
c爬虫抓取网页数据
c爬虫抓取网页数据(由C#编写的多线程异步抓取网页的网络爬虫控制台程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-17 08:11
C#编写的一个多线程异步网络爬虫控制台程序
描述:C#编写的多线程异步网络爬虫控制台程序。功能:目前只能提取网络链接,使用的两个记录文件不需要很大。暂时无法抓取网页文字、图片、视频和html代码,敬请谅解。但是需要注意的是,网页的数量非常多。下面的代码理论上可以捕获整个Internet网页链接。但实际上,由于处理器功能和网络条件(主要是网速)的限制,一般家用电脑最多可以处理12个线程的爬虫任务,爬虫速度是有限的。它可以爬行,但需要时间和耐心。当然,这个程序是可以捕获所有链接的,因为链接不占用太多系统空间,并且借助日志文件,可以将爬取的网页数量堆积起来,甚至可以访问所有互联网网络链接,当然最好是分批进行。建议将maxNum设置为500-1000左右,慢慢积累。另外,由于是控制台程序,有时显示的字符过多,系统会暂停显示。这时候,只需点击控制台并按回车键即可。当程序暂停时,您可以按 Enter 尝试。/// 要使用这个程序,请确保已经创建了相应的记录文件。为简化代码,本程序不够健壮,请见谅。/// 默认文件创建在E盘根目录下的两个文本文件:“待爬取的URL.txt”和“待爬取的URL.txt”。并注意不要有后缀出错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接用多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。并注意不要有后缀出错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接用多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接用多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接用多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。
现在就下载 查看全部
c爬虫抓取网页数据(由C#编写的多线程异步抓取网页的网络爬虫控制台程序)
C#编写的一个多线程异步网络爬虫控制台程序
描述:C#编写的多线程异步网络爬虫控制台程序。功能:目前只能提取网络链接,使用的两个记录文件不需要很大。暂时无法抓取网页文字、图片、视频和html代码,敬请谅解。但是需要注意的是,网页的数量非常多。下面的代码理论上可以捕获整个Internet网页链接。但实际上,由于处理器功能和网络条件(主要是网速)的限制,一般家用电脑最多可以处理12个线程的爬虫任务,爬虫速度是有限的。它可以爬行,但需要时间和耐心。当然,这个程序是可以捕获所有链接的,因为链接不占用太多系统空间,并且借助日志文件,可以将爬取的网页数量堆积起来,甚至可以访问所有互联网网络链接,当然最好是分批进行。建议将maxNum设置为500-1000左右,慢慢积累。另外,由于是控制台程序,有时显示的字符过多,系统会暂停显示。这时候,只需点击控制台并按回车键即可。当程序暂停时,您可以按 Enter 尝试。/// 要使用这个程序,请确保已经创建了相应的记录文件。为简化代码,本程序不够健壮,请见谅。/// 默认文件创建在E盘根目录下的两个文本文件:“待爬取的URL.txt”和“待爬取的URL.txt”。并注意不要有后缀出错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接用多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。并注意不要有后缀出错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接用多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接用多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接用多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。
现在就下载
c爬虫抓取网页数据(不同时间段的网络表格数据节点获取需要注意的事项!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-11-17 03:01
(1)数据URL获取
网易财经、新浪财经等网站数据可免费获取。我们可以使用爬虫方法(通过rvest包)抓取对应的网站表数据。首先,我们可以在网易财经抢到600550,以2019年第三季度的数据为例。它的网站是:
,
可以看出,不同时间段的网址是有规律的,只需更改其中的股票代码、年份和季节即可循环抓取多只股票。
(2)Web 表数据节点获取
我们需要解析网页表格数据的节点。除了系统地掌握网页设计的原理和基本结构,我们还可以通过FireFox(Firebug插件)和Chrome浏览器解析网页结构,得到相应的分支结构点。这里我们使用火狐浏览器,具体操作是在找到我们需要的表格位置后(请探讨如何找到表格位置),右键复制XPath路径。
table部分的XPath是/html/body/div[2]/div[4]/table[1]。
(3) 抓取单个股票的单页数据
library(rvest)
symbol=600550
year=2019
season=3
url=paste0("http://quotes.money.163.com/trade/lsjysj_",symbol,".html?year=",year,"&season=",season)
web=read_html(url)
xpath="/html/body/div[2]/div[4]/table[1]"
web.table=web%>%html_nodes(xpath=xpath)%>%html_table()
此时的web.table就是爬取到的数据
(4) 从单个股票的多个页面抓取并合并数据
library(lubridate)
symbol=600550
from="2001-05-28"
from=as.Date(from)
to=Sys.Date()
time.index=seq(from=from,to=to,by="quarter")#生成以季度为开始的时间序列
year.id=year(time.index)#获取年份
quarter.id=quarter(time.index)#获取季度
price=list()
for(t in 1:length(time.index)){
year=year.id[t]
season=quarter.id[t]
url=paste0("http://quotes.money.163.com/trade/lsjysj_",symbol,".html?year=",year,"&season=",season)
web=read_html(url)
xpath="/html/body/div[2]/div[4]/table[1]"
web.table=web%>%html_nodes(xpath=xpath)%>%html_table()
web.table=web.table[[1]][-1,]
price[[t]]=web.table
}
(5) 多只股票多页数据抓取合并
get.wangyi.stock=function(symbol,from,to){
from=as.Date(from)
to=as.Date(to)
if(mday(from==1)){
from=from-1
}
time.index=seq(from=from,to=to,by="quarter")
year.id=year(time.index)
quarter.id=quarter(time.index)
prices=list()
for(t in 1:length(time.index)){
year=year.id[t]
season=quarter.id[t] url=paste0("http://quotes.money.163.com/trade/lsjysj_",symbol,".html?year=",year,"&season=",season)
web=read_html(url)
xpath="/html/body/div[2]/div[4]/table[1]"
web.table=web%>%html_nodes(xpath=xpath)%>%html_table()
web.table=web.table[[1]][-1,]
prices[[t]]=web.table
}
}
to=Sys.Date()
stock.index=matrix(nrow=6,ncol=2)
stock.index[,1]=c("600550.ss","600192.ss","600152.ss","600644.ss","600885.ss","600151.ss")
stock.index[,2]=c("2017-05-28","2017-05-28","2017-05-28","2017-05-28","2017-05-28","2017-05-28")
for(i in nrow(stock.index)){
symbol=stock.index[i,1]
from=stock.index[i,2]
prices=get.wangyi.stock(symbol,from,to)
filenames=paste0("D://dataset//",symbol,".csv")
}
(6) 读取所有A股数据
我们也可以将所有A股代码整理成一个文件,阅读后实时更新所有A股股票数据。这个方法可以用来建立我们自己的数据库进行实时分析。同时,通过网络爬虫,我们也可以抓取到很多有意义的数据,并实时更新。 查看全部
c爬虫抓取网页数据(不同时间段的网络表格数据节点获取需要注意的事项!)
(1)数据URL获取
网易财经、新浪财经等网站数据可免费获取。我们可以使用爬虫方法(通过rvest包)抓取对应的网站表数据。首先,我们可以在网易财经抢到600550,以2019年第三季度的数据为例。它的网站是:
,
可以看出,不同时间段的网址是有规律的,只需更改其中的股票代码、年份和季节即可循环抓取多只股票。
(2)Web 表数据节点获取
我们需要解析网页表格数据的节点。除了系统地掌握网页设计的原理和基本结构,我们还可以通过FireFox(Firebug插件)和Chrome浏览器解析网页结构,得到相应的分支结构点。这里我们使用火狐浏览器,具体操作是在找到我们需要的表格位置后(请探讨如何找到表格位置),右键复制XPath路径。
table部分的XPath是/html/body/div[2]/div[4]/table[1]。
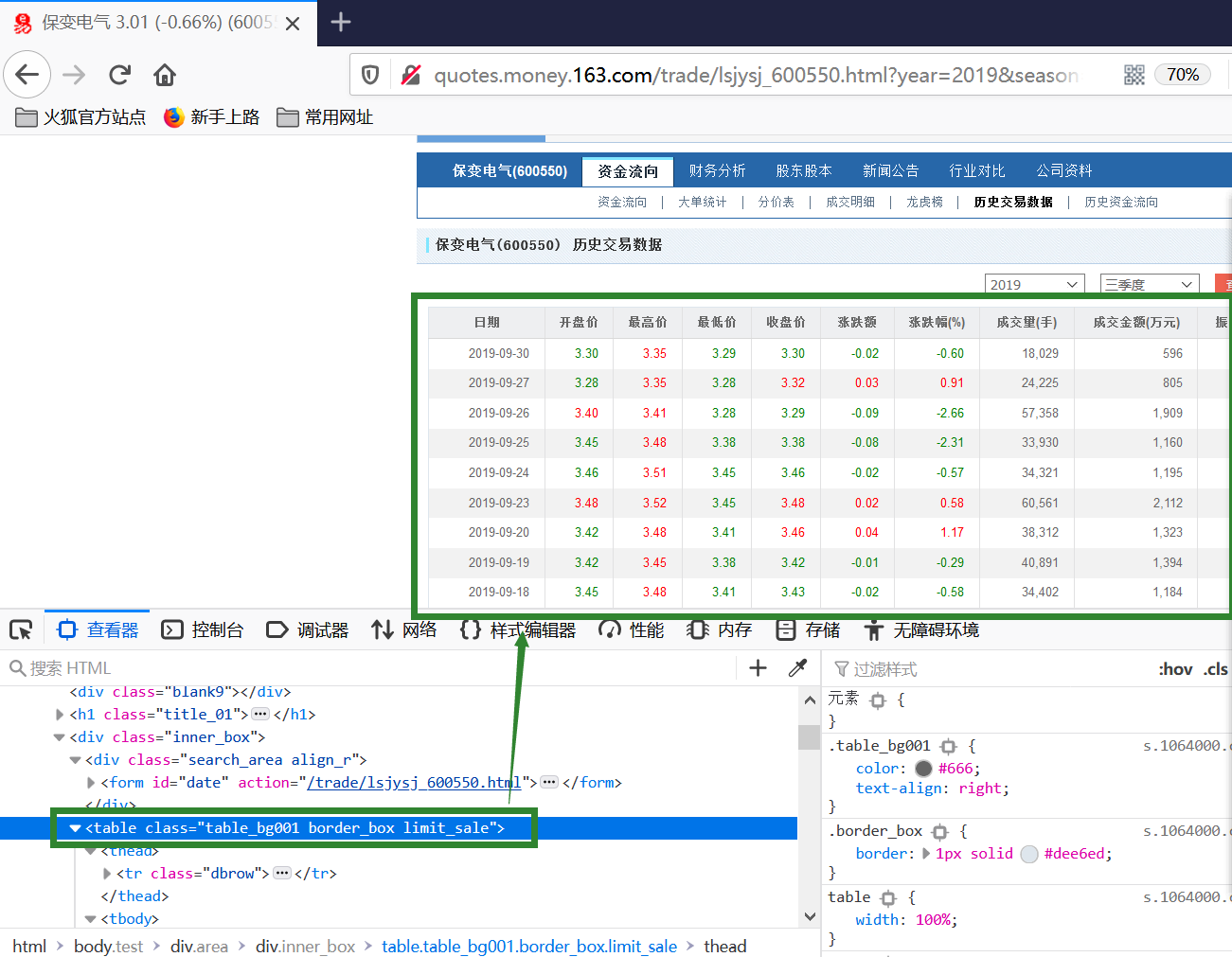
(3) 抓取单个股票的单页数据
library(rvest)
symbol=600550
year=2019
season=3
url=paste0("http://quotes.money.163.com/trade/lsjysj_",symbol,".html?year=",year,"&season=",season)
web=read_html(url)
xpath="/html/body/div[2]/div[4]/table[1]"
web.table=web%>%html_nodes(xpath=xpath)%>%html_table()
此时的web.table就是爬取到的数据
(4) 从单个股票的多个页面抓取并合并数据
library(lubridate)
symbol=600550
from="2001-05-28"
from=as.Date(from)
to=Sys.Date()
time.index=seq(from=from,to=to,by="quarter")#生成以季度为开始的时间序列
year.id=year(time.index)#获取年份
quarter.id=quarter(time.index)#获取季度
price=list()
for(t in 1:length(time.index)){
year=year.id[t]
season=quarter.id[t]
url=paste0("http://quotes.money.163.com/trade/lsjysj_",symbol,".html?year=",year,"&season=",season)
web=read_html(url)
xpath="/html/body/div[2]/div[4]/table[1]"
web.table=web%>%html_nodes(xpath=xpath)%>%html_table()
web.table=web.table[[1]][-1,]
price[[t]]=web.table
}
(5) 多只股票多页数据抓取合并
get.wangyi.stock=function(symbol,from,to){
from=as.Date(from)
to=as.Date(to)
if(mday(from==1)){
from=from-1
}
time.index=seq(from=from,to=to,by="quarter")
year.id=year(time.index)
quarter.id=quarter(time.index)
prices=list()
for(t in 1:length(time.index)){
year=year.id[t]
season=quarter.id[t] url=paste0("http://quotes.money.163.com/trade/lsjysj_",symbol,".html?year=",year,"&season=",season)
web=read_html(url)
xpath="/html/body/div[2]/div[4]/table[1]"
web.table=web%>%html_nodes(xpath=xpath)%>%html_table()
web.table=web.table[[1]][-1,]
prices[[t]]=web.table
}
}
to=Sys.Date()
stock.index=matrix(nrow=6,ncol=2)
stock.index[,1]=c("600550.ss","600192.ss","600152.ss","600644.ss","600885.ss","600151.ss")
stock.index[,2]=c("2017-05-28","2017-05-28","2017-05-28","2017-05-28","2017-05-28","2017-05-28")
for(i in nrow(stock.index)){
symbol=stock.index[i,1]
from=stock.index[i,2]
prices=get.wangyi.stock(symbol,from,to)
filenames=paste0("D://dataset//",symbol,".csv")
}
(6) 读取所有A股数据
我们也可以将所有A股代码整理成一个文件,阅读后实时更新所有A股股票数据。这个方法可以用来建立我们自己的数据库进行实时分析。同时,通过网络爬虫,我们也可以抓取到很多有意义的数据,并实时更新。
c爬虫抓取网页数据(java程序中获取后台js完后的完整页面是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-13 18:11
很多网站使用js或者jquery来生成数据。后台获取数据后,使用 document.write() 或 ("#id").html="" 写入页面。这时候用浏览器看源码是看不到数据的。
HttpClient 不起作用。看网上的HtmlUnit,说是加载后台js后可以得到完整的页面,但是我按照文章写的,但是不行。一般代码是这样写的:
String url = "http://xinjinqiao.tprtc.com/ad ... 3B%3B
try {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10);
//设置webClient的相关参数
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
//webClient.getOptions().setTimeout(50000);
webClient.getOptions().setThrowExceptionOnScriptError(false);
//模拟浏览器打开一个目标网址
HtmlPage rootPage = webClient.getPage(url);
System.out.println("为了获取js执行的数据 线程开始沉睡等待");
Thread.sleep(3000);//主要是这个线程的等待 因为js加载也是需要时间的
System.out.println("线程结束沉睡");
String html = rootPage.asText();
System.out.println(html);
} catch (Exception e) {
}
事实上,它根本不起作用。
典型的是这个链接的页面。 java程序中如何获取数据? 查看全部
c爬虫抓取网页数据(java程序中获取后台js完后的完整页面是什么?)
很多网站使用js或者jquery来生成数据。后台获取数据后,使用 document.write() 或 ("#id").html="" 写入页面。这时候用浏览器看源码是看不到数据的。
HttpClient 不起作用。看网上的HtmlUnit,说是加载后台js后可以得到完整的页面,但是我按照文章写的,但是不行。一般代码是这样写的:
String url = "http://xinjinqiao.tprtc.com/ad ... 3B%3B
try {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10);
//设置webClient的相关参数
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
//webClient.getOptions().setTimeout(50000);
webClient.getOptions().setThrowExceptionOnScriptError(false);
//模拟浏览器打开一个目标网址
HtmlPage rootPage = webClient.getPage(url);
System.out.println("为了获取js执行的数据 线程开始沉睡等待");
Thread.sleep(3000);//主要是这个线程的等待 因为js加载也是需要时间的
System.out.println("线程结束沉睡");
String html = rootPage.asText();
System.out.println(html);
} catch (Exception e) {
}
事实上,它根本不起作用。
典型的是这个链接的页面。 java程序中如何获取数据?
c爬虫抓取网页数据(Python爬虫开发环境搭建.x的爬虫笔记)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-13 18:11
原作者及原文链接:Jack-Cui, /c406495762/...
操作平台:Windows Python版本:Python3.x IDE:Sublime text3
一直想学习Python爬虫的知识,上网搜了一下,大部分都是基于Python2.x。所以打算写一篇Python3.x的爬虫笔记,供后续复习。欢迎交流,共同进步。
一、预备知识1.Python3.x基础知识学习:2.开发环境搭建:二、网络爬虫的定义
网络爬虫也称为网络蜘蛛。如果将 Internet 比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络爬虫根据网页的地址,即 URL 搜索网页。举个简单的例子,我们在浏览器地址栏中输入的字符串就是URL,例如:。
URL是Uniform Resource Locator,其一般格式如下(方括号[]是可选的):
协议://主机名[:端口]/路径/[;参数][?查询]#fragment
URL格式由三部分组成:
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分为主机名(端口号为可选参数)。一般网站的默认端口号为80。例如host百度的名字是这个是服务器的地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
三、简单爬虫示例
在 Python3.x 中,我们可以使用 urlib 组件来抓取网页。urllib 是一个 URL 处理包。这个包收录一些处理 URL 的模块,如下:
urllib.request 模块用于打开和读取 URL;
urllib.error 模块中收录了 urllib.request 产生的一些错误,可以通过 try 捕获和处理;
urllib.parse 模块收录一些解析 URL 的方法;
urllib.robotparser 模块用于解析 robots.txt 文本文件。它提供了一个单独的RobotFileParser类来测试爬虫是否可以通过该类提供的can_fetch()方法下载一个页面。
我们使用 urllib.request.urlopen() 接口函数轻松打开一个网站,读取和打印信息。
urlopen 有一些可选参数。具体信息请参考Python自带的文档。
知道了这一点,我们就可以写出最简单的程序了,文件名是urllib_test01.py,感受一下一个urllib库的魅力:
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com")
html = response.read()
print(html)
复制代码
urllib 使用 request.urlopen() 打开和读取 URLs 信息,返回的对象 response 就像一个文本对象,我们可以调用 read() 来读取它。然后通过print(),打印出读取到的信息。
运行程序ctrl+b,可以在Sublime中查看结果,如下:
您也可以在 cmd(控制台)中输入命令:
python urllib_test01.py
复制代码
运行py文件,输出信息相同,如下:
其实这是浏览器接收到的信息,但是我们在使用浏览器的时候,浏览器已经把这些信息转换成界面信息供我们浏览了。当然,我们也可以从浏览器中查看这些代码。比如使用谷歌浏览器,在任意界面右击选择Check,就是勾选元素(不是所有页面都可以勾选元素,比如起点中文网站的付费版块。)。以百度界面为例。截图如下:
如您所见,我们的审核结果在右侧。我们可以在本地更改元素,即浏览器(客户端),但这不会上传到服务器。例如,我可以修改我的支付宝余额并安装一个包,例如:
我真的有钱吗?显然,如果我被迫这样做,我就没有钱了。我刚刚修改了关于review元素的信息。
有一些偏差,但事实是浏览器作为客户端从服务器获取信息,然后解析信息,然后显示给我们。
回到正题,虽然我们成功获取到了信息,但很明显,都是二进制乱码,看起来很不方便。我们该怎么办?
我们可以通过一个简单的decode()命令来解码网页的信息并显示出来。我们新建一个文件,命名为urllib_test02.py,编写如下代码(或以百度翻译网站为例):
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://www.fanyi.baidu.com/")
html = response.read()
html = html.decode("utf-8")
print(html)
复制代码
这样,我们就可以得到这个结果。显然,解码后的信息看起来更整洁、更舒服:
当然,前提是我们已经知道这个网页是utf-8编码的,如何查看网页的编码方式呢?需要人工操作,一个很简单的方法就是使用浏览器查看元素。只需要找到head标签开头的chareset就知道网页使用的是哪种编码。如下:
所以我们知道这个网站的编码方式,但这需要我们每次打开浏览器,找到编码方式。显然,这有点麻烦。使用几行代码来解决它更容易更酷。
四、自动获取网页编码的方法
获取网页代码的方法有很多,我更喜欢使用第三方库。
首先我们需要安装第三方库chardet,它是一个用来判断编码的模块。安装方法如下图所示。只需输入命令:
pip install chardet
复制代码
安装后,我们可以使用chardet.detect()方法来判断网页的编码。此时,我们可以编写一个小程序来判断网页的编码方式,新建的文件名为chardet_test01.py:
# -*- coding: UTF-8 -*-
from urllib import request
import chardet
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com/")
html = response.read()
charset = chardet.detect(html)
print(charset)
复制代码
运行程序,查看输出结果如下:
看,返回的是字典,所以我们知道了网页的编码方式,我们可以根据得到的信息使用不同的解码方式。
PS:关于编码方式的内容,可以自行百度 查看全部
c爬虫抓取网页数据(Python爬虫开发环境搭建.x的爬虫笔记)
原作者及原文链接:Jack-Cui, /c406495762/...
操作平台:Windows Python版本:Python3.x IDE:Sublime text3
一直想学习Python爬虫的知识,上网搜了一下,大部分都是基于Python2.x。所以打算写一篇Python3.x的爬虫笔记,供后续复习。欢迎交流,共同进步。
一、预备知识1.Python3.x基础知识学习:2.开发环境搭建:二、网络爬虫的定义
网络爬虫也称为网络蜘蛛。如果将 Internet 比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络爬虫根据网页的地址,即 URL 搜索网页。举个简单的例子,我们在浏览器地址栏中输入的字符串就是URL,例如:。
URL是Uniform Resource Locator,其一般格式如下(方括号[]是可选的):
协议://主机名[:端口]/路径/[;参数][?查询]#fragment
URL格式由三部分组成:
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分为主机名(端口号为可选参数)。一般网站的默认端口号为80。例如host百度的名字是这个是服务器的地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
三、简单爬虫示例
在 Python3.x 中,我们可以使用 urlib 组件来抓取网页。urllib 是一个 URL 处理包。这个包收录一些处理 URL 的模块,如下:
urllib.request 模块用于打开和读取 URL;
urllib.error 模块中收录了 urllib.request 产生的一些错误,可以通过 try 捕获和处理;
urllib.parse 模块收录一些解析 URL 的方法;
urllib.robotparser 模块用于解析 robots.txt 文本文件。它提供了一个单独的RobotFileParser类来测试爬虫是否可以通过该类提供的can_fetch()方法下载一个页面。
我们使用 urllib.request.urlopen() 接口函数轻松打开一个网站,读取和打印信息。
urlopen 有一些可选参数。具体信息请参考Python自带的文档。
知道了这一点,我们就可以写出最简单的程序了,文件名是urllib_test01.py,感受一下一个urllib库的魅力:
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com";)
html = response.read()
print(html)
复制代码
urllib 使用 request.urlopen() 打开和读取 URLs 信息,返回的对象 response 就像一个文本对象,我们可以调用 read() 来读取它。然后通过print(),打印出读取到的信息。
运行程序ctrl+b,可以在Sublime中查看结果,如下:
您也可以在 cmd(控制台)中输入命令:
python urllib_test01.py
复制代码
运行py文件,输出信息相同,如下:
其实这是浏览器接收到的信息,但是我们在使用浏览器的时候,浏览器已经把这些信息转换成界面信息供我们浏览了。当然,我们也可以从浏览器中查看这些代码。比如使用谷歌浏览器,在任意界面右击选择Check,就是勾选元素(不是所有页面都可以勾选元素,比如起点中文网站的付费版块。)。以百度界面为例。截图如下:
如您所见,我们的审核结果在右侧。我们可以在本地更改元素,即浏览器(客户端),但这不会上传到服务器。例如,我可以修改我的支付宝余额并安装一个包,例如:
我真的有钱吗?显然,如果我被迫这样做,我就没有钱了。我刚刚修改了关于review元素的信息。
有一些偏差,但事实是浏览器作为客户端从服务器获取信息,然后解析信息,然后显示给我们。
回到正题,虽然我们成功获取到了信息,但很明显,都是二进制乱码,看起来很不方便。我们该怎么办?
我们可以通过一个简单的decode()命令来解码网页的信息并显示出来。我们新建一个文件,命名为urllib_test02.py,编写如下代码(或以百度翻译网站为例):
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://www.fanyi.baidu.com/";)
html = response.read()
html = html.decode("utf-8")
print(html)
复制代码
这样,我们就可以得到这个结果。显然,解码后的信息看起来更整洁、更舒服:
当然,前提是我们已经知道这个网页是utf-8编码的,如何查看网页的编码方式呢?需要人工操作,一个很简单的方法就是使用浏览器查看元素。只需要找到head标签开头的chareset就知道网页使用的是哪种编码。如下:
所以我们知道这个网站的编码方式,但这需要我们每次打开浏览器,找到编码方式。显然,这有点麻烦。使用几行代码来解决它更容易更酷。
四、自动获取网页编码的方法
获取网页代码的方法有很多,我更喜欢使用第三方库。
首先我们需要安装第三方库chardet,它是一个用来判断编码的模块。安装方法如下图所示。只需输入命令:
pip install chardet
复制代码
安装后,我们可以使用chardet.detect()方法来判断网页的编码。此时,我们可以编写一个小程序来判断网页的编码方式,新建的文件名为chardet_test01.py:
# -*- coding: UTF-8 -*-
from urllib import request
import chardet
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com/";)
html = response.read()
charset = chardet.detect(html)
print(charset)
复制代码
运行程序,查看输出结果如下:
看,返回的是字典,所以我们知道了网页的编码方式,我们可以根据得到的信息使用不同的解码方式。
PS:关于编码方式的内容,可以自行百度
c爬虫抓取网页数据(.4win7框架:如何获取网页上动态加载的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-13 04:21
环境:python3.4
赢7
框架:scrapy
继上一篇之后,这次我将讲如何获取网页上动态加载的数据:
作为初学者,刚开始接触爬虫的时候,我们一般只会爬取一些静态内容(如何区分静态内容和动态内容,这里不讲理论,只教一些小方法):
首先打开谷歌浏览器,然后按F12,就会弹出谷歌自带的开发者工具,首先在“元素”下找到你需要抓取的内容;
然后,在网页可视化界面上右键,选择查看网页源代码。网页源码就是我们按照抓取静态网页的方法在网页中可以看到的所有东西,开发者工具可以查看。有些东西我们在网页的源代码中是看不到的;
最后,通过将我们在F12中查看的内容与网页源代码中的内容进行对比,我们可以初步判断哪些数据是静态加载的,哪些数据是动态加载的。
--------- ---分割线-----------
一般的请求方法有两种,post请求方法和get请求方法。在这篇文章中,我们先说一下get请求方法。
说到get请求,这应该是最常用的请求之一。表达 get 请求的最直观方式是什么?其实我们把网址放在地址栏中打开网页,这是一个get请求。
--------- ---分割线-----------
好的,现在让我们进入主题:让我们先用一个例子来描述它。抓取大型购物的商品评论时网站:
当我们点击 1 或 2 3 4 时,我们会发现 URL 根本没有变化,这意味着这些评论是动态加载的。然后我们使用F12下的抓包工具尝试抓包:(F12,然后选择“网络”),出现下图:
接下来是最重要的:在可视化界面中,我们点击“2”按钮,让评论页面跳转到第二页,看看能否顺利抓包:
OK,可以看到有2个gif文件,2个png文件,还有一个脚本文件。一开始,我们不知道应该检查哪个文件。好吧,最笨的办法,一个一个点进去:所以你管我把它们都订了,除了脚本文件,其他的都是这样的:
哈哈,如果没有next,那我们只能检查脚本文件了。看Response,发现只是一堆代码,查起来好像不方便?好的,没问题,我们试试预览,效果会很好。. . . 很高兴找到结果:
你看到吗!评论评论,大家应该相信网站大写手的英文是绝对没问题的,不会像我一样给评论起个“pinglun”的吧!
然后点击这条评论看看里面有什么:
好了,就是我们要的注释了,所以这个文件所在的URL就是我们需要的,接下来我们通过看Headers来获取URL!
URL就是我们需要的URL(URL被马赛克抹掉了,不好意思各位,因为我哥也怕被水表查),状态值为200表示访问成功,访问方法: GET,回显话题,使用get请求获取网页的动态加载数据。好了,今天的教程到此结束。什么?不构造一个获取请求?那请到我的第一篇博文找大神的爬虫教程链接~~~~
好了,这篇文章到此结束。我从头到尾都没有看到任何代码。哈哈,有时候教他们钓鱼不如教他们钓鱼。代码很重要,方法也很重要。有了这些分析方法,相信大家都能快速掌握获取动态网页内容的技巧。下一篇我们会讲如何使用post请求来获取网页的动态加载数据~我们下期再见 查看全部
c爬虫抓取网页数据(.4win7框架:如何获取网页上动态加载的数据)
环境:python3.4
赢7
框架:scrapy
继上一篇之后,这次我将讲如何获取网页上动态加载的数据:
作为初学者,刚开始接触爬虫的时候,我们一般只会爬取一些静态内容(如何区分静态内容和动态内容,这里不讲理论,只教一些小方法):
首先打开谷歌浏览器,然后按F12,就会弹出谷歌自带的开发者工具,首先在“元素”下找到你需要抓取的内容;
然后,在网页可视化界面上右键,选择查看网页源代码。网页源码就是我们按照抓取静态网页的方法在网页中可以看到的所有东西,开发者工具可以查看。有些东西我们在网页的源代码中是看不到的;
最后,通过将我们在F12中查看的内容与网页源代码中的内容进行对比,我们可以初步判断哪些数据是静态加载的,哪些数据是动态加载的。
--------- ---分割线-----------
一般的请求方法有两种,post请求方法和get请求方法。在这篇文章中,我们先说一下get请求方法。
说到get请求,这应该是最常用的请求之一。表达 get 请求的最直观方式是什么?其实我们把网址放在地址栏中打开网页,这是一个get请求。
--------- ---分割线-----------
好的,现在让我们进入主题:让我们先用一个例子来描述它。抓取大型购物的商品评论时网站:

当我们点击 1 或 2 3 4 时,我们会发现 URL 根本没有变化,这意味着这些评论是动态加载的。然后我们使用F12下的抓包工具尝试抓包:(F12,然后选择“网络”),出现下图:

接下来是最重要的:在可视化界面中,我们点击“2”按钮,让评论页面跳转到第二页,看看能否顺利抓包:

OK,可以看到有2个gif文件,2个png文件,还有一个脚本文件。一开始,我们不知道应该检查哪个文件。好吧,最笨的办法,一个一个点进去:所以你管我把它们都订了,除了脚本文件,其他的都是这样的:

哈哈,如果没有next,那我们只能检查脚本文件了。看Response,发现只是一堆代码,查起来好像不方便?好的,没问题,我们试试预览,效果会很好。. . . 很高兴找到结果:

你看到吗!评论评论,大家应该相信网站大写手的英文是绝对没问题的,不会像我一样给评论起个“pinglun”的吧!
然后点击这条评论看看里面有什么:

好了,就是我们要的注释了,所以这个文件所在的URL就是我们需要的,接下来我们通过看Headers来获取URL!

