
c爬虫抓取网页数据
c爬虫抓取网页数据( 利用PIL包的crop函数得到标签大小将标签剪切保存)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-22 23:18
利用PIL包的crop函数得到标签大小将标签剪切保存)
contents_list = driver.find_elements_by_css_selector('dl.board-wrapper dd')
注意这里我们使用的是 find_elements_by_css_selector,并且在元素之后添加了 s。如果不加s,find_element方法只能得到第一个节点。添加s后,可以得到所有满足条件的节点,并以列表形式返回。
获取label的文本内容也很简单,比如提取电影排名:
content['index']= content.find_element_by_css_selector('i.board-index').text
找到标签后,添加 .text 即可获取标签内容。获取标签中的属性值也很简单,比如提取电影名称:contents['title'] = content.find_element_by_css_selector('img.board-img').get_attribute('alt')
找到标签后,添加 .get_attribute('attribute name') 即可获取标签中的属性值。具体例子如下:
for content in contents_list:
contents['index'] = content.find_element_by_css_selector('i.board-index').text
; contents['image_url'] = content.find_element_by_css_selector('img.boardimg').get_attribute('src')
;contents['title'] = content.find_element_by_css_selector('img.boardimg').get_attribute('alt')
try:
contents['actor'] = content.find_element_by_css_selector('p.star').text
; except NoSuchElementException:
;contents['actor'] = ''
; contents['time'] = content.find_element_by_css_selector('p.releasetime').t;
3. 将票房信息保存为图片,使用PIL对图片进行二值化、锐化等预处理操作
保存要获取信息的标签图片的一般步骤如下:
a) 拦截当前窗口(selenium 不能直接拦截单个标签)
b) 获取标签位置坐标和标签大小
c) 使用PIL包的裁剪功能,根据标签的坐标和大小对标签进行裁剪保存
示例如下:
图片
上图是网页截图。使用 save_screenshot 函数获取当前窗口的屏幕截图。我们需要将票房数据裁剪保存在蓝框中,所以需要它们的坐标和大小。幸运的是,我们可以使用 .location 和。size函数获取标签的坐标和大小,最后使用PIL包的crop函数根据标签的坐标和大小对标签进行裁剪和保存。
上述步骤在第一屏捕获信息时非常有用,但是当窗口超过一个屏幕并且需要捕获的元素在后面时,您只能寻找其他方法。
来抓一下猫眼影业的电影票房网页,比较长,不能一屏显示。当然我们也可以用js把网页下拉然后截图,这样也可以截取下面网页的信息,但是获取到的标签位置坐标的参考点在网页的左上角(如上图),并且crop功能在裁剪时使用当前图片的左上角为基准,所以不同基准截取的内容肯定是错误的。
我在网上发现,WebDriver.PhantomJS的内置方法支持整个网页的截图,不是很爽,但是我用的时候就糊涂了。PhantomJS 可以拦截整个网页,但是拦截结果是这样的:
图片
我不能给尼玛什么?同时程序还提示警告selenium不再允许使用PhantomJS。让我们回去默默地使用 chrome。突然,灵光一闪。刚才不能用chrome的原因是location函数和crop函数得到的label坐标在裁剪坐标上是不同的。做吧,这个网页一共有10部电影。我只是下拉 10 次就可以了,所以这里我们有一个 for 循环。window.scrollTo 函数使用下拉网页。它有两个参数。第一个是代表水平方向的参数。要拖动的像素数,第二个代表要垂直拖动的像素数。但是你每次拉下来多少?270px(像素),
咦,你怎么知道?
告诉你一个我们使用微信截图的小技巧,它会显示截图图片的大小。对于这个例子,让我们每次拉下两个电影票房之间的长度。长度为270px,如下图所示。
图片
这样,您应该可以获取每个票房数据标签。得到票房数据标签后,我们需要进行图像预处理(二值化、锐化),最后保存标签。部分代码如下:
length = n*270driver.execute_script('window.scrollTo(0, {}*270)'.format(n))# 保存当前窗口为图片driver.save_screenshot('b.png')# time.sleep(2)# 定位div地址location = div.location# print(location)# 得到div尺寸size = div.size# print(size)left = location['x']top = location['y'] - lengthright = location['x'] + size['width']bottom = location['y'] + size['height'] - length
4. 使用tesseract识别保存的图片,获取票房数据
原票房数据图片:
图片
预处理后的票房数据图片:
图片
使用tesseract对处理后的图片进行识别,部分代码如下:
# 调用tesseract进行文字数字识别,目前对于浅颜色的字体识别率较低,若想提高识别率需要对图片做预处理os.system('echo off')#关闭命令行窗口运行命令的显示os.system('tesseract' + ' ' + filename + ' ' + output + ' ' + '-l num+chi_tra') #默认已配置好系统变量time.sleep(2)f = open(output + ".txt", encoding='utf-8')try: t = f.readlines()[0]
目前没有训练自己的数据识别包,直接使用tesseract已有的数据包,经过多次试验,实时票房识别率达到97%以上。由于总票房字体颜色偏浅,字体偏小,目前识别率还比较低,在60%左右。得到的数据如下图所示:
图片
这是第一次尝试使用图像识别来解决爬虫和到达问题。感觉真的很好玩。目前已经开放了获取标签图像的流程,但在图像预处理和图像识别方面还有很多工作要做。目前使用的是第三方软件Tesseract。-OCR识别,一方面我们会继续研究Tesseract-OCR,另一方面我们也会尝试使用深度学习的方法来提高图像文本的识别准确率。
图片 查看全部
c爬虫抓取网页数据(
利用PIL包的crop函数得到标签大小将标签剪切保存)
contents_list = driver.find_elements_by_css_selector('dl.board-wrapper dd')
注意这里我们使用的是 find_elements_by_css_selector,并且在元素之后添加了 s。如果不加s,find_element方法只能得到第一个节点。添加s后,可以得到所有满足条件的节点,并以列表形式返回。
获取label的文本内容也很简单,比如提取电影排名:
content['index']= content.find_element_by_css_selector('i.board-index').text
找到标签后,添加 .text 即可获取标签内容。获取标签中的属性值也很简单,比如提取电影名称:contents['title'] = content.find_element_by_css_selector('img.board-img').get_attribute('alt')
找到标签后,添加 .get_attribute('attribute name') 即可获取标签中的属性值。具体例子如下:
for content in contents_list:
contents['index'] = content.find_element_by_css_selector('i.board-index').text
; contents['image_url'] = content.find_element_by_css_selector('img.boardimg').get_attribute('src')
;contents['title'] = content.find_element_by_css_selector('img.boardimg').get_attribute('alt')
try:
contents['actor'] = content.find_element_by_css_selector('p.star').text
; except NoSuchElementException:
;contents['actor'] = ''
; contents['time'] = content.find_element_by_css_selector('p.releasetime').t;
3. 将票房信息保存为图片,使用PIL对图片进行二值化、锐化等预处理操作
保存要获取信息的标签图片的一般步骤如下:
a) 拦截当前窗口(selenium 不能直接拦截单个标签)
b) 获取标签位置坐标和标签大小
c) 使用PIL包的裁剪功能,根据标签的坐标和大小对标签进行裁剪保存
示例如下:

图片
上图是网页截图。使用 save_screenshot 函数获取当前窗口的屏幕截图。我们需要将票房数据裁剪保存在蓝框中,所以需要它们的坐标和大小。幸运的是,我们可以使用 .location 和。size函数获取标签的坐标和大小,最后使用PIL包的crop函数根据标签的坐标和大小对标签进行裁剪和保存。
上述步骤在第一屏捕获信息时非常有用,但是当窗口超过一个屏幕并且需要捕获的元素在后面时,您只能寻找其他方法。
来抓一下猫眼影业的电影票房网页,比较长,不能一屏显示。当然我们也可以用js把网页下拉然后截图,这样也可以截取下面网页的信息,但是获取到的标签位置坐标的参考点在网页的左上角(如上图),并且crop功能在裁剪时使用当前图片的左上角为基准,所以不同基准截取的内容肯定是错误的。
我在网上发现,WebDriver.PhantomJS的内置方法支持整个网页的截图,不是很爽,但是我用的时候就糊涂了。PhantomJS 可以拦截整个网页,但是拦截结果是这样的:
图片
我不能给尼玛什么?同时程序还提示警告selenium不再允许使用PhantomJS。让我们回去默默地使用 chrome。突然,灵光一闪。刚才不能用chrome的原因是location函数和crop函数得到的label坐标在裁剪坐标上是不同的。做吧,这个网页一共有10部电影。我只是下拉 10 次就可以了,所以这里我们有一个 for 循环。window.scrollTo 函数使用下拉网页。它有两个参数。第一个是代表水平方向的参数。要拖动的像素数,第二个代表要垂直拖动的像素数。但是你每次拉下来多少?270px(像素),
咦,你怎么知道?
告诉你一个我们使用微信截图的小技巧,它会显示截图图片的大小。对于这个例子,让我们每次拉下两个电影票房之间的长度。长度为270px,如下图所示。
图片
这样,您应该可以获取每个票房数据标签。得到票房数据标签后,我们需要进行图像预处理(二值化、锐化),最后保存标签。部分代码如下:
length = n*270driver.execute_script('window.scrollTo(0, {}*270)'.format(n))# 保存当前窗口为图片driver.save_screenshot('b.png')# time.sleep(2)# 定位div地址location = div.location# print(location)# 得到div尺寸size = div.size# print(size)left = location['x']top = location['y'] - lengthright = location['x'] + size['width']bottom = location['y'] + size['height'] - length
4. 使用tesseract识别保存的图片,获取票房数据
原票房数据图片:
图片
预处理后的票房数据图片:
图片
使用tesseract对处理后的图片进行识别,部分代码如下:
# 调用tesseract进行文字数字识别,目前对于浅颜色的字体识别率较低,若想提高识别率需要对图片做预处理os.system('echo off')#关闭命令行窗口运行命令的显示os.system('tesseract' + ' ' + filename + ' ' + output + ' ' + '-l num+chi_tra') #默认已配置好系统变量time.sleep(2)f = open(output + ".txt", encoding='utf-8')try: t = f.readlines()[0]
目前没有训练自己的数据识别包,直接使用tesseract已有的数据包,经过多次试验,实时票房识别率达到97%以上。由于总票房字体颜色偏浅,字体偏小,目前识别率还比较低,在60%左右。得到的数据如下图所示:
图片
这是第一次尝试使用图像识别来解决爬虫和到达问题。感觉真的很好玩。目前已经开放了获取标签图像的流程,但在图像预处理和图像识别方面还有很多工作要做。目前使用的是第三方软件Tesseract。-OCR识别,一方面我们会继续研究Tesseract-OCR,另一方面我们也会尝试使用深度学习的方法来提高图像文本的识别准确率。

图片
c爬虫抓取网页数据(爬取框架中分两类爬虫 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-22 13:20
)
Scrapy 框架中有两种爬虫,Spider 和 CrawlSpider。本案例使用 CrawlSpider 类来实现全站抓取的爬虫。
CrawlSpider 是 Spider 的派生类。Spider类的设计原理是只抓取start_url列表中的网页,而CrawlSpider类则定义了一些规则来提供一种方便的机制来跟踪链接,从抓取到的网页中获取链接并继续抓取。
创建一个 CrawlSpider 模板:
scrapy genspider -t crawl spider名称 www.xxxx.com
LinkExtractors:Link Extractors 的目的是提取链接。Extract_links() 被调用,它提供过滤器以方便提取包括正则表达式在内的链接。过滤器配置有以下构造函数参数:
Rule:规则中收录一个或多个Rule对象,每个Rule定义了爬取网站的具体操作。如果多个规则匹配同一个链接,将根据规则在此集中定义的顺序使用第一个。
下面是一个爬钩网的案例:
蜘蛛.pyi
项目.py
import scrapy
from scrapy.loader.processors import MapCompose, TakeFirst, Join
from scrapy.loader import ItemLoader
from w3lib.html import remove_tags
from LaGouSpider.settings import SQL_DATETIME_FORMAT
class LagouJobItemLoader(ItemLoader):
#自定义Itemloader
default_output_processor = TakeFirst()
def remove_splash(value):
#去掉斜杠
return value.replace("/","")
def handle_jobaddr(value):
addr_list = value.split("\n")
addr_list = [item.strip() for item in addr_list if item.strip()!="查看地图"]
return "".join(addr_list)
class LagouspiderItem(scrapy.Item):
title = scrapy.Field()
url = scrapy.Field()
url_object_id = scrapy.Field()
salary = scrapy.Field()
job_city = scrapy.Field(
input_processor=MapCompose(remove_splash),
)
work_years = scrapy.Field(
input_processor=MapCompose(remove_splash),
)
degree_need = scrapy.Field(
input_processor=MapCompose(remove_splash),
)
job_type = scrapy.Field()
publish_time = scrapy.Field()
job_advantage = scrapy.Field()
job_desc = scrapy.Field()
job_address = scrapy.Field(
input_processor=MapCompose(remove_tags, handle_jobaddr),
)
company_name = scrapy.Field()
company_url = scrapy.Field()
tags = scrapy.Field(
input_processor=Join(",")
)
crawl_time = scrapy.Field()
def get_insert_sql(self):
insert_sql = """
insert into lagou_job(title, url, url_object_id, salary, job_city, work_years, degree_need,
job_type, publish_time, job_advantage, job_desc, job_address, company_name, company_url,
tags, crawl_time) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE salary=VALUES(salary), job_desc=VALUES(job_desc)
"""
params = (
self["title"], self["url"], self["url_object_id"], self["salary"], self["job_city"],
self["work_years"], self["degree_need"], self["job_type"],
self["publish_time"], self["job_advantage"], self["job_desc"],
self["job_address"], self["company_name"], self["company_url"],
self["tags"], self["crawl_time"].strftime(SQL_DATETIME_FORMAT),
)
return insert_sql, params
管道.py
from twisted.enterprise import adbapi
import MySQLdb
import MySQLdb.cursors
class LagouspiderPipeline(object):
def process_item(self, item, spider):
return item
class MysqlTwistedPipeline(object):
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(clsc,setting):
dbparms = dict(
host =setting["MYSQL_HOST"],
db = setting["MYSQL_DBNAME"],
user = setting["MYSQL_USER"],
password = setting["MYSQL_PASSWORD"],
charset = 'utf8',
cursorclass = MySQLdb.cursors.DictCursor,
use_unicode = True,
)
dbpool = adbapi.ConnectionPool("MySQLdb",**dbparms)
return clsc(dbpool)
def process_item(self, item, spider):
#使用twisted将mysql插入变成异步执行
query = self.dbpool.runInteraction(self.do_insert,item)
query.addErrback(self.handle_error,item,spider) #处理异常
def handle_error(self,failure,item,spider):
#处理异步插入的异常
print(failure)
def do_insert(self,cursor,item):
#执行具体的插入
# 根据不同的item 构建不同的sql语句并插入到mysql中
insert_sql,params = item.get_insert_sql()
cursor.execute(insert_sql, params) 查看全部
c爬虫抓取网页数据(爬取框架中分两类爬虫
)
Scrapy 框架中有两种爬虫,Spider 和 CrawlSpider。本案例使用 CrawlSpider 类来实现全站抓取的爬虫。
CrawlSpider 是 Spider 的派生类。Spider类的设计原理是只抓取start_url列表中的网页,而CrawlSpider类则定义了一些规则来提供一种方便的机制来跟踪链接,从抓取到的网页中获取链接并继续抓取。
创建一个 CrawlSpider 模板:
scrapy genspider -t crawl spider名称 www.xxxx.com
LinkExtractors:Link Extractors 的目的是提取链接。Extract_links() 被调用,它提供过滤器以方便提取包括正则表达式在内的链接。过滤器配置有以下构造函数参数:
Rule:规则中收录一个或多个Rule对象,每个Rule定义了爬取网站的具体操作。如果多个规则匹配同一个链接,将根据规则在此集中定义的顺序使用第一个。
下面是一个爬钩网的案例:
蜘蛛.pyi
项目.py
import scrapy
from scrapy.loader.processors import MapCompose, TakeFirst, Join
from scrapy.loader import ItemLoader
from w3lib.html import remove_tags
from LaGouSpider.settings import SQL_DATETIME_FORMAT
class LagouJobItemLoader(ItemLoader):
#自定义Itemloader
default_output_processor = TakeFirst()
def remove_splash(value):
#去掉斜杠
return value.replace("/","")
def handle_jobaddr(value):
addr_list = value.split("\n")
addr_list = [item.strip() for item in addr_list if item.strip()!="查看地图"]
return "".join(addr_list)
class LagouspiderItem(scrapy.Item):
title = scrapy.Field()
url = scrapy.Field()
url_object_id = scrapy.Field()
salary = scrapy.Field()
job_city = scrapy.Field(
input_processor=MapCompose(remove_splash),
)
work_years = scrapy.Field(
input_processor=MapCompose(remove_splash),
)
degree_need = scrapy.Field(
input_processor=MapCompose(remove_splash),
)
job_type = scrapy.Field()
publish_time = scrapy.Field()
job_advantage = scrapy.Field()
job_desc = scrapy.Field()
job_address = scrapy.Field(
input_processor=MapCompose(remove_tags, handle_jobaddr),
)
company_name = scrapy.Field()
company_url = scrapy.Field()
tags = scrapy.Field(
input_processor=Join(",")
)
crawl_time = scrapy.Field()
def get_insert_sql(self):
insert_sql = """
insert into lagou_job(title, url, url_object_id, salary, job_city, work_years, degree_need,
job_type, publish_time, job_advantage, job_desc, job_address, company_name, company_url,
tags, crawl_time) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE salary=VALUES(salary), job_desc=VALUES(job_desc)
"""
params = (
self["title"], self["url"], self["url_object_id"], self["salary"], self["job_city"],
self["work_years"], self["degree_need"], self["job_type"],
self["publish_time"], self["job_advantage"], self["job_desc"],
self["job_address"], self["company_name"], self["company_url"],
self["tags"], self["crawl_time"].strftime(SQL_DATETIME_FORMAT),
)
return insert_sql, params
管道.py
from twisted.enterprise import adbapi
import MySQLdb
import MySQLdb.cursors
class LagouspiderPipeline(object):
def process_item(self, item, spider):
return item
class MysqlTwistedPipeline(object):
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(clsc,setting):
dbparms = dict(
host =setting["MYSQL_HOST"],
db = setting["MYSQL_DBNAME"],
user = setting["MYSQL_USER"],
password = setting["MYSQL_PASSWORD"],
charset = 'utf8',
cursorclass = MySQLdb.cursors.DictCursor,
use_unicode = True,
)
dbpool = adbapi.ConnectionPool("MySQLdb",**dbparms)
return clsc(dbpool)
def process_item(self, item, spider):
#使用twisted将mysql插入变成异步执行
query = self.dbpool.runInteraction(self.do_insert,item)
query.addErrback(self.handle_error,item,spider) #处理异常
def handle_error(self,failure,item,spider):
#处理异步插入的异常
print(failure)
def do_insert(self,cursor,item):
#执行具体的插入
# 根据不同的item 构建不同的sql语句并插入到mysql中
insert_sql,params = item.get_insert_sql()
cursor.execute(insert_sql, params)
c爬虫抓取网页数据(如何自学Python爬虫?新手入门到精通的爬虫技能!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-21 12:28
如何自学 Python 爬虫?在大家学会自己爬之前,有两个常见的问题需要解决。首先,什么是爬虫?二是问为什么要用Python做爬虫?爬虫其实就是一个自动抓取页面信息的网络机器人。至于使用Python作为爬虫的原因,当然是为了方便。本文将为您提供详细的初学者入门教程,带您从入门到精通Python爬虫技巧。
一、什么是爬虫?
网络爬虫也被称为网络蜘蛛、网络机器人,在 FOAF 社区中,它们更多地被称为网络追逐者。它是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不常用的名称包括蚂蚁、自动索引和模拟程序。其实说白了就是爬虫可以模拟浏览器的行为为所欲为,自定义搜索下载的内容,实现自动化操作。比如浏览器可以下载小说,但是有时候不能批量下载,所以爬虫功能很有用。
二、为什么python适合爬行?
实现爬虫技术的编程环境有很多,Java、Python、C++等都可以用于爬虫。但是为什么大家都选择Python呢?因为Python真的很适合爬虫。丰富的第三方库非常强大。几行代码就可以实现你想要的功能;它是跨平台的,对 Linux 和 windows 有很好的支持。. 更重要的是,Python 还擅长数据挖掘和分析。使用Python进行数据爬取和分析的一站式服务,真的很方便。最后,如果你的时间不是很紧,又想快速提高python,最重要的是不怕吃苦,建议你可以群:[832357663],真的很好,很多人都在飞速进步,需要你不怕吃苦!
三、自学Python爬虫的步骤是什么?
1、先学习Python语法基础知识
2、学习Python爬虫常用的几个重要的内置库,urllib,http等,用于下载网页
3、学习正则表达式re、BeautifulSoup(bs4)、Xpath(lxml)等网页解析工具
4、开始一些简单的网站爬取(博主从百度开始的,哈哈),了解爬取数据的过程
5、了解爬虫的一些反爬虫机制,header,robot,时间间隔,代理ip,隐藏域等。
6、学习一些特殊的网站爬虫,解决登录、cookie、动态网页等问题
7、了解爬虫与数据库的结合,以及如何存储爬取的数据
8、学习应用Python的多线程多进程爬取提高爬虫效率
9、学习爬虫框架,Scrapy,PySpider等。
10、学习分布式爬虫(海量数据需求)
四、自学Python爬虫免费教程推荐
《3天掌握Python爬虫》课程主要包括爬虫基础知识和软件准备,HTTP和HTTPS的学习和请求模块的使用,重试模块的使用和处理cookie相关请求,数据提取方法值json,数据提取值 xpath 使用lxml模块学习,xpath和lxml模块练习等。完成本课程后,大家将能够了解爬虫的原理,学会使用python进行网络请求,掌握爬取网页的方法数据。
以上是Python爬虫初学者教程的介绍。其实,如果你有一定的Python编程基础,自学Python爬虫并不难。行动不如心。无论是视频还是其他学习资源,都可以在网上轻松获取。
如何领取python福利教程:
1、喜欢+评论(勾选“同时转发”)
2、关注小编。并回复私信关键词[19]
(一定要发私信哦~点我头像看私信按钮) 查看全部
c爬虫抓取网页数据(如何自学Python爬虫?新手入门到精通的爬虫技能!)
如何自学 Python 爬虫?在大家学会自己爬之前,有两个常见的问题需要解决。首先,什么是爬虫?二是问为什么要用Python做爬虫?爬虫其实就是一个自动抓取页面信息的网络机器人。至于使用Python作为爬虫的原因,当然是为了方便。本文将为您提供详细的初学者入门教程,带您从入门到精通Python爬虫技巧。

一、什么是爬虫?
网络爬虫也被称为网络蜘蛛、网络机器人,在 FOAF 社区中,它们更多地被称为网络追逐者。它是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不常用的名称包括蚂蚁、自动索引和模拟程序。其实说白了就是爬虫可以模拟浏览器的行为为所欲为,自定义搜索下载的内容,实现自动化操作。比如浏览器可以下载小说,但是有时候不能批量下载,所以爬虫功能很有用。
二、为什么python适合爬行?
实现爬虫技术的编程环境有很多,Java、Python、C++等都可以用于爬虫。但是为什么大家都选择Python呢?因为Python真的很适合爬虫。丰富的第三方库非常强大。几行代码就可以实现你想要的功能;它是跨平台的,对 Linux 和 windows 有很好的支持。. 更重要的是,Python 还擅长数据挖掘和分析。使用Python进行数据爬取和分析的一站式服务,真的很方便。最后,如果你的时间不是很紧,又想快速提高python,最重要的是不怕吃苦,建议你可以群:[832357663],真的很好,很多人都在飞速进步,需要你不怕吃苦!
三、自学Python爬虫的步骤是什么?
1、先学习Python语法基础知识
2、学习Python爬虫常用的几个重要的内置库,urllib,http等,用于下载网页
3、学习正则表达式re、BeautifulSoup(bs4)、Xpath(lxml)等网页解析工具
4、开始一些简单的网站爬取(博主从百度开始的,哈哈),了解爬取数据的过程
5、了解爬虫的一些反爬虫机制,header,robot,时间间隔,代理ip,隐藏域等。
6、学习一些特殊的网站爬虫,解决登录、cookie、动态网页等问题
7、了解爬虫与数据库的结合,以及如何存储爬取的数据
8、学习应用Python的多线程多进程爬取提高爬虫效率
9、学习爬虫框架,Scrapy,PySpider等。
10、学习分布式爬虫(海量数据需求)
四、自学Python爬虫免费教程推荐
《3天掌握Python爬虫》课程主要包括爬虫基础知识和软件准备,HTTP和HTTPS的学习和请求模块的使用,重试模块的使用和处理cookie相关请求,数据提取方法值json,数据提取值 xpath 使用lxml模块学习,xpath和lxml模块练习等。完成本课程后,大家将能够了解爬虫的原理,学会使用python进行网络请求,掌握爬取网页的方法数据。
以上是Python爬虫初学者教程的介绍。其实,如果你有一定的Python编程基础,自学Python爬虫并不难。行动不如心。无论是视频还是其他学习资源,都可以在网上轻松获取。
如何领取python福利教程:
1、喜欢+评论(勾选“同时转发”)
2、关注小编。并回复私信关键词[19]
(一定要发私信哦~点我头像看私信按钮)
c爬虫抓取网页数据(一个通用的网络爬虫的基本结构及工作流程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-21 11:06
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要是对爬虫和爬虫系统的简要介绍。
一、网络爬虫的基本结构和工作流程
一个通用的网络爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选择一些精心挑选的种子网址;
2.将这些URL放入URL队列进行抓取;
3. 从待爬取的URL队列中取出待爬取的URL,解析DNS,获取主机ip,下载该URL对应的网页,并保存到下载的网页库中。另外,将这些网址放入已爬取的网址队列中。
4.对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入待爬取的URL队列中,从而进入下一个循环。
二、从爬虫的角度划分互联网
相应地,互联网的所有页面可以分为五个部分:
1.下载了未过期的网页
2.已下载并过期的网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态变化的,互联网上的一些内容已经发生了变化。此时,这部分爬取到的页面已经过期。
3.要下载的页面:URL队列中要爬取的那些页面
4. 已知网页:尚未被抓取,也不在待抓取的URL队列中,但通过分析抓取的页面得到的URL或待抓取的URL对应的页面可以认为是已知的网页 。
5.还有一些网页是爬虫无法直接抓取下载的。它被称为不可知页面。
三、抓取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL按什么顺序排列也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,逐个跟踪每一个链接,处理完这一行后转移到下一个起始页,继续跟踪链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.宽度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接插入到待爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中所有链接的网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。以上图为例:
遍历路径:ABCDEF GHI
3.反向链接计数策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
4.部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,连同要爬取的URL队列中的URL,组成一个网页集,计算每个页面的PageRank值,经过计算完成后,将要爬取的URL队列中的URL按照PageRank值的大小进行排列,依次爬取页面。
如果每个页面都被抓取,则重新计算 PageRank 值。一个折衷的方案是:每爬取K个页面后,重新计算PageRank值。但是,这种情况下仍然存在一个问题:对于已经从下载页面中分析出来的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,这些页面会被赋予一个临时的PageRank值:将所有传入该页面链中的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排名。以下示例说明:
5.OPIC 策略
该算法实际上对页面的重要性进行评分。在算法开始之前,给所有页面相同的初始现金(cash)。下载某个页面P后,将P的现金分配给所有从P解析的链接,清空P的现金。待抓取的 URL 队列中的所有页面均按照现金的数量进行排序。
6.大站优先策略
URL队列中所有要爬取的网页,按照所属的网站进行分类。网站需要下载的页面较多,优先下载。这种策略因此被称为大站优先策略。
参考书目:
1. 《这是搜索引擎-核心技术详解》张俊林电子工业出版社
2. 《搜索引擎技术基础》刘义群等清华大学出版社 查看全部
c爬虫抓取网页数据(一个通用的网络爬虫的基本结构及工作流程(组图))
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要是对爬虫和爬虫系统的简要介绍。
一、网络爬虫的基本结构和工作流程
一个通用的网络爬虫的框架如图所示:

网络爬虫的基本工作流程如下:
1.首先选择一些精心挑选的种子网址;
2.将这些URL放入URL队列进行抓取;
3. 从待爬取的URL队列中取出待爬取的URL,解析DNS,获取主机ip,下载该URL对应的网页,并保存到下载的网页库中。另外,将这些网址放入已爬取的网址队列中。
4.对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入待爬取的URL队列中,从而进入下一个循环。
二、从爬虫的角度划分互联网
相应地,互联网的所有页面可以分为五个部分:

1.下载了未过期的网页
2.已下载并过期的网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态变化的,互联网上的一些内容已经发生了变化。此时,这部分爬取到的页面已经过期。
3.要下载的页面:URL队列中要爬取的那些页面
4. 已知网页:尚未被抓取,也不在待抓取的URL队列中,但通过分析抓取的页面得到的URL或待抓取的URL对应的页面可以认为是已知的网页 。
5.还有一些网页是爬虫无法直接抓取下载的。它被称为不可知页面。
三、抓取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL按什么顺序排列也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,逐个跟踪每一个链接,处理完这一行后转移到下一个起始页,继续跟踪链接。我们以下图为例:

遍历的路径:AFG EHI BCD
2.宽度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接插入到待爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中所有链接的网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。以上图为例:
遍历路径:ABCDEF GHI
3.反向链接计数策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
4.部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,连同要爬取的URL队列中的URL,组成一个网页集,计算每个页面的PageRank值,经过计算完成后,将要爬取的URL队列中的URL按照PageRank值的大小进行排列,依次爬取页面。
如果每个页面都被抓取,则重新计算 PageRank 值。一个折衷的方案是:每爬取K个页面后,重新计算PageRank值。但是,这种情况下仍然存在一个问题:对于已经从下载页面中分析出来的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,这些页面会被赋予一个临时的PageRank值:将所有传入该页面链中的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排名。以下示例说明:
5.OPIC 策略
该算法实际上对页面的重要性进行评分。在算法开始之前,给所有页面相同的初始现金(cash)。下载某个页面P后,将P的现金分配给所有从P解析的链接,清空P的现金。待抓取的 URL 队列中的所有页面均按照现金的数量进行排序。
6.大站优先策略
URL队列中所有要爬取的网页,按照所属的网站进行分类。网站需要下载的页面较多,优先下载。这种策略因此被称为大站优先策略。
参考书目:
1. 《这是搜索引擎-核心技术详解》张俊林电子工业出版社
2. 《搜索引擎技术基础》刘义群等清华大学出版社
c爬虫抓取网页数据(如何抓取ajax形式加载的网页数据(一)_恢复内容开始)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2021-12-20 06:03
---恢复内容开始---
下面记录如何抓取ajax形式加载的网页数据:
目标:获取"%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action="下的网页数据
第一步:网页数据分析-----》特点:当列表栏滚动到页面底部时,数据自动加载,页面的url没有变化
第二步:使用Fiddler抓包,如下图:
图 1:请求数据
图2:表格形式
数据规律是通过抓包得到的:图2中from形式的start对应数据和图1中url中的start对应数据随着每次加载增加,其他数据没有变化。对应这个规律,我们可以构造相应的请求来获取数据
注意数据格式为json
代码显示如下:
1).urllib 格式
import urllib2
import urllib
#此处的url为上述抓包获取的url去掉start以及limit,start以及limit数据后边以form表单的形式传入
url = \' https://movie.douban.com/j/cha ... on%3D\'
#请求投信息,伪造成浏览器,方式被反爬虫策略拦截
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
#构建form表单
formdata = {
"start":"20",
"limit":"20"
}
#urlencode()urllib中的函数,作用:将key:value形式的键值对转换为"key=value"形式的字符串
data = urllib.urlencode(formdata)
#构建request实例对象
request = urllib2.Request(url,data=data,headers=headers)
#发送请求并返回响应信息
response = urllib2.urlopen(request)
#注意此处的数据形式并不是html文档,而是json数据
json = response.read()
print html
2).request 库获取请求代码
#coding=utf-8
import requests
url = \' https://movie.douban.com/j/cha ... on%3D\'
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
data = {
"start":"20",
"limit":"20",
}
response = requests.get(url,params = data,headers = headers)
print response.text
3).request 库发布请求
#coding=utf-8
import requests
url = \' https://movie.douban.com/j/cha ... on%3D\'
formdata = {
"start":"20",
"limit":"20"
}
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
response = requests.post(url,data=formdata,headers=headers)
print response.text
---恢复内容结束--- 查看全部
c爬虫抓取网页数据(如何抓取ajax形式加载的网页数据(一)_恢复内容开始)
---恢复内容开始---
下面记录如何抓取ajax形式加载的网页数据:
目标:获取"%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action="下的网页数据
第一步:网页数据分析-----》特点:当列表栏滚动到页面底部时,数据自动加载,页面的url没有变化
第二步:使用Fiddler抓包,如下图:
图 1:请求数据
图2:表格形式
数据规律是通过抓包得到的:图2中from形式的start对应数据和图1中url中的start对应数据随着每次加载增加,其他数据没有变化。对应这个规律,我们可以构造相应的请求来获取数据
注意数据格式为json
代码显示如下:
1).urllib 格式
import urllib2
import urllib
#此处的url为上述抓包获取的url去掉start以及limit,start以及limit数据后边以form表单的形式传入
url = \' https://movie.douban.com/j/cha ... on%3D\'
#请求投信息,伪造成浏览器,方式被反爬虫策略拦截
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
#构建form表单
formdata = {
"start":"20",
"limit":"20"
}
#urlencode()urllib中的函数,作用:将key:value形式的键值对转换为"key=value"形式的字符串
data = urllib.urlencode(formdata)
#构建request实例对象
request = urllib2.Request(url,data=data,headers=headers)
#发送请求并返回响应信息
response = urllib2.urlopen(request)
#注意此处的数据形式并不是html文档,而是json数据
json = response.read()
print html
2).request 库获取请求代码
#coding=utf-8
import requests
url = \' https://movie.douban.com/j/cha ... on%3D\'
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
data = {
"start":"20",
"limit":"20",
}
response = requests.get(url,params = data,headers = headers)
print response.text
3).request 库发布请求
#coding=utf-8
import requests
url = \' https://movie.douban.com/j/cha ... on%3D\'
formdata = {
"start":"20",
"limit":"20"
}
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
response = requests.post(url,data=formdata,headers=headers)
print response.text
---恢复内容结束---
c爬虫抓取网页数据(1.网络爬虫的基本概念网络蜘蛛,机器人都能够做到! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-20 06:03
)
1.网络爬虫的基本概念
网络爬虫(又称网络蜘蛛、机器人)是一种模拟客户端发送网络请求和接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做,原则上爬虫都能做。
2.网络爬虫的功能
网络爬虫可以做很多事情而不是手动。比如可以作为搜索引擎,还可以爬取网站上面的图片。比如有的朋友爬取一些网站上的所有图片,然后重点关注。同时,网络爬虫还可以应用在金融投资领域,比如可以自动爬取一些金融信息,进行投资分析。
有时候,可能会有几个我们比较喜欢的新闻网站,每次都要打开这些新闻网站浏览,比较麻烦。这时候就可以用网络爬虫把这多条新闻网站中的新闻信息爬下来,一起阅读。
有时,我们在浏览网页信息时,会发现有很多广告。这时候也可以使用爬虫爬取对应网页上的信息,让这些广告自动过滤掉,方便信息的阅读和使用。
有时,我们需要进行营销,因此如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以在网上手动搜索,但是效率会很低。这时,我们可以使用爬虫设置相应的规则,自动从互联网上采集目标用户的联系方式等数据,用于我们的营销。
有时,我们要分析某个网站的用户信息,比如分析网站的用户活跃度、评论数、热门文章等信息。如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时就可以使用爬虫轻松获取这些数据采集进行进一步分析,而且所有的爬取操作都是自动进行的,我们只需要编写相应的爬虫,设计相应的规则就可以了。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫自动化,从而可以更有效地使用互联网中的有效信息。.
3.安装第三方库
在抓取和解析数据之前,您需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面上输入pip install requests,按回车键安装。(注意网络连接)如下图
安装完成,如图
查看全部
c爬虫抓取网页数据(1.网络爬虫的基本概念网络蜘蛛,机器人都能够做到!
)
1.网络爬虫的基本概念
网络爬虫(又称网络蜘蛛、机器人)是一种模拟客户端发送网络请求和接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做,原则上爬虫都能做。
2.网络爬虫的功能

网络爬虫可以做很多事情而不是手动。比如可以作为搜索引擎,还可以爬取网站上面的图片。比如有的朋友爬取一些网站上的所有图片,然后重点关注。同时,网络爬虫还可以应用在金融投资领域,比如可以自动爬取一些金融信息,进行投资分析。
有时候,可能会有几个我们比较喜欢的新闻网站,每次都要打开这些新闻网站浏览,比较麻烦。这时候就可以用网络爬虫把这多条新闻网站中的新闻信息爬下来,一起阅读。
有时,我们在浏览网页信息时,会发现有很多广告。这时候也可以使用爬虫爬取对应网页上的信息,让这些广告自动过滤掉,方便信息的阅读和使用。
有时,我们需要进行营销,因此如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以在网上手动搜索,但是效率会很低。这时,我们可以使用爬虫设置相应的规则,自动从互联网上采集目标用户的联系方式等数据,用于我们的营销。
有时,我们要分析某个网站的用户信息,比如分析网站的用户活跃度、评论数、热门文章等信息。如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时就可以使用爬虫轻松获取这些数据采集进行进一步分析,而且所有的爬取操作都是自动进行的,我们只需要编写相应的爬虫,设计相应的规则就可以了。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫自动化,从而可以更有效地使用互联网中的有效信息。.
3.安装第三方库
在抓取和解析数据之前,您需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面上输入pip install requests,按回车键安装。(注意网络连接)如下图

安装完成,如图

c爬虫抓取网页数据(Python爬虫大数据建模微+无忧全拼加零一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 39 次浏览 • 2021-12-20 01:13
今天是一个彻头彻尾的大数据时代。大数据贯穿我们的衣食住行。可以说,大数据是目前最宝贵的数据宝藏!
什么是 Python 爬虫?
Python爬虫也叫网络爬虫
关于Python爬虫,我们需要知道:
Python 基本语法
HTML页面的内容爬取(数据爬取)
从 HTML 页面中提取数据(数据清理)
Scrapy框架和scrapy-redis分布式策略(第三方框架)
蜘蛛、反蜘蛛和反反蜘蛛之间的斗争。
网络爬虫可分为通用爬虫和聚焦爬虫。
1.通用网络爬虫
从网上采集网页,进入采集信息。此网页信息用于索引搜索引擎以提供支持。它决定了整个引擎系统的内容是否丰富,信息是否及时,因此性能的好坏直接影响搜索引擎的有效性。
2.关注爬虫
Focused crawler是一个“面向特定主题需求”的网络爬虫程序。它与一般搜索引擎爬虫的区别在于:聚焦爬虫在实现网页爬取时会对内容进行处理和过滤,并尽量保证只有爬取到的页面信息与需求页面信息相关。
运营商大数据建模捕捉微+无忧获客全拼加零一
在中国,运营商拥有庞大且绝对真实的数据资源和数据存储能力。运营商在数据利用方面的经验和经验拥有绝对的发言权。运营商的大数据,无论是大数据的抓取,数据管理,数据能力,标签能力,产品服务,这些主要业务都有突出的表现。
运营商大数据是数据变现的最佳利器!相关企业只需要利用好运营商的数据和标注能力即可。运营商的大数据平台能力将能够为相关企业提供数据服务,最终实现数据变现。运营商是数据采集、数据处理、数据分析、数据访问、数据应用等全方位的数据管理平台。一个大数据平台应该有一个标准的架构。不同的行业和企业必须与之合作。您可以将您的业务发展到一个新的高度!
数据建模
运营商一直强调数据标准化和数据可视化。通过与运营商的大数据平台合作,相关企业可以按需建模。你所有的模型都应该和你公司的业务相符,这样整个公司使用的运营商数据才有效。通过运营商大数据,所有合作伙伴都可以拥有标准的建模和优秀的数据。
数据管理
实现数据管理是所有企业的追求。中小企业很难实现自己的数据管理。如果公司做大,数据管理的成本还是会很高的。因此,运营商的大数据可以系统化、透明化。一种无障碍的方式来帮助您的公司进行数据管理。
数据应用
Python爬虫更适合依赖互联网的数据爬取。
运营商大数据可以进行有针对性的建模,进行多维度、多维度的数据抓取和数据分析。运营商大数据可抓取任意网站、网页、URL、手机APP、400电话、固话、小程序、关键词、APP新注册用户等数据信息,助力整体行业和不同企业精准获取客户,提供营销服务! 查看全部
c爬虫抓取网页数据(Python爬虫大数据建模微+无忧全拼加零一)
今天是一个彻头彻尾的大数据时代。大数据贯穿我们的衣食住行。可以说,大数据是目前最宝贵的数据宝藏!
什么是 Python 爬虫?
Python爬虫也叫网络爬虫
关于Python爬虫,我们需要知道:
Python 基本语法
HTML页面的内容爬取(数据爬取)
从 HTML 页面中提取数据(数据清理)
Scrapy框架和scrapy-redis分布式策略(第三方框架)
蜘蛛、反蜘蛛和反反蜘蛛之间的斗争。
网络爬虫可分为通用爬虫和聚焦爬虫。
1.通用网络爬虫
从网上采集网页,进入采集信息。此网页信息用于索引搜索引擎以提供支持。它决定了整个引擎系统的内容是否丰富,信息是否及时,因此性能的好坏直接影响搜索引擎的有效性。
2.关注爬虫
Focused crawler是一个“面向特定主题需求”的网络爬虫程序。它与一般搜索引擎爬虫的区别在于:聚焦爬虫在实现网页爬取时会对内容进行处理和过滤,并尽量保证只有爬取到的页面信息与需求页面信息相关。
运营商大数据建模捕捉微+无忧获客全拼加零一
在中国,运营商拥有庞大且绝对真实的数据资源和数据存储能力。运营商在数据利用方面的经验和经验拥有绝对的发言权。运营商的大数据,无论是大数据的抓取,数据管理,数据能力,标签能力,产品服务,这些主要业务都有突出的表现。
运营商大数据是数据变现的最佳利器!相关企业只需要利用好运营商的数据和标注能力即可。运营商的大数据平台能力将能够为相关企业提供数据服务,最终实现数据变现。运营商是数据采集、数据处理、数据分析、数据访问、数据应用等全方位的数据管理平台。一个大数据平台应该有一个标准的架构。不同的行业和企业必须与之合作。您可以将您的业务发展到一个新的高度!
数据建模
运营商一直强调数据标准化和数据可视化。通过与运营商的大数据平台合作,相关企业可以按需建模。你所有的模型都应该和你公司的业务相符,这样整个公司使用的运营商数据才有效。通过运营商大数据,所有合作伙伴都可以拥有标准的建模和优秀的数据。
数据管理
实现数据管理是所有企业的追求。中小企业很难实现自己的数据管理。如果公司做大,数据管理的成本还是会很高的。因此,运营商的大数据可以系统化、透明化。一种无障碍的方式来帮助您的公司进行数据管理。
数据应用
Python爬虫更适合依赖互联网的数据爬取。
运营商大数据可以进行有针对性的建模,进行多维度、多维度的数据抓取和数据分析。运营商大数据可抓取任意网站、网页、URL、手机APP、400电话、固话、小程序、关键词、APP新注册用户等数据信息,助力整体行业和不同企业精准获取客户,提供营销服务!
c爬虫抓取网页数据(Python网络爬虫反爬破解策略实战作者(组图)作者)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-12-17 22:34
阿里云>云栖社区>主题图>C>c网络爬虫源码
推荐活动:
更多优惠>
当前话题:c网络爬虫源码加入采集
相关话题:
c 网络爬虫源码相关博客查看更多博客
C#网络爬虫
作者:街角盒饭712人浏览评论:05年前
公司编辑妹需要抓取网页内容。我让我帮忙做一个简单的爬虫工具。这是为了抓取网页的内容。似乎这对每个人来说都不是罕见的,但这里有一些小的变化。代码在这里。请参考 1 私有字符串 GetHttpWebRequest(string url) 2 {3 Ht
阅读全文
C#HttpHelper爬虫类源码分享--苏飞版
作者:苏飞 2071人浏览评论:03年前
简介 C#HttpHelper实现了在爬取C#HttpWebRequest时忽略编码、忽略证书、忽略cookies、实现代理的功能。有了它,您可以发出 Get 和 Post 请求,还可以轻松设置 cookie、证书、代理和编码。你不关心问题,因为类会自动为你识别页面
阅读全文
Python网络爬虫反爬虫破解策略实战
作者:薇薇 8128人浏览评论:04年前
作者:薇薇转载,请注明出处。我们经常写一些网络爬虫。我想每个人都会有一种感觉。写爬虫虽然不难,但是对付反爬是比较困难的,因为大部分网站都有自己的反爬机制,所以我们爬这个数据会比较困难。但是,对于每一种反爬虫机制,我们其实都会有相应的解决方案。作为爬虫的我们,
阅读全文
C#网络爬虫增强的多线程处理
作者:街角盒饭688人浏览评论:05年前
上次给公司妹子做爬虫,不是很精致。这次需要在公司项目中用到,所以做了一些改动,功能增加了URL图片采集、下载、线程处理接口URL图片下载等。 说说思路:总理获取初始URL 采集图片到初始URL 采集链接中的初始URL的所有内容将采集中的链接放入队列继续采集图片
阅读全文
Python网络爬虫爬取最好的妹妹的视频并保存到文件中
作者:keitwotest1060人浏览评论:03年前
项目描述 使用Python编写一个网络爬虫,抓取最好的妹妹的视频并保存到文件中。示例使用工具 Python2.7.X, pycharm 如何在pycharm .py文件中创建爬取最好的妹妹的视频,并在当前目录下创建video文件夹存放抓取的视频文件,写代码,然后运行
阅读全文
一篇文章教你如何使用Python网络爬虫获取差旅攻略
作者:python进阶者13人浏览评论:01年前
【一、项目背景】侨游网提供原创实用的出境游攻略、攻略、旅游社区和问答交流平台,以及智能出行规划解决方案,以及签证、保险、机票、和酒店 在线增值服务,如预订和汽车租赁。亲游“鼓励并帮助中国游客以自己的视角和方式体验世界。” 今天教大家获取侨友网的城市信息,
阅读全文
Java版网络爬虫的基础知识(传输)
作者:developerguy851 浏览评论人数:06年前
网络爬虫不仅可以抓取网站的网页、图片,甚至还可以实现抢票、在线抢购、查询票等功能。这几天我读了一些基础知识并记录下来。网页之间的关系可以看成是一张大图,图片的遍历可以分为深度优先和广度优先。网络爬虫以广度为先,一般来说如下:2个数组,一个
阅读全文
一篇文章教你使用Python网络爬虫抓取百度贴吧评论区图片和视频
作者:pythonadvanced 26人浏览评论:01年前
【一、项目背景】百度贴吧是全球最大的中文交流平台。你像我么?有时候在评论区看到图片就想下载?或者看到视频并想下载它?今天小编就带大家在评论区搜索关键词获取图片和视频。【二、项目目标】实现将贴吧获取的图片或视频保存在
阅读全文 查看全部
c爬虫抓取网页数据(Python网络爬虫反爬破解策略实战作者(组图)作者)
阿里云>云栖社区>主题图>C>c网络爬虫源码

推荐活动:
更多优惠>
当前话题:c网络爬虫源码加入采集
相关话题:
c 网络爬虫源码相关博客查看更多博客
C#网络爬虫


作者:街角盒饭712人浏览评论:05年前
公司编辑妹需要抓取网页内容。我让我帮忙做一个简单的爬虫工具。这是为了抓取网页的内容。似乎这对每个人来说都不是罕见的,但这里有一些小的变化。代码在这里。请参考 1 私有字符串 GetHttpWebRequest(string url) 2 {3 Ht
阅读全文
C#HttpHelper爬虫类源码分享--苏飞版


作者:苏飞 2071人浏览评论:03年前
简介 C#HttpHelper实现了在爬取C#HttpWebRequest时忽略编码、忽略证书、忽略cookies、实现代理的功能。有了它,您可以发出 Get 和 Post 请求,还可以轻松设置 cookie、证书、代理和编码。你不关心问题,因为类会自动为你识别页面
阅读全文
Python网络爬虫反爬虫破解策略实战


作者:薇薇 8128人浏览评论:04年前
作者:薇薇转载,请注明出处。我们经常写一些网络爬虫。我想每个人都会有一种感觉。写爬虫虽然不难,但是对付反爬是比较困难的,因为大部分网站都有自己的反爬机制,所以我们爬这个数据会比较困难。但是,对于每一种反爬虫机制,我们其实都会有相应的解决方案。作为爬虫的我们,
阅读全文
C#网络爬虫增强的多线程处理

作者:街角盒饭688人浏览评论:05年前
上次给公司妹子做爬虫,不是很精致。这次需要在公司项目中用到,所以做了一些改动,功能增加了URL图片采集、下载、线程处理接口URL图片下载等。 说说思路:总理获取初始URL 采集图片到初始URL 采集链接中的初始URL的所有内容将采集中的链接放入队列继续采集图片
阅读全文
Python网络爬虫爬取最好的妹妹的视频并保存到文件中


作者:keitwotest1060人浏览评论:03年前
项目描述 使用Python编写一个网络爬虫,抓取最好的妹妹的视频并保存到文件中。示例使用工具 Python2.7.X, pycharm 如何在pycharm .py文件中创建爬取最好的妹妹的视频,并在当前目录下创建video文件夹存放抓取的视频文件,写代码,然后运行
阅读全文
一篇文章教你如何使用Python网络爬虫获取差旅攻略


作者:python进阶者13人浏览评论:01年前
【一、项目背景】侨游网提供原创实用的出境游攻略、攻略、旅游社区和问答交流平台,以及智能出行规划解决方案,以及签证、保险、机票、和酒店 在线增值服务,如预订和汽车租赁。亲游“鼓励并帮助中国游客以自己的视角和方式体验世界。” 今天教大家获取侨友网的城市信息,
阅读全文
Java版网络爬虫的基础知识(传输)

作者:developerguy851 浏览评论人数:06年前
网络爬虫不仅可以抓取网站的网页、图片,甚至还可以实现抢票、在线抢购、查询票等功能。这几天我读了一些基础知识并记录下来。网页之间的关系可以看成是一张大图,图片的遍历可以分为深度优先和广度优先。网络爬虫以广度为先,一般来说如下:2个数组,一个
阅读全文
一篇文章教你使用Python网络爬虫抓取百度贴吧评论区图片和视频

