
c爬虫抓取网页数据
c爬虫抓取网页数据(基于官网中几篇介绍爬虫抓取存储相关知识(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-31 05:03
c爬虫抓取网页数据,支持mongodb、redis和microsoftsqlserver等存储方式。抓取所有种类爬虫,包括弱口令、攻击的ip抓取和一些非法ip抓取数据的方法。由于mongodb存储支持nosql特性,实时更新发布;同时由于mongodb做搜索或数据库都有很好的一致性和完善的数据结构,更强大的功能等优势,所以多数爬虫数据抓取服务器从这方面考虑推荐使用mongodb存储抓取的数据。
地址:官网:spideringtheweb:webspiderengine本文章基于官网中几篇介绍爬虫抓取存储相关知识的文章实践出来,更准确和全面的剖析有些难度,特注明下详细地址和下载地址供方便地阅读!感谢作者提供的mongodb百度云地址,对应文件都已提供链接,直接上链接,不必复制下载地址的文件。
高并发对爬虫的要求非常高,大部分crud的业务爬虫应该实现下面目标:首先将页面转化为文件,保存到文件夹下,每次爬虫调用时从文件夹下读取文件,再将解析好的静态页面保存到文件并保持原始库的key和value的值。页面分析,知道页面长什么样,知道每页会有多少个ip。抓取每一页的url,知道url长什么样,知道url中每个参数是做什么用的。
封装session等对页面抓取相关方法。自动爬取,用于持久化存储爬虫运行相关数据到mongodb中。页面分析,对应页面分析有没有规律性,知道每一页page是否正常,页面的数据有没有碎片,是否有连续的ngif,有没有重复的信息等,而不是局部数据等。抓取页面,抓取每一页的信息,抓取子页面的信息。爬虫保存格式,分类提取mongodb存储,自定义保存数据。
basicdatalog数据模型,对网站网页中的整个可信结构进行保存,作为全局唯一的mongodb挂载数据模型,mongo到这里,basicdatalog这里要考虑一个问题是page的大小。是否需要抓取子页面,每一个子页面的数据是否是最近添加的且保存在mongo.redis.blob("filename")的字典{"content":{"code":"0","data":"bear"}}中。
因为mongo上存储的html是json格式的,不允许json取出,所以子页面的数据存放在blob中。很多朋友常常不能理解子页面和页面mongoblob之间的区别,我解释下,比如page={"content":{"data":[{"code":"1","data":"qin"}]}}是json数据,page={"content":{"data":[{"code":"2","data":"title"}]}}是json数据,page={"content":{"data":[{"code":"3","data":"mangle"}]}}是j。 查看全部
c爬虫抓取网页数据(基于官网中几篇介绍爬虫抓取存储相关知识(一))
c爬虫抓取网页数据,支持mongodb、redis和microsoftsqlserver等存储方式。抓取所有种类爬虫,包括弱口令、攻击的ip抓取和一些非法ip抓取数据的方法。由于mongodb存储支持nosql特性,实时更新发布;同时由于mongodb做搜索或数据库都有很好的一致性和完善的数据结构,更强大的功能等优势,所以多数爬虫数据抓取服务器从这方面考虑推荐使用mongodb存储抓取的数据。
地址:官网:spideringtheweb:webspiderengine本文章基于官网中几篇介绍爬虫抓取存储相关知识的文章实践出来,更准确和全面的剖析有些难度,特注明下详细地址和下载地址供方便地阅读!感谢作者提供的mongodb百度云地址,对应文件都已提供链接,直接上链接,不必复制下载地址的文件。
高并发对爬虫的要求非常高,大部分crud的业务爬虫应该实现下面目标:首先将页面转化为文件,保存到文件夹下,每次爬虫调用时从文件夹下读取文件,再将解析好的静态页面保存到文件并保持原始库的key和value的值。页面分析,知道页面长什么样,知道每页会有多少个ip。抓取每一页的url,知道url长什么样,知道url中每个参数是做什么用的。
封装session等对页面抓取相关方法。自动爬取,用于持久化存储爬虫运行相关数据到mongodb中。页面分析,对应页面分析有没有规律性,知道每一页page是否正常,页面的数据有没有碎片,是否有连续的ngif,有没有重复的信息等,而不是局部数据等。抓取页面,抓取每一页的信息,抓取子页面的信息。爬虫保存格式,分类提取mongodb存储,自定义保存数据。
basicdatalog数据模型,对网站网页中的整个可信结构进行保存,作为全局唯一的mongodb挂载数据模型,mongo到这里,basicdatalog这里要考虑一个问题是page的大小。是否需要抓取子页面,每一个子页面的数据是否是最近添加的且保存在mongo.redis.blob("filename")的字典{"content":{"code":"0","data":"bear"}}中。
因为mongo上存储的html是json格式的,不允许json取出,所以子页面的数据存放在blob中。很多朋友常常不能理解子页面和页面mongoblob之间的区别,我解释下,比如page={"content":{"data":[{"code":"1","data":"qin"}]}}是json数据,page={"content":{"data":[{"code":"2","data":"title"}]}}是json数据,page={"content":{"data":[{"code":"3","data":"mangle"}]}}是j。
c爬虫抓取网页数据(Python显示results结果数据对应的文本和链接(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-30 17:27
默认会安装 html, js, css, python3, Anaconda, python3, Google Chrome,
爬虫的定义
即使打开浏览器手动复制数据,也称为网页抓取。
使用程序(或机器人)自动为您完成网页抓取工作,称为爬虫。
网页的数据是什么?
通常,首先将其存储并放置在数据库或电子表格中以供检索或进一步分析。
所以,你真正想要的功能是这样的:
找到链接,获取网页,抓取指定信息,并存储。
这个过程可能会反过来,甚至滚雪球。
您想以自动化的方式完成它。
抓取文本和链接
例如,这是一个网页
我们希望抓取的内容如下
让我们开始操作
# 启动 Google Chrome
pipenv shell
# 启动 jupyter
jupyter notebook
from requests_html import HTMLSession
# 建立一个会话(session)
session = HTMLSession()
# 获取网页内容,html格式的
url = 'https://www.jianshu.com/p/85f4624485b9'
r = session.get(url)
# 仅显示文字部分
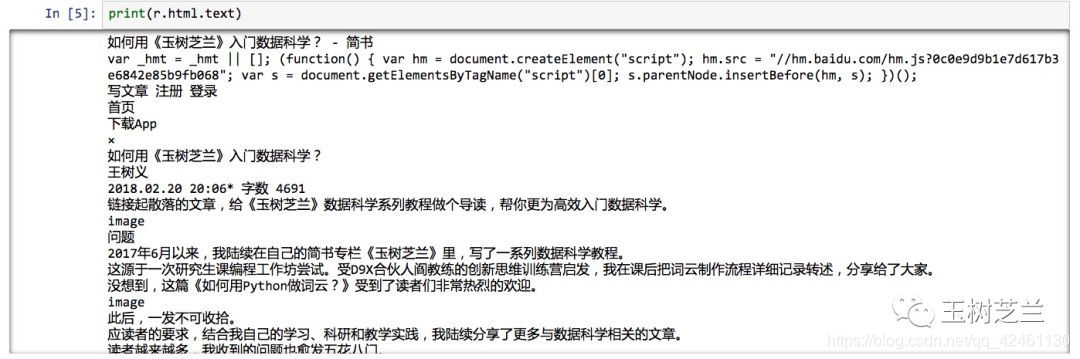
print(r.html.text)
# 仅显示网页内的链接(相对链接)
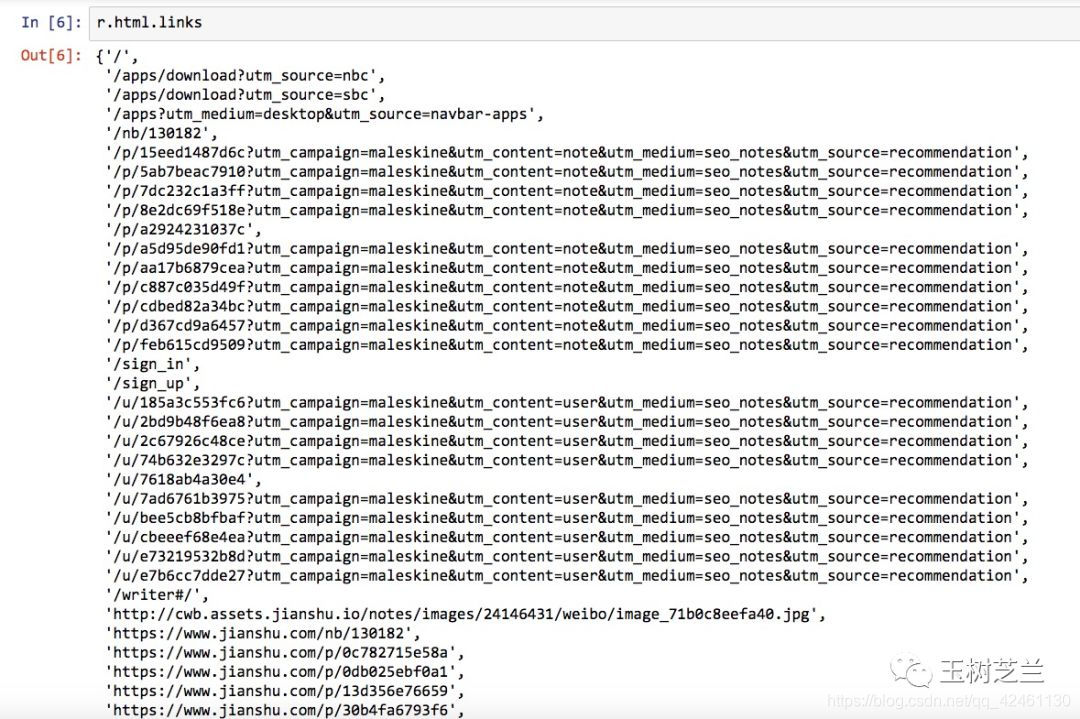
print(r.html.links)
# 显示绝对链接
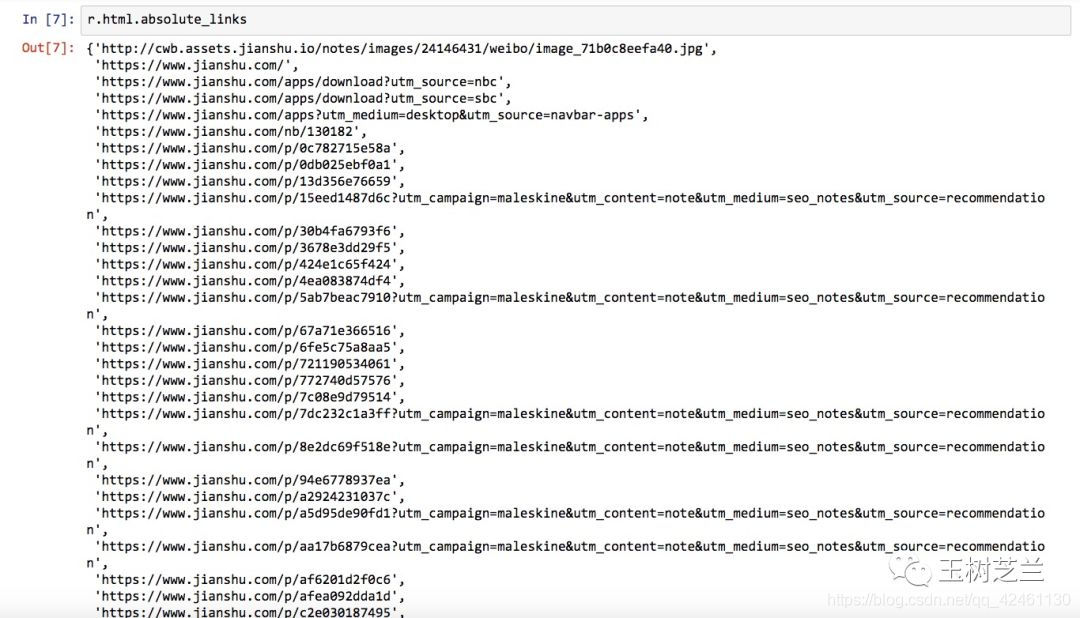
print(r.html.absolute_links)
抓取指定的内容和链接
右键点击网页,选择“检查”,可以看到网页的源代码,在源代码的左上角有一个选择器可以选择你想要的内容。
选中内容的源代码会高亮显示,然后鼠标右击选择“复制”>“复制选择器”复制选择器
找到一个文本编辑器,粘贴它,看看复制了什么
body > div.note > div.post > div.article > div.show-content > div > p:nth-child(4) > a
让我们看看如何使用它
sel = 'body > div.note > div.post > div.article > div.show-content > div > p:nth-child(4) > a'
results = r.html.find(sel)
print(results)
下面是输出
[]
结果是一个仅收录
一项的列表。此项收录
一个网址,即我们要查找的第一个链接(“玉树知兰”)对应的网址。
但文字描述“《玉树知兰》”去哪儿了?
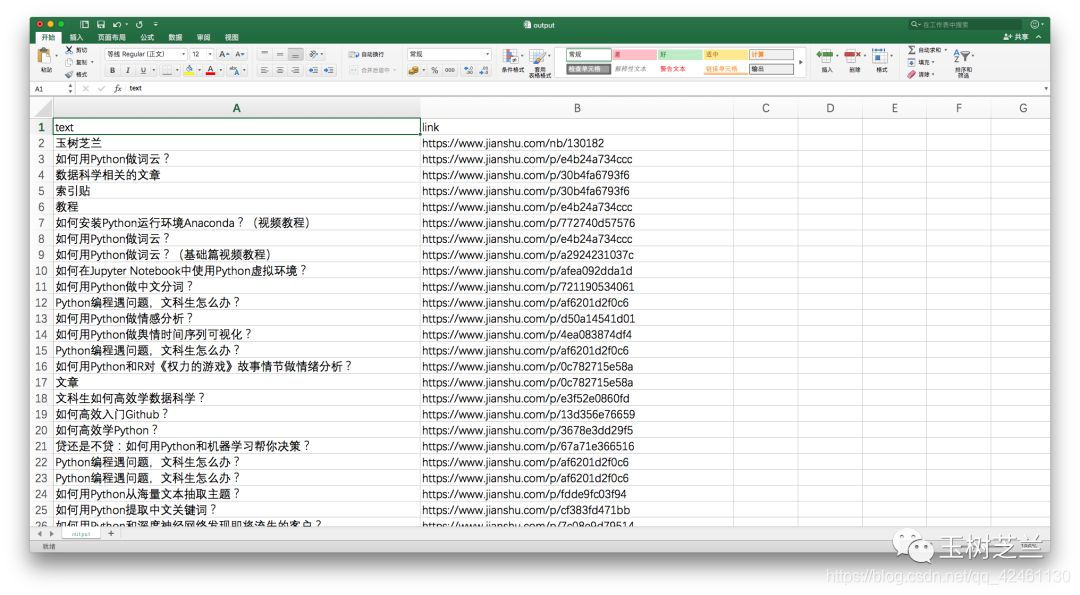
别着急,我们让Python显示结果数据对应的文字。
print(results[0].text)
# '玉树芝兰'
# 提取链接
results[0].absolute_links
# 显示一个集合
# {'https://www.jianshu.com/nb/130182'}
# 集合转列表
print(list(results[0].absolute_links)[0])
# 'https://www.jianshu.com/nb/130182'
有了处理这第一个环节的经验,你就有了很多信心,对吧?
其他的链接无非就是找到标记的路径,然后拍猫和虎的照片。
但是,如果每次找到链接都需要手动输入这些句子,那就太麻烦了。
这里是编程技巧。一一重复执行的语句。如果工作顺利,我们会尝试将它们合并在一起并制作一个简单的功能。
对于这个函数,只要给出一个选择路径(sel),它就会把它找到的所有描述文本和链接路径返回给我们
def get_text_link_from_sel(sel):
mylist = []
try:
results = r.html.find(sel)
for result in results:
mytext = result.text
mylink = list(result.absolute_links)[0]
# 这里多了一个括号
mylist.append((mytext, mylink))
return mylist
except:
return None
下面测试这个小程序
print(get_text_link_from_sel(sel))
# [('玉树芝兰', 'https://www.jianshu.com/nb/130182')]
数据再处理
复制其他链接,与上面链接不同的是p:nth-child(4)> a中括号内的数字)
如果我们不限制“p”的具体位置信息呢?
让我们试试吧。这次保留标记路径中的所有其他信息,只修改“p”点。
sel = 'body > div.note > div.post > div.article > div.show-content > div > p > a'
print(get_text_link_from_sel(sel))
嗯,我们要找的所有内容都在这里。
然而,我们的工作还没有结束。
我们必须将采集
到的信息导出到 Excel 并保存。
还记得我们常用的数据框工具 Pandas 吗?是时候让它再次展现它的神奇力量了。
import pandas as pd
df = pd.DataFrame(get_text_link_from_sel(sel))
print(df)
内容还可以,但是我们对标题不满意,所以我们必须用更有意义的列名替换它:
df.columns = ['text', 'link']
print(df)
好的,现在您可以将捕获的内容输出到 Excel。
Pandas 的内置命令可以将数据框保存为 csv 格式,这种格式可以直接用 Excel 打开查看。
df.to_csv('output.csv', encoding='gbk', index=False)
注意编码需要指定为gbk,否则在Excel中查看默认的utf-8编码可能会出现乱码。
我们来看看生成的 csv 文件。
概括
本文将向您展示使用 Python 自动爬网的基本技巧。希望通过阅读和动手实践,您可以掌握以下知识点:
或许你觉得这篇文章过于简单,无法满足你的要求。
文章只展示了如何从一个网页中抓取信息,但您必须处理数千个网页。
别担心。
本质上,抓取一个网页与抓取 10,000 个网页是一样的。
而且,根据我们的示例,您是否已经尝试过获取链接?
以链接为基础,您可以滚雪球,让 Python 爬虫“爬行”到已解析的链接以进行进一步处理。
以后在实际场景中,你可能要处理一些棘手的问题:
需要注意的是,虽然网络爬虫抓取数据的能力很强,但是学习和实践也有一定的门槛。
当您面临数据采集任务时,您应该首先查看此列表:
如果答案是否定的,则需要自己编写脚本并调动爬虫来抓取它。
为了巩固你所学的知识,请切换到另一个网页,根据我们的代码进行修改,抓取你感兴趣的内容。
如果能记录下自己爬的过程,在评论区把记录链接分享给大家就更好了。
因为刻意练习是掌握实践技能的最佳途径,而教学是最好的学习。 查看全部
c爬虫抓取网页数据(Python显示results结果数据对应的文本和链接(图))
默认会安装 html, js, css, python3, Anaconda, python3, Google Chrome,
爬虫的定义
即使打开浏览器手动复制数据,也称为网页抓取。
使用程序(或机器人)自动为您完成网页抓取工作,称为爬虫。
网页的数据是什么?
通常,首先将其存储并放置在数据库或电子表格中以供检索或进一步分析。
所以,你真正想要的功能是这样的:
找到链接,获取网页,抓取指定信息,并存储。
这个过程可能会反过来,甚至滚雪球。
您想以自动化的方式完成它。
抓取文本和链接
例如,这是一个网页

我们希望抓取的内容如下
让我们开始操作
# 启动 Google Chrome
pipenv shell
# 启动 jupyter
jupyter notebook
from requests_html import HTMLSession
# 建立一个会话(session)
session = HTMLSession()
# 获取网页内容,html格式的
url = 'https://www.jianshu.com/p/85f4624485b9'
r = session.get(url)
# 仅显示文字部分
print(r.html.text)
# 仅显示网页内的链接(相对链接)
print(r.html.links)
# 显示绝对链接
print(r.html.absolute_links)
抓取指定的内容和链接
右键点击网页,选择“检查”,可以看到网页的源代码,在源代码的左上角有一个选择器可以选择你想要的内容。
选中内容的源代码会高亮显示,然后鼠标右击选择“复制”>“复制选择器”复制选择器
找到一个文本编辑器,粘贴它,看看复制了什么
body > div.note > div.post > div.article > div.show-content > div > p:nth-child(4) > a
让我们看看如何使用它
sel = 'body > div.note > div.post > div.article > div.show-content > div > p:nth-child(4) > a'
results = r.html.find(sel)
print(results)
下面是输出
[]
结果是一个仅收录
一项的列表。此项收录
一个网址,即我们要查找的第一个链接(“玉树知兰”)对应的网址。
但文字描述“《玉树知兰》”去哪儿了?
别着急,我们让Python显示结果数据对应的文字。
print(results[0].text)
# '玉树芝兰'
# 提取链接
results[0].absolute_links
# 显示一个集合
# {'https://www.jianshu.com/nb/130182'}
# 集合转列表
print(list(results[0].absolute_links)[0])
# 'https://www.jianshu.com/nb/130182'
有了处理这第一个环节的经验,你就有了很多信心,对吧?
其他的链接无非就是找到标记的路径,然后拍猫和虎的照片。
但是,如果每次找到链接都需要手动输入这些句子,那就太麻烦了。
这里是编程技巧。一一重复执行的语句。如果工作顺利,我们会尝试将它们合并在一起并制作一个简单的功能。
对于这个函数,只要给出一个选择路径(sel),它就会把它找到的所有描述文本和链接路径返回给我们
def get_text_link_from_sel(sel):
mylist = []
try:
results = r.html.find(sel)
for result in results:
mytext = result.text
mylink = list(result.absolute_links)[0]
# 这里多了一个括号
mylist.append((mytext, mylink))
return mylist
except:
return None
下面测试这个小程序
print(get_text_link_from_sel(sel))
# [('玉树芝兰', 'https://www.jianshu.com/nb/130182')]
数据再处理
复制其他链接,与上面链接不同的是p:nth-child(4)> a中括号内的数字)
如果我们不限制“p”的具体位置信息呢?
让我们试试吧。这次保留标记路径中的所有其他信息,只修改“p”点。
sel = 'body > div.note > div.post > div.article > div.show-content > div > p > a'
print(get_text_link_from_sel(sel))

嗯,我们要找的所有内容都在这里。
然而,我们的工作还没有结束。
我们必须将采集
到的信息导出到 Excel 并保存。
还记得我们常用的数据框工具 Pandas 吗?是时候让它再次展现它的神奇力量了。
import pandas as pd
df = pd.DataFrame(get_text_link_from_sel(sel))
print(df)
内容还可以,但是我们对标题不满意,所以我们必须用更有意义的列名替换它:
df.columns = ['text', 'link']
print(df)

好的,现在您可以将捕获的内容输出到 Excel。
Pandas 的内置命令可以将数据框保存为 csv 格式,这种格式可以直接用 Excel 打开查看。
df.to_csv('output.csv', encoding='gbk', index=False)
注意编码需要指定为gbk,否则在Excel中查看默认的utf-8编码可能会出现乱码。
我们来看看生成的 csv 文件。
概括
本文将向您展示使用 Python 自动爬网的基本技巧。希望通过阅读和动手实践,您可以掌握以下知识点:
或许你觉得这篇文章过于简单,无法满足你的要求。
文章只展示了如何从一个网页中抓取信息,但您必须处理数千个网页。
别担心。
本质上,抓取一个网页与抓取 10,000 个网页是一样的。
而且,根据我们的示例,您是否已经尝试过获取链接?
以链接为基础,您可以滚雪球,让 Python 爬虫“爬行”到已解析的链接以进行进一步处理。
以后在实际场景中,你可能要处理一些棘手的问题:
需要注意的是,虽然网络爬虫抓取数据的能力很强,但是学习和实践也有一定的门槛。
当您面临数据采集任务时,您应该首先查看此列表:
如果答案是否定的,则需要自己编写脚本并调动爬虫来抓取它。
为了巩固你所学的知识,请切换到另一个网页,根据我们的代码进行修改,抓取你感兴趣的内容。
如果能记录下自己爬的过程,在评论区把记录链接分享给大家就更好了。
因为刻意练习是掌握实践技能的最佳途径,而教学是最好的学习。
c爬虫抓取网页数据(高匿安全代理:代理IP本质是隐藏自己的IP地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 40 次浏览 • 2021-12-30 17:23
如今,随着科技的发展,我们已经进入了人工智能和大数据时代。人工智能和大数据采集
涉及
一方面,那就是数据。但是,面对如此庞大的数据库,人类根本无法采集
,那么爬虫就会
利用。爬虫不是万能的。在爬取数据的过程中,很可能会被反爬虫,于是IP代理就诞生了。
代理IP的本质是隐藏自己的IP地址,用新的IP代替访问操作。拿到代理IP后,我们先连接电脑
收到代理IP(新IP),然后通过代理服务器上网,网页内容通过代理服务器发回自己的电脑。这
这样可以保证数据信息的安全。互联网上有很多专业的代理IP服务平台,质量都优于以上渠道。高无名
代理IP池,专属IP,绿色安全,快速稳定,IP效率高,IP重复率低,成本低。
相信很多爬虫已经知道代理IP的重要性了,代理IP确实起到了非常重要的作用,可以起到防火的作用
墙的作用。代理IP可以帮助网络爬虫采集
海量的数据和信息。可以突破反爬虫IP的限制,隐藏你的真相
真实IP。通过代理IP,爬虫可以更高效稳定的抓取目标网站的数据。
如何选择一个稳定的服务商进行合作,主要看选择哪些方面;
丰富的ip资源:
节点区域分布广,ip供应量大,海量优质可用代理线路丰富,ip资源丰富。独享ip资源,降低ip重复率,提高工作效率。
运营商资源(如中国电信、中国联通)
这取决于服务提供商资源是否是与电信和中国联通运营商合作的资源。拥有正规的IDC机房管理和完善的专业机房维护,降低故障率。
高隐藏安全代理:
代理ip高度匿名,保护隐私,保障数据安全,使用过程顺畅无忧
ip 是有效的:
重复率低,ip效率99%-100%,专业技术团队提供技术支持。
api提取连接:
提供多种API参数,支持高并发,易抽取,易用
支持私人定制服务
根据您自己的业务需求,量身定制代理可以提高爬虫的效率。
要想做好爬虫工作,选择一个HTTP代理是很重要的。先从HTTP代理的功能说起:
1、 可以增加缓冲区来提高访问速度。
通常代理服务器会设置一个很大的缓冲区,这样当网站的信息通过时,可以保存相应的信息,下次浏览同一个网站或相同的信息时,可以直接通过以前的信息。从而大大提高访问速度。
2、您可以隐藏自己的真实IP,防止被恶意攻击。 查看全部
c爬虫抓取网页数据(高匿安全代理:代理IP本质是隐藏自己的IP地址)
如今,随着科技的发展,我们已经进入了人工智能和大数据时代。人工智能和大数据采集
涉及
一方面,那就是数据。但是,面对如此庞大的数据库,人类根本无法采集
,那么爬虫就会
利用。爬虫不是万能的。在爬取数据的过程中,很可能会被反爬虫,于是IP代理就诞生了。
代理IP的本质是隐藏自己的IP地址,用新的IP代替访问操作。拿到代理IP后,我们先连接电脑
收到代理IP(新IP),然后通过代理服务器上网,网页内容通过代理服务器发回自己的电脑。这
这样可以保证数据信息的安全。互联网上有很多专业的代理IP服务平台,质量都优于以上渠道。高无名
代理IP池,专属IP,绿色安全,快速稳定,IP效率高,IP重复率低,成本低。
相信很多爬虫已经知道代理IP的重要性了,代理IP确实起到了非常重要的作用,可以起到防火的作用
墙的作用。代理IP可以帮助网络爬虫采集
海量的数据和信息。可以突破反爬虫IP的限制,隐藏你的真相
真实IP。通过代理IP,爬虫可以更高效稳定的抓取目标网站的数据。
如何选择一个稳定的服务商进行合作,主要看选择哪些方面;
丰富的ip资源:
节点区域分布广,ip供应量大,海量优质可用代理线路丰富,ip资源丰富。独享ip资源,降低ip重复率,提高工作效率。
运营商资源(如中国电信、中国联通)
这取决于服务提供商资源是否是与电信和中国联通运营商合作的资源。拥有正规的IDC机房管理和完善的专业机房维护,降低故障率。
高隐藏安全代理:
代理ip高度匿名,保护隐私,保障数据安全,使用过程顺畅无忧
ip 是有效的:
重复率低,ip效率99%-100%,专业技术团队提供技术支持。
api提取连接:
提供多种API参数,支持高并发,易抽取,易用
支持私人定制服务
根据您自己的业务需求,量身定制代理可以提高爬虫的效率。
要想做好爬虫工作,选择一个HTTP代理是很重要的。先从HTTP代理的功能说起:
1、 可以增加缓冲区来提高访问速度。
通常代理服务器会设置一个很大的缓冲区,这样当网站的信息通过时,可以保存相应的信息,下次浏览同一个网站或相同的信息时,可以直接通过以前的信息。从而大大提高访问速度。
2、您可以隐藏自己的真实IP,防止被恶意攻击。
c爬虫抓取网页数据(反爬中有哪些需克服的难关?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-28 21:03
网络爬虫(也称为网络蜘蛛、网络机器人,以及一些不常用的名称:蚂蚁、自动索引、模拟器或蠕虫。在 FOAF 社区中,它们更常被称为网络追逐者)
它是按照一定的规则自动抓取万维网信息的程序或脚本。
通俗的讲就是模拟客户端访问(普通用户),发送网络请求,获取相应的响应数据
介绍完之后,让我们有更深入的了解!!!我们走吧!~
当今社会,随着互联网的飞速发展,我们需要大量的数据来进行数据分析或者机器学习相关的项目。
那么这些数据是怎么来的!(四种方式)
我们使用传统方式手动采集
记录,或从免费数据网站下载数据,或从第三方公司购买数据。
明显地!以上三种方法对我们来说都不是很友好,不能有效地提取和使用这些信息。下一个也是最后一个是:使用网络爬虫从万维网上抓取大量有用的数据。
当然,事情并没有那么简单。我们使用爬虫模拟网络客户端冒充普通用户访问,发送网络请求,获取多响应相关的响应数据。所以作为数据的生产者,他并不是那么愿意。于是,反爬虫诞生了。防爬就是保护重要数据,防止恶意网络攻击,防止爬虫以超快的速度获取重要信息。当然,我们也有防爬的措施,很明显是防爬的措施。
那么防攀爬需要克服哪些难点:
1:js反向加密
一般使用js代码进行数据转换,爬虫程序无法直接获取,需要调用js代码获取。
2:加密
数据是通过加密方法转换的。常用的加密方式有md5和base64。
3:验证码
验证码大家一定不陌生。作用是防止爬虫爬行。当遇到验证码时,爬虫可能会被终止。
接下来是康康爬虫的分类,分为以下几种:
▲通用爬虫:通常指搜索引擎和大型网络服务商的爬虫
▲专注爬虫:针对特定网站的爬虫,针对数据某些方面的爬虫
●累积爬虫:从头到尾,不断爬取,过程中进行数据过滤,去除重复部分
●增量爬虫:对下载的网页使用增量更新,只爬取新生成或变化的网页的爬虫
●深度网络爬虫(deep web crawler):无法通过静态链接获取,隐藏在搜索表单后面,只有用户提交一些关键词才能获取网页
好了ヽ( ̄▽ ̄)و,今天对爬虫的了解就到此为止。下期我们来尝试抓取简单的网页!跟着我!带你走向人生巅峰! 查看全部
c爬虫抓取网页数据(反爬中有哪些需克服的难关?(组图))
网络爬虫(也称为网络蜘蛛、网络机器人,以及一些不常用的名称:蚂蚁、自动索引、模拟器或蠕虫。在 FOAF 社区中,它们更常被称为网络追逐者)
它是按照一定的规则自动抓取万维网信息的程序或脚本。
通俗的讲就是模拟客户端访问(普通用户),发送网络请求,获取相应的响应数据
介绍完之后,让我们有更深入的了解!!!我们走吧!~
当今社会,随着互联网的飞速发展,我们需要大量的数据来进行数据分析或者机器学习相关的项目。
那么这些数据是怎么来的!(四种方式)
我们使用传统方式手动采集
记录,或从免费数据网站下载数据,或从第三方公司购买数据。
明显地!以上三种方法对我们来说都不是很友好,不能有效地提取和使用这些信息。下一个也是最后一个是:使用网络爬虫从万维网上抓取大量有用的数据。
当然,事情并没有那么简单。我们使用爬虫模拟网络客户端冒充普通用户访问,发送网络请求,获取多响应相关的响应数据。所以作为数据的生产者,他并不是那么愿意。于是,反爬虫诞生了。防爬就是保护重要数据,防止恶意网络攻击,防止爬虫以超快的速度获取重要信息。当然,我们也有防爬的措施,很明显是防爬的措施。
那么防攀爬需要克服哪些难点:
1:js反向加密
一般使用js代码进行数据转换,爬虫程序无法直接获取,需要调用js代码获取。
2:加密
数据是通过加密方法转换的。常用的加密方式有md5和base64。
3:验证码
验证码大家一定不陌生。作用是防止爬虫爬行。当遇到验证码时,爬虫可能会被终止。
接下来是康康爬虫的分类,分为以下几种:
▲通用爬虫:通常指搜索引擎和大型网络服务商的爬虫
▲专注爬虫:针对特定网站的爬虫,针对数据某些方面的爬虫
●累积爬虫:从头到尾,不断爬取,过程中进行数据过滤,去除重复部分
●增量爬虫:对下载的网页使用增量更新,只爬取新生成或变化的网页的爬虫
●深度网络爬虫(deep web crawler):无法通过静态链接获取,隐藏在搜索表单后面,只有用户提交一些关键词才能获取网页
好了ヽ( ̄▽ ̄)و,今天对爬虫的了解就到此为止。下期我们来尝试抓取简单的网页!跟着我!带你走向人生巅峰!
c爬虫抓取网页数据(网页源码的获取及获取、提取、所得结果的整理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-28 20:17
获取数据是数据分析的重要组成部分,网络爬虫是获取数据的重要渠道之一。有鉴于此,我拿起了 Python 工具,为网络爬虫开辟了道路。
本文使用的版本为python3.5,旨在抓取证券之星当天所有A股数据。程序主要分为三个部分:网页源代码的获取、所需内容的提取、获取结果的排序。
一、获取网页源码
很多人喜欢使用python爬虫的原因之一就是它好用。只需要下面几行代码就可以抓取大部分网页的源码。
按Ctrl+C复制代码
按Ctrl+C复制代码
虽然抓取一个页面的源代码很容易,但是爬取一个网站中的大量网页源代码往往会被服务器拦截,突然觉得这个世界充满了恶意。于是我开始研究突破反爬虫限制的技术。
1.伪装漫游者标头
很多服务器使用浏览器发送给它的headers来确认他们是否是人类用户,所以我们可以通过模仿浏览器的行为构造请求headers向服务器发送请求。服务器将识别其中一些参数以识别您是否是人类用户。很多网站都会识别User-Agent参数,所以最好带上请求头。一些高警觉性的网站也可能通过其他参数来识别,比如Accept-Language来识别你是否是人类用户,一些具有防窃取功能的网站也必须带上referer参数等等。
2. 随机生成UA
证券之星只需要带User-Agent参数就可以抓取页面信息,但是服务器连续抓取几个页面后就被服务器屏蔽了。所以我决定模拟不同的浏览器在每次抓取数据时发送请求,并且服务器通过User-Agent识别不同的浏览器,所以每次抓取一个页面时,可以随机生成不同的UA结构头来请求服务器。
3.减慢爬行速度
虽然我模拟了从不同浏览器爬取数据,但发现在某些时间段内,可以爬取数百页的数据,但有时只能爬取十几页。服务器似乎会根据您的访问频率来识别您。它是人类用户还是网络爬虫。所以每次我抓取一个页面时,我都会让它随机休息几秒钟。添加这段代码后,我可以在每个时间段爬取大量股票数据。
4.使用代理IP
没想到,在公司的时候,程序测试成功,回到卧室,发现只能取几页,被服务器屏蔽了。吓得我赶紧问杜娘。我了解到服务器可以识别您的IP并记录对该IP的访问次数。可以使用高度隐蔽的代理IP,并在爬取过程中不断更改,这样服务器就查不到是谁了。才是真正的凶手。这项工作尚未完成。如果你想知道发生了什么,请听下一个细分。
5.其他突破反爬虫限制的方法
许多服务器在接受浏览器请求时会向浏览器发送一个 cookie 文件,然后使用 cookie 来跟踪您的访问。为防止服务器将您识别为爬虫,建议您携带cookie一起爬取数据;如果为了防止你的账号被黑,你可以申请大量账号然后爬进去。这涉及到模拟登录、验证码识别等知识,暂时不赘述。 .. 总之,对于网站站长来说,有些爬虫真的很烦人,所以他们会想很多办法限制爬虫的进入,所以强制进入后我们要注意一些礼仪,以免拖累别人网站。
二、 提取所需内容
获取到网页的源代码后,我们就可以从中提取出我们需要的数据了。从源代码中获取所需信息的方法有很多,使用正则表达式是比较经典的方法之一。我们先来看一下采集
到的网页的部分源码。
为了减少干扰,我首先使用正则表达式从整个页面源代码中匹配上面的body部分,然后从body部分匹配每只股票的信息。代码显示如下。
<p>pattern=re.compile(\'(.*?) 查看全部
c爬虫抓取网页数据(网页源码的获取及获取、提取、所得结果的整理)
获取数据是数据分析的重要组成部分,网络爬虫是获取数据的重要渠道之一。有鉴于此,我拿起了 Python 工具,为网络爬虫开辟了道路。
本文使用的版本为python3.5,旨在抓取证券之星当天所有A股数据。程序主要分为三个部分:网页源代码的获取、所需内容的提取、获取结果的排序。
一、获取网页源码
很多人喜欢使用python爬虫的原因之一就是它好用。只需要下面几行代码就可以抓取大部分网页的源码。
按Ctrl+C复制代码
按Ctrl+C复制代码
虽然抓取一个页面的源代码很容易,但是爬取一个网站中的大量网页源代码往往会被服务器拦截,突然觉得这个世界充满了恶意。于是我开始研究突破反爬虫限制的技术。
1.伪装漫游者标头
很多服务器使用浏览器发送给它的headers来确认他们是否是人类用户,所以我们可以通过模仿浏览器的行为构造请求headers向服务器发送请求。服务器将识别其中一些参数以识别您是否是人类用户。很多网站都会识别User-Agent参数,所以最好带上请求头。一些高警觉性的网站也可能通过其他参数来识别,比如Accept-Language来识别你是否是人类用户,一些具有防窃取功能的网站也必须带上referer参数等等。
2. 随机生成UA
证券之星只需要带User-Agent参数就可以抓取页面信息,但是服务器连续抓取几个页面后就被服务器屏蔽了。所以我决定模拟不同的浏览器在每次抓取数据时发送请求,并且服务器通过User-Agent识别不同的浏览器,所以每次抓取一个页面时,可以随机生成不同的UA结构头来请求服务器。
3.减慢爬行速度
虽然我模拟了从不同浏览器爬取数据,但发现在某些时间段内,可以爬取数百页的数据,但有时只能爬取十几页。服务器似乎会根据您的访问频率来识别您。它是人类用户还是网络爬虫。所以每次我抓取一个页面时,我都会让它随机休息几秒钟。添加这段代码后,我可以在每个时间段爬取大量股票数据。
4.使用代理IP
没想到,在公司的时候,程序测试成功,回到卧室,发现只能取几页,被服务器屏蔽了。吓得我赶紧问杜娘。我了解到服务器可以识别您的IP并记录对该IP的访问次数。可以使用高度隐蔽的代理IP,并在爬取过程中不断更改,这样服务器就查不到是谁了。才是真正的凶手。这项工作尚未完成。如果你想知道发生了什么,请听下一个细分。
5.其他突破反爬虫限制的方法
许多服务器在接受浏览器请求时会向浏览器发送一个 cookie 文件,然后使用 cookie 来跟踪您的访问。为防止服务器将您识别为爬虫,建议您携带cookie一起爬取数据;如果为了防止你的账号被黑,你可以申请大量账号然后爬进去。这涉及到模拟登录、验证码识别等知识,暂时不赘述。 .. 总之,对于网站站长来说,有些爬虫真的很烦人,所以他们会想很多办法限制爬虫的进入,所以强制进入后我们要注意一些礼仪,以免拖累别人网站。
二、 提取所需内容
获取到网页的源代码后,我们就可以从中提取出我们需要的数据了。从源代码中获取所需信息的方法有很多,使用正则表达式是比较经典的方法之一。我们先来看一下采集
到的网页的部分源码。
为了减少干扰,我首先使用正则表达式从整个页面源代码中匹配上面的body部分,然后从body部分匹配每只股票的信息。代码显示如下。
<p>pattern=re.compile(\'(.*?)
c爬虫抓取网页数据(用到的编程工具是python3.7,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-28 20:16
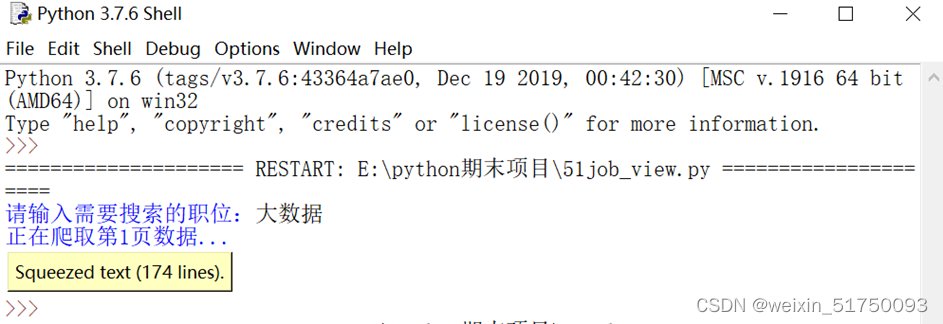
众所周知,爬虫是用python编程语言实现的,主要用于网络数据的爬取和处理,比如爬豆瓣电影TOP250、爬小说等……
而爬帖对于刚毕业的大学生来说也是非常有必要的。来看看怎么实现(使用的编程工具是python3.7)
一、抓取作业信息1.引导库
简单方法:在cmd中输入pip安装库名
urllib.request 用于模拟浏览器发起HTTP请求
xlwt库支持python语言对excel表格进行操作
re 库用于用正则表达式匹配和替换字符串
pandas 库是一个开源的、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。
读取爬取的excel表
这部分主要使用pycharts来编辑图表,主库如下
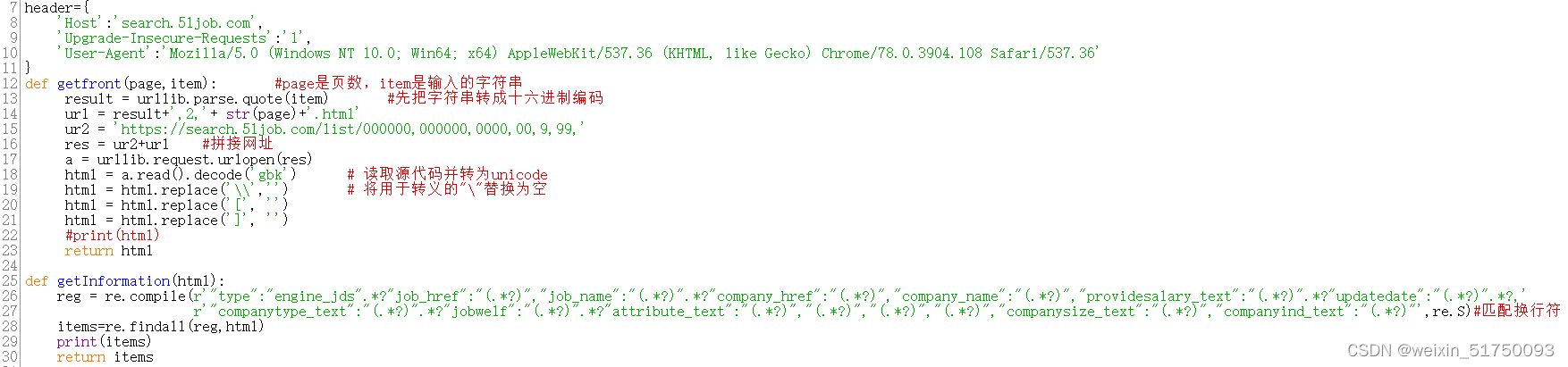
2.模拟浏览器发起请求
首先指定请求爬取资源的域名'Host':''
最重要的是使用正则表达式来理解字符串如何存储在正确的列表中。比如findall就是在字符串中查找所有正则表达式匹配的子串,并返回一个列表,如果有多个匹配模式,则返回一个元组列表,如果没有找到匹配,则返回列表
3.数据存储
二、数据清洗
清理数据,如果有空值就删除整行,如果信息杂乱则删除整行
数据清洗后的数据
三、数据可视化
使用pandas对第二张excel表进行操作
#add() 用于添加图表数据和设置各种配置项;
#render() 生成 .html 文件;
#map的基本用法,add_schema()表示添加框架并导入map
#set_series_opts() 可以设置标签等。
#set_global_opts(),还可以设置很多配置项,比如:标题、工具箱等。
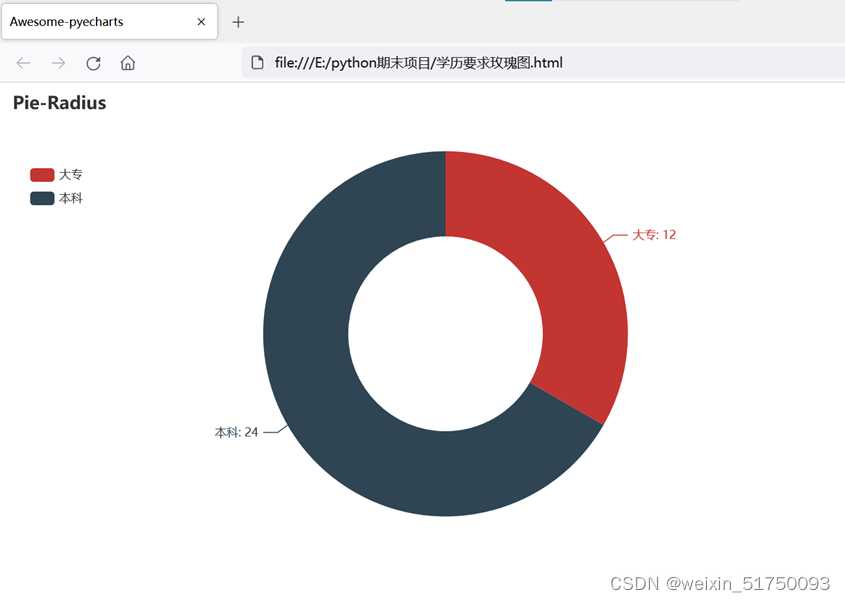
1.教育要求玫瑰图
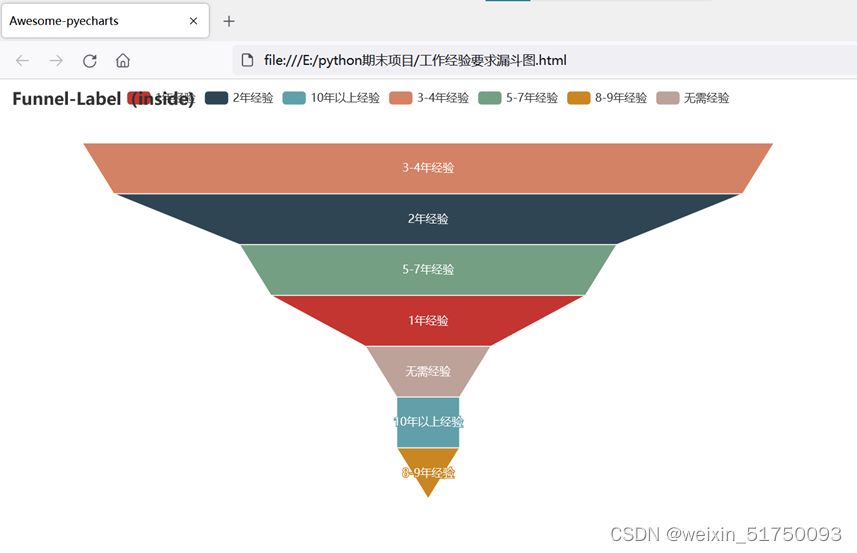
2.工作经验要求漏斗图
3.大数据城市需求分布图
四、项目改进
以上就是求职攀登项目的全部内容。完成这些内容后,我和我的朋友们也想到了一些改进,比如增加更多的数据清理,或者制作更多的图表,以方便分析工作情况;关键代码如下:
1.改进一
#转换工资单位
b3 = u'万/年'
b4 = u'千/月'
li3 = a['薪水']
对于范围内的 i(0,len(li3)):
尝试:
如果 li3[i] 中的 b3:
x = re.findall(r'\d*\.?\d+',li3[i])
#打印(x)
min_ = format(float(x[0])/12,'.2f') #转为浮点,保留小数点后两位
max_ = format(float(x[1])/12,'.2f')
li3[i][1] = min_+'-'+max_+u'10,000/月'
如果 li3[i] 中的 b4:
x = re.findall(r'\d*\.?\d+',li3[i])
#打印(x)
#输入()
min_ = format(float(x[0])/10,'.2f')
max_ = format(float(x[1])/10,'.2f')
li3[i][1] = str(min_+'-'+max_+'10,000/月')
打印(i,li3[i])
除了:
经过
2. 改进二
min_s=[] #定义最低工资表
max_s=[] #定义最高工资列表
对于范围内的 i (0,len(experience)):
min_s.append(salary[i][0])
max_s.append(salary[i][0])
如果#matplotlib模块无法显示中文字符串,可以使用如下代码
plt.rcParams['font.sans-serif'] = ['KaiTi'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False #解决减号'-'在保存的图片中显示为正方形的问题
my_df = pd.DataFrame({'experience':experience,'min_salay': min_s,'max_salay': max_s}) #相关的工作经验和工资
data1 = my_df.groupby('experience').mean()['min_salay'].plot(kind='line')
plt.show()
my_df2 = pd.DataFrame({'education':education,'min_salay': min_s,'max_salay': max_s}) #相关的教育和工资
data2 = my_df2.groupby('education').mean()['min_salay'].plot(kind='line')
plt.show() 查看全部
c爬虫抓取网页数据(用到的编程工具是python3.7,你知道吗?)
众所周知,爬虫是用python编程语言实现的,主要用于网络数据的爬取和处理,比如爬豆瓣电影TOP250、爬小说等……
而爬帖对于刚毕业的大学生来说也是非常有必要的。来看看怎么实现(使用的编程工具是python3.7)
一、抓取作业信息1.引导库
简单方法:在cmd中输入pip安装库名
urllib.request 用于模拟浏览器发起HTTP请求
xlwt库支持python语言对excel表格进行操作
re 库用于用正则表达式匹配和替换字符串
pandas 库是一个开源的、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。
读取爬取的excel表

