
c爬虫抓取网页数据
c爬虫抓取网页数据(1.网络爬虫的基本概念网络蜘蛛,机器人都能够做到! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-04-09 06:27
)
1.网络爬虫基本概念
网络爬虫(也称为网络蜘蛛或机器人)是模拟客户端发送网络请求并接收请求响应的程序,根据一定的规则自动抓取互联网信息的程序。
只要浏览器能做任何事情,原则上爬虫都能做到。
2.网络爬虫函数
网络爬虫可以手动替换很多东西,比如用作搜索引擎,或者爬取网站上的图片。比如有的朋友把一些网站上的所有图片都爬进去,集中在上面。可以进行投资分析。
有时候,可能有几个我们比较喜欢的新闻网站,每次浏览都单独打开这些新闻网站比较麻烦。这时候就可以用网络爬虫来爬取这多条新闻网站中的新闻信息,集中阅读。
有时候,我们在网上浏览信息的时候,会发现有很多广告。这时也可以利用爬虫来爬取相应网页上的信息,从而自动过滤掉这些广告,方便信息的阅读和使用。
有时候,我们需要做营销,所以如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以手动搜索互联网,但这会非常低效。这时,我们可以通过爬虫设置相应的规则,自动采集从互联网上获取目标用户的联系方式,供我们营销使用。
有时候,我们想分析某个网站的用户信息,比如分析网站的用户活跃度、发言次数、热门文章等信息,如果我们没有网站@ >管理员,手动统计将是一个非常庞大的工程。此时,您可以使用爬虫轻松采集对这些数据进行进一步分析,并且所有这些爬取操作都是自动进行的,我们只需要编写相应的爬虫并设计相应的爬虫即可。规则会做。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫实现自动化,可以更好地利用互联网中的有效信息。.
3.安装第三方库
在爬取和解析数据之前,需要在 Python 运行环境中下载并安装第三方库请求。
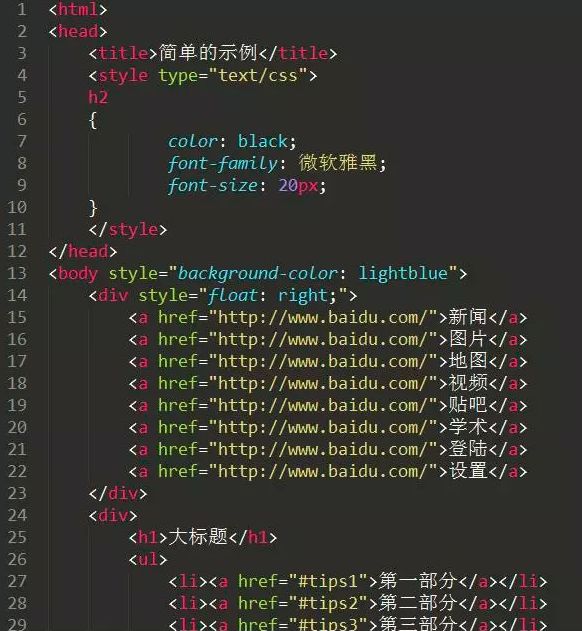
在Windows系统中,打开cmd(命令提示符)界面,在界面输入pip install requests,回车安装。(注意连接网络)如下图
安装完成,如图
查看全部
c爬虫抓取网页数据(1.网络爬虫的基本概念网络蜘蛛,机器人都能够做到!
)
1.网络爬虫基本概念
网络爬虫(也称为网络蜘蛛或机器人)是模拟客户端发送网络请求并接收请求响应的程序,根据一定的规则自动抓取互联网信息的程序。
只要浏览器能做任何事情,原则上爬虫都能做到。
2.网络爬虫函数

网络爬虫可以手动替换很多东西,比如用作搜索引擎,或者爬取网站上的图片。比如有的朋友把一些网站上的所有图片都爬进去,集中在上面。可以进行投资分析。
有时候,可能有几个我们比较喜欢的新闻网站,每次浏览都单独打开这些新闻网站比较麻烦。这时候就可以用网络爬虫来爬取这多条新闻网站中的新闻信息,集中阅读。
有时候,我们在网上浏览信息的时候,会发现有很多广告。这时也可以利用爬虫来爬取相应网页上的信息,从而自动过滤掉这些广告,方便信息的阅读和使用。
有时候,我们需要做营销,所以如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以手动搜索互联网,但这会非常低效。这时,我们可以通过爬虫设置相应的规则,自动采集从互联网上获取目标用户的联系方式,供我们营销使用。
有时候,我们想分析某个网站的用户信息,比如分析网站的用户活跃度、发言次数、热门文章等信息,如果我们没有网站@ >管理员,手动统计将是一个非常庞大的工程。此时,您可以使用爬虫轻松采集对这些数据进行进一步分析,并且所有这些爬取操作都是自动进行的,我们只需要编写相应的爬虫并设计相应的爬虫即可。规则会做。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫实现自动化,可以更好地利用互联网中的有效信息。.
3.安装第三方库
在爬取和解析数据之前,需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面输入pip install requests,回车安装。(注意连接网络)如下图

安装完成,如图

c爬虫抓取网页数据(关于爬虫的知识后,你了解多少?(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-04-07 23:27
)
如今,大前端理念已经深入人心,需要涉及的知识很多。所以,对于现在的前端来说,也是不可抗拒的。在修炼吸星大法时,尽可能多地吸收知识,最终达到物尽其用的效果。
最近也在学习爬虫,因为之前项目中需要用到的地铁信息数据不是爬虫爬下来的数据,而是直接复制过来的。
虽然这些数据暂时不会有太大变化,但感觉还是有点低。所以在了解了爬虫之后,打算和大家讨论交流,然后直接进入正题。
首先说一下爬虫和Robots协议是什么
然后介绍爬虫的基本流程
最后根据实际栗子爬个豆瓣最近上映的电影来试试小刀
2、爬虫和机器人协议
首先看定义:爬虫是自动获取网页内容的程序。它是搜索引擎的重要组成部分,因此搜索引擎优化主要针对爬虫进行优化。
下面我们来看看Robots协议的介绍。robots.txt 是文本文件,robots.txt 是协议,而不是命令。
robots.txt 是爬虫要查看的第一个文件。robots.txt 告诉爬虫可以在服务器上查看哪些文件。爬虫机器人会根据文件内容确定访问范围。
下图是豆瓣电影页面列出的robots协议的访问范围。
爬虫和机器人协议密切相关。如果您看到不允许抓取的页面,请不要抓取它们。万一涉及到用户隐私的某些方面,稍后会被发现并带到合法渠道。
因此,业内每个人都认可这个 Robots 协议。不想爬网页就别爬了,上网就可以安宁了。
有点跑题了,我们看下面一张图,简单梳理一下上面提到的内容。
其实有人会问,爬行动物到底在爬什么?
这是一个非常有见地的问题。说白了就是爬虫拿到的那段html代码,所以这对我们来说并不陌生,只要我们把它转换成DOM树就行了。
所以,现在看上图的右半部分,是一张对比图。
左边的那个没有机器人协议限制。从逻辑上讲,admin/private 和 tmp 这三个文件夹是不能被抓取的,但是由于没有 Robots 协议,人们可以肆无忌惮的爬取。
从右侧看,Robots 协议是有限的。相反,像谷歌这样的搜索引擎也会使用 Robots.txt 文件来查看无法捕获的内容,然后直接跳到 admin 或 private。去抢吧。
好了,介绍到此为止。凡是不包括真刀真枪的,都只是纸上谈兵。
3、爬虫基本流程
其实对于爬虫的使用来说,过程无非就是这四个步骤。
专用数据
数据存储
启动服务
渲染数据
专用数据
现在到了激动人心的部分,不要停下来,跟着我,敲出一页爬豆瓣电影,供自己欣赏。
我们先来看看整体的目录结构。
既然是抓数据,就得用业界知名的神器——request
请求工件
那么如何使用request,我们一起听风看代码
// 使用起来超简单let request = require('request');
request('http://www.baidu.com', function (error, response, body) { console.log('error:', error); // 当有错误发生时打印错误日志 console.log('statusCode:', response && response.statusCode); // 打印响应状态码 console.log('body:', body); // 打印百度页面的html代码});
看了上面的代码,是不是还觉得不明显。小伙伴们,html代码已经出现在你们面前了,不要犹豫,只要把它变成熟悉的DOM,就可以为所欲为。
于是,cheerio 出道,大家都称它为 Node 版的 jq。你可以完全按照jq的习惯来操作DOM。
下面不再走弯路,一起来写爬虫吧!
阅读内容
首页应该先分析豆瓣电影的页面,也就是热映的电影,我们先来看看DOM结构。
好了,读完噻吩后,我们需要的内容也标注出来了,然后进入read.js文件,一步步开始舔。
// read.js文件
// request-promise是让request支持了promise的语法,可以说是request的小弟const rp = require('request-promise');// 将抓取页面的html代码转为DOM,可以称之为是node版的jqconst cheerio = require('cheerio');// 这个是为了在调试时查看日志const debug = require('debug')('movie:read');
// 读取页面的方法,重点来了const read = async (url) => { debug('开始读取最近上映的电影');
const opts = { url, // 目标页面 transform: body => { // body为目标页面抓取到的html代码 // 通过cheerio.load方法可以把html代码转换成可以操作的DOM结构 return cheerio.load(body); } };
return rp(opts).then($ => { let result = []; // 结果数组 // 遍历这些热映电影的li $('#screening li.ui-slide-item').each((index, item) => { let ele = $(item); let name = ele.data('title'); let score = ele.data('rate') || '暂无评分'; let href = ele.find('.poster a').attr('href'); let image = ele.find('img').attr('src'); // 影片id可以从影片href中获取到 let id = href && href.match(/(\d+)/)[1]; // 为了防止豆瓣防盗链导致裂图,换成webp格式加载图片 image = image && image.replace(/jpg$/, 'webp');
if (!name || !image || !href) { return; }
result.push({ name, score, href, image, id }); debug(`正在读取电影:${name}`); }); // 返回结果数组 return result; });};// 导出方法module.exports = read;
写完代码,让我们回忆一下你做了什么。
4、数据存储
这里我们使用mysql建一个数据库来存储数据,不懂的没关系,我先一步一步来。我们首先安装 XAMPP 和 Navicat 可视化数据库管理工具,安装完成后,按照下面的说明进行操作。
XAMPP启动mysql
Navicat 连接数据库并创建表
几句话可能不像有图有真相那么真实。我们先来看看图片。
嗯,看图的时代到此结束。我真的很惭愧消耗了大量的流量。现在让我们回到编码阶段。
连接到数据库
首先,我们需要在 src 目录下创建一个 sql 文件。它需要和我们刚刚创建的数据库同名,所以我们称之为my_movie.sql(当然目录结构已经创建好了)
然后,回到 db.js 文件,编写连接数据库的代码
// db.js
const mysql = require('mysql');const bluebird = require('bluebird');
// 创建连接const connection = mysql.createConnection({ host: 'localhost', // host port: 3306, // 端口号默认3306 database: 'my_movie', // 对应的数据库 user: 'root', password: ''});
connection.connect(); // 连接数据库
// bluebird是为了方便支持promise语法化// 然后直接把数据库的query查询语句导出方便之后调用module.exports = bluebird.promisify(connection.query).bind(connection);
上面的代码已经创建了连接Mysql数据库的操作。接下来,不要放慢速度,将内容直接写入数据库。
写入数据库
这时候我们来看看write.js这个文件。是的,顾名思义,就是用来写数据库的,直接上代码
// write.js文件
// 从db.js那里导入query方法const query = require('./db');const debug = require('debug')('movie:write');// 写入数据库的方法const write = async (movies) => { debug('开始写入电影');
// movies即为read.js读取出来的结果数组 for (let movie of movies) { // 通过query方法去查询一下是不是已经在数据库里存过了 let oldMovie = await query('SELECT * FROM movies WHERE id=? LIMIT 1', [movie.id]);
// sql查询语句返回的是一个数组,如果不为空数组的话就表示有数据存过 // 直接就进行更新操作了 if (Array.isArray(oldMovie) && oldMovie.length) { // 更新movies表里的数据 let old = oldMovie[0]; await query('UPDATE movies SET name=?,href=?,image=?,score=? WHERE id=?', [movie.name, movie.href, movie.image, movie.score, old.id]); } else { // 插入内容到movies表 await query('INSERT INTO movies(id,name,href,image,score) VALUES(?,?,?,?,?)', [movie.id, movie.name, movie.href, movie.image, movie.score]); }
debug(`正在写入电影:${movie.name}`); }};
module.exports = write;
上面写的可能有点混乱,毕竟纯前端很少写SQL语句。不过不要害羞,我先把上面的代码整理好之后再简单介绍一下SQL语句部分。
write.js 到底写了什么?
好了,上面也实现了写入数据库的方法。接下来,趁热打铁,稍微聊聊SQL语句。
SQL语句学习
? 表示占位符。顺便说一下,我将简要介绍将在 SQL 语句中使用的语法,以及无处不在的增删改查。
插入数据
语法: INSERT INTO 表名(列名) VALUES(列名值)栗子: INSERT INTO tags(name,id,url) VALUES('爬虫',10,'https://news.so.com/hotnews')解释: 向标签表(tags)里插入一条,姓名,id和访问地址分别为VALUES内对应的值
更新数据
语法: UPDATE 表名 SET 列名=更新值 WHERE 更新条件栗子: UPDATE articles SET title='你好,世界',content='世界没你想的那么糟!' WHERE id=1解释: 更新id为1的文章,标题和内容都进行了修改
删除数据
语法: DELETE FROM 表名 WHERE 删除条件栗子: DELETE FROM tags WHERE id=11解释: 从标签表(tags)里删除id为11的数据
查询
语法: SELECT 列名 FROM 表名 WHERE 查询条件 ORDER BY 排序列名栗子: SELECT name,title,content FROM tags WHERE id=8解释: 查询id为8的标签表里对应信息
至此,我已经把所有的读写方法都写完了,所以大家一定是有点累了。是时候测试结果了,否则都是废话
5、执行读写操作
现在来到 index.js 并开始检查它。
// index.js文件
const read = require('./read');const write = require('./write');const url = 'https://movie.douban.com'; // 目标页面
(async () => { // 异步抓取目标页面 const movies = await read(url); // 写入数据到数据库 await write(movies); // 完毕后退出程序 process.exit();})();
完了,执行一下看看效果如何,直接上图
代码已执行。接下来回到Navicat,看看数据是否已经写入。我们用图片来说话。
至此,我们已经完成了数据采集和存储操作,但似乎还缺少什么?
也就是我们需要写一个页面来展示它,因为爬取和写数据只允许在node环境下进行。所以我们还要创建一个web服务来显示页面,坚持下去很快就OK了,加油。
6、启动服务
既然我们要创建一个 web 服务,让我们开始编写 server.js 的内容
服务器服务
// server.js文件
const express = require('express');const path = require('path');const query = require('../src/db');const app = express();
// 设置模板引擎app.set('view engine', 'html');app.set('views', path.join(__dirname, 'views'));app.engine('html', require('ejs').__express);
// 首页路由app.get('/', async (req, res) => { // 通过SQL查询语句拿到库里的movies表数据 const movies = await query('SELECT * FROM movies'); // 渲染首页模板并把movies数据传过去 res.render('index', { movies });});// 监听localhost:9000端口app.listen(9000);
写完服务端服务,我们再来看看 index.html 模板。这是最后一件事。写完,就大功告成了。
7、渲染数据
// index.html
热映的电影 正在热映的电影 %=movie.image% <p class="score">评分: </a>
</p>
通过模板引擎遍历movies数组,然后渲染
现在,看看最终效果
和你一起来到这里是缘分。我很高兴经历了这么长时间的文章 学习。每个人都应该对爬行动物的知识有一个很好的了解。
对了,这里是代码地址:爬虫研究/电影
为了您的方便,敲敲敲。
感谢阅读,886。
查看全部
c爬虫抓取网页数据(关于爬虫的知识后,你了解多少?(一)
)
如今,大前端理念已经深入人心,需要涉及的知识很多。所以,对于现在的前端来说,也是不可抗拒的。在修炼吸星大法时,尽可能多地吸收知识,最终达到物尽其用的效果。
最近也在学习爬虫,因为之前项目中需要用到的地铁信息数据不是爬虫爬下来的数据,而是直接复制过来的。
虽然这些数据暂时不会有太大变化,但感觉还是有点低。所以在了解了爬虫之后,打算和大家讨论交流,然后直接进入正题。
首先说一下爬虫和Robots协议是什么
然后介绍爬虫的基本流程
最后根据实际栗子爬个豆瓣最近上映的电影来试试小刀
2、爬虫和机器人协议
首先看定义:爬虫是自动获取网页内容的程序。它是搜索引擎的重要组成部分,因此搜索引擎优化主要针对爬虫进行优化。
下面我们来看看Robots协议的介绍。robots.txt 是文本文件,robots.txt 是协议,而不是命令。
robots.txt 是爬虫要查看的第一个文件。robots.txt 告诉爬虫可以在服务器上查看哪些文件。爬虫机器人会根据文件内容确定访问范围。
下图是豆瓣电影页面列出的robots协议的访问范围。
爬虫和机器人协议密切相关。如果您看到不允许抓取的页面,请不要抓取它们。万一涉及到用户隐私的某些方面,稍后会被发现并带到合法渠道。
因此,业内每个人都认可这个 Robots 协议。不想爬网页就别爬了,上网就可以安宁了。
有点跑题了,我们看下面一张图,简单梳理一下上面提到的内容。
其实有人会问,爬行动物到底在爬什么?
这是一个非常有见地的问题。说白了就是爬虫拿到的那段html代码,所以这对我们来说并不陌生,只要我们把它转换成DOM树就行了。
所以,现在看上图的右半部分,是一张对比图。
左边的那个没有机器人协议限制。从逻辑上讲,admin/private 和 tmp 这三个文件夹是不能被抓取的,但是由于没有 Robots 协议,人们可以肆无忌惮的爬取。
从右侧看,Robots 协议是有限的。相反,像谷歌这样的搜索引擎也会使用 Robots.txt 文件来查看无法捕获的内容,然后直接跳到 admin 或 private。去抢吧。
好了,介绍到此为止。凡是不包括真刀真枪的,都只是纸上谈兵。
3、爬虫基本流程
其实对于爬虫的使用来说,过程无非就是这四个步骤。
专用数据
数据存储
启动服务
渲染数据
专用数据
现在到了激动人心的部分,不要停下来,跟着我,敲出一页爬豆瓣电影,供自己欣赏。
我们先来看看整体的目录结构。
既然是抓数据,就得用业界知名的神器——request
请求工件
那么如何使用request,我们一起听风看代码
// 使用起来超简单let request = require('request');
request('http://www.baidu.com', function (error, response, body) { console.log('error:', error); // 当有错误发生时打印错误日志 console.log('statusCode:', response && response.statusCode); // 打印响应状态码 console.log('body:', body); // 打印百度页面的html代码});
看了上面的代码,是不是还觉得不明显。小伙伴们,html代码已经出现在你们面前了,不要犹豫,只要把它变成熟悉的DOM,就可以为所欲为。
于是,cheerio 出道,大家都称它为 Node 版的 jq。你可以完全按照jq的习惯来操作DOM。
下面不再走弯路,一起来写爬虫吧!
阅读内容
首页应该先分析豆瓣电影的页面,也就是热映的电影,我们先来看看DOM结构。
好了,读完噻吩后,我们需要的内容也标注出来了,然后进入read.js文件,一步步开始舔。
// read.js文件
// request-promise是让request支持了promise的语法,可以说是request的小弟const rp = require('request-promise');// 将抓取页面的html代码转为DOM,可以称之为是node版的jqconst cheerio = require('cheerio');// 这个是为了在调试时查看日志const debug = require('debug')('movie:read');
// 读取页面的方法,重点来了const read = async (url) => { debug('开始读取最近上映的电影');
const opts = { url, // 目标页面 transform: body => { // body为目标页面抓取到的html代码 // 通过cheerio.load方法可以把html代码转换成可以操作的DOM结构 return cheerio.load(body); } };
return rp(opts).then($ => { let result = []; // 结果数组 // 遍历这些热映电影的li $('#screening li.ui-slide-item').each((index, item) => { let ele = $(item); let name = ele.data('title'); let score = ele.data('rate') || '暂无评分'; let href = ele.find('.poster a').attr('href'); let image = ele.find('img').attr('src'); // 影片id可以从影片href中获取到 let id = href && href.match(/(\d+)/)[1]; // 为了防止豆瓣防盗链导致裂图,换成webp格式加载图片 image = image && image.replace(/jpg$/, 'webp');
if (!name || !image || !href) { return; }
result.push({ name, score, href, image, id }); debug(`正在读取电影:${name}`); }); // 返回结果数组 return result; });};// 导出方法module.exports = read;
写完代码,让我们回忆一下你做了什么。
4、数据存储
这里我们使用mysql建一个数据库来存储数据,不懂的没关系,我先一步一步来。我们首先安装 XAMPP 和 Navicat 可视化数据库管理工具,安装完成后,按照下面的说明进行操作。
XAMPP启动mysql
Navicat 连接数据库并创建表
几句话可能不像有图有真相那么真实。我们先来看看图片。
嗯,看图的时代到此结束。我真的很惭愧消耗了大量的流量。现在让我们回到编码阶段。
连接到数据库
首先,我们需要在 src 目录下创建一个 sql 文件。它需要和我们刚刚创建的数据库同名,所以我们称之为my_movie.sql(当然目录结构已经创建好了)
然后,回到 db.js 文件,编写连接数据库的代码
// db.js
const mysql = require('mysql');const bluebird = require('bluebird');
// 创建连接const connection = mysql.createConnection({ host: 'localhost', // host port: 3306, // 端口号默认3306 database: 'my_movie', // 对应的数据库 user: 'root', password: ''});
connection.connect(); // 连接数据库
// bluebird是为了方便支持promise语法化// 然后直接把数据库的query查询语句导出方便之后调用module.exports = bluebird.promisify(connection.query).bind(connection);
上面的代码已经创建了连接Mysql数据库的操作。接下来,不要放慢速度,将内容直接写入数据库。
写入数据库
这时候我们来看看write.js这个文件。是的,顾名思义,就是用来写数据库的,直接上代码
// write.js文件
// 从db.js那里导入query方法const query = require('./db');const debug = require('debug')('movie:write');// 写入数据库的方法const write = async (movies) => { debug('开始写入电影');
// movies即为read.js读取出来的结果数组 for (let movie of movies) { // 通过query方法去查询一下是不是已经在数据库里存过了 let oldMovie = await query('SELECT * FROM movies WHERE id=? LIMIT 1', [movie.id]);
// sql查询语句返回的是一个数组,如果不为空数组的话就表示有数据存过 // 直接就进行更新操作了 if (Array.isArray(oldMovie) && oldMovie.length) { // 更新movies表里的数据 let old = oldMovie[0]; await query('UPDATE movies SET name=?,href=?,image=?,score=? WHERE id=?', [movie.name, movie.href, movie.image, movie.score, old.id]); } else { // 插入内容到movies表 await query('INSERT INTO movies(id,name,href,image,score) VALUES(?,?,?,?,?)', [movie.id, movie.name, movie.href, movie.image, movie.score]); }
debug(`正在写入电影:${movie.name}`); }};
module.exports = write;
上面写的可能有点混乱,毕竟纯前端很少写SQL语句。不过不要害羞,我先把上面的代码整理好之后再简单介绍一下SQL语句部分。
write.js 到底写了什么?
好了,上面也实现了写入数据库的方法。接下来,趁热打铁,稍微聊聊SQL语句。
SQL语句学习
? 表示占位符。顺便说一下,我将简要介绍将在 SQL 语句中使用的语法,以及无处不在的增删改查。
插入数据
语法: INSERT INTO 表名(列名) VALUES(列名值)栗子: INSERT INTO tags(name,id,url) VALUES('爬虫',10,'https://news.so.com/hotnews')解释: 向标签表(tags)里插入一条,姓名,id和访问地址分别为VALUES内对应的值
更新数据
语法: UPDATE 表名 SET 列名=更新值 WHERE 更新条件栗子: UPDATE articles SET title='你好,世界',content='世界没你想的那么糟!' WHERE id=1解释: 更新id为1的文章,标题和内容都进行了修改
删除数据
语法: DELETE FROM 表名 WHERE 删除条件栗子: DELETE FROM tags WHERE id=11解释: 从标签表(tags)里删除id为11的数据
查询
语法: SELECT 列名 FROM 表名 WHERE 查询条件 ORDER BY 排序列名栗子: SELECT name,title,content FROM tags WHERE id=8解释: 查询id为8的标签表里对应信息
至此,我已经把所有的读写方法都写完了,所以大家一定是有点累了。是时候测试结果了,否则都是废话
5、执行读写操作
现在来到 index.js 并开始检查它。
// index.js文件
const read = require('./read');const write = require('./write');const url = 'https://movie.douban.com'; // 目标页面
(async () => { // 异步抓取目标页面 const movies = await read(url); // 写入数据到数据库 await write(movies); // 完毕后退出程序 process.exit();})();
完了,执行一下看看效果如何,直接上图
代码已执行。接下来回到Navicat,看看数据是否已经写入。我们用图片来说话。
至此,我们已经完成了数据采集和存储操作,但似乎还缺少什么?
也就是我们需要写一个页面来展示它,因为爬取和写数据只允许在node环境下进行。所以我们还要创建一个web服务来显示页面,坚持下去很快就OK了,加油。
6、启动服务
既然我们要创建一个 web 服务,让我们开始编写 server.js 的内容
服务器服务
// server.js文件
const express = require('express');const path = require('path');const query = require('../src/db');const app = express();
// 设置模板引擎app.set('view engine', 'html');app.set('views', path.join(__dirname, 'views'));app.engine('html', require('ejs').__express);
// 首页路由app.get('/', async (req, res) => { // 通过SQL查询语句拿到库里的movies表数据 const movies = await query('SELECT * FROM movies'); // 渲染首页模板并把movies数据传过去 res.render('index', { movies });});// 监听localhost:9000端口app.listen(9000);
写完服务端服务,我们再来看看 index.html 模板。这是最后一件事。写完,就大功告成了。
7、渲染数据
// index.html
热映的电影 正在热映的电影 %=movie.image% <p class="score">评分: </a>
</p>
通过模板引擎遍历movies数组,然后渲染
现在,看看最终效果
和你一起来到这里是缘分。我很高兴经历了这么长时间的文章 学习。每个人都应该对爬行动物的知识有一个很好的了解。
对了,这里是代码地址:爬虫研究/电影
为了您的方便,敲敲敲。
感谢阅读,886。
c爬虫抓取网页数据( 如何找出发送请求的js在控制数据的生成,我根本无法找到是哪一个js实现的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-04-07 14:27
如何找出发送请求的js在控制数据的生成,我根本无法找到是哪一个js实现的
)
有很多页。当我们使用request发送请求时,返回的内容中没有页面显示数据。主要有两种情况。一种是通过ajax异步发送请求,得到响应并把数据放入页面。对于这种情况,我们可以查看ajax请求,然后分析ajax请求路径和响应,得到想要的数据;另一种是js动态加载的数据,然后放到页面中。在这两种情况下,用户在通过浏览器访问时都不会发现任何异常,并且会很快得到完整的页面。
其实我们之前学过一个selenium模块。通过操作浏览器,然后获取浏览器显示的数据,我们可以通过这种方式获取数据,但是本节是分析如何找到控制数据生成的js。以及js发送请求的路径,这样我们就可以向这个路径发送请求,直接获取数据。
在之前的爬取过程中,最困扰我的是js动态生成的数据。我找不到哪个js实现了它(因为js太多了)。今天看了大佬的博客,顿时觉得简单多了。,谢谢大佬提供大佬的博客:
一、需求描述及页面分析一、需求描述
基本页面路径:
点击进入每个标题:
要求是爬取每个标题下的新闻内容
2.页面分析
2.1 主页
查看ajax请求:
接下来,我们将解析如何找出发送请求的js
二、找到发送请求的js
在响应数据中收录了这条新闻的新闻标题和详情页路径,所以现在我们去访问详情页,分析详情页
访问详情页,查看详情页的响应,数据中不收录具体数据,则和主页面一样,然后去ajax:
Ajax 没有与新闻相关的数据,因此它不使用 ajax 请求来获取数据。只剩下js了。我们会找出是哪个js发送了请求来获取数据。步骤与上面相同:
详情页数据的js请求路径:
详情页请求路径:
我们可以看到,最后一个斜杠之前的详情页数据的请求路径和最后一个斜杠之前的详情页的请求路径是一样的。所以我们可以这样做:
第一步:拿到详情页的请求路径:
url1='https://www.xuexi.cn/1ed1e76f885a3c19576e495ad2b279e5/e43e220633a65f9b6d8b53712cba9caa.html'
第二步:把url1最后一个斜杠后面的内容替换掉
url2='https://www.xuexi.cn/%s/datae43e220633a65f9b6d8b53712cba9caa.js'%(url1.split('/')[3]) #把url1用‘/’分割,拿到第四部分,即索引为3,然后拼接进去既可
这样就构造好了一个详情页数据请求路径,然后直接去访问这个路径既可拿到数据,就不用去访问详情页了 查看全部
c爬虫抓取网页数据(
如何找出发送请求的js在控制数据的生成,我根本无法找到是哪一个js实现的
)



有很多页。当我们使用request发送请求时,返回的内容中没有页面显示数据。主要有两种情况。一种是通过ajax异步发送请求,得到响应并把数据放入页面。对于这种情况,我们可以查看ajax请求,然后分析ajax请求路径和响应,得到想要的数据;另一种是js动态加载的数据,然后放到页面中。在这两种情况下,用户在通过浏览器访问时都不会发现任何异常,并且会很快得到完整的页面。
其实我们之前学过一个selenium模块。通过操作浏览器,然后获取浏览器显示的数据,我们可以通过这种方式获取数据,但是本节是分析如何找到控制数据生成的js。以及js发送请求的路径,这样我们就可以向这个路径发送请求,直接获取数据。
在之前的爬取过程中,最困扰我的是js动态生成的数据。我找不到哪个js实现了它(因为js太多了)。今天看了大佬的博客,顿时觉得简单多了。,谢谢大佬提供大佬的博客:
一、需求描述及页面分析一、需求描述
基本页面路径:

点击进入每个标题:

要求是爬取每个标题下的新闻内容
2.页面分析
2.1 主页

查看ajax请求:

接下来,我们将解析如何找出发送请求的js
二、找到发送请求的js

在响应数据中收录了这条新闻的新闻标题和详情页路径,所以现在我们去访问详情页,分析详情页

访问详情页,查看详情页的响应,数据中不收录具体数据,则和主页面一样,然后去ajax:

Ajax 没有与新闻相关的数据,因此它不使用 ajax 请求来获取数据。只剩下js了。我们会找出是哪个js发送了请求来获取数据。步骤与上面相同:

详情页数据的js请求路径:

详情页请求路径:

我们可以看到,最后一个斜杠之前的详情页数据的请求路径和最后一个斜杠之前的详情页的请求路径是一样的。所以我们可以这样做:
第一步:拿到详情页的请求路径:
url1='https://www.xuexi.cn/1ed1e76f885a3c19576e495ad2b279e5/e43e220633a65f9b6d8b53712cba9caa.html'
第二步:把url1最后一个斜杠后面的内容替换掉
url2='https://www.xuexi.cn/%s/datae43e220633a65f9b6d8b53712cba9caa.js'%(url1.split('/')[3]) #把url1用‘/’分割,拿到第四部分,即索引为3,然后拼接进去既可
这样就构造好了一个详情页数据请求路径,然后直接去访问这个路径既可拿到数据,就不用去访问详情页了
c爬虫抓取网页数据(推荐阅读python如何从无到有成长为一个python开发工程师)
网站优化 • 优采云 发表了文章 • 0 个评论 • 40 次浏览 • 2022-04-05 13:04
c爬虫抓取网页数据可以编写python代码,
新手可以从上面那位大哥的这篇回答入手。自学的方法有多种,不要单单想靠编程挣钱就好,如果想通过技术来赚钱,那就要付出比别人更多的时间精力来学习。
推荐阅读python如何从无到有成长为一个python开发工程师-慕课网
python主要可以去做爬虫,数据分析,机器学习,
可以看看这篇高级python爬虫学习笔记
一、高级python爬虫学习笔记
二、爬虫自动化之数据采集篇
一、python爬虫的入门路线
二、python爬虫的进阶路线
黄哥推荐学习python的三本书:《黄哥:黄哥python提醒:学习python固然重要,但是并不是全部》、《转行需要学习的十大知识点》、《python核心编程:从小白到架构师的修炼》。知乎专栏从入门到进阶,学习完这三本书,python基本能解决80%的问题了。
要说要学什么的话,爬虫是一个比较容易提上日程的事情。下面给出程序员们的学习路线,可以参考下。
1、豆瓣电影爬虫豆瓣电影下面可以爬取电影信息,豆瓣电影网的很多电影都可以爬取到,
2、美剧网爬虫爬虫能够爬取到电影、电视剧、喜剧、动漫等1080p高清视频,代码可以去python爬虫,集搜客,bilibili,抓豆瓣电影-抓取豆瓣电影;可以去集搜客,抓豆瓣电影。
3、地图爬虫urlscheme的代码在这里:web_district_siteurls.py,爬虫案例中抓取到的有些是要进行采集得到,所以是存放在数据库中。代码可以去集搜客,抓豆瓣电影-抓取豆瓣电影,集搜客抓豆瓣电影;集搜客。
4、记账爬虫获取不同类型的记账日历,代码示例如下。urlschemeindex.py(注意需要看url,有的可能是以数组的形式存放的)。其他url根据需要根据自己代码中实际的代码爬取使用。
5、电影评分爬虫采集豆瓣上电影评分的评分信息并保存,因为电影的评分可能出现多次,所以爬取的时候要确定是第一次爬取。代码案例可以看黄哥的这篇:,可以根据在豆瓣看到的很多电影的详细信息进行爬取,爬取完之后如果需要联系客服了可以去复制评分出来进行二次分析。
6、股票爬虫爬取电影、电视剧、喜剧、动漫等1080p高清视频后同时抓取到每个视频下每个电影的评分、画面尺寸、评论内容等信息并保存,就可以得到一个电影的excel表格代码可以看bilibili或者抓豆瓣电影;其实也可以看集搜客,抓豆瓣电影。
7、房产相关爬虫 查看全部
c爬虫抓取网页数据(推荐阅读python如何从无到有成长为一个python开发工程师)
c爬虫抓取网页数据可以编写python代码,
新手可以从上面那位大哥的这篇回答入手。自学的方法有多种,不要单单想靠编程挣钱就好,如果想通过技术来赚钱,那就要付出比别人更多的时间精力来学习。
推荐阅读python如何从无到有成长为一个python开发工程师-慕课网
python主要可以去做爬虫,数据分析,机器学习,
可以看看这篇高级python爬虫学习笔记
一、高级python爬虫学习笔记
二、爬虫自动化之数据采集篇
一、python爬虫的入门路线
二、python爬虫的进阶路线
黄哥推荐学习python的三本书:《黄哥:黄哥python提醒:学习python固然重要,但是并不是全部》、《转行需要学习的十大知识点》、《python核心编程:从小白到架构师的修炼》。知乎专栏从入门到进阶,学习完这三本书,python基本能解决80%的问题了。
要说要学什么的话,爬虫是一个比较容易提上日程的事情。下面给出程序员们的学习路线,可以参考下。
1、豆瓣电影爬虫豆瓣电影下面可以爬取电影信息,豆瓣电影网的很多电影都可以爬取到,
2、美剧网爬虫爬虫能够爬取到电影、电视剧、喜剧、动漫等1080p高清视频,代码可以去python爬虫,集搜客,bilibili,抓豆瓣电影-抓取豆瓣电影;可以去集搜客,抓豆瓣电影。
3、地图爬虫urlscheme的代码在这里:web_district_siteurls.py,爬虫案例中抓取到的有些是要进行采集得到,所以是存放在数据库中。代码可以去集搜客,抓豆瓣电影-抓取豆瓣电影,集搜客抓豆瓣电影;集搜客。
4、记账爬虫获取不同类型的记账日历,代码示例如下。urlschemeindex.py(注意需要看url,有的可能是以数组的形式存放的)。其他url根据需要根据自己代码中实际的代码爬取使用。
5、电影评分爬虫采集豆瓣上电影评分的评分信息并保存,因为电影的评分可能出现多次,所以爬取的时候要确定是第一次爬取。代码案例可以看黄哥的这篇:,可以根据在豆瓣看到的很多电影的详细信息进行爬取,爬取完之后如果需要联系客服了可以去复制评分出来进行二次分析。
6、股票爬虫爬取电影、电视剧、喜剧、动漫等1080p高清视频后同时抓取到每个视频下每个电影的评分、画面尺寸、评论内容等信息并保存,就可以得到一个电影的excel表格代码可以看bilibili或者抓豆瓣电影;其实也可以看集搜客,抓豆瓣电影。
7、房产相关爬虫
c爬虫抓取网页数据(Python开发的一个快速、高层次引擎(Scrapy)())
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-03 23:09
一、概览
Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。
Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。它最初是为页面抓取(更准确地说,网络抓取)而设计的,后端也用于获取 API(例如 Amazon Associates Web Services)或通用网络爬虫返回的数据。 Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。
还提供了各类爬虫的基类,如BaseSpider、sitemap爬虫等。最新版本提供了对web2.0爬虫的支持。
二、Scrapy 五个基本组件:
Scrapy 框架组件
调度器
下载器
爬虫
物理管道
Scrapy 引擎
(1),调度器:
调度器,说白了就是假设它是一个优先级的URL队列(被爬取的网站或链接),它决定了下一个要爬取的URL是什么,并移除重复的URL(不是无用的工作)。用户可以根据自己的需要自定义调度器。
(2),下载器:
下载器是所有组件中最繁重的组件,用于在网络上高速下载资源。 Scrapy 的下载器代码并不太复杂,但是效率很高。主要原因是Scrapy下载器是建立在twisted的高效异步模型之上的(其实整个框架都是建立在这个模型之上的)。
(3)、蜘蛛:
爬虫是用户最关心的部分。用户自定义自己的爬虫(通过自定义正则表达式等语法),从特定网页中提取自己需要的信息,即所谓的实体(Item)。用户还可以从中提取链接,让 Scrapy 继续抓取下一页。
(4),项目管道:
实体管道用于处理蜘蛛提取的实体。主要功能是持久化实体,验证实体的有效性,清除不必要的信息。
(5),Scrapy 引擎:
Scrapy 引擎是整个框架的核心。它用于控制调试器、下载器和爬虫。其实引擎相当于计算机的CPU,控制着整个过程。
三、整体架构
四、Scrapy 安装和项目生成
1Scrapy 安装
Microsoft Windows [版本 10.0.19043.1586]
(c) 微软公司。保留所有权利。
C:\WINDOWS\system32>python -m pip install --upgrade pip
C:\WINDOWS\system32>pip 安装轮子
C:\WINDOWS\system32>pip install lxml
C:\WINDOWS\system32>pip install twisted
C:\WINDOWS\system32>pip install pywin32
C:\WINDOWS\system32>pip install scrapy
2 构建项目
scrapy startproject 项目名称
scrapy genspider爬虫名称域名
scrapy crawler 名称
Microsoft Windows [版本 10.0.19043.1586]
(c) 微软公司。保留所有权利。
C:\WINDOWS\system32>scrapy startproject TXmovies
新建 Scrapy 项目 'TXmovies',使用模板目录 'C:\Users\1234\anaconda3\lib\site-packages\scrapy\templates\project',创建于:
C:\WINDOWS\system32\TXmovies
您可以通过以下方式启动您的第一个蜘蛛:
cd TXmovies
scrapy genspider 示例
C:\WINDOWS\system32>cd TXmovies
C:\Windows\System32\TXmovies>scrapy genspider txms
在模块中使用模板“basic”创建了蜘蛛“txms”:
TXmovies.spiders.txms
C:\Windows\System32\TXmovies>
3 创建后目录的大体页面如下
ProjectName #项目文件夹
ProjectName #项目目录
items.py #定义数据结构
middlewares.py #middleware
pipelines.py #数据处理
settings.py #全局配置
蜘蛛
__init__.py #crawler 文件
百度.py
scrapy.cfg #项目基础配置文件
五、案例
1.创建一个项目
打开终端输入(建议放在合适的路径,默认是C盘)
Microsoft Windows [版本 10.0.19043.1586]
(c) 微软公司。保留所有权利。
C:\WINDOWS\system32>scrapy startproject TXmovies
新建 Scrapy 项目 'TXmovies',使用模板目录 'C:\Users\1234\anaconda3\lib\site-packages\scrapy\templates\project',创建于:
C:\WINDOWS\system32\TXmovies
您可以通过以下方式启动您的第一个蜘蛛:
cd TXmovies
scrapy genspider 示例
C:\WINDOWS\system32>cd TXmovies
C:\Windows\System32\TXmovies>scrapy genspider txms
在模块中使用模板“basic”创建了蜘蛛“txms”:
TXmovies.spiders.txms
C:\Windows\System32\TXmovies>
2.修改设置
修改三项,第一是不遵循机器人协议,第二是下载间隙。由于下面的程序需要下载多个页面,所以需要给一个gap(不给也可以,但是很容易被检测到),第三个是请求头,添加一个User-Agent,四是打开管道
ROBOTSTXT_OBEY = 假
DOWNLOAD_DELAY = 1
DEFAULT_REQUEST_HEADERS = {
'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent':'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome /27.0.1453.94 Safari/537.36'
}
ITEM_PIPELINES = {
'TXmovies.pipelines.TxmoviesPipeline':300,
}
3.确认要提取的数据,item item
item 定义要提取的内容(定义数据结构)。比如我提取的内容是电影名和电影描述,所以我创建了两个变量。 Field方法的实际做法是创建一个字典,给字典添加一个新的值,暂时不赋值,等数据提取出来再赋值。下面的item结构可以表示为:{'name':'','description':''}。
# -*- 编码:utf-8 -*-
# 在这里为你的抓取物品定义模型
#
# 参见文档:
#
导入scrapy
类 TxmoviesItem(scrapy.Item):
# 在此处为您的项目定义字段,例如:
# name = scrapy.Field()
name = scrapy.Field()
description = scrapy.Field()
4.写一个爬虫
我们要写的部分是parse方法的内容,重点是xpath怎么写,xpath我就不多说了,有兴趣可以看我的其他文章 , XPATH 教程
介绍一下刚才写的item,刚才说item中创建的变量是字典的key值,可以直接赋值。赋值后交给管道处理。
简单说一下这段代码的思路,首先腾讯视频的url是
我们注意到偏移项,第一页的偏移量为0,第二页为30,列依次推送。
程序中这个项是用来控制第一页的抓取,但是也必须给一个范围,不能无限,否则会报错。你可以去看看腾讯总共有多少视频页,也可以写一个异常捕获机制,当请求错误被捕获时退出。我这里只是演示,所以只给了120,也就是4页。
产量
程序中有两个收益。我更喜欢称之为中断。当然,中断只发生在 CPU 中。它的功能是转移控制权。在这个程序中,我们封装好item数据后,调用yield将Control交给管道,管道处理完返回,再返回程序。这是对第一次收益的解释。
第二个产量有点复杂。本程序使用回调机制,即回调。回调的对象是 parse,也就是当前方法。通过不断的回调,程序会陷入循环。条件,就会陷入死循环。如果我把这个程序中的 if 去掉,那将是一个无限循环。
yield scrapy.Request(url=url,callback=self.parse)
xpath
另外需要注意的是如何在xpathl中提取数据。有四种写法。第一种写法是获取selector选择器,也就是原创数据,里面收录一些我们不用的东西。第二个 extract() 将选择器序列号转换为字符串。第三个和第四个一样,获取字符串中的第一个数据,就是我们要的数据。
items['name']=i.xpath('./a/@title')[0]
items['name']=i.xpath('./a/@title').extract()
items['name']=i.xpath('./a/@title').extract_first()
items['name']=i.xpath('./a/@title').get()
# -*- 编码:utf-8 -*-
导入scrapy
从 ..items 导入 TxmoviesItem
类 TxmsSpider(scrapy.Spider):
名称 = 'txms'
allowed_domains = ['']
start_urls = ['#39;]
偏移量=0
def 解析(自我,响应):
items=TxmoviesItem()
lists=response.xpath('//div[@class="list_item"]')
对于列表中的 i:
items['name']=i.xpath('./a/@title').get()
items['description']=i.xpath('./div/div/@title').get()
收益项目
如果 self.offset < 120:
self.offset += 30
url = '{}&pagesize=30'.format(str(self.offset))
yield scrapy.Request(url=url,callback=self.parse)
5.交给管道输出
管道可以处理提取的数据,例如将其存储在数据库中。我们只在这里输出。
# -*- 编码:utf-8 -*-
# 在此处定义您的项目管道
#
# 不要忘记将管道添加到 ITEM_PIPELINES 设置中
#参见:
类TxmoviesPipeline(对象):
def process_item(self, item, spider):
打印(项目)
退货
6.运行,执行项目
从 scrapy 导入命令行
cmdline.execute('scrapy crawl txms'.split())
7.测试结果
管道输出结果为白色,调试信息为红色 查看全部
c爬虫抓取网页数据(Python开发的一个快速、高层次引擎(Scrapy)())
一、概览
Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。
Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。它最初是为页面抓取(更准确地说,网络抓取)而设计的,后端也用于获取 API(例如 Amazon Associates Web Services)或通用网络爬虫返回的数据。 Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。
还提供了各类爬虫的基类,如BaseSpider、sitemap爬虫等。最新版本提供了对web2.0爬虫的支持。
二、Scrapy 五个基本组件:
Scrapy 框架组件
调度器
下载器
爬虫
物理管道
Scrapy 引擎
(1),调度器:
调度器,说白了就是假设它是一个优先级的URL队列(被爬取的网站或链接),它决定了下一个要爬取的URL是什么,并移除重复的URL(不是无用的工作)。用户可以根据自己的需要自定义调度器。
(2),下载器:
下载器是所有组件中最繁重的组件,用于在网络上高速下载资源。 Scrapy 的下载器代码并不太复杂,但是效率很高。主要原因是Scrapy下载器是建立在twisted的高效异步模型之上的(其实整个框架都是建立在这个模型之上的)。
(3)、蜘蛛:
爬虫是用户最关心的部分。用户自定义自己的爬虫(通过自定义正则表达式等语法),从特定网页中提取自己需要的信息,即所谓的实体(Item)。用户还可以从中提取链接,让 Scrapy 继续抓取下一页。
(4),项目管道:
实体管道用于处理蜘蛛提取的实体。主要功能是持久化实体,验证实体的有效性,清除不必要的信息。
(5),Scrapy 引擎:
Scrapy 引擎是整个框架的核心。它用于控制调试器、下载器和爬虫。其实引擎相当于计算机的CPU,控制着整个过程。
三、整体架构
四、Scrapy 安装和项目生成
1Scrapy 安装
Microsoft Windows [版本 10.0.19043.1586]
(c) 微软公司。保留所有权利。
C:\WINDOWS\system32>python -m pip install --upgrade pip
C:\WINDOWS\system32>pip 安装轮子
C:\WINDOWS\system32>pip install lxml
C:\WINDOWS\system32>pip install twisted
C:\WINDOWS\system32>pip install pywin32
C:\WINDOWS\system32>pip install scrapy
2 构建项目
scrapy startproject 项目名称
scrapy genspider爬虫名称域名
scrapy crawler 名称
Microsoft Windows [版本 10.0.19043.1586]
(c) 微软公司。保留所有权利。
C:\WINDOWS\system32>scrapy startproject TXmovies
新建 Scrapy 项目 'TXmovies',使用模板目录 'C:\Users\1234\anaconda3\lib\site-packages\scrapy\templates\project',创建于:
C:\WINDOWS\system32\TXmovies
您可以通过以下方式启动您的第一个蜘蛛:
cd TXmovies
scrapy genspider 示例
C:\WINDOWS\system32>cd TXmovies
C:\Windows\System32\TXmovies>scrapy genspider txms
在模块中使用模板“basic”创建了蜘蛛“txms”:
TXmovies.spiders.txms
C:\Windows\System32\TXmovies>
3 创建后目录的大体页面如下
ProjectName #项目文件夹
ProjectName #项目目录
items.py #定义数据结构
middlewares.py #middleware
pipelines.py #数据处理
settings.py #全局配置
蜘蛛
__init__.py #crawler 文件
百度.py
scrapy.cfg #项目基础配置文件
五、案例
1.创建一个项目
打开终端输入(建议放在合适的路径,默认是C盘)
Microsoft Windows [版本 10.0.19043.1586]
(c) 微软公司。保留所有权利。
C:\WINDOWS\system32>scrapy startproject TXmovies
新建 Scrapy 项目 'TXmovies',使用模板目录 'C:\Users\1234\anaconda3\lib\site-packages\scrapy\templates\project',创建于:
C:\WINDOWS\system32\TXmovies
您可以通过以下方式启动您的第一个蜘蛛:
cd TXmovies
scrapy genspider 示例
C:\WINDOWS\system32>cd TXmovies
C:\Windows\System32\TXmovies>scrapy genspider txms
在模块中使用模板“basic”创建了蜘蛛“txms”:
TXmovies.spiders.txms
C:\Windows\System32\TXmovies>
2.修改设置
修改三项,第一是不遵循机器人协议,第二是下载间隙。由于下面的程序需要下载多个页面,所以需要给一个gap(不给也可以,但是很容易被检测到),第三个是请求头,添加一个User-Agent,四是打开管道
ROBOTSTXT_OBEY = 假
DOWNLOAD_DELAY = 1
DEFAULT_REQUEST_HEADERS = {
'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent':'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome /27.0.1453.94 Safari/537.36'
}
ITEM_PIPELINES = {
'TXmovies.pipelines.TxmoviesPipeline':300,
}
3.确认要提取的数据,item item
item 定义要提取的内容(定义数据结构)。比如我提取的内容是电影名和电影描述,所以我创建了两个变量。 Field方法的实际做法是创建一个字典,给字典添加一个新的值,暂时不赋值,等数据提取出来再赋值。下面的item结构可以表示为:{'name':'','description':''}。
# -*- 编码:utf-8 -*-
# 在这里为你的抓取物品定义模型
#
# 参见文档:
#
导入scrapy
类 TxmoviesItem(scrapy.Item):
# 在此处为您的项目定义字段,例如:
# name = scrapy.Field()
name = scrapy.Field()
description = scrapy.Field()
4.写一个爬虫
我们要写的部分是parse方法的内容,重点是xpath怎么写,xpath我就不多说了,有兴趣可以看我的其他文章 , XPATH 教程
介绍一下刚才写的item,刚才说item中创建的变量是字典的key值,可以直接赋值。赋值后交给管道处理。
简单说一下这段代码的思路,首先腾讯视频的url是
我们注意到偏移项,第一页的偏移量为0,第二页为30,列依次推送。
程序中这个项是用来控制第一页的抓取,但是也必须给一个范围,不能无限,否则会报错。你可以去看看腾讯总共有多少视频页,也可以写一个异常捕获机制,当请求错误被捕获时退出。我这里只是演示,所以只给了120,也就是4页。
产量
程序中有两个收益。我更喜欢称之为中断。当然,中断只发生在 CPU 中。它的功能是转移控制权。在这个程序中,我们封装好item数据后,调用yield将Control交给管道,管道处理完返回,再返回程序。这是对第一次收益的解释。
第二个产量有点复杂。本程序使用回调机制,即回调。回调的对象是 parse,也就是当前方法。通过不断的回调,程序会陷入循环。条件,就会陷入死循环。如果我把这个程序中的 if 去掉,那将是一个无限循环。
yield scrapy.Request(url=url,callback=self.parse)
xpath
另外需要注意的是如何在xpathl中提取数据。有四种写法。第一种写法是获取selector选择器,也就是原创数据,里面收录一些我们不用的东西。第二个 extract() 将选择器序列号转换为字符串。第三个和第四个一样,获取字符串中的第一个数据,就是我们要的数据。
items['name']=i.xpath('./a/@title')[0]
items['name']=i.xpath('./a/@title').extract()
items['name']=i.xpath('./a/@title').extract_first()
items['name']=i.xpath('./a/@title').get()
# -*- 编码:utf-8 -*-
导入scrapy
从 ..items 导入 TxmoviesItem
类 TxmsSpider(scrapy.Spider):
名称 = 'txms'
allowed_domains = ['']
start_urls = ['#39;]
偏移量=0
def 解析(自我,响应):
items=TxmoviesItem()
lists=response.xpath('//div[@class="list_item"]')
对于列表中的 i:
items['name']=i.xpath('./a/@title').get()
items['description']=i.xpath('./div/div/@title').get()
收益项目
如果 self.offset < 120:
self.offset += 30
url = '{}&pagesize=30'.format(str(self.offset))
yield scrapy.Request(url=url,callback=self.parse)
5.交给管道输出
管道可以处理提取的数据,例如将其存储在数据库中。我们只在这里输出。
# -*- 编码:utf-8 -*-
# 在此处定义您的项目管道
#
# 不要忘记将管道添加到 ITEM_PIPELINES 设置中
#参见:
类TxmoviesPipeline(对象):
def process_item(self, item, spider):
打印(项目)
退货
6.运行,执行项目
从 scrapy 导入命令行
cmdline.execute('scrapy crawl txms'.split())
7.测试结果
管道输出结果为白色,调试信息为红色
c爬虫抓取网页数据(2.通用爬虫框架流程a精选部分网页链接(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-04-03 12:13
(公众号:9z营销大数据)
2014年,一本名为《这就是搜索引擎:核心技术详解》的书,将“搜索”这个核心话题再次带入大众视野。撇开本书第一版和第二版折射出的隐藏魅力不谈,正如书中所说,“搜索引擎”基于其作为互联网门户的作用及其复杂的实现方式,是目前最流行的互联网产品。有技术含量的产品,如果不是唯一的,至少也是其中之一。
今天我们要讨论的话题是围绕“爬虫爬取策略”对爬虫做一个简单的介绍,并通过这个来带领身边的“老司机”去发现那些可能被忽略的理论。
1.一句话总结爬虫
“将海量网页数据传输到本地,形成亿万网页的镜像备份”高效下载系统设计。
2. 通用爬虫框架流程
一种。选择部分网页链接地址作为种子网址,将种子网址放入待抓取的网址队列中;
湾。从待爬取的URL队列中依次读取URL,将URL链接地址通过DNS转换为网站服务器对应的IP地址;
C。将网页的网站IP地址和相对路径名交给网页下载器下载网页内容;
d。将下载的网页对应的URL放入已经爬取的URL队列中,将下载的网页内容存储在页库中,供后续处理;
e. 将刚刚下载的网页中的所有链接提取出来,并与已经爬取的URL队列进行比较,将没有被爬取的URL链接检查出来放入待爬取的URL队列中,重复新一轮的爬取操作;
F。循环直到所有网页都被爬取完毕,完成一个完整的爬取过程。
PS。动态爬取中的爬虫及与网页的相对关系
已下载网页合集:已被爬虫从互联网下载到本地索引的网页合集;
过期网页集合:对应的互联网网页已动态更新,但未被爬虫抓取,已下载到本地网页集合;
待下载网页集合:URL队列中待抓取网页的集合;
已知网页集合:存在于已被抓取或将被抓取且尚未被抓取的网页中,但迟早会被爬虫通过链接关系发现,并将被抓取并被抓取的网页的集合。索引;
不可知的网页集合:爬虫无法抓取的网页集合;
3. 三种爬虫类
一种。批量爬虫
有明确的爬取范围和目标,达到设定目标(特定页数或特定时长)时停止爬取的爬虫类型;
湾。增量爬虫
不断爬取网页并定期更新爬取网页的爬虫类型;
C。垂直爬行动物
只爬取行业特定网页或主题内容的爬虫类型
4. 优秀爬虫需要满足的条件
一种。高性能
单位时间内爬取尽可能多的网页;
湾。可扩展
通过增加爬取服务器和爬虫数量可以轻松解决缩短爬取周期的问题;
C。鲁棒性
能正确处理网页HTML编码不规范、服务器突然崩溃、爬虫陷阱等异常情况,避免工作中断,或在中断后轻松恢复之前抓取的数据;
d。友好的
保护网站的部分隐私(避免爬取爬虫禁止协议下的网页,避免爬取网页禁止标记下的部分内容),减少被爬取的网站@的网络负载>;
5. 爬虫策略
爬取的一般原则是优先对重要的网页进行爬取(PageRank是评价网页重要性的常用标准),确定待爬取URL的队列是技术的关键。
根据URL优先级确定方法的不同,四种爬取策略分为以下几种:
一种。广度优先遍历策略
含义:一种通过“直接机械地将新下载的网页中收录的链接附加到待爬取的URL队列末尾”的方式,合理安排URL下载顺序的爬取策略。
特点:简单直观,历史悠久,功能强大,比较各种抢策略的标杆策略。
优缺点:基本可以保证要爬取的url列表按照网页的重要性排序,效果很好。
湾。不完整的PageRank策略
PageRank:一种众所周知的全球链接分析算法,用于确定网页的重要性。
不完整的PageRank策略:一种爬虫策略,“在不完整的互联网页面的一个子集中计算PageRank,形成待爬取URL队列”,即与下载的网页和待爬取URL队列中的URL一起,形成一个网页集合,计算形成的网页集合中的PageRank,将待爬取URL队列按照PageRank得分从高到低的顺序重新排列,形成新的待爬取URL队列,这样的爬取策略.
l 不完整PageRank往往采用“每次有足够K个新下载的页面,重新计算所有下载页面的不完整PageRank”的方法进行;
l 在进行新一轮不完整的PageRank计算之前,给新提取的没有PageRank值的网页分配一个临时的PageRank值,与待爬取的URL列表形成大小对比,考虑到新提取的网页需要先被抓取。需要。
利弊:众说纷纭
c.OCIP策略
含义:OCIP,在线页面重要性计算。在算法开始之前,所有互联网页面都被赋予相同的现金(cash),每下载一个页面,就会将相应的现金分配给该页面所收录的页面链接,以清除下载页面的现金价值。待爬取URL队列中的网页按现金降序排列,按顺序获取”
效果:更好的重要性度量策略,效果优于广度优先遍历策略。
优缺点:无需迭代,计算速度快,适合实时计算。
d。大网站优先策略
含义:优先下载大的网站,即以网站为单位衡量网页的重要性,对于URL队列中待抓取的网页,根据其< @网站, if which 网站 网站等待下载的页面最多,会先下载这些链接。
公众号:9z营销大数据 查看全部
c爬虫抓取网页数据(2.通用爬虫框架流程a精选部分网页链接(组图))
(公众号:9z营销大数据)
2014年,一本名为《这就是搜索引擎:核心技术详解》的书,将“搜索”这个核心话题再次带入大众视野。撇开本书第一版和第二版折射出的隐藏魅力不谈,正如书中所说,“搜索引擎”基于其作为互联网门户的作用及其复杂的实现方式,是目前最流行的互联网产品。有技术含量的产品,如果不是唯一的,至少也是其中之一。
今天我们要讨论的话题是围绕“爬虫爬取策略”对爬虫做一个简单的介绍,并通过这个来带领身边的“老司机”去发现那些可能被忽略的理论。
1.一句话总结爬虫
“将海量网页数据传输到本地,形成亿万网页的镜像备份”高效下载系统设计。
2. 通用爬虫框架流程
一种。选择部分网页链接地址作为种子网址,将种子网址放入待抓取的网址队列中;
湾。从待爬取的URL队列中依次读取URL,将URL链接地址通过DNS转换为网站服务器对应的IP地址;
C。将网页的网站IP地址和相对路径名交给网页下载器下载网页内容;
d。将下载的网页对应的URL放入已经爬取的URL队列中,将下载的网页内容存储在页库中,供后续处理;
e. 将刚刚下载的网页中的所有链接提取出来,并与已经爬取的URL队列进行比较,将没有被爬取的URL链接检查出来放入待爬取的URL队列中,重复新一轮的爬取操作;
F。循环直到所有网页都被爬取完毕,完成一个完整的爬取过程。
PS。动态爬取中的爬虫及与网页的相对关系
已下载网页合集:已被爬虫从互联网下载到本地索引的网页合集;
过期网页集合:对应的互联网网页已动态更新,但未被爬虫抓取,已下载到本地网页集合;
待下载网页集合:URL队列中待抓取网页的集合;
已知网页集合:存在于已被抓取或将被抓取且尚未被抓取的网页中,但迟早会被爬虫通过链接关系发现,并将被抓取并被抓取的网页的集合。索引;
不可知的网页集合:爬虫无法抓取的网页集合;
3. 三种爬虫类
一种。批量爬虫
有明确的爬取范围和目标,达到设定目标(特定页数或特定时长)时停止爬取的爬虫类型;
湾。增量爬虫
不断爬取网页并定期更新爬取网页的爬虫类型;
C。垂直爬行动物
只爬取行业特定网页或主题内容的爬虫类型
4. 优秀爬虫需要满足的条件
一种。高性能
单位时间内爬取尽可能多的网页;
湾。可扩展
通过增加爬取服务器和爬虫数量可以轻松解决缩短爬取周期的问题;
C。鲁棒性
能正确处理网页HTML编码不规范、服务器突然崩溃、爬虫陷阱等异常情况,避免工作中断,或在中断后轻松恢复之前抓取的数据;
d。友好的
保护网站的部分隐私(避免爬取爬虫禁止协议下的网页,避免爬取网页禁止标记下的部分内容),减少被爬取的网站@的网络负载>;
5. 爬虫策略
爬取的一般原则是优先对重要的网页进行爬取(PageRank是评价网页重要性的常用标准),确定待爬取URL的队列是技术的关键。
根据URL优先级确定方法的不同,四种爬取策略分为以下几种:
一种。广度优先遍历策略
含义:一种通过“直接机械地将新下载的网页中收录的链接附加到待爬取的URL队列末尾”的方式,合理安排URL下载顺序的爬取策略。
特点:简单直观,历史悠久,功能强大,比较各种抢策略的标杆策略。
优缺点:基本可以保证要爬取的url列表按照网页的重要性排序,效果很好。
湾。不完整的PageRank策略
PageRank:一种众所周知的全球链接分析算法,用于确定网页的重要性。
不完整的PageRank策略:一种爬虫策略,“在不完整的互联网页面的一个子集中计算PageRank,形成待爬取URL队列”,即与下载的网页和待爬取URL队列中的URL一起,形成一个网页集合,计算形成的网页集合中的PageRank,将待爬取URL队列按照PageRank得分从高到低的顺序重新排列,形成新的待爬取URL队列,这样的爬取策略.
l 不完整PageRank往往采用“每次有足够K个新下载的页面,重新计算所有下载页面的不完整PageRank”的方法进行;
l 在进行新一轮不完整的PageRank计算之前,给新提取的没有PageRank值的网页分配一个临时的PageRank值,与待爬取的URL列表形成大小对比,考虑到新提取的网页需要先被抓取。需要。
利弊:众说纷纭
c.OCIP策略
含义:OCIP,在线页面重要性计算。在算法开始之前,所有互联网页面都被赋予相同的现金(cash),每下载一个页面,就会将相应的现金分配给该页面所收录的页面链接,以清除下载页面的现金价值。待爬取URL队列中的网页按现金降序排列,按顺序获取”
效果:更好的重要性度量策略,效果优于广度优先遍历策略。
优缺点:无需迭代,计算速度快,适合实时计算。
d。大网站优先策略
含义:优先下载大的网站,即以网站为单位衡量网页的重要性,对于URL队列中待抓取的网页,根据其< @网站, if which 网站 网站等待下载的页面最多,会先下载这些链接。
公众号:9z营销大数据
c爬虫抓取网页数据(一个通用的网络爬虫的基本结构及工作流程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2022-03-25 02:18
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要对爬虫和爬虫系统进行简要概述。
一、网络爬虫的基本结构和工作流程
一个通用网络爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环。
二、从爬虫的角度划分互联网
相应地,互联网上的所有页面可以分为五个部分:
1.下载了未过期的网页
2.已下载和过期网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态的,互联网上的一些内容发生了变化。您访问的页面已过期。
3.待下载页面:URL队列中待抓取的页面
4. 已知网页:没有被爬取过,也不在待爬取的URL队列中,但是通过分析已经爬取过的页面得到的URL或者待爬取的URL对应的页面都可以视为已知网页。
5.还有一些网页是爬虫无法直接爬取下载的。称为不可知网页。
三、抓取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个接一个的链接,处理完该行再到下一个起始页,继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
3.反向链接计数策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
4.部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起,形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序. 以下示例说明:
5.OPIC 政策政策
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
6.大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
四、更新政策
互联网实时变化并且非常动态。网页更新策略主要决定何时更新之前已经下载的页面。常见的更新策略有以下三种:
1.历史参考政策
顾名思义,它根据页面过去的历史更新数据来预测未来页面何时会发生变化。通常,预测是通过泊松过程建模来进行的。
2.用户体验策略
尽管搜索引擎可以为某个查询返回大量结果,但用户通常只关注结果的前几页。因此,爬虫系统可以优先更新那些实际在查询结果前几页的页面,然后再更新后面的那些页面。这个更新策略也需要用到历史信息。UX 策略保留网页的多个历史版本,并根据每个过去内容更改对搜索质量的影响得出一个平均值,并以此值作为决定何时重新抓取的基础。
3.聚类抽样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加很多系统负担;第二,如果新网页完全没有历史信息,就无法确定更新策略。
该策略认为网页具有许多属性,具有相似属性的网页可以认为具有相似的更新频率。计算某一类别网页的更新频率,只需对该类别的网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如下:
五、分布式抓取系统结构
一般来说,爬虫系统需要处理整个互联网上数以亿计的网页。单个爬虫不可能完成这样的任务。通常需要多个爬虫程序一起处理它们。一般来说,爬虫系统往往是分布式的三层结构。如图所示:
最底层是分布在不同地理位置的数据中心。每个数据中心有多个爬虫服务器,每个爬虫服务器可能部署多套爬虫程序。这样就构成了一个基本的分布式爬虫系统。
对于数据中心中的不同服务器,有几种方法可以协同工作:
1.主从
主从基本结构如图:
对于主从类型,有一个专门的主服务器来维护要爬取的URL队列,负责每次将URL分发给不同的从服务器,从服务器负责实际的网页下载工作。Master服务器除了维护要爬取的URL队列和分发URL外,还负责调解每个Slave服务器的负载。为了避免一些从服务器过于空闲或过度工作。
在这种模式下,Master往往会成为系统的瓶颈。
2.点对点
等价的基本结构如图所示:
在这种模式下,所有爬虫服务器之间的分工没有区别。每个爬取服务器可以从待爬取的URL队列中获取URL,然后计算该URL主域名的哈希值H,进而计算H mod m(其中m为服务器数量,取上图例如,m 对于 3),计算出来的数字就是处理 URL 的主机号。
例子:假设对于URL,计算器hash值H=8,m=3,那么H mod m=2,那么编号为2的服务器会抓取该链接。假设此时服务器 0 获取了 URL,它会将 URL 传输到服务器 2,服务器 2 将获取它。
这种模式有一个问题,当一个服务器死掉或添加一个新服务器时,所有 URL 的哈希余数的结果都会改变。也就是说,这种方法不能很好地扩展。针对这种情况,提出了另一种改进方案。这种改进的方案是一致的散列以确定服务器划分。其基本结构如图所示:
一致散列对 URL 的主域名进行散列,并将其映射到 0-232 范围内的数字。这个范围平均分配给m台服务器,根据URL的主域名的hash运算值的范围来确定要爬取的服务器。
如果某台服务器出现问题,本应负责该服务器的网页将由下一个服务器顺时针获取。在这种情况下,即使一台服务器出现问题,也不会影响其他工作。 查看全部
c爬虫抓取网页数据(一个通用的网络爬虫的基本结构及工作流程(组图))
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要对爬虫和爬虫系统进行简要概述。
一、网络爬虫的基本结构和工作流程
一个通用网络爬虫的框架如图所示:

网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环。
二、从爬虫的角度划分互联网
相应地,互联网上的所有页面可以分为五个部分:

1.下载了未过期的网页
2.已下载和过期网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态的,互联网上的一些内容发生了变化。您访问的页面已过期。
3.待下载页面:URL队列中待抓取的页面
4. 已知网页:没有被爬取过,也不在待爬取的URL队列中,但是通过分析已经爬取过的页面得到的URL或者待爬取的URL对应的页面都可以视为已知网页。
5.还有一些网页是爬虫无法直接爬取下载的。称为不可知网页。
三、抓取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个接一个的链接,处理完该行再到下一个起始页,继续跟踪该链接。我们以下图为例:

遍历的路径:AFG EHI BCD
2.广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
3.反向链接计数策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
4.部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起,形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序. 以下示例说明:
5.OPIC 政策政策
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
6.大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
四、更新政策
互联网实时变化并且非常动态。网页更新策略主要决定何时更新之前已经下载的页面。常见的更新策略有以下三种:
1.历史参考政策
顾名思义,它根据页面过去的历史更新数据来预测未来页面何时会发生变化。通常,预测是通过泊松过程建模来进行的。
2.用户体验策略
尽管搜索引擎可以为某个查询返回大量结果,但用户通常只关注结果的前几页。因此,爬虫系统可以优先更新那些实际在查询结果前几页的页面,然后再更新后面的那些页面。这个更新策略也需要用到历史信息。UX 策略保留网页的多个历史版本,并根据每个过去内容更改对搜索质量的影响得出一个平均值,并以此值作为决定何时重新抓取的基础。
3.聚类抽样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加很多系统负担;第二,如果新网页完全没有历史信息,就无法确定更新策略。
该策略认为网页具有许多属性,具有相似属性的网页可以认为具有相似的更新频率。计算某一类别网页的更新频率,只需对该类别的网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如下:
五、分布式抓取系统结构
一般来说,爬虫系统需要处理整个互联网上数以亿计的网页。单个爬虫不可能完成这样的任务。通常需要多个爬虫程序一起处理它们。一般来说,爬虫系统往往是分布式的三层结构。如图所示:

最底层是分布在不同地理位置的数据中心。每个数据中心有多个爬虫服务器,每个爬虫服务器可能部署多套爬虫程序。这样就构成了一个基本的分布式爬虫系统。
对于数据中心中的不同服务器,有几种方法可以协同工作:
1.主从
主从基本结构如图:

对于主从类型,有一个专门的主服务器来维护要爬取的URL队列,负责每次将URL分发给不同的从服务器,从服务器负责实际的网页下载工作。Master服务器除了维护要爬取的URL队列和分发URL外,还负责调解每个Slave服务器的负载。为了避免一些从服务器过于空闲或过度工作。
在这种模式下,Master往往会成为系统的瓶颈。
2.点对点
等价的基本结构如图所示:

在这种模式下,所有爬虫服务器之间的分工没有区别。每个爬取服务器可以从待爬取的URL队列中获取URL,然后计算该URL主域名的哈希值H,进而计算H mod m(其中m为服务器数量,取上图例如,m 对于 3),计算出来的数字就是处理 URL 的主机号。
例子:假设对于URL,计算器hash值H=8,m=3,那么H mod m=2,那么编号为2的服务器会抓取该链接。假设此时服务器 0 获取了 URL,它会将 URL 传输到服务器 2,服务器 2 将获取它。
这种模式有一个问题,当一个服务器死掉或添加一个新服务器时,所有 URL 的哈希余数的结果都会改变。也就是说,这种方法不能很好地扩展。针对这种情况,提出了另一种改进方案。这种改进的方案是一致的散列以确定服务器划分。其基本结构如图所示:

一致散列对 URL 的主域名进行散列,并将其映射到 0-232 范围内的数字。这个范围平均分配给m台服务器,根据URL的主域名的hash运算值的范围来确定要爬取的服务器。
如果某台服务器出现问题,本应负责该服务器的网页将由下一个服务器顺时针获取。在这种情况下,即使一台服务器出现问题,也不会影响其他工作。
c爬虫抓取网页数据(网页获取和解析速度和性能的应用场景详解! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-03-25 01:16
)
(4)支持代理
(5)支持自动cookie管理等。
Java爬虫开发是应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;import org.apache.http.client.HttpClient;import org.apache.http.client.ResponseHandler;import org.apache.http.client.methods.HttpGet;import org.apache.http.impl.client.BasicResponseHandler;import org.apache.http.impl.client.DefaultHttpClient;/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHttpClientTest{publicstaticvoid main(String[] args)throwsException{//目标页面String url ="http://www.yshjava.cn";//创建一个默认的HttpClientHttpClient httpclient =newDefaultHttpClient();try{//以get方式请求网页http://www.yshjava.cnHttpGet httpget =newHttpGet(url);//打印请求地址System.out.println("executing request "+ httpget.getURI());//创建响应处理器处理服务器响应内容ResponseHandlerresponseHandler=newBasicResponseHandler();//执行请求并获取结果String responseBody = httpclient.execute(httpget, responseHandler);System.out.println("----------------------------------------");System.out.println(responseBody);System.out.println("----------------------------------------");}finally{//关闭连接管理器
httpclient.getConnectionManager().shutdown();}}}
汤
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
示例代码如下:
package cn.ysh.studio.crawler.jsoup;import java.io.IOException;import org.jsoup.Jsoup;/**
* 基于Jsoup抓取网页内容
* @author www.yshjava.cn
*/publicclassJsoupTest{publicstaticvoid main(String[] args)throwsIOException{//目标页面String url ="http://www.yshjava.cn";//使用Jsoup连接目标页面,并执行请求,获取服务器响应内容String html =Jsoup.connect(url).execute().body();//打印页面内容System.out.println(html);}}
html单元
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取和解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;import com.gargoylesoftware.htmlunit.BrowserVersion;import com.gargoylesoftware.htmlunit.Page;import com.gargoylesoftware.htmlunit.WebClient;/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlUnitSpider{publicstaticvoid main(String[] s)throwsException{//目标网页String url ="http://www.yshjava.cn";//模拟特定浏览器FIREFOX_3WebClient spider =newWebClient(BrowserVersion.FIREFOX_3);//获取目标网页Page page = spider.getPage(url);//打印网页内容System.out.println(page.getWebResponse().getContentAsString());//关闭所有窗口
spider.closeAllWindows();}}
瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
示例代码如下:
package cn.ysh.studio.crawler.ie;import watij.runtime.ie.IE;/**
* 基于Watij抓取网页内容,仅限Windows平台
*
* @author www.yshjava.cn
*/publicclassWatijTest{publicstaticvoid main(String[] s){//目标页面String url ="http://www.yshjava.cn";//实例化IE浏览器对象
IE ie =new IE();try{//启动浏览器
ie.start();//转到目标网页
ie.goTo(url);//等待网页加载就绪
ie.waitUntilReady();//打印页面内容System.out.println(ie.html());}catch(Exception e){
e.printStackTrace();}finally{try{//关闭IE浏览器
ie.close();}catch(Exception e){}}}}
硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;import org.openqa.selenium.htmlunit.HtmlUnitDriver;/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlDriverTest{publicstaticvoid main(String[] s){//目标网页String url ="http://www.yshjava.cn";HtmlUnitDriver driver =newHtmlUnitDriver();try{//禁用JS脚本功能
driver.setJavascriptEnabled(false);//打开目标网页
driver.get(url);//获取当前网页源码String html = driver.getPageSource();//打印网页源码System.out.println(html);}catch(Exception e){//打印堆栈信息
e.printStackTrace();}finally{try{//关闭并退出
driver.close();
driver.quit();}catch(Exception e){}}}}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;import org.watij.webspec.dsl.WebSpec;/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/publicclassWebspecTest{publicstaticvoid main(String[] s){//目标网页String url ="http://www.yshjava.cn";//实例化浏览器对象WebSpec spec =newWebSpec().mozilla();//隐藏浏览器窗体
spec.hide();//打开目标页面
spec.open(url);//打印网页源码System.out.println(spec.source());//关闭所有窗口
spec.closeAll();}} 查看全部
c爬虫抓取网页数据(网页获取和解析速度和性能的应用场景详解!
)
(4)支持代理
(5)支持自动cookie管理等。
Java爬虫开发是应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;import org.apache.http.client.HttpClient;import org.apache.http.client.ResponseHandler;import org.apache.http.client.methods.HttpGet;import org.apache.http.impl.client.BasicResponseHandler;import org.apache.http.impl.client.DefaultHttpClient;/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHttpClientTest{publicstaticvoid main(String[] args)throwsException{//目标页面String url ="http://www.yshjava.cn";//创建一个默认的HttpClientHttpClient httpclient =newDefaultHttpClient();try{//以get方式请求网页http://www.yshjava.cnHttpGet httpget =newHttpGet(url);//打印请求地址System.out.println("executing request "+ httpget.getURI());//创建响应处理器处理服务器响应内容ResponseHandlerresponseHandler=newBasicResponseHandler();//执行请求并获取结果String responseBody = httpclient.execute(httpget, responseHandler);System.out.println("----------------------------------------");System.out.println(responseBody);System.out.println("----------------------------------------");}finally{//关闭连接管理器
httpclient.getConnectionManager().shutdown();}}}
汤
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
示例代码如下:
package cn.ysh.studio.crawler.jsoup;import java.io.IOException;import org.jsoup.Jsoup;/**
* 基于Jsoup抓取网页内容
* @author www.yshjava.cn
*/publicclassJsoupTest{publicstaticvoid main(String[] args)throwsIOException{//目标页面String url ="http://www.yshjava.cn";//使用Jsoup连接目标页面,并执行请求,获取服务器响应内容String html =Jsoup.connect(url).execute().body();//打印页面内容System.out.println(html);}}
html单元
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取和解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;import com.gargoylesoftware.htmlunit.BrowserVersion;import com.gargoylesoftware.htmlunit.Page;import com.gargoylesoftware.htmlunit.WebClient;/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlUnitSpider{publicstaticvoid main(String[] s)throwsException{//目标网页String url ="http://www.yshjava.cn";//模拟特定浏览器FIREFOX_3WebClient spider =newWebClient(BrowserVersion.FIREFOX_3);//获取目标网页Page page = spider.getPage(url);//打印网页内容System.out.println(page.getWebResponse().getContentAsString());//关闭所有窗口
spider.closeAllWindows();}}
瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
示例代码如下:
package cn.ysh.studio.crawler.ie;import watij.runtime.ie.IE;/**
* 基于Watij抓取网页内容,仅限Windows平台
*
* @author www.yshjava.cn
*/publicclassWatijTest{publicstaticvoid main(String[] s){//目标页面String url ="http://www.yshjava.cn";//实例化IE浏览器对象
IE ie =new IE();try{//启动浏览器
ie.start();//转到目标网页
ie.goTo(url);//等待网页加载就绪
ie.waitUntilReady();//打印页面内容System.out.println(ie.html());}catch(Exception e){
e.printStackTrace();}finally{try{//关闭IE浏览器
ie.close();}catch(Exception e){}}}}
硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;import org.openqa.selenium.htmlunit.HtmlUnitDriver;/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlDriverTest{publicstaticvoid main(String[] s){//目标网页String url ="http://www.yshjava.cn";HtmlUnitDriver driver =newHtmlUnitDriver();try{//禁用JS脚本功能
driver.setJavascriptEnabled(false);//打开目标网页
driver.get(url);//获取当前网页源码String html = driver.getPageSource();//打印网页源码System.out.println(html);}catch(Exception e){//打印堆栈信息
e.printStackTrace();}finally{try{//关闭并退出
driver.close();
driver.quit();}catch(Exception e){}}}}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;import org.watij.webspec.dsl.WebSpec;/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/publicclassWebspecTest{publicstaticvoid main(String[] s){//目标网页String url ="http://www.yshjava.cn";//实例化浏览器对象WebSpec spec =newWebSpec().mozilla();//隐藏浏览器窗体
spec.hide();//打开目标页面
spec.open(url);//打印网页源码System.out.println(spec.source());//关闭所有窗口
spec.closeAll();}}
c爬虫抓取网页数据(c爬虫抓取网页数据的方法有很多种,基于javascript加载网页获取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-22 13:11
c爬虫抓取网页数据的方法有很多种,最常见的是selenium。我曾经给朋友发过三种selenium抓取网页数据的方法。分别是:第一种:利用webdriver自动抓取cookies获取数据第二种:基于javascript加载网页获取数据第三种:javascript抓取并存入文件获取数据当我是一名程序员,我爬虫基本都是利用前两种,但如果只是想爬取网页的基本数据,可以使用cookies来抓取。
cookies类似一个临时地址。利用cookies可以直接自动获取网页上内容。python爬虫总结——cookies自动抓取这里贴一些爬虫基本示例,爬取电影id、标题、评分,以及每一场演唱会的演唱视频数据,以下所示cookies是一个加密数据,需要设置对应user-agent作为浏览器才能获取。
selenium是我爬虫的第一个工具,相比于selenium自己写程序自动爬取,它有好几个基础驱动模块,首先的是seleniumie驱动,后面有phantomjs,maplejs,webdriver等等,但还是不能满足需求,seleniumie驱动的问题是使用起来比较困难,不利于新手,我是先用maplejs,又加了一个mindnode驱动,之后maplejs中标有三种cookie,weibo,facebook,whisperer来封装cookie,对比其他cookie的缺点来到facebook来进行封装,最后用webdriver驱动封装了一下html5的标签,来实现代码组合。
这样我的代码变的比较优雅,避免了继承的使用的麻烦,而且爬取的数据是以网页元素为单位获取的,无需嵌套其他网页。有问题可以在群里讨论。 查看全部
c爬虫抓取网页数据(c爬虫抓取网页数据的方法有很多种,基于javascript加载网页获取数据)
c爬虫抓取网页数据的方法有很多种,最常见的是selenium。我曾经给朋友发过三种selenium抓取网页数据的方法。分别是:第一种:利用webdriver自动抓取cookies获取数据第二种:基于javascript加载网页获取数据第三种:javascript抓取并存入文件获取数据当我是一名程序员,我爬虫基本都是利用前两种,但如果只是想爬取网页的基本数据,可以使用cookies来抓取。
cookies类似一个临时地址。利用cookies可以直接自动获取网页上内容。python爬虫总结——cookies自动抓取这里贴一些爬虫基本示例,爬取电影id、标题、评分,以及每一场演唱会的演唱视频数据,以下所示cookies是一个加密数据,需要设置对应user-agent作为浏览器才能获取。
selenium是我爬虫的第一个工具,相比于selenium自己写程序自动爬取,它有好几个基础驱动模块,首先的是seleniumie驱动,后面有phantomjs,maplejs,webdriver等等,但还是不能满足需求,seleniumie驱动的问题是使用起来比较困难,不利于新手,我是先用maplejs,又加了一个mindnode驱动,之后maplejs中标有三种cookie,weibo,facebook,whisperer来封装cookie,对比其他cookie的缺点来到facebook来进行封装,最后用webdriver驱动封装了一下html5的标签,来实现代码组合。
这样我的代码变的比较优雅,避免了继承的使用的麻烦,而且爬取的数据是以网页元素为单位获取的,无需嵌套其他网页。有问题可以在群里讨论。
c爬虫抓取网页数据(关于item修改三项内容的一些问题教程引入刚刚写好的item)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-03-21 23:43
1.创建项目
打开终端进入(建议放到合适的路径,默认是C盘)
2.修改设置
修改三项,第一项是不遵循robot协议,第二项是下载gap,因为下面的程序需要下载多个页面,所以需要给gap(不给也可以,但是很容易待检测),第三个是请求头,添加一个User-Agent,第四个是开一个管道ROBOTSTXT_OBEY=False
DOWNLOAD_DELAY=1DEFAULT_REQUEST_HEADERS={'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-语言':'en','User-Agent':'Mozilla/5.0(WindowsNT6.2;WOW64)AppleWebKit/537.36(KHTML,likeGecko )Chrome/27.0.1453.94Safari/537.36'}ITEM_PIPELINES={'TXmovies.pipelines.TxmoviesPipeline':300,}
3.确认要提取的数据,
item item 定义要提取的内容(定义数据结构)。比如我提取的内容是电影名和电影描述,所以我创建了两个变量。Field方法的实际做法是创建一个字典,给字典添加一个新的值,暂时不赋值,等数据提取出来再赋值。下面的item结构可以表示为:{'name':'','description':''}。#-*-coding:utf-8-*-#Defineherethemodelsforyourscrapeditems##Seedocumentationin:#(scrapy.Item):#definethefieldsforyouritemherelike:#name=scrapy.Field()name=scrapy.Field()description=scrapy. 场地()
4.写一个爬虫
我们要写的部分是parse方法的内容,重点是xpath怎么写,XPATH教程介绍了刚才写的item,刚才说item中创建的变量是字典的key值,可以直接赋值。赋值后,交给流水线处理。简单说一下这段代码的思路,首先腾讯视频的url是给我们注意偏移量的,第一页的偏移量为0,第二页的偏移量为30,列推送按顺序。在程序中,此项用于控制第一页的抓取,但也需要给出一个范围。不能无限,否则会报错。你可以去看看腾讯总共有多少个视频页,也可以写一个异常捕获机制。捕获到请求错误时退出。我这里只是演示,所以我只给了120,也就是4页。收益计划中有两个收益。我更喜欢称之为中断。当然,中断只发生在 CPU 中。它的功能是转移控制权。在这个程序中,我们封装了item数据后,调用yield来传递控制权。把它交给管道,管道处理完后,返回并返回程序。这是对第一次收益率的解释。第二个产量有点复杂。本程序使用回调机制,即回调。回调的对象是 parse,也就是当前方法。通过不断的回调,程序会陷入循环。如果程序不加任何条件,就会陷入死循环。如果我在这个程序中删除 if ,这将是一个无限循环。yieldcrapy.Request(url=url,callback=self.parse)xpath 另外需要注意的是如何提取xpathl中的数据,我们有四种写法,第一种获取selector选择器,也就是original data ,其中有一些我们不使用的东西。第二个 extract() 将选择器序列号转换为字符串。第三个和第四个一样,获取字符串中的第一个数据,也就是我们想要的数据。将选择器序列号转换为字符串。第三个和第四个一样,获取字符串中的第一个数据,也就是我们想要的数据。将选择器序列号转换为字符串。第三个和第四个一样,获取字符串中的第一个数据,也就是我们想要的数据。
items['name']=i.xpath('./a/@title')[0]items['name']=i.xpath('./a/@title').extract()items[' name']=i.xpath('./a/@title').extract_first()items['name']=i.xpath('./a/@title').get()
#-*-coding:utf-8-*-importscrapyfrom..itemsimportTxmoviesItemclassTxmsSpider(scrapy.Spider):name='txms'allowed_domains=['']start_urls=['#39;]offset=0defparse(self,response): items=TxmoviesItem()lists=response.xpath('//div[@class="list_item"]')foriinlists:items['name']=i.xpath('./a/@title').get( )items['description']=i.xpath('./div/div/@title').get()yielditemsifself.offset 5. 到管道输出管道
提取的数据可以进行处理,例如存储在数据库中。我们只在这里输出。#-*-coding:utf-8-*-#Defineyouritempipelinehere##Don'tforgettoaddyourpipelinetotheITEM_PIPELINESsetting#See:
classTxmoviesPipeline(object):defprocess_item(self,item,spider):print(item)returnitem
6.run,执行项目
从scrapy导入命令行
cmdline.execute('scrapycrawltxms'.split())
7.测试结果白管输出结果
,红色调试信息8.流程梳理新建项目-》进入项目-》新建爬虫文件-》指定要抓取的内容,写入item-》编写爬虫程序,爬取数据-》交给管道处理数据-“调整全局配置设置-”执行爬虫程序,可以通过终端完成,也可以在程序中完成
8.处理中
新建项目-》进入项目-》新建爬虫文件-》明确要抓取的内容,编写item-》编写爬虫程序,爬取数据-》交给管道处理数据-》调整全局配置设置-》执行爬虫程序, 可以通过终端或者在程序中编写运行程序
9.加速:
多线程爬取如果实现了上面的实验,不难发现爬取速度很慢。根本原因是它是按顺序执行的。从结果可以看出,上一页的内容总是被删除。输出,然后输出以下内容。它不适合处理大量数据。一个好的方法是使用多线程方法。这里的多线程是基于方法的多线程,而不是通过创建一个 Thread 对象。请求被传递给调度程序。我们通过重写start_requests方法来实现我们的想法(这个方法的源码在__init__.py下,有兴趣的可以看看)
#-*-coding:utf-8-*-importscrapyfrom..itemsim
portTxmoviesItemclassTxmsSpider(scrapy.Spider):name='txms'allowed_domains=['']url='{}&pagesize=30'offset=0defstart_requests(self):
范围(0,121,30):
url=self.url.format(i)yieldscrapy.Request(url=url,callback=self.parse)defparse(self,response):items=TxmoviesItem()lists=response.xpath('//div[@class= "list_item"]')foriinlists:
items['name']=i.xpath('./a/@title').get() items['description']=i.xpath('./div/div/@title').get()产量项目 查看全部
c爬虫抓取网页数据(关于item修改三项内容的一些问题教程引入刚刚写好的item)
1.创建项目
打开终端进入(建议放到合适的路径,默认是C盘)
2.修改设置
修改三项,第一项是不遵循robot协议,第二项是下载gap,因为下面的程序需要下载多个页面,所以需要给gap(不给也可以,但是很容易待检测),第三个是请求头,添加一个User-Agent,第四个是开一个管道ROBOTSTXT_OBEY=False
DOWNLOAD_DELAY=1DEFAULT_REQUEST_HEADERS={'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-语言':'en','User-Agent':'Mozilla/5.0(WindowsNT6.2;WOW64)AppleWebKit/537.36(KHTML,likeGecko )Chrome/27.0.1453.94Safari/537.36'}ITEM_PIPELINES={'TXmovies.pipelines.TxmoviesPipeline':300,}
3.确认要提取的数据,
item item 定义要提取的内容(定义数据结构)。比如我提取的内容是电影名和电影描述,所以我创建了两个变量。Field方法的实际做法是创建一个字典,给字典添加一个新的值,暂时不赋值,等数据提取出来再赋值。下面的item结构可以表示为:{'name':'','description':''}。#-*-coding:utf-8-*-#Defineherethemodelsforyourscrapeditems##Seedocumentationin:#(scrapy.Item):#definethefieldsforyouritemherelike:#name=scrapy.Field()name=scrapy.Field()description=scrapy. 场地()
4.写一个爬虫
我们要写的部分是parse方法的内容,重点是xpath怎么写,XPATH教程介绍了刚才写的item,刚才说item中创建的变量是字典的key值,可以直接赋值。赋值后,交给流水线处理。简单说一下这段代码的思路,首先腾讯视频的url是给我们注意偏移量的,第一页的偏移量为0,第二页的偏移量为30,列推送按顺序。在程序中,此项用于控制第一页的抓取,但也需要给出一个范围。不能无限,否则会报错。你可以去看看腾讯总共有多少个视频页,也可以写一个异常捕获机制。捕获到请求错误时退出。我这里只是演示,所以我只给了120,也就是4页。收益计划中有两个收益。我更喜欢称之为中断。当然,中断只发生在 CPU 中。它的功能是转移控制权。在这个程序中,我们封装了item数据后,调用yield来传递控制权。把它交给管道,管道处理完后,返回并返回程序。这是对第一次收益率的解释。第二个产量有点复杂。本程序使用回调机制,即回调。回调的对象是 parse,也就是当前方法。通过不断的回调,程序会陷入循环。如果程序不加任何条件,就会陷入死循环。如果我在这个程序中删除 if ,这将是一个无限循环。yieldcrapy.Request(url=url,callback=self.parse)xpath 另外需要注意的是如何提取xpathl中的数据,我们有四种写法,第一种获取selector选择器,也就是original data ,其中有一些我们不使用的东西。第二个 extract() 将选择器序列号转换为字符串。第三个和第四个一样,获取字符串中的第一个数据,也就是我们想要的数据。将选择器序列号转换为字符串。第三个和第四个一样,获取字符串中的第一个数据,也就是我们想要的数据。将选择器序列号转换为字符串。第三个和第四个一样,获取字符串中的第一个数据,也就是我们想要的数据。
items['name']=i.xpath('./a/@title')[0]items['name']=i.xpath('./a/@title').extract()items[' name']=i.xpath('./a/@title').extract_first()items['name']=i.xpath('./a/@title').get()
#-*-coding:utf-8-*-importscrapyfrom..itemsimportTxmoviesItemclassTxmsSpider(scrapy.Spider):name='txms'allowed_domains=['']start_urls=['#39;]offset=0defparse(self,response): items=TxmoviesItem()lists=response.xpath('//div[@class="list_item"]')foriinlists:items['name']=i.xpath('./a/@title').get( )items['description']=i.xpath('./div/div/@title').get()yielditemsifself.offset 5. 到管道输出管道
提取的数据可以进行处理,例如存储在数据库中。我们只在这里输出。#-*-coding:utf-8-*-#Defineyouritempipelinehere##Don'tforgettoaddyourpipelinetotheITEM_PIPELINESsetting#See:
classTxmoviesPipeline(object):defprocess_item(self,item,spider):print(item)returnitem
6.run,执行项目
从scrapy导入命令行
cmdline.execute('scrapycrawltxms'.split())
7.测试结果白管输出结果
,红色调试信息8.流程梳理新建项目-》进入项目-》新建爬虫文件-》指定要抓取的内容,写入item-》编写爬虫程序,爬取数据-》交给管道处理数据-“调整全局配置设置-”执行爬虫程序,可以通过终端完成,也可以在程序中完成
8.处理中
新建项目-》进入项目-》新建爬虫文件-》明确要抓取的内容,编写item-》编写爬虫程序,爬取数据-》交给管道处理数据-》调整全局配置设置-》执行爬虫程序, 可以通过终端或者在程序中编写运行程序
9.加速:
多线程爬取如果实现了上面的实验,不难发现爬取速度很慢。根本原因是它是按顺序执行的。从结果可以看出,上一页的内容总是被删除。输出,然后输出以下内容。它不适合处理大量数据。一个好的方法是使用多线程方法。这里的多线程是基于方法的多线程,而不是通过创建一个 Thread 对象。请求被传递给调度程序。我们通过重写start_requests方法来实现我们的想法(这个方法的源码在__init__.py下,有兴趣的可以看看)
#-*-coding:utf-8-*-importscrapyfrom..itemsim
portTxmoviesItemclassTxmsSpider(scrapy.Spider):name='txms'allowed_domains=['']url='{}&pagesize=30'offset=0defstart_requests(self):
范围(0,121,30):
url=self.url.format(i)yieldscrapy.Request(url=url,callback=self.parse)defparse(self,response):items=TxmoviesItem()lists=response.xpath('//div[@class= "list_item"]')foriinlists:
items['name']=i.xpath('./a/@title').get() items['description']=i.xpath('./div/div/@title').get()产量项目
c爬虫抓取网页数据(互联网上的网络爬虫是怎么做的?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-21 19:38
1. 什么是爬虫
当今互联网上存储着大量信息。
作为普通网民,我们经常使用浏览器访问互联网上的内容。但是如果你想批量下载散落在网上的某方面的信息(比如某网站的所有图片,某某新闻网站的所有新闻,或者所有的收视率豆瓣上的电影),手动使用浏览器打开网站一一搜索太费时费力。
人工统计太费时费力
因此,编写程序来自动抓取 Internet 以获取有关我们想要的特定内容的信息变得更加重要。
网络爬虫是根据一定规则自动从万维网上抓取信息的程序或脚本。
通过程序,我们模拟浏览器向服务器发送请求,获取信息,分析信息,存储我们想要的内容。
百度/google搜索网站是利用爬虫定期搜索互联网上的链接并更新其服务器,以便我们通过搜索引擎搜索到我们想要的信息。
2. 网页结构
访问网页不仅仅是输入地址并查看它。
在浏览器中按“F12”,或右键单击网页并选择“检查”。你可以看到页面后面的代码。
以谷歌的Chrome浏览器为例,在任意一个网站中,我们按F12,就会出现一个浏览器检查窗口。默认的 Elements 窗口是当前界面的 HTML 代码。
Web 和元素界面
Sources 界面将显示浏览器从每个服务器下载的所有文件。
来源界面
在网络界面,在“记录网络日志”状态下(按Ctrl+E切换该状态),可以依次记录浏览器在每个时间段接收到的文件和文件相关数据。
网络接口
我们这里要实现的抓取具体信息的爬虫,需要我们去对应的网站去分析它的网页结构。根据网页的结构,我们可以通过编写相应的程序得到我们想要的信息。
3.python代码实现
我们将以豆瓣上的《流浪地球》影评为例,一步步讲解python爬虫的实现方法(使用python3).
以下代码可在 github 上下载。
3.1 基本介绍
我们将在本节中使用的 python 库是:
另外,本节我们没有讲,但是使用爬虫时可能用到的库通常包括:
对于上面的python库,bs4可以通过“pip install Beautifulsoup4”命令安装,其他库可以直接通过“pip install library noun”安装。
我们首先创建一个新的 jupyter 文件并导入必要的 python 库。
导入必要的python库
3.2 请求的使用
使用请求
上面的代码允许我们以编程方式访问(百度)网页。
其中,“requests.get(网页地址)”是以get的方式访问网页。
访问网址有两种类型:获取和发布。get和post的区别可以看下图(来自w3school)。两者的区别很容易理解,无需深究。
关于get、post和使用request传参,我们会在以后的爬虫进阶教程中一一介绍。
我们已经使用“response = requests.get(url)”将获取的信息传递给“response”。但是如果我们输出response,得到的不是网站的code,而是response状态码。
响应状态码
响应状态码代表我们之前请求请求的结果。常见的是200,代表成功;403,无访问权限;404,文件不存在;502,服务器错误。
想看看我们之前用“requests.get(url)”得到的网页内容。我们需要先执行“response.enconding = 'utf-8'”。这一步是将网页内容编码为utf-8,否则我们将无法在网页中看到中文。
将生成的内容编码为 utf-8
输入response.text后,我们就可以看到网页的代码了。
3.3 BeautifulSoup 的使用
在使用 BeautifulSoup 之前,建议读者对 html 有一定的了解。如果没有,那很好。
HTML 是一种标记语言,具有很强的结构要求。
html代码示例
我们使用 BeautifulSoup 来分析 HTML 页面的结构来选择我们想要的内容。
我们可以使用 BeautifulSoup(response.text, "lxml") 来自动分析我们之前得到的网页代码。分析结果存储在等号左侧的变量汤中。
html内容信息分析
BeautifulSoup 有很多使用方法。
例如 .find("tag name") 返回找到的第一个标签的内容。
.find("标记名")
值得注意的是,我们找到的第一个 div 标签里面也有 div 标签。但是 BeautifulSoup 不会注意到, .find("div") 只会返回找到的第一个 div 标签,以及该标签内的所有内容。
.find_all("tag name") 返回找到的所有标签。
.find_all("标签名称")
.find_all("tag name", class_="class name", id="id name") 可以找到指定的类别并指定id标签。(注意使用 class_ 而不是 class)
.find_all("标签名", class_="类名", id="id名")
此外,我们还可以继续对.find()和.find_all()的结果进行.find()、.find_all()查询。
3.4 json的使用
除了html格式文件,我们经常需要爬取一些json格式文件。JSON 是一种轻量级的数据交换格式。
html和json格式文件的区别如下。(严格来说左边应该是一个XML格式的文件,但也可以认为是一般的HTML)
html和json格式文件的区别
(图片来自网络)
所以,有时,我们会解析 json 格式的数据。
使用 text = json.loads(字符串格式的json数据)
您可以将字符串格式的 json 数据转换为 python 字典格式。
3.5 组合使用
我们之前提到过:“根据网页的结构,我们可以通过编写相应的程序得到我们想要的信息。”
现在,我们进入豆瓣影评《流浪地球》的短评界面。
()
《流浪地球》短评界面
我们按“F12”打开检查界面。如果你使用的是Chrome浏览器,可以点击下图的小箭头或者Ctrl+Shift+C。这时,当鼠标移动到页面上的某个位置时,浏览器会自动显示该位置对应的代码位置。
Ctrl+Shift+C后可以查看页面中每个元素的位置
具体效果如下:
结合我们之前讲过的requests和Beautifulsoup的对应知识。读者可以尝试写一个爬虫来获取当前网页的所有短评信息。
作者这里爬的是
“”,是一个json文件,所以额外使用了python的json库。
代码显示如下。完整代码可在 github 上找到。建议读者先尝试从零开始写一个爬虫,遇到问题先百度/谷歌,最后参考这个完整的爬虫代码
完整的爬虫代码
完成代码下载:
3.6 最终结果
最后,为了让最终的结果更加美观,作者在这里使用了pandas的DataFrame。
使用熊猫的数据框
爬取的数据结果如下
抓取的数据
3.7 扩展
以上内容只是一个基本的python爬虫。
如果读者细心,他们会发现不登录豆瓣就无法访问。”
"
没有权限
这里的url链接中的start=220表示我们不登录就无法查看第220条评论之后的内容。
在以后的爬虫进阶教程中,我们会介绍如何使用爬虫进行登录、保存cookies等操作。
另外,有些网站可能会使用js进行网站动态渲染、代码加密等,仅仅爬取html和json文件是不够的。同时,我们也可以使用多进程来加速爬虫...
敬请期待以后的爬虫进阶教程。
其他文章
(点击跳转)
长
根据
关闭
笔记
解锁更多精彩内容
跟着一起做一个有灵魂的人 查看全部
c爬虫抓取网页数据(互联网上的网络爬虫是怎么做的?(一))
1. 什么是爬虫
当今互联网上存储着大量信息。
作为普通网民,我们经常使用浏览器访问互联网上的内容。但是如果你想批量下载散落在网上的某方面的信息(比如某网站的所有图片,某某新闻网站的所有新闻,或者所有的收视率豆瓣上的电影),手动使用浏览器打开网站一一搜索太费时费力。
人工统计太费时费力
因此,编写程序来自动抓取 Internet 以获取有关我们想要的特定内容的信息变得更加重要。
网络爬虫是根据一定规则自动从万维网上抓取信息的程序或脚本。
通过程序,我们模拟浏览器向服务器发送请求,获取信息,分析信息,存储我们想要的内容。
百度/google搜索网站是利用爬虫定期搜索互联网上的链接并更新其服务器,以便我们通过搜索引擎搜索到我们想要的信息。
2. 网页结构
访问网页不仅仅是输入地址并查看它。
在浏览器中按“F12”,或右键单击网页并选择“检查”。你可以看到页面后面的代码。
以谷歌的Chrome浏览器为例,在任意一个网站中,我们按F12,就会出现一个浏览器检查窗口。默认的 Elements 窗口是当前界面的 HTML 代码。
Web 和元素界面
Sources 界面将显示浏览器从每个服务器下载的所有文件。
来源界面
在网络界面,在“记录网络日志”状态下(按Ctrl+E切换该状态),可以依次记录浏览器在每个时间段接收到的文件和文件相关数据。
网络接口
我们这里要实现的抓取具体信息的爬虫,需要我们去对应的网站去分析它的网页结构。根据网页的结构,我们可以通过编写相应的程序得到我们想要的信息。
3.python代码实现
我们将以豆瓣上的《流浪地球》影评为例,一步步讲解python爬虫的实现方法(使用python3).
以下代码可在 github 上下载。
3.1 基本介绍
我们将在本节中使用的 python 库是:
另外,本节我们没有讲,但是使用爬虫时可能用到的库通常包括:
对于上面的python库,bs4可以通过“pip install Beautifulsoup4”命令安装,其他库可以直接通过“pip install library noun”安装。
我们首先创建一个新的 jupyter 文件并导入必要的 python 库。

导入必要的python库
3.2 请求的使用

使用请求
上面的代码允许我们以编程方式访问(百度)网页。
其中,“requests.get(网页地址)”是以get的方式访问网页。
访问网址有两种类型:获取和发布。get和post的区别可以看下图(来自w3school)。两者的区别很容易理解,无需深究。

关于get、post和使用request传参,我们会在以后的爬虫进阶教程中一一介绍。
我们已经使用“response = requests.get(url)”将获取的信息传递给“response”。但是如果我们输出response,得到的不是网站的code,而是response状态码。

响应状态码
响应状态码代表我们之前请求请求的结果。常见的是200,代表成功;403,无访问权限;404,文件不存在;502,服务器错误。
想看看我们之前用“requests.get(url)”得到的网页内容。我们需要先执行“response.enconding = 'utf-8'”。这一步是将网页内容编码为utf-8,否则我们将无法在网页中看到中文。

将生成的内容编码为 utf-8
输入response.text后,我们就可以看到网页的代码了。

3.3 BeautifulSoup 的使用
在使用 BeautifulSoup 之前,建议读者对 html 有一定的了解。如果没有,那很好。
HTML 是一种标记语言,具有很强的结构要求。
html代码示例
我们使用 BeautifulSoup 来分析 HTML 页面的结构来选择我们想要的内容。
我们可以使用 BeautifulSoup(response.text, "lxml") 来自动分析我们之前得到的网页代码。分析结果存储在等号左侧的变量汤中。

html内容信息分析
BeautifulSoup 有很多使用方法。
例如 .find("tag name") 返回找到的第一个标签的内容。
.find("标记名")
值得注意的是,我们找到的第一个 div 标签里面也有 div 标签。但是 BeautifulSoup 不会注意到, .find("div") 只会返回找到的第一个 div 标签,以及该标签内的所有内容。
.find_all("tag name") 返回找到的所有标签。