URL就是我们需要的URL(URL被马赛克抹掉了,不好意思各位,因为我哥也怕被水表查),状态值为200表示访问成功,访问方法: GET,回显话题,使用get请求获取网页的动态加载数据。好了,今天的教程到此结束。什么?不构造一个获取请求?那请到我的第一篇博文找大神的爬虫教程链接~~~~
好了,这篇文章到此结束。我从头到尾都没有看到任何代码。哈哈,有时候教他们钓鱼不如教他们钓鱼。代码很重要,方法也很重要。有了这些分析方法,相信大家都能快速掌握获取动态网页内容的技巧。下一篇我们会讲如何使用post请求来获取网页的动态加载数据~我们下期再见
c爬虫抓取网页数据(基于关键字的自动下载网页资源的程序,())
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-12 17:04
网络爬虫 * 简介-crawler 爬虫,即Spider(网络爬虫),其定义可分为广义和狭义。狭义上,是指遵循标准http协议,使用超链接和Web文档检索方式遍历万维网的软件程序;而广义的定义是遵循http协议,检索Web文档的软件称为网络爬虫。网络爬虫是一款功能强大的自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。*关注爬虫 随着互联网的飞速发展,万维网已经成为海量信息的载体,如何有效地提取和利用这些信息成为一个巨大的挑战。搜索引擎,比如传统的通用搜索引擎AltaVista、Yahoo! 而谷歌等作为辅助人们检索信息的工具,已经成为用户访问万维网的入口和向导。但是,这些通用的搜索引擎也有一定的局限性。大量用户不关心的网页。(2)一般搜索引擎的目标是最大化网络覆盖。有限的搜索引擎服务器资源和无限的网络数据资源之间的矛盾将进一步加深。(3)随着数据形式的丰富在万维网和网络技术的不断发展中,图片、数据库、音视频多媒体等不同的数据大量出现,很好的发现和获取。
处理和搜索行为匹配结构化数据和元数据信息。如数码产品mp3:内存、大小、尺寸、电池型号、价格、厂家等,还可以提供比价服务*爬虫基本原理从一个或几个初始网页的URL(通常是一个网站 homepage),遍历网页空间,阅读网页内容,不断从一个站点移动到另一个站点,并自动建立索引。在抓取网页的过程中,找到网页中的其他链接地址,解析HTML文件,取出网页中的子链接,并添加到网页数据库中,不断从当前页面中提取新的URL并将它们放入队列中,因此循环继续。, 直到这个网站的所有网页都被抓取完毕,
*爬虫的基本原理。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询和检索。网络爬虫在分析某个网页时,不依赖用户干预,利用HTML语言的标记结构,获取指向其他网页的URL地址。如果把整个互联网看作一个网站,理论上网络爬虫可以抓取到互联网上的所有网页,可以对后续的抓取过程提供反馈和指导。正是这种行为方式,这些程序被称为蜘蛛、爬虫和机器人。*爬虫基本原理 Spider是如何爬取所有网页的?在 Web 出现之前,传统的文本集合,例如目录数据库和期刊摘要,存储在磁带或 CD 上并用作索引系统。相应地,Web 上所有可访问的 URL 都未分类。采集 URL 的唯一方法是扫描并采集指向其他页面的超链接。这些页面尚未采集。* 查看全部
c爬虫抓取网页数据(基于关键字的自动下载网页资源的程序,())
网络爬虫 * 简介-crawler 爬虫,即Spider(网络爬虫),其定义可分为广义和狭义。狭义上,是指遵循标准http协议,使用超链接和Web文档检索方式遍历万维网的软件程序;而广义的定义是遵循http协议,检索Web文档的软件称为网络爬虫。网络爬虫是一款功能强大的自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。*关注爬虫 随着互联网的飞速发展,万维网已经成为海量信息的载体,如何有效地提取和利用这些信息成为一个巨大的挑战。搜索引擎,比如传统的通用搜索引擎AltaVista、Yahoo! 而谷歌等作为辅助人们检索信息的工具,已经成为用户访问万维网的入口和向导。但是,这些通用的搜索引擎也有一定的局限性。大量用户不关心的网页。(2)一般搜索引擎的目标是最大化网络覆盖。有限的搜索引擎服务器资源和无限的网络数据资源之间的矛盾将进一步加深。(3)随着数据形式的丰富在万维网和网络技术的不断发展中,图片、数据库、音视频多媒体等不同的数据大量出现,很好的发现和获取。
处理和搜索行为匹配结构化数据和元数据信息。如数码产品mp3:内存、大小、尺寸、电池型号、价格、厂家等,还可以提供比价服务*爬虫基本原理从一个或几个初始网页的URL(通常是一个网站 homepage),遍历网页空间,阅读网页内容,不断从一个站点移动到另一个站点,并自动建立索引。在抓取网页的过程中,找到网页中的其他链接地址,解析HTML文件,取出网页中的子链接,并添加到网页数据库中,不断从当前页面中提取新的URL并将它们放入队列中,因此循环继续。, 直到这个网站的所有网页都被抓取完毕,
*爬虫的基本原理。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询和检索。网络爬虫在分析某个网页时,不依赖用户干预,利用HTML语言的标记结构,获取指向其他网页的URL地址。如果把整个互联网看作一个网站,理论上网络爬虫可以抓取到互联网上的所有网页,可以对后续的抓取过程提供反馈和指导。正是这种行为方式,这些程序被称为蜘蛛、爬虫和机器人。*爬虫基本原理 Spider是如何爬取所有网页的?在 Web 出现之前,传统的文本集合,例如目录数据库和期刊摘要,存储在磁带或 CD 上并用作索引系统。相应地,Web 上所有可访问的 URL 都未分类。采集 URL 的唯一方法是扫描并采集指向其他页面的超链接。这些页面尚未采集。*
c爬虫抓取网页数据(Python爬虫学习笔记)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-11 00:14
操作平台:Windows Python版本:Python3.x IDE:Sublime text3
一直想学习Python爬虫的知识,上网搜了一下,大部分都是基于Python2.x。所以打算写一篇Python3.x的爬虫笔记,供后续复习。欢迎交流,共同进步。
一、预备知识
1.Python3.x基础知识学习:
您可以通过以下方式学习:
(1)廖雪峰Python3教程(文档):
网址:
(2)菜鸟教程Python3教程(文档):
网址:
(3) Fish C Studio Python 教程(视频):
小龟老师人很好,讲课风格幽默诙谐。如果时间充裕,可以考虑看视频。
网址:
2.开发环境设置:
Sublime text3搭建Pyhthon IDE,可以查看博客:
网址:
网址:
二、网络爬虫的定义
网络爬虫也称为网络蜘蛛。如果将 Internet 比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络爬虫根据网页的地址,即 URL 搜索网页。举个简单的例子,我们在浏览器地址栏中输入的字符串就是URL,例如:
URL是Uniform Resource Locator,其一般格式如下(方括号[]是可选的):
协议://主机名[:端口]/路径/[;参数][?查询]#fragment
URL格式由三部分组成:
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分为主机名(端口号为可选参数)。一般网站的默认端口号为80。例如host百度的名字是这个是服务器的地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
三、简单爬虫示例
在 Python3.x 中,我们可以使用 urlib 组件来抓取网页。urllib 是一个 URL 处理包。这个包收录一些处理 URL 的模块,如下:
1.urllib.request 模块用于打开和读取 URL;
2.urllib.error 模块中收录了 urllib.request 产生的一些错误,可以通过 try 捕获和处理;
3.urllib.parse 模块收录一些解析 URL 的方法;
4.urllib.robotparser 模块用于解析robots.txt 文本文件。它提供了一个单独的RobotFileParser类,可以通过该类提供的can_fetch()方法来测试爬虫是否可以下载一个页面。
我们可以使用接口函数urllib.request.urlopen()轻松打开一个网站,读取和打印信息。
urlopen 有一些可选参数。具体信息请参考Python自带的文档。
知道了这一点,我们就可以写出最简单的程序了,文件名是urllib_test01.py,感受一下一个urllib库的魅力:
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com")
html = response.read()
print(html)
urllib 使用 request.urlopen() 打开和读取 URLs 信息,返回的对象 response 就像一个文本对象,我们可以调用 read() 来读取它。然后通过print(),打印出读取到的信息。
运行程序ctrl+b,可以在Sublime中查看结果,如下:
您也可以在 cmd(控制台)中输入命令:
python urllib_test01.py
运行py文件,输出信息相同,如下:
其实这是浏览器接收到的信息,但是我们在使用浏览器的时候,浏览器已经把这些信息转换成界面信息供我们浏览了。当然,我们也可以从浏览器中查看这些代码。比如使用谷歌浏览器,在任意界面右击选择Check,即勾选元素(不是所有页面都可以勾选元素,比如起点中文网站的付费版块。)。以百度界面为例。截图如下:
如您所见,我们的审核结果在右侧。我们可以在本地更改元素,即浏览器(客户端),但这不会上传到服务器。例如,我可以修改我的支付宝余额并安装一个包,例如:
我真的有钱吗?显然,如果我被迫这样做,我就没有钱了。我只是修改了关于review元素的信息。
有一些偏差,但事实是浏览器作为客户端从服务器获取信息,然后解析信息,然后将其展示给我们。
回到正题,虽然我们成功获取到了信息,但很明显,都是二进制乱码,看起来很不方便。我们该怎么办?
我们可以通过一个简单的 decode() 命令来解码网页的信息并显示出来。我们新建一个文件,命名为urllib_test02.py,编写如下代码(或以百度翻译网站为例):
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://www.fanyi.baidu.com/")
html = response.read()
html = html.decode("utf-8")
print(html)
这样,我们就可以得到这个结果。显然,解码后的信息看起来更整洁、更舒服:
当然,前提是我们已经知道这个网页是utf-8编码的,如何查看网页的编码方式呢?需要人工操作,一个很简单的方法就是使用浏览器查看元素。只需要找到head标签开头的chareset就知道网页使用的是哪种编码。如下:
所以我们知道这个网站的编码方式,但这需要我们每次打开浏览器,找到编码方式。显然,这有点麻烦。用几行代码来解决,更省事,更爽。
四、自动获取网页编码的方法
获取网页代码的方法有很多,我更喜欢使用第三方库。
首先我们需要安装第三方库chardet,它是一个用来判断编码的模块。安装方法如下图所示。只需输入命令:
pip install chardet
安装后,我们可以使用chardet.detect()方法来判断网页的编码。此时,我们可以编写一个小程序来判断网页的编码方式,新建的文件名为chardet_test01.py:
# -*- coding: UTF-8 -*-
from urllib import request
import chardet
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com/")
html = response.read()
charset = chardet.detect(html)
print(charset)
运行程序,查看输出结果如下:
看,返回的是字典,所以我们知道了网页的编码方式,我们可以根据得到的信息使用不同的解码方式。
PS:关于编码方式的内容,可以自行百度,或者阅读这篇博客:
网址: 查看全部
c爬虫抓取网页数据(Python爬虫学习笔记)
操作平台:Windows Python版本:Python3.x IDE:Sublime text3
一直想学习Python爬虫的知识,上网搜了一下,大部分都是基于Python2.x。所以打算写一篇Python3.x的爬虫笔记,供后续复习。欢迎交流,共同进步。
一、预备知识
1.Python3.x基础知识学习:
您可以通过以下方式学习:
(1)廖雪峰Python3教程(文档):
网址:
(2)菜鸟教程Python3教程(文档):
网址:
(3) Fish C Studio Python 教程(视频):
小龟老师人很好,讲课风格幽默诙谐。如果时间充裕,可以考虑看视频。
网址:
2.开发环境设置:
Sublime text3搭建Pyhthon IDE,可以查看博客:
网址:
网址:
二、网络爬虫的定义
网络爬虫也称为网络蜘蛛。如果将 Internet 比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络爬虫根据网页的地址,即 URL 搜索网页。举个简单的例子,我们在浏览器地址栏中输入的字符串就是URL,例如:
URL是Uniform Resource Locator,其一般格式如下(方括号[]是可选的):
协议://主机名[:端口]/路径/[;参数][?查询]#fragment
URL格式由三部分组成:
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分为主机名(端口号为可选参数)。一般网站的默认端口号为80。例如host百度的名字是这个是服务器的地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
三、简单爬虫示例
在 Python3.x 中,我们可以使用 urlib 组件来抓取网页。urllib 是一个 URL 处理包。这个包收录一些处理 URL 的模块,如下:
1.urllib.request 模块用于打开和读取 URL;
2.urllib.error 模块中收录了 urllib.request 产生的一些错误,可以通过 try 捕获和处理;
3.urllib.parse 模块收录一些解析 URL 的方法;
4.urllib.robotparser 模块用于解析robots.txt 文本文件。它提供了一个单独的RobotFileParser类,可以通过该类提供的can_fetch()方法来测试爬虫是否可以下载一个页面。
我们可以使用接口函数urllib.request.urlopen()轻松打开一个网站,读取和打印信息。
urlopen 有一些可选参数。具体信息请参考Python自带的文档。
知道了这一点,我们就可以写出最简单的程序了,文件名是urllib_test01.py,感受一下一个urllib库的魅力:
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com";)
html = response.read()
print(html)
urllib 使用 request.urlopen() 打开和读取 URLs 信息,返回的对象 response 就像一个文本对象,我们可以调用 read() 来读取它。然后通过print(),打印出读取到的信息。
运行程序ctrl+b,可以在Sublime中查看结果,如下:
您也可以在 cmd(控制台)中输入命令:
python urllib_test01.py
运行py文件,输出信息相同,如下:
其实这是浏览器接收到的信息,但是我们在使用浏览器的时候,浏览器已经把这些信息转换成界面信息供我们浏览了。当然,我们也可以从浏览器中查看这些代码。比如使用谷歌浏览器,在任意界面右击选择Check,即勾选元素(不是所有页面都可以勾选元素,比如起点中文网站的付费版块。)。以百度界面为例。截图如下:
如您所见,我们的审核结果在右侧。我们可以在本地更改元素,即浏览器(客户端),但这不会上传到服务器。例如,我可以修改我的支付宝余额并安装一个包,例如:
我真的有钱吗?显然,如果我被迫这样做,我就没有钱了。我只是修改了关于review元素的信息。
有一些偏差,但事实是浏览器作为客户端从服务器获取信息,然后解析信息,然后将其展示给我们。
回到正题,虽然我们成功获取到了信息,但很明显,都是二进制乱码,看起来很不方便。我们该怎么办?
我们可以通过一个简单的 decode() 命令来解码网页的信息并显示出来。我们新建一个文件,命名为urllib_test02.py,编写如下代码(或以百度翻译网站为例):
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://www.fanyi.baidu.com/";)
html = response.read()
html = html.decode("utf-8")
print(html)
这样,我们就可以得到这个结果。显然,解码后的信息看起来更整洁、更舒服:
当然,前提是我们已经知道这个网页是utf-8编码的,如何查看网页的编码方式呢?需要人工操作,一个很简单的方法就是使用浏览器查看元素。只需要找到head标签开头的chareset就知道网页使用的是哪种编码。如下:
所以我们知道这个网站的编码方式,但这需要我们每次打开浏览器,找到编码方式。显然,这有点麻烦。用几行代码来解决,更省事,更爽。
四、自动获取网页编码的方法
获取网页代码的方法有很多,我更喜欢使用第三方库。
首先我们需要安装第三方库chardet,它是一个用来判断编码的模块。安装方法如下图所示。只需输入命令:
pip install chardet
安装后,我们可以使用chardet.detect()方法来判断网页的编码。此时,我们可以编写一个小程序来判断网页的编码方式,新建的文件名为chardet_test01.py:
# -*- coding: UTF-8 -*-
from urllib import request
import chardet
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com/";)
html = response.read()
charset = chardet.detect(html)
print(charset)
运行程序,查看输出结果如下:
看,返回的是字典,所以我们知道了网页的编码方式,我们可以根据得到的信息使用不同的解码方式。
PS:关于编码方式的内容,可以自行百度,或者阅读这篇博客:
网址:
c爬虫抓取网页数据(一个_selector.xpath.u去重与增量爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-11 00:12
response_selector.xpath(u'//div[contains(@class,"house-title")]/p[contains(@class,"house-update-info c_888 f12")]/text()').extract( )
因为有些数据不能用Xpath提取,所以也需要正则匹配。如有异常,应予处理。一般当页面无法匹配到对应的字段时,应该设置为0,项目处理完毕后,需要对其进行处理。进行过滤处理。
3) 去重和增量爬取
去重和增量爬取对服务器来说意义重大,可以减轻服务器压力,保证数据的准确性。如果不进行去重,被爬取的内容会爬取大量重复的内容,大大降低了爬虫效率。事实上,重复数据删除的过程非常简单。核心是在每次发出请求时判断该请求是否在爬取队列中。如果它已经存在,则丢弃当前请求。
具体实施步骤:
(1)从要爬取的队列中获取url
(2) 判断请求的URL是否已经被抓取,如果已经被抓取,则忽略该请求,不抓取,继续其他操作,将URL插入到抓取队列中
(3) 重复步骤 1
这里我们使用了scrapy-redis去重组件,所以没有实现,但是原理还是需要理解的,具体可以看源码。
4)爬虫中间件
爬虫中间件可以帮助我们在scrapy爬虫过程中自由扩展我们的程序。以下是爬虫反屏蔽中间件、下载器异常状态中间件和非200状态中间件。
(1)爬虫反屏蔽组件的实现
在访问网站的网页时,会给网站带来一定的负载,爬虫程序模拟了我们正常访问网页的过程,但是。大型爬虫会给网站增加很大的负载,影响普通用户的访问。为了保证网页可以被大多数正常用户访问,大多数网站都有相应的反爬虫策略。一旦访问行为被认定为爬虫,网站会采取一定的措施限制您的访问,比如提醒您访问过于频繁,请您输入验证码,如果比较严重,您的ip会被封禁,禁止你访问网站。本系统在有针对性的抓取网页数据时,会持续访问网站的内容。
本系统采用以下方法防止爬虫被拦截:
1.模拟不同的浏览器行为
2. 一定频率更换代理服务器和网关
3. 符合君子协议,降低爬虫爬取网页的频率,减少并发爬取的进程,限制每个IP的并发爬取次数,牺牲一定的效率来换取系统的稳定性。
4.禁用cookies,网站会在cookie中插入一些信息来判断用户访问时是否是机器人。我们屏蔽和调整cookie,这也有利于我们的身份不同意暴露。
5. 手动编码,这应该是无懈可击的反禁措施。所有的系统都不比人工操作好,但它们降低了自动化,效率不高,但它们确实是最有效的措施。当爬虫被禁止时,它会被重定向到一个验证码页面。输入验证码重新访问页面。为此,我添加了一个电子邮件提醒模块。当爬虫被封禁时,我会发邮件提醒管理员解封。同时将重定向的请求重新加入到下载队列中进行爬取,保证数据的完整性。
爬虫预防网站屏蔽的原理如下图所示:
(一)模拟不同浏览器行为的实现思路和代码
原理:从scrapy的介绍可以知道scrapy有下载中间件。在这个中间件中,我们可以自定义请求和响应,类似于spring面向方面的编程,就像在程序运行前后嵌入一个钩子。核心是修改请求的属性
首先是扩展下载中间件,首先在seetings.py中添加中间件,
其次,扩展中间件,主要是写一个useragent列表,将常用的浏览器请求头保存为一个列表,如下图:
让请求的头文件从列表中随机选择一个代理值,然后下载到下载器。
综上所述,每次发出请求,都是模拟使用不同的浏览器访问目标网站。
(B) 使用代理ip爬取的实现思路和代码。
首先,将中间件添加到seetings.py。扩展下载组件请求的头文件会从代理ip池中随机取出一个代理值,然后下载到下载器。
1.代理ip池的设计开发流程如下:
一种。获取免费代理ip网站。
湾 存储和验证代理ip
C。验证存储在数据库中
d. 如果达到最大ip数,停止爬取,一定时间后验证数据ip的有效性,删除无效ip
e. 直到数据库ip小于0,继续爬取ip,重复步骤a。
这里的代理ip模块使用的是七夜代理ip池的开源项目
代理ip爬虫运行截图:
(三)爬虫异常状态组件的处理
爬虫运行时没有被阻塞,访问网站并不总是200请求成功,而是有各种状态,比如上面爬虫被ban的时候,返回的状态其实是302,就是为了防止阻塞组件 捕获要实现的 302 状态。同时,异常情况的处理有利于爬虫的鲁棒性。
扩展中间件在设置中捕捉到异常情况后,将请求重新加入等待下载队列的过程如下:
(D) 数据存储模块
数据存储模块主要负责存储从端爬取解析的页面。使用 Mongodb 存储数据。
Scrapy 支持 json、csv 和 xml 等数据存储格式。用户可以在运行爬虫时进行设置,例如:scrapy crawl spider -o items.json -t json,也可以在Scrapy项目文件ItemPipline文件中定义,同时Scrapy也支持数据库存储,如如Monogdb、Redis等。当数据量很大到一定程度时,可以使用Mongodb或Reids集群来解决。本系统的数据存储如下图所示:
(E) 抓斗设计
本文以网络房屋数据为爬取目标,slave端分析抓取现场数据。因此,采集到的内容必须能够客观、准确地反映网络房屋数据的特点。
以58个同城网络房源数据为例,通过分析网页结构,定义字段的详细信息如下表所示。
序号字段名称字段含义
1title 帖子标题
2money 租金
3method租借方式
4area区域
5community所在的社区
6targeturl 帖子详情
7city所在的城市
8Pub_time 发布发布时间
现场选择主要是基于本系统的应用研究,因为系统开发单机配置比较低,没有图片文件下载到本机。减轻单机压力。
(F) 数据处理
1)对象定义程序
Item 是定义捕获数据的容器。它是通过创建一个 scrapy.item.Item 类来声明的。定义属性为scrapy.item.Field对象,通过实例化需要的item来控制获取的站点数据。系统定义了九个抓取对象,分别是:帖子标题、租金、租赁方式、位置、社区、城市、帖子详情页链接、发布时间。这里的字段定义是根据数据处理端的需要来定义的。关键代码如下:
类 TcZufangItem(Item):
#帖子名称
标题=字段()
#租
钱=字段()
#出租方式
方法=字段()
#您所在的地区
区域=字段()
#地点
社区=字段()
#发布详情网址
目标网址=字段()
#发布发布时间
pub_time=字段()
#位置城市
城市=字段()
2)数据处理程序
Pipeline 类定义了数据保存和输出方法。Spider的parse方法返回的Item,在处理完ITEM_PIPELINES列表中Pipeline类对应的数据后,会以top格式输出数据。本系统返回管道的数据存储在Mongodb中。关键代码如下:
def process_item(self, item, spider):
如果 item['pub_time'] == 0:
raise DropItem("发现重复项:%s"% 项)
如果项目['方法'] == 0:
raise DropItem("发现重复项:%s"% 项)
如果项目['社区']==0:
raise DropItem("发现重复项:%s"% 项)
如果 item['money']==0:
raise DropItem("发现重复项:%s"% 项)
如果 item['area'] == 0:
raise DropItem("发现重复项:%s"% 项)
如果项目['城市'] == 0:
raise DropItem("发现重复项:%s"% 项)
zufang_detail = {
'title': item.get('title'),
'钱':item.get('钱'),
'方法':item.get('方法'),
'area': item.get('area',''),
'社区': item.get('社区',''),
'targeturl': item.get('targeturl'),
'pub_time': item.get('pub_time',''),
'city':item.get('city','')
}
result = self.db['zufang_detail'].insert(zufang_detail)
打印'[成功]'+item['targeturl']+'写入MongoDB数据库'
归还物品
(G) 数据可视化设计
数据的可视化,其实就是把数据库的数据转换成我们用户容易观察的形式。本系统使用Mongodb来存储数据。数据可视化基于Django+Semantiui,效果如下图所示:
四、系统操作
系统以58同城租赁平台为爬取目标。运行十个小时后,系统继续抓取网页上总共数万个列表数据。
Master运行截图:
Slave 运行截图:
五、系统部署
环境部署,因为分布式部署需要的环境类似。如果一个服务器部署程序需要配置环境,那就很麻烦了。这里使用docker镜像部署爬虫程序,使用Daocloud上的scrapy-env对。程序已经部署完毕,具体的docker部署过程可以参考网上。 查看全部
c爬虫抓取网页数据(一个_selector.xpath.u去重与增量爬取)
response_selector.xpath(u'//div[contains(@class,"house-title")]/p[contains(@class,"house-update-info c_888 f12")]/text()').extract( )
因为有些数据不能用Xpath提取,所以也需要正则匹配。如有异常,应予处理。一般当页面无法匹配到对应的字段时,应该设置为0,项目处理完毕后,需要对其进行处理。进行过滤处理。
3) 去重和增量爬取
去重和增量爬取对服务器来说意义重大,可以减轻服务器压力,保证数据的准确性。如果不进行去重,被爬取的内容会爬取大量重复的内容,大大降低了爬虫效率。事实上,重复数据删除的过程非常简单。核心是在每次发出请求时判断该请求是否在爬取队列中。如果它已经存在,则丢弃当前请求。
具体实施步骤:

(1)从要爬取的队列中获取url
(2) 判断请求的URL是否已经被抓取,如果已经被抓取,则忽略该请求,不抓取,继续其他操作,将URL插入到抓取队列中
(3) 重复步骤 1
这里我们使用了scrapy-redis去重组件,所以没有实现,但是原理还是需要理解的,具体可以看源码。
4)爬虫中间件
爬虫中间件可以帮助我们在scrapy爬虫过程中自由扩展我们的程序。以下是爬虫反屏蔽中间件、下载器异常状态中间件和非200状态中间件。
(1)爬虫反屏蔽组件的实现
在访问网站的网页时,会给网站带来一定的负载,爬虫程序模拟了我们正常访问网页的过程,但是。大型爬虫会给网站增加很大的负载,影响普通用户的访问。为了保证网页可以被大多数正常用户访问,大多数网站都有相应的反爬虫策略。一旦访问行为被认定为爬虫,网站会采取一定的措施限制您的访问,比如提醒您访问过于频繁,请您输入验证码,如果比较严重,您的ip会被封禁,禁止你访问网站。本系统在有针对性的抓取网页数据时,会持续访问网站的内容。
本系统采用以下方法防止爬虫被拦截:
1.模拟不同的浏览器行为
2. 一定频率更换代理服务器和网关
3. 符合君子协议,降低爬虫爬取网页的频率,减少并发爬取的进程,限制每个IP的并发爬取次数,牺牲一定的效率来换取系统的稳定性。
4.禁用cookies,网站会在cookie中插入一些信息来判断用户访问时是否是机器人。我们屏蔽和调整cookie,这也有利于我们的身份不同意暴露。
5. 手动编码,这应该是无懈可击的反禁措施。所有的系统都不比人工操作好,但它们降低了自动化,效率不高,但它们确实是最有效的措施。当爬虫被禁止时,它会被重定向到一个验证码页面。输入验证码重新访问页面。为此,我添加了一个电子邮件提醒模块。当爬虫被封禁时,我会发邮件提醒管理员解封。同时将重定向的请求重新加入到下载队列中进行爬取,保证数据的完整性。
爬虫预防网站屏蔽的原理如下图所示:
(一)模拟不同浏览器行为的实现思路和代码
原理:从scrapy的介绍可以知道scrapy有下载中间件。在这个中间件中,我们可以自定义请求和响应,类似于spring面向方面的编程,就像在程序运行前后嵌入一个钩子。核心是修改请求的属性
首先是扩展下载中间件,首先在seetings.py中添加中间件,
其次,扩展中间件,主要是写一个useragent列表,将常用的浏览器请求头保存为一个列表,如下图:
让请求的头文件从列表中随机选择一个代理值,然后下载到下载器。
综上所述,每次发出请求,都是模拟使用不同的浏览器访问目标网站。
(B) 使用代理ip爬取的实现思路和代码。
首先,将中间件添加到seetings.py。扩展下载组件请求的头文件会从代理ip池中随机取出一个代理值,然后下载到下载器。
1.代理ip池的设计开发流程如下:
一种。获取免费代理ip网站。
湾 存储和验证代理ip
C。验证存储在数据库中
d. 如果达到最大ip数,停止爬取,一定时间后验证数据ip的有效性,删除无效ip
e. 直到数据库ip小于0,继续爬取ip,重复步骤a。
这里的代理ip模块使用的是七夜代理ip池的开源项目
代理ip爬虫运行截图:
(三)爬虫异常状态组件的处理
爬虫运行时没有被阻塞,访问网站并不总是200请求成功,而是有各种状态,比如上面爬虫被ban的时候,返回的状态其实是302,就是为了防止阻塞组件 捕获要实现的 302 状态。同时,异常情况的处理有利于爬虫的鲁棒性。
扩展中间件在设置中捕捉到异常情况后,将请求重新加入等待下载队列的过程如下:
(D) 数据存储模块
数据存储模块主要负责存储从端爬取解析的页面。使用 Mongodb 存储数据。
Scrapy 支持 json、csv 和 xml 等数据存储格式。用户可以在运行爬虫时进行设置,例如:scrapy crawl spider -o items.json -t json,也可以在Scrapy项目文件ItemPipline文件中定义,同时Scrapy也支持数据库存储,如如Monogdb、Redis等。当数据量很大到一定程度时,可以使用Mongodb或Reids集群来解决。本系统的数据存储如下图所示:
(E) 抓斗设计
本文以网络房屋数据为爬取目标,slave端分析抓取现场数据。因此,采集到的内容必须能够客观、准确地反映网络房屋数据的特点。
以58个同城网络房源数据为例,通过分析网页结构,定义字段的详细信息如下表所示。
序号字段名称字段含义
1title 帖子标题
2money 租金
3method租借方式
4area区域
5community所在的社区
6targeturl 帖子详情
7city所在的城市
8Pub_time 发布发布时间
现场选择主要是基于本系统的应用研究,因为系统开发单机配置比较低,没有图片文件下载到本机。减轻单机压力。
(F) 数据处理
1)对象定义程序
Item 是定义捕获数据的容器。它是通过创建一个 scrapy.item.Item 类来声明的。定义属性为scrapy.item.Field对象,通过实例化需要的item来控制获取的站点数据。系统定义了九个抓取对象,分别是:帖子标题、租金、租赁方式、位置、社区、城市、帖子详情页链接、发布时间。这里的字段定义是根据数据处理端的需要来定义的。关键代码如下:
类 TcZufangItem(Item):
#帖子名称
标题=字段()
#租
钱=字段()
#出租方式
方法=字段()
#您所在的地区
区域=字段()
#地点
社区=字段()
#发布详情网址
目标网址=字段()
#发布发布时间
pub_time=字段()
#位置城市
城市=字段()
2)数据处理程序
Pipeline 类定义了数据保存和输出方法。Spider的parse方法返回的Item,在处理完ITEM_PIPELINES列表中Pipeline类对应的数据后,会以top格式输出数据。本系统返回管道的数据存储在Mongodb中。关键代码如下:
def process_item(self, item, spider):
如果 item['pub_time'] == 0:
raise DropItem("发现重复项:%s"% 项)
如果项目['方法'] == 0:
raise DropItem("发现重复项:%s"% 项)
如果项目['社区']==0:
raise DropItem("发现重复项:%s"% 项)
如果 item['money']==0:
raise DropItem("发现重复项:%s"% 项)
如果 item['area'] == 0:
raise DropItem("发现重复项:%s"% 项)
如果项目['城市'] == 0:
raise DropItem("发现重复项:%s"% 项)
zufang_detail = {
'title': item.get('title'),
'钱':item.get('钱'),
'方法':item.get('方法'),
'area': item.get('area',''),
'社区': item.get('社区',''),
'targeturl': item.get('targeturl'),
'pub_time': item.get('pub_time',''),
'city':item.get('city','')
}
result = self.db['zufang_detail'].insert(zufang_detail)
打印'[成功]'+item['targeturl']+'写入MongoDB数据库'
归还物品
(G) 数据可视化设计
数据的可视化,其实就是把数据库的数据转换成我们用户容易观察的形式。本系统使用Mongodb来存储数据。数据可视化基于Django+Semantiui,效果如下图所示:
四、系统操作
系统以58同城租赁平台为爬取目标。运行十个小时后,系统继续抓取网页上总共数万个列表数据。
Master运行截图:
Slave 运行截图:
五、系统部署
环境部署,因为分布式部署需要的环境类似。如果一个服务器部署程序需要配置环境,那就很麻烦了。这里使用docker镜像部署爬虫程序,使用Daocloud上的scrapy-env对。程序已经部署完毕,具体的docker部署过程可以参考网上。
c爬虫抓取网页数据(Python模块的安装方法和使用难度-快-困难-简单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-10 01:01
我们需要让爬虫从每个网页中提取一些数据,然后实现某些事情,这种做法叫做数据抓取。
分析网页
查看网页源代码并使用 Firebug Lite 扩展。Firebug 是由 Joe Hewitt 开发的与 Firefox 集成的强大 Web 开发工具。它可以实时编辑、调试和监控任何页面的 CSS、HTML 和 JavaScript。这里用来查看网页的源代码。
安装 Firebug Lite,下载 Firebug Lite 包,然后在浏览器中安装插件。
网页抓取的三种方法
正则表达式,BeatifulSoup 模板,强大的 lxml 模块
正则表达式
def download(url,user_agent=\'wswp\',proxy=None,num_retries=2):
print \'Downloading:\',url
headers={\'User-agent\':user_agent}
request=urllib2.Request(url,headers=headers)
opener=urllib2.build_opener()
if opener:
proxy_params={urlparse.urlparse(url).scheme:proxy}
opener.add_handler(urllib2.ProxyHandler(proxy_params))
try:
html=urllib2.urlopen(request).read()
except urllib2.URLError as e:
print \'Download:\' ,e.reason
html=None
if num_retries>0:
if hasattr(e,\'code\') and 500
Area
Population
"""
测试三种方法的性能
<p>import re
import urllib2
import urlparse
from bs4 import BeautifulSoup
import lxml.html
import time
#
#
#
#获取网页内容
def download(url,user_agent=\'wswp\',proxy=None,num_retries=2):
print \'Downloading:\',url
headers={\'User-agent\':user_agent}
request=urllib2.Request(url,headers=headers)
opener=urllib2.build_opener()
if opener:
proxy_params={urlparse.urlparse(url).scheme:proxy}
opener.add_handler(urllib2.ProxyHandler(proxy_params))
try:
html=urllib2.urlopen(request).read()
except urllib2.URLError as e:
print \'Download:\' ,e.reason
html=None
if num_retries>0:
if hasattr(e,\'code\') and 500 查看全部
c爬虫抓取网页数据(Python模块的安装方法和使用难度-快-困难-简单)
我们需要让爬虫从每个网页中提取一些数据,然后实现某些事情,这种做法叫做数据抓取。
分析网页
查看网页源代码并使用 Firebug Lite 扩展。Firebug 是由 Joe Hewitt 开发的与 Firefox 集成的强大 Web 开发工具。它可以实时编辑、调试和监控任何页面的 CSS、HTML 和 JavaScript。这里用来查看网页的源代码。
安装 Firebug Lite,下载 Firebug Lite 包,然后在浏览器中安装插件。
网页抓取的三种方法
正则表达式,BeatifulSoup 模板,强大的 lxml 模块
正则表达式
def download(url,user_agent=\'wswp\',proxy=None,num_retries=2):
print \'Downloading:\',url
headers={\'User-agent\':user_agent}
request=urllib2.Request(url,headers=headers)
opener=urllib2.build_opener()
if opener:
proxy_params={urlparse.urlparse(url).scheme:proxy}
opener.add_handler(urllib2.ProxyHandler(proxy_params))
try:
html=urllib2.urlopen(request).read()
except urllib2.URLError as e:
print \'Download:\' ,e.reason
html=None
if num_retries>0:
if hasattr(e,\'code\') and 500
Area
Population
"""
测试三种方法的性能
<p>import re
import urllib2
import urlparse
from bs4 import BeautifulSoup
import lxml.html
import time
#
#
#
#获取网页内容
def download(url,user_agent=\'wswp\',proxy=None,num_retries=2):
print \'Downloading:\',url
headers={\'User-agent\':user_agent}
request=urllib2.Request(url,headers=headers)
opener=urllib2.build_opener()
if opener:
proxy_params={urlparse.urlparse(url).scheme:proxy}
opener.add_handler(urllib2.ProxyHandler(proxy_params))
try:
html=urllib2.urlopen(request).read()
except urllib2.URLError as e:
print \'Download:\' ,e.reason
html=None
if num_retries>0:
if hasattr(e,\'code\') and 500
c爬虫抓取网页数据(网络爬虫的爬行策略和存储方法介绍-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-08 20:02
网络爬虫是指按照一定的规则自动爬取网络上的程序(模拟手动登录网页的方式)。简单的说,就是你在网上看到的页面内容被获取并存储。网络爬虫的爬取策略分为深度优先和广度优先。下图展示了从A到B到D到E到C到F的深度优先遍历方法(ABDECF)和广度优先遍历方法ABCDEF。
网络爬虫实现原理
1、获取初始网址。初始URL地址可以由用户手动指定,也可以由用户指定的一个或多个初始抓取网页确定。
2、 根据初始 URL 抓取页面,获取新 URL。获取初始URL地址后,首先需要抓取对应URL地址中的网页。在对应的URL地址中抓取网页后,将网页存储在原创数据库中,在抓取网页的同时发现新的URL爬行过程。
3、将新的 URL 放入 URL 队列。第二步,获取下一个新的URL地址后,将新的URL地址放入URL队列中。
4、 从 URL 队列中读取新的 URL,并根据新的 URL 抓取网页。同时,从新的网页中获取新的URL,重复上面提到的爬取过程。
5、满足爬虫系统设置的停止条件时停止爬行。在写爬虫的时候,一般都会设置相应的停止条件。如果不设置停止条件,爬虫会一直爬到无法获取新的URL地址。如果设置了停止条件,则爬虫会在满足停止条件时停止爬行。 查看全部
c爬虫抓取网页数据(网络爬虫的爬行策略和存储方法介绍-上海怡健医学)
网络爬虫是指按照一定的规则自动爬取网络上的程序(模拟手动登录网页的方式)。简单的说,就是你在网上看到的页面内容被获取并存储。网络爬虫的爬取策略分为深度优先和广度优先。下图展示了从A到B到D到E到C到F的深度优先遍历方法(ABDECF)和广度优先遍历方法ABCDEF。