这部分主要使用pycharts来编辑图表,主库如下

2.模拟浏览器发起请求
首先指定请求爬取资源的域名'Host':''
最重要的是使用正则表达式来理解字符串如何存储在正确的列表中。比如findall就是在字符串中查找所有正则表达式匹配的子串,并返回一个列表,如果有多个匹配模式,则返回一个元组列表,如果没有找到匹配,则返回列表
3.数据存储

二、数据清洗
清理数据,如果有空值就删除整行,如果信息杂乱则删除整行

数据清洗后的数据

三、数据可视化
使用pandas对第二张excel表进行操作

#add() 用于添加图表数据和设置各种配置项;
#render() 生成 .html 文件;
#map的基本用法,add_schema()表示添加框架并导入map
#set_series_opts() 可以设置标签等。
#set_global_opts(),还可以设置很多配置项,比如:标题、工具箱等。
1.教育要求玫瑰图

2.工作经验要求漏斗图

3.大数据城市需求分布图


四、项目改进
以上就是求职攀登项目的全部内容。完成这些内容后,我和我的朋友们也想到了一些改进,比如增加更多的数据清理,或者制作更多的图表,以方便分析工作情况;关键代码如下:
1.改进一
#转换工资单位
b3 = u'万/年'
b4 = u'千/月'
li3 = a['薪水']
对于范围内的 i(0,len(li3)):
尝试:
如果 li3[i] 中的 b3:
x = re.findall(r'\d*\.?\d+',li3[i])
#打印(x)
min_ = format(float(x[0])/12,'.2f') #转为浮点,保留小数点后两位
max_ = format(float(x[1])/12,'.2f')
li3[i][1] = min_+'-'+max_+u'10,000/月'
如果 li3[i] 中的 b4:
x = re.findall(r'\d*\.?\d+',li3[i])
#打印(x)
#输入()
min_ = format(float(x[0])/10,'.2f')
max_ = format(float(x[1])/10,'.2f')
li3[i][1] = str(min_+'-'+max_+'10,000/月')
打印(i,li3[i])
除了:
经过
2. 改进二
min_s=[] #定义最低工资表
max_s=[] #定义最高工资列表
对于范围内的 i (0,len(experience)):
min_s.append(salary[i][0])
max_s.append(salary[i][0])
如果#matplotlib模块无法显示中文字符串,可以使用如下代码
plt.rcParams['font.sans-serif'] = ['KaiTi'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False #解决减号'-'在保存的图片中显示为正方形的问题
my_df = pd.DataFrame({'experience':experience,'min_salay': min_s,'max_salay': max_s}) #相关的工作经验和工资
data1 = my_df.groupby('experience').mean()['min_salay'].plot(kind='line')
plt.show()
my_df2 = pd.DataFrame({'education':education,'min_salay': min_s,'max_salay': max_s}) #相关的教育和工资
data2 = my_df2.groupby('education').mean()['min_salay'].plot(kind='line')
plt.show()
c爬虫抓取网页数据(RequestHeaders请求的方式(getpost)RequestMethod:(主机和端口号))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-28 13:12
HTTP 请求和响应 General All 1.Request URL Request URL2.Request Method Request method (get post) 3.Response Headers Server's response Request Headers Server's request1.Host: (host和端口号)对应的URL2.Connection:(链接类型)3.User-Agent:用户代理4.Accept:(要传输的文件类型)5.referer: (页面跳转的地方)6.Cookie:(记录用户相关信息)7.Query String Paramerers 请求地址的参数
爬虫简介 什么是爬虫?简而言之,为什么需要爬虫而不是人来模拟浏览器进行网页操作?为其他程序提供数据源公司获取数据?1.公司自有数据2.第三方平台获取的数据免费平台:百度指数付费平台:Datatang3.爬虫爬取的数据python作为爬虫的优势1. PHP:对多线程和异步支持不是很好2.Java:代码量大,代码量大3.C/C++:代码量大,难写4.Python:很多支持模块,代码介绍,开发效率高(scrapy框架)爬虫分类1.一般网络爬虫如:百度雅虎谷歌2.专注网络爬虫:根据既定目标选择性抓取特定主题的内容几个概念1. URL组件 URL:全局统一资源定位器 https:网络协议:主机名,可以理解为主机名,这个主机在域名下TWF24000.html:Access Resource path anchor:锚点,用于前端页面定位。注意:当您在浏览器中请求 URL 时,浏览器会对 URL 进行编码。
服务器内部请求5.Cookie 记录服务器相关的用户信息 http 协议是无状态的 什么是无状态?服务端无法确定用户身份Cookie实际上是一小段文本信息(key-value格式) 防爬功能:防爬模拟登录抓包工具1.元素:元素网页源码,提取数据并分析数据(一些经过特殊处理,所以不完全准确)2.Console:控制台(打印信息)用得不多3.Sources:信息源(整个网站加载的文件)用的不多4.Net Work:网络工作(信息抓取)可以看到很多网页请求 Cookie 记录服务器相关的用户信息 http 协议是无状态的 什么是无状态?服务端无法确定用户身份Cookie实际上是一小段文本信息(key-value格式) 防爬功能:防爬模拟登录抓包工具1.元素:元素网页源码,提取数据并分析数据(一些经过特殊处理,所以不完全准确)2.Console:控制台(打印信息)用得不多3.Sources:信息源(整个网站加载的文件)用的不多4.Net Work:网络工作(信息抓取)可以看到很多网页请求 Cookie 记录服务器相关的用户信息 http 协议是无状态的 什么是无状态?服务端无法确定用户身份Cookie实际上是一小段文本信息(key-value格式) 防爬功能:防爬模拟登录抓包工具1.元素:元素网页源码,提取数据并分析数据(一些经过特殊处理,所以不完全准确)2.Console:控制台(打印信息)用得不多3.Sources:信息源(整个网站加载的文件)用的不多4.Net Work:网络工作(信息抓取)可以看到很多网页请求 查看全部
c爬虫抓取网页数据(RequestHeaders请求的方式(getpost)RequestMethod:(主机和端口号))
HTTP 请求和响应 General All 1.Request URL Request URL2.Request Method Request method (get post) 3.Response Headers Server's response Request Headers Server's request1.Host: (host和端口号)对应的URL2.Connection:(链接类型)3.User-Agent:用户代理4.Accept:(要传输的文件类型)5.referer: (页面跳转的地方)6.Cookie:(记录用户相关信息)7.Query String Paramerers 请求地址的参数

爬虫简介 什么是爬虫?简而言之,为什么需要爬虫而不是人来模拟浏览器进行网页操作?为其他程序提供数据源公司获取数据?1.公司自有数据2.第三方平台获取的数据免费平台:百度指数付费平台:Datatang3.爬虫爬取的数据python作为爬虫的优势1. PHP:对多线程和异步支持不是很好2.Java:代码量大,代码量大3.C/C++:代码量大,难写4.Python:很多支持模块,代码介绍,开发效率高(scrapy框架)爬虫分类1.一般网络爬虫如:百度雅虎谷歌2.专注网络爬虫:根据既定目标选择性抓取特定主题的内容几个概念1. URL组件 URL:全局统一资源定位器 https:网络协议:主机名,可以理解为主机名,这个主机在域名下TWF24000.html:Access Resource path anchor:锚点,用于前端页面定位。注意:当您在浏览器中请求 URL 时,浏览器会对 URL 进行编码。
服务器内部请求5.Cookie 记录服务器相关的用户信息 http 协议是无状态的 什么是无状态?服务端无法确定用户身份Cookie实际上是一小段文本信息(key-value格式) 防爬功能:防爬模拟登录抓包工具1.元素:元素网页源码,提取数据并分析数据(一些经过特殊处理,所以不完全准确)2.Console:控制台(打印信息)用得不多3.Sources:信息源(整个网站加载的文件)用的不多4.Net Work:网络工作(信息抓取)可以看到很多网页请求 Cookie 记录服务器相关的用户信息 http 协议是无状态的 什么是无状态?服务端无法确定用户身份Cookie实际上是一小段文本信息(key-value格式) 防爬功能:防爬模拟登录抓包工具1.元素:元素网页源码,提取数据并分析数据(一些经过特殊处理,所以不完全准确)2.Console:控制台(打印信息)用得不多3.Sources:信息源(整个网站加载的文件)用的不多4.Net Work:网络工作(信息抓取)可以看到很多网页请求 Cookie 记录服务器相关的用户信息 http 协议是无状态的 什么是无状态?服务端无法确定用户身份Cookie实际上是一小段文本信息(key-value格式) 防爬功能:防爬模拟登录抓包工具1.元素:元素网页源码,提取数据并分析数据(一些经过特殊处理,所以不完全准确)2.Console:控制台(打印信息)用得不多3.Sources:信息源(整个网站加载的文件)用的不多4.Net Work:网络工作(信息抓取)可以看到很多网页请求
c爬虫抓取网页数据(爬虫在数据分析领域的应用,如何帮助我们提升数据分析质量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-28 13:09
在当今的信息和数字时代,人们离不开互联网搜索。但是想想看,你真的可以在搜索过程中得到相关信息,因为有人在帮你过滤和提交相关内容到你面前。
就像在餐馆里,你点了土豆,你可以吃,因为有人帮你在土豆、萝卜、西红柿等中找到土豆,有些人把它们带到你的桌子上。在网上,这两个动作是由一个叫Crawler的同学实现的。
换句话说,没有爬虫,就没有今天的检索,也就无法准确查找信息,有效获取数据。今天我们就来聊聊爬虫在数据分析领域的应用,以及它如何帮助我们提高数据分析的质量。
一、 数据时代,爬虫的本质是提高效率
网络爬虫也称为网络机器人,可以代替人自动浏览互联网上的信息,采集
和整理数据。
它是一个程序,其基本原理是向网站/网络发起请求,在获取资源后分析并提取有用的数据。从技术角度来说,就是通过程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)抓取到本地,然后提取你的数据需要,并保存以备使用。
每个程序都有自己的规则,网络爬虫也不例外。它穿梭在世界各地的各种网站之间,根据人们制定的规则采集
信息。我们将这些规则称为网络爬虫算法。规则是人定的,是人根据自己的目的和需要设计的。因此,爬虫可以根据用户的目的而具有不同的功能。但所有爬虫的本质都是为了方便人们从海量的互联网信息中找到并下载自己想要的那种,从而提高信息获取的效率。
二、爬虫的应用:搜索,帮助企业做强业务
1.搜索引擎:抓取站点,为网络用户提供便利
在互联网发展之初,能够提供全球范围信息的网站并不多,用户也不多。Internet 只是文件传输协议 (FTP) 站点的集合。用户可以浏览这些站点以查找特定的共享文件。为了查找和组合 Internet 上可用的分布式数据,人们创建了一种称为网络爬虫的自动化程序。/Robots 可以抓取互联网上的所有网页,然后将所有页面上的内容复制到数据库中进行索引。这也是最早的搜索引擎。
如今,随着互联网的飞速发展,我们可以在任何搜索引擎中看到来自全球各个网站的信息。百度搜索引擎的爬虫叫Baiduspider,360的爬虫叫360Spider,搜狗的爬虫叫Sogouspider,必应的爬虫叫Bingbot。搜索引擎离不开爬虫。
例如,百度蜘蛛每天抓取大量互联网信息,抓取并采集
优质信息。当用户在百度搜索引擎上检索到对应的关键词时,百度会对关键词进行分析处理,从收录的网页中找出相关网页,并按照一定的排序规则进行排序,并显示结果给用户,工作原理如图所示。现在,我们可以大胆地说,您每天都在免费享受爬虫带来的好处。
2.企业:监测舆情,高效获取有价值信息
我们说过爬虫的本质是提高效率,爬虫的规则是人定的;那么,企业可以根据自己的业务需求设计爬虫,第一时间获取网络上的相关信息,进行清理整合。
大数据时代的数据分析,首先要有数据源,网络爬虫可以让我们在根据自己的目的进行采集的同时获取更多的数据源,从而去除很多不相关的数据。
例如,在进行大数据分析或数据挖掘时,数据源可以从某些提供统计数据的网站中获取,也可以从某些文档或内部资料中获取。但是这些获取数据的方法有时很难满足我们的数据需求。此时,我们可以利用爬虫技术,自动从互联网上获取更多我们感兴趣的数据内容,从而进行更深入的数据分析,获取更多有价值的信息。
此外,网络爬虫还可用于财务分析,采集
财务数据进行投资分析;应用于舆情监测分析、目标客户精准营销等领域。
三、企业常用的4种网络爬虫
根据实现的技术和结构,网络爬虫可分为通用网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。但是,实际的网络爬虫由于网络环境复杂,通常是这几种爬虫的组合。
1.通用网络爬虫
一般的网络爬虫也称为全网爬虫。顾名思义,爬取的目标资源在整个互联网。爬取的目标数据庞大,爬取的范围也非常大。正是因为它爬取的数据是海量数据,所以对于这类爬虫,对爬取性能的要求非常高。这种网络爬虫主要用于大型搜索引擎,具有非常高的应用价值。
一般的网络爬虫主要由初始URL采集、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块等组成。常见的网络爬虫在爬取时都会采用一定的爬取策略,主要有深度优先爬取策略和广度优先爬取策略。具体细节将在后面介绍。
2.专注于网络爬虫
聚焦网络爬虫也称为主题网络爬虫,是根据预先定义的主题有选择地抓取网页的爬虫。专注网络爬虫主要用于对特定信息的爬取,主要是为特定的人群提供服务。
焦点网络爬虫还由初始URL采集、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块、内容评价模块、链接评价模块等组成。 其中,内容评价模块和链接评价模块模块可以根据链接的重要性和内容来决定优先访问哪些页面。主要针对网络爬虫的爬虫策略有四种,如图:
专注的网络爬虫可以根据相应的主题有针对性地进行爬取,因此在实际应用过程中,可以节省大量的服务器资源和宽带资源,具有很强的实用性。这里以聚焦网络爬虫为例,了解爬虫运行的工作原理和流程。
如图所示,Focus Web Crawler有一个控制中心,负责整个爬虫系统的管理和监控,主要包括控制用户交互、初始化爬虫、确定主题、协调各个模块之间的工作、并控制爬行过程。等等:
(1)控制中心将初始URL集合传递给URL队列,页面爬取模块会从URL队列中读取第一批URL列表;
(2)根据这些URL地址从网上爬取相应的页面;爬取后,将爬取的内容传送到页面数据库中存储;
(3)在爬取过程中会爬取一些新的网址,这时候就需要使用链接过滤模块根据主题集过滤掉不相关的链接,然后使用链接评价模块进行剩余的URL链接根据主题或内容评估模块进行优先排序,完成后将新的URL地址传递给URL队列,供页面爬取模块使用;
(4) 抓取页面并存入页面数据库后,需要使用页面分析模块根据主题对抓取的页面进行页面分析处理,并根据处理结果建立索引数据库. 当用户检索到相应的信息时,可以从索引数据库中进行相应的搜索,得到相应的结果。
3.增量网络爬虫
这里的“增量”对应的是增量更新。增量更新是指更新时只更新变化的区域,不变的区域不更新。
增量式网络爬虫,在抓取网页时,只抓取有内容变化的网页或新生成的网页,不抓取没有内容变化的网页。增量式网络爬虫可以在一定程度上保证被爬取的页面尽可能的新鲜。
4.深网爬虫
在互联网中,网页按其存在方式可分为表层页和深层页。表面页面是指无需提交表单即可使用静态链接访问的静态页面;而深页是提交一定数量的关键词后才能获得的页面。在互联网中,深层页面的数量往往远大于表面页面的数量。
深度网络爬虫可以抓取互联网上的深度页面,抓取深度页面,需要想办法自动填写相应的表单。深网爬虫主要由URL列表、LVS列表(LVS指标签/值集合,即填写表单的数据源)、爬取控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析仪等部分组成。
四、网络爬虫的爬取策略
前面我们说过,网络爬虫算法是根据人强加的规则来采集
信息的,由于网络环境复杂,有各种对应的算法,即爬虫策略。这里主要介绍爬取的顺序和频率。
1. 爬取顺序
网络爬虫在爬取的过程中,爬取的URL列表中可能有很多URL地址,所以爬虫爬取这些URL地址会有一个顺序。
与一般的网络爬虫相比,爬取的顺序并不是那么重要。但是针对网络爬虫来说,爬取的顺序与服务器资源和宽带资源有关,所以非常重要,一般由爬取策略决定。爬取策略主要包括深度优先爬取策略、广度优先爬取策略、大站优先策略、反链策略、其他爬取策略等。
如图,假设有一个网站,ABCDEFG是该网站下的网页,如图所示,它代表了网页的层次结构。如果此时所有的网页ABCDEFG都在爬取队列中,根据不同的爬取策略,爬取的顺序也不同。
深度优先爬取策略:A→D→E→B→C→F→G
广度优先爬取策略:A→B→C→D→E→F→G
除了以上两种爬取策略外,还可以使用大站点爬取策略。可以根据相应网页所属的站点进行分类。如果一个网站有大量的网页,则称为大网站。按照这个策略,网页数量越多,网站越大,然后先爬取网页的大站URL地址。
还有反链策略。一个网页的反向链接数是指该网页被其他网页指向的次数。这个数字在一定程度上代表了该网页被其他网页推荐的次数。所以,如果按照反链策略爬取,那么哪个网页反链多,哪个页面会先被爬取。
但是,在实际情况中,如果仅通过反链策略来确定网页的优先级,则可能会出现大量的作弊行为。因此,使用反向链路策略需要考虑可靠反向链路的数量。除了以上爬取策略,实践中还有很多其他的爬取策略,比如OPIC策略、Partial PageRank策略等。
2. 爬行频率
网站的网页经常更新。作为爬虫,网站的更新频率越接近爬虫访问网站的频率,效果越好。当然,在爬虫服务器资源有限的情况下,爬虫也需要根据相应的策略,让不同的网页有不同的更新优先级,优先级高的网页会以更快的爬取响应进行更新。常见的网页更新策略有以下三种:
(1)用户体验策略:大多数用户在使用搜索引擎查询某个关键词时,只关注排名靠前的网页。因此,当爬虫服务器资源有限时,爬虫会优先更新排名结果最高的页面。
(2)历史数据策略:是指某个网页的历史更新数据,通过泊松过程建模等手段,预测网页下次更新时间,从而确定网页下次更新时间爬。慢慢来。
(3) 聚类分析策略:网页可能有不同的内容,但一般来说属性相似的网页更新频率相近,所以可以对大量网页进行聚类分析。聚类完成后,可以根据同类型网页的平均更新值设置抓取频率。
五、网络爬虫的实现技术
对于实现技术,本文不展开,只为感兴趣的同学提供几种常用语言:Python、Java、PHP、Node.JS、C++、Go语言(另外还有很多web开发语言爬虫)。
Python:爬虫框架非常丰富,多线程处理能力强,简单易学,代码简洁,优点很多。
Java:适合大型爬虫项目的开发。
PHP:后端处理能力很强,代码很简洁,模块也很丰富,但是并发能力比较弱。
Node.JS:支持高并发和多线程处理。
C++:运行速度快,适合大型爬虫项目的开发,成本高。
Go语言:同样高并发性很强。
六、总结
说起爬虫,很多人认为是网络世界中无法回避的灰色地带。恭喜你,看完这篇文章,你比很多人都清楚。
因为爬虫分为善意爬虫和恶意爬虫,比如搜索引擎爬虫。善意爬虫严格遵守Robots协议,抓取网页数据(如URL)。它的存在可以增加网站的曝光度,给网站带来流量;
恶意爬虫无视Robots协议,故意爬取一些深层次的、不愿公开的网站数据,包括个人隐私或商业秘密等重要信息。而且,恶意爬虫的用户希望从网站上获取多条、大量的信息,因此通常会向目标网站发布大量的爬虫。如果大量爬虫同时访问网站,很容易造成网站服务器过载或崩溃,给网站运营者造成损失。
据统计,2017年我国42.2%的互联网流量是由网络机器人创造的,其中恶意机器(主要是恶意爬虫)占21.80%。我们应该依法使用网络爬虫,用技术为企业带来长远发展,用科学为社会创造更高的价值。 查看全部
c爬虫抓取网页数据(爬虫在数据分析领域的应用,如何帮助我们提升数据分析质量)
在当今的信息和数字时代,人们离不开互联网搜索。但是想想看,你真的可以在搜索过程中得到相关信息,因为有人在帮你过滤和提交相关内容到你面前。
就像在餐馆里,你点了土豆,你可以吃,因为有人帮你在土豆、萝卜、西红柿等中找到土豆,有些人把它们带到你的桌子上。在网上,这两个动作是由一个叫Crawler的同学实现的。
换句话说,没有爬虫,就没有今天的检索,也就无法准确查找信息,有效获取数据。今天我们就来聊聊爬虫在数据分析领域的应用,以及它如何帮助我们提高数据分析的质量。
一、 数据时代,爬虫的本质是提高效率
网络爬虫也称为网络机器人,可以代替人自动浏览互联网上的信息,采集
和整理数据。
它是一个程序,其基本原理是向网站/网络发起请求,在获取资源后分析并提取有用的数据。从技术角度来说,就是通过程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)抓取到本地,然后提取你的数据需要,并保存以备使用。
每个程序都有自己的规则,网络爬虫也不例外。它穿梭在世界各地的各种网站之间,根据人们制定的规则采集
信息。我们将这些规则称为网络爬虫算法。规则是人定的,是人根据自己的目的和需要设计的。因此,爬虫可以根据用户的目的而具有不同的功能。但所有爬虫的本质都是为了方便人们从海量的互联网信息中找到并下载自己想要的那种,从而提高信息获取的效率。
二、爬虫的应用:搜索,帮助企业做强业务
1.搜索引擎:抓取站点,为网络用户提供便利
在互联网发展之初,能够提供全球范围信息的网站并不多,用户也不多。Internet 只是文件传输协议 (FTP) 站点的集合。用户可以浏览这些站点以查找特定的共享文件。为了查找和组合 Internet 上可用的分布式数据,人们创建了一种称为网络爬虫的自动化程序。/Robots 可以抓取互联网上的所有网页,然后将所有页面上的内容复制到数据库中进行索引。这也是最早的搜索引擎。
如今,随着互联网的飞速发展,我们可以在任何搜索引擎中看到来自全球各个网站的信息。百度搜索引擎的爬虫叫Baiduspider,360的爬虫叫360Spider,搜狗的爬虫叫Sogouspider,必应的爬虫叫Bingbot。搜索引擎离不开爬虫。
例如,百度蜘蛛每天抓取大量互联网信息,抓取并采集
优质信息。当用户在百度搜索引擎上检索到对应的关键词时,百度会对关键词进行分析处理,从收录的网页中找出相关网页,并按照一定的排序规则进行排序,并显示结果给用户,工作原理如图所示。现在,我们可以大胆地说,您每天都在免费享受爬虫带来的好处。
2.企业:监测舆情,高效获取有价值信息
我们说过爬虫的本质是提高效率,爬虫的规则是人定的;那么,企业可以根据自己的业务需求设计爬虫,第一时间获取网络上的相关信息,进行清理整合。
大数据时代的数据分析,首先要有数据源,网络爬虫可以让我们在根据自己的目的进行采集的同时获取更多的数据源,从而去除很多不相关的数据。
例如,在进行大数据分析或数据挖掘时,数据源可以从某些提供统计数据的网站中获取,也可以从某些文档或内部资料中获取。但是这些获取数据的方法有时很难满足我们的数据需求。此时,我们可以利用爬虫技术,自动从互联网上获取更多我们感兴趣的数据内容,从而进行更深入的数据分析,获取更多有价值的信息。
此外,网络爬虫还可用于财务分析,采集
财务数据进行投资分析;应用于舆情监测分析、目标客户精准营销等领域。
三、企业常用的4种网络爬虫
根据实现的技术和结构,网络爬虫可分为通用网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。但是,实际的网络爬虫由于网络环境复杂,通常是这几种爬虫的组合。
1.通用网络爬虫
一般的网络爬虫也称为全网爬虫。顾名思义,爬取的目标资源在整个互联网。爬取的目标数据庞大,爬取的范围也非常大。正是因为它爬取的数据是海量数据,所以对于这类爬虫,对爬取性能的要求非常高。这种网络爬虫主要用于大型搜索引擎,具有非常高的应用价值。
一般的网络爬虫主要由初始URL采集、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块等组成。常见的网络爬虫在爬取时都会采用一定的爬取策略,主要有深度优先爬取策略和广度优先爬取策略。具体细节将在后面介绍。
2.专注于网络爬虫
聚焦网络爬虫也称为主题网络爬虫,是根据预先定义的主题有选择地抓取网页的爬虫。专注网络爬虫主要用于对特定信息的爬取,主要是为特定的人群提供服务。
焦点网络爬虫还由初始URL采集、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块、内容评价模块、链接评价模块等组成。 其中,内容评价模块和链接评价模块模块可以根据链接的重要性和内容来决定优先访问哪些页面。主要针对网络爬虫的爬虫策略有四种,如图:
专注的网络爬虫可以根据相应的主题有针对性地进行爬取,因此在实际应用过程中,可以节省大量的服务器资源和宽带资源,具有很强的实用性。这里以聚焦网络爬虫为例,了解爬虫运行的工作原理和流程。
如图所示,Focus Web Crawler有一个控制中心,负责整个爬虫系统的管理和监控,主要包括控制用户交互、初始化爬虫、确定主题、协调各个模块之间的工作、并控制爬行过程。等等:
(1)控制中心将初始URL集合传递给URL队列,页面爬取模块会从URL队列中读取第一批URL列表;
(2)根据这些URL地址从网上爬取相应的页面;爬取后,将爬取的内容传送到页面数据库中存储;
(3)在爬取过程中会爬取一些新的网址,这时候就需要使用链接过滤模块根据主题集过滤掉不相关的链接,然后使用链接评价模块进行剩余的URL链接根据主题或内容评估模块进行优先排序,完成后将新的URL地址传递给URL队列,供页面爬取模块使用;
(4) 抓取页面并存入页面数据库后,需要使用页面分析模块根据主题对抓取的页面进行页面分析处理,并根据处理结果建立索引数据库. 当用户检索到相应的信息时,可以从索引数据库中进行相应的搜索,得到相应的结果。
3.增量网络爬虫
这里的“增量”对应的是增量更新。增量更新是指更新时只更新变化的区域,不变的区域不更新。
增量式网络爬虫,在抓取网页时,只抓取有内容变化的网页或新生成的网页,不抓取没有内容变化的网页。增量式网络爬虫可以在一定程度上保证被爬取的页面尽可能的新鲜。
4.深网爬虫
在互联网中,网页按其存在方式可分为表层页和深层页。表面页面是指无需提交表单即可使用静态链接访问的静态页面;而深页是提交一定数量的关键词后才能获得的页面。在互联网中,深层页面的数量往往远大于表面页面的数量。
深度网络爬虫可以抓取互联网上的深度页面,抓取深度页面,需要想办法自动填写相应的表单。深网爬虫主要由URL列表、LVS列表(LVS指标签/值集合,即填写表单的数据源)、爬取控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析仪等部分组成。
四、网络爬虫的爬取策略
前面我们说过,网络爬虫算法是根据人强加的规则来采集
信息的,由于网络环境复杂,有各种对应的算法,即爬虫策略。这里主要介绍爬取的顺序和频率。
1. 爬取顺序
网络爬虫在爬取的过程中,爬取的URL列表中可能有很多URL地址,所以爬虫爬取这些URL地址会有一个顺序。
与一般的网络爬虫相比,爬取的顺序并不是那么重要。但是针对网络爬虫来说,爬取的顺序与服务器资源和宽带资源有关,所以非常重要,一般由爬取策略决定。爬取策略主要包括深度优先爬取策略、广度优先爬取策略、大站优先策略、反链策略、其他爬取策略等。
如图,假设有一个网站,ABCDEFG是该网站下的网页,如图所示,它代表了网页的层次结构。如果此时所有的网页ABCDEFG都在爬取队列中,根据不同的爬取策略,爬取的顺序也不同。
深度优先爬取策略:A→D→E→B→C→F→G
广度优先爬取策略:A→B→C→D→E→F→G
除了以上两种爬取策略外,还可以使用大站点爬取策略。可以根据相应网页所属的站点进行分类。如果一个网站有大量的网页,则称为大网站。按照这个策略,网页数量越多,网站越大,然后先爬取网页的大站URL地址。
还有反链策略。一个网页的反向链接数是指该网页被其他网页指向的次数。这个数字在一定程度上代表了该网页被其他网页推荐的次数。所以,如果按照反链策略爬取,那么哪个网页反链多,哪个页面会先被爬取。
但是,在实际情况中,如果仅通过反链策略来确定网页的优先级,则可能会出现大量的作弊行为。因此,使用反向链路策略需要考虑可靠反向链路的数量。除了以上爬取策略,实践中还有很多其他的爬取策略,比如OPIC策略、Partial PageRank策略等。
2. 爬行频率
网站的网页经常更新。作为爬虫,网站的更新频率越接近爬虫访问网站的频率,效果越好。当然,在爬虫服务器资源有限的情况下,爬虫也需要根据相应的策略,让不同的网页有不同的更新优先级,优先级高的网页会以更快的爬取响应进行更新。常见的网页更新策略有以下三种:
(1)用户体验策略:大多数用户在使用搜索引擎查询某个关键词时,只关注排名靠前的网页。因此,当爬虫服务器资源有限时,爬虫会优先更新排名结果最高的页面。
(2)历史数据策略:是指某个网页的历史更新数据,通过泊松过程建模等手段,预测网页下次更新时间,从而确定网页下次更新时间爬。慢慢来。
(3) 聚类分析策略:网页可能有不同的内容,但一般来说属性相似的网页更新频率相近,所以可以对大量网页进行聚类分析。聚类完成后,可以根据同类型网页的平均更新值设置抓取频率。
五、网络爬虫的实现技术
对于实现技术,本文不展开,只为感兴趣的同学提供几种常用语言:Python、Java、PHP、Node.JS、C++、Go语言(另外还有很多web开发语言爬虫)。
Python:爬虫框架非常丰富,多线程处理能力强,简单易学,代码简洁,优点很多。
Java:适合大型爬虫项目的开发。
PHP:后端处理能力很强,代码很简洁,模块也很丰富,但是并发能力比较弱。
Node.JS:支持高并发和多线程处理。
C++:运行速度快,适合大型爬虫项目的开发,成本高。
Go语言:同样高并发性很强。
六、总结
说起爬虫,很多人认为是网络世界中无法回避的灰色地带。恭喜你,看完这篇文章,你比很多人都清楚。
因为爬虫分为善意爬虫和恶意爬虫,比如搜索引擎爬虫。善意爬虫严格遵守Robots协议,抓取网页数据(如URL)。它的存在可以增加网站的曝光度,给网站带来流量;
恶意爬虫无视Robots协议,故意爬取一些深层次的、不愿公开的网站数据,包括个人隐私或商业秘密等重要信息。而且,恶意爬虫的用户希望从网站上获取多条、大量的信息,因此通常会向目标网站发布大量的爬虫。如果大量爬虫同时访问网站,很容易造成网站服务器过载或崩溃,给网站运营者造成损失。
据统计,2017年我国42.2%的互联网流量是由网络机器人创造的,其中恶意机器(主要是恶意爬虫)占21.80%。我们应该依法使用网络爬虫,用技术为企业带来长远发展,用科学为社会创造更高的价值。
c爬虫抓取网页数据(【Python爬虫】C站软件工程师能力认证模拟大赛对标名企技术标准 )
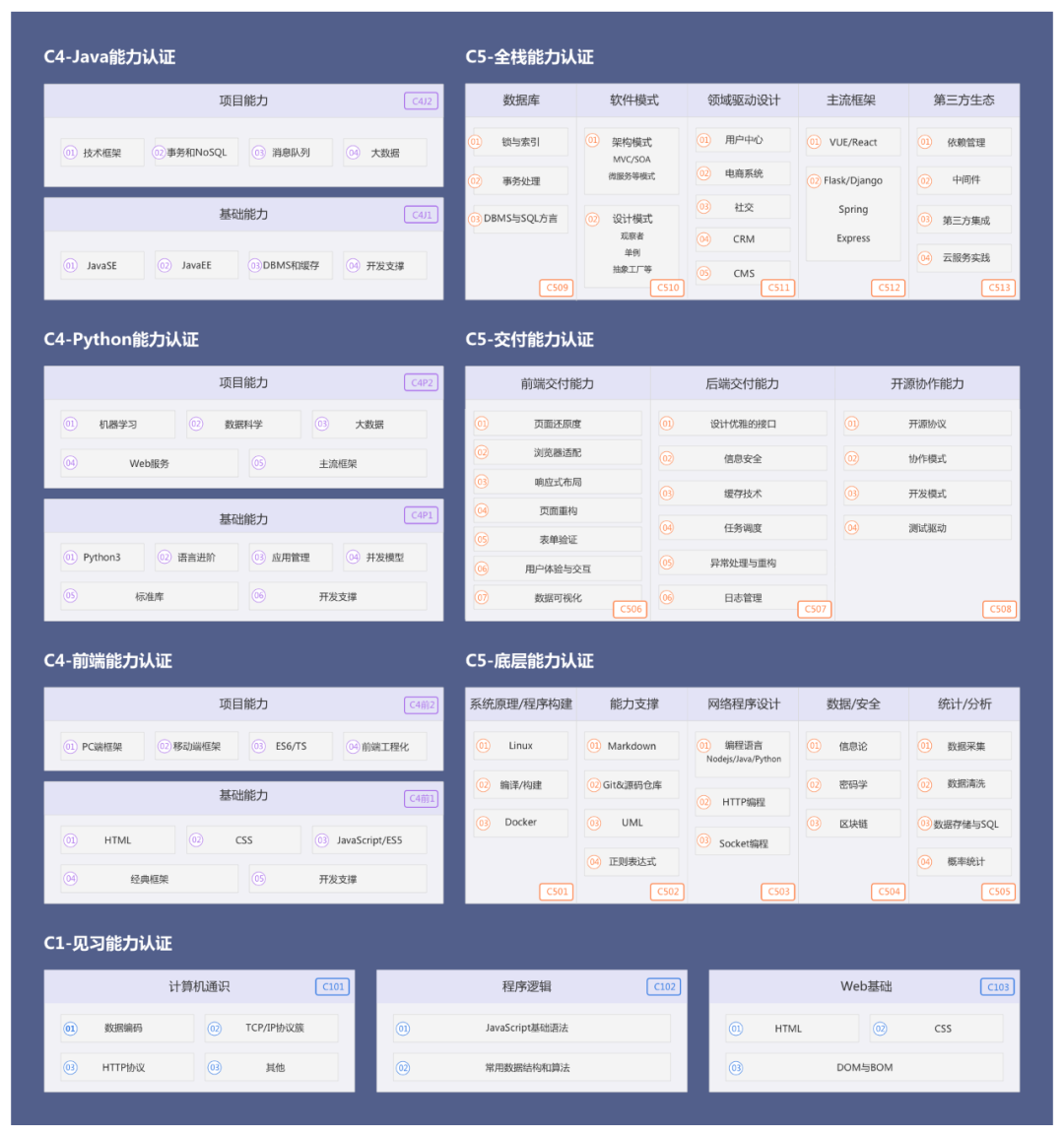
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-28 13:08
)
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常见的网络追逐者)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。
爬虫容易上手,但更难深入。如何编写高效的爬虫,如何编写高度灵活和可扩展的爬虫,都是技术任务。另外,在爬取过程中,往往容易遇到反爬虫,比如字体反爬、IP识别、验证码等,如何克服困难,得到想要的数据,这些问题往往困扰着学爬的小伙伴们。
今天给大家分享99篇与【Python爬虫】相关的精选学习资料,不仅详细讲解了基本概念、正则表达式、Beautiful Soup、lxml、requests等知识点,而且从入门到精通都适用- 全面学习。同时还有6本学习爬虫必读书籍,扫码获取。
参加C认证模拟考试即可领取!
同时,针对Python基础薄弱的同学,我们推出了C站软件工程师能力认证,帮助大家系统学习,全面树立编码学习思维,具备扎实的编码能力。
如果你还想知道你的Python爬虫能力是否符合你喜欢的公司的技术标准?
赶快点击此链接,在C认证模拟大赛中进行测试吧!
C-认证模拟竞赛是针对被贴标企业的技术标准。无论你是从学校招聘、转业,还是加薪,都可以通过这个测试,得到你想要的答案。认证梳理软件工程师开发过程中所需的各种技术技能,结合企业招聘需求和人才申请痛点,本着公开、透明、公平的原则,确保真实的业务场景、代码实践、真实人的容貌,选才的过程 留下的痕迹和档案是不可篡改的。检验技术人才的真实能力,为企业节省招聘培训成本,为行业提供人才储备,为国家数字化战略贡献力量。
一、完成免费模拟测试,带领99本Python爬虫精选学习资料
为了方便大家学习,我们推出了C站百万知识库行动,其中收录
99篇【Python爬虫】学习资料,点击量过万,采集
过千。点击链接()完成C认证模拟大赛中的测试,即Available!收录
基础概念、正则表达式、Beautiful Soup、lxml、requests等知识点。无论您是Java、Python、前端技术的新手,还是已经有一定基础的技术爱好者,在这里都能找到您想要的信息。
扫描二维码添加小龙女即可获取
部分信息显示:
二、Python爬虫好书免费领
学习爬虫,书籍是必不可少的学习工具之一,尤其是对于自学者来说。今天给大家带来6本学习Python爬虫必读的好书,非常全面。
扫描海报二维码参加C认证模拟考试,即可获得CSDN电子书,包括以下书籍!考试结束后,每月电子书卡将在3个工作日内发放到您的账户。
三、数以百万计的知识库等着你!
目前我们整理了Java知识库600篇、Python知识库600篇、前端知识库600篇、IT软件工程师基础能力500篇,其中不仅包括基础能力学习小白+1,也是需要大厂拥有的项目能力。学习教程。知识库持续更新,欢迎加入我们一起学习!
C站的知识库涵盖以下知识点。每日更新,欢迎进群系统学习!
部分数据预览:
信息太多,无法一一截图。完成模拟考试后,欢迎您扫码进入C认证考试福利群。信息每天下午5点更新~
赶快点击此链接,在C认证模拟大赛中进行测试吧!
完成后添加小龙女接收信息
下图是C站(CSDN)软件工程师能力认证标准中的C1/C4-能力认证示意图。分为基础能力和项目能力两个模块。可以看到模块中的技能点可以涵盖一线大厂的开发工程师招聘JD需求。
通过以上,可以清楚地看到,大公司的招聘要求和能力认证是一一对应的,是紧密相连的。
C认证的企业奖学金计划支持梦想,让努力工作发光。同时,C认证的成功离不开以下合作公司的赞助,谢谢你们一路的陪伴~
CSDN软件工程师能力认证(以下简称C系列认证)是由中国软件开发者网CSDN开发推出的能力认证标准。C系列认证经历了近一年的实际线下调研、考察、迭代、测试,梳理出软件工程师开发过程中需要的各种技术技能,结合企业招聘需求和人才申请痛点,基于公开、透明、公平 原则上,在分配人才时,要保证真实的业务场景,所有在船上的实际操作,所有流程的痕迹,不可篡改的档案。
C系列认证步骤:
1.打开官网(),预约认证,注册成功。
2.扫描下方二维码进入群领取学习资料和学习任务。群内也有直播解说和答疑。一起记录下自己的成长历程吧~
预约后即可进入C认证任务组
有:
1、C认证各阶段学习资料
2、C认证在实践任务的每个阶段,完成后还可以获得合作企业赞助的红包!
3、 任务现场讲解和专家问答
4、每天更新系统干货文章合集,整合系统知识库,帮助大家自主学习
赶紧加小龙女,一起记录下自己的成长历程吧~
查看全部
c爬虫抓取网页数据(【Python爬虫】C站软件工程师能力认证模拟大赛对标名企技术标准
)
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常见的网络追逐者)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。
爬虫容易上手,但更难深入。如何编写高效的爬虫,如何编写高度灵活和可扩展的爬虫,都是技术任务。另外,在爬取过程中,往往容易遇到反爬虫,比如字体反爬、IP识别、验证码等,如何克服困难,得到想要的数据,这些问题往往困扰着学爬的小伙伴们。

