
c爬虫抓取网页数据
c爬虫抓取网页数据(2021-07-09pyspider框架介绍框架Scrapy)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-07 21:07
2021-07-09
pyspider框架介绍
pyspider是中文binux编写的强大的网络爬虫系统,它的GitHub地址是,官方文档地址是。
pyspider 带有强大的 WebUI、脚本编辑器、任务监视器、项目管理器和结果处理器。支持多数据库后端,多消息队列,爬取JavaScript渲染页面。使用起来非常方便。
pyspider基本功能
我们将 PySpider 的功能总结如下。
提供方便易用的WebUI系统,可以可视化编写和调试爬虫。
提供爬取进度监控、爬取结果查看、爬虫项目管理等功能。
支持多种后端数据库,如 MySQL、MongoDB、Redis、SQLite、Elasticsearch、PostgreSQL。
支持多个消息队列,如 RabbitMQ、Beanstalk、Redis、Kombu。
提供优先级控制、故障重试、定时捕捉等功能。
使用 PhantomJS,您可以抓取由 JavaScript 呈现的页面。
支持单机和分布式部署,支持Docker部署。
如果你想快速轻松地爬取一个页面,使用 pyspider 是一个不错的选择。
与 Scrapy 的比较
Scrapy,另一个爬虫框架,后面会介绍。学习了 Scrapy 之后,这部分就更容易理解了。我们先来了解一下pyspider和Scrapy的区别。
pyspider 提供 WebUI。爬虫的编写和调试都是在WebUI中进行的,而Scrapy原生没有这个功能。它使用代码和命令行操作,但可以连接到 Portia 以实现可视化配置。
pyspider的调试非常方便,WebUI的操作方便直观。在 Scrapy 中,使用 parse 命令进行调试,不如 pyspider 方便。
pyspider 支持 PhantomJS 在 JavaScript 采集 中渲染页面,并且 ScrapySplash 组件可以停靠在 Scrapy 中,这需要额外的配置。
PyQuery 作为选择器内置在 PySpider 中,XPath、CSS 选择器和正则匹配都停靠在 Scrapy 中。
pyspider的可扩展性不足,可配置程度不高。在Scrapy中,通过对接Middleware、Pipeline、Extension等组件可以实现非常强大的功能。模块间耦合度低,可扩展性极高。
如果想快速抓取一个页面,推荐使用pyspider,开发比较方便,比如快速抓取一个普通新闻网站的新闻内容。如果要处理非常大规模的抓取,反爬度很强,建议使用Scrapy,比如对网站的大规模数据采集的被封IP、被封账号进行抓取, 和高频验证。
pyspider的架构
pyspider的架构主要分为三个部分:Scheduler(调度器)、Fetcher(抓取器)、Processor(处理器)。整个爬取过程由Monitor(监视器)监控,爬取结果为Result Worker(results)。处理器),如图 12-1 所示。
Scheduler发起任务调度,Fetcher负责抓取网页内容,Processor负责解析网页内容,然后将新生成的Request发送给Scheduler进行调度,并保存生成的提取结果输出。
pyspider的任务执行过程逻辑很清晰,具体流程如下。
每个 pyspider 项目都对应一个 Python 脚本,该脚本定义了一个带有 on_start() 方法的 Handler 类。爬取首先调用on_start()方法生成初始爬取任务,然后发送给Scheduler进行调度。
Scheduler 将抓取任务分发给 Fetcher 进行抓取,Fetcher 执行并获取响应,然后将响应发送给 Processor。
Processer处理响应并提取新的URL生成新的爬虫任务,然后通过消息队列通知Schduler当前的爬虫任务执行状态,并将新生成的爬虫任务发送给Scheduler。如果生成了新的 fetch 结果,则将其发送到结果队列中,由 Result Worker 处理。
Scheduler接收到一个新的抓取任务,然后查询数据库,判断是新的抓取任务还是需要重试的任务,然后继续调度,然后发回Fetcher去抓取。
不断重复上述工作,直到所有任务都执行完毕,抓取结束。
捕获后,程序会回调on_finished()方法,这里可以定义后处理过程。结语
本节我们主要了解pyspider的基本功能和架构。接下来我们用一个例子来体验一下pyspider的爬取操作,然后总结一下它的各种用途。
分类:
技术要点:
相关文章: 查看全部
c爬虫抓取网页数据(2021-07-09pyspider框架介绍框架Scrapy)
2021-07-09
pyspider框架介绍
pyspider是中文binux编写的强大的网络爬虫系统,它的GitHub地址是,官方文档地址是。
pyspider 带有强大的 WebUI、脚本编辑器、任务监视器、项目管理器和结果处理器。支持多数据库后端,多消息队列,爬取JavaScript渲染页面。使用起来非常方便。
pyspider基本功能
我们将 PySpider 的功能总结如下。
提供方便易用的WebUI系统,可以可视化编写和调试爬虫。
提供爬取进度监控、爬取结果查看、爬虫项目管理等功能。
支持多种后端数据库,如 MySQL、MongoDB、Redis、SQLite、Elasticsearch、PostgreSQL。
支持多个消息队列,如 RabbitMQ、Beanstalk、Redis、Kombu。
提供优先级控制、故障重试、定时捕捉等功能。
使用 PhantomJS,您可以抓取由 JavaScript 呈现的页面。
支持单机和分布式部署,支持Docker部署。
如果你想快速轻松地爬取一个页面,使用 pyspider 是一个不错的选择。
与 Scrapy 的比较
Scrapy,另一个爬虫框架,后面会介绍。学习了 Scrapy 之后,这部分就更容易理解了。我们先来了解一下pyspider和Scrapy的区别。
pyspider 提供 WebUI。爬虫的编写和调试都是在WebUI中进行的,而Scrapy原生没有这个功能。它使用代码和命令行操作,但可以连接到 Portia 以实现可视化配置。
pyspider的调试非常方便,WebUI的操作方便直观。在 Scrapy 中,使用 parse 命令进行调试,不如 pyspider 方便。
pyspider 支持 PhantomJS 在 JavaScript 采集 中渲染页面,并且 ScrapySplash 组件可以停靠在 Scrapy 中,这需要额外的配置。
PyQuery 作为选择器内置在 PySpider 中,XPath、CSS 选择器和正则匹配都停靠在 Scrapy 中。
pyspider的可扩展性不足,可配置程度不高。在Scrapy中,通过对接Middleware、Pipeline、Extension等组件可以实现非常强大的功能。模块间耦合度低,可扩展性极高。
如果想快速抓取一个页面,推荐使用pyspider,开发比较方便,比如快速抓取一个普通新闻网站的新闻内容。如果要处理非常大规模的抓取,反爬度很强,建议使用Scrapy,比如对网站的大规模数据采集的被封IP、被封账号进行抓取, 和高频验证。
pyspider的架构
pyspider的架构主要分为三个部分:Scheduler(调度器)、Fetcher(抓取器)、Processor(处理器)。整个爬取过程由Monitor(监视器)监控,爬取结果为Result Worker(results)。处理器),如图 12-1 所示。
Scheduler发起任务调度,Fetcher负责抓取网页内容,Processor负责解析网页内容,然后将新生成的Request发送给Scheduler进行调度,并保存生成的提取结果输出。
pyspider的任务执行过程逻辑很清晰,具体流程如下。
每个 pyspider 项目都对应一个 Python 脚本,该脚本定义了一个带有 on_start() 方法的 Handler 类。爬取首先调用on_start()方法生成初始爬取任务,然后发送给Scheduler进行调度。
Scheduler 将抓取任务分发给 Fetcher 进行抓取,Fetcher 执行并获取响应,然后将响应发送给 Processor。
Processer处理响应并提取新的URL生成新的爬虫任务,然后通过消息队列通知Schduler当前的爬虫任务执行状态,并将新生成的爬虫任务发送给Scheduler。如果生成了新的 fetch 结果,则将其发送到结果队列中,由 Result Worker 处理。
Scheduler接收到一个新的抓取任务,然后查询数据库,判断是新的抓取任务还是需要重试的任务,然后继续调度,然后发回Fetcher去抓取。
不断重复上述工作,直到所有任务都执行完毕,抓取结束。
捕获后,程序会回调on_finished()方法,这里可以定义后处理过程。结语
本节我们主要了解pyspider的基本功能和架构。接下来我们用一个例子来体验一下pyspider的爬取操作,然后总结一下它的各种用途。
分类:
技术要点:
相关文章:
c爬虫抓取网页数据(学爬虫的几个误区,你都知道吗?(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-07 21:02
)
我其实没想到人们对爬行的热情如此之高。看来我的粉丝群中的每个人都想学习爬行。
反过来想,也就不足为奇了:爬虫等于数据,没有数据怎么办?
但我发现,这种基于能力和知识点的学习路线虽然看起来不错,但如果没有实际的项目支持,很难实施。
在和很多人的交流中,我也发现了学习爬虫的几个误区。
学习爬虫的几个误区
1.不明白:我开发了一个简单的爬虫对比葫芦画,但原理不明白,稍微改一下也不行。
2.缺乏明确的目标:如果你的目标是学习爬行,这还不够明确。进一步细化和明确目标,例如:学会攀登你最需要的3个网站。
3. 贪多,贪众:我没底子,只想一口吃掉一个胖子。很多人认为某件事并不难,但他们从来没有做过,或者从来没有学过。
4.缺乏实践经验:爬虫所涉及的知识体系非常丰富,超出了任何语言的范畴。如果被知识点驱使去学习爬虫,会非常困难,无法掌握关键点。
我一直主张以实战为切入点,学习技术。比如我在B站的Python_Seven酱也是实战的。小江机器人等项目很多人都很熟悉。
几周前突然想到爬虫的学习路线也可以这样做:
这种学习路径比基于能力和知识的阶梯更容易执行:
1.目标很明确,学习攀登10个不同难度级别网站。
2.目标明确,深度学习成为可能。确保完全理解 10 个 网站 抓取过程,而不仅仅是画一个勺子。
3.不要贪得太多,什么都不要,10个网站(还包括几个练习网站)。但不要太贪心。在你牢牢掌握这些之前,不要想着应用爬取,也不要去追求特别难的网站。
4.实战,up是实战,到底是实战。但经过实战,我学到了知识并付诸实践。
来吧,这是我们筛选的10个项目。
学习爬行的10个项目
具体的网站仅供参考,可以换成同难度的类似网站。
注意:8和9是同一个网站,使用的方法不同。
下面是10个网站及相关知识点的列表:
1.网站仅供参考,可替换为其他相同难度的网站。
2.以学习为目的,抓取过程一定要恰当,不要对网站的操作施加压力。
30天时间表
如果你有一个目标,你就必须有一个计划。我看到很多人说想学Python,一年前来找我,一年后还是那个状态。没有时间计划的目标大多是无法实现的目标。
我为这10个项目制定了30天的学习计划。
这个30天爬虫计划的第一天就是了解爬虫的规则。多条爬虫进公安局的故事大家都听过。所以这件事非常重要。
事实上,爬行动物是无辜的。明白了规则之后,爬虫变色就不用说了。否则,百度、谷歌、天眼查等大公司和平台都会进入。你要明白:什么是不可逾越的红线?什么可以爬?你能爬多少?如何文明优雅地攀登?
那么是时候攻克这10个爬虫项目了,涉及的知识点不同,从最简单的小虫卵到分布式的大型爬虫。
关于Python技术储备
学好 Python 是赚钱的好方法,不管是工作还是副业,但要学好 Python,还是要有学习计划的。最后,我们将分享一套完整的Python学习资料,以帮助那些想学习Python的朋友!
一、Python全方位学习路线
Python的各个方向都是将Python中常用的技术点进行整理,形成各个领域知识点的汇总。它的用处是你可以根据以上知识点找到对应的学习资源,保证你能学得更全面。
二、学习软件
工人要做好工作,首先要磨利他的工具。学习Python常用的开发软件就到这里,为大家节省不少时间。
三、入门视频
当我们看视频学习时,没有手我们就无法移动眼睛和大脑。更科学的学习方式是理解后再使用。这时候动手项目就很合适了。
四、实际案例
光学理论是无用的。你必须学会跟随,你必须先进行实际练习,然后才能将所学应用于实践。这时候可以借鉴实战案例。
五、采访信息
我们必须学习 Python 才能找到一份高薪工作。以下面试题是来自阿里、腾讯、字节跳动等一线互联网公司的最新面试资料,部分阿里大佬给出了权威答案。看完这套面试材料相信大家都能找到一份满意的工作。
本完整版Python全套学习资料已上传至CSDN。需要的可以微信扫描下方官方CSDN认证二维码免费获取【保证100%免费】
查看全部
c爬虫抓取网页数据(学爬虫的几个误区,你都知道吗?(上)
)
我其实没想到人们对爬行的热情如此之高。看来我的粉丝群中的每个人都想学习爬行。
反过来想,也就不足为奇了:爬虫等于数据,没有数据怎么办?

但我发现,这种基于能力和知识点的学习路线虽然看起来不错,但如果没有实际的项目支持,很难实施。
在和很多人的交流中,我也发现了学习爬虫的几个误区。
学习爬虫的几个误区
1.不明白:我开发了一个简单的爬虫对比葫芦画,但原理不明白,稍微改一下也不行。
2.缺乏明确的目标:如果你的目标是学习爬行,这还不够明确。进一步细化和明确目标,例如:学会攀登你最需要的3个网站。
3. 贪多,贪众:我没底子,只想一口吃掉一个胖子。很多人认为某件事并不难,但他们从来没有做过,或者从来没有学过。
4.缺乏实践经验:爬虫所涉及的知识体系非常丰富,超出了任何语言的范畴。如果被知识点驱使去学习爬虫,会非常困难,无法掌握关键点。
我一直主张以实战为切入点,学习技术。比如我在B站的Python_Seven酱也是实战的。小江机器人等项目很多人都很熟悉。
几周前突然想到爬虫的学习路线也可以这样做:
这种学习路径比基于能力和知识的阶梯更容易执行:
1.目标很明确,学习攀登10个不同难度级别网站。
2.目标明确,深度学习成为可能。确保完全理解 10 个 网站 抓取过程,而不仅仅是画一个勺子。
3.不要贪得太多,什么都不要,10个网站(还包括几个练习网站)。但不要太贪心。在你牢牢掌握这些之前,不要想着应用爬取,也不要去追求特别难的网站。
4.实战,up是实战,到底是实战。但经过实战,我学到了知识并付诸实践。
来吧,这是我们筛选的10个项目。
学习爬行的10个项目
具体的网站仅供参考,可以换成同难度的类似网站。


注意:8和9是同一个网站,使用的方法不同。
下面是10个网站及相关知识点的列表:
1.网站仅供参考,可替换为其他相同难度的网站。
2.以学习为目的,抓取过程一定要恰当,不要对网站的操作施加压力。

30天时间表
如果你有一个目标,你就必须有一个计划。我看到很多人说想学Python,一年前来找我,一年后还是那个状态。没有时间计划的目标大多是无法实现的目标。
我为这10个项目制定了30天的学习计划。

这个30天爬虫计划的第一天就是了解爬虫的规则。多条爬虫进公安局的故事大家都听过。所以这件事非常重要。
事实上,爬行动物是无辜的。明白了规则之后,爬虫变色就不用说了。否则,百度、谷歌、天眼查等大公司和平台都会进入。你要明白:什么是不可逾越的红线?什么可以爬?你能爬多少?如何文明优雅地攀登?
那么是时候攻克这10个爬虫项目了,涉及的知识点不同,从最简单的小虫卵到分布式的大型爬虫。
关于Python技术储备
学好 Python 是赚钱的好方法,不管是工作还是副业,但要学好 Python,还是要有学习计划的。最后,我们将分享一套完整的Python学习资料,以帮助那些想学习Python的朋友!
一、Python全方位学习路线
Python的各个方向都是将Python中常用的技术点进行整理,形成各个领域知识点的汇总。它的用处是你可以根据以上知识点找到对应的学习资源,保证你能学得更全面。

二、学习软件
工人要做好工作,首先要磨利他的工具。学习Python常用的开发软件就到这里,为大家节省不少时间。

三、入门视频
当我们看视频学习时,没有手我们就无法移动眼睛和大脑。更科学的学习方式是理解后再使用。这时候动手项目就很合适了。
四、实际案例
光学理论是无用的。你必须学会跟随,你必须先进行实际练习,然后才能将所学应用于实践。这时候可以借鉴实战案例。

五、采访信息
我们必须学习 Python 才能找到一份高薪工作。以下面试题是来自阿里、腾讯、字节跳动等一线互联网公司的最新面试资料,部分阿里大佬给出了权威答案。看完这套面试材料相信大家都能找到一份满意的工作。


本完整版Python全套学习资料已上传至CSDN。需要的可以微信扫描下方官方CSDN认证二维码免费获取【保证100%免费】

c爬虫抓取网页数据(PHPHTML数据爬虫的设计思路及应用的优势)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-05 16:08
内容
1. 为什么是爬虫?
在“大数据时代”,数据获取方式:
从第三方数据平台购买数据爬虫数据2.什么是爬虫?
抓取网络数据的程序
3. 爬虫如何抓取网页数据?
首先,你需要了解一个网页的三个特征:
每个网页都有自己的 URL(Uniform Resource Locator)来定位网页 所有使用 HTML(超文本标记语言)来描述页面信息 所有网页使用 HTTP/HTTPS(超文本传输协议)来传输 HTML 数据
爬虫设计思路:
首先确定需要爬取的网页的URL地址,通过HTTP/HTTPS协议获取对应的HTML页面,提取HTML页面中的有用数据:
一个。如果是需要的数据--保存
湾。如果还有其他网址,继续步骤2 4. Python爬虫的优势?语言的优点和缺点
PHP
世界上最好的语言
对于多线程,异步支持不好,并发处理不够
爪哇
完善的网络爬虫生态系统
Java语言本身繁琐,代码量大,数据重构成本高
C/C++
运营效率和性能几乎是最高的
学习成本高
Python
语法优美,代码简洁,开发效率高,模块多
5.抓取HTML页面的学习路线:解析服务器对应内容:采集动态HTML、Captcha处理Scrapy框架:分布式策略:爬虫、反爬虫、反反之间的较量爬虫:6.爬虫分类6.1 通用爬虫:
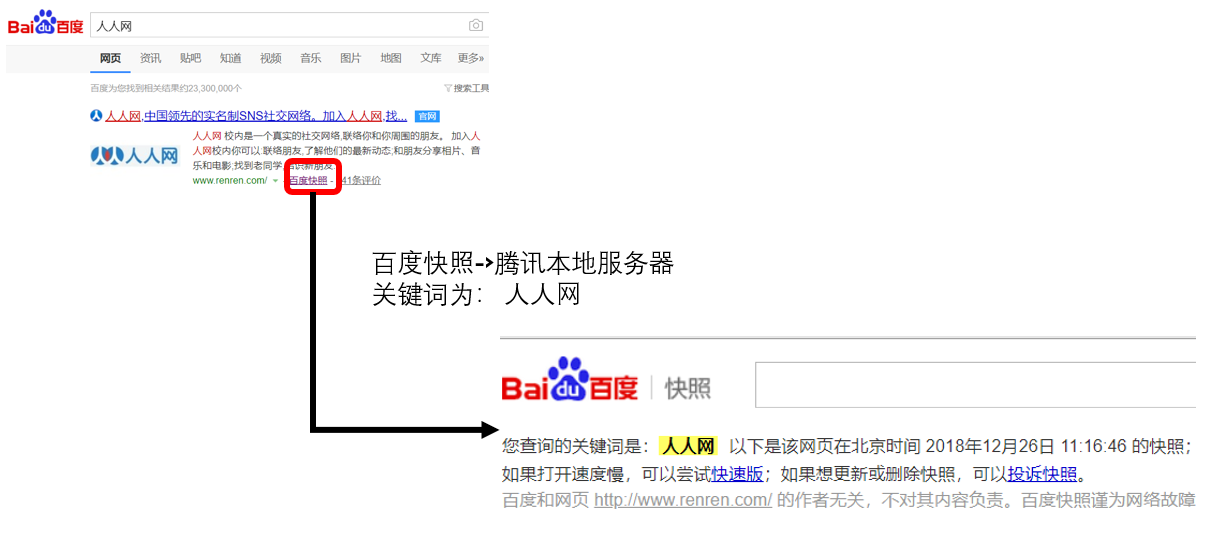
1.定义:搜索引擎爬虫系统
2.目标:爬取互联网上所有的网页,放到本地服务器上形成备份,对这些网页做相关的处理(提取关键词,去除广告),最终为用户提供借口拜访
3.爬取过程:
a) 首先选择一部分已有的URL,将这些URL放入爬取队列
b) 从队列中取出URL,然后解析NDS得到主机IP,然后到这个IP对应的服务器下载HTML页面,保存到搜索引擎的本地服务器,然后把爬取的抓取队列中的 URL
c) 分析网页内容,找出网页中的其他URL连接,继续第二步,直到爬取结束
4.搜索引擎如何获得一个新的网站 URL:
主动向搜索引擎提交网址:在其他网站中设置网站的外部链接:其他网站上方的友好链接搜索引擎会配合DNS服务商,可以快速< @k10@ >新网站
5.一般爬虫注意事项
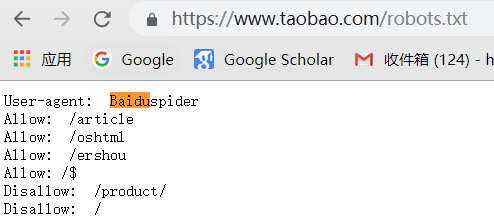
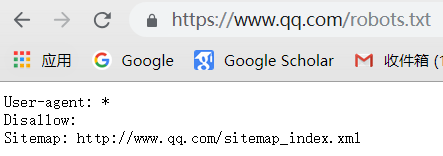
万能爬虫不是万物皆可爬,它必须遵守规则:
机器人协议:该协议将指定通用爬虫爬取网页的权限
我们可以在不同的网页上访问机器人权限
6.一般爬虫一般流程:
7.通用爬虫的缺点
只能提供文本相关的内容(HTML、WORD、PDF)等,不能提供多媒体文件(msic、图片、视频)等二进制文件。结果是一样的,不同背景的人听不同的搜索结果是无法理解的 人的语义检索侧重于爬虫的优势
DNS域名解析成IP:在命令框中输入ping获取服务器的IP
6.2 关注爬虫:
爬虫程序员编写的针对某个内容的爬虫 -> 面向主题的爬虫,需要爬虫的爬虫 查看全部
c爬虫抓取网页数据(PHPHTML数据爬虫的设计思路及应用的优势)
内容
1. 为什么是爬虫?
在“大数据时代”,数据获取方式:
从第三方数据平台购买数据爬虫数据2.什么是爬虫?
抓取网络数据的程序
3. 爬虫如何抓取网页数据?
首先,你需要了解一个网页的三个特征:
每个网页都有自己的 URL(Uniform Resource Locator)来定位网页 所有使用 HTML(超文本标记语言)来描述页面信息 所有网页使用 HTTP/HTTPS(超文本传输协议)来传输 HTML 数据
爬虫设计思路:
首先确定需要爬取的网页的URL地址,通过HTTP/HTTPS协议获取对应的HTML页面,提取HTML页面中的有用数据:
一个。如果是需要的数据--保存
湾。如果还有其他网址,继续步骤2 4. Python爬虫的优势?语言的优点和缺点
PHP
世界上最好的语言
对于多线程,异步支持不好,并发处理不够
爪哇
完善的网络爬虫生态系统
Java语言本身繁琐,代码量大,数据重构成本高
C/C++
运营效率和性能几乎是最高的
学习成本高
Python
语法优美,代码简洁,开发效率高,模块多
5.抓取HTML页面的学习路线:解析服务器对应内容:采集动态HTML、Captcha处理Scrapy框架:分布式策略:爬虫、反爬虫、反反之间的较量爬虫:6.爬虫分类6.1 通用爬虫:
1.定义:搜索引擎爬虫系统
2.目标:爬取互联网上所有的网页,放到本地服务器上形成备份,对这些网页做相关的处理(提取关键词,去除广告),最终为用户提供借口拜访
3.爬取过程:
a) 首先选择一部分已有的URL,将这些URL放入爬取队列
b) 从队列中取出URL,然后解析NDS得到主机IP,然后到这个IP对应的服务器下载HTML页面,保存到搜索引擎的本地服务器,然后把爬取的抓取队列中的 URL
c) 分析网页内容,找出网页中的其他URL连接,继续第二步,直到爬取结束
4.搜索引擎如何获得一个新的网站 URL:
主动向搜索引擎提交网址:在其他网站中设置网站的外部链接:其他网站上方的友好链接搜索引擎会配合DNS服务商,可以快速< @k10@ >新网站
5.一般爬虫注意事项
万能爬虫不是万物皆可爬,它必须遵守规则:
机器人协议:该协议将指定通用爬虫爬取网页的权限
我们可以在不同的网页上访问机器人权限
6.一般爬虫一般流程:

7.通用爬虫的缺点
只能提供文本相关的内容(HTML、WORD、PDF)等,不能提供多媒体文件(msic、图片、视频)等二进制文件。结果是一样的,不同背景的人听不同的搜索结果是无法理解的 人的语义检索侧重于爬虫的优势
DNS域名解析成IP:在命令框中输入ping获取服务器的IP
6.2 关注爬虫:
爬虫程序员编写的针对某个内容的爬虫 -> 面向主题的爬虫,需要爬虫的爬虫
c爬虫抓取网页数据(2021-10-29刚学新浪微博热搜主题讨论量获取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-05 09:16
2021-10-29
刚学python爬虫,用爬虫爬了新浪微博热搜,看看效果如何。也是这段时间学习python的一个总结。
一、目的:
抓取2020年1月3日星期五新浪微博热搜榜,动态展示抓取数据,生成当日微博热词云和微博热搜前20关键词条形图。
二、事情:
分析新浪微博热搜榜,分析网页结构,分析网页,获取当前热门话题、排名、话题讨论量、当前爬取时间。由于微博热搜动态刷新,选择20-30分钟抓取数据,时间范围为9:30-21:00。将上次采集的数据全部导入实现数据动态显示的模块,并进行相关调整。使用口吃分词对获取的数据进行分词,使用WordCloud展示当日热度搜索热点词云
三、相关实现步骤
1.网页分析
定义一个请求头来模拟浏览器并随机生成一个请求头,方法def get_header():
header1 = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0"
}
header2 = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"
}
header3 = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"
}
header_list = [header1,header2,header3]
index = random.randint(0,1)
return header_list[index]
解析 网站 方法:def get_data(url, headers)
使用权
req = requests.get(url=url, headers=headers)
req.encoding = "utf-8"
通过lxml解析网页
bf = BeautifulSoup(html, "lxml")
通过观察,每个热搜都在tr class=""下,所以只需遍历所有class=""
你可以上每一个热搜
div_content = bf.find_all("tr", class_="")
遍历div_content获取各个热搜的排名、话题、讨论量
for item in div_content:
删除顶部消息并将变量 t = 1 添加到循环中
if (t == 1):
t = 0
continue
tr下有3条td信息,分别代表排名、热搜话题和浏览量、标签表达。前两条信息是我们想要得到的。
获取当前热搜排名
num_content = item.select("td")[0].string
热搜话题和浏览量分别在td-02的a标签和span标签下
获取当前热门话题
content = item.select("td")[1].select("a")[0].string
获取当前热搜话题的讨论量
num = item.select("td")[1].select("span")[0].string
获取当前系统时间需要在前面import from time import strftime
current_time = strftime("%Y-%m-%d %H:%M")
将当前热搜排名、当前热搜话题、当前热搜话题讨论量、当前系统时间放入列表存储数据
list = [content,num_content,num,current_time]
将整个列表放入列表中
list_content.append(list)
2.存储数据
存储爬取的数据,存储方式def store_Excel(list):
写入文件,编码方式为utf_8_sig,生成的csv文件不会乱码,不换行的操作为newline=""
with open("微博实时热搜.csv","a",encoding="utf_8_sig",newline="")as file:
csv_writer = csv.writer(file)
遍历列表,写
for item in list:
csv_writer.writerow(item)
关闭文件
file.close()
3.生成词云
想法:
整合一天爬取的所有数据
2、通过累加的方式遍历并累加列表,将列表变成长字符串
3.通过口吃分词和空间分词来分割字符串
4.找一张轮廓清晰的图片打开,使用numpy获取轮廓
5、使用WordCloud生成当天微博热点词云。
导入生成词云的库
rom wordcloud import WordCloud
import Image
import numpy
import jieba
为字符串存储定义字符串
str = ""
阅读热搜热点表
with open("微博实时热搜test.csv","r",encoding="utf_8_sig",newline="") as file:
csv_reader = csv.reader(file)
遍历列表
for item in csv_reader:
去掉第一个无用的信息,在循环外定义变量t=1
if t == 1:
t = 0
continue
字符串拼接,热门话题在第一栏
str += item[0]
关闭文件
file.close()
口吃分词
jieba_content = jieba.cut(str)
空间连接的join方法
join_content=" ".join(jieba_content)
打开图片
wei_bo = Image.open("logo.jpg")
找到轮廓
wei_bo_image = numpy.array(wei_bo)
制作生成的词云
word_cloud = WordCloud(font_path="font1.TTF",background_color="white",mask = wei_bo_image).generate(join_content)
word_cloud.to_file("微博热搜.jpg")
最终词云展示:
微博logo图片勾勒出文字云。字体大小代表受欢迎程度。字体越大,受欢迎程度越高。字体越小,受欢迎程度越低。
4.分析数据
想法:
1.将微博热门话题存储在txt文件中
2.读取txt文件,使用jieba分词进行分词,生成关键词
3. 对 关键词 执行频率统计
4.按频率降序对统计信息进行排序关键词
5. 将排序结果存储在 csv 文件中以供以后操作
定义词典
word_dic = {}
打开文件,读取数据
使用 open("1.txt", "r", encoding="utf-8") 作为文件:
txt = file.read()
文件.close()
jieba分词数据
单词 = jieba.lcut(txt)
循环数据
言归正传:
如果关键字数量为1,则不计入
如果 len(word) == 1:
继续
否则频率增加 1
别的:
word_dic[word] = word_dic.get(word, 0) + 1
将字典数据转换为元组数据,用zip实现
word_zip = zip(word_dic.values(), word_dic.keys())
根据值从大到小对元组中的数据进行排序
word_sort = list(排序(word_zip, reverse=True))
定义两个数据存储列表
list_1 = ["name", "count_name"]
list_2 = []
列表_2.追加(列表_1)
对于 word_sort 中的项目:
# 词频
计数 = 项目 [0]
#关键字
名称 = 项目 [1]
list_1 = [名称,计数]
列表_2.追加(列表_1)
写入文件
以open("微博热搜关键词词频统计.csv", "w", encoding="utf_8_sig", newline="")为文件:
csv_writer = csv.writer(文件)
遍历list_2并写入每一行
对于 list_2 中的 i:
csv_writer.writerow(i)
5.生成绘图
思路:根据热搜关键词的排序文件,提取频率最高的前20位数据,绘制条形图
导入绘图工具包
将熊猫导入为 pd
将 matplotlib.pyplot 导入为 plt
定义绘图样式和颜色
plt.style.use('ggplot')
颜色1 = '#6D6D6D'
读取排序文件
df = pd.read_csv("微博热搜关键词词频统计.csv",encoding="utf-8")
提取前 20 个 关键词 和频率
name1 = df.name[:20]
count1 = df.count_name[:20]
要绘制条形图,请使用 range() 使 x 轴保持正确的顺序
plt.bar(范围(20),count1,tick_label = name1)
设置纵坐标范围
plt.ylim(0,90)
显示中文字体标签
plt.rcParams['font.sans-serif'] = ['SimHei']
标题
plt.title('微博热搜关键词词频统计',color = colors1)
x 轴标题,y 轴标题
plt.title('微博热搜关键词词频统计',color = colors1)
plt.xlabel('关键词')
为每个条添加数字标签
对于枚举中的 x,y (list(count1)):
plt.text(x,y+1,'%s'%round(y,90),ha = 'center',color = colors1)
x轴关键字旋转300度
plt.xticks(旋转 = 300)
自动控制空白边距以显示所有 x 轴坐标
plt.tight_layout()
保存图片
plt.savefig('微博热搜关键词词频统计top20.png')
显示图像
plt.show()
绘图结果显示:
这次爬虫抓取了大约20组数据,每组数据对应50个热搜榜。爬取时间为2020年1月1日9:30-21:00,每次爬取时间间隔为20-30分钟。抓取这么多组数据的主要目的是为了做数据的动态效果,展示过去一天微博热搜的动态变化。
数据动态展示效果图:
完整数据动态效果视频请参考微博热搜数据动态展示.mp4
分类:
技术要点:
相关文章: 查看全部
c爬虫抓取网页数据(2021-10-29刚学新浪微博热搜主题讨论量获取)
2021-10-29
刚学python爬虫,用爬虫爬了新浪微博热搜,看看效果如何。也是这段时间学习python的一个总结。
一、目的:
抓取2020年1月3日星期五新浪微博热搜榜,动态展示抓取数据,生成当日微博热词云和微博热搜前20关键词条形图。
二、事情:
分析新浪微博热搜榜,分析网页结构,分析网页,获取当前热门话题、排名、话题讨论量、当前爬取时间。由于微博热搜动态刷新,选择20-30分钟抓取数据,时间范围为9:30-21:00。将上次采集的数据全部导入实现数据动态显示的模块,并进行相关调整。使用口吃分词对获取的数据进行分词,使用WordCloud展示当日热度搜索热点词云
三、相关实现步骤
1.网页分析
定义一个请求头来模拟浏览器并随机生成一个请求头,方法def get_header():
header1 = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0"
}
header2 = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"
}
header3 = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"
}
header_list = [header1,header2,header3]
index = random.randint(0,1)
return header_list[index]
解析 网站 方法:def get_data(url, headers)
使用权
req = requests.get(url=url, headers=headers)
req.encoding = "utf-8"
通过lxml解析网页
bf = BeautifulSoup(html, "lxml")
通过观察,每个热搜都在tr class=""下,所以只需遍历所有class=""
你可以上每一个热搜
div_content = bf.find_all("tr", class_="")
遍历div_content获取各个热搜的排名、话题、讨论量
for item in div_content:
删除顶部消息并将变量 t = 1 添加到循环中
if (t == 1):
t = 0
continue
tr下有3条td信息,分别代表排名、热搜话题和浏览量、标签表达。前两条信息是我们想要得到的。
获取当前热搜排名
num_content = item.select("td")[0].string
热搜话题和浏览量分别在td-02的a标签和span标签下
获取当前热门话题
content = item.select("td")[1].select("a")[0].string
获取当前热搜话题的讨论量
num = item.select("td")[1].select("span")[0].string
获取当前系统时间需要在前面import from time import strftime
current_time = strftime("%Y-%m-%d %H:%M")
将当前热搜排名、当前热搜话题、当前热搜话题讨论量、当前系统时间放入列表存储数据
list = [content,num_content,num,current_time]
将整个列表放入列表中
list_content.append(list)
2.存储数据
存储爬取的数据,存储方式def store_Excel(list):
写入文件,编码方式为utf_8_sig,生成的csv文件不会乱码,不换行的操作为newline=""
with open("微博实时热搜.csv","a",encoding="utf_8_sig",newline="")as file:
csv_writer = csv.writer(file)
遍历列表,写
for item in list:
csv_writer.writerow(item)
关闭文件
file.close()
3.生成词云
想法:
整合一天爬取的所有数据
2、通过累加的方式遍历并累加列表,将列表变成长字符串
3.通过口吃分词和空间分词来分割字符串
4.找一张轮廓清晰的图片打开,使用numpy获取轮廓
5、使用WordCloud生成当天微博热点词云。
导入生成词云的库
rom wordcloud import WordCloud
import Image
import numpy
import jieba
为字符串存储定义字符串
str = ""
阅读热搜热点表
with open("微博实时热搜test.csv","r",encoding="utf_8_sig",newline="") as file:
csv_reader = csv.reader(file)
遍历列表
for item in csv_reader:
去掉第一个无用的信息,在循环外定义变量t=1
if t == 1:
t = 0
continue
字符串拼接,热门话题在第一栏
str += item[0]
关闭文件
file.close()
口吃分词
jieba_content = jieba.cut(str)
空间连接的join方法
join_content=" ".join(jieba_content)
打开图片
wei_bo = Image.open("logo.jpg")
找到轮廓
wei_bo_image = numpy.array(wei_bo)
制作生成的词云
word_cloud = WordCloud(font_path="font1.TTF",background_color="white",mask = wei_bo_image).generate(join_content)
word_cloud.to_file("微博热搜.jpg")
最终词云展示:
微博logo图片勾勒出文字云。字体大小代表受欢迎程度。字体越大,受欢迎程度越高。字体越小,受欢迎程度越低。
4.分析数据
想法:
1.将微博热门话题存储在txt文件中
2.读取txt文件,使用jieba分词进行分词,生成关键词
3. 对 关键词 执行频率统计
4.按频率降序对统计信息进行排序关键词
5. 将排序结果存储在 csv 文件中以供以后操作
定义词典
word_dic = {}
打开文件,读取数据
使用 open("1.txt", "r", encoding="utf-8") 作为文件:
txt = file.read()
文件.close()
jieba分词数据
单词 = jieba.lcut(txt)
循环数据
言归正传:
如果关键字数量为1,则不计入
如果 len(word) == 1:
继续
否则频率增加 1
别的:
word_dic[word] = word_dic.get(word, 0) + 1
将字典数据转换为元组数据,用zip实现
word_zip = zip(word_dic.values(), word_dic.keys())
根据值从大到小对元组中的数据进行排序
word_sort = list(排序(word_zip, reverse=True))
定义两个数据存储列表
list_1 = ["name", "count_name"]
list_2 = []
列表_2.追加(列表_1)
对于 word_sort 中的项目:
# 词频
计数 = 项目 [0]
#关键字
名称 = 项目 [1]
list_1 = [名称,计数]
列表_2.追加(列表_1)
写入文件
以open("微博热搜关键词词频统计.csv", "w", encoding="utf_8_sig", newline="")为文件:
csv_writer = csv.writer(文件)
遍历list_2并写入每一行
对于 list_2 中的 i:
csv_writer.writerow(i)
5.生成绘图
思路:根据热搜关键词的排序文件,提取频率最高的前20位数据,绘制条形图
导入绘图工具包
将熊猫导入为 pd
将 matplotlib.pyplot 导入为 plt
定义绘图样式和颜色
plt.style.use('ggplot')
颜色1 = '#6D6D6D'
读取排序文件
df = pd.read_csv("微博热搜关键词词频统计.csv",encoding="utf-8")
提取前 20 个 关键词 和频率
name1 = df.name[:20]
count1 = df.count_name[:20]
要绘制条形图,请使用 range() 使 x 轴保持正确的顺序
plt.bar(范围(20),count1,tick_label = name1)
设置纵坐标范围
plt.ylim(0,90)
显示中文字体标签
plt.rcParams['font.sans-serif'] = ['SimHei']
标题
plt.title('微博热搜关键词词频统计',color = colors1)
x 轴标题,y 轴标题
plt.title('微博热搜关键词词频统计',color = colors1)
plt.xlabel('关键词')
为每个条添加数字标签
对于枚举中的 x,y (list(count1)):
plt.text(x,y+1,'%s'%round(y,90),ha = 'center',color = colors1)
x轴关键字旋转300度
plt.xticks(旋转 = 300)
自动控制空白边距以显示所有 x 轴坐标
plt.tight_layout()
保存图片
plt.savefig('微博热搜关键词词频统计top20.png')
显示图像
plt.show()
绘图结果显示:
这次爬虫抓取了大约20组数据,每组数据对应50个热搜榜。爬取时间为2020年1月1日9:30-21:00,每次爬取时间间隔为20-30分钟。抓取这么多组数据的主要目的是为了做数据的动态效果,展示过去一天微博热搜的动态变化。
数据动态展示效果图:
完整数据动态效果视频请参考微博热搜数据动态展示.mp4
分类:
技术要点:
相关文章:
c爬虫抓取网页数据(网络爬虫最基本的思路和处理方法(一)——1.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-02-05 09:12
1. 科普
一般搜索引擎处理的对象是互联网的网页。目前,网页数量已达数亿。因此,搜索引擎面临的第一个问题就是如何设计一个高效的下载系统。互联网页面的镜像。网络爬虫负责这个任务。
爬取网页的过程其实和读者平时使用IE浏览器浏览网页的方式是一样的。假设您在浏览器的地址栏中输入此地址。打开网页的过程其实就是浏览器作为浏览的“客户端”,向服务器端发出请求,将服务器端的文件“抓取”到本地,然后解释并显示出来。浏览器的作用是解析得到的HTML代码,然后将原来的网页转换成我们看到的网站页面。
网络爬虫最基本的思想是:从一个页面开始,分析其中的url,提取出来,然后通过这些链接寻找下一页。如此来回。
2. 通用爬虫框架
@7))。@9) 和 . 重复刚才的故事。
3. 网址
爬虫处理的主要对象是URL。简单地说,url就是输入的URL(例如:)。在了解 URL 之前先了解 URI。
Web 上可用的每个资源,例如 HTML 文档、图像、视频剪辑、程序等,都由通用资源标识符 (URI) 定位。
一个URI通常由三部分组成:
访问资源的命名机制 存储资源的资源的主机名 资源本身的名称,由路径表示
比如URI:
我们可以这样解释:
URL 是 URI 的子集。它是Uniform Resource Locator的缩写,翻译为“统一资源定位器”。
通俗的讲,URL是描述Internet上信息资源的字符串,主要用于各种WWW客户端程序和服务器程序中。
使用 URL 可以使用统一的格式来描述各种信息资源,包括文件、服务器地址和目录。
URL的格式由三部分组成:
第一部分是协议(或服务模式) 第二部分是存储资源的主机的IP地址(有时还包括端口号) 第三部分是主机资源的具体地址,如目录和文件名等
第一部分和第二部分用“://”符号分隔
第二部分和第三部分用“/”符号隔开
第 1 部分和第 2 部分缺一不可,第 3 部分有时可以省略 查看全部
c爬虫抓取网页数据(网络爬虫最基本的思路和处理方法(一)——1.)
1. 科普
一般搜索引擎处理的对象是互联网的网页。目前,网页数量已达数亿。因此,搜索引擎面临的第一个问题就是如何设计一个高效的下载系统。互联网页面的镜像。网络爬虫负责这个任务。
爬取网页的过程其实和读者平时使用IE浏览器浏览网页的方式是一样的。假设您在浏览器的地址栏中输入此地址。打开网页的过程其实就是浏览器作为浏览的“客户端”,向服务器端发出请求,将服务器端的文件“抓取”到本地,然后解释并显示出来。浏览器的作用是解析得到的HTML代码,然后将原来的网页转换成我们看到的网站页面。
网络爬虫最基本的思想是:从一个页面开始,分析其中的url,提取出来,然后通过这些链接寻找下一页。如此来回。
2. 通用爬虫框架
@7))。@9) 和 . 重复刚才的故事。
3. 网址
爬虫处理的主要对象是URL。简单地说,url就是输入的URL(例如:)。在了解 URL 之前先了解 URI。
Web 上可用的每个资源,例如 HTML 文档、图像、视频剪辑、程序等,都由通用资源标识符 (URI) 定位。
一个URI通常由三部分组成:
访问资源的命名机制 存储资源的资源的主机名 资源本身的名称,由路径表示
比如URI:
我们可以这样解释:
URL 是 URI 的子集。它是Uniform Resource Locator的缩写,翻译为“统一资源定位器”。
通俗的讲,URL是描述Internet上信息资源的字符串,主要用于各种WWW客户端程序和服务器程序中。
使用 URL 可以使用统一的格式来描述各种信息资源,包括文件、服务器地址和目录。
URL的格式由三部分组成:
第一部分是协议(或服务模式) 第二部分是存储资源的主机的IP地址(有时还包括端口号) 第三部分是主机资源的具体地址,如目录和文件名等
第一部分和第二部分用“://”符号分隔
第二部分和第三部分用“/”符号隔开
第 1 部分和第 2 部分缺一不可,第 3 部分有时可以省略
c爬虫抓取网页数据(抓取知乎所有用户信息的爬虫代码逻辑以及分析分析方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-05 09:09
2021-11-27
今天用递归写了一个爬虫,抓取知乎的所有用户信息。源代码放在github上。有兴趣的同学可以下载看看。这里介绍一下代码逻辑和分页分析。首先,看网页。,这里我随机选择一个大V作为入口,然后点击他的关注列表,如图
我们都知道 Python 很容易学习,但我们只是不知道如何学习它以及在哪里可以找到信息。在这里,python学习交流QQ群233539995,分享我精心准备的Python学习资料,0基础到高级!希望大家在学习Python的道路上少走弯路!来吧!
注意我的爬虫全名是非登录状态。这里的fan list和follower list是后台ajax请求获取的数据(没听说过ajax的不要慌,ajax请求和普通浏览器请求没什么区别,主要是偷偷发给服务器的)当我们浏览网页的时候请求是为了节省流量,减少请求次数,不然每次看新数据都会刷新网页,服务器压力很大,所以我们有这个东西),然后我们找到粉丝列表和关注者列表的网址,很简单,点击chrome浏览器下的页码开关即可找到,如图
很容易找到关注者和粉丝的 URL。让我们来看看这些数据。这是粉丝数据的一个例子。如图,是一段json
这里找到了粉丝的数据,但这不是用户的详细信息,只是部分数据,但是他提供了一个token_url,我们可以得到这个ID访问用户的详细信息,我们来看看如何提取每个用户的详细信息。在这里楼主发现,在看粉丝或者关注列表的时候,网页会自动触发对用户详细信息的请求,如图
本次获取用户详细信息查询的URL。我们来看看这个详细信息的URL,如图。
上面介绍了网页的基本分析。先说一下代码的思路。本次爬虫使用递归,本次使用scrapy进行爬取,存储mogodb数据库。
首先,我用了一个大V作为爬虫的第一个网页,然后分为三个步骤。第一步是爬取大V的详细信息,然后存入数据库。第二步是爬大V的粉丝。第三步是爬大V的粉丝(其实就是爬粉丝或者粉丝的token_url)。完成后,利用粉丝和关注者的爬取数据,构造他们每一个详细信息的url,然后挖掘详细信息存入数据库。至此,第一步递归完成,接下来爬虫会从每个粉丝和粉丝开始,分别爬取他们粉丝和粉丝的详细数据,继续递归。
代码中还添加了一些自动翻页功能,有兴趣的可以看看。以下是我们项目定义中要捕获的数据:
import scrapyclass 知乎UserItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() answer_count = scrapy.Field()
#回答数article_count = scrapy.Field()
#Written 文章 number follower_count = scrapy.Field()
#关注粉丝数_count = scrapy.Field()
#有多少人关注了educations=scrapy.Field()
#教育背景描述 = scrapy.Field()
#个人描述位置 = scrapy.Field()
#Location url_token =scrapy.Field()
#知乎给每个用户首页的唯一ID name=scrapy.Field()
#用户昵称员工 = scrapy.Field()
#工作信息business=scrapy.Field()
#工作或业务信息的集合 user_type =scrapy.Field()
#用户类型,可以是个人、群组等。headline =scrapy.Field()
#个人主页标签 voteup_count = scrapy.Field()
#获得的点赞数Thanks_count=scrapy.Field()
#感谢次数喜爱的_count = scrapy.Field()
#采集数量 avatar_url = scrapy.Field()
#头像网址
代码总共不到 80 行。运行一分钟后,它捕获了知乎 1000多个用户的信息。这是结果图片。
最近一直在忙别的事情,终于可以天天写爬虫了。不知道大家对这篇文章有没有什么问题,可以随时跟我提。
最后要提的是,爬取一定要伪装headers,里面有一些东西是服务器每次都会检查的。
我们都知道 Python 很容易学习,但我们只是不知道如何学习它以及在哪里可以找到信息。在这里,python学习交流QQ群233539995,分享我精心准备的Python学习资料,0基础到高级!希望大家在学习Python的道路上少走弯路!来吧!
分类:
技术要点:
相关文章: 查看全部
c爬虫抓取网页数据(抓取知乎所有用户信息的爬虫代码逻辑以及分析分析方法)
2021-11-27
今天用递归写了一个爬虫,抓取知乎的所有用户信息。源代码放在github上。有兴趣的同学可以下载看看。这里介绍一下代码逻辑和分页分析。首先,看网页。,这里我随机选择一个大V作为入口,然后点击他的关注列表,如图
我们都知道 Python 很容易学习,但我们只是不知道如何学习它以及在哪里可以找到信息。在这里,python学习交流QQ群233539995,分享我精心准备的Python学习资料,0基础到高级!希望大家在学习Python的道路上少走弯路!来吧!
注意我的爬虫全名是非登录状态。这里的fan list和follower list是后台ajax请求获取的数据(没听说过ajax的不要慌,ajax请求和普通浏览器请求没什么区别,主要是偷偷发给服务器的)当我们浏览网页的时候请求是为了节省流量,减少请求次数,不然每次看新数据都会刷新网页,服务器压力很大,所以我们有这个东西),然后我们找到粉丝列表和关注者列表的网址,很简单,点击chrome浏览器下的页码开关即可找到,如图
很容易找到关注者和粉丝的 URL。让我们来看看这些数据。这是粉丝数据的一个例子。如图,是一段json
这里找到了粉丝的数据,但这不是用户的详细信息,只是部分数据,但是他提供了一个token_url,我们可以得到这个ID访问用户的详细信息,我们来看看如何提取每个用户的详细信息。在这里楼主发现,在看粉丝或者关注列表的时候,网页会自动触发对用户详细信息的请求,如图
本次获取用户详细信息查询的URL。我们来看看这个详细信息的URL,如图。
上面介绍了网页的基本分析。先说一下代码的思路。本次爬虫使用递归,本次使用scrapy进行爬取,存储mogodb数据库。
首先,我用了一个大V作为爬虫的第一个网页,然后分为三个步骤。第一步是爬取大V的详细信息,然后存入数据库。第二步是爬大V的粉丝。第三步是爬大V的粉丝(其实就是爬粉丝或者粉丝的token_url)。完成后,利用粉丝和关注者的爬取数据,构造他们每一个详细信息的url,然后挖掘详细信息存入数据库。至此,第一步递归完成,接下来爬虫会从每个粉丝和粉丝开始,分别爬取他们粉丝和粉丝的详细数据,继续递归。
代码中还添加了一些自动翻页功能,有兴趣的可以看看。以下是我们项目定义中要捕获的数据:
import scrapyclass 知乎UserItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() answer_count = scrapy.Field()
#回答数article_count = scrapy.Field()
#Written 文章 number follower_count = scrapy.Field()
#关注粉丝数_count = scrapy.Field()
#有多少人关注了educations=scrapy.Field()
#教育背景描述 = scrapy.Field()
#个人描述位置 = scrapy.Field()
#Location url_token =scrapy.Field()
#知乎给每个用户首页的唯一ID name=scrapy.Field()
#用户昵称员工 = scrapy.Field()
#工作信息business=scrapy.Field()
#工作或业务信息的集合 user_type =scrapy.Field()
#用户类型,可以是个人、群组等。headline =scrapy.Field()
#个人主页标签 voteup_count = scrapy.Field()
#获得的点赞数Thanks_count=scrapy.Field()
#感谢次数喜爱的_count = scrapy.Field()
#采集数量 avatar_url = scrapy.Field()
#头像网址
代码总共不到 80 行。运行一分钟后,它捕获了知乎 1000多个用户的信息。这是结果图片。
最近一直在忙别的事情,终于可以天天写爬虫了。不知道大家对这篇文章有没有什么问题,可以随时跟我提。
最后要提的是,爬取一定要伪装headers,里面有一些东西是服务器每次都会检查的。
我们都知道 Python 很容易学习,但我们只是不知道如何学习它以及在哪里可以找到信息。在这里,python学习交流QQ群233539995,分享我精心准备的Python学习资料,0基础到高级!希望大家在学习Python的道路上少走弯路!来吧!
分类:
技术要点:
相关文章:
c爬虫抓取网页数据(关于爬虫的知识后,你了解多少?(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-05 00:04
)
如今,大前端理念已经深入人心,需要涉及的知识很多。所以,对于现在的前端来说,也是不可抗拒的。在修炼吸星大法时,尽可能多地吸收知识,最终达到物尽其用的效果。
最近也在学习爬虫,因为之前项目中需要用到的地铁信息数据不是爬虫爬下来的数据,而是直接复制过来的。
虽然这些数据暂时不会有太大变化,但感觉还是有点低。所以在了解了爬虫之后,打算和大家讨论交流,然后直接进入正题。
首先说一下爬虫和Robots协议是什么
然后介绍爬虫的基本流程
最后根据实际栗子爬个豆瓣最近上映的电影来试试小刀
2、爬虫和机器人协议
首先看定义:爬虫是自动获取网页内容的程序。它是搜索引擎的重要组成部分,因此搜索引擎优化主要针对爬虫进行优化。
下面我们来看看Robots协议的介绍。robots.txt 是文本文件,robots.txt 是协议,而不是命令。
robots.txt 是爬虫要查看的第一个文件。robots.txt 告诉爬虫可以在服务器上查看哪些文件。爬虫机器人会根据文件内容确定访问范围。
下图是豆瓣电影页面列出的robots协议的访问范围。
爬虫和机器人协议密切相关。如果您看到不允许抓取的页面,请不要抓取它们。万一涉及到用户隐私的某些方面,稍后会被发现并带到合法渠道。
因此,业内每个人都认可这个 Robots 协议。不想爬网页就别爬了,上网就可以安宁了。
有点跑题了,我们看下面一张图,简单梳理一下上面提到的内容。
其实有人会问,爬行动物到底在爬什么?
这是一个非常有见地的问题。说白了就是爬虫拿到的那段html代码,所以这对我们来说并不陌生,只要我们把它转换成DOM树就行了。
所以,现在看上图的右半部分,是一张对比图。
左边的那个没有受限的机器人协议。从逻辑上讲,admin/private和tmp这三个文件夹是不能被抓到的,但是因为没有Robots协议,人就可以肆无忌惮的爬了。
从右侧看,Robots 协议是有限的。相反,像谷歌这样的搜索引擎,也是通过 Robots.txt 文件来查看哪些是抓不到的,然后去 admin 或者 private 的时候直接跳过。去抢吧。
好了,介绍到此为止。凡是不包括真刀真枪的,都只是纸上谈兵。
3、爬虫基本流程
其实对于爬虫的使用来说,过程无非就是这四个步骤。
专用数据
数据存储
启动服务
渲染数据
专用数据
现在到了激动人心的部分,不要停下来,跟着我,敲出一页爬豆瓣电影,供自己欣赏。
我们先来看看整体的目录结构。
既然是抓数据,就得用业界知名的神器——request
请求工件
那么如何使用request,我们一起听风看代码
// 使用起来超简单let request = require('request');
request('http://www.baidu.com', function (error, response, body) { console.log('error:', error); // 当有错误发生时打印错误日志 console.log('statusCode:', response && response.statusCode); // 打印响应状态码 console.log('body:', body); // 打印百度页面的html代码});
看了上面的代码,是不是还觉得不明显。小伙伴们,html代码已经出现在你们面前了,不要犹豫,只要把它变成熟悉的DOM,就可以为所欲为。
于是,cheerio 出道,大家都称它为 Node 版的 jq。你可以完全按照jq的习惯来操作DOM。
下面不再走弯路,一起来写爬虫吧!
阅读内容
首页应该先分析豆瓣电影的页面,也就是热映的电影,我们先来看看DOM结构。
好了,读完噻吩后,我们需要的内容也标注出来了,然后进入read.js文件,一步步开始舔。
// read.js文件
// request-promise是让request支持了promise的语法,可以说是request的小弟const rp = require('request-promise');// 将抓取页面的html代码转为DOM,可以称之为是node版的jqconst cheerio = require('cheerio');// 这个是为了在调试时查看日志const debug = require('debug')('movie:read');
// 读取页面的方法,重点来了const read = async (url) => { debug('开始读取最近上映的电影');
const opts = { url, // 目标页面 transform: body => { // body为目标页面抓取到的html代码 // 通过cheerio.load方法可以把html代码转换成可以操作的DOM结构 return cheerio.load(body); } };
return rp(opts).then($ => { let result = []; // 结果数组 // 遍历这些热映电影的li $('#screening li.ui-slide-item').each((index, item) => { let ele = $(item); let name = ele.data('title'); let score = ele.data('rate') || '暂无评分'; let href = ele.find('.poster a').attr('href'); let image = ele.find('img').attr('src'); // 影片id可以从影片href中获取到 let id = href && href.match(/(\d+)/)[1]; // 为了防止豆瓣防盗链导致裂图,换成webp格式加载图片 image = image && image.replace(/jpg$/, 'webp');
if (!name || !image || !href) { return; }
result.push({ name, score, href, image, id }); debug(`正在读取电影:${name}`); }); // 返回结果数组 return result; });};// 导出方法module.exports = read;
写完代码,让我们回忆一下你做了什么。
4、数据存储
这里我们使用mysql建一个数据库来存储数据,不懂的没关系,我先一步一步来。我们首先安装 XAMPP 和 Navicat 可视化数据库管理工具,安装完成后,按照下面的说明进行操作。
XAMPP启动mysql
Navicat 连接数据库并创建表
几句话可能不像有图有真相那么真实。我们先来看看图片。
嗯,看图的时代到此结束。我真的很惭愧消耗了大量的流量。现在让我们回到编码阶段。
连接到数据库
首先,我们需要在 src 目录下创建一个 sql 文件。它需要和我们刚刚创建的数据库同名,所以我们称之为my_movie.sql(当然目录结构已经创建好了)
然后,回到 db.js 文件,编写连接数据库的代码
// db.js
const mysql = require('mysql');const bluebird = require('bluebird');
// 创建连接const connection = mysql.createConnection({ host: 'localhost', // host port: 3306, // 端口号默认3306 database: 'my_movie', // 对应的数据库 user: 'root', password: ''});
connection.connect(); // 连接数据库
// bluebird是为了方便支持promise语法化// 然后直接把数据库的query查询语句导出方便之后调用module.exports = bluebird.promisify(connection.query).bind(connection);
上面的代码已经创建了连接Mysql数据库的操作。接下来,不要放慢速度,将内容直接写入数据库。
写入数据库
这时候我们来看看write.js这个文件。是的,顾名思义,就是用来写数据库的,直接上代码
// write.js文件
// 从db.js那里导入query方法const query = require('./db');const debug = require('debug')('movie:write');// 写入数据库的方法const write = async (movies) => { debug('开始写入电影');
// movies即为read.js读取出来的结果数组 for (let movie of movies) { // 通过query方法去查询一下是不是已经在数据库里存过了 let oldMovie = await query('SELECT * FROM movies WHERE id=? LIMIT 1', [movie.id]);
// sql查询语句返回的是一个数组,如果不为空数组的话就表示有数据存过 // 直接就进行更新操作了 if (Array.isArray(oldMovie) && oldMovie.length) { // 更新movies表里的数据 let old = oldMovie[0]; await query('UPDATE movies SET name=?,href=?,image=?,score=? WHERE id=?', [movie.name, movie.href, movie.image, movie.score, old.id]); } else { // 插入内容到movies表 await query('INSERT INTO movies(id,name,href,image,score) VALUES(?,?,?,?,?)', [movie.id, movie.name, movie.href, movie.image, movie.score]); }
debug(`正在写入电影:${movie.name}`); }};
module.exports = write;
上面写的可能有点混乱,毕竟纯前端很少写SQL语句。不过不要害羞,我先把上面的代码整理好之后再简单介绍一下SQL语句部分。
write.js 到底写了什么?
好了,上面也实现了写入数据库的方法。接下来,趁热打铁,稍微聊聊SQL语句。
SQL语句学习
? 表示占位符。顺便说一下,我将简要介绍将在 SQL 语句中使用的语法,以及无处不在的增删改查。
插入数据
语法: INSERT INTO 表名(列名) VALUES(列名值)栗子: INSERT INTO tags(name,id,url) VALUES('爬虫',10,'https://news.so.com/hotnews')解释: 向标签表(tags)里插入一条,姓名,id和访问地址分别为VALUES内对应的值
更新数据
语法: UPDATE 表名 SET 列名=更新值 WHERE 更新条件栗子: UPDATE articles SET title='你好,世界',content='世界没你想的那么糟!' WHERE id=1解释: 更新id为1的文章,标题和内容都进行了修改
删除数据
语法: DELETE FROM 表名 WHERE 删除条件栗子: DELETE FROM tags WHERE id=11解释: 从标签表(tags)里删除id为11的数据
查询
语法: SELECT 列名 FROM 表名 WHERE 查询条件 ORDER BY 排序列名栗子: SELECT name,title,content FROM tags WHERE id=8解释: 查询id为8的标签表里对应信息
至此,我已经把所有的读写方法都写完了,所以大家一定是有点累了。是时候测试结果了,否则都是废话
5、执行读写操作
现在来到 index.js 并开始检查它。
// index.js文件
const read = require('./read');const write = require('./write');const url = 'https://movie.douban.com'; // 目标页面
(async () => { // 异步抓取目标页面 const movies = await read(url); // 写入数据到数据库 await write(movies); // 完毕后退出程序 process.exit();})();
完了,执行一下看看效果如何,直接上图
代码已执行。接下来回到Navicat,看看数据是否已经写入。我们用图片来说话。
至此,我们已经完成了数据采集和存储操作,但似乎还缺少什么?
也就是我们需要写一个页面来展示它,因为爬取和写数据只允许在node环境下进行。所以我们还要创建一个web服务来显示页面,坚持下去很快就OK了,加油。
6、启动服务
既然我们要创建一个 web 服务,让我们开始编写 server.js 的内容
服务器服务
// server.js文件
const express = require('express');const path = require('path');const query = require('../src/db');const app = express();
// 设置模板引擎app.set('view engine', 'html');app.set('views', path.join(__dirname, 'views'));app.engine('html', require('ejs').__express);
// 首页路由app.get('/', async (req, res) => { // 通过SQL查询语句拿到库里的movies表数据 const movies = await query('SELECT * FROM movies'); // 渲染首页模板并把movies数据传过去 res.render('index', { movies });});// 监听localhost:9000端口app.listen(9000);
写完服务端服务,我们再来看看 index.html 模板。这是最后一件事。写完,就大功告成了。
7、渲染数据
// index.html
热映的电影 正在热映的电影 %=movie.image% <p class="score">评分: </a>
</p>
通过模板引擎遍历movies数组,然后渲染
现在,看看最终效果
和你一起来到这里是缘分。我很高兴经历了这么长时间的文章 学习。每个人都应该对爬行动物的知识有一个很好的了解。
对了,这里是代码地址:爬虫研究/电影
为了您的方便,敲敲敲。
感谢阅读,886。
查看全部
c爬虫抓取网页数据(关于爬虫的知识后,你了解多少?(一)
)
如今,大前端理念已经深入人心,需要涉及的知识很多。所以,对于现在的前端来说,也是不可抗拒的。在修炼吸星大法时,尽可能多地吸收知识,最终达到物尽其用的效果。
最近也在学习爬虫,因为之前项目中需要用到的地铁信息数据不是爬虫爬下来的数据,而是直接复制过来的。
虽然这些数据暂时不会有太大变化,但感觉还是有点低。所以在了解了爬虫之后,打算和大家讨论交流,然后直接进入正题。
首先说一下爬虫和Robots协议是什么
然后介绍爬虫的基本流程
最后根据实际栗子爬个豆瓣最近上映的电影来试试小刀
2、爬虫和机器人协议
首先看定义:爬虫是自动获取网页内容的程序。它是搜索引擎的重要组成部分,因此搜索引擎优化主要针对爬虫进行优化。
下面我们来看看Robots协议的介绍。robots.txt 是文本文件,robots.txt 是协议,而不是命令。
robots.txt 是爬虫要查看的第一个文件。robots.txt 告诉爬虫可以在服务器上查看哪些文件。爬虫机器人会根据文件内容确定访问范围。
下图是豆瓣电影页面列出的robots协议的访问范围。
爬虫和机器人协议密切相关。如果您看到不允许抓取的页面,请不要抓取它们。万一涉及到用户隐私的某些方面,稍后会被发现并带到合法渠道。
因此,业内每个人都认可这个 Robots 协议。不想爬网页就别爬了,上网就可以安宁了。
有点跑题了,我们看下面一张图,简单梳理一下上面提到的内容。
其实有人会问,爬行动物到底在爬什么?
这是一个非常有见地的问题。说白了就是爬虫拿到的那段html代码,所以这对我们来说并不陌生,只要我们把它转换成DOM树就行了。
所以,现在看上图的右半部分,是一张对比图。
左边的那个没有受限的机器人协议。从逻辑上讲,admin/private和tmp这三个文件夹是不能被抓到的,但是因为没有Robots协议,人就可以肆无忌惮的爬了。
从右侧看,Robots 协议是有限的。相反,像谷歌这样的搜索引擎,也是通过 Robots.txt 文件来查看哪些是抓不到的,然后去 admin 或者 private 的时候直接跳过。去抢吧。
好了,介绍到此为止。凡是不包括真刀真枪的,都只是纸上谈兵。
3、爬虫基本流程
其实对于爬虫的使用来说,过程无非就是这四个步骤。
专用数据
数据存储
启动服务
渲染数据
专用数据
现在到了激动人心的部分,不要停下来,跟着我,敲出一页爬豆瓣电影,供自己欣赏。
我们先来看看整体的目录结构。
既然是抓数据,就得用业界知名的神器——request
请求工件
那么如何使用request,我们一起听风看代码
// 使用起来超简单let request = require('request');
request('http://www.baidu.com', function (error, response, body) { console.log('error:', error); // 当有错误发生时打印错误日志 console.log('statusCode:', response && response.statusCode); // 打印响应状态码 console.log('body:', body); // 打印百度页面的html代码});
看了上面的代码,是不是还觉得不明显。小伙伴们,html代码已经出现在你们面前了,不要犹豫,只要把它变成熟悉的DOM,就可以为所欲为。
于是,cheerio 出道,大家都称它为 Node 版的 jq。你可以完全按照jq的习惯来操作DOM。
下面不再走弯路,一起来写爬虫吧!
阅读内容
首页应该先分析豆瓣电影的页面,也就是热映的电影,我们先来看看DOM结构。
好了,读完噻吩后,我们需要的内容也标注出来了,然后进入read.js文件,一步步开始舔。
// read.js文件
// request-promise是让request支持了promise的语法,可以说是request的小弟const rp = require('request-promise');// 将抓取页面的html代码转为DOM,可以称之为是node版的jqconst cheerio = require('cheerio');// 这个是为了在调试时查看日志const debug = require('debug')('movie:read');
// 读取页面的方法,重点来了const read = async (url) => { debug('开始读取最近上映的电影');
const opts = { url, // 目标页面 transform: body => { // body为目标页面抓取到的html代码 // 通过cheerio.load方法可以把html代码转换成可以操作的DOM结构 return cheerio.load(body); } };
return rp(opts).then($ => { let result = []; // 结果数组 // 遍历这些热映电影的li $('#screening li.ui-slide-item').each((index, item) => { let ele = $(item); let name = ele.data('title'); let score = ele.data('rate') || '暂无评分'; let href = ele.find('.poster a').attr('href'); let image = ele.find('img').attr('src'); // 影片id可以从影片href中获取到 let id = href && href.match(/(\d+)/)[1]; // 为了防止豆瓣防盗链导致裂图,换成webp格式加载图片 image = image && image.replace(/jpg$/, 'webp');
if (!name || !image || !href) { return; }
result.push({ name, score, href, image, id }); debug(`正在读取电影:${name}`); }); // 返回结果数组 return result; });};// 导出方法module.exports = read;
写完代码,让我们回忆一下你做了什么。
4、数据存储
这里我们使用mysql建一个数据库来存储数据,不懂的没关系,我先一步一步来。我们首先安装 XAMPP 和 Navicat 可视化数据库管理工具,安装完成后,按照下面的说明进行操作。
XAMPP启动mysql
Navicat 连接数据库并创建表
几句话可能不像有图有真相那么真实。我们先来看看图片。
嗯,看图的时代到此结束。我真的很惭愧消耗了大量的流量。现在让我们回到编码阶段。
连接到数据库
首先,我们需要在 src 目录下创建一个 sql 文件。它需要和我们刚刚创建的数据库同名,所以我们称之为my_movie.sql(当然目录结构已经创建好了)
然后,回到 db.js 文件,编写连接数据库的代码
// db.js
const mysql = require('mysql');const bluebird = require('bluebird');
// 创建连接const connection = mysql.createConnection({ host: 'localhost', // host port: 3306, // 端口号默认3306 database: 'my_movie', // 对应的数据库 user: 'root', password: ''});
connection.connect(); // 连接数据库
// bluebird是为了方便支持promise语法化// 然后直接把数据库的query查询语句导出方便之后调用module.exports = bluebird.promisify(connection.query).bind(connection);
上面的代码已经创建了连接Mysql数据库的操作。接下来,不要放慢速度,将内容直接写入数据库。
写入数据库
这时候我们来看看write.js这个文件。是的,顾名思义,就是用来写数据库的,直接上代码
// write.js文件
// 从db.js那里导入query方法const query = require('./db');const debug = require('debug')('movie:write');// 写入数据库的方法const write = async (movies) => { debug('开始写入电影');
// movies即为read.js读取出来的结果数组 for (let movie of movies) { // 通过query方法去查询一下是不是已经在数据库里存过了 let oldMovie = await query('SELECT * FROM movies WHERE id=? LIMIT 1', [movie.id]);
// sql查询语句返回的是一个数组,如果不为空数组的话就表示有数据存过 // 直接就进行更新操作了 if (Array.isArray(oldMovie) && oldMovie.length) { // 更新movies表里的数据 let old = oldMovie[0]; await query('UPDATE movies SET name=?,href=?,image=?,score=? WHERE id=?', [movie.name, movie.href, movie.image, movie.score, old.id]); } else { // 插入内容到movies表 await query('INSERT INTO movies(id,name,href,image,score) VALUES(?,?,?,?,?)', [movie.id, movie.name, movie.href, movie.image, movie.score]); }
debug(`正在写入电影:${movie.name}`); }};
module.exports = write;
上面写的可能有点混乱,毕竟纯前端很少写SQL语句。不过不要害羞,我先把上面的代码整理好之后再简单介绍一下SQL语句部分。
write.js 到底写了什么?
好了,上面也实现了写入数据库的方法。接下来,趁热打铁,稍微聊聊SQL语句。
SQL语句学习
? 表示占位符。顺便说一下,我将简要介绍将在 SQL 语句中使用的语法,以及无处不在的增删改查。
插入数据
语法: INSERT INTO 表名(列名) VALUES(列名值)栗子: INSERT INTO tags(name,id,url) VALUES('爬虫',10,'https://news.so.com/hotnews')解释: 向标签表(tags)里插入一条,姓名,id和访问地址分别为VALUES内对应的值
更新数据
语法: UPDATE 表名 SET 列名=更新值 WHERE 更新条件栗子: UPDATE articles SET title='你好,世界',content='世界没你想的那么糟!' WHERE id=1解释: 更新id为1的文章,标题和内容都进行了修改
删除数据
语法: DELETE FROM 表名 WHERE 删除条件栗子: DELETE FROM tags WHERE id=11解释: 从标签表(tags)里删除id为11的数据
查询
语法: SELECT 列名 FROM 表名 WHERE 查询条件 ORDER BY 排序列名栗子: SELECT name,title,content FROM tags WHERE id=8解释: 查询id为8的标签表里对应信息
至此,我已经把所有的读写方法都写完了,所以大家一定是有点累了。是时候测试结果了,否则都是废话
5、执行读写操作
现在来到 index.js 并开始检查它。
// index.js文件
const read = require('./read');const write = require('./write');const url = 'https://movie.douban.com'; // 目标页面
(async () => { // 异步抓取目标页面 const movies = await read(url); // 写入数据到数据库 await write(movies); // 完毕后退出程序 process.exit();})();
完了,执行一下看看效果如何,直接上图
代码已执行。接下来回到Navicat,看看数据是否已经写入。我们用图片来说话。
至此,我们已经完成了数据采集和存储操作,但似乎还缺少什么?
也就是我们需要写一个页面来展示它,因为爬取和写数据只允许在node环境下进行。所以我们还要创建一个web服务来显示页面,坚持下去很快就OK了,加油。
6、启动服务
既然我们要创建一个 web 服务,让我们开始编写 server.js 的内容
服务器服务
// server.js文件
const express = require('express');const path = require('path');const query = require('../src/db');const app = express();
// 设置模板引擎app.set('view engine', 'html');app.set('views', path.join(__dirname, 'views'));app.engine('html', require('ejs').__express);
// 首页路由app.get('/', async (req, res) => { // 通过SQL查询语句拿到库里的movies表数据 const movies = await query('SELECT * FROM movies'); // 渲染首页模板并把movies数据传过去 res.render('index', { movies });});// 监听localhost:9000端口app.listen(9000);
写完服务端服务,我们再来看看 index.html 模板。这是最后一件事。写完,就大功告成了。
7、渲染数据
// index.html
热映的电影 正在热映的电影 %=movie.image% <p class="score">评分: </a>
</p>
通过模板引擎遍历movies数组,然后渲染
现在,看看最终效果
和你一起来到这里是缘分。我很高兴经历了这么长时间的文章 学习。每个人都应该对爬行动物的知识有一个很好的了解。
对了,这里是代码地址:爬虫研究/电影
为了您的方便,敲敲敲。
感谢阅读,886。
c爬虫抓取网页数据(优采云云采集网络爬虫软件如何用c#实现网站数据的抓取?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-02-04 18:34
优采云云端采集网络爬虫软件如何使用c#实现网站数据抓取?如何使用c#实现网站数据抓取?首先需要明确:网站的任何页面,无论是php、jsp、aspx等动态页面还是后台程序生成的静态页面,都可以在浏览器。所以当你想开发一个data采集程序时,你首先要了解你要采集的网站的首页结构(HTML)。一旦您熟悉了 网站 中您想要 采集 数据的 HTML 源文件的内容,程序的其余部分就很容易了。因为C#对网站数据采集的原理是“把你要的页面的HTML文件下载到采集,
这样,整个采集的工作就会在一个段落中完成。先说怎么抓取吧:1、抓取通用内容需要三个类:WebRequest、WebResponse、StreamReader 需要的命名空间:System.Net、System.IO 核心代码:WebRequest 创建是静态方法,参数是待抓取网页的网址;编码指定编码。Encoding中有ASCII、UTF32、UTF8等全局编码,但是没有gb2312的encoding属性,所以我们使用GetEncoding来获取gb2312编码。优采云云采集网络爬虫软件2、抓取图片或其他二进制文件(如文件) 需要四个类:WebRequest、WebResponse、Stream、FileStream 需要的命名空间:System .Net、System .IO核心代码:使用Stream读取3、 抓取网页内容POST方法抓取网页时,有时需要通过Post向服务器发送一些数据,在网页抓取程序中添加如下代码,实现向服务器发送用户名和密码:优采云Cloud采集Web爬虫软件4、ASP.NET爬取网页内容-防止爬取时重定向 抓取网页时,成功登录服务器应用系统后,应用系统可能会重定向网页通过 Response.Redirect。如果这个重定向不需要响应,那么我们就不需要读取 reader.ReadToEnd() Response.Write out ,就是这样。实现post用户名和密码到服务器:优采云云采集网络爬虫软件4、ASP.NET爬取网页内容-防止爬取时重定向抓取网页时,登录成功后在服务器应用系统中,应用系统可以通过Response.Redirect重定向网页。如果这个重定向不需要响应,那么我们就不需要读取 reader.ReadToEnd() Response.Write out ,就是这样。实现post用户名和密码到服务器:优采云云采集网络爬虫软件4、ASP.NET爬取网页内容-防止爬取时重定向抓取网页时,登录成功后在服务器应用系统中,应用系统可以通过Response.Redirect重定向网页。如果这个重定向不需要响应,那么我们就不需要读取 reader.ReadToEnd() Response.Write out ,就是这样。
5、ASP.NET爬取网页内容-维护登录状态使用Post数据成功登录服务器应用系统后,需要登录的页面就可以获取到了,那么我们可能需要维护登录多个请求之间的状态。优采云云采集Web爬虫软件首先,我们需要使用HttpWebRequest,而不是WebRequest。与WebRequest相比,改代码为: 注意:HttpWebRequest.Create返回的类型还是WebRequest,所以需要进行转换。二、使用CookieContainer。这样,requests和request2之间就使用了同一个Session。如果请求已登录,则 request2 也处于已登录状态。最后,如何在不同页面之间使用同一个CookieContainer。要在不同页面之间使用相同的 CookieContainer,只将 CookieContainer 添加到 Session。优采云云采集网络爬虫软件6、抓取需要登录的网站,因为需要登录的是网站,所以是用户登录时需要分析浏览器的方向。服务器发送的POST请求。1.安装httpwatch 2.使用IE浏览器进入网站的登录页面3.打开httpwatch的记录开始追踪4.输入账号密码,确认登录抓包流程:重点关注POST请求中的Url和postdata,以及服务器返回的cookie采集教程:优采云云采集网络爬虫软件顺奇网企业资料采集 114 黄页企业资料采集 @采集网络爬虫软件6、抓取需要登录的网站,因为需要登录的是网站,所以需要分析浏览器的方向用户登录。服务器发送的 POST 请求。1.安装httpwatch 2.使用IE浏览器进入网站的登录页面3.打开httpwatch的记录开始追踪4.输入账号密码,确认登录抓包流程:重点关注POST请求中的Url和postdata,以及服务器返回的cookie采集教程:优采云云采集网络爬虫软件顺奇网企业资料采集 114 黄页企业资料采集 @采集网络爬虫软件6、抓取需要登录的网站,因为需要登录的是网站,所以需要分析浏览器的方向用户登录。服务器发送的 POST 请求。1.安装httpwatch 2.使用IE浏览器进入网站的登录页面3.打开httpwatch的记录开始追踪4.输入账号密码,确认登录抓包流程:重点关注POST请求中的Url和postdata,以及服务器返回的cookie采集教程:优采云云采集网络爬虫软件顺奇网企业资料采集 114 黄页企业资料采集 需要登录,因为需要登录的是网站,所以需要分析用户登录时浏览器的方向。服务器发送的POST请求。1.安装httpwatch 2.用IE浏览器进入网站的登录页面3.打开httpwatch的记录开始追踪4.输入账号密码,确认登录抓包流程:重点关注POST请求中的Url和postdata,以及服务器返回的cookie采集教程:优采云云采集网络爬虫软件顺奇网企业资料采集 114 黄页企业资料采集 需要登录,因为需要登录的是网站,所以需要分析用户登录时浏览器的方向。服务器发送的POST请求。1.安装httpwatch 2.使用IE浏览器进入网站的登录页面3.打开httpwatch的记录开始追踪4.输入账号密码,确认登录抓包流程:重点关注POST请求中的Url和postdata,以及服务器返回的cookie采集教程:优采云云采集网络爬虫软件顺奇网企业资料采集 114 黄页企业资料采集
1、简单易用,任何人都可以使用:无需技术背景,只需了解互联网采集。全程可视化流程,点击鼠标完成操作,2分钟快速上手。2、功能强大,任何网站都可以使用:点击、登录、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据网页,都可以通过简单的设置进行采集。3、在采集 中,也可以关闭。配置好采集任务后,可以关机,侧边执行任务。庞大的采集集群24*7不间断运行,不用担心IP被封或者网络中断。4、功能免费+增值服务,可以按需选择。免费版具有满足用户基本采集需求的所有功能。同时,设置一些增值服务(如私有制),以满足高端付费企业用户的需求。 查看全部
c爬虫抓取网页数据(优采云云采集网络爬虫软件如何用c#实现网站数据的抓取?)
优采云云端采集网络爬虫软件如何使用c#实现网站数据抓取?如何使用c#实现网站数据抓取?首先需要明确:网站的任何页面,无论是php、jsp、aspx等动态页面还是后台程序生成的静态页面,都可以在浏览器。所以当你想开发一个data采集程序时,你首先要了解你要采集的网站的首页结构(HTML)。一旦您熟悉了 网站 中您想要 采集 数据的 HTML 源文件的内容,程序的其余部分就很容易了。因为C#对网站数据采集的原理是“把你要的页面的HTML文件下载到采集,
这样,整个采集的工作就会在一个段落中完成。先说怎么抓取吧:1、抓取通用内容需要三个类:WebRequest、WebResponse、StreamReader 需要的命名空间:System.Net、System.IO 核心代码:WebRequest 创建是静态方法,参数是待抓取网页的网址;编码指定编码。Encoding中有ASCII、UTF32、UTF8等全局编码,但是没有gb2312的encoding属性,所以我们使用GetEncoding来获取gb2312编码。优采云云采集网络爬虫软件2、抓取图片或其他二进制文件(如文件) 需要四个类:WebRequest、WebResponse、Stream、FileStream 需要的命名空间:System .Net、System .IO核心代码:使用Stream读取3、 抓取网页内容POST方法抓取网页时,有时需要通过Post向服务器发送一些数据,在网页抓取程序中添加如下代码,实现向服务器发送用户名和密码:优采云Cloud采集Web爬虫软件4、ASP.NET爬取网页内容-防止爬取时重定向 抓取网页时,成功登录服务器应用系统后,应用系统可能会重定向网页通过 Response.Redirect。如果这个重定向不需要响应,那么我们就不需要读取 reader.ReadToEnd() Response.Write out ,就是这样。实现post用户名和密码到服务器:优采云云采集网络爬虫软件4、ASP.NET爬取网页内容-防止爬取时重定向抓取网页时,登录成功后在服务器应用系统中,应用系统可以通过Response.Redirect重定向网页。如果这个重定向不需要响应,那么我们就不需要读取 reader.ReadToEnd() Response.Write out ,就是这样。实现post用户名和密码到服务器:优采云云采集网络爬虫软件4、ASP.NET爬取网页内容-防止爬取时重定向抓取网页时,登录成功后在服务器应用系统中,应用系统可以通过Response.Redirect重定向网页。如果这个重定向不需要响应,那么我们就不需要读取 reader.ReadToEnd() Response.Write out ,就是这样。
5、ASP.NET爬取网页内容-维护登录状态使用Post数据成功登录服务器应用系统后,需要登录的页面就可以获取到了,那么我们可能需要维护登录多个请求之间的状态。优采云云采集Web爬虫软件首先,我们需要使用HttpWebRequest,而不是WebRequest。与WebRequest相比,改代码为: 注意:HttpWebRequest.Create返回的类型还是WebRequest,所以需要进行转换。二、使用CookieContainer。这样,requests和request2之间就使用了同一个Session。如果请求已登录,则 request2 也处于已登录状态。最后,如何在不同页面之间使用同一个CookieContainer。要在不同页面之间使用相同的 CookieContainer,只将 CookieContainer 添加到 Session。优采云云采集网络爬虫软件6、抓取需要登录的网站,因为需要登录的是网站,所以是用户登录时需要分析浏览器的方向。服务器发送的POST请求。1.安装httpwatch 2.使用IE浏览器进入网站的登录页面3.打开httpwatch的记录开始追踪4.输入账号密码,确认登录抓包流程:重点关注POST请求中的Url和postdata,以及服务器返回的cookie采集教程:优采云云采集网络爬虫软件顺奇网企业资料采集 114 黄页企业资料采集 @采集网络爬虫软件6、抓取需要登录的网站,因为需要登录的是网站,所以需要分析浏览器的方向用户登录。服务器发送的 POST 请求。1.安装httpwatch 2.使用IE浏览器进入网站的登录页面3.打开httpwatch的记录开始追踪4.输入账号密码,确认登录抓包流程:重点关注POST请求中的Url和postdata,以及服务器返回的cookie采集教程:优采云云采集网络爬虫软件顺奇网企业资料采集 114 黄页企业资料采集 @采集网络爬虫软件6、抓取需要登录的网站,因为需要登录的是网站,所以需要分析浏览器的方向用户登录。服务器发送的 POST 请求。1.安装httpwatch 2.使用IE浏览器进入网站的登录页面3.打开httpwatch的记录开始追踪4.输入账号密码,确认登录抓包流程:重点关注POST请求中的Url和postdata,以及服务器返回的cookie采集教程:优采云云采集网络爬虫软件顺奇网企业资料采集 114 黄页企业资料采集 需要登录,因为需要登录的是网站,所以需要分析用户登录时浏览器的方向。服务器发送的POST请求。1.安装httpwatch 2.用IE浏览器进入网站的登录页面3.打开httpwatch的记录开始追踪4.输入账号密码,确认登录抓包流程:重点关注POST请求中的Url和postdata,以及服务器返回的cookie采集教程:优采云云采集网络爬虫软件顺奇网企业资料采集 114 黄页企业资料采集 需要登录,因为需要登录的是网站,所以需要分析用户登录时浏览器的方向。服务器发送的POST请求。1.安装httpwatch 2.使用IE浏览器进入网站的登录页面3.打开httpwatch的记录开始追踪4.输入账号密码,确认登录抓包流程:重点关注POST请求中的Url和postdata,以及服务器返回的cookie采集教程:优采云云采集网络爬虫软件顺奇网企业资料采集 114 黄页企业资料采集
1、简单易用,任何人都可以使用:无需技术背景,只需了解互联网采集。全程可视化流程,点击鼠标完成操作,2分钟快速上手。2、功能强大,任何网站都可以使用:点击、登录、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据网页,都可以通过简单的设置进行采集。3、在采集 中,也可以关闭。配置好采集任务后,可以关机,侧边执行任务。庞大的采集集群24*7不间断运行,不用担心IP被封或者网络中断。4、功能免费+增值服务,可以按需选择。免费版具有满足用户基本采集需求的所有功能。同时,设置一些增值服务(如私有制),以满足高端付费企业用户的需求。
c爬虫抓取网页数据(爬虫普通爬虫:抓取数据的过程的分类)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-02-04 12:22
爬虫概述 什么是爬虫?
编写程序,让它模拟浏览器上网,然后上网抓取数据的过程
爬行动物的分类
1.普通爬行动物:
抓取整个页面的源内容
2.关注爬虫:
获取页面的部分内容
3.增量爬虫:
它可以检测到 网站 中的数据更新。在 网站 中获取最新更新的数据。
防爬机制: 防爬策略:
爬虫利用相应的策略和技术手段破解门户网站的反爬虫手段,从而爬取对应的数据。
爬行动物的合法性:
爬虫本身不受法律禁止(中立)
爬取数据违法风险的表现:
1.爬虫干扰了访问者网站的正常运行。
2.爬虫爬取某些类型的受法律保护的数据或信息。
如何规避违法风险:
1.严格遵守网站设置的robots协议
2.在避免爬虫措施的同时,需要优化自己的代码,避免干扰被访问网站的正常运行
3.在使用和传播捕获的信息时,应对捕获的内容进行审核。如发现属于用户的个人信息、隐私或其他商业秘密,应及时删除并停止使用
UA反爬机制是什么,如何破解?如何获取动态加载页面的数据:
如何获取动态加载页面的数据:<br /> 通过抓包工具全局搜索找到动态加载数据对应的数据包,数据包中提取该请求的url,
一.Anaxonda安装1.双击Anaconda3-5.0.0-Windows-x86_64.exe文件
2.下一个
1.打开cmd窗口,输入jupyter notebook命令,
如果没有找不到命令并且没有报错,则安装成功!
2.在开始菜单中显示
3.启动 ① 默认端口启动
在终端中输入以下命令:
jupyter notebook
执行命令后,终端会显示一系列notebook服务器信息,浏览器会自动启动Jupyter Notebook。
启动过程中,终端显示如下:
$ jupyter notebook
[I 08:58:24.417 NotebookApp] Serving notebooks from local directory: /Users/catherine
[I 08:58:24.417 NotebookApp] 0 active kernels
[I 08:58:24.417 NotebookApp] The Jupyter Notebook is running at: http://localhost:8888/
[I 08:58:24.417 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
默认情况下,浏览器地址栏会显示::8888。其中,“localhost”是指本机,“8888”是端口号。
网址
如果同时启动多个 Jupyter Notebook,由于默认端口“8888”被占用,地址栏中的数字将从“8888”开始,每次启动另一个 Jupyter Notebook 时数字会增加 1,例如如“8889”、“8890”、“……
② 启动指定端口
如果要自定义启动 Jupyter Notebook 的端口号,可以在终端输入以下命令:
jupyter notebook --port
在,”
"为自定义端口号,直接以数字的形式写在命令中,数字两边不带尖括号""。例如:jupyter notebook --port 9999,即启动Jupyter Notebook端口号为“9999”的服务器。
③ 不打开浏览器启动服务器
如果您只想启动 Jupyter Notebook 服务器但不想立即进入主页,则无需立即启动浏览器。在终端输入:
jupyter notebook --no-browser
此时终端会显示激活服务器的信息,激活服务器后会显示打开浏览器页面的链接。当您需要启动浏览器页面时,只需复制链接,将其粘贴到浏览器的地址栏中,然后按 Enter 键即可转到您的 Jupyter Notebook 页面。
示例图中,由于我在完成以上内容的同时同时启动了多个Jupyter Notebooks,显示我的“8888”端口号被占用,最后“8889”分配给了我。
2. 快捷方式 向上插入单元格:a 向下插入单元格:b 删除单元格:x 将代码切换为 markdown:m 将 markdown 切换为代码:y 运行单元格:shift+enter 查看帮助文档:shift+ Tab 自动提示:标签
3. 魔法指令
运行外部python源文件:%run xxx.py 计算一条语句的运行时间:%time statement 计算一条语句的平均运行时间:%timeit statement 测试多行代码的平均运行时间:
%%时间
声明1
声明2
声明3 查看全部
c爬虫抓取网页数据(爬虫普通爬虫:抓取数据的过程的分类)
爬虫概述 什么是爬虫?
编写程序,让它模拟浏览器上网,然后上网抓取数据的过程
爬行动物的分类
1.普通爬行动物:
抓取整个页面的源内容
2.关注爬虫:
获取页面的部分内容
3.增量爬虫:
它可以检测到 网站 中的数据更新。在 网站 中获取最新更新的数据。
防爬机制: 防爬策略:
爬虫利用相应的策略和技术手段破解门户网站的反爬虫手段,从而爬取对应的数据。
爬行动物的合法性:
爬虫本身不受法律禁止(中立)
爬取数据违法风险的表现:
1.爬虫干扰了访问者网站的正常运行。
2.爬虫爬取某些类型的受法律保护的数据或信息。
如何规避违法风险:
1.严格遵守网站设置的robots协议
2.在避免爬虫措施的同时,需要优化自己的代码,避免干扰被访问网站的正常运行
3.在使用和传播捕获的信息时,应对捕获的内容进行审核。如发现属于用户的个人信息、隐私或其他商业秘密,应及时删除并停止使用
UA反爬机制是什么,如何破解?如何获取动态加载页面的数据:
如何获取动态加载页面的数据:<br /> 通过抓包工具全局搜索找到动态加载数据对应的数据包,数据包中提取该请求的url,
一.Anaxonda安装1.双击Anaconda3-5.0.0-Windows-x86_64.exe文件