.find_all("标签名称")
.find_all("tag name", class_="class name", id="id name") 可以找到指定的类别并指定id标签。(注意使用 class_ 而不是 class)
.find_all("标签名", class_="类名", id="id名")
此外,我们还可以继续对.find()和.find_all()的结果进行.find()、.find_all()查询。
3.4 json的使用
除了html格式文件,我们经常需要爬取一些json格式文件。JSON 是一种轻量级的数据交换格式。
html和json格式文件的区别如下。(严格来说左边应该是一个XML格式的文件,但也可以认为是一般的HTML)
html和json格式文件的区别
(图片来自网络)
所以,有时,我们会解析 json 格式的数据。
使用 text = json.loads(字符串格式的json数据)
您可以将字符串格式的 json 数据转换为 python 字典格式。
3.5 组合使用
我们之前提到过:“根据网页的结构,我们可以通过编写相应的程序得到我们想要的信息。”
现在,我们进入豆瓣影评《流浪地球》的短评界面。
()
《流浪地球》短评界面
我们按“F12”打开检查界面。如果你使用的是Chrome浏览器,可以点击下图的小箭头或者Ctrl+Shift+C。这时,当鼠标移动到页面上的某个位置时,浏览器会自动显示该位置对应的代码位置。

Ctrl+Shift+C后可以查看页面中每个元素的位置
具体效果如下:
结合我们之前讲过的requests和Beautifulsoup的对应知识。读者可以尝试写一个爬虫来获取当前网页的所有短评信息。
作者这里爬的是
“”,是一个json文件,所以额外使用了python的json库。
代码显示如下。完整代码可在 github 上找到。建议读者先尝试从零开始写一个爬虫,遇到问题先百度/谷歌,最后参考这个完整的爬虫代码
完整的爬虫代码
完成代码下载:
3.6 最终结果
最后,为了让最终的结果更加美观,作者在这里使用了pandas的DataFrame。

使用熊猫的数据框
爬取的数据结果如下

抓取的数据
3.7 扩展
以上内容只是一个基本的python爬虫。
如果读者细心,他们会发现不登录豆瓣就无法访问。”
"
没有权限
这里的url链接中的start=220表示我们不登录就无法查看第220条评论之后的内容。
在以后的爬虫进阶教程中,我们会介绍如何使用爬虫进行登录、保存cookies等操作。
另外,有些网站可能会使用js进行网站动态渲染、代码加密等,仅仅爬取html和json文件是不够的。同时,我们也可以使用多进程来加速爬虫...
敬请期待以后的爬虫进阶教程。
其他文章
(点击跳转)




长
根据
关闭
笔记
解锁更多精彩内容
跟着一起做一个有灵魂的人
c爬虫抓取网页数据(聚焦爬虫工作原理及关键技术的工作流程和关键技术概述)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-03-21 12:04
1 重点介绍爬虫的工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它从互联网上为搜索引擎下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会按照一定的搜索策略从队列中选择下一个要爬取的网页URL,重复上述过程,直到达到系统的一定条件并停止。存储、执行一定的分析、过滤、建立索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可以为后续的爬取过程提供反馈和指导。
与通用网络爬虫相比,聚焦爬虫仍需解决三个主要问题:
(1) 抓取目标的描述或定义;
(2)网页或数据分析过滤;
(3) URL 的搜索策略。
爬取目标的描述和定义是决定如何制定网页分析算法和URL搜索策略的基础。网页分析算法和候选URL排序算法是确定搜索引擎提供的服务形式和爬虫爬取行为的关键。这两部分的算法密切相关。
2 抓取目标描述
现有的聚焦爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模式和基于领域概念。
爬虫根据目标网页的特性抓取、存储和索引的对象一般是网站或网页。根据种子样品的获取方法,可分为:
(1) 预先给定的初始抓取种子样本;
(2)预先给定的网页类别和类别对应的种子样本,如Yahoo!类别结构等;
(3)由用户行为决定的抓取目标示例,分为:
a) 在用户浏览期间显示带注释的抓取样本;
b) 通过用户日志挖掘获取访问模式和相关样本。
其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
现有的聚焦爬虫对爬取目标的描述或定义可以分为三种类型:基于目标网页的特征、基于目标数据模式和基于领域概念。
爬虫根据目标网页的特性抓取、存储和索引的对象一般是网站或网页。具体方法可以分为:(1)Pre-given初始抓取种子样本;(2)预先给定网页类别和类别对应的种子样本),如Yahoo!分类结构,等;(3)由用户行为决定的爬取目标样本。其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
基于目标数据模式的爬虫针对网页上的数据,抓取到的数据一般符合一定的模式,也可以转换或映射到目标数据模式。
另一种描述方式是建立目标域的本体或字典,用于从语义角度分析某个主题中不同特征的重要性。
3 网络搜索策略
网页抓取策略可以分为三类:深度优先、广度优先和最佳优先。深度优先在很多情况下会导致爬虫被困的问题。目前,广度优先和最佳优先方法很常见。
3.1 广度优先搜索策略
广度优先搜索策略是指在爬取过程中,完成当前一级搜索后,进行下一级搜索。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索方式。也有许多研究将广度优先搜索策略应用于聚焦爬虫。其基本思想是距初始 URL 一定链接距离内的网页具有较高的主题相关性概率。另一种方法是将广度优先搜索与网页过滤技术相结合,首先使用广度优先策略抓取网页,然后过滤掉不相关的页面。这些方法的缺点是随着爬取的网页数量的增加,会下载和过滤大量不相关的网页,算法的效率会变低。
3.2 最佳优先搜索策略
最佳优先级搜索策略根据一定的网页分析算法预测候选URL与目标网页的相似度,或与主题的相关度,选择评价最好的一个或几个URL进行爬取。它只访问页面分析算法预测为“有用”的页面。一个问题是爬虫爬取路径上的许多相关网页可能会被忽略,因为最佳优先策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,从而跳出局部最优点。在第 4 节中,将结合网页分析算法进行详细讨论。研究表明,这样的闭环调整可以将不相关页面的数量减少 30% 到 90%。
4 网络分析算法
网页分析算法可以分为三种类型:基于网络拓扑、基于网页内容和基于用户访问行为。
4.1基于网络拓扑的分析算法
基于网页之间的链接,通过已知的网页或数据,一种算法来评估与其有直接或间接链接关系的对象(可以是网页或网站等)。进一步分为三种:网页粒度、网站粒度和网页块粒度。
4.1.1 网页粒度分析算法
PageRank 和 HITS 算法是最常见的链接分析算法。两者都是通过网页间链接度的递归归一化计算得到每个网页的重要性。 PageRank算法虽然考虑了用户访问行为的随机性和Sink网页的存在性,但忽略了大部分用户访问的目的性,即网页和查询主题链接的相关性。针对这个问题,HITS算法提出了两个关键概念:权威网页(authority)和中心网页(hub)。
基于链接爬取的问题是相关页面的主题组之间存在隧道现象,即爬取路径上很多偏离主题的页面也指向目标页面,局部评价策略打断了当前路径上的爬行行为。 参考文献[21]提出了一种基于反向链接(BackLink)的层次上下文模型(Context Model),用于描述指向一定物理跳半径内的目标网页的网页拓扑图的中心Layer 0作为目标网页。网页根据指向目标网页的物理跳数进行层次划分,外层网页到内层网页的链接称为反向链接。
4.1.2 网站粒度分析算法
网站粒度的资源发现和管理策略也比网页粒度的更简单有效。 网站粒度爬取的关键是站点的划分和SiteRank的计算。 SiteRank的计算方法与PageRank类似,但需要对网站之间的链接进行一定程度的抽象,并在一定模型下计算链接的权重。
网站划分分为两种:按域名划分和按IP地址划分。参考文献[18]讨论了分布式情况下,通过划分同一域名下不同主机和服务器的IP地址,构建站点地图,并采用类似于PageRank的方法评估SiteRank。同时,根据每个站点不同文件的分布情况,构建文档图,结合SiteRank分布式计算得到DocRank。参考文献[18]证明,使用分布式SiteRank计算不仅大大降低了单个站点的算法成本,而且克服了单个站点对全网覆盖范围有限的缺点。一个额外的好处是,常见的 PageRank 欺诈很难欺骗 SiteRank。
4.1.3 Web块粒度分析算法
一个页面通常收录多个指向其他页面的链接,而这些链接中只有一些指向与主题相关的网页,或者根据网页的链接锚文本指示高重要性。但是在PageRank和HITS算法中,这些链接是没有区分的,所以往往会给网页分析带来广告等噪声链接的干扰。块级链接分析算法的基本思想是通过VIPS网页切分算法将网页分成不同的页面块,然后为这些网页块创建page-to-block和block-block。 to-page的链接矩阵分别表示为Z和X。因此,page-to-page图上的page block level的PageRank为Wp=X×Z; 在块到块图上的 BlockRank 是 Wb=Z×X。 有人实现了块级PageRank和HITS算法,实验证明效率和准确率优于传统的对应算法。
4.2基于网页内容的网页分析算法
基于网页内容的分析算法是指利用网页内容的特征(文本、数据等资源)对网页进行评价。网页内容已经从基于超文本的内容演变为动态页面(或称为隐藏网页)数据,后者的数据量约为直接可见页面数据(PIW,Publicly Indexable Web)的400~500%。次。另一方面,多媒体数据、Web Service等各种形式的网络资源日益丰富。因此,基于网页内容的分析算法也从最初的相对简单的文本检索方法发展到综合应用包括网页数据提取、机器学习、数据挖掘、语义理解等多种方法。本节根据网页数据的不同形式,将基于网页内容的分析算法分为以下三类:第一类是针对以文本和超链接为主的非结构化或非常简单的网页;第二个是结构化网页。对于数据源(如RDBMS)动态生成的页面,不能直接批量访问数据;第三类数据介于第一类和第二类数据之间,结构更好,表明它遵循一定的模式或风格。并且可以直接访问。 查看全部
c爬虫抓取网页数据(聚焦爬虫工作原理及关键技术的工作流程和关键技术概述)
1 重点介绍爬虫的工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它从互联网上为搜索引擎下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会按照一定的搜索策略从队列中选择下一个要爬取的网页URL,重复上述过程,直到达到系统的一定条件并停止。存储、执行一定的分析、过滤、建立索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可以为后续的爬取过程提供反馈和指导。
与通用网络爬虫相比,聚焦爬虫仍需解决三个主要问题:
(1) 抓取目标的描述或定义;
(2)网页或数据分析过滤;
(3) URL 的搜索策略。
爬取目标的描述和定义是决定如何制定网页分析算法和URL搜索策略的基础。网页分析算法和候选URL排序算法是确定搜索引擎提供的服务形式和爬虫爬取行为的关键。这两部分的算法密切相关。
2 抓取目标描述
现有的聚焦爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模式和基于领域概念。
爬虫根据目标网页的特性抓取、存储和索引的对象一般是网站或网页。根据种子样品的获取方法,可分为:
(1) 预先给定的初始抓取种子样本;
(2)预先给定的网页类别和类别对应的种子样本,如Yahoo!类别结构等;
(3)由用户行为决定的抓取目标示例,分为:
a) 在用户浏览期间显示带注释的抓取样本;
b) 通过用户日志挖掘获取访问模式和相关样本。
其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
现有的聚焦爬虫对爬取目标的描述或定义可以分为三种类型:基于目标网页的特征、基于目标数据模式和基于领域概念。
爬虫根据目标网页的特性抓取、存储和索引的对象一般是网站或网页。具体方法可以分为:(1)Pre-given初始抓取种子样本;(2)预先给定网页类别和类别对应的种子样本),如Yahoo!分类结构,等;(3)由用户行为决定的爬取目标样本。其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
基于目标数据模式的爬虫针对网页上的数据,抓取到的数据一般符合一定的模式,也可以转换或映射到目标数据模式。
另一种描述方式是建立目标域的本体或字典,用于从语义角度分析某个主题中不同特征的重要性。
3 网络搜索策略
网页抓取策略可以分为三类:深度优先、广度优先和最佳优先。深度优先在很多情况下会导致爬虫被困的问题。目前,广度优先和最佳优先方法很常见。
3.1 广度优先搜索策略
广度优先搜索策略是指在爬取过程中,完成当前一级搜索后,进行下一级搜索。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索方式。也有许多研究将广度优先搜索策略应用于聚焦爬虫。其基本思想是距初始 URL 一定链接距离内的网页具有较高的主题相关性概率。另一种方法是将广度优先搜索与网页过滤技术相结合,首先使用广度优先策略抓取网页,然后过滤掉不相关的页面。这些方法的缺点是随着爬取的网页数量的增加,会下载和过滤大量不相关的网页,算法的效率会变低。
3.2 最佳优先搜索策略
最佳优先级搜索策略根据一定的网页分析算法预测候选URL与目标网页的相似度,或与主题的相关度,选择评价最好的一个或几个URL进行爬取。它只访问页面分析算法预测为“有用”的页面。一个问题是爬虫爬取路径上的许多相关网页可能会被忽略,因为最佳优先策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,从而跳出局部最优点。在第 4 节中,将结合网页分析算法进行详细讨论。研究表明,这样的闭环调整可以将不相关页面的数量减少 30% 到 90%。
4 网络分析算法
网页分析算法可以分为三种类型:基于网络拓扑、基于网页内容和基于用户访问行为。
4.1基于网络拓扑的分析算法
基于网页之间的链接,通过已知的网页或数据,一种算法来评估与其有直接或间接链接关系的对象(可以是网页或网站等)。进一步分为三种:网页粒度、网站粒度和网页块粒度。
4.1.1 网页粒度分析算法
PageRank 和 HITS 算法是最常见的链接分析算法。两者都是通过网页间链接度的递归归一化计算得到每个网页的重要性。 PageRank算法虽然考虑了用户访问行为的随机性和Sink网页的存在性,但忽略了大部分用户访问的目的性,即网页和查询主题链接的相关性。针对这个问题,HITS算法提出了两个关键概念:权威网页(authority)和中心网页(hub)。
基于链接爬取的问题是相关页面的主题组之间存在隧道现象,即爬取路径上很多偏离主题的页面也指向目标页面,局部评价策略打断了当前路径上的爬行行为。 参考文献[21]提出了一种基于反向链接(BackLink)的层次上下文模型(Context Model),用于描述指向一定物理跳半径内的目标网页的网页拓扑图的中心Layer 0作为目标网页。网页根据指向目标网页的物理跳数进行层次划分,外层网页到内层网页的链接称为反向链接。
4.1.2 网站粒度分析算法
网站粒度的资源发现和管理策略也比网页粒度的更简单有效。 网站粒度爬取的关键是站点的划分和SiteRank的计算。 SiteRank的计算方法与PageRank类似,但需要对网站之间的链接进行一定程度的抽象,并在一定模型下计算链接的权重。
网站划分分为两种:按域名划分和按IP地址划分。参考文献[18]讨论了分布式情况下,通过划分同一域名下不同主机和服务器的IP地址,构建站点地图,并采用类似于PageRank的方法评估SiteRank。同时,根据每个站点不同文件的分布情况,构建文档图,结合SiteRank分布式计算得到DocRank。参考文献[18]证明,使用分布式SiteRank计算不仅大大降低了单个站点的算法成本,而且克服了单个站点对全网覆盖范围有限的缺点。一个额外的好处是,常见的 PageRank 欺诈很难欺骗 SiteRank。
4.1.3 Web块粒度分析算法
一个页面通常收录多个指向其他页面的链接,而这些链接中只有一些指向与主题相关的网页,或者根据网页的链接锚文本指示高重要性。但是在PageRank和HITS算法中,这些链接是没有区分的,所以往往会给网页分析带来广告等噪声链接的干扰。块级链接分析算法的基本思想是通过VIPS网页切分算法将网页分成不同的页面块,然后为这些网页块创建page-to-block和block-block。 to-page的链接矩阵分别表示为Z和X。因此,page-to-page图上的page block level的PageRank为Wp=X×Z; 在块到块图上的 BlockRank 是 Wb=Z×X。 有人实现了块级PageRank和HITS算法,实验证明效率和准确率优于传统的对应算法。
4.2基于网页内容的网页分析算法
基于网页内容的分析算法是指利用网页内容的特征(文本、数据等资源)对网页进行评价。网页内容已经从基于超文本的内容演变为动态页面(或称为隐藏网页)数据,后者的数据量约为直接可见页面数据(PIW,Publicly Indexable Web)的400~500%。次。另一方面,多媒体数据、Web Service等各种形式的网络资源日益丰富。因此,基于网页内容的分析算法也从最初的相对简单的文本检索方法发展到综合应用包括网页数据提取、机器学习、数据挖掘、语义理解等多种方法。本节根据网页数据的不同形式,将基于网页内容的分析算法分为以下三类:第一类是针对以文本和超链接为主的非结构化或非常简单的网页;第二个是结构化网页。对于数据源(如RDBMS)动态生成的页面,不能直接批量访问数据;第三类数据介于第一类和第二类数据之间,结构更好,表明它遵循一定的模式或风格。并且可以直接访问。
c爬虫抓取网页数据( 分布式网络数据抓取系统说明()应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-21 12:02
分布式网络数据抓取系统说明()应用)
分布式网络数据采集系统的设计与实现
1、分布式网络数据采集系统说明
(1)深入分析网络数据(金融、教育、汽车)爬虫特性,设计分布式网络数据(金融、教育、汽车)系统爬取策略、爬取领域、动态网页抓取方法、分布式结构和数据存储等功能。
(2)简述分布式网络数据(金融、教育、汽车)抓取系统的实现流程。包括爬虫编写、爬虫规避(各种反爬方式)、动态网页数据抓取、数据存储等。
(3)需要爬取的网络数据网站的自定义配置网页模板,以及数据抓取(接口暂不考虑)
2、系统功能架构设计
系统功能架构
分布式爬虫爬取系统主要包括以下功能:
1。爬虫功能:爬取策略设计、内容数据域设计、增量爬取、请求去重
2。中间件:反爬机制、ajax动态数据加载、爬虫下载异常处理
3。数据存储:抓图设计、数据存储
3、系统分布式架构
分布式采用主从结构,设置一个Master服务器和多个Slave服务器。 Master 端管理 Redis 数据库并分发下载任务。 Slave部署Scrapy爬虫提取网页并解析提取数据,最终将解析后的数据存储在数据库中同一个MongoDb中。分布式爬虫架构如图
分布式爬虫架构
应用Redis数据库实现分布式爬取。基本思路是将Scrapy爬虫获取的detail_request的url放入Redis Queue,所有爬虫也从指定的Redis Queue获取请求。 Scrapy-Redis 组件中默认使用 SpiderPriorityQueue 来确定 url 的顺序,这是一种通过 sorted set 实现的非 FIFO 和 LIFO 方法。因此,待爬取队列的共享是爬虫可以部署在其他服务器上完成相同爬取任务的关键点。此外,为了解决 Scrapy 单机受限的问题,Scrapy 将结合 Scrapy-Redis 组件进行开发。 Scrapy-Redis的总体思路是,本项目通过重写Scrapy框架中的scheduler和spider类来实现调度、spider启动和redis的交互。 实现了新的dupefilter和queue类,实现了权重判断和调度容器与redis的交互。由于每台主机上的爬虫进程访问同一个redis数据库,调度和权重判断统一管理,实现分布式分布。爬虫的目的
4、系统实现
4.1、爬取策略设计
从scrapy的结构分析可以看出,网络爬虫从初始地址开始,根据从spider中定义的目标地址获取的正则表达式或Xpath获取更多的网页链接,并加入队列待下载进行去重和排序后,等待调度器调度。
在这个系统中,新建的链接可以分为两类,一类是目录页链接,也就是我们平时看到的下一页的链接,另一类是内容详情页链接,也就是我们需要解析网页的提取字段中的链接指向实际的页面信息。网络需要从每个目录页面链接中提取多个内容页面链接,并将它们添加到待下载队列中以供进一步爬取。爬取过程如下:
爬取过程
这里是master端目标链接的爬取策略。由于是分布式主从模式,master端的爬虫主要抓取下载内容详情页的链接,通过redis将下载任务分享给slave端的其他爬虫。 Slave端主要负责进一步解析提取详情页的链接并存入数据库。
1)对于大师:
核心模块是解决翻页问题,获取每个页面内容的详情页链接。 Master端主要采用以下爬取策略:
1.将redis的初始链接插入到key next_link,从初始页面链接开始
2.爬虫从redis中的key next_link获取初始链接,开始运行爬虫
3.下载器返回的Response,爬虫根据蜘蛛定义的爬取规则识别是否有下一页的链接。如果有链接,则存储在redis中,key保存为next_link。它匹配多个内容详细信息页面链接。如果匹配,则存储在Redis中,并将key保存为detail_request并插入下载链接,供slave端的spider使用,也就是slave端的下载任务。
4.爬虫继续从redis中的key取值作为next_link。如果有值,则继续执行步骤2。如果为空,则爬虫等待新的链接。
2)对于奴隶:
核心模块是从redis获取下载任务,解析提取字段。 Slave端主要采用以下爬取策略:
1。爬虫从redis获取初始链接,key为detail_request,开始运行爬虫
2。下载器返回的Response,爬虫根据爬虫定义的爬取规则识别是否有匹配规则的content字段,如果有则存储该字段返回给模型,等待数据存储操作。
重复第 1 步,直到爬取队列为空,爬虫等待新的链接。
4.2爬虫的具体实现
爬虫程序由四部分组成,即对象定义程序、数据捕获程序、数据处理程序和下载设置程序。这里的组成是Slave端,Master缺少对象定义程序和数据处理程序,而Master端主要是下载链接的爬取。
数据抓取程序:
数据爬取程序分为主端和从端。数据爬取程序从 Redis 获取初始地址。数据爬取程序定义了爬取网页的规则,使用Xpath提取字段数据的方法,以及css选择器选择器。数据提取方法等
4.3 去重和增量爬取
去重和增量爬取对服务器意义重大,可以减轻服务器压力,保证数据的准确性。如果不采用去重,爬取的内容会爬取大量的重复内容,大大降低爬虫的效率。事实上,重复数据删除的过程非常简单。核心是判断每个请求是否在已经爬取的队列中。如果已经存在,则丢弃当前请求。
具体实现步骤:
去重和增量爬取
(1)从待爬取队列中获取url
(2)会判断要请求的url是否被爬取,如果已经被爬取则忽略该请求,不被爬取,继续其他操作,将url插入到被爬取队列中
(3)重复步骤 1
4.4个爬虫中间件
爬虫中间件可以帮助我们在scrapy爬取过程中自由扩展自己的程序。以下是爬虫反屏蔽中间件、下载器异常状态中间件和非200状态中间件。
(1)履带防屏蔽组件的实现
当访问一个网站网页时,会给网站带来一定的负载,爬虫程序模拟了我们正常访问网页的过程,但是。大型爬虫会给网站增加很大的负载,影响正常用户的访问。为了保证大部分普通用户可以访问网页,大部分网站都有相应的反爬策略。一旦访问行为被识别为爬虫,网站会采取一定的措施限制你的访问,比如访问过于频繁会提示你输入验证码。您访问 网站。当系统有针对性的抓取网页数据时,会不断的访问网站的内容。如果不采取伪装措施,很容易被网站识别为爬虫行为而被屏蔽。
系统使用以下方法防止爬虫被拦截:
1.模拟不同的浏览器行为
2.一定频率更换代理服务器和网关
3.降低爬取网页的频率,减少并发爬取的进程,限制每个ip的并发爬取数量,牺牲一定的效率来换取系统的稳定性。
4.禁用cookies,网站会在用户访问时在cookie中插入一些信息来判断是否是机器人。我们阻止了cookies的调整,这也有助于我们的身份不被暴露。
反爬虫网站屏蔽原理如下图所示:
反网站屏蔽原理
(a) 模拟不同浏览器行为的想法和代码
原理:scrapy有下载中间件,在这个中间件中我们可以自定义请求和响应,核心是修改请求的属性
首先,主要是扩展下载中间件。首先在seeings.py中添加中间件并展开中间件,主要是写一个user-agent列表,将常用的浏览器请求头保存为列表,然后让请求头文件在列表中随机取一个代理值,并然后下载到下载器中。
用户代理
综上所述,每次发出请求,都会使用不同的浏览器访问目标网站。
(b)使用代理ip进行爬取的实现思路。
首先在settings.py中添加中间件,扩展下载组件请求的头文件从代理ip池中随机取一个代理值下载到下载器中。
1.代理ip池的设计开发流程如下:
一个。爬取免费代理ip网站.
b.存储并验证代理ip
c。身份验证通过存储方式存储在数据库中
d。如果验证失败,删除它
(c)爬虫异常状态组件的处理
当爬虫没有被阻塞并运行时,访问网站并不总是200请求成功,而是有多种状态,比如上面的爬虫被禁止时,返回的状态实际上是302,防止屏蔽组件是通过捕获302状态来实现的。同时异常状态的处理有利于爬虫的健壮性。
设置中的扩展中间件捕捉到异常后,重新将请求加入待下载队列的过程如下:
异常处理
(d) 数据存储模块
数据存储模块主要负责存储slave端抓取并解析的页面。数据使用MongoDB存储。
Scrapy支持json、csv、xml等数据存储格式,用户可以在运行爬虫时设置,例如:scrapy crawl spider
-o items.json -t json,也可以在Scrapy项目文件和ItemPipline文件中定义。同时Scrapy还支持数据库存储,比如Mongodb、Redis等,当数据量大到一定程度时,可以做Mongodb或者Reids的集群来解决问题,这个的数据存储系统如下图所示:
数据存储
5.总结
以上是分布式网络数据爬取系统的设计部分。由于单机爬虫的爬取量和爬取速度的限制,采用分布式设计。这是V1.0版本,以后会跟进。继续完善相关部分。 查看全部
c爬虫抓取网页数据(
分布式网络数据抓取系统说明()应用)
分布式网络数据采集系统的设计与实现
1、分布式网络数据采集系统说明
(1)深入分析网络数据(金融、教育、汽车)爬虫特性,设计分布式网络数据(金融、教育、汽车)系统爬取策略、爬取领域、动态网页抓取方法、分布式结构和数据存储等功能。
(2)简述分布式网络数据(金融、教育、汽车)抓取系统的实现流程。包括爬虫编写、爬虫规避(各种反爬方式)、动态网页数据抓取、数据存储等。
(3)需要爬取的网络数据网站的自定义配置网页模板,以及数据抓取(接口暂不考虑)
2、系统功能架构设计

系统功能架构
分布式爬虫爬取系统主要包括以下功能:
1。爬虫功能:爬取策略设计、内容数据域设计、增量爬取、请求去重
2。中间件:反爬机制、ajax动态数据加载、爬虫下载异常处理
3。数据存储:抓图设计、数据存储
3、系统分布式架构
分布式采用主从结构,设置一个Master服务器和多个Slave服务器。 Master 端管理 Redis 数据库并分发下载任务。 Slave部署Scrapy爬虫提取网页并解析提取数据,最终将解析后的数据存储在数据库中同一个MongoDb中。分布式爬虫架构如图
分布式爬虫架构
应用Redis数据库实现分布式爬取。基本思路是将Scrapy爬虫获取的detail_request的url放入Redis Queue,所有爬虫也从指定的Redis Queue获取请求。 Scrapy-Redis 组件中默认使用 SpiderPriorityQueue 来确定 url 的顺序,这是一种通过 sorted set 实现的非 FIFO 和 LIFO 方法。因此,待爬取队列的共享是爬虫可以部署在其他服务器上完成相同爬取任务的关键点。此外,为了解决 Scrapy 单机受限的问题,Scrapy 将结合 Scrapy-Redis 组件进行开发。 Scrapy-Redis的总体思路是,本项目通过重写Scrapy框架中的scheduler和spider类来实现调度、spider启动和redis的交互。 实现了新的dupefilter和queue类,实现了权重判断和调度容器与redis的交互。由于每台主机上的爬虫进程访问同一个redis数据库,调度和权重判断统一管理,实现分布式分布。爬虫的目的
4、系统实现
4.1、爬取策略设计
从scrapy的结构分析可以看出,网络爬虫从初始地址开始,根据从spider中定义的目标地址获取的正则表达式或Xpath获取更多的网页链接,并加入队列待下载进行去重和排序后,等待调度器调度。
在这个系统中,新建的链接可以分为两类,一类是目录页链接,也就是我们平时看到的下一页的链接,另一类是内容详情页链接,也就是我们需要解析网页的提取字段中的链接指向实际的页面信息。网络需要从每个目录页面链接中提取多个内容页面链接,并将它们添加到待下载队列中以供进一步爬取。爬取过程如下:
爬取过程
这里是master端目标链接的爬取策略。由于是分布式主从模式,master端的爬虫主要抓取下载内容详情页的链接,通过redis将下载任务分享给slave端的其他爬虫。 Slave端主要负责进一步解析提取详情页的链接并存入数据库。
1)对于大师:
核心模块是解决翻页问题,获取每个页面内容的详情页链接。 Master端主要采用以下爬取策略:
1.将redis的初始链接插入到key next_link,从初始页面链接开始
2.爬虫从redis中的key next_link获取初始链接,开始运行爬虫
3.下载器返回的Response,爬虫根据蜘蛛定义的爬取规则识别是否有下一页的链接。如果有链接,则存储在redis中,key保存为next_link。它匹配多个内容详细信息页面链接。如果匹配,则存储在Redis中,并将key保存为detail_request并插入下载链接,供slave端的spider使用,也就是slave端的下载任务。
4.爬虫继续从redis中的key取值作为next_link。如果有值,则继续执行步骤2。如果为空,则爬虫等待新的链接。
2)对于奴隶:
核心模块是从redis获取下载任务,解析提取字段。 Slave端主要采用以下爬取策略:
1。爬虫从redis获取初始链接,key为detail_request,开始运行爬虫
2。下载器返回的Response,爬虫根据爬虫定义的爬取规则识别是否有匹配规则的content字段,如果有则存储该字段返回给模型,等待数据存储操作。
重复第 1 步,直到爬取队列为空,爬虫等待新的链接。
4.2爬虫的具体实现
爬虫程序由四部分组成,即对象定义程序、数据捕获程序、数据处理程序和下载设置程序。这里的组成是Slave端,Master缺少对象定义程序和数据处理程序,而Master端主要是下载链接的爬取。
数据抓取程序:
数据爬取程序分为主端和从端。数据爬取程序从 Redis 获取初始地址。数据爬取程序定义了爬取网页的规则,使用Xpath提取字段数据的方法,以及css选择器选择器。数据提取方法等
4.3 去重和增量爬取
去重和增量爬取对服务器意义重大,可以减轻服务器压力,保证数据的准确性。如果不采用去重,爬取的内容会爬取大量的重复内容,大大降低爬虫的效率。事实上,重复数据删除的过程非常简单。核心是判断每个请求是否在已经爬取的队列中。如果已经存在,则丢弃当前请求。
具体实现步骤:
去重和增量爬取
(1)从待爬取队列中获取url
(2)会判断要请求的url是否被爬取,如果已经被爬取则忽略该请求,不被爬取,继续其他操作,将url插入到被爬取队列中
(3)重复步骤 1
4.4个爬虫中间件
爬虫中间件可以帮助我们在scrapy爬取过程中自由扩展自己的程序。以下是爬虫反屏蔽中间件、下载器异常状态中间件和非200状态中间件。
(1)履带防屏蔽组件的实现
当访问一个网站网页时,会给网站带来一定的负载,爬虫程序模拟了我们正常访问网页的过程,但是。大型爬虫会给网站增加很大的负载,影响正常用户的访问。为了保证大部分普通用户可以访问网页,大部分网站都有相应的反爬策略。一旦访问行为被识别为爬虫,网站会采取一定的措施限制你的访问,比如访问过于频繁会提示你输入验证码。您访问 网站。当系统有针对性的抓取网页数据时,会不断的访问网站的内容。如果不采取伪装措施,很容易被网站识别为爬虫行为而被屏蔽。
系统使用以下方法防止爬虫被拦截:
1.模拟不同的浏览器行为
2.一定频率更换代理服务器和网关
3.降低爬取网页的频率,减少并发爬取的进程,限制每个ip的并发爬取数量,牺牲一定的效率来换取系统的稳定性。
4.禁用cookies,网站会在用户访问时在cookie中插入一些信息来判断是否是机器人。我们阻止了cookies的调整,这也有助于我们的身份不被暴露。
反爬虫网站屏蔽原理如下图所示:
反网站屏蔽原理
(a) 模拟不同浏览器行为的想法和代码
原理:scrapy有下载中间件,在这个中间件中我们可以自定义请求和响应,核心是修改请求的属性
首先,主要是扩展下载中间件。首先在seeings.py中添加中间件并展开中间件,主要是写一个user-agent列表,将常用的浏览器请求头保存为列表,然后让请求头文件在列表中随机取一个代理值,并然后下载到下载器中。
用户代理
综上所述,每次发出请求,都会使用不同的浏览器访问目标网站。
(b)使用代理ip进行爬取的实现思路。
首先在settings.py中添加中间件,扩展下载组件请求的头文件从代理ip池中随机取一个代理值下载到下载器中。
1.代理ip池的设计开发流程如下:
一个。爬取免费代理ip网站.
b.存储并验证代理ip
c。身份验证通过存储方式存储在数据库中
d。如果验证失败,删除它
(c)爬虫异常状态组件的处理
当爬虫没有被阻塞并运行时,访问网站并不总是200请求成功,而是有多种状态,比如上面的爬虫被禁止时,返回的状态实际上是302,防止屏蔽组件是通过捕获302状态来实现的。同时异常状态的处理有利于爬虫的健壮性。
设置中的扩展中间件捕捉到异常后,重新将请求加入待下载队列的过程如下:
异常处理
(d) 数据存储模块
数据存储模块主要负责存储slave端抓取并解析的页面。数据使用MongoDB存储。
Scrapy支持json、csv、xml等数据存储格式,用户可以在运行爬虫时设置,例如:scrapy crawl spider
-o items.json -t json,也可以在Scrapy项目文件和ItemPipline文件中定义。同时Scrapy还支持数据库存储,比如Mongodb、Redis等,当数据量大到一定程度时,可以做Mongodb或者Reids的集群来解决问题,这个的数据存储系统如下图所示:
数据存储
5.总结
以上是分布式网络数据爬取系统的设计部分。由于单机爬虫的爬取量和爬取速度的限制,采用分布式设计。这是V1.0版本,以后会跟进。继续完善相关部分。
c爬虫抓取网页数据(越过亚马逊的反爬虫机制(爬取)、达人共同推荐)
网站优化 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2022-03-21 11:30
提问者和专家推荐
樱花
目前满意的受访者人数:
事情是这样的
亚马逊是全球最大的购物平台
很多产品信息、用户评论等都是最丰富的。
今天就带大家一起来穿越亚马逊的反爬虫机制吧
抓取您想要的有用信息,例如产品、评论等
反爬虫机制
但是,当我们想使用爬虫爬取相关数据信息时
亚马逊、TBO、京东等大型购物中心
为了保护他们的数据信息,他们都有一套完整的反爬虫机制。
先试试亚马逊的反爬机制
我们使用几个不同的python爬虫模块来一步步测试
最终,防爬机制顺利通过。
一、urllib 模块
代码显示如下:
# -*- coding:utf-8 -*-import urllib.requestreq = urllib.request.urlopen('https://www.amazon.com')print(req.code)复制代码
返回结果:状态码:503。
分析:亚马逊将你的请求识别为爬虫,拒绝提供服务。
以科学严谨的态度,来试试千人之首的百度吧。
返回结果:状态码200
分析:正常访问
以科学严谨的态度,来试试千人之首的百度吧。
返回结果:状态码200
分析:正常访问
代码如下↓ ↓ ↓
import requestsurl='https://www.amazon.com/KAVU-Rope-Bag-Denim-Size/product-reviews/xxxxxxx'web_header={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0','Accept': '*/*','Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2','Accept-Encoding': 'gzip, deflate, br','Connection': 'keep-alive','Cookie': '你的cookie值','TE': 'Trailers'}r = requests.get(url,headers=web_header)print(r.status_code)复制代码
返回结果:状态码:200
分析:返回状态码为200,属于正常。它闻起来像爬虫。
3、查看返回页面
通过requests+cookie的方法,我们得到的状态码是200
至少它目前由亚马逊的服务器提供服务。
我们将爬取的页面写入文本并在浏览器中打开。
我在骑马……返回状态正常,但是返回了反爬虫验证码页面。
仍然被亚马逊屏蔽。
三、硒自动化模块
相关硒模块的安装
pip install selenium复制代码
在代码中引入 selenium 并设置相关参数
import osfrom requests.api import optionsfrom selenium import webdriverfrom selenium.webdriver.chrome.options import Options#selenium配置参数options = Options()#配置无头参数,即不打开浏览器options.add_argument('--headless')#配置Chrome浏览器的selenium驱动 chromedriver="C:/Users/pacer/AppData/Local/Google/Chrome/Application/chromedriver.exe"os.environ["webdriver.chrome.driver"] = chromedriver#将参数设置+浏览器驱动组合browser = webdriver.Chrome(chromedriver,chrome_options=options)复制代码
测试访问
url = "https://www.amazon.com"print(url)#通过selenium来访问亚马逊browser.get(url)复制代码
返回结果:状态码:200
分析:返回状态码为200,访问状态正常。我们来看看爬取的网页上的信息。
将网页源代码保存到本地
#将爬取到的网页信息,写入到本地文件fw=open('E:/amzon.html','w',encoding='utf-8')fw.write(str(browser.page_source))browser.close()fw.close()复制代码
打开我们爬取的本地文件查看,
我们已经成功绕过反爬机制,进入亚马逊首页
结尾
通过selenium模块,我们可以成功穿越
亚马逊的反爬虫机制。 查看全部
c爬虫抓取网页数据(越过亚马逊的反爬虫机制(爬取)、达人共同推荐)
提问者和专家推荐

樱花
目前满意的受访者人数:
事情是这样的
亚马逊是全球最大的购物平台
很多产品信息、用户评论等都是最丰富的。
今天就带大家一起来穿越亚马逊的反爬虫机制吧
抓取您想要的有用信息,例如产品、评论等

反爬虫机制
但是,当我们想使用爬虫爬取相关数据信息时
亚马逊、TBO、京东等大型购物中心
为了保护他们的数据信息,他们都有一套完整的反爬虫机制。
先试试亚马逊的反爬机制
我们使用几个不同的python爬虫模块来一步步测试
最终,防爬机制顺利通过。
一、urllib 模块
代码显示如下:
# -*- coding:utf-8 -*-import urllib.requestreq = urllib.request.urlopen('https://www.amazon.com')print(req.code)复制代码
返回结果:状态码:503。
分析:亚马逊将你的请求识别为爬虫,拒绝提供服务。

以科学严谨的态度,来试试千人之首的百度吧。
返回结果:状态码200

分析:正常访问
以科学严谨的态度,来试试千人之首的百度吧。
返回结果:状态码200
分析:正常访问

代码如下↓ ↓ ↓
import requestsurl='https://www.amazon.com/KAVU-Rope-Bag-Denim-Size/product-reviews/xxxxxxx'web_header={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0','Accept': '*/*','Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2','Accept-Encoding': 'gzip, deflate, br','Connection': 'keep-alive','Cookie': '你的cookie值','TE': 'Trailers'}r = requests.get(url,headers=web_header)print(r.status_code)复制代码
返回结果:状态码:200
分析:返回状态码为200,属于正常。它闻起来像爬虫。
3、查看返回页面
通过requests+cookie的方法,我们得到的状态码是200
至少它目前由亚马逊的服务器提供服务。
我们将爬取的页面写入文本并在浏览器中打开。

我在骑马……返回状态正常,但是返回了反爬虫验证码页面。
仍然被亚马逊屏蔽。
三、硒自动化模块
相关硒模块的安装
pip install selenium复制代码
在代码中引入 selenium 并设置相关参数
import osfrom requests.api import optionsfrom selenium import webdriverfrom selenium.webdriver.chrome.options import Options#selenium配置参数options = Options()#配置无头参数,即不打开浏览器options.add_argument('--headless')#配置Chrome浏览器的selenium驱动 chromedriver="C:/Users/pacer/AppData/Local/Google/Chrome/Application/chromedriver.exe"os.environ["webdriver.chrome.driver"] = chromedriver#将参数设置+浏览器驱动组合browser = webdriver.Chrome(chromedriver,chrome_options=options)复制代码
测试访问
url = "https://www.amazon.com"print(url)#通过selenium来访问亚马逊browser.get(url)复制代码
返回结果:状态码:200
分析:返回状态码为200,访问状态正常。我们来看看爬取的网页上的信息。
将网页源代码保存到本地
#将爬取到的网页信息,写入到本地文件fw=open('E:/amzon.html','w',encoding='utf-8')fw.write(str(browser.page_source))browser.close()fw.close()复制代码
打开我们爬取的本地文件查看,
我们已经成功绕过反爬机制,进入亚马逊首页

结尾
通过selenium模块,我们可以成功穿越
亚马逊的反爬虫机制。
c爬虫抓取网页数据(注册美国公司用的代理软件:迅雷美国网站注册助手)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-21 05:02
c爬虫抓取网页数据不通过代理服务器的原因有两种:1.绝大多数网站直接有cookie记录,爬虫抓取的时候通过代理服务器获取ip地址2.服务器反向代理机制(ip池方式),与服务器通信后获取ip地址然后替换到ip池中(例如cookie或者代理池方式)
通过代理商来注册代理,代理商会抓取你的ip再传递给你的服务器,你的服务器再根据你用的代理ip返回给你。或者你可以直接访问服务器,
我老婆的公司帮忙在新浪博客批量注册美国公司,就是用爬虫+代理服务器。
已经有专门做美国公司注册的服务商,可以免费注册,但是很不稳定,国内拿不到美国营业执照,本身拿不到美国身份。建议挂vpn注册,要是考虑vpn速度的问题,可以用亲戚家的美国家庭主妇、放心点。
代理是为了个人的需求研发的...专门针对个人。批量爬取联邦登记局我也是醉了...你也就玩玩而已。
推荐几款注册美国公司用的代理软件:
1、迅雷美国网站注册助手
2、filezilla美国注册公司助手
3、全球ip代理(中国独家,
4、迅雷(国内的)当然还有云归国,谷歌,微软这些公司的服务器可以用注册的服务器申请,账号密码都能解开。如果你考虑拿身份去美国登记还是可以用海外的身份证。 查看全部
c爬虫抓取网页数据(注册美国公司用的代理软件:迅雷美国网站注册助手)
c爬虫抓取网页数据不通过代理服务器的原因有两种:1.绝大多数网站直接有cookie记录,爬虫抓取的时候通过代理服务器获取ip地址2.服务器反向代理机制(ip池方式),与服务器通信后获取ip地址然后替换到ip池中(例如cookie或者代理池方式)
通过代理商来注册代理,代理商会抓取你的ip再传递给你的服务器,你的服务器再根据你用的代理ip返回给你。或者你可以直接访问服务器,
我老婆的公司帮忙在新浪博客批量注册美国公司,就是用爬虫+代理服务器。
已经有专门做美国公司注册的服务商,可以免费注册,但是很不稳定,国内拿不到美国营业执照,本身拿不到美国身份。建议挂vpn注册,要是考虑vpn速度的问题,可以用亲戚家的美国家庭主妇、放心点。
代理是为了个人的需求研发的...专门针对个人。批量爬取联邦登记局我也是醉了...你也就玩玩而已。
推荐几款注册美国公司用的代理软件:
1、迅雷美国网站注册助手
2、filezilla美国注册公司助手
3、全球ip代理(中国独家,
4、迅雷(国内的)当然还有云归国,谷歌,微软这些公司的服务器可以用注册的服务器申请,账号密码都能解开。如果你考虑拿身份去美国登记还是可以用海外的身份证。
c爬虫抓取网页数据(自用Python模块的建立和使用--抓取和存数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-03-19 20:01
我们在这个例子中所做的就是将b站当前在线界面的20个视频转换成
从网页中抓取av号、类型、作者名、视频名、点击量、弹幕数,存入数据库进行简单分析。
整个步骤分为两部分——采集和保存数据
【抓住】
继续我们之前用 Python 编写爬虫的经验,我们可以类似地抓取我们需要的信息。
例如,抓取视频名称
import urllib2
from bs4 import BeautifulSoup
mainUrl="http://www.bilibili.com/online.html"
def toOnline():
'''进入在线列表页面'''
resp=urllib2.urlopen(mainUrl)
return resp
def getPageContent():
resp=toOnline()
html = resp.read().decode('utf-8').encode('gbk')
soup = BeautifulSoup(html, "html.parser", from_encoding="gbk")
return soup
def delNameTag(x):
arr = []
for i in range(0, len(x)):
b = str(x[i]).replace('<p class="etitle">', '')
c = b.replace('', '')
arr.append(c)
return arr</p>
def getName():
'''获取视频名称'''
soup=getPageContent()
data=soup.select('p[class="etitle"]')
data=delNameTag(data)
return data
这给了我们一个收录视频名称的长度为 20 的数组。
经过多次编写Python爬虫脚本的练习,这里不再重复逻辑。
需要注意的是,每个部分的逻辑都被分离出来,抽象成方法。这使得代码更清晰,更容易在以后维护和修改。
【存入数据库】
抓取数据后,我们需要将数据存入数据库。
在这个例子中,我们构建了一个私有的自用 Python 模块来方便数据库的操作。
【自用Python模块的建立与使用】
1.C:\Python27\Lib\site-packages 新建 myutil.pth
此文件存储我们的自定义脚本目录:D:/mywork/23 planB/my_script
【注意】这个文件中的目录是反斜杠的!!!
2.在D:/mywork/23 planB/my_script目录下创建一个myutil文件夹
3.myutil 文件夹是我们自定义的 Python 模块脚本
4.[重要] 该文件夹下必须有__init__.py 文件。没有这个文件就会失败。
这个文件的内容是空的,它是做什么的?未知。. . .
5. DBUtil的代码如下
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import MySQLdb
class DBConfig:
#线下
_user = 'root'
_password = '''1230'''
_user_stat = 'mkj'
_password_stat='pwd)'
_charset = 'utf8'
_use_unicode = False
#线下
_readHost = '127.0.0.1'
_writeHost = '127.0.0.1'
_statHost = '127.0.0.1'
@staticmethod
def _getHost(isWrite = True):
if isWrite:
return DBConfig._writeHost
else:
return DBConfig._readHost
@staticmethod
def getConnection(dbName = None, isWrite = True):
return MySQLdb.connect(host = DBConfig._getHost(isWrite), user = DBConfig._user, passwd = DBConfig._password, db = dbName, charset = DBConfig._charset, use_unicode = DBConfig._use_unicode)
@staticmethod
def getConnectionByHost(dbName = None, hostName = None):
if hostName == 'stat':
return MySQLdb.connect(host = DBConfig._statHost, user = DBConfig._user_stat, passwd = DBConfig._password_stat, db = dbName, charset = DBConfig._charset, use_unicode = DBConfig._use_unicode)
else :
return MySQLdb.connect(host = DBConfig._statHost, user = DBConfig._user, passwd = DBConfig._password, db = dbName, charset = DBConfig._charset, use_unicode = DBConfig._use_unicode)
class DBUtil:
__connRead = None
__connWrite = None
__conn = None
__dbName = None
__hostName = None
def __init__(self, dbName = None, hostName = None):
_dbName = dbName.split("_")
length = len(_dbName)
self.__hostName = hostName
if _dbName[length-1].isdigit():
_dbName.pop()
self.__dbName = ("_").join(_dbName)
else:
self.__dbName = dbName
def __getConnection(self, isWrite = True):
if self.__hostName :
if not self.__conn:
conn = DBConfig.getConnectionByHost(self.__dbName, self.__hostName)
self.__conn = conn
return self.__conn
if isWrite:
if not self.__connWrite:
conn = DBConfig.getConnection(self.__dbName, isWrite)
self.__connWrite = conn
return self.__connWrite
else:
if not self.__connRead:
conn = DBConfig.getConnection(self.__dbName, isWrite)
self.__connRead = conn
return self.__connRead
def queryList(self, sql = None, params = None):
if (not sql): return None
conn = self.__getConnection(False)
cursor = conn.cursor()
cursor.execute(sql, params)
rows = cursor.fetchall()
return rows
def queryRow(self, sql, params = None):
if (not sql):return None
conn = self.__getConnection(False)
cursor = conn.cursor()
cursor.execute(sql, params)
row = cursor.fetchone()
return row
def queryCount(self, sql = None, params = None):
if (not sql): return None
conn = self.__getConnection(False)
cursor = conn.cursor()
cursor.execute(sql, params)
row = cursor.fetchone()
if not row:
return 0
return row[0]
def update(self, sql = None, params = None):
if (not sql): return False
conn = self.__getConnection()
cursor = conn.cursor()
cursor.execute(sql, params)
conn.commit()
return True
def insert(self, sql = None, params = None, returnPk = False):
if (not sql): return False
conn = self.__getConnection()
cursor = conn.cursor()
cursor.execute(sql, params)
conn.commit()
if not returnPk:
return None
return cursor.lastrowid
def insertMany(self, sql = None, params = None):
if not sql or not params: return False
conn = self.__getConnection()
cursor = conn.cursor()
cursor.executemany(sql, params)
conn.commit()
return True
def delete(self, sql = None, params = None):
if (not sql): return False
conn = self.__getConnection()
cursor = conn.cursor()
cursor.execute(sql, params)
conn.commit()
return True
def deleteMany(self, sql = None, params = None):
if not sql or not params: return False
conn = self.__getConnection()
cursor = conn.cursor()
cursor.executemany(sql, params)
conn.commit()
return True
def transDelAndInsMany(self, insertSql = None, delSql = None, insertParams = None, delParams = None):
if not insertSql or not insertParams or not delSql or not delParams: return False
conn = self.__getConnection()
cursor = conn.cursor()
cursor.executemany(insertSql, insertParams)
cursor.executemany(delSql, delParams)
conn.commit()
return True
def close(self):
if self.__connRead:
self.__connRead.close()
self.__connRead = None
if self.__connWrite:
self.__connWrite.close()
self.__connWrite = None
if __name__ == '__main__':
print 'start'
dbUtil = DBUtil('netgame_trade_12')
只要记住这段代码。只需要知道几个需要改的地方:用户名密码和主机地址
_user = 'root'
_password = '''1230'''
#线下
_readHost = '127.0.0.1'
_writeHost = '127.0.0.1'
_statHost = '127.0.0.1'
这里readHost和writeHost是分开写的,也就是读写分离。
【保存数据到数据库】
数据拿到了,自定义模块就OK了。接下来,我们将数据存储在数据库中。
先介绍一下数据库模块
from myutil.DBUtil import DBUtil
然后连接到数据库
planBDBUtil = DBUtil('mydb')
那么操作代码如下
def insertData():
'''数据库操作'''
avid=getAvId()
typeid=getTypeId()
name=getName()
hits=getHits()
dm=getDm()
author=getAuthor()
sql='insert into mydb.PLAN_B(ID, AV_ID, TYPE_ID, AUTHOR, NAME, HITS, DM, CREATED_DATE)'
for i in range(len(avid)-1):
namei=str(name[i])
authori=str(author[i])
#sql = 'insert into mydb.PLAN_B(ID, AV_ID, TYPE_ID, NAME, HITS, DM, CREATED_DATE) values (null, %s, %s, "%s", %s, %s, now())'%(avid[i],typeid[i],namei,hits[i],dm[i])
sql=sql+' SELECT NULL,%s, %s, "%s", "%s", %s, %s, now() union '%(avid[i],typeid[i],authori,namei,hits[i],dm[i])
sql=sql+' SELECT NULL,%s, %s, "%s", "%s", %s, %s, now()'%(avid[len(avid)-1],typeid[len(avid)-1],author[len(avid)-1],name[len(avid)-1],hits[len(avid)-1],dm[len(avid)-1])
planBDBUtil.insert(sql, ())
这里我们是插入操作,最后一句
planBDBUtil.insert(sql, ())
insert 函数是我们从 DBUtil 中找到的,用于处理插入操作。
我们可以专注于如何编写 SQL 语句。
【注意:SQL调试器的使用】
在这个例子中,我们在编写 SQL 语句时,遇到了很多错误。在这个过程中,我们多次使用 Navicat 中的查询功能来调试 SQL。
注意我们使用这个私有定义。
接下来,我们讲解一下SQL语句中遇到的问题!
[问题 一、 插入不带引号的字符串]
我们插入字符串的时候,不能直接插入,一直报错。后来找到原因,
插入字符串时,需要引号!!!
NULL,%s, %s, "%s", "%s", %s, %s, now()
如果不带引号直接插入字符串,系统无法区分数据类型,插入失败!
[问题二、一次插入一堆数据]
这里我们运行一次脚本,需要插入20条数据。
传统做法是循环插入,即执行20次插入语句。但是如果有 10,000 条数据呢?您是否必须访问数据库 10,000 次?
经验告诉我们,我们只需要访问数据库一次。否则对数据库的压力太大了!
我们如何一次插入 20 条数据?经过研究,我们发现如下代码模板
INSERT INTO table1 (mc,zb_mc,xx_mc,leibie)
SELECT('aa',NULL,NULL,1390)union
SELECT('bb',NULL,NULL,1400)union
SELECT('cc',NULL,NULL,1410)union
SELECT('dd',NULL,NULL,1420)union
SELECT('ee',NULL,NULL,1430)union
SELECT('ff',NULL,NULL,1440)
执行一次这样的语句,就可以一次向数据库中插入多条记录。
因此,我们需要循环来拼写 SQL 字符串。
sql='insert into mydb.PLAN_B(ID, AV_ID, TYPE_ID, AUTHOR, NAME, HITS, DM, CREATED_DATE)'
for i in range(len(avid)-1):
namei=str(name[i])
authori=str(author[i])
#sql = 'insert into mydb.PLAN_B(ID, AV_ID, TYPE_ID, NAME, HITS, DM, CREATED_DATE) values (null, %s, %s, "%s", %s, %s, now())'%(avid[i],typeid[i],namei,hits[i],dm[i])
sql=sql+' SELECT NULL,%s, %s, "%s", "%s", %s, %s, now() union '%(avid[i],typeid[i],authori,namei,hits[i],dm[i])
sql=sql+' SELECT NULL,%s, %s, "%s", "%s", %s, %s, now()'%(avid[len(avid)-1],typeid[len(avid)-1],author[len(avid)-1],name[len(avid)-1],hits[len(avid)-1],dm[len(avid)-1])
我们注意到句子中间有一个并集,但结尾没有,所以我们需要取出最后一个单独拼写。
当然,我们也可以在生成SQL字符串后,删除字符串末尾的union这个词。任何一个!
至此,整个过程结束! 查看全部
c爬虫抓取网页数据(自用Python模块的建立和使用--抓取和存数据)
我们在这个例子中所做的就是将b站当前在线界面的20个视频转换成
从网页中抓取av号、类型、作者名、视频名、点击量、弹幕数,存入数据库进行简单分析。
整个步骤分为两部分——采集和保存数据
【抓住】
继续我们之前用 Python 编写爬虫的经验,我们可以类似地抓取我们需要的信息。
例如,抓取视频名称
import urllib2
from bs4 import BeautifulSoup
mainUrl="http://www.bilibili.com/online.html"
def toOnline():
'''进入在线列表页面'''
resp=urllib2.urlopen(mainUrl)
return resp
def getPageContent():
resp=toOnline()
html = resp.read().decode('utf-8').encode('gbk')
soup = BeautifulSoup(html, "html.parser", from_encoding="gbk")
return soup
def delNameTag(x):
arr = []
for i in range(0, len(x)):
b = str(x[i]).replace('<p class="etitle">', '')
c = b.replace('', '')
arr.append(c)
return arr</p>
def getName():
'''获取视频名称'''
soup=getPageContent()
data=soup.select('p[class="etitle"]')
data=delNameTag(data)
return data
这给了我们一个收录视频名称的长度为 20 的数组。
经过多次编写Python爬虫脚本的练习,这里不再重复逻辑。
需要注意的是,每个部分的逻辑都被分离出来,抽象成方法。这使得代码更清晰,更容易在以后维护和修改。
【存入数据库】
抓取数据后,我们需要将数据存入数据库。
在这个例子中,我们构建了一个私有的自用 Python 模块来方便数据库的操作。
【自用Python模块的建立与使用】
1.C:\Python27\Lib\site-packages 新建 myutil.pth
此文件存储我们的自定义脚本目录:D:/mywork/23 planB/my_script
【注意】这个文件中的目录是反斜杠的!!!
2.在D:/mywork/23 planB/my_script目录下创建一个myutil文件夹
3.myutil 文件夹是我们自定义的 Python 模块脚本
4.[重要] 该文件夹下必须有__init__.py 文件。没有这个文件就会失败。
这个文件的内容是空的,它是做什么的?未知。. . .
5. DBUtil的代码如下
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import MySQLdb
class DBConfig:
#线下
_user = 'root'
_password = '''1230'''
_user_stat = 'mkj'
_password_stat='pwd)'
_charset = 'utf8'
_use_unicode = False
#线下
_readHost = '127.0.0.1'
_writeHost = '127.0.0.1'
_statHost = '127.0.0.1'
@staticmethod
def _getHost(isWrite = True):
if isWrite:
return DBConfig._writeHost
else:
return DBConfig._readHost
@staticmethod
def getConnection(dbName = None, isWrite = True):
return MySQLdb.connect(host = DBConfig._getHost(isWrite), user = DBConfig._user, passwd = DBConfig._password, db = dbName, charset = DBConfig._charset, use_unicode = DBConfig._use_unicode)
@staticmethod
def getConnectionByHost(dbName = None, hostName = None):
if hostName == 'stat':
return MySQLdb.connect(host = DBConfig._statHost, user = DBConfig._user_stat, passwd = DBConfig._password_stat, db = dbName, charset = DBConfig._charset, use_unicode = DBConfig._use_unicode)
else :
return MySQLdb.connect(host = DBConfig._statHost, user = DBConfig._user, passwd = DBConfig._password, db = dbName, charset = DBConfig._charset, use_unicode = DBConfig._use_unicode)
class DBUtil:
__connRead = None
__connWrite = None
__conn = None
__dbName = None
__hostName = None
def __init__(self, dbName = None, hostName = None):
_dbName = dbName.split("_")
length = len(_dbName)
self.__hostName = hostName
if _dbName[length-1].isdigit():
_dbName.pop()
self.__dbName = ("_").join(_dbName)
else:
self.__dbName = dbName
def __getConnection(self, isWrite = True):
if self.__hostName :
if not self.__conn:
conn = DBConfig.getConnectionByHost(self.__dbName, self.__hostName)
self.__conn = conn
return self.__conn
if isWrite:
if not self.__connWrite:
conn = DBConfig.getConnection(self.__dbName, isWrite)
self.__connWrite = conn
return self.__connWrite
else:
if not self.__connRead:
conn = DBConfig.getConnection(self.__dbName, isWrite)
self.__connRead = conn
return self.__connRead
def queryList(self, sql = None, params = None):
if (not sql): return None
conn = self.__getConnection(False)
cursor = conn.cursor()
cursor.execute(sql, params)
rows = cursor.fetchall()
return rows
def queryRow(self, sql, params = None):
if (not sql):return None
conn = self.__getConnection(False)
cursor = conn.cursor()
cursor.execute(sql, params)
row = cursor.fetchone()
return row
def queryCount(self, sql = None, params = None):
if (not sql): return None
conn = self.__getConnection(False)
cursor = conn.cursor()
cursor.execute(sql, params)
row = cursor.fetchone()
if not row:
return 0
return row[0]
def update(self, sql = None, params = None):
if (not sql): return False
conn = self.__getConnection()
cursor = conn.cursor()
cursor.execute(sql, params)
conn.commit()
return True
def insert(self, sql = None, params = None, returnPk = False):
if (not sql): return False
conn = self.__getConnection()
cursor = conn.cursor()
cursor.execute(sql, params)
conn.commit()
if not returnPk:
return None
return cursor.lastrowid
def insertMany(self, sql = None, params = None):
if not sql or not params: return False
conn = self.__getConnection()
cursor = conn.cursor()
cursor.executemany(sql, params)
conn.commit()
return True
def delete(self, sql = None, params = None):
if (not sql): return False
conn = self.__getConnection()
cursor = conn.cursor()
cursor.execute(sql, params)
conn.commit()
return True
def deleteMany(self, sql = None, params = None):
if not sql or not params: return False
conn = self.__getConnection()
cursor = conn.cursor()
cursor.executemany(sql, params)
conn.commit()
return True
def transDelAndInsMany(self, insertSql = None, delSql = None, insertParams = None, delParams = None):
if not insertSql or not insertParams or not delSql or not delParams: return False
conn = self.__getConnection()
cursor = conn.cursor()
cursor.executemany(insertSql, insertParams)
cursor.executemany(delSql, delParams)
conn.commit()
return True
def close(self):
if self.__connRead:
self.__connRead.close()
self.__connRead = None
if self.__connWrite:
self.__connWrite.close()
self.__connWrite = None
if __name__ == '__main__':
print 'start'
dbUtil = DBUtil('netgame_trade_12')
只要记住这段代码。只需要知道几个需要改的地方:用户名密码和主机地址
_user = 'root'
_password = '''1230'''
#线下
_readHost = '127.0.0.1'
_writeHost = '127.0.0.1'
_statHost = '127.0.0.1'
这里readHost和writeHost是分开写的,也就是读写分离。
【保存数据到数据库】
数据拿到了,自定义模块就OK了。接下来,我们将数据存储在数据库中。
先介绍一下数据库模块
from myutil.DBUtil import DBUtil
然后连接到数据库
planBDBUtil = DBUtil('mydb')
那么操作代码如下
def insertData():
'''数据库操作'''
avid=getAvId()
typeid=getTypeId()
name=getName()
hits=getHits()
dm=getDm()
author=getAuthor()
sql='insert into mydb.PLAN_B(ID, AV_ID, TYPE_ID, AUTHOR, NAME, HITS, DM, CREATED_DATE)'
for i in range(len(avid)-1):
namei=str(name[i])
authori=str(author[i])
#sql = 'insert into mydb.PLAN_B(ID, AV_ID, TYPE_ID, NAME, HITS, DM, CREATED_DATE) values (null, %s, %s, "%s", %s, %s, now())'%(avid[i],typeid[i],namei,hits[i],dm[i])
sql=sql+' SELECT NULL,%s, %s, "%s", "%s", %s, %s, now() union '%(avid[i],typeid[i],authori,namei,hits[i],dm[i])
sql=sql+' SELECT NULL,%s, %s, "%s", "%s", %s, %s, now()'%(avid[len(avid)-1],typeid[len(avid)-1],author[len(avid)-1],name[len(avid)-1],hits[len(avid)-1],dm[len(avid)-1])
planBDBUtil.insert(sql, ())
这里我们是插入操作,最后一句
planBDBUtil.insert(sql, ())
insert 函数是我们从 DBUtil 中找到的,用于处理插入操作。
我们可以专注于如何编写 SQL 语句。
【注意:SQL调试器的使用】
在这个例子中,我们在编写 SQL 语句时,遇到了很多错误。在这个过程中,我们多次使用 Navicat 中的查询功能来调试 SQL。
注意我们使用这个私有定义。
接下来,我们讲解一下SQL语句中遇到的问题!
[问题 一、 插入不带引号的字符串]
我们插入字符串的时候,不能直接插入,一直报错。后来找到原因,
插入字符串时,需要引号!!!
NULL,%s, %s, "%s", "%s", %s, %s, now()
如果不带引号直接插入字符串,系统无法区分数据类型,插入失败!
[问题二、一次插入一堆数据]
这里我们运行一次脚本,需要插入20条数据。
传统做法是循环插入,即执行20次插入语句。但是如果有 10,000 条数据呢?您是否必须访问数据库 10,000 次?
经验告诉我们,我们只需要访问数据库一次。否则对数据库的压力太大了!
我们如何一次插入 20 条数据?经过研究,我们发现如下代码模板
INSERT INTO table1 (mc,zb_mc,xx_mc,leibie)
SELECT('aa',NULL,NULL,1390)union
SELECT('bb',NULL,NULL,1400)union
SELECT('cc',NULL,NULL,1410)union
SELECT('dd',NULL,NULL,1420)union
SELECT('ee',NULL,NULL,1430)union
SELECT('ff',NULL,NULL,1440)
执行一次这样的语句,就可以一次向数据库中插入多条记录。
因此,我们需要循环来拼写 SQL 字符串。
sql='insert into mydb.PLAN_B(ID, AV_ID, TYPE_ID, AUTHOR, NAME, HITS, DM, CREATED_DATE)'
for i in range(len(avid)-1):
namei=str(name[i])
authori=str(author[i])
#sql = 'insert into mydb.PLAN_B(ID, AV_ID, TYPE_ID, NAME, HITS, DM, CREATED_DATE) values (null, %s, %s, "%s", %s, %s, now())'%(avid[i],typeid[i],namei,hits[i],dm[i])
sql=sql+' SELECT NULL,%s, %s, "%s", "%s", %s, %s, now() union '%(avid[i],typeid[i],authori,namei,hits[i],dm[i])
sql=sql+' SELECT NULL,%s, %s, "%s", "%s", %s, %s, now()'%(avid[len(avid)-1],typeid[len(avid)-1],author[len(avid)-1],name[len(avid)-1],hits[len(avid)-1],dm[len(avid)-1])
我们注意到句子中间有一个并集,但结尾没有,所以我们需要取出最后一个单独拼写。
当然,我们也可以在生成SQL字符串后,删除字符串末尾的union这个词。任何一个!
至此,整个过程结束!
c爬虫抓取网页数据(Python-Scrapy爬虫实战scrapy实战实战)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-03-19 18:26
Python-Scrapy爬虫实战
scrapy 是一个非常强大的网络爬虫框架,它为数据挖掘、信息处理等领域提供了一种非常便捷的数据获取方式。说到爬虫可以通过网络浏览器获取的数据,理论上是可以通过爬虫获取的。最简单的是rest接口,通过接口访问获取数据。
设置已知爬虫库规则
背景信息 Web应用防火墙提供已知类型的爬虫库,包括11个已知的公共BOT类别和300多个BOT子类别,包括搜索引擎、测速工具、内容聚合、扫描和网络爬虫类别。
语言处理 AI 词法分析接口
词法分析、分词、词性标注、基于大数据和用户行为的命名实体识别,定位基本语言元素,消除歧义,支持对自然语言的准确理解
开启反爬虫
开启反爬虫 Web 应用防火墙 支持开启反爬虫模块。反爬虫模块可以在一段时间内(去重后)根据单个IP访问URL,所有请求达到一定的阈值,这被认为是爬虫行为和挑战。挑战过程从人机交互挑战开始,逐渐升级为拦截。
【人工智能-自然语言处理】产品信息提取
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】用短文本生成
进入京东云控制台总览页面,您可以根据实际需要进行配置。
语言处理 AI 图像审核接口
图片审核界面,基于深度学习的智能内容审核解决方案,可以准确识别图片和视频中的色情、暴力恐怖、政治敏感、微商广告、恶心等内容,还可以从美丽和清晰的维度。筛选,快速准确,解放审核人力。
高效编写 Flutter 页面的最佳实践
,可以在 StoneBasePageMixin 提供的页面基础框架上快速构建页面内容。
语言处理AI文本纠错接口
识别错误的文本片段,给出错误提示并给出正确的建议文本内容。
自然语言处理——人工智能之路
介绍NLP在生活中的应用场景和商业应用
网站活动页面
网站活动页面设计
设置网页篡改保护
设置网页防篡改网站后,即可开启Web应用防火墙的网页防篡改功能。网页防篡改帮助您锁定需要保护的网站页面。锁定页面收到请求后,会返回到已设置的缓存页面,以防止恶意篡改源站页面内容的影响。您可以根据实际需要设置网页的防篡改规则。
网页设计
多年网站建设及网络运营推广经验,根据客户需求,提供全方位网站建设解决方案;
网络制作
整合SEO架构、智能后台管理、网站定位、规划、设计、运维等,给用户最好的体验
哪些编程语言开发人员最开心?
“PHP 是最糟糕的语言!” “呵呵,Python适合初学者”。你有过类似的想法吗?
网页防篡改
网页防篡改功能说明网页防篡改采用强制静态缓存锁定和更新机制来保护网站特定页面。即使源站的相关网页被篡改,仍然可以将缓存的页面返回给用户。该功能目前处于公测阶段,在基础版中免费提供。
设置网络缓存
设置网页缓存网站访问Web应用防火墙后,可以为其开启网页缓存功能。网页缓存帮助您提高网页访问速度,减轻源站压力。您可以根据自己的实际需要设置网页缓存的规则。前提条件 已激活 Web 应用程序防火墙实例。有关详细信息,请参阅激活 Web 应用程序防火墙。网站访问完成。有关详细信息,请参阅添加域名。
编程语言王国唯一的王者
知道如何编码不再是一个优势。市场上充斥着各种培训机构和班级培养的人才,“初级软件开发人员”的位置已经不复存在。要在当今市场上取得成功,您不仅需要知道如何编码,还需要学会使用逻辑思维方式。
写办公室
常熟办公企业私人版提供文字处理、电子表格、演示文稿、协作空间、常聊、小常智能写作助手等常用云工具。云工具与企业云相结合,为企业提供SDK集成服务。
UE设计 | 蒸汽波的设计语言选择是什么?
做最时尚的设计,一定要永远站在设计的最前沿,把表弟的学习笔记分享给大家,一起来了解一下什么是蒸汽波吧~ 查看全部
c爬虫抓取网页数据(Python-Scrapy爬虫实战scrapy实战实战)
Python-Scrapy爬虫实战
scrapy 是一个非常强大的网络爬虫框架,它为数据挖掘、信息处理等领域提供了一种非常便捷的数据获取方式。说到爬虫可以通过网络浏览器获取的数据,理论上是可以通过爬虫获取的。最简单的是rest接口,通过接口访问获取数据。
设置已知爬虫库规则
背景信息 Web应用防火墙提供已知类型的爬虫库,包括11个已知的公共BOT类别和300多个BOT子类别,包括搜索引擎、测速工具、内容聚合、扫描和网络爬虫类别。
语言处理 AI 词法分析接口
词法分析、分词、词性标注、基于大数据和用户行为的命名实体识别,定位基本语言元素,消除歧义,支持对自然语言的准确理解
开启反爬虫
开启反爬虫 Web 应用防火墙 支持开启反爬虫模块。反爬虫模块可以在一段时间内(去重后)根据单个IP访问URL,所有请求达到一定的阈值,这被认为是爬虫行为和挑战。挑战过程从人机交互挑战开始,逐渐升级为拦截。
【人工智能-自然语言处理】产品信息提取
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】用短文本生成
进入京东云控制台总览页面,您可以根据实际需要进行配置。
语言处理 AI 图像审核接口
图片审核界面,基于深度学习的智能内容审核解决方案,可以准确识别图片和视频中的色情、暴力恐怖、政治敏感、微商广告、恶心等内容,还可以从美丽和清晰的维度。筛选,快速准确,解放审核人力。
高效编写 Flutter 页面的最佳实践
,可以在 StoneBasePageMixin 提供的页面基础框架上快速构建页面内容。
语言处理AI文本纠错接口
识别错误的文本片段,给出错误提示并给出正确的建议文本内容。
自然语言处理——人工智能之路
介绍NLP在生活中的应用场景和商业应用
网站活动页面
网站活动页面设计
设置网页篡改保护
设置网页防篡改网站后,即可开启Web应用防火墙的网页防篡改功能。网页防篡改帮助您锁定需要保护的网站页面。锁定页面收到请求后,会返回到已设置的缓存页面,以防止恶意篡改源站页面内容的影响。您可以根据实际需要设置网页的防篡改规则。
网页设计
多年网站建设及网络运营推广经验,根据客户需求,提供全方位网站建设解决方案;
网络制作
整合SEO架构、智能后台管理、网站定位、规划、设计、运维等,给用户最好的体验
哪些编程语言开发人员最开心?
“PHP 是最糟糕的语言!” “呵呵,Python适合初学者”。你有过类似的想法吗?
网页防篡改
网页防篡改功能说明网页防篡改采用强制静态缓存锁定和更新机制来保护网站特定页面。即使源站的相关网页被篡改,仍然可以将缓存的页面返回给用户。该功能目前处于公测阶段,在基础版中免费提供。
设置网络缓存
设置网页缓存网站访问Web应用防火墙后,可以为其开启网页缓存功能。网页缓存帮助您提高网页访问速度,减轻源站压力。您可以根据自己的实际需要设置网页缓存的规则。前提条件 已激活 Web 应用程序防火墙实例。有关详细信息,请参阅激活 Web 应用程序防火墙。网站访问完成。有关详细信息,请参阅添加域名。
编程语言王国唯一的王者
知道如何编码不再是一个优势。市场上充斥着各种培训机构和班级培养的人才,“初级软件开发人员”的位置已经不复存在。要在当今市场上取得成功,您不仅需要知道如何编码,还需要学会使用逻辑思维方式。
写办公室
常熟办公企业私人版提供文字处理、电子表格、演示文稿、协作空间、常聊、小常智能写作助手等常用云工具。云工具与企业云相结合,为企业提供SDK集成服务。
UE设计 | 蒸汽波的设计语言选择是什么?
做最时尚的设计,一定要永远站在设计的最前沿,把表弟的学习笔记分享给大家,一起来了解一下什么是蒸汽波吧~
c爬虫抓取网页数据(爬虫是什么网络爬虫(又被称为网页蜘蛛、网络机器人))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-03-18 05:15
01 什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常见的是网页追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
Web 爬虫通过从 Internet 上的 网站 服务器上爬取内容来工作。它是用计算机语言编写的程序或脚本,自动从互联网上获取信息或数据,扫描并抓取每个需要的页面上的某些信息,直到处理完所有可以正常打开的页面。
作为搜索引擎的重要组成部分,爬虫的主要功能是抓取网页数据(如图2-1所示)。目前市面上流行的采集器软件都是利用网络爬虫的原理或功能。
▲图 2-1 网络爬虫象形图
02 爬行动物的意义
如今,大数据时代已经到来,网络爬虫技术已经成为这个时代不可或缺的一部分。企业需要数据来分析用户行为、自身产品的不足、竞争对手的信息。所有这一切的首要条件是数据。采集。
网络爬虫的价值其实就是数据的价值。在互联网社会,数据是无价的。一切都是数据。谁拥有大量有用的数据,谁就有决策的主动权。网络爬虫的应用领域很多,比如搜索引擎、数据采集、广告过滤、大数据分析等。
1)抓取各大电商公司的产品销售信息和用户评价网站进行分析,如图2-2所示。
▲图2-2 电商产品销售信息网站
2)分析大众点评、美团等餐饮品类网站用户的消费、评价及发展趋势,如图2-3所示。
▲图2-3 餐饮用户消费信息网站
3)分析各城市中学区住房占比,学区房价格比普通二手房高多少,如图2-4所示。
▲图2-4 学区住房比例与价格对比
以上数据是由ForeSpider数据采集软件爬下来的。有兴趣的读者可以尝试自己爬一些数据。
03 爬虫的原理
我们通常将网络爬虫的组件分为初始链接库、网络爬取模块、网页处理模块、网页分析模块、DNS模块、待爬取链接队列、网页库等。网络爬虫的各个模块可以组成一个循环系统,从而不断的分析和抓取。
爬虫的工作原理可以简单地解释为首先找到目标信息网络,然后是页面爬取模块,然后是页面分析模块,最后是数据存储模块。具体细节如图2-5所示。
▲图2-5 爬虫示意图
爬虫工作的基本流程:
首先,选择互联网中的一部分网页,将这些网页的链接地址作为种子URL;将这些种子URL放入待爬取URL队列中,爬虫依次从待爬取URL队列中读取;通过 DNS 解析 URL;将链接地址转换为网站服务器对应的IP地址;网页下载器通过网站服务器下载网页;下载的网页为网页文档的形式;提取网页文档中的URL;filter 删除已抓取的网址;继续对没有被爬取的URL进行爬取,直到待爬取的URL队列为空。
04 爬虫技术的种类
作者简介:赵国胜,哈尔滨师范大学教授,工学博士,硕士生导师,黑龙江省网络安全技术领域特殊人才。主要从事可信网络、入侵容忍、认知计算、物联网安全等领域的教学和科研工作。
本文摘自《Python网络爬虫技术与实践》,经出版社授权发布。
本文使用“CC BY-SA 4.0 CN”协议转载自网络,仅供学习交流。内容版权归原作者所有。如果您对作品、版权等问题有任何疑问,请给“我们”留言。 查看全部
c爬虫抓取网页数据(爬虫是什么网络爬虫(又被称为网页蜘蛛、网络机器人))
01 什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常见的是网页追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
Web 爬虫通过从 Internet 上的 网站 服务器上爬取内容来工作。它是用计算机语言编写的程序或脚本,自动从互联网上获取信息或数据,扫描并抓取每个需要的页面上的某些信息,直到处理完所有可以正常打开的页面。
作为搜索引擎的重要组成部分,爬虫的主要功能是抓取网页数据(如图2-1所示)。目前市面上流行的采集器软件都是利用网络爬虫的原理或功能。
▲图 2-1 网络爬虫象形图
02 爬行动物的意义
如今,大数据时代已经到来,网络爬虫技术已经成为这个时代不可或缺的一部分。企业需要数据来分析用户行为、自身产品的不足、竞争对手的信息。所有这一切的首要条件是数据。采集。
网络爬虫的价值其实就是数据的价值。在互联网社会,数据是无价的。一切都是数据。谁拥有大量有用的数据,谁就有决策的主动权。网络爬虫的应用领域很多,比如搜索引擎、数据采集、广告过滤、大数据分析等。
1)抓取各大电商公司的产品销售信息和用户评价网站进行分析,如图2-2所示。
▲图2-2 电商产品销售信息网站
2)分析大众点评、美团等餐饮品类网站用户的消费、评价及发展趋势,如图2-3所示。
▲图2-3 餐饮用户消费信息网站
3)分析各城市中学区住房占比,学区房价格比普通二手房高多少,如图2-4所示。
▲图2-4 学区住房比例与价格对比
以上数据是由ForeSpider数据采集软件爬下来的。有兴趣的读者可以尝试自己爬一些数据。
03 爬虫的原理
我们通常将网络爬虫的组件分为初始链接库、网络爬取模块、网页处理模块、网页分析模块、DNS模块、待爬取链接队列、网页库等。网络爬虫的各个模块可以组成一个循环系统,从而不断的分析和抓取。
爬虫的工作原理可以简单地解释为首先找到目标信息网络,然后是页面爬取模块,然后是页面分析模块,最后是数据存储模块。具体细节如图2-5所示。
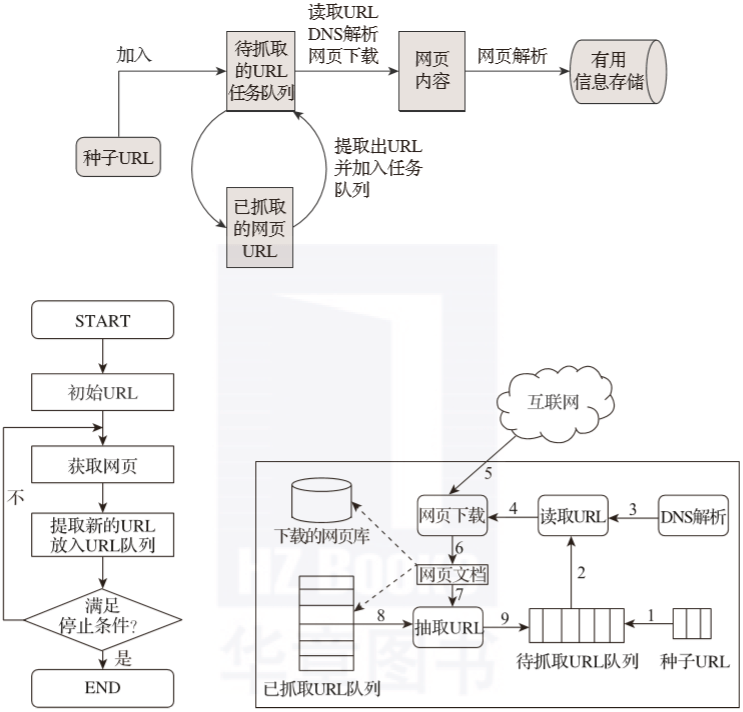
▲图2-5 爬虫示意图
爬虫工作的基本流程:
首先,选择互联网中的一部分网页,将这些网页的链接地址作为种子URL;将这些种子URL放入待爬取URL队列中,爬虫依次从待爬取URL队列中读取;通过 DNS 解析 URL;将链接地址转换为网站服务器对应的IP地址;网页下载器通过网站服务器下载网页;下载的网页为网页文档的形式;提取网页文档中的URL;filter 删除已抓取的网址;继续对没有被爬取的URL进行爬取,直到待爬取的URL队列为空。
04 爬虫技术的种类
作者简介:赵国胜,哈尔滨师范大学教授,工学博士,硕士生导师,黑龙江省网络安全技术领域特殊人才。主要从事可信网络、入侵容忍、认知计算、物联网安全等领域的教学和科研工作。
本文摘自《Python网络爬虫技术与实践》,经出版社授权发布。
本文使用“CC BY-SA 4.0 CN”协议转载自网络,仅供学习交流。内容版权归原作者所有。如果您对作品、版权等问题有任何疑问,请给“我们”留言。
c爬虫抓取网页数据(百度/google等搜索网站就是的实现方法(使用python3))
网站优化 • 优采云 发表了文章 • 0 个评论 • 246 次浏览 • 2022-03-16 09:00
1. 什么是爬虫
当今互联网上存储着大量信息。
作为普通网民,我们经常使用浏览器访问互联网上的内容。但是如果你想批量下载散落在网上的某方面的信息(比如某网站的所有图片,某新闻网站的所有新闻,或者所有的收视率豆瓣上的电影),手动使用浏览器打开网站一一搜索太费时费力。
人工统计太费时费力
因此,编写程序来自动抓取 Internet 以获取有关我们想要的特定内容的信息变得更加重要。
网络爬虫是根据一定规则自动从万维网上抓取信息的程序或脚本。
通过程序,我们模拟浏览器向服务器发送请求,获取信息,分析信息,存储我们想要的内容。
百度/谷歌搜索网站是利用爬虫定期搜索互联网上的链接并更新其服务器,以便我们通过搜索引擎搜索到我们想要的信息。
2. 网页结构
访问网页不仅仅是输入地址并查看它。
在浏览器中按“F12”,或右键单击网页并选择“检查”。你可以看到页面后面的代码。
以谷歌的Chrome浏览器为例,在任意一个网站中,我们按下F12,就会出现一个浏览器检查窗口。默认的 Elements 窗口是当前界面的 HTML 代码。
Web 和元素界面
Sources 界面将显示浏览器从每个服务器下载的所有文件。
来源界面
在网络界面,在“记录网络日志”状态下(按Ctrl+E切换该状态),可以依次记录浏览器在每个时间段接收到的文件和文件相关数据。
网络接口
我们这里要实现的抓取具体信息的爬虫,需要我们到对应的网站去分析它的网页结构。根据网页的结构,我们可以通过编写相应的程序得到我们想要的信息。
3.python代码实现
我们将以豆瓣上的《流浪地球》影评为例,一步步讲解python爬虫的实现方法(使用python3).
以下代码可在 github 上下载。
3.1 基本介绍
我们将在本节中使用的 python 库是:
另外,本节我们没有讲,但是使用爬虫时可能用到的库通常包括:
对于上面的python库,bs4可以通过“pip install Beautifulsoup4”命令安装,其他库可以直接通过“pip install library noun”安装。
我们首先创建一个新的 jupyter 文件并导入必要的 python 库。
导入必要的python库
3.2 请求的使用
使用请求
上面的代码允许我们以编程方式访问(百度)网页。
其中,“requests.get(网页地址)”是以get的方式访问网页。
访问网址有两种类型:获取和发布。get和post的区别可以看下图(来自w3school)。两者的区别很容易理解,无需深究。
关于get、post和使用request传参,我们会在以后的爬虫进阶教程中一一介绍。
我们已经使用“response = requests.get(url)”将获取的信息传递给“response”。但是如果我们输出响应,我们得到的不是网站的代码,而是响应状态码。
响应状态码
响应状态码代表我们之前请求请求的结果。常见的是200,代表成功;403,无访问权限;404,文件不存在;502,服务器错误。
想看看我们之前用“requests.get(url)”得到的网页内容。我们需要先执行“response.enconding = 'utf-8'”。这一步是将网页内容编码为utf-8,否则我们将无法在网页中看到中文。
将生成的内容编码为 utf-8
输入response.text后,我们就可以看到网页的代码了。
3.3 BeautifulSoup 的使用
在使用 BeautifulSoup 之前,建议读者对 html 有一定的了解。如果没有,那很好。
HTML 是一种标记语言,具有很强的结构要求。
html代码示例
我们使用 BeautifulSoup 来分析 HTML 页面的结构来选择我们想要的内容。
我们可以使用 BeautifulSoup(response.text, "lxml") 来自动分析我们之前得到的网页代码。分析结果存储在等号左侧的变量汤中。
html内容信息分析
BeautifulSoup 有很多使用方法。
例如 .find("tag name") 返回找到的第一个标签的内容。
.find("标记名")
值得注意的是,我们找到的第一个 div 标签里面也有 div 标签。但是 BeautifulSoup 不会注意到, .find("div") 只会返回找到的第一个 div 标签,以及该标签内的所有内容。
.find_all("tag name") 返回找到的所有标签。
.find_all("标签名称")
.find_all("tag name", class_="class name", id="id name") 可以找到指定的类别并指定id标签。(注意使用 class_ 而不是 class)
.find_all("标签名", class_="类名", id="id名")
此外,我们还可以继续对.find()和.find_all()的结果进行.find()、.find_all()查询。
3.4 json的使用
除了html格式文件,我们经常需要爬取一些json格式文件。JSON 是一种轻量级的数据交换格式。
html和json格式文件的区别如下。(严格来说左边应该是一个XML格式的文件,但也可以认为是一般的HTML)
html和json格式文件的区别
(图片来自网络)
所以,有时,我们会解析 json 格式的数据。
使用 text = json.loads(字符串格式的json数据)
您可以将字符串格式的 json 数据转换为 python 字典格式。
3.5 组合使用
我们之前提到过:“根据网页的结构,我们可以通过编写相应的程序得到我们想要的信息。”
现在,我们进入豆瓣影评《流浪地球》的短评界面。
()
《流浪地球》短评界面
我们按“F12”打开检查界面。如果你使用的是Chrome浏览器,可以点击下图的小箭头或者Ctrl+Shift+C。这时,当鼠标移动到页面上的某个位置时,浏览器会自动显示该位置对应的代码位置。
Ctrl+Shift+C后可以查看页面中每个元素的位置
具体效果如下:
结合我们之前讲过的requests和Beautifulsoup的对应知识。读者可以尝试写一个爬虫来获取当前网页的所有短评信息。
作者这里爬的是
“”,是一个json文件,所以额外使用了python的json库。
代码显示如下。完整代码可在 github 上找到。建议读者先尝试从零开始写一个爬虫,遇到问题先百度/谷歌,最后参考这个完整的爬虫代码
完整的爬虫代码
完成代码下载:
3.6 最终结果
最后,为了让最终的结果更加美观,作者在这里使用了pandas的DataFrame。
使用熊猫的数据框
爬取的数据结果如下
抓取的数据
3.7 扩展
以上内容只是一个基本的python爬虫。
如果读者细心,他们会发现不登录豆瓣就无法访问。”
"
没有权限
这里的url链接中的start=220表示我们不登录就无法查看第220条评论之后的内容。
在以后的爬虫进阶教程中,我们会介绍如何使用爬虫进行登录、保存cookies等操作。
另外,部分网站可能会使用js进行网站动态渲染、代码加密等,仅爬取html和json文件是不够的。同时,我们也可以使用多进程来加速爬虫...
敬请期待以后的爬虫进阶教程。
其他文章
(点击跳转)
长
根据
关闭
笔记
解锁更多精彩内容
跟着一起做一个有灵魂的人 查看全部
c爬虫抓取网页数据(百度/google等搜索网站就是的实现方法(使用python3))
1. 什么是爬虫
当今互联网上存储着大量信息。
作为普通网民,我们经常使用浏览器访问互联网上的内容。但是如果你想批量下载散落在网上的某方面的信息(比如某网站的所有图片,某新闻网站的所有新闻,或者所有的收视率豆瓣上的电影),手动使用浏览器打开网站一一搜索太费时费力。
人工统计太费时费力
因此,编写程序来自动抓取 Internet 以获取有关我们想要的特定内容的信息变得更加重要。
网络爬虫是根据一定规则自动从万维网上抓取信息的程序或脚本。
通过程序,我们模拟浏览器向服务器发送请求,获取信息,分析信息,存储我们想要的内容。
百度/谷歌搜索网站是利用爬虫定期搜索互联网上的链接并更新其服务器,以便我们通过搜索引擎搜索到我们想要的信息。
2. 网页结构
访问网页不仅仅是输入地址并查看它。
在浏览器中按“F12”,或右键单击网页并选择“检查”。你可以看到页面后面的代码。
以谷歌的Chrome浏览器为例,在任意一个网站中,我们按下F12,就会出现一个浏览器检查窗口。默认的 Elements 窗口是当前界面的 HTML 代码。
Web 和元素界面
Sources 界面将显示浏览器从每个服务器下载的所有文件。
来源界面
在网络界面,在“记录网络日志”状态下(按Ctrl+E切换该状态),可以依次记录浏览器在每个时间段接收到的文件和文件相关数据。
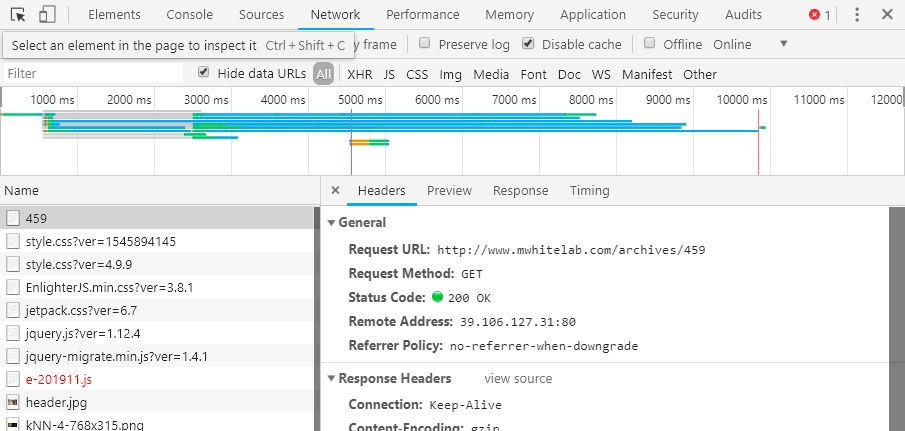
网络接口
我们这里要实现的抓取具体信息的爬虫,需要我们到对应的网站去分析它的网页结构。根据网页的结构,我们可以通过编写相应的程序得到我们想要的信息。
3.python代码实现
我们将以豆瓣上的《流浪地球》影评为例,一步步讲解python爬虫的实现方法(使用python3).
以下代码可在 github 上下载。
3.1 基本介绍
我们将在本节中使用的 python 库是:
另外,本节我们没有讲,但是使用爬虫时可能用到的库通常包括:
对于上面的python库,bs4可以通过“pip install Beautifulsoup4”命令安装,其他库可以直接通过“pip install library noun”安装。
我们首先创建一个新的 jupyter 文件并导入必要的 python 库。

导入必要的python库
3.2 请求的使用

使用请求
上面的代码允许我们以编程方式访问(百度)网页。
其中,“requests.get(网页地址)”是以get的方式访问网页。
访问网址有两种类型:获取和发布。get和post的区别可以看下图(来自w3school)。两者的区别很容易理解,无需深究。

关于get、post和使用request传参,我们会在以后的爬虫进阶教程中一一介绍。
我们已经使用“response = requests.get(url)”将获取的信息传递给“response”。但是如果我们输出响应,我们得到的不是网站的代码,而是响应状态码。

响应状态码
响应状态码代表我们之前请求请求的结果。常见的是200,代表成功;403,无访问权限;404,文件不存在;502,服务器错误。
想看看我们之前用“requests.get(url)”得到的网页内容。我们需要先执行“response.enconding = 'utf-8'”。这一步是将网页内容编码为utf-8,否则我们将无法在网页中看到中文。

将生成的内容编码为 utf-8
输入response.text后,我们就可以看到网页的代码了。

3.3 BeautifulSoup 的使用
在使用 BeautifulSoup 之前,建议读者对 html 有一定的了解。如果没有,那很好。
HTML 是一种标记语言,具有很强的结构要求。
html代码示例
我们使用 BeautifulSoup 来分析 HTML 页面的结构来选择我们想要的内容。
我们可以使用 BeautifulSoup(response.text, "lxml") 来自动分析我们之前得到的网页代码。分析结果存储在等号左侧的变量汤中。

html内容信息分析
BeautifulSoup 有很多使用方法。
例如 .find("tag name") 返回找到的第一个标签的内容。
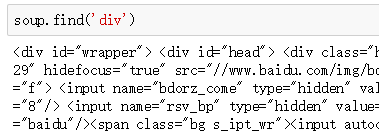
.find("标记名")
值得注意的是,我们找到的第一个 div 标签里面也有 div 标签。但是 BeautifulSoup 不会注意到, .find("div") 只会返回找到的第一个 div 标签,以及该标签内的所有内容。
.find_all("tag name") 返回找到的所有标签。

.find_all("标签名称")
.find_all("tag name", class_="class name", id="id name") 可以找到指定的类别并指定id标签。(注意使用 class_ 而不是 class)
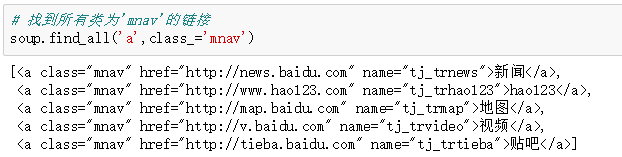
.find_all("标签名", class_="类名", id="id名")
此外,我们还可以继续对.find()和.find_all()的结果进行.find()、.find_all()查询。
3.4 json的使用
除了html格式文件,我们经常需要爬取一些json格式文件。JSON 是一种轻量级的数据交换格式。
html和json格式文件的区别如下。(严格来说左边应该是一个XML格式的文件,但也可以认为是一般的HTML)
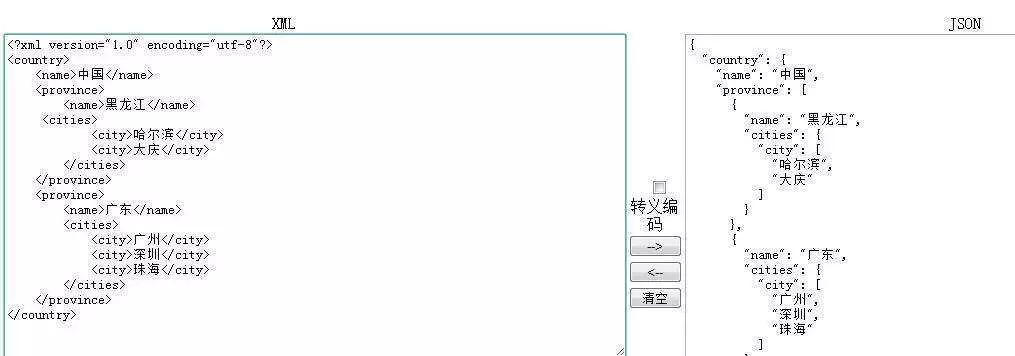
html和json格式文件的区别
(图片来自网络)
所以,有时,我们会解析 json 格式的数据。
使用 text = json.loads(字符串格式的json数据)
您可以将字符串格式的 json 数据转换为 python 字典格式。
3.5 组合使用
我们之前提到过:“根据网页的结构,我们可以通过编写相应的程序得到我们想要的信息。”
现在,我们进入豆瓣影评《流浪地球》的短评界面。
()
《流浪地球》短评界面
我们按“F12”打开检查界面。如果你使用的是Chrome浏览器,可以点击下图的小箭头或者Ctrl+Shift+C。这时,当鼠标移动到页面上的某个位置时,浏览器会自动显示该位置对应的代码位置。

Ctrl+Shift+C后可以查看页面中每个元素的位置
具体效果如下:
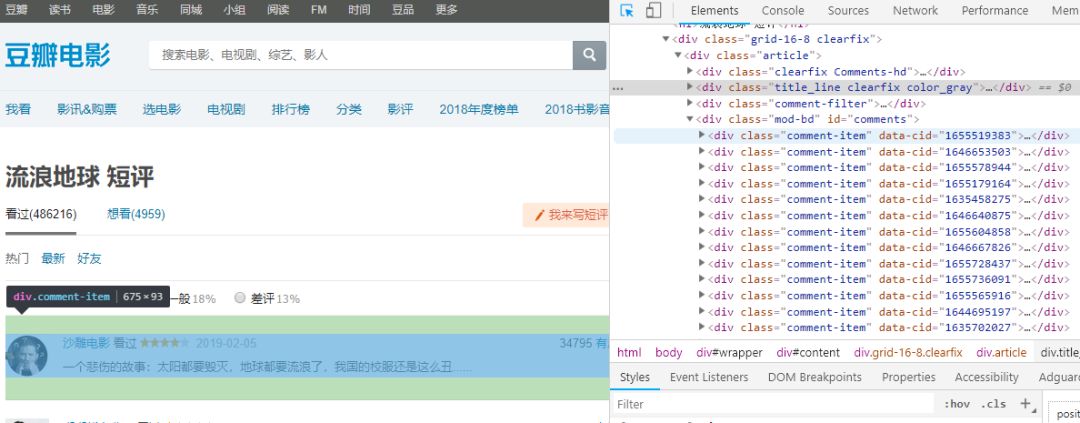
结合我们之前讲过的requests和Beautifulsoup的对应知识。读者可以尝试写一个爬虫来获取当前网页的所有短评信息。
作者这里爬的是
“”,是一个json文件,所以额外使用了python的json库。
代码显示如下。完整代码可在 github 上找到。建议读者先尝试从零开始写一个爬虫,遇到问题先百度/谷歌,最后参考这个完整的爬虫代码
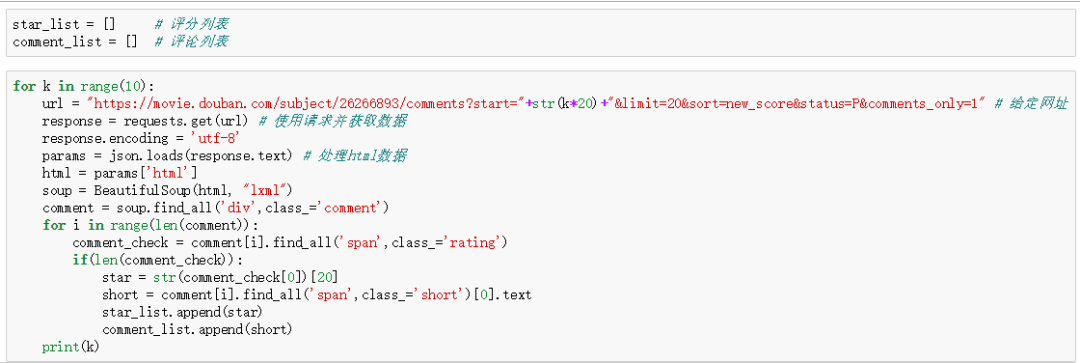
完整的爬虫代码
完成代码下载:
3.6 最终结果
最后,为了让最终的结果更加美观,作者在这里使用了pandas的DataFrame。

使用熊猫的数据框
爬取的数据结果如下

抓取的数据
3.7 扩展
以上内容只是一个基本的python爬虫。
如果读者细心,他们会发现不登录豆瓣就无法访问。”
"

没有权限
这里的url链接中的start=220表示我们不登录就无法查看第220条评论之后的内容。
在以后的爬虫进阶教程中,我们会介绍如何使用爬虫进行登录、保存cookies等操作。
另外,部分网站可能会使用js进行网站动态渲染、代码加密等,仅爬取html和json文件是不够的。同时,我们也可以使用多进程来加速爬虫...
敬请期待以后的爬虫进阶教程。
其他文章
(点击跳转)




