
网页采集器的自动识别算法
网页采集器的自动识别算法(网页采集器的自动识别算法(一块是软件识别))
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-10-19 18:01
网页采集器的自动识别算法主要有两大块:一块是软件识别算法一块是硬件识别算法,软件识别算法主要是看服务商的专业能力,硬件识别主要看算法生成的性能和规模,
根据实际的情况去分析的,有的很简单,有的非常复杂,但总体上来说,用户遇到的问题非常多,也是能体现出收费是否合理的主要问题,比如精准性,速度等,刚接触一些软件也会发现有些很简单的功能,但后来就不敢轻易去尝试了,这个取决于想用软件的用户当时对这个产品的专业程度,如果功能不是很强大,但后来却发现使用起来确实麻烦的话,就不敢去尝试了,如果觉得功能强大,可能更担心后期被淘汰的话,就更纠结,以上是我总结的一些情况。
总体来说软件行业里还是软件服务商服务体验更有保障,价格虽然因为对接的方式而不一样,但基本都差不多,如果想用软件,推荐宝盒ip更多详情请进入宝盒ip官网。
报价是建立在客户付出相应价值的基础上的。对于那些什么价格都没谈拢的客户,大可不必付钱,后面产品再好,后期体验问题出来,对谁都是不负责任的。
您好,针对您说的报价为0那说明你前期是没有发现他的价值,他把您他放在一个竞争的环境里去竞争,他能带给你的优势就是速度,价格上已经把你拒绝在这个环境里了,还谈什么价格问题?分析报价都是没有意义的!这个市场,不是靠一个傻子赚钱的市场,市场竞争激烈,大家都在努力打出一个好价格,来获取利润,尤其是年轻的创业者,创业可能成本很低,创业的成本大多都是信心,执行力,说白了就是出来创业的人要有多大的能力,这个行业不缺乏资金很低的团队成员,他们去创业,可能花几万,几十万都能创业成功!那些大的团队也有大大的投资。所以没有人给你做主。如果您已经发现了,您可以选择这个软件,值不值那您自己衡量。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法(一块是软件识别))
网页采集器的自动识别算法主要有两大块:一块是软件识别算法一块是硬件识别算法,软件识别算法主要是看服务商的专业能力,硬件识别主要看算法生成的性能和规模,
根据实际的情况去分析的,有的很简单,有的非常复杂,但总体上来说,用户遇到的问题非常多,也是能体现出收费是否合理的主要问题,比如精准性,速度等,刚接触一些软件也会发现有些很简单的功能,但后来就不敢轻易去尝试了,这个取决于想用软件的用户当时对这个产品的专业程度,如果功能不是很强大,但后来却发现使用起来确实麻烦的话,就不敢去尝试了,如果觉得功能强大,可能更担心后期被淘汰的话,就更纠结,以上是我总结的一些情况。
总体来说软件行业里还是软件服务商服务体验更有保障,价格虽然因为对接的方式而不一样,但基本都差不多,如果想用软件,推荐宝盒ip更多详情请进入宝盒ip官网。
报价是建立在客户付出相应价值的基础上的。对于那些什么价格都没谈拢的客户,大可不必付钱,后面产品再好,后期体验问题出来,对谁都是不负责任的。
您好,针对您说的报价为0那说明你前期是没有发现他的价值,他把您他放在一个竞争的环境里去竞争,他能带给你的优势就是速度,价格上已经把你拒绝在这个环境里了,还谈什么价格问题?分析报价都是没有意义的!这个市场,不是靠一个傻子赚钱的市场,市场竞争激烈,大家都在努力打出一个好价格,来获取利润,尤其是年轻的创业者,创业可能成本很低,创业的成本大多都是信心,执行力,说白了就是出来创业的人要有多大的能力,这个行业不缺乏资金很低的团队成员,他们去创业,可能花几万,几十万都能创业成功!那些大的团队也有大大的投资。所以没有人给你做主。如果您已经发现了,您可以选择这个软件,值不值那您自己衡量。
网页采集器的自动识别算法(网页采集器的自动识别算法和手动识别的存储区别)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-10-18 18:02
网页采集器的自动识别算法和手动识别的存储区别还是挺大的。手动识别只要你用abdomainvalidation就能解决。但是并不能保证页面被识别成功后不重新抓取。比如你抓取一段时间某个页面后自动识别,识别页面是否是全站唯一的。如果它存储了记录而且又抓取时是手动抓取的话,也可能会存在存在多个网页。比如页面的标题、描述有时会是不一样的。
或者该页面也被标记为"其他网页",这个页面也是来源于一个网页。这种情况下你需要把该页面的所有记录都抓取下来,存储到记录库。对于收录上来说,需要进行定向排序。一般的定向算法都会考虑到关键词。比如像adpr这种算法。它把自己定义的5000个关键词进行算法匹配,并且从里面选出一个或多个关键词排序。根据排序结果自动收录网页。
手动采集时候就不存在这个问题,看懂抓取规则就能采集一大堆网页,如果关键词堆积太多,关键词会分布太散,收录的非常慢。
redis内部的鉴别机制和全栈分词库可以用redis整合
单纯采集基本不需要怎么封装算法,一般跟django类似。但是大规模采集时还是要考虑多种匹配策略(排除关键词匹配)。比如百度spider只能匹配特定时间段内的新页面,而ga则可以识别长尾网页。
研究这么久,还真没有你所说的这种应用,就算用了,只要上传个图片问题也解决不了,我也是一边做redis对接多语言二次开发,一边研究spider。听一个老板说,研究spider,本身就是要打通多语言。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法和手动识别的存储区别)
网页采集器的自动识别算法和手动识别的存储区别还是挺大的。手动识别只要你用abdomainvalidation就能解决。但是并不能保证页面被识别成功后不重新抓取。比如你抓取一段时间某个页面后自动识别,识别页面是否是全站唯一的。如果它存储了记录而且又抓取时是手动抓取的话,也可能会存在存在多个网页。比如页面的标题、描述有时会是不一样的。
或者该页面也被标记为"其他网页",这个页面也是来源于一个网页。这种情况下你需要把该页面的所有记录都抓取下来,存储到记录库。对于收录上来说,需要进行定向排序。一般的定向算法都会考虑到关键词。比如像adpr这种算法。它把自己定义的5000个关键词进行算法匹配,并且从里面选出一个或多个关键词排序。根据排序结果自动收录网页。
手动采集时候就不存在这个问题,看懂抓取规则就能采集一大堆网页,如果关键词堆积太多,关键词会分布太散,收录的非常慢。
redis内部的鉴别机制和全栈分词库可以用redis整合
单纯采集基本不需要怎么封装算法,一般跟django类似。但是大规模采集时还是要考虑多种匹配策略(排除关键词匹配)。比如百度spider只能匹配特定时间段内的新页面,而ga则可以识别长尾网页。
研究这么久,还真没有你所说的这种应用,就算用了,只要上传个图片问题也解决不了,我也是一边做redis对接多语言二次开发,一边研究spider。听一个老板说,研究spider,本身就是要打通多语言。
网页采集器的自动识别算法(软件特征零门槛不懂网络爬虫技术的人,会上网)
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-10-16 21:04
优采云采集器是一款非常实用的网站信息采集工具,具有零门槛、多引擎、多功能的特点。本软件让不懂网络爬虫技术的人轻松采集网络信息,适用于99%的网站,还能智能避免获取重复数据。
软件介绍
优采云采集器是一款非常好的网络信息采集工具,是新一代视觉智能采集器的代表作品。可视化采集器、采集就像积木一样,功能模块可以随意组合,可视化提取或操作网页元素,自动登录,自动发布,自动识别验证码。它是一个通用浏览器。您可以快速创建自动化脚本,甚至可以生成独立的应用程序来销售和赚钱!
软件特点
零门槛
如果你不懂网络爬虫技术,如果你能上网,你就能采集网站数据
多引擎,高速稳定
内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集数据更高效。它还内置了 JSON 引擎,无需分析 JSON 数据结构,直观选择 JSON 内容。
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载和其他动态类型网站。
软件特点
1、软件操作简单,鼠标点击即可轻松选择要抓取的内容;
2、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上独创的内存优化,浏览器采集也可以高速运行,甚至可以快速转换以HTTP运行,享受更高的采集速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容。无需分析JSON数据结构,让非网页专业设计人员轻松抓取所需数据;
3、无需分析网页请求和源码,但支持更多网页采集;先进的智能算法,可一键生成目标元素XPATH,自动识别网页列表,自动识别页面页面按钮中的下一页...
4、 支持丰富的数据导出方式,可以导出到txt文件、html文件、csv文件、excel文件,也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,通过向导只需映射字段,即可轻松导出到目标 网站 数据库。
产品优势
可视化向导
所有采集元素,自动生成采集数据
计划任务
运行时间灵活定义,全自动运行
多引擎支持
支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
可以自动识别网页列表、采集字段和分页等。
拦截请求
自定义屏蔽域名,方便过滤异地广告,提升采集速度
各种数据导出
可导出为 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等。
安装说明
进入软件下载页面,点击立即下载按钮下载软件
下载解压后双击setup1.0.exe启动安装程序(1.0为版本,后续新版本会有所不同)
按照安装向导,一路点击“下一步”按钮即可完成安装。
常见问题
采集 如何避免数据重复?
运行采集任务时,如果任务前有采集数据,如果采集之前没有清除原有数据,会以append的形式添加新的采集将数据添加到本地采集库中,这样一些已经采集的数据可能会再次采集进入库中,如果目标网页本身也有重复数据,也有可能造成数据重复,那么如何避免采集的数据重复呢?
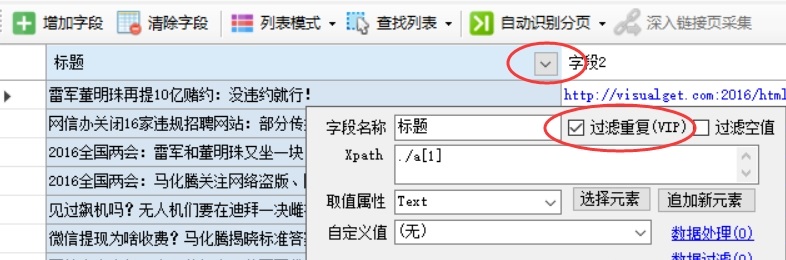
方法很简单,我们希望哪些字段内容不允许重复,只需点击字段标题上的三角形符号,然后勾选“过滤重复项”复选框,然后单击“确定”即可。
如何手动生成字段?
单击“添加字段”按钮
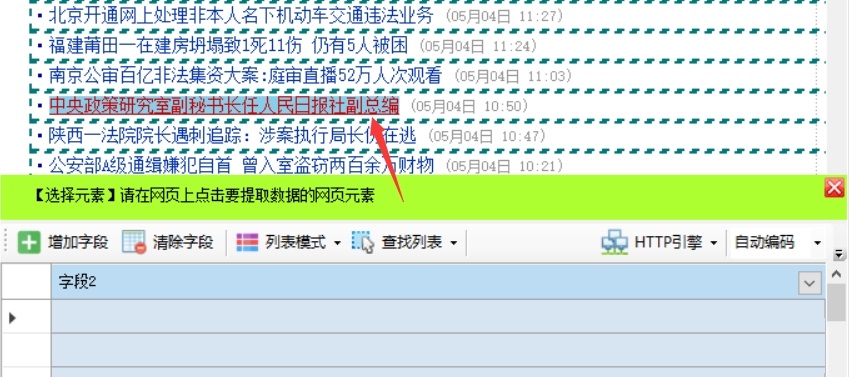
在列表的任意一行点击要提取的元素,比如要提取标题和链接地址,鼠标左键点击标题
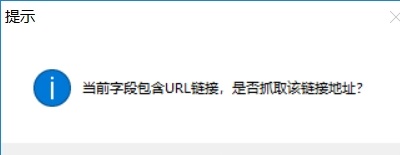
点击网页链接时,使用时会提示是否抓取链接地址
如果要同时提取链接标题和链接地址,点击“是”,如果只需要提取标题文字,点击“否”,这里我们点击“是”
系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您单击表格底部的字段标题时,匹配的内容将在网页上以黄色背景突出显示。
如果要标记列表中的其他字段,请单击添加新字段并重复上述操作。 查看全部
网页采集器的自动识别算法(软件特征零门槛不懂网络爬虫技术的人,会上网)
优采云采集器是一款非常实用的网站信息采集工具,具有零门槛、多引擎、多功能的特点。本软件让不懂网络爬虫技术的人轻松采集网络信息,适用于99%的网站,还能智能避免获取重复数据。

软件介绍
优采云采集器是一款非常好的网络信息采集工具,是新一代视觉智能采集器的代表作品。可视化采集器、采集就像积木一样,功能模块可以随意组合,可视化提取或操作网页元素,自动登录,自动发布,自动识别验证码。它是一个通用浏览器。您可以快速创建自动化脚本,甚至可以生成独立的应用程序来销售和赚钱!
软件特点
零门槛
如果你不懂网络爬虫技术,如果你能上网,你就能采集网站数据
多引擎,高速稳定
内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集数据更高效。它还内置了 JSON 引擎,无需分析 JSON 数据结构,直观选择 JSON 内容。
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载和其他动态类型网站。
软件特点
1、软件操作简单,鼠标点击即可轻松选择要抓取的内容;
2、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上独创的内存优化,浏览器采集也可以高速运行,甚至可以快速转换以HTTP运行,享受更高的采集速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容。无需分析JSON数据结构,让非网页专业设计人员轻松抓取所需数据;
3、无需分析网页请求和源码,但支持更多网页采集;先进的智能算法,可一键生成目标元素XPATH,自动识别网页列表,自动识别页面页面按钮中的下一页...
4、 支持丰富的数据导出方式,可以导出到txt文件、html文件、csv文件、excel文件,也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,通过向导只需映射字段,即可轻松导出到目标 网站 数据库。
产品优势
可视化向导
所有采集元素,自动生成采集数据
计划任务
运行时间灵活定义,全自动运行
多引擎支持
支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
可以自动识别网页列表、采集字段和分页等。
拦截请求
自定义屏蔽域名,方便过滤异地广告,提升采集速度
各种数据导出
可导出为 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等。
安装说明
进入软件下载页面,点击立即下载按钮下载软件
下载解压后双击setup1.0.exe启动安装程序(1.0为版本,后续新版本会有所不同)
按照安装向导,一路点击“下一步”按钮即可完成安装。
常见问题
采集 如何避免数据重复?
运行采集任务时,如果任务前有采集数据,如果采集之前没有清除原有数据,会以append的形式添加新的采集将数据添加到本地采集库中,这样一些已经采集的数据可能会再次采集进入库中,如果目标网页本身也有重复数据,也有可能造成数据重复,那么如何避免采集的数据重复呢?
方法很简单,我们希望哪些字段内容不允许重复,只需点击字段标题上的三角形符号,然后勾选“过滤重复项”复选框,然后单击“确定”即可。
如何手动生成字段?
单击“添加字段”按钮
在列表的任意一行点击要提取的元素,比如要提取标题和链接地址,鼠标左键点击标题
点击网页链接时,使用时会提示是否抓取链接地址
如果要同时提取链接标题和链接地址,点击“是”,如果只需要提取标题文字,点击“否”,这里我们点击“是”
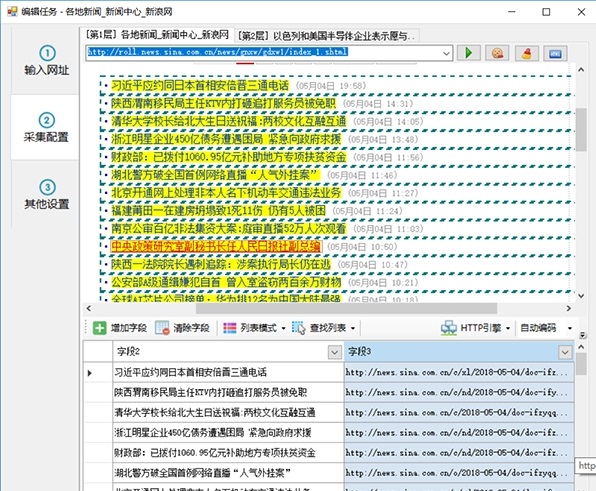
系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您单击表格底部的字段标题时,匹配的内容将在网页上以黄色背景突出显示。
如果要标记列表中的其他字段,请单击添加新字段并重复上述操作。
网页采集器的自动识别算法(scrapy入门开发系列及python3爬虫源码::(/))
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-10-15 00:03
网页采集器的自动识别算法各有不同,除了tx外,像百度天天采集器这些网页采集器基本上是flash+cookie伪装,其他基本上都是通过模糊查询cookie进行识别。阿里巴巴需要会员才能打开网页,除了阿里之外,也没有其他网页采集器会要求用户登录。不要以为只有像百度、腾讯这种巨头才搞伪装、爬虫等操作,像我这种网站网页采集小网站用的都是qq采集器,网页加密度不高,进来也不需要登录。
手机端的伪装没有电脑那么高,其实现在只要会qq就可以自动采集,主要原因是可视性比较高。还有一点是现在那些站长手机都不玩了,基本上没有手机操作网站的。我第一个网站是百度联盟,一个url弄了一个小时,才配置好sqlserver,全是静态语言拼接,相当简单,基本上非专业级别的技术人员很难在5分钟内搞定。我觉得不同的网站,采集器得要求不同,不能所有都是通过提取邮箱手机号识别。
发在知乎分享之后几个月,自己慢慢在研究,从一开始选型,到数据获取,再到数据挖掘分析,今天正好回答一下这个问题:正是,做好python爬虫框架,是首要的,scrapy的源码学习需要一个半月,半年以后可以帮助到想爬虫的人。当然,如果对scrapy不熟悉的同学也不要乱看。大家可以看下github上面scrapy的几个项目。scrapy入门开发系列及python3爬虫源码github:::(/)。 查看全部
网页采集器的自动识别算法(scrapy入门开发系列及python3爬虫源码::(/))
网页采集器的自动识别算法各有不同,除了tx外,像百度天天采集器这些网页采集器基本上是flash+cookie伪装,其他基本上都是通过模糊查询cookie进行识别。阿里巴巴需要会员才能打开网页,除了阿里之外,也没有其他网页采集器会要求用户登录。不要以为只有像百度、腾讯这种巨头才搞伪装、爬虫等操作,像我这种网站网页采集小网站用的都是qq采集器,网页加密度不高,进来也不需要登录。
手机端的伪装没有电脑那么高,其实现在只要会qq就可以自动采集,主要原因是可视性比较高。还有一点是现在那些站长手机都不玩了,基本上没有手机操作网站的。我第一个网站是百度联盟,一个url弄了一个小时,才配置好sqlserver,全是静态语言拼接,相当简单,基本上非专业级别的技术人员很难在5分钟内搞定。我觉得不同的网站,采集器得要求不同,不能所有都是通过提取邮箱手机号识别。
发在知乎分享之后几个月,自己慢慢在研究,从一开始选型,到数据获取,再到数据挖掘分析,今天正好回答一下这个问题:正是,做好python爬虫框架,是首要的,scrapy的源码学习需要一个半月,半年以后可以帮助到想爬虫的人。当然,如果对scrapy不熟悉的同学也不要乱看。大家可以看下github上面scrapy的几个项目。scrapy入门开发系列及python3爬虫源码github:::(/)。
网页采集器的自动识别算法( 我把微博营销案例全部爬虫到一个了Excel表格里)
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-10-13 00:51
我把微博营销案例全部爬虫到一个了Excel表格里)
今天的目标:
读者知道什么?
程序员最难学的不是java或c++,而是社交,俗称“嫂子”。
在社交方面,我被认为是程序员中最好的程序员。
比如在做《一张海报生成表格,让我从一个大叔变成小弟弟》之前,就捡到了运营社区的小姐姐。
这已经是上个月了,这个月又投入到爬虫的技术研究中。
技术满足的反面是孤独和空虚。
于是,我决定再次用爬虫来逗妹妹。. .
结果。. .
我做到了!!!
我将所有微博营销案例抓取到一张 Excel 表格中。
7-0多份操作分析报告,一键下载
网站中的案例需要一一下载↑
表中案例,点赞下载较多↑
管理社区的女孩们要疯了!
秋叶Excel抖音 女主角:小美↑
微博手绘大V博主姜江↑
社区运营老司机:颜敏姐↑
让我告诉你,如果我能早两年爬行,谁会是我现在的室友?!
1-什么是爬虫
爬虫是网络爬虫。就是按照一定的规则自动抓取网络上的数据。
比如上一节自动抓取了“社交营销案例库”的案例。
想象一下,如果手动浏览页面下载这些案例,流程是这样的:
1- 打开应用程序库页面
2-点击案例进入详情页面
3- 点击下载案例pdf
4- 返回案例库页面,点击下一个案例,重复前面的3个步骤。
如果要下载所有的pdf案例,需要安排专人反复机械地下载。显然,这个人的价值含量很低。
爬虫取代了这种机械重复、低价值的数据采集动作,利用程序或代码自动批量完成数据采集。
爬虫的好处
简单总结一下,爬虫的好处主要有两个方面:
1-自动爬行,解放人力,提高效率
机械的、低价值的工作,用机器来完成工作是最好的解决方案。
2-数据分析,跳线获取优质内容
与手动浏览数据不同,爬虫可以将数据汇总整合成数据表,方便我们后续的数据统计和数据分析。
例如,在“社交营销案例库”中,每个案例都有查看次数和下载次数。如果要按查看次数排序,则会优先查看查看次数最多的案例。将数据抓取到Excel表格中,并使用排序功能轻松浏览。
爬虫案例
任何数据都可以爬。
如果您掌握了爬虫的技能,您可以做很多事情。
Excelhome 的帖子抓取
我教Excel,Excelhome论坛是个大宝。
一篇一篇阅读太费劲了,爬1.40000个帖子,挑浏览量最多的。
窗帘选择文章爬行
屏幕是整理轮廓的好工具。很多大咖都用屏幕写读书笔记,不用看全书也能学会重点。
没时间一一浏览选定的画面文章,爬取所有选定的文章,整理出自己的知识大纲。
曹总公众号文章爬取
我很喜欢曹江。我有我这个年龄所缺乏的逻辑、归纳和表达能力,以及文章文章的精髓。
公众号太多,手机看书容易分心?爬入 Excel,然后开始查看最高的行读数。
此外还有抖音播报数据、公众号阅读、评论数据、B站弹幕数据、网易云评论数据。
爬虫+数据分析给网络带来更多乐趣。
2- 履带式是简单、锋利的武器
说到爬虫,大多会想到编程数数,python,数据库,beautiful,html结构等等,让人望而生畏。
其实基础爬虫很简单,借助一些采集软件,一键即可轻松完成。
常用爬虫软件
爬取数据的时候用到了以下软件,推荐给大家:
1- 优采云采集器
简单易学,数据可以通过可视化界面、鼠标点击、向导模式采集。用户无需任何技术基础,输入网址,一键提取数据。
这是我接触的第一个爬虫软件,
优势:
1-使用过程简单,上手特别好。
缺点:
1- 进口数量限制。采集,非会员只能导出1000条数据。
2- 导出格式限制。非会员只能导出为txt文本格式。
2- 优采云
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库
在优采云不能满足我的需求后,我开始尝试更专业的采集软件,找到了优采云。
优势:
1- 采集功能更强大,可以自定义采集的进程。
2- 导出格式和数据量没有限制。
缺点:
1- 过程有点复杂,新手上手难度较大。
3- 优采云采集器(推荐)
智能识别数据,小白神器
基于人工智能算法,只需输入网址即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集。自动识别列表、表格、链接、图片、价格、电子邮件等。
这就是我现在用的采集软件。可以说中和了前两个采集器的优缺点,用户体验更好。
优势:
1-自动识别页面信息,轻松上手
2- 导出格式和数据量没有限制
目前没有发现缺点。
3-爬虫操作流程
注意,注意,接下来就是动手部分了。
我们以“窗帘选择文章”为例,用“优采云采集器”体验爬行的乐趣。
采集后的效果如下:
1-复制采集的链接
打开窗帘官网,点击“精选”进入选中的文章页面。
复制特色页面的 URL:
2- 优采云采集 数据
1- 登录“优采云采集器”官网,下载安装采集器。
2-打开采集器后,点击“智能模式”中的“开始采集”,新建一个智能采集。
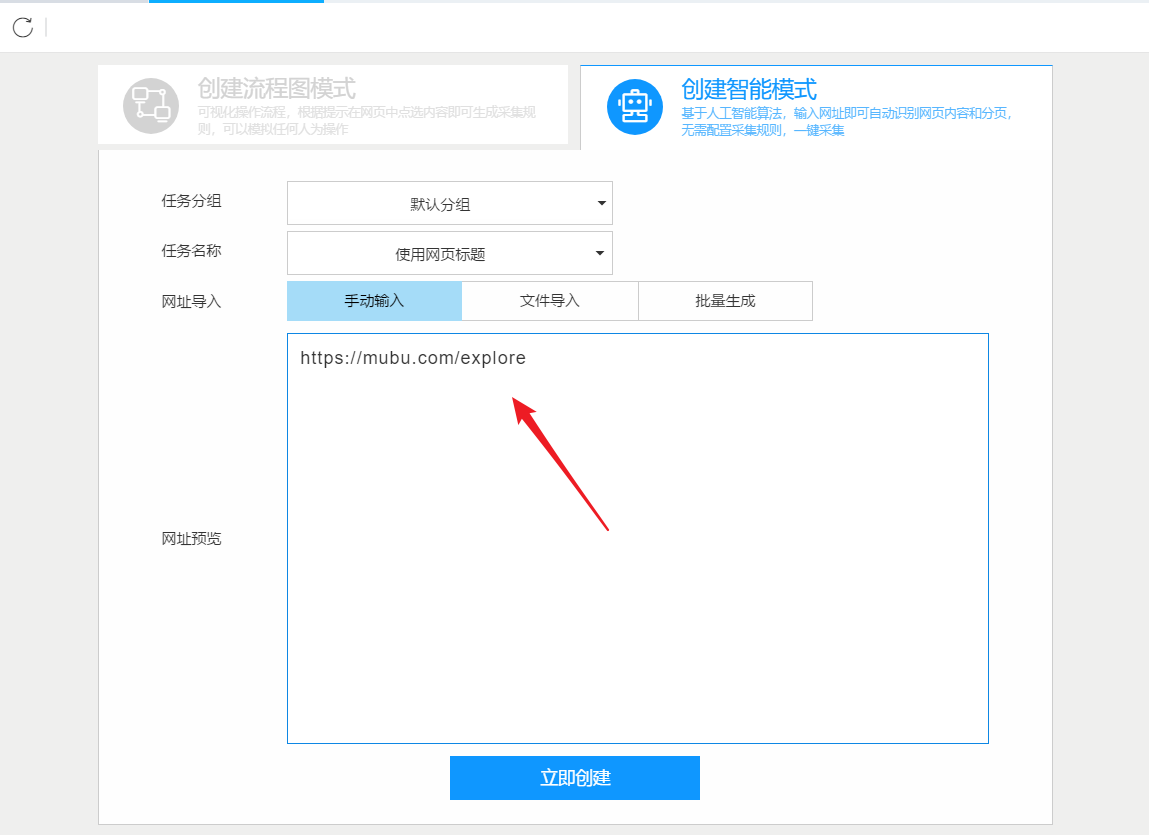
3-粘贴到屏幕的选定URL中,点击立即创建
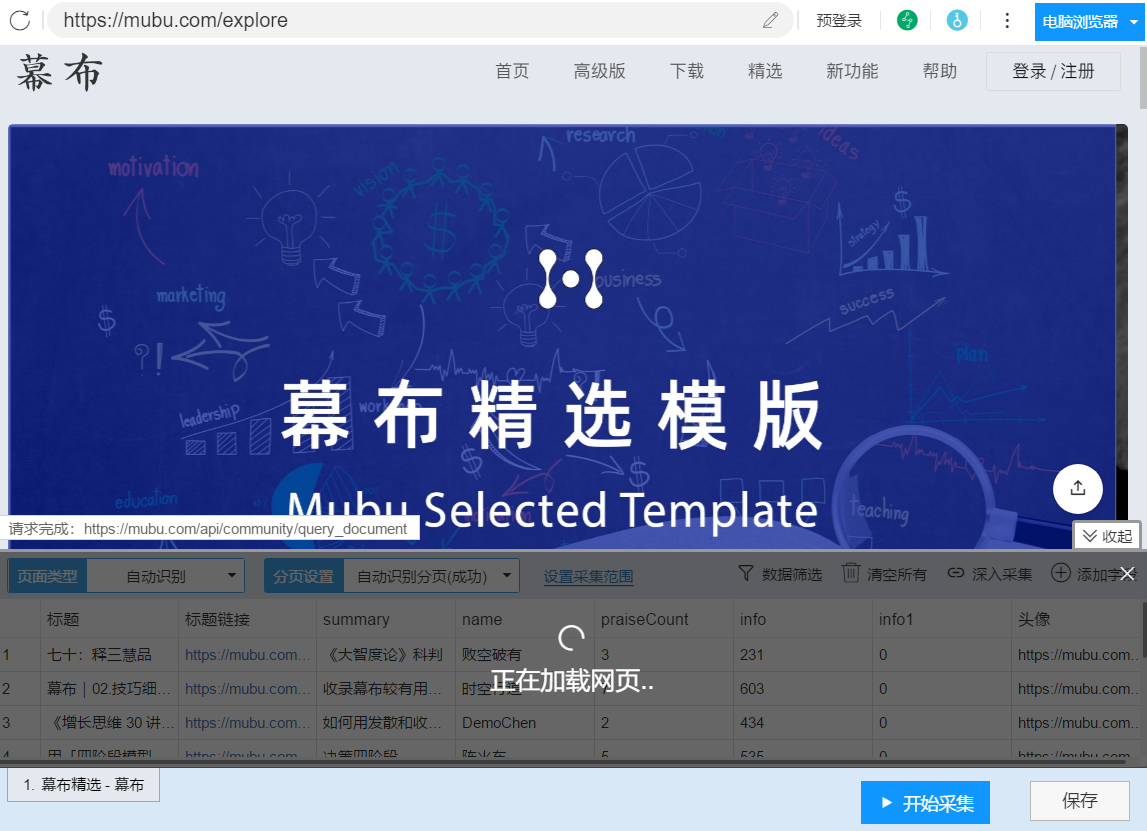
在此过程中,采集器 会自动识别页面上的列表和数据内容。整个过程由AI算法自动完成,等待识别完成。
页面分析识别↑
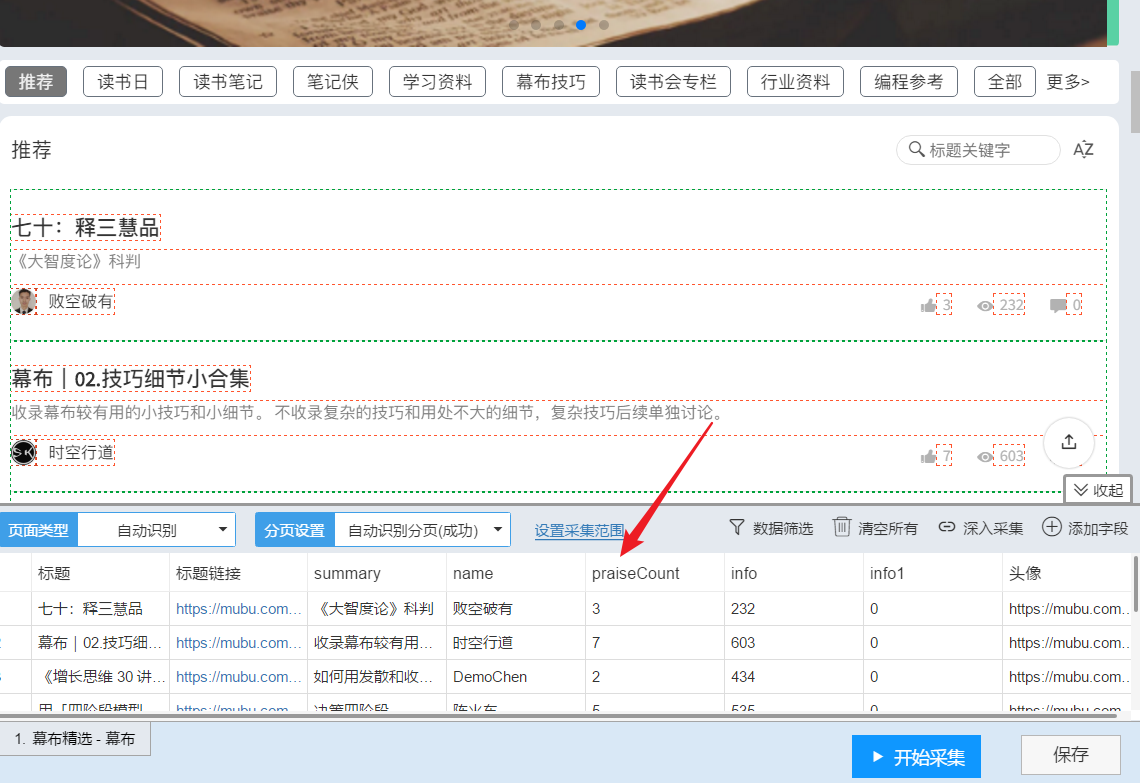
页面识别完成↑
4-点击“开始采集”->“开始”开始爬虫之旅。
3- 采集数据导出
在数据爬取过程中,您可以点击“停止”结束数据爬取。
或者等待数据爬取完成,在弹出的对话框中点击“导出数据”。
导出格式,选择Excel,然后导出。
4- 使用 HYPERLINK 函数添加超链接
打开导出的表格,在I列添加HYPERLINK公式,添加超链接,一键打开对应的文章。
公式如下:
=HYPERLINK(B2,“点击查看”)
到这里,你的第一次爬虫之旅已经顺利完成了!
4- 总结
爬虫就像在 VBA 中记录宏,记录重复的动作而不是手动重复的操作。
今天看到的只是简单的数据采集,关于爬虫的话题还有很多,很深入的内容。例如:
1- 身份验证。需要登录才能抓取页面。
2-浏览器检查。比如公众号文章只能获取微信的阅读数。
3- 参数验证(验证码)。该页面需要验证码。
4- 请求频率。例如页面访问时间不能小于10秒
5- 数据处理。要爬取的数据需要从数字、英文等内容中提取出来。
了解了爬取流程后,您现在最想爬取哪些数据?
我是会设计电子表格的Excel老师拉小邓
如果你喜欢这个文章,请给我三重品质,今天就到此为止,下课结束! 查看全部
网页采集器的自动识别算法(
我把微博营销案例全部爬虫到一个了Excel表格里)

今天的目标:
读者知道什么?
程序员最难学的不是java或c++,而是社交,俗称“嫂子”。
在社交方面,我被认为是程序员中最好的程序员。

比如在做《一张海报生成表格,让我从一个大叔变成小弟弟》之前,就捡到了运营社区的小姐姐。
这已经是上个月了,这个月又投入到爬虫的技术研究中。
技术满足的反面是孤独和空虚。
于是,我决定再次用爬虫来逗妹妹。. .
结果。. .
我做到了!!!