2.下一个

1.打开cmd窗口,输入jupyter notebook命令,
如果没有找不到命令并且没有报错,则安装成功!
2.在开始菜单中显示
3.启动 ① 默认端口启动
在终端中输入以下命令:
jupyter notebook
执行命令后,终端会显示一系列notebook服务器信息,浏览器会自动启动Jupyter Notebook。
启动过程中,终端显示如下:
$ jupyter notebook
[I 08:58:24.417 NotebookApp] Serving notebooks from local directory: /Users/catherine
[I 08:58:24.417 NotebookApp] 0 active kernels
[I 08:58:24.417 NotebookApp] The Jupyter Notebook is running at: http://localhost:8888/
[I 08:58:24.417 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
默认情况下,浏览器地址栏会显示::8888。其中,“localhost”是指本机,“8888”是端口号。
网址
如果同时启动多个 Jupyter Notebook,由于默认端口“8888”被占用,地址栏中的数字将从“8888”开始,每次启动另一个 Jupyter Notebook 时数字会增加 1,例如如“8889”、“8890”、“……
② 启动指定端口
如果要自定义启动 Jupyter Notebook 的端口号,可以在终端输入以下命令:
jupyter notebook --port
在,”
"为自定义端口号,直接以数字的形式写在命令中,数字两边不带尖括号""。例如:jupyter notebook --port 9999,即启动Jupyter Notebook端口号为“9999”的服务器。
③ 不打开浏览器启动服务器
如果您只想启动 Jupyter Notebook 服务器但不想立即进入主页,则无需立即启动浏览器。在终端输入:
jupyter notebook --no-browser
此时终端会显示激活服务器的信息,激活服务器后会显示打开浏览器页面的链接。当您需要启动浏览器页面时,只需复制链接,将其粘贴到浏览器的地址栏中,然后按 Enter 键即可转到您的 Jupyter Notebook 页面。
示例图中,由于我在完成以上内容的同时同时启动了多个Jupyter Notebooks,显示我的“8888”端口号被占用,最后“8889”分配给了我。
2. 快捷方式 向上插入单元格:a 向下插入单元格:b 删除单元格:x 将代码切换为 markdown:m 将 markdown 切换为代码:y 运行单元格:shift+enter 查看帮助文档:shift+ Tab 自动提示:标签
3. 魔法指令
运行外部python源文件:%run xxx.py 计算一条语句的运行时间:%time statement 计算一条语句的平均运行时间:%timeit statement 测试多行代码的平均运行时间:
%%时间
声明1
声明2
声明3
c爬虫抓取网页数据(种子网站存储7万多条记录()时间送达!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-04 12:16
关键时刻,第一时间发货!
节前的一次误操作,清空了mysql中的记录表和电影表。显然,我没有做任何mysql备份。于是,我干脆清空了所有表数据,一夜之间又回到了解放前……
在之前的版本中,记录表存储了7万多条记录,爬取了4万多条记录,但是可以明显的发现,爬取的数据越多,卡机越多。又报错了,是关于JDBC的,又一次机器卡住了。
经过仔细考虑,之前版本的爬虫程序和数据库的读写次数过于频繁,存在以下问题:
3.存储电影详情页记录和短评数据全部解析后立即存入数据库。
显然,上面的方法一看就效率低下,所以今天下午修改了相关代码,部分实现批量插入,尽可能减少与数据库的交互,从而降低时间和空间成本。
既然出现了问题,我们再来看看这个版本,最后发现问题的原因是种子URL没有存储在mysql的记录表中,所以是在DoubanCrawler类中。
执行 stmt.executeUpdate(sql) > 0 返回值 0,所以爬取为 0 的记录不会从数据库中读取,最后会在 while 循环中爬取种子 网站。
解决方案:由于种子网站没有存储在记录中,那么对种子网站进行特殊处理,将if的判断条件改为if(stmt.executeUpdate(sql)>0 || frontPage.equals(url)),这样对于种子网站,即使没有成功的更新操作,仍然可以进入读取爬取到0的数据库的操作。
对于第一个问题,使用批量插入操作
具体实现如下:
1. 通过正则匹配,找到符合条件的链接,加入nextLinkList集合
2.遍历后,将数据存入数据库
3. 在批处理操作中,使用了 addBatch() 方法和 executeBatch() 方法。注意需要添加 conn.setAutoCommit(false); mit() 表示手动提交。
第二题,一次查询多条记录
实现思路:一次只改一条记录,一次查询10条记录,将这10条记录存入list集合中,将原来的String类型url改为list类型urlList并传入 查看全部
c爬虫抓取网页数据(种子网站存储7万多条记录()时间送达!)
关键时刻,第一时间发货!
节前的一次误操作,清空了mysql中的记录表和电影表。显然,我没有做任何mysql备份。于是,我干脆清空了所有表数据,一夜之间又回到了解放前……
在之前的版本中,记录表存储了7万多条记录,爬取了4万多条记录,但是可以明显的发现,爬取的数据越多,卡机越多。又报错了,是关于JDBC的,又一次机器卡住了。
经过仔细考虑,之前版本的爬虫程序和数据库的读写次数过于频繁,存在以下问题:
3.存储电影详情页记录和短评数据全部解析后立即存入数据库。
显然,上面的方法一看就效率低下,所以今天下午修改了相关代码,部分实现批量插入,尽可能减少与数据库的交互,从而降低时间和空间成本。
既然出现了问题,我们再来看看这个版本,最后发现问题的原因是种子URL没有存储在mysql的记录表中,所以是在DoubanCrawler类中。
执行 stmt.executeUpdate(sql) > 0 返回值 0,所以爬取为 0 的记录不会从数据库中读取,最后会在 while 循环中爬取种子 网站。
解决方案:由于种子网站没有存储在记录中,那么对种子网站进行特殊处理,将if的判断条件改为if(stmt.executeUpdate(sql)>0 || frontPage.equals(url)),这样对于种子网站,即使没有成功的更新操作,仍然可以进入读取爬取到0的数据库的操作。
对于第一个问题,使用批量插入操作
具体实现如下:



1. 通过正则匹配,找到符合条件的链接,加入nextLinkList集合
2.遍历后,将数据存入数据库
3. 在批处理操作中,使用了 addBatch() 方法和 executeBatch() 方法。注意需要添加 conn.setAutoCommit(false); mit() 表示手动提交。
第二题,一次查询多条记录
实现思路:一次只改一条记录,一次查询10条记录,将这10条记录存入list集合中,将原来的String类型url改为list类型urlList并传入
c爬虫抓取网页数据( 如何替代人工从网页中找到数据并复制粘贴到excel中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-02-03 20:02
如何替代人工从网页中找到数据并复制粘贴到excel中)
为什么要学习网络爬虫
它可以代替人工从网页中查找数据并将其复制粘贴到excel中。这种重复性的工作,不仅浪费时间,而且一不留神,容易出错,解决了这些无法自动化、无法实时获取的公共数据的应用价值,我们可以借助KYC框架来了解,了解你的公司(了解您的公司),了解您的竞争对手(了解您的竞争对手),了解您的客户(了解您的客户)。这是通过理解和执行对公共数据的简单描述性分析可以带来的价值。进一步,通过机器学习和统计算法分析,可以帮助企业做4Ps(产品)、价格(价格)、渠道(地点)促销(promotion))
网络爬虫的基本协议
robots协议
python爬虫的流程
主要可以分为三个部分:1.获取网页;2.解析网页(提取数据);3.存储数据;
1.获取网页就是向URL发送请求,会返回整个网页的数据
2.解析一个网页就是从整个网页的数据中提取出想要的数据
3.存数据就是存数据
三道工序的技术实现
1.获取网页
获取网页的基本技术:request、urllib和selenium(模拟浏览器)
获取网页先进技术:多进程多线程爬取、登录爬取、破IP封禁、服务器爬取
2.解析网页
解析网页的基本技术:re正则表达式、beautifulsoup和lxml
网页解析高级技术:解决中文乱码
3.存储的数据
数据存储的基本技术:存txt文件和存csv文件
存储数据的先进技术:存储在MySQL数据库中和存储在mongodb数据库中 查看全部
c爬虫抓取网页数据(
如何替代人工从网页中找到数据并复制粘贴到excel中)
为什么要学习网络爬虫
它可以代替人工从网页中查找数据并将其复制粘贴到excel中。这种重复性的工作,不仅浪费时间,而且一不留神,容易出错,解决了这些无法自动化、无法实时获取的公共数据的应用价值,我们可以借助KYC框架来了解,了解你的公司(了解您的公司),了解您的竞争对手(了解您的竞争对手),了解您的客户(了解您的客户)。这是通过理解和执行对公共数据的简单描述性分析可以带来的价值。进一步,通过机器学习和统计算法分析,可以帮助企业做4Ps(产品)、价格(价格)、渠道(地点)促销(promotion))
网络爬虫的基本协议
robots协议
python爬虫的流程
主要可以分为三个部分:1.获取网页;2.解析网页(提取数据);3.存储数据;
1.获取网页就是向URL发送请求,会返回整个网页的数据
2.解析一个网页就是从整个网页的数据中提取出想要的数据
3.存数据就是存数据
三道工序的技术实现
1.获取网页
获取网页的基本技术:request、urllib和selenium(模拟浏览器)
获取网页先进技术:多进程多线程爬取、登录爬取、破IP封禁、服务器爬取
2.解析网页
解析网页的基本技术:re正则表达式、beautifulsoup和lxml
网页解析高级技术:解决中文乱码
3.存储的数据
数据存储的基本技术:存txt文件和存csv文件
存储数据的先进技术:存储在MySQL数据库中和存储在mongodb数据库中
c爬虫抓取网页数据(最简单的过程可以用如下代码表示:importurllib2request=urllib2.Request())
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-01 14:30
概念
爬虫是网页的采集。
通常,在获取的网页中存在到其他网页的路径,称为超链接。然后,通过这样的路径可以获取更多的其他网页,就像蜘蛛在网上爬行一样,所以俗称爬虫。
爬虫的工作原理类似于浏览器浏览网页。它是一种请求/返回模式,即客户端向服务器发出请求访问某个页面(请求),服务器返回客户端请求的内容(响应)。URL是代表互联网上每个文件的唯一标志,也就是我们所说的网址。客户端通过 URL 向特定网页发送请求。最简单的过程可以用以下代码表示:
import urllib2request = urllib2.Request("")#构造请求请求 response = urllib2.urlopen(request)#发送请求并得到响应打印 response.read()#使用read()来获取返回的内容并打印出Http协议的POST和GET
对于简单的静态网页,这样就足够了,可以顺利获取html文本。
但对于这个日新月异的互联网来说,这东西根本就不够用。首先要考虑的是动态网页,它需要我们动态地向它传递参数。例如,在登录时,我们需要提交用户名和密码等表单信息,以便我们获取更多信息。这需要我们在构造请求时向服务器传递更多信息。
说到传递参数,就不得不说一下HTTP协议与服务器交互的方式了。HTTP协议有六种请求方法,分别是get、head、put、delete、post、options,其中最基本的四种是GET、POST和PUT、DELET。我们知道 URL 地址是用来描述网络上的资源的。HTTP中的GET、POST、PUT、DELETE对应了查询、修改、添加、删除这四种操作。对于爬虫中的数据传输,使用 POST 和 GET。我们来看看GET和POST的区别:
1.GET提交的数据会放在URL后面,URL和传输数据用?分隔,参数用&连接
2.GET方法提交的数据大小是有限制的(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制。
3.GET方法需要使用Request.QueryString获取变量的值,POST方法使用Request.Form获取变量的值。
4.GET方式提交数据会带来安全问题。例如,通过 GET 方法提交数据时,用户名和密码会出现在 URL 上。如果页面可以被缓存或者其他人可以访问机器,则可以从访问历史记录中获取用户的账号和密码。下面介绍两种提交方法。
POST方法导入urllib2值 ={“username”:“”,“password”:“XXXX”}data = urllib.urlencode(values)url=":///my/mycsdn"request = urllib2.@ >请求(url,data)response = urllib2.urlopen(request)print response.read()
可以看出,该方法首先将要提交的信息构造成一个数据,然后连同URL一起构造请求对象。
GET方法 import urllib2 import urllibvalues ={"username":"","password":"XXXX"}data = urllib.urlencode(values)url = ""geturl = url +"?"+ datarequest = urllib2. Request(geturl)response = urllib2.urlopen(request)print response.read()
可以看到GET方式是直接在URL后面加参数
设置标题
即便如此,还是有一些网站不被允许访问,会出现识别问题。这时候,为了真正的伪装成浏览器,我们还需要在构造请求的时候设置一些Headers属性。打开浏览器查看网页标题,可以看到如下内容:
我们可以根据自己的需要选择某些属性来构造请求,比如下面使用了user-agent和referer。
headers ={'User-Agent':'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)','Referer':''}request = urllib2.Request (网址,标题=标题)
User-agent全称为用户代理,是向网站提供所用浏览器的类型和版本、操作系统、浏览器内核等信息的标志,是伪装成浏览器。真正的浏览器提供这个属性是为了方便网站为用户提供更好的展示和体验。Referer 显示当前页面来自哪个页面。可以用来防止防盗链。服务器将识别 headers 中的 referer 是否是它自己。如果没有,某些服务器将不会响应。
有了以上的基础知识,就可以开始了解和实现真正的爬虫了。 查看全部
c爬虫抓取网页数据(最简单的过程可以用如下代码表示:importurllib2request=urllib2.Request())
概念
爬虫是网页的采集。
通常,在获取的网页中存在到其他网页的路径,称为超链接。然后,通过这样的路径可以获取更多的其他网页,就像蜘蛛在网上爬行一样,所以俗称爬虫。
爬虫的工作原理类似于浏览器浏览网页。它是一种请求/返回模式,即客户端向服务器发出请求访问某个页面(请求),服务器返回客户端请求的内容(响应)。URL是代表互联网上每个文件的唯一标志,也就是我们所说的网址。客户端通过 URL 向特定网页发送请求。最简单的过程可以用以下代码表示:
import urllib2request = urllib2.Request("")#构造请求请求 response = urllib2.urlopen(request)#发送请求并得到响应打印 response.read()#使用read()来获取返回的内容并打印出Http协议的POST和GET
对于简单的静态网页,这样就足够了,可以顺利获取html文本。
但对于这个日新月异的互联网来说,这东西根本就不够用。首先要考虑的是动态网页,它需要我们动态地向它传递参数。例如,在登录时,我们需要提交用户名和密码等表单信息,以便我们获取更多信息。这需要我们在构造请求时向服务器传递更多信息。
说到传递参数,就不得不说一下HTTP协议与服务器交互的方式了。HTTP协议有六种请求方法,分别是get、head、put、delete、post、options,其中最基本的四种是GET、POST和PUT、DELET。我们知道 URL 地址是用来描述网络上的资源的。HTTP中的GET、POST、PUT、DELETE对应了查询、修改、添加、删除这四种操作。对于爬虫中的数据传输,使用 POST 和 GET。我们来看看GET和POST的区别:
1.GET提交的数据会放在URL后面,URL和传输数据用?分隔,参数用&连接
2.GET方法提交的数据大小是有限制的(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制。
3.GET方法需要使用Request.QueryString获取变量的值,POST方法使用Request.Form获取变量的值。
4.GET方式提交数据会带来安全问题。例如,通过 GET 方法提交数据时,用户名和密码会出现在 URL 上。如果页面可以被缓存或者其他人可以访问机器,则可以从访问历史记录中获取用户的账号和密码。下面介绍两种提交方法。
POST方法导入urllib2值 ={“username”:“”,“password”:“XXXX”}data = urllib.urlencode(values)url=":///my/mycsdn"request = urllib2.@ >请求(url,data)response = urllib2.urlopen(request)print response.read()
可以看出,该方法首先将要提交的信息构造成一个数据,然后连同URL一起构造请求对象。
GET方法 import urllib2 import urllibvalues ={"username":"","password":"XXXX"}data = urllib.urlencode(values)url = ""geturl = url +"?"+ datarequest = urllib2. Request(geturl)response = urllib2.urlopen(request)print response.read()
可以看到GET方式是直接在URL后面加参数
设置标题
即便如此,还是有一些网站不被允许访问,会出现识别问题。这时候,为了真正的伪装成浏览器,我们还需要在构造请求的时候设置一些Headers属性。打开浏览器查看网页标题,可以看到如下内容:
我们可以根据自己的需要选择某些属性来构造请求,比如下面使用了user-agent和referer。
headers ={'User-Agent':'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)','Referer':''}request = urllib2.Request (网址,标题=标题)
User-agent全称为用户代理,是向网站提供所用浏览器的类型和版本、操作系统、浏览器内核等信息的标志,是伪装成浏览器。真正的浏览器提供这个属性是为了方便网站为用户提供更好的展示和体验。Referer 显示当前页面来自哪个页面。可以用来防止防盗链。服务器将识别 headers 中的 referer 是否是它自己。如果没有,某些服务器将不会响应。
有了以上的基础知识,就可以开始了解和实现真正的爬虫了。
c爬虫抓取网页数据(主流爬虫框架简介-1.地址 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-01 12:27
)
一、前言
目前市面上的爬虫框架比较多,有不同语言、不同类型的爬虫框架。然而,在开展预研时,很难选择哪一项
框架是许多开发人员特别头疼的问题。
本文主要总结了市面上主流开发语言中的主流爬虫框架,以及爬虫框架的优缺点;希望对大家选择合适的爬虫框架有所帮助。
二、主流语言爬虫框架列表 常用爬虫框架列表 JAVA PYTHON PHP C# C/C++
阿帕奇纳奇2
刮擦
php蜘蛛
点网蜘蛛
开源搜索引擎
网络魔术
克劳利
豆包
网络爬虫
蛛网
赫里特里克斯
波西亚
PHP抓取
智能蜘蛛
阿普顿
网络采集器
PySpider
php硒
阿博特
袋熊
爬虫4j
抓
网络
蜘蛛
蜘蛛侠
可乐
锐角
拉尔宾
SeimiCrawler
蟒蛇硒
HtmlAgilityPack
汤
查询
java硒
htmlunit
三、主流爬虫框架介绍1.Java爬虫框架Apache Nutch2
地址:
Nutch 是一个搜索引擎的开源 Java 实现。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫。
Nutch 致力于让每个人都能轻松、廉价地配置世界级的网络搜索引擎。为了实现这一雄心勃勃的目标,Nutch 必须能够:
* 每月获取数十亿网页
* 维护这些页面的索引
* 每秒数以千计的索引文件搜索
简而言之,Nutch 支持分发。您可以通过配置网站地址、规则和采集的深度(通用爬虫或全网爬虫)对网站执行采集,并提供完整的-文本搜索功能,可以对来自采集的海量数据进行全文搜索;如果要完成站点所有内容的采集,而不关心采集和解析准确性(不是特定页面来满足特定字段内容采集的需要) ,建议您使用Apache Nutch。如果要为站点的指定内容版块指定字段采集,建议使用垂直爬虫更加灵活。
webmgaic(推荐)
地址:
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
特征:
快速入门的简单 API
模块化结构,易于扩展
提供多线程和分布式支持
赫里特里克斯
地址:
Heritrix是java开发的开源网络爬虫,用户可以使用它从互联网上爬取想要的资源。它最好的地方在于其良好的扩展性,方便用户实现自己的爬取逻辑。
网络采集器
地址:
WebCollector是一个无需配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需少量代码即可实现强大的爬虫。WebCollector-Hadoop 是支持分布式爬取的 WebCollector 的 Hadoop 版本。
爬虫4j
地址::
crawler4j 是一个基于 Java 的轻量级独立开源爬虫框架,最大的特点之一就是简单。此外,它还支持多线程,支持代理,并且可以过滤重复的URL
基本上,从将jar加载到项目中,只需修改示例代码即可简单实现爬虫的所有功能,所有这些动作不超过半小时。
蜘蛛侠
地址:
Spiderman 是一个 Java 开源 Web 数据提取工具。它能够采集指定的网页并从这些页面中提取有用的数据。Spiderman主要使用XPath、正则表达式、表达式引擎等技术来实现数据提取。
SeimiCrawler
地址:
一个敏捷、独立部署的分布式Java爬虫框架
SeimiCrawler 是一个强大、高效、敏捷的框架,支持分布式爬虫开发。希望能够最大程度的降低新手开发高可用性能好的爬虫系统的门槛,提高爬虫系统开发的开发效率。在 SeimiCrawler 的世界里,大部分人只关心编写爬虫的业务逻辑,剩下的交给 Seimi 来处理。在设计思路上,SeimiCrawler 很大程度上受到了 Python 的爬虫框架 Scrapy 的启发,同时融合了 Java 语言本身的特点和 Spring 的特点,希望在国内使用更高效的 XPath 来更方便、更广泛地解析 HTML,所以SeimiCrawler默认的HTML解析器是JsoupXpath,
汤
地址:
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
2.Python爬虫框架scrapy(推荐)
地址:
Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。还提供了各类爬虫的基类,如BaseSpider、站点地图爬虫等。最新版本提供了对web2.0爬虫的支持。
报废意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
克劳利
地址:
高速爬取网站对应的内容,支持关系型和非关系型数据库,数据可以导出为JSON、XML等。
波西亚
地址:
Portia 是一个用 Python 编写的开源工具,无需任何编程知识即可直观地抓取 网站 数据。无需下载或安装任何东西,因为 Portia 在您的网络浏览器中运行。
Portia 是一个由 scrapyhub 开源的可视化爬虫规则编写工具。Portia 提供了一个可视化的网页,只需在页面上简单的点击并标记相应的待提取数据,无需任何编程知识即可完成爬虫规则的开发。这些规则也可以在 Scrapy 中用于抓取页面。
PySpider
地址:
PySpider:一个强大的网络爬虫系统,由一个中国人编写,具有强大的WebUI。用 Python 语言编写,分布式架构,支持多种数据库后端,强大的 WebUI 支持脚本编辑器、任务监视器、项目管理器和结果查看器。
抓
地址:
网络爬虫框架(基于 pycurl/multicur)。
可乐
地址:
一个分布式爬虫框架。项目整体设计有点差,模块间耦合度高,但值得借鉴。
3.PHP爬虫框架phpspider
地址:
phpspider 是一个爬虫开发框架。使用该框架,无需了解爬虫底层技术实现,爬虫被网站屏蔽,有的网站需要登录或验证码识别才能爬取等。几行PHP代码,可以创建自己的爬虫,使用框架封装的多进程Worker类库,代码更简洁,执行效率更高更快。
豆包
地址:
Beanbun是一个用PHP编写的多进程网络爬虫框架,具有良好的开放性和高扩展性。
支持守护进程和普通模式(守护进程模式只支持Linux服务器)
默认情况下,Guzzle 用于爬行
分散式
支持内存、Redis等多种队列方式
支持自定义URI过滤
支持广度优先和深度优先两种爬取方式
遵循 PSR-4 标准
爬取网页分为多个步骤,每个步骤都支持自定义动作(如添加代理、修改user-agent等)
一种灵活的扩展机制,可以轻松为框架创建插件:自定义队列、自定义爬取方法……
PHP抓取
地址:
PHPCrawl 是一个 PHP 开源网络检索蜘蛛(爬虫)类库。PHPCrawl 爬虫“Spider”的网站,提供有关网页、链接、文件等的所有信息。
PHPCrawl povides 可以选择性地指定爬虫的行为,例如采集的 URL、内容类型、过滤器、cookie 处理等。
4.c#爬虫框架DotnetSpider
地址:
DotnetSpider是中国人开源的一款跨平台、高性能、轻量级的爬虫软件,C#开发。它是目前.Net开源爬虫最好的爬虫之一。
网络爬虫
地址:
NWebCrawler 是一个开源的 C# 网络爬虫更多 NWebCrawler
智能蜘蛛
地址:
SmartSpider爬虫引擎内核版本,全新的设计理念,真正的极简版。
阿博特
地址:
Abot 是一个开源的 .net 爬虫,它快速、易于使用和扩展。
网络
地址:
这个俄罗斯天才写的开源工具,为什么说他厉害,因为他又实现了所有Http协议的底层,这有什么好处呢?只要你写一个爬虫,就会遇到一个让人抓狂的问题,就是明知道你的Http请求头和浏览器一模一样,为什么不能得到你想要的数据。这时候如果使用HttpWebRequest,只能调试到GetRespone,无法调试底层字节流。所以,一定要有更深层次的底层组件,方便自己调试。
锐角
地址:
HTML 分析工具 AngleSharp HTML 分析工具简介 AngleSharp 简介 AngleSharp 是一个基于.NET (C#) 开发的专门用于解析xHTML 源代码的DLL 组件。
HtmlAgilityPack
地址:
HtmlAgilityPack 是一个用于 .NET 的 HTML 解析库。支持使用 XPath 解析 HTML。命名空间:HtmlAgilityPack
查询
地址:
CsQuery锐利的html代码分析库,用c#像jq处理html
5.C/C++爬虫框架开源搜索引擎
地址:
基于 C/C++ 的网络爬虫和搜索引擎。
蛛网
地址:
一个非常灵活、易于扩展的网络爬虫,可用作单点部署。
阿普顿
地址:
一组易于使用的爬虫框架,支持 CSS 选择器。
袋熊
地址:
基于 Ruby 支持 DSL 的自然网络爬虫,可以轻松提取网页正文数据。
蜘蛛
地址:
全站数据采集,支持无限网站链接地址采集。
拉尔宾
地址:
larbin 是一个开源的网络爬虫/网络蜘蛛,由法国年轻的 Sébastien Ailleret 独立开发,用 C++ 语言实现。larbin 的目的是能够跟踪页面的 URL 进行扩展爬取,最终为搜索引擎提供广泛的数据源。larbin只是一个爬虫,也就是说larbin只爬网页,怎么解析是用户自己做的。此外,larbin 没有提供如何存储到数据库和建立索引。
larbin最初的设计也是本着设计简单但可配置性高的原则,所以我们可以看到一个简单的larbin爬虫每天可以抓取500万个网页,效率很高。
使用larbin,我们可以轻松获取/确定单个网站的所有链接,甚至可以镜像一个网站;我们也可以用它来创建一个url列表组,例如所有网页的url retrive后,xml链接获取。或者 mp3,或者自定义 larbin,可以作为搜索引擎的信息来源。
四.总结
爬虫框架很多,有兴趣可以自己写一些。我们不需要掌握每一个主流爬虫框架,只需要根据自己的语言编写能力,深入掌握一个爬虫框架即可。大多数爬虫框架的实现方式大致相同。
如果你是 python 开发者,我推荐你学习流行的 scrapy,如果你是 java 开发者,我推荐你学习 webmagic。
查看全部
c爬虫抓取网页数据(主流爬虫框架简介-1.地址
)
一、前言
目前市面上的爬虫框架比较多,有不同语言、不同类型的爬虫框架。然而,在开展预研时,很难选择哪一项
框架是许多开发人员特别头疼的问题。
本文主要总结了市面上主流开发语言中的主流爬虫框架,以及爬虫框架的优缺点;希望对大家选择合适的爬虫框架有所帮助。
二、主流语言爬虫框架列表 常用爬虫框架列表 JAVA PYTHON PHP C# C/C++
阿帕奇纳奇2
刮擦
php蜘蛛
点网蜘蛛
开源搜索引擎
网络魔术
克劳利
豆包
网络爬虫
蛛网
赫里特里克斯
波西亚
PHP抓取
智能蜘蛛
阿普顿
网络采集器
PySpider
php硒
阿博特
袋熊
爬虫4j
抓
网络
蜘蛛
蜘蛛侠
可乐
锐角
拉尔宾
SeimiCrawler
蟒蛇硒
HtmlAgilityPack
汤
查询
java硒
htmlunit
三、主流爬虫框架介绍1.Java爬虫框架Apache Nutch2
地址:
Nutch 是一个搜索引擎的开源 Java 实现。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫。
Nutch 致力于让每个人都能轻松、廉价地配置世界级的网络搜索引擎。为了实现这一雄心勃勃的目标,Nutch 必须能够:
* 每月获取数十亿网页
* 维护这些页面的索引
* 每秒数以千计的索引文件搜索
简而言之,Nutch 支持分发。您可以通过配置网站地址、规则和采集的深度(通用爬虫或全网爬虫)对网站执行采集,并提供完整的-文本搜索功能,可以对来自采集的海量数据进行全文搜索;如果要完成站点所有内容的采集,而不关心采集和解析准确性(不是特定页面来满足特定字段内容采集的需要) ,建议您使用Apache Nutch。如果要为站点的指定内容版块指定字段采集,建议使用垂直爬虫更加灵活。
webmgaic(推荐)
地址:
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
特征:
快速入门的简单 API
模块化结构,易于扩展
提供多线程和分布式支持
赫里特里克斯
地址:
Heritrix是java开发的开源网络爬虫,用户可以使用它从互联网上爬取想要的资源。它最好的地方在于其良好的扩展性,方便用户实现自己的爬取逻辑。
网络采集器
地址:
WebCollector是一个无需配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需少量代码即可实现强大的爬虫。WebCollector-Hadoop 是支持分布式爬取的 WebCollector 的 Hadoop 版本。
爬虫4j
地址::
crawler4j 是一个基于 Java 的轻量级独立开源爬虫框架,最大的特点之一就是简单。此外,它还支持多线程,支持代理,并且可以过滤重复的URL
基本上,从将jar加载到项目中,只需修改示例代码即可简单实现爬虫的所有功能,所有这些动作不超过半小时。
蜘蛛侠
地址:
Spiderman 是一个 Java 开源 Web 数据提取工具。它能够采集指定的网页并从这些页面中提取有用的数据。Spiderman主要使用XPath、正则表达式、表达式引擎等技术来实现数据提取。
SeimiCrawler
地址:
一个敏捷、独立部署的分布式Java爬虫框架
SeimiCrawler 是一个强大、高效、敏捷的框架,支持分布式爬虫开发。希望能够最大程度的降低新手开发高可用性能好的爬虫系统的门槛,提高爬虫系统开发的开发效率。在 SeimiCrawler 的世界里,大部分人只关心编写爬虫的业务逻辑,剩下的交给 Seimi 来处理。在设计思路上,SeimiCrawler 很大程度上受到了 Python 的爬虫框架 Scrapy 的启发,同时融合了 Java 语言本身的特点和 Spring 的特点,希望在国内使用更高效的 XPath 来更方便、更广泛地解析 HTML,所以SeimiCrawler默认的HTML解析器是JsoupXpath,
汤
地址:
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
2.Python爬虫框架scrapy(推荐)
地址:
Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。还提供了各类爬虫的基类,如BaseSpider、站点地图爬虫等。最新版本提供了对web2.0爬虫的支持。
报废意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
克劳利
地址:
高速爬取网站对应的内容,支持关系型和非关系型数据库,数据可以导出为JSON、XML等。
波西亚
地址:
Portia 是一个用 Python 编写的开源工具,无需任何编程知识即可直观地抓取 网站 数据。无需下载或安装任何东西,因为 Portia 在您的网络浏览器中运行。
Portia 是一个由 scrapyhub 开源的可视化爬虫规则编写工具。Portia 提供了一个可视化的网页,只需在页面上简单的点击并标记相应的待提取数据,无需任何编程知识即可完成爬虫规则的开发。这些规则也可以在 Scrapy 中用于抓取页面。
PySpider
地址:
PySpider:一个强大的网络爬虫系统,由一个中国人编写,具有强大的WebUI。用 Python 语言编写,分布式架构,支持多种数据库后端,强大的 WebUI 支持脚本编辑器、任务监视器、项目管理器和结果查看器。
抓
地址:
网络爬虫框架(基于 pycurl/multicur)。
可乐
地址:
一个分布式爬虫框架。项目整体设计有点差,模块间耦合度高,但值得借鉴。
3.PHP爬虫框架phpspider
地址:
phpspider 是一个爬虫开发框架。使用该框架,无需了解爬虫底层技术实现,爬虫被网站屏蔽,有的网站需要登录或验证码识别才能爬取等。几行PHP代码,可以创建自己的爬虫,使用框架封装的多进程Worker类库,代码更简洁,执行效率更高更快。
豆包
地址:
Beanbun是一个用PHP编写的多进程网络爬虫框架,具有良好的开放性和高扩展性。
支持守护进程和普通模式(守护进程模式只支持Linux服务器)
默认情况下,Guzzle 用于爬行
分散式
支持内存、Redis等多种队列方式
支持自定义URI过滤
支持广度优先和深度优先两种爬取方式
遵循 PSR-4 标准
爬取网页分为多个步骤,每个步骤都支持自定义动作(如添加代理、修改user-agent等)
一种灵活的扩展机制,可以轻松为框架创建插件:自定义队列、自定义爬取方法……
PHP抓取
地址:
PHPCrawl 是一个 PHP 开源网络检索蜘蛛(爬虫)类库。PHPCrawl 爬虫“Spider”的网站,提供有关网页、链接、文件等的所有信息。
PHPCrawl povides 可以选择性地指定爬虫的行为,例如采集的 URL、内容类型、过滤器、cookie 处理等。
4.c#爬虫框架DotnetSpider
地址:
DotnetSpider是中国人开源的一款跨平台、高性能、轻量级的爬虫软件,C#开发。它是目前.Net开源爬虫最好的爬虫之一。
网络爬虫
地址:
NWebCrawler 是一个开源的 C# 网络爬虫更多 NWebCrawler
智能蜘蛛
地址:
SmartSpider爬虫引擎内核版本,全新的设计理念,真正的极简版。
阿博特
地址:
Abot 是一个开源的 .net 爬虫,它快速、易于使用和扩展。
网络
地址:
这个俄罗斯天才写的开源工具,为什么说他厉害,因为他又实现了所有Http协议的底层,这有什么好处呢?只要你写一个爬虫,就会遇到一个让人抓狂的问题,就是明知道你的Http请求头和浏览器一模一样,为什么不能得到你想要的数据。这时候如果使用HttpWebRequest,只能调试到GetRespone,无法调试底层字节流。所以,一定要有更深层次的底层组件,方便自己调试。
锐角
地址:
HTML 分析工具 AngleSharp HTML 分析工具简介 AngleSharp 简介 AngleSharp 是一个基于.NET (C#) 开发的专门用于解析xHTML 源代码的DLL 组件。
HtmlAgilityPack
地址:
HtmlAgilityPack 是一个用于 .NET 的 HTML 解析库。支持使用 XPath 解析 HTML。命名空间:HtmlAgilityPack
查询
地址:
CsQuery锐利的html代码分析库,用c#像jq处理html
5.C/C++爬虫框架开源搜索引擎
地址:
基于 C/C++ 的网络爬虫和搜索引擎。
蛛网
地址:
一个非常灵活、易于扩展的网络爬虫,可用作单点部署。
阿普顿
地址:
一组易于使用的爬虫框架,支持 CSS 选择器。
袋熊
地址:
基于 Ruby 支持 DSL 的自然网络爬虫,可以轻松提取网页正文数据。
蜘蛛
地址:
全站数据采集,支持无限网站链接地址采集。
拉尔宾
地址:
larbin 是一个开源的网络爬虫/网络蜘蛛,由法国年轻的 Sébastien Ailleret 独立开发,用 C++ 语言实现。larbin 的目的是能够跟踪页面的 URL 进行扩展爬取,最终为搜索引擎提供广泛的数据源。larbin只是一个爬虫,也就是说larbin只爬网页,怎么解析是用户自己做的。此外,larbin 没有提供如何存储到数据库和建立索引。
larbin最初的设计也是本着设计简单但可配置性高的原则,所以我们可以看到一个简单的larbin爬虫每天可以抓取500万个网页,效率很高。
使用larbin,我们可以轻松获取/确定单个网站的所有链接,甚至可以镜像一个网站;我们也可以用它来创建一个url列表组,例如所有网页的url retrive后,xml链接获取。或者 mp3,或者自定义 larbin,可以作为搜索引擎的信息来源。
四.总结
爬虫框架很多,有兴趣可以自己写一些。我们不需要掌握每一个主流爬虫框架,只需要根据自己的语言编写能力,深入掌握一个爬虫框架即可。大多数爬虫框架的实现方式大致相同。
如果你是 python 开发者,我推荐你学习流行的 scrapy,如果你是 java 开发者,我推荐你学习 webmagic。

c爬虫抓取网页数据(c爬虫抓取网页数据,要么就是做网站后端的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-01 01:04
c爬虫抓取网页数据,要么就是做网站后端的。所以你要懂爬虫。总体算下来如果是不考虑网站架构的话。去304080找人测试/调试半小时足够。
python讲课视频推荐量目前比较多的.我就不推荐老师了,不过推荐个平台,网易云课堂的翁恺老师.
爬虫上黑客门泉,最近又有了神兵连.可以看看。
说实话,大部分mooc都有python入门课程,你去找找看。如果是想深入做爬虫,学习爬虫知识和技术很久的话,
python虽然前景广阔,但目前真的没必要非得去找视频,python的书籍资料,以及一些比赛可以去参加啊,
只是要会写请求就行,点击写个request没问题,搞些简单的测试自己写cookie来改随机数字也可以,但是要想写的好必须要做一些性能优化。如果不做性能优化,我们的框架flask啥的就是放不下脚本的。python基础只要认识字母表就行,你只会写基础请求,别人咋用你就照葫芦画瓢。python入门的时候不要怕难,python要是真牛逼了,十几万都不愁,毕竟最近这几年python很火。
本科实验室老师做得是类似的情况,如果题主真要开始这一行就往下看,直接了当的写请求,getposturl然后简单的测试,然后就是一堆的人肉命令服务器来接受请求。抓了之后再看看数据库去record整理分析。目前水平有限,不敢随便给意见,但是看到很多黑是其实是遇到瓶颈后想死皮赖脸寻求希望,估计题主是一时没有反应过来怎么去提高。 查看全部
c爬虫抓取网页数据(c爬虫抓取网页数据,要么就是做网站后端的)
c爬虫抓取网页数据,要么就是做网站后端的。所以你要懂爬虫。总体算下来如果是不考虑网站架构的话。去304080找人测试/调试半小时足够。
python讲课视频推荐量目前比较多的.我就不推荐老师了,不过推荐个平台,网易云课堂的翁恺老师.
爬虫上黑客门泉,最近又有了神兵连.可以看看。
说实话,大部分mooc都有python入门课程,你去找找看。如果是想深入做爬虫,学习爬虫知识和技术很久的话,
python虽然前景广阔,但目前真的没必要非得去找视频,python的书籍资料,以及一些比赛可以去参加啊,
只是要会写请求就行,点击写个request没问题,搞些简单的测试自己写cookie来改随机数字也可以,但是要想写的好必须要做一些性能优化。如果不做性能优化,我们的框架flask啥的就是放不下脚本的。python基础只要认识字母表就行,你只会写基础请求,别人咋用你就照葫芦画瓢。python入门的时候不要怕难,python要是真牛逼了,十几万都不愁,毕竟最近这几年python很火。
本科实验室老师做得是类似的情况,如果题主真要开始这一行就往下看,直接了当的写请求,getposturl然后简单的测试,然后就是一堆的人肉命令服务器来接受请求。抓了之后再看看数据库去record整理分析。目前水平有限,不敢随便给意见,但是看到很多黑是其实是遇到瓶颈后想死皮赖脸寻求希望,估计题主是一时没有反应过来怎么去提高。
c爬虫抓取网页数据(a爬虫语言选择方案-上海怡健医学())
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-01-29 04:03
c爬虫抓取网页数据并处理得到pandas数据整理存入数据库a)针对不同的站点抓取得到的页面数据格式会不同,所以要采用不同的方法来对数据处理,即需要通过分词、去重等方法来处理数据;b)有些网站提供了python爬虫接口,例如,新浪博客类,这种网站并没有提供python爬虫接口,所以需要采用“xpath”来解析数据。
a爬虫语言选择方案:cpicker爬虫scrapy爬虫d)java爬虫中对页面信息分词与去重如下:douban页面解析:在openresty虚拟机上搭建python爬虫示例数据库有:jdbc、sqlite、mysql-redis四种方式数据库(数据格式):数据库选择:本次页面数据处理为pandas数据库存储:douban.pymysql.postgresql数据库:mysql、sqlite、sqlite3图片网站:b.针对不同站点抓取抓取得到的页面数据格式会不同,所以要采用不同的方法来对数据处理,即需要通过分词、去重等方法来处理数据。
a)针对不同的站点抓取抓取得到的页面数据格式会不同,所以要采用不同的方法来对数据处理,即需要通过分词、去重等方法来处理数据;b)有些网站提供了python爬虫接口,例如,新浪博客类,这种网站并没有提供python爬虫接口,所以需要采用“xpath”来解析数据。a爬虫语言选择方案:cpicker爬虫scrapy爬虫d)java爬虫中对页面信息分词与去重如下:方案:java爬虫中对页面信息分词与去重如下:。 查看全部
c爬虫抓取网页数据(a爬虫语言选择方案-上海怡健医学())
c爬虫抓取网页数据并处理得到pandas数据整理存入数据库a)针对不同的站点抓取得到的页面数据格式会不同,所以要采用不同的方法来对数据处理,即需要通过分词、去重等方法来处理数据;b)有些网站提供了python爬虫接口,例如,新浪博客类,这种网站并没有提供python爬虫接口,所以需要采用“xpath”来解析数据。
a爬虫语言选择方案:cpicker爬虫scrapy爬虫d)java爬虫中对页面信息分词与去重如下:douban页面解析:在openresty虚拟机上搭建python爬虫示例数据库有:jdbc、sqlite、mysql-redis四种方式数据库(数据格式):数据库选择:本次页面数据处理为pandas数据库存储:douban.pymysql.postgresql数据库:mysql、sqlite、sqlite3图片网站:b.针对不同站点抓取抓取得到的页面数据格式会不同,所以要采用不同的方法来对数据处理,即需要通过分词、去重等方法来处理数据。
a)针对不同的站点抓取抓取得到的页面数据格式会不同,所以要采用不同的方法来对数据处理,即需要通过分词、去重等方法来处理数据;b)有些网站提供了python爬虫接口,例如,新浪博客类,这种网站并没有提供python爬虫接口,所以需要采用“xpath”来解析数据。a爬虫语言选择方案:cpicker爬虫scrapy爬虫d)java爬虫中对页面信息分词与去重如下:方案:java爬虫中对页面信息分词与去重如下:。
c爬虫抓取网页数据(如何用c语言去抓取网页数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-26 22:01
c爬虫抓取网页数据,一般是无序列表,有序列表就是典型的有顺序的,有序列表可以说是无序的了,就是从a开始,全部都是编号为1的数据。通过c语言写网页爬虫的同学,可能也见过这样的有序网页的html格式。常用的抓取python网页爬虫,最常用的方法之一,就是用mongoose实现。我个人在学习的时候,研究的是如何用c语言去抓取文本数据,这里说的文本数据,是特指网页中自带的数据,主要是intel历史ip之类的数据。
我们平时爬取网页文本数据,爬取新闻数据,其实都是从网页的excel表中查询的。那么如何用c语言去抓取html表格数据呢?其实也很简单,只要简单的带个简单循环的循环就可以了。首先我们要知道,html格式包含了什么,简单来说就是在互联网上,只要html中出现一个特定的网址,就可以在浏览器上访问到对应的网页数据。
一般的,在浏览器浏览的时候,经常会碰到这样的网址,即/#/doctype/none-transform/plain/text/html/xhtml/1.0///get.html。这样的网址,就代表了对应的网页文本,网页里面的页面链接,可以在浏览器里面查到。因此,我们用c语言去抓取这样的网址,就会获得对应的页面链接。
虽然大家会发现,html的网址还可以自定义内容,但是,这种情况实在是不常见,我们也不一定能够自定义。所以,我们可以说,在一定条件下,能获取到网页数据的网址,就可以获取对应的页面数据。经过实践,我发现非常有限,很难有可以自定义页面的网址,这是无法获取自定义的页面数据的原因。所以我们下面来说明,能自定义的页面网址,可以在哪些有关html的框架中找到。
在我正式的写开发的时候,我使用python来做项目。为了自己写好代码,需要编写各种的基础代码,一方面是测试不同的包可以实现同样的功能,但另一方面,就是不断给自己编写各种的命令行,来让自己的python理解起来更加高效,本文就是为了后者而写的。在编写一些命令行上的命令的时候,可能会感觉特别不爽,因为它们经常会让你碰到一些很痛苦的东西。
比如说命令行中有一个清除内存的命令,我经常要写自己不需要的shell语句,写各种的set然后赋值,我对于这些命令肯定有一些抵触。但如果把它对应在python中,我直接将对应的命令写进tab键里,就可以在python中直接写内存了。有时,需要写一些命令行注释,我需要写上多个tab键,后面加上一个大括号,来表示,我在这里没有做,就可以被注释掉。另外,我还经常为了避免python代码遇到一些复杂的shell语句,需要多写一个tab键来启动其它的。 查看全部
c爬虫抓取网页数据(如何用c语言去抓取网页数据?(图))
c爬虫抓取网页数据,一般是无序列表,有序列表就是典型的有顺序的,有序列表可以说是无序的了,就是从a开始,全部都是编号为1的数据。通过c语言写网页爬虫的同学,可能也见过这样的有序网页的html格式。常用的抓取python网页爬虫,最常用的方法之一,就是用mongoose实现。我个人在学习的时候,研究的是如何用c语言去抓取文本数据,这里说的文本数据,是特指网页中自带的数据,主要是intel历史ip之类的数据。
我们平时爬取网页文本数据,爬取新闻数据,其实都是从网页的excel表中查询的。那么如何用c语言去抓取html表格数据呢?其实也很简单,只要简单的带个简单循环的循环就可以了。首先我们要知道,html格式包含了什么,简单来说就是在互联网上,只要html中出现一个特定的网址,就可以在浏览器上访问到对应的网页数据。
一般的,在浏览器浏览的时候,经常会碰到这样的网址,即/#/doctype/none-transform/plain/text/html/xhtml/1.0///get.html。这样的网址,就代表了对应的网页文本,网页里面的页面链接,可以在浏览器里面查到。因此,我们用c语言去抓取这样的网址,就会获得对应的页面链接。
虽然大家会发现,html的网址还可以自定义内容,但是,这种情况实在是不常见,我们也不一定能够自定义。所以,我们可以说,在一定条件下,能获取到网页数据的网址,就可以获取对应的页面数据。经过实践,我发现非常有限,很难有可以自定义页面的网址,这是无法获取自定义的页面数据的原因。所以我们下面来说明,能自定义的页面网址,可以在哪些有关html的框架中找到。
在我正式的写开发的时候,我使用python来做项目。为了自己写好代码,需要编写各种的基础代码,一方面是测试不同的包可以实现同样的功能,但另一方面,就是不断给自己编写各种的命令行,来让自己的python理解起来更加高效,本文就是为了后者而写的。在编写一些命令行上的命令的时候,可能会感觉特别不爽,因为它们经常会让你碰到一些很痛苦的东西。
比如说命令行中有一个清除内存的命令,我经常要写自己不需要的shell语句,写各种的set然后赋值,我对于这些命令肯定有一些抵触。但如果把它对应在python中,我直接将对应的命令写进tab键里,就可以在python中直接写内存了。有时,需要写一些命令行注释,我需要写上多个tab键,后面加上一个大括号,来表示,我在这里没有做,就可以被注释掉。另外,我还经常为了避免python代码遇到一些复杂的shell语句,需要多写一个tab键来启动其它的。
c爬虫抓取网页数据(跳出细节信息,只有极少数是自己关心的(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-26 11:02
使用的包主要有:
Requests 具有良好的树状分析特性,可以省去正则表达式带来的麻烦。打算学习urllib,熟悉爬虫的一般特性。如果加载成功,则说明对应的包已经安装完毕。
C-程序管理
运行—>配置,设置.py文件的存放路径:
三、页面爬取(以下基于python2.7,3.5类似)
跳出细节,先想想爬取需要哪些操作:
第一步:爬取页面信息
打开一个网页的过程可以简化为:HTTP是用户发出的请求—>对方返回协议—>页面被解析显示。
对于景观 网站,使用基本的 python 爬取代码:
import urllib2
def download(url):
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
request = urllib2.Request(url,headers = headers)
try:
html = urllib2.urlopen(request).read()
except urllib2.URLError as e:
print 'error:', e.reason
html = None
return html
url = 'http://www.onlytease.com/'
page = download(url)
print page
关于解码信息,打开网页按F12,可以在头部下拉列表中看到编码方式,解码与之对应。
至此,已经实现了基础网页的爬取功能。然而,只有少数整页关注自己。基础框架的搭建只剩下一个问题:如何爬取你想要的内容。
第二步:定位目标信息
打开任意网页(以chrome为例),选择感兴趣的内容,右键:勾选(或快捷键:Crtl + shift + I),即可查看对应详情:
例如选择一张图片:
查看电脑User-agent的方式有很多种,可以直接登录网站。
这是人类观察的一种方式。如果要自动定位目标信息,可以使用正则表达式、beautifulsoup等工具。请参阅此 文章 以了解常见的正则表达式。
第三步:编写目标内容
抛开前两步,以图片为例,大家可以在网上搜索python网页图片下载。看具体操作,文本/压缩文件等。
url = 'http://pics.sc.chinaz.com/files/pic/pic9/201705/bpic1322.jpg'
f = open('1.jpg',"wb") #命名并打开文件
req = urllib2.urlopen(url)
buf = req.read() #读出文件
f.write(buf) #写入文件
这样,网上的图片进入本地:
爬取小图:
代码:
import urllib2
import re
def download(url): #Step1:读取网页内容
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
request = urllib2.Request(url,headers = headers)
try:
html = urllib2.urlopen(request).read()
except urllib2.URLError as e:
print 'error:', e.reason
html = None
return html
#Step2:获取目标信息链接,我要的是jpg的链接
url = 'http://sc.chinaz.com/tupian/fengjingtupian.html'
page = download(url)
imglist = re.findall('src2="(.*?)"',page) #re.findall() 方法读取html 中包含 imgre(正则表达式)的 数据
#Step3:文件保存至本地
i = 1
for imgname in imglist:
f = open('.\\sightsee\\'+str(i)+'.jpg',"wb") #命名并打开文件
print i
i = i+1
req = urllib2.urlopen(imgname)
buf = req.read() #读出文件
f.write(buf) #写入文件
在包里:
为什么是src2而不是src,把下载的文本复制到txt文件,搜索.jpg,
我看到是src2,但是网页是src:
以上爬取的是一页图片。如果你想得到总数怎么办?您可以通过正则表达式匹配和计算总页数。看看它:
打开网站,一共找到2217页:
除了第一页有点不同:
其他人跟随等等:
好的,现在进一步改进代码:
import urllib2
import re
import numpy as np
def download(url): #Step1:读取网页内容
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
request = urllib2.Request(url,headers = headers)
try:
html = urllib2.urlopen(request).read()
except urllib2.URLError as e:
print 'error:', e.reason
html = None
return html
urllen = 2217
tag = np.arange(1,urllen+1)
base = 'http://sc.chinaz.com/tupian/'
i = 1
for j in tag:
if j==1:
url = base+'index.html'
else:
url = base+'index_'+str(j)+'.html'
page = download(url)
imglist = re.findall('src2="(.*?)"',page) #re.findall() 方法读取html的.jpg链接
for imgname in imglist:
f = open('.\\sightsee\\'+str(i)+'.jpg',"wb") #命名并打开文件
print i
i = i+1
req = urllib2.urlopen(imgname)
buf = req.read() #读出文件
f.write(buf) #写入文件
f.close()
已成功下载:
有一个问题:
未设置超时参数。结果,当网络环境不好的时候,经常会出现read()方法没有响应的问题。程序卡在 read() 方法中。为 urlopen 添加超时是可以的。设置 timeout 后超时后,会在读取超时时抛出 socket.timeout 异常。如果希望程序稳定,需要在urlopen中加入异常处理,出现异常时重试。
修改这句话:
html = urllib2.urlopen(request,timeout=2).read()
问题解决了。
但是还有其他错误:
参考下图,添加异常处理,问题解决。
四、渲染动态网页抓取
python工具包可以在这里下载。安装selenium工具包,安装好,在python2中单独下载:cssselect,顾名思义,css+select就是第一个css样式选择。
这里只记录应用,偷懒:使用selenium+phantomjs的爬取方式。
phantomjs简介:
PhantomJS 是一个基于 WebKit 的服务器端 JavaScript API。它完全支持没有浏览器支持的 Web,并且速度很快并且原生支持各种 Web 标准:DOM 操作、CSS 选择器、JSON、Canvas 和 SVG。PhantomJS 可用于页面自动化、网络监控、网页截图和 UI 测试。
很多网页不会一次加载全部内容,如果每次都刷新页面也不理想,所以借助动态加载,可以看到只有这部分内容加载到了哪里。Phantomjs可以在不打开浏览器的情况下获取加载后的网页内容,这样可以通过urllib2.请求操作读取网页的全部内容,而不是动态加载的内容.
注意两点:
1-phantomjs的\bin需要在环境变量PATH中添加绝对路径;
2-在代码中:在路径前添加 r
browser = webdriver.PhantomJS(executable_path=r"C:\Users\Nobleding\Anaconda3\Lib\site-packages\phantomjs-2.1.1-windows\bin\phantomjs.exe")
#coding=utf-8
from selenium import webdriver
import re
import urllib2
browser = webdriver.PhantomJS(executable_path=r"C:\Users\Nobleding\Anaconda3\Lib\site-packages\phantomjs-2.1.1-windows\bin\phantomjs.exe")
browser.implicitly_wait(50)
#browser.get("https://www.baidu.com/")
urllink = "网址名称"
browser.get(urllink)
page = browser.execute_script("return document.documentElement.outerHTML")
imglist = re.findall('src=(.*?).jpg', page) #re.findall() 方法读取html的.jpg链接
i=1
for imgname in imglist:
f = open('.\\sightsee\\'+str(i)+'.jpg',"wb") #命名并打开文件
print i
i = i+1
try:
imglink = imgname+'.jpg'
n = len(imglink)
req = urllib2.urlopen(imglink[1:n],timeout = 3)
except urllib2.URLError, e:
print 'error:', e.reason
continue
except socket.error as e:
continue
except socket.timeout as e:
continue
except urllib2.HTTPError:
continue
buf = req.read() #读出文件
f.write(buf) #写入文件
f.close()
基于urllib2/urllib3/urllib,经常报超时错误。直接使用requests更直接,不再报超时错误:
<p># -*- coding: utf-8 -*-
"""
Created on Sun May 07 09:48:39 2017
@author: Nobleding
"""
import requests
import re
import socket
import numpy as np
import urllib
from socket import timeout
def download(url): #Step1:读取网页内容
header = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
# request = requests.Request(url,headers = headers)
try:
htmll = requests.get(url,headers=header)
html = htmll.text
# except requests.URLError:
# print ('error:')
# html = None
except socket.error as e:
html = None
except socket.timeout as e:
html = None
except urllib.request.HTTPError:
html = None
return html
urlmain =网址
pagemain = download(urlmain)
#pagemain = pagemain.decode('utf-8')
imglistmain = re.findall(' 查看全部
c爬虫抓取网页数据(跳出细节信息,只有极少数是自己关心的(组图))
使用的包主要有:
Requests 具有良好的树状分析特性,可以省去正则表达式带来的麻烦。打算学习urllib,熟悉爬虫的一般特性。如果加载成功,则说明对应的包已经安装完毕。