长
根据
关闭
笔记
解锁更多精彩内容
跟着一起做一个有灵魂的人
c爬虫抓取网页数据( Python中的字典如何进行访问网络数据接口访问的相关知识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-03-15 16:19
Python中的字典如何进行访问网络数据接口访问的相关知识)
import requests
# requests的get函数会返回一个Response对象
resp = requests.get('https://www.sohu.com/')
if resp.status_code == 200:
# 通过Response对象的text属性获取服务器返回的文本内容
print(resp.text)
获取百度 Logo 并将其保存到名为 baidu.png 的本地文件中。首先,在百度首页,右击百度Logo,通过“复制图片地址”菜单获取图片的URL。
import requests
resp = requests.get('https://www.baidu.com/img/PCtm ... %2339;)
with open('baidu.png', 'wb') as file:
# 通过Response对象的content属性获取服务器返回的二进制内容
file.write(resp.content)
注:requests库的详细使用可以参考官方文档的内容。接入网络数据接口
国内外很多网站都提供了开放的数据接口。在开发商业项目的时候,如果有一些我们自己解决不了的事情,我们可以使用这些开放的数据接口来处理。例如,根据用户或企业上传的信息进行实名认证或企业认证,我们可以调用第三方提供的开放接口来识别用户或企业信息的真实性;例如,要获取一个城市的天气信息,我们不能直接从气象卫星获取数据,然后自己进行计算。相应的天气信息只能通过第三方提供的数据接口获取。通常,提供具有商业价值的数据的接口,需要付费才能访问。在访问接口时,还需要提供身份标识,以便服务器判断用户是否为付费用户,并进行扣费等相关操作。当然,有些接口可以免费使用,但必须提供个人或公司信息才能访问,例如:深圳市政务数据开放平台、蜻蜓FM开放平台等。如果您找到需要的数据接口,您可以访问 网站 类型的聚合数据。
目前我们访问的大部分网络数据接口都会返回JSON格式的数据。当我们在第 24 课中解释序列化和反序列化时,我们提到了如何将 JSON 格式的字符串转换为 Python 中的字典,并以天为单位使用数据。以行数据为例讲解网络数据接口访问的相关知识,这里不再赘述。
开发爬虫/爬虫程序
有时,我们需要的数据无法通过开放的数据接口获取,但在某些网页上可能有。这时候我们就需要开发一个爬虫程序,通过爬取页面来获取需要的内容。我们可以按照上面提供的方法,使用requests先获取网页的HTML代码。我们可以把整个代码看成一个长字符串,这样就可以使用正则表达式捕获组从字符串中提取出我们需要的内容。下面我们通过代码演示如何从豆瓣电影中获取前 250 部电影的名称。豆瓣电影Top250页面结构及对应代码如下图所示。
import random
import re
import time
import requests
for page in range(1, 11):
resp = requests.get(
# 请求https://movie.douban.com/top250时,start参数代表了从哪一部电影开始
url=f'https://movie.douban.com/top250?start={(page - 1) * 25}',
# 如果不设置HTTP请求头中的User-Agent,豆瓣会检测出爬虫程序而阻止我们的请求
# User-Agent可以设置为浏览器的标识(可以在浏览器的开发者工具查看HTTP请求头找到)
# 由于豆瓣网允许百度爬虫获取它的数据,因此直接将我们的爬虫伪装成百度的爬虫
headers={'User-Agent': 'BaiduSpider'}
)
# 创建正则表达式对象,通过捕获组捕获span标签中的电影标题
pattern = re.compile(r'\([^&]*?)\')
# 通过正则表达式获取class属性为title且标签内容不以&符号开头的span标签
results = pattern.findall(resp.text)
# 循环变量列表中所有的电影标题
for result in results:
print(result)
# 随机休眠1-3秒,避免获取页面过于频繁
time.sleep(random.randint(1, 3))
写爬虫程序最重要的就是让爬虫程序隐藏自己的身份,因为一般的网站对爬虫比较反感。除了修改上面代码中的User-Agent,还可以使用商业IP代理(如蘑菇代理、芝麻代理等)隐藏自己的身份,让爬取的网站无法知道真实的爬虫程序地址的IP,无法通过IP地址屏蔽爬虫程序。当然,爬虫本身也是一个灰色地带的东西。没有人说这是非法的,但也没有人说这是合法的。本着允许的精神,如果法律不禁止,我们可以根据自己工作的需要来写。爬虫程序,但是如果爬取的网站可以证明你的爬虫程序破坏了动产,
另外,虽然通过编写正则表达式从网页中提取内容是可行的,但要编写一个能够满足需求的正则表达式并不容易,尤其是对于初学者而言。在下一课中,我们将介绍另外两种从页面中提取数据的方法。尽管它们在性能方面可能不如正则表达式,但它们降低了编码的复杂性。我相信你会喜欢的。他们的。
简单总结
Python 语言确实可以做很多事情。在获取网络数据方面,Python 几乎是佼佼者。大量的企业和个人会使用 Python 从网络中获取他们需要的数据。我相信这将在现在或将来发生。它也将成为您工作的一部分。
原文来自知乎:Python-Jack
原文链接:Learning Python from scratch - 第030课:用Python获取网络数据 查看全部
c爬虫抓取网页数据(
Python中的字典如何进行访问网络数据接口访问的相关知识)
import requests
# requests的get函数会返回一个Response对象
resp = requests.get('https://www.sohu.com/')
if resp.status_code == 200:
# 通过Response对象的text属性获取服务器返回的文本内容
print(resp.text)
获取百度 Logo 并将其保存到名为 baidu.png 的本地文件中。首先,在百度首页,右击百度Logo,通过“复制图片地址”菜单获取图片的URL。
import requests
resp = requests.get('https://www.baidu.com/img/PCtm ... %2339;)
with open('baidu.png', 'wb') as file:
# 通过Response对象的content属性获取服务器返回的二进制内容
file.write(resp.content)
注:requests库的详细使用可以参考官方文档的内容。接入网络数据接口
国内外很多网站都提供了开放的数据接口。在开发商业项目的时候,如果有一些我们自己解决不了的事情,我们可以使用这些开放的数据接口来处理。例如,根据用户或企业上传的信息进行实名认证或企业认证,我们可以调用第三方提供的开放接口来识别用户或企业信息的真实性;例如,要获取一个城市的天气信息,我们不能直接从气象卫星获取数据,然后自己进行计算。相应的天气信息只能通过第三方提供的数据接口获取。通常,提供具有商业价值的数据的接口,需要付费才能访问。在访问接口时,还需要提供身份标识,以便服务器判断用户是否为付费用户,并进行扣费等相关操作。当然,有些接口可以免费使用,但必须提供个人或公司信息才能访问,例如:深圳市政务数据开放平台、蜻蜓FM开放平台等。如果您找到需要的数据接口,您可以访问 网站 类型的聚合数据。
目前我们访问的大部分网络数据接口都会返回JSON格式的数据。当我们在第 24 课中解释序列化和反序列化时,我们提到了如何将 JSON 格式的字符串转换为 Python 中的字典,并以天为单位使用数据。以行数据为例讲解网络数据接口访问的相关知识,这里不再赘述。
开发爬虫/爬虫程序
有时,我们需要的数据无法通过开放的数据接口获取,但在某些网页上可能有。这时候我们就需要开发一个爬虫程序,通过爬取页面来获取需要的内容。我们可以按照上面提供的方法,使用requests先获取网页的HTML代码。我们可以把整个代码看成一个长字符串,这样就可以使用正则表达式捕获组从字符串中提取出我们需要的内容。下面我们通过代码演示如何从豆瓣电影中获取前 250 部电影的名称。豆瓣电影Top250页面结构及对应代码如下图所示。
import random
import re
import time
import requests
for page in range(1, 11):
resp = requests.get(
# 请求https://movie.douban.com/top250时,start参数代表了从哪一部电影开始
url=f'https://movie.douban.com/top250?start={(page - 1) * 25}',
# 如果不设置HTTP请求头中的User-Agent,豆瓣会检测出爬虫程序而阻止我们的请求
# User-Agent可以设置为浏览器的标识(可以在浏览器的开发者工具查看HTTP请求头找到)
# 由于豆瓣网允许百度爬虫获取它的数据,因此直接将我们的爬虫伪装成百度的爬虫
headers={'User-Agent': 'BaiduSpider'}
)
# 创建正则表达式对象,通过捕获组捕获span标签中的电影标题
pattern = re.compile(r'\([^&]*?)\')
# 通过正则表达式获取class属性为title且标签内容不以&符号开头的span标签
results = pattern.findall(resp.text)
# 循环变量列表中所有的电影标题
for result in results:
print(result)
# 随机休眠1-3秒,避免获取页面过于频繁
time.sleep(random.randint(1, 3))
写爬虫程序最重要的就是让爬虫程序隐藏自己的身份,因为一般的网站对爬虫比较反感。除了修改上面代码中的User-Agent,还可以使用商业IP代理(如蘑菇代理、芝麻代理等)隐藏自己的身份,让爬取的网站无法知道真实的爬虫程序地址的IP,无法通过IP地址屏蔽爬虫程序。当然,爬虫本身也是一个灰色地带的东西。没有人说这是非法的,但也没有人说这是合法的。本着允许的精神,如果法律不禁止,我们可以根据自己工作的需要来写。爬虫程序,但是如果爬取的网站可以证明你的爬虫程序破坏了动产,
另外,虽然通过编写正则表达式从网页中提取内容是可行的,但要编写一个能够满足需求的正则表达式并不容易,尤其是对于初学者而言。在下一课中,我们将介绍另外两种从页面中提取数据的方法。尽管它们在性能方面可能不如正则表达式,但它们降低了编码的复杂性。我相信你会喜欢的。他们的。
简单总结
Python 语言确实可以做很多事情。在获取网络数据方面,Python 几乎是佼佼者。大量的企业和个人会使用 Python 从网络中获取他们需要的数据。我相信这将在现在或将来发生。它也将成为您工作的一部分。
原文来自知乎:Python-Jack
原文链接:Learning Python from scratch - 第030课:用Python获取网络数据
c爬虫抓取网页数据(1.网络爬虫的基本概念网络蜘蛛,机器人都能够做到! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-04-09 06:27
)
1.网络爬虫基本概念
网络爬虫(也称为网络蜘蛛或机器人)是模拟客户端发送网络请求并接收请求响应的程序,根据一定的规则自动抓取互联网信息的程序。
只要浏览器能做任何事情,原则上爬虫都能做到。
2.网络爬虫函数
网络爬虫可以手动替换很多东西,比如用作搜索引擎,或者爬取网站上的图片。比如有的朋友把一些网站上的所有图片都爬进去,集中在上面。可以进行投资分析。
有时候,可能有几个我们比较喜欢的新闻网站,每次浏览都单独打开这些新闻网站比较麻烦。这时候就可以用网络爬虫来爬取这多条新闻网站中的新闻信息,集中阅读。
有时候,我们在网上浏览信息的时候,会发现有很多广告。这时也可以利用爬虫来爬取相应网页上的信息,从而自动过滤掉这些广告,方便信息的阅读和使用。
有时候,我们需要做营销,所以如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以手动搜索互联网,但这会非常低效。这时,我们可以通过爬虫设置相应的规则,自动采集从互联网上获取目标用户的联系方式,供我们营销使用。
有时候,我们想分析某个网站的用户信息,比如分析网站的用户活跃度、发言次数、热门文章等信息,如果我们没有网站@ >管理员,手动统计将是一个非常庞大的工程。此时,您可以使用爬虫轻松采集对这些数据进行进一步分析,并且所有这些爬取操作都是自动进行的,我们只需要编写相应的爬虫并设计相应的爬虫即可。规则会做。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫实现自动化,可以更好地利用互联网中的有效信息。.
3.安装第三方库
在爬取和解析数据之前,需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面输入pip install requests,回车安装。(注意连接网络)如下图
安装完成,如图
查看全部
c爬虫抓取网页数据(1.网络爬虫的基本概念网络蜘蛛,机器人都能够做到!
)
1.网络爬虫基本概念
网络爬虫(也称为网络蜘蛛或机器人)是模拟客户端发送网络请求并接收请求响应的程序,根据一定的规则自动抓取互联网信息的程序。
只要浏览器能做任何事情,原则上爬虫都能做到。
2.网络爬虫函数
网络爬虫可以手动替换很多东西,比如用作搜索引擎,或者爬取网站上的图片。比如有的朋友把一些网站上的所有图片都爬进去,集中在上面。可以进行投资分析。
有时候,可能有几个我们比较喜欢的新闻网站,每次浏览都单独打开这些新闻网站比较麻烦。这时候就可以用网络爬虫来爬取这多条新闻网站中的新闻信息,集中阅读。
有时候,我们在网上浏览信息的时候,会发现有很多广告。这时也可以利用爬虫来爬取相应网页上的信息,从而自动过滤掉这些广告,方便信息的阅读和使用。
有时候,我们需要做营销,所以如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以手动搜索互联网,但这会非常低效。这时,我们可以通过爬虫设置相应的规则,自动采集从互联网上获取目标用户的联系方式,供我们营销使用。
有时候,我们想分析某个网站的用户信息,比如分析网站的用户活跃度、发言次数、热门文章等信息,如果我们没有网站@ >管理员,手动统计将是一个非常庞大的工程。此时,您可以使用爬虫轻松采集对这些数据进行进一步分析,并且所有这些爬取操作都是自动进行的,我们只需要编写相应的爬虫并设计相应的爬虫即可。规则会做。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫实现自动化,可以更好地利用互联网中的有效信息。.
3.安装第三方库
在爬取和解析数据之前,需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面输入pip install requests,回车安装。(注意连接网络)如下图
安装完成,如图
c爬虫抓取网页数据(关于爬虫的知识后,你了解多少?(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-04-07 23:27
)
如今,大前端理念已经深入人心,需要涉及的知识很多。所以,对于现在的前端来说,也是不可抗拒的。在修炼吸星大法时,尽可能多地吸收知识,最终达到物尽其用的效果。
最近也在学习爬虫,因为之前项目中需要用到的地铁信息数据不是爬虫爬下来的数据,而是直接复制过来的。
虽然这些数据暂时不会有太大变化,但感觉还是有点低。所以在了解了爬虫之后,打算和大家讨论交流,然后直接进入正题。
首先说一下爬虫和Robots协议是什么
然后介绍爬虫的基本流程
最后根据实际栗子爬个豆瓣最近上映的电影来试试小刀
2、爬虫和机器人协议
首先看定义:爬虫是自动获取网页内容的程序。它是搜索引擎的重要组成部分,因此搜索引擎优化主要针对爬虫进行优化。
下面我们来看看Robots协议的介绍。robots.txt 是文本文件,robots.txt 是协议,而不是命令。
robots.txt 是爬虫要查看的第一个文件。robots.txt 告诉爬虫可以在服务器上查看哪些文件。爬虫机器人会根据文件内容确定访问范围。
下图是豆瓣电影页面列出的robots协议的访问范围。
爬虫和机器人协议密切相关。如果您看到不允许抓取的页面,请不要抓取它们。万一涉及到用户隐私的某些方面,稍后会被发现并带到合法渠道。
因此,业内每个人都认可这个 Robots 协议。不想爬网页就别爬了,上网就可以安宁了。
有点跑题了,我们看下面一张图,简单梳理一下上面提到的内容。
其实有人会问,爬行动物到底在爬什么?
这是一个非常有见地的问题。说白了就是爬虫拿到的那段html代码,所以这对我们来说并不陌生,只要我们把它转换成DOM树就行了。
所以,现在看上图的右半部分,是一张对比图。
左边的那个没有机器人协议限制。从逻辑上讲,admin/private 和 tmp 这三个文件夹是不能被抓取的,但是由于没有 Robots 协议,人们可以肆无忌惮的爬取。
从右侧看,Robots 协议是有限的。相反,像谷歌这样的搜索引擎也会使用 Robots.txt 文件来查看无法捕获的内容,然后直接跳到 admin 或 private。去抢吧。
好了,介绍到此为止。凡是不包括真刀真枪的,都只是纸上谈兵。
3、爬虫基本流程
其实对于爬虫的使用来说,过程无非就是这四个步骤。
专用数据
数据存储
启动服务
渲染数据
专用数据
现在到了激动人心的部分,不要停下来,跟着我,敲出一页爬豆瓣电影,供自己欣赏。
我们先来看看整体的目录结构。
既然是抓数据,就得用业界知名的神器——request
请求工件
那么如何使用request,我们一起听风看代码
// 使用起来超简单let request = require('request');
request('http://www.baidu.com', function (error, response, body) { console.log('error:', error); // 当有错误发生时打印错误日志 console.log('statusCode:', response && response.statusCode); // 打印响应状态码 console.log('body:', body); // 打印百度页面的html代码});
看了上面的代码,是不是还觉得不明显。小伙伴们,html代码已经出现在你们面前了,不要犹豫,只要把它变成熟悉的DOM,就可以为所欲为。
于是,cheerio 出道,大家都称它为 Node 版的 jq。你可以完全按照jq的习惯来操作DOM。
下面不再走弯路,一起来写爬虫吧!
阅读内容
首页应该先分析豆瓣电影的页面,也就是热映的电影,我们先来看看DOM结构。
好了,读完噻吩后,我们需要的内容也标注出来了,然后进入read.js文件,一步步开始舔。
// read.js文件
// request-promise是让request支持了promise的语法,可以说是request的小弟const rp = require('request-promise');// 将抓取页面的html代码转为DOM,可以称之为是node版的jqconst cheerio = require('cheerio');// 这个是为了在调试时查看日志const debug = require('debug')('movie:read');
// 读取页面的方法,重点来了const read = async (url) => { debug('开始读取最近上映的电影');
const opts = { url, // 目标页面 transform: body => { // body为目标页面抓取到的html代码 // 通过cheerio.load方法可以把html代码转换成可以操作的DOM结构 return cheerio.load(body); } };
return rp(opts).then($ => { let result = []; // 结果数组 // 遍历这些热映电影的li $('#screening li.ui-slide-item').each((index, item) => { let ele = $(item); let name = ele.data('title'); let score = ele.data('rate') || '暂无评分'; let href = ele.find('.poster a').attr('href'); let image = ele.find('img').attr('src'); // 影片id可以从影片href中获取到 let id = href && href.match(/(\d+)/)[1]; // 为了防止豆瓣防盗链导致裂图,换成webp格式加载图片 image = image && image.replace(/jpg$/, 'webp');
if (!name || !image || !href) { return; }
result.push({ name, score, href, image, id }); debug(`正在读取电影:${name}`); }); // 返回结果数组 return result; });};// 导出方法module.exports = read;
写完代码,让我们回忆一下你做了什么。
4、数据存储
这里我们使用mysql建一个数据库来存储数据,不懂的没关系,我先一步一步来。我们首先安装 XAMPP 和 Navicat 可视化数据库管理工具,安装完成后,按照下面的说明进行操作。
XAMPP启动mysql
Navicat 连接数据库并创建表
几句话可能不像有图有真相那么真实。我们先来看看图片。
嗯,看图的时代到此结束。我真的很惭愧消耗了大量的流量。现在让我们回到编码阶段。
连接到数据库
首先,我们需要在 src 目录下创建一个 sql 文件。它需要和我们刚刚创建的数据库同名,所以我们称之为my_movie.sql(当然目录结构已经创建好了)
然后,回到 db.js 文件,编写连接数据库的代码
// db.js
const mysql = require('mysql');const bluebird = require('bluebird');
// 创建连接const connection = mysql.createConnection({ host: 'localhost', // host port: 3306, // 端口号默认3306 database: 'my_movie', // 对应的数据库 user: 'root', password: ''});
connection.connect(); // 连接数据库
// bluebird是为了方便支持promise语法化// 然后直接把数据库的query查询语句导出方便之后调用module.exports = bluebird.promisify(connection.query).bind(connection);
上面的代码已经创建了连接Mysql数据库的操作。接下来,不要放慢速度,将内容直接写入数据库。
写入数据库
这时候我们来看看write.js这个文件。是的,顾名思义,就是用来写数据库的,直接上代码
// write.js文件
// 从db.js那里导入query方法const query = require('./db');const debug = require('debug')('movie:write');// 写入数据库的方法const write = async (movies) => { debug('开始写入电影');
// movies即为read.js读取出来的结果数组 for (let movie of movies) { // 通过query方法去查询一下是不是已经在数据库里存过了 let oldMovie = await query('SELECT * FROM movies WHERE id=? LIMIT 1', [movie.id]);
// sql查询语句返回的是一个数组,如果不为空数组的话就表示有数据存过 // 直接就进行更新操作了 if (Array.isArray(oldMovie) && oldMovie.length) { // 更新movies表里的数据 let old = oldMovie[0]; await query('UPDATE movies SET name=?,href=?,image=?,score=? WHERE id=?', [movie.name, movie.href, movie.image, movie.score, old.id]); } else { // 插入内容到movies表 await query('INSERT INTO movies(id,name,href,image,score) VALUES(?,?,?,?,?)', [movie.id, movie.name, movie.href, movie.image, movie.score]); }
debug(`正在写入电影:${movie.name}`); }};
module.exports = write;
上面写的可能有点混乱,毕竟纯前端很少写SQL语句。不过不要害羞,我先把上面的代码整理好之后再简单介绍一下SQL语句部分。
write.js 到底写了什么?
好了,上面也实现了写入数据库的方法。接下来,趁热打铁,稍微聊聊SQL语句。
SQL语句学习
? 表示占位符。顺便说一下,我将简要介绍将在 SQL 语句中使用的语法,以及无处不在的增删改查。
插入数据
语法: INSERT INTO 表名(列名) VALUES(列名值)栗子: INSERT INTO tags(name,id,url) VALUES('爬虫',10,'https://news.so.com/hotnews')解释: 向标签表(tags)里插入一条,姓名,id和访问地址分别为VALUES内对应的值
更新数据
语法: UPDATE 表名 SET 列名=更新值 WHERE 更新条件栗子: UPDATE articles SET title='你好,世界',content='世界没你想的那么糟!' WHERE id=1解释: 更新id为1的文章,标题和内容都进行了修改
删除数据
语法: DELETE FROM 表名 WHERE 删除条件栗子: DELETE FROM tags WHERE id=11解释: 从标签表(tags)里删除id为11的数据
查询
语法: SELECT 列名 FROM 表名 WHERE 查询条件 ORDER BY 排序列名栗子: SELECT name,title,content FROM tags WHERE id=8解释: 查询id为8的标签表里对应信息
至此,我已经把所有的读写方法都写完了,所以大家一定是有点累了。是时候测试结果了,否则都是废话
5、执行读写操作
现在来到 index.js 并开始检查它。
// index.js文件
const read = require('./read');const write = require('./write');const url = 'https://movie.douban.com'; // 目标页面
(async () => { // 异步抓取目标页面 const movies = await read(url); // 写入数据到数据库 await write(movies); // 完毕后退出程序 process.exit();})();
完了,执行一下看看效果如何,直接上图
代码已执行。接下来回到Navicat,看看数据是否已经写入。我们用图片来说话。
至此,我们已经完成了数据采集和存储操作,但似乎还缺少什么?
也就是我们需要写一个页面来展示它,因为爬取和写数据只允许在node环境下进行。所以我们还要创建一个web服务来显示页面,坚持下去很快就OK了,加油。
6、启动服务
既然我们要创建一个 web 服务,让我们开始编写 server.js 的内容
服务器服务
// server.js文件
const express = require('express');const path = require('path');const query = require('../src/db');const app = express();
// 设置模板引擎app.set('view engine', 'html');app.set('views', path.join(__dirname, 'views'));app.engine('html', require('ejs').__express);
// 首页路由app.get('/', async (req, res) => { // 通过SQL查询语句拿到库里的movies表数据 const movies = await query('SELECT * FROM movies'); // 渲染首页模板并把movies数据传过去 res.render('index', { movies });});// 监听localhost:9000端口app.listen(9000);
写完服务端服务,我们再来看看 index.html 模板。这是最后一件事。写完,就大功告成了。
7、渲染数据
// index.html
热映的电影 正在热映的电影 %=movie.image% <p class="score">评分: </a>
</p>
通过模板引擎遍历movies数组,然后渲染
现在,看看最终效果
和你一起来到这里是缘分。我很高兴经历了这么长时间的文章 学习。每个人都应该对爬行动物的知识有一个很好的了解。
对了,这里是代码地址:爬虫研究/电影
为了您的方便,敲敲敲。
感谢阅读,886。
查看全部
c爬虫抓取网页数据(关于爬虫的知识后,你了解多少?(一)
)
如今,大前端理念已经深入人心,需要涉及的知识很多。所以,对于现在的前端来说,也是不可抗拒的。在修炼吸星大法时,尽可能多地吸收知识,最终达到物尽其用的效果。
最近也在学习爬虫,因为之前项目中需要用到的地铁信息数据不是爬虫爬下来的数据,而是直接复制过来的。
虽然这些数据暂时不会有太大变化,但感觉还是有点低。所以在了解了爬虫之后,打算和大家讨论交流,然后直接进入正题。
首先说一下爬虫和Robots协议是什么
然后介绍爬虫的基本流程
最后根据实际栗子爬个豆瓣最近上映的电影来试试小刀
2、爬虫和机器人协议
首先看定义:爬虫是自动获取网页内容的程序。它是搜索引擎的重要组成部分,因此搜索引擎优化主要针对爬虫进行优化。
下面我们来看看Robots协议的介绍。robots.txt 是文本文件,robots.txt 是协议,而不是命令。
robots.txt 是爬虫要查看的第一个文件。robots.txt 告诉爬虫可以在服务器上查看哪些文件。爬虫机器人会根据文件内容确定访问范围。
下图是豆瓣电影页面列出的robots协议的访问范围。
爬虫和机器人协议密切相关。如果您看到不允许抓取的页面,请不要抓取它们。万一涉及到用户隐私的某些方面,稍后会被发现并带到合法渠道。
因此,业内每个人都认可这个 Robots 协议。不想爬网页就别爬了,上网就可以安宁了。
有点跑题了,我们看下面一张图,简单梳理一下上面提到的内容。
其实有人会问,爬行动物到底在爬什么?
这是一个非常有见地的问题。说白了就是爬虫拿到的那段html代码,所以这对我们来说并不陌生,只要我们把它转换成DOM树就行了。
所以,现在看上图的右半部分,是一张对比图。
左边的那个没有机器人协议限制。从逻辑上讲,admin/private 和 tmp 这三个文件夹是不能被抓取的,但是由于没有 Robots 协议,人们可以肆无忌惮的爬取。
从右侧看,Robots 协议是有限的。相反,像谷歌这样的搜索引擎也会使用 Robots.txt 文件来查看无法捕获的内容,然后直接跳到 admin 或 private。去抢吧。
好了,介绍到此为止。凡是不包括真刀真枪的,都只是纸上谈兵。
3、爬虫基本流程
其实对于爬虫的使用来说,过程无非就是这四个步骤。
专用数据
数据存储
启动服务
渲染数据
专用数据
现在到了激动人心的部分,不要停下来,跟着我,敲出一页爬豆瓣电影,供自己欣赏。
我们先来看看整体的目录结构。
既然是抓数据,就得用业界知名的神器——request
请求工件
那么如何使用request,我们一起听风看代码
// 使用起来超简单let request = require('request');
request('http://www.baidu.com', function (error, response, body) { console.log('error:', error); // 当有错误发生时打印错误日志 console.log('statusCode:', response && response.statusCode); // 打印响应状态码 console.log('body:', body); // 打印百度页面的html代码});
看了上面的代码,是不是还觉得不明显。小伙伴们,html代码已经出现在你们面前了,不要犹豫,只要把它变成熟悉的DOM,就可以为所欲为。
于是,cheerio 出道,大家都称它为 Node 版的 jq。你可以完全按照jq的习惯来操作DOM。
下面不再走弯路,一起来写爬虫吧!
阅读内容
首页应该先分析豆瓣电影的页面,也就是热映的电影,我们先来看看DOM结构。
好了,读完噻吩后,我们需要的内容也标注出来了,然后进入read.js文件,一步步开始舔。
// read.js文件
// request-promise是让request支持了promise的语法,可以说是request的小弟const rp = require('request-promise');// 将抓取页面的html代码转为DOM,可以称之为是node版的jqconst cheerio = require('cheerio');// 这个是为了在调试时查看日志const debug = require('debug')('movie:read');
// 读取页面的方法,重点来了const read = async (url) => { debug('开始读取最近上映的电影');
const opts = { url, // 目标页面 transform: body => { // body为目标页面抓取到的html代码 // 通过cheerio.load方法可以把html代码转换成可以操作的DOM结构 return cheerio.load(body); } };
return rp(opts).then($ => { let result = []; // 结果数组 // 遍历这些热映电影的li $('#screening li.ui-slide-item').each((index, item) => { let ele = $(item); let name = ele.data('title'); let score = ele.data('rate') || '暂无评分'; let href = ele.find('.poster a').attr('href'); let image = ele.find('img').attr('src'); // 影片id可以从影片href中获取到 let id = href && href.match(/(\d+)/)[1]; // 为了防止豆瓣防盗链导致裂图,换成webp格式加载图片 image = image && image.replace(/jpg$/, 'webp');
if (!name || !image || !href) { return; }
result.push({ name, score, href, image, id }); debug(`正在读取电影:${name}`); }); // 返回结果数组 return result; });};// 导出方法module.exports = read;
写完代码,让我们回忆一下你做了什么。
4、数据存储
这里我们使用mysql建一个数据库来存储数据,不懂的没关系,我先一步一步来。我们首先安装 XAMPP 和 Navicat 可视化数据库管理工具,安装完成后,按照下面的说明进行操作。
XAMPP启动mysql
Navicat 连接数据库并创建表
几句话可能不像有图有真相那么真实。我们先来看看图片。
嗯,看图的时代到此结束。我真的很惭愧消耗了大量的流量。现在让我们回到编码阶段。
连接到数据库
首先,我们需要在 src 目录下创建一个 sql 文件。它需要和我们刚刚创建的数据库同名,所以我们称之为my_movie.sql(当然目录结构已经创建好了)
然后,回到 db.js 文件,编写连接数据库的代码
// db.js
const mysql = require('mysql');const bluebird = require('bluebird');
// 创建连接const connection = mysql.createConnection({ host: 'localhost', // host port: 3306, // 端口号默认3306 database: 'my_movie', // 对应的数据库 user: 'root', password: ''});
connection.connect(); // 连接数据库
// bluebird是为了方便支持promise语法化// 然后直接把数据库的query查询语句导出方便之后调用module.exports = bluebird.promisify(connection.query).bind(connection);
上面的代码已经创建了连接Mysql数据库的操作。接下来,不要放慢速度,将内容直接写入数据库。
写入数据库
这时候我们来看看write.js这个文件。是的,顾名思义,就是用来写数据库的,直接上代码
// write.js文件
// 从db.js那里导入query方法const query = require('./db');const debug = require('debug')('movie:write');// 写入数据库的方法const write = async (movies) => { debug('开始写入电影');
// movies即为read.js读取出来的结果数组 for (let movie of movies) { // 通过query方法去查询一下是不是已经在数据库里存过了 let oldMovie = await query('SELECT * FROM movies WHERE id=? LIMIT 1', [movie.id]);
// sql查询语句返回的是一个数组,如果不为空数组的话就表示有数据存过 // 直接就进行更新操作了 if (Array.isArray(oldMovie) && oldMovie.length) { // 更新movies表里的数据 let old = oldMovie[0]; await query('UPDATE movies SET name=?,href=?,image=?,score=? WHERE id=?', [movie.name, movie.href, movie.image, movie.score, old.id]); } else { // 插入内容到movies表 await query('INSERT INTO movies(id,name,href,image,score) VALUES(?,?,?,?,?)', [movie.id, movie.name, movie.href, movie.image, movie.score]); }
debug(`正在写入电影:${movie.name}`); }};
module.exports = write;
上面写的可能有点混乱,毕竟纯前端很少写SQL语句。不过不要害羞,我先把上面的代码整理好之后再简单介绍一下SQL语句部分。
write.js 到底写了什么?
好了,上面也实现了写入数据库的方法。接下来,趁热打铁,稍微聊聊SQL语句。
SQL语句学习
? 表示占位符。顺便说一下,我将简要介绍将在 SQL 语句中使用的语法,以及无处不在的增删改查。
插入数据
语法: INSERT INTO 表名(列名) VALUES(列名值)栗子: INSERT INTO tags(name,id,url) VALUES('爬虫',10,'https://news.so.com/hotnews')解释: 向标签表(tags)里插入一条,姓名,id和访问地址分别为VALUES内对应的值
更新数据
语法: UPDATE 表名 SET 列名=更新值 WHERE 更新条件栗子: UPDATE articles SET title='你好,世界',content='世界没你想的那么糟!' WHERE id=1解释: 更新id为1的文章,标题和内容都进行了修改
删除数据
语法: DELETE FROM 表名 WHERE 删除条件栗子: DELETE FROM tags WHERE id=11解释: 从标签表(tags)里删除id为11的数据
查询
语法: SELECT 列名 FROM 表名 WHERE 查询条件 ORDER BY 排序列名栗子: SELECT name,title,content FROM tags WHERE id=8解释: 查询id为8的标签表里对应信息
至此,我已经把所有的读写方法都写完了,所以大家一定是有点累了。是时候测试结果了,否则都是废话
5、执行读写操作
现在来到 index.js 并开始检查它。
// index.js文件
const read = require('./read');const write = require('./write');const url = 'https://movie.douban.com'; // 目标页面
(async () => { // 异步抓取目标页面 const movies = await read(url); // 写入数据到数据库 await write(movies); // 完毕后退出程序 process.exit();})();
完了,执行一下看看效果如何,直接上图
代码已执行。接下来回到Navicat,看看数据是否已经写入。我们用图片来说话。
至此,我们已经完成了数据采集和存储操作,但似乎还缺少什么?
也就是我们需要写一个页面来展示它,因为爬取和写数据只允许在node环境下进行。所以我们还要创建一个web服务来显示页面,坚持下去很快就OK了,加油。
6、启动服务
既然我们要创建一个 web 服务,让我们开始编写 server.js 的内容
服务器服务
// server.js文件
const express = require('express');const path = require('path');const query = require('../src/db');const app = express();
// 设置模板引擎app.set('view engine', 'html');app.set('views', path.join(__dirname, 'views'));app.engine('html', require('ejs').__express);
// 首页路由app.get('/', async (req, res) => { // 通过SQL查询语句拿到库里的movies表数据 const movies = await query('SELECT * FROM movies'); // 渲染首页模板并把movies数据传过去 res.render('index', { movies });});// 监听localhost:9000端口app.listen(9000);
写完服务端服务,我们再来看看 index.html 模板。这是最后一件事。写完,就大功告成了。
7、渲染数据
// index.html
热映的电影 正在热映的电影 %=movie.image% <p class="score">评分: </a>
</p>
通过模板引擎遍历movies数组,然后渲染
现在,看看最终效果
和你一起来到这里是缘分。我很高兴经历了这么长时间的文章 学习。每个人都应该对爬行动物的知识有一个很好的了解。
对了,这里是代码地址:爬虫研究/电影
为了您的方便,敲敲敲。
感谢阅读,886。
c爬虫抓取网页数据( 如何找出发送请求的js在控制数据的生成,我根本无法找到是哪一个js实现的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-04-07 14:27
如何找出发送请求的js在控制数据的生成,我根本无法找到是哪一个js实现的
)
有很多页。当我们使用request发送请求时,返回的内容中没有页面显示数据。主要有两种情况。一种是通过ajax异步发送请求,得到响应并把数据放入页面。对于这种情况,我们可以查看ajax请求,然后分析ajax请求路径和响应,得到想要的数据;另一种是js动态加载的数据,然后放到页面中。在这两种情况下,用户在通过浏览器访问时都不会发现任何异常,并且会很快得到完整的页面。
其实我们之前学过一个selenium模块。通过操作浏览器,然后获取浏览器显示的数据,我们可以通过这种方式获取数据,但是本节是分析如何找到控制数据生成的js。以及js发送请求的路径,这样我们就可以向这个路径发送请求,直接获取数据。
在之前的爬取过程中,最困扰我的是js动态生成的数据。我找不到哪个js实现了它(因为js太多了)。今天看了大佬的博客,顿时觉得简单多了。,谢谢大佬提供大佬的博客:
一、需求描述及页面分析一、需求描述
基本页面路径:
点击进入每个标题:
要求是爬取每个标题下的新闻内容
2.页面分析
2.1 主页
查看ajax请求:
接下来,我们将解析如何找出发送请求的js
二、找到发送请求的js
在响应数据中收录了这条新闻的新闻标题和详情页路径,所以现在我们去访问详情页,分析详情页
访问详情页,查看详情页的响应,数据中不收录具体数据,则和主页面一样,然后去ajax:
Ajax 没有与新闻相关的数据,因此它不使用 ajax 请求来获取数据。只剩下js了。我们会找出是哪个js发送了请求来获取数据。步骤与上面相同:
详情页数据的js请求路径:
详情页请求路径:
我们可以看到,最后一个斜杠之前的详情页数据的请求路径和最后一个斜杠之前的详情页的请求路径是一样的。所以我们可以这样做:
第一步:拿到详情页的请求路径:
url1='https://www.xuexi.cn/1ed1e76f885a3c19576e495ad2b279e5/e43e220633a65f9b6d8b53712cba9caa.html'
第二步:把url1最后一个斜杠后面的内容替换掉
url2='https://www.xuexi.cn/%s/datae43e220633a65f9b6d8b53712cba9caa.js'%(url1.split('/')[3]) #把url1用‘/’分割,拿到第四部分,即索引为3,然后拼接进去既可
这样就构造好了一个详情页数据请求路径,然后直接去访问这个路径既可拿到数据,就不用去访问详情页了 查看全部
c爬虫抓取网页数据(
如何找出发送请求的js在控制数据的生成,我根本无法找到是哪一个js实现的
)
有很多页。当我们使用request发送请求时,返回的内容中没有页面显示数据。主要有两种情况。一种是通过ajax异步发送请求,得到响应并把数据放入页面。对于这种情况,我们可以查看ajax请求,然后分析ajax请求路径和响应,得到想要的数据;另一种是js动态加载的数据,然后放到页面中。在这两种情况下,用户在通过浏览器访问时都不会发现任何异常,并且会很快得到完整的页面。
其实我们之前学过一个selenium模块。通过操作浏览器,然后获取浏览器显示的数据,我们可以通过这种方式获取数据,但是本节是分析如何找到控制数据生成的js。以及js发送请求的路径,这样我们就可以向这个路径发送请求,直接获取数据。
在之前的爬取过程中,最困扰我的是js动态生成的数据。我找不到哪个js实现了它(因为js太多了)。今天看了大佬的博客,顿时觉得简单多了。,谢谢大佬提供大佬的博客:
一、需求描述及页面分析一、需求描述
基本页面路径:
点击进入每个标题:
要求是爬取每个标题下的新闻内容
2.页面分析
2.1 主页
查看ajax请求:
接下来,我们将解析如何找出发送请求的js
二、找到发送请求的js
在响应数据中收录了这条新闻的新闻标题和详情页路径,所以现在我们去访问详情页,分析详情页
访问详情页,查看详情页的响应,数据中不收录具体数据,则和主页面一样,然后去ajax:
Ajax 没有与新闻相关的数据,因此它不使用 ajax 请求来获取数据。只剩下js了。我们会找出是哪个js发送了请求来获取数据。步骤与上面相同:
详情页数据的js请求路径:
详情页请求路径:
我们可以看到,最后一个斜杠之前的详情页数据的请求路径和最后一个斜杠之前的详情页的请求路径是一样的。所以我们可以这样做:
第一步:拿到详情页的请求路径:
url1='https://www.xuexi.cn/1ed1e76f885a3c19576e495ad2b279e5/e43e220633a65f9b6d8b53712cba9caa.html'
第二步:把url1最后一个斜杠后面的内容替换掉
url2='https://www.xuexi.cn/%s/datae43e220633a65f9b6d8b53712cba9caa.js'%(url1.split('/')[3]) #把url1用‘/’分割,拿到第四部分,即索引为3,然后拼接进去既可
这样就构造好了一个详情页数据请求路径,然后直接去访问这个路径既可拿到数据,就不用去访问详情页了
c爬虫抓取网页数据(推荐阅读python如何从无到有成长为一个python开发工程师)
网站优化 • 优采云 发表了文章 • 0 个评论 • 40 次浏览 • 2022-04-05 13:04
c爬虫抓取网页数据可以编写python代码,
新手可以从上面那位大哥的这篇回答入手。自学的方法有多种,不要单单想靠编程挣钱就好,如果想通过技术来赚钱,那就要付出比别人更多的时间精力来学习。
推荐阅读python如何从无到有成长为一个python开发工程师-慕课网
python主要可以去做爬虫,数据分析,机器学习,
可以看看这篇高级python爬虫学习笔记
一、高级python爬虫学习笔记
二、爬虫自动化之数据采集篇
一、python爬虫的入门路线
二、python爬虫的进阶路线
黄哥推荐学习python的三本书:《黄哥:黄哥python提醒:学习python固然重要,但是并不是全部》、《转行需要学习的十大知识点》、《python核心编程:从小白到架构师的修炼》。知乎专栏从入门到进阶,学习完这三本书,python基本能解决80%的问题了。
要说要学什么的话,爬虫是一个比较容易提上日程的事情。下面给出程序员们的学习路线,可以参考下。
1、豆瓣电影爬虫豆瓣电影下面可以爬取电影信息,豆瓣电影网的很多电影都可以爬取到,
2、美剧网爬虫爬虫能够爬取到电影、电视剧、喜剧、动漫等1080p高清视频,代码可以去python爬虫,集搜客,bilibili,抓豆瓣电影-抓取豆瓣电影;可以去集搜客,抓豆瓣电影。
3、地图爬虫urlscheme的代码在这里:web_district_siteurls.py,爬虫案例中抓取到的有些是要进行采集得到,所以是存放在数据库中。代码可以去集搜客,抓豆瓣电影-抓取豆瓣电影,集搜客抓豆瓣电影;集搜客。
4、记账爬虫获取不同类型的记账日历,代码示例如下。urlschemeindex.py(注意需要看url,有的可能是以数组的形式存放的)。其他url根据需要根据自己代码中实际的代码爬取使用。
5、电影评分爬虫采集豆瓣上电影评分的评分信息并保存,因为电影的评分可能出现多次,所以爬取的时候要确定是第一次爬取。代码案例可以看黄哥的这篇:,可以根据在豆瓣看到的很多电影的详细信息进行爬取,爬取完之后如果需要联系客服了可以去复制评分出来进行二次分析。
6、股票爬虫爬取电影、电视剧、喜剧、动漫等1080p高清视频后同时抓取到每个视频下每个电影的评分、画面尺寸、评论内容等信息并保存,就可以得到一个电影的excel表格代码可以看bilibili或者抓豆瓣电影;其实也可以看集搜客,抓豆瓣电影。
7、房产相关爬虫 查看全部
c爬虫抓取网页数据(推荐阅读python如何从无到有成长为一个python开发工程师)
c爬虫抓取网页数据可以编写python代码,
新手可以从上面那位大哥的这篇回答入手。自学的方法有多种,不要单单想靠编程挣钱就好,如果想通过技术来赚钱,那就要付出比别人更多的时间精力来学习。
推荐阅读python如何从无到有成长为一个python开发工程师-慕课网
python主要可以去做爬虫,数据分析,机器学习,
可以看看这篇高级python爬虫学习笔记
一、高级python爬虫学习笔记
二、爬虫自动化之数据采集篇
一、python爬虫的入门路线
二、python爬虫的进阶路线
黄哥推荐学习python的三本书:《黄哥:黄哥python提醒:学习python固然重要,但是并不是全部》、《转行需要学习的十大知识点》、《python核心编程:从小白到架构师的修炼》。知乎专栏从入门到进阶,学习完这三本书,python基本能解决80%的问题了。
要说要学什么的话,爬虫是一个比较容易提上日程的事情。下面给出程序员们的学习路线,可以参考下。
1、豆瓣电影爬虫豆瓣电影下面可以爬取电影信息,豆瓣电影网的很多电影都可以爬取到,
2、美剧网爬虫爬虫能够爬取到电影、电视剧、喜剧、动漫等1080p高清视频,代码可以去python爬虫,集搜客,bilibili,抓豆瓣电影-抓取豆瓣电影;可以去集搜客,抓豆瓣电影。
3、地图爬虫urlscheme的代码在这里:web_district_siteurls.py,爬虫案例中抓取到的有些是要进行采集得到,所以是存放在数据库中。代码可以去集搜客,抓豆瓣电影-抓取豆瓣电影,集搜客抓豆瓣电影;集搜客。
4、记账爬虫获取不同类型的记账日历,代码示例如下。urlschemeindex.py(注意需要看url,有的可能是以数组的形式存放的)。其他url根据需要根据自己代码中实际的代码爬取使用。
5、电影评分爬虫采集豆瓣上电影评分的评分信息并保存,因为电影的评分可能出现多次,所以爬取的时候要确定是第一次爬取。代码案例可以看黄哥的这篇:,可以根据在豆瓣看到的很多电影的详细信息进行爬取,爬取完之后如果需要联系客服了可以去复制评分出来进行二次分析。
6、股票爬虫爬取电影、电视剧、喜剧、动漫等1080p高清视频后同时抓取到每个视频下每个电影的评分、画面尺寸、评论内容等信息并保存,就可以得到一个电影的excel表格代码可以看bilibili或者抓豆瓣电影;其实也可以看集搜客,抓豆瓣电影。
7、房产相关爬虫
c爬虫抓取网页数据(Python开发的一个快速、高层次引擎(Scrapy)())
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-03 23:09
一、概览
Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。
Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。它最初是为页面抓取(更准确地说,网络抓取)而设计的,后端也用于获取 API(例如 Amazon Associates Web Services)或通用网络爬虫返回的数据。 Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。
还提供了各类爬虫的基类,如BaseSpider、sitemap爬虫等。最新版本提供了对web2.0爬虫的支持。
二、Scrapy 五个基本组件:
Scrapy 框架组件
调度器
下载器
爬虫
物理管道
Scrapy 引擎
(1),调度器:
调度器,说白了就是假设它是一个优先级的URL队列(被爬取的网站或链接),它决定了下一个要爬取的URL是什么,并移除重复的URL(不是无用的工作)。用户可以根据自己的需要自定义调度器。
(2),下载器:
下载器是所有组件中最繁重的组件,用于在网络上高速下载资源。 Scrapy 的下载器代码并不太复杂,但是效率很高。主要原因是Scrapy下载器是建立在twisted的高效异步模型之上的(其实整个框架都是建立在这个模型之上的)。
(3)、蜘蛛:
爬虫是用户最关心的部分。用户自定义自己的爬虫(通过自定义正则表达式等语法),从特定网页中提取自己需要的信息,即所谓的实体(Item)。用户还可以从中提取链接,让 Scrapy 继续抓取下一页。
(4),项目管道:
实体管道用于处理蜘蛛提取的实体。主要功能是持久化实体,验证实体的有效性,清除不必要的信息。
(5),Scrapy 引擎:
Scrapy 引擎是整个框架的核心。它用于控制调试器、下载器和爬虫。其实引擎相当于计算机的CPU,控制着整个过程。
三、整体架构
四、Scrapy 安装和项目生成
1Scrapy 安装
Microsoft Windows [版本 10.0.19043.1586]
(c) 微软公司。保留所有权利。
C:\WINDOWS\system32>python -m pip install --upgrade pip
C:\WINDOWS\system32>pip 安装轮子
C:\WINDOWS\system32>pip install lxml
C:\WINDOWS\system32>pip install twisted
C:\WINDOWS\system32>pip install pywin32
C:\WINDOWS\system32>pip install scrapy
2 构建项目
scrapy startproject 项目名称
scrapy genspider爬虫名称域名
scrapy crawler 名称
Microsoft Windows [版本 10.0.19043.1586]
(c) 微软公司。保留所有权利。
C:\WINDOWS\system32>scrapy startproject TXmovies
新建 Scrapy 项目 'TXmovies',使用模板目录 'C:\Users\1234\anaconda3\lib\site-packages\scrapy\templates\project',创建于:
C:\WINDOWS\system32\TXmovies
您可以通过以下方式启动您的第一个蜘蛛:
cd TXmovies
scrapy genspider 示例
C:\WINDOWS\system32>cd TXmovies
C:\Windows\System32\TXmovies>scrapy genspider txms
在模块中使用模板“basic”创建了蜘蛛“txms”:
TXmovies.spiders.txms
C:\Windows\System32\TXmovies>
3 创建后目录的大体页面如下
ProjectName #项目文件夹
ProjectName #项目目录
items.py #定义数据结构
middlewares.py #middleware
pipelines.py #数据处理
settings.py #全局配置
蜘蛛
__init__.py #crawler 文件
百度.py
scrapy.cfg #项目基础配置文件
五、案例
1.创建一个项目
打开终端输入(建议放在合适的路径,默认是C盘)
Microsoft Windows [版本 10.0.19043.1586]
(c) 微软公司。保留所有权利。
C:\WINDOWS\system32>scrapy startproject TXmovies
新建 Scrapy 项目 'TXmovies',使用模板目录 'C:\Users\1234\anaconda3\lib\site-packages\scrapy\templates\project',创建于:
C:\WINDOWS\system32\TXmovies
您可以通过以下方式启动您的第一个蜘蛛:
cd TXmovies
scrapy genspider 示例
C:\WINDOWS\system32>cd TXmovies
C:\Windows\System32\TXmovies>scrapy genspider txms
在模块中使用模板“basic”创建了蜘蛛“txms”:
TXmovies.spiders.txms
C:\Windows\System32\TXmovies>
2.修改设置
修改三项,第一是不遵循机器人协议,第二是下载间隙。由于下面的程序需要下载多个页面,所以需要给一个gap(不给也可以,但是很容易被检测到),第三个是请求头,添加一个User-Agent,四是打开管道
ROBOTSTXT_OBEY = 假
DOWNLOAD_DELAY = 1
DEFAULT_REQUEST_HEADERS = {
'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent':'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome /27.0.1453.94 Safari/537.36'
}
ITEM_PIPELINES = {
'TXmovies.pipelines.TxmoviesPipeline':300,
}
3.确认要提取的数据,item item
item 定义要提取的内容(定义数据结构)。比如我提取的内容是电影名和电影描述,所以我创建了两个变量。 Field方法的实际做法是创建一个字典,给字典添加一个新的值,暂时不赋值,等数据提取出来再赋值。下面的item结构可以表示为:{'name':'','description':''}。
# -*- 编码:utf-8 -*-
# 在这里为你的抓取物品定义模型
#
# 参见文档:
#
导入scrapy
类 TxmoviesItem(scrapy.Item):
# 在此处为您的项目定义字段,例如:
# name = scrapy.Field()
name = scrapy.Field()
description = scrapy.Field()
4.写一个爬虫
我们要写的部分是parse方法的内容,重点是xpath怎么写,xpath我就不多说了,有兴趣可以看我的其他文章 , XPATH 教程
介绍一下刚才写的item,刚才说item中创建的变量是字典的key值,可以直接赋值。赋值后交给管道处理。
简单说一下这段代码的思路,首先腾讯视频的url是
我们注意到偏移项,第一页的偏移量为0,第二页为30,列依次推送。
程序中这个项是用来控制第一页的抓取,但是也必须给一个范围,不能无限,否则会报错。你可以去看看腾讯总共有多少视频页,也可以写一个异常捕获机制,当请求错误被捕获时退出。我这里只是演示,所以只给了120,也就是4页。
产量
程序中有两个收益。我更喜欢称之为中断。当然,中断只发生在 CPU 中。它的功能是转移控制权。在这个程序中,我们封装好item数据后,调用yield将Control交给管道,管道处理完返回,再返回程序。这是对第一次收益的解释。
第二个产量有点复杂。本程序使用回调机制,即回调。回调的对象是 parse,也就是当前方法。通过不断的回调,程序会陷入循环。条件,就会陷入死循环。如果我把这个程序中的 if 去掉,那将是一个无限循环。
yield scrapy.Request(url=url,callback=self.parse)
xpath
另外需要注意的是如何在xpathl中提取数据。有四种写法。第一种写法是获取selector选择器,也就是原创数据,里面收录一些我们不用的东西。第二个 extract() 将选择器序列号转换为字符串。第三个和第四个一样,获取字符串中的第一个数据,就是我们要的数据。
items['name']=i.xpath('./a/@title')[0]
items['name']=i.xpath('./a/@title').extract()
items['name']=i.xpath('./a/@title').extract_first()
items['name']=i.xpath('./a/@title').get()
# -*- 编码:utf-8 -*-
导入scrapy
从 ..items 导入 TxmoviesItem
类 TxmsSpider(scrapy.Spider):
名称 = 'txms'
allowed_domains = ['']
start_urls = ['#39;]
偏移量=0
def 解析(自我,响应):
items=TxmoviesItem()
lists=response.xpath('//div[@class="list_item"]')
对于列表中的 i:
items['name']=i.xpath('./a/@title').get()
items['description']=i.xpath('./div/div/@title').get()
收益项目
如果 self.offset < 120:
self.offset += 30
url = '{}&pagesize=30'.format(str(self.offset))
yield scrapy.Request(url=url,callback=self.parse)
5.交给管道输出
管道可以处理提取的数据,例如将其存储在数据库中。我们只在这里输出。
# -*- 编码:utf-8 -*-
# 在此处定义您的项目管道
#
# 不要忘记将管道添加到 ITEM_PIPELINES 设置中
#参见:
类TxmoviesPipeline(对象):
def process_item(self, item, spider):
打印(项目)
退货
6.运行,执行项目
从 scrapy 导入命令行
cmdline.execute('scrapy crawl txms'.split())
7.测试结果
管道输出结果为白色,调试信息为红色 查看全部
c爬虫抓取网页数据(Python开发的一个快速、高层次引擎(Scrapy)())
一、概览
Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。
Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。它最初是为页面抓取(更准确地说,网络抓取)而设计的,后端也用于获取 API(例如 Amazon Associates Web Services)或通用网络爬虫返回的数据。 Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。
还提供了各类爬虫的基类,如BaseSpider、sitemap爬虫等。最新版本提供了对web2.0爬虫的支持。
二、Scrapy 五个基本组件:
Scrapy 框架组件
调度器
下载器
爬虫
物理管道
Scrapy 引擎
(1),调度器:
调度器,说白了就是假设它是一个优先级的URL队列(被爬取的网站或链接),它决定了下一个要爬取的URL是什么,并移除重复的URL(不是无用的工作)。用户可以根据自己的需要自定义调度器。
(2),下载器:
下载器是所有组件中最繁重的组件,用于在网络上高速下载资源。 Scrapy 的下载器代码并不太复杂,但是效率很高。主要原因是Scrapy下载器是建立在twisted的高效异步模型之上的(其实整个框架都是建立在这个模型之上的)。
(3)、蜘蛛:
爬虫是用户最关心的部分。用户自定义自己的爬虫(通过自定义正则表达式等语法),从特定网页中提取自己需要的信息,即所谓的实体(Item)。用户还可以从中提取链接,让 Scrapy 继续抓取下一页。
(4),项目管道:
实体管道用于处理蜘蛛提取的实体。主要功能是持久化实体,验证实体的有效性,清除不必要的信息。
(5),Scrapy 引擎:
Scrapy 引擎是整个框架的核心。它用于控制调试器、下载器和爬虫。其实引擎相当于计算机的CPU,控制着整个过程。
三、整体架构
四、Scrapy 安装和项目生成
1Scrapy 安装
Microsoft Windows [版本 10.0.19043.1586]
(c) 微软公司。保留所有权利。
C:\WINDOWS\system32>python -m pip install --upgrade pip
C:\WINDOWS\system32>pip 安装轮子
C:\WINDOWS\system32>pip install lxml
C:\WINDOWS\system32>pip install twisted
C:\WINDOWS\system32>pip install pywin32
C:\WINDOWS\system32>pip install scrapy
2 构建项目
scrapy startproject 项目名称
scrapy genspider爬虫名称域名
scrapy crawler 名称
Microsoft Windows [版本 10.0.19043.1586]
(c) 微软公司。保留所有权利。
C:\WINDOWS\system32>scrapy startproject TXmovies
新建 Scrapy 项目 'TXmovies',使用模板目录 'C:\Users\1234\anaconda3\lib\site-packages\scrapy\templates\project',创建于:
C:\WINDOWS\system32\TXmovies
您可以通过以下方式启动您的第一个蜘蛛:
cd TXmovies
scrapy genspider 示例
C:\WINDOWS\system32>cd TXmovies
C:\Windows\System32\TXmovies>scrapy genspider txms
在模块中使用模板“basic”创建了蜘蛛“txms”:
TXmovies.spiders.txms
C:\Windows\System32\TXmovies>
3 创建后目录的大体页面如下
ProjectName #项目文件夹
ProjectName #项目目录
items.py #定义数据结构
middlewares.py #middleware
pipelines.py #数据处理
settings.py #全局配置
蜘蛛
__init__.py #crawler 文件
百度.py
scrapy.cfg #项目基础配置文件
五、案例
1.创建一个项目
打开终端输入(建议放在合适的路径,默认是C盘)
Microsoft Windows [版本 10.0.19043.1586]
(c) 微软公司。保留所有权利。
C:\WINDOWS\system32>scrapy startproject TXmovies
新建 Scrapy 项目 'TXmovies',使用模板目录 'C:\Users\1234\anaconda3\lib\site-packages\scrapy\templates\project',创建于:
C:\WINDOWS\system32\TXmovies
您可以通过以下方式启动您的第一个蜘蛛:
cd TXmovies
scrapy genspider 示例
C:\WINDOWS\system32>cd TXmovies
C:\Windows\System32\TXmovies>scrapy genspider txms
在模块中使用模板“basic”创建了蜘蛛“txms”:
TXmovies.spiders.txms
C:\Windows\System32\TXmovies>
2.修改设置
修改三项,第一是不遵循机器人协议,第二是下载间隙。由于下面的程序需要下载多个页面,所以需要给一个gap(不给也可以,但是很容易被检测到),第三个是请求头,添加一个User-Agent,四是打开管道
ROBOTSTXT_OBEY = 假
DOWNLOAD_DELAY = 1
DEFAULT_REQUEST_HEADERS = {
'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent':'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome /27.0.1453.94 Safari/537.36'
}
ITEM_PIPELINES = {
'TXmovies.pipelines.TxmoviesPipeline':300,
}
3.确认要提取的数据,item item
item 定义要提取的内容(定义数据结构)。比如我提取的内容是电影名和电影描述,所以我创建了两个变量。 Field方法的实际做法是创建一个字典,给字典添加一个新的值,暂时不赋值,等数据提取出来再赋值。下面的item结构可以表示为:{'name':'','description':''}。
# -*- 编码:utf-8 -*-
# 在这里为你的抓取物品定义模型
#
# 参见文档:
#
导入scrapy
类 TxmoviesItem(scrapy.Item):
# 在此处为您的项目定义字段,例如:
# name = scrapy.Field()
name = scrapy.Field()
description = scrapy.Field()
4.写一个爬虫
我们要写的部分是parse方法的内容,重点是xpath怎么写,xpath我就不多说了,有兴趣可以看我的其他文章 , XPATH 教程
介绍一下刚才写的item,刚才说item中创建的变量是字典的key值,可以直接赋值。赋值后交给管道处理。
简单说一下这段代码的思路,首先腾讯视频的url是
我们注意到偏移项,第一页的偏移量为0,第二页为30,列依次推送。
程序中这个项是用来控制第一页的抓取,但是也必须给一个范围,不能无限,否则会报错。你可以去看看腾讯总共有多少视频页,也可以写一个异常捕获机制,当请求错误被捕获时退出。我这里只是演示,所以只给了120,也就是4页。
产量
程序中有两个收益。我更喜欢称之为中断。当然,中断只发生在 CPU 中。它的功能是转移控制权。在这个程序中,我们封装好item数据后,调用yield将Control交给管道,管道处理完返回,再返回程序。这是对第一次收益的解释。
第二个产量有点复杂。本程序使用回调机制,即回调。回调的对象是 parse,也就是当前方法。通过不断的回调,程序会陷入循环。条件,就会陷入死循环。如果我把这个程序中的 if 去掉,那将是一个无限循环。
yield scrapy.Request(url=url,callback=self.parse)
xpath
另外需要注意的是如何在xpathl中提取数据。有四种写法。第一种写法是获取selector选择器,也就是原创数据,里面收录一些我们不用的东西。第二个 extract() 将选择器序列号转换为字符串。第三个和第四个一样,获取字符串中的第一个数据,就是我们要的数据。
items['name']=i.xpath('./a/@title')[0]
items['name']=i.xpath('./a/@title').extract()
items['name']=i.xpath('./a/@title').extract_first()
items['name']=i.xpath('./a/@title').get()
# -*- 编码:utf-8 -*-
导入scrapy
从 ..items 导入 TxmoviesItem
类 TxmsSpider(scrapy.Spider):
名称 = 'txms'
allowed_domains = ['']
start_urls = ['#39;]
偏移量=0
def 解析(自我,响应):
items=TxmoviesItem()
lists=response.xpath('//div[@class="list_item"]')
对于列表中的 i:
items['name']=i.xpath('./a/@title').get()
items['description']=i.xpath('./div/div/@title').get()
收益项目
如果 self.offset < 120:
self.offset += 30
url = '{}&pagesize=30'.format(str(self.offset))
yield scrapy.Request(url=url,callback=self.parse)
5.交给管道输出
管道可以处理提取的数据,例如将其存储在数据库中。我们只在这里输出。
# -*- 编码:utf-8 -*-
# 在此处定义您的项目管道
#
# 不要忘记将管道添加到 ITEM_PIPELINES 设置中
#参见:
类TxmoviesPipeline(对象):
def process_item(self, item, spider):
打印(项目)
退货
6.运行,执行项目
从 scrapy 导入命令行
cmdline.execute('scrapy crawl txms'.split())
7.测试结果
管道输出结果为白色,调试信息为红色
c爬虫抓取网页数据(2.通用爬虫框架流程a精选部分网页链接(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-04-03 12:13
(公众号:9z营销大数据)
2014年,一本名为《这就是搜索引擎:核心技术详解》的书,将“搜索”这个核心话题再次带入大众视野。撇开本书第一版和第二版折射出的隐藏魅力不谈,正如书中所说,“搜索引擎”基于其作为互联网门户的作用及其复杂的实现方式,是目前最流行的互联网产品。有技术含量的产品,如果不是唯一的,至少也是其中之一。
今天我们要讨论的话题是围绕“爬虫爬取策略”对爬虫做一个简单的介绍,并通过这个来带领身边的“老司机”去发现那些可能被忽略的理论。
1.一句话总结爬虫
“将海量网页数据传输到本地,形成亿万网页的镜像备份”高效下载系统设计。
2. 通用爬虫框架流程
一种。选择部分网页链接地址作为种子网址,将种子网址放入待抓取的网址队列中;
湾。从待爬取的URL队列中依次读取URL,将URL链接地址通过DNS转换为网站服务器对应的IP地址;
C。将网页的网站IP地址和相对路径名交给网页下载器下载网页内容;
d。将下载的网页对应的URL放入已经爬取的URL队列中,将下载的网页内容存储在页库中,供后续处理;
e. 将刚刚下载的网页中的所有链接提取出来,并与已经爬取的URL队列进行比较,将没有被爬取的URL链接检查出来放入待爬取的URL队列中,重复新一轮的爬取操作;
F。循环直到所有网页都被爬取完毕,完成一个完整的爬取过程。
PS。动态爬取中的爬虫及与网页的相对关系
已下载网页合集:已被爬虫从互联网下载到本地索引的网页合集;
过期网页集合:对应的互联网网页已动态更新,但未被爬虫抓取,已下载到本地网页集合;
待下载网页集合:URL队列中待抓取网页的集合;
已知网页集合:存在于已被抓取或将被抓取且尚未被抓取的网页中,但迟早会被爬虫通过链接关系发现,并将被抓取并被抓取的网页的集合。索引;
不可知的网页集合:爬虫无法抓取的网页集合;
3. 三种爬虫类
一种。批量爬虫
有明确的爬取范围和目标,达到设定目标(特定页数或特定时长)时停止爬取的爬虫类型;
湾。增量爬虫
不断爬取网页并定期更新爬取网页的爬虫类型;
C。垂直爬行动物
只爬取行业特定网页或主题内容的爬虫类型
4. 优秀爬虫需要满足的条件
一种。高性能
单位时间内爬取尽可能多的网页;
湾。可扩展
通过增加爬取服务器和爬虫数量可以轻松解决缩短爬取周期的问题;
C。鲁棒性
能正确处理网页HTML编码不规范、服务器突然崩溃、爬虫陷阱等异常情况,避免工作中断,或在中断后轻松恢复之前抓取的数据;
d。友好的
保护网站的部分隐私(避免爬取爬虫禁止协议下的网页,避免爬取网页禁止标记下的部分内容),减少被爬取的网站@的网络负载>;
5. 爬虫策略
爬取的一般原则是优先对重要的网页进行爬取(PageRank是评价网页重要性的常用标准),确定待爬取URL的队列是技术的关键。
根据URL优先级确定方法的不同,四种爬取策略分为以下几种:
一种。广度优先遍历策略
含义:一种通过“直接机械地将新下载的网页中收录的链接附加到待爬取的URL队列末尾”的方式,合理安排URL下载顺序的爬取策略。
特点:简单直观,历史悠久,功能强大,比较各种抢策略的标杆策略。
优缺点:基本可以保证要爬取的url列表按照网页的重要性排序,效果很好。
湾。不完整的PageRank策略
PageRank:一种众所周知的全球链接分析算法,用于确定网页的重要性。
不完整的PageRank策略:一种爬虫策略,“在不完整的互联网页面的一个子集中计算PageRank,形成待爬取URL队列”,即与下载的网页和待爬取URL队列中的URL一起,形成一个网页集合,计算形成的网页集合中的PageRank,将待爬取URL队列按照PageRank得分从高到低的顺序重新排列,形成新的待爬取URL队列,这样的爬取策略.
l 不完整PageRank往往采用“每次有足够K个新下载的页面,重新计算所有下载页面的不完整PageRank”的方法进行;
l 在进行新一轮不完整的PageRank计算之前,给新提取的没有PageRank值的网页分配一个临时的PageRank值,与待爬取的URL列表形成大小对比,考虑到新提取的网页需要先被抓取。需要。
利弊:众说纷纭
c.OCIP策略
含义:OCIP,在线页面重要性计算。在算法开始之前,所有互联网页面都被赋予相同的现金(cash),每下载一个页面,就会将相应的现金分配给该页面所收录的页面链接,以清除下载页面的现金价值。待爬取URL队列中的网页按现金降序排列,按顺序获取”
效果:更好的重要性度量策略,效果优于广度优先遍历策略。
优缺点:无需迭代,计算速度快,适合实时计算。
d。大网站优先策略
含义:优先下载大的网站,即以网站为单位衡量网页的重要性,对于URL队列中待抓取的网页,根据其< @网站, if which 网站 网站等待下载的页面最多,会先下载这些链接。
公众号:9z营销大数据 查看全部
c爬虫抓取网页数据(2.通用爬虫框架流程a精选部分网页链接(组图))
(公众号:9z营销大数据)
2014年,一本名为《这就是搜索引擎:核心技术详解》的书,将“搜索”这个核心话题再次带入大众视野。撇开本书第一版和第二版折射出的隐藏魅力不谈,正如书中所说,“搜索引擎”基于其作为互联网门户的作用及其复杂的实现方式,是目前最流行的互联网产品。有技术含量的产品,如果不是唯一的,至少也是其中之一。
今天我们要讨论的话题是围绕“爬虫爬取策略”对爬虫做一个简单的介绍,并通过这个来带领身边的“老司机”去发现那些可能被忽略的理论。
1.一句话总结爬虫
“将海量网页数据传输到本地,形成亿万网页的镜像备份”高效下载系统设计。
2. 通用爬虫框架流程
一种。选择部分网页链接地址作为种子网址,将种子网址放入待抓取的网址队列中;
湾。从待爬取的URL队列中依次读取URL,将URL链接地址通过DNS转换为网站服务器对应的IP地址;
C。将网页的网站IP地址和相对路径名交给网页下载器下载网页内容;
d。将下载的网页对应的URL放入已经爬取的URL队列中,将下载的网页内容存储在页库中,供后续处理;
e. 将刚刚下载的网页中的所有链接提取出来,并与已经爬取的URL队列进行比较,将没有被爬取的URL链接检查出来放入待爬取的URL队列中,重复新一轮的爬取操作;
F。循环直到所有网页都被爬取完毕,完成一个完整的爬取过程。
PS。动态爬取中的爬虫及与网页的相对关系
已下载网页合集:已被爬虫从互联网下载到本地索引的网页合集;
过期网页集合:对应的互联网网页已动态更新,但未被爬虫抓取,已下载到本地网页集合;
待下载网页集合:URL队列中待抓取网页的集合;
已知网页集合:存在于已被抓取或将被抓取且尚未被抓取的网页中,但迟早会被爬虫通过链接关系发现,并将被抓取并被抓取的网页的集合。索引;
不可知的网页集合:爬虫无法抓取的网页集合;
3. 三种爬虫类
一种。批量爬虫
有明确的爬取范围和目标,达到设定目标(特定页数或特定时长)时停止爬取的爬虫类型;
湾。增量爬虫
不断爬取网页并定期更新爬取网页的爬虫类型;
C。垂直爬行动物
只爬取行业特定网页或主题内容的爬虫类型
4. 优秀爬虫需要满足的条件
一种。高性能
单位时间内爬取尽可能多的网页;
湾。可扩展
通过增加爬取服务器和爬虫数量可以轻松解决缩短爬取周期的问题;
C。鲁棒性
能正确处理网页HTML编码不规范、服务器突然崩溃、爬虫陷阱等异常情况,避免工作中断,或在中断后轻松恢复之前抓取的数据;
d。友好的
保护网站的部分隐私(避免爬取爬虫禁止协议下的网页,避免爬取网页禁止标记下的部分内容),减少被爬取的网站@的网络负载>;
5. 爬虫策略
爬取的一般原则是优先对重要的网页进行爬取(PageRank是评价网页重要性的常用标准),确定待爬取URL的队列是技术的关键。
根据URL优先级确定方法的不同,四种爬取策略分为以下几种:
一种。广度优先遍历策略
含义:一种通过“直接机械地将新下载的网页中收录的链接附加到待爬取的URL队列末尾”的方式,合理安排URL下载顺序的爬取策略。
特点:简单直观,历史悠久,功能强大,比较各种抢策略的标杆策略。
优缺点:基本可以保证要爬取的url列表按照网页的重要性排序,效果很好。
湾。不完整的PageRank策略
PageRank:一种众所周知的全球链接分析算法,用于确定网页的重要性。
不完整的PageRank策略:一种爬虫策略,“在不完整的互联网页面的一个子集中计算PageRank,形成待爬取URL队列”,即与下载的网页和待爬取URL队列中的URL一起,形成一个网页集合,计算形成的网页集合中的PageRank,将待爬取URL队列按照PageRank得分从高到低的顺序重新排列,形成新的待爬取URL队列,这样的爬取策略.
l 不完整PageRank往往采用“每次有足够K个新下载的页面,重新计算所有下载页面的不完整PageRank”的方法进行;
l 在进行新一轮不完整的PageRank计算之前,给新提取的没有PageRank值的网页分配一个临时的PageRank值,与待爬取的URL列表形成大小对比,考虑到新提取的网页需要先被抓取。需要。
利弊:众说纷纭
c.OCIP策略
含义:OCIP,在线页面重要性计算。在算法开始之前,所有互联网页面都被赋予相同的现金(cash),每下载一个页面,就会将相应的现金分配给该页面所收录的页面链接,以清除下载页面的现金价值。待爬取URL队列中的网页按现金降序排列,按顺序获取”
效果:更好的重要性度量策略,效果优于广度优先遍历策略。
优缺点:无需迭代,计算速度快,适合实时计算。
d。大网站优先策略
含义:优先下载大的网站,即以网站为单位衡量网页的重要性,对于URL队列中待抓取的网页,根据其< @网站, if which 网站 网站等待下载的页面最多,会先下载这些链接。
公众号:9z营销大数据
c爬虫抓取网页数据(一个通用的网络爬虫的基本结构及工作流程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2022-03-25 02:18
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要对爬虫和爬虫系统进行简要概述。
一、网络爬虫的基本结构和工作流程
一个通用网络爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环。
二、从爬虫的角度划分互联网
相应地,互联网上的所有页面可以分为五个部分:
1.下载了未过期的网页
2.已下载和过期网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态的,互联网上的一些内容发生了变化。您访问的页面已过期。
3.待下载页面:URL队列中待抓取的页面
4. 已知网页:没有被爬取过,也不在待爬取的URL队列中,但是通过分析已经爬取过的页面得到的URL或者待爬取的URL对应的页面都可以视为已知网页。
5.还有一些网页是爬虫无法直接爬取下载的。称为不可知网页。
三、抓取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个接一个的链接,处理完该行再到下一个起始页,继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
3.反向链接计数策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
4.部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起,形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序. 以下示例说明:
5.OPIC 政策政策
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
6.大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
四、更新政策
互联网实时变化并且非常动态。网页更新策略主要决定何时更新之前已经下载的页面。常见的更新策略有以下三种:
1.历史参考政策
顾名思义,它根据页面过去的历史更新数据来预测未来页面何时会发生变化。通常,预测是通过泊松过程建模来进行的。
2.用户体验策略
尽管搜索引擎可以为某个查询返回大量结果,但用户通常只关注结果的前几页。因此,爬虫系统可以优先更新那些实际在查询结果前几页的页面,然后再更新后面的那些页面。这个更新策略也需要用到历史信息。UX 策略保留网页的多个历史版本,并根据每个过去内容更改对搜索质量的影响得出一个平均值,并以此值作为决定何时重新抓取的基础。
3.聚类抽样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加很多系统负担;第二,如果新网页完全没有历史信息,就无法确定更新策略。
该策略认为网页具有许多属性,具有相似属性的网页可以认为具有相似的更新频率。计算某一类别网页的更新频率,只需对该类别的网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如下:
五、分布式抓取系统结构
一般来说,爬虫系统需要处理整个互联网上数以亿计的网页。单个爬虫不可能完成这样的任务。通常需要多个爬虫程序一起处理它们。一般来说,爬虫系统往往是分布式的三层结构。如图所示:
最底层是分布在不同地理位置的数据中心。每个数据中心有多个爬虫服务器,每个爬虫服务器可能部署多套爬虫程序。这样就构成了一个基本的分布式爬虫系统。
对于数据中心中的不同服务器,有几种方法可以协同工作:
1.主从
主从基本结构如图:
对于主从类型,有一个专门的主服务器来维护要爬取的URL队列,负责每次将URL分发给不同的从服务器,从服务器负责实际的网页下载工作。Master服务器除了维护要爬取的URL队列和分发URL外,还负责调解每个Slave服务器的负载。为了避免一些从服务器过于空闲或过度工作。
在这种模式下,Master往往会成为系统的瓶颈。
2.点对点
等价的基本结构如图所示:
在这种模式下,所有爬虫服务器之间的分工没有区别。每个爬取服务器可以从待爬取的URL队列中获取URL,然后计算该URL主域名的哈希值H,进而计算H mod m(其中m为服务器数量,取上图例如,m 对于 3),计算出来的数字就是处理 URL 的主机号。
例子:假设对于URL,计算器hash值H=8,m=3,那么H mod m=2,那么编号为2的服务器会抓取该链接。假设此时服务器 0 获取了 URL,它会将 URL 传输到服务器 2,服务器 2 将获取它。
这种模式有一个问题,当一个服务器死掉或添加一个新服务器时,所有 URL 的哈希余数的结果都会改变。也就是说,这种方法不能很好地扩展。针对这种情况,提出了另一种改进方案。这种改进的方案是一致的散列以确定服务器划分。其基本结构如图所示:
一致散列对 URL 的主域名进行散列,并将其映射到 0-232 范围内的数字。这个范围平均分配给m台服务器,根据URL的主域名的hash运算值的范围来确定要爬取的服务器。
如果某台服务器出现问题,本应负责该服务器的网页将由下一个服务器顺时针获取。在这种情况下,即使一台服务器出现问题,也不会影响其他工作。 查看全部
c爬虫抓取网页数据(一个通用的网络爬虫的基本结构及工作流程(组图))
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要对爬虫和爬虫系统进行简要概述。
一、网络爬虫的基本结构和工作流程
一个通用网络爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环。
二、从爬虫的角度划分互联网
相应地,互联网上的所有页面可以分为五个部分:
1.下载了未过期的网页
2.已下载和过期网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态的,互联网上的一些内容发生了变化。您访问的页面已过期。
3.待下载页面:URL队列中待抓取的页面
4. 已知网页:没有被爬取过,也不在待爬取的URL队列中,但是通过分析已经爬取过的页面得到的URL或者待爬取的URL对应的页面都可以视为已知网页。
5.还有一些网页是爬虫无法直接爬取下载的。称为不可知网页。
三、抓取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个接一个的链接,处理完该行再到下一个起始页,继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
3.反向链接计数策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
4.部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起,形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序. 以下示例说明:
5.OPIC 政策政策
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
6.大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
四、更新政策
互联网实时变化并且非常动态。网页更新策略主要决定何时更新之前已经下载的页面。常见的更新策略有以下三种:
1.历史参考政策
顾名思义,它根据页面过去的历史更新数据来预测未来页面何时会发生变化。通常,预测是通过泊松过程建模来进行的。
2.用户体验策略
尽管搜索引擎可以为某个查询返回大量结果,但用户通常只关注结果的前几页。因此,爬虫系统可以优先更新那些实际在查询结果前几页的页面,然后再更新后面的那些页面。这个更新策略也需要用到历史信息。UX 策略保留网页的多个历史版本,并根据每个过去内容更改对搜索质量的影响得出一个平均值,并以此值作为决定何时重新抓取的基础。
3.聚类抽样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加很多系统负担;第二,如果新网页完全没有历史信息,就无法确定更新策略。
该策略认为网页具有许多属性,具有相似属性的网页可以认为具有相似的更新频率。计算某一类别网页的更新频率,只需对该类别的网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如下:
五、分布式抓取系统结构
一般来说,爬虫系统需要处理整个互联网上数以亿计的网页。单个爬虫不可能完成这样的任务。通常需要多个爬虫程序一起处理它们。一般来说,爬虫系统往往是分布式的三层结构。如图所示:
最底层是分布在不同地理位置的数据中心。每个数据中心有多个爬虫服务器,每个爬虫服务器可能部署多套爬虫程序。这样就构成了一个基本的分布式爬虫系统。
对于数据中心中的不同服务器,有几种方法可以协同工作:
1.主从
主从基本结构如图:
对于主从类型,有一个专门的主服务器来维护要爬取的URL队列,负责每次将URL分发给不同的从服务器,从服务器负责实际的网页下载工作。Master服务器除了维护要爬取的URL队列和分发URL外,还负责调解每个Slave服务器的负载。为了避免一些从服务器过于空闲或过度工作。
在这种模式下,Master往往会成为系统的瓶颈。
2.点对点
等价的基本结构如图所示:
在这种模式下,所有爬虫服务器之间的分工没有区别。每个爬取服务器可以从待爬取的URL队列中获取URL,然后计算该URL主域名的哈希值H,进而计算H mod m(其中m为服务器数量,取上图例如,m 对于 3),计算出来的数字就是处理 URL 的主机号。
例子:假设对于URL,计算器hash值H=8,m=3,那么H mod m=2,那么编号为2的服务器会抓取该链接。假设此时服务器 0 获取了 URL,它会将 URL 传输到服务器 2,服务器 2 将获取它。
这种模式有一个问题,当一个服务器死掉或添加一个新服务器时,所有 URL 的哈希余数的结果都会改变。也就是说,这种方法不能很好地扩展。针对这种情况,提出了另一种改进方案。这种改进的方案是一致的散列以确定服务器划分。其基本结构如图所示:
一致散列对 URL 的主域名进行散列,并将其映射到 0-232 范围内的数字。这个范围平均分配给m台服务器,根据URL的主域名的hash运算值的范围来确定要爬取的服务器。
如果某台服务器出现问题,本应负责该服务器的网页将由下一个服务器顺时针获取。在这种情况下,即使一台服务器出现问题,也不会影响其他工作。
c爬虫抓取网页数据(网页获取和解析速度和性能的应用场景详解! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-03-25 01:16
)
(4)支持代理
(5)支持自动cookie管理等。
Java爬虫开发是应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;import org.apache.http.client.HttpClient;import org.apache.http.client.ResponseHandler;import org.apache.http.client.methods.HttpGet;import org.apache.http.impl.client.BasicResponseHandler;import org.apache.http.impl.client.DefaultHttpClient;/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHttpClientTest{publicstaticvoid main(String[] args)throwsException{//目标页面String url ="http://www.yshjava.cn";//创建一个默认的HttpClientHttpClient httpclient =newDefaultHttpClient();try{//以get方式请求网页http://www.yshjava.cnHttpGet httpget =newHttpGet(url);//打印请求地址System.out.println("executing request "+ httpget.getURI());//创建响应处理器处理服务器响应内容ResponseHandlerresponseHandler=newBasicResponseHandler();//执行请求并获取结果String responseBody = httpclient.execute(httpget, responseHandler);System.out.println("----------------------------------------");System.out.println(responseBody);System.out.println("----------------------------------------");}finally{//关闭连接管理器
httpclient.getConnectionManager().shutdown();}}}
汤
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
示例代码如下:
package cn.ysh.studio.crawler.jsoup;import java.io.IOException;import org.jsoup.Jsoup;/**
* 基于Jsoup抓取网页内容
* @author www.yshjava.cn
*/publicclassJsoupTest{publicstaticvoid main(String[] args)throwsIOException{//目标页面String url ="http://www.yshjava.cn";//使用Jsoup连接目标页面,并执行请求,获取服务器响应内容String html =Jsoup.connect(url).execute().body();//打印页面内容System.out.println(html);}}
html单元
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取和解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;import com.gargoylesoftware.htmlunit.BrowserVersion;import com.gargoylesoftware.htmlunit.Page;import com.gargoylesoftware.htmlunit.WebClient;/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlUnitSpider{publicstaticvoid main(String[] s)throwsException{//目标网页String url ="http://www.yshjava.cn";//模拟特定浏览器FIREFOX_3WebClient spider =newWebClient(BrowserVersion.FIREFOX_3);//获取目标网页Page page = spider.getPage(url);//打印网页内容System.out.println(page.getWebResponse().getContentAsString());//关闭所有窗口
spider.closeAllWindows();}}
瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
示例代码如下:
package cn.ysh.studio.crawler.ie;import watij.runtime.ie.IE;/**
* 基于Watij抓取网页内容,仅限Windows平台
*
* @author www.yshjava.cn
*/publicclassWatijTest{publicstaticvoid main(String[] s){//目标页面String url ="http://www.yshjava.cn";//实例化IE浏览器对象
IE ie =new IE();try{//启动浏览器
ie.start();//转到目标网页
ie.goTo(url);//等待网页加载就绪
ie.waitUntilReady();//打印页面内容System.out.println(ie.html());}catch(Exception e){
e.printStackTrace();}finally{try{//关闭IE浏览器
ie.close();}catch(Exception e){}}}}
硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;import org.openqa.selenium.htmlunit.HtmlUnitDriver;/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlDriverTest{publicstaticvoid main(String[] s){//目标网页String url ="http://www.yshjava.cn";HtmlUnitDriver driver =newHtmlUnitDriver();try{//禁用JS脚本功能
driver.setJavascriptEnabled(false);//打开目标网页
driver.get(url);//获取当前网页源码String html = driver.getPageSource();//打印网页源码System.out.println(html);}catch(Exception e){//打印堆栈信息
e.printStackTrace();}finally{try{//关闭并退出
driver.close();
driver.quit();}catch(Exception e){}}}}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;import org.watij.webspec.dsl.WebSpec;/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/publicclassWebspecTest{publicstaticvoid main(String[] s){//目标网页String url ="http://www.yshjava.cn";//实例化浏览器对象WebSpec spec =newWebSpec().mozilla();//隐藏浏览器窗体
spec.hide();//打开目标页面
spec.open(url);//打印网页源码System.out.println(spec.source());//关闭所有窗口
spec.closeAll();}} 查看全部
c爬虫抓取网页数据(网页获取和解析速度和性能的应用场景详解!
)
(4)支持代理
(5)支持自动cookie管理等。
Java爬虫开发是应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;import org.apache.http.client.HttpClient;import org.apache.http.client.ResponseHandler;import org.apache.http.client.methods.HttpGet;import org.apache.http.impl.client.BasicResponseHandler;import org.apache.http.impl.client.DefaultHttpClient;/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHttpClientTest{publicstaticvoid main(String[] args)throwsException{//目标页面String url ="http://www.yshjava.cn";//创建一个默认的HttpClientHttpClient httpclient =newDefaultHttpClient();try{//以get方式请求网页http://www.yshjava.cnHttpGet httpget =newHttpGet(url);//打印请求地址System.out.println("executing request "+ httpget.getURI());//创建响应处理器处理服务器响应内容ResponseHandlerresponseHandler=newBasicResponseHandler();//执行请求并获取结果String responseBody = httpclient.execute(httpget, responseHandler);System.out.println("----------------------------------------");System.out.println(responseBody);System.out.println("----------------------------------------");}finally{//关闭连接管理器
httpclient.getConnectionManager().shutdown();}}}
汤
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
示例代码如下:
package cn.ysh.studio.crawler.jsoup;import java.io.IOException;import org.jsoup.Jsoup;/**
* 基于Jsoup抓取网页内容
* @author www.yshjava.cn
*/publicclassJsoupTest{publicstaticvoid main(String[] args)throwsIOException{//目标页面String url ="http://www.yshjava.cn";//使用Jsoup连接目标页面,并执行请求,获取服务器响应内容String html =Jsoup.connect(url).execute().body();//打印页面内容System.out.println(html);}}
html单元
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取和解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;import com.gargoylesoftware.htmlunit.BrowserVersion;import com.gargoylesoftware.htmlunit.Page;import com.gargoylesoftware.htmlunit.WebClient;/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlUnitSpider{publicstaticvoid main(String[] s)throwsException{//目标网页String url ="http://www.yshjava.cn";//模拟特定浏览器FIREFOX_3WebClient spider =newWebClient(BrowserVersion.FIREFOX_3);//获取目标网页Page page = spider.getPage(url);//打印网页内容System.out.println(page.getWebResponse().getContentAsString());//关闭所有窗口
spider.closeAllWindows();}}
瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
示例代码如下:
package cn.ysh.studio.crawler.ie;import watij.runtime.ie.IE;/**
* 基于Watij抓取网页内容,仅限Windows平台
*
* @author www.yshjava.cn
*/publicclassWatijTest{publicstaticvoid main(String[] s){//目标页面String url ="http://www.yshjava.cn";//实例化IE浏览器对象
IE ie =new IE();try{//启动浏览器
ie.start();//转到目标网页
ie.goTo(url);//等待网页加载就绪
ie.waitUntilReady();//打印页面内容System.out.println(ie.html());}catch(Exception e){
e.printStackTrace();}finally{try{//关闭IE浏览器
ie.close();}catch(Exception e){}}}}
硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;import org.openqa.selenium.htmlunit.HtmlUnitDriver;/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlDriverTest{publicstaticvoid main(String[] s){//目标网页String url ="http://www.yshjava.cn";HtmlUnitDriver driver =newHtmlUnitDriver();try{//禁用JS脚本功能
driver.setJavascriptEnabled(false);//打开目标网页
driver.get(url);//获取当前网页源码String html = driver.getPageSource();//打印网页源码System.out.println(html);}catch(Exception e){//打印堆栈信息
e.printStackTrace();}finally{try{//关闭并退出
driver.close();
driver.quit();}catch(Exception e){}}}}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;import org.watij.webspec.dsl.WebSpec;/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/publicclassWebspecTest{publicstaticvoid main(String[] s){//目标网页String url ="http://www.yshjava.cn";//实例化浏览器对象WebSpec spec =newWebSpec().mozilla();//隐藏浏览器窗体
spec.hide();//打开目标页面
spec.open(url);//打印网页源码System.out.println(spec.source());//关闭所有窗口
spec.closeAll();}}
c爬虫抓取网页数据(c爬虫抓取网页数据的方法有很多种,基于javascript加载网页获取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-22 13:11
c爬虫抓取网页数据的方法有很多种,最常见的是selenium。我曾经给朋友发过三种selenium抓取网页数据的方法。分别是:第一种:利用webdriver自动抓取cookies获取数据第二种:基于javascript加载网页获取数据第三种:javascript抓取并存入文件获取数据当我是一名程序员,我爬虫基本都是利用前两种,但如果只是想爬取网页的基本数据,可以使用cookies来抓取。
cookies类似一个临时地址。利用cookies可以直接自动获取网页上内容。python爬虫总结——cookies自动抓取这里贴一些爬虫基本示例,爬取电影id、标题、评分,以及每一场演唱会的演唱视频数据,以下所示cookies是一个加密数据,需要设置对应user-agent作为浏览器才能获取。
selenium是我爬虫的第一个工具,相比于selenium自己写程序自动爬取,它有好几个基础驱动模块,首先的是seleniumie驱动,后面有phantomjs,maplejs,webdriver等等,但还是不能满足需求,seleniumie驱动的问题是使用起来比较困难,不利于新手,我是先用maplejs,又加了一个mindnode驱动,之后maplejs中标有三种cookie,weibo,facebook,whisperer来封装cookie,对比其他cookie的缺点来到facebook来进行封装,最后用webdriver驱动封装了一下html5的标签,来实现代码组合。
这样我的代码变的比较优雅,避免了继承的使用的麻烦,而且爬取的数据是以网页元素为单位获取的,无需嵌套其他网页。有问题可以在群里讨论。 查看全部
c爬虫抓取网页数据(c爬虫抓取网页数据的方法有很多种,基于javascript加载网页获取数据)
c爬虫抓取网页数据的方法有很多种,最常见的是selenium。我曾经给朋友发过三种selenium抓取网页数据的方法。分别是:第一种:利用webdriver自动抓取cookies获取数据第二种:基于javascript加载网页获取数据第三种:javascript抓取并存入文件获取数据当我是一名程序员,我爬虫基本都是利用前两种,但如果只是想爬取网页的基本数据,可以使用cookies来抓取。
cookies类似一个临时地址。利用cookies可以直接自动获取网页上内容。python爬虫总结——cookies自动抓取这里贴一些爬虫基本示例,爬取电影id、标题、评分,以及每一场演唱会的演唱视频数据,以下所示cookies是一个加密数据,需要设置对应user-agent作为浏览器才能获取。
selenium是我爬虫的第一个工具,相比于selenium自己写程序自动爬取,它有好几个基础驱动模块,首先的是seleniumie驱动,后面有phantomjs,maplejs,webdriver等等,但还是不能满足需求,seleniumie驱动的问题是使用起来比较困难,不利于新手,我是先用maplejs,又加了一个mindnode驱动,之后maplejs中标有三种cookie,weibo,facebook,whisperer来封装cookie,对比其他cookie的缺点来到facebook来进行封装,最后用webdriver驱动封装了一下html5的标签,来实现代码组合。
这样我的代码变的比较优雅,避免了继承的使用的麻烦,而且爬取的数据是以网页元素为单位获取的,无需嵌套其他网页。有问题可以在群里讨论。
c爬虫抓取网页数据(关于item修改三项内容的一些问题教程引入刚刚写好的item)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-03-21 23:43
1.创建项目
打开终端进入(建议放到合适的路径,默认是C盘)
2.修改设置
修改三项,第一项是不遵循robot协议,第二项是下载gap,因为下面的程序需要下载多个页面,所以需要给gap(不给也可以,但是很容易待检测),第三个是请求头,添加一个User-Agent,第四个是开一个管道ROBOTSTXT_OBEY=False
DOWNLOAD_DELAY=1DEFAULT_REQUEST_HEADERS={'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-语言':'en','User-Agent':'Mozilla/5.0(WindowsNT6.2;WOW64)AppleWebKit/537.36(KHTML,likeGecko )Chrome/27.0.1453.94Safari/537.36'}ITEM_PIPELINES={'TXmovies.pipelines.TxmoviesPipeline':300,}
3.确认要提取的数据,
item item 定义要提取的内容(定义数据结构)。比如我提取的内容是电影名和电影描述,所以我创建了两个变量。Field方法的实际做法是创建一个字典,给字典添加一个新的值,暂时不赋值,等数据提取出来再赋值。下面的item结构可以表示为:{'name':'','description':''}。#-*-coding:utf-8-*-#Defineherethemodelsforyourscrapeditems##Seedocumentationin:#(scrapy.Item):#definethefieldsforyouritemherelike:#name=scrapy.Field()name=scrapy.Field()description=scrapy. 场地()
4.写一个爬虫
我们要写的部分是parse方法的内容,重点是xpath怎么写,XPATH教程介绍了刚才写的item,刚才说item中创建的变量是字典的key值,可以直接赋值。赋值后,交给流水线处理。简单说一下这段代码的思路,首先腾讯视频的url是给我们注意偏移量的,第一页的偏移量为0,第二页的偏移量为30,列推送按顺序。在程序中,此项用于控制第一页的抓取,但也需要给出一个范围。不能无限,否则会报错。你可以去看看腾讯总共有多少个视频页,也可以写一个异常捕获机制。捕获到请求错误时退出。我这里只是演示,所以我只给了120,也就是4页。收益计划中有两个收益。我更喜欢称之为中断。当然,中断只发生在 CPU 中。它的功能是转移控制权。在这个程序中,我们封装了item数据后,调用yield来传递控制权。把它交给管道,管道处理完后,返回并返回程序。这是对第一次收益率的解释。第二个产量有点复杂。本程序使用回调机制,即回调。回调的对象是 parse,也就是当前方法。通过不断的回调,程序会陷入循环。如果程序不加任何条件,就会陷入死循环。如果我在这个程序中删除 if ,这将是一个无限循环。yieldcrapy.Request(url=url,callback=self.parse)xpath 另外需要注意的是如何提取xpathl中的数据,我们有四种写法,第一种获取selector选择器,也就是original data ,其中有一些我们不使用的东西。第二个 extract() 将选择器序列号转换为字符串。第三个和第四个一样,获取字符串中的第一个数据,也就是我们想要的数据。将选择器序列号转换为字符串。第三个和第四个一样,获取字符串中的第一个数据,也就是我们想要的数据。将选择器序列号转换为字符串。第三个和第四个一样,获取字符串中的第一个数据,也就是我们想要的数据。
items['name']=i.xpath('./a/@title')[0]items['name']=i.xpath('./a/@title').extract()items[' name']=i.xpath('./a/@title').extract_first()items['name']=i.xpath('./a/@title').get()
#-*-coding:utf-8-*-importscrapyfrom..itemsimportTxmoviesItemclassTxmsSpider(scrapy.Spider):name='txms'allowed_domains=['']start_urls=['#39;]offset=0defparse(self,response): items=TxmoviesItem()lists=response.xpath('//div[@class="list_item"]')foriinlists:items['name']=i.xpath('./a/@title').get( )items['description']=i.xpath('./div/div/@title').get()yielditemsifself.offset 5. 到管道输出管道
提取的数据可以进行处理,例如存储在数据库中。我们只在这里输出。#-*-coding:utf-8-*-#Defineyouritempipelinehere##Don'tforgettoaddyourpipelinetotheITEM_PIPELINESsetting#See:
classTxmoviesPipeline(object):defprocess_item(self,item,spider):print(item)returnitem
6.run,执行项目
从scrapy导入命令行
cmdline.execute('scrapycrawltxms'.split())
7.测试结果白管输出结果
,红色调试信息8.流程梳理新建项目-》进入项目-》新建爬虫文件-》指定要抓取的内容,写入item-》编写爬虫程序,爬取数据-》交给管道处理数据-“调整全局配置设置-”执行爬虫程序,可以通过终端完成,也可以在程序中完成
8.处理中
新建项目-》进入项目-》新建爬虫文件-》明确要抓取的内容,编写item-》编写爬虫程序,爬取数据-》交给管道处理数据-》调整全局配置设置-》执行爬虫程序, 可以通过终端或者在程序中编写运行程序
9.加速:
多线程爬取如果实现了上面的实验,不难发现爬取速度很慢。根本原因是它是按顺序执行的。从结果可以看出,上一页的内容总是被删除。输出,然后输出以下内容。它不适合处理大量数据。一个好的方法是使用多线程方法。这里的多线程是基于方法的多线程,而不是通过创建一个 Thread 对象。请求被传递给调度程序。我们通过重写start_requests方法来实现我们的想法(这个方法的源码在__init__.py下,有兴趣的可以看看)
#-*-coding:utf-8-*-importscrapyfrom..itemsim
portTxmoviesItemclassTxmsSpider(scrapy.Spider):name='txms'allowed_domains=['']url='{}&pagesize=30'offset=0defstart_requests(self):
范围(0,121,30):
url=self.url.format(i)yieldscrapy.Request(url=url,callback=self.parse)defparse(self,response):items=TxmoviesItem()lists=response.xpath('//div[@class= "list_item"]')foriinlists:
items['name']=i.xpath('./a/@title').get() items['description']=i.xpath('./div/div/@title').get()产量项目 查看全部
c爬虫抓取网页数据(关于item修改三项内容的一些问题教程引入刚刚写好的item)
1.创建项目
打开终端进入(建议放到合适的路径,默认是C盘)
2.修改设置
修改三项,第一项是不遵循robot协议,第二项是下载gap,因为下面的程序需要下载多个页面,所以需要给gap(不给也可以,但是很容易待检测),第三个是请求头,添加一个User-Agent,第四个是开一个管道ROBOTSTXT_OBEY=False
DOWNLOAD_DELAY=1DEFAULT_REQUEST_HEADERS={'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-语言':'en','User-Agent':'Mozilla/5.0(WindowsNT6.2;WOW64)AppleWebKit/537.36(KHTML,likeGecko )Chrome/27.0.1453.94Safari/537.36'}ITEM_PIPELINES={'TXmovies.pipelines.TxmoviesPipeline':300,}
3.确认要提取的数据,
item item 定义要提取的内容(定义数据结构)。比如我提取的内容是电影名和电影描述,所以我创建了两个变量。Field方法的实际做法是创建一个字典,给字典添加一个新的值,暂时不赋值,等数据提取出来再赋值。下面的item结构可以表示为:{'name':'','description':''}。#-*-coding:utf-8-*-#Defineherethemodelsforyourscrapeditems##Seedocumentationin:#(scrapy.Item):#definethefieldsforyouritemherelike:#name=scrapy.Field()name=scrapy.Field()description=scrapy. 场地()
4.写一个爬虫
我们要写的部分是parse方法的内容,重点是xpath怎么写,XPATH教程介绍了刚才写的item,刚才说item中创建的变量是字典的key值,可以直接赋值。赋值后,交给流水线处理。简单说一下这段代码的思路,首先腾讯视频的url是给我们注意偏移量的,第一页的偏移量为0,第二页的偏移量为30,列推送按顺序。在程序中,此项用于控制第一页的抓取,但也需要给出一个范围。不能无限,否则会报错。你可以去看看腾讯总共有多少个视频页,也可以写一个异常捕获机制。捕获到请求错误时退出。我这里只是演示,所以我只给了120,也就是4页。收益计划中有两个收益。我更喜欢称之为中断。当然,中断只发生在 CPU 中。它的功能是转移控制权。在这个程序中,我们封装了item数据后,调用yield来传递控制权。把它交给管道,管道处理完后,返回并返回程序。这是对第一次收益率的解释。第二个产量有点复杂。本程序使用回调机制,即回调。回调的对象是 parse,也就是当前方法。通过不断的回调,程序会陷入循环。如果程序不加任何条件,就会陷入死循环。如果我在这个程序中删除 if ,这将是一个无限循环。yieldcrapy.Request(url=url,callback=self.parse)xpath 另外需要注意的是如何提取xpathl中的数据,我们有四种写法,第一种获取selector选择器,也就是original data ,其中有一些我们不使用的东西。第二个 extract() 将选择器序列号转换为字符串。第三个和第四个一样,获取字符串中的第一个数据,也就是我们想要的数据。将选择器序列号转换为字符串。第三个和第四个一样,获取字符串中的第一个数据,也就是我们想要的数据。将选择器序列号转换为字符串。第三个和第四个一样,获取字符串中的第一个数据,也就是我们想要的数据。
items['name']=i.xpath('./a/@title')[0]items['name']=i.xpath('./a/@title').extract()items[' name']=i.xpath('./a/@title').extract_first()items['name']=i.xpath('./a/@title').get()
#-*-coding:utf-8-*-importscrapyfrom..itemsimportTxmoviesItemclassTxmsSpider(scrapy.Spider):name='txms'allowed_domains=['']start_urls=['#39;]offset=0defparse(self,response): items=TxmoviesItem()lists=response.xpath('//div[@class="list_item"]')foriinlists:items['name']=i.xpath('./a/@title').get( )items['description']=i.xpath('./div/div/@title').get()yielditemsifself.offset 5. 到管道输出管道
提取的数据可以进行处理,例如存储在数据库中。我们只在这里输出。#-*-coding:utf-8-*-#Defineyouritempipelinehere##Don'tforgettoaddyourpipelinetotheITEM_PIPELINESsetting#See:
classTxmoviesPipeline(object):defprocess_item(self,item,spider):print(item)returnitem
6.run,执行项目
从scrapy导入命令行
cmdline.execute('scrapycrawltxms'.split())
7.测试结果白管输出结果
,红色调试信息8.流程梳理新建项目-》进入项目-》新建爬虫文件-》指定要抓取的内容,写入item-》编写爬虫程序,爬取数据-》交给管道处理数据-“调整全局配置设置-”执行爬虫程序,可以通过终端完成,也可以在程序中完成
8.处理中
新建项目-》进入项目-》新建爬虫文件-》明确要抓取的内容,编写item-》编写爬虫程序,爬取数据-》交给管道处理数据-》调整全局配置设置-》执行爬虫程序, 可以通过终端或者在程序中编写运行程序
9.加速:
多线程爬取如果实现了上面的实验,不难发现爬取速度很慢。根本原因是它是按顺序执行的。从结果可以看出,上一页的内容总是被删除。输出,然后输出以下内容。它不适合处理大量数据。一个好的方法是使用多线程方法。这里的多线程是基于方法的多线程,而不是通过创建一个 Thread 对象。请求被传递给调度程序。我们通过重写start_requests方法来实现我们的想法(这个方法的源码在__init__.py下,有兴趣的可以看看)
#-*-coding:utf-8-*-importscrapyfrom..itemsim
portTxmoviesItemclassTxmsSpider(scrapy.Spider):name='txms'allowed_domains=['']url='{}&pagesize=30'offset=0defstart_requests(self):
范围(0,121,30):
url=self.url.format(i)yieldscrapy.Request(url=url,callback=self.parse)defparse(self,response):items=TxmoviesItem()lists=response.xpath('//div[@class= "list_item"]')foriinlists:
items['name']=i.xpath('./a/@title').get() items['description']=i.xpath('./div/div/@title').get()产量项目
c爬虫抓取网页数据(互联网上的网络爬虫是怎么做的?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-21 19:38
1. 什么是爬虫
当今互联网上存储着大量信息。
作为普通网民,我们经常使用浏览器访问互联网上的内容。但是如果你想批量下载散落在网上的某方面的信息(比如某网站的所有图片,某某新闻网站的所有新闻,或者所有的收视率豆瓣上的电影),手动使用浏览器打开网站一一搜索太费时费力。
人工统计太费时费力
因此,编写程序来自动抓取 Internet 以获取有关我们想要的特定内容的信息变得更加重要。
网络爬虫是根据一定规则自动从万维网上抓取信息的程序或脚本。
通过程序,我们模拟浏览器向服务器发送请求,获取信息,分析信息,存储我们想要的内容。
百度/google搜索网站是利用爬虫定期搜索互联网上的链接并更新其服务器,以便我们通过搜索引擎搜索到我们想要的信息。
2. 网页结构
访问网页不仅仅是输入地址并查看它。
在浏览器中按“F12”,或右键单击网页并选择“检查”。你可以看到页面后面的代码。
以谷歌的Chrome浏览器为例,在任意一个网站中,我们按F12,就会出现一个浏览器检查窗口。默认的 Elements 窗口是当前界面的 HTML 代码。
Web 和元素界面
Sources 界面将显示浏览器从每个服务器下载的所有文件。
来源界面
在网络界面,在“记录网络日志”状态下(按Ctrl+E切换该状态),可以依次记录浏览器在每个时间段接收到的文件和文件相关数据。
网络接口
我们这里要实现的抓取具体信息的爬虫,需要我们去对应的网站去分析它的网页结构。根据网页的结构,我们可以通过编写相应的程序得到我们想要的信息。
3.python代码实现
我们将以豆瓣上的《流浪地球》影评为例,一步步讲解python爬虫的实现方法(使用python3).
以下代码可在 github 上下载。
3.1 基本介绍
我们将在本节中使用的 python 库是:
另外,本节我们没有讲,但是使用爬虫时可能用到的库通常包括:
对于上面的python库,bs4可以通过“pip install Beautifulsoup4”命令安装,其他库可以直接通过“pip install library noun”安装。
我们首先创建一个新的 jupyter 文件并导入必要的 python 库。
导入必要的python库
3.2 请求的使用
使用请求
上面的代码允许我们以编程方式访问(百度)网页。
其中,“requests.get(网页地址)”是以get的方式访问网页。
访问网址有两种类型:获取和发布。get和post的区别可以看下图(来自w3school)。两者的区别很容易理解,无需深究。
关于get、post和使用request传参,我们会在以后的爬虫进阶教程中一一介绍。
我们已经使用“response = requests.get(url)”将获取的信息传递给“response”。但是如果我们输出response,得到的不是网站的code,而是response状态码。
响应状态码
响应状态码代表我们之前请求请求的结果。常见的是200,代表成功;403,无访问权限;404,文件不存在;502,服务器错误。
想看看我们之前用“requests.get(url)”得到的网页内容。我们需要先执行“response.enconding = 'utf-8'”。这一步是将网页内容编码为utf-8,否则我们将无法在网页中看到中文。
将生成的内容编码为 utf-8
输入response.text后,我们就可以看到网页的代码了。
3.3 BeautifulSoup 的使用
在使用 BeautifulSoup 之前,建议读者对 html 有一定的了解。如果没有,那很好。
HTML 是一种标记语言,具有很强的结构要求。
html代码示例
我们使用 BeautifulSoup 来分析 HTML 页面的结构来选择我们想要的内容。
我们可以使用 BeautifulSoup(response.text, "lxml") 来自动分析我们之前得到的网页代码。分析结果存储在等号左侧的变量汤中。
html内容信息分析
BeautifulSoup 有很多使用方法。
例如 .find("tag name") 返回找到的第一个标签的内容。
.find("标记名")
值得注意的是,我们找到的第一个 div 标签里面也有 div 标签。但是 BeautifulSoup 不会注意到, .find("div") 只会返回找到的第一个 div 标签,以及该标签内的所有内容。
.find_all("tag name") 返回找到的所有标签。
.find_all("标签名称")
.find_all("tag name", class_="class name", id="id name") 可以找到指定的类别并指定id标签。(注意使用 class_ 而不是 class)
.find_all("标签名", class_="类名", id="id名")
此外,我们还可以继续对.find()和.find_all()的结果进行.find()、.find_all()查询。
3.4 json的使用
除了html格式文件,我们经常需要爬取一些json格式文件。JSON 是一种轻量级的数据交换格式。
html和json格式文件的区别如下。(严格来说左边应该是一个XML格式的文件,但也可以认为是一般的HTML)
html和json格式文件的区别
(图片来自网络)
所以,有时,我们会解析 json 格式的数据。
使用 text = json.loads(字符串格式的json数据)
您可以将字符串格式的 json 数据转换为 python 字典格式。
3.5 组合使用
我们之前提到过:“根据网页的结构,我们可以通过编写相应的程序得到我们想要的信息。”
现在,我们进入豆瓣影评《流浪地球》的短评界面。
()
《流浪地球》短评界面
我们按“F12”打开检查界面。如果你使用的是Chrome浏览器,可以点击下图的小箭头或者Ctrl+Shift+C。这时,当鼠标移动到页面上的某个位置时,浏览器会自动显示该位置对应的代码位置。
Ctrl+Shift+C后可以查看页面中每个元素的位置
具体效果如下:
结合我们之前讲过的requests和Beautifulsoup的对应知识。读者可以尝试写一个爬虫来获取当前网页的所有短评信息。
作者这里爬的是
“”,是一个json文件,所以额外使用了python的json库。
代码显示如下。完整代码可在 github 上找到。建议读者先尝试从零开始写一个爬虫,遇到问题先百度/谷歌,最后参考这个完整的爬虫代码
完整的爬虫代码
完成代码下载:
3.6 最终结果
最后,为了让最终的结果更加美观,作者在这里使用了pandas的DataFrame。
使用熊猫的数据框
爬取的数据结果如下
抓取的数据
3.7 扩展
以上内容只是一个基本的python爬虫。
如果读者细心,他们会发现不登录豆瓣就无法访问。”
"
没有权限
这里的url链接中的start=220表示我们不登录就无法查看第220条评论之后的内容。
在以后的爬虫进阶教程中,我们会介绍如何使用爬虫进行登录、保存cookies等操作。
另外,有些网站可能会使用js进行网站动态渲染、代码加密等,仅仅爬取html和json文件是不够的。同时,我们也可以使用多进程来加速爬虫...
敬请期待以后的爬虫进阶教程。
其他文章
(点击跳转)
长
根据
关闭
笔记
解锁更多精彩内容
跟着一起做一个有灵魂的人 查看全部
c爬虫抓取网页数据(互联网上的网络爬虫是怎么做的?(一))
1. 什么是爬虫
当今互联网上存储着大量信息。
作为普通网民,我们经常使用浏览器访问互联网上的内容。但是如果你想批量下载散落在网上的某方面的信息(比如某网站的所有图片,某某新闻网站的所有新闻,或者所有的收视率豆瓣上的电影),手动使用浏览器打开网站一一搜索太费时费力。
人工统计太费时费力
因此,编写程序来自动抓取 Internet 以获取有关我们想要的特定内容的信息变得更加重要。
网络爬虫是根据一定规则自动从万维网上抓取信息的程序或脚本。
通过程序,我们模拟浏览器向服务器发送请求,获取信息,分析信息,存储我们想要的内容。
百度/google搜索网站是利用爬虫定期搜索互联网上的链接并更新其服务器,以便我们通过搜索引擎搜索到我们想要的信息。
2. 网页结构
访问网页不仅仅是输入地址并查看它。
在浏览器中按“F12”,或右键单击网页并选择“检查”。你可以看到页面后面的代码。
以谷歌的Chrome浏览器为例,在任意一个网站中,我们按F12,就会出现一个浏览器检查窗口。默认的 Elements 窗口是当前界面的 HTML 代码。
Web 和元素界面
Sources 界面将显示浏览器从每个服务器下载的所有文件。
来源界面
在网络界面,在“记录网络日志”状态下(按Ctrl+E切换该状态),可以依次记录浏览器在每个时间段接收到的文件和文件相关数据。
网络接口
我们这里要实现的抓取具体信息的爬虫,需要我们去对应的网站去分析它的网页结构。根据网页的结构,我们可以通过编写相应的程序得到我们想要的信息。
3.python代码实现
我们将以豆瓣上的《流浪地球》影评为例,一步步讲解python爬虫的实现方法(使用python3).
以下代码可在 github 上下载。
3.1 基本介绍
我们将在本节中使用的 python 库是:
另外,本节我们没有讲,但是使用爬虫时可能用到的库通常包括:
对于上面的python库,bs4可以通过“pip install Beautifulsoup4”命令安装,其他库可以直接通过“pip install library noun”安装。
我们首先创建一个新的 jupyter 文件并导入必要的 python 库。
导入必要的python库
3.2 请求的使用
使用请求
上面的代码允许我们以编程方式访问(百度)网页。
其中,“requests.get(网页地址)”是以get的方式访问网页。
访问网址有两种类型:获取和发布。get和post的区别可以看下图(来自w3school)。两者的区别很容易理解,无需深究。
关于get、post和使用request传参,我们会在以后的爬虫进阶教程中一一介绍。
我们已经使用“response = requests.get(url)”将获取的信息传递给“response”。但是如果我们输出response,得到的不是网站的code,而是response状态码。
响应状态码
响应状态码代表我们之前请求请求的结果。常见的是200,代表成功;403,无访问权限;404,文件不存在;502,服务器错误。
想看看我们之前用“requests.get(url)”得到的网页内容。我们需要先执行“response.enconding = 'utf-8'”。这一步是将网页内容编码为utf-8,否则我们将无法在网页中看到中文。
将生成的内容编码为 utf-8
输入response.text后,我们就可以看到网页的代码了。
3.3 BeautifulSoup 的使用
在使用 BeautifulSoup 之前,建议读者对 html 有一定的了解。如果没有,那很好。
HTML 是一种标记语言,具有很强的结构要求。
html代码示例
我们使用 BeautifulSoup 来分析 HTML 页面的结构来选择我们想要的内容。
我们可以使用 BeautifulSoup(response.text, "lxml") 来自动分析我们之前得到的网页代码。分析结果存储在等号左侧的变量汤中。
html内容信息分析
BeautifulSoup 有很多使用方法。
例如 .find("tag name") 返回找到的第一个标签的内容。
.find("标记名")
值得注意的是,我们找到的第一个 div 标签里面也有 div 标签。但是 BeautifulSoup 不会注意到, .find("div") 只会返回找到的第一个 div 标签,以及该标签内的所有内容。
.find_all("tag name") 返回找到的所有标签。
.find_all("标签名称")
.find_all("tag name", class_="class name", id="id name") 可以找到指定的类别并指定id标签。(注意使用 class_ 而不是 class)
.find_all("标签名", class_="类名", id="id名")
此外,我们还可以继续对.find()和.find_all()的结果进行.find()、.find_all()查询。
3.4 json的使用
除了html格式文件,我们经常需要爬取一些json格式文件。JSON 是一种轻量级的数据交换格式。
html和json格式文件的区别如下。(严格来说左边应该是一个XML格式的文件,但也可以认为是一般的HTML)
html和json格式文件的区别
(图片来自网络)
所以,有时,我们会解析 json 格式的数据。
使用 text = json.loads(字符串格式的json数据)
您可以将字符串格式的 json 数据转换为 python 字典格式。
3.5 组合使用
我们之前提到过:“根据网页的结构,我们可以通过编写相应的程序得到我们想要的信息。”
现在,我们进入豆瓣影评《流浪地球》的短评界面。
()
《流浪地球》短评界面
我们按“F12”打开检查界面。如果你使用的是Chrome浏览器,可以点击下图的小箭头或者Ctrl+Shift+C。这时,当鼠标移动到页面上的某个位置时,浏览器会自动显示该位置对应的代码位置。
Ctrl+Shift+C后可以查看页面中每个元素的位置
具体效果如下:
结合我们之前讲过的requests和Beautifulsoup的对应知识。读者可以尝试写一个爬虫来获取当前网页的所有短评信息。
作者这里爬的是
“”,是一个json文件,所以额外使用了python的json库。
代码显示如下。完整代码可在 github 上找到。建议读者先尝试从零开始写一个爬虫,遇到问题先百度/谷歌,最后参考这个完整的爬虫代码
完整的爬虫代码
完成代码下载:
3.6 最终结果
最后,为了让最终的结果更加美观,作者在这里使用了pandas的DataFrame。
使用熊猫的数据框
爬取的数据结果如下
抓取的数据
3.7 扩展
以上内容只是一个基本的python爬虫。
如果读者细心,他们会发现不登录豆瓣就无法访问。”
"
没有权限
这里的url链接中的start=220表示我们不登录就无法查看第220条评论之后的内容。
在以后的爬虫进阶教程中,我们会介绍如何使用爬虫进行登录、保存cookies等操作。
另外,有些网站可能会使用js进行网站动态渲染、代码加密等,仅仅爬取html和json文件是不够的。同时,我们也可以使用多进程来加速爬虫...
敬请期待以后的爬虫进阶教程。
其他文章
(点击跳转)
长
根据
关闭
笔记
解锁更多精彩内容
跟着一起做一个有灵魂的人
c爬虫抓取网页数据(聚焦爬虫工作原理及关键技术的工作流程和关键技术概述)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-03-21 12:04
1 重点介绍爬虫的工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它从互联网上为搜索引擎下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会按照一定的搜索策略从队列中选择下一个要爬取的网页URL,重复上述过程,直到达到系统的一定条件并停止。存储、执行一定的分析、过滤、建立索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可以为后续的爬取过程提供反馈和指导。
与通用网络爬虫相比,聚焦爬虫仍需解决三个主要问题:
(1) 抓取目标的描述或定义;
(2)网页或数据分析过滤;
(3) URL 的搜索策略。
爬取目标的描述和定义是决定如何制定网页分析算法和URL搜索策略的基础。网页分析算法和候选URL排序算法是确定搜索引擎提供的服务形式和爬虫爬取行为的关键。这两部分的算法密切相关。
2 抓取目标描述
现有的聚焦爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模式和基于领域概念。
爬虫根据目标网页的特性抓取、存储和索引的对象一般是网站或网页。根据种子样品的获取方法,可分为:
(1) 预先给定的初始抓取种子样本;
(2)预先给定的网页类别和类别对应的种子样本,如Yahoo!类别结构等;
(3)由用户行为决定的抓取目标示例,分为:
a) 在用户浏览期间显示带注释的抓取样本;
b) 通过用户日志挖掘获取访问模式和相关样本。
其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
现有的聚焦爬虫对爬取目标的描述或定义可以分为三种类型:基于目标网页的特征、基于目标数据模式和基于领域概念。
爬虫根据目标网页的特性抓取、存储和索引的对象一般是网站或网页。具体方法可以分为:(1)Pre-given初始抓取种子样本;(2)预先给定网页类别和类别对应的种子样本),如Yahoo!分类结构,等;(3)由用户行为决定的爬取目标样本。其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
基于目标数据模式的爬虫针对网页上的数据,抓取到的数据一般符合一定的模式,也可以转换或映射到目标数据模式。
另一种描述方式是建立目标域的本体或字典,用于从语义角度分析某个主题中不同特征的重要性。
3 网络搜索策略
网页抓取策略可以分为三类:深度优先、广度优先和最佳优先。深度优先在很多情况下会导致爬虫被困的问题。目前,广度优先和最佳优先方法很常见。
3.1 广度优先搜索策略
广度优先搜索策略是指在爬取过程中,完成当前一级搜索后,进行下一级搜索。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索方式。也有许多研究将广度优先搜索策略应用于聚焦爬虫。其基本思想是距初始 URL 一定链接距离内的网页具有较高的主题相关性概率。另一种方法是将广度优先搜索与网页过滤技术相结合,首先使用广度优先策略抓取网页,然后过滤掉不相关的页面。这些方法的缺点是随着爬取的网页数量的增加,会下载和过滤大量不相关的网页,算法的效率会变低。
3.2 最佳优先搜索策略
最佳优先级搜索策略根据一定的网页分析算法预测候选URL与目标网页的相似度,或与主题的相关度,选择评价最好的一个或几个URL进行爬取。它只访问页面分析算法预测为“有用”的页面。一个问题是爬虫爬取路径上的许多相关网页可能会被忽略,因为最佳优先策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,从而跳出局部最优点。在第 4 节中,将结合网页分析算法进行详细讨论。研究表明,这样的闭环调整可以将不相关页面的数量减少 30% 到 90%。
4 网络分析算法
网页分析算法可以分为三种类型:基于网络拓扑、基于网页内容和基于用户访问行为。
4.1基于网络拓扑的分析算法
基于网页之间的链接,通过已知的网页或数据,一种算法来评估与其有直接或间接链接关系的对象(可以是网页或网站等)。进一步分为三种:网页粒度、网站粒度和网页块粒度。
4.1.1 网页粒度分析算法
PageRank 和 HITS 算法是最常见的链接分析算法。两者都是通过网页间链接度的递归归一化计算得到每个网页的重要性。 PageRank算法虽然考虑了用户访问行为的随机性和Sink网页的存在性,但忽略了大部分用户访问的目的性,即网页和查询主题链接的相关性。针对这个问题,HITS算法提出了两个关键概念:权威网页(authority)和中心网页(hub)。
基于链接爬取的问题是相关页面的主题组之间存在隧道现象,即爬取路径上很多偏离主题的页面也指向目标页面,局部评价策略打断了当前路径上的爬行行为。 参考文献[21]提出了一种基于反向链接(BackLink)的层次上下文模型(Context Model),用于描述指向一定物理跳半径内的目标网页的网页拓扑图的中心Layer 0作为目标网页。网页根据指向目标网页的物理跳数进行层次划分,外层网页到内层网页的链接称为反向链接。
4.1.2 网站粒度分析算法
网站粒度的资源发现和管理策略也比网页粒度的更简单有效。 网站粒度爬取的关键是站点的划分和SiteRank的计算。 SiteRank的计算方法与PageRank类似,但需要对网站之间的链接进行一定程度的抽象,并在一定模型下计算链接的权重。
网站划分分为两种:按域名划分和按IP地址划分。参考文献[18]讨论了分布式情况下,通过划分同一域名下不同主机和服务器的IP地址,构建站点地图,并采用类似于PageRank的方法评估SiteRank。同时,根据每个站点不同文件的分布情况,构建文档图,结合SiteRank分布式计算得到DocRank。参考文献[18]证明,使用分布式SiteRank计算不仅大大降低了单个站点的算法成本,而且克服了单个站点对全网覆盖范围有限的缺点。一个额外的好处是,常见的 PageRank 欺诈很难欺骗 SiteRank。
4.1.3 Web块粒度分析算法
一个页面通常收录多个指向其他页面的链接,而这些链接中只有一些指向与主题相关的网页,或者根据网页的链接锚文本指示高重要性。但是在PageRank和HITS算法中,这些链接是没有区分的,所以往往会给网页分析带来广告等噪声链接的干扰。块级链接分析算法的基本思想是通过VIPS网页切分算法将网页分成不同的页面块,然后为这些网页块创建page-to-block和block-block。 to-page的链接矩阵分别表示为Z和X。因此,page-to-page图上的page block level的PageRank为Wp=X×Z; 在块到块图上的 BlockRank 是 Wb=Z×X。 有人实现了块级PageRank和HITS算法,实验证明效率和准确率优于传统的对应算法。
4.2基于网页内容的网页分析算法
基于网页内容的分析算法是指利用网页内容的特征(文本、数据等资源)对网页进行评价。网页内容已经从基于超文本的内容演变为动态页面(或称为隐藏网页)数据,后者的数据量约为直接可见页面数据(PIW,Publicly Indexable Web)的400~500%。次。另一方面,多媒体数据、Web Service等各种形式的网络资源日益丰富。因此,基于网页内容的分析算法也从最初的相对简单的文本检索方法发展到综合应用包括网页数据提取、机器学习、数据挖掘、语义理解等多种方法。本节根据网页数据的不同形式,将基于网页内容的分析算法分为以下三类:第一类是针对以文本和超链接为主的非结构化或非常简单的网页;第二个是结构化网页。对于数据源(如RDBMS)动态生成的页面,不能直接批量访问数据;第三类数据介于第一类和第二类数据之间,结构更好,表明它遵循一定的模式或风格。并且可以直接访问。 查看全部
c爬虫抓取网页数据(聚焦爬虫工作原理及关键技术的工作流程和关键技术概述)
1 重点介绍爬虫的工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它从互联网上为搜索引擎下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会按照一定的搜索策略从队列中选择下一个要爬取的网页URL,重复上述过程,直到达到系统的一定条件并停止。存储、执行一定的分析、过滤、建立索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可以为后续的爬取过程提供反馈和指导。
与通用网络爬虫相比,聚焦爬虫仍需解决三个主要问题:
(1) 抓取目标的描述或定义;
(2)网页或数据分析过滤;
(3) URL 的搜索策略。
爬取目标的描述和定义是决定如何制定网页分析算法和URL搜索策略的基础。网页分析算法和候选URL排序算法是确定搜索引擎提供的服务形式和爬虫爬取行为的关键。这两部分的算法密切相关。
2 抓取目标描述
现有的聚焦爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模式和基于领域概念。
爬虫根据目标网页的特性抓取、存储和索引的对象一般是网站或网页。根据种子样品的获取方法,可分为:
(1) 预先给定的初始抓取种子样本;
(2)预先给定的网页类别和类别对应的种子样本,如Yahoo!类别结构等;
(3)由用户行为决定的抓取目标示例,分为:
a) 在用户浏览期间显示带注释的抓取样本;
b) 通过用户日志挖掘获取访问模式和相关样本。
其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
现有的聚焦爬虫对爬取目标的描述或定义可以分为三种类型:基于目标网页的特征、基于目标数据模式和基于领域概念。
爬虫根据目标网页的特性抓取、存储和索引的对象一般是网站或网页。具体方法可以分为:(1)Pre-given初始抓取种子样本;(2)预先给定网页类别和类别对应的种子样本),如Yahoo!分类结构,等;(3)由用户行为决定的爬取目标样本。其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
基于目标数据模式的爬虫针对网页上的数据,抓取到的数据一般符合一定的模式,也可以转换或映射到目标数据模式。
另一种描述方式是建立目标域的本体或字典,用于从语义角度分析某个主题中不同特征的重要性。
3 网络搜索策略
网页抓取策略可以分为三类:深度优先、广度优先和最佳优先。深度优先在很多情况下会导致爬虫被困的问题。目前,广度优先和最佳优先方法很常见。
3.1 广度优先搜索策略
广度优先搜索策略是指在爬取过程中,完成当前一级搜索后,进行下一级搜索。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索方式。也有许多研究将广度优先搜索策略应用于聚焦爬虫。其基本思想是距初始 URL 一定链接距离内的网页具有较高的主题相关性概率。另一种方法是将广度优先搜索与网页过滤技术相结合,首先使用广度优先策略抓取网页,然后过滤掉不相关的页面。这些方法的缺点是随着爬取的网页数量的增加,会下载和过滤大量不相关的网页,算法的效率会变低。
3.2 最佳优先搜索策略
最佳优先级搜索策略根据一定的网页分析算法预测候选URL与目标网页的相似度,或与主题的相关度,选择评价最好的一个或几个URL进行爬取。它只访问页面分析算法预测为“有用”的页面。一个问题是爬虫爬取路径上的许多相关网页可能会被忽略,因为最佳优先策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,从而跳出局部最优点。在第 4 节中,将结合网页分析算法进行详细讨论。研究表明,这样的闭环调整可以将不相关页面的数量减少 30% 到 90%。
4 网络分析算法
网页分析算法可以分为三种类型:基于网络拓扑、基于网页内容和基于用户访问行为。
4.1基于网络拓扑的分析算法
基于网页之间的链接,通过已知的网页或数据,一种算法来评估与其有直接或间接链接关系的对象(可以是网页或网站等)。进一步分为三种:网页粒度、网站粒度和网页块粒度。
4.1.1 网页粒度分析算法
PageRank 和 HITS 算法是最常见的链接分析算法。两者都是通过网页间链接度的递归归一化计算得到每个网页的重要性。 PageRank算法虽然考虑了用户访问行为的随机性和Sink网页的存在性,但忽略了大部分用户访问的目的性,即网页和查询主题链接的相关性。针对这个问题,HITS算法提出了两个关键概念:权威网页(authority)和中心网页(hub)。
基于链接爬取的问题是相关页面的主题组之间存在隧道现象,即爬取路径上很多偏离主题的页面也指向目标页面,局部评价策略打断了当前路径上的爬行行为。 参考文献[21]提出了一种基于反向链接(BackLink)的层次上下文模型(Context Model),用于描述指向一定物理跳半径内的目标网页的网页拓扑图的中心Layer 0作为目标网页。网页根据指向目标网页的物理跳数进行层次划分,外层网页到内层网页的链接称为反向链接。
4.1.2 网站粒度分析算法
网站粒度的资源发现和管理策略也比网页粒度的更简单有效。 网站粒度爬取的关键是站点的划分和SiteRank的计算。 SiteRank的计算方法与PageRank类似,但需要对网站之间的链接进行一定程度的抽象,并在一定模型下计算链接的权重。
网站划分分为两种:按域名划分和按IP地址划分。参考文献[18]讨论了分布式情况下,通过划分同一域名下不同主机和服务器的IP地址,构建站点地图,并采用类似于PageRank的方法评估SiteRank。同时,根据每个站点不同文件的分布情况,构建文档图,结合SiteRank分布式计算得到DocRank。参考文献[18]证明,使用分布式SiteRank计算不仅大大降低了单个站点的算法成本,而且克服了单个站点对全网覆盖范围有限的缺点。一个额外的好处是,常见的 PageRank 欺诈很难欺骗 SiteRank。
4.1.3 Web块粒度分析算法
一个页面通常收录多个指向其他页面的链接,而这些链接中只有一些指向与主题相关的网页,或者根据网页的链接锚文本指示高重要性。但是在PageRank和HITS算法中,这些链接是没有区分的,所以往往会给网页分析带来广告等噪声链接的干扰。块级链接分析算法的基本思想是通过VIPS网页切分算法将网页分成不同的页面块,然后为这些网页块创建page-to-block和block-block。 to-page的链接矩阵分别表示为Z和X。因此,page-to-page图上的page block level的PageRank为Wp=X×Z; 在块到块图上的 BlockRank 是 Wb=Z×X。 有人实现了块级PageRank和HITS算法,实验证明效率和准确率优于传统的对应算法。
4.2基于网页内容的网页分析算法
基于网页内容的分析算法是指利用网页内容的特征(文本、数据等资源)对网页进行评价。网页内容已经从基于超文本的内容演变为动态页面(或称为隐藏网页)数据,后者的数据量约为直接可见页面数据(PIW,Publicly Indexable Web)的400~500%。次。另一方面,多媒体数据、Web Service等各种形式的网络资源日益丰富。因此,基于网页内容的分析算法也从最初的相对简单的文本检索方法发展到综合应用包括网页数据提取、机器学习、数据挖掘、语义理解等多种方法。本节根据网页数据的不同形式,将基于网页内容的分析算法分为以下三类:第一类是针对以文本和超链接为主的非结构化或非常简单的网页;第二个是结构化网页。对于数据源(如RDBMS)动态生成的页面,不能直接批量访问数据;第三类数据介于第一类和第二类数据之间,结构更好,表明它遵循一定的模式或风格。并且可以直接访问。
c爬虫抓取网页数据( 分布式网络数据抓取系统说明()应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-21 12:02
分布式网络数据抓取系统说明()应用)
分布式网络数据采集系统的设计与实现
1、分布式网络数据采集系统说明
(1)深入分析网络数据(金融、教育、汽车)爬虫特性,设计分布式网络数据(金融、教育、汽车)系统爬取策略、爬取领域、动态网页抓取方法、分布式结构和数据存储等功能。
(2)简述分布式网络数据(金融、教育、汽车)抓取系统的实现流程。包括爬虫编写、爬虫规避(各种反爬方式)、动态网页数据抓取、数据存储等。
(3)需要爬取的网络数据网站的自定义配置网页模板,以及数据抓取(接口暂不考虑)
2、系统功能架构设计
系统功能架构
分布式爬虫爬取系统主要包括以下功能:
1。爬虫功能:爬取策略设计、内容数据域设计、增量爬取、请求去重
2。中间件:反爬机制、ajax动态数据加载、爬虫下载异常处理
3。数据存储:抓图设计、数据存储
3、系统分布式架构
分布式采用主从结构,设置一个Master服务器和多个Slave服务器。 Master 端管理 Redis 数据库并分发下载任务。 Slave部署Scrapy爬虫提取网页并解析提取数据,最终将解析后的数据存储在数据库中同一个MongoDb中。分布式爬虫架构如图
分布式爬虫架构
应用Redis数据库实现分布式爬取。基本思路是将Scrapy爬虫获取的detail_request的url放入Redis Queue,所有爬虫也从指定的Redis Queue获取请求。 Scrapy-Redis 组件中默认使用 SpiderPriorityQueue 来确定 url 的顺序,这是一种通过 sorted set 实现的非 FIFO 和 LIFO 方法。因此,待爬取队列的共享是爬虫可以部署在其他服务器上完成相同爬取任务的关键点。此外,为了解决 Scrapy 单机受限的问题,Scrapy 将结合 Scrapy-Redis 组件进行开发。 Scrapy-Redis的总体思路是,本项目通过重写Scrapy框架中的scheduler和spider类来实现调度、spider启动和redis的交互。 实现了新的dupefilter和queue类,实现了权重判断和调度容器与redis的交互。由于每台主机上的爬虫进程访问同一个redis数据库,调度和权重判断统一管理,实现分布式分布。爬虫的目的
4、系统实现
4.1、爬取策略设计
从scrapy的结构分析可以看出,网络爬虫从初始地址开始,根据从spider中定义的目标地址获取的正则表达式或Xpath获取更多的网页链接,并加入队列待下载进行去重和排序后,等待调度器调度。
在这个系统中,新建的链接可以分为两类,一类是目录页链接,也就是我们平时看到的下一页的链接,另一类是内容详情页链接,也就是我们需要解析网页的提取字段中的链接指向实际的页面信息。网络需要从每个目录页面链接中提取多个内容页面链接,并将它们添加到待下载队列中以供进一步爬取。爬取过程如下:
爬取过程
这里是master端目标链接的爬取策略。由于是分布式主从模式,master端的爬虫主要抓取下载内容详情页的链接,通过redis将下载任务分享给slave端的其他爬虫。 Slave端主要负责进一步解析提取详情页的链接并存入数据库。
1)对于大师:
核心模块是解决翻页问题,获取每个页面内容的详情页链接。 Master端主要采用以下爬取策略:
1.将redis的初始链接插入到key next_link,从初始页面链接开始
2.爬虫从redis中的key next_link获取初始链接,开始运行爬虫
3.下载器返回的Response,爬虫根据蜘蛛定义的爬取规则识别是否有下一页的链接。如果有链接,则存储在redis中,key保存为next_link。它匹配多个内容详细信息页面链接。如果匹配,则存储在Redis中,并将key保存为detail_request并插入下载链接,供slave端的spider使用,也就是slave端的下载任务。
4.爬虫继续从redis中的key取值作为next_link。如果有值,则继续执行步骤2。如果为空,则爬虫等待新的链接。
2)对于奴隶:
核心模块是从redis获取下载任务,解析提取字段。 Slave端主要采用以下爬取策略:
1。爬虫从redis获取初始链接,key为detail_request,开始运行爬虫
2。下载器返回的Response,爬虫根据爬虫定义的爬取规则识别是否有匹配规则的content字段,如果有则存储该字段返回给模型,等待数据存储操作。
重复第 1 步,直到爬取队列为空,爬虫等待新的链接。
4.2爬虫的具体实现
爬虫程序由四部分组成,即对象定义程序、数据捕获程序、数据处理程序和下载设置程序。这里的组成是Slave端,Master缺少对象定义程序和数据处理程序,而Master端主要是下载链接的爬取。
数据抓取程序:
数据爬取程序分为主端和从端。数据爬取程序从 Redis 获取初始地址。数据爬取程序定义了爬取网页的规则,使用Xpath提取字段数据的方法,以及css选择器选择器。数据提取方法等
4.3 去重和增量爬取
去重和增量爬取对服务器意义重大,可以减轻服务器压力,保证数据的准确性。如果不采用去重,爬取的内容会爬取大量的重复内容,大大降低爬虫的效率。事实上,重复数据删除的过程非常简单。核心是判断每个请求是否在已经爬取的队列中。如果已经存在,则丢弃当前请求。
具体实现步骤:
去重和增量爬取
(1)从待爬取队列中获取url
(2)会判断要请求的url是否被爬取,如果已经被爬取则忽略该请求,不被爬取,继续其他操作,将url插入到被爬取队列中
(3)重复步骤 1
4.4个爬虫中间件
爬虫中间件可以帮助我们在scrapy爬取过程中自由扩展自己的程序。以下是爬虫反屏蔽中间件、下载器异常状态中间件和非200状态中间件。
(1)履带防屏蔽组件的实现
当访问一个网站网页时,会给网站带来一定的负载,爬虫程序模拟了我们正常访问网页的过程,但是。大型爬虫会给网站增加很大的负载,影响正常用户的访问。为了保证大部分普通用户可以访问网页,大部分网站都有相应的反爬策略。一旦访问行为被识别为爬虫,网站会采取一定的措施限制你的访问,比如访问过于频繁会提示你输入验证码。您访问 网站。当系统有针对性的抓取网页数据时,会不断的访问网站的内容。如果不采取伪装措施,很容易被网站识别为爬虫行为而被屏蔽。
系统使用以下方法防止爬虫被拦截:
1.模拟不同的浏览器行为
2.一定频率更换代理服务器和网关
3.降低爬取网页的频率,减少并发爬取的进程,限制每个ip的并发爬取数量,牺牲一定的效率来换取系统的稳定性。
4.禁用cookies,网站会在用户访问时在cookie中插入一些信息来判断是否是机器人。我们阻止了cookies的调整,这也有助于我们的身份不被暴露。
反爬虫网站屏蔽原理如下图所示:
反网站屏蔽原理
(a) 模拟不同浏览器行为的想法和代码
原理:scrapy有下载中间件,在这个中间件中我们可以自定义请求和响应,核心是修改请求的属性
首先,主要是扩展下载中间件。首先在seeings.py中添加中间件并展开中间件,主要是写一个user-agent列表,将常用的浏览器请求头保存为列表,然后让请求头文件在列表中随机取一个代理值,并然后下载到下载器中。
用户代理
综上所述,每次发出请求,都会使用不同的浏览器访问目标网站。
(b)使用代理ip进行爬取的实现思路。
首先在settings.py中添加中间件,扩展下载组件请求的头文件从代理ip池中随机取一个代理值下载到下载器中。
1.代理ip池的设计开发流程如下:
一个。爬取免费代理ip网站.
b.存储并验证代理ip
c。身份验证通过存储方式存储在数据库中
d。如果验证失败,删除它
(c)爬虫异常状态组件的处理
当爬虫没有被阻塞并运行时,访问网站并不总是200请求成功,而是有多种状态,比如上面的爬虫被禁止时,返回的状态实际上是302,防止屏蔽组件是通过捕获302状态来实现的。同时异常状态的处理有利于爬虫的健壮性。
设置中的扩展中间件捕捉到异常后,重新将请求加入待下载队列的过程如下:
异常处理
(d) 数据存储模块
数据存储模块主要负责存储slave端抓取并解析的页面。数据使用MongoDB存储。
Scrapy支持json、csv、xml等数据存储格式,用户可以在运行爬虫时设置,例如:scrapy crawl spider
-o items.json -t json,也可以在Scrapy项目文件和ItemPipline文件中定义。同时Scrapy还支持数据库存储,比如Mongodb、Redis等,当数据量大到一定程度时,可以做Mongodb或者Reids的集群来解决问题,这个的数据存储系统如下图所示:
数据存储
5.总结
以上是分布式网络数据爬取系统的设计部分。由于单机爬虫的爬取量和爬取速度的限制,采用分布式设计。这是V1.0版本,以后会跟进。继续完善相关部分。 查看全部
c爬虫抓取网页数据(
分布式网络数据抓取系统说明()应用)
分布式网络数据采集系统的设计与实现
1、分布式网络数据采集系统说明
(1)深入分析网络数据(金融、教育、汽车)爬虫特性,设计分布式网络数据(金融、教育、汽车)系统爬取策略、爬取领域、动态网页抓取方法、分布式结构和数据存储等功能。
(2)简述分布式网络数据(金融、教育、汽车)抓取系统的实现流程。包括爬虫编写、爬虫规避(各种反爬方式)、动态网页数据抓取、数据存储等。
(3)需要爬取的网络数据网站的自定义配置网页模板,以及数据抓取(接口暂不考虑)
2、系统功能架构设计
系统功能架构
分布式爬虫爬取系统主要包括以下功能:
1。爬虫功能:爬取策略设计、内容数据域设计、增量爬取、请求去重
2。中间件:反爬机制、ajax动态数据加载、爬虫下载异常处理
3。数据存储:抓图设计、数据存储
3、系统分布式架构
分布式采用主从结构,设置一个Master服务器和多个Slave服务器。 Master 端管理 Redis 数据库并分发下载任务。 Slave部署Scrapy爬虫提取网页并解析提取数据,最终将解析后的数据存储在数据库中同一个MongoDb中。分布式爬虫架构如图
分布式爬虫架构
应用Redis数据库实现分布式爬取。基本思路是将Scrapy爬虫获取的detail_request的url放入Redis Queue,所有爬虫也从指定的Redis Queue获取请求。 Scrapy-Redis 组件中默认使用 SpiderPriorityQueue 来确定 url 的顺序,这是一种通过 sorted set 实现的非 FIFO 和 LIFO 方法。因此,待爬取队列的共享是爬虫可以部署在其他服务器上完成相同爬取任务的关键点。此外,为了解决 Scrapy 单机受限的问题,Scrapy 将结合 Scrapy-Redis 组件进行开发。 Scrapy-Redis的总体思路是,本项目通过重写Scrapy框架中的scheduler和spider类来实现调度、spider启动和redis的交互。 实现了新的dupefilter和queue类,实现了权重判断和调度容器与redis的交互。由于每台主机上的爬虫进程访问同一个redis数据库,调度和权重判断统一管理,实现分布式分布。爬虫的目的
4、系统实现
4.1、爬取策略设计
从scrapy的结构分析可以看出,网络爬虫从初始地址开始,根据从spider中定义的目标地址获取的正则表达式或Xpath获取更多的网页链接,并加入队列待下载进行去重和排序后,等待调度器调度。
在这个系统中,新建的链接可以分为两类,一类是目录页链接,也就是我们平时看到的下一页的链接,另一类是内容详情页链接,也就是我们需要解析网页的提取字段中的链接指向实际的页面信息。网络需要从每个目录页面链接中提取多个内容页面链接,并将它们添加到待下载队列中以供进一步爬取。爬取过程如下:
爬取过程
这里是master端目标链接的爬取策略。由于是分布式主从模式,master端的爬虫主要抓取下载内容详情页的链接,通过redis将下载任务分享给slave端的其他爬虫。 Slave端主要负责进一步解析提取详情页的链接并存入数据库。
1)对于大师:
核心模块是解决翻页问题,获取每个页面内容的详情页链接。 Master端主要采用以下爬取策略:
1.将redis的初始链接插入到key next_link,从初始页面链接开始
2.爬虫从redis中的key next_link获取初始链接,开始运行爬虫
3.下载器返回的Response,爬虫根据蜘蛛定义的爬取规则识别是否有下一页的链接。如果有链接,则存储在redis中,key保存为next_link。它匹配多个内容详细信息页面链接。如果匹配,则存储在Redis中,并将key保存为detail_request并插入下载链接,供slave端的spider使用,也就是slave端的下载任务。
4.爬虫继续从redis中的key取值作为next_link。如果有值,则继续执行步骤2。如果为空,则爬虫等待新的链接。
2)对于奴隶:
核心模块是从redis获取下载任务,解析提取字段。 Slave端主要采用以下爬取策略:
1。爬虫从redis获取初始链接,key为detail_request,开始运行爬虫
2。下载器返回的Response,爬虫根据爬虫定义的爬取规则识别是否有匹配规则的content字段,如果有则存储该字段返回给模型,等待数据存储操作。
重复第 1 步,直到爬取队列为空,爬虫等待新的链接。
4.2爬虫的具体实现
爬虫程序由四部分组成,即对象定义程序、数据捕获程序、数据处理程序和下载设置程序。这里的组成是Slave端,Master缺少对象定义程序和数据处理程序,而Master端主要是下载链接的爬取。
数据抓取程序:
数据爬取程序分为主端和从端。数据爬取程序从 Redis 获取初始地址。数据爬取程序定义了爬取网页的规则,使用Xpath提取字段数据的方法,以及css选择器选择器。数据提取方法等
4.3 去重和增量爬取
去重和增量爬取对服务器意义重大,可以减轻服务器压力,保证数据的准确性。如果不采用去重,爬取的内容会爬取大量的重复内容,大大降低爬虫的效率。事实上,重复数据删除的过程非常简单。核心是判断每个请求是否在已经爬取的队列中。如果已经存在,则丢弃当前请求。
具体实现步骤:
去重和增量爬取
(1)从待爬取队列中获取url
(2)会判断要请求的url是否被爬取,如果已经被爬取则忽略该请求,不被爬取,继续其他操作,将url插入到被爬取队列中
(3)重复步骤 1
4.4个爬虫中间件
爬虫中间件可以帮助我们在scrapy爬取过程中自由扩展自己的程序。以下是爬虫反屏蔽中间件、下载器异常状态中间件和非200状态中间件。
(1)履带防屏蔽组件的实现
当访问一个网站网页时,会给网站带来一定的负载,爬虫程序模拟了我们正常访问网页的过程,但是。大型爬虫会给网站增加很大的负载,影响正常用户的访问。为了保证大部分普通用户可以访问网页,大部分网站都有相应的反爬策略。一旦访问行为被识别为爬虫,网站会采取一定的措施限制你的访问,比如访问过于频繁会提示你输入验证码。您访问 网站。当系统有针对性的抓取网页数据时,会不断的访问网站的内容。如果不采取伪装措施,很容易被网站识别为爬虫行为而被屏蔽。
系统使用以下方法防止爬虫被拦截:
1.模拟不同的浏览器行为
2.一定频率更换代理服务器和网关
3.降低爬取网页的频率,减少并发爬取的进程,限制每个ip的并发爬取数量,牺牲一定的效率来换取系统的稳定性。
4.禁用cookies,网站会在用户访问时在cookie中插入一些信息来判断是否是机器人。我们阻止了cookies的调整,这也有助于我们的身份不被暴露。
反爬虫网站屏蔽原理如下图所示:
反网站屏蔽原理
(a) 模拟不同浏览器行为的想法和代码
原理:scrapy有下载中间件,在这个中间件中我们可以自定义请求和响应,核心是修改请求的属性
首先,主要是扩展下载中间件。首先在seeings.py中添加中间件并展开中间件,主要是写一个user-agent列表,将常用的浏览器请求头保存为列表,然后让请求头文件在列表中随机取一个代理值,并然后下载到下载器中。
用户代理
综上所述,每次发出请求,都会使用不同的浏览器访问目标网站。
(b)使用代理ip进行爬取的实现思路。
首先在settings.py中添加中间件,扩展下载组件请求的头文件从代理ip池中随机取一个代理值下载到下载器中。
1.代理ip池的设计开发流程如下:
一个。爬取免费代理ip网站.
b.存储并验证代理ip
c。身份验证通过存储方式存储在数据库中
d。如果验证失败,删除它
(c)爬虫异常状态组件的处理
当爬虫没有被阻塞并运行时,访问网站并不总是200请求成功,而是有多种状态,比如上面的爬虫被禁止时,返回的状态实际上是302,防止屏蔽组件是通过捕获302状态来实现的。同时异常状态的处理有利于爬虫的健壮性。
设置中的扩展中间件捕捉到异常后,重新将请求加入待下载队列的过程如下:
异常处理
(d) 数据存储模块
数据存储模块主要负责存储slave端抓取并解析的页面。数据使用MongoDB存储。
Scrapy支持json、csv、xml等数据存储格式,用户可以在运行爬虫时设置,例如:scrapy crawl spider
-o items.json -t json,也可以在Scrapy项目文件和ItemPipline文件中定义。同时Scrapy还支持数据库存储,比如Mongodb、Redis等,当数据量大到一定程度时,可以做Mongodb或者Reids的集群来解决问题,这个的数据存储系统如下图所示:
数据存储
5.总结
以上是分布式网络数据爬取系统的设计部分。由于单机爬虫的爬取量和爬取速度的限制,采用分布式设计。这是V1.0版本,以后会跟进。继续完善相关部分。
c爬虫抓取网页数据(越过亚马逊的反爬虫机制(爬取)、达人共同推荐)
网站优化 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2022-03-21 11:30
提问者和专家推荐
樱花
目前满意的受访者人数:
事情是这样的
亚马逊是全球最大的购物平台
很多产品信息、用户评论等都是最丰富的。
今天就带大家一起来穿越亚马逊的反爬虫机制吧
抓取您想要的有用信息,例如产品、评论等
反爬虫机制
但是,当我们想使用爬虫爬取相关数据信息时
亚马逊、TBO、京东等大型购物中心
为了保护他们的数据信息,他们都有一套完整的反爬虫机制。
先试试亚马逊的反爬机制
我们使用几个不同的python爬虫模块来一步步测试
最终,防爬机制顺利通过。
一、urllib 模块
代码显示如下:
# -*- coding:utf-8 -*-import urllib.requestreq = urllib.request.urlopen('https://www.amazon.com')print(req.code)复制代码
返回结果:状态码:503。
分析:亚马逊将你的请求识别为爬虫,拒绝提供服务。
以科学严谨的态度,来试试千人之首的百度吧。
返回结果:状态码200
分析:正常访问
以科学严谨的态度,来试试千人之首的百度吧。
返回结果:状态码200
分析:正常访问
代码如下↓ ↓ ↓
import requestsurl='https://www.amazon.com/KAVU-Rope-Bag-Denim-Size/product-reviews/xxxxxxx'web_header={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0','Accept': '*/*','Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2','Accept-Encoding': 'gzip, deflate, br','Connection': 'keep-alive','Cookie': '你的cookie值','TE': 'Trailers'}r = requests.get(url,headers=web_header)print(r.status_code)复制代码
返回结果:状态码:200
分析:返回状态码为200,属于正常。它闻起来像爬虫。
3、查看返回页面
通过requests+cookie的方法,我们得到的状态码是200
至少它目前由亚马逊的服务器提供服务。
我们将爬取的页面写入文本并在浏览器中打开。
我在骑马……返回状态正常,但是返回了反爬虫验证码页面。
仍然被亚马逊屏蔽。
三、硒自动化模块
相关硒模块的安装
pip install selenium复制代码
在代码中引入 selenium 并设置相关参数
import osfrom requests.api import optionsfrom selenium import webdriverfrom selenium.webdriver.chrome.options import Options#selenium配置参数options = Options()#配置无头参数,即不打开浏览器options.add_argument('--headless')#配置Chrome浏览器的selenium驱动 chromedriver="C:/Users/pacer/AppData/Local/Google/Chrome/Application/chromedriver.exe"os.environ["webdriver.chrome.driver"] = chromedriver#将参数设置+浏览器驱动组合browser = webdriver.Chrome(chromedriver,chrome_options=options)复制代码
测试访问
url = "https://www.amazon.com"print(url)#通过selenium来访问亚马逊browser.get(url)复制代码
返回结果:状态码:200
分析:返回状态码为200,访问状态正常。我们来看看爬取的网页上的信息。
将网页源代码保存到本地
#将爬取到的网页信息,写入到本地文件fw=open('E:/amzon.html','w',encoding='utf-8')fw.write(str(browser.page_source))browser.close()fw.close()复制代码
打开我们爬取的本地文件查看,
我们已经成功绕过反爬机制,进入亚马逊首页
结尾
通过selenium模块,我们可以成功穿越
亚马逊的反爬虫机制。 查看全部
c爬虫抓取网页数据(越过亚马逊的反爬虫机制(爬取)、达人共同推荐)
提问者和专家推荐
樱花
目前满意的受访者人数:
事情是这样的
亚马逊是全球最大的购物平台
很多产品信息、用户评论等都是最丰富的。
今天就带大家一起来穿越亚马逊的反爬虫机制吧
抓取您想要的有用信息,例如产品、评论等
反爬虫机制
但是,当我们想使用爬虫爬取相关数据信息时
亚马逊、TBO、京东等大型购物中心
为了保护他们的数据信息,他们都有一套完整的反爬虫机制。
先试试亚马逊的反爬机制
我们使用几个不同的python爬虫模块来一步步测试
最终,防爬机制顺利通过。
一、urllib 模块
代码显示如下:
# -*- coding:utf-8 -*-import urllib.requestreq = urllib.request.urlopen('https://www.amazon.com')print(req.code)复制代码
返回结果:状态码:503。
分析:亚马逊将你的请求识别为爬虫,拒绝提供服务。
以科学严谨的态度,来试试千人之首的百度吧。
返回结果:状态码200
分析:正常访问
以科学严谨的态度,来试试千人之首的百度吧。
返回结果:状态码200
分析:正常访问
代码如下↓ ↓ ↓
import requestsurl='https://www.amazon.com/KAVU-Rope-Bag-Denim-Size/product-reviews/xxxxxxx'web_header={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0','Accept': '*/*','Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2','Accept-Encoding': 'gzip, deflate, br','Connection': 'keep-alive','Cookie': '你的cookie值','TE': 'Trailers'}r = requests.get(url,headers=web_header)print(r.status_code)复制代码
返回结果:状态码:200
分析:返回状态码为200,属于正常。它闻起来像爬虫。
3、查看返回页面
通过requests+cookie的方法,我们得到的状态码是200
至少它目前由亚马逊的服务器提供服务。
我们将爬取的页面写入文本并在浏览器中打开。
我在骑马……返回状态正常,但是返回了反爬虫验证码页面。
仍然被亚马逊屏蔽。
三、硒自动化模块
相关硒模块的安装
pip install selenium复制代码
在代码中引入 selenium 并设置相关参数
import osfrom requests.api import optionsfrom selenium import webdriverfrom selenium.webdriver.chrome.options import Options#selenium配置参数options = Options()#配置无头参数,即不打开浏览器options.add_argument('--headless')#配置Chrome浏览器的selenium驱动 chromedriver="C:/Users/pacer/AppData/Local/Google/Chrome/Application/chromedriver.exe"os.environ["webdriver.chrome.driver"] = chromedriver#将参数设置+浏览器驱动组合browser = webdriver.Chrome(chromedriver,chrome_options=options)复制代码
测试访问
url = "https://www.amazon.com"print(url)#通过selenium来访问亚马逊browser.get(url)复制代码
返回结果:状态码:200
分析:返回状态码为200,访问状态正常。我们来看看爬取的网页上的信息。
将网页源代码保存到本地
#将爬取到的网页信息,写入到本地文件fw=open('E:/amzon.html','w',encoding='utf-8')fw.write(str(browser.page_source))browser.close()fw.close()复制代码
打开我们爬取的本地文件查看,
我们已经成功绕过反爬机制,进入亚马逊首页
结尾
通过selenium模块,我们可以成功穿越
亚马逊的反爬虫机制。
c爬虫抓取网页数据(注册美国公司用的代理软件:迅雷美国网站注册助手)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-21 05:02
c爬虫抓取网页数据不通过代理服务器的原因有两种:1.绝大多数网站直接有cookie记录,爬虫抓取的时候通过代理服务器获取ip地址2.服务器反向代理机制(ip池方式),与服务器通信后获取ip地址然后替换到ip池中(例如cookie或者代理池方式)
通过代理商来注册代理,代理商会抓取你的ip再传递给你的服务器,你的服务器再根据你用的代理ip返回给你。或者你可以直接访问服务器,
我老婆的公司帮忙在新浪博客批量注册美国公司,就是用爬虫+代理服务器。
已经有专门做美国公司注册的服务商,可以免费注册,但是很不稳定,国内拿不到美国营业执照,本身拿不到美国身份。建议挂vpn注册,要是考虑vpn速度的问题,可以用亲戚家的美国家庭主妇、放心点。
代理是为了个人的需求研发的...专门针对个人。批量爬取联邦登记局我也是醉了...你也就玩玩而已。
推荐几款注册美国公司用的代理软件:
1、迅雷美国网站注册助手
2、filezilla美国注册公司助手
3、全球ip代理(中国独家,
4、迅雷(国内的)当然还有云归国,谷歌,微软这些公司的服务器可以用注册的服务器申请,账号密码都能解开。如果你考虑拿身份去美国登记还是可以用海外的身份证。 查看全部
c爬虫抓取网页数据(注册美国公司用的代理软件:迅雷美国网站注册助手)
c爬虫抓取网页数据不通过代理服务器的原因有两种:1.绝大多数网站直接有cookie记录,爬虫抓取的时候通过代理服务器获取ip地址2.服务器反向代理机制(ip池方式),与服务器通信后获取ip地址然后替换到ip池中(例如cookie或者代理池方式)
通过代理商来注册代理,代理商会抓取你的ip再传递给你的服务器,你的服务器再根据你用的代理ip返回给你。或者你可以直接访问服务器,
我老婆的公司帮忙在新浪博客批量注册美国公司,就是用爬虫+代理服务器。
已经有专门做美国公司注册的服务商,可以免费注册,但是很不稳定,国内拿不到美国营业执照,本身拿不到美国身份。建议挂vpn注册,要是考虑vpn速度的问题,可以用亲戚家的美国家庭主妇、放心点。
代理是为了个人的需求研发的...专门针对个人。批量爬取联邦登记局我也是醉了...你也就玩玩而已。
推荐几款注册美国公司用的代理软件:
1、迅雷美国网站注册助手
2、filezilla美国注册公司助手
3、全球ip代理(中国独家,
4、迅雷(国内的)当然还有云归国,谷歌,微软这些公司的服务器可以用注册的服务器申请,账号密码都能解开。如果你考虑拿身份去美国登记还是可以用海外的身份证。
c爬虫抓取网页数据(自用Python模块的建立和使用--抓取和存数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-03-19 20:01
我们在这个例子中所做的就是将b站当前在线界面的20个视频转换成
从网页中抓取av号、类型、作者名、视频名、点击量、弹幕数,存入数据库进行简单分析。
整个步骤分为两部分——采集和保存数据
【抓住】
继续我们之前用 Python 编写爬虫的经验,我们可以类似地抓取我们需要的信息。
例如,抓取视频名称
import urllib2
from bs4 import BeautifulSoup
mainUrl="http://www.bilibili.com/online.html"
def toOnline():
'''进入在线列表页面'''
resp=urllib2.urlopen(mainUrl)
return resp
def getPageContent():
resp=toOnline()
html = resp.read().decode('utf-8').encode('gbk')
soup = BeautifulSoup(html, "html.parser", from_encoding="gbk")
return soup
def delNameTag(x):
arr = []
for i in range(0, len(x)):
b = str(x[i]).replace('<p class="etitle">', '')
c = b.replace('', '')
arr.append(c)
return arr</p>
def getName():
'''获取视频名称'''
soup=getPageContent()
data=soup.select('p[class="etitle"]')
data=delNameTag(data)
return data
这给了我们一个收录视频名称的长度为 20 的数组。
经过多次编写Python爬虫脚本的练习,这里不再重复逻辑。
需要注意的是,每个部分的逻辑都被分离出来,抽象成方法。这使得代码更清晰,更容易在以后维护和修改。
【存入数据库】
抓取数据后,我们需要将数据存入数据库。
在这个例子中,我们构建了一个私有的自用 Python 模块来方便数据库的操作。
【自用Python模块的建立与使用】
1.C:\Python27\Lib\site-packages 新建 myutil.pth
此文件存储我们的自定义脚本目录:D:/mywork/23 planB/my_script
【注意】这个文件中的目录是反斜杠的!!!
2.在D:/mywork/23 planB/my_script目录下创建一个myutil文件夹
3.myutil 文件夹是我们自定义的 Python 模块脚本
4.[重要] 该文件夹下必须有__init__.py 文件。没有这个文件就会失败。
这个文件的内容是空的,它是做什么的?未知。. . .
5. DBUtil的代码如下
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import MySQLdb
class DBConfig:
#线下
_user = 'root'
_password = '''1230'''
_user_stat = 'mkj'
_password_stat='pwd)'
_charset = 'utf8'
_use_unicode = False
#线下
_readHost = '127.0.0.1'
_writeHost = '127.0.0.1'
_statHost = '127.0.0.1'
@staticmethod
def _getHost(isWrite = True):
if isWrite:
return DBConfig._writeHost
else:
return DBConfig._readHost
@staticmethod
def getConnection(dbName = None, isWrite = True):
return MySQLdb.connect(host = DBConfig._getHost(isWrite), user = DBConfig._user, passwd = DBConfig._password, db = dbName, charset = DBConfig._charset, use_unicode = DBConfig._use_unicode)
@staticmethod
def getConnectionByHost(dbName = None, hostName = None):
if hostName == 'stat':
return MySQLdb.connect(host = DBConfig._statHost, user = DBConfig._user_stat, passwd = DBConfig._password_stat, db = dbName, charset = DBConfig._charset, use_unicode = DBConfig._use_unicode)
else :
return MySQLdb.connect(host = DBConfig._statHost, user = DBConfig._user, passwd = DBConfig._password, db = dbName, charset = DBConfig._charset, use_unicode = DBConfig._use_unicode)
class DBUtil:
__connRead = None
__connWrite = None
__conn = None
__dbName = None
__hostName = None
def __init__(self, dbName = None, hostName = None):
_dbName = dbName.split("_")
length = len(_dbName)
self.__hostName = hostName
if _dbName[length-1].isdigit():
_dbName.pop()
self.__dbName = ("_").join(_dbName)
else:
self.__dbName = dbName
def __getConnection(self, isWrite = True):
if self.__hostName :
if not self.__conn:
conn = DBConfig.getConnectionByHost(self.__dbName, self.__hostName)
self.__conn = conn
return self.__conn
if isWrite:
if not self.__connWrite:
conn = DBConfig.getConnection(self.__dbName, isWrite)
self.__connWrite = conn
return self.__connWrite
else:
if not self.__connRead:
conn = DBConfig.getConnection(self.__dbName, isWrite)
self.__connRead = conn
return self.__connRead
def queryList(self, sql = None, params = None):
if (not sql): return None
conn = self.__getConnection(False)
cursor = conn.cursor()
cursor.execute(sql, params)
rows = cursor.fetchall()
return rows
def queryRow(self, sql, params = None):
if (not sql):return None
conn = self.__getConnection(False)
cursor = conn.cursor()
cursor.execute(sql, params)
row = cursor.fetchone()
return row
def queryCount(self, sql = None, params = None):
if (not sql): return None
conn = self.__getConnection(False)
cursor = conn.cursor()
cursor.execute(sql, params)
row = cursor.fetchone()
if not row:
return 0
return row[0]
def update(self, sql = None, params = None):
