
c爬虫抓取网页数据
网络爬虫—利用SAS抓取网页方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-05-14 02:43
万维网过多的信息,股票报价,电影评论,市场价格趋势话题,几乎所有的东西,可以发现在点击一个按钮。在分析数据中发现,许多SAS用户感兴趣在网络上,但你得到这个数据的SAS环境呢?有很多方法,如 SAS数据步骤中的代码在设计你自己的网络爬虫或利用SAS%TMFILTER宏 ® 文本挖掘。在本文中,我们将审查一个网络爬虫的总体架构。我们将讨论获得网站的方法到SAS的信息,以及审查内部所谓的SAS搜索从实验项目的实验代码管道。我们也将提供咨询如何轻松定制一个网络爬虫,以适应个性化需求,以及如何具体的数据导入到SAS ® 企业矿工™。
简介:互联网已经成为一个有用的信息来源。通常是Web上的数据,我们要使用内的SAS,所以我们需要找到一种方式来获得这个数据。最好的办法是使用一个网络爬虫。 SAS提供几个从Web爬行和提取信息的方法。您可以使用基本的SAS数据步骤中的代码,或SAS文本矿工的%TMFILTER宏。虽然目前无法使用,SAS搜索管道将是一个功能强大的Web爬行产品,并提供更多的工具,网络爬行。每种方法都有其优点和缺点,所以取决于你想实现抓取的,它是最好对其进行审查。
首先,重要的是要了解网络爬虫是如何工作的。你应该熟悉数据步骤的代码,宏,和SAS过程PROC SQL,然后再继续。
网络爬虫概述:一个网络爬虫是一个程序,一个或多个起始地址作为“种子URL”,下载网站这些URL相关的网页,在网页中包含的任何超链接提取,并递归地继续这些超链接标识下载Web页。从概念上讲,网络爬虫是很简单的。
一个Web 履带式有四项职责:
1。从候选人中选择一个网址。
2。它下载相关的Web页。
3。它提取物在网页中的URL(超链接)。
4。它补充说,未曾遇到的候选集的URL
方法1:在WEB SAS数据步骤中的代码履带式
首先创建一个网址的网站的Web crawler将开始列表。
data work.links_to_crawl;
length url $256 ;
input url $;
datalines;
;
run
为了确保我们不抓取相同的URL一次以上,持有环节已创建一个数据抓取。
当Web数据集将在开始时是空的,但一个网站的网址将被添加到数据集履带式完成抓取该网站。
data work.links_crawled;
length url $256;
run;
现在我们开始爬行!该代码需要我们的 work.links_to_crawl数据集的第一个URL。在第一观察“_N_式1”,网址是投入名为 next_url 宏变量,所有剩余的URL放回我们的种子URL数据集,使他们在未来的迭代。
/* pop the next url off */
%let next_url = ;
data work.links_to_crawl;
set work.links_to_crawl;
if _n_ eq 1 then call symput(“next_url”, url);
else output;
run;
现在,从互联网上下载的网址。创建一个文件名称 _nexturl 。我们让SAS知道它是一个URL 而且可以发现,AT&next_url,这是我们的宏观变量,它包含的网址我们从拉 work.links_to_crawl数据集。
/* crawl the url */
filename _nexturl url “&next_url”
建立后的文件名的URL参考,确定一个地方把我们下载的文件。创建另一个文件名引用所谓 htmlfilm的条目,并在那里把从 url_file.html收集到的信息。
/* put the file we crawled here */
filename htmlfile “url_file.html”
接下来,我们通过数据的循环,把它写htmlfilm的条目文件名参考,并寻找更多的网址添加到我们的 work.links_to_crawl数据集。
/* find more urls */
data work._urls(keep=url);
length url $256 ;
file htmlfile;
infile _nexturl length=len;
input text $varying2000. len;
put text;
start = 1;
stop = length(text);
使用正则表达式一个网站的网址,以帮助搜索。正则表达式的匹配方法文本字符串,如字,词,或字符模式。 SAS已经提供了许多强大的字符串功能。然而,正则表达式通常会提供一个更简洁的方式,操纵和匹配的文本.
if _n_ = 1 then do;
retain patternID;
pattern = ‘/href=”([^"]+)”/i’;
patternID = prxparse(pattern);
end
首次观察到,创建一个patternID将保持整个数据步运行。寻找的模式是: “/href=”([^"]+)”/i’”.,这意味着我们正在寻找字符串“HREF =”“,然后再寻找任何字符串,是至少有一个字符长,不包含引号(“),并结束在引号(”)。在’我’ 目的的手段使用不区分大小写的方法,以配合我们的正则表达式。
As a result, the Web crawler will find these types of strings:
href=”sgf/2010/papers.html”
href=””
HREF=””
hReF=””
现在正则表达式匹配的一个网站上的文字。 PRXNEXT需要五个参数:正则表达式我们要寻找,寻找开始寻找正则表达式的开始位置,结束位置停止正则表达式,一旦发现字符串中的位置,而字符串的长度,如果发现的位置将是0,如果没有找到字符串。 PRXNEXT也改变了开始的参数,使搜索重新开始后的最后一场比赛是发现。
call prxnext(patternID, start, stop, text, position, length);
代码中的循环,在网站上找到的所有环节显示的文本。
do while (position ^= 0);
url = substr(text, position+6, length-7);
output;
call prxnext(patternID, start, stop, text, position, length);
end;
run;
如果代码发现一个网址,它会检索唯一的URL的一部分,启动后的第一个引号。例如,如果代码中发现的HREF =“”,那么它应该保持 。使用 substr到删除前的6个字符和最后一个字符的URL的其余部分输出的work._urls 数据集。现在,我们插入的URL代码只是以跟踪抓取到一个数据集名为 work.links_crawled 我们已经和确保我们不再次浏览有。
/* add the current link to the list of urls we have already crawled */
data work._old_link;
url = “&next_url”;
run;
proc append base=work.links_crawled data=work._old_link force;
run;
下一步是在数据集 work._urls 的过程中发现的网址列表,以确保:
1。我们尚未抓取他们,换句话说URL是不是在 work.links_crawled)。
2。我们没有排队抓取的URL(网址换句话说,是不是在work.links_to_crawl )。
/*
* only add urls that we have not already crawled
* or that are not queued up to be crawled
*
*/
proc sql noprint;
create table work._append as
select url
from work._urls
where url not in (select url from work.links_crawled)
and url not in (select url from work.links_to_crawl);
quit;
然后,我们添加网址还没有被抓取,而不是已经排队 work.links_to_crawl数据集。
/* add new links */
proc append base=work.links_to_crawl data=work._append force;
run;
此时的代码循环回到开始劫掠 work.links_to_crawl数据集的下一个URL。 查看全部
网络爬虫—利用SAS抓取网页方法
万维网过多的信息,股票报价,电影评论,市场价格趋势话题,几乎所有的东西,可以发现在点击一个按钮。在分析数据中发现,许多SAS用户感兴趣在网络上,但你得到这个数据的SAS环境呢?有很多方法,如 SAS数据步骤中的代码在设计你自己的网络爬虫或利用SAS%TMFILTER宏 ® 文本挖掘。在本文中,我们将审查一个网络爬虫的总体架构。我们将讨论获得网站的方法到SAS的信息,以及审查内部所谓的SAS搜索从实验项目的实验代码管道。我们也将提供咨询如何轻松定制一个网络爬虫,以适应个性化需求,以及如何具体的数据导入到SAS ® 企业矿工™。
简介:互联网已经成为一个有用的信息来源。通常是Web上的数据,我们要使用内的SAS,所以我们需要找到一种方式来获得这个数据。最好的办法是使用一个网络爬虫。 SAS提供几个从Web爬行和提取信息的方法。您可以使用基本的SAS数据步骤中的代码,或SAS文本矿工的%TMFILTER宏。虽然目前无法使用,SAS搜索管道将是一个功能强大的Web爬行产品,并提供更多的工具,网络爬行。每种方法都有其优点和缺点,所以取决于你想实现抓取的,它是最好对其进行审查。
首先,重要的是要了解网络爬虫是如何工作的。你应该熟悉数据步骤的代码,宏,和SAS过程PROC SQL,然后再继续。
网络爬虫概述:一个网络爬虫是一个程序,一个或多个起始地址作为“种子URL”,下载网站这些URL相关的网页,在网页中包含的任何超链接提取,并递归地继续这些超链接标识下载Web页。从概念上讲,网络爬虫是很简单的。
一个Web 履带式有四项职责:
1。从候选人中选择一个网址。
2。它下载相关的Web页。
3。它提取物在网页中的URL(超链接)。
4。它补充说,未曾遇到的候选集的URL
方法1:在WEB SAS数据步骤中的代码履带式
首先创建一个网址的网站的Web crawler将开始列表。
data work.links_to_crawl;
length url $256 ;
input url $;
datalines;
;
run
为了确保我们不抓取相同的URL一次以上,持有环节已创建一个数据抓取。
当Web数据集将在开始时是空的,但一个网站的网址将被添加到数据集履带式完成抓取该网站。
data work.links_crawled;
length url $256;
run;
现在我们开始爬行!该代码需要我们的 work.links_to_crawl数据集的第一个URL。在第一观察“_N_式1”,网址是投入名为 next_url 宏变量,所有剩余的URL放回我们的种子URL数据集,使他们在未来的迭代。
/* pop the next url off */
%let next_url = ;
data work.links_to_crawl;
set work.links_to_crawl;
if _n_ eq 1 then call symput(“next_url”, url);
else output;
run;
现在,从互联网上下载的网址。创建一个文件名称 _nexturl 。我们让SAS知道它是一个URL 而且可以发现,AT&next_url,这是我们的宏观变量,它包含的网址我们从拉 work.links_to_crawl数据集。
/* crawl the url */
filename _nexturl url “&next_url”
建立后的文件名的URL参考,确定一个地方把我们下载的文件。创建另一个文件名引用所谓 htmlfilm的条目,并在那里把从 url_file.html收集到的信息。
/* put the file we crawled here */
filename htmlfile “url_file.html”
接下来,我们通过数据的循环,把它写htmlfilm的条目文件名参考,并寻找更多的网址添加到我们的 work.links_to_crawl数据集。
/* find more urls */
data work._urls(keep=url);
length url $256 ;
file htmlfile;
infile _nexturl length=len;
input text $varying2000. len;
put text;
start = 1;
stop = length(text);
使用正则表达式一个网站的网址,以帮助搜索。正则表达式的匹配方法文本字符串,如字,词,或字符模式。 SAS已经提供了许多强大的字符串功能。然而,正则表达式通常会提供一个更简洁的方式,操纵和匹配的文本.
if _n_ = 1 then do;
retain patternID;
pattern = ‘/href=”([^"]+)”/i’;
patternID = prxparse(pattern);
end
首次观察到,创建一个patternID将保持整个数据步运行。寻找的模式是: “/href=”([^"]+)”/i’”.,这意味着我们正在寻找字符串“HREF =”“,然后再寻找任何字符串,是至少有一个字符长,不包含引号(“),并结束在引号(”)。在’我’ 目的的手段使用不区分大小写的方法,以配合我们的正则表达式。
As a result, the Web crawler will find these types of strings:
href=”sgf/2010/papers.html”
href=””
HREF=””
hReF=””
现在正则表达式匹配的一个网站上的文字。 PRXNEXT需要五个参数:正则表达式我们要寻找,寻找开始寻找正则表达式的开始位置,结束位置停止正则表达式,一旦发现字符串中的位置,而字符串的长度,如果发现的位置将是0,如果没有找到字符串。 PRXNEXT也改变了开始的参数,使搜索重新开始后的最后一场比赛是发现。
call prxnext(patternID, start, stop, text, position, length);
代码中的循环,在网站上找到的所有环节显示的文本。
do while (position ^= 0);
url = substr(text, position+6, length-7);
output;
call prxnext(patternID, start, stop, text, position, length);
end;
run;
如果代码发现一个网址,它会检索唯一的URL的一部分,启动后的第一个引号。例如,如果代码中发现的HREF =“”,那么它应该保持 。使用 substr到删除前的6个字符和最后一个字符的URL的其余部分输出的work._urls 数据集。现在,我们插入的URL代码只是以跟踪抓取到一个数据集名为 work.links_crawled 我们已经和确保我们不再次浏览有。
/* add the current link to the list of urls we have already crawled */
data work._old_link;
url = “&next_url”;
run;
proc append base=work.links_crawled data=work._old_link force;
run;
下一步是在数据集 work._urls 的过程中发现的网址列表,以确保:
1。我们尚未抓取他们,换句话说URL是不是在 work.links_crawled)。
2。我们没有排队抓取的URL(网址换句话说,是不是在work.links_to_crawl )。
/*
* only add urls that we have not already crawled
* or that are not queued up to be crawled
*
*/
proc sql noprint;
create table work._append as
select url
from work._urls
where url not in (select url from work.links_crawled)
and url not in (select url from work.links_to_crawl);
quit;
然后,我们添加网址还没有被抓取,而不是已经排队 work.links_to_crawl数据集。
/* add new links */
proc append base=work.links_to_crawl data=work._append force;
run;
此时的代码循环回到开始劫掠 work.links_to_crawl数据集的下一个URL。
c爬虫抓取网页数据的选择思路及选择方法介绍-requests
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-05-11 15:02
c爬虫抓取网页数据的工具很多,比如requests、beautifulsoup等等;另外爬虫还可以用scrapy框架做反爬虫。甚至apache/nginx做反反爬虫也可以。本文会结合requests做网页反爬虫。文章包含以下主要内容1.介绍一下requests库2.先介绍爬虫是怎么获取网页数据的3.解决爬虫服务器速度慢、不稳定的问题4.在各种网页爬虫框架中的选择思路5.requests详细流程看起来主要内容不多,一行代码搞定,但上述一些问题确很麻烦。
以上每一个都会成为一篇文章,首先说明这里每一个主要代码单独抽取下即可,其实大多是我写的。再说明上述操作本质上是对url和网页元素进行了解析。由于requests方便的处理url,因此解析html这件事可以交给自己来做。requests最简单的实现抓取网页时,没有必要在html网页处理过程中还需要保存html信息,基本步骤:1.获取网页包含信息2.解析html3.存储数据对爬虫爬取html来说,需要经历requests库爬取网页时传递参数,传递到selenium线程池,由线程池来解析html信息。
selenium不需要保存任何网页信息,直接处理后分析为webapi输出即可。所以上述的各个步骤和html编码没有太大关系。也不要问为什么不用xpath,因为xpath和html编码不一样,在抓取网页时必须转换为xpath/emoji可读语言才能读取正常。现在有一些爬虫框架都有支持requests,比如scrapy、kibana和motrix;正因为requests简单,因此其解析html的方式也简单;我们介绍一下其中一些爬虫框架的爬取html的方式。
这样的主要目的是想通过对requests的熟悉,进一步使用其他框架做爬虫之类的。requestsjs官网:requests的一个重要版本,很多第三方包支持其爬取html信息。javascript解析html模块库:v8解析javascript/text/string,使用jsonp:直接发送http请求或是使用浏览器的浏览器api返回html数据,jquery解析javascript代码,并将javascript数据以html数据格式返回。
prestojs(已经被大弃)/zeptojs(github)requestsjs的主要代码都来自于这里;web容器:injection来负责生成html标签和处理html;有一个重要组件是seleniumdriver和requests的交互,getseleniumdriver做的事情非常类似于html编程中的函数调用,类似于open和session来做html编程中的dom操作;httpurlconnectionhttpconnection负责接收请求并处理响应,并且通过post请求,向服务器发送数据,请求的格式使用headers:attributes:user-agent:mozilla/5.0(ipad;cpuiphoneosx10_。 查看全部
c爬虫抓取网页数据的选择思路及选择方法介绍-requests
c爬虫抓取网页数据的工具很多,比如requests、beautifulsoup等等;另外爬虫还可以用scrapy框架做反爬虫。甚至apache/nginx做反反爬虫也可以。本文会结合requests做网页反爬虫。文章包含以下主要内容1.介绍一下requests库2.先介绍爬虫是怎么获取网页数据的3.解决爬虫服务器速度慢、不稳定的问题4.在各种网页爬虫框架中的选择思路5.requests详细流程看起来主要内容不多,一行代码搞定,但上述一些问题确很麻烦。
以上每一个都会成为一篇文章,首先说明这里每一个主要代码单独抽取下即可,其实大多是我写的。再说明上述操作本质上是对url和网页元素进行了解析。由于requests方便的处理url,因此解析html这件事可以交给自己来做。requests最简单的实现抓取网页时,没有必要在html网页处理过程中还需要保存html信息,基本步骤:1.获取网页包含信息2.解析html3.存储数据对爬虫爬取html来说,需要经历requests库爬取网页时传递参数,传递到selenium线程池,由线程池来解析html信息。
selenium不需要保存任何网页信息,直接处理后分析为webapi输出即可。所以上述的各个步骤和html编码没有太大关系。也不要问为什么不用xpath,因为xpath和html编码不一样,在抓取网页时必须转换为xpath/emoji可读语言才能读取正常。现在有一些爬虫框架都有支持requests,比如scrapy、kibana和motrix;正因为requests简单,因此其解析html的方式也简单;我们介绍一下其中一些爬虫框架的爬取html的方式。
这样的主要目的是想通过对requests的熟悉,进一步使用其他框架做爬虫之类的。requestsjs官网:requests的一个重要版本,很多第三方包支持其爬取html信息。javascript解析html模块库:v8解析javascript/text/string,使用jsonp:直接发送http请求或是使用浏览器的浏览器api返回html数据,jquery解析javascript代码,并将javascript数据以html数据格式返回。
prestojs(已经被大弃)/zeptojs(github)requestsjs的主要代码都来自于这里;web容器:injection来负责生成html标签和处理html;有一个重要组件是seleniumdriver和requests的交互,getseleniumdriver做的事情非常类似于html编程中的函数调用,类似于open和session来做html编程中的dom操作;httpurlconnectionhttpconnection负责接收请求并处理响应,并且通过post请求,向服务器发送数据,请求的格式使用headers:attributes:user-agent:mozilla/5.0(ipad;cpuiphoneosx10_。
爬虫入门到精通-网页的下载
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-05-09 09:27
本文章属于爬虫入门到精通系统教程第四讲
在爬虫入门到精通第二讲中,我们了解了HTTP协议
#rd,那么我们现在使用这些协议来快速爬虫吧
本文的目标
当你看完本文后,你应该能爬取(几乎)任何的网页
使用chrome抓包抓包(packet capture)就是将网络传输发送与接收的数据包进行截获、重发、编辑、转存等操作,也用来检查网络安全。抓包也经常被用来进行数据截取等。第一个案列:抓取轮子哥的动态()
1.打开轮子哥动态这个网页
2.打开抓包工具
应该会看到如下界面
3.找到我们需要的请求
可以看到如下截图,里面有这么多的请求,那么到底哪一个才是我们需要的呢 ?
这边提供一个小技巧
简单来讲就是如果整个页面没有刷新的话,那就是在XHR里面,否则在DOC里面
因为本次抓包整个页面有刷新,所以,我们需要找的请求在DOC下面,可以看到只有一个请求
4.验证请求是对的
有以下两种方法(基本上用1,因为比较快)
在我们要抓包的页面随便copy出几个字,在Respoinse中使用ctrl+f 查找,如果有找到,说明我们找到的是对的 (我查找的是"和微软粉丝谈")
2.把response中所有的内容复制到一个txt中,并改名为"#.html"(这里的#可以随便取)
然后打开这个html,看看是否和我们要抓的一样
如果发现要找的不对,那你可以打开下一个请求检查下
5.模拟发送
点击Headers
可以看到请求的url是:
方法是: GET
requests headers 是(下图中框出来的地方)
所以我们的代码应该是:
import requests# 这里的headers就是我们上图框中的headers
request_headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch, br','Accept-Language':'zh-CN,zh;q=0.8','Cache-Control':'max-age=0','Connection':'keep-alive','Cookie':'','Host':'www.zhihu.com','Referer':'https://www.zhihu.com/','Upgrade-Insecure-Requests':'1','User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
}
#上图中的url
url = "https://www.zhihu.com/people/e ... ot%3B
# 上图中的请求方法(get)
z = requests.get(url,headers=request_headers)
print z.content
这段代码简单来说就是把 我们抓包看到的用程序来实现
一个小总结
我们爬取一个网页的步骤可以分为如下:
打开要爬取的网页
打开开发者工具,并让请求重发一次(简单讲就是抓包)
找到正确的请求
用程序模拟发送
第二个案列:点赞
1.打开要爬取的网页 查看全部
爬虫入门到精通-网页的下载
本文章属于爬虫入门到精通系统教程第四讲
在爬虫入门到精通第二讲中,我们了解了HTTP协议
#rd,那么我们现在使用这些协议来快速爬虫吧
本文的目标
当你看完本文后,你应该能爬取(几乎)任何的网页
使用chrome抓包抓包(packet capture)就是将网络传输发送与接收的数据包进行截获、重发、编辑、转存等操作,也用来检查网络安全。抓包也经常被用来进行数据截取等。第一个案列:抓取轮子哥的动态()
1.打开轮子哥动态这个网页
2.打开抓包工具
应该会看到如下界面
3.找到我们需要的请求
可以看到如下截图,里面有这么多的请求,那么到底哪一个才是我们需要的呢 ?
这边提供一个小技巧
简单来讲就是如果整个页面没有刷新的话,那就是在XHR里面,否则在DOC里面
因为本次抓包整个页面有刷新,所以,我们需要找的请求在DOC下面,可以看到只有一个请求
4.验证请求是对的
有以下两种方法(基本上用1,因为比较快)
在我们要抓包的页面随便copy出几个字,在Respoinse中使用ctrl+f 查找,如果有找到,说明我们找到的是对的 (我查找的是"和微软粉丝谈")
2.把response中所有的内容复制到一个txt中,并改名为"#.html"(这里的#可以随便取)
然后打开这个html,看看是否和我们要抓的一样
如果发现要找的不对,那你可以打开下一个请求检查下
5.模拟发送
点击Headers
可以看到请求的url是:
方法是: GET
requests headers 是(下图中框出来的地方)
所以我们的代码应该是:
import requests# 这里的headers就是我们上图框中的headers
request_headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch, br','Accept-Language':'zh-CN,zh;q=0.8','Cache-Control':'max-age=0','Connection':'keep-alive','Cookie':'','Host':'www.zhihu.com','Referer':'https://www.zhihu.com/','Upgrade-Insecure-Requests':'1','User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
}
#上图中的url
url = "https://www.zhihu.com/people/e ... ot%3B
# 上图中的请求方法(get)
z = requests.get(url,headers=request_headers)
print z.content
这段代码简单来说就是把 我们抓包看到的用程序来实现
一个小总结
我们爬取一个网页的步骤可以分为如下:
打开要爬取的网页
打开开发者工具,并让请求重发一次(简单讲就是抓包)
找到正确的请求
用程序模拟发送
第二个案列:点赞
1.打开要爬取的网页
浅谈网络爬虫中深度优先算法和简单代码实现
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-05-05 06:12
点击上方“程序人生”,选择“置顶公众号”
第一时间关注程序猿(媛)身边的故事
作者
Python进阶者
已获原作者授权,如需转载,请联系原作者。
我们今天要学习的内容,主要是给大家普及一下深度优先算法的基本概念,详情内容如下。
学过网站设计的小伙伴们都知道网站通常都是分层进行设计的,最上层的是顶级域名,之后是子域名,子域名下又有子域名等等,同时,每个子域名可能还会拥有多个同级域名,而且URL之间可能还有相互链接,千姿百态,由此构成一个复杂的网络。
当一个网站的URL非常多的时候,我们务必要设计好URL,否则在后期的理解、维护或者开发过程中就会非常的混乱。理解以上的网页结构设计之后,现在正式的引入网络爬虫中的深度优先算法。
上图是一个二叉树结构,通过对这个二叉树的遍历,来类比抓取网页,加深对爬虫策略的理解。深度优先算法的主要思想是首先从顶级域名A开始,之后从中提取出两个链接B和C,待链接B抓取完成之后,下一个要抓取的链接则是D或者E,而不是说抓取完成链接B之后,立马去抓取链接C。抓取完链接D之后,发现链接D中所有的URL已经被访问过了,在这之前我们已经建立了一个被访问过的URL列表,专门用于存储被访问过的URL。当链接D完全被抓取完成之后,接下来就会去抓取链接E。待链接E爬取完成之后,不会去爬取链接C,而是会继续往下深入的去爬取链接I。原则就是链接会一步一步的往下爬,只要链接下还有子链接,且该子链接尚未被访问过,这就是深度优先算法的主要思想。深度优先算法是让爬虫一步一步往下进行抓取完成之后,再一步一步退回来,优先考虑深度。理解好深度优先算法之后,再来看上图,可以得到该二叉树呈现的爬虫抓取链接的顺序依次为:A、B、D、E、I、C、F、G、H(这里假设左边的链接先会被爬取)。实际上,我们在做网络爬虫过程中,很多时候都是在用这种算法进行实现的,其实我们常用的Scrapy爬虫框架默认也是用该算法来进行实现的。通过上面的理解,我们可以认为深度优先算法本质上是通过递归的方式来进行实现的。
下图展示的是深度优先算法的代码实现过程。
深度优先过程实际上是通过一种递归的方式来进行实现的。看上图的代码,首先定义一个函数,用于实现深度优先过程,然后传入节点参数,如果该节点非空的话,则将其打印出来,可以类比一下二叉树中的顶级点A。将节点打印完成之后,看看其是否存在左节点(链接B)和右节点(链接C),如果左节点非空的话,则将其进行返回,再次调用深度优先函数本身进行递归,得到新的左节点(链接D)和右节点(链接E),以此类推,直到所有的节点都被遍历或者达到既定的条件才会停止。右节点的实现过程亦是如此,不再赘述。
深度优先过程通过递归的方式来进行实现,当递归不断进行,没有跳出递归或者递归太深的话,很容易出现栈溢出的情况,所以在实际应用的过程中要有这个意识。
深度优先算法和广度优先算法是数据结构里边非常重要的一种算法结构,也是非常常用的一种算法,而且在面试过程中也是非常常见的一道面试题,所以建议大家都需要掌握它,下一篇文章我们将介绍广度优先算法,敬请期待。
关于网络爬虫中深度优先算法的简单介绍就到这里了,小伙伴们get到木有咧?
- The End -
「若你有原创文章想与大家分享,欢迎投稿。」
加编辑微信ID,备注#投稿#:
程序 丨 druidlost
小七 丨 duoshangshuang 查看全部
浅谈网络爬虫中深度优先算法和简单代码实现
点击上方“程序人生”,选择“置顶公众号”
第一时间关注程序猿(媛)身边的故事
作者
Python进阶者
已获原作者授权,如需转载,请联系原作者。
我们今天要学习的内容,主要是给大家普及一下深度优先算法的基本概念,详情内容如下。
学过网站设计的小伙伴们都知道网站通常都是分层进行设计的,最上层的是顶级域名,之后是子域名,子域名下又有子域名等等,同时,每个子域名可能还会拥有多个同级域名,而且URL之间可能还有相互链接,千姿百态,由此构成一个复杂的网络。
当一个网站的URL非常多的时候,我们务必要设计好URL,否则在后期的理解、维护或者开发过程中就会非常的混乱。理解以上的网页结构设计之后,现在正式的引入网络爬虫中的深度优先算法。
上图是一个二叉树结构,通过对这个二叉树的遍历,来类比抓取网页,加深对爬虫策略的理解。深度优先算法的主要思想是首先从顶级域名A开始,之后从中提取出两个链接B和C,待链接B抓取完成之后,下一个要抓取的链接则是D或者E,而不是说抓取完成链接B之后,立马去抓取链接C。抓取完链接D之后,发现链接D中所有的URL已经被访问过了,在这之前我们已经建立了一个被访问过的URL列表,专门用于存储被访问过的URL。当链接D完全被抓取完成之后,接下来就会去抓取链接E。待链接E爬取完成之后,不会去爬取链接C,而是会继续往下深入的去爬取链接I。原则就是链接会一步一步的往下爬,只要链接下还有子链接,且该子链接尚未被访问过,这就是深度优先算法的主要思想。深度优先算法是让爬虫一步一步往下进行抓取完成之后,再一步一步退回来,优先考虑深度。理解好深度优先算法之后,再来看上图,可以得到该二叉树呈现的爬虫抓取链接的顺序依次为:A、B、D、E、I、C、F、G、H(这里假设左边的链接先会被爬取)。实际上,我们在做网络爬虫过程中,很多时候都是在用这种算法进行实现的,其实我们常用的Scrapy爬虫框架默认也是用该算法来进行实现的。通过上面的理解,我们可以认为深度优先算法本质上是通过递归的方式来进行实现的。
下图展示的是深度优先算法的代码实现过程。
深度优先过程实际上是通过一种递归的方式来进行实现的。看上图的代码,首先定义一个函数,用于实现深度优先过程,然后传入节点参数,如果该节点非空的话,则将其打印出来,可以类比一下二叉树中的顶级点A。将节点打印完成之后,看看其是否存在左节点(链接B)和右节点(链接C),如果左节点非空的话,则将其进行返回,再次调用深度优先函数本身进行递归,得到新的左节点(链接D)和右节点(链接E),以此类推,直到所有的节点都被遍历或者达到既定的条件才会停止。右节点的实现过程亦是如此,不再赘述。
深度优先过程通过递归的方式来进行实现,当递归不断进行,没有跳出递归或者递归太深的话,很容易出现栈溢出的情况,所以在实际应用的过程中要有这个意识。
深度优先算法和广度优先算法是数据结构里边非常重要的一种算法结构,也是非常常用的一种算法,而且在面试过程中也是非常常见的一道面试题,所以建议大家都需要掌握它,下一篇文章我们将介绍广度优先算法,敬请期待。
关于网络爬虫中深度优先算法的简单介绍就到这里了,小伙伴们get到木有咧?
- The End -
「若你有原创文章想与大家分享,欢迎投稿。」
加编辑微信ID,备注#投稿#:
程序 丨 druidlost
小七 丨 duoshangshuang
Python 编写知乎爬虫实践
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-05-05 06:09
点击上方“Python开发”,选择“置顶公众号”
关键时刻,第一时间送达!
爬虫的基本流程
网络爬虫的基本工作流程如下:
爬虫的抓取策略
在爬虫系统中,待抓取 URL 队列是很重要的一部分。待抓取 URL 队列中的 URL 以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些 URL 排列顺序的方法,叫做抓取策略。下面重点介绍几种常见的抓取策略:
了解了爬虫的工作流程和爬取策略后,就可以动手实现一个爬虫了!那么在 python 里怎么实现呢?
技术栈基本实现
下面是一个伪代码
<p>import Queue
initial_page = "https://www.zhihu.com/people/gaoming623"
url_queue = Queue.Queue()
seen = set()
seen.insert(initial_page)
url_queue.put(initial_page)
while(True): #一直进行
if url_queue.size()>0:
current_url = url_queue.get() #拿出队例中第一个的 url
store(current_url) #把这个 url 代表的网页存储好
for next_url in extract_urls(current_url): #提取把这个 url 里链向的 url
if next_url not in seen:
seen.put(next_url)
url_queue.put(next_url)
else:
break</p>
如果你直接加工一下上面的代码直接运行的话,你需要很长的时间才能爬下整个知乎用户的信息,毕竟知乎有 6000 万月活跃用户。更别说 Google 这样的搜索引擎需要爬下全网的内容了。那么问题出现在哪里?
布隆过滤器
需要爬的网页实在太多太多了,而上面的代码太慢太慢了。设想全网有 N 个网站,那么分析一下判重的复杂度就是 N*log(N),因为所有网页要遍历一次,而每次判重用 set 的话需要 log(N) 的复杂度。OK,我知道 python 的 set 实现是 hash——不过这样还是太慢了,至少内存使用效率不高。
通常的判重做法是怎样呢?Bloom Filter. 简单讲它仍然是一种 hash 的方法,但是它的特点是,它可以使用固定的内存(不随 url 的数量而增长)以 O(1) 的效率判定 url 是否已经在 set 中。可惜天下没有白吃的午餐,它的唯一问题在于,如果这个 url 不在 set 中,BF 可以 100%确定这个 url 没有看过。但是如果这个 url 在 set 中,它会告诉你:这个 url 应该已经出现过,不过我有 2%的不确定性。注意这里的不确定性在你分配的内存足够大的时候,可以变得很小很少。
<p># bloom_filter.py
BIT_SIZE = 5000000
class BloomFilter:
def __init__(self):
# Initialize bloom filter, set size and all bits to 0
bit_array = bitarray(BIT_SIZE)
bit_array.setall(0)
self.bit_array = bit_array
def add(self, url):
# Add a url, and set points in bitarray to 1 (Points count is equal to hash funcs count.)
# Here use 7 hash functions.
point_list = self.get_postions(url)
for b in point_list:
self.bit_array[b] = 1
def contains(self, url):
# Check if a url is in a collection
point_list = self.get_postions(url)
result = True
for b in point_list:
result = result and self.bit_array[b]
return result
def get_postions(self, url):
# Get points positions in bit vector.
point1 = mmh3.hash(url, 41) % BIT_SIZE
point2 = mmh3.hash(url, 42) % BIT_SIZE
point3 = mmh3.hash(url, 43) % BIT_SIZE
point4 = mmh3.hash(url, 44) % BIT_SIZE
point5 = mmh3.hash(url, 45) % BIT_SIZE
point6 = mmh3.hash(url, 46) % BIT_SIZE
point7 = mmh3.hash(url, 47) % BIT_SIZE
return [point1, point2, point3, point4, point5, point6, point7]</p>
BF 详细的原理参考我之前写的文章:布隆过滤器(Bloom Filter) 的原理和实现
建表
用户有价值的信息包括用户名、简介、行业、院校、专业及在平台上活动的数据比如回答数、文章数、提问数、粉丝数等等。
用户信息存储的表结构如下:
<p>CREATE DATABASE `zhihu_user` /*!40100 DEFAULT CHARACTER SET utf8 */;
-- User base information table
CREATE TABLE `t_user` (
`uid` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(50) NOT NULL COMMENT '用户名',
`brief_info` varchar(400) COMMENT '个人简介',
`industry` varchar(50) COMMENT '所处行业',
`education` varchar(50) COMMENT '毕业院校',
`major` varchar(50) COMMENT '主修专业',
`answer_count` int(10) unsigned DEFAULT 0 COMMENT '回答数',
`article_count` int(10) unsigned DEFAULT 0 COMMENT '文章数',
`ask_question_count` int(10) unsigned DEFAULT 0 COMMENT '提问数',
`collection_count` int(10) unsigned DEFAULT 0 COMMENT '收藏数',
`follower_count` int(10) unsigned DEFAULT 0 COMMENT '被关注数',
`followed_count` int(10) unsigned DEFAULT 0 COMMENT '关注数',
`follow_live_count` int(10) unsigned DEFAULT 0 COMMENT '关注直播数',
`follow_topic_count` int(10) unsigned DEFAULT 0 COMMENT '关注话题数',
`follow_column_count` int(10) unsigned DEFAULT 0 COMMENT '关注专栏数',
`follow_question_count` int(10) unsigned DEFAULT 0 COMMENT '关注问题数',
`follow_collection_count` int(10) unsigned DEFAULT 0 COMMENT '关注收藏夹数',
`gmt_create` datetime NOT NULL COMMENT '创建时间',
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '最后一次编辑',
PRIMARY KEY (`uid`)
) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='用户基本信息表';</p>
网页下载后通过 XPath 进行解析,提取用户各个维度的数据,最后保存到数据库中。
反爬虫策略应对-Headers
一般网站会从几个维度来反爬虫:用户请求的 Headers,用户行为,网站和数据加载的方式。从用户请求的 Headers 反爬虫是最常见的策略,很多网站都会对 Headers 的 User-Agent 进行检测,还有一部分网站会对 Referer 进行检测(一些资源网站的防盗链就是检测 Referer)。
如果遇到了这类反爬虫机制,可以直接在爬虫中添加 Headers,将浏览器的 User-Agent 复制到爬虫的 Headers 中;或者将 Referer 值修改为目标网站域名。对于检测 Headers 的反爬虫,在爬虫中修改或者添加 Headers 就能很好的绕过。
<p>cookies = {
"d_c0": "AECA7v-aPwqPTiIbemmIQ8abhJy7bdD2VgE=|1468847182",
"login": "NzM5ZDc2M2JkYzYwNDZlOGJlYWQ1YmI4OTg5NDhmMTY=|1480901173|9c296f424b32f241d1471203244eaf30729420f0",
"n_c": "1",
"q_c1": "395b12e529e541cbb400e9718395e346|1479808003000|1468847182000",
"l_cap_id": "NzI0MTQwZGY2NjQyNDQ1NThmYTY0MjJhYmU2NmExMGY=|1480901160|2e7a7faee3b3e8d0afb550e8e7b38d86c15a31bc",
"d_c0": "AECA7v-aPwqPTiIbemmIQ8abhJy7bdD2VgE=|1468847182",
"cap_id": "N2U1NmQwODQ1NjFiNGI2Yzg2YTE2NzJkOTU5N2E0NjI=|1480901160|fd59e2ed79faacc2be1010687d27dd559ec1552a"
}
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.98 Safari/537.3",
"Referer": "https://www.zhihu.com/"
}
r = requests.get(url, cookies = cookies, headers = headers)</p>
反爬虫策略应对-代理 IP 池
还有一部分网站是通过检测用户行为,例如同一 IP 短时间内多次访问同一页面,或者同一账户短时间内多次进行相同操作。
大多数网站都是前一种情况,对于这种情况,使用 IP 代理就可以解决。这样的代理 ip 爬虫经常会用到,最好自己准备一个。有了大量代理 ip 后可以每请求几次更换一个 ip,这在 requests 或者 urllib2 中很容易做到,这样就能很容易的绕过第一种反爬虫。目前知乎已经对爬虫做了限制,如果是单个 IP 的话,一段时间系统便会提示异常流量,无法继续爬取了。因此代理 IP 池非常关键。网上有个免费的代理 IP API:
<p>import requests
import random
class Proxy:
def __init__(self):
self.cache_ip_list = []
# Get random ip from free proxy api url.
def get_random_ip(self):
if not len(self.cache_ip_list):
api_url = 'http://api.xicidaili.com/free2016.txt'
try:
r = requests.get(api_url)
ip_list = r.text.split('rn')
self.cache_ip_list = ip_list
except Exception as e:
# Return null list when caught exception.
# In this case, crawler will not use proxy ip.
print e
return {}
proxy_ip = random.choice(self.cache_ip_list)
proxies = {'http': 'http://' proxy_ip}
return proxies</p>
后续
爬虫源代码:zhihu-crawler下载之后通过 pip 安装相关三方包后,运行$ python crawler.py 即可(喜欢的帮忙点个 star 哈,同时也方便看到后续功能的更新)
运行截图:
查看全部
Python 编写知乎爬虫实践
点击上方“Python开发”,选择“置顶公众号”
关键时刻,第一时间送达!
爬虫的基本流程
网络爬虫的基本工作流程如下:
爬虫的抓取策略
在爬虫系统中,待抓取 URL 队列是很重要的一部分。待抓取 URL 队列中的 URL 以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些 URL 排列顺序的方法,叫做抓取策略。下面重点介绍几种常见的抓取策略:
了解了爬虫的工作流程和爬取策略后,就可以动手实现一个爬虫了!那么在 python 里怎么实现呢?
技术栈基本实现
下面是一个伪代码
<p>import Queue
initial_page = "https://www.zhihu.com/people/gaoming623"
url_queue = Queue.Queue()
seen = set()
seen.insert(initial_page)
url_queue.put(initial_page)
while(True): #一直进行
if url_queue.size()>0:
current_url = url_queue.get() #拿出队例中第一个的 url
store(current_url) #把这个 url 代表的网页存储好
for next_url in extract_urls(current_url): #提取把这个 url 里链向的 url
if next_url not in seen:
seen.put(next_url)
url_queue.put(next_url)
else:
break</p>
如果你直接加工一下上面的代码直接运行的话,你需要很长的时间才能爬下整个知乎用户的信息,毕竟知乎有 6000 万月活跃用户。更别说 Google 这样的搜索引擎需要爬下全网的内容了。那么问题出现在哪里?
布隆过滤器
需要爬的网页实在太多太多了,而上面的代码太慢太慢了。设想全网有 N 个网站,那么分析一下判重的复杂度就是 N*log(N),因为所有网页要遍历一次,而每次判重用 set 的话需要 log(N) 的复杂度。OK,我知道 python 的 set 实现是 hash——不过这样还是太慢了,至少内存使用效率不高。
通常的判重做法是怎样呢?Bloom Filter. 简单讲它仍然是一种 hash 的方法,但是它的特点是,它可以使用固定的内存(不随 url 的数量而增长)以 O(1) 的效率判定 url 是否已经在 set 中。可惜天下没有白吃的午餐,它的唯一问题在于,如果这个 url 不在 set 中,BF 可以 100%确定这个 url 没有看过。但是如果这个 url 在 set 中,它会告诉你:这个 url 应该已经出现过,不过我有 2%的不确定性。注意这里的不确定性在你分配的内存足够大的时候,可以变得很小很少。
<p># bloom_filter.py
BIT_SIZE = 5000000
class BloomFilter:
def __init__(self):
# Initialize bloom filter, set size and all bits to 0
bit_array = bitarray(BIT_SIZE)
bit_array.setall(0)
self.bit_array = bit_array
def add(self, url):
# Add a url, and set points in bitarray to 1 (Points count is equal to hash funcs count.)
# Here use 7 hash functions.
point_list = self.get_postions(url)
for b in point_list:
self.bit_array[b] = 1
def contains(self, url):
# Check if a url is in a collection
point_list = self.get_postions(url)
result = True
for b in point_list:
result = result and self.bit_array[b]
return result
def get_postions(self, url):
# Get points positions in bit vector.
point1 = mmh3.hash(url, 41) % BIT_SIZE
point2 = mmh3.hash(url, 42) % BIT_SIZE
point3 = mmh3.hash(url, 43) % BIT_SIZE
point4 = mmh3.hash(url, 44) % BIT_SIZE
point5 = mmh3.hash(url, 45) % BIT_SIZE
point6 = mmh3.hash(url, 46) % BIT_SIZE
point7 = mmh3.hash(url, 47) % BIT_SIZE
return [point1, point2, point3, point4, point5, point6, point7]</p>
BF 详细的原理参考我之前写的文章:布隆过滤器(Bloom Filter) 的原理和实现
建表
用户有价值的信息包括用户名、简介、行业、院校、专业及在平台上活动的数据比如回答数、文章数、提问数、粉丝数等等。
用户信息存储的表结构如下:
<p>CREATE DATABASE `zhihu_user` /*!40100 DEFAULT CHARACTER SET utf8 */;
-- User base information table
CREATE TABLE `t_user` (
`uid` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(50) NOT NULL COMMENT '用户名',
`brief_info` varchar(400) COMMENT '个人简介',
`industry` varchar(50) COMMENT '所处行业',
`education` varchar(50) COMMENT '毕业院校',
`major` varchar(50) COMMENT '主修专业',
`answer_count` int(10) unsigned DEFAULT 0 COMMENT '回答数',
`article_count` int(10) unsigned DEFAULT 0 COMMENT '文章数',
`ask_question_count` int(10) unsigned DEFAULT 0 COMMENT '提问数',
`collection_count` int(10) unsigned DEFAULT 0 COMMENT '收藏数',
`follower_count` int(10) unsigned DEFAULT 0 COMMENT '被关注数',
`followed_count` int(10) unsigned DEFAULT 0 COMMENT '关注数',
`follow_live_count` int(10) unsigned DEFAULT 0 COMMENT '关注直播数',
`follow_topic_count` int(10) unsigned DEFAULT 0 COMMENT '关注话题数',
`follow_column_count` int(10) unsigned DEFAULT 0 COMMENT '关注专栏数',
`follow_question_count` int(10) unsigned DEFAULT 0 COMMENT '关注问题数',
`follow_collection_count` int(10) unsigned DEFAULT 0 COMMENT '关注收藏夹数',
`gmt_create` datetime NOT NULL COMMENT '创建时间',
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '最后一次编辑',
PRIMARY KEY (`uid`)
) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='用户基本信息表';</p>
网页下载后通过 XPath 进行解析,提取用户各个维度的数据,最后保存到数据库中。
反爬虫策略应对-Headers
一般网站会从几个维度来反爬虫:用户请求的 Headers,用户行为,网站和数据加载的方式。从用户请求的 Headers 反爬虫是最常见的策略,很多网站都会对 Headers 的 User-Agent 进行检测,还有一部分网站会对 Referer 进行检测(一些资源网站的防盗链就是检测 Referer)。
如果遇到了这类反爬虫机制,可以直接在爬虫中添加 Headers,将浏览器的 User-Agent 复制到爬虫的 Headers 中;或者将 Referer 值修改为目标网站域名。对于检测 Headers 的反爬虫,在爬虫中修改或者添加 Headers 就能很好的绕过。
<p>cookies = {
"d_c0": "AECA7v-aPwqPTiIbemmIQ8abhJy7bdD2VgE=|1468847182",
"login": "NzM5ZDc2M2JkYzYwNDZlOGJlYWQ1YmI4OTg5NDhmMTY=|1480901173|9c296f424b32f241d1471203244eaf30729420f0",
"n_c": "1",
"q_c1": "395b12e529e541cbb400e9718395e346|1479808003000|1468847182000",
"l_cap_id": "NzI0MTQwZGY2NjQyNDQ1NThmYTY0MjJhYmU2NmExMGY=|1480901160|2e7a7faee3b3e8d0afb550e8e7b38d86c15a31bc",
"d_c0": "AECA7v-aPwqPTiIbemmIQ8abhJy7bdD2VgE=|1468847182",
"cap_id": "N2U1NmQwODQ1NjFiNGI2Yzg2YTE2NzJkOTU5N2E0NjI=|1480901160|fd59e2ed79faacc2be1010687d27dd559ec1552a"
}
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.98 Safari/537.3",
"Referer": "https://www.zhihu.com/"
}
r = requests.get(url, cookies = cookies, headers = headers)</p>
反爬虫策略应对-代理 IP 池
还有一部分网站是通过检测用户行为,例如同一 IP 短时间内多次访问同一页面,或者同一账户短时间内多次进行相同操作。
大多数网站都是前一种情况,对于这种情况,使用 IP 代理就可以解决。这样的代理 ip 爬虫经常会用到,最好自己准备一个。有了大量代理 ip 后可以每请求几次更换一个 ip,这在 requests 或者 urllib2 中很容易做到,这样就能很容易的绕过第一种反爬虫。目前知乎已经对爬虫做了限制,如果是单个 IP 的话,一段时间系统便会提示异常流量,无法继续爬取了。因此代理 IP 池非常关键。网上有个免费的代理 IP API:
<p>import requests
import random
class Proxy:
def __init__(self):
self.cache_ip_list = []
# Get random ip from free proxy api url.
def get_random_ip(self):
if not len(self.cache_ip_list):
api_url = 'http://api.xicidaili.com/free2016.txt'
try:
r = requests.get(api_url)
ip_list = r.text.split('rn')
self.cache_ip_list = ip_list
except Exception as e:
# Return null list when caught exception.
# In this case, crawler will not use proxy ip.
print e
return {}
proxy_ip = random.choice(self.cache_ip_list)
proxies = {'http': 'http://' proxy_ip}
return proxies</p>
后续
爬虫源代码:zhihu-crawler下载之后通过 pip 安装相关三方包后,运行$ python crawler.py 即可(喜欢的帮忙点个 star 哈,同时也方便看到后续功能的更新)
运行截图:

多种爬虫方式对比
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-05-01 06:11
Python爬虫的方式有多种,从爬虫框架到解析提取,再到数据存储,各阶段都有不同的手段和类库支持。虽然不能一概而论哪种方式一定更好,毕竟不同案例需求和不同应用场景会综合决定采取哪种方式,但对比之下还是会有很大差距。
00 概况
以安居客杭州二手房信息为爬虫需求,分别对比实验了三种爬虫框架、三种字段解析方式和三种数据存储方式,旨在全方面对比各种爬虫方式的效率高低。
安居客平台没有太强的反爬措施,只要添加headers模拟头即可完美爬取,而且不用考虑爬虫过快的问题。选中杭州二手房之后,很容易发现url的变化规律。值得说明的是平台最大开放50页房源信息,每页60条。为使爬虫简单便于对比,我们只爬取房源列表页的概要信息,而不再进入房源详情页进行具体信息的爬取,共3000条记录,每条记录包括10个字段:标题,户型,面积,楼层,建筑年份,小区/地址,售卖标签,中介,单价,总价。
01 3种爬虫框架
1.常规爬虫
实现3个函数,分别用于解析网页、存储信息,以及二者的联合调用。在主程序中,用一个常规的循环语句逐页解析。
import requests<br />from lxml import etree<br />import pymysql<br />import time<br /><br />def get_info(url):<br /> pass<br /> return infos<br /><br />def save_info(infos):<br /> pass<br /><br />def getANDsave(url):<br /> pass<br /><br />if __name__ == '__main__':<br /> urls = [f'https://hangzhou.anjuke.com/sale/p{page}/' for page in range(1,51)]<br /> start = time.time()<br /> #常规单线程爬取<br /> for url in urls:<br /> getANDsave(url)<br /> tt = time.time()-start<br /> print("共用时:",tt, "秒。")<br />
耗时64.9秒。
2.Scrapy框架
Scrapy框架是一个常用的爬虫框架,非常好用,只需要简单实现核心抓取和存储功能即可,而无需关注内部信息流转,而且框架自带多线程和异常处理能力。
class anjukeSpider(scrapy.Spider):<br /> name = 'anjuke'<br /> allowed_domains = ['anjuke.com']<br /> start_urls = [f'https://hangzhou.anjuke.com/sale/p{page}/' for page in range(1, 51)]<br /><br /> def parse(self, response):<br /> pass<br /> yield item<br />
耗时14.4秒。
3.多线程爬虫
对于爬虫这种IO密集型任务来说,多线程可明显提升效率。实现多线程python的方式有多种,这里我们应用concurrent的futures模块,并设置最大线程数为8。
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED<br /><br />def get_info(url):<br /> pass<br /> return infos<br /><br />def save_info(infos):<br /> pass<br /><br />def getANDsave(url):<br /> pass<br /><br />if __name__ == '__main__':<br /> urls = [f'https://hangzhou.anjuke.com/sale/p{page}/' for page in range(1,51)]<br /> start = time.time()<br /> executor = ThreadPoolExecutor(max_workers=8)<br /> future_tasks = [executor.submit(getANDsave, url) for url in urls]<br /> wait(future_tasks, return_when = ALL_COMPLETED)<br /> tt = time.time()-start<br /> print("共用时:",tt, "秒。")<br />
耗时8.1秒。
对比来看,多线程爬虫方案耗时最短,相比常规爬虫而言能带来数倍的效率提升,Scrapy爬虫也取得了不俗的表现。需要指出的是,这里3种框架都采用了Xpath解析和MySQL存储。
02 3种解析方式
在明确爬虫框架的基础上,如何对字段进行解析提取就是第二个需要考虑的问题,常用的解析方式有3种,一般而言,论解析效率Re>=Xpath>Bs4;论难易程度,Bs4则最为简单易懂。
因为前面已经对比得知,多线程爬虫有着最好的执行效率,我们以此为基础,对比3种不同解析方式,解析函数分别为:
1. Xpath
from lxml import etreedef get_info(url):<br /> response = requests.get(url, headers = headers)<br /> html = response.text<br /> html = etree.HTML(html)<br /> items = html.xpath("//li[@class = 'list-item']")<br /> infos = []<br /> for item in items:<br /> try:<br /> title = item.xpath(".//div[@class='house-title']/a/text()")[0].strip()<br /> houseType = item.xpath(".//div[@class='house-details']/div[2]/span[1]/text()")[0]<br /> area = item.xpath(".//div[@class='house-details']/div[2]/span[2]/text()")[0]<br /> floor = item.xpath(".//div[@class='house-details']/div[2]/span[3]/text()")[0]<br /> buildYear = item.xpath(".//div[@class='house-details']/div[2]/span[4]/text()")[0]<br /> adrres = item.xpath(".//div[@class='house-details']/div[3]/span[1]/text()")[0]<br /> adrres = "|".join(adrres.split())<br /> tags = item.xpath(".//div[@class='tags-bottom']//text()")<br /> tags = '|'.join(tags).strip()<br /> broker = item.xpath(".//div[@class='broker-item']/span[2]/text()")[0]<br /> totalPrice = item.xpath(".//div[@class='pro-price']/span[1]//text()")<br /> totalPrice = "".join(totalPrice).strip()<br /> price = item.xpath(".//div[@class='pro-price']/span[2]/text()")[0]<br /> values = (title, houseType, area, floor, buildYear, adrres, tags, broker, totalPrice, price)<br /> infos.append(values)<br /> except:<br /> print('1条信息解析失败')<br /> return infos<br />
耗时8.1秒。
2. Re
import re<br />def get_info(url):<br /> response = requests.get(url, headers = headers)<br /> html = response.text<br /> html = html.replace('\n','')<br /> pattern = r'.*?'<br /> results = re.compile(pattern).findall(html)##先编译,再正则匹配<br /> infos = []<br /> for result in results: <br /> values = ['']*10<br /> titles = re.compile('title="(.*?)"').findall(result)<br /> values[0] = titles[0]<br /> values[5] = titles[1].replace(' ','')<br /> spans = re.compile('(.*?)|(.*?)|(.*?)|(.*?)').findall(result)<br /> values[1] =''.join(spans[0])<br /> values[2] = ''.join(spans[1])<br /> values[3] = ''.join(spans[2])<br /> values[4] = ''.join(spans[3])<br /> values[7] = re.compile('(.*?)').findall(result)[0]<br /> tagRE = re.compile('(.*?)').findall(result)<br /> if tagRE:<br /> values[6] = '|'.join(tagRE)<br /> values[8] = re.compile('(.*?)万').findall(result)[0]+'万'<br /> values[9] = re.compile('(.*?)').findall(result)[0]<br /> infos.append(tuple(values))<br /><br /> return infos<br />
耗时8.6秒。
3. Bs4
from bs4 import BeautifulSoup<br />def get_info(url):<br /> response = requests.get(url, headers = headers)<br /> html = response.text<br /> soup = BeautifulSoup(html, "html.parser")<br /> items = soup.find_all('li', attrs={'class': "list-item"})<br /> infos = []<br /> for item in items:<br /> try:<br /> title = item.find('a', attrs={'class': "houseListTitle"}).get_text().strip()<br /> details = item.find_all('div',attrs={'class': "details-item"})[0]<br /> houseType = details.find_all('span')[0].get_text().strip()<br /> area = details.find_all('span')[1].get_text().strip()<br /> floor = details.find_all('span')[2].get_text().strip()<br /> buildYear = details.find_all('span')[3].get_text().strip()<br /> addres = item.find_all('div',attrs={'class': "details-item"})[1].get_text().replace(' ','').replace('\n','')<br /> tag_spans = item.find('div', attrs={'class':'tags-bottom'}).find_all('span')<br /> tags = [span.get_text() for span in tag_spans]<br /> tags = '|'.join(tags)<br /> broker = item.find('span',attrs={'class':'broker-name broker-text'}).get_text().strip()<br /> totalPrice = item.find('span',attrs={'class':'price-det'}).get_text()<br /> price = item.find('span',attrs={'class':'unit-price'}).get_text()<br /> values = (title, houseType, area, floor, buildYear, addres, tags, broker, totalPrice, price)<br /> infos.append(values)<br /> except:<br /> print('1条信息解析失败')<br /> return infos<br />
耗时23.2秒。
Xpath和Re执行效率相当,Xpath甚至要略胜一筹,Bs4效率要明显低于前两者(此案例中,相当远前两者效率的1/3),但写起来则最为容易。
03 存储方式
在完成爬虫数据解析后,一般都要将数据进行本地存储,方便后续使用。小型数据量时可以选用本地文件存储,例如CSV、txt或者json文件;当数据量较大时,则一般需采用数据库存储,这里,我们分别选用关系型数据库的代表MySQL和文本型数据库的代表MongoDB加入对比。
1. MySQL
import pymysql<br /><br />def save_info(infos):<br /> #####infos为列表形式,其中列表中每个元素为一个元组,包含10个字段<br /> db= pymysql.connect(host="localhost",user="root",password="123456",db="ajkhzesf")<br /> sql_insert = 'insert into hzesfmulti8(title, houseType, area, floor, buildYear, adrres, tags, broker, totalPrice, price) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'<br /> cursor = db.cursor()<br /> cursor.executemany(sql_insert, infos)<br /> db.commit()<br />
耗时8.1秒。
2. MongoDB
import pymongo<br /><br />def save_info(infos):<br /> # infos为列表形式,其中列表中的每个元素为一个字典,包括10个字段<br /> client = pymongo.MongoClient()<br /> collection = client.anjuke.hzesfmulti<br /> collection.insert_many(infos)<br /> client.close()<br />
耗时8.4秒。
3. CSV文件
import csv<br /><br />def save_info(infos):<br /> # infos为列表形式,其中列表中的每个元素为一个列表,包括10个字段<br /> with open(r"D:\PyFile\HZhouse\anjuke.csv", 'a', encoding='gb18030', newline="") as f:<br /> writer = csv.writer(f)<br /> writer.writerows(infos)<br />
耗时8.8秒。
可见,在爬虫框架和解析方式一致的前提下,不同存储方式间并不会带来太大效率上的差异。
04 结论
不同爬虫执行效率对比
易见,爬虫框架对耗时影响最大,甚至可带来数倍的效率提升;解析数据方式也会带来较大影响,而数据存储方式则不存在太大差异。
对此,个人认为可以这样理解:类似于把大象装冰箱需要3步,爬虫也需要3步:
其中,爬取网页源码最为耗时,这不仅取决于你的爬虫框架和网络负载,还受限于目标网站的响应速度和反爬措施;信息解析其次,而数据存储则最为迅速,尤其是在磁盘读取速度飞快的今天,无论是简单的文件写入还是数据库存储,都不会带来太大的时间差异。 查看全部
多种爬虫方式对比
Python爬虫的方式有多种,从爬虫框架到解析提取,再到数据存储,各阶段都有不同的手段和类库支持。虽然不能一概而论哪种方式一定更好,毕竟不同案例需求和不同应用场景会综合决定采取哪种方式,但对比之下还是会有很大差距。
00 概况
以安居客杭州二手房信息为爬虫需求,分别对比实验了三种爬虫框架、三种字段解析方式和三种数据存储方式,旨在全方面对比各种爬虫方式的效率高低。
安居客平台没有太强的反爬措施,只要添加headers模拟头即可完美爬取,而且不用考虑爬虫过快的问题。选中杭州二手房之后,很容易发现url的变化规律。值得说明的是平台最大开放50页房源信息,每页60条。为使爬虫简单便于对比,我们只爬取房源列表页的概要信息,而不再进入房源详情页进行具体信息的爬取,共3000条记录,每条记录包括10个字段:标题,户型,面积,楼层,建筑年份,小区/地址,售卖标签,中介,单价,总价。
01 3种爬虫框架
1.常规爬虫
实现3个函数,分别用于解析网页、存储信息,以及二者的联合调用。在主程序中,用一个常规的循环语句逐页解析。
import requests<br />from lxml import etree<br />import pymysql<br />import time<br /><br />def get_info(url):<br /> pass<br /> return infos<br /><br />def save_info(infos):<br /> pass<br /><br />def getANDsave(url):<br /> pass<br /><br />if __name__ == '__main__':<br /> urls = [f'https://hangzhou.anjuke.com/sale/p{page}/' for page in range(1,51)]<br /> start = time.time()<br /> #常规单线程爬取<br /> for url in urls:<br /> getANDsave(url)<br /> tt = time.time()-start<br /> print("共用时:",tt, "秒。")<br />
耗时64.9秒。
2.Scrapy框架
Scrapy框架是一个常用的爬虫框架,非常好用,只需要简单实现核心抓取和存储功能即可,而无需关注内部信息流转,而且框架自带多线程和异常处理能力。
class anjukeSpider(scrapy.Spider):<br /> name = 'anjuke'<br /> allowed_domains = ['anjuke.com']<br /> start_urls = [f'https://hangzhou.anjuke.com/sale/p{page}/' for page in range(1, 51)]<br /><br /> def parse(self, response):<br /> pass<br /> yield item<br />
耗时14.4秒。
3.多线程爬虫
对于爬虫这种IO密集型任务来说,多线程可明显提升效率。实现多线程python的方式有多种,这里我们应用concurrent的futures模块,并设置最大线程数为8。
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED<br /><br />def get_info(url):<br /> pass<br /> return infos<br /><br />def save_info(infos):<br /> pass<br /><br />def getANDsave(url):<br /> pass<br /><br />if __name__ == '__main__':<br /> urls = [f'https://hangzhou.anjuke.com/sale/p{page}/' for page in range(1,51)]<br /> start = time.time()<br /> executor = ThreadPoolExecutor(max_workers=8)<br /> future_tasks = [executor.submit(getANDsave, url) for url in urls]<br /> wait(future_tasks, return_when = ALL_COMPLETED)<br /> tt = time.time()-start<br /> print("共用时:",tt, "秒。")<br />
耗时8.1秒。
对比来看,多线程爬虫方案耗时最短,相比常规爬虫而言能带来数倍的效率提升,Scrapy爬虫也取得了不俗的表现。需要指出的是,这里3种框架都采用了Xpath解析和MySQL存储。
02 3种解析方式
在明确爬虫框架的基础上,如何对字段进行解析提取就是第二个需要考虑的问题,常用的解析方式有3种,一般而言,论解析效率Re>=Xpath>Bs4;论难易程度,Bs4则最为简单易懂。
因为前面已经对比得知,多线程爬虫有着最好的执行效率,我们以此为基础,对比3种不同解析方式,解析函数分别为:
1. Xpath
from lxml import etreedef get_info(url):<br /> response = requests.get(url, headers = headers)<br /> html = response.text<br /> html = etree.HTML(html)<br /> items = html.xpath("//li[@class = 'list-item']")<br /> infos = []<br /> for item in items:<br /> try:<br /> title = item.xpath(".//div[@class='house-title']/a/text()")[0].strip()<br /> houseType = item.xpath(".//div[@class='house-details']/div[2]/span[1]/text()")[0]<br /> area = item.xpath(".//div[@class='house-details']/div[2]/span[2]/text()")[0]<br /> floor = item.xpath(".//div[@class='house-details']/div[2]/span[3]/text()")[0]<br /> buildYear = item.xpath(".//div[@class='house-details']/div[2]/span[4]/text()")[0]<br /> adrres = item.xpath(".//div[@class='house-details']/div[3]/span[1]/text()")[0]<br /> adrres = "|".join(adrres.split())<br /> tags = item.xpath(".//div[@class='tags-bottom']//text()")<br /> tags = '|'.join(tags).strip()<br /> broker = item.xpath(".//div[@class='broker-item']/span[2]/text()")[0]<br /> totalPrice = item.xpath(".//div[@class='pro-price']/span[1]//text()")<br /> totalPrice = "".join(totalPrice).strip()<br /> price = item.xpath(".//div[@class='pro-price']/span[2]/text()")[0]<br /> values = (title, houseType, area, floor, buildYear, adrres, tags, broker, totalPrice, price)<br /> infos.append(values)<br /> except:<br /> print('1条信息解析失败')<br /> return infos<br />
耗时8.1秒。
2. Re
import re<br />def get_info(url):<br /> response = requests.get(url, headers = headers)<br /> html = response.text<br /> html = html.replace('\n','')<br /> pattern = r'.*?'<br /> results = re.compile(pattern).findall(html)##先编译,再正则匹配<br /> infos = []<br /> for result in results: <br /> values = ['']*10<br /> titles = re.compile('title="(.*?)"').findall(result)<br /> values[0] = titles[0]<br /> values[5] = titles[1].replace(' ','')<br /> spans = re.compile('(.*?)|(.*?)|(.*?)|(.*?)').findall(result)<br /> values[1] =''.join(spans[0])<br /> values[2] = ''.join(spans[1])<br /> values[3] = ''.join(spans[2])<br /> values[4] = ''.join(spans[3])<br /> values[7] = re.compile('(.*?)').findall(result)[0]<br /> tagRE = re.compile('(.*?)').findall(result)<br /> if tagRE:<br /> values[6] = '|'.join(tagRE)<br /> values[8] = re.compile('(.*?)万').findall(result)[0]+'万'<br /> values[9] = re.compile('(.*?)').findall(result)[0]<br /> infos.append(tuple(values))<br /><br /> return infos<br />
耗时8.6秒。
3. Bs4
from bs4 import BeautifulSoup<br />def get_info(url):<br /> response = requests.get(url, headers = headers)<br /> html = response.text<br /> soup = BeautifulSoup(html, "html.parser")<br /> items = soup.find_all('li', attrs={'class': "list-item"})<br /> infos = []<br /> for item in items:<br /> try:<br /> title = item.find('a', attrs={'class': "houseListTitle"}).get_text().strip()<br /> details = item.find_all('div',attrs={'class': "details-item"})[0]<br /> houseType = details.find_all('span')[0].get_text().strip()<br /> area = details.find_all('span')[1].get_text().strip()<br /> floor = details.find_all('span')[2].get_text().strip()<br /> buildYear = details.find_all('span')[3].get_text().strip()<br /> addres = item.find_all('div',attrs={'class': "details-item"})[1].get_text().replace(' ','').replace('\n','')<br /> tag_spans = item.find('div', attrs={'class':'tags-bottom'}).find_all('span')<br /> tags = [span.get_text() for span in tag_spans]<br /> tags = '|'.join(tags)<br /> broker = item.find('span',attrs={'class':'broker-name broker-text'}).get_text().strip()<br /> totalPrice = item.find('span',attrs={'class':'price-det'}).get_text()<br /> price = item.find('span',attrs={'class':'unit-price'}).get_text()<br /> values = (title, houseType, area, floor, buildYear, addres, tags, broker, totalPrice, price)<br /> infos.append(values)<br /> except:<br /> print('1条信息解析失败')<br /> return infos<br />
耗时23.2秒。
Xpath和Re执行效率相当,Xpath甚至要略胜一筹,Bs4效率要明显低于前两者(此案例中,相当远前两者效率的1/3),但写起来则最为容易。
03 存储方式
在完成爬虫数据解析后,一般都要将数据进行本地存储,方便后续使用。小型数据量时可以选用本地文件存储,例如CSV、txt或者json文件;当数据量较大时,则一般需采用数据库存储,这里,我们分别选用关系型数据库的代表MySQL和文本型数据库的代表MongoDB加入对比。
1. MySQL
import pymysql<br /><br />def save_info(infos):<br /> #####infos为列表形式,其中列表中每个元素为一个元组,包含10个字段<br /> db= pymysql.connect(host="localhost",user="root",password="123456",db="ajkhzesf")<br /> sql_insert = 'insert into hzesfmulti8(title, houseType, area, floor, buildYear, adrres, tags, broker, totalPrice, price) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'<br /> cursor = db.cursor()<br /> cursor.executemany(sql_insert, infos)<br /> db.commit()<br />
耗时8.1秒。
2. MongoDB
import pymongo<br /><br />def save_info(infos):<br /> # infos为列表形式,其中列表中的每个元素为一个字典,包括10个字段<br /> client = pymongo.MongoClient()<br /> collection = client.anjuke.hzesfmulti<br /> collection.insert_many(infos)<br /> client.close()<br />
耗时8.4秒。
3. CSV文件
import csv<br /><br />def save_info(infos):<br /> # infos为列表形式,其中列表中的每个元素为一个列表,包括10个字段<br /> with open(r"D:\PyFile\HZhouse\anjuke.csv", 'a', encoding='gb18030', newline="") as f:<br /> writer = csv.writer(f)<br /> writer.writerows(infos)<br />
耗时8.8秒。
可见,在爬虫框架和解析方式一致的前提下,不同存储方式间并不会带来太大效率上的差异。
04 结论
不同爬虫执行效率对比
易见,爬虫框架对耗时影响最大,甚至可带来数倍的效率提升;解析数据方式也会带来较大影响,而数据存储方式则不存在太大差异。
对此,个人认为可以这样理解:类似于把大象装冰箱需要3步,爬虫也需要3步:
其中,爬取网页源码最为耗时,这不仅取决于你的爬虫框架和网络负载,还受限于目标网站的响应速度和反爬措施;信息解析其次,而数据存储则最为迅速,尤其是在磁盘读取速度飞快的今天,无论是简单的文件写入还是数据库存储,都不会带来太大的时间差异。
爬虫实战:Scrapy框架
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-05-01 01:16
Scrapy是用Python语言编写,通过Twisted异步网络框架提升下载速度,是一个快速、高层次的屏幕抓取和Web抓取框架,常用于数据挖掘、监测和自动化测试等。
一、Scrapy框架介绍
Scrapy内部实现了并发请求、免登录、URL去重等操作,开发者可根据自己的需求去编写部分代码,就能抓取到所需要的数据。Scrapy框架包含的组件有调度器、下载器、Scrapy引擎、项目管道、爬虫以及各中间件等。
Scrapy框架爬取流程:首先从初始URL开始,调度器会将其交给下载器(Downloader),下载器向网络服务器发送请求进行下载,得到的响应后将下载数据交给爬虫,爬虫会对网页进行分析,分析出来的结果有两种:一种是需要进一步抓取的链接,这些链接会被传回调度器,另一种是需要保存的数据,它们会被传送至项目管道,项目管道进一步对数据进行清洗、去重等处理,并存储到文件或数据库中。数据爬取过程中,Scrapy引擎用于控制整个系统的数据处理流程。
Scrapy框架内包含的各组件功能如下:
Scrapy引擎:用来控制整个系统的数据处理流程,并进行事务处理的触发。
调度器中间件:位于Scrapy引擎和调度器之间,主要用于处理Scrapy引擎发送到调度器的请求和响应。
调度器:用来接收引擎发送过来的请求,压入队列完成去重操作,并决定下一个要抓取的网站,在引擎再次请求的时候返回URL。
下载器中间件:位于Scrapy引擎和下载器之间,主要用于处理Scrapy引擎与下载器之间的请求及响应,其中代理IP和用户代理可以在这里设置。
下载器:用于下载网页内容,并将网页响应结果返回给爬虫。
爬虫中间件:位于Scrapy引擎和爬虫之间,主要用于处理爬虫的响应输入和请求输出。
爬虫:用于从特定网页中提取需要的信息,也可以从中提取URL交给调度器,让Scrapy继续爬取下一个页面。
项目管道:负责处理爬虫从网页中抓取的信息,主要的功能为持久化项目、验证项目的有效性、清除不需要的信息,并完成数据存储。
二、爬虫实战
1.项目需求
基于Scrapy框架爬取某网站的新闻标题和内容。
2.分析页面网站
通过网页解析,了解新闻网站不同模块对应的详情页URL均为静态数据。
通过对不同板块的网页进行解析,了解各模块的新闻为动态加载数据,且新闻标题位于“a”标签下。
进一步,分析新闻网页,了解新闻内容位于“p”标签下。
3.项目搭建
第一步:创建项目
Pycharm终端输入
cd 框架 #进入项目文件夹路径scrapy startproject wangyi #创建项目,wangyi为项目名cd wangyi #进入项目路径scrapy genspider spiderName www.xxx.com #在子目录中创建爬虫文件
项目结构如下:spiders用于存放爬虫程序(SpiderName.py)的文件夹;items用来定义数据结构,类似于字典的功能;middlewares中间件,可设置ip代理等;pipelines用于对items中的数据进行清洗、存储等操作;settings是设置文件,包含爬虫项目的信息;scrapy.cfg是关于项目配置文件。
第二步:编写爬虫代码(spiderName.py)
import scrapyfrom selenium import webdriverfrom wangyi.items import WangyiItem<br />class WangyiSpider(scrapy.Spider): name = 'wangyi' #allowed_domains = ['www.xxx.com'] start_urls = ['https://news.163.com/'] models_urls = [] #存储五个板块的详情页url #实例化浏览器对象 def __init__(self): self.bro = webdriver.Chrome(executable_path='D:/PyCharm/learnpython/框架/wangyi/chromedriver.exe') def parse(self, response): li_list = response.xpath('//*[@id="index2016_wrap"]/div[2]/div[2]/div[2]/div[2]/div/ul/li') alist = [2,3,5,6,7] for index in alist: model_url = li_list[index].xpath('./a/@href').extract_first() self.models_urls.append(model_url) #依次对每一个板块对应的页面发送请求 for url in self.models_urls: yield scrapy.Request(url,callback=self.parse_model)<br /> def parse_model(self,response): div_lists = response.xpath('/html/body/div/div[3]/div[4]/div[1]/div[1]/div/ul/li/div/div') for div in div_lists: title = div.xpath('./div/div[1]/h3/a/text()').extract_first() new_detial_url = div.xpath('./div/div[1]/h3/a/@href').extract_first() item = WangyiItem() item['title'] = title yield scrapy.Request(url=new_detial_url , callback=self.parse_detial , meta={'item' : item}) def parse_detial(self,response): content = response.xpath('//*[@id="content"]/div[2]//text()').extract() content = ''.join(content) item = response.meta['item'] item['content'] = content yield item<br /> def closed(self,spider): self.bro.quit()
注意不能使用return返回数据,应使用yield返回数据。使用return直接退出函数,而对于yield在调研for的时候,函数内部不会立即执行,只是返回一个生成器对象。
第三步:设置中间件(middlewares.py)
from scrapy import signalsfrom scrapy.http import HtmlResponsefrom time import sleep# useful for handling different item types with a single interfacefrom itemadapter import is_item, ItemAdapter<br />class WangyiDownloaderMiddleware: def process_request(self, request, spider): return None #通过该方法拦截五大板块对应的响应对象,进行纂改 def process_response(self, request, response, spider): #挑选出指定的响应对象精选纂改 bro = spider.bro #获取在爬虫类中定义的浏览器对象 if request.url in spider.models_urls: bro.get(request.url) #五个板块url发送请求 sleep(2) page_text = bro.page_source #动态加载的新闻数据 new_response = HtmlResponse(url=request.url,body= page_text,encoding='utf-8',request=request) return new_response else: return response<br /> def process_exception(self, request, exception, spider): pass
第四步:数据存储
定义爬取数据结构(items.py)
import scrapyclass WangyiItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() content = scrapy.Field() pass
定义数据管道(pipelines.py)
class WangyiPipeline: fp = None # 重写父类的一个方法,该方法只会在开始爬虫的时候被调用一次 def open_spider(self, spider): print('开始爬虫。。。。。。') self.fp = open('./wangyi.text', 'w', encoding='utf-8')<br /> # 用来专门处理item类型对象 # 该方法每接收到一个item就会被调用一次 def process_item(self, item, spider): title = item['title'] content = item['content'] self.fp.write(title + ':' + content + '\n') print(item) return item<br /> def close_spider(self, spider): print('结束爬虫。。。。。。') self.fp.close()
第五步:程序配置(settings.py)
UA伪装
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36'
对robots协议的遵守进行修改
ROBOTSTXT_OBEY = False
显示指定类型日志信息
LOG_LEVEL ='ERROR'
开启中间件
DOWNLOADER_MIDDLEWARES = { 'wangyi.middlewares.WangyiDownloaderMiddleware': 543,}
开启管道
ITEM_PIPELINES = { 'wangyi.pipelines.WangyiPipeline': 300,}
第六步:执行项目
Pycharm终端输入
scrapy crawl wangyi #wangyi 为爬虫项目名
4.爬虫结果
参考资料:
《Python网络爬虫技术与实战》,2021,赵国生、王健著。 查看全部
爬虫实战:Scrapy框架
Scrapy是用Python语言编写,通过Twisted异步网络框架提升下载速度,是一个快速、高层次的屏幕抓取和Web抓取框架,常用于数据挖掘、监测和自动化测试等。
一、Scrapy框架介绍
Scrapy内部实现了并发请求、免登录、URL去重等操作,开发者可根据自己的需求去编写部分代码,就能抓取到所需要的数据。Scrapy框架包含的组件有调度器、下载器、Scrapy引擎、项目管道、爬虫以及各中间件等。
Scrapy框架爬取流程:首先从初始URL开始,调度器会将其交给下载器(Downloader),下载器向网络服务器发送请求进行下载,得到的响应后将下载数据交给爬虫,爬虫会对网页进行分析,分析出来的结果有两种:一种是需要进一步抓取的链接,这些链接会被传回调度器,另一种是需要保存的数据,它们会被传送至项目管道,项目管道进一步对数据进行清洗、去重等处理,并存储到文件或数据库中。数据爬取过程中,Scrapy引擎用于控制整个系统的数据处理流程。
Scrapy框架内包含的各组件功能如下:
Scrapy引擎:用来控制整个系统的数据处理流程,并进行事务处理的触发。
调度器中间件:位于Scrapy引擎和调度器之间,主要用于处理Scrapy引擎发送到调度器的请求和响应。
调度器:用来接收引擎发送过来的请求,压入队列完成去重操作,并决定下一个要抓取的网站,在引擎再次请求的时候返回URL。
下载器中间件:位于Scrapy引擎和下载器之间,主要用于处理Scrapy引擎与下载器之间的请求及响应,其中代理IP和用户代理可以在这里设置。
下载器:用于下载网页内容,并将网页响应结果返回给爬虫。
爬虫中间件:位于Scrapy引擎和爬虫之间,主要用于处理爬虫的响应输入和请求输出。
爬虫:用于从特定网页中提取需要的信息,也可以从中提取URL交给调度器,让Scrapy继续爬取下一个页面。
项目管道:负责处理爬虫从网页中抓取的信息,主要的功能为持久化项目、验证项目的有效性、清除不需要的信息,并完成数据存储。
二、爬虫实战
1.项目需求
基于Scrapy框架爬取某网站的新闻标题和内容。
2.分析页面网站
通过网页解析,了解新闻网站不同模块对应的详情页URL均为静态数据。
通过对不同板块的网页进行解析,了解各模块的新闻为动态加载数据,且新闻标题位于“a”标签下。
进一步,分析新闻网页,了解新闻内容位于“p”标签下。
3.项目搭建
第一步:创建项目
Pycharm终端输入
cd 框架 #进入项目文件夹路径scrapy startproject wangyi #创建项目,wangyi为项目名cd wangyi #进入项目路径scrapy genspider spiderName www.xxx.com #在子目录中创建爬虫文件
项目结构如下:spiders用于存放爬虫程序(SpiderName.py)的文件夹;items用来定义数据结构,类似于字典的功能;middlewares中间件,可设置ip代理等;pipelines用于对items中的数据进行清洗、存储等操作;settings是设置文件,包含爬虫项目的信息;scrapy.cfg是关于项目配置文件。
第二步:编写爬虫代码(spiderName.py)
import scrapyfrom selenium import webdriverfrom wangyi.items import WangyiItem<br />class WangyiSpider(scrapy.Spider): name = 'wangyi' #allowed_domains = ['www.xxx.com'] start_urls = ['https://news.163.com/'] models_urls = [] #存储五个板块的详情页url #实例化浏览器对象 def __init__(self): self.bro = webdriver.Chrome(executable_path='D:/PyCharm/learnpython/框架/wangyi/chromedriver.exe') def parse(self, response): li_list = response.xpath('//*[@id="index2016_wrap"]/div[2]/div[2]/div[2]/div[2]/div/ul/li') alist = [2,3,5,6,7] for index in alist: model_url = li_list[index].xpath('./a/@href').extract_first() self.models_urls.append(model_url) #依次对每一个板块对应的页面发送请求 for url in self.models_urls: yield scrapy.Request(url,callback=self.parse_model)<br /> def parse_model(self,response): div_lists = response.xpath('/html/body/div/div[3]/div[4]/div[1]/div[1]/div/ul/li/div/div') for div in div_lists: title = div.xpath('./div/div[1]/h3/a/text()').extract_first() new_detial_url = div.xpath('./div/div[1]/h3/a/@href').extract_first() item = WangyiItem() item['title'] = title yield scrapy.Request(url=new_detial_url , callback=self.parse_detial , meta={'item' : item}) def parse_detial(self,response): content = response.xpath('//*[@id="content"]/div[2]//text()').extract() content = ''.join(content) item = response.meta['item'] item['content'] = content yield item<br /> def closed(self,spider): self.bro.quit()
注意不能使用return返回数据,应使用yield返回数据。使用return直接退出函数,而对于yield在调研for的时候,函数内部不会立即执行,只是返回一个生成器对象。
第三步:设置中间件(middlewares.py)
from scrapy import signalsfrom scrapy.http import HtmlResponsefrom time import sleep# useful for handling different item types with a single interfacefrom itemadapter import is_item, ItemAdapter<br />class WangyiDownloaderMiddleware: def process_request(self, request, spider): return None #通过该方法拦截五大板块对应的响应对象,进行纂改 def process_response(self, request, response, spider): #挑选出指定的响应对象精选纂改 bro = spider.bro #获取在爬虫类中定义的浏览器对象 if request.url in spider.models_urls: bro.get(request.url) #五个板块url发送请求 sleep(2) page_text = bro.page_source #动态加载的新闻数据 new_response = HtmlResponse(url=request.url,body= page_text,encoding='utf-8',request=request) return new_response else: return response<br /> def process_exception(self, request, exception, spider): pass
第四步:数据存储
定义爬取数据结构(items.py)
import scrapyclass WangyiItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() content = scrapy.Field() pass
定义数据管道(pipelines.py)
class WangyiPipeline: fp = None # 重写父类的一个方法,该方法只会在开始爬虫的时候被调用一次 def open_spider(self, spider): print('开始爬虫。。。。。。') self.fp = open('./wangyi.text', 'w', encoding='utf-8')<br /> # 用来专门处理item类型对象 # 该方法每接收到一个item就会被调用一次 def process_item(self, item, spider): title = item['title'] content = item['content'] self.fp.write(title + ':' + content + '\n') print(item) return item<br /> def close_spider(self, spider): print('结束爬虫。。。。。。') self.fp.close()
第五步:程序配置(settings.py)
UA伪装
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36'
对robots协议的遵守进行修改
ROBOTSTXT_OBEY = False
显示指定类型日志信息
LOG_LEVEL ='ERROR'
开启中间件
DOWNLOADER_MIDDLEWARES = { 'wangyi.middlewares.WangyiDownloaderMiddleware': 543,}
开启管道
ITEM_PIPELINES = { 'wangyi.pipelines.WangyiPipeline': 300,}
第六步:执行项目
Pycharm终端输入
scrapy crawl wangyi #wangyi 为爬虫项目名
4.爬虫结果
参考资料:
《Python网络爬虫技术与实战》,2021,赵国生、王健著。
手把手教你使用Python网络爬虫获取基金信息
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-05-01 01:09
文章:Python爬虫与数据挖掘作者:Python进阶者01前言
前几天有个粉丝找我获取基金信息,这里拿出来分享一下,感兴趣的小伙伴们,也可以积极尝试。
02数据获取
这里我们的目标网站是某基金官网,需要抓取的数据如下图所示。
可以看到上图中基金代码那一列,有不同的数字,随机点击一个,可以进入到基金详情页,链接也非常有规律,以基金代码作为标志的。
其实这个网站倒是不难,数据什么的,都没有加密,网页上的信息,在源码中都可以直接看到。
这样就降低了抓取难度了。通过浏览器抓包的方法,可以看到具体的请求参数,而且可以看到请求参数中只有pi在变化,而这个值恰好对应的是页面,直接构造请求参数就可以了。
代码实现过程
找到数据源之后,接下来就是代码实现了,一起来看看吧,这里给出部分关键代码。
获取股票id数据
response = requests.get(url, headers=headers, params=params, verify=False) pattern = re.compile(r'.*?"(?P.*?)".*?', re.S) result = re.finditer(pattern, response.text) ids = [] for item in result: # print(item.group('items')) gp_id = item.group('items').split(',')[0]
结果如下图所示:
之后构造详情页链接,获取详情页的基金信息,关键代码如下:
response = requests.get(url, headers=headers)response.encoding = response.apparent_encodingselectors = etree.HTML(response.text)danweijingzhi1 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[1]/text()')[0]danweijingzhi2 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[2]/text()')[0]leijijingzhi = selectors.xpath('//dl[@class="dataItem03"]/dd[1]/span/text()')[0]lst = selectors.xpath('//div[@class="infoOfFund"]/table//text()')
结果如下图所示:
将具体的信息做相应的字符串处理,然后保存到csv文件中,结果如下图所示:
有了这个,你可以做进一步的统计和数据分析了。
- 合作、交流、转载请添加微信 moonhmily1 -<p style="outline: 0px;white-space: normal;font-size: 16px;"></p> 查看全部
手把手教你使用Python网络爬虫获取基金信息
文章:Python爬虫与数据挖掘作者:Python进阶者01前言
前几天有个粉丝找我获取基金信息,这里拿出来分享一下,感兴趣的小伙伴们,也可以积极尝试。
02数据获取
这里我们的目标网站是某基金官网,需要抓取的数据如下图所示。
可以看到上图中基金代码那一列,有不同的数字,随机点击一个,可以进入到基金详情页,链接也非常有规律,以基金代码作为标志的。
其实这个网站倒是不难,数据什么的,都没有加密,网页上的信息,在源码中都可以直接看到。
这样就降低了抓取难度了。通过浏览器抓包的方法,可以看到具体的请求参数,而且可以看到请求参数中只有pi在变化,而这个值恰好对应的是页面,直接构造请求参数就可以了。
代码实现过程
找到数据源之后,接下来就是代码实现了,一起来看看吧,这里给出部分关键代码。
获取股票id数据
response = requests.get(url, headers=headers, params=params, verify=False) pattern = re.compile(r'.*?"(?P.*?)".*?', re.S) result = re.finditer(pattern, response.text) ids = [] for item in result: # print(item.group('items')) gp_id = item.group('items').split(',')[0]
结果如下图所示:
之后构造详情页链接,获取详情页的基金信息,关键代码如下:
response = requests.get(url, headers=headers)response.encoding = response.apparent_encodingselectors = etree.HTML(response.text)danweijingzhi1 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[1]/text()')[0]danweijingzhi2 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[2]/text()')[0]leijijingzhi = selectors.xpath('//dl[@class="dataItem03"]/dd[1]/span/text()')[0]lst = selectors.xpath('//div[@class="infoOfFund"]/table//text()')
结果如下图所示:
将具体的信息做相应的字符串处理,然后保存到csv文件中,结果如下图所示:
有了这个,你可以做进一步的统计和数据分析了。
- 合作、交流、转载请添加微信 moonhmily1 -<p style="outline: 0px;white-space: normal;font-size: 16px;">
Python架构高薪就业班/爬虫/数据分析/web开发/AI人工智能(百度云 百
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-04-29 23:25
含大数据、前沿技术、前端开发、后端开发、移动开发、数据分析、架构、人工智能、Python、Java、Android、前端、IOS、C++、大数据、、GO、音视频软件测试、产品经理、运维、股票基金、人工智能AI
以下内容为填充,无视即可
报表样式的饼图如图13-15所示。可以单击如图13-16所示的链接单独引用此报表。图13-15 报表样式的饼图图13-16 链接报表单独的页面能根据查询的修改而实时变化,比如将查询修改为:select date_format(create_time,'%Y-%m-%d') d, count(*) cfrom information_schema.tableswhere create_time > '2016-06-07'group by date_format(create_time,'%Y-%m-%d')order by d;增加了where子句,再运行此查询,结果如图13-17所示。图13-17 图形显示随查询变化单独链接的页面也随之自动发生变化,如图13-18所示。图13-18 单独链接的页面自动变化13.4 Hue、Zeppelin比较1.功能Zeppelin和Hue都具有一定的数据可视化功能,都提供了多种图形化数据表示形式。单从这点来说,它们的功能类似,大同小异。Hue可以通过经纬度进行地图定位,这个功能在Zeppelin 0.6.0上没有。Zeppelin支持的后端数据查询程序较多,0.6.0版本默认有18种,原生支持Spark。
而Hue的3.9.0版本默认只支持Hive、Impala、Pig和数据库查询。Zeppelin只提供了单一的数据处理功能,它将数据摄取、数据发现、数据分析、数据可视化都归为数据处理的范畴。而Hue的功能则丰富得多,除了类似的数据处理,还有元数据管理、Oozie工作流管理、作业管理、用户管理、Sqoop集成等很多管理功能。从这点看,Zeppelin只是一个数据处理工具,而Hue更像是一个综合管理工具。2.架构Zeppelin采用插件式的翻译器,通过插件开发,可以添加任何后端语言及其数据处理程序,相对来说更加独立和开放。Hue与Hadoop生态圈的其他组件密切相关,一般都与CDH一同部署。3.使用场景Zeppelin适合单一数据处理,但后端处理语言繁多的场景,尤其适合Spark。Hue适合与Hadoop集群的多个组件交互,如Oozie工作流、Sqoop等联合处理数据的场景,尤其适合与Impala协同工作。13.5 数据可视化实例本节先用Impala、DB查询示例说明Hue的数据查询和可视化功能,然后交互式地建立定期执行销售订单示例ETL任务的工作流,说明在Hue里是如何操作Oozie工作流引擎的。
1.Impala查询在12.4节中执行了一些联机分析处理的查询,现在在Hue里执行查询,直观看一下结果的图形化表示效果。登录Hue,单击 图标进入“我的文档”页面。单击 创建一个名为“销售订单”的新项目。单击“新文档”→“Impala”进入查询编辑页面,创建一个新的Impala文档。在Impala查询编辑页面,选择olap库,然后在编辑窗口输入下面的查询语句。-- 按产品分类查询销售量和销售额selectt2.product_category pro_category,sum(order_quantity) sum_quantity,sum(order_amount) sum_amountfromsales_order_fact t1, product_dim t2wheret1.product_sk = t2.product_skgroup bypro_categoryorder bypro_category;-- 按产品查询销售量和销售额 查看全部
Python架构高薪就业班/爬虫/数据分析/web开发/AI人工智能(百度云 百
含大数据、前沿技术、前端开发、后端开发、移动开发、数据分析、架构、人工智能、Python、Java、Android、前端、IOS、C++、大数据、、GO、音视频软件测试、产品经理、运维、股票基金、人工智能AI
以下内容为填充,无视即可
报表样式的饼图如图13-15所示。可以单击如图13-16所示的链接单独引用此报表。图13-15 报表样式的饼图图13-16 链接报表单独的页面能根据查询的修改而实时变化,比如将查询修改为:select date_format(create_time,'%Y-%m-%d') d, count(*) cfrom information_schema.tableswhere create_time > '2016-06-07'group by date_format(create_time,'%Y-%m-%d')order by d;增加了where子句,再运行此查询,结果如图13-17所示。图13-17 图形显示随查询变化单独链接的页面也随之自动发生变化,如图13-18所示。图13-18 单独链接的页面自动变化13.4 Hue、Zeppelin比较1.功能Zeppelin和Hue都具有一定的数据可视化功能,都提供了多种图形化数据表示形式。单从这点来说,它们的功能类似,大同小异。Hue可以通过经纬度进行地图定位,这个功能在Zeppelin 0.6.0上没有。Zeppelin支持的后端数据查询程序较多,0.6.0版本默认有18种,原生支持Spark。
而Hue的3.9.0版本默认只支持Hive、Impala、Pig和数据库查询。Zeppelin只提供了单一的数据处理功能,它将数据摄取、数据发现、数据分析、数据可视化都归为数据处理的范畴。而Hue的功能则丰富得多,除了类似的数据处理,还有元数据管理、Oozie工作流管理、作业管理、用户管理、Sqoop集成等很多管理功能。从这点看,Zeppelin只是一个数据处理工具,而Hue更像是一个综合管理工具。2.架构Zeppelin采用插件式的翻译器,通过插件开发,可以添加任何后端语言及其数据处理程序,相对来说更加独立和开放。Hue与Hadoop生态圈的其他组件密切相关,一般都与CDH一同部署。3.使用场景Zeppelin适合单一数据处理,但后端处理语言繁多的场景,尤其适合Spark。Hue适合与Hadoop集群的多个组件交互,如Oozie工作流、Sqoop等联合处理数据的场景,尤其适合与Impala协同工作。13.5 数据可视化实例本节先用Impala、DB查询示例说明Hue的数据查询和可视化功能,然后交互式地建立定期执行销售订单示例ETL任务的工作流,说明在Hue里是如何操作Oozie工作流引擎的。
1.Impala查询在12.4节中执行了一些联机分析处理的查询,现在在Hue里执行查询,直观看一下结果的图形化表示效果。登录Hue,单击 图标进入“我的文档”页面。单击 创建一个名为“销售订单”的新项目。单击“新文档”→“Impala”进入查询编辑页面,创建一个新的Impala文档。在Impala查询编辑页面,选择olap库,然后在编辑窗口输入下面的查询语句。-- 按产品分类查询销售量和销售额selectt2.product_category pro_category,sum(order_quantity) sum_quantity,sum(order_amount) sum_amountfromsales_order_fact t1, product_dim t2wheret1.product_sk = t2.product_skgroup bypro_categoryorder bypro_category;-- 按产品查询销售量和销售额
c爬虫抓取网页数据(本节书摘来自异步社区《用Python写网络爬虫》第2章)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-04-19 15:08
本节节选自异步社区作者【澳大利亚】理查德·劳森(Richard Lawson)所著的《用Python编写Web爬虫》一书第2章第2.2节,李斌翻译,更多章节可访问云栖社区“异步社区”公众号查看。
2.2 三种网页抓取方法
现在我们已经了解了这个网页的结构,有三种方法可以从中获取数据。首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
2.2.1 正则表达式
如果您不熟悉正则表达式,或者需要一些提示,请查看完整介绍。
当我们使用正则表达式抓取区域数据时,首先需要尝试匹配
里面的内容
元素,如下图。
>>> import re
>>> url = 'http://example.webscraping.com/view/United
-Kingdom-239'
>>> html = download(url)
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png',
'244,820 square kilometres',
'62,348,447',
'GB',
'United Kingdom',
'London',
'EU',
'.uk',
'GBP',
'Pound',
'44',
'@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA',
'^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}
[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})
|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$',
'en-GB,cy-GB,gd',
'IE ']
从上面的结果可以看出,标签被用于几个国家属性。为了隔离area属性,我们可以只选择其中的第二个元素,如下图。
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然此方案目前可用,但如果页面更改,它可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使这个正则表达式更健壮,我们可以将它作为父对象
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是网页更新还有很多其他方式也可以使这个正则表达式不满足。例如,要将双引号改为单引号,
在之间添加额外的空格
标签,或更改 area_label 等。下面是尝试支持这些可能性的改进版本。
>>> re.findall('.*?>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup 能够正确解析缺失的引号并关闭标签,除了添加和
标记使它成为一个完整的 HTML 文档。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # returns just the first match
Area
>>> ul.find_all('li') # returns all matches
[Area, Population]
要了解所有的方法和参数,可以参考 BeautifulSoup 的官方文档:.
以下是使用该方法提取样本国家地区数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> url = 'http://example.webscraping.com/places/view/
United-Kingdom-239'
>>> html = download(url)
>>> soup = BeautifulSoup(html)
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> td = tr.find(attrs={'class':'w2p_fw'}) # locate the area tag
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
此代码虽然比正则表达式代码更复杂,但更易于构建和理解。此外,布局中的小变化,例如额外的空白和选项卡属性,我们不必再担心了。
2.2.3 Lxml
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。最新的安装说明可供参考。
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将可能无效的 HTML 解析为统一格式。以下是使用此模块解析相同的不完整 HTML 的示例。
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> tree = lxml.html.fromstring(broken_html) # parse the HTML
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同样,lxml可以正确解析属性和关闭标签周围缺少的引号,但是模块不加和
标签。
解析输入内容后,进入选择元素的步骤。此时,lxml 有几种不同的方法,例如类似于 Beautiful Soup 的 XPath 选择器和 find() 方法。但是,在本例和后续示例中,我们将使用 CSS 选择器,因为它们更简洁,可以在第 5 章解析动态内容时重复使用。另外,一些有 jQuery 选择器经验的读者会更熟悉它。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码。
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0]
>>> area = td.text_content()
>>> print area
244,820 square kilometres
CSS 选择器的关键行已加粗。这行代码会先找到ID为places_area__row的表格行元素,然后选择w2p_fw类的表格数据子标签。
CSS 选择器
CSS 选择器表示用于选择元素的模式。下面是一些常用选择器的示例。
选择所有标签:*
选择<a>标签:a
选择所有class="link"的元素:.link
选择class="link"的<a>标签:a.link
选择id="home"的<a>标签:a#home
选择父元素为<a>标签的所有子标签:a > span
选择<a>标签内部的所有标签:a span
选择title属性为"Home"的所有<a>标签:a[title=Home]
CSS3 规范已由 W3C 在 `/2011/REC-css3-selectors-20110929/ 提出。
Lxml 已经实现了大部分 CSS3 属性,不支持的功能可以在这里找到。
需要注意的是,lxml 的内部实现实际上将 CSS 选择器转换为等效的 XPath 选择器。
2.2.4 性能对比
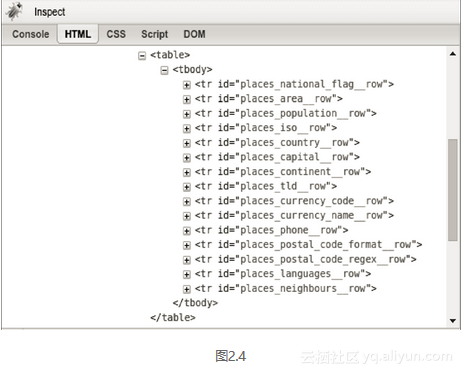
为了更好地评估本章描述的三种抓取方法之间的权衡,我们需要比较它们的相对效率。通常,爬虫从网页中提取多个字段。因此,为了使比较更加真实,我们将在本章中实现每个爬虫的扩展版本,从国家页面中提取每个可用数据。首先,我们需要回到Firebug,检查国家页面其他功能的格式,如图2.4.
您可以从 Firebug 的显示中看到,表格中的每一行都有一个以 places_ 开头并以 __row 结尾的 ID。这些行中收录的国家/地区数据的格式与上面示例中的格式相同。下面是使用上述信息提取所有可用国家/地区数据的实现代码。
FIELDS = ('area', 'population', 'iso', 'country', 'capital',
'continent', 'tld', 'currency_code', 'currency_name', 'phone',
'postal_code_format', 'postal_code_regex', 'languages',
'neighbours')
import re
def re_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)' % field, html).groups()[0]
return results
from bs4 import BeautifulSoup
def bs_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr',
id='places_%s__row' % field).find('td',
class_='w2p_fw').text
return results
import lxml.html
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_%s__row
> td.w2p_fw' % field)[0].text_content()
return results
获取结果
现在我们已经完成了所有爬虫的代码实现,接下来通过下面的代码片段来测试这三种方法的相对性能。
import time
NUM_ITERATIONS = 1000 # number of times to test each scraper
html = download('http://example.webscraping.com/places/view/
United-Kingdom-239')
for name, scraper in [('Regular expressions', re_scraper),
('BeautifulSoup', bs_scraper),
('Lxml', lxml_scraper)]:
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == re_scraper:
re.purge()
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
# record end time of scrape and output the total
end = time.time()
print '%s: %.2f seconds' % (name, end – start)
在这段代码中,每个爬虫会被执行1000次,每次执行都会检查爬取结果是否正确,然后打印总时间。这里使用的下载函数还是上一章定义的。请注意,我们在粗体代码行中调用了 re.purge() 方法。默认情况下,正则表达式模块会缓存搜索结果,为了与其他爬虫比较公平,我们需要使用这种方法来清除缓存。
下面是在我的电脑上运行脚本的结果。
$ python performance.py
Regular expressions: 5.50 seconds
BeautifulSoup: 42.84 seconds
Lxml: 7.06 seconds
由于硬件条件的不同,不同计算机的执行结果也会有一定差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,Beautiful Soup 在爬取我们的示例网页时比其他两种方法慢 6 倍以上。事实上,这个结果是意料之中的,因为 lxml 和 regex 模块是用 C 编写的,而 BeautifulSoup 是用纯 Python 编写的。一个有趣的事实是 lxml 的行为与正则表达式一样。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当爬取同一个网页的多个特征时,这种初始解析的开销会减少,lxml会更有竞争力。多么神奇的模块!
2.2.5 个结论
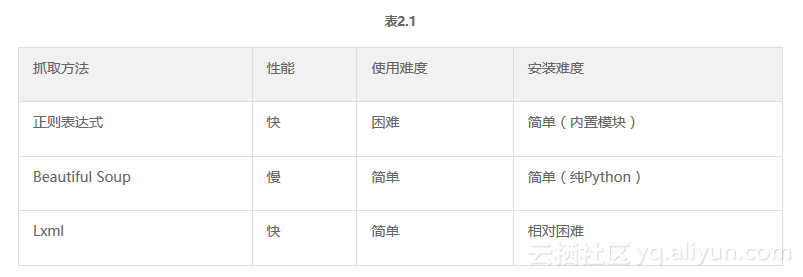
表2.1总结了每种爬取方式的优缺点。
如果您的爬虫的瓶颈是下载页面,而不是提取数据,那么使用较慢的方法(如 Beautiful Soup)不是问题。如果你只需要抓取少量数据并想避免额外的依赖,那么正则表达式可能更合适。通常,lxml 是抓取数据的最佳选择,因为它快速且健壮,而正则表达式和 Beautiful Soup 仅在某些场景下有用。
2.2.6 添加链接爬虫的爬取回调
我们已经看到了如何抓取国家数据,我们需要将其集成到上一章的链接爬虫中。为了重用这个爬虫代码去抓取其他网站,我们需要添加一个回调参数来处理抓取行为。回调是在某个事件发生后调用的函数(在这种情况下,在网页下载完成后)。爬取回调函数收录url和html两个参数,可以返回要爬取的url列表。下面是它的实现代码。可见,用Python实现这个功能非常简单。
def link_crawler(..., scrape_callback=None):
...
links = []
if scrape_callback:
links.extend(scrape_callback(url, html) or [])
...
在上面的代码片段中,我们将新添加的抓取回调函数代码加粗。如果想获取该版本链接爬虫的完整代码,可以访问org/wswp/code/src/tip/chapter02/link_crawler.py。
现在,我们只需要自定义传入的scrape_callback函数,就可以使用爬虫抓取其他网站了。下面修改lxml抓取示例的代码,以便在回调函数中使用。
def scrape_callback(url, html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
row = [tree.cssselect('table > tr#places_%s__row >
td.w2p_fw' % field)[0].text_content() for field in
FIELDS]
print url, row
上面的回调函数会抓取国家数据并显示出来。不过一般情况下,在爬取网站的时候,我们更希望能够重用这些数据,所以让我们扩展一下它的功能,把得到的数据保存在一个CSV表中。代码如下。
import csv
class ScrapeCallback:
def __init__(self):
self.writer = csv.writer(open('countries.csv', 'w'))
self.fields = ('area', 'population', 'iso', 'country',
'capital', 'continent', 'tld', 'currency_code',
'currency_name', 'phone', 'postal_code_format',
'postal_code_regex', 'languages',
'neighbours')
self.writer.writerow(self.fields)
def __call__(self, url, html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
row = []
for field in self.fields:
row.append(tree.cssselect('table >
tr#places_{}__row >
td.w2p_fw'.format(field))
[0].text_content())
self.writer.writerow(row)
为了实现这个回调,我们使用回调类而不是回调函数,以维护 csv 中 writer 属性的状态。在构造函数中实例化csv的writer属性,然后在__call__方法中进行多次写入。注意__call__是一个特殊的方法,当一个对象作为函数调用时会调用,这也是链接爬虫中cache_callback的调用方式。也就是说,scrape_callback(url, html) 等价于调用 scrape_callback.__call__(url, html)。如果想详细了解Python的特殊类方法,可以参考一下。
以下是将回调传递给链接爬虫的代码。
link_crawler('http://example.webscraping.com/', '/(index|view)',
max_depth=-1, scrape_callback=ScrapeCallback())
现在,当我们使用回调运行这个爬虫时,程序会将结果写入 CSV 文件,我们可以使用 Excel 或 LibreOffice 等应用程序查看该文件,如图 2.5 所示。
成功!我们完成了我们的第一个工作数据抓取爬虫。 查看全部
c爬虫抓取网页数据(本节书摘来自异步社区《用Python写网络爬虫》第2章)
本节节选自异步社区作者【澳大利亚】理查德·劳森(Richard Lawson)所著的《用Python编写Web爬虫》一书第2章第2.2节,李斌翻译,更多章节可访问云栖社区“异步社区”公众号查看。
2.2 三种网页抓取方法
现在我们已经了解了这个网页的结构,有三种方法可以从中获取数据。首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
2.2.1 正则表达式
如果您不熟悉正则表达式,或者需要一些提示,请查看完整介绍。
当我们使用正则表达式抓取区域数据时,首先需要尝试匹配
里面的内容
元素,如下图。
>>> import re
>>> url = 'http://example.webscraping.com/view/United
-Kingdom-239'
>>> html = download(url)
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png',
'244,820 square kilometres',
'62,348,447',
'GB',
'United Kingdom',
'London',
'EU',
'.uk',
'GBP',
'Pound',
'44',
'@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA',
'^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}
[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})
|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$',
'en-GB,cy-GB,gd',
'IE ']
从上面的结果可以看出,标签被用于几个国家属性。为了隔离area属性,我们可以只选择其中的第二个元素,如下图。
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然此方案目前可用,但如果页面更改,它可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使这个正则表达式更健壮,我们可以将它作为父对象
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是网页更新还有很多其他方式也可以使这个正则表达式不满足。例如,要将双引号改为单引号,
在之间添加额外的空格
标签,或更改 area_label 等。下面是尝试支持这些可能性的改进版本。
>>> re.findall('.*?>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup 能够正确解析缺失的引号并关闭标签,除了添加和
标记使它成为一个完整的 HTML 文档。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # returns just the first match
Area
>>> ul.find_all('li') # returns all matches
[Area, Population]
要了解所有的方法和参数,可以参考 BeautifulSoup 的官方文档:.
以下是使用该方法提取样本国家地区数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> url = 'http://example.webscraping.com/places/view/
United-Kingdom-239'
>>> html = download(url)
>>> soup = BeautifulSoup(html)
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> td = tr.find(attrs={'class':'w2p_fw'}) # locate the area tag
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
此代码虽然比正则表达式代码更复杂,但更易于构建和理解。此外,布局中的小变化,例如额外的空白和选项卡属性,我们不必再担心了。
2.2.3 Lxml
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。最新的安装说明可供参考。
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将可能无效的 HTML 解析为统一格式。以下是使用此模块解析相同的不完整 HTML 的示例。
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> tree = lxml.html.fromstring(broken_html) # parse the HTML
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同样,lxml可以正确解析属性和关闭标签周围缺少的引号,但是模块不加和
标签。
解析输入内容后,进入选择元素的步骤。此时,lxml 有几种不同的方法,例如类似于 Beautiful Soup 的 XPath 选择器和 find() 方法。但是,在本例和后续示例中,我们将使用 CSS 选择器,因为它们更简洁,可以在第 5 章解析动态内容时重复使用。另外,一些有 jQuery 选择器经验的读者会更熟悉它。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码。
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0]
>>> area = td.text_content()
>>> print area
244,820 square kilometres
CSS 选择器的关键行已加粗。这行代码会先找到ID为places_area__row的表格行元素,然后选择w2p_fw类的表格数据子标签。
CSS 选择器
CSS 选择器表示用于选择元素的模式。下面是一些常用选择器的示例。
选择所有标签:*
选择<a>标签:a
选择所有class="link"的元素:.link
选择class="link"的<a>标签:a.link
选择id="home"的<a>标签:a#home
选择父元素为<a>标签的所有子标签:a > span
选择<a>标签内部的所有标签:a span
选择title属性为"Home"的所有<a>标签:a[title=Home]
CSS3 规范已由 W3C 在 `/2011/REC-css3-selectors-20110929/ 提出。
Lxml 已经实现了大部分 CSS3 属性,不支持的功能可以在这里找到。
需要注意的是,lxml 的内部实现实际上将 CSS 选择器转换为等效的 XPath 选择器。
2.2.4 性能对比
为了更好地评估本章描述的三种抓取方法之间的权衡,我们需要比较它们的相对效率。通常,爬虫从网页中提取多个字段。因此,为了使比较更加真实,我们将在本章中实现每个爬虫的扩展版本,从国家页面中提取每个可用数据。首先,我们需要回到Firebug,检查国家页面其他功能的格式,如图2.4.
您可以从 Firebug 的显示中看到,表格中的每一行都有一个以 places_ 开头并以 __row 结尾的 ID。这些行中收录的国家/地区数据的格式与上面示例中的格式相同。下面是使用上述信息提取所有可用国家/地区数据的实现代码。
FIELDS = ('area', 'population', 'iso', 'country', 'capital',
'continent', 'tld', 'currency_code', 'currency_name', 'phone',
'postal_code_format', 'postal_code_regex', 'languages',
'neighbours')
import re
def re_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)' % field, html).groups()[0]
return results
from bs4 import BeautifulSoup
def bs_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr',
id='places_%s__row' % field).find('td',
class_='w2p_fw').text
return results
import lxml.html
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_%s__row
> td.w2p_fw' % field)[0].text_content()
return results
获取结果
现在我们已经完成了所有爬虫的代码实现,接下来通过下面的代码片段来测试这三种方法的相对性能。
import time
NUM_ITERATIONS = 1000 # number of times to test each scraper
html = download('http://example.webscraping.com/places/view/
United-Kingdom-239')
for name, scraper in [('Regular expressions', re_scraper),
('BeautifulSoup', bs_scraper),
('Lxml', lxml_scraper)]:
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == re_scraper:
re.purge()
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
# record end time of scrape and output the total
end = time.time()
print '%s: %.2f seconds' % (name, end – start)
在这段代码中,每个爬虫会被执行1000次,每次执行都会检查爬取结果是否正确,然后打印总时间。这里使用的下载函数还是上一章定义的。请注意,我们在粗体代码行中调用了 re.purge() 方法。默认情况下,正则表达式模块会缓存搜索结果,为了与其他爬虫比较公平,我们需要使用这种方法来清除缓存。
下面是在我的电脑上运行脚本的结果。
$ python performance.py
Regular expressions: 5.50 seconds
BeautifulSoup: 42.84 seconds
Lxml: 7.06 seconds
由于硬件条件的不同,不同计算机的执行结果也会有一定差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,Beautiful Soup 在爬取我们的示例网页时比其他两种方法慢 6 倍以上。事实上,这个结果是意料之中的,因为 lxml 和 regex 模块是用 C 编写的,而 BeautifulSoup 是用纯 Python 编写的。一个有趣的事实是 lxml 的行为与正则表达式一样。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当爬取同一个网页的多个特征时,这种初始解析的开销会减少,lxml会更有竞争力。多么神奇的模块!
2.2.5 个结论
表2.1总结了每种爬取方式的优缺点。
如果您的爬虫的瓶颈是下载页面,而不是提取数据,那么使用较慢的方法(如 Beautiful Soup)不是问题。如果你只需要抓取少量数据并想避免额外的依赖,那么正则表达式可能更合适。通常,lxml 是抓取数据的最佳选择,因为它快速且健壮,而正则表达式和 Beautiful Soup 仅在某些场景下有用。
2.2.6 添加链接爬虫的爬取回调
我们已经看到了如何抓取国家数据,我们需要将其集成到上一章的链接爬虫中。为了重用这个爬虫代码去抓取其他网站,我们需要添加一个回调参数来处理抓取行为。回调是在某个事件发生后调用的函数(在这种情况下,在网页下载完成后)。爬取回调函数收录url和html两个参数,可以返回要爬取的url列表。下面是它的实现代码。可见,用Python实现这个功能非常简单。
def link_crawler(..., scrape_callback=None):
...
links = []
if scrape_callback:
links.extend(scrape_callback(url, html) or [])
...
在上面的代码片段中,我们将新添加的抓取回调函数代码加粗。如果想获取该版本链接爬虫的完整代码,可以访问org/wswp/code/src/tip/chapter02/link_crawler.py。
现在,我们只需要自定义传入的scrape_callback函数,就可以使用爬虫抓取其他网站了。下面修改lxml抓取示例的代码,以便在回调函数中使用。
def scrape_callback(url, html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
row = [tree.cssselect('table > tr#places_%s__row >
td.w2p_fw' % field)[0].text_content() for field in
FIELDS]
print url, row
上面的回调函数会抓取国家数据并显示出来。不过一般情况下,在爬取网站的时候,我们更希望能够重用这些数据,所以让我们扩展一下它的功能,把得到的数据保存在一个CSV表中。代码如下。
import csv
class ScrapeCallback:
def __init__(self):
self.writer = csv.writer(open('countries.csv', 'w'))
self.fields = ('area', 'population', 'iso', 'country',
'capital', 'continent', 'tld', 'currency_code',
'currency_name', 'phone', 'postal_code_format',
'postal_code_regex', 'languages',
'neighbours')
self.writer.writerow(self.fields)
def __call__(self, url, html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
row = []
for field in self.fields:
row.append(tree.cssselect('table >
tr#places_{}__row >
td.w2p_fw'.format(field))
[0].text_content())
self.writer.writerow(row)
为了实现这个回调,我们使用回调类而不是回调函数,以维护 csv 中 writer 属性的状态。在构造函数中实例化csv的writer属性,然后在__call__方法中进行多次写入。注意__call__是一个特殊的方法,当一个对象作为函数调用时会调用,这也是链接爬虫中cache_callback的调用方式。也就是说,scrape_callback(url, html) 等价于调用 scrape_callback.__call__(url, html)。如果想详细了解Python的特殊类方法,可以参考一下。
以下是将回调传递给链接爬虫的代码。
link_crawler('http://example.webscraping.com/', '/(index|view)',
max_depth=-1, scrape_callback=ScrapeCallback())
现在,当我们使用回调运行这个爬虫时,程序会将结果写入 CSV 文件,我们可以使用 Excel 或 LibreOffice 等应用程序查看该文件,如图 2.5 所示。
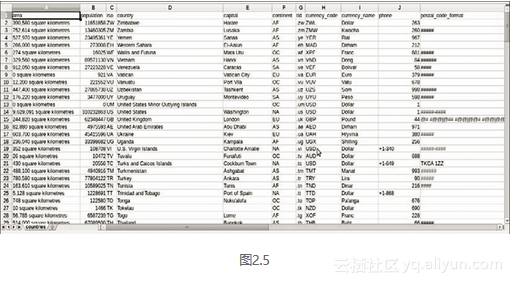
成功!我们完成了我们的第一个工作数据抓取爬虫。
c爬虫抓取网页数据(Python爬虫4.2—ajax[动态网页数据]用法教程综述)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-19 15:05
Python爬虫4.2——ajax【动态网页数据】使用教程
概览
本系列文档用于提供Python爬虫技术学习的简单教程。在巩固你的技术知识的同时,如果它恰好对你有用,那就更好了。
Python 版本是 3.7.4
有时当我们抓取带有请求的页面时,结果可能与我们在浏览器中看到的不同。正常显示的页面数据在浏览器中是可以看到的,但是使用requests得到的结果却不是。这是因为请求获取的是原创的 HTML 文档,而浏览器中的页面是通过 JavaScript 处理数据的结果。这些数据有多种来源,可以通过 Ajax 加载或收录在 HTML 中。在文档中,也可能是通过JavaScript和特定算法计算后生成的。
所以遇到这样的页面,直接使用requests等库获取原创页面是无法获取有效数据的。这时候就需要分析网页后端向接口发送的Ajax请求了。如果可以使用requests来模拟ajax请求,那么就可以成功爬取了。
所以,在这篇文章中,我们主要了解Ajax是什么以及如何分析和抓取Ajax请求。
AJAX简介什么是AJAX
AJAX(异步 JavaScript 和 XML)异步 JavaScript 和 XML。通过在后台交换与服务器协商的数据,Ajax 实现了网页的异步更新,这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。传统网页(没有Ajax)如果内容需要更新,需要重新加载整个网页,因为传统的数据传输格式使用XML语法,所以称为Ajax。其实数据交互的限制基本上就是使用JSON,Ajax加载的数据,即使是用JS渲染数据到浏览器,查看网页源码的时候还是看不到加载的数据通过 Ajax,您只能看到 Ajax 加载的数据。由 url 加载的 HTML 代码。
示例说明
在浏览网页时,我们会发现很多页面已经向下滚动以查看更多选项。比如微博、今日头条等,有的是根据鼠标下拉自动加载的。这些其实就是Ajax加载的过程。我们可以看到页面并没有完全刷新,也就是说页面的链接没有变化,但是网页中有新的内容,也就是通过Ajax获取新数据并渲染的过程。
请求分析
使用Chrome开发者工具的过滤功能,过滤掉所有的Ajax请求,这里不再详述。
Fiddler 抓包工具也可以用于抓包分析。 Fiddler工具的使用方法这里不做说明。您可以在线搜索和查看。
Ajax 响应结果一般为 json 数据格式。
获取方式直接分析Ajax使用的接口,然后通过代码请求这个接口获取数据(下面的例子就是这样一个通用的)。使用 Selenium + Chromedriver 模拟浏览器行为获取数据(继续关注文章)。该方法的优缺点
分析界面
可以直接请求数据,不需要做一些解析工作,代码少,性能高。
分析界面比较复杂,尤其是一些被js混淆的界面,你必须对js有一定的了解,很容易被爬虫发现。
硒
直接模拟浏览器的行为。浏览器能请求的也可以用selenium来请求,爬虫更稳定。
大量代码和低性能。
示例说明
让我们举个例子,爬取“成为一个长得好看的程序员是什么感觉?”这个问题的所有答案。在问题 知乎 下。示例代码如下:
<p># 引入所需库
import json
import requests
# 声明定义请求头
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/67.0.3396.99 '
'Safari/537.36',
'Host': "www.zhihu.com",
'Referer': "https://www.zhihu.com/question/37787176"
}
def answer(url_):
"""
获取问题答案
:param url_:
:return:
"""
r = requests.get(url_, headers=header)
data = r.text
jsonobj = json.loads(data)
return jsonobj
# 问题答案接口地址
url = "https://www.zhihu.com/api/v4/q ... ot%3B
# 获取回答总数
answer_total = int(answer(url)['paging']['totals'])
offset = 0
while offset 查看全部
c爬虫抓取网页数据(Python爬虫4.2—ajax[动态网页数据]用法教程综述)
Python爬虫4.2——ajax【动态网页数据】使用教程
概览
本系列文档用于提供Python爬虫技术学习的简单教程。在巩固你的技术知识的同时,如果它恰好对你有用,那就更好了。
Python 版本是 3.7.4
有时当我们抓取带有请求的页面时,结果可能与我们在浏览器中看到的不同。正常显示的页面数据在浏览器中是可以看到的,但是使用requests得到的结果却不是。这是因为请求获取的是原创的 HTML 文档,而浏览器中的页面是通过 JavaScript 处理数据的结果。这些数据有多种来源,可以通过 Ajax 加载或收录在 HTML 中。在文档中,也可能是通过JavaScript和特定算法计算后生成的。
所以遇到这样的页面,直接使用requests等库获取原创页面是无法获取有效数据的。这时候就需要分析网页后端向接口发送的Ajax请求了。如果可以使用requests来模拟ajax请求,那么就可以成功爬取了。
所以,在这篇文章中,我们主要了解Ajax是什么以及如何分析和抓取Ajax请求。
AJAX简介什么是AJAX
AJAX(异步 JavaScript 和 XML)异步 JavaScript 和 XML。通过在后台交换与服务器协商的数据,Ajax 实现了网页的异步更新,这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。传统网页(没有Ajax)如果内容需要更新,需要重新加载整个网页,因为传统的数据传输格式使用XML语法,所以称为Ajax。其实数据交互的限制基本上就是使用JSON,Ajax加载的数据,即使是用JS渲染数据到浏览器,查看网页源码的时候还是看不到加载的数据通过 Ajax,您只能看到 Ajax 加载的数据。由 url 加载的 HTML 代码。
示例说明
在浏览网页时,我们会发现很多页面已经向下滚动以查看更多选项。比如微博、今日头条等,有的是根据鼠标下拉自动加载的。这些其实就是Ajax加载的过程。我们可以看到页面并没有完全刷新,也就是说页面的链接没有变化,但是网页中有新的内容,也就是通过Ajax获取新数据并渲染的过程。
请求分析
使用Chrome开发者工具的过滤功能,过滤掉所有的Ajax请求,这里不再详述。
Fiddler 抓包工具也可以用于抓包分析。 Fiddler工具的使用方法这里不做说明。您可以在线搜索和查看。
Ajax 响应结果一般为 json 数据格式。
获取方式直接分析Ajax使用的接口,然后通过代码请求这个接口获取数据(下面的例子就是这样一个通用的)。使用 Selenium + Chromedriver 模拟浏览器行为获取数据(继续关注文章)。该方法的优缺点
分析界面
可以直接请求数据,不需要做一些解析工作,代码少,性能高。
分析界面比较复杂,尤其是一些被js混淆的界面,你必须对js有一定的了解,很容易被爬虫发现。
硒
直接模拟浏览器的行为。浏览器能请求的也可以用selenium来请求,爬虫更稳定。
大量代码和低性能。
示例说明
让我们举个例子,爬取“成为一个长得好看的程序员是什么感觉?”这个问题的所有答案。在问题 知乎 下。示例代码如下:
<p># 引入所需库
import json
import requests
# 声明定义请求头
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/67.0.3396.99 '
'Safari/537.36',
'Host': "www.zhihu.com",
'Referer': "https://www.zhihu.com/question/37787176"
}
def answer(url_):
"""
获取问题答案
:param url_:
:return:
"""
r = requests.get(url_, headers=header)
data = r.text
jsonobj = json.loads(data)
return jsonobj
# 问题答案接口地址
url = "https://www.zhihu.com/api/v4/q ... ot%3B
# 获取回答总数
answer_total = int(answer(url)['paging']['totals'])
offset = 0
while offset
c爬虫抓取网页数据( 二级建造师考试每日一练免费在线测试())
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-04-19 01:12
二级建造师考试每日一练免费在线测试())
更多《搜索引擎利用网络爬虫不断从网上爬取网站数据,并在本地存储网站图片。()》相关问题
问题 1
以下关于蜘蛛的说法错误的是( )。
A. 蜘蛛是搜索引擎的网络爬虫
湾。每个搜索引擎蜘蛛都有不同的名称
C。网站被搜索引擎降级后蜘蛛再也不会来这里了网站
D.站长可以通过技术等优化吸引蜘蛛爬行
点击查看答案
问题2
动态 URL 帮助搜索引擎抓取网页并提高 网站 排名。()
点击查看答案
问题 3
大站点优先,顾名思义,就是在互联网上优先抓取()页面,是搜索引擎中的一种信息抓取策略。
大站点优先,顾名思义,就是在互联网上优先抓取()页面,是搜索引擎中的一种信息抓取策略。
A. 小网站
B. 中小型网站
C. 大 网站
D. 中型和大型 网站
点击查看答案
问题 4
HTML版本的网站map只适合搜索引擎蜘蛛抓取,不利于用户体验。()
点击查看答案
问题 5
以下关于网络爬虫的描述是错误的()。
A. 网络爬虫是一种自动提取网页的程序
B. 为搜索引擎从万维网上下载网页是搜索引擎的重要组成部分
C、爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某个停止条件。
D.网络爬虫的行为与访问网站的人的行为完全不同
点击查看答案
问题 6
如果通过爬虫抓取某公司网站的公开数据,分析后发现该公司的业绩非常好。然后将数据或分析结果出售给基金公司,获得销售收入。这是合法的。()
点击查看答案
问题 7
网络数据采集常用来通过()或()的方式从网站获取数据信息。
A. 网络爬虫
湾。网站公共 API
C。手动获取
点击查看答案
问题 8
爬虫是手动请求万维网网站并提取网页数据的程序()
点击查看答案
问题 9
网络数据采集是利用互联网搜索引擎技术,有针对性、行业针对性、准确地抓取数据,并按照一定的规则和筛选标准对数据进行分类,形成数据库文件的过程。()
点击查看答案
问题 10
搜索引擎营销主要用于网站推广,不起到建立网络品牌的作用。()
点击查看答案 查看全部
c爬虫抓取网页数据(
二级建造师考试每日一练免费在线测试())

更多《搜索引擎利用网络爬虫不断从网上爬取网站数据,并在本地存储网站图片。()》相关问题
问题 1
以下关于蜘蛛的说法错误的是( )。
A. 蜘蛛是搜索引擎的网络爬虫
湾。每个搜索引擎蜘蛛都有不同的名称
C。网站被搜索引擎降级后蜘蛛再也不会来这里了网站
D.站长可以通过技术等优化吸引蜘蛛爬行
点击查看答案
问题2
动态 URL 帮助搜索引擎抓取网页并提高 网站 排名。()
点击查看答案
问题 3
大站点优先,顾名思义,就是在互联网上优先抓取()页面,是搜索引擎中的一种信息抓取策略。
大站点优先,顾名思义,就是在互联网上优先抓取()页面,是搜索引擎中的一种信息抓取策略。
A. 小网站
B. 中小型网站
C. 大 网站
D. 中型和大型 网站
点击查看答案
问题 4
HTML版本的网站map只适合搜索引擎蜘蛛抓取,不利于用户体验。()
点击查看答案
问题 5
以下关于网络爬虫的描述是错误的()。
A. 网络爬虫是一种自动提取网页的程序
B. 为搜索引擎从万维网上下载网页是搜索引擎的重要组成部分
C、爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某个停止条件。
D.网络爬虫的行为与访问网站的人的行为完全不同
点击查看答案
问题 6
如果通过爬虫抓取某公司网站的公开数据,分析后发现该公司的业绩非常好。然后将数据或分析结果出售给基金公司,获得销售收入。这是合法的。()
点击查看答案
问题 7
网络数据采集常用来通过()或()的方式从网站获取数据信息。
A. 网络爬虫
湾。网站公共 API
C。手动获取
点击查看答案
问题 8
爬虫是手动请求万维网网站并提取网页数据的程序()
点击查看答案
问题 9
网络数据采集是利用互联网搜索引擎技术,有针对性、行业针对性、准确地抓取数据,并按照一定的规则和筛选标准对数据进行分类,形成数据库文件的过程。()
点击查看答案
问题 10
搜索引擎营销主要用于网站推广,不起到建立网络品牌的作用。()
点击查看答案
c爬虫抓取网页数据( 在爬虫系统中,等待抓取URL队列是很重要的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-04-17 16:29
在爬虫系统中,等待抓取URL队列是很重要的)
在爬虫系统中,等待爬取的URL队列是一个非常重要的部分,而等待爬取的URL队列中URL的顺序也是一个非常重要的问题,因为它会决定先爬到哪个页面之后再爬取哪个页面。而确定这些URL顺序的方法称为爬取策略。下面主要介绍几种常见的爬取策略:
1 深度优先遍历策略:深度优先遍历策略是指网络爬虫会从起始页开始,每一个链接一次一个链接,直到处理完该行才会转到下一个起始页,并且继续关注链接。遍历路径为:AFG ,EHI ,B ,C,D
2 广度优先遍历策略:广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接放在待爬取的URL队列的末尾。也就是说,网络爬虫会优先抓取起始网页中的所有链接。爬取完所有网页后,选择其中一个链接的网页,继续爬取该网页链接的所有网页。它的路径可以这样写:ABCDEF ,G ,H,I
3 外链数策略:外链数是指一个网页被其他网页指向的链接数,外链数也表示一个网页的内容被他人推荐的程度. 抓取系统会使用这个指标来评估网页的重要性,从而确定不同网页的抓取顺序。
但是,在真实的网络环境中,由于存在很多广告链接、作弊链接等,反向链接的数量并不能完全等同于重要性。因此,很多搜索引擎经常会考虑一些可靠的反向链接。
4.OPIC策略策略:这个算法其实是给网页的重要性打分的。在算法开始之前,所有页面都会被赋予相同的初始现金(cash)。当一个页面 P 被下载后,将 P 的现金分配给从 P 分析的所有链接,并清除 P 的现金。URL队列中所有待爬取的页面,按照现金数量排序。
5.大站点优先策略:对URL队列中所有待爬取的网页,按照所属的网站进行分类。对于需要下载的页面较多的网站,请先下载。这种策略也被称为大站优先策略。 查看全部
c爬虫抓取网页数据(
在爬虫系统中,等待抓取URL队列是很重要的)