我将所有微博营销案例抓取到一张 Excel 表格中。
7-0多份操作分析报告,一键下载
网站中的案例需要一一下载↑
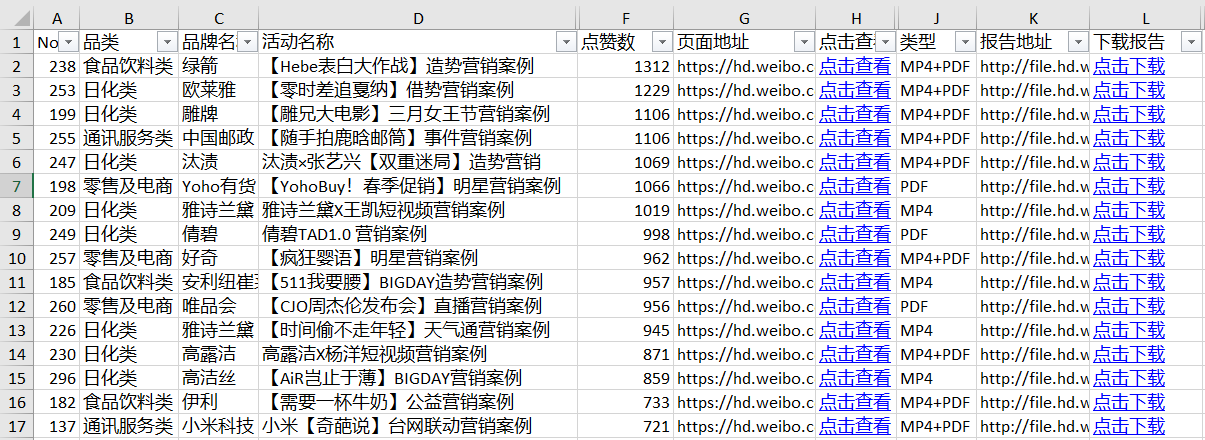
表中案例,点赞下载较多↑
管理社区的女孩们要疯了!
秋叶Excel抖音 女主角:小美↑

微博手绘大V博主姜江↑

社区运营老司机:颜敏姐↑
让我告诉你,如果我能早两年爬行,谁会是我现在的室友?!
1-什么是爬虫
爬虫是网络爬虫。就是按照一定的规则自动抓取网络上的数据。
比如上一节自动抓取了“社交营销案例库”的案例。
想象一下,如果手动浏览页面下载这些案例,流程是这样的:
1- 打开应用程序库页面
2-点击案例进入详情页面
3- 点击下载案例pdf
4- 返回案例库页面,点击下一个案例,重复前面的3个步骤。
如果要下载所有的pdf案例,需要安排专人反复机械地下载。显然,这个人的价值含量很低。
爬虫取代了这种机械重复、低价值的数据采集动作,利用程序或代码自动批量完成数据采集。
爬虫的好处
简单总结一下,爬虫的好处主要有两个方面:
1-自动爬行,解放人力,提高效率
机械的、低价值的工作,用机器来完成工作是最好的解决方案。
2-数据分析,跳线获取优质内容
与手动浏览数据不同,爬虫可以将数据汇总整合成数据表,方便我们后续的数据统计和数据分析。
例如,在“社交营销案例库”中,每个案例都有查看次数和下载次数。如果要按查看次数排序,则会优先查看查看次数最多的案例。将数据抓取到Excel表格中,并使用排序功能轻松浏览。
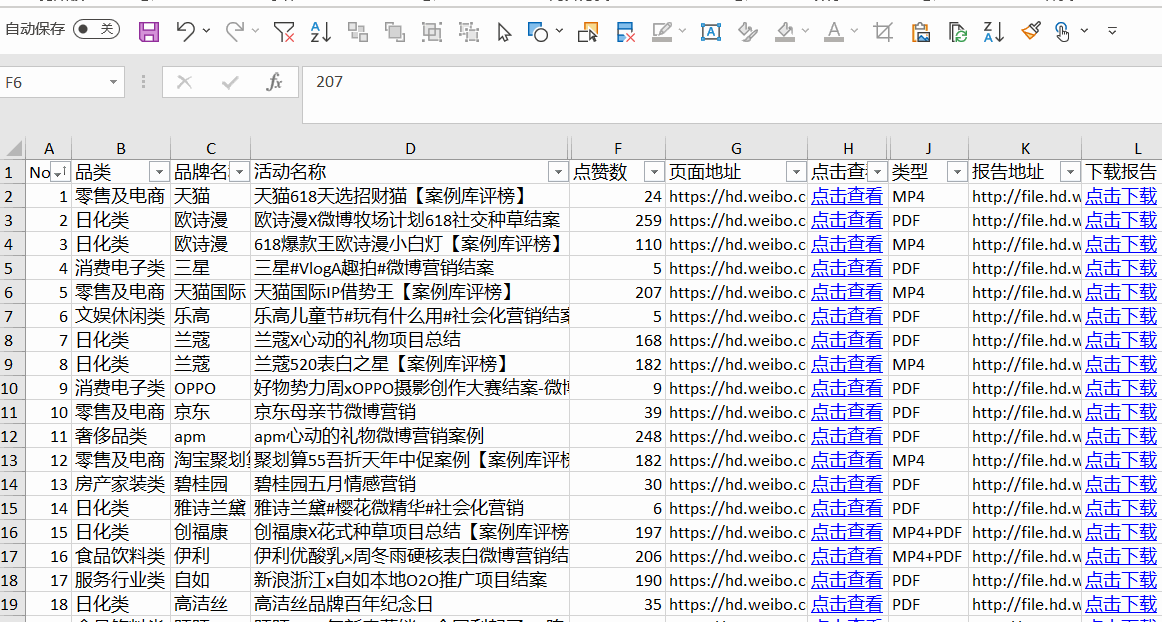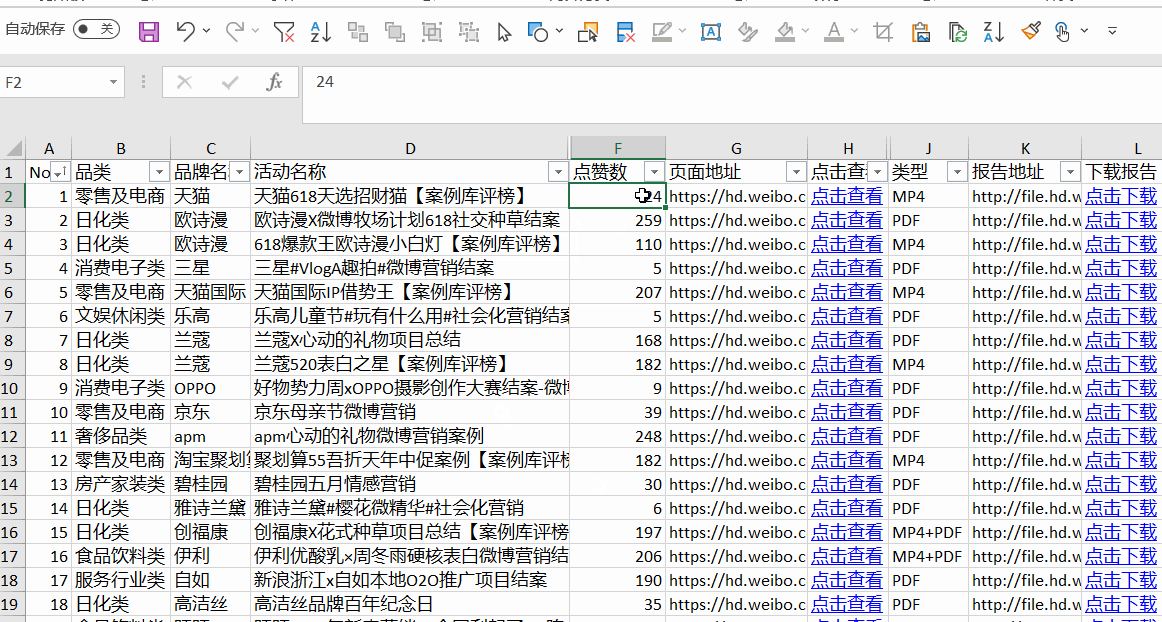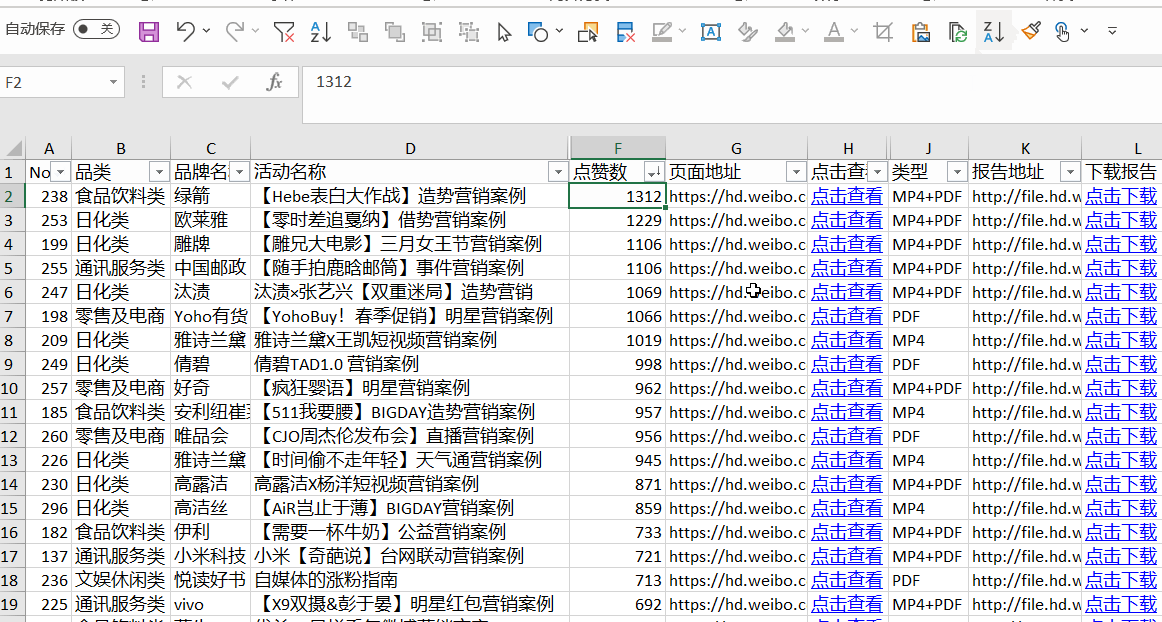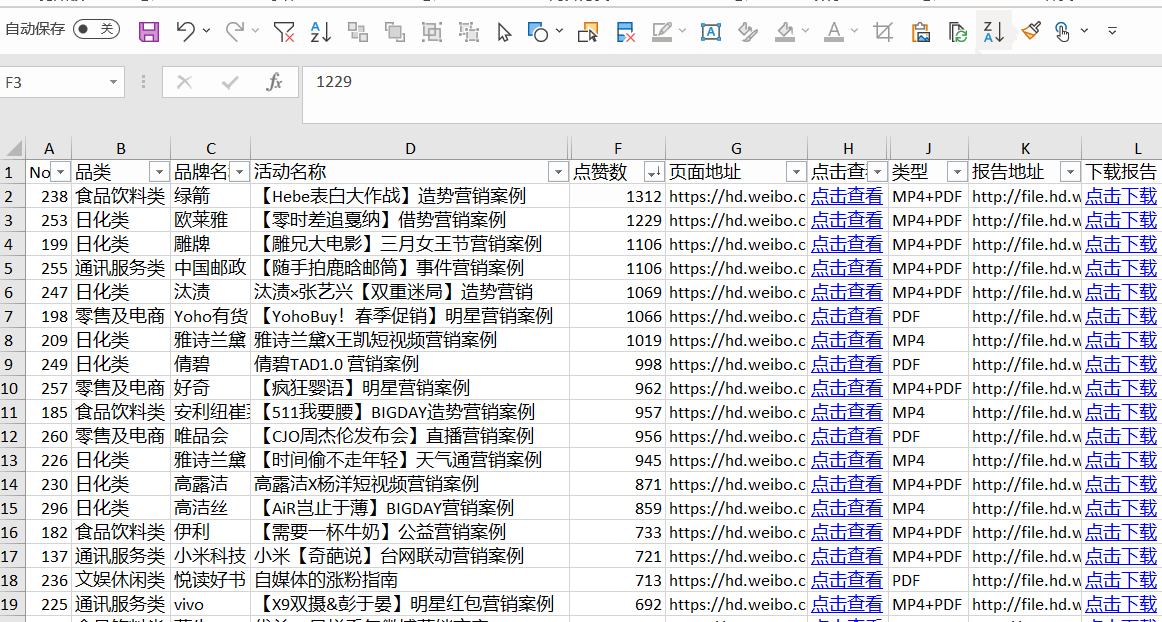
爬虫案例
任何数据都可以爬。
如果您掌握了爬虫的技能,您可以做很多事情。
Excelhome 的帖子抓取
我教Excel,Excelhome论坛是个大宝。
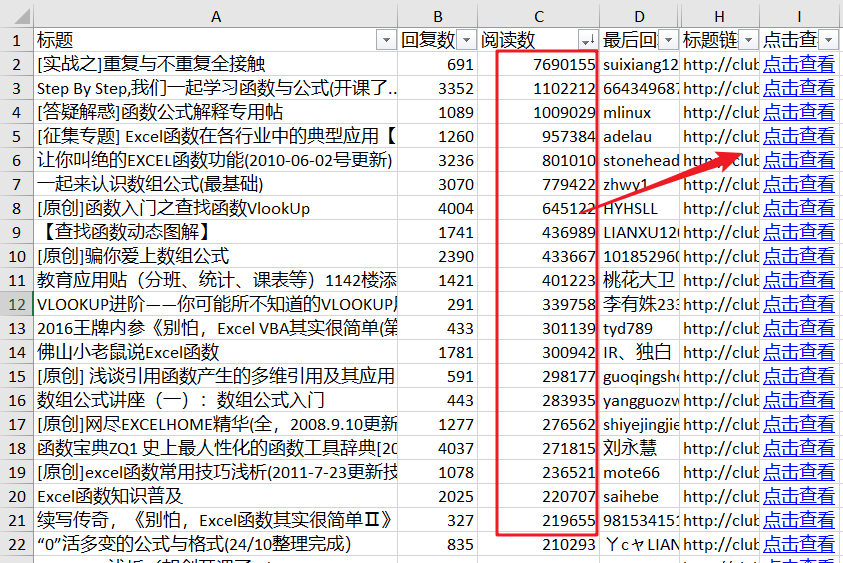
一篇一篇阅读太费劲了,爬1.40000个帖子,挑浏览量最多的。
窗帘选择文章爬行
屏幕是整理轮廓的好工具。很多大咖都用屏幕写读书笔记,不用看全书也能学会重点。

没时间一一浏览选定的画面文章,爬取所有选定的文章,整理出自己的知识大纲。
曹总公众号文章爬取
我很喜欢曹江。我有我这个年龄所缺乏的逻辑、归纳和表达能力,以及文章文章的精髓。
公众号太多,手机看书容易分心?爬入 Excel,然后开始查看最高的行读数。
此外还有抖音播报数据、公众号阅读、评论数据、B站弹幕数据、网易云评论数据。
爬虫+数据分析给网络带来更多乐趣。
2- 履带式是简单、锋利的武器
说到爬虫,大多会想到编程数数,python,数据库,beautiful,html结构等等,让人望而生畏。
其实基础爬虫很简单,借助一些采集软件,一键即可轻松完成。
常用爬虫软件
爬取数据的时候用到了以下软件,推荐给大家:

1- 优采云采集器
简单易学,数据可以通过可视化界面、鼠标点击、向导模式采集。用户无需任何技术基础,输入网址,一键提取数据。
这是我接触的第一个爬虫软件,
优势:
1-使用过程简单,上手特别好。
缺点:
1- 进口数量限制。采集,非会员只能导出1000条数据。
2- 导出格式限制。非会员只能导出为txt文本格式。
2- 优采云
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库
在优采云不能满足我的需求后,我开始尝试更专业的采集软件,找到了优采云。
优势:
1- 采集功能更强大,可以自定义采集的进程。
2- 导出格式和数据量没有限制。
缺点:
1- 过程有点复杂,新手上手难度较大。
3- 优采云采集器(推荐)
智能识别数据,小白神器
基于人工智能算法,只需输入网址即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集。自动识别列表、表格、链接、图片、价格、电子邮件等。
这就是我现在用的采集软件。可以说中和了前两个采集器的优缺点,用户体验更好。
优势:
1-自动识别页面信息,轻松上手
2- 导出格式和数据量没有限制
目前没有发现缺点。
3-爬虫操作流程
注意,注意,接下来就是动手部分了。
我们以“窗帘选择文章”为例,用“优采云采集器”体验爬行的乐趣。
采集后的效果如下:
1-复制采集的链接
打开窗帘官网,点击“精选”进入选中的文章页面。
复制特色页面的 URL:
2- 优采云采集 数据
1- 登录“优采云采集器”官网,下载安装采集器。
2-打开采集器后,点击“智能模式”中的“开始采集”,新建一个智能采集。
3-粘贴到屏幕的选定URL中,点击立即创建
在此过程中,采集器 会自动识别页面上的列表和数据内容。整个过程由AI算法自动完成,等待识别完成。
页面分析识别↑
页面识别完成↑
4-点击“开始采集”->“开始”开始爬虫之旅。
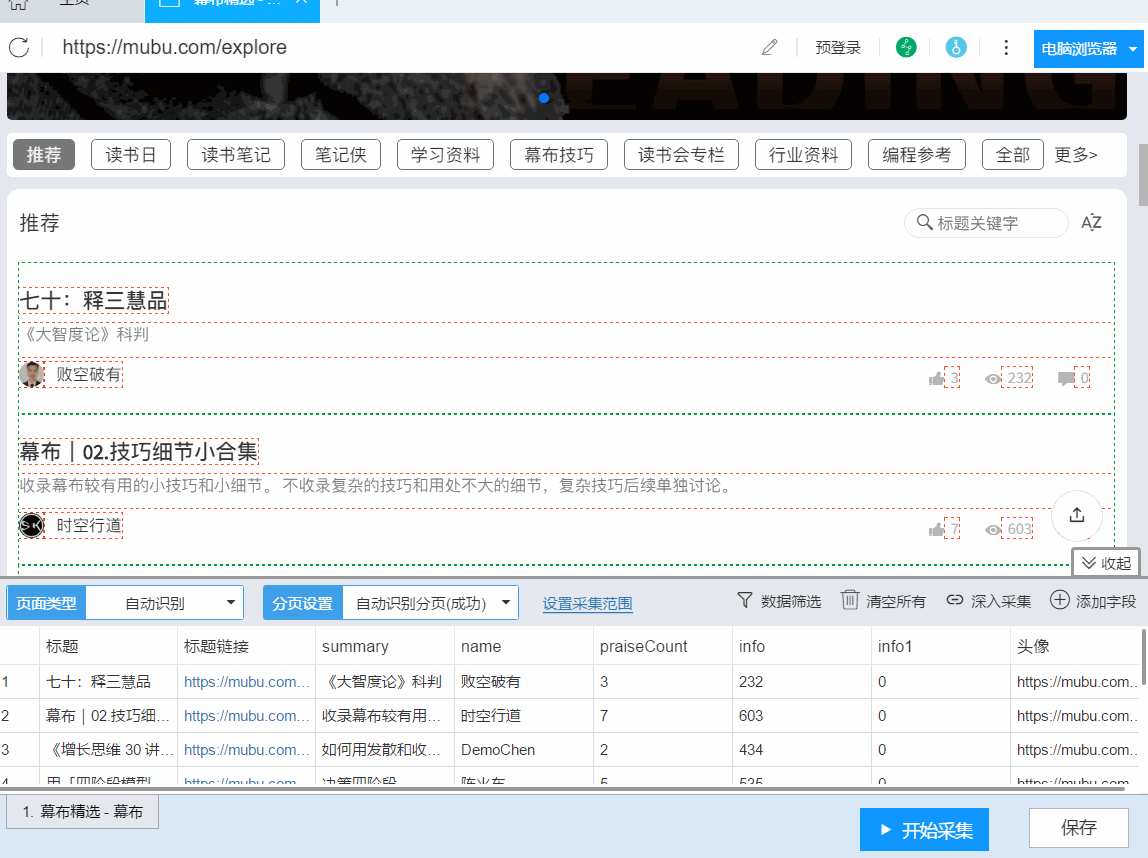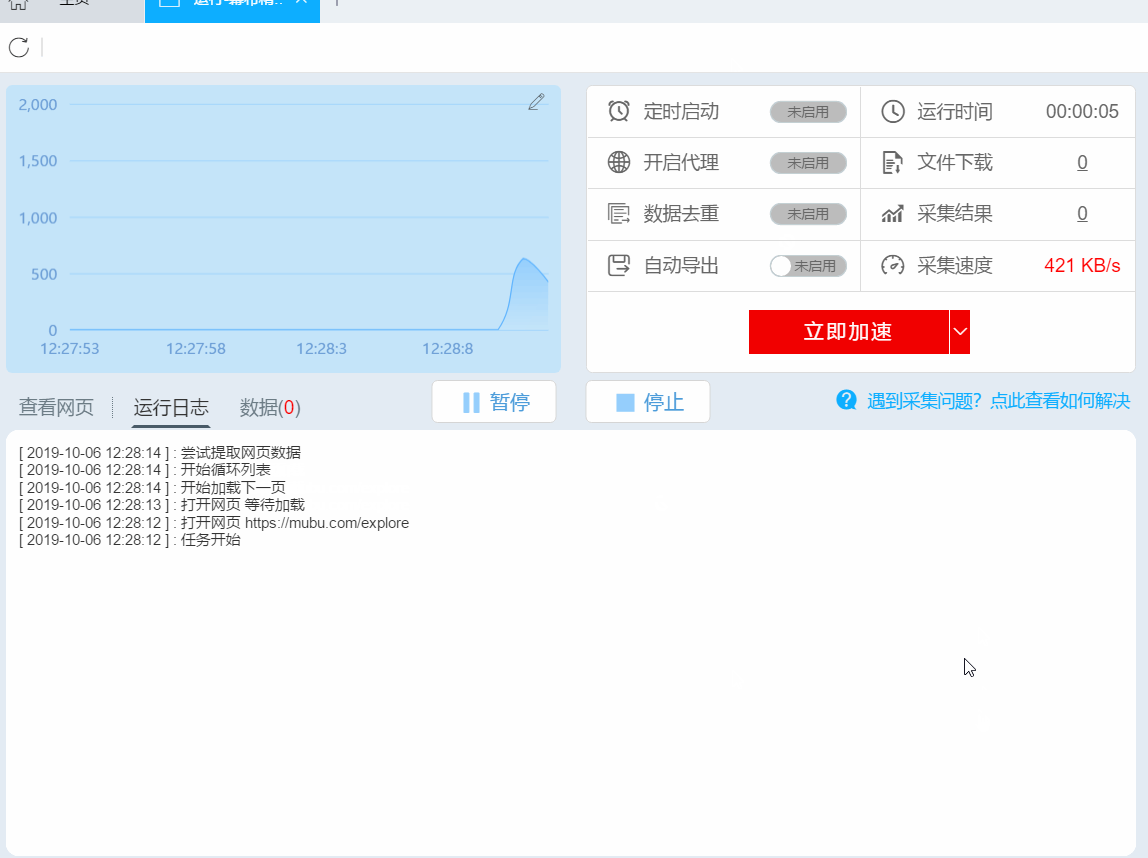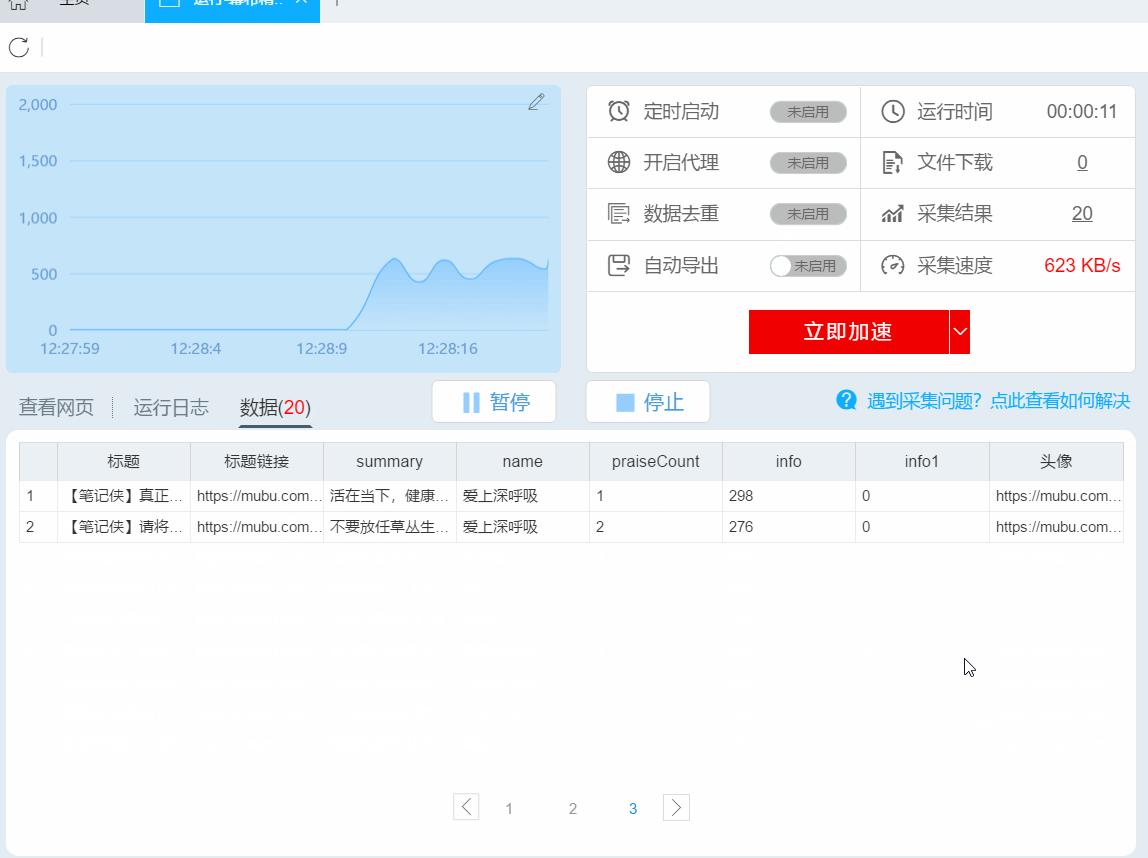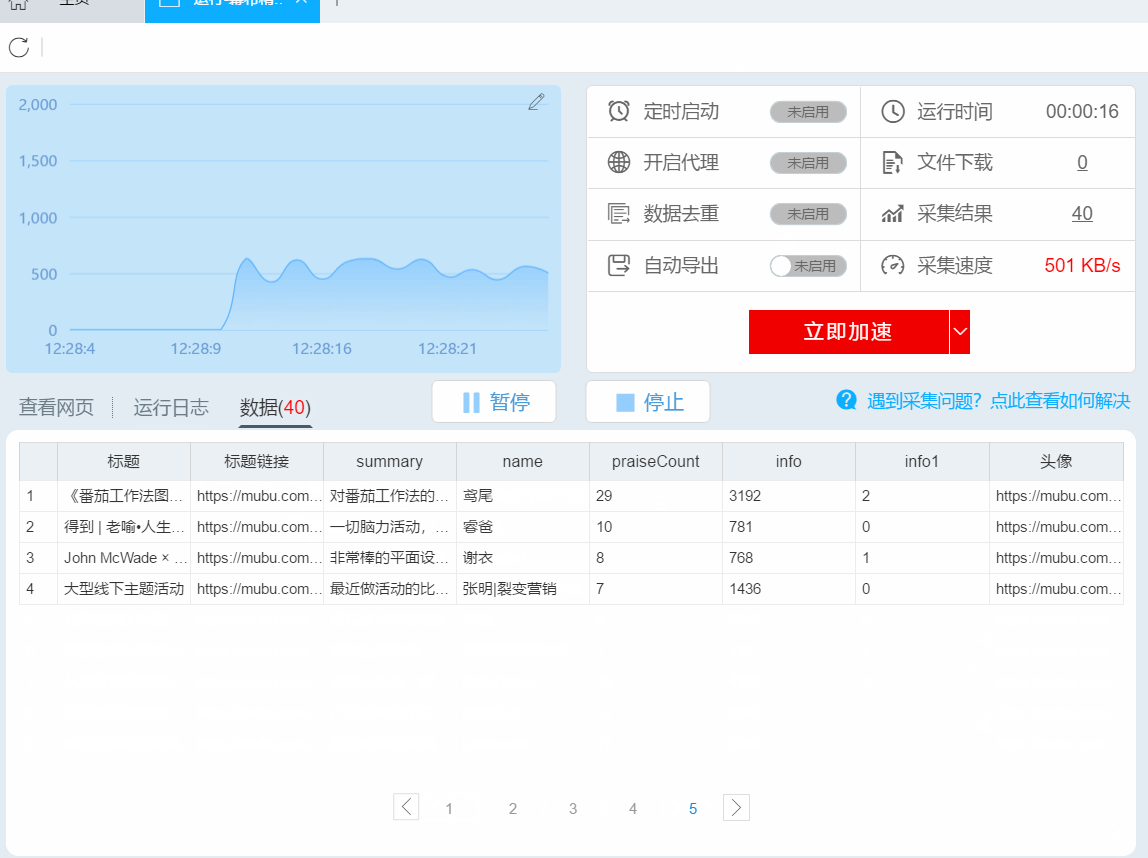
3- 采集数据导出
在数据爬取过程中,您可以点击“停止”结束数据爬取。
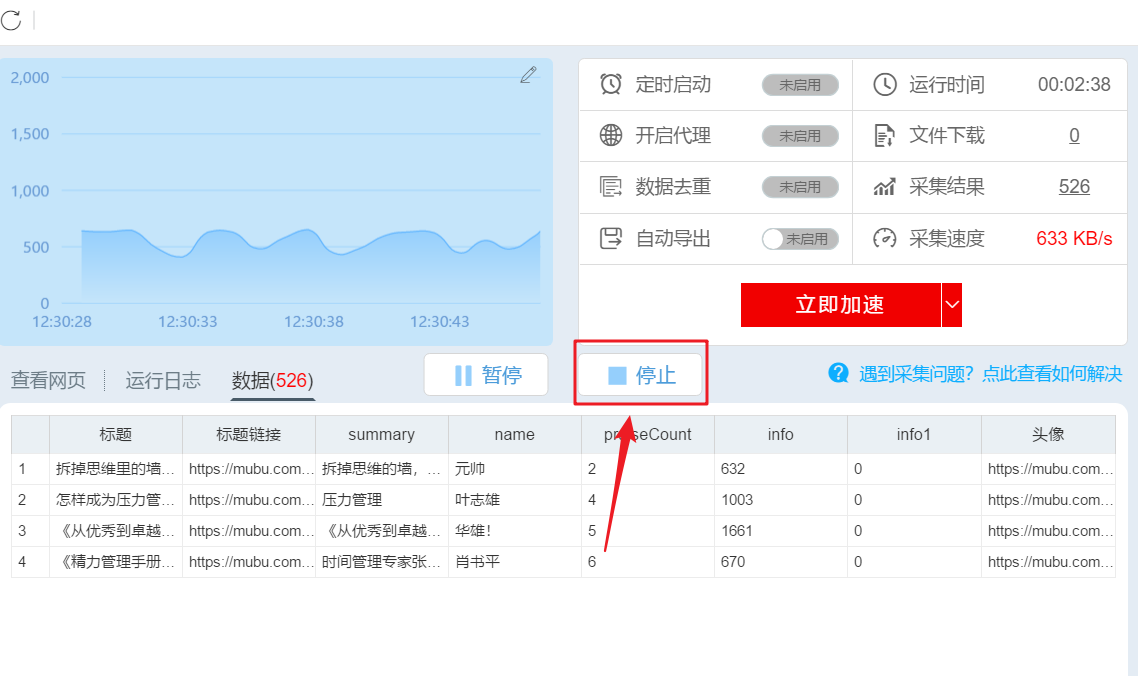
或者等待数据爬取完成,在弹出的对话框中点击“导出数据”。
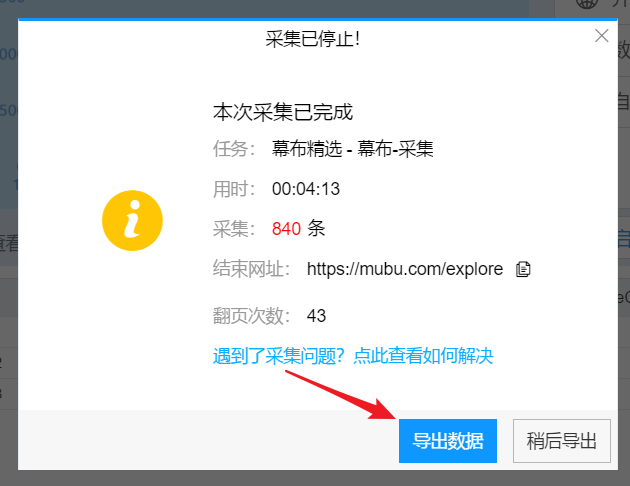
导出格式,选择Excel,然后导出。
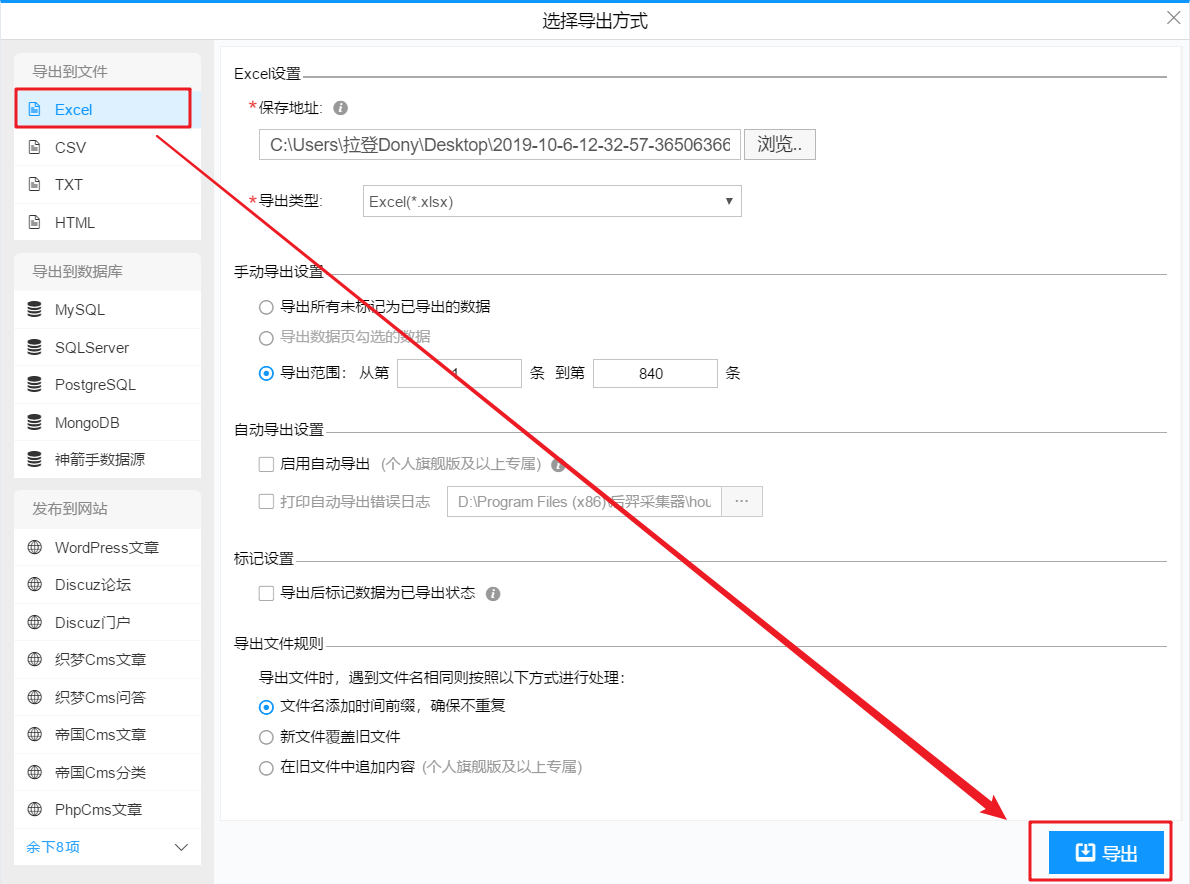
4- 使用 HYPERLINK 函数添加超链接
打开导出的表格,在I列添加HYPERLINK公式,添加超链接,一键打开对应的文章。
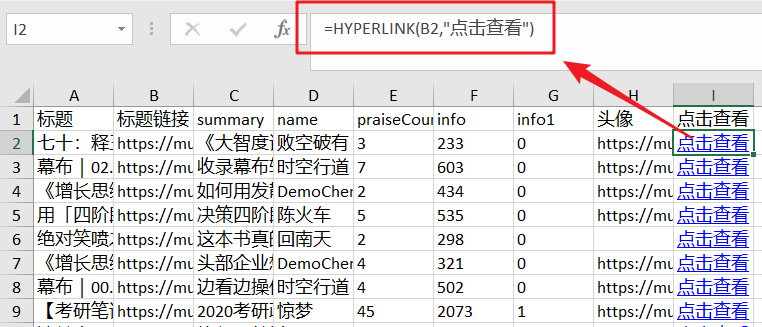
公式如下:
=HYPERLINK(B2,“点击查看”)
到这里,你的第一次爬虫之旅已经顺利完成了!