作者:pythonadvanced 26人浏览评论:01年前
【一、项目背景】百度贴吧是全球最大的中文交流平台。你像我么?有时候在评论区看到图片就想下载?或者看到视频并想下载它?今天小编就带大家在评论区搜索关键词获取图片和视频。【二、项目目标】实现将贴吧获取的图片或视频保存在
阅读全文
c爬虫抓取网页数据(Web网页数据抓取(C/S)繁体(c#))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-17 22:33
网页数据捕获 (C/S) 传统
August 01, 2016-通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。比如我们有一个系统来提取百度网站歌曲搜索排名。分析系统根据获得的数据进行数据分析。为企业提供参考数据。为了满足上述要求,我们需要模拟浏览器浏览网页,获取页面的数据进行分析,最后编写分析的结构,即排序后的数据到数据库中。那
爬取网页数据分析(c#) 繁体
2008年11月26日-通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。比如我们有一个系统来提取百度网站歌曲搜索排名。分析系统根据获得的数据进行数据分析。为企业提供参考数据。为了满足上述要求,我们需要模拟浏览器浏览网页,获取页面的数据进行分析,最后编写分析的结构,即排序后的数据到数据库中。
网页数据抓取(B/S) 传统
2016年8月1日-C#爬取网页内容(转)1、爬取一般内容需要三个类:WebRequest、WebResponse、StreamReader 所需命名空间:System.Net、System.IO 核心代码:1WebRequest request = WebRequest.Create
C#爬虫,抓取网页数据
2016年9月1日-这两天学习了爬虫的基础知识,这里做一个简单的总结。抓取的网页商品数据保存在Excel表格中,效果如下: 使用Jumony Core引擎,非常强大,几乎完美的HTML解析引擎,支持css3选择器,直接抓取网页文档进行分析,并基于 HTTP 标头自动识别。博客园站点导航top信息抓取示例:var do
网页数据抓取繁体中文
2018年6月26日-1.html的常规解析 使用Jsoup包,配合开发者工具(F12)定位需要的数据路径。数据采集往往流程类似,类似的流程可以建议优化结构。2. selenium实例参考geckodriver安装:见
关于抓取网页数据!!!繁体中文
2009年3月6日-昨天去一家公司面试。老板说你回去用jsp做个项目,然后就可以上班了…… 要求是可以从指定的网页抓取需要的数据。例如:我在百度上搜索“电视”,然后我想从他返回的页面中提取他的关键词!(注:只提取客户端显示的网页数据)当我为老板提到这个话题时,我想到了“网络爬虫
网络爬虫抓取网页数据的几个常见问题
2019年2月20日-如果你想爬取数据又懒得写代码,可以试试网络爬虫爬取数据。相关文章:最简单的数据抓取教程,人人都可以用webscraper进阶教程,人人都可以使用如果你使用webscraper抓取数据,你很可能会遇到以下问题中的一个或多个,以及这些问题可能会直接打乱你的计划,甚至
网页数据抓取工具(谷歌插件web Scraper)
2018年2月11日-最简单的数据抓取教程,人人都可以使用Web Scraper是一款适合普通用户(没有专业IT技能)的免费爬虫工具,您可以轻松使用鼠标和简单的配置来获取您想要的数据。例如知乎回答列表、微博热点、微博评论、电商网站产品信息、博客文章列表等。
爬取网页数据分析繁体中文
2011.02.15-发表于 2006-05-24 14:04 北极燕鸥阅读(9793) 评论(42) 编辑采集类别:C#编程通过程序自动读取他人网站信息显示在网页上类似于一个爬虫程序,比如我们有一个系统提取百度网站歌曲搜索排名,分析系统根据得到的数据进行数据分析,为业务提供参数
抓取网页数据并解析繁体中文
2016年03月02日-这一天遇到了这样一个需求:这个页面数据能不能爬?然后提供账号、密码和网站地址: 账号:kytj1 密码:******************** 登录地址: 主要思想:1、 使用 Fiddler4 分析 HTTP 请求交互方式,包括
网页数据捕获 (C/S) 传统
August 01, 2016-通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。比如我们有一个系统来提取百度网站歌曲搜索排名。分析系统根据获得的数据进行数据分析。为企业提供参考数据。为了满足上述要求,我们需要模拟浏览器浏览网页,获取页面的数据进行分析,最后编写分析的结构,即排序后的数据到数据库中。那
爬取网页数据分析(c#) 繁体
2008年11月26日-通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。比如我们有一个系统来提取百度网站歌曲搜索排名。分析系统根据获得的数据进行数据分析。为企业提供参考数据。为了满足上述要求,我们需要模拟浏览器浏览网页,获取页面的数据进行分析,最后编写分析的结构,即排序后的数据到数据库中。
网页数据抓取(B/S) 传统
2016年8月1日-C#爬取网页内容(转)1、爬取一般内容需要三个类:WebRequest、WebResponse、StreamReader 所需命名空间:System.Net、System.IO 核心代码:1WebRequest request = WebRequest.Create
C#爬虫,抓取网页数据
2016年9月1日-这两天学习了爬虫的基础知识,这里做一个简单的总结。抓取的网页商品数据保存在Excel表格中,效果如下: 使用Jumony Core引擎,非常强大,几乎完美的HTML解析引擎,支持css3选择器,直接抓取网页文档进行分析,并基于 HTTP 标头自动识别。博客园站点导航top信息抓取示例:var do
网页数据抓取繁体中文
2018年6月26日-1.html的常规解析 使用Jsoup包,配合开发者工具(F12)定位需要的数据路径。数据采集往往流程类似,类似的流程可以建议优化结构。2. selenium实例参考geckodriver安装:见
关于抓取网页数据!!!繁体中文
2009年3月6日-昨天去一家公司面试。老板说你回去用jsp做个项目,然后就可以上班了…… 要求是可以从指定的网页抓取需要的数据。例如:我在百度上搜索“电视”,然后我想从他返回的页面中提取他的关键词!(注:只提取客户端显示的网页数据)当我为老板提到这个话题时,我想到了“网络爬虫
网络爬虫抓取网页数据的几个常见问题
2019年2月20日-如果你想爬取数据又懒得写代码,可以试试网络爬虫爬取数据。相关文章:最简单的数据抓取教程,人人都可以用webscraper进阶教程,人人都可以使用如果你使用webscraper抓取数据,你很可能会遇到以下问题中的一个或多个,以及这些问题可能会直接打乱你的计划,甚至
网页数据抓取工具(谷歌插件web Scraper)
2018年2月11日-最简单的数据抓取教程,人人都可以使用Web Scraper是一款适合普通用户(没有专业IT技能)的免费爬虫工具,您可以轻松使用鼠标和简单的配置来获取您想要的数据。例如知乎回答列表、微博热点、微博评论、电商网站产品信息、博客文章列表等。
爬取网页数据分析繁体中文
2011.02.15-发表于 2006-05-24 14:04 北极燕鸥阅读(9793) 评论(42) 编辑采集类别:C#编程通过程序自动读取他人网站信息显示在网页上类似于一个爬虫程序,比如我们有一个系统提取百度网站歌曲搜索排名,分析系统根据得到的数据进行数据分析,为业务提供参数
抓取网页数据并解析繁体中文
2016年03月02日-这一天遇到了这样一个需求:这个页面数据能不能爬?然后提供账号、密码和网站地址: 账号:kytj1 密码:******************** 登录地址: 主要思想:1、 使用 Fiddler4 分析 HTTP 请求交互方式,包括
爬取HTML网页数据繁体中文
2013年10月29日-(转)该类用于htmlparse过滤器不是通用的工具类,需要根据自己的需求来实现。这里只记录Htmlparse.jar包的一些用法。而已!有关详细信息,请参见此处:java.util.*;
使用VBA抓取网页数据繁体中文
2014年7月28日-我想用VBA捕捉以上数据,我想捕捉投资者关系信息->研究活动下每条新闻标题中的日期和新闻发布日期
Java爬取网页数据繁体中文
2013年9月23日——我最近处于辞职状态。我正赶着打发我的闲暇时间。我开始了自己的毕业设计。主题是Java Web 购物平台。我打算用SpringMVC+MyBatis来实现。我打算添加一个缓存服务器。我还没想好我会用什么。使用 Maven 进行管理
Matlab抓取网页数据繁体中文
2015年7月23日-本文示例使用正则表达式regexp进行语法识别和抓取网页数据:代码:url='#39;;[str status]=urlread(url,'Charset','GBK'); %
Matlab抓取网页数据繁体中文
2015年7月23日-本文示例使用正则表达式regexp进行语法识别和抓取网页数据:代码:url='';[str status]=urlread(url,'Charset','GBK');%Shanghai股票 suf='
JSON网页数据抓取繁体中文
2014.01.28-各位高手,如何获取以下网址的73条数据?#results/&aud=indv&type=med&state=AZ&county=Coconino&ag
python爬取网页数据传统
June 06, 2016-使用python进行简单的数据分析。在中关村在线采集数据,使用的网页是这个页面。首先,必须分析网页的 HTML。我们要捕获的数据是基于
.net 抓取网页数据 繁体中文
2015年8月3日-1、如果想通过代码获取某个页面的数据,首先根据右键查看该页面的源代码,分析一下。然后通过下面的代码,修改,一步步找出需要的内容,保存到数据库中。//根据Url地址获取网页私有字符串的html源码 GetWebContent(string Url){
C#如何抓取网页数据,分析和去除Html标签
2009年10月16日-由于这一段内容已经在我自己的搜索引擎中实现了,今天我就讲讲如何抓取网页数据,分析和去除Html标签,供大家参考。我的平台是Visual Studio2005,C#。——————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————网页
C#爬虫,繁体中文网页数据抓取笔记
2014年8月21日-第一次用C#写数据捕获,遇到各种问题。开始写模拟登录的时候,发现里面有验证码。我不得不突破验证码才能得到它。好的,那我去找验证码破解的密码。过了很长时间,我无法触摸门。我尝试了很多代码,发现它们并不通用。后来明白了原理。我先把噪点、干扰线等去掉,然后把颜色验证码变成黑色。
Python的BeautifulSoup实现抓取网页数据
2018年1月10-1日环境:pycharm,python3.42.源码分析import requests import refrom bs4 import BeautifulSoup#通过requests.get def getHtmlText(url)获取整个网页的数据:尝试:
goLang多线程抓取网页数据
2018.01.02-突然想用goLang快速爬取网页数据,于是想到了多线程页面爬取包main import("fmt""log""net/http""os""strconv""sync"
使用 HtmlAgilityPack 抓取网页数据
2013 年 12 月 31 日-XPath 使用路径表达式来选择 XML 文档中的节点或节点集。通过以下路径或步骤选择节点。下面列出了最有用的路径表达式: nodename:选择该节点的所有子节点。/:从根节点选择。//: 从匹配选择的当前节点中选择文档中的节点,而不管它们的位置。.:
浅谈抓取网页数据(提供Demo)
2014.04.09-Demo源码后台在公司做了一个比价系统,就是在网站上抓取其他产品的价格,和公司的产品对应,然后展示出来,提供给PM定价参考。后来同事的朋友找工作时,猎头让他做一个程序,抢去去哪儿最便宜的机票。然后,我帮助修复了它。这篇文章的目的就是提供这个程序的源码,然后和大家一起讨论
[.NET] 使用HtmlAgilityPack抓取网页数据繁体中文
2014年10月24日-刚学了XPath路径表达式,主要是在XML文档中搜索节点。通过 XPath 表达式,您可以快速定位和访问 XML 文档中的节点位置。HTML也是类似xml的标记语言,只是语法没有那么严谨。codeplex中有一个开源项目HtmlAgilityPack,提供了使用XPath解析HTML文档。
在Android中抓取和修改网页数据
2017-03-01-在Android中,经常使用WebView来加载网页和显示网页数据,但有时需要从网页中动态抓取数据,进行处理,甚至修改网页的数据,使其动态化显示效果,WebView 显得束手无策。最近的项目有这样的需求,加载本地H5数据,动态修改里面的内容,然后预览。接下来说一下他的实现步骤。
一个抓取网页数据的问题
2006年10月13日-我想抓取网页中的数据,但该网页禁止右键单击,查看源代码,禁止保存,甚至没有生成临时文件。一开始用的是webbrowser控件,使用documentText之类的时候报错。说找不到文件后,我用了这个HttpWebRequest request = (HttpWebRequest)
php抓取网页数据遇到的问题
2019年06月05日-1.file_get_contents无法捕获https安全协议网站使用curl获取数据函数file_get_contents_by_curl($url){$ch = curl_init();curl_setopt($ch, CURLOPT_URL, $url
winfrom 动态获取网页数据 繁体中文
2017年3月13日-我们知道如果网页的数据没有通过http协议加载到页面中,或者ajax延迟加载数据到页面,这时候你的请求url获取到的数据语言不全,说白了就是如果不能抓取到需要的目标数据,就用下面两种方法处理: 方法一:WebBrowser延迟加载采集地址(线程等待)用js处理。1.目标网址:
[.NET] 使用HtmlAgilityPack抓取网页数据繁体中文
2017年7月14日-刚学了XPath路径表达式,主要是在XML文档中搜索节点。通过 XPath 表达式,您可以快速定位和访问 XML 文档中的节点位置。HTML也是类似xml的标记语言,只是语法没有那么严谨。codeplex中有一个开源项目HtmlAgilityPack,提供了使用XPath解析HTML文档。
Java抓取网页数据,登录后抓取数据。繁体中文
2014年10月20日——最近做了一个小程序,从网上抓取数据。主要是关于信用,一些黑名单网站采集,从网站抓取到我们自己的系统。我也找到了一些资料,但我认为没有一个很好的和全面的例子。所以在这里做个笔记以提醒自己。首先需要一个jsoup jar包,我用的是1.6.0。. 下载地址为:
.net2.0 抓取网页数据分析繁体中文
2006年11月22日-效果图后台代码如下:using System;使用 System.Data; 使用 System.Configuration; 使用 System.Web;使用 System.Web.Security;
使用webbrowser控件抓取网页数据,如何抓取多个a标签的url地址对应的网页数据
2011.05.20-由于标题所属,我的页面有四个菜单,分别连接到不同的地址。我现在想用一个按钮来抓取这个页面的数据。在抓取时,我遍历获取了四个 a 标签 url 地址。然后自动进入对应页面抓取数据并保存到数据库中。现在问题如下: ArrayList UrlList = new ArrayList();
Java抓取网页数据(原网页+Javascript返回数据)
2014年05月07日-原文链接:有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据显示方式略有不同!本文用Java来告诉你如何捕获网站的数量
Java抓取网页数据(原网页+Javascript返回数据)
2012年8月26日-转载请注明出处!原文链接:有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据显示方式略有不同!本文使用Java向大家展示如何抓取网站的数据:(1)
网页数据抓取,网页源代码没有需要的数据
2014.10.04-在使用WebClient抓取网页数据时,查看了网页的源码,发现源码中没有网页上可以看到的数据。这种情况下,是不是意味着网页上的数据是通过JS返回的?那么,在这种情况下,您如何提取所需的数据?
谁能抓取一个C#网页数据的源代码,最好是完整的?繁体
2012年12月12日-如何使用C#从类似于搜狐的页面中抓取标题、作者和日期?爬取次数不少于10次。请高手指点,最好能给出完整的源代码?
C#抓取网页数据,分析去除HTML标签【转】繁体
August 09, 2010-首先抓取网页的全部内容,将数据放入byte[]中(网络传输时格式为byte),然后转换为String,方便操作。示例如下: private static string GetPageData (string url){ if (url == null || url.Trim() =
【工作笔记0006】C#调用HtmlAgilityPack类库实现网页数据抓取繁体中文
2015年7月30日-最近在研究HtmlAgilityPack,发现它的类库功能非常强大,非常方便的实现网页数据抓取。下面是一个使用 HtmlAgilityPack 捕获数据的简单示例。目标是抓取我个人博客的文章列表数据。路径如下:adamlevine7个人博客目录核心代码如下:1.第一次参考
C#抓取网页数据,分析(如抓取天气预报) 091016 有更新 091110 再次更新 繁体
2009年8月12日-先看这位大哥的博客。最好先抓取网页的全部内容,将数据放入byte[]中(网络传输时格式为byte),然后再转换为String,方便比较。操作示例如下: private static string GetPageData(string url){ if (url == n
使用 node.js cheerio 抓取网页数据
2015年9月29日-你是想自动抓取网页中的一些数据还是想把从什么博客中提取的数据转换成结构化数据?有没有现有的 API 来检索数据?!!!!@#$@#$...可以解决网页爬虫问题。什么是网络爬虫?你可能会问。. . 网页抓取是一种以编程方式(通常无需浏览器参与)检索网页内容并从中提取数据的过程。这篇论文,小
Java程序抓取网页数据和去重处理
2014年08月05日-如题,等回复,最好带程序,带个大概说明,新手,网上爬虫看起来很简单。
为什么我不能用Delphi抓取网页数据?
2015.06.08-我用delphi自带的IdHttp idhttp1.Get('')来抓取这个网页的数据。为什么我不能抓取下面的数据?有什么好的方法可以做到吗?
8、多级网页数据抓取繁体中文
2013 年 7 月 31 日-使用 System;using System.采集s.Generic;using System.ComponentModel;using System.Data;using System.Drawing;using System.Text;using System.Window
谁有登录后抓取网页数据的例子?
2010 年 12 月 8 日 - 现在迫切需要一个这样的例子,过去两天我一直很伤心。登录包括使用用户名、密码和验证码登录。只需能够完成登录步骤。登录是手动输入登录
Python中使用PhantomJS抓取Javascript网页数据
2015年07月01日-有些网页不是静态加载的,而是通过javascipt函数动态加载的。例如,在下面的网页中,通过javascirpt函数从后台加载了表中看涨合约和看跌合约的数据。仅使用beautifulsoup 无法捕获此表中的数据。找资料,发现可以用PhantomJS来爬取此类网页
网页爬虫-使用Python爬取网页数据繁体中文
2015年8月24日-干货搬家大神童熊!我没有事儿。我看了一下 Python,发现它很酷。废话少说,准备搭建环境。因为是MAC电脑,所以自动安装Python2.7版本并添加库Beautiful Soup,这里有两种方法
网页数据采集系统解决方案 传统
2009年12月29日-1. 项目介绍 项目背景 互联网时代,信息海阔天空。甚至我们获取信息的方式也发生了变化:从传统的翻书到查字典,再到通过搜索引擎搜索。我们已经从信息匮乏的时代走到了信息丰富的今天。今天,困扰我们的问题不是信息太少,而是太多太多,让你无法分辨或选择。因此,提供一个
Node.js 使用cheerio 抓取网页数据DEMO
2015年07月28日-Node.js原本是作为Js服务器使用的,现在一起用它来做个爬虫吧。关键是爬取网页后如何得到你想要的数据?然后我找到了cheerio,解析html非常方便,就像在浏览器中使用jquery一样。使用以下命令安装cheerio [C#]纯文本视图复制代码?01npm 安装
R语言实现简单的网页数据抓取繁体中文
2017年2月17日-我在知乎遇到这样的问题。这是要爬取的内容的网页: R语言代码的实现如下:#Install XML package>install.packages("XML")#Load XML package>
Jsoup介绍-使用Java抓取网页数据
2014年10月15日-转载请注明出处:概述jsoup是一个Java HTML解析器,可以直接解析一个URL地址和HTML文本内容。它提供了一个非常省力的 API,通过 DOM、CSS 和类 查看全部
c爬虫抓取网页数据(Web网页数据抓取(C/S)繁体(c#))
网页数据捕获 (C/S) 传统
August 01, 2016-通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。比如我们有一个系统来提取百度网站歌曲搜索排名。分析系统根据获得的数据进行数据分析。为企业提供参考数据。为了满足上述要求,我们需要模拟浏览器浏览网页,获取页面的数据进行分析,最后编写分析的结构,即排序后的数据到数据库中。那
爬取网页数据分析(c#) 繁体
2008年11月26日-通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。比如我们有一个系统来提取百度网站歌曲搜索排名。分析系统根据获得的数据进行数据分析。为企业提供参考数据。为了满足上述要求,我们需要模拟浏览器浏览网页,获取页面的数据进行分析,最后编写分析的结构,即排序后的数据到数据库中。
网页数据抓取(B/S) 传统
2016年8月1日-C#爬取网页内容(转)1、爬取一般内容需要三个类:WebRequest、WebResponse、StreamReader 所需命名空间:System.Net、System.IO 核心代码:1WebRequest request = WebRequest.Create
C#爬虫,抓取网页数据
2016年9月1日-这两天学习了爬虫的基础知识,这里做一个简单的总结。抓取的网页商品数据保存在Excel表格中,效果如下: 使用Jumony Core引擎,非常强大,几乎完美的HTML解析引擎,支持css3选择器,直接抓取网页文档进行分析,并基于 HTTP 标头自动识别。博客园站点导航top信息抓取示例:var do
网页数据抓取繁体中文
2018年6月26日-1.html的常规解析 使用Jsoup包,配合开发者工具(F12)定位需要的数据路径。数据采集往往流程类似,类似的流程可以建议优化结构。2. selenium实例参考geckodriver安装:见
关于抓取网页数据!!!繁体中文
2009年3月6日-昨天去一家公司面试。老板说你回去用jsp做个项目,然后就可以上班了…… 要求是可以从指定的网页抓取需要的数据。例如:我在百度上搜索“电视”,然后我想从他返回的页面中提取他的关键词!(注:只提取客户端显示的网页数据)当我为老板提到这个话题时,我想到了“网络爬虫
网络爬虫抓取网页数据的几个常见问题
2019年2月20日-如果你想爬取数据又懒得写代码,可以试试网络爬虫爬取数据。相关文章:最简单的数据抓取教程,人人都可以用webscraper进阶教程,人人都可以使用如果你使用webscraper抓取数据,你很可能会遇到以下问题中的一个或多个,以及这些问题可能会直接打乱你的计划,甚至
网页数据抓取工具(谷歌插件web Scraper)
2018年2月11日-最简单的数据抓取教程,人人都可以使用Web Scraper是一款适合普通用户(没有专业IT技能)的免费爬虫工具,您可以轻松使用鼠标和简单的配置来获取您想要的数据。例如知乎回答列表、微博热点、微博评论、电商网站产品信息、博客文章列表等。
爬取网页数据分析繁体中文
2011.02.15-发表于 2006-05-24 14:04 北极燕鸥阅读(9793) 评论(42) 编辑采集类别:C#编程通过程序自动读取他人网站信息显示在网页上类似于一个爬虫程序,比如我们有一个系统提取百度网站歌曲搜索排名,分析系统根据得到的数据进行数据分析,为业务提供参数
抓取网页数据并解析繁体中文
2016年03月02日-这一天遇到了这样一个需求:这个页面数据能不能爬?然后提供账号、密码和网站地址: 账号:kytj1 密码:******************** 登录地址: 主要思想:1、 使用 Fiddler4 分析 HTTP 请求交互方式,包括
网页数据捕获 (C/S) 传统
August 01, 2016-通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。比如我们有一个系统来提取百度网站歌曲搜索排名。分析系统根据获得的数据进行数据分析。为企业提供参考数据。为了满足上述要求,我们需要模拟浏览器浏览网页,获取页面的数据进行分析,最后编写分析的结构,即排序后的数据到数据库中。那
爬取网页数据分析(c#) 繁体
2008年11月26日-通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。比如我们有一个系统来提取百度网站歌曲搜索排名。分析系统根据获得的数据进行数据分析。为企业提供参考数据。为了满足上述要求,我们需要模拟浏览器浏览网页,获取页面的数据进行分析,最后编写分析的结构,即排序后的数据到数据库中。
网页数据抓取(B/S) 传统
2016年8月1日-C#爬取网页内容(转)1、爬取一般内容需要三个类:WebRequest、WebResponse、StreamReader 所需命名空间:System.Net、System.IO 核心代码:1WebRequest request = WebRequest.Create
C#爬虫,抓取网页数据
2016年9月1日-这两天学习了爬虫的基础知识,这里做一个简单的总结。抓取的网页商品数据保存在Excel表格中,效果如下: 使用Jumony Core引擎,非常强大,几乎完美的HTML解析引擎,支持css3选择器,直接抓取网页文档进行分析,并基于 HTTP 标头自动识别。博客园站点导航top信息抓取示例:var do
网页数据抓取繁体中文
2018年6月26日-1.html的常规解析 使用Jsoup包,配合开发者工具(F12)定位需要的数据路径。数据采集往往流程类似,类似的流程可以建议优化结构。2. selenium实例参考geckodriver安装:见
关于抓取网页数据!!!繁体中文
2009年3月6日-昨天去一家公司面试。老板说你回去用jsp做个项目,然后就可以上班了…… 要求是可以从指定的网页抓取需要的数据。例如:我在百度上搜索“电视”,然后我想从他返回的页面中提取他的关键词!(注:只提取客户端显示的网页数据)当我为老板提到这个话题时,我想到了“网络爬虫
网络爬虫抓取网页数据的几个常见问题
2019年2月20日-如果你想爬取数据又懒得写代码,可以试试网络爬虫爬取数据。相关文章:最简单的数据抓取教程,人人都可以用webscraper进阶教程,人人都可以使用如果你使用webscraper抓取数据,你很可能会遇到以下问题中的一个或多个,以及这些问题可能会直接打乱你的计划,甚至
网页数据抓取工具(谷歌插件web Scraper)
2018年2月11日-最简单的数据抓取教程,人人都可以使用Web Scraper是一款适合普通用户(没有专业IT技能)的免费爬虫工具,您可以轻松使用鼠标和简单的配置来获取您想要的数据。例如知乎回答列表、微博热点、微博评论、电商网站产品信息、博客文章列表等。
爬取网页数据分析繁体中文
2011.02.15-发表于 2006-05-24 14:04 北极燕鸥阅读(9793) 评论(42) 编辑采集类别:C#编程通过程序自动读取他人网站信息显示在网页上类似于一个爬虫程序,比如我们有一个系统提取百度网站歌曲搜索排名,分析系统根据得到的数据进行数据分析,为业务提供参数
抓取网页数据并解析繁体中文
2016年03月02日-这一天遇到了这样一个需求:这个页面数据能不能爬?然后提供账号、密码和网站地址: 账号:kytj1 密码:******************** 登录地址: 主要思想:1、 使用 Fiddler4 分析 HTTP 请求交互方式,包括
爬取HTML网页数据繁体中文
2013年10月29日-(转)该类用于htmlparse过滤器不是通用的工具类,需要根据自己的需求来实现。这里只记录Htmlparse.jar包的一些用法。而已!有关详细信息,请参见此处:java.util.*;
使用VBA抓取网页数据繁体中文
2014年7月28日-我想用VBA捕捉以上数据,我想捕捉投资者关系信息->研究活动下每条新闻标题中的日期和新闻发布日期
Java爬取网页数据繁体中文
2013年9月23日——我最近处于辞职状态。我正赶着打发我的闲暇时间。我开始了自己的毕业设计。主题是Java Web 购物平台。我打算用SpringMVC+MyBatis来实现。我打算添加一个缓存服务器。我还没想好我会用什么。使用 Maven 进行管理
Matlab抓取网页数据繁体中文
2015年7月23日-本文示例使用正则表达式regexp进行语法识别和抓取网页数据:代码:url='#39;;[str status]=urlread(url,'Charset','GBK'); %
Matlab抓取网页数据繁体中文
2015年7月23日-本文示例使用正则表达式regexp进行语法识别和抓取网页数据:代码:url='';[str status]=urlread(url,'Charset','GBK');%Shanghai股票 suf='
JSON网页数据抓取繁体中文
2014.01.28-各位高手,如何获取以下网址的73条数据?#results/&aud=indv&type=med&state=AZ&county=Coconino&ag
python爬取网页数据传统
June 06, 2016-使用python进行简单的数据分析。在中关村在线采集数据,使用的网页是这个页面。首先,必须分析网页的 HTML。我们要捕获的数据是基于
.net 抓取网页数据 繁体中文
2015年8月3日-1、如果想通过代码获取某个页面的数据,首先根据右键查看该页面的源代码,分析一下。然后通过下面的代码,修改,一步步找出需要的内容,保存到数据库中。//根据Url地址获取网页私有字符串的html源码 GetWebContent(string Url){
C#如何抓取网页数据,分析和去除Html标签
2009年10月16日-由于这一段内容已经在我自己的搜索引擎中实现了,今天我就讲讲如何抓取网页数据,分析和去除Html标签,供大家参考。我的平台是Visual Studio2005,C#。——————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————网页
C#爬虫,繁体中文网页数据抓取笔记
2014年8月21日-第一次用C#写数据捕获,遇到各种问题。开始写模拟登录的时候,发现里面有验证码。我不得不突破验证码才能得到它。好的,那我去找验证码破解的密码。过了很长时间,我无法触摸门。我尝试了很多代码,发现它们并不通用。后来明白了原理。我先把噪点、干扰线等去掉,然后把颜色验证码变成黑色。
Python的BeautifulSoup实现抓取网页数据
2018年1月10-1日环境:pycharm,python3.42.源码分析import requests import refrom bs4 import BeautifulSoup#通过requests.get def getHtmlText(url)获取整个网页的数据:尝试:
goLang多线程抓取网页数据
2018.01.02-突然想用goLang快速爬取网页数据,于是想到了多线程页面爬取包main import("fmt""log""net/http""os""strconv""sync"
使用 HtmlAgilityPack 抓取网页数据
2013 年 12 月 31 日-XPath 使用路径表达式来选择 XML 文档中的节点或节点集。通过以下路径或步骤选择节点。下面列出了最有用的路径表达式: nodename:选择该节点的所有子节点。/:从根节点选择。//: 从匹配选择的当前节点中选择文档中的节点,而不管它们的位置。.:
浅谈抓取网页数据(提供Demo)
2014.04.09-Demo源码后台在公司做了一个比价系统,就是在网站上抓取其他产品的价格,和公司的产品对应,然后展示出来,提供给PM定价参考。后来同事的朋友找工作时,猎头让他做一个程序,抢去去哪儿最便宜的机票。然后,我帮助修复了它。这篇文章的目的就是提供这个程序的源码,然后和大家一起讨论
[.NET] 使用HtmlAgilityPack抓取网页数据繁体中文
2014年10月24日-刚学了XPath路径表达式,主要是在XML文档中搜索节点。通过 XPath 表达式,您可以快速定位和访问 XML 文档中的节点位置。HTML也是类似xml的标记语言,只是语法没有那么严谨。codeplex中有一个开源项目HtmlAgilityPack,提供了使用XPath解析HTML文档。
在Android中抓取和修改网页数据
2017-03-01-在Android中,经常使用WebView来加载网页和显示网页数据,但有时需要从网页中动态抓取数据,进行处理,甚至修改网页的数据,使其动态化显示效果,WebView 显得束手无策。最近的项目有这样的需求,加载本地H5数据,动态修改里面的内容,然后预览。接下来说一下他的实现步骤。
一个抓取网页数据的问题
2006年10月13日-我想抓取网页中的数据,但该网页禁止右键单击,查看源代码,禁止保存,甚至没有生成临时文件。一开始用的是webbrowser控件,使用documentText之类的时候报错。说找不到文件后,我用了这个HttpWebRequest request = (HttpWebRequest)
php抓取网页数据遇到的问题
2019年06月05日-1.file_get_contents无法捕获https安全协议网站使用curl获取数据函数file_get_contents_by_curl($url){$ch = curl_init();curl_setopt($ch, CURLOPT_URL, $url
winfrom 动态获取网页数据 繁体中文
2017年3月13日-我们知道如果网页的数据没有通过http协议加载到页面中,或者ajax延迟加载数据到页面,这时候你的请求url获取到的数据语言不全,说白了就是如果不能抓取到需要的目标数据,就用下面两种方法处理: 方法一:WebBrowser延迟加载采集地址(线程等待)用js处理。1.目标网址:
[.NET] 使用HtmlAgilityPack抓取网页数据繁体中文
2017年7月14日-刚学了XPath路径表达式,主要是在XML文档中搜索节点。通过 XPath 表达式,您可以快速定位和访问 XML 文档中的节点位置。HTML也是类似xml的标记语言,只是语法没有那么严谨。codeplex中有一个开源项目HtmlAgilityPack,提供了使用XPath解析HTML文档。
Java抓取网页数据,登录后抓取数据。繁体中文
2014年10月20日——最近做了一个小程序,从网上抓取数据。主要是关于信用,一些黑名单网站采集,从网站抓取到我们自己的系统。我也找到了一些资料,但我认为没有一个很好的和全面的例子。所以在这里做个笔记以提醒自己。首先需要一个jsoup jar包,我用的是1.6.0。. 下载地址为:
.net2.0 抓取网页数据分析繁体中文
2006年11月22日-效果图后台代码如下:using System;使用 System.Data; 使用 System.Configuration; 使用 System.Web;使用 System.Web.Security;
使用webbrowser控件抓取网页数据,如何抓取多个a标签的url地址对应的网页数据
2011.05.20-由于标题所属,我的页面有四个菜单,分别连接到不同的地址。我现在想用一个按钮来抓取这个页面的数据。在抓取时,我遍历获取了四个 a 标签 url 地址。然后自动进入对应页面抓取数据并保存到数据库中。现在问题如下: ArrayList UrlList = new ArrayList();
Java抓取网页数据(原网页+Javascript返回数据)
2014年05月07日-原文链接:有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据显示方式略有不同!本文用Java来告诉你如何捕获网站的数量
Java抓取网页数据(原网页+Javascript返回数据)
2012年8月26日-转载请注明出处!原文链接:有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据显示方式略有不同!本文使用Java向大家展示如何抓取网站的数据:(1)
网页数据抓取,网页源代码没有需要的数据
2014.10.04-在使用WebClient抓取网页数据时,查看了网页的源码,发现源码中没有网页上可以看到的数据。这种情况下,是不是意味着网页上的数据是通过JS返回的?那么,在这种情况下,您如何提取所需的数据?
谁能抓取一个C#网页数据的源代码,最好是完整的?繁体
2012年12月12日-如何使用C#从类似于搜狐的页面中抓取标题、作者和日期?爬取次数不少于10次。请高手指点,最好能给出完整的源代码?
C#抓取网页数据,分析去除HTML标签【转】繁体
August 09, 2010-首先抓取网页的全部内容,将数据放入byte[]中(网络传输时格式为byte),然后转换为String,方便操作。示例如下: private static string GetPageData (string url){ if (url == null || url.Trim() =
【工作笔记0006】C#调用HtmlAgilityPack类库实现网页数据抓取繁体中文
2015年7月30日-最近在研究HtmlAgilityPack,发现它的类库功能非常强大,非常方便的实现网页数据抓取。下面是一个使用 HtmlAgilityPack 捕获数据的简单示例。目标是抓取我个人博客的文章列表数据。路径如下:adamlevine7个人博客目录核心代码如下:1.第一次参考
C#抓取网页数据,分析(如抓取天气预报) 091016 有更新 091110 再次更新 繁体
2009年8月12日-先看这位大哥的博客。最好先抓取网页的全部内容,将数据放入byte[]中(网络传输时格式为byte),然后再转换为String,方便比较。操作示例如下: private static string GetPageData(string url){ if (url == n
使用 node.js cheerio 抓取网页数据
2015年9月29日-你是想自动抓取网页中的一些数据还是想把从什么博客中提取的数据转换成结构化数据?有没有现有的 API 来检索数据?!!!!@#$@#$...可以解决网页爬虫问题。什么是网络爬虫?你可能会问。. . 网页抓取是一种以编程方式(通常无需浏览器参与)检索网页内容并从中提取数据的过程。这篇论文,小
Java程序抓取网页数据和去重处理
2014年08月05日-如题,等回复,最好带程序,带个大概说明,新手,网上爬虫看起来很简单。
为什么我不能用Delphi抓取网页数据?
2015.06.08-我用delphi自带的IdHttp idhttp1.Get('')来抓取这个网页的数据。为什么我不能抓取下面的数据?有什么好的方法可以做到吗?
8、多级网页数据抓取繁体中文
2013 年 7 月 31 日-使用 System;using System.采集s.Generic;using System.ComponentModel;using System.Data;using System.Drawing;using System.Text;using System.Window
谁有登录后抓取网页数据的例子?
2010 年 12 月 8 日 - 现在迫切需要一个这样的例子,过去两天我一直很伤心。登录包括使用用户名、密码和验证码登录。只需能够完成登录步骤。登录是手动输入登录
Python中使用PhantomJS抓取Javascript网页数据
2015年07月01日-有些网页不是静态加载的,而是通过javascipt函数动态加载的。例如,在下面的网页中,通过javascirpt函数从后台加载了表中看涨合约和看跌合约的数据。仅使用beautifulsoup 无法捕获此表中的数据。找资料,发现可以用PhantomJS来爬取此类网页
网页爬虫-使用Python爬取网页数据繁体中文
2015年8月24日-干货搬家大神童熊!我没有事儿。我看了一下 Python,发现它很酷。废话少说,准备搭建环境。因为是MAC电脑,所以自动安装Python2.7版本并添加库Beautiful Soup,这里有两种方法
网页数据采集系统解决方案 传统
2009年12月29日-1. 项目介绍 项目背景 互联网时代,信息海阔天空。甚至我们获取信息的方式也发生了变化:从传统的翻书到查字典,再到通过搜索引擎搜索。我们已经从信息匮乏的时代走到了信息丰富的今天。今天,困扰我们的问题不是信息太少,而是太多太多,让你无法分辨或选择。因此,提供一个
Node.js 使用cheerio 抓取网页数据DEMO
2015年07月28日-Node.js原本是作为Js服务器使用的,现在一起用它来做个爬虫吧。关键是爬取网页后如何得到你想要的数据?然后我找到了cheerio,解析html非常方便,就像在浏览器中使用jquery一样。使用以下命令安装cheerio [C#]纯文本视图复制代码?01npm 安装
R语言实现简单的网页数据抓取繁体中文
2017年2月17日-我在知乎遇到这样的问题。这是要爬取的内容的网页: R语言代码的实现如下:#Install XML package>install.packages("XML")#Load XML package>
Jsoup介绍-使用Java抓取网页数据
2014年10月15日-转载请注明出处:概述jsoup是一个Java HTML解析器,可以直接解析一个URL地址和HTML文本内容。它提供了一个非常省力的 API,通过 DOM、CSS 和类
c爬虫抓取网页数据( SEO优化工作的6个策略之前)
网站优化 • 优采云 发表了文章 • 0 个评论 • 35 次浏览 • 2021-12-16 16:16
SEO优化工作的6个策略之前)
搜索引擎爬虫抓取我们的网页是实现 SEO 优化的第一步。如果不爬取,网站就不会搜索到收录,也就没有排名。所以对于每一个SEO从业者来说,爬行是第一步!
事实上,大多数SEO从业者所知道的搜索引擎爬取算法只有深度优先和广度优先的爬取策略。但实际上,爬虫爬取的网页有6种策略。在分享这6个策略之前,你必须先看看搜索引擎爬虫的工作流程,否则你可能看不懂下面的内容。
爬虫的宽度优先爬取策略
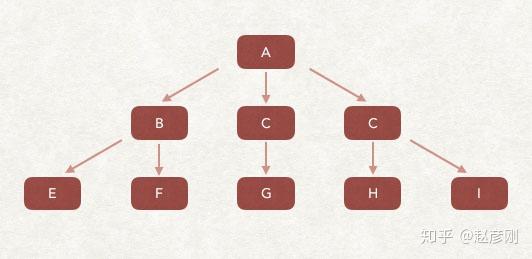
广度优先的爬取策略,一种历史悠久,一直受到关注的爬取策略。搜索引擎爬虫诞生以来就一直在使用的爬虫策略,甚至很多新的策略都是以此为基础的。
广度优先的爬取策略是根据要爬取的URL列表进行爬取。新发现的并判断为未爬取的链接,基本上直接存放在待爬取的URL列表末尾,等待被爬取。
如上图,我们假设爬虫的待爬取的URL列表中只有A。爬虫从A网页开始爬取,从A中提取B、C、D网页,然后将B、C、D放入爬取队列,然后获取E、F、G、H、I页面依次插入到要爬取的URL列表中,以此类推。
Crawler的深度优先爬取策略
深度优先抓取的策略是,爬虫会从待抓取列表中抓取第一个网址,然后沿着这个网址继续抓取该页面的其他网址,直到该行处理完毕,再从待抓取列表中抓取, 抢第二个,依此类推。下面给出了一个说明。
作为列表中第一个要爬取的 URL,爬虫开始爬取,然后爬到 B、C、D、E、F,但是 B、C、D 中没有后续链接(这里也会删除了已经爬过的页面),从E中找到H,跟着H,找到I,然后就没有了。在F中找到G,那么这个链接的爬取就结束了。从要获取的列表中,获取下一个链接继续上述操作。
Crawler 不完整的 PageRank 爬取策略
相信很多人都知道PageRank算法。我们SEO的白话理解就是链接传递权重的算法。而如果应用于爬虫爬行,又是怎样的逻辑呢?首先,爬虫的目的是下载网页。同时,爬虫无法看到指向某个网页的所有链接。因此,在爬取过程中,爬虫无法计算所有网页的pagerank,从而导致爬行。过程中计算出的pagerank不太可靠。
非完全pagerank爬取策略是基于爬虫无法看到某个页面的所有链接,而只能看到部分情况,必须进行pagerank计算结果。
它的具体策略是将已下载的网页和要爬取的URL列表中的网页形成一个汇总。在此摘要中执行 pagerank 计算。计算完成后,待爬取的URL列表中的每个URL都会得到一个pagerank值,然后根据这个值进行倒序排序。先获取最高的pagerank分数,然后一一获取。
这是问题吗?在要爬取的URL列表中,如果最后添加了新的URL,是否需要重新计算?
不是这种情况。搜索引擎会等到待抓取的网址列表中的新网址达到一定数量后,才会重新抓取。这样效率会提高很多。毕竟,爬虫抓取第一个添加的需要时间。
Crawler的OPIC爬取策略
OPIC是在线页面重要性计算的缩写,意思是“在线页面重要性计算”。这是pagerank的升级版。
它的具体策略逻辑是爬虫给互联网上的所有网址分配一个初始分数,每个网址的分数相同。每次下载一个网页时,该网页的分数都会平均分配给该网页中的所有链接。自然而然,这个页面的分数就会被清零。对于要爬取的URL列表(当然,刚才的网页被清空了分数,也是因为已经爬过了),首先爬取的是谁的分数最高。
与pagerank不同,opic是实时计算的。这里提醒我们,如果我们只考虑opic的爬取策略。这个策略和pagerank策略都证实了一个逻辑。我们新生成的网页,被链接的次数越多,被抓取的概率就越大。
是否值得考虑您的网页布局?
爬虫爬取的大站点优先策略
大网站优先爬取,是不是顾名思义?大的网站会先爬吗?但这里有两种解释。我个人认为这两个解释爬虫都在使用。
大站优先爬取说明1:顾名思义,爬虫会对列表中要爬取的URL进行分类,然后确定域名对应的网站级别。比如优先抓取权重较大的网站域名。
大展优先爬取说明2:爬虫根据域名对列表中要爬取的URL进行分类,然后计算数量。它所属的域是待抓取列表中编号最大的域。
两种解释,一种是网站的权重高,另一种是每天发布的文章数量多,发布非常集中。但是让我们想象一下,发布如此集中和如此多文章的网站通常都是大网站,对吗?
我们在这里想什么?
写文章时,一定要及时推送到搜索引擎。一小时不能发一篇,太散了。不过这个还是要验证的,有经验的同学可以考一下。 查看全部
c爬虫抓取网页数据(
SEO优化工作的6个策略之前)

搜索引擎爬虫抓取我们的网页是实现 SEO 优化的第一步。如果不爬取,网站就不会搜索到收录,也就没有排名。所以对于每一个SEO从业者来说,爬行是第一步!
事实上,大多数SEO从业者所知道的搜索引擎爬取算法只有深度优先和广度优先的爬取策略。但实际上,爬虫爬取的网页有6种策略。在分享这6个策略之前,你必须先看看搜索引擎爬虫的工作流程,否则你可能看不懂下面的内容。
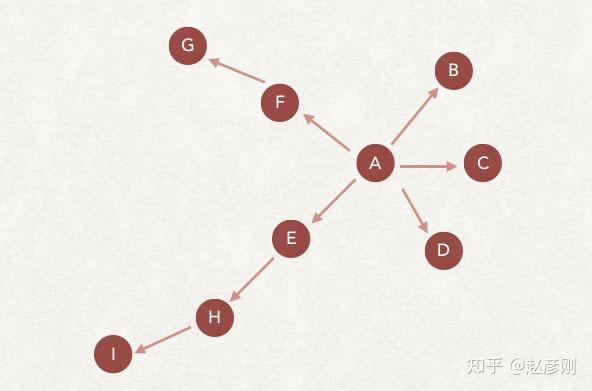
爬虫的宽度优先爬取策略
广度优先的爬取策略,一种历史悠久,一直受到关注的爬取策略。搜索引擎爬虫诞生以来就一直在使用的爬虫策略,甚至很多新的策略都是以此为基础的。
广度优先的爬取策略是根据要爬取的URL列表进行爬取。新发现的并判断为未爬取的链接,基本上直接存放在待爬取的URL列表末尾,等待被爬取。
如上图,我们假设爬虫的待爬取的URL列表中只有A。爬虫从A网页开始爬取,从A中提取B、C、D网页,然后将B、C、D放入爬取队列,然后获取E、F、G、H、I页面依次插入到要爬取的URL列表中,以此类推。
Crawler的深度优先爬取策略
深度优先抓取的策略是,爬虫会从待抓取列表中抓取第一个网址,然后沿着这个网址继续抓取该页面的其他网址,直到该行处理完毕,再从待抓取列表中抓取, 抢第二个,依此类推。下面给出了一个说明。
作为列表中第一个要爬取的 URL,爬虫开始爬取,然后爬到 B、C、D、E、F,但是 B、C、D 中没有后续链接(这里也会删除了已经爬过的页面),从E中找到H,跟着H,找到I,然后就没有了。在F中找到G,那么这个链接的爬取就结束了。从要获取的列表中,获取下一个链接继续上述操作。
Crawler 不完整的 PageRank 爬取策略
相信很多人都知道PageRank算法。我们SEO的白话理解就是链接传递权重的算法。而如果应用于爬虫爬行,又是怎样的逻辑呢?首先,爬虫的目的是下载网页。同时,爬虫无法看到指向某个网页的所有链接。因此,在爬取过程中,爬虫无法计算所有网页的pagerank,从而导致爬行。过程中计算出的pagerank不太可靠。
非完全pagerank爬取策略是基于爬虫无法看到某个页面的所有链接,而只能看到部分情况,必须进行pagerank计算结果。
它的具体策略是将已下载的网页和要爬取的URL列表中的网页形成一个汇总。在此摘要中执行 pagerank 计算。计算完成后,待爬取的URL列表中的每个URL都会得到一个pagerank值,然后根据这个值进行倒序排序。先获取最高的pagerank分数,然后一一获取。
这是问题吗?在要爬取的URL列表中,如果最后添加了新的URL,是否需要重新计算?
不是这种情况。搜索引擎会等到待抓取的网址列表中的新网址达到一定数量后,才会重新抓取。这样效率会提高很多。毕竟,爬虫抓取第一个添加的需要时间。
Crawler的OPIC爬取策略
OPIC是在线页面重要性计算的缩写,意思是“在线页面重要性计算”。这是pagerank的升级版。
它的具体策略逻辑是爬虫给互联网上的所有网址分配一个初始分数,每个网址的分数相同。每次下载一个网页时,该网页的分数都会平均分配给该网页中的所有链接。自然而然,这个页面的分数就会被清零。对于要爬取的URL列表(当然,刚才的网页被清空了分数,也是因为已经爬过了),首先爬取的是谁的分数最高。
与pagerank不同,opic是实时计算的。这里提醒我们,如果我们只考虑opic的爬取策略。这个策略和pagerank策略都证实了一个逻辑。我们新生成的网页,被链接的次数越多,被抓取的概率就越大。
是否值得考虑您的网页布局?
爬虫爬取的大站点优先策略
大网站优先爬取,是不是顾名思义?大的网站会先爬吗?但这里有两种解释。我个人认为这两个解释爬虫都在使用。
大站优先爬取说明1:顾名思义,爬虫会对列表中要爬取的URL进行分类,然后确定域名对应的网站级别。比如优先抓取权重较大的网站域名。
大展优先爬取说明2:爬虫根据域名对列表中要爬取的URL进行分类,然后计算数量。它所属的域是待抓取列表中编号最大的域。
两种解释,一种是网站的权重高,另一种是每天发布的文章数量多,发布非常集中。但是让我们想象一下,发布如此集中和如此多文章的网站通常都是大网站,对吗?
我们在这里想什么?
写文章时,一定要及时推送到搜索引擎。一小时不能发一篇,太散了。不过这个还是要验证的,有经验的同学可以考一下。
c爬虫抓取网页数据(c爬虫抓取网页数据,网页代码动态加载的,可控)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-16 01:04
c爬虫抓取网页数据,运行简单即可。无需搭建环境,不需要采用大型机,也无需编写代码。仅用到小白看的懂的理论知识。思路:本爬虫简单的抓取网页数据,网页代码是动态加载的,可控。大佬请绕路。
1、获取某某某网站的所有url,并获取post方法url。
2、分析post请求,并返回一个json文件,接收返回的json数据。
3、根据json数据解析该url的请求参数。
4、简单实现网站登录。
5、用爬虫框架pyspider代替传统的爬虫程序。
6、返回一个结果页文件,并调用send_response方法。
7、结果页html文件网页中要包含json结构化数据。
8、修改登录方式,注册方式。
9、页面的解析。
1
0、页面的cookie+ua信息,返回页面。
1、保存页面,保存登录信息。python抓取web页面数据,代码简单,非常简单易上手。
实践
1、获取网页所有url;url=(ps:网页目录名+目录内容);match=()html=requests。get(url)print(match)url1=('/'+match+'/'+path。replace('','/')+'')html1=beautifulsoup(url1,'lxml')txt=""forstrinurl1:txt=txt+str#json转换为csv格式txt=""forrootintxt:ifroot。
encoding!='utf-8':txt=""else:txt=json。loads(txt)print(txt)list=requests。get('/'+match+'/'+path。replace('/','')+'/'+path。replace('/','/')+'/'+path。
replace('/','/')+'/'+path。
replace('/','/')+'/'+path。replace('/','/')+'/'。 查看全部
c爬虫抓取网页数据(c爬虫抓取网页数据,网页代码动态加载的,可控)
c爬虫抓取网页数据,运行简单即可。无需搭建环境,不需要采用大型机,也无需编写代码。仅用到小白看的懂的理论知识。思路:本爬虫简单的抓取网页数据,网页代码是动态加载的,可控。大佬请绕路。
1、获取某某某网站的所有url,并获取post方法url。
2、分析post请求,并返回一个json文件,接收返回的json数据。
3、根据json数据解析该url的请求参数。
4、简单实现网站登录。
5、用爬虫框架pyspider代替传统的爬虫程序。
6、返回一个结果页文件,并调用send_response方法。
7、结果页html文件网页中要包含json结构化数据。
8、修改登录方式,注册方式。
9、页面的解析。
1
0、页面的cookie+ua信息,返回页面。
1、保存页面,保存登录信息。python抓取web页面数据,代码简单,非常简单易上手。
实践
1、获取网页所有url;url=(ps:网页目录名+目录内容);match=()html=requests。get(url)print(match)url1=('/'+match+'/'+path。replace('','/')+'')html1=beautifulsoup(url1,'lxml')txt=""forstrinurl1:txt=txt+str#json转换为csv格式txt=""forrootintxt:ifroot。
encoding!='utf-8':txt=""else:txt=json。loads(txt)print(txt)list=requests。get('/'+match+'/'+path。replace('/','')+'/'+path。replace('/','/')+'/'+path。
replace('/','/')+'/'+path。
replace('/','/')+'/'+path。replace('/','/')+'/'。
c爬虫抓取网页数据(网络爬虫学了也已有三个月了,怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-15 01:36
也就是说,网络爬虫技术真的很香!
我已经学习了三个月的网络爬虫,所以让我们进行实践培训,看看它是如何工作的!
这次我们选择爬取“当当网”官方网页,网址“”(也可以选择其他网站)
开始我们的激烈操作吧~
一、新建项目和爬虫文件,搭建scrapy框架(这里我们将项目命名为“当当”)
1、在你的“特定文件夹”中打开cmd并输入以下代码
scrapy startproject dangdang
如果显示和我的一样,说明项目创建成功
2、创建蜘蛛,输入如下代码,注意:“cp”是爬虫的名字,“”是start_url,必不可少
(这里我们给蜘蛛取名“cp”,我选择爬取微机原理和界面设计等书籍,也可以选择其他书籍类型)
先进入创建的项目“当当”,然后创建蜘蛛
>cd dangdang
>scrapy genspider cp dangdang.com
如果你显示的信息和我的一样,说明蜘蛛创建成功
3、打开“pycharm”,打开刚刚创建的“当当”项目,把chromedriver.exe放在这个项目的selenium下,然后新建一个调试“main.py”文件,像这样:
注意:记住!!!
一定要把“chromedriver.exe”和新创建的“main.py”放在“当当”项目的根目录下!!!
OK,scrapy框架搭建完成,接下来就是写代码了~
二、创建“main.py”并写入内容
from scrapy.cmdline import execute
execute("scrapy crawl cp".split())
两行代码写完后,放在一边
三、修改默认的“middleware.py”
在“class DangdangDownloaderMiddleware:”下找到“def process_exception(self, request, exception, spider):”,输入如下代码:
#创建浏览器实例化对象在爬虫文件中,用spider.bro调用
bro = spider.bro
#requst.url就是拦截到的爬虫文件发起的url
bro.get(request.url)
#获取页面源码
page = bro.page_source
#利用HtmlResponse()实例化一个新的响应对象
n_response = HtmlResponse(url=request.url,body=page,encoding='utf-8',request=request)
#返回新的响应对象
return n_response
四、全局配置“settings.py”
打开“settings.py”文件,
注:以下所有需要设置的地方只需要去掉前面的注释号即可(日志输出除外)
1、设置网站的“user_agent”进行爬取,获取当当网的“user_agent”,复制到这里
2、设置——是否符合robots.txt
默认为“True”,即“合规性”。Scrapy启动后,会尽快访问网站的robots.txt文件,然后确定网站的爬取范围。
但是,我们不是作为搜索引擎工作的,在某些情况下,我们想要获取的内容是robots.txt 明确禁止的。因此,在某些时候,我们不得不将此配置项设置为False并拒绝遵守Robot协议!
3、 设置输出日志信息为错误日志信息,输出错误级别为一般级别
#输出日志设为之输出发生错误的日志信息
#输出级别——一般级别
LOG_LEVEL = 'ERROR'
4、设置下载中间件,
5、设置项目管道
当 Item 在 Spider 中被采集到时,它会被传递到 Item Pipeline,这些 Item Pipeline 组件按照定义的顺序处理 Item。以下是Item Pipeline的一些典型应用:
五、修改默认给出的“items.py”
1、Item 对象是一个简单的容器,用于采集捕获的数据。
爬取哪些字段,爬虫解析页面时只能使用定义的字段,所以需要在items.py中定义
2、 Item中只有一种Field,表示传入的任何数据类型都可以接收
3、 下图是默认给的
我们要爬取当当网《微机原理与界面设计》的书名、作者、现价、日期、出版社,所以需要在items.py中定义这些字段,
六、修改默认给出的“pipelines.py”
下图是默认给出的
我们要将抓取到的信息保存到“.xls”中,我们需要重写这个文件
from itemadapter import ItemAdapter
from openpyxl import Workbook
class DangdangPipeline:
def __init__(self):
self.wb = Workbook()
self.ws = self.wb.active
self.ws.append(['书名','作者','现价','日期','出版社'])
def process_item(self, items, spider):
line = [items['book_name'],items['author'],items['price'],items['time'], items['press']]
self.ws.append(line)
self.wb.save('./微机原理与接口设计.xls')
return items
重头戏来了!!!
七、写spider——“cp.py”文件中的主要代码
1、 下图是默认给出的结构,接下来我们需要添加和修改
2、本次培训完整代码
注意理解笔记~
import scrapy
import time
from selenium import webdriver
from dangdang.items import DangdangItem
class CpSpider(scrapy.Spider):
name = 'cp' #指定爬虫文件名称
allowed_domains = ['dangdang.com'] #允许爬取的网站域名
#spider在启动时爬取的url列表,用于定义初始请求
#第一个要爬取的url
start_urls = ['http://search.dangdang.com/?key=%CE%A2%BB%FA%D4%AD%C0%ED%D3%EB%BD%D3%BF%DA%BC%BC%CA%F5&act=input&page_index=1']
page_index = 1 #第一页
offset = 1 #查询字符串参数
def __init__(self): #实例化浏览器对象
#selenium启动配置参数接收是ChromeOptions类
option = webdriver.ChromeOptions() #启动浏览器,最大化
#屏蔽谷歌浏览器正在接受自动化软件控制提示
option.add_experimental_option('excludeSwitches', ['enable-authmation'])
self.bro = webdriver.Chrome(options=option) #初始化
def parse(self, response):
items = DangdangItem()
lists = response.xpath('//*[@id="search_nature_rg"]/ul/li')
#遍历列表
for i in lists:
items['book_name'] = i.xpath('./p[@class="name"]/a/@title')[0].extract()
print('书名',items['book_name'])
author = i.xpath('./p[@class="search_book_author"]/span[1]//text()').extract()
author = ''.join(author).strip()
items['author'] = author
print("作者",items['author'])
items['price'] = i.xpath('./p[@class="price"]/span[1]/text()').get()
print('现价',items['price'])
items['time'] = i.xpath('./p[@class="search_book_author"]/span[2]/text()').get()
print('日期',items['time'])
items['press'] = i.xpath('./p[@class="search_book_author"]/span[3]/a/@title').get()
print('出版社',items['press'])
yield items #回调
time.sleep(5)
#通过parse()方法实现翻页
if self.offset < 6: #只爬取5页
self.offset += 1
self.page_index += 1
url='http://search.dangdang.com/?key=%CE%A2%BB%FA%D4%AD%C0%ED%D3%EB%BD%D3%BF%DA%BC%BC%CA%F5&act=input&page_index={}'
.format(self.offset,self.page_index)
yield scrapy.Request(url=url,callback=self.parse)
#关闭浏览器
def closed(self,spider):
self.bro.close()
3、查看表中存储的内容
运行成功无错误后,你爬取的内容会保存在“微机原理与接口设计.xls”表中
双击打开表格,就是你爬取过的内容!
恭喜完成本次实战! 查看全部
c爬虫抓取网页数据(网络爬虫学了也已有三个月了,怎么办?)
也就是说,网络爬虫技术真的很香!
我已经学习了三个月的网络爬虫,所以让我们进行实践培训,看看它是如何工作的!
这次我们选择爬取“当当网”官方网页,网址“”(也可以选择其他网站)
开始我们的激烈操作吧~
一、新建项目和爬虫文件,搭建scrapy框架(这里我们将项目命名为“当当”)
1、在你的“特定文件夹”中打开cmd并输入以下代码
scrapy startproject dangdang
如果显示和我的一样,说明项目创建成功