网络爬虫实现原理
1、获取初始网址。初始URL地址可以由用户手动指定,也可以由用户指定的一个或多个初始抓取网页确定。
2、 根据初始 URL 抓取页面,获取新 URL。获取初始URL地址后,首先需要抓取对应URL地址中的网页。在对应的URL地址中抓取网页后,将网页存储在原创数据库中,在抓取网页的同时发现新的URL爬行过程。
3、将新的 URL 放入 URL 队列。第二步,获取下一个新的URL地址后,将新的URL地址放入URL队列中。
4、 从 URL 队列中读取新的 URL,并根据新的 URL 抓取网页。同时,从新的网页中获取新的URL,重复上面提到的爬取过程。
5、满足爬虫系统设置的停止条件时停止爬行。在写爬虫的时候,一般都会设置相应的停止条件。如果不设置停止条件,爬虫会一直爬到无法获取新的URL地址。如果设置了停止条件,则爬虫会在满足停止条件时停止爬行。
c爬虫抓取网页数据(网站遇到瓶颈怎么办?如何打开另一扇之门?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-07 06:08
当我在爬取网站时遇到瓶颈,想上前解决的时候,我经常先看网站的robots.txt文件,有时会再打开一个供你捕捉。门。
写爬虫有很多苦恼的地方,比如:
1. 访问频率太高,受限;
2.如何大量找到这个网站的网址;
3.如何抓取网站新生成的URL等;
这些问题困扰着爬虫。如果有大量离散的IP和账号,这些都不是问题,但大多数公司不具备这个条件。
我们工作中编写的爬虫大多是一次性的、临时的任务,需要你快速完成工作。遇到上述情况时,尝试查看robots.txt文件。
举个栗子:
老板给你分配任务,捕捉豆瓣每天生成的影评、书评、群帖、同城帖、个人日志。
想想这个任务有多大。豆瓣拥有1.6亿注册用户。对于抓取个人日志的任务,您必须每天至少访问一次每个人的主页。
这将不得不每天访问1. 6 亿次,并且不计算群组/同城帖子。
设计一个普通的爬虫不能依靠几十个IP来完成任务。
先看robots.txt
当boss给你以上任务的时候,靠你的两把枪,你是怎么完成的,不要跟boss讲技术,他不懂,他只想要结果。
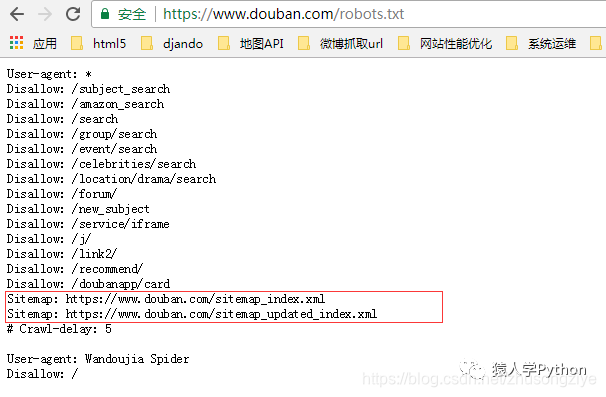
我们来看看豆瓣的robots.txt
看图片上面的红框,里面有两个sitemap文件
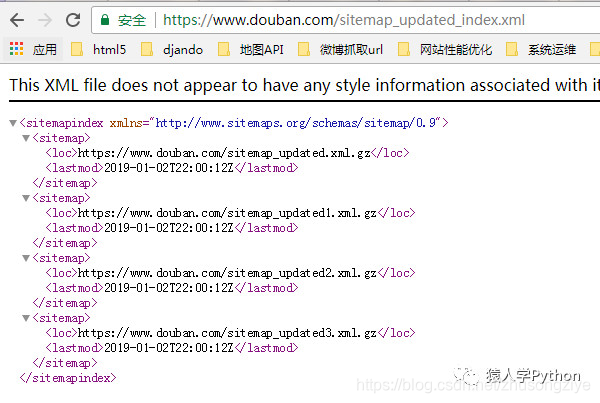
打开 sitemap_updated_index 文件并查看:
里面有一个一个的压缩文件,里面有豆瓣头一天新生成的影评、书评、帖子等。有兴趣的可以打开压缩文件看看。
换句话说,你只需要每天访问robots.txt中的站点地图文件,就可以知道哪些URL是新生成的。
无需遍历豆瓣网站上的数亿个链接,大大节省了您的爬虫时间和爬虫设计的复杂度,同时也降低了豆瓣网站的带宽消耗。这是双赢的,哈哈。
robots.txt 的站点地图文件找到了获取新 URL 网站 的方法。沿着这个思路也可以解决查找大量网站 URL的问题。
再给一个栗子:
老板给你另一个任务。老板说你上次抓豆瓣,你说每天需要大量的IP才能得到豆瓣新发的帖子。这一次,我给你1000个IP,捕捉天眼查过的千万家企业的商业信息。.
看了这么多IP,流口水了,但是分析网站后发现,这种网站的爬取入口很少(爬取入口指的是频道页面,即聚合很多链接的那种页面。)。
获取保留的 URL 很容易,而且查看这么多 IP 也不是很忙。
如果性能发现这个网站几万甚至几十万个URL,放到等待队列中,可以让这么多IP作业满载而归,不偷懒。
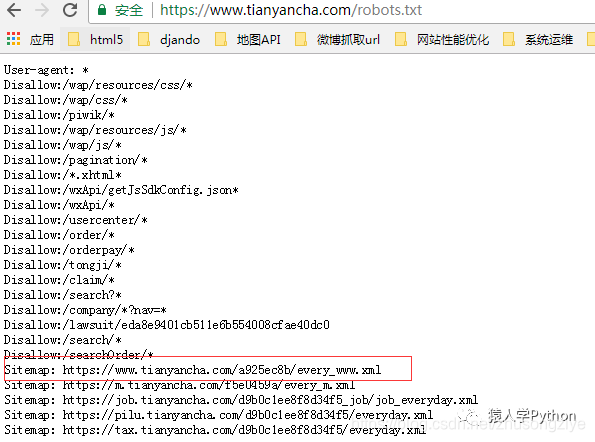
我们来看看他的 robots.txt 文件:
打开红框处的站点地图,有30,000个公司网址。上图是1月3日生成的,URL是根据年月日生成的。你可以把网址改成1月2号,又可以看到2号站点地图有几万个公司网址,所以你可以找到几十万个种子网址供你爬取。
PS:上面的sitemap其实可以解决天眼查新更新新生成的URL爬取的问题。
一个小技巧不仅降低了爬虫设计的复杂度,还降低了对方的带宽消耗。
这在工作中非常适用。在工作中,你不在乎你使用的框架有多好,只在乎你做事有多快,有多好。
如果你善于查看 robots.txt 文件,你会发现一些独特的东西。 查看全部
c爬虫抓取网页数据(网站遇到瓶颈怎么办?如何打开另一扇之门?)
当我在爬取网站时遇到瓶颈,想上前解决的时候,我经常先看网站的robots.txt文件,有时会再打开一个供你捕捉。门。
写爬虫有很多苦恼的地方,比如:
1. 访问频率太高,受限;
2.如何大量找到这个网站的网址;
3.如何抓取网站新生成的URL等;

这些问题困扰着爬虫。如果有大量离散的IP和账号,这些都不是问题,但大多数公司不具备这个条件。
我们工作中编写的爬虫大多是一次性的、临时的任务,需要你快速完成工作。遇到上述情况时,尝试查看robots.txt文件。
举个栗子:
老板给你分配任务,捕捉豆瓣每天生成的影评、书评、群帖、同城帖、个人日志。
想想这个任务有多大。豆瓣拥有1.6亿注册用户。对于抓取个人日志的任务,您必须每天至少访问一次每个人的主页。
这将不得不每天访问1. 6 亿次,并且不计算群组/同城帖子。
设计一个普通的爬虫不能依靠几十个IP来完成任务。
先看robots.txt
当boss给你以上任务的时候,靠你的两把枪,你是怎么完成的,不要跟boss讲技术,他不懂,他只想要结果。
我们来看看豆瓣的robots.txt
看图片上面的红框,里面有两个sitemap文件
打开 sitemap_updated_index 文件并查看:
里面有一个一个的压缩文件,里面有豆瓣头一天新生成的影评、书评、帖子等。有兴趣的可以打开压缩文件看看。
换句话说,你只需要每天访问robots.txt中的站点地图文件,就可以知道哪些URL是新生成的。
无需遍历豆瓣网站上的数亿个链接,大大节省了您的爬虫时间和爬虫设计的复杂度,同时也降低了豆瓣网站的带宽消耗。这是双赢的,哈哈。
robots.txt 的站点地图文件找到了获取新 URL 网站 的方法。沿着这个思路也可以解决查找大量网站 URL的问题。
再给一个栗子:
老板给你另一个任务。老板说你上次抓豆瓣,你说每天需要大量的IP才能得到豆瓣新发的帖子。这一次,我给你1000个IP,捕捉天眼查过的千万家企业的商业信息。.
看了这么多IP,流口水了,但是分析网站后发现,这种网站的爬取入口很少(爬取入口指的是频道页面,即聚合很多链接的那种页面。)。
获取保留的 URL 很容易,而且查看这么多 IP 也不是很忙。
如果性能发现这个网站几万甚至几十万个URL,放到等待队列中,可以让这么多IP作业满载而归,不偷懒。
我们来看看他的 robots.txt 文件:
打开红框处的站点地图,有30,000个公司网址。上图是1月3日生成的,URL是根据年月日生成的。你可以把网址改成1月2号,又可以看到2号站点地图有几万个公司网址,所以你可以找到几十万个种子网址供你爬取。
PS:上面的sitemap其实可以解决天眼查新更新新生成的URL爬取的问题。
一个小技巧不仅降低了爬虫设计的复杂度,还降低了对方的带宽消耗。
这在工作中非常适用。在工作中,你不在乎你使用的框架有多好,只在乎你做事有多快,有多好。
如果你善于查看 robots.txt 文件,你会发现一些独特的东西。
c爬虫抓取网页数据(Chrome浏览器插件WebScraper可轻松实现网页数据的爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-11-07 01:07
Chrome浏览器插件Web Scraper可以轻松抓取网页数据,无需考虑爬虫中的登录、验证码、异步加载等复杂问题。
先粘贴爬虫58数据的sitemap如下:
{"_id":"hefeitongcheng","startUrl":[";ClickID=1"],"selectors":[{"id":"click","type":"SelectorElementClick","parentSelectors" :["_root"],"selector":".list-main-style li","multiple":true,"delay":"5000","clickElementSelector":"strong span","clickType":"clickMore ","discardInitialElements":"do-not-discard","clickElementUniquenessType":"uniqueText"},{"id":"link","type":"SelectorLink","parentSelectors":["click"], "selector":".title a","multiple":false,"delay":0},{"id":"name","type":"SelectorText","parentSelectors":["link"], "selector":"h1","multiple":false,"regex":"","delay":0},{"id":"jiage","type":"SelectorText","parentSelectors":[ "link"],"selector":".house_basic_title_money span","multiple":false,"regex":"","delay":0},{"id":"add","type":"SelectorText ","parentSelectors":["link"],"selector":"p.p_2","multiple":false,"regex":"","delay":0}]}
Web Scraper 爬取过程及要点:
安装Web Scraper插件后,抓取操作分三步完成
1、新建站点地图(创建爬虫项目)
2、选择抓取的网页内容,点击~点击~点击,操作
3、启用抓取和下载 CSV 数据
最关键的一步是第二步,主要有两点:
首先选择数据块Element,我们在页面上取的每一块数据,都是重复的,在数据块中选择Multiple,然后取需要的数据字段(上面Excel中的列)
爬取大量数据的重点是掌握分页的控制。
分页分为3种情况:
1. URL 参数分页(比较组织) ?page=2 或 ?page=[1-27388]
2.滚动加载,点击“加载更多”加载页面数据元素向下滚动
3.点击页码标签(包括“下一页”标签)链接或元素点击
其他例子A:jd爬升hw p30价格信息
{"_id":"huaweip30","startUrl":[";enc=utf-8&wq=%E5%8D%8E%E4%B8%BAp30%20512&pvid=ed449bf16e44461fac90ff6fae2e66cds"][ "id":"element","type":"SelectorElementClick","parentSelectors":["_root"],"selector":"div.gl-i-wrap","multiple":true,"delay": "1500","clickElementSelector":".p-num a:nth-of-type(3)","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType ":"uniqueText"},{"id":"name","type":"SelectorText","parentSelectors":["element"],"selector":"a em","multiple":false," regex":"","delay":0},{"id":"jiage","type":"SelectorText","parentSelectors":["element"],"selector":"div.p-price ","multiple":false,"regex":"","delay":0}]}
其他例子B:爬上百度关键词信息
{ "_ id": "wailaizhu", "startUrl": [ "; pn = 0 & oq = wailaizhu% 20h0101 & tn = baiduhome_pg & ie = utf-8 & rsv_idx = 2 & rsv_pq = f62d1151tv_f0 5b15EoMWRlm3% 2BeroyWXBKI% 2FDZ3H0BlGKJ6lNa6mmYBo4nNDUeJNeeN8BvgiE9S9Orivd"], "selectors": [ {"id":"element","type":"SelectorElementClick","parent_selector"],"div_selector":","[" "multiple":true,"delay":"1500","clickElementSelector":"a span.pc","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType":" uniqueText"},{"id":"name", "type":"SelectorText","parentSelectors":["element"],"selector":"a","multiple":false,"regex":" ","delay":0},{"id":"body","type":"SelectorText","parentSelectors":["element"],"selector":"_parent_","multiple":false, "regex":"","delay":0} ]} 查看全部
c爬虫抓取网页数据(Chrome浏览器插件WebScraper可轻松实现网页数据的爬取)
Chrome浏览器插件Web Scraper可以轻松抓取网页数据,无需考虑爬虫中的登录、验证码、异步加载等复杂问题。
先粘贴爬虫58数据的sitemap如下:
{"_id":"hefeitongcheng","startUrl":[";ClickID=1"],"selectors":[{"id":"click","type":"SelectorElementClick","parentSelectors" :["_root"],"selector":".list-main-style li","multiple":true,"delay":"5000","clickElementSelector":"strong span","clickType":"clickMore ","discardInitialElements":"do-not-discard","clickElementUniquenessType":"uniqueText"},{"id":"link","type":"SelectorLink","parentSelectors":["click"], "selector":".title a","multiple":false,"delay":0},{"id":"name","type":"SelectorText","parentSelectors":["link"], "selector":"h1","multiple":false,"regex":"","delay":0},{"id":"jiage","type":"SelectorText","parentSelectors":[ "link"],"selector":".house_basic_title_money span","multiple":false,"regex":"","delay":0},{"id":"add","type":"SelectorText ","parentSelectors":["link"],"selector":"p.p_2","multiple":false,"regex":"","delay":0}]}

Web Scraper 爬取过程及要点:
安装Web Scraper插件后,抓取操作分三步完成
1、新建站点地图(创建爬虫项目)
2、选择抓取的网页内容,点击~点击~点击,操作
3、启用抓取和下载 CSV 数据
最关键的一步是第二步,主要有两点:
首先选择数据块Element,我们在页面上取的每一块数据,都是重复的,在数据块中选择Multiple,然后取需要的数据字段(上面Excel中的列)
爬取大量数据的重点是掌握分页的控制。
分页分为3种情况:
1. URL 参数分页(比较组织) ?page=2 或 ?page=[1-27388]
2.滚动加载,点击“加载更多”加载页面数据元素向下滚动
3.点击页码标签(包括“下一页”标签)链接或元素点击
其他例子A:jd爬升hw p30价格信息
{"_id":"huaweip30","startUrl":[";enc=utf-8&wq=%E5%8D%8E%E4%B8%BAp30%20512&pvid=ed449bf16e44461fac90ff6fae2e66cds"][ "id":"element","type":"SelectorElementClick","parentSelectors":["_root"],"selector":"div.gl-i-wrap","multiple":true,"delay": "1500","clickElementSelector":".p-num a:nth-of-type(3)","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType ":"uniqueText"},{"id":"name","type":"SelectorText","parentSelectors":["element"],"selector":"a em","multiple":false," regex":"","delay":0},{"id":"jiage","type":"SelectorText","parentSelectors":["element"],"selector":"div.p-price ","multiple":false,"regex":"","delay":0}]}
其他例子B:爬上百度关键词信息
{ "_ id": "wailaizhu", "startUrl": [ "; pn = 0 & oq = wailaizhu% 20h0101 & tn = baiduhome_pg & ie = utf-8 & rsv_idx = 2 & rsv_pq = f62d1151tv_f0 5b15EoMWRlm3% 2BeroyWXBKI% 2FDZ3H0BlGKJ6lNa6mmYBo4nNDUeJNeeN8BvgiE9S9Orivd"], "selectors": [ {"id":"element","type":"SelectorElementClick","parent_selector"],"div_selector":","[" "multiple":true,"delay":"1500","clickElementSelector":"a span.pc","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType":" uniqueText"},{"id":"name", "type":"SelectorText","parentSelectors":["element"],"selector":"a","multiple":false,"regex":" ","delay":0},{"id":"body","type":"SelectorText","parentSelectors":["element"],"selector":"_parent_","multiple":false, "regex":"","delay":0} ]}
c爬虫抓取网页数据( 从HttpFox的POSTData项看到(图)Data(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-05 19:11
从HttpFox的POSTData项看到(图)Data(组图)
)
#表示删不去这一行,这个代码框框啊 啊啊啊啊啊
一、 作为python爬虫,一般需要对网页进行简单的分析,然后才能爬取数据。这里推荐火狐的HttpFox,简单实用。
如下图,巨潮信息网通过查询展示想要的数据,然后抓取。
二、 爬取查询数据,查询类型,表示需要贴过去的相关数据才能得到想要的数据。
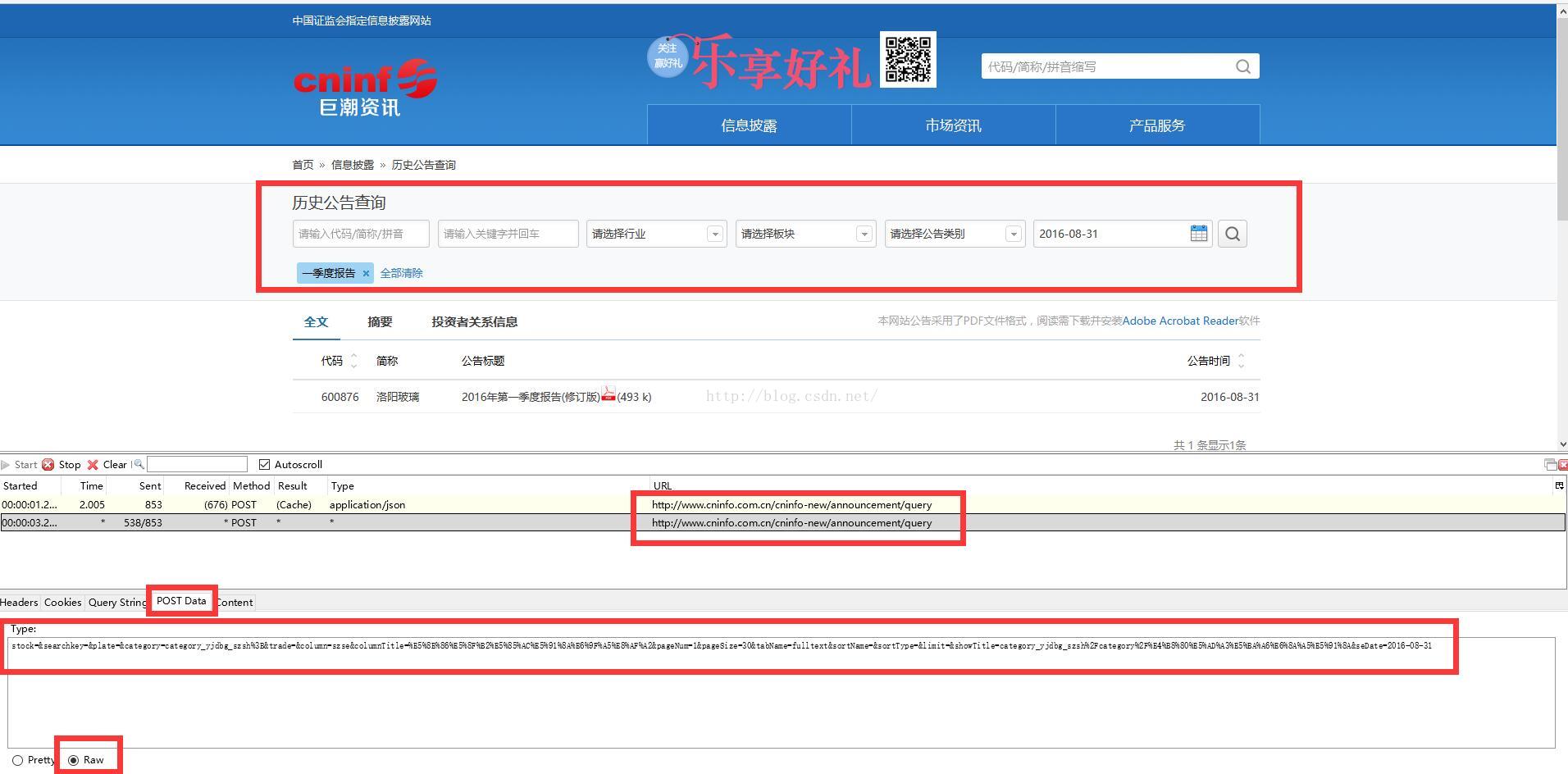
通过HttpFox分析获取相关数据,帖子的过往数据相当复杂。从HttpFox的POST Data项可以看到如下一系列信息:
stock=&searchkey=&plate=sz%3Bszmb%3Bszzx%3Bszcy%3Bshmb%3B&category=category_sjdbg_szsh%3Bcategory_ndbg_szsh
%3Bcategory_bndbg_szsh%3Bcategory_yjdbg_szsh%3B&trade=&column=szse&columnTitle=%E5%8E%86%E5%8F%B2%E5%85
%AC%E5%91%8A%E6%9F%A5%E8%AF%A2&pageNum=1&pageSize=30&tabName=fulltext&sortName=&sortType=&limit=&showTitle
category_sjdbg_szsh%2Fcategory%2F%E4%B8%89%E5%AD%A3%E5%BA%A6%E6%8A%A5%E5%91%8A%3Bcategory_ndbg_szsh
%2Fcategory%2F%E5%B9%B4%E5%BA%A6%E6%8A%A5%E5%91%8A%3Bcategory_bndbg_szsh%2Fcategory%2F%E5%8D%8A%
E5%B9%B4%E5%BA%A6%E6%8A%A5%E5%91%8A%3Bcategory_yjdbg_szsh%2Fcategory%2F%E4%B8%80%E5%AD%A3%E5
%BA%A6%E6%8A%A5%E5%91%8A%3Bsz%2Fplate%2F%E6%B7%B1%E5%B8%82%E5%85%AC%E5%8F%B8% 3Bszmb%2Fplate
%2F%E6%B7%B1%E5%B8%82%E4%B8%BB%E6%9D%BF%3Bszzx%2Fplate%2F%E4%B8%AD%E5%B0%8F%E6% 9D%BF%3Bszcy
%2Fplate%2F%E5%88%9B%E4%B8%9A%E6%9D%BF%3Bshmb%2Fplate%2F%E6%B2%AA%E5%B8%82%E4%B8%BB% E6%9D%B
F&seDate=2016-10-13
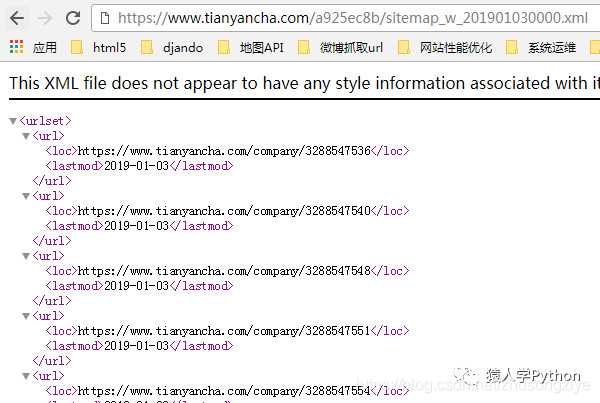
我想专注于捕获第一季度、半年、第三季度和年度报告。查看类别选择:
category=category_sjdbg_szsh%3Bcategory_ndbg_szsh%3Bcategory_bndbg_szsh
%3Bcategory_yjdbg_szsh%3B
面对如此复杂的帖子数据,我不知道如何构建自己的帖子数据项。特别是当某个后变量采用多个值时。注意:%3B 是表示分号“;”的 URL 编码值。解决了一个变量多个值的问题。
#-*- coding: utf8 -*-
import urllib2
import urllib
import re
import time,datetime
import os
import shutil
def getstock(page,strdate):
values = {
'stock':'',
'searchkey':'',
'plate':'sz;szmb;szzx;szcy;shmb',
#%category_bndbg_szsh半年报告;category_sjdbg_szsh三季度;category_ndbg_szsh年度;category_yjdbg_szsh一季度
'category':'category_bndbg_szsh;category_sjdbg_szsh;category_ndbg_szsh;category_yjdbg_szsh',
'trade':'',
'column':'szse',
'columnTitle':'%E5%8E%86%E5%8F%B2%E5%85%AC%E5%91%8A%E6%9F%A5%E8%AF%A2',
'pageNum':page,
'pageSize':'50',
'tabName':'fulltext',
'sortName':'',
'sortType':'',
'limit':'',
'seDate':strdate}
data = urllib.urlencode(values)
url = "http://www.cninfo.com.cn/cninf ... ot%3B
request = urllib2.Request(url,data)
datime = datetime.datetime.now()
response = urllib2.urlopen(request,timeout=4)
re_data = response.read()
re_data = re_data.decode('utf8')
dict_data = eval(re_data.replace('null','None').replace('true','True').replace('false','False'))
print dict_data #转成dict数据,输出看看
return dict_data
try:
date2 = time.strftime('%Y-%m-%d', time.localtime())
page = 1
ret = getstock(str(page),str(date2))
except Exception as error:
print error
good luck! 查看全部
c爬虫抓取网页数据(
从HttpFox的POSTData项看到(图)Data(组图)
)
#表示删不去这一行,这个代码框框啊 啊啊啊啊啊
一、 作为python爬虫,一般需要对网页进行简单的分析,然后才能爬取数据。这里推荐火狐的HttpFox,简单实用。
如下图,巨潮信息网通过查询展示想要的数据,然后抓取。
二、 爬取查询数据,查询类型,表示需要贴过去的相关数据才能得到想要的数据。
通过HttpFox分析获取相关数据,帖子的过往数据相当复杂。从HttpFox的POST Data项可以看到如下一系列信息:
stock=&searchkey=&plate=sz%3Bszmb%3Bszzx%3Bszcy%3Bshmb%3B&category=category_sjdbg_szsh%3Bcategory_ndbg_szsh
%3Bcategory_bndbg_szsh%3Bcategory_yjdbg_szsh%3B&trade=&column=szse&columnTitle=%E5%8E%86%E5%8F%B2%E5%85
%AC%E5%91%8A%E6%9F%A5%E8%AF%A2&pageNum=1&pageSize=30&tabName=fulltext&sortName=&sortType=&limit=&showTitle
category_sjdbg_szsh%2Fcategory%2F%E4%B8%89%E5%AD%A3%E5%BA%A6%E6%8A%A5%E5%91%8A%3Bcategory_ndbg_szsh
%2Fcategory%2F%E5%B9%B4%E5%BA%A6%E6%8A%A5%E5%91%8A%3Bcategory_bndbg_szsh%2Fcategory%2F%E5%8D%8A%
E5%B9%B4%E5%BA%A6%E6%8A%A5%E5%91%8A%3Bcategory_yjdbg_szsh%2Fcategory%2F%E4%B8%80%E5%AD%A3%E5
%BA%A6%E6%8A%A5%E5%91%8A%3Bsz%2Fplate%2F%E6%B7%B1%E5%B8%82%E5%85%AC%E5%8F%B8% 3Bszmb%2Fplate
%2F%E6%B7%B1%E5%B8%82%E4%B8%BB%E6%9D%BF%3Bszzx%2Fplate%2F%E4%B8%AD%E5%B0%8F%E6% 9D%BF%3Bszcy
%2Fplate%2F%E5%88%9B%E4%B8%9A%E6%9D%BF%3Bshmb%2Fplate%2F%E6%B2%AA%E5%B8%82%E4%B8%BB% E6%9D%B
F&seDate=2016-10-13
我想专注于捕获第一季度、半年、第三季度和年度报告。查看类别选择:
category=category_sjdbg_szsh%3Bcategory_ndbg_szsh%3Bcategory_bndbg_szsh
%3Bcategory_yjdbg_szsh%3B
面对如此复杂的帖子数据,我不知道如何构建自己的帖子数据项。特别是当某个后变量采用多个值时。注意:%3B 是表示分号“;”的 URL 编码值。解决了一个变量多个值的问题。
#-*- coding: utf8 -*-
import urllib2
import urllib
import re
import time,datetime
import os
import shutil
def getstock(page,strdate):
values = {
'stock':'',
'searchkey':'',
'plate':'sz;szmb;szzx;szcy;shmb',
#%category_bndbg_szsh半年报告;category_sjdbg_szsh三季度;category_ndbg_szsh年度;category_yjdbg_szsh一季度
'category':'category_bndbg_szsh;category_sjdbg_szsh;category_ndbg_szsh;category_yjdbg_szsh',
'trade':'',
'column':'szse',
'columnTitle':'%E5%8E%86%E5%8F%B2%E5%85%AC%E5%91%8A%E6%9F%A5%E8%AF%A2',
'pageNum':page,
'pageSize':'50',
'tabName':'fulltext',
'sortName':'',
'sortType':'',
'limit':'',
'seDate':strdate}
data = urllib.urlencode(values)
url = "http://www.cninfo.com.cn/cninf ... ot%3B
request = urllib2.Request(url,data)
datime = datetime.datetime.now()
response = urllib2.urlopen(request,timeout=4)
re_data = response.read()
re_data = re_data.decode('utf8')
dict_data = eval(re_data.replace('null','None').replace('true','True').replace('false','False'))
print dict_data #转成dict数据,输出看看
return dict_data
try:
date2 = time.strftime('%Y-%m-%d', time.localtime())
page = 1
ret = getstock(str(page),str(date2))
except Exception as error:
print error
good luck!
c爬虫抓取网页数据(动态网页数据抓取什么是AJAX:异步JavaScript和XML的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-05 19:04
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。
道路
优势
缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium: Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。pip install selenium install chromedriver:下载完成后,放到一个不需要权限的纯英文目录下。安装 Selenium 和 chromedriver:快速入门:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r‘D:\ProgramApp\chromedriver\chromedriver.exe‘
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
find_element_by_id:根据id来查找某个元素。等价于:
submitTag = driver.find_element_by_id(‘su‘)
submitTag1 = driver.find_element(By.ID,‘su‘)
find_element_by_class_name:根据类名查找元素。 等价于:
submitTag = driver.find_element_by_class_name(‘su‘)
submitTag1 = driver.find_element(By.CLASS_NAME,‘su‘)
find_element_by_name:根据name属性的值来查找元素。等价于:
submitTag = driver.find_element_by_name(‘email‘)
submitTag1 = driver.find_element(By.NAME,‘email‘)
find_element_by_tag_name:根据标签名来查找元素。等价于:
submitTag = driver.find_element_by_tag_name(‘div‘)
submitTag1 = driver.find_element(By.TAG_NAME,‘div‘)
find_element_by_xpath:根据xpath语法来获取元素。等价于:
submitTag = driver.find_element_by_xpath(‘//div‘)
submitTag1 = driver.find_element(By.XPATH,‘//div‘)
find_element_by_css_selector:根据css选择器选择元素。等价于:
submitTag = driver.find_element_by_css_selector(‘//div‘)
submitTag1 = driver.find_element(By.CSS_SELECTOR,‘//div‘)
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
记住Tag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
fromselenium.webdriver.support.ui importSelect
# 选中这个标签,然后使用Select创建一个对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
#根据索引选择
selectTag.select_by_index(1)
# 按值选择
selectTag.select_by_value("")
# 根据可见文本选择
selectTag.select_by_visible_text("95 显示客户端")
# 取消所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id(‘kw‘)
submitTag = driver.find_element_by_id(‘su‘)
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,‘python‘)
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有的cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有的cookie:
driver.delete_all_cookies()
删除某个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
2/显示等待:显示等待是表示在执行获取元素的操作之前,一定的条件成立。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
更多条件参考:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。
Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open(‘https://www.baidu.com‘)")
#显示当前页面的url
driver.current_url //还是百度页面
# 切换到这个新的页面中
driver.switch_to_window(driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions() //设置存储浏览器的信息
//添加代理服务器
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get(‘http://httpbin.org/ip‘)
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。
screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
.
爬虫---selenium 动态网页数据抓取
原来的: 查看全部
c爬虫抓取网页数据(动态网页数据抓取什么是AJAX:异步JavaScript和XML的区别)
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。
道路
优势
缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium: Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。pip install selenium install chromedriver:下载完成后,放到一个不需要权限的纯英文目录下。安装 Selenium 和 chromedriver:快速入门:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r‘D:\ProgramApp\chromedriver\chromedriver.exe‘
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
find_element_by_id:根据id来查找某个元素。等价于:
submitTag = driver.find_element_by_id(‘su‘)
submitTag1 = driver.find_element(By.ID,‘su‘)
find_element_by_class_name:根据类名查找元素。 等价于:
submitTag = driver.find_element_by_class_name(‘su‘)
submitTag1 = driver.find_element(By.CLASS_NAME,‘su‘)
find_element_by_name:根据name属性的值来查找元素。等价于:
submitTag = driver.find_element_by_name(‘email‘)
submitTag1 = driver.find_element(By.NAME,‘email‘)
find_element_by_tag_name:根据标签名来查找元素。等价于:
submitTag = driver.find_element_by_tag_name(‘div‘)
submitTag1 = driver.find_element(By.TAG_NAME,‘div‘)
find_element_by_xpath:根据xpath语法来获取元素。等价于:
submitTag = driver.find_element_by_xpath(‘//div‘)
submitTag1 = driver.find_element(By.XPATH,‘//div‘)
find_element_by_css_selector:根据css选择器选择元素。等价于:
submitTag = driver.find_element_by_css_selector(‘//div‘)
submitTag1 = driver.find_element(By.CSS_SELECTOR,‘//div‘)
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
记住Tag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
fromselenium.webdriver.support.ui importSelect
# 选中这个标签,然后使用Select创建一个对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
#根据索引选择
selectTag.select_by_index(1)
# 按值选择
selectTag.select_by_value("")
# 根据可见文本选择
selectTag.select_by_visible_text("95 显示客户端")
# 取消所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id(‘kw‘)
submitTag = driver.find_element_by_id(‘su‘)
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,‘python‘)
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有的cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有的cookie:
driver.delete_all_cookies()
删除某个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
2/显示等待:显示等待是表示在执行获取元素的操作之前,一定的条件成立。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
更多条件参考:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。
Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open(‘https://www.baidu.com‘)")
#显示当前页面的url
driver.current_url //还是百度页面
# 切换到这个新的页面中
driver.switch_to_window(driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions() //设置存储浏览器的信息
//添加代理服务器
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get(‘http://httpbin.org/ip‘)
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。
screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
.
爬虫---selenium 动态网页数据抓取
原来的:
c爬虫抓取网页数据(Android我的博客APP】1.抓取博客首页文章列表内容——网页数据抓取(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-02 15:15
阿里云>云栖社区>主题地图>C>c 抓取网页列表数据库
推荐活动:
更多优惠>
当前主题:c 抓取网页列表数据库并添加到采集夹
相关话题:
c 爬取网页列表数据库相关博客 查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
使用正则表达式抓取博客园列表数据
作者:建筑师郭果860人浏览评论:08年前
鉴于我要完成的MVC 3会使用测试数据来模仿博客园企业系统,自己输入太累了,所以抓了一部分博客园的列表数据,请不要被dudu冒犯。爬取博客园的数据时用到了正则表达式,所以不熟悉正则表达式的朋友可以参考相关资料。其实很容易掌握,就是
阅读全文
【安卓我的博客APP】1.抓取博客首页文章列表内容-网页数据抓取
作者:呵呵 9925975人浏览评论:03年前
打算在博客园做自己的博客APP。首先必须能够访问首页获取数据获取首页文章列表,第一步是抓取博客首页文章列表内容功能,在小米2S中已经实现了以上效果图如下: 思路是通过编写的工具类访问网页,获取页面的源代码,通过正则表达式获取匹配的数据进行处理显示到ListView
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:Jack Chen1527人浏览评论:06年前
原文:PHP 使用 QueryList 抓取网页内容,然后使用 Java Jsoup 抓取网页数据。前几天听说用PHP抓起来比较方便。今天研究了一下,主要是用QueryList来实现。QueryList 是一个基于 phpQuery 的通用列表 采集 类,简单、灵活、功能强大
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
之前,我们使用 Java Jsoup 来捕获网页数据。前几天听说用PHP抓包比较方便。今天简单研究了一下,主要是使用QueryList。
阅读全文
初学者指南 | 使用 Python 抓取网页
作者:小轩峰柴金2425人浏览评论:04年前
简介 从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种在线数据科学课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。
阅读全文
Python抓取欧洲足球联赛数据进行大数据分析
作者:青山无名 12610人浏览评论:14年前
背景网页抓取在大数据时代,一切都必须用数据说话。大数据处理过程一般需要以下几个步骤:数据采集和数据的采集、提取、变形、数据加载分析。, 探索和预测数据的显示。首先要做的是获取数据,提取出有效数据,用于下一步的分析。
阅读全文
使用 Scrapy 抓取数据
作者:雨客6542人浏览评论:05年前
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
《用Python编写网络爬虫》——2.2 三种网络爬虫方法
作者:异步社区 3748人查看评论:04年前
本节摘自异步社区《Writing Web Crawlers in Python》一书第2章2.2,作者[澳大利亚]理查德劳森(Richard Lawson),李斌译,更多章节内容可在云栖社区“异步社区”公众号查看。2.2 三种网页爬取方法 现在我们已经了解了网页的结构,接下来
阅读全文 查看全部
c爬虫抓取网页数据(Android我的博客APP】1.抓取博客首页文章列表内容——网页数据抓取(组图))
阿里云>云栖社区>主题地图>C>c 抓取网页列表数据库

