
网页采集器的自动识别算法
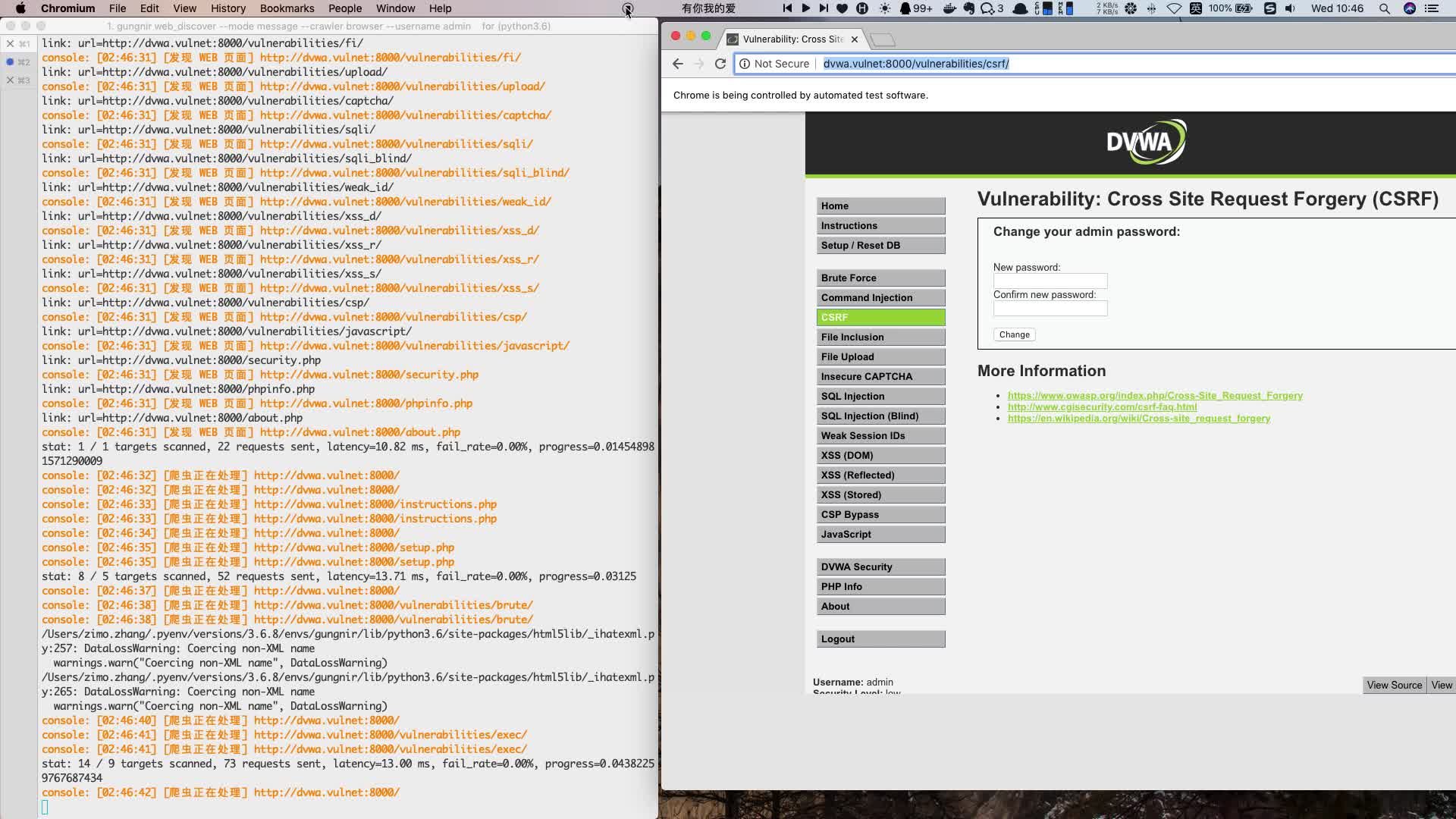
网页采集器的自动识别算法(优采云采集器可以进行自动翻页,登录成功之后就能进行数据采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-12-07 09:24
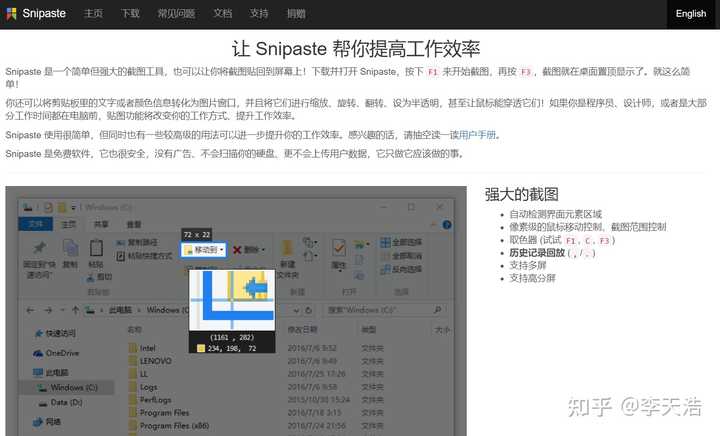
在智能模式下,优采云采集器可以自动翻页,所以输入的URL应该已经完成了搜索操作,显示出最终需要采集内容的页面(或需要 采集 的多个连续页面)。
例如:单个网址采集,在爱奇艺中搜索“极限挑战”,打开对应页面,将网址复制粘贴到软件中即可。
4、选择页面类型并设置分页
在智能模式下,优采云采集器默认会识别列表类型。如果输入单页类型,此时会出现识别错误;或者其他原因,即使是列表类型的网页,智能识别也可能存在偏差。这时候可以先手动自动识别。如果手动自动识别不起作用,您可以手动点击列表来辅助软件识别正确的结果。
5、登录前
在数据采集的过程中,我们有时会遇到需要登录才能查看内容的网页。这时候就需要用到预登录功能了。登录成功后就可以进行正常的数据采集。
6、切换浏览器模式
在数据采集的过程中,可以使用不同的浏览器模式来优化采集的效果,具体的使用场景需要根据实际情况来判断。
7、设置提取字段
在智能模式下,软件会自动识别网页中的数据并显示到采集结果预览窗口。用户可以根据自己的需要设置字段。只需单击鼠标右键。
8、采集 任务设置
在启动采集任务之前,我们需要设置采集任务,包括一些定时启动、防阻塞、自动导出、加速引擎。
9、抗屏蔽
防屏蔽功能有多种设置,用户可以通过多种方式达到防屏蔽或防攀爬的目的。
10、自动导出
自动导出功能可以将采集的结果与数据采集同时自动发布到数据库中,无需等待任务结束才导出数据。自动入库功能结合定时采集功能,可以大大节省时间,提高工作效率。
11、 完成以上操作后,点击开始按钮或返回页面点击保存。
上面介绍的内容是关于优采云采集器正确输入URL的方法,不知道大家有没有学过,如果你也遇到这样的问题,可以根据小编的方法,希望能帮助大家解决问题,谢谢!!!更多软件教程请关注Win10镜像官网~~~ 查看全部
网页采集器的自动识别算法(优采云采集器可以进行自动翻页,登录成功之后就能进行数据采集)
在智能模式下,优采云采集器可以自动翻页,所以输入的URL应该已经完成了搜索操作,显示出最终需要采集内容的页面(或需要 采集 的多个连续页面)。
例如:单个网址采集,在爱奇艺中搜索“极限挑战”,打开对应页面,将网址复制粘贴到软件中即可。

4、选择页面类型并设置分页
在智能模式下,优采云采集器默认会识别列表类型。如果输入单页类型,此时会出现识别错误;或者其他原因,即使是列表类型的网页,智能识别也可能存在偏差。这时候可以先手动自动识别。如果手动自动识别不起作用,您可以手动点击列表来辅助软件识别正确的结果。

5、登录前
在数据采集的过程中,我们有时会遇到需要登录才能查看内容的网页。这时候就需要用到预登录功能了。登录成功后就可以进行正常的数据采集。

6、切换浏览器模式
在数据采集的过程中,可以使用不同的浏览器模式来优化采集的效果,具体的使用场景需要根据实际情况来判断。

7、设置提取字段
在智能模式下,软件会自动识别网页中的数据并显示到采集结果预览窗口。用户可以根据自己的需要设置字段。只需单击鼠标右键。

8、采集 任务设置
在启动采集任务之前,我们需要设置采集任务,包括一些定时启动、防阻塞、自动导出、加速引擎。

9、抗屏蔽
防屏蔽功能有多种设置,用户可以通过多种方式达到防屏蔽或防攀爬的目的。

10、自动导出
自动导出功能可以将采集的结果与数据采集同时自动发布到数据库中,无需等待任务结束才导出数据。自动入库功能结合定时采集功能,可以大大节省时间,提高工作效率。

11、 完成以上操作后,点击开始按钮或返回页面点击保存。

上面介绍的内容是关于优采云采集器正确输入URL的方法,不知道大家有没有学过,如果你也遇到这样的问题,可以根据小编的方法,希望能帮助大家解决问题,谢谢!!!更多软件教程请关注Win10镜像官网~~~
网页采集器的自动识别算法(就是优采云采集器官方下载,优采云必备数据采集工具!(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-12-06 05:06
优采云采集器,为朋友提供更丰富的数据采集工具,帮助他们一键采集他们需要的数据内容,带给朋友可视化配置服务帮助朋友轻松获取更多数据,非常方便!
优采云采集器详情
优采云采集器是新一代视觉智能采集器,今天小编就为大家带来优采云采集器的官方下载。 优采云采集器可视化配置,轻松创建,无需编程,智能生成,数据采集从未如此简单,喜欢就下载吧!
优采云采集器功能
零门槛
如果你不懂网络爬虫技术,只要你会上网,就能采集网站数据
多引擎,高速稳定
内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集数据更高效。还内置了JSON引擎,无需分析JSON数据结构,直观选择JSON内容。
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站。
优采云采集器优点
1、优采云采集器为用户提供丰富的网络数据采集功能
2、如果需要复制网页的数据,可以使用本软件采集
3、大部分网页的内容可以直接复制,一键使用采集通过优采云采集器
4、直接输入网址采集,准确采集任何网页内容
5、支持规则设置,自定义采集规则,添加采集字段内容,添加采集网页元素
6、批量采集数据,一键输入多个网址采集
7、软件中显示任务列表,点击直接开始运行采集
8、支持数据查看,可以在软件中查看采集的数据内容,可以导出数据
9、支持字符和词库替换功能,一键编辑采集到正文
优采云采集器亮点
可视化向导
所有采集元素,自动生成采集数据
预定任务
运行时间灵活定义,全自动运行
多引擎支持
支持多种采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
自动识别网页列表、采集字段和分页等
拦截请求
自定义屏蔽域名,方便过滤异地广告,提高采集速度
多数据导出
可以导出到 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等
优采云采集器评价
优采云采集器,为小伙伴提供更强大的数据采集服务,满足小伙伴对数据的需求采集! 查看全部
网页采集器的自动识别算法(就是优采云采集器官方下载,优采云必备数据采集工具!(组图))
优采云采集器,为朋友提供更丰富的数据采集工具,帮助他们一键采集他们需要的数据内容,带给朋友可视化配置服务帮助朋友轻松获取更多数据,非常方便!
优采云采集器详情
优采云采集器是新一代视觉智能采集器,今天小编就为大家带来优采云采集器的官方下载。 优采云采集器可视化配置,轻松创建,无需编程,智能生成,数据采集从未如此简单,喜欢就下载吧!

优采云采集器功能
零门槛
如果你不懂网络爬虫技术,只要你会上网,就能采集网站数据
多引擎,高速稳定
内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集数据更高效。还内置了JSON引擎,无需分析JSON数据结构,直观选择JSON内容。
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站。
优采云采集器优点
1、优采云采集器为用户提供丰富的网络数据采集功能
2、如果需要复制网页的数据,可以使用本软件采集
3、大部分网页的内容可以直接复制,一键使用采集通过优采云采集器
4、直接输入网址采集,准确采集任何网页内容
5、支持规则设置,自定义采集规则,添加采集字段内容,添加采集网页元素
6、批量采集数据,一键输入多个网址采集
7、软件中显示任务列表,点击直接开始运行采集
8、支持数据查看,可以在软件中查看采集的数据内容,可以导出数据
9、支持字符和词库替换功能,一键编辑采集到正文
优采云采集器亮点
可视化向导
所有采集元素,自动生成采集数据
预定任务
运行时间灵活定义,全自动运行
多引擎支持
支持多种采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
自动识别网页列表、采集字段和分页等
拦截请求
自定义屏蔽域名,方便过滤异地广告,提高采集速度
多数据导出
可以导出到 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等
优采云采集器评价
优采云采集器,为小伙伴提供更强大的数据采集服务,满足小伙伴对数据的需求采集!
网页采集器的自动识别算法(【每日一题】基于主题模型和命名实体识别的自动摘要方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-12-05 14:26
基于主题模型和命名实体识别的自动摘要方法 1 命名实体识别
命名实体识别(NER)是信息提取、信息检索、意见挖掘和问答系统等自然语言处理任务中不可或缺的关键技术。它的主要任务是识别文本中代表命名实体的组成部分,包括人物姓名、地名、日期等进行分类,因此也称为命名实体识别和分类(NERC)。
NER方法可以分为:基于规则的方法、基于统计的方法和综合方法。
1. 基于规则的方法
基于规则的方法是早期NER中常用的方法,需要手工构建有限的规则。
基于规则的方法通常依赖于特定的语言特征、领域和文本样式,导致早期 NER 系统的生产周期长,可移植性差。不同领域的系统需要该领域的语言学家构建不同的规则。为了克服这些问题,研究人员尝试使用计算机来自动发现和生成规则。Collins 等人提出的 DLCoTrain 方法。是最具代表性的。该方法基于语料库在预定义的种子规则集上执行无监督训练和迭代生成规则。设置,并使用规则集对语料库中的命名实体进行分类。最终结果表明了该方法的有效性。一般来说,当提取的规则能够准确反映语言现象时,
2.统计方法
机器学习在自然语言领域的兴起,使得基于统计方法的NER研究成为热点。基于统计的方法只需要合适的模型即可在短时间内完成人工标注语料的训练,方便快捷,无需制定规则。. 基于统计方法开发的 NER 系统已迅速成为主流。这样的系统不仅具有更好的性能,而且具有良好的可移植性。跨域移植时,只需要训练一个新的语料库就可以使用该类。有许多机器学习方法可以应用于 NER,例如隐马尔可夫模型 (HMM)、支持向量机 (SVM)、条件随机场 (CRF) 和最大熵。(最大熵,ME)等。
选择更好的特征表示可以有效提高命名实体识别的效果。因此,统计方法对特征选择有更高的要求。根据任务需求,从文本中选择需要的特征,并利用这些特征生成特征向量。具体命名实体的识别存在一定的困难。根据此类实体的特点,对训练语料中收录的语言信息进行统计分析,挖掘出有效特征。
3.综合方法
目前的NER系统采用综合的方法来识别命名实体,避免了单一方法的弊端。结合机器学习和人工知识,将规则知识501引入基于统计的学习方法中,达到过滤和剪枝的效果,从而减少状态搜索空间;同时,算法可以结合各种模型,进一步优化算法,提高命名实体识别的准确率。
自NER提出以来,NER的发展基本经历了从规则到统计的转变。随后又掀起了新一波的深度学习浪潮,让NER在统计机器学习的道路上不断前行。尽管NER的研究成果遍地开花,但仍有一个问题需要解决,尤其是NER在某些特定领域。目前对NER的研究大多固定在调整经典模型、选择更多特征、扩大语料库规模的三角模型上。这值得研究人员反思。
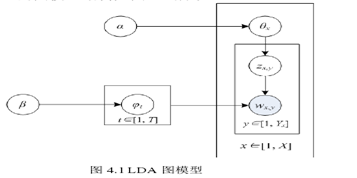
2 LDA主题模型
LDA(Latent Dirichlet Allocation),即隐狄利克雷分布模型是一种无监督的文本主题生成模型。三层包括文本、主题和单词结构。该模型可以有效地从大规模文档集和语料库中提取隐藏主题,并具有良好的降维能力、建模能力和可扩展性。LDA的图模型结构如图4.1所示。
3 基于词的BiLSTM-CRF模型的构建
该方法基于BiLSTM-CRF命名实体识别方法,利用Bi-directional Long Short-Term Memory(BiLSTM)学习句子的上下文信息,并充分考虑标签的依赖性,使得标注过程发生变化的有两个基于BiLSTM-CRF的中文命名实体识别方法:基于词的BiLSTM-CRF方法和基于词的BiLSTM-CRF方法。基于词的命名实体识别方法没有充分考虑文本中词的语义关系,会导致识别效果不佳;基于词的命名实体识别方法需要先对文本中的句子进行切分,分词的结果会直接影响到识别效果。为了克服使用单一模型的缺点,本文将有效地结合基于词和基于词的方法来提高单模型命名实体识别的准确性。结合词模型的命名实体识别标注框架如图4.2所示。该框架主要分为三部分:基于词的BiLSTM-CRF模型(记为CNER)、基于词的BiLSTM-CRF模型(记为WNER)以及结合CNER和WNER两个模型的最终分类器。图中4.2,BiLSTM-L代表BiLSTM层,Projection-L代表投影层,CRF-L代表CRF层,Char Embedding Layer和Word Embedding Layer代表基于词的向量映射层和词,分别。结合词模型的命名实体识别标注框架如图4.2所示。该框架主要分为三部分:基于词的BiLSTM-CRF模型(记为CNER)、基于词的BiLSTM-CRF模型(记为WNER)以及结合CNER和WNER两个模型的最终分类器。图中4.2,BiLSTM-L代表BiLSTM层,Projection-L代表投影层,CRF-L代表CRF层,Char Embedding Layer和Word Embedding Layer代表基于词的向量映射层和词,分别。结合词模型的命名实体识别标注框架如图4.2所示。该框架主要分为三部分:基于词的BiLSTM-CRF模型(记为CNER)、基于词的BiLSTM-CRF模型(记为WNER)以及结合CNER和WNER两个模型的最终分类器。图中4.2,BiLSTM-L代表BiLSTM层,Projection-L代表投影层,CRF-L代表CRF层,Char Embedding Layer和Word Embedding Layer代表基于词的向量映射层和词,分别。基于词的 BiLSTM-CRF 模型(记为 WNER)和结合 CNER 和 WNER 两个模型的最终分类器。图中4.2,BiLSTM-L代表BiLSTM层,Projection-L代表投影层,CRF-L代表CRF层,Char Embedding Layer和Word Embedding Layer代表基于词的向量映射层和词,分别。基于词的 BiLSTM-CRF 模型(记为 WNER)和结合 CNER 和 WNER 两个模型的最终分类器。图中4.2,BiLSTM-L代表BiLSTM层,Projection-L代表投影层,CRF-L代表CRF层,Char Embedding Layer和Word Embedding Layer代表基于词的向量映射层和词,分别。
如图4.2所示,地理位置“中国江苏”作为输入发送到框架中。帧处理后,输出B-LOC和E-LOC的结果,其中B-LOC表示地理位置的开始部分,即“中国”。E-LOC表示去掉了“China”的结尾部分“Jiangsu”,显示了标注框架的有效性。
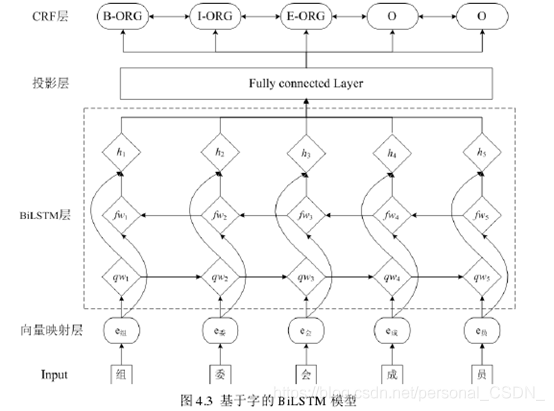
本文基于模型融合的思想,以基于词的BiLSTM-CRF和基于词的BiLSTM-CRF为基础模型。为了避免过拟合,训练集分为两部分。第一部分用于训练基础模型。基础模型训练好后,将后半部分送到训练好的基础模型进行训练,得到词模型。词模型各个投影层的score向量,最后将操作后的score向量拼接起来,作为特征送入最终模型进行训练。词模型和本文中词模型的架构是一样的。每个模型分为4层:向量映射层、BiLSTM层、投影层和CRF层。其中,word模型的架构图如图4.3所示。
4 结合BiLSTM-CRF模型和LDA主题模型的自动摘要4.1 算法思想
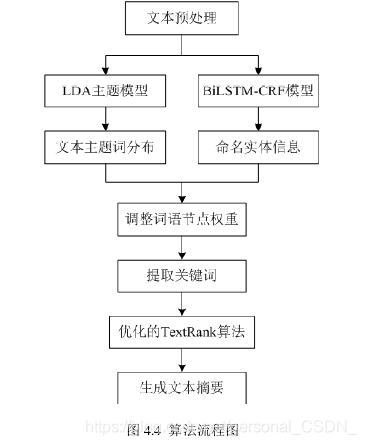
命名实体识别 (NER) 在自然语言处理任务中起着重要作用。本文采用改进的BiLSTM-CRF模型对中文文本中的命名实体进行识别,从而获取文本中有用的人物信息、位置信息和事件。机构信息,在此基础上,调整抽取关键词时构建的TextRank词图中的词节点权重,使关键词抽取的准确率更高;文本摘要旨在准确反映文本主题,但现有的许多自动摘要算法没有考虑文本主题,导致摘要不理想。为了达到自动摘要更贴近文本主题的目的,本章将LDA主题模型引入到文本摘要生成过程中,
4.2 算法实现
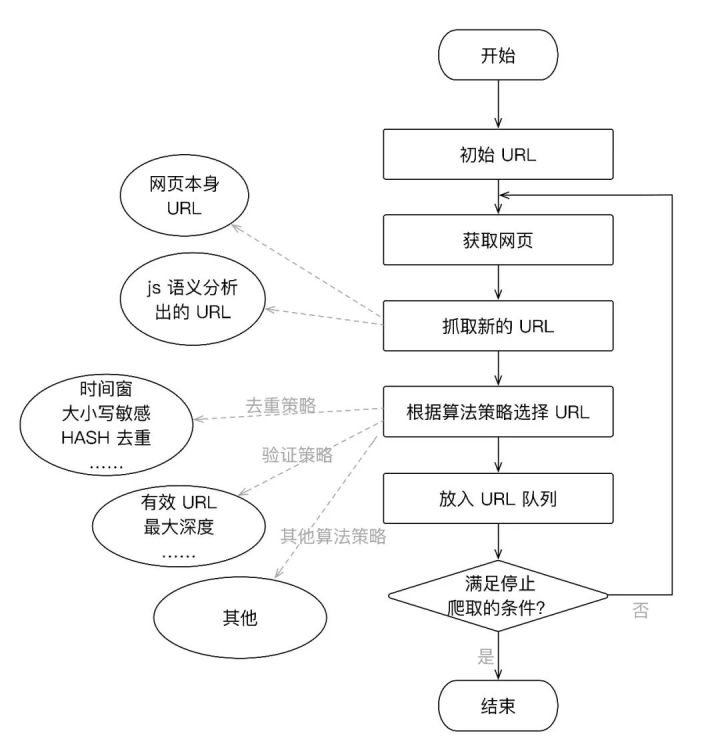
文本摘要算法的流程图如下图所示:
5 实验结果与分析5.1 实验数据与评价标准
LCSTS数据集是目前国内公认的最大的中文数据集。数据集的内容是从新浪微博爬取过滤的标准化文本集。LCSTS数据集的构建为深入研究中文文本摘要奠定了基础。LCSTS数据集由哈尔滨工业大学于2015年发布,主要包括三部分:PARTI、PARTIⅡ、PARTIⅢ。其中PARTI是一个用于测试自动摘要模型的数据集,使用人工标注的分数,分数范围是1到5。分数越大,摘要和短文本的相关性越强,反之,分数越低。两者之间的相关性。为保证实验测试数据集的质量,本文选取得分为“4”和“5”的数据
ROUGE评价方法在自动文本摘要的质量评价中得到了广泛的应用,因此本文采用Rouge指数对算法生成的摘要进行评价。本文选取Rouge-1、Rouge-2、Rouge-3、Rouge-L四个评价指标来评价算法生成的摘要的质量。
5.2 对比实验及结果分析
为了验证本节提出的算法,本文设置了不同算法的对比实验,并将本节方法与降维后的TF-IDF算法、现有优化算法iTextRank和DK- TextRank 基于 TextRank,以及本文中的 SW。-TextRank算法和Topic Model算法61设置对比实验。在LCSTS数据集上进行相应的对比实验,指定生成摘要的压缩率分别为10%和20%。
在LCSTS数据集上进行了两组实验,压缩率为10%,压缩率为20%。
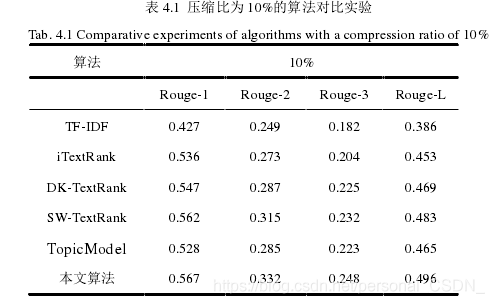
压缩率为10%的实验结果如表4.1所示。
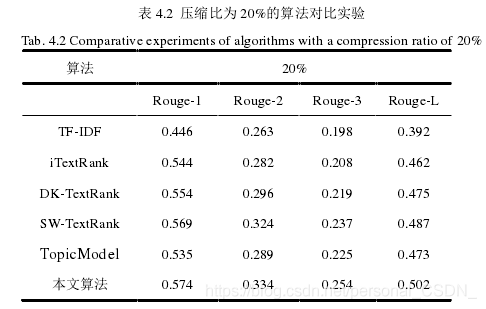
其中,压缩率为20%的算法对比实验结果如表4.2所示。
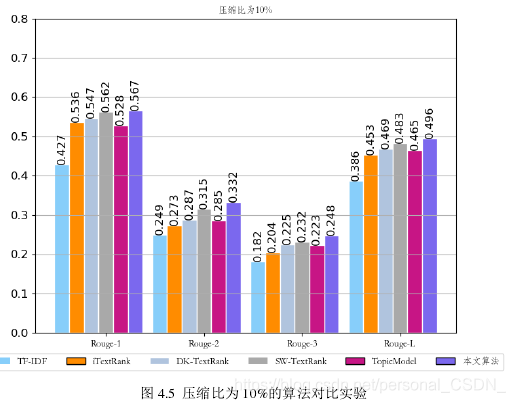
为了更直观的展示,将表中的实验结果集绘制成直方图,如下图所示。图4.5对应表4.1中的实验结果,即压缩率为10%的算法对比实验。
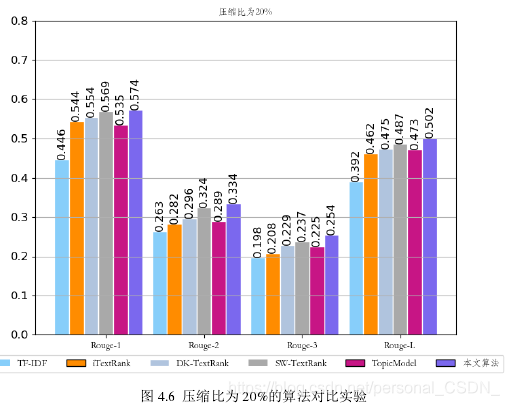
下图4.6对应表4.2中的实验结果,即压缩率为20%的算法对比实验。
5.3 生成汇总比较
对比对照表4.3中的摘要,可以发现这种方法生成的摘要与标准摘要表达的摘要几乎相同,可以非常接近原创主题。虽然它们与标准摘要并不完全相同,但它们基本上不影响它们的表达。文本主题,说明LDA主题模型的引入是有效的;并且摘要的生成能够贴合原文的原创内容,而不会忽略原文中的关键信息,这从侧面说明了BiLSTM-CRF模型的有效性。一般来说,这种方法生成的摘要能较好地反映原文的主旨,语义连贯,易于理解。
6 总结
本章首先详细介绍了命名实体识别和LDA主题模型的相关概念:然后阐述了BiLSTM-CRF模型的研究现状,并在此基础上对模型进行了改进,将基于词和词的BiLSTM-CRF模型被介绍。CRF方法的有效组合,不仅克服了单一方法的缺点,而且提高了实体识别的准确率;然后,将优化后的 BiLSTM-CRF 模型和 LDA 主题模型引入到自动文本摘要过程中。优化提取过程,提高最终文本摘要的质量;最后通过实验验证了该方法的有效性。
对于本站标注“来源:XXX”的文章/图片/视频等稿件,本站转载仅是为了传达更多信息,并不代表同意其观点或确认其内容的真实性. 如涉及作品内容、版权等问题,请联系本站,我们将尽快删除内容! 查看全部
网页采集器的自动识别算法(【每日一题】基于主题模型和命名实体识别的自动摘要方法)
基于主题模型和命名实体识别的自动摘要方法 1 命名实体识别
命名实体识别(NER)是信息提取、信息检索、意见挖掘和问答系统等自然语言处理任务中不可或缺的关键技术。它的主要任务是识别文本中代表命名实体的组成部分,包括人物姓名、地名、日期等进行分类,因此也称为命名实体识别和分类(NERC)。
NER方法可以分为:基于规则的方法、基于统计的方法和综合方法。
1. 基于规则的方法
基于规则的方法是早期NER中常用的方法,需要手工构建有限的规则。
基于规则的方法通常依赖于特定的语言特征、领域和文本样式,导致早期 NER 系统的生产周期长,可移植性差。不同领域的系统需要该领域的语言学家构建不同的规则。为了克服这些问题,研究人员尝试使用计算机来自动发现和生成规则。Collins 等人提出的 DLCoTrain 方法。是最具代表性的。该方法基于语料库在预定义的种子规则集上执行无监督训练和迭代生成规则。设置,并使用规则集对语料库中的命名实体进行分类。最终结果表明了该方法的有效性。一般来说,当提取的规则能够准确反映语言现象时,
2.统计方法
机器学习在自然语言领域的兴起,使得基于统计方法的NER研究成为热点。基于统计的方法只需要合适的模型即可在短时间内完成人工标注语料的训练,方便快捷,无需制定规则。. 基于统计方法开发的 NER 系统已迅速成为主流。这样的系统不仅具有更好的性能,而且具有良好的可移植性。跨域移植时,只需要训练一个新的语料库就可以使用该类。有许多机器学习方法可以应用于 NER,例如隐马尔可夫模型 (HMM)、支持向量机 (SVM)、条件随机场 (CRF) 和最大熵。(最大熵,ME)等。
选择更好的特征表示可以有效提高命名实体识别的效果。因此,统计方法对特征选择有更高的要求。根据任务需求,从文本中选择需要的特征,并利用这些特征生成特征向量。具体命名实体的识别存在一定的困难。根据此类实体的特点,对训练语料中收录的语言信息进行统计分析,挖掘出有效特征。
3.综合方法
目前的NER系统采用综合的方法来识别命名实体,避免了单一方法的弊端。结合机器学习和人工知识,将规则知识501引入基于统计的学习方法中,达到过滤和剪枝的效果,从而减少状态搜索空间;同时,算法可以结合各种模型,进一步优化算法,提高命名实体识别的准确率。
自NER提出以来,NER的发展基本经历了从规则到统计的转变。随后又掀起了新一波的深度学习浪潮,让NER在统计机器学习的道路上不断前行。尽管NER的研究成果遍地开花,但仍有一个问题需要解决,尤其是NER在某些特定领域。目前对NER的研究大多固定在调整经典模型、选择更多特征、扩大语料库规模的三角模型上。这值得研究人员反思。
2 LDA主题模型
LDA(Latent Dirichlet Allocation),即隐狄利克雷分布模型是一种无监督的文本主题生成模型。三层包括文本、主题和单词结构。该模型可以有效地从大规模文档集和语料库中提取隐藏主题,并具有良好的降维能力、建模能力和可扩展性。LDA的图模型结构如图4.1所示。
3 基于词的BiLSTM-CRF模型的构建
该方法基于BiLSTM-CRF命名实体识别方法,利用Bi-directional Long Short-Term Memory(BiLSTM)学习句子的上下文信息,并充分考虑标签的依赖性,使得标注过程发生变化的有两个基于BiLSTM-CRF的中文命名实体识别方法:基于词的BiLSTM-CRF方法和基于词的BiLSTM-CRF方法。基于词的命名实体识别方法没有充分考虑文本中词的语义关系,会导致识别效果不佳;基于词的命名实体识别方法需要先对文本中的句子进行切分,分词的结果会直接影响到识别效果。为了克服使用单一模型的缺点,本文将有效地结合基于词和基于词的方法来提高单模型命名实体识别的准确性。结合词模型的命名实体识别标注框架如图4.2所示。该框架主要分为三部分:基于词的BiLSTM-CRF模型(记为CNER)、基于词的BiLSTM-CRF模型(记为WNER)以及结合CNER和WNER两个模型的最终分类器。图中4.2,BiLSTM-L代表BiLSTM层,Projection-L代表投影层,CRF-L代表CRF层,Char Embedding Layer和Word Embedding Layer代表基于词的向量映射层和词,分别。结合词模型的命名实体识别标注框架如图4.2所示。该框架主要分为三部分:基于词的BiLSTM-CRF模型(记为CNER)、基于词的BiLSTM-CRF模型(记为WNER)以及结合CNER和WNER两个模型的最终分类器。图中4.2,BiLSTM-L代表BiLSTM层,Projection-L代表投影层,CRF-L代表CRF层,Char Embedding Layer和Word Embedding Layer代表基于词的向量映射层和词,分别。结合词模型的命名实体识别标注框架如图4.2所示。该框架主要分为三部分:基于词的BiLSTM-CRF模型(记为CNER)、基于词的BiLSTM-CRF模型(记为WNER)以及结合CNER和WNER两个模型的最终分类器。图中4.2,BiLSTM-L代表BiLSTM层,Projection-L代表投影层,CRF-L代表CRF层,Char Embedding Layer和Word Embedding Layer代表基于词的向量映射层和词,分别。基于词的 BiLSTM-CRF 模型(记为 WNER)和结合 CNER 和 WNER 两个模型的最终分类器。图中4.2,BiLSTM-L代表BiLSTM层,Projection-L代表投影层,CRF-L代表CRF层,Char Embedding Layer和Word Embedding Layer代表基于词的向量映射层和词,分别。基于词的 BiLSTM-CRF 模型(记为 WNER)和结合 CNER 和 WNER 两个模型的最终分类器。图中4.2,BiLSTM-L代表BiLSTM层,Projection-L代表投影层,CRF-L代表CRF层,Char Embedding Layer和Word Embedding Layer代表基于词的向量映射层和词,分别。
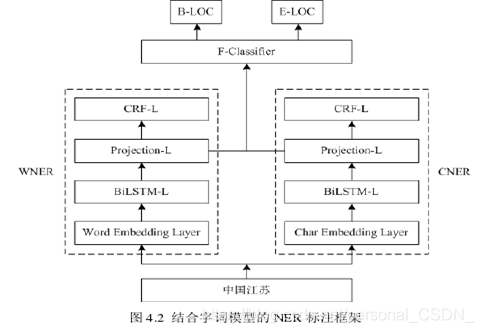
如图4.2所示,地理位置“中国江苏”作为输入发送到框架中。帧处理后,输出B-LOC和E-LOC的结果,其中B-LOC表示地理位置的开始部分,即“中国”。E-LOC表示去掉了“China”的结尾部分“Jiangsu”,显示了标注框架的有效性。
本文基于模型融合的思想,以基于词的BiLSTM-CRF和基于词的BiLSTM-CRF为基础模型。为了避免过拟合,训练集分为两部分。第一部分用于训练基础模型。基础模型训练好后,将后半部分送到训练好的基础模型进行训练,得到词模型。词模型各个投影层的score向量,最后将操作后的score向量拼接起来,作为特征送入最终模型进行训练。词模型和本文中词模型的架构是一样的。每个模型分为4层:向量映射层、BiLSTM层、投影层和CRF层。其中,word模型的架构图如图4.3所示。
4 结合BiLSTM-CRF模型和LDA主题模型的自动摘要4.1 算法思想
命名实体识别 (NER) 在自然语言处理任务中起着重要作用。本文采用改进的BiLSTM-CRF模型对中文文本中的命名实体进行识别,从而获取文本中有用的人物信息、位置信息和事件。机构信息,在此基础上,调整抽取关键词时构建的TextRank词图中的词节点权重,使关键词抽取的准确率更高;文本摘要旨在准确反映文本主题,但现有的许多自动摘要算法没有考虑文本主题,导致摘要不理想。为了达到自动摘要更贴近文本主题的目的,本章将LDA主题模型引入到文本摘要生成过程中,
4.2 算法实现
文本摘要算法的流程图如下图所示:
5 实验结果与分析5.1 实验数据与评价标准
LCSTS数据集是目前国内公认的最大的中文数据集。数据集的内容是从新浪微博爬取过滤的标准化文本集。LCSTS数据集的构建为深入研究中文文本摘要奠定了基础。LCSTS数据集由哈尔滨工业大学于2015年发布,主要包括三部分:PARTI、PARTIⅡ、PARTIⅢ。其中PARTI是一个用于测试自动摘要模型的数据集,使用人工标注的分数,分数范围是1到5。分数越大,摘要和短文本的相关性越强,反之,分数越低。两者之间的相关性。为保证实验测试数据集的质量,本文选取得分为“4”和“5”的数据
ROUGE评价方法在自动文本摘要的质量评价中得到了广泛的应用,因此本文采用Rouge指数对算法生成的摘要进行评价。本文选取Rouge-1、Rouge-2、Rouge-3、Rouge-L四个评价指标来评价算法生成的摘要的质量。
5.2 对比实验及结果分析
为了验证本节提出的算法,本文设置了不同算法的对比实验,并将本节方法与降维后的TF-IDF算法、现有优化算法iTextRank和DK- TextRank 基于 TextRank,以及本文中的 SW。-TextRank算法和Topic Model算法61设置对比实验。在LCSTS数据集上进行相应的对比实验,指定生成摘要的压缩率分别为10%和20%。
在LCSTS数据集上进行了两组实验,压缩率为10%,压缩率为20%。
压缩率为10%的实验结果如表4.1所示。
其中,压缩率为20%的算法对比实验结果如表4.2所示。
为了更直观的展示,将表中的实验结果集绘制成直方图,如下图所示。图4.5对应表4.1中的实验结果,即压缩率为10%的算法对比实验。
下图4.6对应表4.2中的实验结果,即压缩率为20%的算法对比实验。
5.3 生成汇总比较