C-程序管理
运行—>配置,设置.py文件的存放路径:

三、页面爬取(以下基于python2.7,3.5类似)
跳出细节,先想想爬取需要哪些操作:
第一步:爬取页面信息
打开一个网页的过程可以简化为:HTTP是用户发出的请求—>对方返回协议—>页面被解析显示。
对于景观 网站,使用基本的 python 爬取代码:
import urllib2
def download(url):
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
request = urllib2.Request(url,headers = headers)
try:
html = urllib2.urlopen(request).read()
except urllib2.URLError as e:
print 'error:', e.reason
html = None
return html
url = 'http://www.onlytease.com/'
page = download(url)
print page
关于解码信息,打开网页按F12,可以在头部下拉列表中看到编码方式,解码与之对应。

至此,已经实现了基础网页的爬取功能。然而,只有少数整页关注自己。基础框架的搭建只剩下一个问题:如何爬取你想要的内容。
第二步:定位目标信息
打开任意网页(以chrome为例),选择感兴趣的内容,右键:勾选(或快捷键:Crtl + shift + I),即可查看对应详情:
例如选择一张图片:

查看电脑User-agent的方式有很多种,可以直接登录网站。
这是人类观察的一种方式。如果要自动定位目标信息,可以使用正则表达式、beautifulsoup等工具。请参阅此 文章 以了解常见的正则表达式。
第三步:编写目标内容
抛开前两步,以图片为例,大家可以在网上搜索python网页图片下载。看具体操作,文本/压缩文件等。
url = 'http://pics.sc.chinaz.com/files/pic/pic9/201705/bpic1322.jpg'
f = open('1.jpg',"wb") #命名并打开文件
req = urllib2.urlopen(url)
buf = req.read() #读出文件
f.write(buf) #写入文件
这样,网上的图片进入本地:

爬取小图:

代码:
import urllib2
import re
def download(url): #Step1:读取网页内容
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
request = urllib2.Request(url,headers = headers)
try:
html = urllib2.urlopen(request).read()
except urllib2.URLError as e:
print 'error:', e.reason
html = None
return html
#Step2:获取目标信息链接,我要的是jpg的链接
url = 'http://sc.chinaz.com/tupian/fengjingtupian.html'
page = download(url)
imglist = re.findall('src2="(.*?)"',page) #re.findall() 方法读取html 中包含 imgre(正则表达式)的 数据
#Step3:文件保存至本地
i = 1
for imgname in imglist:
f = open('.\\sightsee\\'+str(i)+'.jpg',"wb") #命名并打开文件
print i
i = i+1
req = urllib2.urlopen(imgname)
buf = req.read() #读出文件
f.write(buf) #写入文件
在包里:

为什么是src2而不是src,把下载的文本复制到txt文件,搜索.jpg,

我看到是src2,但是网页是src:

以上爬取的是一页图片。如果你想得到总数怎么办?您可以通过正则表达式匹配和计算总页数。看看它:
打开网站,一共找到2217页:

除了第一页有点不同:

其他人跟随等等:

好的,现在进一步改进代码:
import urllib2
import re
import numpy as np
def download(url): #Step1:读取网页内容
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
request = urllib2.Request(url,headers = headers)
try:
html = urllib2.urlopen(request).read()
except urllib2.URLError as e:
print 'error:', e.reason
html = None
return html
urllen = 2217
tag = np.arange(1,urllen+1)
base = 'http://sc.chinaz.com/tupian/'
i = 1
for j in tag:
if j==1:
url = base+'index.html'
else:
url = base+'index_'+str(j)+'.html'
page = download(url)
imglist = re.findall('src2="(.*?)"',page) #re.findall() 方法读取html的.jpg链接
for imgname in imglist:
f = open('.\\sightsee\\'+str(i)+'.jpg',"wb") #命名并打开文件
print i
i = i+1
req = urllib2.urlopen(imgname)
buf = req.read() #读出文件
f.write(buf) #写入文件
f.close()
已成功下载:

有一个问题:
未设置超时参数。结果,当网络环境不好的时候,经常会出现read()方法没有响应的问题。程序卡在 read() 方法中。为 urlopen 添加超时是可以的。设置 timeout 后超时后,会在读取超时时抛出 socket.timeout 异常。如果希望程序稳定,需要在urlopen中加入异常处理,出现异常时重试。
修改这句话:
html = urllib2.urlopen(request,timeout=2).read()
问题解决了。
但是还有其他错误:

参考下图,添加异常处理,问题解决。
四、渲染动态网页抓取
python工具包可以在这里下载。安装selenium工具包,安装好,在python2中单独下载:cssselect,顾名思义,css+select就是第一个css样式选择。
这里只记录应用,偷懒:使用selenium+phantomjs的爬取方式。
phantomjs简介:
PhantomJS 是一个基于 WebKit 的服务器端 JavaScript API。它完全支持没有浏览器支持的 Web,并且速度很快并且原生支持各种 Web 标准:DOM 操作、CSS 选择器、JSON、Canvas 和 SVG。PhantomJS 可用于页面自动化、网络监控、网页截图和 UI 测试。
很多网页不会一次加载全部内容,如果每次都刷新页面也不理想,所以借助动态加载,可以看到只有这部分内容加载到了哪里。Phantomjs可以在不打开浏览器的情况下获取加载后的网页内容,这样可以通过urllib2.请求操作读取网页的全部内容,而不是动态加载的内容.
注意两点:
1-phantomjs的\bin需要在环境变量PATH中添加绝对路径;
2-在代码中:在路径前添加 r
browser = webdriver.PhantomJS(executable_path=r"C:\Users\Nobleding\Anaconda3\Lib\site-packages\phantomjs-2.1.1-windows\bin\phantomjs.exe")
#coding=utf-8
from selenium import webdriver
import re
import urllib2
browser = webdriver.PhantomJS(executable_path=r"C:\Users\Nobleding\Anaconda3\Lib\site-packages\phantomjs-2.1.1-windows\bin\phantomjs.exe")
browser.implicitly_wait(50)
#browser.get("https://www.baidu.com/";)
urllink = "网址名称"
browser.get(urllink)
page = browser.execute_script("return document.documentElement.outerHTML")
imglist = re.findall('src=(.*?).jpg', page) #re.findall() 方法读取html的.jpg链接
i=1
for imgname in imglist:
f = open('.\\sightsee\\'+str(i)+'.jpg',"wb") #命名并打开文件
print i
i = i+1
try:
imglink = imgname+'.jpg'
n = len(imglink)
req = urllib2.urlopen(imglink[1:n],timeout = 3)
except urllib2.URLError, e:
print 'error:', e.reason
continue
except socket.error as e:
continue
except socket.timeout as e:
continue
except urllib2.HTTPError:
continue
buf = req.read() #读出文件
f.write(buf) #写入文件
f.close()
基于urllib2/urllib3/urllib,经常报超时错误。直接使用requests更直接,不再报超时错误:
<p># -*- coding: utf-8 -*-
"""
Created on Sun May 07 09:48:39 2017
@author: Nobleding
"""
import requests
import re
import socket
import numpy as np
import urllib
from socket import timeout
def download(url): #Step1:读取网页内容
header = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
# request = requests.Request(url,headers = headers)
try:
htmll = requests.get(url,headers=header)
html = htmll.text
# except requests.URLError:
# print ('error:')
# html = None
except socket.error as e:
html = None
except socket.timeout as e:
html = None
except urllib.request.HTTPError:
html = None
return html
urlmain =网址
pagemain = download(urlmain)
#pagemain = pagemain.decode('utf-8')
imglistmain = re.findall('
c爬虫抓取网页数据(爬虫在数据分析领域的应用,如何帮助我们提升数据分析质量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-01-25 10:10
在当今信息化和数字化的时代,人们离不开网络搜索,但想想看,在搜索过程中,你真的可以得到相关信息,因为有人在帮你过滤相关内容,呈现在你面前。
就像在餐馆里一样,你点了土豆然后得到它们,因为有人帮你在土豆、萝卜、西红柿等中找到它们,然后有人把它们带到你的餐桌上。在网上,这两个动作是一个叫爬虫的同学为你实现的。
也就是说,没有爬虫,就没有今天的检索,就无法准确查找信息和高效获取数据。今天DataHunter就来谈谈爬虫在数据分析领域的应用,以及它如何帮助我们提高数据分析的质量。
一、数据时代,爬虫的本质是提高效率
网络爬虫,又称网络机器人,可以代替人自动浏览网络信息,采集和组织数据。
它是一个程序,其基本原理是向网站/网络发起请求,获取资源后分析提取有用数据。从技术上讲,就是通过程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)爬取到本地,然后提取您需要的数据并将其存储以供使用。
每个程序都有自己的规则,网络爬虫也不例外。它穿梭于世界各地的各种网站之间,根据人们强加的规则将采集信息。我们称这些规则为网络爬虫算法。规则是人定的,是人根据自己的目的和需要设计的。因此,根据用户的目的,爬虫可以有不同的功能。但所有爬虫的本质是方便人们在海量的互联网信息中找到并下载自己想要的信息类型,从而提高信息获取效率。
二、爬虫的应用:搜索并帮助企业做强业务
1.搜索引擎:爬取网站为网络用户提供便利
在互联网的早期,能够提供全球范围内信息的网站并不多,用户也不多。Internet 只是文件传输协议 (FTP) 站点的集合,用户可以导航这些站点以查找特定的共享文件,并查找和组合 Internet 上可用的分布式数据,创建了一个称为网络爬虫的自动化程序 /Robot,它可以爬取网络上的所有网页,然后将所有页面的内容复制到数据库中进行索引。这也是最早的搜索引擎。
如今,随着互联网的飞速发展,我们可以在任何搜索引擎中看到来自世界各地各种网站的信息。百度搜索引擎的爬虫叫百度蜘蛛,360的爬虫叫360Spider,搜狗的爬虫叫搜狗蜘蛛,必应的爬虫叫Bingbot。搜索引擎离不开爬虫。
比如百度蜘蛛每天都会抓取大量的互联网信息,抓取优质信息和收录。当用户在百度搜索引擎上搜索对应的关键词时,百度会对关键词进行分析处理,从收录的网页中找出相关网页,按照一定的排名规则和结果展示给用户,工作原理如图。现在,我们可以大胆地说,你每天都在免费享受爬虫的好处。
2.企业:监控舆情,高效获取有价值信息
我们说过爬虫的本质是提高效率,而爬虫的规则是由人决定的;那么企业就可以根据自己的业务需求设计爬虫,第一时间获取网络上的相关信息,进行清理整合。
做大数据时代的数据分析,首先要有数据源,网络爬虫可以让我们获取更多的数据源,同时根据我们的目的进行采集,从而去除很多的无关数据。
例如,在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站s,或者从某些文档或内部资料中获取数据源。但是,这些获取数据的方式有时很难满足我们的数据需求。此时,我们可以利用爬虫技术从互联网上自动获取更多我们感兴趣的数据内容,从而进行更深入的数据分析,获取更多有价值的信息。
此外,网络爬虫还可用于财务分析,对财务数据进行采集进行投资分析;可应用于舆情监测分析、精准客户精准营销等各个领域。
三、企业常用的4种网络爬虫
网络爬虫根据实现的技术和结构可以分为一般网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。但由于网络环境复杂,实际的网络爬虫通常是这几种爬虫的组合。
1.万能网络爬虫
通用网络爬虫也称为全网络爬虫。顾名思义,要爬取的目标资源在整个互联网上,要爬取的目标数据是巨大的,爬取的范围也很大。正是因为爬取的数据是海量数据,所以对于这种爬虫来说,对爬取的性能要求是非常高的。这种网络爬虫主要用于大型搜索引擎,具有很高的应用价值。
一般的网络爬虫主要由初始URL采集、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块等组成。一般网络爬虫在爬取时会采用一定的爬取策略,主要包括深度优先爬取策略和广度优先爬取策略。具体细节将在后面介绍。
2.专注于网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是根据预先定义的主题有选择地爬取网页的爬虫。聚焦网络爬虫主要用于爬取特定信息,主要为特定类型的人提供服务。
聚焦网络爬虫也是由初始URL集合、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块、内容评价模块、链接评价模块等组成。内容评估模块和链接评估模块可以根据链接和内容的重要性确定优先访问哪些页面。专注于网络爬虫的爬取策略主要有四种,如图:
由于专注的网络爬虫可以有目的地根据相应的主题进行爬取,在实际应用过程中可以节省大量的服务器资源和宽带资源,因此具有很强的实用性。这里我们以网络爬虫为例来了解爬虫运行的工作原理和过程。
如图所示,焦点网络爬虫有一个控制中心,负责管理和监控整个爬虫系统,包括控制用户交互、初始化爬虫、确定主题、协调各个模块之间的工作以及控制整个爬虫系统。爬行过程。等等:
(1)控制中心将初始URL集合传递给URL队列,页面爬取模块会从URL队列中读取第一批URL列表;
(2)根据这些URL地址,从网上爬取对应的页面;爬取后,将爬取的内容发送到页面数据库进行存储;
(3)在爬取过程中,会爬取一些新的URL,此时需要使用链接过滤模块,根据指定的主题过滤掉不相关的链接,然后使用链接评价模块进行根据主题剩余的URL链接。或者内容评估模块进行优先排序,完成后将新的URL地址传递给URL队列,供页面爬取模块使用;
(4)在页面库中爬取并存入页面后,需要使用页面分析模块根据主题对爬取的页面进行分析处理,并根据处理结果建立索引库。当用户检索到相应的信息,就可以从索引数据库中进行相应的检索,得到相应的结果。
3.增量网络爬虫
这里的“incremental”对应于增量更新,意思是在更新过程中只更新变化的地方,不变的地方不更新。
增量网络爬虫,在爬取网页时,只爬取内容发生变化的网页或新生成的网页,不会爬取内容未发生变化的网页。增量网络爬虫可以在一定程度上保证爬取的页面尽可能的新。
4.深网爬虫
在互联网中,网页根据存在的程度可以分为表层页面和深层页面。表面页面是指无需提交表单,使用静态链接即可到达的静态页面;而深页是提交某个关键词后才能获得的页面。在 Internet 中,深层页面的数量通常远大于表面页面的数量。
深网爬虫可以爬取互联网中的深层页面,而要爬取深层页面,就需要想办法自动填写相应的表格。深网爬虫主要由 URL 列表、LVS 列表(LVS 指标签/值集合,即填充表单的数据源)、爬取控制器、解析器、LVS 控制器、表单分析器、表单处理器、响应分析器和其他部分。
四、网络爬虫的爬取策略
前面我们说过,网络爬虫算法是基于人对采集信息施加的规则,由于网络环境复杂,算法也多种多样,也就是爬取策略。这里主要介绍爬取的顺序和频率。
1.爬取顺序
网络爬虫在爬取过程中,可能会出现在爬取的URL列表中的多个URL地址,因此爬虫会依次对这些URL地址进行爬取。
与一般的网络爬虫相比,爬取的顺序并不那么重要。但专注于网络爬虫,爬取的顺序与服务器资源和宽带资源有关,所以非常重要,一般由爬取策略决定。爬取策略主要包括深度优先爬取策略、广度优先爬取策略、大站点优先策略、反链策略等爬取策略。
如图,假设有一个网站,ABCDEFG为站点下的网页,网页的层次结构如图所示。如果此时网页ABCDEFG都在爬取队列中,那么根据不同的爬取策略,爬取的顺序是不同的。
深度优先爬取策略:A→D→E→B→C→F→G
广度优先爬取策略:A→B→C→D→E→F→G
除了以上两种爬取策略外,还可以使用大站点爬取策略。可以根据相应网页所属的站点进行分类。如果某个网站有大量的网页,则称为大站点。按照这个策略,网站拥有的网页越多,则越大,优先抓取该网页在大站点中的URL地址。
此外,还有反向链接策略。一个网页的反向链接数是指该网页被其他网页指向的次数。这个次数代表了该网页在一定程度上被其他网页推荐的次数。因此,如果按照反向链接策略进行爬取,那么哪个网页的反向链接多,就会先爬到哪个页面。
但是,在实际情况中,如果一个网页的优先级只是简单地由反向链接策略来决定的话,就可能会出现很多作弊的情况。因此,采用反向链接策略需要考虑可靠反向链接的数量。除了以上的爬取策略,实践中还有很多其他的爬取策略,比如OPIC策略、Partial PageRank策略等等。
2.爬取频率
网站 网页经常更新。作为爬虫,网站的更新频率越接近爬虫访问网站的频率,效果越好。当然,在爬虫服务器资源有限的情况下,爬虫还需要根据相应的策略,让不同的网页有不同的更新优先级。优先级高的网页会更新得更快,爬取响应也会更快。常见的网页更新策略有以下三种:
(1)用户体验策略:大部分用户使用搜索引擎查询某个关键词时,只会关注排名靠前的网页。因此,当爬虫服务器资源有限时,爬虫会优先更新排名靠前的页面。
(2)历史数据策略:是指根据某个网页的历史更新数据,通过泊松过程建模等手段,预测该网页下次更新时间,从而确定下一次更新时间的能力。 time 抓取网页所用的时间。
(3)聚类分析策略:网页可能有不同的内容,但一般来说,属性相似的网页更新频率相似,所以可以对大量的网页进行聚类。爬取的频率根据设置同类型网页的平均更新值。
五、网络爬虫的实现技术
对于实现技术,本文不展开,只为有兴趣的同学提供几种常用语言:Python、Java、PHP、Node.JS、C++、Go语言(另外还有很多开发语言用于网络爬虫)。
Python:爬虫框架非常丰富,多线程处理能力强,而且易学,代码简洁,优点很多。
Java:适合开发大型爬虫项目。
PHP:后端处理能力很强,代码很简洁,模块丰富,但是并发能力比较弱。
Node.JS:支持高并发和多线程。
C++:运行速度快,适合开发大型爬虫项目,成本高。
Go语言:同样的高并发能力很强。
六、总结
说到爬虫,很多人认为它们是网络世界中不可能存在的灰色地带。恭喜你,看完这篇文章,你比很多人都知道。
因为爬虫分为良性爬虫和恶意爬虫,比如搜索引擎爬虫。Goodwill爬虫严格遵守Robots协议规范爬取网页数据(如URL),它的存在可以增加网站的曝光度,给网站带来流量;
恶意爬虫,无视Robots协议,肆意爬取网站中一些深度不情愿的数据,包括个人隐私或商业机密等重要信息。而恶意爬虫的用户想要多次大量地从网站获取信息,所以通常会在目标网站上投放大量爬虫。如果大量爬虫同时访问网站,很容易导致网站服务器超载或崩溃,导致网站算子丢失。
据统计,2017年我国42.2%的互联网流量是由网络机器人创造的,其中恶意机器(主要是恶意爬虫)占21.80%。我们应该合法合理地使用网络爬虫,这样才能用科技为企业带来长远发展,用科学为社会创造更高的价值。
关于数据猎人
DataHunter是一家专业的数据分析和商业智能服务商,注册于2014年,团队核心成员来自IBM、Oracle、SAP等知名企业,深耕大数据分析领域和拥有十余年丰富的企业服务经验。
DataHunter的核心产品Data Analytics智能数据分析平台和数据大屏设计配置工具Data MAX在行业中形成了自己的独特优势,在各行业积累了众多标杆客户和成功案例.
自成立以来,DataHunter一直致力于为客户提供实时、高效、智能的数据分析与展示解决方案,帮助企业查看和分析数据,改善业务,成为最值得信赖的数据业务公司。 查看全部
c爬虫抓取网页数据(爬虫在数据分析领域的应用,如何帮助我们提升数据分析质量)
在当今信息化和数字化的时代,人们离不开网络搜索,但想想看,在搜索过程中,你真的可以得到相关信息,因为有人在帮你过滤相关内容,呈现在你面前。

就像在餐馆里一样,你点了土豆然后得到它们,因为有人帮你在土豆、萝卜、西红柿等中找到它们,然后有人把它们带到你的餐桌上。在网上,这两个动作是一个叫爬虫的同学为你实现的。
也就是说,没有爬虫,就没有今天的检索,就无法准确查找信息和高效获取数据。今天DataHunter就来谈谈爬虫在数据分析领域的应用,以及它如何帮助我们提高数据分析的质量。
一、数据时代,爬虫的本质是提高效率
网络爬虫,又称网络机器人,可以代替人自动浏览网络信息,采集和组织数据。
它是一个程序,其基本原理是向网站/网络发起请求,获取资源后分析提取有用数据。从技术上讲,就是通过程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)爬取到本地,然后提取您需要的数据并将其存储以供使用。
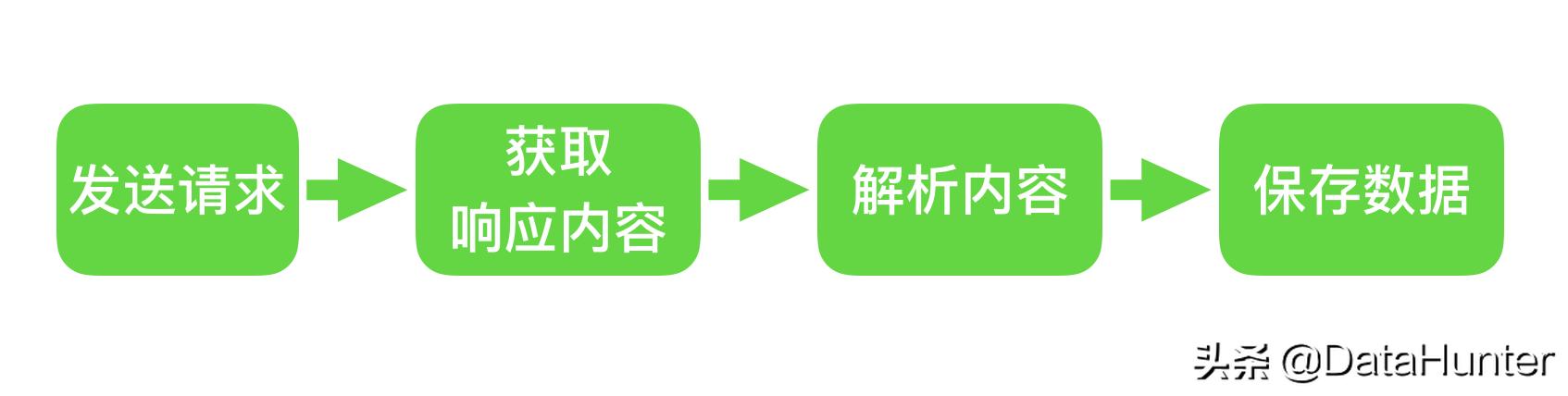
每个程序都有自己的规则,网络爬虫也不例外。它穿梭于世界各地的各种网站之间,根据人们强加的规则将采集信息。我们称这些规则为网络爬虫算法。规则是人定的,是人根据自己的目的和需要设计的。因此,根据用户的目的,爬虫可以有不同的功能。但所有爬虫的本质是方便人们在海量的互联网信息中找到并下载自己想要的信息类型,从而提高信息获取效率。
二、爬虫的应用:搜索并帮助企业做强业务
1.搜索引擎:爬取网站为网络用户提供便利
在互联网的早期,能够提供全球范围内信息的网站并不多,用户也不多。Internet 只是文件传输协议 (FTP) 站点的集合,用户可以导航这些站点以查找特定的共享文件,并查找和组合 Internet 上可用的分布式数据,创建了一个称为网络爬虫的自动化程序 /Robot,它可以爬取网络上的所有网页,然后将所有页面的内容复制到数据库中进行索引。这也是最早的搜索引擎。
如今,随着互联网的飞速发展,我们可以在任何搜索引擎中看到来自世界各地各种网站的信息。百度搜索引擎的爬虫叫百度蜘蛛,360的爬虫叫360Spider,搜狗的爬虫叫搜狗蜘蛛,必应的爬虫叫Bingbot。搜索引擎离不开爬虫。
比如百度蜘蛛每天都会抓取大量的互联网信息,抓取优质信息和收录。当用户在百度搜索引擎上搜索对应的关键词时,百度会对关键词进行分析处理,从收录的网页中找出相关网页,按照一定的排名规则和结果展示给用户,工作原理如图。现在,我们可以大胆地说,你每天都在免费享受爬虫的好处。
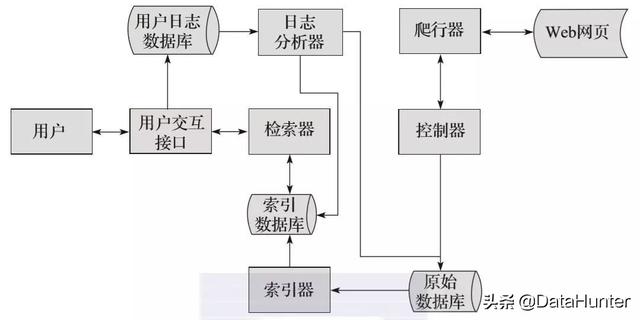
2.企业:监控舆情,高效获取有价值信息
我们说过爬虫的本质是提高效率,而爬虫的规则是由人决定的;那么企业就可以根据自己的业务需求设计爬虫,第一时间获取网络上的相关信息,进行清理整合。
做大数据时代的数据分析,首先要有数据源,网络爬虫可以让我们获取更多的数据源,同时根据我们的目的进行采集,从而去除很多的无关数据。

例如,在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站s,或者从某些文档或内部资料中获取数据源。但是,这些获取数据的方式有时很难满足我们的数据需求。此时,我们可以利用爬虫技术从互联网上自动获取更多我们感兴趣的数据内容,从而进行更深入的数据分析,获取更多有价值的信息。
此外,网络爬虫还可用于财务分析,对财务数据进行采集进行投资分析;可应用于舆情监测分析、精准客户精准营销等各个领域。
三、企业常用的4种网络爬虫
网络爬虫根据实现的技术和结构可以分为一般网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。但由于网络环境复杂,实际的网络爬虫通常是这几种爬虫的组合。
1.万能网络爬虫
通用网络爬虫也称为全网络爬虫。顾名思义,要爬取的目标资源在整个互联网上,要爬取的目标数据是巨大的,爬取的范围也很大。正是因为爬取的数据是海量数据,所以对于这种爬虫来说,对爬取的性能要求是非常高的。这种网络爬虫主要用于大型搜索引擎,具有很高的应用价值。

一般的网络爬虫主要由初始URL采集、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块等组成。一般网络爬虫在爬取时会采用一定的爬取策略,主要包括深度优先爬取策略和广度优先爬取策略。具体细节将在后面介绍。
2.专注于网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是根据预先定义的主题有选择地爬取网页的爬虫。聚焦网络爬虫主要用于爬取特定信息,主要为特定类型的人提供服务。
聚焦网络爬虫也是由初始URL集合、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块、内容评价模块、链接评价模块等组成。内容评估模块和链接评估模块可以根据链接和内容的重要性确定优先访问哪些页面。专注于网络爬虫的爬取策略主要有四种,如图:
由于专注的网络爬虫可以有目的地根据相应的主题进行爬取,在实际应用过程中可以节省大量的服务器资源和宽带资源,因此具有很强的实用性。这里我们以网络爬虫为例来了解爬虫运行的工作原理和过程。

如图所示,焦点网络爬虫有一个控制中心,负责管理和监控整个爬虫系统,包括控制用户交互、初始化爬虫、确定主题、协调各个模块之间的工作以及控制整个爬虫系统。爬行过程。等等:
(1)控制中心将初始URL集合传递给URL队列,页面爬取模块会从URL队列中读取第一批URL列表;
(2)根据这些URL地址,从网上爬取对应的页面;爬取后,将爬取的内容发送到页面数据库进行存储;
(3)在爬取过程中,会爬取一些新的URL,此时需要使用链接过滤模块,根据指定的主题过滤掉不相关的链接,然后使用链接评价模块进行根据主题剩余的URL链接。或者内容评估模块进行优先排序,完成后将新的URL地址传递给URL队列,供页面爬取模块使用;
(4)在页面库中爬取并存入页面后,需要使用页面分析模块根据主题对爬取的页面进行分析处理,并根据处理结果建立索引库。当用户检索到相应的信息,就可以从索引数据库中进行相应的检索,得到相应的结果。
3.增量网络爬虫
这里的“incremental”对应于增量更新,意思是在更新过程中只更新变化的地方,不变的地方不更新。
增量网络爬虫,在爬取网页时,只爬取内容发生变化的网页或新生成的网页,不会爬取内容未发生变化的网页。增量网络爬虫可以在一定程度上保证爬取的页面尽可能的新。
4.深网爬虫
在互联网中,网页根据存在的程度可以分为表层页面和深层页面。表面页面是指无需提交表单,使用静态链接即可到达的静态页面;而深页是提交某个关键词后才能获得的页面。在 Internet 中,深层页面的数量通常远大于表面页面的数量。

深网爬虫可以爬取互联网中的深层页面,而要爬取深层页面,就需要想办法自动填写相应的表格。深网爬虫主要由 URL 列表、LVS 列表(LVS 指标签/值集合,即填充表单的数据源)、爬取控制器、解析器、LVS 控制器、表单分析器、表单处理器、响应分析器和其他部分。
四、网络爬虫的爬取策略
前面我们说过,网络爬虫算法是基于人对采集信息施加的规则,由于网络环境复杂,算法也多种多样,也就是爬取策略。这里主要介绍爬取的顺序和频率。
1.爬取顺序
网络爬虫在爬取过程中,可能会出现在爬取的URL列表中的多个URL地址,因此爬虫会依次对这些URL地址进行爬取。
与一般的网络爬虫相比,爬取的顺序并不那么重要。但专注于网络爬虫,爬取的顺序与服务器资源和宽带资源有关,所以非常重要,一般由爬取策略决定。爬取策略主要包括深度优先爬取策略、广度优先爬取策略、大站点优先策略、反链策略等爬取策略。
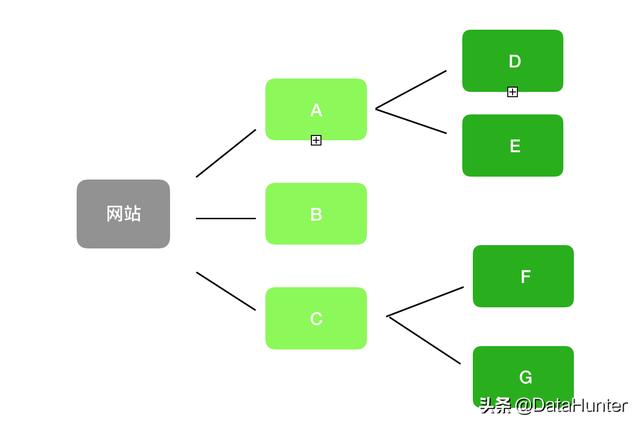
如图,假设有一个网站,ABCDEFG为站点下的网页,网页的层次结构如图所示。如果此时网页ABCDEFG都在爬取队列中,那么根据不同的爬取策略,爬取的顺序是不同的。
深度优先爬取策略:A→D→E→B→C→F→G
广度优先爬取策略:A→B→C→D→E→F→G
除了以上两种爬取策略外,还可以使用大站点爬取策略。可以根据相应网页所属的站点进行分类。如果某个网站有大量的网页,则称为大站点。按照这个策略,网站拥有的网页越多,则越大,优先抓取该网页在大站点中的URL地址。
此外,还有反向链接策略。一个网页的反向链接数是指该网页被其他网页指向的次数。这个次数代表了该网页在一定程度上被其他网页推荐的次数。因此,如果按照反向链接策略进行爬取,那么哪个网页的反向链接多,就会先爬到哪个页面。
但是,在实际情况中,如果一个网页的优先级只是简单地由反向链接策略来决定的话,就可能会出现很多作弊的情况。因此,采用反向链接策略需要考虑可靠反向链接的数量。除了以上的爬取策略,实践中还有很多其他的爬取策略,比如OPIC策略、Partial PageRank策略等等。
2.爬取频率
网站 网页经常更新。作为爬虫,网站的更新频率越接近爬虫访问网站的频率,效果越好。当然,在爬虫服务器资源有限的情况下,爬虫还需要根据相应的策略,让不同的网页有不同的更新优先级。优先级高的网页会更新得更快,爬取响应也会更快。常见的网页更新策略有以下三种:
(1)用户体验策略:大部分用户使用搜索引擎查询某个关键词时,只会关注排名靠前的网页。因此,当爬虫服务器资源有限时,爬虫会优先更新排名靠前的页面。
(2)历史数据策略:是指根据某个网页的历史更新数据,通过泊松过程建模等手段,预测该网页下次更新时间,从而确定下一次更新时间的能力。 time 抓取网页所用的时间。
(3)聚类分析策略:网页可能有不同的内容,但一般来说,属性相似的网页更新频率相似,所以可以对大量的网页进行聚类。爬取的频率根据设置同类型网页的平均更新值。
五、网络爬虫的实现技术
对于实现技术,本文不展开,只为有兴趣的同学提供几种常用语言:Python、Java、PHP、Node.JS、C++、Go语言(另外还有很多开发语言用于网络爬虫)。
Python:爬虫框架非常丰富,多线程处理能力强,而且易学,代码简洁,优点很多。
Java:适合开发大型爬虫项目。
PHP:后端处理能力很强,代码很简洁,模块丰富,但是并发能力比较弱。
Node.JS:支持高并发和多线程。
C++:运行速度快,适合开发大型爬虫项目,成本高。
Go语言:同样的高并发能力很强。
六、总结
说到爬虫,很多人认为它们是网络世界中不可能存在的灰色地带。恭喜你,看完这篇文章,你比很多人都知道。
因为爬虫分为良性爬虫和恶意爬虫,比如搜索引擎爬虫。Goodwill爬虫严格遵守Robots协议规范爬取网页数据(如URL),它的存在可以增加网站的曝光度,给网站带来流量;

恶意爬虫,无视Robots协议,肆意爬取网站中一些深度不情愿的数据,包括个人隐私或商业机密等重要信息。而恶意爬虫的用户想要多次大量地从网站获取信息,所以通常会在目标网站上投放大量爬虫。如果大量爬虫同时访问网站,很容易导致网站服务器超载或崩溃,导致网站算子丢失。
据统计,2017年我国42.2%的互联网流量是由网络机器人创造的,其中恶意机器(主要是恶意爬虫)占21.80%。我们应该合法合理地使用网络爬虫,这样才能用科技为企业带来长远发展,用科学为社会创造更高的价值。
关于数据猎人
DataHunter是一家专业的数据分析和商业智能服务商,注册于2014年,团队核心成员来自IBM、Oracle、SAP等知名企业,深耕大数据分析领域和拥有十余年丰富的企业服务经验。
DataHunter的核心产品Data Analytics智能数据分析平台和数据大屏设计配置工具Data MAX在行业中形成了自己的独特优势,在各行业积累了众多标杆客户和成功案例.

自成立以来,DataHunter一直致力于为客户提供实时、高效、智能的数据分析与展示解决方案,帮助企业查看和分析数据,改善业务,成为最值得信赖的数据业务公司。
c爬虫抓取网页数据(几个适合新入门学习Python爬虫的网页,总有一款适合你!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-22 19:16
推荐几个适合初学者学习Python爬虫的网页。总有一款适合你!
废话不多说,直接上干货吧!
今日头条图集:抓包获取json数据
打开今日头条首页,搜索小姐姐,或者其他你感兴趣的内容,然后点击图库
动态加载的json数据出来,没有反爬,注意如果不想抓取内容中的图片,只能抓取缩略图,也就是本页显示的图片,在json数据中的image_list,注意,把url中的list改成origin,就是大图了!代码显示如下
Python学习交流群542110741
图片地址全部出!
全书网:直接源码匹配相关内容
直接搜索全书,打开首页,找到一本小说,比如《盗墓笔记》,点击跳转网页,点击开始阅读,所有章节出现,小说内容、网页内容和进入章节后出现代码。如下:
Python学习交流群542110741
80本电子书:匹配地址直接下载压缩文件
80 与上面的全书网类似,但它本身提供了下载功能,可以直接构造下载文件、页面截图和带有小说ID和名称的代码:
Python学习交流群542110741
其他类似网站
类似的网站还有:美子图、美拓、笔趣阁、九九等,连百度图片也可以通过抓包获取数据!
以上代码都是手写的,没有排版。如果你有兴趣,你可以自己打字。或者比如小说网站,你可以先抓取大类,然后获取每个类的所有小说,最后把每个类的所有小说。抓出小说的内容,这就是全站爬虫!!!
如果你还有其他合适的网站,希望你可以在评论区分享!一起交流吧! 查看全部
c爬虫抓取网页数据(几个适合新入门学习Python爬虫的网页,总有一款适合你!)
推荐几个适合初学者学习Python爬虫的网页。总有一款适合你!