今天给大家分享99篇与【Python爬虫】相关的精选学习资料,不仅详细讲解了基本概念、正则表达式、Beautiful Soup、lxml、requests等知识点,而且从入门到精通都适用- 全面学习。同时还有6本学习爬虫必读书籍,扫码获取。
参加C认证模拟考试即可领取!
同时,针对Python基础薄弱的同学,我们推出了C站软件工程师能力认证,帮助大家系统学习,全面树立编码学习思维,具备扎实的编码能力。
如果你还想知道你的Python爬虫能力是否符合你喜欢的公司的技术标准?
赶快点击此链接,在C认证模拟大赛中进行测试吧!
C-认证模拟竞赛是针对被贴标企业的技术标准。无论你是从学校招聘、转业,还是加薪,都可以通过这个测试,得到你想要的答案。认证梳理软件工程师开发过程中所需的各种技术技能,结合企业招聘需求和人才申请痛点,本着公开、透明、公平的原则,确保真实的业务场景、代码实践、真实人的容貌,选才的过程 留下的痕迹和档案是不可篡改的。检验技术人才的真实能力,为企业节省招聘培训成本,为行业提供人才储备,为国家数字化战略贡献力量。
一、完成免费模拟测试,带领99本Python爬虫精选学习资料
为了方便大家学习,我们推出了C站百万知识库行动,其中收录
99篇【Python爬虫】学习资料,点击量过万,采集
过千。点击链接()完成C认证模拟大赛中的测试,即Available!收录
基础概念、正则表达式、Beautiful Soup、lxml、requests等知识点。无论您是Java、Python、前端技术的新手,还是已经有一定基础的技术爱好者,在这里都能找到您想要的信息。
扫描二维码添加小龙女即可获取

部分信息显示:


二、Python爬虫好书免费领
学习爬虫,书籍是必不可少的学习工具之一,尤其是对于自学者来说。今天给大家带来6本学习Python爬虫必读的好书,非常全面。
扫描海报二维码参加C认证模拟考试,即可获得CSDN电子书,包括以下书籍!考试结束后,每月电子书卡将在3个工作日内发放到您的账户。

三、数以百万计的知识库等着你!
目前我们整理了Java知识库600篇、Python知识库600篇、前端知识库600篇、IT软件工程师基础能力500篇,其中不仅包括基础能力学习小白+1,也是需要大厂拥有的项目能力。学习教程。知识库持续更新,欢迎加入我们一起学习!
C站的知识库涵盖以下知识点。每日更新,欢迎进群系统学习!
部分数据预览:



信息太多,无法一一截图。完成模拟考试后,欢迎您扫码进入C认证考试福利群。信息每天下午5点更新~
赶快点击此链接,在C认证模拟大赛中进行测试吧!
完成后添加小龙女接收信息

下图是C站(CSDN)软件工程师能力认证标准中的C1/C4-能力认证示意图。分为基础能力和项目能力两个模块。可以看到模块中的技能点可以涵盖一线大厂的开发工程师招聘JD需求。
通过以上,可以清楚地看到,大公司的招聘要求和能力认证是一一对应的,是紧密相连的。
C认证的企业奖学金计划支持梦想,让努力工作发光。同时,C认证的成功离不开以下合作公司的赞助,谢谢你们一路的陪伴~

CSDN软件工程师能力认证(以下简称C系列认证)是由中国软件开发者网CSDN开发推出的能力认证标准。C系列认证经历了近一年的实际线下调研、考察、迭代、测试,梳理出软件工程师开发过程中需要的各种技术技能,结合企业招聘需求和人才申请痛点,基于公开、透明、公平 原则上,在分配人才时,要保证真实的业务场景,所有在船上的实际操作,所有流程的痕迹,不可篡改的档案。
C系列认证步骤:
1.打开官网(),预约认证,注册成功。
2.扫描下方二维码进入群领取学习资料和学习任务。群内也有直播解说和答疑。一起记录下自己的成长历程吧~
预约后即可进入C认证任务组
有:
1、C认证各阶段学习资料
2、C认证在实践任务的每个阶段,完成后还可以获得合作企业赞助的红包!
3、 任务现场讲解和专家问答
4、每天更新系统干货文章合集,整合系统知识库,帮助大家自主学习
赶紧加小龙女,一起记录下自己的成长历程吧~

c爬虫抓取网页数据(2021年最值得关注的10款常见网络安全工具_weixin_34357887)
网站优化 • 优采云 发表了文章 • 0 个评论 • 21 次浏览 • 2021-12-28 11:15
10个常用的网络安全工具_weixin_34357887的博客-CSDN博客。
Open-AudIT Open-AudIT 是一个网络发现、清单和审计程序。这个免费的开源软件可以扫描网络并存储有关发现设备的信息。
它是一个自动检测远程或本地主机安全弱点的程序。一个好的扫描器相当于一千个密码的价值。.
最好的75网络安全工具(转)阿火博客园。
下面是我在学习网络安全时用到的一些工具的总结。1.Wireshark 网址:。
网络安全工具总结_sinat_38598239的博客-CSDN博客。
网络安全工具Logcheck用于自动检查系统入侵事件和异常活动记录。它分析各种 Linux 日志文件,例如 /var/log/mes。
您可以在 Windows 平台上找到移植版本。工具:GFILANguard(商业网络安全扫描软件)网址:。
这也是 THC 贡献的另一个有价值的工具。GFILANguard:Windows 平台上的商用网络安全扫描仪 GFILANguard。
来了解一下2021年最值得关注的10个网络安全测试工具:NMap是NetworkMapper的缩写,NMap是一个开放的。 查看全部
c爬虫抓取网页数据(2021年最值得关注的10款常见网络安全工具_weixin_34357887)
10个常用的网络安全工具_weixin_34357887的博客-CSDN博客。
Open-AudIT Open-AudIT 是一个网络发现、清单和审计程序。这个免费的开源软件可以扫描网络并存储有关发现设备的信息。
它是一个自动检测远程或本地主机安全弱点的程序。一个好的扫描器相当于一千个密码的价值。.
最好的75网络安全工具(转)阿火博客园。
下面是我在学习网络安全时用到的一些工具的总结。1.Wireshark 网址:。

网络安全工具总结_sinat_38598239的博客-CSDN博客。
网络安全工具Logcheck用于自动检查系统入侵事件和异常活动记录。它分析各种 Linux 日志文件,例如 /var/log/mes。

您可以在 Windows 平台上找到移植版本。工具:GFILANguard(商业网络安全扫描软件)网址:。
这也是 THC 贡献的另一个有价值的工具。GFILANguard:Windows 平台上的商用网络安全扫描仪 GFILANguard。
来了解一下2021年最值得关注的10个网络安全测试工具:NMap是NetworkMapper的缩写,NMap是一个开放的。
c爬虫抓取网页数据(一下如何用Python来爬取京东商品(一)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-28 11:14
大家好,我是归零~
今天,我将介绍如何使用Python抓取京东产品类别。数据包括产品名称、价格、出版商、作者等信息。
本次爬虫使用的核心库是Selenium+pyquery,Selenium用于驱动浏览器模拟访问网页,pyquery用于解析页面信息进行数据提取。让我们来看看最终的结果。
脚本启动后,Selenium 会自动打开京东网页,翻到商品页面信息。当浏览器翻页时,它控制后台返回提取的数据。
在介绍主程序之前,这里先介绍一下Selenium包
硒安装
Selenium 主要用作 Web 应用程序的测试工具。可以控制浏览器完成一系列步骤,模拟人的操作;比如自动刷新课程、自动填文、自动查询web端快递单号等都可以。目前,它支持 Java 和 Python。、C#、Ruby等语言;
在做网页爬虫的时候,有些网页的数据是以ajax的方式渲染的,比如微博。标题没有下一页条目。通过刷新页面实现翻页效果;这种类型的网页数据不是直接放在html中的。是通过用户操作触发嵌入在html中的js命令,从而调用json文件中存储的数据,最后呈现;
对于这类网页采集
,一般有两种思路:
所以Selenium工具可以对web端的一些反爬措施实现一些有效的抑制;
Python使用Selenium时,可以使用打包好的Selenium库,使用pip命令完成安装。
pip install selenium
Selenium 目前支持的浏览器包括 Chrome 和 Firefox。建议大家选择Chrome比较好,因为网上关于Chrome的文档比较多。
但是在使用之前,除了确保安装了Chrome浏览器之外,还需要确保chromedriver.exe工具(Selenium的核心是webdriver,chromedriver.exe是Chrome的WebDriver工具)也安装了
chromedriver的版本需要与Chrome浏览器的版本对应,本地下载即可
下载地址如下:
2.爬虫逻辑
使用Selenium模拟人工操作抓取京东数据,需要按顺序执行以下步骤(这里以抓取Python图书产品为例):
首先需要初始化创建webdriver的Chrome浏览器和数据存储文件(这里我用的是txt文件)
def __init__(self,item_name,txt_path):
url = \'https://www.jd.com/\' # 登录网址
self.url = url
self.item_name = item_name
self.txt_file = open(txt_path,encoding=\'utf-8\',mode=\'w+\')
options = webdriver.ChromeOptions() # 谷歌选项
# 设置为开发者模式,避免被识别
options.add_experimental_option(\'excludeSwitches\',
[\'enable-automation\'])
self.browser = webdriver.Chrome(executable_path= "C:/Program Files/Google/Chrome/Application/chromedriver.exe",
options = options)
self.wait = WebDriverWait(self.browser,2)
webdriver.Chrome()方法用于创建驱动浏览器Chrome,并将之前下载到本地的chromedriver.exe文件夹的路径赋值给executable_path参数。
浏览器打开网页时,可能会因为网速原因加载缓慢,所以这里我们使用WebDriverWait方法创建了一个wait方法,每次调用浏览器都需要等待2秒才能继续下一步;
初步操作后,接下来就是主程序,模拟访问、输入、点击等操作;我将所有这些操作封装在一个 run() 函数中,
def run(self):
"""登陆接口"""
self.browser.get(self.url)
input_edit = self.browser.find_element(By.CSS_SELECTOR,\'#key\')
input_edit.clear()
input_edit.send_keys(self.item_name)
search_button = self.browser.find_element(By.CSS_SELECTOR,\'#search > div > div.form > button\')
search_button.click()# 点击
time.sleep(2)
html = self.browser.page_source # 获取 html
self.parse_html(html)
current_url = self.browser.current_url # 获取当前页面 url
initial_url = str(current_url).split(\'&pvid\')[0]
for i in range(1,100):
try:
print(\'正在解析----------------{}图片\'.format(str(i)))
next_page_url = initial_url + \'&page={}&s={}&click=0\'.format(str(i*2+1),str(i*60+1))
print(next_page_url)
self.browser.get(next_page_url)
self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,\'#J_goodsList > ul > li\')))
html = self.browser.page_source
self.parse_html(html)# 对 html 网址进行解析
time.sleep(2) # 设置频率
except Exception as e:
print(\'Error Next page\',e)
self.txt_file.close()# 关闭 txt 文件
首先使用get()方法访问京东主页,然后定位到页面上的搜索栏和搜索按钮标签input_edit和search_button;完成输入并点击操作
关于网页元素标签的定位,如果不能,可以使用浏览器开发者模式,分为以下几个步骤(这里以CSS_Selector为例):
在翻页操作中,这里是按照京东url规则构造的,
第 5 页
https://search.jd.com/Search%3 ... k%3D0
第 6 页
https://search.jd.com/Search%3 ... k%3D0
如果仔细看,你会发现第5页和第6页的urls唯一的区别就是两个参数page和s;
按照这个规则,通过改变page和s参数来构造京东商品的前100页商品信息,完成数据抓取;
关于数据提取部分,我使用parse_html函数来完成
为了提高程序的友好性,我把所有的功能都封装在一个类中,用户只需要输入两个参数,一个是需要采集的产品名称,一个是存储的路径文件; 可以完成数据爬取;
最后将抓取到的数据保存成txt文件,结果如下
4. 总结
selenium虽然可以有效破解web端的一些反爬虫机制,但是对于一些网站,比如拉勾网,就没什么用了。在拉勾官网使用Selenium驱动浏览器模拟翻页操作时,网站可以识别非人类。操作,暂时禁止并警告您的IP;
本文涉及的完整源码,关注微信公众号:程序员大飞,回复后台关键词:京东货,即可获取! 查看全部
c爬虫抓取网页数据(一下如何用Python来爬取京东商品(一)_)
大家好,我是归零~
今天,我将介绍如何使用Python抓取京东产品类别。数据包括产品名称、价格、出版商、作者等信息。
本次爬虫使用的核心库是Selenium+pyquery,Selenium用于驱动浏览器模拟访问网页,pyquery用于解析页面信息进行数据提取。让我们来看看最终的结果。
脚本启动后,Selenium 会自动打开京东网页,翻到商品页面信息。当浏览器翻页时,它控制后台返回提取的数据。
在介绍主程序之前,这里先介绍一下Selenium包
硒安装
Selenium 主要用作 Web 应用程序的测试工具。可以控制浏览器完成一系列步骤,模拟人的操作;比如自动刷新课程、自动填文、自动查询web端快递单号等都可以。目前,它支持 Java 和 Python。、C#、Ruby等语言;
在做网页爬虫的时候,有些网页的数据是以ajax的方式渲染的,比如微博。标题没有下一页条目。通过刷新页面实现翻页效果;这种类型的网页数据不是直接放在html中的。是通过用户操作触发嵌入在html中的js命令,从而调用json文件中存储的数据,最后呈现;
对于这类网页采集
,一般有两种思路:
所以Selenium工具可以对web端的一些反爬措施实现一些有效的抑制;
Python使用Selenium时,可以使用打包好的Selenium库,使用pip命令完成安装。
pip install selenium
Selenium 目前支持的浏览器包括 Chrome 和 Firefox。建议大家选择Chrome比较好,因为网上关于Chrome的文档比较多。
但是在使用之前,除了确保安装了Chrome浏览器之外,还需要确保chromedriver.exe工具(Selenium的核心是webdriver,chromedriver.exe是Chrome的WebDriver工具)也安装了
chromedriver的版本需要与Chrome浏览器的版本对应,本地下载即可
下载地址如下:
2.爬虫逻辑
使用Selenium模拟人工操作抓取京东数据,需要按顺序执行以下步骤(这里以抓取Python图书产品为例):
首先需要初始化创建webdriver的Chrome浏览器和数据存储文件(这里我用的是txt文件)
def __init__(self,item_name,txt_path):
url = \'https://www.jd.com/\' # 登录网址
self.url = url
self.item_name = item_name
self.txt_file = open(txt_path,encoding=\'utf-8\',mode=\'w+\')
options = webdriver.ChromeOptions() # 谷歌选项
# 设置为开发者模式,避免被识别
options.add_experimental_option(\'excludeSwitches\',
[\'enable-automation\'])
self.browser = webdriver.Chrome(executable_path= "C:/Program Files/Google/Chrome/Application/chromedriver.exe",
options = options)
self.wait = WebDriverWait(self.browser,2)
webdriver.Chrome()方法用于创建驱动浏览器Chrome,并将之前下载到本地的chromedriver.exe文件夹的路径赋值给executable_path参数。
浏览器打开网页时,可能会因为网速原因加载缓慢,所以这里我们使用WebDriverWait方法创建了一个wait方法,每次调用浏览器都需要等待2秒才能继续下一步;
初步操作后,接下来就是主程序,模拟访问、输入、点击等操作;我将所有这些操作封装在一个 run() 函数中,
def run(self):
"""登陆接口"""
self.browser.get(self.url)
input_edit = self.browser.find_element(By.CSS_SELECTOR,\'#key\')
input_edit.clear()
input_edit.send_keys(self.item_name)
search_button = self.browser.find_element(By.CSS_SELECTOR,\'#search > div > div.form > button\')
search_button.click()# 点击
time.sleep(2)
html = self.browser.page_source # 获取 html
self.parse_html(html)
current_url = self.browser.current_url # 获取当前页面 url
initial_url = str(current_url).split(\'&pvid\')[0]
for i in range(1,100):
try:
print(\'正在解析----------------{}图片\'.format(str(i)))
next_page_url = initial_url + \'&page={}&s={}&click=0\'.format(str(i*2+1),str(i*60+1))
print(next_page_url)
self.browser.get(next_page_url)
self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,\'#J_goodsList > ul > li\')))
html = self.browser.page_source
self.parse_html(html)# 对 html 网址进行解析
time.sleep(2) # 设置频率
except Exception as e:
print(\'Error Next page\',e)
self.txt_file.close()# 关闭 txt 文件
首先使用get()方法访问京东主页,然后定位到页面上的搜索栏和搜索按钮标签input_edit和search_button;完成输入并点击操作
关于网页元素标签的定位,如果不能,可以使用浏览器开发者模式,分为以下几个步骤(这里以CSS_Selector为例):
在翻页操作中,这里是按照京东url规则构造的,
第 5 页
https://search.jd.com/Search%3 ... k%3D0
第 6 页
https://search.jd.com/Search%3 ... k%3D0
如果仔细看,你会发现第5页和第6页的urls唯一的区别就是两个参数page和s;
按照这个规则,通过改变page和s参数来构造京东商品的前100页商品信息,完成数据抓取;
关于数据提取部分,我使用parse_html函数来完成
为了提高程序的友好性,我把所有的功能都封装在一个类中,用户只需要输入两个参数,一个是需要采集的产品名称,一个是存储的路径文件; 可以完成数据爬取;
最后将抓取到的数据保存成txt文件,结果如下
4. 总结
selenium虽然可以有效破解web端的一些反爬虫机制,但是对于一些网站,比如拉勾网,就没什么用了。在拉勾官网使用Selenium驱动浏览器模拟翻页操作时,网站可以识别非人类。操作,暂时禁止并警告您的IP;
本文涉及的完整源码,关注微信公众号:程序员大飞,回复后台关键词:京东货,即可获取!
c爬虫抓取网页数据( :网络数据是重要的资产形态之一荐5股)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-27 08:01
:网络数据是重要的资产形态之一荐5股)
[摘要] 网络数据是最重要的资产形式之一。改进数据提取和分析项目是目前该领域的关键研究问题之一。本文基于Scrapy开源技术,参考网络编程等其他相关知识,定制一个扩展能力强的网络爬虫原型程序。选择合适的数据库来捕获和保存数据,并支持多线程并发结构,最大限度地提高操作的有效性。
[关键词]Scrapy; 网络爬虫;框架建设;数据抓取
1990年代,网络爬虫逐渐发展起来,如今已经渗透到人们在互联网上日常生活的方方面面。一个高质量的爬虫应该有准确的爬行目标、高效的爬行过程、快速的运行和有效的后处理。为了让爬虫丰富上述特征,构建良好的结构是重要的基础,这将促进爬虫快速识别访问过的页面,更高效地提取主观需要的结构和内容。Scrapy框架的目的是爬取网站内容,准确提取结构化数据,然后编写一个开源的爬虫应用框架。本文主要探讨其在网络爬虫实现和数据抓取中的应用。
1. 设计整体架构
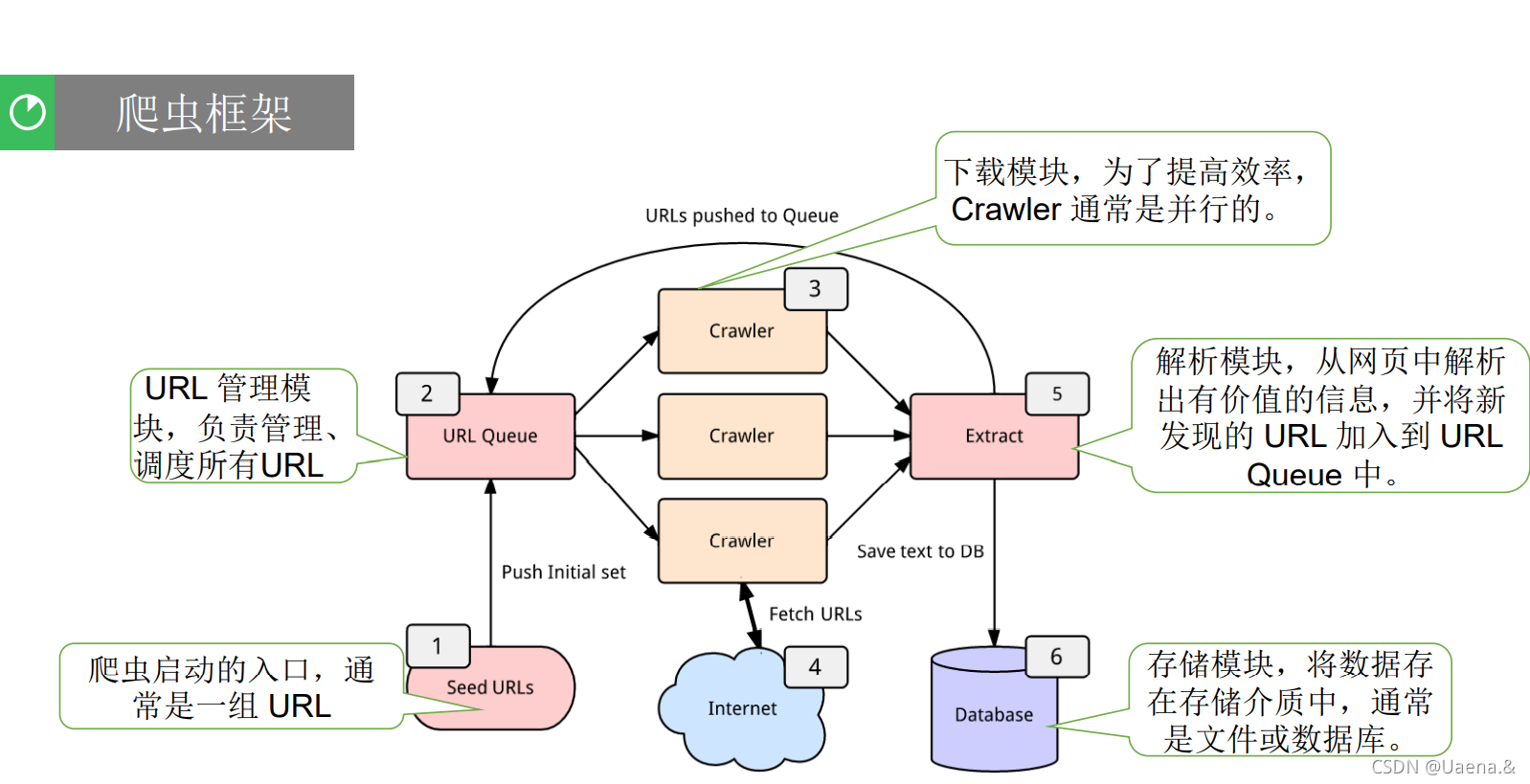
从宏观上看,爬虫可以细化为以下三个模块:(1)预置规则模块:其作用是预先规划要提取的数据格式,以便程序正常运行,以及有针对性地更改User-AgentCookies登录等监控账号;(2)网页抓取模块:该模块在定义原创
URL时开始抓取网页信息,初步提取并进行基础分析,结合反馈结果的类型,检索对应的回调函数;(3)后续数据处理模块:进一步解析网络爬取模块的结果,判断其合法性,存入数据库,或调整到调度器等待调整和爬行。
2.爬虫实现过程
本文选择“新浪微博”为爬虫目标,“新浪微博”为国内知名社交网站。选择它作为爬取目标,可以帮助我们接触到更多的新知识,感知大数据的发展趋势。
2.1 预设规则预设模块
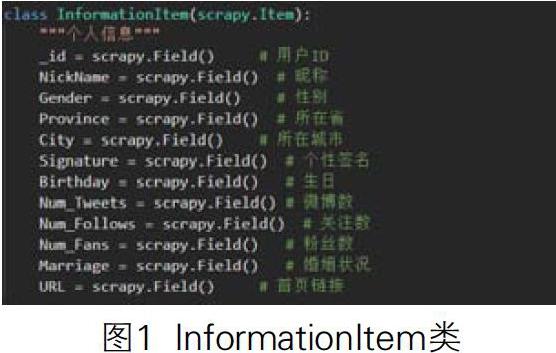
明确设置爬虫爬取数据格式。具体来说,在item.py文件中,根据需要提取的字段规划对应的类型。比如定义了InformationItem类来爬取用户信息,我们基于Field()方法来解释数据字段(图1)[1].
2.1个网页抓取模块
在Spiders.py中设置这个模块的代码是项目的核心部分。在 Spiders 中自定义 SinaSpider 类。这篇文章详细解释了Spiders类的作用如下:
(1)Name和host特性:定义类的名称,是爬虫的唯一标识。host设置爬虫的爬取区域。
(2)start.urls 特性:它是一个原创
URL 列表,它在初始运行时提供了爬虫的目标。爬虫会以这些页面为起点,有针对性地抓取数据。我们使用用户ID替换偏差和完整性更高的URL,然后使用start_requesets()方法推动用户ID和主机地址的有机融合过程,形成完整度更高的原创
URL。
(3)Scrawl_ID 和finish.ID 是Set 类的变量:Python 中的set 类与其他类型的语言有很高的相似度,属于无序和不重复元素的一类。基本功能是去掉出现过多次的元素,这里我们选择Set类变量来表示爬取的页面和被爬取的页面进行调整,效果非常好[2]。
(4)请求处理部分:SinaSpider自定义了start_requests()函数和四个回调函数,回调函数的作用是处理对用户信息、微博内容、粉丝、感兴趣目标对象的抓取. 当我们在回调函数中设置请求后,Scrapy 会自行调整,传输请求,并在请求完成时调用注册的回调函数。根据解析函数中定义的xpath路径或者获取到的字符,将它们存储在item字典中,最后发送到Pipelines进行后处理。
2.3Post数据处理模块
基于Spider类,我们可以平滑的抓取和抓取目标数据,然后需要分析数据存储问题。本文采用Mysq|database进行存储,有效处理爬取结果与数据库的相互传输问题,是本模块设计阶段需要分析的关键问题之一。在Pipelines.py中可以进行一系列的处理,我们可以把它看成一个数据管道。Pipelines.py 建立了 MysqlPipeline 类,共收录
两个方法。功能是初始化数据表,处理项目,并把它集成到库中。建立基于pymsql开源模块和mysql的交互关系。
打开数据库的本地连接,然后建立“新浪”数据库,然后将相关信息进行制表和存储。
如果 process_item() 函数确定字段数满足要求且不为空,则将其集成到数据库中。执行完上述步骤后,会提示后续数据处理结束。
3. 在分析数据捕获结果中呈现
程序运行后,得到“新浪”数据库。数据库中有四个表。本文主要分析Information表的设置(见表)[3]。
4.结论
本文由 Scrapy 技术支持,形成一个易于制作、易于扩展的聚焦爬虫。爬虫以“新浪微博”用户为目标,抓取用户群体的主要信息。实践表明,利用Scrapy技术开发爬虫具有高效、流程便捷等优点,成功达到了预期的标准要求。
参考:
[1]朱丽颖,吴锦靖.基于自动化测试的定向网络爬虫设计与实现[J]. 微机应用, 2019, 35 (10): 8-10.
[2] 刘辉, 石谦, 基于网络爬虫的新闻网站自动生成系统的设计与实现[J]. 电子技术与软件工程, 2019, 20 (13): 18-19.
[3] 邵晓文.多线程并发网络爬虫的设计与实现[J]. 现代计算机(专业版), 2019, 47 (01): 97-100.
关于作者:
谢建辉(1999-09-25) 性别:男 家乡:广东省梅州市 民族:汉族 学历:本科。 查看全部
c爬虫抓取网页数据(
:网络数据是重要的资产形态之一荐5股)

[摘要] 网络数据是最重要的资产形式之一。改进数据提取和分析项目是目前该领域的关键研究问题之一。本文基于Scrapy开源技术,参考网络编程等其他相关知识,定制一个扩展能力强的网络爬虫原型程序。选择合适的数据库来捕获和保存数据,并支持多线程并发结构,最大限度地提高操作的有效性。
[关键词]Scrapy; 网络爬虫;框架建设;数据抓取
1990年代,网络爬虫逐渐发展起来,如今已经渗透到人们在互联网上日常生活的方方面面。一个高质量的爬虫应该有准确的爬行目标、高效的爬行过程、快速的运行和有效的后处理。为了让爬虫丰富上述特征,构建良好的结构是重要的基础,这将促进爬虫快速识别访问过的页面,更高效地提取主观需要的结构和内容。Scrapy框架的目的是爬取网站内容,准确提取结构化数据,然后编写一个开源的爬虫应用框架。本文主要探讨其在网络爬虫实现和数据抓取中的应用。
1. 设计整体架构
从宏观上看,爬虫可以细化为以下三个模块:(1)预置规则模块:其作用是预先规划要提取的数据格式,以便程序正常运行,以及有针对性地更改User-AgentCookies登录等监控账号;(2)网页抓取模块:该模块在定义原创
URL时开始抓取网页信息,初步提取并进行基础分析,结合反馈结果的类型,检索对应的回调函数;(3)后续数据处理模块:进一步解析网络爬取模块的结果,判断其合法性,存入数据库,或调整到调度器等待调整和爬行。
2.爬虫实现过程
本文选择“新浪微博”为爬虫目标,“新浪微博”为国内知名社交网站。选择它作为爬取目标,可以帮助我们接触到更多的新知识,感知大数据的发展趋势。
2.1 预设规则预设模块
明确设置爬虫爬取数据格式。具体来说,在item.py文件中,根据需要提取的字段规划对应的类型。比如定义了InformationItem类来爬取用户信息,我们基于Field()方法来解释数据字段(图1)[1].
2.1个网页抓取模块
在Spiders.py中设置这个模块的代码是项目的核心部分。在 Spiders 中自定义 SinaSpider 类。这篇文章详细解释了Spiders类的作用如下:
(1)Name和host特性:定义类的名称,是爬虫的唯一标识。host设置爬虫的爬取区域。
(2)start.urls 特性:它是一个原创
URL 列表,它在初始运行时提供了爬虫的目标。爬虫会以这些页面为起点,有针对性地抓取数据。我们使用用户ID替换偏差和完整性更高的URL,然后使用start_requesets()方法推动用户ID和主机地址的有机融合过程,形成完整度更高的原创
URL。
(3)Scrawl_ID 和finish.ID 是Set 类的变量:Python 中的set 类与其他类型的语言有很高的相似度,属于无序和不重复元素的一类。基本功能是去掉出现过多次的元素,这里我们选择Set类变量来表示爬取的页面和被爬取的页面进行调整,效果非常好[2]。
(4)请求处理部分:SinaSpider自定义了start_requests()函数和四个回调函数,回调函数的作用是处理对用户信息、微博内容、粉丝、感兴趣目标对象的抓取. 当我们在回调函数中设置请求后,Scrapy 会自行调整,传输请求,并在请求完成时调用注册的回调函数。根据解析函数中定义的xpath路径或者获取到的字符,将它们存储在item字典中,最后发送到Pipelines进行后处理。
2.3Post数据处理模块
基于Spider类,我们可以平滑的抓取和抓取目标数据,然后需要分析数据存储问题。本文采用Mysq|database进行存储,有效处理爬取结果与数据库的相互传输问题,是本模块设计阶段需要分析的关键问题之一。在Pipelines.py中可以进行一系列的处理,我们可以把它看成一个数据管道。Pipelines.py 建立了 MysqlPipeline 类,共收录
两个方法。功能是初始化数据表,处理项目,并把它集成到库中。建立基于pymsql开源模块和mysql的交互关系。
打开数据库的本地连接,然后建立“新浪”数据库,然后将相关信息进行制表和存储。
如果 process_item() 函数确定字段数满足要求且不为空,则将其集成到数据库中。执行完上述步骤后,会提示后续数据处理结束。
3. 在分析数据捕获结果中呈现
程序运行后,得到“新浪”数据库。数据库中有四个表。本文主要分析Information表的设置(见表)[3]。
4.结论
本文由 Scrapy 技术支持,形成一个易于制作、易于扩展的聚焦爬虫。爬虫以“新浪微博”用户为目标,抓取用户群体的主要信息。实践表明,利用Scrapy技术开发爬虫具有高效、流程便捷等优点,成功达到了预期的标准要求。
参考:
[1]朱丽颖,吴锦靖.基于自动化测试的定向网络爬虫设计与实现[J]. 微机应用, 2019, 35 (10): 8-10.
[2] 刘辉, 石谦, 基于网络爬虫的新闻网站自动生成系统的设计与实现[J]. 电子技术与软件工程, 2019, 20 (13): 18-19.
[3] 邵晓文.多线程并发网络爬虫的设计与实现[J]. 现代计算机(专业版), 2019, 47 (01): 97-100.
关于作者:
谢建辉(1999-09-25) 性别:男 家乡:广东省梅州市 民族:汉族 学历:本科。
c爬虫抓取网页数据(第一点没什么捷径可走,或许可以给你省不少事)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-27 08:00
爬虫爬取数据有两个头疼的问题。写过爬虫的人一定深有体会:
网站的反爬虫机制。你要尽量伪装成“一个人”来欺骗对方的服务器进行反爬验证。
提取网站内容。每个网站都需要您做不同的处理,一旦网站被修改,您的代码必须相应更新。
第一点是没有捷径可走。如果你看到很多套路,你就会有经验。关于第二点,今天我们来介绍一个小工具。在一些需求场景下,它可能会为你节省很多事情。
鹅
Goose是一款文章内容提取器,可以从任意信息文章网页中提取文章主体,提取标题、标签、摘要、图片、视频等信息,支持中文网页。它最初是用 Java 编写的。python-goose 是一个用 Python 重写的版本。
有了这个库,你就可以直接从网上抓取下来的网页正文内容,无需使用bs4或正则表达式对文本进行一一处理。
项目地址:
(Py2)
(Py3)
安装
网上大部分教程中提到的python-goose项目目前只支持python2.7。它可以通过 pip 安装:
pip install goose-extractor
或者从官网源码安装方法:
mkvirtualenv --no-site-packages goose
git clone https://github.com/grangier/python-goose.git
cd python-goose
pip install -r requirements.txt
python setup.py install
我找到了一个python 3版本的goose3:
pip install goose3
经过一些简单的测试,我没有发现两个版本之间的结果有太大差异。
快速上手
这里用的是goose3,python-goose只需要把goose3改成goose就可以了,界面是一样的。以一篇文章为爬取目标进行演示。
from goose3 import Goose
from goose3.text import StopWordsChinese
# 初始化,设置中文分词
g = Goose({'stopwords_class': StopWordsChinese})
# 文章地址
url = 'https://mp.weixin.qq.com/s/zfl ... 39%3B
# 获取文章内容
article = g.extract(url=url)
# 标题
print('标题:', article.title)
# 显示正文
print(article.cleaned_text)
输出:
除了标题和正文cleaned_text,还可以获得一些额外的信息,比如:
如果某些网站限制了程序爬取,您还可以根据需要添加user-agent信息:
g = Goose({'browser_user_agent': 'Version/5.1.2 Safari/534.52.7'})
如果是goose3,因为使用requests库作为请求模块,headers、proxy等属性也可以类似的配置。
上面例子中使用的StopWordsChinese是中文分词器,可以在一定程度上提高中文文章的识别准确率,但是比较耗时。
其他说明
1.
Goose虽然方便,但不保证每个网站都能准确获取,所以适用于热点追踪、舆情分析等大规模文章采集,只能概率保证大部分网站可以爬行比较准确。经过一些尝试,我发现爬取英文网站优于中文网站,主流网站优于小众网站,文本提取优于图像提取。
2.
从项目中的requirements.txt文件可以看出goose中使用了Pillow、lxml、cssselect、jieba、beautifulsoup、nltk,goose3中也使用了requests。
3.
如果你使用的是基于python2的goose,你可能会遇到编码问题(尤其是在windows上)。
4.
除了goose,还有其他文本提取库可以尝试,比如python-boilerpipe、python-readability等。
实例
最后我们用goose3写一小段代码,自动抓取爱范儿、雷锋网、DoNews上的新闻文章:
from goose3 import Goose
from goose3.text import StopWordsChinese
from bs4 import BeautifulSoup
g = Goose({'stopwords_class': StopWordsChinese})
urls = [
'https://www.ifanr.com/',
'https://www.leiphone.com/',
'http://www.donews.com/'
]
url_articles = []
for url in urls:
page = g.extract(url=url)
soup = BeautifulSoup(page.raw_html, 'lxml')
links = soup.find_all('a')
for l in links:
link = l.get('href')
if link and link.startswith('http') and any(c.isdigit() for c in link if c) and link not in url_articles:
url_articles.append(link)
print(link)
for url in url_articles:
try:
article = g.extract(url=url)
content = article.cleaned_text
if len(content) > 200:
title = article.title
print(title)
with open('homework/goose/' + title + '.txt', 'w') as f:
f.write(content)
except:
pass
这个程序的作用是: 查看全部
c爬虫抓取网页数据(第一点没什么捷径可走,或许可以给你省不少事)
爬虫爬取数据有两个头疼的问题。写过爬虫的人一定深有体会:
网站的反爬虫机制。你要尽量伪装成“一个人”来欺骗对方的服务器进行反爬验证。
提取网站内容。每个网站都需要您做不同的处理,一旦网站被修改,您的代码必须相应更新。
第一点是没有捷径可走。如果你看到很多套路,你就会有经验。关于第二点,今天我们来介绍一个小工具。在一些需求场景下,它可能会为你节省很多事情。
鹅
Goose是一款文章内容提取器,可以从任意信息文章网页中提取文章主体,提取标题、标签、摘要、图片、视频等信息,支持中文网页。它最初是用 Java 编写的。python-goose 是一个用 Python 重写的版本。
有了这个库,你就可以直接从网上抓取下来的网页正文内容,无需使用bs4或正则表达式对文本进行一一处理。
项目地址:
(Py2)
(Py3)
安装
网上大部分教程中提到的python-goose项目目前只支持python2.7。它可以通过 pip 安装:
pip install goose-extractor
或者从官网源码安装方法:
mkvirtualenv --no-site-packages goose
git clone https://github.com/grangier/python-goose.git
cd python-goose
pip install -r requirements.txt
python setup.py install
我找到了一个python 3版本的goose3:
pip install goose3
经过一些简单的测试,我没有发现两个版本之间的结果有太大差异。
快速上手
这里用的是goose3,python-goose只需要把goose3改成goose就可以了,界面是一样的。以一篇文章为爬取目标进行演示。
from goose3 import Goose
from goose3.text import StopWordsChinese
# 初始化,设置中文分词
g = Goose({'stopwords_class': StopWordsChinese})
# 文章地址
url = 'https://mp.weixin.qq.com/s/zfl ... 39%3B
# 获取文章内容
article = g.extract(url=url)
# 标题
print('标题:', article.title)
# 显示正文
print(article.cleaned_text)
输出:

除了标题和正文cleaned_text,还可以获得一些额外的信息,比如:
如果某些网站限制了程序爬取,您还可以根据需要添加user-agent信息:
g = Goose({'browser_user_agent': 'Version/5.1.2 Safari/534.52.7'})
如果是goose3,因为使用requests库作为请求模块,headers、proxy等属性也可以类似的配置。
上面例子中使用的StopWordsChinese是中文分词器,可以在一定程度上提高中文文章的识别准确率,但是比较耗时。
其他说明
1.
Goose虽然方便,但不保证每个网站都能准确获取,所以适用于热点追踪、舆情分析等大规模文章采集,只能概率保证大部分网站可以爬行比较准确。经过一些尝试,我发现爬取英文网站优于中文网站,主流网站优于小众网站,文本提取优于图像提取。
2.
从项目中的requirements.txt文件可以看出goose中使用了Pillow、lxml、cssselect、jieba、beautifulsoup、nltk,goose3中也使用了requests。
3.
如果你使用的是基于python2的goose,你可能会遇到编码问题(尤其是在windows上)。
4.
除了goose,还有其他文本提取库可以尝试,比如python-boilerpipe、python-readability等。
实例
最后我们用goose3写一小段代码,自动抓取爱范儿、雷锋网、DoNews上的新闻文章:
from goose3 import Goose
from goose3.text import StopWordsChinese
from bs4 import BeautifulSoup
g = Goose({'stopwords_class': StopWordsChinese})
urls = [
'https://www.ifanr.com/',
'https://www.leiphone.com/',
'http://www.donews.com/'
]
url_articles = []
for url in urls:
page = g.extract(url=url)
soup = BeautifulSoup(page.raw_html, 'lxml')
links = soup.find_all('a')
for l in links:
link = l.get('href')
if link and link.startswith('http') and any(c.isdigit() for c in link if c) and link not in url_articles:
url_articles.append(link)
print(link)
for url in url_articles:
try:
article = g.extract(url=url)
content = article.cleaned_text
if len(content) > 200:
title = article.title
print(title)
with open('homework/goose/' + title + '.txt', 'w') as f:
f.write(content)
except:
pass
这个程序的作用是:
c爬虫抓取网页数据(Web前端基础Python与Web框架的开发者框架使用的基本流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-26 17:12
Django 是一个用 Python 编写的开源 Web 应用程序框架。它的主要目标是使开发复杂的、数据库驱动的网站变得容易。本课程首先介绍一些Web前端相关知识,包括用于定义Web内容的HTML语言、用于定义样式的CSS语言、用于向网页添加交互的JavaScript语言以及用于交换网络数据的JSON语言。; 然后详细讲解Django框架的使用方法,包括:Django框架安装、视图和url、模型类、后台管理、模板等知识点;最后,以“列表详情页”的实现为例,对之前学到的知识点进行综合应用和巩固。【课程目标】了解HTML等Web开发相关知识, 查看全部
c爬虫抓取网页数据(Web前端基础Python与Web框架的开发者框架使用的基本流程)
Django 是一个用 Python 编写的开源 Web 应用程序框架。它的主要目标是使开发复杂的、数据库驱动的网站变得容易。本课程首先介绍一些Web前端相关知识,包括用于定义Web内容的HTML语言、用于定义样式的CSS语言、用于向网页添加交互的JavaScript语言以及用于交换网络数据的JSON语言。; 然后详细讲解Django框架的使用方法,包括:Django框架安装、视图和url、模型类、后台管理、模板等知识点;最后,以“列表详情页”的实现为例,对之前学到的知识点进行综合应用和巩固。【课程目标】了解HTML等Web开发相关知识,
c爬虫抓取网页数据(爬虫搜索引擎如何获取一个新网站的数据?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2021-12-26 05:08
爬虫基本概念数据从何而来?
部分数据来源如下:
爬虫是一种获取数据的方式。
什么是爬虫?
爬虫是抓取网络数据的自动化程序。
爬虫是如何抓取网页数据的
网页的三个特点:
每个网页都有自己唯一的URL(Uniform Resource Locator)用于定位;网页使用 HTML(超文本标记语言)来描述页面信息;网页使用 HTTP/HTTPS(超文本传输协议)来传输 HTML 数据。
根据网页的特点,我们提出了爬虫的设计思路:
1. 获取网页
向服务器发送Request请求,得到Response后解析Body部分,即网页的源代码。
Python 库:Urllib、Requests 等。
2. 提取信息
分析网页源代码,提取我们想要的数据。
提取方法
3.保存数据通用爬虫和焦点爬虫通用爬虫
搜索引擎的爬虫系统。
1.目标
尽量将互联网内容下载到本地服务器形成备份,然后对这些网页进行相关处理(提取关键词、去除广告),最终形成用户搜索界面。
2. 获取过程
通用网络爬虫工作流程图
最好选择一部分已有的URL,将这些URL放入待抓取的队列中。从队列中取出这些URL,然后通过DNS解析得到主机IP,然后到这个IP对应的服务器去下载HTML页面并保存到搜索引擎的本地服务器。然后将抓取到的网址放入抓取队列中。分析这些网页的内容,找出网页中其他的URL链接,继续执行第二步,直到爬取条件结束。3.搜索引擎如何获取新网站的网址?主动向搜索引擎提交网址:建立到其他网站的外部链接。搜索引擎将与 DNS 服务提供商合作以快速收录新网站。
DNS:是一种将域名解析为IP的技术。域名必须对应一个IP,但IP可以没有域名。
4.万能爬虫不是所有东西都能爬,也需要遵守规则
Robots协议:该协议会规定一般爬虫爬取网页的权限。
Robots.txt 只是一个建议,并非所有爬虫都遵守。一般来说,只有大型搜索引擎爬虫会遵守它。我们个人编写的爬虫被忽略了。
5.一般爬虫工作流程
抓取网页-存储数据-内容处理-提供检索/排名服务
6.搜索引擎排名PageRank值:根据网站流量(点击量/浏览量/流行度)统计,流量越高,网站价值越高,排名越高。竞价排名:谁出价越多,谁的排名就越高。7.一般爬虫的缺点只能提供与文本相关的内容(HTML、Word、PDF)等,不能提供多媒体文件(音乐、图片、视频)和二进制文件(程序、脚本)等. 提供的结果是一样的,不能为不同背景的人提供不同的搜索结果。无法理解人类语义检索。
为了解决上述问题,出现了聚焦爬虫。
焦点履带
抓取特定内容并尝试抓取与主题相关的信息。 查看全部
c爬虫抓取网页数据(爬虫搜索引擎如何获取一个新网站的数据?(组图))
爬虫基本概念数据从何而来?
部分数据来源如下:
爬虫是一种获取数据的方式。
什么是爬虫?
爬虫是抓取网络数据的自动化程序。
爬虫是如何抓取网页数据的
网页的三个特点:
每个网页都有自己唯一的URL(Uniform Resource Locator)用于定位;网页使用 HTML(超文本标记语言)来描述页面信息;网页使用 HTTP/HTTPS(超文本传输协议)来传输 HTML 数据。
根据网页的特点,我们提出了爬虫的设计思路:

1. 获取网页
向服务器发送Request请求,得到Response后解析Body部分,即网页的源代码。
Python 库:Urllib、Requests 等。
2. 提取信息
分析网页源代码,提取我们想要的数据。
提取方法
3.保存数据通用爬虫和焦点爬虫通用爬虫
搜索引擎的爬虫系统。
1.目标
尽量将互联网内容下载到本地服务器形成备份,然后对这些网页进行相关处理(提取关键词、去除广告),最终形成用户搜索界面。
2. 获取过程
通用网络爬虫工作流程图

最好选择一部分已有的URL,将这些URL放入待抓取的队列中。从队列中取出这些URL,然后通过DNS解析得到主机IP,然后到这个IP对应的服务器去下载HTML页面并保存到搜索引擎的本地服务器。然后将抓取到的网址放入抓取队列中。分析这些网页的内容,找出网页中其他的URL链接,继续执行第二步,直到爬取条件结束。3.搜索引擎如何获取新网站的网址?主动向搜索引擎提交网址:建立到其他网站的外部链接。搜索引擎将与 DNS 服务提供商合作以快速收录新网站。
DNS:是一种将域名解析为IP的技术。域名必须对应一个IP,但IP可以没有域名。
4.万能爬虫不是所有东西都能爬,也需要遵守规则
Robots协议:该协议会规定一般爬虫爬取网页的权限。
Robots.txt 只是一个建议,并非所有爬虫都遵守。一般来说,只有大型搜索引擎爬虫会遵守它。我们个人编写的爬虫被忽略了。
5.一般爬虫工作流程
抓取网页-存储数据-内容处理-提供检索/排名服务
6.搜索引擎排名PageRank值:根据网站流量(点击量/浏览量/流行度)统计,流量越高,网站价值越高,排名越高。竞价排名:谁出价越多,谁的排名就越高。7.一般爬虫的缺点只能提供与文本相关的内容(HTML、Word、PDF)等,不能提供多媒体文件(音乐、图片、视频)和二进制文件(程序、脚本)等. 提供的结果是一样的,不能为不同背景的人提供不同的搜索结果。无法理解人类语义检索。
为了解决上述问题,出现了聚焦爬虫。
焦点履带
抓取特定内容并尝试抓取与主题相关的信息。
c爬虫抓取网页数据(4.网络爬虫的合法性Robots协议:又称机器人协议或爬虫协议)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-12-26 05:07
内容
一、爬虫简介
1.什么是网络爬虫?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者)是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。
2.爬虫类型
根据系统结构和实现技术,网络爬虫大致可以分为以下几类:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深网爬虫(Deep Web Crawler)。实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。
3.网络爬虫的使用范围
① 作为搜索引擎的网页采集器,抓取整个互联网,如谷歌、百度等。
②作为垂直搜索引擎,抓取特定主题信息,如视频网站、招聘网站等。
③作为测试网站前端的检测工具,用于评估网站前端代码的健壮性。
4.网络爬虫的合法性
机器人协议:又称机器人协议或爬虫协议,该协议规定了搜索引擎抓取网站内容的范围,包括网站是否希望被搜索引擎抓取,哪些内容不允许被抓取。网络爬虫“有意识地”在本地抓取或不抓取网页内容。自推出以来,机器人协议已成为网站保护自身敏感数据和网民隐私的国际惯例。
5.网络搜索策略
网络爬取策略可分为深度优先、广度优先和最佳优先。在很多情况下,深度优先会导致爬虫被困。目前,广度优先和最佳优先的方法很常见。
6.爬虫的基本结构
一个网络爬虫通常收录
四个模块:
• URL 管理模块
• 下载模块
• 分析模块
• 存储模块
二、环境准备(一)创建python虚拟环境
使用 conda 创建一个名为 crawler 的 python 虚拟环境。在这个虚拟环境下,使用pip或者conda安装requests、beautifulsoup4等必要的包(如果网络问题请切换国内镜像网站或国外网站仓库,注意使用这两个安装工具不同的仓库)。使用jupyter、pycharm、spyder、vscoder等IDE编程环境时,需要选择设置IDE后端使用的python版本或虚拟环境。比如使用jupyter notebook时,参考(),在jupyter运行的web界面选择对应的python kernel Kernel(带虚拟环境列表);如果使用pycharm,参考()选择对应的现有虚拟环境。
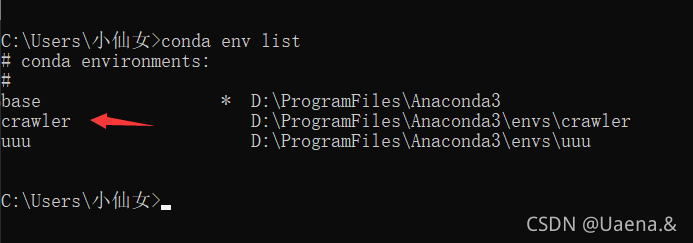
使用 conda create -n crawler python=3.8 命令新建一个名为 crawlerpython version 3.8 的虚拟环境
你开始创造
已创建
使用命令conda env list查看已经存在的虚拟环境,爬虫已经存在,base是conda自带的环境,uuu是我之前创建的
Activate crawler 进入爬虫环境,conda activate 退出当前环境,activate 是进入基础环境
conda remove --name 环境名称 --all 卸载环境
Jupyter notebook 本身不支持选择虚拟环境,每次有新项目时都需要重新配置所有插件。使用nb_conda插件将jupyter notebook变成pycharm一样可选择的运行环境。
在基础环境中使用conda install nb_conda命令安装nb_conda
在conda虚拟环境中使用conda install -n environment name ipykernel命令安装ipykernel
可以在jupyter notebook中显示
(二)安装库
环境准备
Python安装,这部分可以参考我之前的文章Python环境配置&Pycharm安装,到官网下载对应的安装包,安装一路Next;
pip安装,pip是Python的包管理器,目前的Python安装包一般都自带pip,不需要自己安装;
安装requests,beautifulsoup库,通过如下语句完成安装:
pip 安装请求
pip 安装 beautifulsoup4
谷歌浏览器(铬);
pip 安装请求
pip 安装 beautifulsoup4
pip 安装 html5lib
三、 爬取南洋理工ACM主题网站
学习样例代码,对关键代码句写详细注释,编写程序完成南洋理工ACM题库练习题数据的采集和存储;
(一)查看页面源码
点击进入南洋理工ACM专题网站,
右键->查看页面源代码
(二)代码运行
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
# tqdm作业:以进度条方式显示爬取进度
# 爬取11页所有题目信息
for pages in tqdm(range(1, 11 + 1)):
# get请求第pages页
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
# 判断异常
r.raise_for_status()
# 设置编码
r.encoding = 'utf-8'
# 创建BeautifulSoup对象,用于解析该html页面数据
soup = BeautifulSoup(r.text, 'html.parser')
# 获取所有td标签
td = soup.find_all('td')
# 存放某一个题目的所有信息
subject = []
# 遍历所有td
for t in td:
if t.string is not None:
subject.append(t.string) # 获取td中的字符串
if len(subject) == 5: # 每5个为一个题目的信息
subjects.append(subject)
subject = []
# 存放题目
with open('D:/jupyter/package/1.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders) # 写入表头
fileWriter.writerows(subjects) # 写入数据
print('\n题目信息爬取完成!!!')
运行,报错ModuleNotFoundError: No module named'tqdm',tqdm文件丢失,使用命令pip install tqdm安装
错误 FeatureNotFound:找不到具有您请求的功能的树生成器:lxml。需要安装解析器库吗,用pip install lxml安装,然后还是不行,自动安装最新版本,更换刚刚下载的版本删除:pip卸载lxml,下载指定版本试试: pip install lxml==3.7.0. 或不!!
然后第二种方法,把参数lxml改成html.parser
soup = BeautifulSoup(r.text, 'html.parser')
没关系!激动的心和握手~
(三)结果
四、 爬上重庆交通大学新闻网站
重写爬虫示例代码,爬取重庆交通大学新闻网站近年所有信息公告()的发布日期和标题,写入CSV电子表格。
(一)查看网页源码
重庆交通大学新闻网
右键->查看网页源代码
(二)代码运行
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
cqjtu_Headers ={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44'
}
#csv的表头
cqjtu_head=["日期","标题"]
#存放内容
cqjtu_infomation=[]
def get_page_number():
r=requests.get(f"http://news.cqjtu.edu.cn/xxtz.htm",headers=cqjtu_Headers)
r.raise_for_status()
r.encoding="utf-8"
page_array={
'type':'text/javascript'
}
soup = BeautifulSoup(r.text, 'html5lib')
page_num=soup.find_all('script',page_array)
page_number=page_num[4].string#只靠标签这些定位好像不是唯一,只能手动定位了
page_number=page_number.strip('function a204111_gopage_fun(){_simple_list_gotopage_fun(')#删掉除页数以外的其他内容
page_number=page_number.strip(',\'a204111GOPAGE\',2)}')
page_number=int(page_number)#转为数字
return page_number
def get_time_and_title(page_num,cqjtu_Headers):#页数,请求头
if page_num==66 :
url='http://news.cqjtu.edu.cn/xxtz.htm'
else :
url=f'http://news.cqjtu.edu.cn/xxtz/{page_num}.htm'
r=requests.get(url,headers=cqjtu_Headers)
r.raise_for_status()
r.encoding="utf-8"
array={#根据class来选择
'class':'time',
}
title_array={
'target':'_blank'
}
page_array={
'type':'text/javascript'
}
soup = BeautifulSoup(r.text, 'html.parser')
time=soup.find_all('div',array)
title=soup.find_all('a',title_array)
temp=[]
for i in range(0,len(time)):
time_s=time[i].string
time_s=time_s.strip('\n ')
time_s=time_s.strip('\n ')
#清除空格
temp.append(time_s)
temp.append(title[i+1].string)
cqjtu_infomation.append(temp)
temp=[]
def write_csv(cqjtu_info):
with open('D:/jupyter/package/2.csv', 'w', newline='',encoding='utf-8') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(cqjtu_head)
fileWriter.writerows(cqjtu_info)
print('爬取信息成功')
page_num=get_page_number()#获得页数
for i in tqdm(range(page_num,0,-1)):
get_time_and_title(i,cqjtu_Headers)
write_csv(cqjtu_infomation)
跑
(三)结果
像这样打开
记事本打开
参考
Jupyter notebook 选择虚拟环境运行代码
Anaconda安装教程,管理虚拟环境
Python爬虫练习(爬取OJ题和学校信息通知) 查看全部
c爬虫抓取网页数据(4.网络爬虫的合法性Robots协议:又称机器人协议或爬虫协议)
内容
一、爬虫简介
1.什么是网络爬虫?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者)是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。
2.爬虫类型
根据系统结构和实现技术,网络爬虫大致可以分为以下几类:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深网爬虫(Deep Web Crawler)。实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。
3.网络爬虫的使用范围
① 作为搜索引擎的网页采集器,抓取整个互联网,如谷歌、百度等。
②作为垂直搜索引擎,抓取特定主题信息,如视频网站、招聘网站等。
③作为测试网站前端的检测工具,用于评估网站前端代码的健壮性。
4.网络爬虫的合法性
机器人协议:又称机器人协议或爬虫协议,该协议规定了搜索引擎抓取网站内容的范围,包括网站是否希望被搜索引擎抓取,哪些内容不允许被抓取。网络爬虫“有意识地”在本地抓取或不抓取网页内容。自推出以来,机器人协议已成为网站保护自身敏感数据和网民隐私的国际惯例。
5.网络搜索策略
网络爬取策略可分为深度优先、广度优先和最佳优先。在很多情况下,深度优先会导致爬虫被困。目前,广度优先和最佳优先的方法很常见。
6.爬虫的基本结构
一个网络爬虫通常收录
四个模块:
• URL 管理模块
• 下载模块
• 分析模块
• 存储模块
二、环境准备(一)创建python虚拟环境
使用 conda 创建一个名为 crawler 的 python 虚拟环境。在这个虚拟环境下,使用pip或者conda安装requests、beautifulsoup4等必要的包(如果网络问题请切换国内镜像网站或国外网站仓库,注意使用这两个安装工具不同的仓库)。使用jupyter、pycharm、spyder、vscoder等IDE编程环境时,需要选择设置IDE后端使用的python版本或虚拟环境。比如使用jupyter notebook时,参考(),在jupyter运行的web界面选择对应的python kernel Kernel(带虚拟环境列表);如果使用pycharm,参考()选择对应的现有虚拟环境。
使用 conda create -n crawler python=3.8 命令新建一个名为 crawlerpython version 3.8 的虚拟环境
你开始创造
已创建
使用命令conda env list查看已经存在的虚拟环境,爬虫已经存在,base是conda自带的环境,uuu是我之前创建的
Activate crawler 进入爬虫环境,conda activate 退出当前环境,activate 是进入基础环境

conda remove --name 环境名称 --all 卸载环境
Jupyter notebook 本身不支持选择虚拟环境,每次有新项目时都需要重新配置所有插件。使用nb_conda插件将jupyter notebook变成pycharm一样可选择的运行环境。
在基础环境中使用conda install nb_conda命令安装nb_conda
在conda虚拟环境中使用conda install -n environment name ipykernel命令安装ipykernel
可以在jupyter notebook中显示
(二)安装库
环境准备
Python安装,这部分可以参考我之前的文章Python环境配置&Pycharm安装,到官网下载对应的安装包,安装一路Next;
pip安装,pip是Python的包管理器,目前的Python安装包一般都自带pip,不需要自己安装;
安装requests,beautifulsoup库,通过如下语句完成安装:
pip 安装请求
pip 安装 beautifulsoup4
谷歌浏览器(铬);
pip 安装请求
pip 安装 beautifulsoup4
pip 安装 html5lib
三、 爬取南洋理工ACM主题网站
学习样例代码,对关键代码句写详细注释,编写程序完成南洋理工ACM题库练习题数据的采集和存储;
(一)查看页面源码
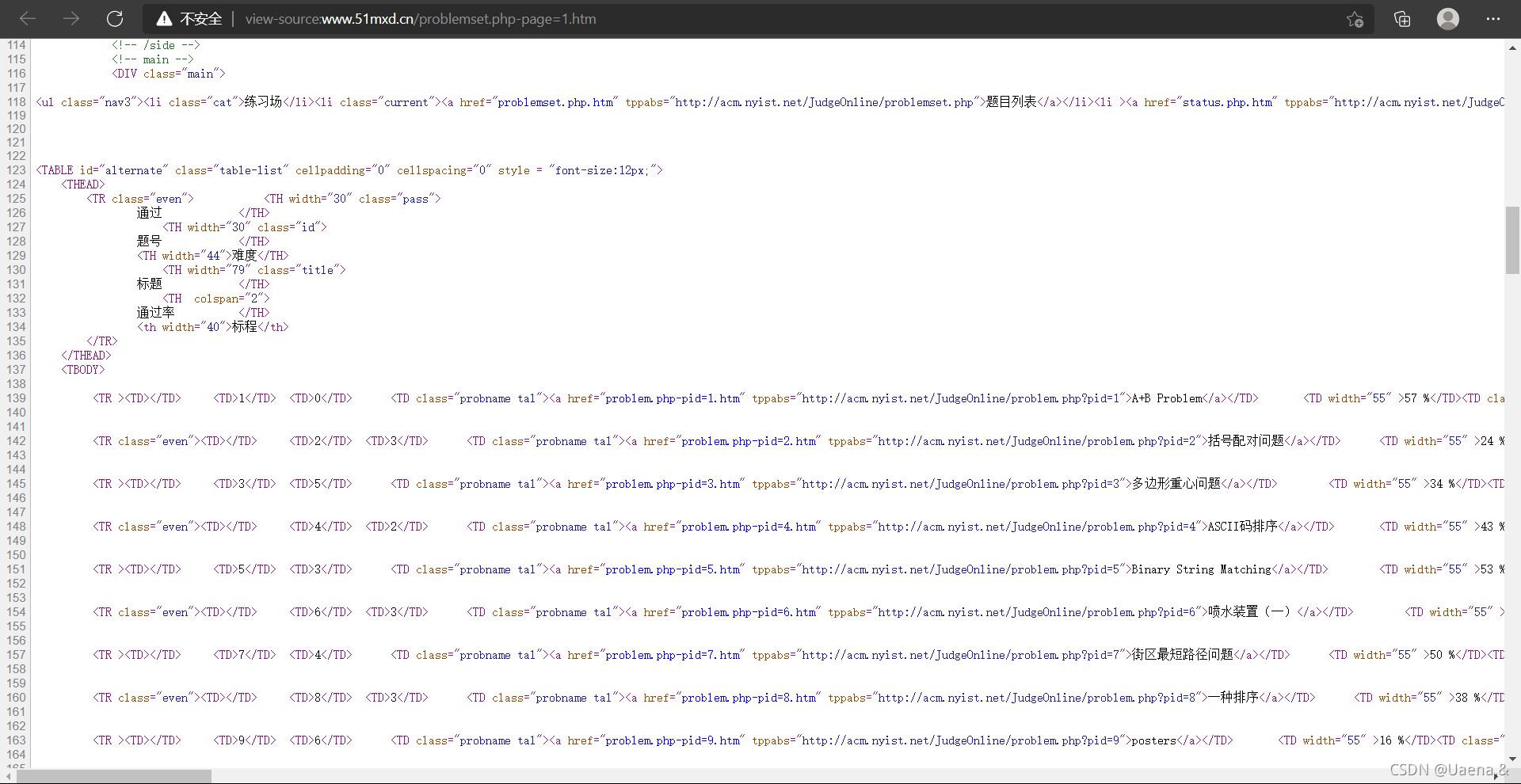
点击进入南洋理工ACM专题网站,
右键->查看页面源代码
(二)代码运行
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
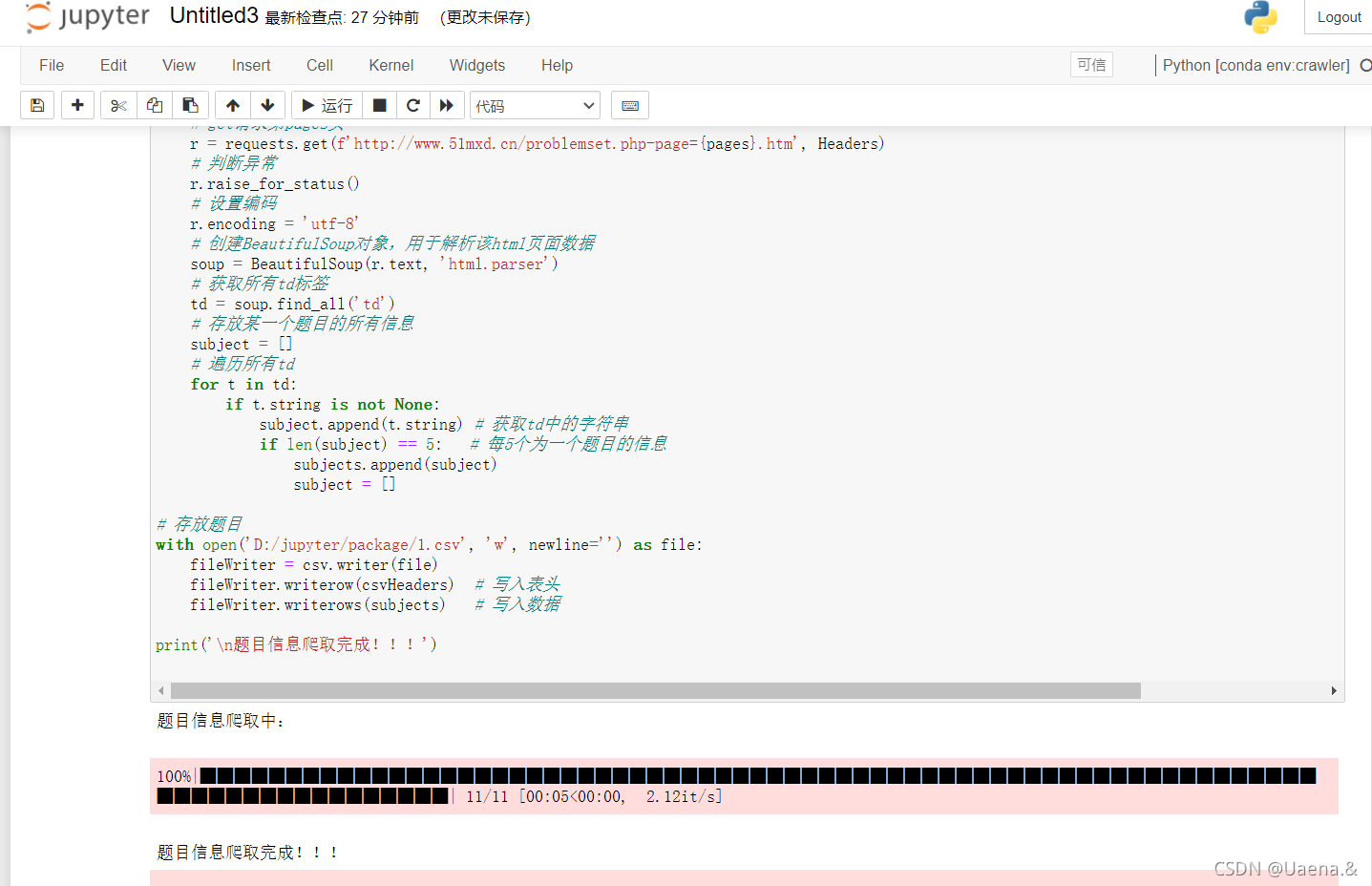
# 爬取题目
print('题目信息爬取中:\n')
# tqdm作业:以进度条方式显示爬取进度
# 爬取11页所有题目信息
for pages in tqdm(range(1, 11 + 1)):
# get请求第pages页
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
# 判断异常
r.raise_for_status()
# 设置编码
r.encoding = 'utf-8'
# 创建BeautifulSoup对象,用于解析该html页面数据
soup = BeautifulSoup(r.text, 'html.parser')
# 获取所有td标签
td = soup.find_all('td')
# 存放某一个题目的所有信息
subject = []
# 遍历所有td
for t in td:
if t.string is not None:
subject.append(t.string) # 获取td中的字符串
if len(subject) == 5: # 每5个为一个题目的信息
subjects.append(subject)
subject = []
# 存放题目
with open('D:/jupyter/package/1.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders) # 写入表头
fileWriter.writerows(subjects) # 写入数据
print('\n题目信息爬取完成!!!')
运行,报错ModuleNotFoundError: No module named'tqdm',tqdm文件丢失,使用命令pip install tqdm安装
错误 FeatureNotFound:找不到具有您请求的功能的树生成器:lxml。需要安装解析器库吗,用pip install lxml安装,然后还是不行,自动安装最新版本,更换刚刚下载的版本删除:pip卸载lxml,下载指定版本试试: pip install lxml==3.7.0. 或不!!
然后第二种方法,把参数lxml改成html.parser
soup = BeautifulSoup(r.text, 'html.parser')
没关系!激动的心和握手~
(三)结果
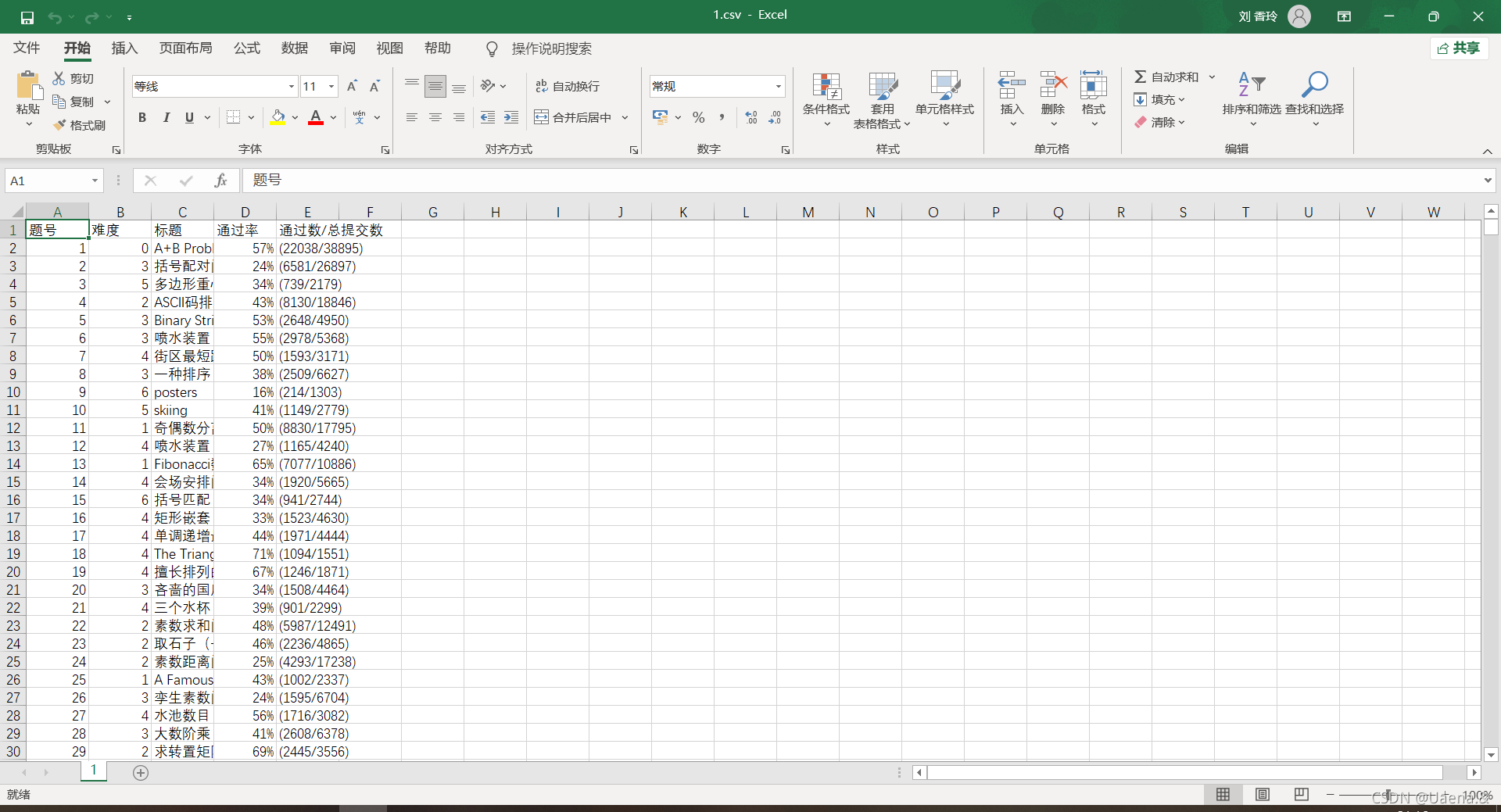
四、 爬上重庆交通大学新闻网站
重写爬虫示例代码,爬取重庆交通大学新闻网站近年所有信息公告()的发布日期和标题,写入CSV电子表格。
(一)查看网页源码
重庆交通大学新闻网
右键->查看网页源代码
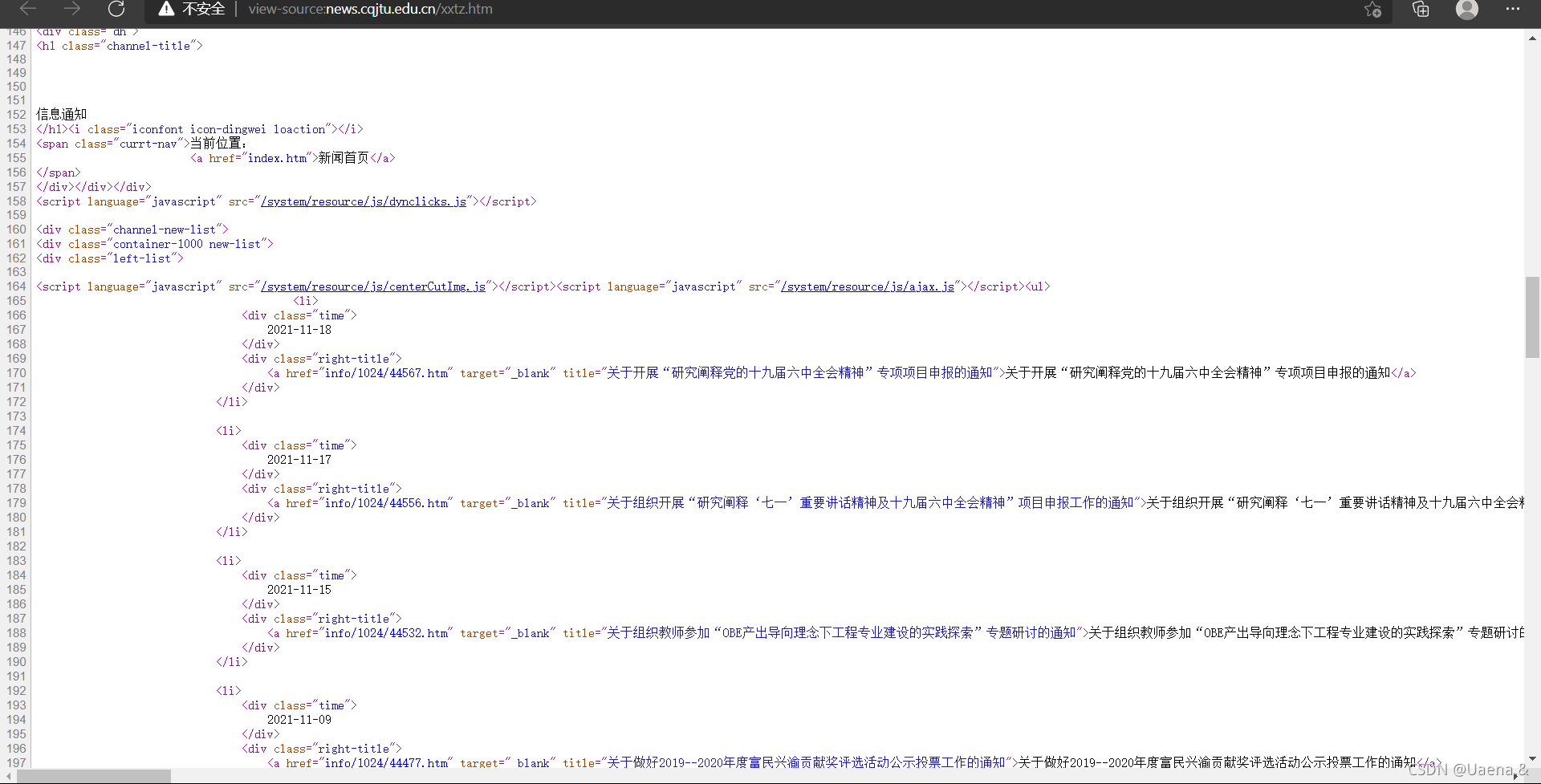
(二)代码运行
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
cqjtu_Headers ={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44'
}
#csv的表头
cqjtu_head=["日期","标题"]
#存放内容
cqjtu_infomation=[]
def get_page_number():
r=requests.get(f"http://news.cqjtu.edu.cn/xxtz.htm",headers=cqjtu_Headers)
r.raise_for_status()
r.encoding="utf-8"
page_array={
'type':'text/javascript'
}
soup = BeautifulSoup(r.text, 'html5lib')
page_num=soup.find_all('script',page_array)
page_number=page_num[4].string#只靠标签这些定位好像不是唯一,只能手动定位了
page_number=page_number.strip('function a204111_gopage_fun(){_simple_list_gotopage_fun(')#删掉除页数以外的其他内容
page_number=page_number.strip(',\'a204111GOPAGE\',2)}')
page_number=int(page_number)#转为数字
return page_number
def get_time_and_title(page_num,cqjtu_Headers):#页数,请求头
if page_num==66 :
url='http://news.cqjtu.edu.cn/xxtz.htm'
else :
url=f'http://news.cqjtu.edu.cn/xxtz/{page_num}.htm'
r=requests.get(url,headers=cqjtu_Headers)
r.raise_for_status()
r.encoding="utf-8"
array={#根据class来选择
'class':'time',
}
title_array={
'target':'_blank'
}
page_array={
'type':'text/javascript'
}
soup = BeautifulSoup(r.text, 'html.parser')
time=soup.find_all('div',array)
title=soup.find_all('a',title_array)
temp=[]
for i in range(0,len(time)):
time_s=time[i].string
time_s=time_s.strip('\n ')
time_s=time_s.strip('\n ')
#清除空格
temp.append(time_s)
temp.append(title[i+1].string)
cqjtu_infomation.append(temp)
temp=[]
def write_csv(cqjtu_info):
with open('D:/jupyter/package/2.csv', 'w', newline='',encoding='utf-8') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(cqjtu_head)
fileWriter.writerows(cqjtu_info)
print('爬取信息成功')
page_num=get_page_number()#获得页数
for i in tqdm(range(page_num,0,-1)):
get_time_and_title(i,cqjtu_Headers)
write_csv(cqjtu_infomation)
跑
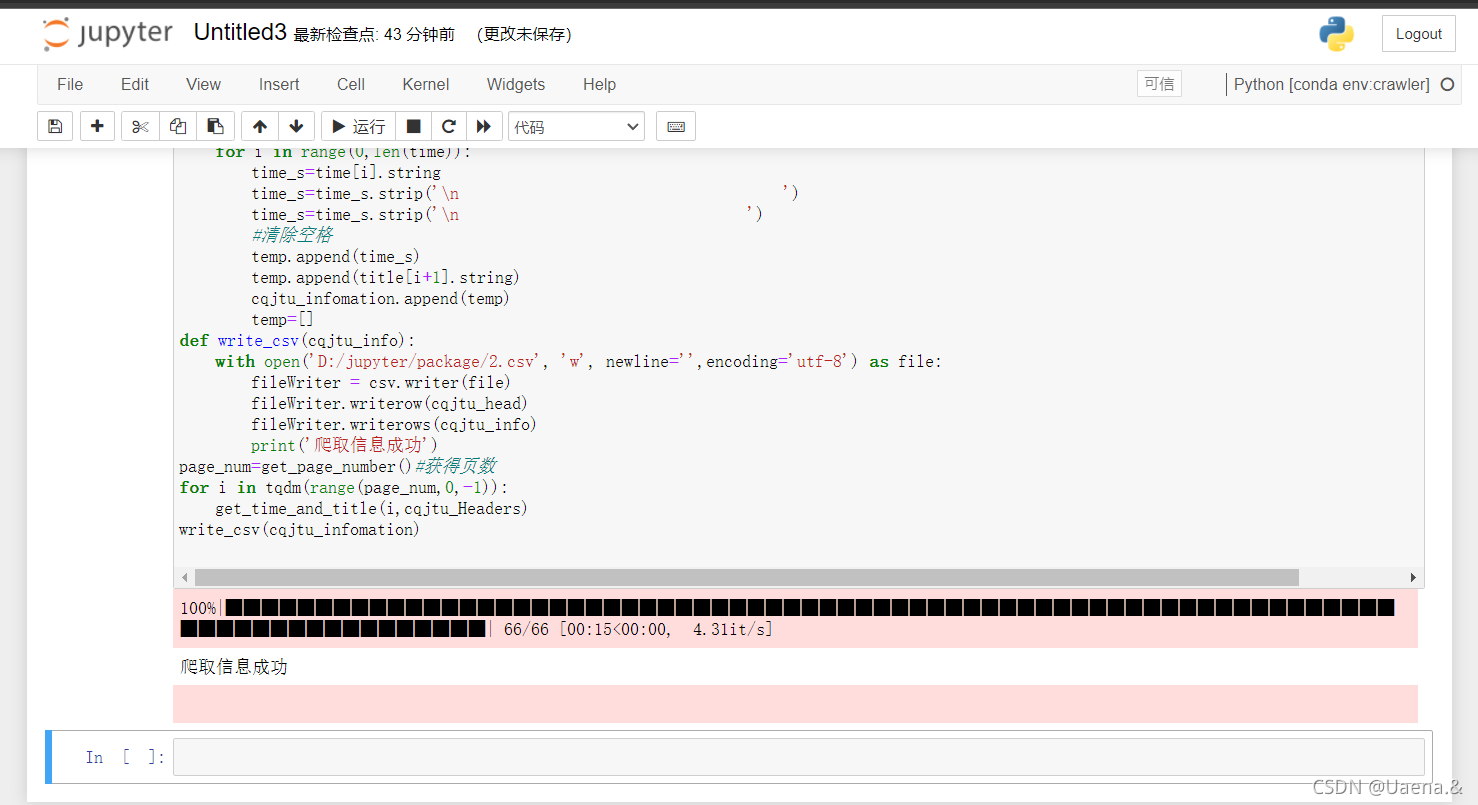
(三)结果
像这样打开
记事本打开
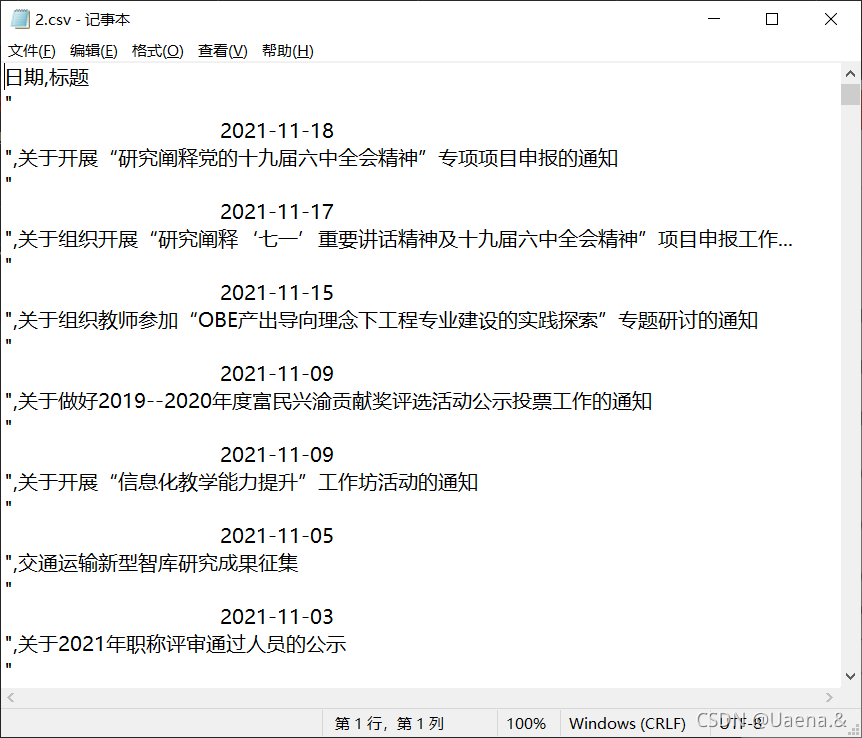
参考
Jupyter notebook 选择虚拟环境运行代码
Anaconda安装教程,管理虚拟环境
Python爬虫练习(爬取OJ题和学校信息通知)
c爬虫抓取网页数据(和StudyTitile的元素包含title元素的titletitle网页爬取实验数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-25 21:03
现在我们要从这个页面抓取实验数据
url = 'https://clinicaltrials.gov/ct2 ... 39%3B
首先打开浏览器加载网址
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get(url) #浏览器加载网页url
sleep(3)
2. 获取网页中的网址
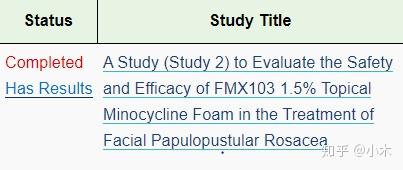
观察到只有 Status 和 Study Titile 列中的元素收录
title,因此我们尝试通过 title 元素从许多元素中过滤出这两列中的元素。 “有结果”中点击的内容就是我们想要的,所以我们要区分“状态”和“研究标题”下的内容,观察这两个元素的区别,发现“状态”下的URL收录
'/结果/',所以我们用这个来区分。
scr1 = driver.find_elements_by_xpath('//td/a[@title]') #找出表格中含有属性title的元素
scr2= [x.get_attribute('href') for x in scr1] #获取元素中的网址
n01 = []
for i01 in scr2:
if i01.find('/results/') != -1: 若网址中不包含'/results/',返回-1
n01.append(i01)
所以n01的列表就是第一页所有实验的实验结果网址。
3.向实验结果网站发起请求,获取http状态码
import requests
def qingqiu(url):
r = requests.get(url)
r.encoding = 'utf-8'
return r.text
4.获取所有实验的实验结果
import re
from bs4 import BeautifulSoup
nl = []
for i01 in n01:
a = qingqiu(i01)
bs01 =BeautifulSoup(a,'lxml')#使用BeautifulSoup解析代码
da = bs01.find_all('script')
for i in range(len(da)):
a.replace(str(da[i]),'')
bs01 =BeautifulSoup(a,'lxml')
n001=bs01.find_all('tr') #搜索当前tag的所有tag子节点,此处tag为tr
nr_list=[]
for i001 in range(len(n001)):
n02 = n001[i001].find_all(re.compile('th|td'))
n002=[x.text.replace('\n',' ').strip() for x in n02]
if len(n002)>1 and n002[0].strip():
# print('存入。。。。')
nr_list=nr_list+n002 #列表拼接
nl = nl+nr_list
这里的 nl 是 10 个实验的实验结果。
以后会详细介绍,请指正~ 查看全部
c爬虫抓取网页数据(和StudyTitile的元素包含title元素的titletitle网页爬取实验数据)
现在我们要从这个页面抓取实验数据
url = 'https://clinicaltrials.gov/ct2 ... 39%3B
首先打开浏览器加载网址
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get(url) #浏览器加载网页url
sleep(3)
2. 获取网页中的网址
观察到只有 Status 和 Study Titile 列中的元素收录
title,因此我们尝试通过 title 元素从许多元素中过滤出这两列中的元素。 “有结果”中点击的内容就是我们想要的,所以我们要区分“状态”和“研究标题”下的内容,观察这两个元素的区别,发现“状态”下的URL收录
'/结果/',所以我们用这个来区分。

scr1 = driver.find_elements_by_xpath('//td/a[@title]') #找出表格中含有属性title的元素
scr2= [x.get_attribute('href') for x in scr1] #获取元素中的网址
n01 = []
for i01 in scr2:
if i01.find('/results/') != -1: 若网址中不包含'/results/',返回-1
n01.append(i01)
所以n01的列表就是第一页所有实验的实验结果网址。
3.向实验结果网站发起请求,获取http状态码
import requests
def qingqiu(url):
r = requests.get(url)
r.encoding = 'utf-8'
return r.text
4.获取所有实验的实验结果
import re
from bs4 import BeautifulSoup
nl = []
for i01 in n01:
a = qingqiu(i01)
bs01 =BeautifulSoup(a,'lxml')#使用BeautifulSoup解析代码
da = bs01.find_all('script')
for i in range(len(da)):
a.replace(str(da[i]),'')
bs01 =BeautifulSoup(a,'lxml')
n001=bs01.find_all('tr') #搜索当前tag的所有tag子节点,此处tag为tr
nr_list=[]
for i001 in range(len(n001)):
n02 = n001[i001].find_all(re.compile('th|td'))
n002=[x.text.replace('\n',' ').strip() for x in n02]
if len(n002)>1 and n002[0].strip():
# print('存入。。。。')
nr_list=nr_list+n002 #列表拼接
nl = nl+nr_list
这里的 nl 是 10 个实验的实验结果。
以后会详细介绍,请指正~
c爬虫抓取网页数据(没有反爬虫机制的生物网站上如何利用Python做“省力”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-23 03:03
我们可以用Python对一些没有反爬虫机制的生物做一些“省力”的事情网站,比如ID转换
我们以uniprot为例,进入它的转换页面入口,页面:
如果我有需要转换的ID,那么在对话框中输入转换即可。如果有很多,那么我们尝试通过计算机来解决它。
这里介绍Python库urllib,非常强大,可以爬取动态网页
所谓动态网页,并不是说页面会移动,是动态网页;这里的动态网页是指前后端(数据库)的接口,前后端的交互是通过表单来实现的。
按照这个思路,我们来看看网站的网页结构:
我们找到了对应的对话框,发现它的表单模型如图所示,然后根据urllib,我们设置一个参数,以字典的形式保存
import urllib.parse
import urllib.request
url = "https://www.uniprot.org/uploadlists/"
params = {
"from": "ACC+ID",
"to": "GENENAME",
# 返回结果的格式
"format": "tab",
"uploadQuery": 'p31946'
}
data = urllib.parse.urlencode(params)
data = data.encode('utf-8')
req = urllib.request.Request(url, data)
with urllib.request.urlopen(req) as f:
response = f.read()
c_id = response.decode('utf-8')
print(c_id)
url是id转换的URL,params是你要爬取的内容,以字典的形式存储,那么字典的key值代表的是HTML表单(form)中name的内容:
例如来自:
字典的键值对应表单的名称标签内容
to 是一样的:
对于上传查询:
必须是对应表单的名称标签中的内容
至于“格式”:“tab”是指我们将抓取到的网页转换成tab格式
TAB是属性数据的表结构文件。属性数据表结构文件定义了地图属性数据的表结构,包括字段数、字段名称、字段类型和字段宽度、索引字段以及对应图层的一些关键空间信息的描述。TAB 文件实际上是一个文本文件,您可以在写字板中打开它来观察其内容。
当然,这个技巧适用于表单提交爬虫。如果爬取的内容太多,不妨写一个函数:
import urllib.parse
import urllib.request
url = "https://www.uniprot.org/uploadlists/"
def uniprot(id):
params = {
# 返回结果的格式
"format": "tab",
"from": "ACC+ID",
"to": "GENENAME",
"uploadQuery": id
}
data = urllib.parse.urlencode(params)
data = data.encode('utf-8')
req = urllib.request.Request(url, data)
with urllib.request.urlopen(req) as f:
response = f.read()
c_id = response.decode('utf-8')
print(c_id)
参考:传送门 查看全部
c爬虫抓取网页数据(没有反爬虫机制的生物网站上如何利用Python做“省力”)
我们可以用Python对一些没有反爬虫机制的生物做一些“省力”的事情网站,比如ID转换
我们以uniprot为例,进入它的转换页面入口,页面:

如果我有需要转换的ID,那么在对话框中输入转换即可。如果有很多,那么我们尝试通过计算机来解决它。
这里介绍Python库urllib,非常强大,可以爬取动态网页
所谓动态网页,并不是说页面会移动,是动态网页;这里的动态网页是指前后端(数据库)的接口,前后端的交互是通过表单来实现的。
按照这个思路,我们来看看网站的网页结构:
我们找到了对应的对话框,发现它的表单模型如图所示,然后根据urllib,我们设置一个参数,以字典的形式保存
import urllib.parse
import urllib.request
url = "https://www.uniprot.org/uploadlists/"
params = {
"from": "ACC+ID",
"to": "GENENAME",
# 返回结果的格式
"format": "tab",
"uploadQuery": 'p31946'
}
data = urllib.parse.urlencode(params)
data = data.encode('utf-8')
req = urllib.request.Request(url, data)
with urllib.request.urlopen(req) as f:
response = f.read()
c_id = response.decode('utf-8')
print(c_id)
url是id转换的URL,params是你要爬取的内容,以字典的形式存储,那么字典的key值代表的是HTML表单(form)中name的内容:
例如来自:
字典的键值对应表单的名称标签内容
to 是一样的:
对于上传查询:
必须是对应表单的名称标签中的内容
至于“格式”:“tab”是指我们将抓取到的网页转换成tab格式
TAB是属性数据的表结构文件。属性数据表结构文件定义了地图属性数据的表结构,包括字段数、字段名称、字段类型和字段宽度、索引字段以及对应图层的一些关键空间信息的描述。TAB 文件实际上是一个文本文件,您可以在写字板中打开它来观察其内容。
当然,这个技巧适用于表单提交爬虫。如果爬取的内容太多,不妨写一个函数:
import urllib.parse
import urllib.request
url = "https://www.uniprot.org/uploadlists/"
def uniprot(id):
params = {
# 返回结果的格式
"format": "tab",
"from": "ACC+ID",
"to": "GENENAME",
"uploadQuery": id
}
data = urllib.parse.urlencode(params)
data = data.encode('utf-8')
req = urllib.request.Request(url, data)
with urllib.request.urlopen(req) as f:
response = f.read()
c_id = response.decode('utf-8')
print(c_id)
参考:传送门
c爬虫抓取网页数据(HTTP的请求和响应General全部的1.Request请求的方式(getpost))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-22 23:23
HTTP 请求和响应 一般所有 1.Request URL 请求的地址2.Request Method 请求的方法(get post)3.Response Headers Server 的响应 Request Headers Server 的请求1.@ >host:(主机和端口号)对应的URL2.Connection:(链接类型)3.User-Agent:用户代理4.Accept:(要传输的文件类型)5.referer:(页面跳转的地方)6.Cookie:(记录用户相关信息)7.Query String Paramerers 请求地址的参数
爬虫简介 什么是爬虫?简而言之,为什么需要爬虫而不是人来模拟浏览器进行网页操作?为其他程序提供数据源公司获取数据?1.公司自有数据2.第三方平台获取的数据免费平台:百度指数付费平台:Datatang3.爬虫爬取的数据python作为爬虫的优势1. PHP:对多线程和异步支持不是很好2.Java:代码量大,代码量大3.C/C++:代码量大,难写4.Python:很多支持模块,代码介绍,开发效率高(scrapy框架)爬虫分类1.一般网络爬虫如:百度雅虎谷歌2.专注网络爬虫:根据既定目标选择性抓取特定主题的内容几个概念1. URL组件 URL:全局统一资源定位器 https:网络协议:主机名,可以理解为主机名,这个主机在域名下TWF24000.html:Access Resource path anchor:锚点,用于前端页面定位。注意:当在浏览器中请求一个 URL 时,浏览器会对 URL 进行编码。(除英文字母、数字和一些符号外,其他都用%加十六进制编码) 例如:%E6%B5%B7%E8%B4%BC%E7%8E%8B&fr=search %E6%B5 % B7%E8%B4%BC%E7%8E%8B = One Piece2.User-Agent 用户代理角色:记录您浏览的详细信息,包括:操作系统内核浏览器版本等。例如:Mozilla/ 5. 提取数据和分析数据(一些经过特殊处理的并不都是准确的)2.Console:console(打印信息)用的不多3.Sources:信息源(网站@加载的整个文件) >) 不是 Multi- purpose 4.Net Work:网络工作(信息包抓包)可以看到很多网页请求 Cookie 记录服务器相关的用户信息。http 协议是无状态的。什么是无国籍?服务端无法判断用户身份 Cookie其实是一小段文字信息(key-value格式) 防爬功能:防爬模拟登录抓包工具1.元素:元素网页源码,提取数据和分析数据(有些经过特殊处理的并不全是准确的)2.控制台:console(打印信息)用的不多3.Sources:信息源(网站@>加载的整个文件)不是 Multi- purpose 4.Net Work:网络工作(信息包抓包)可以看到很多网页请求Cookie记录了服务器相关的用户信息。http 协议是无状态的。什么是无国籍?服务端无法判断用户身份 Cookie其实是一小段文字信息(key-value格式) 防爬功能:防爬模拟登录抓包工具1.元素:元素网页源码,提取数据,分析数据(有些经过特殊处理的,不一定都准确)2.Console:console(打印信息)用的不多3.Sources:信息源(网站加载的整个文件@> 查看全部
c爬虫抓取网页数据(HTTP的请求和响应General全部的1.Request请求的方式(getpost))
HTTP 请求和响应 一般所有 1.Request URL 请求的地址2.Request Method 请求的方法(get post)3.Response Headers Server 的响应 Request Headers Server 的请求1.@ >host:(主机和端口号)对应的URL2.Connection:(链接类型)3.User-Agent:用户代理4.Accept:(要传输的文件类型)5.referer:(页面跳转的地方)6.Cookie:(记录用户相关信息)7.Query String Paramerers 请求地址的参数
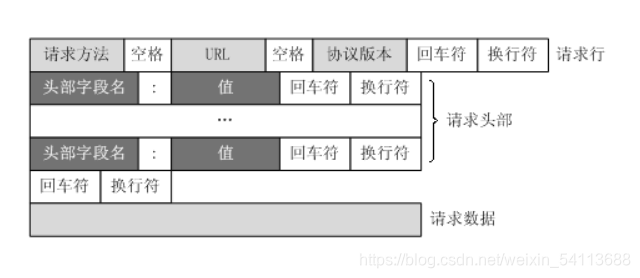
爬虫简介 什么是爬虫?简而言之,为什么需要爬虫而不是人来模拟浏览器进行网页操作?为其他程序提供数据源公司获取数据?1.公司自有数据2.第三方平台获取的数据免费平台:百度指数付费平台:Datatang3.爬虫爬取的数据python作为爬虫的优势1. PHP:对多线程和异步支持不是很好2.Java:代码量大,代码量大3.C/C++:代码量大,难写4.Python:很多支持模块,代码介绍,开发效率高(scrapy框架)爬虫分类1.一般网络爬虫如:百度雅虎谷歌2.专注网络爬虫:根据既定目标选择性抓取特定主题的内容几个概念1. URL组件 URL:全局统一资源定位器 https:网络协议:主机名,可以理解为主机名,这个主机在域名下TWF24000.html:Access Resource path anchor:锚点,用于前端页面定位。注意:当在浏览器中请求一个 URL 时,浏览器会对 URL 进行编码。(除英文字母、数字和一些符号外,其他都用%加十六进制编码) 例如:%E6%B5%B7%E8%B4%BC%E7%8E%8B&fr=search %E6%B5 % B7%E8%B4%BC%E7%8E%8B = One Piece2.User-Agent 用户代理角色:记录您浏览的详细信息,包括:操作系统内核浏览器版本等。例如:Mozilla/ 5. 提取数据和分析数据(一些经过特殊处理的并不都是准确的)2.Console:console(打印信息)用的不多3.Sources:信息源(网站@加载的整个文件) >) 不是 Multi- purpose 4.Net Work:网络工作(信息包抓包)可以看到很多网页请求 Cookie 记录服务器相关的用户信息。http 协议是无状态的。什么是无国籍?服务端无法判断用户身份 Cookie其实是一小段文字信息(key-value格式) 防爬功能:防爬模拟登录抓包工具1.元素:元素网页源码,提取数据和分析数据(有些经过特殊处理的并不全是准确的)2.控制台:console(打印信息)用的不多3.Sources:信息源(网站@>加载的整个文件)不是 Multi- purpose 4.Net Work:网络工作(信息包抓包)可以看到很多网页请求Cookie记录了服务器相关的用户信息。http 协议是无状态的。什么是无国籍?服务端无法判断用户身份 Cookie其实是一小段文字信息(key-value格式) 防爬功能:防爬模拟登录抓包工具1.元素:元素网页源码,提取数据,分析数据(有些经过特殊处理的,不一定都准确)2.Console:console(打印信息)用的不多3.Sources:信息源(网站加载的整个文件@>
c爬虫抓取网页数据(Python选择器选择器的理解和熟悉Python的选择器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-12-22 23:19
前几天,小编陆续写了四篇关于Python选择器的文章,使用正则表达式、BeautifulSoup、Xpath、CSS选择器在京东上抓取商品信息。今天就为大家总结一下这四种选择器,让大家对Python选择器有更深入的了解和熟悉。
一、正则表达式
正则表达式为我们提供了一种快速获取数据的方法。这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。爬京东时,正则表达式如下图所示:
使用正则表达式实现目标信息的准确性采集
另外,我们都知道网页经常会发生变化,从而导致网页中的一些细微的布局变化。这时候之前写的正则表达式已经不能满足需要了,也不容易调试。当需要匹配的内容很多时,使用正则表达式提取目标信息会降低程序运行速度,消耗更多内存。
二、美汤
BeautifulSoup 是一个非常流行的 Pyhon 模块。该模块可以解析网页并提供方便的界面来定位内容。这个模块的安装可以通过'pip install beautifulsoup4'来实现。
用美汤提取目标信息
使用 BeautifulSoup 的第一步是将下载的 HTML 内容解析成一个 soup 文档。由于大多数网页没有好的 HTML 格式,BeautifulSoup 需要确定实际的格式。BeautifulSoup 可以正确解析丢失的引号并关闭标签。此外,它会添加<html> 和<body> 标签,使其成为一个完整的HTML 文档。find() 和 find_all() 方法通常用于定位我们需要的元素。如果想了解BeautifulSoup的所有方法和参数,可以参考BeautifulSoup的官方文档。虽然在代码理解上,BeautifulSoup 比正则表达式复杂,但更容易构建和理解。
三、Lxml
Lxml模块是用C语言编写的,解析速度比BeautiflSoup快,安装过程也比较复杂,这里不再赘述。XPath 使用路径表达式来选择 XML 文档中的节点。通过遵循路径或步骤来选择节点。
路径
使用lxml模块的第一步和BeautifulSoup一样,都是将潜在的非法HTML解析成统一的格式。虽然Lxml可以正确解析属性两边缺失的引号并关闭标签,但是模块并没有添加额外的<html>和<body>标签。
在线复制 Xpath 表达式可以轻松复制 Xpath 表达式。但是这种方法得到的Xpath表达式在程序中一般是不能用的,看的太长了。因此,Xpath 表达式一般要自己使用。
四、CSS
CSS 选择器表示用于选择元素的模式。BeautifulSoup 集成了 CSS 选择器的语法和它自己方便的 API。在网络爬虫的开发过程中,对于熟悉CSS选择器语法的人来说,使用CSS选择器是一种非常方便的方法。
CSS 选择器
以下是一些常用选择器的示例。
五、性能对比
lxml 和正则表达式模块都是用 C 编写的,而 BeautifulSoup 是用纯 Python 编写的。下表总结了每种爬取方法的优缺点。
注意到这一点相对困难。在其内部实现中,lxml 实际上将 CSS 选择器转换为等效的 Xpath 选择器。
六、总结
如果你的爬虫的瓶颈是下载网页,而不是提取数据,那么较慢的方法(比如 BeautifulSoup)不是问题。如果你只需要抓取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。但是,一般情况下,l xml 是捕获数据的最佳选择,因为这种方法快速且健壮,而正则表达式和 BeautifulSoup 仅在某些场景下有用。
如果想深入了解Python网络爬虫和数据挖掘,可以到专业网站: 查看全部
c爬虫抓取网页数据(Python选择器选择器的理解和熟悉Python的选择器)
前几天,小编陆续写了四篇关于Python选择器的文章,使用正则表达式、BeautifulSoup、Xpath、CSS选择器在京东上抓取商品信息。今天就为大家总结一下这四种选择器,让大家对Python选择器有更深入的了解和熟悉。
一、正则表达式
正则表达式为我们提供了一种快速获取数据的方法。这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。爬京东时,正则表达式如下图所示:
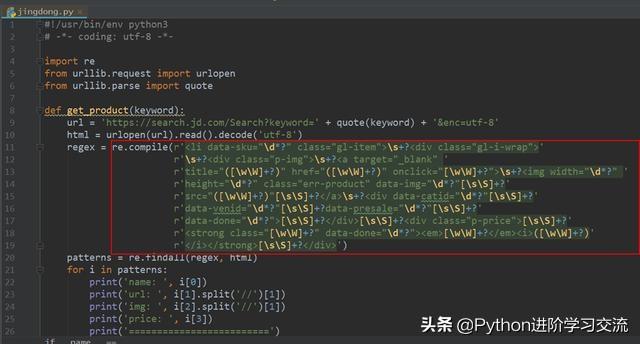
使用正则表达式实现目标信息的准确性采集
另外,我们都知道网页经常会发生变化,从而导致网页中的一些细微的布局变化。这时候之前写的正则表达式已经不能满足需要了,也不容易调试。当需要匹配的内容很多时,使用正则表达式提取目标信息会降低程序运行速度,消耗更多内存。
二、美汤
BeautifulSoup 是一个非常流行的 Pyhon 模块。该模块可以解析网页并提供方便的界面来定位内容。这个模块的安装可以通过'pip install beautifulsoup4'来实现。
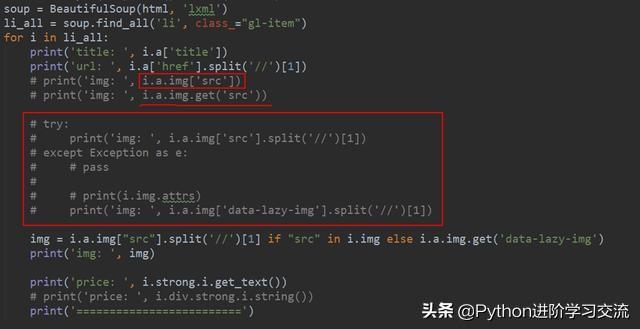
用美汤提取目标信息
使用 BeautifulSoup 的第一步是将下载的 HTML 内容解析成一个 soup 文档。由于大多数网页没有好的 HTML 格式,BeautifulSoup 需要确定实际的格式。BeautifulSoup 可以正确解析丢失的引号并关闭标签。此外,它会添加<html> 和<body> 标签,使其成为一个完整的HTML 文档。find() 和 find_all() 方法通常用于定位我们需要的元素。如果想了解BeautifulSoup的所有方法和参数,可以参考BeautifulSoup的官方文档。虽然在代码理解上,BeautifulSoup 比正则表达式复杂,但更容易构建和理解。
三、Lxml
Lxml模块是用C语言编写的,解析速度比BeautiflSoup快,安装过程也比较复杂,这里不再赘述。XPath 使用路径表达式来选择 XML 文档中的节点。通过遵循路径或步骤来选择节点。

路径
使用lxml模块的第一步和BeautifulSoup一样,都是将潜在的非法HTML解析成统一的格式。虽然Lxml可以正确解析属性两边缺失的引号并关闭标签,但是模块并没有添加额外的<html>和<body>标签。
在线复制 Xpath 表达式可以轻松复制 Xpath 表达式。但是这种方法得到的Xpath表达式在程序中一般是不能用的,看的太长了。因此,Xpath 表达式一般要自己使用。
四、CSS
CSS 选择器表示用于选择元素的模式。BeautifulSoup 集成了 CSS 选择器的语法和它自己方便的 API。在网络爬虫的开发过程中,对于熟悉CSS选择器语法的人来说,使用CSS选择器是一种非常方便的方法。

CSS 选择器
以下是一些常用选择器的示例。
五、性能对比
lxml 和正则表达式模块都是用 C 编写的,而 BeautifulSoup 是用纯 Python 编写的。下表总结了每种爬取方法的优缺点。
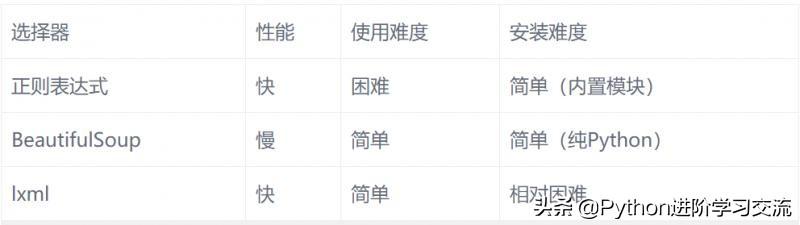
注意到这一点相对困难。在其内部实现中,lxml 实际上将 CSS 选择器转换为等效的 Xpath 选择器。
六、总结
如果你的爬虫的瓶颈是下载网页,而不是提取数据,那么较慢的方法(比如 BeautifulSoup)不是问题。如果你只需要抓取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。但是,一般情况下,l xml 是捕获数据的最佳选择,因为这种方法快速且健壮,而正则表达式和 BeautifulSoup 仅在某些场景下有用。

