c爬虫抓取网页数据(零基础快速入门的学习路径——Python中爬虫相关)
优采云 发布时间: 2021-10-23 08:11c爬虫抓取网页数据(零基础快速入门的学习路径——Python中爬虫相关)
参考视频教程:
**Python爬虫工程师从入门到高级**
图片
互联网上的数据爆炸式增长,使用Python爬虫我们可以获得很多有价值的数据:
1. 爬取数据,进行市场调研和商业分析
抓取知乎优质回答,筛选每个话题下的最佳内容;爬取房产网站交易信息,分析房价走势,做不同区域的房价分析;爬取招聘网站 职位信息,分析各行业的人才需求和薪资水平。
2.作为机器学习和数据挖掘的原创数据
比如你想做一个推荐系统,那么你可以爬取更多维度的数据,做一个更好的模型。
3. 爬取优质资源:图片、文字、视频
爬取商品(店铺)评论和各种图片网站,获取图片资源和评论文字数据。
掌握正确的方法能够在短时间内抓取主流网站数据,其实很容易实现。
但建议您从一开始就有一个特定的目标。在目标的驱动下,您的学习将更加精准和高效。这是一个平滑的、从零开始的快速入门学习路径:
1.了解爬虫的基本原理和流程
2.Requests+Xpath实现一般爬虫例程
3.理解非结构化数据的存储
4.应对特殊的网站反爬虫措施
5.Scrapy 和 MongoDB,高级分布式
大多数爬虫都遵循“发送请求-获取页面-解析页面-提取并存储内容”的过程。这实际上模拟了使用浏览器获取网页信息的过程。
简单的说,我们向服务器发送请求后,会得到返回的页面。解析完页面后,我们就可以提取出我们想要的那部分信息,存放在指定的文档或数据库中。
这部分可以简单的了解一下HTTP协议和网页的基础知识,比如POST\GET、HTML、CSS、JS,简单了解一下,无需系统学习。
Python中有很多爬虫相关的包:urllib、requests、bs4、scrapy、pyspider等,建议从requests+Xpath入手。Requests 负责连接到 网站 并返回网页。Xpath 用于解析网页以方便提取数据。
如果你用过 BeautifulSoup,你会发现 Xpath 省去了很多麻烦。逐层检查元素代码的工作全部省略。掌握了之后,你会发现爬虫的基本套路都差不多。一般静态 网站 根本不是问题。小猪,豆瓣,尴尬百科,腾讯新闻等基本都可以用。
我们来看一个爬取豆瓣短评论的例子:
图片
选择第一条短评论,右键-》勾选,即可查看源码
图片
复制短评论信息的XPath信息
图片
通过定位,我们得到了第一个短评论XPath信息:
图片
如果我们想抓取大量的短评论,那么自然我们应该得到(复制)更多这样的XPath:
图片
观察第3条短注释1、2、的XPath,你会发现模式,只是后面的序号不同,正好对应短注释的序号。那么如果我们想抓取这个页面上的所有短评论信息,那么就不需要这个序列号了。
通过XPath信息,我们可以用简单的代码爬下来:
图片
图片
该页面的所有短评论信息都被爬取了
当然,如果你需要爬取异步加载的网站,可以学习浏览器抓包来分析真实请求,或者学习Selenium来实现自动爬取。这样,知乎、、TripAdvisor等网站基本没问题。
您还需要了解 Python 的基础知识,例如:
文件读写操作:用于读取参数和保存爬取的内容
list(列表)、dict(字典):用于对爬取的数据进行序列化
条件判断(if/else):解决爬虫中的判断是否执行
循环和迭代(for ……while):用于循环爬虫步骤
爬回来的数据可以直接以文档的形式存储在本地,也可以存储在数据库中。
当数据量较小时,可以直接通过Python语法或pandas方法将数据保存为文本或csv文件。继续上面的例子:
使用Python基础语言实现存储:
图片
使用pandas语言来存储:
图片
这两段代码都可以存储爬取的短评论信息,并将代码粘贴到爬取代码的后面。
图片
为该页面存储的短评论数据
当然,你可能会发现爬回来的数据不干净,可能有缺失、错误等,你也需要清理数据,可以学习pandas包,掌握以下知识点:
缺失值处理:删除或填充缺失数据行
重复值处理:判断和删除重复值
空格和异常值的处理:清除不必要的空格和极端和异常数据
数据分组:数据划分、功能分开执行、数据重组
爬取一页的数据没问题,但是我们通常要爬取多个页面。
这时候就需要看看翻页时url是如何变化的,或者以短评论页面为例,我们来看看多页url的区别:
图片
通过前四页,我们可以找到图案,不同的页面,但页面的序号被标记在最后。以抓取5个页面为例,只写一个循环更新页面地址即可。
图片
当然,爬取过程中也会有一些绝望,比如被网站屏蔽,比如各种奇怪的验证码,userAgent访问限制,各种动态加载等等。
遇到这些反爬虫方法,当然需要一些高级技巧来应对,比如访问频率控制、代理IP池的使用、抓包、验证码的OCR处理等等。
比如我们经常发现有些网站的URL在翻页后没有变化,通常是异步加载。我们使用开发者工具分析页面加载信息,通常可以获得意想不到的收获。
图片
通过开发者工具分析加载的信息。比如我们发现网页无法通过代码访问,我们可以尝试添加userAgent信息,甚至浏览器的cookie信息。
往往网站在高效开发和反爬虫之间偏向于前者,这也为爬虫提供了空间。掌握这些反爬虫技巧,大部分网站对你来说不再难。
Scrapy 和 MongoDB,高级分布式
掌握了之前的技术,一般量级的数据和代码基本没有问题,但是在非常复杂的情况下,可能还是做不到自己想做的。这时候,强大的scrapy框架就非常有用了。
Scrapy 是一个非常强大的爬虫框架。它不仅可以方便地构造请求,还拥有强大的选择器,可以轻松解析响应。不过,最让人惊喜的是它的超高性能,可以让你设计爬虫。,模块化。
图片
出租信息的分布式爬取
需要爬取的数据量很大,自然需要一个数据库。MongoDB 可以方便您存储*敏*感*词*数据。因为这里要用到的数据库知识其实很简单,主要是如何存储数据,如何提取,需要的时候学习。
图片
MongoDB 存储作业信息
分布式这个东西听起来很吓人,但实际上,它是利用多线程的原理,让多个爬虫同时工作。你需要掌握Scrapy+MongoDB+Redis这三个工具。
Scrapy用于基本的页面爬取,MongoDB用于存储爬取的数据,Redis用于存储待爬取的网页队列,即任务队列。
这时候就已经可以写分布式爬虫了。
你看,有了这个学习路径,你已经可以成为一个老司机了,非常顺利。所以一开始尽量不要系统地啃东西,找个实际的项目(可以从豆瓣、小猪等简单的东西开始),直接开始。
因为爬虫技术不需要你系统地精通一门语言,也不需要非常先进的数据库技术。高效的姿势就是从实际项目中学习这些零散的知识点,保证每次都能学到。是最需要的部分。
当然,唯一的麻烦是在具体问题中,如何找到具体需要的那部分学习资源,如何筛选筛选,是很多初学者面临的一大难题。
不过不用担心,我们准备了非常系统的爬虫课程。除了为您提供清晰的学习路径,我们精选了最实用的学习资源和海量的主流爬虫案例库。在很短的学习时间内,你将能够很好地掌握爬虫技巧,得到你想要的数据。
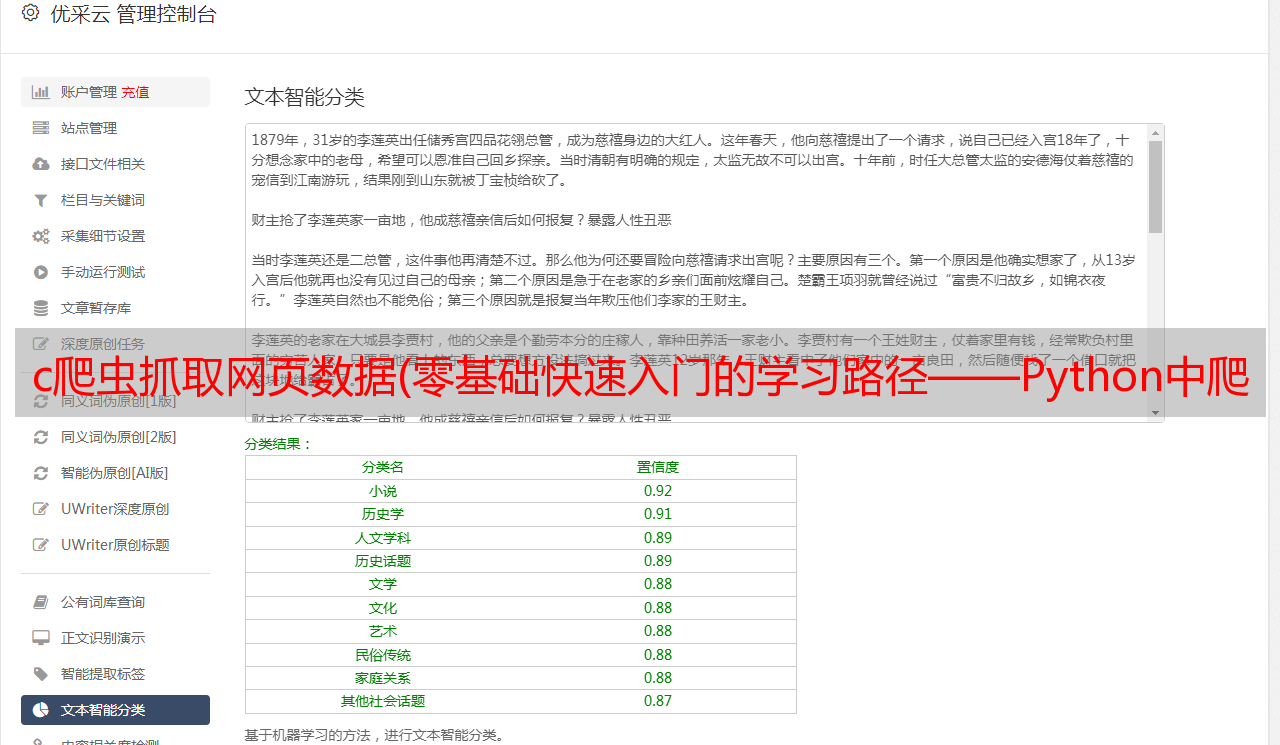
《Python爬虫:入门+进阶》大纲
第 1 章:Python 爬虫入门
1、什么是爬虫
URL组合和翻页机制
网页源码结构及网页请求流程
爬虫的应用及基本原理
2、认识Python爬虫
Python爬虫环境搭建