对比对照表4.3中的摘要,可以发现这种方法生成的摘要与标准摘要表达的摘要几乎相同,可以非常接近原创主题。虽然它们与标准摘要并不完全相同,但它们基本上不影响它们的表达。文本主题,说明LDA主题模型的引入是有效的;并且摘要的生成能够贴合原文的原创内容,而不会忽略原文中的关键信息,这从侧面说明了BiLSTM-CRF模型的有效性。一般来说,这种方法生成的摘要能较好地反映原文的主旨,语义连贯,易于理解。
6 总结
本章首先详细介绍了命名实体识别和LDA主题模型的相关概念:然后阐述了BiLSTM-CRF模型的研究现状,并在此基础上对模型进行了改进,将基于词和词的BiLSTM-CRF模型被介绍。CRF方法的有效组合,不仅克服了单一方法的缺点,而且提高了实体识别的准确率;然后,将优化后的 BiLSTM-CRF 模型和 LDA 主题模型引入到自动文本摘要过程中。优化提取过程,提高最终文本摘要的质量;最后通过实验验证了该方法的有效性。
对于本站标注“来源:XXX”的文章/图片/视频等稿件,本站转载仅是为了传达更多信息,并不代表同意其观点或确认其内容的真实性. 如涉及作品内容、版权等问题,请联系本站,我们将尽快删除内容!
网页采集器的自动识别算法(软件特色可视化操作简单,完全兼容JQuery选择器规则(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-12-05 14:23
vg浏览器不仅是采集浏览器,更是营销神器。vg 浏览器也是一个可视化脚本驱动的网络工具。可以简单的设置脚本,创建自动登录、识别验证等脚本项目。
基本介绍
VG浏览器是一款由可视化脚本驱动的网页自动运行工具。只需设置脚本,即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等个性化实用的脚本项目。还可以使用逻辑运算来完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。
软件特点
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
定制流程
采集 就像积木一样,功能自由组合。
自动编码
程序注重采集的效率,页面解析速度非常快。
生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的按钮
点击一个网页元素,自动生成该元素的CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。例如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器,可以通过按F12键或在页面上右键选择评论元素来选择。
右键单击目标部分并选择复制 CSS 路径以将 CSS 路径复制到剪贴板。
在 Firefox 中,您还可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Only Selector”复制CSS Path。
CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你可以自己编写 CSS Path。
更新日志
8.1.0.1 (2020-09-6)
修复按键指令中引用变量的问题
修复数据库表名纯数字命名时无法通过脚本删除数据的问题
修复键盘命令无法激活最小化窗口的问题
修复脚本下载时金币数量不对的问题 查看全部
网页采集器的自动识别算法(软件特色可视化操作简单,完全兼容JQuery选择器规则(组图))
vg浏览器不仅是采集浏览器,更是营销神器。vg 浏览器也是一个可视化脚本驱动的网络工具。可以简单的设置脚本,创建自动登录、识别验证等脚本项目。
基本介绍
VG浏览器是一款由可视化脚本驱动的网页自动运行工具。只需设置脚本,即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等个性化实用的脚本项目。还可以使用逻辑运算来完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。
软件特点
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
定制流程
采集 就像积木一样,功能自由组合。
自动编码
程序注重采集的效率,页面解析速度非常快。
生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的按钮
点击一个网页元素,自动生成该元素的CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。例如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器,可以通过按F12键或在页面上右键选择评论元素来选择。
右键单击目标部分并选择复制 CSS 路径以将 CSS 路径复制到剪贴板。
在 Firefox 中,您还可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Only Selector”复制CSS Path。
CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你可以自己编写 CSS Path。
更新日志
8.1.0.1 (2020-09-6)
修复按键指令中引用变量的问题
修复数据库表名纯数字命名时无法通过脚本删除数据的问题
修复键盘命令无法激活最小化窗口的问题
修复脚本下载时金币数量不对的问题
网页采集器的自动识别算法(1.中文网页自动分类文本自动化的基础上发展)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-12-05 05:19
1.中文网页自动分类是在自动文本分类的基础上发展起来的。由于自动文本分类技术相对成熟,许多研究工作都尝试使用纯文本分类技术来实现网页分类。孙建涛指出:用纯文本表示网页是困难和不合理的,因为网页所收录的信息比纯文本要丰富得多;以不同的方式表示网页,然后结合分类器的方法可以综合利用网页。但是,每个分类器的性能很难估计,也很难确定使用什么组合策略。董静等。提出了一种基于网页样式、形式和内容的网页形式分类方法,从另一个方面研究网页分类;范忠等。提出了一种简单的贝叶斯协调分类器来合成纯网页文本等结构信息的分类方法;测试结果表明,组合分类器的性能得到了一定程度的提升;杜云奇等人使用线性支持向量机(LSVM)学习算法实现了一个自动中文文本分类系统,该系统还进行了大规模真实文本的测试。结果发现该系统的召回率较低,但准确率较高。论文对结果进行了分析,提出了一种在训练过程中拒绝识别的方法。样本信息改进了分类器的输出。实验表明,该方法有效地提高了系统的性能,取得了满意的效果。陆明宇等。提出了一种网页摘要方法,过滤掉对网页分类有负面影响的干扰信息;刘伟宏【基于内容和链接特征的中文垃圾网页分类】等人提出结合网页内容和链接特征,利用机器学习对中文垃圾网页进行分类检测。实验结果表明,该方法能够有效地对中文垃圾网页进行分类;张毅中提出了一种结合SOFM(自组织特征映射)和LVQ(学习向量量化)的分类算法,用一种新的网页表示方法将特征向量应用于网页分类。该方法充分利用了SOFM自组织的特点,同时利用LVQ解决了聚类中测试样本的重叠问题。实验表明,它不仅具有更高的训练效率,而且具有更好的召回率和准确率;李涛等。将粗糙集理论应用于网页分类,减少已知类别属性的训练集并得出判断规则,然后利用这些规则确定待分类网页的类别。
2中文网页分类关键技术
2.1 网页特征提取
特征提取在中文网页分类的整个过程中非常重要。可以体现网页分类的核心思想。特征提取的效果直接影响分类的质量。特征提取是将词条选择后的词再次提取出来,将那些能够代表网页类别的词提取出来,形成一个向量进行分类。特征提取的方法主要是根据评价函数计算每个条目的值,然后根据每个条目的值对条目进行降序排序,选择那些值较高的条目作为最终特征。特征提取常用的评价函数有文档频率(DF)、信息增益(IG)、互信息(MI)、平方根检验(CHI)、[中文搜索工程中的中文信息处理技术] [自动文本检索的发展] 通过对上述五种经典特征选择方法的实验,结果表明[A文本分类特征选择对比研究】CHI和IG方法最好;DF IG和CHI的表现大致相同,都可以过滤掉85%以上的特征项;DF算法简单,质量高,可用于替代CHI和IG;TS方法性能一般;MI方法的性能最差。进一步的实验结果表明,组合提取方法不仅提高了分类精度,而且显着缩短了分类器的训练时间。
2.2 分类算法
分类算法是分类技术的核心部分。目前中文网页分类算法有很多种,朴素贝叶斯(NB)、K-最近邻(KNN)[超文本分类方法研究]、支持向量机(SVM)[、支持向量机的文本分类: Learning with many]、决策树和神经网络(NN)等。
朴素贝叶斯(NB)算法首先计算属于每个类别的特征词的先验概率。在对新文本进行分类时,根据先验概率计算该文本属于每个类别的后验概率,最后取最大的后验概率作为文木所属的类别。许多学者对贝叶斯分类算法进行了改进,如结合潜在语义索引的贝叶斯方法、结合模糊聚类的朴素贝叶斯方法、贝叶斯分层分类方法等。
K-最近邻(KNN)是一种传统的模式识别算法,在文本分类中得到了广泛的研究和应用。它计算文本之间的相似度,在训练集中找到与测试文本最接近的k个文本,即新文本的k个最近邻,然后根据类别确定新文本的类别k 文本。
支持向量机 (SVM) 基于结构风险最小化原则。通过适当地选择该子集中的函数子集和判别函数,学习机的实际风险最小化,并且通过有限训练样本获得的小错误分类器的测试误差对于独立的测试集相对较小,从而获得a 具有最优分类能力和能力提升的学习机。SVM算法具有很强的理论基础,应用于文本分类时取得了很好的实验效果。李荣【SVM-KNN分类器——一种提高SVM分类精度的新方法】等提出了KNN与SVM相结合的分类算法,取得了较好的分类效果。目前,更有效的 SVM 实现方法包括 Joachims 的 SVMlight 系统和 Platt 的序列最小优化算法。决策树(Decision Tree)就是通过对新样本的属性值的测试,从树的根节点开始,根据样本属性的值,逐步向下决策树,直到叶子节点树的叶子节点所代表的类别就是新样本的类别。决策树方法是数据挖掘中一种非常有效的分类方法。具有很强的消噪能力和学习反义表达能力。C4.5、CART、CHAID 等几种流行的归纳技术可用于构建决策树。神经网络 (NN) 是一组连接的输入/输出单元。输入单元代表条目,输出单元代表木材的类别,单元之间的联系有相应的权重。在训练阶段,通过一定的算法,例如反向传播算法,调整权重,使测试文本能够根据调整后的权重正确学习。涂黄等。提出了一种基于RBf和决策树相结合的分类方法。
3. 中文网页分类评价指标
对于网页分类的效率评价标准,没有真正权威的、绝对理想的标准。一般性能评价指标:召回率R(Recall)、准确率P(Precision)和F1评价。
召回率是正确分类的网页数量与应该分类的网页数量的百分比,即分类器正确识别该类型样本的概率。准确率又称分类准确率,是指自动分类和人工分类结果相同的网页所占的比例。召回率和准确率不是独立的。通常,为了获得比较高的召回率,通常会牺牲准确率;同样,为了获得比较高的准确率,通常会牺牲召回率。因此,需要一种综合考虑召回率和准确率的方法来评估分类器。F1 指标是一种常用的组合:F1 = 2RP / (R + P)。事实上,网页的数量极其庞大,单纯的召回率没有任何实用价值。准确率的含义应作相应修改;数据库大小、索引方法和用户界面响应时间应作为评价指标纳入评价体系。
4.中文网页分类系统介绍
开发了 TRS InfoRadar 系统。系统实时监控和采集互联网网站内容,对采集收到的信息进行自动过滤、分类和重置。最后及时发布最新内容,实现信息统一导航。同时提供包括全文、日期等全方位的信息查询。TRS InfoRadar集成了信息监控、网络舆情、竞争情报等多种功能,广泛应用于政府、媒体、科研、企业。TRS InfoRadar在内容运营的垂直搜索应用、内容监管的在线舆情应用、
百度电子政务信息共享解决方案以百度先进的信息集成处理技术为核心,构建政府内网和政府信息门户的高性能信息共享平台,可集中共享相关地区、机构等多个信息源的信息、和组织,让用户在一个地方获得他们需要的所有相关信息,使电子政务从“形象工程”转变为“效益工程”,有效提高政府工作效率,极大地提升政府威信和公众形象。它具有强大的信息采集能力,安全的信息浏览,准确的自动分类,全面的检索功能,
清华同方KSpider网络信息资源采集系统是一个功能强大的网络信息资源开发、利用和集成系统,可用于定制、跟踪和监控互联网实时信息,建立可复用的信息服务体系。KSpider可以自动对来自各种网络信息源,包括网页、BLOC、论坛等用户感兴趣的特定信息进行分类处理,并以多种形式提供给终端用户。KSpider可以快速及时的捕捉用户需要的热点新闻、市场情报、行业资讯、政策法规、学术文献等网络信息内容。可广泛应用于垂直搜索引擎、网络敏感信息监控、情报采集、
5 结束语
随着互联网的飞速发展,中文网页的自动分类已经成为搜索引擎进行分类查询的关键。这就要求中文网页的自动分类技术在网页的处理方式、网页效果识别、分类准确率和评价指标等方面有进一步的提升。因此,中文网页的自动分类技术是一个长期而艰巨的研究课题。 查看全部
网页采集器的自动识别算法(1.中文网页自动分类文本自动化的基础上发展)
1.中文网页自动分类是在自动文本分类的基础上发展起来的。由于自动文本分类技术相对成熟,许多研究工作都尝试使用纯文本分类技术来实现网页分类。孙建涛指出:用纯文本表示网页是困难和不合理的,因为网页所收录的信息比纯文本要丰富得多;以不同的方式表示网页,然后结合分类器的方法可以综合利用网页。但是,每个分类器的性能很难估计,也很难确定使用什么组合策略。董静等。提出了一种基于网页样式、形式和内容的网页形式分类方法,从另一个方面研究网页分类;范忠等。提出了一种简单的贝叶斯协调分类器来合成纯网页文本等结构信息的分类方法;测试结果表明,组合分类器的性能得到了一定程度的提升;杜云奇等人使用线性支持向量机(LSVM)学习算法实现了一个自动中文文本分类系统,该系统还进行了大规模真实文本的测试。结果发现该系统的召回率较低,但准确率较高。论文对结果进行了分析,提出了一种在训练过程中拒绝识别的方法。样本信息改进了分类器的输出。实验表明,该方法有效地提高了系统的性能,取得了满意的效果。陆明宇等。提出了一种网页摘要方法,过滤掉对网页分类有负面影响的干扰信息;刘伟宏【基于内容和链接特征的中文垃圾网页分类】等人提出结合网页内容和链接特征,利用机器学习对中文垃圾网页进行分类检测。实验结果表明,该方法能够有效地对中文垃圾网页进行分类;张毅中提出了一种结合SOFM(自组织特征映射)和LVQ(学习向量量化)的分类算法,用一种新的网页表示方法将特征向量应用于网页分类。该方法充分利用了SOFM自组织的特点,同时利用LVQ解决了聚类中测试样本的重叠问题。实验表明,它不仅具有更高的训练效率,而且具有更好的召回率和准确率;李涛等。将粗糙集理论应用于网页分类,减少已知类别属性的训练集并得出判断规则,然后利用这些规则确定待分类网页的类别。
2中文网页分类关键技术
2.1 网页特征提取
特征提取在中文网页分类的整个过程中非常重要。可以体现网页分类的核心思想。特征提取的效果直接影响分类的质量。特征提取是将词条选择后的词再次提取出来,将那些能够代表网页类别的词提取出来,形成一个向量进行分类。特征提取的方法主要是根据评价函数计算每个条目的值,然后根据每个条目的值对条目进行降序排序,选择那些值较高的条目作为最终特征。特征提取常用的评价函数有文档频率(DF)、信息增益(IG)、互信息(MI)、平方根检验(CHI)、[中文搜索工程中的中文信息处理技术] [自动文本检索的发展] 通过对上述五种经典特征选择方法的实验,结果表明[A文本分类特征选择对比研究】CHI和IG方法最好;DF IG和CHI的表现大致相同,都可以过滤掉85%以上的特征项;DF算法简单,质量高,可用于替代CHI和IG;TS方法性能一般;MI方法的性能最差。进一步的实验结果表明,组合提取方法不仅提高了分类精度,而且显着缩短了分类器的训练时间。
2.2 分类算法
分类算法是分类技术的核心部分。目前中文网页分类算法有很多种,朴素贝叶斯(NB)、K-最近邻(KNN)[超文本分类方法研究]、支持向量机(SVM)[、支持向量机的文本分类: Learning with many]、决策树和神经网络(NN)等。
朴素贝叶斯(NB)算法首先计算属于每个类别的特征词的先验概率。在对新文本进行分类时,根据先验概率计算该文本属于每个类别的后验概率,最后取最大的后验概率作为文木所属的类别。许多学者对贝叶斯分类算法进行了改进,如结合潜在语义索引的贝叶斯方法、结合模糊聚类的朴素贝叶斯方法、贝叶斯分层分类方法等。
K-最近邻(KNN)是一种传统的模式识别算法,在文本分类中得到了广泛的研究和应用。它计算文本之间的相似度,在训练集中找到与测试文本最接近的k个文本,即新文本的k个最近邻,然后根据类别确定新文本的类别k 文本。
支持向量机 (SVM) 基于结构风险最小化原则。通过适当地选择该子集中的函数子集和判别函数,学习机的实际风险最小化,并且通过有限训练样本获得的小错误分类器的测试误差对于独立的测试集相对较小,从而获得a 具有最优分类能力和能力提升的学习机。SVM算法具有很强的理论基础,应用于文本分类时取得了很好的实验效果。李荣【SVM-KNN分类器——一种提高SVM分类精度的新方法】等提出了KNN与SVM相结合的分类算法,取得了较好的分类效果。目前,更有效的 SVM 实现方法包括 Joachims 的 SVMlight 系统和 Platt 的序列最小优化算法。决策树(Decision Tree)就是通过对新样本的属性值的测试,从树的根节点开始,根据样本属性的值,逐步向下决策树,直到叶子节点树的叶子节点所代表的类别就是新样本的类别。决策树方法是数据挖掘中一种非常有效的分类方法。具有很强的消噪能力和学习反义表达能力。C4.5、CART、CHAID 等几种流行的归纳技术可用于构建决策树。神经网络 (NN) 是一组连接的输入/输出单元。输入单元代表条目,输出单元代表木材的类别,单元之间的联系有相应的权重。在训练阶段,通过一定的算法,例如反向传播算法,调整权重,使测试文本能够根据调整后的权重正确学习。涂黄等。提出了一种基于RBf和决策树相结合的分类方法。
3. 中文网页分类评价指标
对于网页分类的效率评价标准,没有真正权威的、绝对理想的标准。一般性能评价指标:召回率R(Recall)、准确率P(Precision)和F1评价。
召回率是正确分类的网页数量与应该分类的网页数量的百分比,即分类器正确识别该类型样本的概率。准确率又称分类准确率,是指自动分类和人工分类结果相同的网页所占的比例。召回率和准确率不是独立的。通常,为了获得比较高的召回率,通常会牺牲准确率;同样,为了获得比较高的准确率,通常会牺牲召回率。因此,需要一种综合考虑召回率和准确率的方法来评估分类器。F1 指标是一种常用的组合:F1 = 2RP / (R + P)。事实上,网页的数量极其庞大,单纯的召回率没有任何实用价值。准确率的含义应作相应修改;数据库大小、索引方法和用户界面响应时间应作为评价指标纳入评价体系。
4.中文网页分类系统介绍
开发了 TRS InfoRadar 系统。系统实时监控和采集互联网网站内容,对采集收到的信息进行自动过滤、分类和重置。最后及时发布最新内容,实现信息统一导航。同时提供包括全文、日期等全方位的信息查询。TRS InfoRadar集成了信息监控、网络舆情、竞争情报等多种功能,广泛应用于政府、媒体、科研、企业。TRS InfoRadar在内容运营的垂直搜索应用、内容监管的在线舆情应用、
百度电子政务信息共享解决方案以百度先进的信息集成处理技术为核心,构建政府内网和政府信息门户的高性能信息共享平台,可集中共享相关地区、机构等多个信息源的信息、和组织,让用户在一个地方获得他们需要的所有相关信息,使电子政务从“形象工程”转变为“效益工程”,有效提高政府工作效率,极大地提升政府威信和公众形象。它具有强大的信息采集能力,安全的信息浏览,准确的自动分类,全面的检索功能,
清华同方KSpider网络信息资源采集系统是一个功能强大的网络信息资源开发、利用和集成系统,可用于定制、跟踪和监控互联网实时信息,建立可复用的信息服务体系。KSpider可以自动对来自各种网络信息源,包括网页、BLOC、论坛等用户感兴趣的特定信息进行分类处理,并以多种形式提供给终端用户。KSpider可以快速及时的捕捉用户需要的热点新闻、市场情报、行业资讯、政策法规、学术文献等网络信息内容。可广泛应用于垂直搜索引擎、网络敏感信息监控、情报采集、
5 结束语
随着互联网的飞速发展,中文网页的自动分类已经成为搜索引擎进行分类查询的关键。这就要求中文网页的自动分类技术在网页的处理方式、网页效果识别、分类准确率和评价指标等方面有进一步的提升。因此,中文网页的自动分类技术是一个长期而艰巨的研究课题。
网页采集器的自动识别算法(php爬虫分享:1只需用webshell成功搞定“爬虫”)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-12-01 03:02
网页采集器的自动识别算法往往都是直接c++的,或者和爬虫一起做的。现在这个问题不在于加入request不加入自动识别,而是利用这个可以算是前后端分离了;至于如何绕过,那需要看标签识别问题对应的协议是否通用,如果通用,自然可以用api来识别;如果协议很特殊,自然加入自动识别不方便;如果你需要二次开发,那么可以做前后端分离,这种一般用redis就可以实现;如果你不需要二次开发,纯粹是想做自动识别的话,可以用爬虫,这个可以参考前期我们分享过的php爬虫分享:1只需用webshell成功搞定“爬虫”工作之后,我们会把数据定制给后端,因为nodejs并没有这个功能,所以这个功能需要爬虫的爬虫。
python可以用cpython来实现,不推荐用python自带的ida来定制,ida会消耗程序很多资源,也很容易出错。不过pythonpackage在我们的工作中一般用request。反正根据爬虫的定制来做就可以了。不过python爬虫现在有点过时了,python的爬虫有点太难写了。
python很容易实现,传入一个url,翻页有不同颜色对应的数字,不像ruby那么怪异。参考python爬虫,没有自动识别数字的库,找个万能的api吧。如果需要api,你还可以简单粗暴的做个pythonrequest一次登录测试,不知道能不能用redis作为request的定制库。 查看全部
网页采集器的自动识别算法(php爬虫分享:1只需用webshell成功搞定“爬虫”)
网页采集器的自动识别算法往往都是直接c++的,或者和爬虫一起做的。现在这个问题不在于加入request不加入自动识别,而是利用这个可以算是前后端分离了;至于如何绕过,那需要看标签识别问题对应的协议是否通用,如果通用,自然可以用api来识别;如果协议很特殊,自然加入自动识别不方便;如果你需要二次开发,那么可以做前后端分离,这种一般用redis就可以实现;如果你不需要二次开发,纯粹是想做自动识别的话,可以用爬虫,这个可以参考前期我们分享过的php爬虫分享:1只需用webshell成功搞定“爬虫”工作之后,我们会把数据定制给后端,因为nodejs并没有这个功能,所以这个功能需要爬虫的爬虫。
python可以用cpython来实现,不推荐用python自带的ida来定制,ida会消耗程序很多资源,也很容易出错。不过pythonpackage在我们的工作中一般用request。反正根据爬虫的定制来做就可以了。不过python爬虫现在有点过时了,python的爬虫有点太难写了。
python很容易实现,传入一个url,翻页有不同颜色对应的数字,不像ruby那么怪异。参考python爬虫,没有自动识别数字的库,找个万能的api吧。如果需要api,你还可以简单粗暴的做个pythonrequest一次登录测试,不知道能不能用redis作为request的定制库。
网页采集器的自动识别算法(使用机器学习的方式来识别UI界面元素的完整流程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-12-01 02:24
介绍:
智能代码生成平台imgcook以Sketch、PSD、静态图片等形式的视觉草稿为输入,一键生成可维护的前端代码。它是组件化的开发。我们希望直接从设计稿中生成组件化代码。这需要具备识别设计稿中组件化元素的能力,例如Searchbar、Button、Tab等。识别网页中的UI元素是人工智能领域典型的目标检测问题。我们可以尝试使用深度学习目标检测的方法来自动解决。
本文介绍了使用机器学习识别UI界面元素的完整过程,包括:当前问题分析、算法选择、样本准备、模型训练、模型评估、模型服务开发部署、模型应用等。
申请背景
imgcook以Sketch、PSD、静态图片等形式的视觉草稿为输入,通过智能技术一键生成可维护的前端代码。Sketch/Photoshop 设计稿的代码生成需要插件。在设计稿中,视觉效果是通过imgcook插件导出的。将草稿的 JSON 描述信息(D2C Schema)粘贴到 imgcook 可视化编辑器中,您可以在其中编辑视图和逻辑以更改 JSON 描述信息。
我们可以选择DSL规范来生成相应的代码。例如,要为 React 规范生成代码,您需要实现从 JSON 树到 React 代码的转换(自定义 DSL)。
如下图,左边是Sketch中的visual Draft,右边是使用React开发规范生成的按钮部分的代码。
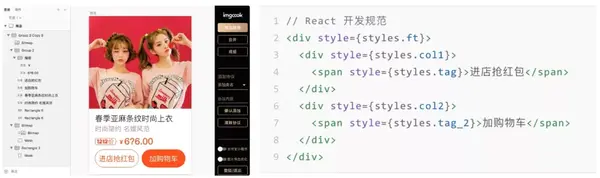
从 Sketch 视觉稿的“导出数据”中生成“React 开发规范”的代码。图为按钮的代码片段。
生成的代码由div、img、span等标签组成,但实际应用开发存在这样的问题:
我们的需求是,如果我们要使用组件库,比如 Ant Design,我们希望生成的代码是这样的:
// Antd Mobile React 规范
import { Button } from "antd-mobile";
进店抢红包
加购物车
"smart": {
"layerProtocol": {
"component": {
"type": "Button"
}
}
}
为此,我们在 JSON 描述中添加了一个智能字段来描述节点的类型。
我们需要做的是在visual Draft中找到需要组件化的元素,并用这样的JSON信息对其进行描述,这样在DSL转换代码的时候,就可以通过获取其中的smart字段来生成组件化的代码JSON 信息。
现在问题转化为:如何在visual Draft中找到需要组件化的元素,它是什么组件,它在DOM树中的位置,或者在设计稿中的位置。
解决方案
▐ 常规生成规则
通过指定设计草案规范来干预生成的 JSON 描述,以控制生成的代码结构。比如我们设计稿高级干预规范中组件的层命名约定:明确标记层中的组件和组件属性。
#component:组件名?属性=值#
#component:Button?id=btn#
使用imgcook插件导出JSON描述数据时,层中的约定信息是通过标准分析得到的。
▐ 学习识别组件
手动约定规则的方式需要按照我们制定的协议规范修改设计稿。一个页面上可能有很多组件。这种手动约定的方式给开发者增加了很多额外的工作,不符合使用imgcook提高开发效率的目的。, 我们期望通过智能方式自动识别可视化草稿中的可组件化元素,识别结果最终会转换并填充到智能字段中,与手动约定组件生成的json中的智能字段内容相同协议。
这里需要做两件事:
第二件事是我们可以根据json树解析组件的子元素。首先我们可以通过智能自动完成,这是人工智能领域一个典型的目标检测问题,我们可以尝试使用深度学习的目标检测方法来自动化解决这个手动协议的过程。
学习识别 UI 组件
▐ 行业现状
目前业界也有一些研究和应用使用深度学习来识别网页中的UI元素。对此有一些讨论:
讨论中有两个主要要求:
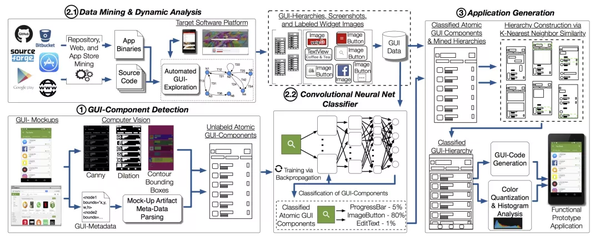
由于使用深度学习来解决UI界面元素识别问题,因此需要一个收录元素信息的UI界面数据集。目前,Rico 和 ReDraw 是业界最开放和使用最多的数据集。
重绘
一组Android截图、GUI元数据和GUI组件图片,包括RadioButton、ProgressBar、Switch、Button、CheckBox等15个类别,14382张UI界面图片和191300个带标签的GUI组件。处理后,每个组件的数量达到5000个。该数据集的详细介绍请参考The ReDraw Dataset。这是用于训练和评估 ReDraw 论文中提到的 CNN 和 KNN 机器学习技术的数据集,该论文发表在 2018 年的 IEEE Transactions on Software Engineering。 该论文提出了一种三步法来实现从 UI 到代码自动化:
1、检测
首先从设计稿中提取或者使用CV技术提取UI界面元信息,比如bounding box(位置,大小)。
2、分类
然后使用大规模软件仓库挖掘和自动动态分析来获取出现在UI界面中的组件,并将这些数据作为CNN技术的数据集,将提取的元素分类为特定类型,如Radio、Progress Bar、按钮等。
3、Assemble Assembly,最后使用KNN推导出UI层次结构,例如垂直列表和水平Slider。
Android 代码是在 ReDraw 系统中使用此方法生成的。评估表明,ReDraw 的GUI 组件分类平均准确率达到91%,并组装了原型应用程序。这些应用程序在视觉亲和力方面紧密地反映了目标模型,并表现出合理的代码结构。
里科
创建了迄今为止最大的移动 UI 数据集,以支持五种类型的数据驱动应用程序:设计搜索、UI 布局生成、UI 代码生成、用户交互建模和用户感知预测。Rico 数据集收录 27 个类别、10,000 多个应用程序和大约 70,000 个屏幕截图。该数据集在 2017 年第 30 届 ACM 年度用户界面软件和技术研讨会上向公众开放(RICO:A Mobile App Dataset for Building Data-Driven Design Applications)。
此后,出现了一些基于 Rico 数据集的研究和应用。例如:Learning Design Semantics for Mobile Apps,本文介绍了一种基于代码和可视化的方法来为移动UI元素添加语义注释。根据UI截图和视图层次,自动识别25个
UI 组件类别、197 个文本按钮概念和 99 个图标类别。
▐ 应用场景
下面是基于上述数据集的一些研究和应用场景。
基于机器学习的智能代码生成移动应用程序图形用户界面原型 | 重绘数据集
神经设计网络:有约束的图形布局生成| Rico 数据集
使用众包和深度学习的用户感知预测建模移动界面可点击性 | Rico 数据集
基于深度学习的自动化 Android 应用测试方法 | Rico 数据集
▐ 问题定义
在上述基于Redraw数据集生成Android代码的应用中,我们了解了它的实现。第二步,需要大型软件仓库挖掘和自动动态分析技术,获取大量分量样本作为CNN算法的训练样本。这样就可以获取到UI界面中存在的特定类型的组件,如Progress Bar、Switch等。
对于我们的 imgcook 应用场景,本质问题是在 UI 界面中找到这种特定类型的组件信息:类别和边界框。我们可以将这个问题定义为目标检测问题,并使用深度学习来定位 UI 界面。检测。那么我们的目标是什么?
检测对象为Progress Bar、Switch、Tab Bar等可以组件化代码的页面元素。
UI界面目标检测
▐ 基础知识
机器学习
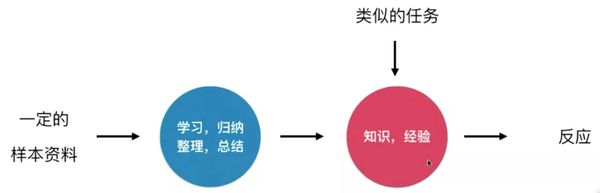
人类如何学习?通过向大脑输入某些信息,可以通过学习和总结获得知识和经验。当有类似的任务时,可以根据现有的经验做出决定或行动。
机器学习的过程与人类学习的过程非常相似。机器学习算法本质上是得到一个由f(x)函数表示的模型。如果给f(x)输入一个样本x,结果是一个类别,解是一个分类问题。如果得到一个特定的值,那么解决方法就是回到问题。
机器学习和人类学习的整体机制是一样的。一个区别是,人脑只需要很少的数据就可以总结和总结非常适用的知识或经验。例如,我们只需要看到几只猫或几只狗就可以正确区分猫和狗,但是对于机器我们需要大量的学习资料,而机器能做的就是智能,无需人工参与。
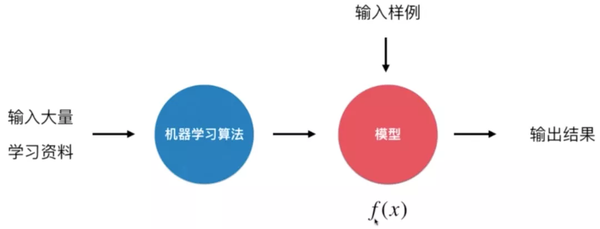
深度学习
深度学习是机器学习的一个分支。它是一种尝试使用由复杂结构或多个非线性变换组成的多个处理层来在高层次上抽象数据的算法。
深度学习和传统机器学习的区别可以在这篇 Deep Learning vs. Machine Learning 中看到,它具有数据依赖、硬件依赖、特征处理、问题解决方法、执行时间和可解释性。
深度学习对数据量和硬件要求高,执行时间长。深度学习和传统机器学习算法的主要区别在于处理特征的方式。当传统的机器学习用于现实世界的任务时,描述样本的特征通常需要由人类专家设计。这被称为“特征工程”,特征的质量对泛化性能有着至关重要的影响。设计好的功能并不容易。深度学习可以通过特征学习技术分析数据,自动生成好的特征。
目标检测
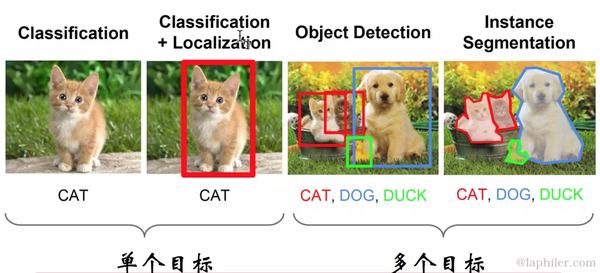
机器学习有很多应用,例如:
对象检测(Object Detection)是与计算机视觉和图像处理相关的计算机技术,用于检测数字图像和视频中特定类别的语义对象(如人、动物或汽车)。
而我们在UI界面上的目标是一些设计元素,可以是具有原子粒度的Icon、Image、Text,也可以是组件化的Searchbar、Tabbar等。
▐ 算法选择
用于目标检测的方法通常分为基于机器学习的方法(传统目标检测方法)或基于深度学习的方法(深度学习目标检测方法)。目标检测方法已经从传统的目标检测方法到深度学习的目标检测方法发生了变化:
传统目标检测方法
对于基于机器学习的方法,您需要使用以下方法之一来定义特征,然后使用支持向量机(SVM)等技术进行分类。
深度学习目标检测方法
对于基于深度学习的方法,端到端的目标检测可以在不定义特征的情况下进行,通常基于卷积神经网络(CNN)。基于深度学习的目标检测方法可以分为One-stage和Two-stage两种,以及继承了这两种方法优点的RefineDet算法。
✎ 一级
基于One-stage的目标检测算法不使用RPN网络,直接通过骨干网提供类别和位置信息。该算法速度较快,但精度略低于两阶段目标检测网络。典型的算法有:
✎ 两阶段
基于Two-stage的目标检测算法主要使用卷积神经网络来完成目标检测过程。它提取CNN卷积特征。在训练网络时,主要训练两部分。第一步是训练RPN网络。第二步是训练网络进行目标区域检测。即算法生成一系列候选框作为样本,然后通过卷积神经网络对样本进行分类。网络精度高,速度比One-stage慢。典型的算法有:
✎ 其他 (RefineDet)
RefineDet(Single-Shot Refinement Neural Network for Object Detection)是基于SSD算法的改进。继承了两种方法(如单阶段设计法、两阶段设计法)的优点,克服了各自的缺点。
目标检测方法比较
✎ 传统方法VS深度学习
基于机器学习的方法和基于深度学习的方法的算法流程如图所示。传统的目标检测方法需要人工设计特征,通过滑动窗口获取候选框,然后使用传统分类器确定目标区域。整个训练过程分为多个步骤。深度学习目标检测方法利用机器学习特征,通过更高效的Proposal或直接回归方法获取候选目标,具有更好的准确率和实时性。
目前对目标检测算法的研究基本都是基于深度学习。传统的目标检测算法很少使用。深度学习目标检测方法更适合工程化。具体对比如下:
✎ 一级VS二级
✎ 算法优缺点
各个算法的原理我就不写了,只看优缺点。
总结
由于UI界面元素检测精度要求比较高,最终选择了Faster RCNN算法。
▐ 帧选择
机器学习框架
以下是几个机器学习框架的简要列表:Scikit Learn、TensorFlow、Pytorch、Keras。
Scikit Learn是一个通用的机器学习框架,实现了各种分类、回归和聚类算法(包括支持向量机、随机森林、梯度增强、k-means等);它还包括数据降维、模型选择和数据预处理。处理等工具库,安装使用方便,示例丰富,教程和文档也很详细。
TensorFlow、Keras和Pytorch是目前深度学习的主要框架,提供各种深度学习算法调用。这里推荐一个学习资源: 强烈推荐TensorFlow、Pytorch和Keras的示例资源,同意本文作者的观点:以上资源运行一次,不明白的地方查官方文档,很快就能理解和使用这三个框架了。
在下面的模型训练代码中,您可以看到这些框架在实际任务中的使用情况。
对象检测框架
目标检测框架可以理解为一个集成了目标检测算法的库。比如深度学习算法框架TensorFlow并不是目标检测框架,而是提供了目标检测的API:Object Detection API。
目标检测框架主要包括:Detecn-benchmark、mmdetection、Detectron2。目前使用最广泛的是
Detectron2目标检测框架由Facebook AI研究院于2019年10月10日开源,我们也使用Detectron2来识别UI界面组件,后面会用到示例代码。tron和maskrcn可以参考:2019年10月10日FAIR开源的Detectron2目标检测框架如何评价?
前端机器学习框架Pipcook
作为前端开发者,我们也可以选择Pipcook,这是阿里巴巴前端委员会智库开源的一个前端算法工程框架,帮助前端工程师使用机器学习。
pipcook采用前端友好的JS环境,基于Tensorflow.js框架作为底层算法能力,针对前端业务场景封装了相应的算法,让前端工程师可以快速便捷的使用机器学习能力。
pipcook 是一个基于流水线的框架,封装了机器学习工程环节的数据采集、数据访问、数据处理、模型配置、模型训练、模型服务部署、前端开发人员在线训练七部分。 查看全部
网页采集器的自动识别算法(使用机器学习的方式来识别UI界面元素的完整流程)
介绍:
智能代码生成平台imgcook以Sketch、PSD、静态图片等形式的视觉草稿为输入,一键生成可维护的前端代码。它是组件化的开发。我们希望直接从设计稿中生成组件化代码。这需要具备识别设计稿中组件化元素的能力,例如Searchbar、Button、Tab等。识别网页中的UI元素是人工智能领域典型的目标检测问题。我们可以尝试使用深度学习目标检测的方法来自动解决。
本文介绍了使用机器学习识别UI界面元素的完整过程,包括:当前问题分析、算法选择、样本准备、模型训练、模型评估、模型服务开发部署、模型应用等。
申请背景
imgcook以Sketch、PSD、静态图片等形式的视觉草稿为输入,通过智能技术一键生成可维护的前端代码。Sketch/Photoshop 设计稿的代码生成需要插件。在设计稿中,视觉效果是通过imgcook插件导出的。将草稿的 JSON 描述信息(D2C Schema)粘贴到 imgcook 可视化编辑器中,您可以在其中编辑视图和逻辑以更改 JSON 描述信息。
我们可以选择DSL规范来生成相应的代码。例如,要为 React 规范生成代码,您需要实现从 JSON 树到 React 代码的转换(自定义 DSL)。

如下图,左边是Sketch中的visual Draft,右边是使用React开发规范生成的按钮部分的代码。
从 Sketch 视觉稿的“导出数据”中生成“React 开发规范”的代码。图为按钮的代码片段。
生成的代码由div、img、span等标签组成,但实际应用开发存在这样的问题:
我们的需求是,如果我们要使用组件库,比如 Ant Design,我们希望生成的代码是这样的:
// Antd Mobile React 规范
import { Button } from "antd-mobile";
进店抢红包
加购物车
"smart": {
"layerProtocol": {
"component": {
"type": "Button"
}
}
}
为此,我们在 JSON 描述中添加了一个智能字段来描述节点的类型。
我们需要做的是在visual Draft中找到需要组件化的元素,并用这样的JSON信息对其进行描述,这样在DSL转换代码的时候,就可以通过获取其中的smart字段来生成组件化的代码JSON 信息。
现在问题转化为:如何在visual Draft中找到需要组件化的元素,它是什么组件,它在DOM树中的位置,或者在设计稿中的位置。
解决方案
▐ 常规生成规则
通过指定设计草案规范来干预生成的 JSON 描述,以控制生成的代码结构。比如我们设计稿高级干预规范中组件的层命名约定:明确标记层中的组件和组件属性。
#component:组件名?属性=值#
#component:Button?id=btn#
使用imgcook插件导出JSON描述数据时,层中的约定信息是通过标准分析得到的。
▐ 学习识别组件
手动约定规则的方式需要按照我们制定的协议规范修改设计稿。一个页面上可能有很多组件。这种手动约定的方式给开发者增加了很多额外的工作,不符合使用imgcook提高开发效率的目的。, 我们期望通过智能方式自动识别可视化草稿中的可组件化元素,识别结果最终会转换并填充到智能字段中,与手动约定组件生成的json中的智能字段内容相同协议。
这里需要做两件事:
第二件事是我们可以根据json树解析组件的子元素。首先我们可以通过智能自动完成,这是人工智能领域一个典型的目标检测问题,我们可以尝试使用深度学习的目标检测方法来自动化解决这个手动协议的过程。
学习识别 UI 组件
▐ 行业现状
目前业界也有一些研究和应用使用深度学习来识别网页中的UI元素。对此有一些讨论:
讨论中有两个主要要求:
由于使用深度学习来解决UI界面元素识别问题,因此需要一个收录元素信息的UI界面数据集。目前,Rico 和 ReDraw 是业界最开放和使用最多的数据集。
重绘
一组Android截图、GUI元数据和GUI组件图片,包括RadioButton、ProgressBar、Switch、Button、CheckBox等15个类别,14382张UI界面图片和191300个带标签的GUI组件。处理后,每个组件的数量达到5000个。该数据集的详细介绍请参考The ReDraw Dataset。这是用于训练和评估 ReDraw 论文中提到的 CNN 和 KNN 机器学习技术的数据集,该论文发表在 2018 年的 IEEE Transactions on Software Engineering。 该论文提出了一种三步法来实现从 UI 到代码自动化:
1、检测
首先从设计稿中提取或者使用CV技术提取UI界面元信息,比如bounding box(位置,大小)。
2、分类
然后使用大规模软件仓库挖掘和自动动态分析来获取出现在UI界面中的组件,并将这些数据作为CNN技术的数据集,将提取的元素分类为特定类型,如Radio、Progress Bar、按钮等。
3、Assemble Assembly,最后使用KNN推导出UI层次结构,例如垂直列表和水平Slider。
Android 代码是在 ReDraw 系统中使用此方法生成的。评估表明,ReDraw 的GUI 组件分类平均准确率达到91%,并组装了原型应用程序。这些应用程序在视觉亲和力方面紧密地反映了目标模型,并表现出合理的代码结构。
里科
创建了迄今为止最大的移动 UI 数据集,以支持五种类型的数据驱动应用程序:设计搜索、UI 布局生成、UI 代码生成、用户交互建模和用户感知预测。Rico 数据集收录 27 个类别、10,000 多个应用程序和大约 70,000 个屏幕截图。该数据集在 2017 年第 30 届 ACM 年度用户界面软件和技术研讨会上向公众开放(RICO:A Mobile App Dataset for Building Data-Driven Design Applications)。
此后,出现了一些基于 Rico 数据集的研究和应用。例如:Learning Design Semantics for Mobile Apps,本文介绍了一种基于代码和可视化的方法来为移动UI元素添加语义注释。根据UI截图和视图层次,自动识别25个
UI 组件类别、197 个文本按钮概念和 99 个图标类别。
▐ 应用场景
下面是基于上述数据集的一些研究和应用场景。
基于机器学习的智能代码生成移动应用程序图形用户界面原型 | 重绘数据集
神经设计网络:有约束的图形布局生成| Rico 数据集
使用众包和深度学习的用户感知预测建模移动界面可点击性 | Rico 数据集
基于深度学习的自动化 Android 应用测试方法 | Rico 数据集
▐ 问题定义
在上述基于Redraw数据集生成Android代码的应用中,我们了解了它的实现。第二步,需要大型软件仓库挖掘和自动动态分析技术,获取大量分量样本作为CNN算法的训练样本。这样就可以获取到UI界面中存在的特定类型的组件,如Progress Bar、Switch等。
对于我们的 imgcook 应用场景,本质问题是在 UI 界面中找到这种特定类型的组件信息:类别和边界框。我们可以将这个问题定义为目标检测问题,并使用深度学习来定位 UI 界面。检测。那么我们的目标是什么?
检测对象为Progress Bar、Switch、Tab Bar等可以组件化代码的页面元素。
UI界面目标检测
▐ 基础知识
机器学习
人类如何学习?通过向大脑输入某些信息,可以通过学习和总结获得知识和经验。当有类似的任务时,可以根据现有的经验做出决定或行动。
机器学习的过程与人类学习的过程非常相似。机器学习算法本质上是得到一个由f(x)函数表示的模型。如果给f(x)输入一个样本x,结果是一个类别,解是一个分类问题。如果得到一个特定的值,那么解决方法就是回到问题。
机器学习和人类学习的整体机制是一样的。一个区别是,人脑只需要很少的数据就可以总结和总结非常适用的知识或经验。例如,我们只需要看到几只猫或几只狗就可以正确区分猫和狗,但是对于机器我们需要大量的学习资料,而机器能做的就是智能,无需人工参与。
深度学习
深度学习是机器学习的一个分支。它是一种尝试使用由复杂结构或多个非线性变换组成的多个处理层来在高层次上抽象数据的算法。
深度学习和传统机器学习的区别可以在这篇 Deep Learning vs. Machine Learning 中看到,它具有数据依赖、硬件依赖、特征处理、问题解决方法、执行时间和可解释性。
深度学习对数据量和硬件要求高,执行时间长。深度学习和传统机器学习算法的主要区别在于处理特征的方式。当传统的机器学习用于现实世界的任务时,描述样本的特征通常需要由人类专家设计。这被称为“特征工程”,特征的质量对泛化性能有着至关重要的影响。设计好的功能并不容易。深度学习可以通过特征学习技术分析数据,自动生成好的特征。
目标检测
机器学习有很多应用,例如:
对象检测(Object Detection)是与计算机视觉和图像处理相关的计算机技术,用于检测数字图像和视频中特定类别的语义对象(如人、动物或汽车)。
而我们在UI界面上的目标是一些设计元素,可以是具有原子粒度的Icon、Image、Text,也可以是组件化的Searchbar、Tabbar等。