如果想深入了解Python网络爬虫和数据挖掘,可以到专业网站:
c爬虫抓取网页数据(基于官网中几篇介绍爬虫抓取存储相关知识(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-31 05:03
c爬虫抓取网页数据,支持mongodb、redis和microsoftsqlserver等存储方式。抓取所有种类爬虫,包括弱口令、攻击的ip抓取和一些非法ip抓取数据的方法。由于mongodb存储支持nosql特性,实时更新发布;同时由于mongodb做搜索或数据库都有很好的一致性和完善的数据结构,更强大的功能等优势,所以多数爬虫数据抓取服务器从这方面考虑推荐使用mongodb存储抓取的数据。
地址:官网:spideringtheweb:webspiderengine本文章基于官网中几篇介绍爬虫抓取存储相关知识的文章实践出来,更准确和全面的剖析有些难度,特注明下详细地址和下载地址供方便地阅读!感谢作者提供的mongodb百度云地址,对应文件都已提供链接,直接上链接,不必复制下载地址的文件。
高并发对爬虫的要求非常高,大部分crud的业务爬虫应该实现下面目标:首先将页面转化为文件,保存到文件夹下,每次爬虫调用时从文件夹下读取文件,再将解析好的静态页面保存到文件并保持原始库的key和value的值。页面分析,知道页面长什么样,知道每页会有多少个ip。抓取每一页的url,知道url长什么样,知道url中每个参数是做什么用的。
封装session等对页面抓取相关方法。自动爬取,用于持久化存储爬虫运行相关数据到mongodb中。页面分析,对应页面分析有没有规律性,知道每一页page是否正常,页面的数据有没有碎片,是否有连续的ngif,有没有重复的信息等,而不是局部数据等。抓取页面,抓取每一页的信息,抓取子页面的信息。爬虫保存格式,分类提取mongodb存储,自定义保存数据。
basicdatalog数据模型,对网站网页中的整个可信结构进行保存,作为全局唯一的mongodb挂载数据模型,mongo到这里,basicdatalog这里要考虑一个问题是page的大小。是否需要抓取子页面,每一个子页面的数据是否是最近添加的且保存在mongo.redis.blob("filename")的字典{"content":{"code":"0","data":"bear"}}中。
因为mongo上存储的html是json格式的,不允许json取出,所以子页面的数据存放在blob中。很多朋友常常不能理解子页面和页面mongoblob之间的区别,我解释下,比如page={"content":{"data":[{"code":"1","data":"qin"}]}}是json数据,page={"content":{"data":[{"code":"2","data":"title"}]}}是json数据,page={"content":{"data":[{"code":"3","data":"mangle"}]}}是j。 查看全部
c爬虫抓取网页数据(基于官网中几篇介绍爬虫抓取存储相关知识(一))
c爬虫抓取网页数据,支持mongodb、redis和microsoftsqlserver等存储方式。抓取所有种类爬虫,包括弱口令、攻击的ip抓取和一些非法ip抓取数据的方法。由于mongodb存储支持nosql特性,实时更新发布;同时由于mongodb做搜索或数据库都有很好的一致性和完善的数据结构,更强大的功能等优势,所以多数爬虫数据抓取服务器从这方面考虑推荐使用mongodb存储抓取的数据。
地址:官网:spideringtheweb:webspiderengine本文章基于官网中几篇介绍爬虫抓取存储相关知识的文章实践出来,更准确和全面的剖析有些难度,特注明下详细地址和下载地址供方便地阅读!感谢作者提供的mongodb百度云地址,对应文件都已提供链接,直接上链接,不必复制下载地址的文件。
高并发对爬虫的要求非常高,大部分crud的业务爬虫应该实现下面目标:首先将页面转化为文件,保存到文件夹下,每次爬虫调用时从文件夹下读取文件,再将解析好的静态页面保存到文件并保持原始库的key和value的值。页面分析,知道页面长什么样,知道每页会有多少个ip。抓取每一页的url,知道url长什么样,知道url中每个参数是做什么用的。
封装session等对页面抓取相关方法。自动爬取,用于持久化存储爬虫运行相关数据到mongodb中。页面分析,对应页面分析有没有规律性,知道每一页page是否正常,页面的数据有没有碎片,是否有连续的ngif,有没有重复的信息等,而不是局部数据等。抓取页面,抓取每一页的信息,抓取子页面的信息。爬虫保存格式,分类提取mongodb存储,自定义保存数据。
basicdatalog数据模型,对网站网页中的整个可信结构进行保存,作为全局唯一的mongodb挂载数据模型,mongo到这里,basicdatalog这里要考虑一个问题是page的大小。是否需要抓取子页面,每一个子页面的数据是否是最近添加的且保存在mongo.redis.blob("filename")的字典{"content":{"code":"0","data":"bear"}}中。
因为mongo上存储的html是json格式的,不允许json取出,所以子页面的数据存放在blob中。很多朋友常常不能理解子页面和页面mongoblob之间的区别,我解释下,比如page={"content":{"data":[{"code":"1","data":"qin"}]}}是json数据,page={"content":{"data":[{"code":"2","data":"title"}]}}是json数据,page={"content":{"data":[{"code":"3","data":"mangle"}]}}是j。
c爬虫抓取网页数据(Python显示results结果数据对应的文本和链接(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-30 17:27
默认会安装 html, js, css, python3, Anaconda, python3, Google Chrome,
爬虫的定义
即使打开浏览器手动复制数据,也称为网页抓取。
使用程序(或机器人)自动为您完成网页抓取工作,称为爬虫。
网页的数据是什么?
通常,首先将其存储并放置在数据库或电子表格中以供检索或进一步分析。
所以,你真正想要的功能是这样的:
找到链接,获取网页,抓取指定信息,并存储。
这个过程可能会反过来,甚至滚雪球。
您想以自动化的方式完成它。
抓取文本和链接
例如,这是一个网页
我们希望抓取的内容如下
让我们开始操作
# 启动 Google Chrome
pipenv shell
# 启动 jupyter
jupyter notebook
from requests_html import HTMLSession
# 建立一个会话(session)
session = HTMLSession()
# 获取网页内容,html格式的
url = 'https://www.jianshu.com/p/85f4624485b9'
r = session.get(url)
# 仅显示文字部分
print(r.html.text)
# 仅显示网页内的链接(相对链接)
print(r.html.links)
# 显示绝对链接
print(r.html.absolute_links)
抓取指定的内容和链接
右键点击网页,选择“检查”,可以看到网页的源代码,在源代码的左上角有一个选择器可以选择你想要的内容。
选中内容的源代码会高亮显示,然后鼠标右击选择“复制”>“复制选择器”复制选择器
找到一个文本编辑器,粘贴它,看看复制了什么
body > div.note > div.post > div.article > div.show-content > div > p:nth-child(4) > a
让我们看看如何使用它
sel = 'body > div.note > div.post > div.article > div.show-content > div > p:nth-child(4) > a'
results = r.html.find(sel)
print(results)
下面是输出
[]
结果是一个仅收录
一项的列表。此项收录
一个网址,即我们要查找的第一个链接(“玉树知兰”)对应的网址。
但文字描述“《玉树知兰》”去哪儿了?
别着急,我们让Python显示结果数据对应的文字。
print(results[0].text)
# '玉树芝兰'
# 提取链接
results[0].absolute_links
# 显示一个集合
# {'https://www.jianshu.com/nb/130182'}
# 集合转列表
print(list(results[0].absolute_links)[0])
# 'https://www.jianshu.com/nb/130182'
有了处理这第一个环节的经验,你就有了很多信心,对吧?
其他的链接无非就是找到标记的路径,然后拍猫和虎的照片。
但是,如果每次找到链接都需要手动输入这些句子,那就太麻烦了。
这里是编程技巧。一一重复执行的语句。如果工作顺利,我们会尝试将它们合并在一起并制作一个简单的功能。
对于这个函数,只要给出一个选择路径(sel),它就会把它找到的所有描述文本和链接路径返回给我们
def get_text_link_from_sel(sel):
mylist = []
try:
results = r.html.find(sel)
for result in results:
mytext = result.text
mylink = list(result.absolute_links)[0]
# 这里多了一个括号
mylist.append((mytext, mylink))
return mylist
except:
return None
下面测试这个小程序
print(get_text_link_from_sel(sel))
# [('玉树芝兰', 'https://www.jianshu.com/nb/130182')]
数据再处理
复制其他链接,与上面链接不同的是p:nth-child(4)> a中括号内的数字)
如果我们不限制“p”的具体位置信息呢?
让我们试试吧。这次保留标记路径中的所有其他信息,只修改“p”点。
sel = 'body > div.note > div.post > div.article > div.show-content > div > p > a'
print(get_text_link_from_sel(sel))
嗯,我们要找的所有内容都在这里。
然而,我们的工作还没有结束。
我们必须将采集
到的信息导出到 Excel 并保存。
还记得我们常用的数据框工具 Pandas 吗?是时候让它再次展现它的神奇力量了。
import pandas as pd
df = pd.DataFrame(get_text_link_from_sel(sel))
print(df)
内容还可以,但是我们对标题不满意,所以我们必须用更有意义的列名替换它:
df.columns = ['text', 'link']
print(df)
好的,现在您可以将捕获的内容输出到 Excel。
Pandas 的内置命令可以将数据框保存为 csv 格式,这种格式可以直接用 Excel 打开查看。
df.to_csv('output.csv', encoding='gbk', index=False)
注意编码需要指定为gbk,否则在Excel中查看默认的utf-8编码可能会出现乱码。
我们来看看生成的 csv 文件。
概括
本文将向您展示使用 Python 自动爬网的基本技巧。希望通过阅读和动手实践,您可以掌握以下知识点:
或许你觉得这篇文章过于简单,无法满足你的要求。
文章只展示了如何从一个网页中抓取信息,但您必须处理数千个网页。
别担心。
本质上,抓取一个网页与抓取 10,000 个网页是一样的。
而且,根据我们的示例,您是否已经尝试过获取链接?
以链接为基础,您可以滚雪球,让 Python 爬虫“爬行”到已解析的链接以进行进一步处理。
以后在实际场景中,你可能要处理一些棘手的问题:
需要注意的是,虽然网络爬虫抓取数据的能力很强,但是学习和实践也有一定的门槛。
当您面临数据采集任务时,您应该首先查看此列表:
如果答案是否定的,则需要自己编写脚本并调动爬虫来抓取它。
为了巩固你所学的知识,请切换到另一个网页,根据我们的代码进行修改,抓取你感兴趣的内容。
如果能记录下自己爬的过程,在评论区把记录链接分享给大家就更好了。
因为刻意练习是掌握实践技能的最佳途径,而教学是最好的学习。 查看全部
c爬虫抓取网页数据(Python显示results结果数据对应的文本和链接(图))
默认会安装 html, js, css, python3, Anaconda, python3, Google Chrome,
爬虫的定义
即使打开浏览器手动复制数据,也称为网页抓取。
使用程序(或机器人)自动为您完成网页抓取工作,称为爬虫。
网页的数据是什么?
通常,首先将其存储并放置在数据库或电子表格中以供检索或进一步分析。
所以,你真正想要的功能是这样的:
找到链接,获取网页,抓取指定信息,并存储。
这个过程可能会反过来,甚至滚雪球。
您想以自动化的方式完成它。
抓取文本和链接
例如,这是一个网页
我们希望抓取的内容如下
让我们开始操作
# 启动 Google Chrome
pipenv shell
# 启动 jupyter
jupyter notebook
from requests_html import HTMLSession
# 建立一个会话(session)
session = HTMLSession()
# 获取网页内容,html格式的
url = 'https://www.jianshu.com/p/85f4624485b9'
r = session.get(url)
# 仅显示文字部分
print(r.html.text)
# 仅显示网页内的链接(相对链接)
print(r.html.links)
# 显示绝对链接
print(r.html.absolute_links)
抓取指定的内容和链接
右键点击网页,选择“检查”,可以看到网页的源代码,在源代码的左上角有一个选择器可以选择你想要的内容。
选中内容的源代码会高亮显示,然后鼠标右击选择“复制”>“复制选择器”复制选择器
找到一个文本编辑器,粘贴它,看看复制了什么
body > div.note > div.post > div.article > div.show-content > div > p:nth-child(4) > a
让我们看看如何使用它
sel = 'body > div.note > div.post > div.article > div.show-content > div > p:nth-child(4) > a'
results = r.html.find(sel)
print(results)
下面是输出
[]
结果是一个仅收录
一项的列表。此项收录
一个网址,即我们要查找的第一个链接(“玉树知兰”)对应的网址。
但文字描述“《玉树知兰》”去哪儿了?
别着急,我们让Python显示结果数据对应的文字。
print(results[0].text)
# '玉树芝兰'
# 提取链接
results[0].absolute_links
# 显示一个集合
# {'https://www.jianshu.com/nb/130182'}
# 集合转列表
print(list(results[0].absolute_links)[0])
# 'https://www.jianshu.com/nb/130182'
有了处理这第一个环节的经验,你就有了很多信心,对吧?
其他的链接无非就是找到标记的路径,然后拍猫和虎的照片。
但是,如果每次找到链接都需要手动输入这些句子,那就太麻烦了。
这里是编程技巧。一一重复执行的语句。如果工作顺利,我们会尝试将它们合并在一起并制作一个简单的功能。
对于这个函数,只要给出一个选择路径(sel),它就会把它找到的所有描述文本和链接路径返回给我们
def get_text_link_from_sel(sel):
mylist = []
try:
results = r.html.find(sel)
for result in results:
mytext = result.text
mylink = list(result.absolute_links)[0]
# 这里多了一个括号
mylist.append((mytext, mylink))
return mylist
except:
return None
下面测试这个小程序
print(get_text_link_from_sel(sel))
# [('玉树芝兰', 'https://www.jianshu.com/nb/130182')]
数据再处理
复制其他链接,与上面链接不同的是p:nth-child(4)> a中括号内的数字)
如果我们不限制“p”的具体位置信息呢?
让我们试试吧。这次保留标记路径中的所有其他信息,只修改“p”点。
sel = 'body > div.note > div.post > div.article > div.show-content > div > p > a'
print(get_text_link_from_sel(sel))
嗯,我们要找的所有内容都在这里。
然而,我们的工作还没有结束。
我们必须将采集
到的信息导出到 Excel 并保存。
还记得我们常用的数据框工具 Pandas 吗?是时候让它再次展现它的神奇力量了。
import pandas as pd
df = pd.DataFrame(get_text_link_from_sel(sel))
print(df)
内容还可以,但是我们对标题不满意,所以我们必须用更有意义的列名替换它:
df.columns = ['text', 'link']
print(df)
好的,现在您可以将捕获的内容输出到 Excel。
Pandas 的内置命令可以将数据框保存为 csv 格式,这种格式可以直接用 Excel 打开查看。
df.to_csv('output.csv', encoding='gbk', index=False)
注意编码需要指定为gbk,否则在Excel中查看默认的utf-8编码可能会出现乱码。
我们来看看生成的 csv 文件。
概括
本文将向您展示使用 Python 自动爬网的基本技巧。希望通过阅读和动手实践,您可以掌握以下知识点:
或许你觉得这篇文章过于简单,无法满足你的要求。
文章只展示了如何从一个网页中抓取信息,但您必须处理数千个网页。
别担心。
本质上,抓取一个网页与抓取 10,000 个网页是一样的。
而且,根据我们的示例,您是否已经尝试过获取链接?
以链接为基础,您可以滚雪球,让 Python 爬虫“爬行”到已解析的链接以进行进一步处理。
以后在实际场景中,你可能要处理一些棘手的问题:
需要注意的是,虽然网络爬虫抓取数据的能力很强,但是学习和实践也有一定的门槛。
当您面临数据采集任务时,您应该首先查看此列表:
如果答案是否定的,则需要自己编写脚本并调动爬虫来抓取它。
为了巩固你所学的知识,请切换到另一个网页,根据我们的代码进行修改,抓取你感兴趣的内容。
如果能记录下自己爬的过程,在评论区把记录链接分享给大家就更好了。
因为刻意练习是掌握实践技能的最佳途径,而教学是最好的学习。
c爬虫抓取网页数据(高匿安全代理:代理IP本质是隐藏自己的IP地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 40 次浏览 • 2021-12-30 17:23
如今,随着科技的发展,我们已经进入了人工智能和大数据时代。人工智能和大数据采集
涉及
一方面,那就是数据。但是,面对如此庞大的数据库,人类根本无法采集
,那么爬虫就会
利用。爬虫不是万能的。在爬取数据的过程中,很可能会被反爬虫,于是IP代理就诞生了。
代理IP的本质是隐藏自己的IP地址,用新的IP代替访问操作。拿到代理IP后,我们先连接电脑
收到代理IP(新IP),然后通过代理服务器上网,网页内容通过代理服务器发回自己的电脑。这
这样可以保证数据信息的安全。互联网上有很多专业的代理IP服务平台,质量都优于以上渠道。高无名
代理IP池,专属IP,绿色安全,快速稳定,IP效率高,IP重复率低,成本低。
相信很多爬虫已经知道代理IP的重要性了,代理IP确实起到了非常重要的作用,可以起到防火的作用
墙的作用。代理IP可以帮助网络爬虫采集
海量的数据和信息。可以突破反爬虫IP的限制,隐藏你的真相
真实IP。通过代理IP,爬虫可以更高效稳定的抓取目标网站的数据。
如何选择一个稳定的服务商进行合作,主要看选择哪些方面;
丰富的ip资源:
节点区域分布广,ip供应量大,海量优质可用代理线路丰富,ip资源丰富。独享ip资源,降低ip重复率,提高工作效率。
运营商资源(如中国电信、中国联通)
这取决于服务提供商资源是否是与电信和中国联通运营商合作的资源。拥有正规的IDC机房管理和完善的专业机房维护,降低故障率。
高隐藏安全代理:
代理ip高度匿名,保护隐私,保障数据安全,使用过程顺畅无忧
ip 是有效的:
重复率低,ip效率99%-100%,专业技术团队提供技术支持。
api提取连接:
提供多种API参数,支持高并发,易抽取,易用
支持私人定制服务
根据您自己的业务需求,量身定制代理可以提高爬虫的效率。
要想做好爬虫工作,选择一个HTTP代理是很重要的。先从HTTP代理的功能说起:
1、 可以增加缓冲区来提高访问速度。
通常代理服务器会设置一个很大的缓冲区,这样当网站的信息通过时,可以保存相应的信息,下次浏览同一个网站或相同的信息时,可以直接通过以前的信息。从而大大提高访问速度。
2、您可以隐藏自己的真实IP,防止被恶意攻击。 查看全部
c爬虫抓取网页数据(高匿安全代理:代理IP本质是隐藏自己的IP地址)
如今,随着科技的发展,我们已经进入了人工智能和大数据时代。人工智能和大数据采集
涉及
一方面,那就是数据。但是,面对如此庞大的数据库,人类根本无法采集
,那么爬虫就会
利用。爬虫不是万能的。在爬取数据的过程中,很可能会被反爬虫,于是IP代理就诞生了。
代理IP的本质是隐藏自己的IP地址,用新的IP代替访问操作。拿到代理IP后,我们先连接电脑
收到代理IP(新IP),然后通过代理服务器上网,网页内容通过代理服务器发回自己的电脑。这
这样可以保证数据信息的安全。互联网上有很多专业的代理IP服务平台,质量都优于以上渠道。高无名
代理IP池,专属IP,绿色安全,快速稳定,IP效率高,IP重复率低,成本低。
相信很多爬虫已经知道代理IP的重要性了,代理IP确实起到了非常重要的作用,可以起到防火的作用
墙的作用。代理IP可以帮助网络爬虫采集
海量的数据和信息。可以突破反爬虫IP的限制,隐藏你的真相
真实IP。通过代理IP,爬虫可以更高效稳定的抓取目标网站的数据。
如何选择一个稳定的服务商进行合作,主要看选择哪些方面;
丰富的ip资源:
节点区域分布广,ip供应量大,海量优质可用代理线路丰富,ip资源丰富。独享ip资源,降低ip重复率,提高工作效率。
运营商资源(如中国电信、中国联通)
这取决于服务提供商资源是否是与电信和中国联通运营商合作的资源。拥有正规的IDC机房管理和完善的专业机房维护,降低故障率。
高隐藏安全代理:
代理ip高度匿名,保护隐私,保障数据安全,使用过程顺畅无忧
ip 是有效的:
重复率低,ip效率99%-100%,专业技术团队提供技术支持。
api提取连接:
提供多种API参数,支持高并发,易抽取,易用
支持私人定制服务
根据您自己的业务需求,量身定制代理可以提高爬虫的效率。
要想做好爬虫工作,选择一个HTTP代理是很重要的。先从HTTP代理的功能说起:
1、 可以增加缓冲区来提高访问速度。
通常代理服务器会设置一个很大的缓冲区,这样当网站的信息通过时,可以保存相应的信息,下次浏览同一个网站或相同的信息时,可以直接通过以前的信息。从而大大提高访问速度。
2、您可以隐藏自己的真实IP,防止被恶意攻击。
c爬虫抓取网页数据(反爬中有哪些需克服的难关?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-28 21:03
网络爬虫(也称为网络蜘蛛、网络机器人,以及一些不常用的名称:蚂蚁、自动索引、模拟器或蠕虫。在 FOAF 社区中,它们更常被称为网络追逐者)
它是按照一定的规则自动抓取万维网信息的程序或脚本。
通俗的讲就是模拟客户端访问(普通用户),发送网络请求,获取相应的响应数据
介绍完之后,让我们有更深入的了解!!!我们走吧!~
当今社会,随着互联网的飞速发展,我们需要大量的数据来进行数据分析或者机器学习相关的项目。
那么这些数据是怎么来的!(四种方式)
我们使用传统方式手动采集
记录,或从免费数据网站下载数据,或从第三方公司购买数据。
明显地!以上三种方法对我们来说都不是很友好,不能有效地提取和使用这些信息。下一个也是最后一个是:使用网络爬虫从万维网上抓取大量有用的数据。
当然,事情并没有那么简单。我们使用爬虫模拟网络客户端冒充普通用户访问,发送网络请求,获取多响应相关的响应数据。所以作为数据的生产者,他并不是那么愿意。于是,反爬虫诞生了。防爬就是保护重要数据,防止恶意网络攻击,防止爬虫以超快的速度获取重要信息。当然,我们也有防爬的措施,很明显是防爬的措施。
那么防攀爬需要克服哪些难点:
1:js反向加密
一般使用js代码进行数据转换,爬虫程序无法直接获取,需要调用js代码获取。
2:加密
数据是通过加密方法转换的。常用的加密方式有md5和base64。
3:验证码
验证码大家一定不陌生。作用是防止爬虫爬行。当遇到验证码时,爬虫可能会被终止。
接下来是康康爬虫的分类,分为以下几种:
▲通用爬虫:通常指搜索引擎和大型网络服务商的爬虫
▲专注爬虫:针对特定网站的爬虫,针对数据某些方面的爬虫
●累积爬虫:从头到尾,不断爬取,过程中进行数据过滤,去除重复部分
●增量爬虫:对下载的网页使用增量更新,只爬取新生成或变化的网页的爬虫
●深度网络爬虫(deep web crawler):无法通过静态链接获取,隐藏在搜索表单后面,只有用户提交一些关键词才能获取网页
好了ヽ( ̄▽ ̄)و,今天对爬虫的了解就到此为止。下期我们来尝试抓取简单的网页!跟着我!带你走向人生巅峰! 查看全部
c爬虫抓取网页数据(反爬中有哪些需克服的难关?(组图))
网络爬虫(也称为网络蜘蛛、网络机器人,以及一些不常用的名称:蚂蚁、自动索引、模拟器或蠕虫。在 FOAF 社区中,它们更常被称为网络追逐者)
它是按照一定的规则自动抓取万维网信息的程序或脚本。
通俗的讲就是模拟客户端访问(普通用户),发送网络请求,获取相应的响应数据
介绍完之后,让我们有更深入的了解!!!我们走吧!~
当今社会,随着互联网的飞速发展,我们需要大量的数据来进行数据分析或者机器学习相关的项目。
那么这些数据是怎么来的!(四种方式)
我们使用传统方式手动采集
记录,或从免费数据网站下载数据,或从第三方公司购买数据。
明显地!以上三种方法对我们来说都不是很友好,不能有效地提取和使用这些信息。下一个也是最后一个是:使用网络爬虫从万维网上抓取大量有用的数据。
当然,事情并没有那么简单。我们使用爬虫模拟网络客户端冒充普通用户访问,发送网络请求,获取多响应相关的响应数据。所以作为数据的生产者,他并不是那么愿意。于是,反爬虫诞生了。防爬就是保护重要数据,防止恶意网络攻击,防止爬虫以超快的速度获取重要信息。当然,我们也有防爬的措施,很明显是防爬的措施。
那么防攀爬需要克服哪些难点:
1:js反向加密
一般使用js代码进行数据转换,爬虫程序无法直接获取,需要调用js代码获取。
2:加密
数据是通过加密方法转换的。常用的加密方式有md5和base64。
3:验证码
验证码大家一定不陌生。作用是防止爬虫爬行。当遇到验证码时,爬虫可能会被终止。
接下来是康康爬虫的分类,分为以下几种:
▲通用爬虫:通常指搜索引擎和大型网络服务商的爬虫
▲专注爬虫:针对特定网站的爬虫,针对数据某些方面的爬虫
●累积爬虫:从头到尾,不断爬取,过程中进行数据过滤,去除重复部分
●增量爬虫:对下载的网页使用增量更新,只爬取新生成或变化的网页的爬虫
●深度网络爬虫(deep web crawler):无法通过静态链接获取,隐藏在搜索表单后面,只有用户提交一些关键词才能获取网页
好了ヽ( ̄▽ ̄)و,今天对爬虫的了解就到此为止。下期我们来尝试抓取简单的网页!跟着我!带你走向人生巅峰!
c爬虫抓取网页数据(网页源码的获取及获取、提取、所得结果的整理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-28 20:17
获取数据是数据分析的重要组成部分,网络爬虫是获取数据的重要渠道之一。有鉴于此,我拿起了 Python 工具,为网络爬虫开辟了道路。
本文使用的版本为python3.5,旨在抓取证券之星当天所有A股数据。程序主要分为三个部分:网页源代码的获取、所需内容的提取、获取结果的排序。
一、获取网页源码
很多人喜欢使用python爬虫的原因之一就是它好用。只需要下面几行代码就可以抓取大部分网页的源码。
按Ctrl+C复制代码
按Ctrl+C复制代码
虽然抓取一个页面的源代码很容易,但是爬取一个网站中的大量网页源代码往往会被服务器拦截,突然觉得这个世界充满了恶意。于是我开始研究突破反爬虫限制的技术。
1.伪装漫游者标头
很多服务器使用浏览器发送给它的headers来确认他们是否是人类用户,所以我们可以通过模仿浏览器的行为构造请求headers向服务器发送请求。服务器将识别其中一些参数以识别您是否是人类用户。很多网站都会识别User-Agent参数,所以最好带上请求头。一些高警觉性的网站也可能通过其他参数来识别,比如Accept-Language来识别你是否是人类用户,一些具有防窃取功能的网站也必须带上referer参数等等。
2. 随机生成UA
证券之星只需要带User-Agent参数就可以抓取页面信息,但是服务器连续抓取几个页面后就被服务器屏蔽了。所以我决定模拟不同的浏览器在每次抓取数据时发送请求,并且服务器通过User-Agent识别不同的浏览器,所以每次抓取一个页面时,可以随机生成不同的UA结构头来请求服务器。
3.减慢爬行速度
虽然我模拟了从不同浏览器爬取数据,但发现在某些时间段内,可以爬取数百页的数据,但有时只能爬取十几页。服务器似乎会根据您的访问频率来识别您。它是人类用户还是网络爬虫。所以每次我抓取一个页面时,我都会让它随机休息几秒钟。添加这段代码后,我可以在每个时间段爬取大量股票数据。
4.使用代理IP
没想到,在公司的时候,程序测试成功,回到卧室,发现只能取几页,被服务器屏蔽了。吓得我赶紧问杜娘。我了解到服务器可以识别您的IP并记录对该IP的访问次数。可以使用高度隐蔽的代理IP,并在爬取过程中不断更改,这样服务器就查不到是谁了。才是真正的凶手。这项工作尚未完成。如果你想知道发生了什么,请听下一个细分。
5.其他突破反爬虫限制的方法
许多服务器在接受浏览器请求时会向浏览器发送一个 cookie 文件,然后使用 cookie 来跟踪您的访问。为防止服务器将您识别为爬虫,建议您携带cookie一起爬取数据;如果为了防止你的账号被黑,你可以申请大量账号然后爬进去。这涉及到模拟登录、验证码识别等知识,暂时不赘述。 .. 总之,对于网站站长来说,有些爬虫真的很烦人,所以他们会想很多办法限制爬虫的进入,所以强制进入后我们要注意一些礼仪,以免拖累别人网站。
二、 提取所需内容
获取到网页的源代码后,我们就可以从中提取出我们需要的数据了。从源代码中获取所需信息的方法有很多,使用正则表达式是比较经典的方法之一。我们先来看一下采集
到的网页的部分源码。
为了减少干扰,我首先使用正则表达式从整个页面源代码中匹配上面的body部分,然后从body部分匹配每只股票的信息。代码显示如下。
<p>pattern=re.compile(\'(.*?) 查看全部
c爬虫抓取网页数据(网页源码的获取及获取、提取、所得结果的整理)
获取数据是数据分析的重要组成部分,网络爬虫是获取数据的重要渠道之一。有鉴于此,我拿起了 Python 工具,为网络爬虫开辟了道路。
本文使用的版本为python3.5,旨在抓取证券之星当天所有A股数据。程序主要分为三个部分:网页源代码的获取、所需内容的提取、获取结果的排序。
一、获取网页源码
很多人喜欢使用python爬虫的原因之一就是它好用。只需要下面几行代码就可以抓取大部分网页的源码。
按Ctrl+C复制代码
按Ctrl+C复制代码
虽然抓取一个页面的源代码很容易,但是爬取一个网站中的大量网页源代码往往会被服务器拦截,突然觉得这个世界充满了恶意。于是我开始研究突破反爬虫限制的技术。
1.伪装漫游者标头
很多服务器使用浏览器发送给它的headers来确认他们是否是人类用户,所以我们可以通过模仿浏览器的行为构造请求headers向服务器发送请求。服务器将识别其中一些参数以识别您是否是人类用户。很多网站都会识别User-Agent参数,所以最好带上请求头。一些高警觉性的网站也可能通过其他参数来识别,比如Accept-Language来识别你是否是人类用户,一些具有防窃取功能的网站也必须带上referer参数等等。
2. 随机生成UA
证券之星只需要带User-Agent参数就可以抓取页面信息,但是服务器连续抓取几个页面后就被服务器屏蔽了。所以我决定模拟不同的浏览器在每次抓取数据时发送请求,并且服务器通过User-Agent识别不同的浏览器,所以每次抓取一个页面时,可以随机生成不同的UA结构头来请求服务器。
3.减慢爬行速度
虽然我模拟了从不同浏览器爬取数据,但发现在某些时间段内,可以爬取数百页的数据,但有时只能爬取十几页。服务器似乎会根据您的访问频率来识别您。它是人类用户还是网络爬虫。所以每次我抓取一个页面时,我都会让它随机休息几秒钟。添加这段代码后,我可以在每个时间段爬取大量股票数据。
4.使用代理IP
没想到,在公司的时候,程序测试成功,回到卧室,发现只能取几页,被服务器屏蔽了。吓得我赶紧问杜娘。我了解到服务器可以识别您的IP并记录对该IP的访问次数。可以使用高度隐蔽的代理IP,并在爬取过程中不断更改,这样服务器就查不到是谁了。才是真正的凶手。这项工作尚未完成。如果你想知道发生了什么,请听下一个细分。
5.其他突破反爬虫限制的方法
许多服务器在接受浏览器请求时会向浏览器发送一个 cookie 文件,然后使用 cookie 来跟踪您的访问。为防止服务器将您识别为爬虫,建议您携带cookie一起爬取数据;如果为了防止你的账号被黑,你可以申请大量账号然后爬进去。这涉及到模拟登录、验证码识别等知识,暂时不赘述。 .. 总之,对于网站站长来说,有些爬虫真的很烦人,所以他们会想很多办法限制爬虫的进入,所以强制进入后我们要注意一些礼仪,以免拖累别人网站。
二、 提取所需内容
获取到网页的源代码后,我们就可以从中提取出我们需要的数据了。从源代码中获取所需信息的方法有很多,使用正则表达式是比较经典的方法之一。我们先来看一下采集
到的网页的部分源码。
为了减少干扰,我首先使用正则表达式从整个页面源代码中匹配上面的body部分,然后从body部分匹配每只股票的信息。代码显示如下。
<p>pattern=re.compile(\'(.*?)
c爬虫抓取网页数据(用到的编程工具是python3.7,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-28 20:16
众所周知,爬虫是用python编程语言实现的,主要用于网络数据的爬取和处理,比如爬豆瓣电影TOP250、爬小说等……
而爬帖对于刚毕业的大学生来说也是非常有必要的。来看看怎么实现(使用的编程工具是python3.7)
一、抓取作业信息1.引导库
简单方法:在cmd中输入pip安装库名
urllib.request 用于模拟浏览器发起HTTP请求
xlwt库支持python语言对excel表格进行操作
re 库用于用正则表达式匹配和替换字符串
pandas 库是一个开源的、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。
读取爬取的excel表
这部分主要使用pycharts来编辑图表,主库如下
2.模拟浏览器发起请求
首先指定请求爬取资源的域名'Host':''
最重要的是使用正则表达式来理解字符串如何存储在正确的列表中。比如findall就是在字符串中查找所有正则表达式匹配的子串,并返回一个列表,如果有多个匹配模式,则返回一个元组列表,如果没有找到匹配,则返回列表
3.数据存储
二、数据清洗
清理数据,如果有空值就删除整行,如果信息杂乱则删除整行
数据清洗后的数据
三、数据可视化
使用pandas对第二张excel表进行操作
#add() 用于添加图表数据和设置各种配置项;
#render() 生成 .html 文件;
#map的基本用法,add_schema()表示添加框架并导入map
#set_series_opts() 可以设置标签等。
#set_global_opts(),还可以设置很多配置项,比如:标题、工具箱等。
1.教育要求玫瑰图
2.工作经验要求漏斗图
3.大数据城市需求分布图
四、项目改进
以上就是求职攀登项目的全部内容。完成这些内容后,我和我的朋友们也想到了一些改进,比如增加更多的数据清理,或者制作更多的图表,以方便分析工作情况;关键代码如下:
1.改进一
#转换工资单位
b3 = u'万/年'
b4 = u'千/月'
li3 = a['薪水']
对于范围内的 i(0,len(li3)):
尝试:
如果 li3[i] 中的 b3:
x = re.findall(r'\d*\.?\d+',li3[i])
#打印(x)
min_ = format(float(x[0])/12,'.2f') #转为浮点,保留小数点后两位
max_ = format(float(x[1])/12,'.2f')
li3[i][1] = min_+'-'+max_+u'10,000/月'
如果 li3[i] 中的 b4:
x = re.findall(r'\d*\.?\d+',li3[i])
#打印(x)
#输入()
min_ = format(float(x[0])/10,'.2f')
max_ = format(float(x[1])/10,'.2f')
li3[i][1] = str(min_+'-'+max_+'10,000/月')
打印(i,li3[i])
除了:
经过
2. 改进二
min_s=[] #定义最低工资表
max_s=[] #定义最高工资列表
对于范围内的 i (0,len(experience)):
min_s.append(salary[i][0])
max_s.append(salary[i][0])
如果#matplotlib模块无法显示中文字符串,可以使用如下代码
plt.rcParams['font.sans-serif'] = ['KaiTi'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False #解决减号'-'在保存的图片中显示为正方形的问题
my_df = pd.DataFrame({'experience':experience,'min_salay': min_s,'max_salay': max_s}) #相关的工作经验和工资
data1 = my_df.groupby('experience').mean()['min_salay'].plot(kind='line')
plt.show()
my_df2 = pd.DataFrame({'education':education,'min_salay': min_s,'max_salay': max_s}) #相关的教育和工资
data2 = my_df2.groupby('education').mean()['min_salay'].plot(kind='line')
plt.show() 查看全部
c爬虫抓取网页数据(用到的编程工具是python3.7,你知道吗?)
众所周知,爬虫是用python编程语言实现的,主要用于网络数据的爬取和处理,比如爬豆瓣电影TOP250、爬小说等……
而爬帖对于刚毕业的大学生来说也是非常有必要的。来看看怎么实现(使用的编程工具是python3.7)
一、抓取作业信息1.引导库
简单方法:在cmd中输入pip安装库名
urllib.request 用于模拟浏览器发起HTTP请求
xlwt库支持python语言对excel表格进行操作
re 库用于用正则表达式匹配和替换字符串
pandas 库是一个开源的、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。
读取爬取的excel表
这部分主要使用pycharts来编辑图表,主库如下
2.模拟浏览器发起请求
首先指定请求爬取资源的域名'Host':''
最重要的是使用正则表达式来理解字符串如何存储在正确的列表中。比如findall就是在字符串中查找所有正则表达式匹配的子串,并返回一个列表,如果有多个匹配模式,则返回一个元组列表,如果没有找到匹配,则返回列表
3.数据存储
二、数据清洗
清理数据,如果有空值就删除整行,如果信息杂乱则删除整行
数据清洗后的数据
三、数据可视化
使用pandas对第二张excel表进行操作
#add() 用于添加图表数据和设置各种配置项;
#render() 生成 .html 文件;
#map的基本用法,add_schema()表示添加框架并导入map
#set_series_opts() 可以设置标签等。
#set_global_opts(),还可以设置很多配置项,比如:标题、工具箱等。
1.教育要求玫瑰图
2.工作经验要求漏斗图
3.大数据城市需求分布图
四、项目改进
以上就是求职攀登项目的全部内容。完成这些内容后,我和我的朋友们也想到了一些改进,比如增加更多的数据清理,或者制作更多的图表,以方便分析工作情况;关键代码如下:
1.改进一
#转换工资单位
b3 = u'万/年'
b4 = u'千/月'
li3 = a['薪水']
对于范围内的 i(0,len(li3)):
尝试:
如果 li3[i] 中的 b3:
x = re.findall(r'\d*\.?\d+',li3[i])
#打印(x)
min_ = format(float(x[0])/12,'.2f') #转为浮点,保留小数点后两位
max_ = format(float(x[1])/12,'.2f')
li3[i][1] = min_+'-'+max_+u'10,000/月'
如果 li3[i] 中的 b4:
x = re.findall(r'\d*\.?\d+',li3[i])
#打印(x)
#输入()
min_ = format(float(x[0])/10,'.2f')
max_ = format(float(x[1])/10,'.2f')
li3[i][1] = str(min_+'-'+max_+'10,000/月')
打印(i,li3[i])
除了:
经过
2. 改进二
min_s=[] #定义最低工资表
max_s=[] #定义最高工资列表
对于范围内的 i (0,len(experience)):
min_s.append(salary[i][0])
max_s.append(salary[i][0])
如果#matplotlib模块无法显示中文字符串,可以使用如下代码
plt.rcParams['font.sans-serif'] = ['KaiTi'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False #解决减号'-'在保存的图片中显示为正方形的问题
my_df = pd.DataFrame({'experience':experience,'min_salay': min_s,'max_salay': max_s}) #相关的工作经验和工资
data1 = my_df.groupby('experience').mean()['min_salay'].plot(kind='line')
plt.show()
my_df2 = pd.DataFrame({'education':education,'min_salay': min_s,'max_salay': max_s}) #相关的教育和工资
data2 = my_df2.groupby('education').mean()['min_salay'].plot(kind='line')
plt.show()
c爬虫抓取网页数据(RequestHeaders请求的方式(getpost)RequestMethod:(主机和端口号))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-28 13:12
HTTP 请求和响应 General All 1.Request URL Request URL2.Request Method Request method (get post) 3.Response Headers Server's response Request Headers Server's request1.Host: (host和端口号)对应的URL2.Connection:(链接类型)3.User-Agent:用户代理4.Accept:(要传输的文件类型)5.referer: (页面跳转的地方)6.Cookie:(记录用户相关信息)7.Query String Paramerers 请求地址的参数
爬虫简介 什么是爬虫?简而言之,为什么需要爬虫而不是人来模拟浏览器进行网页操作?为其他程序提供数据源公司获取数据?1.公司自有数据2.第三方平台获取的数据免费平台:百度指数付费平台:Datatang3.爬虫爬取的数据python作为爬虫的优势1. PHP:对多线程和异步支持不是很好2.Java:代码量大,代码量大3.C/C++:代码量大,难写4.Python:很多支持模块,代码介绍,开发效率高(scrapy框架)爬虫分类1.一般网络爬虫如:百度雅虎谷歌2.专注网络爬虫:根据既定目标选择性抓取特定主题的内容几个概念1. URL组件 URL:全局统一资源定位器 https:网络协议:主机名,可以理解为主机名,这个主机在域名下TWF24000.html:Access Resource path anchor:锚点,用于前端页面定位。注意:当您在浏览器中请求 URL 时,浏览器会对 URL 进行编码。
服务器内部请求5.Cookie 记录服务器相关的用户信息 http 协议是无状态的 什么是无状态?服务端无法确定用户身份Cookie实际上是一小段文本信息(key-value格式) 防爬功能:防爬模拟登录抓包工具1.元素:元素网页源码,提取数据并分析数据(一些经过特殊处理,所以不完全准确)2.Console:控制台(打印信息)用得不多3.Sources:信息源(整个网站加载的文件)用的不多4.Net Work:网络工作(信息抓取)可以看到很多网页请求 Cookie 记录服务器相关的用户信息 http 协议是无状态的 什么是无状态?服务端无法确定用户身份Cookie实际上是一小段文本信息(key-value格式) 防爬功能:防爬模拟登录抓包工具1.元素:元素网页源码,提取数据并分析数据(一些经过特殊处理,所以不完全准确)2.Console:控制台(打印信息)用得不多3.Sources:信息源(整个网站加载的文件)用的不多4.Net Work:网络工作(信息抓取)可以看到很多网页请求 Cookie 记录服务器相关的用户信息 http 协议是无状态的 什么是无状态?服务端无法确定用户身份Cookie实际上是一小段文本信息(key-value格式) 防爬功能:防爬模拟登录抓包工具1.元素:元素网页源码,提取数据并分析数据(一些经过特殊处理,所以不完全准确)2.Console:控制台(打印信息)用得不多3.Sources:信息源(整个网站加载的文件)用的不多4.Net Work:网络工作(信息抓取)可以看到很多网页请求 查看全部
c爬虫抓取网页数据(RequestHeaders请求的方式(getpost)RequestMethod:(主机和端口号))
HTTP 请求和响应 General All 1.Request URL Request URL2.Request Method Request method (get post) 3.Response Headers Server's response Request Headers Server's request1.Host: (host和端口号)对应的URL2.Connection:(链接类型)3.User-Agent:用户代理4.Accept:(要传输的文件类型)5.referer: (页面跳转的地方)6.Cookie:(记录用户相关信息)7.Query String Paramerers 请求地址的参数
爬虫简介 什么是爬虫?简而言之,为什么需要爬虫而不是人来模拟浏览器进行网页操作?为其他程序提供数据源公司获取数据?1.公司自有数据2.第三方平台获取的数据免费平台:百度指数付费平台:Datatang3.爬虫爬取的数据python作为爬虫的优势1. PHP:对多线程和异步支持不是很好2.Java:代码量大,代码量大3.C/C++:代码量大,难写4.Python:很多支持模块,代码介绍,开发效率高(scrapy框架)爬虫分类1.一般网络爬虫如:百度雅虎谷歌2.专注网络爬虫:根据既定目标选择性抓取特定主题的内容几个概念1. URL组件 URL:全局统一资源定位器 https:网络协议:主机名,可以理解为主机名,这个主机在域名下TWF24000.html:Access Resource path anchor:锚点,用于前端页面定位。注意:当您在浏览器中请求 URL 时,浏览器会对 URL 进行编码。
服务器内部请求5.Cookie 记录服务器相关的用户信息 http 协议是无状态的 什么是无状态?服务端无法确定用户身份Cookie实际上是一小段文本信息(key-value格式) 防爬功能:防爬模拟登录抓包工具1.元素:元素网页源码,提取数据并分析数据(一些经过特殊处理,所以不完全准确)2.Console:控制台(打印信息)用得不多3.Sources:信息源(整个网站加载的文件)用的不多4.Net Work:网络工作(信息抓取)可以看到很多网页请求 Cookie 记录服务器相关的用户信息 http 协议是无状态的 什么是无状态?服务端无法确定用户身份Cookie实际上是一小段文本信息(key-value格式) 防爬功能:防爬模拟登录抓包工具1.元素:元素网页源码,提取数据并分析数据(一些经过特殊处理,所以不完全准确)2.Console:控制台(打印信息)用得不多3.Sources:信息源(整个网站加载的文件)用的不多4.Net Work:网络工作(信息抓取)可以看到很多网页请求 Cookie 记录服务器相关的用户信息 http 协议是无状态的 什么是无状态?服务端无法确定用户身份Cookie实际上是一小段文本信息(key-value格式) 防爬功能:防爬模拟登录抓包工具1.元素:元素网页源码,提取数据并分析数据(一些经过特殊处理,所以不完全准确)2.Console:控制台(打印信息)用得不多3.Sources:信息源(整个网站加载的文件)用的不多4.Net Work:网络工作(信息抓取)可以看到很多网页请求
c爬虫抓取网页数据(爬虫在数据分析领域的应用,如何帮助我们提升数据分析质量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-28 13:09
在当今的信息和数字时代,人们离不开互联网搜索。但是想想看,你真的可以在搜索过程中得到相关信息,因为有人在帮你过滤和提交相关内容到你面前。
就像在餐馆里,你点了土豆,你可以吃,因为有人帮你在土豆、萝卜、西红柿等中找到土豆,有些人把它们带到你的桌子上。在网上,这两个动作是由一个叫Crawler的同学实现的。
换句话说,没有爬虫,就没有今天的检索,也就无法准确查找信息,有效获取数据。今天我们就来聊聊爬虫在数据分析领域的应用,以及它如何帮助我们提高数据分析的质量。
一、 数据时代,爬虫的本质是提高效率
网络爬虫也称为网络机器人,可以代替人自动浏览互联网上的信息,采集
和整理数据。
它是一个程序,其基本原理是向网站/网络发起请求,在获取资源后分析并提取有用的数据。从技术角度来说,就是通过程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)抓取到本地,然后提取你的数据需要,并保存以备使用。
每个程序都有自己的规则,网络爬虫也不例外。它穿梭在世界各地的各种网站之间,根据人们制定的规则采集
信息。我们将这些规则称为网络爬虫算法。规则是人定的,是人根据自己的目的和需要设计的。因此,爬虫可以根据用户的目的而具有不同的功能。但所有爬虫的本质都是为了方便人们从海量的互联网信息中找到并下载自己想要的那种,从而提高信息获取的效率。
二、爬虫的应用:搜索,帮助企业做强业务
1.搜索引擎:抓取站点,为网络用户提供便利
在互联网发展之初,能够提供全球范围信息的网站并不多,用户也不多。Internet 只是文件传输协议 (FTP) 站点的集合。用户可以浏览这些站点以查找特定的共享文件。为了查找和组合 Internet 上可用的分布式数据,人们创建了一种称为网络爬虫的自动化程序。/Robots 可以抓取互联网上的所有网页,然后将所有页面上的内容复制到数据库中进行索引。这也是最早的搜索引擎。
如今,随着互联网的飞速发展,我们可以在任何搜索引擎中看到来自全球各个网站的信息。百度搜索引擎的爬虫叫Baiduspider,360的爬虫叫360Spider,搜狗的爬虫叫Sogouspider,必应的爬虫叫Bingbot。搜索引擎离不开爬虫。
例如,百度蜘蛛每天抓取大量互联网信息,抓取并采集
优质信息。当用户在百度搜索引擎上检索到对应的关键词时,百度会对关键词进行分析处理,从收录的网页中找出相关网页,并按照一定的排序规则进行排序,并显示结果给用户,工作原理如图所示。现在,我们可以大胆地说,您每天都在免费享受爬虫带来的好处。
2.企业:监测舆情,高效获取有价值信息
我们说过爬虫的本质是提高效率,爬虫的规则是人定的;那么,企业可以根据自己的业务需求设计爬虫,第一时间获取网络上的相关信息,进行清理整合。
大数据时代的数据分析,首先要有数据源,网络爬虫可以让我们在根据自己的目的进行采集的同时获取更多的数据源,从而去除很多不相关的数据。
例如,在进行大数据分析或数据挖掘时,数据源可以从某些提供统计数据的网站中获取,也可以从某些文档或内部资料中获取。但是这些获取数据的方法有时很难满足我们的数据需求。此时,我们可以利用爬虫技术,自动从互联网上获取更多我们感兴趣的数据内容,从而进行更深入的数据分析,获取更多有价值的信息。
此外,网络爬虫还可用于财务分析,采集
财务数据进行投资分析;应用于舆情监测分析、目标客户精准营销等领域。
三、企业常用的4种网络爬虫
根据实现的技术和结构,网络爬虫可分为通用网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。但是,实际的网络爬虫由于网络环境复杂,通常是这几种爬虫的组合。
1.通用网络爬虫
一般的网络爬虫也称为全网爬虫。顾名思义,爬取的目标资源在整个互联网。爬取的目标数据庞大,爬取的范围也非常大。正是因为它爬取的数据是海量数据,所以对于这类爬虫,对爬取性能的要求非常高。这种网络爬虫主要用于大型搜索引擎,具有非常高的应用价值。
一般的网络爬虫主要由初始URL采集、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块等组成。常见的网络爬虫在爬取时都会采用一定的爬取策略,主要有深度优先爬取策略和广度优先爬取策略。具体细节将在后面介绍。
2.专注于网络爬虫
聚焦网络爬虫也称为主题网络爬虫,是根据预先定义的主题有选择地抓取网页的爬虫。专注网络爬虫主要用于对特定信息的爬取,主要是为特定的人群提供服务。
焦点网络爬虫还由初始URL采集、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块、内容评价模块、链接评价模块等组成。 其中,内容评价模块和链接评价模块模块可以根据链接的重要性和内容来决定优先访问哪些页面。主要针对网络爬虫的爬虫策略有四种,如图:
专注的网络爬虫可以根据相应的主题有针对性地进行爬取,因此在实际应用过程中,可以节省大量的服务器资源和宽带资源,具有很强的实用性。这里以聚焦网络爬虫为例,了解爬虫运行的工作原理和流程。
如图所示,Focus Web Crawler有一个控制中心,负责整个爬虫系统的管理和监控,主要包括控制用户交互、初始化爬虫、确定主题、协调各个模块之间的工作、并控制爬行过程。等等:
(1)控制中心将初始URL集合传递给URL队列,页面爬取模块会从URL队列中读取第一批URL列表;
(2)根据这些URL地址从网上爬取相应的页面;爬取后,将爬取的内容传送到页面数据库中存储;
(3)在爬取过程中会爬取一些新的网址,这时候就需要使用链接过滤模块根据主题集过滤掉不相关的链接,然后使用链接评价模块进行剩余的URL链接根据主题或内容评估模块进行优先排序,完成后将新的URL地址传递给URL队列,供页面爬取模块使用;
(4) 抓取页面并存入页面数据库后,需要使用页面分析模块根据主题对抓取的页面进行页面分析处理,并根据处理结果建立索引数据库. 当用户检索到相应的信息时,可以从索引数据库中进行相应的搜索,得到相应的结果。
3.增量网络爬虫
这里的“增量”对应的是增量更新。增量更新是指更新时只更新变化的区域,不变的区域不更新。
增量式网络爬虫,在抓取网页时,只抓取有内容变化的网页或新生成的网页,不抓取没有内容变化的网页。增量式网络爬虫可以在一定程度上保证被爬取的页面尽可能的新鲜。
4.深网爬虫
在互联网中,网页按其存在方式可分为表层页和深层页。表面页面是指无需提交表单即可使用静态链接访问的静态页面;而深页是提交一定数量的关键词后才能获得的页面。在互联网中,深层页面的数量往往远大于表面页面的数量。
深度网络爬虫可以抓取互联网上的深度页面,抓取深度页面,需要想办法自动填写相应的表单。深网爬虫主要由URL列表、LVS列表(LVS指标签/值集合,即填写表单的数据源)、爬取控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析仪等部分组成。
四、网络爬虫的爬取策略
前面我们说过,网络爬虫算法是根据人强加的规则来采集
信息的,由于网络环境复杂,有各种对应的算法,即爬虫策略。这里主要介绍爬取的顺序和频率。
1. 爬取顺序
网络爬虫在爬取的过程中,爬取的URL列表中可能有很多URL地址,所以爬虫爬取这些URL地址会有一个顺序。
与一般的网络爬虫相比,爬取的顺序并不是那么重要。但是针对网络爬虫来说,爬取的顺序与服务器资源和宽带资源有关,所以非常重要,一般由爬取策略决定。爬取策略主要包括深度优先爬取策略、广度优先爬取策略、大站优先策略、反链策略、其他爬取策略等。
如图,假设有一个网站,ABCDEFG是该网站下的网页,如图所示,它代表了网页的层次结构。如果此时所有的网页ABCDEFG都在爬取队列中,根据不同的爬取策略,爬取的顺序也不同。
深度优先爬取策略:A→D→E→B→C→F→G
广度优先爬取策略:A→B→C→D→E→F→G
除了以上两种爬取策略外,还可以使用大站点爬取策略。可以根据相应网页所属的站点进行分类。如果一个网站有大量的网页,则称为大网站。按照这个策略,网页数量越多,网站越大,然后先爬取网页的大站URL地址。
还有反链策略。一个网页的反向链接数是指该网页被其他网页指向的次数。这个数字在一定程度上代表了该网页被其他网页推荐的次数。所以,如果按照反链策略爬取,那么哪个网页反链多,哪个页面会先被爬取。
但是,在实际情况中,如果仅通过反链策略来确定网页的优先级,则可能会出现大量的作弊行为。因此,使用反向链路策略需要考虑可靠反向链路的数量。除了以上爬取策略,实践中还有很多其他的爬取策略,比如OPIC策略、Partial PageRank策略等。
2. 爬行频率
