
c爬虫抓取网页数据
c爬虫抓取网页数据(几种-博客园爬虫的基本流程网络爬虫的抓取策略 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-10-26 12:10
)
原文:知乎 爬虫练习写在python-cpselvis-博客园
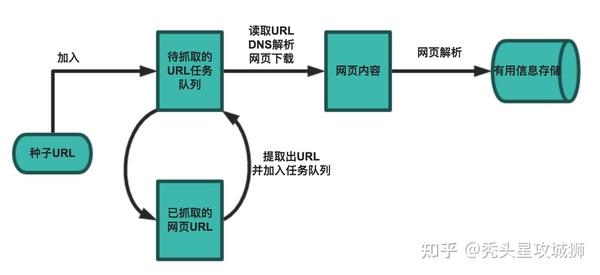
网络爬虫的基本工作流程如下:
爬虫的爬取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL的顺序也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
了解了爬虫的工作流程和爬取策略后,就可以开始实现爬虫了!那么如何在python中实现呢?
技术栈的基本实现
下面是伪代码
import Queue
initial_page = "https://www.zhihu.com/people/gaoming623"
url_queue = Queue.Queue()
seen = set()
seen.insert(initial_page)
url_queue.put(initial_page)
while(True): #一直进行
if url_queue.size()>0:
current_url = url_queue.get() #拿出队例中第一个的url
store(current_url) #把这个url代表的网页存储好
for next_url in extract_urls(current_url): #提取把这个url里链向的url
if next_url not in seen:
seen.put(next_url)
url_queue.put(next_url)
else:
break
如果直接处理上面的代码,直接运行,爬下整个知乎用户信息需要很长时间。毕竟,知乎 每月有 6000 万活跃用户。更不用说像谷歌这样的搜索引擎需要爬下整个网络。那么问题出在哪里呢?
布隆过滤器
需要爬取的网页太多,上面的代码太慢太慢了。假设全网有N个网站,那么分析判断的复杂度是N*log(N),因为所有网页都需要遍历一次,每次判断集合的时候,复杂度log(N) 是必需的。. OK,我知道python的set实现是hash-但是这样还是太慢了,至少内存使用效率不高。
通常的判断方式是什么?布隆过滤器。简单的说还是hash方法,但是它的特点是可以使用固定内存(不随url数增加)以O(1)的效率来判断url是否已经设置好可惜世界上没有免费的午餐,唯一的问题是如果url不在set中,BF可以100%确定url没有被浏览过。但是如果url在set中,它会告诉你:这个url应该已经出现了,但是我有2%的不确定性。注意这里的不确定性在你分配的内存足够大的情况下会变得非常小。
# bloom_filter.py
BIT_SIZE = 5000000
class BloomFilter:
def __init__(self):
# Initialize bloom filter, set size and all bits to 0
bit_array = bitarray(BIT_SIZE)
bit_array.setall(0)
self.bit_array = bit_array
def add(self, url):
# Add a url, and set points in bitarray to 1 (Points count is equal to hash funcs count.)
# Here use 7 hash functions.
point_list = self.get_postions(url)
for b in point_list:
self.bit_array[b] = 1
def contains(self, url):
# Check if a url is in a collection
point_list = self.get_postions(url)
result = True
for b in point_list:
result = result and self.bit_array[b]
return result
def get_postions(self, url):
# Get points positions in bit vector.
point1 = mmh3.hash(url, 41) % BIT_SIZE
point2 = mmh3.hash(url, 42) % BIT_SIZE
point3 = mmh3.hash(url, 43) % BIT_SIZE
point4 = mmh3.hash(url, 44) % BIT_SIZE
point5 = mmh3.hash(url, 45) % BIT_SIZE
point6 = mmh3.hash(url, 46) % BIT_SIZE
point7 = mmh3.hash(url, 47) % BIT_SIZE
return [point1, point2, point3, point4, point5, point6, point7]
BF的详细原理请参考我之前写的文章:Bloom Filter的原理与实现
建一张桌子
用户有价值的信息包括用户名、简介、行业、学院、专业、平台活动数据,如回答数、文章数、提问数、粉丝数、等等。
用户信息存储的表结构如下:
CREATE DATABASE `zhihu_user` /*!40100 DEFAULT CHARACTER SET utf8 */;
-- User base information table
CREATE TABLE `t_user` (
`uid` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(50) NOT NULL COMMENT '用户名',
`brief_info` varchar(400) COMMENT '个人简介',
`industry` varchar(50) COMMENT '所处行业',
`education` varchar(50) COMMENT '毕业院校',
`major` varchar(50) COMMENT '主修专业',
`answer_count` int(10) unsigned DEFAULT 0 COMMENT '回答数',
`article_count` int(10) unsigned DEFAULT 0 COMMENT '文章数',
`ask_question_count` int(10) unsigned DEFAULT 0 COMMENT '提问数',
`collection_count` int(10) unsigned DEFAULT 0 COMMENT '收藏数',
`follower_count` int(10) unsigned DEFAULT 0 COMMENT '被关注数',
`followed_count` int(10) unsigned DEFAULT 0 COMMENT '关注数',
`follow_live_count` int(10) unsigned DEFAULT 0 COMMENT '关注直播数',
`follow_topic_count` int(10) unsigned DEFAULT 0 COMMENT '关注话题数',
`follow_column_count` int(10) unsigned DEFAULT 0 COMMENT '关注专栏数',
`follow_question_count` int(10) unsigned DEFAULT 0 COMMENT '关注问题数',
`follow_collection_count` int(10) unsigned DEFAULT 0 COMMENT '关注收藏夹数',
`gmt_create` datetime NOT NULL COMMENT '创建时间',
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '最后一次编辑',
PRIMARY KEY (`uid`)
) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='用户基本信息表';
网页下载后,通过XPath解析,提取出用户各个维度的数据,最后保存到数据库中。
反爬虫策略 response-Headers
一般网站会从几个维度进行反爬:用户请求的Headers、用户行为、网站以及数据加载的方式。用户请求的Headers反爬虫是最常见的策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源网站的反盗链就是检测Referer)。
如果遇到这种反爬虫机制,可以直接给爬虫添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者修改Referer值为目标网站域名。对于检测header的反爬虫,在爬虫中修改或添加header很容易绕过。
cookies = {
"d_c0": "AECA7v-aPwqPTiIbemmIQ8abhJy7bdD2VgE=|1468847182",
"login": "NzM5ZDc2M2JkYzYwNDZlOGJlYWQ1YmI4OTg5NDhmMTY=|1480901173|9c296f424b32f241d1471203244eaf30729420f0",
"n_c": "1",
"q_c1": "395b12e529e541cbb400e9718395e346|1479808003000|1468847182000",
"l_cap_id": "NzI0MTQwZGY2NjQyNDQ1NThmYTY0MjJhYmU2NmExMGY=|1480901160|2e7a7faee3b3e8d0afb550e8e7b38d86c15a31bc",
"d_c0": "AECA7v-aPwqPTiIbemmIQ8abhJy7bdD2VgE=|1468847182",
"cap_id": "N2U1NmQwODQ1NjFiNGI2Yzg2YTE2NzJkOTU5N2E0NjI=|1480901160|fd59e2ed79faacc2be1010687d27dd559ec1552a"
}
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.98 Safari/537.3",
"Referer": "https://www.zhihu.com/"
}
r = requests.get(url, cookies = cookies, headers = headers)
反爬虫策略响应-代理IP池
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。
大部分网站都是前一种情况。在这种情况下,使用IP代理来解决它。这类代理ip爬虫经常用到,最好自己准备一个。有大量代理ip后,每次请求都可以换一个ip。这在requests或urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。目前知乎已经对爬虫进行了限制。如果是单个IP,系统会在一段时间内提示流量异常,无法继续爬取。因此,代理IP池非常关键。网上有一个免费的代理IP API:/free2016.txt
import requests
import random
class Proxy:
def __init__(self):
self.cache_ip_list = []
# Get random ip from free proxy api url.
def get_random_ip(self):
if not len(self.cache_ip_list):
api_url = 'http://api.xicidaili.com/free2016.txt'
try:
r = requests.get(api_url)
ip_list = r.text.split('\r\n')
self.cache_ip_list = ip_list
except Exception as e:
# Return null list when caught exception.
# In this case, crawler will not use proxy ip.
print e
return {}
proxy_ip = random.choice(self.cache_ip_list)
proxies = {'http': 'http://' + proxy_ip}
return proxies
跟进
爬虫源码:下载知乎-crawler后,通过pip安装相关的三方包,运行$ python crawler.py(喜欢的请点个star,看后续功能更新也方便)
运行截图:
查看全部
c爬虫抓取网页数据(几种-博客园爬虫的基本流程网络爬虫的抓取策略
)
原文:知乎 爬虫练习写在python-cpselvis-博客园
网络爬虫的基本工作流程如下:
爬虫的爬取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL的顺序也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
了解了爬虫的工作流程和爬取策略后,就可以开始实现爬虫了!那么如何在python中实现呢?
技术栈的基本实现
下面是伪代码
import Queue
initial_page = "https://www.zhihu.com/people/gaoming623"
url_queue = Queue.Queue()
seen = set()
seen.insert(initial_page)
url_queue.put(initial_page)
while(True): #一直进行
if url_queue.size()>0:
current_url = url_queue.get() #拿出队例中第一个的url
store(current_url) #把这个url代表的网页存储好
for next_url in extract_urls(current_url): #提取把这个url里链向的url
if next_url not in seen:
seen.put(next_url)
url_queue.put(next_url)
else:
break
如果直接处理上面的代码,直接运行,爬下整个知乎用户信息需要很长时间。毕竟,知乎 每月有 6000 万活跃用户。更不用说像谷歌这样的搜索引擎需要爬下整个网络。那么问题出在哪里呢?
布隆过滤器
需要爬取的网页太多,上面的代码太慢太慢了。假设全网有N个网站,那么分析判断的复杂度是N*log(N),因为所有网页都需要遍历一次,每次判断集合的时候,复杂度log(N) 是必需的。. OK,我知道python的set实现是hash-但是这样还是太慢了,至少内存使用效率不高。
通常的判断方式是什么?布隆过滤器。简单的说还是hash方法,但是它的特点是可以使用固定内存(不随url数增加)以O(1)的效率来判断url是否已经设置好可惜世界上没有免费的午餐,唯一的问题是如果url不在set中,BF可以100%确定url没有被浏览过。但是如果url在set中,它会告诉你:这个url应该已经出现了,但是我有2%的不确定性。注意这里的不确定性在你分配的内存足够大的情况下会变得非常小。
# bloom_filter.py
BIT_SIZE = 5000000
class BloomFilter:
def __init__(self):
# Initialize bloom filter, set size and all bits to 0
bit_array = bitarray(BIT_SIZE)
bit_array.setall(0)
self.bit_array = bit_array
def add(self, url):
# Add a url, and set points in bitarray to 1 (Points count is equal to hash funcs count.)
# Here use 7 hash functions.
point_list = self.get_postions(url)
for b in point_list:
self.bit_array[b] = 1
def contains(self, url):
# Check if a url is in a collection
point_list = self.get_postions(url)
result = True
for b in point_list:
result = result and self.bit_array[b]
return result
def get_postions(self, url):
# Get points positions in bit vector.
point1 = mmh3.hash(url, 41) % BIT_SIZE
point2 = mmh3.hash(url, 42) % BIT_SIZE
point3 = mmh3.hash(url, 43) % BIT_SIZE
point4 = mmh3.hash(url, 44) % BIT_SIZE
point5 = mmh3.hash(url, 45) % BIT_SIZE
point6 = mmh3.hash(url, 46) % BIT_SIZE
point7 = mmh3.hash(url, 47) % BIT_SIZE
return [point1, point2, point3, point4, point5, point6, point7]
BF的详细原理请参考我之前写的文章:Bloom Filter的原理与实现
建一张桌子
用户有价值的信息包括用户名、简介、行业、学院、专业、平台活动数据,如回答数、文章数、提问数、粉丝数、等等。
用户信息存储的表结构如下:
CREATE DATABASE `zhihu_user` /*!40100 DEFAULT CHARACTER SET utf8 */;
-- User base information table
CREATE TABLE `t_user` (
`uid` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(50) NOT NULL COMMENT '用户名',
`brief_info` varchar(400) COMMENT '个人简介',
`industry` varchar(50) COMMENT '所处行业',
`education` varchar(50) COMMENT '毕业院校',
`major` varchar(50) COMMENT '主修专业',
`answer_count` int(10) unsigned DEFAULT 0 COMMENT '回答数',
`article_count` int(10) unsigned DEFAULT 0 COMMENT '文章数',
`ask_question_count` int(10) unsigned DEFAULT 0 COMMENT '提问数',
`collection_count` int(10) unsigned DEFAULT 0 COMMENT '收藏数',
`follower_count` int(10) unsigned DEFAULT 0 COMMENT '被关注数',
`followed_count` int(10) unsigned DEFAULT 0 COMMENT '关注数',
`follow_live_count` int(10) unsigned DEFAULT 0 COMMENT '关注直播数',
`follow_topic_count` int(10) unsigned DEFAULT 0 COMMENT '关注话题数',
`follow_column_count` int(10) unsigned DEFAULT 0 COMMENT '关注专栏数',
`follow_question_count` int(10) unsigned DEFAULT 0 COMMENT '关注问题数',
`follow_collection_count` int(10) unsigned DEFAULT 0 COMMENT '关注收藏夹数',
`gmt_create` datetime NOT NULL COMMENT '创建时间',
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '最后一次编辑',
PRIMARY KEY (`uid`)
) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='用户基本信息表';
网页下载后,通过XPath解析,提取出用户各个维度的数据,最后保存到数据库中。
反爬虫策略 response-Headers
一般网站会从几个维度进行反爬:用户请求的Headers、用户行为、网站以及数据加载的方式。用户请求的Headers反爬虫是最常见的策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源网站的反盗链就是检测Referer)。
如果遇到这种反爬虫机制,可以直接给爬虫添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者修改Referer值为目标网站域名。对于检测header的反爬虫,在爬虫中修改或添加header很容易绕过。
cookies = {
"d_c0": "AECA7v-aPwqPTiIbemmIQ8abhJy7bdD2VgE=|1468847182",
"login": "NzM5ZDc2M2JkYzYwNDZlOGJlYWQ1YmI4OTg5NDhmMTY=|1480901173|9c296f424b32f241d1471203244eaf30729420f0",
"n_c": "1",
"q_c1": "395b12e529e541cbb400e9718395e346|1479808003000|1468847182000",
"l_cap_id": "NzI0MTQwZGY2NjQyNDQ1NThmYTY0MjJhYmU2NmExMGY=|1480901160|2e7a7faee3b3e8d0afb550e8e7b38d86c15a31bc",
"d_c0": "AECA7v-aPwqPTiIbemmIQ8abhJy7bdD2VgE=|1468847182",
"cap_id": "N2U1NmQwODQ1NjFiNGI2Yzg2YTE2NzJkOTU5N2E0NjI=|1480901160|fd59e2ed79faacc2be1010687d27dd559ec1552a"
}
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.98 Safari/537.3",
"Referer": "https://www.zhihu.com/"
}
r = requests.get(url, cookies = cookies, headers = headers)
反爬虫策略响应-代理IP池
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。
大部分网站都是前一种情况。在这种情况下,使用IP代理来解决它。这类代理ip爬虫经常用到,最好自己准备一个。有大量代理ip后,每次请求都可以换一个ip。这在requests或urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。目前知乎已经对爬虫进行了限制。如果是单个IP,系统会在一段时间内提示流量异常,无法继续爬取。因此,代理IP池非常关键。网上有一个免费的代理IP API:/free2016.txt
import requests
import random
class Proxy:
def __init__(self):
self.cache_ip_list = []
# Get random ip from free proxy api url.
def get_random_ip(self):
if not len(self.cache_ip_list):
api_url = 'http://api.xicidaili.com/free2016.txt'
try:
r = requests.get(api_url)
ip_list = r.text.split('\r\n')
self.cache_ip_list = ip_list
except Exception as e:
# Return null list when caught exception.
# In this case, crawler will not use proxy ip.
print e
return {}
proxy_ip = random.choice(self.cache_ip_list)
proxies = {'http': 'http://' + proxy_ip}
return proxies
跟进
爬虫源码:下载知乎-crawler后,通过pip安装相关的三方包,运行$ python crawler.py(喜欢的请点个star,看后续功能更新也方便)
运行截图:
c爬虫抓取网页数据(一下安装mysql需要屏蔽掉的代码:抓取网页数据格式 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-10-25 05:07
)
本文文章主要介绍python2.7详细实现爬虫网页数据。有一定的参考价值,感兴趣的朋友可以参考
最近刚学了Python,做了一个简单的爬虫。作为一个简单的demo,希望对我这样的初学者有所帮助。
代码使用python制作的爬虫2.7抓取51job上的职位名称、公司名称、薪水、发布时间等。
直接上代码。代码中的注释相当清楚。如果没有安装mysql,需要屏蔽相关代码:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
from bs4 import BeautifulSoup
import urllib
import urllib2
import codecs
import re
import time
import logging
import MySQLdb
class Jobs(object):
# 初始化
"""docstring for Jobs"""
def __init__(self):
super(Jobs, self).__init__()
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s')
#数据库的操作,没有mysql可以做屏蔽
self.db = MySQLdb.connect('127.0.0.1','root','rootroot','MySQL_Test',charset='utf8')
self.cursor = self.db.cursor()
#log日志的显示
self.logger = logging.getLogger("sjk")
self.logger.setLevel(level=logging.DEBUG)
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler = logging.FileHandler('log.txt')
handler.setFormatter(formatter)
handler.setLevel(logging.DEBUG)
self.logger.addHandler(handler)
self.logger.info('初始化完成')
# 模拟请求数据
def jobshtml(self, key, page='1'):
try:
self.logger.info('开始请求第' + page + '页')
#网页url
searchurl = "https://search.51job.com/list/040000,000000,0000,00,9,99,{key},2,{page}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare="
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:59.0) Gecko/20100101 Firefox/59.0'
#设置请求头
header = {'User-Agent': user_agent, 'Host': 'search.51job.com',
'Referer': 'https://www.51job.com/'}
#拼接url
finalUrl = searchurl.format(key=key, page=page)
request = urllib2.Request(finalUrl, headers=header)
response = urllib2.urlopen(request)
#等待网页加载完成
time.sleep(3)
#gbk格式解码
info = response.read().decode('gbk')
self.logger.info('请求网页网页')
self.decodeHtml(info=info, key=key, page=page)
except urllib2.HTTPError as e:
print e.reason
# 解析网页数据
def decodeHtml(self, info, key, page):
self.logger.info('开始解析网页数据')
#BeautifulSoup 解析网页
soup = BeautifulSoup(info, 'html.parser')
#找到class = t1 t2 t3 t4 t5 的标签数据
ps = soup.find_all(attrs={"class": re.compile(r'^t[1-5].*')})
#打开txt文件 a+ 代表追加
f = codecs.open(key + '.txt', 'a+', 'UTF-8')
#清除之前的数据信息
f.truncate()
f.write('\n------------' + page + '--------------\n')
count = 1
arr = []
#做一些字符串的处理,形成数据格式 iOS开发工程师 有限公司 深圳-南山区 0.9-1.6万/月 05-16
for pi in ps:
spe = " "
finalstr = pi.getText().strip()
arr.append(finalstr)
if count % 5 == 0:
#每一条数据插入数据库,如果没有安装mysql 可以将当前行注释掉
self.connectMySQL(arr=arr)
arr = []
spe = "\n"
writestr = finalstr + spe
count += 1
f.write(writestr)
f.close()
self.logger.info('解析完成')
#数据库操作 没有安装mysql 可以屏蔽掉
def connectMySQL(self,arr):
work=arr[0]
company=arr[1]
place=arr[2]
salary=arr[3]
time=arr[4]
query = "select * from Jobs_tab where \
company_name='%s' and work_name='%s' and work_place='%s' \
and salary='%s' and time='%s'" %(company,work,place,salary,time)
self.cursor.execute(query)
queryresult = self.cursor.fetchall()
#数据库中不存在就插入数据 存在就可以更新数据 不过我这边没有写
if len(queryresult) > 0:
sql = "insert into Jobs_tab(work_name,company_name,work_place,salary\
,time) values('%s','%s','%s','%s','%s')" %(work,company,place,salary,time)
try:
self.cursor.execute(sql)
self.db.commit()
except Exception as e:
self.logger.info('写入数据库失败')
#模拟登陆
# def login(self):
# data = {'action':'save','isread':'on','loginname':'18086514327','password':'kui4131sjk'}
# 开始抓取 主函数
def run(self, key):
# 只要前5页的数据 key代表搜索工做类型 这边我是用的ios page是页数
for x in xrange(1, 6):
self.jobshtml(key=key, page=str(x))
self.logger.info('写入数据库完成')
self.db.close()
if __name__ == '__main__':
Jobs().run(key='iOS')
这种方式抓取的网页数据格式如下:
查看全部
c爬虫抓取网页数据(一下安装mysql需要屏蔽掉的代码:抓取网页数据格式
)
本文文章主要介绍python2.7详细实现爬虫网页数据。有一定的参考价值,感兴趣的朋友可以参考
最近刚学了Python,做了一个简单的爬虫。作为一个简单的demo,希望对我这样的初学者有所帮助。
代码使用python制作的爬虫2.7抓取51job上的职位名称、公司名称、薪水、发布时间等。
直接上代码。代码中的注释相当清楚。如果没有安装mysql,需要屏蔽相关代码:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
from bs4 import BeautifulSoup
import urllib
import urllib2
import codecs
import re
import time
import logging
import MySQLdb
class Jobs(object):
# 初始化
"""docstring for Jobs"""
def __init__(self):
super(Jobs, self).__init__()
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s')
#数据库的操作,没有mysql可以做屏蔽
self.db = MySQLdb.connect('127.0.0.1','root','rootroot','MySQL_Test',charset='utf8')
self.cursor = self.db.cursor()
#log日志的显示
self.logger = logging.getLogger("sjk")
self.logger.setLevel(level=logging.DEBUG)
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler = logging.FileHandler('log.txt')
handler.setFormatter(formatter)
handler.setLevel(logging.DEBUG)
self.logger.addHandler(handler)
self.logger.info('初始化完成')
# 模拟请求数据
def jobshtml(self, key, page='1'):
try:
self.logger.info('开始请求第' + page + '页')
#网页url
searchurl = "https://search.51job.com/list/040000,000000,0000,00,9,99,{key},2,{page}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare="
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:59.0) Gecko/20100101 Firefox/59.0'
#设置请求头
header = {'User-Agent': user_agent, 'Host': 'search.51job.com',
'Referer': 'https://www.51job.com/'}
#拼接url
finalUrl = searchurl.format(key=key, page=page)
request = urllib2.Request(finalUrl, headers=header)
response = urllib2.urlopen(request)
#等待网页加载完成
time.sleep(3)
#gbk格式解码
info = response.read().decode('gbk')
self.logger.info('请求网页网页')
self.decodeHtml(info=info, key=key, page=page)
except urllib2.HTTPError as e:
print e.reason
# 解析网页数据
def decodeHtml(self, info, key, page):
self.logger.info('开始解析网页数据')
#BeautifulSoup 解析网页
soup = BeautifulSoup(info, 'html.parser')
#找到class = t1 t2 t3 t4 t5 的标签数据
ps = soup.find_all(attrs={"class": re.compile(r'^t[1-5].*')})
#打开txt文件 a+ 代表追加
f = codecs.open(key + '.txt', 'a+', 'UTF-8')
#清除之前的数据信息
f.truncate()
f.write('\n------------' + page + '--------------\n')
count = 1
arr = []
#做一些字符串的处理,形成数据格式 iOS开发工程师 有限公司 深圳-南山区 0.9-1.6万/月 05-16
for pi in ps:
spe = " "
finalstr = pi.getText().strip()
arr.append(finalstr)
if count % 5 == 0:
#每一条数据插入数据库,如果没有安装mysql 可以将当前行注释掉
self.connectMySQL(arr=arr)
arr = []
spe = "\n"
writestr = finalstr + spe
count += 1
f.write(writestr)
f.close()
self.logger.info('解析完成')
#数据库操作 没有安装mysql 可以屏蔽掉
def connectMySQL(self,arr):
work=arr[0]
company=arr[1]
place=arr[2]
salary=arr[3]
time=arr[4]
query = "select * from Jobs_tab where \
company_name='%s' and work_name='%s' and work_place='%s' \
and salary='%s' and time='%s'" %(company,work,place,salary,time)
self.cursor.execute(query)
queryresult = self.cursor.fetchall()
#数据库中不存在就插入数据 存在就可以更新数据 不过我这边没有写
if len(queryresult) > 0:
sql = "insert into Jobs_tab(work_name,company_name,work_place,salary\
,time) values('%s','%s','%s','%s','%s')" %(work,company,place,salary,time)
try:
self.cursor.execute(sql)
self.db.commit()
except Exception as e:
self.logger.info('写入数据库失败')
#模拟登陆
# def login(self):
# data = {'action':'save','isread':'on','loginname':'18086514327','password':'kui4131sjk'}
# 开始抓取 主函数
def run(self, key):
# 只要前5页的数据 key代表搜索工做类型 这边我是用的ios page是页数
for x in xrange(1, 6):
self.jobshtml(key=key, page=str(x))
self.logger.info('写入数据库完成')
self.db.close()
if __name__ == '__main__':
Jobs().run(key='iOS')
这种方式抓取的网页数据格式如下:

c爬虫抓取网页数据(简化人工操作的必要过程,本文分享一下获取交互信息的爬虫经历)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-10-24 08:03
删除线格式# C#获取动态网页中的数据
在实际工作需要中,编辑的文档需要获取历史地震信息,因此使用计算机语言获取是简化人工操作的必要过程。本文分享我第一次爬虫获取交互信息的经验!
操作流程 我要获取的信息如下图所示。通过填写不同的日期、经纬度、震级等,我可以搜索到想要的结果。
一开始,没有任何线索。查看网页的源代码无法找到搜索结果,所以我们首先要做的就是找到数据的位置。第一步:右键查看元素,点击网络,会出现下图所示的两个文件:
点击第一个文件,看到它的预览有我们想要的信息。Response 收录这部分代码,也就是我们想要的数据:
第二部分:查找URL、请求方法和参数。这部分信息收录在标题中:
第三步:C#编程获取网页,这里直接上代码
// An highlighted block
//url目标地址
string url = "网址";
//要提交的数据
string postString = "DISPLAY_TYPE=1&PAGEID=earthquake_subao&catalog_ALLDATASETS_RECORDCOUNT=catalog__default_default_default_key__default_default_default_key%3D65%3B"
+"&refreshComponentGuid=earthquake_subao_guid_catalog&begtime=2019-09-10&endtime=2019-10-10"
+"&minM=3&maxM=10&minLon=-180.0&maxLon=180.0&minLat=-90.0&maxLat=90.0"
+"&minDepths=0&maxDepths=1000&SEARCHREPORT_ID=catalog&WX_ISAJAXLOAD=true";
//这里即为传递的参数,可以用工具抓包分析,也可以自己分析,主要是form里面每一个name都要加进来
byte[] postData = Encoding.UTF8.GetBytes(postString);//编码,尤其是汉字,事先要看下抓取网页的编码方式
WebClient webClient = new WebClient();
webClient.Headers.Add("Content-Type", "application/x-www-form-urlencoded");//采取POST方式必须加的header,如果改为GET方式的话就去掉这句话即可
byte[] responseData = webClient.UploadData(url, "POST", postData);//得到返回字符流
string srcString = Encoding.UTF8.GetString(responseData);//解码
//解析获取到的网页
HtmlAgilityPack.HtmlDocument History_doc = new HtmlAgilityPack.HtmlDocument();
History_doc.LoadHtml(srcString);
下一步是阅读网页的内容。这是第一次写。感谢您的批评和指正!!! 查看全部
c爬虫抓取网页数据(简化人工操作的必要过程,本文分享一下获取交互信息的爬虫经历)
删除线格式# C#获取动态网页中的数据
在实际工作需要中,编辑的文档需要获取历史地震信息,因此使用计算机语言获取是简化人工操作的必要过程。本文分享我第一次爬虫获取交互信息的经验!
操作流程 我要获取的信息如下图所示。通过填写不同的日期、经纬度、震级等,我可以搜索到想要的结果。

一开始,没有任何线索。查看网页的源代码无法找到搜索结果,所以我们首先要做的就是找到数据的位置。第一步:右键查看元素,点击网络,会出现下图所示的两个文件:

点击第一个文件,看到它的预览有我们想要的信息。Response 收录这部分代码,也就是我们想要的数据:


第二部分:查找URL、请求方法和参数。这部分信息收录在标题中:


第三步:C#编程获取网页,这里直接上代码
// An highlighted block
//url目标地址
string url = "网址";
//要提交的数据
string postString = "DISPLAY_TYPE=1&PAGEID=earthquake_subao&catalog_ALLDATASETS_RECORDCOUNT=catalog__default_default_default_key__default_default_default_key%3D65%3B"
+"&refreshComponentGuid=earthquake_subao_guid_catalog&begtime=2019-09-10&endtime=2019-10-10"
+"&minM=3&maxM=10&minLon=-180.0&maxLon=180.0&minLat=-90.0&maxLat=90.0"
+"&minDepths=0&maxDepths=1000&SEARCHREPORT_ID=catalog&WX_ISAJAXLOAD=true";
//这里即为传递的参数,可以用工具抓包分析,也可以自己分析,主要是form里面每一个name都要加进来
byte[] postData = Encoding.UTF8.GetBytes(postString);//编码,尤其是汉字,事先要看下抓取网页的编码方式
WebClient webClient = new WebClient();
webClient.Headers.Add("Content-Type", "application/x-www-form-urlencoded");//采取POST方式必须加的header,如果改为GET方式的话就去掉这句话即可
byte[] responseData = webClient.UploadData(url, "POST", postData);//得到返回字符流
string srcString = Encoding.UTF8.GetString(responseData);//解码
//解析获取到的网页
HtmlAgilityPack.HtmlDocument History_doc = new HtmlAgilityPack.HtmlDocument();
History_doc.LoadHtml(srcString);
下一步是阅读网页的内容。这是第一次写。感谢您的批评和指正!!!
c爬虫抓取网页数据(零基础快速入门的学习路径——Python中爬虫相关)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-23 08:11
参考视频教程:
**Python爬虫工程师从入门到高级**
图片
互联网上的数据爆炸式增长,使用Python爬虫我们可以获得很多有价值的数据:
1. 爬取数据,进行市场调研和商业分析
抓取知乎优质回答,筛选每个话题下的最佳内容;爬取房产网站交易信息,分析房价走势,做不同区域的房价分析;爬取招聘网站 职位信息,分析各行业的人才需求和薪资水平。
2.作为机器学习和数据挖掘的原创数据
比如你想做一个推荐系统,那么你可以爬取更多维度的数据,做一个更好的模型。
3. 爬取优质资源:图片、文字、视频
爬取商品(店铺)评论和各种图片网站,获取图片资源和评论文字数据。
掌握正确的方法能够在短时间内抓取主流网站数据,其实很容易实现。
但建议您从一开始就有一个特定的目标。在目标的驱动下,您的学习将更加精准和高效。这是一个平滑的、从零开始的快速入门学习路径:
1.了解爬虫的基本原理和流程
2.Requests+Xpath实现一般爬虫例程
3.理解非结构化数据的存储
4.应对特殊的网站反爬虫措施
5.Scrapy 和 MongoDB,高级分布式
大多数爬虫都遵循“发送请求-获取页面-解析页面-提取并存储内容”的过程。这实际上模拟了使用浏览器获取网页信息的过程。
简单的说,我们向服务器发送请求后,会得到返回的页面。解析完页面后,我们就可以提取出我们想要的那部分信息,存放在指定的文档或数据库中。
这部分可以简单的了解一下HTTP协议和网页的基础知识,比如POST\GET、HTML、CSS、JS,简单了解一下,无需系统学习。
Python中有很多爬虫相关的包:urllib、requests、bs4、scrapy、pyspider等,建议从requests+Xpath入手。Requests 负责连接到 网站 并返回网页。Xpath 用于解析网页以方便提取数据。
如果你用过 BeautifulSoup,你会发现 Xpath 省去了很多麻烦。逐层检查元素代码的工作全部省略。掌握了之后,你会发现爬虫的基本套路都差不多。一般静态 网站 根本不是问题。小猪,豆瓣,尴尬百科,腾讯新闻等基本都可以用。
我们来看一个爬取豆瓣短评论的例子:
图片
选择第一条短评论,右键-》勾选,即可查看源码
图片
复制短评论信息的XPath信息
图片
通过定位,我们得到了第一个短评论XPath信息:
图片
如果我们想抓取大量的短评论,那么自然我们应该得到(复制)更多这样的XPath:
图片
观察第3条短注释1、2、的XPath,你会发现模式,只是后面的序号不同,正好对应短注释的序号。那么如果我们想抓取这个页面上的所有短评论信息,那么就不需要这个序列号了。
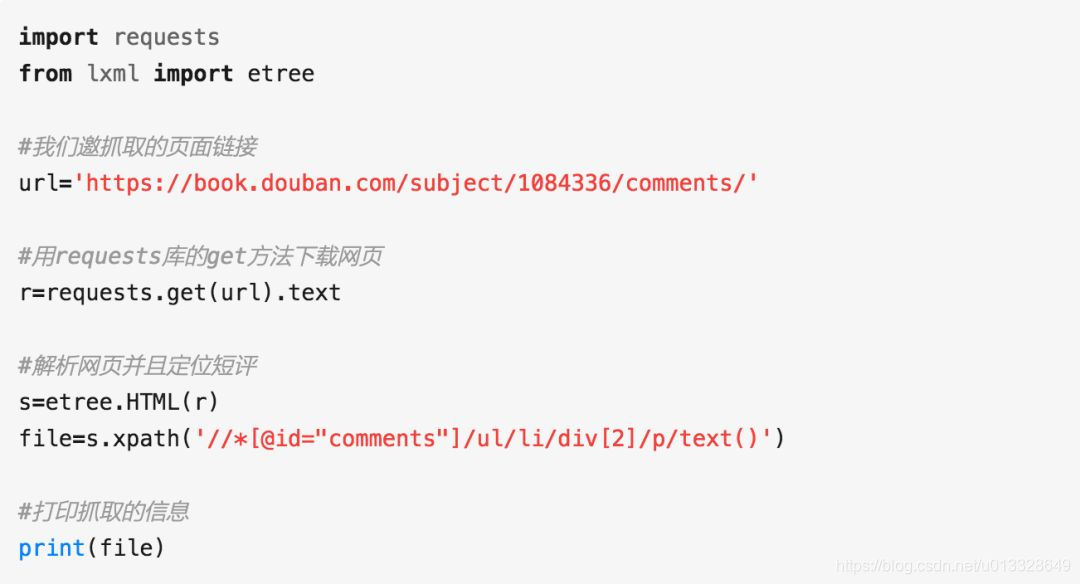
通过XPath信息,我们可以用简单的代码爬下来:
图片
图片
该页面的所有短评论信息都被爬取了
当然,如果你需要爬取异步加载的网站,可以学习浏览器抓包来分析真实请求,或者学习Selenium来实现自动爬取。这样,知乎、、TripAdvisor等网站基本没问题。
您还需要了解 Python 的基础知识,例如:
文件读写操作:用于读取参数和保存爬取的内容
list(列表)、dict(字典):用于对爬取的数据进行序列化
条件判断(if/else):解决爬虫中的判断是否执行
循环和迭代(for ……while):用于循环爬虫步骤
爬回来的数据可以直接以文档的形式存储在本地,也可以存储在数据库中。
当数据量较小时,可以直接通过Python语法或pandas方法将数据保存为文本或csv文件。继续上面的例子:
使用Python基础语言实现存储:
图片
使用pandas语言来存储:
图片
这两段代码都可以存储爬取的短评论信息,并将代码粘贴到爬取代码的后面。
图片
为该页面存储的短评论数据
当然,你可能会发现爬回来的数据不干净,可能有缺失、错误等,你也需要清理数据,可以学习pandas包,掌握以下知识点:
缺失值处理:删除或填充缺失数据行
重复值处理:判断和删除重复值
空格和异常值的处理:清除不必要的空格和极端和异常数据
数据分组:数据划分、功能分开执行、数据重组
爬取一页的数据没问题,但是我们通常要爬取多个页面。
这时候就需要看看翻页时url是如何变化的,或者以短评论页面为例,我们来看看多页url的区别:
图片
通过前四页,我们可以找到图案,不同的页面,但页面的序号被标记在最后。以抓取5个页面为例,只写一个循环更新页面地址即可。
图片
当然,爬取过程中也会有一些绝望,比如被网站屏蔽,比如各种奇怪的验证码,userAgent访问限制,各种动态加载等等。
遇到这些反爬虫方法,当然需要一些高级技巧来应对,比如访问频率控制、代理IP池的使用、抓包、验证码的OCR处理等等。
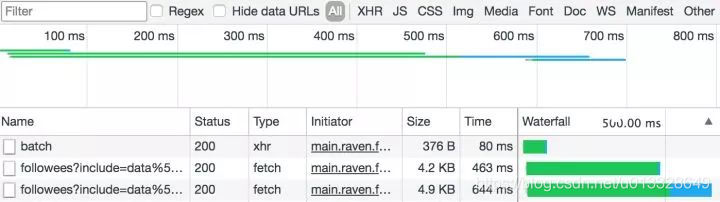
比如我们经常发现有些网站的URL在翻页后没有变化,通常是异步加载。我们使用开发者工具分析页面加载信息,通常可以获得意想不到的收获。
图片
通过开发者工具分析加载的信息。比如我们发现网页无法通过代码访问,我们可以尝试添加userAgent信息,甚至浏览器的cookie信息。
往往网站在高效开发和反爬虫之间偏向于前者,这也为爬虫提供了空间。掌握这些反爬虫技巧,大部分网站对你来说不再难。
Scrapy 和 MongoDB,高级分布式
掌握了之前的技术,一般量级的数据和代码基本没有问题,但是在非常复杂的情况下,可能还是做不到自己想做的。这时候,强大的scrapy框架就非常有用了。
Scrapy 是一个非常强大的爬虫框架。它不仅可以方便地构造请求,还拥有强大的选择器,可以轻松解析响应。不过,最让人惊喜的是它的超高性能,可以让你设计爬虫。,模块化。
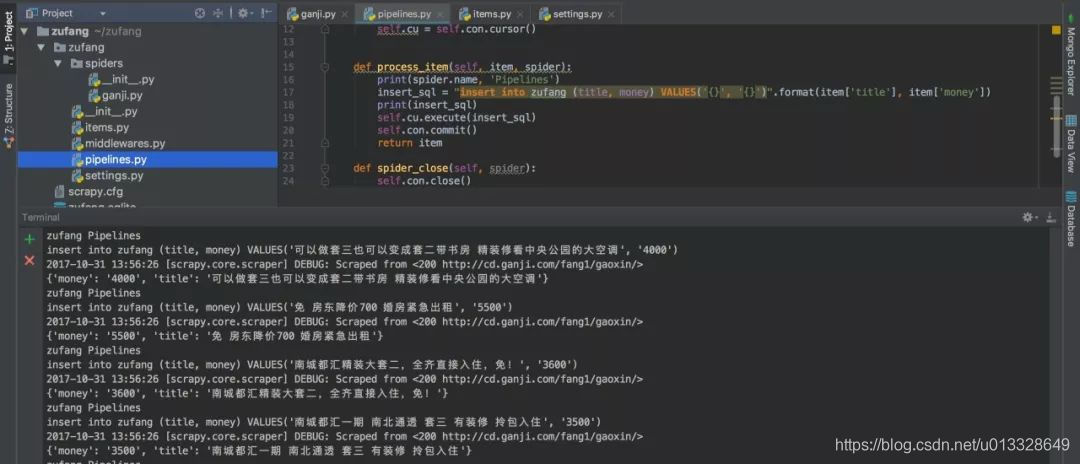
图片
出租信息的分布式爬取
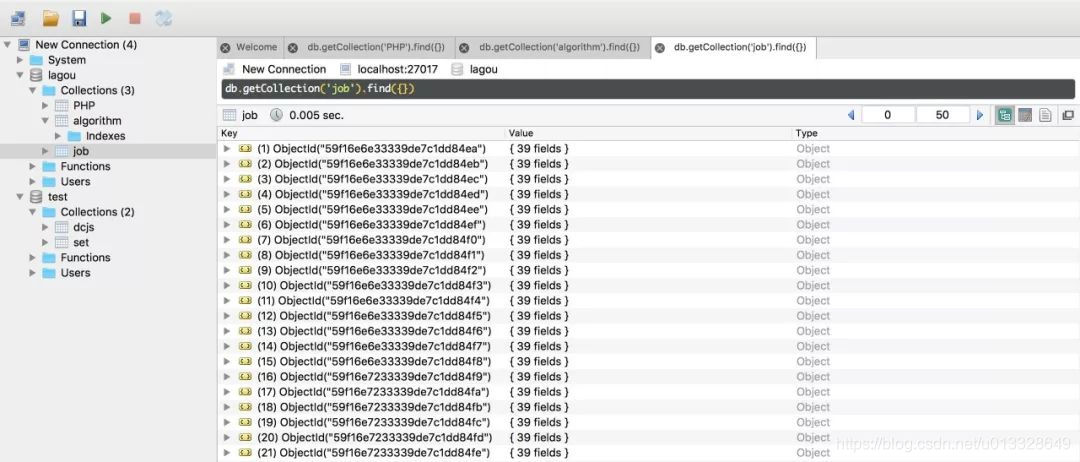
需要爬取的数据量很大,自然需要一个数据库。MongoDB 可以方便您存储大规模数据。因为这里要用到的数据库知识其实很简单,主要是如何存储数据,如何提取,需要的时候学习。
图片
MongoDB 存储作业信息
分布式这个东西听起来很吓人,但实际上,它是利用多线程的原理,让多个爬虫同时工作。你需要掌握Scrapy+MongoDB+Redis这三个工具。
Scrapy用于基本的页面爬取,MongoDB用于存储爬取的数据,Redis用于存储待爬取的网页队列,即任务队列。
这时候就已经可以写分布式爬虫了。
你看,有了这个学习路径,你已经可以成为一个老司机了,非常顺利。所以一开始尽量不要系统地啃东西,找个实际的项目(可以从豆瓣、小猪等简单的东西开始),直接开始。
因为爬虫技术不需要你系统地精通一门语言,也不需要非常先进的数据库技术。高效的姿势就是从实际项目中学习这些零散的知识点,保证每次都能学到。是最需要的部分。
当然,唯一的麻烦是在具体问题中,如何找到具体需要的那部分学习资源,如何筛选筛选,是很多初学者面临的一大难题。
不过不用担心,我们准备了非常系统的爬虫课程。除了为您提供清晰的学习路径,我们精选了最实用的学习资源和海量的主流爬虫案例库。在很短的学习时间内,你将能够很好地掌握爬虫技巧,得到你想要的数据。
《Python爬虫:入门+进阶》大纲
第 1 章:Python 爬虫入门
1、什么是爬虫
URL组合和翻页机制
网页源码结构及网页请求流程
爬虫的应用及基本原理
2、认识Python爬虫
Python爬虫环境搭建 查看全部
c爬虫抓取网页数据(零基础快速入门的学习路径——Python中爬虫相关)
参考视频教程:
**Python爬虫工程师从入门到高级**

图片
互联网上的数据爆炸式增长,使用Python爬虫我们可以获得很多有价值的数据:
1. 爬取数据,进行市场调研和商业分析
抓取知乎优质回答,筛选每个话题下的最佳内容;爬取房产网站交易信息,分析房价走势,做不同区域的房价分析;爬取招聘网站 职位信息,分析各行业的人才需求和薪资水平。
2.作为机器学习和数据挖掘的原创数据
比如你想做一个推荐系统,那么你可以爬取更多维度的数据,做一个更好的模型。
3. 爬取优质资源:图片、文字、视频
爬取商品(店铺)评论和各种图片网站,获取图片资源和评论文字数据。
掌握正确的方法能够在短时间内抓取主流网站数据,其实很容易实现。
但建议您从一开始就有一个特定的目标。在目标的驱动下,您的学习将更加精准和高效。这是一个平滑的、从零开始的快速入门学习路径:
1.了解爬虫的基本原理和流程
2.Requests+Xpath实现一般爬虫例程
3.理解非结构化数据的存储
4.应对特殊的网站反爬虫措施
5.Scrapy 和 MongoDB,高级分布式
大多数爬虫都遵循“发送请求-获取页面-解析页面-提取并存储内容”的过程。这实际上模拟了使用浏览器获取网页信息的过程。
简单的说,我们向服务器发送请求后,会得到返回的页面。解析完页面后,我们就可以提取出我们想要的那部分信息,存放在指定的文档或数据库中。
这部分可以简单的了解一下HTTP协议和网页的基础知识,比如POST\GET、HTML、CSS、JS,简单了解一下,无需系统学习。
Python中有很多爬虫相关的包:urllib、requests、bs4、scrapy、pyspider等,建议从requests+Xpath入手。Requests 负责连接到 网站 并返回网页。Xpath 用于解析网页以方便提取数据。
如果你用过 BeautifulSoup,你会发现 Xpath 省去了很多麻烦。逐层检查元素代码的工作全部省略。掌握了之后,你会发现爬虫的基本套路都差不多。一般静态 网站 根本不是问题。小猪,豆瓣,尴尬百科,腾讯新闻等基本都可以用。
我们来看一个爬取豆瓣短评论的例子:
图片
选择第一条短评论,右键-》勾选,即可查看源码
图片
复制短评论信息的XPath信息

图片
通过定位,我们得到了第一个短评论XPath信息:

图片
如果我们想抓取大量的短评论,那么自然我们应该得到(复制)更多这样的XPath:

图片
观察第3条短注释1、2、的XPath,你会发现模式,只是后面的序号不同,正好对应短注释的序号。那么如果我们想抓取这个页面上的所有短评论信息,那么就不需要这个序列号了。
通过XPath信息,我们可以用简单的代码爬下来:
图片

图片
该页面的所有短评论信息都被爬取了
当然,如果你需要爬取异步加载的网站,可以学习浏览器抓包来分析真实请求,或者学习Selenium来实现自动爬取。这样,知乎、、TripAdvisor等网站基本没问题。
您还需要了解 Python 的基础知识,例如:
文件读写操作:用于读取参数和保存爬取的内容
list(列表)、dict(字典):用于对爬取的数据进行序列化
条件判断(if/else):解决爬虫中的判断是否执行
循环和迭代(for ……while):用于循环爬虫步骤
爬回来的数据可以直接以文档的形式存储在本地,也可以存储在数据库中。
当数据量较小时,可以直接通过Python语法或pandas方法将数据保存为文本或csv文件。继续上面的例子:
使用Python基础语言实现存储:

图片
使用pandas语言来存储:

图片
这两段代码都可以存储爬取的短评论信息,并将代码粘贴到爬取代码的后面。

图片
为该页面存储的短评论数据
当然,你可能会发现爬回来的数据不干净,可能有缺失、错误等,你也需要清理数据,可以学习pandas包,掌握以下知识点:
缺失值处理:删除或填充缺失数据行
重复值处理:判断和删除重复值
空格和异常值的处理:清除不必要的空格和极端和异常数据
数据分组:数据划分、功能分开执行、数据重组
爬取一页的数据没问题,但是我们通常要爬取多个页面。
这时候就需要看看翻页时url是如何变化的,或者以短评论页面为例,我们来看看多页url的区别:

图片
通过前四页,我们可以找到图案,不同的页面,但页面的序号被标记在最后。以抓取5个页面为例,只写一个循环更新页面地址即可。

图片
当然,爬取过程中也会有一些绝望,比如被网站屏蔽,比如各种奇怪的验证码,userAgent访问限制,各种动态加载等等。
遇到这些反爬虫方法,当然需要一些高级技巧来应对,比如访问频率控制、代理IP池的使用、抓包、验证码的OCR处理等等。
比如我们经常发现有些网站的URL在翻页后没有变化,通常是异步加载。我们使用开发者工具分析页面加载信息,通常可以获得意想不到的收获。
图片
通过开发者工具分析加载的信息。比如我们发现网页无法通过代码访问,我们可以尝试添加userAgent信息,甚至浏览器的cookie信息。
往往网站在高效开发和反爬虫之间偏向于前者,这也为爬虫提供了空间。掌握这些反爬虫技巧,大部分网站对你来说不再难。
Scrapy 和 MongoDB,高级分布式
掌握了之前的技术,一般量级的数据和代码基本没有问题,但是在非常复杂的情况下,可能还是做不到自己想做的。这时候,强大的scrapy框架就非常有用了。
Scrapy 是一个非常强大的爬虫框架。它不仅可以方便地构造请求,还拥有强大的选择器,可以轻松解析响应。不过,最让人惊喜的是它的超高性能,可以让你设计爬虫。,模块化。
图片
出租信息的分布式爬取
需要爬取的数据量很大,自然需要一个数据库。MongoDB 可以方便您存储大规模数据。因为这里要用到的数据库知识其实很简单,主要是如何存储数据,如何提取,需要的时候学习。
图片
MongoDB 存储作业信息
分布式这个东西听起来很吓人,但实际上,它是利用多线程的原理,让多个爬虫同时工作。你需要掌握Scrapy+MongoDB+Redis这三个工具。
Scrapy用于基本的页面爬取,MongoDB用于存储爬取的数据,Redis用于存储待爬取的网页队列,即任务队列。
这时候就已经可以写分布式爬虫了。
你看,有了这个学习路径,你已经可以成为一个老司机了,非常顺利。所以一开始尽量不要系统地啃东西,找个实际的项目(可以从豆瓣、小猪等简单的东西开始),直接开始。
因为爬虫技术不需要你系统地精通一门语言,也不需要非常先进的数据库技术。高效的姿势就是从实际项目中学习这些零散的知识点,保证每次都能学到。是最需要的部分。
当然,唯一的麻烦是在具体问题中,如何找到具体需要的那部分学习资源,如何筛选筛选,是很多初学者面临的一大难题。
不过不用担心,我们准备了非常系统的爬虫课程。除了为您提供清晰的学习路径,我们精选了最实用的学习资源和海量的主流爬虫案例库。在很短的学习时间内,你将能够很好地掌握爬虫技巧,得到你想要的数据。
《Python爬虫:入门+进阶》大纲
第 1 章:Python 爬虫入门
1、什么是爬虫
URL组合和翻页机制
网页源码结构及网页请求流程
爬虫的应用及基本原理
2、认识Python爬虫
Python爬虫环境搭建
c爬虫抓取网页数据(阿里云数据库ApsaraDB(42)(组图)网页显示)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-23 04:06
阿里云>云栖社区>主题图>P>Crawler抓取网页指定数据库
推荐活动:
更多优惠>
当前主题:爬虫爬取网页指定数据库添加到采集夹
相关话题:
爬虫爬取网页指定数据库相关的博客。查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
【网络爬虫】使用node.jscheerio爬取网页数据
作者:自娱自乐 5358人浏览评论:05年前
您是想自动从网页中抓取一些数据,还是想将从某个博客中提取的一堆数据转换为结构化数据?有没有现有的 API 来检索数据?!!!!@#$@#$... 可以解决网页爬虫就好了。什么是网络爬虫?你可能会问。. . 网络爬虫是以编程方式(通常无需浏览器参与)检索网页内容。
阅读全文
使用Python爬虫抓取免费代理IP
作者:小技术专家 2872人浏览评论:03年前
不知道大家有没有遇到过“访问频率太高”之类的网站提示。我们需要等待一段时间或输入验证码才能解锁,但此后仍会出现这种情况。出现这种现象的原因是我们要爬取的网页采取了反爬虫措施。比如某个ip单位时间请求一个网页的次数过多,服务器就会拒绝服务。在这种情况下,
阅读全文
爬取网页数据分析
作者:y0umer606 浏览评论人数:010年前
发表于 2006-05-24 14:04 北极燕鸥阅读(9793) 评论(42) 编辑采集类别:C#编程自动阅读其他网站网页显示信息类似于a爬虫程序,比如我们有一个系统提取百度网站歌曲搜索排名分析系统
阅读全文
抓取网页数据分析(c#)
作者:wenvi_wu1489 浏览评论人数:012年前
其他网站网页上显示的信息是通过程序自动读取的,类似于爬虫程序。比如我们有一个系统来提取百度网站歌曲搜索排名。分析系统根据获得的数据进行数据分析。为企业提供参考数据。为了完成上述需求,我们需要模拟浏览器浏览网页,并获取页面的数据进行分析。
阅读全文
如何使用 Python 抓取数据?(一)网页抓取
作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的消息。很多评论都是来自读者的提问。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
爬虫和 urllib 库概述(一)
作者:蓝の流星VIP1588人浏览评论:03年前
1 爬虫概述(1)互联网爬虫是一种根据Url抓取网页并获取有用信息的程序(2)抓取网页解析数据的核心任务。难点:爬虫与反的博弈-crawlers(3)爬虫语言php多进程多线程支持不好。Java目前对java爬虫的需求旺盛,但是代码臃肿,重构成本高。
阅读全文
一个小型网络爬虫系统的架构设计
作者:技术组合 902人浏览评论:03年前
一个小型网络爬虫系统的架构设计。网络爬虫服务是互联网上经常使用的服务。在搜索引擎中,蜘蛛(网络爬虫)是必不可少的核心服务。搜索引擎衡量的四个指标“多、快、准、新”中,多、快、新都是对蜘蛛的要求。google、baidu等搜索引擎公司维护
阅读全文
Scrapy分布式、去重增量爬虫的开发设计
作者:技术小能手8758人浏览评论:03年前
基于python的分布式房屋数据采集系统为数据的进一步应用提供数据支持,即房屋推荐系统。本课题致力于解决单进程单机爬虫的瓶颈,创建基于Redis分布式多爬虫共享队列的主题爬虫。本系统使用python开发的Scrapy框架开发,使用Xpath
阅读全文 查看全部
c爬虫抓取网页数据(阿里云数据库ApsaraDB(42)(组图)网页显示)
阿里云>云栖社区>主题图>P>Crawler抓取网页指定数据库

推荐活动:
更多优惠>
当前主题:爬虫爬取网页指定数据库添加到采集夹
相关话题:
爬虫爬取网页指定数据库相关的博客。查看更多博客
云数据库产品概述

作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
【网络爬虫】使用node.jscheerio爬取网页数据

作者:自娱自乐 5358人浏览评论:05年前
您是想自动从网页中抓取一些数据,还是想将从某个博客中提取的一堆数据转换为结构化数据?有没有现有的 API 来检索数据?!!!!@#$@#$... 可以解决网页爬虫就好了。什么是网络爬虫?你可能会问。. . 网络爬虫是以编程方式(通常无需浏览器参与)检索网页内容。
阅读全文
使用Python爬虫抓取免费代理IP

