点击浏览,那么搜索引擎可能不会首先更新这些过时的网页。这就是为什么新页面不一定在搜索结果中排名靠前的原因。排名更多地取决于页面的质量,而不是更新的时间。
3.整群抽样策略
以上两种更新策略主要参考网页的历史信息。然而,存储大量历史信息对于搜索引擎来说是一种负担。另外,如果收录是一个新的网页,没有历史信息可以参考,怎么办?聚类抽样策略是指:拿出一些属性对很多相似的网页进行分类,分类后的页面按照相同的规则进行更新。
从了解搜索引擎蜘蛛工作原理的过程中,我们会知道:网站内容的相关性、网站与网页内容的更新规律、网页链接的分布和权重网站 等因素会影响蜘蛛的爬取效率。知己知彼,让蜘蛛来得更猛烈!
更多北碚商城产品介绍:抚顺电梯轿厢广告
c爬虫抓取网页数据( Scraoy入门实例一—Scrapy介绍与安装ampamp的安装)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-09 01:12
Scraoy入门实例一—Scrapy介绍与安装ampamp的安装)
Scraoy入门示例1-Scrapy介绍与安装&PyCharm安装&项目实战
一、Scrapy 的安装
1.Scrapy介绍
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。
2.Scrapy 安装
建议使用 Anaconda 安装 Scrapy
Anaconda 是一个开源包和环境管理神器。Anaconda 包括 180 多个科学包及其依赖项,包括 conda 和 Python。从官网下载安装Anaconda(个人版),根据自己的系统选择下载,安装,选择next继续安装,Install for选项选择Just for me,选择安装位置,等待安装完成。
安装完成后,打开命令行,输入conda install scrapy,根据提示按Y,即可下载所有Scrapy及其依赖包,从而完成安装。
注意:使用命令行安装scrapy包时,会出现下载超时问题,即下载失败。我们可以通过修改scrapy包的镜像文件来提高scrapy包的下载速度。你可以参考博客:
这时候测试Scrapy是否安装成功:在命令行窗口输入scrapy,回车。如果出现如下界面,则表示安装成功:
二、安装 PyCharm
1.PyCharm介绍
PyCharm 是一个 Python IDE,拥有一套完整的工具,可以帮助用户在使用 Python 语言进行开发时提高效率,例如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试和版本控制。此外,IDE 还提供高级功能以支持 Django 框架下的专业 Web 开发。
2.PyCharm 安装
进入PyCharm官网,直接点击DownLoad下载,左边是专业版,右边是社区版,社区版免费,专业版免费试用。
如果我们之前没有下载过Python解释器,可以在等待安装的同时下载Python解释器,进入Python官网,根据系统和版本下载对应的压缩包。安装完成后,在环境变量 Path 中配置 Python 解释器的安装路径。你可以参考博客:
三、Scrapy 抓豆瓣项目在行动
前提条件:如果要在 PyCharm 中使用 Scrapy,首先必须在 PyCharm 中安装支持的 Scrapy 包。流程如下,点击文件>>设置... 两个包,如果点击的时候看到一个Scrapy包,那么就不需要安装了,继续下一步。
如果没有Scrapy包,点击“+”,搜索Scrapy包,点击Install Package进行安装
等待安装完成。
1.新项目
打开新安装的PyCharm,使用软件终端中的pycharm工具,如果找不到PyCharm终端在哪里,就是左下角的Terminal。
输入命令:scrapy startproject douban 这是使用命令行新建爬虫项目,如下图,图中项目名称为pythonProject
然后在命令行输入命令:cd douban进入生成项目的根目录
然后在终端继续输入命令:scrapy genspider douban_spider 生成douban_spider爬虫文件。
此时的项目结构如下图所示:
2.明确目标
我们要练习的 网站 是:
假设,我们获取 top250 电影的序列号、电影名称、介绍、星级、评论数、电影描述选项
至此,我们在 items.py 文件中定义抓取的数据项,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.接下来,我们需要创建爬虫并存储爬取的内容
在douban_spider.py爬虫文件中编写具体的逻辑代码,如下:
# -*- coding: utf-8 -*-
import scrapy
from ..items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
name = "douban_spider"
# 允许的域名
allowed_domains = ["movie.douban.com"]
# 入口URL
start_urls = ["https://movie.douban.com/top250"]
def parse(self, response):
movie_list = response.xpath("//div[@class="article"]//ol[@class="grid_view"]/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item["serial_number"] = i_item.xpath(".//div[@class="item"]//em/text()").extract_first()
douban_item["movie_name"] = i_item.xpath(".//div[@class="info"]//div[@class="hd"]/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class="info"]//div[@class="bd"]/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item["introduce"] = content_s
douban_item["star"] = i_item.xpath(".//span[@class="rating_num"]/text()").extract_first()
douban_item["evaluate"] = i_item.xpath(".//div[@class="star"]//span[4]/text()").extract_first()
douban_item["describe"] = i_item.xpath(".//p[@class="quote"]/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class="next"]/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
这个时候不需要运行这个python文件,因为我们不单独使用,所以不需要运行,允许报错。import引入的问题,主目录的绝对路径和相对路径,原因是我们使用的是相对路径“..items”,对相关内容感兴趣的同学可以去网上找一下此类问题的解释.
4.存储内容
将爬取的内容存储为 json 或 csv 格式的文件
在命令行输入:scrapy crawl douban_spider -o test.json 或者 scrapy crawl douban_spider -o test.csv
将爬取的数据存储在 json 文件或 csv 文件中。
执行爬取命令后,当鼠标聚焦到项目面板时,会显示生成的 json 文件或 csv 文件。打开json或者csv文件后,如果里面什么都没有,那么我们需要做进一步的修改,修改代理USER_AGENT的内容,
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.8 Safari/537.36"
如果存储在json文件中,所有内容都会以十六进制形式显示,可以通过相应的方法进行转码。这里就不多解释了,如下图所示:
并且存储在csv文件中,它会直接显示我们要爬取的所有内容,如下图:
至此,我们就完成了网站具体内容的爬取。接下来,我们需要对爬取的数据进行处理。
分界线 —————————————————————————————————————————————- 分界线
Scraoy 入门示例 2 - 使用管道实现
在本次实战中,需要重新创建项目或者安装scrapy包。参考上面的内容,新建项目的方法也参考上面的内容,这里不再赘述。
项目目录结构如下图所示:
一、流水线介绍
当我们通过Spider爬取数据,通过Item采集数据时,我们需要对数据做一些处理,因为我们爬取的数据不一定是我们想要的最终数据,可能还需要对数据进行清洗和验证。数据有效性。Scripy 中的 Pipeline 组件用于数据处理。Pipeline 组件是一个收录特定接口的类。它通常只负责一项功能的数据处理。在一个项目中可以同时启用多个管道。
二、在items.py中定义你要抓取的数据
首先打开一个新的pycharm项目,通过终端新建一个项目教程,在item中定义你要抓取的数据,比如电影名,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、定义 pipeline.py 文件
每个 item 管道组件都是一个独立的 pyhton 类,必须实现 process_item(self, item, spider) 方法。每个item管道组件都需要调用这个方法。该方法必须返回一个带有数据的dict,或者一个item对象,或者抛出一个DropItem异常,并且被丢弃的item不会被后续管道组件处理。定义的 pipelines.py 代码如下所示:
# Define your item pipelines here
#
# Don"t forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/lat ... .html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class TutorialPipeline(object):
def process_item(self, item, spider):
return item
import time
class DoubanmoviePipeline(object):
def process_item(self, item, spider):
now = time.strftime("%Y-%m-%d", time.localtime())
fileName = "douban" + now + ".txt"
with open(fileName, "a", encoding="utf-8") as fp:
fp.write(item["moiveName"][0]+"")
return item
四、配置设置.py
由于这次使用的是管道,所以我们需要在settings.py中打开管道通道注释,并在其中添加一条新记录,如下图所示:
五、写爬虫文件
在tutorial/spiders目录下创建quotes_spider.py文件,目录结构如下,编写初步代码:
quote_spider.py 代码如下:
import scrapy
from items import DoubanmovieItem
class QuotesSpider(scrapy.Spider):
name = "doubanSpider"
allowed_domains = ["douban.com"]
start_urls = ["http://movie.douban.com/cinema/nowplaying",
"http://movie.douban.com/cinema ... ot%3B]
def parse(self, response):
print("--" * 20 )
#print(response.body)
print("==" * 20 )
subSelector = response.xpath("//li[@class="stitle"]")
items = []
for sub in subSelector:
#print(sub.xpath("normalize-space(./a/text())").extract())
print(sub)
item = DoubanmovieItem()
item["moiveName"] = sub.xpath("normalize-space(./a/text())").extract()
items.append(item)
print(items)
return items
六、从启动文件运行
在豆瓣文件目录下新建启动文件douban_spider_run.py(文件名可取不同),运行文件查看结果。编写代码如下:
from scrapy import cmdline
cmdline.execute("scrapy crawl doubanSpider".split())
最后,处理后的爬取数据如下图(部分)所示:
最后,希望大家在写代码的时候可以小心,不要马虎。实验的时候写了方法DoubanmovieItem作为DobanmovieItem引入,导致整个程序失败,而且PyCharm也没有告诉我哪里错了,我到处找问题的解决方法也没找到。最后查了很多遍,都是在生成方法的时候才发现的,所以一定要小心。该错误如下图所示。提示找不到DobanmovieItem模块。它可能告诉我错误的地方。因为懒得找,找了很久。希望大家多多注意!