2、创建蜘蛛,输入如下代码,注意:“cp”是爬虫的名字,“”是start_url,必不可少
(这里我们给蜘蛛取名“cp”,我选择爬取微机原理和界面设计等书籍,也可以选择其他书籍类型)
先进入创建的项目“当当”,然后创建蜘蛛
>cd dangdang
>scrapy genspider cp dangdang.com
如果你显示的信息和我的一样,说明蜘蛛创建成功
3、打开“pycharm”,打开刚刚创建的“当当”项目,把chromedriver.exe放在这个项目的selenium下,然后新建一个调试“main.py”文件,像这样:
注意:记住!!!
一定要把“chromedriver.exe”和新创建的“main.py”放在“当当”项目的根目录下!!!
OK,scrapy框架搭建完成,接下来就是写代码了~
二、创建“main.py”并写入内容
from scrapy.cmdline import execute
execute("scrapy crawl cp".split())
两行代码写完后,放在一边
三、修改默认的“middleware.py”
在“class DangdangDownloaderMiddleware:”下找到“def process_exception(self, request, exception, spider):”,输入如下代码:
#创建浏览器实例化对象在爬虫文件中,用spider.bro调用
bro = spider.bro
#requst.url就是拦截到的爬虫文件发起的url
bro.get(request.url)
#获取页面源码
page = bro.page_source
#利用HtmlResponse()实例化一个新的响应对象
n_response = HtmlResponse(url=request.url,body=page,encoding='utf-8',request=request)
#返回新的响应对象
return n_response
四、全局配置“settings.py”
打开“settings.py”文件,
注:以下所有需要设置的地方只需要去掉前面的注释号即可(日志输出除外)
1、设置网站的“user_agent”进行爬取,获取当当网的“user_agent”,复制到这里
2、设置——是否符合robots.txt
默认为“True”,即“合规性”。Scrapy启动后,会尽快访问网站的robots.txt文件,然后确定网站的爬取范围。
但是,我们不是作为搜索引擎工作的,在某些情况下,我们想要获取的内容是robots.txt 明确禁止的。因此,在某些时候,我们不得不将此配置项设置为False并拒绝遵守Robot协议!
3、 设置输出日志信息为错误日志信息,输出错误级别为一般级别
#输出日志设为之输出发生错误的日志信息
#输出级别——一般级别
LOG_LEVEL = 'ERROR'
4、设置下载中间件,
5、设置项目管道
当 Item 在 Spider 中被采集到时,它会被传递到 Item Pipeline,这些 Item Pipeline 组件按照定义的顺序处理 Item。以下是Item Pipeline的一些典型应用:
五、修改默认给出的“items.py”
1、Item 对象是一个简单的容器,用于采集捕获的数据。
爬取哪些字段,爬虫解析页面时只能使用定义的字段,所以需要在items.py中定义
2、 Item中只有一种Field,表示传入的任何数据类型都可以接收
3、 下图是默认给的
我们要爬取当当网《微机原理与界面设计》的书名、作者、现价、日期、出版社,所以需要在items.py中定义这些字段,
六、修改默认给出的“pipelines.py”
下图是默认给出的
我们要将抓取到的信息保存到“.xls”中,我们需要重写这个文件
from itemadapter import ItemAdapter
from openpyxl import Workbook
class DangdangPipeline:
def __init__(self):
self.wb = Workbook()
self.ws = self.wb.active
self.ws.append(['书名','作者','现价','日期','出版社'])
def process_item(self, items, spider):
line = [items['book_name'],items['author'],items['price'],items['time'], items['press']]
self.ws.append(line)
self.wb.save('./微机原理与接口设计.xls')
return items
重头戏来了!!!
七、写spider——“cp.py”文件中的主要代码
1、 下图是默认给出的结构,接下来我们需要添加和修改
2、本次培训完整代码
注意理解笔记~
import scrapy
import time
from selenium import webdriver
from dangdang.items import DangdangItem
class CpSpider(scrapy.Spider):
name = 'cp' #指定爬虫文件名称
allowed_domains = ['dangdang.com'] #允许爬取的网站域名
#spider在启动时爬取的url列表,用于定义初始请求
#第一个要爬取的url
start_urls = ['http://search.dangdang.com/?key=%CE%A2%BB%FA%D4%AD%C0%ED%D3%EB%BD%D3%BF%DA%BC%BC%CA%F5&act=input&page_index=1']
page_index = 1 #第一页
offset = 1 #查询字符串参数
def __init__(self): #实例化浏览器对象
#selenium启动配置参数接收是ChromeOptions类
option = webdriver.ChromeOptions() #启动浏览器,最大化
#屏蔽谷歌浏览器正在接受自动化软件控制提示
option.add_experimental_option('excludeSwitches', ['enable-authmation'])
self.bro = webdriver.Chrome(options=option) #初始化
def parse(self, response):
items = DangdangItem()
lists = response.xpath('//*[@id="search_nature_rg"]/ul/li')
#遍历列表
for i in lists:
items['book_name'] = i.xpath('./p[@class="name"]/a/@title')[0].extract()
print('书名',items['book_name'])
author = i.xpath('./p[@class="search_book_author"]/span[1]//text()').extract()
author = ''.join(author).strip()
items['author'] = author
print("作者",items['author'])
items['price'] = i.xpath('./p[@class="price"]/span[1]/text()').get()
print('现价',items['price'])
items['time'] = i.xpath('./p[@class="search_book_author"]/span[2]/text()').get()
print('日期',items['time'])
items['press'] = i.xpath('./p[@class="search_book_author"]/span[3]/a/@title').get()
print('出版社',items['press'])
yield items #回调
time.sleep(5)
#通过parse()方法实现翻页
if self.offset < 6: #只爬取5页
self.offset += 1
self.page_index += 1
url='http://search.dangdang.com/?key=%CE%A2%BB%FA%D4%AD%C0%ED%D3%EB%BD%D3%BF%DA%BC%BC%CA%F5&act=input&page_index={}'
.format(self.offset,self.page_index)
yield scrapy.Request(url=url,callback=self.parse)
#关闭浏览器
def closed(self,spider):
self.bro.close()
3、查看表中存储的内容
运行成功无错误后,你爬取的内容会保存在“微机原理与接口设计.xls”表中
双击打开表格,就是你爬取过的内容!
恭喜完成本次实战!
c爬虫抓取网页数据(抓取智联招聘的招聘信息助你换工作成功(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2021-12-14 21:35
)
对于每个上班族来说,总会有几次工作变动。如何在网上选择自己喜欢的工作?如何提前准备心仪工作的面试?今天我们就来抢夺智联招聘的招聘信息,助您顺利转岗!
操作平台:Windows
Python版本:Python3.6
IDE:崇高的文本
其他工具:Chrome 浏览器
1、Web 分析1.1 分析请求地址
以北京市海淀区python工程师为例进行网页分析。打开智联招聘首页,选择北京地区,在搜索框中输入“python工程师”,点击“搜索职位”:
接下来跳转到搜索结果页面,按“F12”打开开发者工具,然后在“热点区”一栏中选择“海淀”,我们来看看地址栏:
从地址栏searchresult.ashx?jl=Beijing&kw=pythonengineer&sm=0&isfilter=1&p=1&re=2005的后半部分可以看出,我们必须自己构造地址。接下来,我们需要分析开发者工具,按照如图所示的步骤,找到我们需要的数据:Request Headers和Query String Parameters:
构造请求地址:
paras = {
'jl': '北京', # 搜索城市
'kw': 'python工程师', # 搜索关键词
'isadv': 0, # 是否打开更详细搜索选项
'isfilter': 1, # 是否对结果过滤
'p': 1, # 页数
're': 2005 # region的缩写,地区,2005代表海淀
}
url = 'https://sou.zhaopin.com/jobs/searchresult.ashx?' + urlencode(paras)
请求头:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Host': 'sou.zhaopin.com',
'Referer': 'https://www.zhaopin.com/',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
1.2 分析有用的数据
接下来,我们需要分析有用的数据。我们从搜索结果中需要的数据有:职位名称、公司名称、公司详情页地址、职位月薪:
通过定位网页元素,找到这些项目在HTML文件中的位置,如下图所示:
使用正则表达式提取这四项:
# 正则表达式进行解析
pattern = re.compile('<a style=.*? target="_blank">(.*?)</a>.*?' # 匹配职位信息
'(.*?).*?' # 匹配公司网址和公司名称
'(.*?)', re.S) # 匹配月薪
# 匹配所有符合条件的内容
items = re.findall(pattern, html)
注:部分解析出的职位有标注,如下图:
然后解析后,对数据进行处理,去除标签,实现代码如下:
for item in items:
job_name = item[0]
job_name = job_name.replace('', '')
job_name = job_name.replace('', '')
yield {
'job': job_name,
'website': item[1],
'company': item[2],
'salary': item[3]
}
2、写入文件
我们得到的数据,每个位置都有相同的信息项,可以写入数据库,但是本文选择了一个csv文件。以下是百度百科的解释:
逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。纯文本意味着该文件是一个字符序列,不含必须像二进制数字那样被解读的数据。
由于python内置了对csv文件操作的库函数,非常方便:
import csv
def write_csv_headers(path, headers):
'''
写入表头
'''
with open(path, 'a', encoding='gb18030', newline='') as f:
f_csv = csv.DictWriter(f, headers)
f_csv.writeheader()
def write_csv_rows(path, headers, rows):
'''
写入行
'''
with open(path, 'a', encoding='gb18030', newline='') as f:
f_csv = csv.DictWriter(f, headers)
f_csv.writerows(rows)
3、进度显示
如果你想找到理想的工作,你必须筛选更多的职位。那么我们抓取的数据量一定非常大,几十页,几百页,甚至上千页。那么就必须掌握爬取的进度,才能更可靠。啊,所以我们需要添加一个进度条显示功能。
本文选择tqdm显示进度,看看效果很酷(图片来源网络):
执行以下命令安装:pip install tqdm。
简单的例子:
from tqdm import tqdm
from time import sleep
for i in tqdm(range(1000)):
sleep(0.01)
4、完整代码
以上就是对所有函数的分析,完整代码如下:
#-*- coding: utf-8 -*-
import re
import csv
import requests
from tqdm import tqdm
from urllib.parse import urlencode
from requests.exceptions import RequestException
def get_one_page(city, keyword, region, page):
'''
获取网页html内容并返回
'''
paras = {
'jl': city, # 搜索城市
'kw': keyword, # 搜索关键词
'isadv': 0, # 是否打开更详细搜索选项
'isfilter': 1, # 是否对结果过滤
'p': page, # 页数
're': region # region的缩写,地区,2005代表海淀
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Host': 'sou.zhaopin.com',
'Referer': 'https://www.zhaopin.com/',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
url = 'https://sou.zhaopin.com/jobs/searchresult.ashx?' + urlencode(paras)
try:
# 获取网页内容,返回html数据
response = requests.get(url, headers=headers)
# 通过状态码判断是否获取成功
if response.status_code == 200:
return response.text
return None
except RequestException as e:
return None
def parse_one_page(html):
'''
解析HTML代码,提取有用信息并返回
'''
# 正则表达式进行解析
pattern = re.compile('<a style=.*? target="_blank">(.*?)</a>.*?' # 匹配职位信息
'(.*?).*?' # 匹配公司网址和公司名称
'(.*?)', re.S) # 匹配月薪
# 匹配所有符合条件的内容
items = re.findall(pattern, html)
for item in items:
job_name = item[0]
job_name = job_name.replace('', '')
job_name = job_name.replace('', '')
yield {
'job': job_name,
'website': item[1],
'company': item[2],
'salary': item[3]
}
def write_csv_file(path, headers, rows):
'''
将表头和行写入csv文件
'''
# 加入encoding防止中文写入报错
# newline参数防止每写入一行都多一个空行
with open(path, 'a', encoding='gb18030', newline='') as f:
f_csv = csv.DictWriter(f, headers)
f_csv.writeheader()
f_csv.writerows(rows)
def write_csv_headers(path, headers):
'''
写入表头
'''
with open(path, 'a', encoding='gb18030', newline='') as f:
f_csv = csv.DictWriter(f, headers)
f_csv.writeheader()
def write_csv_rows(path, headers, rows):
'''
写入行
'''
with open(path, 'a', encoding='gb18030', newline='') as f:
f_csv = csv.DictWriter(f, headers)
f_csv.writerows(rows)
def main(city, keyword, region, pages):
'''
主函数
'''
filename = 'zl_' + city + '_' + keyword + '.csv'
headers = ['job', 'website', 'company', 'salary']
write_csv_headers(filename, headers)
for i in tqdm(range(pages)):
'''
获取该页中所有职位信息,写入csv文件
'''
jobs = []
html = get_one_page(city, keyword, region, i)
items = parse_one_page(html)
for item in items:
jobs.append(item)
write_csv_rows(filename, headers, jobs)
if __name__ == '__main__':
main('北京', 'python工程师', 2005, 10)
以上代码的执行效果如图:
执行完成后会在同级py文件夹中生成一个名为:zl_Beijing_pythonengineer.csv的文件,打开后效果如下:
这个例子的功能比较简单。它只捕获数据,不分析数据。下次我会捕捉更多信息,分析薪资、岗位技能要求等各种数据,敬请期待!
欢迎关注公众号:
查看全部
c爬虫抓取网页数据(抓取智联招聘的招聘信息助你换工作成功(组图)
)
对于每个上班族来说,总会有几次工作变动。如何在网上选择自己喜欢的工作?如何提前准备心仪工作的面试?今天我们就来抢夺智联招聘的招聘信息,助您顺利转岗!
操作平台:Windows
Python版本:Python3.6
IDE:崇高的文本
其他工具:Chrome 浏览器
1、Web 分析1.1 分析请求地址
以北京市海淀区python工程师为例进行网页分析。打开智联招聘首页,选择北京地区,在搜索框中输入“python工程师”,点击“搜索职位”:

接下来跳转到搜索结果页面,按“F12”打开开发者工具,然后在“热点区”一栏中选择“海淀”,我们来看看地址栏:

从地址栏searchresult.ashx?jl=Beijing&kw=pythonengineer&sm=0&isfilter=1&p=1&re=2005的后半部分可以看出,我们必须自己构造地址。接下来,我们需要分析开发者工具,按照如图所示的步骤,找到我们需要的数据:Request Headers和Query String Parameters:

构造请求地址:
paras = {
'jl': '北京', # 搜索城市
'kw': 'python工程师', # 搜索关键词
'isadv': 0, # 是否打开更详细搜索选项
'isfilter': 1, # 是否对结果过滤
'p': 1, # 页数
're': 2005 # region的缩写,地区,2005代表海淀
}
url = 'https://sou.zhaopin.com/jobs/searchresult.ashx?' + urlencode(paras)
请求头:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Host': 'sou.zhaopin.com',
'Referer': 'https://www.zhaopin.com/',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
1.2 分析有用的数据
接下来,我们需要分析有用的数据。我们从搜索结果中需要的数据有:职位名称、公司名称、公司详情页地址、职位月薪:

通过定位网页元素,找到这些项目在HTML文件中的位置,如下图所示:

使用正则表达式提取这四项:
# 正则表达式进行解析
pattern = re.compile('<a style=.*? target="_blank">(.*?)</a>.*?' # 匹配职位信息
'(.*?).*?' # 匹配公司网址和公司名称
'(.*?)', re.S) # 匹配月薪
# 匹配所有符合条件的内容
items = re.findall(pattern, html)
注:部分解析出的职位有标注,如下图:

然后解析后,对数据进行处理,去除标签,实现代码如下:
for item in items:
job_name = item[0]
job_name = job_name.replace('', '')
job_name = job_name.replace('', '')
yield {
'job': job_name,
'website': item[1],
'company': item[2],
'salary': item[3]
}
2、写入文件
我们得到的数据,每个位置都有相同的信息项,可以写入数据库,但是本文选择了一个csv文件。以下是百度百科的解释:
逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。纯文本意味着该文件是一个字符序列,不含必须像二进制数字那样被解读的数据。
由于python内置了对csv文件操作的库函数,非常方便:
import csv
def write_csv_headers(path, headers):
'''
写入表头
'''
with open(path, 'a', encoding='gb18030', newline='') as f:
f_csv = csv.DictWriter(f, headers)
f_csv.writeheader()
def write_csv_rows(path, headers, rows):
'''
写入行
'''
with open(path, 'a', encoding='gb18030', newline='') as f:
f_csv = csv.DictWriter(f, headers)
f_csv.writerows(rows)
3、进度显示
如果你想找到理想的工作,你必须筛选更多的职位。那么我们抓取的数据量一定非常大,几十页,几百页,甚至上千页。那么就必须掌握爬取的进度,才能更可靠。啊,所以我们需要添加一个进度条显示功能。
本文选择tqdm显示进度,看看效果很酷(图片来源网络):

执行以下命令安装:pip install tqdm。
简单的例子:
from tqdm import tqdm
from time import sleep
for i in tqdm(range(1000)):
sleep(0.01)
4、完整代码
以上就是对所有函数的分析,完整代码如下:
#-*- coding: utf-8 -*-
import re
import csv
import requests
from tqdm import tqdm
from urllib.parse import urlencode
from requests.exceptions import RequestException
def get_one_page(city, keyword, region, page):
'''
获取网页html内容并返回
'''
paras = {
'jl': city, # 搜索城市
'kw': keyword, # 搜索关键词
'isadv': 0, # 是否打开更详细搜索选项
'isfilter': 1, # 是否对结果过滤
'p': page, # 页数
're': region # region的缩写,地区,2005代表海淀
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Host': 'sou.zhaopin.com',
'Referer': 'https://www.zhaopin.com/',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
url = 'https://sou.zhaopin.com/jobs/searchresult.ashx?' + urlencode(paras)
try:
# 获取网页内容,返回html数据
response = requests.get(url, headers=headers)
# 通过状态码判断是否获取成功
if response.status_code == 200:
return response.text
return None
except RequestException as e:
return None
def parse_one_page(html):
'''
解析HTML代码,提取有用信息并返回
'''
# 正则表达式进行解析
pattern = re.compile('<a style=.*? target="_blank">(.*?)</a>.*?' # 匹配职位信息
'(.*?).*?' # 匹配公司网址和公司名称
'(.*?)', re.S) # 匹配月薪
# 匹配所有符合条件的内容
items = re.findall(pattern, html)
for item in items:
job_name = item[0]
job_name = job_name.replace('', '')
job_name = job_name.replace('', '')
yield {
'job': job_name,
'website': item[1],
'company': item[2],
'salary': item[3]
}
def write_csv_file(path, headers, rows):
'''
将表头和行写入csv文件
'''
# 加入encoding防止中文写入报错
# newline参数防止每写入一行都多一个空行
with open(path, 'a', encoding='gb18030', newline='') as f:
f_csv = csv.DictWriter(f, headers)
f_csv.writeheader()
f_csv.writerows(rows)
def write_csv_headers(path, headers):
'''
写入表头
'''
with open(path, 'a', encoding='gb18030', newline='') as f:
f_csv = csv.DictWriter(f, headers)
f_csv.writeheader()
def write_csv_rows(path, headers, rows):
'''
写入行
'''
with open(path, 'a', encoding='gb18030', newline='') as f:
f_csv = csv.DictWriter(f, headers)
f_csv.writerows(rows)
def main(city, keyword, region, pages):
'''
主函数
'''
filename = 'zl_' + city + '_' + keyword + '.csv'
headers = ['job', 'website', 'company', 'salary']
write_csv_headers(filename, headers)
for i in tqdm(range(pages)):
'''
获取该页中所有职位信息,写入csv文件
'''
jobs = []
html = get_one_page(city, keyword, region, i)
items = parse_one_page(html)
for item in items:
jobs.append(item)
write_csv_rows(filename, headers, jobs)
if __name__ == '__main__':
main('北京', 'python工程师', 2005, 10)
以上代码的执行效果如图:

执行完成后会在同级py文件夹中生成一个名为:zl_Beijing_pythonengineer.csv的文件,打开后效果如下:

这个例子的功能比较简单。它只捕获数据,不分析数据。下次我会捕捉更多信息,分析薪资、岗位技能要求等各种数据,敬请期待!
欢迎关注公众号:

c爬虫抓取网页数据(Scraoy入门实例一--Scrapy介绍与安装ampamp的安装)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-11 05:15
Scraoy入门实例一---Scrapy介绍与安装&PyCharm安装&项目实战
一、Scrapy 安装
1.Scrapy 介绍
Scrapy 是一个应用框架,用于抓取 网站 数据并提取结构化数据。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中。它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
2.Scrapy 安装
推荐使用Anaconda安装Scrapy
Anaconda 是一个开源包和环境管理工件。Anaconda 收录 180 多个科学包及其依赖项,包括 conda 和 Python。从官网下载安装Anaconda(个人版),根据自己的系统选择下载安装,选择next继续安装,Install for选项选择Just for me。选择安装位置后,等待安装完成。
安装完成后,打开命令行,输入conda install scrapy,根据提示按Y,就会下载Scrapy及其依赖的所有包,从而完成安装。
注意:使用命令行安装scrapy包时,会出现下载超时问题,即下载失败。我们可以修改它的镜像文件来提高scrapy包的下载速度。可以参考博客:
这时测试Scrapy是否安装成功:在命令行窗口输入scrapy,回车。如果出现如下界面,则说明安装成功:
二、PyCharm 安装
1.PyCharm 介绍
PyCharm 是一个 PythonIDE,带有一组工具,可以帮助用户在使用 Python 语言进行开发时提高效率,例如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试和版本控制。此外,IDE 提供了一些高级功能,以支持 Django 框架下的专业 Web 开发。
2.PyCharm 安装
进入PyCharm官网,点击DownLoad下载,左边专业版,右边社区版,社区版免费,专业版免费试用。
如果之前没有下载过Python解释器,可以在等待安装的同时下载Python解释器,进入Python官网,根据系统和版本下载对应的压缩包。安装完成后,在环境变量Path中配置Python解释器的安装路径。可以参考博客:
三、Scrapy抓取豆瓣项目实战
前提条件:如果要在PyCharm中使用Scrapy,必须先在PyCharm中安装支持的Scrapy包。流程如下,点击File>>Settings...,步骤如下图,我安装Scrapy之前的绿框只有两个Package。如果点击后看到一个Scrapy包,则无需安装,直接进行下一步操作即可。
如果没有Scrapy包,点击“+”,搜索Scrapy包,点击Install Package进行安装
等待安装完成。
1.新项目
打开新安装的PyCharm,在软件终端使用pycharm工具。如果找不到 PyCharm 终端,则是左下角底部的终端。
输入命令:scrapy startproject douban 这是使用命令行新建一个爬虫项目,如下图,图中项目名称为pythonProject
然后在命令行输入命令:cd douban进入生成项目的根目录
然后在终端继续输入命令:scrapy genspider douban_spider,生成douban_spider爬虫文件。
此时的项目结构如下图所示:
2.明确的目标
我们要练习的网站是:
假设,我们抓取top250电影的序列号、电影名称、介绍、星级、评分数量、电影描述选项
此时,我们在items.py文件中定义捕获的数据项,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.接下来需要制作爬虫并存储爬取的内容
在douban_spider.py爬虫文件中编写具体逻辑代码,如下:
# -*- coding: utf-8 -*-
import scrapy
from ..items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider'
# 允许的域名
allowed_domains = ['movie.douban.com']
# 入口URL
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//div[@class='hd']/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
douban_item['describe'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class='next']/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
这个时候不需要运行这个python文件,因为我们不是单独使用的,所以不需要运行,并且允许报错,与import相关的问题,绝对的问题主目录的路径和相对路径。原因是我们使用了相对路径。“..Items”,对相关内容感兴趣的同学可以上网查找对此类问题的解释。
4.存储内容
将抓取到的内容存入json或csv格式的文件中
在命令行输入:scrapy crawl douban_spider -o test.json 或者scrapy crawl douban_spider -o test.csv
将抓取到的数据存储在一个json文件或者一个csv文件中。
执行crawl命令后,当鼠标焦点放在项目面板上时,会显示生成的json文件或csv文件。打开json或者csv文件后,如果里面什么都没有,那么我们需要进一步修改,修改代理USER_AGENT的内容,
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.8 Safari/537.36'
如果存储在一个json文件中,所有的内容都会以16进制的形式显示,可以通过相应的方法进行转码。这里就不多解释了,如下图所示:
并且保存在csv文件中,会直接显示我们要抓取的所有内容,如下图:
至此,我们就完成了对网站具体内容的抓取。接下来,我们需要处理爬取的数据。
分割线------------------------------------------------ -------------------------------------------------- --------------------分割线
Scraoy 介绍示例二——使用Pipeline来实现
在这次实战中,需要重新创建一个项目,或者需要安装scrapy包。参考以上内容。创建新项目的方法也参考上述内容,这里不再赘述。
项目目录结构如下图所示:
一、管道介绍
当我们通过Spider爬取数据,通过Item采集数据时,需要对数据进行处理,因为我们爬取的数据不一定是我们想要的最终数据,可能还需要进行数据清洗和校验。数据的有效性。Scripy 中的 Pipeline 组件用于数据处理。Pipeline 组件是一个收录特定接口的类。它通常只负责一个功能的数据处理。可以在一个项目中同时启用多个管道。
二、在items.py中定义要捕获的数据
首先打开一个新的pycharm项目,通过终端新建一个项目教程,在item中定义要抓取的数据,比如电影的名字,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、定义pipeline.py文件
每个item管道组件都是一个独立的pyhton类,必须通过process_item(self, item, spider)方法实现。每个item管道组件都需要调用这个方法。该方法必须返回一个带有数据的dict,或者一个item对象,或者抛出一个DropItem异常,丢弃的item不会被后续的管道组件处理。定义的 pipelines.py 代码如下:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/lat ... .html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class TutorialPipeline(object):
def process_item(self, item, spider):
return item
import time
class DoubanmoviePipeline(object):
def process_item(self, item, spider):
now = time.strftime('%Y-%m-%d', time.localtime())
fileName = 'douban' + now + '.txt'
with open(fileName, 'a', encoding='utf-8') as fp:
fp.write(item['moiveName'][0]+"\n")
return item
四、配置setting.py
由于这次用到了管道,我们需要在settings.py中打开管道通道注释,在管道中添加一条新的记录,如下图所示:
五、写爬虫文件
在tutorial/spiders目录下创建quotes_spider.py文件,目录结构如下,编写初步代码:
quotes_spider.py 的代码如下:
import scrapy
from items import DoubanmovieItem
class QuotesSpider(scrapy.Spider):
name = "doubanSpider"
allowed_domains = ['douban.com']
start_urls = ['http://movie.douban.com/cinema/nowplaying',
'http://movie.douban.com/cinema/nowplaying/beijing/']
def parse(self, response):
print("--" * 20 )
#print(response.body)
print("==" * 20 )
subSelector = response.xpath('//li[@class="stitle"]')
items = []
for sub in subSelector:
#print(sub.xpath('normalize-space(./a/text())').extract())
print(sub)
item = DoubanmovieItem()
item['moiveName'] = sub.xpath('normalize-space(./a/text())').extract()
items.append(item)
print(items)
return items
六、通过启动文件运行
在豆瓣文件目录下新建一个启动文件douban_spider_run.py(文件名可取),运行该文件查看结果,编写代码如下:
from scrapy import cmdline
cmdline.execute("scrapy crawl doubanSpider".split())
最后,处理后的爬取数据如下图(部分):
最后,希望大家在写代码的时候能更加细心,不要马虎。在我的实验过程中,是因为要引入的方法DoubanmovieItem写成DobanmovieItem,导致整个程序失败,PyCharm没有告诉我在哪里。我错了。我到处搜索,但找不到解决问题的方法。最后查了很多次,才发现方法是什么时候生成的,所以一定要小心。这个错误如下图所示。它说找不到模块 DobanmovieItem。它可能已经告诉我错误的地方,因为我太傻了没有找到,所以花了很长时间。希望大家多多指教!
至此,使用Scrapy对网页内容进行爬取,并对爬取的内容进行清洗和处理的实验已经完成。要求熟悉和使用这个过程中的代码和操作,不会在网上找内容消化。吸收,记在心里,这才是真正的知识学习,而不是画葫芦。 查看全部
c爬虫抓取网页数据(Scraoy入门实例一--Scrapy介绍与安装ampamp的安装)
Scraoy入门实例一---Scrapy介绍与安装&PyCharm安装&项目实战
一、Scrapy 安装
1.Scrapy 介绍
Scrapy 是一个应用框架,用于抓取 网站 数据并提取结构化数据。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中。它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
2.Scrapy 安装
推荐使用Anaconda安装Scrapy
Anaconda 是一个开源包和环境管理工件。Anaconda 收录 180 多个科学包及其依赖项,包括 conda 和 Python。从官网下载安装Anaconda(个人版),根据自己的系统选择下载安装,选择next继续安装,Install for选项选择Just for me。选择安装位置后,等待安装完成。
安装完成后,打开命令行,输入conda install scrapy,根据提示按Y,就会下载Scrapy及其依赖的所有包,从而完成安装。
注意:使用命令行安装scrapy包时,会出现下载超时问题,即下载失败。我们可以修改它的镜像文件来提高scrapy包的下载速度。可以参考博客:
这时测试Scrapy是否安装成功:在命令行窗口输入scrapy,回车。如果出现如下界面,则说明安装成功:
二、PyCharm 安装
1.PyCharm 介绍
PyCharm 是一个 PythonIDE,带有一组工具,可以帮助用户在使用 Python 语言进行开发时提高效率,例如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试和版本控制。此外,IDE 提供了一些高级功能,以支持 Django 框架下的专业 Web 开发。
2.PyCharm 安装
进入PyCharm官网,点击DownLoad下载,左边专业版,右边社区版,社区版免费,专业版免费试用。
如果之前没有下载过Python解释器,可以在等待安装的同时下载Python解释器,进入Python官网,根据系统和版本下载对应的压缩包。安装完成后,在环境变量Path中配置Python解释器的安装路径。可以参考博客:
三、Scrapy抓取豆瓣项目实战
前提条件:如果要在PyCharm中使用Scrapy,必须先在PyCharm中安装支持的Scrapy包。流程如下,点击File>>Settings...,步骤如下图,我安装Scrapy之前的绿框只有两个Package。如果点击后看到一个Scrapy包,则无需安装,直接进行下一步操作即可。
如果没有Scrapy包,点击“+”,搜索Scrapy包,点击Install Package进行安装
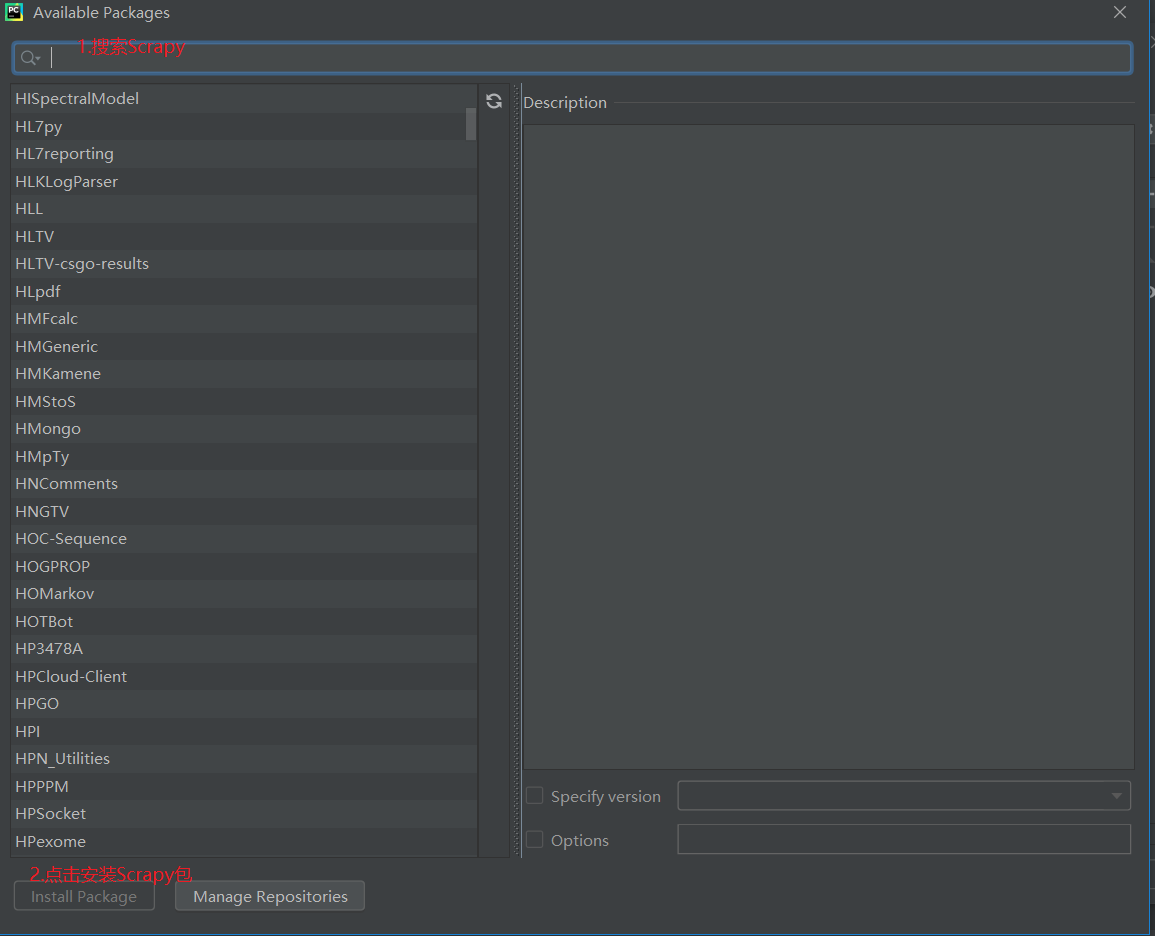
等待安装完成。
1.新项目
打开新安装的PyCharm,在软件终端使用pycharm工具。如果找不到 PyCharm 终端,则是左下角底部的终端。

输入命令:scrapy startproject douban 这是使用命令行新建一个爬虫项目,如下图,图中项目名称为pythonProject
然后在命令行输入命令:cd douban进入生成项目的根目录
然后在终端继续输入命令:scrapy genspider douban_spider,生成douban_spider爬虫文件。
此时的项目结构如下图所示:
2.明确的目标
我们要练习的网站是:
假设,我们抓取top250电影的序列号、电影名称、介绍、星级、评分数量、电影描述选项
此时,我们在items.py文件中定义捕获的数据项,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.接下来需要制作爬虫并存储爬取的内容
在douban_spider.py爬虫文件中编写具体逻辑代码,如下:
# -*- coding: utf-8 -*-
import scrapy
from ..items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider'
# 允许的域名
allowed_domains = ['movie.douban.com']
# 入口URL
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//div[@class='hd']/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
douban_item['describe'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class='next']/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
这个时候不需要运行这个python文件,因为我们不是单独使用的,所以不需要运行,并且允许报错,与import相关的问题,绝对的问题主目录的路径和相对路径。原因是我们使用了相对路径。“..Items”,对相关内容感兴趣的同学可以上网查找对此类问题的解释。
4.存储内容
将抓取到的内容存入json或csv格式的文件中
在命令行输入:scrapy crawl douban_spider -o test.json 或者scrapy crawl douban_spider -o test.csv
将抓取到的数据存储在一个json文件或者一个csv文件中。
执行crawl命令后,当鼠标焦点放在项目面板上时,会显示生成的json文件或csv文件。打开json或者csv文件后,如果里面什么都没有,那么我们需要进一步修改,修改代理USER_AGENT的内容,
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.8 Safari/537.36'
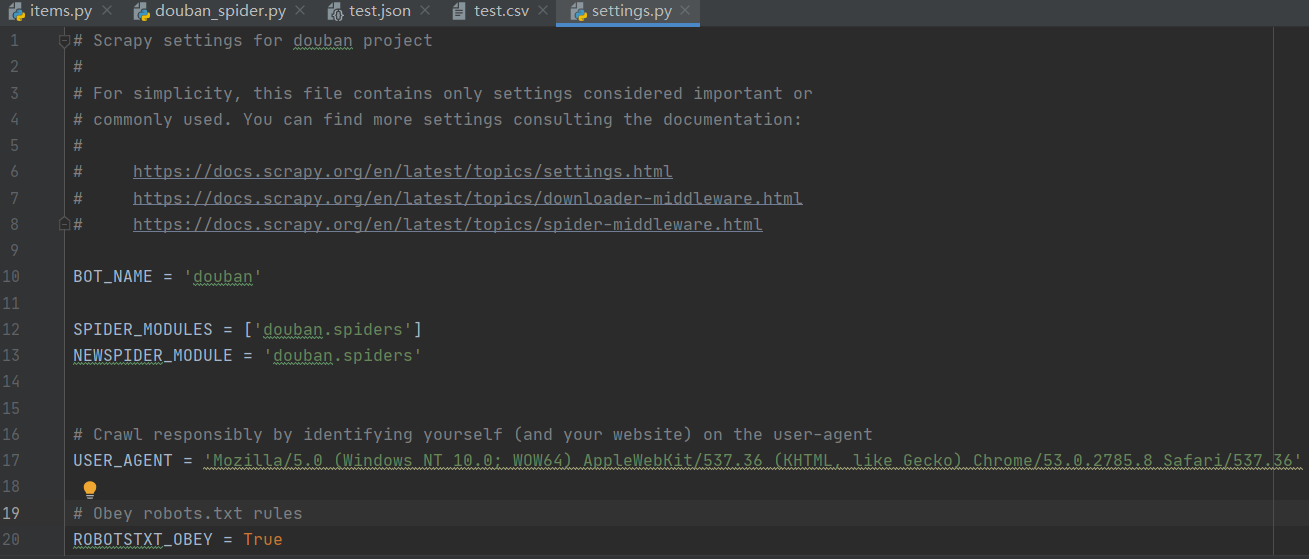
如果存储在一个json文件中,所有的内容都会以16进制的形式显示,可以通过相应的方法进行转码。这里就不多解释了,如下图所示:
并且保存在csv文件中,会直接显示我们要抓取的所有内容,如下图:
至此,我们就完成了对网站具体内容的抓取。接下来,我们需要处理爬取的数据。
分割线------------------------------------------------ -------------------------------------------------- --------------------分割线
Scraoy 介绍示例二——使用Pipeline来实现
在这次实战中,需要重新创建一个项目,或者需要安装scrapy包。参考以上内容。创建新项目的方法也参考上述内容,这里不再赘述。
项目目录结构如下图所示:
一、管道介绍
当我们通过Spider爬取数据,通过Item采集数据时,需要对数据进行处理,因为我们爬取的数据不一定是我们想要的最终数据,可能还需要进行数据清洗和校验。数据的有效性。Scripy 中的 Pipeline 组件用于数据处理。Pipeline 组件是一个收录特定接口的类。它通常只负责一个功能的数据处理。可以在一个项目中同时启用多个管道。
二、在items.py中定义要捕获的数据
首先打开一个新的pycharm项目,通过终端新建一个项目教程,在item中定义要抓取的数据,比如电影的名字,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、定义pipeline.py文件
每个item管道组件都是一个独立的pyhton类,必须通过process_item(self, item, spider)方法实现。每个item管道组件都需要调用这个方法。该方法必须返回一个带有数据的dict,或者一个item对象,或者抛出一个DropItem异常,丢弃的item不会被后续的管道组件处理。定义的 pipelines.py 代码如下:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/lat ... .html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class TutorialPipeline(object):
def process_item(self, item, spider):
return item
import time
class DoubanmoviePipeline(object):
def process_item(self, item, spider):
now = time.strftime('%Y-%m-%d', time.localtime())
fileName = 'douban' + now + '.txt'
with open(fileName, 'a', encoding='utf-8') as fp:
fp.write(item['moiveName'][0]+"\n")
return item
四、配置setting.py
由于这次用到了管道,我们需要在settings.py中打开管道通道注释,在管道中添加一条新的记录,如下图所示:
五、写爬虫文件
在tutorial/spiders目录下创建quotes_spider.py文件,目录结构如下,编写初步代码:
quotes_spider.py 的代码如下:
import scrapy
from items import DoubanmovieItem
class QuotesSpider(scrapy.Spider):
name = "doubanSpider"
allowed_domains = ['douban.com']
start_urls = ['http://movie.douban.com/cinema/nowplaying',
'http://movie.douban.com/cinema/nowplaying/beijing/']
def parse(self, response):
print("--" * 20 )
#print(response.body)
print("==" * 20 )
subSelector = response.xpath('//li[@class="stitle"]')
items = []
for sub in subSelector:
#print(sub.xpath('normalize-space(./a/text())').extract())
print(sub)
item = DoubanmovieItem()
item['moiveName'] = sub.xpath('normalize-space(./a/text())').extract()
items.append(item)
print(items)
return items
六、通过启动文件运行
在豆瓣文件目录下新建一个启动文件douban_spider_run.py(文件名可取),运行该文件查看结果,编写代码如下:
from scrapy import cmdline
cmdline.execute("scrapy crawl doubanSpider".split())
最后,处理后的爬取数据如下图(部分):
最后,希望大家在写代码的时候能更加细心,不要马虎。在我的实验过程中,是因为要引入的方法DoubanmovieItem写成DobanmovieItem,导致整个程序失败,PyCharm没有告诉我在哪里。我错了。我到处搜索,但找不到解决问题的方法。最后查了很多次,才发现方法是什么时候生成的,所以一定要小心。这个错误如下图所示。它说找不到模块 DobanmovieItem。它可能已经告诉我错误的地方,因为我太傻了没有找到,所以花了很长时间。希望大家多多指教!
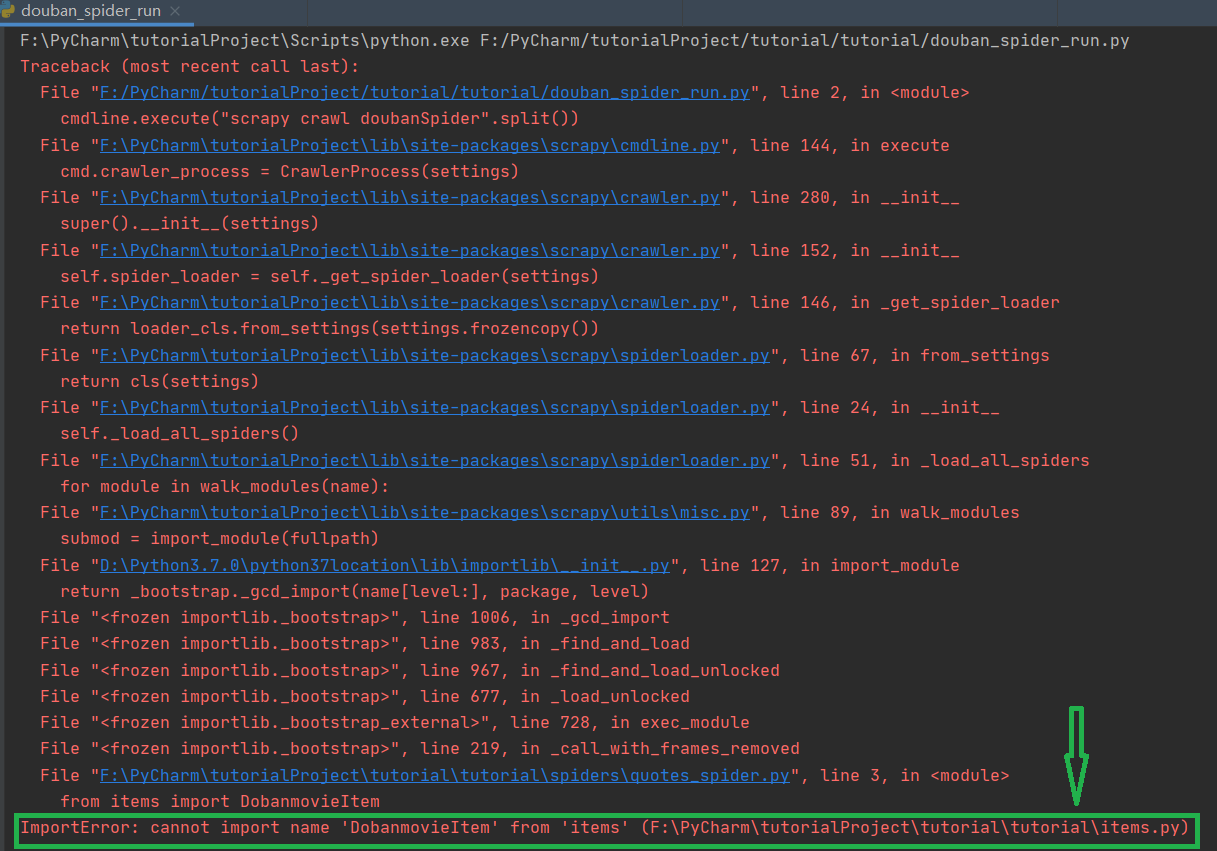
至此,使用Scrapy对网页内容进行爬取,并对爬取的内容进行清洗和处理的实验已经完成。要求熟悉和使用这个过程中的代码和操作,不会在网上找内容消化。吸收,记在心里,这才是真正的知识学习,而不是画葫芦。
c爬虫抓取网页数据(Python开发的一个快速,高层次处理网络通讯的整体架构大致)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-11 03:08
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体结构大致如下(注:图片来自网络):
Scrapy主要包括以下组件:
使用Scrapy可以轻松完成在线数据采集的工作,它已经为我们完成了很多工作,无需自己开发。
1. 安装python
目前最新的Scrapy版本是0.22.2。这个版本需要python 2.7,所以需要先安装python 2.7。这里我使用centos服务器进行测试,因为系统自带python,需要先查看python版本。
检查python版本:
$ python -V
Python 2.6.6
升级版本到2.7:
$ Python 2.7.6: $ wget http://python.org/ftp/python/2 ... ar.xz $ tar xf Python-2.7.6.tar.xz $ cd Python-2.7.6 $ ./configure --prefix=/usr/local --enable-unicode=ucs4 --enable-shared LDFLAGS="-Wl,-rpath /usr/local/lib" $ make && make altinstall
建立软连接并使系统默认python指向python2.7
$ mv /usr/bin/python /usr/bin/python2.6.6
$ ln -s /usr/local/bin/python2.7 /usr/bin/python
再次检查python版本:
$ python -V
Python 2.7.6
安装
这里我们使用 wget 来安装 setuptools:
$ wget https://bootstrap.pypa.io/ez_setup.py -O - | python
安装 zope.interface
$ easy_install zope.interface
安装扭曲
Scrapy使用Twisted异步网络库来处理网络通信,所以需要安装twisted。
在安装twisted之前,需要先安装gcc:
$ yum install gcc -y
然后,通过easy_install安装twisted:
$ easy_install twisted
如果出现以下错误:
$ easy_install twisted
Searching for twisted
Reading https://pypi.python.org/simple/twisted/
Best match: Twisted 14.0.0 Downloading https://pypi.python.org/packag ... c9815 Processing Twisted-14.0.0.tar.bz2 Writing /tmp/easy_install-kYHKjn/Twisted-14.0.0/setup.cfg Running Twisted-14.0.0/setup.py -q bdist_egg --dist-dir /tmp/easy_install-kYHKjn/Twisted-14.0.0/egg-dist-tmp-vu1n6Y twisted/runner/portmap.c:10:20: error: Python.h: No such file or directory twisted/runner/portmap.c:14: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘*’ token twisted/runner/portmap.c:31: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘*’ token twisted/runner/portmap.c:45: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘PortmapMethods’ twisted/runner/portmap.c: In function ‘initportmap’: twisted/runner/portmap.c:55: warning: implicit declaration of function ‘Py_InitModule’ twisted/runner/portmap.c:55: error: ‘PortmapMethods’ undeclared (first use in this function) twisted/runner/portmap.c:55: error: (Each undeclared identifier is reported only once twisted/runner/portmap.c:55: error: for each function it appears in.)
请安装 python-devel 并再次运行:
$ yum install python-devel -y
$ easy_install twisted
如果出现以下异常:
error: Not a recognized archive type: /tmp/easy_install-tVwC5O/Twisted-14.0.0.tar.bz2
请手动下载安装,下载地址在这里
$ wget https://pypi.python.org/packag ... c9815 $ tar -vxjf Twisted-14.0.0.tar.bz2 $ cd Twisted-14.0.0 $ python setup.py install
安装 pyOpenSSL
先安装一些依赖:
$ yum install libffi libffi-devel openssl-devel -y
然后,通过easy_install安装pyOpenSSL:
$ easy_install pyOpenSSL
安装 Scrapy
先安装一些依赖:
$ yum install libxml2 libxslt libxslt-devel -y
最后,安装 Scrapy:
$ easy_install scrapy
2. 使用 Scrapy
安装成功后,可以了解Scrapy的一些基本概念和用法,学习Scrapy项目dirbot的例子。
Dirbot 项目所在地。该项目收录一个 README 文件,详细描述了该项目的内容。如果您熟悉 Git,可以查看其源代码。或者,您可以通过单击下载以 tarball 或 zip 格式下载文件。
这里以一个例子来说明如何使用Scrapy创建爬虫项目。
新建筑
在爬取之前,您需要创建一个新的 Scrapy 项目。输入要保存代码的目录,然后执行:
$ scrapy startproject tutorial
该命令会在当前目录下新建一个目录tutorial,其结构如下:
.
├── scrapy.cfg
└── tutorial
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
这些文件主要是:
定义项目
Items 是将加载捕获数据的容器。它的工作原理类似于 Python 中的字典,但它提供了更多保护,例如填充未定义的字段以防止拼写错误。
它是通过创建一个scrapy.item.Item 类并将其属性定义为scrpy.item.Field 对象来声明的,就像一个对象关系映射(ORM)。
我们控制通过建模所需项目获得的站点数据。例如,我们要获取站点的名称、url 和 网站 描述。我们定义了这三个属性的域。为此,我们编辑教程目录中的 items.py 文件,我们的 Item 类将如下所示
from scrapy.item import Item, Field
class DmozItem(Item): title = Field() link = Field() desc = Field()
一开始可能看起来有点混乱,但是定义这些项目会让您在使用其他 Scrapy 组件时知道您的项目是什么。
写蜘蛛
Spider 是一个用户编写的类,用于从域(或域组)中获取信息。我们定义了用于下载的 URL 的初步列表、如何跟踪链接以及如何解析这些网页的内容以提取项目。
要创建 Spider,您可以为 scrapy.spider.BaseSpider 创建一个子类并确定三个主要的强制性属性:
该方法负责解析返回的数据,匹配捕获的数据(解析为item),跟踪更多的URL。
在tutorial/spiders目录下创建DmozSpider.py
from scrapy.spider import BaseSpider
class DmozSpider(BaseSpider): name = "dmoz" allowed_domains = ["dmoz.org"] start_urls = [ "http://www.dmoz.org/Computers/ ... ot%3B, "http://www.dmoz.org/Computers/ ... ot%3B ] def parse(self, response): filename = response.url.split("/")[-2] open(filename, 'wb').write(response.body)
运行项目
$ scrapy crawl dmoz
该命令从域启动爬虫,第三个参数是DmozSpider.py中name属性的值。
xpath 选择器
Scrapy 使用一种称为 XPath 选择器的机制,该机制基于 XPath 表达式。如果您想了解有关选择器和其他机制的更多信息,可以查看。
以下是 XPath 表达式及其含义的一些示例:
这些只是使用 XPath 的几个简单示例,但实际上 XPath 非常强大。如果您想了解更多关于 XPATH 的知识,我们向您推荐这个 XPath 教程
为了方便XPaths的使用,Scrapy提供了Selector类,共有三种方法
提取数据
我们可以使用以下命令选择 网站 中的每个元素:
sel.xpath('//ul/li')
然后网站描述:
sel.xpath('//ul/li/text()').extract()
网站标题:
sel.xpath('//ul/li/a/text()').extract()
网站 链接:
sel.xpath('//ul/li/a/@href').extract()
如前所述,每个 xpath() 调用都会返回一个选择器列表,因此我们可以结合 xpath() 来挖掘更深的节点。我们将使用这些功能,因此:
sites = sel.xpath('//ul/li')
for site in sites:
title = site.xpath('a/text()').extract()
link = site.xpath('a/@href').extract() desc = site.xpath('text()').extract() print title, link, desc
使用物品
scrapy.item.Item的调用接口类似于python的dict,Item收录多个scrapy.item.Field。这类似于 django 的模型和
Item通常用在Spider的parse方法中,用于保存解析后的数据。
最后修改爬虫类,使用Item保存数据,代码如下:
from scrapy.spider import Spider
from scrapy.selector import Selector from dirbot.items import Website class DmozSpider(Spider): name = "dmoz" allowed_domains = ["dmoz.org"] start_urls = [ "http://www.dmoz.org/Computers/ ... ot%3B, "http://www.dmoz.org/Computers/ ... ot%3B, ] def parse(self, response): """ The lines below is a spider contract. For more info see: http://doc.scrapy.org/en/lates ... .html @url http://www.dmoz.org/Computers/ ... rces/ @scrapes name """ sel = Selector(response) sites = sel.xpath('//ul[@class="directory-url"]/li') items = [] for site in sites: item = Website() item['name'] = site.xpath('a/text()').extract() item['url'] = site.xpath('a/@href').extract() item['description'] = site.xpath('text()').re('-\s([^\n]*?)\\n') items.append(item) return items
现在,您可以再次运行该项目以查看结果:
$ scrapy crawl dmoz
使用项目管道
在settings.py中设置ITEM_PIPELINES,默认为[],类似django的MIDDLEWARE_CLASSES等。
Spider的解析返回的Item数据会依次被ITEM_PIPELINES列表中的Pipeline类处理。
Item Pipeline 类必须实现以下方法:
可以另外实现以下两种方法:
保存捕获的数据
保存信息最简单的方法是通过,命令如下:
$ scrapy crawl dmoz -o items.json -t json
除了 json 格式,还支持 JSON 行、CSV 和 XML 格式。您还可以通过接口扩展一些格式。
这种方法对于小项目来说已经足够了。如果是比较复杂的数据,可能需要写一个Item Pipeline进行处理。
所有抓到的物品都会以JSON格式保存在新生成的items.json文件中
总结
以上介绍了如何创建爬虫项目的过程,可以参考以上过程再次联系。作为学习示例,也可以参考这个文章:scrapy中文教程(爬取cnbeta示例)。
这个文章中的爬虫代码如下:
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor from scrapy.selector import Selector from cnbeta.items import CnbetaItem class CBSpider(CrawlSpider): name = 'cnbeta' allowed_domains = ['cnbeta.com'] start_urls = ['http://www.cnbeta.com'] rules = ( Rule(SgmlLinkExtractor(allow=('/articles/.*\.htm', )), callback='parse_page', follow=True), ) def parse_page(self, response): item = CnbetaItem() sel = Selector(response) item['title'] = sel.xpath('//title/text()').extract() item['url'] = response.url return item
需要注意的是:
3. 学习资料
联系Scrapy是因为想爬取知乎的一些数据。一开始找了一些相关的资料和其他人的实现方法。
Github上有人或多或少意识到了知乎数据的爬取。我搜索了以下仓库:
其他信息:
抓取和交互式示例:
有一些知识点需要梳理:
4. 总结
以上是这几天学习Scrapy的笔记和知识汇总。参考网上的一些文章,写了这篇文章。谢谢你,希望这篇文章文章 能对你有所帮助。如果您有任何想法,请留言;如果你喜欢这篇文章,请帮忙分享一下,谢谢!
最初发表于: 查看全部
c爬虫抓取网页数据(Python开发的一个快速,高层次处理网络通讯的整体架构大致)
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体结构大致如下(注:图片来自网络):