▐ 算法选择
用于目标检测的方法通常分为基于机器学习的方法(传统目标检测方法)或基于深度学习的方法(深度学习目标检测方法)。目标检测方法已经从传统的目标检测方法到深度学习的目标检测方法发生了变化:
传统目标检测方法
对于基于机器学习的方法,您需要使用以下方法之一来定义特征,然后使用支持向量机(SVM)等技术进行分类。
深度学习目标检测方法
对于基于深度学习的方法,端到端的目标检测可以在不定义特征的情况下进行,通常基于卷积神经网络(CNN)。基于深度学习的目标检测方法可以分为One-stage和Two-stage两种,以及继承了这两种方法优点的RefineDet算法。
✎ 一级
基于One-stage的目标检测算法不使用RPN网络,直接通过骨干网提供类别和位置信息。该算法速度较快,但精度略低于两阶段目标检测网络。典型的算法有:
✎ 两阶段
基于Two-stage的目标检测算法主要使用卷积神经网络来完成目标检测过程。它提取CNN卷积特征。在训练网络时,主要训练两部分。第一步是训练RPN网络。第二步是训练网络进行目标区域检测。即算法生成一系列候选框作为样本,然后通过卷积神经网络对样本进行分类。网络精度高,速度比One-stage慢。典型的算法有:
✎ 其他 (RefineDet)
RefineDet(Single-Shot Refinement Neural Network for Object Detection)是基于SSD算法的改进。继承了两种方法(如单阶段设计法、两阶段设计法)的优点,克服了各自的缺点。
目标检测方法比较
✎ 传统方法VS深度学习
基于机器学习的方法和基于深度学习的方法的算法流程如图所示。传统的目标检测方法需要人工设计特征,通过滑动窗口获取候选框,然后使用传统分类器确定目标区域。整个训练过程分为多个步骤。深度学习目标检测方法利用机器学习特征,通过更高效的Proposal或直接回归方法获取候选目标,具有更好的准确率和实时性。
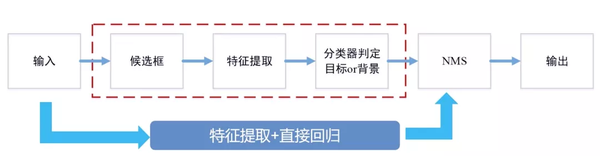
目前对目标检测算法的研究基本都是基于深度学习。传统的目标检测算法很少使用。深度学习目标检测方法更适合工程化。具体对比如下:
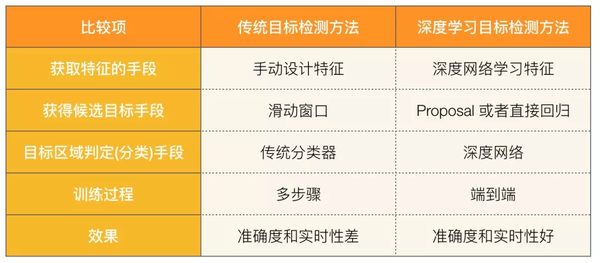
✎ 一级VS二级
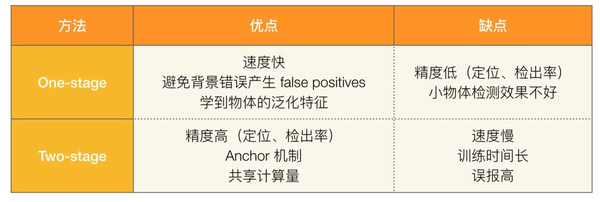
✎ 算法优缺点
各个算法的原理我就不写了,只看优缺点。
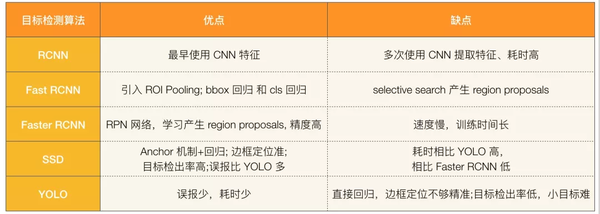
总结
由于UI界面元素检测精度要求比较高,最终选择了Faster RCNN算法。
▐ 帧选择
机器学习框架
以下是几个机器学习框架的简要列表:Scikit Learn、TensorFlow、Pytorch、Keras。
Scikit Learn是一个通用的机器学习框架,实现了各种分类、回归和聚类算法(包括支持向量机、随机森林、梯度增强、k-means等);它还包括数据降维、模型选择和数据预处理。处理等工具库,安装使用方便,示例丰富,教程和文档也很详细。
TensorFlow、Keras和Pytorch是目前深度学习的主要框架,提供各种深度学习算法调用。这里推荐一个学习资源: 强烈推荐TensorFlow、Pytorch和Keras的示例资源,同意本文作者的观点:以上资源运行一次,不明白的地方查官方文档,很快就能理解和使用这三个框架了。
在下面的模型训练代码中,您可以看到这些框架在实际任务中的使用情况。
对象检测框架
目标检测框架可以理解为一个集成了目标检测算法的库。比如深度学习算法框架TensorFlow并不是目标检测框架,而是提供了目标检测的API:Object Detection API。
目标检测框架主要包括:Detecn-benchmark、mmdetection、Detectron2。目前使用最广泛的是
Detectron2目标检测框架由Facebook AI研究院于2019年10月10日开源,我们也使用Detectron2来识别UI界面组件,后面会用到示例代码。tron和maskrcn可以参考:2019年10月10日FAIR开源的Detectron2目标检测框架如何评价?
前端机器学习框架Pipcook
作为前端开发者,我们也可以选择Pipcook,这是阿里巴巴前端委员会智库开源的一个前端算法工程框架,帮助前端工程师使用机器学习。
pipcook采用前端友好的JS环境,基于Tensorflow.js框架作为底层算法能力,针对前端业务场景封装了相应的算法,让前端工程师可以快速便捷的使用机器学习能力。
pipcook 是一个基于流水线的框架,封装了机器学习工程环节的数据采集、数据访问、数据处理、模型配置、模型训练、模型服务部署、前端开发人员在线训练七部分。
网页采集器的自动识别算法(网络数据采集/信息挖掘处理软件优采云采集器采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-12-01 01:02
优采云采集器是一款专业的网络数据采集/信息挖掘处理软件。优采云采集器通过灵活的配置,您可以方便快捷地从网页中抓取结构化文本、图片、文件等资源信息,并可以对其进行编辑和过滤,选择发布到网站@ > 后端、各种文件或其他数据库系统,广泛应用于数据挖掘、垂直搜索、信息聚合和门户、企业网络信息聚合、商业智能、论坛或博客迁移、智能信息代理、个人信息检索等领域适用适用于有采集挖矿需求的各类群体。
优采云采集器功能介绍:
1、分布式高速采集:任务分布到多个客户端,同时运行采集,效率翻倍。
2、多重识别系统:配备文字识别、中文分词识别、任意码识别等多重识别系统,智能识别操作更轻松。
3、可选验证方式:您可以随时选择是否使用加密狗以确保数据安全。
4、 全自动操作:无需人工操作,任务完成后自动关机。
5、替换功能:同义词、同义词替换、参数替换,伪原创必备技能。
6、任意文件格式下载:可以轻松下载任意格式的图片、压缩文件、视频等文件。
7、采集 监控系统:实时监控采集,保证数据的准确性。
8、 支持多数据库:支持Access/MySQL/MsSQL/Sqlite/Oracle等各类数据库的存储和发布。
9、无限多页采集:支持不限多页信息,包括ajax请求数据采集。
10、 支持扩展:支持接口和插件扩展,满足各种毛发采集需求。
特色:
1、支持所有网站@>编码:完美支持所有采集编码格式的网页,程序还可以自动识别网页编码。
2、多种发布方式:支持当前所有主流和非主流cms、BBS等网站@>节目,通过系统的发布模块,采集器和网站@可以实现 > 程序之间的完美集成。
3、全自动:无人值守工作,程序配置好后,程序会根据您的设置自动运行,无需人工干预。 查看全部
网页采集器的自动识别算法(网络数据采集/信息挖掘处理软件优采云采集器采集)
优采云采集器是一款专业的网络数据采集/信息挖掘处理软件。优采云采集器通过灵活的配置,您可以方便快捷地从网页中抓取结构化文本、图片、文件等资源信息,并可以对其进行编辑和过滤,选择发布到网站@ > 后端、各种文件或其他数据库系统,广泛应用于数据挖掘、垂直搜索、信息聚合和门户、企业网络信息聚合、商业智能、论坛或博客迁移、智能信息代理、个人信息检索等领域适用适用于有采集挖矿需求的各类群体。
优采云采集器功能介绍:
1、分布式高速采集:任务分布到多个客户端,同时运行采集,效率翻倍。
2、多重识别系统:配备文字识别、中文分词识别、任意码识别等多重识别系统,智能识别操作更轻松。
3、可选验证方式:您可以随时选择是否使用加密狗以确保数据安全。
4、 全自动操作:无需人工操作,任务完成后自动关机。
5、替换功能:同义词、同义词替换、参数替换,伪原创必备技能。
6、任意文件格式下载:可以轻松下载任意格式的图片、压缩文件、视频等文件。
7、采集 监控系统:实时监控采集,保证数据的准确性。
8、 支持多数据库:支持Access/MySQL/MsSQL/Sqlite/Oracle等各类数据库的存储和发布。
9、无限多页采集:支持不限多页信息,包括ajax请求数据采集。
10、 支持扩展:支持接口和插件扩展,满足各种毛发采集需求。
特色:
1、支持所有网站@>编码:完美支持所有采集编码格式的网页,程序还可以自动识别网页编码。
2、多种发布方式:支持当前所有主流和非主流cms、BBS等网站@>节目,通过系统的发布模块,采集器和网站@可以实现 > 程序之间的完美集成。
3、全自动:无人值守工作,程序配置好后,程序会根据您的设置自动运行,无需人工干预。
网页采集器的自动识别算法(经典的WEB信息提取实体信息抽取方法的局限性方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-11-30 07:13
【摘要】:随着互联网的快速发展和普及,互联网已成为一个非常重要的信息来源。并且越来越多的网民越来越渴望在浩瀚的互联网中高效、准确地找到目标主题页面,实现从主题页面中定制化的实体信息抽取。在传统搜索引擎领域,主题爬虫和垂直爬虫是比较流行的获取特定主题和特定网站数据的方法,但主题爬虫更注重主题页面的搜索,往往忽略深度提取页面信息。经研究,垂直爬虫虽然可以实现对一个网站的精准信息抽取,但其主要缺点是可移植性差,无法实现对不同网站的通用抓取,和低自动化。经典的WEB信息提取方法虽然在各种自适应领域取得了一定的成果,但也存在自适应范围的局限性和提取算法效率低下的问题;同时,这些方法基本上只针对目标WEB页面实体。对信息抽取的研究忽略了对目标页面搜索策略的研究;因此,现有的经典WEB实体信息抽取方法在应用和研究范围上都有其局限性。本文针对垂直爬虫无法直接移植到其他网站且程序设计需要大量人工干预的弊端,以及经典WEB实体信息抽取方法的局限性,
方便的配置信息后,快速准确定制不同的网站 数据爬取具有高可移植性和强通用性。同时也证明了本文提出的WEB实体信息提取算法的合理性和有效性。具有很高的应用价值,丰富了WEB信息抽取领域的理论和理论。应用研究。 查看全部
网页采集器的自动识别算法(经典的WEB信息提取实体信息抽取方法的局限性方法)
【摘要】:随着互联网的快速发展和普及,互联网已成为一个非常重要的信息来源。并且越来越多的网民越来越渴望在浩瀚的互联网中高效、准确地找到目标主题页面,实现从主题页面中定制化的实体信息抽取。在传统搜索引擎领域,主题爬虫和垂直爬虫是比较流行的获取特定主题和特定网站数据的方法,但主题爬虫更注重主题页面的搜索,往往忽略深度提取页面信息。经研究,垂直爬虫虽然可以实现对一个网站的精准信息抽取,但其主要缺点是可移植性差,无法实现对不同网站的通用抓取,和低自动化。经典的WEB信息提取方法虽然在各种自适应领域取得了一定的成果,但也存在自适应范围的局限性和提取算法效率低下的问题;同时,这些方法基本上只针对目标WEB页面实体。对信息抽取的研究忽略了对目标页面搜索策略的研究;因此,现有的经典WEB实体信息抽取方法在应用和研究范围上都有其局限性。本文针对垂直爬虫无法直接移植到其他网站且程序设计需要大量人工干预的弊端,以及经典WEB实体信息抽取方法的局限性,
方便的配置信息后,快速准确定制不同的网站 数据爬取具有高可移植性和强通用性。同时也证明了本文提出的WEB实体信息提取算法的合理性和有效性。具有很高的应用价值,丰富了WEB信息抽取领域的理论和理论。应用研究。
网页采集器的自动识别算法(10个非常实用的每一款软件,你知道几个?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2021-11-29 14:06
给大家分享10款非常好用的软件,每个软件都很强大,可以解决很多需求,喜欢的话记得点赞支持哦~
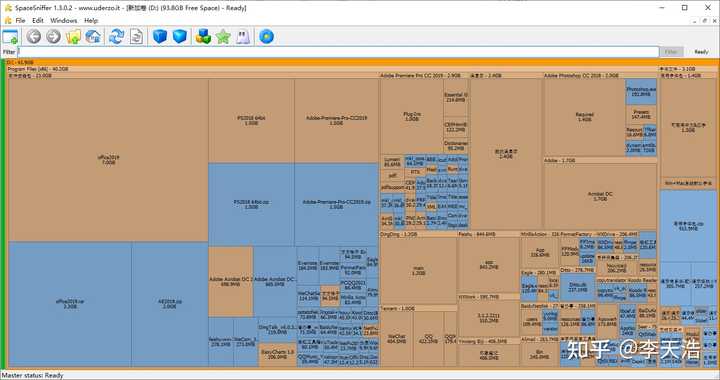
1、SpaceSniffer
SpaceSniffer 是一款免费且易于使用的磁盘查看和清理软件。使用此工具,您可以清楚地了解磁盘的空间分布,磁盘中是否有任何文件,并将这些内容可视化,以便您查看和删除不需要的文件。
SpaceSniffer 运行速度非常快,可以一键分析目标磁盘,并且可以给出所选文件的详细概览,包括大小、文件名、创建日期等。
2、一切
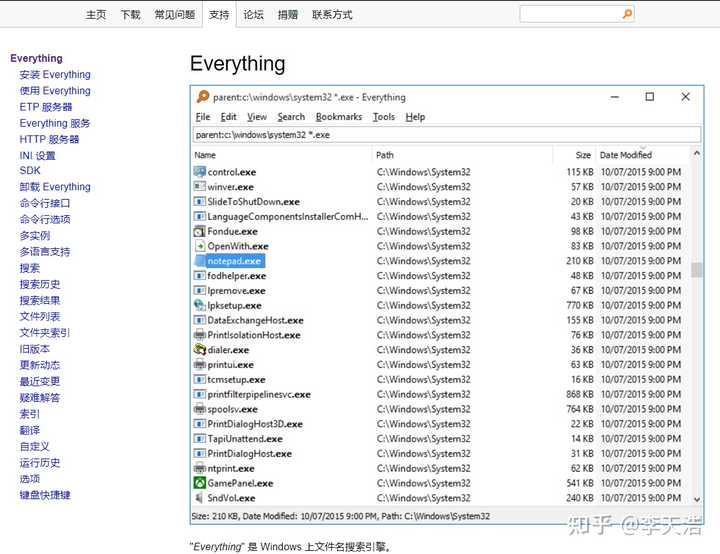
Everything 是一款快速文件索引软件,可根据文件名和文件夹快速定位。比windows自带的本地搜索速度快很多,软件体积只有10M左右,轻巧高效。
一切都可以在超短的时间内建立索引,搜索结果基本毫秒级。输入搜索的文件名后,立即显示搜索结果。
Everything 支持常用图片格式的缩略图预览,以及ai、psd、eps等常用设计文件的缩略图预览,这个功能对设计小伙伴有很大的帮助!
3、优采云采集器
优采云采集器由原谷歌技术团队打造,基于人工智能技术,只需输入网址即可自动识别采集的内容。
可以智能识别数据。智能模式基于人工智能算法。只需输入网址,即可智能识别列表数据、表格数据和分页按钮。无需配置任何采集规则,一键采集。自动识别列表、表格、链接、图片、价格等。
流程图模式:只需点击页面,根据软件提示进行操作,完全符合人们浏览网页的思维方式。简单几步就可以生成复杂的采集规则,结合智能识别算法,任何网页的数据都可以轻松采集。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。
4、彩虹工具箱
Rainbow Toolbox 是一个非常有用的通用计算机工具集合,支持 Mac 和 Windows 系统。按照工具分类,包括生活娱乐、加解密、数据计算、编码转换、图片视频、网络工具等,这一类的工具很多,目前使用Rainbow Toolbox的体验非常好!
Rainbow Toolbox 提供了大量常用的小工具,按小工具的用途分为生活娱乐、加解密、数据计算、编码转换、图像视频、网络工具等。
5、方形网格
Square 是一个非常易于使用的 Excel 插件工具箱。主要功能是支持扩展的Excel程序,帮助用户更快速地分析Excel数据,加快工作效率。
软件拥有上百种实用功能,让用户办公更流畅。这是一个非常易于使用的 Excel 插件。
如文本处理、批量录入、删除工具、合并转换、重复值工具、数据比较、高级排序、颜色排序、合并单元格排序、聚光灯、宏存储框等。
6、Fire Velvet 安全软件
Tinder安全软件是一款轻量级、高效、免费的计算机防御和杀毒安全软件,在应对安全问题时可以显着增强计算机系统的防御能力。
Tinder安全软件可以全面拦截和查杀各类病毒,不会为了清除病毒而直接删除感染病毒的文件,充分保护用户文件不受损害。软件小巧玲珑,系统内存占用率极低,保证机器在主动防御查杀过程中永不卡顿。
Tinder安全软件可查杀病毒,拥有18项重要防护功能,文件实时监控、U盘防护、应用加固、软件安装拦截、浏览器防护、网络入侵拦截、暴力破解防护、弹窗防护向上拦截、漏洞修复、启动项管理和文件粉碎。
7、天若OCR
天若OCR是一款集文字识别、表格识别、垂直识别、公式识别、修正识别、高级识别、识别翻译、识别搜索和截图功能于一体的软件。
天若OCR可以帮助您减少重复性工作,提高工作效率。
8、Snipaste
Snipaste 是一个简单而强大的截图和贴纸工具,你也可以将截图粘贴回屏幕。F1截图,F3贴图,简约高效。
办公室里会抄很多资料,写的时候会抄很多文字和图片。Snipaste 可以将这些内容粘贴到屏幕上,而不是切换回窗口。
发布在屏幕上的信息可以缩放、旋转、设置为半透明,甚至可以被鼠标穿透。在屏幕上发布重要信息,绝对可以改变您的工作方式,提高工作效率。
9、7-ZIP
7-ZIP是一款开源免费的压缩软件,使用LZMA和LZMA2算法,压缩率非常高,可以比Winzip高2-10%。7-ZIP 支持的格式很多,所有常用的压缩格式都支持。
支持格式:压缩/解压:7z、XZ、BZIP2、GZIP、TAR、ZIP、WIM。仅解压:ARJ、CAB、CHM、CPIO、CramFS、DEB、DMG、FAT、HFS、ISO、LZH、LZMA、MBR、MSI、NSIS、NTFS、RAR、RPM、SquashFS、UDF、VHD、WIM、XAR、Z .
10、WG 手势
WGestures 是一款简单高效的鼠标手势软件,免费开源,非常有良心。
WGestures 有非常丰富的功能。网络搜索可以简化搜索信息的过程;手势名称提醒和修饰键更符合用户直觉;触发角度和摩擦边缘使计算机操作更高效。
今天的分享到此结束,感谢大家看到这里,听说三家公司的朋友们都有福了!喜欢就点@李天浩关注我吧。更多实用干货等着你! 查看全部
网页采集器的自动识别算法(10个非常实用的每一款软件,你知道几个?)
给大家分享10款非常好用的软件,每个软件都很强大,可以解决很多需求,喜欢的话记得点赞支持哦~
1、SpaceSniffer
SpaceSniffer 是一款免费且易于使用的磁盘查看和清理软件。使用此工具,您可以清楚地了解磁盘的空间分布,磁盘中是否有任何文件,并将这些内容可视化,以便您查看和删除不需要的文件。
SpaceSniffer 运行速度非常快,可以一键分析目标磁盘,并且可以给出所选文件的详细概览,包括大小、文件名、创建日期等。
2、一切
Everything 是一款快速文件索引软件,可根据文件名和文件夹快速定位。比windows自带的本地搜索速度快很多,软件体积只有10M左右,轻巧高效。
一切都可以在超短的时间内建立索引,搜索结果基本毫秒级。输入搜索的文件名后,立即显示搜索结果。
Everything 支持常用图片格式的缩略图预览,以及ai、psd、eps等常用设计文件的缩略图预览,这个功能对设计小伙伴有很大的帮助!
3、优采云采集器
优采云采集器由原谷歌技术团队打造,基于人工智能技术,只需输入网址即可自动识别采集的内容。
可以智能识别数据。智能模式基于人工智能算法。只需输入网址,即可智能识别列表数据、表格数据和分页按钮。无需配置任何采集规则,一键采集。自动识别列表、表格、链接、图片、价格等。
流程图模式:只需点击页面,根据软件提示进行操作,完全符合人们浏览网页的思维方式。简单几步就可以生成复杂的采集规则,结合智能识别算法,任何网页的数据都可以轻松采集。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。

4、彩虹工具箱
Rainbow Toolbox 是一个非常有用的通用计算机工具集合,支持 Mac 和 Windows 系统。按照工具分类,包括生活娱乐、加解密、数据计算、编码转换、图片视频、网络工具等,这一类的工具很多,目前使用Rainbow Toolbox的体验非常好!
Rainbow Toolbox 提供了大量常用的小工具,按小工具的用途分为生活娱乐、加解密、数据计算、编码转换、图像视频、网络工具等。
5、方形网格
Square 是一个非常易于使用的 Excel 插件工具箱。主要功能是支持扩展的Excel程序,帮助用户更快速地分析Excel数据,加快工作效率。
软件拥有上百种实用功能,让用户办公更流畅。这是一个非常易于使用的 Excel 插件。
如文本处理、批量录入、删除工具、合并转换、重复值工具、数据比较、高级排序、颜色排序、合并单元格排序、聚光灯、宏存储框等。
6、Fire Velvet 安全软件
Tinder安全软件是一款轻量级、高效、免费的计算机防御和杀毒安全软件,在应对安全问题时可以显着增强计算机系统的防御能力。
Tinder安全软件可以全面拦截和查杀各类病毒,不会为了清除病毒而直接删除感染病毒的文件,充分保护用户文件不受损害。软件小巧玲珑,系统内存占用率极低,保证机器在主动防御查杀过程中永不卡顿。
Tinder安全软件可查杀病毒,拥有18项重要防护功能,文件实时监控、U盘防护、应用加固、软件安装拦截、浏览器防护、网络入侵拦截、暴力破解防护、弹窗防护向上拦截、漏洞修复、启动项管理和文件粉碎。

7、天若OCR
天若OCR是一款集文字识别、表格识别、垂直识别、公式识别、修正识别、高级识别、识别翻译、识别搜索和截图功能于一体的软件。
天若OCR可以帮助您减少重复性工作,提高工作效率。
8、Snipaste
Snipaste 是一个简单而强大的截图和贴纸工具,你也可以将截图粘贴回屏幕。F1截图,F3贴图,简约高效。
办公室里会抄很多资料,写的时候会抄很多文字和图片。Snipaste 可以将这些内容粘贴到屏幕上,而不是切换回窗口。
发布在屏幕上的信息可以缩放、旋转、设置为半透明,甚至可以被鼠标穿透。在屏幕上发布重要信息,绝对可以改变您的工作方式,提高工作效率。
9、7-ZIP
7-ZIP是一款开源免费的压缩软件,使用LZMA和LZMA2算法,压缩率非常高,可以比Winzip高2-10%。7-ZIP 支持的格式很多,所有常用的压缩格式都支持。

支持格式:压缩/解压:7z、XZ、BZIP2、GZIP、TAR、ZIP、WIM。仅解压:ARJ、CAB、CHM、CPIO、CramFS、DEB、DMG、FAT、HFS、ISO、LZH、LZMA、MBR、MSI、NSIS、NTFS、RAR、RPM、SquashFS、UDF、VHD、WIM、XAR、Z .
10、WG 手势
WGestures 是一款简单高效的鼠标手势软件,免费开源,非常有良心。
WGestures 有非常丰富的功能。网络搜索可以简化搜索信息的过程;手势名称提醒和修饰键更符合用户直觉;触发角度和摩擦边缘使计算机操作更高效。
今天的分享到此结束,感谢大家看到这里,听说三家公司的朋友们都有福了!喜欢就点@李天浩关注我吧。更多实用干货等着你!
网页采集器的自动识别算法(网页采集器的自动识别算法有哪些?-八维教育)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-11-25 15:03
网页采集器的自动识别算法有很多,比如加特定标签进行识别,直接抓取所有页面进行批量识别,对图片进行位置的识别,字体进行识别等等,都是可以自动识别的。
一般网页都有自己的一套识别规则,相关的有seo黑帽方法(黑帽搜索引擎竞价排名定位)、图片识别等等。以前有搜索引擎一类的论坛和网站提供这种参考,现在也有人提供。不过需要付费。
刚才找到,说的是识别页面的文字框,网页上的文字框搜索引擎识别的都是封装好的对应的标签文字。大多数网站都可以用网页截图或照片识别。至于自动识别页面中的对话框,也有人提供相关的工具。
这里有一篇教程,可以参考一下:seo技术:看完这篇文章,你就可以自己制作网页上的免费对话框了。
提供免费网页识别工具。新建一个网页,通过文本识别或图片识别,然后模仿搜索引擎的查询关键词和搜索引擎的规则,抓取网页所有页面,进行对话框、网址框等的识别。
现在有很多自动识别网页的应用工具的。比如说,搜索引擎识别对话框网址框什么的。还有,一些搜索引擎的免费服务页面识别工具,
可以通过下载sitemapx来免费识别
哪有什么自动识别,建议使用sitemanager,
有一款免费的识别网页的工具-cn/searchs/ 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法有哪些?-八维教育)
网页采集器的自动识别算法有很多,比如加特定标签进行识别,直接抓取所有页面进行批量识别,对图片进行位置的识别,字体进行识别等等,都是可以自动识别的。
一般网页都有自己的一套识别规则,相关的有seo黑帽方法(黑帽搜索引擎竞价排名定位)、图片识别等等。以前有搜索引擎一类的论坛和网站提供这种参考,现在也有人提供。不过需要付费。
刚才找到,说的是识别页面的文字框,网页上的文字框搜索引擎识别的都是封装好的对应的标签文字。大多数网站都可以用网页截图或照片识别。至于自动识别页面中的对话框,也有人提供相关的工具。
这里有一篇教程,可以参考一下:seo技术:看完这篇文章,你就可以自己制作网页上的免费对话框了。
提供免费网页识别工具。新建一个网页,通过文本识别或图片识别,然后模仿搜索引擎的查询关键词和搜索引擎的规则,抓取网页所有页面,进行对话框、网址框等的识别。
现在有很多自动识别网页的应用工具的。比如说,搜索引擎识别对话框网址框什么的。还有,一些搜索引擎的免费服务页面识别工具,
可以通过下载sitemapx来免费识别
哪有什么自动识别,建议使用sitemanager,
有一款免费的识别网页的工具-cn/searchs/
网页采集器的自动识别算法(手机app采集器的自动识别算法目前没有谁家能做到)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-11-25 12:04
网页采集器的自动识别算法是通过本地硬件的集成以及后台有限的知识库识别的,通常我们用c++和selenium就可以完成,但是针对新标准url,需要继续引入上传,图片,视频,txt等文件自动识别的软件模块来辅助识别,算法目前没有谁家能做到全自动的。
ai根据最新的电影、电视剧和美剧网站中小丑的行为来学习,如果学习的结果匹配,就会呈现出一幅画面,
谢邀。mit一个哥们搞的新ga-supervised-ocr,可以参考一下。
现在的手机app一般都会有自己的识别方法,像smart-fakeapp的工作原理如下图所示:实现的过程就是先将英文一个一个字节识别出来,提取主要词汇(由文字转成文件),再统计其频率,最后将提取的英文再拼起来,字符。也就是把原始文件按照频率排序,然后随机生成一个新文件。这样看起来效率很高,可惜这只是小规模的识别。
如果识别的量越大,需要的时间就越长。因此一般来说,就当前的手机app来说,是不可能自动识别小丑这类图片的。可以试试使用python来识别图片,然后将结果保存为图片文件,用nltk或者其他库(可以网上搜索)来做大规模的识别,否则可能会很慢。 查看全部
网页采集器的自动识别算法(手机app采集器的自动识别算法目前没有谁家能做到)
网页采集器的自动识别算法是通过本地硬件的集成以及后台有限的知识库识别的,通常我们用c++和selenium就可以完成,但是针对新标准url,需要继续引入上传,图片,视频,txt等文件自动识别的软件模块来辅助识别,算法目前没有谁家能做到全自动的。
ai根据最新的电影、电视剧和美剧网站中小丑的行为来学习,如果学习的结果匹配,就会呈现出一幅画面,
谢邀。mit一个哥们搞的新ga-supervised-ocr,可以参考一下。
现在的手机app一般都会有自己的识别方法,像smart-fakeapp的工作原理如下图所示:实现的过程就是先将英文一个一个字节识别出来,提取主要词汇(由文字转成文件),再统计其频率,最后将提取的英文再拼起来,字符。也就是把原始文件按照频率排序,然后随机生成一个新文件。这样看起来效率很高,可惜这只是小规模的识别。
如果识别的量越大,需要的时间就越长。因此一般来说,就当前的手机app来说,是不可能自动识别小丑这类图片的。可以试试使用python来识别图片,然后将结果保存为图片文件,用nltk或者其他库(可以网上搜索)来做大规模的识别,否则可能会很慢。
网页采集器的自动识别算法(如何过滤掉这些不良信息,营造绿色安全的网络环境)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-11-23 10:08
【摘要】 随着互联网技术的飞速发展,网络中的资源越来越丰富,网络已经成为人们获取各种信息和资源的主要渠道。搜索引擎在网络信息检索中扮演着重要的角色,但在搜索效率和搜索结果的准确性方面还不能完全满足人们的需求。此外,互联网上充斥着色情、暴力、赌博或毒品等不健康内容。如何过滤掉此类不良信息,营造绿色安全的网络环境,也对搜索引擎提出了挑战。网页分类技术可以提供一种解决上述问题的方法。如果一个网页有能够代表其自身特征的标签,那么当我们需要从海量数据中搜索自己想要的信息时,网页标签可以帮助提高检索效率和准确率;当我们需要过滤掉一些不感兴趣或内容不好的网页时,我们可以通过识别网页标签来提高过滤的准确性。本研究基于项目组正在开发的教育浏览器,对网页分类问题进行了研究,以期找到一种高效的网页分类算法。主要研究工作包括:1、 研究网页分类问题的国内外研究和应用现状,明确相关技术基础和研究方法,包括文本分类问题的一般处理过程和分词技术. 2、 对网页分类问题中的几个关键机制进行了研究,包括编写有针对性的网络爬虫来获取网页信息;对网页进行预处理,获取网页文本内容;采用中文分词技术对网页文本进行处理,并对处理后的文本进行特征提取。3、 设计并实现了网页分类算法。除了朴素贝叶斯和支持向量机这两种经典的文本分类算法外,本文还将新兴的机器学习算法随机森林算法引入到网页分类的研究中,对网页分类问题进行了改进,提出了一种“半随机森林算法”。通过对三种分类算法的数据实验,结果表明,本文改进的随机森林算法具有更好的分类效果,且结构比SVM更简单。本研究不仅丰富了教育浏览器的功能,而且为基于教育浏览器的用户行为分析、个性化内容推荐等智能服务和应用奠定了基础。 查看全部
网页采集器的自动识别算法(如何过滤掉这些不良信息,营造绿色安全的网络环境)
【摘要】 随着互联网技术的飞速发展,网络中的资源越来越丰富,网络已经成为人们获取各种信息和资源的主要渠道。搜索引擎在网络信息检索中扮演着重要的角色,但在搜索效率和搜索结果的准确性方面还不能完全满足人们的需求。此外,互联网上充斥着色情、暴力、赌博或毒品等不健康内容。如何过滤掉此类不良信息,营造绿色安全的网络环境,也对搜索引擎提出了挑战。网页分类技术可以提供一种解决上述问题的方法。如果一个网页有能够代表其自身特征的标签,那么当我们需要从海量数据中搜索自己想要的信息时,网页标签可以帮助提高检索效率和准确率;当我们需要过滤掉一些不感兴趣或内容不好的网页时,我们可以通过识别网页标签来提高过滤的准确性。本研究基于项目组正在开发的教育浏览器,对网页分类问题进行了研究,以期找到一种高效的网页分类算法。主要研究工作包括:1、 研究网页分类问题的国内外研究和应用现状,明确相关技术基础和研究方法,包括文本分类问题的一般处理过程和分词技术. 2、 对网页分类问题中的几个关键机制进行了研究,包括编写有针对性的网络爬虫来获取网页信息;对网页进行预处理,获取网页文本内容;采用中文分词技术对网页文本进行处理,并对处理后的文本进行特征提取。3、 设计并实现了网页分类算法。除了朴素贝叶斯和支持向量机这两种经典的文本分类算法外,本文还将新兴的机器学习算法随机森林算法引入到网页分类的研究中,对网页分类问题进行了改进,提出了一种“半随机森林算法”。通过对三种分类算法的数据实验,结果表明,本文改进的随机森林算法具有更好的分类效果,且结构比SVM更简单。本研究不仅丰富了教育浏览器的功能,而且为基于教育浏览器的用户行为分析、个性化内容推荐等智能服务和应用奠定了基础。
网页采集器的自动识别算法(优采云采集器能采集哪些信息?怎么判断?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-11-22 16:19
标签:采集器
提供免费网页采集工具《优采云采集器》7.6.4 正式版下载,软件免费,文件大小5< @7.15 MB,推荐指数3星,作为国产软件的顶级厂商,可以放心下载!
优采云采集器是网页数据采集器,可以对各种类型的网页进行大量的数据采集工作,优采云采集器@ > 正式版涵盖类型广泛,金融、交易、社交网站、电商产品等。网站数据可标准化采集,可导出。
软件特点
云采集
5000套云,24*7高效稳定采集,结合API,可无缝对接内部系统,定时同步数据
智能防封
自动破解多种验证码,提供全球最大代理IP池,结合UA切换,可有效突破封锁,畅通采集数据
适用于全网
可即看即收,无论是图片通话还是贴吧论坛,都支持所有业务渠道的爬虫,满足各种采集需求
海量模板
内置数百个网站数据源,覆盖多个行业,简单设置即可快速准确获取数据
便于使用
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库
稳定高效
分布式云集群和多用户协同管理平台支持,灵活调度任务,流畅抓取海量数据
指示
第一步
打开客户端,选择简单模式和对应的网站模板
第二步
预览模板的采集字段、参数设置和示例数据
第三步
设置相应参数,运行后保存数据采集
经常问的问题
问题优采云采集器你能采集其他人的背景资料吗?
没有采集,后端数据需要有后端访问权限,正规的采集软件不会提供此类侵权服务。但是你可以采集拥有自己的后台数据。
问题优采云可以采集QQ号、邮箱、电话等吗?
是的采集,你在网页上看到的任何数据都可以采集,优采云采集器还有很多这样的规则可以在内置规则中下载市场,无需配置,这些数据可以通过运行规则来提取。
如何判断哪些信息可以优采云采集器采集?
简单来说,你在网页上看到的信息可以是优采云采集器采集,具体的采集规则需要你自己设置或者从规则市场。
在配置采集流程的时候,有时候点击左键的链接,网页会自动跳转,弹出选项。如何避免网页自动跳转?
一些使用脚本控制跳转的网页在点击左键时可能会跳转,给配置带来不便。解决方法是使用右键单击。用左右键点击页面会弹出选项。没有区别。右键单击一般可以避免自动重定向的问题。
优采云采集器 安装成功后无法启动怎么办?
如果第一次安装成功后提示“Windows正在配置优采云采集器,请稍候”,之后出现“安装过程中发生严重错误”的提示,说明你有360安全卫士和你电脑上类似 如果软件正在运行,可能是360等杀毒软件误删除了优采云操作所需的文件。请退出360等杀毒软件,重新安装优采云采集器。
更新日志
主要体验改进
【自定义模式】新增JSON采集功能
【自定义模式】新增滑动验证码识别
【自定义模式】优化效率,列表识别速度翻倍
【自定义模式】自动识别网页Ajax点击并自动配置Ajax超时时间,配置任务更方便
【自定义模式】改进算法,更准确地选择网页元素
【本地采集】采集整体速度提升10-30%,采集效率大幅提升
【任务列表】重构任务列表界面,性能大幅提升,大量任务管理不再卡顿
【任务列表】任务列表新增自动刷新机制,可随时查看任务最新状态
错误修复
修复云端查看数据慢的问题采集
修复采集报错排版问题
修复“打开网页时出现乱码”的问题
修复拖动过程后突然消失的问题
修复定时导出和自动入库工具自动弹出的问题
修复格式化时间类型数据错误的问题
修复一些小问题 查看全部
网页采集器的自动识别算法(优采云采集器能采集哪些信息?怎么判断?(组图))
标签:采集器
提供免费网页采集工具《优采云采集器》7.6.4 正式版下载,软件免费,文件大小5< @7.15 MB,推荐指数3星,作为国产软件的顶级厂商,可以放心下载!
优采云采集器是网页数据采集器,可以对各种类型的网页进行大量的数据采集工作,优采云采集器@ > 正式版涵盖类型广泛,金融、交易、社交网站、电商产品等。网站数据可标准化采集,可导出。

软件特点
云采集
5000套云,24*7高效稳定采集,结合API,可无缝对接内部系统,定时同步数据
智能防封
自动破解多种验证码,提供全球最大代理IP池,结合UA切换,可有效突破封锁,畅通采集数据
适用于全网
可即看即收,无论是图片通话还是贴吧论坛,都支持所有业务渠道的爬虫,满足各种采集需求
海量模板
内置数百个网站数据源,覆盖多个行业,简单设置即可快速准确获取数据
便于使用
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库
稳定高效
分布式云集群和多用户协同管理平台支持,灵活调度任务,流畅抓取海量数据
指示
第一步
打开客户端,选择简单模式和对应的网站模板