至此,使用Scrapy抓取网页内容,并对抓取到的内容进行清理和处理的实验已经完成。要求熟悉并使用此过程中的代码和操作,不要在网上搜索和消化。吸收它并记住它,这是学习知识的真正方法,而不仅仅是画一个勺子。
本文地址:H5W3 » python爬虫示例:使用Scrapy爬取网页采集数据 查看全部
c爬虫抓取网页数据(
Scraoy入门实例一—Scrapy介绍与安装ampamp的安装)
https://www.h5w3.com/wp-conten ... 3.jpg 150w" />Scraoy入门示例1-Scrapy介绍与安装&PyCharm安装&项目实战
一、Scrapy 的安装
1.Scrapy介绍
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。
2.Scrapy 安装
建议使用 Anaconda 安装 Scrapy
Anaconda 是一个开源包和环境管理神器。Anaconda 包括 180 多个科学包及其依赖项,包括 conda 和 Python。从官网下载安装Anaconda(个人版),根据自己的系统选择下载,安装,选择next继续安装,Install for选项选择Just for me,选择安装位置,等待安装完成。
安装完成后,打开命令行,输入conda install scrapy,根据提示按Y,即可下载所有Scrapy及其依赖包,从而完成安装。
注意:使用命令行安装scrapy包时,会出现下载超时问题,即下载失败。我们可以通过修改scrapy包的镜像文件来提高scrapy包的下载速度。你可以参考博客:
这时候测试Scrapy是否安装成功:在命令行窗口输入scrapy,回车。如果出现如下界面,则表示安装成功:
https://www.h5w3.com/wp-conten ... 9.png 150w" />二、安装 PyCharm
1.PyCharm介绍
PyCharm 是一个 Python IDE,拥有一套完整的工具,可以帮助用户在使用 Python 语言进行开发时提高效率,例如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试和版本控制。此外,IDE 还提供高级功能以支持 Django 框架下的专业 Web 开发。
2.PyCharm 安装
进入PyCharm官网,直接点击DownLoad下载,左边是专业版,右边是社区版,社区版免费,专业版免费试用。
如果我们之前没有下载过Python解释器,可以在等待安装的同时下载Python解释器,进入Python官网,根据系统和版本下载对应的压缩包。安装完成后,在环境变量 Path 中配置 Python 解释器的安装路径。你可以参考博客:
三、Scrapy 抓豆瓣项目在行动
前提条件:如果要在 PyCharm 中使用 Scrapy,首先必须在 PyCharm 中安装支持的 Scrapy 包。流程如下,点击文件>>设置... 两个包,如果点击的时候看到一个Scrapy包,那么就不需要安装了,继续下一步。
https://www.h5w3.com/wp-conten ... 7.png 150w" />如果没有Scrapy包,点击“+”,搜索Scrapy包,点击Install Package进行安装
https://www.h5w3.com/wp-conten ... 1.png 150w" />等待安装完成。
1.新项目
打开新安装的PyCharm,使用软件终端中的pycharm工具,如果找不到PyCharm终端在哪里,就是左下角的Terminal。
输入命令:scrapy startproject douban 这是使用命令行新建爬虫项目,如下图,图中项目名称为pythonProject
https://www.h5w3.com/wp-conten ... 0.png 150w" />然后在命令行输入命令:cd douban进入生成项目的根目录
然后在终端继续输入命令:scrapy genspider douban_spider 生成douban_spider爬虫文件。
此时的项目结构如下图所示:
https://www.h5w3.com/wp-conten ... 0.png 136w" />2.明确目标
我们要练习的 网站 是:
假设,我们获取 top250 电影的序列号、电影名称、介绍、星级、评论数、电影描述选项
至此,我们在 items.py 文件中定义抓取的数据项,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.接下来,我们需要创建爬虫并存储爬取的内容
在douban_spider.py爬虫文件中编写具体的逻辑代码,如下:
# -*- coding: utf-8 -*-
import scrapy
from ..items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
name = "douban_spider"
# 允许的域名
allowed_domains = ["movie.douban.com"]
# 入口URL
start_urls = ["https://movie.douban.com/top250"]
def parse(self, response):
movie_list = response.xpath("//div[@class="article"]//ol[@class="grid_view"]/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item["serial_number"] = i_item.xpath(".//div[@class="item"]//em/text()").extract_first()
douban_item["movie_name"] = i_item.xpath(".//div[@class="info"]//div[@class="hd"]/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class="info"]//div[@class="bd"]/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item["introduce"] = content_s
douban_item["star"] = i_item.xpath(".//span[@class="rating_num"]/text()").extract_first()
douban_item["evaluate"] = i_item.xpath(".//div[@class="star"]//span[4]/text()").extract_first()
douban_item["describe"] = i_item.xpath(".//p[@class="quote"]/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class="next"]/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
这个时候不需要运行这个python文件,因为我们不单独使用,所以不需要运行,允许报错。import引入的问题,主目录的绝对路径和相对路径,原因是我们使用的是相对路径“..items”,对相关内容感兴趣的同学可以去网上找一下此类问题的解释.
4.存储内容
将爬取的内容存储为 json 或 csv 格式的文件
在命令行输入:scrapy crawl douban_spider -o test.json 或者 scrapy crawl douban_spider -o test.csv
将爬取的数据存储在 json 文件或 csv 文件中。
执行爬取命令后,当鼠标聚焦到项目面板时,会显示生成的 json 文件或 csv 文件。打开json或者csv文件后,如果里面什么都没有,那么我们需要做进一步的修改,修改代理USER_AGENT的内容,
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.8 Safari/537.36"
https://www.h5w3.com/wp-conten ... 4.png 150w" />如果存储在json文件中,所有内容都会以十六进制形式显示,可以通过相应的方法进行转码。这里就不多解释了,如下图所示:
https://www.h5w3.com/wp-conten ... 4.png 150w" />并且存储在csv文件中,它会直接显示我们要爬取的所有内容,如下图:
https://www.h5w3.com/wp-conten ... 9.png 150w" />至此,我们就完成了网站具体内容的爬取。接下来,我们需要对爬取的数据进行处理。
分界线 —————————————————————————————————————————————- 分界线
Scraoy 入门示例 2 - 使用管道实现
在本次实战中,需要重新创建项目或者安装scrapy包。参考上面的内容,新建项目的方法也参考上面的内容,这里不再赘述。
项目目录结构如下图所示:
https://www.h5w3.com/wp-conten ... 0.png 78w" />一、流水线介绍
当我们通过Spider爬取数据,通过Item采集数据时,我们需要对数据做一些处理,因为我们爬取的数据不一定是我们想要的最终数据,可能还需要对数据进行清洗和验证。数据有效性。Scripy 中的 Pipeline 组件用于数据处理。Pipeline 组件是一个收录特定接口的类。它通常只负责一项功能的数据处理。在一个项目中可以同时启用多个管道。
二、在items.py中定义你要抓取的数据
首先打开一个新的pycharm项目,通过终端新建一个项目教程,在item中定义你要抓取的数据,比如电影名,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、定义 pipeline.py 文件
每个 item 管道组件都是一个独立的 pyhton 类,必须实现 process_item(self, item, spider) 方法。每个item管道组件都需要调用这个方法。该方法必须返回一个带有数据的dict,或者一个item对象,或者抛出一个DropItem异常,并且被丢弃的item不会被后续管道组件处理。定义的 pipelines.py 代码如下所示:
# Define your item pipelines here
#
# Don"t forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/lat ... .html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class TutorialPipeline(object):
def process_item(self, item, spider):
return item
import time
class DoubanmoviePipeline(object):
def process_item(self, item, spider):
now = time.strftime("%Y-%m-%d", time.localtime())
fileName = "douban" + now + ".txt"
with open(fileName, "a", encoding="utf-8") as fp:
fp.write(item["moiveName"][0]+"")
return item
四、配置设置.py
由于这次使用的是管道,所以我们需要在settings.py中打开管道通道注释,并在其中添加一条新记录,如下图所示:
https://www.h5w3.com/wp-conten ... 2.png 150w" />五、写爬虫文件
在tutorial/spiders目录下创建quotes_spider.py文件,目录结构如下,编写初步代码:
https://www.h5w3.com/wp-conten ... 0.png 93w" />quote_spider.py 代码如下:
import scrapy
from items import DoubanmovieItem
class QuotesSpider(scrapy.Spider):
name = "doubanSpider"
allowed_domains = ["douban.com"]
start_urls = ["http://movie.douban.com/cinema/nowplaying",
"http://movie.douban.com/cinema ... ot%3B]
def parse(self, response):
print("--" * 20 )
#print(response.body)
print("==" * 20 )
subSelector = response.xpath("//li[@class="stitle"]")
items = []
for sub in subSelector:
#print(sub.xpath("normalize-space(./a/text())").extract())
print(sub)
item = DoubanmovieItem()
item["moiveName"] = sub.xpath("normalize-space(./a/text())").extract()
items.append(item)
print(items)
return items
六、从启动文件运行
在豆瓣文件目录下新建启动文件douban_spider_run.py(文件名可取不同),运行文件查看结果。编写代码如下:
from scrapy import cmdline
cmdline.execute("scrapy crawl doubanSpider".split())
最后,处理后的爬取数据如下图(部分)所示:
https://www.h5w3.com/wp-conten ... 7.png 150w" />最后,希望大家在写代码的时候可以小心,不要马虎。实验的时候写了方法DoubanmovieItem作为DobanmovieItem引入,导致整个程序失败,而且PyCharm也没有告诉我哪里错了,我到处找问题的解决方法也没找到。最后查了很多遍,都是在生成方法的时候才发现的,所以一定要小心。该错误如下图所示。提示找不到DobanmovieItem模块。它可能告诉我错误的地方。因为懒得找,找了很久。希望大家多多注意!
https://www.h5w3.com/wp-conten ... 5.png 150w" />至此,使用Scrapy抓取网页内容,并对抓取到的内容进行清理和处理的实验已经完成。要求熟悉并使用此过程中的代码和操作,不要在网上搜索和消化。吸收它并记住它,这是学习知识的真正方法,而不仅仅是画一个勺子。
本文地址:H5W3 » python爬虫示例:使用Scrapy爬取网页采集数据
c爬虫抓取网页数据(开始定位,也即这两个写法在XML包中都是适用的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-07 22:07
开始定位,即
div[@class='first']/a/text()
这两种写法都适用于 XML 包。
由于不是主要内容,更多关于HTML的知识这里不再赘述。详细的可以自己学习HTML和CSS相关知识,是爬虫的基础。
我们通常使用chrome浏览器右键->查看源代码,或者右键要查看的内容->检查,然后会看到如下界面:
这时候如果我们在Khaled Hosseini那一行右键,可以右键->复制->选择器或者Xpath直接复制对应的层次定位。需要注意的是,我们还需要将复制的定位代码替换成XML包可以识别的格式。例如,属性值使用单引号,“//”表示该类型的所有节点等。
下面重点介绍XML中常见的节点定位方法和代码,可以作为参考:
<p>getNodeSet(doc,'/bookstore/book[1]')
# 选取属于 bookstore 子元素的最后一个 book 元素。
getNodeSet(doc,'/bookstore/book[last()]')
# 选取最前面的两个属于 bookstore 元素的子元素的 book 元素
getNodeSet(doc,'/bookstore/book[position() 查看全部
c爬虫抓取网页数据(开始定位,也即这两个写法在XML包中都是适用的)
开始定位,即
div[@class='first']/a/text()
这两种写法都适用于 XML 包。
由于不是主要内容,更多关于HTML的知识这里不再赘述。详细的可以自己学习HTML和CSS相关知识,是爬虫的基础。
我们通常使用chrome浏览器右键->查看源代码,或者右键要查看的内容->检查,然后会看到如下界面:
这时候如果我们在Khaled Hosseini那一行右键,可以右键->复制->选择器或者Xpath直接复制对应的层次定位。需要注意的是,我们还需要将复制的定位代码替换成XML包可以识别的格式。例如,属性值使用单引号,“//”表示该类型的所有节点等。
下面重点介绍XML中常见的节点定位方法和代码,可以作为参考:
<p>getNodeSet(doc,'/bookstore/book[1]')
# 选取属于 bookstore 子元素的最后一个 book 元素。
getNodeSet(doc,'/bookstore/book[last()]')
# 选取最前面的两个属于 bookstore 元素的子元素的 book 元素
getNodeSet(doc,'/bookstore/book[position()
c爬虫抓取网页数据(:网络爬虫;Python;MySQL;正则表达式;)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-03-06 05:20
吴永聪
摘要: 近年来,随着互联网的发展,如何有效地从互联网上获取所需信息已成为众多互联网公司竞争研究的新方向。从互联网获取数据最常用的方法是网络爬虫。网络爬虫,也称为网络蜘蛛和网络机器人,是一种根据特定规则和给定 URL 自动采集互联网数据和信息的程序。文章讨论了网络爬虫实现过程中的主要问题:如何使用python模拟登录、如何使用正则表达式匹配字符串获取信息、如何使用mysql存储数据等,并实现一个使用 python 的网络爬虫系统。
关键词:网络爬虫;Python; MySQL;常用表达
CLC 编号:TP311.11 文号:A文章编号:1006-8228 (2019)08-94-03
摘要:近年来,随着互联网的发展,如何有效地从互联网上获取所需的信息成为众多互联网公司争相研究的新方向,而最常见的从互联网上获取数据的手段是网络爬虫。网络爬虫也称为网络蜘蛛或网络机器人,它是根据给定的 URL 和特定规则自动采集互联网数据和信息的程序。本文讨论了网络爬虫实现中的主要问题,如如何使用Python模拟登录、如何使用正则表达式匹配字符串获取信息以及如何使用MySQL存储数据等。最后通过对Python语言的研究,实现了一个基于Python的网络爬虫程序系统。
关键词:网络爬虫;Python; MySQL;正则表达式
0 前言
在网络信息和数据爆炸式增长的时代,尽管互联网信息技术飞速发展,但仍然难以从如此海量的信息数据中找到真正有用的信息。于是,谷歌、百度、雅虎等搜索引擎应运而生。搜索引擎可以根据用户输入的关键字检索互联网上的网页,为用户查找与关键字相关或收录关键字的信息。网络爬虫作为搜索引擎的重要组成部分,在信息检索过程中发挥着重要作用。因此,网络爬虫的研究对搜索引擎的发展具有重要意义。对于编写网络爬虫,python有其独特的优势。比如python中有很多爬虫框架,使得网络爬虫爬取数据的效率更高。同时,Python 是一种面向对象的解释型高级编程语言。它的语法比其他高级编程语言更简单、更容易阅读和理解。因此,使用 Python 实现网络爬虫是一个不错的选择。
1 网络爬虫概述
1.1 网络爬虫原理
网络爬虫,又称网络蜘蛛、网络机器人,主要用于采集互联网上的各种资源。它是搜索引擎的重要组成部分,是一种自动提取 Internet 上特定页面内容的程序。通用搜索引擎网络爬虫工作流程[1]:①将种子URL放入等待URL队列;② 将等待URL从等待URL队列中取出,进行读取URL、DNS解析、网页下载等操作;③ 下载 将下载的网页放入下载的网页库;④ 将下载的网页网址放入抓取的网址队列中;爬行循环。
爬虫的工作流程:①通过URL抓取页面代码;② 通过正则匹配获取页面的有用数据或页面上有用的URL;③ 对获取的数据进行处理或通过获取的新URL进入下一轮爬取循环。
1.2 网络爬虫的分类
网络爬虫大致可以分为一般网络爬虫和专注网络爬虫[2]。
通用网络爬虫,又称全网爬虫,从一个或多个初始URL开始,获取初始页面的代码,同时从页面中提取相关URL放入队列中直到满足程序停止条件。与一般网络爬虫相比,聚焦网络爬虫的工作流程更为复杂。它需要提前通过一定的网页分析算法过滤掉一些与主题无关的URL,以保证剩余的URL在一定程度上与主题相关。放入等待抓取的 URL 队列。然后根据搜索策略,从队列中选择下一步要爬取的URL,重复上述操作,直到满足程序的停止条件。专注的网络爬虫可以爬取与主题更相关的信息。例如,为了快速获取微博中的数据,我们可以利用聚焦爬虫技术开发微博数据抓取工具[3-5]。在当今大数据时代,专注爬虫可以大海捞针,从网络数据的海洋中找到人们需要的信息,过滤掉那些“垃圾数据”(广告信息等与检索主题无关的数据) )。
2 蟒蛇
Python的作者是荷兰人Guido von Rossum。1982 年,Guido 获得了阿姆斯特丹大学的数学和计算硕士学位[6]。相比现在,在他那个年代,个人电脑的频率和内存都非常低,导致电脑的配置偏低。为了让程序在 PC 上运行,所有编译器都在其核心进行了优化,因为如果不进行优化,更大的数组可能会填满内存。Guido 想要编写一种全面、易于学习、易于使用和可扩展的新语言。1989 年,Guido 开始为 Python 语言编写编译器。
3 系统分析
本系统是一个基于Python的网络爬虫系统,用于登录并爬取豆瓣上的相册、日记、话题、评论等一些动态数据信息。并且可以将关键字查询到的动态信息数据存入数据库,将部分数据存入数据库,存入本地txt文件,同时可以将相册动态中的图片下载到本地,还记录专辑信息,在每一页上。操作完成后,可以翻页,选择页面继续操作。因此系统应满足以下要求。
(1)可以通过验证码验证模拟登录豆瓣。即不需要通过浏览器登录,输入用户名、密码和验证即可登录豆瓣。控制台中的代码。
(2)登录成功后可以抓取豆瓣首页的代码。即通过登录成功后的cookie,可以访问游客无法访问的页面,抓取页面代码.