在爬虫系统中,等待爬取的URL队列是一个非常重要的部分,而等待爬取的URL队列中URL的顺序也是一个非常重要的问题,因为它会决定先爬到哪个页面之后再爬取哪个页面。而确定这些URL顺序的方法称为爬取策略。下面主要介绍几种常见的爬取策略:
1 深度优先遍历策略:深度优先遍历策略是指网络爬虫会从起始页开始,每一个链接一次一个链接,直到处理完该行才会转到下一个起始页,并且继续关注链接。遍历路径为:AFG ,EHI ,B ,C,D
2 广度优先遍历策略:广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接放在待爬取的URL队列的末尾。也就是说,网络爬虫会优先抓取起始网页中的所有链接。爬取完所有网页后,选择其中一个链接的网页,继续爬取该网页链接的所有网页。它的路径可以这样写:ABCDEF ,G ,H,I
3 外链数策略:外链数是指一个网页被其他网页指向的链接数,外链数也表示一个网页的内容被他人推荐的程度. 抓取系统会使用这个指标来评估网页的重要性,从而确定不同网页的抓取顺序。
但是,在真实的网络环境中,由于存在很多广告链接、作弊链接等,反向链接的数量并不能完全等同于重要性。因此,很多搜索引擎经常会考虑一些可靠的反向链接。
4.OPIC策略策略:这个算法其实是给网页的重要性打分的。在算法开始之前,所有页面都会被赋予相同的初始现金(cash)。当一个页面 P 被下载后,将 P 的现金分配给从 P 分析的所有链接,并清除 P 的现金。URL队列中所有待爬取的页面,按照现金数量排序。
5.大站点优先策略:对URL队列中所有待爬取的网页,按照所属的网站进行分类。对于需要下载的页面较多的网站,请先下载。这种策略也被称为大站优先策略。
c爬虫抓取网页数据(农村最恐怖的还是蚂蝗,它无处不在吸你多少血了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-04-15 06:33
农村最可怕的就是水蛭,到处都是。当它无意识地咬你,当你感觉到它。我不知道我从你身上吸了多少血,也吸不出来。你要拍它才肯下来,这东西更可怕。只是不容易死。你把它分成几段。
它也不会死,记得我小时候。我们的几个朋友去堰和池塘洗澡。没学过游泳,只是边玩边玩。洗漱完毕,上岸。他的屁股上有一只巨大的水蛭,吓得他哭了。这东西吸血,太可怕了,恶心。农村的大人小孩都害怕。
尤其是女孩子,她们的父母让她帮忙种水稻。先问有没有蚂蟥,杀了就不去了。大人就好了,习惯就好。如果你看到几个耳光,就一拍即合。我们小时候被咬过很多次,很多次。我倒不是太害怕,我只是看到自己吸了那么多血。
有点疼,现在稻田里没有那么多水蛭了。稻谷是用收割机收割的,是时候收割了。在收割机下田收割之前,必须排干稻田中的所有水。没有水,水蛭就会减少。动物只有在有水的情况下才能吸血。我希望这东西可以灭绝。
python爬虫是怎么做的?
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本篇文章将介绍如何编写一个网络爬虫从零开始爬取数据,进而逐步完善爬虫的爬取功能。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
通过以上步骤,我们就可以写出一个最原创的爬虫了。在了解爬虫原理的基础上,我们可以进一步完善爬虫。
写了一个关于爬虫的系列文章:。如果你有兴趣,你可以去看看。
Python基础环境搭建、爬虫基本原理及爬虫原型
Python 爬虫入门(第 1 部分)
如何使用 BeautifulSoup 提取网页内容
Python 爬虫入门(第 2 部分)
爬虫运行时数据的存储数据,以 SQLite 和 MySQL 为例
Python 爬虫入门(第 3 部分)
使用 selenium webdriver 抓取动态网页
Python 爬虫入门(第 4 部分)
讨论了如何处理网站的反爬策略
Python 爬虫入门(第 5 部分)
介绍了Python的Scrapy爬虫框架,并简要演示了如何在Scrapy下开发
Python 爬虫入门(第 6 部分) 查看全部
c爬虫抓取网页数据(农村最恐怖的还是蚂蝗,它无处不在吸你多少血了)
农村最可怕的就是水蛭,到处都是。当它无意识地咬你,当你感觉到它。我不知道我从你身上吸了多少血,也吸不出来。你要拍它才肯下来,这东西更可怕。只是不容易死。你把它分成几段。
它也不会死,记得我小时候。我们的几个朋友去堰和池塘洗澡。没学过游泳,只是边玩边玩。洗漱完毕,上岸。他的屁股上有一只巨大的水蛭,吓得他哭了。这东西吸血,太可怕了,恶心。农村的大人小孩都害怕。
尤其是女孩子,她们的父母让她帮忙种水稻。先问有没有蚂蟥,杀了就不去了。大人就好了,习惯就好。如果你看到几个耳光,就一拍即合。我们小时候被咬过很多次,很多次。我倒不是太害怕,我只是看到自己吸了那么多血。
有点疼,现在稻田里没有那么多水蛭了。稻谷是用收割机收割的,是时候收割了。在收割机下田收割之前,必须排干稻田中的所有水。没有水,水蛭就会减少。动物只有在有水的情况下才能吸血。我希望这东西可以灭绝。
python爬虫是怎么做的?
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本篇文章将介绍如何编写一个网络爬虫从零开始爬取数据,进而逐步完善爬虫的爬取功能。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
通过以上步骤,我们就可以写出一个最原创的爬虫了。在了解爬虫原理的基础上,我们可以进一步完善爬虫。
写了一个关于爬虫的系列文章:。如果你有兴趣,你可以去看看。
Python基础环境搭建、爬虫基本原理及爬虫原型
Python 爬虫入门(第 1 部分)
如何使用 BeautifulSoup 提取网页内容
Python 爬虫入门(第 2 部分)
爬虫运行时数据的存储数据,以 SQLite 和 MySQL 为例
Python 爬虫入门(第 3 部分)
使用 selenium webdriver 抓取动态网页
Python 爬虫入门(第 4 部分)
讨论了如何处理网站的反爬策略
Python 爬虫入门(第 5 部分)
介绍了Python的Scrapy爬虫框架,并简要演示了如何在Scrapy下开发
Python 爬虫入门(第 6 部分)
c爬虫抓取网页数据(imarowadtencc语言treefindall抓取国家面积数据的方法-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-04-15 06:09
标签: imarowadtencc 语言 treefindall 将是新版本
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1. 正则表达式
? 如果您是正则表达式的新手,或者需要一些提示,请查看正则表达式 HOWTO 以获得完整的介绍。
?当我们使用正则表达式抓取国家地区数据时,我们首先尝试匹配元素中的内容,像这样:
>>> import re
>>> import urllib2
>>> url = ‘http://example.webscraping.com ... m-239‘
>>> html = urllib2.urlopen(url).read()
>>> re.findall(‘(.*?)‘, html)
[‘‘, ‘244,820 square kilometres‘, ‘62,348,447‘, ‘GB‘, ‘United Kingdom‘, ‘London‘, ‘EU‘, ‘.uk‘, ‘GBP‘, ‘Pound‘, ‘44‘, ‘@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA‘, ‘^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$‘, ‘en-GB,cy-GB,gd‘, ‘IE ‘]
>>>
? 从以上结果可以看出,<td class=”w2p_fw” > 标签用于多个国家属性。要隔离 area 属性,我们只需选择其中的第二个元素,如下所示:
>>> re.findall(‘(.*?)‘, html)[1]
‘244,820 square kilometres‘
• 虽然这个方案现在可用,但如果页面发生变化,它很可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们也可以添加它的父元素 <tr>。由于元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)['244820平方公里'] Python爬虫三种网络爬取方式的性能对比 查看全部
c爬虫抓取网页数据(imarowadtencc语言treefindall抓取国家面积数据的方法-苏州安嘉)
标签: imarowadtencc 语言 treefindall 将是新版本
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1. 正则表达式
? 如果您是正则表达式的新手,或者需要一些提示,请查看正则表达式 HOWTO 以获得完整的介绍。
?当我们使用正则表达式抓取国家地区数据时,我们首先尝试匹配元素中的内容,像这样:
>>> import re
>>> import urllib2
>>> url = ‘http://example.webscraping.com ... m-239‘
>>> html = urllib2.urlopen(url).read()
>>> re.findall(‘(.*?)‘, html)
[‘
 ‘, ‘244,820 square kilometres‘, ‘62,348,447‘, ‘GB‘, ‘United Kingdom‘, ‘London‘, ‘EU‘, ‘.uk‘, ‘GBP‘, ‘Pound‘, ‘44‘, ‘@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA‘, ‘^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$‘, ‘en-GB,cy-GB,gd‘, ‘IE ‘]
‘, ‘244,820 square kilometres‘, ‘62,348,447‘, ‘GB‘, ‘United Kingdom‘, ‘London‘, ‘EU‘, ‘.uk‘, ‘GBP‘, ‘Pound‘, ‘44‘, ‘@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA‘, ‘^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$‘, ‘en-GB,cy-GB,gd‘, ‘IE ‘]>>>
? 从以上结果可以看出,<td class=”w2p_fw” > 标签用于多个国家属性。要隔离 area 属性,我们只需选择其中的第二个元素,如下所示:
>>> re.findall(‘(.*?)‘, html)[1]
‘244,820 square kilometres‘
• 虽然这个方案现在可用,但如果页面发生变化,它很可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们也可以添加它的父元素 <tr>。由于元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)['244820平方公里'] Python爬虫三种网络爬取方式的性能对比
c爬虫抓取网页数据(我组开发遗留下来的分类保存到的文件和扒取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-04-14 14:01
2021-09-27
需要:
我们组的研究课题是编写一个更实用的爬虫软件,将其应用到一些前辈的代码中,并在此基础上进行完善和创新。
鉴于高级代码已经实现了基本功能,即从网站中爬取相关Word文档和其他计算机相关文件资料,过滤掉无关信息。我组将从以下几个方面着手改进和完善:
1.增强的去广告功能:
如今的网页情况,很多网页,包括贴吧、微博都充斥着广告,其中一些不可避免地与电脑有关,但这些广告的作用并没有实际意义。高级代码中确实有相应的删除广告的功能,但效果并不明显。在很多情况下,无法识别网络广告和实际有用的信息,因此会出现一些数据浪费或数据丢失。. 针对这种情况,我们小组决定对其广告过滤功能进行改进和修改。
2.按类别保存提取的文件:
对爬虫抓取的数据进行分类非常重要。学长的代码中,获取的数据没有入库分类存储,给下一组的开发留下了一些问题。,我组研究后认为应该增加保存党的分类的功能。
3.添加视频采集功能:
前辈的代码只实现了部分文本文件的提取,并没有进行视频数据的提取。但是由于网上很多视频都有相应的版权问题,而且大部分视频占用了很大的硬盘容量,所以我们会抓取视频的地址并存入数据库。
4.CSS 和 Javascript网站:
在原创代码中,只能抓取 HTTP6 网页。我们认为数据采集将过于有限。因此,我们想在这个问题中加入 CSS 和 Javascript 网站 的抓取功能。生成大量的代码工作量,只是一个初步的想法。
5.网页质量判断:
有些网站由于缺乏相关的和计算机知识的内容,重复搜索只会造成时间和资源的浪费。针对这种情况,我们认为应该增加一个判断网页质量的功能,把不合适的网站去掉,提高软件运行效率。
方法(实践):
1.对于抓取到的网站,获取URL,查看下一级网站的AD字段以及下一级网站与关键字的关联度
上学年对这个项目的评测中,去广告的功能并不完善,还夹杂了很多广告。他们在博客上写道,说是根据AD领域来判断这是否网站 是一个广告网站。我们觉得如果只根据AD字段来判断,有可能在网站中间的网站中抓取一些无用的广告。因此,我们觉得应该再往下检查一级。如果下一级网站中有很多广告网站,则排除这个网站。因为我们考虑到如果投放了一个广告,最多会经过一次网站传输,否则广告投放是不会生效的。因此,我们考虑多一个检测级别的方法,这应该可以在很大程度上解决问题。得到的网站中的广告有很多问题。
2.抓取的不同文件会根据文件格式的不同分别保存(先按文件夹分开)
捕获的 网站 根据它们与关键字的相关性进行分级和排序。上学年项目负责组评价写道,该组抓到的文件没有分类,所有文件都混在一起,给用户使用带来不便。我们想在这个软件中添加一个对捕获的文件进行分类和存储的功能。当某个文件被抓取时,会根据文件的类型,将其放置在该文件所在的存储区域中,从而完成软件运行。之后得到分类文件,方便用户使用。
3.提供视频链接,以便用户观看源视频
上一组没有完成相关视频的爬取功能。我们认为,如果它是一个网络爬虫,它的初衷是为互联网上的用户爬取有用的资源,而现在视频资源也很重要。因此,我们要增加视频捕捉功能。与内容和关键词相关的视频也会反馈给用户,以便用户观看相关视频。
4.CSS 和 Javascript网站
暂定。
5.检查关键词是否出现在被捕获的网站或者文件的标题中,如果在被捕获的网站或者文件的文本中频繁出现,用这个来判断此 网站 或文件的值给用户
我们认为,如果我们抓取其中出现关键词的所有资源,我们可能会抓取一些网站或不相关但出现关键词的文件,但在排除网站@之后> 以及对用户来说价值不大的文件,通过以上方法,我们抓取的东西质量会大大提高。
好处(好处):
1.能够更好地从结果中去除广告网站,优化用户体验
去除广告是我们爬虫非常重要的功能。爬虫的初衷是为用户高效地爬取互联网上有用的相关资源。如果可爬取资源中有大量的广告,会让用户的浏览很不方便,也就失去了爬虫的意义。. 我们将检查到下一个级别网站,并使用此方法排除广告网站。这样可以提高抓取资源的质量,用户可以更方便的使用爬虫的功能。
2.让用户更容易找到资源
如果爬虫把所有抓取到的资源放在一起,当用户需要一个格式单一的文件时会很麻烦。我们将采集到的资源按照类型分别保存,让用户可以更方便的使用软件,获得更好的用户体验。
3.让用户可以观看相关视频
这是一个全新的功能。之前的版本无法采集视频资源。虽然由于版权原因我们无法完全下载视频,但我们可以为用户提供源视频的链接,以便用户观看。现在互联网上有很多资源以视频的形式存在。我们加入这个功能是为了让这个软件更实用,更能满足用户不断增长的需求。
4.不限于HTML5网站,可以获得更多资源(暂定)
目前的版本只能爬取HTML5的网站,但是网站里面也有很多有用的资源是用javascript或者css的。我们更新了这个软件,支持javascript和css,可以让爬虫抓取更多的资源,为用户提供更多的服务。
5.提高采集结果的质量,增加剔除低质量资源的功能(暂定)
如果只关注捕获文件的数量和网站,可能会导致捕获文件和网站的质量很差,但是会减少结果中有用的文件和网站里面的成分让用户体验更差。我们将通过检测关键词是否出现在其标题及其出现频率等方法来确定该文件或网站对用户的价值。如果值不高,那么这个文件或 网站 @> 被排除。这将使我们能够抓取更高质量的文件和 网站。
竞争对手:
网络爬虫是一种自动获取网页内容的程序,是搜索引擎的重要组成部分。现在的搜索引擎基本上都涉及到爬虫的设计和优化。搜索引擎的速度也与爬虫的优化程度密切相关。从另一个角度来看,不仅仅是搜索引擎,所有的数据挖掘软件都会涉及到爬虫。因此,爬虫在整个软件行业的地位很高,应用范围非常广泛。这里我们主要通过搜索引擎中的爬虫来分析竞争。
首先,拿两个最常用的搜索引擎:百度和谷歌。从爬取信息来看,两者都是行业的佼佼者,爬取算法也很不错,可以按类型分类。,以方便用户操作。它爬取整个万维网的速度非常快。虽然我们的软件在速度和爬取算法方面还不是很成熟,但是我们的软件会为了方便用户而设计。我们会检查爬取文件的匹配度,对它们的优先级进行排序。这也将大大提高用户体验的质量。我将从以下几个方面来讨论我们软件的竞争力。
1.爬行速度和爬行负载,这也是衡量爬虫的标准
与其他软件相比,我们的软件在速度上还不错。我们通过广度优先的搜索顺序进行搜索,可以提高爬虫的爬取速度。同时,我们使用多个队列进行数据处理,这也使得爬虫可以同时处理多个数据。分组数据,承载能力更强。
2.爬取质量和特异性
很多网站爬虫爬取给定URL中的所有内容,不仅影响爬取内容的质量,还拖慢了预算。我们的爬虫会专门爬取电脑相关的数据,让爬取的内容更符合用户的需求。同时我们会对广告进行处理,也可以让爬虫的爬取质量更高。同时,我们会在爬取时与关键词进行匹配比较,可以大大减少广告和无关信息。
3.分类存储
用户的下一步操作可能会使用不同类型的数据。爬虫会在爬取过程中轻松对数据进行分类。分类可以让用户获得更好的用户体验,让用户在搜索的过程中可以更快的找到自己需要的信息。这应该更受程序员的欢迎。
4.接口与实现
用户在获取爬虫时,需要知道爬虫的输出形式和爬取速度,这就需要我们设计一个简单的接口来实现。我们的界面将以最简单的方式将输出呈现给用户,这将非常直观。
5.创新功能
我们将为原创爬虫添加新功能。比如抓取视频文件时,我们会将视频地址反馈给用户。这允许用户直接通过地址观看视频。此外,我们还计划实现不限于 html5 网页的爬取,甚至尝试爬取 CSS 或 javascript。这样可以更方便用户操作。
分类:
技术要点:
相关文章: 查看全部
c爬虫抓取网页数据(我组开发遗留下来的分类保存到的文件和扒取)
2021-09-27
需要:
我们组的研究课题是编写一个更实用的爬虫软件,将其应用到一些前辈的代码中,并在此基础上进行完善和创新。
鉴于高级代码已经实现了基本功能,即从网站中爬取相关Word文档和其他计算机相关文件资料,过滤掉无关信息。我组将从以下几个方面着手改进和完善:
1.增强的去广告功能:
如今的网页情况,很多网页,包括贴吧、微博都充斥着广告,其中一些不可避免地与电脑有关,但这些广告的作用并没有实际意义。高级代码中确实有相应的删除广告的功能,但效果并不明显。在很多情况下,无法识别网络广告和实际有用的信息,因此会出现一些数据浪费或数据丢失。. 针对这种情况,我们小组决定对其广告过滤功能进行改进和修改。
2.按类别保存提取的文件:
对爬虫抓取的数据进行分类非常重要。学长的代码中,获取的数据没有入库分类存储,给下一组的开发留下了一些问题。,我组研究后认为应该增加保存党的分类的功能。
3.添加视频采集功能:
前辈的代码只实现了部分文本文件的提取,并没有进行视频数据的提取。但是由于网上很多视频都有相应的版权问题,而且大部分视频占用了很大的硬盘容量,所以我们会抓取视频的地址并存入数据库。
4.CSS 和 Javascript网站:
在原创代码中,只能抓取 HTTP6 网页。我们认为数据采集将过于有限。因此,我们想在这个问题中加入 CSS 和 Javascript 网站 的抓取功能。生成大量的代码工作量,只是一个初步的想法。
5.网页质量判断:
有些网站由于缺乏相关的和计算机知识的内容,重复搜索只会造成时间和资源的浪费。针对这种情况,我们认为应该增加一个判断网页质量的功能,把不合适的网站去掉,提高软件运行效率。
方法(实践):
1.对于抓取到的网站,获取URL,查看下一级网站的AD字段以及下一级网站与关键字的关联度
上学年对这个项目的评测中,去广告的功能并不完善,还夹杂了很多广告。他们在博客上写道,说是根据AD领域来判断这是否网站 是一个广告网站。我们觉得如果只根据AD字段来判断,有可能在网站中间的网站中抓取一些无用的广告。因此,我们觉得应该再往下检查一级。如果下一级网站中有很多广告网站,则排除这个网站。因为我们考虑到如果投放了一个广告,最多会经过一次网站传输,否则广告投放是不会生效的。因此,我们考虑多一个检测级别的方法,这应该可以在很大程度上解决问题。得到的网站中的广告有很多问题。
2.抓取的不同文件会根据文件格式的不同分别保存(先按文件夹分开)
捕获的 网站 根据它们与关键字的相关性进行分级和排序。上学年项目负责组评价写道,该组抓到的文件没有分类,所有文件都混在一起,给用户使用带来不便。我们想在这个软件中添加一个对捕获的文件进行分类和存储的功能。当某个文件被抓取时,会根据文件的类型,将其放置在该文件所在的存储区域中,从而完成软件运行。之后得到分类文件,方便用户使用。
3.提供视频链接,以便用户观看源视频
上一组没有完成相关视频的爬取功能。我们认为,如果它是一个网络爬虫,它的初衷是为互联网上的用户爬取有用的资源,而现在视频资源也很重要。因此,我们要增加视频捕捉功能。与内容和关键词相关的视频也会反馈给用户,以便用户观看相关视频。
4.CSS 和 Javascript网站
暂定。
5.检查关键词是否出现在被捕获的网站或者文件的标题中,如果在被捕获的网站或者文件的文本中频繁出现,用这个来判断此 网站 或文件的值给用户
我们认为,如果我们抓取其中出现关键词的所有资源,我们可能会抓取一些网站或不相关但出现关键词的文件,但在排除网站@之后> 以及对用户来说价值不大的文件,通过以上方法,我们抓取的东西质量会大大提高。
好处(好处):
1.能够更好地从结果中去除广告网站,优化用户体验
去除广告是我们爬虫非常重要的功能。爬虫的初衷是为用户高效地爬取互联网上有用的相关资源。如果可爬取资源中有大量的广告,会让用户的浏览很不方便,也就失去了爬虫的意义。. 我们将检查到下一个级别网站,并使用此方法排除广告网站。这样可以提高抓取资源的质量,用户可以更方便的使用爬虫的功能。
2.让用户更容易找到资源
如果爬虫把所有抓取到的资源放在一起,当用户需要一个格式单一的文件时会很麻烦。我们将采集到的资源按照类型分别保存,让用户可以更方便的使用软件,获得更好的用户体验。
3.让用户可以观看相关视频
这是一个全新的功能。之前的版本无法采集视频资源。虽然由于版权原因我们无法完全下载视频,但我们可以为用户提供源视频的链接,以便用户观看。现在互联网上有很多资源以视频的形式存在。我们加入这个功能是为了让这个软件更实用,更能满足用户不断增长的需求。
4.不限于HTML5网站,可以获得更多资源(暂定)
目前的版本只能爬取HTML5的网站,但是网站里面也有很多有用的资源是用javascript或者css的。我们更新了这个软件,支持javascript和css,可以让爬虫抓取更多的资源,为用户提供更多的服务。
5.提高采集结果的质量,增加剔除低质量资源的功能(暂定)
如果只关注捕获文件的数量和网站,可能会导致捕获文件和网站的质量很差,但是会减少结果中有用的文件和网站里面的成分让用户体验更差。我们将通过检测关键词是否出现在其标题及其出现频率等方法来确定该文件或网站对用户的价值。如果值不高,那么这个文件或 网站 @> 被排除。这将使我们能够抓取更高质量的文件和 网站。
竞争对手:
网络爬虫是一种自动获取网页内容的程序,是搜索引擎的重要组成部分。现在的搜索引擎基本上都涉及到爬虫的设计和优化。搜索引擎的速度也与爬虫的优化程度密切相关。从另一个角度来看,不仅仅是搜索引擎,所有的数据挖掘软件都会涉及到爬虫。因此,爬虫在整个软件行业的地位很高,应用范围非常广泛。这里我们主要通过搜索引擎中的爬虫来分析竞争。
首先,拿两个最常用的搜索引擎:百度和谷歌。从爬取信息来看,两者都是行业的佼佼者,爬取算法也很不错,可以按类型分类。,以方便用户操作。它爬取整个万维网的速度非常快。虽然我们的软件在速度和爬取算法方面还不是很成熟,但是我们的软件会为了方便用户而设计。我们会检查爬取文件的匹配度,对它们的优先级进行排序。这也将大大提高用户体验的质量。我将从以下几个方面来讨论我们软件的竞争力。
1.爬行速度和爬行负载,这也是衡量爬虫的标准
与其他软件相比,我们的软件在速度上还不错。我们通过广度优先的搜索顺序进行搜索,可以提高爬虫的爬取速度。同时,我们使用多个队列进行数据处理,这也使得爬虫可以同时处理多个数据。分组数据,承载能力更强。
2.爬取质量和特异性
很多网站爬虫爬取给定URL中的所有内容,不仅影响爬取内容的质量,还拖慢了预算。我们的爬虫会专门爬取电脑相关的数据,让爬取的内容更符合用户的需求。同时我们会对广告进行处理,也可以让爬虫的爬取质量更高。同时,我们会在爬取时与关键词进行匹配比较,可以大大减少广告和无关信息。
3.分类存储
用户的下一步操作可能会使用不同类型的数据。爬虫会在爬取过程中轻松对数据进行分类。分类可以让用户获得更好的用户体验,让用户在搜索的过程中可以更快的找到自己需要的信息。这应该更受程序员的欢迎。
4.接口与实现
用户在获取爬虫时,需要知道爬虫的输出形式和爬取速度,这就需要我们设计一个简单的接口来实现。我们的界面将以最简单的方式将输出呈现给用户,这将非常直观。
5.创新功能
我们将为原创爬虫添加新功能。比如抓取视频文件时,我们会将视频地址反馈给用户。这允许用户直接通过地址观看视频。此外,我们还计划实现不限于 html5 网页的爬取,甚至尝试爬取 CSS 或 javascript。这样可以更方便用户操作。
分类:
技术要点:
相关文章:
c爬虫抓取网页数据(Python对象的bs4解析方式和属性的方法和方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-04-13 09:39
bs4,全称BeautifulSoup 4,是Python独有的解析方式。也就是说,只有 Python 语言可以这样解析数据。
BeautifulSoup 3 只支持 Python 2,所以它已经过时了。
官网的介绍是这样的
Beautiful Soup 提供了简单的类似 python 的函数来处理导航、搜索、修改解析树等。它是一个工具箱,通过解析文档为用户提供他们需要抓取的数据。由于其简单性,编写完整的应用程序不需要太多代码。Beautiful Soup 自动将输入文档转换为 Unicode 编码,将输出文档自动转换为 utf-8 编码。不需要考虑编码方式,除非文档没有指定编码方式,否则Beautiful Soup无法自动识别编码方式。然后,您只需要指定原创编码。Beautiful Soup 已经成为与 lxml 和 html6lib 一样优秀的 python 解释器,为用户提供不同解析策略的灵活性或强大的速度。
看起来很复杂,我用自己的理解简单解释一下
我们知道一个网页的源代码是由多个标签组成的,比如,
,,,等等,而bs4是用来帮助我们准确定位标签位置的工具,从而获取标签的内容或标签属性。bs4默认自带的解析器,但官方推荐的是更强大更快的lxml解析器
其他解析器的优缺点
一、bs4的安装
pip install bs4
pip install lxml
用bs4解析时,推荐使用lxml解析器。使用 xpath 解析时也会用到
二、bs4解析原理1、如何实例化BeautySoup对象 导入bs4包
from bs4 import BeautifulSoup
湾。实例化对象
网页源代码进一步分为本地已经持久化的HTML文件和网络上直接获取的源代码。
如果是本地持久化文件,可以通过如下方式将源码加载到bs4对象中
fp = open('xxx.html', 'r', encoding='utf-8')
# lxml:解析器
soup = BeautifulSoup(fp, 'lxml')
如果是通过requests库获取的网页源代码,按如下方式加载
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, 'lxml')
C。数据解析的方法和属性
bs4 能够将复杂的 HTML 转换为树结构,其中每个节点都是一个 Python 对象。
soup.tagName(标签名):返回文档中第一次出现tagName对应的标签及其对应的内容
soup.tageName1.tageName2:返回tag1中tag1的标签和内容
soup.find:等价于soup.tagName,返回第一个匹配的对象
soup.find_all:返回所有匹配的对象。
通过查看源码你会发现find的本质就是调用find_all然后返回第一个元素
参数说明:
def find(self, name=None, attrs={}, recursive=True, text=None,
**kwargs):
"""Return only the first child of this Tag matching the given
criteria."""
r = None
l = self.find_all(name, attrs, recursive, text, 1, **kwargs)
if l:
r = l[0]
return r
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-iXUox6yw-53)(C:UsersAdministratorAppDataRoamingTyporatypora-user-imagesimage-23454< @0.png )]
上图是我从某网站中截取的部分画面,翻译成HTML如下(只保留对本次分析有用的部分,删除地址的域名信息为阅读方便)
测试Title
<p>尼古拉斯赵四

郑爽

朱一龙

周冬雨

胡一天

易烊千玺

迪丽热巴
</p>
看下面的例子
# 获取第一个li标签
# <p>郑爽
print(soup.li)
# # 获取第一个li标签中a标签
# 
郑爽
print(soup.li.a)
#获取第一个li标签中a标签
print(soup.find('li').a)
# 获取所有li标签
print(soup.find_all('li'))
# 获取title标签
print(soup.title)
# 获取a标签的父级标签
print(soup.a.parent)
# 获取a标签的父级标签的名字
print(soup.a.parent.name)</p>
如何在 HTML 中获取href?
分析:href是a标签中的一个属性,a标签在li标签中
提取bs4中tags中的属性可以通过attrs获取
其他补充剂
# 返回子孙节点
# children返回迭代器
result = soup.a.children
for i in result:
print(i)
# 返回子孙节点, contents返回列表
r = soup.a.contents
print(r)
# 可以通过正则对某个属性进行匹配
# 比如返回href中以zh开头的标签
import re
reg = re.compile('^zh')
result = soup.find_all(href=reg)
print(result)
选择器
bs4 非常强大,也支持 css 选择器。通过选择完成
测试Title
<p>尼古拉斯赵四

郑爽

朱一龙

周冬雨

胡一天

易烊千玺

迪丽热巴
</p>
from bs4 import BeautifulSoup
fp = open('baidu.html', 'r', encoding='utf-8')
soup = BeautifulSoup(fp, 'lxml')
# 返回一个所有a标签的列表
result = soup.select('a')
# 返回第一个
result1 = soup.select('a')[0]
"""
class选择器 : .className
"""
# 一层一层的进行选择,用 > 连接 即 > : 表示一个层级
# 输出 class = nr_zt 下ul下的li下的a标签集合
a = soup.select('.nr_zt > ul > li > a')
# 多个层级关联,使用 空格。
# 输出 class= 'nr_zt' 下的a标签集合
b = soup.select('.nr_zt a')
"""
id选择器: # idName
"""
result = soup.select('#star')
# 通过href属性查找,返回列表
soup.select('a[href="zhengshuang.html"]')
# 获取对应标签中img标签的src值
a = soup.select('a[href="zhengshuang.html"]')[0]
print(a.img['src']) # 5940f2cd6b759.jpg
以上是bs4的常用操作代码。其实在具体的爬取过程中,匹配的方式比较灵活,大家不用死记硬背,记住原理即可。
网络爬虫
Python 查看全部
c爬虫抓取网页数据(Python对象的bs4解析方式和属性的方法和方法)
bs4,全称BeautifulSoup 4,是Python独有的解析方式。也就是说,只有 Python 语言可以这样解析数据。
BeautifulSoup 3 只支持 Python 2,所以它已经过时了。
官网的介绍是这样的
Beautiful Soup 提供了简单的类似 python 的函数来处理导航、搜索、修改解析树等。它是一个工具箱,通过解析文档为用户提供他们需要抓取的数据。由于其简单性,编写完整的应用程序不需要太多代码。Beautiful Soup 自动将输入文档转换为 Unicode 编码,将输出文档自动转换为 utf-8 编码。不需要考虑编码方式,除非文档没有指定编码方式,否则Beautiful Soup无法自动识别编码方式。然后,您只需要指定原创编码。Beautiful Soup 已经成为与 lxml 和 html6lib 一样优秀的 python 解释器,为用户提供不同解析策略的灵活性或强大的速度。
看起来很复杂,我用自己的理解简单解释一下
我们知道一个网页的源代码是由多个标签组成的,比如,
,,,等等,而bs4是用来帮助我们准确定位标签位置的工具,从而获取标签的内容或标签属性。bs4默认自带的解析器,但官方推荐的是更强大更快的lxml解析器
其他解析器的优缺点

一、bs4的安装
pip install bs4
pip install lxml
用bs4解析时,推荐使用lxml解析器。使用 xpath 解析时也会用到
二、bs4解析原理1、如何实例化BeautySoup对象 导入bs4包
from bs4 import BeautifulSoup
湾。实例化对象
网页源代码进一步分为本地已经持久化的HTML文件和网络上直接获取的源代码。
如果是本地持久化文件,可以通过如下方式将源码加载到bs4对象中
fp = open('xxx.html', 'r', encoding='utf-8')
# lxml:解析器
soup = BeautifulSoup(fp, 'lxml')
如果是通过requests库获取的网页源代码,按如下方式加载
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, 'lxml')
C。数据解析的方法和属性
bs4 能够将复杂的 HTML 转换为树结构,其中每个节点都是一个 Python 对象。
soup.tagName(标签名):返回文档中第一次出现tagName对应的标签及其对应的内容
soup.tageName1.tageName2:返回tag1中tag1的标签和内容
soup.find:等价于soup.tagName,返回第一个匹配的对象
soup.find_all:返回所有匹配的对象。
通过查看源码你会发现find的本质就是调用find_all然后返回第一个元素
参数说明:
def find(self, name=None, attrs={}, recursive=True, text=None,
**kwargs):
"""Return only the first child of this Tag matching the given
criteria."""
r = None
l = self.find_all(name, attrs, recursive, text, 1, **kwargs)
if l:
r = l[0]
return r
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-iXUox6yw-53)(C:UsersAdministratorAppDataRoamingTyporatypora-user-imagesimage-23454< @0.png )]
上图是我从某网站中截取的部分画面,翻译成HTML如下(只保留对本次分析有用的部分,删除地址的域名信息为阅读方便)
测试Title
<p>尼古拉斯赵四

郑爽

朱一龙

周冬雨

胡一天

易烊千玺

迪丽热巴
</p>
看下面的例子
# 获取第一个li标签
# <p>郑爽
print(soup.li)
# # 获取第一个li标签中a标签
# 
郑爽
print(soup.li.a)
#获取第一个li标签中a标签
print(soup.find('li').a)
# 获取所有li标签
print(soup.find_all('li'))
# 获取title标签
print(soup.title)
# 获取a标签的父级标签
print(soup.a.parent)
# 获取a标签的父级标签的名字
print(soup.a.parent.name)</p>
如何在 HTML 中获取href?
分析:href是a标签中的一个属性,a标签在li标签中
提取bs4中tags中的属性可以通过attrs获取
其他补充剂
# 返回子孙节点
# children返回迭代器
result = soup.a.children
for i in result:
print(i)
# 返回子孙节点, contents返回列表
r = soup.a.contents
print(r)
# 可以通过正则对某个属性进行匹配
# 比如返回href中以zh开头的标签
import re
reg = re.compile('^zh')
result = soup.find_all(href=reg)
print(result)
选择器
bs4 非常强大,也支持 css 选择器。通过选择完成
测试Title
<p>尼古拉斯赵四

郑爽

朱一龙

周冬雨

胡一天

易烊千玺

迪丽热巴
</p>
from bs4 import BeautifulSoup
fp = open('baidu.html', 'r', encoding='utf-8')
soup = BeautifulSoup(fp, 'lxml')
# 返回一个所有a标签的列表
result = soup.select('a')
# 返回第一个
result1 = soup.select('a')[0]
"""
class选择器 : .className
"""
# 一层一层的进行选择,用 > 连接 即 > : 表示一个层级
# 输出 class = nr_zt 下ul下的li下的a标签集合
a = soup.select('.nr_zt > ul > li > a')
# 多个层级关联,使用 空格。
# 输出 class= 'nr_zt' 下的a标签集合
b = soup.select('.nr_zt a')
"""
id选择器: # idName
"""
result = soup.select('#star')
# 通过href属性查找,返回列表
soup.select('a[href="zhengshuang.html"]')
# 获取对应标签中img标签的src值
a = soup.select('a[href="zhengshuang.html"]')[0]
print(a.img['src']) # 5940f2cd6b759.jpg
以上是bs4的常用操作代码。其实在具体的爬取过程中,匹配的方式比较灵活,大家不用死记硬背,记住原理即可。

网络爬虫

Python
c爬虫抓取网页数据( 在学习Python之前,我们要知道,,Python的用途)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-04-13 09:37
在学习Python之前,我们要知道,,Python的用途)
在学习 Python 之前,我们需要了解 Python 的用途以及学习它能给我们带来什么?
Python主要包括网络爬虫、网站开发、人工智能、自动化运维
这里我们主要看一下网络爬虫,什么是网络爬虫?
网络爬虫,又称网络蜘蛛,是指一种脚本程序,它按照一定的规则在网络上爬取想要的内容。众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个URL依次进入其他网址,获取想要的内容。
爬行动物有什么用?
做垂直搜索引擎(google、baidu等)。
科学研究:在线人类行为、在线社区进化、人类动力学研究、定量社会学、复杂网络、数据挖掘等实证研究领域需要大量数据,而网络爬虫是采集相关数据的有力工具。
偷窥、黑客攻击、垃圾邮件……
爬行是搜索引擎的第一步,也是最简单的一步。
用什么语言编写爬虫?
C、C++。高效、快速,适合一般搜索引擎爬取全网。缺点,开发慢,写起来又臭又长,例如:天网搜索源码。
脚本语言:Perl、Python、Java、Ruby。简单易学,良好的文本处理可以方便网页内容的详细提取,但效率往往不高,适合少量网站的集中抓取
C#?
为什么 Python 现在最流行?
就个人而言,我用 c# 和 java 编写了爬虫。差别不大,原则是用好正则表达式。只是平台问题。后来才知道很多爬虫都是用python写的,所以一发不可收拾。Python有很多优点,总结两个要点:
1)抓取网页本身的接口
相比其他静态编程语言,如java、c#、C++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2)网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要蟒蛇。 查看全部
c爬虫抓取网页数据(
在学习Python之前,我们要知道,,Python的用途)

在学习 Python 之前,我们需要了解 Python 的用途以及学习它能给我们带来什么?
Python主要包括网络爬虫、网站开发、人工智能、自动化运维
这里我们主要看一下网络爬虫,什么是网络爬虫?
网络爬虫,又称网络蜘蛛,是指一种脚本程序,它按照一定的规则在网络上爬取想要的内容。众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个URL依次进入其他网址,获取想要的内容。

爬行动物有什么用?
做垂直搜索引擎(google、baidu等)。
科学研究:在线人类行为、在线社区进化、人类动力学研究、定量社会学、复杂网络、数据挖掘等实证研究领域需要大量数据,而网络爬虫是采集相关数据的有力工具。
偷窥、黑客攻击、垃圾邮件……
爬行是搜索引擎的第一步,也是最简单的一步。
用什么语言编写爬虫?
C、C++。高效、快速,适合一般搜索引擎爬取全网。缺点,开发慢,写起来又臭又长,例如:天网搜索源码。
脚本语言:Perl、Python、Java、Ruby。简单易学,良好的文本处理可以方便网页内容的详细提取,但效率往往不高,适合少量网站的集中抓取
C#?
为什么 Python 现在最流行?