推荐活动:
更多优惠>
当前主题:c 抓取网页列表数据库并添加到采集夹
相关话题:
c 爬取网页列表数据库相关博客 查看更多博客
云数据库产品概述

作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
使用正则表达式抓取博客园列表数据


作者:建筑师郭果860人浏览评论:08年前
鉴于我要完成的MVC 3会使用测试数据来模仿博客园企业系统,自己输入太累了,所以抓了一部分博客园的列表数据,请不要被dudu冒犯。爬取博客园的数据时用到了正则表达式,所以不熟悉正则表达式的朋友可以参考相关资料。其实很容易掌握,就是
阅读全文
【安卓我的博客APP】1.抓取博客首页文章列表内容-网页数据抓取

作者:呵呵 9925975人浏览评论:03年前
打算在博客园做自己的博客APP。首先必须能够访问首页获取数据获取首页文章列表,第一步是抓取博客首页文章列表内容功能,在小米2S中已经实现了以上效果图如下: 思路是通过编写的工具类访问网页,获取页面的源代码,通过正则表达式获取匹配的数据进行处理显示到ListView
阅读全文
PHP 使用 QueryList 抓取网页内容


作者:Jack Chen1527人浏览评论:06年前
原文:PHP 使用 QueryList 抓取网页内容,然后使用 Java Jsoup 抓取网页数据。前几天听说用PHP抓起来比较方便。今天研究了一下,主要是用QueryList来实现。QueryList 是一个基于 phpQuery 的通用列表 采集 类,简单、灵活、功能强大
阅读全文
PHP 使用 QueryList 抓取网页内容


作者:thinkyoung1544 人浏览评论:06年前
之前,我们使用 Java Jsoup 来捕获网页数据。前几天听说用PHP抓包比较方便。今天简单研究了一下,主要是使用QueryList。
阅读全文
初学者指南 | 使用 Python 抓取网页


作者:小轩峰柴金2425人浏览评论:04年前
简介 从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种在线数据科学课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。
阅读全文
Python抓取欧洲足球联赛数据进行大数据分析


作者:青山无名 12610人浏览评论:14年前
背景网页抓取在大数据时代,一切都必须用数据说话。大数据处理过程一般需要以下几个步骤:数据采集和数据的采集、提取、变形、数据加载分析。, 探索和预测数据的显示。首先要做的是获取数据,提取出有效数据,用于下一步的分析。
阅读全文
使用 Scrapy 抓取数据
作者:雨客6542人浏览评论:05年前
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
《用Python编写网络爬虫》——2.2 三种网络爬虫方法


作者:异步社区 3748人查看评论:04年前
本节摘自异步社区《Writing Web Crawlers in Python》一书第2章2.2,作者[澳大利亚]理查德劳森(Richard Lawson),李斌译,更多章节内容可在云栖社区“异步社区”公众号查看。2.2 三种网页爬取方法 现在我们已经了解了网页的结构,接下来
阅读全文
c爬虫抓取网页数据(安装python运行pipinstallBeautifulSoup抓取网页完成必要工具安装后)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-11-01 18:03
本期文章将与大家分享如何使用Python爬虫爬取数据的内容。小编觉得很实用,所以分享出来供大家参考,跟着小编一起来看看吧。
工具安装
首先,您需要安装 Python requests 和 BeautifulSoup 库。我们使用 Requests 库抓取网页内容,使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。举个例子,我们先来看看如何抓取网页的内容。
提取内容
抓取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个例子中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用BeautifulSoup,我们可以非常简单的提取网页的具体内容。
持续的网络爬行
至此,我们已经能够抓取单个网页的内容,现在让我们看看如何抓取网站的整个内容。我们知道网页是通过超链接相互连接的,我们可以通过链接访问整个网络。所以我们可以从每个页面中提取到其他网页的链接,然后重复抓取新的链接。
准备
IDE:pyCharm
库:请求,lxm
即将介绍,这两个库主要为我们服务
requests:获取网页源代码
lxml:获取网页源代码中的指定数据
简洁明了,有没有^_^
设置环境
这里的搭建环境不是搭建python开发环境。这里的构建环境是指我们使用pycharm新建一个python项目,然后用requests和lxml新建一个项目。里面什么都没有。创建一个新的 src 文件夹。然后直接在里面新建一个Test.py。
依赖库导入
在 Test.py 中输入:
进口请求
此时,请求将报告一条红线。这时候我们将光标指向requests,按快捷键:alt+enter,pycharm会给出解决方案。这时候选择安装包请求,pycharm会自动为我们安装。,我们只需要稍等片刻,库就安装好了。lxml的安装方法是一样的。
安装这两个库后,编译器不会报红线。
获取网页源代码
请求可以很容易地让我们得到网页的源代码。
获取源代码:
# 获取源代码
html = requests.get("")
# 打印源代码
打印 html.text
代码就这么简单,这个html.text就是这个网址的源码
获取指定数据
现在我们有了网页的源代码,我们需要使用lxml过滤掉我们需要的信息。
首先,我们需要分析源代码。我这里使用的是 Chrome 浏览器,所以右键点击查看。
然后在源代码中,找到第一个。
首先点击源页面右上角的箭头,然后在网页内容中选择文章标题。这时候源码会定位到这里的标题。
这时候选择源码的title元素,右键复制。
获取xpath,相当于一个地址。比如源代码中网页长图的位置。
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h5/a
首先,//表示根节点,也就是说,这个//后面的东西是根,表示只有一个。我们需要的就在这里。
然后 / 表示寻找下层。根据图片也很明显,div -> main -> div[2] -> div[1] -> h5 -> a
跟踪到a这里,然后我们在最后加上/text表示我们要提取元素的内容,所以我们最终的表达式是这样的:
//*[@id="mainBox"]/main/div[2]/div[1]/h5/a/text()
这个表达只针对这个网页的这个元素,是不是很难理解?
那么这个东西是如何工作的呢?
所有代码:
进口请求
从 lxml 导入 etree
html = requests.get("")
# 打印 html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h5/a/text()')
对于每个内容:
打印(每个)
这时候每个里面的数据就是我们想要得到的数据
打印结果:
如何拍打 ArrayList
打印结果就是这个结果,我们去掉了换行符和空格
进口请求
从 lxml 导入 etree
html = requests.get("")
# 打印 html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h5/a/text()')
对于每个内容:
replace = each.replace('\n','').replace('','')
如果替换 =='\n' 或替换 =='':
继续
别的:
打印(替换)
打印结果:
如何拍打 ArrayList
感谢您的阅读!关于《如何使用Python爬虫抓取数据》这篇文章分享到这里,希望以上内容可以对大家有所帮助,让大家学到更多的知识,如果你觉得文章可以,可以分享出去让更多人看到! 查看全部
c爬虫抓取网页数据(安装python运行pipinstallBeautifulSoup抓取网页完成必要工具安装后)
本期文章将与大家分享如何使用Python爬虫爬取数据的内容。小编觉得很实用,所以分享出来供大家参考,跟着小编一起来看看吧。
工具安装
首先,您需要安装 Python requests 和 BeautifulSoup 库。我们使用 Requests 库抓取网页内容,使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。举个例子,我们先来看看如何抓取网页的内容。
提取内容
抓取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个例子中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用BeautifulSoup,我们可以非常简单的提取网页的具体内容。
持续的网络爬行
至此,我们已经能够抓取单个网页的内容,现在让我们看看如何抓取网站的整个内容。我们知道网页是通过超链接相互连接的,我们可以通过链接访问整个网络。所以我们可以从每个页面中提取到其他网页的链接,然后重复抓取新的链接。
准备
IDE:pyCharm
库:请求,lxm
即将介绍,这两个库主要为我们服务
requests:获取网页源代码
lxml:获取网页源代码中的指定数据
简洁明了,有没有^_^
设置环境
这里的搭建环境不是搭建python开发环境。这里的构建环境是指我们使用pycharm新建一个python项目,然后用requests和lxml新建一个项目。里面什么都没有。创建一个新的 src 文件夹。然后直接在里面新建一个Test.py。
依赖库导入
在 Test.py 中输入:
进口请求
此时,请求将报告一条红线。这时候我们将光标指向requests,按快捷键:alt+enter,pycharm会给出解决方案。这时候选择安装包请求,pycharm会自动为我们安装。,我们只需要稍等片刻,库就安装好了。lxml的安装方法是一样的。
安装这两个库后,编译器不会报红线。
获取网页源代码
请求可以很容易地让我们得到网页的源代码。
获取源代码:
# 获取源代码
html = requests.get("")
# 打印源代码
打印 html.text
代码就这么简单,这个html.text就是这个网址的源码
获取指定数据
现在我们有了网页的源代码,我们需要使用lxml过滤掉我们需要的信息。
首先,我们需要分析源代码。我这里使用的是 Chrome 浏览器,所以右键点击查看。
然后在源代码中,找到第一个。
首先点击源页面右上角的箭头,然后在网页内容中选择文章标题。这时候源码会定位到这里的标题。
这时候选择源码的title元素,右键复制。
获取xpath,相当于一个地址。比如源代码中网页长图的位置。
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h5/a
首先,//表示根节点,也就是说,这个//后面的东西是根,表示只有一个。我们需要的就在这里。
然后 / 表示寻找下层。根据图片也很明显,div -> main -> div[2] -> div[1] -> h5 -> a
跟踪到a这里,然后我们在最后加上/text表示我们要提取元素的内容,所以我们最终的表达式是这样的:
//*[@id="mainBox"]/main/div[2]/div[1]/h5/a/text()
这个表达只针对这个网页的这个元素,是不是很难理解?
那么这个东西是如何工作的呢?
所有代码:
进口请求
从 lxml 导入 etree
html = requests.get("")
# 打印 html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h5/a/text()')
对于每个内容:
打印(每个)
这时候每个里面的数据就是我们想要得到的数据
打印结果:
如何拍打 ArrayList
打印结果就是这个结果,我们去掉了换行符和空格
进口请求
从 lxml 导入 etree
html = requests.get("")
# 打印 html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h5/a/text()')
对于每个内容:
replace = each.replace('\n','').replace('','')
如果替换 =='\n' 或替换 =='':
继续
别的:
打印(替换)
打印结果:
如何拍打 ArrayList
感谢您的阅读!关于《如何使用Python爬虫抓取数据》这篇文章分享到这里,希望以上内容可以对大家有所帮助,让大家学到更多的知识,如果你觉得文章可以,可以分享出去让更多人看到!
c爬虫抓取网页数据(零基础快速入门的学习路径:1.了解爬虫与进阶分布式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-31 05:19
我不会说爬虫现在有多热。先说一下这个技术能做什么,主要有以下三个方面:
1. 爬取数据,进行市场调研和商业分析
抓取知乎、豆瓣等网站等优质话题;捕捉房地产网站交易信息,分析房价走势,做不同区域的房价分析;爬取招聘网站职位信息,分析各行业及薪资水平对人才的需求。
2.作为机器学习和数据挖掘的原创数据
比如你想做一个推荐系统,那么你可以爬取更多维度的数据,做一个更好的模型。
3. 爬取优质资源:图片、文字、视频
爬取游戏中的精美图片,获取图片资源和评论文字数据。
掌握正确的方法能够在短时间内抓取主流网站数据,其实很容易实现。
但建议您从一开始就有一个特定的目标。在目标的驱动下,您的学习将更加精准和高效。这是一个平滑的、从零开始的快速入门学习路径:
1.了解爬虫是如何实现的
2. 实现简单的信息爬取
3.应对特殊的网站反爬虫措施
4.Scrapy 和高级分布式
01
了解爬虫是如何实现的
大多数爬虫都遵循“发送请求-获取页面-解析页面-提取并存储内容”的过程。这实际上模拟了使用浏览器获取网页信息的过程。最后,如果你的时间不是很紧,又想快速提高python,最重要的是不怕吃苦,建议你定价(同名):762459510,那真的很好,很多人进步很快,需要你不怕吃苦!大家可以去补充看看~
简单的说,我们向服务器发送请求后,会得到返回的页面。解析完页面后,我们就可以提取出我们想要的那部分信息,存放在指定的文档或数据库中。
这部分可以对HTTP协议和网页基础知识,如POST\GET、HTML、CSS、JS等有一个简单的了解,简单了解一下,无需系统学习。
02
实现简单的信息抓取
Python中有很多爬虫相关的包:urllib、requests、bs4、scrapy、pyspider等,建议从requests+Xpath入手。Requests 负责连接到 网站 并返回网页。Xpath 用于解析网页以方便提取数据。
如果你用过BeautifulSoup,你会发现Xpath省了很多麻烦,层层检查元素代码的工作全部省略了。掌握了之后,你会发现爬虫的基本套路都差不多。一般静态 网站 根本不是问题。可以抓取知乎、豆瓣等网站等公开信息。
当然,如果你需要爬取异步加载的网站,可以学习浏览器抓包来分析真实请求,或者学习Selenium来实现自动爬取。这样,知乎、、TripAdvisor等网站基本没问题。
还需要了解Python的基础知识,比如:文件读写操作:用于读取参数,保存爬取内容列表(list),dict(dictionary):用于序列化爬取数据条件判断(if/else):解析爬虫中是否执行循环和迭代的判断(for ……while):用于循环爬虫步骤
03
特殊网站的防攀爬机制
在爬取的过程中,也会遇到一些绝望,比如被网站屏蔽,比如各种奇怪的验证码,userAgent访问限制,各种动态加载等等。
遇到这些反爬虫方法,当然需要一些高级技巧来应对,比如访问频率控制、代理IP池的使用、抓包、验证码的OCR处理等等。
比如我们经常会发现有些网站的网址在翻页后没有变化,通常是异步加载。我们使用开发者工具分析网页加载信息,通常可以获得意想不到的收获。
经常网站在高效开发和反爬虫之间偏向于前者。这也为爬虫提供了空间。掌握这些反爬虫技巧,大部分网站对你来说不再难。最后,如果你时间不是很紧,又想快速提高python,最重要的是不怕吃苦,我建议你可以价格(同名):762459510,那真的很好,很多人进步很快,需要你不怕吃苦!可以去加进去看看~
04
Scrapy 和高级分布式
使用requests+xpath和抓包大法确实可以解决很多网站信息的爬取,但是如果信息量很大或者需要模块爬取的话,就比较困难了。
后来应用到了强大的Scrapy框架中,不仅可以轻松构建Request,而且强大的Selector可以轻松解析Response。然而,最令人惊讶的是它的超高性能,可以对爬虫进行工程化和模块化。
在学习了 Scrapy 之后,我尝试构建了一个简单的爬虫框架。在做大规模数据爬取的时候,可以考虑结构化、工程化的大规模爬取。这让我可以从爬虫工程的维度去思考问题。
后来开始慢慢接触分布式爬虫。这听起来很傻,但实际上它利用了多线程的原理,让多个爬虫同时工作,可以达到更高的效率。
其实学了这个,基本可以说自己是爬虫老司机了。外行人很难看,但也没有那么复杂。
因为爬虫技术不需要你系统地精通一门语言,也不需要任何高级的数据库技术。高效的姿势就是从实际项目中学习这些零散的知识点,保证每次都能学到。是最需要的部分。最后,如果你时间不是很紧,又想快速提高python,最重要的是不怕吃苦,我建议你可以价格(同名):762459510,那真的很好,很多人进步很快,需要你不怕吃苦!可以去加进去看看~
当然,唯一的麻烦在于,在具体问题中,如何找到具体需要的那部分学习资源,以及如何过滤筛选,是很多初学者面临的一大难题。
不过不用担心,我们准备了非常系统的爬虫课程。除了为您提供清晰的学习路径,我们精选了最实用的学习资源和海量的主流爬虫案例库。在很短的学习时间内,你将能够很好地掌握爬虫技巧,得到你想要的数据。 查看全部
c爬虫抓取网页数据(零基础快速入门的学习路径:1.了解爬虫与进阶分布式)
我不会说爬虫现在有多热。先说一下这个技术能做什么,主要有以下三个方面:
1. 爬取数据,进行市场调研和商业分析
抓取知乎、豆瓣等网站等优质话题;捕捉房地产网站交易信息,分析房价走势,做不同区域的房价分析;爬取招聘网站职位信息,分析各行业及薪资水平对人才的需求。
2.作为机器学习和数据挖掘的原创数据
比如你想做一个推荐系统,那么你可以爬取更多维度的数据,做一个更好的模型。
3. 爬取优质资源:图片、文字、视频
爬取游戏中的精美图片,获取图片资源和评论文字数据。
掌握正确的方法能够在短时间内抓取主流网站数据,其实很容易实现。
但建议您从一开始就有一个特定的目标。在目标的驱动下,您的学习将更加精准和高效。这是一个平滑的、从零开始的快速入门学习路径:
1.了解爬虫是如何实现的
2. 实现简单的信息爬取
3.应对特殊的网站反爬虫措施
4.Scrapy 和高级分布式
01
了解爬虫是如何实现的
大多数爬虫都遵循“发送请求-获取页面-解析页面-提取并存储内容”的过程。这实际上模拟了使用浏览器获取网页信息的过程。最后,如果你的时间不是很紧,又想快速提高python,最重要的是不怕吃苦,建议你定价(同名):762459510,那真的很好,很多人进步很快,需要你不怕吃苦!大家可以去补充看看~
简单的说,我们向服务器发送请求后,会得到返回的页面。解析完页面后,我们就可以提取出我们想要的那部分信息,存放在指定的文档或数据库中。
这部分可以对HTTP协议和网页基础知识,如POST\GET、HTML、CSS、JS等有一个简单的了解,简单了解一下,无需系统学习。
02
实现简单的信息抓取
Python中有很多爬虫相关的包:urllib、requests、bs4、scrapy、pyspider等,建议从requests+Xpath入手。Requests 负责连接到 网站 并返回网页。Xpath 用于解析网页以方便提取数据。
如果你用过BeautifulSoup,你会发现Xpath省了很多麻烦,层层检查元素代码的工作全部省略了。掌握了之后,你会发现爬虫的基本套路都差不多。一般静态 网站 根本不是问题。可以抓取知乎、豆瓣等网站等公开信息。
当然,如果你需要爬取异步加载的网站,可以学习浏览器抓包来分析真实请求,或者学习Selenium来实现自动爬取。这样,知乎、、TripAdvisor等网站基本没问题。
还需要了解Python的基础知识,比如:文件读写操作:用于读取参数,保存爬取内容列表(list),dict(dictionary):用于序列化爬取数据条件判断(if/else):解析爬虫中是否执行循环和迭代的判断(for ……while):用于循环爬虫步骤
03
特殊网站的防攀爬机制
在爬取的过程中,也会遇到一些绝望,比如被网站屏蔽,比如各种奇怪的验证码,userAgent访问限制,各种动态加载等等。
遇到这些反爬虫方法,当然需要一些高级技巧来应对,比如访问频率控制、代理IP池的使用、抓包、验证码的OCR处理等等。
比如我们经常会发现有些网站的网址在翻页后没有变化,通常是异步加载。我们使用开发者工具分析网页加载信息,通常可以获得意想不到的收获。
经常网站在高效开发和反爬虫之间偏向于前者。这也为爬虫提供了空间。掌握这些反爬虫技巧,大部分网站对你来说不再难。最后,如果你时间不是很紧,又想快速提高python,最重要的是不怕吃苦,我建议你可以价格(同名):762459510,那真的很好,很多人进步很快,需要你不怕吃苦!可以去加进去看看~
04
Scrapy 和高级分布式
使用requests+xpath和抓包大法确实可以解决很多网站信息的爬取,但是如果信息量很大或者需要模块爬取的话,就比较困难了。
后来应用到了强大的Scrapy框架中,不仅可以轻松构建Request,而且强大的Selector可以轻松解析Response。然而,最令人惊讶的是它的超高性能,可以对爬虫进行工程化和模块化。
在学习了 Scrapy 之后,我尝试构建了一个简单的爬虫框架。在做大规模数据爬取的时候,可以考虑结构化、工程化的大规模爬取。这让我可以从爬虫工程的维度去思考问题。
后来开始慢慢接触分布式爬虫。这听起来很傻,但实际上它利用了多线程的原理,让多个爬虫同时工作,可以达到更高的效率。
其实学了这个,基本可以说自己是爬虫老司机了。外行人很难看,但也没有那么复杂。
因为爬虫技术不需要你系统地精通一门语言,也不需要任何高级的数据库技术。高效的姿势就是从实际项目中学习这些零散的知识点,保证每次都能学到。是最需要的部分。最后,如果你时间不是很紧,又想快速提高python,最重要的是不怕吃苦,我建议你可以价格(同名):762459510,那真的很好,很多人进步很快,需要你不怕吃苦!可以去加进去看看~
当然,唯一的麻烦在于,在具体问题中,如何找到具体需要的那部分学习资源,以及如何过滤筛选,是很多初学者面临的一大难题。
不过不用担心,我们准备了非常系统的爬虫课程。除了为您提供清晰的学习路径,我们精选了最实用的学习资源和海量的主流爬虫案例库。在很短的学习时间内,你将能够很好地掌握爬虫技巧,得到你想要的数据。
c爬虫抓取网页数据(本文软件属于破坏计算机信息系统罪的抓取策略分析手法分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-10-27 19:04
)
爬虫理论是关于爬行的难易程度。一是爬取加密内容,难度很大,尤其是app端的内容加密。有些人可能需要反转应用程序。二是抓取登录后才能查看的内容,加上登录账号的IP访问控制次数。这可能是一大群爬虫。
本文不讨论应用反向问题。这种问题似乎不应该公开陈述。刑法第286条规定,反编译软件是破坏计算机信息系统罪。
如果被证明,风险是相当高的,尤其是竞品之间的抢夺行为太高调。我在猿人学Python的两篇文章文章中写了爬取数据的法律风险。"", ""
本文讨论如何抓取未加密但只能通过登录查看的应用程序。
没有写爬虫的学校教授,所以没有统一的武术套路。强大的数据公司拥有各类武林人才、账号、IP、机器等渠道资源。一般来说,企业资源和人才不足,想要抓取大规模数据,巧妙的招数是可行的方法。
本文提到的巧妙爬取方法就是正确设计爬取策略,通过制定正确的爬取策略,高效爬取需要登录的APP。
制定正确的抓取策略,包括使用和熟悉抓取对象的产品形态(PC、H5、APP)和功能;测试抓取对象的账号在登录后对不同渠道的访问频次控制边界(例如,有的只对产品页面的频次控制进行了详细说明,对渠道页和分类页的控制较弱)。分析抓取的对象在分享到微信等渠道后是否需要授权从微信打开页面,是否需要登录。
这是一套通用的爬取策略分析方法。我可以使用这种策略为大多数应用程序捕获数千万条数据。
理论比较晕,我们以麦麦APP为例,如何分析和制定抢夺策略。
我们的目标是捕捉脉搏上的个人和专业信息(此类数据不应直接用于商业用途,简历也可以视为个人隐私数据)。
按照三面分析步骤,首先分析麦麦的产品形态。初步分析,麦麦的PC网站需要登录,并没有特殊的H5网站,APP也需要登录才能查看。据初步分析,无从下手。
第二步,分析各路段的频率控制。需要一些时间自己点击观察。测试结果是对个别详细页面的频率控制能力很强,对搜索功能也控制能力很强。对频道页面(例如类别)的控制较弱。大约一个账号可以快速访问200多个详细页面,并且会有提示。
这意味着,如果你想每天抓取 100,000 个脉冲详情页,则需要注册 100,000/200=500 个帐户。如果您每天抓取 100 万页,您将需要 5,000 个帐户。这样一来,企业实际上是为数百个账户付费,不到几块钱,但很多企业不愿意支付这个数额。
所以通过批量注册帐户,它停止了。另外,上面提到的大量账号爬取的方法,简化了IP问题。一个账号频繁更换IP也是有问题的,尤其是IP在江苏有一段时间,江西有一段时间。
分析了上面的一、二步骤,好像还没有找到好的方法。然后分析第三步,观察详情页的分享功能。我把详细页面分享到微信后,尝试在微信中打开,发现不用登录也可以访问详细页面。
抓包似乎找到了突破口,于是抓起包包仔细观察。
可以对抓包和分享到微信过程中的数据进行分析:
查看全部
c爬虫抓取网页数据(本文软件属于破坏计算机信息系统罪的抓取策略分析手法分析
)
爬虫理论是关于爬行的难易程度。一是爬取加密内容,难度很大,尤其是app端的内容加密。有些人可能需要反转应用程序。二是抓取登录后才能查看的内容,加上登录账号的IP访问控制次数。这可能是一大群爬虫。

本文不讨论应用反向问题。这种问题似乎不应该公开陈述。刑法第286条规定,反编译软件是破坏计算机信息系统罪。

如果被证明,风险是相当高的,尤其是竞品之间的抢夺行为太高调。我在猿人学Python的两篇文章文章中写了爬取数据的法律风险。"", ""
本文讨论如何抓取未加密但只能通过登录查看的应用程序。
没有写爬虫的学校教授,所以没有统一的武术套路。强大的数据公司拥有各类武林人才、账号、IP、机器等渠道资源。一般来说,企业资源和人才不足,想要抓取大规模数据,巧妙的招数是可行的方法。
本文提到的巧妙爬取方法就是正确设计爬取策略,通过制定正确的爬取策略,高效爬取需要登录的APP。
制定正确的抓取策略,包括使用和熟悉抓取对象的产品形态(PC、H5、APP)和功能;测试抓取对象的账号在登录后对不同渠道的访问频次控制边界(例如,有的只对产品页面的频次控制进行了详细说明,对渠道页和分类页的控制较弱)。分析抓取的对象在分享到微信等渠道后是否需要授权从微信打开页面,是否需要登录。
这是一套通用的爬取策略分析方法。我可以使用这种策略为大多数应用程序捕获数千万条数据。
理论比较晕,我们以麦麦APP为例,如何分析和制定抢夺策略。
我们的目标是捕捉脉搏上的个人和专业信息(此类数据不应直接用于商业用途,简历也可以视为个人隐私数据)。
按照三面分析步骤,首先分析麦麦的产品形态。初步分析,麦麦的PC网站需要登录,并没有特殊的H5网站,APP也需要登录才能查看。据初步分析,无从下手。
第二步,分析各路段的频率控制。需要一些时间自己点击观察。测试结果是对个别详细页面的频率控制能力很强,对搜索功能也控制能力很强。对频道页面(例如类别)的控制较弱。大约一个账号可以快速访问200多个详细页面,并且会有提示。
这意味着,如果你想每天抓取 100,000 个脉冲详情页,则需要注册 100,000/200=500 个帐户。如果您每天抓取 100 万页,您将需要 5,000 个帐户。这样一来,企业实际上是为数百个账户付费,不到几块钱,但很多企业不愿意支付这个数额。
所以通过批量注册帐户,它停止了。另外,上面提到的大量账号爬取的方法,简化了IP问题。一个账号频繁更换IP也是有问题的,尤其是IP在江苏有一段时间,江西有一段时间。
分析了上面的一、二步骤,好像还没有找到好的方法。然后分析第三步,观察详情页的分享功能。我把详细页面分享到微信后,尝试在微信中打开,发现不用登录也可以访问详细页面。