(3)可以从页面代码中提取出需要的信息,即需要通过正则表达式匹配等方法从抓取的页面中获取有用的数据信息。
(4)可以实现翻页和分页功能。即访问网站的动态页面时,可以通过在控制台输入具体内容进行翻页或者输入页码选择页面,然后抓取其他页面。
(5)实现关键字查询的功能,爬取找到的数据并存入数据库表中。即在爬取页面获取数据后,在控制台输入关键字即可爬取获取需要的信息。
(6)可以将爬取的图片的url下载到本地,图片的详细信息可以保存在本地txt[12]。也就是说,不仅要下载图片到本地,还有图片的主题信息、图片的用户、图片的具体网址等信息都保存在txt文件中。
(7) 将日记等动态信息存储在不同的本地文件中。即针对抓取到的不同数据信息,采用不同的存储方式和存储路径。
(8)在登录成功的情况下,可以进入个人中心,将当前用户关注的用户信息存储在数据库表中。这些信息可能包括用户id、昵称、主页url、个性化签名等
以上是本课程对爬虫系统的一些基本要求,据此可以明确系统的功能。因为这个系统注重网络信息资源的爬取,所以在用户交互方面可能不是很美观。本系统没有编写界面,所有操作都在Eclipse控制台中进行。例如:在控制台输入用户名、密码和验证码登录,登录成功后的页面选择,页面选择后的数据爬取等。
但是系统运行后爬取的数据可以在数据所在的本地txt文件或数据库中查看。因此,测试系统是否真的可以爬取数据,可以通过观察本地txt文件内容的变化或者数据库表中记录的变化来验证。
该爬虫系统包括模拟登录、页面爬取、信息爬取、数据存储等主要功能。其中,页面爬取包括翻页爬取、页面选择爬取、个人页面爬取;信息爬取包括动态爬取和跟随用户爬取;数据存储包括写入文件、下载到本地和存储数据库,如图1所示。
自动爬取 Internet 信息的程序称为爬虫。它主要由爬虫调度器、URL管理器、网页下载器和网页解析器组成。
(1)爬虫调度器:程序的入口点,主要负责爬虫程序的控制。
⑵ 网址管理器:
① 为要爬取的集合添加新的URL;
②判断要添加的URL是否已经存在;
③ 判断是否还有待爬取的URL,将待爬取集合中的URL移动到爬取集合中。
URL存储方式:Python内存是set()集合、关系数据库、缓存数据库。
(3)网页下载器:根据URL获取网页内容,通过urllib2和request实现。
⑷网页解析器:从网页中提取有价值的数据。实现方式包括正则表达式、html.parser、BeautifulSoup、lxml。
4。结论
爬虫是一种自动下载网页的程序。它根据给定的爬取目标有选择地访问万维网上的网页及其相关链接,以获取所需的信息。
本文中,爬虫旨在爬取与特定主题内容相关的网页,为面向主题的用户查询准备数据资源,实现网页数据的抓取和分析。
参考:
[1] 曾小虎. 基于主题的微博网络爬虫研究[D]. 武汉理工大学, 2014.
[2] 周丽珠,林玲.爬虫技术研究综述[J]. 计算机应用,2005. 25 (9): 1965-1969
[3] 周中华,张惠然,谢江。Python中的新浪微博数据爬虫[J]. 计算机应用,2014.34 (11): 3131-3134
[4] 刘晶晶. 面向微博的网络爬虫研究与实现[D]. 复旦大学,2012.
[5] 王静,朱可,王斌强。基于信息数据分析的微博研究综述[J]. 计算机应用, 2012. 32 (7): 2027-2029, 2037.@ >
[6](挪威)Magnus Lie Hetland。思伟,曾俊伟,谭英华,译。Python基础教程[M].人民邮电出版社,2014. 查看全部
c爬虫抓取网页数据(:网络爬虫;Python;MySQL;正则表达式;)
吴永聪
摘要: 近年来,随着互联网的发展,如何有效地从互联网上获取所需信息已成为众多互联网公司竞争研究的新方向。从互联网获取数据最常用的方法是网络爬虫。网络爬虫,也称为网络蜘蛛和网络机器人,是一种根据特定规则和给定 URL 自动采集互联网数据和信息的程序。文章讨论了网络爬虫实现过程中的主要问题:如何使用python模拟登录、如何使用正则表达式匹配字符串获取信息、如何使用mysql存储数据等,并实现一个使用 python 的网络爬虫系统。
关键词:网络爬虫;Python; MySQL;常用表达
CLC 编号:TP311.11 文号:A文章编号:1006-8228 (2019)08-94-03
摘要:近年来,随着互联网的发展,如何有效地从互联网上获取所需的信息成为众多互联网公司争相研究的新方向,而最常见的从互联网上获取数据的手段是网络爬虫。网络爬虫也称为网络蜘蛛或网络机器人,它是根据给定的 URL 和特定规则自动采集互联网数据和信息的程序。本文讨论了网络爬虫实现中的主要问题,如如何使用Python模拟登录、如何使用正则表达式匹配字符串获取信息以及如何使用MySQL存储数据等。最后通过对Python语言的研究,实现了一个基于Python的网络爬虫程序系统。
关键词:网络爬虫;Python; MySQL;正则表达式
0 前言
在网络信息和数据爆炸式增长的时代,尽管互联网信息技术飞速发展,但仍然难以从如此海量的信息数据中找到真正有用的信息。于是,谷歌、百度、雅虎等搜索引擎应运而生。搜索引擎可以根据用户输入的关键字检索互联网上的网页,为用户查找与关键字相关或收录关键字的信息。网络爬虫作为搜索引擎的重要组成部分,在信息检索过程中发挥着重要作用。因此,网络爬虫的研究对搜索引擎的发展具有重要意义。对于编写网络爬虫,python有其独特的优势。比如python中有很多爬虫框架,使得网络爬虫爬取数据的效率更高。同时,Python 是一种面向对象的解释型高级编程语言。它的语法比其他高级编程语言更简单、更容易阅读和理解。因此,使用 Python 实现网络爬虫是一个不错的选择。
1 网络爬虫概述
1.1 网络爬虫原理
网络爬虫,又称网络蜘蛛、网络机器人,主要用于采集互联网上的各种资源。它是搜索引擎的重要组成部分,是一种自动提取 Internet 上特定页面内容的程序。通用搜索引擎网络爬虫工作流程[1]:①将种子URL放入等待URL队列;② 将等待URL从等待URL队列中取出,进行读取URL、DNS解析、网页下载等操作;③ 下载 将下载的网页放入下载的网页库;④ 将下载的网页网址放入抓取的网址队列中;爬行循环。
爬虫的工作流程:①通过URL抓取页面代码;② 通过正则匹配获取页面的有用数据或页面上有用的URL;③ 对获取的数据进行处理或通过获取的新URL进入下一轮爬取循环。
1.2 网络爬虫的分类
网络爬虫大致可以分为一般网络爬虫和专注网络爬虫[2]。
通用网络爬虫,又称全网爬虫,从一个或多个初始URL开始,获取初始页面的代码,同时从页面中提取相关URL放入队列中直到满足程序停止条件。与一般网络爬虫相比,聚焦网络爬虫的工作流程更为复杂。它需要提前通过一定的网页分析算法过滤掉一些与主题无关的URL,以保证剩余的URL在一定程度上与主题相关。放入等待抓取的 URL 队列。然后根据搜索策略,从队列中选择下一步要爬取的URL,重复上述操作,直到满足程序的停止条件。专注的网络爬虫可以爬取与主题更相关的信息。例如,为了快速获取微博中的数据,我们可以利用聚焦爬虫技术开发微博数据抓取工具[3-5]。在当今大数据时代,专注爬虫可以大海捞针,从网络数据的海洋中找到人们需要的信息,过滤掉那些“垃圾数据”(广告信息等与检索主题无关的数据) )。
2 蟒蛇
Python的作者是荷兰人Guido von Rossum。1982 年,Guido 获得了阿姆斯特丹大学的数学和计算硕士学位[6]。相比现在,在他那个年代,个人电脑的频率和内存都非常低,导致电脑的配置偏低。为了让程序在 PC 上运行,所有编译器都在其核心进行了优化,因为如果不进行优化,更大的数组可能会填满内存。Guido 想要编写一种全面、易于学习、易于使用和可扩展的新语言。1989 年,Guido 开始为 Python 语言编写编译器。
3 系统分析
本系统是一个基于Python的网络爬虫系统,用于登录并爬取豆瓣上的相册、日记、话题、评论等一些动态数据信息。并且可以将关键字查询到的动态信息数据存入数据库,将部分数据存入数据库,存入本地txt文件,同时可以将相册动态中的图片下载到本地,还记录专辑信息,在每一页上。操作完成后,可以翻页,选择页面继续操作。因此系统应满足以下要求。
(1)可以通过验证码验证模拟登录豆瓣。即不需要通过浏览器登录,输入用户名、密码和验证即可登录豆瓣。控制台中的代码。
(2)登录成功后可以抓取豆瓣首页的代码。即通过登录成功后的cookie,可以访问游客无法访问的页面,抓取页面代码.
(3)可以从页面代码中提取出需要的信息,即需要通过正则表达式匹配等方法从抓取的页面中获取有用的数据信息。
(4)可以实现翻页和分页功能。即访问网站的动态页面时,可以通过在控制台输入具体内容进行翻页或者输入页码选择页面,然后抓取其他页面。
(5)实现关键字查询的功能,爬取找到的数据并存入数据库表中。即在爬取页面获取数据后,在控制台输入关键字即可爬取获取需要的信息。
(6)可以将爬取的图片的url下载到本地,图片的详细信息可以保存在本地txt[12]。也就是说,不仅要下载图片到本地,还有图片的主题信息、图片的用户、图片的具体网址等信息都保存在txt文件中。
(7) 将日记等动态信息存储在不同的本地文件中。即针对抓取到的不同数据信息,采用不同的存储方式和存储路径。
(8)在登录成功的情况下,可以进入个人中心,将当前用户关注的用户信息存储在数据库表中。这些信息可能包括用户id、昵称、主页url、个性化签名等
以上是本课程对爬虫系统的一些基本要求,据此可以明确系统的功能。因为这个系统注重网络信息资源的爬取,所以在用户交互方面可能不是很美观。本系统没有编写界面,所有操作都在Eclipse控制台中进行。例如:在控制台输入用户名、密码和验证码登录,登录成功后的页面选择,页面选择后的数据爬取等。
但是系统运行后爬取的数据可以在数据所在的本地txt文件或数据库中查看。因此,测试系统是否真的可以爬取数据,可以通过观察本地txt文件内容的变化或者数据库表中记录的变化来验证。
该爬虫系统包括模拟登录、页面爬取、信息爬取、数据存储等主要功能。其中,页面爬取包括翻页爬取、页面选择爬取、个人页面爬取;信息爬取包括动态爬取和跟随用户爬取;数据存储包括写入文件、下载到本地和存储数据库,如图1所示。
自动爬取 Internet 信息的程序称为爬虫。它主要由爬虫调度器、URL管理器、网页下载器和网页解析器组成。
(1)爬虫调度器:程序的入口点,主要负责爬虫程序的控制。
⑵ 网址管理器:
① 为要爬取的集合添加新的URL;
②判断要添加的URL是否已经存在;
③ 判断是否还有待爬取的URL,将待爬取集合中的URL移动到爬取集合中。
URL存储方式:Python内存是set()集合、关系数据库、缓存数据库。
(3)网页下载器:根据URL获取网页内容,通过urllib2和request实现。
⑷网页解析器:从网页中提取有价值的数据。实现方式包括正则表达式、html.parser、BeautifulSoup、lxml。
4。结论
爬虫是一种自动下载网页的程序。它根据给定的爬取目标有选择地访问万维网上的网页及其相关链接,以获取所需的信息。
本文中,爬虫旨在爬取与特定主题内容相关的网页,为面向主题的用户查询准备数据资源,实现网页数据的抓取和分析。
参考:
[1] 曾小虎. 基于主题的微博网络爬虫研究[D]. 武汉理工大学, 2014.
[2] 周丽珠,林玲.爬虫技术研究综述[J]. 计算机应用,2005. 25 (9): 1965-1969
[3] 周中华,张惠然,谢江。Python中的新浪微博数据爬虫[J]. 计算机应用,2014.34 (11): 3131-3134
[4] 刘晶晶. 面向微博的网络爬虫研究与实现[D]. 复旦大学,2012.
[5] 王静,朱可,王斌强。基于信息数据分析的微博研究综述[J]. 计算机应用, 2012. 32 (7): 2027-2029, 2037.@ >
[6](挪威)Magnus Lie Hetland。思伟,曾俊伟,谭英华,译。Python基础教程[M].人民邮电出版社,2014.
c爬虫抓取网页数据(soup(爬虫)隐形条约下的DOM结构,常伴吾身)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-06 02:08
爬行动物就像风,一直陪伴着我……
在日常的折腾中,无论是我的网站被别人爬取,还是别人的网站被我爬取,这就像一个游戏过程。双方在“隐形条约”下完成了各自的任务。正所谓君子之情如水,我不知道他是谁,他也不知道我是谁。我们互相提供他们需要的信息。或许这种关系更像是江湖,纯洁的江湖,不是说盈盈嫣嫣和世界。只谈江上轻舟饮酒,竹林歌声。说完,双方收剑离开,没有人啰嗦一句:“谁来?报名就来。”
爬虫的一个重要部分是数据处理。虽然静态加载的网页结构千差万别,界面看起来也不一样,但是爬取的数据是单一的,都是DOM结构的“后代”。即使你明白过滤数据的本质是处理字符串,但处理它的方法是无穷无尽的。以下是根据不同网页风格对症下药。
一:《好孩子》网页
特点:有完整的DOM结构,虽然有时会使用“混乱”的编码,例如:gb2312等,但其本质仍然是“好孩子”。
示例网址:百度搜索广告牌
分析:看源码,不难看出Billboard的新闻格式是
子节点,而我们需要的部分正是子节点标签。a标签的属性类是“list-title”。
像这样的网页是典型的“好孩子”网页,具有良好的可视化 DOM 结构,所需的信息来自同一个结构,解析起来并不费力。
分析方法:
1.使用BeautifulSoup
部分代码如下:
从 bs4 导入 BeautifulSoup 作为汤
source_code = "..." #你得到的网页的源代码
汤域 = 汤(源代码,'lxml')
all_a = soup_dom.find_all('a',attrs={'class':'list-title'})
对于 all_a 中的 a:
href_title = {'href':a.get('href'),'title':a.text}
结果如下:
2、使用xpath方法解析
部分代码如下:
从 lxml 导入 etree
source_code = "..." #你得到的网页的源代码
all_a = etree.Html(source_code).xpath("//a[@class='list-title']")
对于 all_a 中的 a:
href_title = {'href':a.attrib['href'],'title':a.text}
打印(href_title)
结果如下:
从以上两种方法可以看出,可以使用bs4或者Xpath来获取“好孩子”网页的数据。毕竟管教“好孩子”的成本远低于管教“坏孩子”的成本,所以大家都喜欢好孩子。
二:“坏小子”网页
特点:大部分是古代(2010年之前)的页面,DOM乱七八糟。(有些网页甚至只有一个封闭标签,其余的都是由
标签被拆分,甚至使用虚假的 API 页面来“冒充”真实的 API。)
但是:这些网址大多是丹尼尔博主,不拘一格,当你找到它们时,就像在悬崖下发现秘密一样!
示例网址:清华大学Penny Hot于2003年编写的linuxc教程~yhf/linux_c/
分析:如果能用简单的方法,就用简单的方法,如果不能用常规的方法
我要再次感谢 PennyHot 组织了我在 2003 年获得的 Linux C 文档,以方便您使用!
解决方法:使用正则
示例代码:
重新进口
source_code = "..." #你得到的网页的源代码
compile = pile("[\u4e00-\u9fa5]*") #匹配尽可能多的中文
find_all = compile.findall(source_code)
对于我在 find_all 中:
如果我!=””:
打印(一)
结果如下:
总结:没有好方法,只要能拿到自己需要的数据,就是好方法。
最后,感谢为互联网后来者做出贡献的先辈们。尽管很多人做着普通的工作,但他们留下的东西就像宝藏一样,藏宝图隐藏在互联网的每一个角落。让我自强!
2020.3.19 维科斯 查看全部
c爬虫抓取网页数据(soup(爬虫)隐形条约下的DOM结构,常伴吾身)
爬行动物就像风,一直陪伴着我……
在日常的折腾中,无论是我的网站被别人爬取,还是别人的网站被我爬取,这就像一个游戏过程。双方在“隐形条约”下完成了各自的任务。正所谓君子之情如水,我不知道他是谁,他也不知道我是谁。我们互相提供他们需要的信息。或许这种关系更像是江湖,纯洁的江湖,不是说盈盈嫣嫣和世界。只谈江上轻舟饮酒,竹林歌声。说完,双方收剑离开,没有人啰嗦一句:“谁来?报名就来。”
爬虫的一个重要部分是数据处理。虽然静态加载的网页结构千差万别,界面看起来也不一样,但是爬取的数据是单一的,都是DOM结构的“后代”。即使你明白过滤数据的本质是处理字符串,但处理它的方法是无穷无尽的。以下是根据不同网页风格对症下药。
一:《好孩子》网页
特点:有完整的DOM结构,虽然有时会使用“混乱”的编码,例如:gb2312等,但其本质仍然是“好孩子”。
示例网址:百度搜索广告牌
分析:看源码,不难看出Billboard的新闻格式是
子节点,而我们需要的部分正是子节点标签。a标签的属性类是“list-title”。
像这样的网页是典型的“好孩子”网页,具有良好的可视化 DOM 结构,所需的信息来自同一个结构,解析起来并不费力。
分析方法:
1.使用BeautifulSoup
部分代码如下:
从 bs4 导入 BeautifulSoup 作为汤
source_code = "..." #你得到的网页的源代码
汤域 = 汤(源代码,'lxml')
all_a = soup_dom.find_all('a',attrs={'class':'list-title'})
对于 all_a 中的 a:
href_title = {'href':a.get('href'),'title':a.text}
结果如下:
2、使用xpath方法解析
部分代码如下:
从 lxml 导入 etree
source_code = "..." #你得到的网页的源代码
all_a = etree.Html(source_code).xpath("//a[@class='list-title']")
对于 all_a 中的 a:
href_title = {'href':a.attrib['href'],'title':a.text}
打印(href_title)
结果如下:
从以上两种方法可以看出,可以使用bs4或者Xpath来获取“好孩子”网页的数据。毕竟管教“好孩子”的成本远低于管教“坏孩子”的成本,所以大家都喜欢好孩子。
二:“坏小子”网页
特点:大部分是古代(2010年之前)的页面,DOM乱七八糟。(有些网页甚至只有一个封闭标签,其余的都是由
标签被拆分,甚至使用虚假的 API 页面来“冒充”真实的 API。)
但是:这些网址大多是丹尼尔博主,不拘一格,当你找到它们时,就像在悬崖下发现秘密一样!
示例网址:清华大学Penny Hot于2003年编写的linuxc教程~yhf/linux_c/
分析:如果能用简单的方法,就用简单的方法,如果不能用常规的方法
我要再次感谢 PennyHot 组织了我在 2003 年获得的 Linux C 文档,以方便您使用!
解决方法:使用正则
示例代码:
重新进口
source_code = "..." #你得到的网页的源代码
compile = pile("[\u4e00-\u9fa5]*") #匹配尽可能多的中文
find_all = compile.findall(source_code)
对于我在 find_all 中:
如果我!=””:
打印(一)
结果如下:
总结:没有好方法,只要能拿到自己需要的数据,就是好方法。
最后,感谢为互联网后来者做出贡献的先辈们。尽管很多人做着普通的工作,但他们留下的东西就像宝藏一样,藏宝图隐藏在互联网的每一个角落。让我自强!