网站的网页经常更新。作为爬虫,网站的更新频率越接近爬虫访问网站的频率,效果越好。当然,在爬虫服务器资源有限的情况下,爬虫也需要根据相应的策略,让不同的网页有不同的更新优先级,优先级高的网页会以更快的爬取响应进行更新。常见的网页更新策略有以下三种:
(1)用户体验策略:大多数用户在使用搜索引擎查询某个关键词时,只关注排名靠前的网页。因此,当爬虫服务器资源有限时,爬虫会优先更新排名结果最高的页面。
(2)历史数据策略:是指某个网页的历史更新数据,通过泊松过程建模等手段,预测网页下次更新时间,从而确定网页下次更新时间爬。慢慢来。
(3) 聚类分析策略:网页可能有不同的内容,但一般来说属性相似的网页更新频率相近,所以可以对大量网页进行聚类分析。聚类完成后,可以根据同类型网页的平均更新值设置抓取频率。
五、网络爬虫的实现技术
对于实现技术,本文不展开,只为感兴趣的同学提供几种常用语言:Python、Java、PHP、Node.JS、C++、Go语言(另外还有很多web开发语言爬虫)。
Python:爬虫框架非常丰富,多线程处理能力强,简单易学,代码简洁,优点很多。
Java:适合大型爬虫项目的开发。
PHP:后端处理能力很强,代码很简洁,模块也很丰富,但是并发能力比较弱。
Node.JS:支持高并发和多线程处理。
C++:运行速度快,适合大型爬虫项目的开发,成本高。
Go语言:同样高并发性很强。
六、总结
说起爬虫,很多人认为是网络世界中无法回避的灰色地带。恭喜你,看完这篇文章,你比很多人都清楚。
因为爬虫分为善意爬虫和恶意爬虫,比如搜索引擎爬虫。善意爬虫严格遵守Robots协议,抓取网页数据(如URL)。它的存在可以增加网站的曝光度,给网站带来流量;
恶意爬虫无视Robots协议,故意爬取一些深层次的、不愿公开的网站数据,包括个人隐私或商业秘密等重要信息。而且,恶意爬虫的用户希望从网站上获取多条、大量的信息,因此通常会向目标网站发布大量的爬虫。如果大量爬虫同时访问网站,很容易造成网站服务器过载或崩溃,给网站运营者造成损失。
据统计,2017年我国42.2%的互联网流量是由网络机器人创造的,其中恶意机器(主要是恶意爬虫)占21.80%。我们应该依法使用网络爬虫,用技术为企业带来长远发展,用科学为社会创造更高的价值。 查看全部
c爬虫抓取网页数据(爬虫在数据分析领域的应用,如何帮助我们提升数据分析质量)
在当今的信息和数字时代,人们离不开互联网搜索。但是想想看,你真的可以在搜索过程中得到相关信息,因为有人在帮你过滤和提交相关内容到你面前。
就像在餐馆里,你点了土豆,你可以吃,因为有人帮你在土豆、萝卜、西红柿等中找到土豆,有些人把它们带到你的桌子上。在网上,这两个动作是由一个叫Crawler的同学实现的。
换句话说,没有爬虫,就没有今天的检索,也就无法准确查找信息,有效获取数据。今天我们就来聊聊爬虫在数据分析领域的应用,以及它如何帮助我们提高数据分析的质量。
一、 数据时代,爬虫的本质是提高效率
网络爬虫也称为网络机器人,可以代替人自动浏览互联网上的信息,采集
和整理数据。
它是一个程序,其基本原理是向网站/网络发起请求,在获取资源后分析并提取有用的数据。从技术角度来说,就是通过程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)抓取到本地,然后提取你的数据需要,并保存以备使用。
每个程序都有自己的规则,网络爬虫也不例外。它穿梭在世界各地的各种网站之间,根据人们制定的规则采集
信息。我们将这些规则称为网络爬虫算法。规则是人定的,是人根据自己的目的和需要设计的。因此,爬虫可以根据用户的目的而具有不同的功能。但所有爬虫的本质都是为了方便人们从海量的互联网信息中找到并下载自己想要的那种,从而提高信息获取的效率。
二、爬虫的应用:搜索,帮助企业做强业务
1.搜索引擎:抓取站点,为网络用户提供便利
在互联网发展之初,能够提供全球范围信息的网站并不多,用户也不多。Internet 只是文件传输协议 (FTP) 站点的集合。用户可以浏览这些站点以查找特定的共享文件。为了查找和组合 Internet 上可用的分布式数据,人们创建了一种称为网络爬虫的自动化程序。/Robots 可以抓取互联网上的所有网页,然后将所有页面上的内容复制到数据库中进行索引。这也是最早的搜索引擎。
如今,随着互联网的飞速发展,我们可以在任何搜索引擎中看到来自全球各个网站的信息。百度搜索引擎的爬虫叫Baiduspider,360的爬虫叫360Spider,搜狗的爬虫叫Sogouspider,必应的爬虫叫Bingbot。搜索引擎离不开爬虫。
例如,百度蜘蛛每天抓取大量互联网信息,抓取并采集
优质信息。当用户在百度搜索引擎上检索到对应的关键词时,百度会对关键词进行分析处理,从收录的网页中找出相关网页,并按照一定的排序规则进行排序,并显示结果给用户,工作原理如图所示。现在,我们可以大胆地说,您每天都在免费享受爬虫带来的好处。
2.企业:监测舆情,高效获取有价值信息
我们说过爬虫的本质是提高效率,爬虫的规则是人定的;那么,企业可以根据自己的业务需求设计爬虫,第一时间获取网络上的相关信息,进行清理整合。
大数据时代的数据分析,首先要有数据源,网络爬虫可以让我们在根据自己的目的进行采集的同时获取更多的数据源,从而去除很多不相关的数据。
例如,在进行大数据分析或数据挖掘时,数据源可以从某些提供统计数据的网站中获取,也可以从某些文档或内部资料中获取。但是这些获取数据的方法有时很难满足我们的数据需求。此时,我们可以利用爬虫技术,自动从互联网上获取更多我们感兴趣的数据内容,从而进行更深入的数据分析,获取更多有价值的信息。
此外,网络爬虫还可用于财务分析,采集
财务数据进行投资分析;应用于舆情监测分析、目标客户精准营销等领域。
三、企业常用的4种网络爬虫
根据实现的技术和结构,网络爬虫可分为通用网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。但是,实际的网络爬虫由于网络环境复杂,通常是这几种爬虫的组合。
1.通用网络爬虫
一般的网络爬虫也称为全网爬虫。顾名思义,爬取的目标资源在整个互联网。爬取的目标数据庞大,爬取的范围也非常大。正是因为它爬取的数据是海量数据,所以对于这类爬虫,对爬取性能的要求非常高。这种网络爬虫主要用于大型搜索引擎,具有非常高的应用价值。
一般的网络爬虫主要由初始URL采集、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块等组成。常见的网络爬虫在爬取时都会采用一定的爬取策略,主要有深度优先爬取策略和广度优先爬取策略。具体细节将在后面介绍。
2.专注于网络爬虫
聚焦网络爬虫也称为主题网络爬虫,是根据预先定义的主题有选择地抓取网页的爬虫。专注网络爬虫主要用于对特定信息的爬取,主要是为特定的人群提供服务。
焦点网络爬虫还由初始URL采集、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块、内容评价模块、链接评价模块等组成。 其中,内容评价模块和链接评价模块模块可以根据链接的重要性和内容来决定优先访问哪些页面。主要针对网络爬虫的爬虫策略有四种,如图:
专注的网络爬虫可以根据相应的主题有针对性地进行爬取,因此在实际应用过程中,可以节省大量的服务器资源和宽带资源,具有很强的实用性。这里以聚焦网络爬虫为例,了解爬虫运行的工作原理和流程。
如图所示,Focus Web Crawler有一个控制中心,负责整个爬虫系统的管理和监控,主要包括控制用户交互、初始化爬虫、确定主题、协调各个模块之间的工作、并控制爬行过程。等等:
(1)控制中心将初始URL集合传递给URL队列,页面爬取模块会从URL队列中读取第一批URL列表;
(2)根据这些URL地址从网上爬取相应的页面;爬取后,将爬取的内容传送到页面数据库中存储;
(3)在爬取过程中会爬取一些新的网址,这时候就需要使用链接过滤模块根据主题集过滤掉不相关的链接,然后使用链接评价模块进行剩余的URL链接根据主题或内容评估模块进行优先排序,完成后将新的URL地址传递给URL队列,供页面爬取模块使用;
(4) 抓取页面并存入页面数据库后,需要使用页面分析模块根据主题对抓取的页面进行页面分析处理,并根据处理结果建立索引数据库. 当用户检索到相应的信息时,可以从索引数据库中进行相应的搜索,得到相应的结果。
3.增量网络爬虫
这里的“增量”对应的是增量更新。增量更新是指更新时只更新变化的区域,不变的区域不更新。
增量式网络爬虫,在抓取网页时,只抓取有内容变化的网页或新生成的网页,不抓取没有内容变化的网页。增量式网络爬虫可以在一定程度上保证被爬取的页面尽可能的新鲜。
4.深网爬虫
在互联网中,网页按其存在方式可分为表层页和深层页。表面页面是指无需提交表单即可使用静态链接访问的静态页面;而深页是提交一定数量的关键词后才能获得的页面。在互联网中,深层页面的数量往往远大于表面页面的数量。
深度网络爬虫可以抓取互联网上的深度页面,抓取深度页面,需要想办法自动填写相应的表单。深网爬虫主要由URL列表、LVS列表(LVS指标签/值集合,即填写表单的数据源)、爬取控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析仪等部分组成。
四、网络爬虫的爬取策略
前面我们说过,网络爬虫算法是根据人强加的规则来采集
信息的,由于网络环境复杂,有各种对应的算法,即爬虫策略。这里主要介绍爬取的顺序和频率。
1. 爬取顺序
网络爬虫在爬取的过程中,爬取的URL列表中可能有很多URL地址,所以爬虫爬取这些URL地址会有一个顺序。
与一般的网络爬虫相比,爬取的顺序并不是那么重要。但是针对网络爬虫来说,爬取的顺序与服务器资源和宽带资源有关,所以非常重要,一般由爬取策略决定。爬取策略主要包括深度优先爬取策略、广度优先爬取策略、大站优先策略、反链策略、其他爬取策略等。
如图,假设有一个网站,ABCDEFG是该网站下的网页,如图所示,它代表了网页的层次结构。如果此时所有的网页ABCDEFG都在爬取队列中,根据不同的爬取策略,爬取的顺序也不同。
深度优先爬取策略:A→D→E→B→C→F→G
广度优先爬取策略:A→B→C→D→E→F→G
除了以上两种爬取策略外,还可以使用大站点爬取策略。可以根据相应网页所属的站点进行分类。如果一个网站有大量的网页,则称为大网站。按照这个策略,网页数量越多,网站越大,然后先爬取网页的大站URL地址。
还有反链策略。一个网页的反向链接数是指该网页被其他网页指向的次数。这个数字在一定程度上代表了该网页被其他网页推荐的次数。所以,如果按照反链策略爬取,那么哪个网页反链多,哪个页面会先被爬取。
但是,在实际情况中,如果仅通过反链策略来确定网页的优先级,则可能会出现大量的作弊行为。因此,使用反向链路策略需要考虑可靠反向链路的数量。除了以上爬取策略,实践中还有很多其他的爬取策略,比如OPIC策略、Partial PageRank策略等。
2. 爬行频率
网站的网页经常更新。作为爬虫,网站的更新频率越接近爬虫访问网站的频率,效果越好。当然,在爬虫服务器资源有限的情况下,爬虫也需要根据相应的策略,让不同的网页有不同的更新优先级,优先级高的网页会以更快的爬取响应进行更新。常见的网页更新策略有以下三种:
(1)用户体验策略:大多数用户在使用搜索引擎查询某个关键词时,只关注排名靠前的网页。因此,当爬虫服务器资源有限时,爬虫会优先更新排名结果最高的页面。
(2)历史数据策略:是指某个网页的历史更新数据,通过泊松过程建模等手段,预测网页下次更新时间,从而确定网页下次更新时间爬。慢慢来。
(3) 聚类分析策略:网页可能有不同的内容,但一般来说属性相似的网页更新频率相近,所以可以对大量网页进行聚类分析。聚类完成后,可以根据同类型网页的平均更新值设置抓取频率。
五、网络爬虫的实现技术
对于实现技术,本文不展开,只为感兴趣的同学提供几种常用语言:Python、Java、PHP、Node.JS、C++、Go语言(另外还有很多web开发语言爬虫)。
Python:爬虫框架非常丰富,多线程处理能力强,简单易学,代码简洁,优点很多。
Java:适合大型爬虫项目的开发。
PHP:后端处理能力很强,代码很简洁,模块也很丰富,但是并发能力比较弱。
Node.JS:支持高并发和多线程处理。
C++:运行速度快,适合大型爬虫项目的开发,成本高。
Go语言:同样高并发性很强。
六、总结
说起爬虫,很多人认为是网络世界中无法回避的灰色地带。恭喜你,看完这篇文章,你比很多人都清楚。
因为爬虫分为善意爬虫和恶意爬虫,比如搜索引擎爬虫。善意爬虫严格遵守Robots协议,抓取网页数据(如URL)。它的存在可以增加网站的曝光度,给网站带来流量;
恶意爬虫无视Robots协议,故意爬取一些深层次的、不愿公开的网站数据,包括个人隐私或商业秘密等重要信息。而且,恶意爬虫的用户希望从网站上获取多条、大量的信息,因此通常会向目标网站发布大量的爬虫。如果大量爬虫同时访问网站,很容易造成网站服务器过载或崩溃,给网站运营者造成损失。
据统计,2017年我国42.2%的互联网流量是由网络机器人创造的,其中恶意机器(主要是恶意爬虫)占21.80%。我们应该依法使用网络爬虫,用技术为企业带来长远发展,用科学为社会创造更高的价值。
c爬虫抓取网页数据(【Python爬虫】C站软件工程师能力认证模拟大赛对标名企技术标准 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-28 13:08
)
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常见的网络追逐者)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。
爬虫容易上手,但更难深入。如何编写高效的爬虫,如何编写高度灵活和可扩展的爬虫,都是技术任务。另外,在爬取过程中,往往容易遇到反爬虫,比如字体反爬、IP识别、验证码等,如何克服困难,得到想要的数据,这些问题往往困扰着学爬的小伙伴们。
今天给大家分享99篇与【Python爬虫】相关的精选学习资料,不仅详细讲解了基本概念、正则表达式、Beautiful Soup、lxml、requests等知识点,而且从入门到精通都适用- 全面学习。同时还有6本学习爬虫必读书籍,扫码获取。
参加C认证模拟考试即可领取!
同时,针对Python基础薄弱的同学,我们推出了C站软件工程师能力认证,帮助大家系统学习,全面树立编码学习思维,具备扎实的编码能力。
如果你还想知道你的Python爬虫能力是否符合你喜欢的公司的技术标准?
赶快点击此链接,在C认证模拟大赛中进行测试吧!
C-认证模拟竞赛是针对被贴标企业的技术标准。无论你是从学校招聘、转业,还是加薪,都可以通过这个测试,得到你想要的答案。认证梳理软件工程师开发过程中所需的各种技术技能,结合企业招聘需求和人才申请痛点,本着公开、透明、公平的原则,确保真实的业务场景、代码实践、真实人的容貌,选才的过程 留下的痕迹和档案是不可篡改的。检验技术人才的真实能力,为企业节省招聘培训成本,为行业提供人才储备,为国家数字化战略贡献力量。
一、完成免费模拟测试,带领99本Python爬虫精选学习资料
为了方便大家学习,我们推出了C站百万知识库行动,其中收录
99篇【Python爬虫】学习资料,点击量过万,采集
过千。点击链接()完成C认证模拟大赛中的测试,即Available!收录
基础概念、正则表达式、Beautiful Soup、lxml、requests等知识点。无论您是Java、Python、前端技术的新手,还是已经有一定基础的技术爱好者,在这里都能找到您想要的信息。
扫描二维码添加小龙女即可获取
部分信息显示:
二、Python爬虫好书免费领
学习爬虫,书籍是必不可少的学习工具之一,尤其是对于自学者来说。今天给大家带来6本学习Python爬虫必读的好书,非常全面。
扫描海报二维码参加C认证模拟考试,即可获得CSDN电子书,包括以下书籍!考试结束后,每月电子书卡将在3个工作日内发放到您的账户。
三、数以百万计的知识库等着你!
目前我们整理了Java知识库600篇、Python知识库600篇、前端知识库600篇、IT软件工程师基础能力500篇,其中不仅包括基础能力学习小白+1,也是需要大厂拥有的项目能力。学习教程。知识库持续更新,欢迎加入我们一起学习!
C站的知识库涵盖以下知识点。每日更新,欢迎进群系统学习!
部分数据预览:
信息太多,无法一一截图。完成模拟考试后,欢迎您扫码进入C认证考试福利群。信息每天下午5点更新~
赶快点击此链接,在C认证模拟大赛中进行测试吧!
完成后添加小龙女接收信息
下图是C站(CSDN)软件工程师能力认证标准中的C1/C4-能力认证示意图。分为基础能力和项目能力两个模块。可以看到模块中的技能点可以涵盖一线大厂的开发工程师招聘JD需求。
通过以上,可以清楚地看到,大公司的招聘要求和能力认证是一一对应的,是紧密相连的。
C认证的企业奖学金计划支持梦想,让努力工作发光。同时,C认证的成功离不开以下合作公司的赞助,谢谢你们一路的陪伴~
CSDN软件工程师能力认证(以下简称C系列认证)是由中国软件开发者网CSDN开发推出的能力认证标准。C系列认证经历了近一年的实际线下调研、考察、迭代、测试,梳理出软件工程师开发过程中需要的各种技术技能,结合企业招聘需求和人才申请痛点,基于公开、透明、公平 原则上,在分配人才时,要保证真实的业务场景,所有在船上的实际操作,所有流程的痕迹,不可篡改的档案。
C系列认证步骤:
1.打开官网(),预约认证,注册成功。
2.扫描下方二维码进入群领取学习资料和学习任务。群内也有直播解说和答疑。一起记录下自己的成长历程吧~
预约后即可进入C认证任务组
有:
1、C认证各阶段学习资料
2、C认证在实践任务的每个阶段,完成后还可以获得合作企业赞助的红包!
3、 任务现场讲解和专家问答
4、每天更新系统干货文章合集,整合系统知识库,帮助大家自主学习
赶紧加小龙女,一起记录下自己的成长历程吧~
查看全部
c爬虫抓取网页数据(【Python爬虫】C站软件工程师能力认证模拟大赛对标名企技术标准
)
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常见的网络追逐者)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。
爬虫容易上手,但更难深入。如何编写高效的爬虫,如何编写高度灵活和可扩展的爬虫,都是技术任务。另外,在爬取过程中,往往容易遇到反爬虫,比如字体反爬、IP识别、验证码等,如何克服困难,得到想要的数据,这些问题往往困扰着学爬的小伙伴们。
今天给大家分享99篇与【Python爬虫】相关的精选学习资料,不仅详细讲解了基本概念、正则表达式、Beautiful Soup、lxml、requests等知识点,而且从入门到精通都适用- 全面学习。同时还有6本学习爬虫必读书籍,扫码获取。
参加C认证模拟考试即可领取!
同时,针对Python基础薄弱的同学,我们推出了C站软件工程师能力认证,帮助大家系统学习,全面树立编码学习思维,具备扎实的编码能力。
如果你还想知道你的Python爬虫能力是否符合你喜欢的公司的技术标准?
赶快点击此链接,在C认证模拟大赛中进行测试吧!
C-认证模拟竞赛是针对被贴标企业的技术标准。无论你是从学校招聘、转业,还是加薪,都可以通过这个测试,得到你想要的答案。认证梳理软件工程师开发过程中所需的各种技术技能,结合企业招聘需求和人才申请痛点,本着公开、透明、公平的原则,确保真实的业务场景、代码实践、真实人的容貌,选才的过程 留下的痕迹和档案是不可篡改的。检验技术人才的真实能力,为企业节省招聘培训成本,为行业提供人才储备,为国家数字化战略贡献力量。
一、完成免费模拟测试,带领99本Python爬虫精选学习资料
为了方便大家学习,我们推出了C站百万知识库行动,其中收录
99篇【Python爬虫】学习资料,点击量过万,采集
过千。点击链接()完成C认证模拟大赛中的测试,即Available!收录
基础概念、正则表达式、Beautiful Soup、lxml、requests等知识点。无论您是Java、Python、前端技术的新手,还是已经有一定基础的技术爱好者,在这里都能找到您想要的信息。
扫描二维码添加小龙女即可获取
部分信息显示:
二、Python爬虫好书免费领
学习爬虫,书籍是必不可少的学习工具之一,尤其是对于自学者来说。今天给大家带来6本学习Python爬虫必读的好书,非常全面。
扫描海报二维码参加C认证模拟考试,即可获得CSDN电子书,包括以下书籍!考试结束后,每月电子书卡将在3个工作日内发放到您的账户。
三、数以百万计的知识库等着你!
目前我们整理了Java知识库600篇、Python知识库600篇、前端知识库600篇、IT软件工程师基础能力500篇,其中不仅包括基础能力学习小白+1,也是需要大厂拥有的项目能力。学习教程。知识库持续更新,欢迎加入我们一起学习!
C站的知识库涵盖以下知识点。每日更新,欢迎进群系统学习!
部分数据预览:
信息太多,无法一一截图。完成模拟考试后,欢迎您扫码进入C认证考试福利群。信息每天下午5点更新~
赶快点击此链接,在C认证模拟大赛中进行测试吧!
完成后添加小龙女接收信息
下图是C站(CSDN)软件工程师能力认证标准中的C1/C4-能力认证示意图。分为基础能力和项目能力两个模块。可以看到模块中的技能点可以涵盖一线大厂的开发工程师招聘JD需求。
通过以上,可以清楚地看到,大公司的招聘要求和能力认证是一一对应的,是紧密相连的。
C认证的企业奖学金计划支持梦想,让努力工作发光。同时,C认证的成功离不开以下合作公司的赞助,谢谢你们一路的陪伴~
CSDN软件工程师能力认证(以下简称C系列认证)是由中国软件开发者网CSDN开发推出的能力认证标准。C系列认证经历了近一年的实际线下调研、考察、迭代、测试,梳理出软件工程师开发过程中需要的各种技术技能,结合企业招聘需求和人才申请痛点,基于公开、透明、公平 原则上,在分配人才时,要保证真实的业务场景,所有在船上的实际操作,所有流程的痕迹,不可篡改的档案。
C系列认证步骤:
1.打开官网(),预约认证,注册成功。
2.扫描下方二维码进入群领取学习资料和学习任务。群内也有直播解说和答疑。一起记录下自己的成长历程吧~
预约后即可进入C认证任务组
有:
1、C认证各阶段学习资料
2、C认证在实践任务的每个阶段,完成后还可以获得合作企业赞助的红包!
3、 任务现场讲解和专家问答
4、每天更新系统干货文章合集,整合系统知识库,帮助大家自主学习
赶紧加小龙女,一起记录下自己的成长历程吧~
c爬虫抓取网页数据(2021年最值得关注的10款常见网络安全工具_weixin_34357887)
网站优化 • 优采云 发表了文章 • 0 个评论 • 21 次浏览 • 2021-12-28 11:15
10个常用的网络安全工具_weixin_34357887的博客-CSDN博客。
Open-AudIT Open-AudIT 是一个网络发现、清单和审计程序。这个免费的开源软件可以扫描网络并存储有关发现设备的信息。
它是一个自动检测远程或本地主机安全弱点的程序。一个好的扫描器相当于一千个密码的价值。.
最好的75网络安全工具(转)阿火博客园。
下面是我在学习网络安全时用到的一些工具的总结。1.Wireshark 网址:。
网络安全工具总结_sinat_38598239的博客-CSDN博客。
网络安全工具Logcheck用于自动检查系统入侵事件和异常活动记录。它分析各种 Linux 日志文件,例如 /var/log/mes。
您可以在 Windows 平台上找到移植版本。工具:GFILANguard(商业网络安全扫描软件)网址:。
这也是 THC 贡献的另一个有价值的工具。GFILANguard:Windows 平台上的商用网络安全扫描仪 GFILANguard。
来了解一下2021年最值得关注的10个网络安全测试工具:NMap是NetworkMapper的缩写,NMap是一个开放的。 查看全部
c爬虫抓取网页数据(2021年最值得关注的10款常见网络安全工具_weixin_34357887)
10个常用的网络安全工具_weixin_34357887的博客-CSDN博客。
Open-AudIT Open-AudIT 是一个网络发现、清单和审计程序。这个免费的开源软件可以扫描网络并存储有关发现设备的信息。
它是一个自动检测远程或本地主机安全弱点的程序。一个好的扫描器相当于一千个密码的价值。.
最好的75网络安全工具(转)阿火博客园。
下面是我在学习网络安全时用到的一些工具的总结。1.Wireshark 网址:。
网络安全工具总结_sinat_38598239的博客-CSDN博客。
网络安全工具Logcheck用于自动检查系统入侵事件和异常活动记录。它分析各种 Linux 日志文件,例如 /var/log/mes。
您可以在 Windows 平台上找到移植版本。工具:GFILANguard(商业网络安全扫描软件)网址:。
这也是 THC 贡献的另一个有价值的工具。GFILANguard:Windows 平台上的商用网络安全扫描仪 GFILANguard。
来了解一下2021年最值得关注的10个网络安全测试工具:NMap是NetworkMapper的缩写,NMap是一个开放的。
c爬虫抓取网页数据(一下如何用Python来爬取京东商品(一)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-28 11:14
大家好,我是归零~
今天,我将介绍如何使用Python抓取京东产品类别。数据包括产品名称、价格、出版商、作者等信息。
本次爬虫使用的核心库是Selenium+pyquery,Selenium用于驱动浏览器模拟访问网页,pyquery用于解析页面信息进行数据提取。让我们来看看最终的结果。
脚本启动后,Selenium 会自动打开京东网页,翻到商品页面信息。当浏览器翻页时,它控制后台返回提取的数据。
在介绍主程序之前,这里先介绍一下Selenium包
硒安装
Selenium 主要用作 Web 应用程序的测试工具。可以控制浏览器完成一系列步骤,模拟人的操作;比如自动刷新课程、自动填文、自动查询web端快递单号等都可以。目前,它支持 Java 和 Python。、C#、Ruby等语言;
在做网页爬虫的时候,有些网页的数据是以ajax的方式渲染的,比如微博。标题没有下一页条目。通过刷新页面实现翻页效果;这种类型的网页数据不是直接放在html中的。是通过用户操作触发嵌入在html中的js命令,从而调用json文件中存储的数据,最后呈现;
对于这类网页采集
,一般有两种思路:
所以Selenium工具可以对web端的一些反爬措施实现一些有效的抑制;
Python使用Selenium时,可以使用打包好的Selenium库,使用pip命令完成安装。
pip install selenium
Selenium 目前支持的浏览器包括 Chrome 和 Firefox。建议大家选择Chrome比较好,因为网上关于Chrome的文档比较多。
但是在使用之前,除了确保安装了Chrome浏览器之外,还需要确保chromedriver.exe工具(Selenium的核心是webdriver,chromedriver.exe是Chrome的WebDriver工具)也安装了
chromedriver的版本需要与Chrome浏览器的版本对应,本地下载即可
下载地址如下:
2.爬虫逻辑
使用Selenium模拟人工操作抓取京东数据,需要按顺序执行以下步骤(这里以抓取Python图书产品为例):
首先需要初始化创建webdriver的Chrome浏览器和数据存储文件(这里我用的是txt文件)
def __init__(self,item_name,txt_path):
url = \'https://www.jd.com/\' # 登录网址
self.url = url
self.item_name = item_name
self.txt_file = open(txt_path,encoding=\'utf-8\',mode=\'w+\')
options = webdriver.ChromeOptions() # 谷歌选项
# 设置为开发者模式,避免被识别
options.add_experimental_option(\'excludeSwitches\',
[\'enable-automation\'])
self.browser = webdriver.Chrome(executable_path= "C:/Program Files/Google/Chrome/Application/chromedriver.exe",
options = options)
self.wait = WebDriverWait(self.browser,2)
webdriver.Chrome()方法用于创建驱动浏览器Chrome,并将之前下载到本地的chromedriver.exe文件夹的路径赋值给executable_path参数。
浏览器打开网页时,可能会因为网速原因加载缓慢,所以这里我们使用WebDriverWait方法创建了一个wait方法,每次调用浏览器都需要等待2秒才能继续下一步;
初步操作后,接下来就是主程序,模拟访问、输入、点击等操作;我将所有这些操作封装在一个 run() 函数中,
def run(self):
"""登陆接口"""
self.browser.get(self.url)
input_edit = self.browser.find_element(By.CSS_SELECTOR,\'#key\')
input_edit.clear()
input_edit.send_keys(self.item_name)
search_button = self.browser.find_element(By.CSS_SELECTOR,\'#search > div > div.form > button\')
search_button.click()# 点击
time.sleep(2)
html = self.browser.page_source # 获取 html
self.parse_html(html)
current_url = self.browser.current_url # 获取当前页面 url
initial_url = str(current_url).split(\'&pvid\')[0]
for i in range(1,100):
try:
print(\'正在解析----------------{}图片\'.format(str(i)))
next_page_url = initial_url + \'&page={}&s={}&click=0\'.format(str(i*2+1),str(i*60+1))
print(next_page_url)
self.browser.get(next_page_url)
self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,\'#J_goodsList > ul > li\')))
html = self.browser.page_source
self.parse_html(html)# 对 html 网址进行解析
time.sleep(2) # 设置频率
except Exception as e:
print(\'Error Next page\',e)
self.txt_file.close()# 关闭 txt 文件
首先使用get()方法访问京东主页,然后定位到页面上的搜索栏和搜索按钮标签input_edit和search_button;完成输入并点击操作
关于网页元素标签的定位,如果不能,可以使用浏览器开发者模式,分为以下几个步骤(这里以CSS_Selector为例):
在翻页操作中,这里是按照京东url规则构造的,
第 5 页
https://search.jd.com/Search%3 ... k%3D0
第 6 页
https://search.jd.com/Search%3 ... k%3D0
如果仔细看,你会发现第5页和第6页的urls唯一的区别就是两个参数page和s;
按照这个规则,通过改变page和s参数来构造京东商品的前100页商品信息,完成数据抓取;
关于数据提取部分,我使用parse_html函数来完成
为了提高程序的友好性,我把所有的功能都封装在一个类中,用户只需要输入两个参数,一个是需要采集的产品名称,一个是存储的路径文件; 可以完成数据爬取;
最后将抓取到的数据保存成txt文件,结果如下
4. 总结
selenium虽然可以有效破解web端的一些反爬虫机制,但是对于一些网站,比如拉勾网,就没什么用了。在拉勾官网使用Selenium驱动浏览器模拟翻页操作时,网站可以识别非人类。操作,暂时禁止并警告您的IP;
本文涉及的完整源码,关注微信公众号:程序员大飞,回复后台关键词:京东货,即可获取! 查看全部
c爬虫抓取网页数据(一下如何用Python来爬取京东商品(一)_)
大家好,我是归零~
今天,我将介绍如何使用Python抓取京东产品类别。数据包括产品名称、价格、出版商、作者等信息。
本次爬虫使用的核心库是Selenium+pyquery,Selenium用于驱动浏览器模拟访问网页,pyquery用于解析页面信息进行数据提取。让我们来看看最终的结果。
脚本启动后,Selenium 会自动打开京东网页,翻到商品页面信息。当浏览器翻页时,它控制后台返回提取的数据。
在介绍主程序之前,这里先介绍一下Selenium包
硒安装
Selenium 主要用作 Web 应用程序的测试工具。可以控制浏览器完成一系列步骤,模拟人的操作;比如自动刷新课程、自动填文、自动查询web端快递单号等都可以。目前,它支持 Java 和 Python。、C#、Ruby等语言;
在做网页爬虫的时候,有些网页的数据是以ajax的方式渲染的,比如微博。标题没有下一页条目。通过刷新页面实现翻页效果;这种类型的网页数据不是直接放在html中的。是通过用户操作触发嵌入在html中的js命令,从而调用json文件中存储的数据,最后呈现;
对于这类网页采集
,一般有两种思路:
所以Selenium工具可以对web端的一些反爬措施实现一些有效的抑制;
Python使用Selenium时,可以使用打包好的Selenium库,使用pip命令完成安装。
pip install selenium
Selenium 目前支持的浏览器包括 Chrome 和 Firefox。建议大家选择Chrome比较好,因为网上关于Chrome的文档比较多。
但是在使用之前,除了确保安装了Chrome浏览器之外,还需要确保chromedriver.exe工具(Selenium的核心是webdriver,chromedriver.exe是Chrome的WebDriver工具)也安装了
chromedriver的版本需要与Chrome浏览器的版本对应,本地下载即可
下载地址如下:
2.爬虫逻辑
使用Selenium模拟人工操作抓取京东数据,需要按顺序执行以下步骤(这里以抓取Python图书产品为例):
首先需要初始化创建webdriver的Chrome浏览器和数据存储文件(这里我用的是txt文件)
def __init__(self,item_name,txt_path):
url = \'https://www.jd.com/\' # 登录网址
self.url = url
self.item_name = item_name
self.txt_file = open(txt_path,encoding=\'utf-8\',mode=\'w+\')
options = webdriver.ChromeOptions() # 谷歌选项
# 设置为开发者模式,避免被识别
options.add_experimental_option(\'excludeSwitches\',
[\'enable-automation\'])
self.browser = webdriver.Chrome(executable_path= "C:/Program Files/Google/Chrome/Application/chromedriver.exe",
options = options)
self.wait = WebDriverWait(self.browser,2)
webdriver.Chrome()方法用于创建驱动浏览器Chrome,并将之前下载到本地的chromedriver.exe文件夹的路径赋值给executable_path参数。
浏览器打开网页时,可能会因为网速原因加载缓慢,所以这里我们使用WebDriverWait方法创建了一个wait方法,每次调用浏览器都需要等待2秒才能继续下一步;
初步操作后,接下来就是主程序,模拟访问、输入、点击等操作;我将所有这些操作封装在一个 run() 函数中,
def run(self):
"""登陆接口"""
self.browser.get(self.url)
input_edit = self.browser.find_element(By.CSS_SELECTOR,\'#key\')
input_edit.clear()
input_edit.send_keys(self.item_name)
search_button = self.browser.find_element(By.CSS_SELECTOR,\'#search > div > div.form > button\')
search_button.click()# 点击
time.sleep(2)
html = self.browser.page_source # 获取 html
self.parse_html(html)
current_url = self.browser.current_url # 获取当前页面 url
initial_url = str(current_url).split(\'&pvid\')[0]
for i in range(1,100):
try:
print(\'正在解析----------------{}图片\'.format(str(i)))
next_page_url = initial_url + \'&page={}&s={}&click=0\'.format(str(i*2+1),str(i*60+1))
print(next_page_url)
self.browser.get(next_page_url)
self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,\'#J_goodsList > ul > li\')))
html = self.browser.page_source
self.parse_html(html)# 对 html 网址进行解析
time.sleep(2) # 设置频率
except Exception as e:
print(\'Error Next page\',e)
self.txt_file.close()# 关闭 txt 文件
首先使用get()方法访问京东主页,然后定位到页面上的搜索栏和搜索按钮标签input_edit和search_button;完成输入并点击操作
关于网页元素标签的定位,如果不能,可以使用浏览器开发者模式,分为以下几个步骤(这里以CSS_Selector为例):
在翻页操作中,这里是按照京东url规则构造的,
第 5 页
https://search.jd.com/Search%3 ... k%3D0
第 6 页
https://search.jd.com/Search%3 ... k%3D0
如果仔细看,你会发现第5页和第6页的urls唯一的区别就是两个参数page和s;
按照这个规则,通过改变page和s参数来构造京东商品的前100页商品信息,完成数据抓取;
关于数据提取部分,我使用parse_html函数来完成
为了提高程序的友好性,我把所有的功能都封装在一个类中,用户只需要输入两个参数,一个是需要采集的产品名称,一个是存储的路径文件; 可以完成数据爬取;
最后将抓取到的数据保存成txt文件,结果如下
4. 总结
selenium虽然可以有效破解web端的一些反爬虫机制,但是对于一些网站,比如拉勾网,就没什么用了。在拉勾官网使用Selenium驱动浏览器模拟翻页操作时,网站可以识别非人类。操作,暂时禁止并警告您的IP;
本文涉及的完整源码,关注微信公众号:程序员大飞,回复后台关键词:京东货,即可获取!
c爬虫抓取网页数据( :网络数据是重要的资产形态之一荐5股)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-27 08:01
:网络数据是重要的资产形态之一荐5股)
[摘要] 网络数据是最重要的资产形式之一。改进数据提取和分析项目是目前该领域的关键研究问题之一。本文基于Scrapy开源技术,参考网络编程等其他相关知识,定制一个扩展能力强的网络爬虫原型程序。选择合适的数据库来捕获和保存数据,并支持多线程并发结构,最大限度地提高操作的有效性。
[关键词]Scrapy; 网络爬虫;框架建设;数据抓取
1990年代,网络爬虫逐渐发展起来,如今已经渗透到人们在互联网上日常生活的方方面面。一个高质量的爬虫应该有准确的爬行目标、高效的爬行过程、快速的运行和有效的后处理。为了让爬虫丰富上述特征,构建良好的结构是重要的基础,这将促进爬虫快速识别访问过的页面,更高效地提取主观需要的结构和内容。Scrapy框架的目的是爬取网站内容,准确提取结构化数据,然后编写一个开源的爬虫应用框架。本文主要探讨其在网络爬虫实现和数据抓取中的应用。
1. 设计整体架构
从宏观上看,爬虫可以细化为以下三个模块:(1)预置规则模块:其作用是预先规划要提取的数据格式,以便程序正常运行,以及有针对性地更改User-AgentCookies登录等监控账号;(2)网页抓取模块:该模块在定义原创
URL时开始抓取网页信息,初步提取并进行基础分析,结合反馈结果的类型,检索对应的回调函数;(3)后续数据处理模块:进一步解析网络爬取模块的结果,判断其合法性,存入数据库,或调整到调度器等待调整和爬行。
2.爬虫实现过程
本文选择“新浪微博”为爬虫目标,“新浪微博”为国内知名社交网站。选择它作为爬取目标,可以帮助我们接触到更多的新知识,感知大数据的发展趋势。
2.1 预设规则预设模块
明确设置爬虫爬取数据格式。具体来说,在item.py文件中,根据需要提取的字段规划对应的类型。比如定义了InformationItem类来爬取用户信息,我们基于Field()方法来解释数据字段(图1)[1].
2.1个网页抓取模块
在Spiders.py中设置这个模块的代码是项目的核心部分。在 Spiders 中自定义 SinaSpider 类。这篇文章详细解释了Spiders类的作用如下:
(1)Name和host特性:定义类的名称,是爬虫的唯一标识。host设置爬虫的爬取区域。
(2)start.urls 特性:它是一个原创
URL 列表,它在初始运行时提供了爬虫的目标。爬虫会以这些页面为起点,有针对性地抓取数据。我们使用用户ID替换偏差和完整性更高的URL,然后使用start_requesets()方法推动用户ID和主机地址的有机融合过程,形成完整度更高的原创
URL。
(3)Scrawl_ID 和finish.ID 是Set 类的变量:Python 中的set 类与其他类型的语言有很高的相似度,属于无序和不重复元素的一类。基本功能是去掉出现过多次的元素,这里我们选择Set类变量来表示爬取的页面和被爬取的页面进行调整,效果非常好[2]。
(4)请求处理部分:SinaSpider自定义了start_requests()函数和四个回调函数,回调函数的作用是处理对用户信息、微博内容、粉丝、感兴趣目标对象的抓取. 当我们在回调函数中设置请求后,Scrapy 会自行调整,传输请求,并在请求完成时调用注册的回调函数。根据解析函数中定义的xpath路径或者获取到的字符,将它们存储在item字典中,最后发送到Pipelines进行后处理。
2.3Post数据处理模块
基于Spider类,我们可以平滑的抓取和抓取目标数据,然后需要分析数据存储问题。本文采用Mysq|database进行存储,有效处理爬取结果与数据库的相互传输问题,是本模块设计阶段需要分析的关键问题之一。在Pipelines.py中可以进行一系列的处理,我们可以把它看成一个数据管道。Pipelines.py 建立了 MysqlPipeline 类,共收录
两个方法。功能是初始化数据表,处理项目,并把它集成到库中。建立基于pymsql开源模块和mysql的交互关系。
打开数据库的本地连接,然后建立“新浪”数据库,然后将相关信息进行制表和存储。
如果 process_item() 函数确定字段数满足要求且不为空,则将其集成到数据库中。执行完上述步骤后,会提示后续数据处理结束。
3. 在分析数据捕获结果中呈现
程序运行后,得到“新浪”数据库。数据库中有四个表。本文主要分析Information表的设置(见表)[3]。
4.结论
本文由 Scrapy 技术支持,形成一个易于制作、易于扩展的聚焦爬虫。爬虫以“新浪微博”用户为目标,抓取用户群体的主要信息。实践表明,利用Scrapy技术开发爬虫具有高效、流程便捷等优点,成功达到了预期的标准要求。
参考:
[1]朱丽颖,吴锦靖.基于自动化测试的定向网络爬虫设计与实现[J]. 微机应用, 2019, 35 (10): 8-10.
[2] 刘辉, 石谦, 基于网络爬虫的新闻网站自动生成系统的设计与实现[J]. 电子技术与软件工程, 2019, 20 (13): 18-19.
[3] 邵晓文.多线程并发网络爬虫的设计与实现[J]. 现代计算机(专业版), 2019, 47 (01): 97-100.
关于作者:
谢建辉(1999-09-25) 性别:男 家乡:广东省梅州市 民族:汉族 学历:本科。 查看全部
c爬虫抓取网页数据(
:网络数据是重要的资产形态之一荐5股)
[摘要] 网络数据是最重要的资产形式之一。改进数据提取和分析项目是目前该领域的关键研究问题之一。本文基于Scrapy开源技术,参考网络编程等其他相关知识,定制一个扩展能力强的网络爬虫原型程序。选择合适的数据库来捕获和保存数据,并支持多线程并发结构,最大限度地提高操作的有效性。
[关键词]Scrapy; 网络爬虫;框架建设;数据抓取
1990年代,网络爬虫逐渐发展起来,如今已经渗透到人们在互联网上日常生活的方方面面。一个高质量的爬虫应该有准确的爬行目标、高效的爬行过程、快速的运行和有效的后处理。为了让爬虫丰富上述特征,构建良好的结构是重要的基础,这将促进爬虫快速识别访问过的页面,更高效地提取主观需要的结构和内容。Scrapy框架的目的是爬取网站内容,准确提取结构化数据,然后编写一个开源的爬虫应用框架。本文主要探讨其在网络爬虫实现和数据抓取中的应用。
1. 设计整体架构
从宏观上看,爬虫可以细化为以下三个模块:(1)预置规则模块:其作用是预先规划要提取的数据格式,以便程序正常运行,以及有针对性地更改User-AgentCookies登录等监控账号;(2)网页抓取模块:该模块在定义原创
URL时开始抓取网页信息,初步提取并进行基础分析,结合反馈结果的类型,检索对应的回调函数;(3)后续数据处理模块:进一步解析网络爬取模块的结果,判断其合法性,存入数据库,或调整到调度器等待调整和爬行。
2.爬虫实现过程
本文选择“新浪微博”为爬虫目标,“新浪微博”为国内知名社交网站。选择它作为爬取目标,可以帮助我们接触到更多的新知识,感知大数据的发展趋势。
2.1 预设规则预设模块
明确设置爬虫爬取数据格式。具体来说,在item.py文件中,根据需要提取的字段规划对应的类型。比如定义了InformationItem类来爬取用户信息,我们基于Field()方法来解释数据字段(图1)[1].
2.1个网页抓取模块
在Spiders.py中设置这个模块的代码是项目的核心部分。在 Spiders 中自定义 SinaSpider 类。这篇文章详细解释了Spiders类的作用如下:
(1)Name和host特性:定义类的名称,是爬虫的唯一标识。host设置爬虫的爬取区域。
(2)start.urls 特性:它是一个原创
URL 列表,它在初始运行时提供了爬虫的目标。爬虫会以这些页面为起点,有针对性地抓取数据。我们使用用户ID替换偏差和完整性更高的URL,然后使用start_requesets()方法推动用户ID和主机地址的有机融合过程,形成完整度更高的原创
URL。
(3)Scrawl_ID 和finish.ID 是Set 类的变量:Python 中的set 类与其他类型的语言有很高的相似度,属于无序和不重复元素的一类。基本功能是去掉出现过多次的元素,这里我们选择Set类变量来表示爬取的页面和被爬取的页面进行调整,效果非常好[2]。
(4)请求处理部分:SinaSpider自定义了start_requests()函数和四个回调函数,回调函数的作用是处理对用户信息、微博内容、粉丝、感兴趣目标对象的抓取. 当我们在回调函数中设置请求后,Scrapy 会自行调整,传输请求,并在请求完成时调用注册的回调函数。根据解析函数中定义的xpath路径或者获取到的字符,将它们存储在item字典中,最后发送到Pipelines进行后处理。
2.3Post数据处理模块
基于Spider类,我们可以平滑的抓取和抓取目标数据,然后需要分析数据存储问题。本文采用Mysq|database进行存储,有效处理爬取结果与数据库的相互传输问题,是本模块设计阶段需要分析的关键问题之一。在Pipelines.py中可以进行一系列的处理,我们可以把它看成一个数据管道。Pipelines.py 建立了 MysqlPipeline 类,共收录
两个方法。功能是初始化数据表,处理项目,并把它集成到库中。建立基于pymsql开源模块和mysql的交互关系。
打开数据库的本地连接,然后建立“新浪”数据库,然后将相关信息进行制表和存储。
如果 process_item() 函数确定字段数满足要求且不为空,则将其集成到数据库中。执行完上述步骤后,会提示后续数据处理结束。
3. 在分析数据捕获结果中呈现
程序运行后,得到“新浪”数据库。数据库中有四个表。本文主要分析Information表的设置(见表)[3]。
4.结论
本文由 Scrapy 技术支持,形成一个易于制作、易于扩展的聚焦爬虫。爬虫以“新浪微博”用户为目标,抓取用户群体的主要信息。实践表明,利用Scrapy技术开发爬虫具有高效、流程便捷等优点,成功达到了预期的标准要求。
参考:
[1]朱丽颖,吴锦靖.基于自动化测试的定向网络爬虫设计与实现[J]. 微机应用, 2019, 35 (10): 8-10.
[2] 刘辉, 石谦, 基于网络爬虫的新闻网站自动生成系统的设计与实现[J]. 电子技术与软件工程, 2019, 20 (13): 18-19.
[3] 邵晓文.多线程并发网络爬虫的设计与实现[J]. 现代计算机(专业版), 2019, 47 (01): 97-100.
关于作者:
谢建辉(1999-09-25) 性别:男 家乡:广东省梅州市 民族:汉族 学历:本科。
c爬虫抓取网页数据(第一点没什么捷径可走,或许可以给你省不少事)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-27 08:00
爬虫爬取数据有两个头疼的问题。写过爬虫的人一定深有体会:
网站的反爬虫机制。你要尽量伪装成“一个人”来欺骗对方的服务器进行反爬验证。
提取网站内容。每个网站都需要您做不同的处理,一旦网站被修改,您的代码必须相应更新。
第一点是没有捷径可走。如果你看到很多套路,你就会有经验。关于第二点,今天我们来介绍一个小工具。在一些需求场景下,它可能会为你节省很多事情。
鹅
Goose是一款文章内容提取器,可以从任意信息文章网页中提取文章主体,提取标题、标签、摘要、图片、视频等信息,支持中文网页。它最初是用 Java 编写的。python-goose 是一个用 Python 重写的版本。
有了这个库,你就可以直接从网上抓取下来的网页正文内容,无需使用bs4或正则表达式对文本进行一一处理。
项目地址:
(Py2)
(Py3)
安装
网上大部分教程中提到的python-goose项目目前只支持python2.7。它可以通过 pip 安装:
pip install goose-extractor
或者从官网源码安装方法:
mkvirtualenv --no-site-packages goose
git clone https://github.com/grangier/python-goose.git
cd python-goose
pip install -r requirements.txt
python setup.py install
我找到了一个python 3版本的goose3:
pip install goose3
经过一些简单的测试,我没有发现两个版本之间的结果有太大差异。
快速上手
这里用的是goose3,python-goose只需要把goose3改成goose就可以了,界面是一样的。以一篇文章为爬取目标进行演示。
from goose3 import Goose
from goose3.text import StopWordsChinese
# 初始化,设置中文分词
g = Goose({'stopwords_class': StopWordsChinese})
# 文章地址
url = 'https://mp.weixin.qq.com/s/zfl ... 39%3B
# 获取文章内容
article = g.extract(url=url)
# 标题
print('标题:', article.title)
# 显示正文
print(article.cleaned_text)
输出:
除了标题和正文cleaned_text,还可以获得一些额外的信息,比如:
如果某些网站限制了程序爬取,您还可以根据需要添加user-agent信息:
g = Goose({'browser_user_agent': 'Version/5.1.2 Safari/534.52.7'})
如果是goose3,因为使用requests库作为请求模块,headers、proxy等属性也可以类似的配置。
上面例子中使用的StopWordsChinese是中文分词器,可以在一定程度上提高中文文章的识别准确率,但是比较耗时。
其他说明
1.
Goose虽然方便,但不保证每个网站都能准确获取,所以适用于热点追踪、舆情分析等大规模文章采集,只能概率保证大部分网站可以爬行比较准确。经过一些尝试,我发现爬取英文网站优于中文网站,主流网站优于小众网站,文本提取优于图像提取。
2.
从项目中的requirements.txt文件可以看出goose中使用了Pillow、lxml、cssselect、jieba、beautifulsoup、nltk,goose3中也使用了requests。
3.
如果你使用的是基于python2的goose,你可能会遇到编码问题(尤其是在windows上)。
4.
除了goose,还有其他文本提取库可以尝试,比如python-boilerpipe、python-readability等。
实例
最后我们用goose3写一小段代码,自动抓取爱范儿、雷锋网、DoNews上的新闻文章:
from goose3 import Goose
from goose3.text import StopWordsChinese
from bs4 import BeautifulSoup
g = Goose({'stopwords_class': StopWordsChinese})
urls = [
'https://www.ifanr.com/',
'https://www.leiphone.com/',
'http://www.donews.com/'
]
url_articles = []
for url in urls:
page = g.extract(url=url)
soup = BeautifulSoup(page.raw_html, 'lxml')
links = soup.find_all('a')
for l in links:
link = l.get('href')
if link and link.startswith('http') and any(c.isdigit() for c in link if c) and link not in url_articles:
url_articles.append(link)
print(link)
for url in url_articles:
try:
article = g.extract(url=url)
content = article.cleaned_text
if len(content) > 200:
title = article.title
print(title)
with open('homework/goose/' + title + '.txt', 'w') as f:
f.write(content)
except:
pass
这个程序的作用是: 查看全部
c爬虫抓取网页数据(第一点没什么捷径可走,或许可以给你省不少事)
爬虫爬取数据有两个头疼的问题。写过爬虫的人一定深有体会:
网站的反爬虫机制。你要尽量伪装成“一个人”来欺骗对方的服务器进行反爬验证。
提取网站内容。每个网站都需要您做不同的处理,一旦网站被修改,您的代码必须相应更新。
第一点是没有捷径可走。如果你看到很多套路,你就会有经验。关于第二点,今天我们来介绍一个小工具。在一些需求场景下,它可能会为你节省很多事情。
鹅
Goose是一款文章内容提取器,可以从任意信息文章网页中提取文章主体,提取标题、标签、摘要、图片、视频等信息,支持中文网页。它最初是用 Java 编写的。python-goose 是一个用 Python 重写的版本。
有了这个库,你就可以直接从网上抓取下来的网页正文内容,无需使用bs4或正则表达式对文本进行一一处理。
项目地址:
(Py2)
(Py3)
安装
网上大部分教程中提到的python-goose项目目前只支持python2.7。它可以通过 pip 安装:
pip install goose-extractor
或者从官网源码安装方法:
mkvirtualenv --no-site-packages goose
git clone https://github.com/grangier/python-goose.git
cd python-goose
pip install -r requirements.txt
python setup.py install
我找到了一个python 3版本的goose3:
pip install goose3
经过一些简单的测试,我没有发现两个版本之间的结果有太大差异。
快速上手
这里用的是goose3,python-goose只需要把goose3改成goose就可以了,界面是一样的。以一篇文章为爬取目标进行演示。
from goose3 import Goose
from goose3.text import StopWordsChinese
# 初始化,设置中文分词
g = Goose({'stopwords_class': StopWordsChinese})
# 文章地址
url = 'https://mp.weixin.qq.com/s/zfl ... 39%3B
# 获取文章内容
article = g.extract(url=url)
# 标题
print('标题:', article.title)
# 显示正文
print(article.cleaned_text)
输出:
除了标题和正文cleaned_text,还可以获得一些额外的信息,比如:
如果某些网站限制了程序爬取,您还可以根据需要添加user-agent信息:
g = Goose({'browser_user_agent': 'Version/5.1.2 Safari/534.52.7'})
如果是goose3,因为使用requests库作为请求模块,headers、proxy等属性也可以类似的配置。
上面例子中使用的StopWordsChinese是中文分词器,可以在一定程度上提高中文文章的识别准确率,但是比较耗时。
其他说明
1.