抓包似乎找到了突破口,于是抓起包包仔细观察。
可以对抓包和分享到微信过程中的数据进行分析:

c爬虫抓取网页数据(c爬虫抓取网页数据有三种模式:requests,beautifulsoup,pyquery)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-27 10:04
c爬虫抓取网页数据有三种模式:requests,pyquery,beautifulsoup:beautifulsoup模式简介网页数据就是经过html代码加载后形成的网页文档,网页文档就是一个文本文件。html可以是xml格式的也可以是json格式的,json格式可以是纯文本格式,也可以是二进制格式。
所以对于json格式网页数据抓取过程中又分为三种操作,一种是解析json格式数据,例如get,一种是ocr数据的识别,例如find,一种是将html转换成web容器比如webpages,webpages模式简介网页数据是通过键盘输入,然后服务器返回给浏览器一个html网页文档。简单的说,通过键盘输入的网页数据大多是html代码,然后经过处理转换而成,这些html代码往往很小,通常被分为多个标签,例如<a></a>等等,主要是识别标签,通过html/css语言把标签添加到相应位置上。
html代码的输入很简单,不需要复杂的编程。但是要解析通过键盘输入的页面的html代码需要大量的编程以及大量的数据库操作。工作量往往是事先无法想象的,你需要把很多代码编写成文件方便下次使用,而且每次编写还需要重新编译,另外你发现输入的html很长,可能数以百计,那么每次需要解析的代码又得花费不少时间。
beautifulsoup模式就是利用已有的html模板(css样式或javascript代码),编写一个简单的html代码,它基于浏览器环境的脚本解析器(python),然后传递给前端程序员处理,前端程序员根据html模板读取并解析我们编写的这个html,并显示在浏览器上。网页文档可以简单的可以分为多个区块,每个区块都会存在一个文本文件中,所以你可以通过解析它们生成一个html文档,然后上传到web服务器,再输出显示到我们的页面上。
这种抓取对计算机要求非常高,需要浏览器或者服务器操作优化良好,对性能要求也非常高。comet就是其中之一。 查看全部
c爬虫抓取网页数据(c爬虫抓取网页数据有三种模式:requests,beautifulsoup,pyquery)
c爬虫抓取网页数据有三种模式:requests,pyquery,beautifulsoup:beautifulsoup模式简介网页数据就是经过html代码加载后形成的网页文档,网页文档就是一个文本文件。html可以是xml格式的也可以是json格式的,json格式可以是纯文本格式,也可以是二进制格式。
所以对于json格式网页数据抓取过程中又分为三种操作,一种是解析json格式数据,例如get,一种是ocr数据的识别,例如find,一种是将html转换成web容器比如webpages,webpages模式简介网页数据是通过键盘输入,然后服务器返回给浏览器一个html网页文档。简单的说,通过键盘输入的网页数据大多是html代码,然后经过处理转换而成,这些html代码往往很小,通常被分为多个标签,例如<a></a>等等,主要是识别标签,通过html/css语言把标签添加到相应位置上。
html代码的输入很简单,不需要复杂的编程。但是要解析通过键盘输入的页面的html代码需要大量的编程以及大量的数据库操作。工作量往往是事先无法想象的,你需要把很多代码编写成文件方便下次使用,而且每次编写还需要重新编译,另外你发现输入的html很长,可能数以百计,那么每次需要解析的代码又得花费不少时间。
beautifulsoup模式就是利用已有的html模板(css样式或javascript代码),编写一个简单的html代码,它基于浏览器环境的脚本解析器(python),然后传递给前端程序员处理,前端程序员根据html模板读取并解析我们编写的这个html,并显示在浏览器上。网页文档可以简单的可以分为多个区块,每个区块都会存在一个文本文件中,所以你可以通过解析它们生成一个html文档,然后上传到web服务器,再输出显示到我们的页面上。
这种抓取对计算机要求非常高,需要浏览器或者服务器操作优化良好,对性能要求也非常高。comet就是其中之一。
c爬虫抓取网页数据(UI自动化月前写的一些事儿--)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-26 20:19
写在前面
本来这个文章是几个月前写的,后来忙忘了。
ps:事情太多有时会耽误事情。
几个月前,记得群里有个朋友说要用selenium来爬取数据。关于爬取数据,我一般是模拟访问一些固定的网站,爬取我关心的信息,然后爬出来。数据被处理。
他的要求是将文章直接导入富文本编辑器进行发布,其实这也是一种爬虫。
其实这并不难,就是UI自动化的过程,我们开始吧。
准备工具/原材料
1、java 语言
2、IDEA 开发工具
3、jdk1.8
4、selenium-server-standalone (3.0 及以上)
步骤 1、 分解需求:2、 代码实现思路:3、 示例代码
import org.junit.AfterClass;
import org.junit.BeforeClass;
import org.junit.Test;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import java.awt.*;
import java.awt.event.KeyEvent;
import java.util.concurrent.TimeUnit;
/**
* @author rongrong
* Selenium模拟访问网站爬虫操作代码示例
*/
public class Demo {
private static WebDriver driver;
static final int MAX_TIMEOUT_IN_SECONDS = 5;
@BeforeClass
public static void setUpBeforeClass() throws Exception {
driver = new ChromeDriver();
String url = "https://temai.snssdk.com/artic ... 3B%3B
driver.manage().window().maximize();
driver.manage().timeouts().implicitlyWait(MAX_TIMEOUT_IN_SECONDS, TimeUnit.SECONDS);
driver.get(url);
}
@AfterClass
public static void tearDownAfterClass() throws Exception {
if (driver != null) {
System.out.println("运行结束!");
driver.quit();
}
}
@Test
public void test() throws InterruptedException {
Robot robot = null;
try {
robot = new Robot();
} catch (AWTException e1) {
e1.printStackTrace();
}
robot.keyPress(KeyEvent.VK_CONTROL);
robot.keyPress(KeyEvent.VK_A);
robot.keyRelease(KeyEvent.VK_A);
Thread.sleep(2000);
robot.keyPress(KeyEvent.VK_C);
robot.keyRelease(KeyEvent.VK_C);
robot.keyRelease(KeyEvent.VK_CONTROL);
driver.get("https://ueditor.baidu.com/webs ... 6quot;);
Thread.sleep(2000);
driver.switchTo().frame(0);
driver.findElement(By.tagName("body")).click();
robot.keyPress(KeyEvent.VK_CONTROL);
robot.keyPress(KeyEvent.VK_V);
robot.keyRelease(KeyEvent.VK_V);
robot.keyRelease(KeyEvent.VK_CONTROL);
Thread.sleep(2000);
}
}
写在后面
作者不特别推荐使用selenium作为爬虫,原因如下:
每次运行爬虫都要打开浏览器,初始化需要加载图片、JS渲染等很多东西;
有人说改成无头浏览器的原理是一样的。就是打开浏览器,很多网站都会验证参数。如果对方看到您的恶意访问请求,就会执行您的请求。然后你必须考虑更改请求头。不知道事情有多复杂,还要改代码,很麻烦。
加载了很多可能对你没有价值的补充文件(比如css、js、图片文件)。与真正需要的资源(使用单独的 HTTP 请求)相比,这可能会产生更多的流量。 查看全部
c爬虫抓取网页数据(UI自动化月前写的一些事儿--)
写在前面
本来这个文章是几个月前写的,后来忙忘了。
ps:事情太多有时会耽误事情。
几个月前,记得群里有个朋友说要用selenium来爬取数据。关于爬取数据,我一般是模拟访问一些固定的网站,爬取我关心的信息,然后爬出来。数据被处理。
他的要求是将文章直接导入富文本编辑器进行发布,其实这也是一种爬虫。
其实这并不难,就是UI自动化的过程,我们开始吧。
准备工具/原材料
1、java 语言
2、IDEA 开发工具
3、jdk1.8
4、selenium-server-standalone (3.0 及以上)
步骤 1、 分解需求:2、 代码实现思路:3、 示例代码
import org.junit.AfterClass;
import org.junit.BeforeClass;
import org.junit.Test;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import java.awt.*;
import java.awt.event.KeyEvent;
import java.util.concurrent.TimeUnit;
/**
* @author rongrong
* Selenium模拟访问网站爬虫操作代码示例
*/
public class Demo {
private static WebDriver driver;
static final int MAX_TIMEOUT_IN_SECONDS = 5;
@BeforeClass
public static void setUpBeforeClass() throws Exception {
driver = new ChromeDriver();
String url = "https://temai.snssdk.com/artic ... 3B%3B
driver.manage().window().maximize();
driver.manage().timeouts().implicitlyWait(MAX_TIMEOUT_IN_SECONDS, TimeUnit.SECONDS);
driver.get(url);
}
@AfterClass
public static void tearDownAfterClass() throws Exception {
if (driver != null) {
System.out.println("运行结束!");
driver.quit();
}
}
@Test
public void test() throws InterruptedException {
Robot robot = null;
try {
robot = new Robot();
} catch (AWTException e1) {
e1.printStackTrace();
}
robot.keyPress(KeyEvent.VK_CONTROL);
robot.keyPress(KeyEvent.VK_A);
robot.keyRelease(KeyEvent.VK_A);
Thread.sleep(2000);
robot.keyPress(KeyEvent.VK_C);
robot.keyRelease(KeyEvent.VK_C);
robot.keyRelease(KeyEvent.VK_CONTROL);
driver.get("https://ueditor.baidu.com/webs ... 6quot;);
Thread.sleep(2000);
driver.switchTo().frame(0);
driver.findElement(By.tagName("body")).click();
robot.keyPress(KeyEvent.VK_CONTROL);
robot.keyPress(KeyEvent.VK_V);
robot.keyRelease(KeyEvent.VK_V);
robot.keyRelease(KeyEvent.VK_CONTROL);
Thread.sleep(2000);
}
}
写在后面
作者不特别推荐使用selenium作为爬虫,原因如下:
每次运行爬虫都要打开浏览器,初始化需要加载图片、JS渲染等很多东西;
有人说改成无头浏览器的原理是一样的。就是打开浏览器,很多网站都会验证参数。如果对方看到您的恶意访问请求,就会执行您的请求。然后你必须考虑更改请求头。不知道事情有多复杂,还要改代码,很麻烦。
加载了很多可能对你没有价值的补充文件(比如css、js、图片文件)。与真正需要的资源(使用单独的 HTTP 请求)相比,这可能会产生更多的流量。
c爬虫抓取网页数据(由C#编写的多线程异步抓取网页的网络爬虫控制台程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-17 08:11
C#编写的一个多线程异步网络爬虫控制台程序
描述:C#编写的多线程异步网络爬虫控制台程序。功能:目前只能提取网络链接,使用的两个记录文件不需要很大。暂时无法抓取网页文字、图片、视频和html代码,敬请谅解。但是需要注意的是,网页的数量非常多。下面的代码理论上可以捕获整个Internet网页链接。但实际上,由于处理器功能和网络条件(主要是网速)的限制,一般家用电脑最多可以处理12个线程的爬虫任务,爬虫速度是有限的。它可以爬行,但需要时间和耐心。当然,这个程序是可以捕获所有链接的,因为链接不占用太多系统空间,并且借助日志文件,可以将爬取的网页数量堆积起来,甚至可以访问所有互联网网络链接,当然最好是分批进行。建议将maxNum设置为500-1000左右,慢慢积累。另外,由于是控制台程序,有时显示的字符过多,系统会暂停显示。这时候,只需点击控制台并按回车键即可。当程序暂停时,您可以按 Enter 尝试。/// 要使用这个程序,请确保已经创建了相应的记录文件。为简化代码,本程序不够健壮,请见谅。/// 默认文件创建在E盘根目录下的两个文本文件:“待爬取的URL.txt”和“待爬取的URL.txt”。并注意不要有后缀出错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接用多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。并注意不要有后缀出错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接用多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接用多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接用多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。
现在就下载 查看全部
c爬虫抓取网页数据(由C#编写的多线程异步抓取网页的网络爬虫控制台程序)
C#编写的一个多线程异步网络爬虫控制台程序
描述:C#编写的多线程异步网络爬虫控制台程序。功能:目前只能提取网络链接,使用的两个记录文件不需要很大。暂时无法抓取网页文字、图片、视频和html代码,敬请谅解。但是需要注意的是,网页的数量非常多。下面的代码理论上可以捕获整个Internet网页链接。但实际上,由于处理器功能和网络条件(主要是网速)的限制,一般家用电脑最多可以处理12个线程的爬虫任务,爬虫速度是有限的。它可以爬行,但需要时间和耐心。当然,这个程序是可以捕获所有链接的,因为链接不占用太多系统空间,并且借助日志文件,可以将爬取的网页数量堆积起来,甚至可以访问所有互联网网络链接,当然最好是分批进行。建议将maxNum设置为500-1000左右,慢慢积累。另外,由于是控制台程序,有时显示的字符过多,系统会暂停显示。这时候,只需点击控制台并按回车键即可。当程序暂停时,您可以按 Enter 尝试。/// 要使用这个程序,请确保已经创建了相应的记录文件。为简化代码,本程序不够健壮,请见谅。/// 默认文件创建在E盘根目录下的两个文本文件:“待爬取的URL.txt”和“待爬取的URL.txt”。并注意不要有后缀出错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接用多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。并注意不要有后缀出错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接用多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接用多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接用多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。
现在就下载
c爬虫抓取网页数据(不同时间段的网络表格数据节点获取需要注意的事项!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-11-17 03:01
(1)数据URL获取
网易财经、新浪财经等网站数据可免费获取。我们可以使用爬虫方法(通过rvest包)抓取对应的网站表数据。首先,我们可以在网易财经抢到600550,以2019年第三季度的数据为例。它的网站是:
,
可以看出,不同时间段的网址是有规律的,只需更改其中的股票代码、年份和季节即可循环抓取多只股票。
(2)Web 表数据节点获取
我们需要解析网页表格数据的节点。除了系统地掌握网页设计的原理和基本结构,我们还可以通过FireFox(Firebug插件)和Chrome浏览器解析网页结构,得到相应的分支结构点。这里我们使用火狐浏览器,具体操作是在找到我们需要的表格位置后(请探讨如何找到表格位置),右键复制XPath路径。
table部分的XPath是/html/body/div[2]/div[4]/table[1]。
(3) 抓取单个股票的单页数据
library(rvest)
symbol=600550
year=2019
season=3
url=paste0("http://quotes.money.163.com/trade/lsjysj_",symbol,".html?year=",year,"&season=",season)
web=read_html(url)
xpath="/html/body/div[2]/div[4]/table[1]"
web.table=web%>%html_nodes(xpath=xpath)%>%html_table()
此时的web.table就是爬取到的数据
(4) 从单个股票的多个页面抓取并合并数据
library(lubridate)
symbol=600550
from="2001-05-28"
from=as.Date(from)
to=Sys.Date()
time.index=seq(from=from,to=to,by="quarter")#生成以季度为开始的时间序列
year.id=year(time.index)#获取年份
quarter.id=quarter(time.index)#获取季度
price=list()
for(t in 1:length(time.index)){
year=year.id[t]
season=quarter.id[t]
url=paste0("http://quotes.money.163.com/trade/lsjysj_",symbol,".html?year=",year,"&season=",season)
web=read_html(url)
xpath="/html/body/div[2]/div[4]/table[1]"
web.table=web%>%html_nodes(xpath=xpath)%>%html_table()
web.table=web.table[[1]][-1,]
price[[t]]=web.table
}
(5) 多只股票多页数据抓取合并
get.wangyi.stock=function(symbol,from,to){
from=as.Date(from)
to=as.Date(to)
if(mday(from==1)){
from=from-1
}
time.index=seq(from=from,to=to,by="quarter")
year.id=year(time.index)
quarter.id=quarter(time.index)
prices=list()
for(t in 1:length(time.index)){
year=year.id[t]
season=quarter.id[t] url=paste0("http://quotes.money.163.com/trade/lsjysj_",symbol,".html?year=",year,"&season=",season)
web=read_html(url)
xpath="/html/body/div[2]/div[4]/table[1]"
web.table=web%>%html_nodes(xpath=xpath)%>%html_table()
web.table=web.table[[1]][-1,]
prices[[t]]=web.table
}
}
to=Sys.Date()
stock.index=matrix(nrow=6,ncol=2)
stock.index[,1]=c("600550.ss","600192.ss","600152.ss","600644.ss","600885.ss","600151.ss")
stock.index[,2]=c("2017-05-28","2017-05-28","2017-05-28","2017-05-28","2017-05-28","2017-05-28")
for(i in nrow(stock.index)){
symbol=stock.index[i,1]
from=stock.index[i,2]
prices=get.wangyi.stock(symbol,from,to)
filenames=paste0("D://dataset//",symbol,".csv")
}
(6) 读取所有A股数据
我们也可以将所有A股代码整理成一个文件,阅读后实时更新所有A股股票数据。这个方法可以用来建立我们自己的数据库进行实时分析。同时,通过网络爬虫,我们也可以抓取到很多有意义的数据,并实时更新。 查看全部
c爬虫抓取网页数据(不同时间段的网络表格数据节点获取需要注意的事项!)
(1)数据URL获取
网易财经、新浪财经等网站数据可免费获取。我们可以使用爬虫方法(通过rvest包)抓取对应的网站表数据。首先,我们可以在网易财经抢到600550,以2019年第三季度的数据为例。它的网站是:
,
可以看出,不同时间段的网址是有规律的,只需更改其中的股票代码、年份和季节即可循环抓取多只股票。
(2)Web 表数据节点获取
我们需要解析网页表格数据的节点。除了系统地掌握网页设计的原理和基本结构,我们还可以通过FireFox(Firebug插件)和Chrome浏览器解析网页结构,得到相应的分支结构点。这里我们使用火狐浏览器,具体操作是在找到我们需要的表格位置后(请探讨如何找到表格位置),右键复制XPath路径。
table部分的XPath是/html/body/div[2]/div[4]/table[1]。
(3) 抓取单个股票的单页数据
library(rvest)
symbol=600550
year=2019
season=3
url=paste0("http://quotes.money.163.com/trade/lsjysj_",symbol,".html?year=",year,"&season=",season)
web=read_html(url)
xpath="/html/body/div[2]/div[4]/table[1]"
web.table=web%>%html_nodes(xpath=xpath)%>%html_table()
此时的web.table就是爬取到的数据
(4) 从单个股票的多个页面抓取并合并数据
library(lubridate)
symbol=600550
from="2001-05-28"
from=as.Date(from)
to=Sys.Date()
time.index=seq(from=from,to=to,by="quarter")#生成以季度为开始的时间序列
year.id=year(time.index)#获取年份
quarter.id=quarter(time.index)#获取季度
price=list()
for(t in 1:length(time.index)){
year=year.id[t]
season=quarter.id[t]
url=paste0("http://quotes.money.163.com/trade/lsjysj_",symbol,".html?year=",year,"&season=",season)
web=read_html(url)
xpath="/html/body/div[2]/div[4]/table[1]"
web.table=web%>%html_nodes(xpath=xpath)%>%html_table()
web.table=web.table[[1]][-1,]
price[[t]]=web.table
}
(5) 多只股票多页数据抓取合并
get.wangyi.stock=function(symbol,from,to){
from=as.Date(from)
to=as.Date(to)
if(mday(from==1)){
from=from-1
}
time.index=seq(from=from,to=to,by="quarter")
year.id=year(time.index)
quarter.id=quarter(time.index)
prices=list()
for(t in 1:length(time.index)){
year=year.id[t]
season=quarter.id[t] url=paste0("http://quotes.money.163.com/trade/lsjysj_",symbol,".html?year=",year,"&season=",season)
web=read_html(url)
xpath="/html/body/div[2]/div[4]/table[1]"
web.table=web%>%html_nodes(xpath=xpath)%>%html_table()
web.table=web.table[[1]][-1,]
prices[[t]]=web.table
}
}
to=Sys.Date()
stock.index=matrix(nrow=6,ncol=2)
stock.index[,1]=c("600550.ss","600192.ss","600152.ss","600644.ss","600885.ss","600151.ss")
stock.index[,2]=c("2017-05-28","2017-05-28","2017-05-28","2017-05-28","2017-05-28","2017-05-28")
for(i in nrow(stock.index)){
symbol=stock.index[i,1]
from=stock.index[i,2]
prices=get.wangyi.stock(symbol,from,to)
filenames=paste0("D://dataset//",symbol,".csv")
}
(6) 读取所有A股数据
我们也可以将所有A股代码整理成一个文件,阅读后实时更新所有A股股票数据。这个方法可以用来建立我们自己的数据库进行实时分析。同时,通过网络爬虫,我们也可以抓取到很多有意义的数据,并实时更新。
c爬虫抓取网页数据(java程序中获取后台js完后的完整页面是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-13 18:11
很多网站使用js或者jquery来生成数据。后台获取数据后,使用 document.write() 或 ("#id").html="" 写入页面。这时候用浏览器看源码是看不到数据的。
HttpClient 不起作用。看网上的HtmlUnit,说是加载后台js后可以得到完整的页面,但是我按照文章写的,但是不行。一般代码是这样写的:
String url = "http://xinjinqiao.tprtc.com/ad ... 3B%3B
try {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10);
//设置webClient的相关参数
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
//webClient.getOptions().setTimeout(50000);
webClient.getOptions().setThrowExceptionOnScriptError(false);
//模拟浏览器打开一个目标网址
HtmlPage rootPage = webClient.getPage(url);
System.out.println("为了获取js执行的数据 线程开始沉睡等待");
Thread.sleep(3000);//主要是这个线程的等待 因为js加载也是需要时间的
System.out.println("线程结束沉睡");
String html = rootPage.asText();
System.out.println(html);
} catch (Exception e) {
}
事实上,它根本不起作用。
典型的是这个链接的页面。 java程序中如何获取数据? 查看全部
c爬虫抓取网页数据(java程序中获取后台js完后的完整页面是什么?)
很多网站使用js或者jquery来生成数据。后台获取数据后,使用 document.write() 或 ("#id").html="" 写入页面。这时候用浏览器看源码是看不到数据的。
HttpClient 不起作用。看网上的HtmlUnit,说是加载后台js后可以得到完整的页面,但是我按照文章写的,但是不行。一般代码是这样写的:
String url = "http://xinjinqiao.tprtc.com/ad ... 3B%3B
try {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10);
//设置webClient的相关参数
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
//webClient.getOptions().setTimeout(50000);
webClient.getOptions().setThrowExceptionOnScriptError(false);
//模拟浏览器打开一个目标网址
HtmlPage rootPage = webClient.getPage(url);
System.out.println("为了获取js执行的数据 线程开始沉睡等待");
Thread.sleep(3000);//主要是这个线程的等待 因为js加载也是需要时间的
System.out.println("线程结束沉睡");
String html = rootPage.asText();
System.out.println(html);
} catch (Exception e) {
}
事实上,它根本不起作用。
典型的是这个链接的页面。 java程序中如何获取数据?
c爬虫抓取网页数据(Python爬虫开发环境搭建.x的爬虫笔记)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-13 18:11
原作者及原文链接:Jack-Cui, /c406495762/...
操作平台:Windows Python版本:Python3.x IDE:Sublime text3
一直想学习Python爬虫的知识,上网搜了一下,大部分都是基于Python2.x。所以打算写一篇Python3.x的爬虫笔记,供后续复习。欢迎交流,共同进步。
一、预备知识1.Python3.x基础知识学习:2.开发环境搭建:二、网络爬虫的定义
网络爬虫也称为网络蜘蛛。如果将 Internet 比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络爬虫根据网页的地址,即 URL 搜索网页。举个简单的例子,我们在浏览器地址栏中输入的字符串就是URL,例如:。
URL是Uniform Resource Locator,其一般格式如下(方括号[]是可选的):
协议://主机名[:端口]/路径/[;参数][?查询]#fragment
URL格式由三部分组成:
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分为主机名(端口号为可选参数)。一般网站的默认端口号为80。例如host百度的名字是这个是服务器的地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
三、简单爬虫示例
在 Python3.x 中,我们可以使用 urlib 组件来抓取网页。urllib 是一个 URL 处理包。这个包收录一些处理 URL 的模块,如下:
urllib.request 模块用于打开和读取 URL;
urllib.error 模块中收录了 urllib.request 产生的一些错误,可以通过 try 捕获和处理;
urllib.parse 模块收录一些解析 URL 的方法;
urllib.robotparser 模块用于解析 robots.txt 文本文件。它提供了一个单独的RobotFileParser类来测试爬虫是否可以通过该类提供的can_fetch()方法下载一个页面。
我们使用 urllib.request.urlopen() 接口函数轻松打开一个网站,读取和打印信息。
urlopen 有一些可选参数。具体信息请参考Python自带的文档。
知道了这一点,我们就可以写出最简单的程序了,文件名是urllib_test01.py,感受一下一个urllib库的魅力:
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com")
html = response.read()
print(html)
复制代码
urllib 使用 request.urlopen() 打开和读取 URLs 信息,返回的对象 response 就像一个文本对象,我们可以调用 read() 来读取它。然后通过print(),打印出读取到的信息。
运行程序ctrl+b,可以在Sublime中查看结果,如下:
您也可以在 cmd(控制台)中输入命令:
python urllib_test01.py
复制代码
运行py文件,输出信息相同,如下:
其实这是浏览器接收到的信息,但是我们在使用浏览器的时候,浏览器已经把这些信息转换成界面信息供我们浏览了。当然,我们也可以从浏览器中查看这些代码。比如使用谷歌浏览器,在任意界面右击选择Check,就是勾选元素(不是所有页面都可以勾选元素,比如起点中文网站的付费版块。)。以百度界面为例。截图如下:
如您所见,我们的审核结果在右侧。我们可以在本地更改元素,即浏览器(客户端),但这不会上传到服务器。例如,我可以修改我的支付宝余额并安装一个包,例如:
我真的有钱吗?显然,如果我被迫这样做,我就没有钱了。我刚刚修改了关于review元素的信息。
有一些偏差,但事实是浏览器作为客户端从服务器获取信息,然后解析信息,然后显示给我们。
回到正题,虽然我们成功获取到了信息,但很明显,都是二进制乱码,看起来很不方便。我们该怎么办?
我们可以通过一个简单的decode()命令来解码网页的信息并显示出来。我们新建一个文件,命名为urllib_test02.py,编写如下代码(或以百度翻译网站为例):
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://www.fanyi.baidu.com/")
html = response.read()
html = html.decode("utf-8")
print(html)
复制代码
这样,我们就可以得到这个结果。显然,解码后的信息看起来更整洁、更舒服:
当然,前提是我们已经知道这个网页是utf-8编码的,如何查看网页的编码方式呢?需要人工操作,一个很简单的方法就是使用浏览器查看元素。只需要找到head标签开头的chareset就知道网页使用的是哪种编码。如下:
所以我们知道这个网站的编码方式,但这需要我们每次打开浏览器,找到编码方式。显然,这有点麻烦。使用几行代码来解决它更容易更酷。
四、自动获取网页编码的方法
获取网页代码的方法有很多,我更喜欢使用第三方库。
首先我们需要安装第三方库chardet,它是一个用来判断编码的模块。安装方法如下图所示。只需输入命令:
pip install chardet
复制代码
安装后,我们可以使用chardet.detect()方法来判断网页的编码。此时,我们可以编写一个小程序来判断网页的编码方式,新建的文件名为chardet_test01.py:
# -*- coding: UTF-8 -*-
from urllib import request
import chardet
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com/")
html = response.read()
charset = chardet.detect(html)
print(charset)
复制代码
运行程序,查看输出结果如下:
看,返回的是字典,所以我们知道了网页的编码方式,我们可以根据得到的信息使用不同的解码方式。
PS:关于编码方式的内容,可以自行百度 查看全部
c爬虫抓取网页数据(Python爬虫开发环境搭建.x的爬虫笔记)
原作者及原文链接:Jack-Cui, /c406495762/...
操作平台:Windows Python版本:Python3.x IDE:Sublime text3
一直想学习Python爬虫的知识,上网搜了一下,大部分都是基于Python2.x。所以打算写一篇Python3.x的爬虫笔记,供后续复习。欢迎交流,共同进步。
一、预备知识1.Python3.x基础知识学习:2.开发环境搭建:二、网络爬虫的定义
网络爬虫也称为网络蜘蛛。如果将 Internet 比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络爬虫根据网页的地址,即 URL 搜索网页。举个简单的例子,我们在浏览器地址栏中输入的字符串就是URL,例如:。
URL是Uniform Resource Locator,其一般格式如下(方括号[]是可选的):
协议://主机名[:端口]/路径/[;参数][?查询]#fragment
URL格式由三部分组成:
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分为主机名(端口号为可选参数)。一般网站的默认端口号为80。例如host百度的名字是这个是服务器的地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
三、简单爬虫示例
在 Python3.x 中,我们可以使用 urlib 组件来抓取网页。urllib 是一个 URL 处理包。这个包收录一些处理 URL 的模块,如下:
urllib.request 模块用于打开和读取 URL;
urllib.error 模块中收录了 urllib.request 产生的一些错误,可以通过 try 捕获和处理;
urllib.parse 模块收录一些解析 URL 的方法;
urllib.robotparser 模块用于解析 robots.txt 文本文件。它提供了一个单独的RobotFileParser类来测试爬虫是否可以通过该类提供的can_fetch()方法下载一个页面。
我们使用 urllib.request.urlopen() 接口函数轻松打开一个网站,读取和打印信息。
urlopen 有一些可选参数。具体信息请参考Python自带的文档。
知道了这一点,我们就可以写出最简单的程序了,文件名是urllib_test01.py,感受一下一个urllib库的魅力:
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com";)
html = response.read()
print(html)
复制代码
urllib 使用 request.urlopen() 打开和读取 URLs 信息,返回的对象 response 就像一个文本对象,我们可以调用 read() 来读取它。然后通过print(),打印出读取到的信息。
运行程序ctrl+b,可以在Sublime中查看结果,如下:
您也可以在 cmd(控制台)中输入命令:
python urllib_test01.py
复制代码
运行py文件,输出信息相同,如下:
其实这是浏览器接收到的信息,但是我们在使用浏览器的时候,浏览器已经把这些信息转换成界面信息供我们浏览了。当然,我们也可以从浏览器中查看这些代码。比如使用谷歌浏览器,在任意界面右击选择Check,就是勾选元素(不是所有页面都可以勾选元素,比如起点中文网站的付费版块。)。以百度界面为例。截图如下:
如您所见,我们的审核结果在右侧。我们可以在本地更改元素,即浏览器(客户端),但这不会上传到服务器。例如,我可以修改我的支付宝余额并安装一个包,例如:
我真的有钱吗?显然,如果我被迫这样做,我就没有钱了。我刚刚修改了关于review元素的信息。
有一些偏差,但事实是浏览器作为客户端从服务器获取信息,然后解析信息,然后显示给我们。
回到正题,虽然我们成功获取到了信息,但很明显,都是二进制乱码,看起来很不方便。我们该怎么办?
我们可以通过一个简单的decode()命令来解码网页的信息并显示出来。我们新建一个文件,命名为urllib_test02.py,编写如下代码(或以百度翻译网站为例):
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://www.fanyi.baidu.com/";)
html = response.read()
html = html.decode("utf-8")
print(html)
复制代码
这样,我们就可以得到这个结果。显然,解码后的信息看起来更整洁、更舒服:
当然,前提是我们已经知道这个网页是utf-8编码的,如何查看网页的编码方式呢?需要人工操作,一个很简单的方法就是使用浏览器查看元素。只需要找到head标签开头的chareset就知道网页使用的是哪种编码。如下:
所以我们知道这个网站的编码方式,但这需要我们每次打开浏览器,找到编码方式。显然,这有点麻烦。使用几行代码来解决它更容易更酷。
四、自动获取网页编码的方法
获取网页代码的方法有很多,我更喜欢使用第三方库。
首先我们需要安装第三方库chardet,它是一个用来判断编码的模块。安装方法如下图所示。只需输入命令:
pip install chardet
复制代码
安装后,我们可以使用chardet.detect()方法来判断网页的编码。此时,我们可以编写一个小程序来判断网页的编码方式,新建的文件名为chardet_test01.py:
# -*- coding: UTF-8 -*-
from urllib import request
import chardet
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com/";)
html = response.read()
charset = chardet.detect(html)
print(charset)
复制代码
运行程序,查看输出结果如下:
看,返回的是字典,所以我们知道了网页的编码方式,我们可以根据得到的信息使用不同的解码方式。
PS:关于编码方式的内容,可以自行百度
c爬虫抓取网页数据(.4win7框架:如何获取网页上动态加载的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-13 04:21
环境:python3.4
赢7
框架:scrapy
继上一篇之后,这次我将讲如何获取网页上动态加载的数据:
作为初学者,刚开始接触爬虫的时候,我们一般只会爬取一些静态内容(如何区分静态内容和动态内容,这里不讲理论,只教一些小方法):
首先打开谷歌浏览器,然后按F12,就会弹出谷歌自带的开发者工具,首先在“元素”下找到你需要抓取的内容;
然后,在网页可视化界面上右键,选择查看网页源代码。网页源码就是我们按照抓取静态网页的方法在网页中可以看到的所有东西,开发者工具可以查看。有些东西我们在网页的源代码中是看不到的;
最后,通过将我们在F12中查看的内容与网页源代码中的内容进行对比,我们可以初步判断哪些数据是静态加载的,哪些数据是动态加载的。
--------- ---分割线-----------
一般的请求方法有两种,post请求方法和get请求方法。在这篇文章中,我们先说一下get请求方法。