2020.3.19 维科斯
c爬虫抓取网页数据(静态网页抓取的介绍及应用方法-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-06 02:07
一、静态网页抓取简介
静态网页是纯 HTML 格式的网页。早期的 网站 是由静态网页组成的。静态网页的数据更容易获取,因为我们需要的代码隐藏在 HTML 代码中。为了抓取静态网页,我们使用 requests 库。Requests 允许您轻松发送 HTTP 请求。该库使用简单,功能齐全。
二、获取响应内容
获取响应内容的过程相当于使用浏览器的过程。我们在浏览器中输入URL,浏览器会向服务器请求内容,服务器会返回HTML代码,浏览器会自动解析代码。我们的爬虫和浏览器发送请求的过程是一样的,都是通过requests向浏览器发送请求,获取请求内容。
import requests
# 发送请求,获取服务器响应内容
r = requests.get("http://www.santostang.com/")
print("文本编码:", r.encoding)
print("响应状态码:", r.status_code)
print("字符串方式的响应体:", r.text)
三、自定义请求
我们使用requets发送请求获取数据,但是有些网页需要设置参数来获取需要的数据,那么我们设置这些参数
1. 传递 URL 参数
有时我们需要在 URL 中添加一些参数来请求特定的数据。URL中加参数的形式是在问号之后,以key/value的形式放在URL中。我们可以将参数保存在字典中,并将参数构建到 URL 中。
key_dict = {'key1': 'value1', 'key2': 'value2'}
r = requests.get('http://httpbin.org/get', params=key_dict)
print("URL已经正确编码:", r.url)
print("字符串方式的响应体:\n", r.text)
2. 自定义请求标头
请求标头是 Headers 部分,标头提供有关请求、响应或其他发送请求的实体的信息。简单来说就是模拟浏览器的作用,所以请求头是必须要学习的,那么我们如何构造请求头,我们使用谷歌浏览器。可以点击鼠标右键,点击Check,然后看下图,可以找到请求需要的参数。
# 构建请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'Host': 'www.santostang.com'
}
r = requests.get("http://www.santostang.com/", headers=headers)
print("响应状态码:", r.status_code)
响应状态码: 200
3. 发送 POST 请求
除了get请求之外,还需要以编码格式的形式发送一些数据,有些网站需要登录才能访问,所以需要使用POST请求,我们还需要传递一个字典到请求中的数据参数。发出请求时,此数据字典将自动编码到表单中。
key_dict = {'key1': 'value1', 'key2': 'value2'}
r = requests.post('http://httpbin.org/post', data=key_dict)
print(r.text)
4. 超时
有时候我们发送一个请求,服务器会很长时间没有响应,爬虫会一直等待。如果爬虫程序执行不顺畅,可以使用requests在超时参数设置的秒数后停止等待响应。我们将其设置为 0.001 秒。
url = "http://www.santostang.com/"
r = requests.get(url, timeout=0.001)
ConnectTimeout: HTTPConnectionPool(host='www.santostang.com', port=80): Max retries exceeded with url: / (Caused by ConnectTimeoutError(, 'Connection to www.santostang.com timed out. (connect timeout=0.001)'))
四、项目实例
爬豆瓣前250名电影名
# 导入包
import requests
from bs4 import BeautifulSoup
# 发送请求,获取响应内容
def get_movies():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'Host': 'movie.douban.com'
}
movie_list = []
for i in range(0, 10):
# 构建url,发送请求
url = "https://movie.douban.com/top250?start={}" + str(i * 25)
r = requests.get(url, headers=headers, timeout=10)
print(str(i + 1), "页面响应状态:", r.status_code)
# 解析网页
soup = BeautifulSoup(r.text, "lxml")
div_list = soup.find_all('div', class_= 'hd')
for each in div_list:
movie = each.a.span.text.strip()
movie_list.append(movie)
return movie_list
movies = get_movies()
print(movies)
总结:本篇笔记主要学习爬取静态网页时如何发送请求,包括url参数的设置方法。最后,实现一个小案例。 查看全部
c爬虫抓取网页数据(静态网页抓取的介绍及应用方法-上海怡健医学)
一、静态网页抓取简介
静态网页是纯 HTML 格式的网页。早期的 网站 是由静态网页组成的。静态网页的数据更容易获取,因为我们需要的代码隐藏在 HTML 代码中。为了抓取静态网页,我们使用 requests 库。Requests 允许您轻松发送 HTTP 请求。该库使用简单,功能齐全。
二、获取响应内容
获取响应内容的过程相当于使用浏览器的过程。我们在浏览器中输入URL,浏览器会向服务器请求内容,服务器会返回HTML代码,浏览器会自动解析代码。我们的爬虫和浏览器发送请求的过程是一样的,都是通过requests向浏览器发送请求,获取请求内容。
import requests
# 发送请求,获取服务器响应内容
r = requests.get("http://www.santostang.com/";)
print("文本编码:", r.encoding)
print("响应状态码:", r.status_code)
print("字符串方式的响应体:", r.text)
三、自定义请求
我们使用requets发送请求获取数据,但是有些网页需要设置参数来获取需要的数据,那么我们设置这些参数
1. 传递 URL 参数
有时我们需要在 URL 中添加一些参数来请求特定的数据。URL中加参数的形式是在问号之后,以key/value的形式放在URL中。我们可以将参数保存在字典中,并将参数构建到 URL 中。
key_dict = {'key1': 'value1', 'key2': 'value2'}
r = requests.get('http://httpbin.org/get', params=key_dict)
print("URL已经正确编码:", r.url)
print("字符串方式的响应体:\n", r.text)
2. 自定义请求标头
请求标头是 Headers 部分,标头提供有关请求、响应或其他发送请求的实体的信息。简单来说就是模拟浏览器的作用,所以请求头是必须要学习的,那么我们如何构造请求头,我们使用谷歌浏览器。可以点击鼠标右键,点击Check,然后看下图,可以找到请求需要的参数。
# 构建请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'Host': 'www.santostang.com'
}
r = requests.get("http://www.santostang.com/", headers=headers)
print("响应状态码:", r.status_code)
响应状态码: 200
3. 发送 POST 请求
除了get请求之外,还需要以编码格式的形式发送一些数据,有些网站需要登录才能访问,所以需要使用POST请求,我们还需要传递一个字典到请求中的数据参数。发出请求时,此数据字典将自动编码到表单中。
key_dict = {'key1': 'value1', 'key2': 'value2'}
r = requests.post('http://httpbin.org/post', data=key_dict)
print(r.text)
4. 超时
有时候我们发送一个请求,服务器会很长时间没有响应,爬虫会一直等待。如果爬虫程序执行不顺畅,可以使用requests在超时参数设置的秒数后停止等待响应。我们将其设置为 0.001 秒。
url = "http://www.santostang.com/"
r = requests.get(url, timeout=0.001)
ConnectTimeout: HTTPConnectionPool(host='www.santostang.com', port=80): Max retries exceeded with url: / (Caused by ConnectTimeoutError(, 'Connection to www.santostang.com timed out. (connect timeout=0.001)'))
四、项目实例
爬豆瓣前250名电影名
# 导入包
import requests
from bs4 import BeautifulSoup
# 发送请求,获取响应内容
def get_movies():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'Host': 'movie.douban.com'
}
movie_list = []
for i in range(0, 10):
# 构建url,发送请求
url = "https://movie.douban.com/top250?start={}" + str(i * 25)
r = requests.get(url, headers=headers, timeout=10)
print(str(i + 1), "页面响应状态:", r.status_code)
# 解析网页
soup = BeautifulSoup(r.text, "lxml")
div_list = soup.find_all('div', class_= 'hd')
for each in div_list:
movie = each.a.span.text.strip()
movie_list.append(movie)
return movie_list
movies = get_movies()
print(movies)
总结:本篇笔记主要学习爬取静态网页时如何发送请求,包括url参数的设置方法。最后,实现一个小案例。
c爬虫抓取网页数据(苏宁百万级商品爬取索引讲解4.1代码讲解(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-02 06:00
阿里云>云栖社区>主题地图>C>c爬网数据库
推荐活动:
更多优惠>
当前话题:c爬网数据库添加到采集夹
相关话题:
c 爬网数据库相关博客查看更多博客
云数据库产品概述
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
图数据库综述及Nebula在图数据库设计中的实践
作者:NebulaGraph2433 浏览评论:02年前
Nebula Graph:一个开源的分布式图数据库。Nebula Graph 作为唯一可以存储万亿级节点和带属性边的在线图数据库,不仅可以满足高并发场景下毫秒级的低延迟查询需求,还可以实现高服务可用性和数据安全性。第三届nMeetup(nMeet
阅读全文
Python爬虫入门教程3-100 数据爬取
作者:梦橡皮擦 1100人评论:02年前
1.湄公河网络资料-介绍从今天开始,我们尝试使用2篇博客的内容,得到一个名为“湄公河网络”的网站网址:这个网站我分析了一下,图片我们想抓取的是在以下网址
阅读全文
苏宁百万级商品爬取简述
作者:HappyFox1045 人浏览评论:03年前
代码下载链接 苏宁万级商品爬虫目录思路讲解分类爬取思路讲解分类页面爬取商品爬取3.1思路讲解商品爬取13.2思路讲解商品爬取23.3 代码解释产品爬取索引解释4.1 代码解释索引建立4.2 代码解释索引查询语句本部门
阅读全文
一个存储大量爬虫数据的数据库,懂吗?
作者:fesoncn3336 浏览人数:03年前
“当然,不是所有的数据都适合” 在学习爬虫的过程中,遇到了很多坑。你今天可能会遇到这个坑,随着爬取数据量的增加,以及爬取的网站数据字段的变化,以往爬虫上手的方法的局限性可能会突然增加。什么是突增法?介绍示例当开始使用爬虫时,
阅读全文
Python3中如何解决乱码爬取网页信息?(更新:已解决)
作者:大连瓦工2696 浏览评论:04年前
更新:乱码问题已解决。把下面代码中的红色部分改成下面这样,这样就不会有个别职位信息出现乱码了。soup2 = BeautifulSoup(wbdata2, 'html.parser',from_encoding="GBK") 还有:创建微信公众号
阅读全文
Python爬虫:用BeautifulSoup爬取NBA数据
作者:夜李2725查看评论:04年前
爬虫的主要目的是过滤掉网页中的无用信息,抓取网页中的有用信息。一般的爬虫架构是:在使用python爬虫之前,必须对网页的结构知识有一定的了解,比如网页的标签、网页的语言等知识,推荐爬之前去W3School:W3school链接了解一些工具:1
阅读全文
【Python爬虫2】网页数据提取
作者:wu_being1266 浏览评论:05年前
提取数据方法 1 正则表达式 2 流行BeautifulSoup 模块 3 强大的Lxml 模块性能对比 添加链接爬虫的爬取回调 1 回调函数1 2 回调函数2 3 复用上一章的链接爬虫代码 我们让这个爬虫比较从每一个中提取一些数据网页,然后实现某些东西,这种做法也
阅读全文
php爬虫:知乎用户数据爬取分析
作者:cuixiaozhuai2345 浏览评论:05年前
背景说明:小燕使用PHP的curl写的爬虫实验爬取知乎5w个用户的基本信息;同时对爬取的数据进行了简单的分析和展示。演示地址是php的蜘蛛代码和用户仪表盘的显示代码。整理好后上传到github,在个人博客和公众号更新代码库。
阅读全文
c爬网数据库相关问答
基础语言问题-Python
作者:薯片酱 55293 浏览评论:494年前
#基础语言100题——Python#最近软件界有一句很流行的一句话,“人生苦短,快用Python”,这句话说明了Python的特点,那就是快。当然,这个快并不代表 Python 跑得快,毕竟它是一种脚本语言,不管它有多快,而是 C 语言和 C++ 等底层语言,这里的快是指使用 Python
阅读全文 查看全部
c爬虫抓取网页数据(苏宁百万级商品爬取索引讲解4.1代码讲解(组图))
阿里云>云栖社区>主题地图>C>c爬网数据库
推荐活动:
更多优惠>
当前话题:c爬网数据库添加到采集夹
相关话题:
c 爬网数据库相关博客查看更多博客
云数据库产品概述
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
图数据库综述及Nebula在图数据库设计中的实践
作者:NebulaGraph2433 浏览评论:02年前
Nebula Graph:一个开源的分布式图数据库。Nebula Graph 作为唯一可以存储万亿级节点和带属性边的在线图数据库,不仅可以满足高并发场景下毫秒级的低延迟查询需求,还可以实现高服务可用性和数据安全性。第三届nMeetup(nMeet
阅读全文
Python爬虫入门教程3-100 数据爬取
作者:梦橡皮擦 1100人评论:02年前
1.湄公河网络资料-介绍从今天开始,我们尝试使用2篇博客的内容,得到一个名为“湄公河网络”的网站网址:这个网站我分析了一下,图片我们想抓取的是在以下网址
阅读全文
苏宁百万级商品爬取简述
作者:HappyFox1045 人浏览评论:03年前
代码下载链接 苏宁万级商品爬虫目录思路讲解分类爬取思路讲解分类页面爬取商品爬取3.1思路讲解商品爬取13.2思路讲解商品爬取23.3 代码解释产品爬取索引解释4.1 代码解释索引建立4.2 代码解释索引查询语句本部门
阅读全文
一个存储大量爬虫数据的数据库,懂吗?