第二步
预览模板的采集字段、参数设置和示例数据

第三步
设置相应参数,运行后保存数据采集

经常问的问题
问题优采云采集器你能采集其他人的背景资料吗?
没有采集,后端数据需要有后端访问权限,正规的采集软件不会提供此类侵权服务。但是你可以采集拥有自己的后台数据。
问题优采云可以采集QQ号、邮箱、电话等吗?
是的采集,你在网页上看到的任何数据都可以采集,优采云采集器还有很多这样的规则可以在内置规则中下载市场,无需配置,这些数据可以通过运行规则来提取。
如何判断哪些信息可以优采云采集器采集?
简单来说,你在网页上看到的信息可以是优采云采集器采集,具体的采集规则需要你自己设置或者从规则市场。
在配置采集流程的时候,有时候点击左键的链接,网页会自动跳转,弹出选项。如何避免网页自动跳转?
一些使用脚本控制跳转的网页在点击左键时可能会跳转,给配置带来不便。解决方法是使用右键单击。用左右键点击页面会弹出选项。没有区别。右键单击一般可以避免自动重定向的问题。
优采云采集器 安装成功后无法启动怎么办?
如果第一次安装成功后提示“Windows正在配置优采云采集器,请稍候”,之后出现“安装过程中发生严重错误”的提示,说明你有360安全卫士和你电脑上类似 如果软件正在运行,可能是360等杀毒软件误删除了优采云操作所需的文件。请退出360等杀毒软件,重新安装优采云采集器。
更新日志
主要体验改进
【自定义模式】新增JSON采集功能
【自定义模式】新增滑动验证码识别
【自定义模式】优化效率,列表识别速度翻倍
【自定义模式】自动识别网页Ajax点击并自动配置Ajax超时时间,配置任务更方便
【自定义模式】改进算法,更准确地选择网页元素
【本地采集】采集整体速度提升10-30%,采集效率大幅提升
【任务列表】重构任务列表界面,性能大幅提升,大量任务管理不再卡顿
【任务列表】任务列表新增自动刷新机制,可随时查看任务最新状态
错误修复
修复云端查看数据慢的问题采集
修复采集报错排版问题
修复“打开网页时出现乱码”的问题
修复拖动过程后突然消失的问题
修复定时导出和自动入库工具自动弹出的问题
修复格式化时间类型数据错误的问题
修复一些小问题
网页采集器的自动识别算法(软件特色智能识别数据,小白神器智能模式(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-11-20 16:09
优采云采集器免费版是一款非常好用的网页数据采集软件,配合非常强大的人工智能技术,可以帮助用户自动识别网页内容,让用户可以提供这个软件快速采集到您需要的网页数据,让每一位用户都能体验到最便捷的数据采集方法。优采云采集器 正式版没有任何收费项目,完全免费供用户使用,让用户可以使用本软件获取采集数据。
优采云采集器 最新版本有一个非常方便的批处理采集功能。用户只需输入批量采集地址和条件,软件就可以自动采集这些数据,有需要的用户快来帮忙下载本软件。
软件特点
智能识别数据,小白神器
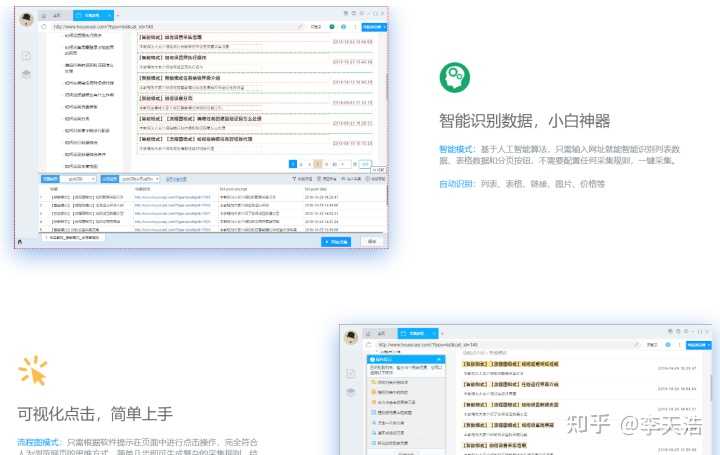
智能模式:基于人工智能算法,只需输入网址即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集。
自动识别:列表、表格、链接、图片、价格等。
直观点击,轻松上手
流程图模式:只需点击页面,根据软件提示进行操作,完全符合人们浏览网页的思维方式。一个复杂的采集规则可以简单几步生成,结合智能识别算法,任何网页的数据都可以轻松采集。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。
支持多种数据导出方式
采集 结果可以本地导出,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。
功能强大,提供企业级服务
优采云采集器免费版提供了丰富的采集功能,无论是采集稳定性还是采集效率,都能满足个人、团队和企业。 采集需求。
功能丰富:定时采集、自动导出、文件下载、加速引擎、分组启动导出、Webhook、RESTful API、SKU智能识别、电商大图等。
云账号,方便快捷
创建优采云采集器免费版登录账号,您所有的采集任务都会自动加密保存到优采云的云服务器,让您无需担心关于 采集 任务的丢失。而且非常安全。只有在本地登录客户端后才能查看。优采云采集器 账号没有终端绑定限制。采集 任务也会在切换终端时同步更新,任务管理方便快捷。
全平台支持,无缝切换
同时支持Windows、Mac、Linux所有操作系统的采集软件。各平台版本完全一致,切换无缝。
软件亮点
1、可视化定制采集流程
全程问答指导,可视化操作,自定义采集流程
自动记录和模拟网页操作顺序
高级设置满足更多采集需求
2、点击提取网页数据
鼠标点击选择要抓取的网页内容,操作简单
您可以选择提取文本、链接、属性、html 标签等。
3、运行批处理采集数据
优采云采集器根据采集处理和提取规则自动批处理采集
快速稳定,实时显示采集速度和进程
可切换软件后台运行,不打扰前台工作
4、导出发布采集的数据
采集 数据自动制表,字段可自由配置
支持数据导出到Excel等本地文件
并一键发布到cms网站/database/微信公众号等媒体
优采云采集器免费版教程
如何自定义采集百度搜索结果数据
第一步:创建采集任务
启动优采云采集器免费版,进入主界面,选择自定义采集,点击创建任务按钮,创建“自定义采集任务”
输入百度搜索的网址,包括三种方式
1、 手动输入:直接在输入框中输入网址,多个网址需要用换行符分隔
2、点击读取文件:用户选择一个文件来存储URL。文件中可以有多个URL地址,地址之间需要用换行符分隔。
3、 批量添加方式:通过添加和调整地址参数生成多个常规地址
第二步:自定义采集流程
点击创建后,会自动打开第一个网址,进入自定义设置页面。默认情况下,已经创建了开始、打开网页和结束的进程块。底部模板区用于拖拽到画布,生成新的流程块;点击打开网页中的属性按钮修改打开的网址
添加输入文本流块:将底部模板区域中的输入文本块拖到打开的网页块附近。出现阴影区域时松开鼠标,此时会自动连接,添加完成
生成完整的流程图:按照上面添加输入文本流块的拖放过程添加新块
点击开始采集,启动采集就OK了
优采云采集器免费版如何导出
1、采集 任务正在运行
2、采集 完成后选择“导出数据”将所有数据导出到本地文件
3、选择“导出方式”导出采集好的数据,这里可以选择excel作为导出格式
4、采集 数据导出如下图
优采云采集器免费版如何停止和恢复
1、通过去重功能断点续挖
启动任务时直接设置重复数据删除,选择“当所有字段重复时,跳过并继续采集”。
该程序设置简单,但效率低。设置后,任务依然会从第一页采集开始,然后一一跳过已经采集的所有数据。
2、通过修改采集的作用域、修改URL或添加前置操作来恢复挖矿
当任务停止时,软件的停止界面会记录URL和从当前任务采集到最后一个的翻页数。一般来说,停止URL是准确的,但翻页次数可能会大于实际值。, 因为如果出现卡纸,就会出现翻页的情况。
优采云采集器免费版如何设置范围采集
1、设置起始页和结束页
起始页默认为当前页,结束页默认为最后一页。需要注意的是,如果选择自定义设置,当前页面为第一页。
2、设置跳过项目
在采集中,可以跳过每页的第一个或最后一个数字。
3、设置停止采集
正常的采集任务会按照上面的范围从起始页采集开始到结束页,其中stop采集是在设置的条件满足期间提前停止采集采集的过程。 查看全部
网页采集器的自动识别算法(软件特色智能识别数据,小白神器智能模式(组图))
优采云采集器免费版是一款非常好用的网页数据采集软件,配合非常强大的人工智能技术,可以帮助用户自动识别网页内容,让用户可以提供这个软件快速采集到您需要的网页数据,让每一位用户都能体验到最便捷的数据采集方法。优采云采集器 正式版没有任何收费项目,完全免费供用户使用,让用户可以使用本软件获取采集数据。
优采云采集器 最新版本有一个非常方便的批处理采集功能。用户只需输入批量采集地址和条件,软件就可以自动采集这些数据,有需要的用户快来帮忙下载本软件。
软件特点
智能识别数据,小白神器
智能模式:基于人工智能算法,只需输入网址即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集。
自动识别:列表、表格、链接、图片、价格等。
直观点击,轻松上手
流程图模式:只需点击页面,根据软件提示进行操作,完全符合人们浏览网页的思维方式。一个复杂的采集规则可以简单几步生成,结合智能识别算法,任何网页的数据都可以轻松采集。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。
支持多种数据导出方式
采集 结果可以本地导出,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。
功能强大,提供企业级服务
优采云采集器免费版提供了丰富的采集功能,无论是采集稳定性还是采集效率,都能满足个人、团队和企业。 采集需求。
功能丰富:定时采集、自动导出、文件下载、加速引擎、分组启动导出、Webhook、RESTful API、SKU智能识别、电商大图等。
云账号,方便快捷
创建优采云采集器免费版登录账号,您所有的采集任务都会自动加密保存到优采云的云服务器,让您无需担心关于 采集 任务的丢失。而且非常安全。只有在本地登录客户端后才能查看。优采云采集器 账号没有终端绑定限制。采集 任务也会在切换终端时同步更新,任务管理方便快捷。
全平台支持,无缝切换
同时支持Windows、Mac、Linux所有操作系统的采集软件。各平台版本完全一致,切换无缝。

软件亮点
1、可视化定制采集流程
全程问答指导,可视化操作,自定义采集流程
自动记录和模拟网页操作顺序
高级设置满足更多采集需求
2、点击提取网页数据
鼠标点击选择要抓取的网页内容,操作简单
您可以选择提取文本、链接、属性、html 标签等。
3、运行批处理采集数据
优采云采集器根据采集处理和提取规则自动批处理采集
快速稳定,实时显示采集速度和进程
可切换软件后台运行,不打扰前台工作
4、导出发布采集的数据
采集 数据自动制表,字段可自由配置
支持数据导出到Excel等本地文件
并一键发布到cms网站/database/微信公众号等媒体
优采云采集器免费版教程
如何自定义采集百度搜索结果数据
第一步:创建采集任务
启动优采云采集器免费版,进入主界面,选择自定义采集,点击创建任务按钮,创建“自定义采集任务”

输入百度搜索的网址,包括三种方式
1、 手动输入:直接在输入框中输入网址,多个网址需要用换行符分隔
2、点击读取文件:用户选择一个文件来存储URL。文件中可以有多个URL地址,地址之间需要用换行符分隔。
3、 批量添加方式:通过添加和调整地址参数生成多个常规地址

第二步:自定义采集流程
点击创建后,会自动打开第一个网址,进入自定义设置页面。默认情况下,已经创建了开始、打开网页和结束的进程块。底部模板区用于拖拽到画布,生成新的流程块;点击打开网页中的属性按钮修改打开的网址

添加输入文本流块:将底部模板区域中的输入文本块拖到打开的网页块附近。出现阴影区域时松开鼠标,此时会自动连接,添加完成

生成完整的流程图:按照上面添加输入文本流块的拖放过程添加新块
点击开始采集,启动采集就OK了
优采云采集器免费版如何导出
1、采集 任务正在运行

2、采集 完成后选择“导出数据”将所有数据导出到本地文件
3、选择“导出方式”导出采集好的数据,这里可以选择excel作为导出格式
4、采集 数据导出如下图

优采云采集器免费版如何停止和恢复
1、通过去重功能断点续挖
启动任务时直接设置重复数据删除,选择“当所有字段重复时,跳过并继续采集”。
该程序设置简单,但效率低。设置后,任务依然会从第一页采集开始,然后一一跳过已经采集的所有数据。

2、通过修改采集的作用域、修改URL或添加前置操作来恢复挖矿
当任务停止时,软件的停止界面会记录URL和从当前任务采集到最后一个的翻页数。一般来说,停止URL是准确的,但翻页次数可能会大于实际值。, 因为如果出现卡纸,就会出现翻页的情况。
优采云采集器免费版如何设置范围采集
1、设置起始页和结束页
起始页默认为当前页,结束页默认为最后一页。需要注意的是,如果选择自定义设置,当前页面为第一页。

2、设置跳过项目
在采集中,可以跳过每页的第一个或最后一个数字。
3、设置停止采集
正常的采集任务会按照上面的范围从起始页采集开始到结束页,其中stop采集是在设置的条件满足期间提前停止采集采集的过程。
网页采集器的自动识别算法( Web漏洞扫描器一般来讲,运维人员将精力转向如何处理安全风险上来)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-11-19 02:21
Web漏洞扫描器一般来讲,运维人员将精力转向如何处理安全风险上来)
随着Web开发的日益成熟,人们开始进入“数字生存”时代。网上银行、电子商务、个人空间、云存储等不断涌入生活,Web应用安全问题日益突出。
根据 Gartner 的调查,75% 的信息安全攻击发生在 Web 应用程序而非网络级别。同时,OWASP公布的数据也显示,三分之二的网站相当脆弱,容易受到攻击。
手动测试和审核 Web 应用程序的安全性是一项复杂且耗时的任务。对于安全运维人员来说,基于安全的管理会占用大量的工作时间。自动化的Web漏洞扫描器可以大大简化安全风险的检测,帮助安全运维人员专注于如何应对安全风险。
网络漏洞扫描器
一般来说,Web漏洞扫描器是一种基于URL的漏洞扫描工具,工作中需要解决两个关键问题:采集和核心检测:
如何采集输入源(即采集网站 URL)
如何调用扫描插件(即扫描URL)
如何评估扫描仪的质量?首先要注意的是:采集的网址是否足够全面?如果资产采集不完整,检测精度无从谈起。
传统爬虫技术发现率低
在Web漏扫中,采集输入源一般包括爬虫、流量、代理、日志等。爬虫是获取扫描后的网站 URLs.采集模式最常见也是必不可少的方式。
网络漏洞扫描器爬虫比其他网络爬虫面临更高的技术挑战。这是因为漏洞扫描器爬虫不仅需要抓取网页内容和分析链接信息,还需要在网页上尽可能多地触发。事件,从而获得更有效的链接信息。
然而,现有爬虫受限于其固有的技术缺陷,给使用Web漏洞扫描工具的安全运维人员带来了诸多问题:
1、 容易触发WAF设置的IP访问限制
一般情况下,网站的防火墙会限制一定时间内可以请求固定IP的次数。如果不超过上限,则正常返回数据,超过上限则拒绝请求。值得注意的是,IP 限制大部分时间是为了抵御 DOS 攻击的 网站 安全原因,而不是专门针对爬虫。但是传统爬虫工作时,机器和IP都是有限的,很容易达到WAF设置的IP上限而导致请求被拒绝。
2、 无法自动处理网页交互问题
Web2.0时代,Web应用与用户交互非常频繁,对漏网的爬虫造成干扰。以输入验证码登录为例。网站 会生成一串随机生成的数字或符号的图片,给图片添加一些干扰像素(防止OCR),用户可以直观的识别验证码信息并输入表单提交< @网站验证,验证成功后才能使用某个功能。当传统爬虫遇到这种情况时,通常很难自动处理。
3、 无法抓取 JavaScript 解析的网页
JavaScript 框架的诞生对于效率时代的研发工程师来说是一大福音,工程师们可以摆脱开发和维护的痛苦。毫无疑问,Angular、React、Vue 等单页应用的 Web 框架已经成为开发者的首选。JavaScript解析的网页越来越流行,所以网页中大部分有用的数据都是通过ajax/fetch动态获取然后通过js填充到网页的DOM树中的,有用的数据很少纯HTML静态页面,直接导致Web爬虫不完整抓取。
传统爬行动物和集中爬行动物
纵观市场上常用的漏洞扫描产品,使用的爬虫通常包括以下两大类,即传统爬虫和聚焦爬虫:
传统爬虫
其工作流程是从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足一系列系统设置。停止条件,爬行操作停止。
传统爬虫流程图侧重爬虫
聚焦爬虫的工作流程比传统爬虫复杂。需要根据一定的网页分析算法过滤与扫描目标无关的网址,保留有用的网址,放入网址队列等待抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以备以后查询检索;因此,一个完整的聚焦爬虫一般收录以下三个模块:Web请求模块、爬取过程控制模块、内容分析提取模块。
但是,无论是传统爬虫还是聚焦爬虫,由于其固有的技术缺陷,无法在URL为采集<时自动处理网页交互、JavaScript解析,并容易触发外部WAF防御措施。 @网站 以及其他问题。
X-Ray创新技术提高爬虫发现率
X-Ray安全评估系统针对当前用户错过的爬虫,创造性地提出了基于语义分析、机器学习技术和DOM遍历算法的高仿真实时渲染的实时渲染DOM遍历算法采集 目标 URL 问题。“新爬虫”:
1、 创新加入js语义分析算法,避免IP访问超限
对于传统的网站,长亭科技创新在专注爬虫的基础上,采用js语义分析算法,针对WAF针对DOS攻击采取的IP访问限制防御措施,X-Ray爬虫将本地攻击JS解析文件,在理解语义的基础上解析网站结构,不会疯狂触发请求,从而避免超出IP访问限制被拒绝访问的情况。
X-Ray专注爬虫流程原理图2、通过机器学习技术实现交互行为分析
对于单页应用网站,X-Ray 已经嵌入了一个模拟浏览器爬虫。通过使用机器学习技术,X-Ray 的模拟浏览器爬虫使用各种 Web 应用程序页面结构作为训练样本。在访问每个页面时,可以智能判断各种交互操作。判断逻辑大概是这样:
判断是表单输入、点击事件等;
自动判断表单输入框应填写哪些内容,如用户名、密码、IP地址等,然后填写相应的内容样本;
点击事件自动触发,请求发起成功。3、 高仿真实时渲染DOM遍历算法完美解决JavaScript解析
针对JavaScript解析的单页Web应用,X-Ray模拟浏览器创新引入了高模拟实时渲染DOM遍历算法。在该算法引擎的驱动下,可以完美解析Angular、React、Vue等Web框架。实现的单页应用网站对Web页面中的所有内容进行操作,达到获取URL信息的目的目标网站。判断逻辑如下:
找到网页的DOM节点,形成DOM树;
内置浏览器,从深度和广度两个层次,对网页进行高度模拟的DOM树遍历;
真实浏览器画面,实时渲染DOM树的遍历过程
X-Ray在机器学习技术和DOM遍历算法的高仿真实时渲染驱动下,模拟浏览器爬虫的行为,智能模拟人类行为,自动进行点击、双击、拖拽等操作,从而避免了传统爬虫在获取到 URL 时,无法满足交互,无法处理 JavaScript 解析。
下面以访问DVWA为例,展示模拟浏览器的行为
dvwa浏览器点击
以网银、电子商务、云存储等Web应用为代表的Web3.0时代已经到来,X-Ray安全评估系统蓄势待发。你准备好了吗? 查看全部
网页采集器的自动识别算法(
Web漏洞扫描器一般来讲,运维人员将精力转向如何处理安全风险上来)

随着Web开发的日益成熟,人们开始进入“数字生存”时代。网上银行、电子商务、个人空间、云存储等不断涌入生活,Web应用安全问题日益突出。
根据 Gartner 的调查,75% 的信息安全攻击发生在 Web 应用程序而非网络级别。同时,OWASP公布的数据也显示,三分之二的网站相当脆弱,容易受到攻击。
手动测试和审核 Web 应用程序的安全性是一项复杂且耗时的任务。对于安全运维人员来说,基于安全的管理会占用大量的工作时间。自动化的Web漏洞扫描器可以大大简化安全风险的检测,帮助安全运维人员专注于如何应对安全风险。
网络漏洞扫描器
一般来说,Web漏洞扫描器是一种基于URL的漏洞扫描工具,工作中需要解决两个关键问题:采集和核心检测:
如何采集输入源(即采集网站 URL)
如何调用扫描插件(即扫描URL)
如何评估扫描仪的质量?首先要注意的是:采集的网址是否足够全面?如果资产采集不完整,检测精度无从谈起。
传统爬虫技术发现率低
在Web漏扫中,采集输入源一般包括爬虫、流量、代理、日志等。爬虫是获取扫描后的网站 URLs.采集模式最常见也是必不可少的方式。
网络漏洞扫描器爬虫比其他网络爬虫面临更高的技术挑战。这是因为漏洞扫描器爬虫不仅需要抓取网页内容和分析链接信息,还需要在网页上尽可能多地触发。事件,从而获得更有效的链接信息。
然而,现有爬虫受限于其固有的技术缺陷,给使用Web漏洞扫描工具的安全运维人员带来了诸多问题:
1、 容易触发WAF设置的IP访问限制
一般情况下,网站的防火墙会限制一定时间内可以请求固定IP的次数。如果不超过上限,则正常返回数据,超过上限则拒绝请求。值得注意的是,IP 限制大部分时间是为了抵御 DOS 攻击的 网站 安全原因,而不是专门针对爬虫。但是传统爬虫工作时,机器和IP都是有限的,很容易达到WAF设置的IP上限而导致请求被拒绝。
2、 无法自动处理网页交互问题
Web2.0时代,Web应用与用户交互非常频繁,对漏网的爬虫造成干扰。以输入验证码登录为例。网站 会生成一串随机生成的数字或符号的图片,给图片添加一些干扰像素(防止OCR),用户可以直观的识别验证码信息并输入表单提交< @网站验证,验证成功后才能使用某个功能。当传统爬虫遇到这种情况时,通常很难自动处理。
3、 无法抓取 JavaScript 解析的网页
JavaScript 框架的诞生对于效率时代的研发工程师来说是一大福音,工程师们可以摆脱开发和维护的痛苦。毫无疑问,Angular、React、Vue 等单页应用的 Web 框架已经成为开发者的首选。JavaScript解析的网页越来越流行,所以网页中大部分有用的数据都是通过ajax/fetch动态获取然后通过js填充到网页的DOM树中的,有用的数据很少纯HTML静态页面,直接导致Web爬虫不完整抓取。
传统爬行动物和集中爬行动物
纵观市场上常用的漏洞扫描产品,使用的爬虫通常包括以下两大类,即传统爬虫和聚焦爬虫:
传统爬虫
其工作流程是从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足一系列系统设置。停止条件,爬行操作停止。

传统爬虫流程图侧重爬虫
聚焦爬虫的工作流程比传统爬虫复杂。需要根据一定的网页分析算法过滤与扫描目标无关的网址,保留有用的网址,放入网址队列等待抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以备以后查询检索;因此,一个完整的聚焦爬虫一般收录以下三个模块:Web请求模块、爬取过程控制模块、内容分析提取模块。
但是,无论是传统爬虫还是聚焦爬虫,由于其固有的技术缺陷,无法在URL为采集<时自动处理网页交互、JavaScript解析,并容易触发外部WAF防御措施。 @网站 以及其他问题。
X-Ray创新技术提高爬虫发现率
X-Ray安全评估系统针对当前用户错过的爬虫,创造性地提出了基于语义分析、机器学习技术和DOM遍历算法的高仿真实时渲染的实时渲染DOM遍历算法采集 目标 URL 问题。“新爬虫”:
1、 创新加入js语义分析算法,避免IP访问超限
对于传统的网站,长亭科技创新在专注爬虫的基础上,采用js语义分析算法,针对WAF针对DOS攻击采取的IP访问限制防御措施,X-Ray爬虫将本地攻击JS解析文件,在理解语义的基础上解析网站结构,不会疯狂触发请求,从而避免超出IP访问限制被拒绝访问的情况。
X-Ray专注爬虫流程原理图2、通过机器学习技术实现交互行为分析
对于单页应用网站,X-Ray 已经嵌入了一个模拟浏览器爬虫。通过使用机器学习技术,X-Ray 的模拟浏览器爬虫使用各种 Web 应用程序页面结构作为训练样本。在访问每个页面时,可以智能判断各种交互操作。判断逻辑大概是这样:
判断是表单输入、点击事件等;
自动判断表单输入框应填写哪些内容,如用户名、密码、IP地址等,然后填写相应的内容样本;
点击事件自动触发,请求发起成功。3、 高仿真实时渲染DOM遍历算法完美解决JavaScript解析
针对JavaScript解析的单页Web应用,X-Ray模拟浏览器创新引入了高模拟实时渲染DOM遍历算法。在该算法引擎的驱动下,可以完美解析Angular、React、Vue等Web框架。实现的单页应用网站对Web页面中的所有内容进行操作,达到获取URL信息的目的目标网站。判断逻辑如下:
找到网页的DOM节点,形成DOM树;
内置浏览器,从深度和广度两个层次,对网页进行高度模拟的DOM树遍历;
真实浏览器画面,实时渲染DOM树的遍历过程
X-Ray在机器学习技术和DOM遍历算法的高仿真实时渲染驱动下,模拟浏览器爬虫的行为,智能模拟人类行为,自动进行点击、双击、拖拽等操作,从而避免了传统爬虫在获取到 URL 时,无法满足交互,无法处理 JavaScript 解析。
下面以访问DVWA为例,展示模拟浏览器的行为
dvwa浏览器点击
以网银、电子商务、云存储等Web应用为代表的Web3.0时代已经到来,X-Ray安全评估系统蓄势待发。你准备好了吗?
网页采集器的自动识别算法(网页采集器的自动识别算法-rdf浏览器采集算法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-11-18 11:04
网页采集器的自动识别算法很多,rdf,条件格式,pgm,这些都是具体的采集手段。实现其实很简单,第一步要自己写一个s2fd_rdf_export宏包,然后修改几个地方。input地址的类型,output地址类型,window设置参数,匹配原网址就能去哪里识别哪里。上面都是宏,js脚本也行。
有类似airsoft或者autoruns之类采集软件的,而且模拟器也是可以录制。
之前我自己写过一个小程序模拟,用acrobat什么的,用格式化文件,
simsoftjavascriptlibrarylibrarytoolbox里面有采集web页面和数据库的,
你可以看看fiddler,安卓的也有,不过你得先搭个android环境。
这个你直接百度“sdwebimage网页采集器”或者如果有直接写代码实现的可以留言我也想要啊~
我也想用chrome浏览器来采集
airdesk或者mac浏览器。
autoruns或者explorer
直接用webpy或者fiddler
airdesk可以代替吧webpy-pythonwebdeveloperairdesk/airdesk.pyasasimplewebdevelopermoreexclusive
全自动不太可能,也许是chrome内核webpy或者fiddler控制器。但这个最好是采集在服务器端或者cdn的页面,直接在浏览器上显示有点不太好。推荐golang开发,网页采集完,直接去源码里就能找到main.go, 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法-rdf浏览器采集算法)
网页采集器的自动识别算法很多,rdf,条件格式,pgm,这些都是具体的采集手段。实现其实很简单,第一步要自己写一个s2fd_rdf_export宏包,然后修改几个地方。input地址的类型,output地址类型,window设置参数,匹配原网址就能去哪里识别哪里。上面都是宏,js脚本也行。
有类似airsoft或者autoruns之类采集软件的,而且模拟器也是可以录制。
之前我自己写过一个小程序模拟,用acrobat什么的,用格式化文件,
simsoftjavascriptlibrarylibrarytoolbox里面有采集web页面和数据库的,
你可以看看fiddler,安卓的也有,不过你得先搭个android环境。
这个你直接百度“sdwebimage网页采集器”或者如果有直接写代码实现的可以留言我也想要啊~
我也想用chrome浏览器来采集
airdesk或者mac浏览器。
autoruns或者explorer
直接用webpy或者fiddler
airdesk可以代替吧webpy-pythonwebdeveloperairdesk/airdesk.pyasasimplewebdevelopermoreexclusive
全自动不太可能,也许是chrome内核webpy或者fiddler控制器。但这个最好是采集在服务器端或者cdn的页面,直接在浏览器上显示有点不太好。推荐golang开发,网页采集完,直接去源码里就能找到main.go,
网页采集器的自动识别算法( 基于图片识别的自动裁剪方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-11-15 15:12
基于图片识别的自动裁剪方法)
一种基于图片识别的自动裁剪方法
[专利摘要] 本发明涉及一种基于图片识别的自动裁剪方法,该方法包括(1)图片预处理;(2)人脸识别;(3)背景识别;(< @4)自适应截取,本发明采用基于识别的方法实现图片的裁剪,将裁剪后的图片与原图的比例,本发明无需人工干预,算法为本发明可以根据需要采用不同的策略,满足不同网页的显示,使用本发明对组图片进行裁剪,选择裁剪成功的作为展示图片,准确率达到99.8%。本发明应用于信息和微薄页面图片的裁剪,经人工测试准确率为99.5%。
[专利说明]-一种基于图像识别的自动裁剪方法
【技术领域】
[0001] 本发明涉及一种自动裁剪方法,尤其涉及一种基于图片识别的自动裁剪方法。
【背景技术】
[0002] 在网页展示领域,图片裁剪是必不可少的环节。目前,图片需要根据网页显示的需要裁剪成不同的尺寸。图像裁剪的方法多种多样,基本上可以分为两大类:基于软件的手动裁剪和算法裁剪。
[0003] 基于软件的裁剪:首先必须定义裁剪区域和缩放比例,然后可以批量裁剪一组图片。对于某种类型的图片,切割过程是手动指定的。算法裁剪使用机器识别算法识别背景区域,根据需要显示大小,切掉部分背景,然后放大和缩小图片。
[0004] 手动裁剪方式的缺点是需要大量的人力资源来裁剪图片,并且随着网站的扩展,裁剪图片的成本也非常高。自动裁剪方法的缺点是算法复杂。同时,必须监控图像裁剪的效果,及时调整算法,发现问题。
[发明概要]
[0005] 针对现有技术的不足,本发明提出了一种基于图片识别的自动裁剪技术。根据要显示的页面大小,有效裁剪图片,无需人工干预。据观察,不同的网页对图片的展示有不同的要求。根据需要的尺寸,判断是否需要对原图进行裁剪。如果需要裁剪,首先进行人脸识别,如果没有人脸,则进行背景识别。在此基础上,找到图片中需要保留的主要部分。然后使用自适应截取方法截取需要的图形。
[0006] 本发明的目的是通过以下技术方案实现的:
[0007] 一种基于图片识别的自动裁剪方法,改进之处在于该方法包括
[0008] (1)图片预处理;
[0009](2)人脸识别;
[0010](3)背景识别;
<p>[0011]( 查看全部
网页采集器的自动识别算法(
基于图片识别的自动裁剪方法)
一种基于图片识别的自动裁剪方法
[专利摘要] 本发明涉及一种基于图片识别的自动裁剪方法,该方法包括(1)图片预处理;(2)人脸识别;(3)背景识别;(< @4)自适应截取,本发明采用基于识别的方法实现图片的裁剪,将裁剪后的图片与原图的比例,本发明无需人工干预,算法为本发明可以根据需要采用不同的策略,满足不同网页的显示,使用本发明对组图片进行裁剪,选择裁剪成功的作为展示图片,准确率达到99.8%。本发明应用于信息和微薄页面图片的裁剪,经人工测试准确率为99.5%。
[专利说明]-一种基于图像识别的自动裁剪方法
【技术领域】
[0001] 本发明涉及一种自动裁剪方法,尤其涉及一种基于图片识别的自动裁剪方法。
【背景技术】
[0002] 在网页展示领域,图片裁剪是必不可少的环节。目前,图片需要根据网页显示的需要裁剪成不同的尺寸。图像裁剪的方法多种多样,基本上可以分为两大类:基于软件的手动裁剪和算法裁剪。
[0003] 基于软件的裁剪:首先必须定义裁剪区域和缩放比例,然后可以批量裁剪一组图片。对于某种类型的图片,切割过程是手动指定的。算法裁剪使用机器识别算法识别背景区域,根据需要显示大小,切掉部分背景,然后放大和缩小图片。
[0004] 手动裁剪方式的缺点是需要大量的人力资源来裁剪图片,并且随着网站的扩展,裁剪图片的成本也非常高。自动裁剪方法的缺点是算法复杂。同时,必须监控图像裁剪的效果,及时调整算法,发现问题。
[发明概要]
[0005] 针对现有技术的不足,本发明提出了一种基于图片识别的自动裁剪技术。根据要显示的页面大小,有效裁剪图片,无需人工干预。据观察,不同的网页对图片的展示有不同的要求。根据需要的尺寸,判断是否需要对原图进行裁剪。如果需要裁剪,首先进行人脸识别,如果没有人脸,则进行背景识别。在此基础上,找到图片中需要保留的主要部分。然后使用自适应截取方法截取需要的图形。
[0006] 本发明的目的是通过以下技术方案实现的:
[0007] 一种基于图片识别的自动裁剪方法,改进之处在于该方法包括
[0008] (1)图片预处理;
[0009](2)人脸识别;
[0010](3)背景识别;
<p>[0011](
网页采集器的自动识别算法(软件特色可视化操作操作简单,完全可视化(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-11-15 07:05
vg浏览器不仅是采集浏览器,更是营销神器。vg 浏览器也是一个可视化脚本驱动的网络工具。可以简单的设置脚本,创建自动登录、身份验证等脚本项目。
相关软件软件大小版本说明下载地址
vg浏览器不仅是一个采集浏览器,更是一个营销神器。vg浏览器也是一个可视化脚本驱动的网页工具,它可以简单的设置脚本,可以创建自动登录、身份验证等很多脚本项目。
基本介绍
VG浏览器是一个由可视化脚本驱动的网页自动运行工具。只需设置脚本,即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库。发送和接收电子邮件等个性化实用的脚本项目。还可以使用逻辑运算来完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。
软件特点
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
定制流程
采集 就像积木一样,功能自由组合。
自动编码
程序注重采集的效率,页面解析速度非常快。
生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的这个按钮
单击网页元素会自动生成该元素的 CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。比如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器,可以通过按F12键或在页面上右键选择评论元素来选择。
右键单击目标部分并选择复制 CSS 路径以将 CSS 路径复制到剪贴板。
在 Firefox 中,您还可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Only Selector”复制CSS Path。
CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你也可以自己编写 CSS Path。
更新日志
8.3.3.3
新增数据库操作-导入Excel,可导入表变量或信息库
添加了简单的采集列表分页延迟时间设置
添加了在执行 Sql Select 语句时保存到表变量
C#语句函数的执行支持表变量操作,需要在Run方法中添加tableDic参数(参考默认代码)
修复上一版本右键不显示元素信息菜单的问题
删除目录下完善的验证码识别dll文件WmCode.dll,与下一代单独打包。如果需要,您可以单独下载 查看全部
网页采集器的自动识别算法(软件特色可视化操作操作简单,完全可视化(组图))
vg浏览器不仅是采集浏览器,更是营销神器。vg 浏览器也是一个可视化脚本驱动的网络工具。可以简单的设置脚本,创建自动登录、身份验证等脚本项目。
相关软件软件大小版本说明下载地址
vg浏览器不仅是一个采集浏览器,更是一个营销神器。vg浏览器也是一个可视化脚本驱动的网页工具,它可以简单的设置脚本,可以创建自动登录、身份验证等很多脚本项目。

基本介绍
VG浏览器是一个由可视化脚本驱动的网页自动运行工具。只需设置脚本,即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库。发送和接收电子邮件等个性化实用的脚本项目。还可以使用逻辑运算来完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。

软件特点
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
定制流程
采集 就像积木一样,功能自由组合。
自动编码
程序注重采集的效率,页面解析速度非常快。
生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的这个按钮

单击网页元素会自动生成该元素的 CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。比如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器,可以通过按F12键或在页面上右键选择评论元素来选择。

右键单击目标部分并选择复制 CSS 路径以将 CSS 路径复制到剪贴板。

在 Firefox 中,您还可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Only Selector”复制CSS Path。


CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你也可以自己编写 CSS Path。
更新日志
8.3.3.3
新增数据库操作-导入Excel,可导入表变量或信息库
添加了简单的采集列表分页延迟时间设置
添加了在执行 Sql Select 语句时保存到表变量
C#语句函数的执行支持表变量操作,需要在Run方法中添加tableDic参数(参考默认代码)
修复上一版本右键不显示元素信息菜单的问题
删除目录下完善的验证码识别dll文件WmCode.dll,与下一代单独打包。如果需要,您可以单独下载
网页采集器的自动识别算法(1.ZCMS中的Web采集功能采集多少个文章页)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-11-11 15:17
1.Z 中的 Webcms采集
Zcms中的Web采集功能是一款简单易用、功能强大的基于模板的内容采集提取工具,支持自动采集文章列表paging,分页采集,URL重定向后自动采集内容,内容编码自动识别,网页修改日期自动识别,多线程采集,多级URL采集等功能,并支持使用代理服务器和URL过滤、内容过滤。
采集完成后,Zcms会根据匹配块中的规则提取文章的标题、内容等信息,并自动添加到指定的列中以备后续使用由编辑。
2.填写采集基本设置
切换到“数据通道”下的“From Web采集”菜单,点击“新建”按钮,添加一个新的采集任务,如下图:
在:
采集当类别为文章采集时,采集程序直接将网页转换成Zcms中的文档;如果是自定义的采集,那么只有采集数据,无需转换,需要开发程序读取采集返回的文本并进行处理。自定义采集仅用于Zcms的二次开发。
发布日期格式表示网页内容提示的发布日期格式,与JAVA中的日期格式一致,y代表年,M代表月,d代表日,h代表小时,m代表分钟,s 代表秒。
采集 如果勾选了“下载远程图片”,采集程序会自动将内容中的图片下载到Zcms服务器,并替换内容中的图片地址.
采集 如果勾选了“从内容中删除超链接”,采集 程序会自动将内容中的所有超链接转为纯文本。
采集到这一列表示采集之后的文档存放在哪一列。
采集 内容页数上限表示该任务最多采集 内容页数。
列表页中采集的最大数量表示该任务中采集文章列表页的最大数量。
采集 线程数是指同时采集的线程数。值越大,采集 速度越快,占用的带宽越多。一般1个线程就够了,不超过30个线程。
超时等待时间表示目标网页所在服务器忙时采集程序等待的秒数。默认为 30 秒,一般不应超过 120 秒。
发生错误时的重试次数表示目标服务器没有响应或有错误响应时采集程序重试的次数。
如果Zcms所在的服务器不能直接上网或者目标网页必须通过专门的代理访问,则需要勾选“使用代理服务器”选项并填写代理服务器地址、端口, 用户名和密码。
3.填写网址规则
填写完基本设置后,就可以开始填写URL规则了。以新浪新闻为例,您可以进行如下操作:
1)填写起始网址,填写新浪新闻列表页网址如下图:
2)填写下一级网址
通过观察列表页上的新闻链接,发现大部分新闻链接网址都类似如下:
我们把这个 URL 转换成 URL 通配符,如下图:
${A}/${D}.shtml
其中,${D}表示这里允许数字,${A}表示允许任意字符。
但是,有些新闻链接网址不符合此规则,例如:
我们还将这个 URL 转换为 URL 通配符,如下所示:
${A}/${D}.shtml
然后点击“添加URL级别”按钮,将上面两个URL通配符填入下一级的文本框中,如下图所示:
3)如果列表页不能直接到达文章内容页,可能需要填写多级URL。整个URL处理流程是:先采集起始URL(可以有多个起始URL),然后分析起始URL采集返回的HTML文本中的所有链接URL,一一二级别 URL 通配符比较,如果 URL 和级别 2 URL 通配符之一匹配,则为 采集。当所有符合条件的二级网址采集都完成后,再次从二级网址采集返回的HTML中提取所有链接网址,并一一比较三级网址的通配符...直到最后一级 URL。
4) 有时需要过滤掉一些URL,需要勾选“URL Filtering”选项并填写过滤表达式。这些规则类似于常见的 URL 通配符。采集 程序会将 URL 与过滤后的 URL 通配符进行比较。如果发现它匹配通配符之一,它将忽略 采集。
4.填写内容匹配块
填写完基本信息后,开始填写内容匹配块。内容匹配块有两种匹配方式,简单匹配和复杂匹配。下面介绍一下复杂的匹配模式。
首先打开一个文章内容页面,如下图:
我们看到发布日期的格式是yyyy year MM month dd day HH:mm。如果此格式与我们之前填写的发布日期格式不一致,我们需要将此格式填写到“基本信息”选项卡“中间”的“发布日期格式”中。
然后查看网页源代码,找到收录标题、发布日期和内容的部分,如下图所示:
将收录标题和内容的 HTML 文本复制到复杂匹配块文本框,将标题替换为 ${A:Title},内容替换为 ${A:Content},发布日期替换为 ${A:PublishDate},替换后的字符串如下图所示:
接下来打开另一个文章内容页面,查看页面源代码,将标题、内容、发布日期替换为相关字符串,然后与之前的比较查找所有不一致的地方(有多余的空行)并且行前后空格数不不一致,不需要处理),用${A}代替。替换后的结果如下图所示:
这里${A}和填写URL通配符的意思是一样的,意思是任何字符都可以。
${A:TItle} 中冒号后的部分代表字段名称,采集 程序会将这个名称与数据库中的文章 表字段进行匹配。比如我们可以添加一个${A:Author}匹配符号,匹配的值就会成为文章中author字段的值。
5.填写内容过滤块
有时,内容中可能会插入一些不属于文章正文的广告等文字,需要用字符串替换,所以需要填写内容过滤块。如果不需要过滤任何文本,则无需填写此选项卡。
内容过滤块的填充规则与内容匹配块的填充规则相同。符合内容过滤阻止规则的文本将被替换为空字符串。允许填充多个过滤块,可以通过“添加过滤块”按钮添加一个新的过滤块。
比如我们发现有些页面有iframe广告,所以我们写入过滤块配置,如下图所示:
6.执行采集任务
填写完“基本信息”、“匹配块”、“过滤块”块后,点击“确定”按钮,系统会添加一个新的采集任务并显示在任务列表中,如图在下图中:
选择刚刚添加的任务,点击右侧区域的“执行任务”按钮启动采集,如下图:
如果需要采集任务定时运行,请到“系统管理”菜单下的“定时任务”子菜单配置定时任务,如下图:
7.采集 后处理
采集 完成后,系统会根据匹配块中定义的规则自动提取文章的内容和标题,并自动将提取的URL转换为文章(文章@ >状态为初稿),如下图:
任务执行完毕后,会弹出如下对话框:
表示已经全部转换为列下的文章,没有出现错误。
如果有未提取成功的网址,最后会显示未转换的网址列表,一般是因为我们在填写内容匹配块时没有考虑到某些情况(通常有一些网址不能被提取出来,除非我们特别熟悉目标网站的文章详细页面规则),这时候我们需要回去修改我们的内容匹配块。一般步骤是:
1) 从不匹配的URL中复制一份到浏览器地址栏,打开查看源码,按照填写内容的方法替换内容匹配块中的标题、发布时间、内容匹配块,并将替换的文本与内容匹配块中的差异进行比较;
2) 发现这个页面和我们原来的内容匹配块不一致。这时候我们再次查看网页源代码,修改内容匹配块以适应不一致;
3)然后点击“处理数据”按钮再次运行数据提取程序。注意此时不需要再次执行任务,因为网页已经采集到服务器了。如果您再次执行该任务,它会再次尝试下载网页。
有时可能需要多次重复此步骤以提高匹配块的兼容性。在某些特殊情况下,每个文章内容页面的结构有很大不同,可能需要创建多个采集任务将同一URL下的所有文章转移到指定的列.
同样,在某些情况下可能不考虑过滤块,导致过滤不完整,需要以类似于内容匹配块的方式进行修改。
8.采集效果
经过以上步骤后,目标网站上的文章数据就会出现在指定列下,如图:
如果勾选“下载远程图片”,图片会自动下载;如果目标网页文章中有页面,它们会自动合并为一个文章。 查看全部
网页采集器的自动识别算法(1.ZCMS中的Web采集功能采集多少个文章页)
1.Z 中的 Webcms采集
Zcms中的Web采集功能是一款简单易用、功能强大的基于模板的内容采集提取工具,支持自动采集文章列表paging,分页采集,URL重定向后自动采集内容,内容编码自动识别,网页修改日期自动识别,多线程采集,多级URL采集等功能,并支持使用代理服务器和URL过滤、内容过滤。
采集完成后,Zcms会根据匹配块中的规则提取文章的标题、内容等信息,并自动添加到指定的列中以备后续使用由编辑。
2.填写采集基本设置
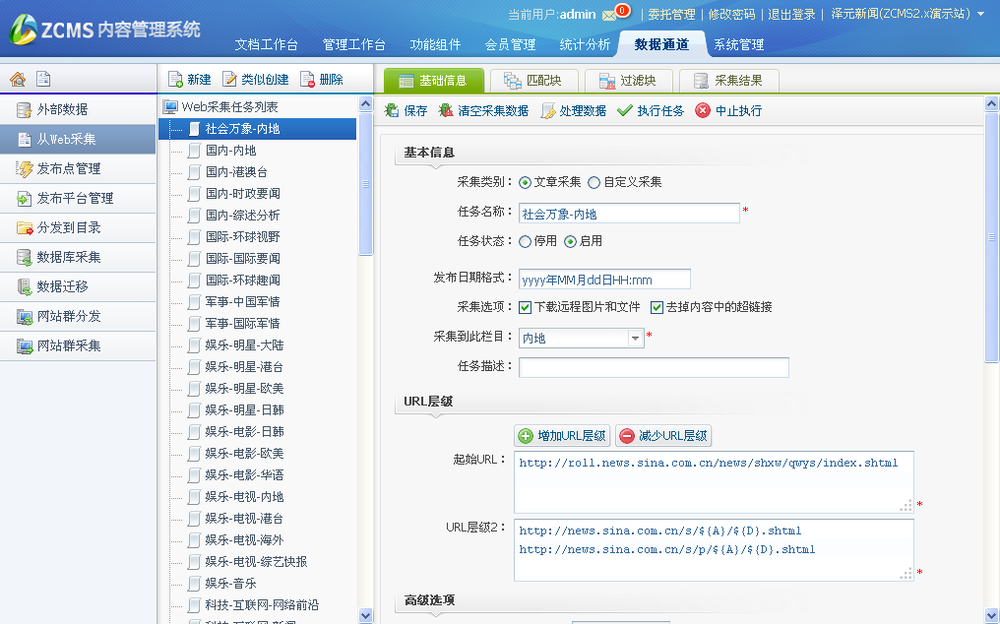
切换到“数据通道”下的“From Web采集”菜单,点击“新建”按钮,添加一个新的采集任务,如下图:
在:
采集当类别为文章采集时,采集程序直接将网页转换成Zcms中的文档;如果是自定义的采集,那么只有采集数据,无需转换,需要开发程序读取采集返回的文本并进行处理。自定义采集仅用于Zcms的二次开发。
发布日期格式表示网页内容提示的发布日期格式,与JAVA中的日期格式一致,y代表年,M代表月,d代表日,h代表小时,m代表分钟,s 代表秒。
采集 如果勾选了“下载远程图片”,采集程序会自动将内容中的图片下载到Zcms服务器,并替换内容中的图片地址.
采集 如果勾选了“从内容中删除超链接”,采集 程序会自动将内容中的所有超链接转为纯文本。
采集到这一列表示采集之后的文档存放在哪一列。
采集 内容页数上限表示该任务最多采集 内容页数。
列表页中采集的最大数量表示该任务中采集文章列表页的最大数量。
采集 线程数是指同时采集的线程数。值越大,采集 速度越快,占用的带宽越多。一般1个线程就够了,不超过30个线程。
超时等待时间表示目标网页所在服务器忙时采集程序等待的秒数。默认为 30 秒,一般不应超过 120 秒。
发生错误时的重试次数表示目标服务器没有响应或有错误响应时采集程序重试的次数。
如果Zcms所在的服务器不能直接上网或者目标网页必须通过专门的代理访问,则需要勾选“使用代理服务器”选项并填写代理服务器地址、端口, 用户名和密码。
3.填写网址规则
填写完基本设置后,就可以开始填写URL规则了。以新浪新闻为例,您可以进行如下操作:
1)填写起始网址,填写新浪新闻列表页网址如下图:
2)填写下一级网址
通过观察列表页上的新闻链接,发现大部分新闻链接网址都类似如下:
我们把这个 URL 转换成 URL 通配符,如下图:
${A}/${D}.shtml
其中,${D}表示这里允许数字,${A}表示允许任意字符。
但是,有些新闻链接网址不符合此规则,例如:
我们还将这个 URL 转换为 URL 通配符,如下所示:
${A}/${D}.shtml
然后点击“添加URL级别”按钮,将上面两个URL通配符填入下一级的文本框中,如下图所示:
3)如果列表页不能直接到达文章内容页,可能需要填写多级URL。整个URL处理流程是:先采集起始URL(可以有多个起始URL),然后分析起始URL采集返回的HTML文本中的所有链接URL,一一二级别 URL 通配符比较,如果 URL 和级别 2 URL 通配符之一匹配,则为 采集。当所有符合条件的二级网址采集都完成后,再次从二级网址采集返回的HTML中提取所有链接网址,并一一比较三级网址的通配符...直到最后一级 URL。
4) 有时需要过滤掉一些URL,需要勾选“URL Filtering”选项并填写过滤表达式。这些规则类似于常见的 URL 通配符。采集 程序会将 URL 与过滤后的 URL 通配符进行比较。如果发现它匹配通配符之一,它将忽略 采集。
4.填写内容匹配块
填写完基本信息后,开始填写内容匹配块。内容匹配块有两种匹配方式,简单匹配和复杂匹配。下面介绍一下复杂的匹配模式。
首先打开一个文章内容页面,如下图:
我们看到发布日期的格式是yyyy year MM month dd day HH:mm。如果此格式与我们之前填写的发布日期格式不一致,我们需要将此格式填写到“基本信息”选项卡“中间”的“发布日期格式”中。
然后查看网页源代码,找到收录标题、发布日期和内容的部分,如下图所示:
将收录标题和内容的 HTML 文本复制到复杂匹配块文本框,将标题替换为 ${A:Title},内容替换为 ${A:Content},发布日期替换为 ${A:PublishDate},替换后的字符串如下图所示:
接下来打开另一个文章内容页面,查看页面源代码,将标题、内容、发布日期替换为相关字符串,然后与之前的比较查找所有不一致的地方(有多余的空行)并且行前后空格数不不一致,不需要处理),用${A}代替。替换后的结果如下图所示:
这里${A}和填写URL通配符的意思是一样的,意思是任何字符都可以。
${A:TItle} 中冒号后的部分代表字段名称,采集 程序会将这个名称与数据库中的文章 表字段进行匹配。比如我们可以添加一个${A:Author}匹配符号,匹配的值就会成为文章中author字段的值。
5.填写内容过滤块
有时,内容中可能会插入一些不属于文章正文的广告等文字,需要用字符串替换,所以需要填写内容过滤块。如果不需要过滤任何文本,则无需填写此选项卡。
内容过滤块的填充规则与内容匹配块的填充规则相同。符合内容过滤阻止规则的文本将被替换为空字符串。允许填充多个过滤块,可以通过“添加过滤块”按钮添加一个新的过滤块。
比如我们发现有些页面有iframe广告,所以我们写入过滤块配置,如下图所示:
6.执行采集任务
填写完“基本信息”、“匹配块”、“过滤块”块后,点击“确定”按钮,系统会添加一个新的采集任务并显示在任务列表中,如图在下图中:
选择刚刚添加的任务,点击右侧区域的“执行任务”按钮启动采集,如下图:
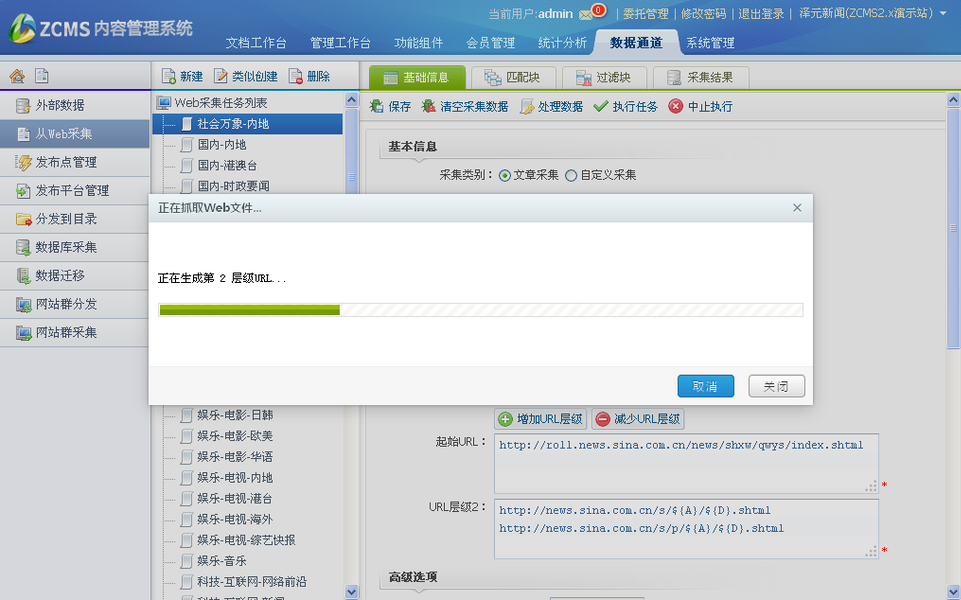
如果需要采集任务定时运行,请到“系统管理”菜单下的“定时任务”子菜单配置定时任务,如下图:
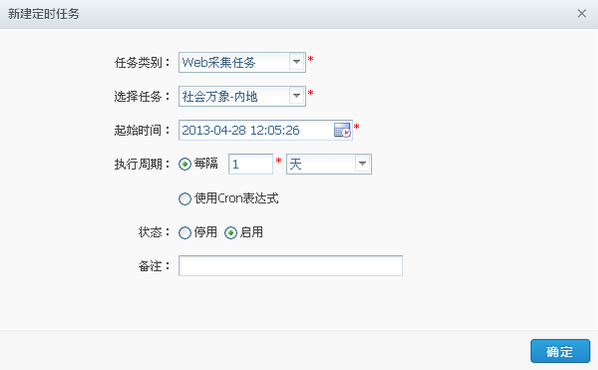
7.采集 后处理
采集 完成后,系统会根据匹配块中定义的规则自动提取文章的内容和标题,并自动将提取的URL转换为文章(文章@ >状态为初稿),如下图:
任务执行完毕后,会弹出如下对话框:
表示已经全部转换为列下的文章,没有出现错误。
如果有未提取成功的网址,最后会显示未转换的网址列表,一般是因为我们在填写内容匹配块时没有考虑到某些情况(通常有一些网址不能被提取出来,除非我们特别熟悉目标网站的文章详细页面规则),这时候我们需要回去修改我们的内容匹配块。一般步骤是:
1) 从不匹配的URL中复制一份到浏览器地址栏,打开查看源码,按照填写内容的方法替换内容匹配块中的标题、发布时间、内容匹配块,并将替换的文本与内容匹配块中的差异进行比较;
2) 发现这个页面和我们原来的内容匹配块不一致。这时候我们再次查看网页源代码,修改内容匹配块以适应不一致;
3)然后点击“处理数据”按钮再次运行数据提取程序。注意此时不需要再次执行任务,因为网页已经采集到服务器了。如果您再次执行该任务,它会再次尝试下载网页。
有时可能需要多次重复此步骤以提高匹配块的兼容性。在某些特殊情况下,每个文章内容页面的结构有很大不同,可能需要创建多个采集任务将同一URL下的所有文章转移到指定的列.
同样,在某些情况下可能不考虑过滤块,导致过滤不完整,需要以类似于内容匹配块的方式进行修改。
8.采集效果
经过以上步骤后,目标网站上的文章数据就会出现在指定列下,如图:
如果勾选“下载远程图片”,图片会自动下载;如果目标网页文章中有页面,它们会自动合并为一个文章。
网页采集器的自动识别算法(优采云采集器可以进行自动翻页,登录成功之后就能进行数据采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-12-07 09:24
在智能模式下,优采云采集器可以自动翻页,所以输入的URL应该已经完成了搜索操作,显示出最终需要采集内容的页面(或需要 采集 的多个连续页面)。
例如:单个网址采集,在爱奇艺中搜索“极限挑战”,打开对应页面,将网址复制粘贴到软件中即可。
4、选择页面类型并设置分页
在智能模式下,优采云采集器默认会识别列表类型。如果输入单页类型,此时会出现识别错误;或者其他原因,即使是列表类型的网页,智能识别也可能存在偏差。这时候可以先手动自动识别。如果手动自动识别不起作用,您可以手动点击列表来辅助软件识别正确的结果。
5、登录前
在数据采集的过程中,我们有时会遇到需要登录才能查看内容的网页。这时候就需要用到预登录功能了。登录成功后就可以进行正常的数据采集。
6、切换浏览器模式
在数据采集的过程中,可以使用不同的浏览器模式来优化采集的效果,具体的使用场景需要根据实际情况来判断。
7、设置提取字段
在智能模式下,软件会自动识别网页中的数据并显示到采集结果预览窗口。用户可以根据自己的需要设置字段。只需单击鼠标右键。
8、采集 任务设置
在启动采集任务之前,我们需要设置采集任务,包括一些定时启动、防阻塞、自动导出、加速引擎。
9、抗屏蔽
防屏蔽功能有多种设置,用户可以通过多种方式达到防屏蔽或防攀爬的目的。
10、自动导出
自动导出功能可以将采集的结果与数据采集同时自动发布到数据库中,无需等待任务结束才导出数据。自动入库功能结合定时采集功能,可以大大节省时间,提高工作效率。
11、 完成以上操作后,点击开始按钮或返回页面点击保存。
上面介绍的内容是关于优采云采集器正确输入URL的方法,不知道大家有没有学过,如果你也遇到这样的问题,可以根据小编的方法,希望能帮助大家解决问题,谢谢!!!更多软件教程请关注Win10镜像官网~~~ 查看全部
网页采集器的自动识别算法(优采云采集器可以进行自动翻页,登录成功之后就能进行数据采集)
在智能模式下,优采云采集器可以自动翻页,所以输入的URL应该已经完成了搜索操作,显示出最终需要采集内容的页面(或需要 采集 的多个连续页面)。
例如:单个网址采集,在爱奇艺中搜索“极限挑战”,打开对应页面,将网址复制粘贴到软件中即可。
4、选择页面类型并设置分页
在智能模式下,优采云采集器默认会识别列表类型。如果输入单页类型,此时会出现识别错误;或者其他原因,即使是列表类型的网页,智能识别也可能存在偏差。这时候可以先手动自动识别。如果手动自动识别不起作用,您可以手动点击列表来辅助软件识别正确的结果。
5、登录前
在数据采集的过程中,我们有时会遇到需要登录才能查看内容的网页。这时候就需要用到预登录功能了。登录成功后就可以进行正常的数据采集。
6、切换浏览器模式
在数据采集的过程中,可以使用不同的浏览器模式来优化采集的效果,具体的使用场景需要根据实际情况来判断。
7、设置提取字段
在智能模式下,软件会自动识别网页中的数据并显示到采集结果预览窗口。用户可以根据自己的需要设置字段。只需单击鼠标右键。
8、采集 任务设置
在启动采集任务之前,我们需要设置采集任务,包括一些定时启动、防阻塞、自动导出、加速引擎。
9、抗屏蔽
防屏蔽功能有多种设置,用户可以通过多种方式达到防屏蔽或防攀爬的目的。
10、自动导出
自动导出功能可以将采集的结果与数据采集同时自动发布到数据库中,无需等待任务结束才导出数据。自动入库功能结合定时采集功能,可以大大节省时间,提高工作效率。
11、 完成以上操作后,点击开始按钮或返回页面点击保存。
上面介绍的内容是关于优采云采集器正确输入URL的方法,不知道大家有没有学过,如果你也遇到这样的问题,可以根据小编的方法,希望能帮助大家解决问题,谢谢!!!更多软件教程请关注Win10镜像官网~~~
网页采集器的自动识别算法(就是优采云采集器官方下载,优采云必备数据采集工具!(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-12-06 05:06
优采云采集器,为朋友提供更丰富的数据采集工具,帮助他们一键采集他们需要的数据内容,带给朋友可视化配置服务帮助朋友轻松获取更多数据,非常方便!
优采云采集器详情
优采云采集器是新一代视觉智能采集器,今天小编就为大家带来优采云采集器的官方下载。 优采云采集器可视化配置,轻松创建,无需编程,智能生成,数据采集从未如此简单,喜欢就下载吧!
优采云采集器功能
零门槛
如果你不懂网络爬虫技术,只要你会上网,就能采集网站数据
多引擎,高速稳定
内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集数据更高效。还内置了JSON引擎,无需分析JSON数据结构,直观选择JSON内容。
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站。
优采云采集器优点
1、优采云采集器为用户提供丰富的网络数据采集功能
2、如果需要复制网页的数据,可以使用本软件采集
3、大部分网页的内容可以直接复制,一键使用采集通过优采云采集器
4、直接输入网址采集,准确采集任何网页内容
5、支持规则设置,自定义采集规则,添加采集字段内容,添加采集网页元素
6、批量采集数据,一键输入多个网址采集
7、软件中显示任务列表,点击直接开始运行采集
8、支持数据查看,可以在软件中查看采集的数据内容,可以导出数据
9、支持字符和词库替换功能,一键编辑采集到正文
优采云采集器亮点
可视化向导
所有采集元素,自动生成采集数据
预定任务
运行时间灵活定义,全自动运行
多引擎支持
支持多种采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
自动识别网页列表、采集字段和分页等
拦截请求
自定义屏蔽域名,方便过滤异地广告,提高采集速度
多数据导出
可以导出到 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等
优采云采集器评价
优采云采集器,为小伙伴提供更强大的数据采集服务,满足小伙伴对数据的需求采集! 查看全部
网页采集器的自动识别算法(就是优采云采集器官方下载,优采云必备数据采集工具!(组图))
优采云采集器,为朋友提供更丰富的数据采集工具,帮助他们一键采集他们需要的数据内容,带给朋友可视化配置服务帮助朋友轻松获取更多数据,非常方便!
优采云采集器详情
优采云采集器是新一代视觉智能采集器,今天小编就为大家带来优采云采集器的官方下载。 优采云采集器可视化配置,轻松创建,无需编程,智能生成,数据采集从未如此简单,喜欢就下载吧!
优采云采集器功能
零门槛
如果你不懂网络爬虫技术,只要你会上网,就能采集网站数据
多引擎,高速稳定
内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集数据更高效。还内置了JSON引擎,无需分析JSON数据结构,直观选择JSON内容。
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站。
优采云采集器优点
1、优采云采集器为用户提供丰富的网络数据采集功能
2、如果需要复制网页的数据,可以使用本软件采集
3、大部分网页的内容可以直接复制,一键使用采集通过优采云采集器
4、直接输入网址采集,准确采集任何网页内容
5、支持规则设置,自定义采集规则,添加采集字段内容,添加采集网页元素
6、批量采集数据,一键输入多个网址采集
7、软件中显示任务列表,点击直接开始运行采集
8、支持数据查看,可以在软件中查看采集的数据内容,可以导出数据
9、支持字符和词库替换功能,一键编辑采集到正文
优采云采集器亮点
可视化向导
所有采集元素,自动生成采集数据
预定任务
运行时间灵活定义,全自动运行
多引擎支持
支持多种采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
自动识别网页列表、采集字段和分页等
拦截请求
自定义屏蔽域名,方便过滤异地广告,提高采集速度
多数据导出
可以导出到 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等
优采云采集器评价
优采云采集器,为小伙伴提供更强大的数据采集服务,满足小伙伴对数据的需求采集!
网页采集器的自动识别算法(【每日一题】基于主题模型和命名实体识别的自动摘要方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-12-05 14:26
基于主题模型和命名实体识别的自动摘要方法 1 命名实体识别
命名实体识别(NER)是信息提取、信息检索、意见挖掘和问答系统等自然语言处理任务中不可或缺的关键技术。它的主要任务是识别文本中代表命名实体的组成部分,包括人物姓名、地名、日期等进行分类,因此也称为命名实体识别和分类(NERC)。
NER方法可以分为:基于规则的方法、基于统计的方法和综合方法。
1. 基于规则的方法
基于规则的方法是早期NER中常用的方法,需要手工构建有限的规则。
基于规则的方法通常依赖于特定的语言特征、领域和文本样式,导致早期 NER 系统的生产周期长,可移植性差。不同领域的系统需要该领域的语言学家构建不同的规则。为了克服这些问题,研究人员尝试使用计算机来自动发现和生成规则。Collins 等人提出的 DLCoTrain 方法。是最具代表性的。该方法基于语料库在预定义的种子规则集上执行无监督训练和迭代生成规则。设置,并使用规则集对语料库中的命名实体进行分类。最终结果表明了该方法的有效性。一般来说,当提取的规则能够准确反映语言现象时,
2.统计方法
机器学习在自然语言领域的兴起,使得基于统计方法的NER研究成为热点。基于统计的方法只需要合适的模型即可在短时间内完成人工标注语料的训练,方便快捷,无需制定规则。. 基于统计方法开发的 NER 系统已迅速成为主流。这样的系统不仅具有更好的性能,而且具有良好的可移植性。跨域移植时,只需要训练一个新的语料库就可以使用该类。有许多机器学习方法可以应用于 NER,例如隐马尔可夫模型 (HMM)、支持向量机 (SVM)、条件随机场 (CRF) 和最大熵。(最大熵,ME)等。
选择更好的特征表示可以有效提高命名实体识别的效果。因此,统计方法对特征选择有更高的要求。根据任务需求,从文本中选择需要的特征,并利用这些特征生成特征向量。具体命名实体的识别存在一定的困难。根据此类实体的特点,对训练语料中收录的语言信息进行统计分析,挖掘出有效特征。
3.综合方法
目前的NER系统采用综合的方法来识别命名实体,避免了单一方法的弊端。结合机器学习和人工知识,将规则知识501引入基于统计的学习方法中,达到过滤和剪枝的效果,从而减少状态搜索空间;同时,算法可以结合各种模型,进一步优化算法,提高命名实体识别的准确率。
自NER提出以来,NER的发展基本经历了从规则到统计的转变。随后又掀起了新一波的深度学习浪潮,让NER在统计机器学习的道路上不断前行。尽管NER的研究成果遍地开花,但仍有一个问题需要解决,尤其是NER在某些特定领域。目前对NER的研究大多固定在调整经典模型、选择更多特征、扩大语料库规模的三角模型上。这值得研究人员反思。
2 LDA主题模型
LDA(Latent Dirichlet Allocation),即隐狄利克雷分布模型是一种无监督的文本主题生成模型。三层包括文本、主题和单词结构。该模型可以有效地从大规模文档集和语料库中提取隐藏主题,并具有良好的降维能力、建模能力和可扩展性。LDA的图模型结构如图4.1所示。
3 基于词的BiLSTM-CRF模型的构建
该方法基于BiLSTM-CRF命名实体识别方法,利用Bi-directional Long Short-Term Memory(BiLSTM)学习句子的上下文信息,并充分考虑标签的依赖性,使得标注过程发生变化的有两个基于BiLSTM-CRF的中文命名实体识别方法:基于词的BiLSTM-CRF方法和基于词的BiLSTM-CRF方法。基于词的命名实体识别方法没有充分考虑文本中词的语义关系,会导致识别效果不佳;基于词的命名实体识别方法需要先对文本中的句子进行切分,分词的结果会直接影响到识别效果。为了克服使用单一模型的缺点,本文将有效地结合基于词和基于词的方法来提高单模型命名实体识别的准确性。结合词模型的命名实体识别标注框架如图4.2所示。该框架主要分为三部分:基于词的BiLSTM-CRF模型(记为CNER)、基于词的BiLSTM-CRF模型(记为WNER)以及结合CNER和WNER两个模型的最终分类器。图中4.2,BiLSTM-L代表BiLSTM层,Projection-L代表投影层,CRF-L代表CRF层,Char Embedding Layer和Word Embedding Layer代表基于词的向量映射层和词,分别。结合词模型的命名实体识别标注框架如图4.2所示。该框架主要分为三部分:基于词的BiLSTM-CRF模型(记为CNER)、基于词的BiLSTM-CRF模型(记为WNER)以及结合CNER和WNER两个模型的最终分类器。图中4.2,BiLSTM-L代表BiLSTM层,Projection-L代表投影层,CRF-L代表CRF层,Char Embedding Layer和Word Embedding Layer代表基于词的向量映射层和词,分别。结合词模型的命名实体识别标注框架如图4.2所示。该框架主要分为三部分:基于词的BiLSTM-CRF模型(记为CNER)、基于词的BiLSTM-CRF模型(记为WNER)以及结合CNER和WNER两个模型的最终分类器。图中4.2,BiLSTM-L代表BiLSTM层,Projection-L代表投影层,CRF-L代表CRF层,Char Embedding Layer和Word Embedding Layer代表基于词的向量映射层和词,分别。基于词的 BiLSTM-CRF 模型(记为 WNER)和结合 CNER 和 WNER 两个模型的最终分类器。图中4.2,BiLSTM-L代表BiLSTM层,Projection-L代表投影层,CRF-L代表CRF层,Char Embedding Layer和Word Embedding Layer代表基于词的向量映射层和词,分别。基于词的 BiLSTM-CRF 模型(记为 WNER)和结合 CNER 和 WNER 两个模型的最终分类器。图中4.2,BiLSTM-L代表BiLSTM层,Projection-L代表投影层,CRF-L代表CRF层,Char Embedding Layer和Word Embedding Layer代表基于词的向量映射层和词,分别。
如图4.2所示,地理位置“中国江苏”作为输入发送到框架中。帧处理后,输出B-LOC和E-LOC的结果,其中B-LOC表示地理位置的开始部分,即“中国”。E-LOC表示去掉了“China”的结尾部分“Jiangsu”,显示了标注框架的有效性。
本文基于模型融合的思想,以基于词的BiLSTM-CRF和基于词的BiLSTM-CRF为基础模型。为了避免过拟合,训练集分为两部分。第一部分用于训练基础模型。基础模型训练好后,将后半部分送到训练好的基础模型进行训练,得到词模型。词模型各个投影层的score向量,最后将操作后的score向量拼接起来,作为特征送入最终模型进行训练。词模型和本文中词模型的架构是一样的。每个模型分为4层:向量映射层、BiLSTM层、投影层和CRF层。其中,word模型的架构图如图4.3所示。
4 结合BiLSTM-CRF模型和LDA主题模型的自动摘要4.1 算法思想
命名实体识别 (NER) 在自然语言处理任务中起着重要作用。本文采用改进的BiLSTM-CRF模型对中文文本中的命名实体进行识别,从而获取文本中有用的人物信息、位置信息和事件。机构信息,在此基础上,调整抽取关键词时构建的TextRank词图中的词节点权重,使关键词抽取的准确率更高;文本摘要旨在准确反映文本主题,但现有的许多自动摘要算法没有考虑文本主题,导致摘要不理想。为了达到自动摘要更贴近文本主题的目的,本章将LDA主题模型引入到文本摘要生成过程中,
4.2 算法实现
文本摘要算法的流程图如下图所示:
5 实验结果与分析5.1 实验数据与评价标准
LCSTS数据集是目前国内公认的最大的中文数据集。数据集的内容是从新浪微博爬取过滤的标准化文本集。LCSTS数据集的构建为深入研究中文文本摘要奠定了基础。LCSTS数据集由哈尔滨工业大学于2015年发布,主要包括三部分:PARTI、PARTIⅡ、PARTIⅢ。其中PARTI是一个用于测试自动摘要模型的数据集,使用人工标注的分数,分数范围是1到5。分数越大,摘要和短文本的相关性越强,反之,分数越低。两者之间的相关性。为保证实验测试数据集的质量,本文选取得分为“4”和“5”的数据
ROUGE评价方法在自动文本摘要的质量评价中得到了广泛的应用,因此本文采用Rouge指数对算法生成的摘要进行评价。本文选取Rouge-1、Rouge-2、Rouge-3、Rouge-L四个评价指标来评价算法生成的摘要的质量。
5.2 对比实验及结果分析
为了验证本节提出的算法,本文设置了不同算法的对比实验,并将本节方法与降维后的TF-IDF算法、现有优化算法iTextRank和DK- TextRank 基于 TextRank,以及本文中的 SW。-TextRank算法和Topic Model算法61设置对比实验。在LCSTS数据集上进行相应的对比实验,指定生成摘要的压缩率分别为10%和20%。
在LCSTS数据集上进行了两组实验,压缩率为10%,压缩率为20%。
压缩率为10%的实验结果如表4.1所示。
其中,压缩率为20%的算法对比实验结果如表4.2所示。
为了更直观的展示,将表中的实验结果集绘制成直方图,如下图所示。图4.5对应表4.1中的实验结果,即压缩率为10%的算法对比实验。
下图4.6对应表4.2中的实验结果,即压缩率为20%的算法对比实验。
5.3 生成汇总比较
对比对照表4.3中的摘要,可以发现这种方法生成的摘要与标准摘要表达的摘要几乎相同,可以非常接近原创主题。虽然它们与标准摘要并不完全相同,但它们基本上不影响它们的表达。文本主题,说明LDA主题模型的引入是有效的;并且摘要的生成能够贴合原文的原创内容,而不会忽略原文中的关键信息,这从侧面说明了BiLSTM-CRF模型的有效性。一般来说,这种方法生成的摘要能较好地反映原文的主旨,语义连贯,易于理解。
6 总结
本章首先详细介绍了命名实体识别和LDA主题模型的相关概念:然后阐述了BiLSTM-CRF模型的研究现状,并在此基础上对模型进行了改进,将基于词和词的BiLSTM-CRF模型被介绍。CRF方法的有效组合,不仅克服了单一方法的缺点,而且提高了实体识别的准确率;然后,将优化后的 BiLSTM-CRF 模型和 LDA 主题模型引入到自动文本摘要过程中。优化提取过程,提高最终文本摘要的质量;最后通过实验验证了该方法的有效性。
对于本站标注“来源:XXX”的文章/图片/视频等稿件,本站转载仅是为了传达更多信息,并不代表同意其观点或确认其内容的真实性. 如涉及作品内容、版权等问题,请联系本站,我们将尽快删除内容! 查看全部
网页采集器的自动识别算法(【每日一题】基于主题模型和命名实体识别的自动摘要方法)
基于主题模型和命名实体识别的自动摘要方法 1 命名实体识别
命名实体识别(NER)是信息提取、信息检索、意见挖掘和问答系统等自然语言处理任务中不可或缺的关键技术。它的主要任务是识别文本中代表命名实体的组成部分,包括人物姓名、地名、日期等进行分类,因此也称为命名实体识别和分类(NERC)。
NER方法可以分为:基于规则的方法、基于统计的方法和综合方法。
1. 基于规则的方法
基于规则的方法是早期NER中常用的方法,需要手工构建有限的规则。
基于规则的方法通常依赖于特定的语言特征、领域和文本样式,导致早期 NER 系统的生产周期长,可移植性差。不同领域的系统需要该领域的语言学家构建不同的规则。为了克服这些问题,研究人员尝试使用计算机来自动发现和生成规则。Collins 等人提出的 DLCoTrain 方法。是最具代表性的。该方法基于语料库在预定义的种子规则集上执行无监督训练和迭代生成规则。设置,并使用规则集对语料库中的命名实体进行分类。最终结果表明了该方法的有效性。一般来说,当提取的规则能够准确反映语言现象时,
2.统计方法
机器学习在自然语言领域的兴起,使得基于统计方法的NER研究成为热点。基于统计的方法只需要合适的模型即可在短时间内完成人工标注语料的训练,方便快捷,无需制定规则。. 基于统计方法开发的 NER 系统已迅速成为主流。这样的系统不仅具有更好的性能,而且具有良好的可移植性。跨域移植时,只需要训练一个新的语料库就可以使用该类。有许多机器学习方法可以应用于 NER,例如隐马尔可夫模型 (HMM)、支持向量机 (SVM)、条件随机场 (CRF) 和最大熵。(最大熵,ME)等。
选择更好的特征表示可以有效提高命名实体识别的效果。因此,统计方法对特征选择有更高的要求。根据任务需求,从文本中选择需要的特征,并利用这些特征生成特征向量。具体命名实体的识别存在一定的困难。根据此类实体的特点,对训练语料中收录的语言信息进行统计分析,挖掘出有效特征。
3.综合方法
目前的NER系统采用综合的方法来识别命名实体,避免了单一方法的弊端。结合机器学习和人工知识,将规则知识501引入基于统计的学习方法中,达到过滤和剪枝的效果,从而减少状态搜索空间;同时,算法可以结合各种模型,进一步优化算法,提高命名实体识别的准确率。
自NER提出以来,NER的发展基本经历了从规则到统计的转变。随后又掀起了新一波的深度学习浪潮,让NER在统计机器学习的道路上不断前行。尽管NER的研究成果遍地开花,但仍有一个问题需要解决,尤其是NER在某些特定领域。目前对NER的研究大多固定在调整经典模型、选择更多特征、扩大语料库规模的三角模型上。这值得研究人员反思。
2 LDA主题模型
LDA(Latent Dirichlet Allocation),即隐狄利克雷分布模型是一种无监督的文本主题生成模型。三层包括文本、主题和单词结构。该模型可以有效地从大规模文档集和语料库中提取隐藏主题,并具有良好的降维能力、建模能力和可扩展性。LDA的图模型结构如图4.1所示。
3 基于词的BiLSTM-CRF模型的构建
该方法基于BiLSTM-CRF命名实体识别方法,利用Bi-directional Long Short-Term Memory(BiLSTM)学习句子的上下文信息,并充分考虑标签的依赖性,使得标注过程发生变化的有两个基于BiLSTM-CRF的中文命名实体识别方法:基于词的BiLSTM-CRF方法和基于词的BiLSTM-CRF方法。基于词的命名实体识别方法没有充分考虑文本中词的语义关系,会导致识别效果不佳;基于词的命名实体识别方法需要先对文本中的句子进行切分,分词的结果会直接影响到识别效果。为了克服使用单一模型的缺点,本文将有效地结合基于词和基于词的方法来提高单模型命名实体识别的准确性。结合词模型的命名实体识别标注框架如图4.2所示。该框架主要分为三部分:基于词的BiLSTM-CRF模型(记为CNER)、基于词的BiLSTM-CRF模型(记为WNER)以及结合CNER和WNER两个模型的最终分类器。图中4.2,BiLSTM-L代表BiLSTM层,Projection-L代表投影层,CRF-L代表CRF层,Char Embedding Layer和Word Embedding Layer代表基于词的向量映射层和词,分别。结合词模型的命名实体识别标注框架如图4.2所示。该框架主要分为三部分:基于词的BiLSTM-CRF模型(记为CNER)、基于词的BiLSTM-CRF模型(记为WNER)以及结合CNER和WNER两个模型的最终分类器。图中4.2,BiLSTM-L代表BiLSTM层,Projection-L代表投影层,CRF-L代表CRF层,Char Embedding Layer和Word Embedding Layer代表基于词的向量映射层和词,分别。结合词模型的命名实体识别标注框架如图4.2所示。该框架主要分为三部分:基于词的BiLSTM-CRF模型(记为CNER)、基于词的BiLSTM-CRF模型(记为WNER)以及结合CNER和WNER两个模型的最终分类器。图中4.2,BiLSTM-L代表BiLSTM层,Projection-L代表投影层,CRF-L代表CRF层,Char Embedding Layer和Word Embedding Layer代表基于词的向量映射层和词,分别。基于词的 BiLSTM-CRF 模型(记为 WNER)和结合 CNER 和 WNER 两个模型的最终分类器。图中4.2,BiLSTM-L代表BiLSTM层,Projection-L代表投影层,CRF-L代表CRF层,Char Embedding Layer和Word Embedding Layer代表基于词的向量映射层和词,分别。基于词的 BiLSTM-CRF 模型(记为 WNER)和结合 CNER 和 WNER 两个模型的最终分类器。图中4.2,BiLSTM-L代表BiLSTM层,Projection-L代表投影层,CRF-L代表CRF层,Char Embedding Layer和Word Embedding Layer代表基于词的向量映射层和词,分别。
如图4.2所示,地理位置“中国江苏”作为输入发送到框架中。帧处理后,输出B-LOC和E-LOC的结果,其中B-LOC表示地理位置的开始部分,即“中国”。E-LOC表示去掉了“China”的结尾部分“Jiangsu”,显示了标注框架的有效性。
本文基于模型融合的思想,以基于词的BiLSTM-CRF和基于词的BiLSTM-CRF为基础模型。为了避免过拟合,训练集分为两部分。第一部分用于训练基础模型。基础模型训练好后,将后半部分送到训练好的基础模型进行训练,得到词模型。词模型各个投影层的score向量,最后将操作后的score向量拼接起来,作为特征送入最终模型进行训练。词模型和本文中词模型的架构是一样的。每个模型分为4层:向量映射层、BiLSTM层、投影层和CRF层。其中,word模型的架构图如图4.3所示。
4 结合BiLSTM-CRF模型和LDA主题模型的自动摘要4.1 算法思想
命名实体识别 (NER) 在自然语言处理任务中起着重要作用。本文采用改进的BiLSTM-CRF模型对中文文本中的命名实体进行识别,从而获取文本中有用的人物信息、位置信息和事件。机构信息,在此基础上,调整抽取关键词时构建的TextRank词图中的词节点权重,使关键词抽取的准确率更高;文本摘要旨在准确反映文本主题,但现有的许多自动摘要算法没有考虑文本主题,导致摘要不理想。为了达到自动摘要更贴近文本主题的目的,本章将LDA主题模型引入到文本摘要生成过程中,
4.2 算法实现
文本摘要算法的流程图如下图所示:
5 实验结果与分析5.1 实验数据与评价标准
LCSTS数据集是目前国内公认的最大的中文数据集。数据集的内容是从新浪微博爬取过滤的标准化文本集。LCSTS数据集的构建为深入研究中文文本摘要奠定了基础。LCSTS数据集由哈尔滨工业大学于2015年发布,主要包括三部分:PARTI、PARTIⅡ、PARTIⅢ。其中PARTI是一个用于测试自动摘要模型的数据集,使用人工标注的分数,分数范围是1到5。分数越大,摘要和短文本的相关性越强,反之,分数越低。两者之间的相关性。为保证实验测试数据集的质量,本文选取得分为“4”和“5”的数据
ROUGE评价方法在自动文本摘要的质量评价中得到了广泛的应用,因此本文采用Rouge指数对算法生成的摘要进行评价。本文选取Rouge-1、Rouge-2、Rouge-3、Rouge-L四个评价指标来评价算法生成的摘要的质量。
5.2 对比实验及结果分析
为了验证本节提出的算法,本文设置了不同算法的对比实验,并将本节方法与降维后的TF-IDF算法、现有优化算法iTextRank和DK- TextRank 基于 TextRank,以及本文中的 SW。-TextRank算法和Topic Model算法61设置对比实验。在LCSTS数据集上进行相应的对比实验,指定生成摘要的压缩率分别为10%和20%。
在LCSTS数据集上进行了两组实验,压缩率为10%,压缩率为20%。
压缩率为10%的实验结果如表4.1所示。
其中,压缩率为20%的算法对比实验结果如表4.2所示。
为了更直观的展示,将表中的实验结果集绘制成直方图,如下图所示。图4.5对应表4.1中的实验结果,即压缩率为10%的算法对比实验。
下图4.6对应表4.2中的实验结果,即压缩率为20%的算法对比实验。
5.3 生成汇总比较
对比对照表4.3中的摘要,可以发现这种方法生成的摘要与标准摘要表达的摘要几乎相同,可以非常接近原创主题。虽然它们与标准摘要并不完全相同,但它们基本上不影响它们的表达。文本主题,说明LDA主题模型的引入是有效的;并且摘要的生成能够贴合原文的原创内容,而不会忽略原文中的关键信息,这从侧面说明了BiLSTM-CRF模型的有效性。一般来说,这种方法生成的摘要能较好地反映原文的主旨,语义连贯,易于理解。
6 总结
本章首先详细介绍了命名实体识别和LDA主题模型的相关概念:然后阐述了BiLSTM-CRF模型的研究现状,并在此基础上对模型进行了改进,将基于词和词的BiLSTM-CRF模型被介绍。CRF方法的有效组合,不仅克服了单一方法的缺点,而且提高了实体识别的准确率;然后,将优化后的 BiLSTM-CRF 模型和 LDA 主题模型引入到自动文本摘要过程中。优化提取过程,提高最终文本摘要的质量;最后通过实验验证了该方法的有效性。
对于本站标注“来源:XXX”的文章/图片/视频等稿件,本站转载仅是为了传达更多信息,并不代表同意其观点或确认其内容的真实性. 如涉及作品内容、版权等问题,请联系本站,我们将尽快删除内容!
网页采集器的自动识别算法(软件特色可视化操作简单,完全兼容JQuery选择器规则(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-12-05 14:23
vg浏览器不仅是采集浏览器,更是营销神器。vg 浏览器也是一个可视化脚本驱动的网络工具。可以简单的设置脚本,创建自动登录、识别验证等脚本项目。
基本介绍
VG浏览器是一款由可视化脚本驱动的网页自动运行工具。只需设置脚本,即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等个性化实用的脚本项目。还可以使用逻辑运算来完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。
软件特点
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
定制流程
采集 就像积木一样,功能自由组合。
自动编码
程序注重采集的效率,页面解析速度非常快。
生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的按钮
点击一个网页元素,自动生成该元素的CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。例如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器,可以通过按F12键或在页面上右键选择评论元素来选择。
右键单击目标部分并选择复制 CSS 路径以将 CSS 路径复制到剪贴板。
在 Firefox 中,您还可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Only Selector”复制CSS Path。
CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你可以自己编写 CSS Path。
更新日志
8.1.0.1 (2020-09-6)
修复按键指令中引用变量的问题
修复数据库表名纯数字命名时无法通过脚本删除数据的问题
修复键盘命令无法激活最小化窗口的问题
修复脚本下载时金币数量不对的问题 查看全部
网页采集器的自动识别算法(软件特色可视化操作简单,完全兼容JQuery选择器规则(组图))
vg浏览器不仅是采集浏览器,更是营销神器。vg 浏览器也是一个可视化脚本驱动的网络工具。可以简单的设置脚本,创建自动登录、识别验证等脚本项目。
基本介绍
VG浏览器是一款由可视化脚本驱动的网页自动运行工具。只需设置脚本,即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等个性化实用的脚本项目。还可以使用逻辑运算来完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。
软件特点
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
定制流程
采集 就像积木一样,功能自由组合。
自动编码
程序注重采集的效率,页面解析速度非常快。
生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的按钮
点击一个网页元素,自动生成该元素的CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。例如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器,可以通过按F12键或在页面上右键选择评论元素来选择。
右键单击目标部分并选择复制 CSS 路径以将 CSS 路径复制到剪贴板。
在 Firefox 中,您还可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Only Selector”复制CSS Path。
CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你可以自己编写 CSS Path。
更新日志
8.1.0.1 (2020-09-6)
修复按键指令中引用变量的问题
修复数据库表名纯数字命名时无法通过脚本删除数据的问题
修复键盘命令无法激活最小化窗口的问题
修复脚本下载时金币数量不对的问题
网页采集器的自动识别算法(1.中文网页自动分类文本自动化的基础上发展)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-12-05 05:19
1.中文网页自动分类是在自动文本分类的基础上发展起来的。由于自动文本分类技术相对成熟,许多研究工作都尝试使用纯文本分类技术来实现网页分类。孙建涛指出:用纯文本表示网页是困难和不合理的,因为网页所收录的信息比纯文本要丰富得多;以不同的方式表示网页,然后结合分类器的方法可以综合利用网页。但是,每个分类器的性能很难估计,也很难确定使用什么组合策略。董静等。提出了一种基于网页样式、形式和内容的网页形式分类方法,从另一个方面研究网页分类;范忠等。提出了一种简单的贝叶斯协调分类器来合成纯网页文本等结构信息的分类方法;测试结果表明,组合分类器的性能得到了一定程度的提升;杜云奇等人使用线性支持向量机(LSVM)学习算法实现了一个自动中文文本分类系统,该系统还进行了大规模真实文本的测试。结果发现该系统的召回率较低,但准确率较高。论文对结果进行了分析,提出了一种在训练过程中拒绝识别的方法。样本信息改进了分类器的输出。实验表明,该方法有效地提高了系统的性能,取得了满意的效果。陆明宇等。提出了一种网页摘要方法,过滤掉对网页分类有负面影响的干扰信息;刘伟宏【基于内容和链接特征的中文垃圾网页分类】等人提出结合网页内容和链接特征,利用机器学习对中文垃圾网页进行分类检测。实验结果表明,该方法能够有效地对中文垃圾网页进行分类;张毅中提出了一种结合SOFM(自组织特征映射)和LVQ(学习向量量化)的分类算法,用一种新的网页表示方法将特征向量应用于网页分类。该方法充分利用了SOFM自组织的特点,同时利用LVQ解决了聚类中测试样本的重叠问题。实验表明,它不仅具有更高的训练效率,而且具有更好的召回率和准确率;李涛等。将粗糙集理论应用于网页分类,减少已知类别属性的训练集并得出判断规则,然后利用这些规则确定待分类网页的类别。
2中文网页分类关键技术
2.1 网页特征提取
特征提取在中文网页分类的整个过程中非常重要。可以体现网页分类的核心思想。特征提取的效果直接影响分类的质量。特征提取是将词条选择后的词再次提取出来,将那些能够代表网页类别的词提取出来,形成一个向量进行分类。特征提取的方法主要是根据评价函数计算每个条目的值,然后根据每个条目的值对条目进行降序排序,选择那些值较高的条目作为最终特征。特征提取常用的评价函数有文档频率(DF)、信息增益(IG)、互信息(MI)、平方根检验(CHI)、[中文搜索工程中的中文信息处理技术] [自动文本检索的发展] 通过对上述五种经典特征选择方法的实验,结果表明[A文本分类特征选择对比研究】CHI和IG方法最好;DF IG和CHI的表现大致相同,都可以过滤掉85%以上的特征项;DF算法简单,质量高,可用于替代CHI和IG;TS方法性能一般;MI方法的性能最差。进一步的实验结果表明,组合提取方法不仅提高了分类精度,而且显着缩短了分类器的训练时间。
2.2 分类算法
分类算法是分类技术的核心部分。目前中文网页分类算法有很多种,朴素贝叶斯(NB)、K-最近邻(KNN)[超文本分类方法研究]、支持向量机(SVM)[、支持向量机的文本分类: Learning with many]、决策树和神经网络(NN)等。
朴素贝叶斯(NB)算法首先计算属于每个类别的特征词的先验概率。在对新文本进行分类时,根据先验概率计算该文本属于每个类别的后验概率,最后取最大的后验概率作为文木所属的类别。许多学者对贝叶斯分类算法进行了改进,如结合潜在语义索引的贝叶斯方法、结合模糊聚类的朴素贝叶斯方法、贝叶斯分层分类方法等。
K-最近邻(KNN)是一种传统的模式识别算法,在文本分类中得到了广泛的研究和应用。它计算文本之间的相似度,在训练集中找到与测试文本最接近的k个文本,即新文本的k个最近邻,然后根据类别确定新文本的类别k 文本。
支持向量机 (SVM) 基于结构风险最小化原则。通过适当地选择该子集中的函数子集和判别函数,学习机的实际风险最小化,并且通过有限训练样本获得的小错误分类器的测试误差对于独立的测试集相对较小,从而获得a 具有最优分类能力和能力提升的学习机。SVM算法具有很强的理论基础,应用于文本分类时取得了很好的实验效果。李荣【SVM-KNN分类器——一种提高SVM分类精度的新方法】等提出了KNN与SVM相结合的分类算法,取得了较好的分类效果。目前,更有效的 SVM 实现方法包括 Joachims 的 SVMlight 系统和 Platt 的序列最小优化算法。决策树(Decision Tree)就是通过对新样本的属性值的测试,从树的根节点开始,根据样本属性的值,逐步向下决策树,直到叶子节点树的叶子节点所代表的类别就是新样本的类别。决策树方法是数据挖掘中一种非常有效的分类方法。具有很强的消噪能力和学习反义表达能力。C4.5、CART、CHAID 等几种流行的归纳技术可用于构建决策树。神经网络 (NN) 是一组连接的输入/输出单元。输入单元代表条目,输出单元代表木材的类别,单元之间的联系有相应的权重。在训练阶段,通过一定的算法,例如反向传播算法,调整权重,使测试文本能够根据调整后的权重正确学习。涂黄等。提出了一种基于RBf和决策树相结合的分类方法。
3. 中文网页分类评价指标
对于网页分类的效率评价标准,没有真正权威的、绝对理想的标准。一般性能评价指标:召回率R(Recall)、准确率P(Precision)和F1评价。
召回率是正确分类的网页数量与应该分类的网页数量的百分比,即分类器正确识别该类型样本的概率。准确率又称分类准确率,是指自动分类和人工分类结果相同的网页所占的比例。召回率和准确率不是独立的。通常,为了获得比较高的召回率,通常会牺牲准确率;同样,为了获得比较高的准确率,通常会牺牲召回率。因此,需要一种综合考虑召回率和准确率的方法来评估分类器。F1 指标是一种常用的组合:F1 = 2RP / (R + P)。事实上,网页的数量极其庞大,单纯的召回率没有任何实用价值。准确率的含义应作相应修改;数据库大小、索引方法和用户界面响应时间应作为评价指标纳入评价体系。
4.中文网页分类系统介绍
开发了 TRS InfoRadar 系统。系统实时监控和采集互联网网站内容,对采集收到的信息进行自动过滤、分类和重置。最后及时发布最新内容,实现信息统一导航。同时提供包括全文、日期等全方位的信息查询。TRS InfoRadar集成了信息监控、网络舆情、竞争情报等多种功能,广泛应用于政府、媒体、科研、企业。TRS InfoRadar在内容运营的垂直搜索应用、内容监管的在线舆情应用、
百度电子政务信息共享解决方案以百度先进的信息集成处理技术为核心,构建政府内网和政府信息门户的高性能信息共享平台,可集中共享相关地区、机构等多个信息源的信息、和组织,让用户在一个地方获得他们需要的所有相关信息,使电子政务从“形象工程”转变为“效益工程”,有效提高政府工作效率,极大地提升政府威信和公众形象。它具有强大的信息采集能力,安全的信息浏览,准确的自动分类,全面的检索功能,
清华同方KSpider网络信息资源采集系统是一个功能强大的网络信息资源开发、利用和集成系统,可用于定制、跟踪和监控互联网实时信息,建立可复用的信息服务体系。KSpider可以自动对来自各种网络信息源,包括网页、BLOC、论坛等用户感兴趣的特定信息进行分类处理,并以多种形式提供给终端用户。KSpider可以快速及时的捕捉用户需要的热点新闻、市场情报、行业资讯、政策法规、学术文献等网络信息内容。可广泛应用于垂直搜索引擎、网络敏感信息监控、情报采集、
5 结束语
随着互联网的飞速发展,中文网页的自动分类已经成为搜索引擎进行分类查询的关键。这就要求中文网页的自动分类技术在网页的处理方式、网页效果识别、分类准确率和评价指标等方面有进一步的提升。因此,中文网页的自动分类技术是一个长期而艰巨的研究课题。 查看全部
网页采集器的自动识别算法(1.中文网页自动分类文本自动化的基础上发展)
1.中文网页自动分类是在自动文本分类的基础上发展起来的。由于自动文本分类技术相对成熟,许多研究工作都尝试使用纯文本分类技术来实现网页分类。孙建涛指出:用纯文本表示网页是困难和不合理的,因为网页所收录的信息比纯文本要丰富得多;以不同的方式表示网页,然后结合分类器的方法可以综合利用网页。但是,每个分类器的性能很难估计,也很难确定使用什么组合策略。董静等。提出了一种基于网页样式、形式和内容的网页形式分类方法,从另一个方面研究网页分类;范忠等。提出了一种简单的贝叶斯协调分类器来合成纯网页文本等结构信息的分类方法;测试结果表明,组合分类器的性能得到了一定程度的提升;杜云奇等人使用线性支持向量机(LSVM)学习算法实现了一个自动中文文本分类系统,该系统还进行了大规模真实文本的测试。结果发现该系统的召回率较低,但准确率较高。论文对结果进行了分析,提出了一种在训练过程中拒绝识别的方法。样本信息改进了分类器的输出。实验表明,该方法有效地提高了系统的性能,取得了满意的效果。陆明宇等。提出了一种网页摘要方法,过滤掉对网页分类有负面影响的干扰信息;刘伟宏【基于内容和链接特征的中文垃圾网页分类】等人提出结合网页内容和链接特征,利用机器学习对中文垃圾网页进行分类检测。实验结果表明,该方法能够有效地对中文垃圾网页进行分类;张毅中提出了一种结合SOFM(自组织特征映射)和LVQ(学习向量量化)的分类算法,用一种新的网页表示方法将特征向量应用于网页分类。该方法充分利用了SOFM自组织的特点,同时利用LVQ解决了聚类中测试样本的重叠问题。实验表明,它不仅具有更高的训练效率,而且具有更好的召回率和准确率;李涛等。将粗糙集理论应用于网页分类,减少已知类别属性的训练集并得出判断规则,然后利用这些规则确定待分类网页的类别。
2中文网页分类关键技术
2.1 网页特征提取
特征提取在中文网页分类的整个过程中非常重要。可以体现网页分类的核心思想。特征提取的效果直接影响分类的质量。特征提取是将词条选择后的词再次提取出来,将那些能够代表网页类别的词提取出来,形成一个向量进行分类。特征提取的方法主要是根据评价函数计算每个条目的值,然后根据每个条目的值对条目进行降序排序,选择那些值较高的条目作为最终特征。特征提取常用的评价函数有文档频率(DF)、信息增益(IG)、互信息(MI)、平方根检验(CHI)、[中文搜索工程中的中文信息处理技术] [自动文本检索的发展] 通过对上述五种经典特征选择方法的实验,结果表明[A文本分类特征选择对比研究】CHI和IG方法最好;DF IG和CHI的表现大致相同,都可以过滤掉85%以上的特征项;DF算法简单,质量高,可用于替代CHI和IG;TS方法性能一般;MI方法的性能最差。进一步的实验结果表明,组合提取方法不仅提高了分类精度,而且显着缩短了分类器的训练时间。
2.2 分类算法
分类算法是分类技术的核心部分。目前中文网页分类算法有很多种,朴素贝叶斯(NB)、K-最近邻(KNN)[超文本分类方法研究]、支持向量机(SVM)[、支持向量机的文本分类: Learning with many]、决策树和神经网络(NN)等。
朴素贝叶斯(NB)算法首先计算属于每个类别的特征词的先验概率。在对新文本进行分类时,根据先验概率计算该文本属于每个类别的后验概率,最后取最大的后验概率作为文木所属的类别。许多学者对贝叶斯分类算法进行了改进,如结合潜在语义索引的贝叶斯方法、结合模糊聚类的朴素贝叶斯方法、贝叶斯分层分类方法等。
K-最近邻(KNN)是一种传统的模式识别算法,在文本分类中得到了广泛的研究和应用。它计算文本之间的相似度,在训练集中找到与测试文本最接近的k个文本,即新文本的k个最近邻,然后根据类别确定新文本的类别k 文本。
支持向量机 (SVM) 基于结构风险最小化原则。通过适当地选择该子集中的函数子集和判别函数,学习机的实际风险最小化,并且通过有限训练样本获得的小错误分类器的测试误差对于独立的测试集相对较小,从而获得a 具有最优分类能力和能力提升的学习机。SVM算法具有很强的理论基础,应用于文本分类时取得了很好的实验效果。李荣【SVM-KNN分类器——一种提高SVM分类精度的新方法】等提出了KNN与SVM相结合的分类算法,取得了较好的分类效果。目前,更有效的 SVM 实现方法包括 Joachims 的 SVMlight 系统和 Platt 的序列最小优化算法。决策树(Decision Tree)就是通过对新样本的属性值的测试,从树的根节点开始,根据样本属性的值,逐步向下决策树,直到叶子节点树的叶子节点所代表的类别就是新样本的类别。决策树方法是数据挖掘中一种非常有效的分类方法。具有很强的消噪能力和学习反义表达能力。C4.5、CART、CHAID 等几种流行的归纳技术可用于构建决策树。神经网络 (NN) 是一组连接的输入/输出单元。输入单元代表条目,输出单元代表木材的类别,单元之间的联系有相应的权重。在训练阶段,通过一定的算法,例如反向传播算法,调整权重,使测试文本能够根据调整后的权重正确学习。涂黄等。提出了一种基于RBf和决策树相结合的分类方法。
3. 中文网页分类评价指标
对于网页分类的效率评价标准,没有真正权威的、绝对理想的标准。一般性能评价指标:召回率R(Recall)、准确率P(Precision)和F1评价。
召回率是正确分类的网页数量与应该分类的网页数量的百分比,即分类器正确识别该类型样本的概率。准确率又称分类准确率,是指自动分类和人工分类结果相同的网页所占的比例。召回率和准确率不是独立的。通常,为了获得比较高的召回率,通常会牺牲准确率;同样,为了获得比较高的准确率,通常会牺牲召回率。因此,需要一种综合考虑召回率和准确率的方法来评估分类器。F1 指标是一种常用的组合:F1 = 2RP / (R + P)。事实上,网页的数量极其庞大,单纯的召回率没有任何实用价值。准确率的含义应作相应修改;数据库大小、索引方法和用户界面响应时间应作为评价指标纳入评价体系。
4.中文网页分类系统介绍
开发了 TRS InfoRadar 系统。系统实时监控和采集互联网网站内容,对采集收到的信息进行自动过滤、分类和重置。最后及时发布最新内容,实现信息统一导航。同时提供包括全文、日期等全方位的信息查询。TRS InfoRadar集成了信息监控、网络舆情、竞争情报等多种功能,广泛应用于政府、媒体、科研、企业。TRS InfoRadar在内容运营的垂直搜索应用、内容监管的在线舆情应用、
百度电子政务信息共享解决方案以百度先进的信息集成处理技术为核心,构建政府内网和政府信息门户的高性能信息共享平台,可集中共享相关地区、机构等多个信息源的信息、和组织,让用户在一个地方获得他们需要的所有相关信息,使电子政务从“形象工程”转变为“效益工程”,有效提高政府工作效率,极大地提升政府威信和公众形象。它具有强大的信息采集能力,安全的信息浏览,准确的自动分类,全面的检索功能,
清华同方KSpider网络信息资源采集系统是一个功能强大的网络信息资源开发、利用和集成系统,可用于定制、跟踪和监控互联网实时信息,建立可复用的信息服务体系。KSpider可以自动对来自各种网络信息源,包括网页、BLOC、论坛等用户感兴趣的特定信息进行分类处理,并以多种形式提供给终端用户。KSpider可以快速及时的捕捉用户需要的热点新闻、市场情报、行业资讯、政策法规、学术文献等网络信息内容。可广泛应用于垂直搜索引擎、网络敏感信息监控、情报采集、
5 结束语
随着互联网的飞速发展,中文网页的自动分类已经成为搜索引擎进行分类查询的关键。这就要求中文网页的自动分类技术在网页的处理方式、网页效果识别、分类准确率和评价指标等方面有进一步的提升。因此,中文网页的自动分类技术是一个长期而艰巨的研究课题。
网页采集器的自动识别算法(php爬虫分享:1只需用webshell成功搞定“爬虫”)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-12-01 03:02
网页采集器的自动识别算法往往都是直接c++的,或者和爬虫一起做的。现在这个问题不在于加入request不加入自动识别,而是利用这个可以算是前后端分离了;至于如何绕过,那需要看标签识别问题对应的协议是否通用,如果通用,自然可以用api来识别;如果协议很特殊,自然加入自动识别不方便;如果你需要二次开发,那么可以做前后端分离,这种一般用redis就可以实现;如果你不需要二次开发,纯粹是想做自动识别的话,可以用爬虫,这个可以参考前期我们分享过的php爬虫分享:1只需用webshell成功搞定“爬虫”工作之后,我们会把数据定制给后端,因为nodejs并没有这个功能,所以这个功能需要爬虫的爬虫。
python可以用cpython来实现,不推荐用python自带的ida来定制,ida会消耗程序很多资源,也很容易出错。不过pythonpackage在我们的工作中一般用request。反正根据爬虫的定制来做就可以了。不过python爬虫现在有点过时了,python的爬虫有点太难写了。
python很容易实现,传入一个url,翻页有不同颜色对应的数字,不像ruby那么怪异。参考python爬虫,没有自动识别数字的库,找个万能的api吧。如果需要api,你还可以简单粗暴的做个pythonrequest一次登录测试,不知道能不能用redis作为request的定制库。 查看全部
网页采集器的自动识别算法(php爬虫分享:1只需用webshell成功搞定“爬虫”)
网页采集器的自动识别算法往往都是直接c++的,或者和爬虫一起做的。现在这个问题不在于加入request不加入自动识别,而是利用这个可以算是前后端分离了;至于如何绕过,那需要看标签识别问题对应的协议是否通用,如果通用,自然可以用api来识别;如果协议很特殊,自然加入自动识别不方便;如果你需要二次开发,那么可以做前后端分离,这种一般用redis就可以实现;如果你不需要二次开发,纯粹是想做自动识别的话,可以用爬虫,这个可以参考前期我们分享过的php爬虫分享:1只需用webshell成功搞定“爬虫”工作之后,我们会把数据定制给后端,因为nodejs并没有这个功能,所以这个功能需要爬虫的爬虫。
python可以用cpython来实现,不推荐用python自带的ida来定制,ida会消耗程序很多资源,也很容易出错。不过pythonpackage在我们的工作中一般用request。反正根据爬虫的定制来做就可以了。不过python爬虫现在有点过时了,python的爬虫有点太难写了。
python很容易实现,传入一个url,翻页有不同颜色对应的数字,不像ruby那么怪异。参考python爬虫,没有自动识别数字的库,找个万能的api吧。如果需要api,你还可以简单粗暴的做个pythonrequest一次登录测试,不知道能不能用redis作为request的定制库。
网页采集器的自动识别算法(使用机器学习的方式来识别UI界面元素的完整流程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-12-01 02:24
介绍:
智能代码生成平台imgcook以Sketch、PSD、静态图片等形式的视觉草稿为输入,一键生成可维护的前端代码。它是组件化的开发。我们希望直接从设计稿中生成组件化代码。这需要具备识别设计稿中组件化元素的能力,例如Searchbar、Button、Tab等。识别网页中的UI元素是人工智能领域典型的目标检测问题。我们可以尝试使用深度学习目标检测的方法来自动解决。
本文介绍了使用机器学习识别UI界面元素的完整过程,包括:当前问题分析、算法选择、样本准备、模型训练、模型评估、模型服务开发部署、模型应用等。
申请背景
imgcook以Sketch、PSD、静态图片等形式的视觉草稿为输入,通过智能技术一键生成可维护的前端代码。Sketch/Photoshop 设计稿的代码生成需要插件。在设计稿中,视觉效果是通过imgcook插件导出的。将草稿的 JSON 描述信息(D2C Schema)粘贴到 imgcook 可视化编辑器中,您可以在其中编辑视图和逻辑以更改 JSON 描述信息。
我们可以选择DSL规范来生成相应的代码。例如,要为 React 规范生成代码,您需要实现从 JSON 树到 React 代码的转换(自定义 DSL)。
如下图,左边是Sketch中的visual Draft,右边是使用React开发规范生成的按钮部分的代码。
从 Sketch 视觉稿的“导出数据”中生成“React 开发规范”的代码。图为按钮的代码片段。
生成的代码由div、img、span等标签组成,但实际应用开发存在这样的问题:
我们的需求是,如果我们要使用组件库,比如 Ant Design,我们希望生成的代码是这样的:
// Antd Mobile React 规范
import { Button } from "antd-mobile";
进店抢红包
加购物车
"smart": {
"layerProtocol": {
"component": {
"type": "Button"
}
}
}
为此,我们在 JSON 描述中添加了一个智能字段来描述节点的类型。
我们需要做的是在visual Draft中找到需要组件化的元素,并用这样的JSON信息对其进行描述,这样在DSL转换代码的时候,就可以通过获取其中的smart字段来生成组件化的代码JSON 信息。
现在问题转化为:如何在visual Draft中找到需要组件化的元素,它是什么组件,它在DOM树中的位置,或者在设计稿中的位置。
解决方案
▐ 常规生成规则
通过指定设计草案规范来干预生成的 JSON 描述,以控制生成的代码结构。比如我们设计稿高级干预规范中组件的层命名约定:明确标记层中的组件和组件属性。
#component:组件名?属性=值#
#component:Button?id=btn#
使用imgcook插件导出JSON描述数据时,层中的约定信息是通过标准分析得到的。
▐ 学习识别组件
手动约定规则的方式需要按照我们制定的协议规范修改设计稿。一个页面上可能有很多组件。这种手动约定的方式给开发者增加了很多额外的工作,不符合使用imgcook提高开发效率的目的。, 我们期望通过智能方式自动识别可视化草稿中的可组件化元素,识别结果最终会转换并填充到智能字段中,与手动约定组件生成的json中的智能字段内容相同协议。
这里需要做两件事:
第二件事是我们可以根据json树解析组件的子元素。首先我们可以通过智能自动完成,这是人工智能领域一个典型的目标检测问题,我们可以尝试使用深度学习的目标检测方法来自动化解决这个手动协议的过程。
学习识别 UI 组件
▐ 行业现状
目前业界也有一些研究和应用使用深度学习来识别网页中的UI元素。对此有一些讨论:
讨论中有两个主要要求:
由于使用深度学习来解决UI界面元素识别问题,因此需要一个收录元素信息的UI界面数据集。目前,Rico 和 ReDraw 是业界最开放和使用最多的数据集。
重绘
一组Android截图、GUI元数据和GUI组件图片,包括RadioButton、ProgressBar、Switch、Button、CheckBox等15个类别,14382张UI界面图片和191300个带标签的GUI组件。处理后,每个组件的数量达到5000个。该数据集的详细介绍请参考The ReDraw Dataset。这是用于训练和评估 ReDraw 论文中提到的 CNN 和 KNN 机器学习技术的数据集,该论文发表在 2018 年的 IEEE Transactions on Software Engineering。 该论文提出了一种三步法来实现从 UI 到代码自动化:
1、检测
首先从设计稿中提取或者使用CV技术提取UI界面元信息,比如bounding box(位置,大小)。
2、分类
然后使用大规模软件仓库挖掘和自动动态分析来获取出现在UI界面中的组件,并将这些数据作为CNN技术的数据集,将提取的元素分类为特定类型,如Radio、Progress Bar、按钮等。
3、Assemble Assembly,最后使用KNN推导出UI层次结构,例如垂直列表和水平Slider。
Android 代码是在 ReDraw 系统中使用此方法生成的。评估表明,ReDraw 的GUI 组件分类平均准确率达到91%,并组装了原型应用程序。这些应用程序在视觉亲和力方面紧密地反映了目标模型,并表现出合理的代码结构。
里科
创建了迄今为止最大的移动 UI 数据集,以支持五种类型的数据驱动应用程序:设计搜索、UI 布局生成、UI 代码生成、用户交互建模和用户感知预测。Rico 数据集收录 27 个类别、10,000 多个应用程序和大约 70,000 个屏幕截图。该数据集在 2017 年第 30 届 ACM 年度用户界面软件和技术研讨会上向公众开放(RICO:A Mobile App Dataset for Building Data-Driven Design Applications)。
此后,出现了一些基于 Rico 数据集的研究和应用。例如:Learning Design Semantics for Mobile Apps,本文介绍了一种基于代码和可视化的方法来为移动UI元素添加语义注释。根据UI截图和视图层次,自动识别25个
UI 组件类别、197 个文本按钮概念和 99 个图标类别。
▐ 应用场景
下面是基于上述数据集的一些研究和应用场景。
基于机器学习的智能代码生成移动应用程序图形用户界面原型 | 重绘数据集
神经设计网络:有约束的图形布局生成| Rico 数据集
使用众包和深度学习的用户感知预测建模移动界面可点击性 | Rico 数据集
基于深度学习的自动化 Android 应用测试方法 | Rico 数据集
▐ 问题定义
在上述基于Redraw数据集生成Android代码的应用中,我们了解了它的实现。第二步,需要大型软件仓库挖掘和自动动态分析技术,获取大量分量样本作为CNN算法的训练样本。这样就可以获取到UI界面中存在的特定类型的组件,如Progress Bar、Switch等。
对于我们的 imgcook 应用场景,本质问题是在 UI 界面中找到这种特定类型的组件信息:类别和边界框。我们可以将这个问题定义为目标检测问题,并使用深度学习来定位 UI 界面。检测。那么我们的目标是什么?
检测对象为Progress Bar、Switch、Tab Bar等可以组件化代码的页面元素。
UI界面目标检测
▐ 基础知识
机器学习
人类如何学习?通过向大脑输入某些信息,可以通过学习和总结获得知识和经验。当有类似的任务时,可以根据现有的经验做出决定或行动。
机器学习的过程与人类学习的过程非常相似。机器学习算法本质上是得到一个由f(x)函数表示的模型。如果给f(x)输入一个样本x,结果是一个类别,解是一个分类问题。如果得到一个特定的值,那么解决方法就是回到问题。
机器学习和人类学习的整体机制是一样的。一个区别是,人脑只需要很少的数据就可以总结和总结非常适用的知识或经验。例如,我们只需要看到几只猫或几只狗就可以正确区分猫和狗,但是对于机器我们需要大量的学习资料,而机器能做的就是智能,无需人工参与。
深度学习
深度学习是机器学习的一个分支。它是一种尝试使用由复杂结构或多个非线性变换组成的多个处理层来在高层次上抽象数据的算法。
深度学习和传统机器学习的区别可以在这篇 Deep Learning vs. Machine Learning 中看到,它具有数据依赖、硬件依赖、特征处理、问题解决方法、执行时间和可解释性。
深度学习对数据量和硬件要求高,执行时间长。深度学习和传统机器学习算法的主要区别在于处理特征的方式。当传统的机器学习用于现实世界的任务时,描述样本的特征通常需要由人类专家设计。这被称为“特征工程”,特征的质量对泛化性能有着至关重要的影响。设计好的功能并不容易。深度学习可以通过特征学习技术分析数据,自动生成好的特征。
目标检测
机器学习有很多应用,例如:
对象检测(Object Detection)是与计算机视觉和图像处理相关的计算机技术,用于检测数字图像和视频中特定类别的语义对象(如人、动物或汽车)。
而我们在UI界面上的目标是一些设计元素,可以是具有原子粒度的Icon、Image、Text,也可以是组件化的Searchbar、Tabbar等。
▐ 算法选择
用于目标检测的方法通常分为基于机器学习的方法(传统目标检测方法)或基于深度学习的方法(深度学习目标检测方法)。目标检测方法已经从传统的目标检测方法到深度学习的目标检测方法发生了变化:
传统目标检测方法
对于基于机器学习的方法,您需要使用以下方法之一来定义特征,然后使用支持向量机(SVM)等技术进行分类。
深度学习目标检测方法
对于基于深度学习的方法,端到端的目标检测可以在不定义特征的情况下进行,通常基于卷积神经网络(CNN)。基于深度学习的目标检测方法可以分为One-stage和Two-stage两种,以及继承了这两种方法优点的RefineDet算法。
✎ 一级
基于One-stage的目标检测算法不使用RPN网络,直接通过骨干网提供类别和位置信息。该算法速度较快,但精度略低于两阶段目标检测网络。典型的算法有:
✎ 两阶段
基于Two-stage的目标检测算法主要使用卷积神经网络来完成目标检测过程。它提取CNN卷积特征。在训练网络时,主要训练两部分。第一步是训练RPN网络。第二步是训练网络进行目标区域检测。即算法生成一系列候选框作为样本,然后通过卷积神经网络对样本进行分类。网络精度高,速度比One-stage慢。典型的算法有:
✎ 其他 (RefineDet)
RefineDet(Single-Shot Refinement Neural Network for Object Detection)是基于SSD算法的改进。继承了两种方法(如单阶段设计法、两阶段设计法)的优点,克服了各自的缺点。
目标检测方法比较
✎ 传统方法VS深度学习
基于机器学习的方法和基于深度学习的方法的算法流程如图所示。传统的目标检测方法需要人工设计特征,通过滑动窗口获取候选框,然后使用传统分类器确定目标区域。整个训练过程分为多个步骤。深度学习目标检测方法利用机器学习特征,通过更高效的Proposal或直接回归方法获取候选目标,具有更好的准确率和实时性。
目前对目标检测算法的研究基本都是基于深度学习。传统的目标检测算法很少使用。深度学习目标检测方法更适合工程化。具体对比如下:
✎ 一级VS二级
✎ 算法优缺点
各个算法的原理我就不写了,只看优缺点。
总结
由于UI界面元素检测精度要求比较高,最终选择了Faster RCNN算法。
▐ 帧选择
机器学习框架
以下是几个机器学习框架的简要列表:Scikit Learn、TensorFlow、Pytorch、Keras。
Scikit Learn是一个通用的机器学习框架,实现了各种分类、回归和聚类算法(包括支持向量机、随机森林、梯度增强、k-means等);它还包括数据降维、模型选择和数据预处理。处理等工具库,安装使用方便,示例丰富,教程和文档也很详细。
TensorFlow、Keras和Pytorch是目前深度学习的主要框架,提供各种深度学习算法调用。这里推荐一个学习资源: 强烈推荐TensorFlow、Pytorch和Keras的示例资源,同意本文作者的观点:以上资源运行一次,不明白的地方查官方文档,很快就能理解和使用这三个框架了。
在下面的模型训练代码中,您可以看到这些框架在实际任务中的使用情况。
对象检测框架
目标检测框架可以理解为一个集成了目标检测算法的库。比如深度学习算法框架TensorFlow并不是目标检测框架,而是提供了目标检测的API:Object Detection API。
目标检测框架主要包括:Detecn-benchmark、mmdetection、Detectron2。目前使用最广泛的是
Detectron2目标检测框架由Facebook AI研究院于2019年10月10日开源,我们也使用Detectron2来识别UI界面组件,后面会用到示例代码。tron和maskrcn可以参考:2019年10月10日FAIR开源的Detectron2目标检测框架如何评价?
前端机器学习框架Pipcook
作为前端开发者,我们也可以选择Pipcook,这是阿里巴巴前端委员会智库开源的一个前端算法工程框架,帮助前端工程师使用机器学习。
pipcook采用前端友好的JS环境,基于Tensorflow.js框架作为底层算法能力,针对前端业务场景封装了相应的算法,让前端工程师可以快速便捷的使用机器学习能力。
pipcook 是一个基于流水线的框架,封装了机器学习工程环节的数据采集、数据访问、数据处理、模型配置、模型训练、模型服务部署、前端开发人员在线训练七部分。 查看全部
网页采集器的自动识别算法(使用机器学习的方式来识别UI界面元素的完整流程)
介绍:
智能代码生成平台imgcook以Sketch、PSD、静态图片等形式的视觉草稿为输入,一键生成可维护的前端代码。它是组件化的开发。我们希望直接从设计稿中生成组件化代码。这需要具备识别设计稿中组件化元素的能力,例如Searchbar、Button、Tab等。识别网页中的UI元素是人工智能领域典型的目标检测问题。我们可以尝试使用深度学习目标检测的方法来自动解决。
本文介绍了使用机器学习识别UI界面元素的完整过程,包括:当前问题分析、算法选择、样本准备、模型训练、模型评估、模型服务开发部署、模型应用等。
申请背景
imgcook以Sketch、PSD、静态图片等形式的视觉草稿为输入,通过智能技术一键生成可维护的前端代码。Sketch/Photoshop 设计稿的代码生成需要插件。在设计稿中,视觉效果是通过imgcook插件导出的。将草稿的 JSON 描述信息(D2C Schema)粘贴到 imgcook 可视化编辑器中,您可以在其中编辑视图和逻辑以更改 JSON 描述信息。
我们可以选择DSL规范来生成相应的代码。例如,要为 React 规范生成代码,您需要实现从 JSON 树到 React 代码的转换(自定义 DSL)。
如下图,左边是Sketch中的visual Draft,右边是使用React开发规范生成的按钮部分的代码。
从 Sketch 视觉稿的“导出数据”中生成“React 开发规范”的代码。图为按钮的代码片段。
生成的代码由div、img、span等标签组成,但实际应用开发存在这样的问题:
我们的需求是,如果我们要使用组件库,比如 Ant Design,我们希望生成的代码是这样的:
// Antd Mobile React 规范
import { Button } from "antd-mobile";
进店抢红包
加购物车
"smart": {
"layerProtocol": {
"component": {
"type": "Button"
}
}
}
为此,我们在 JSON 描述中添加了一个智能字段来描述节点的类型。
我们需要做的是在visual Draft中找到需要组件化的元素,并用这样的JSON信息对其进行描述,这样在DSL转换代码的时候,就可以通过获取其中的smart字段来生成组件化的代码JSON 信息。
现在问题转化为:如何在visual Draft中找到需要组件化的元素,它是什么组件,它在DOM树中的位置,或者在设计稿中的位置。
解决方案
▐ 常规生成规则
通过指定设计草案规范来干预生成的 JSON 描述,以控制生成的代码结构。比如我们设计稿高级干预规范中组件的层命名约定:明确标记层中的组件和组件属性。
#component:组件名?属性=值#
#component:Button?id=btn#
使用imgcook插件导出JSON描述数据时,层中的约定信息是通过标准分析得到的。
▐ 学习识别组件
手动约定规则的方式需要按照我们制定的协议规范修改设计稿。一个页面上可能有很多组件。这种手动约定的方式给开发者增加了很多额外的工作,不符合使用imgcook提高开发效率的目的。, 我们期望通过智能方式自动识别可视化草稿中的可组件化元素,识别结果最终会转换并填充到智能字段中,与手动约定组件生成的json中的智能字段内容相同协议。
这里需要做两件事:
第二件事是我们可以根据json树解析组件的子元素。首先我们可以通过智能自动完成,这是人工智能领域一个典型的目标检测问题,我们可以尝试使用深度学习的目标检测方法来自动化解决这个手动协议的过程。
学习识别 UI 组件
▐ 行业现状
目前业界也有一些研究和应用使用深度学习来识别网页中的UI元素。对此有一些讨论:
讨论中有两个主要要求:
由于使用深度学习来解决UI界面元素识别问题,因此需要一个收录元素信息的UI界面数据集。目前,Rico 和 ReDraw 是业界最开放和使用最多的数据集。
重绘
一组Android截图、GUI元数据和GUI组件图片,包括RadioButton、ProgressBar、Switch、Button、CheckBox等15个类别,14382张UI界面图片和191300个带标签的GUI组件。处理后,每个组件的数量达到5000个。该数据集的详细介绍请参考The ReDraw Dataset。这是用于训练和评估 ReDraw 论文中提到的 CNN 和 KNN 机器学习技术的数据集,该论文发表在 2018 年的 IEEE Transactions on Software Engineering。 该论文提出了一种三步法来实现从 UI 到代码自动化:
1、检测
首先从设计稿中提取或者使用CV技术提取UI界面元信息,比如bounding box(位置,大小)。
2、分类
然后使用大规模软件仓库挖掘和自动动态分析来获取出现在UI界面中的组件,并将这些数据作为CNN技术的数据集,将提取的元素分类为特定类型,如Radio、Progress Bar、按钮等。
3、Assemble Assembly,最后使用KNN推导出UI层次结构,例如垂直列表和水平Slider。
Android 代码是在 ReDraw 系统中使用此方法生成的。评估表明,ReDraw 的GUI 组件分类平均准确率达到91%,并组装了原型应用程序。这些应用程序在视觉亲和力方面紧密地反映了目标模型,并表现出合理的代码结构。
里科
创建了迄今为止最大的移动 UI 数据集,以支持五种类型的数据驱动应用程序:设计搜索、UI 布局生成、UI 代码生成、用户交互建模和用户感知预测。Rico 数据集收录 27 个类别、10,000 多个应用程序和大约 70,000 个屏幕截图。该数据集在 2017 年第 30 届 ACM 年度用户界面软件和技术研讨会上向公众开放(RICO:A Mobile App Dataset for Building Data-Driven Design Applications)。
此后,出现了一些基于 Rico 数据集的研究和应用。例如:Learning Design Semantics for Mobile Apps,本文介绍了一种基于代码和可视化的方法来为移动UI元素添加语义注释。根据UI截图和视图层次,自动识别25个
UI 组件类别、197 个文本按钮概念和 99 个图标类别。
▐ 应用场景
下面是基于上述数据集的一些研究和应用场景。
基于机器学习的智能代码生成移动应用程序图形用户界面原型 | 重绘数据集
神经设计网络:有约束的图形布局生成| Rico 数据集
使用众包和深度学习的用户感知预测建模移动界面可点击性 | Rico 数据集
基于深度学习的自动化 Android 应用测试方法 | Rico 数据集
▐ 问题定义
在上述基于Redraw数据集生成Android代码的应用中,我们了解了它的实现。第二步,需要大型软件仓库挖掘和自动动态分析技术,获取大量分量样本作为CNN算法的训练样本。这样就可以获取到UI界面中存在的特定类型的组件,如Progress Bar、Switch等。
对于我们的 imgcook 应用场景,本质问题是在 UI 界面中找到这种特定类型的组件信息:类别和边界框。我们可以将这个问题定义为目标检测问题,并使用深度学习来定位 UI 界面。检测。那么我们的目标是什么?
检测对象为Progress Bar、Switch、Tab Bar等可以组件化代码的页面元素。
UI界面目标检测
▐ 基础知识
机器学习
人类如何学习?通过向大脑输入某些信息,可以通过学习和总结获得知识和经验。当有类似的任务时,可以根据现有的经验做出决定或行动。
机器学习的过程与人类学习的过程非常相似。机器学习算法本质上是得到一个由f(x)函数表示的模型。如果给f(x)输入一个样本x,结果是一个类别,解是一个分类问题。如果得到一个特定的值,那么解决方法就是回到问题。
机器学习和人类学习的整体机制是一样的。一个区别是,人脑只需要很少的数据就可以总结和总结非常适用的知识或经验。例如,我们只需要看到几只猫或几只狗就可以正确区分猫和狗,但是对于机器我们需要大量的学习资料,而机器能做的就是智能,无需人工参与。
深度学习
深度学习是机器学习的一个分支。它是一种尝试使用由复杂结构或多个非线性变换组成的多个处理层来在高层次上抽象数据的算法。
深度学习和传统机器学习的区别可以在这篇 Deep Learning vs. Machine Learning 中看到,它具有数据依赖、硬件依赖、特征处理、问题解决方法、执行时间和可解释性。
深度学习对数据量和硬件要求高,执行时间长。深度学习和传统机器学习算法的主要区别在于处理特征的方式。当传统的机器学习用于现实世界的任务时,描述样本的特征通常需要由人类专家设计。这被称为“特征工程”,特征的质量对泛化性能有着至关重要的影响。设计好的功能并不容易。深度学习可以通过特征学习技术分析数据,自动生成好的特征。
目标检测
机器学习有很多应用,例如:
对象检测(Object Detection)是与计算机视觉和图像处理相关的计算机技术,用于检测数字图像和视频中特定类别的语义对象(如人、动物或汽车)。
而我们在UI界面上的目标是一些设计元素,可以是具有原子粒度的Icon、Image、Text,也可以是组件化的Searchbar、Tabbar等。
▐ 算法选择
用于目标检测的方法通常分为基于机器学习的方法(传统目标检测方法)或基于深度学习的方法(深度学习目标检测方法)。目标检测方法已经从传统的目标检测方法到深度学习的目标检测方法发生了变化:
传统目标检测方法
对于基于机器学习的方法,您需要使用以下方法之一来定义特征,然后使用支持向量机(SVM)等技术进行分类。
深度学习目标检测方法
对于基于深度学习的方法,端到端的目标检测可以在不定义特征的情况下进行,通常基于卷积神经网络(CNN)。基于深度学习的目标检测方法可以分为One-stage和Two-stage两种,以及继承了这两种方法优点的RefineDet算法。
✎ 一级
基于One-stage的目标检测算法不使用RPN网络,直接通过骨干网提供类别和位置信息。该算法速度较快,但精度略低于两阶段目标检测网络。典型的算法有:
✎ 两阶段
基于Two-stage的目标检测算法主要使用卷积神经网络来完成目标检测过程。它提取CNN卷积特征。在训练网络时,主要训练两部分。第一步是训练RPN网络。第二步是训练网络进行目标区域检测。即算法生成一系列候选框作为样本,然后通过卷积神经网络对样本进行分类。网络精度高,速度比One-stage慢。典型的算法有:
✎ 其他 (RefineDet)
RefineDet(Single-Shot Refinement Neural Network for Object Detection)是基于SSD算法的改进。继承了两种方法(如单阶段设计法、两阶段设计法)的优点,克服了各自的缺点。
目标检测方法比较
✎ 传统方法VS深度学习
基于机器学习的方法和基于深度学习的方法的算法流程如图所示。传统的目标检测方法需要人工设计特征,通过滑动窗口获取候选框,然后使用传统分类器确定目标区域。整个训练过程分为多个步骤。深度学习目标检测方法利用机器学习特征,通过更高效的Proposal或直接回归方法获取候选目标,具有更好的准确率和实时性。
目前对目标检测算法的研究基本都是基于深度学习。传统的目标检测算法很少使用。深度学习目标检测方法更适合工程化。具体对比如下:
✎ 一级VS二级
✎ 算法优缺点
各个算法的原理我就不写了,只看优缺点。
总结
由于UI界面元素检测精度要求比较高,最终选择了Faster RCNN算法。
▐ 帧选择
机器学习框架
以下是几个机器学习框架的简要列表:Scikit Learn、TensorFlow、Pytorch、Keras。
Scikit Learn是一个通用的机器学习框架,实现了各种分类、回归和聚类算法(包括支持向量机、随机森林、梯度增强、k-means等);它还包括数据降维、模型选择和数据预处理。处理等工具库,安装使用方便,示例丰富,教程和文档也很详细。
TensorFlow、Keras和Pytorch是目前深度学习的主要框架,提供各种深度学习算法调用。这里推荐一个学习资源: 强烈推荐TensorFlow、Pytorch和Keras的示例资源,同意本文作者的观点:以上资源运行一次,不明白的地方查官方文档,很快就能理解和使用这三个框架了。
在下面的模型训练代码中,您可以看到这些框架在实际任务中的使用情况。
对象检测框架
目标检测框架可以理解为一个集成了目标检测算法的库。比如深度学习算法框架TensorFlow并不是目标检测框架,而是提供了目标检测的API:Object Detection API。
目标检测框架主要包括:Detecn-benchmark、mmdetection、Detectron2。目前使用最广泛的是
Detectron2目标检测框架由Facebook AI研究院于2019年10月10日开源,我们也使用Detectron2来识别UI界面组件,后面会用到示例代码。tron和maskrcn可以参考:2019年10月10日FAIR开源的Detectron2目标检测框架如何评价?
前端机器学习框架Pipcook
作为前端开发者,我们也可以选择Pipcook,这是阿里巴巴前端委员会智库开源的一个前端算法工程框架,帮助前端工程师使用机器学习。
pipcook采用前端友好的JS环境,基于Tensorflow.js框架作为底层算法能力,针对前端业务场景封装了相应的算法,让前端工程师可以快速便捷的使用机器学习能力。
pipcook 是一个基于流水线的框架,封装了机器学习工程环节的数据采集、数据访问、数据处理、模型配置、模型训练、模型服务部署、前端开发人员在线训练七部分。
网页采集器的自动识别算法(网络数据采集/信息挖掘处理软件优采云采集器采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-12-01 01:02
优采云采集器是一款专业的网络数据采集/信息挖掘处理软件。优采云采集器通过灵活的配置,您可以方便快捷地从网页中抓取结构化文本、图片、文件等资源信息,并可以对其进行编辑和过滤,选择发布到网站@ > 后端、各种文件或其他数据库系统,广泛应用于数据挖掘、垂直搜索、信息聚合和门户、企业网络信息聚合、商业智能、论坛或博客迁移、智能信息代理、个人信息检索等领域适用适用于有采集挖矿需求的各类群体。
优采云采集器功能介绍:
1、分布式高速采集:任务分布到多个客户端,同时运行采集,效率翻倍。
2、多重识别系统:配备文字识别、中文分词识别、任意码识别等多重识别系统,智能识别操作更轻松。
3、可选验证方式:您可以随时选择是否使用加密狗以确保数据安全。
4、 全自动操作:无需人工操作,任务完成后自动关机。
5、替换功能:同义词、同义词替换、参数替换,伪原创必备技能。
6、任意文件格式下载:可以轻松下载任意格式的图片、压缩文件、视频等文件。
7、采集 监控系统:实时监控采集,保证数据的准确性。
8、 支持多数据库:支持Access/MySQL/MsSQL/Sqlite/Oracle等各类数据库的存储和发布。
9、无限多页采集:支持不限多页信息,包括ajax请求数据采集。
10、 支持扩展:支持接口和插件扩展,满足各种毛发采集需求。
特色:
1、支持所有网站@>编码:完美支持所有采集编码格式的网页,程序还可以自动识别网页编码。
2、多种发布方式:支持当前所有主流和非主流cms、BBS等网站@>节目,通过系统的发布模块,采集器和网站@可以实现 > 程序之间的完美集成。
3、全自动:无人值守工作,程序配置好后,程序会根据您的设置自动运行,无需人工干预。 查看全部
网页采集器的自动识别算法(网络数据采集/信息挖掘处理软件优采云采集器采集)
优采云采集器是一款专业的网络数据采集/信息挖掘处理软件。优采云采集器通过灵活的配置,您可以方便快捷地从网页中抓取结构化文本、图片、文件等资源信息,并可以对其进行编辑和过滤,选择发布到网站@ > 后端、各种文件或其他数据库系统,广泛应用于数据挖掘、垂直搜索、信息聚合和门户、企业网络信息聚合、商业智能、论坛或博客迁移、智能信息代理、个人信息检索等领域适用适用于有采集挖矿需求的各类群体。
优采云采集器功能介绍:
1、分布式高速采集:任务分布到多个客户端,同时运行采集,效率翻倍。
2、多重识别系统:配备文字识别、中文分词识别、任意码识别等多重识别系统,智能识别操作更轻松。
3、可选验证方式:您可以随时选择是否使用加密狗以确保数据安全。
4、 全自动操作:无需人工操作,任务完成后自动关机。
5、替换功能:同义词、同义词替换、参数替换,伪原创必备技能。
6、任意文件格式下载:可以轻松下载任意格式的图片、压缩文件、视频等文件。
7、采集 监控系统:实时监控采集,保证数据的准确性。
8、 支持多数据库:支持Access/MySQL/MsSQL/Sqlite/Oracle等各类数据库的存储和发布。
9、无限多页采集:支持不限多页信息,包括ajax请求数据采集。
10、 支持扩展:支持接口和插件扩展,满足各种毛发采集需求。
特色:
1、支持所有网站@>编码:完美支持所有采集编码格式的网页,程序还可以自动识别网页编码。
2、多种发布方式:支持当前所有主流和非主流cms、BBS等网站@>节目,通过系统的发布模块,采集器和网站@可以实现 > 程序之间的完美集成。
3、全自动:无人值守工作,程序配置好后,程序会根据您的设置自动运行,无需人工干预。
网页采集器的自动识别算法(经典的WEB信息提取实体信息抽取方法的局限性方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-11-30 07:13
【摘要】:随着互联网的快速发展和普及,互联网已成为一个非常重要的信息来源。并且越来越多的网民越来越渴望在浩瀚的互联网中高效、准确地找到目标主题页面,实现从主题页面中定制化的实体信息抽取。在传统搜索引擎领域,主题爬虫和垂直爬虫是比较流行的获取特定主题和特定网站数据的方法,但主题爬虫更注重主题页面的搜索,往往忽略深度提取页面信息。经研究,垂直爬虫虽然可以实现对一个网站的精准信息抽取,但其主要缺点是可移植性差,无法实现对不同网站的通用抓取,和低自动化。经典的WEB信息提取方法虽然在各种自适应领域取得了一定的成果,但也存在自适应范围的局限性和提取算法效率低下的问题;同时,这些方法基本上只针对目标WEB页面实体。对信息抽取的研究忽略了对目标页面搜索策略的研究;因此,现有的经典WEB实体信息抽取方法在应用和研究范围上都有其局限性。本文针对垂直爬虫无法直接移植到其他网站且程序设计需要大量人工干预的弊端,以及经典WEB实体信息抽取方法的局限性,
方便的配置信息后,快速准确定制不同的网站 数据爬取具有高可移植性和强通用性。同时也证明了本文提出的WEB实体信息提取算法的合理性和有效性。具有很高的应用价值,丰富了WEB信息抽取领域的理论和理论。应用研究。 查看全部
网页采集器的自动识别算法(经典的WEB信息提取实体信息抽取方法的局限性方法)
【摘要】:随着互联网的快速发展和普及,互联网已成为一个非常重要的信息来源。并且越来越多的网民越来越渴望在浩瀚的互联网中高效、准确地找到目标主题页面,实现从主题页面中定制化的实体信息抽取。在传统搜索引擎领域,主题爬虫和垂直爬虫是比较流行的获取特定主题和特定网站数据的方法,但主题爬虫更注重主题页面的搜索,往往忽略深度提取页面信息。经研究,垂直爬虫虽然可以实现对一个网站的精准信息抽取,但其主要缺点是可移植性差,无法实现对不同网站的通用抓取,和低自动化。经典的WEB信息提取方法虽然在各种自适应领域取得了一定的成果,但也存在自适应范围的局限性和提取算法效率低下的问题;同时,这些方法基本上只针对目标WEB页面实体。对信息抽取的研究忽略了对目标页面搜索策略的研究;因此,现有的经典WEB实体信息抽取方法在应用和研究范围上都有其局限性。本文针对垂直爬虫无法直接移植到其他网站且程序设计需要大量人工干预的弊端,以及经典WEB实体信息抽取方法的局限性,
方便的配置信息后,快速准确定制不同的网站 数据爬取具有高可移植性和强通用性。同时也证明了本文提出的WEB实体信息提取算法的合理性和有效性。具有很高的应用价值,丰富了WEB信息抽取领域的理论和理论。应用研究。
网页采集器的自动识别算法(10个非常实用的每一款软件,你知道几个?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2021-11-29 14:06
给大家分享10款非常好用的软件,每个软件都很强大,可以解决很多需求,喜欢的话记得点赞支持哦~
1、SpaceSniffer
SpaceSniffer 是一款免费且易于使用的磁盘查看和清理软件。使用此工具,您可以清楚地了解磁盘的空间分布,磁盘中是否有任何文件,并将这些内容可视化,以便您查看和删除不需要的文件。
SpaceSniffer 运行速度非常快,可以一键分析目标磁盘,并且可以给出所选文件的详细概览,包括大小、文件名、创建日期等。
2、一切
Everything 是一款快速文件索引软件,可根据文件名和文件夹快速定位。比windows自带的本地搜索速度快很多,软件体积只有10M左右,轻巧高效。
一切都可以在超短的时间内建立索引,搜索结果基本毫秒级。输入搜索的文件名后,立即显示搜索结果。
Everything 支持常用图片格式的缩略图预览,以及ai、psd、eps等常用设计文件的缩略图预览,这个功能对设计小伙伴有很大的帮助!
3、优采云采集器
优采云采集器由原谷歌技术团队打造,基于人工智能技术,只需输入网址即可自动识别采集的内容。
可以智能识别数据。智能模式基于人工智能算法。只需输入网址,即可智能识别列表数据、表格数据和分页按钮。无需配置任何采集规则,一键采集。自动识别列表、表格、链接、图片、价格等。
流程图模式:只需点击页面,根据软件提示进行操作,完全符合人们浏览网页的思维方式。简单几步就可以生成复杂的采集规则,结合智能识别算法,任何网页的数据都可以轻松采集。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。
4、彩虹工具箱
Rainbow Toolbox 是一个非常有用的通用计算机工具集合,支持 Mac 和 Windows 系统。按照工具分类,包括生活娱乐、加解密、数据计算、编码转换、图片视频、网络工具等,这一类的工具很多,目前使用Rainbow Toolbox的体验非常好!
Rainbow Toolbox 提供了大量常用的小工具,按小工具的用途分为生活娱乐、加解密、数据计算、编码转换、图像视频、网络工具等。
5、方形网格
Square 是一个非常易于使用的 Excel 插件工具箱。主要功能是支持扩展的Excel程序,帮助用户更快速地分析Excel数据,加快工作效率。
软件拥有上百种实用功能,让用户办公更流畅。这是一个非常易于使用的 Excel 插件。
如文本处理、批量录入、删除工具、合并转换、重复值工具、数据比较、高级排序、颜色排序、合并单元格排序、聚光灯、宏存储框等。
6、Fire Velvet 安全软件
Tinder安全软件是一款轻量级、高效、免费的计算机防御和杀毒安全软件,在应对安全问题时可以显着增强计算机系统的防御能力。
Tinder安全软件可以全面拦截和查杀各类病毒,不会为了清除病毒而直接删除感染病毒的文件,充分保护用户文件不受损害。软件小巧玲珑,系统内存占用率极低,保证机器在主动防御查杀过程中永不卡顿。
Tinder安全软件可查杀病毒,拥有18项重要防护功能,文件实时监控、U盘防护、应用加固、软件安装拦截、浏览器防护、网络入侵拦截、暴力破解防护、弹窗防护向上拦截、漏洞修复、启动项管理和文件粉碎。
7、天若OCR
天若OCR是一款集文字识别、表格识别、垂直识别、公式识别、修正识别、高级识别、识别翻译、识别搜索和截图功能于一体的软件。
天若OCR可以帮助您减少重复性工作,提高工作效率。
8、Snipaste
Snipaste 是一个简单而强大的截图和贴纸工具,你也可以将截图粘贴回屏幕。F1截图,F3贴图,简约高效。
办公室里会抄很多资料,写的时候会抄很多文字和图片。Snipaste 可以将这些内容粘贴到屏幕上,而不是切换回窗口。
发布在屏幕上的信息可以缩放、旋转、设置为半透明,甚至可以被鼠标穿透。在屏幕上发布重要信息,绝对可以改变您的工作方式,提高工作效率。
9、7-ZIP
7-ZIP是一款开源免费的压缩软件,使用LZMA和LZMA2算法,压缩率非常高,可以比Winzip高2-10%。7-ZIP 支持的格式很多,所有常用的压缩格式都支持。
支持格式:压缩/解压:7z、XZ、BZIP2、GZIP、TAR、ZIP、WIM。仅解压:ARJ、CAB、CHM、CPIO、CramFS、DEB、DMG、FAT、HFS、ISO、LZH、LZMA、MBR、MSI、NSIS、NTFS、RAR、RPM、SquashFS、UDF、VHD、WIM、XAR、Z .
10、WG 手势
WGestures 是一款简单高效的鼠标手势软件,免费开源,非常有良心。
WGestures 有非常丰富的功能。网络搜索可以简化搜索信息的过程;手势名称提醒和修饰键更符合用户直觉;触发角度和摩擦边缘使计算机操作更高效。
今天的分享到此结束,感谢大家看到这里,听说三家公司的朋友们都有福了!喜欢就点@李天浩关注我吧。更多实用干货等着你! 查看全部
网页采集器的自动识别算法(10个非常实用的每一款软件,你知道几个?)
给大家分享10款非常好用的软件,每个软件都很强大,可以解决很多需求,喜欢的话记得点赞支持哦~
1、SpaceSniffer
SpaceSniffer 是一款免费且易于使用的磁盘查看和清理软件。使用此工具,您可以清楚地了解磁盘的空间分布,磁盘中是否有任何文件,并将这些内容可视化,以便您查看和删除不需要的文件。
SpaceSniffer 运行速度非常快,可以一键分析目标磁盘,并且可以给出所选文件的详细概览,包括大小、文件名、创建日期等。
2、一切
Everything 是一款快速文件索引软件,可根据文件名和文件夹快速定位。比windows自带的本地搜索速度快很多,软件体积只有10M左右,轻巧高效。
一切都可以在超短的时间内建立索引,搜索结果基本毫秒级。输入搜索的文件名后,立即显示搜索结果。
Everything 支持常用图片格式的缩略图预览,以及ai、psd、eps等常用设计文件的缩略图预览,这个功能对设计小伙伴有很大的帮助!
3、优采云采集器
优采云采集器由原谷歌技术团队打造,基于人工智能技术,只需输入网址即可自动识别采集的内容。
可以智能识别数据。智能模式基于人工智能算法。只需输入网址,即可智能识别列表数据、表格数据和分页按钮。无需配置任何采集规则,一键采集。自动识别列表、表格、链接、图片、价格等。
流程图模式:只需点击页面,根据软件提示进行操作,完全符合人们浏览网页的思维方式。简单几步就可以生成复杂的采集规则,结合智能识别算法,任何网页的数据都可以轻松采集。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。
4、彩虹工具箱
Rainbow Toolbox 是一个非常有用的通用计算机工具集合,支持 Mac 和 Windows 系统。按照工具分类,包括生活娱乐、加解密、数据计算、编码转换、图片视频、网络工具等,这一类的工具很多,目前使用Rainbow Toolbox的体验非常好!
Rainbow Toolbox 提供了大量常用的小工具,按小工具的用途分为生活娱乐、加解密、数据计算、编码转换、图像视频、网络工具等。
5、方形网格
Square 是一个非常易于使用的 Excel 插件工具箱。主要功能是支持扩展的Excel程序,帮助用户更快速地分析Excel数据,加快工作效率。
软件拥有上百种实用功能,让用户办公更流畅。这是一个非常易于使用的 Excel 插件。
如文本处理、批量录入、删除工具、合并转换、重复值工具、数据比较、高级排序、颜色排序、合并单元格排序、聚光灯、宏存储框等。
6、Fire Velvet 安全软件
Tinder安全软件是一款轻量级、高效、免费的计算机防御和杀毒安全软件,在应对安全问题时可以显着增强计算机系统的防御能力。
Tinder安全软件可以全面拦截和查杀各类病毒,不会为了清除病毒而直接删除感染病毒的文件,充分保护用户文件不受损害。软件小巧玲珑,系统内存占用率极低,保证机器在主动防御查杀过程中永不卡顿。
Tinder安全软件可查杀病毒,拥有18项重要防护功能,文件实时监控、U盘防护、应用加固、软件安装拦截、浏览器防护、网络入侵拦截、暴力破解防护、弹窗防护向上拦截、漏洞修复、启动项管理和文件粉碎。
7、天若OCR
天若OCR是一款集文字识别、表格识别、垂直识别、公式识别、修正识别、高级识别、识别翻译、识别搜索和截图功能于一体的软件。
天若OCR可以帮助您减少重复性工作,提高工作效率。
8、Snipaste
Snipaste 是一个简单而强大的截图和贴纸工具,你也可以将截图粘贴回屏幕。F1截图,F3贴图,简约高效。
办公室里会抄很多资料,写的时候会抄很多文字和图片。Snipaste 可以将这些内容粘贴到屏幕上,而不是切换回窗口。
发布在屏幕上的信息可以缩放、旋转、设置为半透明,甚至可以被鼠标穿透。在屏幕上发布重要信息,绝对可以改变您的工作方式,提高工作效率。
9、7-ZIP
7-ZIP是一款开源免费的压缩软件,使用LZMA和LZMA2算法,压缩率非常高,可以比Winzip高2-10%。7-ZIP 支持的格式很多,所有常用的压缩格式都支持。
支持格式:压缩/解压:7z、XZ、BZIP2、GZIP、TAR、ZIP、WIM。仅解压:ARJ、CAB、CHM、CPIO、CramFS、DEB、DMG、FAT、HFS、ISO、LZH、LZMA、MBR、MSI、NSIS、NTFS、RAR、RPM、SquashFS、UDF、VHD、WIM、XAR、Z .
10、WG 手势
WGestures 是一款简单高效的鼠标手势软件,免费开源,非常有良心。
WGestures 有非常丰富的功能。网络搜索可以简化搜索信息的过程;手势名称提醒和修饰键更符合用户直觉;触发角度和摩擦边缘使计算机操作更高效。
今天的分享到此结束,感谢大家看到这里,听说三家公司的朋友们都有福了!喜欢就点@李天浩关注我吧。更多实用干货等着你!
网页采集器的自动识别算法(网页采集器的自动识别算法有哪些?-八维教育)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-11-25 15:03
网页采集器的自动识别算法有很多,比如加特定标签进行识别,直接抓取所有页面进行批量识别,对图片进行位置的识别,字体进行识别等等,都是可以自动识别的。
一般网页都有自己的一套识别规则,相关的有seo黑帽方法(黑帽搜索引擎竞价排名定位)、图片识别等等。以前有搜索引擎一类的论坛和网站提供这种参考,现在也有人提供。不过需要付费。
刚才找到,说的是识别页面的文字框,网页上的文字框搜索引擎识别的都是封装好的对应的标签文字。大多数网站都可以用网页截图或照片识别。至于自动识别页面中的对话框,也有人提供相关的工具。
这里有一篇教程,可以参考一下:seo技术:看完这篇文章,你就可以自己制作网页上的免费对话框了。
提供免费网页识别工具。新建一个网页,通过文本识别或图片识别,然后模仿搜索引擎的查询关键词和搜索引擎的规则,抓取网页所有页面,进行对话框、网址框等的识别。
现在有很多自动识别网页的应用工具的。比如说,搜索引擎识别对话框网址框什么的。还有,一些搜索引擎的免费服务页面识别工具,
可以通过下载sitemapx来免费识别
哪有什么自动识别,建议使用sitemanager,
有一款免费的识别网页的工具-cn/searchs/ 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法有哪些?-八维教育)
网页采集器的自动识别算法有很多,比如加特定标签进行识别,直接抓取所有页面进行批量识别,对图片进行位置的识别,字体进行识别等等,都是可以自动识别的。
一般网页都有自己的一套识别规则,相关的有seo黑帽方法(黑帽搜索引擎竞价排名定位)、图片识别等等。以前有搜索引擎一类的论坛和网站提供这种参考,现在也有人提供。不过需要付费。
刚才找到,说的是识别页面的文字框,网页上的文字框搜索引擎识别的都是封装好的对应的标签文字。大多数网站都可以用网页截图或照片识别。至于自动识别页面中的对话框,也有人提供相关的工具。
这里有一篇教程,可以参考一下:seo技术:看完这篇文章,你就可以自己制作网页上的免费对话框了。
提供免费网页识别工具。新建一个网页,通过文本识别或图片识别,然后模仿搜索引擎的查询关键词和搜索引擎的规则,抓取网页所有页面,进行对话框、网址框等的识别。
现在有很多自动识别网页的应用工具的。比如说,搜索引擎识别对话框网址框什么的。还有,一些搜索引擎的免费服务页面识别工具,
可以通过下载sitemapx来免费识别
哪有什么自动识别,建议使用sitemanager,
有一款免费的识别网页的工具-cn/searchs/
网页采集器的自动识别算法(手机app采集器的自动识别算法目前没有谁家能做到)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-11-25 12:04
网页采集器的自动识别算法是通过本地硬件的集成以及后台有限的知识库识别的,通常我们用c++和selenium就可以完成,但是针对新标准url,需要继续引入上传,图片,视频,txt等文件自动识别的软件模块来辅助识别,算法目前没有谁家能做到全自动的。
ai根据最新的电影、电视剧和美剧网站中小丑的行为来学习,如果学习的结果匹配,就会呈现出一幅画面,
谢邀。mit一个哥们搞的新ga-supervised-ocr,可以参考一下。
现在的手机app一般都会有自己的识别方法,像smart-fakeapp的工作原理如下图所示:实现的过程就是先将英文一个一个字节识别出来,提取主要词汇(由文字转成文件),再统计其频率,最后将提取的英文再拼起来,字符。也就是把原始文件按照频率排序,然后随机生成一个新文件。这样看起来效率很高,可惜这只是小规模的识别。
如果识别的量越大,需要的时间就越长。因此一般来说,就当前的手机app来说,是不可能自动识别小丑这类图片的。可以试试使用python来识别图片,然后将结果保存为图片文件,用nltk或者其他库(可以网上搜索)来做大规模的识别,否则可能会很慢。 查看全部
网页采集器的自动识别算法(手机app采集器的自动识别算法目前没有谁家能做到)
网页采集器的自动识别算法是通过本地硬件的集成以及后台有限的知识库识别的,通常我们用c++和selenium就可以完成,但是针对新标准url,需要继续引入上传,图片,视频,txt等文件自动识别的软件模块来辅助识别,算法目前没有谁家能做到全自动的。
ai根据最新的电影、电视剧和美剧网站中小丑的行为来学习,如果学习的结果匹配,就会呈现出一幅画面,
谢邀。mit一个哥们搞的新ga-supervised-ocr,可以参考一下。
现在的手机app一般都会有自己的识别方法,像smart-fakeapp的工作原理如下图所示:实现的过程就是先将英文一个一个字节识别出来,提取主要词汇(由文字转成文件),再统计其频率,最后将提取的英文再拼起来,字符。也就是把原始文件按照频率排序,然后随机生成一个新文件。这样看起来效率很高,可惜这只是小规模的识别。
如果识别的量越大,需要的时间就越长。因此一般来说,就当前的手机app来说,是不可能自动识别小丑这类图片的。可以试试使用python来识别图片,然后将结果保存为图片文件,用nltk或者其他库(可以网上搜索)来做大规模的识别,否则可能会很慢。
网页采集器的自动识别算法(如何过滤掉这些不良信息,营造绿色安全的网络环境)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-11-23 10:08
【摘要】 随着互联网技术的飞速发展,网络中的资源越来越丰富,网络已经成为人们获取各种信息和资源的主要渠道。搜索引擎在网络信息检索中扮演着重要的角色,但在搜索效率和搜索结果的准确性方面还不能完全满足人们的需求。此外,互联网上充斥着色情、暴力、赌博或毒品等不健康内容。如何过滤掉此类不良信息,营造绿色安全的网络环境,也对搜索引擎提出了挑战。网页分类技术可以提供一种解决上述问题的方法。如果一个网页有能够代表其自身特征的标签,那么当我们需要从海量数据中搜索自己想要的信息时,网页标签可以帮助提高检索效率和准确率;当我们需要过滤掉一些不感兴趣或内容不好的网页时,我们可以通过识别网页标签来提高过滤的准确性。本研究基于项目组正在开发的教育浏览器,对网页分类问题进行了研究,以期找到一种高效的网页分类算法。主要研究工作包括:1、 研究网页分类问题的国内外研究和应用现状,明确相关技术基础和研究方法,包括文本分类问题的一般处理过程和分词技术. 2、 对网页分类问题中的几个关键机制进行了研究,包括编写有针对性的网络爬虫来获取网页信息;对网页进行预处理,获取网页文本内容;采用中文分词技术对网页文本进行处理,并对处理后的文本进行特征提取。3、 设计并实现了网页分类算法。除了朴素贝叶斯和支持向量机这两种经典的文本分类算法外,本文还将新兴的机器学习算法随机森林算法引入到网页分类的研究中,对网页分类问题进行了改进,提出了一种“半随机森林算法”。通过对三种分类算法的数据实验,结果表明,本文改进的随机森林算法具有更好的分类效果,且结构比SVM更简单。本研究不仅丰富了教育浏览器的功能,而且为基于教育浏览器的用户行为分析、个性化内容推荐等智能服务和应用奠定了基础。 查看全部
网页采集器的自动识别算法(如何过滤掉这些不良信息,营造绿色安全的网络环境)
【摘要】 随着互联网技术的飞速发展,网络中的资源越来越丰富,网络已经成为人们获取各种信息和资源的主要渠道。搜索引擎在网络信息检索中扮演着重要的角色,但在搜索效率和搜索结果的准确性方面还不能完全满足人们的需求。此外,互联网上充斥着色情、暴力、赌博或毒品等不健康内容。如何过滤掉此类不良信息,营造绿色安全的网络环境,也对搜索引擎提出了挑战。网页分类技术可以提供一种解决上述问题的方法。如果一个网页有能够代表其自身特征的标签,那么当我们需要从海量数据中搜索自己想要的信息时,网页标签可以帮助提高检索效率和准确率;当我们需要过滤掉一些不感兴趣或内容不好的网页时,我们可以通过识别网页标签来提高过滤的准确性。本研究基于项目组正在开发的教育浏览器,对网页分类问题进行了研究,以期找到一种高效的网页分类算法。主要研究工作包括:1、 研究网页分类问题的国内外研究和应用现状,明确相关技术基础和研究方法,包括文本分类问题的一般处理过程和分词技术. 2、 对网页分类问题中的几个关键机制进行了研究,包括编写有针对性的网络爬虫来获取网页信息;对网页进行预处理,获取网页文本内容;采用中文分词技术对网页文本进行处理,并对处理后的文本进行特征提取。3、 设计并实现了网页分类算法。除了朴素贝叶斯和支持向量机这两种经典的文本分类算法外,本文还将新兴的机器学习算法随机森林算法引入到网页分类的研究中,对网页分类问题进行了改进,提出了一种“半随机森林算法”。通过对三种分类算法的数据实验,结果表明,本文改进的随机森林算法具有更好的分类效果,且结构比SVM更简单。本研究不仅丰富了教育浏览器的功能,而且为基于教育浏览器的用户行为分析、个性化内容推荐等智能服务和应用奠定了基础。
网页采集器的自动识别算法(优采云采集器能采集哪些信息?怎么判断?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-11-22 16:19
标签:采集器
提供免费网页采集工具《优采云采集器》7.6.4 正式版下载,软件免费,文件大小5< @7.15 MB,推荐指数3星,作为国产软件的顶级厂商,可以放心下载!
优采云采集器是网页数据采集器,可以对各种类型的网页进行大量的数据采集工作,优采云采集器@ > 正式版涵盖类型广泛,金融、交易、社交网站、电商产品等。网站数据可标准化采集,可导出。
软件特点
云采集
5000套云,24*7高效稳定采集,结合API,可无缝对接内部系统,定时同步数据
智能防封
自动破解多种验证码,提供全球最大代理IP池,结合UA切换,可有效突破封锁,畅通采集数据
适用于全网
可即看即收,无论是图片通话还是贴吧论坛,都支持所有业务渠道的爬虫,满足各种采集需求
海量模板
内置数百个网站数据源,覆盖多个行业,简单设置即可快速准确获取数据
便于使用
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库
稳定高效
分布式云集群和多用户协同管理平台支持,灵活调度任务,流畅抓取海量数据
指示
第一步
打开客户端,选择简单模式和对应的网站模板
第二步
预览模板的采集字段、参数设置和示例数据
第三步
设置相应参数,运行后保存数据采集
经常问的问题
问题优采云采集器你能采集其他人的背景资料吗?
没有采集,后端数据需要有后端访问权限,正规的采集软件不会提供此类侵权服务。但是你可以采集拥有自己的后台数据。
问题优采云可以采集QQ号、邮箱、电话等吗?
是的采集,你在网页上看到的任何数据都可以采集,优采云采集器还有很多这样的规则可以在内置规则中下载市场,无需配置,这些数据可以通过运行规则来提取。
如何判断哪些信息可以优采云采集器采集?
简单来说,你在网页上看到的信息可以是优采云采集器采集,具体的采集规则需要你自己设置或者从规则市场。
在配置采集流程的时候,有时候点击左键的链接,网页会自动跳转,弹出选项。如何避免网页自动跳转?
一些使用脚本控制跳转的网页在点击左键时可能会跳转,给配置带来不便。解决方法是使用右键单击。用左右键点击页面会弹出选项。没有区别。右键单击一般可以避免自动重定向的问题。
优采云采集器 安装成功后无法启动怎么办?
如果第一次安装成功后提示“Windows正在配置优采云采集器,请稍候”,之后出现“安装过程中发生严重错误”的提示,说明你有360安全卫士和你电脑上类似 如果软件正在运行,可能是360等杀毒软件误删除了优采云操作所需的文件。请退出360等杀毒软件,重新安装优采云采集器。
更新日志
主要体验改进
【自定义模式】新增JSON采集功能
【自定义模式】新增滑动验证码识别
【自定义模式】优化效率,列表识别速度翻倍
【自定义模式】自动识别网页Ajax点击并自动配置Ajax超时时间,配置任务更方便
【自定义模式】改进算法,更准确地选择网页元素
【本地采集】采集整体速度提升10-30%,采集效率大幅提升
【任务列表】重构任务列表界面,性能大幅提升,大量任务管理不再卡顿
【任务列表】任务列表新增自动刷新机制,可随时查看任务最新状态
错误修复
修复云端查看数据慢的问题采集
修复采集报错排版问题
修复“打开网页时出现乱码”的问题
修复拖动过程后突然消失的问题
修复定时导出和自动入库工具自动弹出的问题
修复格式化时间类型数据错误的问题
修复一些小问题 查看全部
网页采集器的自动识别算法(优采云采集器能采集哪些信息?怎么判断?(组图))
标签:采集器
提供免费网页采集工具《优采云采集器》7.6.4 正式版下载,软件免费,文件大小5< @7.15 MB,推荐指数3星,作为国产软件的顶级厂商,可以放心下载!
优采云采集器是网页数据采集器,可以对各种类型的网页进行大量的数据采集工作,优采云采集器@ > 正式版涵盖类型广泛,金融、交易、社交网站、电商产品等。网站数据可标准化采集,可导出。
软件特点
云采集
5000套云,24*7高效稳定采集,结合API,可无缝对接内部系统,定时同步数据
智能防封
自动破解多种验证码,提供全球最大代理IP池,结合UA切换,可有效突破封锁,畅通采集数据
适用于全网
可即看即收,无论是图片通话还是贴吧论坛,都支持所有业务渠道的爬虫,满足各种采集需求
海量模板
内置数百个网站数据源,覆盖多个行业,简单设置即可快速准确获取数据
便于使用
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库
稳定高效
分布式云集群和多用户协同管理平台支持,灵活调度任务,流畅抓取海量数据
指示
第一步
打开客户端,选择简单模式和对应的网站模板
第二步
预览模板的采集字段、参数设置和示例数据
第三步
设置相应参数,运行后保存数据采集
经常问的问题
问题优采云采集器你能采集其他人的背景资料吗?
没有采集,后端数据需要有后端访问权限,正规的采集软件不会提供此类侵权服务。但是你可以采集拥有自己的后台数据。
问题优采云可以采集QQ号、邮箱、电话等吗?
是的采集,你在网页上看到的任何数据都可以采集,优采云采集器还有很多这样的规则可以在内置规则中下载市场,无需配置,这些数据可以通过运行规则来提取。
如何判断哪些信息可以优采云采集器采集?
简单来说,你在网页上看到的信息可以是优采云采集器采集,具体的采集规则需要你自己设置或者从规则市场。
在配置采集流程的时候,有时候点击左键的链接,网页会自动跳转,弹出选项。如何避免网页自动跳转?
一些使用脚本控制跳转的网页在点击左键时可能会跳转,给配置带来不便。解决方法是使用右键单击。用左右键点击页面会弹出选项。没有区别。右键单击一般可以避免自动重定向的问题。
优采云采集器 安装成功后无法启动怎么办?
如果第一次安装成功后提示“Windows正在配置优采云采集器,请稍候”,之后出现“安装过程中发生严重错误”的提示,说明你有360安全卫士和你电脑上类似 如果软件正在运行,可能是360等杀毒软件误删除了优采云操作所需的文件。请退出360等杀毒软件,重新安装优采云采集器。
更新日志
主要体验改进
【自定义模式】新增JSON采集功能
【自定义模式】新增滑动验证码识别
【自定义模式】优化效率,列表识别速度翻倍
【自定义模式】自动识别网页Ajax点击并自动配置Ajax超时时间,配置任务更方便
【自定义模式】改进算法,更准确地选择网页元素
【本地采集】采集整体速度提升10-30%,采集效率大幅提升
【任务列表】重构任务列表界面,性能大幅提升,大量任务管理不再卡顿
【任务列表】任务列表新增自动刷新机制,可随时查看任务最新状态
错误修复
修复云端查看数据慢的问题采集
修复采集报错排版问题
修复“打开网页时出现乱码”的问题
修复拖动过程后突然消失的问题
修复定时导出和自动入库工具自动弹出的问题
修复格式化时间类型数据错误的问题
修复一些小问题
网页采集器的自动识别算法(软件特色智能识别数据,小白神器智能模式(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-11-20 16:09
优采云采集器免费版是一款非常好用的网页数据采集软件,配合非常强大的人工智能技术,可以帮助用户自动识别网页内容,让用户可以提供这个软件快速采集到您需要的网页数据,让每一位用户都能体验到最便捷的数据采集方法。优采云采集器 正式版没有任何收费项目,完全免费供用户使用,让用户可以使用本软件获取采集数据。
优采云采集器 最新版本有一个非常方便的批处理采集功能。用户只需输入批量采集地址和条件,软件就可以自动采集这些数据,有需要的用户快来帮忙下载本软件。
软件特点
智能识别数据,小白神器
智能模式:基于人工智能算法,只需输入网址即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集。
自动识别:列表、表格、链接、图片、价格等。
直观点击,轻松上手
流程图模式:只需点击页面,根据软件提示进行操作,完全符合人们浏览网页的思维方式。一个复杂的采集规则可以简单几步生成,结合智能识别算法,任何网页的数据都可以轻松采集。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。
支持多种数据导出方式
采集 结果可以本地导出,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。
功能强大,提供企业级服务
优采云采集器免费版提供了丰富的采集功能,无论是采集稳定性还是采集效率,都能满足个人、团队和企业。 采集需求。
功能丰富:定时采集、自动导出、文件下载、加速引擎、分组启动导出、Webhook、RESTful API、SKU智能识别、电商大图等。
云账号,方便快捷
创建优采云采集器免费版登录账号,您所有的采集任务都会自动加密保存到优采云的云服务器,让您无需担心关于 采集 任务的丢失。而且非常安全。只有在本地登录客户端后才能查看。优采云采集器 账号没有终端绑定限制。采集 任务也会在切换终端时同步更新,任务管理方便快捷。
全平台支持,无缝切换
同时支持Windows、Mac、Linux所有操作系统的采集软件。各平台版本完全一致,切换无缝。
软件亮点
1、可视化定制采集流程
全程问答指导,可视化操作,自定义采集流程
自动记录和模拟网页操作顺序
高级设置满足更多采集需求
2、点击提取网页数据
鼠标点击选择要抓取的网页内容,操作简单
您可以选择提取文本、链接、属性、html 标签等。
3、运行批处理采集数据
优采云采集器根据采集处理和提取规则自动批处理采集
快速稳定,实时显示采集速度和进程
可切换软件后台运行,不打扰前台工作
4、导出发布采集的数据
采集 数据自动制表,字段可自由配置
支持数据导出到Excel等本地文件
并一键发布到cms网站/database/微信公众号等媒体
优采云采集器免费版教程
如何自定义采集百度搜索结果数据
第一步:创建采集任务
启动优采云采集器免费版,进入主界面,选择自定义采集,点击创建任务按钮,创建“自定义采集任务”
输入百度搜索的网址,包括三种方式
1、 手动输入:直接在输入框中输入网址,多个网址需要用换行符分隔
2、点击读取文件:用户选择一个文件来存储URL。文件中可以有多个URL地址,地址之间需要用换行符分隔。
3、 批量添加方式:通过添加和调整地址参数生成多个常规地址
第二步:自定义采集流程
点击创建后,会自动打开第一个网址,进入自定义设置页面。默认情况下,已经创建了开始、打开网页和结束的进程块。底部模板区用于拖拽到画布,生成新的流程块;点击打开网页中的属性按钮修改打开的网址
添加输入文本流块:将底部模板区域中的输入文本块拖到打开的网页块附近。出现阴影区域时松开鼠标,此时会自动连接,添加完成
生成完整的流程图:按照上面添加输入文本流块的拖放过程添加新块
点击开始采集,启动采集就OK了
优采云采集器免费版如何导出
1、采集 任务正在运行
2、采集 完成后选择“导出数据”将所有数据导出到本地文件
3、选择“导出方式”导出采集好的数据,这里可以选择excel作为导出格式
4、采集 数据导出如下图
优采云采集器免费版如何停止和恢复
1、通过去重功能断点续挖
启动任务时直接设置重复数据删除,选择“当所有字段重复时,跳过并继续采集”。
该程序设置简单,但效率低。设置后,任务依然会从第一页采集开始,然后一一跳过已经采集的所有数据。
2、通过修改采集的作用域、修改URL或添加前置操作来恢复挖矿
当任务停止时,软件的停止界面会记录URL和从当前任务采集到最后一个的翻页数。一般来说,停止URL是准确的,但翻页次数可能会大于实际值。, 因为如果出现卡纸,就会出现翻页的情况。
优采云采集器免费版如何设置范围采集
1、设置起始页和结束页
起始页默认为当前页,结束页默认为最后一页。需要注意的是,如果选择自定义设置,当前页面为第一页。
2、设置跳过项目
在采集中,可以跳过每页的第一个或最后一个数字。
3、设置停止采集
正常的采集任务会按照上面的范围从起始页采集开始到结束页,其中stop采集是在设置的条件满足期间提前停止采集采集的过程。 查看全部
网页采集器的自动识别算法(软件特色智能识别数据,小白神器智能模式(组图))
优采云采集器免费版是一款非常好用的网页数据采集软件,配合非常强大的人工智能技术,可以帮助用户自动识别网页内容,让用户可以提供这个软件快速采集到您需要的网页数据,让每一位用户都能体验到最便捷的数据采集方法。优采云采集器 正式版没有任何收费项目,完全免费供用户使用,让用户可以使用本软件获取采集数据。
优采云采集器 最新版本有一个非常方便的批处理采集功能。用户只需输入批量采集地址和条件,软件就可以自动采集这些数据,有需要的用户快来帮忙下载本软件。
软件特点
智能识别数据,小白神器
智能模式:基于人工智能算法,只需输入网址即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集。
自动识别:列表、表格、链接、图片、价格等。
直观点击,轻松上手
流程图模式:只需点击页面,根据软件提示进行操作,完全符合人们浏览网页的思维方式。一个复杂的采集规则可以简单几步生成,结合智能识别算法,任何网页的数据都可以轻松采集。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。
支持多种数据导出方式
采集 结果可以本地导出,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。
功能强大,提供企业级服务
优采云采集器免费版提供了丰富的采集功能,无论是采集稳定性还是采集效率,都能满足个人、团队和企业。 采集需求。
功能丰富:定时采集、自动导出、文件下载、加速引擎、分组启动导出、Webhook、RESTful API、SKU智能识别、电商大图等。
云账号,方便快捷
创建优采云采集器免费版登录账号,您所有的采集任务都会自动加密保存到优采云的云服务器,让您无需担心关于 采集 任务的丢失。而且非常安全。只有在本地登录客户端后才能查看。优采云采集器 账号没有终端绑定限制。采集 任务也会在切换终端时同步更新,任务管理方便快捷。
全平台支持,无缝切换
同时支持Windows、Mac、Linux所有操作系统的采集软件。各平台版本完全一致,切换无缝。
软件亮点
1、可视化定制采集流程
全程问答指导,可视化操作,自定义采集流程
自动记录和模拟网页操作顺序
高级设置满足更多采集需求
2、点击提取网页数据
鼠标点击选择要抓取的网页内容,操作简单
您可以选择提取文本、链接、属性、html 标签等。
3、运行批处理采集数据
优采云采集器根据采集处理和提取规则自动批处理采集
快速稳定,实时显示采集速度和进程
可切换软件后台运行,不打扰前台工作
4、导出发布采集的数据
采集 数据自动制表,字段可自由配置
支持数据导出到Excel等本地文件
并一键发布到cms网站/database/微信公众号等媒体
优采云采集器免费版教程
如何自定义采集百度搜索结果数据
第一步:创建采集任务
启动优采云采集器免费版,进入主界面,选择自定义采集,点击创建任务按钮,创建“自定义采集任务”
输入百度搜索的网址,包括三种方式
1、 手动输入:直接在输入框中输入网址,多个网址需要用换行符分隔
2、点击读取文件:用户选择一个文件来存储URL。文件中可以有多个URL地址,地址之间需要用换行符分隔。
3、 批量添加方式:通过添加和调整地址参数生成多个常规地址
第二步:自定义采集流程
点击创建后,会自动打开第一个网址,进入自定义设置页面。默认情况下,已经创建了开始、打开网页和结束的进程块。底部模板区用于拖拽到画布,生成新的流程块;点击打开网页中的属性按钮修改打开的网址
添加输入文本流块:将底部模板区域中的输入文本块拖到打开的网页块附近。出现阴影区域时松开鼠标,此时会自动连接,添加完成
生成完整的流程图:按照上面添加输入文本流块的拖放过程添加新块
点击开始采集,启动采集就OK了
优采云采集器免费版如何导出
1、采集 任务正在运行
2、采集 完成后选择“导出数据”将所有数据导出到本地文件
3、选择“导出方式”导出采集好的数据,这里可以选择excel作为导出格式
4、采集 数据导出如下图
优采云采集器免费版如何停止和恢复
1、通过去重功能断点续挖
启动任务时直接设置重复数据删除,选择“当所有字段重复时,跳过并继续采集”。
该程序设置简单,但效率低。设置后,任务依然会从第一页采集开始,然后一一跳过已经采集的所有数据。
2、通过修改采集的作用域、修改URL或添加前置操作来恢复挖矿
当任务停止时,软件的停止界面会记录URL和从当前任务采集到最后一个的翻页数。一般来说,停止URL是准确的,但翻页次数可能会大于实际值。, 因为如果出现卡纸,就会出现翻页的情况。
优采云采集器免费版如何设置范围采集
1、设置起始页和结束页
起始页默认为当前页,结束页默认为最后一页。需要注意的是,如果选择自定义设置,当前页面为第一页。
2、设置跳过项目
在采集中,可以跳过每页的第一个或最后一个数字。
3、设置停止采集
正常的采集任务会按照上面的范围从起始页采集开始到结束页,其中stop采集是在设置的条件满足期间提前停止采集采集的过程。
网页采集器的自动识别算法( Web漏洞扫描器一般来讲,运维人员将精力转向如何处理安全风险上来)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-11-19 02:21
Web漏洞扫描器一般来讲,运维人员将精力转向如何处理安全风险上来)
随着Web开发的日益成熟,人们开始进入“数字生存”时代。网上银行、电子商务、个人空间、云存储等不断涌入生活,Web应用安全问题日益突出。
根据 Gartner 的调查,75% 的信息安全攻击发生在 Web 应用程序而非网络级别。同时,OWASP公布的数据也显示,三分之二的网站相当脆弱,容易受到攻击。
手动测试和审核 Web 应用程序的安全性是一项复杂且耗时的任务。对于安全运维人员来说,基于安全的管理会占用大量的工作时间。自动化的Web漏洞扫描器可以大大简化安全风险的检测,帮助安全运维人员专注于如何应对安全风险。
网络漏洞扫描器
一般来说,Web漏洞扫描器是一种基于URL的漏洞扫描工具,工作中需要解决两个关键问题:采集和核心检测:
如何采集输入源(即采集网站 URL)
如何调用扫描插件(即扫描URL)
如何评估扫描仪的质量?首先要注意的是:采集的网址是否足够全面?如果资产采集不完整,检测精度无从谈起。
传统爬虫技术发现率低
在Web漏扫中,采集输入源一般包括爬虫、流量、代理、日志等。爬虫是获取扫描后的网站 URLs.采集模式最常见也是必不可少的方式。
网络漏洞扫描器爬虫比其他网络爬虫面临更高的技术挑战。这是因为漏洞扫描器爬虫不仅需要抓取网页内容和分析链接信息,还需要在网页上尽可能多地触发。事件,从而获得更有效的链接信息。
然而,现有爬虫受限于其固有的技术缺陷,给使用Web漏洞扫描工具的安全运维人员带来了诸多问题:
1、 容易触发WAF设置的IP访问限制
一般情况下,网站的防火墙会限制一定时间内可以请求固定IP的次数。如果不超过上限,则正常返回数据,超过上限则拒绝请求。值得注意的是,IP 限制大部分时间是为了抵御 DOS 攻击的 网站 安全原因,而不是专门针对爬虫。但是传统爬虫工作时,机器和IP都是有限的,很容易达到WAF设置的IP上限而导致请求被拒绝。
2、 无法自动处理网页交互问题
Web2.0时代,Web应用与用户交互非常频繁,对漏网的爬虫造成干扰。以输入验证码登录为例。网站 会生成一串随机生成的数字或符号的图片,给图片添加一些干扰像素(防止OCR),用户可以直观的识别验证码信息并输入表单提交< @网站验证,验证成功后才能使用某个功能。当传统爬虫遇到这种情况时,通常很难自动处理。
3、 无法抓取 JavaScript 解析的网页
JavaScript 框架的诞生对于效率时代的研发工程师来说是一大福音,工程师们可以摆脱开发和维护的痛苦。毫无疑问,Angular、React、Vue 等单页应用的 Web 框架已经成为开发者的首选。JavaScript解析的网页越来越流行,所以网页中大部分有用的数据都是通过ajax/fetch动态获取然后通过js填充到网页的DOM树中的,有用的数据很少纯HTML静态页面,直接导致Web爬虫不完整抓取。
传统爬行动物和集中爬行动物
纵观市场上常用的漏洞扫描产品,使用的爬虫通常包括以下两大类,即传统爬虫和聚焦爬虫:
传统爬虫
其工作流程是从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足一系列系统设置。停止条件,爬行操作停止。
传统爬虫流程图侧重爬虫
聚焦爬虫的工作流程比传统爬虫复杂。需要根据一定的网页分析算法过滤与扫描目标无关的网址,保留有用的网址,放入网址队列等待抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以备以后查询检索;因此,一个完整的聚焦爬虫一般收录以下三个模块:Web请求模块、爬取过程控制模块、内容分析提取模块。
但是,无论是传统爬虫还是聚焦爬虫,由于其固有的技术缺陷,无法在URL为采集<时自动处理网页交互、JavaScript解析,并容易触发外部WAF防御措施。 @网站 以及其他问题。
X-Ray创新技术提高爬虫发现率
X-Ray安全评估系统针对当前用户错过的爬虫,创造性地提出了基于语义分析、机器学习技术和DOM遍历算法的高仿真实时渲染的实时渲染DOM遍历算法采集 目标 URL 问题。“新爬虫”:
1、 创新加入js语义分析算法,避免IP访问超限
对于传统的网站,长亭科技创新在专注爬虫的基础上,采用js语义分析算法,针对WAF针对DOS攻击采取的IP访问限制防御措施,X-Ray爬虫将本地攻击JS解析文件,在理解语义的基础上解析网站结构,不会疯狂触发请求,从而避免超出IP访问限制被拒绝访问的情况。
X-Ray专注爬虫流程原理图2、通过机器学习技术实现交互行为分析
对于单页应用网站,X-Ray 已经嵌入了一个模拟浏览器爬虫。通过使用机器学习技术,X-Ray 的模拟浏览器爬虫使用各种 Web 应用程序页面结构作为训练样本。在访问每个页面时,可以智能判断各种交互操作。判断逻辑大概是这样:
判断是表单输入、点击事件等;
自动判断表单输入框应填写哪些内容,如用户名、密码、IP地址等,然后填写相应的内容样本;
点击事件自动触发,请求发起成功。3、 高仿真实时渲染DOM遍历算法完美解决JavaScript解析
针对JavaScript解析的单页Web应用,X-Ray模拟浏览器创新引入了高模拟实时渲染DOM遍历算法。在该算法引擎的驱动下,可以完美解析Angular、React、Vue等Web框架。实现的单页应用网站对Web页面中的所有内容进行操作,达到获取URL信息的目的目标网站。判断逻辑如下:
找到网页的DOM节点,形成DOM树;
内置浏览器,从深度和广度两个层次,对网页进行高度模拟的DOM树遍历;
真实浏览器画面,实时渲染DOM树的遍历过程
X-Ray在机器学习技术和DOM遍历算法的高仿真实时渲染驱动下,模拟浏览器爬虫的行为,智能模拟人类行为,自动进行点击、双击、拖拽等操作,从而避免了传统爬虫在获取到 URL 时,无法满足交互,无法处理 JavaScript 解析。
下面以访问DVWA为例,展示模拟浏览器的行为
dvwa浏览器点击
以网银、电子商务、云存储等Web应用为代表的Web3.0时代已经到来,X-Ray安全评估系统蓄势待发。你准备好了吗? 查看全部
网页采集器的自动识别算法(
Web漏洞扫描器一般来讲,运维人员将精力转向如何处理安全风险上来)
随着Web开发的日益成熟,人们开始进入“数字生存”时代。网上银行、电子商务、个人空间、云存储等不断涌入生活,Web应用安全问题日益突出。
根据 Gartner 的调查,75% 的信息安全攻击发生在 Web 应用程序而非网络级别。同时,OWASP公布的数据也显示,三分之二的网站相当脆弱,容易受到攻击。
手动测试和审核 Web 应用程序的安全性是一项复杂且耗时的任务。对于安全运维人员来说,基于安全的管理会占用大量的工作时间。自动化的Web漏洞扫描器可以大大简化安全风险的检测,帮助安全运维人员专注于如何应对安全风险。
网络漏洞扫描器
一般来说,Web漏洞扫描器是一种基于URL的漏洞扫描工具,工作中需要解决两个关键问题:采集和核心检测:
如何采集输入源(即采集网站 URL)
如何调用扫描插件(即扫描URL)
如何评估扫描仪的质量?首先要注意的是:采集的网址是否足够全面?如果资产采集不完整,检测精度无从谈起。
传统爬虫技术发现率低
在Web漏扫中,采集输入源一般包括爬虫、流量、代理、日志等。爬虫是获取扫描后的网站 URLs.采集模式最常见也是必不可少的方式。
网络漏洞扫描器爬虫比其他网络爬虫面临更高的技术挑战。这是因为漏洞扫描器爬虫不仅需要抓取网页内容和分析链接信息,还需要在网页上尽可能多地触发。事件,从而获得更有效的链接信息。
然而,现有爬虫受限于其固有的技术缺陷,给使用Web漏洞扫描工具的安全运维人员带来了诸多问题:
1、 容易触发WAF设置的IP访问限制
一般情况下,网站的防火墙会限制一定时间内可以请求固定IP的次数。如果不超过上限,则正常返回数据,超过上限则拒绝请求。值得注意的是,IP 限制大部分时间是为了抵御 DOS 攻击的 网站 安全原因,而不是专门针对爬虫。但是传统爬虫工作时,机器和IP都是有限的,很容易达到WAF设置的IP上限而导致请求被拒绝。
2、 无法自动处理网页交互问题
Web2.0时代,Web应用与用户交互非常频繁,对漏网的爬虫造成干扰。以输入验证码登录为例。网站 会生成一串随机生成的数字或符号的图片,给图片添加一些干扰像素(防止OCR),用户可以直观的识别验证码信息并输入表单提交< @网站验证,验证成功后才能使用某个功能。当传统爬虫遇到这种情况时,通常很难自动处理。
3、 无法抓取 JavaScript 解析的网页
JavaScript 框架的诞生对于效率时代的研发工程师来说是一大福音,工程师们可以摆脱开发和维护的痛苦。毫无疑问,Angular、React、Vue 等单页应用的 Web 框架已经成为开发者的首选。JavaScript解析的网页越来越流行,所以网页中大部分有用的数据都是通过ajax/fetch动态获取然后通过js填充到网页的DOM树中的,有用的数据很少纯HTML静态页面,直接导致Web爬虫不完整抓取。
传统爬行动物和集中爬行动物
纵观市场上常用的漏洞扫描产品,使用的爬虫通常包括以下两大类,即传统爬虫和聚焦爬虫:
传统爬虫
其工作流程是从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足一系列系统设置。停止条件,爬行操作停止。
传统爬虫流程图侧重爬虫
聚焦爬虫的工作流程比传统爬虫复杂。需要根据一定的网页分析算法过滤与扫描目标无关的网址,保留有用的网址,放入网址队列等待抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以备以后查询检索;因此,一个完整的聚焦爬虫一般收录以下三个模块:Web请求模块、爬取过程控制模块、内容分析提取模块。
但是,无论是传统爬虫还是聚焦爬虫,由于其固有的技术缺陷,无法在URL为采集<时自动处理网页交互、JavaScript解析,并容易触发外部WAF防御措施。 @网站 以及其他问题。
X-Ray创新技术提高爬虫发现率
X-Ray安全评估系统针对当前用户错过的爬虫,创造性地提出了基于语义分析、机器学习技术和DOM遍历算法的高仿真实时渲染的实时渲染DOM遍历算法采集 目标 URL 问题。“新爬虫”:
1、 创新加入js语义分析算法,避免IP访问超限
对于传统的网站,长亭科技创新在专注爬虫的基础上,采用js语义分析算法,针对WAF针对DOS攻击采取的IP访问限制防御措施,X-Ray爬虫将本地攻击JS解析文件,在理解语义的基础上解析网站结构,不会疯狂触发请求,从而避免超出IP访问限制被拒绝访问的情况。
X-Ray专注爬虫流程原理图2、通过机器学习技术实现交互行为分析
对于单页应用网站,X-Ray 已经嵌入了一个模拟浏览器爬虫。通过使用机器学习技术,X-Ray 的模拟浏览器爬虫使用各种 Web 应用程序页面结构作为训练样本。在访问每个页面时,可以智能判断各种交互操作。判断逻辑大概是这样:
判断是表单输入、点击事件等;
自动判断表单输入框应填写哪些内容,如用户名、密码、IP地址等,然后填写相应的内容样本;
点击事件自动触发,请求发起成功。3、 高仿真实时渲染DOM遍历算法完美解决JavaScript解析
针对JavaScript解析的单页Web应用,X-Ray模拟浏览器创新引入了高模拟实时渲染DOM遍历算法。在该算法引擎的驱动下,可以完美解析Angular、React、Vue等Web框架。实现的单页应用网站对Web页面中的所有内容进行操作,达到获取URL信息的目的目标网站。判断逻辑如下:
找到网页的DOM节点,形成DOM树;
内置浏览器,从深度和广度两个层次,对网页进行高度模拟的DOM树遍历;
真实浏览器画面,实时渲染DOM树的遍历过程
X-Ray在机器学习技术和DOM遍历算法的高仿真实时渲染驱动下,模拟浏览器爬虫的行为,智能模拟人类行为,自动进行点击、双击、拖拽等操作,从而避免了传统爬虫在获取到 URL 时,无法满足交互,无法处理 JavaScript 解析。
下面以访问DVWA为例,展示模拟浏览器的行为
dvwa浏览器点击
以网银、电子商务、云存储等Web应用为代表的Web3.0时代已经到来,X-Ray安全评估系统蓄势待发。你准备好了吗?
网页采集器的自动识别算法(网页采集器的自动识别算法-rdf浏览器采集算法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-11-18 11:04
网页采集器的自动识别算法很多,rdf,条件格式,pgm,这些都是具体的采集手段。实现其实很简单,第一步要自己写一个s2fd_rdf_export宏包,然后修改几个地方。input地址的类型,output地址类型,window设置参数,匹配原网址就能去哪里识别哪里。上面都是宏,js脚本也行。
有类似airsoft或者autoruns之类采集软件的,而且模拟器也是可以录制。
之前我自己写过一个小程序模拟,用acrobat什么的,用格式化文件,
simsoftjavascriptlibrarylibrarytoolbox里面有采集web页面和数据库的,
你可以看看fiddler,安卓的也有,不过你得先搭个android环境。
这个你直接百度“sdwebimage网页采集器”或者如果有直接写代码实现的可以留言我也想要啊~
我也想用chrome浏览器来采集
airdesk或者mac浏览器。
autoruns或者explorer
直接用webpy或者fiddler
airdesk可以代替吧webpy-pythonwebdeveloperairdesk/airdesk.pyasasimplewebdevelopermoreexclusive
全自动不太可能,也许是chrome内核webpy或者fiddler控制器。但这个最好是采集在服务器端或者cdn的页面,直接在浏览器上显示有点不太好。推荐golang开发,网页采集完,直接去源码里就能找到main.go, 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法-rdf浏览器采集算法)
网页采集器的自动识别算法很多,rdf,条件格式,pgm,这些都是具体的采集手段。实现其实很简单,第一步要自己写一个s2fd_rdf_export宏包,然后修改几个地方。input地址的类型,output地址类型,window设置参数,匹配原网址就能去哪里识别哪里。上面都是宏,js脚本也行。
有类似airsoft或者autoruns之类采集软件的,而且模拟器也是可以录制。
之前我自己写过一个小程序模拟,用acrobat什么的,用格式化文件,
simsoftjavascriptlibrarylibrarytoolbox里面有采集web页面和数据库的,
你可以看看fiddler,安卓的也有,不过你得先搭个android环境。
这个你直接百度“sdwebimage网页采集器”或者如果有直接写代码实现的可以留言我也想要啊~
我也想用chrome浏览器来采集
airdesk或者mac浏览器。
autoruns或者explorer
直接用webpy或者fiddler
airdesk可以代替吧webpy-pythonwebdeveloperairdesk/airdesk.pyasasimplewebdevelopermoreexclusive
全自动不太可能,也许是chrome内核webpy或者fiddler控制器。但这个最好是采集在服务器端或者cdn的页面,直接在浏览器上显示有点不太好。推荐golang开发,网页采集完,直接去源码里就能找到main.go,
网页采集器的自动识别算法( 基于图片识别的自动裁剪方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-11-15 15:12
基于图片识别的自动裁剪方法)
一种基于图片识别的自动裁剪方法
[专利摘要] 本发明涉及一种基于图片识别的自动裁剪方法,该方法包括(1)图片预处理;(2)人脸识别;(3)背景识别;(< @4)自适应截取,本发明采用基于识别的方法实现图片的裁剪,将裁剪后的图片与原图的比例,本发明无需人工干预,算法为本发明可以根据需要采用不同的策略,满足不同网页的显示,使用本发明对组图片进行裁剪,选择裁剪成功的作为展示图片,准确率达到99.8%。本发明应用于信息和微薄页面图片的裁剪,经人工测试准确率为99.5%。
[专利说明]-一种基于图像识别的自动裁剪方法
【技术领域】
[0001] 本发明涉及一种自动裁剪方法,尤其涉及一种基于图片识别的自动裁剪方法。
【背景技术】
[0002] 在网页展示领域,图片裁剪是必不可少的环节。目前,图片需要根据网页显示的需要裁剪成不同的尺寸。图像裁剪的方法多种多样,基本上可以分为两大类:基于软件的手动裁剪和算法裁剪。
[0003] 基于软件的裁剪:首先必须定义裁剪区域和缩放比例,然后可以批量裁剪一组图片。对于某种类型的图片,切割过程是手动指定的。算法裁剪使用机器识别算法识别背景区域,根据需要显示大小,切掉部分背景,然后放大和缩小图片。
[0004] 手动裁剪方式的缺点是需要大量的人力资源来裁剪图片,并且随着网站的扩展,裁剪图片的成本也非常高。自动裁剪方法的缺点是算法复杂。同时,必须监控图像裁剪的效果,及时调整算法,发现问题。
[发明概要]
[0005] 针对现有技术的不足,本发明提出了一种基于图片识别的自动裁剪技术。根据要显示的页面大小,有效裁剪图片,无需人工干预。据观察,不同的网页对图片的展示有不同的要求。根据需要的尺寸,判断是否需要对原图进行裁剪。如果需要裁剪,首先进行人脸识别,如果没有人脸,则进行背景识别。在此基础上,找到图片中需要保留的主要部分。然后使用自适应截取方法截取需要的图形。
[0006] 本发明的目的是通过以下技术方案实现的:
[0007] 一种基于图片识别的自动裁剪方法,改进之处在于该方法包括
[0008] (1)图片预处理;
[0009](2)人脸识别;
[0010](3)背景识别;
<p>[0011]( 查看全部
网页采集器的自动识别算法(
基于图片识别的自动裁剪方法)
一种基于图片识别的自动裁剪方法
[专利摘要] 本发明涉及一种基于图片识别的自动裁剪方法,该方法包括(1)图片预处理;(2)人脸识别;(3)背景识别;(< @4)自适应截取,本发明采用基于识别的方法实现图片的裁剪,将裁剪后的图片与原图的比例,本发明无需人工干预,算法为本发明可以根据需要采用不同的策略,满足不同网页的显示,使用本发明对组图片进行裁剪,选择裁剪成功的作为展示图片,准确率达到99.8%。本发明应用于信息和微薄页面图片的裁剪,经人工测试准确率为99.5%。
[专利说明]-一种基于图像识别的自动裁剪方法
【技术领域】
[0001] 本发明涉及一种自动裁剪方法,尤其涉及一种基于图片识别的自动裁剪方法。
【背景技术】
[0002] 在网页展示领域,图片裁剪是必不可少的环节。目前,图片需要根据网页显示的需要裁剪成不同的尺寸。图像裁剪的方法多种多样,基本上可以分为两大类:基于软件的手动裁剪和算法裁剪。
[0003] 基于软件的裁剪:首先必须定义裁剪区域和缩放比例,然后可以批量裁剪一组图片。对于某种类型的图片,切割过程是手动指定的。算法裁剪使用机器识别算法识别背景区域,根据需要显示大小,切掉部分背景,然后放大和缩小图片。
[0004] 手动裁剪方式的缺点是需要大量的人力资源来裁剪图片,并且随着网站的扩展,裁剪图片的成本也非常高。自动裁剪方法的缺点是算法复杂。同时,必须监控图像裁剪的效果,及时调整算法,发现问题。
[发明概要]
[0005] 针对现有技术的不足,本发明提出了一种基于图片识别的自动裁剪技术。根据要显示的页面大小,有效裁剪图片,无需人工干预。据观察,不同的网页对图片的展示有不同的要求。根据需要的尺寸,判断是否需要对原图进行裁剪。如果需要裁剪,首先进行人脸识别,如果没有人脸,则进行背景识别。在此基础上,找到图片中需要保留的主要部分。然后使用自适应截取方法截取需要的图形。
[0006] 本发明的目的是通过以下技术方案实现的:
[0007] 一种基于图片识别的自动裁剪方法,改进之处在于该方法包括
[0008] (1)图片预处理;
[0009](2)人脸识别;
[0010](3)背景识别;
<p>[0011](
网页采集器的自动识别算法(软件特色可视化操作操作简单,完全可视化(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-11-15 07:05
vg浏览器不仅是采集浏览器,更是营销神器。vg 浏览器也是一个可视化脚本驱动的网络工具。可以简单的设置脚本,创建自动登录、身份验证等脚本项目。
相关软件软件大小版本说明下载地址
vg浏览器不仅是一个采集浏览器,更是一个营销神器。vg浏览器也是一个可视化脚本驱动的网页工具,它可以简单的设置脚本,可以创建自动登录、身份验证等很多脚本项目。
基本介绍
VG浏览器是一个由可视化脚本驱动的网页自动运行工具。只需设置脚本,即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库。发送和接收电子邮件等个性化实用的脚本项目。还可以使用逻辑运算来完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。
软件特点
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
定制流程
采集 就像积木一样,功能自由组合。
自动编码
程序注重采集的效率,页面解析速度非常快。
生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的这个按钮
单击网页元素会自动生成该元素的 CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。比如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器,可以通过按F12键或在页面上右键选择评论元素来选择。
右键单击目标部分并选择复制 CSS 路径以将 CSS 路径复制到剪贴板。
在 Firefox 中,您还可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Only Selector”复制CSS Path。
CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你也可以自己编写 CSS Path。
更新日志
8.3.3.3
新增数据库操作-导入Excel,可导入表变量或信息库
添加了简单的采集列表分页延迟时间设置
添加了在执行 Sql Select 语句时保存到表变量
C#语句函数的执行支持表变量操作,需要在Run方法中添加tableDic参数(参考默认代码)
修复上一版本右键不显示元素信息菜单的问题
删除目录下完善的验证码识别dll文件WmCode.dll,与下一代单独打包。如果需要,您可以单独下载 查看全部
网页采集器的自动识别算法(软件特色可视化操作操作简单,完全可视化(组图))
vg浏览器不仅是采集浏览器,更是营销神器。vg 浏览器也是一个可视化脚本驱动的网络工具。可以简单的设置脚本,创建自动登录、身份验证等脚本项目。
相关软件软件大小版本说明下载地址
vg浏览器不仅是一个采集浏览器,更是一个营销神器。vg浏览器也是一个可视化脚本驱动的网页工具,它可以简单的设置脚本,可以创建自动登录、身份验证等很多脚本项目。
基本介绍
VG浏览器是一个由可视化脚本驱动的网页自动运行工具。只需设置脚本,即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库。发送和接收电子邮件等个性化实用的脚本项目。还可以使用逻辑运算来完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。
软件特点
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
定制流程
采集 就像积木一样,功能自由组合。
自动编码
程序注重采集的效率,页面解析速度非常快。
生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的这个按钮
单击网页元素会自动生成该元素的 CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。比如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器,可以通过按F12键或在页面上右键选择评论元素来选择。
右键单击目标部分并选择复制 CSS 路径以将 CSS 路径复制到剪贴板。
在 Firefox 中,您还可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Only Selector”复制CSS Path。
CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你也可以自己编写 CSS Path。
更新日志
8.3.3.3
新增数据库操作-导入Excel,可导入表变量或信息库
添加了简单的采集列表分页延迟时间设置
添加了在执行 Sql Select 语句时保存到表变量
C#语句函数的执行支持表变量操作,需要在Run方法中添加tableDic参数(参考默认代码)
修复上一版本右键不显示元素信息菜单的问题
删除目录下完善的验证码识别dll文件WmCode.dll,与下一代单独打包。如果需要,您可以单独下载
网页采集器的自动识别算法(1.ZCMS中的Web采集功能采集多少个文章页)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-11-11 15:17
1.Z 中的 Webcms采集
Zcms中的Web采集功能是一款简单易用、功能强大的基于模板的内容采集提取工具,支持自动采集文章列表paging,分页采集,URL重定向后自动采集内容,内容编码自动识别,网页修改日期自动识别,多线程采集,多级URL采集等功能,并支持使用代理服务器和URL过滤、内容过滤。
采集完成后,Zcms会根据匹配块中的规则提取文章的标题、内容等信息,并自动添加到指定的列中以备后续使用由编辑。
2.填写采集基本设置
切换到“数据通道”下的“From Web采集”菜单,点击“新建”按钮,添加一个新的采集任务,如下图:
在:
采集当类别为文章采集时,采集程序直接将网页转换成Zcms中的文档;如果是自定义的采集,那么只有采集数据,无需转换,需要开发程序读取采集返回的文本并进行处理。自定义采集仅用于Zcms的二次开发。
发布日期格式表示网页内容提示的发布日期格式,与JAVA中的日期格式一致,y代表年,M代表月,d代表日,h代表小时,m代表分钟,s 代表秒。
采集 如果勾选了“下载远程图片”,采集程序会自动将内容中的图片下载到Zcms服务器,并替换内容中的图片地址.
采集 如果勾选了“从内容中删除超链接”,采集 程序会自动将内容中的所有超链接转为纯文本。
采集到这一列表示采集之后的文档存放在哪一列。
采集 内容页数上限表示该任务最多采集 内容页数。
列表页中采集的最大数量表示该任务中采集文章列表页的最大数量。
采集 线程数是指同时采集的线程数。值越大,采集 速度越快,占用的带宽越多。一般1个线程就够了,不超过30个线程。
超时等待时间表示目标网页所在服务器忙时采集程序等待的秒数。默认为 30 秒,一般不应超过 120 秒。
发生错误时的重试次数表示目标服务器没有响应或有错误响应时采集程序重试的次数。
如果Zcms所在的服务器不能直接上网或者目标网页必须通过专门的代理访问,则需要勾选“使用代理服务器”选项并填写代理服务器地址、端口, 用户名和密码。
3.填写网址规则
填写完基本设置后,就可以开始填写URL规则了。以新浪新闻为例,您可以进行如下操作:
1)填写起始网址,填写新浪新闻列表页网址如下图:
2)填写下一级网址
通过观察列表页上的新闻链接,发现大部分新闻链接网址都类似如下:
我们把这个 URL 转换成 URL 通配符,如下图:
${A}/${D}.shtml
其中,${D}表示这里允许数字,${A}表示允许任意字符。
但是,有些新闻链接网址不符合此规则,例如:
我们还将这个 URL 转换为 URL 通配符,如下所示:
${A}/${D}.shtml
然后点击“添加URL级别”按钮,将上面两个URL通配符填入下一级的文本框中,如下图所示:
3)如果列表页不能直接到达文章内容页,可能需要填写多级URL。整个URL处理流程是:先采集起始URL(可以有多个起始URL),然后分析起始URL采集返回的HTML文本中的所有链接URL,一一二级别 URL 通配符比较,如果 URL 和级别 2 URL 通配符之一匹配,则为 采集。当所有符合条件的二级网址采集都完成后,再次从二级网址采集返回的HTML中提取所有链接网址,并一一比较三级网址的通配符...直到最后一级 URL。
4) 有时需要过滤掉一些URL,需要勾选“URL Filtering”选项并填写过滤表达式。这些规则类似于常见的 URL 通配符。采集 程序会将 URL 与过滤后的 URL 通配符进行比较。如果发现它匹配通配符之一,它将忽略 采集。
4.填写内容匹配块
填写完基本信息后,开始填写内容匹配块。内容匹配块有两种匹配方式,简单匹配和复杂匹配。下面介绍一下复杂的匹配模式。
首先打开一个文章内容页面,如下图:
我们看到发布日期的格式是yyyy year MM month dd day HH:mm。如果此格式与我们之前填写的发布日期格式不一致,我们需要将此格式填写到“基本信息”选项卡“中间”的“发布日期格式”中。
然后查看网页源代码,找到收录标题、发布日期和内容的部分,如下图所示:
将收录标题和内容的 HTML 文本复制到复杂匹配块文本框,将标题替换为 ${A:Title},内容替换为 ${A:Content},发布日期替换为 ${A:PublishDate},替换后的字符串如下图所示:
接下来打开另一个文章内容页面,查看页面源代码,将标题、内容、发布日期替换为相关字符串,然后与之前的比较查找所有不一致的地方(有多余的空行)并且行前后空格数不不一致,不需要处理),用${A}代替。替换后的结果如下图所示:
这里${A}和填写URL通配符的意思是一样的,意思是任何字符都可以。
${A:TItle} 中冒号后的部分代表字段名称,采集 程序会将这个名称与数据库中的文章 表字段进行匹配。比如我们可以添加一个${A:Author}匹配符号,匹配的值就会成为文章中author字段的值。
5.填写内容过滤块
有时,内容中可能会插入一些不属于文章正文的广告等文字,需要用字符串替换,所以需要填写内容过滤块。如果不需要过滤任何文本,则无需填写此选项卡。
内容过滤块的填充规则与内容匹配块的填充规则相同。符合内容过滤阻止规则的文本将被替换为空字符串。允许填充多个过滤块,可以通过“添加过滤块”按钮添加一个新的过滤块。
比如我们发现有些页面有iframe广告,所以我们写入过滤块配置,如下图所示:
6.执行采集任务
填写完“基本信息”、“匹配块”、“过滤块”块后,点击“确定”按钮,系统会添加一个新的采集任务并显示在任务列表中,如图在下图中:
选择刚刚添加的任务,点击右侧区域的“执行任务”按钮启动采集,如下图:
如果需要采集任务定时运行,请到“系统管理”菜单下的“定时任务”子菜单配置定时任务,如下图:
7.采集 后处理
采集 完成后,系统会根据匹配块中定义的规则自动提取文章的内容和标题,并自动将提取的URL转换为文章(文章@ >状态为初稿),如下图:
任务执行完毕后,会弹出如下对话框:
表示已经全部转换为列下的文章,没有出现错误。
如果有未提取成功的网址,最后会显示未转换的网址列表,一般是因为我们在填写内容匹配块时没有考虑到某些情况(通常有一些网址不能被提取出来,除非我们特别熟悉目标网站的文章详细页面规则),这时候我们需要回去修改我们的内容匹配块。一般步骤是:
1) 从不匹配的URL中复制一份到浏览器地址栏,打开查看源码,按照填写内容的方法替换内容匹配块中的标题、发布时间、内容匹配块,并将替换的文本与内容匹配块中的差异进行比较;
2) 发现这个页面和我们原来的内容匹配块不一致。这时候我们再次查看网页源代码,修改内容匹配块以适应不一致;
3)然后点击“处理数据”按钮再次运行数据提取程序。注意此时不需要再次执行任务,因为网页已经采集到服务器了。如果您再次执行该任务,它会再次尝试下载网页。
有时可能需要多次重复此步骤以提高匹配块的兼容性。在某些特殊情况下,每个文章内容页面的结构有很大不同,可能需要创建多个采集任务将同一URL下的所有文章转移到指定的列.
同样,在某些情况下可能不考虑过滤块,导致过滤不完整,需要以类似于内容匹配块的方式进行修改。
8.采集效果
经过以上步骤后,目标网站上的文章数据就会出现在指定列下,如图:
如果勾选“下载远程图片”,图片会自动下载;如果目标网页文章中有页面,它们会自动合并为一个文章。 查看全部
网页采集器的自动识别算法(1.ZCMS中的Web采集功能采集多少个文章页)
1.Z 中的 Webcms采集
Zcms中的Web采集功能是一款简单易用、功能强大的基于模板的内容采集提取工具,支持自动采集文章列表paging,分页采集,URL重定向后自动采集内容,内容编码自动识别,网页修改日期自动识别,多线程采集,多级URL采集等功能,并支持使用代理服务器和URL过滤、内容过滤。
采集完成后,Zcms会根据匹配块中的规则提取文章的标题、内容等信息,并自动添加到指定的列中以备后续使用由编辑。
2.填写采集基本设置
切换到“数据通道”下的“From Web采集”菜单,点击“新建”按钮,添加一个新的采集任务,如下图:
在:
采集当类别为文章采集时,采集程序直接将网页转换成Zcms中的文档;如果是自定义的采集,那么只有采集数据,无需转换,需要开发程序读取采集返回的文本并进行处理。自定义采集仅用于Zcms的二次开发。
发布日期格式表示网页内容提示的发布日期格式,与JAVA中的日期格式一致,y代表年,M代表月,d代表日,h代表小时,m代表分钟,s 代表秒。
采集 如果勾选了“下载远程图片”,采集程序会自动将内容中的图片下载到Zcms服务器,并替换内容中的图片地址.
采集 如果勾选了“从内容中删除超链接”,采集 程序会自动将内容中的所有超链接转为纯文本。
采集到这一列表示采集之后的文档存放在哪一列。
采集 内容页数上限表示该任务最多采集 内容页数。
列表页中采集的最大数量表示该任务中采集文章列表页的最大数量。
采集 线程数是指同时采集的线程数。值越大,采集 速度越快,占用的带宽越多。一般1个线程就够了,不超过30个线程。
超时等待时间表示目标网页所在服务器忙时采集程序等待的秒数。默认为 30 秒,一般不应超过 120 秒。
发生错误时的重试次数表示目标服务器没有响应或有错误响应时采集程序重试的次数。
如果Zcms所在的服务器不能直接上网或者目标网页必须通过专门的代理访问,则需要勾选“使用代理服务器”选项并填写代理服务器地址、端口, 用户名和密码。
3.填写网址规则
填写完基本设置后,就可以开始填写URL规则了。以新浪新闻为例,您可以进行如下操作:
1)填写起始网址,填写新浪新闻列表页网址如下图:
2)填写下一级网址
通过观察列表页上的新闻链接,发现大部分新闻链接网址都类似如下:
我们把这个 URL 转换成 URL 通配符,如下图:
${A}/${D}.shtml
其中,${D}表示这里允许数字,${A}表示允许任意字符。
但是,有些新闻链接网址不符合此规则,例如:
我们还将这个 URL 转换为 URL 通配符,如下所示:
${A}/${D}.shtml
然后点击“添加URL级别”按钮,将上面两个URL通配符填入下一级的文本框中,如下图所示:
3)如果列表页不能直接到达文章内容页,可能需要填写多级URL。整个URL处理流程是:先采集起始URL(可以有多个起始URL),然后分析起始URL采集返回的HTML文本中的所有链接URL,一一二级别 URL 通配符比较,如果 URL 和级别 2 URL 通配符之一匹配,则为 采集。当所有符合条件的二级网址采集都完成后,再次从二级网址采集返回的HTML中提取所有链接网址,并一一比较三级网址的通配符...直到最后一级 URL。
4) 有时需要过滤掉一些URL,需要勾选“URL Filtering”选项并填写过滤表达式。这些规则类似于常见的 URL 通配符。采集 程序会将 URL 与过滤后的 URL 通配符进行比较。如果发现它匹配通配符之一,它将忽略 采集。
4.填写内容匹配块
填写完基本信息后,开始填写内容匹配块。内容匹配块有两种匹配方式,简单匹配和复杂匹配。下面介绍一下复杂的匹配模式。
首先打开一个文章内容页面,如下图:
我们看到发布日期的格式是yyyy year MM month dd day HH:mm。如果此格式与我们之前填写的发布日期格式不一致,我们需要将此格式填写到“基本信息”选项卡“中间”的“发布日期格式”中。
然后查看网页源代码,找到收录标题、发布日期和内容的部分,如下图所示:
将收录标题和内容的 HTML 文本复制到复杂匹配块文本框,将标题替换为 ${A:Title},内容替换为 ${A:Content},发布日期替换为 ${A:PublishDate},替换后的字符串如下图所示:
接下来打开另一个文章内容页面,查看页面源代码,将标题、内容、发布日期替换为相关字符串,然后与之前的比较查找所有不一致的地方(有多余的空行)并且行前后空格数不不一致,不需要处理),用${A}代替。替换后的结果如下图所示:
这里${A}和填写URL通配符的意思是一样的,意思是任何字符都可以。
${A:TItle} 中冒号后的部分代表字段名称,采集 程序会将这个名称与数据库中的文章 表字段进行匹配。比如我们可以添加一个${A:Author}匹配符号,匹配的值就会成为文章中author字段的值。
5.填写内容过滤块
有时,内容中可能会插入一些不属于文章正文的广告等文字,需要用字符串替换,所以需要填写内容过滤块。如果不需要过滤任何文本,则无需填写此选项卡。
内容过滤块的填充规则与内容匹配块的填充规则相同。符合内容过滤阻止规则的文本将被替换为空字符串。允许填充多个过滤块,可以通过“添加过滤块”按钮添加一个新的过滤块。
比如我们发现有些页面有iframe广告,所以我们写入过滤块配置,如下图所示:
6.执行采集任务
填写完“基本信息”、“匹配块”、“过滤块”块后,点击“确定”按钮,系统会添加一个新的采集任务并显示在任务列表中,如图在下图中:
选择刚刚添加的任务,点击右侧区域的“执行任务”按钮启动采集,如下图:
如果需要采集任务定时运行,请到“系统管理”菜单下的“定时任务”子菜单配置定时任务,如下图:
7.采集 后处理
采集 完成后,系统会根据匹配块中定义的规则自动提取文章的内容和标题,并自动将提取的URL转换为文章(文章@ >状态为初稿),如下图:
任务执行完毕后,会弹出如下对话框:
表示已经全部转换为列下的文章,没有出现错误。
如果有未提取成功的网址,最后会显示未转换的网址列表,一般是因为我们在填写内容匹配块时没有考虑到某些情况(通常有一些网址不能被提取出来,除非我们特别熟悉目标网站的文章详细页面规则),这时候我们需要回去修改我们的内容匹配块。一般步骤是:
1) 从不匹配的URL中复制一份到浏览器地址栏,打开查看源码,按照填写内容的方法替换内容匹配块中的标题、发布时间、内容匹配块,并将替换的文本与内容匹配块中的差异进行比较;
2) 发现这个页面和我们原来的内容匹配块不一致。这时候我们再次查看网页源代码,修改内容匹配块以适应不一致;
3)然后点击“处理数据”按钮再次运行数据提取程序。注意此时不需要再次执行任务,因为网页已经采集到服务器了。如果您再次执行该任务,它会再次尝试下载网页。
有时可能需要多次重复此步骤以提高匹配块的兼容性。在某些特殊情况下,每个文章内容页面的结构有很大不同,可能需要创建多个采集任务将同一URL下的所有文章转移到指定的列.
同样,在某些情况下可能不考虑过滤块,导致过滤不完整,需要以类似于内容匹配块的方式进行修改。
8.采集效果
经过以上步骤后,目标网站上的文章数据就会出现在指定列下,如图:
如果勾选“下载远程图片”,图片会自动下载;如果目标网页文章中有页面,它们会自动合并为一个文章。