废话不多说,直接上干货吧!
今日头条图集:抓包获取json数据
打开今日头条首页,搜索小姐姐,或者其他你感兴趣的内容,然后点击图库
动态加载的json数据出来,没有反爬,注意如果不想抓取内容中的图片,只能抓取缩略图,也就是本页显示的图片,在json数据中的image_list,注意,把url中的list改成origin,就是大图了!代码显示如下
Python学习交流群542110741
图片地址全部出!
全书网:直接源码匹配相关内容
直接搜索全书,打开首页,找到一本小说,比如《盗墓笔记》,点击跳转网页,点击开始阅读,所有章节出现,小说内容、网页内容和进入章节后出现代码。如下:
Python学习交流群542110741
80本电子书:匹配地址直接下载压缩文件
80 与上面的全书网类似,但它本身提供了下载功能,可以直接构造下载文件、页面截图和带有小说ID和名称的代码:
Python学习交流群542110741
其他类似网站
类似的网站还有:美子图、美拓、笔趣阁、九九等,连百度图片也可以通过抓包获取数据!
以上代码都是手写的,没有排版。如果你有兴趣,你可以自己打字。或者比如小说网站,你可以先抓取大类,然后获取每个类的所有小说,最后把每个类的所有小说。抓出小说的内容,这就是全站爬虫!!!
如果你还有其他合适的网站,希望你可以在评论区分享!一起交流吧!
c爬虫抓取网页数据(python网络爬虫-爬取网页的三种方式10.抓取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-21 07:20
Python网络爬虫——爬取网页的三种方式
10.前言0.1 爬取网页本文将介绍三种爬取网页数据的方式:正则表达式、BeautifulSoup、lxml。有关用于获取 Web 内容的代码的详细信息,请参阅 Python Web Crawler - Your First Crawler。使用此代码来抓取整个网页。
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
20.2 爬取目标爬取网页上所有显示的内容。
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
3 分析网页的结构,我们可以看到所有的内容都在标签中。以面积为例,我们可以看到面积的值为:
7,686,850平方公里
根据这个结构,我们用不同的方式来表达,就可以抓取到所有我们想要的数据。
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
4Chrome浏览器可以轻松复制各种表情:
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
5 有了上面的下载功能和不同的表达方式,我们可以通过三种不同的方式抓取数据。1.以不同的方式爬取数据1.1 正则表达式爬取网页正则表达式在python或其他语言中有很好的应用,用简单的规定符号来表达不同的字符串组成形式,简洁高效。学习正则表达式很有必要。Python 内置正则表达式,无需额外安装。
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
61.2BeautifulSoup爬取数据BeautifulSoup的使用可以在python网络爬虫-BeautifulSoup爬取网络数据中看到代码如下:
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
71.3 lxml抓包数据
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
81.4 个运行结果
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
9 从结果可以看出,正则表达式在某些地方返回了额外的元素,而不是纯文本。这是因为这些地方的网页结构与其他地方不同,所以正则表达式不能完全覆盖相同的内容,例如某些地方的链接和图片。并且 BeautifulSoup 和 lxml 具有提取文本的特殊功能,因此不会出现类似的错误。 查看全部
c爬虫抓取网页数据(python网络爬虫-爬取网页的三种方式10.抓取数据)
Python网络爬虫——爬取网页的三种方式
10.前言0.1 爬取网页本文将介绍三种爬取网页数据的方式:正则表达式、BeautifulSoup、lxml。有关用于获取 Web 内容的代码的详细信息,请参阅 Python Web Crawler - Your First Crawler。使用此代码来抓取整个网页。
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
20.2 爬取目标爬取网页上所有显示的内容。
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
3 分析网页的结构,我们可以看到所有的内容都在标签中。以面积为例,我们可以看到面积的值为:
7,686,850平方公里
根据这个结构,我们用不同的方式来表达,就可以抓取到所有我们想要的数据。
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
4Chrome浏览器可以轻松复制各种表情:
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
5 有了上面的下载功能和不同的表达方式,我们可以通过三种不同的方式抓取数据。1.以不同的方式爬取数据1.1 正则表达式爬取网页正则表达式在python或其他语言中有很好的应用,用简单的规定符号来表达不同的字符串组成形式,简洁高效。学习正则表达式很有必要。Python 内置正则表达式,无需额外安装。
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
61.2BeautifulSoup爬取数据BeautifulSoup的使用可以在python网络爬虫-BeautifulSoup爬取网络数据中看到代码如下:
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
71.3 lxml抓包数据
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
81.4 个运行结果
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
9 从结果可以看出,正则表达式在某些地方返回了额外的元素,而不是纯文本。这是因为这些地方的网页结构与其他地方不同,所以正则表达式不能完全覆盖相同的内容,例如某些地方的链接和图片。并且 BeautifulSoup 和 lxml 具有提取文本的特殊功能,因此不会出现类似的错误。
c爬虫抓取网页数据(2021-07-09pyspider框架介绍框架Scrapy)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-07 21:07
2021-07-09
pyspider框架介绍
pyspider是中文binux编写的强大的网络爬虫系统,它的GitHub地址是,官方文档地址是。
pyspider 带有强大的 WebUI、脚本编辑器、任务监视器、项目管理器和结果处理器。支持多数据库后端,多消息队列,爬取JavaScript渲染页面。使用起来非常方便。
pyspider基本功能
我们将 PySpider 的功能总结如下。
提供方便易用的WebUI系统,可以可视化编写和调试爬虫。
提供爬取进度监控、爬取结果查看、爬虫项目管理等功能。
支持多种后端数据库,如 MySQL、MongoDB、Redis、SQLite、Elasticsearch、PostgreSQL。
支持多个消息队列,如 RabbitMQ、Beanstalk、Redis、Kombu。
提供优先级控制、故障重试、定时捕捉等功能。
使用 PhantomJS,您可以抓取由 JavaScript 呈现的页面。
支持单机和分布式部署,支持Docker部署。
如果你想快速轻松地爬取一个页面,使用 pyspider 是一个不错的选择。
与 Scrapy 的比较
Scrapy,另一个爬虫框架,后面会介绍。学习了 Scrapy 之后,这部分就更容易理解了。我们先来了解一下pyspider和Scrapy的区别。
pyspider 提供 WebUI。爬虫的编写和调试都是在WebUI中进行的,而Scrapy原生没有这个功能。它使用代码和命令行操作,但可以连接到 Portia 以实现可视化配置。
pyspider的调试非常方便,WebUI的操作方便直观。在 Scrapy 中,使用 parse 命令进行调试,不如 pyspider 方便。
pyspider 支持 PhantomJS 在 JavaScript 采集 中渲染页面,并且 ScrapySplash 组件可以停靠在 Scrapy 中,这需要额外的配置。
PyQuery 作为选择器内置在 PySpider 中,XPath、CSS 选择器和正则匹配都停靠在 Scrapy 中。
pyspider的可扩展性不足,可配置程度不高。在Scrapy中,通过对接Middleware、Pipeline、Extension等组件可以实现非常强大的功能。模块间耦合度低,可扩展性极高。
如果想快速抓取一个页面,推荐使用pyspider,开发比较方便,比如快速抓取一个普通新闻网站的新闻内容。如果要处理非常大规模的抓取,反爬度很强,建议使用Scrapy,比如对网站的大规模数据采集的被封IP、被封账号进行抓取, 和高频验证。
pyspider的架构
pyspider的架构主要分为三个部分:Scheduler(调度器)、Fetcher(抓取器)、Processor(处理器)。整个爬取过程由Monitor(监视器)监控,爬取结果为Result Worker(results)。处理器),如图 12-1 所示。
Scheduler发起任务调度,Fetcher负责抓取网页内容,Processor负责解析网页内容,然后将新生成的Request发送给Scheduler进行调度,并保存生成的提取结果输出。
pyspider的任务执行过程逻辑很清晰,具体流程如下。
每个 pyspider 项目都对应一个 Python 脚本,该脚本定义了一个带有 on_start() 方法的 Handler 类。爬取首先调用on_start()方法生成初始爬取任务,然后发送给Scheduler进行调度。
Scheduler 将抓取任务分发给 Fetcher 进行抓取,Fetcher 执行并获取响应,然后将响应发送给 Processor。
Processer处理响应并提取新的URL生成新的爬虫任务,然后通过消息队列通知Schduler当前的爬虫任务执行状态,并将新生成的爬虫任务发送给Scheduler。如果生成了新的 fetch 结果,则将其发送到结果队列中,由 Result Worker 处理。
Scheduler接收到一个新的抓取任务,然后查询数据库,判断是新的抓取任务还是需要重试的任务,然后继续调度,然后发回Fetcher去抓取。
不断重复上述工作,直到所有任务都执行完毕,抓取结束。
捕获后,程序会回调on_finished()方法,这里可以定义后处理过程。结语
本节我们主要了解pyspider的基本功能和架构。接下来我们用一个例子来体验一下pyspider的爬取操作,然后总结一下它的各种用途。
分类:
技术要点:
相关文章: 查看全部
c爬虫抓取网页数据(2021-07-09pyspider框架介绍框架Scrapy)
2021-07-09
pyspider框架介绍
pyspider是中文binux编写的强大的网络爬虫系统,它的GitHub地址是,官方文档地址是。
pyspider 带有强大的 WebUI、脚本编辑器、任务监视器、项目管理器和结果处理器。支持多数据库后端,多消息队列,爬取JavaScript渲染页面。使用起来非常方便。
pyspider基本功能
我们将 PySpider 的功能总结如下。
提供方便易用的WebUI系统,可以可视化编写和调试爬虫。
提供爬取进度监控、爬取结果查看、爬虫项目管理等功能。
支持多种后端数据库,如 MySQL、MongoDB、Redis、SQLite、Elasticsearch、PostgreSQL。
支持多个消息队列,如 RabbitMQ、Beanstalk、Redis、Kombu。
提供优先级控制、故障重试、定时捕捉等功能。
使用 PhantomJS,您可以抓取由 JavaScript 呈现的页面。
支持单机和分布式部署,支持Docker部署。
如果你想快速轻松地爬取一个页面,使用 pyspider 是一个不错的选择。
与 Scrapy 的比较
Scrapy,另一个爬虫框架,后面会介绍。学习了 Scrapy 之后,这部分就更容易理解了。我们先来了解一下pyspider和Scrapy的区别。
pyspider 提供 WebUI。爬虫的编写和调试都是在WebUI中进行的,而Scrapy原生没有这个功能。它使用代码和命令行操作,但可以连接到 Portia 以实现可视化配置。
pyspider的调试非常方便,WebUI的操作方便直观。在 Scrapy 中,使用 parse 命令进行调试,不如 pyspider 方便。
pyspider 支持 PhantomJS 在 JavaScript 采集 中渲染页面,并且 ScrapySplash 组件可以停靠在 Scrapy 中,这需要额外的配置。
PyQuery 作为选择器内置在 PySpider 中,XPath、CSS 选择器和正则匹配都停靠在 Scrapy 中。
pyspider的可扩展性不足,可配置程度不高。在Scrapy中,通过对接Middleware、Pipeline、Extension等组件可以实现非常强大的功能。模块间耦合度低,可扩展性极高。
如果想快速抓取一个页面,推荐使用pyspider,开发比较方便,比如快速抓取一个普通新闻网站的新闻内容。如果要处理非常大规模的抓取,反爬度很强,建议使用Scrapy,比如对网站的大规模数据采集的被封IP、被封账号进行抓取, 和高频验证。
pyspider的架构
pyspider的架构主要分为三个部分:Scheduler(调度器)、Fetcher(抓取器)、Processor(处理器)。整个爬取过程由Monitor(监视器)监控,爬取结果为Result Worker(results)。处理器),如图 12-1 所示。
Scheduler发起任务调度,Fetcher负责抓取网页内容,Processor负责解析网页内容,然后将新生成的Request发送给Scheduler进行调度,并保存生成的提取结果输出。
pyspider的任务执行过程逻辑很清晰,具体流程如下。
每个 pyspider 项目都对应一个 Python 脚本,该脚本定义了一个带有 on_start() 方法的 Handler 类。爬取首先调用on_start()方法生成初始爬取任务,然后发送给Scheduler进行调度。
Scheduler 将抓取任务分发给 Fetcher 进行抓取,Fetcher 执行并获取响应,然后将响应发送给 Processor。
Processer处理响应并提取新的URL生成新的爬虫任务,然后通过消息队列通知Schduler当前的爬虫任务执行状态,并将新生成的爬虫任务发送给Scheduler。如果生成了新的 fetch 结果,则将其发送到结果队列中,由 Result Worker 处理。
Scheduler接收到一个新的抓取任务,然后查询数据库,判断是新的抓取任务还是需要重试的任务,然后继续调度,然后发回Fetcher去抓取。
不断重复上述工作,直到所有任务都执行完毕,抓取结束。
捕获后,程序会回调on_finished()方法,这里可以定义后处理过程。结语
本节我们主要了解pyspider的基本功能和架构。接下来我们用一个例子来体验一下pyspider的爬取操作,然后总结一下它的各种用途。
分类:
技术要点:
相关文章:
c爬虫抓取网页数据(学爬虫的几个误区,你都知道吗?(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-07 21:02
)
我其实没想到人们对爬行的热情如此之高。看来我的粉丝群中的每个人都想学习爬行。
反过来想,也就不足为奇了:爬虫等于数据,没有数据怎么办?
但我发现,这种基于能力和知识点的学习路线虽然看起来不错,但如果没有实际的项目支持,很难实施。
在和很多人的交流中,我也发现了学习爬虫的几个误区。
学习爬虫的几个误区
1.不明白:我开发了一个简单的爬虫对比葫芦画,但原理不明白,稍微改一下也不行。
2.缺乏明确的目标:如果你的目标是学习爬行,这还不够明确。进一步细化和明确目标,例如:学会攀登你最需要的3个网站。
3. 贪多,贪众:我没底子,只想一口吃掉一个胖子。很多人认为某件事并不难,但他们从来没有做过,或者从来没有学过。
4.缺乏实践经验:爬虫所涉及的知识体系非常丰富,超出了任何语言的范畴。如果被知识点驱使去学习爬虫,会非常困难,无法掌握关键点。
我一直主张以实战为切入点,学习技术。比如我在B站的Python_Seven酱也是实战的。小江机器人等项目很多人都很熟悉。
几周前突然想到爬虫的学习路线也可以这样做:
这种学习路径比基于能力和知识的阶梯更容易执行:
1.目标很明确,学习攀登10个不同难度级别网站。
2.目标明确,深度学习成为可能。确保完全理解 10 个 网站 抓取过程,而不仅仅是画一个勺子。
3.不要贪得太多,什么都不要,10个网站(还包括几个练习网站)。但不要太贪心。在你牢牢掌握这些之前,不要想着应用爬取,也不要去追求特别难的网站。
4.实战,up是实战,到底是实战。但经过实战,我学到了知识并付诸实践。
来吧,这是我们筛选的10个项目。
学习爬行的10个项目
具体的网站仅供参考,可以换成同难度的类似网站。
注意:8和9是同一个网站,使用的方法不同。
下面是10个网站及相关知识点的列表:
1.网站仅供参考,可替换为其他相同难度的网站。
2.以学习为目的,抓取过程一定要恰当,不要对网站的操作施加压力。
30天时间表
如果你有一个目标,你就必须有一个计划。我看到很多人说想学Python,一年前来找我,一年后还是那个状态。没有时间计划的目标大多是无法实现的目标。
我为这10个项目制定了30天的学习计划。
这个30天爬虫计划的第一天就是了解爬虫的规则。多条爬虫进公安局的故事大家都听过。所以这件事非常重要。
事实上,爬行动物是无辜的。明白了规则之后,爬虫变色就不用说了。否则,百度、谷歌、天眼查等大公司和平台都会进入。你要明白:什么是不可逾越的红线?什么可以爬?你能爬多少?如何文明优雅地攀登?
那么是时候攻克这10个爬虫项目了,涉及的知识点不同,从最简单的小虫卵到分布式的大型爬虫。
关于Python技术储备
学好 Python 是赚钱的好方法,不管是工作还是副业,但要学好 Python,还是要有学习计划的。最后,我们将分享一套完整的Python学习资料,以帮助那些想学习Python的朋友!
一、Python全方位学习路线
Python的各个方向都是将Python中常用的技术点进行整理,形成各个领域知识点的汇总。它的用处是你可以根据以上知识点找到对应的学习资源,保证你能学得更全面。
二、学习软件
工人要做好工作,首先要磨利他的工具。学习Python常用的开发软件就到这里,为大家节省不少时间。
三、入门视频
当我们看视频学习时,没有手我们就无法移动眼睛和大脑。更科学的学习方式是理解后再使用。这时候动手项目就很合适了。
四、实际案例
光学理论是无用的。你必须学会跟随,你必须先进行实际练习,然后才能将所学应用于实践。这时候可以借鉴实战案例。
五、采访信息
我们必须学习 Python 才能找到一份高薪工作。以下面试题是来自阿里、腾讯、字节跳动等一线互联网公司的最新面试资料,部分阿里大佬给出了权威答案。看完这套面试材料相信大家都能找到一份满意的工作。
本完整版Python全套学习资料已上传至CSDN。需要的可以微信扫描下方官方CSDN认证二维码免费获取【保证100%免费】
查看全部
c爬虫抓取网页数据(学爬虫的几个误区,你都知道吗?(上)
)
我其实没想到人们对爬行的热情如此之高。看来我的粉丝群中的每个人都想学习爬行。
反过来想,也就不足为奇了:爬虫等于数据,没有数据怎么办?
但我发现,这种基于能力和知识点的学习路线虽然看起来不错,但如果没有实际的项目支持,很难实施。
在和很多人的交流中,我也发现了学习爬虫的几个误区。
学习爬虫的几个误区
1.不明白:我开发了一个简单的爬虫对比葫芦画,但原理不明白,稍微改一下也不行。
2.缺乏明确的目标:如果你的目标是学习爬行,这还不够明确。进一步细化和明确目标,例如:学会攀登你最需要的3个网站。
3. 贪多,贪众:我没底子,只想一口吃掉一个胖子。很多人认为某件事并不难,但他们从来没有做过,或者从来没有学过。
4.缺乏实践经验:爬虫所涉及的知识体系非常丰富,超出了任何语言的范畴。如果被知识点驱使去学习爬虫,会非常困难,无法掌握关键点。
我一直主张以实战为切入点,学习技术。比如我在B站的Python_Seven酱也是实战的。小江机器人等项目很多人都很熟悉。
几周前突然想到爬虫的学习路线也可以这样做:
这种学习路径比基于能力和知识的阶梯更容易执行:
1.目标很明确,学习攀登10个不同难度级别网站。
2.目标明确,深度学习成为可能。确保完全理解 10 个 网站 抓取过程,而不仅仅是画一个勺子。
3.不要贪得太多,什么都不要,10个网站(还包括几个练习网站)。但不要太贪心。在你牢牢掌握这些之前,不要想着应用爬取,也不要去追求特别难的网站。
4.实战,up是实战,到底是实战。但经过实战,我学到了知识并付诸实践。
来吧,这是我们筛选的10个项目。
学习爬行的10个项目
具体的网站仅供参考,可以换成同难度的类似网站。
注意:8和9是同一个网站,使用的方法不同。
下面是10个网站及相关知识点的列表:
1.网站仅供参考,可替换为其他相同难度的网站。
2.以学习为目的,抓取过程一定要恰当,不要对网站的操作施加压力。
30天时间表
如果你有一个目标,你就必须有一个计划。我看到很多人说想学Python,一年前来找我,一年后还是那个状态。没有时间计划的目标大多是无法实现的目标。
我为这10个项目制定了30天的学习计划。
这个30天爬虫计划的第一天就是了解爬虫的规则。多条爬虫进公安局的故事大家都听过。所以这件事非常重要。
事实上,爬行动物是无辜的。明白了规则之后,爬虫变色就不用说了。否则,百度、谷歌、天眼查等大公司和平台都会进入。你要明白:什么是不可逾越的红线?什么可以爬?你能爬多少?如何文明优雅地攀登?
那么是时候攻克这10个爬虫项目了,涉及的知识点不同,从最简单的小虫卵到分布式的大型爬虫。
关于Python技术储备
学好 Python 是赚钱的好方法,不管是工作还是副业,但要学好 Python,还是要有学习计划的。最后,我们将分享一套完整的Python学习资料,以帮助那些想学习Python的朋友!
一、Python全方位学习路线
Python的各个方向都是将Python中常用的技术点进行整理,形成各个领域知识点的汇总。它的用处是你可以根据以上知识点找到对应的学习资源,保证你能学得更全面。
二、学习软件
工人要做好工作,首先要磨利他的工具。学习Python常用的开发软件就到这里,为大家节省不少时间。
三、入门视频
当我们看视频学习时,没有手我们就无法移动眼睛和大脑。更科学的学习方式是理解后再使用。这时候动手项目就很合适了。
四、实际案例
光学理论是无用的。你必须学会跟随,你必须先进行实际练习,然后才能将所学应用于实践。这时候可以借鉴实战案例。
五、采访信息
我们必须学习 Python 才能找到一份高薪工作。以下面试题是来自阿里、腾讯、字节跳动等一线互联网公司的最新面试资料,部分阿里大佬给出了权威答案。看完这套面试材料相信大家都能找到一份满意的工作。
本完整版Python全套学习资料已上传至CSDN。需要的可以微信扫描下方官方CSDN认证二维码免费获取【保证100%免费】
c爬虫抓取网页数据(PHPHTML数据爬虫的设计思路及应用的优势)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-05 16:08
内容
1. 为什么是爬虫?
在“大数据时代”,数据获取方式:
从第三方数据平台购买数据爬虫数据2.什么是爬虫?
抓取网络数据的程序
3. 爬虫如何抓取网页数据?
首先,你需要了解一个网页的三个特征:
每个网页都有自己的 URL(Uniform Resource Locator)来定位网页 所有使用 HTML(超文本标记语言)来描述页面信息 所有网页使用 HTTP/HTTPS(超文本传输协议)来传输 HTML 数据
爬虫设计思路:
首先确定需要爬取的网页的URL地址,通过HTTP/HTTPS协议获取对应的HTML页面,提取HTML页面中的有用数据:
一个。如果是需要的数据--保存
湾。如果还有其他网址,继续步骤2 4. Python爬虫的优势?语言的优点和缺点
PHP
世界上最好的语言
对于多线程,异步支持不好,并发处理不够
爪哇
完善的网络爬虫生态系统
Java语言本身繁琐,代码量大,数据重构成本高
C/C++
运营效率和性能几乎是最高的
学习成本高
Python
语法优美,代码简洁,开发效率高,模块多
5.抓取HTML页面的学习路线:解析服务器对应内容:采集动态HTML、Captcha处理Scrapy框架:分布式策略:爬虫、反爬虫、反反之间的较量爬虫:6.爬虫分类6.1 通用爬虫:
1.定义:搜索引擎爬虫系统
2.目标:爬取互联网上所有的网页,放到本地服务器上形成备份,对这些网页做相关的处理(提取关键词,去除广告),最终为用户提供借口拜访
3.爬取过程:
a) 首先选择一部分已有的URL,将这些URL放入爬取队列
b) 从队列中取出URL,然后解析NDS得到主机IP,然后到这个IP对应的服务器下载HTML页面,保存到搜索引擎的本地服务器,然后把爬取的抓取队列中的 URL
c) 分析网页内容,找出网页中的其他URL连接,继续第二步,直到爬取结束
4.搜索引擎如何获得一个新的网站 URL:
主动向搜索引擎提交网址:在其他网站中设置网站的外部链接:其他网站上方的友好链接搜索引擎会配合DNS服务商,可以快速< @k10@ >新网站
5.一般爬虫注意事项
万能爬虫不是万物皆可爬,它必须遵守规则:
机器人协议:该协议将指定通用爬虫爬取网页的权限
我们可以在不同的网页上访问机器人权限
6.一般爬虫一般流程:
7.通用爬虫的缺点
只能提供文本相关的内容(HTML、WORD、PDF)等,不能提供多媒体文件(msic、图片、视频)等二进制文件。结果是一样的,不同背景的人听不同的搜索结果是无法理解的 人的语义检索侧重于爬虫的优势
DNS域名解析成IP:在命令框中输入ping获取服务器的IP
6.2 关注爬虫:
爬虫程序员编写的针对某个内容的爬虫 -> 面向主题的爬虫,需要爬虫的爬虫 查看全部
c爬虫抓取网页数据(PHPHTML数据爬虫的设计思路及应用的优势)
内容
1. 为什么是爬虫?
在“大数据时代”,数据获取方式:
从第三方数据平台购买数据爬虫数据2.什么是爬虫?
抓取网络数据的程序
3. 爬虫如何抓取网页数据?
首先,你需要了解一个网页的三个特征:
每个网页都有自己的 URL(Uniform Resource Locator)来定位网页 所有使用 HTML(超文本标记语言)来描述页面信息 所有网页使用 HTTP/HTTPS(超文本传输协议)来传输 HTML 数据
爬虫设计思路:
首先确定需要爬取的网页的URL地址,通过HTTP/HTTPS协议获取对应的HTML页面,提取HTML页面中的有用数据:
一个。如果是需要的数据--保存
湾。如果还有其他网址,继续步骤2 4. Python爬虫的优势?语言的优点和缺点
PHP
世界上最好的语言
对于多线程,异步支持不好,并发处理不够
爪哇
完善的网络爬虫生态系统
Java语言本身繁琐,代码量大,数据重构成本高
C/C++
运营效率和性能几乎是最高的
学习成本高
Python
语法优美,代码简洁,开发效率高,模块多
5.抓取HTML页面的学习路线:解析服务器对应内容:采集动态HTML、Captcha处理Scrapy框架:分布式策略:爬虫、反爬虫、反反之间的较量爬虫:6.爬虫分类6.1 通用爬虫:
1.定义:搜索引擎爬虫系统
2.目标:爬取互联网上所有的网页,放到本地服务器上形成备份,对这些网页做相关的处理(提取关键词,去除广告),最终为用户提供借口拜访
3.爬取过程:
a) 首先选择一部分已有的URL,将这些URL放入爬取队列
b) 从队列中取出URL,然后解析NDS得到主机IP,然后到这个IP对应的服务器下载HTML页面,保存到搜索引擎的本地服务器,然后把爬取的抓取队列中的 URL
c) 分析网页内容,找出网页中的其他URL连接,继续第二步,直到爬取结束
4.搜索引擎如何获得一个新的网站 URL:
主动向搜索引擎提交网址:在其他网站中设置网站的外部链接:其他网站上方的友好链接搜索引擎会配合DNS服务商,可以快速< @k10@ >新网站
5.一般爬虫注意事项
万能爬虫不是万物皆可爬,它必须遵守规则:
机器人协议:该协议将指定通用爬虫爬取网页的权限
我们可以在不同的网页上访问机器人权限
6.一般爬虫一般流程:
7.通用爬虫的缺点
只能提供文本相关的内容(HTML、WORD、PDF)等,不能提供多媒体文件(msic、图片、视频)等二进制文件。结果是一样的,不同背景的人听不同的搜索结果是无法理解的 人的语义检索侧重于爬虫的优势
DNS域名解析成IP:在命令框中输入ping获取服务器的IP
6.2 关注爬虫:
爬虫程序员编写的针对某个内容的爬虫 -> 面向主题的爬虫,需要爬虫的爬虫
c爬虫抓取网页数据(2021-10-29刚学新浪微博热搜主题讨论量获取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-05 09:16
2021-10-29
刚学python爬虫,用爬虫爬了新浪微博热搜,看看效果如何。也是这段时间学习python的一个总结。
一、目的:
抓取2020年1月3日星期五新浪微博热搜榜,动态展示抓取数据,生成当日微博热词云和微博热搜前20关键词条形图。
二、事情:
分析新浪微博热搜榜,分析网页结构,分析网页,获取当前热门话题、排名、话题讨论量、当前爬取时间。由于微博热搜动态刷新,选择20-30分钟抓取数据,时间范围为9:30-21:00。将上次采集的数据全部导入实现数据动态显示的模块,并进行相关调整。使用口吃分词对获取的数据进行分词,使用WordCloud展示当日热度搜索热点词云
三、相关实现步骤
1.网页分析
定义一个请求头来模拟浏览器并随机生成一个请求头,方法def get_header():
header1 = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0"
}
header2 = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"
}
header3 = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"
}
header_list = [header1,header2,header3]
index = random.randint(0,1)
return header_list[index]
解析 网站 方法:def get_data(url, headers)
使用权
req = requests.get(url=url, headers=headers)
req.encoding = "utf-8"
通过lxml解析网页
bf = BeautifulSoup(html, "lxml")
通过观察,每个热搜都在tr class=""下,所以只需遍历所有class=""
你可以上每一个热搜
div_content = bf.find_all("tr", class_="")
遍历div_content获取各个热搜的排名、话题、讨论量
for item in div_content:
删除顶部消息并将变量 t = 1 添加到循环中
if (t == 1):
t = 0
continue
tr下有3条td信息,分别代表排名、热搜话题和浏览量、标签表达。前两条信息是我们想要得到的。
获取当前热搜排名
num_content = item.select("td")[0].string
热搜话题和浏览量分别在td-02的a标签和span标签下
获取当前热门话题
content = item.select("td")[1].select("a")[0].string
获取当前热搜话题的讨论量
num = item.select("td")[1].select("span")[0].string
获取当前系统时间需要在前面import from time import strftime
current_time = strftime("%Y-%m-%d %H:%M")
将当前热搜排名、当前热搜话题、当前热搜话题讨论量、当前系统时间放入列表存储数据
list = [content,num_content,num,current_time]
将整个列表放入列表中
list_content.append(list)
2.存储数据
存储爬取的数据,存储方式def store_Excel(list):
写入文件,编码方式为utf_8_sig,生成的csv文件不会乱码,不换行的操作为newline=""
with open("微博实时热搜.csv","a",encoding="utf_8_sig",newline="")as file:
csv_writer = csv.writer(file)
遍历列表,写
for item in list:
csv_writer.writerow(item)
关闭文件
file.close()
3.生成词云
想法:
整合一天爬取的所有数据
2、通过累加的方式遍历并累加列表,将列表变成长字符串
3.通过口吃分词和空间分词来分割字符串
4.找一张轮廓清晰的图片打开,使用numpy获取轮廓
5、使用WordCloud生成当天微博热点词云。
导入生成词云的库
rom wordcloud import WordCloud
import Image
import numpy
import jieba
为字符串存储定义字符串
str = ""
阅读热搜热点表
with open("微博实时热搜test.csv","r",encoding="utf_8_sig",newline="") as file:
csv_reader = csv.reader(file)
遍历列表
for item in csv_reader:
去掉第一个无用的信息,在循环外定义变量t=1
if t == 1:
t = 0
continue
字符串拼接,热门话题在第一栏
str += item[0]
关闭文件
file.close()
口吃分词
jieba_content = jieba.cut(str)
空间连接的join方法
join_content=" ".join(jieba_content)
打开图片
wei_bo = Image.open("logo.jpg")
找到轮廓
wei_bo_image = numpy.array(wei_bo)
制作生成的词云
word_cloud = WordCloud(font_path="font1.TTF",background_color="white",mask = wei_bo_image).generate(join_content)
word_cloud.to_file("微博热搜.jpg")
最终词云展示:
微博logo图片勾勒出文字云。字体大小代表受欢迎程度。字体越大,受欢迎程度越高。字体越小,受欢迎程度越低。
4.分析数据
想法:
1.将微博热门话题存储在txt文件中
2.读取txt文件,使用jieba分词进行分词,生成关键词
3. 对 关键词 执行频率统计
4.按频率降序对统计信息进行排序关键词
5. 将排序结果存储在 csv 文件中以供以后操作
定义词典
word_dic = {}
打开文件,读取数据
使用 open("1.txt", "r", encoding="utf-8") 作为文件:
txt = file.read()
文件.close()
jieba分词数据
单词 = jieba.lcut(txt)
循环数据
言归正传:
如果关键字数量为1,则不计入
如果 len(word) == 1:
继续
否则频率增加 1
别的:
word_dic[word] = word_dic.get(word, 0) + 1
将字典数据转换为元组数据,用zip实现
word_zip = zip(word_dic.values(), word_dic.keys())
根据值从大到小对元组中的数据进行排序
word_sort = list(排序(word_zip, reverse=True))
定义两个数据存储列表
list_1 = ["name", "count_name"]
list_2 = []
列表_2.追加(列表_1)
对于 word_sort 中的项目:
# 词频
计数 = 项目 [0]
#关键字
名称 = 项目 [1]
list_1 = [名称,计数]
列表_2.追加(列表_1)
写入文件
以open("微博热搜关键词词频统计.csv", "w", encoding="utf_8_sig", newline="")为文件:
csv_writer = csv.writer(文件)
遍历list_2并写入每一行
对于 list_2 中的 i:
csv_writer.writerow(i)
5.生成绘图
思路:根据热搜关键词的排序文件,提取频率最高的前20位数据,绘制条形图
导入绘图工具包
将熊猫导入为 pd
将 matplotlib.pyplot 导入为 plt
定义绘图样式和颜色
plt.style.use('ggplot')
颜色1 = '#6D6D6D'
读取排序文件
df = pd.read_csv("微博热搜关键词词频统计.csv",encoding="utf-8")
提取前 20 个 关键词 和频率
name1 = df.name[:20]
count1 = df.count_name[:20]
要绘制条形图,请使用 range() 使 x 轴保持正确的顺序
plt.bar(范围(20),count1,tick_label = name1)
设置纵坐标范围
plt.ylim(0,90)
显示中文字体标签
plt.rcParams['font.sans-serif'] = ['SimHei']
标题
plt.title('微博热搜关键词词频统计',color = colors1)
x 轴标题,y 轴标题
plt.title('微博热搜关键词词频统计',color = colors1)
plt.xlabel('关键词')
为每个条添加数字标签
对于枚举中的 x,y (list(count1)):
plt.text(x,y+1,'%s'%round(y,90),ha = 'center',color = colors1)
x轴关键字旋转300度
plt.xticks(旋转 = 300)
自动控制空白边距以显示所有 x 轴坐标
plt.tight_layout()
保存图片
plt.savefig('微博热搜关键词词频统计top20.png')
显示图像
plt.show()
绘图结果显示:
这次爬虫抓取了大约20组数据,每组数据对应50个热搜榜。爬取时间为2020年1月1日9:30-21:00,每次爬取时间间隔为20-30分钟。抓取这么多组数据的主要目的是为了做数据的动态效果,展示过去一天微博热搜的动态变化。
数据动态展示效果图:
完整数据动态效果视频请参考微博热搜数据动态展示.mp4
分类:
技术要点:
相关文章: 查看全部
c爬虫抓取网页数据(2021-10-29刚学新浪微博热搜主题讨论量获取)
2021-10-29
刚学python爬虫,用爬虫爬了新浪微博热搜,看看效果如何。也是这段时间学习python的一个总结。
一、目的:
抓取2020年1月3日星期五新浪微博热搜榜,动态展示抓取数据,生成当日微博热词云和微博热搜前20关键词条形图。
二、事情:
分析新浪微博热搜榜,分析网页结构,分析网页,获取当前热门话题、排名、话题讨论量、当前爬取时间。由于微博热搜动态刷新,选择20-30分钟抓取数据,时间范围为9:30-21:00。将上次采集的数据全部导入实现数据动态显示的模块,并进行相关调整。使用口吃分词对获取的数据进行分词,使用WordCloud展示当日热度搜索热点词云
三、相关实现步骤
1.网页分析
定义一个请求头来模拟浏览器并随机生成一个请求头,方法def get_header():
header1 = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0"
}
header2 = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"
}
header3 = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"
}
header_list = [header1,header2,header3]
index = random.randint(0,1)
return header_list[index]
解析 网站 方法:def get_data(url, headers)
使用权
req = requests.get(url=url, headers=headers)
req.encoding = "utf-8"
通过lxml解析网页
bf = BeautifulSoup(html, "lxml")
通过观察,每个热搜都在tr class=""下,所以只需遍历所有class=""
你可以上每一个热搜
div_content = bf.find_all("tr", class_="")
遍历div_content获取各个热搜的排名、话题、讨论量
for item in div_content:
删除顶部消息并将变量 t = 1 添加到循环中
if (t == 1):
t = 0
continue
tr下有3条td信息,分别代表排名、热搜话题和浏览量、标签表达。前两条信息是我们想要得到的。
获取当前热搜排名
num_content = item.select("td")[0].string
热搜话题和浏览量分别在td-02的a标签和span标签下
获取当前热门话题
content = item.select("td")[1].select("a")[0].string
获取当前热搜话题的讨论量
num = item.select("td")[1].select("span")[0].string
获取当前系统时间需要在前面import from time import strftime
current_time = strftime("%Y-%m-%d %H:%M")
将当前热搜排名、当前热搜话题、当前热搜话题讨论量、当前系统时间放入列表存储数据
list = [content,num_content,num,current_time]
将整个列表放入列表中
list_content.append(list)
2.存储数据
存储爬取的数据,存储方式def store_Excel(list):
写入文件,编码方式为utf_8_sig,生成的csv文件不会乱码,不换行的操作为newline=""
with open("微博实时热搜.csv","a",encoding="utf_8_sig",newline="")as file:
csv_writer = csv.writer(file)
遍历列表,写
for item in list:
csv_writer.writerow(item)
关闭文件
file.close()
3.生成词云
想法:
整合一天爬取的所有数据
2、通过累加的方式遍历并累加列表,将列表变成长字符串
3.通过口吃分词和空间分词来分割字符串
4.找一张轮廓清晰的图片打开,使用numpy获取轮廓
5、使用WordCloud生成当天微博热点词云。
导入生成词云的库
rom wordcloud import WordCloud
import Image
import numpy
import jieba
为字符串存储定义字符串
str = ""
阅读热搜热点表
with open("微博实时热搜test.csv","r",encoding="utf_8_sig",newline="") as file:
csv_reader = csv.reader(file)
遍历列表
for item in csv_reader:
去掉第一个无用的信息,在循环外定义变量t=1
if t == 1:
t = 0
continue
字符串拼接,热门话题在第一栏
str += item[0]
关闭文件
file.close()
口吃分词
jieba_content = jieba.cut(str)
空间连接的join方法
join_content=" ".join(jieba_content)
打开图片
wei_bo = Image.open("logo.jpg")
找到轮廓
wei_bo_image = numpy.array(wei_bo)
制作生成的词云
word_cloud = WordCloud(font_path="font1.TTF",background_color="white",mask = wei_bo_image).generate(join_content)
word_cloud.to_file("微博热搜.jpg")
最终词云展示:
微博logo图片勾勒出文字云。字体大小代表受欢迎程度。字体越大,受欢迎程度越高。字体越小,受欢迎程度越低。
4.分析数据
想法:
1.将微博热门话题存储在txt文件中
2.读取txt文件,使用jieba分词进行分词,生成关键词
3. 对 关键词 执行频率统计
4.按频率降序对统计信息进行排序关键词
5. 将排序结果存储在 csv 文件中以供以后操作
定义词典
word_dic = {}
打开文件,读取数据
使用 open("1.txt", "r", encoding="utf-8") 作为文件:
txt = file.read()
文件.close()
jieba分词数据
单词 = jieba.lcut(txt)
循环数据
言归正传:
如果关键字数量为1,则不计入
如果 len(word) == 1:
继续
否则频率增加 1
别的:
word_dic[word] = word_dic.get(word, 0) + 1
将字典数据转换为元组数据,用zip实现
word_zip = zip(word_dic.values(), word_dic.keys())
根据值从大到小对元组中的数据进行排序
word_sort = list(排序(word_zip, reverse=True))
定义两个数据存储列表
list_1 = ["name", "count_name"]
list_2 = []
列表_2.追加(列表_1)
对于 word_sort 中的项目:
# 词频
计数 = 项目 [0]
#关键字
名称 = 项目 [1]
list_1 = [名称,计数]
列表_2.追加(列表_1)
写入文件
以open("微博热搜关键词词频统计.csv", "w", encoding="utf_8_sig", newline="")为文件:
csv_writer = csv.writer(文件)
遍历list_2并写入每一行
对于 list_2 中的 i:
csv_writer.writerow(i)
5.生成绘图
思路:根据热搜关键词的排序文件,提取频率最高的前20位数据,绘制条形图
导入绘图工具包
将熊猫导入为 pd
将 matplotlib.pyplot 导入为 plt
定义绘图样式和颜色
plt.style.use('ggplot')
颜色1 = '#6D6D6D'
读取排序文件
df = pd.read_csv("微博热搜关键词词频统计.csv",encoding="utf-8")
提取前 20 个 关键词 和频率
name1 = df.name[:20]
count1 = df.count_name[:20]
要绘制条形图,请使用 range() 使 x 轴保持正确的顺序
plt.bar(范围(20),count1,tick_label = name1)
设置纵坐标范围
plt.ylim(0,90)
显示中文字体标签
plt.rcParams['font.sans-serif'] = ['SimHei']
标题
plt.title('微博热搜关键词词频统计',color = colors1)
x 轴标题,y 轴标题
plt.title('微博热搜关键词词频统计',color = colors1)
plt.xlabel('关键词')
为每个条添加数字标签
对于枚举中的 x,y (list(count1)):
plt.text(x,y+1,'%s'%round(y,90),ha = 'center',color = colors1)
x轴关键字旋转300度
plt.xticks(旋转 = 300)
自动控制空白边距以显示所有 x 轴坐标
plt.tight_layout()
保存图片
plt.savefig('微博热搜关键词词频统计top20.png')
显示图像
plt.show()
绘图结果显示:
这次爬虫抓取了大约20组数据,每组数据对应50个热搜榜。爬取时间为2020年1月1日9:30-21:00,每次爬取时间间隔为20-30分钟。抓取这么多组数据的主要目的是为了做数据的动态效果,展示过去一天微博热搜的动态变化。
数据动态展示效果图:
完整数据动态效果视频请参考微博热搜数据动态展示.mp4
分类:
技术要点:
相关文章:
c爬虫抓取网页数据(网络爬虫最基本的思路和处理方法(一)——1.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-02-05 09:12
1. 科普
一般搜索引擎处理的对象是互联网的网页。目前,网页数量已达数亿。因此,搜索引擎面临的第一个问题就是如何设计一个高效的下载系统。互联网页面的镜像。网络爬虫负责这个任务。
爬取网页的过程其实和读者平时使用IE浏览器浏览网页的方式是一样的。假设您在浏览器的地址栏中输入此地址。打开网页的过程其实就是浏览器作为浏览的“客户端”,向服务器端发出请求,将服务器端的文件“抓取”到本地,然后解释并显示出来。浏览器的作用是解析得到的HTML代码,然后将原来的网页转换成我们看到的网站页面。
网络爬虫最基本的思想是:从一个页面开始,分析其中的url,提取出来,然后通过这些链接寻找下一页。如此来回。
2. 通用爬虫框架
@7))。@9) 和 . 重复刚才的故事。
3. 网址
爬虫处理的主要对象是URL。简单地说,url就是输入的URL(例如:)。在了解 URL 之前先了解 URI。
Web 上可用的每个资源,例如 HTML 文档、图像、视频剪辑、程序等,都由通用资源标识符 (URI) 定位。
一个URI通常由三部分组成:
访问资源的命名机制 存储资源的资源的主机名 资源本身的名称,由路径表示
比如URI:
我们可以这样解释:
URL 是 URI 的子集。它是Uniform Resource Locator的缩写,翻译为“统一资源定位器”。
通俗的讲,URL是描述Internet上信息资源的字符串,主要用于各种WWW客户端程序和服务器程序中。
使用 URL 可以使用统一的格式来描述各种信息资源,包括文件、服务器地址和目录。
URL的格式由三部分组成:
第一部分是协议(或服务模式) 第二部分是存储资源的主机的IP地址(有时还包括端口号) 第三部分是主机资源的具体地址,如目录和文件名等
第一部分和第二部分用“://”符号分隔
第二部分和第三部分用“/”符号隔开
第 1 部分和第 2 部分缺一不可,第 3 部分有时可以省略 查看全部
c爬虫抓取网页数据(网络爬虫最基本的思路和处理方法(一)——1.)
1. 科普
一般搜索引擎处理的对象是互联网的网页。目前,网页数量已达数亿。因此,搜索引擎面临的第一个问题就是如何设计一个高效的下载系统。互联网页面的镜像。网络爬虫负责这个任务。
爬取网页的过程其实和读者平时使用IE浏览器浏览网页的方式是一样的。假设您在浏览器的地址栏中输入此地址。打开网页的过程其实就是浏览器作为浏览的“客户端”,向服务器端发出请求,将服务器端的文件“抓取”到本地,然后解释并显示出来。浏览器的作用是解析得到的HTML代码,然后将原来的网页转换成我们看到的网站页面。
网络爬虫最基本的思想是:从一个页面开始,分析其中的url,提取出来,然后通过这些链接寻找下一页。如此来回。
2. 通用爬虫框架
@7))。@9) 和 . 重复刚才的故事。
3. 网址
爬虫处理的主要对象是URL。简单地说,url就是输入的URL(例如:)。在了解 URL 之前先了解 URI。
Web 上可用的每个资源,例如 HTML 文档、图像、视频剪辑、程序等,都由通用资源标识符 (URI) 定位。
一个URI通常由三部分组成:
访问资源的命名机制 存储资源的资源的主机名 资源本身的名称,由路径表示
比如URI:
我们可以这样解释:
URL 是 URI 的子集。它是Uniform Resource Locator的缩写,翻译为“统一资源定位器”。
通俗的讲,URL是描述Internet上信息资源的字符串,主要用于各种WWW客户端程序和服务器程序中。
使用 URL 可以使用统一的格式来描述各种信息资源,包括文件、服务器地址和目录。
URL的格式由三部分组成:
第一部分是协议(或服务模式) 第二部分是存储资源的主机的IP地址(有时还包括端口号) 第三部分是主机资源的具体地址,如目录和文件名等
第一部分和第二部分用“://”符号分隔
第二部分和第三部分用“/”符号隔开
第 1 部分和第 2 部分缺一不可,第 3 部分有时可以省略
c爬虫抓取网页数据(抓取知乎所有用户信息的爬虫代码逻辑以及分析分析方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-05 09:09
2021-11-27
今天用递归写了一个爬虫,抓取知乎的所有用户信息。源代码放在github上。有兴趣的同学可以下载看看。这里介绍一下代码逻辑和分页分析。首先,看网页。,这里我随机选择一个大V作为入口,然后点击他的关注列表,如图
我们都知道 Python 很容易学习,但我们只是不知道如何学习它以及在哪里可以找到信息。在这里,python学习交流QQ群233539995,分享我精心准备的Python学习资料,0基础到高级!希望大家在学习Python的道路上少走弯路!来吧!
注意我的爬虫全名是非登录状态。这里的fan list和follower list是后台ajax请求获取的数据(没听说过ajax的不要慌,ajax请求和普通浏览器请求没什么区别,主要是偷偷发给服务器的)当我们浏览网页的时候请求是为了节省流量,减少请求次数,不然每次看新数据都会刷新网页,服务器压力很大,所以我们有这个东西),然后我们找到粉丝列表和关注者列表的网址,很简单,点击chrome浏览器下的页码开关即可找到,如图