作者:fesoncn3336 浏览人数:03年前
“当然,不是所有的数据都适合” 在学习爬虫的过程中,遇到了很多坑。你今天可能会遇到这个坑,随着爬取数据量的增加,以及爬取的网站数据字段的变化,以往爬虫上手的方法的局限性可能会突然增加。什么是突增法?介绍示例当开始使用爬虫时,
阅读全文
Python3中如何解决乱码爬取网页信息?(更新:已解决)
作者:大连瓦工2696 浏览评论:04年前
更新:乱码问题已解决。把下面代码中的红色部分改成下面这样,这样就不会有个别职位信息出现乱码了。soup2 = BeautifulSoup(wbdata2, 'html.parser',from_encoding="GBK") 还有:创建微信公众号
阅读全文
Python爬虫:用BeautifulSoup爬取NBA数据
作者:夜李2725查看评论:04年前
爬虫的主要目的是过滤掉网页中的无用信息,抓取网页中的有用信息。一般的爬虫架构是:在使用python爬虫之前,必须对网页的结构知识有一定的了解,比如网页的标签、网页的语言等知识,推荐爬之前去W3School:W3school链接了解一些工具:1
阅读全文
【Python爬虫2】网页数据提取
作者:wu_being1266 浏览评论:05年前
提取数据方法 1 正则表达式 2 流行BeautifulSoup 模块 3 强大的Lxml 模块性能对比 添加链接爬虫的爬取回调 1 回调函数1 2 回调函数2 3 复用上一章的链接爬虫代码 我们让这个爬虫比较从每一个中提取一些数据网页,然后实现某些东西,这种做法也
阅读全文
php爬虫:知乎用户数据爬取分析
作者:cuixiaozhuai2345 浏览评论:05年前
背景说明:小燕使用PHP的curl写的爬虫实验爬取知乎5w个用户的基本信息;同时对爬取的数据进行了简单的分析和展示。演示地址是php的蜘蛛代码和用户仪表盘的显示代码。整理好后上传到github,在个人博客和公众号更新代码库。
阅读全文
c爬网数据库相关问答
基础语言问题-Python
作者:薯片酱 55293 浏览评论:494年前
#基础语言100题——Python#最近软件界有一句很流行的一句话,“人生苦短,快用Python”,这句话说明了Python的特点,那就是快。当然,这个快并不代表 Python 跑得快,毕竟它是一种脚本语言,不管它有多快,而是 C 语言和 C++ 等底层语言,这里的快是指使用 Python
阅读全文
c爬虫抓取网页数据(一下如何用Excel快速抓取网页数据(图)的技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-28 23:02
网站 上的数据源是我们统计分析的重要信息来源。我们生活中经常听到一个词叫“爬虫”,它可以快速爬取网页上的数据,这对于数据分析相关的工作来说是极其重要的,也是必备的技能之一。但是,大多数爬虫都需要编程知识,普通人很难上手。今天我将向您展示如何使用 Excel 快速抓取 Web 数据。
1、首先打开要抓取数据的网站,复制网站的地址。
2、创建一个新的 Excel 工作簿,然后单击“数据”菜单 >“获取外部数据”选项卡中的“来自 网站”选项。
在弹出的“New Web Query”对话框中,在地址栏中输入要捕获的网站的地址,点击“Go”
点击黄色导入箭头,选择要抓取的部分,如图。点击导入。
3、选择存储数据的位置(默认选中的单元格),点击确定。一般建议将数据存储在“A1”单元格中。
4、如果想让Excel工作簿数据根据网站的数据实时自动更新,那么我们需要在“属性”中进行设置。可以设置“允许后台刷新”、“刷新频率”、“打开文件时刷新数据”等。
拿到数据之后,就需要对数据进行处理,而处理数据是比较重要的一环。更多数据处理技巧,请关注我!
郑重声明:本文版权归原作者所有,转载文章仅出于传播更多信息之目的。如果作者信息标注有误,请尽快联系我们修改或删除,谢谢。 查看全部
c爬虫抓取网页数据(一下如何用Excel快速抓取网页数据(图)的技巧)
网站 上的数据源是我们统计分析的重要信息来源。我们生活中经常听到一个词叫“爬虫”,它可以快速爬取网页上的数据,这对于数据分析相关的工作来说是极其重要的,也是必备的技能之一。但是,大多数爬虫都需要编程知识,普通人很难上手。今天我将向您展示如何使用 Excel 快速抓取 Web 数据。
1、首先打开要抓取数据的网站,复制网站的地址。
2、创建一个新的 Excel 工作簿,然后单击“数据”菜单 >“获取外部数据”选项卡中的“来自 网站”选项。
在弹出的“New Web Query”对话框中,在地址栏中输入要捕获的网站的地址,点击“Go”
点击黄色导入箭头,选择要抓取的部分,如图。点击导入。
3、选择存储数据的位置(默认选中的单元格),点击确定。一般建议将数据存储在“A1”单元格中。
4、如果想让Excel工作簿数据根据网站的数据实时自动更新,那么我们需要在“属性”中进行设置。可以设置“允许后台刷新”、“刷新频率”、“打开文件时刷新数据”等。
拿到数据之后,就需要对数据进行处理,而处理数据是比较重要的一环。更多数据处理技巧,请关注我!
郑重声明:本文版权归原作者所有,转载文章仅出于传播更多信息之目的。如果作者信息标注有误,请尽快联系我们修改或删除,谢谢。
c爬虫抓取网页数据(通用爬虫如何获取一个新网站的工作流程及解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-02-28 22:20
万能爬虫是一个自动提取网页的程序。它从互联网上为搜索引擎下载网页,是搜索引擎的重要组成部分。
万能爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某个停止条件。图1展示了一般爬虫爬取网页的过程。
通用网络爬虫从 Internet 采集网页和 采集 信息。这些网页信息用于为搜索引擎的索引提供支持。它决定了整个引擎系统的内容是否丰富,信息是否及时,从而决定其性能的好坏。直接影响搜索引擎的效果。
但是用于搜索引擎的通用爬虫的爬取行为需要遵守一定的规则,遵守一些命令或文件的内容,比如标有nofollow的链接,或者Robots协议(后面会有相关介绍) .
了解更多:搜索引擎工作流程
搜索引擎是通用爬虫最重要的应用领域,也是大家使用网络功能时最大的助手。接下来介绍一下搜索引擎的工作流程,主要包括以下几个步骤。
1. 爬网
搜索引擎使用通用爬虫来爬取网页。基本工作流程与其他爬虫类似。一般步骤如下:
(1)先选择一部分种子URL,将这些URL放入待爬取的URL队列中;
(2)取出要爬取的URL,解析DNS得到主机的IP,下载该URL对应的网页,存入下载的网页库,将这些URL放入已爬取的URL队列中.
(3)分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列中,从而进入下一个循环。
那么搜索引擎如何获得一个新的网站 URL呢?
(1)新增网站主动向搜索引擎提交网址:(如百度)。
(2)在其他网站上设置新的网站外部链接(尽量在搜索引擎爬虫范围内)。
(3)搜索引擎与DNS解析服务商(如DNSPod等)合作,新的网站域名会被快速抓取。
2. 数据存储
搜索引擎通过爬虫爬取网页后,将数据存储在原创页面数据库中。页面数据与用户浏览器获取的 HTML 完全相同。
搜索引擎蜘蛛在抓取页面时也会进行某些重复内容检测。一旦他们遇到大量抄袭、采集 或复制访问权重低的网站 上的内容,很有可能不再使用。爬行。
3. 预处理
搜索引擎将从爬虫中抓取回页面并执行各种预处理步骤,包括:
· 提取文本
·中文分词 查看全部
c爬虫抓取网页数据(通用爬虫如何获取一个新网站的工作流程及解决方法)
万能爬虫是一个自动提取网页的程序。它从互联网上为搜索引擎下载网页,是搜索引擎的重要组成部分。
万能爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某个停止条件。图1展示了一般爬虫爬取网页的过程。
通用网络爬虫从 Internet 采集网页和 采集 信息。这些网页信息用于为搜索引擎的索引提供支持。它决定了整个引擎系统的内容是否丰富,信息是否及时,从而决定其性能的好坏。直接影响搜索引擎的效果。
但是用于搜索引擎的通用爬虫的爬取行为需要遵守一定的规则,遵守一些命令或文件的内容,比如标有nofollow的链接,或者Robots协议(后面会有相关介绍) .
了解更多:搜索引擎工作流程
搜索引擎是通用爬虫最重要的应用领域,也是大家使用网络功能时最大的助手。接下来介绍一下搜索引擎的工作流程,主要包括以下几个步骤。
1. 爬网
搜索引擎使用通用爬虫来爬取网页。基本工作流程与其他爬虫类似。一般步骤如下:
(1)先选择一部分种子URL,将这些URL放入待爬取的URL队列中;
(2)取出要爬取的URL,解析DNS得到主机的IP,下载该URL对应的网页,存入下载的网页库,将这些URL放入已爬取的URL队列中.
(3)分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列中,从而进入下一个循环。
那么搜索引擎如何获得一个新的网站 URL呢?