说到get请求,这应该是最常用的请求之一。表达 get 请求的最直观方式是什么?其实我们把网址放在地址栏中打开网页,这是一个get请求。
--------- ---分割线-----------
好的,现在让我们进入主题:让我们先用一个例子来描述它。抓取大型购物的商品评论时网站:
当我们点击 1 或 2 3 4 时,我们会发现 URL 根本没有变化,这意味着这些评论是动态加载的。然后我们使用F12下的抓包工具尝试抓包:(F12,然后选择“网络”),出现下图:
接下来是最重要的:在可视化界面中,我们点击“2”按钮,让评论页面跳转到第二页,看看能否顺利抓包:
OK,可以看到有2个gif文件,2个png文件,还有一个脚本文件。一开始,我们不知道应该检查哪个文件。好吧,最笨的办法,一个一个点进去:所以你管我把它们都订了,除了脚本文件,其他的都是这样的:
哈哈,如果没有next,那我们只能检查脚本文件了。看Response,发现只是一堆代码,查起来好像不方便?好的,没问题,我们试试预览,效果会很好。. . . 很高兴找到结果:
你看到吗!评论评论,大家应该相信网站大写手的英文是绝对没问题的,不会像我一样给评论起个“pinglun”的吧!
然后点击这条评论看看里面有什么:
好了,就是我们要的注释了,所以这个文件所在的URL就是我们需要的,接下来我们通过看Headers来获取URL!
URL就是我们需要的URL(URL被马赛克抹掉了,不好意思各位,因为我哥也怕被水表查),状态值为200表示访问成功,访问方法: GET,回显话题,使用get请求获取网页的动态加载数据。好了,今天的教程到此结束。什么?不构造一个获取请求?那请到我的第一篇博文找大神的爬虫教程链接~~~~
好了,这篇文章到此结束。我从头到尾都没有看到任何代码。哈哈,有时候教他们钓鱼不如教他们钓鱼。代码很重要,方法也很重要。有了这些分析方法,相信大家都能快速掌握获取动态网页内容的技巧。下一篇我们会讲如何使用post请求来获取网页的动态加载数据~我们下期再见 查看全部
c爬虫抓取网页数据(.4win7框架:如何获取网页上动态加载的数据)
环境:python3.4
赢7
框架:scrapy
继上一篇之后,这次我将讲如何获取网页上动态加载的数据:
作为初学者,刚开始接触爬虫的时候,我们一般只会爬取一些静态内容(如何区分静态内容和动态内容,这里不讲理论,只教一些小方法):
首先打开谷歌浏览器,然后按F12,就会弹出谷歌自带的开发者工具,首先在“元素”下找到你需要抓取的内容;
然后,在网页可视化界面上右键,选择查看网页源代码。网页源码就是我们按照抓取静态网页的方法在网页中可以看到的所有东西,开发者工具可以查看。有些东西我们在网页的源代码中是看不到的;
最后,通过将我们在F12中查看的内容与网页源代码中的内容进行对比,我们可以初步判断哪些数据是静态加载的,哪些数据是动态加载的。
--------- ---分割线-----------
一般的请求方法有两种,post请求方法和get请求方法。在这篇文章中,我们先说一下get请求方法。
说到get请求,这应该是最常用的请求之一。表达 get 请求的最直观方式是什么?其实我们把网址放在地址栏中打开网页,这是一个get请求。
--------- ---分割线-----------
好的,现在让我们进入主题:让我们先用一个例子来描述它。抓取大型购物的商品评论时网站:
当我们点击 1 或 2 3 4 时,我们会发现 URL 根本没有变化,这意味着这些评论是动态加载的。然后我们使用F12下的抓包工具尝试抓包:(F12,然后选择“网络”),出现下图:
接下来是最重要的:在可视化界面中,我们点击“2”按钮,让评论页面跳转到第二页,看看能否顺利抓包:
OK,可以看到有2个gif文件,2个png文件,还有一个脚本文件。一开始,我们不知道应该检查哪个文件。好吧,最笨的办法,一个一个点进去:所以你管我把它们都订了,除了脚本文件,其他的都是这样的:
哈哈,如果没有next,那我们只能检查脚本文件了。看Response,发现只是一堆代码,查起来好像不方便?好的,没问题,我们试试预览,效果会很好。. . . 很高兴找到结果:
你看到吗!评论评论,大家应该相信网站大写手的英文是绝对没问题的,不会像我一样给评论起个“pinglun”的吧!
然后点击这条评论看看里面有什么:
好了,就是我们要的注释了,所以这个文件所在的URL就是我们需要的,接下来我们通过看Headers来获取URL!
URL就是我们需要的URL(URL被马赛克抹掉了,不好意思各位,因为我哥也怕被水表查),状态值为200表示访问成功,访问方法: GET,回显话题,使用get请求获取网页的动态加载数据。好了,今天的教程到此结束。什么?不构造一个获取请求?那请到我的第一篇博文找大神的爬虫教程链接~~~~
好了,这篇文章到此结束。我从头到尾都没有看到任何代码。哈哈,有时候教他们钓鱼不如教他们钓鱼。代码很重要,方法也很重要。有了这些分析方法,相信大家都能快速掌握获取动态网页内容的技巧。下一篇我们会讲如何使用post请求来获取网页的动态加载数据~我们下期再见
c爬虫抓取网页数据(基于关键字的自动下载网页资源的程序,())
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-12 17:04
网络爬虫 * 简介-crawler 爬虫,即Spider(网络爬虫),其定义可分为广义和狭义。狭义上,是指遵循标准http协议,使用超链接和Web文档检索方式遍历万维网的软件程序;而广义的定义是遵循http协议,检索Web文档的软件称为网络爬虫。网络爬虫是一款功能强大的自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。*关注爬虫 随着互联网的飞速发展,万维网已经成为海量信息的载体,如何有效地提取和利用这些信息成为一个巨大的挑战。搜索引擎,比如传统的通用搜索引擎AltaVista、Yahoo! 而谷歌等作为辅助人们检索信息的工具,已经成为用户访问万维网的入口和向导。但是,这些通用的搜索引擎也有一定的局限性。大量用户不关心的网页。(2)一般搜索引擎的目标是最大化网络覆盖。有限的搜索引擎服务器资源和无限的网络数据资源之间的矛盾将进一步加深。(3)随着数据形式的丰富在万维网和网络技术的不断发展中,图片、数据库、音视频多媒体等不同的数据大量出现,很好的发现和获取。
处理和搜索行为匹配结构化数据和元数据信息。如数码产品mp3:内存、大小、尺寸、电池型号、价格、厂家等,还可以提供比价服务*爬虫基本原理从一个或几个初始网页的URL(通常是一个网站 homepage),遍历网页空间,阅读网页内容,不断从一个站点移动到另一个站点,并自动建立索引。在抓取网页的过程中,找到网页中的其他链接地址,解析HTML文件,取出网页中的子链接,并添加到网页数据库中,不断从当前页面中提取新的URL并将它们放入队列中,因此循环继续。, 直到这个网站的所有网页都被抓取完毕,
*爬虫的基本原理。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询和检索。网络爬虫在分析某个网页时,不依赖用户干预,利用HTML语言的标记结构,获取指向其他网页的URL地址。如果把整个互联网看作一个网站,理论上网络爬虫可以抓取到互联网上的所有网页,可以对后续的抓取过程提供反馈和指导。正是这种行为方式,这些程序被称为蜘蛛、爬虫和机器人。*爬虫基本原理 Spider是如何爬取所有网页的?在 Web 出现之前,传统的文本集合,例如目录数据库和期刊摘要,存储在磁带或 CD 上并用作索引系统。相应地,Web 上所有可访问的 URL 都未分类。采集 URL 的唯一方法是扫描并采集指向其他页面的超链接。这些页面尚未采集。* 查看全部
c爬虫抓取网页数据(基于关键字的自动下载网页资源的程序,())
网络爬虫 * 简介-crawler 爬虫,即Spider(网络爬虫),其定义可分为广义和狭义。狭义上,是指遵循标准http协议,使用超链接和Web文档检索方式遍历万维网的软件程序;而广义的定义是遵循http协议,检索Web文档的软件称为网络爬虫。网络爬虫是一款功能强大的自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。*关注爬虫 随着互联网的飞速发展,万维网已经成为海量信息的载体,如何有效地提取和利用这些信息成为一个巨大的挑战。搜索引擎,比如传统的通用搜索引擎AltaVista、Yahoo! 而谷歌等作为辅助人们检索信息的工具,已经成为用户访问万维网的入口和向导。但是,这些通用的搜索引擎也有一定的局限性。大量用户不关心的网页。(2)一般搜索引擎的目标是最大化网络覆盖。有限的搜索引擎服务器资源和无限的网络数据资源之间的矛盾将进一步加深。(3)随着数据形式的丰富在万维网和网络技术的不断发展中,图片、数据库、音视频多媒体等不同的数据大量出现,很好的发现和获取。
处理和搜索行为匹配结构化数据和元数据信息。如数码产品mp3:内存、大小、尺寸、电池型号、价格、厂家等,还可以提供比价服务*爬虫基本原理从一个或几个初始网页的URL(通常是一个网站 homepage),遍历网页空间,阅读网页内容,不断从一个站点移动到另一个站点,并自动建立索引。在抓取网页的过程中,找到网页中的其他链接地址,解析HTML文件,取出网页中的子链接,并添加到网页数据库中,不断从当前页面中提取新的URL并将它们放入队列中,因此循环继续。, 直到这个网站的所有网页都被抓取完毕,
*爬虫的基本原理。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询和检索。网络爬虫在分析某个网页时,不依赖用户干预,利用HTML语言的标记结构,获取指向其他网页的URL地址。如果把整个互联网看作一个网站,理论上网络爬虫可以抓取到互联网上的所有网页,可以对后续的抓取过程提供反馈和指导。正是这种行为方式,这些程序被称为蜘蛛、爬虫和机器人。*爬虫基本原理 Spider是如何爬取所有网页的?在 Web 出现之前,传统的文本集合,例如目录数据库和期刊摘要,存储在磁带或 CD 上并用作索引系统。相应地,Web 上所有可访问的 URL 都未分类。采集 URL 的唯一方法是扫描并采集指向其他页面的超链接。这些页面尚未采集。*
c爬虫抓取网页数据(Python爬虫学习笔记)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-11 00:14
操作平台:Windows Python版本:Python3.x IDE:Sublime text3
一直想学习Python爬虫的知识,上网搜了一下,大部分都是基于Python2.x。所以打算写一篇Python3.x的爬虫笔记,供后续复习。欢迎交流,共同进步。
一、预备知识
1.Python3.x基础知识学习:
您可以通过以下方式学习:
(1)廖雪峰Python3教程(文档):
网址:
(2)菜鸟教程Python3教程(文档):
网址:
(3) Fish C Studio Python 教程(视频):
小龟老师人很好,讲课风格幽默诙谐。如果时间充裕,可以考虑看视频。
网址:
2.开发环境设置:
Sublime text3搭建Pyhthon IDE,可以查看博客:
网址:
网址:
二、网络爬虫的定义
网络爬虫也称为网络蜘蛛。如果将 Internet 比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络爬虫根据网页的地址,即 URL 搜索网页。举个简单的例子,我们在浏览器地址栏中输入的字符串就是URL,例如:
URL是Uniform Resource Locator,其一般格式如下(方括号[]是可选的):
协议://主机名[:端口]/路径/[;参数][?查询]#fragment
URL格式由三部分组成:
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分为主机名(端口号为可选参数)。一般网站的默认端口号为80。例如host百度的名字是这个是服务器的地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
三、简单爬虫示例
在 Python3.x 中,我们可以使用 urlib 组件来抓取网页。urllib 是一个 URL 处理包。这个包收录一些处理 URL 的模块,如下:
1.urllib.request 模块用于打开和读取 URL;
2.urllib.error 模块中收录了 urllib.request 产生的一些错误,可以通过 try 捕获和处理;
3.urllib.parse 模块收录一些解析 URL 的方法;
4.urllib.robotparser 模块用于解析robots.txt 文本文件。它提供了一个单独的RobotFileParser类,可以通过该类提供的can_fetch()方法来测试爬虫是否可以下载一个页面。
我们可以使用接口函数urllib.request.urlopen()轻松打开一个网站,读取和打印信息。
urlopen 有一些可选参数。具体信息请参考Python自带的文档。
知道了这一点,我们就可以写出最简单的程序了,文件名是urllib_test01.py,感受一下一个urllib库的魅力:
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com")
html = response.read()
print(html)
urllib 使用 request.urlopen() 打开和读取 URLs 信息,返回的对象 response 就像一个文本对象,我们可以调用 read() 来读取它。然后通过print(),打印出读取到的信息。
运行程序ctrl+b,可以在Sublime中查看结果,如下:
您也可以在 cmd(控制台)中输入命令:
python urllib_test01.py
运行py文件,输出信息相同,如下:
其实这是浏览器接收到的信息,但是我们在使用浏览器的时候,浏览器已经把这些信息转换成界面信息供我们浏览了。当然,我们也可以从浏览器中查看这些代码。比如使用谷歌浏览器,在任意界面右击选择Check,即勾选元素(不是所有页面都可以勾选元素,比如起点中文网站的付费版块。)。以百度界面为例。截图如下:
如您所见,我们的审核结果在右侧。我们可以在本地更改元素,即浏览器(客户端),但这不会上传到服务器。例如,我可以修改我的支付宝余额并安装一个包,例如:
我真的有钱吗?显然,如果我被迫这样做,我就没有钱了。我只是修改了关于review元素的信息。
有一些偏差,但事实是浏览器作为客户端从服务器获取信息,然后解析信息,然后将其展示给我们。
回到正题,虽然我们成功获取到了信息,但很明显,都是二进制乱码,看起来很不方便。我们该怎么办?
我们可以通过一个简单的 decode() 命令来解码网页的信息并显示出来。我们新建一个文件,命名为urllib_test02.py,编写如下代码(或以百度翻译网站为例):
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://www.fanyi.baidu.com/")
html = response.read()
html = html.decode("utf-8")
print(html)
这样,我们就可以得到这个结果。显然,解码后的信息看起来更整洁、更舒服:
当然,前提是我们已经知道这个网页是utf-8编码的,如何查看网页的编码方式呢?需要人工操作,一个很简单的方法就是使用浏览器查看元素。只需要找到head标签开头的chareset就知道网页使用的是哪种编码。如下:
所以我们知道这个网站的编码方式,但这需要我们每次打开浏览器,找到编码方式。显然,这有点麻烦。用几行代码来解决,更省事,更爽。
四、自动获取网页编码的方法
获取网页代码的方法有很多,我更喜欢使用第三方库。
首先我们需要安装第三方库chardet,它是一个用来判断编码的模块。安装方法如下图所示。只需输入命令:
pip install chardet
安装后,我们可以使用chardet.detect()方法来判断网页的编码。此时,我们可以编写一个小程序来判断网页的编码方式,新建的文件名为chardet_test01.py:
# -*- coding: UTF-8 -*-
from urllib import request
import chardet
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com/")
html = response.read()
charset = chardet.detect(html)
print(charset)
运行程序,查看输出结果如下:
看,返回的是字典,所以我们知道了网页的编码方式,我们可以根据得到的信息使用不同的解码方式。
PS:关于编码方式的内容,可以自行百度,或者阅读这篇博客:
网址: 查看全部
c爬虫抓取网页数据(Python爬虫学习笔记)
操作平台:Windows Python版本:Python3.x IDE:Sublime text3
一直想学习Python爬虫的知识,上网搜了一下,大部分都是基于Python2.x。所以打算写一篇Python3.x的爬虫笔记,供后续复习。欢迎交流,共同进步。
一、预备知识
1.Python3.x基础知识学习:
您可以通过以下方式学习:
(1)廖雪峰Python3教程(文档):
网址:
(2)菜鸟教程Python3教程(文档):
网址:
(3) Fish C Studio Python 教程(视频):
小龟老师人很好,讲课风格幽默诙谐。如果时间充裕,可以考虑看视频。
网址:
2.开发环境设置:
Sublime text3搭建Pyhthon IDE,可以查看博客:
网址:
网址:
二、网络爬虫的定义
网络爬虫也称为网络蜘蛛。如果将 Internet 比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络爬虫根据网页的地址,即 URL 搜索网页。举个简单的例子,我们在浏览器地址栏中输入的字符串就是URL,例如:
URL是Uniform Resource Locator,其一般格式如下(方括号[]是可选的):
协议://主机名[:端口]/路径/[;参数][?查询]#fragment
URL格式由三部分组成:
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分为主机名(端口号为可选参数)。一般网站的默认端口号为80。例如host百度的名字是这个是服务器的地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
三、简单爬虫示例
在 Python3.x 中,我们可以使用 urlib 组件来抓取网页。urllib 是一个 URL 处理包。这个包收录一些处理 URL 的模块,如下:
1.urllib.request 模块用于打开和读取 URL;
2.urllib.error 模块中收录了 urllib.request 产生的一些错误,可以通过 try 捕获和处理;
3.urllib.parse 模块收录一些解析 URL 的方法;
4.urllib.robotparser 模块用于解析robots.txt 文本文件。它提供了一个单独的RobotFileParser类,可以通过该类提供的can_fetch()方法来测试爬虫是否可以下载一个页面。
我们可以使用接口函数urllib.request.urlopen()轻松打开一个网站,读取和打印信息。
urlopen 有一些可选参数。具体信息请参考Python自带的文档。
知道了这一点,我们就可以写出最简单的程序了,文件名是urllib_test01.py,感受一下一个urllib库的魅力:
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com";)
html = response.read()
print(html)
urllib 使用 request.urlopen() 打开和读取 URLs 信息,返回的对象 response 就像一个文本对象,我们可以调用 read() 来读取它。然后通过print(),打印出读取到的信息。
运行程序ctrl+b,可以在Sublime中查看结果,如下:
您也可以在 cmd(控制台)中输入命令:
python urllib_test01.py
运行py文件,输出信息相同,如下:
其实这是浏览器接收到的信息,但是我们在使用浏览器的时候,浏览器已经把这些信息转换成界面信息供我们浏览了。当然,我们也可以从浏览器中查看这些代码。比如使用谷歌浏览器,在任意界面右击选择Check,即勾选元素(不是所有页面都可以勾选元素,比如起点中文网站的付费版块。)。以百度界面为例。截图如下:
如您所见,我们的审核结果在右侧。我们可以在本地更改元素,即浏览器(客户端),但这不会上传到服务器。例如,我可以修改我的支付宝余额并安装一个包,例如:
我真的有钱吗?显然,如果我被迫这样做,我就没有钱了。我只是修改了关于review元素的信息。
有一些偏差,但事实是浏览器作为客户端从服务器获取信息,然后解析信息,然后将其展示给我们。
回到正题,虽然我们成功获取到了信息,但很明显,都是二进制乱码,看起来很不方便。我们该怎么办?
我们可以通过一个简单的 decode() 命令来解码网页的信息并显示出来。我们新建一个文件,命名为urllib_test02.py,编写如下代码(或以百度翻译网站为例):
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://www.fanyi.baidu.com/";)
html = response.read()
html = html.decode("utf-8")
print(html)
这样,我们就可以得到这个结果。显然,解码后的信息看起来更整洁、更舒服:
当然,前提是我们已经知道这个网页是utf-8编码的,如何查看网页的编码方式呢?需要人工操作,一个很简单的方法就是使用浏览器查看元素。只需要找到head标签开头的chareset就知道网页使用的是哪种编码。如下:
所以我们知道这个网站的编码方式,但这需要我们每次打开浏览器,找到编码方式。显然,这有点麻烦。用几行代码来解决,更省事,更爽。
四、自动获取网页编码的方法
获取网页代码的方法有很多,我更喜欢使用第三方库。
首先我们需要安装第三方库chardet,它是一个用来判断编码的模块。安装方法如下图所示。只需输入命令:
pip install chardet
安装后,我们可以使用chardet.detect()方法来判断网页的编码。此时,我们可以编写一个小程序来判断网页的编码方式,新建的文件名为chardet_test01.py:
# -*- coding: UTF-8 -*-
from urllib import request
import chardet
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com/";)
html = response.read()
charset = chardet.detect(html)
print(charset)
运行程序,查看输出结果如下:
看,返回的是字典,所以我们知道了网页的编码方式,我们可以根据得到的信息使用不同的解码方式。
PS:关于编码方式的内容,可以自行百度,或者阅读这篇博客:
网址:
c爬虫抓取网页数据(一个_selector.xpath.u去重与增量爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-11 00:12
response_selector.xpath(u'//div[contains(@class,"house-title")]/p[contains(@class,"house-update-info c_888 f12")]/text()').extract( )
因为有些数据不能用Xpath提取,所以也需要正则匹配。如有异常,应予处理。一般当页面无法匹配到对应的字段时,应该设置为0,项目处理完毕后,需要对其进行处理。进行过滤处理。
3) 去重和增量爬取
去重和增量爬取对服务器来说意义重大,可以减轻服务器压力,保证数据的准确性。如果不进行去重,被爬取的内容会爬取大量重复的内容,大大降低了爬虫效率。事实上,重复数据删除的过程非常简单。核心是在每次发出请求时判断该请求是否在爬取队列中。如果它已经存在,则丢弃当前请求。
具体实施步骤:
(1)从要爬取的队列中获取url
(2) 判断请求的URL是否已经被抓取,如果已经被抓取,则忽略该请求,不抓取,继续其他操作,将URL插入到抓取队列中
(3) 重复步骤 1
这里我们使用了scrapy-redis去重组件,所以没有实现,但是原理还是需要理解的,具体可以看源码。
4)爬虫中间件
爬虫中间件可以帮助我们在scrapy爬虫过程中自由扩展我们的程序。以下是爬虫反屏蔽中间件、下载器异常状态中间件和非200状态中间件。
(1)爬虫反屏蔽组件的实现
在访问网站的网页时,会给网站带来一定的负载,爬虫程序模拟了我们正常访问网页的过程,但是。大型爬虫会给网站增加很大的负载,影响普通用户的访问。为了保证网页可以被大多数正常用户访问,大多数网站都有相应的反爬虫策略。一旦访问行为被认定为爬虫,网站会采取一定的措施限制您的访问,比如提醒您访问过于频繁,请您输入验证码,如果比较严重,您的ip会被封禁,禁止你访问网站。本系统在有针对性的抓取网页数据时,会持续访问网站的内容。
本系统采用以下方法防止爬虫被拦截:
1.模拟不同的浏览器行为
2. 一定频率更换代理服务器和网关
3. 符合君子协议,降低爬虫爬取网页的频率,减少并发爬取的进程,限制每个IP的并发爬取次数,牺牲一定的效率来换取系统的稳定性。
4.禁用cookies,网站会在cookie中插入一些信息来判断用户访问时是否是机器人。我们屏蔽和调整cookie,这也有利于我们的身份不同意暴露。
5. 手动编码,这应该是无懈可击的反禁措施。所有的系统都不比人工操作好,但它们降低了自动化,效率不高,但它们确实是最有效的措施。当爬虫被禁止时,它会被重定向到一个验证码页面。输入验证码重新访问页面。为此,我添加了一个电子邮件提醒模块。当爬虫被封禁时,我会发邮件提醒管理员解封。同时将重定向的请求重新加入到下载队列中进行爬取,保证数据的完整性。
爬虫预防网站屏蔽的原理如下图所示:
(一)模拟不同浏览器行为的实现思路和代码
原理:从scrapy的介绍可以知道scrapy有下载中间件。在这个中间件中,我们可以自定义请求和响应,类似于spring面向方面的编程,就像在程序运行前后嵌入一个钩子。核心是修改请求的属性
首先是扩展下载中间件,首先在seetings.py中添加中间件,
其次,扩展中间件,主要是写一个useragent列表,将常用的浏览器请求头保存为一个列表,如下图:
让请求的头文件从列表中随机选择一个代理值,然后下载到下载器。
综上所述,每次发出请求,都是模拟使用不同的浏览器访问目标网站。
(B) 使用代理ip爬取的实现思路和代码。
首先,将中间件添加到seetings.py。扩展下载组件请求的头文件会从代理ip池中随机取出一个代理值,然后下载到下载器。
1.代理ip池的设计开发流程如下:
一种。获取免费代理ip网站。
湾 存储和验证代理ip
C。验证存储在数据库中
d. 如果达到最大ip数,停止爬取,一定时间后验证数据ip的有效性,删除无效ip
e. 直到数据库ip小于0,继续爬取ip,重复步骤a。
这里的代理ip模块使用的是七夜代理ip池的开源项目
代理ip爬虫运行截图:
(三)爬虫异常状态组件的处理
爬虫运行时没有被阻塞,访问网站并不总是200请求成功,而是有各种状态,比如上面爬虫被ban的时候,返回的状态其实是302,就是为了防止阻塞组件 捕获要实现的 302 状态。同时,异常情况的处理有利于爬虫的鲁棒性。
扩展中间件在设置中捕捉到异常情况后,将请求重新加入等待下载队列的过程如下:
(D) 数据存储模块
数据存储模块主要负责存储从端爬取解析的页面。使用 Mongodb 存储数据。
Scrapy 支持 json、csv 和 xml 等数据存储格式。用户可以在运行爬虫时进行设置,例如:scrapy crawl spider -o items.json -t json,也可以在Scrapy项目文件ItemPipline文件中定义,同时Scrapy也支持数据库存储,如如Monogdb、Redis等。当数据量很大到一定程度时,可以使用Mongodb或Reids集群来解决。本系统的数据存储如下图所示:
(E) 抓斗设计
本文以网络房屋数据为爬取目标,slave端分析抓取现场数据。因此,采集到的内容必须能够客观、准确地反映网络房屋数据的特点。
以58个同城网络房源数据为例,通过分析网页结构,定义字段的详细信息如下表所示。
序号字段名称字段含义
1title 帖子标题
2money 租金
3method租借方式
4area区域
5community所在的社区
6targeturl 帖子详情
7city所在的城市
8Pub_time 发布发布时间
现场选择主要是基于本系统的应用研究,因为系统开发单机配置比较低,没有图片文件下载到本机。减轻单机压力。
(F) 数据处理
1)对象定义程序
Item 是定义捕获数据的容器。它是通过创建一个 scrapy.item.Item 类来声明的。定义属性为scrapy.item.Field对象,通过实例化需要的item来控制获取的站点数据。系统定义了九个抓取对象,分别是:帖子标题、租金、租赁方式、位置、社区、城市、帖子详情页链接、发布时间。这里的字段定义是根据数据处理端的需要来定义的。关键代码如下:
类 TcZufangItem(Item):
#帖子名称
标题=字段()
#租
钱=字段()
#出租方式
方法=字段()
#您所在的地区
区域=字段()
#地点
社区=字段()
#发布详情网址
目标网址=字段()
#发布发布时间
pub_time=字段()
#位置城市
城市=字段()
2)数据处理程序
Pipeline 类定义了数据保存和输出方法。Spider的parse方法返回的Item,在处理完ITEM_PIPELINES列表中Pipeline类对应的数据后,会以top格式输出数据。本系统返回管道的数据存储在Mongodb中。关键代码如下:
def process_item(self, item, spider):
如果 item['pub_time'] == 0:
raise DropItem("发现重复项:%s"% 项)
如果项目['方法'] == 0:
raise DropItem("发现重复项:%s"% 项)
如果项目['社区']==0:
raise DropItem("发现重复项:%s"% 项)
如果 item['money']==0:
raise DropItem("发现重复项:%s"% 项)
如果 item['area'] == 0:
raise DropItem("发现重复项:%s"% 项)
如果项目['城市'] == 0:
raise DropItem("发现重复项:%s"% 项)
zufang_detail = {
'title': item.get('title'),
'钱':item.get('钱'),
'方法':item.get('方法'),
'area': item.get('area',''),
'社区': item.get('社区',''),
'targeturl': item.get('targeturl'),
'pub_time': item.get('pub_time',''),
'city':item.get('city','')
}
result = self.db['zufang_detail'].insert(zufang_detail)
打印'[成功]'+item['targeturl']+'写入MongoDB数据库'
归还物品
(G) 数据可视化设计
数据的可视化,其实就是把数据库的数据转换成我们用户容易观察的形式。本系统使用Mongodb来存储数据。数据可视化基于Django+Semantiui,效果如下图所示:
四、系统操作
系统以58同城租赁平台为爬取目标。运行十个小时后,系统继续抓取网页上总共数万个列表数据。
Master运行截图:
Slave 运行截图:
五、系统部署
环境部署,因为分布式部署需要的环境类似。如果一个服务器部署程序需要配置环境,那就很麻烦了。这里使用docker镜像部署爬虫程序,使用Daocloud上的scrapy-env对。程序已经部署完毕,具体的docker部署过程可以参考网上。 查看全部
c爬虫抓取网页数据(一个_selector.xpath.u去重与增量爬取)
response_selector.xpath(u'//div[contains(@class,"house-title")]/p[contains(@class,"house-update-info c_888 f12")]/text()').extract( )
因为有些数据不能用Xpath提取,所以也需要正则匹配。如有异常,应予处理。一般当页面无法匹配到对应的字段时,应该设置为0,项目处理完毕后,需要对其进行处理。进行过滤处理。
3) 去重和增量爬取
去重和增量爬取对服务器来说意义重大,可以减轻服务器压力,保证数据的准确性。如果不进行去重,被爬取的内容会爬取大量重复的内容,大大降低了爬虫效率。事实上,重复数据删除的过程非常简单。核心是在每次发出请求时判断该请求是否在爬取队列中。如果它已经存在,则丢弃当前请求。
具体实施步骤:
(1)从要爬取的队列中获取url
(2) 判断请求的URL是否已经被抓取,如果已经被抓取,则忽略该请求,不抓取,继续其他操作,将URL插入到抓取队列中
(3) 重复步骤 1
这里我们使用了scrapy-redis去重组件,所以没有实现,但是原理还是需要理解的,具体可以看源码。
4)爬虫中间件
爬虫中间件可以帮助我们在scrapy爬虫过程中自由扩展我们的程序。以下是爬虫反屏蔽中间件、下载器异常状态中间件和非200状态中间件。
(1)爬虫反屏蔽组件的实现
在访问网站的网页时,会给网站带来一定的负载,爬虫程序模拟了我们正常访问网页的过程,但是。大型爬虫会给网站增加很大的负载,影响普通用户的访问。为了保证网页可以被大多数正常用户访问,大多数网站都有相应的反爬虫策略。一旦访问行为被认定为爬虫,网站会采取一定的措施限制您的访问,比如提醒您访问过于频繁,请您输入验证码,如果比较严重,您的ip会被封禁,禁止你访问网站。本系统在有针对性的抓取网页数据时,会持续访问网站的内容。
本系统采用以下方法防止爬虫被拦截:
1.模拟不同的浏览器行为
2. 一定频率更换代理服务器和网关
3. 符合君子协议,降低爬虫爬取网页的频率,减少并发爬取的进程,限制每个IP的并发爬取次数,牺牲一定的效率来换取系统的稳定性。
4.禁用cookies,网站会在cookie中插入一些信息来判断用户访问时是否是机器人。我们屏蔽和调整cookie,这也有利于我们的身份不同意暴露。
5. 手动编码,这应该是无懈可击的反禁措施。所有的系统都不比人工操作好,但它们降低了自动化,效率不高,但它们确实是最有效的措施。当爬虫被禁止时,它会被重定向到一个验证码页面。输入验证码重新访问页面。为此,我添加了一个电子邮件提醒模块。当爬虫被封禁时,我会发邮件提醒管理员解封。同时将重定向的请求重新加入到下载队列中进行爬取,保证数据的完整性。
爬虫预防网站屏蔽的原理如下图所示:
(一)模拟不同浏览器行为的实现思路和代码
原理:从scrapy的介绍可以知道scrapy有下载中间件。在这个中间件中,我们可以自定义请求和响应,类似于spring面向方面的编程,就像在程序运行前后嵌入一个钩子。核心是修改请求的属性
首先是扩展下载中间件,首先在seetings.py中添加中间件,
其次,扩展中间件,主要是写一个useragent列表,将常用的浏览器请求头保存为一个列表,如下图:
让请求的头文件从列表中随机选择一个代理值,然后下载到下载器。
综上所述,每次发出请求,都是模拟使用不同的浏览器访问目标网站。
(B) 使用代理ip爬取的实现思路和代码。
首先,将中间件添加到seetings.py。扩展下载组件请求的头文件会从代理ip池中随机取出一个代理值,然后下载到下载器。
1.代理ip池的设计开发流程如下:
一种。获取免费代理ip网站。
湾 存储和验证代理ip
C。验证存储在数据库中
d. 如果达到最大ip数,停止爬取,一定时间后验证数据ip的有效性,删除无效ip
e. 直到数据库ip小于0,继续爬取ip,重复步骤a。
这里的代理ip模块使用的是七夜代理ip池的开源项目
代理ip爬虫运行截图:
(三)爬虫异常状态组件的处理
爬虫运行时没有被阻塞,访问网站并不总是200请求成功,而是有各种状态,比如上面爬虫被ban的时候,返回的状态其实是302,就是为了防止阻塞组件 捕获要实现的 302 状态。同时,异常情况的处理有利于爬虫的鲁棒性。
扩展中间件在设置中捕捉到异常情况后,将请求重新加入等待下载队列的过程如下:
(D) 数据存储模块
数据存储模块主要负责存储从端爬取解析的页面。使用 Mongodb 存储数据。
Scrapy 支持 json、csv 和 xml 等数据存储格式。用户可以在运行爬虫时进行设置,例如:scrapy crawl spider -o items.json -t json,也可以在Scrapy项目文件ItemPipline文件中定义,同时Scrapy也支持数据库存储,如如Monogdb、Redis等。当数据量很大到一定程度时,可以使用Mongodb或Reids集群来解决。本系统的数据存储如下图所示:
(E) 抓斗设计
本文以网络房屋数据为爬取目标,slave端分析抓取现场数据。因此,采集到的内容必须能够客观、准确地反映网络房屋数据的特点。
以58个同城网络房源数据为例,通过分析网页结构,定义字段的详细信息如下表所示。
序号字段名称字段含义
1title 帖子标题
2money 租金
3method租借方式
4area区域
5community所在的社区
6targeturl 帖子详情
7city所在的城市
8Pub_time 发布发布时间
现场选择主要是基于本系统的应用研究,因为系统开发单机配置比较低,没有图片文件下载到本机。减轻单机压力。
(F) 数据处理
1)对象定义程序
Item 是定义捕获数据的容器。它是通过创建一个 scrapy.item.Item 类来声明的。定义属性为scrapy.item.Field对象,通过实例化需要的item来控制获取的站点数据。系统定义了九个抓取对象,分别是:帖子标题、租金、租赁方式、位置、社区、城市、帖子详情页链接、发布时间。这里的字段定义是根据数据处理端的需要来定义的。关键代码如下:
类 TcZufangItem(Item):
#帖子名称
标题=字段()
#租
钱=字段()
#出租方式
方法=字段()
#您所在的地区
区域=字段()
#地点
社区=字段()
#发布详情网址
目标网址=字段()
#发布发布时间
pub_time=字段()
#位置城市
城市=字段()
2)数据处理程序
Pipeline 类定义了数据保存和输出方法。Spider的parse方法返回的Item,在处理完ITEM_PIPELINES列表中Pipeline类对应的数据后,会以top格式输出数据。本系统返回管道的数据存储在Mongodb中。关键代码如下:
def process_item(self, item, spider):
如果 item['pub_time'] == 0:
raise DropItem("发现重复项:%s"% 项)
如果项目['方法'] == 0:
raise DropItem("发现重复项:%s"% 项)
如果项目['社区']==0:
raise DropItem("发现重复项:%s"% 项)
如果 item['money']==0:
raise DropItem("发现重复项:%s"% 项)
如果 item['area'] == 0:
raise DropItem("发现重复项:%s"% 项)
如果项目['城市'] == 0:
raise DropItem("发现重复项:%s"% 项)
zufang_detail = {
'title': item.get('title'),
'钱':item.get('钱'),
'方法':item.get('方法'),
'area': item.get('area',''),
'社区': item.get('社区',''),
'targeturl': item.get('targeturl'),
'pub_time': item.get('pub_time',''),
'city':item.get('city','')
}
result = self.db['zufang_detail'].insert(zufang_detail)
打印'[成功]'+item['targeturl']+'写入MongoDB数据库'
归还物品
(G) 数据可视化设计
数据的可视化,其实就是把数据库的数据转换成我们用户容易观察的形式。本系统使用Mongodb来存储数据。数据可视化基于Django+Semantiui,效果如下图所示:
四、系统操作
系统以58同城租赁平台为爬取目标。运行十个小时后,系统继续抓取网页上总共数万个列表数据。
Master运行截图:
Slave 运行截图:
五、系统部署
环境部署,因为分布式部署需要的环境类似。如果一个服务器部署程序需要配置环境,那就很麻烦了。这里使用docker镜像部署爬虫程序,使用Daocloud上的scrapy-env对。程序已经部署完毕,具体的docker部署过程可以参考网上。
c爬虫抓取网页数据(Python模块的安装方法和使用难度-快-困难-简单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-10 01:01
我们需要让爬虫从每个网页中提取一些数据,然后实现某些事情,这种做法叫做数据抓取。
分析网页
查看网页源代码并使用 Firebug Lite 扩展。Firebug 是由 Joe Hewitt 开发的与 Firefox 集成的强大 Web 开发工具。它可以实时编辑、调试和监控任何页面的 CSS、HTML 和 JavaScript。这里用来查看网页的源代码。
安装 Firebug Lite,下载 Firebug Lite 包,然后在浏览器中安装插件。
网页抓取的三种方法
正则表达式,BeatifulSoup 模板,强大的 lxml 模块
正则表达式
def download(url,user_agent=\'wswp\',proxy=None,num_retries=2):
print \'Downloading:\',url
headers={\'User-agent\':user_agent}
request=urllib2.Request(url,headers=headers)
opener=urllib2.build_opener()
if opener:
proxy_params={urlparse.urlparse(url).scheme:proxy}
opener.add_handler(urllib2.ProxyHandler(proxy_params))
try:
html=urllib2.urlopen(request).read()
except urllib2.URLError as e:
print \'Download:\' ,e.reason
html=None
if num_retries>0:
if hasattr(e,\'code\') and 500
Area
Population
"""
测试三种方法的性能
<p>import re
import urllib2
import urlparse
from bs4 import BeautifulSoup
import lxml.html
import time
#
#
#
#获取网页内容
def download(url,user_agent=\'wswp\',proxy=None,num_retries=2):
print \'Downloading:\',url
headers={\'User-agent\':user_agent}
request=urllib2.Request(url,headers=headers)
opener=urllib2.build_opener()
if opener:
proxy_params={urlparse.urlparse(url).scheme:proxy}
opener.add_handler(urllib2.ProxyHandler(proxy_params))
try:
html=urllib2.urlopen(request).read()
except urllib2.URLError as e:
print \'Download:\' ,e.reason
html=None
if num_retries>0:
if hasattr(e,\'code\') and 500 查看全部
c爬虫抓取网页数据(Python模块的安装方法和使用难度-快-困难-简单)
我们需要让爬虫从每个网页中提取一些数据,然后实现某些事情,这种做法叫做数据抓取。
分析网页
查看网页源代码并使用 Firebug Lite 扩展。Firebug 是由 Joe Hewitt 开发的与 Firefox 集成的强大 Web 开发工具。它可以实时编辑、调试和监控任何页面的 CSS、HTML 和 JavaScript。这里用来查看网页的源代码。
安装 Firebug Lite,下载 Firebug Lite 包,然后在浏览器中安装插件。
网页抓取的三种方法
正则表达式,BeatifulSoup 模板,强大的 lxml 模块
正则表达式
def download(url,user_agent=\'wswp\',proxy=None,num_retries=2):
print \'Downloading:\',url
headers={\'User-agent\':user_agent}
request=urllib2.Request(url,headers=headers)
opener=urllib2.build_opener()
if opener:
proxy_params={urlparse.urlparse(url).scheme:proxy}
opener.add_handler(urllib2.ProxyHandler(proxy_params))
try:
html=urllib2.urlopen(request).read()
except urllib2.URLError as e:
print \'Download:\' ,e.reason
html=None
if num_retries>0:
if hasattr(e,\'code\') and 500
Area
Population
"""
测试三种方法的性能
<p>import re
import urllib2
import urlparse
from bs4 import BeautifulSoup
import lxml.html