就个人而言,我用 c# 和 java 编写了爬虫。差别不大,原则是用好正则表达式。只是平台问题。后来才知道很多爬虫都是用python写的,所以一发不可收拾。Python有很多优点,总结两个要点:
1)抓取网页本身的接口
相比其他静态编程语言,如java、c#、C++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2)网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要蟒蛇。
c爬虫抓取网页数据(如何通过谷歌浏览器开发者工具分析真实请求的三个步骤分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-04-13 07:19
爬虫的大致思路:抓取网页,分析请求
解析网页并查找数据
存储数据,多页面处理
本课主要讲授如何通过谷歌浏览器开发者工具分析真实请求。
三步找到真正的请求
分析:使用 Google Chrome 开发者工具分析网页请求
测试:测试URL请求中各个参数的作用,找出控制翻页等功能的参数
Repeat:反复寻找满足爬虫需求的真实请求
实用链接:爬取知乎
通过爬取知乎“轮子哥”——vczh相关人士分析Ajax或JavaScript加载数据的真实请求,并展示该爬取方式的具体过程。
1. 寻找真实请求的测试首先进入“轮子哥-vczh”关注者的页面(注意:需要登录个人知乎帐户优先)
通过禁用javascript加载发现页面无法正常加载,确认页面的翻页是通过javascript加载数据实现的
使用谷歌浏览器开发者工具查找收录关注者信息的真实请求。可以发现,真正的请求是以“followees”开头的请求,返回的是一个JSON格式的数据,对应下一页的“Followees”。人”:
双击该请求返回JSON格式的数据,通过安装JSONView插件可以更好的显示在浏览器中
然后您可以尝试抓取请求的数据
2. 尝试爬取真实请求的数据 先尝试使用前几课学习的requests.get() 来爬取数据
可以发现返回“500 Server Error”,即由于网站反爬虫,服务器返回“500 Service Error”
这个问题可以通过添加headers请求头信息来解决
3. 添加headers请求头信息,模拟浏览器访问。请求头信息携带客户端浏览器、请求页面、服务器等信息,用于通知服务器发起请求的客户端的具体信息
p>
知乎反爬机制是通过检查请求头信息实现的,所以在使用request请求数据的时候需要加上需要的请求头
对比知乎的请求头信息和普通请求头信息,发现知乎的请求头有更多的授权和X-UDID信息
向爬虫添加请求头信息,即添加headers# -*- coding:utf-8 -*-
导入请求
标题 = {
'authorization':' ',#括号内填写你的授权
'User-Agent':' ',#括号里填你的User-Agent
}
url = '*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%ics&offset=20&limit=20'
response=requests.get(url, headers = headers).json()
打印(响应)
最终代码:#!/usr/bin/env python3
# -*- 编码:utf-8 -*-
"""
创建于 2018 年 3 月 20 日星期二 16:01:47
@作者:杰基
"""
导入请求
将熊猫导入为 pd
进口时间
标题 = {
'授权': '承载 2 | 1:0 | 10:1519627538 | 4:z_c0 | 92: Mi4xYzBvWkFBQUFBQUFBSU1JaTVqRU1EQ1lBQUFCZ0FsVk5FdnVBV3dEdHdaRmtBR1lmZEpqT3VvdmtpSm5QMWtkZ1ZB | 787597598f41757929f46f687f78434dbc66d6abc980e40fb50b55cd09062b07',
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/6< @4.0.3282.186 Safari/537.36',
'x-udid':'ACDCIuYxDAyPTg7eVnDe8ytVGX6ivGdKZ9E=',
}
user_data = []
def get_user_data(page):
for i in range(page):
url = '*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%ics&offset={}&limit=20'.format(i*20)
response = requests.get(url, headers = headers).json()['data']
user_data.extend(响应)
print('爬取页面 %s' %str(i+1))
时间.sleep(1)
如果 __name__ == '__main__':
get_user_data(3)
df = pd.DataFrame(user_data)
df.to_csv('users.csv')
补充知识
1. JSONJSON 是一种轻量级的数据交换格式。连接API爬取数据时,一般数据返回格式为JSON。
JSONView 插件:前往 Chrome JSONView 插件安装,下载并安装 JSONView 插件,以使 JSON 格式的数据在 Google Chrome 中更好地呈现 查看全部
c爬虫抓取网页数据(如何通过谷歌浏览器开发者工具分析真实请求的三个步骤分析)
爬虫的大致思路:抓取网页,分析请求
解析网页并查找数据
存储数据,多页面处理
本课主要讲授如何通过谷歌浏览器开发者工具分析真实请求。
三步找到真正的请求
分析:使用 Google Chrome 开发者工具分析网页请求
测试:测试URL请求中各个参数的作用,找出控制翻页等功能的参数
Repeat:反复寻找满足爬虫需求的真实请求
实用链接:爬取知乎
通过爬取知乎“轮子哥”——vczh相关人士分析Ajax或JavaScript加载数据的真实请求,并展示该爬取方式的具体过程。
1. 寻找真实请求的测试首先进入“轮子哥-vczh”关注者的页面(注意:需要登录个人知乎帐户优先)
通过禁用javascript加载发现页面无法正常加载,确认页面的翻页是通过javascript加载数据实现的
使用谷歌浏览器开发者工具查找收录关注者信息的真实请求。可以发现,真正的请求是以“followees”开头的请求,返回的是一个JSON格式的数据,对应下一页的“Followees”。人”:
双击该请求返回JSON格式的数据,通过安装JSONView插件可以更好的显示在浏览器中
然后您可以尝试抓取请求的数据
2. 尝试爬取真实请求的数据 先尝试使用前几课学习的requests.get() 来爬取数据
可以发现返回“500 Server Error”,即由于网站反爬虫,服务器返回“500 Service Error”
这个问题可以通过添加headers请求头信息来解决
3. 添加headers请求头信息,模拟浏览器访问。请求头信息携带客户端浏览器、请求页面、服务器等信息,用于通知服务器发起请求的客户端的具体信息
p>
知乎反爬机制是通过检查请求头信息实现的,所以在使用request请求数据的时候需要加上需要的请求头
对比知乎的请求头信息和普通请求头信息,发现知乎的请求头有更多的授权和X-UDID信息
向爬虫添加请求头信息,即添加headers# -*- coding:utf-8 -*-
导入请求
标题 = {
'authorization':' ',#括号内填写你的授权
'User-Agent':' ',#括号里填你的User-Agent
}
url = '*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%ics&offset=20&limit=20'
response=requests.get(url, headers = headers).json()
打印(响应)
最终代码:#!/usr/bin/env python3
# -*- 编码:utf-8 -*-
"""
创建于 2018 年 3 月 20 日星期二 16:01:47
@作者:杰基
"""
导入请求
将熊猫导入为 pd
进口时间
标题 = {
'授权': '承载 2 | 1:0 | 10:1519627538 | 4:z_c0 | 92: Mi4xYzBvWkFBQUFBQUFBSU1JaTVqRU1EQ1lBQUFCZ0FsVk5FdnVBV3dEdHdaRmtBR1lmZEpqT3VvdmtpSm5QMWtkZ1ZB | 787597598f41757929f46f687f78434dbc66d6abc980e40fb50b55cd09062b07',
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/6< @4.0.3282.186 Safari/537.36',
'x-udid':'ACDCIuYxDAyPTg7eVnDe8ytVGX6ivGdKZ9E=',
}
user_data = []
def get_user_data(page):
for i in range(page):
url = '*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%ics&offset={}&limit=20'.format(i*20)
response = requests.get(url, headers = headers).json()['data']
user_data.extend(响应)
print('爬取页面 %s' %str(i+1))
时间.sleep(1)
如果 __name__ == '__main__':
get_user_data(3)
df = pd.DataFrame(user_data)
df.to_csv('users.csv')
补充知识
1. JSONJSON 是一种轻量级的数据交换格式。连接API爬取数据时,一般数据返回格式为JSON。
JSONView 插件:前往 Chrome JSONView 插件安装,下载并安装 JSONView 插件,以使 JSON 格式的数据在 Google Chrome 中更好地呈现
c爬虫抓取网页数据(Python爬虫如何写爬虫“贼船”等上了贼船才发现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-04-11 06:10
写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是一行代码骗你上“贼船”,上贼船才发现,水好深~
例如,爬取一个网页可以是非常简单的一行代码:
r = requests.get('http://news.baidu.com')
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
网络爬虫难点一:只爬 HTML 页面但可扩展
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本上就是一行。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
我们先来看一下新闻爬虫的简单流程图:
从一些种子页开始,种子页往往是一些新闻网站的首页,爬虫抓取该页面,从中提取出网站的URL,放入URL池中进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内抓取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。爬虫如何在织网抓取“旧”新闻的同时兼顾“新”新闻的获取?
如何存储大量捕获的新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、正文内容等,给内容提取带来困难。
网络爬虫难点二:需要登录才能抓取想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能看到。也就是说,爬虫在请求的时候必须登录才能抓取数据。
如何获取登录状态? 查看全部
c爬虫抓取网页数据(Python爬虫如何写爬虫“贼船”等上了贼船才发现)
写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是一行代码骗你上“贼船”,上贼船才发现,水好深~
例如,爬取一个网页可以是非常简单的一行代码:
r = requests.get('http://news.baidu.com')
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
网络爬虫难点一:只爬 HTML 页面但可扩展
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本上就是一行。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
我们先来看一下新闻爬虫的简单流程图:
从一些种子页开始,种子页往往是一些新闻网站的首页,爬虫抓取该页面,从中提取出网站的URL,放入URL池中进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内抓取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。爬虫如何在织网抓取“旧”新闻的同时兼顾“新”新闻的获取?
如何存储大量捕获的新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、正文内容等,给内容提取带来困难。
网络爬虫难点二:需要登录才能抓取想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能看到。也就是说,爬虫在请求的时候必须登录才能抓取数据。
如何获取登录状态?
网络爬虫—利用SAS抓取网页方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-05-14 02:43
万维网过多的信息,股票报价,电影评论,市场价格趋势话题,几乎所有的东西,可以发现在点击一个按钮。在分析数据中发现,许多SAS用户感兴趣在网络上,但你得到这个数据的SAS环境呢?有很多方法,如 SAS数据步骤中的代码在设计你自己的网络爬虫或利用SAS%TMFILTER宏 ® 文本挖掘。在本文中,我们将审查一个网络爬虫的总体架构。我们将讨论获得网站的方法到SAS的信息,以及审查内部所谓的SAS搜索从实验项目的实验代码管道。我们也将提供咨询如何轻松定制一个网络爬虫,以适应个性化需求,以及如何具体的数据导入到SAS ® 企业矿工™。
简介:互联网已经成为一个有用的信息来源。通常是Web上的数据,我们要使用内的SAS,所以我们需要找到一种方式来获得这个数据。最好的办法是使用一个网络爬虫。 SAS提供几个从Web爬行和提取信息的方法。您可以使用基本的SAS数据步骤中的代码,或SAS文本矿工的%TMFILTER宏。虽然目前无法使用,SAS搜索管道将是一个功能强大的Web爬行产品,并提供更多的工具,网络爬行。每种方法都有其优点和缺点,所以取决于你想实现抓取的,它是最好对其进行审查。
首先,重要的是要了解网络爬虫是如何工作的。你应该熟悉数据步骤的代码,宏,和SAS过程PROC SQL,然后再继续。
网络爬虫概述:一个网络爬虫是一个程序,一个或多个起始地址作为“种子URL”,下载网站这些URL相关的网页,在网页中包含的任何超链接提取,并递归地继续这些超链接标识下载Web页。从概念上讲,网络爬虫是很简单的。
一个Web 履带式有四项职责:
1。从候选人中选择一个网址。
2。它下载相关的Web页。
3。它提取物在网页中的URL(超链接)。
4。它补充说,未曾遇到的候选集的URL
方法1:在WEB SAS数据步骤中的代码履带式
首先创建一个网址的网站的Web crawler将开始列表。
data work.links_to_crawl;
length url $256 ;
input url $;
datalines;
;
run
为了确保我们不抓取相同的URL一次以上,持有环节已创建一个数据抓取。
当Web数据集将在开始时是空的,但一个网站的网址将被添加到数据集履带式完成抓取该网站。
data work.links_crawled;
length url $256;
run;
现在我们开始爬行!该代码需要我们的 work.links_to_crawl数据集的第一个URL。在第一观察“_N_式1”,网址是投入名为 next_url 宏变量,所有剩余的URL放回我们的种子URL数据集,使他们在未来的迭代。
/* pop the next url off */
%let next_url = ;
data work.links_to_crawl;
set work.links_to_crawl;
if _n_ eq 1 then call symput(“next_url”, url);
else output;
run;
现在,从互联网上下载的网址。创建一个文件名称 _nexturl 。我们让SAS知道它是一个URL 而且可以发现,AT&next_url,这是我们的宏观变量,它包含的网址我们从拉 work.links_to_crawl数据集。
/* crawl the url */
filename _nexturl url “&next_url”
建立后的文件名的URL参考,确定一个地方把我们下载的文件。创建另一个文件名引用所谓 htmlfilm的条目,并在那里把从 url_file.html收集到的信息。
/* put the file we crawled here */
filename htmlfile “url_file.html”
接下来,我们通过数据的循环,把它写htmlfilm的条目文件名参考,并寻找更多的网址添加到我们的 work.links_to_crawl数据集。
/* find more urls */
data work._urls(keep=url);
length url $256 ;
file htmlfile;
infile _nexturl length=len;
input text $varying2000. len;
put text;
start = 1;
stop = length(text);
使用正则表达式一个网站的网址,以帮助搜索。正则表达式的匹配方法文本字符串,如字,词,或字符模式。 SAS已经提供了许多强大的字符串功能。然而,正则表达式通常会提供一个更简洁的方式,操纵和匹配的文本.
if _n_ = 1 then do;
retain patternID;
pattern = ‘/href=”([^"]+)”/i’;
patternID = prxparse(pattern);
end
首次观察到,创建一个patternID将保持整个数据步运行。寻找的模式是: “/href=”([^"]+)”/i’”.,这意味着我们正在寻找字符串“HREF =”“,然后再寻找任何字符串,是至少有一个字符长,不包含引号(“),并结束在引号(”)。在’我’ 目的的手段使用不区分大小写的方法,以配合我们的正则表达式。
As a result, the Web crawler will find these types of strings:
href=”sgf/2010/papers.html”
href=””
HREF=””
hReF=””
现在正则表达式匹配的一个网站上的文字。 PRXNEXT需要五个参数:正则表达式我们要寻找,寻找开始寻找正则表达式的开始位置,结束位置停止正则表达式,一旦发现字符串中的位置,而字符串的长度,如果发现的位置将是0,如果没有找到字符串。 PRXNEXT也改变了开始的参数,使搜索重新开始后的最后一场比赛是发现。
call prxnext(patternID, start, stop, text, position, length);
代码中的循环,在网站上找到的所有环节显示的文本。
do while (position ^= 0);
url = substr(text, position+6, length-7);
output;
call prxnext(patternID, start, stop, text, position, length);
end;
run;
如果代码发现一个网址,它会检索唯一的URL的一部分,启动后的第一个引号。例如,如果代码中发现的HREF =“”,那么它应该保持 。使用 substr到删除前的6个字符和最后一个字符的URL的其余部分输出的work._urls 数据集。现在,我们插入的URL代码只是以跟踪抓取到一个数据集名为 work.links_crawled 我们已经和确保我们不再次浏览有。
/* add the current link to the list of urls we have already crawled */
data work._old_link;
url = “&next_url”;
run;
proc append base=work.links_crawled data=work._old_link force;
run;
下一步是在数据集 work._urls 的过程中发现的网址列表,以确保:
1。我们尚未抓取他们,换句话说URL是不是在 work.links_crawled)。
2。我们没有排队抓取的URL(网址换句话说,是不是在work.links_to_crawl )。
/*
* only add urls that we have not already crawled
* or that are not queued up to be crawled
*
*/
proc sql noprint;
create table work._append as
select url
from work._urls
where url not in (select url from work.links_crawled)
and url not in (select url from work.links_to_crawl);
quit;
然后,我们添加网址还没有被抓取,而不是已经排队 work.links_to_crawl数据集。
/* add new links */
proc append base=work.links_to_crawl data=work._append force;
run;
此时的代码循环回到开始劫掠 work.links_to_crawl数据集的下一个URL。 查看全部
网络爬虫—利用SAS抓取网页方法
万维网过多的信息,股票报价,电影评论,市场价格趋势话题,几乎所有的东西,可以发现在点击一个按钮。在分析数据中发现,许多SAS用户感兴趣在网络上,但你得到这个数据的SAS环境呢?有很多方法,如 SAS数据步骤中的代码在设计你自己的网络爬虫或利用SAS%TMFILTER宏 ® 文本挖掘。在本文中,我们将审查一个网络爬虫的总体架构。我们将讨论获得网站的方法到SAS的信息,以及审查内部所谓的SAS搜索从实验项目的实验代码管道。我们也将提供咨询如何轻松定制一个网络爬虫,以适应个性化需求,以及如何具体的数据导入到SAS ® 企业矿工™。
简介:互联网已经成为一个有用的信息来源。通常是Web上的数据,我们要使用内的SAS,所以我们需要找到一种方式来获得这个数据。最好的办法是使用一个网络爬虫。 SAS提供几个从Web爬行和提取信息的方法。您可以使用基本的SAS数据步骤中的代码,或SAS文本矿工的%TMFILTER宏。虽然目前无法使用,SAS搜索管道将是一个功能强大的Web爬行产品,并提供更多的工具,网络爬行。每种方法都有其优点和缺点,所以取决于你想实现抓取的,它是最好对其进行审查。
首先,重要的是要了解网络爬虫是如何工作的。你应该熟悉数据步骤的代码,宏,和SAS过程PROC SQL,然后再继续。
网络爬虫概述:一个网络爬虫是一个程序,一个或多个起始地址作为“种子URL”,下载网站这些URL相关的网页,在网页中包含的任何超链接提取,并递归地继续这些超链接标识下载Web页。从概念上讲,网络爬虫是很简单的。
一个Web 履带式有四项职责:
1。从候选人中选择一个网址。
2。它下载相关的Web页。
3。它提取物在网页中的URL(超链接)。
4。它补充说,未曾遇到的候选集的URL
方法1:在WEB SAS数据步骤中的代码履带式
首先创建一个网址的网站的Web crawler将开始列表。
data work.links_to_crawl;
length url $256 ;
input url $;
datalines;
;
run
为了确保我们不抓取相同的URL一次以上,持有环节已创建一个数据抓取。
当Web数据集将在开始时是空的,但一个网站的网址将被添加到数据集履带式完成抓取该网站。
data work.links_crawled;
length url $256;
run;
现在我们开始爬行!该代码需要我们的 work.links_to_crawl数据集的第一个URL。在第一观察“_N_式1”,网址是投入名为 next_url 宏变量,所有剩余的URL放回我们的种子URL数据集,使他们在未来的迭代。
/* pop the next url off */
%let next_url = ;
data work.links_to_crawl;
set work.links_to_crawl;
if _n_ eq 1 then call symput(“next_url”, url);
else output;
run;
现在,从互联网上下载的网址。创建一个文件名称 _nexturl 。我们让SAS知道它是一个URL 而且可以发现,AT&next_url,这是我们的宏观变量,它包含的网址我们从拉 work.links_to_crawl数据集。
/* crawl the url */
filename _nexturl url “&next_url”
建立后的文件名的URL参考,确定一个地方把我们下载的文件。创建另一个文件名引用所谓 htmlfilm的条目,并在那里把从 url_file.html收集到的信息。
/* put the file we crawled here */
filename htmlfile “url_file.html”
接下来,我们通过数据的循环,把它写htmlfilm的条目文件名参考,并寻找更多的网址添加到我们的 work.links_to_crawl数据集。
/* find more urls */
data work._urls(keep=url);
length url $256 ;
file htmlfile;
infile _nexturl length=len;
input text $varying2000. len;
put text;
start = 1;
stop = length(text);
使用正则表达式一个网站的网址,以帮助搜索。正则表达式的匹配方法文本字符串,如字,词,或字符模式。 SAS已经提供了许多强大的字符串功能。然而,正则表达式通常会提供一个更简洁的方式,操纵和匹配的文本.
if _n_ = 1 then do;
retain patternID;
pattern = ‘/href=”([^"]+)”/i’;
patternID = prxparse(pattern);
end
首次观察到,创建一个patternID将保持整个数据步运行。寻找的模式是: “/href=”([^"]+)”/i’”.,这意味着我们正在寻找字符串“HREF =”“,然后再寻找任何字符串,是至少有一个字符长,不包含引号(“),并结束在引号(”)。在’我’ 目的的手段使用不区分大小写的方法,以配合我们的正则表达式。
As a result, the Web crawler will find these types of strings:
href=”sgf/2010/papers.html”
href=””
HREF=””
hReF=””
现在正则表达式匹配的一个网站上的文字。 PRXNEXT需要五个参数:正则表达式我们要寻找,寻找开始寻找正则表达式的开始位置,结束位置停止正则表达式,一旦发现字符串中的位置,而字符串的长度,如果发现的位置将是0,如果没有找到字符串。 PRXNEXT也改变了开始的参数,使搜索重新开始后的最后一场比赛是发现。
call prxnext(patternID, start, stop, text, position, length);
代码中的循环,在网站上找到的所有环节显示的文本。
do while (position ^= 0);
url = substr(text, position+6, length-7);
output;
call prxnext(patternID, start, stop, text, position, length);
end;
run;
如果代码发现一个网址,它会检索唯一的URL的一部分,启动后的第一个引号。例如,如果代码中发现的HREF =“”,那么它应该保持 。使用 substr到删除前的6个字符和最后一个字符的URL的其余部分输出的work._urls 数据集。现在,我们插入的URL代码只是以跟踪抓取到一个数据集名为 work.links_crawled 我们已经和确保我们不再次浏览有。
/* add the current link to the list of urls we have already crawled */
data work._old_link;
url = “&next_url”;
run;
proc append base=work.links_crawled data=work._old_link force;
run;
下一步是在数据集 work._urls 的过程中发现的网址列表,以确保:
1。我们尚未抓取他们,换句话说URL是不是在 work.links_crawled)。
2。我们没有排队抓取的URL(网址换句话说,是不是在work.links_to_crawl )。
/*
* only add urls that we have not already crawled
* or that are not queued up to be crawled
*
*/
proc sql noprint;
create table work._append as
select url
from work._urls
where url not in (select url from work.links_crawled)
and url not in (select url from work.links_to_crawl);
quit;
然后,我们添加网址还没有被抓取,而不是已经排队 work.links_to_crawl数据集。
/* add new links */
proc append base=work.links_to_crawl data=work._append force;
run;
此时的代码循环回到开始劫掠 work.links_to_crawl数据集的下一个URL。
c爬虫抓取网页数据的选择思路及选择方法介绍-requests
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-05-11 15:02
c爬虫抓取网页数据的工具很多,比如requests、beautifulsoup等等;另外爬虫还可以用scrapy框架做反爬虫。甚至apache/nginx做反反爬虫也可以。本文会结合requests做网页反爬虫。文章包含以下主要内容1.介绍一下requests库2.先介绍爬虫是怎么获取网页数据的3.解决爬虫服务器速度慢、不稳定的问题4.在各种网页爬虫框架中的选择思路5.requests详细流程看起来主要内容不多,一行代码搞定,但上述一些问题确很麻烦。
以上每一个都会成为一篇文章,首先说明这里每一个主要代码单独抽取下即可,其实大多是我写的。再说明上述操作本质上是对url和网页元素进行了解析。由于requests方便的处理url,因此解析html这件事可以交给自己来做。requests最简单的实现抓取网页时,没有必要在html网页处理过程中还需要保存html信息,基本步骤:1.获取网页包含信息2.解析html3.存储数据对爬虫爬取html来说,需要经历requests库爬取网页时传递参数,传递到selenium线程池,由线程池来解析html信息。
selenium不需要保存任何网页信息,直接处理后分析为webapi输出即可。所以上述的各个步骤和html编码没有太大关系。也不要问为什么不用xpath,因为xpath和html编码不一样,在抓取网页时必须转换为xpath/emoji可读语言才能读取正常。现在有一些爬虫框架都有支持requests,比如scrapy、kibana和motrix;正因为requests简单,因此其解析html的方式也简单;我们介绍一下其中一些爬虫框架的爬取html的方式。
这样的主要目的是想通过对requests的熟悉,进一步使用其他框架做爬虫之类的。requestsjs官网:requests的一个重要版本,很多第三方包支持其爬取html信息。javascript解析html模块库:v8解析javascript/text/string,使用jsonp:直接发送http请求或是使用浏览器的浏览器api返回html数据,jquery解析javascript代码,并将javascript数据以html数据格式返回。
prestojs(已经被大弃)/zeptojs(github)requestsjs的主要代码都来自于这里;web容器:injection来负责生成html标签和处理html;有一个重要组件是seleniumdriver和requests的交互,getseleniumdriver做的事情非常类似于html编程中的函数调用,类似于open和session来做html编程中的dom操作;httpurlconnectionhttpconnection负责接收请求并处理响应,并且通过post请求,向服务器发送数据,请求的格式使用headers:attributes:user-agent:mozilla/5.0(ipad;cpuiphoneosx10_。 查看全部
c爬虫抓取网页数据的选择思路及选择方法介绍-requests
c爬虫抓取网页数据的工具很多,比如requests、beautifulsoup等等;另外爬虫还可以用scrapy框架做反爬虫。甚至apache/nginx做反反爬虫也可以。本文会结合requests做网页反爬虫。文章包含以下主要内容1.介绍一下requests库2.先介绍爬虫是怎么获取网页数据的3.解决爬虫服务器速度慢、不稳定的问题4.在各种网页爬虫框架中的选择思路5.requests详细流程看起来主要内容不多,一行代码搞定,但上述一些问题确很麻烦。
以上每一个都会成为一篇文章,首先说明这里每一个主要代码单独抽取下即可,其实大多是我写的。再说明上述操作本质上是对url和网页元素进行了解析。由于requests方便的处理url,因此解析html这件事可以交给自己来做。requests最简单的实现抓取网页时,没有必要在html网页处理过程中还需要保存html信息,基本步骤:1.获取网页包含信息2.解析html3.存储数据对爬虫爬取html来说,需要经历requests库爬取网页时传递参数,传递到selenium线程池,由线程池来解析html信息。
selenium不需要保存任何网页信息,直接处理后分析为webapi输出即可。所以上述的各个步骤和html编码没有太大关系。也不要问为什么不用xpath,因为xpath和html编码不一样,在抓取网页时必须转换为xpath/emoji可读语言才能读取正常。现在有一些爬虫框架都有支持requests,比如scrapy、kibana和motrix;正因为requests简单,因此其解析html的方式也简单;我们介绍一下其中一些爬虫框架的爬取html的方式。
这样的主要目的是想通过对requests的熟悉,进一步使用其他框架做爬虫之类的。requestsjs官网:requests的一个重要版本,很多第三方包支持其爬取html信息。javascript解析html模块库:v8解析javascript/text/string,使用jsonp:直接发送http请求或是使用浏览器的浏览器api返回html数据,jquery解析javascript代码,并将javascript数据以html数据格式返回。
prestojs(已经被大弃)/zeptojs(github)requestsjs的主要代码都来自于这里;web容器:injection来负责生成html标签和处理html;有一个重要组件是seleniumdriver和requests的交互,getseleniumdriver做的事情非常类似于html编程中的函数调用,类似于open和session来做html编程中的dom操作;httpurlconnectionhttpconnection负责接收请求并处理响应,并且通过post请求,向服务器发送数据,请求的格式使用headers:attributes:user-agent:mozilla/5.0(ipad;cpuiphoneosx10_。
爬虫入门到精通-网页的下载
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-05-09 09:27
本文章属于爬虫入门到精通系统教程第四讲
在爬虫入门到精通第二讲中,我们了解了HTTP协议
#rd,那么我们现在使用这些协议来快速爬虫吧
本文的目标
当你看完本文后,你应该能爬取(几乎)任何的网页
使用chrome抓包抓包(packet capture)就是将网络传输发送与接收的数据包进行截获、重发、编辑、转存等操作,也用来检查网络安全。抓包也经常被用来进行数据截取等。第一个案列:抓取轮子哥的动态()
1.打开轮子哥动态这个网页
2.打开抓包工具
应该会看到如下界面
3.找到我们需要的请求
可以看到如下截图,里面有这么多的请求,那么到底哪一个才是我们需要的呢 ?
这边提供一个小技巧
简单来讲就是如果整个页面没有刷新的话,那就是在XHR里面,否则在DOC里面
因为本次抓包整个页面有刷新,所以,我们需要找的请求在DOC下面,可以看到只有一个请求
4.验证请求是对的
有以下两种方法(基本上用1,因为比较快)
在我们要抓包的页面随便copy出几个字,在Respoinse中使用ctrl+f 查找,如果有找到,说明我们找到的是对的 (我查找的是"和微软粉丝谈")
2.把response中所有的内容复制到一个txt中,并改名为"#.html"(这里的#可以随便取)
然后打开这个html,看看是否和我们要抓的一样
如果发现要找的不对,那你可以打开下一个请求检查下
5.模拟发送
点击Headers
可以看到请求的url是:
方法是: GET
requests headers 是(下图中框出来的地方)
所以我们的代码应该是:
import requests# 这里的headers就是我们上图框中的headers
request_headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch, br','Accept-Language':'zh-CN,zh;q=0.8','Cache-Control':'max-age=0','Connection':'keep-alive','Cookie':'','Host':'www.zhihu.com','Referer':'https://www.zhihu.com/','Upgrade-Insecure-Requests':'1','User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
}
#上图中的url
url = "https://www.zhihu.com/people/e ... ot%3B
# 上图中的请求方法(get)
z = requests.get(url,headers=request_headers)
print z.content
这段代码简单来说就是把 我们抓包看到的用程序来实现
一个小总结
我们爬取一个网页的步骤可以分为如下:
打开要爬取的网页
打开开发者工具,并让请求重发一次(简单讲就是抓包)
找到正确的请求
用程序模拟发送
第二个案列:点赞
1.打开要爬取的网页 查看全部
爬虫入门到精通-网页的下载
本文章属于爬虫入门到精通系统教程第四讲
在爬虫入门到精通第二讲中,我们了解了HTTP协议
#rd,那么我们现在使用这些协议来快速爬虫吧
本文的目标
当你看完本文后,你应该能爬取(几乎)任何的网页
使用chrome抓包抓包(packet capture)就是将网络传输发送与接收的数据包进行截获、重发、编辑、转存等操作,也用来检查网络安全。抓包也经常被用来进行数据截取等。第一个案列:抓取轮子哥的动态()
1.打开轮子哥动态这个网页
2.打开抓包工具
应该会看到如下界面
3.找到我们需要的请求
可以看到如下截图,里面有这么多的请求,那么到底哪一个才是我们需要的呢 ?
这边提供一个小技巧
简单来讲就是如果整个页面没有刷新的话,那就是在XHR里面,否则在DOC里面
因为本次抓包整个页面有刷新,所以,我们需要找的请求在DOC下面,可以看到只有一个请求
4.验证请求是对的
有以下两种方法(基本上用1,因为比较快)
在我们要抓包的页面随便copy出几个字,在Respoinse中使用ctrl+f 查找,如果有找到,说明我们找到的是对的 (我查找的是"和微软粉丝谈")
2.把response中所有的内容复制到一个txt中,并改名为"#.html"(这里的#可以随便取)
然后打开这个html,看看是否和我们要抓的一样
如果发现要找的不对,那你可以打开下一个请求检查下
5.模拟发送
点击Headers
可以看到请求的url是:
方法是: GET
requests headers 是(下图中框出来的地方)
所以我们的代码应该是:
import requests# 这里的headers就是我们上图框中的headers
request_headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch, br','Accept-Language':'zh-CN,zh;q=0.8','Cache-Control':'max-age=0','Connection':'keep-alive','Cookie':'','Host':'www.zhihu.com','Referer':'https://www.zhihu.com/','Upgrade-Insecure-Requests':'1','User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
}
#上图中的url
url = "https://www.zhihu.com/people/e ... ot%3B
# 上图中的请求方法(get)
z = requests.get(url,headers=request_headers)
print z.content
这段代码简单来说就是把 我们抓包看到的用程序来实现
一个小总结
我们爬取一个网页的步骤可以分为如下:
打开要爬取的网页
打开开发者工具,并让请求重发一次(简单讲就是抓包)
找到正确的请求
用程序模拟发送
第二个案列:点赞
1.打开要爬取的网页
浅谈网络爬虫中深度优先算法和简单代码实现
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-05-05 06:12
点击上方“程序人生”,选择“置顶公众号”
第一时间关注程序猿(媛)身边的故事
作者
Python进阶者
已获原作者授权,如需转载,请联系原作者。
我们今天要学习的内容,主要是给大家普及一下深度优先算法的基本概念,详情内容如下。
学过网站设计的小伙伴们都知道网站通常都是分层进行设计的,最上层的是顶级域名,之后是子域名,子域名下又有子域名等等,同时,每个子域名可能还会拥有多个同级域名,而且URL之间可能还有相互链接,千姿百态,由此构成一个复杂的网络。
当一个网站的URL非常多的时候,我们务必要设计好URL,否则在后期的理解、维护或者开发过程中就会非常的混乱。理解以上的网页结构设计之后,现在正式的引入网络爬虫中的深度优先算法。
上图是一个二叉树结构,通过对这个二叉树的遍历,来类比抓取网页,加深对爬虫策略的理解。深度优先算法的主要思想是首先从顶级域名A开始,之后从中提取出两个链接B和C,待链接B抓取完成之后,下一个要抓取的链接则是D或者E,而不是说抓取完成链接B之后,立马去抓取链接C。抓取完链接D之后,发现链接D中所有的URL已经被访问过了,在这之前我们已经建立了一个被访问过的URL列表,专门用于存储被访问过的URL。当链接D完全被抓取完成之后,接下来就会去抓取链接E。待链接E爬取完成之后,不会去爬取链接C,而是会继续往下深入的去爬取链接I。原则就是链接会一步一步的往下爬,只要链接下还有子链接,且该子链接尚未被访问过,这就是深度优先算法的主要思想。深度优先算法是让爬虫一步一步往下进行抓取完成之后,再一步一步退回来,优先考虑深度。理解好深度优先算法之后,再来看上图,可以得到该二叉树呈现的爬虫抓取链接的顺序依次为:A、B、D、E、I、C、F、G、H(这里假设左边的链接先会被爬取)。实际上,我们在做网络爬虫过程中,很多时候都是在用这种算法进行实现的,其实我们常用的Scrapy爬虫框架默认也是用该算法来进行实现的。通过上面的理解,我们可以认为深度优先算法本质上是通过递归的方式来进行实现的。
下图展示的是深度优先算法的代码实现过程。
深度优先过程实际上是通过一种递归的方式来进行实现的。看上图的代码,首先定义一个函数,用于实现深度优先过程,然后传入节点参数,如果该节点非空的话,则将其打印出来,可以类比一下二叉树中的顶级点A。将节点打印完成之后,看看其是否存在左节点(链接B)和右节点(链接C),如果左节点非空的话,则将其进行返回,再次调用深度优先函数本身进行递归,得到新的左节点(链接D)和右节点(链接E),以此类推,直到所有的节点都被遍历或者达到既定的条件才会停止。右节点的实现过程亦是如此,不再赘述。
深度优先过程通过递归的方式来进行实现,当递归不断进行,没有跳出递归或者递归太深的话,很容易出现栈溢出的情况,所以在实际应用的过程中要有这个意识。
深度优先算法和广度优先算法是数据结构里边非常重要的一种算法结构,也是非常常用的一种算法,而且在面试过程中也是非常常见的一道面试题,所以建议大家都需要掌握它,下一篇文章我们将介绍广度优先算法,敬请期待。
关于网络爬虫中深度优先算法的简单介绍就到这里了,小伙伴们get到木有咧?
- The End -
「若你有原创文章想与大家分享,欢迎投稿。」
加编辑微信ID,备注#投稿#:
程序 丨 druidlost
小七 丨 duoshangshuang 查看全部
浅谈网络爬虫中深度优先算法和简单代码实现
点击上方“程序人生”,选择“置顶公众号”
第一时间关注程序猿(媛)身边的故事
作者
Python进阶者
已获原作者授权,如需转载,请联系原作者。
我们今天要学习的内容,主要是给大家普及一下深度优先算法的基本概念,详情内容如下。
学过网站设计的小伙伴们都知道网站通常都是分层进行设计的,最上层的是顶级域名,之后是子域名,子域名下又有子域名等等,同时,每个子域名可能还会拥有多个同级域名,而且URL之间可能还有相互链接,千姿百态,由此构成一个复杂的网络。
当一个网站的URL非常多的时候,我们务必要设计好URL,否则在后期的理解、维护或者开发过程中就会非常的混乱。理解以上的网页结构设计之后,现在正式的引入网络爬虫中的深度优先算法。
上图是一个二叉树结构,通过对这个二叉树的遍历,来类比抓取网页,加深对爬虫策略的理解。深度优先算法的主要思想是首先从顶级域名A开始,之后从中提取出两个链接B和C,待链接B抓取完成之后,下一个要抓取的链接则是D或者E,而不是说抓取完成链接B之后,立马去抓取链接C。抓取完链接D之后,发现链接D中所有的URL已经被访问过了,在这之前我们已经建立了一个被访问过的URL列表,专门用于存储被访问过的URL。当链接D完全被抓取完成之后,接下来就会去抓取链接E。待链接E爬取完成之后,不会去爬取链接C,而是会继续往下深入的去爬取链接I。原则就是链接会一步一步的往下爬,只要链接下还有子链接,且该子链接尚未被访问过,这就是深度优先算法的主要思想。深度优先算法是让爬虫一步一步往下进行抓取完成之后,再一步一步退回来,优先考虑深度。理解好深度优先算法之后,再来看上图,可以得到该二叉树呈现的爬虫抓取链接的顺序依次为:A、B、D、E、I、C、F、G、H(这里假设左边的链接先会被爬取)。实际上,我们在做网络爬虫过程中,很多时候都是在用这种算法进行实现的,其实我们常用的Scrapy爬虫框架默认也是用该算法来进行实现的。通过上面的理解,我们可以认为深度优先算法本质上是通过递归的方式来进行实现的。
下图展示的是深度优先算法的代码实现过程。
深度优先过程实际上是通过一种递归的方式来进行实现的。看上图的代码,首先定义一个函数,用于实现深度优先过程,然后传入节点参数,如果该节点非空的话,则将其打印出来,可以类比一下二叉树中的顶级点A。将节点打印完成之后,看看其是否存在左节点(链接B)和右节点(链接C),如果左节点非空的话,则将其进行返回,再次调用深度优先函数本身进行递归,得到新的左节点(链接D)和右节点(链接E),以此类推,直到所有的节点都被遍历或者达到既定的条件才会停止。右节点的实现过程亦是如此,不再赘述。
深度优先过程通过递归的方式来进行实现,当递归不断进行,没有跳出递归或者递归太深的话,很容易出现栈溢出的情况,所以在实际应用的过程中要有这个意识。
深度优先算法和广度优先算法是数据结构里边非常重要的一种算法结构,也是非常常用的一种算法,而且在面试过程中也是非常常见的一道面试题,所以建议大家都需要掌握它,下一篇文章我们将介绍广度优先算法,敬请期待。
关于网络爬虫中深度优先算法的简单介绍就到这里了,小伙伴们get到木有咧?
- The End -
「若你有原创文章想与大家分享,欢迎投稿。」
加编辑微信ID,备注#投稿#:
程序 丨 druidlost
小七 丨 duoshangshuang
Python 编写知乎爬虫实践
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-05-05 06:09
点击上方“Python开发”,选择“置顶公众号”
关键时刻,第一时间送达!
爬虫的基本流程
网络爬虫的基本工作流程如下:
爬虫的抓取策略
在爬虫系统中,待抓取 URL 队列是很重要的一部分。待抓取 URL 队列中的 URL 以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些 URL 排列顺序的方法,叫做抓取策略。下面重点介绍几种常见的抓取策略:
了解了爬虫的工作流程和爬取策略后,就可以动手实现一个爬虫了!那么在 python 里怎么实现呢?
技术栈基本实现
下面是一个伪代码
<p>import Queue
initial_page = "https://www.zhihu.com/people/gaoming623"
url_queue = Queue.Queue()
seen = set()
seen.insert(initial_page)
url_queue.put(initial_page)
while(True): #一直进行
if url_queue.size()>0:
current_url = url_queue.get() #拿出队例中第一个的 url
store(current_url) #把这个 url 代表的网页存储好
for next_url in extract_urls(current_url): #提取把这个 url 里链向的 url
if next_url not in seen:
seen.put(next_url)
url_queue.put(next_url)
else:
break</p>
如果你直接加工一下上面的代码直接运行的话,你需要很长的时间才能爬下整个知乎用户的信息,毕竟知乎有 6000 万月活跃用户。更别说 Google 这样的搜索引擎需要爬下全网的内容了。那么问题出现在哪里?
布隆过滤器
需要爬的网页实在太多太多了,而上面的代码太慢太慢了。设想全网有 N 个网站,那么分析一下判重的复杂度就是 N*log(N),因为所有网页要遍历一次,而每次判重用 set 的话需要 log(N) 的复杂度。OK,我知道 python 的 set 实现是 hash——不过这样还是太慢了,至少内存使用效率不高。
通常的判重做法是怎样呢?Bloom Filter. 简单讲它仍然是一种 hash 的方法,但是它的特点是,它可以使用固定的内存(不随 url 的数量而增长)以 O(1) 的效率判定 url 是否已经在 set 中。可惜天下没有白吃的午餐,它的唯一问题在于,如果这个 url 不在 set 中,BF 可以 100%确定这个 url 没有看过。但是如果这个 url 在 set 中,它会告诉你:这个 url 应该已经出现过,不过我有 2%的不确定性。注意这里的不确定性在你分配的内存足够大的时候,可以变得很小很少。
<p># bloom_filter.py
BIT_SIZE = 5000000
class BloomFilter:
def __init__(self):
# Initialize bloom filter, set size and all bits to 0
bit_array = bitarray(BIT_SIZE)
bit_array.setall(0)
self.bit_array = bit_array
def add(self, url):
# Add a url, and set points in bitarray to 1 (Points count is equal to hash funcs count.)
# Here use 7 hash functions.
point_list = self.get_postions(url)
for b in point_list:
self.bit_array[b] = 1
def contains(self, url):
# Check if a url is in a collection
point_list = self.get_postions(url)
result = True
for b in point_list:
result = result and self.bit_array[b]
return result
def get_postions(self, url):
# Get points positions in bit vector.
point1 = mmh3.hash(url, 41) % BIT_SIZE
point2 = mmh3.hash(url, 42) % BIT_SIZE
point3 = mmh3.hash(url, 43) % BIT_SIZE
point4 = mmh3.hash(url, 44) % BIT_SIZE
point5 = mmh3.hash(url, 45) % BIT_SIZE
point6 = mmh3.hash(url, 46) % BIT_SIZE
point7 = mmh3.hash(url, 47) % BIT_SIZE
return [point1, point2, point3, point4, point5, point6, point7]</p>
BF 详细的原理参考我之前写的文章:布隆过滤器(Bloom Filter) 的原理和实现
建表
用户有价值的信息包括用户名、简介、行业、院校、专业及在平台上活动的数据比如回答数、文章数、提问数、粉丝数等等。
用户信息存储的表结构如下:
<p>CREATE DATABASE `zhihu_user` /*!40100 DEFAULT CHARACTER SET utf8 */;
-- User base information table
CREATE TABLE `t_user` (
`uid` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(50) NOT NULL COMMENT '用户名',
`brief_info` varchar(400) COMMENT '个人简介',
`industry` varchar(50) COMMENT '所处行业',
`education` varchar(50) COMMENT '毕业院校',
`major` varchar(50) COMMENT '主修专业',
`answer_count` int(10) unsigned DEFAULT 0 COMMENT '回答数',
`article_count` int(10) unsigned DEFAULT 0 COMMENT '文章数',
`ask_question_count` int(10) unsigned DEFAULT 0 COMMENT '提问数',
`collection_count` int(10) unsigned DEFAULT 0 COMMENT '收藏数',
`follower_count` int(10) unsigned DEFAULT 0 COMMENT '被关注数',
`followed_count` int(10) unsigned DEFAULT 0 COMMENT '关注数',
`follow_live_count` int(10) unsigned DEFAULT 0 COMMENT '关注直播数',
`follow_topic_count` int(10) unsigned DEFAULT 0 COMMENT '关注话题数',
`follow_column_count` int(10) unsigned DEFAULT 0 COMMENT '关注专栏数',
`follow_question_count` int(10) unsigned DEFAULT 0 COMMENT '关注问题数',
`follow_collection_count` int(10) unsigned DEFAULT 0 COMMENT '关注收藏夹数',
`gmt_create` datetime NOT NULL COMMENT '创建时间',
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '最后一次编辑',
PRIMARY KEY (`uid`)
) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='用户基本信息表';</p>
网页下载后通过 XPath 进行解析,提取用户各个维度的数据,最后保存到数据库中。
反爬虫策略应对-Headers
一般网站会从几个维度来反爬虫:用户请求的 Headers,用户行为,网站和数据加载的方式。从用户请求的 Headers 反爬虫是最常见的策略,很多网站都会对 Headers 的 User-Agent 进行检测,还有一部分网站会对 Referer 进行检测(一些资源网站的防盗链就是检测 Referer)。
如果遇到了这类反爬虫机制,可以直接在爬虫中添加 Headers,将浏览器的 User-Agent 复制到爬虫的 Headers 中;或者将 Referer 值修改为目标网站域名。对于检测 Headers 的反爬虫,在爬虫中修改或者添加 Headers 就能很好的绕过。
<p>cookies = {
"d_c0": "AECA7v-aPwqPTiIbemmIQ8abhJy7bdD2VgE=|1468847182",
"login": "NzM5ZDc2M2JkYzYwNDZlOGJlYWQ1YmI4OTg5NDhmMTY=|1480901173|9c296f424b32f241d1471203244eaf30729420f0",
"n_c": "1",
"q_c1": "395b12e529e541cbb400e9718395e346|1479808003000|1468847182000",
"l_cap_id": "NzI0MTQwZGY2NjQyNDQ1NThmYTY0MjJhYmU2NmExMGY=|1480901160|2e7a7faee3b3e8d0afb550e8e7b38d86c15a31bc",
"d_c0": "AECA7v-aPwqPTiIbemmIQ8abhJy7bdD2VgE=|1468847182",
"cap_id": "N2U1NmQwODQ1NjFiNGI2Yzg2YTE2NzJkOTU5N2E0NjI=|1480901160|fd59e2ed79faacc2be1010687d27dd559ec1552a"
}
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.98 Safari/537.3",
"Referer": "https://www.zhihu.com/"
}
r = requests.get(url, cookies = cookies, headers = headers)</p>
反爬虫策略应对-代理 IP 池
还有一部分网站是通过检测用户行为,例如同一 IP 短时间内多次访问同一页面,或者同一账户短时间内多次进行相同操作。
大多数网站都是前一种情况,对于这种情况,使用 IP 代理就可以解决。这样的代理 ip 爬虫经常会用到,最好自己准备一个。有了大量代理 ip 后可以每请求几次更换一个 ip,这在 requests 或者 urllib2 中很容易做到,这样就能很容易的绕过第一种反爬虫。目前知乎已经对爬虫做了限制,如果是单个 IP 的话,一段时间系统便会提示异常流量,无法继续爬取了。因此代理 IP 池非常关键。网上有个免费的代理 IP API:
<p>import requests
import random
class Proxy:
def __init__(self):
self.cache_ip_list = []
# Get random ip from free proxy api url.
def get_random_ip(self):
if not len(self.cache_ip_list):
api_url = 'http://api.xicidaili.com/free2016.txt'
try:
r = requests.get(api_url)
ip_list = r.text.split('rn')
self.cache_ip_list = ip_list
except Exception as e:
# Return null list when caught exception.
# In this case, crawler will not use proxy ip.
print e
return {}
proxy_ip = random.choice(self.cache_ip_list)
proxies = {'http': 'http://' proxy_ip}
return proxies</p>
后续
爬虫源代码:zhihu-crawler下载之后通过 pip 安装相关三方包后,运行$ python crawler.py 即可(喜欢的帮忙点个 star 哈,同时也方便看到后续功能的更新)
运行截图:
查看全部
Python 编写知乎爬虫实践
点击上方“Python开发”,选择“置顶公众号”
关键时刻,第一时间送达!
爬虫的基本流程
网络爬虫的基本工作流程如下:
爬虫的抓取策略
在爬虫系统中,待抓取 URL 队列是很重要的一部分。待抓取 URL 队列中的 URL 以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些 URL 排列顺序的方法,叫做抓取策略。下面重点介绍几种常见的抓取策略:
了解了爬虫的工作流程和爬取策略后,就可以动手实现一个爬虫了!那么在 python 里怎么实现呢?
技术栈基本实现
下面是一个伪代码
<p>import Queue
initial_page = "https://www.zhihu.com/people/gaoming623"
url_queue = Queue.Queue()
seen = set()
seen.insert(initial_page)
url_queue.put(initial_page)
while(True): #一直进行
if url_queue.size()>0:
current_url = url_queue.get() #拿出队例中第一个的 url
store(current_url) #把这个 url 代表的网页存储好
for next_url in extract_urls(current_url): #提取把这个 url 里链向的 url
if next_url not in seen:
seen.put(next_url)
url_queue.put(next_url)
else:
break</p>
如果你直接加工一下上面的代码直接运行的话,你需要很长的时间才能爬下整个知乎用户的信息,毕竟知乎有 6000 万月活跃用户。更别说 Google 这样的搜索引擎需要爬下全网的内容了。那么问题出现在哪里?
布隆过滤器
需要爬的网页实在太多太多了,而上面的代码太慢太慢了。设想全网有 N 个网站,那么分析一下判重的复杂度就是 N*log(N),因为所有网页要遍历一次,而每次判重用 set 的话需要 log(N) 的复杂度。OK,我知道 python 的 set 实现是 hash——不过这样还是太慢了,至少内存使用效率不高。
通常的判重做法是怎样呢?Bloom Filter. 简单讲它仍然是一种 hash 的方法,但是它的特点是,它可以使用固定的内存(不随 url 的数量而增长)以 O(1) 的效率判定 url 是否已经在 set 中。可惜天下没有白吃的午餐,它的唯一问题在于,如果这个 url 不在 set 中,BF 可以 100%确定这个 url 没有看过。但是如果这个 url 在 set 中,它会告诉你:这个 url 应该已经出现过,不过我有 2%的不确定性。注意这里的不确定性在你分配的内存足够大的时候,可以变得很小很少。
<p># bloom_filter.py
BIT_SIZE = 5000000
class BloomFilter:
def __init__(self):
# Initialize bloom filter, set size and all bits to 0
bit_array = bitarray(BIT_SIZE)
bit_array.setall(0)
self.bit_array = bit_array
def add(self, url):
# Add a url, and set points in bitarray to 1 (Points count is equal to hash funcs count.)
# Here use 7 hash functions.
point_list = self.get_postions(url)
for b in point_list:
self.bit_array[b] = 1
def contains(self, url):
# Check if a url is in a collection
point_list = self.get_postions(url)
result = True
for b in point_list:
result = result and self.bit_array[b]
return result
def get_postions(self, url):
# Get points positions in bit vector.
point1 = mmh3.hash(url, 41) % BIT_SIZE
point2 = mmh3.hash(url, 42) % BIT_SIZE
point3 = mmh3.hash(url, 43) % BIT_SIZE
point4 = mmh3.hash(url, 44) % BIT_SIZE
point5 = mmh3.hash(url, 45) % BIT_SIZE
point6 = mmh3.hash(url, 46) % BIT_SIZE
point7 = mmh3.hash(url, 47) % BIT_SIZE
return [point1, point2, point3, point4, point5, point6, point7]</p>
BF 详细的原理参考我之前写的文章:布隆过滤器(Bloom Filter) 的原理和实现
建表
用户有价值的信息包括用户名、简介、行业、院校、专业及在平台上活动的数据比如回答数、文章数、提问数、粉丝数等等。
用户信息存储的表结构如下:
<p>CREATE DATABASE `zhihu_user` /*!40100 DEFAULT CHARACTER SET utf8 */;
-- User base information table
CREATE TABLE `t_user` (
`uid` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(50) NOT NULL COMMENT '用户名',
`brief_info` varchar(400) COMMENT '个人简介',
`industry` varchar(50) COMMENT '所处行业',
`education` varchar(50) COMMENT '毕业院校',
`major` varchar(50) COMMENT '主修专业',
`answer_count` int(10) unsigned DEFAULT 0 COMMENT '回答数',
`article_count` int(10) unsigned DEFAULT 0 COMMENT '文章数',
`ask_question_count` int(10) unsigned DEFAULT 0 COMMENT '提问数',
`collection_count` int(10) unsigned DEFAULT 0 COMMENT '收藏数',
`follower_count` int(10) unsigned DEFAULT 0 COMMENT '被关注数',
`followed_count` int(10) unsigned DEFAULT 0 COMMENT '关注数',
`follow_live_count` int(10) unsigned DEFAULT 0 COMMENT '关注直播数',
`follow_topic_count` int(10) unsigned DEFAULT 0 COMMENT '关注话题数',
`follow_column_count` int(10) unsigned DEFAULT 0 COMMENT '关注专栏数',
`follow_question_count` int(10) unsigned DEFAULT 0 COMMENT '关注问题数',
`follow_collection_count` int(10) unsigned DEFAULT 0 COMMENT '关注收藏夹数',
`gmt_create` datetime NOT NULL COMMENT '创建时间',
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '最后一次编辑',
PRIMARY KEY (`uid`)
) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='用户基本信息表';</p>
网页下载后通过 XPath 进行解析,提取用户各个维度的数据,最后保存到数据库中。
反爬虫策略应对-Headers
一般网站会从几个维度来反爬虫:用户请求的 Headers,用户行为,网站和数据加载的方式。从用户请求的 Headers 反爬虫是最常见的策略,很多网站都会对 Headers 的 User-Agent 进行检测,还有一部分网站会对 Referer 进行检测(一些资源网站的防盗链就是检测 Referer)。
如果遇到了这类反爬虫机制,可以直接在爬虫中添加 Headers,将浏览器的 User-Agent 复制到爬虫的 Headers 中;或者将 Referer 值修改为目标网站域名。对于检测 Headers 的反爬虫,在爬虫中修改或者添加 Headers 就能很好的绕过。
<p>cookies = {
"d_c0": "AECA7v-aPwqPTiIbemmIQ8abhJy7bdD2VgE=|1468847182",
"login": "NzM5ZDc2M2JkYzYwNDZlOGJlYWQ1YmI4OTg5NDhmMTY=|1480901173|9c296f424b32f241d1471203244eaf30729420f0",
"n_c": "1",
"q_c1": "395b12e529e541cbb400e9718395e346|1479808003000|1468847182000",
"l_cap_id": "NzI0MTQwZGY2NjQyNDQ1NThmYTY0MjJhYmU2NmExMGY=|1480901160|2e7a7faee3b3e8d0afb550e8e7b38d86c15a31bc",
"d_c0": "AECA7v-aPwqPTiIbemmIQ8abhJy7bdD2VgE=|1468847182",
"cap_id": "N2U1NmQwODQ1NjFiNGI2Yzg2YTE2NzJkOTU5N2E0NjI=|1480901160|fd59e2ed79faacc2be1010687d27dd559ec1552a"
}
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.98 Safari/537.3",
"Referer": "https://www.zhihu.com/"
}
r = requests.get(url, cookies = cookies, headers = headers)</p>
反爬虫策略应对-代理 IP 池
还有一部分网站是通过检测用户行为,例如同一 IP 短时间内多次访问同一页面,或者同一账户短时间内多次进行相同操作。
大多数网站都是前一种情况,对于这种情况,使用 IP 代理就可以解决。这样的代理 ip 爬虫经常会用到,最好自己准备一个。有了大量代理 ip 后可以每请求几次更换一个 ip,这在 requests 或者 urllib2 中很容易做到,这样就能很容易的绕过第一种反爬虫。目前知乎已经对爬虫做了限制,如果是单个 IP 的话,一段时间系统便会提示异常流量,无法继续爬取了。因此代理 IP 池非常关键。网上有个免费的代理 IP API:
<p>import requests
import random