很容易找到关注者和粉丝的 URL。让我们来看看这些数据。这是粉丝数据的一个例子。如图,是一段json
这里找到了粉丝的数据,但这不是用户的详细信息,只是部分数据,但是他提供了一个token_url,我们可以得到这个ID访问用户的详细信息,我们来看看如何提取每个用户的详细信息。在这里楼主发现,在看粉丝或者关注列表的时候,网页会自动触发对用户详细信息的请求,如图
本次获取用户详细信息查询的URL。我们来看看这个详细信息的URL,如图。
上面介绍了网页的基本分析。先说一下代码的思路。本次爬虫使用递归,本次使用scrapy进行爬取,存储mogodb数据库。
首先,我用了一个大V作为爬虫的第一个网页,然后分为三个步骤。第一步是爬取大V的详细信息,然后存入数据库。第二步是爬大V的粉丝。第三步是爬大V的粉丝(其实就是爬粉丝或者粉丝的token_url)。完成后,利用粉丝和关注者的爬取数据,构造他们每一个详细信息的url,然后挖掘详细信息存入数据库。至此,第一步递归完成,接下来爬虫会从每个粉丝和粉丝开始,分别爬取他们粉丝和粉丝的详细数据,继续递归。
代码中还添加了一些自动翻页功能,有兴趣的可以看看。以下是我们项目定义中要捕获的数据:
import scrapyclass 知乎UserItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() answer_count = scrapy.Field()
#回答数article_count = scrapy.Field()
#Written 文章 number follower_count = scrapy.Field()
#关注粉丝数_count = scrapy.Field()
#有多少人关注了educations=scrapy.Field()
#教育背景描述 = scrapy.Field()
#个人描述位置 = scrapy.Field()
#Location url_token =scrapy.Field()
#知乎给每个用户首页的唯一ID name=scrapy.Field()
#用户昵称员工 = scrapy.Field()
#工作信息business=scrapy.Field()
#工作或业务信息的集合 user_type =scrapy.Field()
#用户类型,可以是个人、群组等。headline =scrapy.Field()
#个人主页标签 voteup_count = scrapy.Field()
#获得的点赞数Thanks_count=scrapy.Field()
#感谢次数喜爱的_count = scrapy.Field()
#采集数量 avatar_url = scrapy.Field()
#头像网址
代码总共不到 80 行。运行一分钟后,它捕获了知乎 1000多个用户的信息。这是结果图片。
最近一直在忙别的事情,终于可以天天写爬虫了。不知道大家对这篇文章有没有什么问题,可以随时跟我提。
最后要提的是,爬取一定要伪装headers,里面有一些东西是服务器每次都会检查的。
我们都知道 Python 很容易学习,但我们只是不知道如何学习它以及在哪里可以找到信息。在这里,python学习交流QQ群233539995,分享我精心准备的Python学习资料,0基础到高级!希望大家在学习Python的道路上少走弯路!来吧!
分类:
技术要点:
相关文章: 查看全部
c爬虫抓取网页数据(抓取知乎所有用户信息的爬虫代码逻辑以及分析分析方法)
2021-11-27
今天用递归写了一个爬虫,抓取知乎的所有用户信息。源代码放在github上。有兴趣的同学可以下载看看。这里介绍一下代码逻辑和分页分析。首先,看网页。,这里我随机选择一个大V作为入口,然后点击他的关注列表,如图
我们都知道 Python 很容易学习,但我们只是不知道如何学习它以及在哪里可以找到信息。在这里,python学习交流QQ群233539995,分享我精心准备的Python学习资料,0基础到高级!希望大家在学习Python的道路上少走弯路!来吧!
注意我的爬虫全名是非登录状态。这里的fan list和follower list是后台ajax请求获取的数据(没听说过ajax的不要慌,ajax请求和普通浏览器请求没什么区别,主要是偷偷发给服务器的)当我们浏览网页的时候请求是为了节省流量,减少请求次数,不然每次看新数据都会刷新网页,服务器压力很大,所以我们有这个东西),然后我们找到粉丝列表和关注者列表的网址,很简单,点击chrome浏览器下的页码开关即可找到,如图
很容易找到关注者和粉丝的 URL。让我们来看看这些数据。这是粉丝数据的一个例子。如图,是一段json
这里找到了粉丝的数据,但这不是用户的详细信息,只是部分数据,但是他提供了一个token_url,我们可以得到这个ID访问用户的详细信息,我们来看看如何提取每个用户的详细信息。在这里楼主发现,在看粉丝或者关注列表的时候,网页会自动触发对用户详细信息的请求,如图
本次获取用户详细信息查询的URL。我们来看看这个详细信息的URL,如图。
上面介绍了网页的基本分析。先说一下代码的思路。本次爬虫使用递归,本次使用scrapy进行爬取,存储mogodb数据库。
首先,我用了一个大V作为爬虫的第一个网页,然后分为三个步骤。第一步是爬取大V的详细信息,然后存入数据库。第二步是爬大V的粉丝。第三步是爬大V的粉丝(其实就是爬粉丝或者粉丝的token_url)。完成后,利用粉丝和关注者的爬取数据,构造他们每一个详细信息的url,然后挖掘详细信息存入数据库。至此,第一步递归完成,接下来爬虫会从每个粉丝和粉丝开始,分别爬取他们粉丝和粉丝的详细数据,继续递归。
代码中还添加了一些自动翻页功能,有兴趣的可以看看。以下是我们项目定义中要捕获的数据:
import scrapyclass 知乎UserItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() answer_count = scrapy.Field()
#回答数article_count = scrapy.Field()
#Written 文章 number follower_count = scrapy.Field()
#关注粉丝数_count = scrapy.Field()
#有多少人关注了educations=scrapy.Field()
#教育背景描述 = scrapy.Field()
#个人描述位置 = scrapy.Field()
#Location url_token =scrapy.Field()
#知乎给每个用户首页的唯一ID name=scrapy.Field()
#用户昵称员工 = scrapy.Field()
#工作信息business=scrapy.Field()
#工作或业务信息的集合 user_type =scrapy.Field()
#用户类型,可以是个人、群组等。headline =scrapy.Field()
#个人主页标签 voteup_count = scrapy.Field()
#获得的点赞数Thanks_count=scrapy.Field()
#感谢次数喜爱的_count = scrapy.Field()
#采集数量 avatar_url = scrapy.Field()
#头像网址
代码总共不到 80 行。运行一分钟后,它捕获了知乎 1000多个用户的信息。这是结果图片。
最近一直在忙别的事情,终于可以天天写爬虫了。不知道大家对这篇文章有没有什么问题,可以随时跟我提。
最后要提的是,爬取一定要伪装headers,里面有一些东西是服务器每次都会检查的。
我们都知道 Python 很容易学习,但我们只是不知道如何学习它以及在哪里可以找到信息。在这里,python学习交流QQ群233539995,分享我精心准备的Python学习资料,0基础到高级!希望大家在学习Python的道路上少走弯路!来吧!
分类:
技术要点:
相关文章:
c爬虫抓取网页数据(关于爬虫的知识后,你了解多少?(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-05 00:04
)
如今,大前端理念已经深入人心,需要涉及的知识很多。所以,对于现在的前端来说,也是不可抗拒的。在修炼吸星大法时,尽可能多地吸收知识,最终达到物尽其用的效果。
最近也在学习爬虫,因为之前项目中需要用到的地铁信息数据不是爬虫爬下来的数据,而是直接复制过来的。
虽然这些数据暂时不会有太大变化,但感觉还是有点低。所以在了解了爬虫之后,打算和大家讨论交流,然后直接进入正题。
首先说一下爬虫和Robots协议是什么
然后介绍爬虫的基本流程
最后根据实际栗子爬个豆瓣最近上映的电影来试试小刀
2、爬虫和机器人协议
首先看定义:爬虫是自动获取网页内容的程序。它是搜索引擎的重要组成部分,因此搜索引擎优化主要针对爬虫进行优化。
下面我们来看看Robots协议的介绍。robots.txt 是文本文件,robots.txt 是协议,而不是命令。
robots.txt 是爬虫要查看的第一个文件。robots.txt 告诉爬虫可以在服务器上查看哪些文件。爬虫机器人会根据文件内容确定访问范围。
下图是豆瓣电影页面列出的robots协议的访问范围。
爬虫和机器人协议密切相关。如果您看到不允许抓取的页面,请不要抓取它们。万一涉及到用户隐私的某些方面,稍后会被发现并带到合法渠道。
因此,业内每个人都认可这个 Robots 协议。不想爬网页就别爬了,上网就可以安宁了。
有点跑题了,我们看下面一张图,简单梳理一下上面提到的内容。
其实有人会问,爬行动物到底在爬什么?
这是一个非常有见地的问题。说白了就是爬虫拿到的那段html代码,所以这对我们来说并不陌生,只要我们把它转换成DOM树就行了。
所以,现在看上图的右半部分,是一张对比图。
左边的那个没有受限的机器人协议。从逻辑上讲,admin/private和tmp这三个文件夹是不能被抓到的,但是因为没有Robots协议,人就可以肆无忌惮的爬了。
从右侧看,Robots 协议是有限的。相反,像谷歌这样的搜索引擎,也是通过 Robots.txt 文件来查看哪些是抓不到的,然后去 admin 或者 private 的时候直接跳过。去抢吧。
好了,介绍到此为止。凡是不包括真刀真枪的,都只是纸上谈兵。
3、爬虫基本流程
其实对于爬虫的使用来说,过程无非就是这四个步骤。
专用数据
数据存储
启动服务
渲染数据
专用数据
现在到了激动人心的部分,不要停下来,跟着我,敲出一页爬豆瓣电影,供自己欣赏。
我们先来看看整体的目录结构。
既然是抓数据,就得用业界知名的神器——request
请求工件
那么如何使用request,我们一起听风看代码
// 使用起来超简单let request = require('request');
request('http://www.baidu.com', function (error, response, body) { console.log('error:', error); // 当有错误发生时打印错误日志 console.log('statusCode:', response && response.statusCode); // 打印响应状态码 console.log('body:', body); // 打印百度页面的html代码});
看了上面的代码,是不是还觉得不明显。小伙伴们,html代码已经出现在你们面前了,不要犹豫,只要把它变成熟悉的DOM,就可以为所欲为。
于是,cheerio 出道,大家都称它为 Node 版的 jq。你可以完全按照jq的习惯来操作DOM。
下面不再走弯路,一起来写爬虫吧!
阅读内容
首页应该先分析豆瓣电影的页面,也就是热映的电影,我们先来看看DOM结构。
好了,读完噻吩后,我们需要的内容也标注出来了,然后进入read.js文件,一步步开始舔。
// read.js文件
// request-promise是让request支持了promise的语法,可以说是request的小弟const rp = require('request-promise');// 将抓取页面的html代码转为DOM,可以称之为是node版的jqconst cheerio = require('cheerio');// 这个是为了在调试时查看日志const debug = require('debug')('movie:read');
// 读取页面的方法,重点来了const read = async (url) => { debug('开始读取最近上映的电影');
const opts = { url, // 目标页面 transform: body => { // body为目标页面抓取到的html代码 // 通过cheerio.load方法可以把html代码转换成可以操作的DOM结构 return cheerio.load(body); } };
return rp(opts).then($ => { let result = []; // 结果数组 // 遍历这些热映电影的li $('#screening li.ui-slide-item').each((index, item) => { let ele = $(item); let name = ele.data('title'); let score = ele.data('rate') || '暂无评分'; let href = ele.find('.poster a').attr('href'); let image = ele.find('img').attr('src'); // 影片id可以从影片href中获取到 let id = href && href.match(/(\d+)/)[1]; // 为了防止豆瓣防盗链导致裂图,换成webp格式加载图片 image = image && image.replace(/jpg$/, 'webp');
if (!name || !image || !href) { return; }
result.push({ name, score, href, image, id }); debug(`正在读取电影:${name}`); }); // 返回结果数组 return result; });};// 导出方法module.exports = read;
写完代码,让我们回忆一下你做了什么。
4、数据存储
这里我们使用mysql建一个数据库来存储数据,不懂的没关系,我先一步一步来。我们首先安装 XAMPP 和 Navicat 可视化数据库管理工具,安装完成后,按照下面的说明进行操作。
XAMPP启动mysql
Navicat 连接数据库并创建表
几句话可能不像有图有真相那么真实。我们先来看看图片。
嗯,看图的时代到此结束。我真的很惭愧消耗了大量的流量。现在让我们回到编码阶段。
连接到数据库
首先,我们需要在 src 目录下创建一个 sql 文件。它需要和我们刚刚创建的数据库同名,所以我们称之为my_movie.sql(当然目录结构已经创建好了)
然后,回到 db.js 文件,编写连接数据库的代码
// db.js
const mysql = require('mysql');const bluebird = require('bluebird');
// 创建连接const connection = mysql.createConnection({ host: 'localhost', // host port: 3306, // 端口号默认3306 database: 'my_movie', // 对应的数据库 user: 'root', password: ''});
connection.connect(); // 连接数据库
// bluebird是为了方便支持promise语法化// 然后直接把数据库的query查询语句导出方便之后调用module.exports = bluebird.promisify(connection.query).bind(connection);
上面的代码已经创建了连接Mysql数据库的操作。接下来,不要放慢速度,将内容直接写入数据库。
写入数据库
这时候我们来看看write.js这个文件。是的,顾名思义,就是用来写数据库的,直接上代码
// write.js文件
// 从db.js那里导入query方法const query = require('./db');const debug = require('debug')('movie:write');// 写入数据库的方法const write = async (movies) => { debug('开始写入电影');
// movies即为read.js读取出来的结果数组 for (let movie of movies) { // 通过query方法去查询一下是不是已经在数据库里存过了 let oldMovie = await query('SELECT * FROM movies WHERE id=? LIMIT 1', [movie.id]);
// sql查询语句返回的是一个数组,如果不为空数组的话就表示有数据存过 // 直接就进行更新操作了 if (Array.isArray(oldMovie) && oldMovie.length) { // 更新movies表里的数据 let old = oldMovie[0]; await query('UPDATE movies SET name=?,href=?,image=?,score=? WHERE id=?', [movie.name, movie.href, movie.image, movie.score, old.id]); } else { // 插入内容到movies表 await query('INSERT INTO movies(id,name,href,image,score) VALUES(?,?,?,?,?)', [movie.id, movie.name, movie.href, movie.image, movie.score]); }
debug(`正在写入电影:${movie.name}`); }};
module.exports = write;
上面写的可能有点混乱,毕竟纯前端很少写SQL语句。不过不要害羞,我先把上面的代码整理好之后再简单介绍一下SQL语句部分。
write.js 到底写了什么?
好了,上面也实现了写入数据库的方法。接下来,趁热打铁,稍微聊聊SQL语句。
SQL语句学习
? 表示占位符。顺便说一下,我将简要介绍将在 SQL 语句中使用的语法,以及无处不在的增删改查。
插入数据
语法: INSERT INTO 表名(列名) VALUES(列名值)栗子: INSERT INTO tags(name,id,url) VALUES('爬虫',10,'https://news.so.com/hotnews')解释: 向标签表(tags)里插入一条,姓名,id和访问地址分别为VALUES内对应的值
更新数据
语法: UPDATE 表名 SET 列名=更新值 WHERE 更新条件栗子: UPDATE articles SET title='你好,世界',content='世界没你想的那么糟!' WHERE id=1解释: 更新id为1的文章,标题和内容都进行了修改
删除数据
语法: DELETE FROM 表名 WHERE 删除条件栗子: DELETE FROM tags WHERE id=11解释: 从标签表(tags)里删除id为11的数据
查询
语法: SELECT 列名 FROM 表名 WHERE 查询条件 ORDER BY 排序列名栗子: SELECT name,title,content FROM tags WHERE id=8解释: 查询id为8的标签表里对应信息
至此,我已经把所有的读写方法都写完了,所以大家一定是有点累了。是时候测试结果了,否则都是废话
5、执行读写操作
现在来到 index.js 并开始检查它。
// index.js文件
const read = require('./read');const write = require('./write');const url = 'https://movie.douban.com'; // 目标页面
(async () => { // 异步抓取目标页面 const movies = await read(url); // 写入数据到数据库 await write(movies); // 完毕后退出程序 process.exit();})();
完了,执行一下看看效果如何,直接上图
代码已执行。接下来回到Navicat,看看数据是否已经写入。我们用图片来说话。
至此,我们已经完成了数据采集和存储操作,但似乎还缺少什么?
也就是我们需要写一个页面来展示它,因为爬取和写数据只允许在node环境下进行。所以我们还要创建一个web服务来显示页面,坚持下去很快就OK了,加油。
6、启动服务
既然我们要创建一个 web 服务,让我们开始编写 server.js 的内容
服务器服务
// server.js文件
const express = require('express');const path = require('path');const query = require('../src/db');const app = express();
// 设置模板引擎app.set('view engine', 'html');app.set('views', path.join(__dirname, 'views'));app.engine('html', require('ejs').__express);
// 首页路由app.get('/', async (req, res) => { // 通过SQL查询语句拿到库里的movies表数据 const movies = await query('SELECT * FROM movies'); // 渲染首页模板并把movies数据传过去 res.render('index', { movies });});// 监听localhost:9000端口app.listen(9000);
写完服务端服务,我们再来看看 index.html 模板。这是最后一件事。写完,就大功告成了。
7、渲染数据
// index.html
热映的电影 正在热映的电影 %=movie.image% <p class="score">评分: </a>
</p>
通过模板引擎遍历movies数组,然后渲染
现在,看看最终效果
和你一起来到这里是缘分。我很高兴经历了这么长时间的文章 学习。每个人都应该对爬行动物的知识有一个很好的了解。
对了,这里是代码地址:爬虫研究/电影
为了您的方便,敲敲敲。
感谢阅读,886。
查看全部
c爬虫抓取网页数据(关于爬虫的知识后,你了解多少?(一)
)
如今,大前端理念已经深入人心,需要涉及的知识很多。所以,对于现在的前端来说,也是不可抗拒的。在修炼吸星大法时,尽可能多地吸收知识,最终达到物尽其用的效果。
最近也在学习爬虫,因为之前项目中需要用到的地铁信息数据不是爬虫爬下来的数据,而是直接复制过来的。
虽然这些数据暂时不会有太大变化,但感觉还是有点低。所以在了解了爬虫之后,打算和大家讨论交流,然后直接进入正题。
首先说一下爬虫和Robots协议是什么
然后介绍爬虫的基本流程
最后根据实际栗子爬个豆瓣最近上映的电影来试试小刀
2、爬虫和机器人协议
首先看定义:爬虫是自动获取网页内容的程序。它是搜索引擎的重要组成部分,因此搜索引擎优化主要针对爬虫进行优化。
下面我们来看看Robots协议的介绍。robots.txt 是文本文件,robots.txt 是协议,而不是命令。
robots.txt 是爬虫要查看的第一个文件。robots.txt 告诉爬虫可以在服务器上查看哪些文件。爬虫机器人会根据文件内容确定访问范围。
下图是豆瓣电影页面列出的robots协议的访问范围。
爬虫和机器人协议密切相关。如果您看到不允许抓取的页面,请不要抓取它们。万一涉及到用户隐私的某些方面,稍后会被发现并带到合法渠道。
因此,业内每个人都认可这个 Robots 协议。不想爬网页就别爬了,上网就可以安宁了。
有点跑题了,我们看下面一张图,简单梳理一下上面提到的内容。
其实有人会问,爬行动物到底在爬什么?
这是一个非常有见地的问题。说白了就是爬虫拿到的那段html代码,所以这对我们来说并不陌生,只要我们把它转换成DOM树就行了。
所以,现在看上图的右半部分,是一张对比图。
左边的那个没有受限的机器人协议。从逻辑上讲,admin/private和tmp这三个文件夹是不能被抓到的,但是因为没有Robots协议,人就可以肆无忌惮的爬了。
从右侧看,Robots 协议是有限的。相反,像谷歌这样的搜索引擎,也是通过 Robots.txt 文件来查看哪些是抓不到的,然后去 admin 或者 private 的时候直接跳过。去抢吧。
好了,介绍到此为止。凡是不包括真刀真枪的,都只是纸上谈兵。
3、爬虫基本流程
其实对于爬虫的使用来说,过程无非就是这四个步骤。
专用数据
数据存储
启动服务
渲染数据
专用数据
现在到了激动人心的部分,不要停下来,跟着我,敲出一页爬豆瓣电影,供自己欣赏。
我们先来看看整体的目录结构。
既然是抓数据,就得用业界知名的神器——request
请求工件
那么如何使用request,我们一起听风看代码
// 使用起来超简单let request = require('request');
request('http://www.baidu.com', function (error, response, body) { console.log('error:', error); // 当有错误发生时打印错误日志 console.log('statusCode:', response && response.statusCode); // 打印响应状态码 console.log('body:', body); // 打印百度页面的html代码});
看了上面的代码,是不是还觉得不明显。小伙伴们,html代码已经出现在你们面前了,不要犹豫,只要把它变成熟悉的DOM,就可以为所欲为。
于是,cheerio 出道,大家都称它为 Node 版的 jq。你可以完全按照jq的习惯来操作DOM。
下面不再走弯路,一起来写爬虫吧!
阅读内容
首页应该先分析豆瓣电影的页面,也就是热映的电影,我们先来看看DOM结构。
好了,读完噻吩后,我们需要的内容也标注出来了,然后进入read.js文件,一步步开始舔。
// read.js文件
// request-promise是让request支持了promise的语法,可以说是request的小弟const rp = require('request-promise');// 将抓取页面的html代码转为DOM,可以称之为是node版的jqconst cheerio = require('cheerio');// 这个是为了在调试时查看日志const debug = require('debug')('movie:read');
// 读取页面的方法,重点来了const read = async (url) => { debug('开始读取最近上映的电影');
const opts = { url, // 目标页面 transform: body => { // body为目标页面抓取到的html代码 // 通过cheerio.load方法可以把html代码转换成可以操作的DOM结构 return cheerio.load(body); } };
return rp(opts).then($ => { let result = []; // 结果数组 // 遍历这些热映电影的li $('#screening li.ui-slide-item').each((index, item) => { let ele = $(item); let name = ele.data('title'); let score = ele.data('rate') || '暂无评分'; let href = ele.find('.poster a').attr('href'); let image = ele.find('img').attr('src'); // 影片id可以从影片href中获取到 let id = href && href.match(/(\d+)/)[1]; // 为了防止豆瓣防盗链导致裂图,换成webp格式加载图片 image = image && image.replace(/jpg$/, 'webp');
if (!name || !image || !href) { return; }
result.push({ name, score, href, image, id }); debug(`正在读取电影:${name}`); }); // 返回结果数组 return result; });};// 导出方法module.exports = read;
写完代码,让我们回忆一下你做了什么。
4、数据存储
这里我们使用mysql建一个数据库来存储数据,不懂的没关系,我先一步一步来。我们首先安装 XAMPP 和 Navicat 可视化数据库管理工具,安装完成后,按照下面的说明进行操作。
XAMPP启动mysql
Navicat 连接数据库并创建表
几句话可能不像有图有真相那么真实。我们先来看看图片。
嗯,看图的时代到此结束。我真的很惭愧消耗了大量的流量。现在让我们回到编码阶段。
连接到数据库
首先,我们需要在 src 目录下创建一个 sql 文件。它需要和我们刚刚创建的数据库同名,所以我们称之为my_movie.sql(当然目录结构已经创建好了)
然后,回到 db.js 文件,编写连接数据库的代码
// db.js
const mysql = require('mysql');const bluebird = require('bluebird');
// 创建连接const connection = mysql.createConnection({ host: 'localhost', // host port: 3306, // 端口号默认3306 database: 'my_movie', // 对应的数据库 user: 'root', password: ''});
connection.connect(); // 连接数据库
// bluebird是为了方便支持promise语法化// 然后直接把数据库的query查询语句导出方便之后调用module.exports = bluebird.promisify(connection.query).bind(connection);
上面的代码已经创建了连接Mysql数据库的操作。接下来,不要放慢速度,将内容直接写入数据库。
写入数据库
这时候我们来看看write.js这个文件。是的,顾名思义,就是用来写数据库的,直接上代码
// write.js文件
// 从db.js那里导入query方法const query = require('./db');const debug = require('debug')('movie:write');// 写入数据库的方法const write = async (movies) => { debug('开始写入电影');
// movies即为read.js读取出来的结果数组 for (let movie of movies) { // 通过query方法去查询一下是不是已经在数据库里存过了 let oldMovie = await query('SELECT * FROM movies WHERE id=? LIMIT 1', [movie.id]);
// sql查询语句返回的是一个数组,如果不为空数组的话就表示有数据存过 // 直接就进行更新操作了 if (Array.isArray(oldMovie) && oldMovie.length) { // 更新movies表里的数据 let old = oldMovie[0]; await query('UPDATE movies SET name=?,href=?,image=?,score=? WHERE id=?', [movie.name, movie.href, movie.image, movie.score, old.id]); } else { // 插入内容到movies表 await query('INSERT INTO movies(id,name,href,image,score) VALUES(?,?,?,?,?)', [movie.id, movie.name, movie.href, movie.image, movie.score]); }
debug(`正在写入电影:${movie.name}`); }};
module.exports = write;
上面写的可能有点混乱,毕竟纯前端很少写SQL语句。不过不要害羞,我先把上面的代码整理好之后再简单介绍一下SQL语句部分。
write.js 到底写了什么?
好了,上面也实现了写入数据库的方法。接下来,趁热打铁,稍微聊聊SQL语句。
SQL语句学习
? 表示占位符。顺便说一下,我将简要介绍将在 SQL 语句中使用的语法,以及无处不在的增删改查。
插入数据
语法: INSERT INTO 表名(列名) VALUES(列名值)栗子: INSERT INTO tags(name,id,url) VALUES('爬虫',10,'https://news.so.com/hotnews')解释: 向标签表(tags)里插入一条,姓名,id和访问地址分别为VALUES内对应的值
更新数据
语法: UPDATE 表名 SET 列名=更新值 WHERE 更新条件栗子: UPDATE articles SET title='你好,世界',content='世界没你想的那么糟!' WHERE id=1解释: 更新id为1的文章,标题和内容都进行了修改
删除数据
语法: DELETE FROM 表名 WHERE 删除条件栗子: DELETE FROM tags WHERE id=11解释: 从标签表(tags)里删除id为11的数据
查询
语法: SELECT 列名 FROM 表名 WHERE 查询条件 ORDER BY 排序列名栗子: SELECT name,title,content FROM tags WHERE id=8解释: 查询id为8的标签表里对应信息
至此,我已经把所有的读写方法都写完了,所以大家一定是有点累了。是时候测试结果了,否则都是废话
5、执行读写操作
现在来到 index.js 并开始检查它。
// index.js文件
const read = require('./read');const write = require('./write');const url = 'https://movie.douban.com'; // 目标页面
(async () => { // 异步抓取目标页面 const movies = await read(url); // 写入数据到数据库 await write(movies); // 完毕后退出程序 process.exit();})();
完了,执行一下看看效果如何,直接上图
代码已执行。接下来回到Navicat,看看数据是否已经写入。我们用图片来说话。
至此,我们已经完成了数据采集和存储操作,但似乎还缺少什么?
也就是我们需要写一个页面来展示它,因为爬取和写数据只允许在node环境下进行。所以我们还要创建一个web服务来显示页面,坚持下去很快就OK了,加油。
6、启动服务
既然我们要创建一个 web 服务,让我们开始编写 server.js 的内容
服务器服务
// server.js文件
const express = require('express');const path = require('path');const query = require('../src/db');const app = express();
// 设置模板引擎app.set('view engine', 'html');app.set('views', path.join(__dirname, 'views'));app.engine('html', require('ejs').__express);
// 首页路由app.get('/', async (req, res) => { // 通过SQL查询语句拿到库里的movies表数据 const movies = await query('SELECT * FROM movies'); // 渲染首页模板并把movies数据传过去 res.render('index', { movies });});// 监听localhost:9000端口app.listen(9000);
写完服务端服务,我们再来看看 index.html 模板。这是最后一件事。写完,就大功告成了。
7、渲染数据
// index.html
热映的电影 正在热映的电影 %=movie.image% <p class="score">评分: </a>
</p>
通过模板引擎遍历movies数组,然后渲染
现在,看看最终效果
和你一起来到这里是缘分。我很高兴经历了这么长时间的文章 学习。每个人都应该对爬行动物的知识有一个很好的了解。
对了,这里是代码地址:爬虫研究/电影
为了您的方便,敲敲敲。
感谢阅读,886。
c爬虫抓取网页数据(优采云云采集网络爬虫软件如何用c#实现网站数据的抓取?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-02-04 18:34
优采云云端采集网络爬虫软件如何使用c#实现网站数据抓取?如何使用c#实现网站数据抓取?首先需要明确:网站的任何页面,无论是php、jsp、aspx等动态页面还是后台程序生成的静态页面,都可以在浏览器。所以当你想开发一个data采集程序时,你首先要了解你要采集的网站的首页结构(HTML)。一旦您熟悉了 网站 中您想要 采集 数据的 HTML 源文件的内容,程序的其余部分就很容易了。因为C#对网站数据采集的原理是“把你要的页面的HTML文件下载到采集,
这样,整个采集的工作就会在一个段落中完成。先说怎么抓取吧:1、抓取通用内容需要三个类:WebRequest、WebResponse、StreamReader 需要的命名空间:System.Net、System.IO 核心代码:WebRequest 创建是静态方法,参数是待抓取网页的网址;编码指定编码。Encoding中有ASCII、UTF32、UTF8等全局编码,但是没有gb2312的encoding属性,所以我们使用GetEncoding来获取gb2312编码。优采云云采集网络爬虫软件2、抓取图片或其他二进制文件(如文件) 需要四个类:WebRequest、WebResponse、Stream、FileStream 需要的命名空间:System .Net、System .IO核心代码:使用Stream读取3、 抓取网页内容POST方法抓取网页时,有时需要通过Post向服务器发送一些数据,在网页抓取程序中添加如下代码,实现向服务器发送用户名和密码:优采云Cloud采集Web爬虫软件4、ASP.NET爬取网页内容-防止爬取时重定向 抓取网页时,成功登录服务器应用系统后,应用系统可能会重定向网页通过 Response.Redirect。如果这个重定向不需要响应,那么我们就不需要读取 reader.ReadToEnd() Response.Write out ,就是这样。实现post用户名和密码到服务器:优采云云采集网络爬虫软件4、ASP.NET爬取网页内容-防止爬取时重定向抓取网页时,登录成功后在服务器应用系统中,应用系统可以通过Response.Redirect重定向网页。如果这个重定向不需要响应,那么我们就不需要读取 reader.ReadToEnd() Response.Write out ,就是这样。实现post用户名和密码到服务器:优采云云采集网络爬虫软件4、ASP.NET爬取网页内容-防止爬取时重定向抓取网页时,登录成功后在服务器应用系统中,应用系统可以通过Response.Redirect重定向网页。如果这个重定向不需要响应,那么我们就不需要读取 reader.ReadToEnd() Response.Write out ,就是这样。
5、ASP.NET爬取网页内容-维护登录状态使用Post数据成功登录服务器应用系统后,需要登录的页面就可以获取到了,那么我们可能需要维护登录多个请求之间的状态。优采云云采集Web爬虫软件首先,我们需要使用HttpWebRequest,而不是WebRequest。与WebRequest相比,改代码为: 注意:HttpWebRequest.Create返回的类型还是WebRequest,所以需要进行转换。二、使用CookieContainer。这样,requests和request2之间就使用了同一个Session。如果请求已登录,则 request2 也处于已登录状态。最后,如何在不同页面之间使用同一个CookieContainer。要在不同页面之间使用相同的 CookieContainer,只将 CookieContainer 添加到 Session。优采云云采集网络爬虫软件6、抓取需要登录的网站,因为需要登录的是网站,所以是用户登录时需要分析浏览器的方向。服务器发送的POST请求。1.安装httpwatch 2.使用IE浏览器进入网站的登录页面3.打开httpwatch的记录开始追踪4.输入账号密码,确认登录抓包流程:重点关注POST请求中的Url和postdata,以及服务器返回的cookie采集教程:优采云云采集网络爬虫软件顺奇网企业资料采集 114 黄页企业资料采集 @采集网络爬虫软件6、抓取需要登录的网站,因为需要登录的是网站,所以需要分析浏览器的方向用户登录。服务器发送的 POST 请求。1.安装httpwatch 2.使用IE浏览器进入网站的登录页面3.打开httpwatch的记录开始追踪4.输入账号密码,确认登录抓包流程:重点关注POST请求中的Url和postdata,以及服务器返回的cookie采集教程:优采云云采集网络爬虫软件顺奇网企业资料采集 114 黄页企业资料采集 @采集网络爬虫软件6、抓取需要登录的网站,因为需要登录的是网站,所以需要分析浏览器的方向用户登录。服务器发送的 POST 请求。1.安装httpwatch 2.使用IE浏览器进入网站的登录页面3.打开httpwatch的记录开始追踪4.输入账号密码,确认登录抓包流程:重点关注POST请求中的Url和postdata,以及服务器返回的cookie采集教程:优采云云采集网络爬虫软件顺奇网企业资料采集 114 黄页企业资料采集 需要登录,因为需要登录的是网站,所以需要分析用户登录时浏览器的方向。服务器发送的POST请求。1.安装httpwatch 2.用IE浏览器进入网站的登录页面3.打开httpwatch的记录开始追踪4.输入账号密码,确认登录抓包流程:重点关注POST请求中的Url和postdata,以及服务器返回的cookie采集教程:优采云云采集网络爬虫软件顺奇网企业资料采集 114 黄页企业资料采集 需要登录,因为需要登录的是网站,所以需要分析用户登录时浏览器的方向。服务器发送的POST请求。1.安装httpwatch 2.使用IE浏览器进入网站的登录页面3.打开httpwatch的记录开始追踪4.输入账号密码,确认登录抓包流程:重点关注POST请求中的Url和postdata,以及服务器返回的cookie采集教程:优采云云采集网络爬虫软件顺奇网企业资料采集 114 黄页企业资料采集
1、简单易用,任何人都可以使用:无需技术背景,只需了解互联网采集。全程可视化流程,点击鼠标完成操作,2分钟快速上手。2、功能强大,任何网站都可以使用:点击、登录、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据网页,都可以通过简单的设置进行采集。3、在采集 中,也可以关闭。配置好采集任务后,可以关机,侧边执行任务。庞大的采集集群24*7不间断运行,不用担心IP被封或者网络中断。4、功能免费+增值服务,可以按需选择。免费版具有满足用户基本采集需求的所有功能。同时,设置一些增值服务(如私有制),以满足高端付费企业用户的需求。 查看全部
c爬虫抓取网页数据(优采云云采集网络爬虫软件如何用c#实现网站数据的抓取?)
优采云云端采集网络爬虫软件如何使用c#实现网站数据抓取?如何使用c#实现网站数据抓取?首先需要明确:网站的任何页面,无论是php、jsp、aspx等动态页面还是后台程序生成的静态页面,都可以在浏览器。所以当你想开发一个data采集程序时,你首先要了解你要采集的网站的首页结构(HTML)。一旦您熟悉了 网站 中您想要 采集 数据的 HTML 源文件的内容,程序的其余部分就很容易了。因为C#对网站数据采集的原理是“把你要的页面的HTML文件下载到采集,
这样,整个采集的工作就会在一个段落中完成。先说怎么抓取吧:1、抓取通用内容需要三个类:WebRequest、WebResponse、StreamReader 需要的命名空间:System.Net、System.IO 核心代码:WebRequest 创建是静态方法,参数是待抓取网页的网址;编码指定编码。Encoding中有ASCII、UTF32、UTF8等全局编码,但是没有gb2312的encoding属性,所以我们使用GetEncoding来获取gb2312编码。优采云云采集网络爬虫软件2、抓取图片或其他二进制文件(如文件) 需要四个类:WebRequest、WebResponse、Stream、FileStream 需要的命名空间:System .Net、System .IO核心代码:使用Stream读取3、 抓取网页内容POST方法抓取网页时,有时需要通过Post向服务器发送一些数据,在网页抓取程序中添加如下代码,实现向服务器发送用户名和密码:优采云Cloud采集Web爬虫软件4、ASP.NET爬取网页内容-防止爬取时重定向 抓取网页时,成功登录服务器应用系统后,应用系统可能会重定向网页通过 Response.Redirect。如果这个重定向不需要响应,那么我们就不需要读取 reader.ReadToEnd() Response.Write out ,就是这样。实现post用户名和密码到服务器:优采云云采集网络爬虫软件4、ASP.NET爬取网页内容-防止爬取时重定向抓取网页时,登录成功后在服务器应用系统中,应用系统可以通过Response.Redirect重定向网页。如果这个重定向不需要响应,那么我们就不需要读取 reader.ReadToEnd() Response.Write out ,就是这样。实现post用户名和密码到服务器:优采云云采集网络爬虫软件4、ASP.NET爬取网页内容-防止爬取时重定向抓取网页时,登录成功后在服务器应用系统中,应用系统可以通过Response.Redirect重定向网页。如果这个重定向不需要响应,那么我们就不需要读取 reader.ReadToEnd() Response.Write out ,就是这样。
5、ASP.NET爬取网页内容-维护登录状态使用Post数据成功登录服务器应用系统后,需要登录的页面就可以获取到了,那么我们可能需要维护登录多个请求之间的状态。优采云云采集Web爬虫软件首先,我们需要使用HttpWebRequest,而不是WebRequest。与WebRequest相比,改代码为: 注意:HttpWebRequest.Create返回的类型还是WebRequest,所以需要进行转换。二、使用CookieContainer。这样,requests和request2之间就使用了同一个Session。如果请求已登录,则 request2 也处于已登录状态。最后,如何在不同页面之间使用同一个CookieContainer。要在不同页面之间使用相同的 CookieContainer,只将 CookieContainer 添加到 Session。优采云云采集网络爬虫软件6、抓取需要登录的网站,因为需要登录的是网站,所以是用户登录时需要分析浏览器的方向。服务器发送的POST请求。1.安装httpwatch 2.使用IE浏览器进入网站的登录页面3.打开httpwatch的记录开始追踪4.输入账号密码,确认登录抓包流程:重点关注POST请求中的Url和postdata,以及服务器返回的cookie采集教程:优采云云采集网络爬虫软件顺奇网企业资料采集 114 黄页企业资料采集 @采集网络爬虫软件6、抓取需要登录的网站,因为需要登录的是网站,所以需要分析浏览器的方向用户登录。服务器发送的 POST 请求。1.安装httpwatch 2.使用IE浏览器进入网站的登录页面3.打开httpwatch的记录开始追踪4.输入账号密码,确认登录抓包流程:重点关注POST请求中的Url和postdata,以及服务器返回的cookie采集教程:优采云云采集网络爬虫软件顺奇网企业资料采集 114 黄页企业资料采集 @采集网络爬虫软件6、抓取需要登录的网站,因为需要登录的是网站,所以需要分析浏览器的方向用户登录。服务器发送的 POST 请求。1.安装httpwatch 2.使用IE浏览器进入网站的登录页面3.打开httpwatch的记录开始追踪4.输入账号密码,确认登录抓包流程:重点关注POST请求中的Url和postdata,以及服务器返回的cookie采集教程:优采云云采集网络爬虫软件顺奇网企业资料采集 114 黄页企业资料采集 需要登录,因为需要登录的是网站,所以需要分析用户登录时浏览器的方向。服务器发送的POST请求。1.安装httpwatch 2.用IE浏览器进入网站的登录页面3.打开httpwatch的记录开始追踪4.输入账号密码,确认登录抓包流程:重点关注POST请求中的Url和postdata,以及服务器返回的cookie采集教程:优采云云采集网络爬虫软件顺奇网企业资料采集 114 黄页企业资料采集 需要登录,因为需要登录的是网站,所以需要分析用户登录时浏览器的方向。服务器发送的POST请求。1.安装httpwatch 2.使用IE浏览器进入网站的登录页面3.打开httpwatch的记录开始追踪4.输入账号密码,确认登录抓包流程:重点关注POST请求中的Url和postdata,以及服务器返回的cookie采集教程:优采云云采集网络爬虫软件顺奇网企业资料采集 114 黄页企业资料采集
1、简单易用,任何人都可以使用:无需技术背景,只需了解互联网采集。全程可视化流程,点击鼠标完成操作,2分钟快速上手。2、功能强大,任何网站都可以使用:点击、登录、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据网页,都可以通过简单的设置进行采集。3、在采集 中,也可以关闭。配置好采集任务后,可以关机,侧边执行任务。庞大的采集集群24*7不间断运行,不用担心IP被封或者网络中断。4、功能免费+增值服务,可以按需选择。免费版具有满足用户基本采集需求的所有功能。同时,设置一些增值服务(如私有制),以满足高端付费企业用户的需求。
c爬虫抓取网页数据(爬虫普通爬虫:抓取数据的过程的分类)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-02-04 12:22
爬虫概述 什么是爬虫?
编写程序,让它模拟浏览器上网,然后上网抓取数据的过程
爬行动物的分类
1.普通爬行动物:
抓取整个页面的源内容
2.关注爬虫:
获取页面的部分内容
3.增量爬虫:
它可以检测到 网站 中的数据更新。在 网站 中获取最新更新的数据。
防爬机制: 防爬策略:
爬虫利用相应的策略和技术手段破解门户网站的反爬虫手段,从而爬取对应的数据。
爬行动物的合法性:
爬虫本身不受法律禁止(中立)
爬取数据违法风险的表现:
1.爬虫干扰了访问者网站的正常运行。
2.爬虫爬取某些类型的受法律保护的数据或信息。
如何规避违法风险:
1.严格遵守网站设置的robots协议
2.在避免爬虫措施的同时,需要优化自己的代码,避免干扰被访问网站的正常运行
3.在使用和传播捕获的信息时,应对捕获的内容进行审核。如发现属于用户的个人信息、隐私或其他商业秘密,应及时删除并停止使用
UA反爬机制是什么,如何破解?如何获取动态加载页面的数据:
如何获取动态加载页面的数据:<br /> 通过抓包工具全局搜索找到动态加载数据对应的数据包,数据包中提取该请求的url,
一.Anaxonda安装1.双击Anaconda3-5.0.0-Windows-x86_64.exe文件
2.下一个
1.打开cmd窗口,输入jupyter notebook命令,
如果没有找不到命令并且没有报错,则安装成功!
2.在开始菜单中显示
3.启动 ① 默认端口启动
在终端中输入以下命令:
jupyter notebook
执行命令后,终端会显示一系列notebook服务器信息,浏览器会自动启动Jupyter Notebook。
启动过程中,终端显示如下:
$ jupyter notebook
[I 08:58:24.417 NotebookApp] Serving notebooks from local directory: /Users/catherine
[I 08:58:24.417 NotebookApp] 0 active kernels
[I 08:58:24.417 NotebookApp] The Jupyter Notebook is running at: http://localhost:8888/
[I 08:58:24.417 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
默认情况下,浏览器地址栏会显示::8888。其中,“localhost”是指本机,“8888”是端口号。
网址
如果同时启动多个 Jupyter Notebook,由于默认端口“8888”被占用,地址栏中的数字将从“8888”开始,每次启动另一个 Jupyter Notebook 时数字会增加 1,例如如“8889”、“8890”、“……
② 启动指定端口
如果要自定义启动 Jupyter Notebook 的端口号,可以在终端输入以下命令:
jupyter notebook --port
在,”
"为自定义端口号,直接以数字的形式写在命令中,数字两边不带尖括号""。例如:jupyter notebook --port 9999,即启动Jupyter Notebook端口号为“9999”的服务器。
③ 不打开浏览器启动服务器
如果您只想启动 Jupyter Notebook 服务器但不想立即进入主页,则无需立即启动浏览器。在终端输入:
jupyter notebook --no-browser
此时终端会显示激活服务器的信息,激活服务器后会显示打开浏览器页面的链接。当您需要启动浏览器页面时,只需复制链接,将其粘贴到浏览器的地址栏中,然后按 Enter 键即可转到您的 Jupyter Notebook 页面。
示例图中,由于我在完成以上内容的同时同时启动了多个Jupyter Notebooks,显示我的“8888”端口号被占用,最后“8889”分配给了我。
2. 快捷方式 向上插入单元格:a 向下插入单元格:b 删除单元格:x 将代码切换为 markdown:m 将 markdown 切换为代码:y 运行单元格:shift+enter 查看帮助文档:shift+ Tab 自动提示:标签
3. 魔法指令
运行外部python源文件:%run xxx.py 计算一条语句的运行时间:%time statement 计算一条语句的平均运行时间:%timeit statement 测试多行代码的平均运行时间:
%%时间
声明1
声明2
声明3 查看全部
c爬虫抓取网页数据(爬虫普通爬虫:抓取数据的过程的分类)
爬虫概述 什么是爬虫?
编写程序,让它模拟浏览器上网,然后上网抓取数据的过程
爬行动物的分类
1.普通爬行动物:
抓取整个页面的源内容
2.关注爬虫:
获取页面的部分内容
3.增量爬虫:
它可以检测到 网站 中的数据更新。在 网站 中获取最新更新的数据。
防爬机制: 防爬策略:
爬虫利用相应的策略和技术手段破解门户网站的反爬虫手段,从而爬取对应的数据。
爬行动物的合法性:
爬虫本身不受法律禁止(中立)
爬取数据违法风险的表现:
1.爬虫干扰了访问者网站的正常运行。
2.爬虫爬取某些类型的受法律保护的数据或信息。
如何规避违法风险:
1.严格遵守网站设置的robots协议
2.在避免爬虫措施的同时,需要优化自己的代码,避免干扰被访问网站的正常运行
3.在使用和传播捕获的信息时,应对捕获的内容进行审核。如发现属于用户的个人信息、隐私或其他商业秘密,应及时删除并停止使用
UA反爬机制是什么,如何破解?如何获取动态加载页面的数据:
如何获取动态加载页面的数据:<br /> 通过抓包工具全局搜索找到动态加载数据对应的数据包,数据包中提取该请求的url,
一.Anaxonda安装1.双击Anaconda3-5.0.0-Windows-x86_64.exe文件
2.下一个
1.打开cmd窗口,输入jupyter notebook命令,
如果没有找不到命令并且没有报错,则安装成功!
2.在开始菜单中显示
3.启动 ① 默认端口启动
在终端中输入以下命令:
jupyter notebook
执行命令后,终端会显示一系列notebook服务器信息,浏览器会自动启动Jupyter Notebook。
启动过程中,终端显示如下:
$ jupyter notebook
[I 08:58:24.417 NotebookApp] Serving notebooks from local directory: /Users/catherine
[I 08:58:24.417 NotebookApp] 0 active kernels
[I 08:58:24.417 NotebookApp] The Jupyter Notebook is running at: http://localhost:8888/
[I 08:58:24.417 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
默认情况下,浏览器地址栏会显示::8888。其中,“localhost”是指本机,“8888”是端口号。
网址
如果同时启动多个 Jupyter Notebook,由于默认端口“8888”被占用,地址栏中的数字将从“8888”开始,每次启动另一个 Jupyter Notebook 时数字会增加 1,例如如“8889”、“8890”、“……
② 启动指定端口
如果要自定义启动 Jupyter Notebook 的端口号,可以在终端输入以下命令:
jupyter notebook --port
在,”
"为自定义端口号,直接以数字的形式写在命令中,数字两边不带尖括号""。例如:jupyter notebook --port 9999,即启动Jupyter Notebook端口号为“9999”的服务器。
③ 不打开浏览器启动服务器
如果您只想启动 Jupyter Notebook 服务器但不想立即进入主页,则无需立即启动浏览器。在终端输入:
jupyter notebook --no-browser
此时终端会显示激活服务器的信息,激活服务器后会显示打开浏览器页面的链接。当您需要启动浏览器页面时,只需复制链接,将其粘贴到浏览器的地址栏中,然后按 Enter 键即可转到您的 Jupyter Notebook 页面。
示例图中,由于我在完成以上内容的同时同时启动了多个Jupyter Notebooks,显示我的“8888”端口号被占用,最后“8889”分配给了我。
2. 快捷方式 向上插入单元格:a 向下插入单元格:b 删除单元格:x 将代码切换为 markdown:m 将 markdown 切换为代码:y 运行单元格:shift+enter 查看帮助文档:shift+ Tab 自动提示:标签
3. 魔法指令
运行外部python源文件:%run xxx.py 计算一条语句的运行时间:%time statement 计算一条语句的平均运行时间:%timeit statement 测试多行代码的平均运行时间:
%%时间
声明1
声明2
声明3
c爬虫抓取网页数据(种子网站存储7万多条记录()时间送达!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-04 12:16
关键时刻,第一时间发货!
节前的一次误操作,清空了mysql中的记录表和电影表。显然,我没有做任何mysql备份。于是,我干脆清空了所有表数据,一夜之间又回到了解放前……
在之前的版本中,记录表存储了7万多条记录,爬取了4万多条记录,但是可以明显的发现,爬取的数据越多,卡机越多。又报错了,是关于JDBC的,又一次机器卡住了。
经过仔细考虑,之前版本的爬虫程序和数据库的读写次数过于频繁,存在以下问题:
3.存储电影详情页记录和短评数据全部解析后立即存入数据库。
显然,上面的方法一看就效率低下,所以今天下午修改了相关代码,部分实现批量插入,尽可能减少与数据库的交互,从而降低时间和空间成本。
既然出现了问题,我们再来看看这个版本,最后发现问题的原因是种子URL没有存储在mysql的记录表中,所以是在DoubanCrawler类中。
执行 stmt.executeUpdate(sql) > 0 返回值 0,所以爬取为 0 的记录不会从数据库中读取,最后会在 while 循环中爬取种子 网站。
解决方案:由于种子网站没有存储在记录中,那么对种子网站进行特殊处理,将if的判断条件改为if(stmt.executeUpdate(sql)>0 || frontPage.equals(url)),这样对于种子网站,即使没有成功的更新操作,仍然可以进入读取爬取到0的数据库的操作。
对于第一个问题,使用批量插入操作
具体实现如下:
1. 通过正则匹配,找到符合条件的链接,加入nextLinkList集合
2.遍历后,将数据存入数据库
3. 在批处理操作中,使用了 addBatch() 方法和 executeBatch() 方法。注意需要添加 conn.setAutoCommit(false); mit() 表示手动提交。
第二题,一次查询多条记录
实现思路:一次只改一条记录,一次查询10条记录,将这10条记录存入list集合中,将原来的String类型url改为list类型urlList并传入 查看全部
c爬虫抓取网页数据(种子网站存储7万多条记录()时间送达!)
关键时刻,第一时间发货!
节前的一次误操作,清空了mysql中的记录表和电影表。显然,我没有做任何mysql备份。于是,我干脆清空了所有表数据,一夜之间又回到了解放前……
在之前的版本中,记录表存储了7万多条记录,爬取了4万多条记录,但是可以明显的发现,爬取的数据越多,卡机越多。又报错了,是关于JDBC的,又一次机器卡住了。
经过仔细考虑,之前版本的爬虫程序和数据库的读写次数过于频繁,存在以下问题:
3.存储电影详情页记录和短评数据全部解析后立即存入数据库。
显然,上面的方法一看就效率低下,所以今天下午修改了相关代码,部分实现批量插入,尽可能减少与数据库的交互,从而降低时间和空间成本。
既然出现了问题,我们再来看看这个版本,最后发现问题的原因是种子URL没有存储在mysql的记录表中,所以是在DoubanCrawler类中。
执行 stmt.executeUpdate(sql) > 0 返回值 0,所以爬取为 0 的记录不会从数据库中读取,最后会在 while 循环中爬取种子 网站。
解决方案:由于种子网站没有存储在记录中,那么对种子网站进行特殊处理,将if的判断条件改为if(stmt.executeUpdate(sql)>0 || frontPage.equals(url)),这样对于种子网站,即使没有成功的更新操作,仍然可以进入读取爬取到0的数据库的操作。
对于第一个问题,使用批量插入操作
具体实现如下:
1. 通过正则匹配,找到符合条件的链接,加入nextLinkList集合
2.遍历后,将数据存入数据库
3. 在批处理操作中,使用了 addBatch() 方法和 executeBatch() 方法。注意需要添加 conn.setAutoCommit(false); mit() 表示手动提交。
第二题,一次查询多条记录
实现思路:一次只改一条记录,一次查询10条记录,将这10条记录存入list集合中,将原来的String类型url改为list类型urlList并传入
c爬虫抓取网页数据( 如何替代人工从网页中找到数据并复制粘贴到excel中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-02-03 20:02
如何替代人工从网页中找到数据并复制粘贴到excel中)
为什么要学习网络爬虫
它可以代替人工从网页中查找数据并将其复制粘贴到excel中。这种重复性的工作,不仅浪费时间,而且一不留神,容易出错,解决了这些无法自动化、无法实时获取的公共数据的应用价值,我们可以借助KYC框架来了解,了解你的公司(了解您的公司),了解您的竞争对手(了解您的竞争对手),了解您的客户(了解您的客户)。这是通过理解和执行对公共数据的简单描述性分析可以带来的价值。进一步,通过机器学习和统计算法分析,可以帮助企业做4Ps(产品)、价格(价格)、渠道(地点)促销(promotion))
网络爬虫的基本协议
robots协议
python爬虫的流程
主要可以分为三个部分:1.获取网页;2.解析网页(提取数据);3.存储数据;
1.获取网页就是向URL发送请求,会返回整个网页的数据
2.解析一个网页就是从整个网页的数据中提取出想要的数据
3.存数据就是存数据
三道工序的技术实现
1.获取网页
获取网页的基本技术:request、urllib和selenium(模拟浏览器)
获取网页先进技术:多进程多线程爬取、登录爬取、破IP封禁、服务器爬取
2.解析网页
解析网页的基本技术:re正则表达式、beautifulsoup和lxml
网页解析高级技术:解决中文乱码
3.存储的数据
数据存储的基本技术:存txt文件和存csv文件
存储数据的先进技术:存储在MySQL数据库中和存储在mongodb数据库中 查看全部
c爬虫抓取网页数据(
如何替代人工从网页中找到数据并复制粘贴到excel中)
为什么要学习网络爬虫
它可以代替人工从网页中查找数据并将其复制粘贴到excel中。这种重复性的工作,不仅浪费时间,而且一不留神,容易出错,解决了这些无法自动化、无法实时获取的公共数据的应用价值,我们可以借助KYC框架来了解,了解你的公司(了解您的公司),了解您的竞争对手(了解您的竞争对手),了解您的客户(了解您的客户)。这是通过理解和执行对公共数据的简单描述性分析可以带来的价值。进一步,通过机器学习和统计算法分析,可以帮助企业做4Ps(产品)、价格(价格)、渠道(地点)促销(promotion))
网络爬虫的基本协议
robots协议
python爬虫的流程
主要可以分为三个部分:1.获取网页;2.解析网页(提取数据);3.存储数据;
1.获取网页就是向URL发送请求,会返回整个网页的数据
2.解析一个网页就是从整个网页的数据中提取出想要的数据
3.存数据就是存数据
三道工序的技术实现
1.获取网页
获取网页的基本技术:request、urllib和selenium(模拟浏览器)
获取网页先进技术:多进程多线程爬取、登录爬取、破IP封禁、服务器爬取
2.解析网页
解析网页的基本技术:re正则表达式、beautifulsoup和lxml
网页解析高级技术:解决中文乱码
3.存储的数据
数据存储的基本技术:存txt文件和存csv文件
存储数据的先进技术:存储在MySQL数据库中和存储在mongodb数据库中
c爬虫抓取网页数据(最简单的过程可以用如下代码表示:importurllib2request=urllib2.Request())
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-01 14:30
概念
爬虫是网页的采集。
通常,在获取的网页中存在到其他网页的路径,称为超链接。然后,通过这样的路径可以获取更多的其他网页,就像蜘蛛在网上爬行一样,所以俗称爬虫。
爬虫的工作原理类似于浏览器浏览网页。它是一种请求/返回模式,即客户端向服务器发出请求访问某个页面(请求),服务器返回客户端请求的内容(响应)。URL是代表互联网上每个文件的唯一标志,也就是我们所说的网址。客户端通过 URL 向特定网页发送请求。最简单的过程可以用以下代码表示:
import urllib2request = urllib2.Request("")#构造请求请求 response = urllib2.urlopen(request)#发送请求并得到响应打印 response.read()#使用read()来获取返回的内容并打印出Http协议的POST和GET
对于简单的静态网页,这样就足够了,可以顺利获取html文本。
但对于这个日新月异的互联网来说,这东西根本就不够用。首先要考虑的是动态网页,它需要我们动态地向它传递参数。例如,在登录时,我们需要提交用户名和密码等表单信息,以便我们获取更多信息。这需要我们在构造请求时向服务器传递更多信息。
说到传递参数,就不得不说一下HTTP协议与服务器交互的方式了。HTTP协议有六种请求方法,分别是get、head、put、delete、post、options,其中最基本的四种是GET、POST和PUT、DELET。我们知道 URL 地址是用来描述网络上的资源的。HTTP中的GET、POST、PUT、DELETE对应了查询、修改、添加、删除这四种操作。对于爬虫中的数据传输,使用 POST 和 GET。我们来看看GET和POST的区别:
1.GET提交的数据会放在URL后面,URL和传输数据用?分隔,参数用&连接
2.GET方法提交的数据大小是有限制的(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制。
3.GET方法需要使用Request.QueryString获取变量的值,POST方法使用Request.Form获取变量的值。
4.GET方式提交数据会带来安全问题。例如,通过 GET 方法提交数据时,用户名和密码会出现在 URL 上。如果页面可以被缓存或者其他人可以访问机器,则可以从访问历史记录中获取用户的账号和密码。下面介绍两种提交方法。
POST方法导入urllib2值 ={“username”:“”,“password”:“XXXX”}data = urllib.urlencode(values)url=":///my/mycsdn"request = urllib2.@ >请求(url,data)response = urllib2.urlopen(request)print response.read()
可以看出,该方法首先将要提交的信息构造成一个数据,然后连同URL一起构造请求对象。
GET方法 import urllib2 import urllibvalues ={"username":"","password":"XXXX"}data = urllib.urlencode(values)url = ""geturl = url +"?"+ datarequest = urllib2. Request(geturl)response = urllib2.urlopen(request)print response.read()
可以看到GET方式是直接在URL后面加参数
设置标题
即便如此,还是有一些网站不被允许访问,会出现识别问题。这时候,为了真正的伪装成浏览器,我们还需要在构造请求的时候设置一些Headers属性。打开浏览器查看网页标题,可以看到如下内容:
我们可以根据自己的需要选择某些属性来构造请求,比如下面使用了user-agent和referer。
headers ={'User-Agent':'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)','Referer':''}request = urllib2.Request (网址,标题=标题)
User-agent全称为用户代理,是向网站提供所用浏览器的类型和版本、操作系统、浏览器内核等信息的标志,是伪装成浏览器。真正的浏览器提供这个属性是为了方便网站为用户提供更好的展示和体验。Referer 显示当前页面来自哪个页面。可以用来防止防盗链。服务器将识别 headers 中的 referer 是否是它自己。如果没有,某些服务器将不会响应。
有了以上的基础知识,就可以开始了解和实现真正的爬虫了。 查看全部
c爬虫抓取网页数据(最简单的过程可以用如下代码表示:importurllib2request=urllib2.Request())
概念
爬虫是网页的采集。
通常,在获取的网页中存在到其他网页的路径,称为超链接。然后,通过这样的路径可以获取更多的其他网页,就像蜘蛛在网上爬行一样,所以俗称爬虫。
爬虫的工作原理类似于浏览器浏览网页。它是一种请求/返回模式,即客户端向服务器发出请求访问某个页面(请求),服务器返回客户端请求的内容(响应)。URL是代表互联网上每个文件的唯一标志,也就是我们所说的网址。客户端通过 URL 向特定网页发送请求。最简单的过程可以用以下代码表示:
import urllib2request = urllib2.Request("")#构造请求请求 response = urllib2.urlopen(request)#发送请求并得到响应打印 response.read()#使用read()来获取返回的内容并打印出Http协议的POST和GET
对于简单的静态网页,这样就足够了,可以顺利获取html文本。
但对于这个日新月异的互联网来说,这东西根本就不够用。首先要考虑的是动态网页,它需要我们动态地向它传递参数。例如,在登录时,我们需要提交用户名和密码等表单信息,以便我们获取更多信息。这需要我们在构造请求时向服务器传递更多信息。
说到传递参数,就不得不说一下HTTP协议与服务器交互的方式了。HTTP协议有六种请求方法,分别是get、head、put、delete、post、options,其中最基本的四种是GET、POST和PUT、DELET。我们知道 URL 地址是用来描述网络上的资源的。HTTP中的GET、POST、PUT、DELETE对应了查询、修改、添加、删除这四种操作。对于爬虫中的数据传输,使用 POST 和 GET。我们来看看GET和POST的区别:
1.GET提交的数据会放在URL后面,URL和传输数据用?分隔,参数用&连接
2.GET方法提交的数据大小是有限制的(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制。
3.GET方法需要使用Request.QueryString获取变量的值,POST方法使用Request.Form获取变量的值。
4.GET方式提交数据会带来安全问题。例如,通过 GET 方法提交数据时,用户名和密码会出现在 URL 上。如果页面可以被缓存或者其他人可以访问机器,则可以从访问历史记录中获取用户的账号和密码。下面介绍两种提交方法。
POST方法导入urllib2值 ={“username”:“”,“password”:“XXXX”}data = urllib.urlencode(values)url=":///my/mycsdn"request = urllib2.@ >请求(url,data)response = urllib2.urlopen(request)print response.read()
可以看出,该方法首先将要提交的信息构造成一个数据,然后连同URL一起构造请求对象。
GET方法 import urllib2 import urllibvalues ={"username":"","password":"XXXX"}data = urllib.urlencode(values)url = ""geturl = url +"?"+ datarequest = urllib2. Request(geturl)response = urllib2.urlopen(request)print response.read()
可以看到GET方式是直接在URL后面加参数
设置标题
即便如此,还是有一些网站不被允许访问,会出现识别问题。这时候,为了真正的伪装成浏览器,我们还需要在构造请求的时候设置一些Headers属性。打开浏览器查看网页标题,可以看到如下内容:
我们可以根据自己的需要选择某些属性来构造请求,比如下面使用了user-agent和referer。
headers ={'User-Agent':'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)','Referer':''}request = urllib2.Request (网址,标题=标题)
User-agent全称为用户代理,是向网站提供所用浏览器的类型和版本、操作系统、浏览器内核等信息的标志,是伪装成浏览器。真正的浏览器提供这个属性是为了方便网站为用户提供更好的展示和体验。Referer 显示当前页面来自哪个页面。可以用来防止防盗链。服务器将识别 headers 中的 referer 是否是它自己。如果没有,某些服务器将不会响应。
有了以上的基础知识,就可以开始了解和实现真正的爬虫了。
c爬虫抓取网页数据(主流爬虫框架简介-1.地址 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-01 12:27
)
一、前言
目前市面上的爬虫框架比较多,有不同语言、不同类型的爬虫框架。然而,在开展预研时,很难选择哪一项
框架是许多开发人员特别头疼的问题。
本文主要总结了市面上主流开发语言中的主流爬虫框架,以及爬虫框架的优缺点;希望对大家选择合适的爬虫框架有所帮助。
二、主流语言爬虫框架列表 常用爬虫框架列表 JAVA PYTHON PHP C# C/C++
阿帕奇纳奇2
刮擦
php蜘蛛
点网蜘蛛
开源搜索引擎
网络魔术
克劳利
豆包
网络爬虫
蛛网
赫里特里克斯
波西亚
PHP抓取
智能蜘蛛
阿普顿
网络采集器
PySpider
php硒
阿博特
袋熊
爬虫4j
抓
网络
蜘蛛
蜘蛛侠
可乐
锐角
拉尔宾
SeimiCrawler
蟒蛇硒
HtmlAgilityPack
汤
查询
java硒
htmlunit
三、主流爬虫框架介绍1.Java爬虫框架Apache Nutch2
地址:
Nutch 是一个搜索引擎的开源 Java 实现。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫。
Nutch 致力于让每个人都能轻松、廉价地配置世界级的网络搜索引擎。为了实现这一雄心勃勃的目标,Nutch 必须能够:
* 每月获取数十亿网页
* 维护这些页面的索引
* 每秒数以千计的索引文件搜索
简而言之,Nutch 支持分发。您可以通过配置网站地址、规则和采集的深度(通用爬虫或全网爬虫)对网站执行采集,并提供完整的-文本搜索功能,可以对来自采集的海量数据进行全文搜索;如果要完成站点所有内容的采集,而不关心采集和解析准确性(不是特定页面来满足特定字段内容采集的需要) ,建议您使用Apache Nutch。如果要为站点的指定内容版块指定字段采集,建议使用垂直爬虫更加灵活。
webmgaic(推荐)
地址:
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
特征:
快速入门的简单 API
模块化结构,易于扩展
提供多线程和分布式支持
赫里特里克斯
地址:
Heritrix是java开发的开源网络爬虫,用户可以使用它从互联网上爬取想要的资源。它最好的地方在于其良好的扩展性,方便用户实现自己的爬取逻辑。
网络采集器
地址:
WebCollector是一个无需配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需少量代码即可实现强大的爬虫。WebCollector-Hadoop 是支持分布式爬取的 WebCollector 的 Hadoop 版本。
爬虫4j
地址::
crawler4j 是一个基于 Java 的轻量级独立开源爬虫框架,最大的特点之一就是简单。此外,它还支持多线程,支持代理,并且可以过滤重复的URL
基本上,从将jar加载到项目中,只需修改示例代码即可简单实现爬虫的所有功能,所有这些动作不超过半小时。
蜘蛛侠
地址:
Spiderman 是一个 Java 开源 Web 数据提取工具。它能够采集指定的网页并从这些页面中提取有用的数据。Spiderman主要使用XPath、正则表达式、表达式引擎等技术来实现数据提取。
SeimiCrawler
地址:
一个敏捷、独立部署的分布式Java爬虫框架
SeimiCrawler 是一个强大、高效、敏捷的框架,支持分布式爬虫开发。希望能够最大程度的降低新手开发高可用性能好的爬虫系统的门槛,提高爬虫系统开发的开发效率。在 SeimiCrawler 的世界里,大部分人只关心编写爬虫的业务逻辑,剩下的交给 Seimi 来处理。在设计思路上,SeimiCrawler 很大程度上受到了 Python 的爬虫框架 Scrapy 的启发,同时融合了 Java 语言本身的特点和 Spring 的特点,希望在国内使用更高效的 XPath 来更方便、更广泛地解析 HTML,所以SeimiCrawler默认的HTML解析器是JsoupXpath,
汤
地址:
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
2.Python爬虫框架scrapy(推荐)
地址:
Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。还提供了各类爬虫的基类,如BaseSpider、站点地图爬虫等。最新版本提供了对web2.0爬虫的支持。
报废意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
克劳利
地址:
高速爬取网站对应的内容,支持关系型和非关系型数据库,数据可以导出为JSON、XML等。
波西亚
地址:
Portia 是一个用 Python 编写的开源工具,无需任何编程知识即可直观地抓取 网站 数据。无需下载或安装任何东西,因为 Portia 在您的网络浏览器中运行。
Portia 是一个由 scrapyhub 开源的可视化爬虫规则编写工具。Portia 提供了一个可视化的网页,只需在页面上简单的点击并标记相应的待提取数据,无需任何编程知识即可完成爬虫规则的开发。这些规则也可以在 Scrapy 中用于抓取页面。
PySpider
地址:
PySpider:一个强大的网络爬虫系统,由一个中国人编写,具有强大的WebUI。用 Python 语言编写,分布式架构,支持多种数据库后端,强大的 WebUI 支持脚本编辑器、任务监视器、项目管理器和结果查看器。
抓
地址:
网络爬虫框架(基于 pycurl/multicur)。
可乐
地址:
一个分布式爬虫框架。项目整体设计有点差,模块间耦合度高,但值得借鉴。
3.PHP爬虫框架phpspider
地址:
phpspider 是一个爬虫开发框架。使用该框架,无需了解爬虫底层技术实现,爬虫被网站屏蔽,有的网站需要登录或验证码识别才能爬取等。几行PHP代码,可以创建自己的爬虫,使用框架封装的多进程Worker类库,代码更简洁,执行效率更高更快。
豆包
地址:
Beanbun是一个用PHP编写的多进程网络爬虫框架,具有良好的开放性和高扩展性。
支持守护进程和普通模式(守护进程模式只支持Linux服务器)
默认情况下,Guzzle 用于爬行
分散式
支持内存、Redis等多种队列方式
支持自定义URI过滤
支持广度优先和深度优先两种爬取方式
遵循 PSR-4 标准
爬取网页分为多个步骤,每个步骤都支持自定义动作(如添加代理、修改user-agent等)
一种灵活的扩展机制,可以轻松为框架创建插件:自定义队列、自定义爬取方法……
PHP抓取
地址:
PHPCrawl 是一个 PHP 开源网络检索蜘蛛(爬虫)类库。PHPCrawl 爬虫“Spider”的网站,提供有关网页、链接、文件等的所有信息。
PHPCrawl povides 可以选择性地指定爬虫的行为,例如采集的 URL、内容类型、过滤器、cookie 处理等。
4.c#爬虫框架DotnetSpider
地址:
DotnetSpider是中国人开源的一款跨平台、高性能、轻量级的爬虫软件,C#开发。它是目前.Net开源爬虫最好的爬虫之一。
网络爬虫
地址:
NWebCrawler 是一个开源的 C# 网络爬虫更多 NWebCrawler
智能蜘蛛
地址:
SmartSpider爬虫引擎内核版本,全新的设计理念,真正的极简版。
阿博特
地址:
Abot 是一个开源的 .net 爬虫,它快速、易于使用和扩展。
网络
地址:
这个俄罗斯天才写的开源工具,为什么说他厉害,因为他又实现了所有Http协议的底层,这有什么好处呢?只要你写一个爬虫,就会遇到一个让人抓狂的问题,就是明知道你的Http请求头和浏览器一模一样,为什么不能得到你想要的数据。这时候如果使用HttpWebRequest,只能调试到GetRespone,无法调试底层字节流。所以,一定要有更深层次的底层组件,方便自己调试。
锐角
地址:
HTML 分析工具 AngleSharp HTML 分析工具简介 AngleSharp 简介 AngleSharp 是一个基于.NET (C#) 开发的专门用于解析xHTML 源代码的DLL 组件。
HtmlAgilityPack
地址:
HtmlAgilityPack 是一个用于 .NET 的 HTML 解析库。支持使用 XPath 解析 HTML。命名空间:HtmlAgilityPack
查询
地址:
CsQuery锐利的html代码分析库,用c#像jq处理html
5.C/C++爬虫框架开源搜索引擎
地址:
基于 C/C++ 的网络爬虫和搜索引擎。
蛛网
地址:
一个非常灵活、易于扩展的网络爬虫,可用作单点部署。
阿普顿
地址:
一组易于使用的爬虫框架,支持 CSS 选择器。
袋熊
地址:
基于 Ruby 支持 DSL 的自然网络爬虫,可以轻松提取网页正文数据。
蜘蛛
地址:
全站数据采集,支持无限网站链接地址采集。
拉尔宾
地址:
larbin 是一个开源的网络爬虫/网络蜘蛛,由法国年轻的 Sébastien Ailleret 独立开发,用 C++ 语言实现。larbin 的目的是能够跟踪页面的 URL 进行扩展爬取,最终为搜索引擎提供广泛的数据源。larbin只是一个爬虫,也就是说larbin只爬网页,怎么解析是用户自己做的。此外,larbin 没有提供如何存储到数据库和建立索引。
larbin最初的设计也是本着设计简单但可配置性高的原则,所以我们可以看到一个简单的larbin爬虫每天可以抓取500万个网页,效率很高。
使用larbin,我们可以轻松获取/确定单个网站的所有链接,甚至可以镜像一个网站;我们也可以用它来创建一个url列表组,例如所有网页的url retrive后,xml链接获取。或者 mp3,或者自定义 larbin,可以作为搜索引擎的信息来源。
四.总结
爬虫框架很多,有兴趣可以自己写一些。我们不需要掌握每一个主流爬虫框架,只需要根据自己的语言编写能力,深入掌握一个爬虫框架即可。大多数爬虫框架的实现方式大致相同。
如果你是 python 开发者,我推荐你学习流行的 scrapy,如果你是 java 开发者,我推荐你学习 webmagic。
查看全部
c爬虫抓取网页数据(主流爬虫框架简介-1.地址
)
一、前言
目前市面上的爬虫框架比较多,有不同语言、不同类型的爬虫框架。然而,在开展预研时,很难选择哪一项
框架是许多开发人员特别头疼的问题。
本文主要总结了市面上主流开发语言中的主流爬虫框架,以及爬虫框架的优缺点;希望对大家选择合适的爬虫框架有所帮助。
二、主流语言爬虫框架列表 常用爬虫框架列表 JAVA PYTHON PHP C# C/C++
阿帕奇纳奇2
刮擦
php蜘蛛
点网蜘蛛
开源搜索引擎
网络魔术
克劳利
豆包
网络爬虫
蛛网
赫里特里克斯
波西亚
PHP抓取
智能蜘蛛
阿普顿
网络采集器
PySpider
php硒
阿博特
袋熊
爬虫4j
抓
网络
蜘蛛
蜘蛛侠
可乐
锐角
拉尔宾
SeimiCrawler
蟒蛇硒
HtmlAgilityPack
汤
查询
java硒
htmlunit
三、主流爬虫框架介绍1.Java爬虫框架Apache Nutch2
地址:
Nutch 是一个搜索引擎的开源 Java 实现。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫。
Nutch 致力于让每个人都能轻松、廉价地配置世界级的网络搜索引擎。为了实现这一雄心勃勃的目标,Nutch 必须能够:
* 每月获取数十亿网页
* 维护这些页面的索引
* 每秒数以千计的索引文件搜索
简而言之,Nutch 支持分发。您可以通过配置网站地址、规则和采集的深度(通用爬虫或全网爬虫)对网站执行采集,并提供完整的-文本搜索功能,可以对来自采集的海量数据进行全文搜索;如果要完成站点所有内容的采集,而不关心采集和解析准确性(不是特定页面来满足特定字段内容采集的需要) ,建议您使用Apache Nutch。如果要为站点的指定内容版块指定字段采集,建议使用垂直爬虫更加灵活。
webmgaic(推荐)
地址:
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
特征:
快速入门的简单 API
模块化结构,易于扩展
提供多线程和分布式支持
赫里特里克斯
地址:
Heritrix是java开发的开源网络爬虫,用户可以使用它从互联网上爬取想要的资源。它最好的地方在于其良好的扩展性,方便用户实现自己的爬取逻辑。
网络采集器
地址:
WebCollector是一个无需配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需少量代码即可实现强大的爬虫。WebCollector-Hadoop 是支持分布式爬取的 WebCollector 的 Hadoop 版本。
爬虫4j
地址::
crawler4j 是一个基于 Java 的轻量级独立开源爬虫框架,最大的特点之一就是简单。此外,它还支持多线程,支持代理,并且可以过滤重复的URL
基本上,从将jar加载到项目中,只需修改示例代码即可简单实现爬虫的所有功能,所有这些动作不超过半小时。
蜘蛛侠
地址:
Spiderman 是一个 Java 开源 Web 数据提取工具。它能够采集指定的网页并从这些页面中提取有用的数据。Spiderman主要使用XPath、正则表达式、表达式引擎等技术来实现数据提取。
SeimiCrawler
地址:
一个敏捷、独立部署的分布式Java爬虫框架
SeimiCrawler 是一个强大、高效、敏捷的框架,支持分布式爬虫开发。希望能够最大程度的降低新手开发高可用性能好的爬虫系统的门槛,提高爬虫系统开发的开发效率。在 SeimiCrawler 的世界里,大部分人只关心编写爬虫的业务逻辑,剩下的交给 Seimi 来处理。在设计思路上,SeimiCrawler 很大程度上受到了 Python 的爬虫框架 Scrapy 的启发,同时融合了 Java 语言本身的特点和 Spring 的特点,希望在国内使用更高效的 XPath 来更方便、更广泛地解析 HTML,所以SeimiCrawler默认的HTML解析器是JsoupXpath,
汤
地址:
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
2.Python爬虫框架scrapy(推荐)
地址:
Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。还提供了各类爬虫的基类,如BaseSpider、站点地图爬虫等。最新版本提供了对web2.0爬虫的支持。
报废意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
克劳利
地址:
高速爬取网站对应的内容,支持关系型和非关系型数据库,数据可以导出为JSON、XML等。
波西亚
地址:
Portia 是一个用 Python 编写的开源工具,无需任何编程知识即可直观地抓取 网站 数据。无需下载或安装任何东西,因为 Portia 在您的网络浏览器中运行。
Portia 是一个由 scrapyhub 开源的可视化爬虫规则编写工具。Portia 提供了一个可视化的网页,只需在页面上简单的点击并标记相应的待提取数据,无需任何编程知识即可完成爬虫规则的开发。这些规则也可以在 Scrapy 中用于抓取页面。
PySpider
地址:
PySpider:一个强大的网络爬虫系统,由一个中国人编写,具有强大的WebUI。用 Python 语言编写,分布式架构,支持多种数据库后端,强大的 WebUI 支持脚本编辑器、任务监视器、项目管理器和结果查看器。
抓
地址:
网络爬虫框架(基于 pycurl/multicur)。
可乐
地址:
一个分布式爬虫框架。项目整体设计有点差,模块间耦合度高,但值得借鉴。
3.PHP爬虫框架phpspider
地址:
phpspider 是一个爬虫开发框架。使用该框架,无需了解爬虫底层技术实现,爬虫被网站屏蔽,有的网站需要登录或验证码识别才能爬取等。几行PHP代码,可以创建自己的爬虫,使用框架封装的多进程Worker类库,代码更简洁,执行效率更高更快。
豆包
地址:
Beanbun是一个用PHP编写的多进程网络爬虫框架,具有良好的开放性和高扩展性。
支持守护进程和普通模式(守护进程模式只支持Linux服务器)
默认情况下,Guzzle 用于爬行
分散式
支持内存、Redis等多种队列方式
支持自定义URI过滤
支持广度优先和深度优先两种爬取方式
遵循 PSR-4 标准
爬取网页分为多个步骤,每个步骤都支持自定义动作(如添加代理、修改user-agent等)
一种灵活的扩展机制,可以轻松为框架创建插件:自定义队列、自定义爬取方法……
PHP抓取
地址:
PHPCrawl 是一个 PHP 开源网络检索蜘蛛(爬虫)类库。PHPCrawl 爬虫“Spider”的网站,提供有关网页、链接、文件等的所有信息。
PHPCrawl povides 可以选择性地指定爬虫的行为,例如采集的 URL、内容类型、过滤器、cookie 处理等。
4.c#爬虫框架DotnetSpider
地址:
DotnetSpider是中国人开源的一款跨平台、高性能、轻量级的爬虫软件,C#开发。它是目前.Net开源爬虫最好的爬虫之一。
网络爬虫
地址:
NWebCrawler 是一个开源的 C# 网络爬虫更多 NWebCrawler
智能蜘蛛
地址:
SmartSpider爬虫引擎内核版本,全新的设计理念,真正的极简版。
阿博特
地址:
Abot 是一个开源的 .net 爬虫,它快速、易于使用和扩展。
网络
地址:
这个俄罗斯天才写的开源工具,为什么说他厉害,因为他又实现了所有Http协议的底层,这有什么好处呢?只要你写一个爬虫,就会遇到一个让人抓狂的问题,就是明知道你的Http请求头和浏览器一模一样,为什么不能得到你想要的数据。这时候如果使用HttpWebRequest,只能调试到GetRespone,无法调试底层字节流。所以,一定要有更深层次的底层组件,方便自己调试。
锐角
地址:
HTML 分析工具 AngleSharp HTML 分析工具简介 AngleSharp 简介 AngleSharp 是一个基于.NET (C#) 开发的专门用于解析xHTML 源代码的DLL 组件。
HtmlAgilityPack
地址:
HtmlAgilityPack 是一个用于 .NET 的 HTML 解析库。支持使用 XPath 解析 HTML。命名空间:HtmlAgilityPack
查询
地址:
CsQuery锐利的html代码分析库,用c#像jq处理html
5.C/C++爬虫框架开源搜索引擎
地址:
基于 C/C++ 的网络爬虫和搜索引擎。
蛛网
地址:
一个非常灵活、易于扩展的网络爬虫,可用作单点部署。
阿普顿
地址:
一组易于使用的爬虫框架,支持 CSS 选择器。
袋熊
地址:
基于 Ruby 支持 DSL 的自然网络爬虫,可以轻松提取网页正文数据。
蜘蛛
地址:
全站数据采集,支持无限网站链接地址采集。
拉尔宾
地址:
larbin 是一个开源的网络爬虫/网络蜘蛛,由法国年轻的 Sébastien Ailleret 独立开发,用 C++ 语言实现。larbin 的目的是能够跟踪页面的 URL 进行扩展爬取,最终为搜索引擎提供广泛的数据源。larbin只是一个爬虫,也就是说larbin只爬网页,怎么解析是用户自己做的。此外,larbin 没有提供如何存储到数据库和建立索引。
larbin最初的设计也是本着设计简单但可配置性高的原则,所以我们可以看到一个简单的larbin爬虫每天可以抓取500万个网页,效率很高。
使用larbin,我们可以轻松获取/确定单个网站的所有链接,甚至可以镜像一个网站;我们也可以用它来创建一个url列表组,例如所有网页的url retrive后,xml链接获取。或者 mp3,或者自定义 larbin,可以作为搜索引擎的信息来源。
四.总结
爬虫框架很多,有兴趣可以自己写一些。我们不需要掌握每一个主流爬虫框架,只需要根据自己的语言编写能力,深入掌握一个爬虫框架即可。大多数爬虫框架的实现方式大致相同。
如果你是 python 开发者,我推荐你学习流行的 scrapy,如果你是 java 开发者,我推荐你学习 webmagic。
c爬虫抓取网页数据(c爬虫抓取网页数据,要么就是做网站后端的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-01 01:04
c爬虫抓取网页数据,要么就是做网站后端的。所以你要懂爬虫。总体算下来如果是不考虑网站架构的话。去304080找人测试/调试半小时足够。
python讲课视频推荐量目前比较多的.我就不推荐老师了,不过推荐个平台,网易云课堂的翁恺老师.
爬虫上黑客门泉,最近又有了神兵连.可以看看。
说实话,大部分mooc都有python入门课程,你去找找看。如果是想深入做爬虫,学习爬虫知识和技术很久的话,
python虽然前景广阔,但目前真的没必要非得去找视频,python的书籍资料,以及一些比赛可以去参加啊,
只是要会写请求就行,点击写个request没问题,搞些简单的测试自己写cookie来改随机数字也可以,但是要想写的好必须要做一些性能优化。如果不做性能优化,我们的框架flask啥的就是放不下脚本的。python基础只要认识字母表就行,你只会写基础请求,别人咋用你就照葫芦画瓢。python入门的时候不要怕难,python要是真牛逼了,十几万都不愁,毕竟最近这几年python很火。
本科实验室老师做得是类似的情况,如果题主真要开始这一行就往下看,直接了当的写请求,getposturl然后简单的测试,然后就是一堆的人肉命令服务器来接受请求。抓了之后再看看数据库去record整理分析。目前水平有限,不敢随便给意见,但是看到很多黑是其实是遇到瓶颈后想死皮赖脸寻求希望,估计题主是一时没有反应过来怎么去提高。 查看全部
c爬虫抓取网页数据(c爬虫抓取网页数据,要么就是做网站后端的)
c爬虫抓取网页数据,要么就是做网站后端的。所以你要懂爬虫。总体算下来如果是不考虑网站架构的话。去304080找人测试/调试半小时足够。
python讲课视频推荐量目前比较多的.我就不推荐老师了,不过推荐个平台,网易云课堂的翁恺老师.
爬虫上黑客门泉,最近又有了神兵连.可以看看。
说实话,大部分mooc都有python入门课程,你去找找看。如果是想深入做爬虫,学习爬虫知识和技术很久的话,
python虽然前景广阔,但目前真的没必要非得去找视频,python的书籍资料,以及一些比赛可以去参加啊,
只是要会写请求就行,点击写个request没问题,搞些简单的测试自己写cookie来改随机数字也可以,但是要想写的好必须要做一些性能优化。如果不做性能优化,我们的框架flask啥的就是放不下脚本的。python基础只要认识字母表就行,你只会写基础请求,别人咋用你就照葫芦画瓢。python入门的时候不要怕难,python要是真牛逼了,十几万都不愁,毕竟最近这几年python很火。
本科实验室老师做得是类似的情况,如果题主真要开始这一行就往下看,直接了当的写请求,getposturl然后简单的测试,然后就是一堆的人肉命令服务器来接受请求。抓了之后再看看数据库去record整理分析。目前水平有限,不敢随便给意见,但是看到很多黑是其实是遇到瓶颈后想死皮赖脸寻求希望,估计题主是一时没有反应过来怎么去提高。
c爬虫抓取网页数据(a爬虫语言选择方案-上海怡健医学())
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-01-29 04:03
c爬虫抓取网页数据并处理得到pandas数据整理存入数据库a)针对不同的站点抓取得到的页面数据格式会不同,所以要采用不同的方法来对数据处理,即需要通过分词、去重等方法来处理数据;b)有些网站提供了python爬虫接口,例如,新浪博客类,这种网站并没有提供python爬虫接口,所以需要采用“xpath”来解析数据。
a爬虫语言选择方案:cpicker爬虫scrapy爬虫d)java爬虫中对页面信息分词与去重如下:douban页面解析:在openresty虚拟机上搭建python爬虫示例数据库有:jdbc、sqlite、mysql-redis四种方式数据库(数据格式):数据库选择:本次页面数据处理为pandas数据库存储:douban.pymysql.postgresql数据库:mysql、sqlite、sqlite3图片网站:b.针对不同站点抓取抓取得到的页面数据格式会不同,所以要采用不同的方法来对数据处理,即需要通过分词、去重等方法来处理数据。
a)针对不同的站点抓取抓取得到的页面数据格式会不同,所以要采用不同的方法来对数据处理,即需要通过分词、去重等方法来处理数据;b)有些网站提供了python爬虫接口,例如,新浪博客类,这种网站并没有提供python爬虫接口,所以需要采用“xpath”来解析数据。a爬虫语言选择方案:cpicker爬虫scrapy爬虫d)java爬虫中对页面信息分词与去重如下:方案:java爬虫中对页面信息分词与去重如下:。 查看全部
c爬虫抓取网页数据(a爬虫语言选择方案-上海怡健医学())
c爬虫抓取网页数据并处理得到pandas数据整理存入数据库a)针对不同的站点抓取得到的页面数据格式会不同,所以要采用不同的方法来对数据处理,即需要通过分词、去重等方法来处理数据;b)有些网站提供了python爬虫接口,例如,新浪博客类,这种网站并没有提供python爬虫接口,所以需要采用“xpath”来解析数据。
a爬虫语言选择方案:cpicker爬虫scrapy爬虫d)java爬虫中对页面信息分词与去重如下:douban页面解析:在openresty虚拟机上搭建python爬虫示例数据库有:jdbc、sqlite、mysql-redis四种方式数据库(数据格式):数据库选择:本次页面数据处理为pandas数据库存储:douban.pymysql.postgresql数据库:mysql、sqlite、sqlite3图片网站:b.针对不同站点抓取抓取得到的页面数据格式会不同,所以要采用不同的方法来对数据处理,即需要通过分词、去重等方法来处理数据。
a)针对不同的站点抓取抓取得到的页面数据格式会不同,所以要采用不同的方法来对数据处理,即需要通过分词、去重等方法来处理数据;b)有些网站提供了python爬虫接口,例如,新浪博客类,这种网站并没有提供python爬虫接口,所以需要采用“xpath”来解析数据。a爬虫语言选择方案:cpicker爬虫scrapy爬虫d)java爬虫中对页面信息分词与去重如下:方案:java爬虫中对页面信息分词与去重如下:。
c爬虫抓取网页数据(如何用c语言去抓取网页数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-26 22:01
c爬虫抓取网页数据,一般是无序列表,有序列表就是典型的有顺序的,有序列表可以说是无序的了,就是从a开始,全部都是编号为1的数据。通过c语言写网页爬虫的同学,可能也见过这样的有序网页的html格式。常用的抓取python网页爬虫,最常用的方法之一,就是用mongoose实现。我个人在学习的时候,研究的是如何用c语言去抓取文本数据,这里说的文本数据,是特指网页中自带的数据,主要是intel历史ip之类的数据。
我们平时爬取网页文本数据,爬取新闻数据,其实都是从网页的excel表中查询的。那么如何用c语言去抓取html表格数据呢?其实也很简单,只要简单的带个简单循环的循环就可以了。首先我们要知道,html格式包含了什么,简单来说就是在互联网上,只要html中出现一个特定的网址,就可以在浏览器上访问到对应的网页数据。
一般的,在浏览器浏览的时候,经常会碰到这样的网址,即/#/doctype/none-transform/plain/text/html/xhtml/1.0///get.html。这样的网址,就代表了对应的网页文本,网页里面的页面链接,可以在浏览器里面查到。因此,我们用c语言去抓取这样的网址,就会获得对应的页面链接。
虽然大家会发现,html的网址还可以自定义内容,但是,这种情况实在是不常见,我们也不一定能够自定义。所以,我们可以说,在一定条件下,能获取到网页数据的网址,就可以获取对应的页面数据。经过实践,我发现非常有限,很难有可以自定义页面的网址,这是无法获取自定义的页面数据的原因。所以我们下面来说明,能自定义的页面网址,可以在哪些有关html的框架中找到。
在我正式的写开发的时候,我使用python来做项目。为了自己写好代码,需要编写各种的基础代码,一方面是测试不同的包可以实现同样的功能,但另一方面,就是不断给自己编写各种的命令行,来让自己的python理解起来更加高效,本文就是为了后者而写的。在编写一些命令行上的命令的时候,可能会感觉特别不爽,因为它们经常会让你碰到一些很痛苦的东西。
比如说命令行中有一个清除内存的命令,我经常要写自己不需要的shell语句,写各种的set然后赋值,我对于这些命令肯定有一些抵触。但如果把它对应在python中,我直接将对应的命令写进tab键里,就可以在python中直接写内存了。有时,需要写一些命令行注释,我需要写上多个tab键,后面加上一个大括号,来表示,我在这里没有做,就可以被注释掉。另外,我还经常为了避免python代码遇到一些复杂的shell语句,需要多写一个tab键来启动其它的。 查看全部
c爬虫抓取网页数据(如何用c语言去抓取网页数据?(图))
c爬虫抓取网页数据,一般是无序列表,有序列表就是典型的有顺序的,有序列表可以说是无序的了,就是从a开始,全部都是编号为1的数据。通过c语言写网页爬虫的同学,可能也见过这样的有序网页的html格式。常用的抓取python网页爬虫,最常用的方法之一,就是用mongoose实现。我个人在学习的时候,研究的是如何用c语言去抓取文本数据,这里说的文本数据,是特指网页中自带的数据,主要是intel历史ip之类的数据。
我们平时爬取网页文本数据,爬取新闻数据,其实都是从网页的excel表中查询的。那么如何用c语言去抓取html表格数据呢?其实也很简单,只要简单的带个简单循环的循环就可以了。首先我们要知道,html格式包含了什么,简单来说就是在互联网上,只要html中出现一个特定的网址,就可以在浏览器上访问到对应的网页数据。
一般的,在浏览器浏览的时候,经常会碰到这样的网址,即/#/doctype/none-transform/plain/text/html/xhtml/1.0///get.html。这样的网址,就代表了对应的网页文本,网页里面的页面链接,可以在浏览器里面查到。因此,我们用c语言去抓取这样的网址,就会获得对应的页面链接。
虽然大家会发现,html的网址还可以自定义内容,但是,这种情况实在是不常见,我们也不一定能够自定义。所以,我们可以说,在一定条件下,能获取到网页数据的网址,就可以获取对应的页面数据。经过实践,我发现非常有限,很难有可以自定义页面的网址,这是无法获取自定义的页面数据的原因。所以我们下面来说明,能自定义的页面网址,可以在哪些有关html的框架中找到。
在我正式的写开发的时候,我使用python来做项目。为了自己写好代码,需要编写各种的基础代码,一方面是测试不同的包可以实现同样的功能,但另一方面,就是不断给自己编写各种的命令行,来让自己的python理解起来更加高效,本文就是为了后者而写的。在编写一些命令行上的命令的时候,可能会感觉特别不爽,因为它们经常会让你碰到一些很痛苦的东西。
比如说命令行中有一个清除内存的命令,我经常要写自己不需要的shell语句,写各种的set然后赋值,我对于这些命令肯定有一些抵触。但如果把它对应在python中,我直接将对应的命令写进tab键里,就可以在python中直接写内存了。有时,需要写一些命令行注释,我需要写上多个tab键,后面加上一个大括号,来表示,我在这里没有做,就可以被注释掉。另外,我还经常为了避免python代码遇到一些复杂的shell语句,需要多写一个tab键来启动其它的。
c爬虫抓取网页数据(跳出细节信息,只有极少数是自己关心的(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-26 11:02
使用的包主要有:
Requests 具有良好的树状分析特性,可以省去正则表达式带来的麻烦。打算学习urllib,熟悉爬虫的一般特性。如果加载成功,则说明对应的包已经安装完毕。
C-程序管理
运行—>配置,设置.py文件的存放路径:
三、页面爬取(以下基于python2.7,3.5类似)
跳出细节,先想想爬取需要哪些操作:
第一步:爬取页面信息
打开一个网页的过程可以简化为:HTTP是用户发出的请求—>对方返回协议—>页面被解析显示。
对于景观 网站,使用基本的 python 爬取代码:
import urllib2
def download(url):
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
request = urllib2.Request(url,headers = headers)
try:
html = urllib2.urlopen(request).read()
except urllib2.URLError as e:
print 'error:', e.reason
html = None
return html
url = 'http://www.onlytease.com/'
page = download(url)
print page
关于解码信息,打开网页按F12,可以在头部下拉列表中看到编码方式,解码与之对应。
至此,已经实现了基础网页的爬取功能。然而,只有少数整页关注自己。基础框架的搭建只剩下一个问题:如何爬取你想要的内容。
第二步:定位目标信息
打开任意网页(以chrome为例),选择感兴趣的内容,右键:勾选(或快捷键:Crtl + shift + I),即可查看对应详情:
例如选择一张图片:
查看电脑User-agent的方式有很多种,可以直接登录网站。
这是人类观察的一种方式。如果要自动定位目标信息,可以使用正则表达式、beautifulsoup等工具。请参阅此 文章 以了解常见的正则表达式。
第三步:编写目标内容
抛开前两步,以图片为例,大家可以在网上搜索python网页图片下载。看具体操作,文本/压缩文件等。
url = 'http://pics.sc.chinaz.com/files/pic/pic9/201705/bpic1322.jpg'
f = open('1.jpg',"wb") #命名并打开文件
req = urllib2.urlopen(url)
buf = req.read() #读出文件
f.write(buf) #写入文件
这样,网上的图片进入本地:
爬取小图:
代码:
import urllib2
import re
def download(url): #Step1:读取网页内容
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
request = urllib2.Request(url,headers = headers)
try:
html = urllib2.urlopen(request).read()
except urllib2.URLError as e:
print 'error:', e.reason
html = None
return html
#Step2:获取目标信息链接,我要的是jpg的链接
url = 'http://sc.chinaz.com/tupian/fengjingtupian.html'
page = download(url)
imglist = re.findall('src2="(.*?)"',page) #re.findall() 方法读取html 中包含 imgre(正则表达式)的 数据
#Step3:文件保存至本地
i = 1
for imgname in imglist:
f = open('.\\sightsee\\'+str(i)+'.jpg',"wb") #命名并打开文件
print i
i = i+1
req = urllib2.urlopen(imgname)
buf = req.read() #读出文件
f.write(buf) #写入文件
在包里:
为什么是src2而不是src,把下载的文本复制到txt文件,搜索.jpg,
我看到是src2,但是网页是src:
以上爬取的是一页图片。如果你想得到总数怎么办?您可以通过正则表达式匹配和计算总页数。看看它:
打开网站,一共找到2217页:
除了第一页有点不同:
其他人跟随等等:
好的,现在进一步改进代码:
import urllib2
import re
import numpy as np
def download(url): #Step1:读取网页内容
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
request = urllib2.Request(url,headers = headers)
try:
html = urllib2.urlopen(request).read()
except urllib2.URLError as e:
print 'error:', e.reason
html = None
return html
urllen = 2217
tag = np.arange(1,urllen+1)
base = 'http://sc.chinaz.com/tupian/'
i = 1
for j in tag:
if j==1:
url = base+'index.html'
else:
url = base+'index_'+str(j)+'.html'
page = download(url)
imglist = re.findall('src2="(.*?)"',page) #re.findall() 方法读取html的.jpg链接
for imgname in imglist:
f = open('.\\sightsee\\'+str(i)+'.jpg',"wb") #命名并打开文件
print i
i = i+1
req = urllib2.urlopen(imgname)
buf = req.read() #读出文件
f.write(buf) #写入文件
f.close()
已成功下载:
有一个问题:
未设置超时参数。结果,当网络环境不好的时候,经常会出现read()方法没有响应的问题。程序卡在 read() 方法中。为 urlopen 添加超时是可以的。设置 timeout 后超时后,会在读取超时时抛出 socket.timeout 异常。如果希望程序稳定,需要在urlopen中加入异常处理,出现异常时重试。
修改这句话:
html = urllib2.urlopen(request,timeout=2).read()
问题解决了。
但是还有其他错误:
参考下图,添加异常处理,问题解决。
四、渲染动态网页抓取
python工具包可以在这里下载。安装selenium工具包,安装好,在python2中单独下载:cssselect,顾名思义,css+select就是第一个css样式选择。
这里只记录应用,偷懒:使用selenium+phantomjs的爬取方式。
phantomjs简介:
PhantomJS 是一个基于 WebKit 的服务器端 JavaScript API。它完全支持没有浏览器支持的 Web,并且速度很快并且原生支持各种 Web 标准:DOM 操作、CSS 选择器、JSON、Canvas 和 SVG。PhantomJS 可用于页面自动化、网络监控、网页截图和 UI 测试。
很多网页不会一次加载全部内容,如果每次都刷新页面也不理想,所以借助动态加载,可以看到只有这部分内容加载到了哪里。Phantomjs可以在不打开浏览器的情况下获取加载后的网页内容,这样可以通过urllib2.请求操作读取网页的全部内容,而不是动态加载的内容.
注意两点:
1-phantomjs的\bin需要在环境变量PATH中添加绝对路径;
2-在代码中:在路径前添加 r
browser = webdriver.PhantomJS(executable_path=r"C:\Users\Nobleding\Anaconda3\Lib\site-packages\phantomjs-2.1.1-windows\bin\phantomjs.exe")
#coding=utf-8
from selenium import webdriver
import re
import urllib2
browser = webdriver.PhantomJS(executable_path=r"C:\Users\Nobleding\Anaconda3\Lib\site-packages\phantomjs-2.1.1-windows\bin\phantomjs.exe")
browser.implicitly_wait(50)
#browser.get("https://www.baidu.com/")
urllink = "网址名称"
browser.get(urllink)
page = browser.execute_script("return document.documentElement.outerHTML")
imglist = re.findall('src=(.*?).jpg', page) #re.findall() 方法读取html的.jpg链接
i=1
for imgname in imglist:
f = open('.\\sightsee\\'+str(i)+'.jpg',"wb") #命名并打开文件
print i
i = i+1
try:
imglink = imgname+'.jpg'
n = len(imglink)
req = urllib2.urlopen(imglink[1:n],timeout = 3)
except urllib2.URLError, e:
print 'error:', e.reason
continue
except socket.error as e:
continue
except socket.timeout as e:
continue
except urllib2.HTTPError:
continue
buf = req.read() #读出文件
f.write(buf) #写入文件
f.close()
基于urllib2/urllib3/urllib,经常报超时错误。直接使用requests更直接,不再报超时错误:
<p># -*- coding: utf-8 -*-
"""
Created on Sun May 07 09:48:39 2017
@author: Nobleding
"""
import requests
import re
import socket
import numpy as np
import urllib
from socket import timeout
def download(url): #Step1:读取网页内容
header = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
# request = requests.Request(url,headers = headers)
try:
htmll = requests.get(url,headers=header)
html = htmll.text
# except requests.URLError:
# print ('error:')
# html = None
except socket.error as e:
html = None
except socket.timeout as e:
html = None
except urllib.request.HTTPError:
html = None
return html
urlmain =网址
pagemain = download(urlmain)
#pagemain = pagemain.decode('utf-8')
imglistmain = re.findall(' 查看全部
c爬虫抓取网页数据(跳出细节信息,只有极少数是自己关心的(组图))
使用的包主要有:
Requests 具有良好的树状分析特性,可以省去正则表达式带来的麻烦。打算学习urllib,熟悉爬虫的一般特性。如果加载成功,则说明对应的包已经安装完毕。
C-程序管理
运行—>配置,设置.py文件的存放路径:
三、页面爬取(以下基于python2.7,3.5类似)
跳出细节,先想想爬取需要哪些操作:
第一步:爬取页面信息
打开一个网页的过程可以简化为:HTTP是用户发出的请求—>对方返回协议—>页面被解析显示。
对于景观 网站,使用基本的 python 爬取代码:
import urllib2
def download(url):
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
request = urllib2.Request(url,headers = headers)
try:
html = urllib2.urlopen(request).read()
except urllib2.URLError as e:
print 'error:', e.reason
html = None
return html
url = 'http://www.onlytease.com/'
page = download(url)
print page
关于解码信息,打开网页按F12,可以在头部下拉列表中看到编码方式,解码与之对应。
至此,已经实现了基础网页的爬取功能。然而,只有少数整页关注自己。基础框架的搭建只剩下一个问题:如何爬取你想要的内容。
第二步:定位目标信息
打开任意网页(以chrome为例),选择感兴趣的内容,右键:勾选(或快捷键:Crtl + shift + I),即可查看对应详情:
例如选择一张图片:
查看电脑User-agent的方式有很多种,可以直接登录网站。
这是人类观察的一种方式。如果要自动定位目标信息,可以使用正则表达式、beautifulsoup等工具。请参阅此 文章 以了解常见的正则表达式。
第三步:编写目标内容
抛开前两步,以图片为例,大家可以在网上搜索python网页图片下载。看具体操作,文本/压缩文件等。
url = 'http://pics.sc.chinaz.com/files/pic/pic9/201705/bpic1322.jpg'
f = open('1.jpg',"wb") #命名并打开文件
req = urllib2.urlopen(url)
buf = req.read() #读出文件
f.write(buf) #写入文件
这样,网上的图片进入本地:
爬取小图:
代码:
import urllib2
import re
def download(url): #Step1:读取网页内容
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
request = urllib2.Request(url,headers = headers)
try:
html = urllib2.urlopen(request).read()
except urllib2.URLError as e:
print 'error:', e.reason
html = None
return html
#Step2:获取目标信息链接,我要的是jpg的链接
url = 'http://sc.chinaz.com/tupian/fengjingtupian.html'
page = download(url)
imglist = re.findall('src2="(.*?)"',page) #re.findall() 方法读取html 中包含 imgre(正则表达式)的 数据
#Step3:文件保存至本地
i = 1
for imgname in imglist:
f = open('.\\sightsee\\'+str(i)+'.jpg',"wb") #命名并打开文件
print i
i = i+1
req = urllib2.urlopen(imgname)
buf = req.read() #读出文件
f.write(buf) #写入文件
在包里:
为什么是src2而不是src,把下载的文本复制到txt文件,搜索.jpg,
我看到是src2,但是网页是src:
以上爬取的是一页图片。如果你想得到总数怎么办?您可以通过正则表达式匹配和计算总页数。看看它:
打开网站,一共找到2217页:
除了第一页有点不同:
其他人跟随等等:
好的,现在进一步改进代码:
import urllib2
import re
import numpy as np
def download(url): #Step1:读取网页内容
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
request = urllib2.Request(url,headers = headers)
try:
html = urllib2.urlopen(request).read()
except urllib2.URLError as e:
print 'error:', e.reason
html = None
return html
urllen = 2217
tag = np.arange(1,urllen+1)
base = 'http://sc.chinaz.com/tupian/'
i = 1
for j in tag:
if j==1:
url = base+'index.html'
else:
url = base+'index_'+str(j)+'.html'
page = download(url)
imglist = re.findall('src2="(.*?)"',page) #re.findall() 方法读取html的.jpg链接
for imgname in imglist:
f = open('.\\sightsee\\'+str(i)+'.jpg',"wb") #命名并打开文件
print i
i = i+1
req = urllib2.urlopen(imgname)
buf = req.read() #读出文件
f.write(buf) #写入文件
f.close()
已成功下载:
有一个问题:
未设置超时参数。结果,当网络环境不好的时候,经常会出现read()方法没有响应的问题。程序卡在 read() 方法中。为 urlopen 添加超时是可以的。设置 timeout 后超时后,会在读取超时时抛出 socket.timeout 异常。如果希望程序稳定,需要在urlopen中加入异常处理,出现异常时重试。
修改这句话:
html = urllib2.urlopen(request,timeout=2).read()
问题解决了。
但是还有其他错误:
参考下图,添加异常处理,问题解决。
四、渲染动态网页抓取
python工具包可以在这里下载。安装selenium工具包,安装好,在python2中单独下载:cssselect,顾名思义,css+select就是第一个css样式选择。
这里只记录应用,偷懒:使用selenium+phantomjs的爬取方式。
phantomjs简介:
PhantomJS 是一个基于 WebKit 的服务器端 JavaScript API。它完全支持没有浏览器支持的 Web,并且速度很快并且原生支持各种 Web 标准:DOM 操作、CSS 选择器、JSON、Canvas 和 SVG。PhantomJS 可用于页面自动化、网络监控、网页截图和 UI 测试。
很多网页不会一次加载全部内容,如果每次都刷新页面也不理想,所以借助动态加载,可以看到只有这部分内容加载到了哪里。Phantomjs可以在不打开浏览器的情况下获取加载后的网页内容,这样可以通过urllib2.请求操作读取网页的全部内容,而不是动态加载的内容.
注意两点:
1-phantomjs的\bin需要在环境变量PATH中添加绝对路径;
2-在代码中:在路径前添加 r
browser = webdriver.PhantomJS(executable_path=r"C:\Users\Nobleding\Anaconda3\Lib\site-packages\phantomjs-2.1.1-windows\bin\phantomjs.exe")
#coding=utf-8
from selenium import webdriver
import re
import urllib2
browser = webdriver.PhantomJS(executable_path=r"C:\Users\Nobleding\Anaconda3\Lib\site-packages\phantomjs-2.1.1-windows\bin\phantomjs.exe")
browser.implicitly_wait(50)
#browser.get("https://www.baidu.com/";)
urllink = "网址名称"
browser.get(urllink)
page = browser.execute_script("return document.documentElement.outerHTML")
imglist = re.findall('src=(.*?).jpg', page) #re.findall() 方法读取html的.jpg链接
i=1
for imgname in imglist:
f = open('.\\sightsee\\'+str(i)+'.jpg',"wb") #命名并打开文件
print i
i = i+1
try:
imglink = imgname+'.jpg'
n = len(imglink)
req = urllib2.urlopen(imglink[1:n],timeout = 3)
except urllib2.URLError, e:
print 'error:', e.reason
continue
except socket.error as e:
continue
except socket.timeout as e:
continue
except urllib2.HTTPError:
continue
buf = req.read() #读出文件
f.write(buf) #写入文件
f.close()
基于urllib2/urllib3/urllib,经常报超时错误。直接使用requests更直接,不再报超时错误:
<p># -*- coding: utf-8 -*-
"""
Created on Sun May 07 09:48:39 2017
@author: Nobleding
"""
import requests
import re
import socket
import numpy as np
import urllib
from socket import timeout
def download(url): #Step1:读取网页内容
header = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
# request = requests.Request(url,headers = headers)
try:
htmll = requests.get(url,headers=header)
html = htmll.text
# except requests.URLError:
# print ('error:')
# html = None
except socket.error as e:
html = None
except socket.timeout as e:
html = None
except urllib.request.HTTPError:
html = None
return html
urlmain =网址
pagemain = download(urlmain)
#pagemain = pagemain.decode('utf-8')
imglistmain = re.findall('
c爬虫抓取网页数据(爬虫在数据分析领域的应用,如何帮助我们提升数据分析质量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-01-25 10:10
在当今信息化和数字化的时代,人们离不开网络搜索,但想想看,在搜索过程中,你真的可以得到相关信息,因为有人在帮你过滤相关内容,呈现在你面前。
就像在餐馆里一样,你点了土豆然后得到它们,因为有人帮你在土豆、萝卜、西红柿等中找到它们,然后有人把它们带到你的餐桌上。在网上,这两个动作是一个叫爬虫的同学为你实现的。
也就是说,没有爬虫,就没有今天的检索,就无法准确查找信息和高效获取数据。今天DataHunter就来谈谈爬虫在数据分析领域的应用,以及它如何帮助我们提高数据分析的质量。
一、数据时代,爬虫的本质是提高效率
网络爬虫,又称网络机器人,可以代替人自动浏览网络信息,采集和组织数据。
它是一个程序,其基本原理是向网站/网络发起请求,获取资源后分析提取有用数据。从技术上讲,就是通过程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)爬取到本地,然后提取您需要的数据并将其存储以供使用。
每个程序都有自己的规则,网络爬虫也不例外。它穿梭于世界各地的各种网站之间,根据人们强加的规则将采集信息。我们称这些规则为网络爬虫算法。规则是人定的,是人根据自己的目的和需要设计的。因此,根据用户的目的,爬虫可以有不同的功能。但所有爬虫的本质是方便人们在海量的互联网信息中找到并下载自己想要的信息类型,从而提高信息获取效率。
二、爬虫的应用:搜索并帮助企业做强业务
1.搜索引擎:爬取网站为网络用户提供便利
在互联网的早期,能够提供全球范围内信息的网站并不多,用户也不多。Internet 只是文件传输协议 (FTP) 站点的集合,用户可以导航这些站点以查找特定的共享文件,并查找和组合 Internet 上可用的分布式数据,创建了一个称为网络爬虫的自动化程序 /Robot,它可以爬取网络上的所有网页,然后将所有页面的内容复制到数据库中进行索引。这也是最早的搜索引擎。
如今,随着互联网的飞速发展,我们可以在任何搜索引擎中看到来自世界各地各种网站的信息。百度搜索引擎的爬虫叫百度蜘蛛,360的爬虫叫360Spider,搜狗的爬虫叫搜狗蜘蛛,必应的爬虫叫Bingbot。搜索引擎离不开爬虫。
比如百度蜘蛛每天都会抓取大量的互联网信息,抓取优质信息和收录。当用户在百度搜索引擎上搜索对应的关键词时,百度会对关键词进行分析处理,从收录的网页中找出相关网页,按照一定的排名规则和结果展示给用户,工作原理如图。现在,我们可以大胆地说,你每天都在免费享受爬虫的好处。
2.企业:监控舆情,高效获取有价值信息
我们说过爬虫的本质是提高效率,而爬虫的规则是由人决定的;那么企业就可以根据自己的业务需求设计爬虫,第一时间获取网络上的相关信息,进行清理整合。
做大数据时代的数据分析,首先要有数据源,网络爬虫可以让我们获取更多的数据源,同时根据我们的目的进行采集,从而去除很多的无关数据。
例如,在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站s,或者从某些文档或内部资料中获取数据源。但是,这些获取数据的方式有时很难满足我们的数据需求。此时,我们可以利用爬虫技术从互联网上自动获取更多我们感兴趣的数据内容,从而进行更深入的数据分析,获取更多有价值的信息。
此外,网络爬虫还可用于财务分析,对财务数据进行采集进行投资分析;可应用于舆情监测分析、精准客户精准营销等各个领域。
三、企业常用的4种网络爬虫
网络爬虫根据实现的技术和结构可以分为一般网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。但由于网络环境复杂,实际的网络爬虫通常是这几种爬虫的组合。
1.万能网络爬虫
通用网络爬虫也称为全网络爬虫。顾名思义,要爬取的目标资源在整个互联网上,要爬取的目标数据是巨大的,爬取的范围也很大。正是因为爬取的数据是海量数据,所以对于这种爬虫来说,对爬取的性能要求是非常高的。这种网络爬虫主要用于大型搜索引擎,具有很高的应用价值。
一般的网络爬虫主要由初始URL采集、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块等组成。一般网络爬虫在爬取时会采用一定的爬取策略,主要包括深度优先爬取策略和广度优先爬取策略。具体细节将在后面介绍。
2.专注于网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是根据预先定义的主题有选择地爬取网页的爬虫。聚焦网络爬虫主要用于爬取特定信息,主要为特定类型的人提供服务。
聚焦网络爬虫也是由初始URL集合、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块、内容评价模块、链接评价模块等组成。内容评估模块和链接评估模块可以根据链接和内容的重要性确定优先访问哪些页面。专注于网络爬虫的爬取策略主要有四种,如图:
由于专注的网络爬虫可以有目的地根据相应的主题进行爬取,在实际应用过程中可以节省大量的服务器资源和宽带资源,因此具有很强的实用性。这里我们以网络爬虫为例来了解爬虫运行的工作原理和过程。
如图所示,焦点网络爬虫有一个控制中心,负责管理和监控整个爬虫系统,包括控制用户交互、初始化爬虫、确定主题、协调各个模块之间的工作以及控制整个爬虫系统。爬行过程。等等:
(1)控制中心将初始URL集合传递给URL队列,页面爬取模块会从URL队列中读取第一批URL列表;
(2)根据这些URL地址,从网上爬取对应的页面;爬取后,将爬取的内容发送到页面数据库进行存储;
(3)在爬取过程中,会爬取一些新的URL,此时需要使用链接过滤模块,根据指定的主题过滤掉不相关的链接,然后使用链接评价模块进行根据主题剩余的URL链接。或者内容评估模块进行优先排序,完成后将新的URL地址传递给URL队列,供页面爬取模块使用;
(4)在页面库中爬取并存入页面后,需要使用页面分析模块根据主题对爬取的页面进行分析处理,并根据处理结果建立索引库。当用户检索到相应的信息,就可以从索引数据库中进行相应的检索,得到相应的结果。
3.增量网络爬虫
这里的“incremental”对应于增量更新,意思是在更新过程中只更新变化的地方,不变的地方不更新。
增量网络爬虫,在爬取网页时,只爬取内容发生变化的网页或新生成的网页,不会爬取内容未发生变化的网页。增量网络爬虫可以在一定程度上保证爬取的页面尽可能的新。
4.深网爬虫
在互联网中,网页根据存在的程度可以分为表层页面和深层页面。表面页面是指无需提交表单,使用静态链接即可到达的静态页面;而深页是提交某个关键词后才能获得的页面。在 Internet 中,深层页面的数量通常远大于表面页面的数量。
深网爬虫可以爬取互联网中的深层页面,而要爬取深层页面,就需要想办法自动填写相应的表格。深网爬虫主要由 URL 列表、LVS 列表(LVS 指标签/值集合,即填充表单的数据源)、爬取控制器、解析器、LVS 控制器、表单分析器、表单处理器、响应分析器和其他部分。
四、网络爬虫的爬取策略
前面我们说过,网络爬虫算法是基于人对采集信息施加的规则,由于网络环境复杂,算法也多种多样,也就是爬取策略。这里主要介绍爬取的顺序和频率。
1.爬取顺序
网络爬虫在爬取过程中,可能会出现在爬取的URL列表中的多个URL地址,因此爬虫会依次对这些URL地址进行爬取。
与一般的网络爬虫相比,爬取的顺序并不那么重要。但专注于网络爬虫,爬取的顺序与服务器资源和宽带资源有关,所以非常重要,一般由爬取策略决定。爬取策略主要包括深度优先爬取策略、广度优先爬取策略、大站点优先策略、反链策略等爬取策略。
如图,假设有一个网站,ABCDEFG为站点下的网页,网页的层次结构如图所示。如果此时网页ABCDEFG都在爬取队列中,那么根据不同的爬取策略,爬取的顺序是不同的。
深度优先爬取策略:A→D→E→B→C→F→G
广度优先爬取策略:A→B→C→D→E→F→G
除了以上两种爬取策略外,还可以使用大站点爬取策略。可以根据相应网页所属的站点进行分类。如果某个网站有大量的网页,则称为大站点。按照这个策略,网站拥有的网页越多,则越大,优先抓取该网页在大站点中的URL地址。
此外,还有反向链接策略。一个网页的反向链接数是指该网页被其他网页指向的次数。这个次数代表了该网页在一定程度上被其他网页推荐的次数。因此,如果按照反向链接策略进行爬取,那么哪个网页的反向链接多,就会先爬到哪个页面。
但是,在实际情况中,如果一个网页的优先级只是简单地由反向链接策略来决定的话,就可能会出现很多作弊的情况。因此,采用反向链接策略需要考虑可靠反向链接的数量。除了以上的爬取策略,实践中还有很多其他的爬取策略,比如OPIC策略、Partial PageRank策略等等。
2.爬取频率
网站 网页经常更新。作为爬虫,网站的更新频率越接近爬虫访问网站的频率,效果越好。当然,在爬虫服务器资源有限的情况下,爬虫还需要根据相应的策略,让不同的网页有不同的更新优先级。优先级高的网页会更新得更快,爬取响应也会更快。常见的网页更新策略有以下三种:
(1)用户体验策略:大部分用户使用搜索引擎查询某个关键词时,只会关注排名靠前的网页。因此,当爬虫服务器资源有限时,爬虫会优先更新排名靠前的页面。
(2)历史数据策略:是指根据某个网页的历史更新数据,通过泊松过程建模等手段,预测该网页下次更新时间,从而确定下一次更新时间的能力。 time 抓取网页所用的时间。
(3)聚类分析策略:网页可能有不同的内容,但一般来说,属性相似的网页更新频率相似,所以可以对大量的网页进行聚类。爬取的频率根据设置同类型网页的平均更新值。
五、网络爬虫的实现技术
对于实现技术,本文不展开,只为有兴趣的同学提供几种常用语言:Python、Java、PHP、Node.JS、C++、Go语言(另外还有很多开发语言用于网络爬虫)。
Python:爬虫框架非常丰富,多线程处理能力强,而且易学,代码简洁,优点很多。
Java:适合开发大型爬虫项目。
PHP:后端处理能力很强,代码很简洁,模块丰富,但是并发能力比较弱。
Node.JS:支持高并发和多线程。
C++:运行速度快,适合开发大型爬虫项目,成本高。
Go语言:同样的高并发能力很强。
六、总结
说到爬虫,很多人认为它们是网络世界中不可能存在的灰色地带。恭喜你,看完这篇文章,你比很多人都知道。
因为爬虫分为良性爬虫和恶意爬虫,比如搜索引擎爬虫。Goodwill爬虫严格遵守Robots协议规范爬取网页数据(如URL),它的存在可以增加网站的曝光度,给网站带来流量;
恶意爬虫,无视Robots协议,肆意爬取网站中一些深度不情愿的数据,包括个人隐私或商业机密等重要信息。而恶意爬虫的用户想要多次大量地从网站获取信息,所以通常会在目标网站上投放大量爬虫。如果大量爬虫同时访问网站,很容易导致网站服务器超载或崩溃,导致网站算子丢失。
据统计,2017年我国42.2%的互联网流量是由网络机器人创造的,其中恶意机器(主要是恶意爬虫)占21.80%。我们应该合法合理地使用网络爬虫,这样才能用科技为企业带来长远发展,用科学为社会创造更高的价值。
关于数据猎人
DataHunter是一家专业的数据分析和商业智能服务商,注册于2014年,团队核心成员来自IBM、Oracle、SAP等知名企业,深耕大数据分析领域和拥有十余年丰富的企业服务经验。
DataHunter的核心产品Data Analytics智能数据分析平台和数据大屏设计配置工具Data MAX在行业中形成了自己的独特优势,在各行业积累了众多标杆客户和成功案例.
自成立以来,DataHunter一直致力于为客户提供实时、高效、智能的数据分析与展示解决方案,帮助企业查看和分析数据,改善业务,成为最值得信赖的数据业务公司。 查看全部
c爬虫抓取网页数据(爬虫在数据分析领域的应用,如何帮助我们提升数据分析质量)
在当今信息化和数字化的时代,人们离不开网络搜索,但想想看,在搜索过程中,你真的可以得到相关信息,因为有人在帮你过滤相关内容,呈现在你面前。
就像在餐馆里一样,你点了土豆然后得到它们,因为有人帮你在土豆、萝卜、西红柿等中找到它们,然后有人把它们带到你的餐桌上。在网上,这两个动作是一个叫爬虫的同学为你实现的。
也就是说,没有爬虫,就没有今天的检索,就无法准确查找信息和高效获取数据。今天DataHunter就来谈谈爬虫在数据分析领域的应用,以及它如何帮助我们提高数据分析的质量。
一、数据时代,爬虫的本质是提高效率
网络爬虫,又称网络机器人,可以代替人自动浏览网络信息,采集和组织数据。
它是一个程序,其基本原理是向网站/网络发起请求,获取资源后分析提取有用数据。从技术上讲,就是通过程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)爬取到本地,然后提取您需要的数据并将其存储以供使用。
每个程序都有自己的规则,网络爬虫也不例外。它穿梭于世界各地的各种网站之间,根据人们强加的规则将采集信息。我们称这些规则为网络爬虫算法。规则是人定的,是人根据自己的目的和需要设计的。因此,根据用户的目的,爬虫可以有不同的功能。但所有爬虫的本质是方便人们在海量的互联网信息中找到并下载自己想要的信息类型,从而提高信息获取效率。
二、爬虫的应用:搜索并帮助企业做强业务
1.搜索引擎:爬取网站为网络用户提供便利
在互联网的早期,能够提供全球范围内信息的网站并不多,用户也不多。Internet 只是文件传输协议 (FTP) 站点的集合,用户可以导航这些站点以查找特定的共享文件,并查找和组合 Internet 上可用的分布式数据,创建了一个称为网络爬虫的自动化程序 /Robot,它可以爬取网络上的所有网页,然后将所有页面的内容复制到数据库中进行索引。这也是最早的搜索引擎。
如今,随着互联网的飞速发展,我们可以在任何搜索引擎中看到来自世界各地各种网站的信息。百度搜索引擎的爬虫叫百度蜘蛛,360的爬虫叫360Spider,搜狗的爬虫叫搜狗蜘蛛,必应的爬虫叫Bingbot。搜索引擎离不开爬虫。
比如百度蜘蛛每天都会抓取大量的互联网信息,抓取优质信息和收录。当用户在百度搜索引擎上搜索对应的关键词时,百度会对关键词进行分析处理,从收录的网页中找出相关网页,按照一定的排名规则和结果展示给用户,工作原理如图。现在,我们可以大胆地说,你每天都在免费享受爬虫的好处。
2.企业:监控舆情,高效获取有价值信息
我们说过爬虫的本质是提高效率,而爬虫的规则是由人决定的;那么企业就可以根据自己的业务需求设计爬虫,第一时间获取网络上的相关信息,进行清理整合。
做大数据时代的数据分析,首先要有数据源,网络爬虫可以让我们获取更多的数据源,同时根据我们的目的进行采集,从而去除很多的无关数据。
例如,在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站s,或者从某些文档或内部资料中获取数据源。但是,这些获取数据的方式有时很难满足我们的数据需求。此时,我们可以利用爬虫技术从互联网上自动获取更多我们感兴趣的数据内容,从而进行更深入的数据分析,获取更多有价值的信息。
此外,网络爬虫还可用于财务分析,对财务数据进行采集进行投资分析;可应用于舆情监测分析、精准客户精准营销等各个领域。
三、企业常用的4种网络爬虫
网络爬虫根据实现的技术和结构可以分为一般网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。但由于网络环境复杂,实际的网络爬虫通常是这几种爬虫的组合。
1.万能网络爬虫
通用网络爬虫也称为全网络爬虫。顾名思义,要爬取的目标资源在整个互联网上,要爬取的目标数据是巨大的,爬取的范围也很大。正是因为爬取的数据是海量数据,所以对于这种爬虫来说,对爬取的性能要求是非常高的。这种网络爬虫主要用于大型搜索引擎,具有很高的应用价值。
一般的网络爬虫主要由初始URL采集、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块等组成。一般网络爬虫在爬取时会采用一定的爬取策略,主要包括深度优先爬取策略和广度优先爬取策略。具体细节将在后面介绍。
2.专注于网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是根据预先定义的主题有选择地爬取网页的爬虫。聚焦网络爬虫主要用于爬取特定信息,主要为特定类型的人提供服务。
聚焦网络爬虫也是由初始URL集合、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块、内容评价模块、链接评价模块等组成。内容评估模块和链接评估模块可以根据链接和内容的重要性确定优先访问哪些页面。专注于网络爬虫的爬取策略主要有四种,如图:
由于专注的网络爬虫可以有目的地根据相应的主题进行爬取,在实际应用过程中可以节省大量的服务器资源和宽带资源,因此具有很强的实用性。这里我们以网络爬虫为例来了解爬虫运行的工作原理和过程。
如图所示,焦点网络爬虫有一个控制中心,负责管理和监控整个爬虫系统,包括控制用户交互、初始化爬虫、确定主题、协调各个模块之间的工作以及控制整个爬虫系统。爬行过程。等等:
(1)控制中心将初始URL集合传递给URL队列,页面爬取模块会从URL队列中读取第一批URL列表;
(2)根据这些URL地址,从网上爬取对应的页面;爬取后,将爬取的内容发送到页面数据库进行存储;
(3)在爬取过程中,会爬取一些新的URL,此时需要使用链接过滤模块,根据指定的主题过滤掉不相关的链接,然后使用链接评价模块进行根据主题剩余的URL链接。或者内容评估模块进行优先排序,完成后将新的URL地址传递给URL队列,供页面爬取模块使用;
(4)在页面库中爬取并存入页面后,需要使用页面分析模块根据主题对爬取的页面进行分析处理,并根据处理结果建立索引库。当用户检索到相应的信息,就可以从索引数据库中进行相应的检索,得到相应的结果。
3.增量网络爬虫
这里的“incremental”对应于增量更新,意思是在更新过程中只更新变化的地方,不变的地方不更新。
增量网络爬虫,在爬取网页时,只爬取内容发生变化的网页或新生成的网页,不会爬取内容未发生变化的网页。增量网络爬虫可以在一定程度上保证爬取的页面尽可能的新。
4.深网爬虫
在互联网中,网页根据存在的程度可以分为表层页面和深层页面。表面页面是指无需提交表单,使用静态链接即可到达的静态页面;而深页是提交某个关键词后才能获得的页面。在 Internet 中,深层页面的数量通常远大于表面页面的数量。
深网爬虫可以爬取互联网中的深层页面,而要爬取深层页面,就需要想办法自动填写相应的表格。深网爬虫主要由 URL 列表、LVS 列表(LVS 指标签/值集合,即填充表单的数据源)、爬取控制器、解析器、LVS 控制器、表单分析器、表单处理器、响应分析器和其他部分。
四、网络爬虫的爬取策略
前面我们说过,网络爬虫算法是基于人对采集信息施加的规则,由于网络环境复杂,算法也多种多样,也就是爬取策略。这里主要介绍爬取的顺序和频率。
1.爬取顺序
网络爬虫在爬取过程中,可能会出现在爬取的URL列表中的多个URL地址,因此爬虫会依次对这些URL地址进行爬取。
与一般的网络爬虫相比,爬取的顺序并不那么重要。但专注于网络爬虫,爬取的顺序与服务器资源和宽带资源有关,所以非常重要,一般由爬取策略决定。爬取策略主要包括深度优先爬取策略、广度优先爬取策略、大站点优先策略、反链策略等爬取策略。
如图,假设有一个网站,ABCDEFG为站点下的网页,网页的层次结构如图所示。如果此时网页ABCDEFG都在爬取队列中,那么根据不同的爬取策略,爬取的顺序是不同的。
深度优先爬取策略:A→D→E→B→C→F→G
广度优先爬取策略:A→B→C→D→E→F→G
除了以上两种爬取策略外,还可以使用大站点爬取策略。可以根据相应网页所属的站点进行分类。如果某个网站有大量的网页,则称为大站点。按照这个策略,网站拥有的网页越多,则越大,优先抓取该网页在大站点中的URL地址。
此外,还有反向链接策略。一个网页的反向链接数是指该网页被其他网页指向的次数。这个次数代表了该网页在一定程度上被其他网页推荐的次数。因此,如果按照反向链接策略进行爬取,那么哪个网页的反向链接多,就会先爬到哪个页面。
但是,在实际情况中,如果一个网页的优先级只是简单地由反向链接策略来决定的话,就可能会出现很多作弊的情况。因此,采用反向链接策略需要考虑可靠反向链接的数量。除了以上的爬取策略,实践中还有很多其他的爬取策略,比如OPIC策略、Partial PageRank策略等等。
2.爬取频率
网站 网页经常更新。作为爬虫,网站的更新频率越接近爬虫访问网站的频率,效果越好。当然,在爬虫服务器资源有限的情况下,爬虫还需要根据相应的策略,让不同的网页有不同的更新优先级。优先级高的网页会更新得更快,爬取响应也会更快。常见的网页更新策略有以下三种:
(1)用户体验策略:大部分用户使用搜索引擎查询某个关键词时,只会关注排名靠前的网页。因此,当爬虫服务器资源有限时,爬虫会优先更新排名靠前的页面。
(2)历史数据策略:是指根据某个网页的历史更新数据,通过泊松过程建模等手段,预测该网页下次更新时间,从而确定下一次更新时间的能力。 time 抓取网页所用的时间。
(3)聚类分析策略:网页可能有不同的内容,但一般来说,属性相似的网页更新频率相似,所以可以对大量的网页进行聚类。爬取的频率根据设置同类型网页的平均更新值。
五、网络爬虫的实现技术
对于实现技术,本文不展开,只为有兴趣的同学提供几种常用语言:Python、Java、PHP、Node.JS、C++、Go语言(另外还有很多开发语言用于网络爬虫)。
Python:爬虫框架非常丰富,多线程处理能力强,而且易学,代码简洁,优点很多。
Java:适合开发大型爬虫项目。
PHP:后端处理能力很强,代码很简洁,模块丰富,但是并发能力比较弱。
Node.JS:支持高并发和多线程。
C++:运行速度快,适合开发大型爬虫项目,成本高。
Go语言:同样的高并发能力很强。
六、总结
说到爬虫,很多人认为它们是网络世界中不可能存在的灰色地带。恭喜你,看完这篇文章,你比很多人都知道。
因为爬虫分为良性爬虫和恶意爬虫,比如搜索引擎爬虫。Goodwill爬虫严格遵守Robots协议规范爬取网页数据(如URL),它的存在可以增加网站的曝光度,给网站带来流量;
恶意爬虫,无视Robots协议,肆意爬取网站中一些深度不情愿的数据,包括个人隐私或商业机密等重要信息。而恶意爬虫的用户想要多次大量地从网站获取信息,所以通常会在目标网站上投放大量爬虫。如果大量爬虫同时访问网站,很容易导致网站服务器超载或崩溃,导致网站算子丢失。
据统计,2017年我国42.2%的互联网流量是由网络机器人创造的,其中恶意机器(主要是恶意爬虫)占21.80%。我们应该合法合理地使用网络爬虫,这样才能用科技为企业带来长远发展,用科学为社会创造更高的价值。
关于数据猎人
DataHunter是一家专业的数据分析和商业智能服务商,注册于2014年,团队核心成员来自IBM、Oracle、SAP等知名企业,深耕大数据分析领域和拥有十余年丰富的企业服务经验。
DataHunter的核心产品Data Analytics智能数据分析平台和数据大屏设计配置工具Data MAX在行业中形成了自己的独特优势,在各行业积累了众多标杆客户和成功案例.
自成立以来,DataHunter一直致力于为客户提供实时、高效、智能的数据分析与展示解决方案,帮助企业查看和分析数据,改善业务,成为最值得信赖的数据业务公司。
c爬虫抓取网页数据(几个适合新入门学习Python爬虫的网页,总有一款适合你!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-22 19:16
推荐几个适合初学者学习Python爬虫的网页。总有一款适合你!
废话不多说,直接上干货吧!
今日头条图集:抓包获取json数据
打开今日头条首页,搜索小姐姐,或者其他你感兴趣的内容,然后点击图库
动态加载的json数据出来,没有反爬,注意如果不想抓取内容中的图片,只能抓取缩略图,也就是本页显示的图片,在json数据中的image_list,注意,把url中的list改成origin,就是大图了!代码显示如下
Python学习交流群542110741
图片地址全部出!
全书网:直接源码匹配相关内容
直接搜索全书,打开首页,找到一本小说,比如《盗墓笔记》,点击跳转网页,点击开始阅读,所有章节出现,小说内容、网页内容和进入章节后出现代码。如下:
Python学习交流群542110741
80本电子书:匹配地址直接下载压缩文件
80 与上面的全书网类似,但它本身提供了下载功能,可以直接构造下载文件、页面截图和带有小说ID和名称的代码:
Python学习交流群542110741
其他类似网站
类似的网站还有:美子图、美拓、笔趣阁、九九等,连百度图片也可以通过抓包获取数据!
以上代码都是手写的,没有排版。如果你有兴趣,你可以自己打字。或者比如小说网站,你可以先抓取大类,然后获取每个类的所有小说,最后把每个类的所有小说。抓出小说的内容,这就是全站爬虫!!!
如果你还有其他合适的网站,希望你可以在评论区分享!一起交流吧! 查看全部
c爬虫抓取网页数据(几个适合新入门学习Python爬虫的网页,总有一款适合你!)
推荐几个适合初学者学习Python爬虫的网页。总有一款适合你!
废话不多说,直接上干货吧!
今日头条图集:抓包获取json数据
打开今日头条首页,搜索小姐姐,或者其他你感兴趣的内容,然后点击图库
动态加载的json数据出来,没有反爬,注意如果不想抓取内容中的图片,只能抓取缩略图,也就是本页显示的图片,在json数据中的image_list,注意,把url中的list改成origin,就是大图了!代码显示如下
Python学习交流群542110741
图片地址全部出!
全书网:直接源码匹配相关内容
直接搜索全书,打开首页,找到一本小说,比如《盗墓笔记》,点击跳转网页,点击开始阅读,所有章节出现,小说内容、网页内容和进入章节后出现代码。如下:
Python学习交流群542110741
80本电子书:匹配地址直接下载压缩文件
80 与上面的全书网类似,但它本身提供了下载功能,可以直接构造下载文件、页面截图和带有小说ID和名称的代码:
Python学习交流群542110741
其他类似网站
类似的网站还有:美子图、美拓、笔趣阁、九九等,连百度图片也可以通过抓包获取数据!
以上代码都是手写的,没有排版。如果你有兴趣,你可以自己打字。或者比如小说网站,你可以先抓取大类,然后获取每个类的所有小说,最后把每个类的所有小说。抓出小说的内容,这就是全站爬虫!!!
如果你还有其他合适的网站,希望你可以在评论区分享!一起交流吧!
c爬虫抓取网页数据(python网络爬虫-爬取网页的三种方式10.抓取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-21 07:20
Python网络爬虫——爬取网页的三种方式
10.前言0.1 爬取网页本文将介绍三种爬取网页数据的方式:正则表达式、BeautifulSoup、lxml。有关用于获取 Web 内容的代码的详细信息,请参阅 Python Web Crawler - Your First Crawler。使用此代码来抓取整个网页。
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
20.2 爬取目标爬取网页上所有显示的内容。
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
3 分析网页的结构,我们可以看到所有的内容都在标签中。以面积为例,我们可以看到面积的值为:
7,686,850平方公里
根据这个结构,我们用不同的方式来表达,就可以抓取到所有我们想要的数据。
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
4Chrome浏览器可以轻松复制各种表情:
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
5 有了上面的下载功能和不同的表达方式,我们可以通过三种不同的方式抓取数据。1.以不同的方式爬取数据1.1 正则表达式爬取网页正则表达式在python或其他语言中有很好的应用,用简单的规定符号来表达不同的字符串组成形式,简洁高效。学习正则表达式很有必要。Python 内置正则表达式,无需额外安装。
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
61.2BeautifulSoup爬取数据BeautifulSoup的使用可以在python网络爬虫-BeautifulSoup爬取网络数据中看到代码如下:
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
71.3 lxml抓包数据
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
81.4 个运行结果
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
9 从结果可以看出,正则表达式在某些地方返回了额外的元素,而不是纯文本。这是因为这些地方的网页结构与其他地方不同,所以正则表达式不能完全覆盖相同的内容,例如某些地方的链接和图片。并且 BeautifulSoup 和 lxml 具有提取文本的特殊功能,因此不会出现类似的错误。 查看全部
c爬虫抓取网页数据(python网络爬虫-爬取网页的三种方式10.抓取数据)
Python网络爬虫——爬取网页的三种方式
10.前言0.1 爬取网页本文将介绍三种爬取网页数据的方式:正则表达式、BeautifulSoup、lxml。有关用于获取 Web 内容的代码的详细信息,请参阅 Python Web Crawler - Your First Crawler。使用此代码来抓取整个网页。
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
20.2 爬取目标爬取网页上所有显示的内容。
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
3 分析网页的结构,我们可以看到所有的内容都在标签中。以面积为例,我们可以看到面积的值为:
7,686,850平方公里
根据这个结构,我们用不同的方式来表达,就可以抓取到所有我们想要的数据。
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
4Chrome浏览器可以轻松复制各种表情:
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
5 有了上面的下载功能和不同的表达方式,我们可以通过三种不同的方式抓取数据。1.以不同的方式爬取数据1.1 正则表达式爬取网页正则表达式在python或其他语言中有很好的应用,用简单的规定符号来表达不同的字符串组成形式,简洁高效。学习正则表达式很有必要。Python 内置正则表达式,无需额外安装。
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
61.2BeautifulSoup爬取数据BeautifulSoup的使用可以在python网络爬虫-BeautifulSoup爬取网络数据中看到代码如下:
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
71.3 lxml抓包数据
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
81.4 个运行结果
//style.80yiju.com/image_small/https://exp-picture.cdn.bcebos ... g.jpg
9 从结果可以看出,正则表达式在某些地方返回了额外的元素,而不是纯文本。这是因为这些地方的网页结构与其他地方不同,所以正则表达式不能完全覆盖相同的内容,例如某些地方的链接和图片。并且 BeautifulSoup 和 lxml 具有提取文本的特殊功能,因此不会出现类似的错误。