作者:小技术专家 2872人浏览评论:03年前
不知道大家有没有遇到过“访问频率太高”之类的网站提示。我们需要等待一段时间或输入验证码才能解锁,但此后仍会出现这种情况。出现这种现象的原因是我们要爬取的网页采取了反爬虫措施。比如某个ip单位时间请求一个网页的次数过多,服务器就会拒绝服务。在这种情况下,
阅读全文
爬取网页数据分析


作者:y0umer606 浏览评论人数:010年前
发表于 2006-05-24 14:04 北极燕鸥阅读(9793) 评论(42) 编辑采集类别:C#编程自动阅读其他网站网页显示信息类似于a爬虫程序,比如我们有一个系统提取百度网站歌曲搜索排名分析系统
阅读全文
抓取网页数据分析(c#)

作者:wenvi_wu1489 浏览评论人数:012年前
其他网站网页上显示的信息是通过程序自动读取的,类似于爬虫程序。比如我们有一个系统来提取百度网站歌曲搜索排名。分析系统根据获得的数据进行数据分析。为企业提供参考数据。为了完成上述需求,我们需要模拟浏览器浏览网页,并获取页面的数据进行分析。
阅读全文
如何使用 Python 抓取数据?(一)网页抓取


作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的消息。很多评论都是来自读者的提问。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
爬虫和 urllib 库概述(一)

作者:蓝の流星VIP1588人浏览评论:03年前
1 爬虫概述(1)互联网爬虫是一种根据Url抓取网页并获取有用信息的程序(2)抓取网页解析数据的核心任务。难点:爬虫与反的博弈-crawlers(3)爬虫语言php多进程多线程支持不好。Java目前对java爬虫的需求旺盛,但是代码臃肿,重构成本高。
阅读全文
一个小型网络爬虫系统的架构设计

作者:技术组合 902人浏览评论:03年前
一个小型网络爬虫系统的架构设计。网络爬虫服务是互联网上经常使用的服务。在搜索引擎中,蜘蛛(网络爬虫)是必不可少的核心服务。搜索引擎衡量的四个指标“多、快、准、新”中,多、快、新都是对蜘蛛的要求。google、baidu等搜索引擎公司维护
阅读全文
Scrapy分布式、去重增量爬虫的开发设计

作者:技术小能手8758人浏览评论:03年前
基于python的分布式房屋数据采集系统为数据的进一步应用提供数据支持,即房屋推荐系统。本课题致力于解决单进程单机爬虫的瓶颈,创建基于Redis分布式多爬虫共享队列的主题爬虫。本系统使用python开发的Scrapy框架开发,使用Xpath
阅读全文
c爬虫抓取网页数据(Python却是最常用的,你知道为什么吗?和神龙IP)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-10-23 01:10
说起网络爬虫,相信大家都不陌生。爬虫可以爬取某个网站或者某个应用的内容,提取有用的价值信息。可以使用多种编程语言来实现爬虫,但最常用的是Python。你知道为什么吗?一起来看看神龙IP吧~
与C、Python 和C 相比Python 是C 开发的语言,但在使用方面,Python 的库完整方便,而C 语言则麻烦很多。要实现同样的功能,Python 只需要 10 行代码,而 C 语言可能需要 100 行甚至更多。但在运行速度方面,C语言更胜一筹。
对比Python和Java,Java有很多解析器,对网页解析的支持非常好。Java 也有爬虫相关的库,但没有 Python 多。不过就爬虫的效果而言,Java和Python都可以做到,只是工程量不同,实现的方式也不同。如果需要处理复杂的网页,解析网页内容生成结构化数据,或者精细解析网页内容,java会更合适。
Python 和其他语言没有本质区别。优势在于Python语法简单明了,开发效率高。另外,python语言的流行还有几个原因:
1. 抓取网页的界面简单;
与其他动态脚本语言相比,Python 提供了更完整的 Web 文档访问 API;与其他静态编程语言相比,Python 拥有更简洁的网页抓取界面。
2.强大的第三方库
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这时候就需要模拟User Agent的行为来构造合适的请求,比如模拟用户登录,模拟Session/Cookie的存储和设置。Python 中有出色的第三方包可以帮助您完成它,例如 Requests 或 Mechanize。
3.数据处理快捷方便
抓取到的网页通常需要进行处理,例如过滤Html标签、提取文本等。Python 的 Beautiful Soup 提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。其实很多语言和工具都可以做到以上功能,但是Python可以做到最快最干净。 查看全部
c爬虫抓取网页数据(Python却是最常用的,你知道为什么吗?和神龙IP)
说起网络爬虫,相信大家都不陌生。爬虫可以爬取某个网站或者某个应用的内容,提取有用的价值信息。可以使用多种编程语言来实现爬虫,但最常用的是Python。你知道为什么吗?一起来看看神龙IP吧~

与C、Python 和C 相比Python 是C 开发的语言,但在使用方面,Python 的库完整方便,而C 语言则麻烦很多。要实现同样的功能,Python 只需要 10 行代码,而 C 语言可能需要 100 行甚至更多。但在运行速度方面,C语言更胜一筹。
对比Python和Java,Java有很多解析器,对网页解析的支持非常好。Java 也有爬虫相关的库,但没有 Python 多。不过就爬虫的效果而言,Java和Python都可以做到,只是工程量不同,实现的方式也不同。如果需要处理复杂的网页,解析网页内容生成结构化数据,或者精细解析网页内容,java会更合适。
Python 和其他语言没有本质区别。优势在于Python语法简单明了,开发效率高。另外,python语言的流行还有几个原因:
1. 抓取网页的界面简单;
与其他动态脚本语言相比,Python 提供了更完整的 Web 文档访问 API;与其他静态编程语言相比,Python 拥有更简洁的网页抓取界面。
2.强大的第三方库
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这时候就需要模拟User Agent的行为来构造合适的请求,比如模拟用户登录,模拟Session/Cookie的存储和设置。Python 中有出色的第三方包可以帮助您完成它,例如 Requests 或 Mechanize。
3.数据处理快捷方便
抓取到的网页通常需要进行处理,例如过滤Html标签、提取文本等。Python 的 Beautiful Soup 提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。其实很多语言和工具都可以做到以上功能,但是Python可以做到最快最干净。
c爬虫抓取网页数据(蜘蛛协议风铃虫的原理简单使用提取器的作用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-10-21 11:15
风铃介绍
风铃是一款轻量级爬虫工具,像风铃一样灵敏,像蜘蛛一样敏捷,可以感知任何微小的风和草,轻松抓取网络内容。是一个对目标服务器比较友好的蜘蛛程序。内置20多个常用或不常用的浏览器标识,可自动处理cookies和网页源信息,轻松绕过服务器限制,智能调整请求间隔,动态调整请求频率,防止干扰目标服务器。此外,Windchime 也是一个非常人性化的工具。它提供了大量的链接提取器和内容提取器,让用户可以根据自己的需要快速配置,甚至提供启动请求地址来配置自己的爬虫。同时,Windchime 还开放了很多自定义界面,让高级用户可以根据需要自定义爬虫功能。最后,风铃自然也支持分布式和集群功能,让你突破单机环境的束缚,释放你的爬虫能力。可以说风铃几乎可以抓取当前网站中的所有内容。
【声明】请不要在任何可能违反法律和道德约束的工作中使用风铃。请友好使用风铃,遵守蜘蛛协议,不要将风铃用于任何非法用途。如果您选择使用风铃,即表示您遵守本协议。作者不承担因您违反本协议而造成的任何法律风险和损失,一切后果由您自行承担。
快速使用
com.yishuifengxiao.common
crawler
2.2.0
交流群:
(群号624646260)
使用简单
从雅虎财经内容页面中提取电子货币名称
// 创建一个提取属性规则
// 该提取规则标识XPATH表示使用XPATH提取器进行提取,
// 该XPATH提取器的XPATH表达式为 //h1/text() , 该提取提取器的作用顺序是0
ExtractFieldRule extractFieldRule = new ExtractFieldRule(Rule.XPATH, "//h1/text()", "", 0);
// 创建一个提取项
ExtractRule extractRule = new ExtractRule();
extractRule
// 提取项代码,不能为空,同一组提取规则之内每一个提取项的编码必须唯一
.setCode("code")
// 提取项名字,可以不设置
.setName("加密电子货币名字")
// 设置提取属性规则
.setRules(Arrays.asList(extractFieldRule));
// 创建一个风铃虫实例
Crawler crawler = CrawlerBuilder.create()
// 风铃虫的起始链接
.startUrl("https://hk.finance.yahoo.com/cryptocurrencies")
// 风铃虫会将请求到的网页中的URL先全部提取出来
// 然后将匹配链接提取规则的链接过滤出来,放入请求池中
// 请求池中的链接会作为下次抓取请求的种子链接
// 可以以添加多个链接提取规则,多个规则之间是并列(或连接)的关系
// 如果不设置则表示提取链接中所有包含域名关键字(例如此例中的yahoo)的链接放入链接池
// 此例中表示符合该正则表达式的链接都会被提取出来
.addLinkRule(new MatcherRule(Pattern.REGEX, "https://hk.finance.yahoo.com/quote/.+"))
// 内容页地址规则是告诉风铃虫哪些页面是内容页
// 对于复杂情况下,可以与 内容匹配规则 配合使用
// 只有符合内容页规则的页面才会被提取数据
// 对于非内容页,风铃虫不会尝试从中提取数据
// 此例中表示符合该正则表达式的网页都是内容页,风铃虫会从这些页面里提取数据
.contentPageRule(new MatcherRule(Pattern.REGEX, "https://hk.finance.yahoo.com/quote/.+"))
// 风铃虫可以设置多个提取项,这里为了演示只设置了一个提取项
// 增加一个提取项规则
.addExtractRule(extractRule)
// 请求间隔时间
// 如果不设置则使用默认时间10秒,此值是为了防止抓取频率太高被服务器封杀
.interval(3000)// 每次进行爬取时的平均间隔时间,单位为毫秒,
.creatCrawler();
// 启动爬虫实例
crawler.start();
// 这里没有设置信息输出器,表示使用默认的信息输出器
// 默认的信息输出器使用的logback日志输出方法,因此需要看控制台信息
// 由于风铃虫是异步运行的,所以演示时这里加入循环
while (Statu.STOP != crawler.getStatu()) {
try {
Thread.sleep(1000 * 20);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
上面例子的功能是在雅虎财经的内容页面上提取电子货币的名称。用户若想提取其他信息,只需根据规则配置其他提取规则即可。
请注意,以上示例仅供学习和演示使用,Windchime 用户在抓取网页内容时应严格遵守相关法律法规和目标网站 的蜘蛛协议
风铃原理
风铃的原理很简单,主要由资源调度器、网页下载器、链接解析器、内容解析器、信息输出器组成。
它们的作用和功能如下:
链接解析器由一系列链接提取器组成。目前,链接提取器主要支持常规提取。
内容解析器由一系列内容提取器组成。不同的内容提取器功能不同,适用于不同的分析场景,支持重复、循环等多种提取器的多种组合。
上述组件均提供了自定义配置接口,方便用户根据实际需求进行自定义配置,满足各种复杂甚至异常场景的需求。
内置的风铃内容提取器包括:
原文抽取器、中文抽取器、常量抽取器、CSS内容抽取器、CSS文本抽取器、邮箱抽取器、号码抽取器、正则抽取器、字符删除抽取器、字符替换抽取器、字符串截取抽取器、XPATH抽取器数组截取...
在提取文本内容时,用户可以自由组合这些提取器来提取他们需要的内容。关于提取器的更多具体用法,请参考内容提取器的使用。
Windchime 的内置浏览器标志为:
Google Chrome(windows版、linux版) Opera浏览器(windows版、MAC版) Firefox(windows版、linux版、MAC版) IE浏览器(IE9、IE11)EDAG Safari浏览器(windows版) , MAC 版)...
抓取js渲染网站
核心代码如下:
Crawler crawler = ...
crawler .setDownloader(new SeleniumDownloader("C:\\Users\\yishui\\Desktop\\geckodriver\\win32.exe",3000L))
分布式支持
核心代码如下:
....
//省略其他代码
....
//创建redis资源调度器
Scheduler scheduler=new RedisScheduler("唯一的名字",redisTemplate)
//创建一个redis资源缓存器
RequestCache requestCache = new RedisRequestCache(redisTemplate);
crawler
.setRequestCache(requestCache) //设置使用redis资源缓存器
.setScheduler(scheduler); //设置使用redis资源调度器
....
//省略其他代码
....
//启动爬虫实例
crawler.start();
状态监控
风铃还提供强大的状态监控和事件监控功能。通过状态监听器和事件监听器,风铃让你实时了解任务的运行状态,实时控制实例运行过程中遇到的各种问题,真正做到洞察运行情况任务,方便操作和维护。
解析模拟器
由于风铃强大的解析功能,规则的定义非常灵活,为了直观了解配置的规则定义的作用,风铃提供了解析模拟器,让用户快速了解规则定义的效果自己设置的符合预期目标,及时调整规则定义,方便风铃实例的配置。
风铃平台效果演示
配置基本信息
配置爬虫名称、使用线程数、超时停止时间
配置链接爬取信息
配置爬虫的起始种子链接和从网页里提取下一次抓取时的链接的提取规则
配置站点信息
此步骤一般可以省略,但是对于某些会校验cookie和请求头参数的网站,此配置非常有用
提取项目配置
配置需要从网站里提取出来的数据,例如新闻标题和网页正文等信息
属性抽取配置
调用内容提取器进行任意组合,以根据需要提取出需要的数据
属性抽取测试
提前检查提取项的配置是否正确,提取的数据是否符合预期目标
相关资源的链接
文件地址:
API 文档:
官方文件: 查看全部
c爬虫抓取网页数据(蜘蛛协议风铃虫的原理简单使用提取器的作用)
风铃介绍
风铃是一款轻量级爬虫工具,像风铃一样灵敏,像蜘蛛一样敏捷,可以感知任何微小的风和草,轻松抓取网络内容。是一个对目标服务器比较友好的蜘蛛程序。内置20多个常用或不常用的浏览器标识,可自动处理cookies和网页源信息,轻松绕过服务器限制,智能调整请求间隔,动态调整请求频率,防止干扰目标服务器。此外,Windchime 也是一个非常人性化的工具。它提供了大量的链接提取器和内容提取器,让用户可以根据自己的需要快速配置,甚至提供启动请求地址来配置自己的爬虫。同时,Windchime 还开放了很多自定义界面,让高级用户可以根据需要自定义爬虫功能。最后,风铃自然也支持分布式和集群功能,让你突破单机环境的束缚,释放你的爬虫能力。可以说风铃几乎可以抓取当前网站中的所有内容。
【声明】请不要在任何可能违反法律和道德约束的工作中使用风铃。请友好使用风铃,遵守蜘蛛协议,不要将风铃用于任何非法用途。如果您选择使用风铃,即表示您遵守本协议。作者不承担因您违反本协议而造成的任何法律风险和损失,一切后果由您自行承担。
快速使用
com.yishuifengxiao.common
crawler
2.2.0
交流群:

(群号624646260)
使用简单
从雅虎财经内容页面中提取电子货币名称
// 创建一个提取属性规则
// 该提取规则标识XPATH表示使用XPATH提取器进行提取,
// 该XPATH提取器的XPATH表达式为 //h1/text() , 该提取提取器的作用顺序是0
ExtractFieldRule extractFieldRule = new ExtractFieldRule(Rule.XPATH, "//h1/text()", "", 0);
// 创建一个提取项
ExtractRule extractRule = new ExtractRule();
extractRule
// 提取项代码,不能为空,同一组提取规则之内每一个提取项的编码必须唯一
.setCode("code")
// 提取项名字,可以不设置
.setName("加密电子货币名字")
// 设置提取属性规则
.setRules(Arrays.asList(extractFieldRule));
// 创建一个风铃虫实例
Crawler crawler = CrawlerBuilder.create()
// 风铃虫的起始链接
.startUrl("https://hk.finance.yahoo.com/cryptocurrencies";)
// 风铃虫会将请求到的网页中的URL先全部提取出来
// 然后将匹配链接提取规则的链接过滤出来,放入请求池中
// 请求池中的链接会作为下次抓取请求的种子链接
// 可以以添加多个链接提取规则,多个规则之间是并列(或连接)的关系
// 如果不设置则表示提取链接中所有包含域名关键字(例如此例中的yahoo)的链接放入链接池
// 此例中表示符合该正则表达式的链接都会被提取出来
.addLinkRule(new MatcherRule(Pattern.REGEX, "https://hk.finance.yahoo.com/quote/.+";))
// 内容页地址规则是告诉风铃虫哪些页面是内容页
// 对于复杂情况下,可以与 内容匹配规则 配合使用
// 只有符合内容页规则的页面才会被提取数据
// 对于非内容页,风铃虫不会尝试从中提取数据
// 此例中表示符合该正则表达式的网页都是内容页,风铃虫会从这些页面里提取数据
.contentPageRule(new MatcherRule(Pattern.REGEX, "https://hk.finance.yahoo.com/quote/.+";))
// 风铃虫可以设置多个提取项,这里为了演示只设置了一个提取项
// 增加一个提取项规则
.addExtractRule(extractRule)
// 请求间隔时间
// 如果不设置则使用默认时间10秒,此值是为了防止抓取频率太高被服务器封杀
.interval(3000)// 每次进行爬取时的平均间隔时间,单位为毫秒,
.creatCrawler();
// 启动爬虫实例
crawler.start();
// 这里没有设置信息输出器,表示使用默认的信息输出器
// 默认的信息输出器使用的logback日志输出方法,因此需要看控制台信息
// 由于风铃虫是异步运行的,所以演示时这里加入循环
while (Statu.STOP != crawler.getStatu()) {
try {
Thread.sleep(1000 * 20);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
上面例子的功能是在雅虎财经的内容页面上提取电子货币的名称。用户若想提取其他信息,只需根据规则配置其他提取规则即可。
请注意,以上示例仅供学习和演示使用,Windchime 用户在抓取网页内容时应严格遵守相关法律法规和目标网站 的蜘蛛协议
风铃原理

风铃的原理很简单,主要由资源调度器、网页下载器、链接解析器、内容解析器、信息输出器组成。
它们的作用和功能如下:
链接解析器由一系列链接提取器组成。目前,链接提取器主要支持常规提取。
内容解析器由一系列内容提取器组成。不同的内容提取器功能不同,适用于不同的分析场景,支持重复、循环等多种提取器的多种组合。
上述组件均提供了自定义配置接口,方便用户根据实际需求进行自定义配置,满足各种复杂甚至异常场景的需求。
内置的风铃内容提取器包括:
原文抽取器、中文抽取器、常量抽取器、CSS内容抽取器、CSS文本抽取器、邮箱抽取器、号码抽取器、正则抽取器、字符删除抽取器、字符替换抽取器、字符串截取抽取器、XPATH抽取器数组截取...
在提取文本内容时,用户可以自由组合这些提取器来提取他们需要的内容。关于提取器的更多具体用法,请参考内容提取器的使用。
Windchime 的内置浏览器标志为:
Google Chrome(windows版、linux版) Opera浏览器(windows版、MAC版) Firefox(windows版、linux版、MAC版) IE浏览器(IE9、IE11)EDAG Safari浏览器(windows版) , MAC 版)...
抓取js渲染网站
核心代码如下:
Crawler crawler = ...
crawler .setDownloader(new SeleniumDownloader("C:\\Users\\yishui\\Desktop\\geckodriver\\win32.exe",3000L))
分布式支持
核心代码如下:
....
//省略其他代码
....
//创建redis资源调度器
Scheduler scheduler=new RedisScheduler("唯一的名字",redisTemplate)
//创建一个redis资源缓存器
RequestCache requestCache = new RedisRequestCache(redisTemplate);
crawler
.setRequestCache(requestCache) //设置使用redis资源缓存器
.setScheduler(scheduler); //设置使用redis资源调度器
....
//省略其他代码
....
//启动爬虫实例
crawler.start();
状态监控
风铃还提供强大的状态监控和事件监控功能。通过状态监听器和事件监听器,风铃让你实时了解任务的运行状态,实时控制实例运行过程中遇到的各种问题,真正做到洞察运行情况任务,方便操作和维护。
解析模拟器
由于风铃强大的解析功能,规则的定义非常灵活,为了直观了解配置的规则定义的作用,风铃提供了解析模拟器,让用户快速了解规则定义的效果自己设置的符合预期目标,及时调整规则定义,方便风铃实例的配置。
风铃平台效果演示
配置基本信息
配置爬虫名称、使用线程数、超时停止时间

配置链接爬取信息
配置爬虫的起始种子链接和从网页里提取下一次抓取时的链接的提取规则

配置站点信息
此步骤一般可以省略,但是对于某些会校验cookie和请求头参数的网站,此配置非常有用

提取项目配置
配置需要从网站里提取出来的数据,例如新闻标题和网页正文等信息

属性抽取配置
调用内容提取器进行任意组合,以根据需要提取出需要的数据

属性抽取测试
提前检查提取项的配置是否正确,提取的数据是否符合预期目标

相关资源的链接
文件地址:
API 文档:
官方文件:
c爬虫抓取网页数据( 爬取漫画图片的大体实现过程的应用框架使用方法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-21 05:30
爬取漫画图片的大体实现过程的应用框架使用方法介绍)
scrapy是为爬取网站数据和提取结构化数据而编写的应用框架。更多关于框架的使用,请参考官方文档。本文文章展示了爬取漫画图片的一般实现过程。
Scrapy环境配置
首先是scrapy的安装。博主使用Mac系统,直接运行命令行:
pip install Scrapy
对于html节点信息的提取,使用了Beautiful Soup库。大概的用法可以看上一篇文章,可以直接通过命令安装:
pip install beautifulsoup4
目标网页的 Beautiful Soup 对象的初始化需要 html5lib 解释器。安装命令:
pip install html5lib
安装完成后,直接在命令行运行命令:
scrapy
可以看到如下输出,证明scrapy安装完成。
Scrapy 1.2.1 - no active projectUsage: scrapy [options] [args]Available commands: bench Run quick benchmark test commands fetch Fetch a URL using the Scrapy downloader genspider Generate new spider using pre-defined templates runspider Run a self-contained spider (without creating a project) settings Get settings values ...
项目创建通过命令行在当前路径下创建一个名为Comics的项目
scrapy startproject Comics
创建完成后,当前目录下会出现对应的工程文件夹,可以看到生成的Comics文件结构为:
|____Comics| |______init__.py| |______pycache__| |____items.py| |____pipelines.py| |____settings.py| |____spiders| | |______init__.py| | |______pycache__|____scrapy.cfg
附言。打印当前文件结构的命令是:
find . -print | sed -e 's;[^/]*/;|____;g;s;____|; |;g'
每个文件对应的具体功能可以在官方文档中找到。这个实现没有涉及很多这些文件,所以没有列出下表。1、创建蜘蛛类创建一个类来实现具体的爬取功能。我们所有的处理和实现都会在这个类中进行。它必须是scrapy.Spider 的子类。在 Comics/spiders 文件路径中创建一个 Comics.py 文件。comics.py 的具体实现:
#coding:utf-8import scrapyclass Comics(scrapy.Spider): name = "comics" def start_requests(self): urls = ['http://www.xeall.com/shenshi'] for url in urls: yield scrapy.Request(url=url, callback=self.parse) def parse(self, response): self.log(response.body);
自定义类是scrapy.Spider的子类,其中name属性是爬虫的唯一标识,作为scrapy爬取命令的参数。其他方法的属性将在后面解释。2、 运行创建的自定义类后,切换到Comics路径,运行命令,启动爬虫任务,开始爬取网页。
scrapy crawl comics
打印的结果是爬虫运行过程中的信息和目标爬取网页的html源代码。
2016-11-26 22:04:35 [scrapy] INFO: Scrapy 1.2.1 started (bot: Comics)2016-11-26 22:04:35 [scrapy] INFO: Overridden settings: {'ROBOTSTXT_OBEY': True, 'BOT_NAME': 'Comics', 'NEWSPIDER_MODULE': 'Comics.spiders', 'SPIDER_MODULES': ['Comics.spiders']}2016-11-26 22:04:35 [scrapy] INFO: Enabled extensions:['scrapy.extensions.corestats.CoreStats', 'scrapy.extensions.telnet.TelnetConsole', 'scrapy.extensions.logstats.LogStats'] ...
至此,一个基本的爬虫就创建好了。下面是具体的实现过程。爬取漫画图片1、起始地址爬虫的起始地址为:
http://www.xeall.com/shenshi
我们主要关注页面中间的漫画列表,列表底部有显示页数的控件。如下所示
爬虫的主要任务是爬取列表中每个漫画的图片。爬完当前页面后,进入漫画列表的下一页继续爬取漫画,继续循环,直到所有的漫画都被爬取完毕。我们将起始地址的 url 放在 start_requests 函数的 urls 数组中。其中,start_requests 是重载父类的方法。该方法会在爬虫任务启动时执行。start_requests方法的主要执行在这行代码:请求指定的url,请求完成后调用对应的回调函数self.parse
scrapy.Request(url=url, callback=self.parse)
其实还有另外一种方式可以实现前面的代码:
#coding:utf-8import scrapyclass Comics(scrapy.Spider): name = "comics" start_urls = ['http://www.xeall.com/shenshi'] def parse(self, response): self.log(response.body);
start_urls 是框架中提供的一个属性。它是一个收录目标网页 URL 的数组。设置 start_urls 的值后,不需要重载 start_requests 方法。爬虫也会依次爬取start_urls中的地址,并在请求完成后自动调用parse。作为回调方法。不过为了方便过程中其他回调函数的调整,demo中还是沿用了之前的实现方式。2、 爬取漫画的url 从最初的网页开始,我们首先要爬取每个漫画的url。当前页漫画列表的起始页为漫画列表的第一页。我们需要从当前页面中提取需要的信息并实现回调解析方法。
from bs4 import BeautifulSoup
请求返回的html源码用于初始化BeautifulSoup。
def parse(self, response): content = response.body; soup = BeautifulSoup(content, "html5lib")
初始化时指定了html5lib解释器,未安装会报错。如果在初始化 BeautifulSoup 时没有提供指定的解释器,它会自动使用它认为匹配的最佳解释器。有一个陷阱。对于目标网页的源代码,默认的最佳解释器是lxml,解析结果会出现Problems,无法进行后续的数据提取。所以当你发现有时提取结果有问题的时候,打印汤看是否正确。查看html源码,可以看到页面显示漫画列表的部分是ul标签,类名是listcon,对应的标签可以通过listcon类唯一确认
提取收录漫画列表的标签
listcon_tag = soup.find('ul', class_='listcon')
上面的find方法就是查找class为listcon的ul标签,返回对应标签的所有内容。在列表标签中查找所有带有 href 属性的标签。这些a标签是每个漫画对应的信息。
com_a_list = listcon_tag.find_all('a', attrs={'href': True})
然后将每个漫画的href属性组合成一个完整的可访问的URL地址,并保存在一个数组中。
comics_url_list = []base = 'http://www.xeall.com' for tag_a in com_a_list: url = base + tag_a['href'] comics_url_list.append(url)
此时,comics_url_list 数组收录当前页面上每个漫画的 url。3、下一页列表,查看列表下方的选择页面控件,我们可以通过这个地方获取下一页的url。
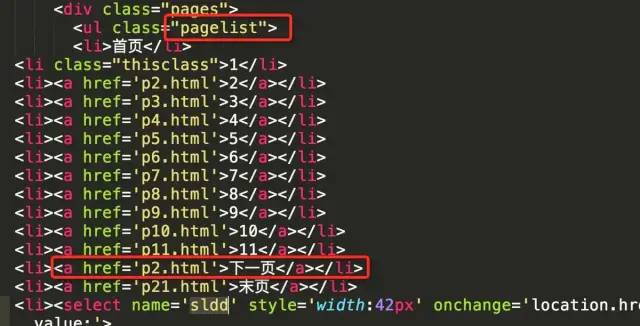
获取所选页面标签中收录 href 属性的所有标签
page_tag = soup.find('ul', class_='pagelist')page_a_list = page_tag.find_all('a', attrs={'href': True})
这部分源代码如下图所示。可以看到,在所有a标签中,倒数第一个代表最后一页的网址,倒数第二个代表下一页的网址。因此,我们可以取page_a_list数组中倒数第二个元素来获取下一页的url。
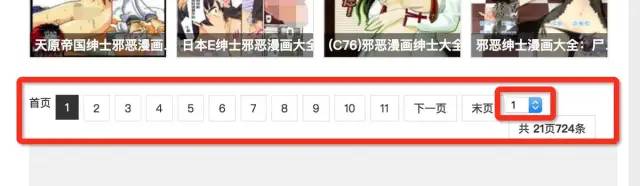
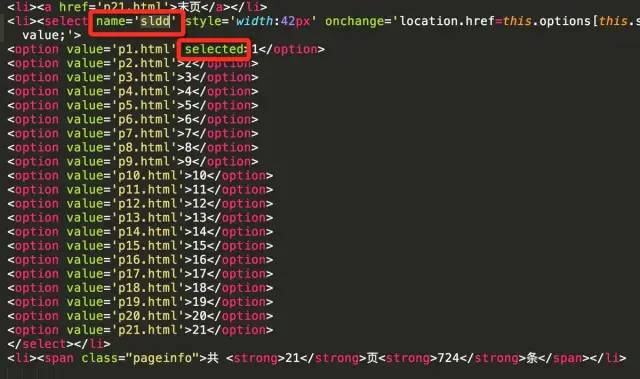
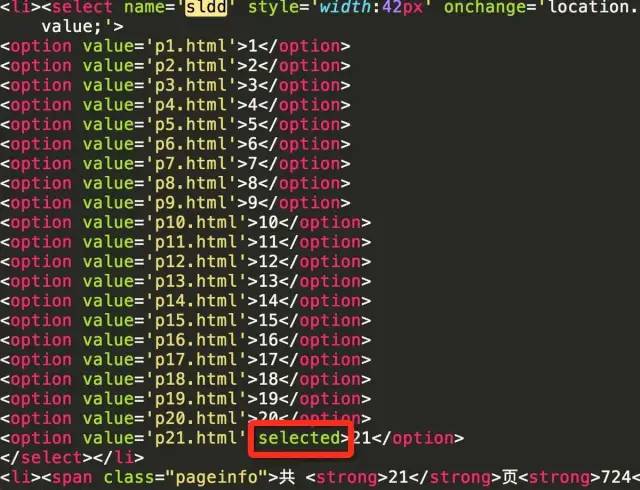
但是这里需要注意的是,如果当前页面是最后一页,则不需要去取下一页。那么如何判断当前页面是否为最后一页呢?可以通过select控件来判断。从源码可以判断当前页面对应的option标签会有selected属性。下图显示当前页面为第一页
下图显示当前页面为最后一页
当前页码与最后页码比较,如果相同,则表示当前页为最后一页。
select_tag = soup.find('select', attrs={'name': 'sldd'})option_list = select_tag.find_all('option')last_option = option_list[-1]current_option = select_tag.find('option' ,attrs={'selected': True})is_last = (last_option.string == current_option.string)
当前页面不是最后一页,那么在下一页继续做同样的处理,请求还是通过回调parse方法处理
if not is_last: next_page = 'http://www.xeall.com/shenshi/' + page_a_list[-2]['href'] if next_page is not None: print('\n------ parse next page --------') print(next_page) yield scrapy.Request(next_page, callback=self.parse)
以相同的方式依次处理每一页,直到处理完所有页。4、 爬取漫画图片,在parse方法中提取当前页面的所有漫画URL时,就可以开始处理每一个漫画了。在得到的comics_url_list数组下面添加如下代码:
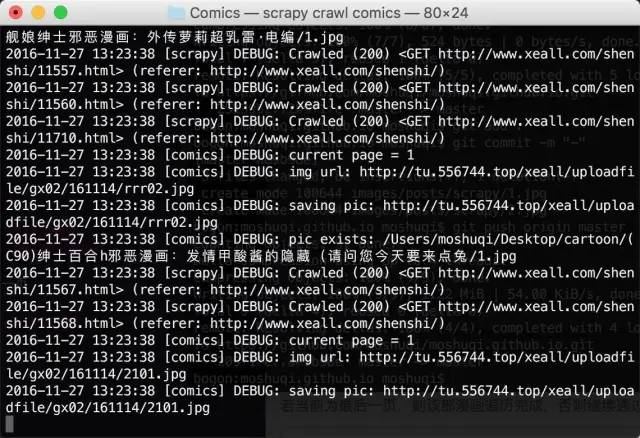
for url in comics_url_list: yield scrapy.Request(url=url, callback=self.comics_parse)
请求每个漫画的url,回调处理方法是ics_parse,comics_parse方法用于处理每个漫画。下面是具体的实现。5、当前页面图片的首相根据请求返回的源码构造一个BeautifulSoup,与上一个基本一致
def comics_parse(self, response): content = response.body; soup = BeautifulSoup(content, "html5lib")
提取select页面控件标签,页面显示及源码如下
提取类为pagelist的ul标签
page_list_tag = soup.find('ul', class_='pagelist')
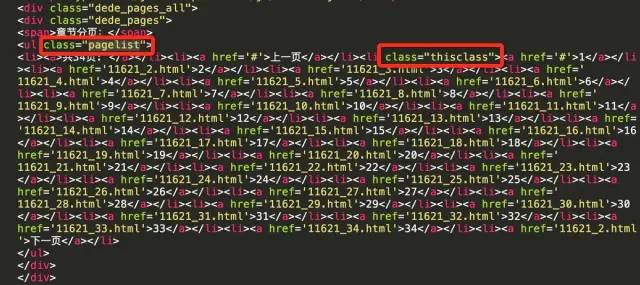
查看源码,可以看到当前页面的li标签的class属性thisclass,从而得到当前页面的编号
current_li = page_list_tag.find('li', class_='thisclass')page_num = current_li.a.string
当前页面图片的标签及对应的源码
获取当前页面图片的url和漫画的标题。漫画标题后,用作存放相应漫画的文件夹名称。
li_tag = soup.find('li', id='imgshow')img_tag = li_tag.find('img')img_url = img_tag['src']title = img_tag['alt']
6、保存到本地 提取图片url后,可以通过url请求图片,保存到本地
self.save_img(page_num, title, img_url)
专门定义了一个方法 save_img 来保存图片。具体完整的实现如下
# 先导入库import osimport urllibimport zlibdef save_img(self, img_mun, title, img_url): # 将图片保存到本地 self.log('saving pic: ' + img_url) # 保存漫画的文件夹 document = '/Users/moshuqi/Desktop/cartoon' # 每部漫画的文件名以标题命名 comics_path = document + '/' + title exists = os.path.exists(comics_path) if not exists: self.log('create document: ' + title) os.makedirs(comics_path) # 每张图片以页数命名 pic_name = comics_path + '/' + img_mun + '.jpg' # 检查图片是否已经下载到本地,若存在则不再重新下载 exists = os.path.exists(pic_name) if exists: self.log('pic exists: ' + pic_name) return try: user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' headers = { 'User-Agent' : user_agent } req = urllib.request.Request(img_url, headers=headers) response = urllib.request.urlopen(req, timeout=30) # 请求返回到的数据 data = response.read() # 若返回数据为压缩数据需要先进行解压 if response.info().get('Content-Encoding') == 'gzip': data = zlib.decompress(data, 16 + zlib.MAX_WBITS) # 图片保存到本地 fp = open(pic_name, "wb") fp.write(data) fp.close self.log('save image finished:' + pic_name) except Exception as e: self.log('save image error.') self.log(e)
该函数主要使用3个参数,当前图片的页数,漫画名称,图片的url。图片将保存在以漫画命名的文件夹中。如果没有对应的文件夹,就创建一个。一般拿到第一张图片的时候就需要创建一个文件夹。文档是本地指定的文件夹,可以自定义。每张图片都以 pages.jpg 格式命名。如果本地已经存在同名图片,则不会重新下载。一般用于判断任务何时重复,避免重复请求已有图片。请求返回的图片数据是经过压缩的,可以通过().get('Content-Encoding')的类型来判断。压缩后的图片必须通过zlib.decompress解压后保存到本地,否则图片无法打开。大体实现思路如上,代码也附上注释。7、下一页图片类似漫画列表界面中的处理方法。在漫画页面中,我们还需要不断的获取下一页的图片,继续遍历,直到最后一页。
当next page标签的href属性为#时,就是漫画的最后一页
a_tag_list = page_list_tag.find_all('a')next_page = a_tag_list[-1]['href']if next_page == '#': self.log('parse comics:' + title + 'finished.')else: next_page = 'http://www.xeall.com/shenshi/' + next_page yield scrapy.Request(next_page, callback=self.comics_parse)
如果当前页是最后一页,则漫画遍历完成,否则继续下一页同理
yield scrapy.Request(next_page, callback=self.comics_parse)
8、 运行结果的大体实现基本完成。运行时可以看到控制台打印
保存在本地文件夹中的图片
在scrapy框架运行时,它使用了多个线程,可以看到多个漫画同时在爬行。目标网站资源服务器感觉慢,经常出现请求超时。跑步时请耐心等待。最后,本文只介绍了scrapy框架非常基础的使用方法,以及各种非常详细的功能配置。如使用 FilesPipeline、ImagesPipeline 来保存下载的文件或图片。该框架本身带有一个用于提取网页信息的 XPath 类。这比 BeautifulSoup 更有效。也可以使用特殊的item类来保存爬取的数据结果并作为类返回。详情请参考官方网站。最后附上完整的Demo源码
-结尾-
原文链接: 查看全部
c爬虫抓取网页数据(
爬取漫画图片的大体实现过程的应用框架使用方法介绍)

scrapy是为爬取网站数据和提取结构化数据而编写的应用框架。更多关于框架的使用,请参考官方文档。本文文章展示了爬取漫画图片的一般实现过程。
Scrapy环境配置
首先是scrapy的安装。博主使用Mac系统,直接运行命令行:
pip install Scrapy
对于html节点信息的提取,使用了Beautiful Soup库。大概的用法可以看上一篇文章,可以直接通过命令安装:
pip install beautifulsoup4
目标网页的 Beautiful Soup 对象的初始化需要 html5lib 解释器。安装命令:
pip install html5lib
安装完成后,直接在命令行运行命令:
scrapy
可以看到如下输出,证明scrapy安装完成。
Scrapy 1.2.1 - no active projectUsage: scrapy [options] [args]Available commands: bench Run quick benchmark test commands fetch Fetch a URL using the Scrapy downloader genspider Generate new spider using pre-defined templates runspider Run a self-contained spider (without creating a project) settings Get settings values ...
项目创建通过命令行在当前路径下创建一个名为Comics的项目
scrapy startproject Comics
创建完成后,当前目录下会出现对应的工程文件夹,可以看到生成的Comics文件结构为:
|____Comics| |______init__.py| |______pycache__| |____items.py| |____pipelines.py| |____settings.py| |____spiders| | |______init__.py| | |______pycache__|____scrapy.cfg
附言。打印当前文件结构的命令是:
find . -print | sed -e 's;[^/]*/;|____;g;s;____|; |;g'
每个文件对应的具体功能可以在官方文档中找到。这个实现没有涉及很多这些文件,所以没有列出下表。1、创建蜘蛛类创建一个类来实现具体的爬取功能。我们所有的处理和实现都会在这个类中进行。它必须是scrapy.Spider 的子类。在 Comics/spiders 文件路径中创建一个 Comics.py 文件。comics.py 的具体实现:
#coding:utf-8import scrapyclass Comics(scrapy.Spider): name = "comics" def start_requests(self): urls = ['http://www.xeall.com/shenshi'] for url in urls: yield scrapy.Request(url=url, callback=self.parse) def parse(self, response): self.log(response.body);
自定义类是scrapy.Spider的子类,其中name属性是爬虫的唯一标识,作为scrapy爬取命令的参数。其他方法的属性将在后面解释。2、 运行创建的自定义类后,切换到Comics路径,运行命令,启动爬虫任务,开始爬取网页。
scrapy crawl comics
打印的结果是爬虫运行过程中的信息和目标爬取网页的html源代码。
2016-11-26 22:04:35 [scrapy] INFO: Scrapy 1.2.1 started (bot: Comics)2016-11-26 22:04:35 [scrapy] INFO: Overridden settings: {'ROBOTSTXT_OBEY': True, 'BOT_NAME': 'Comics', 'NEWSPIDER_MODULE': 'Comics.spiders', 'SPIDER_MODULES': ['Comics.spiders']}2016-11-26 22:04:35 [scrapy] INFO: Enabled extensions:['scrapy.extensions.corestats.CoreStats', 'scrapy.extensions.telnet.TelnetConsole', 'scrapy.extensions.logstats.LogStats'] ...
至此,一个基本的爬虫就创建好了。下面是具体的实现过程。爬取漫画图片1、起始地址爬虫的起始地址为:
http://www.xeall.com/shenshi
我们主要关注页面中间的漫画列表,列表底部有显示页数的控件。如下所示
爬虫的主要任务是爬取列表中每个漫画的图片。爬完当前页面后,进入漫画列表的下一页继续爬取漫画,继续循环,直到所有的漫画都被爬取完毕。我们将起始地址的 url 放在 start_requests 函数的 urls 数组中。其中,start_requests 是重载父类的方法。该方法会在爬虫任务启动时执行。start_requests方法的主要执行在这行代码:请求指定的url,请求完成后调用对应的回调函数self.parse
scrapy.Request(url=url, callback=self.parse)
其实还有另外一种方式可以实现前面的代码:
#coding:utf-8import scrapyclass Comics(scrapy.Spider): name = "comics" start_urls = ['http://www.xeall.com/shenshi'] def parse(self, response): self.log(response.body);
start_urls 是框架中提供的一个属性。它是一个收录目标网页 URL 的数组。设置 start_urls 的值后,不需要重载 start_requests 方法。爬虫也会依次爬取start_urls中的地址,并在请求完成后自动调用parse。作为回调方法。不过为了方便过程中其他回调函数的调整,demo中还是沿用了之前的实现方式。2、 爬取漫画的url 从最初的网页开始,我们首先要爬取每个漫画的url。当前页漫画列表的起始页为漫画列表的第一页。我们需要从当前页面中提取需要的信息并实现回调解析方法。
from bs4 import BeautifulSoup
请求返回的html源码用于初始化BeautifulSoup。
def parse(self, response): content = response.body; soup = BeautifulSoup(content, "html5lib")
初始化时指定了html5lib解释器,未安装会报错。如果在初始化 BeautifulSoup 时没有提供指定的解释器,它会自动使用它认为匹配的最佳解释器。有一个陷阱。对于目标网页的源代码,默认的最佳解释器是lxml,解析结果会出现Problems,无法进行后续的数据提取。所以当你发现有时提取结果有问题的时候,打印汤看是否正确。查看html源码,可以看到页面显示漫画列表的部分是ul标签,类名是listcon,对应的标签可以通过listcon类唯一确认
提取收录漫画列表的标签
listcon_tag = soup.find('ul', class_='listcon')
上面的find方法就是查找class为listcon的ul标签,返回对应标签的所有内容。在列表标签中查找所有带有 href 属性的标签。这些a标签是每个漫画对应的信息。
com_a_list = listcon_tag.find_all('a', attrs={'href': True})
然后将每个漫画的href属性组合成一个完整的可访问的URL地址,并保存在一个数组中。
comics_url_list = []base = 'http://www.xeall.com' for tag_a in com_a_list: url = base + tag_a['href'] comics_url_list.append(url)
此时,comics_url_list 数组收录当前页面上每个漫画的 url。3、下一页列表,查看列表下方的选择页面控件,我们可以通过这个地方获取下一页的url。
获取所选页面标签中收录 href 属性的所有标签
page_tag = soup.find('ul', class_='pagelist')page_a_list = page_tag.find_all('a', attrs={'href': True})
这部分源代码如下图所示。可以看到,在所有a标签中,倒数第一个代表最后一页的网址,倒数第二个代表下一页的网址。因此,我们可以取page_a_list数组中倒数第二个元素来获取下一页的url。
但是这里需要注意的是,如果当前页面是最后一页,则不需要去取下一页。那么如何判断当前页面是否为最后一页呢?可以通过select控件来判断。从源码可以判断当前页面对应的option标签会有selected属性。下图显示当前页面为第一页
下图显示当前页面为最后一页
当前页码与最后页码比较,如果相同,则表示当前页为最后一页。
select_tag = soup.find('select', attrs={'name': 'sldd'})option_list = select_tag.find_all('option')last_option = option_list[-1]current_option = select_tag.find('option' ,attrs={'selected': True})is_last = (last_option.string == current_option.string)
当前页面不是最后一页,那么在下一页继续做同样的处理,请求还是通过回调parse方法处理
if not is_last: next_page = 'http://www.xeall.com/shenshi/' + page_a_list[-2]['href'] if next_page is not None: print('\n------ parse next page --------') print(next_page) yield scrapy.Request(next_page, callback=self.parse)
以相同的方式依次处理每一页,直到处理完所有页。4、 爬取漫画图片,在parse方法中提取当前页面的所有漫画URL时,就可以开始处理每一个漫画了。在得到的comics_url_list数组下面添加如下代码:
for url in comics_url_list: yield scrapy.Request(url=url, callback=self.comics_parse)
请求每个漫画的url,回调处理方法是ics_parse,comics_parse方法用于处理每个漫画。下面是具体的实现。5、当前页面图片的首相根据请求返回的源码构造一个BeautifulSoup,与上一个基本一致
def comics_parse(self, response): content = response.body; soup = BeautifulSoup(content, "html5lib")
提取select页面控件标签,页面显示及源码如下
提取类为pagelist的ul标签
page_list_tag = soup.find('ul', class_='pagelist')
查看源码,可以看到当前页面的li标签的class属性thisclass,从而得到当前页面的编号
current_li = page_list_tag.find('li', class_='thisclass')page_num = current_li.a.string
当前页面图片的标签及对应的源码
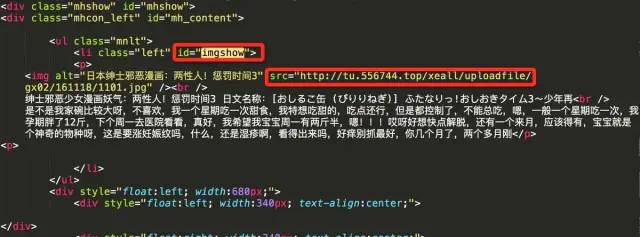
获取当前页面图片的url和漫画的标题。漫画标题后,用作存放相应漫画的文件夹名称。
li_tag = soup.find('li', id='imgshow')img_tag = li_tag.find('img')img_url = img_tag['src']title = img_tag['alt']
6、保存到本地 提取图片url后,可以通过url请求图片,保存到本地
self.save_img(page_num, title, img_url)
专门定义了一个方法 save_img 来保存图片。具体完整的实现如下
# 先导入库import osimport urllibimport zlibdef save_img(self, img_mun, title, img_url): # 将图片保存到本地 self.log('saving pic: ' + img_url) # 保存漫画的文件夹 document = '/Users/moshuqi/Desktop/cartoon' # 每部漫画的文件名以标题命名 comics_path = document + '/' + title exists = os.path.exists(comics_path) if not exists: self.log('create document: ' + title) os.makedirs(comics_path) # 每张图片以页数命名 pic_name = comics_path + '/' + img_mun + '.jpg' # 检查图片是否已经下载到本地,若存在则不再重新下载 exists = os.path.exists(pic_name) if exists: self.log('pic exists: ' + pic_name) return try: user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' headers = { 'User-Agent' : user_agent } req = urllib.request.Request(img_url, headers=headers) response = urllib.request.urlopen(req, timeout=30) # 请求返回到的数据 data = response.read() # 若返回数据为压缩数据需要先进行解压 if response.info().get('Content-Encoding') == 'gzip': data = zlib.decompress(data, 16 + zlib.MAX_WBITS) # 图片保存到本地 fp = open(pic_name, "wb") fp.write(data) fp.close self.log('save image finished:' + pic_name) except Exception as e: self.log('save image error.') self.log(e)
该函数主要使用3个参数,当前图片的页数,漫画名称,图片的url。图片将保存在以漫画命名的文件夹中。如果没有对应的文件夹,就创建一个。一般拿到第一张图片的时候就需要创建一个文件夹。文档是本地指定的文件夹,可以自定义。每张图片都以 pages.jpg 格式命名。如果本地已经存在同名图片,则不会重新下载。一般用于判断任务何时重复,避免重复请求已有图片。请求返回的图片数据是经过压缩的,可以通过().get('Content-Encoding')的类型来判断。压缩后的图片必须通过zlib.decompress解压后保存到本地,否则图片无法打开。大体实现思路如上,代码也附上注释。7、下一页图片类似漫画列表界面中的处理方法。在漫画页面中,我们还需要不断的获取下一页的图片,继续遍历,直到最后一页。
当next page标签的href属性为#时,就是漫画的最后一页
a_tag_list = page_list_tag.find_all('a')next_page = a_tag_list[-1]['href']if next_page == '#': self.log('parse comics:' + title + 'finished.')else: next_page = 'http://www.xeall.com/shenshi/' + next_page yield scrapy.Request(next_page, callback=self.comics_parse)
如果当前页是最后一页,则漫画遍历完成,否则继续下一页同理
yield scrapy.Request(next_page, callback=self.comics_parse)
8、 运行结果的大体实现基本完成。运行时可以看到控制台打印
保存在本地文件夹中的图片
在scrapy框架运行时,它使用了多个线程,可以看到多个漫画同时在爬行。目标网站资源服务器感觉慢,经常出现请求超时。跑步时请耐心等待。最后,本文只介绍了scrapy框架非常基础的使用方法,以及各种非常详细的功能配置。如使用 FilesPipeline、ImagesPipeline 来保存下载的文件或图片。该框架本身带有一个用于提取网页信息的 XPath 类。这比 BeautifulSoup 更有效。也可以使用特殊的item类来保存爬取的数据结果并作为类返回。详情请参考官方网站。最后附上完整的Demo源码
-结尾-
原文链接:
c爬虫抓取网页数据(爬取知乎文章图片爬取器之一(组图)网友留言和回复)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-10-21 04:14
阿里云>云栖社区>主题图>C>c语言爬取网站
推荐活动:
更多优惠>
当前话题:c语言爬取网站加入采集
相关话题:
c语言爬取网站相关博客 查看更多博客
Python爬虫入门教程25-100知乎文章图片爬虫之一
作者:梦之橡皮 1110人浏览评论:02年前
1. 知乎文章 一个图片爬虫写在前面,今天尝试爬一下。知乎,看看这个网站有什么有趣的内容可以爬取,可能会断断续续的写几个文章。最简单的就是先爬,一个文章的所有答案都爬不难。我找到了我们要抓取的页面,我只是选择了一个
阅读全文
Python爬虫入门教程15-100石家庄政民交互数据爬虫
作者:梦之橡皮2057人浏览评论:02年前
1.石家庄政民互动数据爬取-今天写在前面,抓一个网站,这个网站,涉及的内容是网友的评论和回复,很简单,但 网站 来自 gov。URL 是第一个语句,以便
阅读全文
使用多线程抓取招聘网站
作者:等下1209人浏览评论数:02年前
使用多线程获取某招聘信息网站,使用环境py3,更不用说,直接上传代码到你要引导的包中,不能错过import threading import requests from pyquery import PyQuery as pq import json from
阅读全文
基于Scrapy的爬取伯乐在线网站
作者:潇撒坤 829人浏览评论:03年前
标题中英文的第一个字母比较规范,但是在python的实际使用中,都是小写的。2018年7月20日Scrapy官方文档网址说明:网页在chrome浏览器中打开
阅读全文
苏宁百万级商品爬虫简述
作者:HapplyFox1045 人浏览评论:03年前
代码下载链接 苏宁万级商品爬虫目录思路讲解分类爬取思路讲解分类页面抓取商品爬取3.1思路讲解商品爬13.2思路讲解商品爬23.3代码说明商品爬取索引说明4.1代码说明索引建立4.2代码说明索引查询语句本系统
阅读全文
手拉手 | 教你爬下100部电影数据:R语言网页爬虫入门指南
作者:小轩峰柴金 2463人浏览评论:04年前
序言网页上的数据和信息呈指数级增长。今天,我们都将 Google 作为主要的知识来源——无论是寻找某个地方的评论还是学习新术语。所有这些信息都可以轻松在线获得。网络上可用数据的增加为数据科学家开辟了新的可能性。我坚信网络抓取是一种数据科学
阅读全文
Python爬虫:用BeautifulSoup爬取NBA数据
作者:夜李2725人浏览评论:04年前
爬虫的主要目的是过滤掉网页中无用的信息。从网页中抓取有用信息的一般爬虫结构是:在使用python爬虫之前,必须对网页的结构有一定的了解,比如网页的标签、网页的语言等知识,建议去W3School:W3school链接了解爬取前有一些工具:1
阅读全文
【python学习】维基百科程序语言消息框的简单爬取
作者:Xiaoluoluo1432 人浏览评论:06年前
文章主要描述了如何通过Python爬取维基百科的Infobox,主要是通过正则表达式和urllib;下面文章可能会讲一下通过BeautifulSoup爬取网页的知识。由于这方面的文章还比较少,希望提供一些思路和方法来帮助大家
阅读全文 查看全部
c爬虫抓取网页数据(爬取知乎文章图片爬取器之一(组图)网友留言和回复)
阿里云>云栖社区>主题图>C>c语言爬取网站
推荐活动:
更多优惠>
当前话题:c语言爬取网站加入采集
相关话题:
c语言爬取网站相关博客 查看更多博客
Python爬虫入门教程25-100知乎文章图片爬虫之一


作者:梦之橡皮 1110人浏览评论:02年前
1. 知乎文章 一个图片爬虫写在前面,今天尝试爬一下。知乎,看看这个网站有什么有趣的内容可以爬取,可能会断断续续的写几个文章。最简单的就是先爬,一个文章的所有答案都爬不难。我找到了我们要抓取的页面,我只是选择了一个
阅读全文
Python爬虫入门教程15-100石家庄政民交互数据爬虫

作者:梦之橡皮2057人浏览评论:02年前
1.石家庄政民互动数据爬取-今天写在前面,抓一个网站,这个网站,涉及的内容是网友的评论和回复,很简单,但 网站 来自 gov。URL 是第一个语句,以便
阅读全文
使用多线程抓取招聘网站


作者:等下1209人浏览评论数:02年前
使用多线程获取某招聘信息网站,使用环境py3,更不用说,直接上传代码到你要引导的包中,不能错过import threading import requests from pyquery import PyQuery as pq import json from
阅读全文
基于Scrapy的爬取伯乐在线网站

作者:潇撒坤 829人浏览评论:03年前
标题中英文的第一个字母比较规范,但是在python的实际使用中,都是小写的。2018年7月20日Scrapy官方文档网址说明:网页在chrome浏览器中打开
阅读全文
苏宁百万级商品爬虫简述

作者:HapplyFox1045 人浏览评论:03年前
代码下载链接 苏宁万级商品爬虫目录思路讲解分类爬取思路讲解分类页面抓取商品爬取3.1思路讲解商品爬13.2思路讲解商品爬23.3代码说明商品爬取索引说明4.1代码说明索引建立4.2代码说明索引查询语句本系统
阅读全文
手拉手 | 教你爬下100部电影数据:R语言网页爬虫入门指南