class Proxy:
def __init__(self):
self.cache_ip_list = []
# Get random ip from free proxy api url.
def get_random_ip(self):
if not len(self.cache_ip_list):
api_url = 'http://api.xicidaili.com/free2016.txt'
try:
r = requests.get(api_url)
ip_list = r.text.split('rn')
self.cache_ip_list = ip_list
except Exception as e:
# Return null list when caught exception.
# In this case, crawler will not use proxy ip.
print e
return {}
proxy_ip = random.choice(self.cache_ip_list)
proxies = {'http': 'http://' proxy_ip}
return proxies</p>
后续
爬虫源代码:zhihu-crawler下载之后通过 pip 安装相关三方包后,运行$ python crawler.py 即可(喜欢的帮忙点个 star 哈,同时也方便看到后续功能的更新)
运行截图:
多种爬虫方式对比
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-05-01 06:11
Python爬虫的方式有多种,从爬虫框架到解析提取,再到数据存储,各阶段都有不同的手段和类库支持。虽然不能一概而论哪种方式一定更好,毕竟不同案例需求和不同应用场景会综合决定采取哪种方式,但对比之下还是会有很大差距。
00 概况
以安居客杭州二手房信息为爬虫需求,分别对比实验了三种爬虫框架、三种字段解析方式和三种数据存储方式,旨在全方面对比各种爬虫方式的效率高低。
安居客平台没有太强的反爬措施,只要添加headers模拟头即可完美爬取,而且不用考虑爬虫过快的问题。选中杭州二手房之后,很容易发现url的变化规律。值得说明的是平台最大开放50页房源信息,每页60条。为使爬虫简单便于对比,我们只爬取房源列表页的概要信息,而不再进入房源详情页进行具体信息的爬取,共3000条记录,每条记录包括10个字段:标题,户型,面积,楼层,建筑年份,小区/地址,售卖标签,中介,单价,总价。
01 3种爬虫框架
1.常规爬虫
实现3个函数,分别用于解析网页、存储信息,以及二者的联合调用。在主程序中,用一个常规的循环语句逐页解析。
import requests<br />from lxml import etree<br />import pymysql<br />import time<br /><br />def get_info(url):<br /> pass<br /> return infos<br /><br />def save_info(infos):<br /> pass<br /><br />def getANDsave(url):<br /> pass<br /><br />if __name__ == '__main__':<br /> urls = [f'https://hangzhou.anjuke.com/sale/p{page}/' for page in range(1,51)]<br /> start = time.time()<br /> #常规单线程爬取<br /> for url in urls:<br /> getANDsave(url)<br /> tt = time.time()-start<br /> print("共用时:",tt, "秒。")<br />
耗时64.9秒。
2.Scrapy框架
Scrapy框架是一个常用的爬虫框架,非常好用,只需要简单实现核心抓取和存储功能即可,而无需关注内部信息流转,而且框架自带多线程和异常处理能力。
class anjukeSpider(scrapy.Spider):<br /> name = 'anjuke'<br /> allowed_domains = ['anjuke.com']<br /> start_urls = [f'https://hangzhou.anjuke.com/sale/p{page}/' for page in range(1, 51)]<br /><br /> def parse(self, response):<br /> pass<br /> yield item<br />
耗时14.4秒。
3.多线程爬虫
对于爬虫这种IO密集型任务来说,多线程可明显提升效率。实现多线程python的方式有多种,这里我们应用concurrent的futures模块,并设置最大线程数为8。
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED<br /><br />def get_info(url):<br /> pass<br /> return infos<br /><br />def save_info(infos):<br /> pass<br /><br />def getANDsave(url):<br /> pass<br /><br />if __name__ == '__main__':<br /> urls = [f'https://hangzhou.anjuke.com/sale/p{page}/' for page in range(1,51)]<br /> start = time.time()<br /> executor = ThreadPoolExecutor(max_workers=8)<br /> future_tasks = [executor.submit(getANDsave, url) for url in urls]<br /> wait(future_tasks, return_when = ALL_COMPLETED)<br /> tt = time.time()-start<br /> print("共用时:",tt, "秒。")<br />
耗时8.1秒。
对比来看,多线程爬虫方案耗时最短,相比常规爬虫而言能带来数倍的效率提升,Scrapy爬虫也取得了不俗的表现。需要指出的是,这里3种框架都采用了Xpath解析和MySQL存储。
02 3种解析方式
在明确爬虫框架的基础上,如何对字段进行解析提取就是第二个需要考虑的问题,常用的解析方式有3种,一般而言,论解析效率Re>=Xpath>Bs4;论难易程度,Bs4则最为简单易懂。
因为前面已经对比得知,多线程爬虫有着最好的执行效率,我们以此为基础,对比3种不同解析方式,解析函数分别为:
1. Xpath
from lxml import etreedef get_info(url):<br /> response = requests.get(url, headers = headers)<br /> html = response.text<br /> html = etree.HTML(html)<br /> items = html.xpath("//li[@class = 'list-item']")<br /> infos = []<br /> for item in items:<br /> try:<br /> title = item.xpath(".//div[@class='house-title']/a/text()")[0].strip()<br /> houseType = item.xpath(".//div[@class='house-details']/div[2]/span[1]/text()")[0]<br /> area = item.xpath(".//div[@class='house-details']/div[2]/span[2]/text()")[0]<br /> floor = item.xpath(".//div[@class='house-details']/div[2]/span[3]/text()")[0]<br /> buildYear = item.xpath(".//div[@class='house-details']/div[2]/span[4]/text()")[0]<br /> adrres = item.xpath(".//div[@class='house-details']/div[3]/span[1]/text()")[0]<br /> adrres = "|".join(adrres.split())<br /> tags = item.xpath(".//div[@class='tags-bottom']//text()")<br /> tags = '|'.join(tags).strip()<br /> broker = item.xpath(".//div[@class='broker-item']/span[2]/text()")[0]<br /> totalPrice = item.xpath(".//div[@class='pro-price']/span[1]//text()")<br /> totalPrice = "".join(totalPrice).strip()<br /> price = item.xpath(".//div[@class='pro-price']/span[2]/text()")[0]<br /> values = (title, houseType, area, floor, buildYear, adrres, tags, broker, totalPrice, price)<br /> infos.append(values)<br /> except:<br /> print('1条信息解析失败')<br /> return infos<br />
耗时8.1秒。
2. Re
import re<br />def get_info(url):<br /> response = requests.get(url, headers = headers)<br /> html = response.text<br /> html = html.replace('\n','')<br /> pattern = r'.*?'<br /> results = re.compile(pattern).findall(html)##先编译,再正则匹配<br /> infos = []<br /> for result in results: <br /> values = ['']*10<br /> titles = re.compile('title="(.*?)"').findall(result)<br /> values[0] = titles[0]<br /> values[5] = titles[1].replace(' ','')<br /> spans = re.compile('(.*?)|(.*?)|(.*?)|(.*?)').findall(result)<br /> values[1] =''.join(spans[0])<br /> values[2] = ''.join(spans[1])<br /> values[3] = ''.join(spans[2])<br /> values[4] = ''.join(spans[3])<br /> values[7] = re.compile('(.*?)').findall(result)[0]<br /> tagRE = re.compile('(.*?)').findall(result)<br /> if tagRE:<br /> values[6] = '|'.join(tagRE)<br /> values[8] = re.compile('(.*?)万').findall(result)[0]+'万'<br /> values[9] = re.compile('(.*?)').findall(result)[0]<br /> infos.append(tuple(values))<br /><br /> return infos<br />
耗时8.6秒。
3. Bs4
from bs4 import BeautifulSoup<br />def get_info(url):<br /> response = requests.get(url, headers = headers)<br /> html = response.text<br /> soup = BeautifulSoup(html, "html.parser")<br /> items = soup.find_all('li', attrs={'class': "list-item"})<br /> infos = []<br /> for item in items:<br /> try:<br /> title = item.find('a', attrs={'class': "houseListTitle"}).get_text().strip()<br /> details = item.find_all('div',attrs={'class': "details-item"})[0]<br /> houseType = details.find_all('span')[0].get_text().strip()<br /> area = details.find_all('span')[1].get_text().strip()<br /> floor = details.find_all('span')[2].get_text().strip()<br /> buildYear = details.find_all('span')[3].get_text().strip()<br /> addres = item.find_all('div',attrs={'class': "details-item"})[1].get_text().replace(' ','').replace('\n','')<br /> tag_spans = item.find('div', attrs={'class':'tags-bottom'}).find_all('span')<br /> tags = [span.get_text() for span in tag_spans]<br /> tags = '|'.join(tags)<br /> broker = item.find('span',attrs={'class':'broker-name broker-text'}).get_text().strip()<br /> totalPrice = item.find('span',attrs={'class':'price-det'}).get_text()<br /> price = item.find('span',attrs={'class':'unit-price'}).get_text()<br /> values = (title, houseType, area, floor, buildYear, addres, tags, broker, totalPrice, price)<br /> infos.append(values)<br /> except:<br /> print('1条信息解析失败')<br /> return infos<br />
耗时23.2秒。
Xpath和Re执行效率相当,Xpath甚至要略胜一筹,Bs4效率要明显低于前两者(此案例中,相当远前两者效率的1/3),但写起来则最为容易。
03 存储方式
在完成爬虫数据解析后,一般都要将数据进行本地存储,方便后续使用。小型数据量时可以选用本地文件存储,例如CSV、txt或者json文件;当数据量较大时,则一般需采用数据库存储,这里,我们分别选用关系型数据库的代表MySQL和文本型数据库的代表MongoDB加入对比。
1. MySQL
import pymysql<br /><br />def save_info(infos):<br /> #####infos为列表形式,其中列表中每个元素为一个元组,包含10个字段<br /> db= pymysql.connect(host="localhost",user="root",password="123456",db="ajkhzesf")<br /> sql_insert = 'insert into hzesfmulti8(title, houseType, area, floor, buildYear, adrres, tags, broker, totalPrice, price) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'<br /> cursor = db.cursor()<br /> cursor.executemany(sql_insert, infos)<br /> db.commit()<br />
耗时8.1秒。
2. MongoDB
import pymongo<br /><br />def save_info(infos):<br /> # infos为列表形式,其中列表中的每个元素为一个字典,包括10个字段<br /> client = pymongo.MongoClient()<br /> collection = client.anjuke.hzesfmulti<br /> collection.insert_many(infos)<br /> client.close()<br />
耗时8.4秒。
3. CSV文件
import csv<br /><br />def save_info(infos):<br /> # infos为列表形式,其中列表中的每个元素为一个列表,包括10个字段<br /> with open(r"D:\PyFile\HZhouse\anjuke.csv", 'a', encoding='gb18030', newline="") as f:<br /> writer = csv.writer(f)<br /> writer.writerows(infos)<br />
耗时8.8秒。
可见,在爬虫框架和解析方式一致的前提下,不同存储方式间并不会带来太大效率上的差异。
04 结论
不同爬虫执行效率对比
易见,爬虫框架对耗时影响最大,甚至可带来数倍的效率提升;解析数据方式也会带来较大影响,而数据存储方式则不存在太大差异。
对此,个人认为可以这样理解:类似于把大象装冰箱需要3步,爬虫也需要3步:
其中,爬取网页源码最为耗时,这不仅取决于你的爬虫框架和网络负载,还受限于目标网站的响应速度和反爬措施;信息解析其次,而数据存储则最为迅速,尤其是在磁盘读取速度飞快的今天,无论是简单的文件写入还是数据库存储,都不会带来太大的时间差异。 查看全部
多种爬虫方式对比
Python爬虫的方式有多种,从爬虫框架到解析提取,再到数据存储,各阶段都有不同的手段和类库支持。虽然不能一概而论哪种方式一定更好,毕竟不同案例需求和不同应用场景会综合决定采取哪种方式,但对比之下还是会有很大差距。
00 概况
以安居客杭州二手房信息为爬虫需求,分别对比实验了三种爬虫框架、三种字段解析方式和三种数据存储方式,旨在全方面对比各种爬虫方式的效率高低。
安居客平台没有太强的反爬措施,只要添加headers模拟头即可完美爬取,而且不用考虑爬虫过快的问题。选中杭州二手房之后,很容易发现url的变化规律。值得说明的是平台最大开放50页房源信息,每页60条。为使爬虫简单便于对比,我们只爬取房源列表页的概要信息,而不再进入房源详情页进行具体信息的爬取,共3000条记录,每条记录包括10个字段:标题,户型,面积,楼层,建筑年份,小区/地址,售卖标签,中介,单价,总价。
01 3种爬虫框架
1.常规爬虫
实现3个函数,分别用于解析网页、存储信息,以及二者的联合调用。在主程序中,用一个常规的循环语句逐页解析。
import requests<br />from lxml import etree<br />import pymysql<br />import time<br /><br />def get_info(url):<br /> pass<br /> return infos<br /><br />def save_info(infos):<br /> pass<br /><br />def getANDsave(url):<br /> pass<br /><br />if __name__ == '__main__':<br /> urls = [f'https://hangzhou.anjuke.com/sale/p{page}/' for page in range(1,51)]<br /> start = time.time()<br /> #常规单线程爬取<br /> for url in urls:<br /> getANDsave(url)<br /> tt = time.time()-start<br /> print("共用时:",tt, "秒。")<br />
耗时64.9秒。
2.Scrapy框架
Scrapy框架是一个常用的爬虫框架,非常好用,只需要简单实现核心抓取和存储功能即可,而无需关注内部信息流转,而且框架自带多线程和异常处理能力。
class anjukeSpider(scrapy.Spider):<br /> name = 'anjuke'<br /> allowed_domains = ['anjuke.com']<br /> start_urls = [f'https://hangzhou.anjuke.com/sale/p{page}/' for page in range(1, 51)]<br /><br /> def parse(self, response):<br /> pass<br /> yield item<br />
耗时14.4秒。
3.多线程爬虫
对于爬虫这种IO密集型任务来说,多线程可明显提升效率。实现多线程python的方式有多种,这里我们应用concurrent的futures模块,并设置最大线程数为8。
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED<br /><br />def get_info(url):<br /> pass<br /> return infos<br /><br />def save_info(infos):<br /> pass<br /><br />def getANDsave(url):<br /> pass<br /><br />if __name__ == '__main__':<br /> urls = [f'https://hangzhou.anjuke.com/sale/p{page}/' for page in range(1,51)]<br /> start = time.time()<br /> executor = ThreadPoolExecutor(max_workers=8)<br /> future_tasks = [executor.submit(getANDsave, url) for url in urls]<br /> wait(future_tasks, return_when = ALL_COMPLETED)<br /> tt = time.time()-start<br /> print("共用时:",tt, "秒。")<br />
耗时8.1秒。
对比来看,多线程爬虫方案耗时最短,相比常规爬虫而言能带来数倍的效率提升,Scrapy爬虫也取得了不俗的表现。需要指出的是,这里3种框架都采用了Xpath解析和MySQL存储。
02 3种解析方式
在明确爬虫框架的基础上,如何对字段进行解析提取就是第二个需要考虑的问题,常用的解析方式有3种,一般而言,论解析效率Re>=Xpath>Bs4;论难易程度,Bs4则最为简单易懂。
因为前面已经对比得知,多线程爬虫有着最好的执行效率,我们以此为基础,对比3种不同解析方式,解析函数分别为:
1. Xpath
from lxml import etreedef get_info(url):<br /> response = requests.get(url, headers = headers)<br /> html = response.text<br /> html = etree.HTML(html)<br /> items = html.xpath("//li[@class = 'list-item']")<br /> infos = []<br /> for item in items:<br /> try:<br /> title = item.xpath(".//div[@class='house-title']/a/text()")[0].strip()<br /> houseType = item.xpath(".//div[@class='house-details']/div[2]/span[1]/text()")[0]<br /> area = item.xpath(".//div[@class='house-details']/div[2]/span[2]/text()")[0]<br /> floor = item.xpath(".//div[@class='house-details']/div[2]/span[3]/text()")[0]<br /> buildYear = item.xpath(".//div[@class='house-details']/div[2]/span[4]/text()")[0]<br /> adrres = item.xpath(".//div[@class='house-details']/div[3]/span[1]/text()")[0]<br /> adrres = "|".join(adrres.split())<br /> tags = item.xpath(".//div[@class='tags-bottom']//text()")<br /> tags = '|'.join(tags).strip()<br /> broker = item.xpath(".//div[@class='broker-item']/span[2]/text()")[0]<br /> totalPrice = item.xpath(".//div[@class='pro-price']/span[1]//text()")<br /> totalPrice = "".join(totalPrice).strip()<br /> price = item.xpath(".//div[@class='pro-price']/span[2]/text()")[0]<br /> values = (title, houseType, area, floor, buildYear, adrres, tags, broker, totalPrice, price)<br /> infos.append(values)<br /> except:<br /> print('1条信息解析失败')<br /> return infos<br />
耗时8.1秒。
2. Re
import re<br />def get_info(url):<br /> response = requests.get(url, headers = headers)<br /> html = response.text<br /> html = html.replace('\n','')<br /> pattern = r'.*?'<br /> results = re.compile(pattern).findall(html)##先编译,再正则匹配<br /> infos = []<br /> for result in results: <br /> values = ['']*10<br /> titles = re.compile('title="(.*?)"').findall(result)<br /> values[0] = titles[0]<br /> values[5] = titles[1].replace(' ','')<br /> spans = re.compile('(.*?)|(.*?)|(.*?)|(.*?)').findall(result)<br /> values[1] =''.join(spans[0])<br /> values[2] = ''.join(spans[1])<br /> values[3] = ''.join(spans[2])<br /> values[4] = ''.join(spans[3])<br /> values[7] = re.compile('(.*?)').findall(result)[0]<br /> tagRE = re.compile('(.*?)').findall(result)<br /> if tagRE:<br /> values[6] = '|'.join(tagRE)<br /> values[8] = re.compile('(.*?)万').findall(result)[0]+'万'<br /> values[9] = re.compile('(.*?)').findall(result)[0]<br /> infos.append(tuple(values))<br /><br /> return infos<br />
耗时8.6秒。
3. Bs4
from bs4 import BeautifulSoup<br />def get_info(url):<br /> response = requests.get(url, headers = headers)<br /> html = response.text<br /> soup = BeautifulSoup(html, "html.parser")<br /> items = soup.find_all('li', attrs={'class': "list-item"})<br /> infos = []<br /> for item in items:<br /> try:<br /> title = item.find('a', attrs={'class': "houseListTitle"}).get_text().strip()<br /> details = item.find_all('div',attrs={'class': "details-item"})[0]<br /> houseType = details.find_all('span')[0].get_text().strip()<br /> area = details.find_all('span')[1].get_text().strip()<br /> floor = details.find_all('span')[2].get_text().strip()<br /> buildYear = details.find_all('span')[3].get_text().strip()<br /> addres = item.find_all('div',attrs={'class': "details-item"})[1].get_text().replace(' ','').replace('\n','')<br /> tag_spans = item.find('div', attrs={'class':'tags-bottom'}).find_all('span')<br /> tags = [span.get_text() for span in tag_spans]<br /> tags = '|'.join(tags)<br /> broker = item.find('span',attrs={'class':'broker-name broker-text'}).get_text().strip()<br /> totalPrice = item.find('span',attrs={'class':'price-det'}).get_text()<br /> price = item.find('span',attrs={'class':'unit-price'}).get_text()<br /> values = (title, houseType, area, floor, buildYear, addres, tags, broker, totalPrice, price)<br /> infos.append(values)<br /> except:<br /> print('1条信息解析失败')<br /> return infos<br />
耗时23.2秒。
Xpath和Re执行效率相当,Xpath甚至要略胜一筹,Bs4效率要明显低于前两者(此案例中,相当远前两者效率的1/3),但写起来则最为容易。
03 存储方式
在完成爬虫数据解析后,一般都要将数据进行本地存储,方便后续使用。小型数据量时可以选用本地文件存储,例如CSV、txt或者json文件;当数据量较大时,则一般需采用数据库存储,这里,我们分别选用关系型数据库的代表MySQL和文本型数据库的代表MongoDB加入对比。
1. MySQL
import pymysql<br /><br />def save_info(infos):<br /> #####infos为列表形式,其中列表中每个元素为一个元组,包含10个字段<br /> db= pymysql.connect(host="localhost",user="root",password="123456",db="ajkhzesf")<br /> sql_insert = 'insert into hzesfmulti8(title, houseType, area, floor, buildYear, adrres, tags, broker, totalPrice, price) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'<br /> cursor = db.cursor()<br /> cursor.executemany(sql_insert, infos)<br /> db.commit()<br />
耗时8.1秒。
2. MongoDB
import pymongo<br /><br />def save_info(infos):<br /> # infos为列表形式,其中列表中的每个元素为一个字典,包括10个字段<br /> client = pymongo.MongoClient()<br /> collection = client.anjuke.hzesfmulti<br /> collection.insert_many(infos)<br /> client.close()<br />
耗时8.4秒。
3. CSV文件
import csv<br /><br />def save_info(infos):<br /> # infos为列表形式,其中列表中的每个元素为一个列表,包括10个字段<br /> with open(r"D:\PyFile\HZhouse\anjuke.csv", 'a', encoding='gb18030', newline="") as f:<br /> writer = csv.writer(f)<br /> writer.writerows(infos)<br />
耗时8.8秒。
可见,在爬虫框架和解析方式一致的前提下,不同存储方式间并不会带来太大效率上的差异。
04 结论
不同爬虫执行效率对比
易见,爬虫框架对耗时影响最大,甚至可带来数倍的效率提升;解析数据方式也会带来较大影响,而数据存储方式则不存在太大差异。
对此,个人认为可以这样理解:类似于把大象装冰箱需要3步,爬虫也需要3步:
其中,爬取网页源码最为耗时,这不仅取决于你的爬虫框架和网络负载,还受限于目标网站的响应速度和反爬措施;信息解析其次,而数据存储则最为迅速,尤其是在磁盘读取速度飞快的今天,无论是简单的文件写入还是数据库存储,都不会带来太大的时间差异。
爬虫实战:Scrapy框架
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-05-01 01:16
Scrapy是用Python语言编写,通过Twisted异步网络框架提升下载速度,是一个快速、高层次的屏幕抓取和Web抓取框架,常用于数据挖掘、监测和自动化测试等。
一、Scrapy框架介绍
Scrapy内部实现了并发请求、免登录、URL去重等操作,开发者可根据自己的需求去编写部分代码,就能抓取到所需要的数据。Scrapy框架包含的组件有调度器、下载器、Scrapy引擎、项目管道、爬虫以及各中间件等。
Scrapy框架爬取流程:首先从初始URL开始,调度器会将其交给下载器(Downloader),下载器向网络服务器发送请求进行下载,得到的响应后将下载数据交给爬虫,爬虫会对网页进行分析,分析出来的结果有两种:一种是需要进一步抓取的链接,这些链接会被传回调度器,另一种是需要保存的数据,它们会被传送至项目管道,项目管道进一步对数据进行清洗、去重等处理,并存储到文件或数据库中。数据爬取过程中,Scrapy引擎用于控制整个系统的数据处理流程。
Scrapy框架内包含的各组件功能如下:
Scrapy引擎:用来控制整个系统的数据处理流程,并进行事务处理的触发。
调度器中间件:位于Scrapy引擎和调度器之间,主要用于处理Scrapy引擎发送到调度器的请求和响应。
调度器:用来接收引擎发送过来的请求,压入队列完成去重操作,并决定下一个要抓取的网站,在引擎再次请求的时候返回URL。
下载器中间件:位于Scrapy引擎和下载器之间,主要用于处理Scrapy引擎与下载器之间的请求及响应,其中代理IP和用户代理可以在这里设置。
下载器:用于下载网页内容,并将网页响应结果返回给爬虫。
爬虫中间件:位于Scrapy引擎和爬虫之间,主要用于处理爬虫的响应输入和请求输出。
爬虫:用于从特定网页中提取需要的信息,也可以从中提取URL交给调度器,让Scrapy继续爬取下一个页面。
项目管道:负责处理爬虫从网页中抓取的信息,主要的功能为持久化项目、验证项目的有效性、清除不需要的信息,并完成数据存储。
二、爬虫实战
1.项目需求
基于Scrapy框架爬取某网站的新闻标题和内容。
2.分析页面网站
通过网页解析,了解新闻网站不同模块对应的详情页URL均为静态数据。
通过对不同板块的网页进行解析,了解各模块的新闻为动态加载数据,且新闻标题位于“a”标签下。
进一步,分析新闻网页,了解新闻内容位于“p”标签下。
3.项目搭建
第一步:创建项目
Pycharm终端输入
cd 框架 #进入项目文件夹路径scrapy startproject wangyi #创建项目,wangyi为项目名cd wangyi #进入项目路径scrapy genspider spiderName www.xxx.com #在子目录中创建爬虫文件
项目结构如下:spiders用于存放爬虫程序(SpiderName.py)的文件夹;items用来定义数据结构,类似于字典的功能;middlewares中间件,可设置ip代理等;pipelines用于对items中的数据进行清洗、存储等操作;settings是设置文件,包含爬虫项目的信息;scrapy.cfg是关于项目配置文件。
第二步:编写爬虫代码(spiderName.py)
import scrapyfrom selenium import webdriverfrom wangyi.items import WangyiItem<br />class WangyiSpider(scrapy.Spider): name = 'wangyi' #allowed_domains = ['www.xxx.com'] start_urls = ['https://news.163.com/'] models_urls = [] #存储五个板块的详情页url #实例化浏览器对象 def __init__(self): self.bro = webdriver.Chrome(executable_path='D:/PyCharm/learnpython/框架/wangyi/chromedriver.exe') def parse(self, response): li_list = response.xpath('//*[@id="index2016_wrap"]/div[2]/div[2]/div[2]/div[2]/div/ul/li') alist = [2,3,5,6,7] for index in alist: model_url = li_list[index].xpath('./a/@href').extract_first() self.models_urls.append(model_url) #依次对每一个板块对应的页面发送请求 for url in self.models_urls: yield scrapy.Request(url,callback=self.parse_model)<br /> def parse_model(self,response): div_lists = response.xpath('/html/body/div/div[3]/div[4]/div[1]/div[1]/div/ul/li/div/div') for div in div_lists: title = div.xpath('./div/div[1]/h3/a/text()').extract_first() new_detial_url = div.xpath('./div/div[1]/h3/a/@href').extract_first() item = WangyiItem() item['title'] = title yield scrapy.Request(url=new_detial_url , callback=self.parse_detial , meta={'item' : item}) def parse_detial(self,response): content = response.xpath('//*[@id="content"]/div[2]//text()').extract() content = ''.join(content) item = response.meta['item'] item['content'] = content yield item<br /> def closed(self,spider): self.bro.quit()
注意不能使用return返回数据,应使用yield返回数据。使用return直接退出函数,而对于yield在调研for的时候,函数内部不会立即执行,只是返回一个生成器对象。
第三步:设置中间件(middlewares.py)
from scrapy import signalsfrom scrapy.http import HtmlResponsefrom time import sleep# useful for handling different item types with a single interfacefrom itemadapter import is_item, ItemAdapter<br />class WangyiDownloaderMiddleware: def process_request(self, request, spider): return None #通过该方法拦截五大板块对应的响应对象,进行纂改 def process_response(self, request, response, spider): #挑选出指定的响应对象精选纂改 bro = spider.bro #获取在爬虫类中定义的浏览器对象 if request.url in spider.models_urls: bro.get(request.url) #五个板块url发送请求 sleep(2) page_text = bro.page_source #动态加载的新闻数据 new_response = HtmlResponse(url=request.url,body= page_text,encoding='utf-8',request=request) return new_response else: return response<br /> def process_exception(self, request, exception, spider): pass
第四步:数据存储
定义爬取数据结构(items.py)
import scrapyclass WangyiItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() content = scrapy.Field() pass
定义数据管道(pipelines.py)
class WangyiPipeline: fp = None # 重写父类的一个方法,该方法只会在开始爬虫的时候被调用一次 def open_spider(self, spider): print('开始爬虫。。。。。。') self.fp = open('./wangyi.text', 'w', encoding='utf-8')<br /> # 用来专门处理item类型对象 # 该方法每接收到一个item就会被调用一次 def process_item(self, item, spider): title = item['title'] content = item['content'] self.fp.write(title + ':' + content + '\n') print(item) return item<br /> def close_spider(self, spider): print('结束爬虫。。。。。。') self.fp.close()
第五步:程序配置(settings.py)
UA伪装
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36'
对robots协议的遵守进行修改
ROBOTSTXT_OBEY = False
显示指定类型日志信息
LOG_LEVEL ='ERROR'
开启中间件
DOWNLOADER_MIDDLEWARES = { 'wangyi.middlewares.WangyiDownloaderMiddleware': 543,}
开启管道
ITEM_PIPELINES = { 'wangyi.pipelines.WangyiPipeline': 300,}
第六步:执行项目
Pycharm终端输入
scrapy crawl wangyi #wangyi 为爬虫项目名
4.爬虫结果
参考资料:
《Python网络爬虫技术与实战》,2021,赵国生、王健著。 查看全部
爬虫实战:Scrapy框架
Scrapy是用Python语言编写,通过Twisted异步网络框架提升下载速度,是一个快速、高层次的屏幕抓取和Web抓取框架,常用于数据挖掘、监测和自动化测试等。
一、Scrapy框架介绍
Scrapy内部实现了并发请求、免登录、URL去重等操作,开发者可根据自己的需求去编写部分代码,就能抓取到所需要的数据。Scrapy框架包含的组件有调度器、下载器、Scrapy引擎、项目管道、爬虫以及各中间件等。
Scrapy框架爬取流程:首先从初始URL开始,调度器会将其交给下载器(Downloader),下载器向网络服务器发送请求进行下载,得到的响应后将下载数据交给爬虫,爬虫会对网页进行分析,分析出来的结果有两种:一种是需要进一步抓取的链接,这些链接会被传回调度器,另一种是需要保存的数据,它们会被传送至项目管道,项目管道进一步对数据进行清洗、去重等处理,并存储到文件或数据库中。数据爬取过程中,Scrapy引擎用于控制整个系统的数据处理流程。
Scrapy框架内包含的各组件功能如下:
Scrapy引擎:用来控制整个系统的数据处理流程,并进行事务处理的触发。
调度器中间件:位于Scrapy引擎和调度器之间,主要用于处理Scrapy引擎发送到调度器的请求和响应。
调度器:用来接收引擎发送过来的请求,压入队列完成去重操作,并决定下一个要抓取的网站,在引擎再次请求的时候返回URL。
下载器中间件:位于Scrapy引擎和下载器之间,主要用于处理Scrapy引擎与下载器之间的请求及响应,其中代理IP和用户代理可以在这里设置。
下载器:用于下载网页内容,并将网页响应结果返回给爬虫。
爬虫中间件:位于Scrapy引擎和爬虫之间,主要用于处理爬虫的响应输入和请求输出。
爬虫:用于从特定网页中提取需要的信息,也可以从中提取URL交给调度器,让Scrapy继续爬取下一个页面。
项目管道:负责处理爬虫从网页中抓取的信息,主要的功能为持久化项目、验证项目的有效性、清除不需要的信息,并完成数据存储。
二、爬虫实战
1.项目需求
基于Scrapy框架爬取某网站的新闻标题和内容。
2.分析页面网站
通过网页解析,了解新闻网站不同模块对应的详情页URL均为静态数据。
通过对不同板块的网页进行解析,了解各模块的新闻为动态加载数据,且新闻标题位于“a”标签下。
进一步,分析新闻网页,了解新闻内容位于“p”标签下。
3.项目搭建
第一步:创建项目
Pycharm终端输入
cd 框架 #进入项目文件夹路径scrapy startproject wangyi #创建项目,wangyi为项目名cd wangyi #进入项目路径scrapy genspider spiderName www.xxx.com #在子目录中创建爬虫文件
项目结构如下:spiders用于存放爬虫程序(SpiderName.py)的文件夹;items用来定义数据结构,类似于字典的功能;middlewares中间件,可设置ip代理等;pipelines用于对items中的数据进行清洗、存储等操作;settings是设置文件,包含爬虫项目的信息;scrapy.cfg是关于项目配置文件。
第二步:编写爬虫代码(spiderName.py)
import scrapyfrom selenium import webdriverfrom wangyi.items import WangyiItem<br />class WangyiSpider(scrapy.Spider): name = 'wangyi' #allowed_domains = ['www.xxx.com'] start_urls = ['https://news.163.com/'] models_urls = [] #存储五个板块的详情页url #实例化浏览器对象 def __init__(self): self.bro = webdriver.Chrome(executable_path='D:/PyCharm/learnpython/框架/wangyi/chromedriver.exe') def parse(self, response): li_list = response.xpath('//*[@id="index2016_wrap"]/div[2]/div[2]/div[2]/div[2]/div/ul/li') alist = [2,3,5,6,7] for index in alist: model_url = li_list[index].xpath('./a/@href').extract_first() self.models_urls.append(model_url) #依次对每一个板块对应的页面发送请求 for url in self.models_urls: yield scrapy.Request(url,callback=self.parse_model)<br /> def parse_model(self,response): div_lists = response.xpath('/html/body/div/div[3]/div[4]/div[1]/div[1]/div/ul/li/div/div') for div in div_lists: title = div.xpath('./div/div[1]/h3/a/text()').extract_first() new_detial_url = div.xpath('./div/div[1]/h3/a/@href').extract_first() item = WangyiItem() item['title'] = title yield scrapy.Request(url=new_detial_url , callback=self.parse_detial , meta={'item' : item}) def parse_detial(self,response): content = response.xpath('//*[@id="content"]/div[2]//text()').extract() content = ''.join(content) item = response.meta['item'] item['content'] = content yield item<br /> def closed(self,spider): self.bro.quit()
注意不能使用return返回数据,应使用yield返回数据。使用return直接退出函数,而对于yield在调研for的时候,函数内部不会立即执行,只是返回一个生成器对象。
第三步:设置中间件(middlewares.py)
from scrapy import signalsfrom scrapy.http import HtmlResponsefrom time import sleep# useful for handling different item types with a single interfacefrom itemadapter import is_item, ItemAdapter<br />class WangyiDownloaderMiddleware: def process_request(self, request, spider): return None #通过该方法拦截五大板块对应的响应对象,进行纂改 def process_response(self, request, response, spider): #挑选出指定的响应对象精选纂改 bro = spider.bro #获取在爬虫类中定义的浏览器对象 if request.url in spider.models_urls: bro.get(request.url) #五个板块url发送请求 sleep(2) page_text = bro.page_source #动态加载的新闻数据 new_response = HtmlResponse(url=request.url,body= page_text,encoding='utf-8',request=request) return new_response else: return response<br /> def process_exception(self, request, exception, spider): pass
第四步:数据存储
定义爬取数据结构(items.py)
import scrapyclass WangyiItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() content = scrapy.Field() pass
定义数据管道(pipelines.py)
class WangyiPipeline: fp = None # 重写父类的一个方法,该方法只会在开始爬虫的时候被调用一次 def open_spider(self, spider): print('开始爬虫。。。。。。') self.fp = open('./wangyi.text', 'w', encoding='utf-8')<br /> # 用来专门处理item类型对象 # 该方法每接收到一个item就会被调用一次 def process_item(self, item, spider): title = item['title'] content = item['content'] self.fp.write(title + ':' + content + '\n') print(item) return item<br /> def close_spider(self, spider): print('结束爬虫。。。。。。') self.fp.close()
第五步:程序配置(settings.py)
UA伪装
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36'
对robots协议的遵守进行修改
ROBOTSTXT_OBEY = False
显示指定类型日志信息
LOG_LEVEL ='ERROR'
开启中间件
DOWNLOADER_MIDDLEWARES = { 'wangyi.middlewares.WangyiDownloaderMiddleware': 543,}
开启管道
ITEM_PIPELINES = { 'wangyi.pipelines.WangyiPipeline': 300,}
第六步:执行项目
Pycharm终端输入
scrapy crawl wangyi #wangyi 为爬虫项目名
4.爬虫结果
参考资料:
《Python网络爬虫技术与实战》,2021,赵国生、王健著。
手把手教你使用Python网络爬虫获取基金信息
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-05-01 01:09
文章:Python爬虫与数据挖掘作者:Python进阶者01前言
前几天有个粉丝找我获取基金信息,这里拿出来分享一下,感兴趣的小伙伴们,也可以积极尝试。
02数据获取
这里我们的目标网站是某基金官网,需要抓取的数据如下图所示。
可以看到上图中基金代码那一列,有不同的数字,随机点击一个,可以进入到基金详情页,链接也非常有规律,以基金代码作为标志的。
其实这个网站倒是不难,数据什么的,都没有加密,网页上的信息,在源码中都可以直接看到。
这样就降低了抓取难度了。通过浏览器抓包的方法,可以看到具体的请求参数,而且可以看到请求参数中只有pi在变化,而这个值恰好对应的是页面,直接构造请求参数就可以了。
代码实现过程
找到数据源之后,接下来就是代码实现了,一起来看看吧,这里给出部分关键代码。
获取股票id数据
response = requests.get(url, headers=headers, params=params, verify=False) pattern = re.compile(r'.*?"(?P.*?)".*?', re.S) result = re.finditer(pattern, response.text) ids = [] for item in result: # print(item.group('items')) gp_id = item.group('items').split(',')[0]
结果如下图所示:
之后构造详情页链接,获取详情页的基金信息,关键代码如下:
response = requests.get(url, headers=headers)response.encoding = response.apparent_encodingselectors = etree.HTML(response.text)danweijingzhi1 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[1]/text()')[0]danweijingzhi2 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[2]/text()')[0]leijijingzhi = selectors.xpath('//dl[@class="dataItem03"]/dd[1]/span/text()')[0]lst = selectors.xpath('//div[@class="infoOfFund"]/table//text()')
结果如下图所示:
将具体的信息做相应的字符串处理,然后保存到csv文件中,结果如下图所示:
有了这个,你可以做进一步的统计和数据分析了。
- 合作、交流、转载请添加微信 moonhmily1 -<p style="outline: 0px;white-space: normal;font-size: 16px;"></p> 查看全部
手把手教你使用Python网络爬虫获取基金信息
文章:Python爬虫与数据挖掘作者:Python进阶者01前言
前几天有个粉丝找我获取基金信息,这里拿出来分享一下,感兴趣的小伙伴们,也可以积极尝试。
02数据获取
这里我们的目标网站是某基金官网,需要抓取的数据如下图所示。
可以看到上图中基金代码那一列,有不同的数字,随机点击一个,可以进入到基金详情页,链接也非常有规律,以基金代码作为标志的。
其实这个网站倒是不难,数据什么的,都没有加密,网页上的信息,在源码中都可以直接看到。
这样就降低了抓取难度了。通过浏览器抓包的方法,可以看到具体的请求参数,而且可以看到请求参数中只有pi在变化,而这个值恰好对应的是页面,直接构造请求参数就可以了。
代码实现过程
找到数据源之后,接下来就是代码实现了,一起来看看吧,这里给出部分关键代码。
获取股票id数据
response = requests.get(url, headers=headers, params=params, verify=False) pattern = re.compile(r'.*?"(?P.*?)".*?', re.S) result = re.finditer(pattern, response.text) ids = [] for item in result: # print(item.group('items')) gp_id = item.group('items').split(',')[0]
结果如下图所示:
之后构造详情页链接,获取详情页的基金信息,关键代码如下:
response = requests.get(url, headers=headers)response.encoding = response.apparent_encodingselectors = etree.HTML(response.text)danweijingzhi1 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[1]/text()')[0]danweijingzhi2 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[2]/text()')[0]leijijingzhi = selectors.xpath('//dl[@class="dataItem03"]/dd[1]/span/text()')[0]lst = selectors.xpath('//div[@class="infoOfFund"]/table//text()')
结果如下图所示:
将具体的信息做相应的字符串处理,然后保存到csv文件中,结果如下图所示:
有了这个,你可以做进一步的统计和数据分析了。
- 合作、交流、转载请添加微信 moonhmily1 -<p style="outline: 0px;white-space: normal;font-size: 16px;">
Python架构高薪就业班/爬虫/数据分析/web开发/AI人工智能(百度云 百
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-04-29 23:25
含大数据、前沿技术、前端开发、后端开发、移动开发、数据分析、架构、人工智能、Python、Java、Android、前端、IOS、C++、大数据、、GO、音视频软件测试、产品经理、运维、股票基金、人工智能AI
以下内容为填充,无视即可
报表样式的饼图如图13-15所示。可以单击如图13-16所示的链接单独引用此报表。图13-15 报表样式的饼图图13-16 链接报表单独的页面能根据查询的修改而实时变化,比如将查询修改为:select date_format(create_time,'%Y-%m-%d') d, count(*) cfrom information_schema.tableswhere create_time > '2016-06-07'group by date_format(create_time,'%Y-%m-%d')order by d;增加了where子句,再运行此查询,结果如图13-17所示。图13-17 图形显示随查询变化单独链接的页面也随之自动发生变化,如图13-18所示。图13-18 单独链接的页面自动变化13.4 Hue、Zeppelin比较1.功能Zeppelin和Hue都具有一定的数据可视化功能,都提供了多种图形化数据表示形式。单从这点来说,它们的功能类似,大同小异。Hue可以通过经纬度进行地图定位,这个功能在Zeppelin 0.6.0上没有。Zeppelin支持的后端数据查询程序较多,0.6.0版本默认有18种,原生支持Spark。
而Hue的3.9.0版本默认只支持Hive、Impala、Pig和数据库查询。Zeppelin只提供了单一的数据处理功能,它将数据摄取、数据发现、数据分析、数据可视化都归为数据处理的范畴。而Hue的功能则丰富得多,除了类似的数据处理,还有元数据管理、Oozie工作流管理、作业管理、用户管理、Sqoop集成等很多管理功能。从这点看,Zeppelin只是一个数据处理工具,而Hue更像是一个综合管理工具。2.架构Zeppelin采用插件式的翻译器,通过插件开发,可以添加任何后端语言及其数据处理程序,相对来说更加独立和开放。Hue与Hadoop生态圈的其他组件密切相关,一般都与CDH一同部署。3.使用场景Zeppelin适合单一数据处理,但后端处理语言繁多的场景,尤其适合Spark。Hue适合与Hadoop集群的多个组件交互,如Oozie工作流、Sqoop等联合处理数据的场景,尤其适合与Impala协同工作。13.5 数据可视化实例本节先用Impala、DB查询示例说明Hue的数据查询和可视化功能,然后交互式地建立定期执行销售订单示例ETL任务的工作流,说明在Hue里是如何操作Oozie工作流引擎的。
1.Impala查询在12.4节中执行了一些联机分析处理的查询,现在在Hue里执行查询,直观看一下结果的图形化表示效果。登录Hue,单击 图标进入“我的文档”页面。单击 创建一个名为“销售订单”的新项目。单击“新文档”→“Impala”进入查询编辑页面,创建一个新的Impala文档。在Impala查询编辑页面,选择olap库,然后在编辑窗口输入下面的查询语句。-- 按产品分类查询销售量和销售额selectt2.product_category pro_category,sum(order_quantity) sum_quantity,sum(order_amount) sum_amountfromsales_order_fact t1, product_dim t2wheret1.product_sk = t2.product_skgroup bypro_categoryorder bypro_category;-- 按产品查询销售量和销售额 查看全部
Python架构高薪就业班/爬虫/数据分析/web开发/AI人工智能(百度云 百
含大数据、前沿技术、前端开发、后端开发、移动开发、数据分析、架构、人工智能、Python、Java、Android、前端、IOS、C++、大数据、、GO、音视频软件测试、产品经理、运维、股票基金、人工智能AI
以下内容为填充,无视即可
报表样式的饼图如图13-15所示。可以单击如图13-16所示的链接单独引用此报表。图13-15 报表样式的饼图图13-16 链接报表单独的页面能根据查询的修改而实时变化,比如将查询修改为:select date_format(create_time,'%Y-%m-%d') d, count(*) cfrom information_schema.tableswhere create_time > '2016-06-07'group by date_format(create_time,'%Y-%m-%d')order by d;增加了where子句,再运行此查询,结果如图13-17所示。图13-17 图形显示随查询变化单独链接的页面也随之自动发生变化,如图13-18所示。图13-18 单独链接的页面自动变化13.4 Hue、Zeppelin比较1.功能Zeppelin和Hue都具有一定的数据可视化功能,都提供了多种图形化数据表示形式。单从这点来说,它们的功能类似,大同小异。Hue可以通过经纬度进行地图定位,这个功能在Zeppelin 0.6.0上没有。Zeppelin支持的后端数据查询程序较多,0.6.0版本默认有18种,原生支持Spark。
而Hue的3.9.0版本默认只支持Hive、Impala、Pig和数据库查询。Zeppelin只提供了单一的数据处理功能,它将数据摄取、数据发现、数据分析、数据可视化都归为数据处理的范畴。而Hue的功能则丰富得多,除了类似的数据处理,还有元数据管理、Oozie工作流管理、作业管理、用户管理、Sqoop集成等很多管理功能。从这点看,Zeppelin只是一个数据处理工具,而Hue更像是一个综合管理工具。2.架构Zeppelin采用插件式的翻译器,通过插件开发,可以添加任何后端语言及其数据处理程序,相对来说更加独立和开放。Hue与Hadoop生态圈的其他组件密切相关,一般都与CDH一同部署。3.使用场景Zeppelin适合单一数据处理,但后端处理语言繁多的场景,尤其适合Spark。Hue适合与Hadoop集群的多个组件交互,如Oozie工作流、Sqoop等联合处理数据的场景,尤其适合与Impala协同工作。13.5 数据可视化实例本节先用Impala、DB查询示例说明Hue的数据查询和可视化功能,然后交互式地建立定期执行销售订单示例ETL任务的工作流,说明在Hue里是如何操作Oozie工作流引擎的。
1.Impala查询在12.4节中执行了一些联机分析处理的查询,现在在Hue里执行查询,直观看一下结果的图形化表示效果。登录Hue,单击 图标进入“我的文档”页面。单击 创建一个名为“销售订单”的新项目。单击“新文档”→“Impala”进入查询编辑页面,创建一个新的Impala文档。在Impala查询编辑页面,选择olap库,然后在编辑窗口输入下面的查询语句。-- 按产品分类查询销售量和销售额selectt2.product_category pro_category,sum(order_quantity) sum_quantity,sum(order_amount) sum_amountfromsales_order_fact t1, product_dim t2wheret1.product_sk = t2.product_skgroup bypro_categoryorder bypro_category;-- 按产品查询销售量和销售额
c爬虫抓取网页数据(本节书摘来自异步社区《用Python写网络爬虫》第2章)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-04-19 15:08
本节节选自异步社区作者【澳大利亚】理查德·劳森(Richard Lawson)所著的《用Python编写Web爬虫》一书第2章第2.2节,李斌翻译,更多章节可访问云栖社区“异步社区”公众号查看。
2.2 三种网页抓取方法
现在我们已经了解了这个网页的结构,有三种方法可以从中获取数据。首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
2.2.1 正则表达式
如果您不熟悉正则表达式,或者需要一些提示,请查看完整介绍。
当我们使用正则表达式抓取区域数据时,首先需要尝试匹配
里面的内容
元素,如下图。
>>> import re
>>> url = 'http://example.webscraping.com/view/United
-Kingdom-239'
>>> html = download(url)
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png',
'244,820 square kilometres',
'62,348,447',
'GB',
'United Kingdom',
'London',
'EU',
'.uk',
'GBP',
'Pound',
'44',
'@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA',
'^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}
[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})
|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$',
'en-GB,cy-GB,gd',
'IE ']
从上面的结果可以看出,标签被用于几个国家属性。为了隔离area属性,我们可以只选择其中的第二个元素,如下图。
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然此方案目前可用,但如果页面更改,它可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使这个正则表达式更健壮,我们可以将它作为父对象
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是网页更新还有很多其他方式也可以使这个正则表达式不满足。例如,要将双引号改为单引号,
在之间添加额外的空格
标签,或更改 area_label 等。下面是尝试支持这些可能性的改进版本。
>>> re.findall('.*?>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup 能够正确解析缺失的引号并关闭标签,除了添加和
标记使它成为一个完整的 HTML 文档。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # returns just the first match
Area
>>> ul.find_all('li') # returns all matches
[Area, Population]
要了解所有的方法和参数,可以参考 BeautifulSoup 的官方文档:.
以下是使用该方法提取样本国家地区数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> url = 'http://example.webscraping.com/places/view/
United-Kingdom-239'
>>> html = download(url)
>>> soup = BeautifulSoup(html)
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> td = tr.find(attrs={'class':'w2p_fw'}) # locate the area tag
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
此代码虽然比正则表达式代码更复杂,但更易于构建和理解。此外,布局中的小变化,例如额外的空白和选项卡属性,我们不必再担心了。
2.2.3 Lxml
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。最新的安装说明可供参考。
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将可能无效的 HTML 解析为统一格式。以下是使用此模块解析相同的不完整 HTML 的示例。
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> tree = lxml.html.fromstring(broken_html) # parse the HTML
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同样,lxml可以正确解析属性和关闭标签周围缺少的引号,但是模块不加和
标签。
解析输入内容后,进入选择元素的步骤。此时,lxml 有几种不同的方法,例如类似于 Beautiful Soup 的 XPath 选择器和 find() 方法。但是,在本例和后续示例中,我们将使用 CSS 选择器,因为它们更简洁,可以在第 5 章解析动态内容时重复使用。另外,一些有 jQuery 选择器经验的读者会更熟悉它。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码。
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0]
>>> area = td.text_content()
>>> print area
244,820 square kilometres
CSS 选择器的关键行已加粗。这行代码会先找到ID为places_area__row的表格行元素,然后选择w2p_fw类的表格数据子标签。
CSS 选择器
CSS 选择器表示用于选择元素的模式。下面是一些常用选择器的示例。
选择所有标签:*
选择<a>标签:a
选择所有class="link"的元素:.link
选择class="link"的<a>标签:a.link
选择id="home"的<a>标签:a#home
选择父元素为<a>标签的所有子标签:a > span
选择<a>标签内部的所有标签:a span
选择title属性为"Home"的所有<a>标签:a[title=Home]
CSS3 规范已由 W3C 在 `/2011/REC-css3-selectors-20110929/ 提出。
Lxml 已经实现了大部分 CSS3 属性,不支持的功能可以在这里找到。
需要注意的是,lxml 的内部实现实际上将 CSS 选择器转换为等效的 XPath 选择器。
2.2.4 性能对比
为了更好地评估本章描述的三种抓取方法之间的权衡,我们需要比较它们的相对效率。通常,爬虫从网页中提取多个字段。因此,为了使比较更加真实,我们将在本章中实现每个爬虫的扩展版本,从国家页面中提取每个可用数据。首先,我们需要回到Firebug,检查国家页面其他功能的格式,如图2.4.
您可以从 Firebug 的显示中看到,表格中的每一行都有一个以 places_ 开头并以 __row 结尾的 ID。这些行中收录的国家/地区数据的格式与上面示例中的格式相同。下面是使用上述信息提取所有可用国家/地区数据的实现代码。
FIELDS = ('area', 'population', 'iso', 'country', 'capital',
'continent', 'tld', 'currency_code', 'currency_name', 'phone',
'postal_code_format', 'postal_code_regex', 'languages',
'neighbours')
import re
def re_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)' % field, html).groups()[0]
return results
from bs4 import BeautifulSoup
def bs_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr',
id='places_%s__row' % field).find('td',
class_='w2p_fw').text
return results
import lxml.html
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_%s__row
> td.w2p_fw' % field)[0].text_content()
return results
获取结果
现在我们已经完成了所有爬虫的代码实现,接下来通过下面的代码片段来测试这三种方法的相对性能。
import time
NUM_ITERATIONS = 1000 # number of times to test each scraper
html = download('http://example.webscraping.com/places/view/
United-Kingdom-239')
for name, scraper in [('Regular expressions', re_scraper),
('BeautifulSoup', bs_scraper),
('Lxml', lxml_scraper)]:
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == re_scraper:
re.purge()
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
# record end time of scrape and output the total
end = time.time()
print '%s: %.2f seconds' % (name, end – start)
在这段代码中,每个爬虫会被执行1000次,每次执行都会检查爬取结果是否正确,然后打印总时间。这里使用的下载函数还是上一章定义的。请注意,我们在粗体代码行中调用了 re.purge() 方法。默认情况下,正则表达式模块会缓存搜索结果,为了与其他爬虫比较公平,我们需要使用这种方法来清除缓存。
下面是在我的电脑上运行脚本的结果。
$ python performance.py
Regular expressions: 5.50 seconds
BeautifulSoup: 42.84 seconds
Lxml: 7.06 seconds
由于硬件条件的不同,不同计算机的执行结果也会有一定差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,Beautiful Soup 在爬取我们的示例网页时比其他两种方法慢 6 倍以上。事实上,这个结果是意料之中的,因为 lxml 和 regex 模块是用 C 编写的,而 BeautifulSoup 是用纯 Python 编写的。一个有趣的事实是 lxml 的行为与正则表达式一样。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当爬取同一个网页的多个特征时,这种初始解析的开销会减少,lxml会更有竞争力。多么神奇的模块!
2.2.5 个结论
表2.1总结了每种爬取方式的优缺点。
如果您的爬虫的瓶颈是下载页面,而不是提取数据,那么使用较慢的方法(如 Beautiful Soup)不是问题。如果你只需要抓取少量数据并想避免额外的依赖,那么正则表达式可能更合适。通常,lxml 是抓取数据的最佳选择,因为它快速且健壮,而正则表达式和 Beautiful Soup 仅在某些场景下有用。
2.2.6 添加链接爬虫的爬取回调
我们已经看到了如何抓取国家数据,我们需要将其集成到上一章的链接爬虫中。为了重用这个爬虫代码去抓取其他网站,我们需要添加一个回调参数来处理抓取行为。回调是在某个事件发生后调用的函数(在这种情况下,在网页下载完成后)。爬取回调函数收录url和html两个参数,可以返回要爬取的url列表。下面是它的实现代码。可见,用Python实现这个功能非常简单。
def link_crawler(..., scrape_callback=None):
...
links = []
if scrape_callback:
links.extend(scrape_callback(url, html) or [])
...
在上面的代码片段中,我们将新添加的抓取回调函数代码加粗。如果想获取该版本链接爬虫的完整代码,可以访问org/wswp/code/src/tip/chapter02/link_crawler.py。
现在,我们只需要自定义传入的scrape_callback函数,就可以使用爬虫抓取其他网站了。下面修改lxml抓取示例的代码,以便在回调函数中使用。
def scrape_callback(url, html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
row = [tree.cssselect('table > tr#places_%s__row >
td.w2p_fw' % field)[0].text_content() for field in
FIELDS]
print url, row
上面的回调函数会抓取国家数据并显示出来。不过一般情况下,在爬取网站的时候,我们更希望能够重用这些数据,所以让我们扩展一下它的功能,把得到的数据保存在一个CSV表中。代码如下。
import csv
class ScrapeCallback:
def __init__(self):
self.writer = csv.writer(open('countries.csv', 'w'))
self.fields = ('area', 'population', 'iso', 'country',
'capital', 'continent', 'tld', 'currency_code',
'currency_name', 'phone', 'postal_code_format',
'postal_code_regex', 'languages',
'neighbours')
self.writer.writerow(self.fields)
def __call__(self, url, html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
row = []
for field in self.fields:
row.append(tree.cssselect('table >
tr#places_{}__row >
td.w2p_fw'.format(field))
[0].text_content())
self.writer.writerow(row)
为了实现这个回调,我们使用回调类而不是回调函数,以维护 csv 中 writer 属性的状态。在构造函数中实例化csv的writer属性,然后在__call__方法中进行多次写入。注意__call__是一个特殊的方法,当一个对象作为函数调用时会调用,这也是链接爬虫中cache_callback的调用方式。也就是说,scrape_callback(url, html) 等价于调用 scrape_callback.__call__(url, html)。如果想详细了解Python的特殊类方法,可以参考一下。
以下是将回调传递给链接爬虫的代码。
link_crawler('http://example.webscraping.com/', '/(index|view)',
max_depth=-1, scrape_callback=ScrapeCallback())
现在,当我们使用回调运行这个爬虫时,程序会将结果写入 CSV 文件,我们可以使用 Excel 或 LibreOffice 等应用程序查看该文件,如图 2.5 所示。
成功!我们完成了我们的第一个工作数据抓取爬虫。 查看全部
c爬虫抓取网页数据(本节书摘来自异步社区《用Python写网络爬虫》第2章)
本节节选自异步社区作者【澳大利亚】理查德·劳森(Richard Lawson)所著的《用Python编写Web爬虫》一书第2章第2.2节,李斌翻译,更多章节可访问云栖社区“异步社区”公众号查看。
2.2 三种网页抓取方法
现在我们已经了解了这个网页的结构,有三种方法可以从中获取数据。首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
2.2.1 正则表达式
如果您不熟悉正则表达式,或者需要一些提示,请查看完整介绍。
当我们使用正则表达式抓取区域数据时,首先需要尝试匹配
里面的内容
元素,如下图。
>>> import re
>>> url = 'http://example.webscraping.com/view/United
-Kingdom-239'
>>> html = download(url)
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png',
'244,820 square kilometres',
'62,348,447',
'GB',
'United Kingdom',
'London',
'EU',
'.uk',
'GBP',
'Pound',
'44',
'@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA',
'^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}
[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})
|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$',
'en-GB,cy-GB,gd',
'IE ']
从上面的结果可以看出,标签被用于几个国家属性。为了隔离area属性,我们可以只选择其中的第二个元素,如下图。
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然此方案目前可用,但如果页面更改,它可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使这个正则表达式更健壮,我们可以将它作为父对象
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是网页更新还有很多其他方式也可以使这个正则表达式不满足。例如,要将双引号改为单引号,
在之间添加额外的空格
标签,或更改 area_label 等。下面是尝试支持这些可能性的改进版本。
>>> re.findall('.*?>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup 能够正确解析缺失的引号并关闭标签,除了添加和
标记使它成为一个完整的 HTML 文档。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # returns just the first match
Area
>>> ul.find_all('li') # returns all matches
[Area, Population]
要了解所有的方法和参数,可以参考 BeautifulSoup 的官方文档:.
以下是使用该方法提取样本国家地区数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> url = 'http://example.webscraping.com/places/view/
United-Kingdom-239'
>>> html = download(url)
>>> soup = BeautifulSoup(html)
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> td = tr.find(attrs={'class':'w2p_fw'}) # locate the area tag
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
此代码虽然比正则表达式代码更复杂,但更易于构建和理解。此外,布局中的小变化,例如额外的空白和选项卡属性,我们不必再担心了。
2.2.3 Lxml
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。最新的安装说明可供参考。
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将可能无效的 HTML 解析为统一格式。以下是使用此模块解析相同的不完整 HTML 的示例。
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> tree = lxml.html.fromstring(broken_html) # parse the HTML
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同样,lxml可以正确解析属性和关闭标签周围缺少的引号,但是模块不加和
标签。
解析输入内容后,进入选择元素的步骤。此时,lxml 有几种不同的方法,例如类似于 Beautiful Soup 的 XPath 选择器和 find() 方法。但是,在本例和后续示例中,我们将使用 CSS 选择器,因为它们更简洁,可以在第 5 章解析动态内容时重复使用。另外,一些有 jQuery 选择器经验的读者会更熟悉它。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码。
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0]
>>> area = td.text_content()
>>> print area
244,820 square kilometres
CSS 选择器的关键行已加粗。这行代码会先找到ID为places_area__row的表格行元素,然后选择w2p_fw类的表格数据子标签。
CSS 选择器
CSS 选择器表示用于选择元素的模式。下面是一些常用选择器的示例。
选择所有标签:*
选择<a>标签:a
选择所有class="link"的元素:.link
选择class="link"的<a>标签:a.link
选择id="home"的<a>标签:a#home
选择父元素为<a>标签的所有子标签:a > span
选择<a>标签内部的所有标签:a span
选择title属性为"Home"的所有<a>标签:a[title=Home]
CSS3 规范已由 W3C 在 `/2011/REC-css3-selectors-20110929/ 提出。
Lxml 已经实现了大部分 CSS3 属性,不支持的功能可以在这里找到。
需要注意的是,lxml 的内部实现实际上将 CSS 选择器转换为等效的 XPath 选择器。
2.2.4 性能对比
为了更好地评估本章描述的三种抓取方法之间的权衡,我们需要比较它们的相对效率。通常,爬虫从网页中提取多个字段。因此,为了使比较更加真实,我们将在本章中实现每个爬虫的扩展版本,从国家页面中提取每个可用数据。首先,我们需要回到Firebug,检查国家页面其他功能的格式,如图2.4.
您可以从 Firebug 的显示中看到,表格中的每一行都有一个以 places_ 开头并以 __row 结尾的 ID。这些行中收录的国家/地区数据的格式与上面示例中的格式相同。下面是使用上述信息提取所有可用国家/地区数据的实现代码。
FIELDS = ('area', 'population', 'iso', 'country', 'capital',
'continent', 'tld', 'currency_code', 'currency_name', 'phone',
'postal_code_format', 'postal_code_regex', 'languages',
'neighbours')
import re
def re_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)' % field, html).groups()[0]
return results
from bs4 import BeautifulSoup
def bs_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr',
id='places_%s__row' % field).find('td',
class_='w2p_fw').text
return results
import lxml.html
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_%s__row
> td.w2p_fw' % field)[0].text_content()
return results
获取结果
现在我们已经完成了所有爬虫的代码实现,接下来通过下面的代码片段来测试这三种方法的相对性能。
import time
NUM_ITERATIONS = 1000 # number of times to test each scraper
html = download('http://example.webscraping.com/places/view/
United-Kingdom-239')
for name, scraper in [('Regular expressions', re_scraper),
('BeautifulSoup', bs_scraper),
('Lxml', lxml_scraper)]:
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == re_scraper:
re.purge()
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
# record end time of scrape and output the total
end = time.time()
print '%s: %.2f seconds' % (name, end – start)
在这段代码中,每个爬虫会被执行1000次,每次执行都会检查爬取结果是否正确,然后打印总时间。这里使用的下载函数还是上一章定义的。请注意,我们在粗体代码行中调用了 re.purge() 方法。默认情况下,正则表达式模块会缓存搜索结果,为了与其他爬虫比较公平,我们需要使用这种方法来清除缓存。
下面是在我的电脑上运行脚本的结果。
$ python performance.py
Regular expressions: 5.50 seconds
BeautifulSoup: 42.84 seconds
Lxml: 7.06 seconds
由于硬件条件的不同,不同计算机的执行结果也会有一定差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,Beautiful Soup 在爬取我们的示例网页时比其他两种方法慢 6 倍以上。事实上,这个结果是意料之中的,因为 lxml 和 regex 模块是用 C 编写的,而 BeautifulSoup 是用纯 Python 编写的。一个有趣的事实是 lxml 的行为与正则表达式一样。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当爬取同一个网页的多个特征时,这种初始解析的开销会减少,lxml会更有竞争力。多么神奇的模块!
2.2.5 个结论
表2.1总结了每种爬取方式的优缺点。
如果您的爬虫的瓶颈是下载页面,而不是提取数据,那么使用较慢的方法(如 Beautiful Soup)不是问题。如果你只需要抓取少量数据并想避免额外的依赖,那么正则表达式可能更合适。通常,lxml 是抓取数据的最佳选择,因为它快速且健壮,而正则表达式和 Beautiful Soup 仅在某些场景下有用。
2.2.6 添加链接爬虫的爬取回调
我们已经看到了如何抓取国家数据,我们需要将其集成到上一章的链接爬虫中。为了重用这个爬虫代码去抓取其他网站,我们需要添加一个回调参数来处理抓取行为。回调是在某个事件发生后调用的函数(在这种情况下,在网页下载完成后)。爬取回调函数收录url和html两个参数,可以返回要爬取的url列表。下面是它的实现代码。可见,用Python实现这个功能非常简单。
def link_crawler(..., scrape_callback=None):
...
links = []
if scrape_callback:
links.extend(scrape_callback(url, html) or [])
...
在上面的代码片段中,我们将新添加的抓取回调函数代码加粗。如果想获取该版本链接爬虫的完整代码,可以访问org/wswp/code/src/tip/chapter02/link_crawler.py。
现在,我们只需要自定义传入的scrape_callback函数,就可以使用爬虫抓取其他网站了。下面修改lxml抓取示例的代码,以便在回调函数中使用。
def scrape_callback(url, html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
row = [tree.cssselect('table > tr#places_%s__row >
td.w2p_fw' % field)[0].text_content() for field in
FIELDS]
print url, row
上面的回调函数会抓取国家数据并显示出来。不过一般情况下,在爬取网站的时候,我们更希望能够重用这些数据,所以让我们扩展一下它的功能,把得到的数据保存在一个CSV表中。代码如下。
import csv
class ScrapeCallback:
def __init__(self):
self.writer = csv.writer(open('countries.csv', 'w'))
self.fields = ('area', 'population', 'iso', 'country',
'capital', 'continent', 'tld', 'currency_code',
'currency_name', 'phone', 'postal_code_format',
'postal_code_regex', 'languages',
'neighbours')
self.writer.writerow(self.fields)
def __call__(self, url, html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
row = []
for field in self.fields:
row.append(tree.cssselect('table >
tr#places_{}__row >
td.w2p_fw'.format(field))
[0].text_content())
self.writer.writerow(row)
为了实现这个回调,我们使用回调类而不是回调函数,以维护 csv 中 writer 属性的状态。在构造函数中实例化csv的writer属性,然后在__call__方法中进行多次写入。注意__call__是一个特殊的方法,当一个对象作为函数调用时会调用,这也是链接爬虫中cache_callback的调用方式。也就是说,scrape_callback(url, html) 等价于调用 scrape_callback.__call__(url, html)。如果想详细了解Python的特殊类方法,可以参考一下。
以下是将回调传递给链接爬虫的代码。
link_crawler('http://example.webscraping.com/', '/(index|view)',
max_depth=-1, scrape_callback=ScrapeCallback())
现在,当我们使用回调运行这个爬虫时,程序会将结果写入 CSV 文件,我们可以使用 Excel 或 LibreOffice 等应用程序查看该文件,如图 2.5 所示。
成功!我们完成了我们的第一个工作数据抓取爬虫。
c爬虫抓取网页数据(Python爬虫4.2—ajax[动态网页数据]用法教程综述)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-19 15:05
Python爬虫4.2——ajax【动态网页数据】使用教程
概览
本系列文档用于提供Python爬虫技术学习的简单教程。在巩固你的技术知识的同时,如果它恰好对你有用,那就更好了。
Python 版本是 3.7.4
有时当我们抓取带有请求的页面时,结果可能与我们在浏览器中看到的不同。正常显示的页面数据在浏览器中是可以看到的,但是使用requests得到的结果却不是。这是因为请求获取的是原创的 HTML 文档,而浏览器中的页面是通过 JavaScript 处理数据的结果。这些数据有多种来源,可以通过 Ajax 加载或收录在 HTML 中。在文档中,也可能是通过JavaScript和特定算法计算后生成的。
所以遇到这样的页面,直接使用requests等库获取原创页面是无法获取有效数据的。这时候就需要分析网页后端向接口发送的Ajax请求了。如果可以使用requests来模拟ajax请求,那么就可以成功爬取了。
所以,在这篇文章中,我们主要了解Ajax是什么以及如何分析和抓取Ajax请求。
AJAX简介什么是AJAX
AJAX(异步 JavaScript 和 XML)异步 JavaScript 和 XML。通过在后台交换与服务器协商的数据,Ajax 实现了网页的异步更新,这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。传统网页(没有Ajax)如果内容需要更新,需要重新加载整个网页,因为传统的数据传输格式使用XML语法,所以称为Ajax。其实数据交互的限制基本上就是使用JSON,Ajax加载的数据,即使是用JS渲染数据到浏览器,查看网页源码的时候还是看不到加载的数据通过 Ajax,您只能看到 Ajax 加载的数据。由 url 加载的 HTML 代码。
示例说明
在浏览网页时,我们会发现很多页面已经向下滚动以查看更多选项。比如微博、今日头条等,有的是根据鼠标下拉自动加载的。这些其实就是Ajax加载的过程。我们可以看到页面并没有完全刷新,也就是说页面的链接没有变化,但是网页中有新的内容,也就是通过Ajax获取新数据并渲染的过程。
请求分析
使用Chrome开发者工具的过滤功能,过滤掉所有的Ajax请求,这里不再详述。
Fiddler 抓包工具也可以用于抓包分析。 Fiddler工具的使用方法这里不做说明。您可以在线搜索和查看。
Ajax 响应结果一般为 json 数据格式。
获取方式直接分析Ajax使用的接口,然后通过代码请求这个接口获取数据(下面的例子就是这样一个通用的)。使用 Selenium + Chromedriver 模拟浏览器行为获取数据(继续关注文章)。该方法的优缺点
分析界面
可以直接请求数据,不需要做一些解析工作,代码少,性能高。
分析界面比较复杂,尤其是一些被js混淆的界面,你必须对js有一定的了解,很容易被爬虫发现。
硒
直接模拟浏览器的行为。浏览器能请求的也可以用selenium来请求,爬虫更稳定。
大量代码和低性能。
示例说明
让我们举个例子,爬取“成为一个长得好看的程序员是什么感觉?”这个问题的所有答案。在问题 知乎 下。示例代码如下:
<p># 引入所需库
import json
import requests
# 声明定义请求头
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/67.0.3396.99 '
'Safari/537.36',
'Host': "www.zhihu.com",
'Referer': "https://www.zhihu.com/question/37787176"
}
def answer(url_):
"""
获取问题答案
:param url_:
:return:
"""
r = requests.get(url_, headers=header)
data = r.text
jsonobj = json.loads(data)
return jsonobj
# 问题答案接口地址
url = "https://www.zhihu.com/api/v4/q ... ot%3B
# 获取回答总数
answer_total = int(answer(url)['paging']['totals'])
offset = 0
while offset 查看全部
c爬虫抓取网页数据(Python爬虫4.2—ajax[动态网页数据]用法教程综述)
Python爬虫4.2——ajax【动态网页数据】使用教程
概览
本系列文档用于提供Python爬虫技术学习的简单教程。在巩固你的技术知识的同时,如果它恰好对你有用,那就更好了。
Python 版本是 3.7.4
有时当我们抓取带有请求的页面时,结果可能与我们在浏览器中看到的不同。正常显示的页面数据在浏览器中是可以看到的,但是使用requests得到的结果却不是。这是因为请求获取的是原创的 HTML 文档,而浏览器中的页面是通过 JavaScript 处理数据的结果。这些数据有多种来源,可以通过 Ajax 加载或收录在 HTML 中。在文档中,也可能是通过JavaScript和特定算法计算后生成的。
所以遇到这样的页面,直接使用requests等库获取原创页面是无法获取有效数据的。这时候就需要分析网页后端向接口发送的Ajax请求了。如果可以使用requests来模拟ajax请求,那么就可以成功爬取了。
所以,在这篇文章中,我们主要了解Ajax是什么以及如何分析和抓取Ajax请求。
AJAX简介什么是AJAX
AJAX(异步 JavaScript 和 XML)异步 JavaScript 和 XML。通过在后台交换与服务器协商的数据,Ajax 实现了网页的异步更新,这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。传统网页(没有Ajax)如果内容需要更新,需要重新加载整个网页,因为传统的数据传输格式使用XML语法,所以称为Ajax。其实数据交互的限制基本上就是使用JSON,Ajax加载的数据,即使是用JS渲染数据到浏览器,查看网页源码的时候还是看不到加载的数据通过 Ajax,您只能看到 Ajax 加载的数据。由 url 加载的 HTML 代码。
示例说明
在浏览网页时,我们会发现很多页面已经向下滚动以查看更多选项。比如微博、今日头条等,有的是根据鼠标下拉自动加载的。这些其实就是Ajax加载的过程。我们可以看到页面并没有完全刷新,也就是说页面的链接没有变化,但是网页中有新的内容,也就是通过Ajax获取新数据并渲染的过程。
请求分析
使用Chrome开发者工具的过滤功能,过滤掉所有的Ajax请求,这里不再详述。
Fiddler 抓包工具也可以用于抓包分析。 Fiddler工具的使用方法这里不做说明。您可以在线搜索和查看。
Ajax 响应结果一般为 json 数据格式。
获取方式直接分析Ajax使用的接口,然后通过代码请求这个接口获取数据(下面的例子就是这样一个通用的)。使用 Selenium + Chromedriver 模拟浏览器行为获取数据(继续关注文章)。该方法的优缺点
分析界面
可以直接请求数据,不需要做一些解析工作,代码少,性能高。
分析界面比较复杂,尤其是一些被js混淆的界面,你必须对js有一定的了解,很容易被爬虫发现。
硒
直接模拟浏览器的行为。浏览器能请求的也可以用selenium来请求,爬虫更稳定。
大量代码和低性能。
示例说明
让我们举个例子,爬取“成为一个长得好看的程序员是什么感觉?”这个问题的所有答案。在问题 知乎 下。示例代码如下:
<p># 引入所需库
import json
import requests
# 声明定义请求头
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/67.0.3396.99 '
'Safari/537.36',
'Host': "www.zhihu.com",
'Referer': "https://www.zhihu.com/question/37787176"
}
def answer(url_):
"""
获取问题答案
:param url_:
:return:
"""
r = requests.get(url_, headers=header)
data = r.text
jsonobj = json.loads(data)
return jsonobj
# 问题答案接口地址
url = "https://www.zhihu.com/api/v4/q ... ot%3B
# 获取回答总数
answer_total = int(answer(url)['paging']['totals'])
offset = 0
while offset
c爬虫抓取网页数据( 二级建造师考试每日一练免费在线测试())
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-04-19 01:12
二级建造师考试每日一练免费在线测试())
更多《搜索引擎利用网络爬虫不断从网上爬取网站数据,并在本地存储网站图片。()》相关问题
问题 1
以下关于蜘蛛的说法错误的是( )。
A. 蜘蛛是搜索引擎的网络爬虫
湾。每个搜索引擎蜘蛛都有不同的名称
C。网站被搜索引擎降级后蜘蛛再也不会来这里了网站
D.站长可以通过技术等优化吸引蜘蛛爬行
点击查看答案
问题2
动态 URL 帮助搜索引擎抓取网页并提高 网站 排名。()
点击查看答案
问题 3
大站点优先,顾名思义,就是在互联网上优先抓取()页面,是搜索引擎中的一种信息抓取策略。
大站点优先,顾名思义,就是在互联网上优先抓取()页面,是搜索引擎中的一种信息抓取策略。
A. 小网站
B. 中小型网站
C. 大 网站
D. 中型和大型 网站
点击查看答案
问题 4
HTML版本的网站map只适合搜索引擎蜘蛛抓取,不利于用户体验。()
点击查看答案
问题 5
以下关于网络爬虫的描述是错误的()。
A. 网络爬虫是一种自动提取网页的程序
B. 为搜索引擎从万维网上下载网页是搜索引擎的重要组成部分
C、爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某个停止条件。
D.网络爬虫的行为与访问网站的人的行为完全不同
点击查看答案
问题 6
如果通过爬虫抓取某公司网站的公开数据,分析后发现该公司的业绩非常好。然后将数据或分析结果出售给基金公司,获得销售收入。这是合法的。()
点击查看答案
问题 7
网络数据采集常用来通过()或()的方式从网站获取数据信息。
A. 网络爬虫
湾。网站公共 API
C。手动获取
点击查看答案
问题 8
爬虫是手动请求万维网网站并提取网页数据的程序()
点击查看答案
问题 9
网络数据采集是利用互联网搜索引擎技术,有针对性、行业针对性、准确地抓取数据,并按照一定的规则和筛选标准对数据进行分类,形成数据库文件的过程。()
点击查看答案
问题 10
搜索引擎营销主要用于网站推广,不起到建立网络品牌的作用。()
点击查看答案 查看全部
c爬虫抓取网页数据(
二级建造师考试每日一练免费在线测试())
更多《搜索引擎利用网络爬虫不断从网上爬取网站数据,并在本地存储网站图片。()》相关问题
问题 1
以下关于蜘蛛的说法错误的是( )。
A. 蜘蛛是搜索引擎的网络爬虫
湾。每个搜索引擎蜘蛛都有不同的名称
C。网站被搜索引擎降级后蜘蛛再也不会来这里了网站
D.站长可以通过技术等优化吸引蜘蛛爬行
点击查看答案
问题2
动态 URL 帮助搜索引擎抓取网页并提高 网站 排名。()
点击查看答案
问题 3
大站点优先,顾名思义,就是在互联网上优先抓取()页面,是搜索引擎中的一种信息抓取策略。
大站点优先,顾名思义,就是在互联网上优先抓取()页面,是搜索引擎中的一种信息抓取策略。
A. 小网站
B. 中小型网站
C. 大 网站
D. 中型和大型 网站
点击查看答案
问题 4
HTML版本的网站map只适合搜索引擎蜘蛛抓取,不利于用户体验。()
点击查看答案
问题 5
以下关于网络爬虫的描述是错误的()。
A. 网络爬虫是一种自动提取网页的程序
B. 为搜索引擎从万维网上下载网页是搜索引擎的重要组成部分
C、爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某个停止条件。
D.网络爬虫的行为与访问网站的人的行为完全不同
点击查看答案
问题 6
如果通过爬虫抓取某公司网站的公开数据,分析后发现该公司的业绩非常好。然后将数据或分析结果出售给基金公司,获得销售收入。这是合法的。()
点击查看答案
问题 7
网络数据采集常用来通过()或()的方式从网站获取数据信息。
A. 网络爬虫
湾。网站公共 API
C。手动获取
点击查看答案
问题 8
爬虫是手动请求万维网网站并提取网页数据的程序()
点击查看答案
问题 9
网络数据采集是利用互联网搜索引擎技术,有针对性、行业针对性、准确地抓取数据,并按照一定的规则和筛选标准对数据进行分类,形成数据库文件的过程。()
点击查看答案
问题 10
搜索引擎营销主要用于网站推广,不起到建立网络品牌的作用。()
点击查看答案
c爬虫抓取网页数据( 在爬虫系统中,等待抓取URL队列是很重要的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-04-17 16:29
在爬虫系统中,等待抓取URL队列是很重要的)
在爬虫系统中,等待爬取的URL队列是一个非常重要的部分,而等待爬取的URL队列中URL的顺序也是一个非常重要的问题,因为它会决定先爬到哪个页面之后再爬取哪个页面。而确定这些URL顺序的方法称为爬取策略。下面主要介绍几种常见的爬取策略:
1 深度优先遍历策略:深度优先遍历策略是指网络爬虫会从起始页开始,每一个链接一次一个链接,直到处理完该行才会转到下一个起始页,并且继续关注链接。遍历路径为:AFG ,EHI ,B ,C,D
2 广度优先遍历策略:广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接放在待爬取的URL队列的末尾。也就是说,网络爬虫会优先抓取起始网页中的所有链接。爬取完所有网页后,选择其中一个链接的网页,继续爬取该网页链接的所有网页。它的路径可以这样写:ABCDEF ,G ,H,I
3 外链数策略:外链数是指一个网页被其他网页指向的链接数,外链数也表示一个网页的内容被他人推荐的程度. 抓取系统会使用这个指标来评估网页的重要性,从而确定不同网页的抓取顺序。
但是,在真实的网络环境中,由于存在很多广告链接、作弊链接等,反向链接的数量并不能完全等同于重要性。因此,很多搜索引擎经常会考虑一些可靠的反向链接。
4.OPIC策略策略:这个算法其实是给网页的重要性打分的。在算法开始之前,所有页面都会被赋予相同的初始现金(cash)。当一个页面 P 被下载后,将 P 的现金分配给从 P 分析的所有链接,并清除 P 的现金。URL队列中所有待爬取的页面,按照现金数量排序。
5.大站点优先策略:对URL队列中所有待爬取的网页,按照所属的网站进行分类。对于需要下载的页面较多的网站,请先下载。这种策略也被称为大站优先策略。 查看全部
c爬虫抓取网页数据(
在爬虫系统中,等待抓取URL队列是很重要的)
在爬虫系统中,等待爬取的URL队列是一个非常重要的部分,而等待爬取的URL队列中URL的顺序也是一个非常重要的问题,因为它会决定先爬到哪个页面之后再爬取哪个页面。而确定这些URL顺序的方法称为爬取策略。下面主要介绍几种常见的爬取策略:
1 深度优先遍历策略:深度优先遍历策略是指网络爬虫会从起始页开始,每一个链接一次一个链接,直到处理完该行才会转到下一个起始页,并且继续关注链接。遍历路径为:AFG ,EHI ,B ,C,D
2 广度优先遍历策略:广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接放在待爬取的URL队列的末尾。也就是说,网络爬虫会优先抓取起始网页中的所有链接。爬取完所有网页后,选择其中一个链接的网页,继续爬取该网页链接的所有网页。它的路径可以这样写:ABCDEF ,G ,H,I
3 外链数策略:外链数是指一个网页被其他网页指向的链接数,外链数也表示一个网页的内容被他人推荐的程度. 抓取系统会使用这个指标来评估网页的重要性,从而确定不同网页的抓取顺序。
但是,在真实的网络环境中,由于存在很多广告链接、作弊链接等,反向链接的数量并不能完全等同于重要性。因此,很多搜索引擎经常会考虑一些可靠的反向链接。
4.OPIC策略策略:这个算法其实是给网页的重要性打分的。在算法开始之前,所有页面都会被赋予相同的初始现金(cash)。当一个页面 P 被下载后,将 P 的现金分配给从 P 分析的所有链接,并清除 P 的现金。URL队列中所有待爬取的页面,按照现金数量排序。
5.大站点优先策略:对URL队列中所有待爬取的网页,按照所属的网站进行分类。对于需要下载的页面较多的网站,请先下载。这种策略也被称为大站优先策略。
c爬虫抓取网页数据(农村最恐怖的还是蚂蝗,它无处不在吸你多少血了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-04-15 06:33
农村最可怕的就是水蛭,到处都是。当它无意识地咬你,当你感觉到它。我不知道我从你身上吸了多少血,也吸不出来。你要拍它才肯下来,这东西更可怕。只是不容易死。你把它分成几段。
它也不会死,记得我小时候。我们的几个朋友去堰和池塘洗澡。没学过游泳,只是边玩边玩。洗漱完毕,上岸。他的屁股上有一只巨大的水蛭,吓得他哭了。这东西吸血,太可怕了,恶心。农村的大人小孩都害怕。
尤其是女孩子,她们的父母让她帮忙种水稻。先问有没有蚂蟥,杀了就不去了。大人就好了,习惯就好。如果你看到几个耳光,就一拍即合。我们小时候被咬过很多次,很多次。我倒不是太害怕,我只是看到自己吸了那么多血。
有点疼,现在稻田里没有那么多水蛭了。稻谷是用收割机收割的,是时候收割了。在收割机下田收割之前,必须排干稻田中的所有水。没有水,水蛭就会减少。动物只有在有水的情况下才能吸血。我希望这东西可以灭绝。
python爬虫是怎么做的?
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本篇文章将介绍如何编写一个网络爬虫从零开始爬取数据,进而逐步完善爬虫的爬取功能。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
通过以上步骤,我们就可以写出一个最原创的爬虫了。在了解爬虫原理的基础上,我们可以进一步完善爬虫。
写了一个关于爬虫的系列文章:。如果你有兴趣,你可以去看看。
Python基础环境搭建、爬虫基本原理及爬虫原型
Python 爬虫入门(第 1 部分)
如何使用 BeautifulSoup 提取网页内容
Python 爬虫入门(第 2 部分)
爬虫运行时数据的存储数据,以 SQLite 和 MySQL 为例
Python 爬虫入门(第 3 部分)
使用 selenium webdriver 抓取动态网页
Python 爬虫入门(第 4 部分)
讨论了如何处理网站的反爬策略
Python 爬虫入门(第 5 部分)
介绍了Python的Scrapy爬虫框架,并简要演示了如何在Scrapy下开发
Python 爬虫入门(第 6 部分) 查看全部
c爬虫抓取网页数据(农村最恐怖的还是蚂蝗,它无处不在吸你多少血了)
农村最可怕的就是水蛭,到处都是。当它无意识地咬你,当你感觉到它。我不知道我从你身上吸了多少血,也吸不出来。你要拍它才肯下来,这东西更可怕。只是不容易死。你把它分成几段。
它也不会死,记得我小时候。我们的几个朋友去堰和池塘洗澡。没学过游泳,只是边玩边玩。洗漱完毕,上岸。他的屁股上有一只巨大的水蛭,吓得他哭了。这东西吸血,太可怕了,恶心。农村的大人小孩都害怕。
尤其是女孩子,她们的父母让她帮忙种水稻。先问有没有蚂蟥,杀了就不去了。大人就好了,习惯就好。如果你看到几个耳光,就一拍即合。我们小时候被咬过很多次,很多次。我倒不是太害怕,我只是看到自己吸了那么多血。
有点疼,现在稻田里没有那么多水蛭了。稻谷是用收割机收割的,是时候收割了。在收割机下田收割之前,必须排干稻田中的所有水。没有水,水蛭就会减少。动物只有在有水的情况下才能吸血。我希望这东西可以灭绝。
python爬虫是怎么做的?
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本篇文章将介绍如何编写一个网络爬虫从零开始爬取数据,进而逐步完善爬虫的爬取功能。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
通过以上步骤,我们就可以写出一个最原创的爬虫了。在了解爬虫原理的基础上,我们可以进一步完善爬虫。
写了一个关于爬虫的系列文章:。如果你有兴趣,你可以去看看。
Python基础环境搭建、爬虫基本原理及爬虫原型
Python 爬虫入门(第 1 部分)
如何使用 BeautifulSoup 提取网页内容
Python 爬虫入门(第 2 部分)
爬虫运行时数据的存储数据,以 SQLite 和 MySQL 为例
Python 爬虫入门(第 3 部分)
使用 selenium webdriver 抓取动态网页
Python 爬虫入门(第 4 部分)
讨论了如何处理网站的反爬策略
Python 爬虫入门(第 5 部分)
介绍了Python的Scrapy爬虫框架,并简要演示了如何在Scrapy下开发
Python 爬虫入门(第 6 部分)
c爬虫抓取网页数据(imarowadtencc语言treefindall抓取国家面积数据的方法-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-04-15 06:09
标签: imarowadtencc 语言 treefindall 将是新版本
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1. 正则表达式
? 如果您是正则表达式的新手,或者需要一些提示,请查看正则表达式 HOWTO 以获得完整的介绍。
?当我们使用正则表达式抓取国家地区数据时,我们首先尝试匹配元素中的内容,像这样:
>>> import re
>>> import urllib2
>>> url = ‘http://example.webscraping.com ... m-239‘
>>> html = urllib2.urlopen(url).read()
>>> re.findall(‘(.*?)‘, html)
[‘‘, ‘244,820 square kilometres‘, ‘62,348,447‘, ‘GB‘, ‘United Kingdom‘, ‘London‘, ‘EU‘, ‘.uk‘, ‘GBP‘, ‘Pound‘, ‘44‘, ‘@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA‘, ‘^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$‘, ‘en-GB,cy-GB,gd‘, ‘IE ‘]
>>>
? 从以上结果可以看出,<td class=”w2p_fw” > 标签用于多个国家属性。要隔离 area 属性,我们只需选择其中的第二个元素,如下所示:
>>> re.findall(‘(.*?)‘, html)[1]
‘244,820 square kilometres‘
• 虽然这个方案现在可用,但如果页面发生变化,它很可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们也可以添加它的父元素 <tr>。由于元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)['244820平方公里'] Python爬虫三种网络爬取方式的性能对比 查看全部
c爬虫抓取网页数据(imarowadtencc语言treefindall抓取国家面积数据的方法-苏州安嘉)
标签: imarowadtencc 语言 treefindall 将是新版本
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1. 正则表达式
? 如果您是正则表达式的新手,或者需要一些提示,请查看正则表达式 HOWTO 以获得完整的介绍。
?当我们使用正则表达式抓取国家地区数据时,我们首先尝试匹配元素中的内容,像这样:
>>> import re
>>> import urllib2
>>> url = ‘http://example.webscraping.com ... m-239‘
>>> html = urllib2.urlopen(url).read()
>>> re.findall(‘(.*?)‘, html)
[‘
‘, ‘244,820 square kilometres‘, ‘62,348,447‘, ‘GB‘, ‘United Kingdom‘, ‘London‘, ‘EU‘, ‘.uk‘, ‘GBP‘, ‘Pound‘, ‘44‘, ‘@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA‘, ‘^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$‘, ‘en-GB,cy-GB,gd‘, ‘IE ‘]>>>
? 从以上结果可以看出,<td class=”w2p_fw” > 标签用于多个国家属性。要隔离 area 属性,我们只需选择其中的第二个元素,如下所示:
>>> re.findall(‘(.*?)‘, html)[1]
‘244,820 square kilometres‘
• 虽然这个方案现在可用,但如果页面发生变化,它很可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们也可以添加它的父元素 <tr>。由于元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)['244820平方公里'] Python爬虫三种网络爬取方式的性能对比
c爬虫抓取网页数据(我组开发遗留下来的分类保存到的文件和扒取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-04-14 14:01
2021-09-27
需要:
我们组的研究课题是编写一个更实用的爬虫软件,将其应用到一些前辈的代码中,并在此基础上进行完善和创新。
鉴于高级代码已经实现了基本功能,即从网站中爬取相关Word文档和其他计算机相关文件资料,过滤掉无关信息。我组将从以下几个方面着手改进和完善:
1.增强的去广告功能:
如今的网页情况,很多网页,包括贴吧、微博都充斥着广告,其中一些不可避免地与电脑有关,但这些广告的作用并没有实际意义。高级代码中确实有相应的删除广告的功能,但效果并不明显。在很多情况下,无法识别网络广告和实际有用的信息,因此会出现一些数据浪费或数据丢失。. 针对这种情况,我们小组决定对其广告过滤功能进行改进和修改。
2.按类别保存提取的文件:
对爬虫抓取的数据进行分类非常重要。学长的代码中,获取的数据没有入库分类存储,给下一组的开发留下了一些问题。,我组研究后认为应该增加保存党的分类的功能。
3.添加视频采集功能:
前辈的代码只实现了部分文本文件的提取,并没有进行视频数据的提取。但是由于网上很多视频都有相应的版权问题,而且大部分视频占用了很大的硬盘容量,所以我们会抓取视频的地址并存入数据库。
4.CSS 和 Javascript网站:
在原创代码中,只能抓取 HTTP6 网页。我们认为数据采集将过于有限。因此,我们想在这个问题中加入 CSS 和 Javascript 网站 的抓取功能。生成大量的代码工作量,只是一个初步的想法。
5.网页质量判断:
有些网站由于缺乏相关的和计算机知识的内容,重复搜索只会造成时间和资源的浪费。针对这种情况,我们认为应该增加一个判断网页质量的功能,把不合适的网站去掉,提高软件运行效率。
方法(实践):
1.对于抓取到的网站,获取URL,查看下一级网站的AD字段以及下一级网站与关键字的关联度
上学年对这个项目的评测中,去广告的功能并不完善,还夹杂了很多广告。他们在博客上写道,说是根据AD领域来判断这是否网站 是一个广告网站。我们觉得如果只根据AD字段来判断,有可能在网站中间的网站中抓取一些无用的广告。因此,我们觉得应该再往下检查一级。如果下一级网站中有很多广告网站,则排除这个网站。因为我们考虑到如果投放了一个广告,最多会经过一次网站传输,否则广告投放是不会生效的。因此,我们考虑多一个检测级别的方法,这应该可以在很大程度上解决问题。得到的网站中的广告有很多问题。
2.抓取的不同文件会根据文件格式的不同分别保存(先按文件夹分开)
捕获的 网站 根据它们与关键字的相关性进行分级和排序。上学年项目负责组评价写道,该组抓到的文件没有分类,所有文件都混在一起,给用户使用带来不便。我们想在这个软件中添加一个对捕获的文件进行分类和存储的功能。当某个文件被抓取时,会根据文件的类型,将其放置在该文件所在的存储区域中,从而完成软件运行。之后得到分类文件,方便用户使用。
3.提供视频链接,以便用户观看源视频
上一组没有完成相关视频的爬取功能。我们认为,如果它是一个网络爬虫,它的初衷是为互联网上的用户爬取有用的资源,而现在视频资源也很重要。因此,我们要增加视频捕捉功能。与内容和关键词相关的视频也会反馈给用户,以便用户观看相关视频。
4.CSS 和 Javascript网站
暂定。
5.检查关键词是否出现在被捕获的网站或者文件的标题中,如果在被捕获的网站或者文件的文本中频繁出现,用这个来判断此 网站 或文件的值给用户
我们认为,如果我们抓取其中出现关键词的所有资源,我们可能会抓取一些网站或不相关但出现关键词的文件,但在排除网站@之后> 以及对用户来说价值不大的文件,通过以上方法,我们抓取的东西质量会大大提高。
好处(好处):
1.能够更好地从结果中去除广告网站,优化用户体验
去除广告是我们爬虫非常重要的功能。爬虫的初衷是为用户高效地爬取互联网上有用的相关资源。如果可爬取资源中有大量的广告,会让用户的浏览很不方便,也就失去了爬虫的意义。. 我们将检查到下一个级别网站,并使用此方法排除广告网站。这样可以提高抓取资源的质量,用户可以更方便的使用爬虫的功能。
2.让用户更容易找到资源
如果爬虫把所有抓取到的资源放在一起,当用户需要一个格式单一的文件时会很麻烦。我们将采集到的资源按照类型分别保存,让用户可以更方便的使用软件,获得更好的用户体验。
3.让用户可以观看相关视频
这是一个全新的功能。之前的版本无法采集视频资源。虽然由于版权原因我们无法完全下载视频,但我们可以为用户提供源视频的链接,以便用户观看。现在互联网上有很多资源以视频的形式存在。我们加入这个功能是为了让这个软件更实用,更能满足用户不断增长的需求。
4.不限于HTML5网站,可以获得更多资源(暂定)
目前的版本只能爬取HTML5的网站,但是网站里面也有很多有用的资源是用javascript或者css的。我们更新了这个软件,支持javascript和css,可以让爬虫抓取更多的资源,为用户提供更多的服务。
5.提高采集结果的质量,增加剔除低质量资源的功能(暂定)
如果只关注捕获文件的数量和网站,可能会导致捕获文件和网站的质量很差,但是会减少结果中有用的文件和网站里面的成分让用户体验更差。我们将通过检测关键词是否出现在其标题及其出现频率等方法来确定该文件或网站对用户的价值。如果值不高,那么这个文件或 网站 @> 被排除。这将使我们能够抓取更高质量的文件和 网站。
竞争对手:
网络爬虫是一种自动获取网页内容的程序,是搜索引擎的重要组成部分。现在的搜索引擎基本上都涉及到爬虫的设计和优化。搜索引擎的速度也与爬虫的优化程度密切相关。从另一个角度来看,不仅仅是搜索引擎,所有的数据挖掘软件都会涉及到爬虫。因此,爬虫在整个软件行业的地位很高,应用范围非常广泛。这里我们主要通过搜索引擎中的爬虫来分析竞争。
首先,拿两个最常用的搜索引擎:百度和谷歌。从爬取信息来看,两者都是行业的佼佼者,爬取算法也很不错,可以按类型分类。,以方便用户操作。它爬取整个万维网的速度非常快。虽然我们的软件在速度和爬取算法方面还不是很成熟,但是我们的软件会为了方便用户而设计。我们会检查爬取文件的匹配度,对它们的优先级进行排序。这也将大大提高用户体验的质量。我将从以下几个方面来讨论我们软件的竞争力。
1.爬行速度和爬行负载,这也是衡量爬虫的标准
与其他软件相比,我们的软件在速度上还不错。我们通过广度优先的搜索顺序进行搜索,可以提高爬虫的爬取速度。同时,我们使用多个队列进行数据处理,这也使得爬虫可以同时处理多个数据。分组数据,承载能力更强。
2.爬取质量和特异性
很多网站爬虫爬取给定URL中的所有内容,不仅影响爬取内容的质量,还拖慢了预算。我们的爬虫会专门爬取电脑相关的数据,让爬取的内容更符合用户的需求。同时我们会对广告进行处理,也可以让爬虫的爬取质量更高。同时,我们会在爬取时与关键词进行匹配比较,可以大大减少广告和无关信息。
3.分类存储
用户的下一步操作可能会使用不同类型的数据。爬虫会在爬取过程中轻松对数据进行分类。分类可以让用户获得更好的用户体验,让用户在搜索的过程中可以更快的找到自己需要的信息。这应该更受程序员的欢迎。
4.接口与实现
用户在获取爬虫时,需要知道爬虫的输出形式和爬取速度,这就需要我们设计一个简单的接口来实现。我们的界面将以最简单的方式将输出呈现给用户,这将非常直观。
5.创新功能
我们将为原创爬虫添加新功能。比如抓取视频文件时,我们会将视频地址反馈给用户。这允许用户直接通过地址观看视频。此外,我们还计划实现不限于 html5 网页的爬取,甚至尝试爬取 CSS 或 javascript。这样可以更方便用户操作。
分类:
技术要点:
相关文章: 查看全部
c爬虫抓取网页数据(我组开发遗留下来的分类保存到的文件和扒取)
2021-09-27
需要:
我们组的研究课题是编写一个更实用的爬虫软件,将其应用到一些前辈的代码中,并在此基础上进行完善和创新。
鉴于高级代码已经实现了基本功能,即从网站中爬取相关Word文档和其他计算机相关文件资料,过滤掉无关信息。我组将从以下几个方面着手改进和完善:
1.增强的去广告功能:
如今的网页情况,很多网页,包括贴吧、微博都充斥着广告,其中一些不可避免地与电脑有关,但这些广告的作用并没有实际意义。高级代码中确实有相应的删除广告的功能,但效果并不明显。在很多情况下,无法识别网络广告和实际有用的信息,因此会出现一些数据浪费或数据丢失。. 针对这种情况,我们小组决定对其广告过滤功能进行改进和修改。
2.按类别保存提取的文件:
对爬虫抓取的数据进行分类非常重要。学长的代码中,获取的数据没有入库分类存储,给下一组的开发留下了一些问题。,我组研究后认为应该增加保存党的分类的功能。
3.添加视频采集功能:
前辈的代码只实现了部分文本文件的提取,并没有进行视频数据的提取。但是由于网上很多视频都有相应的版权问题,而且大部分视频占用了很大的硬盘容量,所以我们会抓取视频的地址并存入数据库。
4.CSS 和 Javascript网站:
在原创代码中,只能抓取 HTTP6 网页。我们认为数据采集将过于有限。因此,我们想在这个问题中加入 CSS 和 Javascript 网站 的抓取功能。生成大量的代码工作量,只是一个初步的想法。
5.网页质量判断:
有些网站由于缺乏相关的和计算机知识的内容,重复搜索只会造成时间和资源的浪费。针对这种情况,我们认为应该增加一个判断网页质量的功能,把不合适的网站去掉,提高软件运行效率。
方法(实践):
1.对于抓取到的网站,获取URL,查看下一级网站的AD字段以及下一级网站与关键字的关联度
上学年对这个项目的评测中,去广告的功能并不完善,还夹杂了很多广告。他们在博客上写道,说是根据AD领域来判断这是否网站 是一个广告网站。我们觉得如果只根据AD字段来判断,有可能在网站中间的网站中抓取一些无用的广告。因此,我们觉得应该再往下检查一级。如果下一级网站中有很多广告网站,则排除这个网站。因为我们考虑到如果投放了一个广告,最多会经过一次网站传输,否则广告投放是不会生效的。因此,我们考虑多一个检测级别的方法,这应该可以在很大程度上解决问题。得到的网站中的广告有很多问题。
2.抓取的不同文件会根据文件格式的不同分别保存(先按文件夹分开)
捕获的 网站 根据它们与关键字的相关性进行分级和排序。上学年项目负责组评价写道,该组抓到的文件没有分类,所有文件都混在一起,给用户使用带来不便。我们想在这个软件中添加一个对捕获的文件进行分类和存储的功能。当某个文件被抓取时,会根据文件的类型,将其放置在该文件所在的存储区域中,从而完成软件运行。之后得到分类文件,方便用户使用。
3.提供视频链接,以便用户观看源视频
上一组没有完成相关视频的爬取功能。我们认为,如果它是一个网络爬虫,它的初衷是为互联网上的用户爬取有用的资源,而现在视频资源也很重要。因此,我们要增加视频捕捉功能。与内容和关键词相关的视频也会反馈给用户,以便用户观看相关视频。
4.CSS 和 Javascript网站
暂定。
5.检查关键词是否出现在被捕获的网站或者文件的标题中,如果在被捕获的网站或者文件的文本中频繁出现,用这个来判断此 网站 或文件的值给用户
我们认为,如果我们抓取其中出现关键词的所有资源,我们可能会抓取一些网站或不相关但出现关键词的文件,但在排除网站@之后> 以及对用户来说价值不大的文件,通过以上方法,我们抓取的东西质量会大大提高。
好处(好处):
1.能够更好地从结果中去除广告网站,优化用户体验
去除广告是我们爬虫非常重要的功能。爬虫的初衷是为用户高效地爬取互联网上有用的相关资源。如果可爬取资源中有大量的广告,会让用户的浏览很不方便,也就失去了爬虫的意义。. 我们将检查到下一个级别网站,并使用此方法排除广告网站。这样可以提高抓取资源的质量,用户可以更方便的使用爬虫的功能。
2.让用户更容易找到资源
如果爬虫把所有抓取到的资源放在一起,当用户需要一个格式单一的文件时会很麻烦。我们将采集到的资源按照类型分别保存,让用户可以更方便的使用软件,获得更好的用户体验。
3.让用户可以观看相关视频
这是一个全新的功能。之前的版本无法采集视频资源。虽然由于版权原因我们无法完全下载视频,但我们可以为用户提供源视频的链接,以便用户观看。现在互联网上有很多资源以视频的形式存在。我们加入这个功能是为了让这个软件更实用,更能满足用户不断增长的需求。
4.不限于HTML5网站,可以获得更多资源(暂定)
目前的版本只能爬取HTML5的网站,但是网站里面也有很多有用的资源是用javascript或者css的。我们更新了这个软件,支持javascript和css,可以让爬虫抓取更多的资源,为用户提供更多的服务。
5.提高采集结果的质量,增加剔除低质量资源的功能(暂定)
如果只关注捕获文件的数量和网站,可能会导致捕获文件和网站的质量很差,但是会减少结果中有用的文件和网站里面的成分让用户体验更差。我们将通过检测关键词是否出现在其标题及其出现频率等方法来确定该文件或网站对用户的价值。如果值不高,那么这个文件或 网站 @> 被排除。这将使我们能够抓取更高质量的文件和 网站。
竞争对手:
网络爬虫是一种自动获取网页内容的程序,是搜索引擎的重要组成部分。现在的搜索引擎基本上都涉及到爬虫的设计和优化。搜索引擎的速度也与爬虫的优化程度密切相关。从另一个角度来看,不仅仅是搜索引擎,所有的数据挖掘软件都会涉及到爬虫。因此,爬虫在整个软件行业的地位很高,应用范围非常广泛。这里我们主要通过搜索引擎中的爬虫来分析竞争。
首先,拿两个最常用的搜索引擎:百度和谷歌。从爬取信息来看,两者都是行业的佼佼者,爬取算法也很不错,可以按类型分类。,以方便用户操作。它爬取整个万维网的速度非常快。虽然我们的软件在速度和爬取算法方面还不是很成熟,但是我们的软件会为了方便用户而设计。我们会检查爬取文件的匹配度,对它们的优先级进行排序。这也将大大提高用户体验的质量。我将从以下几个方面来讨论我们软件的竞争力。
1.爬行速度和爬行负载,这也是衡量爬虫的标准
与其他软件相比,我们的软件在速度上还不错。我们通过广度优先的搜索顺序进行搜索,可以提高爬虫的爬取速度。同时,我们使用多个队列进行数据处理,这也使得爬虫可以同时处理多个数据。分组数据,承载能力更强。
2.爬取质量和特异性
很多网站爬虫爬取给定URL中的所有内容,不仅影响爬取内容的质量,还拖慢了预算。我们的爬虫会专门爬取电脑相关的数据,让爬取的内容更符合用户的需求。同时我们会对广告进行处理,也可以让爬虫的爬取质量更高。同时,我们会在爬取时与关键词进行匹配比较,可以大大减少广告和无关信息。
3.分类存储
用户的下一步操作可能会使用不同类型的数据。爬虫会在爬取过程中轻松对数据进行分类。分类可以让用户获得更好的用户体验,让用户在搜索的过程中可以更快的找到自己需要的信息。这应该更受程序员的欢迎。
4.接口与实现
用户在获取爬虫时,需要知道爬虫的输出形式和爬取速度,这就需要我们设计一个简单的接口来实现。我们的界面将以最简单的方式将输出呈现给用户,这将非常直观。
5.创新功能
我们将为原创爬虫添加新功能。比如抓取视频文件时,我们会将视频地址反馈给用户。这允许用户直接通过地址观看视频。此外,我们还计划实现不限于 html5 网页的爬取,甚至尝试爬取 CSS 或 javascript。这样可以更方便用户操作。
分类:
技术要点:
相关文章:
c爬虫抓取网页数据(Python对象的bs4解析方式和属性的方法和方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-04-13 09:39
bs4,全称BeautifulSoup 4,是Python独有的解析方式。也就是说,只有 Python 语言可以这样解析数据。
BeautifulSoup 3 只支持 Python 2,所以它已经过时了。
官网的介绍是这样的
Beautiful Soup 提供了简单的类似 python 的函数来处理导航、搜索、修改解析树等。它是一个工具箱,通过解析文档为用户提供他们需要抓取的数据。由于其简单性,编写完整的应用程序不需要太多代码。Beautiful Soup 自动将输入文档转换为 Unicode 编码,将输出文档自动转换为 utf-8 编码。不需要考虑编码方式,除非文档没有指定编码方式,否则Beautiful Soup无法自动识别编码方式。然后,您只需要指定原创编码。Beautiful Soup 已经成为与 lxml 和 html6lib 一样优秀的 python 解释器,为用户提供不同解析策略的灵活性或强大的速度。
看起来很复杂,我用自己的理解简单解释一下
我们知道一个网页的源代码是由多个标签组成的,比如,
,,,等等,而bs4是用来帮助我们准确定位标签位置的工具,从而获取标签的内容或标签属性。bs4默认自带的解析器,但官方推荐的是更强大更快的lxml解析器
其他解析器的优缺点
一、bs4的安装
pip install bs4
pip install lxml
用bs4解析时,推荐使用lxml解析器。使用 xpath 解析时也会用到
二、bs4解析原理1、如何实例化BeautySoup对象 导入bs4包
from bs4 import BeautifulSoup
湾。实例化对象
网页源代码进一步分为本地已经持久化的HTML文件和网络上直接获取的源代码。
如果是本地持久化文件,可以通过如下方式将源码加载到bs4对象中
fp = open('xxx.html', 'r', encoding='utf-8')
# lxml:解析器
soup = BeautifulSoup(fp, 'lxml')
如果是通过requests库获取的网页源代码,按如下方式加载
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, 'lxml')
C。数据解析的方法和属性
bs4 能够将复杂的 HTML 转换为树结构,其中每个节点都是一个 Python 对象。
soup.tagName(标签名):返回文档中第一次出现tagName对应的标签及其对应的内容
soup.tageName1.tageName2:返回tag1中tag1的标签和内容
soup.find:等价于soup.tagName,返回第一个匹配的对象
soup.find_all:返回所有匹配的对象。
通过查看源码你会发现find的本质就是调用find_all然后返回第一个元素
参数说明:
def find(self, name=None, attrs={}, recursive=True, text=None,
**kwargs):
"""Return only the first child of this Tag matching the given
criteria."""
r = None
l = self.find_all(name, attrs, recursive, text, 1, **kwargs)
if l:
r = l[0]
return r
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-iXUox6yw-53)(C:UsersAdministratorAppDataRoamingTyporatypora-user-imagesimage-23454< @0.png )]
上图是我从某网站中截取的部分画面,翻译成HTML如下(只保留对本次分析有用的部分,删除地址的域名信息为阅读方便)
测试Title
<p>尼古拉斯赵四

郑爽

朱一龙

周冬雨

胡一天

易烊千玺

迪丽热巴
</p>
看下面的例子
# 获取第一个li标签
# <p>郑爽
print(soup.li)
# # 获取第一个li标签中a标签
# 
郑爽
print(soup.li.a)
#获取第一个li标签中a标签
print(soup.find('li').a)
# 获取所有li标签
print(soup.find_all('li'))
# 获取title标签
print(soup.title)
# 获取a标签的父级标签
print(soup.a.parent)
# 获取a标签的父级标签的名字
print(soup.a.parent.name)</p>
如何在 HTML 中获取href?
分析:href是a标签中的一个属性,a标签在li标签中
提取bs4中tags中的属性可以通过attrs获取
其他补充剂
# 返回子孙节点
# children返回迭代器
result = soup.a.children
for i in result:
print(i)
# 返回子孙节点, contents返回列表
r = soup.a.contents
print(r)
# 可以通过正则对某个属性进行匹配
# 比如返回href中以zh开头的标签
import re
reg = re.compile('^zh')
result = soup.find_all(href=reg)
print(result)
选择器
bs4 非常强大,也支持 css 选择器。通过选择完成
测试Title
<p>尼古拉斯赵四

郑爽

朱一龙

周冬雨

胡一天

易烊千玺

迪丽热巴
</p>
from bs4 import BeautifulSoup
fp = open('baidu.html', 'r', encoding='utf-8')
soup = BeautifulSoup(fp, 'lxml')
# 返回一个所有a标签的列表
result = soup.select('a')
# 返回第一个
result1 = soup.select('a')[0]
"""
class选择器 : .className
"""
# 一层一层的进行选择,用 > 连接 即 > : 表示一个层级
# 输出 class = nr_zt 下ul下的li下的a标签集合
a = soup.select('.nr_zt > ul > li > a')
# 多个层级关联,使用 空格。
# 输出 class= 'nr_zt' 下的a标签集合
b = soup.select('.nr_zt a')
"""
id选择器: # idName
"""
result = soup.select('#star')
# 通过href属性查找,返回列表
soup.select('a[href="zhengshuang.html"]')
# 获取对应标签中img标签的src值
a = soup.select('a[href="zhengshuang.html"]')[0]
print(a.img['src']) # 5940f2cd6b759.jpg
以上是bs4的常用操作代码。其实在具体的爬取过程中,匹配的方式比较灵活,大家不用死记硬背,记住原理即可。
网络爬虫
Python 查看全部
c爬虫抓取网页数据(Python对象的bs4解析方式和属性的方法和方法)
bs4,全称BeautifulSoup 4,是Python独有的解析方式。也就是说,只有 Python 语言可以这样解析数据。
BeautifulSoup 3 只支持 Python 2,所以它已经过时了。
官网的介绍是这样的
Beautiful Soup 提供了简单的类似 python 的函数来处理导航、搜索、修改解析树等。它是一个工具箱,通过解析文档为用户提供他们需要抓取的数据。由于其简单性,编写完整的应用程序不需要太多代码。Beautiful Soup 自动将输入文档转换为 Unicode 编码,将输出文档自动转换为 utf-8 编码。不需要考虑编码方式,除非文档没有指定编码方式,否则Beautiful Soup无法自动识别编码方式。然后,您只需要指定原创编码。Beautiful Soup 已经成为与 lxml 和 html6lib 一样优秀的 python 解释器,为用户提供不同解析策略的灵活性或强大的速度。
看起来很复杂,我用自己的理解简单解释一下
我们知道一个网页的源代码是由多个标签组成的,比如,
,,,等等,而bs4是用来帮助我们准确定位标签位置的工具,从而获取标签的内容或标签属性。bs4默认自带的解析器,但官方推荐的是更强大更快的lxml解析器
其他解析器的优缺点
一、bs4的安装
pip install bs4
pip install lxml
用bs4解析时,推荐使用lxml解析器。使用 xpath 解析时也会用到
二、bs4解析原理1、如何实例化BeautySoup对象 导入bs4包
from bs4 import BeautifulSoup
湾。实例化对象
网页源代码进一步分为本地已经持久化的HTML文件和网络上直接获取的源代码。
如果是本地持久化文件,可以通过如下方式将源码加载到bs4对象中
fp = open('xxx.html', 'r', encoding='utf-8')
# lxml:解析器
soup = BeautifulSoup(fp, 'lxml')
如果是通过requests库获取的网页源代码,按如下方式加载
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, 'lxml')
C。数据解析的方法和属性
bs4 能够将复杂的 HTML 转换为树结构,其中每个节点都是一个 Python 对象。
soup.tagName(标签名):返回文档中第一次出现tagName对应的标签及其对应的内容
soup.tageName1.tageName2:返回tag1中tag1的标签和内容
soup.find:等价于soup.tagName,返回第一个匹配的对象
soup.find_all:返回所有匹配的对象。
通过查看源码你会发现find的本质就是调用find_all然后返回第一个元素
参数说明:
def find(self, name=None, attrs={}, recursive=True, text=None,
**kwargs):
"""Return only the first child of this Tag matching the given
criteria."""
r = None
l = self.find_all(name, attrs, recursive, text, 1, **kwargs)
if l:
r = l[0]
return r
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-iXUox6yw-53)(C:UsersAdministratorAppDataRoamingTyporatypora-user-imagesimage-23454< @0.png )]
上图是我从某网站中截取的部分画面,翻译成HTML如下(只保留对本次分析有用的部分,删除地址的域名信息为阅读方便)
测试Title
<p>尼古拉斯赵四

郑爽

朱一龙

周冬雨

胡一天

易烊千玺

迪丽热巴
</p>
看下面的例子
# 获取第一个li标签
# <p>郑爽
print(soup.li)
# # 获取第一个li标签中a标签
# 
郑爽
print(soup.li.a)
#获取第一个li标签中a标签
print(soup.find('li').a)
# 获取所有li标签
print(soup.find_all('li'))
# 获取title标签
print(soup.title)
# 获取a标签的父级标签
print(soup.a.parent)
# 获取a标签的父级标签的名字
print(soup.a.parent.name)</p>
如何在 HTML 中获取href?
分析:href是a标签中的一个属性,a标签在li标签中
提取bs4中tags中的属性可以通过attrs获取
其他补充剂
# 返回子孙节点
# children返回迭代器
result = soup.a.children
for i in result:
print(i)
# 返回子孙节点, contents返回列表
r = soup.a.contents
print(r)
# 可以通过正则对某个属性进行匹配
# 比如返回href中以zh开头的标签
import re
reg = re.compile('^zh')
result = soup.find_all(href=reg)
print(result)
选择器
bs4 非常强大,也支持 css 选择器。通过选择完成
测试Title
<p>尼古拉斯赵四

郑爽

朱一龙

周冬雨

胡一天

易烊千玺

迪丽热巴
</p>
from bs4 import BeautifulSoup
fp = open('baidu.html', 'r', encoding='utf-8')
soup = BeautifulSoup(fp, 'lxml')
# 返回一个所有a标签的列表
result = soup.select('a')
# 返回第一个
result1 = soup.select('a')[0]
"""
class选择器 : .className
"""
# 一层一层的进行选择,用 > 连接 即 > : 表示一个层级
# 输出 class = nr_zt 下ul下的li下的a标签集合
a = soup.select('.nr_zt > ul > li > a')
# 多个层级关联,使用 空格。
# 输出 class= 'nr_zt' 下的a标签集合
b = soup.select('.nr_zt a')
"""
id选择器: # idName
"""
result = soup.select('#star')
# 通过href属性查找,返回列表
soup.select('a[href="zhengshuang.html"]')
# 获取对应标签中img标签的src值
a = soup.select('a[href="zhengshuang.html"]')[0]
print(a.img['src']) # 5940f2cd6b759.jpg
以上是bs4的常用操作代码。其实在具体的爬取过程中,匹配的方式比较灵活,大家不用死记硬背,记住原理即可。
网络爬虫
Python
c爬虫抓取网页数据( 在学习Python之前,我们要知道,,Python的用途)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-04-13 09:37
在学习Python之前,我们要知道,,Python的用途)
在学习 Python 之前,我们需要了解 Python 的用途以及学习它能给我们带来什么?
Python主要包括网络爬虫、网站开发、人工智能、自动化运维
这里我们主要看一下网络爬虫,什么是网络爬虫?
网络爬虫,又称网络蜘蛛,是指一种脚本程序,它按照一定的规则在网络上爬取想要的内容。众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个URL依次进入其他网址,获取想要的内容。
爬行动物有什么用?
做垂直搜索引擎(google、baidu等)。
科学研究:在线人类行为、在线社区进化、人类动力学研究、定量社会学、复杂网络、数据挖掘等实证研究领域需要大量数据,而网络爬虫是采集相关数据的有力工具。
偷窥、黑客攻击、垃圾邮件……
爬行是搜索引擎的第一步,也是最简单的一步。
用什么语言编写爬虫?
C、C++。高效、快速,适合一般搜索引擎爬取全网。缺点,开发慢,写起来又臭又长,例如:天网搜索源码。
脚本语言:Perl、Python、Java、Ruby。简单易学,良好的文本处理可以方便网页内容的详细提取,但效率往往不高,适合少量网站的集中抓取
C#?
为什么 Python 现在最流行?
就个人而言,我用 c# 和 java 编写了爬虫。差别不大,原则是用好正则表达式。只是平台问题。后来才知道很多爬虫都是用python写的,所以一发不可收拾。Python有很多优点,总结两个要点:
1)抓取网页本身的接口
相比其他静态编程语言,如java、c#、C++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2)网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要蟒蛇。 查看全部
c爬虫抓取网页数据(
在学习Python之前,我们要知道,,Python的用途)
在学习 Python 之前,我们需要了解 Python 的用途以及学习它能给我们带来什么?
Python主要包括网络爬虫、网站开发、人工智能、自动化运维
这里我们主要看一下网络爬虫,什么是网络爬虫?
网络爬虫,又称网络蜘蛛,是指一种脚本程序,它按照一定的规则在网络上爬取想要的内容。众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个URL依次进入其他网址,获取想要的内容。
爬行动物有什么用?
做垂直搜索引擎(google、baidu等)。
科学研究:在线人类行为、在线社区进化、人类动力学研究、定量社会学、复杂网络、数据挖掘等实证研究领域需要大量数据,而网络爬虫是采集相关数据的有力工具。
偷窥、黑客攻击、垃圾邮件……
爬行是搜索引擎的第一步,也是最简单的一步。
用什么语言编写爬虫?
C、C++。高效、快速,适合一般搜索引擎爬取全网。缺点,开发慢,写起来又臭又长,例如:天网搜索源码。
脚本语言:Perl、Python、Java、Ruby。简单易学,良好的文本处理可以方便网页内容的详细提取,但效率往往不高,适合少量网站的集中抓取
C#?
为什么 Python 现在最流行?
就个人而言,我用 c# 和 java 编写了爬虫。差别不大,原则是用好正则表达式。只是平台问题。后来才知道很多爬虫都是用python写的,所以一发不可收拾。Python有很多优点,总结两个要点:
1)抓取网页本身的接口
相比其他静态编程语言,如java、c#、C++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2)网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要蟒蛇。
c爬虫抓取网页数据(如何通过谷歌浏览器开发者工具分析真实请求的三个步骤分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-04-13 07:19
爬虫的大致思路:抓取网页,分析请求
解析网页并查找数据
存储数据,多页面处理
本课主要讲授如何通过谷歌浏览器开发者工具分析真实请求。
三步找到真正的请求
分析:使用 Google Chrome 开发者工具分析网页请求
测试:测试URL请求中各个参数的作用,找出控制翻页等功能的参数
Repeat:反复寻找满足爬虫需求的真实请求
实用链接:爬取知乎
通过爬取知乎“轮子哥”——vczh相关人士分析Ajax或JavaScript加载数据的真实请求,并展示该爬取方式的具体过程。
1. 寻找真实请求的测试首先进入“轮子哥-vczh”关注者的页面(注意:需要登录个人知乎帐户优先)
通过禁用javascript加载发现页面无法正常加载,确认页面的翻页是通过javascript加载数据实现的
使用谷歌浏览器开发者工具查找收录关注者信息的真实请求。可以发现,真正的请求是以“followees”开头的请求,返回的是一个JSON格式的数据,对应下一页的“Followees”。人”:
双击该请求返回JSON格式的数据,通过安装JSONView插件可以更好的显示在浏览器中
然后您可以尝试抓取请求的数据
2. 尝试爬取真实请求的数据 先尝试使用前几课学习的requests.get() 来爬取数据
可以发现返回“500 Server Error”,即由于网站反爬虫,服务器返回“500 Service Error”
这个问题可以通过添加headers请求头信息来解决
3. 添加headers请求头信息,模拟浏览器访问。请求头信息携带客户端浏览器、请求页面、服务器等信息,用于通知服务器发起请求的客户端的具体信息
p>
知乎反爬机制是通过检查请求头信息实现的,所以在使用request请求数据的时候需要加上需要的请求头
对比知乎的请求头信息和普通请求头信息,发现知乎的请求头有更多的授权和X-UDID信息
向爬虫添加请求头信息,即添加headers# -*- coding:utf-8 -*-
导入请求
标题 = {
'authorization':' ',#括号内填写你的授权
'User-Agent':' ',#括号里填你的User-Agent
}
url = '*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%ics&offset=20&limit=20'
response=requests.get(url, headers = headers).json()
打印(响应)
最终代码:#!/usr/bin/env python3
# -*- 编码:utf-8 -*-
"""
创建于 2018 年 3 月 20 日星期二 16:01:47
@作者:杰基
"""
导入请求
将熊猫导入为 pd
进口时间
标题 = {
'授权': '承载 2 | 1:0 | 10:1519627538 | 4:z_c0 | 92: Mi4xYzBvWkFBQUFBQUFBSU1JaTVqRU1EQ1lBQUFCZ0FsVk5FdnVBV3dEdHdaRmtBR1lmZEpqT3VvdmtpSm5QMWtkZ1ZB | 787597598f41757929f46f687f78434dbc66d6abc980e40fb50b55cd09062b07',
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/6< @4.0.3282.186 Safari/537.36',
'x-udid':'ACDCIuYxDAyPTg7eVnDe8ytVGX6ivGdKZ9E=',
}
user_data = []
def get_user_data(page):
for i in range(page):
url = '*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%ics&offset={}&limit=20'.format(i*20)
response = requests.get(url, headers = headers).json()['data']
user_data.extend(响应)
print('爬取页面 %s' %str(i+1))
时间.sleep(1)
如果 __name__ == '__main__':
get_user_data(3)
df = pd.DataFrame(user_data)
df.to_csv('users.csv')
补充知识
1. JSONJSON 是一种轻量级的数据交换格式。连接API爬取数据时,一般数据返回格式为JSON。
JSONView 插件:前往 Chrome JSONView 插件安装,下载并安装 JSONView 插件,以使 JSON 格式的数据在 Google Chrome 中更好地呈现 查看全部
c爬虫抓取网页数据(如何通过谷歌浏览器开发者工具分析真实请求的三个步骤分析)
爬虫的大致思路:抓取网页,分析请求
解析网页并查找数据
存储数据,多页面处理
本课主要讲授如何通过谷歌浏览器开发者工具分析真实请求。
三步找到真正的请求
分析:使用 Google Chrome 开发者工具分析网页请求
测试:测试URL请求中各个参数的作用,找出控制翻页等功能的参数
Repeat:反复寻找满足爬虫需求的真实请求
实用链接:爬取知乎
通过爬取知乎“轮子哥”——vczh相关人士分析Ajax或JavaScript加载数据的真实请求,并展示该爬取方式的具体过程。
1. 寻找真实请求的测试首先进入“轮子哥-vczh”关注者的页面(注意:需要登录个人知乎帐户优先)
通过禁用javascript加载发现页面无法正常加载,确认页面的翻页是通过javascript加载数据实现的
使用谷歌浏览器开发者工具查找收录关注者信息的真实请求。可以发现,真正的请求是以“followees”开头的请求,返回的是一个JSON格式的数据,对应下一页的“Followees”。人”:
双击该请求返回JSON格式的数据,通过安装JSONView插件可以更好的显示在浏览器中
然后您可以尝试抓取请求的数据
2. 尝试爬取真实请求的数据 先尝试使用前几课学习的requests.get() 来爬取数据
可以发现返回“500 Server Error”,即由于网站反爬虫,服务器返回“500 Service Error”
这个问题可以通过添加headers请求头信息来解决
3. 添加headers请求头信息,模拟浏览器访问。请求头信息携带客户端浏览器、请求页面、服务器等信息,用于通知服务器发起请求的客户端的具体信息
p>
知乎反爬机制是通过检查请求头信息实现的,所以在使用request请求数据的时候需要加上需要的请求头
对比知乎的请求头信息和普通请求头信息,发现知乎的请求头有更多的授权和X-UDID信息
向爬虫添加请求头信息,即添加headers# -*- coding:utf-8 -*-
导入请求
标题 = {
'authorization':' ',#括号内填写你的授权
'User-Agent':' ',#括号里填你的User-Agent
}
url = '*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%ics&offset=20&limit=20'
response=requests.get(url, headers = headers).json()
打印(响应)
最终代码:#!/usr/bin/env python3
# -*- 编码:utf-8 -*-
"""
创建于 2018 年 3 月 20 日星期二 16:01:47
@作者:杰基
"""
导入请求
将熊猫导入为 pd
进口时间
标题 = {
'授权': '承载 2 | 1:0 | 10:1519627538 | 4:z_c0 | 92: Mi4xYzBvWkFBQUFBQUFBSU1JaTVqRU1EQ1lBQUFCZ0FsVk5FdnVBV3dEdHdaRmtBR1lmZEpqT3VvdmtpSm5QMWtkZ1ZB | 787597598f41757929f46f687f78434dbc66d6abc980e40fb50b55cd09062b07',
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/6< @4.0.3282.186 Safari/537.36',
'x-udid':'ACDCIuYxDAyPTg7eVnDe8ytVGX6ivGdKZ9E=',
}
user_data = []
def get_user_data(page):
for i in range(page):
url = '*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%ics&offset={}&limit=20'.format(i*20)
response = requests.get(url, headers = headers).json()['data']
user_data.extend(响应)
print('爬取页面 %s' %str(i+1))
时间.sleep(1)
如果 __name__ == '__main__':
get_user_data(3)
df = pd.DataFrame(user_data)
df.to_csv('users.csv')
补充知识
1. JSONJSON 是一种轻量级的数据交换格式。连接API爬取数据时,一般数据返回格式为JSON。
JSONView 插件:前往 Chrome JSONView 插件安装,下载并安装 JSONView 插件,以使 JSON 格式的数据在 Google Chrome 中更好地呈现
c爬虫抓取网页数据(Python爬虫如何写爬虫“贼船”等上了贼船才发现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-04-11 06:10
写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是一行代码骗你上“贼船”,上贼船才发现,水好深~
例如,爬取一个网页可以是非常简单的一行代码:
r = requests.get('http://news.baidu.com')
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
网络爬虫难点一:只爬 HTML 页面但可扩展
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本上就是一行。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
我们先来看一下新闻爬虫的简单流程图:
从一些种子页开始,种子页往往是一些新闻网站的首页,爬虫抓取该页面,从中提取出网站的URL,放入URL池中进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内抓取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。爬虫如何在织网抓取“旧”新闻的同时兼顾“新”新闻的获取?
如何存储大量捕获的新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、正文内容等,给内容提取带来困难。
网络爬虫难点二:需要登录才能抓取想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能看到。也就是说,爬虫在请求的时候必须登录才能抓取数据。
如何获取登录状态? 查看全部
c爬虫抓取网页数据(Python爬虫如何写爬虫“贼船”等上了贼船才发现)
写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是一行代码骗你上“贼船”,上贼船才发现,水好深~
例如,爬取一个网页可以是非常简单的一行代码:
r = requests.get('http://news.baidu.com')
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
网络爬虫难点一:只爬 HTML 页面但可扩展
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本上就是一行。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
我们先来看一下新闻爬虫的简单流程图:
从一些种子页开始,种子页往往是一些新闻网站的首页,爬虫抓取该页面,从中提取出网站的URL,放入URL池中进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内抓取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。爬虫如何在织网抓取“旧”新闻的同时兼顾“新”新闻的获取?
如何存储大量捕获的新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、正文内容等,给内容提取带来困难。
网络爬虫难点二:需要登录才能抓取想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能看到。也就是说,爬虫在请求的时候必须登录才能抓取数据。
如何获取登录状态?