(1)新增网站主动向搜索引擎提交网址:(如百度)。
(2)在其他网站上设置新的网站外部链接(尽量在搜索引擎爬虫范围内)。
(3)搜索引擎与DNS解析服务商(如DNSPod等)合作,新的网站域名会被快速抓取。
2. 数据存储
搜索引擎通过爬虫爬取网页后,将数据存储在原创页面数据库中。页面数据与用户浏览器获取的 HTML 完全相同。
搜索引擎蜘蛛在抓取页面时也会进行某些重复内容检测。一旦他们遇到大量抄袭、采集 或复制访问权重低的网站 上的内容,很有可能不再使用。爬行。
3. 预处理
搜索引擎将从爬虫中抓取回页面并执行各种预处理步骤,包括:
· 提取文本
·中文分词
c爬虫抓取网页数据(【】一个一级-spider页面())
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-28 22:18
前言
在研究数据之前,我零零散散地写了一些数据爬虫,但我写的比较随意。很多地方现在看起来不太合理。这次比较空闲,本来想重构之前的项目。
后来利用这个周末简单的重新写了一个项目,就是这个项目guwen-spider。目前这种爬虫还是比较简单的类型,直接爬取页面,然后从页面中提取数据,将数据保存到数据库中。
通过和我之前写的比较,我认为难点在于整个程序的健壮性和相应的容错机制。其实昨天在写代码的过程中就体现出来了。真正的主代码其实写得很快,大部分时间都花在了
做稳定性调试,寻求更合理的方式处理数据与过程控制的关系。
背景
项目背景是抓取一级页面,即目录列表,点击目录进入章节和长度列表,点击章节或长度进入具体内容页面。
概述
本项目github地址:guwen-spider(PS:***脸上有彩蛋~~逃跑
项目技术细节
项目中大量使用了 ES7 的 async 函数,更直观的反映了程序的流程。为方便起见,在遍历数据的过程中直接使用了众所周知的 async 库,所以难免会用到回调 promise。因为数据处理发生在回调函数中,难免会遇到一些数据传输问题。,其实可以直接用ES7的async await写一个方法来实现同样的功能。其实这里最好的部分是使用Class的静态方法来封装数据库的操作。顾名思义,静态方法就像原型一样,不占用额外空间。
该项目主要使用
ES7 的 async await 协程做异步逻辑处理。使用 npm 的异步库进行循环遍历和并发请求操作。使用log4js做日志处理,使用cheerio处理dom操作。使用 mongoose 连接 mongoDB 进行数据存储和操作。
目录结构
项目实现计划分析
条目是典型的多级爬取案例,目前只有书单、图书条目对应的章节列表、章节链接对应的内容三个等级。有两种方法可以获取这样的结构。一种是直接从外层抓取到内层,然后在内层抓取后执行下一个外层,另一种是先将外层保存到数据库中。,然后根据外层爬取所有内章的链接,再次保存,然后从数据库中查询对应的链接单元爬取内容。这两种方案各有优缺点。其实这两种方法我都试过了。后者有一个优势,因为三个层次是分开捕获的,以便尽可能多地保存相关章节。数据。你可以想象,如果按照正常逻辑使用前者
遍历一级目录抓取对应的二级章节目录,然后遍历章节列表抓取内容。当三级内容单元被爬取,需要保存的时候,如果需要大量的一级目录信息,那么这些分层数据之间的数据传输,想想应该是比较复杂的事情。因此,单独保存数据在一定程度上避免了不必要的复杂数据传输。
目前我们已经考虑到,我们想要采集的古籍数量并不是很多,涵盖各种经文和历史的古籍也只有大约180本。它和章节内容本身是一个很小的数据,即一个集合中有180条文档记录。这180本书的所有章节共有16000个章节,对应的需要访问16000个页面才能爬取到相应的内容。所以选择第二个应该是合理的。
项目实现
主流程有bookListInit、chapterListInit、contentListInit三个方法,分别是抓取图书目录、章节列表、图书内容的方法,都是公开暴露的初始化方法。通过 async 可以控制这三种方法的运行过程。取书目录后,将数据存入数据库,然后将执行结果返回给主程序。如果操作成功,主程序会根据书单执行章节列表的获取。,以同样的方式爬取书籍的内容。
项目主入口
/** * 爬虫抓取主入口 */ const start = async() => { let booklistRes = await bookListInit(); if (!booklistRes) { logger.warn('书籍列表抓取出错,程序终止...'); return; } logger.info('书籍列表抓取成功,现在进行书籍章节抓取...'); let chapterlistRes = await chapterListInit(); if (!chapterlistRes) { logger.warn('书籍章节列表抓取出错,程序终止...'); return; } logger.info('书籍章节列表抓取成功,现在进行书籍内容抓取...'); let contentListRes = await contentListInit(); if (!contentListRes) { logger.warn('书籍章节内容抓取出错,程序终止...'); return; } logger.info('书籍内容抓取成功'); } // 开始入口 if (typeof bookListInit === 'function' && typeof chapterListInit === 'function') { // 开始抓取 start(); }
介绍了 bookListInit、chapterListInit、contentListInit 三个方法
书单.js
/** * 初始化入口 */ const chapterListInit = async() => { const list = await bookHelper.getBookList(bookListModel); if (!list) { logger.error('初始化查询书籍目录失败'); } logger.info('开始抓取书籍章节列表,书籍目录共:' + list.length + '条'); let res = await asyncGetChapter(list); return res; };
章节列表.js
/** * 初始化入口 */ const contentListInit = async() => { //获取书籍列表 const list = await bookHelper.getBookLi(bookListModel); if (!list) { logger.error('初始化查询书籍目录失败'); return; } const res = await mapBookList(list); if (!res) { logger.error('抓取章节信息,调用 getCurBookSectionList() 进行串行遍历操作,执行完成回调出错,错误信息已打印,请查看日志!'); return; } return res; }
关于内容抓取的思考
图书目录抓取的逻辑其实很简单。只需要使用 async.mapLimit 做一次遍历就可以保存数据,但是我们保存内容的简化逻辑其实就是遍历章节列表,抓取链接中的内容。但实际情况是,链接数多达数万。从内存使用的角度来看,我们不能将它们全部保存到一个数组中然后遍历它,所以我们需要将内容捕获统一起来。
常见的遍历方式是每次查询一定数量进行爬取。缺点是分类只用了一定的量,数据之间没有关联,分批插入。如果有错误,在容错方面会出现一些小问题,我们认为单独保存一本书作为集合会有问题。因此,我们采用第二种方法来捕获和保存图书单元中的内容。
这里使用了方法async.mapLimit(list, 1, (series, callback) => {}) 进行遍历,不可避免地用到了回调,感觉很恶心。async.mapLimit() 的第二个参数可以设置同时请求的数量。
提取后如何保存数据是个问题
这里我们通过key对数据进行分类,每次根据key获取链接,并进行遍历。这样做的好处是保存的数据是一个整体。现在我们考虑数据保存的问题。
1、可以整体插入
优点:快速的数据库操作不浪费时间。
缺点:有的书可能有几百章,也就是说插入前必须保存几百页的内容,这样也很消耗内存,可能会导致程序运行不稳定。
2、可以作为每篇文章插入数据库文章。
优点:页面爬取保存的方式,可以及时保存数据。即使出现后续错误,也无需重新保存之前的章节。
缺点:也明显慢。想爬几万个页面,做几万个*N的数据库操作,仔细想想。您还可以制作缓存以一次保存一定数量的记录。不错的选择。
/** * 遍历单条书籍下所有章节 调用内容抓取方法 * @param {*} list */ const mapSectionList = (list) => { return new Promise((resolve, reject) => { async.mapLimit(list, 1, (series, callback) => { let doc = series._doc; getContent(doc, callback) }, (err, result) => { if (err) { logger.error('书籍目录抓取异步执行出错!'); logger.error(err); reject(false); return; } const bookName = list[0].bookName; const key = list[0].key; // 以整体为单元进行保存 saveAllContentToDB(result, bookName, key, resolve); //以每篇文章作为单元进行保存 // logger.info(bookName + '数据抓取完成,进入下一部书籍抓取函数...'); // resolve(true); }) }) }
两者各有利弊,这里我们都尝试过。准备了两个错误保存集合,errContentModel 和 error采集Model。插入错误时,将信息分别保存到相应的集合中。您可以选择两者之一。之所以添加集合保存数据,是为了方便一次性查看和后续操作,无需查看日志。
(PS,其实error采集Model集合可以完全使用,errContentModel集合可以完整保存章节信息)
//保存出错的数据名称 const errorSpider = mongoose.Schema({ chapter: String, section: String, url: String, key: String, bookName: String, author: String, }) // 保存出错的数据名称 只保留key 和 bookName信息 const errorCollection = mongoose.Schema({ key: String, bookName: String, })
我们将每本书信息的内容放入一个新的集合中,集合以key命名。
总结
其实这个项目写的主要难点在于程序稳定性的控制,容错机制的设置,以及错误的记录。目前这个项目基本上可以一次性直接运行整个流程。但是,程序设计上肯定还存在很多问题。欢迎指正和交流。
复活节彩蛋
写完这个项目,我做了一个基于React网站的页面浏览前端和一个基于koa2.x开发的服务器。整体技术栈相当于 React + Redux + Koa2,前后端服务分别部署,各自能够更好的去除前后端服务的耦合。例如,同一组服务器端代码不仅可以为 Web 提供支持,还可以为移动和应用程序提供支持。目前整套还是很简单的,但是可以满足基本的查询和浏览功能。希望以后有时间让项目更加丰富。
该项目非常简单,但有一个额外的环境用于学习和研究从前端到服务器端的开发。 查看全部
c爬虫抓取网页数据(【】一个一级-spider页面())
前言
在研究数据之前,我零零散散地写了一些数据爬虫,但我写的比较随意。很多地方现在看起来不太合理。这次比较空闲,本来想重构之前的项目。
后来利用这个周末简单的重新写了一个项目,就是这个项目guwen-spider。目前这种爬虫还是比较简单的类型,直接爬取页面,然后从页面中提取数据,将数据保存到数据库中。
通过和我之前写的比较,我认为难点在于整个程序的健壮性和相应的容错机制。其实昨天在写代码的过程中就体现出来了。真正的主代码其实写得很快,大部分时间都花在了
做稳定性调试,寻求更合理的方式处理数据与过程控制的关系。
背景
项目背景是抓取一级页面,即目录列表,点击目录进入章节和长度列表,点击章节或长度进入具体内容页面。
概述
本项目github地址:guwen-spider(PS:***脸上有彩蛋~~逃跑
项目技术细节
项目中大量使用了 ES7 的 async 函数,更直观的反映了程序的流程。为方便起见,在遍历数据的过程中直接使用了众所周知的 async 库,所以难免会用到回调 promise。因为数据处理发生在回调函数中,难免会遇到一些数据传输问题。,其实可以直接用ES7的async await写一个方法来实现同样的功能。其实这里最好的部分是使用Class的静态方法来封装数据库的操作。顾名思义,静态方法就像原型一样,不占用额外空间。
该项目主要使用
ES7 的 async await 协程做异步逻辑处理。使用 npm 的异步库进行循环遍历和并发请求操作。使用log4js做日志处理,使用cheerio处理dom操作。使用 mongoose 连接 mongoDB 进行数据存储和操作。
目录结构
项目实现计划分析
条目是典型的多级爬取案例,目前只有书单、图书条目对应的章节列表、章节链接对应的内容三个等级。有两种方法可以获取这样的结构。一种是直接从外层抓取到内层,然后在内层抓取后执行下一个外层,另一种是先将外层保存到数据库中。,然后根据外层爬取所有内章的链接,再次保存,然后从数据库中查询对应的链接单元爬取内容。这两种方案各有优缺点。其实这两种方法我都试过了。后者有一个优势,因为三个层次是分开捕获的,以便尽可能多地保存相关章节。数据。你可以想象,如果按照正常逻辑使用前者
遍历一级目录抓取对应的二级章节目录,然后遍历章节列表抓取内容。当三级内容单元被爬取,需要保存的时候,如果需要大量的一级目录信息,那么这些分层数据之间的数据传输,想想应该是比较复杂的事情。因此,单独保存数据在一定程度上避免了不必要的复杂数据传输。
目前我们已经考虑到,我们想要采集的古籍数量并不是很多,涵盖各种经文和历史的古籍也只有大约180本。它和章节内容本身是一个很小的数据,即一个集合中有180条文档记录。这180本书的所有章节共有16000个章节,对应的需要访问16000个页面才能爬取到相应的内容。所以选择第二个应该是合理的。