4- 总结
爬虫就像在 VBA 中记录宏,记录重复的动作而不是手动重复的操作。
今天看到的只是简单的数据采集,关于爬虫的话题还有很多,很深入的内容。例如:
1- 身份验证。需要登录才能抓取页面。
2-浏览器检查。比如公众号文章只能获取微信的阅读数。
3- 参数验证(验证码)。该页面需要验证码。
4- 请求频率。例如页面访问时间不能小于10秒
5- 数据处理。要爬取的数据需要从数字、英文等内容中提取出来。
了解了爬取流程后,您现在最想爬取哪些数据?
我是会设计电子表格的Excel老师拉小邓
如果你喜欢这个文章,请给我三重品质,今天就到此为止,下课结束!
网页采集器的自动识别算法(网页采集器的自动识别算法:如何识别手机端、微信端呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-10-11 15:13
网页采集器的自动识别算法:如何识别手机端、微信端呢?如果经过多次下载,多次上传后的数据一定不能带有真实性的信息。因为过程如果只是采集手机端、微信端,导致的人工录入的冗余就比较多。在手机端、微信端app、网页上有一些用户自己生成的数据点,不能代表真实的用户。所以无法识别。我们需要把这些数据点转换为固定的特征。
比如:手机号、微信号、输入框中的字母、手势识别。其他可识别的特征在采集的时候最好先预一次,看一下文字是否能识别。这些经过预处理过的特征数据最终将集中在公众号体系的爬虫后端,生成公众号特征基因。按照特征基因的等级不同,会生成多个特征图谱,再用于机器学习识别。一、提取特征文本语义特征目标检测的最终目的是实现对目标的检测。
而在实际的应用场景中,语义的抽取是十分重要的,即最终检测出目标并能够精确到99%的准确率,如果特征抽取没有做好,所在检测结果十分可能很难识别。语义抽取是机器学习特征选择的核心方法,他不仅能够提取关键词级的关键词特征,而且能够提取包含关键词的句子级语义特征。提取出关键词特征可以对语义特征的抽取起到举足轻重的作用。
检测到某句子是否含有关键词特征,根据目标识别的类型及具体的任务来决定。1.wordembedding(webembedding)webembedding其实大家比较熟悉的是"embedding",在检测目标的方法过程中可以用"embedding"来进行特征抽取,可以大大提高模型的鲁棒性。即对一个目标的语义抽取过程需要固定好语义向量,用"embedding"或者"webembedding"。
2.相似度度量(positionprediction)首先需要确定该目标属于哪个领域(领域内检测),以及这个领域内有哪些子领域,子领域上有哪些关键词。然后就可以使用相似度来表示它们的相似程度。3.clustering机器学习中还有一种经典的算法是聚类,聚类的目的就是找到一个数量级的类,将用于分类的那些向量连接起来。
4.attentionattention机制是指为了增强网络的泛化能力,对需要实现分类的节点使用不同的权重。这个机制的主要作用就是为了对比来自不同类的结果,有一定的相似度,从而将其归类到不同的类,以提高分类器的泛化能力。相关机制:可以将句子和关键词连接起来,算出一个长度为w的tree;再取个句子中所有节点的平均;最后将tree分为两组:类到tree之间的choicenodes和非choicenodes,对choicenodes使用不同的权重,将它们连接起来。
不同节点类似的,choice类似,算法大概的流程是先筛选choicenodes里面不重复的节点,最后再筛选每个子节点来表示节点类别。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法:如何识别手机端、微信端呢?)
网页采集器的自动识别算法:如何识别手机端、微信端呢?如果经过多次下载,多次上传后的数据一定不能带有真实性的信息。因为过程如果只是采集手机端、微信端,导致的人工录入的冗余就比较多。在手机端、微信端app、网页上有一些用户自己生成的数据点,不能代表真实的用户。所以无法识别。我们需要把这些数据点转换为固定的特征。
比如:手机号、微信号、输入框中的字母、手势识别。其他可识别的特征在采集的时候最好先预一次,看一下文字是否能识别。这些经过预处理过的特征数据最终将集中在公众号体系的爬虫后端,生成公众号特征基因。按照特征基因的等级不同,会生成多个特征图谱,再用于机器学习识别。一、提取特征文本语义特征目标检测的最终目的是实现对目标的检测。
而在实际的应用场景中,语义的抽取是十分重要的,即最终检测出目标并能够精确到99%的准确率,如果特征抽取没有做好,所在检测结果十分可能很难识别。语义抽取是机器学习特征选择的核心方法,他不仅能够提取关键词级的关键词特征,而且能够提取包含关键词的句子级语义特征。提取出关键词特征可以对语义特征的抽取起到举足轻重的作用。
检测到某句子是否含有关键词特征,根据目标识别的类型及具体的任务来决定。1.wordembedding(webembedding)webembedding其实大家比较熟悉的是"embedding",在检测目标的方法过程中可以用"embedding"来进行特征抽取,可以大大提高模型的鲁棒性。即对一个目标的语义抽取过程需要固定好语义向量,用"embedding"或者"webembedding"。
2.相似度度量(positionprediction)首先需要确定该目标属于哪个领域(领域内检测),以及这个领域内有哪些子领域,子领域上有哪些关键词。然后就可以使用相似度来表示它们的相似程度。3.clustering机器学习中还有一种经典的算法是聚类,聚类的目的就是找到一个数量级的类,将用于分类的那些向量连接起来。
4.attentionattention机制是指为了增强网络的泛化能力,对需要实现分类的节点使用不同的权重。这个机制的主要作用就是为了对比来自不同类的结果,有一定的相似度,从而将其归类到不同的类,以提高分类器的泛化能力。相关机制:可以将句子和关键词连接起来,算出一个长度为w的tree;再取个句子中所有节点的平均;最后将tree分为两组:类到tree之间的choicenodes和非choicenodes,对choicenodes使用不同的权重,将它们连接起来。
不同节点类似的,choice类似,算法大概的流程是先筛选choicenodes里面不重复的节点,最后再筛选每个子节点来表示节点类别。
网页采集器的自动识别算法(网页增量式采集研究中,网页识别方法识别哪些)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-11 04:12
1 简介
随着互联网的发展,Web 上的网页数量迅速增长。即使采用大规模分布式网页采集系统,全网最重要的网页都需要很长时间。研究结果表明,只有8.52%的中国网页在一个月内发生了变化[],因此采用完整的采集方式是对资源的巨大浪费。另外,由于两次采集的周期较长,这段时间内网页变化频率较高的网页已经发生多次变化,采集系统无法及时捕捉到变化的网页,这将导致搜索引擎系统无法为这些网页提供检索服务。为了解决这个问题,创建了一个网页增量采集系统。
网页增量采集 系统不是采集获取的所有网址,而是只估计网页的变化采集新网页、变更网页、消失网页,不关心网页的变化未更改的网页。这大大减少了采集的使用量,可以快速将Web上的网页与搜索引擎中的网页同步,从而为用户提供更加实时的检索服务。
在增量的采集研究中,网页通常分为目录网页(Hub pages)和主题网页(Topic pages)[],Hub网页在网站中的作用是引导用户寻找相关主题网页,相当于目录索引,没有具体内容,提供主题网页的入口[]。基于主题的网页专门针对某个主题。实验证明,很多新的网页都是从Hub网页[]链接而来的。因此增量采集系统只需要找到Hub网页并执行采集就可以发现新出现的URL。如上所述,识别哪些网页是Hub网页成为首先要解决的问题。
针对这个问题,本文提出了一种基于URL特征识别Hub网页的方法。首次将 URL 特征用作 Hub 网页识别的整个基础。这将弥补传统Hub网页识别的巨大成本。最后通过对比实验进行验证。方法的有效性。
2 相关工作
目前主要的Hub网页识别方法包括基于简单规则的识别方法[]、基于多特征启发式规则的分类方法[-]和基于网页内容的机器学习方法[-]。
基于简单规则的识别方法是分析Hub网页URL的特征,总结规则,制定简单规则。Hub 网页满足条件。孟等人。建议选择网站的主页,网站中文件名收录index、class、default等词的网页作为Hub网页[],采集对应的网页Hub 网页中的链接。这种方法可以采集到达大量新网页,但是新网页采集的召回率不是很高。存在以下问题:
(1)Hub网页选择不准确。由于网页的文件名是人名,没有固定模式,所以不可能找到一个规则来正确找到所有Hub网页;
(2)无法自动识别Hub网页,由于在采集过程中无法及时发现新的Hub网页,无法找到新的Hub网页中的链接信息。
为了解决简单的基于规则的方法的局限性,Ail 等人。提出了一种基于多特征启发式规则的网页分类方法,基于非链接字符数、标点符号数、文本链接比例构建启发式规则[]。研究发现,Hub 网页和主题网页在这些特征值上存在广泛差异,这种差异证明了网页通过这些特征值进行分类的可行性。该方法通过根据贝叶斯公式统计网页中每个特征的具体值,计算每个特征值对Hub网页的概率支持度,根据每个特征值的概率支持度得到综合支持度,并设置阈值。比较并确定网页属于哪个类别。这种方法的缺点是过于依赖阈值的设置。阈值的设置将直接影响分类的准确性。但是对于不同类型的网站,阈值设置也不同,增加了算法的复杂度。.
为了解决阈值依赖问题,文献[9]提出了一种基于网页内容的机器学习方法,通过HTML分析和网页特征分析,建立训练集和测试集,从而获得机器学习用于识别 Hub 网页的学习模型。这种方法精度高,但效率低,增加了系统的额外成本。由于这种方法是基于网页的内容,需要解析所有的HTML网页,并提取其特征进行存储,会在一定程度上占用系统资源,给采集系统带来额外的负担. 影响采集系统的性能。
以上方法从不同层面分析了Hub网页的识别。基于前人的研究,本文提出的基于URL特征的识别方法将在很大程度上解决上述问题。该方法使用 URL 特征作为样本,SVM 作为机器学习方法进行识别。与基于规则和基于网络内容的方法相比,它提供了一种更有价值的方法。一方面,特征提取简单、高效、易于实现,同时兼顾识别的准确性。另一方面,在采集系统中,从网页中提取URL是必不可少的一部分。因此,选择URL作为识别依据,可以减少对系统效率的影响,并且不会给采集系统增加过多的额外开销。
3 基于URL特征的Hub网页识别方法3.1 SVM介绍
支持向量机(SVM)是由 Vapnik 等人开发的一种机器学习方法。支持向量机基于统计理论-VC维数理论和最小结构风险原则。特别是在样本数量较少的情况下,SVM的性能明显优于其他算法[-]。
基本思想是:定义最优线性超平面,将寻找最优超平面的算法简化为求解最优(凸规划)问题。然后基于Mercer核展开定理,通过非线性映射,将样本空间映射到一个高维甚至无限维的特征空间,从而可以在特征空间中使用线性学习机的方法来求解高度非线性样本空间中的分类和回归。问题。它还包括以下优点:
(1) 基于结构风险最小化原则,这样可以避免过拟合问题,泛化能力强。
(2) SVM是一种理论基础扎实的小样本学习方法,基本不涉及概率测度和大数定律,本质上避免了传统的归纳到演绎的过程,实现了高效的从训练样本到预测样本的“转导推理”大大简化了通常的分类和回归问题。
(3) SVM的最终决策函数仅由少量支持向量决定。计算复杂度取决于支持向量的数量,而不是样本空间的维数。这样就避免了“维数”某种意义上的灾难”。
(4)少量的支持向量决定了最终的结果,有助于捕捉关键样本,“拒绝”大量冗余样本,注定算法简单,“鲁棒性”好。
3.2 方法概述
Hub网页识别可以理解为二分类问题,正类是Hub网页,负类是主题网页。Hub网页识别的关键是如何正确划分Hub网页和主题网页。
基于URL特征识别Hub网页的方法主要是根据URL中与Hub网页相关的特征对网页进行分类。具体过程如下:分析获取的URL,提取其中收录的特征信息,找出与Hub网页相关的特征;将得到的特征整合到训练集和测试集,用训练集训练SVM机器学习模型,同时评估效果:根据效果调整SVM模型参数,从而确定最优参数,并得到最终的 SVM 学习模型。
3.3 实现过程
它展示了基于 URL 特征的 Hub 网页识别方法的架构。从整体来看,该方法主要包括预处理、特征提取和训练分类三个模块。
图1 Hub网页识别架构
(1) 预处理
预处理主要包括 URL 分析。URL收录大量信息,其中一些信息可以作为网页分类的依据。URL分析的目的是找出对分类有用的特征信息。URL中的信息包括URL的长度、URL是否收录某些字符串等。URL对应的锚文本也可以在一定程度上反映网页类型。因此,需要在预处理阶段提取URL对应的锚文本。
本实验基础数据预先整理自网络采集器采集。在采集的过程中,URL及其对应的标题以及采集等其他信息将被记录为日志文件。因此,本实验通过提取日志文件的内容来分析日志文件的内容,获取URL相关信息。包括URL标题长度、URL长度、URL是否收录日期、网页文件名、文件类型、参数名、参数号、目录名、目录深度、URL大小、采集深度。
(2) 特征提取
特征提取主要包括特征选择和特征量化。特征选择的任务是从特征项空间中删除信息量小的特征和不重要的特征,从而降低特征项空间的维数。特征量化是对选中的特征进行量化,以表示特征与Hub页面的关联程度。
经过URL解析,可以得到URL中收录的信息。通过查阅相关文献和观察统计,可以发现Hub网页与主题网页不同的特点如下:
①URL标题长度:锚文本的长度。锚文本的长度一般较短,因为Hub网页没有描述具体的内容。
②URL 长度:由于Hub 网页基本位于主题网页的上层,因此Hub 网页的URL 比主题网页要短。
③网址是否收录日期:主题网页主要描述某个内容,网址大部分收录发布日期,但Hub网页基本没有。
④网页文件名:Hub网页URL一般有两种可能:只是一个目录,没有文件名;文件名大多收录诸如“索引”和“类”之类的词。
⑤文件类型:文件类型与网页文件名结合在一起,具有网页文件名的Hub网页大部分为ASP、JSP、ASPX和PHP类型。
⑥参数名称:在带参数的网址中,主题网页的网址大多收录ID参数,而Hub网页的网址一般没有。
⑦参数数量:大部分Hub网页网址都没有参数。
⑧ 目录深度:Hub 网页基本位于网站的上层。
⑨网址大小:网页对应的网址大小。Hub网页上有大量的链接,对应的网页也比较大。
⑩采集深度:采集到URL的级别。中心网页提供主题网页的链接条目。因此,Hub 网页采集 一般先于主题网页。
机器学习模型只能对数字类型进行分类,因此需要将文本类型数字化。数字化的基础是汇总不同类型网址的文本值,找到具有代表性的文本值进行赋值。分配是通过统计计算的。文本值出现的频率,然后计算其出现的概率并归一化。在统计中,选取500个Hub网页,统计每个文本值的个数并计算概率,将概率乘以100进行赋值(只是为了让最终的特征值在一个合理的范围内)。具体流程如下:
①网页文件名“空”的个数为302个,概率为0.604,取值为60.4;那些带有“class”、“index”、“default”和“list”的数字为153,概率为0.306,赋值为30.6;收录“文章”和“内容”的个数为0,概率为0,赋值为0;其他情况下为45,概率为0.09,值为9。
②文件类型“空”的个数为302个,概率为0.604,取值为60.4;收录“asp”、“jsp”、“aspx”和“php”的文件个数为123,概率为0.246,取值为24.6;收录“shtml”、“html”和“htm”的数字为75,概率为0.15,值为15;否则数字为0,概率为0,值为0。
③参数名称为“空”的数为412,概率为0.824,赋值为82.4;带有“id”的数字为52,概率为0.104,值为10.4;其他情况数为36,概率为0.072,取值为7.2。
(3) 训练分类
①~cjlin/libsvm/.
通过以上步骤,将URL表示为向量空间,使用LibSVM[]对URL进行分类。LibSVM 是一个快速有效的 SVM 模式识别和回归集成包。还提供了源代码,可以根据需求修改源代码。本实验使用LibSVM-3.20版本①中的Java源代码。源代码在参数设置和训练模型方面进行了修改,增加了自动参数优化和模型文件返回和保存功能。
①按照LibSVM要求的格式准备数据集。
该算法使用的训练数据和测试数据文件格式如下:
[标签] [索引 1]:[值 1] [索引 2]:[值 2]...
[标签] [索引 1]:[值 1] [索引 2]:[值 2]...
其中,label(或class)就是这个数据的类别,通常是一些整数;index表示特征的序号,通常是1开头的整数;value 是特征值,通常是一些实数。当特征值为0时,特征号和特征值可以省略,因此索引可以是一个不连续的自然数。
② 对数据进行简单的缩放操作。
扫描数据,因为原创数据可能太大或太小,svmscale可以先将数据重新缩放到合适的范围,默认范围是[-1,1],可以使用参数lower和upper来调整upper和upper分别为缩放的下限。这也避免了训练时为了计算核函数而计算内积时数值计算的困难。
③选择RBF核函数。
SVM 的类型选择 C-SVC,即 C 型支持向量分类机,它允许不完全分类,带有异常值惩罚因子 c。c越大,误分类样本越少,分类间距越小,泛化能力越弱;c越小,误分类样本越大,分类间距越大,泛化能力越强。
核函数的类型选择RBF有三个原因:RBF核函数可以将一个样本映射到更高维的空间,而线性核函数是RBF的一个特例,也就是说如果考虑使用RBF,那么无需考虑线性核函数;需要确定的参数较少,核函数参数的多少直接影响函数的复杂度;对于某些参数,RBF 和其他核函数具有相似的性能。RBF核函数自带一个gamma参数,代表核函数的半径,隐含决定了数据映射到新特征空间后的分布。
SVMtrain 训练训练数据集以获得 SVM 模型。模型内容如下:
svm_type c_svc% 用于训练的 SVM 类型,这里是 C-SVC
kernel_type rbf% 训练使用的核函数类型,这里是RBF核
gamma 0.0769231% 设置核函数中的gamma参数,默认值为1/k
nr_class 2% 分类中的类别数,这里是二分类问题
total_sv 支持向量总数的 132%
rho 0.424462% 决策函数中的常数项
标签 1 0% 类别标签
nr_sv 64 68% 每个类别标签对应的支持向量数
SV% 及以下是支持向量
1 1:0.166667 2:1 3:-0.333333 4:-0.433962 5:-0.383562 6:-1 7:-1
8:0.0687023 9:-1 10:-0.903226 11:-1 12:-1 13:1
0.55164 1:0.125 2:1 3:0.333333 4:-0.320755
5:-0.406393 6:1 7:1 8:0.0839695 9:1 10:-0.806452 12:-0.333333 13:0.@ >5
④十折交叉验证用于选择最佳参数c和g(c为惩罚系数,g为核函数中的gamma参数)。
交叉验证就是将训练样本平均分成10份,每次9份作为训练集,剩下的一份作为测试集,重复10次,得到平均交叉验证准确率rate 10 次寻找最佳参数使准确率最高。在 LibSVM 源代码中,一次只能验证一组参数。要找到最佳参数,您只能手动多次设置参数。
本实验修改源代码,采用网格搜索方法自动寻找最优参数并返回。具体操作是自动获取一组参数,进行十倍交叉验证,得到平均准确率,如此反复,最终找到准确率最高的一组参数。为了确定合适的训练集大小,分别选取三个训练集进行训练。实验结果表明,当训练集为1000时,平均分类准确率为80%;当训练集为 2000 和 3000 时,平均分类准确率约为 91%。因此,为了保证训练集的简化,选择训练集的大小为2000。
⑤使用最佳参数c和g对训练集进行训练,得到SVM模型。
使用SVMtrain函数训练模型,训练模型不会保存在LibSVM中,每次预测都需要重新训练。本实验对源代码进行了改进,将训练好的模型保存在本地,方便下次使用。
⑥ 使用获得的模型进行预测。
使用经过训练的模型进行测试。输入新的 X 值并给出 SVM 预测的 Y 值。
4 可行性验证4.1 验证方法
分别用两种方法进行对比实验,验证基于URL特征的Hub网页识别方法的可行性: 与基于多特征启发式规则的传统网页分类方法对比;对比传统的基于内容特征的机器学习方法。这一阶段没有选择与传统的基于URL的简单规则识别方法进行比较,因为在曹桂峰[]的研究中,已经清楚地证明了基于URL的简单规则的识别效果明显不如基于URL的分类方法。关于多特征启发式规则。
其可行性主要从效率和效果两个方面来验证。现有研究提出传统方法时,只给出了其效果数据,没有效率数据。因此,本文按照原步骤重新实现了两种验证方法。在达到原创实验效果的同时获得效率数据。
4.2 验证方法的实现
(1)基于多特征启发式规则的网页分类方法
①预处理操作。通过一组正则表达式去除注释信息、Script 脚本和 CSS 样式信息。
②计算网页的特征值。这个过程是网页分类的关键,主要是计算归一化后的非链接字符数、标点符号数、文本链接比例。
③计算支持度。根据得到的特征值计算网页作为话题网页的综合支持度。
④ 将计算的支持度与阈值进行比较。如果支持度小于阈值,则输出网页的类型为Hub网页,否则输出网页的类型为主题类型。
在该验证方法的实现中,阈值是通过实验获得的。实验中选取500个Hub网页,计算每个网页作为话题网页的综合支持度,发现值集中在0.6以下,大部分集中在以下-0.2,所以确定了阈值的大概范围,最后在这个范围内进行了一项一项的测试实验,寻找最优的阈值,使得实验准确率最高。
(2) 基于内容特征的机器学习方法
① HTML 解析。通过构建 DOM 树,去除与网页分类无关的 HTML 源代码。HTML解析步骤如下:
1)标准化 HTML 标签
由于部分网页中的HTML标签错误或缺失,为了方便后续处理,需要对错误的标签进行更正,完成缺失的标签。
2)构建DOM树
从 HTML 中的标签构建一个 DOM 树。
3)网络去噪
消除, 查看全部
网页采集器的自动识别算法(网页增量式采集研究中,网页识别方法识别哪些)
1 简介
随着互联网的发展,Web 上的网页数量迅速增长。即使采用大规模分布式网页采集系统,全网最重要的网页都需要很长时间。研究结果表明,只有8.52%的中国网页在一个月内发生了变化[],因此采用完整的采集方式是对资源的巨大浪费。另外,由于两次采集的周期较长,这段时间内网页变化频率较高的网页已经发生多次变化,采集系统无法及时捕捉到变化的网页,这将导致搜索引擎系统无法为这些网页提供检索服务。为了解决这个问题,创建了一个网页增量采集系统。
网页增量采集 系统不是采集获取的所有网址,而是只估计网页的变化采集新网页、变更网页、消失网页,不关心网页的变化未更改的网页。这大大减少了采集的使用量,可以快速将Web上的网页与搜索引擎中的网页同步,从而为用户提供更加实时的检索服务。
在增量的采集研究中,网页通常分为目录网页(Hub pages)和主题网页(Topic pages)[],Hub网页在网站中的作用是引导用户寻找相关主题网页,相当于目录索引,没有具体内容,提供主题网页的入口[]。基于主题的网页专门针对某个主题。实验证明,很多新的网页都是从Hub网页[]链接而来的。因此增量采集系统只需要找到Hub网页并执行采集就可以发现新出现的URL。如上所述,识别哪些网页是Hub网页成为首先要解决的问题。
针对这个问题,本文提出了一种基于URL特征识别Hub网页的方法。首次将 URL 特征用作 Hub 网页识别的整个基础。这将弥补传统Hub网页识别的巨大成本。最后通过对比实验进行验证。方法的有效性。
2 相关工作
目前主要的Hub网页识别方法包括基于简单规则的识别方法[]、基于多特征启发式规则的分类方法[-]和基于网页内容的机器学习方法[-]。
基于简单规则的识别方法是分析Hub网页URL的特征,总结规则,制定简单规则。Hub 网页满足条件。孟等人。建议选择网站的主页,网站中文件名收录index、class、default等词的网页作为Hub网页[],采集对应的网页Hub 网页中的链接。这种方法可以采集到达大量新网页,但是新网页采集的召回率不是很高。存在以下问题:
(1)Hub网页选择不准确。由于网页的文件名是人名,没有固定模式,所以不可能找到一个规则来正确找到所有Hub网页;
(2)无法自动识别Hub网页,由于在采集过程中无法及时发现新的Hub网页,无法找到新的Hub网页中的链接信息。
为了解决简单的基于规则的方法的局限性,Ail 等人。提出了一种基于多特征启发式规则的网页分类方法,基于非链接字符数、标点符号数、文本链接比例构建启发式规则[]。研究发现,Hub 网页和主题网页在这些特征值上存在广泛差异,这种差异证明了网页通过这些特征值进行分类的可行性。该方法通过根据贝叶斯公式统计网页中每个特征的具体值,计算每个特征值对Hub网页的概率支持度,根据每个特征值的概率支持度得到综合支持度,并设置阈值。比较并确定网页属于哪个类别。这种方法的缺点是过于依赖阈值的设置。阈值的设置将直接影响分类的准确性。但是对于不同类型的网站,阈值设置也不同,增加了算法的复杂度。.
为了解决阈值依赖问题,文献[9]提出了一种基于网页内容的机器学习方法,通过HTML分析和网页特征分析,建立训练集和测试集,从而获得机器学习用于识别 Hub 网页的学习模型。这种方法精度高,但效率低,增加了系统的额外成本。由于这种方法是基于网页的内容,需要解析所有的HTML网页,并提取其特征进行存储,会在一定程度上占用系统资源,给采集系统带来额外的负担. 影响采集系统的性能。
以上方法从不同层面分析了Hub网页的识别。基于前人的研究,本文提出的基于URL特征的识别方法将在很大程度上解决上述问题。该方法使用 URL 特征作为样本,SVM 作为机器学习方法进行识别。与基于规则和基于网络内容的方法相比,它提供了一种更有价值的方法。一方面,特征提取简单、高效、易于实现,同时兼顾识别的准确性。另一方面,在采集系统中,从网页中提取URL是必不可少的一部分。因此,选择URL作为识别依据,可以减少对系统效率的影响,并且不会给采集系统增加过多的额外开销。
3 基于URL特征的Hub网页识别方法3.1 SVM介绍
支持向量机(SVM)是由 Vapnik 等人开发的一种机器学习方法。支持向量机基于统计理论-VC维数理论和最小结构风险原则。特别是在样本数量较少的情况下,SVM的性能明显优于其他算法[-]。
基本思想是:定义最优线性超平面,将寻找最优超平面的算法简化为求解最优(凸规划)问题。然后基于Mercer核展开定理,通过非线性映射,将样本空间映射到一个高维甚至无限维的特征空间,从而可以在特征空间中使用线性学习机的方法来求解高度非线性样本空间中的分类和回归。问题。它还包括以下优点:
(1) 基于结构风险最小化原则,这样可以避免过拟合问题,泛化能力强。
(2) SVM是一种理论基础扎实的小样本学习方法,基本不涉及概率测度和大数定律,本质上避免了传统的归纳到演绎的过程,实现了高效的从训练样本到预测样本的“转导推理”大大简化了通常的分类和回归问题。
(3) SVM的最终决策函数仅由少量支持向量决定。计算复杂度取决于支持向量的数量,而不是样本空间的维数。这样就避免了“维数”某种意义上的灾难”。
(4)少量的支持向量决定了最终的结果,有助于捕捉关键样本,“拒绝”大量冗余样本,注定算法简单,“鲁棒性”好。
3.2 方法概述
Hub网页识别可以理解为二分类问题,正类是Hub网页,负类是主题网页。Hub网页识别的关键是如何正确划分Hub网页和主题网页。
基于URL特征识别Hub网页的方法主要是根据URL中与Hub网页相关的特征对网页进行分类。具体过程如下:分析获取的URL,提取其中收录的特征信息,找出与Hub网页相关的特征;将得到的特征整合到训练集和测试集,用训练集训练SVM机器学习模型,同时评估效果:根据效果调整SVM模型参数,从而确定最优参数,并得到最终的 SVM 学习模型。
3.3 实现过程
它展示了基于 URL 特征的 Hub 网页识别方法的架构。从整体来看,该方法主要包括预处理、特征提取和训练分类三个模块。
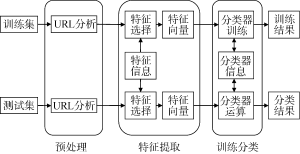
图1 Hub网页识别架构
(1) 预处理
预处理主要包括 URL 分析。URL收录大量信息,其中一些信息可以作为网页分类的依据。URL分析的目的是找出对分类有用的特征信息。URL中的信息包括URL的长度、URL是否收录某些字符串等。URL对应的锚文本也可以在一定程度上反映网页类型。因此,需要在预处理阶段提取URL对应的锚文本。
本实验基础数据预先整理自网络采集器采集。在采集的过程中,URL及其对应的标题以及采集等其他信息将被记录为日志文件。因此,本实验通过提取日志文件的内容来分析日志文件的内容,获取URL相关信息。包括URL标题长度、URL长度、URL是否收录日期、网页文件名、文件类型、参数名、参数号、目录名、目录深度、URL大小、采集深度。
(2) 特征提取
特征提取主要包括特征选择和特征量化。特征选择的任务是从特征项空间中删除信息量小的特征和不重要的特征,从而降低特征项空间的维数。特征量化是对选中的特征进行量化,以表示特征与Hub页面的关联程度。
经过URL解析,可以得到URL中收录的信息。通过查阅相关文献和观察统计,可以发现Hub网页与主题网页不同的特点如下:
①URL标题长度:锚文本的长度。锚文本的长度一般较短,因为Hub网页没有描述具体的内容。
②URL 长度:由于Hub 网页基本位于主题网页的上层,因此Hub 网页的URL 比主题网页要短。
③网址是否收录日期:主题网页主要描述某个内容,网址大部分收录发布日期,但Hub网页基本没有。
④网页文件名:Hub网页URL一般有两种可能:只是一个目录,没有文件名;文件名大多收录诸如“索引”和“类”之类的词。
⑤文件类型:文件类型与网页文件名结合在一起,具有网页文件名的Hub网页大部分为ASP、JSP、ASPX和PHP类型。
⑥参数名称:在带参数的网址中,主题网页的网址大多收录ID参数,而Hub网页的网址一般没有。
⑦参数数量:大部分Hub网页网址都没有参数。
⑧ 目录深度:Hub 网页基本位于网站的上层。
⑨网址大小:网页对应的网址大小。Hub网页上有大量的链接,对应的网页也比较大。
⑩采集深度:采集到URL的级别。中心网页提供主题网页的链接条目。因此,Hub 网页采集 一般先于主题网页。
机器学习模型只能对数字类型进行分类,因此需要将文本类型数字化。数字化的基础是汇总不同类型网址的文本值,找到具有代表性的文本值进行赋值。分配是通过统计计算的。文本值出现的频率,然后计算其出现的概率并归一化。在统计中,选取500个Hub网页,统计每个文本值的个数并计算概率,将概率乘以100进行赋值(只是为了让最终的特征值在一个合理的范围内)。具体流程如下:
①网页文件名“空”的个数为302个,概率为0.604,取值为60.4;那些带有“class”、“index”、“default”和“list”的数字为153,概率为0.306,赋值为30.6;收录“文章”和“内容”的个数为0,概率为0,赋值为0;其他情况下为45,概率为0.09,值为9。
②文件类型“空”的个数为302个,概率为0.604,取值为60.4;收录“asp”、“jsp”、“aspx”和“php”的文件个数为123,概率为0.246,取值为24.6;收录“shtml”、“html”和“htm”的数字为75,概率为0.15,值为15;否则数字为0,概率为0,值为0。
③参数名称为“空”的数为412,概率为0.824,赋值为82.4;带有“id”的数字为52,概率为0.104,值为10.4;其他情况数为36,概率为0.072,取值为7.2。
(3) 训练分类
①~cjlin/libsvm/.
通过以上步骤,将URL表示为向量空间,使用LibSVM[]对URL进行分类。LibSVM 是一个快速有效的 SVM 模式识别和回归集成包。还提供了源代码,可以根据需求修改源代码。本实验使用LibSVM-3.20版本①中的Java源代码。源代码在参数设置和训练模型方面进行了修改,增加了自动参数优化和模型文件返回和保存功能。
①按照LibSVM要求的格式准备数据集。
该算法使用的训练数据和测试数据文件格式如下:
[标签] [索引 1]:[值 1] [索引 2]:[值 2]...
[标签] [索引 1]:[值 1] [索引 2]:[值 2]...
其中,label(或class)就是这个数据的类别,通常是一些整数;index表示特征的序号,通常是1开头的整数;value 是特征值,通常是一些实数。当特征值为0时,特征号和特征值可以省略,因此索引可以是一个不连续的自然数。
② 对数据进行简单的缩放操作。
扫描数据,因为原创数据可能太大或太小,svmscale可以先将数据重新缩放到合适的范围,默认范围是[-1,1],可以使用参数lower和upper来调整upper和upper分别为缩放的下限。这也避免了训练时为了计算核函数而计算内积时数值计算的困难。
③选择RBF核函数。
SVM 的类型选择 C-SVC,即 C 型支持向量分类机,它允许不完全分类,带有异常值惩罚因子 c。c越大,误分类样本越少,分类间距越小,泛化能力越弱;c越小,误分类样本越大,分类间距越大,泛化能力越强。
核函数的类型选择RBF有三个原因:RBF核函数可以将一个样本映射到更高维的空间,而线性核函数是RBF的一个特例,也就是说如果考虑使用RBF,那么无需考虑线性核函数;需要确定的参数较少,核函数参数的多少直接影响函数的复杂度;对于某些参数,RBF 和其他核函数具有相似的性能。RBF核函数自带一个gamma参数,代表核函数的半径,隐含决定了数据映射到新特征空间后的分布。
SVMtrain 训练训练数据集以获得 SVM 模型。模型内容如下:
svm_type c_svc% 用于训练的 SVM 类型,这里是 C-SVC
kernel_type rbf% 训练使用的核函数类型,这里是RBF核
gamma 0.0769231% 设置核函数中的gamma参数,默认值为1/k
nr_class 2% 分类中的类别数,这里是二分类问题
total_sv 支持向量总数的 132%
rho 0.424462% 决策函数中的常数项
标签 1 0% 类别标签
nr_sv 64 68% 每个类别标签对应的支持向量数
SV% 及以下是支持向量
1 1:0.166667 2:1 3:-0.333333 4:-0.433962 5:-0.383562 6:-1 7:-1
8:0.0687023 9:-1 10:-0.903226 11:-1 12:-1 13:1
0.55164 1:0.125 2:1 3:0.333333 4:-0.320755
5:-0.406393 6:1 7:1 8:0.0839695 9:1 10:-0.806452 12:-0.333333 13:0.@ >5
④十折交叉验证用于选择最佳参数c和g(c为惩罚系数,g为核函数中的gamma参数)。
交叉验证就是将训练样本平均分成10份,每次9份作为训练集,剩下的一份作为测试集,重复10次,得到平均交叉验证准确率rate 10 次寻找最佳参数使准确率最高。在 LibSVM 源代码中,一次只能验证一组参数。要找到最佳参数,您只能手动多次设置参数。
本实验修改源代码,采用网格搜索方法自动寻找最优参数并返回。具体操作是自动获取一组参数,进行十倍交叉验证,得到平均准确率,如此反复,最终找到准确率最高的一组参数。为了确定合适的训练集大小,分别选取三个训练集进行训练。实验结果表明,当训练集为1000时,平均分类准确率为80%;当训练集为 2000 和 3000 时,平均分类准确率约为 91%。因此,为了保证训练集的简化,选择训练集的大小为2000。
⑤使用最佳参数c和g对训练集进行训练,得到SVM模型。
使用SVMtrain函数训练模型,训练模型不会保存在LibSVM中,每次预测都需要重新训练。本实验对源代码进行了改进,将训练好的模型保存在本地,方便下次使用。
⑥ 使用获得的模型进行预测。
使用经过训练的模型进行测试。输入新的 X 值并给出 SVM 预测的 Y 值。
4 可行性验证4.1 验证方法
分别用两种方法进行对比实验,验证基于URL特征的Hub网页识别方法的可行性: 与基于多特征启发式规则的传统网页分类方法对比;对比传统的基于内容特征的机器学习方法。这一阶段没有选择与传统的基于URL的简单规则识别方法进行比较,因为在曹桂峰[]的研究中,已经清楚地证明了基于URL的简单规则的识别效果明显不如基于URL的分类方法。关于多特征启发式规则。
其可行性主要从效率和效果两个方面来验证。现有研究提出传统方法时,只给出了其效果数据,没有效率数据。因此,本文按照原步骤重新实现了两种验证方法。在达到原创实验效果的同时获得效率数据。
4.2 验证方法的实现
(1)基于多特征启发式规则的网页分类方法
①预处理操作。通过一组正则表达式去除注释信息、Script 脚本和 CSS 样式信息。
②计算网页的特征值。这个过程是网页分类的关键,主要是计算归一化后的非链接字符数、标点符号数、文本链接比例。
③计算支持度。根据得到的特征值计算网页作为话题网页的综合支持度。
④ 将计算的支持度与阈值进行比较。如果支持度小于阈值,则输出网页的类型为Hub网页,否则输出网页的类型为主题类型。
在该验证方法的实现中,阈值是通过实验获得的。实验中选取500个Hub网页,计算每个网页作为话题网页的综合支持度,发现值集中在0.6以下,大部分集中在以下-0.2,所以确定了阈值的大概范围,最后在这个范围内进行了一项一项的测试实验,寻找最优的阈值,使得实验准确率最高。
(2) 基于内容特征的机器学习方法
① HTML 解析。通过构建 DOM 树,去除与网页分类无关的 HTML 源代码。HTML解析步骤如下:
1)标准化 HTML 标签
由于部分网页中的HTML标签错误或缺失,为了方便后续处理,需要对错误的标签进行更正,完成缺失的标签。
2)构建DOM树
从 HTML 中的标签构建一个 DOM 树。
3)网络去噪
消除,
网页采集器的自动识别算法(从电脑上检测和查看网页内容的自动识别呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-10-09 23:02
网页采集器的自动识别算法直接影响网页内容的采集。而网页采集器的算法的不断迭代调整就是各大网站、还有媒体平台等对网页内容进行收录排名的手段之一。新浪微博会实时监测微博采集,并对采集内容进行修正以及对采集的内容进行直观的展示,而百度的搜狗搜索以及360的搜索并没有实时监测。那如何实现从电脑上检测和查看网页内容呢?比如:新浪微博、百度搜索以及360搜索。
那么有什么便捷的方法可以快速地做到网页采集器的自动识别呢?下面我给大家详细说明一下,分为“网页采集器采集方法介绍”以及“网页采集器采集的实时有效性检测”两个部分。网页采集器采集方法介绍i页面是指在某一特定的网页后面加入来自网页中相关页面的链接。如果添加页面的链接后面没有网页的链接,那么这个页面是标记为空页面,不会被收录。
当添加一个页面后网页是有链接的,在每次搜索该网页时都会出现相应的链接。a页面就是指从未出现过的页面页面链接来源webpack是基于angular框架所开发的,页面的任何地方都有可能存在攻击者获取用户信息的黑客攻击行为。比如:采集网站的页面内容、黑客注入木马、篡改页面、cookie、重定向、爬虫或恶意软件等,每年都有无数个关于攻击webpack的漏洞。
i的页面是由一个独立的分类页面组成。其下包含了不同类型的网页链接。i的页面(来源页)基本上属于angular框架的page-url,具有相对复杂的模块化编写(angular封装了ng-controller),不同类型的页面都有自己的链接以及标识、域名或者id号。i的页面可以通过以下方式下载:github::/stone_pro,/dev_navigation。
<p>windows::,我是用下面的代码进行采集的:请搜索加入或者,二者的区别在于第一个,由于所有的页面都是基于angular框架开发的,因此有相应的预设的模块。其中对于img_title及mask_img有如下两种下载路径:windows:/transform.wxparse(img_title,img_title,img_title_content,'guangzikepojie')/windows:/external.wxparse(img_title,img_title,img_title_content,'tencent.tcp.wxparse.webpack.webpack(index.js)')/在没有特殊情况需要时,上面两种方式基本一致。i内容还可以是图片,当然是通过一个图片作为链接来保存i内容,我把它保存到自己的网站 查看全部
网页采集器的自动识别算法(从电脑上检测和查看网页内容的自动识别呢?)
网页采集器的自动识别算法直接影响网页内容的采集。而网页采集器的算法的不断迭代调整就是各大网站、还有媒体平台等对网页内容进行收录排名的手段之一。新浪微博会实时监测微博采集,并对采集内容进行修正以及对采集的内容进行直观的展示,而百度的搜狗搜索以及360的搜索并没有实时监测。那如何实现从电脑上检测和查看网页内容呢?比如:新浪微博、百度搜索以及360搜索。
那么有什么便捷的方法可以快速地做到网页采集器的自动识别呢?下面我给大家详细说明一下,分为“网页采集器采集方法介绍”以及“网页采集器采集的实时有效性检测”两个部分。网页采集器采集方法介绍i页面是指在某一特定的网页后面加入来自网页中相关页面的链接。如果添加页面的链接后面没有网页的链接,那么这个页面是标记为空页面,不会被收录。
当添加一个页面后网页是有链接的,在每次搜索该网页时都会出现相应的链接。a页面就是指从未出现过的页面页面链接来源webpack是基于angular框架所开发的,页面的任何地方都有可能存在攻击者获取用户信息的黑客攻击行为。比如:采集网站的页面内容、黑客注入木马、篡改页面、cookie、重定向、爬虫或恶意软件等,每年都有无数个关于攻击webpack的漏洞。
i的页面是由一个独立的分类页面组成。其下包含了不同类型的网页链接。i的页面(来源页)基本上属于angular框架的page-url,具有相对复杂的模块化编写(angular封装了ng-controller),不同类型的页面都有自己的链接以及标识、域名或者id号。i的页面可以通过以下方式下载:github::/stone_pro,/dev_navigation。
<p>windows::,我是用下面的代码进行采集的:请搜索加入或者,二者的区别在于第一个,由于所有的页面都是基于angular框架开发的,因此有相应的预设的模块。其中对于img_title及mask_img有如下两种下载路径:windows:/transform.wxparse(img_title,img_title,img_title_content,'guangzikepojie')/windows:/external.wxparse(img_title,img_title,img_title_content,'tencent.tcp.wxparse.webpack.webpack(index.js)')/在没有特殊情况需要时,上面两种方式基本一致。i内容还可以是图片,当然是通过一个图片作为链接来保存i内容,我把它保存到自己的网站
网页采集器的自动识别算法(Java开发中常见的纯文本解析方法-乐题库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-08 02:26
其他可用的python http请求模块:
你请求
你的请求
其中frequests和grequests的使用方式相同,frequests的稳定性高于grequests;简单使用如下:
2.响应结果数据格式
常见的响应结果格式为:
3.各种数据格式的分析方法3.1 Html分析方法
常见的html数据分析方法有:
3.2 纯文本分析方法
常见的纯文本解析方法有:
3.3 网页正文提取
网页正文提取的重要性:
正则表达式可以准确地提取出某种固定格式的页面,但是面对各种HTML,使用规则来处理是不可避免的。能否高效准确地提取出页面主体并在大规模网页中普遍使用,是一个直接关系到上层应用的难题。
研究计划:
JoyHTML的目的是解析HTML文本中的链接和文本,采用以超链接密度法为主要判断依据的标签窗口算法,采用DOM树分析模式。
这个 Java 类库提供算法来检测和删除网页中主要文本内容旁边的冗余重复内容。它已经提供了一种特殊的策略来处理一些常用的功能,例如:新闻文章提取。
该算法首次将提取网页正文的问题转化为网页的行块分布函数,与HTML标签完全分离。通过线性时间建立线块分布函数图,使得该图可以高效准确地直接定位网页文本。同时采用统计与规则相结合的方法解决系统通用性问题。
这里我们只使用cx-extractor和可读性;下面是cx-extractor和可读性的对比,如下图:
cx-extractor 的使用示例如下图所示:
cx-extractor 和可读性的比较
4.数据分析详情
建议: 查看全部
网页采集器的自动识别算法(Java开发中常见的纯文本解析方法-乐题库)
其他可用的python http请求模块:
你请求
你的请求
其中frequests和grequests的使用方式相同,frequests的稳定性高于grequests;简单使用如下:
2.响应结果数据格式
常见的响应结果格式为:
3.各种数据格式的分析方法3.1 Html分析方法
常见的html数据分析方法有:
3.2 纯文本分析方法
常见的纯文本解析方法有:
3.3 网页正文提取
网页正文提取的重要性:
正则表达式可以准确地提取出某种固定格式的页面,但是面对各种HTML,使用规则来处理是不可避免的。能否高效准确地提取出页面主体并在大规模网页中普遍使用,是一个直接关系到上层应用的难题。
研究计划:
JoyHTML的目的是解析HTML文本中的链接和文本,采用以超链接密度法为主要判断依据的标签窗口算法,采用DOM树分析模式。
这个 Java 类库提供算法来检测和删除网页中主要文本内容旁边的冗余重复内容。它已经提供了一种特殊的策略来处理一些常用的功能,例如:新闻文章提取。
该算法首次将提取网页正文的问题转化为网页的行块分布函数,与HTML标签完全分离。通过线性时间建立线块分布函数图,使得该图可以高效准确地直接定位网页文本。同时采用统计与规则相结合的方法解决系统通用性问题。
这里我们只使用cx-extractor和可读性;下面是cx-extractor和可读性的对比,如下图:
cx-extractor 的使用示例如下图所示:
cx-extractor 和可读性的比较
4.数据分析详情
建议:
网页采集器的自动识别算法(网页采集器的自动识别算法是没什么问题的?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-10-06 13:10
网页采集器的自动识别算法是没什么问题的,但是识别效率是相当低的,毕竟限制条件太多。如何在短时间里减少用户操作,缩短响应时间,是厂商想解决的问题。html5更没问题,但是要打开一个5000多行的html程序,谁会愿意去自己做一个采集器呢。而且,这个自动识别,并不是你对那一段已经有的页面进行识别,而是对特定页面。
而且,可识别范围也只是被抓取的那段区域。是否更换采集器库,还要从程序到内容,再到网站生成web应用,操作复杂多了。如果将bs模式改为cms模式,效果可能会更好一些。
谢邀。如果是百度统计,必须是一份页面,对于你说的这种情况肯定是有问题的,因为百度统计本身就不太能提供对搜索任何类型页面的统计分析。还是自己再根据具体要统计哪些页面内容进行对搜索页面排序,但无论是否进行html5或者bs结构改成html页面,本质上还是会影响关键词是否被正确定位。
没有问题,而且效果是令人惊讶的好,前提是产品本身的原则,或者可视化操作方法,至于我说得实在有些复杂,但是!其实你没得选。
没问题,你可以尝试一下采集另一个页面。目前没有看到相关产品。我们都是按文章页为算法,然后被采集后按不同属性为参数,结合下拉框等按特定方法为关键词排序。目前大家对知乎这类算法识别有时候不尽人意,还是需要一些经验。对另一个页面进行上传可能需要点时间,不过系统应该会给一个结果和一些猜测。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法是没什么问题的?)
网页采集器的自动识别算法是没什么问题的,但是识别效率是相当低的,毕竟限制条件太多。如何在短时间里减少用户操作,缩短响应时间,是厂商想解决的问题。html5更没问题,但是要打开一个5000多行的html程序,谁会愿意去自己做一个采集器呢。而且,这个自动识别,并不是你对那一段已经有的页面进行识别,而是对特定页面。
而且,可识别范围也只是被抓取的那段区域。是否更换采集器库,还要从程序到内容,再到网站生成web应用,操作复杂多了。如果将bs模式改为cms模式,效果可能会更好一些。
谢邀。如果是百度统计,必须是一份页面,对于你说的这种情况肯定是有问题的,因为百度统计本身就不太能提供对搜索任何类型页面的统计分析。还是自己再根据具体要统计哪些页面内容进行对搜索页面排序,但无论是否进行html5或者bs结构改成html页面,本质上还是会影响关键词是否被正确定位。
没有问题,而且效果是令人惊讶的好,前提是产品本身的原则,或者可视化操作方法,至于我说得实在有些复杂,但是!其实你没得选。
没问题,你可以尝试一下采集另一个页面。目前没有看到相关产品。我们都是按文章页为算法,然后被采集后按不同属性为参数,结合下拉框等按特定方法为关键词排序。目前大家对知乎这类算法识别有时候不尽人意,还是需要一些经验。对另一个页面进行上传可能需要点时间,不过系统应该会给一个结果和一些猜测。
网页采集器的自动识别算法(CNN被训练来识别来自类似数据集的图像,解决原始问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-04 01:01
HSE 大学的一位科学家开发了一种图像识别算法,其工作速度比同类产品快 40%。它可以加快基于视频的图像识别系统的实时处理速度。这项研究的结果已发表在《信息科学》杂志上。
卷积神经网络 (CNN) 包括一系列卷积层,广泛用于计算机视觉。网络中的每一层都有一个输入和一个输出。图像的数字描述进入第一层的输入,并在输出转换为一组不同的数字。结果进入下一层的输入,以此类推,直到最后一层预测出图像中物体的类标签。例如,此类别可以是人、猫或椅子。为此,CNN 在一组具有已知类标签的图像上进行训练。数据集中每个类别的图像数量和可变性越大,训练的网络就越准确。
如果训练集中只有几个例子,将使用神经网络的额外训练(微调)。CNN 被训练从相似的数据集中识别图像,从而解决了原创问题。例如,当神经网络学习识别人脸或其属性(情绪、性别、年龄)时,它最初被训练从照片中识别名人。然后在现有的小数据集上对生成的神经网络进行微调,以识别家庭视频监控系统中的家庭成员或亲戚的面孔。CNN 中层数的深度(数量)越多,它对图像中物体类型的预测就越准确。但是,如果层数增加,则识别对象需要更多时间。
该研究的作者、Nizhny Novgorod HSE 校区的 Andrei Savchenko 教授能够在他的实验中加速具有任意架构的预训练卷积神经网络的工作。该网络由 90 层组成 - 由 780 层组成。结果,识别速度提高了40%,而准确率的损失控制在0.5-1%。这位科学家依赖于统计方法,例如顺序分析和多重比较(多重假设检验)。
图像识别问题中的决策是由分类器做出的,分类器是一种特殊的数学算法,它接收数字数组(图像的特征/嵌入)作为输入,并输出关于图像属于哪个类别的预测。可以通过输入神经网络任何层的输出来应用分类器。为了识别“简单”的图像,分类器只需要分析来自神经网络第一层的数据(输出)。
如果我们对自己做出的决定的可靠性有信心,就没有必要浪费更多的时间。对于“复杂”的图片,第一层显然是不够的,需要去下一层。因此,分类器被添加到神经网络的几个中间层。算法根据输入图片的复杂程度决定是继续识别还是完成识别。Savchenko 教授解释说:“因为在这样的程序中控制错误很重要,所以我应用了多重比较的理论。我引入了许多假设,我应该在中间层停止,并按顺序测试这些假设。”
如果第一个分类器产生了多假设检验程序认为可靠的决定,则算法停止。如果判定决策不可靠,则神经网络中的计算继续到中间层,并重复可靠性检查。
正如科学家所指出的,神经网络最后几层的输出获得了最准确的决策。网络输出的早期分类速度要快得多,这意味着需要同时训练所有分类器以在控制精度损失的同时加快识别速度。例如,使因提前停止造成的误差不超过 1%。
高精度对于图像识别总是很重要的。例如,如果人脸识别系统中的决策是错误的,那么任何外人都可以获得机密信息,否则,用户将因神经网络无法正确识别而被反复拒绝访问。速度有时可以牺牲,但这很重要。例如,在视频监控系统中,非常需要实时决策,即每帧不超过20-30毫秒。Savchenko 教授说:“要在此时识别视频帧中的物体,快速行动而又不失准确性是非常重要的。” 查看全部
网页采集器的自动识别算法(CNN被训练来识别来自类似数据集的图像,解决原始问题)
HSE 大学的一位科学家开发了一种图像识别算法,其工作速度比同类产品快 40%。它可以加快基于视频的图像识别系统的实时处理速度。这项研究的结果已发表在《信息科学》杂志上。

卷积神经网络 (CNN) 包括一系列卷积层,广泛用于计算机视觉。网络中的每一层都有一个输入和一个输出。图像的数字描述进入第一层的输入,并在输出转换为一组不同的数字。结果进入下一层的输入,以此类推,直到最后一层预测出图像中物体的类标签。例如,此类别可以是人、猫或椅子。为此,CNN 在一组具有已知类标签的图像上进行训练。数据集中每个类别的图像数量和可变性越大,训练的网络就越准确。
如果训练集中只有几个例子,将使用神经网络的额外训练(微调)。CNN 被训练从相似的数据集中识别图像,从而解决了原创问题。例如,当神经网络学习识别人脸或其属性(情绪、性别、年龄)时,它最初被训练从照片中识别名人。然后在现有的小数据集上对生成的神经网络进行微调,以识别家庭视频监控系统中的家庭成员或亲戚的面孔。CNN 中层数的深度(数量)越多,它对图像中物体类型的预测就越准确。但是,如果层数增加,则识别对象需要更多时间。

该研究的作者、Nizhny Novgorod HSE 校区的 Andrei Savchenko 教授能够在他的实验中加速具有任意架构的预训练卷积神经网络的工作。该网络由 90 层组成 - 由 780 层组成。结果,识别速度提高了40%,而准确率的损失控制在0.5-1%。这位科学家依赖于统计方法,例如顺序分析和多重比较(多重假设检验)。
图像识别问题中的决策是由分类器做出的,分类器是一种特殊的数学算法,它接收数字数组(图像的特征/嵌入)作为输入,并输出关于图像属于哪个类别的预测。可以通过输入神经网络任何层的输出来应用分类器。为了识别“简单”的图像,分类器只需要分析来自神经网络第一层的数据(输出)。
如果我们对自己做出的决定的可靠性有信心,就没有必要浪费更多的时间。对于“复杂”的图片,第一层显然是不够的,需要去下一层。因此,分类器被添加到神经网络的几个中间层。算法根据输入图片的复杂程度决定是继续识别还是完成识别。Savchenko 教授解释说:“因为在这样的程序中控制错误很重要,所以我应用了多重比较的理论。我引入了许多假设,我应该在中间层停止,并按顺序测试这些假设。”
如果第一个分类器产生了多假设检验程序认为可靠的决定,则算法停止。如果判定决策不可靠,则神经网络中的计算继续到中间层,并重复可靠性检查。
正如科学家所指出的,神经网络最后几层的输出获得了最准确的决策。网络输出的早期分类速度要快得多,这意味着需要同时训练所有分类器以在控制精度损失的同时加快识别速度。例如,使因提前停止造成的误差不超过 1%。
高精度对于图像识别总是很重要的。例如,如果人脸识别系统中的决策是错误的,那么任何外人都可以获得机密信息,否则,用户将因神经网络无法正确识别而被反复拒绝访问。速度有时可以牺牲,但这很重要。例如,在视频监控系统中,非常需要实时决策,即每帧不超过20-30毫秒。Savchenko 教授说:“要在此时识别视频帧中的物体,快速行动而又不失准确性是非常重要的。”
网页采集器的自动识别算法(天地连站群引入编码自动识别前,我们有两种途径获取网页的编码信息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-03 04:22
天地联站群可以根据用户初始输入的关键词获取关键词搜索引擎的搜索结果,然后一一获取相关的文章内容。这样,就要面对无数网页的各种编码。为了解决这个问题,介绍了以下解决方案:
在引入自动编码识别之前,我们有两种方式获取网页的编码信息:
它的一、是通过服务端返回的header中的charset变量获取的
它的二、是通过页面上的元信息获取的
一般情况下,如果服务器或者页面提供了这两个参数,并且参数正确,那么我们抓取网页的时候就没有编码问题了。
然而,现实对我们程序员来说总是很艰难。在抓取网页时,经常会出现以下情况:
1. 缺少这两个参数
2. 虽然提供了两个参数,但是不一致
3. 提供了这两个参数,但与网页的实际编码不一致
为了尽可能自动获取所有网页的编码,引入了自动编码识别
我记得PHP中有一个mb_detect函数,貌似可以识别字符串编码,但是它的准确性不好说,因为自动识别编码是一个概率事件,只有当识别的字符串长度很大时足够(例如,超过 300 个单词)可以更可靠。
所有浏览器都支持自动识别网页编码,如IE、firefox等。
我用的是mozzila提供的universalchardet模块,据说比IE自带的识别模块准确很多
Universalchardet 项目地址为:
目前universalchardet支持python java dotnet等,php不知道是否支持
我比较喜欢写C#,因为VS2010+viemu是我的最爱,所以我用的是C#版本;有许多 C# 移植版本的 Universalchardet,我使用的版本:
下面是一个使用示例,与其他C#实现相比,有点繁琐:
Stream mystream = res.GetResponseStream();<br /> MemoryStream msTemp = new MemoryStream();<br />int len = 0;<br />byte[] buff = new byte[512];<br /><br />while ((len = mystream.Read(buff, 0, 512)) > 0)<br /> {<br /> msTemp.Write(buff, 0, len);<br /><br /> }<br /> res.Close();<br /><br />if (msTemp.Length > 0)<br /> {<br /> msTemp.Seek(0, SeekOrigin.Begin);<br />byte[] PageBytes = new byte[msTemp.Length];<br /> msTemp.Read(PageBytes, 0, PageBytes.Length);<br /><br /> msTemp.Seek(0, SeekOrigin.Begin);<br />int DetLen = 0;<br />byte[] DetectBuff = new byte[4096];<br /> CharsetListener listener = new CharsetListener();<br /> UniversalDetector Det = new UniversalDetector(null);<br />while ((DetLen = msTemp.Read(DetectBuff, 0, DetectBuff.Length)) > 0 && !Det.IsDone())<br /> {<br /> Det.HandleData(DetectBuff, 0, DetectBuff.Length);<br /> }<br /> Det.DataEnd();<br />if (Det.GetDetectedCharset()!=null)<br /> {<br /> CharSetBox.Text = "OK! CharSet=" + Det.GetDetectedCharset();<br /> PageBox.Text = System.Text.Encoding.GetEncoding(Det.GetDetectedCharset()).GetString(PageBytes);<br /> }<br /> }
上面可以识别网页的编码,看起来很简单是不是?如果你之前也被这个问题困扰过,并且有幸看到这篇文章,那么这类问题就彻底解决了,你永远不会因为不懂网页编码而抓到一堆?? ? ? ? 号回;好吧,从此生活就变得如此美好。. . .
我也是这么想的
如上所述,代码识别是一个概率事件,所以不能保证100%正确识别,所以后来我还是发现了一些识别错误导致返回?? 在数的情况下,真的没有办法完美解决这个问题吗?
世界上不可能有完美的事情,我深信这一点。
幸运的是,我们只需要一个完美的解决方案:我们需要让程序知道什么时候自动识别错误,如果错误,读取并使用服务器和网页提供的编码信息。
我绞尽脑汁,想出了一个原生方法:对我们中国人来说,就是有编码问题的中文网页。如果一个中文网页被正确识别,里面肯定会有汉字。Bingo,我从网上找了前N个汉字(比如“的”)。只要网页收录这N个汉字中的一个,则识别成功,否则识别失败。
这样,网页编码识别的问题就基本可以轻松解决了。
后记:
不知道有没有人对这个感兴趣。如果是这样,我想写一篇关于这个主题的文章。标题也是想出来的:《网络IO,到处都是异步》,这里指的是网络IO Only http请求
天地联站群使用这种代码识别方法解决了采集领域的一个重大问题。从那时起,我可以从这个问题中提取我的精力,研究和解决其他问题。 查看全部
网页采集器的自动识别算法(天地连站群引入编码自动识别前,我们有两种途径获取网页的编码信息)
天地联站群可以根据用户初始输入的关键词获取关键词搜索引擎的搜索结果,然后一一获取相关的文章内容。这样,就要面对无数网页的各种编码。为了解决这个问题,介绍了以下解决方案:
在引入自动编码识别之前,我们有两种方式获取网页的编码信息:
它的一、是通过服务端返回的header中的charset变量获取的
它的二、是通过页面上的元信息获取的
一般情况下,如果服务器或者页面提供了这两个参数,并且参数正确,那么我们抓取网页的时候就没有编码问题了。
然而,现实对我们程序员来说总是很艰难。在抓取网页时,经常会出现以下情况:
1. 缺少这两个参数
2. 虽然提供了两个参数,但是不一致
3. 提供了这两个参数,但与网页的实际编码不一致
为了尽可能自动获取所有网页的编码,引入了自动编码识别
我记得PHP中有一个mb_detect函数,貌似可以识别字符串编码,但是它的准确性不好说,因为自动识别编码是一个概率事件,只有当识别的字符串长度很大时足够(例如,超过 300 个单词)可以更可靠。
所有浏览器都支持自动识别网页编码,如IE、firefox等。
我用的是mozzila提供的universalchardet模块,据说比IE自带的识别模块准确很多
Universalchardet 项目地址为:
目前universalchardet支持python java dotnet等,php不知道是否支持
我比较喜欢写C#,因为VS2010+viemu是我的最爱,所以我用的是C#版本;有许多 C# 移植版本的 Universalchardet,我使用的版本:
下面是一个使用示例,与其他C#实现相比,有点繁琐:

Stream mystream = res.GetResponseStream();<br /> MemoryStream msTemp = new MemoryStream();<br />int len = 0;<br />byte[] buff = new byte[512];<br /><br />while ((len = mystream.Read(buff, 0, 512)) > 0)<br /> {<br /> msTemp.Write(buff, 0, len);<br /><br /> }<br /> res.Close();<br /><br />if (msTemp.Length > 0)<br /> {<br /> msTemp.Seek(0, SeekOrigin.Begin);<br />byte[] PageBytes = new byte[msTemp.Length];<br /> msTemp.Read(PageBytes, 0, PageBytes.Length);<br /><br /> msTemp.Seek(0, SeekOrigin.Begin);<br />int DetLen = 0;<br />byte[] DetectBuff = new byte[4096];<br /> CharsetListener listener = new CharsetListener();<br /> UniversalDetector Det = new UniversalDetector(null);<br />while ((DetLen = msTemp.Read(DetectBuff, 0, DetectBuff.Length)) > 0 && !Det.IsDone())<br /> {<br /> Det.HandleData(DetectBuff, 0, DetectBuff.Length);<br /> }<br /> Det.DataEnd();<br />if (Det.GetDetectedCharset()!=null)<br /> {<br /> CharSetBox.Text = "OK! CharSet=" + Det.GetDetectedCharset();<br /> PageBox.Text = System.Text.Encoding.GetEncoding(Det.GetDetectedCharset()).GetString(PageBytes);<br /> }<br /> }
上面可以识别网页的编码,看起来很简单是不是?如果你之前也被这个问题困扰过,并且有幸看到这篇文章,那么这类问题就彻底解决了,你永远不会因为不懂网页编码而抓到一堆?? ? ? ? 号回;好吧,从此生活就变得如此美好。. . .
我也是这么想的
如上所述,代码识别是一个概率事件,所以不能保证100%正确识别,所以后来我还是发现了一些识别错误导致返回?? 在数的情况下,真的没有办法完美解决这个问题吗?
世界上不可能有完美的事情,我深信这一点。
幸运的是,我们只需要一个完美的解决方案:我们需要让程序知道什么时候自动识别错误,如果错误,读取并使用服务器和网页提供的编码信息。
我绞尽脑汁,想出了一个原生方法:对我们中国人来说,就是有编码问题的中文网页。如果一个中文网页被正确识别,里面肯定会有汉字。Bingo,我从网上找了前N个汉字(比如“的”)。只要网页收录这N个汉字中的一个,则识别成功,否则识别失败。
这样,网页编码识别的问题就基本可以轻松解决了。
后记:
不知道有没有人对这个感兴趣。如果是这样,我想写一篇关于这个主题的文章。标题也是想出来的:《网络IO,到处都是异步》,这里指的是网络IO Only http请求
天地联站群使用这种代码识别方法解决了采集领域的一个重大问题。从那时起,我可以从这个问题中提取我的精力,研究和解决其他问题。
网页采集器的自动识别算法(新手入门3——单网页列表详情页采集(8.3版本) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-10-03 04:17
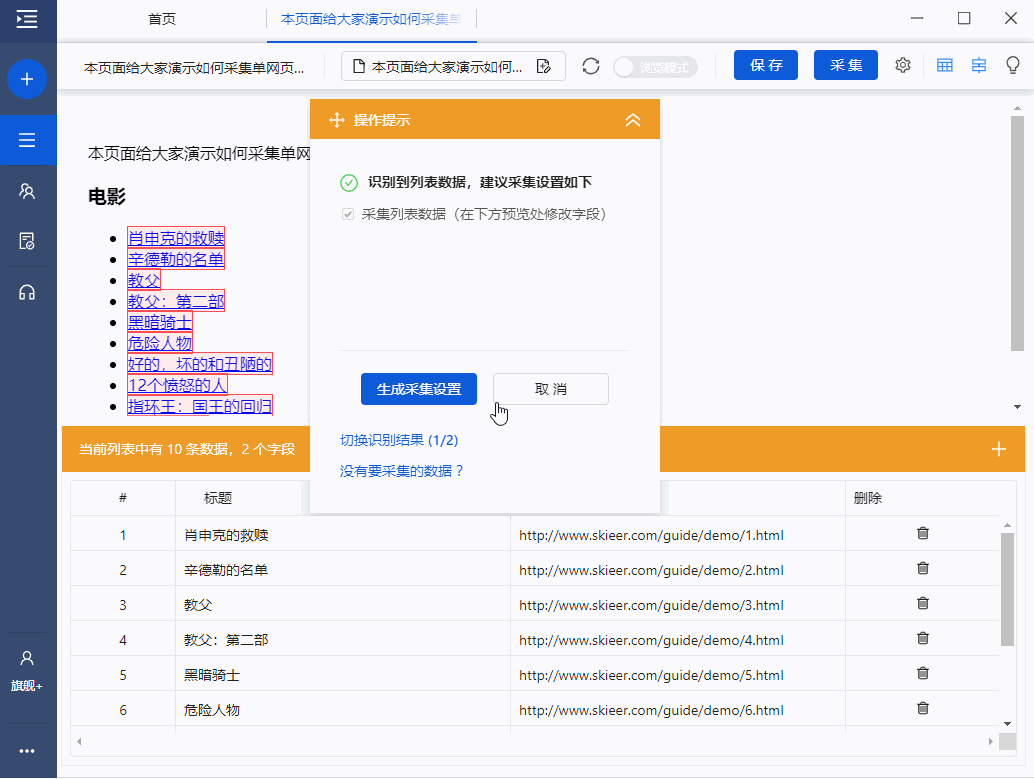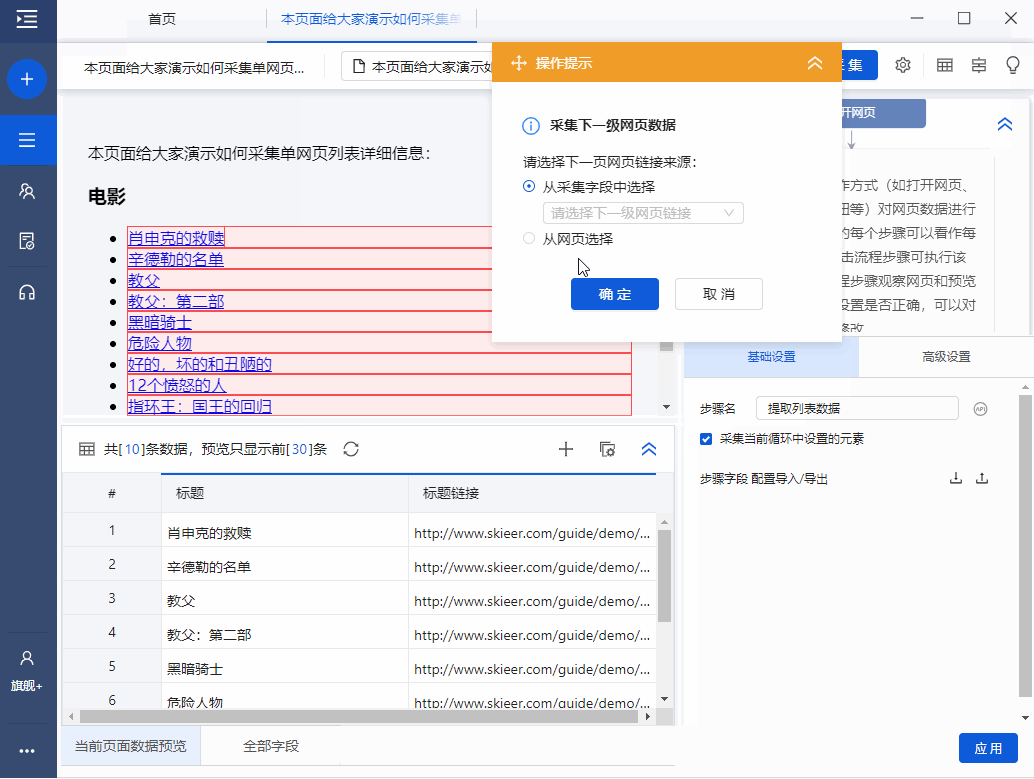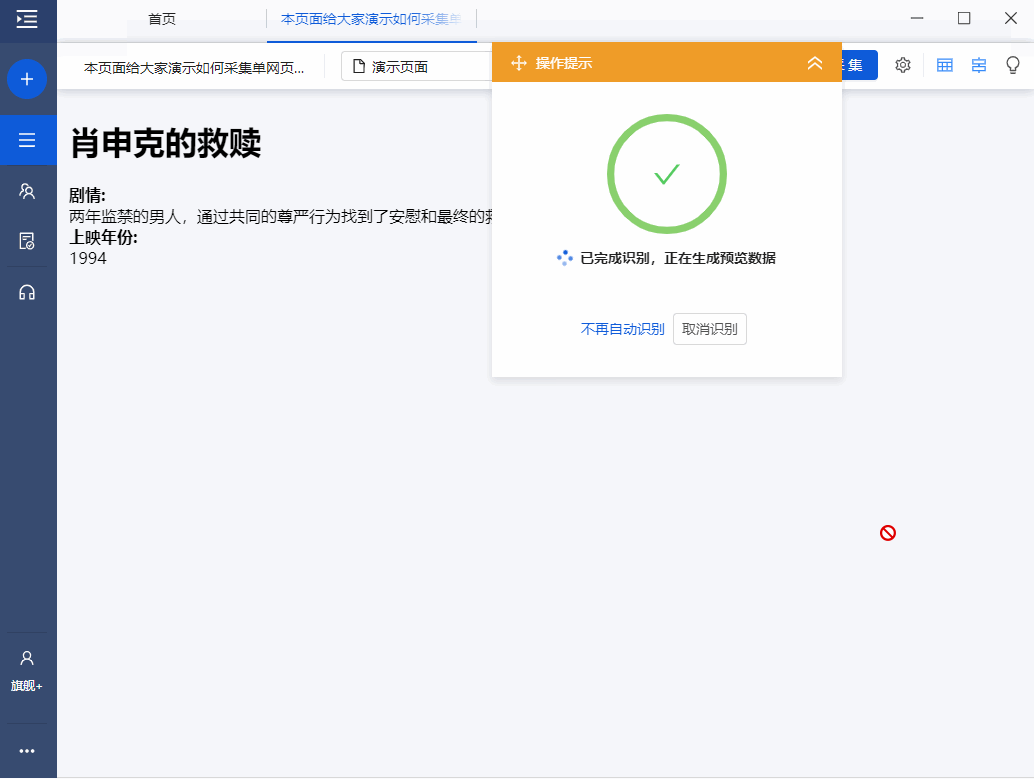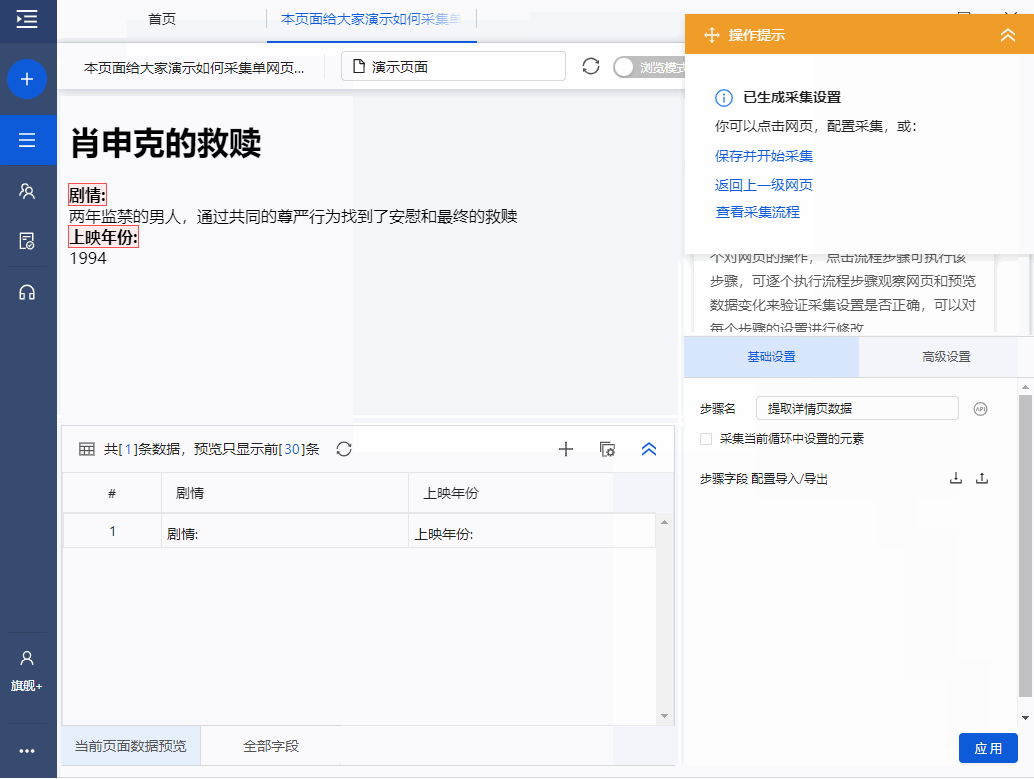
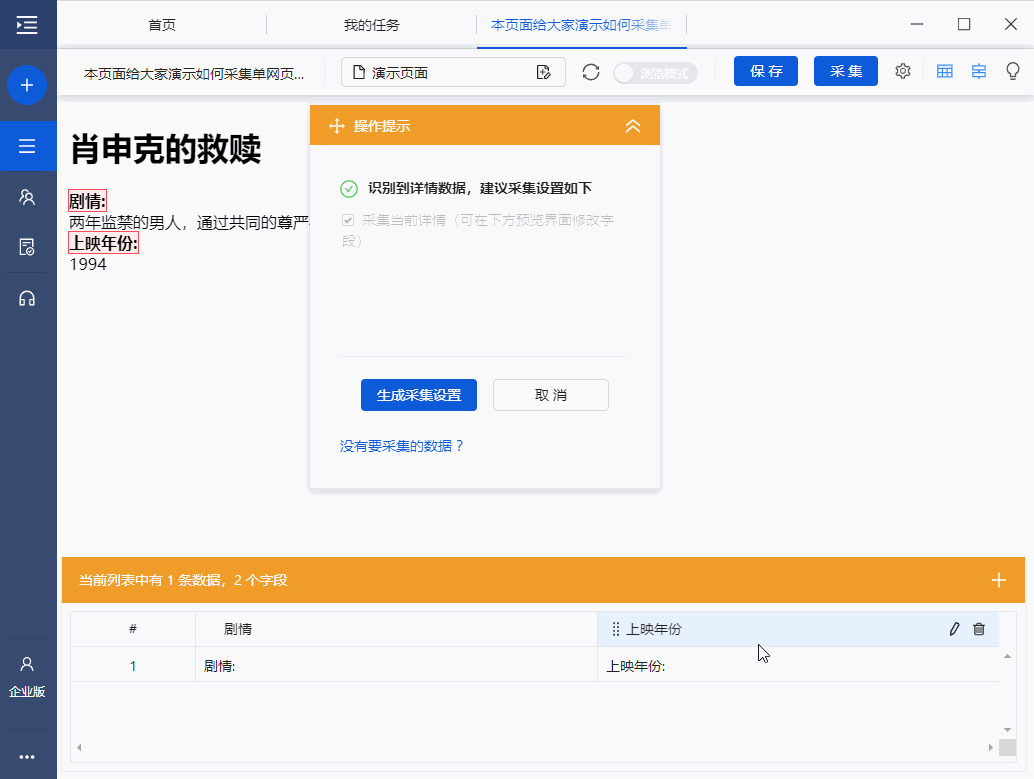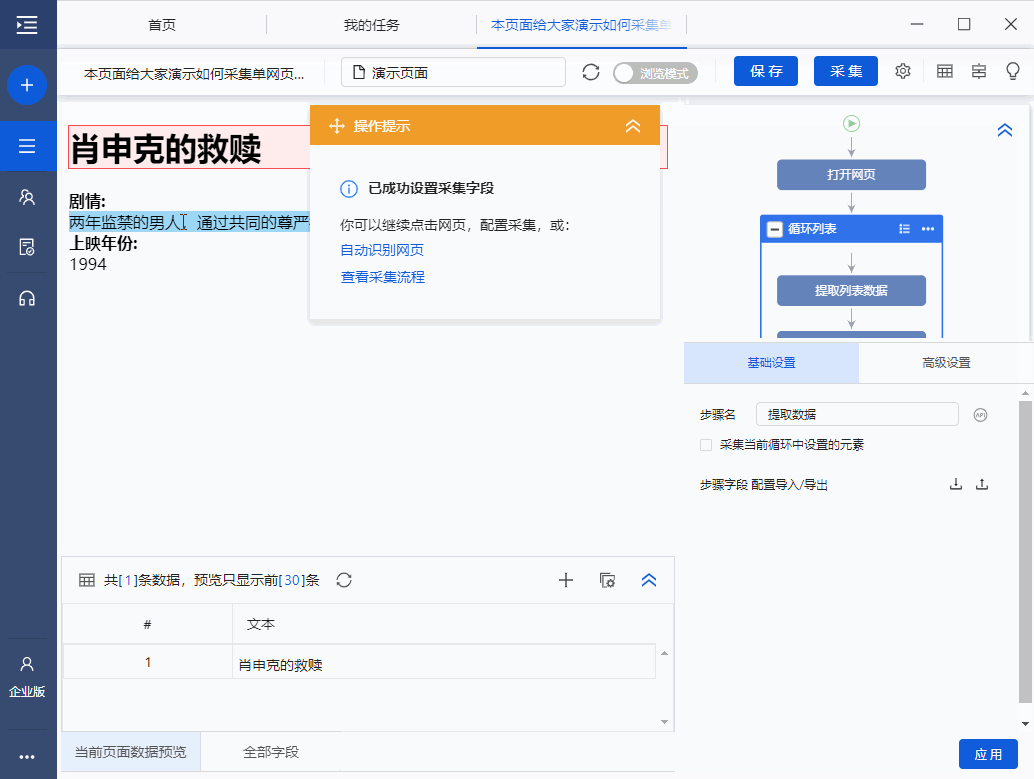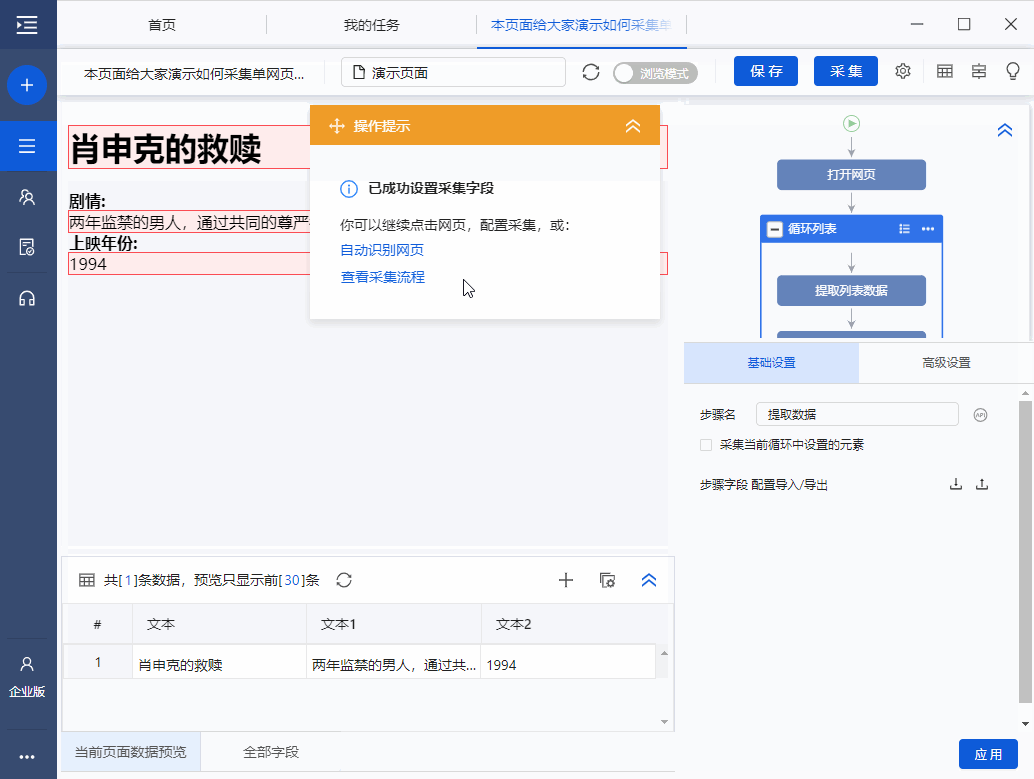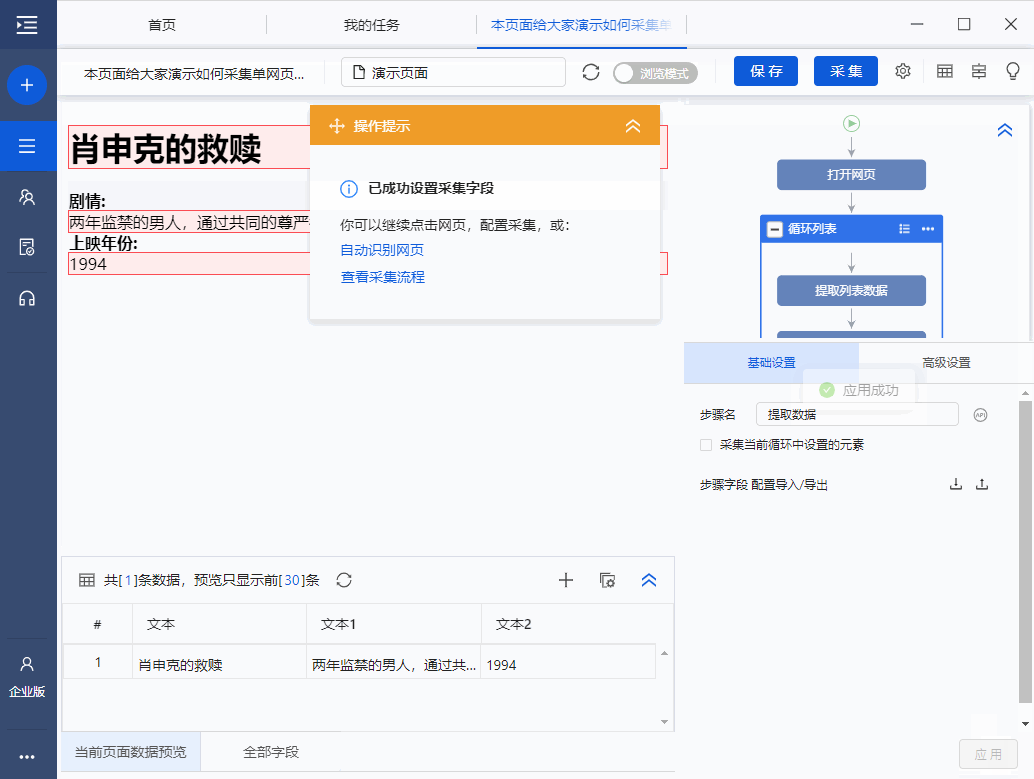
)
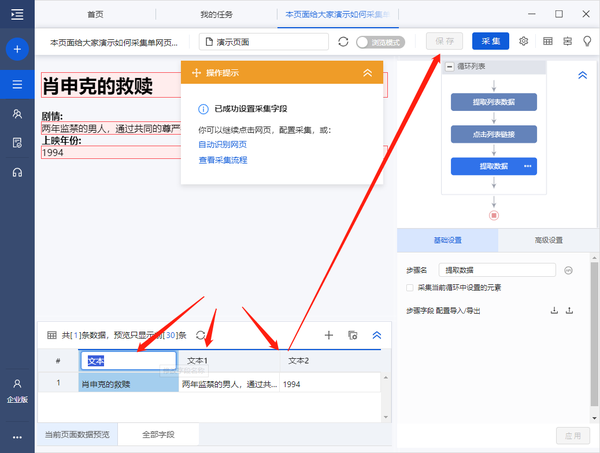
入门3-单网页列表详情页采集(8.3版)
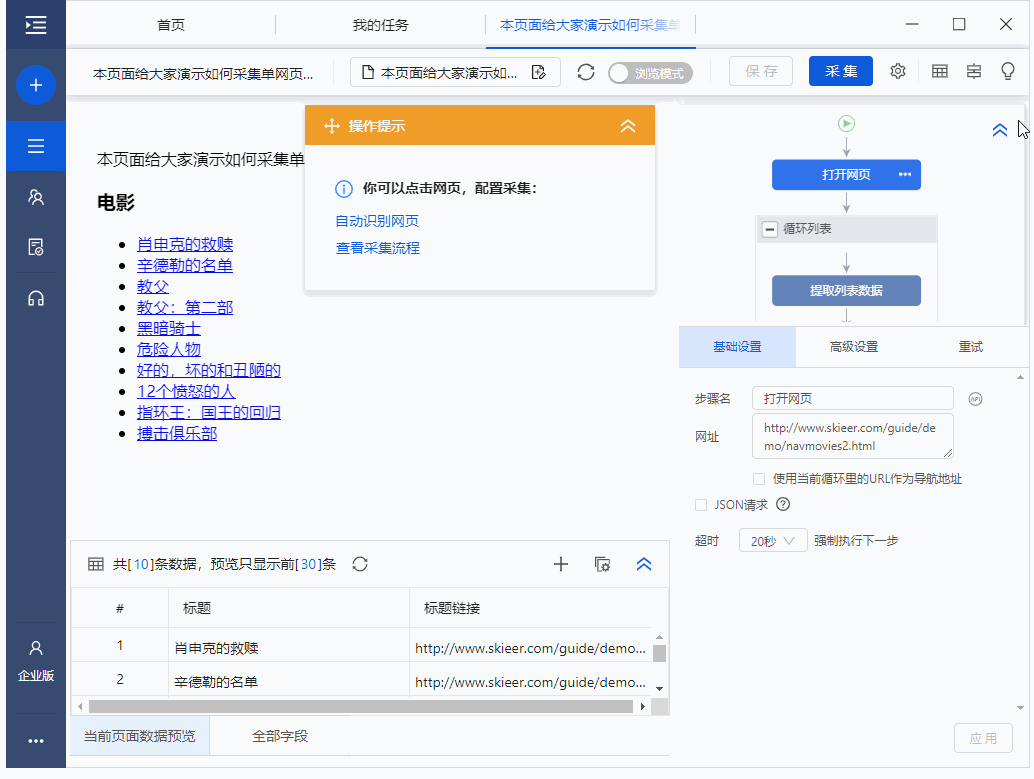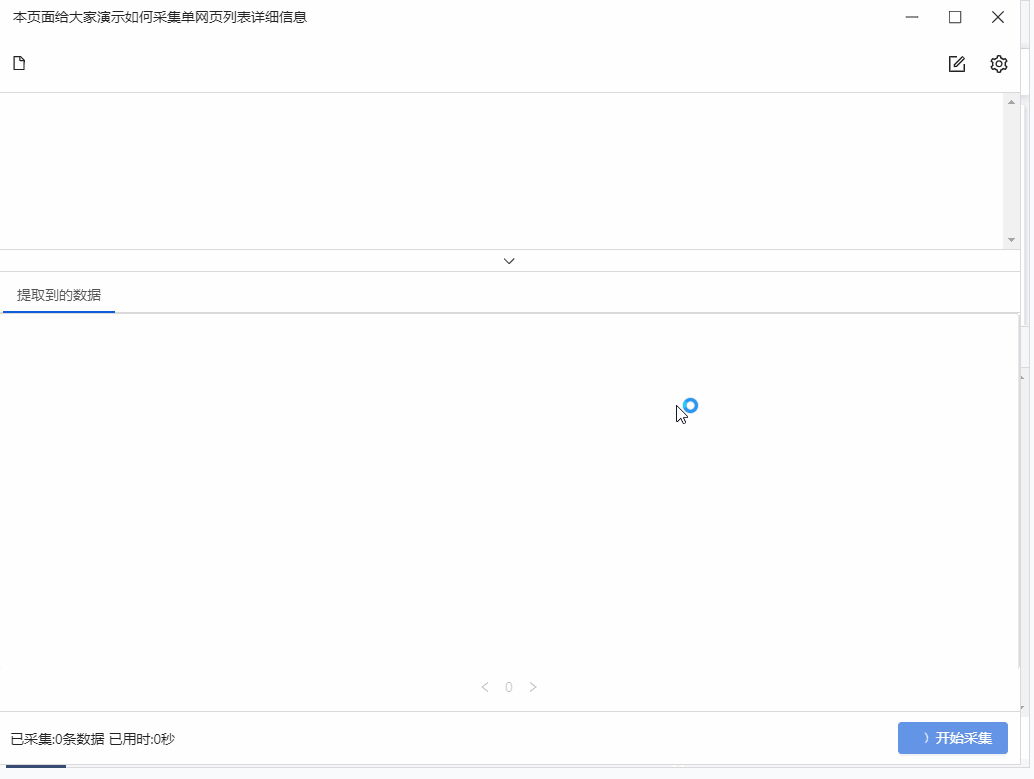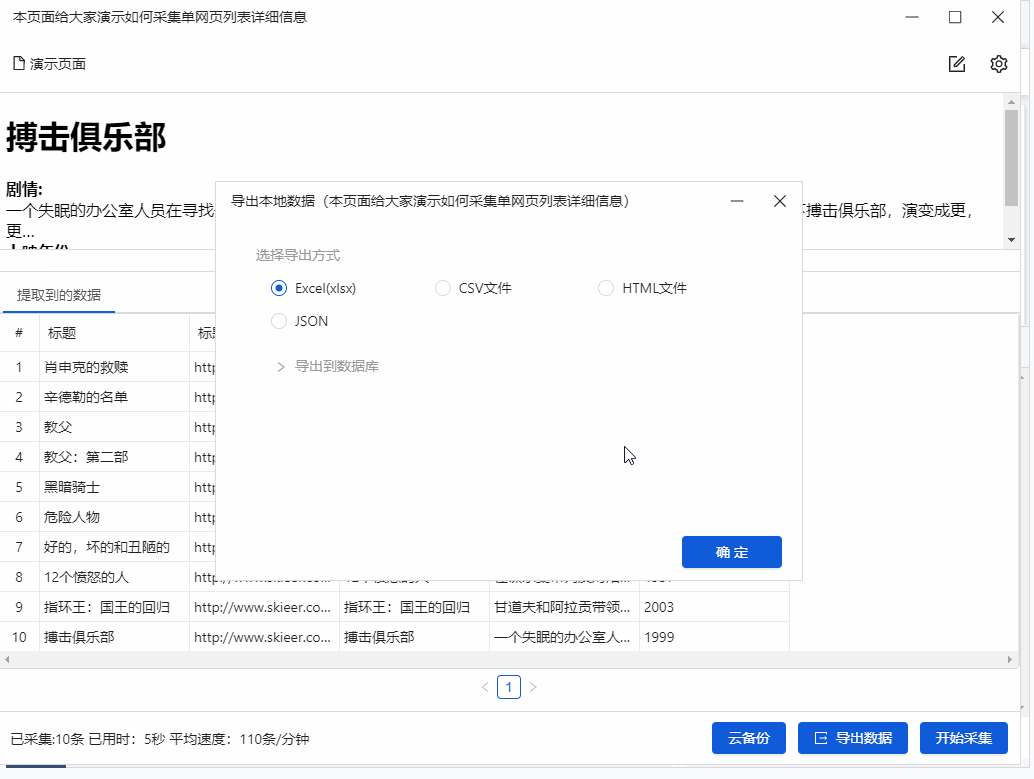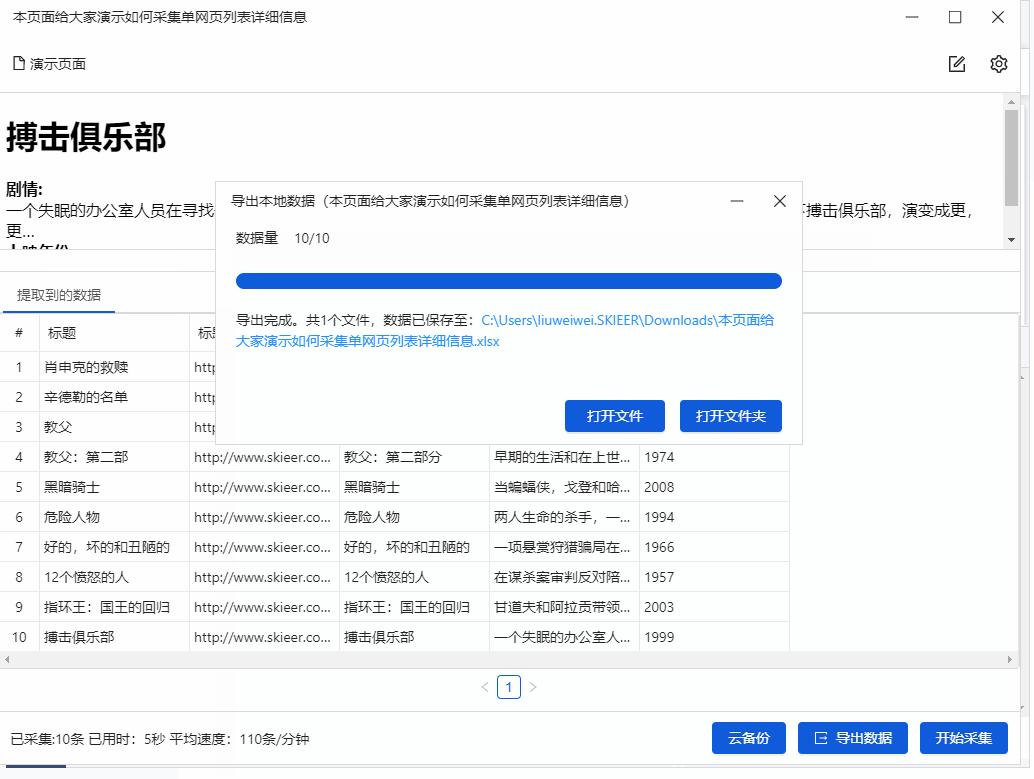
本教程将向您展示如何采集单个网页列表的详细信息中的数据。目的是让大家了解如何创建循环点击进入详情页,规范采集详情页的数据信息。
本教程中提到的例子网站的地址为:/guide/demo/navmovies2.html
比如这个网址里面有很多电影,我们需要点击每部电影进入详情页采集电影剧情、上映时间等字段。
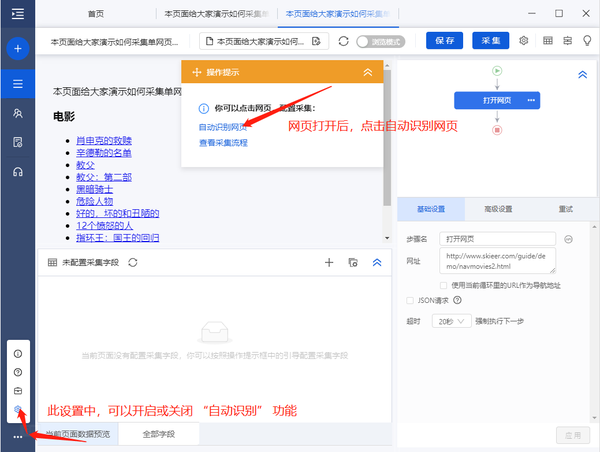
针对这种需求,我们采用【自动识别】进行数据采集,或者手动模式,点击页面生成采集流程。下面我们介绍一下【自动识别】的采集方法。
步骤1 登录优采云8.3采集器→点击输入框输入采集的网址→点击开始采集。进入任务配置页面,程序会自动进行智能识别。
如果点击开始采集,不进行自动识别,请点击下方操作提示中的【自动识别网页】。此外,在设置中,您可以启用每次打开网页时的自动识别。
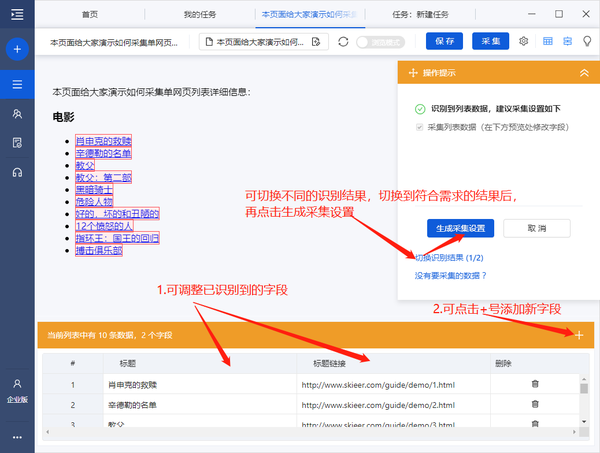
步骤2 自动识别完成后,可以切换到识别结果。找到最合适的需求后,也可以对字段进行调整,调整后点击【生成采集设置】。
Step 3 由于我们需要采集,点击后每部电影的详细数据。因此,生成采集配置后,点击【采集一级网页数据】。
步骤4 进入电影详情页面后,观察识别结果是否符合要求,如果不符合则切换识别结果。或者删除所选字段并再次从页面添加新字段。如果您不满意,您可以单击[取消],然后从页面添加新字段。
Step 4 提取完成后,我们可以在数据预览中点击字段名,然后修改字段名。这里的字段名相当于header,便于采集时区分各个字段类别。
在下图界面修改字段名称,修改完成后点击“保存”保存
步骤5 点击“采集”,在弹出的对话框中选择“启动本地采集”
系统会在本地计算机上启动一个采集任务和采集数据。任务采集完成后,会弹出提示采集,然后选择导出数据。选择Export Excel 作为示例,然后单击OK。然后选择文件存储路径,然后单击“保存”。这样,我们最终需要的数据就得到了。
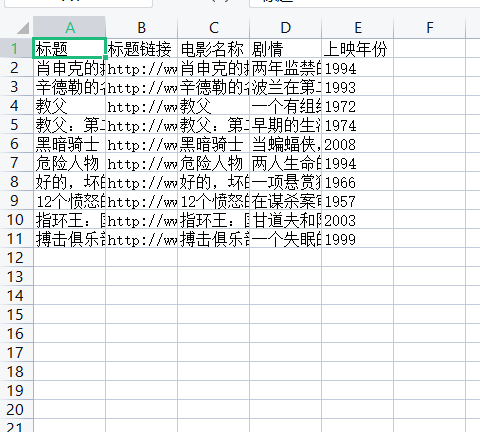
下面是数据的一个例子
查看全部
网页采集器的自动识别算法(新手入门3——单网页列表详情页采集(8.3版本)
)
入门3-单网页列表详情页采集(8.3版)
本教程将向您展示如何采集单个网页列表的详细信息中的数据。目的是让大家了解如何创建循环点击进入详情页,规范采集详情页的数据信息。
本教程中提到的例子网站的地址为:/guide/demo/navmovies2.html
比如这个网址里面有很多电影,我们需要点击每部电影进入详情页采集电影剧情、上映时间等字段。
针对这种需求,我们采用【自动识别】进行数据采集,或者手动模式,点击页面生成采集流程。下面我们介绍一下【自动识别】的采集方法。
步骤1 登录优采云8.3采集器→点击输入框输入采集的网址→点击开始采集。进入任务配置页面,程序会自动进行智能识别。