Goose虽然方便,但不保证每个网站都能准确获取,所以适用于热点追踪、舆情分析等大规模文章采集,只能概率保证大部分网站可以爬行比较准确。经过一些尝试,我发现爬取英文网站优于中文网站,主流网站优于小众网站,文本提取优于图像提取。
2.
从项目中的requirements.txt文件可以看出goose中使用了Pillow、lxml、cssselect、jieba、beautifulsoup、nltk,goose3中也使用了requests。
3.
如果你使用的是基于python2的goose,你可能会遇到编码问题(尤其是在windows上)。
4.
除了goose,还有其他文本提取库可以尝试,比如python-boilerpipe、python-readability等。
实例
最后我们用goose3写一小段代码,自动抓取爱范儿、雷锋网、DoNews上的新闻文章:
from goose3 import Goose
from goose3.text import StopWordsChinese
from bs4 import BeautifulSoup
g = Goose({'stopwords_class': StopWordsChinese})
urls = [
'https://www.ifanr.com/',
'https://www.leiphone.com/',
'http://www.donews.com/'
]
url_articles = []
for url in urls:
page = g.extract(url=url)
soup = BeautifulSoup(page.raw_html, 'lxml')
links = soup.find_all('a')
for l in links:
link = l.get('href')
if link and link.startswith('http') and any(c.isdigit() for c in link if c) and link not in url_articles:
url_articles.append(link)
print(link)
for url in url_articles:
try:
article = g.extract(url=url)
content = article.cleaned_text
if len(content) > 200:
title = article.title
print(title)
with open('homework/goose/' + title + '.txt', 'w') as f:
f.write(content)
except:
pass
这个程序的作用是:
c爬虫抓取网页数据(Web前端基础Python与Web框架的开发者框架使用的基本流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-26 17:12
Django 是一个用 Python 编写的开源 Web 应用程序框架。它的主要目标是使开发复杂的、数据库驱动的网站变得容易。本课程首先介绍一些Web前端相关知识,包括用于定义Web内容的HTML语言、用于定义样式的CSS语言、用于向网页添加交互的JavaScript语言以及用于交换网络数据的JSON语言。; 然后详细讲解Django框架的使用方法,包括:Django框架安装、视图和url、模型类、后台管理、模板等知识点;最后,以“列表详情页”的实现为例,对之前学到的知识点进行综合应用和巩固。【课程目标】了解HTML等Web开发相关知识, 查看全部
c爬虫抓取网页数据(Web前端基础Python与Web框架的开发者框架使用的基本流程)
Django 是一个用 Python 编写的开源 Web 应用程序框架。它的主要目标是使开发复杂的、数据库驱动的网站变得容易。本课程首先介绍一些Web前端相关知识,包括用于定义Web内容的HTML语言、用于定义样式的CSS语言、用于向网页添加交互的JavaScript语言以及用于交换网络数据的JSON语言。; 然后详细讲解Django框架的使用方法,包括:Django框架安装、视图和url、模型类、后台管理、模板等知识点;最后,以“列表详情页”的实现为例,对之前学到的知识点进行综合应用和巩固。【课程目标】了解HTML等Web开发相关知识,
c爬虫抓取网页数据(爬虫搜索引擎如何获取一个新网站的数据?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2021-12-26 05:08
爬虫基本概念数据从何而来?
部分数据来源如下:
爬虫是一种获取数据的方式。
什么是爬虫?
爬虫是抓取网络数据的自动化程序。
爬虫是如何抓取网页数据的
网页的三个特点:
每个网页都有自己唯一的URL(Uniform Resource Locator)用于定位;网页使用 HTML(超文本标记语言)来描述页面信息;网页使用 HTTP/HTTPS(超文本传输协议)来传输 HTML 数据。
根据网页的特点,我们提出了爬虫的设计思路:
1. 获取网页
向服务器发送Request请求,得到Response后解析Body部分,即网页的源代码。
Python 库:Urllib、Requests 等。
2. 提取信息
分析网页源代码,提取我们想要的数据。
提取方法
3.保存数据通用爬虫和焦点爬虫通用爬虫
搜索引擎的爬虫系统。
1.目标
尽量将互联网内容下载到本地服务器形成备份,然后对这些网页进行相关处理(提取关键词、去除广告),最终形成用户搜索界面。
2. 获取过程
通用网络爬虫工作流程图
最好选择一部分已有的URL,将这些URL放入待抓取的队列中。从队列中取出这些URL,然后通过DNS解析得到主机IP,然后到这个IP对应的服务器去下载HTML页面并保存到搜索引擎的本地服务器。然后将抓取到的网址放入抓取队列中。分析这些网页的内容,找出网页中其他的URL链接,继续执行第二步,直到爬取条件结束。3.搜索引擎如何获取新网站的网址?主动向搜索引擎提交网址:建立到其他网站的外部链接。搜索引擎将与 DNS 服务提供商合作以快速收录新网站。
DNS:是一种将域名解析为IP的技术。域名必须对应一个IP,但IP可以没有域名。
4.万能爬虫不是所有东西都能爬,也需要遵守规则
Robots协议:该协议会规定一般爬虫爬取网页的权限。
Robots.txt 只是一个建议,并非所有爬虫都遵守。一般来说,只有大型搜索引擎爬虫会遵守它。我们个人编写的爬虫被忽略了。
5.一般爬虫工作流程
抓取网页-存储数据-内容处理-提供检索/排名服务
6.搜索引擎排名PageRank值:根据网站流量(点击量/浏览量/流行度)统计,流量越高,网站价值越高,排名越高。竞价排名:谁出价越多,谁的排名就越高。7.一般爬虫的缺点只能提供与文本相关的内容(HTML、Word、PDF)等,不能提供多媒体文件(音乐、图片、视频)和二进制文件(程序、脚本)等. 提供的结果是一样的,不能为不同背景的人提供不同的搜索结果。无法理解人类语义检索。
为了解决上述问题,出现了聚焦爬虫。
焦点履带
抓取特定内容并尝试抓取与主题相关的信息。 查看全部
c爬虫抓取网页数据(爬虫搜索引擎如何获取一个新网站的数据?(组图))
爬虫基本概念数据从何而来?
部分数据来源如下:
爬虫是一种获取数据的方式。
什么是爬虫?
爬虫是抓取网络数据的自动化程序。
爬虫是如何抓取网页数据的
网页的三个特点:
每个网页都有自己唯一的URL(Uniform Resource Locator)用于定位;网页使用 HTML(超文本标记语言)来描述页面信息;网页使用 HTTP/HTTPS(超文本传输协议)来传输 HTML 数据。
根据网页的特点,我们提出了爬虫的设计思路:
1. 获取网页
向服务器发送Request请求,得到Response后解析Body部分,即网页的源代码。
Python 库:Urllib、Requests 等。
2. 提取信息
分析网页源代码,提取我们想要的数据。
提取方法
3.保存数据通用爬虫和焦点爬虫通用爬虫
搜索引擎的爬虫系统。
1.目标
尽量将互联网内容下载到本地服务器形成备份,然后对这些网页进行相关处理(提取关键词、去除广告),最终形成用户搜索界面。
2. 获取过程
通用网络爬虫工作流程图
最好选择一部分已有的URL,将这些URL放入待抓取的队列中。从队列中取出这些URL,然后通过DNS解析得到主机IP,然后到这个IP对应的服务器去下载HTML页面并保存到搜索引擎的本地服务器。然后将抓取到的网址放入抓取队列中。分析这些网页的内容,找出网页中其他的URL链接,继续执行第二步,直到爬取条件结束。3.搜索引擎如何获取新网站的网址?主动向搜索引擎提交网址:建立到其他网站的外部链接。搜索引擎将与 DNS 服务提供商合作以快速收录新网站。
DNS:是一种将域名解析为IP的技术。域名必须对应一个IP,但IP可以没有域名。
4.万能爬虫不是所有东西都能爬,也需要遵守规则
Robots协议:该协议会规定一般爬虫爬取网页的权限。
Robots.txt 只是一个建议,并非所有爬虫都遵守。一般来说,只有大型搜索引擎爬虫会遵守它。我们个人编写的爬虫被忽略了。
5.一般爬虫工作流程
抓取网页-存储数据-内容处理-提供检索/排名服务
6.搜索引擎排名PageRank值:根据网站流量(点击量/浏览量/流行度)统计,流量越高,网站价值越高,排名越高。竞价排名:谁出价越多,谁的排名就越高。7.一般爬虫的缺点只能提供与文本相关的内容(HTML、Word、PDF)等,不能提供多媒体文件(音乐、图片、视频)和二进制文件(程序、脚本)等. 提供的结果是一样的,不能为不同背景的人提供不同的搜索结果。无法理解人类语义检索。
为了解决上述问题,出现了聚焦爬虫。
焦点履带
抓取特定内容并尝试抓取与主题相关的信息。
c爬虫抓取网页数据(4.网络爬虫的合法性Robots协议:又称机器人协议或爬虫协议)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-12-26 05:07
内容
一、爬虫简介
1.什么是网络爬虫?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者)是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。
2.爬虫类型
根据系统结构和实现技术,网络爬虫大致可以分为以下几类:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深网爬虫(Deep Web Crawler)。实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。
3.网络爬虫的使用范围
① 作为搜索引擎的网页采集器,抓取整个互联网,如谷歌、百度等。
②作为垂直搜索引擎,抓取特定主题信息,如视频网站、招聘网站等。
③作为测试网站前端的检测工具,用于评估网站前端代码的健壮性。
4.网络爬虫的合法性
机器人协议:又称机器人协议或爬虫协议,该协议规定了搜索引擎抓取网站内容的范围,包括网站是否希望被搜索引擎抓取,哪些内容不允许被抓取。网络爬虫“有意识地”在本地抓取或不抓取网页内容。自推出以来,机器人协议已成为网站保护自身敏感数据和网民隐私的国际惯例。
5.网络搜索策略
网络爬取策略可分为深度优先、广度优先和最佳优先。在很多情况下,深度优先会导致爬虫被困。目前,广度优先和最佳优先的方法很常见。
6.爬虫的基本结构
一个网络爬虫通常收录
四个模块:
• URL 管理模块
• 下载模块
• 分析模块
• 存储模块
二、环境准备(一)创建python虚拟环境
使用 conda 创建一个名为 crawler 的 python 虚拟环境。在这个虚拟环境下,使用pip或者conda安装requests、beautifulsoup4等必要的包(如果网络问题请切换国内镜像网站或国外网站仓库,注意使用这两个安装工具不同的仓库)。使用jupyter、pycharm、spyder、vscoder等IDE编程环境时,需要选择设置IDE后端使用的python版本或虚拟环境。比如使用jupyter notebook时,参考(),在jupyter运行的web界面选择对应的python kernel Kernel(带虚拟环境列表);如果使用pycharm,参考()选择对应的现有虚拟环境。
使用 conda create -n crawler python=3.8 命令新建一个名为 crawlerpython version 3.8 的虚拟环境
你开始创造
已创建
使用命令conda env list查看已经存在的虚拟环境,爬虫已经存在,base是conda自带的环境,uuu是我之前创建的
Activate crawler 进入爬虫环境,conda activate 退出当前环境,activate 是进入基础环境
conda remove --name 环境名称 --all 卸载环境
Jupyter notebook 本身不支持选择虚拟环境,每次有新项目时都需要重新配置所有插件。使用nb_conda插件将jupyter notebook变成pycharm一样可选择的运行环境。
在基础环境中使用conda install nb_conda命令安装nb_conda
在conda虚拟环境中使用conda install -n environment name ipykernel命令安装ipykernel
可以在jupyter notebook中显示
(二)安装库
环境准备
Python安装,这部分可以参考我之前的文章Python环境配置&Pycharm安装,到官网下载对应的安装包,安装一路Next;
pip安装,pip是Python的包管理器,目前的Python安装包一般都自带pip,不需要自己安装;
安装requests,beautifulsoup库,通过如下语句完成安装:
pip 安装请求
pip 安装 beautifulsoup4
谷歌浏览器(铬);
pip 安装请求
pip 安装 beautifulsoup4
pip 安装 html5lib
三、 爬取南洋理工ACM主题网站
学习样例代码,对关键代码句写详细注释,编写程序完成南洋理工ACM题库练习题数据的采集和存储;
(一)查看页面源码
点击进入南洋理工ACM专题网站,
右键->查看页面源代码
(二)代码运行
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
# tqdm作业:以进度条方式显示爬取进度
# 爬取11页所有题目信息
for pages in tqdm(range(1, 11 + 1)):
# get请求第pages页
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
# 判断异常
r.raise_for_status()
# 设置编码
r.encoding = 'utf-8'
# 创建BeautifulSoup对象,用于解析该html页面数据
soup = BeautifulSoup(r.text, 'html.parser')
# 获取所有td标签
td = soup.find_all('td')
# 存放某一个题目的所有信息
subject = []
# 遍历所有td
for t in td:
if t.string is not None:
subject.append(t.string) # 获取td中的字符串
if len(subject) == 5: # 每5个为一个题目的信息
subjects.append(subject)
subject = []
# 存放题目
with open('D:/jupyter/package/1.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders) # 写入表头
fileWriter.writerows(subjects) # 写入数据
print('\n题目信息爬取完成!!!')
运行,报错ModuleNotFoundError: No module named'tqdm',tqdm文件丢失,使用命令pip install tqdm安装
错误 FeatureNotFound:找不到具有您请求的功能的树生成器:lxml。需要安装解析器库吗,用pip install lxml安装,然后还是不行,自动安装最新版本,更换刚刚下载的版本删除:pip卸载lxml,下载指定版本试试: pip install lxml==3.7.0. 或不!!
然后第二种方法,把参数lxml改成html.parser
soup = BeautifulSoup(r.text, 'html.parser')
没关系!激动的心和握手~
(三)结果
四、 爬上重庆交通大学新闻网站
重写爬虫示例代码,爬取重庆交通大学新闻网站近年所有信息公告()的发布日期和标题,写入CSV电子表格。
(一)查看网页源码
重庆交通大学新闻网
右键->查看网页源代码
(二)代码运行
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
cqjtu_Headers ={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44'
}
#csv的表头
cqjtu_head=["日期","标题"]
#存放内容
cqjtu_infomation=[]
def get_page_number():
r=requests.get(f"http://news.cqjtu.edu.cn/xxtz.htm",headers=cqjtu_Headers)
r.raise_for_status()
r.encoding="utf-8"
page_array={
'type':'text/javascript'
}
soup = BeautifulSoup(r.text, 'html5lib')
page_num=soup.find_all('script',page_array)
page_number=page_num[4].string#只靠标签这些定位好像不是唯一,只能手动定位了
page_number=page_number.strip('function a204111_gopage_fun(){_simple_list_gotopage_fun(')#删掉除页数以外的其他内容
page_number=page_number.strip(',\'a204111GOPAGE\',2)}')
page_number=int(page_number)#转为数字
return page_number
def get_time_and_title(page_num,cqjtu_Headers):#页数,请求头
if page_num==66 :
url='http://news.cqjtu.edu.cn/xxtz.htm'
else :
url=f'http://news.cqjtu.edu.cn/xxtz/{page_num}.htm'
r=requests.get(url,headers=cqjtu_Headers)
r.raise_for_status()
r.encoding="utf-8"
array={#根据class来选择
'class':'time',
}
title_array={
'target':'_blank'
}
page_array={
'type':'text/javascript'
}
soup = BeautifulSoup(r.text, 'html.parser')
time=soup.find_all('div',array)
title=soup.find_all('a',title_array)
temp=[]
for i in range(0,len(time)):
time_s=time[i].string
time_s=time_s.strip('\n ')
time_s=time_s.strip('\n ')
#清除空格
temp.append(time_s)
temp.append(title[i+1].string)
cqjtu_infomation.append(temp)
temp=[]
def write_csv(cqjtu_info):
with open('D:/jupyter/package/2.csv', 'w', newline='',encoding='utf-8') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(cqjtu_head)
fileWriter.writerows(cqjtu_info)
print('爬取信息成功')
page_num=get_page_number()#获得页数
for i in tqdm(range(page_num,0,-1)):
get_time_and_title(i,cqjtu_Headers)
write_csv(cqjtu_infomation)
跑
(三)结果
像这样打开
记事本打开
参考
Jupyter notebook 选择虚拟环境运行代码
Anaconda安装教程,管理虚拟环境
Python爬虫练习(爬取OJ题和学校信息通知) 查看全部
c爬虫抓取网页数据(4.网络爬虫的合法性Robots协议:又称机器人协议或爬虫协议)
内容
一、爬虫简介
1.什么是网络爬虫?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者)是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。
2.爬虫类型
根据系统结构和实现技术,网络爬虫大致可以分为以下几类:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深网爬虫(Deep Web Crawler)。实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。
3.网络爬虫的使用范围
① 作为搜索引擎的网页采集器,抓取整个互联网,如谷歌、百度等。
②作为垂直搜索引擎,抓取特定主题信息,如视频网站、招聘网站等。
③作为测试网站前端的检测工具,用于评估网站前端代码的健壮性。
4.网络爬虫的合法性
机器人协议:又称机器人协议或爬虫协议,该协议规定了搜索引擎抓取网站内容的范围,包括网站是否希望被搜索引擎抓取,哪些内容不允许被抓取。网络爬虫“有意识地”在本地抓取或不抓取网页内容。自推出以来,机器人协议已成为网站保护自身敏感数据和网民隐私的国际惯例。
5.网络搜索策略
网络爬取策略可分为深度优先、广度优先和最佳优先。在很多情况下,深度优先会导致爬虫被困。目前,广度优先和最佳优先的方法很常见。
6.爬虫的基本结构
一个网络爬虫通常收录
四个模块:
• URL 管理模块
• 下载模块
• 分析模块
• 存储模块
二、环境准备(一)创建python虚拟环境
使用 conda 创建一个名为 crawler 的 python 虚拟环境。在这个虚拟环境下,使用pip或者conda安装requests、beautifulsoup4等必要的包(如果网络问题请切换国内镜像网站或国外网站仓库,注意使用这两个安装工具不同的仓库)。使用jupyter、pycharm、spyder、vscoder等IDE编程环境时,需要选择设置IDE后端使用的python版本或虚拟环境。比如使用jupyter notebook时,参考(),在jupyter运行的web界面选择对应的python kernel Kernel(带虚拟环境列表);如果使用pycharm,参考()选择对应的现有虚拟环境。
使用 conda create -n crawler python=3.8 命令新建一个名为 crawlerpython version 3.8 的虚拟环境
你开始创造
已创建
使用命令conda env list查看已经存在的虚拟环境,爬虫已经存在,base是conda自带的环境,uuu是我之前创建的
Activate crawler 进入爬虫环境,conda activate 退出当前环境,activate 是进入基础环境
conda remove --name 环境名称 --all 卸载环境
Jupyter notebook 本身不支持选择虚拟环境,每次有新项目时都需要重新配置所有插件。使用nb_conda插件将jupyter notebook变成pycharm一样可选择的运行环境。
在基础环境中使用conda install nb_conda命令安装nb_conda
在conda虚拟环境中使用conda install -n environment name ipykernel命令安装ipykernel
可以在jupyter notebook中显示
(二)安装库
环境准备
Python安装,这部分可以参考我之前的文章Python环境配置&Pycharm安装,到官网下载对应的安装包,安装一路Next;
pip安装,pip是Python的包管理器,目前的Python安装包一般都自带pip,不需要自己安装;
安装requests,beautifulsoup库,通过如下语句完成安装:
pip 安装请求
pip 安装 beautifulsoup4
谷歌浏览器(铬);
pip 安装请求
pip 安装 beautifulsoup4
pip 安装 html5lib
三、 爬取南洋理工ACM主题网站
学习样例代码,对关键代码句写详细注释,编写程序完成南洋理工ACM题库练习题数据的采集和存储;
(一)查看页面源码
点击进入南洋理工ACM专题网站,
右键->查看页面源代码
(二)代码运行
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
# tqdm作业:以进度条方式显示爬取进度
# 爬取11页所有题目信息
for pages in tqdm(range(1, 11 + 1)):
# get请求第pages页
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
# 判断异常
r.raise_for_status()
# 设置编码
r.encoding = 'utf-8'
# 创建BeautifulSoup对象,用于解析该html页面数据
soup = BeautifulSoup(r.text, 'html.parser')
# 获取所有td标签
td = soup.find_all('td')
# 存放某一个题目的所有信息
subject = []
# 遍历所有td
for t in td:
if t.string is not None:
subject.append(t.string) # 获取td中的字符串
if len(subject) == 5: # 每5个为一个题目的信息
subjects.append(subject)
subject = []
# 存放题目
with open('D:/jupyter/package/1.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders) # 写入表头
fileWriter.writerows(subjects) # 写入数据
print('\n题目信息爬取完成!!!')
运行,报错ModuleNotFoundError: No module named'tqdm',tqdm文件丢失,使用命令pip install tqdm安装
错误 FeatureNotFound:找不到具有您请求的功能的树生成器:lxml。需要安装解析器库吗,用pip install lxml安装,然后还是不行,自动安装最新版本,更换刚刚下载的版本删除:pip卸载lxml,下载指定版本试试: pip install lxml==3.7.0. 或不!!
然后第二种方法,把参数lxml改成html.parser
soup = BeautifulSoup(r.text, 'html.parser')
没关系!激动的心和握手~
(三)结果
四、 爬上重庆交通大学新闻网站
重写爬虫示例代码,爬取重庆交通大学新闻网站近年所有信息公告()的发布日期和标题,写入CSV电子表格。
(一)查看网页源码
重庆交通大学新闻网
右键->查看网页源代码
(二)代码运行
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
cqjtu_Headers ={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44'
}
#csv的表头
cqjtu_head=["日期","标题"]
#存放内容
cqjtu_infomation=[]
def get_page_number():
r=requests.get(f"http://news.cqjtu.edu.cn/xxtz.htm",headers=cqjtu_Headers)
r.raise_for_status()
r.encoding="utf-8"
page_array={
'type':'text/javascript'
}
soup = BeautifulSoup(r.text, 'html5lib')
page_num=soup.find_all('script',page_array)
page_number=page_num[4].string#只靠标签这些定位好像不是唯一,只能手动定位了
page_number=page_number.strip('function a204111_gopage_fun(){_simple_list_gotopage_fun(')#删掉除页数以外的其他内容
page_number=page_number.strip(',\'a204111GOPAGE\',2)}')
page_number=int(page_number)#转为数字
return page_number
def get_time_and_title(page_num,cqjtu_Headers):#页数,请求头
if page_num==66 :
url='http://news.cqjtu.edu.cn/xxtz.htm'
else :
url=f'http://news.cqjtu.edu.cn/xxtz/{page_num}.htm'
r=requests.get(url,headers=cqjtu_Headers)
r.raise_for_status()
r.encoding="utf-8"
array={#根据class来选择
'class':'time',
}
title_array={
'target':'_blank'
}
page_array={
'type':'text/javascript'
}
soup = BeautifulSoup(r.text, 'html.parser')
time=soup.find_all('div',array)
title=soup.find_all('a',title_array)
temp=[]
for i in range(0,len(time)):
time_s=time[i].string
time_s=time_s.strip('\n ')
time_s=time_s.strip('\n ')
#清除空格
temp.append(time_s)
temp.append(title[i+1].string)
cqjtu_infomation.append(temp)
temp=[]
def write_csv(cqjtu_info):
with open('D:/jupyter/package/2.csv', 'w', newline='',encoding='utf-8') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(cqjtu_head)
fileWriter.writerows(cqjtu_info)
print('爬取信息成功')
page_num=get_page_number()#获得页数
for i in tqdm(range(page_num,0,-1)):
get_time_and_title(i,cqjtu_Headers)
write_csv(cqjtu_infomation)
跑
(三)结果
像这样打开
记事本打开
参考
Jupyter notebook 选择虚拟环境运行代码
Anaconda安装教程,管理虚拟环境
Python爬虫练习(爬取OJ题和学校信息通知)
c爬虫抓取网页数据(和StudyTitile的元素包含title元素的titletitle网页爬取实验数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-25 21:03
现在我们要从这个页面抓取实验数据
url = 'https://clinicaltrials.gov/ct2 ... 39%3B
首先打开浏览器加载网址
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get(url) #浏览器加载网页url
sleep(3)
2. 获取网页中的网址
观察到只有 Status 和 Study Titile 列中的元素收录
title,因此我们尝试通过 title 元素从许多元素中过滤出这两列中的元素。 “有结果”中点击的内容就是我们想要的,所以我们要区分“状态”和“研究标题”下的内容,观察这两个元素的区别,发现“状态”下的URL收录
'/结果/',所以我们用这个来区分。
scr1 = driver.find_elements_by_xpath('//td/a[@title]') #找出表格中含有属性title的元素
scr2= [x.get_attribute('href') for x in scr1] #获取元素中的网址
n01 = []
for i01 in scr2:
if i01.find('/results/') != -1: 若网址中不包含'/results/',返回-1
n01.append(i01)
所以n01的列表就是第一页所有实验的实验结果网址。
3.向实验结果网站发起请求,获取http状态码
import requests
def qingqiu(url):
r = requests.get(url)
r.encoding = 'utf-8'
return r.text
4.获取所有实验的实验结果
import re
from bs4 import BeautifulSoup
nl = []
for i01 in n01:
a = qingqiu(i01)
bs01 =BeautifulSoup(a,'lxml')#使用BeautifulSoup解析代码
da = bs01.find_all('script')
for i in range(len(da)):
a.replace(str(da[i]),'')
bs01 =BeautifulSoup(a,'lxml')
n001=bs01.find_all('tr') #搜索当前tag的所有tag子节点,此处tag为tr
nr_list=[]
for i001 in range(len(n001)):
n02 = n001[i001].find_all(re.compile('th|td'))
n002=[x.text.replace('\n',' ').strip() for x in n02]
if len(n002)>1 and n002[0].strip():
# print('存入。。。。')
nr_list=nr_list+n002 #列表拼接
nl = nl+nr_list
这里的 nl 是 10 个实验的实验结果。
以后会详细介绍,请指正~ 查看全部
c爬虫抓取网页数据(和StudyTitile的元素包含title元素的titletitle网页爬取实验数据)
现在我们要从这个页面抓取实验数据
url = 'https://clinicaltrials.gov/ct2 ... 39%3B
首先打开浏览器加载网址
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get(url) #浏览器加载网页url
sleep(3)
2. 获取网页中的网址
观察到只有 Status 和 Study Titile 列中的元素收录
title,因此我们尝试通过 title 元素从许多元素中过滤出这两列中的元素。 “有结果”中点击的内容就是我们想要的,所以我们要区分“状态”和“研究标题”下的内容,观察这两个元素的区别,发现“状态”下的URL收录
'/结果/',所以我们用这个来区分。
scr1 = driver.find_elements_by_xpath('//td/a[@title]') #找出表格中含有属性title的元素
scr2= [x.get_attribute('href') for x in scr1] #获取元素中的网址
n01 = []
for i01 in scr2:
if i01.find('/results/') != -1: 若网址中不包含'/results/',返回-1
n01.append(i01)
所以n01的列表就是第一页所有实验的实验结果网址。
3.向实验结果网站发起请求,获取http状态码
import requests
def qingqiu(url):
r = requests.get(url)
r.encoding = 'utf-8'
return r.text
4.获取所有实验的实验结果
import re
from bs4 import BeautifulSoup
nl = []
for i01 in n01:
a = qingqiu(i01)
bs01 =BeautifulSoup(a,'lxml')#使用BeautifulSoup解析代码
da = bs01.find_all('script')
for i in range(len(da)):
a.replace(str(da[i]),'')
bs01 =BeautifulSoup(a,'lxml')
n001=bs01.find_all('tr') #搜索当前tag的所有tag子节点,此处tag为tr
nr_list=[]
for i001 in range(len(n001)):
n02 = n001[i001].find_all(re.compile('th|td'))
n002=[x.text.replace('\n',' ').strip() for x in n02]
if len(n002)>1 and n002[0].strip():
# print('存入。。。。')
nr_list=nr_list+n002 #列表拼接
nl = nl+nr_list
这里的 nl 是 10 个实验的实验结果。
以后会详细介绍,请指正~
c爬虫抓取网页数据(没有反爬虫机制的生物网站上如何利用Python做“省力”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-23 03:03
我们可以用Python对一些没有反爬虫机制的生物做一些“省力”的事情网站,比如ID转换
我们以uniprot为例,进入它的转换页面入口,页面:
如果我有需要转换的ID,那么在对话框中输入转换即可。如果有很多,那么我们尝试通过计算机来解决它。
这里介绍Python库urllib,非常强大,可以爬取动态网页
所谓动态网页,并不是说页面会移动,是动态网页;这里的动态网页是指前后端(数据库)的接口,前后端的交互是通过表单来实现的。
按照这个思路,我们来看看网站的网页结构:
我们找到了对应的对话框,发现它的表单模型如图所示,然后根据urllib,我们设置一个参数,以字典的形式保存
import urllib.parse
import urllib.request
url = "https://www.uniprot.org/uploadlists/"
params = {
"from": "ACC+ID",
"to": "GENENAME",
# 返回结果的格式
"format": "tab",
"uploadQuery": 'p31946'
}
data = urllib.parse.urlencode(params)
data = data.encode('utf-8')
req = urllib.request.Request(url, data)
with urllib.request.urlopen(req) as f:
response = f.read()
c_id = response.decode('utf-8')
print(c_id)
url是id转换的URL,params是你要爬取的内容,以字典的形式存储,那么字典的key值代表的是HTML表单(form)中name的内容:
例如来自:
字典的键值对应表单的名称标签内容
to 是一样的:
对于上传查询:
必须是对应表单的名称标签中的内容
至于“格式”:“tab”是指我们将抓取到的网页转换成tab格式
TAB是属性数据的表结构文件。属性数据表结构文件定义了地图属性数据的表结构,包括字段数、字段名称、字段类型和字段宽度、索引字段以及对应图层的一些关键空间信息的描述。TAB 文件实际上是一个文本文件,您可以在写字板中打开它来观察其内容。
当然,这个技巧适用于表单提交爬虫。如果爬取的内容太多,不妨写一个函数:
import urllib.parse
import urllib.request
url = "https://www.uniprot.org/uploadlists/"
def uniprot(id):
params = {
# 返回结果的格式
"format": "tab",
"from": "ACC+ID",
"to": "GENENAME",
"uploadQuery": id
}
data = urllib.parse.urlencode(params)
data = data.encode('utf-8')
req = urllib.request.Request(url, data)
with urllib.request.urlopen(req) as f:
response = f.read()
c_id = response.decode('utf-8')
print(c_id)
参考:传送门 查看全部
c爬虫抓取网页数据(没有反爬虫机制的生物网站上如何利用Python做“省力”)
我们可以用Python对一些没有反爬虫机制的生物做一些“省力”的事情网站,比如ID转换
我们以uniprot为例,进入它的转换页面入口,页面:
如果我有需要转换的ID,那么在对话框中输入转换即可。如果有很多,那么我们尝试通过计算机来解决它。
这里介绍Python库urllib,非常强大,可以爬取动态网页
所谓动态网页,并不是说页面会移动,是动态网页;这里的动态网页是指前后端(数据库)的接口,前后端的交互是通过表单来实现的。
按照这个思路,我们来看看网站的网页结构:
我们找到了对应的对话框,发现它的表单模型如图所示,然后根据urllib,我们设置一个参数,以字典的形式保存
import urllib.parse
import urllib.request
url = "https://www.uniprot.org/uploadlists/"
params = {
"from": "ACC+ID",
"to": "GENENAME",
# 返回结果的格式
"format": "tab",
"uploadQuery": 'p31946'
}
data = urllib.parse.urlencode(params)
data = data.encode('utf-8')
req = urllib.request.Request(url, data)
with urllib.request.urlopen(req) as f:
response = f.read()
c_id = response.decode('utf-8')
print(c_id)
url是id转换的URL,params是你要爬取的内容,以字典的形式存储,那么字典的key值代表的是HTML表单(form)中name的内容:
例如来自:
字典的键值对应表单的名称标签内容
to 是一样的:
对于上传查询:
必须是对应表单的名称标签中的内容
至于“格式”:“tab”是指我们将抓取到的网页转换成tab格式
TAB是属性数据的表结构文件。属性数据表结构文件定义了地图属性数据的表结构,包括字段数、字段名称、字段类型和字段宽度、索引字段以及对应图层的一些关键空间信息的描述。TAB 文件实际上是一个文本文件,您可以在写字板中打开它来观察其内容。
当然,这个技巧适用于表单提交爬虫。如果爬取的内容太多,不妨写一个函数:
import urllib.parse
import urllib.request
url = "https://www.uniprot.org/uploadlists/"
def uniprot(id):
params = {
# 返回结果的格式
"format": "tab",
"from": "ACC+ID",
"to": "GENENAME",
"uploadQuery": id
}
data = urllib.parse.urlencode(params)
data = data.encode('utf-8')
req = urllib.request.Request(url, data)
with urllib.request.urlopen(req) as f:
response = f.read()
c_id = response.decode('utf-8')
print(c_id)
参考:传送门
c爬虫抓取网页数据(HTTP的请求和响应General全部的1.Request请求的方式(getpost))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-22 23:23
HTTP 请求和响应 一般所有 1.Request URL 请求的地址2.Request Method 请求的方法(get post)3.Response Headers Server 的响应 Request Headers Server 的请求1.@ >host:(主机和端口号)对应的URL2.Connection:(链接类型)3.User-Agent:用户代理4.Accept:(要传输的文件类型)5.referer:(页面跳转的地方)6.Cookie:(记录用户相关信息)7.Query String Paramerers 请求地址的参数
爬虫简介 什么是爬虫?简而言之,为什么需要爬虫而不是人来模拟浏览器进行网页操作?为其他程序提供数据源公司获取数据?1.公司自有数据2.第三方平台获取的数据免费平台:百度指数付费平台:Datatang3.爬虫爬取的数据python作为爬虫的优势1. PHP:对多线程和异步支持不是很好2.Java:代码量大,代码量大3.C/C++:代码量大,难写4.Python:很多支持模块,代码介绍,开发效率高(scrapy框架)爬虫分类1.一般网络爬虫如:百度雅虎谷歌2.专注网络爬虫:根据既定目标选择性抓取特定主题的内容几个概念1. URL组件 URL:全局统一资源定位器 https:网络协议:主机名,可以理解为主机名,这个主机在域名下TWF24000.html:Access Resource path anchor:锚点,用于前端页面定位。注意:当在浏览器中请求一个 URL 时,浏览器会对 URL 进行编码。(除英文字母、数字和一些符号外,其他都用%加十六进制编码) 例如:%E6%B5%B7%E8%B4%BC%E7%8E%8B&fr=search %E6%B5 % B7%E8%B4%BC%E7%8E%8B = One Piece2.User-Agent 用户代理角色:记录您浏览的详细信息,包括:操作系统内核浏览器版本等。例如:Mozilla/ 5. 提取数据和分析数据(一些经过特殊处理的并不都是准确的)2.Console:console(打印信息)用的不多3.Sources:信息源(网站@加载的整个文件) >) 不是 Multi- purpose 4.Net Work:网络工作(信息包抓包)可以看到很多网页请求 Cookie 记录服务器相关的用户信息。http 协议是无状态的。什么是无国籍?服务端无法判断用户身份 Cookie其实是一小段文字信息(key-value格式) 防爬功能:防爬模拟登录抓包工具1.元素:元素网页源码,提取数据和分析数据(有些经过特殊处理的并不全是准确的)2.控制台:console(打印信息)用的不多3.Sources:信息源(网站@>加载的整个文件)不是 Multi- purpose 4.Net Work:网络工作(信息包抓包)可以看到很多网页请求Cookie记录了服务器相关的用户信息。http 协议是无状态的。什么是无国籍?服务端无法判断用户身份 Cookie其实是一小段文字信息(key-value格式) 防爬功能:防爬模拟登录抓包工具1.元素:元素网页源码,提取数据,分析数据(有些经过特殊处理的,不一定都准确)2.Console:console(打印信息)用的不多3.Sources:信息源(网站加载的整个文件@> 查看全部
c爬虫抓取网页数据(HTTP的请求和响应General全部的1.Request请求的方式(getpost))
HTTP 请求和响应 一般所有 1.Request URL 请求的地址2.Request Method 请求的方法(get post)3.Response Headers Server 的响应 Request Headers Server 的请求1.@ >host:(主机和端口号)对应的URL2.Connection:(链接类型)3.User-Agent:用户代理4.Accept:(要传输的文件类型)5.referer:(页面跳转的地方)6.Cookie:(记录用户相关信息)7.Query String Paramerers 请求地址的参数
爬虫简介 什么是爬虫?简而言之,为什么需要爬虫而不是人来模拟浏览器进行网页操作?为其他程序提供数据源公司获取数据?1.公司自有数据2.第三方平台获取的数据免费平台:百度指数付费平台:Datatang3.爬虫爬取的数据python作为爬虫的优势1. PHP:对多线程和异步支持不是很好2.Java:代码量大,代码量大3.C/C++:代码量大,难写4.Python:很多支持模块,代码介绍,开发效率高(scrapy框架)爬虫分类1.一般网络爬虫如:百度雅虎谷歌2.专注网络爬虫:根据既定目标选择性抓取特定主题的内容几个概念1. URL组件 URL:全局统一资源定位器 https:网络协议:主机名,可以理解为主机名,这个主机在域名下TWF24000.html:Access Resource path anchor:锚点,用于前端页面定位。注意:当在浏览器中请求一个 URL 时,浏览器会对 URL 进行编码。(除英文字母、数字和一些符号外,其他都用%加十六进制编码) 例如:%E6%B5%B7%E8%B4%BC%E7%8E%8B&fr=search %E6%B5 % B7%E8%B4%BC%E7%8E%8B = One Piece2.User-Agent 用户代理角色:记录您浏览的详细信息,包括:操作系统内核浏览器版本等。例如:Mozilla/ 5. 提取数据和分析数据(一些经过特殊处理的并不都是准确的)2.Console:console(打印信息)用的不多3.Sources:信息源(网站@加载的整个文件) >) 不是 Multi- purpose 4.Net Work:网络工作(信息包抓包)可以看到很多网页请求 Cookie 记录服务器相关的用户信息。http 协议是无状态的。什么是无国籍?服务端无法判断用户身份 Cookie其实是一小段文字信息(key-value格式) 防爬功能:防爬模拟登录抓包工具1.元素:元素网页源码,提取数据和分析数据(有些经过特殊处理的并不全是准确的)2.控制台:console(打印信息)用的不多3.Sources:信息源(网站@>加载的整个文件)不是 Multi- purpose 4.Net Work:网络工作(信息包抓包)可以看到很多网页请求Cookie记录了服务器相关的用户信息。http 协议是无状态的。什么是无国籍?服务端无法判断用户身份 Cookie其实是一小段文字信息(key-value格式) 防爬功能:防爬模拟登录抓包工具1.元素:元素网页源码,提取数据,分析数据(有些经过特殊处理的,不一定都准确)2.Console:console(打印信息)用的不多3.Sources:信息源(网站加载的整个文件@>
c爬虫抓取网页数据(Python选择器选择器的理解和熟悉Python的选择器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-12-22 23:19
前几天,小编陆续写了四篇关于Python选择器的文章,使用正则表达式、BeautifulSoup、Xpath、CSS选择器在京东上抓取商品信息。今天就为大家总结一下这四种选择器,让大家对Python选择器有更深入的了解和熟悉。
一、正则表达式
正则表达式为我们提供了一种快速获取数据的方法。这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。爬京东时,正则表达式如下图所示:
使用正则表达式实现目标信息的准确性采集
另外,我们都知道网页经常会发生变化,从而导致网页中的一些细微的布局变化。这时候之前写的正则表达式已经不能满足需要了,也不容易调试。当需要匹配的内容很多时,使用正则表达式提取目标信息会降低程序运行速度,消耗更多内存。
二、美汤
BeautifulSoup 是一个非常流行的 Pyhon 模块。该模块可以解析网页并提供方便的界面来定位内容。这个模块的安装可以通过'pip install beautifulsoup4'来实现。
用美汤提取目标信息
使用 BeautifulSoup 的第一步是将下载的 HTML 内容解析成一个 soup 文档。由于大多数网页没有好的 HTML 格式,BeautifulSoup 需要确定实际的格式。BeautifulSoup 可以正确解析丢失的引号并关闭标签。此外,它会添加<html> 和<body> 标签,使其成为一个完整的HTML 文档。find() 和 find_all() 方法通常用于定位我们需要的元素。如果想了解BeautifulSoup的所有方法和参数,可以参考BeautifulSoup的官方文档。虽然在代码理解上,BeautifulSoup 比正则表达式复杂,但更容易构建和理解。
三、Lxml
Lxml模块是用C语言编写的,解析速度比BeautiflSoup快,安装过程也比较复杂,这里不再赘述。XPath 使用路径表达式来选择 XML 文档中的节点。通过遵循路径或步骤来选择节点。
路径
使用lxml模块的第一步和BeautifulSoup一样,都是将潜在的非法HTML解析成统一的格式。虽然Lxml可以正确解析属性两边缺失的引号并关闭标签,但是模块并没有添加额外的<html>和<body>标签。
在线复制 Xpath 表达式可以轻松复制 Xpath 表达式。但是这种方法得到的Xpath表达式在程序中一般是不能用的,看的太长了。因此,Xpath 表达式一般要自己使用。
四、CSS
CSS 选择器表示用于选择元素的模式。BeautifulSoup 集成了 CSS 选择器的语法和它自己方便的 API。在网络爬虫的开发过程中,对于熟悉CSS选择器语法的人来说,使用CSS选择器是一种非常方便的方法。
CSS 选择器
以下是一些常用选择器的示例。
五、性能对比
lxml 和正则表达式模块都是用 C 编写的,而 BeautifulSoup 是用纯 Python 编写的。下表总结了每种爬取方法的优缺点。
注意到这一点相对困难。在其内部实现中,lxml 实际上将 CSS 选择器转换为等效的 Xpath 选择器。
六、总结
如果你的爬虫的瓶颈是下载网页,而不是提取数据,那么较慢的方法(比如 BeautifulSoup)不是问题。如果你只需要抓取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。但是,一般情况下,l xml 是捕获数据的最佳选择,因为这种方法快速且健壮,而正则表达式和 BeautifulSoup 仅在某些场景下有用。
如果想深入了解Python网络爬虫和数据挖掘,可以到专业网站: 查看全部
c爬虫抓取网页数据(Python选择器选择器的理解和熟悉Python的选择器)
前几天,小编陆续写了四篇关于Python选择器的文章,使用正则表达式、BeautifulSoup、Xpath、CSS选择器在京东上抓取商品信息。今天就为大家总结一下这四种选择器,让大家对Python选择器有更深入的了解和熟悉。
一、正则表达式
正则表达式为我们提供了一种快速获取数据的方法。这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。爬京东时,正则表达式如下图所示:
使用正则表达式实现目标信息的准确性采集
另外,我们都知道网页经常会发生变化,从而导致网页中的一些细微的布局变化。这时候之前写的正则表达式已经不能满足需要了,也不容易调试。当需要匹配的内容很多时,使用正则表达式提取目标信息会降低程序运行速度,消耗更多内存。
二、美汤
BeautifulSoup 是一个非常流行的 Pyhon 模块。该模块可以解析网页并提供方便的界面来定位内容。这个模块的安装可以通过'pip install beautifulsoup4'来实现。
用美汤提取目标信息
使用 BeautifulSoup 的第一步是将下载的 HTML 内容解析成一个 soup 文档。由于大多数网页没有好的 HTML 格式,BeautifulSoup 需要确定实际的格式。BeautifulSoup 可以正确解析丢失的引号并关闭标签。此外,它会添加<html> 和<body> 标签,使其成为一个完整的HTML 文档。find() 和 find_all() 方法通常用于定位我们需要的元素。如果想了解BeautifulSoup的所有方法和参数,可以参考BeautifulSoup的官方文档。虽然在代码理解上,BeautifulSoup 比正则表达式复杂,但更容易构建和理解。
三、Lxml
Lxml模块是用C语言编写的,解析速度比BeautiflSoup快,安装过程也比较复杂,这里不再赘述。XPath 使用路径表达式来选择 XML 文档中的节点。通过遵循路径或步骤来选择节点。
路径
使用lxml模块的第一步和BeautifulSoup一样,都是将潜在的非法HTML解析成统一的格式。虽然Lxml可以正确解析属性两边缺失的引号并关闭标签,但是模块并没有添加额外的<html>和<body>标签。
在线复制 Xpath 表达式可以轻松复制 Xpath 表达式。但是这种方法得到的Xpath表达式在程序中一般是不能用的,看的太长了。因此,Xpath 表达式一般要自己使用。
四、CSS
CSS 选择器表示用于选择元素的模式。BeautifulSoup 集成了 CSS 选择器的语法和它自己方便的 API。在网络爬虫的开发过程中,对于熟悉CSS选择器语法的人来说,使用CSS选择器是一种非常方便的方法。
CSS 选择器
以下是一些常用选择器的示例。
五、性能对比
lxml 和正则表达式模块都是用 C 编写的,而 BeautifulSoup 是用纯 Python 编写的。下表总结了每种爬取方法的优缺点。
注意到这一点相对困难。在其内部实现中,lxml 实际上将 CSS 选择器转换为等效的 Xpath 选择器。
六、总结
如果你的爬虫的瓶颈是下载网页,而不是提取数据,那么较慢的方法(比如 BeautifulSoup)不是问题。如果你只需要抓取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。但是,一般情况下,l xml 是捕获数据的最佳选择,因为这种方法快速且健壮,而正则表达式和 BeautifulSoup 仅在某些场景下有用。
如果想深入了解Python网络爬虫和数据挖掘,可以到专业网站:

