网页采集器的自动识别算法( 我把微博营销案例全部爬虫到一个了Excel表格里)
优采云 发布时间: 2021-10-13 00:51网页采集器的自动识别算法(
我把微博营销案例全部爬虫到一个了Excel表格里)
今天的目标:
读者知道什么?
程序员最难学的不是java或c++,而是社交,俗称“嫂子”。
在社交方面,我被认为是程序员中最好的程序员。
比如在做《一张海报生成表格,让我从一个大叔变成小弟弟》之前,就捡到了运营社区的*敏*感*词*姐。
这已经是上个月了,这个月又投入到爬虫的技术研究中。
技术满足的反面是孤独和空虚。
于是,我决定再次用爬虫来逗妹妹。. .
结果。. .
我做到了!!!
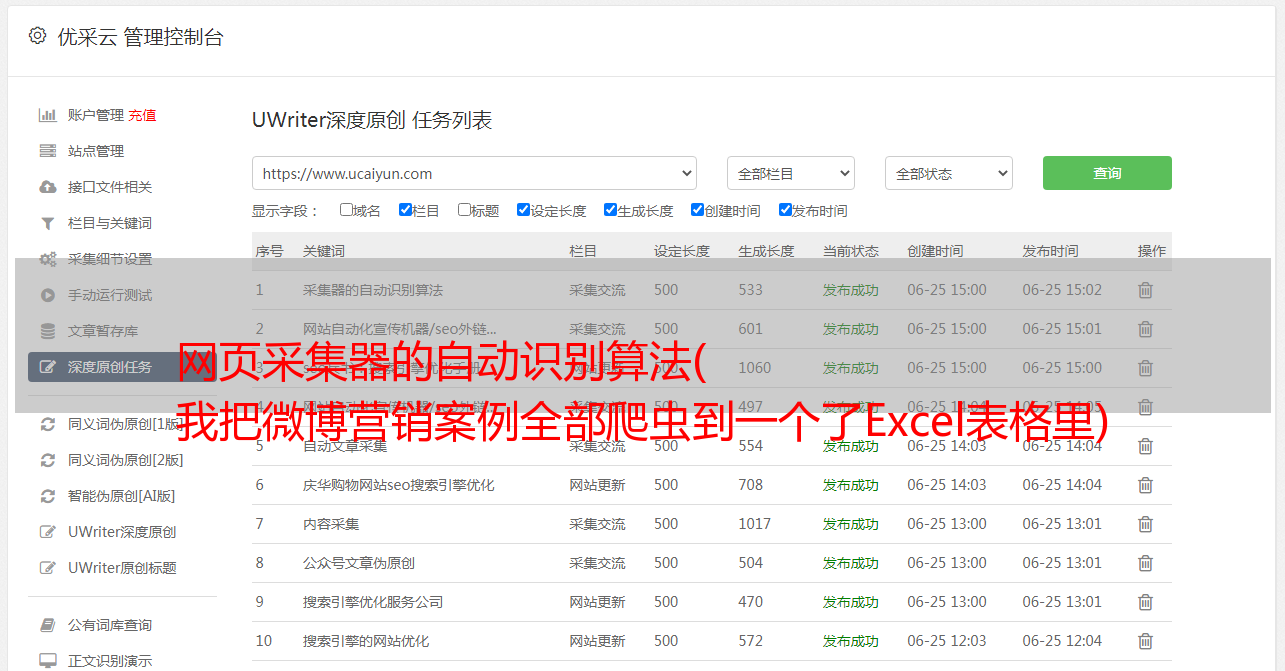
我将所有微博营销案例抓取到一张 Excel 表格中。
7-0多份操作分析报告,一键下载
网站中的案例需要一一下载↑
表中案例,点赞下载较多↑
管理社区的女孩们要疯了!
秋叶Excel抖音 *敏*感*词*:小美↑
微博手绘大V博主姜江↑
社区运营老司机:颜敏姐↑
让我告诉你,如果我能早两年爬行,谁会是我现在的室友?!
1-什么是爬虫
爬虫是网络爬虫。就是按照一定的规则自动抓取网络上的数据。
比如上一节自动抓取了“社交营销案例库”的案例。
想象一下,如果手动浏览页面下载这些案例,流程是这样的:
1- 打开应用程序库页面
2-点击案例进入详情页面
3- 点击下载案例pdf
4- 返回案例库页面,点击下一个案例,重复前面的3个步骤。
如果要下载所有的pdf案例,需要安排专人反复机械地下载。显然,这个人的价值含量很低。
爬虫取代了这种机械重复、低价值的数据采集动作,利用程序或代码自动批量完成数据采集。
爬虫的好处
简单总结一下,爬虫的好处主要有两个方面:
1-自动爬行,解放人力,提高效率
机械的、低价值的工作,用机器来完成工作是最好的解决方案。
2-数据分析,跳线获取优质内容
与手动浏览数据不同,爬虫可以将数据汇总整合成数据表,方便我们后续的数据统计和数据分析。
例如,在“社交营销案例库”中,每个案例都有查看次数和下载次数。如果要按查看次数排序,则会优先查看查看次数最多的案例。将数据抓取到Excel表格中,并使用排序功能轻松浏览。
爬虫案例
任何数据都可以爬。
如果您掌握了爬虫的技能,您可以做很多事情。
Excelhome 的帖子抓取
我教Excel,Excelhome论坛是个大宝。
一篇一篇阅读太费劲了,爬1.40000个帖子,挑浏览量最多的。
窗帘选择文章爬行
屏幕是整理轮廓的好工具。很多大咖都用屏幕写读书笔记,不用看全书也能学会重点。
没时间一一浏览选定的画面文章,爬取所有选定的文章,整理出自己的知识大纲。
曹总公众号文章爬取
我很喜欢曹江。我有我这个年龄所缺乏的逻辑、归纳和表达能力,以及文章文章的精髓。
公众号太多,手机看书容易分心?爬入 Excel,然后开始查看最高的行读数。
此外还有抖音播报数据、公众号阅读、评论数据、B站弹幕数据、网易云评论数据。
爬虫+数据分析给网络带来更多乐趣。
2- 履带式是简单、锋利的武器
说到爬虫,大多会想到编程数数,python,数据库,beautiful,html结构等等,让人望而生畏。
其实基础爬虫很简单,借助一些采集软件,一键即可轻松完成。
常用爬虫软件
爬取数据的时候用到了以下软件,推荐给大家:
1- 优采云采集器
简单易学,数据可以通过可视化界面、鼠标点击、向导模式采集。用户无需任何技术基础,输入网址,一键提取数据。
这是我接触的第一个爬虫软件,
优势:
1-使用过程简单,上手特别好。
缺点:
1- *敏*感*词*数量限制。采集,非会员只能导出1000条数据。
2- 导出格式限制。非会员只能导出为txt文本格式。
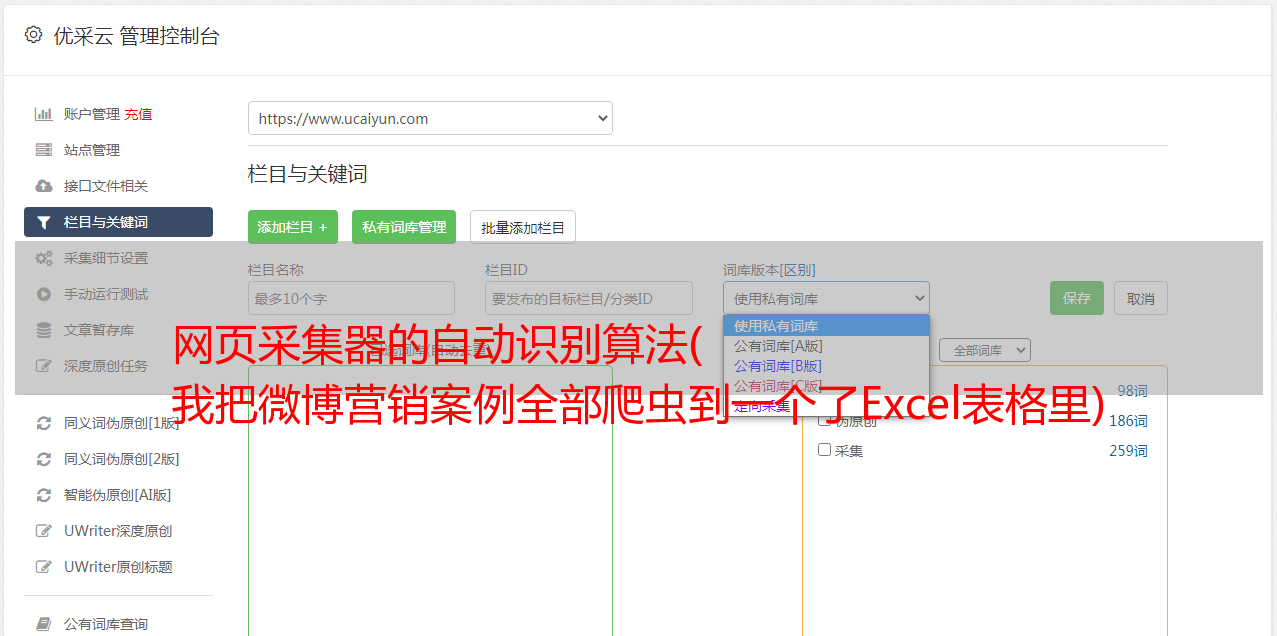
2- 优采云
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库
在优采云不能满足我的需求后,我开始尝试更专业的采集软件,找到了优采云。
优势:
1- 采集功能更强大,可以自定义采集的进程。
2- 导出格式和数据量没有限制。
缺点:
1- 过程有点复杂,新手上手难度较大。
3- 优采云采集器(推荐)
智能识别数据,小白神器
基于人工智能算法,只需输入网址即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集。自动识别列表、表格、链接、图片、价格、电子邮件等。
这就是我现在用的采集软件。可以说中和了前两个采集器的优缺点,用户体验更好。
优势:
1-自动识别页面信息,轻松上手
2- 导出格式和数据量没有限制
目前没有发现缺点。
3-爬虫操作流程
注意,注意,接下来就是动手部分了。
我们以“窗帘选择文章”为例,用“优采云采集器”体验爬行的乐趣。
采集后的效果如下:
1-复制采集的链接
打开窗帘官网,点击“精选”进入选中的文章页面。
复制特色页面的 URL:
2- 优采云采集 数据
1- 登录“优采云采集器”官网,下载安装采集器。
2-打开采集器后,点击“智能模式”中的“开始采集”,新建一个智能采集。
3-粘贴到屏幕的选定URL中,点击立即创建
在此过程中,采集器 会自动识别页面上的列表和数据内容。整个过程由AI算法自动完成,等待识别完成。
页面分析识别↑
页面识别完成↑
4-点击“开始采集”->“开始”开始爬虫之旅。
3- 采集数据导出
在数据爬取过程中,您可以点击“停止”结束数据爬取。
或者等待数据爬取完成,在弹出的对话框中点击“导出数据”。
导出格式,选择Excel,然后导出。
4- 使用 HYPERLINK 函数添加超链接
打开导出的表格,在I列添加HYPERLINK公式,添加超链接,一键打开对应的文章。
公式如下:
=HYPERLINK(B2,“点击查看”)
到这里,你的第一次爬虫之旅已经顺利完成了!
4- 总结
爬虫就像在 VBA 中记录宏,记录重复的动作而不是手动重复的操作。
今天看到的只是简单的数据采集,关于爬虫的话题还有很多,很深入的内容。例如:
1- 身份验证。需要登录才能抓取页面。
2-浏览器检查。比如公众号文章只能获取微信的阅读数。
3- 参数验证(验证码)。该页面需要验证码。
4- 请求频率。例如页面访问时间不能小于10秒
5- 数据处理。要爬取的数据需要从数字、英文等内容中提取出来。
了解了爬取流程后,您现在最想爬取哪些数据?
我是会设计电子表格的Excel老师拉小邓
如果你喜欢这个文章,请给我三重品质,今天就到此为止,下课结束!