Scrapy主要包括以下组件:
使用Scrapy可以轻松完成在线数据采集的工作,它已经为我们完成了很多工作,无需自己开发。
1. 安装python
目前最新的Scrapy版本是0.22.2。这个版本需要python 2.7,所以需要先安装python 2.7。这里我使用centos服务器进行测试,因为系统自带python,需要先查看python版本。
检查python版本:
$ python -V
Python 2.6.6
升级版本到2.7:
$ Python 2.7.6: $ wget http://python.org/ftp/python/2 ... ar.xz $ tar xf Python-2.7.6.tar.xz $ cd Python-2.7.6 $ ./configure --prefix=/usr/local --enable-unicode=ucs4 --enable-shared LDFLAGS="-Wl,-rpath /usr/local/lib" $ make && make altinstall
建立软连接并使系统默认python指向python2.7
$ mv /usr/bin/python /usr/bin/python2.6.6
$ ln -s /usr/local/bin/python2.7 /usr/bin/python
再次检查python版本:
$ python -V
Python 2.7.6
安装
这里我们使用 wget 来安装 setuptools:
$ wget https://bootstrap.pypa.io/ez_setup.py -O - | python
安装 zope.interface
$ easy_install zope.interface
安装扭曲
Scrapy使用Twisted异步网络库来处理网络通信,所以需要安装twisted。
在安装twisted之前,需要先安装gcc:
$ yum install gcc -y
然后,通过easy_install安装twisted:
$ easy_install twisted
如果出现以下错误:
$ easy_install twisted
Searching for twisted
Reading https://pypi.python.org/simple/twisted/
Best match: Twisted 14.0.0 Downloading https://pypi.python.org/packag ... c9815 Processing Twisted-14.0.0.tar.bz2 Writing /tmp/easy_install-kYHKjn/Twisted-14.0.0/setup.cfg Running Twisted-14.0.0/setup.py -q bdist_egg --dist-dir /tmp/easy_install-kYHKjn/Twisted-14.0.0/egg-dist-tmp-vu1n6Y twisted/runner/portmap.c:10:20: error: Python.h: No such file or directory twisted/runner/portmap.c:14: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘*’ token twisted/runner/portmap.c:31: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘*’ token twisted/runner/portmap.c:45: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘PortmapMethods’ twisted/runner/portmap.c: In function ‘initportmap’: twisted/runner/portmap.c:55: warning: implicit declaration of function ‘Py_InitModule’ twisted/runner/portmap.c:55: error: ‘PortmapMethods’ undeclared (first use in this function) twisted/runner/portmap.c:55: error: (Each undeclared identifier is reported only once twisted/runner/portmap.c:55: error: for each function it appears in.)
请安装 python-devel 并再次运行:
$ yum install python-devel -y
$ easy_install twisted
如果出现以下异常:
error: Not a recognized archive type: /tmp/easy_install-tVwC5O/Twisted-14.0.0.tar.bz2
请手动下载安装,下载地址在这里
$ wget https://pypi.python.org/packag ... c9815 $ tar -vxjf Twisted-14.0.0.tar.bz2 $ cd Twisted-14.0.0 $ python setup.py install
安装 pyOpenSSL
先安装一些依赖:
$ yum install libffi libffi-devel openssl-devel -y
然后,通过easy_install安装pyOpenSSL:
$ easy_install pyOpenSSL
安装 Scrapy
先安装一些依赖:
$ yum install libxml2 libxslt libxslt-devel -y
最后,安装 Scrapy:
$ easy_install scrapy
2. 使用 Scrapy
安装成功后,可以了解Scrapy的一些基本概念和用法,学习Scrapy项目dirbot的例子。
Dirbot 项目所在地。该项目收录一个 README 文件,详细描述了该项目的内容。如果您熟悉 Git,可以查看其源代码。或者,您可以通过单击下载以 tarball 或 zip 格式下载文件。
这里以一个例子来说明如何使用Scrapy创建爬虫项目。
新建筑
在爬取之前,您需要创建一个新的 Scrapy 项目。输入要保存代码的目录,然后执行:
$ scrapy startproject tutorial
该命令会在当前目录下新建一个目录tutorial,其结构如下:
.
├── scrapy.cfg
└── tutorial
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
这些文件主要是:
定义项目
Items 是将加载捕获数据的容器。它的工作原理类似于 Python 中的字典,但它提供了更多保护,例如填充未定义的字段以防止拼写错误。
它是通过创建一个scrapy.item.Item 类并将其属性定义为scrpy.item.Field 对象来声明的,就像一个对象关系映射(ORM)。
我们控制通过建模所需项目获得的站点数据。例如,我们要获取站点的名称、url 和 网站 描述。我们定义了这三个属性的域。为此,我们编辑教程目录中的 items.py 文件,我们的 Item 类将如下所示
from scrapy.item import Item, Field
class DmozItem(Item): title = Field() link = Field() desc = Field()
一开始可能看起来有点混乱,但是定义这些项目会让您在使用其他 Scrapy 组件时知道您的项目是什么。
写蜘蛛
Spider 是一个用户编写的类,用于从域(或域组)中获取信息。我们定义了用于下载的 URL 的初步列表、如何跟踪链接以及如何解析这些网页的内容以提取项目。
要创建 Spider,您可以为 scrapy.spider.BaseSpider 创建一个子类并确定三个主要的强制性属性:
该方法负责解析返回的数据,匹配捕获的数据(解析为item),跟踪更多的URL。
在tutorial/spiders目录下创建DmozSpider.py
from scrapy.spider import BaseSpider
class DmozSpider(BaseSpider): name = "dmoz" allowed_domains = ["dmoz.org"] start_urls = [ "http://www.dmoz.org/Computers/ ... ot%3B, "http://www.dmoz.org/Computers/ ... ot%3B ] def parse(self, response): filename = response.url.split("/")[-2] open(filename, 'wb').write(response.body)
运行项目
$ scrapy crawl dmoz
该命令从域启动爬虫,第三个参数是DmozSpider.py中name属性的值。
xpath 选择器
Scrapy 使用一种称为 XPath 选择器的机制,该机制基于 XPath 表达式。如果您想了解有关选择器和其他机制的更多信息,可以查看。
以下是 XPath 表达式及其含义的一些示例:
这些只是使用 XPath 的几个简单示例,但实际上 XPath 非常强大。如果您想了解更多关于 XPATH 的知识,我们向您推荐这个 XPath 教程
为了方便XPaths的使用,Scrapy提供了Selector类,共有三种方法
提取数据
我们可以使用以下命令选择 网站 中的每个元素:
sel.xpath('//ul/li')
然后网站描述:
sel.xpath('//ul/li/text()').extract()
网站标题:
sel.xpath('//ul/li/a/text()').extract()
网站 链接:
sel.xpath('//ul/li/a/@href').extract()
如前所述,每个 xpath() 调用都会返回一个选择器列表,因此我们可以结合 xpath() 来挖掘更深的节点。我们将使用这些功能,因此:
sites = sel.xpath('//ul/li')
for site in sites:
title = site.xpath('a/text()').extract()
link = site.xpath('a/@href').extract() desc = site.xpath('text()').extract() print title, link, desc
使用物品
scrapy.item.Item的调用接口类似于python的dict,Item收录多个scrapy.item.Field。这类似于 django 的模型和
Item通常用在Spider的parse方法中,用于保存解析后的数据。
最后修改爬虫类,使用Item保存数据,代码如下:
from scrapy.spider import Spider
from scrapy.selector import Selector from dirbot.items import Website class DmozSpider(Spider): name = "dmoz" allowed_domains = ["dmoz.org"] start_urls = [ "http://www.dmoz.org/Computers/ ... ot%3B, "http://www.dmoz.org/Computers/ ... ot%3B, ] def parse(self, response): """ The lines below is a spider contract. For more info see: http://doc.scrapy.org/en/lates ... .html @url http://www.dmoz.org/Computers/ ... rces/ @scrapes name """ sel = Selector(response) sites = sel.xpath('//ul[@class="directory-url"]/li') items = [] for site in sites: item = Website() item['name'] = site.xpath('a/text()').extract() item['url'] = site.xpath('a/@href').extract() item['description'] = site.xpath('text()').re('-\s([^\n]*?)\\n') items.append(item) return items
现在,您可以再次运行该项目以查看结果:
$ scrapy crawl dmoz
使用项目管道
在settings.py中设置ITEM_PIPELINES,默认为[],类似django的MIDDLEWARE_CLASSES等。
Spider的解析返回的Item数据会依次被ITEM_PIPELINES列表中的Pipeline类处理。
Item Pipeline 类必须实现以下方法:
可以另外实现以下两种方法:
保存捕获的数据
保存信息最简单的方法是通过,命令如下:
$ scrapy crawl dmoz -o items.json -t json
除了 json 格式,还支持 JSON 行、CSV 和 XML 格式。您还可以通过接口扩展一些格式。
这种方法对于小项目来说已经足够了。如果是比较复杂的数据,可能需要写一个Item Pipeline进行处理。
所有抓到的物品都会以JSON格式保存在新生成的items.json文件中
总结
以上介绍了如何创建爬虫项目的过程,可以参考以上过程再次联系。作为学习示例,也可以参考这个文章:scrapy中文教程(爬取cnbeta示例)。
这个文章中的爬虫代码如下:
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor from scrapy.selector import Selector from cnbeta.items import CnbetaItem class CBSpider(CrawlSpider): name = 'cnbeta' allowed_domains = ['cnbeta.com'] start_urls = ['http://www.cnbeta.com'] rules = ( Rule(SgmlLinkExtractor(allow=('/articles/.*\.htm', )), callback='parse_page', follow=True), ) def parse_page(self, response): item = CnbetaItem() sel = Selector(response) item['title'] = sel.xpath('//title/text()').extract() item['url'] = response.url return item
需要注意的是:
3. 学习资料
联系Scrapy是因为想爬取知乎的一些数据。一开始找了一些相关的资料和其他人的实现方法。
Github上有人或多或少意识到了知乎数据的爬取。我搜索了以下仓库:
其他信息:
抓取和交互式示例:
有一些知识点需要梳理:
4. 总结
以上是这几天学习Scrapy的笔记和知识汇总。参考网上的一些文章,写了这篇文章。谢谢你,希望这篇文章文章 能对你有所帮助。如果您有任何想法,请留言;如果你喜欢这篇文章,请帮忙分享一下,谢谢!
最初发表于:
c爬虫抓取网页数据(C++爬虫原理:C++原理(一):C++原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-10 22:21
C++爬虫原理:C++爬虫原理(一):爬虫简介
C++爬虫原理:C++爬虫原理(二):读取URL策略
下面介绍读取URL的策略,即网页的有限爬取方法:
网络爬取策略可分为深度优先、广度优先和最佳优先。在很多情况下,深度优先会导致爬虫被困。目前,广度优先和最佳优先的方法很常见。这里,聚焦爬虫推荐使用广度优先搜索和定向覆盖。
广度优先搜索
广度优先搜索策略是指在爬取过程中,当前一级搜索完成后,再进行下一级搜索。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索的方法。也有许多研究将广度优先搜索策略应用于聚焦爬虫。基本思想是,距离初始 URL 一定链接距离内的网页具有很高的主题相关性概率。另一种方法是将广度优先搜索与网络过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增加,
最佳优先搜索
最佳优先级搜索策略根据一定的网页分析算法预测候选URL与目标页面的相似度或与主题的相关性,选择一个或几个评价最好的URL进行爬取。它只访问被网络分析算法预测为“有用”的网页。一个问题是爬虫的爬取路径中很多相关的网页可能会被忽略,因为最好的优先级策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,才能跳出局部最佳点。将在第 4 节中结合网页分析算法进行详细讨论。
深度优先搜索
深度优先搜索策略从起始网页开始,选择一个网址进入,分析该网页中的网址,选择一个进入。这样一个链接被一个一个地爬取,直到处理完一条路由,然后再处理下一条路由。深度优先的策略设计比较简单。但是,门户网站网站提供的链接往往是最有价值的,PageRank也非常高。但是,网页的价值和 PageRank 会随着级别的增加而相应降低。这意味着重要的网页通常更接近种子,而被抓取过深的网页价值较低。同时,该策略的抓取深度直接影响抓取命中率和抓取效率,抓取深度是该策略的关键。与其他两种策略相比。
广度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接插入到待爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中所有链接的网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。
反向链接计数策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
其他包括 PageRank 等。
题外话:好久没更新了。网站 去备案。这个文章也参考了网上,总结了一下,不过我觉得已经用尽了。关注百度百科,wawlian的博客。 查看全部
c爬虫抓取网页数据(C++爬虫原理:C++原理(一):C++原理)
C++爬虫原理:C++爬虫原理(一):爬虫简介
C++爬虫原理:C++爬虫原理(二):读取URL策略
下面介绍读取URL的策略,即网页的有限爬取方法:
网络爬取策略可分为深度优先、广度优先和最佳优先。在很多情况下,深度优先会导致爬虫被困。目前,广度优先和最佳优先的方法很常见。这里,聚焦爬虫推荐使用广度优先搜索和定向覆盖。
广度优先搜索
广度优先搜索策略是指在爬取过程中,当前一级搜索完成后,再进行下一级搜索。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索的方法。也有许多研究将广度优先搜索策略应用于聚焦爬虫。基本思想是,距离初始 URL 一定链接距离内的网页具有很高的主题相关性概率。另一种方法是将广度优先搜索与网络过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增加,
最佳优先搜索
最佳优先级搜索策略根据一定的网页分析算法预测候选URL与目标页面的相似度或与主题的相关性,选择一个或几个评价最好的URL进行爬取。它只访问被网络分析算法预测为“有用”的网页。一个问题是爬虫的爬取路径中很多相关的网页可能会被忽略,因为最好的优先级策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,才能跳出局部最佳点。将在第 4 节中结合网页分析算法进行详细讨论。
深度优先搜索
深度优先搜索策略从起始网页开始,选择一个网址进入,分析该网页中的网址,选择一个进入。这样一个链接被一个一个地爬取,直到处理完一条路由,然后再处理下一条路由。深度优先的策略设计比较简单。但是,门户网站网站提供的链接往往是最有价值的,PageRank也非常高。但是,网页的价值和 PageRank 会随着级别的增加而相应降低。这意味着重要的网页通常更接近种子,而被抓取过深的网页价值较低。同时,该策略的抓取深度直接影响抓取命中率和抓取效率,抓取深度是该策略的关键。与其他两种策略相比。
广度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接插入到待爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中所有链接的网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。
反向链接计数策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
其他包括 PageRank 等。
题外话:好久没更新了。网站 去备案。这个文章也参考了网上,总结了一下,不过我觉得已经用尽了。关注百度百科,wawlian的博客。
c爬虫抓取网页数据( 图片来源于网络1.爬虫的流程架构大致的工作流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-10 20:08
图片来源于网络1.爬虫的流程架构大致的工作流程)
网络爬虫的基本概念和认知
图片来自网络
1. 爬虫的定义
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。——百度百科定义详细定义参考
Mukenet评论:爬虫实际上是一种自动化的信息程序或脚本,可以方便地帮助大家获取自己想要的具体信息。比如百度、谷歌这样的搜索引擎,其背后的重要技术支持就是爬虫。当我们使用搜索引擎搜索某个信息时,展示在我们面前的搜索结果是由爬虫程序预先从万维网上爬取而来的。我们之所以称其为爬虫,只是比喻自动获取万维网。
2. 爬虫的进程架构
爬虫的一般工作流程如下图所示:首先获取数据,然后清洗处理数据,最后持久化存储数据,然后可视化数据。在接下来的章节中,我们将遵循这个过程并详细介绍它们。
爬虫进程架构图
3. 爬虫分类
根据系统结构和实现技术,爬虫大致可以分为以下几类:
3.1 个通用网络爬虫
一般爬虫主要是指谷歌、百度等搜索引擎。它们爬取范围广,种类多,存储信息量大,技术要求比较高。
3.2 聚焦网络爬虫
关注爬虫,主要是基于特定主题的爬取。这是大家使用时间最长的爬虫类型。例如,我们抓取金融,或电影、书籍和其他特定信息。由于我们限制了主题和网站,可以大大节省我们的硬盘和网络资源,更好地满足特定业务的需求。
3.3 增量爬网
增量爬虫主要是指我们定期爬取一些网站时,只爬取网站变化的内容,而不是再次爬取所有网站数据。. 这样可以有效降低运维成本。
3.4 深网爬虫
深度网络爬虫主要是指一些我们无法直接爬取的网站。比如这些网站,需要用户登录,或者填写一些特定的表格,才能继续爬取信息。
Tips:在实际项目中,我们通常会结合两种或两种以上的爬虫技术来达到更好的效果。
4. 爬虫的爬取策略
爬虫根据不同的业务需求,大致可以分为两种不同的爬虫策略:
4.1 深度优先策略
深度优先策略是指在爬取HTML页面时,如果爬虫在页面中发现了新的URL,就会对新的URL进行深度优先搜索,依此类推,沿着URL爬行直到找不到深入。直到。然后,返回到最后一个 URL 地址并搜索其他 URL。当页面上没有可供选择的新 URL 时,搜索结束。
举个简单的例子,比如我们访问,假设的首页只有两个课程链接,一个是爬虫类,一个是Python类。深度优先算法是先进入爬虫类,然后进入爬虫类的一个章节链接中,如果本章没有子章节,爬虫会退到上层继续从另一个访问未访问的章节。访问完所有章节后,爬虫会返回首页。对Python课链接也进行相应的搜索,直到找不到新的URL,搜索结束。
4.2 广度优先策略
广度优先策略是指爬虫需要爬取一个完整网页的所有网址,然后才能继续搜索下一页直到底部。
它仍然是我们的例子。来到的首页后,我们需要在的首页获取Python和爬取课程的URL,才能继续搜索这两个课程的子章节的URL。然后逐层进行,直到结束。
Tips:深度优先适用于网站嵌套较深的搜索网站,而广度优先策略更适用于时间要求高、网站@同级别的URL较多的页面> 页。
5. 爬虫的学习基础
学习爬虫,我们需要以下基础知识:
如果你没有Python语言或数据库的基础知识,可以参考Mukenet的相关wiki进行学习。
当然,为了方便大家理解,我会在代码中添加详细的注释。即使你没有Python语言基础,也可以先了解大致流程,然后再排查遗漏,学习相应的知识。
有同学可能会疑惑,为什么一定要用python语言来开发爬虫。不能用其他语言吗?
这不得不说是Python的第三方库。Python之所以如此受欢迎,官方是因为它拥有大量的库,而且这些库的性能和使用都比较简单高效。凭借Python语言本身的高效率,只需一行代码就可以实现10个简单的爬虫,而在java/C/C++等其他语言中,至少需要编写几十行代码. 因此,使用Python开发爬虫程序,赢得了众多程序员的青睐。
比如,人们习惯在楼下的便利店买饮料。虽然离门口一公里有一家比较大的超市,但相信大家都不愿意买,因为太麻烦,不方便。这就是Python语言成为爬虫主流语言的精髓所在。
在接下来的学习中,我们将使用 Python 的几个第三方库。所谓第三方库是指Python的官方库(例如system“os”和time“time”\等库),非官方发布的库,如requests等库,称为第三方库。
安装Python解释器时默认已经安装了官方的Python库,需要手动安装第三方库。比如我们在爬虫开发中经常用到Requests库。安装第三方库很简单,在终端执行如下命令即可:
pip install requests
后面讲到具体的库时,我们会做详细的介绍。
下面是爬虫开发中常用的Python库对比:
套餐介绍
网址库
不需要安装 Python 自带的库。但是,在不同的python版本中,urlib在细节上有所不同。实际开发中过于繁琐,header无法伪装,很容易被阻塞。因此,现在使用它的人并不多。
要求
与urllib相比,它不仅拥有url的所有功能,更重要的是语法简洁优雅,而且在兼容性方面完全兼容python2和python3,非常方便。同时,它还可以伪装请求。
urllib3
urllib3 库提供了一些 urllib 没有的重要特性,例如线程安全、连接池和对压缩编码的支持。
这里推荐requests库,简单方便,容易上手,非常适合使用爬虫的新手。如果没有特殊说明,我们将在后续课程中默认使用 requests 库。
6. 爬虫的法律伦理问题
近年来,可以说通过编写爬虫程序来抓取大量数据而获利的程序员层出不穷。您可能会担心在使用爬虫的过程中是否会触犯法律。其实只要合理使用爬虫,就不会轻易触犯法律。那么,什么是爬虫的合理使用呢?我总结了以下三点供大家参考:
不管法律方面,我们也必须严于律己,遵守一些特定的规则。这里我想说的是爬虫世界中的robots协议。这是网站的所有者为爬虫设计的协议,通常位于网站的根目录下。它指定哪些目录可以被爬取,哪些不能。我们需要遵守这个约定好的协议,以避免不必要的麻烦。
7. 个人经历
在实际工作项目中,如果我们是做爬虫工作的工程师,在精通爬虫基础技术的同时,应该熟悉和了解数据清洗和处理技术。只有这样,我们才能更好地与团队协作。. 当然,这些技术会在后面的章节中一一为大家介绍。
好的,让我们开始爬虫世界的欢乐之旅吧! 查看全部
c爬虫抓取网页数据(
图片来源于网络1.爬虫的流程架构大致的工作流程)
网络爬虫的基本概念和认知

图片来自网络
1. 爬虫的定义
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。——百度百科定义详细定义参考
Mukenet评论:爬虫实际上是一种自动化的信息程序或脚本,可以方便地帮助大家获取自己想要的具体信息。比如百度、谷歌这样的搜索引擎,其背后的重要技术支持就是爬虫。当我们使用搜索引擎搜索某个信息时,展示在我们面前的搜索结果是由爬虫程序预先从万维网上爬取而来的。我们之所以称其为爬虫,只是比喻自动获取万维网。
2. 爬虫的进程架构
爬虫的一般工作流程如下图所示:首先获取数据,然后清洗处理数据,最后持久化存储数据,然后可视化数据。在接下来的章节中,我们将遵循这个过程并详细介绍它们。
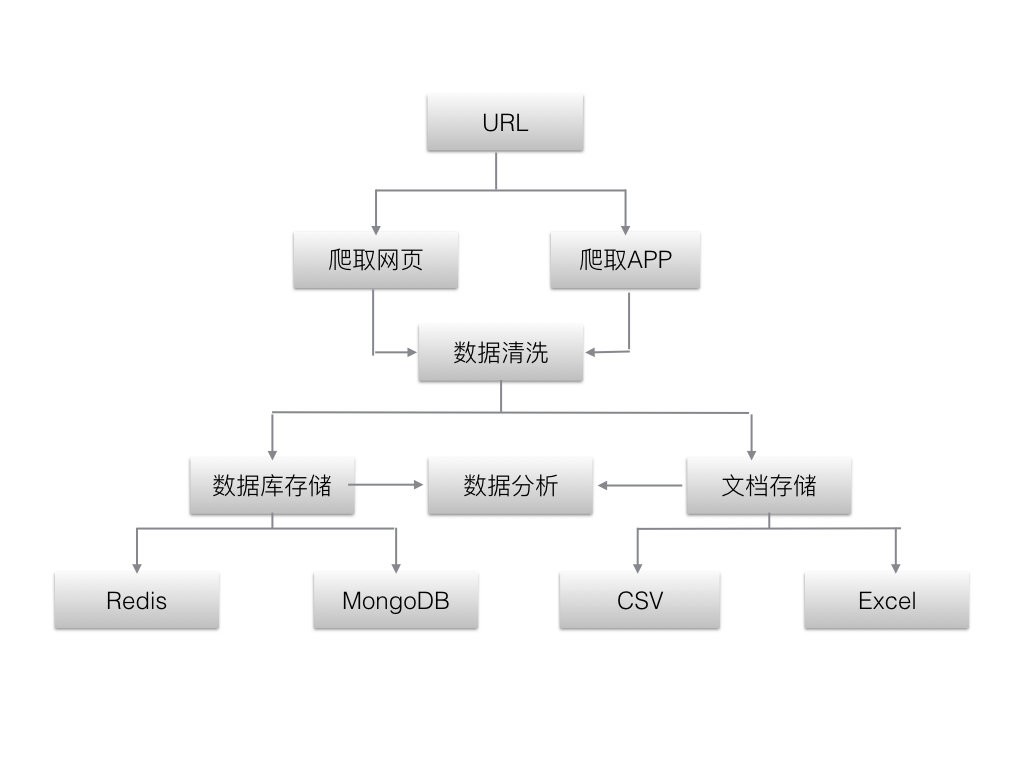
爬虫进程架构图
3. 爬虫分类
根据系统结构和实现技术,爬虫大致可以分为以下几类:
3.1 个通用网络爬虫
一般爬虫主要是指谷歌、百度等搜索引擎。它们爬取范围广,种类多,存储信息量大,技术要求比较高。
3.2 聚焦网络爬虫
关注爬虫,主要是基于特定主题的爬取。这是大家使用时间最长的爬虫类型。例如,我们抓取金融,或电影、书籍和其他特定信息。由于我们限制了主题和网站,可以大大节省我们的硬盘和网络资源,更好地满足特定业务的需求。
3.3 增量爬网
增量爬虫主要是指我们定期爬取一些网站时,只爬取网站变化的内容,而不是再次爬取所有网站数据。. 这样可以有效降低运维成本。
3.4 深网爬虫
深度网络爬虫主要是指一些我们无法直接爬取的网站。比如这些网站,需要用户登录,或者填写一些特定的表格,才能继续爬取信息。
Tips:在实际项目中,我们通常会结合两种或两种以上的爬虫技术来达到更好的效果。
4. 爬虫的爬取策略
爬虫根据不同的业务需求,大致可以分为两种不同的爬虫策略:
4.1 深度优先策略
深度优先策略是指在爬取HTML页面时,如果爬虫在页面中发现了新的URL,就会对新的URL进行深度优先搜索,依此类推,沿着URL爬行直到找不到深入。直到。然后,返回到最后一个 URL 地址并搜索其他 URL。当页面上没有可供选择的新 URL 时,搜索结束。
举个简单的例子,比如我们访问,假设的首页只有两个课程链接,一个是爬虫类,一个是Python类。深度优先算法是先进入爬虫类,然后进入爬虫类的一个章节链接中,如果本章没有子章节,爬虫会退到上层继续从另一个访问未访问的章节。访问完所有章节后,爬虫会返回首页。对Python课链接也进行相应的搜索,直到找不到新的URL,搜索结束。
4.2 广度优先策略
广度优先策略是指爬虫需要爬取一个完整网页的所有网址,然后才能继续搜索下一页直到底部。
它仍然是我们的例子。来到的首页后,我们需要在的首页获取Python和爬取课程的URL,才能继续搜索这两个课程的子章节的URL。然后逐层进行,直到结束。
Tips:深度优先适用于网站嵌套较深的搜索网站,而广度优先策略更适用于时间要求高、网站@同级别的URL较多的页面> 页。
5. 爬虫的学习基础
学习爬虫,我们需要以下基础知识:
如果你没有Python语言或数据库的基础知识,可以参考Mukenet的相关wiki进行学习。
当然,为了方便大家理解,我会在代码中添加详细的注释。即使你没有Python语言基础,也可以先了解大致流程,然后再排查遗漏,学习相应的知识。
有同学可能会疑惑,为什么一定要用python语言来开发爬虫。不能用其他语言吗?
这不得不说是Python的第三方库。Python之所以如此受欢迎,官方是因为它拥有大量的库,而且这些库的性能和使用都比较简单高效。凭借Python语言本身的高效率,只需一行代码就可以实现10个简单的爬虫,而在java/C/C++等其他语言中,至少需要编写几十行代码. 因此,使用Python开发爬虫程序,赢得了众多程序员的青睐。
比如,人们习惯在楼下的便利店买饮料。虽然离门口一公里有一家比较大的超市,但相信大家都不愿意买,因为太麻烦,不方便。这就是Python语言成为爬虫主流语言的精髓所在。
在接下来的学习中,我们将使用 Python 的几个第三方库。所谓第三方库是指Python的官方库(例如system“os”和time“time”\等库),非官方发布的库,如requests等库,称为第三方库。
安装Python解释器时默认已经安装了官方的Python库,需要手动安装第三方库。比如我们在爬虫开发中经常用到Requests库。安装第三方库很简单,在终端执行如下命令即可:
pip install requests
后面讲到具体的库时,我们会做详细的介绍。
下面是爬虫开发中常用的Python库对比:
套餐介绍
网址库
不需要安装 Python 自带的库。但是,在不同的python版本中,urlib在细节上有所不同。实际开发中过于繁琐,header无法伪装,很容易被阻塞。因此,现在使用它的人并不多。
要求
与urllib相比,它不仅拥有url的所有功能,更重要的是语法简洁优雅,而且在兼容性方面完全兼容python2和python3,非常方便。同时,它还可以伪装请求。
urllib3
urllib3 库提供了一些 urllib 没有的重要特性,例如线程安全、连接池和对压缩编码的支持。
这里推荐requests库,简单方便,容易上手,非常适合使用爬虫的新手。如果没有特殊说明,我们将在后续课程中默认使用 requests 库。
6. 爬虫的法律伦理问题
近年来,可以说通过编写爬虫程序来抓取大量数据而获利的程序员层出不穷。您可能会担心在使用爬虫的过程中是否会触犯法律。其实只要合理使用爬虫,就不会轻易触犯法律。那么,什么是爬虫的合理使用呢?我总结了以下三点供大家参考:
不管法律方面,我们也必须严于律己,遵守一些特定的规则。这里我想说的是爬虫世界中的robots协议。这是网站的所有者为爬虫设计的协议,通常位于网站的根目录下。它指定哪些目录可以被爬取,哪些不能。我们需要遵守这个约定好的协议,以避免不必要的麻烦。
7. 个人经历
在实际工作项目中,如果我们是做爬虫工作的工程师,在精通爬虫基础技术的同时,应该熟悉和了解数据清洗和处理技术。只有这样,我们才能更好地与团队协作。. 当然,这些技术会在后面的章节中一一为大家介绍。
好的,让我们开始爬虫世界的欢乐之旅吧!
c爬虫抓取网页数据(深耕Python、数据库、seienium、JS逆向、安卓逆向)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-10 20:05
作者简介:机械专业本科,野程序员,学过C语言,玩过前端,也修过嵌入式,设计过一点,但现在迷上了爬虫,所以现在在培养Python,数据库、seienium、JS逆向工程、Android逆向等,本人目前是全职爬虫工程师。我喜欢记录学习过程。写了15W的电子笔记,你看下面的文章~
技术栈:Python、HTML、CSS、JavaScript、C、Xpath语法、regular、MySQL、Redis、MongoDB、Scrapy、Pyspider、Fiddler、Mitmproxy、分布式爬虫、JAVA等。
个人博客:
大学作品集:
欢迎点赞
爬得高,自尊心低,必须远行。
我始终相信越努力越幸运
⭐️打不倒我们的人,终会让我们变得更强大
希望深耕编程之路的朋友越来越好
文章内容
爬虫爬取数据的步骤!爬虫获取数据的步骤!
第一:找到需要爬取数据的URL地址
第二:(打包请求头)向这个url地址发起请求
第三:获取url服务器发送的响应数据(网页源码)
第四:使用python数据分析库在源码中获取你想要的数据!
第五:清理并保存数据(csv、数据库、Excel)!
第六:是否需要跳转到原网页然后抓取数据! 查看全部
c爬虫抓取网页数据(深耕Python、数据库、seienium、JS逆向、安卓逆向)
作者简介:机械专业本科,野程序员,学过C语言,玩过前端,也修过嵌入式,设计过一点,但现在迷上了爬虫,所以现在在培养Python,数据库、seienium、JS逆向工程、Android逆向等,本人目前是全职爬虫工程师。我喜欢记录学习过程。写了15W的电子笔记,你看下面的文章~
技术栈:Python、HTML、CSS、JavaScript、C、Xpath语法、regular、MySQL、Redis、MongoDB、Scrapy、Pyspider、Fiddler、Mitmproxy、分布式爬虫、JAVA等。
个人博客:
大学作品集:
欢迎点赞
爬得高,自尊心低,必须远行。
我始终相信越努力越幸运
⭐️打不倒我们的人,终会让我们变得更强大
希望深耕编程之路的朋友越来越好
文章内容
爬虫爬取数据的步骤!爬虫获取数据的步骤!
第一:找到需要爬取数据的URL地址
第二:(打包请求头)向这个url地址发起请求
第三:获取url服务器发送的响应数据(网页源码)
第四:使用python数据分析库在源码中获取你想要的数据!
第五:清理并保存数据(csv、数据库、Excel)!
第六:是否需要跳转到原网页然后抓取数据!
c爬虫抓取网页数据(专业搜索引擎中网络爬虫的分类及其工作原理(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-09 14:21
随着互联网的不断发展,搜索引擎技术发展迅速。搜索引擎已经成为人们在广阔的网络世界中获取信息不可或缺的工具。采用何种策略有效访问网络资源,成为专业搜索引擎中网络爬虫研究的一大课题。文章 介绍了搜索引擎的分类及其工作原理。描述了网络爬虫技术的搜索策略,展望了新一代搜索引擎的发展趋势。关键词 网络爬虫;战略; 搜索引擎概念:网络爬虫又称网络蜘蛛。它是一种按照一定的规则自动提取网页的程序。它会通过网络自动抓取互联网上的网页。这项技术是通用的,可用于检查您网站上的所有链接是否有效。当然,更先进的技术是在网页中保存相关数据,可以成为搜索引擎。搜索引擎使用网络爬虫来查找网络内容。网络上的 HTML 文档通过超链接连接,就像网络一样。网络爬虫也称为网络蜘蛛。他们沿着这个网络爬行并在每次访问网页时使用它们。爬虫程序抓取这个网页,提取内容,同时提取超链接作为进一步爬取的线索。网络爬虫总是从某个起点开始爬行。这个起点称为种子。你可以告诉它,或者你可以在一些 URL 列表 网站 上得到它。网络爬虫的组成和分类。网络爬虫也被称为网络蜘蛛和网络机器人。它们主要用于采集网络资源。在进行网络舆情分析时,首先要获取舆情信息的内容。这需要使用网络爬虫(蜘蛛程序),这是一个可以自动提取网页内容的程序。它通过搜索引擎从互联网上抓取网址并抓取它们。获取相应的网页内容是搜索引擎(Search Engine)的重要组成部分。它通过搜索引擎从互联网上抓取网址并抓取它们。获取相应的网页内容是搜索引擎(Search Engine)的重要组成部分。它通过搜索引擎从互联网上抓取网址并抓取它们。获取相应的网页内容是搜索引擎(Search Engine)的重要组成部分。
一个典型的网络爬虫的主要组成部分如下: URL链接库,主要用于存储爬取的网络链接。文档内容模块主要用于访问从Web 下载的Web 内容。文档解析模块用于解析下载的文档中网页的内容,如解析PDF、Word、HTML等标准化URL模块,用于将URL转换为标准格式。URL 过滤器主要用于过滤掉不需要的 URL。以上模块的设计和实现主要是确定爬取的内容和爬取的范围。最简单的例子是从已知站点抓取一些网页。这个爬虫用少量的代码就可以完成。但是在实际的互联网应用中,可能会遇到需要爬取大量内容的情况,你需要设计一个更复杂的爬虫。这个爬虫是一个组合的应用,难度是基于分布式的。网络爬虫的工作原理传统网络爬虫的工作原理是先选择初始网址,获取初始网页的域名或IP地址,然后在抓取网页时不断从当前页面获取新的网址并将它们放入候选队列。直到满足停止条件。焦点爬虫(topic-driven crawlers)不同于传统爬虫。它的工作流程更为复杂。首先需要过滤掉与主题无关的链接,只保留有用的链接,放入候选URL队列。然后,根据搜索策略从候选队列中选择下一个要抓取的网页链接,
同时,所有爬取的网页内容都被保存,并进行过滤、分析、索引等,以进行性检索和查询。一般来说,网络爬虫主要有以下两个阶段: 第一阶段,URL库初始化,然后开始爬虫。在第二阶段,爬虫读取未访问过的 URL 以确定其工作范围。其中,对于要爬取的URL链接,执行以下步骤: 获取URL链接。解析内容并获取 URL 和相关数据。规范化新抓取的 URL。过滤掉不相关的 URL。将要爬取的 URL 更新为 URL 重复步骤 2,直到满足终止条件。网络爬虫的搜索策略目前常见的网络爬虫搜索策略有以下三种:1、广度优先搜索策略。主要思想是从根节点开始,先遍历当前一层搜索,然后再进行下一层搜索,以此类推,一层一层的进行搜索。这种策略主要用于主题爬虫,因为网页越接近初始 URL,主题相关性就越大。2、深度优先搜索策略。这个策略的主要思想是从根节点开始寻找叶子节点,以此类推。在网页中,选择一个超链接,链接的网页将进行深度优先搜索,形成一个单一的搜索链。当没有其他超链接时,搜索结束。3、最佳优先级搜索策略。该策略计算 URL 描述文本与目标网页的相似度,或与主题的相关性,
爬取算法数据采集的效率和覆盖率受爬取算法的影响。流行和经典的爬虫算法都是在Best-Frist算法的基础上改进和演进的。各种算法的区别 是:对要爬取的网址按照不同的启发式规则进行评分和排序,在爬取前或爬取过程中优化算法参数。Best-First 算法 Best-First 算法维护一个排序的 URLs 优先级队列,通过计算主题和被抓取网页之间的余弦相似度(cosinesimilarity)来确定 Urls 在 Urls 前沿的优先级。相似度计算公式如下:(2-1)为主题,p为爬取的网页。Best-Frist爬取算法如下:初始化,设置查询主题(topic)、初始种子节点集(starting_urls)、最大爬取页面数(MAX_PAGES)和边界容量限制(MAX_BUFFER);ii. 将初始节点集(starting_urls)中的所有链接插入前沿队列(初始为空);三、循环(当边界队列不为空时)和爬取的页面数) a)从边界(link)中取优先级最高的链接:link=dequeue_link_with_max_score(frontier) b) 访问并下载该链接对应的页面(doc): doc=fetch_new_page(link) c) 计算页面与主题的相似度(score): score=sim(topic,doc) d) 提取doc中的所有超链接(outlinks) e) Loop (for页面文档中的每个超链接外链) If(#frontier> 爬取的最大页面数(MAX_PAGES)和边界容量限制(MAX_BUFFER);ii. 将初始节点集(starting_urls)中的所有链接插入前沿队列(初始为空);三、循环(当边界队列不为空时)和爬取的页面数) a)从边界(link)中取优先级最高的链接:link=dequeue_link_with_max_score(frontier) b) 访问并下载该链接对应的页面(doc): doc=fetch_new_page(link) c) 计算页面与主题的相似度(score): score=sim(topic,doc) d) 提取doc中的所有超链接(outlinks) e) Loop (for页面文档中的每个超链接外链) If(#frontier> 爬取的最大页面数(MAX_PAGES)和边界容量限制(MAX_BUFFER);ii. 将初始节点集(starting_urls)中的所有链接插入前沿队列(初始为空);三、循环(当边界队列不为空时)和爬取的页面数) a)从边界(link)中取优先级最高的链接:link=dequeue_link_with_max_score(frontier) b) 访问并下载该链接对应的页面(doc): doc=fetch_new_page(link) c) 计算页面与主题的相似度(score): score=sim(topic,doc) d) 提取doc中的所有超链接(outlinks) e) Loop (for页面文档中的每个超链接外链) If(#frontier>
与 Fish-Search 算法一样,该算法也为爬行设置了深度边界。爬行队列中的每个链接都与深度限制和优先级度量相关联。深度限制由用户设置,链接的优先级值由父页面、锚文本和链接附近文本的相关性决定。具体算法如下: 初始化:设置初始节点、深度限制(D)、爬行规模(S)、时间限制、搜索查询q;ii. 设置初始节点depth=D的深度限制,将节点插入爬取队列(初始为空);三、循环(当队列不为空且下载节点数为0时(当前节点相关)inherit_score(child_node)=*sim(q, current_node) 其中预设衰减因子=0. 5; 否则inherited_score(child_node)= *inherited_score(current_node); 提取anchor_text和anchor_text_context(通过预设边界,如:1);Elseanchor_context_score计算anchor的相关性,neihgorhood_score:其中预设常数等于0.8;子节点,其中预设常数小于1,一般设置为0.5。
四、循环结束。网络爬虫技术的最新发展 传统的网络爬虫技术应该主要用于抓取静态网页。31、随着AJAX/Web2.0的普及,如何抓取AJAX等动态页面成为搜索引擎亟待解决的问题,因为AJAX颠覆了传统的纯HTTP请求/响应协议机制。如果搜索引擎仍然使用“爬行”机制,就不可能抓取到AJAX表面的有效数据。AJAX 使用由 JavaScript 驱动的异步请求/响应机制。过去的爬虫缺乏对 JavaScript 语义的理解。基本上无法模拟触发JavaScript的异步调用,解析返回的异步返回逻辑和内容。此外。在 AJAX 应用程序中,JavaScript 会对 D0M 结构做很多改动,甚至页面的所有内容都是通过 JavaScript 直接从服务器读取并动态绘制。这对于习惯于相对不变的D0M结构的静态页面来说是不可理解的。过去爬虫是基于协议驱动的,对于AJAX这样的技术,所需要的爬虫引擎必须是事件驱动的。要实现事件驱动,首先需要解决JavaScript的交互分析和解释问题。综上所述,近年来,国内对互联网搜索引擎的研究从无到有,逐渐成为热点,研究现象的主题聚类特征更加明显。甚至页面的所有内容都是通过JavaScript直接从服务器读取并动态绘制的。这对于习惯于相对不变的D0M结构的静态页面来说是不可理解的。过去爬虫是基于协议驱动的,对于AJAX这样的技术,所需要的爬虫引擎必须是事件驱动的。要实现事件驱动,首先需要解决JavaScript的交互分析和解释问题。综上所述,近年来,国内对互联网搜索引擎的研究从无到有,逐渐成为热点,研究现象的主题聚类特征更加明显。甚至页面的所有内容都是通过JavaScript直接从服务器读取并动态绘制的。这对于习惯于相对不变的D0M结构的静态页面来说是不可理解的。过去爬虫是基于协议驱动的,对于AJAX这样的技术,所需要的爬虫引擎必须是事件驱动的。要实现事件驱动,首先需要解决JavaScript的交互分析和解释问题。综上所述,近年来,国内对互联网搜索引擎的研究从无到有,逐渐成为热点,研究现象的主题聚类特征更加明显。过去爬虫是基于协议驱动的,对于AJAX这样的技术,所需要的爬虫引擎必须是事件驱动的。要实现事件驱动,首先需要解决JavaScript的交互分析和解释问题。综上所述,近年来,国内对互联网搜索引擎的研究从无到有,逐渐成为热点,研究现象的主题聚类特征更加明显。过去爬虫是基于协议驱动的,对于AJAX这样的技术,所需要的爬虫引擎必须是事件驱动的。要实现事件驱动,首先需要解决JavaScript的交互分析和解释问题。综上所述,近年来,国内对互联网搜索引擎的研究从无到有,逐渐成为热点,研究现象的主题聚类特征更加明显。
综合性研究论文数量远远超过该研究领域。国外搜索引擎的研究较热,水平高于国内。随着 lucene 和其他开源项目的出现,搜索引擎研究也出现了高潮。在搜索引擎中爬行是一个更昂贵且非常重要的部分。那么爬虫的效率、特性和质量就很重要了。那么爬虫技术与人工智能、分布式技术的结合自然成为研究热点。 查看全部
c爬虫抓取网页数据(专业搜索引擎中网络爬虫的分类及其工作原理(图))
随着互联网的不断发展,搜索引擎技术发展迅速。搜索引擎已经成为人们在广阔的网络世界中获取信息不可或缺的工具。采用何种策略有效访问网络资源,成为专业搜索引擎中网络爬虫研究的一大课题。文章 介绍了搜索引擎的分类及其工作原理。描述了网络爬虫技术的搜索策略,展望了新一代搜索引擎的发展趋势。关键词 网络爬虫;战略; 搜索引擎概念:网络爬虫又称网络蜘蛛。它是一种按照一定的规则自动提取网页的程序。它会通过网络自动抓取互联网上的网页。这项技术是通用的,可用于检查您网站上的所有链接是否有效。当然,更先进的技术是在网页中保存相关数据,可以成为搜索引擎。搜索引擎使用网络爬虫来查找网络内容。网络上的 HTML 文档通过超链接连接,就像网络一样。网络爬虫也称为网络蜘蛛。他们沿着这个网络爬行并在每次访问网页时使用它们。爬虫程序抓取这个网页,提取内容,同时提取超链接作为进一步爬取的线索。网络爬虫总是从某个起点开始爬行。这个起点称为种子。你可以告诉它,或者你可以在一些 URL 列表 网站 上得到它。网络爬虫的组成和分类。网络爬虫也被称为网络蜘蛛和网络机器人。它们主要用于采集网络资源。在进行网络舆情分析时,首先要获取舆情信息的内容。这需要使用网络爬虫(蜘蛛程序),这是一个可以自动提取网页内容的程序。它通过搜索引擎从互联网上抓取网址并抓取它们。获取相应的网页内容是搜索引擎(Search Engine)的重要组成部分。它通过搜索引擎从互联网上抓取网址并抓取它们。获取相应的网页内容是搜索引擎(Search Engine)的重要组成部分。它通过搜索引擎从互联网上抓取网址并抓取它们。获取相应的网页内容是搜索引擎(Search Engine)的重要组成部分。
一个典型的网络爬虫的主要组成部分如下: URL链接库,主要用于存储爬取的网络链接。文档内容模块主要用于访问从Web 下载的Web 内容。文档解析模块用于解析下载的文档中网页的内容,如解析PDF、Word、HTML等标准化URL模块,用于将URL转换为标准格式。URL 过滤器主要用于过滤掉不需要的 URL。以上模块的设计和实现主要是确定爬取的内容和爬取的范围。最简单的例子是从已知站点抓取一些网页。这个爬虫用少量的代码就可以完成。但是在实际的互联网应用中,可能会遇到需要爬取大量内容的情况,你需要设计一个更复杂的爬虫。这个爬虫是一个组合的应用,难度是基于分布式的。网络爬虫的工作原理传统网络爬虫的工作原理是先选择初始网址,获取初始网页的域名或IP地址,然后在抓取网页时不断从当前页面获取新的网址并将它们放入候选队列。直到满足停止条件。焦点爬虫(topic-driven crawlers)不同于传统爬虫。它的工作流程更为复杂。首先需要过滤掉与主题无关的链接,只保留有用的链接,放入候选URL队列。然后,根据搜索策略从候选队列中选择下一个要抓取的网页链接,
同时,所有爬取的网页内容都被保存,并进行过滤、分析、索引等,以进行性检索和查询。一般来说,网络爬虫主要有以下两个阶段: 第一阶段,URL库初始化,然后开始爬虫。在第二阶段,爬虫读取未访问过的 URL 以确定其工作范围。其中,对于要爬取的URL链接,执行以下步骤: 获取URL链接。解析内容并获取 URL 和相关数据。规范化新抓取的 URL。过滤掉不相关的 URL。将要爬取的 URL 更新为 URL 重复步骤 2,直到满足终止条件。网络爬虫的搜索策略目前常见的网络爬虫搜索策略有以下三种:1、广度优先搜索策略。主要思想是从根节点开始,先遍历当前一层搜索,然后再进行下一层搜索,以此类推,一层一层的进行搜索。这种策略主要用于主题爬虫,因为网页越接近初始 URL,主题相关性就越大。2、深度优先搜索策略。这个策略的主要思想是从根节点开始寻找叶子节点,以此类推。在网页中,选择一个超链接,链接的网页将进行深度优先搜索,形成一个单一的搜索链。当没有其他超链接时,搜索结束。3、最佳优先级搜索策略。该策略计算 URL 描述文本与目标网页的相似度,或与主题的相关性,
爬取算法数据采集的效率和覆盖率受爬取算法的影响。流行和经典的爬虫算法都是在Best-Frist算法的基础上改进和演进的。各种算法的区别 是:对要爬取的网址按照不同的启发式规则进行评分和排序,在爬取前或爬取过程中优化算法参数。Best-First 算法 Best-First 算法维护一个排序的 URLs 优先级队列,通过计算主题和被抓取网页之间的余弦相似度(cosinesimilarity)来确定 Urls 在 Urls 前沿的优先级。相似度计算公式如下:(2-1)为主题,p为爬取的网页。Best-Frist爬取算法如下:初始化,设置查询主题(topic)、初始种子节点集(starting_urls)、最大爬取页面数(MAX_PAGES)和边界容量限制(MAX_BUFFER);ii. 将初始节点集(starting_urls)中的所有链接插入前沿队列(初始为空);三、循环(当边界队列不为空时)和爬取的页面数) a)从边界(link)中取优先级最高的链接:link=dequeue_link_with_max_score(frontier) b) 访问并下载该链接对应的页面(doc): doc=fetch_new_page(link) c) 计算页面与主题的相似度(score): score=sim(topic,doc) d) 提取doc中的所有超链接(outlinks) e) Loop (for页面文档中的每个超链接外链) If(#frontier> 爬取的最大页面数(MAX_PAGES)和边界容量限制(MAX_BUFFER);ii. 将初始节点集(starting_urls)中的所有链接插入前沿队列(初始为空);三、循环(当边界队列不为空时)和爬取的页面数) a)从边界(link)中取优先级最高的链接:link=dequeue_link_with_max_score(frontier) b) 访问并下载该链接对应的页面(doc): doc=fetch_new_page(link) c) 计算页面与主题的相似度(score): score=sim(topic,doc) d) 提取doc中的所有超链接(outlinks) e) Loop (for页面文档中的每个超链接外链) If(#frontier> 爬取的最大页面数(MAX_PAGES)和边界容量限制(MAX_BUFFER);ii. 将初始节点集(starting_urls)中的所有链接插入前沿队列(初始为空);三、循环(当边界队列不为空时)和爬取的页面数) a)从边界(link)中取优先级最高的链接:link=dequeue_link_with_max_score(frontier) b) 访问并下载该链接对应的页面(doc): doc=fetch_new_page(link) c) 计算页面与主题的相似度(score): score=sim(topic,doc) d) 提取doc中的所有超链接(outlinks) e) Loop (for页面文档中的每个超链接外链) If(#frontier>
与 Fish-Search 算法一样,该算法也为爬行设置了深度边界。爬行队列中的每个链接都与深度限制和优先级度量相关联。深度限制由用户设置,链接的优先级值由父页面、锚文本和链接附近文本的相关性决定。具体算法如下: 初始化:设置初始节点、深度限制(D)、爬行规模(S)、时间限制、搜索查询q;ii. 设置初始节点depth=D的深度限制,将节点插入爬取队列(初始为空);三、循环(当队列不为空且下载节点数为0时(当前节点相关)inherit_score(child_node)=*sim(q, current_node) 其中预设衰减因子=0. 5; 否则inherited_score(child_node)= *inherited_score(current_node); 提取anchor_text和anchor_text_context(通过预设边界,如:1);Elseanchor_context_score计算anchor的相关性,neihgorhood_score:其中预设常数等于0.8;子节点,其中预设常数小于1,一般设置为0.5。
四、循环结束。网络爬虫技术的最新发展 传统的网络爬虫技术应该主要用于抓取静态网页。31、随着AJAX/Web2.0的普及,如何抓取AJAX等动态页面成为搜索引擎亟待解决的问题,因为AJAX颠覆了传统的纯HTTP请求/响应协议机制。如果搜索引擎仍然使用“爬行”机制,就不可能抓取到AJAX表面的有效数据。AJAX 使用由 JavaScript 驱动的异步请求/响应机制。过去的爬虫缺乏对 JavaScript 语义的理解。基本上无法模拟触发JavaScript的异步调用,解析返回的异步返回逻辑和内容。此外。在 AJAX 应用程序中,JavaScript 会对 D0M 结构做很多改动,甚至页面的所有内容都是通过 JavaScript 直接从服务器读取并动态绘制。这对于习惯于相对不变的D0M结构的静态页面来说是不可理解的。过去爬虫是基于协议驱动的,对于AJAX这样的技术,所需要的爬虫引擎必须是事件驱动的。要实现事件驱动,首先需要解决JavaScript的交互分析和解释问题。综上所述,近年来,国内对互联网搜索引擎的研究从无到有,逐渐成为热点,研究现象的主题聚类特征更加明显。甚至页面的所有内容都是通过JavaScript直接从服务器读取并动态绘制的。这对于习惯于相对不变的D0M结构的静态页面来说是不可理解的。过去爬虫是基于协议驱动的,对于AJAX这样的技术,所需要的爬虫引擎必须是事件驱动的。要实现事件驱动,首先需要解决JavaScript的交互分析和解释问题。综上所述,近年来,国内对互联网搜索引擎的研究从无到有,逐渐成为热点,研究现象的主题聚类特征更加明显。甚至页面的所有内容都是通过JavaScript直接从服务器读取并动态绘制的。这对于习惯于相对不变的D0M结构的静态页面来说是不可理解的。过去爬虫是基于协议驱动的,对于AJAX这样的技术,所需要的爬虫引擎必须是事件驱动的。要实现事件驱动,首先需要解决JavaScript的交互分析和解释问题。综上所述,近年来,国内对互联网搜索引擎的研究从无到有,逐渐成为热点,研究现象的主题聚类特征更加明显。过去爬虫是基于协议驱动的,对于AJAX这样的技术,所需要的爬虫引擎必须是事件驱动的。要实现事件驱动,首先需要解决JavaScript的交互分析和解释问题。综上所述,近年来,国内对互联网搜索引擎的研究从无到有,逐渐成为热点,研究现象的主题聚类特征更加明显。过去爬虫是基于协议驱动的,对于AJAX这样的技术,所需要的爬虫引擎必须是事件驱动的。要实现事件驱动,首先需要解决JavaScript的交互分析和解释问题。综上所述,近年来,国内对互联网搜索引擎的研究从无到有,逐渐成为热点,研究现象的主题聚类特征更加明显。
综合性研究论文数量远远超过该研究领域。国外搜索引擎的研究较热,水平高于国内。随着 lucene 和其他开源项目的出现,搜索引擎研究也出现了高潮。在搜索引擎中爬行是一个更昂贵且非常重要的部分。那么爬虫的效率、特性和质量就很重要了。那么爬虫技术与人工智能、分布式技术的结合自然成为研究热点。
c爬虫抓取网页数据(1.爬虫的流程是怎样的?(一)教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-07 08:23
爬虫技术文章很少从整体上讲,这次从宏观的角度讲,希望这篇文章文章能澄清三个问题:
1. 爬取的过程是什么?
2. 每道工序都有哪些技术方案?
3. 你会遇到什么困难?
所以这个文章也为后面的文章设置了教程的框架。
1. 爬取的过程是什么?
爬虫其实很简单,可以分为三个部分:获取网页--->解析网页,提取需要的数据--->存储。在文章:爬行者一号中,我简单地举例说明了每个部分。
一种。访问页面是什么?
获取一个网页就是向一个网址发送请求,然后该网址会返回整个网页的数据。类似:你在浏览器中输入网址,回车,然后你就看到了网站的整个页面。
湾 什么是解析页面?
解析一个网页就是从整个网页的数据中提取出你想要的数据。类似:你在浏览器中看到了网站的整个页面,但是你想找到产品的价格,而价格就是你想要的数据。
C。什么是存储?
存储很简单,就是保存数据。
2. 三个进程的技术是什么?
以下技术均在python下,本文不涉及Java
一种。获取网页:
要求
url2 和 url
模拟浏览器:selenium 或 PhantomJS
湾 解析网页:
常规的
美汤
C。贮存
将txt、csv等文件保存到mysql、mongodb等数据库中。
还有一些爬虫框架,比如Scrapy。在一个框架下解决并完成这三大流程。
另外,还会有提升爬虫速度的需求,这会涉及到:分布式爬虫。
3. 每个过程会遇到什么问题?
一种。获取网页:
爬虫会自动快速获取网页内容,所以如果短时间内访问过多,网站肯定不会喜欢。所以网站会反爬虫,可以分为:
增加获取数据难度:登录查看,登录设置验证码
不返回数据:不返回内容,延迟页面返回时间
返回数据到非目标页面:返回错误页面,返回空白页面,抓取多个页面时返回同一个页面
解决这些问题的方法有:使用cookies模拟登录、使用图片识别输入验证码、模拟真实header和切换user-agents、模拟浏览器爬取网站、增加爬网间隔、更改IP、爬取wap或手机客户端等
所以爬虫是个大坑,慎入。
湾 解析网页
解析网页的问题比较少见。主要是:中文乱码。
C。贮存
存储也很简单,连接数据库或者本地存储即可。
总结:获取网页是一个对抗各个公司爬虫的过程。路漫漫其修远兮。我会爬上爬下。祝你好运!请关注我接下来的文章,会一一讲述每一部分的知识。 查看全部
c爬虫抓取网页数据(1.爬虫的流程是怎样的?(一)教程)
爬虫技术文章很少从整体上讲,这次从宏观的角度讲,希望这篇文章文章能澄清三个问题:
1. 爬取的过程是什么?
2. 每道工序都有哪些技术方案?
3. 你会遇到什么困难?
所以这个文章也为后面的文章设置了教程的框架。
1. 爬取的过程是什么?
爬虫其实很简单,可以分为三个部分:获取网页--->解析网页,提取需要的数据--->存储。在文章:爬行者一号中,我简单地举例说明了每个部分。
一种。访问页面是什么?
获取一个网页就是向一个网址发送请求,然后该网址会返回整个网页的数据。类似:你在浏览器中输入网址,回车,然后你就看到了网站的整个页面。
湾 什么是解析页面?
解析一个网页就是从整个网页的数据中提取出你想要的数据。类似:你在浏览器中看到了网站的整个页面,但是你想找到产品的价格,而价格就是你想要的数据。
C。什么是存储?
存储很简单,就是保存数据。
2. 三个进程的技术是什么?
以下技术均在python下,本文不涉及Java
一种。获取网页:
要求
url2 和 url
模拟浏览器:selenium 或 PhantomJS
湾 解析网页:
常规的
美汤
C。贮存
将txt、csv等文件保存到mysql、mongodb等数据库中。
还有一些爬虫框架,比如Scrapy。在一个框架下解决并完成这三大流程。
另外,还会有提升爬虫速度的需求,这会涉及到:分布式爬虫。
3. 每个过程会遇到什么问题?
一种。获取网页:
爬虫会自动快速获取网页内容,所以如果短时间内访问过多,网站肯定不会喜欢。所以网站会反爬虫,可以分为:
增加获取数据难度:登录查看,登录设置验证码
不返回数据:不返回内容,延迟页面返回时间
返回数据到非目标页面:返回错误页面,返回空白页面,抓取多个页面时返回同一个页面
解决这些问题的方法有:使用cookies模拟登录、使用图片识别输入验证码、模拟真实header和切换user-agents、模拟浏览器爬取网站、增加爬网间隔、更改IP、爬取wap或手机客户端等
所以爬虫是个大坑,慎入。
湾 解析网页
解析网页的问题比较少见。主要是:中文乱码。
C。贮存
存储也很简单,连接数据库或者本地存储即可。
总结:获取网页是一个对抗各个公司爬虫的过程。路漫漫其修远兮。我会爬上爬下。祝你好运!请关注我接下来的文章,会一一讲述每一部分的知识。
c爬虫抓取网页数据( 利用PIL包的crop函数得到标签大小将标签剪切保存)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-22 23:18
利用PIL包的crop函数得到标签大小将标签剪切保存)
contents_list = driver.find_elements_by_css_selector('dl.board-wrapper dd')
注意这里我们使用的是 find_elements_by_css_selector,并且在元素之后添加了 s。如果不加s,find_element方法只能得到第一个节点。添加s后,可以得到所有满足条件的节点,并以列表形式返回。
获取label的文本内容也很简单,比如提取电影排名:
content['index']= content.find_element_by_css_selector('i.board-index').text
找到标签后,添加 .text 即可获取标签内容。获取标签中的属性值也很简单,比如提取电影名称:contents['title'] = content.find_element_by_css_selector('img.board-img').get_attribute('alt')
找到标签后,添加 .get_attribute('attribute name') 即可获取标签中的属性值。具体例子如下:
for content in contents_list:
contents['index'] = content.find_element_by_css_selector('i.board-index').text
; contents['image_url'] = content.find_element_by_css_selector('img.boardimg').get_attribute('src')
;contents['title'] = content.find_element_by_css_selector('img.boardimg').get_attribute('alt')
try:
contents['actor'] = content.find_element_by_css_selector('p.star').text
; except NoSuchElementException:
;contents['actor'] = ''
; contents['time'] = content.find_element_by_css_selector('p.releasetime').t;
3. 将票房信息保存为图片,使用PIL对图片进行二值化、锐化等预处理操作
保存要获取信息的标签图片的一般步骤如下:
a) 拦截当前窗口(selenium 不能直接拦截单个标签)
b) 获取标签位置坐标和标签大小
c) 使用PIL包的裁剪功能,根据标签的坐标和大小对标签进行裁剪保存
示例如下:
图片
上图是网页截图。使用 save_screenshot 函数获取当前窗口的屏幕截图。我们需要将票房数据裁剪保存在蓝框中,所以需要它们的坐标和大小。幸运的是,我们可以使用 .location 和。size函数获取标签的坐标和大小,最后使用PIL包的crop函数根据标签的坐标和大小对标签进行裁剪和保存。
上述步骤在第一屏捕获信息时非常有用,但是当窗口超过一个屏幕并且需要捕获的元素在后面时,您只能寻找其他方法。
来抓一下猫眼影业的电影票房网页,比较长,不能一屏显示。当然我们也可以用js把网页下拉然后截图,这样也可以截取下面网页的信息,但是获取到的标签位置坐标的参考点在网页的左上角(如上图),并且crop功能在裁剪时使用当前图片的左上角为基准,所以不同基准截取的内容肯定是错误的。
我在网上发现,WebDriver.PhantomJS的内置方法支持整个网页的截图,不是很爽,但是我用的时候就糊涂了。PhantomJS 可以拦截整个网页,但是拦截结果是这样的:
图片
我不能给尼玛什么?同时程序还提示警告selenium不再允许使用PhantomJS。让我们回去默默地使用 chrome。突然,灵光一闪。刚才不能用chrome的原因是location函数和crop函数得到的label坐标在裁剪坐标上是不同的。做吧,这个网页一共有10部电影。我只是下拉 10 次就可以了,所以这里我们有一个 for 循环。window.scrollTo 函数使用下拉网页。它有两个参数。第一个是代表水平方向的参数。要拖动的像素数,第二个代表要垂直拖动的像素数。但是你每次拉下来多少?270px(像素),
咦,你怎么知道?
告诉你一个我们使用微信截图的小技巧,它会显示截图图片的大小。对于这个例子,让我们每次拉下两个电影票房之间的长度。长度为270px,如下图所示。
图片
这样,您应该可以获取每个票房数据标签。得到票房数据标签后,我们需要进行图像预处理(二值化、锐化),最后保存标签。部分代码如下:
length = n*270driver.execute_script('window.scrollTo(0, {}*270)'.format(n))# 保存当前窗口为图片driver.save_screenshot('b.png')# time.sleep(2)# 定位div地址location = div.location# print(location)# 得到div尺寸size = div.size# print(size)left = location['x']top = location['y'] - lengthright = location['x'] + size['width']bottom = location['y'] + size['height'] - length
4. 使用tesseract识别保存的图片,获取票房数据
原票房数据图片:
图片
预处理后的票房数据图片:
图片
使用tesseract对处理后的图片进行识别,部分代码如下:
# 调用tesseract进行文字数字识别,目前对于浅颜色的字体识别率较低,若想提高识别率需要对图片做预处理os.system('echo off')#关闭命令行窗口运行命令的显示os.system('tesseract' + ' ' + filename + ' ' + output + ' ' + '-l num+chi_tra') #默认已配置好系统变量time.sleep(2)f = open(output + ".txt", encoding='utf-8')try: t = f.readlines()[0]
目前没有训练自己的数据识别包,直接使用tesseract已有的数据包,经过多次试验,实时票房识别率达到97%以上。由于总票房字体颜色偏浅,字体偏小,目前识别率还比较低,在60%左右。得到的数据如下图所示:
图片
这是第一次尝试使用图像识别来解决爬虫和到达问题。感觉真的很好玩。目前已经开放了获取标签图像的流程,但在图像预处理和图像识别方面还有很多工作要做。目前使用的是第三方软件Tesseract。-OCR识别,一方面我们会继续研究Tesseract-OCR,另一方面我们也会尝试使用深度学习的方法来提高图像文本的识别准确率。
图片 查看全部
c爬虫抓取网页数据(
利用PIL包的crop函数得到标签大小将标签剪切保存)
contents_list = driver.find_elements_by_css_selector('dl.board-wrapper dd')
注意这里我们使用的是 find_elements_by_css_selector,并且在元素之后添加了 s。如果不加s,find_element方法只能得到第一个节点。添加s后,可以得到所有满足条件的节点,并以列表形式返回。
获取label的文本内容也很简单,比如提取电影排名:
content['index']= content.find_element_by_css_selector('i.board-index').text
找到标签后,添加 .text 即可获取标签内容。获取标签中的属性值也很简单,比如提取电影名称:contents['title'] = content.find_element_by_css_selector('img.board-img').get_attribute('alt')
找到标签后,添加 .get_attribute('attribute name') 即可获取标签中的属性值。具体例子如下:
for content in contents_list:
contents['index'] = content.find_element_by_css_selector('i.board-index').text
; contents['image_url'] = content.find_element_by_css_selector('img.boardimg').get_attribute('src')
;contents['title'] = content.find_element_by_css_selector('img.boardimg').get_attribute('alt')
try:
contents['actor'] = content.find_element_by_css_selector('p.star').text
; except NoSuchElementException:
;contents['actor'] = ''
; contents['time'] = content.find_element_by_css_selector('p.releasetime').t;
3. 将票房信息保存为图片,使用PIL对图片进行二值化、锐化等预处理操作
保存要获取信息的标签图片的一般步骤如下:
a) 拦截当前窗口(selenium 不能直接拦截单个标签)
b) 获取标签位置坐标和标签大小
c) 使用PIL包的裁剪功能,根据标签的坐标和大小对标签进行裁剪保存
示例如下:
图片
上图是网页截图。使用 save_screenshot 函数获取当前窗口的屏幕截图。我们需要将票房数据裁剪保存在蓝框中,所以需要它们的坐标和大小。幸运的是,我们可以使用 .location 和。size函数获取标签的坐标和大小,最后使用PIL包的crop函数根据标签的坐标和大小对标签进行裁剪和保存。
上述步骤在第一屏捕获信息时非常有用,但是当窗口超过一个屏幕并且需要捕获的元素在后面时,您只能寻找其他方法。
来抓一下猫眼影业的电影票房网页,比较长,不能一屏显示。当然我们也可以用js把网页下拉然后截图,这样也可以截取下面网页的信息,但是获取到的标签位置坐标的参考点在网页的左上角(如上图),并且crop功能在裁剪时使用当前图片的左上角为基准,所以不同基准截取的内容肯定是错误的。
我在网上发现,WebDriver.PhantomJS的内置方法支持整个网页的截图,不是很爽,但是我用的时候就糊涂了。PhantomJS 可以拦截整个网页,但是拦截结果是这样的:
图片
我不能给尼玛什么?同时程序还提示警告selenium不再允许使用PhantomJS。让我们回去默默地使用 chrome。突然,灵光一闪。刚才不能用chrome的原因是location函数和crop函数得到的label坐标在裁剪坐标上是不同的。做吧,这个网页一共有10部电影。我只是下拉 10 次就可以了,所以这里我们有一个 for 循环。window.scrollTo 函数使用下拉网页。它有两个参数。第一个是代表水平方向的参数。要拖动的像素数,第二个代表要垂直拖动的像素数。但是你每次拉下来多少?270px(像素),
咦,你怎么知道?
告诉你一个我们使用微信截图的小技巧,它会显示截图图片的大小。对于这个例子,让我们每次拉下两个电影票房之间的长度。长度为270px,如下图所示。
图片
这样,您应该可以获取每个票房数据标签。得到票房数据标签后,我们需要进行图像预处理(二值化、锐化),最后保存标签。部分代码如下:
length = n*270driver.execute_script('window.scrollTo(0, {}*270)'.format(n))# 保存当前窗口为图片driver.save_screenshot('b.png')# time.sleep(2)# 定位div地址location = div.location# print(location)# 得到div尺寸size = div.size# print(size)left = location['x']top = location['y'] - lengthright = location['x'] + size['width']bottom = location['y'] + size['height'] - length
4. 使用tesseract识别保存的图片,获取票房数据
原票房数据图片:
图片
预处理后的票房数据图片:
图片
使用tesseract对处理后的图片进行识别,部分代码如下:
# 调用tesseract进行文字数字识别,目前对于浅颜色的字体识别率较低,若想提高识别率需要对图片做预处理os.system('echo off')#关闭命令行窗口运行命令的显示os.system('tesseract' + ' ' + filename + ' ' + output + ' ' + '-l num+chi_tra') #默认已配置好系统变量time.sleep(2)f = open(output + ".txt", encoding='utf-8')try: t = f.readlines()[0]
目前没有训练自己的数据识别包,直接使用tesseract已有的数据包,经过多次试验,实时票房识别率达到97%以上。由于总票房字体颜色偏浅,字体偏小,目前识别率还比较低,在60%左右。得到的数据如下图所示:
图片
这是第一次尝试使用图像识别来解决爬虫和到达问题。感觉真的很好玩。目前已经开放了获取标签图像的流程,但在图像预处理和图像识别方面还有很多工作要做。目前使用的是第三方软件Tesseract。-OCR识别,一方面我们会继续研究Tesseract-OCR,另一方面我们也会尝试使用深度学习的方法来提高图像文本的识别准确率。
图片
c爬虫抓取网页数据(爬取框架中分两类爬虫 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-22 13:20
)
Scrapy 框架中有两种爬虫,Spider 和 CrawlSpider。本案例使用 CrawlSpider 类来实现全站抓取的爬虫。
CrawlSpider 是 Spider 的派生类。Spider类的设计原理是只抓取start_url列表中的网页,而CrawlSpider类则定义了一些规则来提供一种方便的机制来跟踪链接,从抓取到的网页中获取链接并继续抓取。
创建一个 CrawlSpider 模板:
scrapy genspider -t crawl spider名称 www.xxxx.com
LinkExtractors:Link Extractors 的目的是提取链接。Extract_links() 被调用,它提供过滤器以方便提取包括正则表达式在内的链接。过滤器配置有以下构造函数参数:
Rule:规则中收录一个或多个Rule对象,每个Rule定义了爬取网站的具体操作。如果多个规则匹配同一个链接,将根据规则在此集中定义的顺序使用第一个。
下面是一个爬钩网的案例:
蜘蛛.pyi
项目.py
import scrapy
from scrapy.loader.processors import MapCompose, TakeFirst, Join
from scrapy.loader import ItemLoader
from w3lib.html import remove_tags
from LaGouSpider.settings import SQL_DATETIME_FORMAT
class LagouJobItemLoader(ItemLoader):
#自定义Itemloader
default_output_processor = TakeFirst()
def remove_splash(value):
#去掉斜杠
return value.replace("/","")
def handle_jobaddr(value):
addr_list = value.split("\n")
addr_list = [item.strip() for item in addr_list if item.strip()!="查看地图"]
return "".join(addr_list)
class LagouspiderItem(scrapy.Item):
title = scrapy.Field()
url = scrapy.Field()
url_object_id = scrapy.Field()
salary = scrapy.Field()
job_city = scrapy.Field(
input_processor=MapCompose(remove_splash),
)
work_years = scrapy.Field(
input_processor=MapCompose(remove_splash),
)
degree_need = scrapy.Field(
input_processor=MapCompose(remove_splash),
)
job_type = scrapy.Field()
publish_time = scrapy.Field()
job_advantage = scrapy.Field()
job_desc = scrapy.Field()
job_address = scrapy.Field(
input_processor=MapCompose(remove_tags, handle_jobaddr),
)
company_name = scrapy.Field()
company_url = scrapy.Field()
tags = scrapy.Field(
input_processor=Join(",")
)
crawl_time = scrapy.Field()
def get_insert_sql(self):
insert_sql = """
insert into lagou_job(title, url, url_object_id, salary, job_city, work_years, degree_need,
job_type, publish_time, job_advantage, job_desc, job_address, company_name, company_url,
tags, crawl_time) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE salary=VALUES(salary), job_desc=VALUES(job_desc)
"""
params = (
self["title"], self["url"], self["url_object_id"], self["salary"], self["job_city"],
self["work_years"], self["degree_need"], self["job_type"],
self["publish_time"], self["job_advantage"], self["job_desc"],
self["job_address"], self["company_name"], self["company_url"],
self["tags"], self["crawl_time"].strftime(SQL_DATETIME_FORMAT),
)
return insert_sql, params
管道.py
from twisted.enterprise import adbapi
import MySQLdb
import MySQLdb.cursors
class LagouspiderPipeline(object):
def process_item(self, item, spider):
return item
class MysqlTwistedPipeline(object):
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(clsc,setting):
dbparms = dict(
host =setting["MYSQL_HOST"],
db = setting["MYSQL_DBNAME"],
user = setting["MYSQL_USER"],
password = setting["MYSQL_PASSWORD"],
charset = 'utf8',
cursorclass = MySQLdb.cursors.DictCursor,
use_unicode = True,
)
dbpool = adbapi.ConnectionPool("MySQLdb",**dbparms)
return clsc(dbpool)
def process_item(self, item, spider):
#使用twisted将mysql插入变成异步执行
query = self.dbpool.runInteraction(self.do_insert,item)
query.addErrback(self.handle_error,item,spider) #处理异常
def handle_error(self,failure,item,spider):
#处理异步插入的异常
print(failure)
def do_insert(self,cursor,item):
#执行具体的插入
# 根据不同的item 构建不同的sql语句并插入到mysql中
insert_sql,params = item.get_insert_sql()
cursor.execute(insert_sql, params) 查看全部
c爬虫抓取网页数据(爬取框架中分两类爬虫
)
Scrapy 框架中有两种爬虫,Spider 和 CrawlSpider。本案例使用 CrawlSpider 类来实现全站抓取的爬虫。
CrawlSpider 是 Spider 的派生类。Spider类的设计原理是只抓取start_url列表中的网页,而CrawlSpider类则定义了一些规则来提供一种方便的机制来跟踪链接,从抓取到的网页中获取链接并继续抓取。
创建一个 CrawlSpider 模板:
scrapy genspider -t crawl spider名称 www.xxxx.com
LinkExtractors:Link Extractors 的目的是提取链接。Extract_links() 被调用,它提供过滤器以方便提取包括正则表达式在内的链接。过滤器配置有以下构造函数参数:
Rule:规则中收录一个或多个Rule对象,每个Rule定义了爬取网站的具体操作。如果多个规则匹配同一个链接,将根据规则在此集中定义的顺序使用第一个。
下面是一个爬钩网的案例:
蜘蛛.pyi
项目.py
import scrapy
from scrapy.loader.processors import MapCompose, TakeFirst, Join
from scrapy.loader import ItemLoader
from w3lib.html import remove_tags
from LaGouSpider.settings import SQL_DATETIME_FORMAT
class LagouJobItemLoader(ItemLoader):
#自定义Itemloader
default_output_processor = TakeFirst()
def remove_splash(value):
#去掉斜杠
return value.replace("/","")
def handle_jobaddr(value):
addr_list = value.split("\n")
addr_list = [item.strip() for item in addr_list if item.strip()!="查看地图"]
return "".join(addr_list)
class LagouspiderItem(scrapy.Item):
title = scrapy.Field()
url = scrapy.Field()
url_object_id = scrapy.Field()
salary = scrapy.Field()
job_city = scrapy.Field(
input_processor=MapCompose(remove_splash),
)
work_years = scrapy.Field(
input_processor=MapCompose(remove_splash),
)
degree_need = scrapy.Field(
input_processor=MapCompose(remove_splash),
)
job_type = scrapy.Field()
publish_time = scrapy.Field()
job_advantage = scrapy.Field()
job_desc = scrapy.Field()
job_address = scrapy.Field(
input_processor=MapCompose(remove_tags, handle_jobaddr),
)
company_name = scrapy.Field()
company_url = scrapy.Field()
tags = scrapy.Field(
input_processor=Join(",")
)
crawl_time = scrapy.Field()
def get_insert_sql(self):
insert_sql = """
insert into lagou_job(title, url, url_object_id, salary, job_city, work_years, degree_need,
job_type, publish_time, job_advantage, job_desc, job_address, company_name, company_url,
tags, crawl_time) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE salary=VALUES(salary), job_desc=VALUES(job_desc)
"""
params = (
self["title"], self["url"], self["url_object_id"], self["salary"], self["job_city"],
self["work_years"], self["degree_need"], self["job_type"],
self["publish_time"], self["job_advantage"], self["job_desc"],
self["job_address"], self["company_name"], self["company_url"],
self["tags"], self["crawl_time"].strftime(SQL_DATETIME_FORMAT),
)
return insert_sql, params
管道.py
from twisted.enterprise import adbapi
import MySQLdb
import MySQLdb.cursors
class LagouspiderPipeline(object):
def process_item(self, item, spider):
return item
class MysqlTwistedPipeline(object):
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(clsc,setting):
dbparms = dict(
host =setting["MYSQL_HOST"],
db = setting["MYSQL_DBNAME"],
user = setting["MYSQL_USER"],
password = setting["MYSQL_PASSWORD"],
charset = 'utf8',
cursorclass = MySQLdb.cursors.DictCursor,
use_unicode = True,
)
dbpool = adbapi.ConnectionPool("MySQLdb",**dbparms)
return clsc(dbpool)
def process_item(self, item, spider):
#使用twisted将mysql插入变成异步执行
query = self.dbpool.runInteraction(self.do_insert,item)
query.addErrback(self.handle_error,item,spider) #处理异常
def handle_error(self,failure,item,spider):
#处理异步插入的异常
print(failure)
def do_insert(self,cursor,item):
#执行具体的插入
# 根据不同的item 构建不同的sql语句并插入到mysql中
insert_sql,params = item.get_insert_sql()
cursor.execute(insert_sql, params)
c爬虫抓取网页数据(如何自学Python爬虫?新手入门到精通的爬虫技能!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-21 12:28
如何自学 Python 爬虫?在大家学会自己爬之前,有两个常见的问题需要解决。首先,什么是爬虫?二是问为什么要用Python做爬虫?爬虫其实就是一个自动抓取页面信息的网络机器人。至于使用Python作为爬虫的原因,当然是为了方便。本文将为您提供详细的初学者入门教程,带您从入门到精通Python爬虫技巧。
一、什么是爬虫?
网络爬虫也被称为网络蜘蛛、网络机器人,在 FOAF 社区中,它们更多地被称为网络追逐者。它是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不常用的名称包括蚂蚁、自动索引和模拟程序。其实说白了就是爬虫可以模拟浏览器的行为为所欲为,自定义搜索下载的内容,实现自动化操作。比如浏览器可以下载小说,但是有时候不能批量下载,所以爬虫功能很有用。
二、为什么python适合爬行?
实现爬虫技术的编程环境有很多,Java、Python、C++等都可以用于爬虫。但是为什么大家都选择Python呢?因为Python真的很适合爬虫。丰富的第三方库非常强大。几行代码就可以实现你想要的功能;它是跨平台的,对 Linux 和 windows 有很好的支持。. 更重要的是,Python 还擅长数据挖掘和分析。使用Python进行数据爬取和分析的一站式服务,真的很方便。最后,如果你的时间不是很紧,又想快速提高python,最重要的是不怕吃苦,建议你可以群:[832357663],真的很好,很多人都在飞速进步,需要你不怕吃苦!
三、自学Python爬虫的步骤是什么?
1、先学习Python语法基础知识
2、学习Python爬虫常用的几个重要的内置库,urllib,http等,用于下载网页
3、学习正则表达式re、BeautifulSoup(bs4)、Xpath(lxml)等网页解析工具
4、开始一些简单的网站爬取(博主从百度开始的,哈哈),了解爬取数据的过程
5、了解爬虫的一些反爬虫机制,header,robot,时间间隔,代理ip,隐藏域等。
6、学习一些特殊的网站爬虫,解决登录、cookie、动态网页等问题
7、了解爬虫与数据库的结合,以及如何存储爬取的数据
8、学习应用Python的多线程多进程爬取提高爬虫效率
9、学习爬虫框架,Scrapy,PySpider等。
10、学习分布式爬虫(海量数据需求)
四、自学Python爬虫免费教程推荐
《3天掌握Python爬虫》课程主要包括爬虫基础知识和软件准备,HTTP和HTTPS的学习和请求模块的使用,重试模块的使用和处理cookie相关请求,数据提取方法值json,数据提取值 xpath 使用lxml模块学习,xpath和lxml模块练习等。完成本课程后,大家将能够了解爬虫的原理,学会使用python进行网络请求,掌握爬取网页的方法数据。
以上是Python爬虫初学者教程的介绍。其实,如果你有一定的Python编程基础,自学Python爬虫并不难。行动不如心。无论是视频还是其他学习资源,都可以在网上轻松获取。
如何领取python福利教程:
1、喜欢+评论(勾选“同时转发”)
2、关注小编。并回复私信关键词[19]
(一定要发私信哦~点我头像看私信按钮) 查看全部
c爬虫抓取网页数据(如何自学Python爬虫?新手入门到精通的爬虫技能!)
如何自学 Python 爬虫?在大家学会自己爬之前,有两个常见的问题需要解决。首先,什么是爬虫?二是问为什么要用Python做爬虫?爬虫其实就是一个自动抓取页面信息的网络机器人。至于使用Python作为爬虫的原因,当然是为了方便。本文将为您提供详细的初学者入门教程,带您从入门到精通Python爬虫技巧。
一、什么是爬虫?
网络爬虫也被称为网络蜘蛛、网络机器人,在 FOAF 社区中,它们更多地被称为网络追逐者。它是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不常用的名称包括蚂蚁、自动索引和模拟程序。其实说白了就是爬虫可以模拟浏览器的行为为所欲为,自定义搜索下载的内容,实现自动化操作。比如浏览器可以下载小说,但是有时候不能批量下载,所以爬虫功能很有用。
二、为什么python适合爬行?
实现爬虫技术的编程环境有很多,Java、Python、C++等都可以用于爬虫。但是为什么大家都选择Python呢?因为Python真的很适合爬虫。丰富的第三方库非常强大。几行代码就可以实现你想要的功能;它是跨平台的,对 Linux 和 windows 有很好的支持。. 更重要的是,Python 还擅长数据挖掘和分析。使用Python进行数据爬取和分析的一站式服务,真的很方便。最后,如果你的时间不是很紧,又想快速提高python,最重要的是不怕吃苦,建议你可以群:[832357663],真的很好,很多人都在飞速进步,需要你不怕吃苦!
三、自学Python爬虫的步骤是什么?
1、先学习Python语法基础知识
2、学习Python爬虫常用的几个重要的内置库,urllib,http等,用于下载网页
3、学习正则表达式re、BeautifulSoup(bs4)、Xpath(lxml)等网页解析工具
4、开始一些简单的网站爬取(博主从百度开始的,哈哈),了解爬取数据的过程
5、了解爬虫的一些反爬虫机制,header,robot,时间间隔,代理ip,隐藏域等。
6、学习一些特殊的网站爬虫,解决登录、cookie、动态网页等问题
7、了解爬虫与数据库的结合,以及如何存储爬取的数据
8、学习应用Python的多线程多进程爬取提高爬虫效率
9、学习爬虫框架,Scrapy,PySpider等。
10、学习分布式爬虫(海量数据需求)
四、自学Python爬虫免费教程推荐
《3天掌握Python爬虫》课程主要包括爬虫基础知识和软件准备,HTTP和HTTPS的学习和请求模块的使用,重试模块的使用和处理cookie相关请求,数据提取方法值json,数据提取值 xpath 使用lxml模块学习,xpath和lxml模块练习等。完成本课程后,大家将能够了解爬虫的原理,学会使用python进行网络请求,掌握爬取网页的方法数据。
以上是Python爬虫初学者教程的介绍。其实,如果你有一定的Python编程基础,自学Python爬虫并不难。行动不如心。无论是视频还是其他学习资源,都可以在网上轻松获取。
如何领取python福利教程:
1、喜欢+评论(勾选“同时转发”)
2、关注小编。并回复私信关键词[19]
(一定要发私信哦~点我头像看私信按钮)
c爬虫抓取网页数据(一个通用的网络爬虫的基本结构及工作流程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-21 11:06
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要是对爬虫和爬虫系统的简要介绍。
一、网络爬虫的基本结构和工作流程
一个通用的网络爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选择一些精心挑选的种子网址;
2.将这些URL放入URL队列进行抓取;
3. 从待爬取的URL队列中取出待爬取的URL,解析DNS,获取主机ip,下载该URL对应的网页,并保存到下载的网页库中。另外,将这些网址放入已爬取的网址队列中。
4.对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入待爬取的URL队列中,从而进入下一个循环。
二、从爬虫的角度划分互联网
相应地,互联网的所有页面可以分为五个部分:
1.下载了未过期的网页
2.已下载并过期的网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态变化的,互联网上的一些内容已经发生了变化。此时,这部分爬取到的页面已经过期。
3.要下载的页面:URL队列中要爬取的那些页面
4. 已知网页:尚未被抓取,也不在待抓取的URL队列中,但通过分析抓取的页面得到的URL或待抓取的URL对应的页面可以认为是已知的网页 。
5.还有一些网页是爬虫无法直接抓取下载的。它被称为不可知页面。
三、抓取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL按什么顺序排列也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,逐个跟踪每一个链接,处理完这一行后转移到下一个起始页,继续跟踪链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.宽度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接插入到待爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中所有链接的网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。以上图为例:
遍历路径:ABCDEF GHI
3.反向链接计数策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
4.部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,连同要爬取的URL队列中的URL,组成一个网页集,计算每个页面的PageRank值,经过计算完成后,将要爬取的URL队列中的URL按照PageRank值的大小进行排列,依次爬取页面。
如果每个页面都被抓取,则重新计算 PageRank 值。一个折衷的方案是:每爬取K个页面后,重新计算PageRank值。但是,这种情况下仍然存在一个问题:对于已经从下载页面中分析出来的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,这些页面会被赋予一个临时的PageRank值:将所有传入该页面链中的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排名。以下示例说明:
5.OPIC 策略
该算法实际上对页面的重要性进行评分。在算法开始之前,给所有页面相同的初始现金(cash)。下载某个页面P后,将P的现金分配给所有从P解析的链接,清空P的现金。待抓取的 URL 队列中的所有页面均按照现金的数量进行排序。
6.大站优先策略
URL队列中所有要爬取的网页,按照所属的网站进行分类。网站需要下载的页面较多,优先下载。这种策略因此被称为大站优先策略。
参考书目:
1. 《这是搜索引擎-核心技术详解》张俊林电子工业出版社
2. 《搜索引擎技术基础》刘义群等清华大学出版社 查看全部
c爬虫抓取网页数据(一个通用的网络爬虫的基本结构及工作流程(组图))
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要是对爬虫和爬虫系统的简要介绍。
一、网络爬虫的基本结构和工作流程
一个通用的网络爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选择一些精心挑选的种子网址;
2.将这些URL放入URL队列进行抓取;
3. 从待爬取的URL队列中取出待爬取的URL,解析DNS,获取主机ip,下载该URL对应的网页,并保存到下载的网页库中。另外,将这些网址放入已爬取的网址队列中。
4.对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入待爬取的URL队列中,从而进入下一个循环。
二、从爬虫的角度划分互联网
相应地,互联网的所有页面可以分为五个部分:
1.下载了未过期的网页
2.已下载并过期的网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态变化的,互联网上的一些内容已经发生了变化。此时,这部分爬取到的页面已经过期。
3.要下载的页面:URL队列中要爬取的那些页面
4. 已知网页:尚未被抓取,也不在待抓取的URL队列中,但通过分析抓取的页面得到的URL或待抓取的URL对应的页面可以认为是已知的网页 。
5.还有一些网页是爬虫无法直接抓取下载的。它被称为不可知页面。
三、抓取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL按什么顺序排列也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,逐个跟踪每一个链接,处理完这一行后转移到下一个起始页,继续跟踪链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.宽度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接插入到待爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中所有链接的网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。以上图为例:
遍历路径:ABCDEF GHI
3.反向链接计数策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
4.部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,连同要爬取的URL队列中的URL,组成一个网页集,计算每个页面的PageRank值,经过计算完成后,将要爬取的URL队列中的URL按照PageRank值的大小进行排列,依次爬取页面。
如果每个页面都被抓取,则重新计算 PageRank 值。一个折衷的方案是:每爬取K个页面后,重新计算PageRank值。但是,这种情况下仍然存在一个问题:对于已经从下载页面中分析出来的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,这些页面会被赋予一个临时的PageRank值:将所有传入该页面链中的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排名。以下示例说明:
5.OPIC 策略
该算法实际上对页面的重要性进行评分。在算法开始之前,给所有页面相同的初始现金(cash)。下载某个页面P后,将P的现金分配给所有从P解析的链接,清空P的现金。待抓取的 URL 队列中的所有页面均按照现金的数量进行排序。
6.大站优先策略
URL队列中所有要爬取的网页,按照所属的网站进行分类。网站需要下载的页面较多,优先下载。这种策略因此被称为大站优先策略。
参考书目:
1. 《这是搜索引擎-核心技术详解》张俊林电子工业出版社
2. 《搜索引擎技术基础》刘义群等清华大学出版社
c爬虫抓取网页数据(如何抓取ajax形式加载的网页数据(一)_恢复内容开始)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2021-12-20 06:03
---恢复内容开始---
下面记录如何抓取ajax形式加载的网页数据:
目标:获取"%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action="下的网页数据
第一步:网页数据分析-----》特点:当列表栏滚动到页面底部时,数据自动加载,页面的url没有变化
第二步:使用Fiddler抓包,如下图:
图 1:请求数据
图2:表格形式
数据规律是通过抓包得到的:图2中from形式的start对应数据和图1中url中的start对应数据随着每次加载增加,其他数据没有变化。对应这个规律,我们可以构造相应的请求来获取数据
注意数据格式为json
代码显示如下:
1).urllib 格式
import urllib2
import urllib
#此处的url为上述抓包获取的url去掉start以及limit,start以及limit数据后边以form表单的形式传入
url = \' https://movie.douban.com/j/cha ... on%3D\'
#请求投信息,伪造成浏览器,方式被反爬虫策略拦截
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
#构建form表单
formdata = {
"start":"20",
"limit":"20"
}
#urlencode()urllib中的函数,作用:将key:value形式的键值对转换为"key=value"形式的字符串
data = urllib.urlencode(formdata)
#构建request实例对象
request = urllib2.Request(url,data=data,headers=headers)
#发送请求并返回响应信息
response = urllib2.urlopen(request)
#注意此处的数据形式并不是html文档,而是json数据
json = response.read()
print html
2).request 库获取请求代码
#coding=utf-8
import requests
url = \' https://movie.douban.com/j/cha ... on%3D\'
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
data = {
"start":"20",
"limit":"20",
}
response = requests.get(url,params = data,headers = headers)
print response.text
3).request 库发布请求
#coding=utf-8
import requests
url = \' https://movie.douban.com/j/cha ... on%3D\'
formdata = {
"start":"20",
"limit":"20"
}
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
response = requests.post(url,data=formdata,headers=headers)
print response.text
---恢复内容结束--- 查看全部
c爬虫抓取网页数据(如何抓取ajax形式加载的网页数据(一)_恢复内容开始)
---恢复内容开始---
下面记录如何抓取ajax形式加载的网页数据:
目标:获取"%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action="下的网页数据
第一步:网页数据分析-----》特点:当列表栏滚动到页面底部时,数据自动加载,页面的url没有变化
第二步:使用Fiddler抓包,如下图:
图 1:请求数据
图2:表格形式
数据规律是通过抓包得到的:图2中from形式的start对应数据和图1中url中的start对应数据随着每次加载增加,其他数据没有变化。对应这个规律,我们可以构造相应的请求来获取数据
注意数据格式为json
代码显示如下:
1).urllib 格式
import urllib2
import urllib
#此处的url为上述抓包获取的url去掉start以及limit,start以及limit数据后边以form表单的形式传入
url = \' https://movie.douban.com/j/cha ... on%3D\'
#请求投信息,伪造成浏览器,方式被反爬虫策略拦截
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
#构建form表单
formdata = {
"start":"20",
"limit":"20"
}
#urlencode()urllib中的函数,作用:将key:value形式的键值对转换为"key=value"形式的字符串
data = urllib.urlencode(formdata)
#构建request实例对象
request = urllib2.Request(url,data=data,headers=headers)
#发送请求并返回响应信息
response = urllib2.urlopen(request)
#注意此处的数据形式并不是html文档,而是json数据
json = response.read()
print html
2).request 库获取请求代码
#coding=utf-8
import requests
url = \' https://movie.douban.com/j/cha ... on%3D\'
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
data = {
"start":"20",
"limit":"20",
}
response = requests.get(url,params = data,headers = headers)
print response.text
3).request 库发布请求
#coding=utf-8
import requests
url = \' https://movie.douban.com/j/cha ... on%3D\'
formdata = {
"start":"20",
"limit":"20"
}
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
response = requests.post(url,data=formdata,headers=headers)
print response.text
---恢复内容结束---
c爬虫抓取网页数据(1.网络爬虫的基本概念网络蜘蛛,机器人都能够做到! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-20 06:03
)
1.网络爬虫的基本概念
网络爬虫(又称网络蜘蛛、机器人)是一种模拟客户端发送网络请求和接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做,原则上爬虫都能做。
2.网络爬虫的功能
网络爬虫可以做很多事情而不是手动。比如可以作为搜索引擎,还可以爬取网站上面的图片。比如有的朋友爬取一些网站上的所有图片,然后重点关注。同时,网络爬虫还可以应用在金融投资领域,比如可以自动爬取一些金融信息,进行投资分析。
有时候,可能会有几个我们比较喜欢的新闻网站,每次都要打开这些新闻网站浏览,比较麻烦。这时候就可以用网络爬虫把这多条新闻网站中的新闻信息爬下来,一起阅读。
有时,我们在浏览网页信息时,会发现有很多广告。这时候也可以使用爬虫爬取对应网页上的信息,让这些广告自动过滤掉,方便信息的阅读和使用。
有时,我们需要进行营销,因此如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以在网上手动搜索,但是效率会很低。这时,我们可以使用爬虫设置相应的规则,自动从互联网上采集目标用户的联系方式等数据,用于我们的营销。
有时,我们要分析某个网站的用户信息,比如分析网站的用户活跃度、评论数、热门文章等信息。如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时就可以使用爬虫轻松获取这些数据采集进行进一步分析,而且所有的爬取操作都是自动进行的,我们只需要编写相应的爬虫,设计相应的规则就可以了。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫自动化,从而可以更有效地使用互联网中的有效信息。.
3.安装第三方库
在抓取和解析数据之前,您需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面上输入pip install requests,按回车键安装。(注意网络连接)如下图
安装完成,如图
查看全部
c爬虫抓取网页数据(1.网络爬虫的基本概念网络蜘蛛,机器人都能够做到!
)
1.网络爬虫的基本概念
网络爬虫(又称网络蜘蛛、机器人)是一种模拟客户端发送网络请求和接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做,原则上爬虫都能做。
2.网络爬虫的功能
网络爬虫可以做很多事情而不是手动。比如可以作为搜索引擎,还可以爬取网站上面的图片。比如有的朋友爬取一些网站上的所有图片,然后重点关注。同时,网络爬虫还可以应用在金融投资领域,比如可以自动爬取一些金融信息,进行投资分析。
有时候,可能会有几个我们比较喜欢的新闻网站,每次都要打开这些新闻网站浏览,比较麻烦。这时候就可以用网络爬虫把这多条新闻网站中的新闻信息爬下来,一起阅读。
有时,我们在浏览网页信息时,会发现有很多广告。这时候也可以使用爬虫爬取对应网页上的信息,让这些广告自动过滤掉,方便信息的阅读和使用。
有时,我们需要进行营销,因此如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以在网上手动搜索,但是效率会很低。这时,我们可以使用爬虫设置相应的规则,自动从互联网上采集目标用户的联系方式等数据,用于我们的营销。
有时,我们要分析某个网站的用户信息,比如分析网站的用户活跃度、评论数、热门文章等信息。如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时就可以使用爬虫轻松获取这些数据采集进行进一步分析,而且所有的爬取操作都是自动进行的,我们只需要编写相应的爬虫,设计相应的规则就可以了。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫自动化,从而可以更有效地使用互联网中的有效信息。.
3.安装第三方库
在抓取和解析数据之前,您需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面上输入pip install requests,按回车键安装。(注意网络连接)如下图
安装完成,如图
c爬虫抓取网页数据(Python爬虫大数据建模微+无忧全拼加零一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 39 次浏览 • 2021-12-20 01:13
今天是一个彻头彻尾的大数据时代。大数据贯穿我们的衣食住行。可以说,大数据是目前最宝贵的数据宝藏!
什么是 Python 爬虫?
Python爬虫也叫网络爬虫
关于Python爬虫,我们需要知道:
Python 基本语法
HTML页面的内容爬取(数据爬取)
从 HTML 页面中提取数据(数据清理)
Scrapy框架和scrapy-redis分布式策略(第三方框架)
蜘蛛、反蜘蛛和反反蜘蛛之间的斗争。
网络爬虫可分为通用爬虫和聚焦爬虫。
1.通用网络爬虫
从网上采集网页,进入采集信息。此网页信息用于索引搜索引擎以提供支持。它决定了整个引擎系统的内容是否丰富,信息是否及时,因此性能的好坏直接影响搜索引擎的有效性。
2.关注爬虫
Focused crawler是一个“面向特定主题需求”的网络爬虫程序。它与一般搜索引擎爬虫的区别在于:聚焦爬虫在实现网页爬取时会对内容进行处理和过滤,并尽量保证只有爬取到的页面信息与需求页面信息相关。
运营商大数据建模捕捉微+无忧获客全拼加零一
在中国,运营商拥有庞大且绝对真实的数据资源和数据存储能力。运营商在数据利用方面的经验和经验拥有绝对的发言权。运营商的大数据,无论是大数据的抓取,数据管理,数据能力,标签能力,产品服务,这些主要业务都有突出的表现。
运营商大数据是数据变现的最佳利器!相关企业只需要利用好运营商的数据和标注能力即可。运营商的大数据平台能力将能够为相关企业提供数据服务,最终实现数据变现。运营商是数据采集、数据处理、数据分析、数据访问、数据应用等全方位的数据管理平台。一个大数据平台应该有一个标准的架构。不同的行业和企业必须与之合作。您可以将您的业务发展到一个新的高度!
数据建模
运营商一直强调数据标准化和数据可视化。通过与运营商的大数据平台合作,相关企业可以按需建模。你所有的模型都应该和你公司的业务相符,这样整个公司使用的运营商数据才有效。通过运营商大数据,所有合作伙伴都可以拥有标准的建模和优秀的数据。
数据管理
实现数据管理是所有企业的追求。中小企业很难实现自己的数据管理。如果公司做大,数据管理的成本还是会很高的。因此,运营商的大数据可以系统化、透明化。一种无障碍的方式来帮助您的公司进行数据管理。
数据应用
Python爬虫更适合依赖互联网的数据爬取。
运营商大数据可以进行有针对性的建模,进行多维度、多维度的数据抓取和数据分析。运营商大数据可抓取任意网站、网页、URL、手机APP、400电话、固话、小程序、关键词、APP新注册用户等数据信息,助力整体行业和不同企业精准获取客户,提供营销服务! 查看全部
c爬虫抓取网页数据(Python爬虫大数据建模微+无忧全拼加零一)
今天是一个彻头彻尾的大数据时代。大数据贯穿我们的衣食住行。可以说,大数据是目前最宝贵的数据宝藏!
什么是 Python 爬虫?
Python爬虫也叫网络爬虫
关于Python爬虫,我们需要知道:
Python 基本语法
HTML页面的内容爬取(数据爬取)
从 HTML 页面中提取数据(数据清理)
Scrapy框架和scrapy-redis分布式策略(第三方框架)
蜘蛛、反蜘蛛和反反蜘蛛之间的斗争。
网络爬虫可分为通用爬虫和聚焦爬虫。
1.通用网络爬虫
从网上采集网页,进入采集信息。此网页信息用于索引搜索引擎以提供支持。它决定了整个引擎系统的内容是否丰富,信息是否及时,因此性能的好坏直接影响搜索引擎的有效性。
2.关注爬虫
Focused crawler是一个“面向特定主题需求”的网络爬虫程序。它与一般搜索引擎爬虫的区别在于:聚焦爬虫在实现网页爬取时会对内容进行处理和过滤,并尽量保证只有爬取到的页面信息与需求页面信息相关。
运营商大数据建模捕捉微+无忧获客全拼加零一
在中国,运营商拥有庞大且绝对真实的数据资源和数据存储能力。运营商在数据利用方面的经验和经验拥有绝对的发言权。运营商的大数据,无论是大数据的抓取,数据管理,数据能力,标签能力,产品服务,这些主要业务都有突出的表现。
运营商大数据是数据变现的最佳利器!相关企业只需要利用好运营商的数据和标注能力即可。运营商的大数据平台能力将能够为相关企业提供数据服务,最终实现数据变现。运营商是数据采集、数据处理、数据分析、数据访问、数据应用等全方位的数据管理平台。一个大数据平台应该有一个标准的架构。不同的行业和企业必须与之合作。您可以将您的业务发展到一个新的高度!
数据建模
运营商一直强调数据标准化和数据可视化。通过与运营商的大数据平台合作,相关企业可以按需建模。你所有的模型都应该和你公司的业务相符,这样整个公司使用的运营商数据才有效。通过运营商大数据,所有合作伙伴都可以拥有标准的建模和优秀的数据。
数据管理
实现数据管理是所有企业的追求。中小企业很难实现自己的数据管理。如果公司做大,数据管理的成本还是会很高的。因此,运营商的大数据可以系统化、透明化。一种无障碍的方式来帮助您的公司进行数据管理。
数据应用
Python爬虫更适合依赖互联网的数据爬取。
运营商大数据可以进行有针对性的建模,进行多维度、多维度的数据抓取和数据分析。运营商大数据可抓取任意网站、网页、URL、手机APP、400电话、固话、小程序、关键词、APP新注册用户等数据信息,助力整体行业和不同企业精准获取客户,提供营销服务!
c爬虫抓取网页数据(Python网络爬虫反爬破解策略实战作者(组图)作者)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-12-17 22:34
阿里云>云栖社区>主题图>C>c网络爬虫源码
推荐活动:
更多优惠>
当前话题:c网络爬虫源码加入采集
相关话题:
c 网络爬虫源码相关博客查看更多博客
C#网络爬虫
作者:街角盒饭712人浏览评论:05年前
公司编辑妹需要抓取网页内容。我让我帮忙做一个简单的爬虫工具。这是为了抓取网页的内容。似乎这对每个人来说都不是罕见的,但这里有一些小的变化。代码在这里。请参考 1 私有字符串 GetHttpWebRequest(string url) 2 {3 Ht
阅读全文
C#HttpHelper爬虫类源码分享--苏飞版
作者:苏飞 2071人浏览评论:03年前
简介 C#HttpHelper实现了在爬取C#HttpWebRequest时忽略编码、忽略证书、忽略cookies、实现代理的功能。有了它,您可以发出 Get 和 Post 请求,还可以轻松设置 cookie、证书、代理和编码。你不关心问题,因为类会自动为你识别页面
阅读全文
Python网络爬虫反爬虫破解策略实战
作者:薇薇 8128人浏览评论:04年前
作者:薇薇转载,请注明出处。我们经常写一些网络爬虫。我想每个人都会有一种感觉。写爬虫虽然不难,但是对付反爬是比较困难的,因为大部分网站都有自己的反爬机制,所以我们爬这个数据会比较困难。但是,对于每一种反爬虫机制,我们其实都会有相应的解决方案。作为爬虫的我们,
阅读全文
C#网络爬虫增强的多线程处理
作者:街角盒饭688人浏览评论:05年前
上次给公司妹子做爬虫,不是很精致。这次需要在公司项目中用到,所以做了一些改动,功能增加了URL图片采集、下载、线程处理接口URL图片下载等。 说说思路:总理获取初始URL 采集图片到初始URL 采集链接中的初始URL的所有内容将采集中的链接放入队列继续采集图片
阅读全文
Python网络爬虫爬取最好的妹妹的视频并保存到文件中
作者:keitwotest1060人浏览评论:03年前
项目描述 使用Python编写一个网络爬虫,抓取最好的妹妹的视频并保存到文件中。示例使用工具 Python2.7.X, pycharm 如何在pycharm .py文件中创建爬取最好的妹妹的视频,并在当前目录下创建video文件夹存放抓取的视频文件,写代码,然后运行
阅读全文
一篇文章教你如何使用Python网络爬虫获取差旅攻略
作者:python进阶者13人浏览评论:01年前
【一、项目背景】侨游网提供原创实用的出境游攻略、攻略、旅游社区和问答交流平台,以及智能出行规划解决方案,以及签证、保险、机票、和酒店 在线增值服务,如预订和汽车租赁。亲游“鼓励并帮助中国游客以自己的视角和方式体验世界。” 今天教大家获取侨友网的城市信息,
阅读全文
Java版网络爬虫的基础知识(传输)
作者:developerguy851 浏览评论人数:06年前
网络爬虫不仅可以抓取网站的网页、图片,甚至还可以实现抢票、在线抢购、查询票等功能。这几天我读了一些基础知识并记录下来。网页之间的关系可以看成是一张大图,图片的遍历可以分为深度优先和广度优先。网络爬虫以广度为先,一般来说如下:2个数组,一个
阅读全文
一篇文章教你使用Python网络爬虫抓取百度贴吧评论区图片和视频
作者:pythonadvanced 26人浏览评论:01年前
【一、项目背景】百度贴吧是全球最大的中文交流平台。你像我么?有时候在评论区看到图片就想下载?或者看到视频并想下载它?今天小编就带大家在评论区搜索关键词获取图片和视频。【二、项目目标】实现将贴吧获取的图片或视频保存在
阅读全文 查看全部
c爬虫抓取网页数据(Python网络爬虫反爬破解策略实战作者(组图)作者)
阿里云>云栖社区>主题图>C>c网络爬虫源码
推荐活动:
更多优惠>
当前话题:c网络爬虫源码加入采集
相关话题:
c 网络爬虫源码相关博客查看更多博客
C#网络爬虫
作者:街角盒饭712人浏览评论:05年前
公司编辑妹需要抓取网页内容。我让我帮忙做一个简单的爬虫工具。这是为了抓取网页的内容。似乎这对每个人来说都不是罕见的,但这里有一些小的变化。代码在这里。请参考 1 私有字符串 GetHttpWebRequest(string url) 2 {3 Ht
阅读全文
C#HttpHelper爬虫类源码分享--苏飞版
作者:苏飞 2071人浏览评论:03年前
简介 C#HttpHelper实现了在爬取C#HttpWebRequest时忽略编码、忽略证书、忽略cookies、实现代理的功能。有了它,您可以发出 Get 和 Post 请求,还可以轻松设置 cookie、证书、代理和编码。你不关心问题,因为类会自动为你识别页面
阅读全文
Python网络爬虫反爬虫破解策略实战
作者:薇薇 8128人浏览评论:04年前
作者:薇薇转载,请注明出处。我们经常写一些网络爬虫。我想每个人都会有一种感觉。写爬虫虽然不难,但是对付反爬是比较困难的,因为大部分网站都有自己的反爬机制,所以我们爬这个数据会比较困难。但是,对于每一种反爬虫机制,我们其实都会有相应的解决方案。作为爬虫的我们,
阅读全文
C#网络爬虫增强的多线程处理
作者:街角盒饭688人浏览评论:05年前
上次给公司妹子做爬虫,不是很精致。这次需要在公司项目中用到,所以做了一些改动,功能增加了URL图片采集、下载、线程处理接口URL图片下载等。 说说思路:总理获取初始URL 采集图片到初始URL 采集链接中的初始URL的所有内容将采集中的链接放入队列继续采集图片
阅读全文
Python网络爬虫爬取最好的妹妹的视频并保存到文件中
作者:keitwotest1060人浏览评论:03年前
项目描述 使用Python编写一个网络爬虫,抓取最好的妹妹的视频并保存到文件中。示例使用工具 Python2.7.X, pycharm 如何在pycharm .py文件中创建爬取最好的妹妹的视频,并在当前目录下创建video文件夹存放抓取的视频文件,写代码,然后运行
阅读全文
一篇文章教你如何使用Python网络爬虫获取差旅攻略
作者:python进阶者13人浏览评论:01年前
【一、项目背景】侨游网提供原创实用的出境游攻略、攻略、旅游社区和问答交流平台,以及智能出行规划解决方案,以及签证、保险、机票、和酒店 在线增值服务,如预订和汽车租赁。亲游“鼓励并帮助中国游客以自己的视角和方式体验世界。” 今天教大家获取侨友网的城市信息,
阅读全文
Java版网络爬虫的基础知识(传输)
作者:developerguy851 浏览评论人数:06年前
网络爬虫不仅可以抓取网站的网页、图片,甚至还可以实现抢票、在线抢购、查询票等功能。这几天我读了一些基础知识并记录下来。网页之间的关系可以看成是一张大图,图片的遍历可以分为深度优先和广度优先。网络爬虫以广度为先,一般来说如下:2个数组,一个
阅读全文
一篇文章教你使用Python网络爬虫抓取百度贴吧评论区图片和视频
作者:pythonadvanced 26人浏览评论:01年前
【一、项目背景】百度贴吧是全球最大的中文交流平台。你像我么?有时候在评论区看到图片就想下载?或者看到视频并想下载它?今天小编就带大家在评论区搜索关键词获取图片和视频。【二、项目目标】实现将贴吧获取的图片或视频保存在
阅读全文
c爬虫抓取网页数据(Web网页数据抓取(C/S)繁体(c#))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-17 22:33
网页数据捕获 (C/S) 传统
August 01, 2016-通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。比如我们有一个系统来提取百度网站歌曲搜索排名。分析系统根据获得的数据进行数据分析。为企业提供参考数据。为了满足上述要求,我们需要模拟浏览器浏览网页,获取页面的数据进行分析,最后编写分析的结构,即排序后的数据到数据库中。那
爬取网页数据分析(c#) 繁体
2008年11月26日-通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。比如我们有一个系统来提取百度网站歌曲搜索排名。分析系统根据获得的数据进行数据分析。为企业提供参考数据。为了满足上述要求,我们需要模拟浏览器浏览网页,获取页面的数据进行分析,最后编写分析的结构,即排序后的数据到数据库中。
网页数据抓取(B/S) 传统
2016年8月1日-C#爬取网页内容(转)1、爬取一般内容需要三个类:WebRequest、WebResponse、StreamReader 所需命名空间:System.Net、System.IO 核心代码:1WebRequest request = WebRequest.Create
C#爬虫,抓取网页数据
2016年9月1日-这两天学习了爬虫的基础知识,这里做一个简单的总结。抓取的网页商品数据保存在Excel表格中,效果如下: 使用Jumony Core引擎,非常强大,几乎完美的HTML解析引擎,支持css3选择器,直接抓取网页文档进行分析,并基于 HTTP 标头自动识别。博客园站点导航top信息抓取示例:var do
网页数据抓取繁体中文
2018年6月26日-1.html的常规解析 使用Jsoup包,配合开发者工具(F12)定位需要的数据路径。数据采集往往流程类似,类似的流程可以建议优化结构。2. selenium实例参考geckodriver安装:见
关于抓取网页数据!!!繁体中文
2009年3月6日-昨天去一家公司面试。老板说你回去用jsp做个项目,然后就可以上班了…… 要求是可以从指定的网页抓取需要的数据。例如:我在百度上搜索“电视”,然后我想从他返回的页面中提取他的关键词!(注:只提取客户端显示的网页数据)当我为老板提到这个话题时,我想到了“网络爬虫
网络爬虫抓取网页数据的几个常见问题
2019年2月20日-如果你想爬取数据又懒得写代码,可以试试网络爬虫爬取数据。相关文章:最简单的数据抓取教程,人人都可以用webscraper进阶教程,人人都可以使用如果你使用webscraper抓取数据,你很可能会遇到以下问题中的一个或多个,以及这些问题可能会直接打乱你的计划,甚至
网页数据抓取工具(谷歌插件web Scraper)
2018年2月11日-最简单的数据抓取教程,人人都可以使用Web Scraper是一款适合普通用户(没有专业IT技能)的免费爬虫工具,您可以轻松使用鼠标和简单的配置来获取您想要的数据。例如知乎回答列表、微博热点、微博评论、电商网站产品信息、博客文章列表等。
爬取网页数据分析繁体中文
2011.02.15-发表于 2006-05-24 14:04 北极燕鸥阅读(9793) 评论(42) 编辑采集类别:C#编程通过程序自动读取他人网站信息显示在网页上类似于一个爬虫程序,比如我们有一个系统提取百度网站歌曲搜索排名,分析系统根据得到的数据进行数据分析,为业务提供参数
抓取网页数据并解析繁体中文
2016年03月02日-这一天遇到了这样一个需求:这个页面数据能不能爬?然后提供账号、密码和网站地址: 账号:kytj1 密码:******************** 登录地址: 主要思想:1、 使用 Fiddler4 分析 HTTP 请求交互方式,包括
网页数据捕获 (C/S) 传统
August 01, 2016-通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。比如我们有一个系统来提取百度网站歌曲搜索排名。分析系统根据获得的数据进行数据分析。为企业提供参考数据。为了满足上述要求,我们需要模拟浏览器浏览网页,获取页面的数据进行分析,最后编写分析的结构,即排序后的数据到数据库中。那
爬取网页数据分析(c#) 繁体
2008年11月26日-通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。比如我们有一个系统来提取百度网站歌曲搜索排名。分析系统根据获得的数据进行数据分析。为企业提供参考数据。为了满足上述要求,我们需要模拟浏览器浏览网页,获取页面的数据进行分析,最后编写分析的结构,即排序后的数据到数据库中。
网页数据抓取(B/S) 传统
2016年8月1日-C#爬取网页内容(转)1、爬取一般内容需要三个类:WebRequest、WebResponse、StreamReader 所需命名空间:System.Net、System.IO 核心代码:1WebRequest request = WebRequest.Create
C#爬虫,抓取网页数据
2016年9月1日-这两天学习了爬虫的基础知识,这里做一个简单的总结。抓取的网页商品数据保存在Excel表格中,效果如下: 使用Jumony Core引擎,非常强大,几乎完美的HTML解析引擎,支持css3选择器,直接抓取网页文档进行分析,并基于 HTTP 标头自动识别。博客园站点导航top信息抓取示例:var do
网页数据抓取繁体中文
2018年6月26日-1.html的常规解析 使用Jsoup包,配合开发者工具(F12)定位需要的数据路径。数据采集往往流程类似,类似的流程可以建议优化结构。2. selenium实例参考geckodriver安装:见
关于抓取网页数据!!!繁体中文
2009年3月6日-昨天去一家公司面试。老板说你回去用jsp做个项目,然后就可以上班了…… 要求是可以从指定的网页抓取需要的数据。例如:我在百度上搜索“电视”,然后我想从他返回的页面中提取他的关键词!(注:只提取客户端显示的网页数据)当我为老板提到这个话题时,我想到了“网络爬虫
网络爬虫抓取网页数据的几个常见问题
2019年2月20日-如果你想爬取数据又懒得写代码,可以试试网络爬虫爬取数据。相关文章:最简单的数据抓取教程,人人都可以用webscraper进阶教程,人人都可以使用如果你使用webscraper抓取数据,你很可能会遇到以下问题中的一个或多个,以及这些问题可能会直接打乱你的计划,甚至
网页数据抓取工具(谷歌插件web Scraper)
2018年2月11日-最简单的数据抓取教程,人人都可以使用Web Scraper是一款适合普通用户(没有专业IT技能)的免费爬虫工具,您可以轻松使用鼠标和简单的配置来获取您想要的数据。例如知乎回答列表、微博热点、微博评论、电商网站产品信息、博客文章列表等。
爬取网页数据分析繁体中文
2011.02.15-发表于 2006-05-24 14:04 北极燕鸥阅读(9793) 评论(42) 编辑采集类别:C#编程通过程序自动读取他人网站信息显示在网页上类似于一个爬虫程序,比如我们有一个系统提取百度网站歌曲搜索排名,分析系统根据得到的数据进行数据分析,为业务提供参数
抓取网页数据并解析繁体中文
2016年03月02日-这一天遇到了这样一个需求:这个页面数据能不能爬?然后提供账号、密码和网站地址: 账号:kytj1 密码:******************** 登录地址: 主要思想:1、 使用 Fiddler4 分析 HTTP 请求交互方式,包括
爬取HTML网页数据繁体中文
2013年10月29日-(转)该类用于htmlparse过滤器不是通用的工具类,需要根据自己的需求来实现。这里只记录Htmlparse.jar包的一些用法。而已!有关详细信息,请参见此处:java.util.*;
使用VBA抓取网页数据繁体中文
2014年7月28日-我想用VBA捕捉以上数据,我想捕捉投资者关系信息->研究活动下每条新闻标题中的日期和新闻发布日期
Java爬取网页数据繁体中文
2013年9月23日——我最近处于辞职状态。我正赶着打发我的闲暇时间。我开始了自己的毕业设计。主题是Java Web 购物平台。我打算用SpringMVC+MyBatis来实现。我打算添加一个缓存服务器。我还没想好我会用什么。使用 Maven 进行管理
Matlab抓取网页数据繁体中文
2015年7月23日-本文示例使用正则表达式regexp进行语法识别和抓取网页数据:代码:url='#39;;[str status]=urlread(url,'Charset','GBK'); %
Matlab抓取网页数据繁体中文
2015年7月23日-本文示例使用正则表达式regexp进行语法识别和抓取网页数据:代码:url='';[str status]=urlread(url,'Charset','GBK');%Shanghai股票 suf='
JSON网页数据抓取繁体中文
2014.01.28-各位高手,如何获取以下网址的73条数据?#results/&aud=indv&type=med&state=AZ&county=Coconino&ag
python爬取网页数据传统
June 06, 2016-使用python进行简单的数据分析。在中关村在线采集数据,使用的网页是这个页面。首先,必须分析网页的 HTML。我们要捕获的数据是基于
.net 抓取网页数据 繁体中文
2015年8月3日-1、如果想通过代码获取某个页面的数据,首先根据右键查看该页面的源代码,分析一下。然后通过下面的代码,修改,一步步找出需要的内容,保存到数据库中。//根据Url地址获取网页私有字符串的html源码 GetWebContent(string Url){
C#如何抓取网页数据,分析和去除Html标签
2009年10月16日-由于这一段内容已经在我自己的搜索引擎中实现了,今天我就讲讲如何抓取网页数据,分析和去除Html标签,供大家参考。我的平台是Visual Studio2005,C#。——————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————网页
C#爬虫,繁体中文网页数据抓取笔记
2014年8月21日-第一次用C#写数据捕获,遇到各种问题。开始写模拟登录的时候,发现里面有验证码。我不得不突破验证码才能得到它。好的,那我去找验证码破解的密码。过了很长时间,我无法触摸门。我尝试了很多代码,发现它们并不通用。后来明白了原理。我先把噪点、干扰线等去掉,然后把颜色验证码变成黑色。
Python的BeautifulSoup实现抓取网页数据
2018年1月10-1日环境:pycharm,python3.42.源码分析import requests import refrom bs4 import BeautifulSoup#通过requests.get def getHtmlText(url)获取整个网页的数据:尝试:
goLang多线程抓取网页数据
2018.01.02-突然想用goLang快速爬取网页数据,于是想到了多线程页面爬取包main import("fmt""log""net/http""os""strconv""sync"
使用 HtmlAgilityPack 抓取网页数据
2013 年 12 月 31 日-XPath 使用路径表达式来选择 XML 文档中的节点或节点集。通过以下路径或步骤选择节点。下面列出了最有用的路径表达式: nodename:选择该节点的所有子节点。/:从根节点选择。//: 从匹配选择的当前节点中选择文档中的节点,而不管它们的位置。.:
浅谈抓取网页数据(提供Demo)
2014.04.09-Demo源码后台在公司做了一个比价系统,就是在网站上抓取其他产品的价格,和公司的产品对应,然后展示出来,提供给PM定价参考。后来同事的朋友找工作时,猎头让他做一个程序,抢去去哪儿最便宜的机票。然后,我帮助修复了它。这篇文章的目的就是提供这个程序的源码,然后和大家一起讨论
[.NET] 使用HtmlAgilityPack抓取网页数据繁体中文
2014年10月24日-刚学了XPath路径表达式,主要是在XML文档中搜索节点。通过 XPath 表达式,您可以快速定位和访问 XML 文档中的节点位置。HTML也是类似xml的标记语言,只是语法没有那么严谨。codeplex中有一个开源项目HtmlAgilityPack,提供了使用XPath解析HTML文档。
在Android中抓取和修改网页数据
2017-03-01-在Android中,经常使用WebView来加载网页和显示网页数据,但有时需要从网页中动态抓取数据,进行处理,甚至修改网页的数据,使其动态化显示效果,WebView 显得束手无策。最近的项目有这样的需求,加载本地H5数据,动态修改里面的内容,然后预览。接下来说一下他的实现步骤。
一个抓取网页数据的问题
2006年10月13日-我想抓取网页中的数据,但该网页禁止右键单击,查看源代码,禁止保存,甚至没有生成临时文件。一开始用的是webbrowser控件,使用documentText之类的时候报错。说找不到文件后,我用了这个HttpWebRequest request = (HttpWebRequest)
php抓取网页数据遇到的问题
2019年06月05日-1.file_get_contents无法捕获https安全协议网站使用curl获取数据函数file_get_contents_by_curl($url){$ch = curl_init();curl_setopt($ch, CURLOPT_URL, $url
winfrom 动态获取网页数据 繁体中文
2017年3月13日-我们知道如果网页的数据没有通过http协议加载到页面中,或者ajax延迟加载数据到页面,这时候你的请求url获取到的数据语言不全,说白了就是如果不能抓取到需要的目标数据,就用下面两种方法处理: 方法一:WebBrowser延迟加载采集地址(线程等待)用js处理。1.目标网址:
[.NET] 使用HtmlAgilityPack抓取网页数据繁体中文
2017年7月14日-刚学了XPath路径表达式,主要是在XML文档中搜索节点。通过 XPath 表达式,您可以快速定位和访问 XML 文档中的节点位置。HTML也是类似xml的标记语言,只是语法没有那么严谨。codeplex中有一个开源项目HtmlAgilityPack,提供了使用XPath解析HTML文档。
Java抓取网页数据,登录后抓取数据。繁体中文
2014年10月20日——最近做了一个小程序,从网上抓取数据。主要是关于信用,一些黑名单网站采集,从网站抓取到我们自己的系统。我也找到了一些资料,但我认为没有一个很好的和全面的例子。所以在这里做个笔记以提醒自己。首先需要一个jsoup jar包,我用的是1.6.0。. 下载地址为:
.net2.0 抓取网页数据分析繁体中文
2006年11月22日-效果图后台代码如下:using System;使用 System.Data; 使用 System.Configuration; 使用 System.Web;使用 System.Web.Security;
使用webbrowser控件抓取网页数据,如何抓取多个a标签的url地址对应的网页数据
2011.05.20-由于标题所属,我的页面有四个菜单,分别连接到不同的地址。我现在想用一个按钮来抓取这个页面的数据。在抓取时,我遍历获取了四个 a 标签 url 地址。然后自动进入对应页面抓取数据并保存到数据库中。现在问题如下: ArrayList UrlList = new ArrayList();
Java抓取网页数据(原网页+Javascript返回数据)
2014年05月07日-原文链接:有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据显示方式略有不同!本文用Java来告诉你如何捕获网站的数量
Java抓取网页数据(原网页+Javascript返回数据)
2012年8月26日-转载请注明出处!原文链接:有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据显示方式略有不同!本文使用Java向大家展示如何抓取网站的数据:(1)
网页数据抓取,网页源代码没有需要的数据
2014.10.04-在使用WebClient抓取网页数据时,查看了网页的源码,发现源码中没有网页上可以看到的数据。这种情况下,是不是意味着网页上的数据是通过JS返回的?那么,在这种情况下,您如何提取所需的数据?
谁能抓取一个C#网页数据的源代码,最好是完整的?繁体
2012年12月12日-如何使用C#从类似于搜狐的页面中抓取标题、作者和日期?爬取次数不少于10次。请高手指点,最好能给出完整的源代码?
C#抓取网页数据,分析去除HTML标签【转】繁体
August 09, 2010-首先抓取网页的全部内容,将数据放入byte[]中(网络传输时格式为byte),然后转换为String,方便操作。示例如下: private static string GetPageData (string url){ if (url == null || url.Trim() =
【工作笔记0006】C#调用HtmlAgilityPack类库实现网页数据抓取繁体中文
2015年7月30日-最近在研究HtmlAgilityPack,发现它的类库功能非常强大,非常方便的实现网页数据抓取。下面是一个使用 HtmlAgilityPack 捕获数据的简单示例。目标是抓取我个人博客的文章列表数据。路径如下:adamlevine7个人博客目录核心代码如下:1.第一次参考
C#抓取网页数据,分析(如抓取天气预报) 091016 有更新 091110 再次更新 繁体
2009年8月12日-先看这位大哥的博客。最好先抓取网页的全部内容,将数据放入byte[]中(网络传输时格式为byte),然后再转换为String,方便比较。操作示例如下: private static string GetPageData(string url){ if (url == n
使用 node.js cheerio 抓取网页数据
2015年9月29日-你是想自动抓取网页中的一些数据还是想把从什么博客中提取的数据转换成结构化数据?有没有现有的 API 来检索数据?!!!!@#$@#$...可以解决网页爬虫问题。什么是网络爬虫?你可能会问。. . 网页抓取是一种以编程方式(通常无需浏览器参与)检索网页内容并从中提取数据的过程。这篇论文,小
Java程序抓取网页数据和去重处理
2014年08月05日-如题,等回复,最好带程序,带个大概说明,新手,网上爬虫看起来很简单。
为什么我不能用Delphi抓取网页数据?
2015.06.08-我用delphi自带的IdHttp idhttp1.Get('')来抓取这个网页的数据。为什么我不能抓取下面的数据?有什么好的方法可以做到吗?
8、多级网页数据抓取繁体中文
2013 年 7 月 31 日-使用 System;using System.采集s.Generic;using System.ComponentModel;using System.Data;using System.Drawing;using System.Text;using System.Window
谁有登录后抓取网页数据的例子?
2010 年 12 月 8 日 - 现在迫切需要一个这样的例子,过去两天我一直很伤心。登录包括使用用户名、密码和验证码登录。只需能够完成登录步骤。登录是手动输入登录
Python中使用PhantomJS抓取Javascript网页数据
2015年07月01日-有些网页不是静态加载的,而是通过javascipt函数动态加载的。例如,在下面的网页中,通过javascirpt函数从后台加载了表中看涨合约和看跌合约的数据。仅使用beautifulsoup 无法捕获此表中的数据。找资料,发现可以用PhantomJS来爬取此类网页
网页爬虫-使用Python爬取网页数据繁体中文
2015年8月24日-干货搬家大神童熊!我没有事儿。我看了一下 Python,发现它很酷。废话少说,准备搭建环境。因为是MAC电脑,所以自动安装Python2.7版本并添加库Beautiful Soup,这里有两种方法
网页数据采集系统解决方案 传统
2009年12月29日-1. 项目介绍 项目背景 互联网时代,信息海阔天空。甚至我们获取信息的方式也发生了变化:从传统的翻书到查字典,再到通过搜索引擎搜索。我们已经从信息匮乏的时代走到了信息丰富的今天。今天,困扰我们的问题不是信息太少,而是太多太多,让你无法分辨或选择。因此,提供一个
Node.js 使用cheerio 抓取网页数据DEMO
2015年07月28日-Node.js原本是作为Js服务器使用的,现在一起用它来做个爬虫吧。关键是爬取网页后如何得到你想要的数据?然后我找到了cheerio,解析html非常方便,就像在浏览器中使用jquery一样。使用以下命令安装cheerio [C#]纯文本视图复制代码?01npm 安装
R语言实现简单的网页数据抓取繁体中文
2017年2月17日-我在知乎遇到这样的问题。这是要爬取的内容的网页: R语言代码的实现如下:#Install XML package>install.packages("XML")#Load XML package>
Jsoup介绍-使用Java抓取网页数据
2014年10月15日-转载请注明出处:概述jsoup是一个Java HTML解析器,可以直接解析一个URL地址和HTML文本内容。它提供了一个非常省力的 API,通过 DOM、CSS 和类 查看全部
c爬虫抓取网页数据(Web网页数据抓取(C/S)繁体(c#))
网页数据捕获 (C/S) 传统
August 01, 2016-通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。比如我们有一个系统来提取百度网站歌曲搜索排名。分析系统根据获得的数据进行数据分析。为企业提供参考数据。为了满足上述要求,我们需要模拟浏览器浏览网页,获取页面的数据进行分析,最后编写分析的结构,即排序后的数据到数据库中。那
爬取网页数据分析(c#) 繁体
2008年11月26日-通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。比如我们有一个系统来提取百度网站歌曲搜索排名。分析系统根据获得的数据进行数据分析。为企业提供参考数据。为了满足上述要求,我们需要模拟浏览器浏览网页,获取页面的数据进行分析,最后编写分析的结构,即排序后的数据到数据库中。
网页数据抓取(B/S) 传统
2016年8月1日-C#爬取网页内容(转)1、爬取一般内容需要三个类:WebRequest、WebResponse、StreamReader 所需命名空间:System.Net、System.IO 核心代码:1WebRequest request = WebRequest.Create
C#爬虫,抓取网页数据
2016年9月1日-这两天学习了爬虫的基础知识,这里做一个简单的总结。抓取的网页商品数据保存在Excel表格中,效果如下: 使用Jumony Core引擎,非常强大,几乎完美的HTML解析引擎,支持css3选择器,直接抓取网页文档进行分析,并基于 HTTP 标头自动识别。博客园站点导航top信息抓取示例:var do
网页数据抓取繁体中文
2018年6月26日-1.html的常规解析 使用Jsoup包,配合开发者工具(F12)定位需要的数据路径。数据采集往往流程类似,类似的流程可以建议优化结构。2. selenium实例参考geckodriver安装:见
关于抓取网页数据!!!繁体中文
2009年3月6日-昨天去一家公司面试。老板说你回去用jsp做个项目,然后就可以上班了…… 要求是可以从指定的网页抓取需要的数据。例如:我在百度上搜索“电视”,然后我想从他返回的页面中提取他的关键词!(注:只提取客户端显示的网页数据)当我为老板提到这个话题时,我想到了“网络爬虫
网络爬虫抓取网页数据的几个常见问题
2019年2月20日-如果你想爬取数据又懒得写代码,可以试试网络爬虫爬取数据。相关文章:最简单的数据抓取教程,人人都可以用webscraper进阶教程,人人都可以使用如果你使用webscraper抓取数据,你很可能会遇到以下问题中的一个或多个,以及这些问题可能会直接打乱你的计划,甚至
网页数据抓取工具(谷歌插件web Scraper)
2018年2月11日-最简单的数据抓取教程,人人都可以使用Web Scraper是一款适合普通用户(没有专业IT技能)的免费爬虫工具,您可以轻松使用鼠标和简单的配置来获取您想要的数据。例如知乎回答列表、微博热点、微博评论、电商网站产品信息、博客文章列表等。
爬取网页数据分析繁体中文
2011.02.15-发表于 2006-05-24 14:04 北极燕鸥阅读(9793) 评论(42) 编辑采集类别:C#编程通过程序自动读取他人网站信息显示在网页上类似于一个爬虫程序,比如我们有一个系统提取百度网站歌曲搜索排名,分析系统根据得到的数据进行数据分析,为业务提供参数
抓取网页数据并解析繁体中文
2016年03月02日-这一天遇到了这样一个需求:这个页面数据能不能爬?然后提供账号、密码和网站地址: 账号:kytj1 密码:******************** 登录地址: 主要思想:1、 使用 Fiddler4 分析 HTTP 请求交互方式,包括
网页数据捕获 (C/S) 传统
August 01, 2016-通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。比如我们有一个系统来提取百度网站歌曲搜索排名。分析系统根据获得的数据进行数据分析。为企业提供参考数据。为了满足上述要求,我们需要模拟浏览器浏览网页,获取页面的数据进行分析,最后编写分析的结构,即排序后的数据到数据库中。那
爬取网页数据分析(c#) 繁体
2008年11月26日-通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。比如我们有一个系统来提取百度网站歌曲搜索排名。分析系统根据获得的数据进行数据分析。为企业提供参考数据。为了满足上述要求,我们需要模拟浏览器浏览网页,获取页面的数据进行分析,最后编写分析的结构,即排序后的数据到数据库中。
网页数据抓取(B/S) 传统
2016年8月1日-C#爬取网页内容(转)1、爬取一般内容需要三个类:WebRequest、WebResponse、StreamReader 所需命名空间:System.Net、System.IO 核心代码:1WebRequest request = WebRequest.Create
C#爬虫,抓取网页数据
2016年9月1日-这两天学习了爬虫的基础知识,这里做一个简单的总结。抓取的网页商品数据保存在Excel表格中,效果如下: 使用Jumony Core引擎,非常强大,几乎完美的HTML解析引擎,支持css3选择器,直接抓取网页文档进行分析,并基于 HTTP 标头自动识别。博客园站点导航top信息抓取示例:var do
网页数据抓取繁体中文
2018年6月26日-1.html的常规解析 使用Jsoup包,配合开发者工具(F12)定位需要的数据路径。数据采集往往流程类似,类似的流程可以建议优化结构。2. selenium实例参考geckodriver安装:见
关于抓取网页数据!!!繁体中文
2009年3月6日-昨天去一家公司面试。老板说你回去用jsp做个项目,然后就可以上班了…… 要求是可以从指定的网页抓取需要的数据。例如:我在百度上搜索“电视”,然后我想从他返回的页面中提取他的关键词!(注:只提取客户端显示的网页数据)当我为老板提到这个话题时,我想到了“网络爬虫
网络爬虫抓取网页数据的几个常见问题
2019年2月20日-如果你想爬取数据又懒得写代码,可以试试网络爬虫爬取数据。相关文章:最简单的数据抓取教程,人人都可以用webscraper进阶教程,人人都可以使用如果你使用webscraper抓取数据,你很可能会遇到以下问题中的一个或多个,以及这些问题可能会直接打乱你的计划,甚至
网页数据抓取工具(谷歌插件web Scraper)
2018年2月11日-最简单的数据抓取教程,人人都可以使用Web Scraper是一款适合普通用户(没有专业IT技能)的免费爬虫工具,您可以轻松使用鼠标和简单的配置来获取您想要的数据。例如知乎回答列表、微博热点、微博评论、电商网站产品信息、博客文章列表等。
爬取网页数据分析繁体中文
2011.02.15-发表于 2006-05-24 14:04 北极燕鸥阅读(9793) 评论(42) 编辑采集类别:C#编程通过程序自动读取他人网站信息显示在网页上类似于一个爬虫程序,比如我们有一个系统提取百度网站歌曲搜索排名,分析系统根据得到的数据进行数据分析,为业务提供参数
抓取网页数据并解析繁体中文
2016年03月02日-这一天遇到了这样一个需求:这个页面数据能不能爬?然后提供账号、密码和网站地址: 账号:kytj1 密码:******************** 登录地址: 主要思想:1、 使用 Fiddler4 分析 HTTP 请求交互方式,包括
爬取HTML网页数据繁体中文
2013年10月29日-(转)该类用于htmlparse过滤器不是通用的工具类,需要根据自己的需求来实现。这里只记录Htmlparse.jar包的一些用法。而已!有关详细信息,请参见此处:java.util.*;
使用VBA抓取网页数据繁体中文
2014年7月28日-我想用VBA捕捉以上数据,我想捕捉投资者关系信息->研究活动下每条新闻标题中的日期和新闻发布日期
Java爬取网页数据繁体中文
2013年9月23日——我最近处于辞职状态。我正赶着打发我的闲暇时间。我开始了自己的毕业设计。主题是Java Web 购物平台。我打算用SpringMVC+MyBatis来实现。我打算添加一个缓存服务器。我还没想好我会用什么。使用 Maven 进行管理
Matlab抓取网页数据繁体中文
2015年7月23日-本文示例使用正则表达式regexp进行语法识别和抓取网页数据:代码:url='#39;;[str status]=urlread(url,'Charset','GBK'); %
Matlab抓取网页数据繁体中文
2015年7月23日-本文示例使用正则表达式regexp进行语法识别和抓取网页数据:代码:url='';[str status]=urlread(url,'Charset','GBK');%Shanghai股票 suf='
JSON网页数据抓取繁体中文
2014.01.28-各位高手,如何获取以下网址的73条数据?#results/&aud=indv&type=med&state=AZ&county=Coconino&ag
python爬取网页数据传统
June 06, 2016-使用python进行简单的数据分析。在中关村在线采集数据,使用的网页是这个页面。首先,必须分析网页的 HTML。我们要捕获的数据是基于
.net 抓取网页数据 繁体中文
2015年8月3日-1、如果想通过代码获取某个页面的数据,首先根据右键查看该页面的源代码,分析一下。然后通过下面的代码,修改,一步步找出需要的内容,保存到数据库中。//根据Url地址获取网页私有字符串的html源码 GetWebContent(string Url){
C#如何抓取网页数据,分析和去除Html标签
2009年10月16日-由于这一段内容已经在我自己的搜索引擎中实现了,今天我就讲讲如何抓取网页数据,分析和去除Html标签,供大家参考。我的平台是Visual Studio2005,C#。——————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————网页
C#爬虫,繁体中文网页数据抓取笔记
2014年8月21日-第一次用C#写数据捕获,遇到各种问题。开始写模拟登录的时候,发现里面有验证码。我不得不突破验证码才能得到它。好的,那我去找验证码破解的密码。过了很长时间,我无法触摸门。我尝试了很多代码,发现它们并不通用。后来明白了原理。我先把噪点、干扰线等去掉,然后把颜色验证码变成黑色。
Python的BeautifulSoup实现抓取网页数据
2018年1月10-1日环境:pycharm,python3.42.源码分析import requests import refrom bs4 import BeautifulSoup#通过requests.get def getHtmlText(url)获取整个网页的数据:尝试:
goLang多线程抓取网页数据
2018.01.02-突然想用goLang快速爬取网页数据,于是想到了多线程页面爬取包main import("fmt""log""net/http""os""strconv""sync"
使用 HtmlAgilityPack 抓取网页数据
2013 年 12 月 31 日-XPath 使用路径表达式来选择 XML 文档中的节点或节点集。通过以下路径或步骤选择节点。下面列出了最有用的路径表达式: nodename:选择该节点的所有子节点。/:从根节点选择。//: 从匹配选择的当前节点中选择文档中的节点,而不管它们的位置。.:
浅谈抓取网页数据(提供Demo)
2014.04.09-Demo源码后台在公司做了一个比价系统,就是在网站上抓取其他产品的价格,和公司的产品对应,然后展示出来,提供给PM定价参考。后来同事的朋友找工作时,猎头让他做一个程序,抢去去哪儿最便宜的机票。然后,我帮助修复了它。这篇文章的目的就是提供这个程序的源码,然后和大家一起讨论
[.NET] 使用HtmlAgilityPack抓取网页数据繁体中文
2014年10月24日-刚学了XPath路径表达式,主要是在XML文档中搜索节点。通过 XPath 表达式,您可以快速定位和访问 XML 文档中的节点位置。HTML也是类似xml的标记语言,只是语法没有那么严谨。codeplex中有一个开源项目HtmlAgilityPack,提供了使用XPath解析HTML文档。
在Android中抓取和修改网页数据
2017-03-01-在Android中,经常使用WebView来加载网页和显示网页数据,但有时需要从网页中动态抓取数据,进行处理,甚至修改网页的数据,使其动态化显示效果,WebView 显得束手无策。最近的项目有这样的需求,加载本地H5数据,动态修改里面的内容,然后预览。接下来说一下他的实现步骤。
一个抓取网页数据的问题
2006年10月13日-我想抓取网页中的数据,但该网页禁止右键单击,查看源代码,禁止保存,甚至没有生成临时文件。一开始用的是webbrowser控件,使用documentText之类的时候报错。说找不到文件后,我用了这个HttpWebRequest request = (HttpWebRequest)
php抓取网页数据遇到的问题
2019年06月05日-1.file_get_contents无法捕获https安全协议网站使用curl获取数据函数file_get_contents_by_curl($url){$ch = curl_init();curl_setopt($ch, CURLOPT_URL, $url
winfrom 动态获取网页数据 繁体中文
2017年3月13日-我们知道如果网页的数据没有通过http协议加载到页面中,或者ajax延迟加载数据到页面,这时候你的请求url获取到的数据语言不全,说白了就是如果不能抓取到需要的目标数据,就用下面两种方法处理: 方法一:WebBrowser延迟加载采集地址(线程等待)用js处理。1.目标网址:
[.NET] 使用HtmlAgilityPack抓取网页数据繁体中文
2017年7月14日-刚学了XPath路径表达式,主要是在XML文档中搜索节点。通过 XPath 表达式,您可以快速定位和访问 XML 文档中的节点位置。HTML也是类似xml的标记语言,只是语法没有那么严谨。codeplex中有一个开源项目HtmlAgilityPack,提供了使用XPath解析HTML文档。
Java抓取网页数据,登录后抓取数据。繁体中文
2014年10月20日——最近做了一个小程序,从网上抓取数据。主要是关于信用,一些黑名单网站采集,从网站抓取到我们自己的系统。我也找到了一些资料,但我认为没有一个很好的和全面的例子。所以在这里做个笔记以提醒自己。首先需要一个jsoup jar包,我用的是1.6.0。. 下载地址为:
.net2.0 抓取网页数据分析繁体中文
2006年11月22日-效果图后台代码如下:using System;使用 System.Data; 使用 System.Configuration; 使用 System.Web;使用 System.Web.Security;
使用webbrowser控件抓取网页数据,如何抓取多个a标签的url地址对应的网页数据
2011.05.20-由于标题所属,我的页面有四个菜单,分别连接到不同的地址。我现在想用一个按钮来抓取这个页面的数据。在抓取时,我遍历获取了四个 a 标签 url 地址。然后自动进入对应页面抓取数据并保存到数据库中。现在问题如下: ArrayList UrlList = new ArrayList();
Java抓取网页数据(原网页+Javascript返回数据)
2014年05月07日-原文链接:有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据显示方式略有不同!本文用Java来告诉你如何捕获网站的数量
Java抓取网页数据(原网页+Javascript返回数据)
2012年8月26日-转载请注明出处!原文链接:有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据显示方式略有不同!本文使用Java向大家展示如何抓取网站的数据:(1)
网页数据抓取,网页源代码没有需要的数据
2014.10.04-在使用WebClient抓取网页数据时,查看了网页的源码,发现源码中没有网页上可以看到的数据。这种情况下,是不是意味着网页上的数据是通过JS返回的?那么,在这种情况下,您如何提取所需的数据?
谁能抓取一个C#网页数据的源代码,最好是完整的?繁体
2012年12月12日-如何使用C#从类似于搜狐的页面中抓取标题、作者和日期?爬取次数不少于10次。请高手指点,最好能给出完整的源代码?
C#抓取网页数据,分析去除HTML标签【转】繁体
August 09, 2010-首先抓取网页的全部内容,将数据放入byte[]中(网络传输时格式为byte),然后转换为String,方便操作。示例如下: private static string GetPageData (string url){ if (url == null || url.Trim() =
【工作笔记0006】C#调用HtmlAgilityPack类库实现网页数据抓取繁体中文
2015年7月30日-最近在研究HtmlAgilityPack,发现它的类库功能非常强大,非常方便的实现网页数据抓取。下面是一个使用 HtmlAgilityPack 捕获数据的简单示例。目标是抓取我个人博客的文章列表数据。路径如下:adamlevine7个人博客目录核心代码如下:1.第一次参考
C#抓取网页数据,分析(如抓取天气预报) 091016 有更新 091110 再次更新 繁体
2009年8月12日-先看这位大哥的博客。最好先抓取网页的全部内容,将数据放入byte[]中(网络传输时格式为byte),然后再转换为String,方便比较。操作示例如下: private static string GetPageData(string url){ if (url == n
使用 node.js cheerio 抓取网页数据
2015年9月29日-你是想自动抓取网页中的一些数据还是想把从什么博客中提取的数据转换成结构化数据?有没有现有的 API 来检索数据?!!!!@#$@#$...可以解决网页爬虫问题。什么是网络爬虫?你可能会问。. . 网页抓取是一种以编程方式(通常无需浏览器参与)检索网页内容并从中提取数据的过程。这篇论文,小
Java程序抓取网页数据和去重处理
2014年08月05日-如题,等回复,最好带程序,带个大概说明,新手,网上爬虫看起来很简单。
为什么我不能用Delphi抓取网页数据?
2015.06.08-我用delphi自带的IdHttp idhttp1.Get('')来抓取这个网页的数据。为什么我不能抓取下面的数据?有什么好的方法可以做到吗?
8、多级网页数据抓取繁体中文
2013 年 7 月 31 日-使用 System;using System.采集s.Generic;using System.ComponentModel;using System.Data;using System.Drawing;using System.Text;using System.Window
谁有登录后抓取网页数据的例子?
2010 年 12 月 8 日 - 现在迫切需要一个这样的例子,过去两天我一直很伤心。登录包括使用用户名、密码和验证码登录。只需能够完成登录步骤。登录是手动输入登录
Python中使用PhantomJS抓取Javascript网页数据
2015年07月01日-有些网页不是静态加载的,而是通过javascipt函数动态加载的。例如,在下面的网页中,通过javascirpt函数从后台加载了表中看涨合约和看跌合约的数据。仅使用beautifulsoup 无法捕获此表中的数据。找资料,发现可以用PhantomJS来爬取此类网页
网页爬虫-使用Python爬取网页数据繁体中文
2015年8月24日-干货搬家大神童熊!我没有事儿。我看了一下 Python,发现它很酷。废话少说,准备搭建环境。因为是MAC电脑,所以自动安装Python2.7版本并添加库Beautiful Soup,这里有两种方法
网页数据采集系统解决方案 传统
2009年12月29日-1. 项目介绍 项目背景 互联网时代,信息海阔天空。甚至我们获取信息的方式也发生了变化:从传统的翻书到查字典,再到通过搜索引擎搜索。我们已经从信息匮乏的时代走到了信息丰富的今天。今天,困扰我们的问题不是信息太少,而是太多太多,让你无法分辨或选择。因此,提供一个
Node.js 使用cheerio 抓取网页数据DEMO
2015年07月28日-Node.js原本是作为Js服务器使用的,现在一起用它来做个爬虫吧。关键是爬取网页后如何得到你想要的数据?然后我找到了cheerio,解析html非常方便,就像在浏览器中使用jquery一样。使用以下命令安装cheerio [C#]纯文本视图复制代码?01npm 安装
R语言实现简单的网页数据抓取繁体中文
2017年2月17日-我在知乎遇到这样的问题。这是要爬取的内容的网页: R语言代码的实现如下:#Install XML package>install.packages("XML")#Load XML package>
Jsoup介绍-使用Java抓取网页数据
2014年10月15日-转载请注明出处:概述jsoup是一个Java HTML解析器,可以直接解析一个URL地址和HTML文本内容。它提供了一个非常省力的 API,通过 DOM、CSS 和类
c爬虫抓取网页数据( SEO优化工作的6个策略之前)
网站优化 • 优采云 发表了文章 • 0 个评论 • 35 次浏览 • 2021-12-16 16:16
SEO优化工作的6个策略之前)
搜索引擎爬虫抓取我们的网页是实现 SEO 优化的第一步。如果不爬取,网站就不会搜索到收录,也就没有排名。所以对于每一个SEO从业者来说,爬行是第一步!
事实上,大多数SEO从业者所知道的搜索引擎爬取算法只有深度优先和广度优先的爬取策略。但实际上,爬虫爬取的网页有6种策略。在分享这6个策略之前,你必须先看看搜索引擎爬虫的工作流程,否则你可能看不懂下面的内容。
爬虫的宽度优先爬取策略
广度优先的爬取策略,一种历史悠久,一直受到关注的爬取策略。搜索引擎爬虫诞生以来就一直在使用的爬虫策略,甚至很多新的策略都是以此为基础的。
广度优先的爬取策略是根据要爬取的URL列表进行爬取。新发现的并判断为未爬取的链接,基本上直接存放在待爬取的URL列表末尾,等待被爬取。
如上图,我们假设爬虫的待爬取的URL列表中只有A。爬虫从A网页开始爬取,从A中提取B、C、D网页,然后将B、C、D放入爬取队列,然后获取E、F、G、H、I页面依次插入到要爬取的URL列表中,以此类推。
Crawler的深度优先爬取策略
深度优先抓取的策略是,爬虫会从待抓取列表中抓取第一个网址,然后沿着这个网址继续抓取该页面的其他网址,直到该行处理完毕,再从待抓取列表中抓取, 抢第二个,依此类推。下面给出了一个说明。
作为列表中第一个要爬取的 URL,爬虫开始爬取,然后爬到 B、C、D、E、F,但是 B、C、D 中没有后续链接(这里也会删除了已经爬过的页面),从E中找到H,跟着H,找到I,然后就没有了。在F中找到G,那么这个链接的爬取就结束了。从要获取的列表中,获取下一个链接继续上述操作。
Crawler 不完整的 PageRank 爬取策略
相信很多人都知道PageRank算法。我们SEO的白话理解就是链接传递权重的算法。而如果应用于爬虫爬行,又是怎样的逻辑呢?首先,爬虫的目的是下载网页。同时,爬虫无法看到指向某个网页的所有链接。因此,在爬取过程中,爬虫无法计算所有网页的pagerank,从而导致爬行。过程中计算出的pagerank不太可靠。
非完全pagerank爬取策略是基于爬虫无法看到某个页面的所有链接,而只能看到部分情况,必须进行pagerank计算结果。
它的具体策略是将已下载的网页和要爬取的URL列表中的网页形成一个汇总。在此摘要中执行 pagerank 计算。计算完成后,待爬取的URL列表中的每个URL都会得到一个pagerank值,然后根据这个值进行倒序排序。先获取最高的pagerank分数,然后一一获取。
这是问题吗?在要爬取的URL列表中,如果最后添加了新的URL,是否需要重新计算?
不是这种情况。搜索引擎会等到待抓取的网址列表中的新网址达到一定数量后,才会重新抓取。这样效率会提高很多。毕竟,爬虫抓取第一个添加的需要时间。
Crawler的OPIC爬取策略
OPIC是在线页面重要性计算的缩写,意思是“在线页面重要性计算”。这是pagerank的升级版。
它的具体策略逻辑是爬虫给互联网上的所有网址分配一个初始分数,每个网址的分数相同。每次下载一个网页时,该网页的分数都会平均分配给该网页中的所有链接。自然而然,这个页面的分数就会被清零。对于要爬取的URL列表(当然,刚才的网页被清空了分数,也是因为已经爬过了),首先爬取的是谁的分数最高。
与pagerank不同,opic是实时计算的。这里提醒我们,如果我们只考虑opic的爬取策略。这个策略和pagerank策略都证实了一个逻辑。我们新生成的网页,被链接的次数越多,被抓取的概率就越大。
是否值得考虑您的网页布局?
爬虫爬取的大站点优先策略
大网站优先爬取,是不是顾名思义?大的网站会先爬吗?但这里有两种解释。我个人认为这两个解释爬虫都在使用。
大站优先爬取说明1:顾名思义,爬虫会对列表中要爬取的URL进行分类,然后确定域名对应的网站级别。比如优先抓取权重较大的网站域名。
大展优先爬取说明2:爬虫根据域名对列表中要爬取的URL进行分类,然后计算数量。它所属的域是待抓取列表中编号最大的域。
两种解释,一种是网站的权重高,另一种是每天发布的文章数量多,发布非常集中。但是让我们想象一下,发布如此集中和如此多文章的网站通常都是大网站,对吗?
我们在这里想什么?
写文章时,一定要及时推送到搜索引擎。一小时不能发一篇,太散了。不过这个还是要验证的,有经验的同学可以考一下。 查看全部
c爬虫抓取网页数据(
SEO优化工作的6个策略之前)
搜索引擎爬虫抓取我们的网页是实现 SEO 优化的第一步。如果不爬取,网站就不会搜索到收录,也就没有排名。所以对于每一个SEO从业者来说,爬行是第一步!
事实上,大多数SEO从业者所知道的搜索引擎爬取算法只有深度优先和广度优先的爬取策略。但实际上,爬虫爬取的网页有6种策略。在分享这6个策略之前,你必须先看看搜索引擎爬虫的工作流程,否则你可能看不懂下面的内容。
爬虫的宽度优先爬取策略
广度优先的爬取策略,一种历史悠久,一直受到关注的爬取策略。搜索引擎爬虫诞生以来就一直在使用的爬虫策略,甚至很多新的策略都是以此为基础的。
广度优先的爬取策略是根据要爬取的URL列表进行爬取。新发现的并判断为未爬取的链接,基本上直接存放在待爬取的URL列表末尾,等待被爬取。
如上图,我们假设爬虫的待爬取的URL列表中只有A。爬虫从A网页开始爬取,从A中提取B、C、D网页,然后将B、C、D放入爬取队列,然后获取E、F、G、H、I页面依次插入到要爬取的URL列表中,以此类推。
Crawler的深度优先爬取策略
深度优先抓取的策略是,爬虫会从待抓取列表中抓取第一个网址,然后沿着这个网址继续抓取该页面的其他网址,直到该行处理完毕,再从待抓取列表中抓取, 抢第二个,依此类推。下面给出了一个说明。
作为列表中第一个要爬取的 URL,爬虫开始爬取,然后爬到 B、C、D、E、F,但是 B、C、D 中没有后续链接(这里也会删除了已经爬过的页面),从E中找到H,跟着H,找到I,然后就没有了。在F中找到G,那么这个链接的爬取就结束了。从要获取的列表中,获取下一个链接继续上述操作。
Crawler 不完整的 PageRank 爬取策略
相信很多人都知道PageRank算法。我们SEO的白话理解就是链接传递权重的算法。而如果应用于爬虫爬行,又是怎样的逻辑呢?首先,爬虫的目的是下载网页。同时,爬虫无法看到指向某个网页的所有链接。因此,在爬取过程中,爬虫无法计算所有网页的pagerank,从而导致爬行。过程中计算出的pagerank不太可靠。
非完全pagerank爬取策略是基于爬虫无法看到某个页面的所有链接,而只能看到部分情况,必须进行pagerank计算结果。
它的具体策略是将已下载的网页和要爬取的URL列表中的网页形成一个汇总。在此摘要中执行 pagerank 计算。计算完成后,待爬取的URL列表中的每个URL都会得到一个pagerank值,然后根据这个值进行倒序排序。先获取最高的pagerank分数,然后一一获取。
这是问题吗?在要爬取的URL列表中,如果最后添加了新的URL,是否需要重新计算?
不是这种情况。搜索引擎会等到待抓取的网址列表中的新网址达到一定数量后,才会重新抓取。这样效率会提高很多。毕竟,爬虫抓取第一个添加的需要时间。
Crawler的OPIC爬取策略
OPIC是在线页面重要性计算的缩写,意思是“在线页面重要性计算”。这是pagerank的升级版。
它的具体策略逻辑是爬虫给互联网上的所有网址分配一个初始分数,每个网址的分数相同。每次下载一个网页时,该网页的分数都会平均分配给该网页中的所有链接。自然而然,这个页面的分数就会被清零。对于要爬取的URL列表(当然,刚才的网页被清空了分数,也是因为已经爬过了),首先爬取的是谁的分数最高。
与pagerank不同,opic是实时计算的。这里提醒我们,如果我们只考虑opic的爬取策略。这个策略和pagerank策略都证实了一个逻辑。我们新生成的网页,被链接的次数越多,被抓取的概率就越大。
是否值得考虑您的网页布局?
爬虫爬取的大站点优先策略
大网站优先爬取,是不是顾名思义?大的网站会先爬吗?但这里有两种解释。我个人认为这两个解释爬虫都在使用。
大站优先爬取说明1:顾名思义,爬虫会对列表中要爬取的URL进行分类,然后确定域名对应的网站级别。比如优先抓取权重较大的网站域名。
大展优先爬取说明2:爬虫根据域名对列表中要爬取的URL进行分类,然后计算数量。它所属的域是待抓取列表中编号最大的域。
两种解释,一种是网站的权重高,另一种是每天发布的文章数量多,发布非常集中。但是让我们想象一下,发布如此集中和如此多文章的网站通常都是大网站,对吗?
我们在这里想什么?
写文章时,一定要及时推送到搜索引擎。一小时不能发一篇,太散了。不过这个还是要验证的,有经验的同学可以考一下。
c爬虫抓取网页数据(c爬虫抓取网页数据,网页代码动态加载的,可控)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-16 01:04
c爬虫抓取网页数据,运行简单即可。无需搭建环境,不需要采用大型机,也无需编写代码。仅用到小白看的懂的理论知识。思路:本爬虫简单的抓取网页数据,网页代码是动态加载的,可控。大佬请绕路。
1、获取某某某网站的所有url,并获取post方法url。
2、分析post请求,并返回一个json文件,接收返回的json数据。
3、根据json数据解析该url的请求参数。
4、简单实现网站登录。
5、用爬虫框架pyspider代替传统的爬虫程序。
6、返回一个结果页文件,并调用send_response方法。
7、结果页html文件网页中要包含json结构化数据。
8、修改登录方式,注册方式。
9、页面的解析。
1
0、页面的cookie+ua信息,返回页面。
1、保存页面,保存登录信息。python抓取web页面数据,代码简单,非常简单易上手。
实践
1、获取网页所有url;url=(ps:网页目录名+目录内容);match=()html=requests。get(url)print(match)url1=('/'+match+'/'+path。replace('','/')+'')html1=beautifulsoup(url1,'lxml')txt=""forstrinurl1:txt=txt+str#json转换为csv格式txt=""forrootintxt:ifroot。
encoding!='utf-8':txt=""else:txt=json。loads(txt)print(txt)list=requests。get('/'+match+'/'+path。replace('/','')+'/'+path。replace('/','/')+'/'+path。
replace('/','/')+'/'+path。
replace('/','/')+'/'+path。replace('/','/')+'/'。 查看全部
c爬虫抓取网页数据(c爬虫抓取网页数据,网页代码动态加载的,可控)
c爬虫抓取网页数据,运行简单即可。无需搭建环境,不需要采用大型机,也无需编写代码。仅用到小白看的懂的理论知识。思路:本爬虫简单的抓取网页数据,网页代码是动态加载的,可控。大佬请绕路。
1、获取某某某网站的所有url,并获取post方法url。
2、分析post请求,并返回一个json文件,接收返回的json数据。
3、根据json数据解析该url的请求参数。
4、简单实现网站登录。
5、用爬虫框架pyspider代替传统的爬虫程序。
6、返回一个结果页文件,并调用send_response方法。
7、结果页html文件网页中要包含json结构化数据。
8、修改登录方式,注册方式。
9、页面的解析。
1
0、页面的cookie+ua信息,返回页面。
1、保存页面,保存登录信息。python抓取web页面数据,代码简单,非常简单易上手。
实践
1、获取网页所有url;url=(ps:网页目录名+目录内容);match=()html=requests。get(url)print(match)url1=('/'+match+'/'+path。replace('','/')+'')html1=beautifulsoup(url1,'lxml')txt=""forstrinurl1:txt=txt+str#json转换为csv格式txt=""forrootintxt:ifroot。
encoding!='utf-8':txt=""else:txt=json。loads(txt)print(txt)list=requests。get('/'+match+'/'+path。replace('/','')+'/'+path。replace('/','/')+'/'+path。
replace('/','/')+'/'+path。
replace('/','/')+'/'+path。replace('/','/')+'/'。
c爬虫抓取网页数据(网络爬虫学了也已有三个月了,怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-15 01:36
也就是说,网络爬虫技术真的很香!
我已经学习了三个月的网络爬虫,所以让我们进行实践培训,看看它是如何工作的!
这次我们选择爬取“当当网”官方网页,网址“”(也可以选择其他网站)
开始我们的激烈操作吧~
一、新建项目和爬虫文件,搭建scrapy框架(这里我们将项目命名为“当当”)
1、在你的“特定文件夹”中打开cmd并输入以下代码
scrapy startproject dangdang
如果显示和我的一样,说明项目创建成功
2、创建蜘蛛,输入如下代码,注意:“cp”是爬虫的名字,“”是start_url,必不可少
(这里我们给蜘蛛取名“cp”,我选择爬取微机原理和界面设计等书籍,也可以选择其他书籍类型)
先进入创建的项目“当当”,然后创建蜘蛛
>cd dangdang
>scrapy genspider cp dangdang.com
如果你显示的信息和我的一样,说明蜘蛛创建成功
3、打开“pycharm”,打开刚刚创建的“当当”项目,把chromedriver.exe放在这个项目的selenium下,然后新建一个调试“main.py”文件,像这样:
注意:记住!!!
一定要把“chromedriver.exe”和新创建的“main.py”放在“当当”项目的根目录下!!!
OK,scrapy框架搭建完成,接下来就是写代码了~
二、创建“main.py”并写入内容
from scrapy.cmdline import execute
execute("scrapy crawl cp".split())
两行代码写完后,放在一边
三、修改默认的“middleware.py”
在“class DangdangDownloaderMiddleware:”下找到“def process_exception(self, request, exception, spider):”,输入如下代码:
#创建浏览器实例化对象在爬虫文件中,用spider.bro调用
bro = spider.bro
#requst.url就是拦截到的爬虫文件发起的url
bro.get(request.url)
#获取页面源码
page = bro.page_source
#利用HtmlResponse()实例化一个新的响应对象
n_response = HtmlResponse(url=request.url,body=page,encoding='utf-8',request=request)
#返回新的响应对象
return n_response
四、全局配置“settings.py”
打开“settings.py”文件,
注:以下所有需要设置的地方只需要去掉前面的注释号即可(日志输出除外)
1、设置网站的“user_agent”进行爬取,获取当当网的“user_agent”,复制到这里
2、设置——是否符合robots.txt
默认为“True”,即“合规性”。Scrapy启动后,会尽快访问网站的robots.txt文件,然后确定网站的爬取范围。
但是,我们不是作为搜索引擎工作的,在某些情况下,我们想要获取的内容是robots.txt 明确禁止的。因此,在某些时候,我们不得不将此配置项设置为False并拒绝遵守Robot协议!
3、 设置输出日志信息为错误日志信息,输出错误级别为一般级别
#输出日志设为之输出发生错误的日志信息
#输出级别——一般级别
LOG_LEVEL = 'ERROR'
4、设置下载中间件,
5、设置项目管道
当 Item 在 Spider 中被采集到时,它会被传递到 Item Pipeline,这些 Item Pipeline 组件按照定义的顺序处理 Item。以下是Item Pipeline的一些典型应用:
五、修改默认给出的“items.py”
1、Item 对象是一个简单的容器,用于采集捕获的数据。
爬取哪些字段,爬虫解析页面时只能使用定义的字段,所以需要在items.py中定义
2、 Item中只有一种Field,表示传入的任何数据类型都可以接收
3、 下图是默认给的
我们要爬取当当网《微机原理与界面设计》的书名、作者、现价、日期、出版社,所以需要在items.py中定义这些字段,
六、修改默认给出的“pipelines.py”
下图是默认给出的
我们要将抓取到的信息保存到“.xls”中,我们需要重写这个文件
from itemadapter import ItemAdapter
from openpyxl import Workbook
class DangdangPipeline:
def __init__(self):
self.wb = Workbook()
self.ws = self.wb.active
self.ws.append(['书名','作者','现价','日期','出版社'])
def process_item(self, items, spider):
line = [items['book_name'],items['author'],items['price'],items['time'], items['press']]
self.ws.append(line)
self.wb.save('./微机原理与接口设计.xls')
return items
重头戏来了!!!
七、写spider——“cp.py”文件中的主要代码
1、 下图是默认给出的结构,接下来我们需要添加和修改
2、本次培训完整代码
注意理解笔记~
import scrapy
import time
from selenium import webdriver
from dangdang.items import DangdangItem
class CpSpider(scrapy.Spider):
name = 'cp' #指定爬虫文件名称
allowed_domains = ['dangdang.com'] #允许爬取的网站域名
#spider在启动时爬取的url列表,用于定义初始请求
#第一个要爬取的url
start_urls = ['http://search.dangdang.com/?key=%CE%A2%BB%FA%D4%AD%C0%ED%D3%EB%BD%D3%BF%DA%BC%BC%CA%F5&act=input&page_index=1']
page_index = 1 #第一页
offset = 1 #查询字符串参数
def __init__(self): #实例化浏览器对象
#selenium启动配置参数接收是ChromeOptions类
option = webdriver.ChromeOptions() #启动浏览器,最大化
#屏蔽谷歌浏览器正在接受自动化软件控制提示
option.add_experimental_option('excludeSwitches', ['enable-authmation'])
self.bro = webdriver.Chrome(options=option) #初始化
def parse(self, response):
items = DangdangItem()
lists = response.xpath('//*[@id="search_nature_rg"]/ul/li')
#遍历列表
for i in lists:
items['book_name'] = i.xpath('./p[@class="name"]/a/@title')[0].extract()
print('书名',items['book_name'])
author = i.xpath('./p[@class="search_book_author"]/span[1]//text()').extract()
author = ''.join(author).strip()
items['author'] = author
print("作者",items['author'])
items['price'] = i.xpath('./p[@class="price"]/span[1]/text()').get()
print('现价',items['price'])
items['time'] = i.xpath('./p[@class="search_book_author"]/span[2]/text()').get()
print('日期',items['time'])
items['press'] = i.xpath('./p[@class="search_book_author"]/span[3]/a/@title').get()
print('出版社',items['press'])
yield items #回调
time.sleep(5)
#通过parse()方法实现翻页
if self.offset < 6: #只爬取5页
self.offset += 1
self.page_index += 1
url='http://search.dangdang.com/?key=%CE%A2%BB%FA%D4%AD%C0%ED%D3%EB%BD%D3%BF%DA%BC%BC%CA%F5&act=input&page_index={}'
.format(self.offset,self.page_index)
yield scrapy.Request(url=url,callback=self.parse)
#关闭浏览器
def closed(self,spider):
self.bro.close()
3、查看表中存储的内容
运行成功无错误后,你爬取的内容会保存在“微机原理与接口设计.xls”表中
双击打开表格,就是你爬取过的内容!
恭喜完成本次实战! 查看全部
c爬虫抓取网页数据(网络爬虫学了也已有三个月了,怎么办?)
也就是说,网络爬虫技术真的很香!
我已经学习了三个月的网络爬虫,所以让我们进行实践培训,看看它是如何工作的!
这次我们选择爬取“当当网”官方网页,网址“”(也可以选择其他网站)
开始我们的激烈操作吧~
一、新建项目和爬虫文件,搭建scrapy框架(这里我们将项目命名为“当当”)
1、在你的“特定文件夹”中打开cmd并输入以下代码
scrapy startproject dangdang
如果显示和我的一样,说明项目创建成功
2、创建蜘蛛,输入如下代码,注意:“cp”是爬虫的名字,“”是start_url,必不可少
(这里我们给蜘蛛取名“cp”,我选择爬取微机原理和界面设计等书籍,也可以选择其他书籍类型)
先进入创建的项目“当当”,然后创建蜘蛛
>cd dangdang
>scrapy genspider cp dangdang.com
如果你显示的信息和我的一样,说明蜘蛛创建成功
3、打开“pycharm”,打开刚刚创建的“当当”项目,把chromedriver.exe放在这个项目的selenium下,然后新建一个调试“main.py”文件,像这样:
注意:记住!!!
一定要把“chromedriver.exe”和新创建的“main.py”放在“当当”项目的根目录下!!!
OK,scrapy框架搭建完成,接下来就是写代码了~
二、创建“main.py”并写入内容
from scrapy.cmdline import execute
execute("scrapy crawl cp".split())
两行代码写完后,放在一边
三、修改默认的“middleware.py”
在“class DangdangDownloaderMiddleware:”下找到“def process_exception(self, request, exception, spider):”,输入如下代码:
#创建浏览器实例化对象在爬虫文件中,用spider.bro调用
bro = spider.bro
#requst.url就是拦截到的爬虫文件发起的url
bro.get(request.url)
#获取页面源码
page = bro.page_source
#利用HtmlResponse()实例化一个新的响应对象
n_response = HtmlResponse(url=request.url,body=page,encoding='utf-8',request=request)
#返回新的响应对象
return n_response
四、全局配置“settings.py”
打开“settings.py”文件,
注:以下所有需要设置的地方只需要去掉前面的注释号即可(日志输出除外)
1、设置网站的“user_agent”进行爬取,获取当当网的“user_agent”,复制到这里
2、设置——是否符合robots.txt
默认为“True”,即“合规性”。Scrapy启动后,会尽快访问网站的robots.txt文件,然后确定网站的爬取范围。
但是,我们不是作为搜索引擎工作的,在某些情况下,我们想要获取的内容是robots.txt 明确禁止的。因此,在某些时候,我们不得不将此配置项设置为False并拒绝遵守Robot协议!
3、 设置输出日志信息为错误日志信息,输出错误级别为一般级别
#输出日志设为之输出发生错误的日志信息
#输出级别——一般级别
LOG_LEVEL = 'ERROR'
4、设置下载中间件,
5、设置项目管道
当 Item 在 Spider 中被采集到时,它会被传递到 Item Pipeline,这些 Item Pipeline 组件按照定义的顺序处理 Item。以下是Item Pipeline的一些典型应用:
五、修改默认给出的“items.py”
1、Item 对象是一个简单的容器,用于采集捕获的数据。
爬取哪些字段,爬虫解析页面时只能使用定义的字段,所以需要在items.py中定义
2、 Item中只有一种Field,表示传入的任何数据类型都可以接收
3、 下图是默认给的
我们要爬取当当网《微机原理与界面设计》的书名、作者、现价、日期、出版社,所以需要在items.py中定义这些字段,
六、修改默认给出的“pipelines.py”
下图是默认给出的
我们要将抓取到的信息保存到“.xls”中,我们需要重写这个文件
from itemadapter import ItemAdapter
from openpyxl import Workbook
class DangdangPipeline:
def __init__(self):
self.wb = Workbook()
self.ws = self.wb.active
self.ws.append(['书名','作者','现价','日期','出版社'])
def process_item(self, items, spider):
line = [items['book_name'],items['author'],items['price'],items['time'], items['press']]
self.ws.append(line)
self.wb.save('./微机原理与接口设计.xls')
return items
重头戏来了!!!
七、写spider——“cp.py”文件中的主要代码
1、 下图是默认给出的结构,接下来我们需要添加和修改
2、本次培训完整代码
注意理解笔记~
import scrapy
import time
from selenium import webdriver
from dangdang.items import DangdangItem
class CpSpider(scrapy.Spider):
name = 'cp' #指定爬虫文件名称
allowed_domains = ['dangdang.com'] #允许爬取的网站域名
#spider在启动时爬取的url列表,用于定义初始请求
#第一个要爬取的url
start_urls = ['http://search.dangdang.com/?key=%CE%A2%BB%FA%D4%AD%C0%ED%D3%EB%BD%D3%BF%DA%BC%BC%CA%F5&act=input&page_index=1']
page_index = 1 #第一页
offset = 1 #查询字符串参数
def __init__(self): #实例化浏览器对象
#selenium启动配置参数接收是ChromeOptions类
option = webdriver.ChromeOptions() #启动浏览器,最大化
#屏蔽谷歌浏览器正在接受自动化软件控制提示
option.add_experimental_option('excludeSwitches', ['enable-authmation'])
self.bro = webdriver.Chrome(options=option) #初始化
def parse(self, response):
items = DangdangItem()
lists = response.xpath('//*[@id="search_nature_rg"]/ul/li')
#遍历列表
for i in lists:
items['book_name'] = i.xpath('./p[@class="name"]/a/@title')[0].extract()
print('书名',items['book_name'])
author = i.xpath('./p[@class="search_book_author"]/span[1]//text()').extract()
author = ''.join(author).strip()
items['author'] = author
print("作者",items['author'])
items['price'] = i.xpath('./p[@class="price"]/span[1]/text()').get()
print('现价',items['price'])
items['time'] = i.xpath('./p[@class="search_book_author"]/span[2]/text()').get()
print('日期',items['time'])
items['press'] = i.xpath('./p[@class="search_book_author"]/span[3]/a/@title').get()
print('出版社',items['press'])
yield items #回调
time.sleep(5)
#通过parse()方法实现翻页
if self.offset < 6: #只爬取5页
self.offset += 1
self.page_index += 1
url='http://search.dangdang.com/?key=%CE%A2%BB%FA%D4%AD%C0%ED%D3%EB%BD%D3%BF%DA%BC%BC%CA%F5&act=input&page_index={}'
.format(self.offset,self.page_index)
yield scrapy.Request(url=url,callback=self.parse)
#关闭浏览器
def closed(self,spider):
self.bro.close()
3、查看表中存储的内容
运行成功无错误后,你爬取的内容会保存在“微机原理与接口设计.xls”表中
双击打开表格,就是你爬取过的内容!
恭喜完成本次实战!
c爬虫抓取网页数据(抓取智联招聘的招聘信息助你换工作成功(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2021-12-14 21:35
)
对于每个上班族来说,总会有几次工作变动。如何在网上选择自己喜欢的工作?如何提前准备心仪工作的面试?今天我们就来抢夺智联招聘的招聘信息,助您顺利转岗!
操作平台:Windows
Python版本:Python3.6
IDE:崇高的文本
其他工具:Chrome 浏览器
1、Web 分析1.1 分析请求地址
以北京市海淀区python工程师为例进行网页分析。打开智联招聘首页,选择北京地区,在搜索框中输入“python工程师”,点击“搜索职位”:
接下来跳转到搜索结果页面,按“F12”打开开发者工具,然后在“热点区”一栏中选择“海淀”,我们来看看地址栏:
从地址栏searchresult.ashx?jl=Beijing&kw=pythonengineer&sm=0&isfilter=1&p=1&re=2005的后半部分可以看出,我们必须自己构造地址。接下来,我们需要分析开发者工具,按照如图所示的步骤,找到我们需要的数据:Request Headers和Query String Parameters:
构造请求地址:
paras = {
'jl': '北京', # 搜索城市
'kw': 'python工程师', # 搜索关键词
'isadv': 0, # 是否打开更详细搜索选项
'isfilter': 1, # 是否对结果过滤
'p': 1, # 页数
're': 2005 # region的缩写,地区,2005代表海淀
}
url = 'https://sou.zhaopin.com/jobs/searchresult.ashx?' + urlencode(paras)
请求头:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Host': 'sou.zhaopin.com',
'Referer': 'https://www.zhaopin.com/',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
1.2 分析有用的数据
接下来,我们需要分析有用的数据。我们从搜索结果中需要的数据有:职位名称、公司名称、公司详情页地址、职位月薪:
通过定位网页元素,找到这些项目在HTML文件中的位置,如下图所示:
使用正则表达式提取这四项:
# 正则表达式进行解析
pattern = re.compile('<a style=.*? target="_blank">(.*?)</a>.*?' # 匹配职位信息
'(.*?).*?' # 匹配公司网址和公司名称
'(.*?)', re.S) # 匹配月薪
# 匹配所有符合条件的内容
items = re.findall(pattern, html)
注:部分解析出的职位有标注,如下图:
然后解析后,对数据进行处理,去除标签,实现代码如下:
for item in items:
job_name = item[0]
job_name = job_name.replace('', '')
job_name = job_name.replace('', '')
yield {
'job': job_name,
'website': item[1],
'company': item[2],
'salary': item[3]
}
2、写入文件
我们得到的数据,每个位置都有相同的信息项,可以写入数据库,但是本文选择了一个csv文件。以下是百度百科的解释:
逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。纯文本意味着该文件是一个字符序列,不含必须像二进制数字那样被解读的数据。
由于python内置了对csv文件操作的库函数,非常方便:
import csv
def write_csv_headers(path, headers):
'''
写入表头
'''
with open(path, 'a', encoding='gb18030', newline='') as f:
f_csv = csv.DictWriter(f, headers)
f_csv.writeheader()
def write_csv_rows(path, headers, rows):
'''
写入行
'''
with open(path, 'a', encoding='gb18030', newline='') as f:
f_csv = csv.DictWriter(f, headers)
f_csv.writerows(rows)
3、进度显示
如果你想找到理想的工作,你必须筛选更多的职位。那么我们抓取的数据量一定非常大,几十页,几百页,甚至上千页。那么就必须掌握爬取的进度,才能更可靠。啊,所以我们需要添加一个进度条显示功能。
本文选择tqdm显示进度,看看效果很酷(图片来源网络):
执行以下命令安装:pip install tqdm。
简单的例子:
from tqdm import tqdm
from time import sleep
for i in tqdm(range(1000)):
sleep(0.01)
4、完整代码
以上就是对所有函数的分析,完整代码如下:
#-*- coding: utf-8 -*-
import re
import csv
import requests
from tqdm import tqdm
from urllib.parse import urlencode
from requests.exceptions import RequestException
def get_one_page(city, keyword, region, page):
'''
获取网页html内容并返回
'''
paras = {
'jl': city, # 搜索城市
'kw': keyword, # 搜索关键词
'isadv': 0, # 是否打开更详细搜索选项
'isfilter': 1, # 是否对结果过滤
'p': page, # 页数
're': region # region的缩写,地区,2005代表海淀
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Host': 'sou.zhaopin.com',
'Referer': 'https://www.zhaopin.com/',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
url = 'https://sou.zhaopin.com/jobs/searchresult.ashx?' + urlencode(paras)
try:
# 获取网页内容,返回html数据
response = requests.get(url, headers=headers)
# 通过状态码判断是否获取成功
if response.status_code == 200:
return response.text
return None
except RequestException as e:
return None
def parse_one_page(html):
'''
解析HTML代码,提取有用信息并返回
'''
# 正则表达式进行解析
pattern = re.compile('<a style=.*? target="_blank">(.*?)</a>.*?' # 匹配职位信息
'(.*?).*?' # 匹配公司网址和公司名称
'(.*?)', re.S) # 匹配月薪
# 匹配所有符合条件的内容
items = re.findall(pattern, html)
for item in items:
job_name = item[0]
job_name = job_name.replace('', '')
job_name = job_name.replace('', '')
yield {
'job': job_name,
'website': item[1],
'company': item[2],
'salary': item[3]
}
def write_csv_file(path, headers, rows):
'''
将表头和行写入csv文件
'''
# 加入encoding防止中文写入报错
# newline参数防止每写入一行都多一个空行
with open(path, 'a', encoding='gb18030', newline='') as f:
f_csv = csv.DictWriter(f, headers)
f_csv.writeheader()
f_csv.writerows(rows)
def write_csv_headers(path, headers):
'''
写入表头
'''
with open(path, 'a', encoding='gb18030', newline='') as f:
f_csv = csv.DictWriter(f, headers)
f_csv.writeheader()
def write_csv_rows(path, headers, rows):
'''
写入行
'''
with open(path, 'a', encoding='gb18030', newline='') as f:
f_csv = csv.DictWriter(f, headers)
f_csv.writerows(rows)
def main(city, keyword, region, pages):
'''
主函数
'''
filename = 'zl_' + city + '_' + keyword + '.csv'
headers = ['job', 'website', 'company', 'salary']
write_csv_headers(filename, headers)
for i in tqdm(range(pages)):
'''
获取该页中所有职位信息,写入csv文件
'''
jobs = []
html = get_one_page(city, keyword, region, i)
items = parse_one_page(html)
for item in items:
jobs.append(item)
write_csv_rows(filename, headers, jobs)
if __name__ == '__main__':
main('北京', 'python工程师', 2005, 10)
以上代码的执行效果如图:
执行完成后会在同级py文件夹中生成一个名为:zl_Beijing_pythonengineer.csv的文件,打开后效果如下:
这个例子的功能比较简单。它只捕获数据,不分析数据。下次我会捕捉更多信息,分析薪资、岗位技能要求等各种数据,敬请期待!
欢迎关注公众号:
查看全部
c爬虫抓取网页数据(抓取智联招聘的招聘信息助你换工作成功(组图)
)
对于每个上班族来说,总会有几次工作变动。如何在网上选择自己喜欢的工作?如何提前准备心仪工作的面试?今天我们就来抢夺智联招聘的招聘信息,助您顺利转岗!
操作平台:Windows
Python版本:Python3.6
IDE:崇高的文本
其他工具:Chrome 浏览器
1、Web 分析1.1 分析请求地址
以北京市海淀区python工程师为例进行网页分析。打开智联招聘首页,选择北京地区,在搜索框中输入“python工程师”,点击“搜索职位”:
接下来跳转到搜索结果页面,按“F12”打开开发者工具,然后在“热点区”一栏中选择“海淀”,我们来看看地址栏:
从地址栏searchresult.ashx?jl=Beijing&kw=pythonengineer&sm=0&isfilter=1&p=1&re=2005的后半部分可以看出,我们必须自己构造地址。接下来,我们需要分析开发者工具,按照如图所示的步骤,找到我们需要的数据:Request Headers和Query String Parameters:
构造请求地址:
paras = {
'jl': '北京', # 搜索城市
'kw': 'python工程师', # 搜索关键词
'isadv': 0, # 是否打开更详细搜索选项
'isfilter': 1, # 是否对结果过滤
'p': 1, # 页数
're': 2005 # region的缩写,地区,2005代表海淀
}
url = 'https://sou.zhaopin.com/jobs/searchresult.ashx?' + urlencode(paras)
请求头:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Host': 'sou.zhaopin.com',
'Referer': 'https://www.zhaopin.com/',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
1.2 分析有用的数据
接下来,我们需要分析有用的数据。我们从搜索结果中需要的数据有:职位名称、公司名称、公司详情页地址、职位月薪:
通过定位网页元素,找到这些项目在HTML文件中的位置,如下图所示:
使用正则表达式提取这四项:
# 正则表达式进行解析
pattern = re.compile('<a style=.*? target="_blank">(.*?)</a>.*?' # 匹配职位信息
'(.*?).*?' # 匹配公司网址和公司名称
'(.*?)', re.S) # 匹配月薪
# 匹配所有符合条件的内容
items = re.findall(pattern, html)
注:部分解析出的职位有标注,如下图:
然后解析后,对数据进行处理,去除标签,实现代码如下:
for item in items:
job_name = item[0]
job_name = job_name.replace('', '')
job_name = job_name.replace('', '')
yield {
'job': job_name,
'website': item[1],
'company': item[2],
'salary': item[3]
}
2、写入文件
我们得到的数据,每个位置都有相同的信息项,可以写入数据库,但是本文选择了一个csv文件。以下是百度百科的解释:
逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。纯文本意味着该文件是一个字符序列,不含必须像二进制数字那样被解读的数据。
由于python内置了对csv文件操作的库函数,非常方便:
import csv
def write_csv_headers(path, headers):
'''
写入表头
'''
with open(path, 'a', encoding='gb18030', newline='') as f:
f_csv = csv.DictWriter(f, headers)
f_csv.writeheader()
def write_csv_rows(path, headers, rows):
'''
写入行
'''
with open(path, 'a', encoding='gb18030', newline='') as f:
f_csv = csv.DictWriter(f, headers)
f_csv.writerows(rows)
3、进度显示
如果你想找到理想的工作,你必须筛选更多的职位。那么我们抓取的数据量一定非常大,几十页,几百页,甚至上千页。那么就必须掌握爬取的进度,才能更可靠。啊,所以我们需要添加一个进度条显示功能。
本文选择tqdm显示进度,看看效果很酷(图片来源网络):
执行以下命令安装:pip install tqdm。
简单的例子:
from tqdm import tqdm
from time import sleep
for i in tqdm(range(1000)):
sleep(0.01)
4、完整代码
以上就是对所有函数的分析,完整代码如下:
#-*- coding: utf-8 -*-
import re
import csv
import requests
from tqdm import tqdm
from urllib.parse import urlencode
from requests.exceptions import RequestException
def get_one_page(city, keyword, region, page):
'''
获取网页html内容并返回
'''
paras = {
'jl': city, # 搜索城市
'kw': keyword, # 搜索关键词
'isadv': 0, # 是否打开更详细搜索选项
'isfilter': 1, # 是否对结果过滤
'p': page, # 页数
're': region # region的缩写,地区,2005代表海淀
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Host': 'sou.zhaopin.com',
'Referer': 'https://www.zhaopin.com/',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
url = 'https://sou.zhaopin.com/jobs/searchresult.ashx?' + urlencode(paras)
try:
# 获取网页内容,返回html数据
response = requests.get(url, headers=headers)
# 通过状态码判断是否获取成功
if response.status_code == 200:
return response.text
return None
except RequestException as e:
return None
def parse_one_page(html):
'''
解析HTML代码,提取有用信息并返回
'''
# 正则表达式进行解析
pattern = re.compile('<a style=.*? target="_blank">(.*?)</a>.*?' # 匹配职位信息
'(.*?).*?' # 匹配公司网址和公司名称
'(.*?)', re.S) # 匹配月薪
# 匹配所有符合条件的内容
items = re.findall(pattern, html)
for item in items:
job_name = item[0]
job_name = job_name.replace('', '')
job_name = job_name.replace('', '')
yield {
'job': job_name,
'website': item[1],
'company': item[2],
'salary': item[3]
}
def write_csv_file(path, headers, rows):
'''
将表头和行写入csv文件
'''
# 加入encoding防止中文写入报错
# newline参数防止每写入一行都多一个空行
with open(path, 'a', encoding='gb18030', newline='') as f:
f_csv = csv.DictWriter(f, headers)
f_csv.writeheader()
f_csv.writerows(rows)
def write_csv_headers(path, headers):
'''
写入表头
'''
with open(path, 'a', encoding='gb18030', newline='') as f:
f_csv = csv.DictWriter(f, headers)
f_csv.writeheader()
def write_csv_rows(path, headers, rows):
'''
写入行
'''
with open(path, 'a', encoding='gb18030', newline='') as f:
f_csv = csv.DictWriter(f, headers)
f_csv.writerows(rows)
def main(city, keyword, region, pages):
'''
主函数
'''
filename = 'zl_' + city + '_' + keyword + '.csv'
headers = ['job', 'website', 'company', 'salary']
write_csv_headers(filename, headers)
for i in tqdm(range(pages)):
'''
获取该页中所有职位信息,写入csv文件
'''
jobs = []
html = get_one_page(city, keyword, region, i)
items = parse_one_page(html)
for item in items:
jobs.append(item)
write_csv_rows(filename, headers, jobs)
if __name__ == '__main__':
main('北京', 'python工程师', 2005, 10)
以上代码的执行效果如图:
执行完成后会在同级py文件夹中生成一个名为:zl_Beijing_pythonengineer.csv的文件,打开后效果如下:
这个例子的功能比较简单。它只捕获数据,不分析数据。下次我会捕捉更多信息,分析薪资、岗位技能要求等各种数据,敬请期待!
欢迎关注公众号:
c爬虫抓取网页数据(Scraoy入门实例一--Scrapy介绍与安装ampamp的安装)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-11 05:15
Scraoy入门实例一---Scrapy介绍与安装&PyCharm安装&项目实战
一、Scrapy 安装
1.Scrapy 介绍
Scrapy 是一个应用框架,用于抓取 网站 数据并提取结构化数据。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中。它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
2.Scrapy 安装
推荐使用Anaconda安装Scrapy
Anaconda 是一个开源包和环境管理工件。Anaconda 收录 180 多个科学包及其依赖项,包括 conda 和 Python。从官网下载安装Anaconda(个人版),根据自己的系统选择下载安装,选择next继续安装,Install for选项选择Just for me。选择安装位置后,等待安装完成。
安装完成后,打开命令行,输入conda install scrapy,根据提示按Y,就会下载Scrapy及其依赖的所有包,从而完成安装。
注意:使用命令行安装scrapy包时,会出现下载超时问题,即下载失败。我们可以修改它的镜像文件来提高scrapy包的下载速度。可以参考博客:
这时测试Scrapy是否安装成功:在命令行窗口输入scrapy,回车。如果出现如下界面,则说明安装成功:
二、PyCharm 安装
1.PyCharm 介绍
PyCharm 是一个 PythonIDE,带有一组工具,可以帮助用户在使用 Python 语言进行开发时提高效率,例如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试和版本控制。此外,IDE 提供了一些高级功能,以支持 Django 框架下的专业 Web 开发。
2.PyCharm 安装
进入PyCharm官网,点击DownLoad下载,左边专业版,右边社区版,社区版免费,专业版免费试用。
如果之前没有下载过Python解释器,可以在等待安装的同时下载Python解释器,进入Python官网,根据系统和版本下载对应的压缩包。安装完成后,在环境变量Path中配置Python解释器的安装路径。可以参考博客:
三、Scrapy抓取豆瓣项目实战
前提条件:如果要在PyCharm中使用Scrapy,必须先在PyCharm中安装支持的Scrapy包。流程如下,点击File>>Settings...,步骤如下图,我安装Scrapy之前的绿框只有两个Package。如果点击后看到一个Scrapy包,则无需安装,直接进行下一步操作即可。
如果没有Scrapy包,点击“+”,搜索Scrapy包,点击Install Package进行安装
等待安装完成。
1.新项目
打开新安装的PyCharm,在软件终端使用pycharm工具。如果找不到 PyCharm 终端,则是左下角底部的终端。
输入命令:scrapy startproject douban 这是使用命令行新建一个爬虫项目,如下图,图中项目名称为pythonProject
然后在命令行输入命令:cd douban进入生成项目的根目录
然后在终端继续输入命令:scrapy genspider douban_spider,生成douban_spider爬虫文件。
此时的项目结构如下图所示:
2.明确的目标
我们要练习的网站是:
假设,我们抓取top250电影的序列号、电影名称、介绍、星级、评分数量、电影描述选项
此时,我们在items.py文件中定义捕获的数据项,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.接下来需要制作爬虫并存储爬取的内容
在douban_spider.py爬虫文件中编写具体逻辑代码,如下:
# -*- coding: utf-8 -*-
import scrapy
from ..items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider'
# 允许的域名
allowed_domains = ['movie.douban.com']
# 入口URL
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//div[@class='hd']/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
douban_item['describe'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class='next']/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
这个时候不需要运行这个python文件,因为我们不是单独使用的,所以不需要运行,并且允许报错,与import相关的问题,绝对的问题主目录的路径和相对路径。原因是我们使用了相对路径。“..Items”,对相关内容感兴趣的同学可以上网查找对此类问题的解释。
4.存储内容
将抓取到的内容存入json或csv格式的文件中
在命令行输入:scrapy crawl douban_spider -o test.json 或者scrapy crawl douban_spider -o test.csv
将抓取到的数据存储在一个json文件或者一个csv文件中。
执行crawl命令后,当鼠标焦点放在项目面板上时,会显示生成的json文件或csv文件。打开json或者csv文件后,如果里面什么都没有,那么我们需要进一步修改,修改代理USER_AGENT的内容,
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.8 Safari/537.36'
如果存储在一个json文件中,所有的内容都会以16进制的形式显示,可以通过相应的方法进行转码。这里就不多解释了,如下图所示:
并且保存在csv文件中,会直接显示我们要抓取的所有内容,如下图:
至此,我们就完成了对网站具体内容的抓取。接下来,我们需要处理爬取的数据。
分割线------------------------------------------------ -------------------------------------------------- --------------------分割线
Scraoy 介绍示例二——使用Pipeline来实现
在这次实战中,需要重新创建一个项目,或者需要安装scrapy包。参考以上内容。创建新项目的方法也参考上述内容,这里不再赘述。
项目目录结构如下图所示:
一、管道介绍
当我们通过Spider爬取数据,通过Item采集数据时,需要对数据进行处理,因为我们爬取的数据不一定是我们想要的最终数据,可能还需要进行数据清洗和校验。数据的有效性。Scripy 中的 Pipeline 组件用于数据处理。Pipeline 组件是一个收录特定接口的类。它通常只负责一个功能的数据处理。可以在一个项目中同时启用多个管道。
二、在items.py中定义要捕获的数据
首先打开一个新的pycharm项目,通过终端新建一个项目教程,在item中定义要抓取的数据,比如电影的名字,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、定义pipeline.py文件
每个item管道组件都是一个独立的pyhton类,必须通过process_item(self, item, spider)方法实现。每个item管道组件都需要调用这个方法。该方法必须返回一个带有数据的dict,或者一个item对象,或者抛出一个DropItem异常,丢弃的item不会被后续的管道组件处理。定义的 pipelines.py 代码如下:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/lat ... .html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class TutorialPipeline(object):
def process_item(self, item, spider):
return item
import time
class DoubanmoviePipeline(object):
def process_item(self, item, spider):
now = time.strftime('%Y-%m-%d', time.localtime())
fileName = 'douban' + now + '.txt'
with open(fileName, 'a', encoding='utf-8') as fp:
fp.write(item['moiveName'][0]+"\n")
return item
四、配置setting.py
由于这次用到了管道,我们需要在settings.py中打开管道通道注释,在管道中添加一条新的记录,如下图所示:
五、写爬虫文件
在tutorial/spiders目录下创建quotes_spider.py文件,目录结构如下,编写初步代码:
quotes_spider.py 的代码如下:
import scrapy
from items import DoubanmovieItem
class QuotesSpider(scrapy.Spider):
name = "doubanSpider"
allowed_domains = ['douban.com']
start_urls = ['http://movie.douban.com/cinema/nowplaying',
'http://movie.douban.com/cinema/nowplaying/beijing/']
def parse(self, response):
print("--" * 20 )
#print(response.body)
print("==" * 20 )
subSelector = response.xpath('//li[@class="stitle"]')
items = []
for sub in subSelector:
#print(sub.xpath('normalize-space(./a/text())').extract())
print(sub)
item = DoubanmovieItem()
item['moiveName'] = sub.xpath('normalize-space(./a/text())').extract()
items.append(item)
print(items)
return items
六、通过启动文件运行
在豆瓣文件目录下新建一个启动文件douban_spider_run.py(文件名可取),运行该文件查看结果,编写代码如下:
from scrapy import cmdline
cmdline.execute("scrapy crawl doubanSpider".split())
最后,处理后的爬取数据如下图(部分):
最后,希望大家在写代码的时候能更加细心,不要马虎。在我的实验过程中,是因为要引入的方法DoubanmovieItem写成DobanmovieItem,导致整个程序失败,PyCharm没有告诉我在哪里。我错了。我到处搜索,但找不到解决问题的方法。最后查了很多次,才发现方法是什么时候生成的,所以一定要小心。这个错误如下图所示。它说找不到模块 DobanmovieItem。它可能已经告诉我错误的地方,因为我太傻了没有找到,所以花了很长时间。希望大家多多指教!
至此,使用Scrapy对网页内容进行爬取,并对爬取的内容进行清洗和处理的实验已经完成。要求熟悉和使用这个过程中的代码和操作,不会在网上找内容消化。吸收,记在心里,这才是真正的知识学习,而不是画葫芦。 查看全部
c爬虫抓取网页数据(Scraoy入门实例一--Scrapy介绍与安装ampamp的安装)
Scraoy入门实例一---Scrapy介绍与安装&PyCharm安装&项目实战
一、Scrapy 安装
1.Scrapy 介绍
Scrapy 是一个应用框架,用于抓取 网站 数据并提取结构化数据。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中。它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
2.Scrapy 安装
推荐使用Anaconda安装Scrapy
Anaconda 是一个开源包和环境管理工件。Anaconda 收录 180 多个科学包及其依赖项,包括 conda 和 Python。从官网下载安装Anaconda(个人版),根据自己的系统选择下载安装,选择next继续安装,Install for选项选择Just for me。选择安装位置后,等待安装完成。
安装完成后,打开命令行,输入conda install scrapy,根据提示按Y,就会下载Scrapy及其依赖的所有包,从而完成安装。
注意:使用命令行安装scrapy包时,会出现下载超时问题,即下载失败。我们可以修改它的镜像文件来提高scrapy包的下载速度。可以参考博客:
这时测试Scrapy是否安装成功:在命令行窗口输入scrapy,回车。如果出现如下界面,则说明安装成功:
二、PyCharm 安装
1.PyCharm 介绍
PyCharm 是一个 PythonIDE,带有一组工具,可以帮助用户在使用 Python 语言进行开发时提高效率,例如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试和版本控制。此外,IDE 提供了一些高级功能,以支持 Django 框架下的专业 Web 开发。
2.PyCharm 安装
进入PyCharm官网,点击DownLoad下载,左边专业版,右边社区版,社区版免费,专业版免费试用。
如果之前没有下载过Python解释器,可以在等待安装的同时下载Python解释器,进入Python官网,根据系统和版本下载对应的压缩包。安装完成后,在环境变量Path中配置Python解释器的安装路径。可以参考博客:
三、Scrapy抓取豆瓣项目实战
前提条件:如果要在PyCharm中使用Scrapy,必须先在PyCharm中安装支持的Scrapy包。流程如下,点击File>>Settings...,步骤如下图,我安装Scrapy之前的绿框只有两个Package。如果点击后看到一个Scrapy包,则无需安装,直接进行下一步操作即可。
如果没有Scrapy包,点击“+”,搜索Scrapy包,点击Install Package进行安装
等待安装完成。
1.新项目
打开新安装的PyCharm,在软件终端使用pycharm工具。如果找不到 PyCharm 终端,则是左下角底部的终端。
输入命令:scrapy startproject douban 这是使用命令行新建一个爬虫项目,如下图,图中项目名称为pythonProject
然后在命令行输入命令:cd douban进入生成项目的根目录
然后在终端继续输入命令:scrapy genspider douban_spider,生成douban_spider爬虫文件。
此时的项目结构如下图所示:
2.明确的目标
我们要练习的网站是:
假设,我们抓取top250电影的序列号、电影名称、介绍、星级、评分数量、电影描述选项
此时,我们在items.py文件中定义捕获的数据项,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.接下来需要制作爬虫并存储爬取的内容
在douban_spider.py爬虫文件中编写具体逻辑代码,如下:
# -*- coding: utf-8 -*-
import scrapy
from ..items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider'
# 允许的域名
allowed_domains = ['movie.douban.com']
# 入口URL
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//div[@class='hd']/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
douban_item['describe'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class='next']/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
这个时候不需要运行这个python文件,因为我们不是单独使用的,所以不需要运行,并且允许报错,与import相关的问题,绝对的问题主目录的路径和相对路径。原因是我们使用了相对路径。“..Items”,对相关内容感兴趣的同学可以上网查找对此类问题的解释。
4.存储内容
将抓取到的内容存入json或csv格式的文件中
在命令行输入:scrapy crawl douban_spider -o test.json 或者scrapy crawl douban_spider -o test.csv
将抓取到的数据存储在一个json文件或者一个csv文件中。
执行crawl命令后,当鼠标焦点放在项目面板上时,会显示生成的json文件或csv文件。打开json或者csv文件后,如果里面什么都没有,那么我们需要进一步修改,修改代理USER_AGENT的内容,
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.8 Safari/537.36'
如果存储在一个json文件中,所有的内容都会以16进制的形式显示,可以通过相应的方法进行转码。这里就不多解释了,如下图所示:
并且保存在csv文件中,会直接显示我们要抓取的所有内容,如下图:
至此,我们就完成了对网站具体内容的抓取。接下来,我们需要处理爬取的数据。
分割线------------------------------------------------ -------------------------------------------------- --------------------分割线
Scraoy 介绍示例二——使用Pipeline来实现
在这次实战中,需要重新创建一个项目,或者需要安装scrapy包。参考以上内容。创建新项目的方法也参考上述内容,这里不再赘述。
项目目录结构如下图所示:
一、管道介绍
当我们通过Spider爬取数据,通过Item采集数据时,需要对数据进行处理,因为我们爬取的数据不一定是我们想要的最终数据,可能还需要进行数据清洗和校验。数据的有效性。Scripy 中的 Pipeline 组件用于数据处理。Pipeline 组件是一个收录特定接口的类。它通常只负责一个功能的数据处理。可以在一个项目中同时启用多个管道。
二、在items.py中定义要捕获的数据
首先打开一个新的pycharm项目,通过终端新建一个项目教程,在item中定义要抓取的数据,比如电影的名字,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、定义pipeline.py文件
每个item管道组件都是一个独立的pyhton类,必须通过process_item(self, item, spider)方法实现。每个item管道组件都需要调用这个方法。该方法必须返回一个带有数据的dict,或者一个item对象,或者抛出一个DropItem异常,丢弃的item不会被后续的管道组件处理。定义的 pipelines.py 代码如下:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/lat ... .html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class TutorialPipeline(object):
def process_item(self, item, spider):
return item
import time
class DoubanmoviePipeline(object):
def process_item(self, item, spider):
now = time.strftime('%Y-%m-%d', time.localtime())
fileName = 'douban' + now + '.txt'
with open(fileName, 'a', encoding='utf-8') as fp:
fp.write(item['moiveName'][0]+"\n")
return item
四、配置setting.py
由于这次用到了管道,我们需要在settings.py中打开管道通道注释,在管道中添加一条新的记录,如下图所示:
五、写爬虫文件
在tutorial/spiders目录下创建quotes_spider.py文件,目录结构如下,编写初步代码:
quotes_spider.py 的代码如下:
import scrapy
from items import DoubanmovieItem
class QuotesSpider(scrapy.Spider):
name = "doubanSpider"
allowed_domains = ['douban.com']
start_urls = ['http://movie.douban.com/cinema/nowplaying',
'http://movie.douban.com/cinema/nowplaying/beijing/']
def parse(self, response):
print("--" * 20 )
#print(response.body)
print("==" * 20 )
subSelector = response.xpath('//li[@class="stitle"]')
items = []
for sub in subSelector:
#print(sub.xpath('normalize-space(./a/text())').extract())
print(sub)
item = DoubanmovieItem()
item['moiveName'] = sub.xpath('normalize-space(./a/text())').extract()
items.append(item)
print(items)
return items
六、通过启动文件运行
在豆瓣文件目录下新建一个启动文件douban_spider_run.py(文件名可取),运行该文件查看结果,编写代码如下:
from scrapy import cmdline
cmdline.execute("scrapy crawl doubanSpider".split())
最后,处理后的爬取数据如下图(部分):
最后,希望大家在写代码的时候能更加细心,不要马虎。在我的实验过程中,是因为要引入的方法DoubanmovieItem写成DobanmovieItem,导致整个程序失败,PyCharm没有告诉我在哪里。我错了。我到处搜索,但找不到解决问题的方法。最后查了很多次,才发现方法是什么时候生成的,所以一定要小心。这个错误如下图所示。它说找不到模块 DobanmovieItem。它可能已经告诉我错误的地方,因为我太傻了没有找到,所以花了很长时间。希望大家多多指教!
至此,使用Scrapy对网页内容进行爬取,并对爬取的内容进行清洗和处理的实验已经完成。要求熟悉和使用这个过程中的代码和操作,不会在网上找内容消化。吸收,记在心里,这才是真正的知识学习,而不是画葫芦。
c爬虫抓取网页数据(Python开发的一个快速,高层次处理网络通讯的整体架构大致)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-11 03:08
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体结构大致如下(注:图片来自网络):
Scrapy主要包括以下组件:
使用Scrapy可以轻松完成在线数据采集的工作,它已经为我们完成了很多工作,无需自己开发。
1. 安装python
目前最新的Scrapy版本是0.22.2。这个版本需要python 2.7,所以需要先安装python 2.7。这里我使用centos服务器进行测试,因为系统自带python,需要先查看python版本。
检查python版本:
$ python -V
Python 2.6.6
升级版本到2.7:
$ Python 2.7.6: $ wget http://python.org/ftp/python/2 ... ar.xz $ tar xf Python-2.7.6.tar.xz $ cd Python-2.7.6 $ ./configure --prefix=/usr/local --enable-unicode=ucs4 --enable-shared LDFLAGS="-Wl,-rpath /usr/local/lib" $ make && make altinstall
建立软连接并使系统默认python指向python2.7
$ mv /usr/bin/python /usr/bin/python2.6.6
$ ln -s /usr/local/bin/python2.7 /usr/bin/python
再次检查python版本:
$ python -V
Python 2.7.6
安装
这里我们使用 wget 来安装 setuptools:
$ wget https://bootstrap.pypa.io/ez_setup.py -O - | python
安装 zope.interface
$ easy_install zope.interface
安装扭曲
Scrapy使用Twisted异步网络库来处理网络通信,所以需要安装twisted。
在安装twisted之前,需要先安装gcc:
$ yum install gcc -y
然后,通过easy_install安装twisted:
$ easy_install twisted
如果出现以下错误:
$ easy_install twisted
Searching for twisted
Reading https://pypi.python.org/simple/twisted/
Best match: Twisted 14.0.0 Downloading https://pypi.python.org/packag ... c9815 Processing Twisted-14.0.0.tar.bz2 Writing /tmp/easy_install-kYHKjn/Twisted-14.0.0/setup.cfg Running Twisted-14.0.0/setup.py -q bdist_egg --dist-dir /tmp/easy_install-kYHKjn/Twisted-14.0.0/egg-dist-tmp-vu1n6Y twisted/runner/portmap.c:10:20: error: Python.h: No such file or directory twisted/runner/portmap.c:14: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘*’ token twisted/runner/portmap.c:31: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘*’ token twisted/runner/portmap.c:45: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘PortmapMethods’ twisted/runner/portmap.c: In function ‘initportmap’: twisted/runner/portmap.c:55: warning: implicit declaration of function ‘Py_InitModule’ twisted/runner/portmap.c:55: error: ‘PortmapMethods’ undeclared (first use in this function) twisted/runner/portmap.c:55: error: (Each undeclared identifier is reported only once twisted/runner/portmap.c:55: error: for each function it appears in.)
请安装 python-devel 并再次运行:
$ yum install python-devel -y
$ easy_install twisted
如果出现以下异常:
error: Not a recognized archive type: /tmp/easy_install-tVwC5O/Twisted-14.0.0.tar.bz2
请手动下载安装,下载地址在这里
$ wget https://pypi.python.org/packag ... c9815 $ tar -vxjf Twisted-14.0.0.tar.bz2 $ cd Twisted-14.0.0 $ python setup.py install
安装 pyOpenSSL
先安装一些依赖:
$ yum install libffi libffi-devel openssl-devel -y
然后,通过easy_install安装pyOpenSSL:
$ easy_install pyOpenSSL
安装 Scrapy
先安装一些依赖:
$ yum install libxml2 libxslt libxslt-devel -y
最后,安装 Scrapy:
$ easy_install scrapy
2. 使用 Scrapy
安装成功后,可以了解Scrapy的一些基本概念和用法,学习Scrapy项目dirbot的例子。
Dirbot 项目所在地。该项目收录一个 README 文件,详细描述了该项目的内容。如果您熟悉 Git,可以查看其源代码。或者,您可以通过单击下载以 tarball 或 zip 格式下载文件。
这里以一个例子来说明如何使用Scrapy创建爬虫项目。
新建筑
在爬取之前,您需要创建一个新的 Scrapy 项目。输入要保存代码的目录,然后执行:
$ scrapy startproject tutorial
该命令会在当前目录下新建一个目录tutorial,其结构如下:
.
├── scrapy.cfg
└── tutorial
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
这些文件主要是:
定义项目
Items 是将加载捕获数据的容器。它的工作原理类似于 Python 中的字典,但它提供了更多保护,例如填充未定义的字段以防止拼写错误。
它是通过创建一个scrapy.item.Item 类并将其属性定义为scrpy.item.Field 对象来声明的,就像一个对象关系映射(ORM)。
我们控制通过建模所需项目获得的站点数据。例如,我们要获取站点的名称、url 和 网站 描述。我们定义了这三个属性的域。为此,我们编辑教程目录中的 items.py 文件,我们的 Item 类将如下所示
from scrapy.item import Item, Field
class DmozItem(Item): title = Field() link = Field() desc = Field()
一开始可能看起来有点混乱,但是定义这些项目会让您在使用其他 Scrapy 组件时知道您的项目是什么。
写蜘蛛
Spider 是一个用户编写的类,用于从域(或域组)中获取信息。我们定义了用于下载的 URL 的初步列表、如何跟踪链接以及如何解析这些网页的内容以提取项目。
要创建 Spider,您可以为 scrapy.spider.BaseSpider 创建一个子类并确定三个主要的强制性属性:
该方法负责解析返回的数据,匹配捕获的数据(解析为item),跟踪更多的URL。
在tutorial/spiders目录下创建DmozSpider.py
from scrapy.spider import BaseSpider
class DmozSpider(BaseSpider): name = "dmoz" allowed_domains = ["dmoz.org"] start_urls = [ "http://www.dmoz.org/Computers/ ... ot%3B, "http://www.dmoz.org/Computers/ ... ot%3B ] def parse(self, response): filename = response.url.split("/")[-2] open(filename, 'wb').write(response.body)
运行项目
$ scrapy crawl dmoz
该命令从域启动爬虫,第三个参数是DmozSpider.py中name属性的值。
xpath 选择器
Scrapy 使用一种称为 XPath 选择器的机制,该机制基于 XPath 表达式。如果您想了解有关选择器和其他机制的更多信息,可以查看。
以下是 XPath 表达式及其含义的一些示例:
这些只是使用 XPath 的几个简单示例,但实际上 XPath 非常强大。如果您想了解更多关于 XPATH 的知识,我们向您推荐这个 XPath 教程
为了方便XPaths的使用,Scrapy提供了Selector类,共有三种方法
提取数据
我们可以使用以下命令选择 网站 中的每个元素:
sel.xpath('//ul/li')
然后网站描述:
sel.xpath('//ul/li/text()').extract()
网站标题:
sel.xpath('//ul/li/a/text()').extract()
网站 链接:
sel.xpath('//ul/li/a/@href').extract()
如前所述,每个 xpath() 调用都会返回一个选择器列表,因此我们可以结合 xpath() 来挖掘更深的节点。我们将使用这些功能,因此:
sites = sel.xpath('//ul/li')
for site in sites:
title = site.xpath('a/text()').extract()
link = site.xpath('a/@href').extract() desc = site.xpath('text()').extract() print title, link, desc
使用物品
scrapy.item.Item的调用接口类似于python的dict,Item收录多个scrapy.item.Field。这类似于 django 的模型和
Item通常用在Spider的parse方法中,用于保存解析后的数据。
最后修改爬虫类,使用Item保存数据,代码如下:
from scrapy.spider import Spider
from scrapy.selector import Selector from dirbot.items import Website class DmozSpider(Spider): name = "dmoz" allowed_domains = ["dmoz.org"] start_urls = [ "http://www.dmoz.org/Computers/ ... ot%3B, "http://www.dmoz.org/Computers/ ... ot%3B, ] def parse(self, response): """ The lines below is a spider contract. For more info see: http://doc.scrapy.org/en/lates ... .html @url http://www.dmoz.org/Computers/ ... rces/ @scrapes name """ sel = Selector(response) sites = sel.xpath('//ul[@class="directory-url"]/li') items = [] for site in sites: item = Website() item['name'] = site.xpath('a/text()').extract() item['url'] = site.xpath('a/@href').extract() item['description'] = site.xpath('text()').re('-\s([^\n]*?)\\n') items.append(item) return items
现在,您可以再次运行该项目以查看结果:
$ scrapy crawl dmoz
使用项目管道
在settings.py中设置ITEM_PIPELINES,默认为[],类似django的MIDDLEWARE_CLASSES等。
Spider的解析返回的Item数据会依次被ITEM_PIPELINES列表中的Pipeline类处理。
Item Pipeline 类必须实现以下方法:
可以另外实现以下两种方法:
保存捕获的数据
保存信息最简单的方法是通过,命令如下:
$ scrapy crawl dmoz -o items.json -t json
除了 json 格式,还支持 JSON 行、CSV 和 XML 格式。您还可以通过接口扩展一些格式。
这种方法对于小项目来说已经足够了。如果是比较复杂的数据,可能需要写一个Item Pipeline进行处理。
所有抓到的物品都会以JSON格式保存在新生成的items.json文件中
总结
以上介绍了如何创建爬虫项目的过程,可以参考以上过程再次联系。作为学习示例,也可以参考这个文章:scrapy中文教程(爬取cnbeta示例)。
这个文章中的爬虫代码如下:
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor from scrapy.selector import Selector from cnbeta.items import CnbetaItem class CBSpider(CrawlSpider): name = 'cnbeta' allowed_domains = ['cnbeta.com'] start_urls = ['http://www.cnbeta.com'] rules = ( Rule(SgmlLinkExtractor(allow=('/articles/.*\.htm', )), callback='parse_page', follow=True), ) def parse_page(self, response): item = CnbetaItem() sel = Selector(response) item['title'] = sel.xpath('//title/text()').extract() item['url'] = response.url return item
需要注意的是:
3. 学习资料
联系Scrapy是因为想爬取知乎的一些数据。一开始找了一些相关的资料和其他人的实现方法。
Github上有人或多或少意识到了知乎数据的爬取。我搜索了以下仓库:
其他信息:
抓取和交互式示例:
有一些知识点需要梳理:
4. 总结
以上是这几天学习Scrapy的笔记和知识汇总。参考网上的一些文章,写了这篇文章。谢谢你,希望这篇文章文章 能对你有所帮助。如果您有任何想法,请留言;如果你喜欢这篇文章,请帮忙分享一下,谢谢!
最初发表于: 查看全部
c爬虫抓取网页数据(Python开发的一个快速,高层次处理网络通讯的整体架构大致)
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体结构大致如下(注:图片来自网络):
Scrapy主要包括以下组件:
使用Scrapy可以轻松完成在线数据采集的工作,它已经为我们完成了很多工作,无需自己开发。
1. 安装python
目前最新的Scrapy版本是0.22.2。这个版本需要python 2.7,所以需要先安装python 2.7。这里我使用centos服务器进行测试,因为系统自带python,需要先查看python版本。
检查python版本:
$ python -V
Python 2.6.6
升级版本到2.7:
$ Python 2.7.6: $ wget http://python.org/ftp/python/2 ... ar.xz $ tar xf Python-2.7.6.tar.xz $ cd Python-2.7.6 $ ./configure --prefix=/usr/local --enable-unicode=ucs4 --enable-shared LDFLAGS="-Wl,-rpath /usr/local/lib" $ make && make altinstall
建立软连接并使系统默认python指向python2.7
$ mv /usr/bin/python /usr/bin/python2.6.6
$ ln -s /usr/local/bin/python2.7 /usr/bin/python
再次检查python版本:
$ python -V
Python 2.7.6
安装
这里我们使用 wget 来安装 setuptools:
$ wget https://bootstrap.pypa.io/ez_setup.py -O - | python
安装 zope.interface
$ easy_install zope.interface
安装扭曲
Scrapy使用Twisted异步网络库来处理网络通信,所以需要安装twisted。
在安装twisted之前,需要先安装gcc:
$ yum install gcc -y
然后,通过easy_install安装twisted:
$ easy_install twisted
如果出现以下错误:
$ easy_install twisted
Searching for twisted
Reading https://pypi.python.org/simple/twisted/
Best match: Twisted 14.0.0 Downloading https://pypi.python.org/packag ... c9815 Processing Twisted-14.0.0.tar.bz2 Writing /tmp/easy_install-kYHKjn/Twisted-14.0.0/setup.cfg Running Twisted-14.0.0/setup.py -q bdist_egg --dist-dir /tmp/easy_install-kYHKjn/Twisted-14.0.0/egg-dist-tmp-vu1n6Y twisted/runner/portmap.c:10:20: error: Python.h: No such file or directory twisted/runner/portmap.c:14: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘*’ token twisted/runner/portmap.c:31: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘*’ token twisted/runner/portmap.c:45: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘PortmapMethods’ twisted/runner/portmap.c: In function ‘initportmap’: twisted/runner/portmap.c:55: warning: implicit declaration of function ‘Py_InitModule’ twisted/runner/portmap.c:55: error: ‘PortmapMethods’ undeclared (first use in this function) twisted/runner/portmap.c:55: error: (Each undeclared identifier is reported only once twisted/runner/portmap.c:55: error: for each function it appears in.)
请安装 python-devel 并再次运行:
$ yum install python-devel -y
$ easy_install twisted
如果出现以下异常:
error: Not a recognized archive type: /tmp/easy_install-tVwC5O/Twisted-14.0.0.tar.bz2
请手动下载安装,下载地址在这里
$ wget https://pypi.python.org/packag ... c9815 $ tar -vxjf Twisted-14.0.0.tar.bz2 $ cd Twisted-14.0.0 $ python setup.py install
安装 pyOpenSSL
先安装一些依赖:
$ yum install libffi libffi-devel openssl-devel -y
然后,通过easy_install安装pyOpenSSL:
$ easy_install pyOpenSSL
安装 Scrapy
先安装一些依赖:
$ yum install libxml2 libxslt libxslt-devel -y
最后,安装 Scrapy:
$ easy_install scrapy
2. 使用 Scrapy
安装成功后,可以了解Scrapy的一些基本概念和用法,学习Scrapy项目dirbot的例子。
Dirbot 项目所在地。该项目收录一个 README 文件,详细描述了该项目的内容。如果您熟悉 Git,可以查看其源代码。或者,您可以通过单击下载以 tarball 或 zip 格式下载文件。
这里以一个例子来说明如何使用Scrapy创建爬虫项目。
新建筑
在爬取之前,您需要创建一个新的 Scrapy 项目。输入要保存代码的目录,然后执行:
$ scrapy startproject tutorial
该命令会在当前目录下新建一个目录tutorial,其结构如下:
.
├── scrapy.cfg
└── tutorial
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
这些文件主要是:
定义项目
Items 是将加载捕获数据的容器。它的工作原理类似于 Python 中的字典,但它提供了更多保护,例如填充未定义的字段以防止拼写错误。
它是通过创建一个scrapy.item.Item 类并将其属性定义为scrpy.item.Field 对象来声明的,就像一个对象关系映射(ORM)。
我们控制通过建模所需项目获得的站点数据。例如,我们要获取站点的名称、url 和 网站 描述。我们定义了这三个属性的域。为此,我们编辑教程目录中的 items.py 文件,我们的 Item 类将如下所示
from scrapy.item import Item, Field
class DmozItem(Item): title = Field() link = Field() desc = Field()
一开始可能看起来有点混乱,但是定义这些项目会让您在使用其他 Scrapy 组件时知道您的项目是什么。
写蜘蛛
Spider 是一个用户编写的类,用于从域(或域组)中获取信息。我们定义了用于下载的 URL 的初步列表、如何跟踪链接以及如何解析这些网页的内容以提取项目。
要创建 Spider,您可以为 scrapy.spider.BaseSpider 创建一个子类并确定三个主要的强制性属性:
该方法负责解析返回的数据,匹配捕获的数据(解析为item),跟踪更多的URL。
在tutorial/spiders目录下创建DmozSpider.py
from scrapy.spider import BaseSpider
class DmozSpider(BaseSpider): name = "dmoz" allowed_domains = ["dmoz.org"] start_urls = [ "http://www.dmoz.org/Computers/ ... ot%3B, "http://www.dmoz.org/Computers/ ... ot%3B ] def parse(self, response): filename = response.url.split("/")[-2] open(filename, 'wb').write(response.body)
运行项目
$ scrapy crawl dmoz
该命令从域启动爬虫,第三个参数是DmozSpider.py中name属性的值。
xpath 选择器
Scrapy 使用一种称为 XPath 选择器的机制,该机制基于 XPath 表达式。如果您想了解有关选择器和其他机制的更多信息,可以查看。
以下是 XPath 表达式及其含义的一些示例:
这些只是使用 XPath 的几个简单示例,但实际上 XPath 非常强大。如果您想了解更多关于 XPATH 的知识,我们向您推荐这个 XPath 教程
为了方便XPaths的使用,Scrapy提供了Selector类,共有三种方法
提取数据
我们可以使用以下命令选择 网站 中的每个元素:
sel.xpath('//ul/li')
然后网站描述:
sel.xpath('//ul/li/text()').extract()
网站标题:
sel.xpath('//ul/li/a/text()').extract()
网站 链接:
sel.xpath('//ul/li/a/@href').extract()
如前所述,每个 xpath() 调用都会返回一个选择器列表,因此我们可以结合 xpath() 来挖掘更深的节点。我们将使用这些功能,因此:
sites = sel.xpath('//ul/li')
for site in sites:
title = site.xpath('a/text()').extract()
link = site.xpath('a/@href').extract() desc = site.xpath('text()').extract() print title, link, desc
使用物品
scrapy.item.Item的调用接口类似于python的dict,Item收录多个scrapy.item.Field。这类似于 django 的模型和
Item通常用在Spider的parse方法中,用于保存解析后的数据。
最后修改爬虫类,使用Item保存数据,代码如下:
from scrapy.spider import Spider
from scrapy.selector import Selector from dirbot.items import Website class DmozSpider(Spider): name = "dmoz" allowed_domains = ["dmoz.org"] start_urls = [ "http://www.dmoz.org/Computers/ ... ot%3B, "http://www.dmoz.org/Computers/ ... ot%3B, ] def parse(self, response): """ The lines below is a spider contract. For more info see: http://doc.scrapy.org/en/lates ... .html @url http://www.dmoz.org/Computers/ ... rces/ @scrapes name """ sel = Selector(response) sites = sel.xpath('//ul[@class="directory-url"]/li') items = [] for site in sites: item = Website() item['name'] = site.xpath('a/text()').extract() item['url'] = site.xpath('a/@href').extract() item['description'] = site.xpath('text()').re('-\s([^\n]*?)\\n') items.append(item) return items
现在,您可以再次运行该项目以查看结果:
$ scrapy crawl dmoz
使用项目管道
在settings.py中设置ITEM_PIPELINES,默认为[],类似django的MIDDLEWARE_CLASSES等。
Spider的解析返回的Item数据会依次被ITEM_PIPELINES列表中的Pipeline类处理。
Item Pipeline 类必须实现以下方法:
可以另外实现以下两种方法:
保存捕获的数据
保存信息最简单的方法是通过,命令如下:
$ scrapy crawl dmoz -o items.json -t json
除了 json 格式,还支持 JSON 行、CSV 和 XML 格式。您还可以通过接口扩展一些格式。
这种方法对于小项目来说已经足够了。如果是比较复杂的数据,可能需要写一个Item Pipeline进行处理。
所有抓到的物品都会以JSON格式保存在新生成的items.json文件中
总结
以上介绍了如何创建爬虫项目的过程,可以参考以上过程再次联系。作为学习示例,也可以参考这个文章:scrapy中文教程(爬取cnbeta示例)。
这个文章中的爬虫代码如下:
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor from scrapy.selector import Selector from cnbeta.items import CnbetaItem class CBSpider(CrawlSpider): name = 'cnbeta' allowed_domains = ['cnbeta.com'] start_urls = ['http://www.cnbeta.com'] rules = ( Rule(SgmlLinkExtractor(allow=('/articles/.*\.htm', )), callback='parse_page', follow=True), ) def parse_page(self, response): item = CnbetaItem() sel = Selector(response) item['title'] = sel.xpath('//title/text()').extract() item['url'] = response.url return item
需要注意的是:
3. 学习资料
联系Scrapy是因为想爬取知乎的一些数据。一开始找了一些相关的资料和其他人的实现方法。
Github上有人或多或少意识到了知乎数据的爬取。我搜索了以下仓库:
其他信息:
抓取和交互式示例:
有一些知识点需要梳理:
4. 总结
以上是这几天学习Scrapy的笔记和知识汇总。参考网上的一些文章,写了这篇文章。谢谢你,希望这篇文章文章 能对你有所帮助。如果您有任何想法,请留言;如果你喜欢这篇文章,请帮忙分享一下,谢谢!
最初发表于:
c爬虫抓取网页数据(C++爬虫原理:C++原理(一):C++原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-10 22:21
C++爬虫原理:C++爬虫原理(一):爬虫简介
C++爬虫原理:C++爬虫原理(二):读取URL策略
下面介绍读取URL的策略,即网页的有限爬取方法:
网络爬取策略可分为深度优先、广度优先和最佳优先。在很多情况下,深度优先会导致爬虫被困。目前,广度优先和最佳优先的方法很常见。这里,聚焦爬虫推荐使用广度优先搜索和定向覆盖。
广度优先搜索
广度优先搜索策略是指在爬取过程中,当前一级搜索完成后,再进行下一级搜索。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索的方法。也有许多研究将广度优先搜索策略应用于聚焦爬虫。基本思想是,距离初始 URL 一定链接距离内的网页具有很高的主题相关性概率。另一种方法是将广度优先搜索与网络过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增加,
最佳优先搜索
最佳优先级搜索策略根据一定的网页分析算法预测候选URL与目标页面的相似度或与主题的相关性,选择一个或几个评价最好的URL进行爬取。它只访问被网络分析算法预测为“有用”的网页。一个问题是爬虫的爬取路径中很多相关的网页可能会被忽略,因为最好的优先级策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,才能跳出局部最佳点。将在第 4 节中结合网页分析算法进行详细讨论。
深度优先搜索
深度优先搜索策略从起始网页开始,选择一个网址进入,分析该网页中的网址,选择一个进入。这样一个链接被一个一个地爬取,直到处理完一条路由,然后再处理下一条路由。深度优先的策略设计比较简单。但是,门户网站网站提供的链接往往是最有价值的,PageRank也非常高。但是,网页的价值和 PageRank 会随着级别的增加而相应降低。这意味着重要的网页通常更接近种子,而被抓取过深的网页价值较低。同时,该策略的抓取深度直接影响抓取命中率和抓取效率,抓取深度是该策略的关键。与其他两种策略相比。
广度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接插入到待爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中所有链接的网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。
反向链接计数策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
其他包括 PageRank 等。
题外话:好久没更新了。网站 去备案。这个文章也参考了网上,总结了一下,不过我觉得已经用尽了。关注百度百科,wawlian的博客。 查看全部
c爬虫抓取网页数据(C++爬虫原理:C++原理(一):C++原理)
C++爬虫原理:C++爬虫原理(一):爬虫简介
C++爬虫原理:C++爬虫原理(二):读取URL策略
下面介绍读取URL的策略,即网页的有限爬取方法:
网络爬取策略可分为深度优先、广度优先和最佳优先。在很多情况下,深度优先会导致爬虫被困。目前,广度优先和最佳优先的方法很常见。这里,聚焦爬虫推荐使用广度优先搜索和定向覆盖。
广度优先搜索
广度优先搜索策略是指在爬取过程中,当前一级搜索完成后,再进行下一级搜索。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索的方法。也有许多研究将广度优先搜索策略应用于聚焦爬虫。基本思想是,距离初始 URL 一定链接距离内的网页具有很高的主题相关性概率。另一种方法是将广度优先搜索与网络过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增加,
最佳优先搜索
最佳优先级搜索策略根据一定的网页分析算法预测候选URL与目标页面的相似度或与主题的相关性,选择一个或几个评价最好的URL进行爬取。它只访问被网络分析算法预测为“有用”的网页。一个问题是爬虫的爬取路径中很多相关的网页可能会被忽略,因为最好的优先级策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,才能跳出局部最佳点。将在第 4 节中结合网页分析算法进行详细讨论。
深度优先搜索
深度优先搜索策略从起始网页开始,选择一个网址进入,分析该网页中的网址,选择一个进入。这样一个链接被一个一个地爬取,直到处理完一条路由,然后再处理下一条路由。深度优先的策略设计比较简单。但是,门户网站网站提供的链接往往是最有价值的,PageRank也非常高。但是,网页的价值和 PageRank 会随着级别的增加而相应降低。这意味着重要的网页通常更接近种子,而被抓取过深的网页价值较低。同时,该策略的抓取深度直接影响抓取命中率和抓取效率,抓取深度是该策略的关键。与其他两种策略相比。
广度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接插入到待爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中所有链接的网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。
反向链接计数策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
其他包括 PageRank 等。
题外话:好久没更新了。网站 去备案。这个文章也参考了网上,总结了一下,不过我觉得已经用尽了。关注百度百科,wawlian的博客。
c爬虫抓取网页数据( 图片来源于网络1.爬虫的流程架构大致的工作流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-10 20:08
图片来源于网络1.爬虫的流程架构大致的工作流程)
网络爬虫的基本概念和认知
图片来自网络
1. 爬虫的定义
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。——百度百科定义详细定义参考
Mukenet评论:爬虫实际上是一种自动化的信息程序或脚本,可以方便地帮助大家获取自己想要的具体信息。比如百度、谷歌这样的搜索引擎,其背后的重要技术支持就是爬虫。当我们使用搜索引擎搜索某个信息时,展示在我们面前的搜索结果是由爬虫程序预先从万维网上爬取而来的。我们之所以称其为爬虫,只是比喻自动获取万维网。
2. 爬虫的进程架构
爬虫的一般工作流程如下图所示:首先获取数据,然后清洗处理数据,最后持久化存储数据,然后可视化数据。在接下来的章节中,我们将遵循这个过程并详细介绍它们。
爬虫进程架构图
3. 爬虫分类
根据系统结构和实现技术,爬虫大致可以分为以下几类:
3.1 个通用网络爬虫
一般爬虫主要是指谷歌、百度等搜索引擎。它们爬取范围广,种类多,存储信息量大,技术要求比较高。
3.2 聚焦网络爬虫
关注爬虫,主要是基于特定主题的爬取。这是大家使用时间最长的爬虫类型。例如,我们抓取金融,或电影、书籍和其他特定信息。由于我们限制了主题和网站,可以大大节省我们的硬盘和网络资源,更好地满足特定业务的需求。
3.3 增量爬网
增量爬虫主要是指我们定期爬取一些网站时,只爬取网站变化的内容,而不是再次爬取所有网站数据。. 这样可以有效降低运维成本。
3.4 深网爬虫
深度网络爬虫主要是指一些我们无法直接爬取的网站。比如这些网站,需要用户登录,或者填写一些特定的表格,才能继续爬取信息。
Tips:在实际项目中,我们通常会结合两种或两种以上的爬虫技术来达到更好的效果。
4. 爬虫的爬取策略
爬虫根据不同的业务需求,大致可以分为两种不同的爬虫策略:
4.1 深度优先策略
深度优先策略是指在爬取HTML页面时,如果爬虫在页面中发现了新的URL,就会对新的URL进行深度优先搜索,依此类推,沿着URL爬行直到找不到深入。直到。然后,返回到最后一个 URL 地址并搜索其他 URL。当页面上没有可供选择的新 URL 时,搜索结束。
举个简单的例子,比如我们访问,假设的首页只有两个课程链接,一个是爬虫类,一个是Python类。深度优先算法是先进入爬虫类,然后进入爬虫类的一个章节链接中,如果本章没有子章节,爬虫会退到上层继续从另一个访问未访问的章节。访问完所有章节后,爬虫会返回首页。对Python课链接也进行相应的搜索,直到找不到新的URL,搜索结束。
4.2 广度优先策略
广度优先策略是指爬虫需要爬取一个完整网页的所有网址,然后才能继续搜索下一页直到底部。
它仍然是我们的例子。来到的首页后,我们需要在的首页获取Python和爬取课程的URL,才能继续搜索这两个课程的子章节的URL。然后逐层进行,直到结束。
Tips:深度优先适用于网站嵌套较深的搜索网站,而广度优先策略更适用于时间要求高、网站@同级别的URL较多的页面> 页。
5. 爬虫的学习基础
学习爬虫,我们需要以下基础知识:
如果你没有Python语言或数据库的基础知识,可以参考Mukenet的相关wiki进行学习。
当然,为了方便大家理解,我会在代码中添加详细的注释。即使你没有Python语言基础,也可以先了解大致流程,然后再排查遗漏,学习相应的知识。
有同学可能会疑惑,为什么一定要用python语言来开发爬虫。不能用其他语言吗?
这不得不说是Python的第三方库。Python之所以如此受欢迎,官方是因为它拥有大量的库,而且这些库的性能和使用都比较简单高效。凭借Python语言本身的高效率,只需一行代码就可以实现10个简单的爬虫,而在java/C/C++等其他语言中,至少需要编写几十行代码. 因此,使用Python开发爬虫程序,赢得了众多程序员的青睐。
比如,人们习惯在楼下的便利店买饮料。虽然离门口一公里有一家比较大的超市,但相信大家都不愿意买,因为太麻烦,不方便。这就是Python语言成为爬虫主流语言的精髓所在。
在接下来的学习中,我们将使用 Python 的几个第三方库。所谓第三方库是指Python的官方库(例如system“os”和time“time”\等库),非官方发布的库,如requests等库,称为第三方库。
安装Python解释器时默认已经安装了官方的Python库,需要手动安装第三方库。比如我们在爬虫开发中经常用到Requests库。安装第三方库很简单,在终端执行如下命令即可:
pip install requests
后面讲到具体的库时,我们会做详细的介绍。
下面是爬虫开发中常用的Python库对比:
套餐介绍
网址库
不需要安装 Python 自带的库。但是,在不同的python版本中,urlib在细节上有所不同。实际开发中过于繁琐,header无法伪装,很容易被阻塞。因此,现在使用它的人并不多。
要求
与urllib相比,它不仅拥有url的所有功能,更重要的是语法简洁优雅,而且在兼容性方面完全兼容python2和python3,非常方便。同时,它还可以伪装请求。
urllib3
urllib3 库提供了一些 urllib 没有的重要特性,例如线程安全、连接池和对压缩编码的支持。
这里推荐requests库,简单方便,容易上手,非常适合使用爬虫的新手。如果没有特殊说明,我们将在后续课程中默认使用 requests 库。
6. 爬虫的法律伦理问题
近年来,可以说通过编写爬虫程序来抓取大量数据而获利的程序员层出不穷。您可能会担心在使用爬虫的过程中是否会触犯法律。其实只要合理使用爬虫,就不会轻易触犯法律。那么,什么是爬虫的合理使用呢?我总结了以下三点供大家参考:
不管法律方面,我们也必须严于律己,遵守一些特定的规则。这里我想说的是爬虫世界中的robots协议。这是网站的所有者为爬虫设计的协议,通常位于网站的根目录下。它指定哪些目录可以被爬取,哪些不能。我们需要遵守这个约定好的协议,以避免不必要的麻烦。
7. 个人经历
在实际工作项目中,如果我们是做爬虫工作的工程师,在精通爬虫基础技术的同时,应该熟悉和了解数据清洗和处理技术。只有这样,我们才能更好地与团队协作。. 当然,这些技术会在后面的章节中一一为大家介绍。
好的,让我们开始爬虫世界的欢乐之旅吧! 查看全部
c爬虫抓取网页数据(
图片来源于网络1.爬虫的流程架构大致的工作流程)
网络爬虫的基本概念和认知
图片来自网络
1. 爬虫的定义
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。——百度百科定义详细定义参考
Mukenet评论:爬虫实际上是一种自动化的信息程序或脚本,可以方便地帮助大家获取自己想要的具体信息。比如百度、谷歌这样的搜索引擎,其背后的重要技术支持就是爬虫。当我们使用搜索引擎搜索某个信息时,展示在我们面前的搜索结果是由爬虫程序预先从万维网上爬取而来的。我们之所以称其为爬虫,只是比喻自动获取万维网。
2. 爬虫的进程架构
爬虫的一般工作流程如下图所示:首先获取数据,然后清洗处理数据,最后持久化存储数据,然后可视化数据。在接下来的章节中,我们将遵循这个过程并详细介绍它们。
爬虫进程架构图
3. 爬虫分类
根据系统结构和实现技术,爬虫大致可以分为以下几类:
3.1 个通用网络爬虫
一般爬虫主要是指谷歌、百度等搜索引擎。它们爬取范围广,种类多,存储信息量大,技术要求比较高。
3.2 聚焦网络爬虫
关注爬虫,主要是基于特定主题的爬取。这是大家使用时间最长的爬虫类型。例如,我们抓取金融,或电影、书籍和其他特定信息。由于我们限制了主题和网站,可以大大节省我们的硬盘和网络资源,更好地满足特定业务的需求。
3.3 增量爬网
增量爬虫主要是指我们定期爬取一些网站时,只爬取网站变化的内容,而不是再次爬取所有网站数据。. 这样可以有效降低运维成本。
3.4 深网爬虫
深度网络爬虫主要是指一些我们无法直接爬取的网站。比如这些网站,需要用户登录,或者填写一些特定的表格,才能继续爬取信息。
Tips:在实际项目中,我们通常会结合两种或两种以上的爬虫技术来达到更好的效果。
4. 爬虫的爬取策略
爬虫根据不同的业务需求,大致可以分为两种不同的爬虫策略:
4.1 深度优先策略
深度优先策略是指在爬取HTML页面时,如果爬虫在页面中发现了新的URL,就会对新的URL进行深度优先搜索,依此类推,沿着URL爬行直到找不到深入。直到。然后,返回到最后一个 URL 地址并搜索其他 URL。当页面上没有可供选择的新 URL 时,搜索结束。
举个简单的例子,比如我们访问,假设的首页只有两个课程链接,一个是爬虫类,一个是Python类。深度优先算法是先进入爬虫类,然后进入爬虫类的一个章节链接中,如果本章没有子章节,爬虫会退到上层继续从另一个访问未访问的章节。访问完所有章节后,爬虫会返回首页。对Python课链接也进行相应的搜索,直到找不到新的URL,搜索结束。
4.2 广度优先策略
广度优先策略是指爬虫需要爬取一个完整网页的所有网址,然后才能继续搜索下一页直到底部。
它仍然是我们的例子。来到的首页后,我们需要在的首页获取Python和爬取课程的URL,才能继续搜索这两个课程的子章节的URL。然后逐层进行,直到结束。
Tips:深度优先适用于网站嵌套较深的搜索网站,而广度优先策略更适用于时间要求高、网站@同级别的URL较多的页面> 页。
5. 爬虫的学习基础
学习爬虫,我们需要以下基础知识:
如果你没有Python语言或数据库的基础知识,可以参考Mukenet的相关wiki进行学习。
当然,为了方便大家理解,我会在代码中添加详细的注释。即使你没有Python语言基础,也可以先了解大致流程,然后再排查遗漏,学习相应的知识。
有同学可能会疑惑,为什么一定要用python语言来开发爬虫。不能用其他语言吗?
这不得不说是Python的第三方库。Python之所以如此受欢迎,官方是因为它拥有大量的库,而且这些库的性能和使用都比较简单高效。凭借Python语言本身的高效率,只需一行代码就可以实现10个简单的爬虫,而在java/C/C++等其他语言中,至少需要编写几十行代码. 因此,使用Python开发爬虫程序,赢得了众多程序员的青睐。
比如,人们习惯在楼下的便利店买饮料。虽然离门口一公里有一家比较大的超市,但相信大家都不愿意买,因为太麻烦,不方便。这就是Python语言成为爬虫主流语言的精髓所在。
在接下来的学习中,我们将使用 Python 的几个第三方库。所谓第三方库是指Python的官方库(例如system“os”和time“time”\等库),非官方发布的库,如requests等库,称为第三方库。
安装Python解释器时默认已经安装了官方的Python库,需要手动安装第三方库。比如我们在爬虫开发中经常用到Requests库。安装第三方库很简单,在终端执行如下命令即可:
pip install requests
后面讲到具体的库时,我们会做详细的介绍。
下面是爬虫开发中常用的Python库对比:
套餐介绍
网址库
不需要安装 Python 自带的库。但是,在不同的python版本中,urlib在细节上有所不同。实际开发中过于繁琐,header无法伪装,很容易被阻塞。因此,现在使用它的人并不多。
要求
与urllib相比,它不仅拥有url的所有功能,更重要的是语法简洁优雅,而且在兼容性方面完全兼容python2和python3,非常方便。同时,它还可以伪装请求。
urllib3
urllib3 库提供了一些 urllib 没有的重要特性,例如线程安全、连接池和对压缩编码的支持。
这里推荐requests库,简单方便,容易上手,非常适合使用爬虫的新手。如果没有特殊说明,我们将在后续课程中默认使用 requests 库。
6. 爬虫的法律伦理问题
近年来,可以说通过编写爬虫程序来抓取大量数据而获利的程序员层出不穷。您可能会担心在使用爬虫的过程中是否会触犯法律。其实只要合理使用爬虫,就不会轻易触犯法律。那么,什么是爬虫的合理使用呢?我总结了以下三点供大家参考:
不管法律方面,我们也必须严于律己,遵守一些特定的规则。这里我想说的是爬虫世界中的robots协议。这是网站的所有者为爬虫设计的协议,通常位于网站的根目录下。它指定哪些目录可以被爬取,哪些不能。我们需要遵守这个约定好的协议,以避免不必要的麻烦。
7. 个人经历
在实际工作项目中,如果我们是做爬虫工作的工程师,在精通爬虫基础技术的同时,应该熟悉和了解数据清洗和处理技术。只有这样,我们才能更好地与团队协作。. 当然,这些技术会在后面的章节中一一为大家介绍。
好的,让我们开始爬虫世界的欢乐之旅吧!
c爬虫抓取网页数据(深耕Python、数据库、seienium、JS逆向、安卓逆向)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-10 20:05
作者简介:机械专业本科,野程序员,学过C语言,玩过前端,也修过嵌入式,设计过一点,但现在迷上了爬虫,所以现在在培养Python,数据库、seienium、JS逆向工程、Android逆向等,本人目前是全职爬虫工程师。我喜欢记录学习过程。写了15W的电子笔记,你看下面的文章~
技术栈:Python、HTML、CSS、JavaScript、C、Xpath语法、regular、MySQL、Redis、MongoDB、Scrapy、Pyspider、Fiddler、Mitmproxy、分布式爬虫、JAVA等。
个人博客:
大学作品集:
欢迎点赞
爬得高,自尊心低,必须远行。
我始终相信越努力越幸运
⭐️打不倒我们的人,终会让我们变得更强大
希望深耕编程之路的朋友越来越好
文章内容
爬虫爬取数据的步骤!爬虫获取数据的步骤!
第一:找到需要爬取数据的URL地址
第二:(打包请求头)向这个url地址发起请求
第三:获取url服务器发送的响应数据(网页源码)
第四:使用python数据分析库在源码中获取你想要的数据!
第五:清理并保存数据(csv、数据库、Excel)!
第六:是否需要跳转到原网页然后抓取数据! 查看全部
c爬虫抓取网页数据(深耕Python、数据库、seienium、JS逆向、安卓逆向)
作者简介:机械专业本科,野程序员,学过C语言,玩过前端,也修过嵌入式,设计过一点,但现在迷上了爬虫,所以现在在培养Python,数据库、seienium、JS逆向工程、Android逆向等,本人目前是全职爬虫工程师。我喜欢记录学习过程。写了15W的电子笔记,你看下面的文章~
技术栈:Python、HTML、CSS、JavaScript、C、Xpath语法、regular、MySQL、Redis、MongoDB、Scrapy、Pyspider、Fiddler、Mitmproxy、分布式爬虫、JAVA等。
个人博客:
大学作品集:
欢迎点赞
爬得高,自尊心低,必须远行。
我始终相信越努力越幸运
⭐️打不倒我们的人,终会让我们变得更强大
希望深耕编程之路的朋友越来越好
文章内容
爬虫爬取数据的步骤!爬虫获取数据的步骤!
第一:找到需要爬取数据的URL地址
第二:(打包请求头)向这个url地址发起请求
第三:获取url服务器发送的响应数据(网页源码)
第四:使用python数据分析库在源码中获取你想要的数据!
第五:清理并保存数据(csv、数据库、Excel)!
第六:是否需要跳转到原网页然后抓取数据!
c爬虫抓取网页数据(专业搜索引擎中网络爬虫的分类及其工作原理(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-09 14:21
随着互联网的不断发展,搜索引擎技术发展迅速。搜索引擎已经成为人们在广阔的网络世界中获取信息不可或缺的工具。采用何种策略有效访问网络资源,成为专业搜索引擎中网络爬虫研究的一大课题。文章 介绍了搜索引擎的分类及其工作原理。描述了网络爬虫技术的搜索策略,展望了新一代搜索引擎的发展趋势。关键词 网络爬虫;战略; 搜索引擎概念:网络爬虫又称网络蜘蛛。它是一种按照一定的规则自动提取网页的程序。它会通过网络自动抓取互联网上的网页。这项技术是通用的,可用于检查您网站上的所有链接是否有效。当然,更先进的技术是在网页中保存相关数据,可以成为搜索引擎。搜索引擎使用网络爬虫来查找网络内容。网络上的 HTML 文档通过超链接连接,就像网络一样。网络爬虫也称为网络蜘蛛。他们沿着这个网络爬行并在每次访问网页时使用它们。爬虫程序抓取这个网页,提取内容,同时提取超链接作为进一步爬取的线索。网络爬虫总是从某个起点开始爬行。这个起点称为种子。你可以告诉它,或者你可以在一些 URL 列表 网站 上得到它。网络爬虫的组成和分类。网络爬虫也被称为网络蜘蛛和网络机器人。它们主要用于采集网络资源。在进行网络舆情分析时,首先要获取舆情信息的内容。这需要使用网络爬虫(蜘蛛程序),这是一个可以自动提取网页内容的程序。它通过搜索引擎从互联网上抓取网址并抓取它们。获取相应的网页内容是搜索引擎(Search Engine)的重要组成部分。它通过搜索引擎从互联网上抓取网址并抓取它们。获取相应的网页内容是搜索引擎(Search Engine)的重要组成部分。它通过搜索引擎从互联网上抓取网址并抓取它们。获取相应的网页内容是搜索引擎(Search Engine)的重要组成部分。
一个典型的网络爬虫的主要组成部分如下: URL链接库,主要用于存储爬取的网络链接。文档内容模块主要用于访问从Web 下载的Web 内容。文档解析模块用于解析下载的文档中网页的内容,如解析PDF、Word、HTML等标准化URL模块,用于将URL转换为标准格式。URL 过滤器主要用于过滤掉不需要的 URL。以上模块的设计和实现主要是确定爬取的内容和爬取的范围。最简单的例子是从已知站点抓取一些网页。这个爬虫用少量的代码就可以完成。但是在实际的互联网应用中,可能会遇到需要爬取大量内容的情况,你需要设计一个更复杂的爬虫。这个爬虫是一个组合的应用,难度是基于分布式的。网络爬虫的工作原理传统网络爬虫的工作原理是先选择初始网址,获取初始网页的域名或IP地址,然后在抓取网页时不断从当前页面获取新的网址并将它们放入候选队列。直到满足停止条件。焦点爬虫(topic-driven crawlers)不同于传统爬虫。它的工作流程更为复杂。首先需要过滤掉与主题无关的链接,只保留有用的链接,放入候选URL队列。然后,根据搜索策略从候选队列中选择下一个要抓取的网页链接,
同时,所有爬取的网页内容都被保存,并进行过滤、分析、索引等,以进行性检索和查询。一般来说,网络爬虫主要有以下两个阶段: 第一阶段,URL库初始化,然后开始爬虫。在第二阶段,爬虫读取未访问过的 URL 以确定其工作范围。其中,对于要爬取的URL链接,执行以下步骤: 获取URL链接。解析内容并获取 URL 和相关数据。规范化新抓取的 URL。过滤掉不相关的 URL。将要爬取的 URL 更新为 URL 重复步骤 2,直到满足终止条件。网络爬虫的搜索策略目前常见的网络爬虫搜索策略有以下三种:1、广度优先搜索策略。主要思想是从根节点开始,先遍历当前一层搜索,然后再进行下一层搜索,以此类推,一层一层的进行搜索。这种策略主要用于主题爬虫,因为网页越接近初始 URL,主题相关性就越大。2、深度优先搜索策略。这个策略的主要思想是从根节点开始寻找叶子节点,以此类推。在网页中,选择一个超链接,链接的网页将进行深度优先搜索,形成一个单一的搜索链。当没有其他超链接时,搜索结束。3、最佳优先级搜索策略。该策略计算 URL 描述文本与目标网页的相似度,或与主题的相关性,
爬取算法数据采集的效率和覆盖率受爬取算法的影响。流行和经典的爬虫算法都是在Best-Frist算法的基础上改进和演进的。各种算法的区别 是:对要爬取的网址按照不同的启发式规则进行评分和排序,在爬取前或爬取过程中优化算法参数。Best-First 算法 Best-First 算法维护一个排序的 URLs 优先级队列,通过计算主题和被抓取网页之间的余弦相似度(cosinesimilarity)来确定 Urls 在 Urls 前沿的优先级。相似度计算公式如下:(2-1)为主题,p为爬取的网页。Best-Frist爬取算法如下:初始化,设置查询主题(topic)、初始种子节点集(starting_urls)、最大爬取页面数(MAX_PAGES)和边界容量限制(MAX_BUFFER);ii. 将初始节点集(starting_urls)中的所有链接插入前沿队列(初始为空);三、循环(当边界队列不为空时)和爬取的页面数) a)从边界(link)中取优先级最高的链接:link=dequeue_link_with_max_score(frontier) b) 访问并下载该链接对应的页面(doc): doc=fetch_new_page(link) c) 计算页面与主题的相似度(score): score=sim(topic,doc) d) 提取doc中的所有超链接(outlinks) e) Loop (for页面文档中的每个超链接外链) If(#frontier> 爬取的最大页面数(MAX_PAGES)和边界容量限制(MAX_BUFFER);ii. 将初始节点集(starting_urls)中的所有链接插入前沿队列(初始为空);三、循环(当边界队列不为空时)和爬取的页面数) a)从边界(link)中取优先级最高的链接:link=dequeue_link_with_max_score(frontier) b) 访问并下载该链接对应的页面(doc): doc=fetch_new_page(link) c) 计算页面与主题的相似度(score): score=sim(topic,doc) d) 提取doc中的所有超链接(outlinks) e) Loop (for页面文档中的每个超链接外链) If(#frontier> 爬取的最大页面数(MAX_PAGES)和边界容量限制(MAX_BUFFER);ii. 将初始节点集(starting_urls)中的所有链接插入前沿队列(初始为空);三、循环(当边界队列不为空时)和爬取的页面数) a)从边界(link)中取优先级最高的链接:link=dequeue_link_with_max_score(frontier) b) 访问并下载该链接对应的页面(doc): doc=fetch_new_page(link) c) 计算页面与主题的相似度(score): score=sim(topic,doc) d) 提取doc中的所有超链接(outlinks) e) Loop (for页面文档中的每个超链接外链) If(#frontier>
与 Fish-Search 算法一样,该算法也为爬行设置了深度边界。爬行队列中的每个链接都与深度限制和优先级度量相关联。深度限制由用户设置,链接的优先级值由父页面、锚文本和链接附近文本的相关性决定。具体算法如下: 初始化:设置初始节点、深度限制(D)、爬行规模(S)、时间限制、搜索查询q;ii. 设置初始节点depth=D的深度限制,将节点插入爬取队列(初始为空);三、循环(当队列不为空且下载节点数为0时(当前节点相关)inherit_score(child_node)=*sim(q, current_node) 其中预设衰减因子=0. 5; 否则inherited_score(child_node)= *inherited_score(current_node); 提取anchor_text和anchor_text_context(通过预设边界,如:1);Elseanchor_context_score计算anchor的相关性,neihgorhood_score:其中预设常数等于0.8;子节点,其中预设常数小于1,一般设置为0.5。
四、循环结束。网络爬虫技术的最新发展 传统的网络爬虫技术应该主要用于抓取静态网页。31、随着AJAX/Web2.0的普及,如何抓取AJAX等动态页面成为搜索引擎亟待解决的问题,因为AJAX颠覆了传统的纯HTTP请求/响应协议机制。如果搜索引擎仍然使用“爬行”机制,就不可能抓取到AJAX表面的有效数据。AJAX 使用由 JavaScript 驱动的异步请求/响应机制。过去的爬虫缺乏对 JavaScript 语义的理解。基本上无法模拟触发JavaScript的异步调用,解析返回的异步返回逻辑和内容。此外。在 AJAX 应用程序中,JavaScript 会对 D0M 结构做很多改动,甚至页面的所有内容都是通过 JavaScript 直接从服务器读取并动态绘制。这对于习惯于相对不变的D0M结构的静态页面来说是不可理解的。过去爬虫是基于协议驱动的,对于AJAX这样的技术,所需要的爬虫引擎必须是事件驱动的。要实现事件驱动,首先需要解决JavaScript的交互分析和解释问题。综上所述,近年来,国内对互联网搜索引擎的研究从无到有,逐渐成为热点,研究现象的主题聚类特征更加明显。甚至页面的所有内容都是通过JavaScript直接从服务器读取并动态绘制的。这对于习惯于相对不变的D0M结构的静态页面来说是不可理解的。过去爬虫是基于协议驱动的,对于AJAX这样的技术,所需要的爬虫引擎必须是事件驱动的。要实现事件驱动,首先需要解决JavaScript的交互分析和解释问题。综上所述,近年来,国内对互联网搜索引擎的研究从无到有,逐渐成为热点,研究现象的主题聚类特征更加明显。甚至页面的所有内容都是通过JavaScript直接从服务器读取并动态绘制的。这对于习惯于相对不变的D0M结构的静态页面来说是不可理解的。过去爬虫是基于协议驱动的,对于AJAX这样的技术,所需要的爬虫引擎必须是事件驱动的。要实现事件驱动,首先需要解决JavaScript的交互分析和解释问题。综上所述,近年来,国内对互联网搜索引擎的研究从无到有,逐渐成为热点,研究现象的主题聚类特征更加明显。过去爬虫是基于协议驱动的,对于AJAX这样的技术,所需要的爬虫引擎必须是事件驱动的。要实现事件驱动,首先需要解决JavaScript的交互分析和解释问题。综上所述,近年来,国内对互联网搜索引擎的研究从无到有,逐渐成为热点,研究现象的主题聚类特征更加明显。过去爬虫是基于协议驱动的,对于AJAX这样的技术,所需要的爬虫引擎必须是事件驱动的。要实现事件驱动,首先需要解决JavaScript的交互分析和解释问题。综上所述,近年来,国内对互联网搜索引擎的研究从无到有,逐渐成为热点,研究现象的主题聚类特征更加明显。
综合性研究论文数量远远超过该研究领域。国外搜索引擎的研究较热,水平高于国内。随着 lucene 和其他开源项目的出现,搜索引擎研究也出现了高潮。在搜索引擎中爬行是一个更昂贵且非常重要的部分。那么爬虫的效率、特性和质量就很重要了。那么爬虫技术与人工智能、分布式技术的结合自然成为研究热点。 查看全部
c爬虫抓取网页数据(专业搜索引擎中网络爬虫的分类及其工作原理(图))
随着互联网的不断发展,搜索引擎技术发展迅速。搜索引擎已经成为人们在广阔的网络世界中获取信息不可或缺的工具。采用何种策略有效访问网络资源,成为专业搜索引擎中网络爬虫研究的一大课题。文章 介绍了搜索引擎的分类及其工作原理。描述了网络爬虫技术的搜索策略,展望了新一代搜索引擎的发展趋势。关键词 网络爬虫;战略; 搜索引擎概念:网络爬虫又称网络蜘蛛。它是一种按照一定的规则自动提取网页的程序。它会通过网络自动抓取互联网上的网页。这项技术是通用的,可用于检查您网站上的所有链接是否有效。当然,更先进的技术是在网页中保存相关数据,可以成为搜索引擎。搜索引擎使用网络爬虫来查找网络内容。网络上的 HTML 文档通过超链接连接,就像网络一样。网络爬虫也称为网络蜘蛛。他们沿着这个网络爬行并在每次访问网页时使用它们。爬虫程序抓取这个网页,提取内容,同时提取超链接作为进一步爬取的线索。网络爬虫总是从某个起点开始爬行。这个起点称为种子。你可以告诉它,或者你可以在一些 URL 列表 网站 上得到它。网络爬虫的组成和分类。网络爬虫也被称为网络蜘蛛和网络机器人。它们主要用于采集网络资源。在进行网络舆情分析时,首先要获取舆情信息的内容。这需要使用网络爬虫(蜘蛛程序),这是一个可以自动提取网页内容的程序。它通过搜索引擎从互联网上抓取网址并抓取它们。获取相应的网页内容是搜索引擎(Search Engine)的重要组成部分。它通过搜索引擎从互联网上抓取网址并抓取它们。获取相应的网页内容是搜索引擎(Search Engine)的重要组成部分。它通过搜索引擎从互联网上抓取网址并抓取它们。获取相应的网页内容是搜索引擎(Search Engine)的重要组成部分。
一个典型的网络爬虫的主要组成部分如下: URL链接库,主要用于存储爬取的网络链接。文档内容模块主要用于访问从Web 下载的Web 内容。文档解析模块用于解析下载的文档中网页的内容,如解析PDF、Word、HTML等标准化URL模块,用于将URL转换为标准格式。URL 过滤器主要用于过滤掉不需要的 URL。以上模块的设计和实现主要是确定爬取的内容和爬取的范围。最简单的例子是从已知站点抓取一些网页。这个爬虫用少量的代码就可以完成。但是在实际的互联网应用中,可能会遇到需要爬取大量内容的情况,你需要设计一个更复杂的爬虫。这个爬虫是一个组合的应用,难度是基于分布式的。网络爬虫的工作原理传统网络爬虫的工作原理是先选择初始网址,获取初始网页的域名或IP地址,然后在抓取网页时不断从当前页面获取新的网址并将它们放入候选队列。直到满足停止条件。焦点爬虫(topic-driven crawlers)不同于传统爬虫。它的工作流程更为复杂。首先需要过滤掉与主题无关的链接,只保留有用的链接,放入候选URL队列。然后,根据搜索策略从候选队列中选择下一个要抓取的网页链接,
同时,所有爬取的网页内容都被保存,并进行过滤、分析、索引等,以进行性检索和查询。一般来说,网络爬虫主要有以下两个阶段: 第一阶段,URL库初始化,然后开始爬虫。在第二阶段,爬虫读取未访问过的 URL 以确定其工作范围。其中,对于要爬取的URL链接,执行以下步骤: 获取URL链接。解析内容并获取 URL 和相关数据。规范化新抓取的 URL。过滤掉不相关的 URL。将要爬取的 URL 更新为 URL 重复步骤 2,直到满足终止条件。网络爬虫的搜索策略目前常见的网络爬虫搜索策略有以下三种:1、广度优先搜索策略。主要思想是从根节点开始,先遍历当前一层搜索,然后再进行下一层搜索,以此类推,一层一层的进行搜索。这种策略主要用于主题爬虫,因为网页越接近初始 URL,主题相关性就越大。2、深度优先搜索策略。这个策略的主要思想是从根节点开始寻找叶子节点,以此类推。在网页中,选择一个超链接,链接的网页将进行深度优先搜索,形成一个单一的搜索链。当没有其他超链接时,搜索结束。3、最佳优先级搜索策略。该策略计算 URL 描述文本与目标网页的相似度,或与主题的相关性,
爬取算法数据采集的效率和覆盖率受爬取算法的影响。流行和经典的爬虫算法都是在Best-Frist算法的基础上改进和演进的。各种算法的区别 是:对要爬取的网址按照不同的启发式规则进行评分和排序,在爬取前或爬取过程中优化算法参数。Best-First 算法 Best-First 算法维护一个排序的 URLs 优先级队列,通过计算主题和被抓取网页之间的余弦相似度(cosinesimilarity)来确定 Urls 在 Urls 前沿的优先级。相似度计算公式如下:(2-1)为主题,p为爬取的网页。Best-Frist爬取算法如下:初始化,设置查询主题(topic)、初始种子节点集(starting_urls)、最大爬取页面数(MAX_PAGES)和边界容量限制(MAX_BUFFER);ii. 将初始节点集(starting_urls)中的所有链接插入前沿队列(初始为空);三、循环(当边界队列不为空时)和爬取的页面数) a)从边界(link)中取优先级最高的链接:link=dequeue_link_with_max_score(frontier) b) 访问并下载该链接对应的页面(doc): doc=fetch_new_page(link) c) 计算页面与主题的相似度(score): score=sim(topic,doc) d) 提取doc中的所有超链接(outlinks) e) Loop (for页面文档中的每个超链接外链) If(#frontier> 爬取的最大页面数(MAX_PAGES)和边界容量限制(MAX_BUFFER);ii. 将初始节点集(starting_urls)中的所有链接插入前沿队列(初始为空);三、循环(当边界队列不为空时)和爬取的页面数) a)从边界(link)中取优先级最高的链接:link=dequeue_link_with_max_score(frontier) b) 访问并下载该链接对应的页面(doc): doc=fetch_new_page(link) c) 计算页面与主题的相似度(score): score=sim(topic,doc) d) 提取doc中的所有超链接(outlinks) e) Loop (for页面文档中的每个超链接外链) If(#frontier> 爬取的最大页面数(MAX_PAGES)和边界容量限制(MAX_BUFFER);ii. 将初始节点集(starting_urls)中的所有链接插入前沿队列(初始为空);三、循环(当边界队列不为空时)和爬取的页面数) a)从边界(link)中取优先级最高的链接:link=dequeue_link_with_max_score(frontier) b) 访问并下载该链接对应的页面(doc): doc=fetch_new_page(link) c) 计算页面与主题的相似度(score): score=sim(topic,doc) d) 提取doc中的所有超链接(outlinks) e) Loop (for页面文档中的每个超链接外链) If(#frontier>
与 Fish-Search 算法一样,该算法也为爬行设置了深度边界。爬行队列中的每个链接都与深度限制和优先级度量相关联。深度限制由用户设置,链接的优先级值由父页面、锚文本和链接附近文本的相关性决定。具体算法如下: 初始化:设置初始节点、深度限制(D)、爬行规模(S)、时间限制、搜索查询q;ii. 设置初始节点depth=D的深度限制,将节点插入爬取队列(初始为空);三、循环(当队列不为空且下载节点数为0时(当前节点相关)inherit_score(child_node)=*sim(q, current_node) 其中预设衰减因子=0. 5; 否则inherited_score(child_node)= *inherited_score(current_node); 提取anchor_text和anchor_text_context(通过预设边界,如:1);Elseanchor_context_score计算anchor的相关性,neihgorhood_score:其中预设常数等于0.8;子节点,其中预设常数小于1,一般设置为0.5。
四、循环结束。网络爬虫技术的最新发展 传统的网络爬虫技术应该主要用于抓取静态网页。31、随着AJAX/Web2.0的普及,如何抓取AJAX等动态页面成为搜索引擎亟待解决的问题,因为AJAX颠覆了传统的纯HTTP请求/响应协议机制。如果搜索引擎仍然使用“爬行”机制,就不可能抓取到AJAX表面的有效数据。AJAX 使用由 JavaScript 驱动的异步请求/响应机制。过去的爬虫缺乏对 JavaScript 语义的理解。基本上无法模拟触发JavaScript的异步调用,解析返回的异步返回逻辑和内容。此外。在 AJAX 应用程序中,JavaScript 会对 D0M 结构做很多改动,甚至页面的所有内容都是通过 JavaScript 直接从服务器读取并动态绘制。这对于习惯于相对不变的D0M结构的静态页面来说是不可理解的。过去爬虫是基于协议驱动的,对于AJAX这样的技术,所需要的爬虫引擎必须是事件驱动的。要实现事件驱动,首先需要解决JavaScript的交互分析和解释问题。综上所述,近年来,国内对互联网搜索引擎的研究从无到有,逐渐成为热点,研究现象的主题聚类特征更加明显。甚至页面的所有内容都是通过JavaScript直接从服务器读取并动态绘制的。这对于习惯于相对不变的D0M结构的静态页面来说是不可理解的。过去爬虫是基于协议驱动的,对于AJAX这样的技术,所需要的爬虫引擎必须是事件驱动的。要实现事件驱动,首先需要解决JavaScript的交互分析和解释问题。综上所述,近年来,国内对互联网搜索引擎的研究从无到有,逐渐成为热点,研究现象的主题聚类特征更加明显。甚至页面的所有内容都是通过JavaScript直接从服务器读取并动态绘制的。这对于习惯于相对不变的D0M结构的静态页面来说是不可理解的。过去爬虫是基于协议驱动的,对于AJAX这样的技术,所需要的爬虫引擎必须是事件驱动的。要实现事件驱动,首先需要解决JavaScript的交互分析和解释问题。综上所述,近年来,国内对互联网搜索引擎的研究从无到有,逐渐成为热点,研究现象的主题聚类特征更加明显。过去爬虫是基于协议驱动的,对于AJAX这样的技术,所需要的爬虫引擎必须是事件驱动的。要实现事件驱动,首先需要解决JavaScript的交互分析和解释问题。综上所述,近年来,国内对互联网搜索引擎的研究从无到有,逐渐成为热点,研究现象的主题聚类特征更加明显。过去爬虫是基于协议驱动的,对于AJAX这样的技术,所需要的爬虫引擎必须是事件驱动的。要实现事件驱动,首先需要解决JavaScript的交互分析和解释问题。综上所述,近年来,国内对互联网搜索引擎的研究从无到有,逐渐成为热点,研究现象的主题聚类特征更加明显。
综合性研究论文数量远远超过该研究领域。国外搜索引擎的研究较热,水平高于国内。随着 lucene 和其他开源项目的出现,搜索引擎研究也出现了高潮。在搜索引擎中爬行是一个更昂贵且非常重要的部分。那么爬虫的效率、特性和质量就很重要了。那么爬虫技术与人工智能、分布式技术的结合自然成为研究热点。
c爬虫抓取网页数据(1.爬虫的流程是怎样的?(一)教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-07 08:23
爬虫技术文章很少从整体上讲,这次从宏观的角度讲,希望这篇文章文章能澄清三个问题:
1. 爬取的过程是什么?
2. 每道工序都有哪些技术方案?
3. 你会遇到什么困难?
所以这个文章也为后面的文章设置了教程的框架。
1. 爬取的过程是什么?
爬虫其实很简单,可以分为三个部分:获取网页--->解析网页,提取需要的数据--->存储。在文章:爬行者一号中,我简单地举例说明了每个部分。
一种。访问页面是什么?
获取一个网页就是向一个网址发送请求,然后该网址会返回整个网页的数据。类似:你在浏览器中输入网址,回车,然后你就看到了网站的整个页面。
湾 什么是解析页面?
解析一个网页就是从整个网页的数据中提取出你想要的数据。类似:你在浏览器中看到了网站的整个页面,但是你想找到产品的价格,而价格就是你想要的数据。
C。什么是存储?
存储很简单,就是保存数据。
2. 三个进程的技术是什么?
以下技术均在python下,本文不涉及Java
一种。获取网页:
要求
url2 和 url
模拟浏览器:selenium 或 PhantomJS
湾 解析网页:
常规的
美汤
C。贮存
将txt、csv等文件保存到mysql、mongodb等数据库中。
还有一些爬虫框架,比如Scrapy。在一个框架下解决并完成这三大流程。
另外,还会有提升爬虫速度的需求,这会涉及到:分布式爬虫。
3. 每个过程会遇到什么问题?
一种。获取网页:
爬虫会自动快速获取网页内容,所以如果短时间内访问过多,网站肯定不会喜欢。所以网站会反爬虫,可以分为:
增加获取数据难度:登录查看,登录设置验证码
不返回数据:不返回内容,延迟页面返回时间
返回数据到非目标页面:返回错误页面,返回空白页面,抓取多个页面时返回同一个页面
解决这些问题的方法有:使用cookies模拟登录、使用图片识别输入验证码、模拟真实header和切换user-agents、模拟浏览器爬取网站、增加爬网间隔、更改IP、爬取wap或手机客户端等
所以爬虫是个大坑,慎入。
湾 解析网页
解析网页的问题比较少见。主要是:中文乱码。
C。贮存
存储也很简单,连接数据库或者本地存储即可。
总结:获取网页是一个对抗各个公司爬虫的过程。路漫漫其修远兮。我会爬上爬下。祝你好运!请关注我接下来的文章,会一一讲述每一部分的知识。 查看全部
c爬虫抓取网页数据(1.爬虫的流程是怎样的?(一)教程)
爬虫技术文章很少从整体上讲,这次从宏观的角度讲,希望这篇文章文章能澄清三个问题:
1. 爬取的过程是什么?
2. 每道工序都有哪些技术方案?
3. 你会遇到什么困难?
所以这个文章也为后面的文章设置了教程的框架。
1. 爬取的过程是什么?
爬虫其实很简单,可以分为三个部分:获取网页--->解析网页,提取需要的数据--->存储。在文章:爬行者一号中,我简单地举例说明了每个部分。
一种。访问页面是什么?
获取一个网页就是向一个网址发送请求,然后该网址会返回整个网页的数据。类似:你在浏览器中输入网址,回车,然后你就看到了网站的整个页面。
湾 什么是解析页面?
解析一个网页就是从整个网页的数据中提取出你想要的数据。类似:你在浏览器中看到了网站的整个页面,但是你想找到产品的价格,而价格就是你想要的数据。
C。什么是存储?
存储很简单,就是保存数据。
2. 三个进程的技术是什么?
以下技术均在python下,本文不涉及Java
一种。获取网页:
要求
url2 和 url
模拟浏览器:selenium 或 PhantomJS
湾 解析网页:
常规的
美汤
C。贮存
将txt、csv等文件保存到mysql、mongodb等数据库中。
还有一些爬虫框架,比如Scrapy。在一个框架下解决并完成这三大流程。
另外,还会有提升爬虫速度的需求,这会涉及到:分布式爬虫。
3. 每个过程会遇到什么问题?
一种。获取网页:
爬虫会自动快速获取网页内容,所以如果短时间内访问过多,网站肯定不会喜欢。所以网站会反爬虫,可以分为:
增加获取数据难度:登录查看,登录设置验证码
不返回数据:不返回内容,延迟页面返回时间
返回数据到非目标页面:返回错误页面,返回空白页面,抓取多个页面时返回同一个页面
解决这些问题的方法有:使用cookies模拟登录、使用图片识别输入验证码、模拟真实header和切换user-agents、模拟浏览器爬取网站、增加爬网间隔、更改IP、爬取wap或手机客户端等
所以爬虫是个大坑,慎入。
湾 解析网页
解析网页的问题比较少见。主要是:中文乱码。
C。贮存
存储也很简单,连接数据库或者本地存储即可。
总结:获取网页是一个对抗各个公司爬虫的过程。路漫漫其修远兮。我会爬上爬下。祝你好运!请关注我接下来的文章,会一一讲述每一部分的知识。