if (not sql): return False
conn = self.__getConnection()
cursor = conn.cursor()
cursor.execute(sql, params)
conn.commit()
return True
def insert(self, sql = None, params = None, returnPk = False):
if (not sql): return False
conn = self.__getConnection()
cursor = conn.cursor()
cursor.execute(sql, params)
conn.commit()
if not returnPk:
return None
return cursor.lastrowid
def insertMany(self, sql = None, params = None):
if not sql or not params: return False
conn = self.__getConnection()
cursor = conn.cursor()
cursor.executemany(sql, params)
conn.commit()
return True
def delete(self, sql = None, params = None):
if (not sql): return False
conn = self.__getConnection()
cursor = conn.cursor()
cursor.execute(sql, params)
conn.commit()
return True
def deleteMany(self, sql = None, params = None):
if not sql or not params: return False
conn = self.__getConnection()
cursor = conn.cursor()
cursor.executemany(sql, params)
conn.commit()
return True
def transDelAndInsMany(self, insertSql = None, delSql = None, insertParams = None, delParams = None):
if not insertSql or not insertParams or not delSql or not delParams: return False
conn = self.__getConnection()
cursor = conn.cursor()
cursor.executemany(insertSql, insertParams)
cursor.executemany(delSql, delParams)
conn.commit()
return True
def close(self):
if self.__connRead:
self.__connRead.close()
self.__connRead = None
if self.__connWrite:
self.__connWrite.close()
self.__connWrite = None
if __name__ == '__main__':
print 'start'
dbUtil = DBUtil('netgame_trade_12')
只要记住这段代码。只需要知道几个需要改的地方:用户名密码和主机地址
_user = 'root'
_password = '''1230'''
#线下
_readHost = '127.0.0.1'
_writeHost = '127.0.0.1'
_statHost = '127.0.0.1'
这里readHost和writeHost是分开写的,也就是读写分离。
【保存数据到数据库】
数据拿到了,自定义模块就OK了。接下来,我们将数据存储在数据库中。
先介绍一下数据库模块
from myutil.DBUtil import DBUtil
然后连接到数据库
planBDBUtil = DBUtil('mydb')
那么操作代码如下
def insertData():
'''数据库操作'''
avid=getAvId()
typeid=getTypeId()
name=getName()
hits=getHits()
dm=getDm()
author=getAuthor()
sql='insert into mydb.PLAN_B(ID, AV_ID, TYPE_ID, AUTHOR, NAME, HITS, DM, CREATED_DATE)'
for i in range(len(avid)-1):
namei=str(name[i])
authori=str(author[i])
#sql = 'insert into mydb.PLAN_B(ID, AV_ID, TYPE_ID, NAME, HITS, DM, CREATED_DATE) values (null, %s, %s, "%s", %s, %s, now())'%(avid[i],typeid[i],namei,hits[i],dm[i])
sql=sql+' SELECT NULL,%s, %s, "%s", "%s", %s, %s, now() union '%(avid[i],typeid[i],authori,namei,hits[i],dm[i])
sql=sql+' SELECT NULL,%s, %s, "%s", "%s", %s, %s, now()'%(avid[len(avid)-1],typeid[len(avid)-1],author[len(avid)-1],name[len(avid)-1],hits[len(avid)-1],dm[len(avid)-1])
planBDBUtil.insert(sql, ())
这里我们是插入操作,最后一句
planBDBUtil.insert(sql, ())
insert 函数是我们从 DBUtil 中找到的,用于处理插入操作。
我们可以专注于如何编写 SQL 语句。
【注意:SQL调试器的使用】
在这个例子中,我们在编写 SQL 语句时,遇到了很多错误。在这个过程中,我们多次使用 Navicat 中的查询功能来调试 SQL。
注意我们使用这个私有定义。
接下来,我们讲解一下SQL语句中遇到的问题!
[问题 一、 插入不带引号的字符串]
我们插入字符串的时候,不能直接插入,一直报错。后来找到原因,
插入字符串时,需要引号!!!
NULL,%s, %s, "%s", "%s", %s, %s, now()
如果不带引号直接插入字符串,系统无法区分数据类型,插入失败!
[问题二、一次插入一堆数据]
这里我们运行一次脚本,需要插入20条数据。
传统做法是循环插入,即执行20次插入语句。但是如果有 10,000 条数据呢?您是否必须访问数据库 10,000 次?
经验告诉我们,我们只需要访问数据库一次。否则对数据库的压力太大了!
我们如何一次插入 20 条数据?经过研究,我们发现如下代码模板
INSERT INTO table1 (mc,zb_mc,xx_mc,leibie)
SELECT('aa',NULL,NULL,1390)union
SELECT('bb',NULL,NULL,1400)union
SELECT('cc',NULL,NULL,1410)union
SELECT('dd',NULL,NULL,1420)union
SELECT('ee',NULL,NULL,1430)union
SELECT('ff',NULL,NULL,1440)
执行一次这样的语句,就可以一次向数据库中插入多条记录。
因此,我们需要循环来拼写 SQL 字符串。
sql='insert into mydb.PLAN_B(ID, AV_ID, TYPE_ID, AUTHOR, NAME, HITS, DM, CREATED_DATE)'
for i in range(len(avid)-1):
namei=str(name[i])
authori=str(author[i])
#sql = 'insert into mydb.PLAN_B(ID, AV_ID, TYPE_ID, NAME, HITS, DM, CREATED_DATE) values (null, %s, %s, "%s", %s, %s, now())'%(avid[i],typeid[i],namei,hits[i],dm[i])
sql=sql+' SELECT NULL,%s, %s, "%s", "%s", %s, %s, now() union '%(avid[i],typeid[i],authori,namei,hits[i],dm[i])
sql=sql+' SELECT NULL,%s, %s, "%s", "%s", %s, %s, now()'%(avid[len(avid)-1],typeid[len(avid)-1],author[len(avid)-1],name[len(avid)-1],hits[len(avid)-1],dm[len(avid)-1])
我们注意到句子中间有一个并集,但结尾没有,所以我们需要取出最后一个单独拼写。
当然,我们也可以在生成SQL字符串后,删除字符串末尾的union这个词。任何一个!
至此,整个过程结束! 查看全部
c爬虫抓取网页数据(自用Python模块的建立和使用--抓取和存数据)
我们在这个例子中所做的就是将b站当前在线界面的20个视频转换成
从网页中抓取av号、类型、作者名、视频名、点击量、弹幕数,存入数据库进行简单分析。
整个步骤分为两部分——采集和保存数据
【抓住】
继续我们之前用 Python 编写爬虫的经验,我们可以类似地抓取我们需要的信息。
例如,抓取视频名称
import urllib2
from bs4 import BeautifulSoup
mainUrl="http://www.bilibili.com/online.html"
def toOnline():
'''进入在线列表页面'''
resp=urllib2.urlopen(mainUrl)
return resp
def getPageContent():
resp=toOnline()
html = resp.read().decode('utf-8').encode('gbk')
soup = BeautifulSoup(html, "html.parser", from_encoding="gbk")
return soup
def delNameTag(x):
arr = []
for i in range(0, len(x)):
b = str(x[i]).replace('<p class="etitle">', '')
c = b.replace('', '')
arr.append(c)
return arr</p>
def getName():
'''获取视频名称'''
soup=getPageContent()
data=soup.select('p[class="etitle"]')
data=delNameTag(data)
return data
这给了我们一个收录视频名称的长度为 20 的数组。
经过多次编写Python爬虫脚本的练习,这里不再重复逻辑。
需要注意的是,每个部分的逻辑都被分离出来,抽象成方法。这使得代码更清晰,更容易在以后维护和修改。
【存入数据库】
抓取数据后,我们需要将数据存入数据库。
在这个例子中,我们构建了一个私有的自用 Python 模块来方便数据库的操作。
【自用Python模块的建立与使用】
1.C:\Python27\Lib\site-packages 新建 myutil.pth
此文件存储我们的自定义脚本目录:D:/mywork/23 planB/my_script
【注意】这个文件中的目录是反斜杠的!!!
2.在D:/mywork/23 planB/my_script目录下创建一个myutil文件夹
3.myutil 文件夹是我们自定义的 Python 模块脚本
4.[重要] 该文件夹下必须有__init__.py 文件。没有这个文件就会失败。
这个文件的内容是空的,它是做什么的?未知。. . .
5. DBUtil的代码如下
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import MySQLdb
class DBConfig:
#线下
_user = 'root'
_password = '''1230'''
_user_stat = 'mkj'
_password_stat='pwd)'
_charset = 'utf8'
_use_unicode = False
#线下
_readHost = '127.0.0.1'
_writeHost = '127.0.0.1'
_statHost = '127.0.0.1'
@staticmethod
def _getHost(isWrite = True):
if isWrite:
return DBConfig._writeHost
else:
return DBConfig._readHost
@staticmethod
def getConnection(dbName = None, isWrite = True):
return MySQLdb.connect(host = DBConfig._getHost(isWrite), user = DBConfig._user, passwd = DBConfig._password, db = dbName, charset = DBConfig._charset, use_unicode = DBConfig._use_unicode)
@staticmethod
def getConnectionByHost(dbName = None, hostName = None):
if hostName == 'stat':
return MySQLdb.connect(host = DBConfig._statHost, user = DBConfig._user_stat, passwd = DBConfig._password_stat, db = dbName, charset = DBConfig._charset, use_unicode = DBConfig._use_unicode)
else :
return MySQLdb.connect(host = DBConfig._statHost, user = DBConfig._user, passwd = DBConfig._password, db = dbName, charset = DBConfig._charset, use_unicode = DBConfig._use_unicode)
class DBUtil:
__connRead = None
__connWrite = None
__conn = None
__dbName = None
__hostName = None
def __init__(self, dbName = None, hostName = None):
_dbName = dbName.split("_")
length = len(_dbName)
self.__hostName = hostName
if _dbName[length-1].isdigit():
_dbName.pop()
self.__dbName = ("_").join(_dbName)
else:
self.__dbName = dbName
def __getConnection(self, isWrite = True):
if self.__hostName :
if not self.__conn:
conn = DBConfig.getConnectionByHost(self.__dbName, self.__hostName)
self.__conn = conn
return self.__conn
if isWrite:
if not self.__connWrite:
conn = DBConfig.getConnection(self.__dbName, isWrite)
self.__connWrite = conn
return self.__connWrite
else:
if not self.__connRead:
conn = DBConfig.getConnection(self.__dbName, isWrite)
self.__connRead = conn
return self.__connRead
def queryList(self, sql = None, params = None):
if (not sql): return None
conn = self.__getConnection(False)
cursor = conn.cursor()
cursor.execute(sql, params)
rows = cursor.fetchall()
return rows
def queryRow(self, sql, params = None):
if (not sql):return None
conn = self.__getConnection(False)
cursor = conn.cursor()
cursor.execute(sql, params)
row = cursor.fetchone()
return row
def queryCount(self, sql = None, params = None):
if (not sql): return None
conn = self.__getConnection(False)
cursor = conn.cursor()
cursor.execute(sql, params)
row = cursor.fetchone()
if not row:
return 0
return row[0]
def update(self, sql = None, params = None):
if (not sql): return False
conn = self.__getConnection()
cursor = conn.cursor()
cursor.execute(sql, params)
conn.commit()
return True
def insert(self, sql = None, params = None, returnPk = False):
if (not sql): return False
conn = self.__getConnection()
cursor = conn.cursor()
cursor.execute(sql, params)
conn.commit()
if not returnPk:
return None
return cursor.lastrowid
def insertMany(self, sql = None, params = None):
if not sql or not params: return False
conn = self.__getConnection()
cursor = conn.cursor()
cursor.executemany(sql, params)
conn.commit()
return True
def delete(self, sql = None, params = None):
if (not sql): return False
conn = self.__getConnection()
cursor = conn.cursor()
cursor.execute(sql, params)
conn.commit()
return True
def deleteMany(self, sql = None, params = None):
if not sql or not params: return False
conn = self.__getConnection()
cursor = conn.cursor()
cursor.executemany(sql, params)
conn.commit()
return True
def transDelAndInsMany(self, insertSql = None, delSql = None, insertParams = None, delParams = None):
if not insertSql or not insertParams or not delSql or not delParams: return False
conn = self.__getConnection()
cursor = conn.cursor()
cursor.executemany(insertSql, insertParams)
cursor.executemany(delSql, delParams)
conn.commit()
return True
def close(self):
if self.__connRead:
self.__connRead.close()
self.__connRead = None
if self.__connWrite:
self.__connWrite.close()
self.__connWrite = None
if __name__ == '__main__':
print 'start'
dbUtil = DBUtil('netgame_trade_12')
只要记住这段代码。只需要知道几个需要改的地方:用户名密码和主机地址
_user = 'root'
_password = '''1230'''
#线下
_readHost = '127.0.0.1'
_writeHost = '127.0.0.1'
_statHost = '127.0.0.1'
这里readHost和writeHost是分开写的,也就是读写分离。
【保存数据到数据库】
数据拿到了,自定义模块就OK了。接下来,我们将数据存储在数据库中。
先介绍一下数据库模块
from myutil.DBUtil import DBUtil
然后连接到数据库
planBDBUtil = DBUtil('mydb')
那么操作代码如下
def insertData():
'''数据库操作'''
avid=getAvId()
typeid=getTypeId()
name=getName()
hits=getHits()
dm=getDm()
author=getAuthor()
sql='insert into mydb.PLAN_B(ID, AV_ID, TYPE_ID, AUTHOR, NAME, HITS, DM, CREATED_DATE)'
for i in range(len(avid)-1):
namei=str(name[i])
authori=str(author[i])
#sql = 'insert into mydb.PLAN_B(ID, AV_ID, TYPE_ID, NAME, HITS, DM, CREATED_DATE) values (null, %s, %s, "%s", %s, %s, now())'%(avid[i],typeid[i],namei,hits[i],dm[i])
sql=sql+' SELECT NULL,%s, %s, "%s", "%s", %s, %s, now() union '%(avid[i],typeid[i],authori,namei,hits[i],dm[i])
sql=sql+' SELECT NULL,%s, %s, "%s", "%s", %s, %s, now()'%(avid[len(avid)-1],typeid[len(avid)-1],author[len(avid)-1],name[len(avid)-1],hits[len(avid)-1],dm[len(avid)-1])
planBDBUtil.insert(sql, ())
这里我们是插入操作,最后一句
planBDBUtil.insert(sql, ())
insert 函数是我们从 DBUtil 中找到的,用于处理插入操作。
我们可以专注于如何编写 SQL 语句。
【注意:SQL调试器的使用】
在这个例子中,我们在编写 SQL 语句时,遇到了很多错误。在这个过程中,我们多次使用 Navicat 中的查询功能来调试 SQL。
注意我们使用这个私有定义。
接下来,我们讲解一下SQL语句中遇到的问题!
[问题 一、 插入不带引号的字符串]
我们插入字符串的时候,不能直接插入,一直报错。后来找到原因,
插入字符串时,需要引号!!!
NULL,%s, %s, "%s", "%s", %s, %s, now()
如果不带引号直接插入字符串,系统无法区分数据类型,插入失败!
[问题二、一次插入一堆数据]
这里我们运行一次脚本,需要插入20条数据。
传统做法是循环插入,即执行20次插入语句。但是如果有 10,000 条数据呢?您是否必须访问数据库 10,000 次?
经验告诉我们,我们只需要访问数据库一次。否则对数据库的压力太大了!
我们如何一次插入 20 条数据?经过研究,我们发现如下代码模板
INSERT INTO table1 (mc,zb_mc,xx_mc,leibie)
SELECT('aa',NULL,NULL,1390)union
SELECT('bb',NULL,NULL,1400)union
SELECT('cc',NULL,NULL,1410)union
SELECT('dd',NULL,NULL,1420)union
SELECT('ee',NULL,NULL,1430)union
SELECT('ff',NULL,NULL,1440)
执行一次这样的语句,就可以一次向数据库中插入多条记录。
因此,我们需要循环来拼写 SQL 字符串。
sql='insert into mydb.PLAN_B(ID, AV_ID, TYPE_ID, AUTHOR, NAME, HITS, DM, CREATED_DATE)'
for i in range(len(avid)-1):
namei=str(name[i])
authori=str(author[i])
#sql = 'insert into mydb.PLAN_B(ID, AV_ID, TYPE_ID, NAME, HITS, DM, CREATED_DATE) values (null, %s, %s, "%s", %s, %s, now())'%(avid[i],typeid[i],namei,hits[i],dm[i])
sql=sql+' SELECT NULL,%s, %s, "%s", "%s", %s, %s, now() union '%(avid[i],typeid[i],authori,namei,hits[i],dm[i])
sql=sql+' SELECT NULL,%s, %s, "%s", "%s", %s, %s, now()'%(avid[len(avid)-1],typeid[len(avid)-1],author[len(avid)-1],name[len(avid)-1],hits[len(avid)-1],dm[len(avid)-1])
我们注意到句子中间有一个并集,但结尾没有,所以我们需要取出最后一个单独拼写。
当然,我们也可以在生成SQL字符串后,删除字符串末尾的union这个词。任何一个!
至此,整个过程结束!
c爬虫抓取网页数据(Python-Scrapy爬虫实战scrapy实战实战)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-03-19 18:26
Python-Scrapy爬虫实战
scrapy 是一个非常强大的网络爬虫框架,它为数据挖掘、信息处理等领域提供了一种非常便捷的数据获取方式。说到爬虫可以通过网络浏览器获取的数据,理论上是可以通过爬虫获取的。最简单的是rest接口,通过接口访问获取数据。
设置已知爬虫库规则
背景信息 Web应用防火墙提供已知类型的爬虫库,包括11个已知的公共BOT类别和300多个BOT子类别,包括搜索引擎、测速工具、内容聚合、扫描和网络爬虫类别。
语言处理 AI 词法分析接口
词法分析、分词、词性标注、基于大数据和用户行为的命名实体识别,定位基本语言元素,消除歧义,支持对自然语言的准确理解
开启反爬虫
开启反爬虫 Web 应用防火墙 支持开启反爬虫模块。反爬虫模块可以在一段时间内(去重后)根据单个IP访问URL,所有请求达到一定的阈值,这被认为是爬虫行为和挑战。挑战过程从人机交互挑战开始,逐渐升级为拦截。
【人工智能-自然语言处理】产品信息提取
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】用短文本生成
进入京东云控制台总览页面,您可以根据实际需要进行配置。
语言处理 AI 图像审核接口
图片审核界面,基于深度学习的智能内容审核解决方案,可以准确识别图片和视频中的色情、暴力恐怖、政治敏感、微商广告、恶心等内容,还可以从美丽和清晰的维度。筛选,快速准确,解放审核人力。
高效编写 Flutter 页面的最佳实践
,可以在 StoneBasePageMixin 提供的页面基础框架上快速构建页面内容。
语言处理AI文本纠错接口
识别错误的文本片段,给出错误提示并给出正确的建议文本内容。
自然语言处理——人工智能之路
介绍NLP在生活中的应用场景和商业应用
网站活动页面
网站活动页面设计
设置网页篡改保护
设置网页防篡改网站后,即可开启Web应用防火墙的网页防篡改功能。网页防篡改帮助您锁定需要保护的网站页面。锁定页面收到请求后,会返回到已设置的缓存页面,以防止恶意篡改源站页面内容的影响。您可以根据实际需要设置网页的防篡改规则。
网页设计
多年网站建设及网络运营推广经验,根据客户需求,提供全方位网站建设解决方案;
网络制作
整合SEO架构、智能后台管理、网站定位、规划、设计、运维等,给用户最好的体验
哪些编程语言开发人员最开心?
“PHP 是最糟糕的语言!” “呵呵,Python适合初学者”。你有过类似的想法吗?
网页防篡改
网页防篡改功能说明网页防篡改采用强制静态缓存锁定和更新机制来保护网站特定页面。即使源站的相关网页被篡改,仍然可以将缓存的页面返回给用户。该功能目前处于公测阶段,在基础版中免费提供。
设置网络缓存
设置网页缓存网站访问Web应用防火墙后,可以为其开启网页缓存功能。网页缓存帮助您提高网页访问速度,减轻源站压力。您可以根据自己的实际需要设置网页缓存的规则。前提条件 已激活 Web 应用程序防火墙实例。有关详细信息,请参阅激活 Web 应用程序防火墙。网站访问完成。有关详细信息,请参阅添加域名。
编程语言王国唯一的王者
知道如何编码不再是一个优势。市场上充斥着各种培训机构和班级培养的人才,“初级软件开发人员”的位置已经不复存在。要在当今市场上取得成功,您不仅需要知道如何编码,还需要学会使用逻辑思维方式。
写办公室
常熟办公企业私人版提供文字处理、电子表格、演示文稿、协作空间、常聊、小常智能写作助手等常用云工具。云工具与企业云相结合,为企业提供SDK集成服务。
UE设计 | 蒸汽波的设计语言选择是什么?
做最时尚的设计,一定要永远站在设计的最前沿,把表弟的学习笔记分享给大家,一起来了解一下什么是蒸汽波吧~ 查看全部
c爬虫抓取网页数据(Python-Scrapy爬虫实战scrapy实战实战)
Python-Scrapy爬虫实战
scrapy 是一个非常强大的网络爬虫框架,它为数据挖掘、信息处理等领域提供了一种非常便捷的数据获取方式。说到爬虫可以通过网络浏览器获取的数据,理论上是可以通过爬虫获取的。最简单的是rest接口,通过接口访问获取数据。
设置已知爬虫库规则
背景信息 Web应用防火墙提供已知类型的爬虫库,包括11个已知的公共BOT类别和300多个BOT子类别,包括搜索引擎、测速工具、内容聚合、扫描和网络爬虫类别。
语言处理 AI 词法分析接口
词法分析、分词、词性标注、基于大数据和用户行为的命名实体识别,定位基本语言元素,消除歧义,支持对自然语言的准确理解
开启反爬虫
开启反爬虫 Web 应用防火墙 支持开启反爬虫模块。反爬虫模块可以在一段时间内(去重后)根据单个IP访问URL,所有请求达到一定的阈值,这被认为是爬虫行为和挑战。挑战过程从人机交互挑战开始,逐渐升级为拦截。
【人工智能-自然语言处理】产品信息提取
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】用短文本生成
进入京东云控制台总览页面,您可以根据实际需要进行配置。
语言处理 AI 图像审核接口
图片审核界面,基于深度学习的智能内容审核解决方案,可以准确识别图片和视频中的色情、暴力恐怖、政治敏感、微商广告、恶心等内容,还可以从美丽和清晰的维度。筛选,快速准确,解放审核人力。
高效编写 Flutter 页面的最佳实践
,可以在 StoneBasePageMixin 提供的页面基础框架上快速构建页面内容。
语言处理AI文本纠错接口
识别错误的文本片段,给出错误提示并给出正确的建议文本内容。
自然语言处理——人工智能之路
介绍NLP在生活中的应用场景和商业应用
网站活动页面
网站活动页面设计
设置网页篡改保护
设置网页防篡改网站后,即可开启Web应用防火墙的网页防篡改功能。网页防篡改帮助您锁定需要保护的网站页面。锁定页面收到请求后,会返回到已设置的缓存页面,以防止恶意篡改源站页面内容的影响。您可以根据实际需要设置网页的防篡改规则。
网页设计
多年网站建设及网络运营推广经验,根据客户需求,提供全方位网站建设解决方案;
网络制作
整合SEO架构、智能后台管理、网站定位、规划、设计、运维等,给用户最好的体验
哪些编程语言开发人员最开心?
“PHP 是最糟糕的语言!” “呵呵,Python适合初学者”。你有过类似的想法吗?
网页防篡改
网页防篡改功能说明网页防篡改采用强制静态缓存锁定和更新机制来保护网站特定页面。即使源站的相关网页被篡改,仍然可以将缓存的页面返回给用户。该功能目前处于公测阶段,在基础版中免费提供。
设置网络缓存
设置网页缓存网站访问Web应用防火墙后,可以为其开启网页缓存功能。网页缓存帮助您提高网页访问速度,减轻源站压力。您可以根据自己的实际需要设置网页缓存的规则。前提条件 已激活 Web 应用程序防火墙实例。有关详细信息,请参阅激活 Web 应用程序防火墙。网站访问完成。有关详细信息,请参阅添加域名。
编程语言王国唯一的王者
知道如何编码不再是一个优势。市场上充斥着各种培训机构和班级培养的人才,“初级软件开发人员”的位置已经不复存在。要在当今市场上取得成功,您不仅需要知道如何编码,还需要学会使用逻辑思维方式。
写办公室
常熟办公企业私人版提供文字处理、电子表格、演示文稿、协作空间、常聊、小常智能写作助手等常用云工具。云工具与企业云相结合,为企业提供SDK集成服务。
UE设计 | 蒸汽波的设计语言选择是什么?
做最时尚的设计,一定要永远站在设计的最前沿,把表弟的学习笔记分享给大家,一起来了解一下什么是蒸汽波吧~
c爬虫抓取网页数据(爬虫是什么网络爬虫(又被称为网页蜘蛛、网络机器人))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-03-18 05:15
01 什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常见的是网页追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
Web 爬虫通过从 Internet 上的 网站 服务器上爬取内容来工作。它是用计算机语言编写的程序或脚本,自动从互联网上获取信息或数据,扫描并抓取每个需要的页面上的某些信息,直到处理完所有可以正常打开的页面。
作为搜索引擎的重要组成部分,爬虫的主要功能是抓取网页数据(如图2-1所示)。目前市面上流行的采集器软件都是利用网络爬虫的原理或功能。
▲图 2-1 网络爬虫象形图
02 爬行动物的意义
如今,大数据时代已经到来,网络爬虫技术已经成为这个时代不可或缺的一部分。企业需要数据来分析用户行为、自身产品的不足、竞争对手的信息。所有这一切的首要条件是数据。采集。
网络爬虫的价值其实就是数据的价值。在互联网社会,数据是无价的。一切都是数据。谁拥有大量有用的数据,谁就有决策的主动权。网络爬虫的应用领域很多,比如搜索引擎、数据采集、广告过滤、大数据分析等。
1)抓取各大电商公司的产品销售信息和用户评价网站进行分析,如图2-2所示。
▲图2-2 电商产品销售信息网站
2)分析大众点评、美团等餐饮品类网站用户的消费、评价及发展趋势,如图2-3所示。
▲图2-3 餐饮用户消费信息网站
3)分析各城市中学区住房占比,学区房价格比普通二手房高多少,如图2-4所示。
▲图2-4 学区住房比例与价格对比
以上数据是由ForeSpider数据采集软件爬下来的。有兴趣的读者可以尝试自己爬一些数据。
03 爬虫的原理
我们通常将网络爬虫的组件分为初始链接库、网络爬取模块、网页处理模块、网页分析模块、DNS模块、待爬取链接队列、网页库等。网络爬虫的各个模块可以组成一个循环系统,从而不断的分析和抓取。
爬虫的工作原理可以简单地解释为首先找到目标信息网络,然后是页面爬取模块,然后是页面分析模块,最后是数据存储模块。具体细节如图2-5所示。
▲图2-5 爬虫示意图
爬虫工作的基本流程:
首先,选择互联网中的一部分网页,将这些网页的链接地址作为种子URL;将这些种子URL放入待爬取URL队列中,爬虫依次从待爬取URL队列中读取;通过 DNS 解析 URL;将链接地址转换为网站服务器对应的IP地址;网页下载器通过网站服务器下载网页;下载的网页为网页文档的形式;提取网页文档中的URL;filter 删除已抓取的网址;继续对没有被爬取的URL进行爬取,直到待爬取的URL队列为空。
04 爬虫技术的种类
作者简介:赵国胜,哈尔滨师范大学教授,工学博士,硕士生导师,黑龙江省网络安全技术领域特殊人才。主要从事可信网络、入侵容忍、认知计算、物联网安全等领域的教学和科研工作。
本文摘自《Python网络爬虫技术与实践》,经出版社授权发布。
本文使用“CC BY-SA 4.0 CN”协议转载自网络,仅供学习交流。内容版权归原作者所有。如果您对作品、版权等问题有任何疑问,请给“我们”留言。 查看全部
c爬虫抓取网页数据(爬虫是什么网络爬虫(又被称为网页蜘蛛、网络机器人))
01 什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常见的是网页追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
Web 爬虫通过从 Internet 上的 网站 服务器上爬取内容来工作。它是用计算机语言编写的程序或脚本,自动从互联网上获取信息或数据,扫描并抓取每个需要的页面上的某些信息,直到处理完所有可以正常打开的页面。
作为搜索引擎的重要组成部分,爬虫的主要功能是抓取网页数据(如图2-1所示)。目前市面上流行的采集器软件都是利用网络爬虫的原理或功能。
▲图 2-1 网络爬虫象形图
02 爬行动物的意义
如今,大数据时代已经到来,网络爬虫技术已经成为这个时代不可或缺的一部分。企业需要数据来分析用户行为、自身产品的不足、竞争对手的信息。所有这一切的首要条件是数据。采集。
网络爬虫的价值其实就是数据的价值。在互联网社会,数据是无价的。一切都是数据。谁拥有大量有用的数据,谁就有决策的主动权。网络爬虫的应用领域很多,比如搜索引擎、数据采集、广告过滤、大数据分析等。
1)抓取各大电商公司的产品销售信息和用户评价网站进行分析,如图2-2所示。
▲图2-2 电商产品销售信息网站
2)分析大众点评、美团等餐饮品类网站用户的消费、评价及发展趋势,如图2-3所示。
▲图2-3 餐饮用户消费信息网站
3)分析各城市中学区住房占比,学区房价格比普通二手房高多少,如图2-4所示。
▲图2-4 学区住房比例与价格对比
以上数据是由ForeSpider数据采集软件爬下来的。有兴趣的读者可以尝试自己爬一些数据。
03 爬虫的原理
我们通常将网络爬虫的组件分为初始链接库、网络爬取模块、网页处理模块、网页分析模块、DNS模块、待爬取链接队列、网页库等。网络爬虫的各个模块可以组成一个循环系统,从而不断的分析和抓取。
爬虫的工作原理可以简单地解释为首先找到目标信息网络,然后是页面爬取模块,然后是页面分析模块,最后是数据存储模块。具体细节如图2-5所示。
▲图2-5 爬虫示意图
爬虫工作的基本流程:
首先,选择互联网中的一部分网页,将这些网页的链接地址作为种子URL;将这些种子URL放入待爬取URL队列中,爬虫依次从待爬取URL队列中读取;通过 DNS 解析 URL;将链接地址转换为网站服务器对应的IP地址;网页下载器通过网站服务器下载网页;下载的网页为网页文档的形式;提取网页文档中的URL;filter 删除已抓取的网址;继续对没有被爬取的URL进行爬取,直到待爬取的URL队列为空。
04 爬虫技术的种类
作者简介:赵国胜,哈尔滨师范大学教授,工学博士,硕士生导师,黑龙江省网络安全技术领域特殊人才。主要从事可信网络、入侵容忍、认知计算、物联网安全等领域的教学和科研工作。
本文摘自《Python网络爬虫技术与实践》,经出版社授权发布。
本文使用“CC BY-SA 4.0 CN”协议转载自网络,仅供学习交流。内容版权归原作者所有。如果您对作品、版权等问题有任何疑问,请给“我们”留言。
c爬虫抓取网页数据(百度/google等搜索网站就是的实现方法(使用python3))
网站优化 • 优采云 发表了文章 • 0 个评论 • 246 次浏览 • 2022-03-16 09:00
1. 什么是爬虫
当今互联网上存储着大量信息。
作为普通网民,我们经常使用浏览器访问互联网上的内容。但是如果你想批量下载散落在网上的某方面的信息(比如某网站的所有图片,某新闻网站的所有新闻,或者所有的收视率豆瓣上的电影),手动使用浏览器打开网站一一搜索太费时费力。
人工统计太费时费力
因此,编写程序来自动抓取 Internet 以获取有关我们想要的特定内容的信息变得更加重要。
网络爬虫是根据一定规则自动从万维网上抓取信息的程序或脚本。
通过程序,我们模拟浏览器向服务器发送请求,获取信息,分析信息,存储我们想要的内容。
百度/谷歌搜索网站是利用爬虫定期搜索互联网上的链接并更新其服务器,以便我们通过搜索引擎搜索到我们想要的信息。
2. 网页结构
访问网页不仅仅是输入地址并查看它。
在浏览器中按“F12”,或右键单击网页并选择“检查”。你可以看到页面后面的代码。
以谷歌的Chrome浏览器为例,在任意一个网站中,我们按下F12,就会出现一个浏览器检查窗口。默认的 Elements 窗口是当前界面的 HTML 代码。
Web 和元素界面
Sources 界面将显示浏览器从每个服务器下载的所有文件。
来源界面
在网络界面,在“记录网络日志”状态下(按Ctrl+E切换该状态),可以依次记录浏览器在每个时间段接收到的文件和文件相关数据。
网络接口
我们这里要实现的抓取具体信息的爬虫,需要我们到对应的网站去分析它的网页结构。根据网页的结构,我们可以通过编写相应的程序得到我们想要的信息。
3.python代码实现
我们将以豆瓣上的《流浪地球》影评为例,一步步讲解python爬虫的实现方法(使用python3).
以下代码可在 github 上下载。
3.1 基本介绍
我们将在本节中使用的 python 库是:
另外,本节我们没有讲,但是使用爬虫时可能用到的库通常包括:
对于上面的python库,bs4可以通过“pip install Beautifulsoup4”命令安装,其他库可以直接通过“pip install library noun”安装。
我们首先创建一个新的 jupyter 文件并导入必要的 python 库。
导入必要的python库
3.2 请求的使用
使用请求
上面的代码允许我们以编程方式访问(百度)网页。
其中,“requests.get(网页地址)”是以get的方式访问网页。
访问网址有两种类型:获取和发布。get和post的区别可以看下图(来自w3school)。两者的区别很容易理解,无需深究。
关于get、post和使用request传参,我们会在以后的爬虫进阶教程中一一介绍。
我们已经使用“response = requests.get(url)”将获取的信息传递给“response”。但是如果我们输出响应,我们得到的不是网站的代码,而是响应状态码。
响应状态码
响应状态码代表我们之前请求请求的结果。常见的是200,代表成功;403,无访问权限;404,文件不存在;502,服务器错误。
想看看我们之前用“requests.get(url)”得到的网页内容。我们需要先执行“response.enconding = 'utf-8'”。这一步是将网页内容编码为utf-8,否则我们将无法在网页中看到中文。
将生成的内容编码为 utf-8
输入response.text后,我们就可以看到网页的代码了。
3.3 BeautifulSoup 的使用
在使用 BeautifulSoup 之前,建议读者对 html 有一定的了解。如果没有,那很好。
HTML 是一种标记语言,具有很强的结构要求。
html代码示例
我们使用 BeautifulSoup 来分析 HTML 页面的结构来选择我们想要的内容。
我们可以使用 BeautifulSoup(response.text, "lxml") 来自动分析我们之前得到的网页代码。分析结果存储在等号左侧的变量汤中。
html内容信息分析
BeautifulSoup 有很多使用方法。
例如 .find("tag name") 返回找到的第一个标签的内容。
.find("标记名")
值得注意的是,我们找到的第一个 div 标签里面也有 div 标签。但是 BeautifulSoup 不会注意到, .find("div") 只会返回找到的第一个 div 标签,以及该标签内的所有内容。
.find_all("tag name") 返回找到的所有标签。
.find_all("标签名称")
.find_all("tag name", class_="class name", id="id name") 可以找到指定的类别并指定id标签。(注意使用 class_ 而不是 class)
.find_all("标签名", class_="类名", id="id名")
此外,我们还可以继续对.find()和.find_all()的结果进行.find()、.find_all()查询。
3.4 json的使用
除了html格式文件,我们经常需要爬取一些json格式文件。JSON 是一种轻量级的数据交换格式。
html和json格式文件的区别如下。(严格来说左边应该是一个XML格式的文件,但也可以认为是一般的HTML)
html和json格式文件的区别
(图片来自网络)
所以,有时,我们会解析 json 格式的数据。
使用 text = json.loads(字符串格式的json数据)
您可以将字符串格式的 json 数据转换为 python 字典格式。
3.5 组合使用
我们之前提到过:“根据网页的结构,我们可以通过编写相应的程序得到我们想要的信息。”
现在,我们进入豆瓣影评《流浪地球》的短评界面。
()
《流浪地球》短评界面
我们按“F12”打开检查界面。如果你使用的是Chrome浏览器,可以点击下图的小箭头或者Ctrl+Shift+C。这时,当鼠标移动到页面上的某个位置时,浏览器会自动显示该位置对应的代码位置。
Ctrl+Shift+C后可以查看页面中每个元素的位置
具体效果如下:
结合我们之前讲过的requests和Beautifulsoup的对应知识。读者可以尝试写一个爬虫来获取当前网页的所有短评信息。
作者这里爬的是
“”,是一个json文件,所以额外使用了python的json库。
代码显示如下。完整代码可在 github 上找到。建议读者先尝试从零开始写一个爬虫,遇到问题先百度/谷歌,最后参考这个完整的爬虫代码
完整的爬虫代码
完成代码下载:
3.6 最终结果
最后,为了让最终的结果更加美观,作者在这里使用了pandas的DataFrame。
使用熊猫的数据框
爬取的数据结果如下
抓取的数据
3.7 扩展
以上内容只是一个基本的python爬虫。
如果读者细心,他们会发现不登录豆瓣就无法访问。”
"
没有权限
这里的url链接中的start=220表示我们不登录就无法查看第220条评论之后的内容。
在以后的爬虫进阶教程中,我们会介绍如何使用爬虫进行登录、保存cookies等操作。
另外,部分网站可能会使用js进行网站动态渲染、代码加密等,仅爬取html和json文件是不够的。同时,我们也可以使用多进程来加速爬虫...
敬请期待以后的爬虫进阶教程。
其他文章
(点击跳转)
长
根据
关闭
笔记
解锁更多精彩内容
跟着一起做一个有灵魂的人 查看全部
c爬虫抓取网页数据(百度/google等搜索网站就是的实现方法(使用python3))
1. 什么是爬虫
当今互联网上存储着大量信息。
作为普通网民,我们经常使用浏览器访问互联网上的内容。但是如果你想批量下载散落在网上的某方面的信息(比如某网站的所有图片,某新闻网站的所有新闻,或者所有的收视率豆瓣上的电影),手动使用浏览器打开网站一一搜索太费时费力。
人工统计太费时费力
因此,编写程序来自动抓取 Internet 以获取有关我们想要的特定内容的信息变得更加重要。
网络爬虫是根据一定规则自动从万维网上抓取信息的程序或脚本。
通过程序,我们模拟浏览器向服务器发送请求,获取信息,分析信息,存储我们想要的内容。
百度/谷歌搜索网站是利用爬虫定期搜索互联网上的链接并更新其服务器,以便我们通过搜索引擎搜索到我们想要的信息。
2. 网页结构
访问网页不仅仅是输入地址并查看它。
在浏览器中按“F12”,或右键单击网页并选择“检查”。你可以看到页面后面的代码。
以谷歌的Chrome浏览器为例,在任意一个网站中,我们按下F12,就会出现一个浏览器检查窗口。默认的 Elements 窗口是当前界面的 HTML 代码。
Web 和元素界面
Sources 界面将显示浏览器从每个服务器下载的所有文件。
来源界面
在网络界面,在“记录网络日志”状态下(按Ctrl+E切换该状态),可以依次记录浏览器在每个时间段接收到的文件和文件相关数据。
网络接口
我们这里要实现的抓取具体信息的爬虫,需要我们到对应的网站去分析它的网页结构。根据网页的结构,我们可以通过编写相应的程序得到我们想要的信息。
3.python代码实现
我们将以豆瓣上的《流浪地球》影评为例,一步步讲解python爬虫的实现方法(使用python3).
以下代码可在 github 上下载。
3.1 基本介绍
我们将在本节中使用的 python 库是:
另外,本节我们没有讲,但是使用爬虫时可能用到的库通常包括:
对于上面的python库,bs4可以通过“pip install Beautifulsoup4”命令安装,其他库可以直接通过“pip install library noun”安装。
我们首先创建一个新的 jupyter 文件并导入必要的 python 库。
导入必要的python库
3.2 请求的使用
使用请求
上面的代码允许我们以编程方式访问(百度)网页。
其中,“requests.get(网页地址)”是以get的方式访问网页。
访问网址有两种类型:获取和发布。get和post的区别可以看下图(来自w3school)。两者的区别很容易理解,无需深究。
关于get、post和使用request传参,我们会在以后的爬虫进阶教程中一一介绍。
我们已经使用“response = requests.get(url)”将获取的信息传递给“response”。但是如果我们输出响应,我们得到的不是网站的代码,而是响应状态码。
响应状态码
响应状态码代表我们之前请求请求的结果。常见的是200,代表成功;403,无访问权限;404,文件不存在;502,服务器错误。
想看看我们之前用“requests.get(url)”得到的网页内容。我们需要先执行“response.enconding = 'utf-8'”。这一步是将网页内容编码为utf-8,否则我们将无法在网页中看到中文。
将生成的内容编码为 utf-8
输入response.text后,我们就可以看到网页的代码了。
3.3 BeautifulSoup 的使用
在使用 BeautifulSoup 之前,建议读者对 html 有一定的了解。如果没有,那很好。
HTML 是一种标记语言,具有很强的结构要求。
html代码示例
我们使用 BeautifulSoup 来分析 HTML 页面的结构来选择我们想要的内容。
我们可以使用 BeautifulSoup(response.text, "lxml") 来自动分析我们之前得到的网页代码。分析结果存储在等号左侧的变量汤中。
html内容信息分析
BeautifulSoup 有很多使用方法。
例如 .find("tag name") 返回找到的第一个标签的内容。
.find("标记名")
值得注意的是,我们找到的第一个 div 标签里面也有 div 标签。但是 BeautifulSoup 不会注意到, .find("div") 只会返回找到的第一个 div 标签,以及该标签内的所有内容。
.find_all("tag name") 返回找到的所有标签。
.find_all("标签名称")
.find_all("tag name", class_="class name", id="id name") 可以找到指定的类别并指定id标签。(注意使用 class_ 而不是 class)
.find_all("标签名", class_="类名", id="id名")
此外,我们还可以继续对.find()和.find_all()的结果进行.find()、.find_all()查询。
3.4 json的使用
除了html格式文件,我们经常需要爬取一些json格式文件。JSON 是一种轻量级的数据交换格式。
html和json格式文件的区别如下。(严格来说左边应该是一个XML格式的文件,但也可以认为是一般的HTML)
html和json格式文件的区别
(图片来自网络)
所以,有时,我们会解析 json 格式的数据。
使用 text = json.loads(字符串格式的json数据)
您可以将字符串格式的 json 数据转换为 python 字典格式。
3.5 组合使用
我们之前提到过:“根据网页的结构,我们可以通过编写相应的程序得到我们想要的信息。”
现在,我们进入豆瓣影评《流浪地球》的短评界面。
()
《流浪地球》短评界面
我们按“F12”打开检查界面。如果你使用的是Chrome浏览器,可以点击下图的小箭头或者Ctrl+Shift+C。这时,当鼠标移动到页面上的某个位置时,浏览器会自动显示该位置对应的代码位置。
Ctrl+Shift+C后可以查看页面中每个元素的位置
具体效果如下:
结合我们之前讲过的requests和Beautifulsoup的对应知识。读者可以尝试写一个爬虫来获取当前网页的所有短评信息。
作者这里爬的是
“”,是一个json文件,所以额外使用了python的json库。
代码显示如下。完整代码可在 github 上找到。建议读者先尝试从零开始写一个爬虫,遇到问题先百度/谷歌,最后参考这个完整的爬虫代码
完整的爬虫代码
完成代码下载:
3.6 最终结果
最后,为了让最终的结果更加美观,作者在这里使用了pandas的DataFrame。
使用熊猫的数据框
爬取的数据结果如下
抓取的数据
3.7 扩展
以上内容只是一个基本的python爬虫。
如果读者细心,他们会发现不登录豆瓣就无法访问。”
"
没有权限
这里的url链接中的start=220表示我们不登录就无法查看第220条评论之后的内容。
在以后的爬虫进阶教程中,我们会介绍如何使用爬虫进行登录、保存cookies等操作。
另外,部分网站可能会使用js进行网站动态渲染、代码加密等,仅爬取html和json文件是不够的。同时,我们也可以使用多进程来加速爬虫...
敬请期待以后的爬虫进阶教程。
其他文章
(点击跳转)
长
根据
关闭
笔记
解锁更多精彩内容
跟着一起做一个有灵魂的人
c爬虫抓取网页数据( Python中的字典如何进行访问网络数据接口访问的相关知识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-03-15 16:19
Python中的字典如何进行访问网络数据接口访问的相关知识)
import requests
# requests的get函数会返回一个Response对象
resp = requests.get('https://www.sohu.com/')
if resp.status_code == 200:
# 通过Response对象的text属性获取服务器返回的文本内容
print(resp.text)
获取百度 Logo 并将其保存到名为 baidu.png 的本地文件中。首先,在百度首页,右击百度Logo,通过“复制图片地址”菜单获取图片的URL。
import requests
resp = requests.get('https://www.baidu.com/img/PCtm ... %2339;)
with open('baidu.png', 'wb') as file:
# 通过Response对象的content属性获取服务器返回的二进制内容
file.write(resp.content)
注:requests库的详细使用可以参考官方文档的内容。接入网络数据接口
国内外很多网站都提供了开放的数据接口。在开发商业项目的时候,如果有一些我们自己解决不了的事情,我们可以使用这些开放的数据接口来处理。例如,根据用户或企业上传的信息进行实名认证或企业认证,我们可以调用第三方提供的开放接口来识别用户或企业信息的真实性;例如,要获取一个城市的天气信息,我们不能直接从气象卫星获取数据,然后自己进行计算。相应的天气信息只能通过第三方提供的数据接口获取。通常,提供具有商业价值的数据的接口,需要付费才能访问。在访问接口时,还需要提供身份标识,以便服务器判断用户是否为付费用户,并进行扣费等相关操作。当然,有些接口可以免费使用,但必须提供个人或公司信息才能访问,例如:深圳市政务数据开放平台、蜻蜓FM开放平台等。如果您找到需要的数据接口,您可以访问 网站 类型的聚合数据。
目前我们访问的大部分网络数据接口都会返回JSON格式的数据。当我们在第 24 课中解释序列化和反序列化时,我们提到了如何将 JSON 格式的字符串转换为 Python 中的字典,并以天为单位使用数据。以行数据为例讲解网络数据接口访问的相关知识,这里不再赘述。
开发爬虫/爬虫程序
有时,我们需要的数据无法通过开放的数据接口获取,但在某些网页上可能有。这时候我们就需要开发一个爬虫程序,通过爬取页面来获取需要的内容。我们可以按照上面提供的方法,使用requests先获取网页的HTML代码。我们可以把整个代码看成一个长字符串,这样就可以使用正则表达式捕获组从字符串中提取出我们需要的内容。下面我们通过代码演示如何从豆瓣电影中获取前 250 部电影的名称。豆瓣电影Top250页面结构及对应代码如下图所示。
import random
import re
import time
import requests
for page in range(1, 11):
resp = requests.get(
# 请求https://movie.douban.com/top250时,start参数代表了从哪一部电影开始
url=f'https://movie.douban.com/top250?start={(page - 1) * 25}',
# 如果不设置HTTP请求头中的User-Agent,豆瓣会检测出爬虫程序而阻止我们的请求
# User-Agent可以设置为浏览器的标识(可以在浏览器的开发者工具查看HTTP请求头找到)
# 由于豆瓣网允许百度爬虫获取它的数据,因此直接将我们的爬虫伪装成百度的爬虫
headers={'User-Agent': 'BaiduSpider'}
)
# 创建正则表达式对象,通过捕获组捕获span标签中的电影标题
pattern = re.compile(r'\([^&]*?)\')
# 通过正则表达式获取class属性为title且标签内容不以&符号开头的span标签
results = pattern.findall(resp.text)
# 循环变量列表中所有的电影标题
for result in results:
print(result)
# 随机休眠1-3秒,避免获取页面过于频繁
time.sleep(random.randint(1, 3))
写爬虫程序最重要的就是让爬虫程序隐藏自己的身份,因为一般的网站对爬虫比较反感。除了修改上面代码中的User-Agent,还可以使用商业IP代理(如蘑菇代理、芝麻代理等)隐藏自己的身份,让爬取的网站无法知道真实的爬虫程序地址的IP,无法通过IP地址屏蔽爬虫程序。当然,爬虫本身也是一个灰色地带的东西。没有人说这是非法的,但也没有人说这是合法的。本着允许的精神,如果法律不禁止,我们可以根据自己工作的需要来写。爬虫程序,但是如果爬取的网站可以证明你的爬虫程序破坏了动产,
另外,虽然通过编写正则表达式从网页中提取内容是可行的,但要编写一个能够满足需求的正则表达式并不容易,尤其是对于初学者而言。在下一课中,我们将介绍另外两种从页面中提取数据的方法。尽管它们在性能方面可能不如正则表达式,但它们降低了编码的复杂性。我相信你会喜欢的。他们的。
简单总结
Python 语言确实可以做很多事情。在获取网络数据方面,Python 几乎是佼佼者。大量的企业和个人会使用 Python 从网络中获取他们需要的数据。我相信这将在现在或将来发生。它也将成为您工作的一部分。
原文来自知乎:Python-Jack
原文链接:Learning Python from scratch - 第030课:用Python获取网络数据 查看全部
c爬虫抓取网页数据(
Python中的字典如何进行访问网络数据接口访问的相关知识)
import requests
# requests的get函数会返回一个Response对象
resp = requests.get('https://www.sohu.com/')
if resp.status_code == 200:
# 通过Response对象的text属性获取服务器返回的文本内容
print(resp.text)
获取百度 Logo 并将其保存到名为 baidu.png 的本地文件中。首先,在百度首页,右击百度Logo,通过“复制图片地址”菜单获取图片的URL。
import requests
resp = requests.get('https://www.baidu.com/img/PCtm ... %2339;)
with open('baidu.png', 'wb') as file:
# 通过Response对象的content属性获取服务器返回的二进制内容
file.write(resp.content)
注:requests库的详细使用可以参考官方文档的内容。接入网络数据接口
国内外很多网站都提供了开放的数据接口。在开发商业项目的时候,如果有一些我们自己解决不了的事情,我们可以使用这些开放的数据接口来处理。例如,根据用户或企业上传的信息进行实名认证或企业认证,我们可以调用第三方提供的开放接口来识别用户或企业信息的真实性;例如,要获取一个城市的天气信息,我们不能直接从气象卫星获取数据,然后自己进行计算。相应的天气信息只能通过第三方提供的数据接口获取。通常,提供具有商业价值的数据的接口,需要付费才能访问。在访问接口时,还需要提供身份标识,以便服务器判断用户是否为付费用户,并进行扣费等相关操作。当然,有些接口可以免费使用,但必须提供个人或公司信息才能访问,例如:深圳市政务数据开放平台、蜻蜓FM开放平台等。如果您找到需要的数据接口,您可以访问 网站 类型的聚合数据。
目前我们访问的大部分网络数据接口都会返回JSON格式的数据。当我们在第 24 课中解释序列化和反序列化时,我们提到了如何将 JSON 格式的字符串转换为 Python 中的字典,并以天为单位使用数据。以行数据为例讲解网络数据接口访问的相关知识,这里不再赘述。
开发爬虫/爬虫程序
有时,我们需要的数据无法通过开放的数据接口获取,但在某些网页上可能有。这时候我们就需要开发一个爬虫程序,通过爬取页面来获取需要的内容。我们可以按照上面提供的方法,使用requests先获取网页的HTML代码。我们可以把整个代码看成一个长字符串,这样就可以使用正则表达式捕获组从字符串中提取出我们需要的内容。下面我们通过代码演示如何从豆瓣电影中获取前 250 部电影的名称。豆瓣电影Top250页面结构及对应代码如下图所示。
import random
import re
import time
import requests
for page in range(1, 11):
resp = requests.get(
# 请求https://movie.douban.com/top250时,start参数代表了从哪一部电影开始
url=f'https://movie.douban.com/top250?start={(page - 1) * 25}',
# 如果不设置HTTP请求头中的User-Agent,豆瓣会检测出爬虫程序而阻止我们的请求
# User-Agent可以设置为浏览器的标识(可以在浏览器的开发者工具查看HTTP请求头找到)
# 由于豆瓣网允许百度爬虫获取它的数据,因此直接将我们的爬虫伪装成百度的爬虫
headers={'User-Agent': 'BaiduSpider'}
)
# 创建正则表达式对象,通过捕获组捕获span标签中的电影标题
pattern = re.compile(r'\([^&]*?)\')
# 通过正则表达式获取class属性为title且标签内容不以&符号开头的span标签
results = pattern.findall(resp.text)
# 循环变量列表中所有的电影标题
for result in results:
print(result)
# 随机休眠1-3秒,避免获取页面过于频繁
time.sleep(random.randint(1, 3))
写爬虫程序最重要的就是让爬虫程序隐藏自己的身份,因为一般的网站对爬虫比较反感。除了修改上面代码中的User-Agent,还可以使用商业IP代理(如蘑菇代理、芝麻代理等)隐藏自己的身份,让爬取的网站无法知道真实的爬虫程序地址的IP,无法通过IP地址屏蔽爬虫程序。当然,爬虫本身也是一个灰色地带的东西。没有人说这是非法的,但也没有人说这是合法的。本着允许的精神,如果法律不禁止,我们可以根据自己工作的需要来写。爬虫程序,但是如果爬取的网站可以证明你的爬虫程序破坏了动产,
另外,虽然通过编写正则表达式从网页中提取内容是可行的,但要编写一个能够满足需求的正则表达式并不容易,尤其是对于初学者而言。在下一课中,我们将介绍另外两种从页面中提取数据的方法。尽管它们在性能方面可能不如正则表达式,但它们降低了编码的复杂性。我相信你会喜欢的。他们的。
简单总结
Python 语言确实可以做很多事情。在获取网络数据方面,Python 几乎是佼佼者。大量的企业和个人会使用 Python 从网络中获取他们需要的数据。我相信这将在现在或将来发生。它也将成为您工作的一部分。
原文来自知乎:Python-Jack
原文链接:Learning Python from scratch - 第030课:用Python获取网络数据