import time
#
#
#
#获取网页内容
def download(url,user_agent=\'wswp\',proxy=None,num_retries=2):
print \'Downloading:\',url
headers={\'User-agent\':user_agent}
request=urllib2.Request(url,headers=headers)
opener=urllib2.build_opener()
if opener:
proxy_params={urlparse.urlparse(url).scheme:proxy}
opener.add_handler(urllib2.ProxyHandler(proxy_params))
try:
html=urllib2.urlopen(request).read()
except urllib2.URLError as e:
print \'Download:\' ,e.reason
html=None
if num_retries>0:
if hasattr(e,\'code\') and 500
c爬虫抓取网页数据(网络爬虫的爬行策略和存储方法介绍-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-08 20:02
网络爬虫是指按照一定的规则自动爬取网络上的程序(模拟手动登录网页的方式)。简单的说,就是你在网上看到的页面内容被获取并存储。网络爬虫的爬取策略分为深度优先和广度优先。下图展示了从A到B到D到E到C到F的深度优先遍历方法(ABDECF)和广度优先遍历方法ABCDEF。
网络爬虫实现原理
1、获取初始网址。初始URL地址可以由用户手动指定,也可以由用户指定的一个或多个初始抓取网页确定。
2、 根据初始 URL 抓取页面,获取新 URL。获取初始URL地址后,首先需要抓取对应URL地址中的网页。在对应的URL地址中抓取网页后,将网页存储在原创数据库中,在抓取网页的同时发现新的URL爬行过程。
3、将新的 URL 放入 URL 队列。第二步,获取下一个新的URL地址后,将新的URL地址放入URL队列中。
4、 从 URL 队列中读取新的 URL,并根据新的 URL 抓取网页。同时,从新的网页中获取新的URL,重复上面提到的爬取过程。
5、满足爬虫系统设置的停止条件时停止爬行。在写爬虫的时候,一般都会设置相应的停止条件。如果不设置停止条件,爬虫会一直爬到无法获取新的URL地址。如果设置了停止条件,则爬虫会在满足停止条件时停止爬行。 查看全部
c爬虫抓取网页数据(网络爬虫的爬行策略和存储方法介绍-上海怡健医学)
网络爬虫是指按照一定的规则自动爬取网络上的程序(模拟手动登录网页的方式)。简单的说,就是你在网上看到的页面内容被获取并存储。网络爬虫的爬取策略分为深度优先和广度优先。下图展示了从A到B到D到E到C到F的深度优先遍历方法(ABDECF)和广度优先遍历方法ABCDEF。
网络爬虫实现原理
1、获取初始网址。初始URL地址可以由用户手动指定,也可以由用户指定的一个或多个初始抓取网页确定。
2、 根据初始 URL 抓取页面,获取新 URL。获取初始URL地址后,首先需要抓取对应URL地址中的网页。在对应的URL地址中抓取网页后,将网页存储在原创数据库中,在抓取网页的同时发现新的URL爬行过程。
3、将新的 URL 放入 URL 队列。第二步,获取下一个新的URL地址后,将新的URL地址放入URL队列中。
4、 从 URL 队列中读取新的 URL,并根据新的 URL 抓取网页。同时,从新的网页中获取新的URL,重复上面提到的爬取过程。
5、满足爬虫系统设置的停止条件时停止爬行。在写爬虫的时候,一般都会设置相应的停止条件。如果不设置停止条件,爬虫会一直爬到无法获取新的URL地址。如果设置了停止条件,则爬虫会在满足停止条件时停止爬行。
c爬虫抓取网页数据(网站遇到瓶颈怎么办?如何打开另一扇之门?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-07 06:08
当我在爬取网站时遇到瓶颈,想上前解决的时候,我经常先看网站的robots.txt文件,有时会再打开一个供你捕捉。门。
写爬虫有很多苦恼的地方,比如:
1. 访问频率太高,受限;
2.如何大量找到这个网站的网址;
3.如何抓取网站新生成的URL等;
这些问题困扰着爬虫。如果有大量离散的IP和账号,这些都不是问题,但大多数公司不具备这个条件。
我们工作中编写的爬虫大多是一次性的、临时的任务,需要你快速完成工作。遇到上述情况时,尝试查看robots.txt文件。
举个栗子:
老板给你分配任务,捕捉豆瓣每天生成的影评、书评、群帖、同城帖、个人日志。
想想这个任务有多大。豆瓣拥有1.6亿注册用户。对于抓取个人日志的任务,您必须每天至少访问一次每个人的主页。
这将不得不每天访问1. 6 亿次,并且不计算群组/同城帖子。
设计一个普通的爬虫不能依靠几十个IP来完成任务。
先看robots.txt
当boss给你以上任务的时候,靠你的两把枪,你是怎么完成的,不要跟boss讲技术,他不懂,他只想要结果。
我们来看看豆瓣的robots.txt
看图片上面的红框,里面有两个sitemap文件
打开 sitemap_updated_index 文件并查看:
里面有一个一个的压缩文件,里面有豆瓣头一天新生成的影评、书评、帖子等。有兴趣的可以打开压缩文件看看。
换句话说,你只需要每天访问robots.txt中的站点地图文件,就可以知道哪些URL是新生成的。
无需遍历豆瓣网站上的数亿个链接,大大节省了您的爬虫时间和爬虫设计的复杂度,同时也降低了豆瓣网站的带宽消耗。这是双赢的,哈哈。
robots.txt 的站点地图文件找到了获取新 URL 网站 的方法。沿着这个思路也可以解决查找大量网站 URL的问题。
再给一个栗子:
老板给你另一个任务。老板说你上次抓豆瓣,你说每天需要大量的IP才能得到豆瓣新发的帖子。这一次,我给你1000个IP,捕捉天眼查过的千万家企业的商业信息。.
看了这么多IP,流口水了,但是分析网站后发现,这种网站的爬取入口很少(爬取入口指的是频道页面,即聚合很多链接的那种页面。)。
获取保留的 URL 很容易,而且查看这么多 IP 也不是很忙。
如果性能发现这个网站几万甚至几十万个URL,放到等待队列中,可以让这么多IP作业满载而归,不偷懒。
我们来看看他的 robots.txt 文件:
打开红框处的站点地图,有30,000个公司网址。上图是1月3日生成的,URL是根据年月日生成的。你可以把网址改成1月2号,又可以看到2号站点地图有几万个公司网址,所以你可以找到几十万个种子网址供你爬取。
PS:上面的sitemap其实可以解决天眼查新更新新生成的URL爬取的问题。
一个小技巧不仅降低了爬虫设计的复杂度,还降低了对方的带宽消耗。
这在工作中非常适用。在工作中,你不在乎你使用的框架有多好,只在乎你做事有多快,有多好。
如果你善于查看 robots.txt 文件,你会发现一些独特的东西。 查看全部
c爬虫抓取网页数据(网站遇到瓶颈怎么办?如何打开另一扇之门?)
当我在爬取网站时遇到瓶颈,想上前解决的时候,我经常先看网站的robots.txt文件,有时会再打开一个供你捕捉。门。
写爬虫有很多苦恼的地方,比如:
1. 访问频率太高,受限;
2.如何大量找到这个网站的网址;
3.如何抓取网站新生成的URL等;
这些问题困扰着爬虫。如果有大量离散的IP和账号,这些都不是问题,但大多数公司不具备这个条件。
我们工作中编写的爬虫大多是一次性的、临时的任务,需要你快速完成工作。遇到上述情况时,尝试查看robots.txt文件。
举个栗子:
老板给你分配任务,捕捉豆瓣每天生成的影评、书评、群帖、同城帖、个人日志。
想想这个任务有多大。豆瓣拥有1.6亿注册用户。对于抓取个人日志的任务,您必须每天至少访问一次每个人的主页。
这将不得不每天访问1. 6 亿次,并且不计算群组/同城帖子。
设计一个普通的爬虫不能依靠几十个IP来完成任务。
先看robots.txt
当boss给你以上任务的时候,靠你的两把枪,你是怎么完成的,不要跟boss讲技术,他不懂,他只想要结果。
我们来看看豆瓣的robots.txt
看图片上面的红框,里面有两个sitemap文件
打开 sitemap_updated_index 文件并查看:
里面有一个一个的压缩文件,里面有豆瓣头一天新生成的影评、书评、帖子等。有兴趣的可以打开压缩文件看看。
换句话说,你只需要每天访问robots.txt中的站点地图文件,就可以知道哪些URL是新生成的。
无需遍历豆瓣网站上的数亿个链接,大大节省了您的爬虫时间和爬虫设计的复杂度,同时也降低了豆瓣网站的带宽消耗。这是双赢的,哈哈。
robots.txt 的站点地图文件找到了获取新 URL 网站 的方法。沿着这个思路也可以解决查找大量网站 URL的问题。
再给一个栗子:
老板给你另一个任务。老板说你上次抓豆瓣,你说每天需要大量的IP才能得到豆瓣新发的帖子。这一次,我给你1000个IP,捕捉天眼查过的千万家企业的商业信息。.
看了这么多IP,流口水了,但是分析网站后发现,这种网站的爬取入口很少(爬取入口指的是频道页面,即聚合很多链接的那种页面。)。
获取保留的 URL 很容易,而且查看这么多 IP 也不是很忙。
如果性能发现这个网站几万甚至几十万个URL,放到等待队列中,可以让这么多IP作业满载而归,不偷懒。
我们来看看他的 robots.txt 文件:
打开红框处的站点地图,有30,000个公司网址。上图是1月3日生成的,URL是根据年月日生成的。你可以把网址改成1月2号,又可以看到2号站点地图有几万个公司网址,所以你可以找到几十万个种子网址供你爬取。
PS:上面的sitemap其实可以解决天眼查新更新新生成的URL爬取的问题。
一个小技巧不仅降低了爬虫设计的复杂度,还降低了对方的带宽消耗。
这在工作中非常适用。在工作中,你不在乎你使用的框架有多好,只在乎你做事有多快,有多好。
如果你善于查看 robots.txt 文件,你会发现一些独特的东西。
c爬虫抓取网页数据(Chrome浏览器插件WebScraper可轻松实现网页数据的爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-11-07 01:07
Chrome浏览器插件Web Scraper可以轻松抓取网页数据,无需考虑爬虫中的登录、验证码、异步加载等复杂问题。
先粘贴爬虫58数据的sitemap如下:
{"_id":"hefeitongcheng","startUrl":[";ClickID=1"],"selectors":[{"id":"click","type":"SelectorElementClick","parentSelectors" :["_root"],"selector":".list-main-style li","multiple":true,"delay":"5000","clickElementSelector":"strong span","clickType":"clickMore ","discardInitialElements":"do-not-discard","clickElementUniquenessType":"uniqueText"},{"id":"link","type":"SelectorLink","parentSelectors":["click"], "selector":".title a","multiple":false,"delay":0},{"id":"name","type":"SelectorText","parentSelectors":["link"], "selector":"h1","multiple":false,"regex":"","delay":0},{"id":"jiage","type":"SelectorText","parentSelectors":[ "link"],"selector":".house_basic_title_money span","multiple":false,"regex":"","delay":0},{"id":"add","type":"SelectorText ","parentSelectors":["link"],"selector":"p.p_2","multiple":false,"regex":"","delay":0}]}
Web Scraper 爬取过程及要点:
安装Web Scraper插件后,抓取操作分三步完成
1、新建站点地图(创建爬虫项目)
2、选择抓取的网页内容,点击~点击~点击,操作
3、启用抓取和下载 CSV 数据
最关键的一步是第二步,主要有两点:
首先选择数据块Element,我们在页面上取的每一块数据,都是重复的,在数据块中选择Multiple,然后取需要的数据字段(上面Excel中的列)
爬取大量数据的重点是掌握分页的控制。
分页分为3种情况:
1. URL 参数分页(比较组织) ?page=2 或 ?page=[1-27388]
2.滚动加载,点击“加载更多”加载页面数据元素向下滚动
3.点击页码标签(包括“下一页”标签)链接或元素点击
其他例子A:jd爬升hw p30价格信息
{"_id":"huaweip30","startUrl":[";enc=utf-8&wq=%E5%8D%8E%E4%B8%BAp30%20512&pvid=ed449bf16e44461fac90ff6fae2e66cds"][ "id":"element","type":"SelectorElementClick","parentSelectors":["_root"],"selector":"div.gl-i-wrap","multiple":true,"delay": "1500","clickElementSelector":".p-num a:nth-of-type(3)","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType ":"uniqueText"},{"id":"name","type":"SelectorText","parentSelectors":["element"],"selector":"a em","multiple":false," regex":"","delay":0},{"id":"jiage","type":"SelectorText","parentSelectors":["element"],"selector":"div.p-price ","multiple":false,"regex":"","delay":0}]}
其他例子B:爬上百度关键词信息
{ "_ id": "wailaizhu", "startUrl": [ "; pn = 0 & oq = wailaizhu% 20h0101 & tn = baiduhome_pg & ie = utf-8 & rsv_idx = 2 & rsv_pq = f62d1151tv_f0 5b15EoMWRlm3% 2BeroyWXBKI% 2FDZ3H0BlGKJ6lNa6mmYBo4nNDUeJNeeN8BvgiE9S9Orivd"], "selectors": [ {"id":"element","type":"SelectorElementClick","parent_selector"],"div_selector":","[" "multiple":true,"delay":"1500","clickElementSelector":"a span.pc","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType":" uniqueText"},{"id":"name", "type":"SelectorText","parentSelectors":["element"],"selector":"a","multiple":false,"regex":" ","delay":0},{"id":"body","type":"SelectorText","parentSelectors":["element"],"selector":"_parent_","multiple":false, "regex":"","delay":0} ]} 查看全部
c爬虫抓取网页数据(Chrome浏览器插件WebScraper可轻松实现网页数据的爬取)
Chrome浏览器插件Web Scraper可以轻松抓取网页数据,无需考虑爬虫中的登录、验证码、异步加载等复杂问题。
先粘贴爬虫58数据的sitemap如下:
{"_id":"hefeitongcheng","startUrl":[";ClickID=1"],"selectors":[{"id":"click","type":"SelectorElementClick","parentSelectors" :["_root"],"selector":".list-main-style li","multiple":true,"delay":"5000","clickElementSelector":"strong span","clickType":"clickMore ","discardInitialElements":"do-not-discard","clickElementUniquenessType":"uniqueText"},{"id":"link","type":"SelectorLink","parentSelectors":["click"], "selector":".title a","multiple":false,"delay":0},{"id":"name","type":"SelectorText","parentSelectors":["link"], "selector":"h1","multiple":false,"regex":"","delay":0},{"id":"jiage","type":"SelectorText","parentSelectors":[ "link"],"selector":".house_basic_title_money span","multiple":false,"regex":"","delay":0},{"id":"add","type":"SelectorText ","parentSelectors":["link"],"selector":"p.p_2","multiple":false,"regex":"","delay":0}]}
Web Scraper 爬取过程及要点:
安装Web Scraper插件后,抓取操作分三步完成
1、新建站点地图(创建爬虫项目)
2、选择抓取的网页内容,点击~点击~点击,操作
3、启用抓取和下载 CSV 数据
最关键的一步是第二步,主要有两点:
首先选择数据块Element,我们在页面上取的每一块数据,都是重复的,在数据块中选择Multiple,然后取需要的数据字段(上面Excel中的列)
爬取大量数据的重点是掌握分页的控制。
分页分为3种情况:
1. URL 参数分页(比较组织) ?page=2 或 ?page=[1-27388]
2.滚动加载,点击“加载更多”加载页面数据元素向下滚动
3.点击页码标签(包括“下一页”标签)链接或元素点击
其他例子A:jd爬升hw p30价格信息
{"_id":"huaweip30","startUrl":[";enc=utf-8&wq=%E5%8D%8E%E4%B8%BAp30%20512&pvid=ed449bf16e44461fac90ff6fae2e66cds"][ "id":"element","type":"SelectorElementClick","parentSelectors":["_root"],"selector":"div.gl-i-wrap","multiple":true,"delay": "1500","clickElementSelector":".p-num a:nth-of-type(3)","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType ":"uniqueText"},{"id":"name","type":"SelectorText","parentSelectors":["element"],"selector":"a em","multiple":false," regex":"","delay":0},{"id":"jiage","type":"SelectorText","parentSelectors":["element"],"selector":"div.p-price ","multiple":false,"regex":"","delay":0}]}
其他例子B:爬上百度关键词信息
{ "_ id": "wailaizhu", "startUrl": [ "; pn = 0 & oq = wailaizhu% 20h0101 & tn = baiduhome_pg & ie = utf-8 & rsv_idx = 2 & rsv_pq = f62d1151tv_f0 5b15EoMWRlm3% 2BeroyWXBKI% 2FDZ3H0BlGKJ6lNa6mmYBo4nNDUeJNeeN8BvgiE9S9Orivd"], "selectors": [ {"id":"element","type":"SelectorElementClick","parent_selector"],"div_selector":","[" "multiple":true,"delay":"1500","clickElementSelector":"a span.pc","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType":" uniqueText"},{"id":"name", "type":"SelectorText","parentSelectors":["element"],"selector":"a","multiple":false,"regex":" ","delay":0},{"id":"body","type":"SelectorText","parentSelectors":["element"],"selector":"_parent_","multiple":false, "regex":"","delay":0} ]}
c爬虫抓取网页数据( 从HttpFox的POSTData项看到(图)Data(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-05 19:11
从HttpFox的POSTData项看到(图)Data(组图)
)
#表示删不去这一行,这个代码框框啊 啊啊啊啊啊
一、 作为python爬虫,一般需要对网页进行简单的分析,然后才能爬取数据。这里推荐火狐的HttpFox,简单实用。
如下图,巨潮信息网通过查询展示想要的数据,然后抓取。
二、 爬取查询数据,查询类型,表示需要贴过去的相关数据才能得到想要的数据。
通过HttpFox分析获取相关数据,帖子的过往数据相当复杂。从HttpFox的POST Data项可以看到如下一系列信息:
stock=&searchkey=&plate=sz%3Bszmb%3Bszzx%3Bszcy%3Bshmb%3B&category=category_sjdbg_szsh%3Bcategory_ndbg_szsh
%3Bcategory_bndbg_szsh%3Bcategory_yjdbg_szsh%3B&trade=&column=szse&columnTitle=%E5%8E%86%E5%8F%B2%E5%85
%AC%E5%91%8A%E6%9F%A5%E8%AF%A2&pageNum=1&pageSize=30&tabName=fulltext&sortName=&sortType=&limit=&showTitle
category_sjdbg_szsh%2Fcategory%2F%E4%B8%89%E5%AD%A3%E5%BA%A6%E6%8A%A5%E5%91%8A%3Bcategory_ndbg_szsh
%2Fcategory%2F%E5%B9%B4%E5%BA%A6%E6%8A%A5%E5%91%8A%3Bcategory_bndbg_szsh%2Fcategory%2F%E5%8D%8A%
E5%B9%B4%E5%BA%A6%E6%8A%A5%E5%91%8A%3Bcategory_yjdbg_szsh%2Fcategory%2F%E4%B8%80%E5%AD%A3%E5
%BA%A6%E6%8A%A5%E5%91%8A%3Bsz%2Fplate%2F%E6%B7%B1%E5%B8%82%E5%85%AC%E5%8F%B8% 3Bszmb%2Fplate
%2F%E6%B7%B1%E5%B8%82%E4%B8%BB%E6%9D%BF%3Bszzx%2Fplate%2F%E4%B8%AD%E5%B0%8F%E6% 9D%BF%3Bszcy
%2Fplate%2F%E5%88%9B%E4%B8%9A%E6%9D%BF%3Bshmb%2Fplate%2F%E6%B2%AA%E5%B8%82%E4%B8%BB% E6%9D%B
F&seDate=2016-10-13
我想专注于捕获第一季度、半年、第三季度和年度报告。查看类别选择:
category=category_sjdbg_szsh%3Bcategory_ndbg_szsh%3Bcategory_bndbg_szsh
%3Bcategory_yjdbg_szsh%3B
面对如此复杂的帖子数据,我不知道如何构建自己的帖子数据项。特别是当某个后变量采用多个值时。注意:%3B 是表示分号“;”的 URL 编码值。解决了一个变量多个值的问题。
#-*- coding: utf8 -*-
import urllib2
import urllib
import re
import time,datetime
import os
import shutil
def getstock(page,strdate):
values = {
'stock':'',
'searchkey':'',
'plate':'sz;szmb;szzx;szcy;shmb',
#%category_bndbg_szsh半年报告;category_sjdbg_szsh三季度;category_ndbg_szsh年度;category_yjdbg_szsh一季度
'category':'category_bndbg_szsh;category_sjdbg_szsh;category_ndbg_szsh;category_yjdbg_szsh',
'trade':'',
'column':'szse',
'columnTitle':'%E5%8E%86%E5%8F%B2%E5%85%AC%E5%91%8A%E6%9F%A5%E8%AF%A2',
'pageNum':page,
'pageSize':'50',
'tabName':'fulltext',
'sortName':'',
'sortType':'',
'limit':'',
'seDate':strdate}
data = urllib.urlencode(values)
url = "http://www.cninfo.com.cn/cninf ... ot%3B
request = urllib2.Request(url,data)
datime = datetime.datetime.now()
response = urllib2.urlopen(request,timeout=4)
re_data = response.read()
re_data = re_data.decode('utf8')
dict_data = eval(re_data.replace('null','None').replace('true','True').replace('false','False'))
print dict_data #转成dict数据,输出看看
return dict_data
try:
date2 = time.strftime('%Y-%m-%d', time.localtime())
page = 1
ret = getstock(str(page),str(date2))
except Exception as error:
print error
good luck! 查看全部
c爬虫抓取网页数据(
从HttpFox的POSTData项看到(图)Data(组图)
)
#表示删不去这一行,这个代码框框啊 啊啊啊啊啊
一、 作为python爬虫,一般需要对网页进行简单的分析,然后才能爬取数据。这里推荐火狐的HttpFox,简单实用。
如下图,巨潮信息网通过查询展示想要的数据,然后抓取。
二、 爬取查询数据,查询类型,表示需要贴过去的相关数据才能得到想要的数据。
通过HttpFox分析获取相关数据,帖子的过往数据相当复杂。从HttpFox的POST Data项可以看到如下一系列信息:
stock=&searchkey=&plate=sz%3Bszmb%3Bszzx%3Bszcy%3Bshmb%3B&category=category_sjdbg_szsh%3Bcategory_ndbg_szsh
%3Bcategory_bndbg_szsh%3Bcategory_yjdbg_szsh%3B&trade=&column=szse&columnTitle=%E5%8E%86%E5%8F%B2%E5%85
%AC%E5%91%8A%E6%9F%A5%E8%AF%A2&pageNum=1&pageSize=30&tabName=fulltext&sortName=&sortType=&limit=&showTitle
category_sjdbg_szsh%2Fcategory%2F%E4%B8%89%E5%AD%A3%E5%BA%A6%E6%8A%A5%E5%91%8A%3Bcategory_ndbg_szsh
%2Fcategory%2F%E5%B9%B4%E5%BA%A6%E6%8A%A5%E5%91%8A%3Bcategory_bndbg_szsh%2Fcategory%2F%E5%8D%8A%
E5%B9%B4%E5%BA%A6%E6%8A%A5%E5%91%8A%3Bcategory_yjdbg_szsh%2Fcategory%2F%E4%B8%80%E5%AD%A3%E5
%BA%A6%E6%8A%A5%E5%91%8A%3Bsz%2Fplate%2F%E6%B7%B1%E5%B8%82%E5%85%AC%E5%8F%B8% 3Bszmb%2Fplate
%2F%E6%B7%B1%E5%B8%82%E4%B8%BB%E6%9D%BF%3Bszzx%2Fplate%2F%E4%B8%AD%E5%B0%8F%E6% 9D%BF%3Bszcy
%2Fplate%2F%E5%88%9B%E4%B8%9A%E6%9D%BF%3Bshmb%2Fplate%2F%E6%B2%AA%E5%B8%82%E4%B8%BB% E6%9D%B
F&seDate=2016-10-13
我想专注于捕获第一季度、半年、第三季度和年度报告。查看类别选择:
category=category_sjdbg_szsh%3Bcategory_ndbg_szsh%3Bcategory_bndbg_szsh
%3Bcategory_yjdbg_szsh%3B
面对如此复杂的帖子数据,我不知道如何构建自己的帖子数据项。特别是当某个后变量采用多个值时。注意:%3B 是表示分号“;”的 URL 编码值。解决了一个变量多个值的问题。
#-*- coding: utf8 -*-
import urllib2
import urllib
import re
import time,datetime
import os
import shutil
def getstock(page,strdate):
values = {
'stock':'',
'searchkey':'',
'plate':'sz;szmb;szzx;szcy;shmb',
#%category_bndbg_szsh半年报告;category_sjdbg_szsh三季度;category_ndbg_szsh年度;category_yjdbg_szsh一季度
'category':'category_bndbg_szsh;category_sjdbg_szsh;category_ndbg_szsh;category_yjdbg_szsh',
'trade':'',
'column':'szse',
'columnTitle':'%E5%8E%86%E5%8F%B2%E5%85%AC%E5%91%8A%E6%9F%A5%E8%AF%A2',
'pageNum':page,
'pageSize':'50',
'tabName':'fulltext',
'sortName':'',
'sortType':'',
'limit':'',
'seDate':strdate}
data = urllib.urlencode(values)
url = "http://www.cninfo.com.cn/cninf ... ot%3B
request = urllib2.Request(url,data)
datime = datetime.datetime.now()
response = urllib2.urlopen(request,timeout=4)
re_data = response.read()
re_data = re_data.decode('utf8')
dict_data = eval(re_data.replace('null','None').replace('true','True').replace('false','False'))
print dict_data #转成dict数据,输出看看
return dict_data
try:
date2 = time.strftime('%Y-%m-%d', time.localtime())
page = 1
ret = getstock(str(page),str(date2))
except Exception as error:
print error
good luck!
c爬虫抓取网页数据(动态网页数据抓取什么是AJAX:异步JavaScript和XML的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-05 19:04
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。
道路
优势
缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium: Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。pip install selenium install chromedriver:下载完成后,放到一个不需要权限的纯英文目录下。安装 Selenium 和 chromedriver:快速入门:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r‘D:\ProgramApp\chromedriver\chromedriver.exe‘
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
find_element_by_id:根据id来查找某个元素。等价于:
submitTag = driver.find_element_by_id(‘su‘)
submitTag1 = driver.find_element(By.ID,‘su‘)
find_element_by_class_name:根据类名查找元素。 等价于:
submitTag = driver.find_element_by_class_name(‘su‘)
submitTag1 = driver.find_element(By.CLASS_NAME,‘su‘)
find_element_by_name:根据name属性的值来查找元素。等价于:
submitTag = driver.find_element_by_name(‘email‘)
submitTag1 = driver.find_element(By.NAME,‘email‘)
find_element_by_tag_name:根据标签名来查找元素。等价于:
submitTag = driver.find_element_by_tag_name(‘div‘)
submitTag1 = driver.find_element(By.TAG_NAME,‘div‘)
find_element_by_xpath:根据xpath语法来获取元素。等价于:
submitTag = driver.find_element_by_xpath(‘//div‘)
submitTag1 = driver.find_element(By.XPATH,‘//div‘)
find_element_by_css_selector:根据css选择器选择元素。等价于:
submitTag = driver.find_element_by_css_selector(‘//div‘)
submitTag1 = driver.find_element(By.CSS_SELECTOR,‘//div‘)
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
记住Tag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
fromselenium.webdriver.support.ui importSelect
# 选中这个标签,然后使用Select创建一个对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
#根据索引选择
selectTag.select_by_index(1)
# 按值选择
selectTag.select_by_value("")
# 根据可见文本选择
selectTag.select_by_visible_text("95 显示客户端")
# 取消所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id(‘kw‘)
submitTag = driver.find_element_by_id(‘su‘)
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,‘python‘)
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有的cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有的cookie:
driver.delete_all_cookies()
删除某个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
2/显示等待:显示等待是表示在执行获取元素的操作之前,一定的条件成立。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
更多条件参考:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。
Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open(‘https://www.baidu.com‘)")
#显示当前页面的url
driver.current_url //还是百度页面
# 切换到这个新的页面中
driver.switch_to_window(driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions() //设置存储浏览器的信息
//添加代理服务器
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get(‘http://httpbin.org/ip‘)
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。
screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
.
爬虫---selenium 动态网页数据抓取
原来的: 查看全部
c爬虫抓取网页数据(动态网页数据抓取什么是AJAX:异步JavaScript和XML的区别)
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。
道路
优势
缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium: Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。pip install selenium install chromedriver:下载完成后,放到一个不需要权限的纯英文目录下。安装 Selenium 和 chromedriver:快速入门:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r‘D:\ProgramApp\chromedriver\chromedriver.exe‘
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
find_element_by_id:根据id来查找某个元素。等价于:
submitTag = driver.find_element_by_id(‘su‘)
submitTag1 = driver.find_element(By.ID,‘su‘)
find_element_by_class_name:根据类名查找元素。 等价于:
submitTag = driver.find_element_by_class_name(‘su‘)
submitTag1 = driver.find_element(By.CLASS_NAME,‘su‘)
find_element_by_name:根据name属性的值来查找元素。等价于:
submitTag = driver.find_element_by_name(‘email‘)
submitTag1 = driver.find_element(By.NAME,‘email‘)
find_element_by_tag_name:根据标签名来查找元素。等价于:
submitTag = driver.find_element_by_tag_name(‘div‘)
submitTag1 = driver.find_element(By.TAG_NAME,‘div‘)
find_element_by_xpath:根据xpath语法来获取元素。等价于:
submitTag = driver.find_element_by_xpath(‘//div‘)
submitTag1 = driver.find_element(By.XPATH,‘//div‘)
find_element_by_css_selector:根据css选择器选择元素。等价于:
submitTag = driver.find_element_by_css_selector(‘//div‘)
submitTag1 = driver.find_element(By.CSS_SELECTOR,‘//div‘)
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
记住Tag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
fromselenium.webdriver.support.ui importSelect
# 选中这个标签,然后使用Select创建一个对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
#根据索引选择
selectTag.select_by_index(1)
# 按值选择
selectTag.select_by_value("")
# 根据可见文本选择
selectTag.select_by_visible_text("95 显示客户端")
# 取消所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id(‘kw‘)
submitTag = driver.find_element_by_id(‘su‘)
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,‘python‘)
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有的cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有的cookie:
driver.delete_all_cookies()
删除某个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
2/显示等待:显示等待是表示在执行获取元素的操作之前,一定的条件成立。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
更多条件参考:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。
Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open(‘https://www.baidu.com‘)")
#显示当前页面的url
driver.current_url //还是百度页面
# 切换到这个新的页面中
driver.switch_to_window(driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions() //设置存储浏览器的信息
//添加代理服务器
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get(‘http://httpbin.org/ip‘)
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。
screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
.
爬虫---selenium 动态网页数据抓取
原来的:
c爬虫抓取网页数据(Android我的博客APP】1.抓取博客首页文章列表内容——网页数据抓取(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-02 15:15
阿里云>云栖社区>主题地图>C>c 抓取网页列表数据库
推荐活动:
更多优惠>
当前主题:c 抓取网页列表数据库并添加到采集夹
相关话题:
c 爬取网页列表数据库相关博客 查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
使用正则表达式抓取博客园列表数据
作者:建筑师郭果860人浏览评论:08年前
鉴于我要完成的MVC 3会使用测试数据来模仿博客园企业系统,自己输入太累了,所以抓了一部分博客园的列表数据,请不要被dudu冒犯。爬取博客园的数据时用到了正则表达式,所以不熟悉正则表达式的朋友可以参考相关资料。其实很容易掌握,就是
阅读全文
【安卓我的博客APP】1.抓取博客首页文章列表内容-网页数据抓取
作者:呵呵 9925975人浏览评论:03年前
打算在博客园做自己的博客APP。首先必须能够访问首页获取数据获取首页文章列表,第一步是抓取博客首页文章列表内容功能,在小米2S中已经实现了以上效果图如下: 思路是通过编写的工具类访问网页,获取页面的源代码,通过正则表达式获取匹配的数据进行处理显示到ListView
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:Jack Chen1527人浏览评论:06年前
原文:PHP 使用 QueryList 抓取网页内容,然后使用 Java Jsoup 抓取网页数据。前几天听说用PHP抓起来比较方便。今天研究了一下,主要是用QueryList来实现。QueryList 是一个基于 phpQuery 的通用列表 采集 类,简单、灵活、功能强大
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
之前,我们使用 Java Jsoup 来捕获网页数据。前几天听说用PHP抓包比较方便。今天简单研究了一下,主要是使用QueryList。
阅读全文
初学者指南 | 使用 Python 抓取网页
作者:小轩峰柴金2425人浏览评论:04年前
简介 从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种在线数据科学课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。
阅读全文
Python抓取欧洲足球联赛数据进行大数据分析
作者:青山无名 12610人浏览评论:14年前
背景网页抓取在大数据时代,一切都必须用数据说话。大数据处理过程一般需要以下几个步骤:数据采集和数据的采集、提取、变形、数据加载分析。, 探索和预测数据的显示。首先要做的是获取数据,提取出有效数据,用于下一步的分析。
阅读全文
使用 Scrapy 抓取数据
作者:雨客6542人浏览评论:05年前
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
《用Python编写网络爬虫》——2.2 三种网络爬虫方法
作者:异步社区 3748人查看评论:04年前
本节摘自异步社区《Writing Web Crawlers in Python》一书第2章2.2,作者[澳大利亚]理查德劳森(Richard Lawson),李斌译,更多章节内容可在云栖社区“异步社区”公众号查看。2.2 三种网页爬取方法 现在我们已经了解了网页的结构,接下来
阅读全文 查看全部
c爬虫抓取网页数据(Android我的博客APP】1.抓取博客首页文章列表内容——网页数据抓取(组图))
阿里云>云栖社区>主题地图>C>c 抓取网页列表数据库
推荐活动:
更多优惠>
当前主题:c 抓取网页列表数据库并添加到采集夹
相关话题:
c 爬取网页列表数据库相关博客 查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
使用正则表达式抓取博客园列表数据
作者:建筑师郭果860人浏览评论:08年前
鉴于我要完成的MVC 3会使用测试数据来模仿博客园企业系统,自己输入太累了,所以抓了一部分博客园的列表数据,请不要被dudu冒犯。爬取博客园的数据时用到了正则表达式,所以不熟悉正则表达式的朋友可以参考相关资料。其实很容易掌握,就是
阅读全文
【安卓我的博客APP】1.抓取博客首页文章列表内容-网页数据抓取
作者:呵呵 9925975人浏览评论:03年前
打算在博客园做自己的博客APP。首先必须能够访问首页获取数据获取首页文章列表,第一步是抓取博客首页文章列表内容功能,在小米2S中已经实现了以上效果图如下: 思路是通过编写的工具类访问网页,获取页面的源代码,通过正则表达式获取匹配的数据进行处理显示到ListView
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:Jack Chen1527人浏览评论:06年前
原文:PHP 使用 QueryList 抓取网页内容,然后使用 Java Jsoup 抓取网页数据。前几天听说用PHP抓起来比较方便。今天研究了一下,主要是用QueryList来实现。QueryList 是一个基于 phpQuery 的通用列表 采集 类,简单、灵活、功能强大
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
之前,我们使用 Java Jsoup 来捕获网页数据。前几天听说用PHP抓包比较方便。今天简单研究了一下,主要是使用QueryList。
阅读全文
初学者指南 | 使用 Python 抓取网页
作者:小轩峰柴金2425人浏览评论:04年前
简介 从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种在线数据科学课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。
阅读全文
Python抓取欧洲足球联赛数据进行大数据分析
作者:青山无名 12610人浏览评论:14年前
背景网页抓取在大数据时代,一切都必须用数据说话。大数据处理过程一般需要以下几个步骤:数据采集和数据的采集、提取、变形、数据加载分析。, 探索和预测数据的显示。首先要做的是获取数据,提取出有效数据,用于下一步的分析。
阅读全文
使用 Scrapy 抓取数据
作者:雨客6542人浏览评论:05年前
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
《用Python编写网络爬虫》——2.2 三种网络爬虫方法
作者:异步社区 3748人查看评论:04年前
本节摘自异步社区《Writing Web Crawlers in Python》一书第2章2.2,作者[澳大利亚]理查德劳森(Richard Lawson),李斌译,更多章节内容可在云栖社区“异步社区”公众号查看。2.2 三种网页爬取方法 现在我们已经了解了网页的结构,接下来
阅读全文
c爬虫抓取网页数据(安装python运行pipinstallBeautifulSoup抓取网页完成必要工具安装后)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-11-01 18:03
本期文章将与大家分享如何使用Python爬虫爬取数据的内容。小编觉得很实用,所以分享出来供大家参考,跟着小编一起来看看吧。
工具安装
首先,您需要安装 Python requests 和 BeautifulSoup 库。我们使用 Requests 库抓取网页内容,使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。举个例子,我们先来看看如何抓取网页的内容。
提取内容
抓取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个例子中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用BeautifulSoup,我们可以非常简单的提取网页的具体内容。
持续的网络爬行
至此,我们已经能够抓取单个网页的内容,现在让我们看看如何抓取网站的整个内容。我们知道网页是通过超链接相互连接的,我们可以通过链接访问整个网络。所以我们可以从每个页面中提取到其他网页的链接,然后重复抓取新的链接。
准备
IDE:pyCharm
库:请求,lxm
即将介绍,这两个库主要为我们服务
requests:获取网页源代码
lxml:获取网页源代码中的指定数据
简洁明了,有没有^_^
设置环境
这里的搭建环境不是搭建python开发环境。这里的构建环境是指我们使用pycharm新建一个python项目,然后用requests和lxml新建一个项目。里面什么都没有。创建一个新的 src 文件夹。然后直接在里面新建一个Test.py。
依赖库导入
在 Test.py 中输入:
进口请求
此时,请求将报告一条红线。这时候我们将光标指向requests,按快捷键:alt+enter,pycharm会给出解决方案。这时候选择安装包请求,pycharm会自动为我们安装。,我们只需要稍等片刻,库就安装好了。lxml的安装方法是一样的。
安装这两个库后,编译器不会报红线。
获取网页源代码
请求可以很容易地让我们得到网页的源代码。
获取源代码:
# 获取源代码
html = requests.get("")
# 打印源代码
打印 html.text
代码就这么简单,这个html.text就是这个网址的源码
获取指定数据
现在我们有了网页的源代码,我们需要使用lxml过滤掉我们需要的信息。
首先,我们需要分析源代码。我这里使用的是 Chrome 浏览器,所以右键点击查看。
然后在源代码中,找到第一个。
首先点击源页面右上角的箭头,然后在网页内容中选择文章标题。这时候源码会定位到这里的标题。
这时候选择源码的title元素,右键复制。
获取xpath,相当于一个地址。比如源代码中网页长图的位置。
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h5/a
首先,//表示根节点,也就是说,这个//后面的东西是根,表示只有一个。我们需要的就在这里。
然后 / 表示寻找下层。根据图片也很明显,div -> main -> div[2] -> div[1] -> h5 -> a
跟踪到a这里,然后我们在最后加上/text表示我们要提取元素的内容,所以我们最终的表达式是这样的:
//*[@id="mainBox"]/main/div[2]/div[1]/h5/a/text()
这个表达只针对这个网页的这个元素,是不是很难理解?
那么这个东西是如何工作的呢?
所有代码:
进口请求
从 lxml 导入 etree
html = requests.get("")
# 打印 html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h5/a/text()')
对于每个内容:
打印(每个)
这时候每个里面的数据就是我们想要得到的数据
打印结果:
如何拍打 ArrayList
打印结果就是这个结果,我们去掉了换行符和空格
进口请求
从 lxml 导入 etree
html = requests.get("")
# 打印 html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h5/a/text()')
对于每个内容:
replace = each.replace('\n','').replace('','')
如果替换 =='\n' 或替换 =='':
继续
别的:
打印(替换)
打印结果:
如何拍打 ArrayList
感谢您的阅读!关于《如何使用Python爬虫抓取数据》这篇文章分享到这里,希望以上内容可以对大家有所帮助,让大家学到更多的知识,如果你觉得文章可以,可以分享出去让更多人看到! 查看全部
c爬虫抓取网页数据(安装python运行pipinstallBeautifulSoup抓取网页完成必要工具安装后)
本期文章将与大家分享如何使用Python爬虫爬取数据的内容。小编觉得很实用,所以分享出来供大家参考,跟着小编一起来看看吧。
工具安装
首先,您需要安装 Python requests 和 BeautifulSoup 库。我们使用 Requests 库抓取网页内容,使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。举个例子,我们先来看看如何抓取网页的内容。
提取内容
抓取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个例子中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用BeautifulSoup,我们可以非常简单的提取网页的具体内容。
持续的网络爬行
至此,我们已经能够抓取单个网页的内容,现在让我们看看如何抓取网站的整个内容。我们知道网页是通过超链接相互连接的,我们可以通过链接访问整个网络。所以我们可以从每个页面中提取到其他网页的链接,然后重复抓取新的链接。
准备
IDE:pyCharm
库:请求,lxm
即将介绍,这两个库主要为我们服务
requests:获取网页源代码
lxml:获取网页源代码中的指定数据
简洁明了,有没有^_^
设置环境
这里的搭建环境不是搭建python开发环境。这里的构建环境是指我们使用pycharm新建一个python项目,然后用requests和lxml新建一个项目。里面什么都没有。创建一个新的 src 文件夹。然后直接在里面新建一个Test.py。
依赖库导入
在 Test.py 中输入:
进口请求
此时,请求将报告一条红线。这时候我们将光标指向requests,按快捷键:alt+enter,pycharm会给出解决方案。这时候选择安装包请求,pycharm会自动为我们安装。,我们只需要稍等片刻,库就安装好了。lxml的安装方法是一样的。
安装这两个库后,编译器不会报红线。
获取网页源代码
请求可以很容易地让我们得到网页的源代码。
获取源代码:
# 获取源代码
html = requests.get("")
# 打印源代码
打印 html.text
代码就这么简单,这个html.text就是这个网址的源码
获取指定数据
现在我们有了网页的源代码,我们需要使用lxml过滤掉我们需要的信息。
首先,我们需要分析源代码。我这里使用的是 Chrome 浏览器,所以右键点击查看。
然后在源代码中,找到第一个。
首先点击源页面右上角的箭头,然后在网页内容中选择文章标题。这时候源码会定位到这里的标题。
这时候选择源码的title元素,右键复制。
获取xpath,相当于一个地址。比如源代码中网页长图的位置。
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h5/a
首先,//表示根节点,也就是说,这个//后面的东西是根,表示只有一个。我们需要的就在这里。
然后 / 表示寻找下层。根据图片也很明显,div -> main -> div[2] -> div[1] -> h5 -> a
跟踪到a这里,然后我们在最后加上/text表示我们要提取元素的内容,所以我们最终的表达式是这样的:
//*[@id="mainBox"]/main/div[2]/div[1]/h5/a/text()
这个表达只针对这个网页的这个元素,是不是很难理解?
那么这个东西是如何工作的呢?
所有代码:
进口请求
从 lxml 导入 etree
html = requests.get("")
# 打印 html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h5/a/text()')
对于每个内容:
打印(每个)
这时候每个里面的数据就是我们想要得到的数据
打印结果:
如何拍打 ArrayList
打印结果就是这个结果,我们去掉了换行符和空格
进口请求
从 lxml 导入 etree
html = requests.get("")
# 打印 html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h5/a/text()')
对于每个内容:
replace = each.replace('\n','').replace('','')
如果替换 =='\n' 或替换 =='':
继续
别的:
打印(替换)
打印结果:
如何拍打 ArrayList
感谢您的阅读!关于《如何使用Python爬虫抓取数据》这篇文章分享到这里,希望以上内容可以对大家有所帮助,让大家学到更多的知识,如果你觉得文章可以,可以分享出去让更多人看到!
c爬虫抓取网页数据(零基础快速入门的学习路径:1.了解爬虫与进阶分布式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-31 05:19
我不会说爬虫现在有多热。先说一下这个技术能做什么,主要有以下三个方面:
1. 爬取数据,进行市场调研和商业分析
抓取知乎、豆瓣等网站等优质话题;捕捉房地产网站交易信息,分析房价走势,做不同区域的房价分析;爬取招聘网站职位信息,分析各行业及薪资水平对人才的需求。
2.作为机器学习和数据挖掘的原创数据
比如你想做一个推荐系统,那么你可以爬取更多维度的数据,做一个更好的模型。
3. 爬取优质资源:图片、文字、视频
爬取游戏中的精美图片,获取图片资源和评论文字数据。
掌握正确的方法能够在短时间内抓取主流网站数据,其实很容易实现。
但建议您从一开始就有一个特定的目标。在目标的驱动下,您的学习将更加精准和高效。这是一个平滑的、从零开始的快速入门学习路径:
1.了解爬虫是如何实现的
2. 实现简单的信息爬取
3.应对特殊的网站反爬虫措施
4.Scrapy 和高级分布式
01
了解爬虫是如何实现的
大多数爬虫都遵循“发送请求-获取页面-解析页面-提取并存储内容”的过程。这实际上模拟了使用浏览器获取网页信息的过程。最后,如果你的时间不是很紧,又想快速提高python,最重要的是不怕吃苦,建议你定价(同名):762459510,那真的很好,很多人进步很快,需要你不怕吃苦!大家可以去补充看看~
简单的说,我们向服务器发送请求后,会得到返回的页面。解析完页面后,我们就可以提取出我们想要的那部分信息,存放在指定的文档或数据库中。
这部分可以对HTTP协议和网页基础知识,如POST\GET、HTML、CSS、JS等有一个简单的了解,简单了解一下,无需系统学习。
02
实现简单的信息抓取
Python中有很多爬虫相关的包:urllib、requests、bs4、scrapy、pyspider等,建议从requests+Xpath入手。Requests 负责连接到 网站 并返回网页。Xpath 用于解析网页以方便提取数据。
如果你用过BeautifulSoup,你会发现Xpath省了很多麻烦,层层检查元素代码的工作全部省略了。掌握了之后,你会发现爬虫的基本套路都差不多。一般静态 网站 根本不是问题。可以抓取知乎、豆瓣等网站等公开信息。
当然,如果你需要爬取异步加载的网站,可以学习浏览器抓包来分析真实请求,或者学习Selenium来实现自动爬取。这样,知乎、、TripAdvisor等网站基本没问题。
还需要了解Python的基础知识,比如:文件读写操作:用于读取参数,保存爬取内容列表(list),dict(dictionary):用于序列化爬取数据条件判断(if/else):解析爬虫中是否执行循环和迭代的判断(for ……while):用于循环爬虫步骤
03
特殊网站的防攀爬机制
在爬取的过程中,也会遇到一些绝望,比如被网站屏蔽,比如各种奇怪的验证码,userAgent访问限制,各种动态加载等等。
遇到这些反爬虫方法,当然需要一些高级技巧来应对,比如访问频率控制、代理IP池的使用、抓包、验证码的OCR处理等等。
比如我们经常会发现有些网站的网址在翻页后没有变化,通常是异步加载。我们使用开发者工具分析网页加载信息,通常可以获得意想不到的收获。
经常网站在高效开发和反爬虫之间偏向于前者。这也为爬虫提供了空间。掌握这些反爬虫技巧,大部分网站对你来说不再难。最后,如果你时间不是很紧,又想快速提高python,最重要的是不怕吃苦,我建议你可以价格(同名):762459510,那真的很好,很多人进步很快,需要你不怕吃苦!可以去加进去看看~
04
Scrapy 和高级分布式
使用requests+xpath和抓包大法确实可以解决很多网站信息的爬取,但是如果信息量很大或者需要模块爬取的话,就比较困难了。
后来应用到了强大的Scrapy框架中,不仅可以轻松构建Request,而且强大的Selector可以轻松解析Response。然而,最令人惊讶的是它的超高性能,可以对爬虫进行工程化和模块化。
在学习了 Scrapy 之后,我尝试构建了一个简单的爬虫框架。在做大规模数据爬取的时候,可以考虑结构化、工程化的大规模爬取。这让我可以从爬虫工程的维度去思考问题。
后来开始慢慢接触分布式爬虫。这听起来很傻,但实际上它利用了多线程的原理,让多个爬虫同时工作,可以达到更高的效率。
其实学了这个,基本可以说自己是爬虫老司机了。外行人很难看,但也没有那么复杂。
因为爬虫技术不需要你系统地精通一门语言,也不需要任何高级的数据库技术。高效的姿势就是从实际项目中学习这些零散的知识点,保证每次都能学到。是最需要的部分。最后,如果你时间不是很紧,又想快速提高python,最重要的是不怕吃苦,我建议你可以价格(同名):762459510,那真的很好,很多人进步很快,需要你不怕吃苦!可以去加进去看看~
当然,唯一的麻烦在于,在具体问题中,如何找到具体需要的那部分学习资源,以及如何过滤筛选,是很多初学者面临的一大难题。
不过不用担心,我们准备了非常系统的爬虫课程。除了为您提供清晰的学习路径,我们精选了最实用的学习资源和海量的主流爬虫案例库。在很短的学习时间内,你将能够很好地掌握爬虫技巧,得到你想要的数据。 查看全部
c爬虫抓取网页数据(零基础快速入门的学习路径:1.了解爬虫与进阶分布式)
我不会说爬虫现在有多热。先说一下这个技术能做什么,主要有以下三个方面:
1. 爬取数据,进行市场调研和商业分析
抓取知乎、豆瓣等网站等优质话题;捕捉房地产网站交易信息,分析房价走势,做不同区域的房价分析;爬取招聘网站职位信息,分析各行业及薪资水平对人才的需求。
2.作为机器学习和数据挖掘的原创数据
比如你想做一个推荐系统,那么你可以爬取更多维度的数据,做一个更好的模型。
3. 爬取优质资源:图片、文字、视频
爬取游戏中的精美图片,获取图片资源和评论文字数据。
掌握正确的方法能够在短时间内抓取主流网站数据,其实很容易实现。
但建议您从一开始就有一个特定的目标。在目标的驱动下,您的学习将更加精准和高效。这是一个平滑的、从零开始的快速入门学习路径:
1.了解爬虫是如何实现的
2. 实现简单的信息爬取
3.应对特殊的网站反爬虫措施
4.Scrapy 和高级分布式
01
了解爬虫是如何实现的
大多数爬虫都遵循“发送请求-获取页面-解析页面-提取并存储内容”的过程。这实际上模拟了使用浏览器获取网页信息的过程。最后,如果你的时间不是很紧,又想快速提高python,最重要的是不怕吃苦,建议你定价(同名):762459510,那真的很好,很多人进步很快,需要你不怕吃苦!大家可以去补充看看~
简单的说,我们向服务器发送请求后,会得到返回的页面。解析完页面后,我们就可以提取出我们想要的那部分信息,存放在指定的文档或数据库中。
这部分可以对HTTP协议和网页基础知识,如POST\GET、HTML、CSS、JS等有一个简单的了解,简单了解一下,无需系统学习。
02
实现简单的信息抓取
Python中有很多爬虫相关的包:urllib、requests、bs4、scrapy、pyspider等,建议从requests+Xpath入手。Requests 负责连接到 网站 并返回网页。Xpath 用于解析网页以方便提取数据。
如果你用过BeautifulSoup,你会发现Xpath省了很多麻烦,层层检查元素代码的工作全部省略了。掌握了之后,你会发现爬虫的基本套路都差不多。一般静态 网站 根本不是问题。可以抓取知乎、豆瓣等网站等公开信息。
当然,如果你需要爬取异步加载的网站,可以学习浏览器抓包来分析真实请求,或者学习Selenium来实现自动爬取。这样,知乎、、TripAdvisor等网站基本没问题。
还需要了解Python的基础知识,比如:文件读写操作:用于读取参数,保存爬取内容列表(list),dict(dictionary):用于序列化爬取数据条件判断(if/else):解析爬虫中是否执行循环和迭代的判断(for ……while):用于循环爬虫步骤
03
特殊网站的防攀爬机制
在爬取的过程中,也会遇到一些绝望,比如被网站屏蔽,比如各种奇怪的验证码,userAgent访问限制,各种动态加载等等。
遇到这些反爬虫方法,当然需要一些高级技巧来应对,比如访问频率控制、代理IP池的使用、抓包、验证码的OCR处理等等。
比如我们经常会发现有些网站的网址在翻页后没有变化,通常是异步加载。我们使用开发者工具分析网页加载信息,通常可以获得意想不到的收获。
经常网站在高效开发和反爬虫之间偏向于前者。这也为爬虫提供了空间。掌握这些反爬虫技巧,大部分网站对你来说不再难。最后,如果你时间不是很紧,又想快速提高python,最重要的是不怕吃苦,我建议你可以价格(同名):762459510,那真的很好,很多人进步很快,需要你不怕吃苦!可以去加进去看看~
04
Scrapy 和高级分布式
使用requests+xpath和抓包大法确实可以解决很多网站信息的爬取,但是如果信息量很大或者需要模块爬取的话,就比较困难了。
后来应用到了强大的Scrapy框架中,不仅可以轻松构建Request,而且强大的Selector可以轻松解析Response。然而,最令人惊讶的是它的超高性能,可以对爬虫进行工程化和模块化。
在学习了 Scrapy 之后,我尝试构建了一个简单的爬虫框架。在做大规模数据爬取的时候,可以考虑结构化、工程化的大规模爬取。这让我可以从爬虫工程的维度去思考问题。
后来开始慢慢接触分布式爬虫。这听起来很傻,但实际上它利用了多线程的原理,让多个爬虫同时工作,可以达到更高的效率。
其实学了这个,基本可以说自己是爬虫老司机了。外行人很难看,但也没有那么复杂。
因为爬虫技术不需要你系统地精通一门语言,也不需要任何高级的数据库技术。高效的姿势就是从实际项目中学习这些零散的知识点,保证每次都能学到。是最需要的部分。最后,如果你时间不是很紧,又想快速提高python,最重要的是不怕吃苦,我建议你可以价格(同名):762459510,那真的很好,很多人进步很快,需要你不怕吃苦!可以去加进去看看~
当然,唯一的麻烦在于,在具体问题中,如何找到具体需要的那部分学习资源,以及如何过滤筛选,是很多初学者面临的一大难题。
不过不用担心,我们准备了非常系统的爬虫课程。除了为您提供清晰的学习路径,我们精选了最实用的学习资源和海量的主流爬虫案例库。在很短的学习时间内,你将能够很好地掌握爬虫技巧,得到你想要的数据。
c爬虫抓取网页数据(本文软件属于破坏计算机信息系统罪的抓取策略分析手法分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-10-27 19:04
)
爬虫理论是关于爬行的难易程度。一是爬取加密内容,难度很大,尤其是app端的内容加密。有些人可能需要反转应用程序。二是抓取登录后才能查看的内容,加上登录账号的IP访问控制次数。这可能是一大群爬虫。
本文不讨论应用反向问题。这种问题似乎不应该公开陈述。刑法第286条规定,反编译软件是破坏计算机信息系统罪。
如果被证明,风险是相当高的,尤其是竞品之间的抢夺行为太高调。我在猿人学Python的两篇文章文章中写了爬取数据的法律风险。"", ""
本文讨论如何抓取未加密但只能通过登录查看的应用程序。
没有写爬虫的学校教授,所以没有统一的武术套路。强大的数据公司拥有各类武林人才、账号、IP、机器等渠道资源。一般来说,企业资源和人才不足,想要抓取大规模数据,巧妙的招数是可行的方法。
本文提到的巧妙爬取方法就是正确设计爬取策略,通过制定正确的爬取策略,高效爬取需要登录的APP。
制定正确的抓取策略,包括使用和熟悉抓取对象的产品形态(PC、H5、APP)和功能;测试抓取对象的账号在登录后对不同渠道的访问频次控制边界(例如,有的只对产品页面的频次控制进行了详细说明,对渠道页和分类页的控制较弱)。分析抓取的对象在分享到微信等渠道后是否需要授权从微信打开页面,是否需要登录。
这是一套通用的爬取策略分析方法。我可以使用这种策略为大多数应用程序捕获数千万条数据。
理论比较晕,我们以麦麦APP为例,如何分析和制定抢夺策略。
我们的目标是捕捉脉搏上的个人和专业信息(此类数据不应直接用于商业用途,简历也可以视为个人隐私数据)。
按照三面分析步骤,首先分析麦麦的产品形态。初步分析,麦麦的PC网站需要登录,并没有特殊的H5网站,APP也需要登录才能查看。据初步分析,无从下手。
第二步,分析各路段的频率控制。需要一些时间自己点击观察。测试结果是对个别详细页面的频率控制能力很强,对搜索功能也控制能力很强。对频道页面(例如类别)的控制较弱。大约一个账号可以快速访问200多个详细页面,并且会有提示。
这意味着,如果你想每天抓取 100,000 个脉冲详情页,则需要注册 100,000/200=500 个帐户。如果您每天抓取 100 万页,您将需要 5,000 个帐户。这样一来,企业实际上是为数百个账户付费,不到几块钱,但很多企业不愿意支付这个数额。
所以通过批量注册帐户,它停止了。另外,上面提到的大量账号爬取的方法,简化了IP问题。一个账号频繁更换IP也是有问题的,尤其是IP在江苏有一段时间,江西有一段时间。
分析了上面的一、二步骤,好像还没有找到好的方法。然后分析第三步,观察详情页的分享功能。我把详细页面分享到微信后,尝试在微信中打开,发现不用登录也可以访问详细页面。
抓包似乎找到了突破口,于是抓起包包仔细观察。
可以对抓包和分享到微信过程中的数据进行分析:
查看全部
c爬虫抓取网页数据(本文软件属于破坏计算机信息系统罪的抓取策略分析手法分析
)
爬虫理论是关于爬行的难易程度。一是爬取加密内容,难度很大,尤其是app端的内容加密。有些人可能需要反转应用程序。二是抓取登录后才能查看的内容,加上登录账号的IP访问控制次数。这可能是一大群爬虫。
本文不讨论应用反向问题。这种问题似乎不应该公开陈述。刑法第286条规定,反编译软件是破坏计算机信息系统罪。
如果被证明,风险是相当高的,尤其是竞品之间的抢夺行为太高调。我在猿人学Python的两篇文章文章中写了爬取数据的法律风险。"", ""
本文讨论如何抓取未加密但只能通过登录查看的应用程序。
没有写爬虫的学校教授,所以没有统一的武术套路。强大的数据公司拥有各类武林人才、账号、IP、机器等渠道资源。一般来说,企业资源和人才不足,想要抓取大规模数据,巧妙的招数是可行的方法。
本文提到的巧妙爬取方法就是正确设计爬取策略,通过制定正确的爬取策略,高效爬取需要登录的APP。
制定正确的抓取策略,包括使用和熟悉抓取对象的产品形态(PC、H5、APP)和功能;测试抓取对象的账号在登录后对不同渠道的访问频次控制边界(例如,有的只对产品页面的频次控制进行了详细说明,对渠道页和分类页的控制较弱)。分析抓取的对象在分享到微信等渠道后是否需要授权从微信打开页面,是否需要登录。
这是一套通用的爬取策略分析方法。我可以使用这种策略为大多数应用程序捕获数千万条数据。
理论比较晕,我们以麦麦APP为例,如何分析和制定抢夺策略。
我们的目标是捕捉脉搏上的个人和专业信息(此类数据不应直接用于商业用途,简历也可以视为个人隐私数据)。
按照三面分析步骤,首先分析麦麦的产品形态。初步分析,麦麦的PC网站需要登录,并没有特殊的H5网站,APP也需要登录才能查看。据初步分析,无从下手。
第二步,分析各路段的频率控制。需要一些时间自己点击观察。测试结果是对个别详细页面的频率控制能力很强,对搜索功能也控制能力很强。对频道页面(例如类别)的控制较弱。大约一个账号可以快速访问200多个详细页面,并且会有提示。
这意味着,如果你想每天抓取 100,000 个脉冲详情页,则需要注册 100,000/200=500 个帐户。如果您每天抓取 100 万页,您将需要 5,000 个帐户。这样一来,企业实际上是为数百个账户付费,不到几块钱,但很多企业不愿意支付这个数额。
所以通过批量注册帐户,它停止了。另外,上面提到的大量账号爬取的方法,简化了IP问题。一个账号频繁更换IP也是有问题的,尤其是IP在江苏有一段时间,江西有一段时间。
分析了上面的一、二步骤,好像还没有找到好的方法。然后分析第三步,观察详情页的分享功能。我把详细页面分享到微信后,尝试在微信中打开,发现不用登录也可以访问详细页面。
抓包似乎找到了突破口,于是抓起包包仔细观察。
可以对抓包和分享到微信过程中的数据进行分析:
c爬虫抓取网页数据(c爬虫抓取网页数据有三种模式:requests,beautifulsoup,pyquery)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-27 10:04
c爬虫抓取网页数据有三种模式:requests,pyquery,beautifulsoup:beautifulsoup模式简介网页数据就是经过html代码加载后形成的网页文档,网页文档就是一个文本文件。html可以是xml格式的也可以是json格式的,json格式可以是纯文本格式,也可以是二进制格式。
所以对于json格式网页数据抓取过程中又分为三种操作,一种是解析json格式数据,例如get,一种是ocr数据的识别,例如find,一种是将html转换成web容器比如webpages,webpages模式简介网页数据是通过键盘输入,然后服务器返回给浏览器一个html网页文档。简单的说,通过键盘输入的网页数据大多是html代码,然后经过处理转换而成,这些html代码往往很小,通常被分为多个标签,例如<a></a>等等,主要是识别标签,通过html/css语言把标签添加到相应位置上。
html代码的输入很简单,不需要复杂的编程。但是要解析通过键盘输入的页面的html代码需要大量的编程以及大量的数据库操作。工作量往往是事先无法想象的,你需要把很多代码编写成文件方便下次使用,而且每次编写还需要重新编译,另外你发现输入的html很长,可能数以百计,那么每次需要解析的代码又得花费不少时间。
beautifulsoup模式就是利用已有的html模板(css样式或javascript代码),编写一个简单的html代码,它基于浏览器环境的脚本解析器(python),然后传递给前端程序员处理,前端程序员根据html模板读取并解析我们编写的这个html,并显示在浏览器上。网页文档可以简单的可以分为多个区块,每个区块都会存在一个文本文件中,所以你可以通过解析它们生成一个html文档,然后上传到web服务器,再输出显示到我们的页面上。
这种抓取对计算机要求非常高,需要浏览器或者服务器操作优化良好,对性能要求也非常高。comet就是其中之一。 查看全部
c爬虫抓取网页数据(c爬虫抓取网页数据有三种模式:requests,beautifulsoup,pyquery)
c爬虫抓取网页数据有三种模式:requests,pyquery,beautifulsoup:beautifulsoup模式简介网页数据就是经过html代码加载后形成的网页文档,网页文档就是一个文本文件。html可以是xml格式的也可以是json格式的,json格式可以是纯文本格式,也可以是二进制格式。
所以对于json格式网页数据抓取过程中又分为三种操作,一种是解析json格式数据,例如get,一种是ocr数据的识别,例如find,一种是将html转换成web容器比如webpages,webpages模式简介网页数据是通过键盘输入,然后服务器返回给浏览器一个html网页文档。简单的说,通过键盘输入的网页数据大多是html代码,然后经过处理转换而成,这些html代码往往很小,通常被分为多个标签,例如<a></a>等等,主要是识别标签,通过html/css语言把标签添加到相应位置上。
html代码的输入很简单,不需要复杂的编程。但是要解析通过键盘输入的页面的html代码需要大量的编程以及大量的数据库操作。工作量往往是事先无法想象的,你需要把很多代码编写成文件方便下次使用,而且每次编写还需要重新编译,另外你发现输入的html很长,可能数以百计,那么每次需要解析的代码又得花费不少时间。
beautifulsoup模式就是利用已有的html模板(css样式或javascript代码),编写一个简单的html代码,它基于浏览器环境的脚本解析器(python),然后传递给前端程序员处理,前端程序员根据html模板读取并解析我们编写的这个html,并显示在浏览器上。网页文档可以简单的可以分为多个区块,每个区块都会存在一个文本文件中,所以你可以通过解析它们生成一个html文档,然后上传到web服务器,再输出显示到我们的页面上。
这种抓取对计算机要求非常高,需要浏览器或者服务器操作优化良好,对性能要求也非常高。comet就是其中之一。
c爬虫抓取网页数据(UI自动化月前写的一些事儿--)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-26 20:19
写在前面
本来这个文章是几个月前写的,后来忙忘了。
ps:事情太多有时会耽误事情。
几个月前,记得群里有个朋友说要用selenium来爬取数据。关于爬取数据,我一般是模拟访问一些固定的网站,爬取我关心的信息,然后爬出来。数据被处理。
他的要求是将文章直接导入富文本编辑器进行发布,其实这也是一种爬虫。
其实这并不难,就是UI自动化的过程,我们开始吧。
准备工具/原材料
1、java 语言
2、IDEA 开发工具
3、jdk1.8
4、selenium-server-standalone (3.0 及以上)
步骤 1、 分解需求:2、 代码实现思路:3、 示例代码
import org.junit.AfterClass;
import org.junit.BeforeClass;
import org.junit.Test;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import java.awt.*;
import java.awt.event.KeyEvent;
import java.util.concurrent.TimeUnit;
/**
* @author rongrong
* Selenium模拟访问网站爬虫操作代码示例
*/
public class Demo {
private static WebDriver driver;
static final int MAX_TIMEOUT_IN_SECONDS = 5;
@BeforeClass
public static void setUpBeforeClass() throws Exception {
driver = new ChromeDriver();
String url = "https://temai.snssdk.com/artic ... 3B%3B
driver.manage().window().maximize();
driver.manage().timeouts().implicitlyWait(MAX_TIMEOUT_IN_SECONDS, TimeUnit.SECONDS);
driver.get(url);
}
@AfterClass
public static void tearDownAfterClass() throws Exception {
if (driver != null) {
System.out.println("运行结束!");
driver.quit();
}
}
@Test
public void test() throws InterruptedException {
Robot robot = null;
try {
robot = new Robot();
} catch (AWTException e1) {
e1.printStackTrace();
}
robot.keyPress(KeyEvent.VK_CONTROL);
robot.keyPress(KeyEvent.VK_A);
robot.keyRelease(KeyEvent.VK_A);
Thread.sleep(2000);
robot.keyPress(KeyEvent.VK_C);
robot.keyRelease(KeyEvent.VK_C);
robot.keyRelease(KeyEvent.VK_CONTROL);
driver.get("https://ueditor.baidu.com/webs ... 6quot;);
Thread.sleep(2000);
driver.switchTo().frame(0);
driver.findElement(By.tagName("body")).click();
robot.keyPress(KeyEvent.VK_CONTROL);
robot.keyPress(KeyEvent.VK_V);
robot.keyRelease(KeyEvent.VK_V);
robot.keyRelease(KeyEvent.VK_CONTROL);
Thread.sleep(2000);
}
}
写在后面
作者不特别推荐使用selenium作为爬虫,原因如下:
每次运行爬虫都要打开浏览器,初始化需要加载图片、JS渲染等很多东西;
有人说改成无头浏览器的原理是一样的。就是打开浏览器,很多网站都会验证参数。如果对方看到您的恶意访问请求,就会执行您的请求。然后你必须考虑更改请求头。不知道事情有多复杂,还要改代码,很麻烦。
加载了很多可能对你没有价值的补充文件(比如css、js、图片文件)。与真正需要的资源(使用单独的 HTTP 请求)相比,这可能会产生更多的流量。 查看全部
c爬虫抓取网页数据(UI自动化月前写的一些事儿--)
写在前面
本来这个文章是几个月前写的,后来忙忘了。
ps:事情太多有时会耽误事情。
几个月前,记得群里有个朋友说要用selenium来爬取数据。关于爬取数据,我一般是模拟访问一些固定的网站,爬取我关心的信息,然后爬出来。数据被处理。
他的要求是将文章直接导入富文本编辑器进行发布,其实这也是一种爬虫。
其实这并不难,就是UI自动化的过程,我们开始吧。
准备工具/原材料
1、java 语言
2、IDEA 开发工具
3、jdk1.8
4、selenium-server-standalone (3.0 及以上)
步骤 1、 分解需求:2、 代码实现思路:3、 示例代码
import org.junit.AfterClass;
import org.junit.BeforeClass;
import org.junit.Test;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import java.awt.*;
import java.awt.event.KeyEvent;
import java.util.concurrent.TimeUnit;
/**
* @author rongrong
* Selenium模拟访问网站爬虫操作代码示例
*/
public class Demo {
private static WebDriver driver;
static final int MAX_TIMEOUT_IN_SECONDS = 5;
@BeforeClass
public static void setUpBeforeClass() throws Exception {
driver = new ChromeDriver();
String url = "https://temai.snssdk.com/artic ... 3B%3B
driver.manage().window().maximize();
driver.manage().timeouts().implicitlyWait(MAX_TIMEOUT_IN_SECONDS, TimeUnit.SECONDS);
driver.get(url);
}
@AfterClass
public static void tearDownAfterClass() throws Exception {
if (driver != null) {
System.out.println("运行结束!");
driver.quit();
}
}
@Test
public void test() throws InterruptedException {
Robot robot = null;
try {
robot = new Robot();
} catch (AWTException e1) {
e1.printStackTrace();
}
robot.keyPress(KeyEvent.VK_CONTROL);
robot.keyPress(KeyEvent.VK_A);
robot.keyRelease(KeyEvent.VK_A);
Thread.sleep(2000);
robot.keyPress(KeyEvent.VK_C);
robot.keyRelease(KeyEvent.VK_C);
robot.keyRelease(KeyEvent.VK_CONTROL);
driver.get("https://ueditor.baidu.com/webs ... 6quot;);
Thread.sleep(2000);
driver.switchTo().frame(0);
driver.findElement(By.tagName("body")).click();
robot.keyPress(KeyEvent.VK_CONTROL);
robot.keyPress(KeyEvent.VK_V);
robot.keyRelease(KeyEvent.VK_V);
robot.keyRelease(KeyEvent.VK_CONTROL);
Thread.sleep(2000);
}
}
写在后面
作者不特别推荐使用selenium作为爬虫,原因如下:
每次运行爬虫都要打开浏览器,初始化需要加载图片、JS渲染等很多东西;
有人说改成无头浏览器的原理是一样的。就是打开浏览器,很多网站都会验证参数。如果对方看到您的恶意访问请求,就会执行您的请求。然后你必须考虑更改请求头。不知道事情有多复杂,还要改代码,很麻烦。
加载了很多可能对你没有价值的补充文件(比如css、js、图片文件)。与真正需要的资源(使用单独的 HTTP 请求)相比,这可能会产生更多的流量。