作者:小轩峰柴金 2463人浏览评论:04年前
序言网页上的数据和信息呈指数级增长。今天,我们都将 Google 作为主要的知识来源——无论是寻找某个地方的评论还是学习新术语。所有这些信息都可以轻松在线获得。网络上可用数据的增加为数据科学家开辟了新的可能性。我坚信网络抓取是一种数据科学
阅读全文
Python爬虫:用BeautifulSoup爬取NBA数据

作者:夜李2725人浏览评论:04年前
爬虫的主要目的是过滤掉网页中无用的信息。从网页中抓取有用信息的一般爬虫结构是:在使用python爬虫之前,必须对网页的结构有一定的了解,比如网页的标签、网页的语言等知识,建议去W3School:W3school链接了解爬取前有一些工具:1
阅读全文
【python学习】维基百科程序语言消息框的简单爬取

作者:Xiaoluoluo1432 人浏览评论:06年前
文章主要描述了如何通过Python爬取维基百科的Infobox,主要是通过正则表达式和urllib;下面文章可能会讲一下通过BeautifulSoup爬取网页的知识。由于这方面的文章还比较少,希望提供一些思路和方法来帮助大家
阅读全文
c爬虫抓取网页数据(Python开发的一个快速,高层次处理网络通讯的整体架构大致)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-10-18 06:00
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体结构大致如下(注:图片来自网络):
Scrapy主要包括以下组件:
使用Scrapy可以轻松完成在线数据采集的工作,它为我们做了很多工作,无需自己开发。
1. 安装python
目前最新的Scrapy版本是0.22.2。这个版本需要python 2.7,所以需要先安装python 2.7。这里我使用centos服务器进行测试,因为系统自带python,需要先查看python版本。
检查python版本:
$ python -V
Python 2.6.6
升级版本到2.7:
$ Python 2.7.6:
$ wget http://python.org/ftp/python/2 ... ar.xz
$ tar xf Python-2.7.6.tar.xz
$ cd Python-2.7.6
$ ./configure --prefix=/usr/local --enable-unicode=ucs4 --enable-shared LDFLAGS="-Wl,-rpath /usr/local/lib"
$ make && make altinstall
建立软连接并使系统默认python指向python2.7
$ mv /usr/bin/python /usr/bin/python2.6.6
$ ln -s /usr/local/bin/python2.7 /usr/bin/python
再次检查python版本:
$ python -V
Python 2.7.6
安装
这里我们使用 wget 来安装 setuptools:
$ wget https://bootstrap.pypa.io/ez_setup.py -O - | python
安装 zope.interface
$ easy_install zope.interface
安装扭曲
Scrapy使用Twisted异步网络库来处理网络通信,所以需要安装twisted。
在安装twisted之前,需要先安装gcc:
$ yum install gcc -y
然后,通过easy_install安装twisted:
$ easy_install twisted
如果出现以下错误:
$ easy_install twisted
Searching for twisted
Reading https://pypi.python.org/simple/twisted/
Best match: Twisted 14.0.0
Downloading https://pypi.python.org/packag ... c9815
Processing Twisted-14.0.0.tar.bz2
Writing /tmp/easy_install-kYHKjn/Twisted-14.0.0/setup.cfg
Running Twisted-14.0.0/setup.py -q bdist_egg --dist-dir /tmp/easy_install-kYHKjn/Twisted-14.0.0/egg-dist-tmp-vu1n6Y
twisted/runner/portmap.c:10:20: error: Python.h: No such file or directory
twisted/runner/portmap.c:14: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘*’ token
twisted/runner/portmap.c:31: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘*’ token
twisted/runner/portmap.c:45: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘PortmapMethods’
twisted/runner/portmap.c: In function ‘initportmap’:
twisted/runner/portmap.c:55: warning: implicit declaration of function ‘Py_InitModule’
twisted/runner/portmap.c:55: error: ‘PortmapMethods’ undeclared (first use in this function)
twisted/runner/portmap.c:55: error: (Each undeclared identifier is reported only once
twisted/runner/portmap.c:55: error: for each function it appears in.)
请安装 python-devel 并再次运行:
$ yum install python-devel -y
$ easy_install twisted
如果出现以下异常:
error: Not a recognized archive type: /tmp/easy_install-tVwC5O/Twisted-14.0.0.tar.bz2
请手动下载安装,下载地址在这里
$ wget https://pypi.python.org/packag ... c9815
$ tar -vxjf Twisted-14.0.0.tar.bz2
$ cd Twisted-14.0.0
$ python setup.py install
安装 pyOpenSSL
先安装一些依赖:
$ yum install libffi libffi-devel openssl-devel -y
然后,通过easy_install安装pyOpenSSL:
$ easy_install pyOpenSSL
安装 Scrapy
先安装一些依赖:
$ yum install libxml2 libxslt libxslt-devel -y
最后,安装 Scrapy:
$ easy_install scrapy
2. 使用 Scrapy
安装成功后,可以了解Scrapy的一些基本概念和用法,学习Scrapy项目dirbot的例子。
Dirbot 项目所在地。该项目收录一个 README 文件,详细描述了该项目的内容。如果您熟悉 Git,可以查看其源代码。或者,您可以通过单击下载以 tarball 或 zip 格式下载文件。
这里以一个例子来说明如何使用Scrapy创建爬虫项目。
新建筑
在爬取之前,您需要创建一个新的 Scrapy 项目。输入要保存代码的目录,然后执行:
$ scrapy startproject tutorial
该命令会在当前目录下新建一个目录tutorial,其结构如下:
.
├── scrapy.cfg
└── tutorial
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
这些文件主要是:
定义项目
Items 是将加载捕获数据的容器。它的工作原理类似于 Python 中的字典,但它提供了更多保护,例如填充未定义的字段以防止拼写错误。
它是通过创建一个scrapy.item.Item 类并将其属性定义为scrpy.item.Field 对象来声明的,就像一个对象关系映射(ORM)。
我们控制通过建模所需项目获得的站点数据。例如,我们要获取站点的名称、url 和 网站 描述。我们定义了这三个属性的域。为此,我们编辑教程目录中的 items.py 文件,我们的 Item 类将如下所示
from scrapy.item import Item, Field
class DmozItem(Item):
title = Field()
link = Field()
desc = Field()
一开始可能看起来有点混乱,但是定义这些项目会让你知道在使用其他 Scrapy 组件时你的项目是什么。
写一个蜘蛛(蜘蛛)
Spider 是一个用户编写的类,用于从域(或域组)中获取信息。我们定义了用于下载的 URL 的初步列表、如何跟踪链接以及如何解析这些网页的内容以提取项目。
要创建 Spider,您可以为 scrapy.spider.BaseSpider 创建一个子类并确定三个主要的强制性属性:
该方法负责解析返回的数据,匹配捕获的数据(解析为item),跟踪更多的URL。
在tutorial/spiders目录下创建DmozSpider.py
from scrapy.spider import BaseSpider
class DmozSpider(BaseSpider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B
]
def parse(self, response):
filename = response.url.split("/")[-2]
open(filename, \'wb\').write(response.body)
运行项目
$ scrapy crawl dmoz
该命令从域启动爬虫,第三个参数是DmozSpider.py中name属性的值。
xpath 选择器
Scrapy 使用一种称为 XPath 选择器的机制,该机制基于 XPath 表达式。如果您想了解有关选择器和其他机制的更多信息,可以查看。
以下是 XPath 表达式及其含义的一些示例:
这些只是使用 XPath 的几个简单示例,但实际上 XPath 非常强大。如果您想了解更多关于 XPATH 的信息,我们向您推荐这个 XPath 教程
为了方便XPaths的使用,Scrapy提供了Selector类,共有三种方法
提取数据
我们可以使用以下命令选择 网站 中的每个元素:
sel.xpath(\'//ul/li\')
然后网站描述:
sel.xpath(\'//ul/li/text()\').extract()
网站标题:
sel.xpath(\'//ul/li/a/text()\').extract()
网站 链接:
sel.xpath(\'//ul/li/a/@href\').extract()
如前所述,每个 xpath() 调用都会返回一个选择器列表,因此我们可以结合 xpath() 来挖掘更深的节点。我们将使用这些功能,因此:
sites = sel.xpath(\'//ul/li\')
for site in sites:
title = site.xpath(\'a/text()\').extract()
link = site.xpath(\'a/@href\').extract()
desc = site.xpath(\'text()\').extract()
print title, link, desc
使用物品
scrapy.item.Item的调用接口类似于python的dict,Item收录多个scrapy.item.Field。这类似于 django 的模型和
Item通常用于Spider的parse方法,用于保存解析后的数据。
最后修改爬虫类,使用Item保存数据,代码如下:
from scrapy.spider import Spider
from scrapy.selector import Selector
from dirbot.items import Website
class DmozSpider(Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B,
]
def parse(self, response):
"""
The lines below is a spider contract. For more info see:
http://doc.scrapy.org/en/lates ... .html
@url http://www.dmoz.org/Computers/ ... rces/
@scrapes name
"""
sel = Selector(response)
sites = sel.xpath(\'//ul[@class="directory-url"]/li\')
items = []
for site in sites:
item = Website()
item[\'name\'] = site.xpath(\'a/text()\').extract()
item[\'url\'] = site.xpath(\'a/@href\').extract()
item[\'description\'] = site.xpath(\'text()\').re(\'-\s([^\n]*?)\\n\')
items.append(item)
return items
现在,您可以再次运行该项目以查看结果:
$ scrapy crawl dmoz
使用项目管道
在settings.py中设置ITEM_PIPELINES,默认为[],类似django的MIDDLEWARE_CLASSES等。
Spider的解析返回的Item数据会依次被ITEM_PIPELINES列表中的Pipeline类处理。
Item Pipeline 类必须实现以下方法:
还可以另外实现以下两种方法:
保存捕获的数据
保存信息最简单的方法是通过,命令如下:
$ scrapy crawl dmoz -o items.json -t json
除了 json 格式,还支持 JSON 行、CSV 和 XML 格式。您还可以通过接口扩展一些格式。
这种方法对于小项目来说已经足够了。如果是比较复杂的数据,可能需要写一个Item Pipeline进行处理。
所有抓到的物品都会以JSON格式保存在新生成的items.json文件中
总结
以上介绍了如何创建爬虫项目的过程,可以参考以上过程再次联系。作为学习示例,也可以参考这个文章:scrapy中文教程(爬取cnbeta示例)。
这个文章中的爬虫代码如下:
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
from scrapy.selector import Selector
from cnbeta.items import CnbetaItem
class CBSpider(CrawlSpider):
name = \'cnbeta\'
allowed_domains = [\'cnbeta.com\']
start_urls = [\'http://www.cnbeta.com\']
rules = (
Rule(SgmlLinkExtractor(allow=(\'/articles/.*\.htm\', )),
callback=\'parse_page\', follow=True),
)
def parse_page(self, response):
item = CnbetaItem()
sel = Selector(response)
item[\'title\'] = sel.xpath(\'//title/text()\').extract()
item[\'url\'] = response.url
return item
需要注意的是:
3. 学习资料
联系Scrapy是因为想爬取知乎的一些数据。一开始找了一些相关资料和别人的实现方法。
Github上有人或多或少意识到了知乎数据的爬取。我搜索了以下仓库:
其他信息:
抓取和交互式示例:
有一些知识点需要梳理:
4. 总结
以上是这几天学习Scrapy的笔记和知识汇总。参考了网上的一些文章,写了这篇文章。这次真是万分感谢。希望这篇文章文章能对你有所帮助。如果您有任何想法,请留言;如果你喜欢这篇文章,请帮忙分享,谢谢!
最初发表于: 查看全部
c爬虫抓取网页数据(Python开发的一个快速,高层次处理网络通讯的整体架构大致)
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体结构大致如下(注:图片来自网络):
Scrapy主要包括以下组件:
使用Scrapy可以轻松完成在线数据采集的工作,它为我们做了很多工作,无需自己开发。
1. 安装python
目前最新的Scrapy版本是0.22.2。这个版本需要python 2.7,所以需要先安装python 2.7。这里我使用centos服务器进行测试,因为系统自带python,需要先查看python版本。
检查python版本:
$ python -V
Python 2.6.6
升级版本到2.7:
$ Python 2.7.6:
$ wget http://python.org/ftp/python/2 ... ar.xz
$ tar xf Python-2.7.6.tar.xz
$ cd Python-2.7.6
$ ./configure --prefix=/usr/local --enable-unicode=ucs4 --enable-shared LDFLAGS="-Wl,-rpath /usr/local/lib"
$ make && make altinstall
建立软连接并使系统默认python指向python2.7
$ mv /usr/bin/python /usr/bin/python2.6.6
$ ln -s /usr/local/bin/python2.7 /usr/bin/python
再次检查python版本:
$ python -V
Python 2.7.6
安装
这里我们使用 wget 来安装 setuptools:
$ wget https://bootstrap.pypa.io/ez_setup.py -O - | python
安装 zope.interface
$ easy_install zope.interface
安装扭曲
Scrapy使用Twisted异步网络库来处理网络通信,所以需要安装twisted。
在安装twisted之前,需要先安装gcc:
$ yum install gcc -y
然后,通过easy_install安装twisted:
$ easy_install twisted
如果出现以下错误:
$ easy_install twisted
Searching for twisted
Reading https://pypi.python.org/simple/twisted/
Best match: Twisted 14.0.0
Downloading https://pypi.python.org/packag ... c9815
Processing Twisted-14.0.0.tar.bz2
Writing /tmp/easy_install-kYHKjn/Twisted-14.0.0/setup.cfg
Running Twisted-14.0.0/setup.py -q bdist_egg --dist-dir /tmp/easy_install-kYHKjn/Twisted-14.0.0/egg-dist-tmp-vu1n6Y
twisted/runner/portmap.c:10:20: error: Python.h: No such file or directory
twisted/runner/portmap.c:14: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘*’ token
twisted/runner/portmap.c:31: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘*’ token
twisted/runner/portmap.c:45: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘PortmapMethods’
twisted/runner/portmap.c: In function ‘initportmap’:
twisted/runner/portmap.c:55: warning: implicit declaration of function ‘Py_InitModule’
twisted/runner/portmap.c:55: error: ‘PortmapMethods’ undeclared (first use in this function)
twisted/runner/portmap.c:55: error: (Each undeclared identifier is reported only once
twisted/runner/portmap.c:55: error: for each function it appears in.)
请安装 python-devel 并再次运行:
$ yum install python-devel -y
$ easy_install twisted
如果出现以下异常:
error: Not a recognized archive type: /tmp/easy_install-tVwC5O/Twisted-14.0.0.tar.bz2
请手动下载安装,下载地址在这里
$ wget https://pypi.python.org/packag ... c9815
$ tar -vxjf Twisted-14.0.0.tar.bz2
$ cd Twisted-14.0.0
$ python setup.py install
安装 pyOpenSSL
先安装一些依赖:
$ yum install libffi libffi-devel openssl-devel -y
然后,通过easy_install安装pyOpenSSL:
$ easy_install pyOpenSSL
安装 Scrapy
先安装一些依赖:
$ yum install libxml2 libxslt libxslt-devel -y
最后,安装 Scrapy:
$ easy_install scrapy
2. 使用 Scrapy
安装成功后,可以了解Scrapy的一些基本概念和用法,学习Scrapy项目dirbot的例子。
Dirbot 项目所在地。该项目收录一个 README 文件,详细描述了该项目的内容。如果您熟悉 Git,可以查看其源代码。或者,您可以通过单击下载以 tarball 或 zip 格式下载文件。
这里以一个例子来说明如何使用Scrapy创建爬虫项目。
新建筑
在爬取之前,您需要创建一个新的 Scrapy 项目。输入要保存代码的目录,然后执行:
$ scrapy startproject tutorial
该命令会在当前目录下新建一个目录tutorial,其结构如下:
.
├── scrapy.cfg
└── tutorial
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
这些文件主要是:
定义项目
Items 是将加载捕获数据的容器。它的工作原理类似于 Python 中的字典,但它提供了更多保护,例如填充未定义的字段以防止拼写错误。
它是通过创建一个scrapy.item.Item 类并将其属性定义为scrpy.item.Field 对象来声明的,就像一个对象关系映射(ORM)。
我们控制通过建模所需项目获得的站点数据。例如,我们要获取站点的名称、url 和 网站 描述。我们定义了这三个属性的域。为此,我们编辑教程目录中的 items.py 文件,我们的 Item 类将如下所示
from scrapy.item import Item, Field
class DmozItem(Item):
title = Field()
link = Field()
desc = Field()
一开始可能看起来有点混乱,但是定义这些项目会让你知道在使用其他 Scrapy 组件时你的项目是什么。
写一个蜘蛛(蜘蛛)
Spider 是一个用户编写的类,用于从域(或域组)中获取信息。我们定义了用于下载的 URL 的初步列表、如何跟踪链接以及如何解析这些网页的内容以提取项目。
要创建 Spider,您可以为 scrapy.spider.BaseSpider 创建一个子类并确定三个主要的强制性属性:
该方法负责解析返回的数据,匹配捕获的数据(解析为item),跟踪更多的URL。
在tutorial/spiders目录下创建DmozSpider.py
from scrapy.spider import BaseSpider
class DmozSpider(BaseSpider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B
]
def parse(self, response):
filename = response.url.split("/")[-2]
open(filename, \'wb\').write(response.body)
运行项目
$ scrapy crawl dmoz
该命令从域启动爬虫,第三个参数是DmozSpider.py中name属性的值。
xpath 选择器
Scrapy 使用一种称为 XPath 选择器的机制,该机制基于 XPath 表达式。如果您想了解有关选择器和其他机制的更多信息,可以查看。
以下是 XPath 表达式及其含义的一些示例:
这些只是使用 XPath 的几个简单示例,但实际上 XPath 非常强大。如果您想了解更多关于 XPATH 的信息,我们向您推荐这个 XPath 教程
为了方便XPaths的使用,Scrapy提供了Selector类,共有三种方法
提取数据
我们可以使用以下命令选择 网站 中的每个元素:
sel.xpath(\'//ul/li\')
然后网站描述:
sel.xpath(\'//ul/li/text()\').extract()
网站标题:
sel.xpath(\'//ul/li/a/text()\').extract()
网站 链接:
sel.xpath(\'//ul/li/a/@href\').extract()
如前所述,每个 xpath() 调用都会返回一个选择器列表,因此我们可以结合 xpath() 来挖掘更深的节点。我们将使用这些功能,因此:
sites = sel.xpath(\'//ul/li\')
for site in sites:
title = site.xpath(\'a/text()\').extract()
link = site.xpath(\'a/@href\').extract()
desc = site.xpath(\'text()\').extract()
print title, link, desc
使用物品
scrapy.item.Item的调用接口类似于python的dict,Item收录多个scrapy.item.Field。这类似于 django 的模型和
Item通常用于Spider的parse方法,用于保存解析后的数据。
最后修改爬虫类,使用Item保存数据,代码如下:
from scrapy.spider import Spider
from scrapy.selector import Selector
from dirbot.items import Website
class DmozSpider(Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B,
]
def parse(self, response):
"""
The lines below is a spider contract. For more info see:
http://doc.scrapy.org/en/lates ... .html
@url http://www.dmoz.org/Computers/ ... rces/
@scrapes name
"""
sel = Selector(response)
sites = sel.xpath(\'//ul[@class="directory-url"]/li\')
items = []
for site in sites:
item = Website()
item[\'name\'] = site.xpath(\'a/text()\').extract()
item[\'url\'] = site.xpath(\'a/@href\').extract()
item[\'description\'] = site.xpath(\'text()\').re(\'-\s([^\n]*?)\\n\')
items.append(item)
return items
现在,您可以再次运行该项目以查看结果:
$ scrapy crawl dmoz
使用项目管道
在settings.py中设置ITEM_PIPELINES,默认为[],类似django的MIDDLEWARE_CLASSES等。
Spider的解析返回的Item数据会依次被ITEM_PIPELINES列表中的Pipeline类处理。
Item Pipeline 类必须实现以下方法:
还可以另外实现以下两种方法:
保存捕获的数据
保存信息最简单的方法是通过,命令如下:
$ scrapy crawl dmoz -o items.json -t json
除了 json 格式,还支持 JSON 行、CSV 和 XML 格式。您还可以通过接口扩展一些格式。
这种方法对于小项目来说已经足够了。如果是比较复杂的数据,可能需要写一个Item Pipeline进行处理。
所有抓到的物品都会以JSON格式保存在新生成的items.json文件中
总结
以上介绍了如何创建爬虫项目的过程,可以参考以上过程再次联系。作为学习示例,也可以参考这个文章:scrapy中文教程(爬取cnbeta示例)。
这个文章中的爬虫代码如下:
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
from scrapy.selector import Selector
from cnbeta.items import CnbetaItem
class CBSpider(CrawlSpider):
name = \'cnbeta\'
allowed_domains = [\'cnbeta.com\']
start_urls = [\'http://www.cnbeta.com\']
rules = (
Rule(SgmlLinkExtractor(allow=(\'/articles/.*\.htm\', )),
callback=\'parse_page\', follow=True),
)
def parse_page(self, response):
item = CnbetaItem()
sel = Selector(response)
item[\'title\'] = sel.xpath(\'//title/text()\').extract()
item[\'url\'] = response.url
return item
需要注意的是:
3. 学习资料
联系Scrapy是因为想爬取知乎的一些数据。一开始找了一些相关资料和别人的实现方法。
Github上有人或多或少意识到了知乎数据的爬取。我搜索了以下仓库:
其他信息:
抓取和交互式示例:
有一些知识点需要梳理:
4. 总结
以上是这几天学习Scrapy的笔记和知识汇总。参考了网上的一些文章,写了这篇文章。这次真是万分感谢。希望这篇文章文章能对你有所帮助。如果您有任何想法,请留言;如果你喜欢这篇文章,请帮忙分享,谢谢!
最初发表于:
c爬虫抓取网页数据(具有一定的参考价值安装mysql需要屏蔽掉相关代码:抓取网页数据格式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-10-18 05:18
本文文章主要介绍python2.7,详细实现爬虫网页数据。有一定的参考价值,感兴趣的朋友可以参考
最近刚学了Python,做了一个简单的爬虫。作为一个简单的demo,希望对我这样的初学者有所帮助。
代码使用python制作的爬虫2.7抓取51job上的职位名称、公司名称、薪水、发布时间等。
直接上代码。代码中的注释相当清楚。如果没有安装mysql,需要屏蔽相关代码:
#!/usr/bin/python # -*- coding: UTF-8 -*- from bs4 import BeautifulSoup import urllib import urllib2 import codecs import re import time import logging import MySQLdb class Jobs(object): # 初始化 """docstring for Jobs""" def __init__(self): super(Jobs, self).__init__() logging.basicConfig(level=logging.DEBUG, format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s') #数据库的操作,没有mysql可以做屏蔽 self.db = MySQLdb.connect('127.0.0.1','root','rootroot','MySQL_Test',charset='utf8') self.cursor = self.db.cursor() #log日志的显示 self.logger = logging.getLogger("sjk") self.logger.setLevel(level=logging.DEBUG) formatter = logging.Formatter( '%(asctime)s - %(name)s - %(levelname)s - %(message)s') handler = logging.FileHandler('log.txt') handler.setFormatter(formatter) handler.setLevel(logging.DEBUG) self.logger.addHandler(handler) self.logger.info('初始化完成') # 模拟请求数据 def jobshtml(self, key, page='1'): try: self.logger.info('开始请求第' + page + '页') #网页url searchurl = "https://search.51job.com/list/040000,000000,0000,00,9,99,{key},2,{page}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=" user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:59.0) Gecko/20100101 Firefox/59.0' #设置请求头 header = {'User-Agent': user_agent, 'Host': 'search.51job.com', 'Referer': 'https://www.51job.com/'} #拼接url finalUrl = searchurl.format(key=key, page=page) request = urllib2.Request(finalUrl, headers=header) response = urllib2.urlopen(request) #等待网页加载完成 time.sleep(3) #gbk格式解码 info = response.read().decode('gbk') self.logger.info('请求网页网页') self.decodeHtml(info=info, key=key, page=page) except urllib2.HTTPError as e: print e.reason # 解析网页数据 def decodeHtml(self, info, key, page): self.logger.info('开始解析网页数据') #BeautifulSoup 解析网页 soup = BeautifulSoup(info, 'html.parser') #找到class = t1 t2 t3 t4 t5 的标签数据 ps = soup.find_all(attrs={"class": re.compile(r'^t[1-5].*')}) #打开txt文件 a+ 代表追加 f = codecs.open(key + '.txt', 'a+', 'UTF-8') #清除之前的数据信息 f.truncate() f.write('\n------------' + page + '--------------\n') count = 1 arr = [] #做一些字符串的处理,形成数据格式 iOS开发工程师 有限公司 深圳-南山区 0.9-1.6万/月 05-16 for pi in ps: spe = " " finalstr = pi.getText().strip() arr.append(finalstr) if count % 5 == 0: #每一条数据插入数据库,如果没有安装mysql 可以将当前行注释掉 self.connectMySQL(arr=arr) arr = [] spe = "\n" writestr = finalstr + spe count += 1 f.write(writestr) f.close() self.logger.info('解析完成') #数据库操作 没有安装mysql 可以屏蔽掉 def connectMySQL(self,arr): work=arr[0] company=arr[1] place=arr[2] salary=arr[3] time=arr[4] query = "select * from Jobs_tab where \ company_name='%s' and work_name='%s' and work_place='%s' \ and salary='%s' and time='%s'" %(company,work,place,salary,time) self.cursor.execute(query) queryresult = self.cursor.fetchall() #数据库中不存在就插入数据 存在就可以更新数据 不过我这边没有写 if len(queryresult) > 0: sql = "insert into Jobs_tab(work_name,company_name,work_place,salary\ ,time) values('%s','%s','%s','%s','%s')" %(work,company,place,salary,time) try: self.cursor.execute(sql) self.db.commit() except Exception as e: self.logger.info('写入数据库失败') #模拟登陆 # def login(self): # data = {'action':'save','isread':'on','loginname':'18086514327','password':'kui4131sjk'} # 开始抓取 主函数 def run(self, key): # 只要前5页的数据 key代表搜索工做类型 这边我是用的ios page是页数 for x in xrange(1, 6): self.jobshtml(key=key, page=str(x)) self.logger.info('写入数据库完成') self.db.close() if __name__ == '__main__': Jobs().run(key='iOS')
这种方式捕获的网页数据格式如下:
以上是python2.7实现抓取网页数据的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
c爬虫抓取网页数据(具有一定的参考价值安装mysql需要屏蔽掉相关代码:抓取网页数据格式)
本文文章主要介绍python2.7,详细实现爬虫网页数据。有一定的参考价值,感兴趣的朋友可以参考
最近刚学了Python,做了一个简单的爬虫。作为一个简单的demo,希望对我这样的初学者有所帮助。
代码使用python制作的爬虫2.7抓取51job上的职位名称、公司名称、薪水、发布时间等。
直接上代码。代码中的注释相当清楚。如果没有安装mysql,需要屏蔽相关代码:
#!/usr/bin/python # -*- coding: UTF-8 -*- from bs4 import BeautifulSoup import urllib import urllib2 import codecs import re import time import logging import MySQLdb class Jobs(object): # 初始化 """docstring for Jobs""" def __init__(self): super(Jobs, self).__init__() logging.basicConfig(level=logging.DEBUG, format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s') #数据库的操作,没有mysql可以做屏蔽 self.db = MySQLdb.connect('127.0.0.1','root','rootroot','MySQL_Test',charset='utf8') self.cursor = self.db.cursor() #log日志的显示 self.logger = logging.getLogger("sjk") self.logger.setLevel(level=logging.DEBUG) formatter = logging.Formatter( '%(asctime)s - %(name)s - %(levelname)s - %(message)s') handler = logging.FileHandler('log.txt') handler.setFormatter(formatter) handler.setLevel(logging.DEBUG) self.logger.addHandler(handler) self.logger.info('初始化完成') # 模拟请求数据 def jobshtml(self, key, page='1'): try: self.logger.info('开始请求第' + page + '页') #网页url searchurl = "https://search.51job.com/list/040000,000000,0000,00,9,99,{key},2,{page}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=" user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:59.0) Gecko/20100101 Firefox/59.0' #设置请求头 header = {'User-Agent': user_agent, 'Host': 'search.51job.com', 'Referer': 'https://www.51job.com/'} #拼接url finalUrl = searchurl.format(key=key, page=page) request = urllib2.Request(finalUrl, headers=header) response = urllib2.urlopen(request) #等待网页加载完成 time.sleep(3) #gbk格式解码 info = response.read().decode('gbk') self.logger.info('请求网页网页') self.decodeHtml(info=info, key=key, page=page) except urllib2.HTTPError as e: print e.reason # 解析网页数据 def decodeHtml(self, info, key, page): self.logger.info('开始解析网页数据') #BeautifulSoup 解析网页 soup = BeautifulSoup(info, 'html.parser') #找到class = t1 t2 t3 t4 t5 的标签数据 ps = soup.find_all(attrs={"class": re.compile(r'^t[1-5].*')}) #打开txt文件 a+ 代表追加 f = codecs.open(key + '.txt', 'a+', 'UTF-8') #清除之前的数据信息 f.truncate() f.write('\n------------' + page + '--------------\n') count = 1 arr = [] #做一些字符串的处理,形成数据格式 iOS开发工程师 有限公司 深圳-南山区 0.9-1.6万/月 05-16 for pi in ps: spe = " " finalstr = pi.getText().strip() arr.append(finalstr) if count % 5 == 0: #每一条数据插入数据库,如果没有安装mysql 可以将当前行注释掉 self.connectMySQL(arr=arr) arr = [] spe = "\n" writestr = finalstr + spe count += 1 f.write(writestr) f.close() self.logger.info('解析完成') #数据库操作 没有安装mysql 可以屏蔽掉 def connectMySQL(self,arr): work=arr[0] company=arr[1] place=arr[2] salary=arr[3] time=arr[4] query = "select * from Jobs_tab where \ company_name='%s' and work_name='%s' and work_place='%s' \ and salary='%s' and time='%s'" %(company,work,place,salary,time) self.cursor.execute(query) queryresult = self.cursor.fetchall() #数据库中不存在就插入数据 存在就可以更新数据 不过我这边没有写 if len(queryresult) > 0: sql = "insert into Jobs_tab(work_name,company_name,work_place,salary\ ,time) values('%s','%s','%s','%s','%s')" %(work,company,place,salary,time) try: self.cursor.execute(sql) self.db.commit() except Exception as e: self.logger.info('写入数据库失败') #模拟登陆 # def login(self): # data = {'action':'save','isread':'on','loginname':'18086514327','password':'kui4131sjk'} # 开始抓取 主函数 def run(self, key): # 只要前5页的数据 key代表搜索工做类型 这边我是用的ios page是页数 for x in xrange(1, 6): self.jobshtml(key=key, page=str(x)) self.logger.info('写入数据库完成') self.db.close() if __name__ == '__main__': Jobs().run(key='iOS')
这种方式捕获的网页数据格式如下:

以上是python2.7实现抓取网页数据的详细内容。更多详情请关注其他相关html中文网站文章!
c爬虫抓取网页数据(如何抓取ajax形式加载的网页数据(一)_恢复内容开始)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-10-17 22:13
---恢复内容开始---
下面记录如何抓取ajax形式加载的网页数据:
目标:获取“%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=”下的网页数据
第一步:网页数据分析-----》特点:当列表栏滚动到页面底部时,数据自动加载,页面的url没有变化
第二步:使用Fiddler抓包,如下图:
图 1:请求数据
图2:表格形式
数据规律是通过抓包得到的:图2中from表单中的start对应数据和图1中url中的start对应数据随着每次加载增加,其他数据没有变化。对应这个规律,我们可以构造相应的请求来获取数据
注意数据格式为json
代码显示如下:
1).urllib 表单
import urllib2
import urllib
#此处的url为上述抓包获取的url去掉start以及limit,start以及limit数据后边以form表单的形式传入
url = ' https://movie.douban.com/j/cha ... ction='
#请求投信息,伪造成浏览器,方式被反爬虫策略拦截
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
#构建form表单
formdata = {
"start":"20",
"limit":"20"
}
#urlencode()urllib中的函数,作用:将key:value形式的键值对转换为"key=value"形式的字符串
data = urllib.urlencode(formdata)
#构建request实例对象
request = urllib2.Request(url,data=data,headers=headers)
#发送请求并返回响应信息
response = urllib2.urlopen(request)
#注意此处的数据形式并不是html文档,而是json数据
json = response.read()
print html
2).request 库获取请求代码
#coding=utf-8
import requests
url = ' https://movie.douban.com/j/cha ... ction='
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
data = {
"start":"20",
"limit":"20",
}
response = requests.get(url,params = data,headers = headers)
print response.text
3).request 库发布请求
#coding=utf-8
import requests
url = ' https://movie.douban.com/j/cha ... ction='
formdata = {
"start":"20",
"limit":"20"
}
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
response = requests.post(url,data=formdata,headers=headers)
print response.text
---恢复内容结束--- 查看全部
c爬虫抓取网页数据(如何抓取ajax形式加载的网页数据(一)_恢复内容开始)
---恢复内容开始---
下面记录如何抓取ajax形式加载的网页数据:
目标:获取“%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=”下的网页数据
第一步:网页数据分析-----》特点:当列表栏滚动到页面底部时,数据自动加载,页面的url没有变化
第二步:使用Fiddler抓包,如下图:
图 1:请求数据

图2:表格形式

数据规律是通过抓包得到的:图2中from表单中的start对应数据和图1中url中的start对应数据随着每次加载增加,其他数据没有变化。对应这个规律,我们可以构造相应的请求来获取数据
注意数据格式为json
代码显示如下:
1).urllib 表单
import urllib2
import urllib
#此处的url为上述抓包获取的url去掉start以及limit,start以及limit数据后边以form表单的形式传入
url = ' https://movie.douban.com/j/cha ... ction='
#请求投信息,伪造成浏览器,方式被反爬虫策略拦截
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
#构建form表单
formdata = {
"start":"20",
"limit":"20"
}
#urlencode()urllib中的函数,作用:将key:value形式的键值对转换为"key=value"形式的字符串
data = urllib.urlencode(formdata)
#构建request实例对象
request = urllib2.Request(url,data=data,headers=headers)
#发送请求并返回响应信息
response = urllib2.urlopen(request)
#注意此处的数据形式并不是html文档,而是json数据
json = response.read()
print html
2).request 库获取请求代码
#coding=utf-8
import requests
url = ' https://movie.douban.com/j/cha ... ction='
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
data = {
"start":"20",
"limit":"20",
}
response = requests.get(url,params = data,headers = headers)
print response.text
3).request 库发布请求
#coding=utf-8
import requests
url = ' https://movie.douban.com/j/cha ... ction='
formdata = {
"start":"20",
"limit":"20"
}
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
response = requests.post(url,data=formdata,headers=headers)
print response.text
---恢复内容结束---
c爬虫抓取网页数据(Python的内置标准库、执行速度适中、文档容错能力强 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-17 06:18
)
1、基本情况
对于静态网页,您只需要应用两个库,requests 库和 BeautifulSoup4 库。
1.1简介
Beautiful Soup 是一个python库,主要功能是抓取网页数据。
BeautifulSoup4 是爬虫必备的技能。 BeautifulSoup 的主要功能是从网页中抓取数据。
Beautiful Soup 自动将输入文档转换为 Unicode 编码,输出文档为 utf-8 编码。
BeautifulSoup 支持 Python 标准库中的 HTML 解析器,以及一些第三方解析器。如果我们不安装它,Python 将使用 Python 默认解析器。 lxml 解析器功能更强大,速度更快。推荐使用lxml解析器。
Beautiful Soup 提供了一些简单的 Python 风格的函数来处理导航、搜索、修改分析树等功能。
1.2安装
安装:pip install beautifulsoup4
导入:导入bs4(注意不能导入beautifulsoup)
1.3 种主要解析器的比较
使用解析器的优缺点
Python 标准库
BeautifulSoup(markup, “html.parser”)
Python内置标准库,执行速度适中,文档容错能力强
Python 2.7.3 or 3.2.2)之前的版本中文容错能力差
lxml HTML 解析器
BeautifulSoup(markup, “lxml”)
速度快,文档容错能力强
需要安装C语言库
lxml XML 解析器
BeautifulSoup(markup, “xml”)
速度快,唯一支持XML的解析器
需要安装C语言库
html5lib
BeautifulSoup(markup, “html5lib”)
最佳容错性,浏览器解析文档,生成HTML5格式文档
速度慢,不依赖外部扩展
2、基本使用方法
基本用法如下:
代码示例:
import requests
from bs4 import BeautifulSoup
url = "http://jinyongxiaoshuo.com/xue ... ot%3B
#要爬取的网页,这里我找了个金庸小说的网页
res = requests.get('https://cuiqingcai.com/authors/%E5%B4%94%E5%BA%86%E6%89%8D/page/2/')
#向网页发送请求
res.encoding='utf-8'
#编码为utf-8模式
soup=BeautifulSoup(res.text,'html.parser')
#用Python自带的解析器‘html.parser’解析
print(soup)
#打印出整个HTML文档
3、BeautifulSoup4 四种对象
BeautifulSoup4 将复杂的 HTML 文档转换成复杂的树结构,每个节点都是一个 Python 对象,所有对象可以归纳为 4 种类型:
3.1.标签
我们可以通过使用soup 和标签名称轻松获取这些标签的内容。这些对象的类型是 bs4.element.Tag。但请注意,它会查找所有内容中满足要求的第一个标签。
print(type(bs.a))
对于 Tag,它有两个重要的属性,name 和 attrs:
3.2.NavigableString
既然我们已经拿到了标签的内容,那么问题来了,如果我们想要拿到标签里面的文字,我们应该怎么做呢?很简单,直接用.string
print(type(bs.title.string))
3.3.美汤
BeautifulSoup 对象表示文档的内容。大多数时候,它可以看作是一个 Tag 对象,是一个特殊的 Tag。我们可以分别获取它的类型、名称和属性
3.4.评论
注释对象是一种特殊类型的 NavigableString 对象,其输出不收录注释符号。
4、遍历文档树
4.1、.contents:获取Tag的所有子节点并返回一个列表
# tag的.content 属性可以将tag的子节点以列表的方式输出
print(bs.head.contents)
# 用列表索引来获取它的某一个元素
print(bs.head.contents[1])
4.2、.children:获取Tag的所有子节点并返回一个生成器
for child in bs.body.children:
print(child)
4.3、.descendants:获取Tag的所有后代
4.4、.strings:如果Tag收录多个字符串,也就是后代节点有内容,可以用这个获取,然后遍历
4.5、.stripped_strings:与字符串的用法一致,只是可以去掉多余的空白内容
4.6、.parent:获取Tag的父节点
4.7、.parents:递归获取父元素的所有节点并返回一个生成器
4.8、.previous_sibling:获取当前Tag的上一个节点。该属性通常是字符串或空白。真正的结果是当前标签和前一个标签之间的逗号和换行符。
4.9、.next_sibling:获取当前Tag的下一个节点。该属性通常是字符串或空白。结果是当前标签和下一个标签之间的逗号和换行符。
4.10、.previous_siblings:获取当前Tag之上的所有兄弟节点,并返回一个生成器
4.11、.next_siblings:获取当前Tag下的所有兄弟节点,并返回一个生成器
4.12、.previous_element:获取解析过程中最后解析的对象(字符串或标签),可能与previous_sibling相同,但通常不同
4.13、.next_element:获取解析过程中下一个要解析的对象(字符串或标签),可能与next_sibling相同,但通常不同
4.14、.previous_elements:返回一个生成器向前访问文档的解析内容
4.15、.next_elements:返回一个生成器,允许您向后访问文档的解析内容
4.16、.has_attr:判断标签是否收录属性
5、搜索文档树
5.1find_all( name, attrs, recursive, text, **kwargs )
find_all()方法查找当前标签的所有标签子节点,判断是否满足过滤条件
5.1.1name 参数
name参数可以找到所有名为name的标签,string对象会被自动忽略。
5.1.1.传输字符串
最简单的过滤器是一个字符串。在搜索方法中传入一个字符串参数,Beautiful Soup 会找到与字符串完全匹配的内容。以下示例用于查找文档中的所有标签
soup.find_all('b')
# [The Dormouse's story]
print soup.find_all('a')
#[, Lacie, Tillie]
5.1.1.B 传正则表达式
如果传入一个正则表达式作为参数,Beautiful Soup会通过正则表达式的match()来匹配内容。在下面的例子中,所有以 b 开头的标签都被找到了,这意味着应该找到 and 标签。
import re
for tag in soup.find_all(re.compile("^b")): print(tag.name)
# body
# b
5.1.1.C.传输列表
如果传入 list 参数,Beautiful Soup 将返回匹配列表中任何元素的内容。以下代码查找文档中的所有标签和标签
soup.find_all(["a", "b"])
# [<b>The Dormouse's story,
# Elsie,
# Lacie,
# Tillie]
5.1.1.D.通过真
True 可以匹配任何值,以下代码查找所有标签,但不会返回字符串节点
for tag in soup.find_all(True):
print(tag.name)
# html
# head
# title
# body
# p
# b
# p
# a
# a
5.1.1.E.传输方式
如果没有合适的过滤器,那么也可以定义一个方法,该方法只接受一个元素参数[4],如果这个方法返回True,则表示匹配并找到当前元素,如果没有,则返回错误
以下方法验证当前元素。如果它收录 class 属性但不收录 id 属性,它将返回 True:
def has_class_but_no_id(tag):
return tag.has_attr('class') and not tag.has_attr('id')
#将这个方法作为参数传入 find_all() 方法,将得到所有<p>标签:
soup.find_all(has_class_but_no_id)
# [<p class="title">The Dormouse's story,
#
Once upon a time there were...,
#
...]</p>
5.1.2、关键字参数
注意:如果指定名称的参数不是搜索内置参数名称,则搜索时将作为指定名称标签的属性进行搜索。如果收录一个名为 id 的参数,Beautiful Soup 会搜索每个标签的“Id”属性
soup.find_all(id='link2')
# [Lacie]
如果传入href参数,Beautiful Soup会搜索每个标签的“href”属性
soup.find_all(href=re.compile("elsie"))
# [Elsie]
使用指定名称的多个参数同时过滤标签的多个属性
soup.find_all(href=re.compile("elsie"), id='link1')
# [three]
这里想按class过滤,class是python的关键词,怎么办?加一个下划线
soup.find_all("a", class_="sister")
# [Elsie,
# Lacie,
# Tillie]
有些标签属性不能用于搜索,比如HTML5中的data-*属性
soup.find_all("a", class_="sister")
# [Elsie,
# Lacie,
# Tillie]
但是可以通过find_all()方法的attrs参数定义一个字典参数来搜索收录特殊属性的标签
data_soup.find_all(attrs={"data-foo": "value"})
# [foo!]
5.1.3、文本参数
文档中的字符串内容可以通过text参数进行搜索。与name参数的可选值一样,text参数接受字符串、正则表达式、列表和True
soup.find_all(text="Elsie")
# [u'Elsie']
soup.find_all(text=["Tillie", "Elsie", "Lacie"])
# [u'Elsie', u'Lacie', u'Tillie']
soup.find_all(text=re.compile("Dormouse"))
#[u"The Dormouse's story", u"The Dormouse's story"]
5.1.4、限制参数
find_all() 方法返回所有搜索结构。如果文档树很大,搜索会很慢。如果我们不需要所有的结果,我们可以使用 limit 参数来限制返回结果的数量。作用类似于SQL中的limit关键字,当搜索结果数达到limit限制时,停止搜索返回结果。
文档树中有3个标签符合搜索条件,但由于我们限制了返回次数,只返回了2个结果
soup.find_all("a", limit=2)
# [Elsie,
# Lacie]
5.1.5、递归参数
当调用标签的 find_all() 方法时,Beautiful Soup 将检索当前标签的所有后代。如果只想搜索标签的直接子节点,可以使用参数 recursive=False 。
一个简单的文档:
复制代码代码如下:
The Dormouse's story
是否使用递归参数搜索结果:
soup.html.find_all("title")
# [The Dormouse's story]
soup.html.find_all("title", recursive=False)
# []
5.2、find( name, attrs, recursive, text, **kwargs )
它和find_all()方法唯一的区别是find_all()方法的返回结果是一个收录一个元素的值列表,而find()方法直接返回结果
5.3、find_parents(), find_parent()
find_all() 和 find() 只搜索当前节点的所有子节点、孙节点等。 find_parents() 和 find_parent() 用于搜索当前节点的父节点。查找方法与普通标签相同。搜索文档 搜索文档收录内容
5.4、find_next_siblings() find_next_sibling()
这两个方法使用.next_siblings属性来迭代所有后面解析的兄弟标签节点。一个标签节点
5.5、find_previous_siblings() find_previous_sibling()
这两个方法使用 .previous_siblings 属性来迭代当前标签之前解析的兄弟标签节点。 find_previous_siblings() 方法返回之前所有满足条件的兄弟节点, find_previous_sibling() 方法返回第一个满足条件的兄弟节点。兄弟节点
5.6、find_all_next() find_next()
这两个方法使用 .next_elements 属性来迭代当前标签之后的标签和字符串。 find_all_next() 方法返回所有符合条件的节点, find_next() 方法返回第一个符合条件的节点
5.7、find_all_previous() 和 find_previous()
这两个方法使用 .previous_elements 属性来迭代当前节点前面的标签和字符串。 find_all_previous() 方法返回所有符合条件的节点, find_previous() 方法返回第一个符合条件的节点
<p>注意:上述5.2--5.7方法参数用法与find_all()完全相同,原理也类似,这里不再赘述。 查看全部
c爬虫抓取网页数据(Python的内置标准库、执行速度适中、文档容错能力强
)
1、基本情况
对于静态网页,您只需要应用两个库,requests 库和 BeautifulSoup4 库。
1.1简介
Beautiful Soup 是一个python库,主要功能是抓取网页数据。
BeautifulSoup4 是爬虫必备的技能。 BeautifulSoup 的主要功能是从网页中抓取数据。
Beautiful Soup 自动将输入文档转换为 Unicode 编码,输出文档为 utf-8 编码。
BeautifulSoup 支持 Python 标准库中的 HTML 解析器,以及一些第三方解析器。如果我们不安装它,Python 将使用 Python 默认解析器。 lxml 解析器功能更强大,速度更快。推荐使用lxml解析器。
Beautiful Soup 提供了一些简单的 Python 风格的函数来处理导航、搜索、修改分析树等功能。
1.2安装
安装:pip install beautifulsoup4
导入:导入bs4(注意不能导入beautifulsoup)
1.3 种主要解析器的比较
使用解析器的优缺点
Python 标准库
BeautifulSoup(markup, “html.parser”)
Python内置标准库,执行速度适中,文档容错能力强
Python 2.7.3 or 3.2.2)之前的版本中文容错能力差
lxml HTML 解析器
BeautifulSoup(markup, “lxml”)
速度快,文档容错能力强
需要安装C语言库
lxml XML 解析器
BeautifulSoup(markup, “xml”)
速度快,唯一支持XML的解析器
需要安装C语言库
html5lib
BeautifulSoup(markup, “html5lib”)
最佳容错性,浏览器解析文档,生成HTML5格式文档
速度慢,不依赖外部扩展
2、基本使用方法
基本用法如下:

代码示例:
import requests
from bs4 import BeautifulSoup
url = "http://jinyongxiaoshuo.com/xue ... ot%3B
#要爬取的网页,这里我找了个金庸小说的网页
res = requests.get('https://cuiqingcai.com/authors/%E5%B4%94%E5%BA%86%E6%89%8D/page/2/')
#向网页发送请求
res.encoding='utf-8'
#编码为utf-8模式
soup=BeautifulSoup(res.text,'html.parser')
#用Python自带的解析器‘html.parser’解析
print(soup)
#打印出整个HTML文档
3、BeautifulSoup4 四种对象
BeautifulSoup4 将复杂的 HTML 文档转换成复杂的树结构,每个节点都是一个 Python 对象,所有对象可以归纳为 4 种类型:
3.1.标签
我们可以通过使用soup 和标签名称轻松获取这些标签的内容。这些对象的类型是 bs4.element.Tag。但请注意,它会查找所有内容中满足要求的第一个标签。
print(type(bs.a))
对于 Tag,它有两个重要的属性,name 和 attrs:
3.2.NavigableString
既然我们已经拿到了标签的内容,那么问题来了,如果我们想要拿到标签里面的文字,我们应该怎么做呢?很简单,直接用.string
print(type(bs.title.string))
3.3.美汤
BeautifulSoup 对象表示文档的内容。大多数时候,它可以看作是一个 Tag 对象,是一个特殊的 Tag。我们可以分别获取它的类型、名称和属性
3.4.评论
注释对象是一种特殊类型的 NavigableString 对象,其输出不收录注释符号。
4、遍历文档树
4.1、.contents:获取Tag的所有子节点并返回一个列表
# tag的.content 属性可以将tag的子节点以列表的方式输出
print(bs.head.contents)
# 用列表索引来获取它的某一个元素
print(bs.head.contents[1])
4.2、.children:获取Tag的所有子节点并返回一个生成器
for child in bs.body.children:
print(child)
4.3、.descendants:获取Tag的所有后代
4.4、.strings:如果Tag收录多个字符串,也就是后代节点有内容,可以用这个获取,然后遍历
4.5、.stripped_strings:与字符串的用法一致,只是可以去掉多余的空白内容
4.6、.parent:获取Tag的父节点
4.7、.parents:递归获取父元素的所有节点并返回一个生成器
4.8、.previous_sibling:获取当前Tag的上一个节点。该属性通常是字符串或空白。真正的结果是当前标签和前一个标签之间的逗号和换行符。
4.9、.next_sibling:获取当前Tag的下一个节点。该属性通常是字符串或空白。结果是当前标签和下一个标签之间的逗号和换行符。
4.10、.previous_siblings:获取当前Tag之上的所有兄弟节点,并返回一个生成器
4.11、.next_siblings:获取当前Tag下的所有兄弟节点,并返回一个生成器
4.12、.previous_element:获取解析过程中最后解析的对象(字符串或标签),可能与previous_sibling相同,但通常不同
4.13、.next_element:获取解析过程中下一个要解析的对象(字符串或标签),可能与next_sibling相同,但通常不同
4.14、.previous_elements:返回一个生成器向前访问文档的解析内容
4.15、.next_elements:返回一个生成器,允许您向后访问文档的解析内容
4.16、.has_attr:判断标签是否收录属性
5、搜索文档树
5.1find_all( name, attrs, recursive, text, **kwargs )
find_all()方法查找当前标签的所有标签子节点,判断是否满足过滤条件
5.1.1name 参数
name参数可以找到所有名为name的标签,string对象会被自动忽略。
5.1.1.传输字符串
最简单的过滤器是一个字符串。在搜索方法中传入一个字符串参数,Beautiful Soup 会找到与字符串完全匹配的内容。以下示例用于查找文档中的所有标签
soup.find_all('b')
# [The Dormouse's story]
print soup.find_all('a')
#[, Lacie, Tillie]
5.1.1.B 传正则表达式
如果传入一个正则表达式作为参数,Beautiful Soup会通过正则表达式的match()来匹配内容。在下面的例子中,所有以 b 开头的标签都被找到了,这意味着应该找到 and 标签。
import re
for tag in soup.find_all(re.compile("^b")): print(tag.name)
# body
# b
5.1.1.C.传输列表
如果传入 list 参数,Beautiful Soup 将返回匹配列表中任何元素的内容。以下代码查找文档中的所有标签和标签
soup.find_all(["a", "b"])
# [<b>The Dormouse's story,
# Elsie,
# Lacie,
# Tillie]
5.1.1.D.通过真
True 可以匹配任何值,以下代码查找所有标签,但不会返回字符串节点
for tag in soup.find_all(True):
print(tag.name)
# html
# head
# title
# body
# p
# b
# p
# a
# a
5.1.1.E.传输方式
如果没有合适的过滤器,那么也可以定义一个方法,该方法只接受一个元素参数[4],如果这个方法返回True,则表示匹配并找到当前元素,如果没有,则返回错误
以下方法验证当前元素。如果它收录 class 属性但不收录 id 属性,它将返回 True:
def has_class_but_no_id(tag):
return tag.has_attr('class') and not tag.has_attr('id')
#将这个方法作为参数传入 find_all() 方法,将得到所有<p>标签:
soup.find_all(has_class_but_no_id)
# [<p class="title">The Dormouse's story,
#
Once upon a time there were...,
#
...]</p>
5.1.2、关键字参数
注意:如果指定名称的参数不是搜索内置参数名称,则搜索时将作为指定名称标签的属性进行搜索。如果收录一个名为 id 的参数,Beautiful Soup 会搜索每个标签的“Id”属性
soup.find_all(id='link2')
# [Lacie]
如果传入href参数,Beautiful Soup会搜索每个标签的“href”属性
soup.find_all(href=re.compile("elsie"))
# [Elsie]
使用指定名称的多个参数同时过滤标签的多个属性
soup.find_all(href=re.compile("elsie"), id='link1')
# [three]
这里想按class过滤,class是python的关键词,怎么办?加一个下划线
soup.find_all("a", class_="sister")
# [Elsie,
# Lacie,
# Tillie]
有些标签属性不能用于搜索,比如HTML5中的data-*属性
soup.find_all("a", class_="sister")
# [Elsie,
# Lacie,
# Tillie]
但是可以通过find_all()方法的attrs参数定义一个字典参数来搜索收录特殊属性的标签
data_soup.find_all(attrs={"data-foo": "value"})
# [foo!]
5.1.3、文本参数
文档中的字符串内容可以通过text参数进行搜索。与name参数的可选值一样,text参数接受字符串、正则表达式、列表和True
soup.find_all(text="Elsie")
# [u'Elsie']
soup.find_all(text=["Tillie", "Elsie", "Lacie"])
# [u'Elsie', u'Lacie', u'Tillie']
soup.find_all(text=re.compile("Dormouse"))
#[u"The Dormouse's story", u"The Dormouse's story"]
5.1.4、限制参数
find_all() 方法返回所有搜索结构。如果文档树很大,搜索会很慢。如果我们不需要所有的结果,我们可以使用 limit 参数来限制返回结果的数量。作用类似于SQL中的limit关键字,当搜索结果数达到limit限制时,停止搜索返回结果。
文档树中有3个标签符合搜索条件,但由于我们限制了返回次数,只返回了2个结果
soup.find_all("a", limit=2)
# [Elsie,
# Lacie]
5.1.5、递归参数
当调用标签的 find_all() 方法时,Beautiful Soup 将检索当前标签的所有后代。如果只想搜索标签的直接子节点,可以使用参数 recursive=False 。
一个简单的文档:
复制代码代码如下:
The Dormouse's story
是否使用递归参数搜索结果:
soup.html.find_all("title")
# [The Dormouse's story]
soup.html.find_all("title", recursive=False)
# []
5.2、find( name, attrs, recursive, text, **kwargs )
它和find_all()方法唯一的区别是find_all()方法的返回结果是一个收录一个元素的值列表,而find()方法直接返回结果
5.3、find_parents(), find_parent()
find_all() 和 find() 只搜索当前节点的所有子节点、孙节点等。 find_parents() 和 find_parent() 用于搜索当前节点的父节点。查找方法与普通标签相同。搜索文档 搜索文档收录内容
5.4、find_next_siblings() find_next_sibling()
这两个方法使用.next_siblings属性来迭代所有后面解析的兄弟标签节点。一个标签节点
5.5、find_previous_siblings() find_previous_sibling()
这两个方法使用 .previous_siblings 属性来迭代当前标签之前解析的兄弟标签节点。 find_previous_siblings() 方法返回之前所有满足条件的兄弟节点, find_previous_sibling() 方法返回第一个满足条件的兄弟节点。兄弟节点
5.6、find_all_next() find_next()
这两个方法使用 .next_elements 属性来迭代当前标签之后的标签和字符串。 find_all_next() 方法返回所有符合条件的节点, find_next() 方法返回第一个符合条件的节点
5.7、find_all_previous() 和 find_previous()
这两个方法使用 .previous_elements 属性来迭代当前节点前面的标签和字符串。 find_all_previous() 方法返回所有符合条件的节点, find_previous() 方法返回第一个符合条件的节点
<p>注意:上述5.2--5.7方法参数用法与find_all()完全相同,原理也类似,这里不再赘述。
c爬虫抓取网页数据(封装一个简单总结(一):抓取网页文档分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-16 06:24
)
这两天学习了爬虫的基础知识,这里简单总结一下。
获取的网页商品数据保存在Excel表格中,效果如下:
使用Jumony Core引擎,是一个非常强大且近乎完美的HTML解析引擎,支持css3选择器,直接抓取网页文档进行分析,并根据HTTP头自动识别。
一个抓取博客园站点导航顶部信息的例子:
var documents = new JumonyParser().LoadDocument("http://www.cnblogs.com/").Find("#site_nav_top").FirstOrDefault();
太强大了。如果您熟悉 CSS,则无需手动编写大量可读性差的正则表达式来匹配和获取数据。
封装一个简单的操作库:
public class BaseAnalyzer
{
///
/// 根据Url加载html文档对象
///
///
///
protected virtual IHtmlDocument LoadDocument(string url)
{
return new JumonyParser().LoadDocument(url);
}
///
/// 查询指定url中指定选择器的元素集
///
///
///
///
protected virtual List QueryHtmlElements(string url, string selector, Func predicate = null)
{
var elementsCollection = new List();
IEnumerable elements = LoadDocument(url).Find(selector);
if (predicate != null)
{
elements = elements.Where(predicate);
}
if (elements != null)
elementsCollection.AddRange(elements);
return elementsCollection;
}
///
/// 分析Html文档,获取指定元素集第一个元素的文本内容
///
/// html文档对象
/// 选择器
/// 文本内容
protected virtual string GetFirstElementText(IHtmlContainer html, string selector)
{
var findList = html.Find(selector);
var result = findList.FirstOrDefault();
return result == null ? string.Empty : result.InnerText();
}
///
/// 分析Html文档,获取指定元素集的文本内容
///
/// html文档对象
/// 选择器
/// 自定义处理获取到的元素集,若没有,就返回第一个元素的文本内容
///
protected virtual string GetElementsText(IHtmlContainer html, string selector, Func func)
{
var findList = html.Find(selector);
if (func != null)
return func(findList);
return GetFirstElementText(html, selector);
}
}
获取产品名称的示例:
private ProductInfo AnalyzeProductInfo(string detailUrl)
{
var product = new ProductInfo();
//详情页html文档对象
var html = LoadDocument(detailUrl);
product.ProductName = GetFirstElementText(html, ".goods_particulars h1");
} 查看全部
c爬虫抓取网页数据(封装一个简单总结(一):抓取网页文档分析
)
这两天学习了爬虫的基础知识,这里简单总结一下。
获取的网页商品数据保存在Excel表格中,效果如下:

使用Jumony Core引擎,是一个非常强大且近乎完美的HTML解析引擎,支持css3选择器,直接抓取网页文档进行分析,并根据HTTP头自动识别。
一个抓取博客园站点导航顶部信息的例子:
var documents = new JumonyParser().LoadDocument("http://www.cnblogs.com/";).Find("#site_nav_top").FirstOrDefault();
太强大了。如果您熟悉 CSS,则无需手动编写大量可读性差的正则表达式来匹配和获取数据。
封装一个简单的操作库:
public class BaseAnalyzer
{
///
/// 根据Url加载html文档对象
///
///
///
protected virtual IHtmlDocument LoadDocument(string url)
{
return new JumonyParser().LoadDocument(url);
}
///
/// 查询指定url中指定选择器的元素集
///
///
///
///
protected virtual List QueryHtmlElements(string url, string selector, Func predicate = null)
{
var elementsCollection = new List();
IEnumerable elements = LoadDocument(url).Find(selector);
if (predicate != null)
{
elements = elements.Where(predicate);
}
if (elements != null)
elementsCollection.AddRange(elements);
return elementsCollection;
}
///
/// 分析Html文档,获取指定元素集第一个元素的文本内容
///
/// html文档对象
/// 选择器
/// 文本内容
protected virtual string GetFirstElementText(IHtmlContainer html, string selector)
{
var findList = html.Find(selector);
var result = findList.FirstOrDefault();
return result == null ? string.Empty : result.InnerText();
}
///
/// 分析Html文档,获取指定元素集的文本内容
///
/// html文档对象
/// 选择器
/// 自定义处理获取到的元素集,若没有,就返回第一个元素的文本内容
///
protected virtual string GetElementsText(IHtmlContainer html, string selector, Func func)
{
var findList = html.Find(selector);
if (func != null)
return func(findList);
return GetFirstElementText(html, selector);
}
}
获取产品名称的示例:
private ProductInfo AnalyzeProductInfo(string detailUrl)
{
var product = new ProductInfo();
//详情页html文档对象
var html = LoadDocument(detailUrl);
product.ProductName = GetFirstElementText(html, ".goods_particulars h1");
}
c爬虫抓取网页数据(封装一个简单总结(一):抓取网页文档分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-16 06:19
)
这两天学习了爬虫的基础知识,这里简单总结一下。
获取的网页商品数据保存在Excel表格中,效果如下:
使用Jumony Core引擎,是一个非常强大且近乎完美的HTML解析引擎,支持css3选择器,直接抓取网页文档进行分析,并根据HTTP头自动识别。
一个抓取博客园站点导航顶部信息的例子:
var documents = new JumonyParser().LoadDocument("http://www.cnblogs.com/").Find("#site_nav_top").FirstOrDefault();
太强大了。如果您熟悉 CSS,则无需手动编写大量可读性差的正则表达式来匹配和获取数据。
封装一个简单的操作库:
public class BaseAnalyzer
{
///
/// 根据Url加载html文档对象
///
///
///
protected virtual IHtmlDocument LoadDocument(string url)
{
return new JumonyParser().LoadDocument(url);
}
///
/// 查询指定url中指定选择器的元素集
///
///
///
///
protected virtual List QueryHtmlElements(string url, string selector, Func predicate = null)
{
var elementsCollection = new List();
IEnumerable elements = LoadDocument(url).Find(selector);
if (predicate != null)
{
elements = elements.Where(predicate);
}
if (elements != null)
elementsCollection.AddRange(elements);
return elementsCollection;
}
///
/// 分析Html文档,获取指定元素集第一个元素的文本内容
///
/// html文档对象
/// 选择器
/// 文本内容
protected virtual string GetFirstElementText(IHtmlContainer html, string selector)
{
var findList = html.Find(selector);
var result = findList.FirstOrDefault();
return result == null ? string.Empty : result.InnerText();
}
///
/// 分析Html文档,获取指定元素集的文本内容
///
/// html文档对象
/// 选择器
/// 自定义处理获取到的元素集,若没有,就返回第一个元素的文本内容
///
protected virtual string GetElementsText(IHtmlContainer html, string selector, Func func)
{
var findList = html.Find(selector);
if (func != null)
return func(findList);
return GetFirstElementText(html, selector);
}
}
获取产品名称的示例:
private ProductInfo AnalyzeProductInfo(string detailUrl)
{
var product = new ProductInfo();
//详情页html文档对象
var html = LoadDocument(detailUrl);
product.ProductName = GetFirstElementText(html, ".goods_particulars h1");
} 查看全部
c爬虫抓取网页数据(封装一个简单总结(一):抓取网页文档分析
)
这两天学习了爬虫的基础知识,这里简单总结一下。
获取的网页商品数据保存在Excel表格中,效果如下:
使用Jumony Core引擎,是一个非常强大且近乎完美的HTML解析引擎,支持css3选择器,直接抓取网页文档进行分析,并根据HTTP头自动识别。
一个抓取博客园站点导航顶部信息的例子:
var documents = new JumonyParser().LoadDocument("http://www.cnblogs.com/";).Find("#site_nav_top").FirstOrDefault();
太强大了。如果您熟悉 CSS,则无需手动编写大量可读性差的正则表达式来匹配和获取数据。
封装一个简单的操作库:
public class BaseAnalyzer
{
///
/// 根据Url加载html文档对象
///
///
///
protected virtual IHtmlDocument LoadDocument(string url)
{
return new JumonyParser().LoadDocument(url);
}
///
/// 查询指定url中指定选择器的元素集
///
///
///
///
protected virtual List QueryHtmlElements(string url, string selector, Func predicate = null)
{
var elementsCollection = new List();
IEnumerable elements = LoadDocument(url).Find(selector);
if (predicate != null)
{
elements = elements.Where(predicate);
}
if (elements != null)
elementsCollection.AddRange(elements);
return elementsCollection;
}
///
/// 分析Html文档,获取指定元素集第一个元素的文本内容
///
/// html文档对象
/// 选择器
/// 文本内容
protected virtual string GetFirstElementText(IHtmlContainer html, string selector)
{
var findList = html.Find(selector);
var result = findList.FirstOrDefault();
return result == null ? string.Empty : result.InnerText();
}
///
/// 分析Html文档,获取指定元素集的文本内容
///
/// html文档对象
/// 选择器
/// 自定义处理获取到的元素集,若没有,就返回第一个元素的文本内容
///
protected virtual string GetElementsText(IHtmlContainer html, string selector, Func func)
{
var findList = html.Find(selector);
if (func != null)
return func(findList);
return GetFirstElementText(html, selector);
}
}
获取产品名称的示例:
private ProductInfo AnalyzeProductInfo(string detailUrl)
{
var product = new ProductInfo();
//详情页html文档对象
var html = LoadDocument(detailUrl);
product.ProductName = GetFirstElementText(html, ".goods_particulars h1");
}
c爬虫抓取网页数据(2017年本科毕业论文主题网络爬虫的设计与实现-orientedcrawler)
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-10-16 00:14
本科毕业论文题目:面向学科爬虫的设计与实现 姓名:陆刚 学号:234 学院:软件学院 系:软件工程专业:软件工程 年级:2005级 导师:石亮副教授 2009 年 6 月 I 总结 目前,信息网络中信息量很大,但通过人工浏览很难安全地浏览和整理信息,大量有用的信息白白丢失,造成大量信息不能及时应用的矛盾,这对用户来说。这造成了很多不便。为了解决这个问题,新的搜索引擎热门技术应运而生。本文结合信息网络的特点,利用信息抽取和网页分析技术,设计并实现了搜索引擎最重要的部分。——网络爬虫,为互联网搜索服务提供分类更细致准确、数据更全面深入、更新更及时的互联网搜索服务。本文首先总结了网络爬虫的发展历程,然后分析了网络爬虫的架构和实现原理,深入分析了Web上主题页面的分布特征和主题相关性的判别算法。具体工作如下:(1)爬虫部分,爬取设计种子网站,下载尽可能完整且满足用户要求的网站。
但不能仅通过人为方式访问和清理所有信息,过多的导入信息会丢失,还会导致破获刑事案件,给用户带来很大的不便。为了解决这个问题,搜索引擎技术成为了新的热点。,利用信息提取和网络分析技术提供更详细的分类精度, 查看全部
c爬虫抓取网页数据(2017年本科毕业论文主题网络爬虫的设计与实现-orientedcrawler)
本科毕业论文题目:面向学科爬虫的设计与实现 姓名:陆刚 学号:234 学院:软件学院 系:软件工程专业:软件工程 年级:2005级 导师:石亮副教授 2009 年 6 月 I 总结 目前,信息网络中信息量很大,但通过人工浏览很难安全地浏览和整理信息,大量有用的信息白白丢失,造成大量信息不能及时应用的矛盾,这对用户来说。这造成了很多不便。为了解决这个问题,新的搜索引擎热门技术应运而生。本文结合信息网络的特点,利用信息抽取和网页分析技术,设计并实现了搜索引擎最重要的部分。——网络爬虫,为互联网搜索服务提供分类更细致准确、数据更全面深入、更新更及时的互联网搜索服务。本文首先总结了网络爬虫的发展历程,然后分析了网络爬虫的架构和实现原理,深入分析了Web上主题页面的分布特征和主题相关性的判别算法。具体工作如下:(1)爬虫部分,爬取设计种子网站,下载尽可能完整且满足用户要求的网站。
但不能仅通过人为方式访问和清理所有信息,过多的导入信息会丢失,还会导致破获刑事案件,给用户带来很大的不便。为了解决这个问题,搜索引擎技术成为了新的热点。,利用信息提取和网络分析技术提供更详细的分类精度,
c爬虫抓取网页数据(基于使用宽度有限的策略(电子商务研究中心)())
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-15 21:19
(电商研究中心新闻)1:从种子站开始爬取
基于万维网的蝴蝶结构,这种非线性的网页组织结构会存在爬取顺序问题。这种爬取顺序策略必须保证尽可能多地爬取所有网页。
一般来说,爬虫选择抓取蝴蝶形状左侧的结构来抓取发送点。一个典型的例子是网站等门户网站的首页。每次抓取网页时,都会分析其中的 URL。这个字符串形式的Links是指向其他网页的URL,它们引导爬虫去爬取其他网页。(基于此,我们可以初步了解引擎从左到右,先上后下爬的原因)
a:深度优先遍历
深度优先遍历策略类似于家族继承策略。通常,如封建皇帝的遗产,长子通常是长子。大孙子去世了,所以老二继承,这种继承上的优先关系也称为深度优先策略。(从这点我们就可以理解蜘蛛爬列页面的顺序了)
b: 广度优先遍历
广度优先也称为广度优先,或层次优先。例如,当我们给祖父母、父母和同龄人上茶时,我们先给最年长的祖父茶,然后是父亲,最后是同龄人,爬行。这个策略也被采用了。基于使用宽度有限的策略主要有以下三个原因:
1>首页重要的网页往往离种子很近。例如,当我们打开新闻台时,往往是最热门的新闻。随着我们继续深入冲浪,PV值会越来越大,我们看到的网页的重要性就变得越来越不重要了。
2>万维网的实际深度可达17层,某个网页的路径要深得多,但总有很短的路径。
3>宽度优先有利于多个爬虫的协同爬取(Mozk是根据前人的数据分析和IIS日志分析得出的,暂时我觉得如果大家有不同意见,欢迎讨论交流)。多个爬虫的合作通常会先爬取内部连接,再遇到站点。然后外链开始抓取,抓取非常封闭。
附:链接优化,避免爬取链接死循环,同时避免爬取资源不被爬取,浪费大量资源做无用功。(如何建立合理的内部链接可以参考肖战)。
2:网页抓取优先策略
网络爬取优先策略也称为“页面选择”(page selection),通常会爬取重要的网页,以保证有限的资源(爬虫、服务器负载)尽可能地照顾到最重要的网页。这一点应该很容易理解。
那么哪些网页是最重要的网页呢?
判断网页重要性的因素有很多,主要包括链接流行度(你知道链接的重要性)、链接重要性和平均深度链接、网站质量、历史权重等主要因素。
链接的受欢迎程度主要取决于反向链接的数量和质量,我们将其定义为 IB(P)。
链接的重要性是 URL 字符串的函数。它只检查字符串本身。例如,认为“.com”和“home”的URL重要性高于“.cc”和“map”(这里例如,不是绝对的,就像我们通常默认的主页索引一样。 **,我们也可以定义其他名称,另外,排名是一个综合因素,com的排名不一定好,只是其中一个小因素),我们定义为IL(P)
平均连接深度是我个人的蔑视。根据上面分析的广度优先原则,计算整个站点的平均链接深度,然后你离种子站点越近,它就越重要。我们将其定义为 ID(P)
我们将网页的重要性定义为 I(P)
所以:
I(p)=X*IB(P)+Y*IL(P)
ID(P)是由广度优先遍历规则保证的,所以不作为重要的指标函数。为了保证最重要的网页被抓取,这样的抓取是完全合理和科学的。
本文第一点是解释点,第二点是分析方面。文笔不是很好,看明白了。
SEO的目标是提升网站的质量,提升网站的质量是提升网站的用户体验友好度,提升网站的最终目的@> 用户优化就是离开SE,做正规的事情。清书,以上是莫兹克的蔑视。毕竟,SEO是排名的逆向推理过程。不可能一帆风顺。这只是对数据的分析。任何信息仅供参考。它仍然更多地取决于您自己的实践。: 中国电子商务研究中心) 查看全部
c爬虫抓取网页数据(基于使用宽度有限的策略(电子商务研究中心)())
(电商研究中心新闻)1:从种子站开始爬取
基于万维网的蝴蝶结构,这种非线性的网页组织结构会存在爬取顺序问题。这种爬取顺序策略必须保证尽可能多地爬取所有网页。
一般来说,爬虫选择抓取蝴蝶形状左侧的结构来抓取发送点。一个典型的例子是网站等门户网站的首页。每次抓取网页时,都会分析其中的 URL。这个字符串形式的Links是指向其他网页的URL,它们引导爬虫去爬取其他网页。(基于此,我们可以初步了解引擎从左到右,先上后下爬的原因)
a:深度优先遍历
深度优先遍历策略类似于家族继承策略。通常,如封建皇帝的遗产,长子通常是长子。大孙子去世了,所以老二继承,这种继承上的优先关系也称为深度优先策略。(从这点我们就可以理解蜘蛛爬列页面的顺序了)
b: 广度优先遍历
广度优先也称为广度优先,或层次优先。例如,当我们给祖父母、父母和同龄人上茶时,我们先给最年长的祖父茶,然后是父亲,最后是同龄人,爬行。这个策略也被采用了。基于使用宽度有限的策略主要有以下三个原因:
1>首页重要的网页往往离种子很近。例如,当我们打开新闻台时,往往是最热门的新闻。随着我们继续深入冲浪,PV值会越来越大,我们看到的网页的重要性就变得越来越不重要了。
2>万维网的实际深度可达17层,某个网页的路径要深得多,但总有很短的路径。
3>宽度优先有利于多个爬虫的协同爬取(Mozk是根据前人的数据分析和IIS日志分析得出的,暂时我觉得如果大家有不同意见,欢迎讨论交流)。多个爬虫的合作通常会先爬取内部连接,再遇到站点。然后外链开始抓取,抓取非常封闭。
附:链接优化,避免爬取链接死循环,同时避免爬取资源不被爬取,浪费大量资源做无用功。(如何建立合理的内部链接可以参考肖战)。
2:网页抓取优先策略
网络爬取优先策略也称为“页面选择”(page selection),通常会爬取重要的网页,以保证有限的资源(爬虫、服务器负载)尽可能地照顾到最重要的网页。这一点应该很容易理解。
那么哪些网页是最重要的网页呢?
判断网页重要性的因素有很多,主要包括链接流行度(你知道链接的重要性)、链接重要性和平均深度链接、网站质量、历史权重等主要因素。
链接的受欢迎程度主要取决于反向链接的数量和质量,我们将其定义为 IB(P)。
链接的重要性是 URL 字符串的函数。它只检查字符串本身。例如,认为“.com”和“home”的URL重要性高于“.cc”和“map”(这里例如,不是绝对的,就像我们通常默认的主页索引一样。 **,我们也可以定义其他名称,另外,排名是一个综合因素,com的排名不一定好,只是其中一个小因素),我们定义为IL(P)
平均连接深度是我个人的蔑视。根据上面分析的广度优先原则,计算整个站点的平均链接深度,然后你离种子站点越近,它就越重要。我们将其定义为 ID(P)
我们将网页的重要性定义为 I(P)
所以:
I(p)=X*IB(P)+Y*IL(P)
ID(P)是由广度优先遍历规则保证的,所以不作为重要的指标函数。为了保证最重要的网页被抓取,这样的抓取是完全合理和科学的。
本文第一点是解释点,第二点是分析方面。文笔不是很好,看明白了。
SEO的目标是提升网站的质量,提升网站的质量是提升网站的用户体验友好度,提升网站的最终目的@> 用户优化就是离开SE,做正规的事情。清书,以上是莫兹克的蔑视。毕竟,SEO是排名的逆向推理过程。不可能一帆风顺。这只是对数据的分析。任何信息仅供参考。它仍然更多地取决于您自己的实践。: 中国电子商务研究中心)
c爬虫抓取网页数据(文章目录《Python网络爬虫Scrapy框架》-陈磊/主编)
网站优化 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-10-15 10:29
文章内容
《Python 网络爬虫 Scrapy 框架》
全文主要参考《Python Web Crawler Scrapy Framework》-肖瑞陈磊/主编-刘新杰王莹莹秦丽娟/人民邮电出版社副主编。
本书章节列表如下
通读前两章和本书章节列表。前四章可以使用。后续章节可能会用到Scrapy反爬技术和分布式爬虫Scrapy+Redis。谈未来,把握现在。
第一章
掌握4个概念:lxml库、xpath语法、多级网络爬取逻辑、数据存储与展示。
用于解析 HTML 的库
请求网页URL,获取到HTML源代码后,需要解析HTML源代码,得到想要的数据。lxml库是解析html的第三方库。
Python标准库自带xml模块,可以解析xml文件和html页面的内容,但性能和界面不人性化。第三方库lxml由Cython实现,增加了很多功能,大部分都存放在lxml.etree中。
使用 lxml 库提取网页内容的步骤如下:
导入对应的库: from lxml import etree
使用HTML()方法生成要解析的对象:tree=etree.HTML(html),其中html为目标页面的html源代码
调用待解析对象的xpath()方法tree.xpath(),填入xpath语句作为html解析的参数
解析 XML/HTML 的语法
xpath 是一组解析 XML/HTML 的语法,使用路径表达式来选择 xml/html 中的节点集。值得一提的是,编写xpath需要熟悉html元素。
多级网络爬取逻辑
页面嵌套问题:抓取一个网页的数据很容易,但是如何抓取网页的嵌套网页呢?即让爬虫定期爬取所有嵌套的详情页。
这种情况涉及到爬虫的多级网络爬取逻辑。以二级网页为例,组织爬取逻辑:
请求一级网页(目标数据为嵌套页面的链接)使用xpath解析网页,获取嵌套页面的链接,遍历嵌套页面链接,逐个发送请求,使用xpath解析二级网页,获取最终目标数据并保存目标数据
这里应该有爬虫算法,比如Scrapy使用的深度优先算法,数据结构已经学会了,看深度优先算法和网络爬虫中的简单代码实现。
保存数据和显示数据
将 URL-Method-Params-Status-Title-Length 格式的数据保存为 csv 文件还是 txt 文件?后面还有问题需要考虑。您需要对这些目标资源进行分类吗?未分类的数据量太大,除非对每个URL的请求量进行压缩,或者分类,这些都是fuzzing时需要考虑的事情。
目前我们只需要考虑保存数据的可读性,具体点就是阅读的舒适度。以后fuzz可能保存为txt或csv,但目前我个人更喜欢保存为py,因为编辑器读起来很舒服。
参考csv、txt和tsv数据文件的异同,以及如何使用Python读取和生成: 一般来说,为了更好的处理多种语言的数据,建议将数据保存为csv格式(csv文件之间用逗号隔开)后缀可以直接改成其他类型的文件),可以同时在excle、python、matlab、sas、R等语言中自由切换,数据格式没有损坏!
选择:将 URL-Method-Params-Status-Title-Length 格式的数据保存为 csv 文件。
这一天即将结束。回顾那天,没有实质性的结果。编写爬虫是目标,其他一切都是假的。
第 2 章垂直搜索爬虫
根据使用场景,爬虫分为通用搜索爬虫和垂直搜索爬虫。垂直搜索爬虫在运行时尽量只爬取与需求相关的网页信息。这里主要使用垂直搜索爬虫。
安装 Scrapy 爬虫框架
参考Windows环境下安装Scrapy框架的步骤,本地一步执行命令pip3 install scrapy。
创建并启动 Scrapy 爬虫项目
开发一个Scrapy爬虫项目,需要使用Scrapy命令创建一个爬虫项目,这是一个半成品的爬虫项目。在命令行创建爬虫项目的步骤如下
创建爬虫项目:scrapy startproject 项目名称切换到项目根目录创建爬虫文件:scrapy genspider 爬虫名称启动爬虫项目的网址:scrapy crawl 爬虫名称
#创建爬虫项目并运行爬虫
scrapy startproject helloSpider
cd helloSpider
scrapy genspider test http://127.0.0.1/DVWA-master/
scrapy crawl test # 工程根目录执行
#执行回显模块
[scrapy.utils.log]
[scrapy.crawler]
[scrapy.extensions.telnet]
[scrapy.middleware]
[scrapy.core.engine]
[scrapy.extensions.logstats]
[scrapy.downloadermiddlewares.retry]
[scrapy.downloadermiddlewares.robotstxt]
# helloSpider/spiders/test.py文件
import scrapy
class TestSpider(scrapy.Spider):
name = 'test'
allowed_domains = ['http://127.0.0.1/DVWA-master/']
start_urls = ['http://http://127.0.0.1/DVWA-master//']
def parse(self, response):
pass
部分执行结果如下,可以看到打印的内容有点混乱。
整体把握scrapy项目
创建项目的文件结构如下,项目配置文件scrapy.cfg进行了过滤,因为开发爬虫的时候不需要修改这个文件。如图所示,Scrapy爬虫项目主要由5个模块组成:爬虫、items模块、中间件模块、数据存储模块、配置模块,然后对各个模块进行简单说明。
Scrapy框架的引擎和调度器暂时忽略
#流程图代码
graph TB
A(项目根目录helloSpider)
B(helloSpider)
B3(spiders)
B4(items.py)
B5(middlewares.py)
B6(pipelines.py)
B7(settings.py)
A-->B
B-->B3
B-->B4
B-->B5
B-->B6
B-->B7
b31(test.py)
B3-->b31
(1)spiders文件夹:是Scrapy爬虫项目的爬虫模块,可以有多个爬虫文件。设计理念是方便一站一个爬虫,爬虫可以共享项目中的其他模块以提高重用和开发效率。
爬虫文件的内容一目了然。值得注意的是,爬虫默认是无状态的,所以Scrapy框架允许你通过覆盖爬虫文件中的start_requests()方法来自定义爬虫起始页的爬取设置。
(2)items.py 文件:爬取的数据可能需要在模块之间进行传输,所以items.py 中定义了统一的数据格式。
(3)pipelines.py 文件:Pipeline的意思是管道,是框架中的一个数据处理模块,经常用来完成数据的持久化,也可以对爬取的数据进行过滤和去重。
(4)middlewares.py文件:Middlewares就是中间件,中间件的存在方便了爬虫框架的功能扩展。在Scrapy爬虫框架中,中间件分为下载器和蜘蛛两大类。
(5)settings.py文件:Settings模块负责设置爬虫行为模式、模块激活等配置功能,是爬虫框架中非常重要的一个模块。列举一些开发中常用的配置:
管道模块的启动和激活顺序配置蜘蛛抓取网页数据的频率、默认headers等属性配置启动或关闭指定蜘蛛中间件配置、下载器中间件配置爬虫请求流程
结合第3章的部分内容,列出执行过程。
# 流程图代码
graph TB
a(启动爬虫)
b(引擎访问start_urls获取URL)
c(引擎调用Downloader模块下载网页)
d(引擎把下载结果传递给Spider的parse方法)
e(用户处理Response类对象response提取数据)
a-->b
b-->c
c-->d
d-->e
下一章3的内容最终会涉及到爬虫的编写和登陆(数据处理和数据存储)的问题
目前了解scrapy项目的执行流程,但是不知道scrapy引擎是怎么运行的,scrapy的入口文件是哪个,尤其是如何定义request类,这些对二次开发非常重要。那么接下来,审计scrapy框架的源代码。
审计scrapy框架
让审计先行,主要目标是定制爬虫,不要迷失在知识的海洋中。
框架文件和入口文件,显然入口文件是__main__.py文件:
请求类Request:查看scrapy根目录下的http文件夹。该目录下的__init__.py文件定义了请求类:class Request(object_ref)
scrapy通过Request类对象发起请求,参考:scrapy中的python-Request参数。
第三章:数据抽取和多级网络爬取,明确进度和目标
第 2 章重写了 start_requests(self) 方法。test.py 文件中收录以下变量,这些变量会随着目标的变化而变化:
当前爬虫变量的描述
allowed_domains
允许抓取的 URL。如果不定义,所有网页都会被抓取,即通用搜索爬虫
起始网址
爬虫起始页
饼干
验证
完成第一次网页访问后,本章需要完成两个任务:数据筛选和提取,以及多级网页爬取。
响应对象
爬虫访问网页后,将收录网页结果的响应对象返回给 parse() 方法。其常用属性和方法如下:
属性或方法描述
网址
当前返回页面对应的url
地位 查看全部
c爬虫抓取网页数据(文章目录《Python网络爬虫Scrapy框架》-陈磊/主编)
文章内容
《Python 网络爬虫 Scrapy 框架》
全文主要参考《Python Web Crawler Scrapy Framework》-肖瑞陈磊/主编-刘新杰王莹莹秦丽娟/人民邮电出版社副主编。
本书章节列表如下
通读前两章和本书章节列表。前四章可以使用。后续章节可能会用到Scrapy反爬技术和分布式爬虫Scrapy+Redis。谈未来,把握现在。
第一章
掌握4个概念:lxml库、xpath语法、多级网络爬取逻辑、数据存储与展示。
用于解析 HTML 的库
请求网页URL,获取到HTML源代码后,需要解析HTML源代码,得到想要的数据。lxml库是解析html的第三方库。
Python标准库自带xml模块,可以解析xml文件和html页面的内容,但性能和界面不人性化。第三方库lxml由Cython实现,增加了很多功能,大部分都存放在lxml.etree中。
使用 lxml 库提取网页内容的步骤如下:
导入对应的库: from lxml import etree
使用HTML()方法生成要解析的对象:tree=etree.HTML(html),其中html为目标页面的html源代码
调用待解析对象的xpath()方法tree.xpath(),填入xpath语句作为html解析的参数
解析 XML/HTML 的语法
xpath 是一组解析 XML/HTML 的语法,使用路径表达式来选择 xml/html 中的节点集。值得一提的是,编写xpath需要熟悉html元素。
多级网络爬取逻辑
页面嵌套问题:抓取一个网页的数据很容易,但是如何抓取网页的嵌套网页呢?即让爬虫定期爬取所有嵌套的详情页。
这种情况涉及到爬虫的多级网络爬取逻辑。以二级网页为例,组织爬取逻辑:
请求一级网页(目标数据为嵌套页面的链接)使用xpath解析网页,获取嵌套页面的链接,遍历嵌套页面链接,逐个发送请求,使用xpath解析二级网页,获取最终目标数据并保存目标数据
这里应该有爬虫算法,比如Scrapy使用的深度优先算法,数据结构已经学会了,看深度优先算法和网络爬虫中的简单代码实现。
保存数据和显示数据
将 URL-Method-Params-Status-Title-Length 格式的数据保存为 csv 文件还是 txt 文件?后面还有问题需要考虑。您需要对这些目标资源进行分类吗?未分类的数据量太大,除非对每个URL的请求量进行压缩,或者分类,这些都是fuzzing时需要考虑的事情。
目前我们只需要考虑保存数据的可读性,具体点就是阅读的舒适度。以后fuzz可能保存为txt或csv,但目前我个人更喜欢保存为py,因为编辑器读起来很舒服。
参考csv、txt和tsv数据文件的异同,以及如何使用Python读取和生成: 一般来说,为了更好的处理多种语言的数据,建议将数据保存为csv格式(csv文件之间用逗号隔开)后缀可以直接改成其他类型的文件),可以同时在excle、python、matlab、sas、R等语言中自由切换,数据格式没有损坏!
选择:将 URL-Method-Params-Status-Title-Length 格式的数据保存为 csv 文件。
这一天即将结束。回顾那天,没有实质性的结果。编写爬虫是目标,其他一切都是假的。
第 2 章垂直搜索爬虫
根据使用场景,爬虫分为通用搜索爬虫和垂直搜索爬虫。垂直搜索爬虫在运行时尽量只爬取与需求相关的网页信息。这里主要使用垂直搜索爬虫。
安装 Scrapy 爬虫框架
参考Windows环境下安装Scrapy框架的步骤,本地一步执行命令pip3 install scrapy。

创建并启动 Scrapy 爬虫项目
开发一个Scrapy爬虫项目,需要使用Scrapy命令创建一个爬虫项目,这是一个半成品的爬虫项目。在命令行创建爬虫项目的步骤如下
创建爬虫项目:scrapy startproject 项目名称切换到项目根目录创建爬虫文件:scrapy genspider 爬虫名称启动爬虫项目的网址:scrapy crawl 爬虫名称
#创建爬虫项目并运行爬虫
scrapy startproject helloSpider
cd helloSpider
scrapy genspider test http://127.0.0.1/DVWA-master/
scrapy crawl test # 工程根目录执行
#执行回显模块
[scrapy.utils.log]
[scrapy.crawler]
[scrapy.extensions.telnet]
[scrapy.middleware]
[scrapy.core.engine]
[scrapy.extensions.logstats]
[scrapy.downloadermiddlewares.retry]
[scrapy.downloadermiddlewares.robotstxt]
# helloSpider/spiders/test.py文件
import scrapy
class TestSpider(scrapy.Spider):
name = 'test'
allowed_domains = ['http://127.0.0.1/DVWA-master/']
start_urls = ['http://http://127.0.0.1/DVWA-master//']
def parse(self, response):
pass
部分执行结果如下,可以看到打印的内容有点混乱。
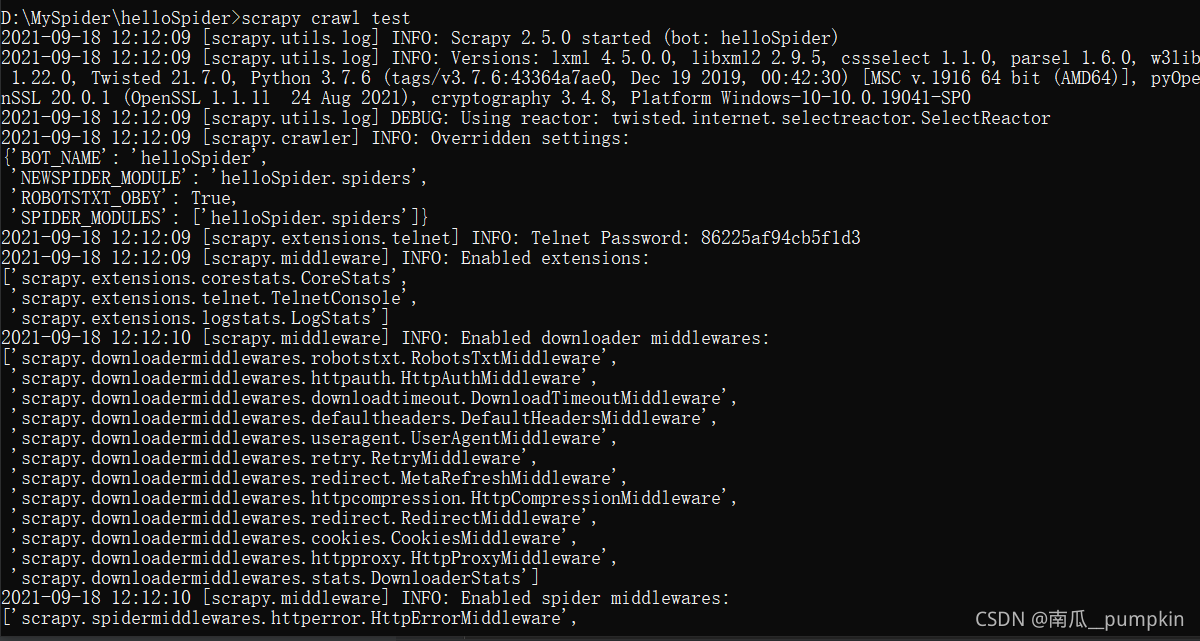
整体把握scrapy项目
创建项目的文件结构如下,项目配置文件scrapy.cfg进行了过滤,因为开发爬虫的时候不需要修改这个文件。如图所示,Scrapy爬虫项目主要由5个模块组成:爬虫、items模块、中间件模块、数据存储模块、配置模块,然后对各个模块进行简单说明。
Scrapy框架的引擎和调度器暂时忽略
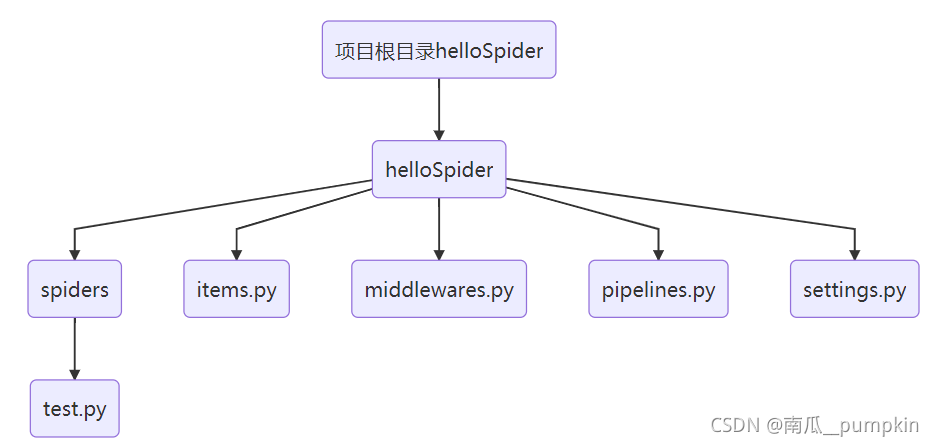
#流程图代码
graph TB
A(项目根目录helloSpider)
B(helloSpider)
B3(spiders)
B4(items.py)
B5(middlewares.py)
B6(pipelines.py)
B7(settings.py)
A-->B
B-->B3
B-->B4
B-->B5
B-->B6
B-->B7
b31(test.py)
B3-->b31
(1)spiders文件夹:是Scrapy爬虫项目的爬虫模块,可以有多个爬虫文件。设计理念是方便一站一个爬虫,爬虫可以共享项目中的其他模块以提高重用和开发效率。
爬虫文件的内容一目了然。值得注意的是,爬虫默认是无状态的,所以Scrapy框架允许你通过覆盖爬虫文件中的start_requests()方法来自定义爬虫起始页的爬取设置。
(2)items.py 文件:爬取的数据可能需要在模块之间进行传输,所以items.py 中定义了统一的数据格式。
(3)pipelines.py 文件:Pipeline的意思是管道,是框架中的一个数据处理模块,经常用来完成数据的持久化,也可以对爬取的数据进行过滤和去重。
(4)middlewares.py文件:Middlewares就是中间件,中间件的存在方便了爬虫框架的功能扩展。在Scrapy爬虫框架中,中间件分为下载器和蜘蛛两大类。
(5)settings.py文件:Settings模块负责设置爬虫行为模式、模块激活等配置功能,是爬虫框架中非常重要的一个模块。列举一些开发中常用的配置:
管道模块的启动和激活顺序配置蜘蛛抓取网页数据的频率、默认headers等属性配置启动或关闭指定蜘蛛中间件配置、下载器中间件配置爬虫请求流程
结合第3章的部分内容,列出执行过程。
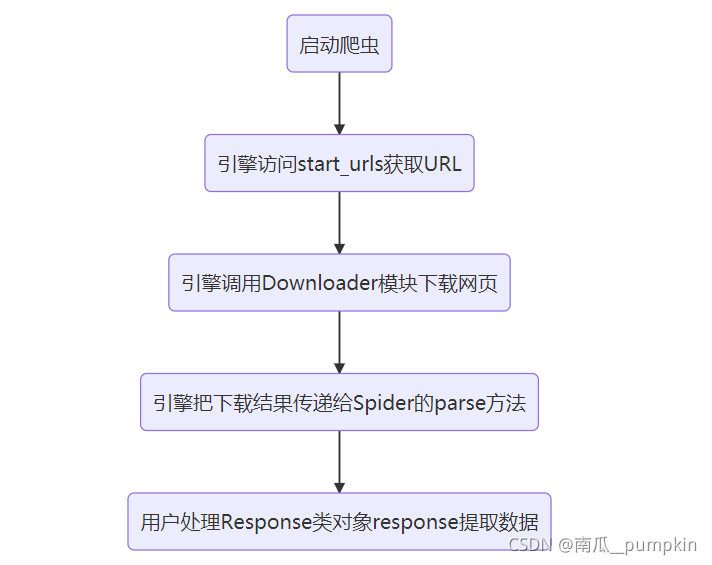
# 流程图代码
graph TB
a(启动爬虫)
b(引擎访问start_urls获取URL)
c(引擎调用Downloader模块下载网页)
d(引擎把下载结果传递给Spider的parse方法)
e(用户处理Response类对象response提取数据)
a-->b
b-->c
c-->d
d-->e
下一章3的内容最终会涉及到爬虫的编写和登陆(数据处理和数据存储)的问题
目前了解scrapy项目的执行流程,但是不知道scrapy引擎是怎么运行的,scrapy的入口文件是哪个,尤其是如何定义request类,这些对二次开发非常重要。那么接下来,审计scrapy框架的源代码。
审计scrapy框架
让审计先行,主要目标是定制爬虫,不要迷失在知识的海洋中。
框架文件和入口文件,显然入口文件是__main__.py文件:
请求类Request:查看scrapy根目录下的http文件夹。该目录下的__init__.py文件定义了请求类:class Request(object_ref)
scrapy通过Request类对象发起请求,参考:scrapy中的python-Request参数。
第三章:数据抽取和多级网络爬取,明确进度和目标
第 2 章重写了 start_requests(self) 方法。test.py 文件中收录以下变量,这些变量会随着目标的变化而变化:
当前爬虫变量的描述
allowed_domains
允许抓取的 URL。如果不定义,所有网页都会被抓取,即通用搜索爬虫
起始网址
爬虫起始页
饼干
验证
完成第一次网页访问后,本章需要完成两个任务:数据筛选和提取,以及多级网页爬取。
响应对象
爬虫访问网页后,将收录网页结果的响应对象返回给 parse() 方法。其常用属性和方法如下:
属性或方法描述
网址
当前返回页面对应的url
地位
c爬虫抓取网页数据(模拟浏览器发送请求,获取服务器响应的文件3、解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-14 11:28
b) 处理后的请求可以模拟浏览器发送的请求,获取服务器响应的文件
3、 解析服务器响应内容
a) re, xpath, beautifulSoup4(bs4), jsonpath, pyquery
b) 使用某种描述语言为我们需要提取的数据定义一个匹配规则,符合这个规则的数据就会匹配
4、如何处理采集动态HTML和验证码
a) 通用动态页面采集,Selenium+Phantomjs(无接口):模拟真实浏览器加载js,Ajax非静态页面数据
b) tesseract:机器学习库,机器图像识别系统,可以处理简单的验证码,复杂的验证码可以手动输入,编码平台
5、 Scrapy 框架(Scrapy、Pyspider)
高定制和高性能(异步网络框架扭曲),所以数据下载速度非常快,提供数据存储、数据下载、提取规则等组件
6、 分布式策略:
a)scrapy redis,在scrapy的基础上,增加了一套以redis数据库为核心的组件
b) 功能:主要做请求指纹去重、请求分发、数据在redis中的临时存储
7、 爬虫、反爬虫、反爬虫斗争:
a) 爬虫最头疼的不是复杂的页面,而是网站背后的另一个人
反爬虫:用户代理、代理、验证码、动态数据加载、加密数据
反爬虫主要看数据的价值,做反爬虫是否值得
主要考虑以下几个方面:机器成本+人工成本“数据价值,倒也不是,一般IP封堵结束
通用爬虫专注爬虫
1、万能爬虫:搜索引擎的爬虫系统
-1 目的:尽可能下载互联网上所有的网页,放到本地服务器上形成备份,然后对这些网页进行相应的处理(提取关键词,去除广告),最后提供一个借口要登录的用户
-2 抓取过程:
一种。优先选择一部分已有的网址,将这些网址放入待抓取的队列中
湾 从队列中取出这些URL,然后解析DNS得到主机IP,然后去这个IP对应的服务器下载HTML页面,保存到搜索引擎对应的服务器,然后把爬取到的URL进入抓取队列
C。分析这些网页的内容,找出网页中的其他网址链接,继续执行第二部分,直到爬虫条件结束
-3、搜索引擎如何获取新的网站 URL?
1、 主动提交网址给搜索引擎(百度连接提交)
2、在其他网站中设置外部链接:
3、搜索引擎会与DNS服务商合作,可以快速收录new网站
DNS:是一种将域名解析为IP的技术
-4、万能爬虫不是万能的,也需要遵守规则
机器人协议:协议会规定一般爬虫爬取网页的权限
Robots.txt 只是一个建议,不是所有爬虫都关注,只有大型搜索引擎爬虫需要关注
-5 一般爬虫工作流程:抓取网页、存储数据、内容处理、提供索引/排名服务
-6、搜索引擎排名:
一种。PageRank:根据网站流量统计(点击量/浏览量/流行度),流量越高
湾 竞价排名:谁出的钱越多,谁的排名就越高
-7、 一般爬虫的缺点:
1、 只能提供文本相关内容(HTML\WORD\PDF)等,不能提供多媒体、二进制
2、 上一篇提供的结果都是一样的,不要等不同背景的人提供不同的搜索结果
3、无法理解人类语义的检索
为了解决这个问题,出现了聚焦爬虫:
专注于爬虫:爬虫程序员针对某个内容编写的爬虫
面向主题的爬虫,面向需求的爬虫:会针对特定的内容爬取信息,并且会尽可能保证信息和需求的相关性 查看全部
c爬虫抓取网页数据(模拟浏览器发送请求,获取服务器响应的文件3、解析)
b) 处理后的请求可以模拟浏览器发送的请求,获取服务器响应的文件
3、 解析服务器响应内容
a) re, xpath, beautifulSoup4(bs4), jsonpath, pyquery
b) 使用某种描述语言为我们需要提取的数据定义一个匹配规则,符合这个规则的数据就会匹配
4、如何处理采集动态HTML和验证码
a) 通用动态页面采集,Selenium+Phantomjs(无接口):模拟真实浏览器加载js,Ajax非静态页面数据
b) tesseract:机器学习库,机器图像识别系统,可以处理简单的验证码,复杂的验证码可以手动输入,编码平台
5、 Scrapy 框架(Scrapy、Pyspider)
高定制和高性能(异步网络框架扭曲),所以数据下载速度非常快,提供数据存储、数据下载、提取规则等组件
6、 分布式策略:
a)scrapy redis,在scrapy的基础上,增加了一套以redis数据库为核心的组件
b) 功能:主要做请求指纹去重、请求分发、数据在redis中的临时存储
7、 爬虫、反爬虫、反爬虫斗争:
a) 爬虫最头疼的不是复杂的页面,而是网站背后的另一个人
反爬虫:用户代理、代理、验证码、动态数据加载、加密数据
反爬虫主要看数据的价值,做反爬虫是否值得
主要考虑以下几个方面:机器成本+人工成本“数据价值,倒也不是,一般IP封堵结束
通用爬虫专注爬虫
1、万能爬虫:搜索引擎的爬虫系统
-1 目的:尽可能下载互联网上所有的网页,放到本地服务器上形成备份,然后对这些网页进行相应的处理(提取关键词,去除广告),最后提供一个借口要登录的用户
-2 抓取过程:
一种。优先选择一部分已有的网址,将这些网址放入待抓取的队列中
湾 从队列中取出这些URL,然后解析DNS得到主机IP,然后去这个IP对应的服务器下载HTML页面,保存到搜索引擎对应的服务器,然后把爬取到的URL进入抓取队列
C。分析这些网页的内容,找出网页中的其他网址链接,继续执行第二部分,直到爬虫条件结束
-3、搜索引擎如何获取新的网站 URL?
1、 主动提交网址给搜索引擎(百度连接提交)
2、在其他网站中设置外部链接:
3、搜索引擎会与DNS服务商合作,可以快速收录new网站
DNS:是一种将域名解析为IP的技术
-4、万能爬虫不是万能的,也需要遵守规则
机器人协议:协议会规定一般爬虫爬取网页的权限
Robots.txt 只是一个建议,不是所有爬虫都关注,只有大型搜索引擎爬虫需要关注
-5 一般爬虫工作流程:抓取网页、存储数据、内容处理、提供索引/排名服务
-6、搜索引擎排名:
一种。PageRank:根据网站流量统计(点击量/浏览量/流行度),流量越高
湾 竞价排名:谁出的钱越多,谁的排名就越高
-7、 一般爬虫的缺点:
1、 只能提供文本相关内容(HTML\WORD\PDF)等,不能提供多媒体、二进制
2、 上一篇提供的结果都是一样的,不要等不同背景的人提供不同的搜索结果
3、无法理解人类语义的检索
为了解决这个问题,出现了聚焦爬虫:
专注于爬虫:爬虫程序员针对某个内容编写的爬虫
面向主题的爬虫,面向需求的爬虫:会针对特定的内容爬取信息,并且会尽可能保证信息和需求的相关性
c爬虫抓取网页数据(网络爬虫有什么用呢?如何学习更多Golang语言? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-13 04:24
)
安利
如果想了解更多Golang语言,请关注我的公众号。我会第一时间发送文章到公众号,第一时间拿到学习资料。你想学的,我这里都有!!!
添加方法:微信搜索:Golang DreamWorks,或直接扫描下方二维码:
前言
大家好,我是阿松,这是我的第四篇文章原创文章。在这篇文章中,我将介绍网络爬虫系列教程,使用GO和python实现最简单的爬虫---爬虫小说。其实这篇文章就是教大家如何利用妓女。在这个网站的广告环境中,我们想要单纯的看小说已经成了一个难题,于是我们可以利用爬虫技术,爬下小说,不用看烦人的广告。话不多说,全开...
什么是爬虫
对于这类问题,我们可以直接上百度百科看介绍。网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者)是一种从万维网上抓取信息的自动程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。看看百度百科介绍的多好,多好理解。
网络爬虫有什么用?网络爬虫是大数据行业数据采集的核心工具。如果没有网络爬虫,日夜自动抓取互联网上的免费数据,而且智能化程度高,那些大数据相关的公司可能不到四分之三。目前的爬虫基本上都是围绕网页进行的,所以我们的爬虫是根据网页地址(URL),也就是我们在浏览器中输入的网站链接来抓取网页的内容。比如我们经常使用百度:,这是一个网址。URL的专业名称是Uniform Resource Locator,格式如下:
协议/主机名[:端口]/路径/[;参数][?查询]#fragment
URL的格式主要由前三部分组成:
所以有了URL,我们就可以到指定的位置去获取我们想要的数据信息了。有了数据,我们就需要对数据进行分析,所以爬虫还有一个必备技能:审查元素。
我们可以在浏览器中查看我们浏览的每一个网页的源代码,也就是HTML。这些 HTML 决定了 网站 的原创外观。HTML的具体使用这里就不介绍了。我想学习的网络资源有很多。比如我们在使用Chrome浏览器的时候,右击查看谷歌主页(其他浏览器不同,这里不介绍),右侧会出现很多代码,这些代码叫做HTML。
浏览器是作为客户端从服务器获取信息,然后解析信息展示给我们。所以我们可以基于HTML来分析网页的内容。好了,基本的基础知识已经知道了,现在就开始我们的练习吧!!!
爬虫示例1. 爬虫网站 小说介绍
在这里的例子中,我们下载文本内容,也就是下载一本小说。小说网站,我们的新笔曲歌。关联:。
这个网站只支持在线浏览,不支持小说打包下载,所以我们可以利用我们的爬虫技术下载小说,解决本地无法阅读小说的问题。因为不看小说,直接上小说排行榜,选了第一名,《三国修行》。名字很吸引人!!!!
2. 相关技术介绍
本教程使用两种语言进行开发,即Golang和Python。对于Golang,我们使用网站内置的HTTP库来获取和google自己的库x/net/html进行网页数据分析。在Python中,我们使用requests库进行网页获取,使用BeautifulSoup进行网页数据分析。
2.1 /x/net/html
x/net/html 是一个由 Google 维护的库。它主要帮助我们解析网页数据。我们只需要导入 /x/net/html 包。使用方法很简单,这里就不做具体介绍了,大家可以去GO Bible:#Parse
学习了,里面有例子,简单易懂。
2.2 美人汤
BeautifulSoup是python的第三方库,主要帮助我们解析网页数据。如果我们要使用这个工具,我们需要提前安装它。在cmd中,我们使用pip命令进行安装,命令如下:
pip 安装 beautifulsoup4
安装完成后,我们还需要安装lxml,这是解析HTML所需的一个依赖:
pip 安装 lxml
这个就可以用了,具体的学习教程可以去官方中文教程:
2.3 个请求
requests库非常强大,我们可以使用requests库进行网络爬虫。requests 库是第三方库,需要我们自己安装。安装很简单,直接使用pip命令安装即可:
pip 安装请求
requests库的github地址:
具体学习可以通过demo来完成。
3. 爬虫步骤
总共分为三个步骤:
4. 开始练习
评论:
我已经将我的整个项目发布到了我的 github 上。Golang代码GitHub地址如下:
Python代码Github地址如下:
4.1 获取网页
我们严格按照步骤操作。第一步,我们首先获取网页数据。因为要获取小说的整章,我们先查看小说目录,查看其网页源码,如下:
网页的解析在下一节解释。我们先获取目录页面,再获取文章页面,这样章节标题和内容对应起来。小说的第一章是这样的:
知道这两个网页的地址,我们就可以得到网页了。
Golang 可以使用标准库 net/http 来获取网页。示例如下:
resp,err := http.Get(target)
if err!=nil{
fmt.Println("get err http",err)
return err
}
直接调用Get方法,目标就是要获取的网页的URL。
Python可以使用requests库来获取网页,示例如下:
req = requests.get(url=target)
req.encoding = 'utf-8'
html = req.text
直接调用get方法就行了,目标是URL,req.tex表示可以把获取到的网站的内容打印出来看更清楚。编码方式设置为utf-8。这次爬取的网站是utf-8编码,不需要转换。如果抓取到的网站是GBK编码的,需要进行编码转换。
4.2 解析网页
获取到网页后,我们将开始解析网页。对于 Golang,我们使用 x/net/html 库,并使用 go get 命令获取第三方库。代码示例如下:
doc,err := html.Parse(resp.Body)
if err != nil{
fmt.Println("html parse err",err)
return err
}
parseList(doc)
直接调用 Parse 方法,将网页数据放入其中,将解析树的根(文档元素)作为 *Node 返回,然后我们可以按照深度优先的顺序处理每个节点标签。
我们首先分析文章目录,提取文章内容对应的文章标题和URL参数。具体分析,我们需要查看部分网页的源码如下:
我们可以看到文章title都在a标签下,href属性存放的是URL参数。,而且都属于div标签,id等于list,这样我们就可以定位到位置了。所以基于这个特征,我们可以进行分析和提取。Golang语言代码如下:
<p>//找到文章列表
func parseList(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "div"{
for _,a := range n.Attr{
if a.Key == "id" && a.Val == "list"{
listFind = true
parseTitle(n)
break
}
}
}
if !listFind{
for c := n.FirstChild;c!=nil;c=c.NextSibling{
parseList(c)
}
}
}
//获取文章头部
func parseTitle(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "a"{
for _, a := range n.Attr {
if a.Key == "href"{
//获取文章title
for c:=n.FirstChild;c!=nil;c=c.NextSibling{
buf.WriteString(c.Data+ "\n")
}
url := a.Val
target := server + url // 得到 文章url
everyChapter(target)
num--
}
}
}
if num 查看全部
c爬虫抓取网页数据(网络爬虫有什么用呢?如何学习更多Golang语言?
)
安利
如果想了解更多Golang语言,请关注我的公众号。我会第一时间发送文章到公众号,第一时间拿到学习资料。你想学的,我这里都有!!!
添加方法:微信搜索:Golang DreamWorks,或直接扫描下方二维码:

前言
大家好,我是阿松,这是我的第四篇文章原创文章。在这篇文章中,我将介绍网络爬虫系列教程,使用GO和python实现最简单的爬虫---爬虫小说。其实这篇文章就是教大家如何利用妓女。在这个网站的广告环境中,我们想要单纯的看小说已经成了一个难题,于是我们可以利用爬虫技术,爬下小说,不用看烦人的广告。话不多说,全开...
什么是爬虫
对于这类问题,我们可以直接上百度百科看介绍。网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者)是一种从万维网上抓取信息的自动程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。看看百度百科介绍的多好,多好理解。
网络爬虫有什么用?网络爬虫是大数据行业数据采集的核心工具。如果没有网络爬虫,日夜自动抓取互联网上的免费数据,而且智能化程度高,那些大数据相关的公司可能不到四分之三。目前的爬虫基本上都是围绕网页进行的,所以我们的爬虫是根据网页地址(URL),也就是我们在浏览器中输入的网站链接来抓取网页的内容。比如我们经常使用百度:,这是一个网址。URL的专业名称是Uniform Resource Locator,格式如下:
协议/主机名[:端口]/路径/[;参数][?查询]#fragment
URL的格式主要由前三部分组成:
所以有了URL,我们就可以到指定的位置去获取我们想要的数据信息了。有了数据,我们就需要对数据进行分析,所以爬虫还有一个必备技能:审查元素。
我们可以在浏览器中查看我们浏览的每一个网页的源代码,也就是HTML。这些 HTML 决定了 网站 的原创外观。HTML的具体使用这里就不介绍了。我想学习的网络资源有很多。比如我们在使用Chrome浏览器的时候,右击查看谷歌主页(其他浏览器不同,这里不介绍),右侧会出现很多代码,这些代码叫做HTML。
浏览器是作为客户端从服务器获取信息,然后解析信息展示给我们。所以我们可以基于HTML来分析网页的内容。好了,基本的基础知识已经知道了,现在就开始我们的练习吧!!!
爬虫示例1. 爬虫网站 小说介绍
在这里的例子中,我们下载文本内容,也就是下载一本小说。小说网站,我们的新笔曲歌。关联:。
这个网站只支持在线浏览,不支持小说打包下载,所以我们可以利用我们的爬虫技术下载小说,解决本地无法阅读小说的问题。因为不看小说,直接上小说排行榜,选了第一名,《三国修行》。名字很吸引人!!!!
2. 相关技术介绍
本教程使用两种语言进行开发,即Golang和Python。对于Golang,我们使用网站内置的HTTP库来获取和google自己的库x/net/html进行网页数据分析。在Python中,我们使用requests库进行网页获取,使用BeautifulSoup进行网页数据分析。
2.1 /x/net/html
x/net/html 是一个由 Google 维护的库。它主要帮助我们解析网页数据。我们只需要导入 /x/net/html 包。使用方法很简单,这里就不做具体介绍了,大家可以去GO Bible:#Parse
学习了,里面有例子,简单易懂。
2.2 美人汤
BeautifulSoup是python的第三方库,主要帮助我们解析网页数据。如果我们要使用这个工具,我们需要提前安装它。在cmd中,我们使用pip命令进行安装,命令如下:
pip 安装 beautifulsoup4
安装完成后,我们还需要安装lxml,这是解析HTML所需的一个依赖:
pip 安装 lxml
这个就可以用了,具体的学习教程可以去官方中文教程:
2.3 个请求
requests库非常强大,我们可以使用requests库进行网络爬虫。requests 库是第三方库,需要我们自己安装。安装很简单,直接使用pip命令安装即可:
pip 安装请求
requests库的github地址:
具体学习可以通过demo来完成。
3. 爬虫步骤
总共分为三个步骤:
4. 开始练习
评论:
我已经将我的整个项目发布到了我的 github 上。Golang代码GitHub地址如下:
Python代码Github地址如下:
4.1 获取网页
我们严格按照步骤操作。第一步,我们首先获取网页数据。因为要获取小说的整章,我们先查看小说目录,查看其网页源码,如下:
网页的解析在下一节解释。我们先获取目录页面,再获取文章页面,这样章节标题和内容对应起来。小说的第一章是这样的:
知道这两个网页的地址,我们就可以得到网页了。
Golang 可以使用标准库 net/http 来获取网页。示例如下:
resp,err := http.Get(target)
if err!=nil{
fmt.Println("get err http",err)
return err
}
直接调用Get方法,目标就是要获取的网页的URL。
Python可以使用requests库来获取网页,示例如下:
req = requests.get(url=target)
req.encoding = 'utf-8'
html = req.text
直接调用get方法就行了,目标是URL,req.tex表示可以把获取到的网站的内容打印出来看更清楚。编码方式设置为utf-8。这次爬取的网站是utf-8编码,不需要转换。如果抓取到的网站是GBK编码的,需要进行编码转换。
4.2 解析网页
获取到网页后,我们将开始解析网页。对于 Golang,我们使用 x/net/html 库,并使用 go get 命令获取第三方库。代码示例如下:
doc,err := html.Parse(resp.Body)
if err != nil{
fmt.Println("html parse err",err)
return err
}
parseList(doc)
直接调用 Parse 方法,将网页数据放入其中,将解析树的根(文档元素)作为 *Node 返回,然后我们可以按照深度优先的顺序处理每个节点标签。
我们首先分析文章目录,提取文章内容对应的文章标题和URL参数。具体分析,我们需要查看部分网页的源码如下:
我们可以看到文章title都在a标签下,href属性存放的是URL参数。,而且都属于div标签,id等于list,这样我们就可以定位到位置了。所以基于这个特征,我们可以进行分析和提取。Golang语言代码如下:
<p>//找到文章列表
func parseList(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "div"{
for _,a := range n.Attr{
if a.Key == "id" && a.Val == "list"{
listFind = true
parseTitle(n)
break
}
}
}
if !listFind{
for c := n.FirstChild;c!=nil;c=c.NextSibling{
parseList(c)
}
}
}
//获取文章头部
func parseTitle(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "a"{
for _, a := range n.Attr {
if a.Key == "href"{
//获取文章title
for c:=n.FirstChild;c!=nil;c=c.NextSibling{
buf.WriteString(c.Data+ "\n")
}
url := a.Val
target := server + url // 得到 文章url
everyChapter(target)
num--
}
}
}
if num
c爬虫抓取网页数据(几种-博客园爬虫的基本流程网络爬虫的抓取策略 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-10-26 12:10
)
原文:知乎 爬虫练习写在python-cpselvis-博客园
网络爬虫的基本工作流程如下:
爬虫的爬取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL的顺序也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
了解了爬虫的工作流程和爬取策略后,就可以开始实现爬虫了!那么如何在python中实现呢?
技术栈的基本实现
下面是伪代码
import Queue
initial_page = "https://www.zhihu.com/people/gaoming623"
url_queue = Queue.Queue()
seen = set()
seen.insert(initial_page)
url_queue.put(initial_page)
while(True): #一直进行
if url_queue.size()>0:
current_url = url_queue.get() #拿出队例中第一个的url
store(current_url) #把这个url代表的网页存储好
for next_url in extract_urls(current_url): #提取把这个url里链向的url
if next_url not in seen:
seen.put(next_url)
url_queue.put(next_url)
else:
break
如果直接处理上面的代码,直接运行,爬下整个知乎用户信息需要很长时间。毕竟,知乎 每月有 6000 万活跃用户。更不用说像谷歌这样的搜索引擎需要爬下整个网络。那么问题出在哪里呢?
布隆过滤器
需要爬取的网页太多,上面的代码太慢太慢了。假设全网有N个网站,那么分析判断的复杂度是N*log(N),因为所有网页都需要遍历一次,每次判断集合的时候,复杂度log(N) 是必需的。. OK,我知道python的set实现是hash-但是这样还是太慢了,至少内存使用效率不高。
通常的判断方式是什么?布隆过滤器。简单的说还是hash方法,但是它的特点是可以使用固定内存(不随url数增加)以O(1)的效率来判断url是否已经设置好可惜世界上没有免费的午餐,唯一的问题是如果url不在set中,BF可以100%确定url没有被浏览过。但是如果url在set中,它会告诉你:这个url应该已经出现了,但是我有2%的不确定性。注意这里的不确定性在你分配的内存足够大的情况下会变得非常小。
# bloom_filter.py
BIT_SIZE = 5000000
class BloomFilter:
def __init__(self):
# Initialize bloom filter, set size and all bits to 0
bit_array = bitarray(BIT_SIZE)
bit_array.setall(0)
self.bit_array = bit_array
def add(self, url):
# Add a url, and set points in bitarray to 1 (Points count is equal to hash funcs count.)
# Here use 7 hash functions.
point_list = self.get_postions(url)
for b in point_list:
self.bit_array[b] = 1
def contains(self, url):
# Check if a url is in a collection
point_list = self.get_postions(url)
result = True
for b in point_list:
result = result and self.bit_array[b]
return result
def get_postions(self, url):
# Get points positions in bit vector.
point1 = mmh3.hash(url, 41) % BIT_SIZE
point2 = mmh3.hash(url, 42) % BIT_SIZE
point3 = mmh3.hash(url, 43) % BIT_SIZE
point4 = mmh3.hash(url, 44) % BIT_SIZE
point5 = mmh3.hash(url, 45) % BIT_SIZE
point6 = mmh3.hash(url, 46) % BIT_SIZE
point7 = mmh3.hash(url, 47) % BIT_SIZE
return [point1, point2, point3, point4, point5, point6, point7]
BF的详细原理请参考我之前写的文章:Bloom Filter的原理与实现
建一张桌子
用户有价值的信息包括用户名、简介、行业、学院、专业、平台活动数据,如回答数、文章数、提问数、粉丝数、等等。
用户信息存储的表结构如下:
CREATE DATABASE `zhihu_user` /*!40100 DEFAULT CHARACTER SET utf8 */;
-- User base information table
CREATE TABLE `t_user` (
`uid` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(50) NOT NULL COMMENT '用户名',
`brief_info` varchar(400) COMMENT '个人简介',
`industry` varchar(50) COMMENT '所处行业',
`education` varchar(50) COMMENT '毕业院校',
`major` varchar(50) COMMENT '主修专业',
`answer_count` int(10) unsigned DEFAULT 0 COMMENT '回答数',
`article_count` int(10) unsigned DEFAULT 0 COMMENT '文章数',
`ask_question_count` int(10) unsigned DEFAULT 0 COMMENT '提问数',
`collection_count` int(10) unsigned DEFAULT 0 COMMENT '收藏数',
`follower_count` int(10) unsigned DEFAULT 0 COMMENT '被关注数',
`followed_count` int(10) unsigned DEFAULT 0 COMMENT '关注数',
`follow_live_count` int(10) unsigned DEFAULT 0 COMMENT '关注直播数',
`follow_topic_count` int(10) unsigned DEFAULT 0 COMMENT '关注话题数',
`follow_column_count` int(10) unsigned DEFAULT 0 COMMENT '关注专栏数',
`follow_question_count` int(10) unsigned DEFAULT 0 COMMENT '关注问题数',
`follow_collection_count` int(10) unsigned DEFAULT 0 COMMENT '关注收藏夹数',
`gmt_create` datetime NOT NULL COMMENT '创建时间',
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '最后一次编辑',
PRIMARY KEY (`uid`)
) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='用户基本信息表';
网页下载后,通过XPath解析,提取出用户各个维度的数据,最后保存到数据库中。
反爬虫策略 response-Headers
一般网站会从几个维度进行反爬:用户请求的Headers、用户行为、网站以及数据加载的方式。用户请求的Headers反爬虫是最常见的策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源网站的反盗链就是检测Referer)。
如果遇到这种反爬虫机制,可以直接给爬虫添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者修改Referer值为目标网站域名。对于检测header的反爬虫,在爬虫中修改或添加header很容易绕过。
cookies = {
"d_c0": "AECA7v-aPwqPTiIbemmIQ8abhJy7bdD2VgE=|1468847182",
"login": "NzM5ZDc2M2JkYzYwNDZlOGJlYWQ1YmI4OTg5NDhmMTY=|1480901173|9c296f424b32f241d1471203244eaf30729420f0",
"n_c": "1",
"q_c1": "395b12e529e541cbb400e9718395e346|1479808003000|1468847182000",
"l_cap_id": "NzI0MTQwZGY2NjQyNDQ1NThmYTY0MjJhYmU2NmExMGY=|1480901160|2e7a7faee3b3e8d0afb550e8e7b38d86c15a31bc",
"d_c0": "AECA7v-aPwqPTiIbemmIQ8abhJy7bdD2VgE=|1468847182",
"cap_id": "N2U1NmQwODQ1NjFiNGI2Yzg2YTE2NzJkOTU5N2E0NjI=|1480901160|fd59e2ed79faacc2be1010687d27dd559ec1552a"
}
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.98 Safari/537.3",
"Referer": "https://www.zhihu.com/"
}
r = requests.get(url, cookies = cookies, headers = headers)
反爬虫策略响应-代理IP池
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。
大部分网站都是前一种情况。在这种情况下,使用IP代理来解决它。这类代理ip爬虫经常用到,最好自己准备一个。有大量代理ip后,每次请求都可以换一个ip。这在requests或urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。目前知乎已经对爬虫进行了限制。如果是单个IP,系统会在一段时间内提示流量异常,无法继续爬取。因此,代理IP池非常关键。网上有一个免费的代理IP API:/free2016.txt
import requests
import random
class Proxy:
def __init__(self):
self.cache_ip_list = []
# Get random ip from free proxy api url.
def get_random_ip(self):
if not len(self.cache_ip_list):
api_url = 'http://api.xicidaili.com/free2016.txt'
try:
r = requests.get(api_url)
ip_list = r.text.split('\r\n')
self.cache_ip_list = ip_list
except Exception as e:
# Return null list when caught exception.
# In this case, crawler will not use proxy ip.
print e
return {}
proxy_ip = random.choice(self.cache_ip_list)
proxies = {'http': 'http://' + proxy_ip}
return proxies
跟进
爬虫源码:下载知乎-crawler后,通过pip安装相关的三方包,运行$ python crawler.py(喜欢的请点个star,看后续功能更新也方便)
运行截图:
查看全部
c爬虫抓取网页数据(几种-博客园爬虫的基本流程网络爬虫的抓取策略
)
原文:知乎 爬虫练习写在python-cpselvis-博客园
网络爬虫的基本工作流程如下:
爬虫的爬取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL的顺序也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
了解了爬虫的工作流程和爬取策略后,就可以开始实现爬虫了!那么如何在python中实现呢?
技术栈的基本实现
下面是伪代码
import Queue
initial_page = "https://www.zhihu.com/people/gaoming623"
url_queue = Queue.Queue()
seen = set()
seen.insert(initial_page)
url_queue.put(initial_page)
while(True): #一直进行
if url_queue.size()>0:
current_url = url_queue.get() #拿出队例中第一个的url
store(current_url) #把这个url代表的网页存储好
for next_url in extract_urls(current_url): #提取把这个url里链向的url
if next_url not in seen:
seen.put(next_url)
url_queue.put(next_url)
else:
break
如果直接处理上面的代码,直接运行,爬下整个知乎用户信息需要很长时间。毕竟,知乎 每月有 6000 万活跃用户。更不用说像谷歌这样的搜索引擎需要爬下整个网络。那么问题出在哪里呢?
布隆过滤器
需要爬取的网页太多,上面的代码太慢太慢了。假设全网有N个网站,那么分析判断的复杂度是N*log(N),因为所有网页都需要遍历一次,每次判断集合的时候,复杂度log(N) 是必需的。. OK,我知道python的set实现是hash-但是这样还是太慢了,至少内存使用效率不高。
通常的判断方式是什么?布隆过滤器。简单的说还是hash方法,但是它的特点是可以使用固定内存(不随url数增加)以O(1)的效率来判断url是否已经设置好可惜世界上没有免费的午餐,唯一的问题是如果url不在set中,BF可以100%确定url没有被浏览过。但是如果url在set中,它会告诉你:这个url应该已经出现了,但是我有2%的不确定性。注意这里的不确定性在你分配的内存足够大的情况下会变得非常小。
# bloom_filter.py
BIT_SIZE = 5000000
class BloomFilter:
def __init__(self):
# Initialize bloom filter, set size and all bits to 0
bit_array = bitarray(BIT_SIZE)
bit_array.setall(0)
self.bit_array = bit_array
def add(self, url):
# Add a url, and set points in bitarray to 1 (Points count is equal to hash funcs count.)
# Here use 7 hash functions.
point_list = self.get_postions(url)
for b in point_list:
self.bit_array[b] = 1
def contains(self, url):
# Check if a url is in a collection
point_list = self.get_postions(url)
result = True
for b in point_list:
result = result and self.bit_array[b]
return result
def get_postions(self, url):
# Get points positions in bit vector.
point1 = mmh3.hash(url, 41) % BIT_SIZE
point2 = mmh3.hash(url, 42) % BIT_SIZE
point3 = mmh3.hash(url, 43) % BIT_SIZE
point4 = mmh3.hash(url, 44) % BIT_SIZE
point5 = mmh3.hash(url, 45) % BIT_SIZE
point6 = mmh3.hash(url, 46) % BIT_SIZE
point7 = mmh3.hash(url, 47) % BIT_SIZE
return [point1, point2, point3, point4, point5, point6, point7]
BF的详细原理请参考我之前写的文章:Bloom Filter的原理与实现
建一张桌子
用户有价值的信息包括用户名、简介、行业、学院、专业、平台活动数据,如回答数、文章数、提问数、粉丝数、等等。
用户信息存储的表结构如下:
CREATE DATABASE `zhihu_user` /*!40100 DEFAULT CHARACTER SET utf8 */;
-- User base information table
CREATE TABLE `t_user` (
`uid` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(50) NOT NULL COMMENT '用户名',
`brief_info` varchar(400) COMMENT '个人简介',
`industry` varchar(50) COMMENT '所处行业',
`education` varchar(50) COMMENT '毕业院校',
`major` varchar(50) COMMENT '主修专业',
`answer_count` int(10) unsigned DEFAULT 0 COMMENT '回答数',
`article_count` int(10) unsigned DEFAULT 0 COMMENT '文章数',
`ask_question_count` int(10) unsigned DEFAULT 0 COMMENT '提问数',
`collection_count` int(10) unsigned DEFAULT 0 COMMENT '收藏数',
`follower_count` int(10) unsigned DEFAULT 0 COMMENT '被关注数',
`followed_count` int(10) unsigned DEFAULT 0 COMMENT '关注数',
`follow_live_count` int(10) unsigned DEFAULT 0 COMMENT '关注直播数',
`follow_topic_count` int(10) unsigned DEFAULT 0 COMMENT '关注话题数',
`follow_column_count` int(10) unsigned DEFAULT 0 COMMENT '关注专栏数',
`follow_question_count` int(10) unsigned DEFAULT 0 COMMENT '关注问题数',
`follow_collection_count` int(10) unsigned DEFAULT 0 COMMENT '关注收藏夹数',
`gmt_create` datetime NOT NULL COMMENT '创建时间',
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '最后一次编辑',
PRIMARY KEY (`uid`)
) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='用户基本信息表';
网页下载后,通过XPath解析,提取出用户各个维度的数据,最后保存到数据库中。
反爬虫策略 response-Headers
一般网站会从几个维度进行反爬:用户请求的Headers、用户行为、网站以及数据加载的方式。用户请求的Headers反爬虫是最常见的策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源网站的反盗链就是检测Referer)。
如果遇到这种反爬虫机制,可以直接给爬虫添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者修改Referer值为目标网站域名。对于检测header的反爬虫,在爬虫中修改或添加header很容易绕过。
cookies = {
"d_c0": "AECA7v-aPwqPTiIbemmIQ8abhJy7bdD2VgE=|1468847182",
"login": "NzM5ZDc2M2JkYzYwNDZlOGJlYWQ1YmI4OTg5NDhmMTY=|1480901173|9c296f424b32f241d1471203244eaf30729420f0",
"n_c": "1",
"q_c1": "395b12e529e541cbb400e9718395e346|1479808003000|1468847182000",
"l_cap_id": "NzI0MTQwZGY2NjQyNDQ1NThmYTY0MjJhYmU2NmExMGY=|1480901160|2e7a7faee3b3e8d0afb550e8e7b38d86c15a31bc",
"d_c0": "AECA7v-aPwqPTiIbemmIQ8abhJy7bdD2VgE=|1468847182",
"cap_id": "N2U1NmQwODQ1NjFiNGI2Yzg2YTE2NzJkOTU5N2E0NjI=|1480901160|fd59e2ed79faacc2be1010687d27dd559ec1552a"
}
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.98 Safari/537.3",
"Referer": "https://www.zhihu.com/"
}
r = requests.get(url, cookies = cookies, headers = headers)
反爬虫策略响应-代理IP池
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。
大部分网站都是前一种情况。在这种情况下,使用IP代理来解决它。这类代理ip爬虫经常用到,最好自己准备一个。有大量代理ip后,每次请求都可以换一个ip。这在requests或urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。目前知乎已经对爬虫进行了限制。如果是单个IP,系统会在一段时间内提示流量异常,无法继续爬取。因此,代理IP池非常关键。网上有一个免费的代理IP API:/free2016.txt
import requests
import random
class Proxy:
def __init__(self):
self.cache_ip_list = []
# Get random ip from free proxy api url.
def get_random_ip(self):
if not len(self.cache_ip_list):
api_url = 'http://api.xicidaili.com/free2016.txt'
try:
r = requests.get(api_url)
ip_list = r.text.split('\r\n')
self.cache_ip_list = ip_list
except Exception as e:
# Return null list when caught exception.
# In this case, crawler will not use proxy ip.
print e
return {}
proxy_ip = random.choice(self.cache_ip_list)
proxies = {'http': 'http://' + proxy_ip}
return proxies
跟进
爬虫源码:下载知乎-crawler后,通过pip安装相关的三方包,运行$ python crawler.py(喜欢的请点个star,看后续功能更新也方便)
运行截图:
c爬虫抓取网页数据(一下安装mysql需要屏蔽掉的代码:抓取网页数据格式 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-10-25 05:07
)
本文文章主要介绍python2.7详细实现爬虫网页数据。有一定的参考价值,感兴趣的朋友可以参考
最近刚学了Python,做了一个简单的爬虫。作为一个简单的demo,希望对我这样的初学者有所帮助。
代码使用python制作的爬虫2.7抓取51job上的职位名称、公司名称、薪水、发布时间等。
直接上代码。代码中的注释相当清楚。如果没有安装mysql,需要屏蔽相关代码:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
from bs4 import BeautifulSoup
import urllib
import urllib2
import codecs
import re
import time
import logging
import MySQLdb
class Jobs(object):
# 初始化
"""docstring for Jobs"""
def __init__(self):
super(Jobs, self).__init__()
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s')
#数据库的操作,没有mysql可以做屏蔽
self.db = MySQLdb.connect('127.0.0.1','root','rootroot','MySQL_Test',charset='utf8')
self.cursor = self.db.cursor()
#log日志的显示
self.logger = logging.getLogger("sjk")
self.logger.setLevel(level=logging.DEBUG)
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler = logging.FileHandler('log.txt')
handler.setFormatter(formatter)
handler.setLevel(logging.DEBUG)
self.logger.addHandler(handler)
self.logger.info('初始化完成')
# 模拟请求数据
def jobshtml(self, key, page='1'):
try:
self.logger.info('开始请求第' + page + '页')
#网页url
searchurl = "https://search.51job.com/list/040000,000000,0000,00,9,99,{key},2,{page}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare="
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:59.0) Gecko/20100101 Firefox/59.0'
#设置请求头
header = {'User-Agent': user_agent, 'Host': 'search.51job.com',
'Referer': 'https://www.51job.com/'}
#拼接url
finalUrl = searchurl.format(key=key, page=page)
request = urllib2.Request(finalUrl, headers=header)
response = urllib2.urlopen(request)
#等待网页加载完成
time.sleep(3)
#gbk格式解码
info = response.read().decode('gbk')
self.logger.info('请求网页网页')
self.decodeHtml(info=info, key=key, page=page)
except urllib2.HTTPError as e:
print e.reason
# 解析网页数据
def decodeHtml(self, info, key, page):
self.logger.info('开始解析网页数据')
#BeautifulSoup 解析网页
soup = BeautifulSoup(info, 'html.parser')
#找到class = t1 t2 t3 t4 t5 的标签数据
ps = soup.find_all(attrs={"class": re.compile(r'^t[1-5].*')})
#打开txt文件 a+ 代表追加
f = codecs.open(key + '.txt', 'a+', 'UTF-8')
#清除之前的数据信息
f.truncate()
f.write('\n------------' + page + '--------------\n')
count = 1
arr = []
#做一些字符串的处理,形成数据格式 iOS开发工程师 有限公司 深圳-南山区 0.9-1.6万/月 05-16
for pi in ps:
spe = " "
finalstr = pi.getText().strip()
arr.append(finalstr)
if count % 5 == 0:
#每一条数据插入数据库,如果没有安装mysql 可以将当前行注释掉
self.connectMySQL(arr=arr)
arr = []
spe = "\n"
writestr = finalstr + spe
count += 1
f.write(writestr)
f.close()
self.logger.info('解析完成')
#数据库操作 没有安装mysql 可以屏蔽掉
def connectMySQL(self,arr):
work=arr[0]
company=arr[1]
place=arr[2]
salary=arr[3]
time=arr[4]
query = "select * from Jobs_tab where \
company_name='%s' and work_name='%s' and work_place='%s' \
and salary='%s' and time='%s'" %(company,work,place,salary,time)
self.cursor.execute(query)
queryresult = self.cursor.fetchall()
#数据库中不存在就插入数据 存在就可以更新数据 不过我这边没有写
if len(queryresult) > 0:
sql = "insert into Jobs_tab(work_name,company_name,work_place,salary\
,time) values('%s','%s','%s','%s','%s')" %(work,company,place,salary,time)
try:
self.cursor.execute(sql)
self.db.commit()
except Exception as e:
self.logger.info('写入数据库失败')
#模拟登陆
# def login(self):
# data = {'action':'save','isread':'on','loginname':'18086514327','password':'kui4131sjk'}
# 开始抓取 主函数
def run(self, key):
# 只要前5页的数据 key代表搜索工做类型 这边我是用的ios page是页数
for x in xrange(1, 6):
self.jobshtml(key=key, page=str(x))
self.logger.info('写入数据库完成')
self.db.close()
if __name__ == '__main__':
Jobs().run(key='iOS')
这种方式抓取的网页数据格式如下:
查看全部
c爬虫抓取网页数据(一下安装mysql需要屏蔽掉的代码:抓取网页数据格式
)
本文文章主要介绍python2.7详细实现爬虫网页数据。有一定的参考价值,感兴趣的朋友可以参考
最近刚学了Python,做了一个简单的爬虫。作为一个简单的demo,希望对我这样的初学者有所帮助。
代码使用python制作的爬虫2.7抓取51job上的职位名称、公司名称、薪水、发布时间等。
直接上代码。代码中的注释相当清楚。如果没有安装mysql,需要屏蔽相关代码:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
from bs4 import BeautifulSoup
import urllib
import urllib2
import codecs
import re
import time
import logging
import MySQLdb
class Jobs(object):
# 初始化
"""docstring for Jobs"""
def __init__(self):
super(Jobs, self).__init__()
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s')
#数据库的操作,没有mysql可以做屏蔽
self.db = MySQLdb.connect('127.0.0.1','root','rootroot','MySQL_Test',charset='utf8')
self.cursor = self.db.cursor()
#log日志的显示
self.logger = logging.getLogger("sjk")
self.logger.setLevel(level=logging.DEBUG)
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler = logging.FileHandler('log.txt')
handler.setFormatter(formatter)
handler.setLevel(logging.DEBUG)
self.logger.addHandler(handler)
self.logger.info('初始化完成')
# 模拟请求数据
def jobshtml(self, key, page='1'):
try:
self.logger.info('开始请求第' + page + '页')
#网页url
searchurl = "https://search.51job.com/list/040000,000000,0000,00,9,99,{key},2,{page}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare="
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:59.0) Gecko/20100101 Firefox/59.0'
#设置请求头
header = {'User-Agent': user_agent, 'Host': 'search.51job.com',
'Referer': 'https://www.51job.com/'}
#拼接url
finalUrl = searchurl.format(key=key, page=page)
request = urllib2.Request(finalUrl, headers=header)
response = urllib2.urlopen(request)
#等待网页加载完成
time.sleep(3)
#gbk格式解码
info = response.read().decode('gbk')
self.logger.info('请求网页网页')
self.decodeHtml(info=info, key=key, page=page)
except urllib2.HTTPError as e:
print e.reason
# 解析网页数据
def decodeHtml(self, info, key, page):
self.logger.info('开始解析网页数据')
#BeautifulSoup 解析网页
soup = BeautifulSoup(info, 'html.parser')
#找到class = t1 t2 t3 t4 t5 的标签数据
ps = soup.find_all(attrs={"class": re.compile(r'^t[1-5].*')})
#打开txt文件 a+ 代表追加
f = codecs.open(key + '.txt', 'a+', 'UTF-8')
#清除之前的数据信息
f.truncate()
f.write('\n------------' + page + '--------------\n')
count = 1
arr = []
#做一些字符串的处理,形成数据格式 iOS开发工程师 有限公司 深圳-南山区 0.9-1.6万/月 05-16
for pi in ps:
spe = " "
finalstr = pi.getText().strip()
arr.append(finalstr)
if count % 5 == 0:
#每一条数据插入数据库,如果没有安装mysql 可以将当前行注释掉
self.connectMySQL(arr=arr)
arr = []
spe = "\n"
writestr = finalstr + spe
count += 1
f.write(writestr)
f.close()
self.logger.info('解析完成')
#数据库操作 没有安装mysql 可以屏蔽掉
def connectMySQL(self,arr):
work=arr[0]
company=arr[1]
place=arr[2]
salary=arr[3]
time=arr[4]
query = "select * from Jobs_tab where \
company_name='%s' and work_name='%s' and work_place='%s' \
and salary='%s' and time='%s'" %(company,work,place,salary,time)
self.cursor.execute(query)
queryresult = self.cursor.fetchall()
#数据库中不存在就插入数据 存在就可以更新数据 不过我这边没有写
if len(queryresult) > 0:
sql = "insert into Jobs_tab(work_name,company_name,work_place,salary\
,time) values('%s','%s','%s','%s','%s')" %(work,company,place,salary,time)
try:
self.cursor.execute(sql)
self.db.commit()
except Exception as e:
self.logger.info('写入数据库失败')
#模拟登陆
# def login(self):
# data = {'action':'save','isread':'on','loginname':'18086514327','password':'kui4131sjk'}
# 开始抓取 主函数
def run(self, key):
# 只要前5页的数据 key代表搜索工做类型 这边我是用的ios page是页数
for x in xrange(1, 6):
self.jobshtml(key=key, page=str(x))
self.logger.info('写入数据库完成')
self.db.close()
if __name__ == '__main__':
Jobs().run(key='iOS')
这种方式抓取的网页数据格式如下:
c爬虫抓取网页数据(简化人工操作的必要过程,本文分享一下获取交互信息的爬虫经历)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-10-24 08:03
删除线格式# C#获取动态网页中的数据
在实际工作需要中,编辑的文档需要获取历史地震信息,因此使用计算机语言获取是简化人工操作的必要过程。本文分享我第一次爬虫获取交互信息的经验!
操作流程 我要获取的信息如下图所示。通过填写不同的日期、经纬度、震级等,我可以搜索到想要的结果。
一开始,没有任何线索。查看网页的源代码无法找到搜索结果,所以我们首先要做的就是找到数据的位置。第一步:右键查看元素,点击网络,会出现下图所示的两个文件:
点击第一个文件,看到它的预览有我们想要的信息。Response 收录这部分代码,也就是我们想要的数据:
第二部分:查找URL、请求方法和参数。这部分信息收录在标题中:
第三步:C#编程获取网页,这里直接上代码
// An highlighted block
//url目标地址
string url = "网址";
//要提交的数据
string postString = "DISPLAY_TYPE=1&PAGEID=earthquake_subao&catalog_ALLDATASETS_RECORDCOUNT=catalog__default_default_default_key__default_default_default_key%3D65%3B"
+"&refreshComponentGuid=earthquake_subao_guid_catalog&begtime=2019-09-10&endtime=2019-10-10"
+"&minM=3&maxM=10&minLon=-180.0&maxLon=180.0&minLat=-90.0&maxLat=90.0"
+"&minDepths=0&maxDepths=1000&SEARCHREPORT_ID=catalog&WX_ISAJAXLOAD=true";
//这里即为传递的参数,可以用工具抓包分析,也可以自己分析,主要是form里面每一个name都要加进来
byte[] postData = Encoding.UTF8.GetBytes(postString);//编码,尤其是汉字,事先要看下抓取网页的编码方式
WebClient webClient = new WebClient();
webClient.Headers.Add("Content-Type", "application/x-www-form-urlencoded");//采取POST方式必须加的header,如果改为GET方式的话就去掉这句话即可
byte[] responseData = webClient.UploadData(url, "POST", postData);//得到返回字符流
string srcString = Encoding.UTF8.GetString(responseData);//解码
//解析获取到的网页
HtmlAgilityPack.HtmlDocument History_doc = new HtmlAgilityPack.HtmlDocument();
History_doc.LoadHtml(srcString);
下一步是阅读网页的内容。这是第一次写。感谢您的批评和指正!!! 查看全部
c爬虫抓取网页数据(简化人工操作的必要过程,本文分享一下获取交互信息的爬虫经历)
删除线格式# C#获取动态网页中的数据
在实际工作需要中,编辑的文档需要获取历史地震信息,因此使用计算机语言获取是简化人工操作的必要过程。本文分享我第一次爬虫获取交互信息的经验!
操作流程 我要获取的信息如下图所示。通过填写不同的日期、经纬度、震级等,我可以搜索到想要的结果。
一开始,没有任何线索。查看网页的源代码无法找到搜索结果,所以我们首先要做的就是找到数据的位置。第一步:右键查看元素,点击网络,会出现下图所示的两个文件:
点击第一个文件,看到它的预览有我们想要的信息。Response 收录这部分代码,也就是我们想要的数据:
第二部分:查找URL、请求方法和参数。这部分信息收录在标题中:
第三步:C#编程获取网页,这里直接上代码
// An highlighted block
//url目标地址
string url = "网址";
//要提交的数据
string postString = "DISPLAY_TYPE=1&PAGEID=earthquake_subao&catalog_ALLDATASETS_RECORDCOUNT=catalog__default_default_default_key__default_default_default_key%3D65%3B"
+"&refreshComponentGuid=earthquake_subao_guid_catalog&begtime=2019-09-10&endtime=2019-10-10"
+"&minM=3&maxM=10&minLon=-180.0&maxLon=180.0&minLat=-90.0&maxLat=90.0"
+"&minDepths=0&maxDepths=1000&SEARCHREPORT_ID=catalog&WX_ISAJAXLOAD=true";
//这里即为传递的参数,可以用工具抓包分析,也可以自己分析,主要是form里面每一个name都要加进来
byte[] postData = Encoding.UTF8.GetBytes(postString);//编码,尤其是汉字,事先要看下抓取网页的编码方式
WebClient webClient = new WebClient();
webClient.Headers.Add("Content-Type", "application/x-www-form-urlencoded");//采取POST方式必须加的header,如果改为GET方式的话就去掉这句话即可
byte[] responseData = webClient.UploadData(url, "POST", postData);//得到返回字符流
string srcString = Encoding.UTF8.GetString(responseData);//解码
//解析获取到的网页
HtmlAgilityPack.HtmlDocument History_doc = new HtmlAgilityPack.HtmlDocument();
History_doc.LoadHtml(srcString);
下一步是阅读网页的内容。这是第一次写。感谢您的批评和指正!!!
c爬虫抓取网页数据(零基础快速入门的学习路径——Python中爬虫相关)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-23 08:11
参考视频教程:
**Python爬虫工程师从入门到高级**
图片
互联网上的数据爆炸式增长,使用Python爬虫我们可以获得很多有价值的数据:
1. 爬取数据,进行市场调研和商业分析
抓取知乎优质回答,筛选每个话题下的最佳内容;爬取房产网站交易信息,分析房价走势,做不同区域的房价分析;爬取招聘网站 职位信息,分析各行业的人才需求和薪资水平。
2.作为机器学习和数据挖掘的原创数据
比如你想做一个推荐系统,那么你可以爬取更多维度的数据,做一个更好的模型。
3. 爬取优质资源:图片、文字、视频
爬取商品(店铺)评论和各种图片网站,获取图片资源和评论文字数据。
掌握正确的方法能够在短时间内抓取主流网站数据,其实很容易实现。
但建议您从一开始就有一个特定的目标。在目标的驱动下,您的学习将更加精准和高效。这是一个平滑的、从零开始的快速入门学习路径:
1.了解爬虫的基本原理和流程
2.Requests+Xpath实现一般爬虫例程
3.理解非结构化数据的存储
4.应对特殊的网站反爬虫措施
5.Scrapy 和 MongoDB,高级分布式
大多数爬虫都遵循“发送请求-获取页面-解析页面-提取并存储内容”的过程。这实际上模拟了使用浏览器获取网页信息的过程。
简单的说,我们向服务器发送请求后,会得到返回的页面。解析完页面后,我们就可以提取出我们想要的那部分信息,存放在指定的文档或数据库中。
这部分可以简单的了解一下HTTP协议和网页的基础知识,比如POST\GET、HTML、CSS、JS,简单了解一下,无需系统学习。
Python中有很多爬虫相关的包:urllib、requests、bs4、scrapy、pyspider等,建议从requests+Xpath入手。Requests 负责连接到 网站 并返回网页。Xpath 用于解析网页以方便提取数据。
如果你用过 BeautifulSoup,你会发现 Xpath 省去了很多麻烦。逐层检查元素代码的工作全部省略。掌握了之后,你会发现爬虫的基本套路都差不多。一般静态 网站 根本不是问题。小猪,豆瓣,尴尬百科,腾讯新闻等基本都可以用。
我们来看一个爬取豆瓣短评论的例子:
图片
选择第一条短评论,右键-》勾选,即可查看源码
图片
复制短评论信息的XPath信息
图片
通过定位,我们得到了第一个短评论XPath信息:
图片
如果我们想抓取大量的短评论,那么自然我们应该得到(复制)更多这样的XPath:
图片
观察第3条短注释1、2、的XPath,你会发现模式,只是后面的序号不同,正好对应短注释的序号。那么如果我们想抓取这个页面上的所有短评论信息,那么就不需要这个序列号了。
通过XPath信息,我们可以用简单的代码爬下来:
图片
图片
该页面的所有短评论信息都被爬取了
当然,如果你需要爬取异步加载的网站,可以学习浏览器抓包来分析真实请求,或者学习Selenium来实现自动爬取。这样,知乎、、TripAdvisor等网站基本没问题。
您还需要了解 Python 的基础知识,例如:
文件读写操作:用于读取参数和保存爬取的内容
list(列表)、dict(字典):用于对爬取的数据进行序列化
条件判断(if/else):解决爬虫中的判断是否执行
循环和迭代(for ……while):用于循环爬虫步骤
爬回来的数据可以直接以文档的形式存储在本地,也可以存储在数据库中。
当数据量较小时,可以直接通过Python语法或pandas方法将数据保存为文本或csv文件。继续上面的例子:
使用Python基础语言实现存储:
图片
使用pandas语言来存储:
图片
这两段代码都可以存储爬取的短评论信息,并将代码粘贴到爬取代码的后面。
图片
为该页面存储的短评论数据
当然,你可能会发现爬回来的数据不干净,可能有缺失、错误等,你也需要清理数据,可以学习pandas包,掌握以下知识点:
缺失值处理:删除或填充缺失数据行
重复值处理:判断和删除重复值
空格和异常值的处理:清除不必要的空格和极端和异常数据
数据分组:数据划分、功能分开执行、数据重组
爬取一页的数据没问题,但是我们通常要爬取多个页面。
这时候就需要看看翻页时url是如何变化的,或者以短评论页面为例,我们来看看多页url的区别:
图片
通过前四页,我们可以找到图案,不同的页面,但页面的序号被标记在最后。以抓取5个页面为例,只写一个循环更新页面地址即可。
图片
当然,爬取过程中也会有一些绝望,比如被网站屏蔽,比如各种奇怪的验证码,userAgent访问限制,各种动态加载等等。
遇到这些反爬虫方法,当然需要一些高级技巧来应对,比如访问频率控制、代理IP池的使用、抓包、验证码的OCR处理等等。
比如我们经常发现有些网站的URL在翻页后没有变化,通常是异步加载。我们使用开发者工具分析页面加载信息,通常可以获得意想不到的收获。
图片
通过开发者工具分析加载的信息。比如我们发现网页无法通过代码访问,我们可以尝试添加userAgent信息,甚至浏览器的cookie信息。
往往网站在高效开发和反爬虫之间偏向于前者,这也为爬虫提供了空间。掌握这些反爬虫技巧,大部分网站对你来说不再难。
Scrapy 和 MongoDB,高级分布式
掌握了之前的技术,一般量级的数据和代码基本没有问题,但是在非常复杂的情况下,可能还是做不到自己想做的。这时候,强大的scrapy框架就非常有用了。
Scrapy 是一个非常强大的爬虫框架。它不仅可以方便地构造请求,还拥有强大的选择器,可以轻松解析响应。不过,最让人惊喜的是它的超高性能,可以让你设计爬虫。,模块化。
图片
出租信息的分布式爬取
需要爬取的数据量很大,自然需要一个数据库。MongoDB 可以方便您存储大规模数据。因为这里要用到的数据库知识其实很简单,主要是如何存储数据,如何提取,需要的时候学习。
图片
MongoDB 存储作业信息
分布式这个东西听起来很吓人,但实际上,它是利用多线程的原理,让多个爬虫同时工作。你需要掌握Scrapy+MongoDB+Redis这三个工具。
Scrapy用于基本的页面爬取,MongoDB用于存储爬取的数据,Redis用于存储待爬取的网页队列,即任务队列。
这时候就已经可以写分布式爬虫了。
你看,有了这个学习路径,你已经可以成为一个老司机了,非常顺利。所以一开始尽量不要系统地啃东西,找个实际的项目(可以从豆瓣、小猪等简单的东西开始),直接开始。
因为爬虫技术不需要你系统地精通一门语言,也不需要非常先进的数据库技术。高效的姿势就是从实际项目中学习这些零散的知识点,保证每次都能学到。是最需要的部分。
当然,唯一的麻烦是在具体问题中,如何找到具体需要的那部分学习资源,如何筛选筛选,是很多初学者面临的一大难题。
不过不用担心,我们准备了非常系统的爬虫课程。除了为您提供清晰的学习路径,我们精选了最实用的学习资源和海量的主流爬虫案例库。在很短的学习时间内,你将能够很好地掌握爬虫技巧,得到你想要的数据。
《Python爬虫:入门+进阶》大纲
第 1 章:Python 爬虫入门
1、什么是爬虫
URL组合和翻页机制
网页源码结构及网页请求流程
爬虫的应用及基本原理
2、认识Python爬虫
Python爬虫环境搭建 查看全部
c爬虫抓取网页数据(零基础快速入门的学习路径——Python中爬虫相关)
参考视频教程:
**Python爬虫工程师从入门到高级**
图片
互联网上的数据爆炸式增长,使用Python爬虫我们可以获得很多有价值的数据:
1. 爬取数据,进行市场调研和商业分析
抓取知乎优质回答,筛选每个话题下的最佳内容;爬取房产网站交易信息,分析房价走势,做不同区域的房价分析;爬取招聘网站 职位信息,分析各行业的人才需求和薪资水平。
2.作为机器学习和数据挖掘的原创数据
比如你想做一个推荐系统,那么你可以爬取更多维度的数据,做一个更好的模型。
3. 爬取优质资源:图片、文字、视频
爬取商品(店铺)评论和各种图片网站,获取图片资源和评论文字数据。
掌握正确的方法能够在短时间内抓取主流网站数据,其实很容易实现。
但建议您从一开始就有一个特定的目标。在目标的驱动下,您的学习将更加精准和高效。这是一个平滑的、从零开始的快速入门学习路径:
1.了解爬虫的基本原理和流程
2.Requests+Xpath实现一般爬虫例程
3.理解非结构化数据的存储
4.应对特殊的网站反爬虫措施
5.Scrapy 和 MongoDB,高级分布式
大多数爬虫都遵循“发送请求-获取页面-解析页面-提取并存储内容”的过程。这实际上模拟了使用浏览器获取网页信息的过程。
简单的说,我们向服务器发送请求后,会得到返回的页面。解析完页面后,我们就可以提取出我们想要的那部分信息,存放在指定的文档或数据库中。
这部分可以简单的了解一下HTTP协议和网页的基础知识,比如POST\GET、HTML、CSS、JS,简单了解一下,无需系统学习。
Python中有很多爬虫相关的包:urllib、requests、bs4、scrapy、pyspider等,建议从requests+Xpath入手。Requests 负责连接到 网站 并返回网页。Xpath 用于解析网页以方便提取数据。
如果你用过 BeautifulSoup,你会发现 Xpath 省去了很多麻烦。逐层检查元素代码的工作全部省略。掌握了之后,你会发现爬虫的基本套路都差不多。一般静态 网站 根本不是问题。小猪,豆瓣,尴尬百科,腾讯新闻等基本都可以用。
我们来看一个爬取豆瓣短评论的例子:
图片
选择第一条短评论,右键-》勾选,即可查看源码
图片
复制短评论信息的XPath信息
图片
通过定位,我们得到了第一个短评论XPath信息:
图片
如果我们想抓取大量的短评论,那么自然我们应该得到(复制)更多这样的XPath:
图片
观察第3条短注释1、2、的XPath,你会发现模式,只是后面的序号不同,正好对应短注释的序号。那么如果我们想抓取这个页面上的所有短评论信息,那么就不需要这个序列号了。
通过XPath信息,我们可以用简单的代码爬下来:
图片
图片
该页面的所有短评论信息都被爬取了
当然,如果你需要爬取异步加载的网站,可以学习浏览器抓包来分析真实请求,或者学习Selenium来实现自动爬取。这样,知乎、、TripAdvisor等网站基本没问题。
您还需要了解 Python 的基础知识,例如:
文件读写操作:用于读取参数和保存爬取的内容
list(列表)、dict(字典):用于对爬取的数据进行序列化
条件判断(if/else):解决爬虫中的判断是否执行
循环和迭代(for ……while):用于循环爬虫步骤
爬回来的数据可以直接以文档的形式存储在本地,也可以存储在数据库中。
当数据量较小时,可以直接通过Python语法或pandas方法将数据保存为文本或csv文件。继续上面的例子:
使用Python基础语言实现存储:
图片
使用pandas语言来存储:
图片
这两段代码都可以存储爬取的短评论信息,并将代码粘贴到爬取代码的后面。
图片
为该页面存储的短评论数据
当然,你可能会发现爬回来的数据不干净,可能有缺失、错误等,你也需要清理数据,可以学习pandas包,掌握以下知识点:
缺失值处理:删除或填充缺失数据行
重复值处理:判断和删除重复值
空格和异常值的处理:清除不必要的空格和极端和异常数据
数据分组:数据划分、功能分开执行、数据重组
爬取一页的数据没问题,但是我们通常要爬取多个页面。
这时候就需要看看翻页时url是如何变化的,或者以短评论页面为例,我们来看看多页url的区别:
图片
通过前四页,我们可以找到图案,不同的页面,但页面的序号被标记在最后。以抓取5个页面为例,只写一个循环更新页面地址即可。
图片
当然,爬取过程中也会有一些绝望,比如被网站屏蔽,比如各种奇怪的验证码,userAgent访问限制,各种动态加载等等。
遇到这些反爬虫方法,当然需要一些高级技巧来应对,比如访问频率控制、代理IP池的使用、抓包、验证码的OCR处理等等。
比如我们经常发现有些网站的URL在翻页后没有变化,通常是异步加载。我们使用开发者工具分析页面加载信息,通常可以获得意想不到的收获。
图片
通过开发者工具分析加载的信息。比如我们发现网页无法通过代码访问,我们可以尝试添加userAgent信息,甚至浏览器的cookie信息。
往往网站在高效开发和反爬虫之间偏向于前者,这也为爬虫提供了空间。掌握这些反爬虫技巧,大部分网站对你来说不再难。
Scrapy 和 MongoDB,高级分布式
掌握了之前的技术,一般量级的数据和代码基本没有问题,但是在非常复杂的情况下,可能还是做不到自己想做的。这时候,强大的scrapy框架就非常有用了。
Scrapy 是一个非常强大的爬虫框架。它不仅可以方便地构造请求,还拥有强大的选择器,可以轻松解析响应。不过,最让人惊喜的是它的超高性能,可以让你设计爬虫。,模块化。
图片
出租信息的分布式爬取
需要爬取的数据量很大,自然需要一个数据库。MongoDB 可以方便您存储大规模数据。因为这里要用到的数据库知识其实很简单,主要是如何存储数据,如何提取,需要的时候学习。
图片
MongoDB 存储作业信息
分布式这个东西听起来很吓人,但实际上,它是利用多线程的原理,让多个爬虫同时工作。你需要掌握Scrapy+MongoDB+Redis这三个工具。
Scrapy用于基本的页面爬取,MongoDB用于存储爬取的数据,Redis用于存储待爬取的网页队列,即任务队列。
这时候就已经可以写分布式爬虫了。
你看,有了这个学习路径,你已经可以成为一个老司机了,非常顺利。所以一开始尽量不要系统地啃东西,找个实际的项目(可以从豆瓣、小猪等简单的东西开始),直接开始。
因为爬虫技术不需要你系统地精通一门语言,也不需要非常先进的数据库技术。高效的姿势就是从实际项目中学习这些零散的知识点,保证每次都能学到。是最需要的部分。
当然,唯一的麻烦是在具体问题中,如何找到具体需要的那部分学习资源,如何筛选筛选,是很多初学者面临的一大难题。
不过不用担心,我们准备了非常系统的爬虫课程。除了为您提供清晰的学习路径,我们精选了最实用的学习资源和海量的主流爬虫案例库。在很短的学习时间内,你将能够很好地掌握爬虫技巧,得到你想要的数据。
《Python爬虫:入门+进阶》大纲
第 1 章:Python 爬虫入门
1、什么是爬虫
URL组合和翻页机制
网页源码结构及网页请求流程
爬虫的应用及基本原理
2、认识Python爬虫
Python爬虫环境搭建
c爬虫抓取网页数据(阿里云数据库ApsaraDB(42)(组图)网页显示)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-23 04:06
阿里云>云栖社区>主题图>P>Crawler抓取网页指定数据库
推荐活动:
更多优惠>
当前主题:爬虫爬取网页指定数据库添加到采集夹
相关话题:
爬虫爬取网页指定数据库相关的博客。查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
【网络爬虫】使用node.jscheerio爬取网页数据
作者:自娱自乐 5358人浏览评论:05年前
您是想自动从网页中抓取一些数据,还是想将从某个博客中提取的一堆数据转换为结构化数据?有没有现有的 API 来检索数据?!!!!@#$@#$... 可以解决网页爬虫就好了。什么是网络爬虫?你可能会问。. . 网络爬虫是以编程方式(通常无需浏览器参与)检索网页内容。
阅读全文
使用Python爬虫抓取免费代理IP
作者:小技术专家 2872人浏览评论:03年前
不知道大家有没有遇到过“访问频率太高”之类的网站提示。我们需要等待一段时间或输入验证码才能解锁,但此后仍会出现这种情况。出现这种现象的原因是我们要爬取的网页采取了反爬虫措施。比如某个ip单位时间请求一个网页的次数过多,服务器就会拒绝服务。在这种情况下,
阅读全文
爬取网页数据分析
作者:y0umer606 浏览评论人数:010年前
发表于 2006-05-24 14:04 北极燕鸥阅读(9793) 评论(42) 编辑采集类别:C#编程自动阅读其他网站网页显示信息类似于a爬虫程序,比如我们有一个系统提取百度网站歌曲搜索排名分析系统
阅读全文
抓取网页数据分析(c#)
作者:wenvi_wu1489 浏览评论人数:012年前
其他网站网页上显示的信息是通过程序自动读取的,类似于爬虫程序。比如我们有一个系统来提取百度网站歌曲搜索排名。分析系统根据获得的数据进行数据分析。为企业提供参考数据。为了完成上述需求,我们需要模拟浏览器浏览网页,并获取页面的数据进行分析。
阅读全文
如何使用 Python 抓取数据?(一)网页抓取
作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的消息。很多评论都是来自读者的提问。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
爬虫和 urllib 库概述(一)
作者:蓝の流星VIP1588人浏览评论:03年前
1 爬虫概述(1)互联网爬虫是一种根据Url抓取网页并获取有用信息的程序(2)抓取网页解析数据的核心任务。难点:爬虫与反的博弈-crawlers(3)爬虫语言php多进程多线程支持不好。Java目前对java爬虫的需求旺盛,但是代码臃肿,重构成本高。
阅读全文
一个小型网络爬虫系统的架构设计
作者:技术组合 902人浏览评论:03年前
一个小型网络爬虫系统的架构设计。网络爬虫服务是互联网上经常使用的服务。在搜索引擎中,蜘蛛(网络爬虫)是必不可少的核心服务。搜索引擎衡量的四个指标“多、快、准、新”中,多、快、新都是对蜘蛛的要求。google、baidu等搜索引擎公司维护
阅读全文
Scrapy分布式、去重增量爬虫的开发设计
作者:技术小能手8758人浏览评论:03年前
基于python的分布式房屋数据采集系统为数据的进一步应用提供数据支持,即房屋推荐系统。本课题致力于解决单进程单机爬虫的瓶颈,创建基于Redis分布式多爬虫共享队列的主题爬虫。本系统使用python开发的Scrapy框架开发,使用Xpath
阅读全文 查看全部
c爬虫抓取网页数据(阿里云数据库ApsaraDB(42)(组图)网页显示)
阿里云>云栖社区>主题图>P>Crawler抓取网页指定数据库
推荐活动:
更多优惠>
当前主题:爬虫爬取网页指定数据库添加到采集夹
相关话题:
爬虫爬取网页指定数据库相关的博客。查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
【网络爬虫】使用node.jscheerio爬取网页数据
作者:自娱自乐 5358人浏览评论:05年前
您是想自动从网页中抓取一些数据,还是想将从某个博客中提取的一堆数据转换为结构化数据?有没有现有的 API 来检索数据?!!!!@#$@#$... 可以解决网页爬虫就好了。什么是网络爬虫?你可能会问。. . 网络爬虫是以编程方式(通常无需浏览器参与)检索网页内容。
阅读全文
使用Python爬虫抓取免费代理IP
作者:小技术专家 2872人浏览评论:03年前
不知道大家有没有遇到过“访问频率太高”之类的网站提示。我们需要等待一段时间或输入验证码才能解锁,但此后仍会出现这种情况。出现这种现象的原因是我们要爬取的网页采取了反爬虫措施。比如某个ip单位时间请求一个网页的次数过多,服务器就会拒绝服务。在这种情况下,
阅读全文
爬取网页数据分析
作者:y0umer606 浏览评论人数:010年前
发表于 2006-05-24 14:04 北极燕鸥阅读(9793) 评论(42) 编辑采集类别:C#编程自动阅读其他网站网页显示信息类似于a爬虫程序,比如我们有一个系统提取百度网站歌曲搜索排名分析系统
阅读全文
抓取网页数据分析(c#)
作者:wenvi_wu1489 浏览评论人数:012年前
其他网站网页上显示的信息是通过程序自动读取的,类似于爬虫程序。比如我们有一个系统来提取百度网站歌曲搜索排名。分析系统根据获得的数据进行数据分析。为企业提供参考数据。为了完成上述需求,我们需要模拟浏览器浏览网页,并获取页面的数据进行分析。
阅读全文
如何使用 Python 抓取数据?(一)网页抓取
作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的消息。很多评论都是来自读者的提问。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
爬虫和 urllib 库概述(一)
作者:蓝の流星VIP1588人浏览评论:03年前
1 爬虫概述(1)互联网爬虫是一种根据Url抓取网页并获取有用信息的程序(2)抓取网页解析数据的核心任务。难点:爬虫与反的博弈-crawlers(3)爬虫语言php多进程多线程支持不好。Java目前对java爬虫的需求旺盛,但是代码臃肿,重构成本高。
阅读全文
一个小型网络爬虫系统的架构设计
作者:技术组合 902人浏览评论:03年前
一个小型网络爬虫系统的架构设计。网络爬虫服务是互联网上经常使用的服务。在搜索引擎中,蜘蛛(网络爬虫)是必不可少的核心服务。搜索引擎衡量的四个指标“多、快、准、新”中,多、快、新都是对蜘蛛的要求。google、baidu等搜索引擎公司维护
阅读全文
Scrapy分布式、去重增量爬虫的开发设计
作者:技术小能手8758人浏览评论:03年前
基于python的分布式房屋数据采集系统为数据的进一步应用提供数据支持,即房屋推荐系统。本课题致力于解决单进程单机爬虫的瓶颈,创建基于Redis分布式多爬虫共享队列的主题爬虫。本系统使用python开发的Scrapy框架开发,使用Xpath
阅读全文
c爬虫抓取网页数据(Python却是最常用的,你知道为什么吗?和神龙IP)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-10-23 01:10
说起网络爬虫,相信大家都不陌生。爬虫可以爬取某个网站或者某个应用的内容,提取有用的价值信息。可以使用多种编程语言来实现爬虫,但最常用的是Python。你知道为什么吗?一起来看看神龙IP吧~
与C、Python 和C 相比Python 是C 开发的语言,但在使用方面,Python 的库完整方便,而C 语言则麻烦很多。要实现同样的功能,Python 只需要 10 行代码,而 C 语言可能需要 100 行甚至更多。但在运行速度方面,C语言更胜一筹。
对比Python和Java,Java有很多解析器,对网页解析的支持非常好。Java 也有爬虫相关的库,但没有 Python 多。不过就爬虫的效果而言,Java和Python都可以做到,只是工程量不同,实现的方式也不同。如果需要处理复杂的网页,解析网页内容生成结构化数据,或者精细解析网页内容,java会更合适。
Python 和其他语言没有本质区别。优势在于Python语法简单明了,开发效率高。另外,python语言的流行还有几个原因:
1. 抓取网页的界面简单;
与其他动态脚本语言相比,Python 提供了更完整的 Web 文档访问 API;与其他静态编程语言相比,Python 拥有更简洁的网页抓取界面。
2.强大的第三方库
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这时候就需要模拟User Agent的行为来构造合适的请求,比如模拟用户登录,模拟Session/Cookie的存储和设置。Python 中有出色的第三方包可以帮助您完成它,例如 Requests 或 Mechanize。
3.数据处理快捷方便
抓取到的网页通常需要进行处理,例如过滤Html标签、提取文本等。Python 的 Beautiful Soup 提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。其实很多语言和工具都可以做到以上功能,但是Python可以做到最快最干净。 查看全部
c爬虫抓取网页数据(Python却是最常用的,你知道为什么吗?和神龙IP)
说起网络爬虫,相信大家都不陌生。爬虫可以爬取某个网站或者某个应用的内容,提取有用的价值信息。可以使用多种编程语言来实现爬虫,但最常用的是Python。你知道为什么吗?一起来看看神龙IP吧~
与C、Python 和C 相比Python 是C 开发的语言,但在使用方面,Python 的库完整方便,而C 语言则麻烦很多。要实现同样的功能,Python 只需要 10 行代码,而 C 语言可能需要 100 行甚至更多。但在运行速度方面,C语言更胜一筹。
对比Python和Java,Java有很多解析器,对网页解析的支持非常好。Java 也有爬虫相关的库,但没有 Python 多。不过就爬虫的效果而言,Java和Python都可以做到,只是工程量不同,实现的方式也不同。如果需要处理复杂的网页,解析网页内容生成结构化数据,或者精细解析网页内容,java会更合适。
Python 和其他语言没有本质区别。优势在于Python语法简单明了,开发效率高。另外,python语言的流行还有几个原因:
1. 抓取网页的界面简单;
与其他动态脚本语言相比,Python 提供了更完整的 Web 文档访问 API;与其他静态编程语言相比,Python 拥有更简洁的网页抓取界面。
2.强大的第三方库
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这时候就需要模拟User Agent的行为来构造合适的请求,比如模拟用户登录,模拟Session/Cookie的存储和设置。Python 中有出色的第三方包可以帮助您完成它,例如 Requests 或 Mechanize。
3.数据处理快捷方便
抓取到的网页通常需要进行处理,例如过滤Html标签、提取文本等。Python 的 Beautiful Soup 提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。其实很多语言和工具都可以做到以上功能,但是Python可以做到最快最干净。
c爬虫抓取网页数据(蜘蛛协议风铃虫的原理简单使用提取器的作用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-10-21 11:15
风铃介绍
风铃是一款轻量级爬虫工具,像风铃一样灵敏,像蜘蛛一样敏捷,可以感知任何微小的风和草,轻松抓取网络内容。是一个对目标服务器比较友好的蜘蛛程序。内置20多个常用或不常用的浏览器标识,可自动处理cookies和网页源信息,轻松绕过服务器限制,智能调整请求间隔,动态调整请求频率,防止干扰目标服务器。此外,Windchime 也是一个非常人性化的工具。它提供了大量的链接提取器和内容提取器,让用户可以根据自己的需要快速配置,甚至提供启动请求地址来配置自己的爬虫。同时,Windchime 还开放了很多自定义界面,让高级用户可以根据需要自定义爬虫功能。最后,风铃自然也支持分布式和集群功能,让你突破单机环境的束缚,释放你的爬虫能力。可以说风铃几乎可以抓取当前网站中的所有内容。
【声明】请不要在任何可能违反法律和道德约束的工作中使用风铃。请友好使用风铃,遵守蜘蛛协议,不要将风铃用于任何非法用途。如果您选择使用风铃,即表示您遵守本协议。作者不承担因您违反本协议而造成的任何法律风险和损失,一切后果由您自行承担。
快速使用
com.yishuifengxiao.common
crawler
2.2.0
交流群:
(群号624646260)
使用简单
从雅虎财经内容页面中提取电子货币名称
// 创建一个提取属性规则
// 该提取规则标识XPATH表示使用XPATH提取器进行提取,
// 该XPATH提取器的XPATH表达式为 //h1/text() , 该提取提取器的作用顺序是0
ExtractFieldRule extractFieldRule = new ExtractFieldRule(Rule.XPATH, "//h1/text()", "", 0);
// 创建一个提取项
ExtractRule extractRule = new ExtractRule();
extractRule
// 提取项代码,不能为空,同一组提取规则之内每一个提取项的编码必须唯一
.setCode("code")
// 提取项名字,可以不设置
.setName("加密电子货币名字")
// 设置提取属性规则
.setRules(Arrays.asList(extractFieldRule));
// 创建一个风铃虫实例
Crawler crawler = CrawlerBuilder.create()
// 风铃虫的起始链接
.startUrl("https://hk.finance.yahoo.com/cryptocurrencies")
// 风铃虫会将请求到的网页中的URL先全部提取出来
// 然后将匹配链接提取规则的链接过滤出来,放入请求池中
// 请求池中的链接会作为下次抓取请求的种子链接
// 可以以添加多个链接提取规则,多个规则之间是并列(或连接)的关系
// 如果不设置则表示提取链接中所有包含域名关键字(例如此例中的yahoo)的链接放入链接池
// 此例中表示符合该正则表达式的链接都会被提取出来
.addLinkRule(new MatcherRule(Pattern.REGEX, "https://hk.finance.yahoo.com/quote/.+"))
// 内容页地址规则是告诉风铃虫哪些页面是内容页
// 对于复杂情况下,可以与 内容匹配规则 配合使用
// 只有符合内容页规则的页面才会被提取数据
// 对于非内容页,风铃虫不会尝试从中提取数据
// 此例中表示符合该正则表达式的网页都是内容页,风铃虫会从这些页面里提取数据
.contentPageRule(new MatcherRule(Pattern.REGEX, "https://hk.finance.yahoo.com/quote/.+"))
// 风铃虫可以设置多个提取项,这里为了演示只设置了一个提取项
// 增加一个提取项规则
.addExtractRule(extractRule)
// 请求间隔时间
// 如果不设置则使用默认时间10秒,此值是为了防止抓取频率太高被服务器封杀
.interval(3000)// 每次进行爬取时的平均间隔时间,单位为毫秒,
.creatCrawler();
// 启动爬虫实例
crawler.start();
// 这里没有设置信息输出器,表示使用默认的信息输出器
// 默认的信息输出器使用的logback日志输出方法,因此需要看控制台信息
// 由于风铃虫是异步运行的,所以演示时这里加入循环
while (Statu.STOP != crawler.getStatu()) {
try {
Thread.sleep(1000 * 20);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
上面例子的功能是在雅虎财经的内容页面上提取电子货币的名称。用户若想提取其他信息,只需根据规则配置其他提取规则即可。
请注意,以上示例仅供学习和演示使用,Windchime 用户在抓取网页内容时应严格遵守相关法律法规和目标网站 的蜘蛛协议
风铃原理
风铃的原理很简单,主要由资源调度器、网页下载器、链接解析器、内容解析器、信息输出器组成。
它们的作用和功能如下:
链接解析器由一系列链接提取器组成。目前,链接提取器主要支持常规提取。
内容解析器由一系列内容提取器组成。不同的内容提取器功能不同,适用于不同的分析场景,支持重复、循环等多种提取器的多种组合。
上述组件均提供了自定义配置接口,方便用户根据实际需求进行自定义配置,满足各种复杂甚至异常场景的需求。
内置的风铃内容提取器包括:
原文抽取器、中文抽取器、常量抽取器、CSS内容抽取器、CSS文本抽取器、邮箱抽取器、号码抽取器、正则抽取器、字符删除抽取器、字符替换抽取器、字符串截取抽取器、XPATH抽取器数组截取...
在提取文本内容时,用户可以自由组合这些提取器来提取他们需要的内容。关于提取器的更多具体用法,请参考内容提取器的使用。
Windchime 的内置浏览器标志为:
Google Chrome(windows版、linux版) Opera浏览器(windows版、MAC版) Firefox(windows版、linux版、MAC版) IE浏览器(IE9、IE11)EDAG Safari浏览器(windows版) , MAC 版)...
抓取js渲染网站
核心代码如下:
Crawler crawler = ...
crawler .setDownloader(new SeleniumDownloader("C:\\Users\\yishui\\Desktop\\geckodriver\\win32.exe",3000L))
分布式支持
核心代码如下:
....
//省略其他代码
....
//创建redis资源调度器
Scheduler scheduler=new RedisScheduler("唯一的名字",redisTemplate)
//创建一个redis资源缓存器
RequestCache requestCache = new RedisRequestCache(redisTemplate);
crawler
.setRequestCache(requestCache) //设置使用redis资源缓存器
.setScheduler(scheduler); //设置使用redis资源调度器
....
//省略其他代码
....
//启动爬虫实例
crawler.start();
状态监控
风铃还提供强大的状态监控和事件监控功能。通过状态监听器和事件监听器,风铃让你实时了解任务的运行状态,实时控制实例运行过程中遇到的各种问题,真正做到洞察运行情况任务,方便操作和维护。
解析模拟器
由于风铃强大的解析功能,规则的定义非常灵活,为了直观了解配置的规则定义的作用,风铃提供了解析模拟器,让用户快速了解规则定义的效果自己设置的符合预期目标,及时调整规则定义,方便风铃实例的配置。
风铃平台效果演示
配置基本信息
配置爬虫名称、使用线程数、超时停止时间
配置链接爬取信息
配置爬虫的起始种子链接和从网页里提取下一次抓取时的链接的提取规则
配置站点信息
此步骤一般可以省略,但是对于某些会校验cookie和请求头参数的网站,此配置非常有用
提取项目配置
配置需要从网站里提取出来的数据,例如新闻标题和网页正文等信息
属性抽取配置
调用内容提取器进行任意组合,以根据需要提取出需要的数据
属性抽取测试
提前检查提取项的配置是否正确,提取的数据是否符合预期目标
相关资源的链接
文件地址:
API 文档:
官方文件: 查看全部
c爬虫抓取网页数据(蜘蛛协议风铃虫的原理简单使用提取器的作用)
风铃介绍
风铃是一款轻量级爬虫工具,像风铃一样灵敏,像蜘蛛一样敏捷,可以感知任何微小的风和草,轻松抓取网络内容。是一个对目标服务器比较友好的蜘蛛程序。内置20多个常用或不常用的浏览器标识,可自动处理cookies和网页源信息,轻松绕过服务器限制,智能调整请求间隔,动态调整请求频率,防止干扰目标服务器。此外,Windchime 也是一个非常人性化的工具。它提供了大量的链接提取器和内容提取器,让用户可以根据自己的需要快速配置,甚至提供启动请求地址来配置自己的爬虫。同时,Windchime 还开放了很多自定义界面,让高级用户可以根据需要自定义爬虫功能。最后,风铃自然也支持分布式和集群功能,让你突破单机环境的束缚,释放你的爬虫能力。可以说风铃几乎可以抓取当前网站中的所有内容。
【声明】请不要在任何可能违反法律和道德约束的工作中使用风铃。请友好使用风铃,遵守蜘蛛协议,不要将风铃用于任何非法用途。如果您选择使用风铃,即表示您遵守本协议。作者不承担因您违反本协议而造成的任何法律风险和损失,一切后果由您自行承担。
快速使用
com.yishuifengxiao.common
crawler
2.2.0
交流群:
(群号624646260)
使用简单
从雅虎财经内容页面中提取电子货币名称
// 创建一个提取属性规则
// 该提取规则标识XPATH表示使用XPATH提取器进行提取,
// 该XPATH提取器的XPATH表达式为 //h1/text() , 该提取提取器的作用顺序是0
ExtractFieldRule extractFieldRule = new ExtractFieldRule(Rule.XPATH, "//h1/text()", "", 0);
// 创建一个提取项
ExtractRule extractRule = new ExtractRule();
extractRule
// 提取项代码,不能为空,同一组提取规则之内每一个提取项的编码必须唯一
.setCode("code")
// 提取项名字,可以不设置
.setName("加密电子货币名字")
// 设置提取属性规则
.setRules(Arrays.asList(extractFieldRule));
// 创建一个风铃虫实例
Crawler crawler = CrawlerBuilder.create()
// 风铃虫的起始链接
.startUrl("https://hk.finance.yahoo.com/cryptocurrencies";)
// 风铃虫会将请求到的网页中的URL先全部提取出来
// 然后将匹配链接提取规则的链接过滤出来,放入请求池中
// 请求池中的链接会作为下次抓取请求的种子链接
// 可以以添加多个链接提取规则,多个规则之间是并列(或连接)的关系
// 如果不设置则表示提取链接中所有包含域名关键字(例如此例中的yahoo)的链接放入链接池
// 此例中表示符合该正则表达式的链接都会被提取出来
.addLinkRule(new MatcherRule(Pattern.REGEX, "https://hk.finance.yahoo.com/quote/.+";))
// 内容页地址规则是告诉风铃虫哪些页面是内容页
// 对于复杂情况下,可以与 内容匹配规则 配合使用
// 只有符合内容页规则的页面才会被提取数据
// 对于非内容页,风铃虫不会尝试从中提取数据
// 此例中表示符合该正则表达式的网页都是内容页,风铃虫会从这些页面里提取数据
.contentPageRule(new MatcherRule(Pattern.REGEX, "https://hk.finance.yahoo.com/quote/.+";))
// 风铃虫可以设置多个提取项,这里为了演示只设置了一个提取项
// 增加一个提取项规则
.addExtractRule(extractRule)
// 请求间隔时间
// 如果不设置则使用默认时间10秒,此值是为了防止抓取频率太高被服务器封杀
.interval(3000)// 每次进行爬取时的平均间隔时间,单位为毫秒,
.creatCrawler();
// 启动爬虫实例
crawler.start();
// 这里没有设置信息输出器,表示使用默认的信息输出器
// 默认的信息输出器使用的logback日志输出方法,因此需要看控制台信息
// 由于风铃虫是异步运行的,所以演示时这里加入循环
while (Statu.STOP != crawler.getStatu()) {
try {
Thread.sleep(1000 * 20);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
上面例子的功能是在雅虎财经的内容页面上提取电子货币的名称。用户若想提取其他信息,只需根据规则配置其他提取规则即可。
请注意,以上示例仅供学习和演示使用,Windchime 用户在抓取网页内容时应严格遵守相关法律法规和目标网站 的蜘蛛协议
风铃原理
风铃的原理很简单,主要由资源调度器、网页下载器、链接解析器、内容解析器、信息输出器组成。
它们的作用和功能如下:
链接解析器由一系列链接提取器组成。目前,链接提取器主要支持常规提取。
内容解析器由一系列内容提取器组成。不同的内容提取器功能不同,适用于不同的分析场景,支持重复、循环等多种提取器的多种组合。
上述组件均提供了自定义配置接口,方便用户根据实际需求进行自定义配置,满足各种复杂甚至异常场景的需求。
内置的风铃内容提取器包括:
原文抽取器、中文抽取器、常量抽取器、CSS内容抽取器、CSS文本抽取器、邮箱抽取器、号码抽取器、正则抽取器、字符删除抽取器、字符替换抽取器、字符串截取抽取器、XPATH抽取器数组截取...
在提取文本内容时,用户可以自由组合这些提取器来提取他们需要的内容。关于提取器的更多具体用法,请参考内容提取器的使用。
Windchime 的内置浏览器标志为:
Google Chrome(windows版、linux版) Opera浏览器(windows版、MAC版) Firefox(windows版、linux版、MAC版) IE浏览器(IE9、IE11)EDAG Safari浏览器(windows版) , MAC 版)...
抓取js渲染网站
核心代码如下:
Crawler crawler = ...
crawler .setDownloader(new SeleniumDownloader("C:\\Users\\yishui\\Desktop\\geckodriver\\win32.exe",3000L))
分布式支持
核心代码如下:
....
//省略其他代码
....
//创建redis资源调度器
Scheduler scheduler=new RedisScheduler("唯一的名字",redisTemplate)
//创建一个redis资源缓存器
RequestCache requestCache = new RedisRequestCache(redisTemplate);
crawler
.setRequestCache(requestCache) //设置使用redis资源缓存器
.setScheduler(scheduler); //设置使用redis资源调度器
....
//省略其他代码
....
//启动爬虫实例
crawler.start();
状态监控
风铃还提供强大的状态监控和事件监控功能。通过状态监听器和事件监听器,风铃让你实时了解任务的运行状态,实时控制实例运行过程中遇到的各种问题,真正做到洞察运行情况任务,方便操作和维护。
解析模拟器
由于风铃强大的解析功能,规则的定义非常灵活,为了直观了解配置的规则定义的作用,风铃提供了解析模拟器,让用户快速了解规则定义的效果自己设置的符合预期目标,及时调整规则定义,方便风铃实例的配置。
风铃平台效果演示
配置基本信息
配置爬虫名称、使用线程数、超时停止时间
配置链接爬取信息
配置爬虫的起始种子链接和从网页里提取下一次抓取时的链接的提取规则
配置站点信息
此步骤一般可以省略,但是对于某些会校验cookie和请求头参数的网站,此配置非常有用
提取项目配置
配置需要从网站里提取出来的数据,例如新闻标题和网页正文等信息
属性抽取配置
调用内容提取器进行任意组合,以根据需要提取出需要的数据
属性抽取测试
提前检查提取项的配置是否正确,提取的数据是否符合预期目标
相关资源的链接
文件地址:
API 文档:
官方文件:
c爬虫抓取网页数据( 爬取漫画图片的大体实现过程的应用框架使用方法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-21 05:30
爬取漫画图片的大体实现过程的应用框架使用方法介绍)
scrapy是为爬取网站数据和提取结构化数据而编写的应用框架。更多关于框架的使用,请参考官方文档。本文文章展示了爬取漫画图片的一般实现过程。
Scrapy环境配置
首先是scrapy的安装。博主使用Mac系统,直接运行命令行:
pip install Scrapy
对于html节点信息的提取,使用了Beautiful Soup库。大概的用法可以看上一篇文章,可以直接通过命令安装:
pip install beautifulsoup4
目标网页的 Beautiful Soup 对象的初始化需要 html5lib 解释器。安装命令:
pip install html5lib
安装完成后,直接在命令行运行命令:
scrapy
可以看到如下输出,证明scrapy安装完成。
Scrapy 1.2.1 - no active projectUsage: scrapy [options] [args]Available commands: bench Run quick benchmark test commands fetch Fetch a URL using the Scrapy downloader genspider Generate new spider using pre-defined templates runspider Run a self-contained spider (without creating a project) settings Get settings values ...
项目创建通过命令行在当前路径下创建一个名为Comics的项目
scrapy startproject Comics
创建完成后,当前目录下会出现对应的工程文件夹,可以看到生成的Comics文件结构为:
|____Comics| |______init__.py| |______pycache__| |____items.py| |____pipelines.py| |____settings.py| |____spiders| | |______init__.py| | |______pycache__|____scrapy.cfg
附言。打印当前文件结构的命令是:
find . -print | sed -e 's;[^/]*/;|____;g;s;____|; |;g'
每个文件对应的具体功能可以在官方文档中找到。这个实现没有涉及很多这些文件,所以没有列出下表。1、创建蜘蛛类创建一个类来实现具体的爬取功能。我们所有的处理和实现都会在这个类中进行。它必须是scrapy.Spider 的子类。在 Comics/spiders 文件路径中创建一个 Comics.py 文件。comics.py 的具体实现:
#coding:utf-8import scrapyclass Comics(scrapy.Spider): name = "comics" def start_requests(self): urls = ['http://www.xeall.com/shenshi'] for url in urls: yield scrapy.Request(url=url, callback=self.parse) def parse(self, response): self.log(response.body);
自定义类是scrapy.Spider的子类,其中name属性是爬虫的唯一标识,作为scrapy爬取命令的参数。其他方法的属性将在后面解释。2、 运行创建的自定义类后,切换到Comics路径,运行命令,启动爬虫任务,开始爬取网页。
scrapy crawl comics
打印的结果是爬虫运行过程中的信息和目标爬取网页的html源代码。
2016-11-26 22:04:35 [scrapy] INFO: Scrapy 1.2.1 started (bot: Comics)2016-11-26 22:04:35 [scrapy] INFO: Overridden settings: {'ROBOTSTXT_OBEY': True, 'BOT_NAME': 'Comics', 'NEWSPIDER_MODULE': 'Comics.spiders', 'SPIDER_MODULES': ['Comics.spiders']}2016-11-26 22:04:35 [scrapy] INFO: Enabled extensions:['scrapy.extensions.corestats.CoreStats', 'scrapy.extensions.telnet.TelnetConsole', 'scrapy.extensions.logstats.LogStats'] ...
至此,一个基本的爬虫就创建好了。下面是具体的实现过程。爬取漫画图片1、起始地址爬虫的起始地址为:
http://www.xeall.com/shenshi
我们主要关注页面中间的漫画列表,列表底部有显示页数的控件。如下所示
爬虫的主要任务是爬取列表中每个漫画的图片。爬完当前页面后,进入漫画列表的下一页继续爬取漫画,继续循环,直到所有的漫画都被爬取完毕。我们将起始地址的 url 放在 start_requests 函数的 urls 数组中。其中,start_requests 是重载父类的方法。该方法会在爬虫任务启动时执行。start_requests方法的主要执行在这行代码:请求指定的url,请求完成后调用对应的回调函数self.parse
scrapy.Request(url=url, callback=self.parse)
其实还有另外一种方式可以实现前面的代码:
#coding:utf-8import scrapyclass Comics(scrapy.Spider): name = "comics" start_urls = ['http://www.xeall.com/shenshi'] def parse(self, response): self.log(response.body);
start_urls 是框架中提供的一个属性。它是一个收录目标网页 URL 的数组。设置 start_urls 的值后,不需要重载 start_requests 方法。爬虫也会依次爬取start_urls中的地址,并在请求完成后自动调用parse。作为回调方法。不过为了方便过程中其他回调函数的调整,demo中还是沿用了之前的实现方式。2、 爬取漫画的url 从最初的网页开始,我们首先要爬取每个漫画的url。当前页漫画列表的起始页为漫画列表的第一页。我们需要从当前页面中提取需要的信息并实现回调解析方法。
from bs4 import BeautifulSoup
请求返回的html源码用于初始化BeautifulSoup。
def parse(self, response): content = response.body; soup = BeautifulSoup(content, "html5lib")
初始化时指定了html5lib解释器,未安装会报错。如果在初始化 BeautifulSoup 时没有提供指定的解释器,它会自动使用它认为匹配的最佳解释器。有一个陷阱。对于目标网页的源代码,默认的最佳解释器是lxml,解析结果会出现Problems,无法进行后续的数据提取。所以当你发现有时提取结果有问题的时候,打印汤看是否正确。查看html源码,可以看到页面显示漫画列表的部分是ul标签,类名是listcon,对应的标签可以通过listcon类唯一确认
提取收录漫画列表的标签
listcon_tag = soup.find('ul', class_='listcon')
上面的find方法就是查找class为listcon的ul标签,返回对应标签的所有内容。在列表标签中查找所有带有 href 属性的标签。这些a标签是每个漫画对应的信息。
com_a_list = listcon_tag.find_all('a', attrs={'href': True})
然后将每个漫画的href属性组合成一个完整的可访问的URL地址,并保存在一个数组中。
comics_url_list = []base = 'http://www.xeall.com' for tag_a in com_a_list: url = base + tag_a['href'] comics_url_list.append(url)
此时,comics_url_list 数组收录当前页面上每个漫画的 url。3、下一页列表,查看列表下方的选择页面控件,我们可以通过这个地方获取下一页的url。
获取所选页面标签中收录 href 属性的所有标签
page_tag = soup.find('ul', class_='pagelist')page_a_list = page_tag.find_all('a', attrs={'href': True})
这部分源代码如下图所示。可以看到,在所有a标签中,倒数第一个代表最后一页的网址,倒数第二个代表下一页的网址。因此,我们可以取page_a_list数组中倒数第二个元素来获取下一页的url。
但是这里需要注意的是,如果当前页面是最后一页,则不需要去取下一页。那么如何判断当前页面是否为最后一页呢?可以通过select控件来判断。从源码可以判断当前页面对应的option标签会有selected属性。下图显示当前页面为第一页
下图显示当前页面为最后一页
当前页码与最后页码比较,如果相同,则表示当前页为最后一页。
select_tag = soup.find('select', attrs={'name': 'sldd'})option_list = select_tag.find_all('option')last_option = option_list[-1]current_option = select_tag.find('option' ,attrs={'selected': True})is_last = (last_option.string == current_option.string)
当前页面不是最后一页,那么在下一页继续做同样的处理,请求还是通过回调parse方法处理
if not is_last: next_page = 'http://www.xeall.com/shenshi/' + page_a_list[-2]['href'] if next_page is not None: print('\n------ parse next page --------') print(next_page) yield scrapy.Request(next_page, callback=self.parse)
以相同的方式依次处理每一页,直到处理完所有页。4、 爬取漫画图片,在parse方法中提取当前页面的所有漫画URL时,就可以开始处理每一个漫画了。在得到的comics_url_list数组下面添加如下代码:
for url in comics_url_list: yield scrapy.Request(url=url, callback=self.comics_parse)
请求每个漫画的url,回调处理方法是ics_parse,comics_parse方法用于处理每个漫画。下面是具体的实现。5、当前页面图片的首相根据请求返回的源码构造一个BeautifulSoup,与上一个基本一致
def comics_parse(self, response): content = response.body; soup = BeautifulSoup(content, "html5lib")
提取select页面控件标签,页面显示及源码如下
提取类为pagelist的ul标签
page_list_tag = soup.find('ul', class_='pagelist')
查看源码,可以看到当前页面的li标签的class属性thisclass,从而得到当前页面的编号
current_li = page_list_tag.find('li', class_='thisclass')page_num = current_li.a.string
当前页面图片的标签及对应的源码
获取当前页面图片的url和漫画的标题。漫画标题后,用作存放相应漫画的文件夹名称。
li_tag = soup.find('li', id='imgshow')img_tag = li_tag.find('img')img_url = img_tag['src']title = img_tag['alt']
6、保存到本地 提取图片url后,可以通过url请求图片,保存到本地
self.save_img(page_num, title, img_url)
专门定义了一个方法 save_img 来保存图片。具体完整的实现如下
# 先导入库import osimport urllibimport zlibdef save_img(self, img_mun, title, img_url): # 将图片保存到本地 self.log('saving pic: ' + img_url) # 保存漫画的文件夹 document = '/Users/moshuqi/Desktop/cartoon' # 每部漫画的文件名以标题命名 comics_path = document + '/' + title exists = os.path.exists(comics_path) if not exists: self.log('create document: ' + title) os.makedirs(comics_path) # 每张图片以页数命名 pic_name = comics_path + '/' + img_mun + '.jpg' # 检查图片是否已经下载到本地,若存在则不再重新下载 exists = os.path.exists(pic_name) if exists: self.log('pic exists: ' + pic_name) return try: user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' headers = { 'User-Agent' : user_agent } req = urllib.request.Request(img_url, headers=headers) response = urllib.request.urlopen(req, timeout=30) # 请求返回到的数据 data = response.read() # 若返回数据为压缩数据需要先进行解压 if response.info().get('Content-Encoding') == 'gzip': data = zlib.decompress(data, 16 + zlib.MAX_WBITS) # 图片保存到本地 fp = open(pic_name, "wb") fp.write(data) fp.close self.log('save image finished:' + pic_name) except Exception as e: self.log('save image error.') self.log(e)
该函数主要使用3个参数,当前图片的页数,漫画名称,图片的url。图片将保存在以漫画命名的文件夹中。如果没有对应的文件夹,就创建一个。一般拿到第一张图片的时候就需要创建一个文件夹。文档是本地指定的文件夹,可以自定义。每张图片都以 pages.jpg 格式命名。如果本地已经存在同名图片,则不会重新下载。一般用于判断任务何时重复,避免重复请求已有图片。请求返回的图片数据是经过压缩的,可以通过().get('Content-Encoding')的类型来判断。压缩后的图片必须通过zlib.decompress解压后保存到本地,否则图片无法打开。大体实现思路如上,代码也附上注释。7、下一页图片类似漫画列表界面中的处理方法。在漫画页面中,我们还需要不断的获取下一页的图片,继续遍历,直到最后一页。
当next page标签的href属性为#时,就是漫画的最后一页
a_tag_list = page_list_tag.find_all('a')next_page = a_tag_list[-1]['href']if next_page == '#': self.log('parse comics:' + title + 'finished.')else: next_page = 'http://www.xeall.com/shenshi/' + next_page yield scrapy.Request(next_page, callback=self.comics_parse)
如果当前页是最后一页,则漫画遍历完成,否则继续下一页同理
yield scrapy.Request(next_page, callback=self.comics_parse)
8、 运行结果的大体实现基本完成。运行时可以看到控制台打印
保存在本地文件夹中的图片
在scrapy框架运行时,它使用了多个线程,可以看到多个漫画同时在爬行。目标网站资源服务器感觉慢,经常出现请求超时。跑步时请耐心等待。最后,本文只介绍了scrapy框架非常基础的使用方法,以及各种非常详细的功能配置。如使用 FilesPipeline、ImagesPipeline 来保存下载的文件或图片。该框架本身带有一个用于提取网页信息的 XPath 类。这比 BeautifulSoup 更有效。也可以使用特殊的item类来保存爬取的数据结果并作为类返回。详情请参考官方网站。最后附上完整的Demo源码
-结尾-
原文链接: 查看全部
c爬虫抓取网页数据(
爬取漫画图片的大体实现过程的应用框架使用方法介绍)
scrapy是为爬取网站数据和提取结构化数据而编写的应用框架。更多关于框架的使用,请参考官方文档。本文文章展示了爬取漫画图片的一般实现过程。
Scrapy环境配置
首先是scrapy的安装。博主使用Mac系统,直接运行命令行:
pip install Scrapy
对于html节点信息的提取,使用了Beautiful Soup库。大概的用法可以看上一篇文章,可以直接通过命令安装:
pip install beautifulsoup4
目标网页的 Beautiful Soup 对象的初始化需要 html5lib 解释器。安装命令:
pip install html5lib
安装完成后,直接在命令行运行命令:
scrapy
可以看到如下输出,证明scrapy安装完成。
Scrapy 1.2.1 - no active projectUsage: scrapy [options] [args]Available commands: bench Run quick benchmark test commands fetch Fetch a URL using the Scrapy downloader genspider Generate new spider using pre-defined templates runspider Run a self-contained spider (without creating a project) settings Get settings values ...
项目创建通过命令行在当前路径下创建一个名为Comics的项目
scrapy startproject Comics
创建完成后,当前目录下会出现对应的工程文件夹,可以看到生成的Comics文件结构为:
|____Comics| |______init__.py| |______pycache__| |____items.py| |____pipelines.py| |____settings.py| |____spiders| | |______init__.py| | |______pycache__|____scrapy.cfg
附言。打印当前文件结构的命令是:
find . -print | sed -e 's;[^/]*/;|____;g;s;____|; |;g'
每个文件对应的具体功能可以在官方文档中找到。这个实现没有涉及很多这些文件,所以没有列出下表。1、创建蜘蛛类创建一个类来实现具体的爬取功能。我们所有的处理和实现都会在这个类中进行。它必须是scrapy.Spider 的子类。在 Comics/spiders 文件路径中创建一个 Comics.py 文件。comics.py 的具体实现:
#coding:utf-8import scrapyclass Comics(scrapy.Spider): name = "comics" def start_requests(self): urls = ['http://www.xeall.com/shenshi'] for url in urls: yield scrapy.Request(url=url, callback=self.parse) def parse(self, response): self.log(response.body);
自定义类是scrapy.Spider的子类,其中name属性是爬虫的唯一标识,作为scrapy爬取命令的参数。其他方法的属性将在后面解释。2、 运行创建的自定义类后,切换到Comics路径,运行命令,启动爬虫任务,开始爬取网页。
scrapy crawl comics
打印的结果是爬虫运行过程中的信息和目标爬取网页的html源代码。
2016-11-26 22:04:35 [scrapy] INFO: Scrapy 1.2.1 started (bot: Comics)2016-11-26 22:04:35 [scrapy] INFO: Overridden settings: {'ROBOTSTXT_OBEY': True, 'BOT_NAME': 'Comics', 'NEWSPIDER_MODULE': 'Comics.spiders', 'SPIDER_MODULES': ['Comics.spiders']}2016-11-26 22:04:35 [scrapy] INFO: Enabled extensions:['scrapy.extensions.corestats.CoreStats', 'scrapy.extensions.telnet.TelnetConsole', 'scrapy.extensions.logstats.LogStats'] ...
至此,一个基本的爬虫就创建好了。下面是具体的实现过程。爬取漫画图片1、起始地址爬虫的起始地址为:
http://www.xeall.com/shenshi
我们主要关注页面中间的漫画列表,列表底部有显示页数的控件。如下所示
爬虫的主要任务是爬取列表中每个漫画的图片。爬完当前页面后,进入漫画列表的下一页继续爬取漫画,继续循环,直到所有的漫画都被爬取完毕。我们将起始地址的 url 放在 start_requests 函数的 urls 数组中。其中,start_requests 是重载父类的方法。该方法会在爬虫任务启动时执行。start_requests方法的主要执行在这行代码:请求指定的url,请求完成后调用对应的回调函数self.parse
scrapy.Request(url=url, callback=self.parse)
其实还有另外一种方式可以实现前面的代码:
#coding:utf-8import scrapyclass Comics(scrapy.Spider): name = "comics" start_urls = ['http://www.xeall.com/shenshi'] def parse(self, response): self.log(response.body);
start_urls 是框架中提供的一个属性。它是一个收录目标网页 URL 的数组。设置 start_urls 的值后,不需要重载 start_requests 方法。爬虫也会依次爬取start_urls中的地址,并在请求完成后自动调用parse。作为回调方法。不过为了方便过程中其他回调函数的调整,demo中还是沿用了之前的实现方式。2、 爬取漫画的url 从最初的网页开始,我们首先要爬取每个漫画的url。当前页漫画列表的起始页为漫画列表的第一页。我们需要从当前页面中提取需要的信息并实现回调解析方法。
from bs4 import BeautifulSoup
请求返回的html源码用于初始化BeautifulSoup。
def parse(self, response): content = response.body; soup = BeautifulSoup(content, "html5lib")
初始化时指定了html5lib解释器,未安装会报错。如果在初始化 BeautifulSoup 时没有提供指定的解释器,它会自动使用它认为匹配的最佳解释器。有一个陷阱。对于目标网页的源代码,默认的最佳解释器是lxml,解析结果会出现Problems,无法进行后续的数据提取。所以当你发现有时提取结果有问题的时候,打印汤看是否正确。查看html源码,可以看到页面显示漫画列表的部分是ul标签,类名是listcon,对应的标签可以通过listcon类唯一确认
提取收录漫画列表的标签
listcon_tag = soup.find('ul', class_='listcon')
上面的find方法就是查找class为listcon的ul标签,返回对应标签的所有内容。在列表标签中查找所有带有 href 属性的标签。这些a标签是每个漫画对应的信息。
com_a_list = listcon_tag.find_all('a', attrs={'href': True})
然后将每个漫画的href属性组合成一个完整的可访问的URL地址,并保存在一个数组中。
comics_url_list = []base = 'http://www.xeall.com' for tag_a in com_a_list: url = base + tag_a['href'] comics_url_list.append(url)
此时,comics_url_list 数组收录当前页面上每个漫画的 url。3、下一页列表,查看列表下方的选择页面控件,我们可以通过这个地方获取下一页的url。
获取所选页面标签中收录 href 属性的所有标签
page_tag = soup.find('ul', class_='pagelist')page_a_list = page_tag.find_all('a', attrs={'href': True})
这部分源代码如下图所示。可以看到,在所有a标签中,倒数第一个代表最后一页的网址,倒数第二个代表下一页的网址。因此,我们可以取page_a_list数组中倒数第二个元素来获取下一页的url。
但是这里需要注意的是,如果当前页面是最后一页,则不需要去取下一页。那么如何判断当前页面是否为最后一页呢?可以通过select控件来判断。从源码可以判断当前页面对应的option标签会有selected属性。下图显示当前页面为第一页
下图显示当前页面为最后一页
当前页码与最后页码比较,如果相同,则表示当前页为最后一页。
select_tag = soup.find('select', attrs={'name': 'sldd'})option_list = select_tag.find_all('option')last_option = option_list[-1]current_option = select_tag.find('option' ,attrs={'selected': True})is_last = (last_option.string == current_option.string)
当前页面不是最后一页,那么在下一页继续做同样的处理,请求还是通过回调parse方法处理
if not is_last: next_page = 'http://www.xeall.com/shenshi/' + page_a_list[-2]['href'] if next_page is not None: print('\n------ parse next page --------') print(next_page) yield scrapy.Request(next_page, callback=self.parse)
以相同的方式依次处理每一页,直到处理完所有页。4、 爬取漫画图片,在parse方法中提取当前页面的所有漫画URL时,就可以开始处理每一个漫画了。在得到的comics_url_list数组下面添加如下代码:
for url in comics_url_list: yield scrapy.Request(url=url, callback=self.comics_parse)
请求每个漫画的url,回调处理方法是ics_parse,comics_parse方法用于处理每个漫画。下面是具体的实现。5、当前页面图片的首相根据请求返回的源码构造一个BeautifulSoup,与上一个基本一致
def comics_parse(self, response): content = response.body; soup = BeautifulSoup(content, "html5lib")
提取select页面控件标签,页面显示及源码如下
提取类为pagelist的ul标签
page_list_tag = soup.find('ul', class_='pagelist')
查看源码,可以看到当前页面的li标签的class属性thisclass,从而得到当前页面的编号
current_li = page_list_tag.find('li', class_='thisclass')page_num = current_li.a.string
当前页面图片的标签及对应的源码
获取当前页面图片的url和漫画的标题。漫画标题后,用作存放相应漫画的文件夹名称。
li_tag = soup.find('li', id='imgshow')img_tag = li_tag.find('img')img_url = img_tag['src']title = img_tag['alt']
6、保存到本地 提取图片url后,可以通过url请求图片,保存到本地
self.save_img(page_num, title, img_url)
专门定义了一个方法 save_img 来保存图片。具体完整的实现如下
# 先导入库import osimport urllibimport zlibdef save_img(self, img_mun, title, img_url): # 将图片保存到本地 self.log('saving pic: ' + img_url) # 保存漫画的文件夹 document = '/Users/moshuqi/Desktop/cartoon' # 每部漫画的文件名以标题命名 comics_path = document + '/' + title exists = os.path.exists(comics_path) if not exists: self.log('create document: ' + title) os.makedirs(comics_path) # 每张图片以页数命名 pic_name = comics_path + '/' + img_mun + '.jpg' # 检查图片是否已经下载到本地,若存在则不再重新下载 exists = os.path.exists(pic_name) if exists: self.log('pic exists: ' + pic_name) return try: user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' headers = { 'User-Agent' : user_agent } req = urllib.request.Request(img_url, headers=headers) response = urllib.request.urlopen(req, timeout=30) # 请求返回到的数据 data = response.read() # 若返回数据为压缩数据需要先进行解压 if response.info().get('Content-Encoding') == 'gzip': data = zlib.decompress(data, 16 + zlib.MAX_WBITS) # 图片保存到本地 fp = open(pic_name, "wb") fp.write(data) fp.close self.log('save image finished:' + pic_name) except Exception as e: self.log('save image error.') self.log(e)
该函数主要使用3个参数,当前图片的页数,漫画名称,图片的url。图片将保存在以漫画命名的文件夹中。如果没有对应的文件夹,就创建一个。一般拿到第一张图片的时候就需要创建一个文件夹。文档是本地指定的文件夹,可以自定义。每张图片都以 pages.jpg 格式命名。如果本地已经存在同名图片,则不会重新下载。一般用于判断任务何时重复,避免重复请求已有图片。请求返回的图片数据是经过压缩的,可以通过().get('Content-Encoding')的类型来判断。压缩后的图片必须通过zlib.decompress解压后保存到本地,否则图片无法打开。大体实现思路如上,代码也附上注释。7、下一页图片类似漫画列表界面中的处理方法。在漫画页面中,我们还需要不断的获取下一页的图片,继续遍历,直到最后一页。
当next page标签的href属性为#时,就是漫画的最后一页
a_tag_list = page_list_tag.find_all('a')next_page = a_tag_list[-1]['href']if next_page == '#': self.log('parse comics:' + title + 'finished.')else: next_page = 'http://www.xeall.com/shenshi/' + next_page yield scrapy.Request(next_page, callback=self.comics_parse)
如果当前页是最后一页,则漫画遍历完成,否则继续下一页同理
yield scrapy.Request(next_page, callback=self.comics_parse)
8、 运行结果的大体实现基本完成。运行时可以看到控制台打印
保存在本地文件夹中的图片
在scrapy框架运行时,它使用了多个线程,可以看到多个漫画同时在爬行。目标网站资源服务器感觉慢,经常出现请求超时。跑步时请耐心等待。最后,本文只介绍了scrapy框架非常基础的使用方法,以及各种非常详细的功能配置。如使用 FilesPipeline、ImagesPipeline 来保存下载的文件或图片。该框架本身带有一个用于提取网页信息的 XPath 类。这比 BeautifulSoup 更有效。也可以使用特殊的item类来保存爬取的数据结果并作为类返回。详情请参考官方网站。最后附上完整的Demo源码
-结尾-
原文链接:
c爬虫抓取网页数据(爬取知乎文章图片爬取器之一(组图)网友留言和回复)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-10-21 04:14
阿里云>云栖社区>主题图>C>c语言爬取网站
推荐活动:
更多优惠>
当前话题:c语言爬取网站加入采集
相关话题:
c语言爬取网站相关博客 查看更多博客
Python爬虫入门教程25-100知乎文章图片爬虫之一
作者:梦之橡皮 1110人浏览评论:02年前
1. 知乎文章 一个图片爬虫写在前面,今天尝试爬一下。知乎,看看这个网站有什么有趣的内容可以爬取,可能会断断续续的写几个文章。最简单的就是先爬,一个文章的所有答案都爬不难。我找到了我们要抓取的页面,我只是选择了一个
阅读全文
Python爬虫入门教程15-100石家庄政民交互数据爬虫
作者:梦之橡皮2057人浏览评论:02年前
1.石家庄政民互动数据爬取-今天写在前面,抓一个网站,这个网站,涉及的内容是网友的评论和回复,很简单,但 网站 来自 gov。URL 是第一个语句,以便
阅读全文
使用多线程抓取招聘网站
作者:等下1209人浏览评论数:02年前
使用多线程获取某招聘信息网站,使用环境py3,更不用说,直接上传代码到你要引导的包中,不能错过import threading import requests from pyquery import PyQuery as pq import json from
阅读全文
基于Scrapy的爬取伯乐在线网站
作者:潇撒坤 829人浏览评论:03年前
标题中英文的第一个字母比较规范,但是在python的实际使用中,都是小写的。2018年7月20日Scrapy官方文档网址说明:网页在chrome浏览器中打开
阅读全文
苏宁百万级商品爬虫简述
作者:HapplyFox1045 人浏览评论:03年前
代码下载链接 苏宁万级商品爬虫目录思路讲解分类爬取思路讲解分类页面抓取商品爬取3.1思路讲解商品爬13.2思路讲解商品爬23.3代码说明商品爬取索引说明4.1代码说明索引建立4.2代码说明索引查询语句本系统
阅读全文
手拉手 | 教你爬下100部电影数据:R语言网页爬虫入门指南
作者:小轩峰柴金 2463人浏览评论:04年前
序言网页上的数据和信息呈指数级增长。今天,我们都将 Google 作为主要的知识来源——无论是寻找某个地方的评论还是学习新术语。所有这些信息都可以轻松在线获得。网络上可用数据的增加为数据科学家开辟了新的可能性。我坚信网络抓取是一种数据科学
阅读全文
Python爬虫:用BeautifulSoup爬取NBA数据
作者:夜李2725人浏览评论:04年前
爬虫的主要目的是过滤掉网页中无用的信息。从网页中抓取有用信息的一般爬虫结构是:在使用python爬虫之前,必须对网页的结构有一定的了解,比如网页的标签、网页的语言等知识,建议去W3School:W3school链接了解爬取前有一些工具:1
阅读全文
【python学习】维基百科程序语言消息框的简单爬取
作者:Xiaoluoluo1432 人浏览评论:06年前
文章主要描述了如何通过Python爬取维基百科的Infobox,主要是通过正则表达式和urllib;下面文章可能会讲一下通过BeautifulSoup爬取网页的知识。由于这方面的文章还比较少,希望提供一些思路和方法来帮助大家
阅读全文 查看全部
c爬虫抓取网页数据(爬取知乎文章图片爬取器之一(组图)网友留言和回复)
阿里云>云栖社区>主题图>C>c语言爬取网站
推荐活动:
更多优惠>
当前话题:c语言爬取网站加入采集
相关话题:
c语言爬取网站相关博客 查看更多博客
Python爬虫入门教程25-100知乎文章图片爬虫之一
作者:梦之橡皮 1110人浏览评论:02年前
1. 知乎文章 一个图片爬虫写在前面,今天尝试爬一下。知乎,看看这个网站有什么有趣的内容可以爬取,可能会断断续续的写几个文章。最简单的就是先爬,一个文章的所有答案都爬不难。我找到了我们要抓取的页面,我只是选择了一个
阅读全文
Python爬虫入门教程15-100石家庄政民交互数据爬虫
作者:梦之橡皮2057人浏览评论:02年前
1.石家庄政民互动数据爬取-今天写在前面,抓一个网站,这个网站,涉及的内容是网友的评论和回复,很简单,但 网站 来自 gov。URL 是第一个语句,以便
阅读全文
使用多线程抓取招聘网站
作者:等下1209人浏览评论数:02年前
使用多线程获取某招聘信息网站,使用环境py3,更不用说,直接上传代码到你要引导的包中,不能错过import threading import requests from pyquery import PyQuery as pq import json from
阅读全文
基于Scrapy的爬取伯乐在线网站
作者:潇撒坤 829人浏览评论:03年前
标题中英文的第一个字母比较规范,但是在python的实际使用中,都是小写的。2018年7月20日Scrapy官方文档网址说明:网页在chrome浏览器中打开
阅读全文
苏宁百万级商品爬虫简述
作者:HapplyFox1045 人浏览评论:03年前
代码下载链接 苏宁万级商品爬虫目录思路讲解分类爬取思路讲解分类页面抓取商品爬取3.1思路讲解商品爬13.2思路讲解商品爬23.3代码说明商品爬取索引说明4.1代码说明索引建立4.2代码说明索引查询语句本系统
阅读全文
手拉手 | 教你爬下100部电影数据:R语言网页爬虫入门指南
作者:小轩峰柴金 2463人浏览评论:04年前
序言网页上的数据和信息呈指数级增长。今天,我们都将 Google 作为主要的知识来源——无论是寻找某个地方的评论还是学习新术语。所有这些信息都可以轻松在线获得。网络上可用数据的增加为数据科学家开辟了新的可能性。我坚信网络抓取是一种数据科学
阅读全文
Python爬虫:用BeautifulSoup爬取NBA数据
作者:夜李2725人浏览评论:04年前
爬虫的主要目的是过滤掉网页中无用的信息。从网页中抓取有用信息的一般爬虫结构是:在使用python爬虫之前,必须对网页的结构有一定的了解,比如网页的标签、网页的语言等知识,建议去W3School:W3school链接了解爬取前有一些工具:1
阅读全文
【python学习】维基百科程序语言消息框的简单爬取
作者:Xiaoluoluo1432 人浏览评论:06年前
文章主要描述了如何通过Python爬取维基百科的Infobox,主要是通过正则表达式和urllib;下面文章可能会讲一下通过BeautifulSoup爬取网页的知识。由于这方面的文章还比较少,希望提供一些思路和方法来帮助大家
阅读全文
c爬虫抓取网页数据(Python开发的一个快速,高层次处理网络通讯的整体架构大致)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-10-18 06:00
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体结构大致如下(注:图片来自网络):
Scrapy主要包括以下组件:
使用Scrapy可以轻松完成在线数据采集的工作,它为我们做了很多工作,无需自己开发。
1. 安装python
目前最新的Scrapy版本是0.22.2。这个版本需要python 2.7,所以需要先安装python 2.7。这里我使用centos服务器进行测试,因为系统自带python,需要先查看python版本。
检查python版本:
$ python -V
Python 2.6.6
升级版本到2.7:
$ Python 2.7.6:
$ wget http://python.org/ftp/python/2 ... ar.xz
$ tar xf Python-2.7.6.tar.xz
$ cd Python-2.7.6
$ ./configure --prefix=/usr/local --enable-unicode=ucs4 --enable-shared LDFLAGS="-Wl,-rpath /usr/local/lib"
$ make && make altinstall
建立软连接并使系统默认python指向python2.7
$ mv /usr/bin/python /usr/bin/python2.6.6
$ ln -s /usr/local/bin/python2.7 /usr/bin/python
再次检查python版本:
$ python -V
Python 2.7.6
安装
这里我们使用 wget 来安装 setuptools:
$ wget https://bootstrap.pypa.io/ez_setup.py -O - | python
安装 zope.interface
$ easy_install zope.interface
安装扭曲
Scrapy使用Twisted异步网络库来处理网络通信,所以需要安装twisted。
在安装twisted之前,需要先安装gcc:
$ yum install gcc -y
然后,通过easy_install安装twisted:
$ easy_install twisted
如果出现以下错误:
$ easy_install twisted
Searching for twisted
Reading https://pypi.python.org/simple/twisted/
Best match: Twisted 14.0.0
Downloading https://pypi.python.org/packag ... c9815
Processing Twisted-14.0.0.tar.bz2
Writing /tmp/easy_install-kYHKjn/Twisted-14.0.0/setup.cfg
Running Twisted-14.0.0/setup.py -q bdist_egg --dist-dir /tmp/easy_install-kYHKjn/Twisted-14.0.0/egg-dist-tmp-vu1n6Y
twisted/runner/portmap.c:10:20: error: Python.h: No such file or directory
twisted/runner/portmap.c:14: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘*’ token
twisted/runner/portmap.c:31: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘*’ token
twisted/runner/portmap.c:45: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘PortmapMethods’
twisted/runner/portmap.c: In function ‘initportmap’:
twisted/runner/portmap.c:55: warning: implicit declaration of function ‘Py_InitModule’
twisted/runner/portmap.c:55: error: ‘PortmapMethods’ undeclared (first use in this function)
twisted/runner/portmap.c:55: error: (Each undeclared identifier is reported only once
twisted/runner/portmap.c:55: error: for each function it appears in.)
请安装 python-devel 并再次运行:
$ yum install python-devel -y
$ easy_install twisted
如果出现以下异常:
error: Not a recognized archive type: /tmp/easy_install-tVwC5O/Twisted-14.0.0.tar.bz2
请手动下载安装,下载地址在这里
$ wget https://pypi.python.org/packag ... c9815
$ tar -vxjf Twisted-14.0.0.tar.bz2
$ cd Twisted-14.0.0
$ python setup.py install
安装 pyOpenSSL
先安装一些依赖:
$ yum install libffi libffi-devel openssl-devel -y
然后,通过easy_install安装pyOpenSSL:
$ easy_install pyOpenSSL
安装 Scrapy
先安装一些依赖:
$ yum install libxml2 libxslt libxslt-devel -y
最后,安装 Scrapy:
$ easy_install scrapy
2. 使用 Scrapy
安装成功后,可以了解Scrapy的一些基本概念和用法,学习Scrapy项目dirbot的例子。
Dirbot 项目所在地。该项目收录一个 README 文件,详细描述了该项目的内容。如果您熟悉 Git,可以查看其源代码。或者,您可以通过单击下载以 tarball 或 zip 格式下载文件。
这里以一个例子来说明如何使用Scrapy创建爬虫项目。
新建筑
在爬取之前,您需要创建一个新的 Scrapy 项目。输入要保存代码的目录,然后执行:
$ scrapy startproject tutorial
该命令会在当前目录下新建一个目录tutorial,其结构如下:
.
├── scrapy.cfg
└── tutorial
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
这些文件主要是:
定义项目
Items 是将加载捕获数据的容器。它的工作原理类似于 Python 中的字典,但它提供了更多保护,例如填充未定义的字段以防止拼写错误。
它是通过创建一个scrapy.item.Item 类并将其属性定义为scrpy.item.Field 对象来声明的,就像一个对象关系映射(ORM)。
我们控制通过建模所需项目获得的站点数据。例如,我们要获取站点的名称、url 和 网站 描述。我们定义了这三个属性的域。为此,我们编辑教程目录中的 items.py 文件,我们的 Item 类将如下所示
from scrapy.item import Item, Field
class DmozItem(Item):
title = Field()
link = Field()
desc = Field()
一开始可能看起来有点混乱,但是定义这些项目会让你知道在使用其他 Scrapy 组件时你的项目是什么。
写一个蜘蛛(蜘蛛)
Spider 是一个用户编写的类,用于从域(或域组)中获取信息。我们定义了用于下载的 URL 的初步列表、如何跟踪链接以及如何解析这些网页的内容以提取项目。
要创建 Spider,您可以为 scrapy.spider.BaseSpider 创建一个子类并确定三个主要的强制性属性:
该方法负责解析返回的数据,匹配捕获的数据(解析为item),跟踪更多的URL。
在tutorial/spiders目录下创建DmozSpider.py
from scrapy.spider import BaseSpider
class DmozSpider(BaseSpider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B
]
def parse(self, response):
filename = response.url.split("/")[-2]
open(filename, \'wb\').write(response.body)
运行项目
$ scrapy crawl dmoz
该命令从域启动爬虫,第三个参数是DmozSpider.py中name属性的值。
xpath 选择器
Scrapy 使用一种称为 XPath 选择器的机制,该机制基于 XPath 表达式。如果您想了解有关选择器和其他机制的更多信息,可以查看。
以下是 XPath 表达式及其含义的一些示例:
这些只是使用 XPath 的几个简单示例,但实际上 XPath 非常强大。如果您想了解更多关于 XPATH 的信息,我们向您推荐这个 XPath 教程
为了方便XPaths的使用,Scrapy提供了Selector类,共有三种方法
提取数据
我们可以使用以下命令选择 网站 中的每个元素:
sel.xpath(\'//ul/li\')
然后网站描述:
sel.xpath(\'//ul/li/text()\').extract()
网站标题:
sel.xpath(\'//ul/li/a/text()\').extract()
网站 链接:
sel.xpath(\'//ul/li/a/@href\').extract()
如前所述,每个 xpath() 调用都会返回一个选择器列表,因此我们可以结合 xpath() 来挖掘更深的节点。我们将使用这些功能,因此:
sites = sel.xpath(\'//ul/li\')
for site in sites:
title = site.xpath(\'a/text()\').extract()
link = site.xpath(\'a/@href\').extract()
desc = site.xpath(\'text()\').extract()
print title, link, desc
使用物品
scrapy.item.Item的调用接口类似于python的dict,Item收录多个scrapy.item.Field。这类似于 django 的模型和
Item通常用于Spider的parse方法,用于保存解析后的数据。
最后修改爬虫类,使用Item保存数据,代码如下:
from scrapy.spider import Spider
from scrapy.selector import Selector
from dirbot.items import Website
class DmozSpider(Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B,
]
def parse(self, response):
"""
The lines below is a spider contract. For more info see:
http://doc.scrapy.org/en/lates ... .html
@url http://www.dmoz.org/Computers/ ... rces/
@scrapes name
"""
sel = Selector(response)
sites = sel.xpath(\'//ul[@class="directory-url"]/li\')
items = []
for site in sites:
item = Website()
item[\'name\'] = site.xpath(\'a/text()\').extract()
item[\'url\'] = site.xpath(\'a/@href\').extract()
item[\'description\'] = site.xpath(\'text()\').re(\'-\s([^\n]*?)\\n\')
items.append(item)
return items
现在,您可以再次运行该项目以查看结果:
$ scrapy crawl dmoz
使用项目管道
在settings.py中设置ITEM_PIPELINES,默认为[],类似django的MIDDLEWARE_CLASSES等。
Spider的解析返回的Item数据会依次被ITEM_PIPELINES列表中的Pipeline类处理。
Item Pipeline 类必须实现以下方法:
还可以另外实现以下两种方法:
保存捕获的数据
保存信息最简单的方法是通过,命令如下:
$ scrapy crawl dmoz -o items.json -t json
除了 json 格式,还支持 JSON 行、CSV 和 XML 格式。您还可以通过接口扩展一些格式。
这种方法对于小项目来说已经足够了。如果是比较复杂的数据,可能需要写一个Item Pipeline进行处理。
所有抓到的物品都会以JSON格式保存在新生成的items.json文件中
总结
以上介绍了如何创建爬虫项目的过程,可以参考以上过程再次联系。作为学习示例,也可以参考这个文章:scrapy中文教程(爬取cnbeta示例)。
这个文章中的爬虫代码如下:
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
from scrapy.selector import Selector
from cnbeta.items import CnbetaItem
class CBSpider(CrawlSpider):
name = \'cnbeta\'
allowed_domains = [\'cnbeta.com\']
start_urls = [\'http://www.cnbeta.com\']
rules = (
Rule(SgmlLinkExtractor(allow=(\'/articles/.*\.htm\', )),
callback=\'parse_page\', follow=True),
)
def parse_page(self, response):
item = CnbetaItem()
sel = Selector(response)
item[\'title\'] = sel.xpath(\'//title/text()\').extract()
item[\'url\'] = response.url
return item
需要注意的是:
3. 学习资料
联系Scrapy是因为想爬取知乎的一些数据。一开始找了一些相关资料和别人的实现方法。
Github上有人或多或少意识到了知乎数据的爬取。我搜索了以下仓库:
其他信息:
抓取和交互式示例:
有一些知识点需要梳理:
4. 总结
以上是这几天学习Scrapy的笔记和知识汇总。参考了网上的一些文章,写了这篇文章。这次真是万分感谢。希望这篇文章文章能对你有所帮助。如果您有任何想法,请留言;如果你喜欢这篇文章,请帮忙分享,谢谢!
最初发表于: 查看全部
c爬虫抓取网页数据(Python开发的一个快速,高层次处理网络通讯的整体架构大致)
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体结构大致如下(注:图片来自网络):
Scrapy主要包括以下组件:
使用Scrapy可以轻松完成在线数据采集的工作,它为我们做了很多工作,无需自己开发。
1. 安装python
目前最新的Scrapy版本是0.22.2。这个版本需要python 2.7,所以需要先安装python 2.7。这里我使用centos服务器进行测试,因为系统自带python,需要先查看python版本。
检查python版本:
$ python -V
Python 2.6.6
升级版本到2.7:
$ Python 2.7.6:
$ wget http://python.org/ftp/python/2 ... ar.xz
$ tar xf Python-2.7.6.tar.xz
$ cd Python-2.7.6
$ ./configure --prefix=/usr/local --enable-unicode=ucs4 --enable-shared LDFLAGS="-Wl,-rpath /usr/local/lib"
$ make && make altinstall
建立软连接并使系统默认python指向python2.7
$ mv /usr/bin/python /usr/bin/python2.6.6
$ ln -s /usr/local/bin/python2.7 /usr/bin/python
再次检查python版本:
$ python -V
Python 2.7.6
安装
这里我们使用 wget 来安装 setuptools:
$ wget https://bootstrap.pypa.io/ez_setup.py -O - | python
安装 zope.interface
$ easy_install zope.interface
安装扭曲
Scrapy使用Twisted异步网络库来处理网络通信,所以需要安装twisted。
在安装twisted之前,需要先安装gcc:
$ yum install gcc -y
然后,通过easy_install安装twisted:
$ easy_install twisted
如果出现以下错误:
$ easy_install twisted
Searching for twisted
Reading https://pypi.python.org/simple/twisted/
Best match: Twisted 14.0.0
Downloading https://pypi.python.org/packag ... c9815
Processing Twisted-14.0.0.tar.bz2
Writing /tmp/easy_install-kYHKjn/Twisted-14.0.0/setup.cfg
Running Twisted-14.0.0/setup.py -q bdist_egg --dist-dir /tmp/easy_install-kYHKjn/Twisted-14.0.0/egg-dist-tmp-vu1n6Y
twisted/runner/portmap.c:10:20: error: Python.h: No such file or directory
twisted/runner/portmap.c:14: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘*’ token
twisted/runner/portmap.c:31: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘*’ token
twisted/runner/portmap.c:45: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘PortmapMethods’
twisted/runner/portmap.c: In function ‘initportmap’:
twisted/runner/portmap.c:55: warning: implicit declaration of function ‘Py_InitModule’
twisted/runner/portmap.c:55: error: ‘PortmapMethods’ undeclared (first use in this function)
twisted/runner/portmap.c:55: error: (Each undeclared identifier is reported only once
twisted/runner/portmap.c:55: error: for each function it appears in.)
请安装 python-devel 并再次运行:
$ yum install python-devel -y
$ easy_install twisted
如果出现以下异常:
error: Not a recognized archive type: /tmp/easy_install-tVwC5O/Twisted-14.0.0.tar.bz2
请手动下载安装,下载地址在这里
$ wget https://pypi.python.org/packag ... c9815
$ tar -vxjf Twisted-14.0.0.tar.bz2
$ cd Twisted-14.0.0
$ python setup.py install
安装 pyOpenSSL
先安装一些依赖:
$ yum install libffi libffi-devel openssl-devel -y
然后,通过easy_install安装pyOpenSSL:
$ easy_install pyOpenSSL
安装 Scrapy
先安装一些依赖:
$ yum install libxml2 libxslt libxslt-devel -y
最后,安装 Scrapy:
$ easy_install scrapy
2. 使用 Scrapy
安装成功后,可以了解Scrapy的一些基本概念和用法,学习Scrapy项目dirbot的例子。
Dirbot 项目所在地。该项目收录一个 README 文件,详细描述了该项目的内容。如果您熟悉 Git,可以查看其源代码。或者,您可以通过单击下载以 tarball 或 zip 格式下载文件。
这里以一个例子来说明如何使用Scrapy创建爬虫项目。
新建筑
在爬取之前,您需要创建一个新的 Scrapy 项目。输入要保存代码的目录,然后执行:
$ scrapy startproject tutorial
该命令会在当前目录下新建一个目录tutorial,其结构如下:
.
├── scrapy.cfg
└── tutorial
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
这些文件主要是:
定义项目
Items 是将加载捕获数据的容器。它的工作原理类似于 Python 中的字典,但它提供了更多保护,例如填充未定义的字段以防止拼写错误。
它是通过创建一个scrapy.item.Item 类并将其属性定义为scrpy.item.Field 对象来声明的,就像一个对象关系映射(ORM)。
我们控制通过建模所需项目获得的站点数据。例如,我们要获取站点的名称、url 和 网站 描述。我们定义了这三个属性的域。为此,我们编辑教程目录中的 items.py 文件,我们的 Item 类将如下所示
from scrapy.item import Item, Field
class DmozItem(Item):
title = Field()
link = Field()
desc = Field()
一开始可能看起来有点混乱,但是定义这些项目会让你知道在使用其他 Scrapy 组件时你的项目是什么。
写一个蜘蛛(蜘蛛)
Spider 是一个用户编写的类,用于从域(或域组)中获取信息。我们定义了用于下载的 URL 的初步列表、如何跟踪链接以及如何解析这些网页的内容以提取项目。
要创建 Spider,您可以为 scrapy.spider.BaseSpider 创建一个子类并确定三个主要的强制性属性:
该方法负责解析返回的数据,匹配捕获的数据(解析为item),跟踪更多的URL。
在tutorial/spiders目录下创建DmozSpider.py
from scrapy.spider import BaseSpider
class DmozSpider(BaseSpider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B
]
def parse(self, response):
filename = response.url.split("/")[-2]
open(filename, \'wb\').write(response.body)
运行项目
$ scrapy crawl dmoz
该命令从域启动爬虫,第三个参数是DmozSpider.py中name属性的值。
xpath 选择器
Scrapy 使用一种称为 XPath 选择器的机制,该机制基于 XPath 表达式。如果您想了解有关选择器和其他机制的更多信息,可以查看。
以下是 XPath 表达式及其含义的一些示例:
这些只是使用 XPath 的几个简单示例,但实际上 XPath 非常强大。如果您想了解更多关于 XPATH 的信息,我们向您推荐这个 XPath 教程
为了方便XPaths的使用,Scrapy提供了Selector类,共有三种方法
提取数据
我们可以使用以下命令选择 网站 中的每个元素:
sel.xpath(\'//ul/li\')
然后网站描述:
sel.xpath(\'//ul/li/text()\').extract()
网站标题:
sel.xpath(\'//ul/li/a/text()\').extract()
网站 链接:
sel.xpath(\'//ul/li/a/@href\').extract()
如前所述,每个 xpath() 调用都会返回一个选择器列表,因此我们可以结合 xpath() 来挖掘更深的节点。我们将使用这些功能,因此:
sites = sel.xpath(\'//ul/li\')
for site in sites:
title = site.xpath(\'a/text()\').extract()
link = site.xpath(\'a/@href\').extract()
desc = site.xpath(\'text()\').extract()
print title, link, desc
使用物品
scrapy.item.Item的调用接口类似于python的dict,Item收录多个scrapy.item.Field。这类似于 django 的模型和
Item通常用于Spider的parse方法,用于保存解析后的数据。
最后修改爬虫类,使用Item保存数据,代码如下:
from scrapy.spider import Spider
from scrapy.selector import Selector
from dirbot.items import Website
class DmozSpider(Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B,
]
def parse(self, response):
"""
The lines below is a spider contract. For more info see:
http://doc.scrapy.org/en/lates ... .html
@url http://www.dmoz.org/Computers/ ... rces/
@scrapes name
"""
sel = Selector(response)
sites = sel.xpath(\'//ul[@class="directory-url"]/li\')
items = []
for site in sites:
item = Website()
item[\'name\'] = site.xpath(\'a/text()\').extract()
item[\'url\'] = site.xpath(\'a/@href\').extract()
item[\'description\'] = site.xpath(\'text()\').re(\'-\s([^\n]*?)\\n\')
items.append(item)
return items
现在,您可以再次运行该项目以查看结果:
$ scrapy crawl dmoz
使用项目管道
在settings.py中设置ITEM_PIPELINES,默认为[],类似django的MIDDLEWARE_CLASSES等。
Spider的解析返回的Item数据会依次被ITEM_PIPELINES列表中的Pipeline类处理。
Item Pipeline 类必须实现以下方法:
还可以另外实现以下两种方法:
保存捕获的数据
保存信息最简单的方法是通过,命令如下:
$ scrapy crawl dmoz -o items.json -t json
除了 json 格式,还支持 JSON 行、CSV 和 XML 格式。您还可以通过接口扩展一些格式。
这种方法对于小项目来说已经足够了。如果是比较复杂的数据,可能需要写一个Item Pipeline进行处理。
所有抓到的物品都会以JSON格式保存在新生成的items.json文件中
总结
以上介绍了如何创建爬虫项目的过程,可以参考以上过程再次联系。作为学习示例,也可以参考这个文章:scrapy中文教程(爬取cnbeta示例)。
这个文章中的爬虫代码如下:
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
from scrapy.selector import Selector
from cnbeta.items import CnbetaItem
class CBSpider(CrawlSpider):
name = \'cnbeta\'
allowed_domains = [\'cnbeta.com\']
start_urls = [\'http://www.cnbeta.com\']
rules = (
Rule(SgmlLinkExtractor(allow=(\'/articles/.*\.htm\', )),
callback=\'parse_page\', follow=True),
)
def parse_page(self, response):
item = CnbetaItem()
sel = Selector(response)
item[\'title\'] = sel.xpath(\'//title/text()\').extract()
item[\'url\'] = response.url
return item
需要注意的是:
3. 学习资料
联系Scrapy是因为想爬取知乎的一些数据。一开始找了一些相关资料和别人的实现方法。
Github上有人或多或少意识到了知乎数据的爬取。我搜索了以下仓库:
其他信息:
抓取和交互式示例:
有一些知识点需要梳理:
4. 总结
以上是这几天学习Scrapy的笔记和知识汇总。参考了网上的一些文章,写了这篇文章。这次真是万分感谢。希望这篇文章文章能对你有所帮助。如果您有任何想法,请留言;如果你喜欢这篇文章,请帮忙分享,谢谢!
最初发表于:
c爬虫抓取网页数据(具有一定的参考价值安装mysql需要屏蔽掉相关代码:抓取网页数据格式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-10-18 05:18
本文文章主要介绍python2.7,详细实现爬虫网页数据。有一定的参考价值,感兴趣的朋友可以参考
最近刚学了Python,做了一个简单的爬虫。作为一个简单的demo,希望对我这样的初学者有所帮助。
代码使用python制作的爬虫2.7抓取51job上的职位名称、公司名称、薪水、发布时间等。
直接上代码。代码中的注释相当清楚。如果没有安装mysql,需要屏蔽相关代码:
#!/usr/bin/python # -*- coding: UTF-8 -*- from bs4 import BeautifulSoup import urllib import urllib2 import codecs import re import time import logging import MySQLdb class Jobs(object): # 初始化 """docstring for Jobs""" def __init__(self): super(Jobs, self).__init__() logging.basicConfig(level=logging.DEBUG, format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s') #数据库的操作,没有mysql可以做屏蔽 self.db = MySQLdb.connect('127.0.0.1','root','rootroot','MySQL_Test',charset='utf8') self.cursor = self.db.cursor() #log日志的显示 self.logger = logging.getLogger("sjk") self.logger.setLevel(level=logging.DEBUG) formatter = logging.Formatter( '%(asctime)s - %(name)s - %(levelname)s - %(message)s') handler = logging.FileHandler('log.txt') handler.setFormatter(formatter) handler.setLevel(logging.DEBUG) self.logger.addHandler(handler) self.logger.info('初始化完成') # 模拟请求数据 def jobshtml(self, key, page='1'): try: self.logger.info('开始请求第' + page + '页') #网页url searchurl = "https://search.51job.com/list/040000,000000,0000,00,9,99,{key},2,{page}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=" user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:59.0) Gecko/20100101 Firefox/59.0' #设置请求头 header = {'User-Agent': user_agent, 'Host': 'search.51job.com', 'Referer': 'https://www.51job.com/'} #拼接url finalUrl = searchurl.format(key=key, page=page) request = urllib2.Request(finalUrl, headers=header) response = urllib2.urlopen(request) #等待网页加载完成 time.sleep(3) #gbk格式解码 info = response.read().decode('gbk') self.logger.info('请求网页网页') self.decodeHtml(info=info, key=key, page=page) except urllib2.HTTPError as e: print e.reason # 解析网页数据 def decodeHtml(self, info, key, page): self.logger.info('开始解析网页数据') #BeautifulSoup 解析网页 soup = BeautifulSoup(info, 'html.parser') #找到class = t1 t2 t3 t4 t5 的标签数据 ps = soup.find_all(attrs={"class": re.compile(r'^t[1-5].*')}) #打开txt文件 a+ 代表追加 f = codecs.open(key + '.txt', 'a+', 'UTF-8') #清除之前的数据信息 f.truncate() f.write('\n------------' + page + '--------------\n') count = 1 arr = [] #做一些字符串的处理,形成数据格式 iOS开发工程师 有限公司 深圳-南山区 0.9-1.6万/月 05-16 for pi in ps: spe = " " finalstr = pi.getText().strip() arr.append(finalstr) if count % 5 == 0: #每一条数据插入数据库,如果没有安装mysql 可以将当前行注释掉 self.connectMySQL(arr=arr) arr = [] spe = "\n" writestr = finalstr + spe count += 1 f.write(writestr) f.close() self.logger.info('解析完成') #数据库操作 没有安装mysql 可以屏蔽掉 def connectMySQL(self,arr): work=arr[0] company=arr[1] place=arr[2] salary=arr[3] time=arr[4] query = "select * from Jobs_tab where \ company_name='%s' and work_name='%s' and work_place='%s' \ and salary='%s' and time='%s'" %(company,work,place,salary,time) self.cursor.execute(query) queryresult = self.cursor.fetchall() #数据库中不存在就插入数据 存在就可以更新数据 不过我这边没有写 if len(queryresult) > 0: sql = "insert into Jobs_tab(work_name,company_name,work_place,salary\ ,time) values('%s','%s','%s','%s','%s')" %(work,company,place,salary,time) try: self.cursor.execute(sql) self.db.commit() except Exception as e: self.logger.info('写入数据库失败') #模拟登陆 # def login(self): # data = {'action':'save','isread':'on','loginname':'18086514327','password':'kui4131sjk'} # 开始抓取 主函数 def run(self, key): # 只要前5页的数据 key代表搜索工做类型 这边我是用的ios page是页数 for x in xrange(1, 6): self.jobshtml(key=key, page=str(x)) self.logger.info('写入数据库完成') self.db.close() if __name__ == '__main__': Jobs().run(key='iOS')
这种方式捕获的网页数据格式如下:
以上是python2.7实现抓取网页数据的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
c爬虫抓取网页数据(具有一定的参考价值安装mysql需要屏蔽掉相关代码:抓取网页数据格式)
本文文章主要介绍python2.7,详细实现爬虫网页数据。有一定的参考价值,感兴趣的朋友可以参考
最近刚学了Python,做了一个简单的爬虫。作为一个简单的demo,希望对我这样的初学者有所帮助。
代码使用python制作的爬虫2.7抓取51job上的职位名称、公司名称、薪水、发布时间等。
直接上代码。代码中的注释相当清楚。如果没有安装mysql,需要屏蔽相关代码:
#!/usr/bin/python # -*- coding: UTF-8 -*- from bs4 import BeautifulSoup import urllib import urllib2 import codecs import re import time import logging import MySQLdb class Jobs(object): # 初始化 """docstring for Jobs""" def __init__(self): super(Jobs, self).__init__() logging.basicConfig(level=logging.DEBUG, format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s') #数据库的操作,没有mysql可以做屏蔽 self.db = MySQLdb.connect('127.0.0.1','root','rootroot','MySQL_Test',charset='utf8') self.cursor = self.db.cursor() #log日志的显示 self.logger = logging.getLogger("sjk") self.logger.setLevel(level=logging.DEBUG) formatter = logging.Formatter( '%(asctime)s - %(name)s - %(levelname)s - %(message)s') handler = logging.FileHandler('log.txt') handler.setFormatter(formatter) handler.setLevel(logging.DEBUG) self.logger.addHandler(handler) self.logger.info('初始化完成') # 模拟请求数据 def jobshtml(self, key, page='1'): try: self.logger.info('开始请求第' + page + '页') #网页url searchurl = "https://search.51job.com/list/040000,000000,0000,00,9,99,{key},2,{page}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=" user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:59.0) Gecko/20100101 Firefox/59.0' #设置请求头 header = {'User-Agent': user_agent, 'Host': 'search.51job.com', 'Referer': 'https://www.51job.com/'} #拼接url finalUrl = searchurl.format(key=key, page=page) request = urllib2.Request(finalUrl, headers=header) response = urllib2.urlopen(request) #等待网页加载完成 time.sleep(3) #gbk格式解码 info = response.read().decode('gbk') self.logger.info('请求网页网页') self.decodeHtml(info=info, key=key, page=page) except urllib2.HTTPError as e: print e.reason # 解析网页数据 def decodeHtml(self, info, key, page): self.logger.info('开始解析网页数据') #BeautifulSoup 解析网页 soup = BeautifulSoup(info, 'html.parser') #找到class = t1 t2 t3 t4 t5 的标签数据 ps = soup.find_all(attrs={"class": re.compile(r'^t[1-5].*')}) #打开txt文件 a+ 代表追加 f = codecs.open(key + '.txt', 'a+', 'UTF-8') #清除之前的数据信息 f.truncate() f.write('\n------------' + page + '--------------\n') count = 1 arr = [] #做一些字符串的处理,形成数据格式 iOS开发工程师 有限公司 深圳-南山区 0.9-1.6万/月 05-16 for pi in ps: spe = " " finalstr = pi.getText().strip() arr.append(finalstr) if count % 5 == 0: #每一条数据插入数据库,如果没有安装mysql 可以将当前行注释掉 self.connectMySQL(arr=arr) arr = [] spe = "\n" writestr = finalstr + spe count += 1 f.write(writestr) f.close() self.logger.info('解析完成') #数据库操作 没有安装mysql 可以屏蔽掉 def connectMySQL(self,arr): work=arr[0] company=arr[1] place=arr[2] salary=arr[3] time=arr[4] query = "select * from Jobs_tab where \ company_name='%s' and work_name='%s' and work_place='%s' \ and salary='%s' and time='%s'" %(company,work,place,salary,time) self.cursor.execute(query) queryresult = self.cursor.fetchall() #数据库中不存在就插入数据 存在就可以更新数据 不过我这边没有写 if len(queryresult) > 0: sql = "insert into Jobs_tab(work_name,company_name,work_place,salary\ ,time) values('%s','%s','%s','%s','%s')" %(work,company,place,salary,time) try: self.cursor.execute(sql) self.db.commit() except Exception as e: self.logger.info('写入数据库失败') #模拟登陆 # def login(self): # data = {'action':'save','isread':'on','loginname':'18086514327','password':'kui4131sjk'} # 开始抓取 主函数 def run(self, key): # 只要前5页的数据 key代表搜索工做类型 这边我是用的ios page是页数 for x in xrange(1, 6): self.jobshtml(key=key, page=str(x)) self.logger.info('写入数据库完成') self.db.close() if __name__ == '__main__': Jobs().run(key='iOS')
这种方式捕获的网页数据格式如下:
以上是python2.7实现抓取网页数据的详细内容。更多详情请关注其他相关html中文网站文章!
c爬虫抓取网页数据(如何抓取ajax形式加载的网页数据(一)_恢复内容开始)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-10-17 22:13
---恢复内容开始---
下面记录如何抓取ajax形式加载的网页数据:
目标:获取“%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=”下的网页数据
第一步:网页数据分析-----》特点:当列表栏滚动到页面底部时,数据自动加载,页面的url没有变化
第二步:使用Fiddler抓包,如下图:
图 1:请求数据
图2:表格形式
数据规律是通过抓包得到的:图2中from表单中的start对应数据和图1中url中的start对应数据随着每次加载增加,其他数据没有变化。对应这个规律,我们可以构造相应的请求来获取数据
注意数据格式为json
代码显示如下:
1).urllib 表单
import urllib2
import urllib
#此处的url为上述抓包获取的url去掉start以及limit,start以及limit数据后边以form表单的形式传入
url = ' https://movie.douban.com/j/cha ... ction='
#请求投信息,伪造成浏览器,方式被反爬虫策略拦截
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
#构建form表单
formdata = {
"start":"20",
"limit":"20"
}
#urlencode()urllib中的函数,作用:将key:value形式的键值对转换为"key=value"形式的字符串
data = urllib.urlencode(formdata)
#构建request实例对象
request = urllib2.Request(url,data=data,headers=headers)
#发送请求并返回响应信息
response = urllib2.urlopen(request)
#注意此处的数据形式并不是html文档,而是json数据
json = response.read()
print html
2).request 库获取请求代码
#coding=utf-8
import requests
url = ' https://movie.douban.com/j/cha ... ction='
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
data = {
"start":"20",
"limit":"20",
}
response = requests.get(url,params = data,headers = headers)
print response.text
3).request 库发布请求
#coding=utf-8
import requests
url = ' https://movie.douban.com/j/cha ... ction='
formdata = {
"start":"20",
"limit":"20"
}
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
response = requests.post(url,data=formdata,headers=headers)
print response.text
---恢复内容结束--- 查看全部
c爬虫抓取网页数据(如何抓取ajax形式加载的网页数据(一)_恢复内容开始)
---恢复内容开始---
下面记录如何抓取ajax形式加载的网页数据:
目标:获取“%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=”下的网页数据
第一步:网页数据分析-----》特点:当列表栏滚动到页面底部时,数据自动加载,页面的url没有变化
第二步:使用Fiddler抓包,如下图:
图 1:请求数据
图2:表格形式
数据规律是通过抓包得到的:图2中from表单中的start对应数据和图1中url中的start对应数据随着每次加载增加,其他数据没有变化。对应这个规律,我们可以构造相应的请求来获取数据
注意数据格式为json
代码显示如下:
1).urllib 表单
import urllib2
import urllib
#此处的url为上述抓包获取的url去掉start以及limit,start以及limit数据后边以form表单的形式传入
url = ' https://movie.douban.com/j/cha ... ction='
#请求投信息,伪造成浏览器,方式被反爬虫策略拦截
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
#构建form表单
formdata = {
"start":"20",
"limit":"20"
}
#urlencode()urllib中的函数,作用:将key:value形式的键值对转换为"key=value"形式的字符串
data = urllib.urlencode(formdata)
#构建request实例对象
request = urllib2.Request(url,data=data,headers=headers)
#发送请求并返回响应信息
response = urllib2.urlopen(request)
#注意此处的数据形式并不是html文档,而是json数据
json = response.read()
print html
2).request 库获取请求代码
#coding=utf-8
import requests
url = ' https://movie.douban.com/j/cha ... ction='
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
data = {
"start":"20",
"limit":"20",
}
response = requests.get(url,params = data,headers = headers)
print response.text
3).request 库发布请求
#coding=utf-8
import requests
url = ' https://movie.douban.com/j/cha ... ction='
formdata = {
"start":"20",
"limit":"20"
}
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
response = requests.post(url,data=formdata,headers=headers)
print response.text
---恢复内容结束---
c爬虫抓取网页数据(Python的内置标准库、执行速度适中、文档容错能力强 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-17 06:18
)
1、基本情况
对于静态网页,您只需要应用两个库,requests 库和 BeautifulSoup4 库。
1.1简介
Beautiful Soup 是一个python库,主要功能是抓取网页数据。
BeautifulSoup4 是爬虫必备的技能。 BeautifulSoup 的主要功能是从网页中抓取数据。
Beautiful Soup 自动将输入文档转换为 Unicode 编码,输出文档为 utf-8 编码。
BeautifulSoup 支持 Python 标准库中的 HTML 解析器,以及一些第三方解析器。如果我们不安装它,Python 将使用 Python 默认解析器。 lxml 解析器功能更强大,速度更快。推荐使用lxml解析器。
Beautiful Soup 提供了一些简单的 Python 风格的函数来处理导航、搜索、修改分析树等功能。
1.2安装
安装:pip install beautifulsoup4
导入:导入bs4(注意不能导入beautifulsoup)
1.3 种主要解析器的比较
使用解析器的优缺点
Python 标准库
BeautifulSoup(markup, “html.parser”)
Python内置标准库,执行速度适中,文档容错能力强
Python 2.7.3 or 3.2.2)之前的版本中文容错能力差
lxml HTML 解析器
BeautifulSoup(markup, “lxml”)
速度快,文档容错能力强
需要安装C语言库
lxml XML 解析器
BeautifulSoup(markup, “xml”)
速度快,唯一支持XML的解析器
需要安装C语言库
html5lib
BeautifulSoup(markup, “html5lib”)
最佳容错性,浏览器解析文档,生成HTML5格式文档
速度慢,不依赖外部扩展
2、基本使用方法
基本用法如下:
代码示例:
import requests
from bs4 import BeautifulSoup
url = "http://jinyongxiaoshuo.com/xue ... ot%3B
#要爬取的网页,这里我找了个金庸小说的网页
res = requests.get('https://cuiqingcai.com/authors/%E5%B4%94%E5%BA%86%E6%89%8D/page/2/')
#向网页发送请求
res.encoding='utf-8'
#编码为utf-8模式
soup=BeautifulSoup(res.text,'html.parser')
#用Python自带的解析器‘html.parser’解析
print(soup)
#打印出整个HTML文档
3、BeautifulSoup4 四种对象
BeautifulSoup4 将复杂的 HTML 文档转换成复杂的树结构,每个节点都是一个 Python 对象,所有对象可以归纳为 4 种类型:
3.1.标签
我们可以通过使用soup 和标签名称轻松获取这些标签的内容。这些对象的类型是 bs4.element.Tag。但请注意,它会查找所有内容中满足要求的第一个标签。
print(type(bs.a))
对于 Tag,它有两个重要的属性,name 和 attrs:
3.2.NavigableString
既然我们已经拿到了标签的内容,那么问题来了,如果我们想要拿到标签里面的文字,我们应该怎么做呢?很简单,直接用.string
print(type(bs.title.string))
3.3.美汤
BeautifulSoup 对象表示文档的内容。大多数时候,它可以看作是一个 Tag 对象,是一个特殊的 Tag。我们可以分别获取它的类型、名称和属性
3.4.评论
注释对象是一种特殊类型的 NavigableString 对象,其输出不收录注释符号。
4、遍历文档树
4.1、.contents:获取Tag的所有子节点并返回一个列表
# tag的.content 属性可以将tag的子节点以列表的方式输出
print(bs.head.contents)
# 用列表索引来获取它的某一个元素
print(bs.head.contents[1])
4.2、.children:获取Tag的所有子节点并返回一个生成器
for child in bs.body.children:
print(child)
4.3、.descendants:获取Tag的所有后代
4.4、.strings:如果Tag收录多个字符串,也就是后代节点有内容,可以用这个获取,然后遍历
4.5、.stripped_strings:与字符串的用法一致,只是可以去掉多余的空白内容
4.6、.parent:获取Tag的父节点
4.7、.parents:递归获取父元素的所有节点并返回一个生成器
4.8、.previous_sibling:获取当前Tag的上一个节点。该属性通常是字符串或空白。真正的结果是当前标签和前一个标签之间的逗号和换行符。
4.9、.next_sibling:获取当前Tag的下一个节点。该属性通常是字符串或空白。结果是当前标签和下一个标签之间的逗号和换行符。
4.10、.previous_siblings:获取当前Tag之上的所有兄弟节点,并返回一个生成器
4.11、.next_siblings:获取当前Tag下的所有兄弟节点,并返回一个生成器
4.12、.previous_element:获取解析过程中最后解析的对象(字符串或标签),可能与previous_sibling相同,但通常不同
4.13、.next_element:获取解析过程中下一个要解析的对象(字符串或标签),可能与next_sibling相同,但通常不同
4.14、.previous_elements:返回一个生成器向前访问文档的解析内容
4.15、.next_elements:返回一个生成器,允许您向后访问文档的解析内容
4.16、.has_attr:判断标签是否收录属性
5、搜索文档树
5.1find_all( name, attrs, recursive, text, **kwargs )
find_all()方法查找当前标签的所有标签子节点,判断是否满足过滤条件
5.1.1name 参数
name参数可以找到所有名为name的标签,string对象会被自动忽略。
5.1.1.传输字符串
最简单的过滤器是一个字符串。在搜索方法中传入一个字符串参数,Beautiful Soup 会找到与字符串完全匹配的内容。以下示例用于查找文档中的所有标签
soup.find_all('b')
# [The Dormouse's story]
print soup.find_all('a')
#[, Lacie, Tillie]
5.1.1.B 传正则表达式
如果传入一个正则表达式作为参数,Beautiful Soup会通过正则表达式的match()来匹配内容。在下面的例子中,所有以 b 开头的标签都被找到了,这意味着应该找到 and 标签。
import re
for tag in soup.find_all(re.compile("^b")): print(tag.name)
# body
# b
5.1.1.C.传输列表
如果传入 list 参数,Beautiful Soup 将返回匹配列表中任何元素的内容。以下代码查找文档中的所有标签和标签
soup.find_all(["a", "b"])
# [<b>The Dormouse's story,
# Elsie,
# Lacie,
# Tillie]
5.1.1.D.通过真
True 可以匹配任何值,以下代码查找所有标签,但不会返回字符串节点
for tag in soup.find_all(True):
print(tag.name)
# html
# head
# title
# body
# p
# b
# p
# a
# a
5.1.1.E.传输方式
如果没有合适的过滤器,那么也可以定义一个方法,该方法只接受一个元素参数[4],如果这个方法返回True,则表示匹配并找到当前元素,如果没有,则返回错误
以下方法验证当前元素。如果它收录 class 属性但不收录 id 属性,它将返回 True:
def has_class_but_no_id(tag):
return tag.has_attr('class') and not tag.has_attr('id')
#将这个方法作为参数传入 find_all() 方法,将得到所有<p>标签:
soup.find_all(has_class_but_no_id)
# [<p class="title">The Dormouse's story,
#
Once upon a time there were...,
#
...]</p>
5.1.2、关键字参数
注意:如果指定名称的参数不是搜索内置参数名称,则搜索时将作为指定名称标签的属性进行搜索。如果收录一个名为 id 的参数,Beautiful Soup 会搜索每个标签的“Id”属性
soup.find_all(id='link2')
# [Lacie]
如果传入href参数,Beautiful Soup会搜索每个标签的“href”属性
soup.find_all(href=re.compile("elsie"))
# [Elsie]
使用指定名称的多个参数同时过滤标签的多个属性
soup.find_all(href=re.compile("elsie"), id='link1')
# [three]
这里想按class过滤,class是python的关键词,怎么办?加一个下划线
soup.find_all("a", class_="sister")
# [Elsie,
# Lacie,
# Tillie]
有些标签属性不能用于搜索,比如HTML5中的data-*属性
soup.find_all("a", class_="sister")
# [Elsie,
# Lacie,
# Tillie]
但是可以通过find_all()方法的attrs参数定义一个字典参数来搜索收录特殊属性的标签
data_soup.find_all(attrs={"data-foo": "value"})
# [foo!]
5.1.3、文本参数
文档中的字符串内容可以通过text参数进行搜索。与name参数的可选值一样,text参数接受字符串、正则表达式、列表和True
soup.find_all(text="Elsie")
# [u'Elsie']
soup.find_all(text=["Tillie", "Elsie", "Lacie"])
# [u'Elsie', u'Lacie', u'Tillie']
soup.find_all(text=re.compile("Dormouse"))
#[u"The Dormouse's story", u"The Dormouse's story"]
5.1.4、限制参数
find_all() 方法返回所有搜索结构。如果文档树很大,搜索会很慢。如果我们不需要所有的结果,我们可以使用 limit 参数来限制返回结果的数量。作用类似于SQL中的limit关键字,当搜索结果数达到limit限制时,停止搜索返回结果。
文档树中有3个标签符合搜索条件,但由于我们限制了返回次数,只返回了2个结果
soup.find_all("a", limit=2)
# [Elsie,
# Lacie]
5.1.5、递归参数
当调用标签的 find_all() 方法时,Beautiful Soup 将检索当前标签的所有后代。如果只想搜索标签的直接子节点,可以使用参数 recursive=False 。
一个简单的文档:
复制代码代码如下:
The Dormouse's story
是否使用递归参数搜索结果:
soup.html.find_all("title")
# [The Dormouse's story]
soup.html.find_all("title", recursive=False)
# []
5.2、find( name, attrs, recursive, text, **kwargs )
它和find_all()方法唯一的区别是find_all()方法的返回结果是一个收录一个元素的值列表,而find()方法直接返回结果
5.3、find_parents(), find_parent()
find_all() 和 find() 只搜索当前节点的所有子节点、孙节点等。 find_parents() 和 find_parent() 用于搜索当前节点的父节点。查找方法与普通标签相同。搜索文档 搜索文档收录内容
5.4、find_next_siblings() find_next_sibling()
这两个方法使用.next_siblings属性来迭代所有后面解析的兄弟标签节点。一个标签节点
5.5、find_previous_siblings() find_previous_sibling()
这两个方法使用 .previous_siblings 属性来迭代当前标签之前解析的兄弟标签节点。 find_previous_siblings() 方法返回之前所有满足条件的兄弟节点, find_previous_sibling() 方法返回第一个满足条件的兄弟节点。兄弟节点
5.6、find_all_next() find_next()
这两个方法使用 .next_elements 属性来迭代当前标签之后的标签和字符串。 find_all_next() 方法返回所有符合条件的节点, find_next() 方法返回第一个符合条件的节点
5.7、find_all_previous() 和 find_previous()
这两个方法使用 .previous_elements 属性来迭代当前节点前面的标签和字符串。 find_all_previous() 方法返回所有符合条件的节点, find_previous() 方法返回第一个符合条件的节点
<p>注意:上述5.2--5.7方法参数用法与find_all()完全相同,原理也类似,这里不再赘述。 查看全部
c爬虫抓取网页数据(Python的内置标准库、执行速度适中、文档容错能力强
)
1、基本情况
对于静态网页,您只需要应用两个库,requests 库和 BeautifulSoup4 库。
1.1简介
Beautiful Soup 是一个python库,主要功能是抓取网页数据。
BeautifulSoup4 是爬虫必备的技能。 BeautifulSoup 的主要功能是从网页中抓取数据。
Beautiful Soup 自动将输入文档转换为 Unicode 编码,输出文档为 utf-8 编码。
BeautifulSoup 支持 Python 标准库中的 HTML 解析器,以及一些第三方解析器。如果我们不安装它,Python 将使用 Python 默认解析器。 lxml 解析器功能更强大,速度更快。推荐使用lxml解析器。
Beautiful Soup 提供了一些简单的 Python 风格的函数来处理导航、搜索、修改分析树等功能。
1.2安装
安装:pip install beautifulsoup4
导入:导入bs4(注意不能导入beautifulsoup)
1.3 种主要解析器的比较
使用解析器的优缺点
Python 标准库
BeautifulSoup(markup, “html.parser”)
Python内置标准库,执行速度适中,文档容错能力强
Python 2.7.3 or 3.2.2)之前的版本中文容错能力差
lxml HTML 解析器
BeautifulSoup(markup, “lxml”)
速度快,文档容错能力强
需要安装C语言库
lxml XML 解析器
BeautifulSoup(markup, “xml”)
速度快,唯一支持XML的解析器
需要安装C语言库
html5lib
BeautifulSoup(markup, “html5lib”)
最佳容错性,浏览器解析文档,生成HTML5格式文档
速度慢,不依赖外部扩展
2、基本使用方法
基本用法如下:
代码示例:
import requests
from bs4 import BeautifulSoup
url = "http://jinyongxiaoshuo.com/xue ... ot%3B
#要爬取的网页,这里我找了个金庸小说的网页
res = requests.get('https://cuiqingcai.com/authors/%E5%B4%94%E5%BA%86%E6%89%8D/page/2/')
#向网页发送请求
res.encoding='utf-8'
#编码为utf-8模式
soup=BeautifulSoup(res.text,'html.parser')
#用Python自带的解析器‘html.parser’解析
print(soup)
#打印出整个HTML文档
3、BeautifulSoup4 四种对象
BeautifulSoup4 将复杂的 HTML 文档转换成复杂的树结构,每个节点都是一个 Python 对象,所有对象可以归纳为 4 种类型:
3.1.标签
我们可以通过使用soup 和标签名称轻松获取这些标签的内容。这些对象的类型是 bs4.element.Tag。但请注意,它会查找所有内容中满足要求的第一个标签。
print(type(bs.a))
对于 Tag,它有两个重要的属性,name 和 attrs:
3.2.NavigableString
既然我们已经拿到了标签的内容,那么问题来了,如果我们想要拿到标签里面的文字,我们应该怎么做呢?很简单,直接用.string
print(type(bs.title.string))
3.3.美汤
BeautifulSoup 对象表示文档的内容。大多数时候,它可以看作是一个 Tag 对象,是一个特殊的 Tag。我们可以分别获取它的类型、名称和属性
3.4.评论
注释对象是一种特殊类型的 NavigableString 对象,其输出不收录注释符号。
4、遍历文档树
4.1、.contents:获取Tag的所有子节点并返回一个列表
# tag的.content 属性可以将tag的子节点以列表的方式输出
print(bs.head.contents)
# 用列表索引来获取它的某一个元素
print(bs.head.contents[1])
4.2、.children:获取Tag的所有子节点并返回一个生成器
for child in bs.body.children:
print(child)
4.3、.descendants:获取Tag的所有后代
4.4、.strings:如果Tag收录多个字符串,也就是后代节点有内容,可以用这个获取,然后遍历
4.5、.stripped_strings:与字符串的用法一致,只是可以去掉多余的空白内容
4.6、.parent:获取Tag的父节点
4.7、.parents:递归获取父元素的所有节点并返回一个生成器
4.8、.previous_sibling:获取当前Tag的上一个节点。该属性通常是字符串或空白。真正的结果是当前标签和前一个标签之间的逗号和换行符。
4.9、.next_sibling:获取当前Tag的下一个节点。该属性通常是字符串或空白。结果是当前标签和下一个标签之间的逗号和换行符。
4.10、.previous_siblings:获取当前Tag之上的所有兄弟节点,并返回一个生成器
4.11、.next_siblings:获取当前Tag下的所有兄弟节点,并返回一个生成器
4.12、.previous_element:获取解析过程中最后解析的对象(字符串或标签),可能与previous_sibling相同,但通常不同
4.13、.next_element:获取解析过程中下一个要解析的对象(字符串或标签),可能与next_sibling相同,但通常不同
4.14、.previous_elements:返回一个生成器向前访问文档的解析内容
4.15、.next_elements:返回一个生成器,允许您向后访问文档的解析内容
4.16、.has_attr:判断标签是否收录属性
5、搜索文档树
5.1find_all( name, attrs, recursive, text, **kwargs )
find_all()方法查找当前标签的所有标签子节点,判断是否满足过滤条件
5.1.1name 参数
name参数可以找到所有名为name的标签,string对象会被自动忽略。
5.1.1.传输字符串
最简单的过滤器是一个字符串。在搜索方法中传入一个字符串参数,Beautiful Soup 会找到与字符串完全匹配的内容。以下示例用于查找文档中的所有标签
soup.find_all('b')
# [The Dormouse's story]
print soup.find_all('a')
#[, Lacie, Tillie]
5.1.1.B 传正则表达式
如果传入一个正则表达式作为参数,Beautiful Soup会通过正则表达式的match()来匹配内容。在下面的例子中,所有以 b 开头的标签都被找到了,这意味着应该找到 and 标签。
import re
for tag in soup.find_all(re.compile("^b")): print(tag.name)
# body
# b
5.1.1.C.传输列表
如果传入 list 参数,Beautiful Soup 将返回匹配列表中任何元素的内容。以下代码查找文档中的所有标签和标签
soup.find_all(["a", "b"])
# [<b>The Dormouse's story,
# Elsie,
# Lacie,
# Tillie]
5.1.1.D.通过真
True 可以匹配任何值,以下代码查找所有标签,但不会返回字符串节点
for tag in soup.find_all(True):
print(tag.name)
# html
# head
# title
# body
# p
# b
# p
# a
# a
5.1.1.E.传输方式
如果没有合适的过滤器,那么也可以定义一个方法,该方法只接受一个元素参数[4],如果这个方法返回True,则表示匹配并找到当前元素,如果没有,则返回错误
以下方法验证当前元素。如果它收录 class 属性但不收录 id 属性,它将返回 True:
def has_class_but_no_id(tag):
return tag.has_attr('class') and not tag.has_attr('id')
#将这个方法作为参数传入 find_all() 方法,将得到所有<p>标签:
soup.find_all(has_class_but_no_id)
# [<p class="title">The Dormouse's story,
#
Once upon a time there were...,
#
...]</p>
5.1.2、关键字参数
注意:如果指定名称的参数不是搜索内置参数名称,则搜索时将作为指定名称标签的属性进行搜索。如果收录一个名为 id 的参数,Beautiful Soup 会搜索每个标签的“Id”属性
soup.find_all(id='link2')
# [Lacie]
如果传入href参数,Beautiful Soup会搜索每个标签的“href”属性
soup.find_all(href=re.compile("elsie"))
# [Elsie]
使用指定名称的多个参数同时过滤标签的多个属性
soup.find_all(href=re.compile("elsie"), id='link1')
# [three]
这里想按class过滤,class是python的关键词,怎么办?加一个下划线
soup.find_all("a", class_="sister")
# [Elsie,
# Lacie,
# Tillie]
有些标签属性不能用于搜索,比如HTML5中的data-*属性
soup.find_all("a", class_="sister")
# [Elsie,
# Lacie,
# Tillie]
但是可以通过find_all()方法的attrs参数定义一个字典参数来搜索收录特殊属性的标签
data_soup.find_all(attrs={"data-foo": "value"})
# [foo!]
5.1.3、文本参数
文档中的字符串内容可以通过text参数进行搜索。与name参数的可选值一样,text参数接受字符串、正则表达式、列表和True
soup.find_all(text="Elsie")
# [u'Elsie']
soup.find_all(text=["Tillie", "Elsie", "Lacie"])
# [u'Elsie', u'Lacie', u'Tillie']
soup.find_all(text=re.compile("Dormouse"))
#[u"The Dormouse's story", u"The Dormouse's story"]
5.1.4、限制参数
find_all() 方法返回所有搜索结构。如果文档树很大,搜索会很慢。如果我们不需要所有的结果,我们可以使用 limit 参数来限制返回结果的数量。作用类似于SQL中的limit关键字,当搜索结果数达到limit限制时,停止搜索返回结果。
文档树中有3个标签符合搜索条件,但由于我们限制了返回次数,只返回了2个结果
soup.find_all("a", limit=2)
# [Elsie,
# Lacie]
5.1.5、递归参数
当调用标签的 find_all() 方法时,Beautiful Soup 将检索当前标签的所有后代。如果只想搜索标签的直接子节点,可以使用参数 recursive=False 。
一个简单的文档:
复制代码代码如下:
The Dormouse's story
是否使用递归参数搜索结果:
soup.html.find_all("title")
# [The Dormouse's story]
soup.html.find_all("title", recursive=False)
# []
5.2、find( name, attrs, recursive, text, **kwargs )
它和find_all()方法唯一的区别是find_all()方法的返回结果是一个收录一个元素的值列表,而find()方法直接返回结果
5.3、find_parents(), find_parent()
find_all() 和 find() 只搜索当前节点的所有子节点、孙节点等。 find_parents() 和 find_parent() 用于搜索当前节点的父节点。查找方法与普通标签相同。搜索文档 搜索文档收录内容
5.4、find_next_siblings() find_next_sibling()
这两个方法使用.next_siblings属性来迭代所有后面解析的兄弟标签节点。一个标签节点
5.5、find_previous_siblings() find_previous_sibling()
这两个方法使用 .previous_siblings 属性来迭代当前标签之前解析的兄弟标签节点。 find_previous_siblings() 方法返回之前所有满足条件的兄弟节点, find_previous_sibling() 方法返回第一个满足条件的兄弟节点。兄弟节点
5.6、find_all_next() find_next()
这两个方法使用 .next_elements 属性来迭代当前标签之后的标签和字符串。 find_all_next() 方法返回所有符合条件的节点, find_next() 方法返回第一个符合条件的节点
5.7、find_all_previous() 和 find_previous()
这两个方法使用 .previous_elements 属性来迭代当前节点前面的标签和字符串。 find_all_previous() 方法返回所有符合条件的节点, find_previous() 方法返回第一个符合条件的节点
<p>注意:上述5.2--5.7方法参数用法与find_all()完全相同,原理也类似,这里不再赘述。
c爬虫抓取网页数据(封装一个简单总结(一):抓取网页文档分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-16 06:24
)
这两天学习了爬虫的基础知识,这里简单总结一下。
获取的网页商品数据保存在Excel表格中,效果如下:
使用Jumony Core引擎,是一个非常强大且近乎完美的HTML解析引擎,支持css3选择器,直接抓取网页文档进行分析,并根据HTTP头自动识别。
一个抓取博客园站点导航顶部信息的例子:
var documents = new JumonyParser().LoadDocument("http://www.cnblogs.com/").Find("#site_nav_top").FirstOrDefault();
太强大了。如果您熟悉 CSS,则无需手动编写大量可读性差的正则表达式来匹配和获取数据。
封装一个简单的操作库:
public class BaseAnalyzer
{
///
/// 根据Url加载html文档对象
///
///
///
protected virtual IHtmlDocument LoadDocument(string url)
{
return new JumonyParser().LoadDocument(url);
}
///
/// 查询指定url中指定选择器的元素集
///
///
///
///
protected virtual List QueryHtmlElements(string url, string selector, Func predicate = null)
{
var elementsCollection = new List();
IEnumerable elements = LoadDocument(url).Find(selector);
if (predicate != null)
{
elements = elements.Where(predicate);
}
if (elements != null)
elementsCollection.AddRange(elements);
return elementsCollection;
}
///
/// 分析Html文档,获取指定元素集第一个元素的文本内容
///
/// html文档对象
/// 选择器
/// 文本内容
protected virtual string GetFirstElementText(IHtmlContainer html, string selector)
{
var findList = html.Find(selector);
var result = findList.FirstOrDefault();
return result == null ? string.Empty : result.InnerText();
}
///
/// 分析Html文档,获取指定元素集的文本内容
///
/// html文档对象
/// 选择器
/// 自定义处理获取到的元素集,若没有,就返回第一个元素的文本内容
///
protected virtual string GetElementsText(IHtmlContainer html, string selector, Func func)
{
var findList = html.Find(selector);
if (func != null)
return func(findList);
return GetFirstElementText(html, selector);
}
}
获取产品名称的示例:
private ProductInfo AnalyzeProductInfo(string detailUrl)
{
var product = new ProductInfo();
//详情页html文档对象
var html = LoadDocument(detailUrl);
product.ProductName = GetFirstElementText(html, ".goods_particulars h1");
} 查看全部
c爬虫抓取网页数据(封装一个简单总结(一):抓取网页文档分析
)
这两天学习了爬虫的基础知识,这里简单总结一下。
获取的网页商品数据保存在Excel表格中,效果如下:
使用Jumony Core引擎,是一个非常强大且近乎完美的HTML解析引擎,支持css3选择器,直接抓取网页文档进行分析,并根据HTTP头自动识别。
一个抓取博客园站点导航顶部信息的例子:
var documents = new JumonyParser().LoadDocument("http://www.cnblogs.com/";).Find("#site_nav_top").FirstOrDefault();
太强大了。如果您熟悉 CSS,则无需手动编写大量可读性差的正则表达式来匹配和获取数据。
封装一个简单的操作库:
public class BaseAnalyzer
{
///
/// 根据Url加载html文档对象
///
///
///
protected virtual IHtmlDocument LoadDocument(string url)
{
return new JumonyParser().LoadDocument(url);
}
///
/// 查询指定url中指定选择器的元素集
///
///
///
///
protected virtual List QueryHtmlElements(string url, string selector, Func predicate = null)
{
var elementsCollection = new List();
IEnumerable elements = LoadDocument(url).Find(selector);
if (predicate != null)
{
elements = elements.Where(predicate);
}
if (elements != null)
elementsCollection.AddRange(elements);
return elementsCollection;
}
///
/// 分析Html文档,获取指定元素集第一个元素的文本内容
///
/// html文档对象
/// 选择器
/// 文本内容
protected virtual string GetFirstElementText(IHtmlContainer html, string selector)
{
var findList = html.Find(selector);
var result = findList.FirstOrDefault();
return result == null ? string.Empty : result.InnerText();
}
///
/// 分析Html文档,获取指定元素集的文本内容
///
/// html文档对象
/// 选择器
/// 自定义处理获取到的元素集,若没有,就返回第一个元素的文本内容
///
protected virtual string GetElementsText(IHtmlContainer html, string selector, Func func)
{
var findList = html.Find(selector);
if (func != null)
return func(findList);
return GetFirstElementText(html, selector);
}
}
获取产品名称的示例:
private ProductInfo AnalyzeProductInfo(string detailUrl)
{
var product = new ProductInfo();
//详情页html文档对象
var html = LoadDocument(detailUrl);
product.ProductName = GetFirstElementText(html, ".goods_particulars h1");
}
c爬虫抓取网页数据(封装一个简单总结(一):抓取网页文档分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-16 06:19
)
这两天学习了爬虫的基础知识,这里简单总结一下。
获取的网页商品数据保存在Excel表格中,效果如下:
使用Jumony Core引擎,是一个非常强大且近乎完美的HTML解析引擎,支持css3选择器,直接抓取网页文档进行分析,并根据HTTP头自动识别。
一个抓取博客园站点导航顶部信息的例子:
var documents = new JumonyParser().LoadDocument("http://www.cnblogs.com/").Find("#site_nav_top").FirstOrDefault();
太强大了。如果您熟悉 CSS,则无需手动编写大量可读性差的正则表达式来匹配和获取数据。
封装一个简单的操作库:
public class BaseAnalyzer
{
///
/// 根据Url加载html文档对象
///
///
///
protected virtual IHtmlDocument LoadDocument(string url)
{
return new JumonyParser().LoadDocument(url);
}
///
/// 查询指定url中指定选择器的元素集
///
///
///
///
protected virtual List QueryHtmlElements(string url, string selector, Func predicate = null)
{
var elementsCollection = new List();
IEnumerable elements = LoadDocument(url).Find(selector);
if (predicate != null)
{
elements = elements.Where(predicate);
}
if (elements != null)
elementsCollection.AddRange(elements);
return elementsCollection;
}
///
/// 分析Html文档,获取指定元素集第一个元素的文本内容
///
/// html文档对象
/// 选择器
/// 文本内容
protected virtual string GetFirstElementText(IHtmlContainer html, string selector)
{
var findList = html.Find(selector);
var result = findList.FirstOrDefault();
return result == null ? string.Empty : result.InnerText();
}
///
/// 分析Html文档,获取指定元素集的文本内容
///
/// html文档对象
/// 选择器
/// 自定义处理获取到的元素集,若没有,就返回第一个元素的文本内容
///
protected virtual string GetElementsText(IHtmlContainer html, string selector, Func func)
{
var findList = html.Find(selector);
if (func != null)
return func(findList);
return GetFirstElementText(html, selector);
}
}
获取产品名称的示例:
private ProductInfo AnalyzeProductInfo(string detailUrl)
{
var product = new ProductInfo();
//详情页html文档对象
var html = LoadDocument(detailUrl);
product.ProductName = GetFirstElementText(html, ".goods_particulars h1");
} 查看全部
c爬虫抓取网页数据(封装一个简单总结(一):抓取网页文档分析
)
这两天学习了爬虫的基础知识,这里简单总结一下。
获取的网页商品数据保存在Excel表格中,效果如下:
使用Jumony Core引擎,是一个非常强大且近乎完美的HTML解析引擎,支持css3选择器,直接抓取网页文档进行分析,并根据HTTP头自动识别。
一个抓取博客园站点导航顶部信息的例子:
var documents = new JumonyParser().LoadDocument("http://www.cnblogs.com/";).Find("#site_nav_top").FirstOrDefault();
太强大了。如果您熟悉 CSS,则无需手动编写大量可读性差的正则表达式来匹配和获取数据。
封装一个简单的操作库:
public class BaseAnalyzer
{
///
/// 根据Url加载html文档对象
///
///
///
protected virtual IHtmlDocument LoadDocument(string url)
{
return new JumonyParser().LoadDocument(url);
}
///
/// 查询指定url中指定选择器的元素集
///
///
///
///
protected virtual List QueryHtmlElements(string url, string selector, Func predicate = null)
{
var elementsCollection = new List();
IEnumerable elements = LoadDocument(url).Find(selector);
if (predicate != null)
{
elements = elements.Where(predicate);
}
if (elements != null)
elementsCollection.AddRange(elements);
return elementsCollection;
}
///
/// 分析Html文档,获取指定元素集第一个元素的文本内容
///
/// html文档对象
/// 选择器
/// 文本内容
protected virtual string GetFirstElementText(IHtmlContainer html, string selector)
{
var findList = html.Find(selector);
var result = findList.FirstOrDefault();
return result == null ? string.Empty : result.InnerText();
}
///
/// 分析Html文档,获取指定元素集的文本内容
///
/// html文档对象
/// 选择器
/// 自定义处理获取到的元素集,若没有,就返回第一个元素的文本内容
///
protected virtual string GetElementsText(IHtmlContainer html, string selector, Func func)
{
var findList = html.Find(selector);
if (func != null)
return func(findList);
return GetFirstElementText(html, selector);
}
}
获取产品名称的示例:
private ProductInfo AnalyzeProductInfo(string detailUrl)
{
var product = new ProductInfo();
//详情页html文档对象
var html = LoadDocument(detailUrl);
product.ProductName = GetFirstElementText(html, ".goods_particulars h1");
}
c爬虫抓取网页数据(2017年本科毕业论文主题网络爬虫的设计与实现-orientedcrawler)
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-10-16 00:14
本科毕业论文题目:面向学科爬虫的设计与实现 姓名:陆刚 学号:234 学院:软件学院 系:软件工程专业:软件工程 年级:2005级 导师:石亮副教授 2009 年 6 月 I 总结 目前,信息网络中信息量很大,但通过人工浏览很难安全地浏览和整理信息,大量有用的信息白白丢失,造成大量信息不能及时应用的矛盾,这对用户来说。这造成了很多不便。为了解决这个问题,新的搜索引擎热门技术应运而生。本文结合信息网络的特点,利用信息抽取和网页分析技术,设计并实现了搜索引擎最重要的部分。——网络爬虫,为互联网搜索服务提供分类更细致准确、数据更全面深入、更新更及时的互联网搜索服务。本文首先总结了网络爬虫的发展历程,然后分析了网络爬虫的架构和实现原理,深入分析了Web上主题页面的分布特征和主题相关性的判别算法。具体工作如下:(1)爬虫部分,爬取设计种子网站,下载尽可能完整且满足用户要求的网站。
但不能仅通过人为方式访问和清理所有信息,过多的导入信息会丢失,还会导致破获刑事案件,给用户带来很大的不便。为了解决这个问题,搜索引擎技术成为了新的热点。,利用信息提取和网络分析技术提供更详细的分类精度, 查看全部
c爬虫抓取网页数据(2017年本科毕业论文主题网络爬虫的设计与实现-orientedcrawler)
本科毕业论文题目:面向学科爬虫的设计与实现 姓名:陆刚 学号:234 学院:软件学院 系:软件工程专业:软件工程 年级:2005级 导师:石亮副教授 2009 年 6 月 I 总结 目前,信息网络中信息量很大,但通过人工浏览很难安全地浏览和整理信息,大量有用的信息白白丢失,造成大量信息不能及时应用的矛盾,这对用户来说。这造成了很多不便。为了解决这个问题,新的搜索引擎热门技术应运而生。本文结合信息网络的特点,利用信息抽取和网页分析技术,设计并实现了搜索引擎最重要的部分。——网络爬虫,为互联网搜索服务提供分类更细致准确、数据更全面深入、更新更及时的互联网搜索服务。本文首先总结了网络爬虫的发展历程,然后分析了网络爬虫的架构和实现原理,深入分析了Web上主题页面的分布特征和主题相关性的判别算法。具体工作如下:(1)爬虫部分,爬取设计种子网站,下载尽可能完整且满足用户要求的网站。
但不能仅通过人为方式访问和清理所有信息,过多的导入信息会丢失,还会导致破获刑事案件,给用户带来很大的不便。为了解决这个问题,搜索引擎技术成为了新的热点。,利用信息提取和网络分析技术提供更详细的分类精度,
c爬虫抓取网页数据(基于使用宽度有限的策略(电子商务研究中心)())
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-15 21:19
(电商研究中心新闻)1:从种子站开始爬取
基于万维网的蝴蝶结构,这种非线性的网页组织结构会存在爬取顺序问题。这种爬取顺序策略必须保证尽可能多地爬取所有网页。
一般来说,爬虫选择抓取蝴蝶形状左侧的结构来抓取发送点。一个典型的例子是网站等门户网站的首页。每次抓取网页时,都会分析其中的 URL。这个字符串形式的Links是指向其他网页的URL,它们引导爬虫去爬取其他网页。(基于此,我们可以初步了解引擎从左到右,先上后下爬的原因)
a:深度优先遍历
深度优先遍历策略类似于家族继承策略。通常,如封建皇帝的遗产,长子通常是长子。大孙子去世了,所以老二继承,这种继承上的优先关系也称为深度优先策略。(从这点我们就可以理解蜘蛛爬列页面的顺序了)
b: 广度优先遍历
广度优先也称为广度优先,或层次优先。例如,当我们给祖父母、父母和同龄人上茶时,我们先给最年长的祖父茶,然后是父亲,最后是同龄人,爬行。这个策略也被采用了。基于使用宽度有限的策略主要有以下三个原因:
1>首页重要的网页往往离种子很近。例如,当我们打开新闻台时,往往是最热门的新闻。随着我们继续深入冲浪,PV值会越来越大,我们看到的网页的重要性就变得越来越不重要了。
2>万维网的实际深度可达17层,某个网页的路径要深得多,但总有很短的路径。
3>宽度优先有利于多个爬虫的协同爬取(Mozk是根据前人的数据分析和IIS日志分析得出的,暂时我觉得如果大家有不同意见,欢迎讨论交流)。多个爬虫的合作通常会先爬取内部连接,再遇到站点。然后外链开始抓取,抓取非常封闭。
附:链接优化,避免爬取链接死循环,同时避免爬取资源不被爬取,浪费大量资源做无用功。(如何建立合理的内部链接可以参考肖战)。
2:网页抓取优先策略
网络爬取优先策略也称为“页面选择”(page selection),通常会爬取重要的网页,以保证有限的资源(爬虫、服务器负载)尽可能地照顾到最重要的网页。这一点应该很容易理解。
那么哪些网页是最重要的网页呢?
判断网页重要性的因素有很多,主要包括链接流行度(你知道链接的重要性)、链接重要性和平均深度链接、网站质量、历史权重等主要因素。
链接的受欢迎程度主要取决于反向链接的数量和质量,我们将其定义为 IB(P)。
链接的重要性是 URL 字符串的函数。它只检查字符串本身。例如,认为“.com”和“home”的URL重要性高于“.cc”和“map”(这里例如,不是绝对的,就像我们通常默认的主页索引一样。 **,我们也可以定义其他名称,另外,排名是一个综合因素,com的排名不一定好,只是其中一个小因素),我们定义为IL(P)
平均连接深度是我个人的蔑视。根据上面分析的广度优先原则,计算整个站点的平均链接深度,然后你离种子站点越近,它就越重要。我们将其定义为 ID(P)
我们将网页的重要性定义为 I(P)
所以:
I(p)=X*IB(P)+Y*IL(P)
ID(P)是由广度优先遍历规则保证的,所以不作为重要的指标函数。为了保证最重要的网页被抓取,这样的抓取是完全合理和科学的。
本文第一点是解释点,第二点是分析方面。文笔不是很好,看明白了。
SEO的目标是提升网站的质量,提升网站的质量是提升网站的用户体验友好度,提升网站的最终目的@> 用户优化就是离开SE,做正规的事情。清书,以上是莫兹克的蔑视。毕竟,SEO是排名的逆向推理过程。不可能一帆风顺。这只是对数据的分析。任何信息仅供参考。它仍然更多地取决于您自己的实践。: 中国电子商务研究中心) 查看全部
c爬虫抓取网页数据(基于使用宽度有限的策略(电子商务研究中心)())
(电商研究中心新闻)1:从种子站开始爬取
基于万维网的蝴蝶结构,这种非线性的网页组织结构会存在爬取顺序问题。这种爬取顺序策略必须保证尽可能多地爬取所有网页。
一般来说,爬虫选择抓取蝴蝶形状左侧的结构来抓取发送点。一个典型的例子是网站等门户网站的首页。每次抓取网页时,都会分析其中的 URL。这个字符串形式的Links是指向其他网页的URL,它们引导爬虫去爬取其他网页。(基于此,我们可以初步了解引擎从左到右,先上后下爬的原因)
a:深度优先遍历
深度优先遍历策略类似于家族继承策略。通常,如封建皇帝的遗产,长子通常是长子。大孙子去世了,所以老二继承,这种继承上的优先关系也称为深度优先策略。(从这点我们就可以理解蜘蛛爬列页面的顺序了)
b: 广度优先遍历
广度优先也称为广度优先,或层次优先。例如,当我们给祖父母、父母和同龄人上茶时,我们先给最年长的祖父茶,然后是父亲,最后是同龄人,爬行。这个策略也被采用了。基于使用宽度有限的策略主要有以下三个原因:
1>首页重要的网页往往离种子很近。例如,当我们打开新闻台时,往往是最热门的新闻。随着我们继续深入冲浪,PV值会越来越大,我们看到的网页的重要性就变得越来越不重要了。
2>万维网的实际深度可达17层,某个网页的路径要深得多,但总有很短的路径。
3>宽度优先有利于多个爬虫的协同爬取(Mozk是根据前人的数据分析和IIS日志分析得出的,暂时我觉得如果大家有不同意见,欢迎讨论交流)。多个爬虫的合作通常会先爬取内部连接,再遇到站点。然后外链开始抓取,抓取非常封闭。
附:链接优化,避免爬取链接死循环,同时避免爬取资源不被爬取,浪费大量资源做无用功。(如何建立合理的内部链接可以参考肖战)。
2:网页抓取优先策略
网络爬取优先策略也称为“页面选择”(page selection),通常会爬取重要的网页,以保证有限的资源(爬虫、服务器负载)尽可能地照顾到最重要的网页。这一点应该很容易理解。
那么哪些网页是最重要的网页呢?
判断网页重要性的因素有很多,主要包括链接流行度(你知道链接的重要性)、链接重要性和平均深度链接、网站质量、历史权重等主要因素。
链接的受欢迎程度主要取决于反向链接的数量和质量,我们将其定义为 IB(P)。
链接的重要性是 URL 字符串的函数。它只检查字符串本身。例如,认为“.com”和“home”的URL重要性高于“.cc”和“map”(这里例如,不是绝对的,就像我们通常默认的主页索引一样。 **,我们也可以定义其他名称,另外,排名是一个综合因素,com的排名不一定好,只是其中一个小因素),我们定义为IL(P)
平均连接深度是我个人的蔑视。根据上面分析的广度优先原则,计算整个站点的平均链接深度,然后你离种子站点越近,它就越重要。我们将其定义为 ID(P)
我们将网页的重要性定义为 I(P)
所以:
I(p)=X*IB(P)+Y*IL(P)
ID(P)是由广度优先遍历规则保证的,所以不作为重要的指标函数。为了保证最重要的网页被抓取,这样的抓取是完全合理和科学的。
本文第一点是解释点,第二点是分析方面。文笔不是很好,看明白了。
SEO的目标是提升网站的质量,提升网站的质量是提升网站的用户体验友好度,提升网站的最终目的@> 用户优化就是离开SE,做正规的事情。清书,以上是莫兹克的蔑视。毕竟,SEO是排名的逆向推理过程。不可能一帆风顺。这只是对数据的分析。任何信息仅供参考。它仍然更多地取决于您自己的实践。: 中国电子商务研究中心)
c爬虫抓取网页数据(文章目录《Python网络爬虫Scrapy框架》-陈磊/主编)
网站优化 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-10-15 10:29
文章内容
《Python 网络爬虫 Scrapy 框架》
全文主要参考《Python Web Crawler Scrapy Framework》-肖瑞陈磊/主编-刘新杰王莹莹秦丽娟/人民邮电出版社副主编。
本书章节列表如下
通读前两章和本书章节列表。前四章可以使用。后续章节可能会用到Scrapy反爬技术和分布式爬虫Scrapy+Redis。谈未来,把握现在。
第一章
掌握4个概念:lxml库、xpath语法、多级网络爬取逻辑、数据存储与展示。
用于解析 HTML 的库
请求网页URL,获取到HTML源代码后,需要解析HTML源代码,得到想要的数据。lxml库是解析html的第三方库。
Python标准库自带xml模块,可以解析xml文件和html页面的内容,但性能和界面不人性化。第三方库lxml由Cython实现,增加了很多功能,大部分都存放在lxml.etree中。
使用 lxml 库提取网页内容的步骤如下:
导入对应的库: from lxml import etree
使用HTML()方法生成要解析的对象:tree=etree.HTML(html),其中html为目标页面的html源代码
调用待解析对象的xpath()方法tree.xpath(),填入xpath语句作为html解析的参数
解析 XML/HTML 的语法
xpath 是一组解析 XML/HTML 的语法,使用路径表达式来选择 xml/html 中的节点集。值得一提的是,编写xpath需要熟悉html元素。
多级网络爬取逻辑
页面嵌套问题:抓取一个网页的数据很容易,但是如何抓取网页的嵌套网页呢?即让爬虫定期爬取所有嵌套的详情页。
这种情况涉及到爬虫的多级网络爬取逻辑。以二级网页为例,组织爬取逻辑:
请求一级网页(目标数据为嵌套页面的链接)使用xpath解析网页,获取嵌套页面的链接,遍历嵌套页面链接,逐个发送请求,使用xpath解析二级网页,获取最终目标数据并保存目标数据
这里应该有爬虫算法,比如Scrapy使用的深度优先算法,数据结构已经学会了,看深度优先算法和网络爬虫中的简单代码实现。
保存数据和显示数据
将 URL-Method-Params-Status-Title-Length 格式的数据保存为 csv 文件还是 txt 文件?后面还有问题需要考虑。您需要对这些目标资源进行分类吗?未分类的数据量太大,除非对每个URL的请求量进行压缩,或者分类,这些都是fuzzing时需要考虑的事情。
目前我们只需要考虑保存数据的可读性,具体点就是阅读的舒适度。以后fuzz可能保存为txt或csv,但目前我个人更喜欢保存为py,因为编辑器读起来很舒服。
参考csv、txt和tsv数据文件的异同,以及如何使用Python读取和生成: 一般来说,为了更好的处理多种语言的数据,建议将数据保存为csv格式(csv文件之间用逗号隔开)后缀可以直接改成其他类型的文件),可以同时在excle、python、matlab、sas、R等语言中自由切换,数据格式没有损坏!
选择:将 URL-Method-Params-Status-Title-Length 格式的数据保存为 csv 文件。
这一天即将结束。回顾那天,没有实质性的结果。编写爬虫是目标,其他一切都是假的。
第 2 章垂直搜索爬虫
根据使用场景,爬虫分为通用搜索爬虫和垂直搜索爬虫。垂直搜索爬虫在运行时尽量只爬取与需求相关的网页信息。这里主要使用垂直搜索爬虫。
安装 Scrapy 爬虫框架
参考Windows环境下安装Scrapy框架的步骤,本地一步执行命令pip3 install scrapy。
创建并启动 Scrapy 爬虫项目
开发一个Scrapy爬虫项目,需要使用Scrapy命令创建一个爬虫项目,这是一个半成品的爬虫项目。在命令行创建爬虫项目的步骤如下
创建爬虫项目:scrapy startproject 项目名称切换到项目根目录创建爬虫文件:scrapy genspider 爬虫名称启动爬虫项目的网址:scrapy crawl 爬虫名称
#创建爬虫项目并运行爬虫
scrapy startproject helloSpider
cd helloSpider
scrapy genspider test http://127.0.0.1/DVWA-master/
scrapy crawl test # 工程根目录执行
#执行回显模块
[scrapy.utils.log]
[scrapy.crawler]
[scrapy.extensions.telnet]
[scrapy.middleware]
[scrapy.core.engine]
[scrapy.extensions.logstats]
[scrapy.downloadermiddlewares.retry]
[scrapy.downloadermiddlewares.robotstxt]
# helloSpider/spiders/test.py文件
import scrapy
class TestSpider(scrapy.Spider):
name = 'test'
allowed_domains = ['http://127.0.0.1/DVWA-master/']
start_urls = ['http://http://127.0.0.1/DVWA-master//']
def parse(self, response):
pass
部分执行结果如下,可以看到打印的内容有点混乱。
整体把握scrapy项目
创建项目的文件结构如下,项目配置文件scrapy.cfg进行了过滤,因为开发爬虫的时候不需要修改这个文件。如图所示,Scrapy爬虫项目主要由5个模块组成:爬虫、items模块、中间件模块、数据存储模块、配置模块,然后对各个模块进行简单说明。
Scrapy框架的引擎和调度器暂时忽略
#流程图代码
graph TB
A(项目根目录helloSpider)
B(helloSpider)
B3(spiders)
B4(items.py)
B5(middlewares.py)
B6(pipelines.py)
B7(settings.py)
A-->B
B-->B3
B-->B4
B-->B5
B-->B6
B-->B7
b31(test.py)
B3-->b31
(1)spiders文件夹:是Scrapy爬虫项目的爬虫模块,可以有多个爬虫文件。设计理念是方便一站一个爬虫,爬虫可以共享项目中的其他模块以提高重用和开发效率。
爬虫文件的内容一目了然。值得注意的是,爬虫默认是无状态的,所以Scrapy框架允许你通过覆盖爬虫文件中的start_requests()方法来自定义爬虫起始页的爬取设置。
(2)items.py 文件:爬取的数据可能需要在模块之间进行传输,所以items.py 中定义了统一的数据格式。
(3)pipelines.py 文件:Pipeline的意思是管道,是框架中的一个数据处理模块,经常用来完成数据的持久化,也可以对爬取的数据进行过滤和去重。
(4)middlewares.py文件:Middlewares就是中间件,中间件的存在方便了爬虫框架的功能扩展。在Scrapy爬虫框架中,中间件分为下载器和蜘蛛两大类。
(5)settings.py文件:Settings模块负责设置爬虫行为模式、模块激活等配置功能,是爬虫框架中非常重要的一个模块。列举一些开发中常用的配置:
管道模块的启动和激活顺序配置蜘蛛抓取网页数据的频率、默认headers等属性配置启动或关闭指定蜘蛛中间件配置、下载器中间件配置爬虫请求流程
结合第3章的部分内容,列出执行过程。
# 流程图代码
graph TB
a(启动爬虫)
b(引擎访问start_urls获取URL)
c(引擎调用Downloader模块下载网页)
d(引擎把下载结果传递给Spider的parse方法)
e(用户处理Response类对象response提取数据)
a-->b
b-->c
c-->d
d-->e
下一章3的内容最终会涉及到爬虫的编写和登陆(数据处理和数据存储)的问题
目前了解scrapy项目的执行流程,但是不知道scrapy引擎是怎么运行的,scrapy的入口文件是哪个,尤其是如何定义request类,这些对二次开发非常重要。那么接下来,审计scrapy框架的源代码。
审计scrapy框架
让审计先行,主要目标是定制爬虫,不要迷失在知识的海洋中。
框架文件和入口文件,显然入口文件是__main__.py文件:
请求类Request:查看scrapy根目录下的http文件夹。该目录下的__init__.py文件定义了请求类:class Request(object_ref)
scrapy通过Request类对象发起请求,参考:scrapy中的python-Request参数。
第三章:数据抽取和多级网络爬取,明确进度和目标
第 2 章重写了 start_requests(self) 方法。test.py 文件中收录以下变量,这些变量会随着目标的变化而变化:
当前爬虫变量的描述
allowed_domains
允许抓取的 URL。如果不定义,所有网页都会被抓取,即通用搜索爬虫
起始网址
爬虫起始页
饼干
验证
完成第一次网页访问后,本章需要完成两个任务:数据筛选和提取,以及多级网页爬取。
响应对象
爬虫访问网页后,将收录网页结果的响应对象返回给 parse() 方法。其常用属性和方法如下:
属性或方法描述
网址
当前返回页面对应的url
地位 查看全部
c爬虫抓取网页数据(文章目录《Python网络爬虫Scrapy框架》-陈磊/主编)
文章内容
《Python 网络爬虫 Scrapy 框架》
全文主要参考《Python Web Crawler Scrapy Framework》-肖瑞陈磊/主编-刘新杰王莹莹秦丽娟/人民邮电出版社副主编。
本书章节列表如下
通读前两章和本书章节列表。前四章可以使用。后续章节可能会用到Scrapy反爬技术和分布式爬虫Scrapy+Redis。谈未来,把握现在。
第一章
掌握4个概念:lxml库、xpath语法、多级网络爬取逻辑、数据存储与展示。
用于解析 HTML 的库
请求网页URL,获取到HTML源代码后,需要解析HTML源代码,得到想要的数据。lxml库是解析html的第三方库。
Python标准库自带xml模块,可以解析xml文件和html页面的内容,但性能和界面不人性化。第三方库lxml由Cython实现,增加了很多功能,大部分都存放在lxml.etree中。
使用 lxml 库提取网页内容的步骤如下:
导入对应的库: from lxml import etree
使用HTML()方法生成要解析的对象:tree=etree.HTML(html),其中html为目标页面的html源代码
调用待解析对象的xpath()方法tree.xpath(),填入xpath语句作为html解析的参数
解析 XML/HTML 的语法
xpath 是一组解析 XML/HTML 的语法,使用路径表达式来选择 xml/html 中的节点集。值得一提的是,编写xpath需要熟悉html元素。
多级网络爬取逻辑
页面嵌套问题:抓取一个网页的数据很容易,但是如何抓取网页的嵌套网页呢?即让爬虫定期爬取所有嵌套的详情页。
这种情况涉及到爬虫的多级网络爬取逻辑。以二级网页为例,组织爬取逻辑:
请求一级网页(目标数据为嵌套页面的链接)使用xpath解析网页,获取嵌套页面的链接,遍历嵌套页面链接,逐个发送请求,使用xpath解析二级网页,获取最终目标数据并保存目标数据
这里应该有爬虫算法,比如Scrapy使用的深度优先算法,数据结构已经学会了,看深度优先算法和网络爬虫中的简单代码实现。
保存数据和显示数据
将 URL-Method-Params-Status-Title-Length 格式的数据保存为 csv 文件还是 txt 文件?后面还有问题需要考虑。您需要对这些目标资源进行分类吗?未分类的数据量太大,除非对每个URL的请求量进行压缩,或者分类,这些都是fuzzing时需要考虑的事情。
目前我们只需要考虑保存数据的可读性,具体点就是阅读的舒适度。以后fuzz可能保存为txt或csv,但目前我个人更喜欢保存为py,因为编辑器读起来很舒服。
参考csv、txt和tsv数据文件的异同,以及如何使用Python读取和生成: 一般来说,为了更好的处理多种语言的数据,建议将数据保存为csv格式(csv文件之间用逗号隔开)后缀可以直接改成其他类型的文件),可以同时在excle、python、matlab、sas、R等语言中自由切换,数据格式没有损坏!
选择:将 URL-Method-Params-Status-Title-Length 格式的数据保存为 csv 文件。
这一天即将结束。回顾那天,没有实质性的结果。编写爬虫是目标,其他一切都是假的。
第 2 章垂直搜索爬虫
根据使用场景,爬虫分为通用搜索爬虫和垂直搜索爬虫。垂直搜索爬虫在运行时尽量只爬取与需求相关的网页信息。这里主要使用垂直搜索爬虫。
安装 Scrapy 爬虫框架
参考Windows环境下安装Scrapy框架的步骤,本地一步执行命令pip3 install scrapy。
创建并启动 Scrapy 爬虫项目
开发一个Scrapy爬虫项目,需要使用Scrapy命令创建一个爬虫项目,这是一个半成品的爬虫项目。在命令行创建爬虫项目的步骤如下
创建爬虫项目:scrapy startproject 项目名称切换到项目根目录创建爬虫文件:scrapy genspider 爬虫名称启动爬虫项目的网址:scrapy crawl 爬虫名称
#创建爬虫项目并运行爬虫
scrapy startproject helloSpider
cd helloSpider
scrapy genspider test http://127.0.0.1/DVWA-master/
scrapy crawl test # 工程根目录执行
#执行回显模块
[scrapy.utils.log]
[scrapy.crawler]
[scrapy.extensions.telnet]
[scrapy.middleware]
[scrapy.core.engine]
[scrapy.extensions.logstats]
[scrapy.downloadermiddlewares.retry]
[scrapy.downloadermiddlewares.robotstxt]
# helloSpider/spiders/test.py文件
import scrapy
class TestSpider(scrapy.Spider):
name = 'test'
allowed_domains = ['http://127.0.0.1/DVWA-master/']
start_urls = ['http://http://127.0.0.1/DVWA-master//']
def parse(self, response):
pass
部分执行结果如下,可以看到打印的内容有点混乱。
整体把握scrapy项目
创建项目的文件结构如下,项目配置文件scrapy.cfg进行了过滤,因为开发爬虫的时候不需要修改这个文件。如图所示,Scrapy爬虫项目主要由5个模块组成:爬虫、items模块、中间件模块、数据存储模块、配置模块,然后对各个模块进行简单说明。
Scrapy框架的引擎和调度器暂时忽略
#流程图代码
graph TB
A(项目根目录helloSpider)
B(helloSpider)
B3(spiders)
B4(items.py)
B5(middlewares.py)
B6(pipelines.py)
B7(settings.py)
A-->B
B-->B3
B-->B4
B-->B5
B-->B6
B-->B7
b31(test.py)
B3-->b31
(1)spiders文件夹:是Scrapy爬虫项目的爬虫模块,可以有多个爬虫文件。设计理念是方便一站一个爬虫,爬虫可以共享项目中的其他模块以提高重用和开发效率。
爬虫文件的内容一目了然。值得注意的是,爬虫默认是无状态的,所以Scrapy框架允许你通过覆盖爬虫文件中的start_requests()方法来自定义爬虫起始页的爬取设置。
(2)items.py 文件:爬取的数据可能需要在模块之间进行传输,所以items.py 中定义了统一的数据格式。
(3)pipelines.py 文件:Pipeline的意思是管道,是框架中的一个数据处理模块,经常用来完成数据的持久化,也可以对爬取的数据进行过滤和去重。
(4)middlewares.py文件:Middlewares就是中间件,中间件的存在方便了爬虫框架的功能扩展。在Scrapy爬虫框架中,中间件分为下载器和蜘蛛两大类。
(5)settings.py文件:Settings模块负责设置爬虫行为模式、模块激活等配置功能,是爬虫框架中非常重要的一个模块。列举一些开发中常用的配置:
管道模块的启动和激活顺序配置蜘蛛抓取网页数据的频率、默认headers等属性配置启动或关闭指定蜘蛛中间件配置、下载器中间件配置爬虫请求流程
结合第3章的部分内容,列出执行过程。
# 流程图代码
graph TB
a(启动爬虫)
b(引擎访问start_urls获取URL)
c(引擎调用Downloader模块下载网页)
d(引擎把下载结果传递给Spider的parse方法)
e(用户处理Response类对象response提取数据)
a-->b
b-->c
c-->d
d-->e
下一章3的内容最终会涉及到爬虫的编写和登陆(数据处理和数据存储)的问题
目前了解scrapy项目的执行流程,但是不知道scrapy引擎是怎么运行的,scrapy的入口文件是哪个,尤其是如何定义request类,这些对二次开发非常重要。那么接下来,审计scrapy框架的源代码。
审计scrapy框架
让审计先行,主要目标是定制爬虫,不要迷失在知识的海洋中。
框架文件和入口文件,显然入口文件是__main__.py文件:
请求类Request:查看scrapy根目录下的http文件夹。该目录下的__init__.py文件定义了请求类:class Request(object_ref)
scrapy通过Request类对象发起请求,参考:scrapy中的python-Request参数。
第三章:数据抽取和多级网络爬取,明确进度和目标
第 2 章重写了 start_requests(self) 方法。test.py 文件中收录以下变量,这些变量会随着目标的变化而变化:
当前爬虫变量的描述
allowed_domains
允许抓取的 URL。如果不定义,所有网页都会被抓取,即通用搜索爬虫
起始网址
爬虫起始页
饼干
验证
完成第一次网页访问后,本章需要完成两个任务:数据筛选和提取,以及多级网页爬取。
响应对象
爬虫访问网页后,将收录网页结果的响应对象返回给 parse() 方法。其常用属性和方法如下:
属性或方法描述
网址
当前返回页面对应的url
地位
c爬虫抓取网页数据(模拟浏览器发送请求,获取服务器响应的文件3、解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-14 11:28
b) 处理后的请求可以模拟浏览器发送的请求,获取服务器响应的文件
3、 解析服务器响应内容
a) re, xpath, beautifulSoup4(bs4), jsonpath, pyquery
b) 使用某种描述语言为我们需要提取的数据定义一个匹配规则,符合这个规则的数据就会匹配
4、如何处理采集动态HTML和验证码
a) 通用动态页面采集,Selenium+Phantomjs(无接口):模拟真实浏览器加载js,Ajax非静态页面数据
b) tesseract:机器学习库,机器图像识别系统,可以处理简单的验证码,复杂的验证码可以手动输入,编码平台
5、 Scrapy 框架(Scrapy、Pyspider)
高定制和高性能(异步网络框架扭曲),所以数据下载速度非常快,提供数据存储、数据下载、提取规则等组件
6、 分布式策略:
a)scrapy redis,在scrapy的基础上,增加了一套以redis数据库为核心的组件
b) 功能:主要做请求指纹去重、请求分发、数据在redis中的临时存储
7、 爬虫、反爬虫、反爬虫斗争:
a) 爬虫最头疼的不是复杂的页面,而是网站背后的另一个人
反爬虫:用户代理、代理、验证码、动态数据加载、加密数据
反爬虫主要看数据的价值,做反爬虫是否值得
主要考虑以下几个方面:机器成本+人工成本“数据价值,倒也不是,一般IP封堵结束
通用爬虫专注爬虫
1、万能爬虫:搜索引擎的爬虫系统
-1 目的:尽可能下载互联网上所有的网页,放到本地服务器上形成备份,然后对这些网页进行相应的处理(提取关键词,去除广告),最后提供一个借口要登录的用户
-2 抓取过程:
一种。优先选择一部分已有的网址,将这些网址放入待抓取的队列中
湾 从队列中取出这些URL,然后解析DNS得到主机IP,然后去这个IP对应的服务器下载HTML页面,保存到搜索引擎对应的服务器,然后把爬取到的URL进入抓取队列
C。分析这些网页的内容,找出网页中的其他网址链接,继续执行第二部分,直到爬虫条件结束
-3、搜索引擎如何获取新的网站 URL?
1、 主动提交网址给搜索引擎(百度连接提交)
2、在其他网站中设置外部链接:
3、搜索引擎会与DNS服务商合作,可以快速收录new网站
DNS:是一种将域名解析为IP的技术
-4、万能爬虫不是万能的,也需要遵守规则
机器人协议:协议会规定一般爬虫爬取网页的权限
Robots.txt 只是一个建议,不是所有爬虫都关注,只有大型搜索引擎爬虫需要关注
-5 一般爬虫工作流程:抓取网页、存储数据、内容处理、提供索引/排名服务
-6、搜索引擎排名:
一种。PageRank:根据网站流量统计(点击量/浏览量/流行度),流量越高
湾 竞价排名:谁出的钱越多,谁的排名就越高
-7、 一般爬虫的缺点:
1、 只能提供文本相关内容(HTML\WORD\PDF)等,不能提供多媒体、二进制
2、 上一篇提供的结果都是一样的,不要等不同背景的人提供不同的搜索结果
3、无法理解人类语义的检索
为了解决这个问题,出现了聚焦爬虫:
专注于爬虫:爬虫程序员针对某个内容编写的爬虫
面向主题的爬虫,面向需求的爬虫:会针对特定的内容爬取信息,并且会尽可能保证信息和需求的相关性 查看全部
c爬虫抓取网页数据(模拟浏览器发送请求,获取服务器响应的文件3、解析)
b) 处理后的请求可以模拟浏览器发送的请求,获取服务器响应的文件
3、 解析服务器响应内容
a) re, xpath, beautifulSoup4(bs4), jsonpath, pyquery
b) 使用某种描述语言为我们需要提取的数据定义一个匹配规则,符合这个规则的数据就会匹配
4、如何处理采集动态HTML和验证码
a) 通用动态页面采集,Selenium+Phantomjs(无接口):模拟真实浏览器加载js,Ajax非静态页面数据
b) tesseract:机器学习库,机器图像识别系统,可以处理简单的验证码,复杂的验证码可以手动输入,编码平台
5、 Scrapy 框架(Scrapy、Pyspider)
高定制和高性能(异步网络框架扭曲),所以数据下载速度非常快,提供数据存储、数据下载、提取规则等组件
6、 分布式策略:
a)scrapy redis,在scrapy的基础上,增加了一套以redis数据库为核心的组件
b) 功能:主要做请求指纹去重、请求分发、数据在redis中的临时存储
7、 爬虫、反爬虫、反爬虫斗争:
a) 爬虫最头疼的不是复杂的页面,而是网站背后的另一个人
反爬虫:用户代理、代理、验证码、动态数据加载、加密数据
反爬虫主要看数据的价值,做反爬虫是否值得
主要考虑以下几个方面:机器成本+人工成本“数据价值,倒也不是,一般IP封堵结束
通用爬虫专注爬虫
1、万能爬虫:搜索引擎的爬虫系统
-1 目的:尽可能下载互联网上所有的网页,放到本地服务器上形成备份,然后对这些网页进行相应的处理(提取关键词,去除广告),最后提供一个借口要登录的用户
-2 抓取过程:
一种。优先选择一部分已有的网址,将这些网址放入待抓取的队列中
湾 从队列中取出这些URL,然后解析DNS得到主机IP,然后去这个IP对应的服务器下载HTML页面,保存到搜索引擎对应的服务器,然后把爬取到的URL进入抓取队列
C。分析这些网页的内容,找出网页中的其他网址链接,继续执行第二部分,直到爬虫条件结束
-3、搜索引擎如何获取新的网站 URL?
1、 主动提交网址给搜索引擎(百度连接提交)
2、在其他网站中设置外部链接:
3、搜索引擎会与DNS服务商合作,可以快速收录new网站
DNS:是一种将域名解析为IP的技术
-4、万能爬虫不是万能的,也需要遵守规则
机器人协议:协议会规定一般爬虫爬取网页的权限
Robots.txt 只是一个建议,不是所有爬虫都关注,只有大型搜索引擎爬虫需要关注
-5 一般爬虫工作流程:抓取网页、存储数据、内容处理、提供索引/排名服务
-6、搜索引擎排名:
一种。PageRank:根据网站流量统计(点击量/浏览量/流行度),流量越高
湾 竞价排名:谁出的钱越多,谁的排名就越高
-7、 一般爬虫的缺点:
1、 只能提供文本相关内容(HTML\WORD\PDF)等,不能提供多媒体、二进制
2、 上一篇提供的结果都是一样的,不要等不同背景的人提供不同的搜索结果
3、无法理解人类语义的检索
为了解决这个问题,出现了聚焦爬虫:
专注于爬虫:爬虫程序员针对某个内容编写的爬虫
面向主题的爬虫,面向需求的爬虫:会针对特定的内容爬取信息,并且会尽可能保证信息和需求的相关性
c爬虫抓取网页数据(网络爬虫有什么用呢?如何学习更多Golang语言? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-13 04:24
)
安利
如果想了解更多Golang语言,请关注我的公众号。我会第一时间发送文章到公众号,第一时间拿到学习资料。你想学的,我这里都有!!!
添加方法:微信搜索:Golang DreamWorks,或直接扫描下方二维码:
前言
大家好,我是阿松,这是我的第四篇文章原创文章。在这篇文章中,我将介绍网络爬虫系列教程,使用GO和python实现最简单的爬虫---爬虫小说。其实这篇文章就是教大家如何利用妓女。在这个网站的广告环境中,我们想要单纯的看小说已经成了一个难题,于是我们可以利用爬虫技术,爬下小说,不用看烦人的广告。话不多说,全开...
什么是爬虫
对于这类问题,我们可以直接上百度百科看介绍。网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者)是一种从万维网上抓取信息的自动程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。看看百度百科介绍的多好,多好理解。
网络爬虫有什么用?网络爬虫是大数据行业数据采集的核心工具。如果没有网络爬虫,日夜自动抓取互联网上的免费数据,而且智能化程度高,那些大数据相关的公司可能不到四分之三。目前的爬虫基本上都是围绕网页进行的,所以我们的爬虫是根据网页地址(URL),也就是我们在浏览器中输入的网站链接来抓取网页的内容。比如我们经常使用百度:,这是一个网址。URL的专业名称是Uniform Resource Locator,格式如下:
协议/主机名[:端口]/路径/[;参数][?查询]#fragment
URL的格式主要由前三部分组成:
所以有了URL,我们就可以到指定的位置去获取我们想要的数据信息了。有了数据,我们就需要对数据进行分析,所以爬虫还有一个必备技能:审查元素。
我们可以在浏览器中查看我们浏览的每一个网页的源代码,也就是HTML。这些 HTML 决定了 网站 的原创外观。HTML的具体使用这里就不介绍了。我想学习的网络资源有很多。比如我们在使用Chrome浏览器的时候,右击查看谷歌主页(其他浏览器不同,这里不介绍),右侧会出现很多代码,这些代码叫做HTML。
浏览器是作为客户端从服务器获取信息,然后解析信息展示给我们。所以我们可以基于HTML来分析网页的内容。好了,基本的基础知识已经知道了,现在就开始我们的练习吧!!!
爬虫示例1. 爬虫网站 小说介绍
在这里的例子中,我们下载文本内容,也就是下载一本小说。小说网站,我们的新笔曲歌。关联:。
这个网站只支持在线浏览,不支持小说打包下载,所以我们可以利用我们的爬虫技术下载小说,解决本地无法阅读小说的问题。因为不看小说,直接上小说排行榜,选了第一名,《三国修行》。名字很吸引人!!!!
2. 相关技术介绍
本教程使用两种语言进行开发,即Golang和Python。对于Golang,我们使用网站内置的HTTP库来获取和google自己的库x/net/html进行网页数据分析。在Python中,我们使用requests库进行网页获取,使用BeautifulSoup进行网页数据分析。
2.1 /x/net/html
x/net/html 是一个由 Google 维护的库。它主要帮助我们解析网页数据。我们只需要导入 /x/net/html 包。使用方法很简单,这里就不做具体介绍了,大家可以去GO Bible:#Parse
学习了,里面有例子,简单易懂。
2.2 美人汤
BeautifulSoup是python的第三方库,主要帮助我们解析网页数据。如果我们要使用这个工具,我们需要提前安装它。在cmd中,我们使用pip命令进行安装,命令如下:
pip 安装 beautifulsoup4
安装完成后,我们还需要安装lxml,这是解析HTML所需的一个依赖:
pip 安装 lxml
这个就可以用了,具体的学习教程可以去官方中文教程:
2.3 个请求
requests库非常强大,我们可以使用requests库进行网络爬虫。requests 库是第三方库,需要我们自己安装。安装很简单,直接使用pip命令安装即可:
pip 安装请求
requests库的github地址:
具体学习可以通过demo来完成。
3. 爬虫步骤
总共分为三个步骤:
4. 开始练习
评论:
我已经将我的整个项目发布到了我的 github 上。Golang代码GitHub地址如下:
Python代码Github地址如下:
4.1 获取网页
我们严格按照步骤操作。第一步,我们首先获取网页数据。因为要获取小说的整章,我们先查看小说目录,查看其网页源码,如下:
网页的解析在下一节解释。我们先获取目录页面,再获取文章页面,这样章节标题和内容对应起来。小说的第一章是这样的:
知道这两个网页的地址,我们就可以得到网页了。
Golang 可以使用标准库 net/http 来获取网页。示例如下:
resp,err := http.Get(target)
if err!=nil{
fmt.Println("get err http",err)
return err
}
直接调用Get方法,目标就是要获取的网页的URL。
Python可以使用requests库来获取网页,示例如下:
req = requests.get(url=target)
req.encoding = 'utf-8'
html = req.text
直接调用get方法就行了,目标是URL,req.tex表示可以把获取到的网站的内容打印出来看更清楚。编码方式设置为utf-8。这次爬取的网站是utf-8编码,不需要转换。如果抓取到的网站是GBK编码的,需要进行编码转换。
4.2 解析网页
获取到网页后,我们将开始解析网页。对于 Golang,我们使用 x/net/html 库,并使用 go get 命令获取第三方库。代码示例如下:
doc,err := html.Parse(resp.Body)
if err != nil{
fmt.Println("html parse err",err)
return err
}
parseList(doc)
直接调用 Parse 方法,将网页数据放入其中,将解析树的根(文档元素)作为 *Node 返回,然后我们可以按照深度优先的顺序处理每个节点标签。
我们首先分析文章目录,提取文章内容对应的文章标题和URL参数。具体分析,我们需要查看部分网页的源码如下:
我们可以看到文章title都在a标签下,href属性存放的是URL参数。,而且都属于div标签,id等于list,这样我们就可以定位到位置了。所以基于这个特征,我们可以进行分析和提取。Golang语言代码如下:
<p>//找到文章列表
func parseList(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "div"{
for _,a := range n.Attr{
if a.Key == "id" && a.Val == "list"{
listFind = true
parseTitle(n)
break
}
}
}
if !listFind{
for c := n.FirstChild;c!=nil;c=c.NextSibling{
parseList(c)
}
}
}
//获取文章头部
func parseTitle(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "a"{
for _, a := range n.Attr {
if a.Key == "href"{
//获取文章title
for c:=n.FirstChild;c!=nil;c=c.NextSibling{
buf.WriteString(c.Data+ "\n")
}
url := a.Val
target := server + url // 得到 文章url
everyChapter(target)
num--
}
}
}
if num 查看全部
c爬虫抓取网页数据(网络爬虫有什么用呢?如何学习更多Golang语言?
)
安利
如果想了解更多Golang语言,请关注我的公众号。我会第一时间发送文章到公众号,第一时间拿到学习资料。你想学的,我这里都有!!!
添加方法:微信搜索:Golang DreamWorks,或直接扫描下方二维码:
前言
大家好,我是阿松,这是我的第四篇文章原创文章。在这篇文章中,我将介绍网络爬虫系列教程,使用GO和python实现最简单的爬虫---爬虫小说。其实这篇文章就是教大家如何利用妓女。在这个网站的广告环境中,我们想要单纯的看小说已经成了一个难题,于是我们可以利用爬虫技术,爬下小说,不用看烦人的广告。话不多说,全开...
什么是爬虫
对于这类问题,我们可以直接上百度百科看介绍。网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者)是一种从万维网上抓取信息的自动程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。看看百度百科介绍的多好,多好理解。
网络爬虫有什么用?网络爬虫是大数据行业数据采集的核心工具。如果没有网络爬虫,日夜自动抓取互联网上的免费数据,而且智能化程度高,那些大数据相关的公司可能不到四分之三。目前的爬虫基本上都是围绕网页进行的,所以我们的爬虫是根据网页地址(URL),也就是我们在浏览器中输入的网站链接来抓取网页的内容。比如我们经常使用百度:,这是一个网址。URL的专业名称是Uniform Resource Locator,格式如下:
协议/主机名[:端口]/路径/[;参数][?查询]#fragment
URL的格式主要由前三部分组成:
所以有了URL,我们就可以到指定的位置去获取我们想要的数据信息了。有了数据,我们就需要对数据进行分析,所以爬虫还有一个必备技能:审查元素。
我们可以在浏览器中查看我们浏览的每一个网页的源代码,也就是HTML。这些 HTML 决定了 网站 的原创外观。HTML的具体使用这里就不介绍了。我想学习的网络资源有很多。比如我们在使用Chrome浏览器的时候,右击查看谷歌主页(其他浏览器不同,这里不介绍),右侧会出现很多代码,这些代码叫做HTML。
浏览器是作为客户端从服务器获取信息,然后解析信息展示给我们。所以我们可以基于HTML来分析网页的内容。好了,基本的基础知识已经知道了,现在就开始我们的练习吧!!!
爬虫示例1. 爬虫网站 小说介绍
在这里的例子中,我们下载文本内容,也就是下载一本小说。小说网站,我们的新笔曲歌。关联:。
这个网站只支持在线浏览,不支持小说打包下载,所以我们可以利用我们的爬虫技术下载小说,解决本地无法阅读小说的问题。因为不看小说,直接上小说排行榜,选了第一名,《三国修行》。名字很吸引人!!!!
2. 相关技术介绍
本教程使用两种语言进行开发,即Golang和Python。对于Golang,我们使用网站内置的HTTP库来获取和google自己的库x/net/html进行网页数据分析。在Python中,我们使用requests库进行网页获取,使用BeautifulSoup进行网页数据分析。
2.1 /x/net/html
x/net/html 是一个由 Google 维护的库。它主要帮助我们解析网页数据。我们只需要导入 /x/net/html 包。使用方法很简单,这里就不做具体介绍了,大家可以去GO Bible:#Parse
学习了,里面有例子,简单易懂。
2.2 美人汤
BeautifulSoup是python的第三方库,主要帮助我们解析网页数据。如果我们要使用这个工具,我们需要提前安装它。在cmd中,我们使用pip命令进行安装,命令如下:
pip 安装 beautifulsoup4
安装完成后,我们还需要安装lxml,这是解析HTML所需的一个依赖:
pip 安装 lxml
这个就可以用了,具体的学习教程可以去官方中文教程:
2.3 个请求
requests库非常强大,我们可以使用requests库进行网络爬虫。requests 库是第三方库,需要我们自己安装。安装很简单,直接使用pip命令安装即可:
pip 安装请求
requests库的github地址:
具体学习可以通过demo来完成。
3. 爬虫步骤
总共分为三个步骤:
4. 开始练习
评论:
我已经将我的整个项目发布到了我的 github 上。Golang代码GitHub地址如下:
Python代码Github地址如下:
4.1 获取网页
我们严格按照步骤操作。第一步,我们首先获取网页数据。因为要获取小说的整章,我们先查看小说目录,查看其网页源码,如下:
网页的解析在下一节解释。我们先获取目录页面,再获取文章页面,这样章节标题和内容对应起来。小说的第一章是这样的:
知道这两个网页的地址,我们就可以得到网页了。
Golang 可以使用标准库 net/http 来获取网页。示例如下:
resp,err := http.Get(target)
if err!=nil{
fmt.Println("get err http",err)
return err
}
直接调用Get方法,目标就是要获取的网页的URL。
Python可以使用requests库来获取网页,示例如下:
req = requests.get(url=target)
req.encoding = 'utf-8'
html = req.text
直接调用get方法就行了,目标是URL,req.tex表示可以把获取到的网站的内容打印出来看更清楚。编码方式设置为utf-8。这次爬取的网站是utf-8编码,不需要转换。如果抓取到的网站是GBK编码的,需要进行编码转换。
4.2 解析网页
获取到网页后,我们将开始解析网页。对于 Golang,我们使用 x/net/html 库,并使用 go get 命令获取第三方库。代码示例如下:
doc,err := html.Parse(resp.Body)
if err != nil{
fmt.Println("html parse err",err)
return err
}
parseList(doc)
直接调用 Parse 方法,将网页数据放入其中,将解析树的根(文档元素)作为 *Node 返回,然后我们可以按照深度优先的顺序处理每个节点标签。
我们首先分析文章目录,提取文章内容对应的文章标题和URL参数。具体分析,我们需要查看部分网页的源码如下:
我们可以看到文章title都在a标签下,href属性存放的是URL参数。,而且都属于div标签,id等于list,这样我们就可以定位到位置了。所以基于这个特征,我们可以进行分析和提取。Golang语言代码如下:
<p>//找到文章列表
func parseList(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "div"{
for _,a := range n.Attr{
if a.Key == "id" && a.Val == "list"{
listFind = true
parseTitle(n)
break
}
}
}
if !listFind{
for c := n.FirstChild;c!=nil;c=c.NextSibling{
parseList(c)
}
}
}
//获取文章头部
func parseTitle(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "a"{
for _, a := range n.Attr {
if a.Key == "href"{
//获取文章title
for c:=n.FirstChild;c!=nil;c=c.NextSibling{
buf.WriteString(c.Data+ "\n")
}
url := a.Val
target := server + url // 得到 文章url
everyChapter(target)
num--
}
}
}
if num