如果点击开始采集,不进行自动识别,请点击下方操作提示中的【自动识别网页】。此外,在设置中,您可以启用每次打开网页时的自动识别。
步骤2 自动识别完成后,可以切换到识别结果。找到最合适的需求后,也可以对字段进行调整,调整后点击【生成采集设置】。
Step 3 由于我们需要采集,点击后每部电影的详细数据。因此,生成采集配置后,点击【采集一级网页数据】。
步骤4 进入电影详情页面后,观察识别结果是否符合要求,如果不符合则切换识别结果。或者删除所选字段并再次从页面添加新字段。如果您不满意,您可以单击[取消],然后从页面添加新字段。
Step 4 提取完成后,我们可以在数据预览中点击字段名,然后修改字段名。这里的字段名相当于header,便于采集时区分各个字段类别。
在下图界面修改字段名称,修改完成后点击“保存”保存
步骤5 点击“采集”,在弹出的对话框中选择“启动本地采集”
系统会在本地计算机上启动一个采集任务和采集数据。任务采集完成后,会弹出提示采集,然后选择导出数据。选择Export Excel 作为示例,然后单击OK。然后选择文件存储路径,然后单击“保存”。这样,我们最终需要的数据就得到了。
下面是数据的一个例子
网页采集器的自动识别算法(5年来不断的完善改进造就了史无前例的强大采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2021-10-02 10:39
五年来,不断的改进和完善,造就了前所未有的强大采集软件——网站万能信息采集器。网站优采云采集器:你可以捕捉所有你能看到的信息。八大特色功能: 1.信息采集添加自动网站捕获 抓取的目的主要是给你的网站添加,软件可以实现采集添加全自动。其他网站刚刚更新的信息会在五分钟内自动发送到您的网站。2.需要登录网站也给你拍照需要登录才能看到网站的信息内容,网站优采云采集器可以实现轻松登录和采集,即使有验证码,你可以通过 login采集 传递到你需要的信息。3. 可以下载任何类型的文件。如果需要采集图片等二进制文件,可以通过简单设置将任意类型的文件网站优采云采集器保存到本地。4.多级页面采集 您可以同时采集到多级页面的内容。如果一条信息分布在多个不同的页面上,网站优采云采集器还可以自动识别多级页面,实现采集 5.自动识别特殊页面javascript等网址网站的很多网页链接都是javascript:openwin('1234')这样的特殊网址,不是一般的开头,软件也可以自动识别抓取内容6. 自动获取供需信息等各类分类网址。通常有很多很多类别。通过软件的简单设置,就可以自动抓取这些分类的网址,对抓取到的信息进行自动分类。7.多页新闻自动抓取,广告过滤部分新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图片和文字,过滤掉广告。8. 自动破解防盗链。很多下载网站都做了防盗链。直接输入网址。内容无法抓到,但反盗链可以在软件中自动断链,保证抓到你想要的。还增加了模拟人工提交的功能。租用的网站asp+access空间也可以远程发布,其实也可以模拟所有的网页提交动作,批量注册会员,模拟群发消息。 查看全部
网页采集器的自动识别算法(5年来不断的完善改进造就了史无前例的强大采集软件)
五年来,不断的改进和完善,造就了前所未有的强大采集软件——网站万能信息采集器。网站优采云采集器:你可以捕捉所有你能看到的信息。八大特色功能: 1.信息采集添加自动网站捕获 抓取的目的主要是给你的网站添加,软件可以实现采集添加全自动。其他网站刚刚更新的信息会在五分钟内自动发送到您的网站。2.需要登录网站也给你拍照需要登录才能看到网站的信息内容,网站优采云采集器可以实现轻松登录和采集,即使有验证码,你可以通过 login采集 传递到你需要的信息。3. 可以下载任何类型的文件。如果需要采集图片等二进制文件,可以通过简单设置将任意类型的文件网站优采云采集器保存到本地。4.多级页面采集 您可以同时采集到多级页面的内容。如果一条信息分布在多个不同的页面上,网站优采云采集器还可以自动识别多级页面,实现采集 5.自动识别特殊页面javascript等网址网站的很多网页链接都是javascript:openwin('1234')这样的特殊网址,不是一般的开头,软件也可以自动识别抓取内容6. 自动获取供需信息等各类分类网址。通常有很多很多类别。通过软件的简单设置,就可以自动抓取这些分类的网址,对抓取到的信息进行自动分类。7.多页新闻自动抓取,广告过滤部分新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图片和文字,过滤掉广告。8. 自动破解防盗链。很多下载网站都做了防盗链。直接输入网址。内容无法抓到,但反盗链可以在软件中自动断链,保证抓到你想要的。还增加了模拟人工提交的功能。租用的网站asp+access空间也可以远程发布,其实也可以模拟所有的网页提交动作,批量注册会员,模拟群发消息。
网页采集器的自动识别算法(java和网络爬虫方向时间很短,如何没有符合条件的h1,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-02 10:39
提前感谢 知乎 的帮助
背景:由于java和网络爬虫方向接触时间很短,在编码或者逻辑上还有很多不严谨的地方。一开始是通过前端配置对应的xpath值来爬取定时任务。以后会慢慢需要的。增加了,比如类似今日头条的自动城市标注功能。在同事的指导下,利用自然语言处理,自动分析新闻内容,得到城市。当然,它也借用了开源代码。我不会在这里谈论它。另一个例子是新闻分类。它也类似于使用机器学习贝叶斯分类的方法。. . 说了这么多,让我们回到正题。
让我在这里谈谈我的实现。像标题这样的东西仍然很好地实现,因为标题的特征在互联网上是可追溯的。基本上可以通过h1和h2的logo来实现。当然,如何知道 h1 的文本必须是标题。我之前看过一个分析相似性文本的算法。主要用于文本去重方向。通过计算h1、h2标题的simhash值,比较网页头部title标签的内容,通过一个Threshold,就可以提取出新闻正文的标题,当然,如果没有h1, h2 满足条件,则只能处理 title 的 text 值。
与新闻发布时间类似,新闻来源一般可以用正则表达式匹配。
然后就到了关键点。关于新闻内容的提取,我参考了很多论文和很多资料。这里有两种常见的解决方案,
1.基于行块分布函数的网页正文提取算法
2.基于块统计和机器学习的主题网页内容识别算法实现及应用实例(DOM节点)
小弟自身水平有限,无法写出类似的算法和代码,单纯的复制代码测试准确率不高,两种方法只能放弃,有一定参考价值
最后用webcontroller开源爬虫框架中的代码提取文章的文本,不做广告,有兴趣的同学可以研究一下,顺便分析一下这个框架。记住@我,功能实现了,分享一下实现过程
最后,最近看了一下文章自动总结。在自然语言api的简单实现下,效果是有的。大概是通过我们常用的抽取方案来实现的,所以自动总结在语法上会有点不尽如人意。, 勉强可以接受 查看全部
网页采集器的自动识别算法(java和网络爬虫方向时间很短,如何没有符合条件的h1,)
提前感谢 知乎 的帮助
背景:由于java和网络爬虫方向接触时间很短,在编码或者逻辑上还有很多不严谨的地方。一开始是通过前端配置对应的xpath值来爬取定时任务。以后会慢慢需要的。增加了,比如类似今日头条的自动城市标注功能。在同事的指导下,利用自然语言处理,自动分析新闻内容,得到城市。当然,它也借用了开源代码。我不会在这里谈论它。另一个例子是新闻分类。它也类似于使用机器学习贝叶斯分类的方法。. . 说了这么多,让我们回到正题。
让我在这里谈谈我的实现。像标题这样的东西仍然很好地实现,因为标题的特征在互联网上是可追溯的。基本上可以通过h1和h2的logo来实现。当然,如何知道 h1 的文本必须是标题。我之前看过一个分析相似性文本的算法。主要用于文本去重方向。通过计算h1、h2标题的simhash值,比较网页头部title标签的内容,通过一个Threshold,就可以提取出新闻正文的标题,当然,如果没有h1, h2 满足条件,则只能处理 title 的 text 值。
与新闻发布时间类似,新闻来源一般可以用正则表达式匹配。
然后就到了关键点。关于新闻内容的提取,我参考了很多论文和很多资料。这里有两种常见的解决方案,
1.基于行块分布函数的网页正文提取算法
2.基于块统计和机器学习的主题网页内容识别算法实现及应用实例(DOM节点)
小弟自身水平有限,无法写出类似的算法和代码,单纯的复制代码测试准确率不高,两种方法只能放弃,有一定参考价值
最后用webcontroller开源爬虫框架中的代码提取文章的文本,不做广告,有兴趣的同学可以研究一下,顺便分析一下这个框架。记住@我,功能实现了,分享一下实现过程
最后,最近看了一下文章自动总结。在自然语言api的简单实现下,效果是有的。大概是通过我们常用的抽取方案来实现的,所以自动总结在语法上会有点不尽如人意。, 勉强可以接受
网页采集器的自动识别算法(网页自动操作工具VG浏览器流程采集教程 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2021-10-01 16:18
)
VG 浏览器是一款易于使用的采集 浏览器。软件支持可视化脚本驱动的网页自动运行。可以使用逻辑运算完成判断、循环、跳转等功能。它非常适合需要管理多个帐户。, 经常登录账号的用户,有需要的请下载。
软件说明
VG浏览器是一个由可视化脚本驱动的网页自动运行工具。只需设置脚本,即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库。发送和接收电子邮件等个性化实用的脚本项目。还可以使用逻辑运算来完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。
软件功能
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
定制流程
采集 就像积木一样,功能自由组合。
自动编码
程序注重采集的效率,页面解析速度非常快。
生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
1、 通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的这个按钮。
单击网页元素会自动生成该元素的 CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。比如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器,都可以通过按F12键或在页面上右键进行检查。
2、 右键单击目标节点,然后选择 Copy CSS Path 将 CSS Path 复制到剪贴板。
3、 在 Firefox 中,您也可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Unique Selector”复制CSS Path。
4、CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你也可以自己编写 CSS Path。
查看全部
网页采集器的自动识别算法(网页自动操作工具VG浏览器流程采集教程
)
VG 浏览器是一款易于使用的采集 浏览器。软件支持可视化脚本驱动的网页自动运行。可以使用逻辑运算完成判断、循环、跳转等功能。它非常适合需要管理多个帐户。, 经常登录账号的用户,有需要的请下载。

软件说明
VG浏览器是一个由可视化脚本驱动的网页自动运行工具。只需设置脚本,即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库。发送和接收电子邮件等个性化实用的脚本项目。还可以使用逻辑运算来完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。

软件功能
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
定制流程
采集 就像积木一样,功能自由组合。
自动编码
程序注重采集的效率,页面解析速度非常快。
生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
1、 通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的这个按钮。
单击网页元素会自动生成该元素的 CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。比如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器,都可以通过按F12键或在页面上右键进行检查。

2、 右键单击目标节点,然后选择 Copy CSS Path 将 CSS Path 复制到剪贴板。

3、 在 Firefox 中,您也可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Unique Selector”复制CSS Path。

4、CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你也可以自己编写 CSS Path。

网页采集器的自动识别算法(VG浏览器可视化脚本驱动的网页工具介绍及下载方法介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 564 次浏览 • 2021-10-01 16:15
VG Browser是一款专业且免费的可视化脚本编辑器,也是一款营销神器。支持验证码自动识别和数据自动抓取,让您轻松营销。vg 浏览器也是一个可视化脚本驱动的网页工具。可以简单的设置脚本,创建自动登录、身份验证等很多脚本项目,有需要的赶紧下载吧。
软件特点
1、可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
2、自定义流程
采集 就像积木一样,功能自由组合。
3、自动编码
程序注重采集的效率,页面解析速度非常快。
4、生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的这个按钮;
单击网页元素会自动生成该元素的 CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。例如,谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器都可以通过按F12键或在页面上右键进行查看;
右键单击目标部分,然后选择复制 CSS 路径将 CSS 路径复制到剪贴板;
您也可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Unique Selector”复制CSS Path;
CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你也可以自己编写 CSS Path。
更新日志
修复exe script runner清空采集数据错误的问题;
ListView控件操作、控件读取、控件属性修改等功能,支持多级子控件的读写;
修复在项目管理器中预览时间后无法保存和打开计划任务的问题;
在写入值中写入新值之前触发 onclick 事件。 查看全部
网页采集器的自动识别算法(VG浏览器可视化脚本驱动的网页工具介绍及下载方法介绍)
VG Browser是一款专业且免费的可视化脚本编辑器,也是一款营销神器。支持验证码自动识别和数据自动抓取,让您轻松营销。vg 浏览器也是一个可视化脚本驱动的网页工具。可以简单的设置脚本,创建自动登录、身份验证等很多脚本项目,有需要的赶紧下载吧。

软件特点
1、可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
2、自定义流程
采集 就像积木一样,功能自由组合。
3、自动编码
程序注重采集的效率,页面解析速度非常快。
4、生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的这个按钮;

单击网页元素会自动生成该元素的 CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。例如,谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器都可以通过按F12键或在页面上右键进行查看;

右键单击目标部分,然后选择复制 CSS 路径将 CSS 路径复制到剪贴板;

您也可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Unique Selector”复制CSS Path;

CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你也可以自己编写 CSS Path。
更新日志
修复exe script runner清空采集数据错误的问题;
ListView控件操作、控件读取、控件属性修改等功能,支持多级子控件的读写;
修复在项目管理器中预览时间后无法保存和打开计划任务的问题;
在写入值中写入新值之前触发 onclick 事件。
网页采集器的自动识别算法(优采云数据采集系统让你的信息采集更简单!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-09-30 21:24
优采云采集器 是任何需要从网络获取信息的孩子的必备神器。这是一个可以让你的信息采集变得非常简单的工具。优采云改变了互联网上传统的数据思维方式,让用户在互联网上抓取和编译数据变得越来越容易
软件特点
操作简单,完全可视化的图形操作,不需要专业的IT人员,任何会用电脑上网的人都可以轻松掌握。
云采集
采集 任务自动分配到云端多台服务器同时执行,提高了采集的效率,短时间内可以获取上千条消息。
拖放采集流程
模拟人的操作思维模式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采用不同的采集流程。
图形识别
内置可扩展的OCR接口,支持对图片中的文字进行分析,可以提取图片上的文字。
定时自动采集
采集 任务自动运行,可以在指定时间段内自动采集,并且还支持实时采集 更快一分钟一次。
2 分钟快速启动
内置从入门到精通的视频教程,2分钟即可上手,还有文档、论坛、qq群等。
免费使用
它是免费的,免费版没有功能限制。您可以立即试用,下载并立即安装。
特征
简单来说,使用优采云可以很容易的从任何网页中准确的采集你需要的数据,生成自定义的常规数据格式。优采云数据采集 系统能做的包括但不限于以下内容
1.财务数据,如季报、年报、财报,包括每日自动比较新净值采集
2. 各大新闻门户网站 实时监控,自动更新和上传较新发布的新闻
3. 监控竞争对手相对较新的信息,包括商品价格和库存
4. 监控各大社交网络网站、博客,自动获取企业产品相关评论
5. 采集比较新的、比较全面的职位招聘信息
6.监控各大楼盘相关网站,采集新房与二手房对比新市场行情
7. 采集主要车型网站 具体新车和二手车信息
8. 发现和采集潜在客户信息
9. 采集行业网站 产品目录和产品信息
10. 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
更新日志
V7.6.0(官方)2019-01-04
主要体验改进
【自定义模式】新增JSON采集功能
【自定义模式】新增滑动验证码识别
【自定义模式】优化效率,列表识别速度翻倍
【自定义模式】自动识别网页ajax点击并自动配置ajax超时时间,配置任务更方便
【自定义模式】改进算法,使网页元素选择更加精准
[本地采集]采集整体速度提升10~30%,大大提升采集的效率
【任务列表】重构任务列表界面,性能大幅提升,大量任务管理不再卡顿
【任务列表】任务列表新增自动刷新机制,可随时查看任务最新状态
错误修复
修复云端查看数据慢的问题采集
修复采集报错排版问题
修复“打开网页时出现乱码”的问题
修复拖动过程后突然消失的问题
修复定时导出和自动入库工具自动弹出的问题
修复格式化时间类型数据错误的问题
文件信息
文件大小:62419128 字节
文件描述:安装优采云采集器
文件版本:7.6.0.1031
MD5:8D59AE2AE16856D632108F8AF997F0B6
SHA1:9B314DDAAE477E53EDCEF188EEE48CD3035619D4
收录文件
OctopusSetup7.4.6.8011.exe
优采云教程目录.xls
杀毒软件误报说明.txt
配置规则必读.txt
安装前阅读。文本
官方 网站:
相关搜索:采集 查看全部
网页采集器的自动识别算法(优采云数据采集系统让你的信息采集更简单!)
优采云采集器 是任何需要从网络获取信息的孩子的必备神器。这是一个可以让你的信息采集变得非常简单的工具。优采云改变了互联网上传统的数据思维方式,让用户在互联网上抓取和编译数据变得越来越容易
软件特点
操作简单,完全可视化的图形操作,不需要专业的IT人员,任何会用电脑上网的人都可以轻松掌握。
云采集
采集 任务自动分配到云端多台服务器同时执行,提高了采集的效率,短时间内可以获取上千条消息。
拖放采集流程
模拟人的操作思维模式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采用不同的采集流程。
图形识别
内置可扩展的OCR接口,支持对图片中的文字进行分析,可以提取图片上的文字。
定时自动采集
采集 任务自动运行,可以在指定时间段内自动采集,并且还支持实时采集 更快一分钟一次。
2 分钟快速启动
内置从入门到精通的视频教程,2分钟即可上手,还有文档、论坛、qq群等。
免费使用
它是免费的,免费版没有功能限制。您可以立即试用,下载并立即安装。
特征
简单来说,使用优采云可以很容易的从任何网页中准确的采集你需要的数据,生成自定义的常规数据格式。优采云数据采集 系统能做的包括但不限于以下内容
1.财务数据,如季报、年报、财报,包括每日自动比较新净值采集
2. 各大新闻门户网站 实时监控,自动更新和上传较新发布的新闻
3. 监控竞争对手相对较新的信息,包括商品价格和库存
4. 监控各大社交网络网站、博客,自动获取企业产品相关评论
5. 采集比较新的、比较全面的职位招聘信息
6.监控各大楼盘相关网站,采集新房与二手房对比新市场行情
7. 采集主要车型网站 具体新车和二手车信息
8. 发现和采集潜在客户信息
9. 采集行业网站 产品目录和产品信息
10. 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
更新日志
V7.6.0(官方)2019-01-04
主要体验改进
【自定义模式】新增JSON采集功能
【自定义模式】新增滑动验证码识别
【自定义模式】优化效率,列表识别速度翻倍
【自定义模式】自动识别网页ajax点击并自动配置ajax超时时间,配置任务更方便
【自定义模式】改进算法,使网页元素选择更加精准
[本地采集]采集整体速度提升10~30%,大大提升采集的效率
【任务列表】重构任务列表界面,性能大幅提升,大量任务管理不再卡顿
【任务列表】任务列表新增自动刷新机制,可随时查看任务最新状态
错误修复
修复云端查看数据慢的问题采集
修复采集报错排版问题
修复“打开网页时出现乱码”的问题
修复拖动过程后突然消失的问题
修复定时导出和自动入库工具自动弹出的问题
修复格式化时间类型数据错误的问题
文件信息
文件大小:62419128 字节
文件描述:安装优采云采集器
文件版本:7.6.0.1031
MD5:8D59AE2AE16856D632108F8AF997F0B6
SHA1:9B314DDAAE477E53EDCEF188EEE48CD3035619D4
收录文件
OctopusSetup7.4.6.8011.exe
优采云教程目录.xls
杀毒软件误报说明.txt
配置规则必读.txt
安装前阅读。文本
官方 网站:
相关搜索:采集
网页采集器的自动识别算法(软件特色可视化操作简单,完全兼容JQuery选择器规则(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-09-29 21:04
这款VG采集浏览器只需设置一个脚本即可创建自动登录、点击网页、自动提交数据、自动抓取数据、识别验证码、操作数据库、下载文件、收发邮件等个性。实用的脚本项目。
软件介绍
VG浏览器是一个由可视化脚本驱动的网页自动运行工具。只需设置脚本,即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库。发送和接收电子邮件等个性化实用的脚本项目。还可以使用逻辑运算来完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。
软件特点
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
定制流程
采集 就像积木一样,功能自由组合。
自动编码
程序注重采集的效率,页面解析速度非常快。
生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。
选择任何需要填写CSS Path规则的步骤,点击内置浏览器的这个按钮
点击一个网页元素,自动生成该元素的CSS Path,
极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。
您也可以在其他浏览器上复制 CSSPath。目前,各种多核浏览器都支持复制 CSSPath。
比如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器都可以通过按F12键。
或者右击页面,选择review元素,右击目标部分,选择Copy CSS Path将CSS Path复制到剪贴板。
在 Firefox 中,您还可以按 F12 或右键单击来查看元素。显示开发者工具后,
右击底部节点,选择“Copy Unique Selector”复制CSS Path。
CSS 路径规则与 JQuery 选择器规则完全兼容,
如果您知道如何编写 JQuery 选择器,您也可以自己编写 CSS Path。
更新日志
添加自制插件方法识别验证码,添加验证码识别插件开发工具 查看全部
网页采集器的自动识别算法(软件特色可视化操作简单,完全兼容JQuery选择器规则(组图))
这款VG采集浏览器只需设置一个脚本即可创建自动登录、点击网页、自动提交数据、自动抓取数据、识别验证码、操作数据库、下载文件、收发邮件等个性。实用的脚本项目。
软件介绍
VG浏览器是一个由可视化脚本驱动的网页自动运行工具。只需设置脚本,即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库。发送和接收电子邮件等个性化实用的脚本项目。还可以使用逻辑运算来完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。
软件特点
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
定制流程
采集 就像积木一样,功能自由组合。
自动编码
程序注重采集的效率,页面解析速度非常快。
生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。
选择任何需要填写CSS Path规则的步骤,点击内置浏览器的这个按钮
点击一个网页元素,自动生成该元素的CSS Path,
极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。
您也可以在其他浏览器上复制 CSSPath。目前,各种多核浏览器都支持复制 CSSPath。
比如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器都可以通过按F12键。
或者右击页面,选择review元素,右击目标部分,选择Copy CSS Path将CSS Path复制到剪贴板。
在 Firefox 中,您还可以按 F12 或右键单击来查看元素。显示开发者工具后,
右击底部节点,选择“Copy Unique Selector”复制CSS Path。
CSS 路径规则与 JQuery 选择器规则完全兼容,
如果您知道如何编写 JQuery 选择器,您也可以自己编写 CSS Path。
更新日志
添加自制插件方法识别验证码,添加验证码识别插件开发工具
网页采集器的自动识别算法(网站自动seo优化如何采集关键词?网络小编来解答)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-28 20:35
很多朋友在网站seo优化过程中遇到了一些网站优化问题,包括“网站seo自动优化采集:SEO优化订单网站如何优化SEO< @采集关键词”的问题,那么下面搜索网络小编来解答你目前疑惑的问题。
SEO优化关键词一般分为三类:目标关键词、长尾关键词和品牌关键词。其中,长尾关键词一般是从目标关键词展开,所以采集的一般方式是抓住关键词的根来展开。关键词的扩展方式主要有以下几种:
1、下拉框,相关搜索选择方法;网站自动搜索引擎优化采集
2、索引关键词工具的使用;
3、竞价后台,可下载关键词搜索量列表;
4、研究同行业或竞争对手网站关键词;
5、使用关键词开发工具。
选择关键词后,需要分析每个用户搜索到的流量和点击流。一起,你或许可以弄清楚一些用户搜索的意图,过滤掉质量更高的关键词。
网站自动SEO优化采集:什么是SEO自动化?
1、网站更新自动化(软件自动采集更新伪原创)
2、网站 外链自动生成(主要基于各种海量分发软件)
3、网站自动诊断(类似谷歌管理员工具等)
4、网站 自动信息查询(如站长工具等)
如何做网站SEO优化让搜索引擎收录
一般你做网站,搜索引擎会给你收录
SEO优化的目的是让网站更符合搜索引擎收录的偏好,满足用户的搜索需求,优化更多的核心长尾关键词。
SEO优化子站SEO优化+站外SEO优化
一、网站SEO优化
(1)网站 三要素:例如:TITLE、KEYWORDS、DESCRIPTION优化;
(2)内部链接优化,包括相关链接(Tag标签)、锚文本链接、各种导航链接;
(3)文章页面更新:文章页面更新是布局大量长尾词的重要关键点,发布文章长尾关键词 有利于提升关键词的排名。
(4)网站结构优化:包括网站的目录结构、面包屑结构、导航结构、URL结构等,主要包括:树结构、扁平结构等。
(5)图片alt标签、网站地图、robots文件、页面、重定向、网站定位、关键词选择与布局、网站每日一系列SEO更新频率和快照更新等优化步骤。
二、外部优化
(1)外链类:友情链接、博客、论坛、新闻、分类信息、贴吧、知乎、百科、站群、相关信息网等,尽量保持多样性链接;
(2)外链运营:每天增加一定数量的外链,使关键词的排名稳步上升;
(3)外链选择:比较高的有一些网站,整体质量较好的网站交换友情链接,巩固和稳定关键词排名。
网站 如何优化SEO的问题比较大。一般来说,在做SEO的时候,我们是具体网站进行具体分析的。以上都是网站可以参考的SEO优化操作。具体网站前期需要定位,寻找关键词长尾词,布局关键词,制定SEO优化推广方案,SEO效果排名监控等。
如何增加搜索引擎搜索,网站中的网页质量,搜索引擎会派搜索引擎蜘蛛抓取网页,蜘蛛也会判断网站是否已被索引和收录@根据相关分数 > 定期文章发布的价值,快照的更新也是影响搜索引擎收录的条件。
也可以主动提交搜索引擎收录未收到链接通知,搜索引擎会根据链接的好坏来判断是否进行搜索。
以上是关于网站自动seo优化采集、SEO优化命令网站SEO优化如何采集关键词文章的内容,如果你有网站如需优化,请直接联系我们。很高兴为您服务! 查看全部
网页采集器的自动识别算法(网站自动seo优化如何采集关键词?网络小编来解答)
很多朋友在网站seo优化过程中遇到了一些网站优化问题,包括“网站seo自动优化采集:SEO优化订单网站如何优化SEO< @采集关键词”的问题,那么下面搜索网络小编来解答你目前疑惑的问题。
SEO优化关键词一般分为三类:目标关键词、长尾关键词和品牌关键词。其中,长尾关键词一般是从目标关键词展开,所以采集的一般方式是抓住关键词的根来展开。关键词的扩展方式主要有以下几种:
1、下拉框,相关搜索选择方法;网站自动搜索引擎优化采集
2、索引关键词工具的使用;
3、竞价后台,可下载关键词搜索量列表;
4、研究同行业或竞争对手网站关键词;
5、使用关键词开发工具。
选择关键词后,需要分析每个用户搜索到的流量和点击流。一起,你或许可以弄清楚一些用户搜索的意图,过滤掉质量更高的关键词。
网站自动SEO优化采集:什么是SEO自动化?
1、网站更新自动化(软件自动采集更新伪原创)
2、网站 外链自动生成(主要基于各种海量分发软件)
3、网站自动诊断(类似谷歌管理员工具等)
4、网站 自动信息查询(如站长工具等)
如何做网站SEO优化让搜索引擎收录
一般你做网站,搜索引擎会给你收录
SEO优化的目的是让网站更符合搜索引擎收录的偏好,满足用户的搜索需求,优化更多的核心长尾关键词。
SEO优化子站SEO优化+站外SEO优化
一、网站SEO优化
(1)网站 三要素:例如:TITLE、KEYWORDS、DESCRIPTION优化;
(2)内部链接优化,包括相关链接(Tag标签)、锚文本链接、各种导航链接;
(3)文章页面更新:文章页面更新是布局大量长尾词的重要关键点,发布文章长尾关键词 有利于提升关键词的排名。
(4)网站结构优化:包括网站的目录结构、面包屑结构、导航结构、URL结构等,主要包括:树结构、扁平结构等。
(5)图片alt标签、网站地图、robots文件、页面、重定向、网站定位、关键词选择与布局、网站每日一系列SEO更新频率和快照更新等优化步骤。
二、外部优化
(1)外链类:友情链接、博客、论坛、新闻、分类信息、贴吧、知乎、百科、站群、相关信息网等,尽量保持多样性链接;
(2)外链运营:每天增加一定数量的外链,使关键词的排名稳步上升;
(3)外链选择:比较高的有一些网站,整体质量较好的网站交换友情链接,巩固和稳定关键词排名。
网站 如何优化SEO的问题比较大。一般来说,在做SEO的时候,我们是具体网站进行具体分析的。以上都是网站可以参考的SEO优化操作。具体网站前期需要定位,寻找关键词长尾词,布局关键词,制定SEO优化推广方案,SEO效果排名监控等。
如何增加搜索引擎搜索,网站中的网页质量,搜索引擎会派搜索引擎蜘蛛抓取网页,蜘蛛也会判断网站是否已被索引和收录@根据相关分数 > 定期文章发布的价值,快照的更新也是影响搜索引擎收录的条件。
也可以主动提交搜索引擎收录未收到链接通知,搜索引擎会根据链接的好坏来判断是否进行搜索。
以上是关于网站自动seo优化采集、SEO优化命令网站SEO优化如何采集关键词文章的内容,如果你有网站如需优化,请直接联系我们。很高兴为您服务!
网页采集器的自动识别算法(网页采集器的自动识别算法(一块是软件识别))
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-10-19 18:01
网页采集器的自动识别算法主要有两大块:一块是软件识别算法一块是硬件识别算法,软件识别算法主要是看服务商的专业能力,硬件识别主要看算法生成的性能和规模,
根据实际的情况去分析的,有的很简单,有的非常复杂,但总体上来说,用户遇到的问题非常多,也是能体现出收费是否合理的主要问题,比如精准性,速度等,刚接触一些软件也会发现有些很简单的功能,但后来就不敢轻易去尝试了,这个取决于想用软件的用户当时对这个产品的专业程度,如果功能不是很强大,但后来却发现使用起来确实麻烦的话,就不敢去尝试了,如果觉得功能强大,可能更担心后期被淘汰的话,就更纠结,以上是我总结的一些情况。
总体来说软件行业里还是软件服务商服务体验更有保障,价格虽然因为对接的方式而不一样,但基本都差不多,如果想用软件,推荐宝盒ip更多详情请进入宝盒ip官网。
报价是建立在客户付出相应价值的基础上的。对于那些什么价格都没谈拢的客户,大可不必付钱,后面产品再好,后期体验问题出来,对谁都是不负责任的。
您好,针对您说的报价为0那说明你前期是没有发现他的价值,他把您他放在一个竞争的环境里去竞争,他能带给你的优势就是速度,价格上已经把你拒绝在这个环境里了,还谈什么价格问题?分析报价都是没有意义的!这个市场,不是靠一个傻子赚钱的市场,市场竞争激烈,大家都在努力打出一个好价格,来获取利润,尤其是年轻的创业者,创业可能成本很低,创业的成本大多都是信心,执行力,说白了就是出来创业的人要有多大的能力,这个行业不缺乏资金很低的团队成员,他们去创业,可能花几万,几十万都能创业成功!那些大的团队也有大大的投资。所以没有人给你做主。如果您已经发现了,您可以选择这个软件,值不值那您自己衡量。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法(一块是软件识别))
网页采集器的自动识别算法主要有两大块:一块是软件识别算法一块是硬件识别算法,软件识别算法主要是看服务商的专业能力,硬件识别主要看算法生成的性能和规模,
根据实际的情况去分析的,有的很简单,有的非常复杂,但总体上来说,用户遇到的问题非常多,也是能体现出收费是否合理的主要问题,比如精准性,速度等,刚接触一些软件也会发现有些很简单的功能,但后来就不敢轻易去尝试了,这个取决于想用软件的用户当时对这个产品的专业程度,如果功能不是很强大,但后来却发现使用起来确实麻烦的话,就不敢去尝试了,如果觉得功能强大,可能更担心后期被淘汰的话,就更纠结,以上是我总结的一些情况。
总体来说软件行业里还是软件服务商服务体验更有保障,价格虽然因为对接的方式而不一样,但基本都差不多,如果想用软件,推荐宝盒ip更多详情请进入宝盒ip官网。
报价是建立在客户付出相应价值的基础上的。对于那些什么价格都没谈拢的客户,大可不必付钱,后面产品再好,后期体验问题出来,对谁都是不负责任的。
您好,针对您说的报价为0那说明你前期是没有发现他的价值,他把您他放在一个竞争的环境里去竞争,他能带给你的优势就是速度,价格上已经把你拒绝在这个环境里了,还谈什么价格问题?分析报价都是没有意义的!这个市场,不是靠一个傻子赚钱的市场,市场竞争激烈,大家都在努力打出一个好价格,来获取利润,尤其是年轻的创业者,创业可能成本很低,创业的成本大多都是信心,执行力,说白了就是出来创业的人要有多大的能力,这个行业不缺乏资金很低的团队成员,他们去创业,可能花几万,几十万都能创业成功!那些大的团队也有大大的投资。所以没有人给你做主。如果您已经发现了,您可以选择这个软件,值不值那您自己衡量。
网页采集器的自动识别算法(网页采集器的自动识别算法和手动识别的存储区别)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-10-18 18:02
网页采集器的自动识别算法和手动识别的存储区别还是挺大的。手动识别只要你用abdomainvalidation就能解决。但是并不能保证页面被识别成功后不重新抓取。比如你抓取一段时间某个页面后自动识别,识别页面是否是全站唯一的。如果它存储了记录而且又抓取时是手动抓取的话,也可能会存在存在多个网页。比如页面的标题、描述有时会是不一样的。
或者该页面也被标记为"其他网页",这个页面也是来源于一个网页。这种情况下你需要把该页面的所有记录都抓取下来,存储到记录库。对于收录上来说,需要进行定向排序。一般的定向算法都会考虑到关键词。比如像adpr这种算法。它把自己定义的5000个关键词进行算法匹配,并且从里面选出一个或多个关键词排序。根据排序结果自动收录网页。
手动采集时候就不存在这个问题,看懂抓取规则就能采集一大堆网页,如果关键词堆积太多,关键词会分布太散,收录的非常慢。
redis内部的鉴别机制和全栈分词库可以用redis整合
单纯采集基本不需要怎么封装算法,一般跟django类似。但是大规模采集时还是要考虑多种匹配策略(排除关键词匹配)。比如百度spider只能匹配特定时间段内的新页面,而ga则可以识别长尾网页。
研究这么久,还真没有你所说的这种应用,就算用了,只要上传个图片问题也解决不了,我也是一边做redis对接多语言二次开发,一边研究spider。听一个老板说,研究spider,本身就是要打通多语言。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法和手动识别的存储区别)
网页采集器的自动识别算法和手动识别的存储区别还是挺大的。手动识别只要你用abdomainvalidation就能解决。但是并不能保证页面被识别成功后不重新抓取。比如你抓取一段时间某个页面后自动识别,识别页面是否是全站唯一的。如果它存储了记录而且又抓取时是手动抓取的话,也可能会存在存在多个网页。比如页面的标题、描述有时会是不一样的。
或者该页面也被标记为"其他网页",这个页面也是来源于一个网页。这种情况下你需要把该页面的所有记录都抓取下来,存储到记录库。对于收录上来说,需要进行定向排序。一般的定向算法都会考虑到关键词。比如像adpr这种算法。它把自己定义的5000个关键词进行算法匹配,并且从里面选出一个或多个关键词排序。根据排序结果自动收录网页。
手动采集时候就不存在这个问题,看懂抓取规则就能采集一大堆网页,如果关键词堆积太多,关键词会分布太散,收录的非常慢。
redis内部的鉴别机制和全栈分词库可以用redis整合
单纯采集基本不需要怎么封装算法,一般跟django类似。但是大规模采集时还是要考虑多种匹配策略(排除关键词匹配)。比如百度spider只能匹配特定时间段内的新页面,而ga则可以识别长尾网页。
研究这么久,还真没有你所说的这种应用,就算用了,只要上传个图片问题也解决不了,我也是一边做redis对接多语言二次开发,一边研究spider。听一个老板说,研究spider,本身就是要打通多语言。
网页采集器的自动识别算法(软件特征零门槛不懂网络爬虫技术的人,会上网)
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-10-16 21:04
优采云采集器是一款非常实用的网站信息采集工具,具有零门槛、多引擎、多功能的特点。本软件让不懂网络爬虫技术的人轻松采集网络信息,适用于99%的网站,还能智能避免获取重复数据。
软件介绍
优采云采集器是一款非常好的网络信息采集工具,是新一代视觉智能采集器的代表作品。可视化采集器、采集就像积木一样,功能模块可以随意组合,可视化提取或操作网页元素,自动登录,自动发布,自动识别验证码。它是一个通用浏览器。您可以快速创建自动化脚本,甚至可以生成独立的应用程序来销售和赚钱!
软件特点
零门槛
如果你不懂网络爬虫技术,如果你能上网,你就能采集网站数据
多引擎,高速稳定
内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集数据更高效。它还内置了 JSON 引擎,无需分析 JSON 数据结构,直观选择 JSON 内容。
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载和其他动态类型网站。
软件特点
1、软件操作简单,鼠标点击即可轻松选择要抓取的内容;
2、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上独创的内存优化,浏览器采集也可以高速运行,甚至可以快速转换以HTTP运行,享受更高的采集速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容。无需分析JSON数据结构,让非网页专业设计人员轻松抓取所需数据;
3、无需分析网页请求和源码,但支持更多网页采集;先进的智能算法,可一键生成目标元素XPATH,自动识别网页列表,自动识别页面页面按钮中的下一页...
4、 支持丰富的数据导出方式,可以导出到txt文件、html文件、csv文件、excel文件,也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,通过向导只需映射字段,即可轻松导出到目标 网站 数据库。
产品优势
可视化向导
所有采集元素,自动生成采集数据
计划任务
运行时间灵活定义,全自动运行
多引擎支持
支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
可以自动识别网页列表、采集字段和分页等。
拦截请求
自定义屏蔽域名,方便过滤异地广告,提升采集速度
各种数据导出
可导出为 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等。
安装说明
进入软件下载页面,点击立即下载按钮下载软件
下载解压后双击setup1.0.exe启动安装程序(1.0为版本,后续新版本会有所不同)
按照安装向导,一路点击“下一步”按钮即可完成安装。
常见问题
采集 如何避免数据重复?
运行采集任务时,如果任务前有采集数据,如果采集之前没有清除原有数据,会以append的形式添加新的采集将数据添加到本地采集库中,这样一些已经采集的数据可能会再次采集进入库中,如果目标网页本身也有重复数据,也有可能造成数据重复,那么如何避免采集的数据重复呢?
方法很简单,我们希望哪些字段内容不允许重复,只需点击字段标题上的三角形符号,然后勾选“过滤重复项”复选框,然后单击“确定”即可。
如何手动生成字段?
单击“添加字段”按钮
在列表的任意一行点击要提取的元素,比如要提取标题和链接地址,鼠标左键点击标题
点击网页链接时,使用时会提示是否抓取链接地址
如果要同时提取链接标题和链接地址,点击“是”,如果只需要提取标题文字,点击“否”,这里我们点击“是”
系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您单击表格底部的字段标题时,匹配的内容将在网页上以黄色背景突出显示。
如果要标记列表中的其他字段,请单击添加新字段并重复上述操作。 查看全部
网页采集器的自动识别算法(软件特征零门槛不懂网络爬虫技术的人,会上网)
优采云采集器是一款非常实用的网站信息采集工具,具有零门槛、多引擎、多功能的特点。本软件让不懂网络爬虫技术的人轻松采集网络信息,适用于99%的网站,还能智能避免获取重复数据。
软件介绍
优采云采集器是一款非常好的网络信息采集工具,是新一代视觉智能采集器的代表作品。可视化采集器、采集就像积木一样,功能模块可以随意组合,可视化提取或操作网页元素,自动登录,自动发布,自动识别验证码。它是一个通用浏览器。您可以快速创建自动化脚本,甚至可以生成独立的应用程序来销售和赚钱!
软件特点
零门槛
如果你不懂网络爬虫技术,如果你能上网,你就能采集网站数据
多引擎,高速稳定
内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集数据更高效。它还内置了 JSON 引擎,无需分析 JSON 数据结构,直观选择 JSON 内容。
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载和其他动态类型网站。
软件特点
1、软件操作简单,鼠标点击即可轻松选择要抓取的内容;
2、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上独创的内存优化,浏览器采集也可以高速运行,甚至可以快速转换以HTTP运行,享受更高的采集速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容。无需分析JSON数据结构,让非网页专业设计人员轻松抓取所需数据;
3、无需分析网页请求和源码,但支持更多网页采集;先进的智能算法,可一键生成目标元素XPATH,自动识别网页列表,自动识别页面页面按钮中的下一页...
4、 支持丰富的数据导出方式,可以导出到txt文件、html文件、csv文件、excel文件,也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,通过向导只需映射字段,即可轻松导出到目标 网站 数据库。
产品优势
可视化向导
所有采集元素,自动生成采集数据
计划任务
运行时间灵活定义,全自动运行
多引擎支持
支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
可以自动识别网页列表、采集字段和分页等。
拦截请求
自定义屏蔽域名,方便过滤异地广告,提升采集速度
各种数据导出
可导出为 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等。
安装说明
进入软件下载页面,点击立即下载按钮下载软件
下载解压后双击setup1.0.exe启动安装程序(1.0为版本,后续新版本会有所不同)
按照安装向导,一路点击“下一步”按钮即可完成安装。
常见问题
采集 如何避免数据重复?
运行采集任务时,如果任务前有采集数据,如果采集之前没有清除原有数据,会以append的形式添加新的采集将数据添加到本地采集库中,这样一些已经采集的数据可能会再次采集进入库中,如果目标网页本身也有重复数据,也有可能造成数据重复,那么如何避免采集的数据重复呢?
方法很简单,我们希望哪些字段内容不允许重复,只需点击字段标题上的三角形符号,然后勾选“过滤重复项”复选框,然后单击“确定”即可。
如何手动生成字段?
单击“添加字段”按钮
在列表的任意一行点击要提取的元素,比如要提取标题和链接地址,鼠标左键点击标题
点击网页链接时,使用时会提示是否抓取链接地址
如果要同时提取链接标题和链接地址,点击“是”,如果只需要提取标题文字,点击“否”,这里我们点击“是”
系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您单击表格底部的字段标题时,匹配的内容将在网页上以黄色背景突出显示。
如果要标记列表中的其他字段,请单击添加新字段并重复上述操作。
网页采集器的自动识别算法(scrapy入门开发系列及python3爬虫源码::(/))
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-10-15 00:03
网页采集器的自动识别算法各有不同,除了tx外,像百度天天采集器这些网页采集器基本上是flash+cookie伪装,其他基本上都是通过模糊查询cookie进行识别。阿里巴巴需要会员才能打开网页,除了阿里之外,也没有其他网页采集器会要求用户登录。不要以为只有像百度、腾讯这种巨头才搞伪装、爬虫等操作,像我这种网站网页采集小网站用的都是qq采集器,网页加密度不高,进来也不需要登录。
手机端的伪装没有电脑那么高,其实现在只要会qq就可以自动采集,主要原因是可视性比较高。还有一点是现在那些站长手机都不玩了,基本上没有手机操作网站的。我第一个网站是百度联盟,一个url弄了一个小时,才配置好sqlserver,全是静态语言拼接,相当简单,基本上非专业级别的技术人员很难在5分钟内搞定。我觉得不同的网站,采集器得要求不同,不能所有都是通过提取邮箱手机号识别。
发在知乎分享之后几个月,自己慢慢在研究,从一开始选型,到数据获取,再到数据挖掘分析,今天正好回答一下这个问题:正是,做好python爬虫框架,是首要的,scrapy的源码学习需要一个半月,半年以后可以帮助到想爬虫的人。当然,如果对scrapy不熟悉的同学也不要乱看。大家可以看下github上面scrapy的几个项目。scrapy入门开发系列及python3爬虫源码github:::(/)。 查看全部
网页采集器的自动识别算法(scrapy入门开发系列及python3爬虫源码::(/))
网页采集器的自动识别算法各有不同,除了tx外,像百度天天采集器这些网页采集器基本上是flash+cookie伪装,其他基本上都是通过模糊查询cookie进行识别。阿里巴巴需要会员才能打开网页,除了阿里之外,也没有其他网页采集器会要求用户登录。不要以为只有像百度、腾讯这种巨头才搞伪装、爬虫等操作,像我这种网站网页采集小网站用的都是qq采集器,网页加密度不高,进来也不需要登录。
手机端的伪装没有电脑那么高,其实现在只要会qq就可以自动采集,主要原因是可视性比较高。还有一点是现在那些站长手机都不玩了,基本上没有手机操作网站的。我第一个网站是百度联盟,一个url弄了一个小时,才配置好sqlserver,全是静态语言拼接,相当简单,基本上非专业级别的技术人员很难在5分钟内搞定。我觉得不同的网站,采集器得要求不同,不能所有都是通过提取邮箱手机号识别。
发在知乎分享之后几个月,自己慢慢在研究,从一开始选型,到数据获取,再到数据挖掘分析,今天正好回答一下这个问题:正是,做好python爬虫框架,是首要的,scrapy的源码学习需要一个半月,半年以后可以帮助到想爬虫的人。当然,如果对scrapy不熟悉的同学也不要乱看。大家可以看下github上面scrapy的几个项目。scrapy入门开发系列及python3爬虫源码github:::(/)。
网页采集器的自动识别算法( 我把微博营销案例全部爬虫到一个了Excel表格里)
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-10-13 00:51
我把微博营销案例全部爬虫到一个了Excel表格里)
今天的目标:
读者知道什么?
程序员最难学的不是java或c++,而是社交,俗称“嫂子”。
在社交方面,我被认为是程序员中最好的程序员。
比如在做《一张海报生成表格,让我从一个大叔变成小弟弟》之前,就捡到了运营社区的小姐姐。
这已经是上个月了,这个月又投入到爬虫的技术研究中。
技术满足的反面是孤独和空虚。
于是,我决定再次用爬虫来逗妹妹。. .
结果。. .
我做到了!!!
我将所有微博营销案例抓取到一张 Excel 表格中。
7-0多份操作分析报告,一键下载
网站中的案例需要一一下载↑
表中案例,点赞下载较多↑
管理社区的女孩们要疯了!
秋叶Excel抖音 女主角:小美↑
微博手绘大V博主姜江↑
社区运营老司机:颜敏姐↑
让我告诉你,如果我能早两年爬行,谁会是我现在的室友?!
1-什么是爬虫
爬虫是网络爬虫。就是按照一定的规则自动抓取网络上的数据。
比如上一节自动抓取了“社交营销案例库”的案例。
想象一下,如果手动浏览页面下载这些案例,流程是这样的:
1- 打开应用程序库页面
2-点击案例进入详情页面
3- 点击下载案例pdf
4- 返回案例库页面,点击下一个案例,重复前面的3个步骤。
如果要下载所有的pdf案例,需要安排专人反复机械地下载。显然,这个人的价值含量很低。
爬虫取代了这种机械重复、低价值的数据采集动作,利用程序或代码自动批量完成数据采集。
爬虫的好处
简单总结一下,爬虫的好处主要有两个方面:
1-自动爬行,解放人力,提高效率
机械的、低价值的工作,用机器来完成工作是最好的解决方案。
2-数据分析,跳线获取优质内容
与手动浏览数据不同,爬虫可以将数据汇总整合成数据表,方便我们后续的数据统计和数据分析。
例如,在“社交营销案例库”中,每个案例都有查看次数和下载次数。如果要按查看次数排序,则会优先查看查看次数最多的案例。将数据抓取到Excel表格中,并使用排序功能轻松浏览。
爬虫案例
任何数据都可以爬。
如果您掌握了爬虫的技能,您可以做很多事情。
Excelhome 的帖子抓取
我教Excel,Excelhome论坛是个大宝。
一篇一篇阅读太费劲了,爬1.40000个帖子,挑浏览量最多的。
窗帘选择文章爬行
屏幕是整理轮廓的好工具。很多大咖都用屏幕写读书笔记,不用看全书也能学会重点。
没时间一一浏览选定的画面文章,爬取所有选定的文章,整理出自己的知识大纲。
曹总公众号文章爬取
我很喜欢曹江。我有我这个年龄所缺乏的逻辑、归纳和表达能力,以及文章文章的精髓。
公众号太多,手机看书容易分心?爬入 Excel,然后开始查看最高的行读数。
此外还有抖音播报数据、公众号阅读、评论数据、B站弹幕数据、网易云评论数据。
爬虫+数据分析给网络带来更多乐趣。
2- 履带式是简单、锋利的武器
说到爬虫,大多会想到编程数数,python,数据库,beautiful,html结构等等,让人望而生畏。
其实基础爬虫很简单,借助一些采集软件,一键即可轻松完成。
常用爬虫软件
爬取数据的时候用到了以下软件,推荐给大家:
1- 优采云采集器
简单易学,数据可以通过可视化界面、鼠标点击、向导模式采集。用户无需任何技术基础,输入网址,一键提取数据。
这是我接触的第一个爬虫软件,
优势:
1-使用过程简单,上手特别好。
缺点:
1- 进口数量限制。采集,非会员只能导出1000条数据。
2- 导出格式限制。非会员只能导出为txt文本格式。
2- 优采云
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库
在优采云不能满足我的需求后,我开始尝试更专业的采集软件,找到了优采云。
优势:
1- 采集功能更强大,可以自定义采集的进程。
2- 导出格式和数据量没有限制。
缺点:
1- 过程有点复杂,新手上手难度较大。
3- 优采云采集器(推荐)
智能识别数据,小白神器
基于人工智能算法,只需输入网址即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集。自动识别列表、表格、链接、图片、价格、电子邮件等。
这就是我现在用的采集软件。可以说中和了前两个采集器的优缺点,用户体验更好。
优势:
1-自动识别页面信息,轻松上手
2- 导出格式和数据量没有限制
目前没有发现缺点。
3-爬虫操作流程
注意,注意,接下来就是动手部分了。
我们以“窗帘选择文章”为例,用“优采云采集器”体验爬行的乐趣。
采集后的效果如下:
1-复制采集的链接
打开窗帘官网,点击“精选”进入选中的文章页面。
复制特色页面的 URL:
2- 优采云采集 数据
1- 登录“优采云采集器”官网,下载安装采集器。
2-打开采集器后,点击“智能模式”中的“开始采集”,新建一个智能采集。
3-粘贴到屏幕的选定URL中,点击立即创建
在此过程中,采集器 会自动识别页面上的列表和数据内容。整个过程由AI算法自动完成,等待识别完成。
页面分析识别↑
页面识别完成↑
4-点击“开始采集”->“开始”开始爬虫之旅。
3- 采集数据导出
在数据爬取过程中,您可以点击“停止”结束数据爬取。
或者等待数据爬取完成,在弹出的对话框中点击“导出数据”。
导出格式,选择Excel,然后导出。
4- 使用 HYPERLINK 函数添加超链接
打开导出的表格,在I列添加HYPERLINK公式,添加超链接,一键打开对应的文章。
公式如下:
=HYPERLINK(B2,“点击查看”)
到这里,你的第一次爬虫之旅已经顺利完成了!
4- 总结
爬虫就像在 VBA 中记录宏,记录重复的动作而不是手动重复的操作。
今天看到的只是简单的数据采集,关于爬虫的话题还有很多,很深入的内容。例如:
1- 身份验证。需要登录才能抓取页面。
2-浏览器检查。比如公众号文章只能获取微信的阅读数。
3- 参数验证(验证码)。该页面需要验证码。
4- 请求频率。例如页面访问时间不能小于10秒
5- 数据处理。要爬取的数据需要从数字、英文等内容中提取出来。
了解了爬取流程后,您现在最想爬取哪些数据?
我是会设计电子表格的Excel老师拉小邓
如果你喜欢这个文章,请给我三重品质,今天就到此为止,下课结束! 查看全部
网页采集器的自动识别算法(
我把微博营销案例全部爬虫到一个了Excel表格里)
今天的目标:
读者知道什么?
程序员最难学的不是java或c++,而是社交,俗称“嫂子”。
在社交方面,我被认为是程序员中最好的程序员。
比如在做《一张海报生成表格,让我从一个大叔变成小弟弟》之前,就捡到了运营社区的小姐姐。
这已经是上个月了,这个月又投入到爬虫的技术研究中。
技术满足的反面是孤独和空虚。
于是,我决定再次用爬虫来逗妹妹。. .
结果。. .
我做到了!!!
我将所有微博营销案例抓取到一张 Excel 表格中。
7-0多份操作分析报告,一键下载
网站中的案例需要一一下载↑
表中案例,点赞下载较多↑
管理社区的女孩们要疯了!
秋叶Excel抖音 女主角:小美↑
微博手绘大V博主姜江↑
社区运营老司机:颜敏姐↑
让我告诉你,如果我能早两年爬行,谁会是我现在的室友?!
1-什么是爬虫
爬虫是网络爬虫。就是按照一定的规则自动抓取网络上的数据。
比如上一节自动抓取了“社交营销案例库”的案例。
想象一下,如果手动浏览页面下载这些案例,流程是这样的:
1- 打开应用程序库页面
2-点击案例进入详情页面
3- 点击下载案例pdf
4- 返回案例库页面,点击下一个案例,重复前面的3个步骤。
如果要下载所有的pdf案例,需要安排专人反复机械地下载。显然,这个人的价值含量很低。
爬虫取代了这种机械重复、低价值的数据采集动作,利用程序或代码自动批量完成数据采集。
爬虫的好处
简单总结一下,爬虫的好处主要有两个方面:
1-自动爬行,解放人力,提高效率
机械的、低价值的工作,用机器来完成工作是最好的解决方案。
2-数据分析,跳线获取优质内容
与手动浏览数据不同,爬虫可以将数据汇总整合成数据表,方便我们后续的数据统计和数据分析。
例如,在“社交营销案例库”中,每个案例都有查看次数和下载次数。如果要按查看次数排序,则会优先查看查看次数最多的案例。将数据抓取到Excel表格中,并使用排序功能轻松浏览。
爬虫案例
任何数据都可以爬。
如果您掌握了爬虫的技能,您可以做很多事情。
Excelhome 的帖子抓取
我教Excel,Excelhome论坛是个大宝。
一篇一篇阅读太费劲了,爬1.40000个帖子,挑浏览量最多的。
窗帘选择文章爬行
屏幕是整理轮廓的好工具。很多大咖都用屏幕写读书笔记,不用看全书也能学会重点。
没时间一一浏览选定的画面文章,爬取所有选定的文章,整理出自己的知识大纲。
曹总公众号文章爬取
我很喜欢曹江。我有我这个年龄所缺乏的逻辑、归纳和表达能力,以及文章文章的精髓。
公众号太多,手机看书容易分心?爬入 Excel,然后开始查看最高的行读数。
此外还有抖音播报数据、公众号阅读、评论数据、B站弹幕数据、网易云评论数据。
爬虫+数据分析给网络带来更多乐趣。
2- 履带式是简单、锋利的武器
说到爬虫,大多会想到编程数数,python,数据库,beautiful,html结构等等,让人望而生畏。
其实基础爬虫很简单,借助一些采集软件,一键即可轻松完成。
常用爬虫软件
爬取数据的时候用到了以下软件,推荐给大家:
1- 优采云采集器
简单易学,数据可以通过可视化界面、鼠标点击、向导模式采集。用户无需任何技术基础,输入网址,一键提取数据。
这是我接触的第一个爬虫软件,
优势:
1-使用过程简单,上手特别好。
缺点:
1- 进口数量限制。采集,非会员只能导出1000条数据。
2- 导出格式限制。非会员只能导出为txt文本格式。
2- 优采云
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库
在优采云不能满足我的需求后,我开始尝试更专业的采集软件,找到了优采云。
优势:
1- 采集功能更强大,可以自定义采集的进程。
2- 导出格式和数据量没有限制。
缺点:
1- 过程有点复杂,新手上手难度较大。
3- 优采云采集器(推荐)
智能识别数据,小白神器
基于人工智能算法,只需输入网址即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集。自动识别列表、表格、链接、图片、价格、电子邮件等。
这就是我现在用的采集软件。可以说中和了前两个采集器的优缺点,用户体验更好。
优势:
1-自动识别页面信息,轻松上手
2- 导出格式和数据量没有限制
目前没有发现缺点。
3-爬虫操作流程
注意,注意,接下来就是动手部分了。
我们以“窗帘选择文章”为例,用“优采云采集器”体验爬行的乐趣。
采集后的效果如下:
1-复制采集的链接
打开窗帘官网,点击“精选”进入选中的文章页面。
复制特色页面的 URL:
2- 优采云采集 数据
1- 登录“优采云采集器”官网,下载安装采集器。
2-打开采集器后,点击“智能模式”中的“开始采集”,新建一个智能采集。
3-粘贴到屏幕的选定URL中,点击立即创建
在此过程中,采集器 会自动识别页面上的列表和数据内容。整个过程由AI算法自动完成,等待识别完成。
页面分析识别↑
页面识别完成↑
4-点击“开始采集”->“开始”开始爬虫之旅。
3- 采集数据导出
在数据爬取过程中,您可以点击“停止”结束数据爬取。
或者等待数据爬取完成,在弹出的对话框中点击“导出数据”。
导出格式,选择Excel,然后导出。
4- 使用 HYPERLINK 函数添加超链接
打开导出的表格,在I列添加HYPERLINK公式,添加超链接,一键打开对应的文章。
公式如下:
=HYPERLINK(B2,“点击查看”)
到这里,你的第一次爬虫之旅已经顺利完成了!
4- 总结
爬虫就像在 VBA 中记录宏,记录重复的动作而不是手动重复的操作。
今天看到的只是简单的数据采集,关于爬虫的话题还有很多,很深入的内容。例如:
1- 身份验证。需要登录才能抓取页面。
2-浏览器检查。比如公众号文章只能获取微信的阅读数。
3- 参数验证(验证码)。该页面需要验证码。
4- 请求频率。例如页面访问时间不能小于10秒
5- 数据处理。要爬取的数据需要从数字、英文等内容中提取出来。
了解了爬取流程后,您现在最想爬取哪些数据?
我是会设计电子表格的Excel老师拉小邓
如果你喜欢这个文章,请给我三重品质,今天就到此为止,下课结束!
网页采集器的自动识别算法(网页采集器的自动识别算法:如何识别手机端、微信端呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-10-11 15:13
网页采集器的自动识别算法:如何识别手机端、微信端呢?如果经过多次下载,多次上传后的数据一定不能带有真实性的信息。因为过程如果只是采集手机端、微信端,导致的人工录入的冗余就比较多。在手机端、微信端app、网页上有一些用户自己生成的数据点,不能代表真实的用户。所以无法识别。我们需要把这些数据点转换为固定的特征。
比如:手机号、微信号、输入框中的字母、手势识别。其他可识别的特征在采集的时候最好先预一次,看一下文字是否能识别。这些经过预处理过的特征数据最终将集中在公众号体系的爬虫后端,生成公众号特征基因。按照特征基因的等级不同,会生成多个特征图谱,再用于机器学习识别。一、提取特征文本语义特征目标检测的最终目的是实现对目标的检测。
而在实际的应用场景中,语义的抽取是十分重要的,即最终检测出目标并能够精确到99%的准确率,如果特征抽取没有做好,所在检测结果十分可能很难识别。语义抽取是机器学习特征选择的核心方法,他不仅能够提取关键词级的关键词特征,而且能够提取包含关键词的句子级语义特征。提取出关键词特征可以对语义特征的抽取起到举足轻重的作用。
检测到某句子是否含有关键词特征,根据目标识别的类型及具体的任务来决定。1.wordembedding(webembedding)webembedding其实大家比较熟悉的是"embedding",在检测目标的方法过程中可以用"embedding"来进行特征抽取,可以大大提高模型的鲁棒性。即对一个目标的语义抽取过程需要固定好语义向量,用"embedding"或者"webembedding"。
2.相似度度量(positionprediction)首先需要确定该目标属于哪个领域(领域内检测),以及这个领域内有哪些子领域,子领域上有哪些关键词。然后就可以使用相似度来表示它们的相似程度。3.clustering机器学习中还有一种经典的算法是聚类,聚类的目的就是找到一个数量级的类,将用于分类的那些向量连接起来。
4.attentionattention机制是指为了增强网络的泛化能力,对需要实现分类的节点使用不同的权重。这个机制的主要作用就是为了对比来自不同类的结果,有一定的相似度,从而将其归类到不同的类,以提高分类器的泛化能力。相关机制:可以将句子和关键词连接起来,算出一个长度为w的tree;再取个句子中所有节点的平均;最后将tree分为两组:类到tree之间的choicenodes和非choicenodes,对choicenodes使用不同的权重,将它们连接起来。
不同节点类似的,choice类似,算法大概的流程是先筛选choicenodes里面不重复的节点,最后再筛选每个子节点来表示节点类别。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法:如何识别手机端、微信端呢?)
网页采集器的自动识别算法:如何识别手机端、微信端呢?如果经过多次下载,多次上传后的数据一定不能带有真实性的信息。因为过程如果只是采集手机端、微信端,导致的人工录入的冗余就比较多。在手机端、微信端app、网页上有一些用户自己生成的数据点,不能代表真实的用户。所以无法识别。我们需要把这些数据点转换为固定的特征。
比如:手机号、微信号、输入框中的字母、手势识别。其他可识别的特征在采集的时候最好先预一次,看一下文字是否能识别。这些经过预处理过的特征数据最终将集中在公众号体系的爬虫后端,生成公众号特征基因。按照特征基因的等级不同,会生成多个特征图谱,再用于机器学习识别。一、提取特征文本语义特征目标检测的最终目的是实现对目标的检测。
而在实际的应用场景中,语义的抽取是十分重要的,即最终检测出目标并能够精确到99%的准确率,如果特征抽取没有做好,所在检测结果十分可能很难识别。语义抽取是机器学习特征选择的核心方法,他不仅能够提取关键词级的关键词特征,而且能够提取包含关键词的句子级语义特征。提取出关键词特征可以对语义特征的抽取起到举足轻重的作用。
检测到某句子是否含有关键词特征,根据目标识别的类型及具体的任务来决定。1.wordembedding(webembedding)webembedding其实大家比较熟悉的是"embedding",在检测目标的方法过程中可以用"embedding"来进行特征抽取,可以大大提高模型的鲁棒性。即对一个目标的语义抽取过程需要固定好语义向量,用"embedding"或者"webembedding"。
2.相似度度量(positionprediction)首先需要确定该目标属于哪个领域(领域内检测),以及这个领域内有哪些子领域,子领域上有哪些关键词。然后就可以使用相似度来表示它们的相似程度。3.clustering机器学习中还有一种经典的算法是聚类,聚类的目的就是找到一个数量级的类,将用于分类的那些向量连接起来。
4.attentionattention机制是指为了增强网络的泛化能力,对需要实现分类的节点使用不同的权重。这个机制的主要作用就是为了对比来自不同类的结果,有一定的相似度,从而将其归类到不同的类,以提高分类器的泛化能力。相关机制:可以将句子和关键词连接起来,算出一个长度为w的tree;再取个句子中所有节点的平均;最后将tree分为两组:类到tree之间的choicenodes和非choicenodes,对choicenodes使用不同的权重,将它们连接起来。
不同节点类似的,choice类似,算法大概的流程是先筛选choicenodes里面不重复的节点,最后再筛选每个子节点来表示节点类别。
网页采集器的自动识别算法(网页增量式采集研究中,网页识别方法识别哪些)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-11 04:12
1 简介
随着互联网的发展,Web 上的网页数量迅速增长。即使采用大规模分布式网页采集系统,全网最重要的网页都需要很长时间。研究结果表明,只有8.52%的中国网页在一个月内发生了变化[],因此采用完整的采集方式是对资源的巨大浪费。另外,由于两次采集的周期较长,这段时间内网页变化频率较高的网页已经发生多次变化,采集系统无法及时捕捉到变化的网页,这将导致搜索引擎系统无法为这些网页提供检索服务。为了解决这个问题,创建了一个网页增量采集系统。
网页增量采集 系统不是采集获取的所有网址,而是只估计网页的变化采集新网页、变更网页、消失网页,不关心网页的变化未更改的网页。这大大减少了采集的使用量,可以快速将Web上的网页与搜索引擎中的网页同步,从而为用户提供更加实时的检索服务。
在增量的采集研究中,网页通常分为目录网页(Hub pages)和主题网页(Topic pages)[],Hub网页在网站中的作用是引导用户寻找相关主题网页,相当于目录索引,没有具体内容,提供主题网页的入口[]。基于主题的网页专门针对某个主题。实验证明,很多新的网页都是从Hub网页[]链接而来的。因此增量采集系统只需要找到Hub网页并执行采集就可以发现新出现的URL。如上所述,识别哪些网页是Hub网页成为首先要解决的问题。
针对这个问题,本文提出了一种基于URL特征识别Hub网页的方法。首次将 URL 特征用作 Hub 网页识别的整个基础。这将弥补传统Hub网页识别的巨大成本。最后通过对比实验进行验证。方法的有效性。
2 相关工作
目前主要的Hub网页识别方法包括基于简单规则的识别方法[]、基于多特征启发式规则的分类方法[-]和基于网页内容的机器学习方法[-]。
基于简单规则的识别方法是分析Hub网页URL的特征,总结规则,制定简单规则。Hub 网页满足条件。孟等人。建议选择网站的主页,网站中文件名收录index、class、default等词的网页作为Hub网页[],采集对应的网页Hub 网页中的链接。这种方法可以采集到达大量新网页,但是新网页采集的召回率不是很高。存在以下问题:
(1)Hub网页选择不准确。由于网页的文件名是人名,没有固定模式,所以不可能找到一个规则来正确找到所有Hub网页;
(2)无法自动识别Hub网页,由于在采集过程中无法及时发现新的Hub网页,无法找到新的Hub网页中的链接信息。
为了解决简单的基于规则的方法的局限性,Ail 等人。提出了一种基于多特征启发式规则的网页分类方法,基于非链接字符数、标点符号数、文本链接比例构建启发式规则[]。研究发现,Hub 网页和主题网页在这些特征值上存在广泛差异,这种差异证明了网页通过这些特征值进行分类的可行性。该方法通过根据贝叶斯公式统计网页中每个特征的具体值,计算每个特征值对Hub网页的概率支持度,根据每个特征值的概率支持度得到综合支持度,并设置阈值。比较并确定网页属于哪个类别。这种方法的缺点是过于依赖阈值的设置。阈值的设置将直接影响分类的准确性。但是对于不同类型的网站,阈值设置也不同,增加了算法的复杂度。.
为了解决阈值依赖问题,文献[9]提出了一种基于网页内容的机器学习方法,通过HTML分析和网页特征分析,建立训练集和测试集,从而获得机器学习用于识别 Hub 网页的学习模型。这种方法精度高,但效率低,增加了系统的额外成本。由于这种方法是基于网页的内容,需要解析所有的HTML网页,并提取其特征进行存储,会在一定程度上占用系统资源,给采集系统带来额外的负担. 影响采集系统的性能。
以上方法从不同层面分析了Hub网页的识别。基于前人的研究,本文提出的基于URL特征的识别方法将在很大程度上解决上述问题。该方法使用 URL 特征作为样本,SVM 作为机器学习方法进行识别。与基于规则和基于网络内容的方法相比,它提供了一种更有价值的方法。一方面,特征提取简单、高效、易于实现,同时兼顾识别的准确性。另一方面,在采集系统中,从网页中提取URL是必不可少的一部分。因此,选择URL作为识别依据,可以减少对系统效率的影响,并且不会给采集系统增加过多的额外开销。
3 基于URL特征的Hub网页识别方法3.1 SVM介绍
支持向量机(SVM)是由 Vapnik 等人开发的一种机器学习方法。支持向量机基于统计理论-VC维数理论和最小结构风险原则。特别是在样本数量较少的情况下,SVM的性能明显优于其他算法[-]。
基本思想是:定义最优线性超平面,将寻找最优超平面的算法简化为求解最优(凸规划)问题。然后基于Mercer核展开定理,通过非线性映射,将样本空间映射到一个高维甚至无限维的特征空间,从而可以在特征空间中使用线性学习机的方法来求解高度非线性样本空间中的分类和回归。问题。它还包括以下优点:
(1) 基于结构风险最小化原则,这样可以避免过拟合问题,泛化能力强。
(2) SVM是一种理论基础扎实的小样本学习方法,基本不涉及概率测度和大数定律,本质上避免了传统的归纳到演绎的过程,实现了高效的从训练样本到预测样本的“转导推理”大大简化了通常的分类和回归问题。
(3) SVM的最终决策函数仅由少量支持向量决定。计算复杂度取决于支持向量的数量,而不是样本空间的维数。这样就避免了“维数”某种意义上的灾难”。
(4)少量的支持向量决定了最终的结果,有助于捕捉关键样本,“拒绝”大量冗余样本,注定算法简单,“鲁棒性”好。
3.2 方法概述
Hub网页识别可以理解为二分类问题,正类是Hub网页,负类是主题网页。Hub网页识别的关键是如何正确划分Hub网页和主题网页。
基于URL特征识别Hub网页的方法主要是根据URL中与Hub网页相关的特征对网页进行分类。具体过程如下:分析获取的URL,提取其中收录的特征信息,找出与Hub网页相关的特征;将得到的特征整合到训练集和测试集,用训练集训练SVM机器学习模型,同时评估效果:根据效果调整SVM模型参数,从而确定最优参数,并得到最终的 SVM 学习模型。
3.3 实现过程
它展示了基于 URL 特征的 Hub 网页识别方法的架构。从整体来看,该方法主要包括预处理、特征提取和训练分类三个模块。
图1 Hub网页识别架构
(1) 预处理
预处理主要包括 URL 分析。URL收录大量信息,其中一些信息可以作为网页分类的依据。URL分析的目的是找出对分类有用的特征信息。URL中的信息包括URL的长度、URL是否收录某些字符串等。URL对应的锚文本也可以在一定程度上反映网页类型。因此,需要在预处理阶段提取URL对应的锚文本。
本实验基础数据预先整理自网络采集器采集。在采集的过程中,URL及其对应的标题以及采集等其他信息将被记录为日志文件。因此,本实验通过提取日志文件的内容来分析日志文件的内容,获取URL相关信息。包括URL标题长度、URL长度、URL是否收录日期、网页文件名、文件类型、参数名、参数号、目录名、目录深度、URL大小、采集深度。
(2) 特征提取
特征提取主要包括特征选择和特征量化。特征选择的任务是从特征项空间中删除信息量小的特征和不重要的特征,从而降低特征项空间的维数。特征量化是对选中的特征进行量化,以表示特征与Hub页面的关联程度。
经过URL解析,可以得到URL中收录的信息。通过查阅相关文献和观察统计,可以发现Hub网页与主题网页不同的特点如下:
①URL标题长度:锚文本的长度。锚文本的长度一般较短,因为Hub网页没有描述具体的内容。
②URL 长度:由于Hub 网页基本位于主题网页的上层,因此Hub 网页的URL 比主题网页要短。
③网址是否收录日期:主题网页主要描述某个内容,网址大部分收录发布日期,但Hub网页基本没有。
④网页文件名:Hub网页URL一般有两种可能:只是一个目录,没有文件名;文件名大多收录诸如“索引”和“类”之类的词。
⑤文件类型:文件类型与网页文件名结合在一起,具有网页文件名的Hub网页大部分为ASP、JSP、ASPX和PHP类型。
⑥参数名称:在带参数的网址中,主题网页的网址大多收录ID参数,而Hub网页的网址一般没有。
⑦参数数量:大部分Hub网页网址都没有参数。
⑧ 目录深度:Hub 网页基本位于网站的上层。
⑨网址大小:网页对应的网址大小。Hub网页上有大量的链接,对应的网页也比较大。
⑩采集深度:采集到URL的级别。中心网页提供主题网页的链接条目。因此,Hub 网页采集 一般先于主题网页。
机器学习模型只能对数字类型进行分类,因此需要将文本类型数字化。数字化的基础是汇总不同类型网址的文本值,找到具有代表性的文本值进行赋值。分配是通过统计计算的。文本值出现的频率,然后计算其出现的概率并归一化。在统计中,选取500个Hub网页,统计每个文本值的个数并计算概率,将概率乘以100进行赋值(只是为了让最终的特征值在一个合理的范围内)。具体流程如下:
①网页文件名“空”的个数为302个,概率为0.604,取值为60.4;那些带有“class”、“index”、“default”和“list”的数字为153,概率为0.306,赋值为30.6;收录“文章”和“内容”的个数为0,概率为0,赋值为0;其他情况下为45,概率为0.09,值为9。
②文件类型“空”的个数为302个,概率为0.604,取值为60.4;收录“asp”、“jsp”、“aspx”和“php”的文件个数为123,概率为0.246,取值为24.6;收录“shtml”、“html”和“htm”的数字为75,概率为0.15,值为15;否则数字为0,概率为0,值为0。
③参数名称为“空”的数为412,概率为0.824,赋值为82.4;带有“id”的数字为52,概率为0.104,值为10.4;其他情况数为36,概率为0.072,取值为7.2。
(3) 训练分类
①~cjlin/libsvm/.
通过以上步骤,将URL表示为向量空间,使用LibSVM[]对URL进行分类。LibSVM 是一个快速有效的 SVM 模式识别和回归集成包。还提供了源代码,可以根据需求修改源代码。本实验使用LibSVM-3.20版本①中的Java源代码。源代码在参数设置和训练模型方面进行了修改,增加了自动参数优化和模型文件返回和保存功能。
①按照LibSVM要求的格式准备数据集。
该算法使用的训练数据和测试数据文件格式如下:
[标签] [索引 1]:[值 1] [索引 2]:[值 2]...
[标签] [索引 1]:[值 1] [索引 2]:[值 2]...
其中,label(或class)就是这个数据的类别,通常是一些整数;index表示特征的序号,通常是1开头的整数;value 是特征值,通常是一些实数。当特征值为0时,特征号和特征值可以省略,因此索引可以是一个不连续的自然数。
② 对数据进行简单的缩放操作。
扫描数据,因为原创数据可能太大或太小,svmscale可以先将数据重新缩放到合适的范围,默认范围是[-1,1],可以使用参数lower和upper来调整upper和upper分别为缩放的下限。这也避免了训练时为了计算核函数而计算内积时数值计算的困难。
③选择RBF核函数。
SVM 的类型选择 C-SVC,即 C 型支持向量分类机,它允许不完全分类,带有异常值惩罚因子 c。c越大,误分类样本越少,分类间距越小,泛化能力越弱;c越小,误分类样本越大,分类间距越大,泛化能力越强。
核函数的类型选择RBF有三个原因:RBF核函数可以将一个样本映射到更高维的空间,而线性核函数是RBF的一个特例,也就是说如果考虑使用RBF,那么无需考虑线性核函数;需要确定的参数较少,核函数参数的多少直接影响函数的复杂度;对于某些参数,RBF 和其他核函数具有相似的性能。RBF核函数自带一个gamma参数,代表核函数的半径,隐含决定了数据映射到新特征空间后的分布。
SVMtrain 训练训练数据集以获得 SVM 模型。模型内容如下:
svm_type c_svc% 用于训练的 SVM 类型,这里是 C-SVC
kernel_type rbf% 训练使用的核函数类型,这里是RBF核
gamma 0.0769231% 设置核函数中的gamma参数,默认值为1/k
nr_class 2% 分类中的类别数,这里是二分类问题
total_sv 支持向量总数的 132%
rho 0.424462% 决策函数中的常数项
标签 1 0% 类别标签
nr_sv 64 68% 每个类别标签对应的支持向量数
SV% 及以下是支持向量
1 1:0.166667 2:1 3:-0.333333 4:-0.433962 5:-0.383562 6:-1 7:-1
8:0.0687023 9:-1 10:-0.903226 11:-1 12:-1 13:1
0.55164 1:0.125 2:1 3:0.333333 4:-0.320755
5:-0.406393 6:1 7:1 8:0.0839695 9:1 10:-0.806452 12:-0.333333 13:0.@ >5
④十折交叉验证用于选择最佳参数c和g(c为惩罚系数,g为核函数中的gamma参数)。
交叉验证就是将训练样本平均分成10份,每次9份作为训练集,剩下的一份作为测试集,重复10次,得到平均交叉验证准确率rate 10 次寻找最佳参数使准确率最高。在 LibSVM 源代码中,一次只能验证一组参数。要找到最佳参数,您只能手动多次设置参数。
本实验修改源代码,采用网格搜索方法自动寻找最优参数并返回。具体操作是自动获取一组参数,进行十倍交叉验证,得到平均准确率,如此反复,最终找到准确率最高的一组参数。为了确定合适的训练集大小,分别选取三个训练集进行训练。实验结果表明,当训练集为1000时,平均分类准确率为80%;当训练集为 2000 和 3000 时,平均分类准确率约为 91%。因此,为了保证训练集的简化,选择训练集的大小为2000。
⑤使用最佳参数c和g对训练集进行训练,得到SVM模型。
使用SVMtrain函数训练模型,训练模型不会保存在LibSVM中,每次预测都需要重新训练。本实验对源代码进行了改进,将训练好的模型保存在本地,方便下次使用。
⑥ 使用获得的模型进行预测。
使用经过训练的模型进行测试。输入新的 X 值并给出 SVM 预测的 Y 值。
4 可行性验证4.1 验证方法
分别用两种方法进行对比实验,验证基于URL特征的Hub网页识别方法的可行性: 与基于多特征启发式规则的传统网页分类方法对比;对比传统的基于内容特征的机器学习方法。这一阶段没有选择与传统的基于URL的简单规则识别方法进行比较,因为在曹桂峰[]的研究中,已经清楚地证明了基于URL的简单规则的识别效果明显不如基于URL的分类方法。关于多特征启发式规则。
其可行性主要从效率和效果两个方面来验证。现有研究提出传统方法时,只给出了其效果数据,没有效率数据。因此,本文按照原步骤重新实现了两种验证方法。在达到原创实验效果的同时获得效率数据。
4.2 验证方法的实现
(1)基于多特征启发式规则的网页分类方法
①预处理操作。通过一组正则表达式去除注释信息、Script 脚本和 CSS 样式信息。
②计算网页的特征值。这个过程是网页分类的关键,主要是计算归一化后的非链接字符数、标点符号数、文本链接比例。
③计算支持度。根据得到的特征值计算网页作为话题网页的综合支持度。
④ 将计算的支持度与阈值进行比较。如果支持度小于阈值,则输出网页的类型为Hub网页,否则输出网页的类型为主题类型。
在该验证方法的实现中,阈值是通过实验获得的。实验中选取500个Hub网页,计算每个网页作为话题网页的综合支持度,发现值集中在0.6以下,大部分集中在以下-0.2,所以确定了阈值的大概范围,最后在这个范围内进行了一项一项的测试实验,寻找最优的阈值,使得实验准确率最高。
(2) 基于内容特征的机器学习方法
① HTML 解析。通过构建 DOM 树,去除与网页分类无关的 HTML 源代码。HTML解析步骤如下:
1)标准化 HTML 标签
由于部分网页中的HTML标签错误或缺失,为了方便后续处理,需要对错误的标签进行更正,完成缺失的标签。
2)构建DOM树
从 HTML 中的标签构建一个 DOM 树。
3)网络去噪
消除, 查看全部
网页采集器的自动识别算法(网页增量式采集研究中,网页识别方法识别哪些)
1 简介
随着互联网的发展,Web 上的网页数量迅速增长。即使采用大规模分布式网页采集系统,全网最重要的网页都需要很长时间。研究结果表明,只有8.52%的中国网页在一个月内发生了变化[],因此采用完整的采集方式是对资源的巨大浪费。另外,由于两次采集的周期较长,这段时间内网页变化频率较高的网页已经发生多次变化,采集系统无法及时捕捉到变化的网页,这将导致搜索引擎系统无法为这些网页提供检索服务。为了解决这个问题,创建了一个网页增量采集系统。
网页增量采集 系统不是采集获取的所有网址,而是只估计网页的变化采集新网页、变更网页、消失网页,不关心网页的变化未更改的网页。这大大减少了采集的使用量,可以快速将Web上的网页与搜索引擎中的网页同步,从而为用户提供更加实时的检索服务。
在增量的采集研究中,网页通常分为目录网页(Hub pages)和主题网页(Topic pages)[],Hub网页在网站中的作用是引导用户寻找相关主题网页,相当于目录索引,没有具体内容,提供主题网页的入口[]。基于主题的网页专门针对某个主题。实验证明,很多新的网页都是从Hub网页[]链接而来的。因此增量采集系统只需要找到Hub网页并执行采集就可以发现新出现的URL。如上所述,识别哪些网页是Hub网页成为首先要解决的问题。
针对这个问题,本文提出了一种基于URL特征识别Hub网页的方法。首次将 URL 特征用作 Hub 网页识别的整个基础。这将弥补传统Hub网页识别的巨大成本。最后通过对比实验进行验证。方法的有效性。
2 相关工作
目前主要的Hub网页识别方法包括基于简单规则的识别方法[]、基于多特征启发式规则的分类方法[-]和基于网页内容的机器学习方法[-]。
基于简单规则的识别方法是分析Hub网页URL的特征,总结规则,制定简单规则。Hub 网页满足条件。孟等人。建议选择网站的主页,网站中文件名收录index、class、default等词的网页作为Hub网页[],采集对应的网页Hub 网页中的链接。这种方法可以采集到达大量新网页,但是新网页采集的召回率不是很高。存在以下问题:
(1)Hub网页选择不准确。由于网页的文件名是人名,没有固定模式,所以不可能找到一个规则来正确找到所有Hub网页;
(2)无法自动识别Hub网页,由于在采集过程中无法及时发现新的Hub网页,无法找到新的Hub网页中的链接信息。
为了解决简单的基于规则的方法的局限性,Ail 等人。提出了一种基于多特征启发式规则的网页分类方法,基于非链接字符数、标点符号数、文本链接比例构建启发式规则[]。研究发现,Hub 网页和主题网页在这些特征值上存在广泛差异,这种差异证明了网页通过这些特征值进行分类的可行性。该方法通过根据贝叶斯公式统计网页中每个特征的具体值,计算每个特征值对Hub网页的概率支持度,根据每个特征值的概率支持度得到综合支持度,并设置阈值。比较并确定网页属于哪个类别。这种方法的缺点是过于依赖阈值的设置。阈值的设置将直接影响分类的准确性。但是对于不同类型的网站,阈值设置也不同,增加了算法的复杂度。.
为了解决阈值依赖问题,文献[9]提出了一种基于网页内容的机器学习方法,通过HTML分析和网页特征分析,建立训练集和测试集,从而获得机器学习用于识别 Hub 网页的学习模型。这种方法精度高,但效率低,增加了系统的额外成本。由于这种方法是基于网页的内容,需要解析所有的HTML网页,并提取其特征进行存储,会在一定程度上占用系统资源,给采集系统带来额外的负担. 影响采集系统的性能。
以上方法从不同层面分析了Hub网页的识别。基于前人的研究,本文提出的基于URL特征的识别方法将在很大程度上解决上述问题。该方法使用 URL 特征作为样本,SVM 作为机器学习方法进行识别。与基于规则和基于网络内容的方法相比,它提供了一种更有价值的方法。一方面,特征提取简单、高效、易于实现,同时兼顾识别的准确性。另一方面,在采集系统中,从网页中提取URL是必不可少的一部分。因此,选择URL作为识别依据,可以减少对系统效率的影响,并且不会给采集系统增加过多的额外开销。
3 基于URL特征的Hub网页识别方法3.1 SVM介绍
支持向量机(SVM)是由 Vapnik 等人开发的一种机器学习方法。支持向量机基于统计理论-VC维数理论和最小结构风险原则。特别是在样本数量较少的情况下,SVM的性能明显优于其他算法[-]。
基本思想是:定义最优线性超平面,将寻找最优超平面的算法简化为求解最优(凸规划)问题。然后基于Mercer核展开定理,通过非线性映射,将样本空间映射到一个高维甚至无限维的特征空间,从而可以在特征空间中使用线性学习机的方法来求解高度非线性样本空间中的分类和回归。问题。它还包括以下优点:
(1) 基于结构风险最小化原则,这样可以避免过拟合问题,泛化能力强。
(2) SVM是一种理论基础扎实的小样本学习方法,基本不涉及概率测度和大数定律,本质上避免了传统的归纳到演绎的过程,实现了高效的从训练样本到预测样本的“转导推理”大大简化了通常的分类和回归问题。
(3) SVM的最终决策函数仅由少量支持向量决定。计算复杂度取决于支持向量的数量,而不是样本空间的维数。这样就避免了“维数”某种意义上的灾难”。
(4)少量的支持向量决定了最终的结果,有助于捕捉关键样本,“拒绝”大量冗余样本,注定算法简单,“鲁棒性”好。
3.2 方法概述
Hub网页识别可以理解为二分类问题,正类是Hub网页,负类是主题网页。Hub网页识别的关键是如何正确划分Hub网页和主题网页。
基于URL特征识别Hub网页的方法主要是根据URL中与Hub网页相关的特征对网页进行分类。具体过程如下:分析获取的URL,提取其中收录的特征信息,找出与Hub网页相关的特征;将得到的特征整合到训练集和测试集,用训练集训练SVM机器学习模型,同时评估效果:根据效果调整SVM模型参数,从而确定最优参数,并得到最终的 SVM 学习模型。
3.3 实现过程
它展示了基于 URL 特征的 Hub 网页识别方法的架构。从整体来看,该方法主要包括预处理、特征提取和训练分类三个模块。
图1 Hub网页识别架构
(1) 预处理
预处理主要包括 URL 分析。URL收录大量信息,其中一些信息可以作为网页分类的依据。URL分析的目的是找出对分类有用的特征信息。URL中的信息包括URL的长度、URL是否收录某些字符串等。URL对应的锚文本也可以在一定程度上反映网页类型。因此,需要在预处理阶段提取URL对应的锚文本。
本实验基础数据预先整理自网络采集器采集。在采集的过程中,URL及其对应的标题以及采集等其他信息将被记录为日志文件。因此,本实验通过提取日志文件的内容来分析日志文件的内容,获取URL相关信息。包括URL标题长度、URL长度、URL是否收录日期、网页文件名、文件类型、参数名、参数号、目录名、目录深度、URL大小、采集深度。
(2) 特征提取
特征提取主要包括特征选择和特征量化。特征选择的任务是从特征项空间中删除信息量小的特征和不重要的特征,从而降低特征项空间的维数。特征量化是对选中的特征进行量化,以表示特征与Hub页面的关联程度。
经过URL解析,可以得到URL中收录的信息。通过查阅相关文献和观察统计,可以发现Hub网页与主题网页不同的特点如下:
①URL标题长度:锚文本的长度。锚文本的长度一般较短,因为Hub网页没有描述具体的内容。
②URL 长度:由于Hub 网页基本位于主题网页的上层,因此Hub 网页的URL 比主题网页要短。
③网址是否收录日期:主题网页主要描述某个内容,网址大部分收录发布日期,但Hub网页基本没有。
④网页文件名:Hub网页URL一般有两种可能:只是一个目录,没有文件名;文件名大多收录诸如“索引”和“类”之类的词。
⑤文件类型:文件类型与网页文件名结合在一起,具有网页文件名的Hub网页大部分为ASP、JSP、ASPX和PHP类型。
⑥参数名称:在带参数的网址中,主题网页的网址大多收录ID参数,而Hub网页的网址一般没有。
⑦参数数量:大部分Hub网页网址都没有参数。
⑧ 目录深度:Hub 网页基本位于网站的上层。
⑨网址大小:网页对应的网址大小。Hub网页上有大量的链接,对应的网页也比较大。
⑩采集深度:采集到URL的级别。中心网页提供主题网页的链接条目。因此,Hub 网页采集 一般先于主题网页。
机器学习模型只能对数字类型进行分类,因此需要将文本类型数字化。数字化的基础是汇总不同类型网址的文本值,找到具有代表性的文本值进行赋值。分配是通过统计计算的。文本值出现的频率,然后计算其出现的概率并归一化。在统计中,选取500个Hub网页,统计每个文本值的个数并计算概率,将概率乘以100进行赋值(只是为了让最终的特征值在一个合理的范围内)。具体流程如下:
①网页文件名“空”的个数为302个,概率为0.604,取值为60.4;那些带有“class”、“index”、“default”和“list”的数字为153,概率为0.306,赋值为30.6;收录“文章”和“内容”的个数为0,概率为0,赋值为0;其他情况下为45,概率为0.09,值为9。
②文件类型“空”的个数为302个,概率为0.604,取值为60.4;收录“asp”、“jsp”、“aspx”和“php”的文件个数为123,概率为0.246,取值为24.6;收录“shtml”、“html”和“htm”的数字为75,概率为0.15,值为15;否则数字为0,概率为0,值为0。
③参数名称为“空”的数为412,概率为0.824,赋值为82.4;带有“id”的数字为52,概率为0.104,值为10.4;其他情况数为36,概率为0.072,取值为7.2。
(3) 训练分类
①~cjlin/libsvm/.
通过以上步骤,将URL表示为向量空间,使用LibSVM[]对URL进行分类。LibSVM 是一个快速有效的 SVM 模式识别和回归集成包。还提供了源代码,可以根据需求修改源代码。本实验使用LibSVM-3.20版本①中的Java源代码。源代码在参数设置和训练模型方面进行了修改,增加了自动参数优化和模型文件返回和保存功能。
①按照LibSVM要求的格式准备数据集。
该算法使用的训练数据和测试数据文件格式如下:
[标签] [索引 1]:[值 1] [索引 2]:[值 2]...
[标签] [索引 1]:[值 1] [索引 2]:[值 2]...
其中,label(或class)就是这个数据的类别,通常是一些整数;index表示特征的序号,通常是1开头的整数;value 是特征值,通常是一些实数。当特征值为0时,特征号和特征值可以省略,因此索引可以是一个不连续的自然数。
② 对数据进行简单的缩放操作。
扫描数据,因为原创数据可能太大或太小,svmscale可以先将数据重新缩放到合适的范围,默认范围是[-1,1],可以使用参数lower和upper来调整upper和upper分别为缩放的下限。这也避免了训练时为了计算核函数而计算内积时数值计算的困难。
③选择RBF核函数。
SVM 的类型选择 C-SVC,即 C 型支持向量分类机,它允许不完全分类,带有异常值惩罚因子 c。c越大,误分类样本越少,分类间距越小,泛化能力越弱;c越小,误分类样本越大,分类间距越大,泛化能力越强。
核函数的类型选择RBF有三个原因:RBF核函数可以将一个样本映射到更高维的空间,而线性核函数是RBF的一个特例,也就是说如果考虑使用RBF,那么无需考虑线性核函数;需要确定的参数较少,核函数参数的多少直接影响函数的复杂度;对于某些参数,RBF 和其他核函数具有相似的性能。RBF核函数自带一个gamma参数,代表核函数的半径,隐含决定了数据映射到新特征空间后的分布。
SVMtrain 训练训练数据集以获得 SVM 模型。模型内容如下:
svm_type c_svc% 用于训练的 SVM 类型,这里是 C-SVC
kernel_type rbf% 训练使用的核函数类型,这里是RBF核
gamma 0.0769231% 设置核函数中的gamma参数,默认值为1/k
nr_class 2% 分类中的类别数,这里是二分类问题
total_sv 支持向量总数的 132%
rho 0.424462% 决策函数中的常数项
标签 1 0% 类别标签
nr_sv 64 68% 每个类别标签对应的支持向量数
SV% 及以下是支持向量
1 1:0.166667 2:1 3:-0.333333 4:-0.433962 5:-0.383562 6:-1 7:-1
8:0.0687023 9:-1 10:-0.903226 11:-1 12:-1 13:1
0.55164 1:0.125 2:1 3:0.333333 4:-0.320755
5:-0.406393 6:1 7:1 8:0.0839695 9:1 10:-0.806452 12:-0.333333 13:0.@ >5
④十折交叉验证用于选择最佳参数c和g(c为惩罚系数,g为核函数中的gamma参数)。
交叉验证就是将训练样本平均分成10份,每次9份作为训练集,剩下的一份作为测试集,重复10次,得到平均交叉验证准确率rate 10 次寻找最佳参数使准确率最高。在 LibSVM 源代码中,一次只能验证一组参数。要找到最佳参数,您只能手动多次设置参数。
本实验修改源代码,采用网格搜索方法自动寻找最优参数并返回。具体操作是自动获取一组参数,进行十倍交叉验证,得到平均准确率,如此反复,最终找到准确率最高的一组参数。为了确定合适的训练集大小,分别选取三个训练集进行训练。实验结果表明,当训练集为1000时,平均分类准确率为80%;当训练集为 2000 和 3000 时,平均分类准确率约为 91%。因此,为了保证训练集的简化,选择训练集的大小为2000。
⑤使用最佳参数c和g对训练集进行训练,得到SVM模型。
使用SVMtrain函数训练模型,训练模型不会保存在LibSVM中,每次预测都需要重新训练。本实验对源代码进行了改进,将训练好的模型保存在本地,方便下次使用。
⑥ 使用获得的模型进行预测。
使用经过训练的模型进行测试。输入新的 X 值并给出 SVM 预测的 Y 值。
4 可行性验证4.1 验证方法
分别用两种方法进行对比实验,验证基于URL特征的Hub网页识别方法的可行性: 与基于多特征启发式规则的传统网页分类方法对比;对比传统的基于内容特征的机器学习方法。这一阶段没有选择与传统的基于URL的简单规则识别方法进行比较,因为在曹桂峰[]的研究中,已经清楚地证明了基于URL的简单规则的识别效果明显不如基于URL的分类方法。关于多特征启发式规则。
其可行性主要从效率和效果两个方面来验证。现有研究提出传统方法时,只给出了其效果数据,没有效率数据。因此,本文按照原步骤重新实现了两种验证方法。在达到原创实验效果的同时获得效率数据。
4.2 验证方法的实现
(1)基于多特征启发式规则的网页分类方法
①预处理操作。通过一组正则表达式去除注释信息、Script 脚本和 CSS 样式信息。
②计算网页的特征值。这个过程是网页分类的关键,主要是计算归一化后的非链接字符数、标点符号数、文本链接比例。
③计算支持度。根据得到的特征值计算网页作为话题网页的综合支持度。
④ 将计算的支持度与阈值进行比较。如果支持度小于阈值,则输出网页的类型为Hub网页,否则输出网页的类型为主题类型。
在该验证方法的实现中,阈值是通过实验获得的。实验中选取500个Hub网页,计算每个网页作为话题网页的综合支持度,发现值集中在0.6以下,大部分集中在以下-0.2,所以确定了阈值的大概范围,最后在这个范围内进行了一项一项的测试实验,寻找最优的阈值,使得实验准确率最高。
(2) 基于内容特征的机器学习方法
① HTML 解析。通过构建 DOM 树,去除与网页分类无关的 HTML 源代码。HTML解析步骤如下:
1)标准化 HTML 标签
由于部分网页中的HTML标签错误或缺失,为了方便后续处理,需要对错误的标签进行更正,完成缺失的标签。
2)构建DOM树
从 HTML 中的标签构建一个 DOM 树。
3)网络去噪
消除,
网页采集器的自动识别算法(从电脑上检测和查看网页内容的自动识别呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-10-09 23:02
网页采集器的自动识别算法直接影响网页内容的采集。而网页采集器的算法的不断迭代调整就是各大网站、还有媒体平台等对网页内容进行收录排名的手段之一。新浪微博会实时监测微博采集,并对采集内容进行修正以及对采集的内容进行直观的展示,而百度的搜狗搜索以及360的搜索并没有实时监测。那如何实现从电脑上检测和查看网页内容呢?比如:新浪微博、百度搜索以及360搜索。
那么有什么便捷的方法可以快速地做到网页采集器的自动识别呢?下面我给大家详细说明一下,分为“网页采集器采集方法介绍”以及“网页采集器采集的实时有效性检测”两个部分。网页采集器采集方法介绍i页面是指在某一特定的网页后面加入来自网页中相关页面的链接。如果添加页面的链接后面没有网页的链接,那么这个页面是标记为空页面,不会被收录。
当添加一个页面后网页是有链接的,在每次搜索该网页时都会出现相应的链接。a页面就是指从未出现过的页面页面链接来源webpack是基于angular框架所开发的,页面的任何地方都有可能存在攻击者获取用户信息的黑客攻击行为。比如:采集网站的页面内容、黑客注入木马、篡改页面、cookie、重定向、爬虫或恶意软件等,每年都有无数个关于攻击webpack的漏洞。
i的页面是由一个独立的分类页面组成。其下包含了不同类型的网页链接。i的页面(来源页)基本上属于angular框架的page-url,具有相对复杂的模块化编写(angular封装了ng-controller),不同类型的页面都有自己的链接以及标识、域名或者id号。i的页面可以通过以下方式下载:github::/stone_pro,/dev_navigation。
<p>windows::,我是用下面的代码进行采集的:请搜索加入或者,二者的区别在于第一个,由于所有的页面都是基于angular框架开发的,因此有相应的预设的模块。其中对于img_title及mask_img有如下两种下载路径:windows:/transform.wxparse(img_title,img_title,img_title_content,'guangzikepojie')/windows:/external.wxparse(img_title,img_title,img_title_content,'tencent.tcp.wxparse.webpack.webpack(index.js)')/在没有特殊情况需要时,上面两种方式基本一致。i内容还可以是图片,当然是通过一个图片作为链接来保存i内容,我把它保存到自己的网站 查看全部
网页采集器的自动识别算法(从电脑上检测和查看网页内容的自动识别呢?)
网页采集器的自动识别算法直接影响网页内容的采集。而网页采集器的算法的不断迭代调整就是各大网站、还有媒体平台等对网页内容进行收录排名的手段之一。新浪微博会实时监测微博采集,并对采集内容进行修正以及对采集的内容进行直观的展示,而百度的搜狗搜索以及360的搜索并没有实时监测。那如何实现从电脑上检测和查看网页内容呢?比如:新浪微博、百度搜索以及360搜索。
那么有什么便捷的方法可以快速地做到网页采集器的自动识别呢?下面我给大家详细说明一下,分为“网页采集器采集方法介绍”以及“网页采集器采集的实时有效性检测”两个部分。网页采集器采集方法介绍i页面是指在某一特定的网页后面加入来自网页中相关页面的链接。如果添加页面的链接后面没有网页的链接,那么这个页面是标记为空页面,不会被收录。
当添加一个页面后网页是有链接的,在每次搜索该网页时都会出现相应的链接。a页面就是指从未出现过的页面页面链接来源webpack是基于angular框架所开发的,页面的任何地方都有可能存在攻击者获取用户信息的黑客攻击行为。比如:采集网站的页面内容、黑客注入木马、篡改页面、cookie、重定向、爬虫或恶意软件等,每年都有无数个关于攻击webpack的漏洞。
i的页面是由一个独立的分类页面组成。其下包含了不同类型的网页链接。i的页面(来源页)基本上属于angular框架的page-url,具有相对复杂的模块化编写(angular封装了ng-controller),不同类型的页面都有自己的链接以及标识、域名或者id号。i的页面可以通过以下方式下载:github::/stone_pro,/dev_navigation。
<p>windows::,我是用下面的代码进行采集的:请搜索加入或者,二者的区别在于第一个,由于所有的页面都是基于angular框架开发的,因此有相应的预设的模块。其中对于img_title及mask_img有如下两种下载路径:windows:/transform.wxparse(img_title,img_title,img_title_content,'guangzikepojie')/windows:/external.wxparse(img_title,img_title,img_title_content,'tencent.tcp.wxparse.webpack.webpack(index.js)')/在没有特殊情况需要时,上面两种方式基本一致。i内容还可以是图片,当然是通过一个图片作为链接来保存i内容,我把它保存到自己的网站
网页采集器的自动识别算法(Java开发中常见的纯文本解析方法-乐题库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-08 02:26
其他可用的python http请求模块:
你请求
你的请求
其中frequests和grequests的使用方式相同,frequests的稳定性高于grequests;简单使用如下:
2.响应结果数据格式
常见的响应结果格式为:
3.各种数据格式的分析方法3.1 Html分析方法
常见的html数据分析方法有:
3.2 纯文本分析方法
常见的纯文本解析方法有:
3.3 网页正文提取
网页正文提取的重要性:
正则表达式可以准确地提取出某种固定格式的页面,但是面对各种HTML,使用规则来处理是不可避免的。能否高效准确地提取出页面主体并在大规模网页中普遍使用,是一个直接关系到上层应用的难题。
研究计划:
JoyHTML的目的是解析HTML文本中的链接和文本,采用以超链接密度法为主要判断依据的标签窗口算法,采用DOM树分析模式。
这个 Java 类库提供算法来检测和删除网页中主要文本内容旁边的冗余重复内容。它已经提供了一种特殊的策略来处理一些常用的功能,例如:新闻文章提取。
该算法首次将提取网页正文的问题转化为网页的行块分布函数,与HTML标签完全分离。通过线性时间建立线块分布函数图,使得该图可以高效准确地直接定位网页文本。同时采用统计与规则相结合的方法解决系统通用性问题。
这里我们只使用cx-extractor和可读性;下面是cx-extractor和可读性的对比,如下图:
cx-extractor 的使用示例如下图所示:
cx-extractor 和可读性的比较
4.数据分析详情
建议: 查看全部
网页采集器的自动识别算法(Java开发中常见的纯文本解析方法-乐题库)
其他可用的python http请求模块:
你请求
你的请求
其中frequests和grequests的使用方式相同,frequests的稳定性高于grequests;简单使用如下:
2.响应结果数据格式
常见的响应结果格式为:
3.各种数据格式的分析方法3.1 Html分析方法
常见的html数据分析方法有:
3.2 纯文本分析方法
常见的纯文本解析方法有:
3.3 网页正文提取
网页正文提取的重要性:
正则表达式可以准确地提取出某种固定格式的页面,但是面对各种HTML,使用规则来处理是不可避免的。能否高效准确地提取出页面主体并在大规模网页中普遍使用,是一个直接关系到上层应用的难题。
研究计划:
JoyHTML的目的是解析HTML文本中的链接和文本,采用以超链接密度法为主要判断依据的标签窗口算法,采用DOM树分析模式。
这个 Java 类库提供算法来检测和删除网页中主要文本内容旁边的冗余重复内容。它已经提供了一种特殊的策略来处理一些常用的功能,例如:新闻文章提取。
该算法首次将提取网页正文的问题转化为网页的行块分布函数,与HTML标签完全分离。通过线性时间建立线块分布函数图,使得该图可以高效准确地直接定位网页文本。同时采用统计与规则相结合的方法解决系统通用性问题。
这里我们只使用cx-extractor和可读性;下面是cx-extractor和可读性的对比,如下图:
cx-extractor 的使用示例如下图所示:
cx-extractor 和可读性的比较
4.数据分析详情
建议:
网页采集器的自动识别算法(网页采集器的自动识别算法是没什么问题的?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-10-06 13:10
网页采集器的自动识别算法是没什么问题的,但是识别效率是相当低的,毕竟限制条件太多。如何在短时间里减少用户操作,缩短响应时间,是厂商想解决的问题。html5更没问题,但是要打开一个5000多行的html程序,谁会愿意去自己做一个采集器呢。而且,这个自动识别,并不是你对那一段已经有的页面进行识别,而是对特定页面。
而且,可识别范围也只是被抓取的那段区域。是否更换采集器库,还要从程序到内容,再到网站生成web应用,操作复杂多了。如果将bs模式改为cms模式,效果可能会更好一些。
谢邀。如果是百度统计,必须是一份页面,对于你说的这种情况肯定是有问题的,因为百度统计本身就不太能提供对搜索任何类型页面的统计分析。还是自己再根据具体要统计哪些页面内容进行对搜索页面排序,但无论是否进行html5或者bs结构改成html页面,本质上还是会影响关键词是否被正确定位。
没有问题,而且效果是令人惊讶的好,前提是产品本身的原则,或者可视化操作方法,至于我说得实在有些复杂,但是!其实你没得选。
没问题,你可以尝试一下采集另一个页面。目前没有看到相关产品。我们都是按文章页为算法,然后被采集后按不同属性为参数,结合下拉框等按特定方法为关键词排序。目前大家对知乎这类算法识别有时候不尽人意,还是需要一些经验。对另一个页面进行上传可能需要点时间,不过系统应该会给一个结果和一些猜测。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法是没什么问题的?)
网页采集器的自动识别算法是没什么问题的,但是识别效率是相当低的,毕竟限制条件太多。如何在短时间里减少用户操作,缩短响应时间,是厂商想解决的问题。html5更没问题,但是要打开一个5000多行的html程序,谁会愿意去自己做一个采集器呢。而且,这个自动识别,并不是你对那一段已经有的页面进行识别,而是对特定页面。
而且,可识别范围也只是被抓取的那段区域。是否更换采集器库,还要从程序到内容,再到网站生成web应用,操作复杂多了。如果将bs模式改为cms模式,效果可能会更好一些。
谢邀。如果是百度统计,必须是一份页面,对于你说的这种情况肯定是有问题的,因为百度统计本身就不太能提供对搜索任何类型页面的统计分析。还是自己再根据具体要统计哪些页面内容进行对搜索页面排序,但无论是否进行html5或者bs结构改成html页面,本质上还是会影响关键词是否被正确定位。
没有问题,而且效果是令人惊讶的好,前提是产品本身的原则,或者可视化操作方法,至于我说得实在有些复杂,但是!其实你没得选。
没问题,你可以尝试一下采集另一个页面。目前没有看到相关产品。我们都是按文章页为算法,然后被采集后按不同属性为参数,结合下拉框等按特定方法为关键词排序。目前大家对知乎这类算法识别有时候不尽人意,还是需要一些经验。对另一个页面进行上传可能需要点时间,不过系统应该会给一个结果和一些猜测。
网页采集器的自动识别算法(CNN被训练来识别来自类似数据集的图像,解决原始问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-04 01:01
HSE 大学的一位科学家开发了一种图像识别算法,其工作速度比同类产品快 40%。它可以加快基于视频的图像识别系统的实时处理速度。这项研究的结果已发表在《信息科学》杂志上。
卷积神经网络 (CNN) 包括一系列卷积层,广泛用于计算机视觉。网络中的每一层都有一个输入和一个输出。图像的数字描述进入第一层的输入,并在输出转换为一组不同的数字。结果进入下一层的输入,以此类推,直到最后一层预测出图像中物体的类标签。例如,此类别可以是人、猫或椅子。为此,CNN 在一组具有已知类标签的图像上进行训练。数据集中每个类别的图像数量和可变性越大,训练的网络就越准确。
如果训练集中只有几个例子,将使用神经网络的额外训练(微调)。CNN 被训练从相似的数据集中识别图像,从而解决了原创问题。例如,当神经网络学习识别人脸或其属性(情绪、性别、年龄)时,它最初被训练从照片中识别名人。然后在现有的小数据集上对生成的神经网络进行微调,以识别家庭视频监控系统中的家庭成员或亲戚的面孔。CNN 中层数的深度(数量)越多,它对图像中物体类型的预测就越准确。但是,如果层数增加,则识别对象需要更多时间。
该研究的作者、Nizhny Novgorod HSE 校区的 Andrei Savchenko 教授能够在他的实验中加速具有任意架构的预训练卷积神经网络的工作。该网络由 90 层组成 - 由 780 层组成。结果,识别速度提高了40%,而准确率的损失控制在0.5-1%。这位科学家依赖于统计方法,例如顺序分析和多重比较(多重假设检验)。
图像识别问题中的决策是由分类器做出的,分类器是一种特殊的数学算法,它接收数字数组(图像的特征/嵌入)作为输入,并输出关于图像属于哪个类别的预测。可以通过输入神经网络任何层的输出来应用分类器。为了识别“简单”的图像,分类器只需要分析来自神经网络第一层的数据(输出)。
如果我们对自己做出的决定的可靠性有信心,就没有必要浪费更多的时间。对于“复杂”的图片,第一层显然是不够的,需要去下一层。因此,分类器被添加到神经网络的几个中间层。算法根据输入图片的复杂程度决定是继续识别还是完成识别。Savchenko 教授解释说:“因为在这样的程序中控制错误很重要,所以我应用了多重比较的理论。我引入了许多假设,我应该在中间层停止,并按顺序测试这些假设。”
如果第一个分类器产生了多假设检验程序认为可靠的决定,则算法停止。如果判定决策不可靠,则神经网络中的计算继续到中间层,并重复可靠性检查。
正如科学家所指出的,神经网络最后几层的输出获得了最准确的决策。网络输出的早期分类速度要快得多,这意味着需要同时训练所有分类器以在控制精度损失的同时加快识别速度。例如,使因提前停止造成的误差不超过 1%。
高精度对于图像识别总是很重要的。例如,如果人脸识别系统中的决策是错误的,那么任何外人都可以获得机密信息,否则,用户将因神经网络无法正确识别而被反复拒绝访问。速度有时可以牺牲,但这很重要。例如,在视频监控系统中,非常需要实时决策,即每帧不超过20-30毫秒。Savchenko 教授说:“要在此时识别视频帧中的物体,快速行动而又不失准确性是非常重要的。” 查看全部
网页采集器的自动识别算法(CNN被训练来识别来自类似数据集的图像,解决原始问题)
HSE 大学的一位科学家开发了一种图像识别算法,其工作速度比同类产品快 40%。它可以加快基于视频的图像识别系统的实时处理速度。这项研究的结果已发表在《信息科学》杂志上。
卷积神经网络 (CNN) 包括一系列卷积层,广泛用于计算机视觉。网络中的每一层都有一个输入和一个输出。图像的数字描述进入第一层的输入,并在输出转换为一组不同的数字。结果进入下一层的输入,以此类推,直到最后一层预测出图像中物体的类标签。例如,此类别可以是人、猫或椅子。为此,CNN 在一组具有已知类标签的图像上进行训练。数据集中每个类别的图像数量和可变性越大,训练的网络就越准确。
如果训练集中只有几个例子,将使用神经网络的额外训练(微调)。CNN 被训练从相似的数据集中识别图像,从而解决了原创问题。例如,当神经网络学习识别人脸或其属性(情绪、性别、年龄)时,它最初被训练从照片中识别名人。然后在现有的小数据集上对生成的神经网络进行微调,以识别家庭视频监控系统中的家庭成员或亲戚的面孔。CNN 中层数的深度(数量)越多,它对图像中物体类型的预测就越准确。但是,如果层数增加,则识别对象需要更多时间。
该研究的作者、Nizhny Novgorod HSE 校区的 Andrei Savchenko 教授能够在他的实验中加速具有任意架构的预训练卷积神经网络的工作。该网络由 90 层组成 - 由 780 层组成。结果,识别速度提高了40%,而准确率的损失控制在0.5-1%。这位科学家依赖于统计方法,例如顺序分析和多重比较(多重假设检验)。
图像识别问题中的决策是由分类器做出的,分类器是一种特殊的数学算法,它接收数字数组(图像的特征/嵌入)作为输入,并输出关于图像属于哪个类别的预测。可以通过输入神经网络任何层的输出来应用分类器。为了识别“简单”的图像,分类器只需要分析来自神经网络第一层的数据(输出)。
如果我们对自己做出的决定的可靠性有信心,就没有必要浪费更多的时间。对于“复杂”的图片,第一层显然是不够的,需要去下一层。因此,分类器被添加到神经网络的几个中间层。算法根据输入图片的复杂程度决定是继续识别还是完成识别。Savchenko 教授解释说:“因为在这样的程序中控制错误很重要,所以我应用了多重比较的理论。我引入了许多假设,我应该在中间层停止,并按顺序测试这些假设。”
如果第一个分类器产生了多假设检验程序认为可靠的决定,则算法停止。如果判定决策不可靠,则神经网络中的计算继续到中间层,并重复可靠性检查。
正如科学家所指出的,神经网络最后几层的输出获得了最准确的决策。网络输出的早期分类速度要快得多,这意味着需要同时训练所有分类器以在控制精度损失的同时加快识别速度。例如,使因提前停止造成的误差不超过 1%。
高精度对于图像识别总是很重要的。例如,如果人脸识别系统中的决策是错误的,那么任何外人都可以获得机密信息,否则,用户将因神经网络无法正确识别而被反复拒绝访问。速度有时可以牺牲,但这很重要。例如,在视频监控系统中,非常需要实时决策,即每帧不超过20-30毫秒。Savchenko 教授说:“要在此时识别视频帧中的物体,快速行动而又不失准确性是非常重要的。”
网页采集器的自动识别算法(天地连站群引入编码自动识别前,我们有两种途径获取网页的编码信息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-03 04:22
天地联站群可以根据用户初始输入的关键词获取关键词搜索引擎的搜索结果,然后一一获取相关的文章内容。这样,就要面对无数网页的各种编码。为了解决这个问题,介绍了以下解决方案:
在引入自动编码识别之前,我们有两种方式获取网页的编码信息:
它的一、是通过服务端返回的header中的charset变量获取的
它的二、是通过页面上的元信息获取的
一般情况下,如果服务器或者页面提供了这两个参数,并且参数正确,那么我们抓取网页的时候就没有编码问题了。
然而,现实对我们程序员来说总是很艰难。在抓取网页时,经常会出现以下情况:
1. 缺少这两个参数
2. 虽然提供了两个参数,但是不一致
3. 提供了这两个参数,但与网页的实际编码不一致
为了尽可能自动获取所有网页的编码,引入了自动编码识别
我记得PHP中有一个mb_detect函数,貌似可以识别字符串编码,但是它的准确性不好说,因为自动识别编码是一个概率事件,只有当识别的字符串长度很大时足够(例如,超过 300 个单词)可以更可靠。
所有浏览器都支持自动识别网页编码,如IE、firefox等。
我用的是mozzila提供的universalchardet模块,据说比IE自带的识别模块准确很多
Universalchardet 项目地址为:
目前universalchardet支持python java dotnet等,php不知道是否支持
我比较喜欢写C#,因为VS2010+viemu是我的最爱,所以我用的是C#版本;有许多 C# 移植版本的 Universalchardet,我使用的版本:
下面是一个使用示例,与其他C#实现相比,有点繁琐:
Stream mystream = res.GetResponseStream();<br /> MemoryStream msTemp = new MemoryStream();<br />int len = 0;<br />byte[] buff = new byte[512];<br /><br />while ((len = mystream.Read(buff, 0, 512)) > 0)<br /> {<br /> msTemp.Write(buff, 0, len);<br /><br /> }<br /> res.Close();<br /><br />if (msTemp.Length > 0)<br /> {<br /> msTemp.Seek(0, SeekOrigin.Begin);<br />byte[] PageBytes = new byte[msTemp.Length];<br /> msTemp.Read(PageBytes, 0, PageBytes.Length);<br /><br /> msTemp.Seek(0, SeekOrigin.Begin);<br />int DetLen = 0;<br />byte[] DetectBuff = new byte[4096];<br /> CharsetListener listener = new CharsetListener();<br /> UniversalDetector Det = new UniversalDetector(null);<br />while ((DetLen = msTemp.Read(DetectBuff, 0, DetectBuff.Length)) > 0 && !Det.IsDone())<br /> {<br /> Det.HandleData(DetectBuff, 0, DetectBuff.Length);<br /> }<br /> Det.DataEnd();<br />if (Det.GetDetectedCharset()!=null)<br /> {<br /> CharSetBox.Text = "OK! CharSet=" + Det.GetDetectedCharset();<br /> PageBox.Text = System.Text.Encoding.GetEncoding(Det.GetDetectedCharset()).GetString(PageBytes);<br /> }<br /> }
上面可以识别网页的编码,看起来很简单是不是?如果你之前也被这个问题困扰过,并且有幸看到这篇文章,那么这类问题就彻底解决了,你永远不会因为不懂网页编码而抓到一堆?? ? ? ? 号回;好吧,从此生活就变得如此美好。. . .
我也是这么想的
如上所述,代码识别是一个概率事件,所以不能保证100%正确识别,所以后来我还是发现了一些识别错误导致返回?? 在数的情况下,真的没有办法完美解决这个问题吗?
世界上不可能有完美的事情,我深信这一点。
幸运的是,我们只需要一个完美的解决方案:我们需要让程序知道什么时候自动识别错误,如果错误,读取并使用服务器和网页提供的编码信息。
我绞尽脑汁,想出了一个原生方法:对我们中国人来说,就是有编码问题的中文网页。如果一个中文网页被正确识别,里面肯定会有汉字。Bingo,我从网上找了前N个汉字(比如“的”)。只要网页收录这N个汉字中的一个,则识别成功,否则识别失败。
这样,网页编码识别的问题就基本可以轻松解决了。
后记:
不知道有没有人对这个感兴趣。如果是这样,我想写一篇关于这个主题的文章。标题也是想出来的:《网络IO,到处都是异步》,这里指的是网络IO Only http请求
天地联站群使用这种代码识别方法解决了采集领域的一个重大问题。从那时起,我可以从这个问题中提取我的精力,研究和解决其他问题。 查看全部
网页采集器的自动识别算法(天地连站群引入编码自动识别前,我们有两种途径获取网页的编码信息)
天地联站群可以根据用户初始输入的关键词获取关键词搜索引擎的搜索结果,然后一一获取相关的文章内容。这样,就要面对无数网页的各种编码。为了解决这个问题,介绍了以下解决方案:
在引入自动编码识别之前,我们有两种方式获取网页的编码信息:
它的一、是通过服务端返回的header中的charset变量获取的
它的二、是通过页面上的元信息获取的
一般情况下,如果服务器或者页面提供了这两个参数,并且参数正确,那么我们抓取网页的时候就没有编码问题了。
然而,现实对我们程序员来说总是很艰难。在抓取网页时,经常会出现以下情况:
1. 缺少这两个参数
2. 虽然提供了两个参数,但是不一致
3. 提供了这两个参数,但与网页的实际编码不一致
为了尽可能自动获取所有网页的编码,引入了自动编码识别
我记得PHP中有一个mb_detect函数,貌似可以识别字符串编码,但是它的准确性不好说,因为自动识别编码是一个概率事件,只有当识别的字符串长度很大时足够(例如,超过 300 个单词)可以更可靠。
所有浏览器都支持自动识别网页编码,如IE、firefox等。
我用的是mozzila提供的universalchardet模块,据说比IE自带的识别模块准确很多
Universalchardet 项目地址为:
目前universalchardet支持python java dotnet等,php不知道是否支持
我比较喜欢写C#,因为VS2010+viemu是我的最爱,所以我用的是C#版本;有许多 C# 移植版本的 Universalchardet,我使用的版本:
下面是一个使用示例,与其他C#实现相比,有点繁琐:
Stream mystream = res.GetResponseStream();<br /> MemoryStream msTemp = new MemoryStream();<br />int len = 0;<br />byte[] buff = new byte[512];<br /><br />while ((len = mystream.Read(buff, 0, 512)) > 0)<br /> {<br /> msTemp.Write(buff, 0, len);<br /><br /> }<br /> res.Close();<br /><br />if (msTemp.Length > 0)<br /> {<br /> msTemp.Seek(0, SeekOrigin.Begin);<br />byte[] PageBytes = new byte[msTemp.Length];<br /> msTemp.Read(PageBytes, 0, PageBytes.Length);<br /><br /> msTemp.Seek(0, SeekOrigin.Begin);<br />int DetLen = 0;<br />byte[] DetectBuff = new byte[4096];<br /> CharsetListener listener = new CharsetListener();<br /> UniversalDetector Det = new UniversalDetector(null);<br />while ((DetLen = msTemp.Read(DetectBuff, 0, DetectBuff.Length)) > 0 && !Det.IsDone())<br /> {<br /> Det.HandleData(DetectBuff, 0, DetectBuff.Length);<br /> }<br /> Det.DataEnd();<br />if (Det.GetDetectedCharset()!=null)<br /> {<br /> CharSetBox.Text = "OK! CharSet=" + Det.GetDetectedCharset();<br /> PageBox.Text = System.Text.Encoding.GetEncoding(Det.GetDetectedCharset()).GetString(PageBytes);<br /> }<br /> }
上面可以识别网页的编码,看起来很简单是不是?如果你之前也被这个问题困扰过,并且有幸看到这篇文章,那么这类问题就彻底解决了,你永远不会因为不懂网页编码而抓到一堆?? ? ? ? 号回;好吧,从此生活就变得如此美好。. . .
我也是这么想的
如上所述,代码识别是一个概率事件,所以不能保证100%正确识别,所以后来我还是发现了一些识别错误导致返回?? 在数的情况下,真的没有办法完美解决这个问题吗?
世界上不可能有完美的事情,我深信这一点。
幸运的是,我们只需要一个完美的解决方案:我们需要让程序知道什么时候自动识别错误,如果错误,读取并使用服务器和网页提供的编码信息。
我绞尽脑汁,想出了一个原生方法:对我们中国人来说,就是有编码问题的中文网页。如果一个中文网页被正确识别,里面肯定会有汉字。Bingo,我从网上找了前N个汉字(比如“的”)。只要网页收录这N个汉字中的一个,则识别成功,否则识别失败。
这样,网页编码识别的问题就基本可以轻松解决了。
后记:
不知道有没有人对这个感兴趣。如果是这样,我想写一篇关于这个主题的文章。标题也是想出来的:《网络IO,到处都是异步》,这里指的是网络IO Only http请求
天地联站群使用这种代码识别方法解决了采集领域的一个重大问题。从那时起,我可以从这个问题中提取我的精力,研究和解决其他问题。
网页采集器的自动识别算法(新手入门3——单网页列表详情页采集(8.3版本) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-10-03 04:17
)
入门3-单网页列表详情页采集(8.3版)
本教程将向您展示如何采集单个网页列表的详细信息中的数据。目的是让大家了解如何创建循环点击进入详情页,规范采集详情页的数据信息。
本教程中提到的例子网站的地址为:/guide/demo/navmovies2.html
比如这个网址里面有很多电影,我们需要点击每部电影进入详情页采集电影剧情、上映时间等字段。
针对这种需求,我们采用【自动识别】进行数据采集,或者手动模式,点击页面生成采集流程。下面我们介绍一下【自动识别】的采集方法。
步骤1 登录优采云8.3采集器→点击输入框输入采集的网址→点击开始采集。进入任务配置页面,程序会自动进行智能识别。
如果点击开始采集,不进行自动识别,请点击下方操作提示中的【自动识别网页】。此外,在设置中,您可以启用每次打开网页时的自动识别。
步骤2 自动识别完成后,可以切换到识别结果。找到最合适的需求后,也可以对字段进行调整,调整后点击【生成采集设置】。
Step 3 由于我们需要采集,点击后每部电影的详细数据。因此,生成采集配置后,点击【采集一级网页数据】。
步骤4 进入电影详情页面后,观察识别结果是否符合要求,如果不符合则切换识别结果。或者删除所选字段并再次从页面添加新字段。如果您不满意,您可以单击[取消],然后从页面添加新字段。
Step 4 提取完成后,我们可以在数据预览中点击字段名,然后修改字段名。这里的字段名相当于header,便于采集时区分各个字段类别。
在下图界面修改字段名称,修改完成后点击“保存”保存
步骤5 点击“采集”,在弹出的对话框中选择“启动本地采集”
系统会在本地计算机上启动一个采集任务和采集数据。任务采集完成后,会弹出提示采集,然后选择导出数据。选择Export Excel 作为示例,然后单击OK。然后选择文件存储路径,然后单击“保存”。这样,我们最终需要的数据就得到了。
下面是数据的一个例子
查看全部
网页采集器的自动识别算法(新手入门3——单网页列表详情页采集(8.3版本)
)
入门3-单网页列表详情页采集(8.3版)
本教程将向您展示如何采集单个网页列表的详细信息中的数据。目的是让大家了解如何创建循环点击进入详情页,规范采集详情页的数据信息。
本教程中提到的例子网站的地址为:/guide/demo/navmovies2.html
比如这个网址里面有很多电影,我们需要点击每部电影进入详情页采集电影剧情、上映时间等字段。
针对这种需求,我们采用【自动识别】进行数据采集,或者手动模式,点击页面生成采集流程。下面我们介绍一下【自动识别】的采集方法。
步骤1 登录优采云8.3采集器→点击输入框输入采集的网址→点击开始采集。进入任务配置页面,程序会自动进行智能识别。
如果点击开始采集,不进行自动识别,请点击下方操作提示中的【自动识别网页】。此外,在设置中,您可以启用每次打开网页时的自动识别。
步骤2 自动识别完成后,可以切换到识别结果。找到最合适的需求后,也可以对字段进行调整,调整后点击【生成采集设置】。
Step 3 由于我们需要采集,点击后每部电影的详细数据。因此,生成采集配置后,点击【采集一级网页数据】。
步骤4 进入电影详情页面后,观察识别结果是否符合要求,如果不符合则切换识别结果。或者删除所选字段并再次从页面添加新字段。如果您不满意,您可以单击[取消],然后从页面添加新字段。
Step 4 提取完成后,我们可以在数据预览中点击字段名,然后修改字段名。这里的字段名相当于header,便于采集时区分各个字段类别。
在下图界面修改字段名称,修改完成后点击“保存”保存
步骤5 点击“采集”,在弹出的对话框中选择“启动本地采集”
系统会在本地计算机上启动一个采集任务和采集数据。任务采集完成后,会弹出提示采集,然后选择导出数据。选择Export Excel 作为示例,然后单击OK。然后选择文件存储路径,然后单击“保存”。这样,我们最终需要的数据就得到了。
下面是数据的一个例子
网页采集器的自动识别算法(5年来不断的完善改进造就了史无前例的强大采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2021-10-02 10:39
五年来,不断的改进和完善,造就了前所未有的强大采集软件——网站万能信息采集器。网站优采云采集器:你可以捕捉所有你能看到的信息。八大特色功能: 1.信息采集添加自动网站捕获 抓取的目的主要是给你的网站添加,软件可以实现采集添加全自动。其他网站刚刚更新的信息会在五分钟内自动发送到您的网站。2.需要登录网站也给你拍照需要登录才能看到网站的信息内容,网站优采云采集器可以实现轻松登录和采集,即使有验证码,你可以通过 login采集 传递到你需要的信息。3. 可以下载任何类型的文件。如果需要采集图片等二进制文件,可以通过简单设置将任意类型的文件网站优采云采集器保存到本地。4.多级页面采集 您可以同时采集到多级页面的内容。如果一条信息分布在多个不同的页面上,网站优采云采集器还可以自动识别多级页面,实现采集 5.自动识别特殊页面javascript等网址网站的很多网页链接都是javascript:openwin('1234')这样的特殊网址,不是一般的开头,软件也可以自动识别抓取内容6. 自动获取供需信息等各类分类网址。通常有很多很多类别。通过软件的简单设置,就可以自动抓取这些分类的网址,对抓取到的信息进行自动分类。7.多页新闻自动抓取,广告过滤部分新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图片和文字,过滤掉广告。8. 自动破解防盗链。很多下载网站都做了防盗链。直接输入网址。内容无法抓到,但反盗链可以在软件中自动断链,保证抓到你想要的。还增加了模拟人工提交的功能。租用的网站asp+access空间也可以远程发布,其实也可以模拟所有的网页提交动作,批量注册会员,模拟群发消息。 查看全部
网页采集器的自动识别算法(5年来不断的完善改进造就了史无前例的强大采集软件)
五年来,不断的改进和完善,造就了前所未有的强大采集软件——网站万能信息采集器。网站优采云采集器:你可以捕捉所有你能看到的信息。八大特色功能: 1.信息采集添加自动网站捕获 抓取的目的主要是给你的网站添加,软件可以实现采集添加全自动。其他网站刚刚更新的信息会在五分钟内自动发送到您的网站。2.需要登录网站也给你拍照需要登录才能看到网站的信息内容,网站优采云采集器可以实现轻松登录和采集,即使有验证码,你可以通过 login采集 传递到你需要的信息。3. 可以下载任何类型的文件。如果需要采集图片等二进制文件,可以通过简单设置将任意类型的文件网站优采云采集器保存到本地。4.多级页面采集 您可以同时采集到多级页面的内容。如果一条信息分布在多个不同的页面上,网站优采云采集器还可以自动识别多级页面,实现采集 5.自动识别特殊页面javascript等网址网站的很多网页链接都是javascript:openwin('1234')这样的特殊网址,不是一般的开头,软件也可以自动识别抓取内容6. 自动获取供需信息等各类分类网址。通常有很多很多类别。通过软件的简单设置,就可以自动抓取这些分类的网址,对抓取到的信息进行自动分类。7.多页新闻自动抓取,广告过滤部分新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图片和文字,过滤掉广告。8. 自动破解防盗链。很多下载网站都做了防盗链。直接输入网址。内容无法抓到,但反盗链可以在软件中自动断链,保证抓到你想要的。还增加了模拟人工提交的功能。租用的网站asp+access空间也可以远程发布,其实也可以模拟所有的网页提交动作,批量注册会员,模拟群发消息。
网页采集器的自动识别算法(java和网络爬虫方向时间很短,如何没有符合条件的h1,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-02 10:39
提前感谢 知乎 的帮助
背景:由于java和网络爬虫方向接触时间很短,在编码或者逻辑上还有很多不严谨的地方。一开始是通过前端配置对应的xpath值来爬取定时任务。以后会慢慢需要的。增加了,比如类似今日头条的自动城市标注功能。在同事的指导下,利用自然语言处理,自动分析新闻内容,得到城市。当然,它也借用了开源代码。我不会在这里谈论它。另一个例子是新闻分类。它也类似于使用机器学习贝叶斯分类的方法。. . 说了这么多,让我们回到正题。
让我在这里谈谈我的实现。像标题这样的东西仍然很好地实现,因为标题的特征在互联网上是可追溯的。基本上可以通过h1和h2的logo来实现。当然,如何知道 h1 的文本必须是标题。我之前看过一个分析相似性文本的算法。主要用于文本去重方向。通过计算h1、h2标题的simhash值,比较网页头部title标签的内容,通过一个Threshold,就可以提取出新闻正文的标题,当然,如果没有h1, h2 满足条件,则只能处理 title 的 text 值。
与新闻发布时间类似,新闻来源一般可以用正则表达式匹配。
然后就到了关键点。关于新闻内容的提取,我参考了很多论文和很多资料。这里有两种常见的解决方案,
1.基于行块分布函数的网页正文提取算法
2.基于块统计和机器学习的主题网页内容识别算法实现及应用实例(DOM节点)
小弟自身水平有限,无法写出类似的算法和代码,单纯的复制代码测试准确率不高,两种方法只能放弃,有一定参考价值
最后用webcontroller开源爬虫框架中的代码提取文章的文本,不做广告,有兴趣的同学可以研究一下,顺便分析一下这个框架。记住@我,功能实现了,分享一下实现过程
最后,最近看了一下文章自动总结。在自然语言api的简单实现下,效果是有的。大概是通过我们常用的抽取方案来实现的,所以自动总结在语法上会有点不尽如人意。, 勉强可以接受 查看全部
网页采集器的自动识别算法(java和网络爬虫方向时间很短,如何没有符合条件的h1,)
提前感谢 知乎 的帮助
背景:由于java和网络爬虫方向接触时间很短,在编码或者逻辑上还有很多不严谨的地方。一开始是通过前端配置对应的xpath值来爬取定时任务。以后会慢慢需要的。增加了,比如类似今日头条的自动城市标注功能。在同事的指导下,利用自然语言处理,自动分析新闻内容,得到城市。当然,它也借用了开源代码。我不会在这里谈论它。另一个例子是新闻分类。它也类似于使用机器学习贝叶斯分类的方法。. . 说了这么多,让我们回到正题。
让我在这里谈谈我的实现。像标题这样的东西仍然很好地实现,因为标题的特征在互联网上是可追溯的。基本上可以通过h1和h2的logo来实现。当然,如何知道 h1 的文本必须是标题。我之前看过一个分析相似性文本的算法。主要用于文本去重方向。通过计算h1、h2标题的simhash值,比较网页头部title标签的内容,通过一个Threshold,就可以提取出新闻正文的标题,当然,如果没有h1, h2 满足条件,则只能处理 title 的 text 值。
与新闻发布时间类似,新闻来源一般可以用正则表达式匹配。
然后就到了关键点。关于新闻内容的提取,我参考了很多论文和很多资料。这里有两种常见的解决方案,
1.基于行块分布函数的网页正文提取算法
2.基于块统计和机器学习的主题网页内容识别算法实现及应用实例(DOM节点)
小弟自身水平有限,无法写出类似的算法和代码,单纯的复制代码测试准确率不高,两种方法只能放弃,有一定参考价值
最后用webcontroller开源爬虫框架中的代码提取文章的文本,不做广告,有兴趣的同学可以研究一下,顺便分析一下这个框架。记住@我,功能实现了,分享一下实现过程
最后,最近看了一下文章自动总结。在自然语言api的简单实现下,效果是有的。大概是通过我们常用的抽取方案来实现的,所以自动总结在语法上会有点不尽如人意。, 勉强可以接受
网页采集器的自动识别算法(网页自动操作工具VG浏览器流程采集教程 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2021-10-01 16:18
)
VG 浏览器是一款易于使用的采集 浏览器。软件支持可视化脚本驱动的网页自动运行。可以使用逻辑运算完成判断、循环、跳转等功能。它非常适合需要管理多个帐户。, 经常登录账号的用户,有需要的请下载。
软件说明
VG浏览器是一个由可视化脚本驱动的网页自动运行工具。只需设置脚本,即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库。发送和接收电子邮件等个性化实用的脚本项目。还可以使用逻辑运算来完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。
软件功能
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
定制流程
采集 就像积木一样,功能自由组合。
自动编码
程序注重采集的效率,页面解析速度非常快。
生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
1、 通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的这个按钮。
单击网页元素会自动生成该元素的 CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。比如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器,都可以通过按F12键或在页面上右键进行检查。
2、 右键单击目标节点,然后选择 Copy CSS Path 将 CSS Path 复制到剪贴板。
3、 在 Firefox 中,您也可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Unique Selector”复制CSS Path。
4、CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你也可以自己编写 CSS Path。
查看全部
网页采集器的自动识别算法(网页自动操作工具VG浏览器流程采集教程
)
VG 浏览器是一款易于使用的采集 浏览器。软件支持可视化脚本驱动的网页自动运行。可以使用逻辑运算完成判断、循环、跳转等功能。它非常适合需要管理多个帐户。, 经常登录账号的用户,有需要的请下载。
软件说明
VG浏览器是一个由可视化脚本驱动的网页自动运行工具。只需设置脚本,即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库。发送和接收电子邮件等个性化实用的脚本项目。还可以使用逻辑运算来完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。
软件功能
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
定制流程
采集 就像积木一样,功能自由组合。
自动编码
程序注重采集的效率,页面解析速度非常快。
生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
1、 通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的这个按钮。
单击网页元素会自动生成该元素的 CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。比如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器,都可以通过按F12键或在页面上右键进行检查。
2、 右键单击目标节点,然后选择 Copy CSS Path 将 CSS Path 复制到剪贴板。
3、 在 Firefox 中,您也可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Unique Selector”复制CSS Path。
4、CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你也可以自己编写 CSS Path。
网页采集器的自动识别算法(VG浏览器可视化脚本驱动的网页工具介绍及下载方法介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 564 次浏览 • 2021-10-01 16:15
VG Browser是一款专业且免费的可视化脚本编辑器,也是一款营销神器。支持验证码自动识别和数据自动抓取,让您轻松营销。vg 浏览器也是一个可视化脚本驱动的网页工具。可以简单的设置脚本,创建自动登录、身份验证等很多脚本项目,有需要的赶紧下载吧。
软件特点
1、可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
2、自定义流程
采集 就像积木一样,功能自由组合。
3、自动编码
程序注重采集的效率,页面解析速度非常快。
4、生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的这个按钮;
单击网页元素会自动生成该元素的 CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。例如,谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器都可以通过按F12键或在页面上右键进行查看;
右键单击目标部分,然后选择复制 CSS 路径将 CSS 路径复制到剪贴板;
您也可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Unique Selector”复制CSS Path;
CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你也可以自己编写 CSS Path。
更新日志
修复exe script runner清空采集数据错误的问题;
ListView控件操作、控件读取、控件属性修改等功能,支持多级子控件的读写;
修复在项目管理器中预览时间后无法保存和打开计划任务的问题;
在写入值中写入新值之前触发 onclick 事件。 查看全部
网页采集器的自动识别算法(VG浏览器可视化脚本驱动的网页工具介绍及下载方法介绍)
VG Browser是一款专业且免费的可视化脚本编辑器,也是一款营销神器。支持验证码自动识别和数据自动抓取,让您轻松营销。vg 浏览器也是一个可视化脚本驱动的网页工具。可以简单的设置脚本,创建自动登录、身份验证等很多脚本项目,有需要的赶紧下载吧。
软件特点
1、可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
2、自定义流程
采集 就像积木一样,功能自由组合。
3、自动编码
程序注重采集的效率,页面解析速度非常快。
4、生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的这个按钮;
单击网页元素会自动生成该元素的 CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。例如,谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器都可以通过按F12键或在页面上右键进行查看;
右键单击目标部分,然后选择复制 CSS 路径将 CSS 路径复制到剪贴板;
您也可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Unique Selector”复制CSS Path;
CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你也可以自己编写 CSS Path。
更新日志
修复exe script runner清空采集数据错误的问题;
ListView控件操作、控件读取、控件属性修改等功能,支持多级子控件的读写;
修复在项目管理器中预览时间后无法保存和打开计划任务的问题;
在写入值中写入新值之前触发 onclick 事件。
网页采集器的自动识别算法(优采云数据采集系统让你的信息采集更简单!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-09-30 21:24
优采云采集器 是任何需要从网络获取信息的孩子的必备神器。这是一个可以让你的信息采集变得非常简单的工具。优采云改变了互联网上传统的数据思维方式,让用户在互联网上抓取和编译数据变得越来越容易
软件特点
操作简单,完全可视化的图形操作,不需要专业的IT人员,任何会用电脑上网的人都可以轻松掌握。
云采集
采集 任务自动分配到云端多台服务器同时执行,提高了采集的效率,短时间内可以获取上千条消息。
拖放采集流程
模拟人的操作思维模式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采用不同的采集流程。
图形识别
内置可扩展的OCR接口,支持对图片中的文字进行分析,可以提取图片上的文字。
定时自动采集
采集 任务自动运行,可以在指定时间段内自动采集,并且还支持实时采集 更快一分钟一次。
2 分钟快速启动
内置从入门到精通的视频教程,2分钟即可上手,还有文档、论坛、qq群等。
免费使用
它是免费的,免费版没有功能限制。您可以立即试用,下载并立即安装。
特征
简单来说,使用优采云可以很容易的从任何网页中准确的采集你需要的数据,生成自定义的常规数据格式。优采云数据采集 系统能做的包括但不限于以下内容
1.财务数据,如季报、年报、财报,包括每日自动比较新净值采集
2. 各大新闻门户网站 实时监控,自动更新和上传较新发布的新闻
3. 监控竞争对手相对较新的信息,包括商品价格和库存
4. 监控各大社交网络网站、博客,自动获取企业产品相关评论
5. 采集比较新的、比较全面的职位招聘信息
6.监控各大楼盘相关网站,采集新房与二手房对比新市场行情
7. 采集主要车型网站 具体新车和二手车信息
8. 发现和采集潜在客户信息
9. 采集行业网站 产品目录和产品信息
10. 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
更新日志
V7.6.0(官方)2019-01-04
主要体验改进
【自定义模式】新增JSON采集功能
【自定义模式】新增滑动验证码识别
【自定义模式】优化效率,列表识别速度翻倍
【自定义模式】自动识别网页ajax点击并自动配置ajax超时时间,配置任务更方便
【自定义模式】改进算法,使网页元素选择更加精准
[本地采集]采集整体速度提升10~30%,大大提升采集的效率
【任务列表】重构任务列表界面,性能大幅提升,大量任务管理不再卡顿
【任务列表】任务列表新增自动刷新机制,可随时查看任务最新状态
错误修复
修复云端查看数据慢的问题采集
修复采集报错排版问题
修复“打开网页时出现乱码”的问题
修复拖动过程后突然消失的问题
修复定时导出和自动入库工具自动弹出的问题
修复格式化时间类型数据错误的问题
文件信息
文件大小:62419128 字节
文件描述:安装优采云采集器
文件版本:7.6.0.1031
MD5:8D59AE2AE16856D632108F8AF997F0B6
SHA1:9B314DDAAE477E53EDCEF188EEE48CD3035619D4
收录文件
OctopusSetup7.4.6.8011.exe
优采云教程目录.xls
杀毒软件误报说明.txt
配置规则必读.txt
安装前阅读。文本
官方 网站:
相关搜索:采集 查看全部
网页采集器的自动识别算法(优采云数据采集系统让你的信息采集更简单!)
优采云采集器 是任何需要从网络获取信息的孩子的必备神器。这是一个可以让你的信息采集变得非常简单的工具。优采云改变了互联网上传统的数据思维方式,让用户在互联网上抓取和编译数据变得越来越容易
软件特点
操作简单,完全可视化的图形操作,不需要专业的IT人员,任何会用电脑上网的人都可以轻松掌握。
云采集
采集 任务自动分配到云端多台服务器同时执行,提高了采集的效率,短时间内可以获取上千条消息。
拖放采集流程
模拟人的操作思维模式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采用不同的采集流程。
图形识别
内置可扩展的OCR接口,支持对图片中的文字进行分析,可以提取图片上的文字。
定时自动采集
采集 任务自动运行,可以在指定时间段内自动采集,并且还支持实时采集 更快一分钟一次。
2 分钟快速启动
内置从入门到精通的视频教程,2分钟即可上手,还有文档、论坛、qq群等。
免费使用
它是免费的,免费版没有功能限制。您可以立即试用,下载并立即安装。
特征
简单来说,使用优采云可以很容易的从任何网页中准确的采集你需要的数据,生成自定义的常规数据格式。优采云数据采集 系统能做的包括但不限于以下内容
1.财务数据,如季报、年报、财报,包括每日自动比较新净值采集
2. 各大新闻门户网站 实时监控,自动更新和上传较新发布的新闻
3. 监控竞争对手相对较新的信息,包括商品价格和库存
4. 监控各大社交网络网站、博客,自动获取企业产品相关评论
5. 采集比较新的、比较全面的职位招聘信息
6.监控各大楼盘相关网站,采集新房与二手房对比新市场行情
7. 采集主要车型网站 具体新车和二手车信息
8. 发现和采集潜在客户信息
9. 采集行业网站 产品目录和产品信息
10. 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
更新日志
V7.6.0(官方)2019-01-04
主要体验改进
【自定义模式】新增JSON采集功能
【自定义模式】新增滑动验证码识别
【自定义模式】优化效率,列表识别速度翻倍
【自定义模式】自动识别网页ajax点击并自动配置ajax超时时间,配置任务更方便
【自定义模式】改进算法,使网页元素选择更加精准
[本地采集]采集整体速度提升10~30%,大大提升采集的效率
【任务列表】重构任务列表界面,性能大幅提升,大量任务管理不再卡顿
【任务列表】任务列表新增自动刷新机制,可随时查看任务最新状态
错误修复
修复云端查看数据慢的问题采集
修复采集报错排版问题
修复“打开网页时出现乱码”的问题
修复拖动过程后突然消失的问题
修复定时导出和自动入库工具自动弹出的问题
修复格式化时间类型数据错误的问题
文件信息
文件大小:62419128 字节
文件描述:安装优采云采集器
文件版本:7.6.0.1031
MD5:8D59AE2AE16856D632108F8AF997F0B6
SHA1:9B314DDAAE477E53EDCEF188EEE48CD3035619D4
收录文件
OctopusSetup7.4.6.8011.exe
优采云教程目录.xls
杀毒软件误报说明.txt
配置规则必读.txt
安装前阅读。文本
官方 网站:
相关搜索:采集
网页采集器的自动识别算法(软件特色可视化操作简单,完全兼容JQuery选择器规则(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-09-29 21:04
这款VG采集浏览器只需设置一个脚本即可创建自动登录、点击网页、自动提交数据、自动抓取数据、识别验证码、操作数据库、下载文件、收发邮件等个性。实用的脚本项目。
软件介绍
VG浏览器是一个由可视化脚本驱动的网页自动运行工具。只需设置脚本,即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库。发送和接收电子邮件等个性化实用的脚本项目。还可以使用逻辑运算来完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。
软件特点
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
定制流程
采集 就像积木一样,功能自由组合。
自动编码
程序注重采集的效率,页面解析速度非常快。
生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。
选择任何需要填写CSS Path规则的步骤,点击内置浏览器的这个按钮
点击一个网页元素,自动生成该元素的CSS Path,
极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。
您也可以在其他浏览器上复制 CSSPath。目前,各种多核浏览器都支持复制 CSSPath。
比如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器都可以通过按F12键。
或者右击页面,选择review元素,右击目标部分,选择Copy CSS Path将CSS Path复制到剪贴板。
在 Firefox 中,您还可以按 F12 或右键单击来查看元素。显示开发者工具后,
右击底部节点,选择“Copy Unique Selector”复制CSS Path。
CSS 路径规则与 JQuery 选择器规则完全兼容,
如果您知道如何编写 JQuery 选择器,您也可以自己编写 CSS Path。
更新日志
添加自制插件方法识别验证码,添加验证码识别插件开发工具 查看全部
网页采集器的自动识别算法(软件特色可视化操作简单,完全兼容JQuery选择器规则(组图))
这款VG采集浏览器只需设置一个脚本即可创建自动登录、点击网页、自动提交数据、自动抓取数据、识别验证码、操作数据库、下载文件、收发邮件等个性。实用的脚本项目。
软件介绍
VG浏览器是一个由可视化脚本驱动的网页自动运行工具。只需设置脚本,即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库。发送和接收电子邮件等个性化实用的脚本项目。还可以使用逻辑运算来完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。
软件特点
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
定制流程
采集 就像积木一样,功能自由组合。
自动编码
程序注重采集的效率,页面解析速度非常快。
生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。
选择任何需要填写CSS Path规则的步骤,点击内置浏览器的这个按钮
点击一个网页元素,自动生成该元素的CSS Path,
极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。
您也可以在其他浏览器上复制 CSSPath。目前,各种多核浏览器都支持复制 CSSPath。
比如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器都可以通过按F12键。
或者右击页面,选择review元素,右击目标部分,选择Copy CSS Path将CSS Path复制到剪贴板。
在 Firefox 中,您还可以按 F12 或右键单击来查看元素。显示开发者工具后,
右击底部节点,选择“Copy Unique Selector”复制CSS Path。
CSS 路径规则与 JQuery 选择器规则完全兼容,
如果您知道如何编写 JQuery 选择器,您也可以自己编写 CSS Path。
更新日志
添加自制插件方法识别验证码,添加验证码识别插件开发工具
网页采集器的自动识别算法(网站自动seo优化如何采集关键词?网络小编来解答)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-28 20:35
很多朋友在网站seo优化过程中遇到了一些网站优化问题,包括“网站seo自动优化采集:SEO优化订单网站如何优化SEO< @采集关键词”的问题,那么下面搜索网络小编来解答你目前疑惑的问题。
SEO优化关键词一般分为三类:目标关键词、长尾关键词和品牌关键词。其中,长尾关键词一般是从目标关键词展开,所以采集的一般方式是抓住关键词的根来展开。关键词的扩展方式主要有以下几种:
1、下拉框,相关搜索选择方法;网站自动搜索引擎优化采集
2、索引关键词工具的使用;
3、竞价后台,可下载关键词搜索量列表;
4、研究同行业或竞争对手网站关键词;
5、使用关键词开发工具。
选择关键词后,需要分析每个用户搜索到的流量和点击流。一起,你或许可以弄清楚一些用户搜索的意图,过滤掉质量更高的关键词。
网站自动SEO优化采集:什么是SEO自动化?
1、网站更新自动化(软件自动采集更新伪原创)
2、网站 外链自动生成(主要基于各种海量分发软件)
3、网站自动诊断(类似谷歌管理员工具等)
4、网站 自动信息查询(如站长工具等)
如何做网站SEO优化让搜索引擎收录
一般你做网站,搜索引擎会给你收录
SEO优化的目的是让网站更符合搜索引擎收录的偏好,满足用户的搜索需求,优化更多的核心长尾关键词。
SEO优化子站SEO优化+站外SEO优化
一、网站SEO优化
(1)网站 三要素:例如:TITLE、KEYWORDS、DESCRIPTION优化;
(2)内部链接优化,包括相关链接(Tag标签)、锚文本链接、各种导航链接;
(3)文章页面更新:文章页面更新是布局大量长尾词的重要关键点,发布文章长尾关键词 有利于提升关键词的排名。
(4)网站结构优化:包括网站的目录结构、面包屑结构、导航结构、URL结构等,主要包括:树结构、扁平结构等。
(5)图片alt标签、网站地图、robots文件、页面、重定向、网站定位、关键词选择与布局、网站每日一系列SEO更新频率和快照更新等优化步骤。
二、外部优化
(1)外链类:友情链接、博客、论坛、新闻、分类信息、贴吧、知乎、百科、站群、相关信息网等,尽量保持多样性链接;
(2)外链运营:每天增加一定数量的外链,使关键词的排名稳步上升;
(3)外链选择:比较高的有一些网站,整体质量较好的网站交换友情链接,巩固和稳定关键词排名。
网站 如何优化SEO的问题比较大。一般来说,在做SEO的时候,我们是具体网站进行具体分析的。以上都是网站可以参考的SEO优化操作。具体网站前期需要定位,寻找关键词长尾词,布局关键词,制定SEO优化推广方案,SEO效果排名监控等。
如何增加搜索引擎搜索,网站中的网页质量,搜索引擎会派搜索引擎蜘蛛抓取网页,蜘蛛也会判断网站是否已被索引和收录@根据相关分数 > 定期文章发布的价值,快照的更新也是影响搜索引擎收录的条件。
也可以主动提交搜索引擎收录未收到链接通知,搜索引擎会根据链接的好坏来判断是否进行搜索。
以上是关于网站自动seo优化采集、SEO优化命令网站SEO优化如何采集关键词文章的内容,如果你有网站如需优化,请直接联系我们。很高兴为您服务! 查看全部
网页采集器的自动识别算法(网站自动seo优化如何采集关键词?网络小编来解答)
很多朋友在网站seo优化过程中遇到了一些网站优化问题,包括“网站seo自动优化采集:SEO优化订单网站如何优化SEO< @采集关键词”的问题,那么下面搜索网络小编来解答你目前疑惑的问题。
SEO优化关键词一般分为三类:目标关键词、长尾关键词和品牌关键词。其中,长尾关键词一般是从目标关键词展开,所以采集的一般方式是抓住关键词的根来展开。关键词的扩展方式主要有以下几种:
1、下拉框,相关搜索选择方法;网站自动搜索引擎优化采集
2、索引关键词工具的使用;
3、竞价后台,可下载关键词搜索量列表;
4、研究同行业或竞争对手网站关键词;
5、使用关键词开发工具。
选择关键词后,需要分析每个用户搜索到的流量和点击流。一起,你或许可以弄清楚一些用户搜索的意图,过滤掉质量更高的关键词。
网站自动SEO优化采集:什么是SEO自动化?
1、网站更新自动化(软件自动采集更新伪原创)
2、网站 外链自动生成(主要基于各种海量分发软件)
3、网站自动诊断(类似谷歌管理员工具等)
4、网站 自动信息查询(如站长工具等)
如何做网站SEO优化让搜索引擎收录
一般你做网站,搜索引擎会给你收录
SEO优化的目的是让网站更符合搜索引擎收录的偏好,满足用户的搜索需求,优化更多的核心长尾关键词。
SEO优化子站SEO优化+站外SEO优化
一、网站SEO优化
(1)网站 三要素:例如:TITLE、KEYWORDS、DESCRIPTION优化;
(2)内部链接优化,包括相关链接(Tag标签)、锚文本链接、各种导航链接;
(3)文章页面更新:文章页面更新是布局大量长尾词的重要关键点,发布文章长尾关键词 有利于提升关键词的排名。
(4)网站结构优化:包括网站的目录结构、面包屑结构、导航结构、URL结构等,主要包括:树结构、扁平结构等。
(5)图片alt标签、网站地图、robots文件、页面、重定向、网站定位、关键词选择与布局、网站每日一系列SEO更新频率和快照更新等优化步骤。
二、外部优化
(1)外链类:友情链接、博客、论坛、新闻、分类信息、贴吧、知乎、百科、站群、相关信息网等,尽量保持多样性链接;
(2)外链运营:每天增加一定数量的外链,使关键词的排名稳步上升;
(3)外链选择:比较高的有一些网站,整体质量较好的网站交换友情链接,巩固和稳定关键词排名。
网站 如何优化SEO的问题比较大。一般来说,在做SEO的时候,我们是具体网站进行具体分析的。以上都是网站可以参考的SEO优化操作。具体网站前期需要定位,寻找关键词长尾词,布局关键词,制定SEO优化推广方案,SEO效果排名监控等。
如何增加搜索引擎搜索,网站中的网页质量,搜索引擎会派搜索引擎蜘蛛抓取网页,蜘蛛也会判断网站是否已被索引和收录@根据相关分数 > 定期文章发布的价值,快照的更新也是影响搜索引擎收录的条件。
也可以主动提交搜索引擎收录未收到链接通知,搜索引擎会根据链接的好坏来判断是否进行搜索。
以上是关于网站自动seo优化采集、SEO优化命令网站SEO优化如何采集关键词文章的内容,如果你有网站如需优化,请直接联系我们。很高兴为您服务!