项目实现
主流程有bookListInit、chapterListInit、contentListInit三个方法,分别是抓取图书目录、章节列表、图书内容的方法,都是公开暴露的初始化方法。通过 async 可以控制这三种方法的运行过程。取书目录后,将数据存入数据库,然后将执行结果返回给主程序。如果操作成功,主程序会根据书单执行章节列表的获取。,以同样的方式爬取书籍的内容。
项目主入口
/** * 爬虫抓取主入口 */ const start = async() => { let booklistRes = await bookListInit(); if (!booklistRes) { logger.warn('书籍列表抓取出错,程序终止...'); return; } logger.info('书籍列表抓取成功,现在进行书籍章节抓取...'); let chapterlistRes = await chapterListInit(); if (!chapterlistRes) { logger.warn('书籍章节列表抓取出错,程序终止...'); return; } logger.info('书籍章节列表抓取成功,现在进行书籍内容抓取...'); let contentListRes = await contentListInit(); if (!contentListRes) { logger.warn('书籍章节内容抓取出错,程序终止...'); return; } logger.info('书籍内容抓取成功'); } // 开始入口 if (typeof bookListInit === 'function' && typeof chapterListInit === 'function') { // 开始抓取 start(); }
介绍了 bookListInit、chapterListInit、contentListInit 三个方法
书单.js
/** * 初始化入口 */ const chapterListInit = async() => { const list = await bookHelper.getBookList(bookListModel); if (!list) { logger.error('初始化查询书籍目录失败'); } logger.info('开始抓取书籍章节列表,书籍目录共:' + list.length + '条'); let res = await asyncGetChapter(list); return res; };
章节列表.js
/** * 初始化入口 */ const contentListInit = async() => { //获取书籍列表 const list = await bookHelper.getBookLi(bookListModel); if (!list) { logger.error('初始化查询书籍目录失败'); return; } const res = await mapBookList(list); if (!res) { logger.error('抓取章节信息,调用 getCurBookSectionList() 进行串行遍历操作,执行完成回调出错,错误信息已打印,请查看日志!'); return; } return res; }
关于内容抓取的思考
图书目录抓取的逻辑其实很简单。只需要使用 async.mapLimit 做一次遍历就可以保存数据,但是我们保存内容的简化逻辑其实就是遍历章节列表,抓取链接中的内容。但实际情况是,链接数多达数万。从内存使用的角度来看,我们不能将它们全部保存到一个数组中然后遍历它,所以我们需要将内容捕获统一起来。
常见的遍历方式是每次查询一定数量进行爬取。缺点是分类只用了一定的量,数据之间没有关联,分批插入。如果有错误,在容错方面会出现一些小问题,我们认为单独保存一本书作为集合会有问题。因此,我们采用第二种方法来捕获和保存图书单元中的内容。
这里使用了方法async.mapLimit(list, 1, (series, callback) => {}) 进行遍历,不可避免地用到了回调,感觉很恶心。async.mapLimit() 的第二个参数可以设置同时请求的数量。
提取后如何保存数据是个问题
这里我们通过key对数据进行分类,每次根据key获取链接,并进行遍历。这样做的好处是保存的数据是一个整体。现在我们考虑数据保存的问题。
1、可以整体插入
优点:快速的数据库操作不浪费时间。
缺点:有的书可能有几百章,也就是说插入前必须保存几百页的内容,这样也很消耗内存,可能会导致程序运行不稳定。
2、可以作为每篇文章插入数据库文章。
优点:页面爬取保存的方式,可以及时保存数据。即使出现后续错误,也无需重新保存之前的章节。
缺点:也明显慢。想爬几万个页面,做几万个*N的数据库操作,仔细想想。您还可以制作缓存以一次保存一定数量的记录。不错的选择。
/** * 遍历单条书籍下所有章节 调用内容抓取方法 * @param {*} list */ const mapSectionList = (list) => { return new Promise((resolve, reject) => { async.mapLimit(list, 1, (series, callback) => { let doc = series._doc; getContent(doc, callback) }, (err, result) => { if (err) { logger.error('书籍目录抓取异步执行出错!'); logger.error(err); reject(false); return; } const bookName = list[0].bookName; const key = list[0].key; // 以整体为单元进行保存 saveAllContentToDB(result, bookName, key, resolve); //以每篇文章作为单元进行保存 // logger.info(bookName + '数据抓取完成,进入下一部书籍抓取函数...'); // resolve(true); }) }) }
两者各有利弊,这里我们都尝试过。准备了两个错误保存集合,errContentModel 和 error采集Model。插入错误时,将信息分别保存到相应的集合中。您可以选择两者之一。之所以添加集合保存数据,是为了方便一次性查看和后续操作,无需查看日志。
(PS,其实error采集Model集合可以完全使用,errContentModel集合可以完整保存章节信息)
//保存出错的数据名称 const errorSpider = mongoose.Schema({ chapter: String, section: String, url: String, key: String, bookName: String, author: String, }) // 保存出错的数据名称 只保留key 和 bookName信息 const errorCollection = mongoose.Schema({ key: String, bookName: String, })
我们将每本书信息的内容放入一个新的集合中,集合以key命名。
总结
其实这个项目写的主要难点在于程序稳定性的控制,容错机制的设置,以及错误的记录。目前这个项目基本上可以一次性直接运行整个流程。但是,程序设计上肯定还存在很多问题。欢迎指正和交流。
复活节彩蛋
写完这个项目,我做了一个基于React网站的页面浏览前端和一个基于koa2.x开发的服务器。整体技术栈相当于 React + Redux + Koa2,前后端服务分别部署,各自能够更好的去除前后端服务的耦合。例如,同一组服务器端代码不仅可以为 Web 提供支持,还可以为移动和应用程序提供支持。目前整套还是很简单的,但是可以满足基本的查询和浏览功能。希望以后有时间让项目更加丰富。
该项目非常简单,但有一个额外的环境用于学习和研究从前端到服务器端的开发。
c爬虫抓取网页数据(无需你让我学Gooseeker我就只学它吧?|?无需)
网站优化 • 优采云 发表了文章 • 0 个评论 • 347 次浏览 • 2022-02-26 21:19
当您刚开始使用数据可视化时,主要关注点之一通常是学习制作各种图表类型。
但是用那些原创数据练习了半天,心里会有些不安和松懈。毕竟没有真正投入实战的练习都是假的,各种基础数据都是我用来数据可视化的。菜,不不不!
通常,我也会去互联网查找一些现有的数据,但它并不总是适合我的胃口。我无法完全自由地找到我想要的数据,并做我感兴趣的可视化分析。所以,这是理所当然的,我迫不及待地想了解爬行动物。
我不知道如何编程。如果想在短时间内快速掌握爬虫技巧,只能使用网页信息抓取软件,所以@squirrel给我推荐了他的课程《无需编程即可轻松获取网络数据》,学习Jisouke Gooseeker Web Crawler。
因为他的课程非常简洁易懂,而且Gooseeker的操作真的很简单,所以可以很快上手,一个晚上就爬一个简单的网站。
以前觉得爬网数据很难,现在可以这么轻松地爬取信息,真的很兴奋!
所以,如果你和我一样,没有编程基础,又想根据自己的意愿获取更多的数据信息,可以尝试学习 Gooseeker 网络爬虫。
Gooseeker的好处主要有:
Gooseeker拥有独立的网络爬虫浏览器,也可以依赖火狐浏览器一起打包下载。
我选择的软件版本是火狐版本。安装完成后会在火狐浏览器的工具栏上生成一个插件。单击“工具”以查看“MS 计算机”和“DS 计算机”。提取工作将在两个平台上执行。
当然,我们还需要注册一个账号,方便使用它来管理爬虫规则,在社区互动,下载资源等。
在我学习期间,有一位老司机(@squirrel)带我去飞行。确实让我少走了很多弯路,大大提高了我的学习效率,但是作为一个好学的学生……学姐,你不能让我学Gooseeeker,我就只学吧?肯定还有很多其他类似的工具,我需要更多地了解它们!
于是偷偷了解了其他网络数据采集器的优劣,对比对比,发现差距确实不大。黑猫和白猫,能抓到老鼠的猫就是好猫。对于学习来说,真的没必要执着于工具。
我用Gooseeker前后免费爬取了几十条网站数据,基本上所有网站信息都可以通过它轻松获取,还有一小部分网站需要走弯路。
它可以实现的爬虫任务包括:分层爬取、翻页、动态网页爬取等基本爬取方式,还支持爬虫组(不是很好用)等等。
我先学了Squirrel的课程,学会了用它爬取数据后,就去官网了解了更多细节。Gooseeker的官网社区比较齐全。上面有很多文档/视频教程,还有别人制定的免费/付费规则。您也可以在线进行数据DIY。
其产品天数软件中的APP资源也非常丰富,可以高效获取电商、微博数据和做数据挖掘、SaaS模型软件。
其中,文本分割和标注工具——天语影音对我特别有吸引力。它可以轻松完成文本的分词和可视化分析。有机会一定要试试(写论文)。
但是我个人觉得上面的视频教程都不好。很多人都说Gooseeeker前期很难上手。我认为这与他们在上面获得的教程资源的质量有限无关。
总的来说,这是一款免费好用的爬虫神器!Wall Crack推荐小伙伴们去其官网下载软件学习,可以轻松搞定一个看似遥不可及,实则又傻又甜的技能。
在接下来的几篇文章中,我会为大家介绍几个实际案例。如有任何问题,欢迎交流讨论。
资源: 查看全部
c爬虫抓取网页数据(无需你让我学Gooseeker我就只学它吧?|?无需)
当您刚开始使用数据可视化时,主要关注点之一通常是学习制作各种图表类型。
但是用那些原创数据练习了半天,心里会有些不安和松懈。毕竟没有真正投入实战的练习都是假的,各种基础数据都是我用来数据可视化的。菜,不不不!
通常,我也会去互联网查找一些现有的数据,但它并不总是适合我的胃口。我无法完全自由地找到我想要的数据,并做我感兴趣的可视化分析。所以,这是理所当然的,我迫不及待地想了解爬行动物。
我不知道如何编程。如果想在短时间内快速掌握爬虫技巧,只能使用网页信息抓取软件,所以@squirrel给我推荐了他的课程《无需编程即可轻松获取网络数据》,学习Jisouke Gooseeker Web Crawler。
因为他的课程非常简洁易懂,而且Gooseeker的操作真的很简单,所以可以很快上手,一个晚上就爬一个简单的网站。
以前觉得爬网数据很难,现在可以这么轻松地爬取信息,真的很兴奋!
所以,如果你和我一样,没有编程基础,又想根据自己的意愿获取更多的数据信息,可以尝试学习 Gooseeker 网络爬虫。
Gooseeker的好处主要有:
Gooseeker拥有独立的网络爬虫浏览器,也可以依赖火狐浏览器一起打包下载。
我选择的软件版本是火狐版本。安装完成后会在火狐浏览器的工具栏上生成一个插件。单击“工具”以查看“MS 计算机”和“DS 计算机”。提取工作将在两个平台上执行。
当然,我们还需要注册一个账号,方便使用它来管理爬虫规则,在社区互动,下载资源等。
在我学习期间,有一位老司机(@squirrel)带我去飞行。确实让我少走了很多弯路,大大提高了我的学习效率,但是作为一个好学的学生……学姐,你不能让我学Gooseeeker,我就只学吧?肯定还有很多其他类似的工具,我需要更多地了解它们!
于是偷偷了解了其他网络数据采集器的优劣,对比对比,发现差距确实不大。黑猫和白猫,能抓到老鼠的猫就是好猫。对于学习来说,真的没必要执着于工具。
我用Gooseeker前后免费爬取了几十条网站数据,基本上所有网站信息都可以通过它轻松获取,还有一小部分网站需要走弯路。
它可以实现的爬虫任务包括:分层爬取、翻页、动态网页爬取等基本爬取方式,还支持爬虫组(不是很好用)等等。
我先学了Squirrel的课程,学会了用它爬取数据后,就去官网了解了更多细节。Gooseeker的官网社区比较齐全。上面有很多文档/视频教程,还有别人制定的免费/付费规则。您也可以在线进行数据DIY。
其产品天数软件中的APP资源也非常丰富,可以高效获取电商、微博数据和做数据挖掘、SaaS模型软件。
其中,文本分割和标注工具——天语影音对我特别有吸引力。它可以轻松完成文本的分词和可视化分析。有机会一定要试试(写论文)。
但是我个人觉得上面的视频教程都不好。很多人都说Gooseeeker前期很难上手。我认为这与他们在上面获得的教程资源的质量有限无关。
总的来说,这是一款免费好用的爬虫神器!Wall Crack推荐小伙伴们去其官网下载软件学习,可以轻松搞定一个看似遥不可及,实则又傻又甜的技能。
在接下来的几篇文章中,我会为大家介绍几个实际案例。如有任何问题,欢迎交流讨论。
资源:

