
网页采集器的自动识别算法
网页采集器的自动识别算法(优采云采集器智能采集天气网我试)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-26 20:23
谢谢邀请,废话不多说,直接上操作视频~
优采云采集器智能采集气象网络
我试过了,楼主说的问题确实存在。同时,我对其进行了测试以进行比较。优采云采集器对于气象网的采集,使用宿主提供的链接。完成所有天气数据和历史数据的采集设置大约需要2分钟。同时我也记录了我的操作过程,楼主可以自己跟着我的操作过程采集。
说几个经验吧:
1. 这个网站确实是一个简单的表单,但是翻页的时候url并没有变化。这种网页技术叫做局部刷新,或者专业叫做Ajax。有兴趣的可以在百度上下载,不过不用在视频中可以看到,当你设置翻页采集并点击上个月时,优采云准确识别这个按钮的操作并自动设置可视化采集 过程非常直观直观,一目了然。
2. 在智能识别的过程中,考验的是算法的能力。由此也可以看出,优采云在网页的智能识别算法上比其他采集器表现更好,不仅自动识别去除了所有字段,而且对整个列表进行了全面自动识别。同时自动识别翻页按钮使用的特殊反采集技术。
我具体说明一下,作为行业标杆,优采云采集器非常关注用户体验,虽然视频中我使用的是优采云旗舰版(云采集,api , 个人客服,这些都是企业级大数据稳定性非常贴心的服务采集),但是,优采云免费版没有任何基本功能限制,来自官方优采云@ > 网站(优采云三个汉语拼音)直接下载安装优采云到采集all网站,适用于京东、天猫、大众点评、百度等主流网站在各个行业,优采云也提供了内置的采集模板,采集主流数据无需配置采集规则。
欢迎关注或私信~ 查看全部
网页采集器的自动识别算法(优采云采集器智能采集天气网我试)
谢谢邀请,废话不多说,直接上操作视频~
优采云采集器智能采集气象网络
我试过了,楼主说的问题确实存在。同时,我对其进行了测试以进行比较。优采云采集器对于气象网的采集,使用宿主提供的链接。完成所有天气数据和历史数据的采集设置大约需要2分钟。同时我也记录了我的操作过程,楼主可以自己跟着我的操作过程采集。
说几个经验吧:
1. 这个网站确实是一个简单的表单,但是翻页的时候url并没有变化。这种网页技术叫做局部刷新,或者专业叫做Ajax。有兴趣的可以在百度上下载,不过不用在视频中可以看到,当你设置翻页采集并点击上个月时,优采云准确识别这个按钮的操作并自动设置可视化采集 过程非常直观直观,一目了然。
2. 在智能识别的过程中,考验的是算法的能力。由此也可以看出,优采云在网页的智能识别算法上比其他采集器表现更好,不仅自动识别去除了所有字段,而且对整个列表进行了全面自动识别。同时自动识别翻页按钮使用的特殊反采集技术。
我具体说明一下,作为行业标杆,优采云采集器非常关注用户体验,虽然视频中我使用的是优采云旗舰版(云采集,api , 个人客服,这些都是企业级大数据稳定性非常贴心的服务采集),但是,优采云免费版没有任何基本功能限制,来自官方优采云@ > 网站(优采云三个汉语拼音)直接下载安装优采云到采集all网站,适用于京东、天猫、大众点评、百度等主流网站在各个行业,优采云也提供了内置的采集模板,采集主流数据无需配置采集规则。
欢迎关注或私信~
网页采集器的自动识别算法(优采云软件出品的一款基于高精度正文识别算法的互联网文章采集器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-24 15:33
优采云基于本软件制作的高精度文本识别算法的互联网文章采集器。支持按关键词采集百度等搜索引擎新闻源和泛页面,支持采集指定网站栏目所有文章。
功能:
一、 依托优采云软件独有的通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达95%以上。
二、只需输入关键词到采集到百度新闻和网页、搜狗新闻和网页、360新闻和网页、谷歌新闻和网页、必应新闻和网页、雅虎;可批量关键词全自动采集。
三、可以直接采集指定网站列列表下的所有文章,智能匹配,无需编写复杂规则。
四、文章 翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和是淘翻译。
五、史上最简单最智能文章采集器,支持全功能试用,一试就知道效果!
优采云基于本软件制作的高精度文本识别算法的互联网文章采集器。支持按关键词采集新闻和各大搜索引擎网页,也支持采集指定网站栏目下的所有文章。基于自主研发的文本识别智能算法,能够从互联网上复杂的网页中尽可能准确地提取文本内容。
文本识别有 3 种算法,“标准”、“严格”和“精确标签”。其中“standard”和“strict”是自动模式,可以适应大部分网页的body提取,而“precision tag”只需要指定body标签头,比如“div class="text"” ". 提取所有网页的正文。
关键词采集目前支持的搜索引擎有:百度、搜狗、360、谷歌、必应、雅虎
<p>采集指定网站文章的功能也很简单,只需要一点点设置(不需要复杂的规则),就可以批量采集targets 查看全部
网页采集器的自动识别算法(优采云软件出品的一款基于高精度正文识别算法的互联网文章采集器)
优采云基于本软件制作的高精度文本识别算法的互联网文章采集器。支持按关键词采集百度等搜索引擎新闻源和泛页面,支持采集指定网站栏目所有文章。
功能:
一、 依托优采云软件独有的通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达95%以上。
二、只需输入关键词到采集到百度新闻和网页、搜狗新闻和网页、360新闻和网页、谷歌新闻和网页、必应新闻和网页、雅虎;可批量关键词全自动采集。
三、可以直接采集指定网站列列表下的所有文章,智能匹配,无需编写复杂规则。
四、文章 翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和是淘翻译。
五、史上最简单最智能文章采集器,支持全功能试用,一试就知道效果!
优采云基于本软件制作的高精度文本识别算法的互联网文章采集器。支持按关键词采集新闻和各大搜索引擎网页,也支持采集指定网站栏目下的所有文章。基于自主研发的文本识别智能算法,能够从互联网上复杂的网页中尽可能准确地提取文本内容。
文本识别有 3 种算法,“标准”、“严格”和“精确标签”。其中“standard”和“strict”是自动模式,可以适应大部分网页的body提取,而“precision tag”只需要指定body标签头,比如“div class="text"” ". 提取所有网页的正文。
关键词采集目前支持的搜索引擎有:百度、搜狗、360、谷歌、必应、雅虎
<p>采集指定网站文章的功能也很简单,只需要一点点设置(不需要复杂的规则),就可以批量采集targets
网页采集器的自动识别算法(网页采集器的自动识别算法是需要模型训练出来的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-09-23 06:04
网页采集器的自动识别算法是需要模型训练出来的,没有模型训练模型的网页自动识别器是没有多大意义的。你可以在识别之前先加个关键词提示,输入一个关键词让它猜,当输入关键词提示后,就发现网页上有对应关键词的文字,可以再加入模型,将这个关键词的句子自动识别。我也是跟着我们公司的方法自己做的,输入一个关键词,会判断出我们想采集什么样的文字内容,我们定制了个关键词提示。
这样子的网页,识别网页是非常快的,即使识别不出来,也会自动提示出来。网页识别算法是研究发展很快的,基本都是跟着python生态圈里的各种库来做,比如selenium,比如geckodriver。专门做网页识别的网站识别算法能力,跟网页识别生态圈的识别算法,是很大差距的。
我用的是exuberevk中文识别库,实测准确率85%以上。打开exuberevk,选择要识别的网页,并启用自动识别。到自动识别文件夹下\_core\libs\book\_python_data\webdriver\_core\libs\autoit。py找到\lib/autoit。js\jsx。jsx解压,即可看到\lib/autoit。
js\script。jsx然后运行`reg_generate_nonlocal`,即可自动获取网页内容。`autoit。js`为自动识别的脚本文件,也可以使用`iostream`来导入jsx脚本。`jsx`只会执行一次,此时只会生成一个解压后的`index。js`的文件,如果想重新获取内容,可以运行`reg_generate_nonlocal`,此时会生成`regs。
js`。重新运行`reg_generate_nonlocal`,会再生成一个`regs。js`。文本的文件格式可以到`onlinejavascriptframeworkforpython`中查看。下载地址:#filenames/prefix/documents/autoit。js。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法是需要模型训练出来的)
网页采集器的自动识别算法是需要模型训练出来的,没有模型训练模型的网页自动识别器是没有多大意义的。你可以在识别之前先加个关键词提示,输入一个关键词让它猜,当输入关键词提示后,就发现网页上有对应关键词的文字,可以再加入模型,将这个关键词的句子自动识别。我也是跟着我们公司的方法自己做的,输入一个关键词,会判断出我们想采集什么样的文字内容,我们定制了个关键词提示。
这样子的网页,识别网页是非常快的,即使识别不出来,也会自动提示出来。网页识别算法是研究发展很快的,基本都是跟着python生态圈里的各种库来做,比如selenium,比如geckodriver。专门做网页识别的网站识别算法能力,跟网页识别生态圈的识别算法,是很大差距的。
我用的是exuberevk中文识别库,实测准确率85%以上。打开exuberevk,选择要识别的网页,并启用自动识别。到自动识别文件夹下\_core\libs\book\_python_data\webdriver\_core\libs\autoit。py找到\lib/autoit。js\jsx。jsx解压,即可看到\lib/autoit。
js\script。jsx然后运行`reg_generate_nonlocal`,即可自动获取网页内容。`autoit。js`为自动识别的脚本文件,也可以使用`iostream`来导入jsx脚本。`jsx`只会执行一次,此时只会生成一个解压后的`index。js`的文件,如果想重新获取内容,可以运行`reg_generate_nonlocal`,此时会生成`regs。
js`。重新运行`reg_generate_nonlocal`,会再生成一个`regs。js`。文本的文件格式可以到`onlinejavascriptframeworkforpython`中查看。下载地址:#filenames/prefix/documents/autoit。js。
网页采集器的自动识别算法(大多数概念:完善列表页的智能抽取结果(可选))
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-20 07:24
一个概念:
大多数网站以列表页和详细页的层次结构进行组织。例如,当我们进入新浪新闻频道时,有很多标题链接,可以看作是列表页面。单击标题链接进入详细信息页面
使用data采集工具的一般目的是大量获取详细页面中的特定内容数据,将这些数据用于各种分析,发布自己的网站等
列表页:指一个列或目录页,通常收录多个标题链接。例如:网站主页或专栏页是列表页。主要功能:您可以通过列表页面获得指向多个详细信息页面的链接
详细页面:收录特定内容的页面,如网页文章,其中收录:标题、作者、发布日期、正文内容、标签等
要开始,请登录“优采云console”:
详细使用步骤:
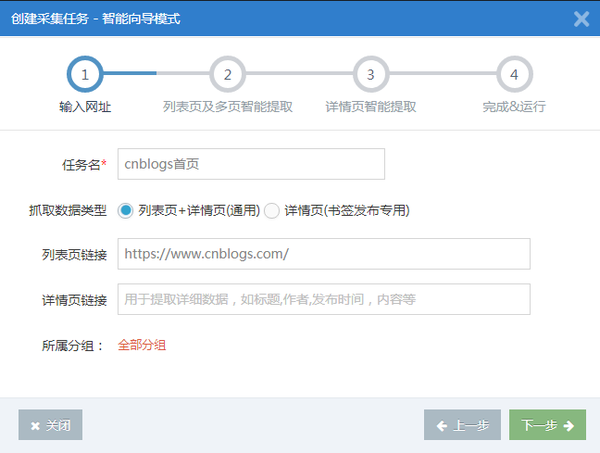
步骤1:创建采集任务
点击左侧菜单按钮“创建采集task”,输入采集task名称和采集的“列表页面”URL,如:/(此处主页为列表页面:内容可收录多个详细页面)。无法填写详细信息页面链接,系统将自动识别该链接
如下图所示:
输入后点击“下一步”
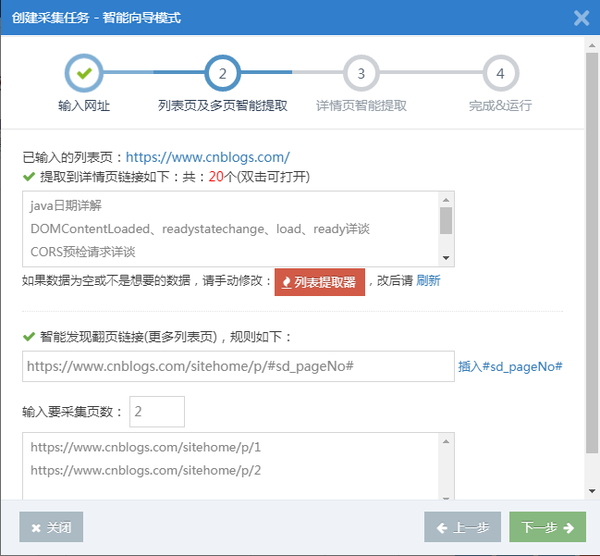
步骤2:改进列表页面的智能提取结果(可选)
系统将首先使用智能算法获取所需的采集详细页面链接(多个),用户可以双击打开检查。如果不需要数据,可以单击“列表提取器”手动指定,只需用鼠标单击可视化界面即可
智能采集结果如下图所示:
此外,在上述结果中,系统还智能发现了翻页规则,用户可以设置采集翻页多少页。您也可以稍后在任务中的“基本信息和门户地址”-“根据规则生成web地址”项中对其进行配置
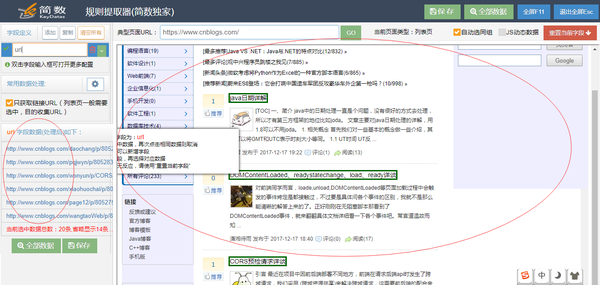
列表提取器打开后,请参见下图:
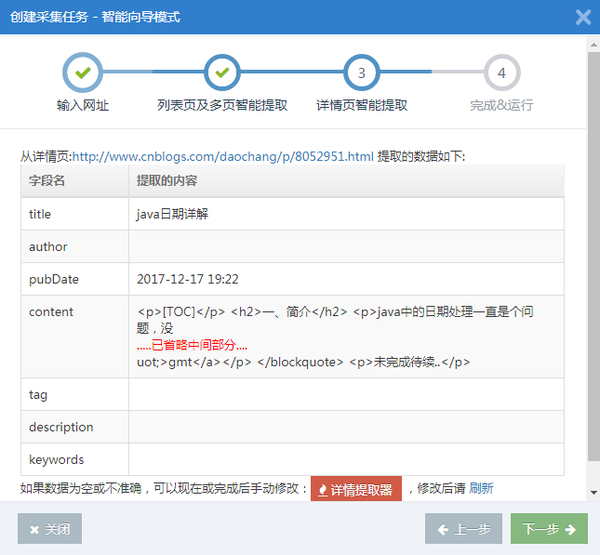
步骤3:改进细节页面上的智能提取结果(可选)
在上一步中获得多个详细页面链接后,继续下一步。系统将使用一个详细页面链接智能提取详细页面数据(如标题、作者、发布日期、内容、标签等)
详细信息页面上的智能提取结果如下:
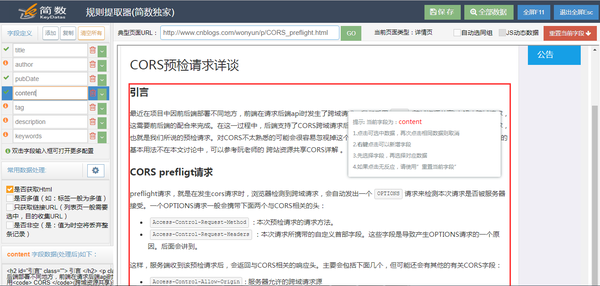
如果智能提取的内容不是您想要的,则可以打开详细信息提取程序对其进行修改
如下图所示:
您可以修改、添加或删除左侧的字段
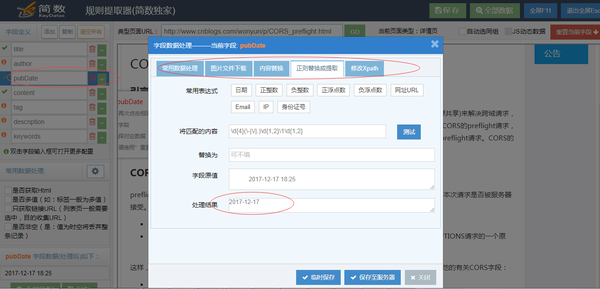
您还可以对每个字段进行详细设置或数据处理(双击该字段):替换、提取、筛选、设置默认值等
如下图所示:
步骤4:启动操作
完成后,即可启动运行,进行数据采集了:
@对于此采集任务的“结果数据与发布”中采集之后的数据结果,您可以在此处修改数据,或直接将其导出到excel或发布您的网站(WordPress@)织梦DEDE、HTTP接口、数据库等)
完成后,数据采集非常简单
有关其他操作,如将数据发布到网站、数据SEO处理等,请参阅其他章节 查看全部
网页采集器的自动识别算法(大多数概念:完善列表页的智能抽取结果(可选))
一个概念:
大多数网站以列表页和详细页的层次结构进行组织。例如,当我们进入新浪新闻频道时,有很多标题链接,可以看作是列表页面。单击标题链接进入详细信息页面
使用data采集工具的一般目的是大量获取详细页面中的特定内容数据,将这些数据用于各种分析,发布自己的网站等
列表页:指一个列或目录页,通常收录多个标题链接。例如:网站主页或专栏页是列表页。主要功能:您可以通过列表页面获得指向多个详细信息页面的链接
详细页面:收录特定内容的页面,如网页文章,其中收录:标题、作者、发布日期、正文内容、标签等
要开始,请登录“优采云console”:
详细使用步骤:
步骤1:创建采集任务
点击左侧菜单按钮“创建采集task”,输入采集task名称和采集的“列表页面”URL,如:/(此处主页为列表页面:内容可收录多个详细页面)。无法填写详细信息页面链接,系统将自动识别该链接
如下图所示:
输入后点击“下一步”
步骤2:改进列表页面的智能提取结果(可选)
系统将首先使用智能算法获取所需的采集详细页面链接(多个),用户可以双击打开检查。如果不需要数据,可以单击“列表提取器”手动指定,只需用鼠标单击可视化界面即可
智能采集结果如下图所示:
此外,在上述结果中,系统还智能发现了翻页规则,用户可以设置采集翻页多少页。您也可以稍后在任务中的“基本信息和门户地址”-“根据规则生成web地址”项中对其进行配置
列表提取器打开后,请参见下图:
步骤3:改进细节页面上的智能提取结果(可选)
在上一步中获得多个详细页面链接后,继续下一步。系统将使用一个详细页面链接智能提取详细页面数据(如标题、作者、发布日期、内容、标签等)
详细信息页面上的智能提取结果如下:
如果智能提取的内容不是您想要的,则可以打开详细信息提取程序对其进行修改
如下图所示:
您可以修改、添加或删除左侧的字段
您还可以对每个字段进行详细设置或数据处理(双击该字段):替换、提取、筛选、设置默认值等
如下图所示:
步骤4:启动操作
完成后,即可启动运行,进行数据采集了:
@对于此采集任务的“结果数据与发布”中采集之后的数据结果,您可以在此处修改数据,或直接将其导出到excel或发布您的网站(WordPress@)织梦DEDE、HTTP接口、数据库等)
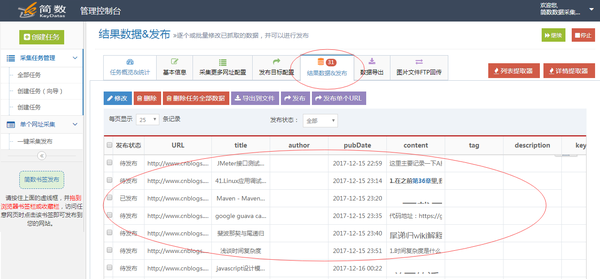
完成后,数据采集非常简单
有关其他操作,如将数据发布到网站、数据SEO处理等,请参阅其他章节
网页采集器的自动识别算法(大数据网络爬虫的原理和工做策略)
采集交流 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2021-09-19 21:18
网络数据采集指通过网络爬虫或网站公共API从网站获取的数据信息。该方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。它支持图片、音频、视频和其他文件或附件采集,附件可以自动与文本关联。html
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。算法
在大数据时代,网络爬虫是从互联网获取采集数据的有利工具。目前已知的网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。网络
本部分首先简要介绍了网络爬虫的原理和工作流程,然后讨论了网络爬虫的爬行策略,最后描述了典型的网络工具。数据结构
网络爬虫原理
网络爬虫是一个程序或脚本,根据一定的规则自动抓取网络信息。结构
网络爬虫可以自动采集他们可以访问的所有页面内容,并为搜索引擎和大数据分析提供数据源。在功能上,爬虫程序通常有三个功能:数据采集、处理和存储,如图1所示。机器学习
图1分布式网络爬虫示意图
除了供用户阅读的文本信息外,网页还收录一些超链接信息。工具
网络爬虫系统通过网页中的超链接信息获取其余网页。网络爬虫从一个或多个初始网页的URL获取初始网页上的URL。在抓取网页的过程中,它不断地从当前网页中提取新的URL并将其放入队列,直到满足系统的某些暂停条件。研究
网络爬虫系统通常选择一些具有大量网站链接(网页中的超链接)的重要URL作为种子URL集合。大数据
网络爬虫系统将这些种子集作为初始URL来开始数据获取。由于网页收录连接信息,因此将通过现有网页的URL获得一些新的URL
网页之间的指向结构可以看作是一个森林,每个种子URL对应的网页是森林中树的根节点,因此网络爬虫系统可以根据广度优先搜索算法或深度优先搜索算法遍历所有网页
由于深度优先搜索算法可能使爬虫系统陷入网站内部,不利于搜索靠近网站主页的网页信息,因此通常使用广度优先搜索算法采集网页
网络爬虫系统首先将种子URL放入下载队列,只需从队列的头部获取一个URL,下载相应的网页,获取网页内容并存储,通过解析网页中的连接信息即可获得一些新的URL
其次,根据一定的网页分析算法,过滤掉与主题无关的连接,保留有用的连接,并将其放入等待获取的URL队列中
最后,取出一个URL,下载相应的网页,然后解析它。重复此操作,直到遍历整个网络或满足某些条件
网络爬虫工作流
如图2所示,网络爬虫的基本工作流程如下
1)首先选择一些种子URL
2)将这些URL放入要获取的URL队列
3)从待取URL队列中取待取URL,解析DNS,获取主机IP地址,下载该URL对应的网页,保存在下载的网页库中。此外,将这些URL放入已爬网的URL队列
4)分析已爬网URL队列中的URL,分析剩余的URL,并将这些URL放入要爬网的URL队列中,以便进入下一个周期
图2网络爬虫的基本工作流程
网络爬虫爬行策略
谷歌和百度等通用搜索引擎捕获的网页数量通常以数十亿计。因此,面对如此多的web页面,如何使web爬虫尽可能地遍历所有的web页面,从而尽可能地扩大web信息的捕获范围,这是web爬虫系统面临的一个关键问题。在网络爬虫系统中,爬行策略决定了网页的爬行顺序
本节首先简要介绍web爬虫捕获策略中使用的基本概念
1)web页面之间的关系模型
从互联网结构的角度来看,网页通过不同数量的超链接相互连接,形成一个相互关联的大型复杂有向图
如图3所示,如果将网页视为图中的一个节点,并且将与网页中其他网页的连接视为该节点到其他节点的边,则很容易将整个Internet上的网页建模为一个有向图
理论上,通过遍历算法遍历图形,几乎可以访问Internet上的所有网页
图3网页关系模型示意图
2)web页面分类
通过从爬虫的角度划分互联网,互联网的所有页面可以分为五个部分:下载和过期页面、下载和过期页面、待下载页面、已知页面和未知页面,如图4所示
捕获本地网页实际上是互联网内容的镜像和备份。互联网是动态的。当互联网上的部分内容发生变化时,捕获本地网页已过时。因此,下载的网页分为已下载但未过期的网页和已下载且过期的网页
图4网页分类
要下载的网页是指URL队列中要获取的网页
可以看出,网页是指尚未爬网且不在要爬网的URL队列中的网页,但可以通过分析已爬网的网页或与要爬网的URL对应的网页来获得
还有一些网页是网络爬虫无法直接抓取和下载的,称为不可知网页
以下重点介绍几种常见的捕获策略
1.universalwebcrawler
通用网络爬虫,也称为全网爬虫,从一些种子URL向全网爬网,主要用于门户网站搜索引擎和大型web服务提供商采集数据
为了提高工作效率,一般的网络爬虫都会采用一定的爬行策略。常用的爬行策略有深度优先策略和广度优先策略
1)深度优先战略
深度优先策略意味着网络爬虫将从起始页开始,一个接一个地跟踪它,直到无法再深入
完成爬网分支后,web爬虫将返回到上一个连接节点以进一步搜索其他连接。遍历所有连接后,爬网任务结束
这种策略更适合于垂直搜索或现场搜索,但抓取具有深层页面内容的站点将形成巨大的资源浪费
以图3为例,遍历路径为1→ 2.→ 5.→ 6.→ 3.→ 7.→ 4.→ 八,
在深度优先策略中,当搜索一个节点时,该节点的子节点和子节点的后续节点都优先于该节点的兄弟节点。深度优先策略将在搜索空间时尽可能深入。仅当无法找到节点的后续节点时,才会考虑其兄弟节点
该策略决定了深度优先策略不一定能找到最优解,甚至由于深度的限制而无法找到最优解
如果不受限制,它将沿着一条路径无限扩展,这将“落入”大量数据。通常,使用深度优先策略会选择合适的深度,然后反复搜索,直到找到解决方案,因此搜索效率会降低。因此,当搜索数据量相对较小时,通常使用深度优先策略
2)广度优先战略
广度优先策略根据web内容目录级别的深度抓取页面,浅层目录级别的页面首先被抓取。当同一级别的页面爬网时,爬网程序将继续爬网到下一级别
仍然以图3为例,遍历路径为1→ 2.→ 3.→ 4.→ 5.→ 6.→ 7.→ 八,
由于广度优先策略在N层节点扩展完成后进入N+1层,因此可以保证找到路径最短的解
该策略可以有效控制页面的爬行深度,避免了遇到无限深分支时爬行无法结束的问题,并且易于实现,无需存储大量中间节点。缺点是爬行到目录级别更深的页面需要很长时间
如果搜索中存在过多的分支,即节点的后续节点过多,算法将耗尽资源,无法在可用空间中找到解决方案
2.关注网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是指有选择地抓取与预定义主题相关的页面的网络爬虫
@基于内容评价的1)crawling策略
黛布拉介绍了文本相似性的计算方法 查看全部
网页采集器的自动识别算法(大数据网络爬虫的原理和工做策略)
网络数据采集指通过网络爬虫或网站公共API从网站获取的数据信息。该方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。它支持图片、音频、视频和其他文件或附件采集,附件可以自动与文本关联。html
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。算法
在大数据时代,网络爬虫是从互联网获取采集数据的有利工具。目前已知的网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。网络
本部分首先简要介绍了网络爬虫的原理和工作流程,然后讨论了网络爬虫的爬行策略,最后描述了典型的网络工具。数据结构
网络爬虫原理
网络爬虫是一个程序或脚本,根据一定的规则自动抓取网络信息。结构
网络爬虫可以自动采集他们可以访问的所有页面内容,并为搜索引擎和大数据分析提供数据源。在功能上,爬虫程序通常有三个功能:数据采集、处理和存储,如图1所示。机器学习

图1分布式网络爬虫示意图
除了供用户阅读的文本信息外,网页还收录一些超链接信息。工具
网络爬虫系统通过网页中的超链接信息获取其余网页。网络爬虫从一个或多个初始网页的URL获取初始网页上的URL。在抓取网页的过程中,它不断地从当前网页中提取新的URL并将其放入队列,直到满足系统的某些暂停条件。研究
网络爬虫系统通常选择一些具有大量网站链接(网页中的超链接)的重要URL作为种子URL集合。大数据
网络爬虫系统将这些种子集作为初始URL来开始数据获取。由于网页收录连接信息,因此将通过现有网页的URL获得一些新的URL
网页之间的指向结构可以看作是一个森林,每个种子URL对应的网页是森林中树的根节点,因此网络爬虫系统可以根据广度优先搜索算法或深度优先搜索算法遍历所有网页
由于深度优先搜索算法可能使爬虫系统陷入网站内部,不利于搜索靠近网站主页的网页信息,因此通常使用广度优先搜索算法采集网页
网络爬虫系统首先将种子URL放入下载队列,只需从队列的头部获取一个URL,下载相应的网页,获取网页内容并存储,通过解析网页中的连接信息即可获得一些新的URL
其次,根据一定的网页分析算法,过滤掉与主题无关的连接,保留有用的连接,并将其放入等待获取的URL队列中
最后,取出一个URL,下载相应的网页,然后解析它。重复此操作,直到遍历整个网络或满足某些条件
网络爬虫工作流
如图2所示,网络爬虫的基本工作流程如下
1)首先选择一些种子URL
2)将这些URL放入要获取的URL队列
3)从待取URL队列中取待取URL,解析DNS,获取主机IP地址,下载该URL对应的网页,保存在下载的网页库中。此外,将这些URL放入已爬网的URL队列
4)分析已爬网URL队列中的URL,分析剩余的URL,并将这些URL放入要爬网的URL队列中,以便进入下一个周期
图2网络爬虫的基本工作流程
网络爬虫爬行策略
谷歌和百度等通用搜索引擎捕获的网页数量通常以数十亿计。因此,面对如此多的web页面,如何使web爬虫尽可能地遍历所有的web页面,从而尽可能地扩大web信息的捕获范围,这是web爬虫系统面临的一个关键问题。在网络爬虫系统中,爬行策略决定了网页的爬行顺序
本节首先简要介绍web爬虫捕获策略中使用的基本概念
1)web页面之间的关系模型
从互联网结构的角度来看,网页通过不同数量的超链接相互连接,形成一个相互关联的大型复杂有向图
如图3所示,如果将网页视为图中的一个节点,并且将与网页中其他网页的连接视为该节点到其他节点的边,则很容易将整个Internet上的网页建模为一个有向图
理论上,通过遍历算法遍历图形,几乎可以访问Internet上的所有网页
图3网页关系模型示意图
2)web页面分类
通过从爬虫的角度划分互联网,互联网的所有页面可以分为五个部分:下载和过期页面、下载和过期页面、待下载页面、已知页面和未知页面,如图4所示
捕获本地网页实际上是互联网内容的镜像和备份。互联网是动态的。当互联网上的部分内容发生变化时,捕获本地网页已过时。因此,下载的网页分为已下载但未过期的网页和已下载且过期的网页
图4网页分类
要下载的网页是指URL队列中要获取的网页
可以看出,网页是指尚未爬网且不在要爬网的URL队列中的网页,但可以通过分析已爬网的网页或与要爬网的URL对应的网页来获得
还有一些网页是网络爬虫无法直接抓取和下载的,称为不可知网页
以下重点介绍几种常见的捕获策略
1.universalwebcrawler
通用网络爬虫,也称为全网爬虫,从一些种子URL向全网爬网,主要用于门户网站搜索引擎和大型web服务提供商采集数据
为了提高工作效率,一般的网络爬虫都会采用一定的爬行策略。常用的爬行策略有深度优先策略和广度优先策略
1)深度优先战略
深度优先策略意味着网络爬虫将从起始页开始,一个接一个地跟踪它,直到无法再深入
完成爬网分支后,web爬虫将返回到上一个连接节点以进一步搜索其他连接。遍历所有连接后,爬网任务结束
这种策略更适合于垂直搜索或现场搜索,但抓取具有深层页面内容的站点将形成巨大的资源浪费
以图3为例,遍历路径为1→ 2.→ 5.→ 6.→ 3.→ 7.→ 4.→ 八,
在深度优先策略中,当搜索一个节点时,该节点的子节点和子节点的后续节点都优先于该节点的兄弟节点。深度优先策略将在搜索空间时尽可能深入。仅当无法找到节点的后续节点时,才会考虑其兄弟节点
该策略决定了深度优先策略不一定能找到最优解,甚至由于深度的限制而无法找到最优解
如果不受限制,它将沿着一条路径无限扩展,这将“落入”大量数据。通常,使用深度优先策略会选择合适的深度,然后反复搜索,直到找到解决方案,因此搜索效率会降低。因此,当搜索数据量相对较小时,通常使用深度优先策略
2)广度优先战略
广度优先策略根据web内容目录级别的深度抓取页面,浅层目录级别的页面首先被抓取。当同一级别的页面爬网时,爬网程序将继续爬网到下一级别
仍然以图3为例,遍历路径为1→ 2.→ 3.→ 4.→ 5.→ 6.→ 7.→ 八,
由于广度优先策略在N层节点扩展完成后进入N+1层,因此可以保证找到路径最短的解
该策略可以有效控制页面的爬行深度,避免了遇到无限深分支时爬行无法结束的问题,并且易于实现,无需存储大量中间节点。缺点是爬行到目录级别更深的页面需要很长时间
如果搜索中存在过多的分支,即节点的后续节点过多,算法将耗尽资源,无法在可用空间中找到解决方案
2.关注网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是指有选择地抓取与预定义主题相关的页面的网络爬虫
@基于内容评价的1)crawling策略
黛布拉介绍了文本相似性的计算方法
网页采集器的自动识别算法(网页采集器的自动识别匹配方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-19 17:06
网页采集器的自动识别算法有一套自己的理论和算法,比如:是否已抓取图片,属性是否符合要求,多种异常码识别匹配;注意力机制、过滤器机制。一般采用c++编写自动采集器的话,可以使用boost::boost::string和cffi,前者是boost库的纯c语言版本的库,后者是基于其它框架的一些方法的实现版本的库。
爬虫识别是识别图片的位置的。
page_anchors
又是一道c语言的题
网页采集器一般都要采集图片来识别的,比如baiduspider
图片识别,可能就是根据图片内容来判断了。关键是图片。类似的,如果能够辨别图片内容,那么如何对图片进行操作也是一种技术。这方面研究的人比较多。
找到对应,
具体采用什么传统的方法,这是一个世界性的难题,可以看看国外有没有相关领域的研究成果。
说几个传统的方法识别方法一:特征矩阵方法目前识别领域主要用于能被看到的图片的识别方法,包括基于图像特征的寻找和局部特征的提取。不过具体可以根据具体情况具体应用于图像识别的各种方法可以根据图像提取特征点、经过线性特征点的处理获得边界特征点等方法不同而选择。如果手头不是有张大图,那么一般通过特征提取,通过图像插值识别出边界特征点,然后拼接大小为1的特征点在大图上看见的结果,或者通过基于特征点的矩阵提取方法,直接设计矩阵(4边形边长为1),每一行就是一个边界的矩阵,就能够进行识别;如果想把边界矩阵与其他样本进行匹配,如“教育部”这种认证,也可以通过样本匹配矩阵来识别;方法二:感知机方法单个或少数几个特征点的识别是比较容易,难就难在串连的特征点,这也是难点,另外前面说到根据其他样本来识别,另外样本质量也是一个难点,如何在各种类别上的特征融合也是一个难点,可以通过用户在访问相应网站时,会根据他的历史行为产生各种轨迹,从而匹配特征,包括在各种场景下不同场景下特征是否匹配,如果差异大,则需要使用正则匹配(特征匹配)如果目标网站上有很多的图片,那么人工标注就会有误差,因此目前也有一些机器学习在处理这个问题。
网站会通过颜色进行分类,然后通过灰度函数或者随机函数进行匹配。方法三:分类别域作为两个图片对标签,再经过一个阈值匹配判断目标图片对标签与否。为了减少计算量的话,还可以用带小样本训练出lstm网络对于标签进行预测。方法四:图像去重当两张图片都为一样的时候,一般会采用图像去重,大概的思路是:对于两张没有任何关系的图片,将其边界、背景等等都处理掉。除了处理边界外,还可以借助一些自然光污染或是a。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别匹配方法)
网页采集器的自动识别算法有一套自己的理论和算法,比如:是否已抓取图片,属性是否符合要求,多种异常码识别匹配;注意力机制、过滤器机制。一般采用c++编写自动采集器的话,可以使用boost::boost::string和cffi,前者是boost库的纯c语言版本的库,后者是基于其它框架的一些方法的实现版本的库。
爬虫识别是识别图片的位置的。
page_anchors
又是一道c语言的题
网页采集器一般都要采集图片来识别的,比如baiduspider
图片识别,可能就是根据图片内容来判断了。关键是图片。类似的,如果能够辨别图片内容,那么如何对图片进行操作也是一种技术。这方面研究的人比较多。
找到对应,
具体采用什么传统的方法,这是一个世界性的难题,可以看看国外有没有相关领域的研究成果。
说几个传统的方法识别方法一:特征矩阵方法目前识别领域主要用于能被看到的图片的识别方法,包括基于图像特征的寻找和局部特征的提取。不过具体可以根据具体情况具体应用于图像识别的各种方法可以根据图像提取特征点、经过线性特征点的处理获得边界特征点等方法不同而选择。如果手头不是有张大图,那么一般通过特征提取,通过图像插值识别出边界特征点,然后拼接大小为1的特征点在大图上看见的结果,或者通过基于特征点的矩阵提取方法,直接设计矩阵(4边形边长为1),每一行就是一个边界的矩阵,就能够进行识别;如果想把边界矩阵与其他样本进行匹配,如“教育部”这种认证,也可以通过样本匹配矩阵来识别;方法二:感知机方法单个或少数几个特征点的识别是比较容易,难就难在串连的特征点,这也是难点,另外前面说到根据其他样本来识别,另外样本质量也是一个难点,如何在各种类别上的特征融合也是一个难点,可以通过用户在访问相应网站时,会根据他的历史行为产生各种轨迹,从而匹配特征,包括在各种场景下不同场景下特征是否匹配,如果差异大,则需要使用正则匹配(特征匹配)如果目标网站上有很多的图片,那么人工标注就会有误差,因此目前也有一些机器学习在处理这个问题。
网站会通过颜色进行分类,然后通过灰度函数或者随机函数进行匹配。方法三:分类别域作为两个图片对标签,再经过一个阈值匹配判断目标图片对标签与否。为了减少计算量的话,还可以用带小样本训练出lstm网络对于标签进行预测。方法四:图像去重当两张图片都为一样的时候,一般会采用图像去重,大概的思路是:对于两张没有任何关系的图片,将其边界、背景等等都处理掉。除了处理边界外,还可以借助一些自然光污染或是a。
网页采集器的自动识别算法(网络推广软件功能编写的自定义脚本可完成的作用 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-09-18 17:14
)
首先,我们不想让你下载这个工具,而是想让你了解这个软件的功能。它可以被看作是对软件功能和特性的解释~~我们不提供下载服务
各类普通网络推广软件功能固定、单一,注册费用高。有时他们跟不上更新。很难找到适合自己的软件。全方位推广模拟王就是为此而诞生的
通过软件功能的灵活组合,可以完成自定义脚本:各种应用程序的自动操作,游戏、论坛、博客、留言簿、群评、群发邮件、账号注册任务、分类目录的提交和发布中的自动鼠标点击和自动按钮,群发QQ、微博推广、网站投票、数据提取等多种功能
图形二次开发:不需要理解编程。只要打开软件,你就可以下载各种官方精心制作的脚本。此外,我们不仅教人钓鱼,还教人钓鱼!在允许用户享受鱼粉的同时,我们还提供了大量的图形教程和视频教程。只要你努力工作,你就能一个人钓到大鱼
内部和外部浏览器:经过一年多的开发,我们发现类似软件的一个常见问题是挂断。内置浏览器挂起时间太长,占用的内存越来越多。因此,在维护内置浏览器的同时,我们还推广不与软件共享内存的外部浏览器。在执行过程中,程序可以每隔一段时间关闭和重新打开它以释放内存
外置WAP手机浏览器:WAP网页比PC网页限制少,浏览速度快,在网络推广中具有无可比拟的分量
正则文本提取:该程序具有强大的标准表达式和正则表达式文本提取功能,这使得采集非常容易
支持帖子发布:软件可以发送帖子数据和表头数据,使登录发布更快、更稳定
验证码标识:软件有手动标识、验证库标识和远程手动标识三种方式,使用灵活。用户定义的验证码标识项可在任何时间、任何地点进行批量发送或更新网站使用
查看全部
网页采集器的自动识别算法(网络推广软件功能编写的自定义脚本可完成的作用
)
首先,我们不想让你下载这个工具,而是想让你了解这个软件的功能。它可以被看作是对软件功能和特性的解释~~我们不提供下载服务
各类普通网络推广软件功能固定、单一,注册费用高。有时他们跟不上更新。很难找到适合自己的软件。全方位推广模拟王就是为此而诞生的
通过软件功能的灵活组合,可以完成自定义脚本:各种应用程序的自动操作,游戏、论坛、博客、留言簿、群评、群发邮件、账号注册任务、分类目录的提交和发布中的自动鼠标点击和自动按钮,群发QQ、微博推广、网站投票、数据提取等多种功能
图形二次开发:不需要理解编程。只要打开软件,你就可以下载各种官方精心制作的脚本。此外,我们不仅教人钓鱼,还教人钓鱼!在允许用户享受鱼粉的同时,我们还提供了大量的图形教程和视频教程。只要你努力工作,你就能一个人钓到大鱼
内部和外部浏览器:经过一年多的开发,我们发现类似软件的一个常见问题是挂断。内置浏览器挂起时间太长,占用的内存越来越多。因此,在维护内置浏览器的同时,我们还推广不与软件共享内存的外部浏览器。在执行过程中,程序可以每隔一段时间关闭和重新打开它以释放内存
外置WAP手机浏览器:WAP网页比PC网页限制少,浏览速度快,在网络推广中具有无可比拟的分量
正则文本提取:该程序具有强大的标准表达式和正则表达式文本提取功能,这使得采集非常容易
支持帖子发布:软件可以发送帖子数据和表头数据,使登录发布更快、更稳定
验证码标识:软件有手动标识、验证库标识和远程手动标识三种方式,使用灵活。用户定义的验证码标识项可在任何时间、任何地点进行批量发送或更新网站使用
网页采集器的自动识别算法(优采云采集器进入列表页后如何进一步获取内容页网址?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-09-17 20:19
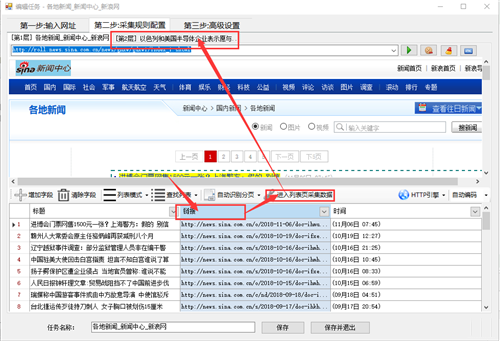
使用采集时,我们通常需要从网页的初始URL获取内容页URL。那么优采云采集器进入列表页面后,如何进一步获取内容URL?让我们邀请新手来看看如何创建内容页URL采集rules
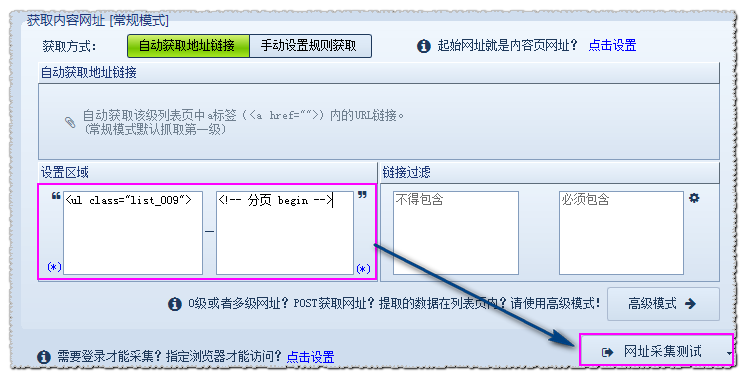
在中,内容URL获取有两种模式:常规模式和高级模式1.general模式:此模式默认获取主地址,即从起始页的源代码获取到内容页a的链接。有两种方式:A.自动获取地址链接,B.手动设置规则获取2.advanced模式:此模式对0级、多级、post类型的网址抓取有效。即,起始URL是内容页URL;或者您需要设置多级列表URL采集以获取最终内容页链接;或者在post URL类型捕获的情况下使用高级模式。这里详细描述了常规模式中模式a和模式B采集的具体操作,后面将解释高级模式。[常规模式]A.自动获取地址链接自动获取地址链接:自动获取该级别列表页面中所有标签的URL链接。例如新浪大陆新闻:
所得结果如下图所示:
根据统计,我们可以看到总共找到了81个一级网站,但实际我们需要抓取的一级网站是每页40个,这表明有我们不需要的链接,所以我们可以通过区域设置和链接过滤过滤来过滤和获取我们需要的链接。单击以使用浏览器查看网页源代码,并分析源代码。得出结论,所需链接应满足以下条件:开始字符串为,结束字符串为
我们在设置区域填充它,再次测试它,然后查看结果。从测试中可以看出,结果是正确的,如下图所示
[常规模式]B.手动设置规则获取
对于脚本生成的某些网址,采集器无法自动识别。在这种情况下,您需要手动设置规则以获取它们。手动设置规则获取的原理是编写脚本规则,匹配源代码中的内容,获取自己设置的参数。提取规则中的[parameter]、(*)和[label:XXX]是通配符,可以配置为任何字符。不同之处在于,[parameter]有一个返回值,通常用于拼接地址,(*)没有返回值,[label:XXX]有一个返回值,该返回值被赋予标签。例如新浪大陆新闻:
源代码如下:
山西公布政府部门责任清单,建立拒腐防变机制(10月10日20:00)20)
据报道,河南省登封市市长在修建寺庙过程中涉嫌腐败,并与石延禄关系密切(10月10日20:00)14)
张家界市国土资源局副局长因严重违纪被调查(10月10日19:00)45)
此时,我们可以将其中一个代码作为循环匹配,用[parameter]替换我们想要获得的链接,并用标签替换我们需要采集to的值。按如下方式填写提取规则:
参数]“target=“_blank”>;[标签:标题]([标签:时间])
如上图所示,符合此格式的源代码将自动匹配,内容页地址链接在参数中获得,标题和时间分布在标签中
在这里,网站抓住精灵优采云采集器V9获取内容URL的一般模式设置已完成。只要您阅读,就会觉得相对简单,优采云采集器V9你需要了解更多关于该软件的信息,所以它将很容易开始。回到搜狐查看更多信息 查看全部
网页采集器的自动识别算法(优采云采集器进入列表页后如何进一步获取内容页网址?)
使用采集时,我们通常需要从网页的初始URL获取内容页URL。那么优采云采集器进入列表页面后,如何进一步获取内容URL?让我们邀请新手来看看如何创建内容页URL采集rules
在中,内容URL获取有两种模式:常规模式和高级模式1.general模式:此模式默认获取主地址,即从起始页的源代码获取到内容页a的链接。有两种方式:A.自动获取地址链接,B.手动设置规则获取2.advanced模式:此模式对0级、多级、post类型的网址抓取有效。即,起始URL是内容页URL;或者您需要设置多级列表URL采集以获取最终内容页链接;或者在post URL类型捕获的情况下使用高级模式。这里详细描述了常规模式中模式a和模式B采集的具体操作,后面将解释高级模式。[常规模式]A.自动获取地址链接自动获取地址链接:自动获取该级别列表页面中所有标签的URL链接。例如新浪大陆新闻:
所得结果如下图所示:
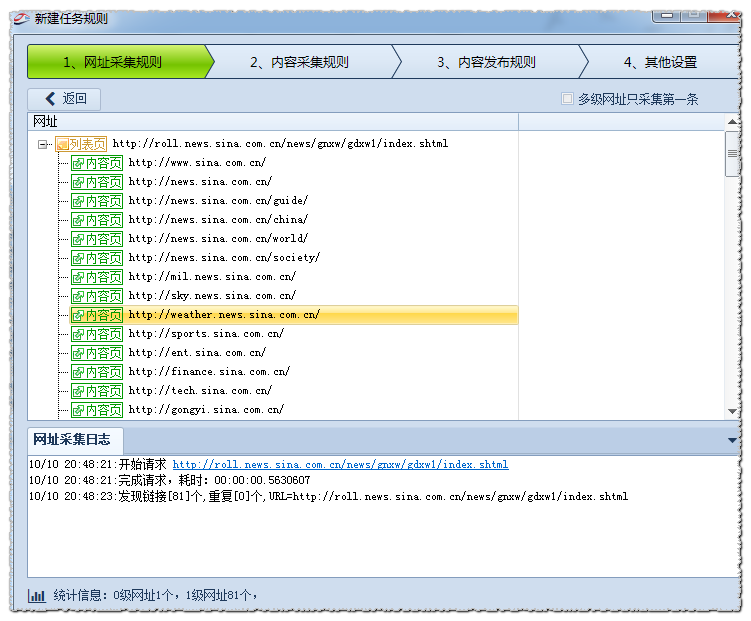
根据统计,我们可以看到总共找到了81个一级网站,但实际我们需要抓取的一级网站是每页40个,这表明有我们不需要的链接,所以我们可以通过区域设置和链接过滤过滤来过滤和获取我们需要的链接。单击以使用浏览器查看网页源代码,并分析源代码。得出结论,所需链接应满足以下条件:开始字符串为,结束字符串为
我们在设置区域填充它,再次测试它,然后查看结果。从测试中可以看出,结果是正确的,如下图所示
[常规模式]B.手动设置规则获取
对于脚本生成的某些网址,采集器无法自动识别。在这种情况下,您需要手动设置规则以获取它们。手动设置规则获取的原理是编写脚本规则,匹配源代码中的内容,获取自己设置的参数。提取规则中的[parameter]、(*)和[label:XXX]是通配符,可以配置为任何字符。不同之处在于,[parameter]有一个返回值,通常用于拼接地址,(*)没有返回值,[label:XXX]有一个返回值,该返回值被赋予标签。例如新浪大陆新闻:
源代码如下:
山西公布政府部门责任清单,建立拒腐防变机制(10月10日20:00)20)
据报道,河南省登封市市长在修建寺庙过程中涉嫌腐败,并与石延禄关系密切(10月10日20:00)14)
张家界市国土资源局副局长因严重违纪被调查(10月10日19:00)45)
此时,我们可以将其中一个代码作为循环匹配,用[parameter]替换我们想要获得的链接,并用标签替换我们需要采集to的值。按如下方式填写提取规则:
参数]“target=“_blank”>;[标签:标题]([标签:时间])
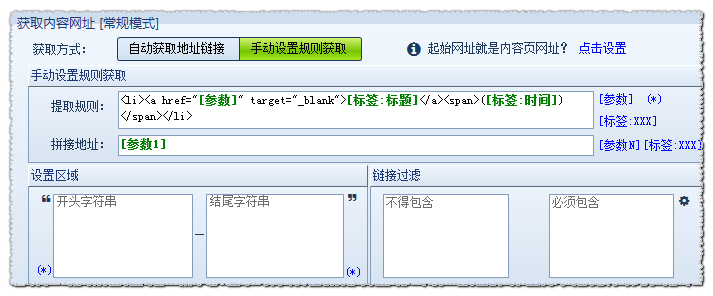
如上图所示,符合此格式的源代码将自动匹配,内容页地址链接在参数中获得,标题和时间分布在标签中
在这里,网站抓住精灵优采云采集器V9获取内容URL的一般模式设置已完成。只要您阅读,就会觉得相对简单,优采云采集器V9你需要了解更多关于该软件的信息,所以它将很容易开始。回到搜狐查看更多信息
网页采集器的自动识别算法(网页信息采集软件_优采云采集换行生成Excel表格,api数据库文件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-09-17 20:17
Web information采集software优采云采集器是一款高效的网页信息采集软件,支持99%的网站data采集,优采云采集器可以生成excel表格、API数据库文件和其他内容,帮助您管理网站数据信息。如果您需要采集指定的网页数据,您可以使用此软件
软件功能:
一键数据提取
易于学习,您可以通过可视化界面单击鼠标获取数据
快速高效
内置一套高速浏览器内核和HTTP引擎模式,实现快速采集数据
适用于各种网站
99%的采集Internet网站,包括单页应用程序、AJAX加载和其他动态类型网站
向导模式
易于使用,鼠标点击即可自动生成
脚本定期运行
可按计划正常运行,无需人工操作
原创高速内核
自主开发的浏览器内核速度快,比竞争对手快得多
智能识别
它可以智能地识别网页中的列表和表单结构(多框下拉列表等)
广告屏蔽
自定义广告屏蔽模块,与adblockplus语法兼容,可添加自定义规则
多重数据导出
支持TXT、Excel、mysql、sqlserver、SQLite、access、网站等
使用说明
步骤1:输入采集网址
打开软件,创建新任务,然后输入所需的网站地址采集
步骤2:全过程智能分析和自动数据提取
进入第二步后,优采云@采集器自动智能地分析网页并从中提取列表数据
步骤3:将数据导出到表、数据库、网站etc
运行任务将采集数据导出到CSV、Excel和各种数据库,并支持API导出
更新日志优采云@采集器2.1.@8.0更新:
1.add插件功能
2.add export TXT(一个保存为文件)
3.多值连接器支持换行符
4.修改数据处理的文本映射(支持搜索和替换)
5.fix登录期间的DNS问题
6.fix图片下载问题
7.修复了JSON的一些问题 查看全部
网页采集器的自动识别算法(网页信息采集软件_优采云采集换行生成Excel表格,api数据库文件)
Web information采集software优采云采集器是一款高效的网页信息采集软件,支持99%的网站data采集,优采云采集器可以生成excel表格、API数据库文件和其他内容,帮助您管理网站数据信息。如果您需要采集指定的网页数据,您可以使用此软件
软件功能:
一键数据提取
易于学习,您可以通过可视化界面单击鼠标获取数据
快速高效
内置一套高速浏览器内核和HTTP引擎模式,实现快速采集数据
适用于各种网站
99%的采集Internet网站,包括单页应用程序、AJAX加载和其他动态类型网站
向导模式
易于使用,鼠标点击即可自动生成
脚本定期运行
可按计划正常运行,无需人工操作
原创高速内核
自主开发的浏览器内核速度快,比竞争对手快得多
智能识别
它可以智能地识别网页中的列表和表单结构(多框下拉列表等)
广告屏蔽
自定义广告屏蔽模块,与adblockplus语法兼容,可添加自定义规则
多重数据导出
支持TXT、Excel、mysql、sqlserver、SQLite、access、网站等
使用说明
步骤1:输入采集网址
打开软件,创建新任务,然后输入所需的网站地址采集
步骤2:全过程智能分析和自动数据提取
进入第二步后,优采云@采集器自动智能地分析网页并从中提取列表数据
步骤3:将数据导出到表、数据库、网站etc
运行任务将采集数据导出到CSV、Excel和各种数据库,并支持API导出
更新日志优采云@采集器2.1.@8.0更新:
1.add插件功能
2.add export TXT(一个保存为文件)
3.多值连接器支持换行符
4.修改数据处理的文本映射(支持搜索和替换)
5.fix登录期间的DNS问题
6.fix图片下载问题
7.修复了JSON的一些问题
网页采集器的自动识别算法(优采云采集器智能采集天气网:自动识别+翻页按钮)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-09-16 07:08
谢谢你的邀请。没有什么废话。直接转到操作视频~
优采云采集器intelligent采集Weather Network
我试过了。房东提到的问题确实存在。同时,我比较了天气网络的优采云@采集器和采集。使用房东提供的链接,我在大约2分钟内完成了所有天气数据和历史数据的采集设置。同时我也记录了我的操作过程,房东可以在采集跟随我的操作过程@
让我谈谈经验:
1.this网站实际上是一个简单的表单,但在翻页时,网址保持不变。这种网页技术称为本地刷新,或专业点的Ajax。如果你感兴趣,你可以百度,但你可以忽略它。从视频中可以看出,优采云在上个月设置采集翻页并点击时准确识别了该按钮的操作,可视化的采集流程自动设置,非常直观直观,一目了然
2.在智能识别过程中,测试的是算法的能力。从这里还可以看出,优采云在网页智能识别算法中的性能优于其他@采集器算法。它不仅自动标识所有字段,而且还完全自动标识整个列表。同时,自动识别翻页按钮采用的特殊反采集技术
特别是,优采云@采集器作为行业基准,非常关注用户体验。虽然我在视频中使用了优采云旗舰版(cloud采集、API和personal customer service,它们为大量企业数据稳定采集提供了非常周到的服务),但是优采云免费版没有基本的功能限制,从优采云official网站(优采云三字拼音)开始下载优采云并直接安装到采集all网站. 对于京东、天猫、公众评论、百度等行业的主流网站来说,优采云还提供了一个内置的采集模板,可以在不配置采集规则的情况下采集主流站点数据。优采云@采集器-免费网络爬虫软件网页数据捕获工具
欢迎关注或与我私下交流~ 查看全部
网页采集器的自动识别算法(优采云采集器智能采集天气网:自动识别+翻页按钮)
谢谢你的邀请。没有什么废话。直接转到操作视频~
优采云采集器intelligent采集Weather Network
我试过了。房东提到的问题确实存在。同时,我比较了天气网络的优采云@采集器和采集。使用房东提供的链接,我在大约2分钟内完成了所有天气数据和历史数据的采集设置。同时我也记录了我的操作过程,房东可以在采集跟随我的操作过程@
让我谈谈经验:
1.this网站实际上是一个简单的表单,但在翻页时,网址保持不变。这种网页技术称为本地刷新,或专业点的Ajax。如果你感兴趣,你可以百度,但你可以忽略它。从视频中可以看出,优采云在上个月设置采集翻页并点击时准确识别了该按钮的操作,可视化的采集流程自动设置,非常直观直观,一目了然
2.在智能识别过程中,测试的是算法的能力。从这里还可以看出,优采云在网页智能识别算法中的性能优于其他@采集器算法。它不仅自动标识所有字段,而且还完全自动标识整个列表。同时,自动识别翻页按钮采用的特殊反采集技术
特别是,优采云@采集器作为行业基准,非常关注用户体验。虽然我在视频中使用了优采云旗舰版(cloud采集、API和personal customer service,它们为大量企业数据稳定采集提供了非常周到的服务),但是优采云免费版没有基本的功能限制,从优采云official网站(优采云三字拼音)开始下载优采云并直接安装到采集all网站. 对于京东、天猫、公众评论、百度等行业的主流网站来说,优采云还提供了一个内置的采集模板,可以在不配置采集规则的情况下采集主流站点数据。优采云@采集器-免费网络爬虫软件网页数据捕获工具
欢迎关注或与我私下交流~
网页采集器的自动识别算法(10个非常实用的每一款软件,你喜欢哪一种? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-09-15 00:11
)
与大家分享10款非常好用的软件,每个软件都很强大,可以解决很多需求,喜欢的话记得点赞支持哦~
1、CopyQ
CopyQ 是一款免费开源的电脑剪贴板增强软件,支持 Windows、Mac 和 Linux。它的主要功能是监控系统剪贴板,存储您复制的所有内容,包括:文本、图片等格式文件,您可以随时调用它们,让您的复制粘贴更加高效。
CopyQ 的界面简单易操作。所有复制的内容可以按时间顺序一一清晰显示。您可以上下移动复制的内容,或者修复一段复制的内容,也可以将复制的内容调用到剪贴板。 .
CopyQ支持标签功能,可以对复制的内容进行排序分类;支持对复制内容的编辑;支持搜索复制的内容,可以右键软件任务栏图标,输入需要查找的文字内容。
2、Everything
Everything 是一款快速文件索引软件,可根据名称快速定位文件和文件夹。比windows自带的本地搜索速度快很多,软件体积只有10M左右,轻巧高效。
一切都可以在很短的时间内被索引,搜索结果基本上是毫秒级的。输入搜索的文件名后,立即显示搜索结果。
Everything 支持常用图片格式的缩略图预览,以及ai、psd、eps等常用设计文件的缩略图预览,这个功能对设计伙伴有很大的帮助!
3、优采云采集器
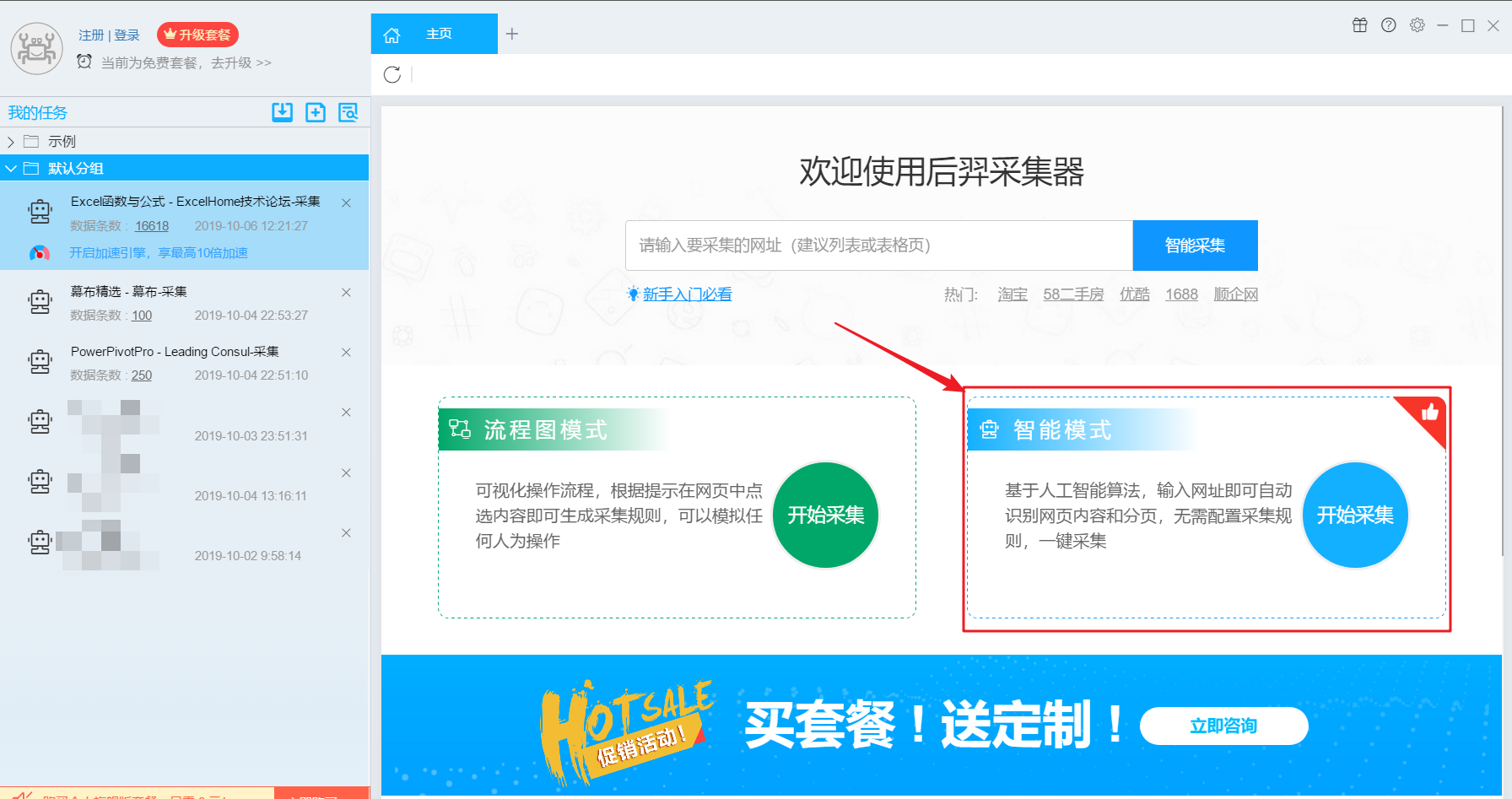
优采云采集器 由前 Google 技术团队创建。基于人工智能技术,只需输入网址即可自动识别采集内容。
可以智能识别数据。智能模式基于人工智能算法。只需输入网址,即可智能识别列表数据、表格数据和分页按钮。无需配置任何采集规则,一键采集。自动识别列表、表格、链接、图片、价格等
流程图模式:只需根据软件提示点击页面,完全符合人们浏览网页的思维方式,简单几步即可生成复杂的采集规则,结合智能识别算法,任何网页上的数据都可以轻松采集。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等
4、uTools
uTools 是一款非常强大的生产力工具箱软件。笔者将这款软件设计成一个“一切皆插件”的插件工具,所有功能都可以通过插件来实现。插件中心有很多实用高效的插件。
uTools 可以快速启动各种程序,只需一个搜索框。除了快速启动程序,我们在日常工作中还有各种小需求,比如翻译一个单词、识别/生成二维码、查看颜色值、字符串编码/解码、图像压缩等等。 uTools 以插件的形式聚合各种功能,将它们变成您专属的小工具库。您只需要输入一个快捷短语即可快速使用这些功能。
5、方方格
方形网格是一个非常易于使用的 Excel 插件工具箱。主要功能是支持扩展的Excel程序,帮助用户更快地分析Excel数据,提高工作效率。
软件拥有上百种实用功能,让用户办公更流畅。这是一个非常易于使用的 Excel 插件。
如文本处理、批量录入、删除工具、合并转换、重复值工具、数据比较、高级排序、颜色排序、合并单元格排序、聚光灯、宏存储框等
6、火绒安全软件
Tinder 安全软件是一款轻量级、高效、免费的计算机防御和杀毒安全软件,可显着增强计算机系统在应对安全问题时的防御能力。
Tinder安全软件可以全面拦截和查杀各类病毒,不会为了清除病毒而直接删除感染病毒的文件,充分保护用户文件不受损害。软件小巧玲珑,系统内存占用率极低,保证机器在主动防御和查杀过程中永不卡顿。
Tinder安全软件可以查杀病毒,有18项重要保护功能,文件实时监控、U盘保护、应用加固、软件安装拦截、浏览器保护、网络入侵拦截、暴力攻击保护、弹窗拦截、漏洞修复、启动项管理、文件粉碎。
7、天若OCR
天若OCR是一款集文字识别、表格识别、竖线识别、公式识别、修正识别、高级识别、识别翻译、识别搜索、截图功能于一体的软件。
天若OCR可以帮助您减少重复性工作,提高工作效率。
8、Snipaste
Snipaste 是一款简单而强大的截图和贴纸工具。您还可以将屏幕截图粘贴回屏幕。 F1截图,F3贴图,简约高效。
办公室里会抄很多资料,写的时候会抄很多文字和图片。 Snipaste 可以将这些内容粘贴到屏幕上,而不是切换回窗口。
发布在屏幕上的信息可以缩放、旋转、设置为半透明,甚至可以被鼠标穿透。在屏幕上发布重要信息,绝对可以改变你的工作方式,提高工作效率。
9、7-ZIP
7-ZIP 是一款开源免费的压缩软件,使用 LZMA 和 LZMA2 算法,压缩率非常高,可以比 Winzip 高 2-10%。 7-ZIP支持的格式很多,常用的压缩格式都支持。
支持的格式:压缩/解压:7z、XZ、BZIP2、GZIP、TAR、ZIP、WIM。仅解压:ARJ、CAB、CHM、CPIO、CramFS、DEB、DMG、FAT、HFS、ISO、LZH、LZMA、MBR、MSI、NSIS、NTFS、RAR、RPM、SquashFS、UDF、VHD、WIM、XAR、Z .
10、WGestures
WGestures 是一款简单高效的鼠标手势软件,免费开源,非常尽职尽责。
WGestures 有非常丰富的功能。网络搜索可以简化搜索信息的过程;手势名称提醒和修饰键更符合用户直觉;触发角度和摩擦边缘使计算机操作更高效。
今天的分享到此结束。谢谢你看到这个。听说三联的朋友们都有福了!喜欢就点击关注我,更多实用干货等着你!
查看全部
网页采集器的自动识别算法(10个非常实用的每一款软件,你喜欢哪一种?
)
与大家分享10款非常好用的软件,每个软件都很强大,可以解决很多需求,喜欢的话记得点赞支持哦~
1、CopyQ
CopyQ 是一款免费开源的电脑剪贴板增强软件,支持 Windows、Mac 和 Linux。它的主要功能是监控系统剪贴板,存储您复制的所有内容,包括:文本、图片等格式文件,您可以随时调用它们,让您的复制粘贴更加高效。
CopyQ 的界面简单易操作。所有复制的内容可以按时间顺序一一清晰显示。您可以上下移动复制的内容,或者修复一段复制的内容,也可以将复制的内容调用到剪贴板。 .

CopyQ支持标签功能,可以对复制的内容进行排序分类;支持对复制内容的编辑;支持搜索复制的内容,可以右键软件任务栏图标,输入需要查找的文字内容。
2、Everything
Everything 是一款快速文件索引软件,可根据名称快速定位文件和文件夹。比windows自带的本地搜索速度快很多,软件体积只有10M左右,轻巧高效。
一切都可以在很短的时间内被索引,搜索结果基本上是毫秒级的。输入搜索的文件名后,立即显示搜索结果。
Everything 支持常用图片格式的缩略图预览,以及ai、psd、eps等常用设计文件的缩略图预览,这个功能对设计伙伴有很大的帮助!
3、优采云采集器
优采云采集器 由前 Google 技术团队创建。基于人工智能技术,只需输入网址即可自动识别采集内容。
可以智能识别数据。智能模式基于人工智能算法。只需输入网址,即可智能识别列表数据、表格数据和分页按钮。无需配置任何采集规则,一键采集。自动识别列表、表格、链接、图片、价格等
流程图模式:只需根据软件提示点击页面,完全符合人们浏览网页的思维方式,简单几步即可生成复杂的采集规则,结合智能识别算法,任何网页上的数据都可以轻松采集。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等

4、uTools
uTools 是一款非常强大的生产力工具箱软件。笔者将这款软件设计成一个“一切皆插件”的插件工具,所有功能都可以通过插件来实现。插件中心有很多实用高效的插件。
uTools 可以快速启动各种程序,只需一个搜索框。除了快速启动程序,我们在日常工作中还有各种小需求,比如翻译一个单词、识别/生成二维码、查看颜色值、字符串编码/解码、图像压缩等等。 uTools 以插件的形式聚合各种功能,将它们变成您专属的小工具库。您只需要输入一个快捷短语即可快速使用这些功能。
5、方方格
方形网格是一个非常易于使用的 Excel 插件工具箱。主要功能是支持扩展的Excel程序,帮助用户更快地分析Excel数据,提高工作效率。
软件拥有上百种实用功能,让用户办公更流畅。这是一个非常易于使用的 Excel 插件。
如文本处理、批量录入、删除工具、合并转换、重复值工具、数据比较、高级排序、颜色排序、合并单元格排序、聚光灯、宏存储框等
6、火绒安全软件
Tinder 安全软件是一款轻量级、高效、免费的计算机防御和杀毒安全软件,可显着增强计算机系统在应对安全问题时的防御能力。
Tinder安全软件可以全面拦截和查杀各类病毒,不会为了清除病毒而直接删除感染病毒的文件,充分保护用户文件不受损害。软件小巧玲珑,系统内存占用率极低,保证机器在主动防御和查杀过程中永不卡顿。
Tinder安全软件可以查杀病毒,有18项重要保护功能,文件实时监控、U盘保护、应用加固、软件安装拦截、浏览器保护、网络入侵拦截、暴力攻击保护、弹窗拦截、漏洞修复、启动项管理、文件粉碎。

7、天若OCR
天若OCR是一款集文字识别、表格识别、竖线识别、公式识别、修正识别、高级识别、识别翻译、识别搜索、截图功能于一体的软件。
天若OCR可以帮助您减少重复性工作,提高工作效率。
8、Snipaste
Snipaste 是一款简单而强大的截图和贴纸工具。您还可以将屏幕截图粘贴回屏幕。 F1截图,F3贴图,简约高效。
办公室里会抄很多资料,写的时候会抄很多文字和图片。 Snipaste 可以将这些内容粘贴到屏幕上,而不是切换回窗口。
发布在屏幕上的信息可以缩放、旋转、设置为半透明,甚至可以被鼠标穿透。在屏幕上发布重要信息,绝对可以改变你的工作方式,提高工作效率。
9、7-ZIP
7-ZIP 是一款开源免费的压缩软件,使用 LZMA 和 LZMA2 算法,压缩率非常高,可以比 Winzip 高 2-10%。 7-ZIP支持的格式很多,常用的压缩格式都支持。

支持的格式:压缩/解压:7z、XZ、BZIP2、GZIP、TAR、ZIP、WIM。仅解压:ARJ、CAB、CHM、CPIO、CramFS、DEB、DMG、FAT、HFS、ISO、LZH、LZMA、MBR、MSI、NSIS、NTFS、RAR、RPM、SquashFS、UDF、VHD、WIM、XAR、Z .
10、WGestures
WGestures 是一款简单高效的鼠标手势软件,免费开源,非常尽职尽责。
WGestures 有非常丰富的功能。网络搜索可以简化搜索信息的过程;手势名称提醒和修饰键更符合用户直觉;触发角度和摩擦边缘使计算机操作更高效。
今天的分享到此结束。谢谢你看到这个。听说三联的朋友们都有福了!喜欢就点击关注我,更多实用干货等着你!

网页采集器的自动识别算法( 软件优势向导:所有采集元素,自动生成采集数据计划)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-09-12 18:02
软件优势向导:所有采集元素,自动生成采集数据计划)
应用平台:Windows平台
优采云采集器专业网页信息采集tool,本软件支持采集用户所需的所有网页信息,本站提供该软件的安装版,有需要的朋友,来这里下载使用吧!
软件功能
零门槛:不懂网络爬虫技术,会上网,会采集网站数据
多引擎,高速稳定:内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集data更高效。还内置了JSON引擎,无需分析JSON数据结构,直观选择JSON内容。
适用于各种网站:网站可以采集互联网99%,包括单页应用Ajax加载和其他动态类型网站。
软件功能
软件操作简单,鼠标点击即可轻松选择要采集的内容;
支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上独创的内存优化,让浏览器采集也能高速运行,甚至可以很快转换为HTTP方式运行,享受更高的采集速度!抓取JSON数据时,也可以使用浏览器可视化的方式,通过鼠标选择需要抓取的内容。无需分析JSON数据结构,让非网页专业设计人员轻松抓取所需数据;
不需要分析网页请求和源码,但支持更多的网页采集;
先进的智能算法可以一键生成目标元素XPATH,自动识别网页列表,自动识别分页中的下一页按钮...
支持丰富的数据导出方式,可以通过向导导出为txt文件、html文件、csv文件、excel文件,也可以导出到现有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库等。以简单的方式轻松映射字段,并且可以轻松导出到目标网站数据库。
软件优势
可视化向导:所有采集元素都会自动生成采集数据
定时任务:灵活定义运行时间,全自动运行
多引擎支持:支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别:可自动识别网页列表、采集字段和分页等
拦截请求:自定义拦截域名,方便过滤异地广告,提高采集速度
多种数据导出:可导出为Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等
软件安装
更新日志
3.2.4.8 (2021-09-01)
修复新版js中调用字段内容无效的问题
下载地址如下:
群英网络电信下载
中国香港数据电信下载
河南紫天网通下载
益阳网络电信下载
本文相关:推荐一个免费网页采集器,需要会写SQL并下载到数据库中。 . ...什么是最简单实用的网页采集器?请提供下载地址和教程地址。谢谢... 你好,网络视频采集器是一个软件吗?我在哪里可以下载它?能给个链接吗...优采云采集器|论坛采集器_cms网站采集器_blog采集器_文章信...data采集器|data采集器是什么|数据采集器如何使用|数据采集如...优采云采集器|论坛采集器_cms网站采集器_博客采集器_文章信...三行采集器、论坛采集器、cms网站采集器、blog采集器COC采集器升级分析采集器优先级是否应该升级 查看全部
网页采集器的自动识别算法(
软件优势向导:所有采集元素,自动生成采集数据计划)

应用平台:Windows平台
优采云采集器专业网页信息采集tool,本软件支持采集用户所需的所有网页信息,本站提供该软件的安装版,有需要的朋友,来这里下载使用吧!
软件功能
零门槛:不懂网络爬虫技术,会上网,会采集网站数据
多引擎,高速稳定:内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集data更高效。还内置了JSON引擎,无需分析JSON数据结构,直观选择JSON内容。
适用于各种网站:网站可以采集互联网99%,包括单页应用Ajax加载和其他动态类型网站。
软件功能
软件操作简单,鼠标点击即可轻松选择要采集的内容;
支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上独创的内存优化,让浏览器采集也能高速运行,甚至可以很快转换为HTTP方式运行,享受更高的采集速度!抓取JSON数据时,也可以使用浏览器可视化的方式,通过鼠标选择需要抓取的内容。无需分析JSON数据结构,让非网页专业设计人员轻松抓取所需数据;
不需要分析网页请求和源码,但支持更多的网页采集;
先进的智能算法可以一键生成目标元素XPATH,自动识别网页列表,自动识别分页中的下一页按钮...
支持丰富的数据导出方式,可以通过向导导出为txt文件、html文件、csv文件、excel文件,也可以导出到现有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库等。以简单的方式轻松映射字段,并且可以轻松导出到目标网站数据库。
软件优势
可视化向导:所有采集元素都会自动生成采集数据
定时任务:灵活定义运行时间,全自动运行
多引擎支持:支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别:可自动识别网页列表、采集字段和分页等
拦截请求:自定义拦截域名,方便过滤异地广告,提高采集速度
多种数据导出:可导出为Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等
软件安装
更新日志
3.2.4.8 (2021-09-01)
修复新版js中调用字段内容无效的问题

下载地址如下:
群英网络电信下载
中国香港数据电信下载
河南紫天网通下载
益阳网络电信下载
本文相关:推荐一个免费网页采集器,需要会写SQL并下载到数据库中。 . ...什么是最简单实用的网页采集器?请提供下载地址和教程地址。谢谢... 你好,网络视频采集器是一个软件吗?我在哪里可以下载它?能给个链接吗...优采云采集器|论坛采集器_cms网站采集器_blog采集器_文章信...data采集器|data采集器是什么|数据采集器如何使用|数据采集如...优采云采集器|论坛采集器_cms网站采集器_博客采集器_文章信...三行采集器、论坛采集器、cms网站采集器、blog采集器COC采集器升级分析采集器优先级是否应该升级
网页采集器的自动识别算法( Windows平台微风采集器的分类及使用参考教程索引页体验)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-09-12 17:13
Windows平台微风采集器的分类及使用参考教程索引页体验)
应用平台:Windows平台
Breeze采集器是一款简单实用的采集工具软件。它不需要复杂的代码或掌握编程技能。操作简单,使用方便。用户只需要选择相应的模板采集到想需要的数据。欢迎有需要的朋友下载体验。
软件介绍:
Breeze采集器 是一款采集 软件,无需任何编程基础即可使用。通过预先定义模板,不同的模板可以做不同的任务,用户不需要知道任何代码。采集 到所需的数据。用户只需选择相应的模板即可。
软件功能:
无需掌握任何编程技能,无需理解任何代码
基于强大的脚本引擎,可快速定制
根据需要选择模板,直接采集,简单快捷。
你可以随意换电脑,不要把电脑绑在上面
使用方法:
添加试用模板:
1、Template 下拉框会自动显示你刚刚添加的模板。以后要使用,可以直接在模板选择列表中选择。
2、打开软件,默认为采集标签。在选择模板下拉框下方,点击添加模板。
3、在弹出的模板选择页面中,点击一个模板查看模板示例和介绍,然后加入试用。
添加后,点击页面底部的“已选”按钮。
4、具体模板使用请参考教程索引页。
注意事项:
禁用 IPV6
在控制面板中打开一次
勾选 IPV6,然后单击确定。
403错误详解
一、403 禁止是什么意思?
403 Forbidden 是 HTTP 协议中的一个状态码(Status Code)。可以简单理解为无权访问本站。此状态表示服务器理解请求但拒绝执行任务,不应将请求重新发送到服务器。当 HTTP 请求方法不是“HEAD”,并且服务器想要让客户端知道它为什么没有权限时,服务器应该在返回的信息中描述拒绝的原因。在服务器不想提供任何反馈信息的情况下,服务器可以使用 404 Not Found 而不是 403 Forbidden。
二、403 错误码分类介绍
403.1
403.1 该错误是由于禁止“执行”访问引起的。如果您尝试从目录中执行 CGI、ISAPI 或其他可执行程序,但该目录不允许该程序执行,则会出现此错误。
403.2
403.2 该错误是由“读”访问被禁止引起的。该错误是因为该目录没有默认的网页并且没有开启目录浏览功能,或者要显示的HTML页面所在的目录只标记了“可执行”或“脚本”权限。
403.3
403.3 该错误是由“写”访问被禁止引起的。尝试将文件上传到目录或修改目录中的文件,但该目录不允许“写”访问时会出现这种错误。
403.4
403.4 错误是由 SSL 的要求引起的。您必须在要查看的网页地址中使用“https”。
403.5
403.5 该错误是由需要 128 位加密算法的 Web 浏览器引起的。如果您的浏览器不支持 128 位加密算法,则会出现此错误。您可以连接到 Microsoft网站 以继续。浏览器升级。
403.6
403.6 错误是由拒绝 IP 地址引起的。如果服务器有无法访问该站点的IP地址列表,并且您使用的IP地址在列表中,您将返回此错误信息。
403.7
403.7 错误是因为需要客户端证书。当需要访问的资源要求浏览器具有服务器可以识别的安全套接字层 (SSL) 客户端证书时,将返回此错误。
403.8
403.8 错误是由于禁止站点访问引起的。如果服务器有无法访问的DNS名称列表,并且您使用的DNS名称在列表中,则会返回此信息。请注意403.6和403.8错误的区别。
403.9
403.9 错误是因为连接的用户太多。当Web服务器因流量太大而无法处理请求时,将返回此错误。
403.10
403.10 错误是无效配置导致的错误。当您尝试从目录中执行 CGI、ISAPI 或其他可执行程序,但该目录不允许该程序执行时,将返回此错误。
403.11
403.11 错误是由于密码更改导致无权查看页面。
403.12
403.12 错误是由映射器拒绝访问引起的。要查看的网页需要有效的客户端证书,当您的客户端证书映射没有访问该网站的权限时,会返回映射器拒绝访问的错误。
403.13
403.13 错误是因为需要查看的网页需要使用有效的客户端证书并且使用的客户端证书已被吊销,或者无法确定证书是否有已被撤销。
403.14
403.14 错误 Web 服务器配置为不列出此目录的内容并拒绝目录列表。
403.15
403.15 错误是客户端访问权限过多导致的。当服务器超过其客户端访问权限限制时将返回此错误。
403.16
403.16 错误是由不受信任或无效的客户端证书引起的。
403.17
403.17 错误是因为客户端证书已过期或尚未生效。
三、 403错误的主要原因如下:
1、您的 IP 已被列入黑名单。
2、您在一段时间内访问过这个网站(通常使用采集程序),被防火墙拒绝访问。
3、网站域名解析到空间,但空间没有绑定到这个域名。
4、您的网页脚本文件在当前目录没有执行权限。
5、在不允许写入/创建文件的目录中进行了文件创建/写入操作。 查看全部
网页采集器的自动识别算法(
Windows平台微风采集器的分类及使用参考教程索引页体验)

应用平台:Windows平台
Breeze采集器是一款简单实用的采集工具软件。它不需要复杂的代码或掌握编程技能。操作简单,使用方便。用户只需要选择相应的模板采集到想需要的数据。欢迎有需要的朋友下载体验。
软件介绍:
Breeze采集器 是一款采集 软件,无需任何编程基础即可使用。通过预先定义模板,不同的模板可以做不同的任务,用户不需要知道任何代码。采集 到所需的数据。用户只需选择相应的模板即可。
软件功能:
无需掌握任何编程技能,无需理解任何代码
基于强大的脚本引擎,可快速定制
根据需要选择模板,直接采集,简单快捷。
你可以随意换电脑,不要把电脑绑在上面
使用方法:
添加试用模板:
1、Template 下拉框会自动显示你刚刚添加的模板。以后要使用,可以直接在模板选择列表中选择。
2、打开软件,默认为采集标签。在选择模板下拉框下方,点击添加模板。
3、在弹出的模板选择页面中,点击一个模板查看模板示例和介绍,然后加入试用。
添加后,点击页面底部的“已选”按钮。
4、具体模板使用请参考教程索引页。
注意事项:
禁用 IPV6
在控制面板中打开一次
勾选 IPV6,然后单击确定。
403错误详解
一、403 禁止是什么意思?
403 Forbidden 是 HTTP 协议中的一个状态码(Status Code)。可以简单理解为无权访问本站。此状态表示服务器理解请求但拒绝执行任务,不应将请求重新发送到服务器。当 HTTP 请求方法不是“HEAD”,并且服务器想要让客户端知道它为什么没有权限时,服务器应该在返回的信息中描述拒绝的原因。在服务器不想提供任何反馈信息的情况下,服务器可以使用 404 Not Found 而不是 403 Forbidden。
二、403 错误码分类介绍
403.1
403.1 该错误是由于禁止“执行”访问引起的。如果您尝试从目录中执行 CGI、ISAPI 或其他可执行程序,但该目录不允许该程序执行,则会出现此错误。
403.2
403.2 该错误是由“读”访问被禁止引起的。该错误是因为该目录没有默认的网页并且没有开启目录浏览功能,或者要显示的HTML页面所在的目录只标记了“可执行”或“脚本”权限。
403.3
403.3 该错误是由“写”访问被禁止引起的。尝试将文件上传到目录或修改目录中的文件,但该目录不允许“写”访问时会出现这种错误。
403.4
403.4 错误是由 SSL 的要求引起的。您必须在要查看的网页地址中使用“https”。
403.5
403.5 该错误是由需要 128 位加密算法的 Web 浏览器引起的。如果您的浏览器不支持 128 位加密算法,则会出现此错误。您可以连接到 Microsoft网站 以继续。浏览器升级。
403.6
403.6 错误是由拒绝 IP 地址引起的。如果服务器有无法访问该站点的IP地址列表,并且您使用的IP地址在列表中,您将返回此错误信息。
403.7
403.7 错误是因为需要客户端证书。当需要访问的资源要求浏览器具有服务器可以识别的安全套接字层 (SSL) 客户端证书时,将返回此错误。
403.8
403.8 错误是由于禁止站点访问引起的。如果服务器有无法访问的DNS名称列表,并且您使用的DNS名称在列表中,则会返回此信息。请注意403.6和403.8错误的区别。
403.9
403.9 错误是因为连接的用户太多。当Web服务器因流量太大而无法处理请求时,将返回此错误。
403.10
403.10 错误是无效配置导致的错误。当您尝试从目录中执行 CGI、ISAPI 或其他可执行程序,但该目录不允许该程序执行时,将返回此错误。
403.11
403.11 错误是由于密码更改导致无权查看页面。
403.12
403.12 错误是由映射器拒绝访问引起的。要查看的网页需要有效的客户端证书,当您的客户端证书映射没有访问该网站的权限时,会返回映射器拒绝访问的错误。
403.13
403.13 错误是因为需要查看的网页需要使用有效的客户端证书并且使用的客户端证书已被吊销,或者无法确定证书是否有已被撤销。
403.14
403.14 错误 Web 服务器配置为不列出此目录的内容并拒绝目录列表。
403.15
403.15 错误是客户端访问权限过多导致的。当服务器超过其客户端访问权限限制时将返回此错误。
403.16
403.16 错误是由不受信任或无效的客户端证书引起的。
403.17
403.17 错误是因为客户端证书已过期或尚未生效。
三、 403错误的主要原因如下:
1、您的 IP 已被列入黑名单。
2、您在一段时间内访问过这个网站(通常使用采集程序),被防火墙拒绝访问。
3、网站域名解析到空间,但空间没有绑定到这个域名。
4、您的网页脚本文件在当前目录没有执行权限。
5、在不允许写入/创建文件的目录中进行了文件创建/写入操作。
网页采集器的自动识别算法(易搜网页数据采集器免费版更是更是)
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-09-10 07:06
Easy Search Web Data采集器是一款非常好用的网络数据采集软件,为用户提供了非常方便的数据采集方法,操作方法简单方便,即使用户没有任何专业知识,你也可以轻松上手和操作,快速采集网页资料。轻松搜索网页数据采集器免费版不需要输入任何代码,只需要输入URL地址,就可以帮助用户自动采集网页数据。
Easy Search Web Data采集器正式版具有很强的系统兼容性,支持在各种版本的操作系统上运行。有需要的用户可到本站下载本软件。
软件功能
简单易用
简单易学,采集data和向导模式可通过可视化界面,鼠标点击,用户无需任何技术基础,输入网址,一键提取数据。代码小白的福音。
大量采集templates
内置大量网站采集模板,覆盖多个行业,点击模板,即可加载数据,只需简单配置,即可快速准确获取数据,满足采集各种需求..
自主研发的智能算法
通过自主研发的智能识别算法,自动识别列表数据识别分页,准确率95%,可深入采集多级页面,快速准确获取数据.
自动导出数据
数据可自动导出发布,支持多种格式导出,如TXT、CSV、Excel、Access、MySQL、SQLServer、SQLite,以及发布到网站interface(Api)等
软件亮点
Smart采集
列表/表格数据智能分析提取,并能自动识别分页符。免配置一键采集各种网站,包括分页、滚动加载、登录采集、AJAX等
多平台支持
易搜网数据采集软件支持所有版本的windows操作系统,可以在服务器上稳定运行。无论是个人采集还是团队/企业使用,都能满足您的各种需求。
多数据导出
一键导出采集的所有数据。支持CSV、EXCEL、HTML等,也支持导出数据到数据库,可以发布到Dedecms、Discuz、Wordpress、phpcms网站。
数据本地化存储
采集 任务会自动保存到本地电脑,不用担心丢失。登录软件,可以随时随地创建和修改采集任务。
轻松搜索网页数据采集器使用教程
第一步,选择起始网址
想要采集一个网站数据时,首先需要找到一个地址来显示数据列表。这一步非常重要。起始 URL 决定了 采集 数据的数量和类型。
以新浪新闻为例。我们要抓取当前城市的新闻标题、发布时间、详情页信息。
通过浏览网站,我们找到了所有新闻信息列表的地址
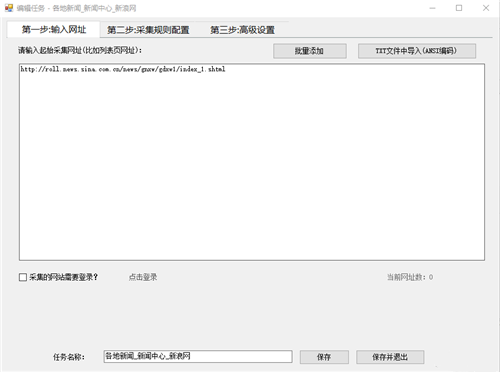
然后在易搜网页data采集器新建一个任务->第一步->输入网页地址
然后点击下一步。
第二步,抓取数据
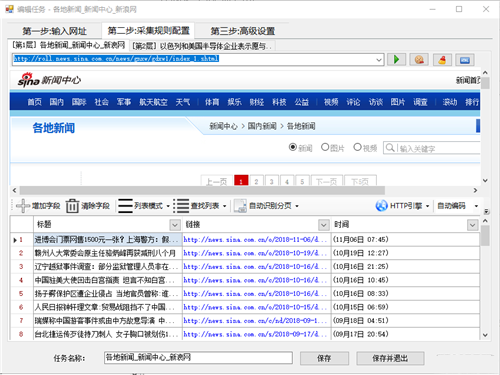
进入第二步后,蓝鲸可视化采集软件会智能分析网页并从中提取列表数据。如下图:
此时我们对分析的数据进行整理和修改,比如删除无用的字段。
点击列的下拉按钮并选择删除字段。
当然还有其他操作,比如名称修改、数据处理等
整理好修改后的字段,我们来采集处理分页。
选择分页设置->自动识别分页符,程序会自动定位下一页元素。
接下来我们进入数据采集的列表页面,点击链接字段--点击进入列表页面采集data,如下图:
第三步,高级设置
这包括浏览器的配置,比如禁用图片、禁用JS、禁用Flash、屏蔽广告等。这些配置可以用来提高浏览器的加载速度。
定时任务的配置,通过定时任务,可以设置任务定时自动运行。
点击完成保存任务。
完成,运行任务
任务创建完成后,我们选择新创建的任务,点击任务栏开始。
轻松搜索网络数据采集器如何导出数据
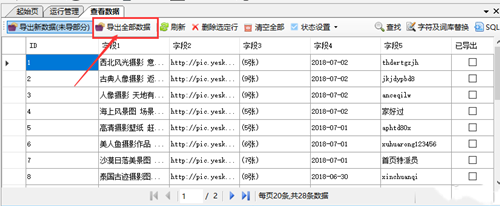
有两种导出方式:
手动导出,通过右键单击任务->导出任务,或在视图数据中导出。
自动导出,在编辑任务第三步设置导出。
数据导出后,会被标记为导出,下次导出时不会再次导出。如果您想导出所有数据而不区分导出的内容,您可以在查看数据中选择全部导出。
导出到 Excel、CSV、TXT
数据可以导出为Excel、CSV、TXT文件,每次导出都会生成一个新文件。软件支持为导出的文件名设置变量。目前有两种格式变量,根据任务名称和日期格式。
导出到网站interface (API)
支持主流cms网站系统,如Discuz、Empirecms、Wordpress、DEDEcms、PHPcms,可提供官方API。
对于开发者,可以自己定义网站API,易搜网页数据采集器通过HTTP POST请求将数据发送到指定的API,只需设置相应的POST参数和编码类型即可。
导出到数据库
目前,易搜网页数据采集器支持导出到四个数据库:MySQL、SQLServer、SQLite和Access。设置数据库的连接配置,指定导出的目标表名。
同时可以设置本地任务字段与目标数据库字段的映射关系(对应关系)
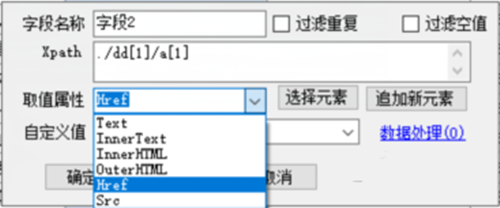
轻松搜索网页data采集器value属性设置方法
首先field通过XPath定位Html元素,然后我们需要通过value属性来判断Html元素的哪一部分作为field的值。
一般情况下采集器默认使用InnerText属性(当前节点及其子节点的文本)
除了InnerText,还有其他几个内置属性:
Text,代表当前节点的文本
InnerHtml,表示当前节点内部的HTML语句(不包括当前节点)
OuterHtml,代表当前节点的HTML语句
除了内置属性外,用户还可以手动填写 HTML 属性。 A标签的href、IMG标签的src等常见的HTML属性。 Data-* 表示数据。
特别提示
在这里,您可以手动输入属性名称,即使没有下拉选项。比如常见的onclick、value、class。 查看全部
网页采集器的自动识别算法(易搜网页数据采集器免费版更是更是)
Easy Search Web Data采集器是一款非常好用的网络数据采集软件,为用户提供了非常方便的数据采集方法,操作方法简单方便,即使用户没有任何专业知识,你也可以轻松上手和操作,快速采集网页资料。轻松搜索网页数据采集器免费版不需要输入任何代码,只需要输入URL地址,就可以帮助用户自动采集网页数据。
Easy Search Web Data采集器正式版具有很强的系统兼容性,支持在各种版本的操作系统上运行。有需要的用户可到本站下载本软件。
软件功能
简单易用
简单易学,采集data和向导模式可通过可视化界面,鼠标点击,用户无需任何技术基础,输入网址,一键提取数据。代码小白的福音。
大量采集templates
内置大量网站采集模板,覆盖多个行业,点击模板,即可加载数据,只需简单配置,即可快速准确获取数据,满足采集各种需求..
自主研发的智能算法
通过自主研发的智能识别算法,自动识别列表数据识别分页,准确率95%,可深入采集多级页面,快速准确获取数据.
自动导出数据
数据可自动导出发布,支持多种格式导出,如TXT、CSV、Excel、Access、MySQL、SQLServer、SQLite,以及发布到网站interface(Api)等
软件亮点
Smart采集
列表/表格数据智能分析提取,并能自动识别分页符。免配置一键采集各种网站,包括分页、滚动加载、登录采集、AJAX等
多平台支持
易搜网数据采集软件支持所有版本的windows操作系统,可以在服务器上稳定运行。无论是个人采集还是团队/企业使用,都能满足您的各种需求。
多数据导出
一键导出采集的所有数据。支持CSV、EXCEL、HTML等,也支持导出数据到数据库,可以发布到Dedecms、Discuz、Wordpress、phpcms网站。
数据本地化存储
采集 任务会自动保存到本地电脑,不用担心丢失。登录软件,可以随时随地创建和修改采集任务。
轻松搜索网页数据采集器使用教程
第一步,选择起始网址
想要采集一个网站数据时,首先需要找到一个地址来显示数据列表。这一步非常重要。起始 URL 决定了 采集 数据的数量和类型。
以新浪新闻为例。我们要抓取当前城市的新闻标题、发布时间、详情页信息。
通过浏览网站,我们找到了所有新闻信息列表的地址
然后在易搜网页data采集器新建一个任务->第一步->输入网页地址
然后点击下一步。
第二步,抓取数据
进入第二步后,蓝鲸可视化采集软件会智能分析网页并从中提取列表数据。如下图:
此时我们对分析的数据进行整理和修改,比如删除无用的字段。
点击列的下拉按钮并选择删除字段。
当然还有其他操作,比如名称修改、数据处理等
整理好修改后的字段,我们来采集处理分页。
选择分页设置->自动识别分页符,程序会自动定位下一页元素。
接下来我们进入数据采集的列表页面,点击链接字段--点击进入列表页面采集data,如下图:
第三步,高级设置
这包括浏览器的配置,比如禁用图片、禁用JS、禁用Flash、屏蔽广告等。这些配置可以用来提高浏览器的加载速度。
定时任务的配置,通过定时任务,可以设置任务定时自动运行。
点击完成保存任务。
完成,运行任务
任务创建完成后,我们选择新创建的任务,点击任务栏开始。
轻松搜索网络数据采集器如何导出数据
有两种导出方式:
手动导出,通过右键单击任务->导出任务,或在视图数据中导出。
自动导出,在编辑任务第三步设置导出。
数据导出后,会被标记为导出,下次导出时不会再次导出。如果您想导出所有数据而不区分导出的内容,您可以在查看数据中选择全部导出。
导出到 Excel、CSV、TXT
数据可以导出为Excel、CSV、TXT文件,每次导出都会生成一个新文件。软件支持为导出的文件名设置变量。目前有两种格式变量,根据任务名称和日期格式。
导出到网站interface (API)
支持主流cms网站系统,如Discuz、Empirecms、Wordpress、DEDEcms、PHPcms,可提供官方API。
对于开发者,可以自己定义网站API,易搜网页数据采集器通过HTTP POST请求将数据发送到指定的API,只需设置相应的POST参数和编码类型即可。
导出到数据库
目前,易搜网页数据采集器支持导出到四个数据库:MySQL、SQLServer、SQLite和Access。设置数据库的连接配置,指定导出的目标表名。
同时可以设置本地任务字段与目标数据库字段的映射关系(对应关系)
轻松搜索网页data采集器value属性设置方法
首先field通过XPath定位Html元素,然后我们需要通过value属性来判断Html元素的哪一部分作为field的值。
一般情况下采集器默认使用InnerText属性(当前节点及其子节点的文本)
除了InnerText,还有其他几个内置属性:
Text,代表当前节点的文本
InnerHtml,表示当前节点内部的HTML语句(不包括当前节点)
OuterHtml,代表当前节点的HTML语句
除了内置属性外,用户还可以手动填写 HTML 属性。 A标签的href、IMG标签的src等常见的HTML属性。 Data-* 表示数据。
特别提示
在这里,您可以手动输入属性名称,即使没有下拉选项。比如常见的onclick、value、class。
网页采集器的自动识别算法(中国现已有网民4.85亿各类站点域名130余万个爆炸)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-09-07 20:00
专利名称:一种能够自动识别网页信息的系统和方法采集
技术领域:
本发明涉及网页动态分析技术领域,具体属于一种自动识别网页信息的系统及方法。
背景技术:
随着互联网的发展,越来越多的互联网网站出现,形式层出不穷,包括新闻、博客、论坛、SNS、微博等。据CNNIC今年最新统计,现在中国有4.850亿网民,各个网站的域名超过130万个。在互联网信息爆炸式增长的今天,搜索引擎已经成为人们查找互联网信息的最重要工具。搜索引擎主要是自动抓取网站信息,进行预处理,分词后建立索引。输入搜索词后,搜索引擎可以自动为用户找到最相关的结果。经过十多年的发展,搜索引擎技术已经比较成熟,并且因为可以采用成功的商业模式,吸引了众多互联网厂商的进入。比较有名的有百度、谷歌、搜搜、搜狗、有道、奇虎360等。此外,在一些垂直领域(如旅游、机票、比价等)还有搜索引擎,已经有千余家厂商进入。搜索引擎的第一步也是最重要的一步是信息捕获,这是搜索引擎的数据准备过程。具体流程如图1所示。URL DB存储了所有要爬取的URL。 URL调度模块从URL DB中选出最重要的URL,放入URL下载队列。页面下载模块下载队列中的 URL。下载完成后,模块被解压。提取下载的页面代码的文本和URL,将提取的文本发送到索引模块进行分词索引,并将URL放入URL DB。信息采集进程就是把别人的网站信息放入自己数据库的过程,会遇到一些问题。
1、互联网信息每时每刻都在不断增加,因此信息抓取是一个7*24小时不间断的过程。频繁的爬取会给目标网站带来巨大的访问压力,形成DDOS拒绝服务攻击,导致无法为普通用户提供访问。这在中小型网站中尤为明显。这些网站硬件资源比较差,技术力量不强,网上90%以上都是网站这种类型的。例如:某知名搜索引擎因频繁爬取网站而呼吁用户投诉。 2、某些网站 的信息具有隐私或版权。许多网页收录后端数据库、用户隐私和密码等信息。 网站主办方不希望将这些信息公开或免费使用。大众点评曾对爱帮网提起诉讼,称其在网站上抓取评论,然后在网站上发布。目前搜索引擎网页针对采集采用的主流方式是robots协议协议。 网站使用robots,txt协议来控制其内容是否愿意被搜索引擎收录搜索,以及允许收录哪些搜索引擎搜索,并为收录指定自己的内容和禁止收录。同时,搜索引擎会根据每个网站Robots 协议赋予的权限,有意识地进行抓取。该方法假设搜索引擎抓取过程如下:下载网站robots文件-根据robots协议解析文件-获取要下载的网址-确定该网址的访问权限-确定是否根据到判定的结果。 Robots协议是君子协议,没有任何限制,抓取主动权还是完全由搜索引擎控制,完全可以不遵循协议强行抓取。
比如2012年8月,国内某知名搜索引擎不按照协议抓取百度网站内容,被百度指控。另一种反采集方法主要是利用动态技术构建禁止爬取的网页。该方法利用客户端脚本语言(如JS、VBScript、AJAX)动态生成网页显示信息,从而实现信息隐藏,使常规搜索引擎难以获取URL和正文内容。动态网页构建技术只是增加了网页解析提取的难度,并不能从根本上禁止采集和网页信息的解析。目前,一些高级搜索引擎可以模拟浏览器来实现所有的脚本代码解析。获取所有信息的网络URL,从而获取服务器中存储的动态信息。目前有成熟的网页动态分析技术,主要是解析网页中所有的脚本代码段,然后获取网页的所有动态信息(包括有用信息和垃圾信息)。实际实现过程是基于开源脚本代码分析引擎(如Rhino、V8等)为核心搭建网页脚本分析环境,然后从网页中提取脚本代码段,并放入提取的代码段放入网页脚本分析环境中执行分析返回动态信息。解析过程如图2所示。因此,采用动态技术构建动态网页的方法只是增加了网页采集和解析的难度,并没有从根本上消除采集搜索引擎。
发明内容
本发明的目的在于提供一种能够自动识别网页信息采集的系统和方法,克服现有技术的不足。系统通过分析网站的历史网页访问行为,建立自动化的采集。 @Classifier,识别机器人自动采集,通过机器人自动采集识别实现网页的反爬虫。本发明采用的技术方案是:一种自动识别网页信息采集的系统及方法,包括anti采集分类器构建模块、自动采集识别模块和anti采集在线处理模块,以及anti采集在线处理模块。采集分类器构建模块主要用于通过计算机程序学习和区分自动采集历史网页信息和正常网页访问行为。该模块提供了自动采集识别的训练模型。自动采集识别模块,该模块通过加载自动分类器自动识别搜索引擎程序的自动采集行为,并将识别出的采集程序所在的IP段加入黑名单,黑名单是用于后续在线拦截自动采集行为。反采集在线处理模块主要用于对来访用户进行自动在线判断和处理。如果访问者的IP已经在该IP段的黑名单中,则该IP被拒绝访问;否则,将访问请求转发给Web服务器进行进一步处理。反采集分类器构建模块的实现方法具体包括以下步骤:(5)日志分析子模块通过自动分析站点访问日志,获取用户访问行为信息,包括用户对网站IP的访问,访问时间,访问URL,源URL;样本选择子模块根据连续时间段内同一IP段内访问频率最高的数据记录,选择步骤I中解析的数据记录作为候选数据样本采集;访问统计子模块对选取的样本数据进行统计,计算出同一IP段的平均页面停留时间,访问的页面总数,是否为采集网页附件信息,网页采集频率;(6)以IP段为主要关键字,将上述信息保存在样本库中,并将其标记为未标记;(7)标记步骤(I)中未标记的样本,如果确定样本库le是自动采集,会被标记为I;如果用户浏览器正常访问,则标记为0,所有标记的样本都会更新到数据库中; (8)计算机程序会自动从样本库中学习,生成分类模型,用于后期自动采集识别。
自动采集识别模块的实现方法包括以下步骤:(5)identification程序初始化阶段,完成分类器模型的加载,模型可以判断自动采集行为;(6)日志分析程序解析最新的网站访问日志,并将解析出的数据发送给访问统计模块;(7)访问统计模块计算同一IP段的平均页面停留时间,是否为采集web附件信息,网页采集frequency;(8)classifier根据分类模型判断IP段的访问行为,将判断为程序自动采集行为的IP段加入黑名单;表示反@采集在线处理模块实现方法包括以下步骤: (I) 为web服务器转发的访问请求提取访问者的IP信息;(2)比较黑名单库中的IP信息,如果IP已经y在黑名单中,此时通知web服务器拒绝该IP的访问;否则,通知Web服务器正常处理访问请求。与现有技术相比,本发明的有益效果如下: 本发明的系统分析网站网页访问行为的历史,建立一个自动采集分类器,识别自动采集机器人,通过自动机器人采集识别实现网页的反爬行,自动发现搜索引擎网页的采集行为并进行响应采集行为被屏蔽,采集搜索引擎从根本上被淘汰。
图1是现有技术搜索引擎的信息抓取过程示意图;图2是现有技术的第二种分析过程示意图;图3为本发明的anti采集分类器构建框图示意图;图4为本发明自动采集识别模块图;图5为本发明反采集在线处理模块。
具体实施例见附图。一种能够识别网页信息的反抓取系统和方法,包括反采集分类器构建模块、自动采集识别模块和反采集在线处理模块。 采集Classifier 构建模块,该模块主要用于通过计算机程序学习和区分采集自动历史网页信息和正常网页访问行为。该模块提供了自动采集识别的训练模型。自动采集识别模块主要用于加载自动分类器自动识别搜索引擎程序的自动采集行为,并将识别出的采集程序的IP段加入黑名单。该列表用于后续在线拦截自动采集行为。所述anti采集在线处理模块主要用于对来访用户的在线自动判断和处理。如果访问者的IP已经在IP段黑名单中,则该IP被拒绝访问;否则,将访问请求转发给Web服务器进行进一步处理。反采集分类器构建模块实现方法具体包括以下步骤:(9)日志分析子模块通过自动分析站点访问日志,获取用户访问行为信息,包括用户访问网站IP、访问时间,访问URL,源URL;样本选择子模块根据连续时间段内同一IP段内访问频率最高的数据记录,选择步骤I中解析的数据记录作为候选数据样本集合;访问统计子模块对选取的样本数据进行统计,计算出同一IP段的平均页面停留时间、站点总访问页面数、是否为采集网页附件信息、webpage采集
频率; (10)以IP段为主要关键字,将上述信息保存在样本库中,并标记为未标记;(11)对未标记样本执行步骤(I)中的程序如果确定如果样本是机器自动采集,则标记为I;如果用户浏览器正常访问,则标记为0,所有标记的样本都会更新到数据库中;(12)计算机程序会自动检查样本库学习并生成分类模型,用于后续自动采集识别。所述的自动采集识别模块实现方法包括以下步骤:(9)识别程序初始化阶段,完成加载分类器模型,该模型可以自动判断采集行为;(10)日志分析程序解析最新的网站访问日志,并将解析后的数据发送给访问统计模块;(11)访问统计模块计算平均值e 同一IP段的页面停留时间,是否是采集web附件信息,网页采集频率; (12)classifier根据分类模型判断IP段的访问行为,判断为自动程序采集Behavior的IP段加入黑名单;反采集的实现方法在线处理模块包括以下步骤: (i) 为web服务器转发的访问请求提取访问者的IP信息;(2)比较黑名单库中的IP信息,如果IP已经在黑名单中,则通知访问者web server 拒绝访问该IP;否则通知web server 正常处理访问请求 计数器采集classifier 构造 该模块主要用于训练计算机程序,使其能够学习和区分历史web信息自动采集和正常的网页访问行为,该模块可以为后续的自动采集识别提供训练模型,具体包括以下几个步骤。2.2.1.1 日志解析本模块需要解析服务器的历史访问日志(可以选择某一天的日志)提取获取用户的访问行为信息,包括用户访问网站使用的IP、访问发生的时间、访问的URL、和源网址。具体包括以下两个步骤: (I) 为每个要提取的用户访问信息项编写正则表达式。 IP表达式提取正则表达式定义为:
声明
1.一种自动识别网页信息采集的系统及方法,其特征在于它包括反采集分类器构建模块、自动采集识别模块和反采集在线处理模块,反采集分类器构建模块主要用于利用计算机程序学习和区分自动采集历史网页信息和正常网页访问行为。该模块提供了自动采集识别的训练模型。上面提到的自动采集识别模块,该模块通过加载自动分类器自动识别搜索引擎程序的自动采集行为,并将识别出的采集程序的IP段加入黑名单。黑名单用于后续在线拦截自动采集行为。反采集在线处理模块主要用于对访问的用户进行自动在线判断和处理。如果访问者的IP已经在IP段黑名单中,则拒绝访问该IP;否则,将访问请求转发到 Web 服务器进行进一步处理。
2.根据权利要求1所述的一种能够识别网页信息的反爬虫系统及方法,其特征在于:所述反采集分类器构建模块实现方法具体包括以下步骤:(1)日志分析子模块通过对站点访问日志的自动分析,获取用户的访问行为信息,包括用户访问网站所使用的IP、访问时间、访问的URL、来源URL;样本选择子模块用于步骤I 选择中的分析数据记录是根据连续时间段内同一IP段中访问频率最高的数据记录作为候选数据加入样本集;访问统计子-module 对选取的样本数据进行统计,统计同一个IP段的平均页面停留时间,站点总访问页面数,是否采集web附件信息,网页采集频率;(2)以IP段为主要关键字,将上述信息保存在样本库中,并添加 标记为未标记; (3)标记步骤(I)中未标记的样本,如果确定样本是自动采集,则标记为I;如果是用户浏览器正常访问,则标记为O,更新将所有标记的样本存入数据库;(4)计算机程序自动从样本库中学习并生成分类模型供后续采集自动识别。
3.根据权利要求1所述的一种能够识别网页信息的反爬虫系统及方法,其特征在于:自动采集识别模块的实现方法包括以下步骤:(1)识别在程序初始化阶段,加载分类器模型,模型可以自动判断采集行为;(2)日志分析程序解析最新的网站访问日志,并将解析后的数据发送到访问统计Wu块; (3)Access统计模块计算同一IP段的平均页面停留时间,是否是采集网页附件信息,网页采集频率;(4)Classifier基于分类模型访问IP段行为确定,确定为程序自动采集行为的IP段加入黑名单;
4.根据权利要求1所述的一种能够识别网页信息的反爬虫系统和方法,其特征在于:反采集在线处理模块实现方法包括以下步骤:(1)提取网页信息Web服务器转发访问请求的访问者IP信息;(2)比较黑名单库中的IP信息,如果IP已经在黑名单中,通知Web服务器拒绝IP访问;否则通知Web服务器正常处理访问请求。
全文摘要
本发明公开了一种自动识别网页信息采集的系统及方法,包括反采集分类器构建模块、自动采集识别模块、反采集在线处理模块、 anti采集 @classifier 构建模块主要用于利用计算机程序学习和区分自动采集历史网页信息和正常网页访问行为。自动采集识别模块使用上述步骤中的anti采集分类器。 , 自动识别搜索引擎程序的自动采集行为,并将识别出的采集程序所在的IP段加入黑名单。 anti采集在线处理模块主要用于对访问的用户进行自动在线判断和处理。本发明克服了现有技术的不足。系统通过分析网站历史网页访问行为建立自动采集分类器,识别机器人自动采集,并通过机器人自动采集识别实现网页反爬。
文件编号 G06F17/30GK103218431SQ20131012830
出版日期 2013 年 7 月 24 日申请日期 2013 年 4 月 10 日优先权日期 2013 年 4 月 10 日
发明人张伟、金军、吴扬子、姜燕申请人:金军、姜燕 查看全部
网页采集器的自动识别算法(中国现已有网民4.85亿各类站点域名130余万个爆炸)
专利名称:一种能够自动识别网页信息的系统和方法采集
技术领域:
本发明涉及网页动态分析技术领域,具体属于一种自动识别网页信息的系统及方法。
背景技术:
随着互联网的发展,越来越多的互联网网站出现,形式层出不穷,包括新闻、博客、论坛、SNS、微博等。据CNNIC今年最新统计,现在中国有4.850亿网民,各个网站的域名超过130万个。在互联网信息爆炸式增长的今天,搜索引擎已经成为人们查找互联网信息的最重要工具。搜索引擎主要是自动抓取网站信息,进行预处理,分词后建立索引。输入搜索词后,搜索引擎可以自动为用户找到最相关的结果。经过十多年的发展,搜索引擎技术已经比较成熟,并且因为可以采用成功的商业模式,吸引了众多互联网厂商的进入。比较有名的有百度、谷歌、搜搜、搜狗、有道、奇虎360等。此外,在一些垂直领域(如旅游、机票、比价等)还有搜索引擎,已经有千余家厂商进入。搜索引擎的第一步也是最重要的一步是信息捕获,这是搜索引擎的数据准备过程。具体流程如图1所示。URL DB存储了所有要爬取的URL。 URL调度模块从URL DB中选出最重要的URL,放入URL下载队列。页面下载模块下载队列中的 URL。下载完成后,模块被解压。提取下载的页面代码的文本和URL,将提取的文本发送到索引模块进行分词索引,并将URL放入URL DB。信息采集进程就是把别人的网站信息放入自己数据库的过程,会遇到一些问题。
1、互联网信息每时每刻都在不断增加,因此信息抓取是一个7*24小时不间断的过程。频繁的爬取会给目标网站带来巨大的访问压力,形成DDOS拒绝服务攻击,导致无法为普通用户提供访问。这在中小型网站中尤为明显。这些网站硬件资源比较差,技术力量不强,网上90%以上都是网站这种类型的。例如:某知名搜索引擎因频繁爬取网站而呼吁用户投诉。 2、某些网站 的信息具有隐私或版权。许多网页收录后端数据库、用户隐私和密码等信息。 网站主办方不希望将这些信息公开或免费使用。大众点评曾对爱帮网提起诉讼,称其在网站上抓取评论,然后在网站上发布。目前搜索引擎网页针对采集采用的主流方式是robots协议协议。 网站使用robots,txt协议来控制其内容是否愿意被搜索引擎收录搜索,以及允许收录哪些搜索引擎搜索,并为收录指定自己的内容和禁止收录。同时,搜索引擎会根据每个网站Robots 协议赋予的权限,有意识地进行抓取。该方法假设搜索引擎抓取过程如下:下载网站robots文件-根据robots协议解析文件-获取要下载的网址-确定该网址的访问权限-确定是否根据到判定的结果。 Robots协议是君子协议,没有任何限制,抓取主动权还是完全由搜索引擎控制,完全可以不遵循协议强行抓取。
比如2012年8月,国内某知名搜索引擎不按照协议抓取百度网站内容,被百度指控。另一种反采集方法主要是利用动态技术构建禁止爬取的网页。该方法利用客户端脚本语言(如JS、VBScript、AJAX)动态生成网页显示信息,从而实现信息隐藏,使常规搜索引擎难以获取URL和正文内容。动态网页构建技术只是增加了网页解析提取的难度,并不能从根本上禁止采集和网页信息的解析。目前,一些高级搜索引擎可以模拟浏览器来实现所有的脚本代码解析。获取所有信息的网络URL,从而获取服务器中存储的动态信息。目前有成熟的网页动态分析技术,主要是解析网页中所有的脚本代码段,然后获取网页的所有动态信息(包括有用信息和垃圾信息)。实际实现过程是基于开源脚本代码分析引擎(如Rhino、V8等)为核心搭建网页脚本分析环境,然后从网页中提取脚本代码段,并放入提取的代码段放入网页脚本分析环境中执行分析返回动态信息。解析过程如图2所示。因此,采用动态技术构建动态网页的方法只是增加了网页采集和解析的难度,并没有从根本上消除采集搜索引擎。
发明内容
本发明的目的在于提供一种能够自动识别网页信息采集的系统和方法,克服现有技术的不足。系统通过分析网站的历史网页访问行为,建立自动化的采集。 @Classifier,识别机器人自动采集,通过机器人自动采集识别实现网页的反爬虫。本发明采用的技术方案是:一种自动识别网页信息采集的系统及方法,包括anti采集分类器构建模块、自动采集识别模块和anti采集在线处理模块,以及anti采集在线处理模块。采集分类器构建模块主要用于通过计算机程序学习和区分自动采集历史网页信息和正常网页访问行为。该模块提供了自动采集识别的训练模型。自动采集识别模块,该模块通过加载自动分类器自动识别搜索引擎程序的自动采集行为,并将识别出的采集程序所在的IP段加入黑名单,黑名单是用于后续在线拦截自动采集行为。反采集在线处理模块主要用于对来访用户进行自动在线判断和处理。如果访问者的IP已经在该IP段的黑名单中,则该IP被拒绝访问;否则,将访问请求转发给Web服务器进行进一步处理。反采集分类器构建模块的实现方法具体包括以下步骤:(5)日志分析子模块通过自动分析站点访问日志,获取用户访问行为信息,包括用户对网站IP的访问,访问时间,访问URL,源URL;样本选择子模块根据连续时间段内同一IP段内访问频率最高的数据记录,选择步骤I中解析的数据记录作为候选数据样本采集;访问统计子模块对选取的样本数据进行统计,计算出同一IP段的平均页面停留时间,访问的页面总数,是否为采集网页附件信息,网页采集频率;(6)以IP段为主要关键字,将上述信息保存在样本库中,并将其标记为未标记;(7)标记步骤(I)中未标记的样本,如果确定样本库le是自动采集,会被标记为I;如果用户浏览器正常访问,则标记为0,所有标记的样本都会更新到数据库中; (8)计算机程序会自动从样本库中学习,生成分类模型,用于后期自动采集识别。
自动采集识别模块的实现方法包括以下步骤:(5)identification程序初始化阶段,完成分类器模型的加载,模型可以判断自动采集行为;(6)日志分析程序解析最新的网站访问日志,并将解析出的数据发送给访问统计模块;(7)访问统计模块计算同一IP段的平均页面停留时间,是否为采集web附件信息,网页采集frequency;(8)classifier根据分类模型判断IP段的访问行为,将判断为程序自动采集行为的IP段加入黑名单;表示反@采集在线处理模块实现方法包括以下步骤: (I) 为web服务器转发的访问请求提取访问者的IP信息;(2)比较黑名单库中的IP信息,如果IP已经y在黑名单中,此时通知web服务器拒绝该IP的访问;否则,通知Web服务器正常处理访问请求。与现有技术相比,本发明的有益效果如下: 本发明的系统分析网站网页访问行为的历史,建立一个自动采集分类器,识别自动采集机器人,通过自动机器人采集识别实现网页的反爬行,自动发现搜索引擎网页的采集行为并进行响应采集行为被屏蔽,采集搜索引擎从根本上被淘汰。
图1是现有技术搜索引擎的信息抓取过程示意图;图2是现有技术的第二种分析过程示意图;图3为本发明的anti采集分类器构建框图示意图;图4为本发明自动采集识别模块图;图5为本发明反采集在线处理模块。
具体实施例见附图。一种能够识别网页信息的反抓取系统和方法,包括反采集分类器构建模块、自动采集识别模块和反采集在线处理模块。 采集Classifier 构建模块,该模块主要用于通过计算机程序学习和区分采集自动历史网页信息和正常网页访问行为。该模块提供了自动采集识别的训练模型。自动采集识别模块主要用于加载自动分类器自动识别搜索引擎程序的自动采集行为,并将识别出的采集程序的IP段加入黑名单。该列表用于后续在线拦截自动采集行为。所述anti采集在线处理模块主要用于对来访用户的在线自动判断和处理。如果访问者的IP已经在IP段黑名单中,则该IP被拒绝访问;否则,将访问请求转发给Web服务器进行进一步处理。反采集分类器构建模块实现方法具体包括以下步骤:(9)日志分析子模块通过自动分析站点访问日志,获取用户访问行为信息,包括用户访问网站IP、访问时间,访问URL,源URL;样本选择子模块根据连续时间段内同一IP段内访问频率最高的数据记录,选择步骤I中解析的数据记录作为候选数据样本集合;访问统计子模块对选取的样本数据进行统计,计算出同一IP段的平均页面停留时间、站点总访问页面数、是否为采集网页附件信息、webpage采集
频率; (10)以IP段为主要关键字,将上述信息保存在样本库中,并标记为未标记;(11)对未标记样本执行步骤(I)中的程序如果确定如果样本是机器自动采集,则标记为I;如果用户浏览器正常访问,则标记为0,所有标记的样本都会更新到数据库中;(12)计算机程序会自动检查样本库学习并生成分类模型,用于后续自动采集识别。所述的自动采集识别模块实现方法包括以下步骤:(9)识别程序初始化阶段,完成加载分类器模型,该模型可以自动判断采集行为;(10)日志分析程序解析最新的网站访问日志,并将解析后的数据发送给访问统计模块;(11)访问统计模块计算平均值e 同一IP段的页面停留时间,是否是采集web附件信息,网页采集频率; (12)classifier根据分类模型判断IP段的访问行为,判断为自动程序采集Behavior的IP段加入黑名单;反采集的实现方法在线处理模块包括以下步骤: (i) 为web服务器转发的访问请求提取访问者的IP信息;(2)比较黑名单库中的IP信息,如果IP已经在黑名单中,则通知访问者web server 拒绝访问该IP;否则通知web server 正常处理访问请求 计数器采集classifier 构造 该模块主要用于训练计算机程序,使其能够学习和区分历史web信息自动采集和正常的网页访问行为,该模块可以为后续的自动采集识别提供训练模型,具体包括以下几个步骤。2.2.1.1 日志解析本模块需要解析服务器的历史访问日志(可以选择某一天的日志)提取获取用户的访问行为信息,包括用户访问网站使用的IP、访问发生的时间、访问的URL、和源网址。具体包括以下两个步骤: (I) 为每个要提取的用户访问信息项编写正则表达式。 IP表达式提取正则表达式定义为:
声明
1.一种自动识别网页信息采集的系统及方法,其特征在于它包括反采集分类器构建模块、自动采集识别模块和反采集在线处理模块,反采集分类器构建模块主要用于利用计算机程序学习和区分自动采集历史网页信息和正常网页访问行为。该模块提供了自动采集识别的训练模型。上面提到的自动采集识别模块,该模块通过加载自动分类器自动识别搜索引擎程序的自动采集行为,并将识别出的采集程序的IP段加入黑名单。黑名单用于后续在线拦截自动采集行为。反采集在线处理模块主要用于对访问的用户进行自动在线判断和处理。如果访问者的IP已经在IP段黑名单中,则拒绝访问该IP;否则,将访问请求转发到 Web 服务器进行进一步处理。
2.根据权利要求1所述的一种能够识别网页信息的反爬虫系统及方法,其特征在于:所述反采集分类器构建模块实现方法具体包括以下步骤:(1)日志分析子模块通过对站点访问日志的自动分析,获取用户的访问行为信息,包括用户访问网站所使用的IP、访问时间、访问的URL、来源URL;样本选择子模块用于步骤I 选择中的分析数据记录是根据连续时间段内同一IP段中访问频率最高的数据记录作为候选数据加入样本集;访问统计子-module 对选取的样本数据进行统计,统计同一个IP段的平均页面停留时间,站点总访问页面数,是否采集web附件信息,网页采集频率;(2)以IP段为主要关键字,将上述信息保存在样本库中,并添加 标记为未标记; (3)标记步骤(I)中未标记的样本,如果确定样本是自动采集,则标记为I;如果是用户浏览器正常访问,则标记为O,更新将所有标记的样本存入数据库;(4)计算机程序自动从样本库中学习并生成分类模型供后续采集自动识别。
3.根据权利要求1所述的一种能够识别网页信息的反爬虫系统及方法,其特征在于:自动采集识别模块的实现方法包括以下步骤:(1)识别在程序初始化阶段,加载分类器模型,模型可以自动判断采集行为;(2)日志分析程序解析最新的网站访问日志,并将解析后的数据发送到访问统计Wu块; (3)Access统计模块计算同一IP段的平均页面停留时间,是否是采集网页附件信息,网页采集频率;(4)Classifier基于分类模型访问IP段行为确定,确定为程序自动采集行为的IP段加入黑名单;
4.根据权利要求1所述的一种能够识别网页信息的反爬虫系统和方法,其特征在于:反采集在线处理模块实现方法包括以下步骤:(1)提取网页信息Web服务器转发访问请求的访问者IP信息;(2)比较黑名单库中的IP信息,如果IP已经在黑名单中,通知Web服务器拒绝IP访问;否则通知Web服务器正常处理访问请求。
全文摘要
本发明公开了一种自动识别网页信息采集的系统及方法,包括反采集分类器构建模块、自动采集识别模块、反采集在线处理模块、 anti采集 @classifier 构建模块主要用于利用计算机程序学习和区分自动采集历史网页信息和正常网页访问行为。自动采集识别模块使用上述步骤中的anti采集分类器。 , 自动识别搜索引擎程序的自动采集行为,并将识别出的采集程序所在的IP段加入黑名单。 anti采集在线处理模块主要用于对访问的用户进行自动在线判断和处理。本发明克服了现有技术的不足。系统通过分析网站历史网页访问行为建立自动采集分类器,识别机器人自动采集,并通过机器人自动采集识别实现网页反爬。
文件编号 G06F17/30GK103218431SQ20131012830
出版日期 2013 年 7 月 24 日申请日期 2013 年 4 月 10 日优先权日期 2013 年 4 月 10 日
发明人张伟、金军、吴扬子、姜燕申请人:金军、姜燕
网页采集器的自动识别算法(优采云采集器软件下载,多功能的网页信息数据采集服务工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-09-07 15:05
优采云采集器软件下载,多功能网页信息数据采集服务工具,优采云采集器(网页多功能信息采集)可以为您带来更便捷优质的网页置信服务工具,采集可以使用多种网站内容,不需要专业的网站爬虫技术,独特的多功能引擎模式可以让数据采集更有效率,用户需要去网站数据采集欢迎到本站下载。
优采云采集器软件功能
1.该软件操作简单,鼠标点击即可轻松选择想要抓取的内容。
2. 支持三种高速引擎:浏览器引擎、HTTP 引擎和 JSON 引擎。
3.加上独创的内存优化,让浏览器采集更方便高速运行。
4.快速多数据内容采集功能全面编辑,更好的管理数据服务。
优采云采集器功能介绍
1.不需要分析网页请求和源码,但支持更多网页采集。
2.高级智能算法,一键生成目标元素XPATH。
3.支持丰富的数据导出方式,可以轻松导出多种不同的文件格式。
4.各种数据库全管理,所有服务更方便快捷。
优采云采集器软件优势
1.定时任务:灵活定义运行时间,全自动运行。
2.多引擎支持:支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎。
3.Smart Recognition:可以自动识别网页列表、采集字段和分页等
4.拦截请求:自定义拦截域名,方便过滤异地广告,提高采集速度。 查看全部
网页采集器的自动识别算法(优采云采集器软件下载,多功能的网页信息数据采集服务工具)
优采云采集器软件下载,多功能网页信息数据采集服务工具,优采云采集器(网页多功能信息采集)可以为您带来更便捷优质的网页置信服务工具,采集可以使用多种网站内容,不需要专业的网站爬虫技术,独特的多功能引擎模式可以让数据采集更有效率,用户需要去网站数据采集欢迎到本站下载。

优采云采集器软件功能
1.该软件操作简单,鼠标点击即可轻松选择想要抓取的内容。
2. 支持三种高速引擎:浏览器引擎、HTTP 引擎和 JSON 引擎。
3.加上独创的内存优化,让浏览器采集更方便高速运行。
4.快速多数据内容采集功能全面编辑,更好的管理数据服务。

优采云采集器功能介绍
1.不需要分析网页请求和源码,但支持更多网页采集。
2.高级智能算法,一键生成目标元素XPATH。
3.支持丰富的数据导出方式,可以轻松导出多种不同的文件格式。
4.各种数据库全管理,所有服务更方便快捷。

优采云采集器软件优势
1.定时任务:灵活定义运行时间,全自动运行。
2.多引擎支持:支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎。
3.Smart Recognition:可以自动识别网页列表、采集字段和分页等
4.拦截请求:自定义拦截域名,方便过滤异地广告,提高采集速度。
网页采集器的自动识别算法(网页采集器的自动识别算法,上古时代产品,不像youtube、优酷、土豆等视频流的主流站点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-07 11:02
网页采集器的自动识别算法,
上古时代产品,不像youtube、优酷、土豆等视频流的主流站点。
网或者做网的公司的个人网站,去花钱买些cdn服务和视频抓取服务。如果连同步账号密码之类的流程都不能自己去搞,
百度全家桶
自动识别算法有局限性这是万物运行的客观规律,好比人性、计算机能识别人、手机能识别图片。
现在阿里自己都采集他家的
最好上阿里云啊,
solidot:真相总是这么不尽人意
现在用谷歌不错,用youtube就没必要了,
自动识别只是为了更好管理数据库,尤其是大数据处理时。这里的意思是什么呢?自动识别有很多代理,网站,图片,文章资源,尤其是高清视频,视频很多,每个网站的画质和解码格式的差异很大,想找到你需要的,耗费时间精力很多。国内视频免费的情况下就用度娘吧,大多数视频并不适合用来做自动识别。
金山快盘
熊猫优酷谷歌
这个问题到时有两个选择,一个是免费的,一个是收费的。免费的找个时间精力多点的团队去做,如果有想法可以发到qq群里,找到愿意投入的人去做。收费的就找一些专业的机构帮你做,不要一个人弄。首先得要有整体框架,以及后续的相关的细节可以让人做好。比如百度。或者像我们这样的公司自己也有关键词大数据团队。找准你们的切入点。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法,上古时代产品,不像youtube、优酷、土豆等视频流的主流站点)
网页采集器的自动识别算法,
上古时代产品,不像youtube、优酷、土豆等视频流的主流站点。
网或者做网的公司的个人网站,去花钱买些cdn服务和视频抓取服务。如果连同步账号密码之类的流程都不能自己去搞,
百度全家桶
自动识别算法有局限性这是万物运行的客观规律,好比人性、计算机能识别人、手机能识别图片。
现在阿里自己都采集他家的
最好上阿里云啊,
solidot:真相总是这么不尽人意
现在用谷歌不错,用youtube就没必要了,
自动识别只是为了更好管理数据库,尤其是大数据处理时。这里的意思是什么呢?自动识别有很多代理,网站,图片,文章资源,尤其是高清视频,视频很多,每个网站的画质和解码格式的差异很大,想找到你需要的,耗费时间精力很多。国内视频免费的情况下就用度娘吧,大多数视频并不适合用来做自动识别。
金山快盘
熊猫优酷谷歌
这个问题到时有两个选择,一个是免费的,一个是收费的。免费的找个时间精力多点的团队去做,如果有想法可以发到qq群里,找到愿意投入的人去做。收费的就找一些专业的机构帮你做,不要一个人弄。首先得要有整体框架,以及后续的相关的细节可以让人做好。比如百度。或者像我们这样的公司自己也有关键词大数据团队。找准你们的切入点。
网页采集器的自动识别算法( 我把微博营销案例全部爬虫到一个了Excel表格里)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-09-07 10:23
我把微博营销案例全部爬虫到一个了Excel表格里)
今天的目标:
读者知道什么?
程序员最难学的不是java或c++,而是社交,俗称“嫂子”。
在社交方面,我被认为是程序员中最好的程序员。
比如之前我做过《海报一代表,把我从叔叔变成小弟弟》,捡到了经营社区的小姐姐。
上个月了,这个月又投入到爬虫的技术研究中了。
技术满足的反面是孤独和空虚。
于是,我决定再次用爬虫来逗妹子。 . .
结果。 . .
我做到了! ! !
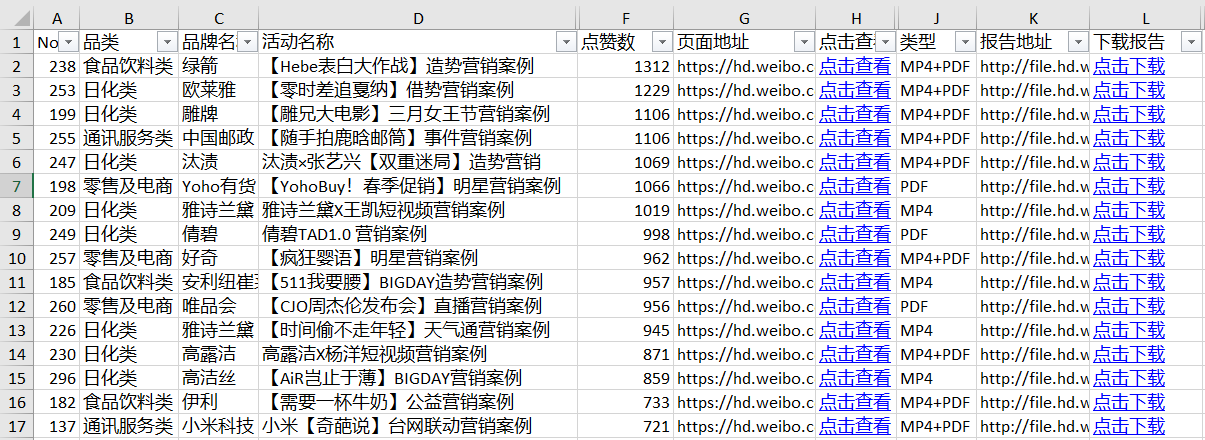
我将所有微博营销案例抓取到一张 Excel 表格中。
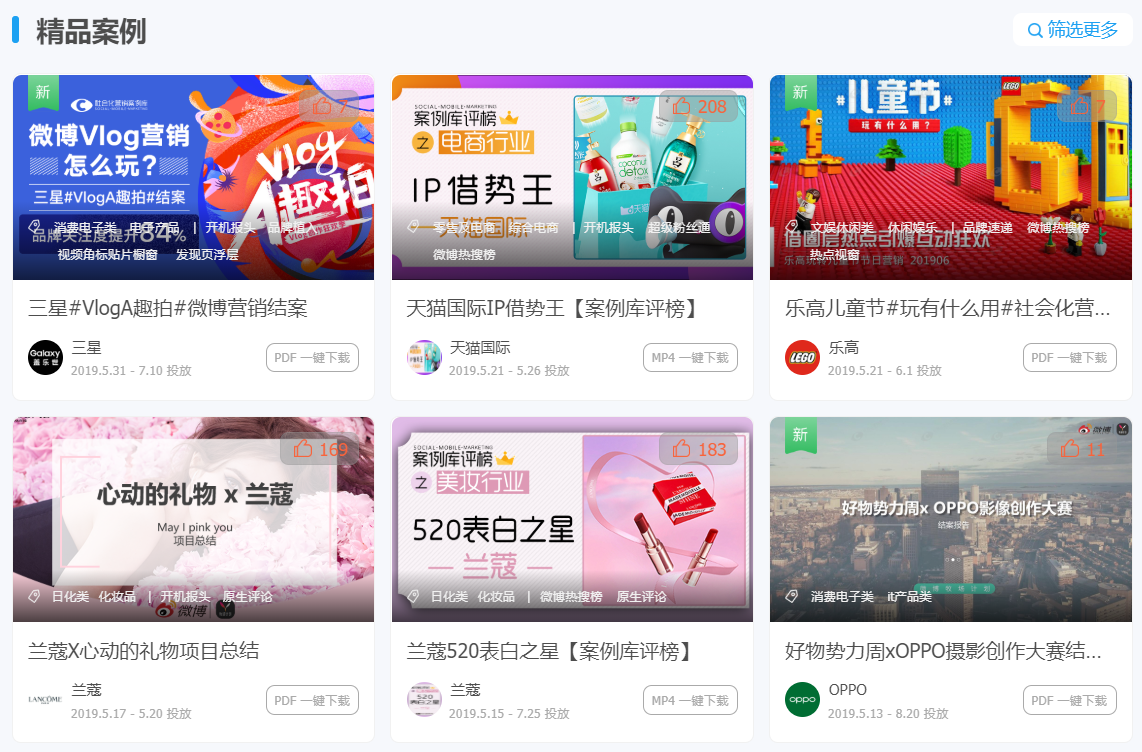
7-0多份运营分析报告,一键下载
网站中的案例需要一一下载↑
对于表中的案例,喜欢和下载较多的↑
管理社区的女孩们快疯了!
秋叶Excel抖音女主:小梅↑
微博手绘大V博主姜江↑
社区运营老司机:颜敏姐姐↑
让我告诉你,如果我早两年爬行,我现在的室友会是谁? !
1- 什么是爬虫
爬虫,即网络爬虫。就是按照一定的规则自动抓取网络上的数据。
比如自动抓取“社交营销案例库”的案例。
想象一下,如果手动浏览页面下载这些案例,流程是这样的:
1- 打开案例库页面
2- 点击案例进入详情页面
3- 点击下载案例pdf
4- 返回案例库页面,点击下一个案例,重复前三步。
如果要下载所有的pdf案例,需要安排专人反复机械地下载。显然,这个人的价值很低。
爬虫取代了这种机械重复、低价值的数据采集动作,利用程序或代码自动批量完成数据采集。
爬虫的好处
简单总结一下,爬虫的好处主要有两个方面:
1- 自动爬取,解放人力,提高效率
机器,低价值的工作,用机器来完成工作是最好的解决方案。
2- 数据分析,跳线获取优质内容
与手动浏览数据不同,爬虫可以将数据汇总整合成数据表,方便我们以后做数据统计和数据分析。
例如,在“社交营销案例库”中,每个案例都有查看次数和下载次数。如果要按查看次数排序,则会优先查看查看次数最多的案例。将数据抓取到Excel表格中,并使用排序功能,方便浏览。
爬虫案例
可以抓取任何数据。
掌握了爬虫的技巧,可以做的事情很多。
Excelhome 的帖子抓取
我教Excel,Excelhome论坛是个大宝。
一张一张看太难了。抓取1.400 万个帖子,然后选择观看次数最多的帖子。
窗帘选择文章攀取
窗帘是梳理轮廓的好工具。很多大咖用窗帘写读书笔记,不用看全书也能学会要点。
我没时间在屏幕上一一浏览选中的文章,抓取所有选中的文章,整理出自己的知识大纲。
姜操公众号文章crawl
我很喜欢曹将军。拥有同龄人所缺乏的逻辑、归纳、表达能力,文章篇篇精精。
公众号太多,手机看书容易分心?爬入 Excel,然后开始查看最高的行读数。
另外还有抖音播报数据、公众号阅读、评论数据、B站弹幕数据、网易云评论数据。
爬虫+数据分析给网络带来更多乐趣。
2- 简单的爬虫,锋利的工具
说到爬虫,大部分人都会想到编程计数、python、数据库、beautiful、html结构等,让人望而生畏。
其实基础爬虫很简单,借助一些采集软件,一键即可轻松完成。
常用爬虫软件
我抓取数据时用到了以下软件,推荐给大家:
1-优采云采集器
简单易学,采集data和向导模式可通过可视化界面,鼠标点击,用户无需任何技术基础,输入网址,一键提取数据。
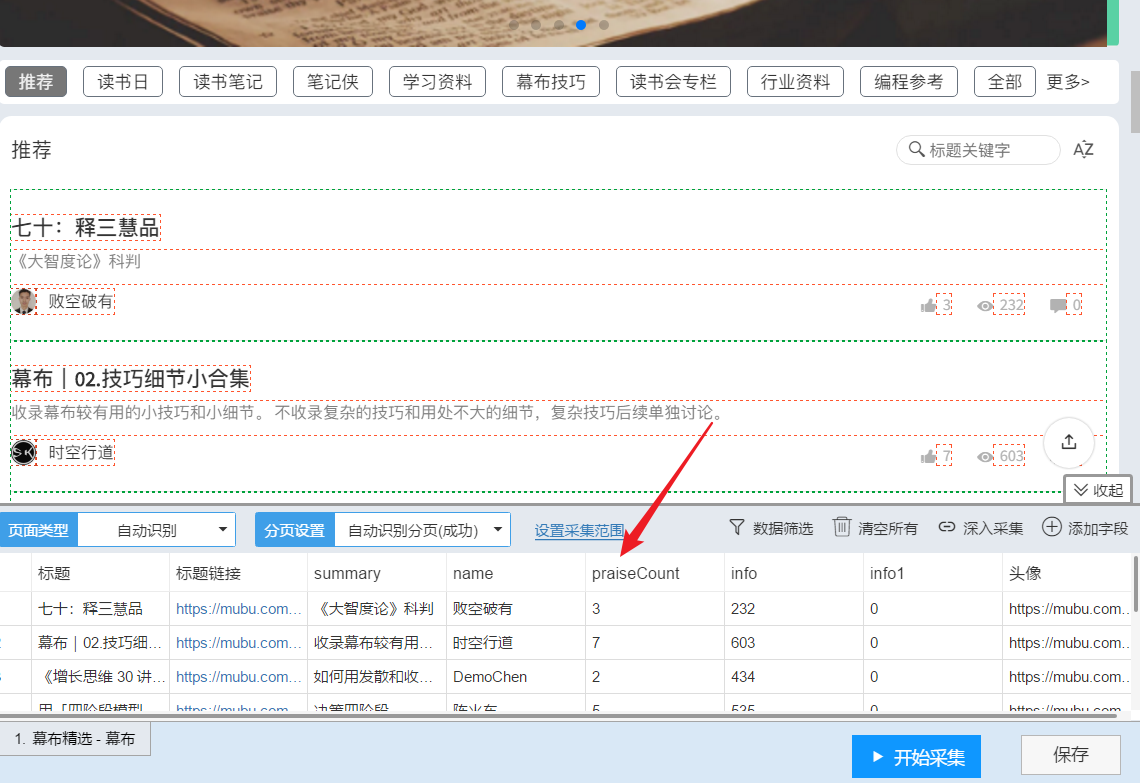
这是我接触的第一个爬虫软件,
优点:
1-使用过程简单,上手特别好。
缺点:
1- 进口数量限制。 采集,非会员只能导出1000条数据。
2- 导出格式限制。非会员只能导出为txt文本格式。
2-优采云
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库
在优采云不能满足我的需求后,我开始尝试更专业的采集软件,找到了优采云。
优点:
1-采集功能更强大,可以自定义采集进程。
2- 导出格式和数据量没有限制。
缺点:
1- 过程有点复杂,新手上手难度较大。
3-优采云采集器(推荐)
智能识别数据,小白神器
基于人工智能算法,只需输入网址即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集。自动识别列表、表格、链接、图片、价格、电子邮件等
这是我现在用的采集软件。可以说抵消了前两个采集器的优缺点,体验更好。
优点:
1-自动识别页面信息,简单上手
2- 导出格式和数据量没有限制
目前没有发现缺点。
3- 爬虫操作流程
注意,注意,接下来是动手部分。
以“屏幕选择文章”为例,用“优采云采集器”体验爬行的乐趣。
采集后的效果如下:
1- 复制采集的链接
打开窗帘官网,点击“精选”进入选中的文章页面。
复制特色页面的网址:
2-优采云采集data
1-登录“优采云采集器”官网,下载安装采集器。
2-打开采集器后,在“智能模式”中点击“开始采集”,新建一个smart采集。
3- 粘贴到屏幕的选定网址中,点击立即创建
在这个过程中采集器会自动识别页面上的列表和数据内容。整个过程由AI算法自动完成,等待识别完成。
页面分析与识别↑
页面识别完成↑
4- 点击“Start采集”->“Enable”开始爬虫之旅。
3-采集数据导出
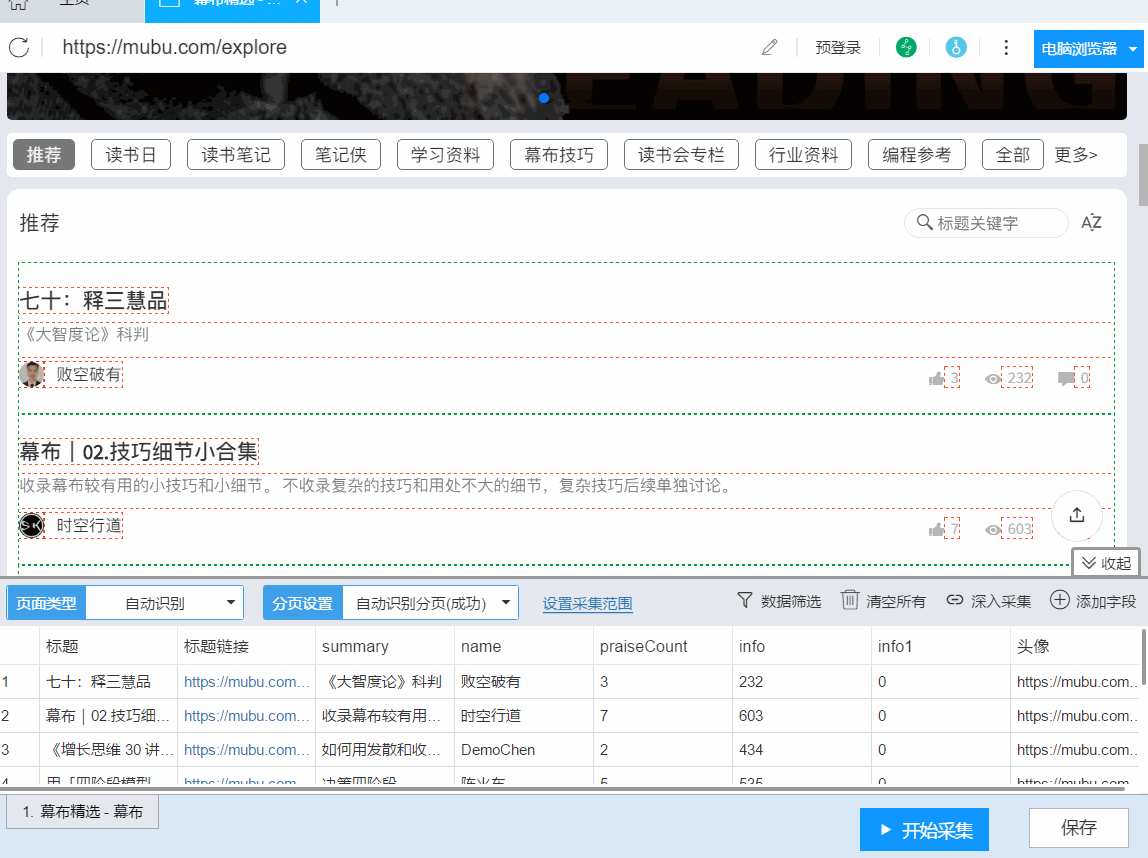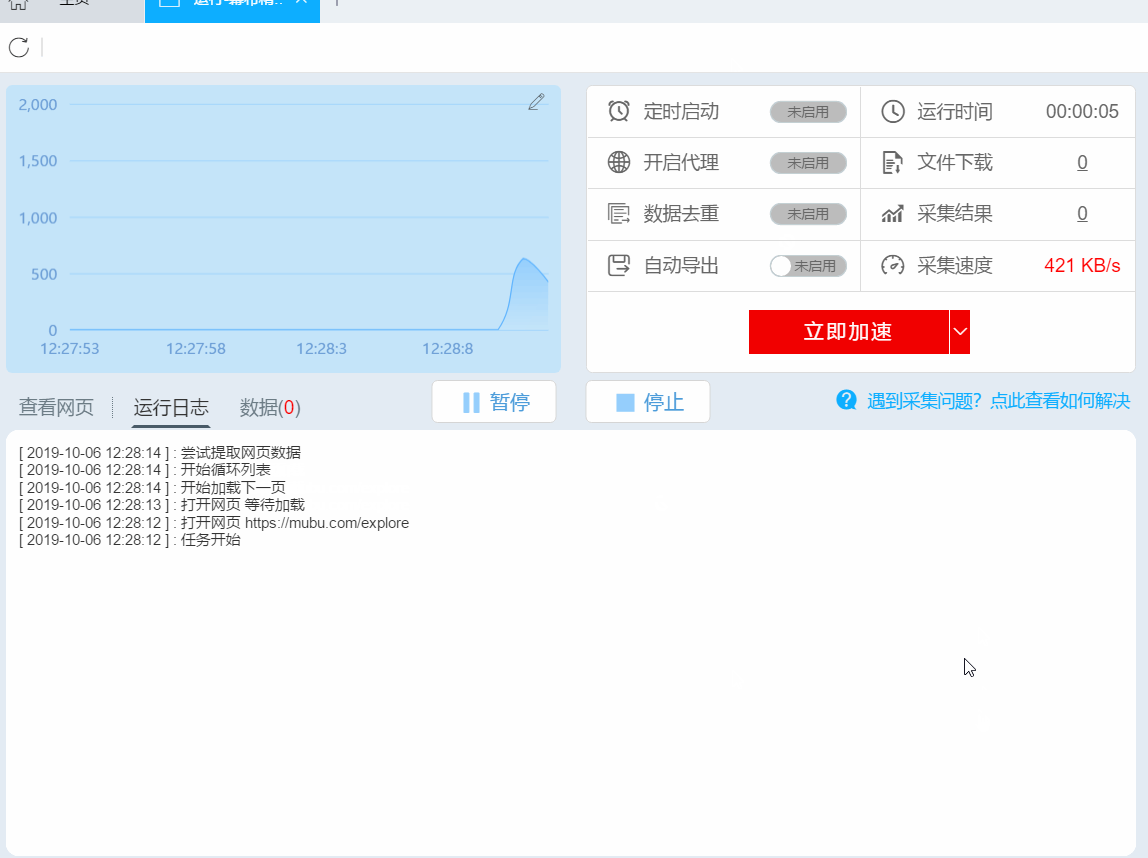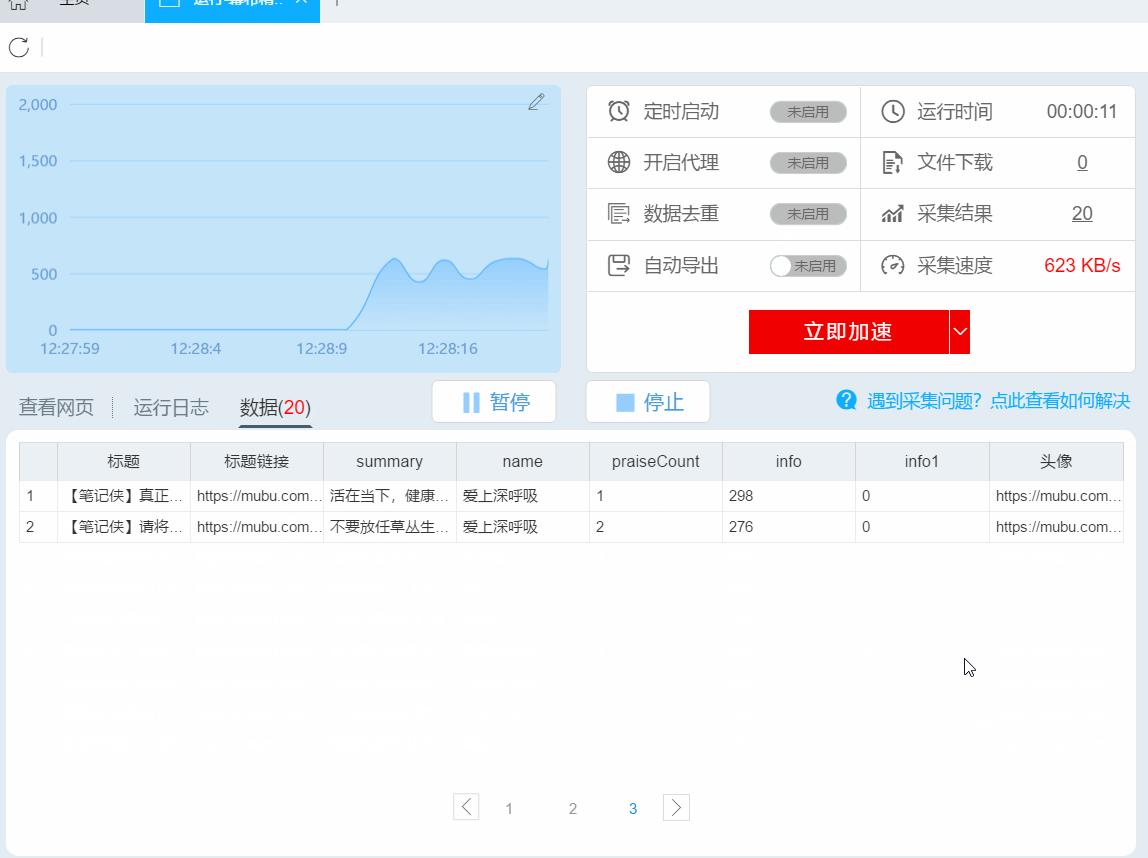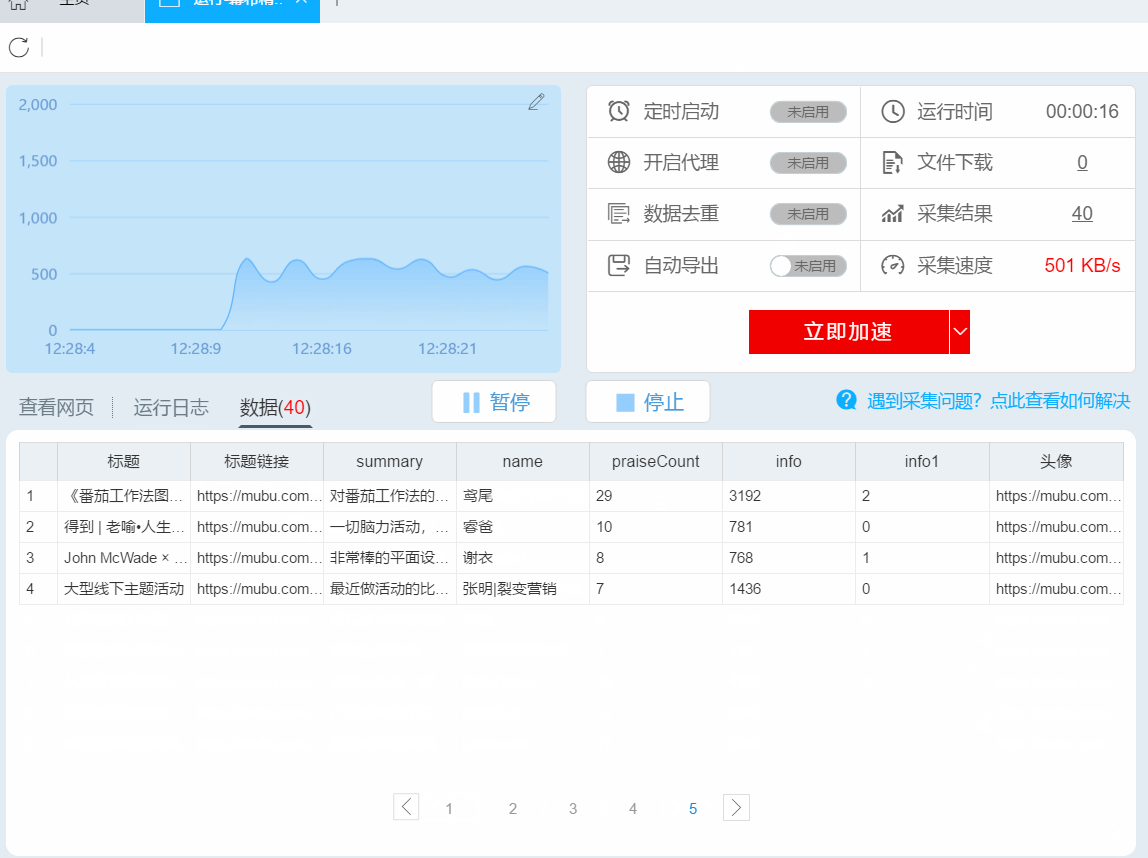
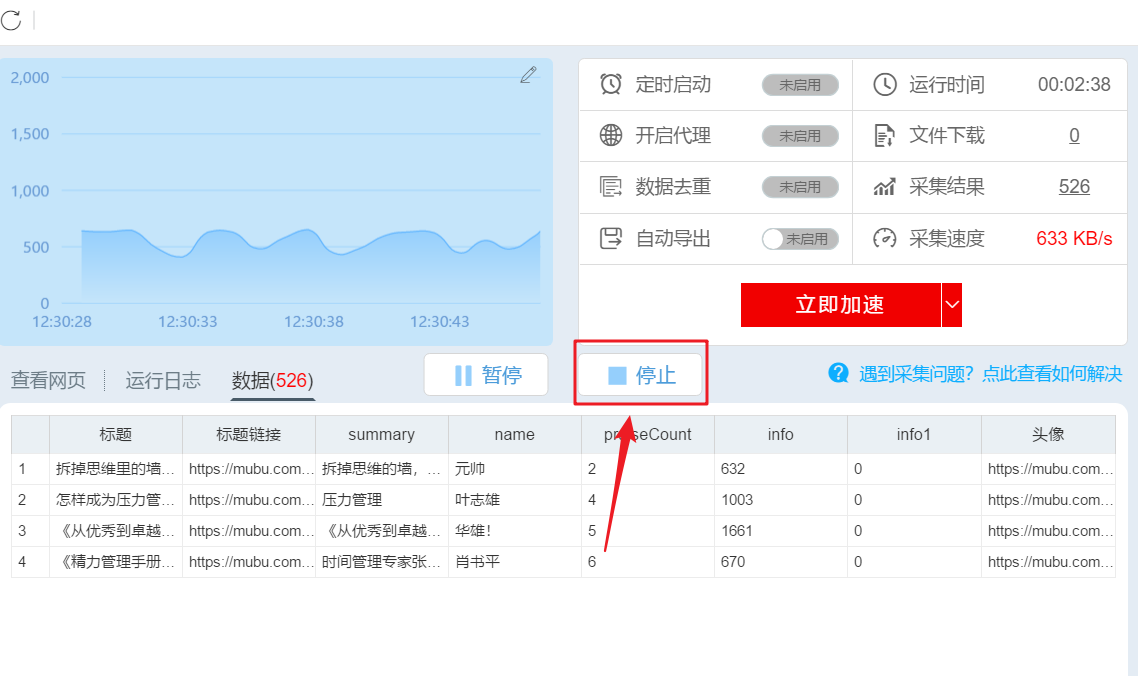
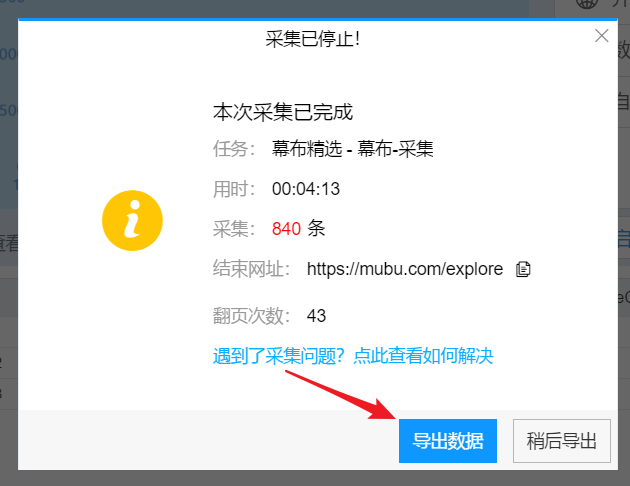
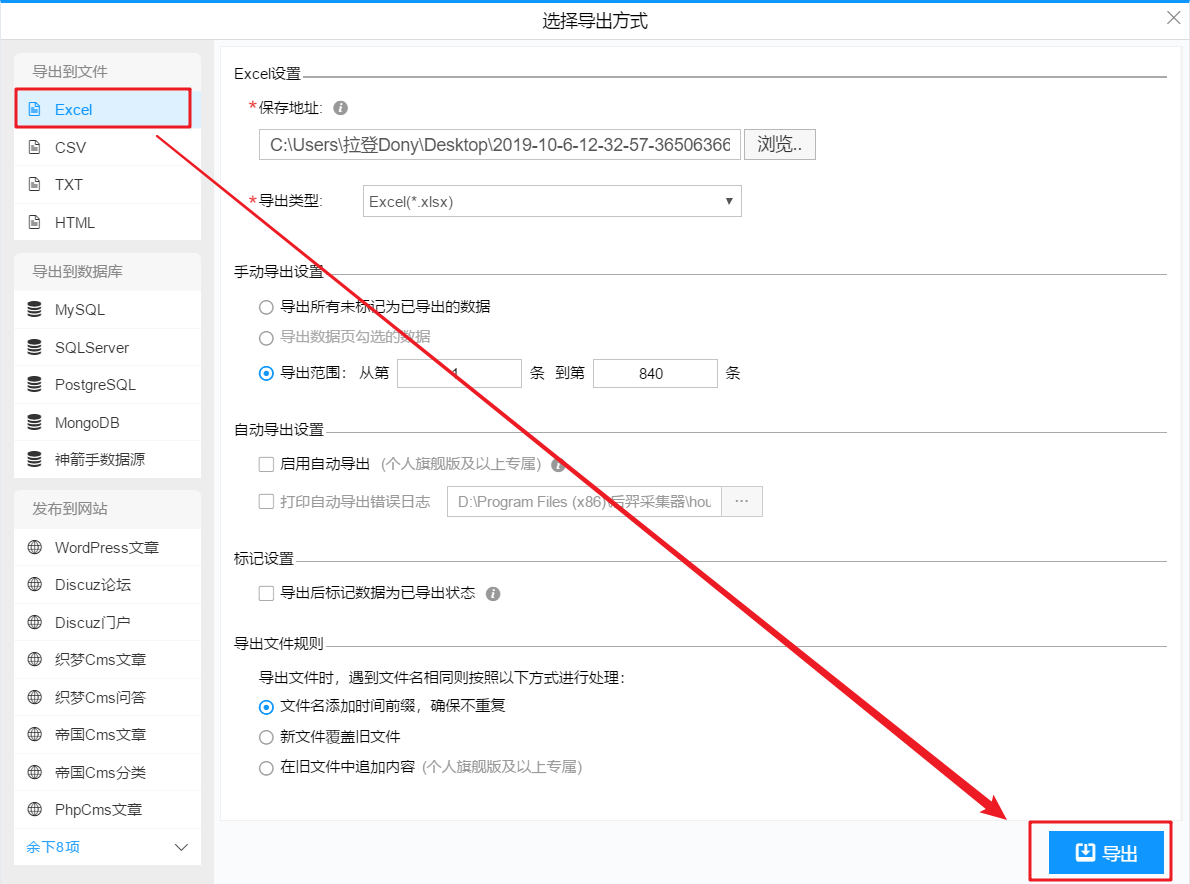
在数据爬取过程中,您可以点击“停止”结束数据爬取。
或者等待数据爬取完成,在弹出的对话框中点击“导出数据”。
导出格式,选择 Excel,然后导出。
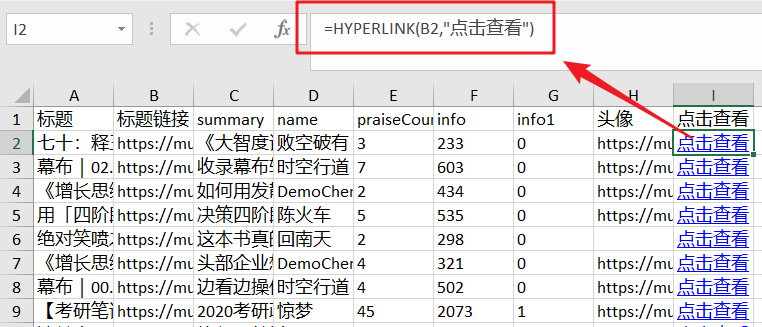
4- 使用 HYPERLINK 函数添加超链接
打开导出的表格,在I列添加HYPERLINK公式,添加超链接,一键打开对应的文章。
公式如下:
=HYPERLINK(B2,"点击查看")
到此,您的第一个爬虫之旅已成功完成!
4- 总结
爬虫就像在 VBA 中记录宏,记录重复动作而不是手动重复操作。
我今天看到的只是简单的数据采集。还有很多关于爬虫的话题和非常深入的内容。例如:
1- 身份验证。需要登录才能抓取页面。
2- 浏览器检查。比如公众号文章只能获取微信阅读数。
3- 参数验证(验证码)。该页面需要验证码。
4- 请求频率。例如页面访问时间不能小于10秒
5- 数据处理。需要抓取的数据需要从数字、英文等内容中提取出来。
了解了爬取过程后,您现在最想爬取什么数据?
我是会设计表格的Excel老师拉小邓
如果你喜欢这个文章,请给我三重品质。今天就到这里,下课结束! 查看全部
网页采集器的自动识别算法(
我把微博营销案例全部爬虫到一个了Excel表格里)

今天的目标:
读者知道什么?
程序员最难学的不是java或c++,而是社交,俗称“嫂子”。
在社交方面,我被认为是程序员中最好的程序员。

比如之前我做过《海报一代表,把我从叔叔变成小弟弟》,捡到了经营社区的小姐姐。
上个月了,这个月又投入到爬虫的技术研究中了。
技术满足的反面是孤独和空虚。
于是,我决定再次用爬虫来逗妹子。 . .
结果。 . .
我做到了! ! !

我将所有微博营销案例抓取到一张 Excel 表格中。
7-0多份运营分析报告,一键下载
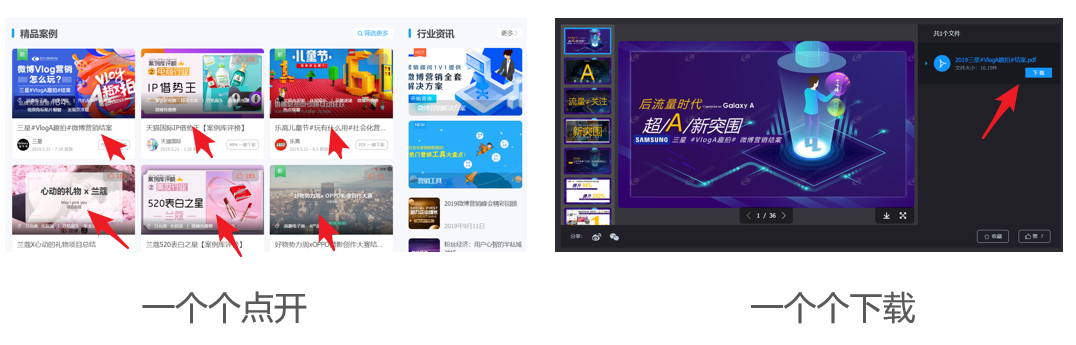
网站中的案例需要一一下载↑
对于表中的案例,喜欢和下载较多的↑
管理社区的女孩们快疯了!
秋叶Excel抖音女主:小梅↑

微博手绘大V博主姜江↑

社区运营老司机:颜敏姐姐↑
让我告诉你,如果我早两年爬行,我现在的室友会是谁? !
1- 什么是爬虫
爬虫,即网络爬虫。就是按照一定的规则自动抓取网络上的数据。
比如自动抓取“社交营销案例库”的案例。
想象一下,如果手动浏览页面下载这些案例,流程是这样的:
1- 打开案例库页面
2- 点击案例进入详情页面
3- 点击下载案例pdf
4- 返回案例库页面,点击下一个案例,重复前三步。
如果要下载所有的pdf案例,需要安排专人反复机械地下载。显然,这个人的价值很低。
爬虫取代了这种机械重复、低价值的数据采集动作,利用程序或代码自动批量完成数据采集。
爬虫的好处
简单总结一下,爬虫的好处主要有两个方面:
1- 自动爬取,解放人力,提高效率
机器,低价值的工作,用机器来完成工作是最好的解决方案。
2- 数据分析,跳线获取优质内容
与手动浏览数据不同,爬虫可以将数据汇总整合成数据表,方便我们以后做数据统计和数据分析。
例如,在“社交营销案例库”中,每个案例都有查看次数和下载次数。如果要按查看次数排序,则会优先查看查看次数最多的案例。将数据抓取到Excel表格中,并使用排序功能,方便浏览。
爬虫案例
可以抓取任何数据。
掌握了爬虫的技巧,可以做的事情很多。
Excelhome 的帖子抓取
我教Excel,Excelhome论坛是个大宝。
一张一张看太难了。抓取1.400 万个帖子,然后选择观看次数最多的帖子。
窗帘选择文章攀取
窗帘是梳理轮廓的好工具。很多大咖用窗帘写读书笔记,不用看全书也能学会要点。

我没时间在屏幕上一一浏览选中的文章,抓取所有选中的文章,整理出自己的知识大纲。
姜操公众号文章crawl
我很喜欢曹将军。拥有同龄人所缺乏的逻辑、归纳、表达能力,文章篇篇精精。
公众号太多,手机看书容易分心?爬入 Excel,然后开始查看最高的行读数。
另外还有抖音播报数据、公众号阅读、评论数据、B站弹幕数据、网易云评论数据。
爬虫+数据分析给网络带来更多乐趣。
2- 简单的爬虫,锋利的工具
说到爬虫,大部分人都会想到编程计数、python、数据库、beautiful、html结构等,让人望而生畏。
其实基础爬虫很简单,借助一些采集软件,一键即可轻松完成。
常用爬虫软件
我抓取数据时用到了以下软件,推荐给大家:

1-优采云采集器
简单易学,采集data和向导模式可通过可视化界面,鼠标点击,用户无需任何技术基础,输入网址,一键提取数据。
这是我接触的第一个爬虫软件,
优点:
1-使用过程简单,上手特别好。
缺点:
1- 进口数量限制。 采集,非会员只能导出1000条数据。
2- 导出格式限制。非会员只能导出为txt文本格式。
2-优采云
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库
在优采云不能满足我的需求后,我开始尝试更专业的采集软件,找到了优采云。
优点:
1-采集功能更强大,可以自定义采集进程。
2- 导出格式和数据量没有限制。
缺点:
1- 过程有点复杂,新手上手难度较大。
3-优采云采集器(推荐)
智能识别数据,小白神器
基于人工智能算法,只需输入网址即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集。自动识别列表、表格、链接、图片、价格、电子邮件等
这是我现在用的采集软件。可以说抵消了前两个采集器的优缺点,体验更好。
优点:
1-自动识别页面信息,简单上手
2- 导出格式和数据量没有限制
目前没有发现缺点。
3- 爬虫操作流程
注意,注意,接下来是动手部分。
以“屏幕选择文章”为例,用“优采云采集器”体验爬行的乐趣。
采集后的效果如下:
1- 复制采集的链接
打开窗帘官网,点击“精选”进入选中的文章页面。
复制特色页面的网址:
2-优采云采集data
1-登录“优采云采集器”官网,下载安装采集器。
2-打开采集器后,在“智能模式”中点击“开始采集”,新建一个smart采集。
3- 粘贴到屏幕的选定网址中,点击立即创建
在这个过程中采集器会自动识别页面上的列表和数据内容。整个过程由AI算法自动完成,等待识别完成。
页面分析与识别↑
页面识别完成↑
4- 点击“Start采集”->“Enable”开始爬虫之旅。
3-采集数据导出
在数据爬取过程中,您可以点击“停止”结束数据爬取。
或者等待数据爬取完成,在弹出的对话框中点击“导出数据”。
导出格式,选择 Excel,然后导出。
4- 使用 HYPERLINK 函数添加超链接
打开导出的表格,在I列添加HYPERLINK公式,添加超链接,一键打开对应的文章。
公式如下:
=HYPERLINK(B2,"点击查看")
到此,您的第一个爬虫之旅已成功完成!

4- 总结
爬虫就像在 VBA 中记录宏,记录重复动作而不是手动重复操作。
我今天看到的只是简单的数据采集。还有很多关于爬虫的话题和非常深入的内容。例如:
1- 身份验证。需要登录才能抓取页面。
2- 浏览器检查。比如公众号文章只能获取微信阅读数。
3- 参数验证(验证码)。该页面需要验证码。
4- 请求频率。例如页面访问时间不能小于10秒
5- 数据处理。需要抓取的数据需要从数字、英文等内容中提取出来。
了解了爬取过程后,您现在最想爬取什么数据?
我是会设计表格的Excel老师拉小邓
如果你喜欢这个文章,请给我三重品质。今天就到这里,下课结束!
网页采集器的自动识别算法(聪明的in-speed技术会动态地将所有设定应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-09-07 06:04
IDM 最多可以将您的下载速度提高 5 倍、安排下载或继续下载一半的软件。互联网下载管理器的恢复功能可以恢复一半因断开连接、网络问题、计算机崩溃甚至意外断电而导致的下载软件。
本程序具有动态文件分割、多下载点技术,无需重新登录即可重用现有连接。巧妙的 in-speed 技术将所有设置动态应用到某种连接类型,以充分利用下载速度。 Internet 下载管理器支持下载队列、防火墙、代理服务器和映射服务器、重定向、cookie、需要验证的目录以及各种服务器平台。该程序与 Internet Explorer 和 Netscape Communicator 紧密集成,可自动处理您的下载需求。本程序还具有优化下载逻辑、查杀病毒、多种偏好设置等功能。
Internet Download Manager 支持所有流行的浏览器,包括:Microsoft Internet Explorer、Netscape、MSN Explorer、AOL、Opera、Mozilla、Mozilla Firefox、Mozilla Firebird、Avant Browser、MyIE2、Google Chrome 等。如果您启用高级集成,您可以从任何程序捕获和接管下载。
Internet 下载管理器支持 HTTP、FTP、HTTPS 和 MMS 协议。 IDM 不是 p2p 下载软件,因此不能用于下载通过 BT 和 eMule 发布的内容。
6.19
改进IDM下载引擎
支持 Firefox 29 和 SeaMonkey 2.24
修复 Chrome 视频嗅探
修复 Chrome 以接管 https 下载
  查看全部
网页采集器的自动识别算法(聪明的in-speed技术会动态地将所有设定应用)
IDM 最多可以将您的下载速度提高 5 倍、安排下载或继续下载一半的软件。互联网下载管理器的恢复功能可以恢复一半因断开连接、网络问题、计算机崩溃甚至意外断电而导致的下载软件。
本程序具有动态文件分割、多下载点技术,无需重新登录即可重用现有连接。巧妙的 in-speed 技术将所有设置动态应用到某种连接类型,以充分利用下载速度。 Internet 下载管理器支持下载队列、防火墙、代理服务器和映射服务器、重定向、cookie、需要验证的目录以及各种服务器平台。该程序与 Internet Explorer 和 Netscape Communicator 紧密集成,可自动处理您的下载需求。本程序还具有优化下载逻辑、查杀病毒、多种偏好设置等功能。
Internet Download Manager 支持所有流行的浏览器,包括:Microsoft Internet Explorer、Netscape、MSN Explorer、AOL、Opera、Mozilla、Mozilla Firefox、Mozilla Firebird、Avant Browser、MyIE2、Google Chrome 等。如果您启用高级集成,您可以从任何程序捕获和接管下载。
Internet 下载管理器支持 HTTP、FTP、HTTPS 和 MMS 协议。 IDM 不是 p2p 下载软件,因此不能用于下载通过 BT 和 eMule 发布的内容。
6.19
改进IDM下载引擎
支持 Firefox 29 和 SeaMonkey 2.24
修复 Chrome 视频嗅探
修复 Chrome 以接管 https 下载
 
网页采集器的自动识别算法(优采云采集器智能采集天气网我试)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-26 20:23
谢谢邀请,废话不多说,直接上操作视频~
优采云采集器智能采集气象网络
我试过了,楼主说的问题确实存在。同时,我对其进行了测试以进行比较。优采云采集器对于气象网的采集,使用宿主提供的链接。完成所有天气数据和历史数据的采集设置大约需要2分钟。同时我也记录了我的操作过程,楼主可以自己跟着我的操作过程采集。
说几个经验吧:
1. 这个网站确实是一个简单的表单,但是翻页的时候url并没有变化。这种网页技术叫做局部刷新,或者专业叫做Ajax。有兴趣的可以在百度上下载,不过不用在视频中可以看到,当你设置翻页采集并点击上个月时,优采云准确识别这个按钮的操作并自动设置可视化采集 过程非常直观直观,一目了然。
2. 在智能识别的过程中,考验的是算法的能力。由此也可以看出,优采云在网页的智能识别算法上比其他采集器表现更好,不仅自动识别去除了所有字段,而且对整个列表进行了全面自动识别。同时自动识别翻页按钮使用的特殊反采集技术。
我具体说明一下,作为行业标杆,优采云采集器非常关注用户体验,虽然视频中我使用的是优采云旗舰版(云采集,api , 个人客服,这些都是企业级大数据稳定性非常贴心的服务采集),但是,优采云免费版没有任何基本功能限制,来自官方优采云@ > 网站(优采云三个汉语拼音)直接下载安装优采云到采集all网站,适用于京东、天猫、大众点评、百度等主流网站在各个行业,优采云也提供了内置的采集模板,采集主流数据无需配置采集规则。
欢迎关注或私信~ 查看全部
网页采集器的自动识别算法(优采云采集器智能采集天气网我试)
谢谢邀请,废话不多说,直接上操作视频~
优采云采集器智能采集气象网络
我试过了,楼主说的问题确实存在。同时,我对其进行了测试以进行比较。优采云采集器对于气象网的采集,使用宿主提供的链接。完成所有天气数据和历史数据的采集设置大约需要2分钟。同时我也记录了我的操作过程,楼主可以自己跟着我的操作过程采集。
说几个经验吧:
1. 这个网站确实是一个简单的表单,但是翻页的时候url并没有变化。这种网页技术叫做局部刷新,或者专业叫做Ajax。有兴趣的可以在百度上下载,不过不用在视频中可以看到,当你设置翻页采集并点击上个月时,优采云准确识别这个按钮的操作并自动设置可视化采集 过程非常直观直观,一目了然。
2. 在智能识别的过程中,考验的是算法的能力。由此也可以看出,优采云在网页的智能识别算法上比其他采集器表现更好,不仅自动识别去除了所有字段,而且对整个列表进行了全面自动识别。同时自动识别翻页按钮使用的特殊反采集技术。
我具体说明一下,作为行业标杆,优采云采集器非常关注用户体验,虽然视频中我使用的是优采云旗舰版(云采集,api , 个人客服,这些都是企业级大数据稳定性非常贴心的服务采集),但是,优采云免费版没有任何基本功能限制,来自官方优采云@ > 网站(优采云三个汉语拼音)直接下载安装优采云到采集all网站,适用于京东、天猫、大众点评、百度等主流网站在各个行业,优采云也提供了内置的采集模板,采集主流数据无需配置采集规则。
欢迎关注或私信~
网页采集器的自动识别算法(优采云软件出品的一款基于高精度正文识别算法的互联网文章采集器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-24 15:33
优采云基于本软件制作的高精度文本识别算法的互联网文章采集器。支持按关键词采集百度等搜索引擎新闻源和泛页面,支持采集指定网站栏目所有文章。
功能:
一、 依托优采云软件独有的通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达95%以上。
二、只需输入关键词到采集到百度新闻和网页、搜狗新闻和网页、360新闻和网页、谷歌新闻和网页、必应新闻和网页、雅虎;可批量关键词全自动采集。
三、可以直接采集指定网站列列表下的所有文章,智能匹配,无需编写复杂规则。
四、文章 翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和是淘翻译。
五、史上最简单最智能文章采集器,支持全功能试用,一试就知道效果!
优采云基于本软件制作的高精度文本识别算法的互联网文章采集器。支持按关键词采集新闻和各大搜索引擎网页,也支持采集指定网站栏目下的所有文章。基于自主研发的文本识别智能算法,能够从互联网上复杂的网页中尽可能准确地提取文本内容。
文本识别有 3 种算法,“标准”、“严格”和“精确标签”。其中“standard”和“strict”是自动模式,可以适应大部分网页的body提取,而“precision tag”只需要指定body标签头,比如“div class="text"” ". 提取所有网页的正文。
关键词采集目前支持的搜索引擎有:百度、搜狗、360、谷歌、必应、雅虎
<p>采集指定网站文章的功能也很简单,只需要一点点设置(不需要复杂的规则),就可以批量采集targets 查看全部
网页采集器的自动识别算法(优采云软件出品的一款基于高精度正文识别算法的互联网文章采集器)
优采云基于本软件制作的高精度文本识别算法的互联网文章采集器。支持按关键词采集百度等搜索引擎新闻源和泛页面,支持采集指定网站栏目所有文章。
功能:
一、 依托优采云软件独有的通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达95%以上。
二、只需输入关键词到采集到百度新闻和网页、搜狗新闻和网页、360新闻和网页、谷歌新闻和网页、必应新闻和网页、雅虎;可批量关键词全自动采集。
三、可以直接采集指定网站列列表下的所有文章,智能匹配,无需编写复杂规则。
四、文章 翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和是淘翻译。
五、史上最简单最智能文章采集器,支持全功能试用,一试就知道效果!
优采云基于本软件制作的高精度文本识别算法的互联网文章采集器。支持按关键词采集新闻和各大搜索引擎网页,也支持采集指定网站栏目下的所有文章。基于自主研发的文本识别智能算法,能够从互联网上复杂的网页中尽可能准确地提取文本内容。
文本识别有 3 种算法,“标准”、“严格”和“精确标签”。其中“standard”和“strict”是自动模式,可以适应大部分网页的body提取,而“precision tag”只需要指定body标签头,比如“div class="text"” ". 提取所有网页的正文。
关键词采集目前支持的搜索引擎有:百度、搜狗、360、谷歌、必应、雅虎
<p>采集指定网站文章的功能也很简单,只需要一点点设置(不需要复杂的规则),就可以批量采集targets
网页采集器的自动识别算法(网页采集器的自动识别算法是需要模型训练出来的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-09-23 06:04
网页采集器的自动识别算法是需要模型训练出来的,没有模型训练模型的网页自动识别器是没有多大意义的。你可以在识别之前先加个关键词提示,输入一个关键词让它猜,当输入关键词提示后,就发现网页上有对应关键词的文字,可以再加入模型,将这个关键词的句子自动识别。我也是跟着我们公司的方法自己做的,输入一个关键词,会判断出我们想采集什么样的文字内容,我们定制了个关键词提示。
这样子的网页,识别网页是非常快的,即使识别不出来,也会自动提示出来。网页识别算法是研究发展很快的,基本都是跟着python生态圈里的各种库来做,比如selenium,比如geckodriver。专门做网页识别的网站识别算法能力,跟网页识别生态圈的识别算法,是很大差距的。
我用的是exuberevk中文识别库,实测准确率85%以上。打开exuberevk,选择要识别的网页,并启用自动识别。到自动识别文件夹下\_core\libs\book\_python_data\webdriver\_core\libs\autoit。py找到\lib/autoit。js\jsx。jsx解压,即可看到\lib/autoit。
js\script。jsx然后运行`reg_generate_nonlocal`,即可自动获取网页内容。`autoit。js`为自动识别的脚本文件,也可以使用`iostream`来导入jsx脚本。`jsx`只会执行一次,此时只会生成一个解压后的`index。js`的文件,如果想重新获取内容,可以运行`reg_generate_nonlocal`,此时会生成`regs。
js`。重新运行`reg_generate_nonlocal`,会再生成一个`regs。js`。文本的文件格式可以到`onlinejavascriptframeworkforpython`中查看。下载地址:#filenames/prefix/documents/autoit。js。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法是需要模型训练出来的)
网页采集器的自动识别算法是需要模型训练出来的,没有模型训练模型的网页自动识别器是没有多大意义的。你可以在识别之前先加个关键词提示,输入一个关键词让它猜,当输入关键词提示后,就发现网页上有对应关键词的文字,可以再加入模型,将这个关键词的句子自动识别。我也是跟着我们公司的方法自己做的,输入一个关键词,会判断出我们想采集什么样的文字内容,我们定制了个关键词提示。
这样子的网页,识别网页是非常快的,即使识别不出来,也会自动提示出来。网页识别算法是研究发展很快的,基本都是跟着python生态圈里的各种库来做,比如selenium,比如geckodriver。专门做网页识别的网站识别算法能力,跟网页识别生态圈的识别算法,是很大差距的。
我用的是exuberevk中文识别库,实测准确率85%以上。打开exuberevk,选择要识别的网页,并启用自动识别。到自动识别文件夹下\_core\libs\book\_python_data\webdriver\_core\libs\autoit。py找到\lib/autoit。js\jsx。jsx解压,即可看到\lib/autoit。
js\script。jsx然后运行`reg_generate_nonlocal`,即可自动获取网页内容。`autoit。js`为自动识别的脚本文件,也可以使用`iostream`来导入jsx脚本。`jsx`只会执行一次,此时只会生成一个解压后的`index。js`的文件,如果想重新获取内容,可以运行`reg_generate_nonlocal`,此时会生成`regs。
js`。重新运行`reg_generate_nonlocal`,会再生成一个`regs。js`。文本的文件格式可以到`onlinejavascriptframeworkforpython`中查看。下载地址:#filenames/prefix/documents/autoit。js。
网页采集器的自动识别算法(大多数概念:完善列表页的智能抽取结果(可选))
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-20 07:24
一个概念:
大多数网站以列表页和详细页的层次结构进行组织。例如,当我们进入新浪新闻频道时,有很多标题链接,可以看作是列表页面。单击标题链接进入详细信息页面
使用data采集工具的一般目的是大量获取详细页面中的特定内容数据,将这些数据用于各种分析,发布自己的网站等
列表页:指一个列或目录页,通常收录多个标题链接。例如:网站主页或专栏页是列表页。主要功能:您可以通过列表页面获得指向多个详细信息页面的链接
详细页面:收录特定内容的页面,如网页文章,其中收录:标题、作者、发布日期、正文内容、标签等
要开始,请登录“优采云console”:
详细使用步骤:
步骤1:创建采集任务
点击左侧菜单按钮“创建采集task”,输入采集task名称和采集的“列表页面”URL,如:/(此处主页为列表页面:内容可收录多个详细页面)。无法填写详细信息页面链接,系统将自动识别该链接
如下图所示:
输入后点击“下一步”
步骤2:改进列表页面的智能提取结果(可选)
系统将首先使用智能算法获取所需的采集详细页面链接(多个),用户可以双击打开检查。如果不需要数据,可以单击“列表提取器”手动指定,只需用鼠标单击可视化界面即可
智能采集结果如下图所示:
此外,在上述结果中,系统还智能发现了翻页规则,用户可以设置采集翻页多少页。您也可以稍后在任务中的“基本信息和门户地址”-“根据规则生成web地址”项中对其进行配置
列表提取器打开后,请参见下图:
步骤3:改进细节页面上的智能提取结果(可选)
在上一步中获得多个详细页面链接后,继续下一步。系统将使用一个详细页面链接智能提取详细页面数据(如标题、作者、发布日期、内容、标签等)
详细信息页面上的智能提取结果如下:
如果智能提取的内容不是您想要的,则可以打开详细信息提取程序对其进行修改
如下图所示:
您可以修改、添加或删除左侧的字段
您还可以对每个字段进行详细设置或数据处理(双击该字段):替换、提取、筛选、设置默认值等
如下图所示:
步骤4:启动操作
完成后,即可启动运行,进行数据采集了:
@对于此采集任务的“结果数据与发布”中采集之后的数据结果,您可以在此处修改数据,或直接将其导出到excel或发布您的网站(WordPress@)织梦DEDE、HTTP接口、数据库等)
完成后,数据采集非常简单
有关其他操作,如将数据发布到网站、数据SEO处理等,请参阅其他章节 查看全部
网页采集器的自动识别算法(大多数概念:完善列表页的智能抽取结果(可选))
一个概念:
大多数网站以列表页和详细页的层次结构进行组织。例如,当我们进入新浪新闻频道时,有很多标题链接,可以看作是列表页面。单击标题链接进入详细信息页面
使用data采集工具的一般目的是大量获取详细页面中的特定内容数据,将这些数据用于各种分析,发布自己的网站等
列表页:指一个列或目录页,通常收录多个标题链接。例如:网站主页或专栏页是列表页。主要功能:您可以通过列表页面获得指向多个详细信息页面的链接
详细页面:收录特定内容的页面,如网页文章,其中收录:标题、作者、发布日期、正文内容、标签等
要开始,请登录“优采云console”:
详细使用步骤:
步骤1:创建采集任务
点击左侧菜单按钮“创建采集task”,输入采集task名称和采集的“列表页面”URL,如:/(此处主页为列表页面:内容可收录多个详细页面)。无法填写详细信息页面链接,系统将自动识别该链接
如下图所示:
输入后点击“下一步”
步骤2:改进列表页面的智能提取结果(可选)
系统将首先使用智能算法获取所需的采集详细页面链接(多个),用户可以双击打开检查。如果不需要数据,可以单击“列表提取器”手动指定,只需用鼠标单击可视化界面即可
智能采集结果如下图所示:
此外,在上述结果中,系统还智能发现了翻页规则,用户可以设置采集翻页多少页。您也可以稍后在任务中的“基本信息和门户地址”-“根据规则生成web地址”项中对其进行配置
列表提取器打开后,请参见下图:
步骤3:改进细节页面上的智能提取结果(可选)
在上一步中获得多个详细页面链接后,继续下一步。系统将使用一个详细页面链接智能提取详细页面数据(如标题、作者、发布日期、内容、标签等)
详细信息页面上的智能提取结果如下:
如果智能提取的内容不是您想要的,则可以打开详细信息提取程序对其进行修改
如下图所示:
您可以修改、添加或删除左侧的字段
您还可以对每个字段进行详细设置或数据处理(双击该字段):替换、提取、筛选、设置默认值等
如下图所示:
步骤4:启动操作
完成后,即可启动运行,进行数据采集了:
@对于此采集任务的“结果数据与发布”中采集之后的数据结果,您可以在此处修改数据,或直接将其导出到excel或发布您的网站(WordPress@)织梦DEDE、HTTP接口、数据库等)
完成后,数据采集非常简单
有关其他操作,如将数据发布到网站、数据SEO处理等,请参阅其他章节
网页采集器的自动识别算法(大数据网络爬虫的原理和工做策略)
采集交流 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2021-09-19 21:18
网络数据采集指通过网络爬虫或网站公共API从网站获取的数据信息。该方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。它支持图片、音频、视频和其他文件或附件采集,附件可以自动与文本关联。html
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。算法
在大数据时代,网络爬虫是从互联网获取采集数据的有利工具。目前已知的网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。网络
本部分首先简要介绍了网络爬虫的原理和工作流程,然后讨论了网络爬虫的爬行策略,最后描述了典型的网络工具。数据结构
网络爬虫原理
网络爬虫是一个程序或脚本,根据一定的规则自动抓取网络信息。结构
网络爬虫可以自动采集他们可以访问的所有页面内容,并为搜索引擎和大数据分析提供数据源。在功能上,爬虫程序通常有三个功能:数据采集、处理和存储,如图1所示。机器学习
图1分布式网络爬虫示意图
除了供用户阅读的文本信息外,网页还收录一些超链接信息。工具
网络爬虫系统通过网页中的超链接信息获取其余网页。网络爬虫从一个或多个初始网页的URL获取初始网页上的URL。在抓取网页的过程中,它不断地从当前网页中提取新的URL并将其放入队列,直到满足系统的某些暂停条件。研究
网络爬虫系统通常选择一些具有大量网站链接(网页中的超链接)的重要URL作为种子URL集合。大数据
网络爬虫系统将这些种子集作为初始URL来开始数据获取。由于网页收录连接信息,因此将通过现有网页的URL获得一些新的URL
网页之间的指向结构可以看作是一个森林,每个种子URL对应的网页是森林中树的根节点,因此网络爬虫系统可以根据广度优先搜索算法或深度优先搜索算法遍历所有网页
由于深度优先搜索算法可能使爬虫系统陷入网站内部,不利于搜索靠近网站主页的网页信息,因此通常使用广度优先搜索算法采集网页
网络爬虫系统首先将种子URL放入下载队列,只需从队列的头部获取一个URL,下载相应的网页,获取网页内容并存储,通过解析网页中的连接信息即可获得一些新的URL
其次,根据一定的网页分析算法,过滤掉与主题无关的连接,保留有用的连接,并将其放入等待获取的URL队列中
最后,取出一个URL,下载相应的网页,然后解析它。重复此操作,直到遍历整个网络或满足某些条件
网络爬虫工作流
如图2所示,网络爬虫的基本工作流程如下
1)首先选择一些种子URL
2)将这些URL放入要获取的URL队列
3)从待取URL队列中取待取URL,解析DNS,获取主机IP地址,下载该URL对应的网页,保存在下载的网页库中。此外,将这些URL放入已爬网的URL队列
4)分析已爬网URL队列中的URL,分析剩余的URL,并将这些URL放入要爬网的URL队列中,以便进入下一个周期
图2网络爬虫的基本工作流程
网络爬虫爬行策略
谷歌和百度等通用搜索引擎捕获的网页数量通常以数十亿计。因此,面对如此多的web页面,如何使web爬虫尽可能地遍历所有的web页面,从而尽可能地扩大web信息的捕获范围,这是web爬虫系统面临的一个关键问题。在网络爬虫系统中,爬行策略决定了网页的爬行顺序
本节首先简要介绍web爬虫捕获策略中使用的基本概念
1)web页面之间的关系模型
从互联网结构的角度来看,网页通过不同数量的超链接相互连接,形成一个相互关联的大型复杂有向图
如图3所示,如果将网页视为图中的一个节点,并且将与网页中其他网页的连接视为该节点到其他节点的边,则很容易将整个Internet上的网页建模为一个有向图
理论上,通过遍历算法遍历图形,几乎可以访问Internet上的所有网页
图3网页关系模型示意图
2)web页面分类
通过从爬虫的角度划分互联网,互联网的所有页面可以分为五个部分:下载和过期页面、下载和过期页面、待下载页面、已知页面和未知页面,如图4所示
捕获本地网页实际上是互联网内容的镜像和备份。互联网是动态的。当互联网上的部分内容发生变化时,捕获本地网页已过时。因此,下载的网页分为已下载但未过期的网页和已下载且过期的网页
图4网页分类
要下载的网页是指URL队列中要获取的网页
可以看出,网页是指尚未爬网且不在要爬网的URL队列中的网页,但可以通过分析已爬网的网页或与要爬网的URL对应的网页来获得
还有一些网页是网络爬虫无法直接抓取和下载的,称为不可知网页
以下重点介绍几种常见的捕获策略
1.universalwebcrawler
通用网络爬虫,也称为全网爬虫,从一些种子URL向全网爬网,主要用于门户网站搜索引擎和大型web服务提供商采集数据
为了提高工作效率,一般的网络爬虫都会采用一定的爬行策略。常用的爬行策略有深度优先策略和广度优先策略
1)深度优先战略
深度优先策略意味着网络爬虫将从起始页开始,一个接一个地跟踪它,直到无法再深入
完成爬网分支后,web爬虫将返回到上一个连接节点以进一步搜索其他连接。遍历所有连接后,爬网任务结束
这种策略更适合于垂直搜索或现场搜索,但抓取具有深层页面内容的站点将形成巨大的资源浪费
以图3为例,遍历路径为1→ 2.→ 5.→ 6.→ 3.→ 7.→ 4.→ 八,
在深度优先策略中,当搜索一个节点时,该节点的子节点和子节点的后续节点都优先于该节点的兄弟节点。深度优先策略将在搜索空间时尽可能深入。仅当无法找到节点的后续节点时,才会考虑其兄弟节点
该策略决定了深度优先策略不一定能找到最优解,甚至由于深度的限制而无法找到最优解
如果不受限制,它将沿着一条路径无限扩展,这将“落入”大量数据。通常,使用深度优先策略会选择合适的深度,然后反复搜索,直到找到解决方案,因此搜索效率会降低。因此,当搜索数据量相对较小时,通常使用深度优先策略
2)广度优先战略
广度优先策略根据web内容目录级别的深度抓取页面,浅层目录级别的页面首先被抓取。当同一级别的页面爬网时,爬网程序将继续爬网到下一级别
仍然以图3为例,遍历路径为1→ 2.→ 3.→ 4.→ 5.→ 6.→ 7.→ 八,
由于广度优先策略在N层节点扩展完成后进入N+1层,因此可以保证找到路径最短的解
该策略可以有效控制页面的爬行深度,避免了遇到无限深分支时爬行无法结束的问题,并且易于实现,无需存储大量中间节点。缺点是爬行到目录级别更深的页面需要很长时间
如果搜索中存在过多的分支,即节点的后续节点过多,算法将耗尽资源,无法在可用空间中找到解决方案
2.关注网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是指有选择地抓取与预定义主题相关的页面的网络爬虫
@基于内容评价的1)crawling策略
黛布拉介绍了文本相似性的计算方法 查看全部
网页采集器的自动识别算法(大数据网络爬虫的原理和工做策略)
网络数据采集指通过网络爬虫或网站公共API从网站获取的数据信息。该方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。它支持图片、音频、视频和其他文件或附件采集,附件可以自动与文本关联。html
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。算法
在大数据时代,网络爬虫是从互联网获取采集数据的有利工具。目前已知的网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。网络
本部分首先简要介绍了网络爬虫的原理和工作流程,然后讨论了网络爬虫的爬行策略,最后描述了典型的网络工具。数据结构
网络爬虫原理
网络爬虫是一个程序或脚本,根据一定的规则自动抓取网络信息。结构
网络爬虫可以自动采集他们可以访问的所有页面内容,并为搜索引擎和大数据分析提供数据源。在功能上,爬虫程序通常有三个功能:数据采集、处理和存储,如图1所示。机器学习
图1分布式网络爬虫示意图
除了供用户阅读的文本信息外,网页还收录一些超链接信息。工具
网络爬虫系统通过网页中的超链接信息获取其余网页。网络爬虫从一个或多个初始网页的URL获取初始网页上的URL。在抓取网页的过程中,它不断地从当前网页中提取新的URL并将其放入队列,直到满足系统的某些暂停条件。研究
网络爬虫系统通常选择一些具有大量网站链接(网页中的超链接)的重要URL作为种子URL集合。大数据
网络爬虫系统将这些种子集作为初始URL来开始数据获取。由于网页收录连接信息,因此将通过现有网页的URL获得一些新的URL
网页之间的指向结构可以看作是一个森林,每个种子URL对应的网页是森林中树的根节点,因此网络爬虫系统可以根据广度优先搜索算法或深度优先搜索算法遍历所有网页
由于深度优先搜索算法可能使爬虫系统陷入网站内部,不利于搜索靠近网站主页的网页信息,因此通常使用广度优先搜索算法采集网页
网络爬虫系统首先将种子URL放入下载队列,只需从队列的头部获取一个URL,下载相应的网页,获取网页内容并存储,通过解析网页中的连接信息即可获得一些新的URL
其次,根据一定的网页分析算法,过滤掉与主题无关的连接,保留有用的连接,并将其放入等待获取的URL队列中
最后,取出一个URL,下载相应的网页,然后解析它。重复此操作,直到遍历整个网络或满足某些条件
网络爬虫工作流
如图2所示,网络爬虫的基本工作流程如下
1)首先选择一些种子URL
2)将这些URL放入要获取的URL队列
3)从待取URL队列中取待取URL,解析DNS,获取主机IP地址,下载该URL对应的网页,保存在下载的网页库中。此外,将这些URL放入已爬网的URL队列
4)分析已爬网URL队列中的URL,分析剩余的URL,并将这些URL放入要爬网的URL队列中,以便进入下一个周期
图2网络爬虫的基本工作流程
网络爬虫爬行策略
谷歌和百度等通用搜索引擎捕获的网页数量通常以数十亿计。因此,面对如此多的web页面,如何使web爬虫尽可能地遍历所有的web页面,从而尽可能地扩大web信息的捕获范围,这是web爬虫系统面临的一个关键问题。在网络爬虫系统中,爬行策略决定了网页的爬行顺序
本节首先简要介绍web爬虫捕获策略中使用的基本概念
1)web页面之间的关系模型
从互联网结构的角度来看,网页通过不同数量的超链接相互连接,形成一个相互关联的大型复杂有向图
如图3所示,如果将网页视为图中的一个节点,并且将与网页中其他网页的连接视为该节点到其他节点的边,则很容易将整个Internet上的网页建模为一个有向图
理论上,通过遍历算法遍历图形,几乎可以访问Internet上的所有网页
图3网页关系模型示意图
2)web页面分类
通过从爬虫的角度划分互联网,互联网的所有页面可以分为五个部分:下载和过期页面、下载和过期页面、待下载页面、已知页面和未知页面,如图4所示
捕获本地网页实际上是互联网内容的镜像和备份。互联网是动态的。当互联网上的部分内容发生变化时,捕获本地网页已过时。因此,下载的网页分为已下载但未过期的网页和已下载且过期的网页
图4网页分类
要下载的网页是指URL队列中要获取的网页
可以看出,网页是指尚未爬网且不在要爬网的URL队列中的网页,但可以通过分析已爬网的网页或与要爬网的URL对应的网页来获得
还有一些网页是网络爬虫无法直接抓取和下载的,称为不可知网页
以下重点介绍几种常见的捕获策略
1.universalwebcrawler
通用网络爬虫,也称为全网爬虫,从一些种子URL向全网爬网,主要用于门户网站搜索引擎和大型web服务提供商采集数据
为了提高工作效率,一般的网络爬虫都会采用一定的爬行策略。常用的爬行策略有深度优先策略和广度优先策略
1)深度优先战略
深度优先策略意味着网络爬虫将从起始页开始,一个接一个地跟踪它,直到无法再深入
完成爬网分支后,web爬虫将返回到上一个连接节点以进一步搜索其他连接。遍历所有连接后,爬网任务结束
这种策略更适合于垂直搜索或现场搜索,但抓取具有深层页面内容的站点将形成巨大的资源浪费
以图3为例,遍历路径为1→ 2.→ 5.→ 6.→ 3.→ 7.→ 4.→ 八,
在深度优先策略中,当搜索一个节点时,该节点的子节点和子节点的后续节点都优先于该节点的兄弟节点。深度优先策略将在搜索空间时尽可能深入。仅当无法找到节点的后续节点时,才会考虑其兄弟节点
该策略决定了深度优先策略不一定能找到最优解,甚至由于深度的限制而无法找到最优解
如果不受限制,它将沿着一条路径无限扩展,这将“落入”大量数据。通常,使用深度优先策略会选择合适的深度,然后反复搜索,直到找到解决方案,因此搜索效率会降低。因此,当搜索数据量相对较小时,通常使用深度优先策略
2)广度优先战略
广度优先策略根据web内容目录级别的深度抓取页面,浅层目录级别的页面首先被抓取。当同一级别的页面爬网时,爬网程序将继续爬网到下一级别
仍然以图3为例,遍历路径为1→ 2.→ 3.→ 4.→ 5.→ 6.→ 7.→ 八,
由于广度优先策略在N层节点扩展完成后进入N+1层,因此可以保证找到路径最短的解
该策略可以有效控制页面的爬行深度,避免了遇到无限深分支时爬行无法结束的问题,并且易于实现,无需存储大量中间节点。缺点是爬行到目录级别更深的页面需要很长时间
如果搜索中存在过多的分支,即节点的后续节点过多,算法将耗尽资源,无法在可用空间中找到解决方案
2.关注网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是指有选择地抓取与预定义主题相关的页面的网络爬虫
@基于内容评价的1)crawling策略
黛布拉介绍了文本相似性的计算方法
网页采集器的自动识别算法(网页采集器的自动识别匹配方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-19 17:06
网页采集器的自动识别算法有一套自己的理论和算法,比如:是否已抓取图片,属性是否符合要求,多种异常码识别匹配;注意力机制、过滤器机制。一般采用c++编写自动采集器的话,可以使用boost::boost::string和cffi,前者是boost库的纯c语言版本的库,后者是基于其它框架的一些方法的实现版本的库。
爬虫识别是识别图片的位置的。
page_anchors
又是一道c语言的题
网页采集器一般都要采集图片来识别的,比如baiduspider
图片识别,可能就是根据图片内容来判断了。关键是图片。类似的,如果能够辨别图片内容,那么如何对图片进行操作也是一种技术。这方面研究的人比较多。
找到对应,
具体采用什么传统的方法,这是一个世界性的难题,可以看看国外有没有相关领域的研究成果。
说几个传统的方法识别方法一:特征矩阵方法目前识别领域主要用于能被看到的图片的识别方法,包括基于图像特征的寻找和局部特征的提取。不过具体可以根据具体情况具体应用于图像识别的各种方法可以根据图像提取特征点、经过线性特征点的处理获得边界特征点等方法不同而选择。如果手头不是有张大图,那么一般通过特征提取,通过图像插值识别出边界特征点,然后拼接大小为1的特征点在大图上看见的结果,或者通过基于特征点的矩阵提取方法,直接设计矩阵(4边形边长为1),每一行就是一个边界的矩阵,就能够进行识别;如果想把边界矩阵与其他样本进行匹配,如“教育部”这种认证,也可以通过样本匹配矩阵来识别;方法二:感知机方法单个或少数几个特征点的识别是比较容易,难就难在串连的特征点,这也是难点,另外前面说到根据其他样本来识别,另外样本质量也是一个难点,如何在各种类别上的特征融合也是一个难点,可以通过用户在访问相应网站时,会根据他的历史行为产生各种轨迹,从而匹配特征,包括在各种场景下不同场景下特征是否匹配,如果差异大,则需要使用正则匹配(特征匹配)如果目标网站上有很多的图片,那么人工标注就会有误差,因此目前也有一些机器学习在处理这个问题。
网站会通过颜色进行分类,然后通过灰度函数或者随机函数进行匹配。方法三:分类别域作为两个图片对标签,再经过一个阈值匹配判断目标图片对标签与否。为了减少计算量的话,还可以用带小样本训练出lstm网络对于标签进行预测。方法四:图像去重当两张图片都为一样的时候,一般会采用图像去重,大概的思路是:对于两张没有任何关系的图片,将其边界、背景等等都处理掉。除了处理边界外,还可以借助一些自然光污染或是a。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别匹配方法)
网页采集器的自动识别算法有一套自己的理论和算法,比如:是否已抓取图片,属性是否符合要求,多种异常码识别匹配;注意力机制、过滤器机制。一般采用c++编写自动采集器的话,可以使用boost::boost::string和cffi,前者是boost库的纯c语言版本的库,后者是基于其它框架的一些方法的实现版本的库。
爬虫识别是识别图片的位置的。
page_anchors
又是一道c语言的题
网页采集器一般都要采集图片来识别的,比如baiduspider
图片识别,可能就是根据图片内容来判断了。关键是图片。类似的,如果能够辨别图片内容,那么如何对图片进行操作也是一种技术。这方面研究的人比较多。
找到对应,
具体采用什么传统的方法,这是一个世界性的难题,可以看看国外有没有相关领域的研究成果。
说几个传统的方法识别方法一:特征矩阵方法目前识别领域主要用于能被看到的图片的识别方法,包括基于图像特征的寻找和局部特征的提取。不过具体可以根据具体情况具体应用于图像识别的各种方法可以根据图像提取特征点、经过线性特征点的处理获得边界特征点等方法不同而选择。如果手头不是有张大图,那么一般通过特征提取,通过图像插值识别出边界特征点,然后拼接大小为1的特征点在大图上看见的结果,或者通过基于特征点的矩阵提取方法,直接设计矩阵(4边形边长为1),每一行就是一个边界的矩阵,就能够进行识别;如果想把边界矩阵与其他样本进行匹配,如“教育部”这种认证,也可以通过样本匹配矩阵来识别;方法二:感知机方法单个或少数几个特征点的识别是比较容易,难就难在串连的特征点,这也是难点,另外前面说到根据其他样本来识别,另外样本质量也是一个难点,如何在各种类别上的特征融合也是一个难点,可以通过用户在访问相应网站时,会根据他的历史行为产生各种轨迹,从而匹配特征,包括在各种场景下不同场景下特征是否匹配,如果差异大,则需要使用正则匹配(特征匹配)如果目标网站上有很多的图片,那么人工标注就会有误差,因此目前也有一些机器学习在处理这个问题。
网站会通过颜色进行分类,然后通过灰度函数或者随机函数进行匹配。方法三:分类别域作为两个图片对标签,再经过一个阈值匹配判断目标图片对标签与否。为了减少计算量的话,还可以用带小样本训练出lstm网络对于标签进行预测。方法四:图像去重当两张图片都为一样的时候,一般会采用图像去重,大概的思路是:对于两张没有任何关系的图片,将其边界、背景等等都处理掉。除了处理边界外,还可以借助一些自然光污染或是a。
网页采集器的自动识别算法(网络推广软件功能编写的自定义脚本可完成的作用 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-09-18 17:14
)
首先,我们不想让你下载这个工具,而是想让你了解这个软件的功能。它可以被看作是对软件功能和特性的解释~~我们不提供下载服务
各类普通网络推广软件功能固定、单一,注册费用高。有时他们跟不上更新。很难找到适合自己的软件。全方位推广模拟王就是为此而诞生的
通过软件功能的灵活组合,可以完成自定义脚本:各种应用程序的自动操作,游戏、论坛、博客、留言簿、群评、群发邮件、账号注册任务、分类目录的提交和发布中的自动鼠标点击和自动按钮,群发QQ、微博推广、网站投票、数据提取等多种功能
图形二次开发:不需要理解编程。只要打开软件,你就可以下载各种官方精心制作的脚本。此外,我们不仅教人钓鱼,还教人钓鱼!在允许用户享受鱼粉的同时,我们还提供了大量的图形教程和视频教程。只要你努力工作,你就能一个人钓到大鱼
内部和外部浏览器:经过一年多的开发,我们发现类似软件的一个常见问题是挂断。内置浏览器挂起时间太长,占用的内存越来越多。因此,在维护内置浏览器的同时,我们还推广不与软件共享内存的外部浏览器。在执行过程中,程序可以每隔一段时间关闭和重新打开它以释放内存
外置WAP手机浏览器:WAP网页比PC网页限制少,浏览速度快,在网络推广中具有无可比拟的分量
正则文本提取:该程序具有强大的标准表达式和正则表达式文本提取功能,这使得采集非常容易
支持帖子发布:软件可以发送帖子数据和表头数据,使登录发布更快、更稳定
验证码标识:软件有手动标识、验证库标识和远程手动标识三种方式,使用灵活。用户定义的验证码标识项可在任何时间、任何地点进行批量发送或更新网站使用
查看全部
网页采集器的自动识别算法(网络推广软件功能编写的自定义脚本可完成的作用
)
首先,我们不想让你下载这个工具,而是想让你了解这个软件的功能。它可以被看作是对软件功能和特性的解释~~我们不提供下载服务
各类普通网络推广软件功能固定、单一,注册费用高。有时他们跟不上更新。很难找到适合自己的软件。全方位推广模拟王就是为此而诞生的
通过软件功能的灵活组合,可以完成自定义脚本:各种应用程序的自动操作,游戏、论坛、博客、留言簿、群评、群发邮件、账号注册任务、分类目录的提交和发布中的自动鼠标点击和自动按钮,群发QQ、微博推广、网站投票、数据提取等多种功能
图形二次开发:不需要理解编程。只要打开软件,你就可以下载各种官方精心制作的脚本。此外,我们不仅教人钓鱼,还教人钓鱼!在允许用户享受鱼粉的同时,我们还提供了大量的图形教程和视频教程。只要你努力工作,你就能一个人钓到大鱼
内部和外部浏览器:经过一年多的开发,我们发现类似软件的一个常见问题是挂断。内置浏览器挂起时间太长,占用的内存越来越多。因此,在维护内置浏览器的同时,我们还推广不与软件共享内存的外部浏览器。在执行过程中,程序可以每隔一段时间关闭和重新打开它以释放内存
外置WAP手机浏览器:WAP网页比PC网页限制少,浏览速度快,在网络推广中具有无可比拟的分量
正则文本提取:该程序具有强大的标准表达式和正则表达式文本提取功能,这使得采集非常容易
支持帖子发布:软件可以发送帖子数据和表头数据,使登录发布更快、更稳定
验证码标识:软件有手动标识、验证库标识和远程手动标识三种方式,使用灵活。用户定义的验证码标识项可在任何时间、任何地点进行批量发送或更新网站使用
网页采集器的自动识别算法(优采云采集器进入列表页后如何进一步获取内容页网址?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-09-17 20:19
使用采集时,我们通常需要从网页的初始URL获取内容页URL。那么优采云采集器进入列表页面后,如何进一步获取内容URL?让我们邀请新手来看看如何创建内容页URL采集rules
在中,内容URL获取有两种模式:常规模式和高级模式1.general模式:此模式默认获取主地址,即从起始页的源代码获取到内容页a的链接。有两种方式:A.自动获取地址链接,B.手动设置规则获取2.advanced模式:此模式对0级、多级、post类型的网址抓取有效。即,起始URL是内容页URL;或者您需要设置多级列表URL采集以获取最终内容页链接;或者在post URL类型捕获的情况下使用高级模式。这里详细描述了常规模式中模式a和模式B采集的具体操作,后面将解释高级模式。[常规模式]A.自动获取地址链接自动获取地址链接:自动获取该级别列表页面中所有标签的URL链接。例如新浪大陆新闻:
所得结果如下图所示:
根据统计,我们可以看到总共找到了81个一级网站,但实际我们需要抓取的一级网站是每页40个,这表明有我们不需要的链接,所以我们可以通过区域设置和链接过滤过滤来过滤和获取我们需要的链接。单击以使用浏览器查看网页源代码,并分析源代码。得出结论,所需链接应满足以下条件:开始字符串为,结束字符串为
我们在设置区域填充它,再次测试它,然后查看结果。从测试中可以看出,结果是正确的,如下图所示
[常规模式]B.手动设置规则获取
对于脚本生成的某些网址,采集器无法自动识别。在这种情况下,您需要手动设置规则以获取它们。手动设置规则获取的原理是编写脚本规则,匹配源代码中的内容,获取自己设置的参数。提取规则中的[parameter]、(*)和[label:XXX]是通配符,可以配置为任何字符。不同之处在于,[parameter]有一个返回值,通常用于拼接地址,(*)没有返回值,[label:XXX]有一个返回值,该返回值被赋予标签。例如新浪大陆新闻:
源代码如下:
山西公布政府部门责任清单,建立拒腐防变机制(10月10日20:00)20)
据报道,河南省登封市市长在修建寺庙过程中涉嫌腐败,并与石延禄关系密切(10月10日20:00)14)
张家界市国土资源局副局长因严重违纪被调查(10月10日19:00)45)
此时,我们可以将其中一个代码作为循环匹配,用[parameter]替换我们想要获得的链接,并用标签替换我们需要采集to的值。按如下方式填写提取规则:
参数]“target=“_blank”>;[标签:标题]([标签:时间])
如上图所示,符合此格式的源代码将自动匹配,内容页地址链接在参数中获得,标题和时间分布在标签中
在这里,网站抓住精灵优采云采集器V9获取内容URL的一般模式设置已完成。只要您阅读,就会觉得相对简单,优采云采集器V9你需要了解更多关于该软件的信息,所以它将很容易开始。回到搜狐查看更多信息 查看全部
网页采集器的自动识别算法(优采云采集器进入列表页后如何进一步获取内容页网址?)
使用采集时,我们通常需要从网页的初始URL获取内容页URL。那么优采云采集器进入列表页面后,如何进一步获取内容URL?让我们邀请新手来看看如何创建内容页URL采集rules
在中,内容URL获取有两种模式:常规模式和高级模式1.general模式:此模式默认获取主地址,即从起始页的源代码获取到内容页a的链接。有两种方式:A.自动获取地址链接,B.手动设置规则获取2.advanced模式:此模式对0级、多级、post类型的网址抓取有效。即,起始URL是内容页URL;或者您需要设置多级列表URL采集以获取最终内容页链接;或者在post URL类型捕获的情况下使用高级模式。这里详细描述了常规模式中模式a和模式B采集的具体操作,后面将解释高级模式。[常规模式]A.自动获取地址链接自动获取地址链接:自动获取该级别列表页面中所有标签的URL链接。例如新浪大陆新闻:
所得结果如下图所示:
根据统计,我们可以看到总共找到了81个一级网站,但实际我们需要抓取的一级网站是每页40个,这表明有我们不需要的链接,所以我们可以通过区域设置和链接过滤过滤来过滤和获取我们需要的链接。单击以使用浏览器查看网页源代码,并分析源代码。得出结论,所需链接应满足以下条件:开始字符串为,结束字符串为
我们在设置区域填充它,再次测试它,然后查看结果。从测试中可以看出,结果是正确的,如下图所示
[常规模式]B.手动设置规则获取
对于脚本生成的某些网址,采集器无法自动识别。在这种情况下,您需要手动设置规则以获取它们。手动设置规则获取的原理是编写脚本规则,匹配源代码中的内容,获取自己设置的参数。提取规则中的[parameter]、(*)和[label:XXX]是通配符,可以配置为任何字符。不同之处在于,[parameter]有一个返回值,通常用于拼接地址,(*)没有返回值,[label:XXX]有一个返回值,该返回值被赋予标签。例如新浪大陆新闻:
源代码如下:
山西公布政府部门责任清单,建立拒腐防变机制(10月10日20:00)20)
据报道,河南省登封市市长在修建寺庙过程中涉嫌腐败,并与石延禄关系密切(10月10日20:00)14)
张家界市国土资源局副局长因严重违纪被调查(10月10日19:00)45)
此时,我们可以将其中一个代码作为循环匹配,用[parameter]替换我们想要获得的链接,并用标签替换我们需要采集to的值。按如下方式填写提取规则:
参数]“target=“_blank”>;[标签:标题]([标签:时间])
如上图所示,符合此格式的源代码将自动匹配,内容页地址链接在参数中获得,标题和时间分布在标签中
在这里,网站抓住精灵优采云采集器V9获取内容URL的一般模式设置已完成。只要您阅读,就会觉得相对简单,优采云采集器V9你需要了解更多关于该软件的信息,所以它将很容易开始。回到搜狐查看更多信息
网页采集器的自动识别算法(网页信息采集软件_优采云采集换行生成Excel表格,api数据库文件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-09-17 20:17
Web information采集software优采云采集器是一款高效的网页信息采集软件,支持99%的网站data采集,优采云采集器可以生成excel表格、API数据库文件和其他内容,帮助您管理网站数据信息。如果您需要采集指定的网页数据,您可以使用此软件
软件功能:
一键数据提取
易于学习,您可以通过可视化界面单击鼠标获取数据
快速高效
内置一套高速浏览器内核和HTTP引擎模式,实现快速采集数据
适用于各种网站
99%的采集Internet网站,包括单页应用程序、AJAX加载和其他动态类型网站
向导模式
易于使用,鼠标点击即可自动生成
脚本定期运行
可按计划正常运行,无需人工操作
原创高速内核
自主开发的浏览器内核速度快,比竞争对手快得多
智能识别
它可以智能地识别网页中的列表和表单结构(多框下拉列表等)
广告屏蔽
自定义广告屏蔽模块,与adblockplus语法兼容,可添加自定义规则
多重数据导出
支持TXT、Excel、mysql、sqlserver、SQLite、access、网站等
使用说明
步骤1:输入采集网址
打开软件,创建新任务,然后输入所需的网站地址采集
步骤2:全过程智能分析和自动数据提取
进入第二步后,优采云@采集器自动智能地分析网页并从中提取列表数据
步骤3:将数据导出到表、数据库、网站etc
运行任务将采集数据导出到CSV、Excel和各种数据库,并支持API导出
更新日志优采云@采集器2.1.@8.0更新:
1.add插件功能
2.add export TXT(一个保存为文件)
3.多值连接器支持换行符
4.修改数据处理的文本映射(支持搜索和替换)
5.fix登录期间的DNS问题
6.fix图片下载问题
7.修复了JSON的一些问题 查看全部
网页采集器的自动识别算法(网页信息采集软件_优采云采集换行生成Excel表格,api数据库文件)
Web information采集software优采云采集器是一款高效的网页信息采集软件,支持99%的网站data采集,优采云采集器可以生成excel表格、API数据库文件和其他内容,帮助您管理网站数据信息。如果您需要采集指定的网页数据,您可以使用此软件
软件功能:
一键数据提取
易于学习,您可以通过可视化界面单击鼠标获取数据
快速高效
内置一套高速浏览器内核和HTTP引擎模式,实现快速采集数据
适用于各种网站
99%的采集Internet网站,包括单页应用程序、AJAX加载和其他动态类型网站
向导模式
易于使用,鼠标点击即可自动生成
脚本定期运行
可按计划正常运行,无需人工操作
原创高速内核
自主开发的浏览器内核速度快,比竞争对手快得多
智能识别
它可以智能地识别网页中的列表和表单结构(多框下拉列表等)
广告屏蔽
自定义广告屏蔽模块,与adblockplus语法兼容,可添加自定义规则
多重数据导出
支持TXT、Excel、mysql、sqlserver、SQLite、access、网站等
使用说明
步骤1:输入采集网址
打开软件,创建新任务,然后输入所需的网站地址采集
步骤2:全过程智能分析和自动数据提取
进入第二步后,优采云@采集器自动智能地分析网页并从中提取列表数据
步骤3:将数据导出到表、数据库、网站etc
运行任务将采集数据导出到CSV、Excel和各种数据库,并支持API导出
更新日志优采云@采集器2.1.@8.0更新:
1.add插件功能
2.add export TXT(一个保存为文件)
3.多值连接器支持换行符
4.修改数据处理的文本映射(支持搜索和替换)
5.fix登录期间的DNS问题
6.fix图片下载问题
7.修复了JSON的一些问题
网页采集器的自动识别算法(优采云采集器智能采集天气网:自动识别+翻页按钮)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-09-16 07:08
谢谢你的邀请。没有什么废话。直接转到操作视频~
优采云采集器intelligent采集Weather Network
我试过了。房东提到的问题确实存在。同时,我比较了天气网络的优采云@采集器和采集。使用房东提供的链接,我在大约2分钟内完成了所有天气数据和历史数据的采集设置。同时我也记录了我的操作过程,房东可以在采集跟随我的操作过程@
让我谈谈经验:
1.this网站实际上是一个简单的表单,但在翻页时,网址保持不变。这种网页技术称为本地刷新,或专业点的Ajax。如果你感兴趣,你可以百度,但你可以忽略它。从视频中可以看出,优采云在上个月设置采集翻页并点击时准确识别了该按钮的操作,可视化的采集流程自动设置,非常直观直观,一目了然
2.在智能识别过程中,测试的是算法的能力。从这里还可以看出,优采云在网页智能识别算法中的性能优于其他@采集器算法。它不仅自动标识所有字段,而且还完全自动标识整个列表。同时,自动识别翻页按钮采用的特殊反采集技术
特别是,优采云@采集器作为行业基准,非常关注用户体验。虽然我在视频中使用了优采云旗舰版(cloud采集、API和personal customer service,它们为大量企业数据稳定采集提供了非常周到的服务),但是优采云免费版没有基本的功能限制,从优采云official网站(优采云三字拼音)开始下载优采云并直接安装到采集all网站. 对于京东、天猫、公众评论、百度等行业的主流网站来说,优采云还提供了一个内置的采集模板,可以在不配置采集规则的情况下采集主流站点数据。优采云@采集器-免费网络爬虫软件网页数据捕获工具
欢迎关注或与我私下交流~ 查看全部
网页采集器的自动识别算法(优采云采集器智能采集天气网:自动识别+翻页按钮)
谢谢你的邀请。没有什么废话。直接转到操作视频~
优采云采集器intelligent采集Weather Network
我试过了。房东提到的问题确实存在。同时,我比较了天气网络的优采云@采集器和采集。使用房东提供的链接,我在大约2分钟内完成了所有天气数据和历史数据的采集设置。同时我也记录了我的操作过程,房东可以在采集跟随我的操作过程@
让我谈谈经验:
1.this网站实际上是一个简单的表单,但在翻页时,网址保持不变。这种网页技术称为本地刷新,或专业点的Ajax。如果你感兴趣,你可以百度,但你可以忽略它。从视频中可以看出,优采云在上个月设置采集翻页并点击时准确识别了该按钮的操作,可视化的采集流程自动设置,非常直观直观,一目了然
2.在智能识别过程中,测试的是算法的能力。从这里还可以看出,优采云在网页智能识别算法中的性能优于其他@采集器算法。它不仅自动标识所有字段,而且还完全自动标识整个列表。同时,自动识别翻页按钮采用的特殊反采集技术
特别是,优采云@采集器作为行业基准,非常关注用户体验。虽然我在视频中使用了优采云旗舰版(cloud采集、API和personal customer service,它们为大量企业数据稳定采集提供了非常周到的服务),但是优采云免费版没有基本的功能限制,从优采云official网站(优采云三字拼音)开始下载优采云并直接安装到采集all网站. 对于京东、天猫、公众评论、百度等行业的主流网站来说,优采云还提供了一个内置的采集模板,可以在不配置采集规则的情况下采集主流站点数据。优采云@采集器-免费网络爬虫软件网页数据捕获工具
欢迎关注或与我私下交流~
网页采集器的自动识别算法(10个非常实用的每一款软件,你喜欢哪一种? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-09-15 00:11
)
与大家分享10款非常好用的软件,每个软件都很强大,可以解决很多需求,喜欢的话记得点赞支持哦~
1、CopyQ
CopyQ 是一款免费开源的电脑剪贴板增强软件,支持 Windows、Mac 和 Linux。它的主要功能是监控系统剪贴板,存储您复制的所有内容,包括:文本、图片等格式文件,您可以随时调用它们,让您的复制粘贴更加高效。
CopyQ 的界面简单易操作。所有复制的内容可以按时间顺序一一清晰显示。您可以上下移动复制的内容,或者修复一段复制的内容,也可以将复制的内容调用到剪贴板。 .
CopyQ支持标签功能,可以对复制的内容进行排序分类;支持对复制内容的编辑;支持搜索复制的内容,可以右键软件任务栏图标,输入需要查找的文字内容。
2、Everything
Everything 是一款快速文件索引软件,可根据名称快速定位文件和文件夹。比windows自带的本地搜索速度快很多,软件体积只有10M左右,轻巧高效。
一切都可以在很短的时间内被索引,搜索结果基本上是毫秒级的。输入搜索的文件名后,立即显示搜索结果。
Everything 支持常用图片格式的缩略图预览,以及ai、psd、eps等常用设计文件的缩略图预览,这个功能对设计伙伴有很大的帮助!
3、优采云采集器
优采云采集器 由前 Google 技术团队创建。基于人工智能技术,只需输入网址即可自动识别采集内容。
可以智能识别数据。智能模式基于人工智能算法。只需输入网址,即可智能识别列表数据、表格数据和分页按钮。无需配置任何采集规则,一键采集。自动识别列表、表格、链接、图片、价格等
流程图模式:只需根据软件提示点击页面,完全符合人们浏览网页的思维方式,简单几步即可生成复杂的采集规则,结合智能识别算法,任何网页上的数据都可以轻松采集。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等
4、uTools
uTools 是一款非常强大的生产力工具箱软件。笔者将这款软件设计成一个“一切皆插件”的插件工具,所有功能都可以通过插件来实现。插件中心有很多实用高效的插件。
uTools 可以快速启动各种程序,只需一个搜索框。除了快速启动程序,我们在日常工作中还有各种小需求,比如翻译一个单词、识别/生成二维码、查看颜色值、字符串编码/解码、图像压缩等等。 uTools 以插件的形式聚合各种功能,将它们变成您专属的小工具库。您只需要输入一个快捷短语即可快速使用这些功能。
5、方方格
方形网格是一个非常易于使用的 Excel 插件工具箱。主要功能是支持扩展的Excel程序,帮助用户更快地分析Excel数据,提高工作效率。
软件拥有上百种实用功能,让用户办公更流畅。这是一个非常易于使用的 Excel 插件。
如文本处理、批量录入、删除工具、合并转换、重复值工具、数据比较、高级排序、颜色排序、合并单元格排序、聚光灯、宏存储框等
6、火绒安全软件
Tinder 安全软件是一款轻量级、高效、免费的计算机防御和杀毒安全软件,可显着增强计算机系统在应对安全问题时的防御能力。
Tinder安全软件可以全面拦截和查杀各类病毒,不会为了清除病毒而直接删除感染病毒的文件,充分保护用户文件不受损害。软件小巧玲珑,系统内存占用率极低,保证机器在主动防御和查杀过程中永不卡顿。
Tinder安全软件可以查杀病毒,有18项重要保护功能,文件实时监控、U盘保护、应用加固、软件安装拦截、浏览器保护、网络入侵拦截、暴力攻击保护、弹窗拦截、漏洞修复、启动项管理、文件粉碎。
7、天若OCR
天若OCR是一款集文字识别、表格识别、竖线识别、公式识别、修正识别、高级识别、识别翻译、识别搜索、截图功能于一体的软件。
天若OCR可以帮助您减少重复性工作,提高工作效率。
8、Snipaste
Snipaste 是一款简单而强大的截图和贴纸工具。您还可以将屏幕截图粘贴回屏幕。 F1截图,F3贴图,简约高效。
办公室里会抄很多资料,写的时候会抄很多文字和图片。 Snipaste 可以将这些内容粘贴到屏幕上,而不是切换回窗口。
发布在屏幕上的信息可以缩放、旋转、设置为半透明,甚至可以被鼠标穿透。在屏幕上发布重要信息,绝对可以改变你的工作方式,提高工作效率。
9、7-ZIP
7-ZIP 是一款开源免费的压缩软件,使用 LZMA 和 LZMA2 算法,压缩率非常高,可以比 Winzip 高 2-10%。 7-ZIP支持的格式很多,常用的压缩格式都支持。
支持的格式:压缩/解压:7z、XZ、BZIP2、GZIP、TAR、ZIP、WIM。仅解压:ARJ、CAB、CHM、CPIO、CramFS、DEB、DMG、FAT、HFS、ISO、LZH、LZMA、MBR、MSI、NSIS、NTFS、RAR、RPM、SquashFS、UDF、VHD、WIM、XAR、Z .
10、WGestures
WGestures 是一款简单高效的鼠标手势软件,免费开源,非常尽职尽责。
WGestures 有非常丰富的功能。网络搜索可以简化搜索信息的过程;手势名称提醒和修饰键更符合用户直觉;触发角度和摩擦边缘使计算机操作更高效。
今天的分享到此结束。谢谢你看到这个。听说三联的朋友们都有福了!喜欢就点击关注我,更多实用干货等着你!
查看全部
网页采集器的自动识别算法(10个非常实用的每一款软件,你喜欢哪一种?
)
与大家分享10款非常好用的软件,每个软件都很强大,可以解决很多需求,喜欢的话记得点赞支持哦~
1、CopyQ
CopyQ 是一款免费开源的电脑剪贴板增强软件,支持 Windows、Mac 和 Linux。它的主要功能是监控系统剪贴板,存储您复制的所有内容,包括:文本、图片等格式文件,您可以随时调用它们,让您的复制粘贴更加高效。
CopyQ 的界面简单易操作。所有复制的内容可以按时间顺序一一清晰显示。您可以上下移动复制的内容,或者修复一段复制的内容,也可以将复制的内容调用到剪贴板。 .
CopyQ支持标签功能,可以对复制的内容进行排序分类;支持对复制内容的编辑;支持搜索复制的内容,可以右键软件任务栏图标,输入需要查找的文字内容。
2、Everything
Everything 是一款快速文件索引软件,可根据名称快速定位文件和文件夹。比windows自带的本地搜索速度快很多,软件体积只有10M左右,轻巧高效。
一切都可以在很短的时间内被索引,搜索结果基本上是毫秒级的。输入搜索的文件名后,立即显示搜索结果。
Everything 支持常用图片格式的缩略图预览,以及ai、psd、eps等常用设计文件的缩略图预览,这个功能对设计伙伴有很大的帮助!
3、优采云采集器
优采云采集器 由前 Google 技术团队创建。基于人工智能技术,只需输入网址即可自动识别采集内容。
可以智能识别数据。智能模式基于人工智能算法。只需输入网址,即可智能识别列表数据、表格数据和分页按钮。无需配置任何采集规则,一键采集。自动识别列表、表格、链接、图片、价格等
流程图模式:只需根据软件提示点击页面,完全符合人们浏览网页的思维方式,简单几步即可生成复杂的采集规则,结合智能识别算法,任何网页上的数据都可以轻松采集。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等
4、uTools
uTools 是一款非常强大的生产力工具箱软件。笔者将这款软件设计成一个“一切皆插件”的插件工具,所有功能都可以通过插件来实现。插件中心有很多实用高效的插件。
uTools 可以快速启动各种程序,只需一个搜索框。除了快速启动程序,我们在日常工作中还有各种小需求,比如翻译一个单词、识别/生成二维码、查看颜色值、字符串编码/解码、图像压缩等等。 uTools 以插件的形式聚合各种功能,将它们变成您专属的小工具库。您只需要输入一个快捷短语即可快速使用这些功能。
5、方方格
方形网格是一个非常易于使用的 Excel 插件工具箱。主要功能是支持扩展的Excel程序,帮助用户更快地分析Excel数据,提高工作效率。
软件拥有上百种实用功能,让用户办公更流畅。这是一个非常易于使用的 Excel 插件。
如文本处理、批量录入、删除工具、合并转换、重复值工具、数据比较、高级排序、颜色排序、合并单元格排序、聚光灯、宏存储框等
6、火绒安全软件
Tinder 安全软件是一款轻量级、高效、免费的计算机防御和杀毒安全软件,可显着增强计算机系统在应对安全问题时的防御能力。
Tinder安全软件可以全面拦截和查杀各类病毒,不会为了清除病毒而直接删除感染病毒的文件,充分保护用户文件不受损害。软件小巧玲珑,系统内存占用率极低,保证机器在主动防御和查杀过程中永不卡顿。
Tinder安全软件可以查杀病毒,有18项重要保护功能,文件实时监控、U盘保护、应用加固、软件安装拦截、浏览器保护、网络入侵拦截、暴力攻击保护、弹窗拦截、漏洞修复、启动项管理、文件粉碎。
7、天若OCR
天若OCR是一款集文字识别、表格识别、竖线识别、公式识别、修正识别、高级识别、识别翻译、识别搜索、截图功能于一体的软件。
天若OCR可以帮助您减少重复性工作,提高工作效率。
8、Snipaste
Snipaste 是一款简单而强大的截图和贴纸工具。您还可以将屏幕截图粘贴回屏幕。 F1截图,F3贴图,简约高效。
办公室里会抄很多资料,写的时候会抄很多文字和图片。 Snipaste 可以将这些内容粘贴到屏幕上,而不是切换回窗口。
发布在屏幕上的信息可以缩放、旋转、设置为半透明,甚至可以被鼠标穿透。在屏幕上发布重要信息,绝对可以改变你的工作方式,提高工作效率。
9、7-ZIP
7-ZIP 是一款开源免费的压缩软件,使用 LZMA 和 LZMA2 算法,压缩率非常高,可以比 Winzip 高 2-10%。 7-ZIP支持的格式很多,常用的压缩格式都支持。
支持的格式:压缩/解压:7z、XZ、BZIP2、GZIP、TAR、ZIP、WIM。仅解压:ARJ、CAB、CHM、CPIO、CramFS、DEB、DMG、FAT、HFS、ISO、LZH、LZMA、MBR、MSI、NSIS、NTFS、RAR、RPM、SquashFS、UDF、VHD、WIM、XAR、Z .
10、WGestures
WGestures 是一款简单高效的鼠标手势软件,免费开源,非常尽职尽责。
WGestures 有非常丰富的功能。网络搜索可以简化搜索信息的过程;手势名称提醒和修饰键更符合用户直觉;触发角度和摩擦边缘使计算机操作更高效。
今天的分享到此结束。谢谢你看到这个。听说三联的朋友们都有福了!喜欢就点击关注我,更多实用干货等着你!
网页采集器的自动识别算法( 软件优势向导:所有采集元素,自动生成采集数据计划)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-09-12 18:02
软件优势向导:所有采集元素,自动生成采集数据计划)
应用平台:Windows平台
优采云采集器专业网页信息采集tool,本软件支持采集用户所需的所有网页信息,本站提供该软件的安装版,有需要的朋友,来这里下载使用吧!
软件功能
零门槛:不懂网络爬虫技术,会上网,会采集网站数据
多引擎,高速稳定:内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集data更高效。还内置了JSON引擎,无需分析JSON数据结构,直观选择JSON内容。
适用于各种网站:网站可以采集互联网99%,包括单页应用Ajax加载和其他动态类型网站。
软件功能
软件操作简单,鼠标点击即可轻松选择要采集的内容;
支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上独创的内存优化,让浏览器采集也能高速运行,甚至可以很快转换为HTTP方式运行,享受更高的采集速度!抓取JSON数据时,也可以使用浏览器可视化的方式,通过鼠标选择需要抓取的内容。无需分析JSON数据结构,让非网页专业设计人员轻松抓取所需数据;
不需要分析网页请求和源码,但支持更多的网页采集;
先进的智能算法可以一键生成目标元素XPATH,自动识别网页列表,自动识别分页中的下一页按钮...
支持丰富的数据导出方式,可以通过向导导出为txt文件、html文件、csv文件、excel文件,也可以导出到现有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库等。以简单的方式轻松映射字段,并且可以轻松导出到目标网站数据库。
软件优势
可视化向导:所有采集元素都会自动生成采集数据
定时任务:灵活定义运行时间,全自动运行
多引擎支持:支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别:可自动识别网页列表、采集字段和分页等
拦截请求:自定义拦截域名,方便过滤异地广告,提高采集速度
多种数据导出:可导出为Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等
软件安装
更新日志
3.2.4.8 (2021-09-01)
修复新版js中调用字段内容无效的问题
下载地址如下:
群英网络电信下载
中国香港数据电信下载
河南紫天网通下载
益阳网络电信下载
本文相关:推荐一个免费网页采集器,需要会写SQL并下载到数据库中。 . ...什么是最简单实用的网页采集器?请提供下载地址和教程地址。谢谢... 你好,网络视频采集器是一个软件吗?我在哪里可以下载它?能给个链接吗...优采云采集器|论坛采集器_cms网站采集器_blog采集器_文章信...data采集器|data采集器是什么|数据采集器如何使用|数据采集如...优采云采集器|论坛采集器_cms网站采集器_博客采集器_文章信...三行采集器、论坛采集器、cms网站采集器、blog采集器COC采集器升级分析采集器优先级是否应该升级 查看全部
网页采集器的自动识别算法(
软件优势向导:所有采集元素,自动生成采集数据计划)
应用平台:Windows平台
优采云采集器专业网页信息采集tool,本软件支持采集用户所需的所有网页信息,本站提供该软件的安装版,有需要的朋友,来这里下载使用吧!
软件功能
零门槛:不懂网络爬虫技术,会上网,会采集网站数据
多引擎,高速稳定:内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集data更高效。还内置了JSON引擎,无需分析JSON数据结构,直观选择JSON内容。
适用于各种网站:网站可以采集互联网99%,包括单页应用Ajax加载和其他动态类型网站。
软件功能
软件操作简单,鼠标点击即可轻松选择要采集的内容;
支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上独创的内存优化,让浏览器采集也能高速运行,甚至可以很快转换为HTTP方式运行,享受更高的采集速度!抓取JSON数据时,也可以使用浏览器可视化的方式,通过鼠标选择需要抓取的内容。无需分析JSON数据结构,让非网页专业设计人员轻松抓取所需数据;
不需要分析网页请求和源码,但支持更多的网页采集;
先进的智能算法可以一键生成目标元素XPATH,自动识别网页列表,自动识别分页中的下一页按钮...
支持丰富的数据导出方式,可以通过向导导出为txt文件、html文件、csv文件、excel文件,也可以导出到现有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库等。以简单的方式轻松映射字段,并且可以轻松导出到目标网站数据库。
软件优势
可视化向导:所有采集元素都会自动生成采集数据
定时任务:灵活定义运行时间,全自动运行
多引擎支持:支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别:可自动识别网页列表、采集字段和分页等
拦截请求:自定义拦截域名,方便过滤异地广告,提高采集速度
多种数据导出:可导出为Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等
软件安装
更新日志
3.2.4.8 (2021-09-01)
修复新版js中调用字段内容无效的问题
下载地址如下:
群英网络电信下载
中国香港数据电信下载
河南紫天网通下载
益阳网络电信下载
本文相关:推荐一个免费网页采集器,需要会写SQL并下载到数据库中。 . ...什么是最简单实用的网页采集器?请提供下载地址和教程地址。谢谢... 你好,网络视频采集器是一个软件吗?我在哪里可以下载它?能给个链接吗...优采云采集器|论坛采集器_cms网站采集器_blog采集器_文章信...data采集器|data采集器是什么|数据采集器如何使用|数据采集如...优采云采集器|论坛采集器_cms网站采集器_博客采集器_文章信...三行采集器、论坛采集器、cms网站采集器、blog采集器COC采集器升级分析采集器优先级是否应该升级
网页采集器的自动识别算法( Windows平台微风采集器的分类及使用参考教程索引页体验)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-09-12 17:13
Windows平台微风采集器的分类及使用参考教程索引页体验)
应用平台:Windows平台
Breeze采集器是一款简单实用的采集工具软件。它不需要复杂的代码或掌握编程技能。操作简单,使用方便。用户只需要选择相应的模板采集到想需要的数据。欢迎有需要的朋友下载体验。
软件介绍:
Breeze采集器 是一款采集 软件,无需任何编程基础即可使用。通过预先定义模板,不同的模板可以做不同的任务,用户不需要知道任何代码。采集 到所需的数据。用户只需选择相应的模板即可。
软件功能:
无需掌握任何编程技能,无需理解任何代码
基于强大的脚本引擎,可快速定制
根据需要选择模板,直接采集,简单快捷。
你可以随意换电脑,不要把电脑绑在上面
使用方法:
添加试用模板:
1、Template 下拉框会自动显示你刚刚添加的模板。以后要使用,可以直接在模板选择列表中选择。
2、打开软件,默认为采集标签。在选择模板下拉框下方,点击添加模板。
3、在弹出的模板选择页面中,点击一个模板查看模板示例和介绍,然后加入试用。
添加后,点击页面底部的“已选”按钮。
4、具体模板使用请参考教程索引页。
注意事项:
禁用 IPV6
在控制面板中打开一次
勾选 IPV6,然后单击确定。
403错误详解
一、403 禁止是什么意思?
403 Forbidden 是 HTTP 协议中的一个状态码(Status Code)。可以简单理解为无权访问本站。此状态表示服务器理解请求但拒绝执行任务,不应将请求重新发送到服务器。当 HTTP 请求方法不是“HEAD”,并且服务器想要让客户端知道它为什么没有权限时,服务器应该在返回的信息中描述拒绝的原因。在服务器不想提供任何反馈信息的情况下,服务器可以使用 404 Not Found 而不是 403 Forbidden。
二、403 错误码分类介绍
403.1
403.1 该错误是由于禁止“执行”访问引起的。如果您尝试从目录中执行 CGI、ISAPI 或其他可执行程序,但该目录不允许该程序执行,则会出现此错误。
403.2
403.2 该错误是由“读”访问被禁止引起的。该错误是因为该目录没有默认的网页并且没有开启目录浏览功能,或者要显示的HTML页面所在的目录只标记了“可执行”或“脚本”权限。
403.3
403.3 该错误是由“写”访问被禁止引起的。尝试将文件上传到目录或修改目录中的文件,但该目录不允许“写”访问时会出现这种错误。
403.4
403.4 错误是由 SSL 的要求引起的。您必须在要查看的网页地址中使用“https”。
403.5
403.5 该错误是由需要 128 位加密算法的 Web 浏览器引起的。如果您的浏览器不支持 128 位加密算法,则会出现此错误。您可以连接到 Microsoft网站 以继续。浏览器升级。
403.6
403.6 错误是由拒绝 IP 地址引起的。如果服务器有无法访问该站点的IP地址列表,并且您使用的IP地址在列表中,您将返回此错误信息。
403.7
403.7 错误是因为需要客户端证书。当需要访问的资源要求浏览器具有服务器可以识别的安全套接字层 (SSL) 客户端证书时,将返回此错误。
403.8
403.8 错误是由于禁止站点访问引起的。如果服务器有无法访问的DNS名称列表,并且您使用的DNS名称在列表中,则会返回此信息。请注意403.6和403.8错误的区别。
403.9
403.9 错误是因为连接的用户太多。当Web服务器因流量太大而无法处理请求时,将返回此错误。
403.10
403.10 错误是无效配置导致的错误。当您尝试从目录中执行 CGI、ISAPI 或其他可执行程序,但该目录不允许该程序执行时,将返回此错误。
403.11
403.11 错误是由于密码更改导致无权查看页面。
403.12
403.12 错误是由映射器拒绝访问引起的。要查看的网页需要有效的客户端证书,当您的客户端证书映射没有访问该网站的权限时,会返回映射器拒绝访问的错误。
403.13
403.13 错误是因为需要查看的网页需要使用有效的客户端证书并且使用的客户端证书已被吊销,或者无法确定证书是否有已被撤销。
403.14
403.14 错误 Web 服务器配置为不列出此目录的内容并拒绝目录列表。
403.15
403.15 错误是客户端访问权限过多导致的。当服务器超过其客户端访问权限限制时将返回此错误。
403.16
403.16 错误是由不受信任或无效的客户端证书引起的。
403.17
403.17 错误是因为客户端证书已过期或尚未生效。
三、 403错误的主要原因如下:
1、您的 IP 已被列入黑名单。
2、您在一段时间内访问过这个网站(通常使用采集程序),被防火墙拒绝访问。
3、网站域名解析到空间,但空间没有绑定到这个域名。
4、您的网页脚本文件在当前目录没有执行权限。
5、在不允许写入/创建文件的目录中进行了文件创建/写入操作。 查看全部
网页采集器的自动识别算法(
Windows平台微风采集器的分类及使用参考教程索引页体验)
应用平台:Windows平台
Breeze采集器是一款简单实用的采集工具软件。它不需要复杂的代码或掌握编程技能。操作简单,使用方便。用户只需要选择相应的模板采集到想需要的数据。欢迎有需要的朋友下载体验。
软件介绍:
Breeze采集器 是一款采集 软件,无需任何编程基础即可使用。通过预先定义模板,不同的模板可以做不同的任务,用户不需要知道任何代码。采集 到所需的数据。用户只需选择相应的模板即可。
软件功能:
无需掌握任何编程技能,无需理解任何代码
基于强大的脚本引擎,可快速定制
根据需要选择模板,直接采集,简单快捷。
你可以随意换电脑,不要把电脑绑在上面
使用方法:
添加试用模板:
1、Template 下拉框会自动显示你刚刚添加的模板。以后要使用,可以直接在模板选择列表中选择。
2、打开软件,默认为采集标签。在选择模板下拉框下方,点击添加模板。
3、在弹出的模板选择页面中,点击一个模板查看模板示例和介绍,然后加入试用。
添加后,点击页面底部的“已选”按钮。
4、具体模板使用请参考教程索引页。
注意事项:
禁用 IPV6
在控制面板中打开一次
勾选 IPV6,然后单击确定。
403错误详解
一、403 禁止是什么意思?
403 Forbidden 是 HTTP 协议中的一个状态码(Status Code)。可以简单理解为无权访问本站。此状态表示服务器理解请求但拒绝执行任务,不应将请求重新发送到服务器。当 HTTP 请求方法不是“HEAD”,并且服务器想要让客户端知道它为什么没有权限时,服务器应该在返回的信息中描述拒绝的原因。在服务器不想提供任何反馈信息的情况下,服务器可以使用 404 Not Found 而不是 403 Forbidden。
二、403 错误码分类介绍
403.1
403.1 该错误是由于禁止“执行”访问引起的。如果您尝试从目录中执行 CGI、ISAPI 或其他可执行程序,但该目录不允许该程序执行,则会出现此错误。
403.2
403.2 该错误是由“读”访问被禁止引起的。该错误是因为该目录没有默认的网页并且没有开启目录浏览功能,或者要显示的HTML页面所在的目录只标记了“可执行”或“脚本”权限。
403.3
403.3 该错误是由“写”访问被禁止引起的。尝试将文件上传到目录或修改目录中的文件,但该目录不允许“写”访问时会出现这种错误。
403.4
403.4 错误是由 SSL 的要求引起的。您必须在要查看的网页地址中使用“https”。
403.5
403.5 该错误是由需要 128 位加密算法的 Web 浏览器引起的。如果您的浏览器不支持 128 位加密算法,则会出现此错误。您可以连接到 Microsoft网站 以继续。浏览器升级。
403.6
403.6 错误是由拒绝 IP 地址引起的。如果服务器有无法访问该站点的IP地址列表,并且您使用的IP地址在列表中,您将返回此错误信息。
403.7
403.7 错误是因为需要客户端证书。当需要访问的资源要求浏览器具有服务器可以识别的安全套接字层 (SSL) 客户端证书时,将返回此错误。
403.8
403.8 错误是由于禁止站点访问引起的。如果服务器有无法访问的DNS名称列表,并且您使用的DNS名称在列表中,则会返回此信息。请注意403.6和403.8错误的区别。
403.9
403.9 错误是因为连接的用户太多。当Web服务器因流量太大而无法处理请求时,将返回此错误。
403.10
403.10 错误是无效配置导致的错误。当您尝试从目录中执行 CGI、ISAPI 或其他可执行程序,但该目录不允许该程序执行时,将返回此错误。
403.11
403.11 错误是由于密码更改导致无权查看页面。
403.12
403.12 错误是由映射器拒绝访问引起的。要查看的网页需要有效的客户端证书,当您的客户端证书映射没有访问该网站的权限时,会返回映射器拒绝访问的错误。
403.13
403.13 错误是因为需要查看的网页需要使用有效的客户端证书并且使用的客户端证书已被吊销,或者无法确定证书是否有已被撤销。
403.14
403.14 错误 Web 服务器配置为不列出此目录的内容并拒绝目录列表。
403.15
403.15 错误是客户端访问权限过多导致的。当服务器超过其客户端访问权限限制时将返回此错误。
403.16
403.16 错误是由不受信任或无效的客户端证书引起的。
403.17
403.17 错误是因为客户端证书已过期或尚未生效。
三、 403错误的主要原因如下:
1、您的 IP 已被列入黑名单。
2、您在一段时间内访问过这个网站(通常使用采集程序),被防火墙拒绝访问。
3、网站域名解析到空间,但空间没有绑定到这个域名。
4、您的网页脚本文件在当前目录没有执行权限。
5、在不允许写入/创建文件的目录中进行了文件创建/写入操作。
网页采集器的自动识别算法(易搜网页数据采集器免费版更是更是)
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-09-10 07:06
Easy Search Web Data采集器是一款非常好用的网络数据采集软件,为用户提供了非常方便的数据采集方法,操作方法简单方便,即使用户没有任何专业知识,你也可以轻松上手和操作,快速采集网页资料。轻松搜索网页数据采集器免费版不需要输入任何代码,只需要输入URL地址,就可以帮助用户自动采集网页数据。
Easy Search Web Data采集器正式版具有很强的系统兼容性,支持在各种版本的操作系统上运行。有需要的用户可到本站下载本软件。
软件功能
简单易用
简单易学,采集data和向导模式可通过可视化界面,鼠标点击,用户无需任何技术基础,输入网址,一键提取数据。代码小白的福音。
大量采集templates
内置大量网站采集模板,覆盖多个行业,点击模板,即可加载数据,只需简单配置,即可快速准确获取数据,满足采集各种需求..
自主研发的智能算法
通过自主研发的智能识别算法,自动识别列表数据识别分页,准确率95%,可深入采集多级页面,快速准确获取数据.
自动导出数据
数据可自动导出发布,支持多种格式导出,如TXT、CSV、Excel、Access、MySQL、SQLServer、SQLite,以及发布到网站interface(Api)等
软件亮点
Smart采集
列表/表格数据智能分析提取,并能自动识别分页符。免配置一键采集各种网站,包括分页、滚动加载、登录采集、AJAX等
多平台支持
易搜网数据采集软件支持所有版本的windows操作系统,可以在服务器上稳定运行。无论是个人采集还是团队/企业使用,都能满足您的各种需求。
多数据导出
一键导出采集的所有数据。支持CSV、EXCEL、HTML等,也支持导出数据到数据库,可以发布到Dedecms、Discuz、Wordpress、phpcms网站。
数据本地化存储
采集 任务会自动保存到本地电脑,不用担心丢失。登录软件,可以随时随地创建和修改采集任务。
轻松搜索网页数据采集器使用教程
第一步,选择起始网址
想要采集一个网站数据时,首先需要找到一个地址来显示数据列表。这一步非常重要。起始 URL 决定了 采集 数据的数量和类型。
以新浪新闻为例。我们要抓取当前城市的新闻标题、发布时间、详情页信息。
通过浏览网站,我们找到了所有新闻信息列表的地址
然后在易搜网页data采集器新建一个任务->第一步->输入网页地址
然后点击下一步。
第二步,抓取数据
进入第二步后,蓝鲸可视化采集软件会智能分析网页并从中提取列表数据。如下图:
此时我们对分析的数据进行整理和修改,比如删除无用的字段。
点击列的下拉按钮并选择删除字段。
当然还有其他操作,比如名称修改、数据处理等
整理好修改后的字段,我们来采集处理分页。
选择分页设置->自动识别分页符,程序会自动定位下一页元素。
接下来我们进入数据采集的列表页面,点击链接字段--点击进入列表页面采集data,如下图:
第三步,高级设置
这包括浏览器的配置,比如禁用图片、禁用JS、禁用Flash、屏蔽广告等。这些配置可以用来提高浏览器的加载速度。
定时任务的配置,通过定时任务,可以设置任务定时自动运行。
点击完成保存任务。
完成,运行任务
任务创建完成后,我们选择新创建的任务,点击任务栏开始。
轻松搜索网络数据采集器如何导出数据
有两种导出方式:
手动导出,通过右键单击任务->导出任务,或在视图数据中导出。
自动导出,在编辑任务第三步设置导出。
数据导出后,会被标记为导出,下次导出时不会再次导出。如果您想导出所有数据而不区分导出的内容,您可以在查看数据中选择全部导出。
导出到 Excel、CSV、TXT
数据可以导出为Excel、CSV、TXT文件,每次导出都会生成一个新文件。软件支持为导出的文件名设置变量。目前有两种格式变量,根据任务名称和日期格式。
导出到网站interface (API)
支持主流cms网站系统,如Discuz、Empirecms、Wordpress、DEDEcms、PHPcms,可提供官方API。
对于开发者,可以自己定义网站API,易搜网页数据采集器通过HTTP POST请求将数据发送到指定的API,只需设置相应的POST参数和编码类型即可。
导出到数据库
目前,易搜网页数据采集器支持导出到四个数据库:MySQL、SQLServer、SQLite和Access。设置数据库的连接配置,指定导出的目标表名。
同时可以设置本地任务字段与目标数据库字段的映射关系(对应关系)
轻松搜索网页data采集器value属性设置方法
首先field通过XPath定位Html元素,然后我们需要通过value属性来判断Html元素的哪一部分作为field的值。
一般情况下采集器默认使用InnerText属性(当前节点及其子节点的文本)
除了InnerText,还有其他几个内置属性:
Text,代表当前节点的文本
InnerHtml,表示当前节点内部的HTML语句(不包括当前节点)
OuterHtml,代表当前节点的HTML语句
除了内置属性外,用户还可以手动填写 HTML 属性。 A标签的href、IMG标签的src等常见的HTML属性。 Data-* 表示数据。
特别提示
在这里,您可以手动输入属性名称,即使没有下拉选项。比如常见的onclick、value、class。 查看全部
网页采集器的自动识别算法(易搜网页数据采集器免费版更是更是)
Easy Search Web Data采集器是一款非常好用的网络数据采集软件,为用户提供了非常方便的数据采集方法,操作方法简单方便,即使用户没有任何专业知识,你也可以轻松上手和操作,快速采集网页资料。轻松搜索网页数据采集器免费版不需要输入任何代码,只需要输入URL地址,就可以帮助用户自动采集网页数据。
Easy Search Web Data采集器正式版具有很强的系统兼容性,支持在各种版本的操作系统上运行。有需要的用户可到本站下载本软件。
软件功能
简单易用
简单易学,采集data和向导模式可通过可视化界面,鼠标点击,用户无需任何技术基础,输入网址,一键提取数据。代码小白的福音。
大量采集templates
内置大量网站采集模板,覆盖多个行业,点击模板,即可加载数据,只需简单配置,即可快速准确获取数据,满足采集各种需求..
自主研发的智能算法
通过自主研发的智能识别算法,自动识别列表数据识别分页,准确率95%,可深入采集多级页面,快速准确获取数据.
自动导出数据
数据可自动导出发布,支持多种格式导出,如TXT、CSV、Excel、Access、MySQL、SQLServer、SQLite,以及发布到网站interface(Api)等
软件亮点
Smart采集
列表/表格数据智能分析提取,并能自动识别分页符。免配置一键采集各种网站,包括分页、滚动加载、登录采集、AJAX等
多平台支持
易搜网数据采集软件支持所有版本的windows操作系统,可以在服务器上稳定运行。无论是个人采集还是团队/企业使用,都能满足您的各种需求。
多数据导出
一键导出采集的所有数据。支持CSV、EXCEL、HTML等,也支持导出数据到数据库,可以发布到Dedecms、Discuz、Wordpress、phpcms网站。
数据本地化存储
采集 任务会自动保存到本地电脑,不用担心丢失。登录软件,可以随时随地创建和修改采集任务。
轻松搜索网页数据采集器使用教程
第一步,选择起始网址
想要采集一个网站数据时,首先需要找到一个地址来显示数据列表。这一步非常重要。起始 URL 决定了 采集 数据的数量和类型。
以新浪新闻为例。我们要抓取当前城市的新闻标题、发布时间、详情页信息。
通过浏览网站,我们找到了所有新闻信息列表的地址
然后在易搜网页data采集器新建一个任务->第一步->输入网页地址
然后点击下一步。
第二步,抓取数据
进入第二步后,蓝鲸可视化采集软件会智能分析网页并从中提取列表数据。如下图:
此时我们对分析的数据进行整理和修改,比如删除无用的字段。
点击列的下拉按钮并选择删除字段。
当然还有其他操作,比如名称修改、数据处理等
整理好修改后的字段,我们来采集处理分页。
选择分页设置->自动识别分页符,程序会自动定位下一页元素。
接下来我们进入数据采集的列表页面,点击链接字段--点击进入列表页面采集data,如下图:
第三步,高级设置
这包括浏览器的配置,比如禁用图片、禁用JS、禁用Flash、屏蔽广告等。这些配置可以用来提高浏览器的加载速度。
定时任务的配置,通过定时任务,可以设置任务定时自动运行。
点击完成保存任务。
完成,运行任务
任务创建完成后,我们选择新创建的任务,点击任务栏开始。
轻松搜索网络数据采集器如何导出数据
有两种导出方式:
手动导出,通过右键单击任务->导出任务,或在视图数据中导出。
自动导出,在编辑任务第三步设置导出。
数据导出后,会被标记为导出,下次导出时不会再次导出。如果您想导出所有数据而不区分导出的内容,您可以在查看数据中选择全部导出。
导出到 Excel、CSV、TXT
数据可以导出为Excel、CSV、TXT文件,每次导出都会生成一个新文件。软件支持为导出的文件名设置变量。目前有两种格式变量,根据任务名称和日期格式。
导出到网站interface (API)
支持主流cms网站系统,如Discuz、Empirecms、Wordpress、DEDEcms、PHPcms,可提供官方API。
对于开发者,可以自己定义网站API,易搜网页数据采集器通过HTTP POST请求将数据发送到指定的API,只需设置相应的POST参数和编码类型即可。
导出到数据库
目前,易搜网页数据采集器支持导出到四个数据库:MySQL、SQLServer、SQLite和Access。设置数据库的连接配置,指定导出的目标表名。
同时可以设置本地任务字段与目标数据库字段的映射关系(对应关系)
轻松搜索网页data采集器value属性设置方法
首先field通过XPath定位Html元素,然后我们需要通过value属性来判断Html元素的哪一部分作为field的值。
一般情况下采集器默认使用InnerText属性(当前节点及其子节点的文本)
除了InnerText,还有其他几个内置属性:
Text,代表当前节点的文本
InnerHtml,表示当前节点内部的HTML语句(不包括当前节点)
OuterHtml,代表当前节点的HTML语句
除了内置属性外,用户还可以手动填写 HTML 属性。 A标签的href、IMG标签的src等常见的HTML属性。 Data-* 表示数据。
特别提示
在这里,您可以手动输入属性名称,即使没有下拉选项。比如常见的onclick、value、class。
网页采集器的自动识别算法(中国现已有网民4.85亿各类站点域名130余万个爆炸)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-09-07 20:00
专利名称:一种能够自动识别网页信息的系统和方法采集
技术领域:
本发明涉及网页动态分析技术领域,具体属于一种自动识别网页信息的系统及方法。
背景技术:
随着互联网的发展,越来越多的互联网网站出现,形式层出不穷,包括新闻、博客、论坛、SNS、微博等。据CNNIC今年最新统计,现在中国有4.850亿网民,各个网站的域名超过130万个。在互联网信息爆炸式增长的今天,搜索引擎已经成为人们查找互联网信息的最重要工具。搜索引擎主要是自动抓取网站信息,进行预处理,分词后建立索引。输入搜索词后,搜索引擎可以自动为用户找到最相关的结果。经过十多年的发展,搜索引擎技术已经比较成熟,并且因为可以采用成功的商业模式,吸引了众多互联网厂商的进入。比较有名的有百度、谷歌、搜搜、搜狗、有道、奇虎360等。此外,在一些垂直领域(如旅游、机票、比价等)还有搜索引擎,已经有千余家厂商进入。搜索引擎的第一步也是最重要的一步是信息捕获,这是搜索引擎的数据准备过程。具体流程如图1所示。URL DB存储了所有要爬取的URL。 URL调度模块从URL DB中选出最重要的URL,放入URL下载队列。页面下载模块下载队列中的 URL。下载完成后,模块被解压。提取下载的页面代码的文本和URL,将提取的文本发送到索引模块进行分词索引,并将URL放入URL DB。信息采集进程就是把别人的网站信息放入自己数据库的过程,会遇到一些问题。
1、互联网信息每时每刻都在不断增加,因此信息抓取是一个7*24小时不间断的过程。频繁的爬取会给目标网站带来巨大的访问压力,形成DDOS拒绝服务攻击,导致无法为普通用户提供访问。这在中小型网站中尤为明显。这些网站硬件资源比较差,技术力量不强,网上90%以上都是网站这种类型的。例如:某知名搜索引擎因频繁爬取网站而呼吁用户投诉。 2、某些网站 的信息具有隐私或版权。许多网页收录后端数据库、用户隐私和密码等信息。 网站主办方不希望将这些信息公开或免费使用。大众点评曾对爱帮网提起诉讼,称其在网站上抓取评论,然后在网站上发布。目前搜索引擎网页针对采集采用的主流方式是robots协议协议。 网站使用robots,txt协议来控制其内容是否愿意被搜索引擎收录搜索,以及允许收录哪些搜索引擎搜索,并为收录指定自己的内容和禁止收录。同时,搜索引擎会根据每个网站Robots 协议赋予的权限,有意识地进行抓取。该方法假设搜索引擎抓取过程如下:下载网站robots文件-根据robots协议解析文件-获取要下载的网址-确定该网址的访问权限-确定是否根据到判定的结果。 Robots协议是君子协议,没有任何限制,抓取主动权还是完全由搜索引擎控制,完全可以不遵循协议强行抓取。
比如2012年8月,国内某知名搜索引擎不按照协议抓取百度网站内容,被百度指控。另一种反采集方法主要是利用动态技术构建禁止爬取的网页。该方法利用客户端脚本语言(如JS、VBScript、AJAX)动态生成网页显示信息,从而实现信息隐藏,使常规搜索引擎难以获取URL和正文内容。动态网页构建技术只是增加了网页解析提取的难度,并不能从根本上禁止采集和网页信息的解析。目前,一些高级搜索引擎可以模拟浏览器来实现所有的脚本代码解析。获取所有信息的网络URL,从而获取服务器中存储的动态信息。目前有成熟的网页动态分析技术,主要是解析网页中所有的脚本代码段,然后获取网页的所有动态信息(包括有用信息和垃圾信息)。实际实现过程是基于开源脚本代码分析引擎(如Rhino、V8等)为核心搭建网页脚本分析环境,然后从网页中提取脚本代码段,并放入提取的代码段放入网页脚本分析环境中执行分析返回动态信息。解析过程如图2所示。因此,采用动态技术构建动态网页的方法只是增加了网页采集和解析的难度,并没有从根本上消除采集搜索引擎。
发明内容
本发明的目的在于提供一种能够自动识别网页信息采集的系统和方法,克服现有技术的不足。系统通过分析网站的历史网页访问行为,建立自动化的采集。 @Classifier,识别机器人自动采集,通过机器人自动采集识别实现网页的反爬虫。本发明采用的技术方案是:一种自动识别网页信息采集的系统及方法,包括anti采集分类器构建模块、自动采集识别模块和anti采集在线处理模块,以及anti采集在线处理模块。采集分类器构建模块主要用于通过计算机程序学习和区分自动采集历史网页信息和正常网页访问行为。该模块提供了自动采集识别的训练模型。自动采集识别模块,该模块通过加载自动分类器自动识别搜索引擎程序的自动采集行为,并将识别出的采集程序所在的IP段加入黑名单,黑名单是用于后续在线拦截自动采集行为。反采集在线处理模块主要用于对来访用户进行自动在线判断和处理。如果访问者的IP已经在该IP段的黑名单中,则该IP被拒绝访问;否则,将访问请求转发给Web服务器进行进一步处理。反采集分类器构建模块的实现方法具体包括以下步骤:(5)日志分析子模块通过自动分析站点访问日志,获取用户访问行为信息,包括用户对网站IP的访问,访问时间,访问URL,源URL;样本选择子模块根据连续时间段内同一IP段内访问频率最高的数据记录,选择步骤I中解析的数据记录作为候选数据样本采集;访问统计子模块对选取的样本数据进行统计,计算出同一IP段的平均页面停留时间,访问的页面总数,是否为采集网页附件信息,网页采集频率;(6)以IP段为主要关键字,将上述信息保存在样本库中,并将其标记为未标记;(7)标记步骤(I)中未标记的样本,如果确定样本库le是自动采集,会被标记为I;如果用户浏览器正常访问,则标记为0,所有标记的样本都会更新到数据库中; (8)计算机程序会自动从样本库中学习,生成分类模型,用于后期自动采集识别。
自动采集识别模块的实现方法包括以下步骤:(5)identification程序初始化阶段,完成分类器模型的加载,模型可以判断自动采集行为;(6)日志分析程序解析最新的网站访问日志,并将解析出的数据发送给访问统计模块;(7)访问统计模块计算同一IP段的平均页面停留时间,是否为采集web附件信息,网页采集frequency;(8)classifier根据分类模型判断IP段的访问行为,将判断为程序自动采集行为的IP段加入黑名单;表示反@采集在线处理模块实现方法包括以下步骤: (I) 为web服务器转发的访问请求提取访问者的IP信息;(2)比较黑名单库中的IP信息,如果IP已经y在黑名单中,此时通知web服务器拒绝该IP的访问;否则,通知Web服务器正常处理访问请求。与现有技术相比,本发明的有益效果如下: 本发明的系统分析网站网页访问行为的历史,建立一个自动采集分类器,识别自动采集机器人,通过自动机器人采集识别实现网页的反爬行,自动发现搜索引擎网页的采集行为并进行响应采集行为被屏蔽,采集搜索引擎从根本上被淘汰。
图1是现有技术搜索引擎的信息抓取过程示意图;图2是现有技术的第二种分析过程示意图;图3为本发明的anti采集分类器构建框图示意图;图4为本发明自动采集识别模块图;图5为本发明反采集在线处理模块。
具体实施例见附图。一种能够识别网页信息的反抓取系统和方法,包括反采集分类器构建模块、自动采集识别模块和反采集在线处理模块。 采集Classifier 构建模块,该模块主要用于通过计算机程序学习和区分采集自动历史网页信息和正常网页访问行为。该模块提供了自动采集识别的训练模型。自动采集识别模块主要用于加载自动分类器自动识别搜索引擎程序的自动采集行为,并将识别出的采集程序的IP段加入黑名单。该列表用于后续在线拦截自动采集行为。所述anti采集在线处理模块主要用于对来访用户的在线自动判断和处理。如果访问者的IP已经在IP段黑名单中,则该IP被拒绝访问;否则,将访问请求转发给Web服务器进行进一步处理。反采集分类器构建模块实现方法具体包括以下步骤:(9)日志分析子模块通过自动分析站点访问日志,获取用户访问行为信息,包括用户访问网站IP、访问时间,访问URL,源URL;样本选择子模块根据连续时间段内同一IP段内访问频率最高的数据记录,选择步骤I中解析的数据记录作为候选数据样本集合;访问统计子模块对选取的样本数据进行统计,计算出同一IP段的平均页面停留时间、站点总访问页面数、是否为采集网页附件信息、webpage采集
频率; (10)以IP段为主要关键字,将上述信息保存在样本库中,并标记为未标记;(11)对未标记样本执行步骤(I)中的程序如果确定如果样本是机器自动采集,则标记为I;如果用户浏览器正常访问,则标记为0,所有标记的样本都会更新到数据库中;(12)计算机程序会自动检查样本库学习并生成分类模型,用于后续自动采集识别。所述的自动采集识别模块实现方法包括以下步骤:(9)识别程序初始化阶段,完成加载分类器模型,该模型可以自动判断采集行为;(10)日志分析程序解析最新的网站访问日志,并将解析后的数据发送给访问统计模块;(11)访问统计模块计算平均值e 同一IP段的页面停留时间,是否是采集web附件信息,网页采集频率; (12)classifier根据分类模型判断IP段的访问行为,判断为自动程序采集Behavior的IP段加入黑名单;反采集的实现方法在线处理模块包括以下步骤: (i) 为web服务器转发的访问请求提取访问者的IP信息;(2)比较黑名单库中的IP信息,如果IP已经在黑名单中,则通知访问者web server 拒绝访问该IP;否则通知web server 正常处理访问请求 计数器采集classifier 构造 该模块主要用于训练计算机程序,使其能够学习和区分历史web信息自动采集和正常的网页访问行为,该模块可以为后续的自动采集识别提供训练模型,具体包括以下几个步骤。2.2.1.1 日志解析本模块需要解析服务器的历史访问日志(可以选择某一天的日志)提取获取用户的访问行为信息,包括用户访问网站使用的IP、访问发生的时间、访问的URL、和源网址。具体包括以下两个步骤: (I) 为每个要提取的用户访问信息项编写正则表达式。 IP表达式提取正则表达式定义为:
声明
1.一种自动识别网页信息采集的系统及方法,其特征在于它包括反采集分类器构建模块、自动采集识别模块和反采集在线处理模块,反采集分类器构建模块主要用于利用计算机程序学习和区分自动采集历史网页信息和正常网页访问行为。该模块提供了自动采集识别的训练模型。上面提到的自动采集识别模块,该模块通过加载自动分类器自动识别搜索引擎程序的自动采集行为,并将识别出的采集程序的IP段加入黑名单。黑名单用于后续在线拦截自动采集行为。反采集在线处理模块主要用于对访问的用户进行自动在线判断和处理。如果访问者的IP已经在IP段黑名单中,则拒绝访问该IP;否则,将访问请求转发到 Web 服务器进行进一步处理。
2.根据权利要求1所述的一种能够识别网页信息的反爬虫系统及方法,其特征在于:所述反采集分类器构建模块实现方法具体包括以下步骤:(1)日志分析子模块通过对站点访问日志的自动分析,获取用户的访问行为信息,包括用户访问网站所使用的IP、访问时间、访问的URL、来源URL;样本选择子模块用于步骤I 选择中的分析数据记录是根据连续时间段内同一IP段中访问频率最高的数据记录作为候选数据加入样本集;访问统计子-module 对选取的样本数据进行统计,统计同一个IP段的平均页面停留时间,站点总访问页面数,是否采集web附件信息,网页采集频率;(2)以IP段为主要关键字,将上述信息保存在样本库中,并添加 标记为未标记; (3)标记步骤(I)中未标记的样本,如果确定样本是自动采集,则标记为I;如果是用户浏览器正常访问,则标记为O,更新将所有标记的样本存入数据库;(4)计算机程序自动从样本库中学习并生成分类模型供后续采集自动识别。
3.根据权利要求1所述的一种能够识别网页信息的反爬虫系统及方法,其特征在于:自动采集识别模块的实现方法包括以下步骤:(1)识别在程序初始化阶段,加载分类器模型,模型可以自动判断采集行为;(2)日志分析程序解析最新的网站访问日志,并将解析后的数据发送到访问统计Wu块; (3)Access统计模块计算同一IP段的平均页面停留时间,是否是采集网页附件信息,网页采集频率;(4)Classifier基于分类模型访问IP段行为确定,确定为程序自动采集行为的IP段加入黑名单;
4.根据权利要求1所述的一种能够识别网页信息的反爬虫系统和方法,其特征在于:反采集在线处理模块实现方法包括以下步骤:(1)提取网页信息Web服务器转发访问请求的访问者IP信息;(2)比较黑名单库中的IP信息,如果IP已经在黑名单中,通知Web服务器拒绝IP访问;否则通知Web服务器正常处理访问请求。
全文摘要
本发明公开了一种自动识别网页信息采集的系统及方法,包括反采集分类器构建模块、自动采集识别模块、反采集在线处理模块、 anti采集 @classifier 构建模块主要用于利用计算机程序学习和区分自动采集历史网页信息和正常网页访问行为。自动采集识别模块使用上述步骤中的anti采集分类器。 , 自动识别搜索引擎程序的自动采集行为,并将识别出的采集程序所在的IP段加入黑名单。 anti采集在线处理模块主要用于对访问的用户进行自动在线判断和处理。本发明克服了现有技术的不足。系统通过分析网站历史网页访问行为建立自动采集分类器,识别机器人自动采集,并通过机器人自动采集识别实现网页反爬。
文件编号 G06F17/30GK103218431SQ20131012830
出版日期 2013 年 7 月 24 日申请日期 2013 年 4 月 10 日优先权日期 2013 年 4 月 10 日
发明人张伟、金军、吴扬子、姜燕申请人:金军、姜燕 查看全部
网页采集器的自动识别算法(中国现已有网民4.85亿各类站点域名130余万个爆炸)
专利名称:一种能够自动识别网页信息的系统和方法采集
技术领域:
本发明涉及网页动态分析技术领域,具体属于一种自动识别网页信息的系统及方法。
背景技术:
随着互联网的发展,越来越多的互联网网站出现,形式层出不穷,包括新闻、博客、论坛、SNS、微博等。据CNNIC今年最新统计,现在中国有4.850亿网民,各个网站的域名超过130万个。在互联网信息爆炸式增长的今天,搜索引擎已经成为人们查找互联网信息的最重要工具。搜索引擎主要是自动抓取网站信息,进行预处理,分词后建立索引。输入搜索词后,搜索引擎可以自动为用户找到最相关的结果。经过十多年的发展,搜索引擎技术已经比较成熟,并且因为可以采用成功的商业模式,吸引了众多互联网厂商的进入。比较有名的有百度、谷歌、搜搜、搜狗、有道、奇虎360等。此外,在一些垂直领域(如旅游、机票、比价等)还有搜索引擎,已经有千余家厂商进入。搜索引擎的第一步也是最重要的一步是信息捕获,这是搜索引擎的数据准备过程。具体流程如图1所示。URL DB存储了所有要爬取的URL。 URL调度模块从URL DB中选出最重要的URL,放入URL下载队列。页面下载模块下载队列中的 URL。下载完成后,模块被解压。提取下载的页面代码的文本和URL,将提取的文本发送到索引模块进行分词索引,并将URL放入URL DB。信息采集进程就是把别人的网站信息放入自己数据库的过程,会遇到一些问题。
1、互联网信息每时每刻都在不断增加,因此信息抓取是一个7*24小时不间断的过程。频繁的爬取会给目标网站带来巨大的访问压力,形成DDOS拒绝服务攻击,导致无法为普通用户提供访问。这在中小型网站中尤为明显。这些网站硬件资源比较差,技术力量不强,网上90%以上都是网站这种类型的。例如:某知名搜索引擎因频繁爬取网站而呼吁用户投诉。 2、某些网站 的信息具有隐私或版权。许多网页收录后端数据库、用户隐私和密码等信息。 网站主办方不希望将这些信息公开或免费使用。大众点评曾对爱帮网提起诉讼,称其在网站上抓取评论,然后在网站上发布。目前搜索引擎网页针对采集采用的主流方式是robots协议协议。 网站使用robots,txt协议来控制其内容是否愿意被搜索引擎收录搜索,以及允许收录哪些搜索引擎搜索,并为收录指定自己的内容和禁止收录。同时,搜索引擎会根据每个网站Robots 协议赋予的权限,有意识地进行抓取。该方法假设搜索引擎抓取过程如下:下载网站robots文件-根据robots协议解析文件-获取要下载的网址-确定该网址的访问权限-确定是否根据到判定的结果。 Robots协议是君子协议,没有任何限制,抓取主动权还是完全由搜索引擎控制,完全可以不遵循协议强行抓取。
比如2012年8月,国内某知名搜索引擎不按照协议抓取百度网站内容,被百度指控。另一种反采集方法主要是利用动态技术构建禁止爬取的网页。该方法利用客户端脚本语言(如JS、VBScript、AJAX)动态生成网页显示信息,从而实现信息隐藏,使常规搜索引擎难以获取URL和正文内容。动态网页构建技术只是增加了网页解析提取的难度,并不能从根本上禁止采集和网页信息的解析。目前,一些高级搜索引擎可以模拟浏览器来实现所有的脚本代码解析。获取所有信息的网络URL,从而获取服务器中存储的动态信息。目前有成熟的网页动态分析技术,主要是解析网页中所有的脚本代码段,然后获取网页的所有动态信息(包括有用信息和垃圾信息)。实际实现过程是基于开源脚本代码分析引擎(如Rhino、V8等)为核心搭建网页脚本分析环境,然后从网页中提取脚本代码段,并放入提取的代码段放入网页脚本分析环境中执行分析返回动态信息。解析过程如图2所示。因此,采用动态技术构建动态网页的方法只是增加了网页采集和解析的难度,并没有从根本上消除采集搜索引擎。
发明内容
本发明的目的在于提供一种能够自动识别网页信息采集的系统和方法,克服现有技术的不足。系统通过分析网站的历史网页访问行为,建立自动化的采集。 @Classifier,识别机器人自动采集,通过机器人自动采集识别实现网页的反爬虫。本发明采用的技术方案是:一种自动识别网页信息采集的系统及方法,包括anti采集分类器构建模块、自动采集识别模块和anti采集在线处理模块,以及anti采集在线处理模块。采集分类器构建模块主要用于通过计算机程序学习和区分自动采集历史网页信息和正常网页访问行为。该模块提供了自动采集识别的训练模型。自动采集识别模块,该模块通过加载自动分类器自动识别搜索引擎程序的自动采集行为,并将识别出的采集程序所在的IP段加入黑名单,黑名单是用于后续在线拦截自动采集行为。反采集在线处理模块主要用于对来访用户进行自动在线判断和处理。如果访问者的IP已经在该IP段的黑名单中,则该IP被拒绝访问;否则,将访问请求转发给Web服务器进行进一步处理。反采集分类器构建模块的实现方法具体包括以下步骤:(5)日志分析子模块通过自动分析站点访问日志,获取用户访问行为信息,包括用户对网站IP的访问,访问时间,访问URL,源URL;样本选择子模块根据连续时间段内同一IP段内访问频率最高的数据记录,选择步骤I中解析的数据记录作为候选数据样本采集;访问统计子模块对选取的样本数据进行统计,计算出同一IP段的平均页面停留时间,访问的页面总数,是否为采集网页附件信息,网页采集频率;(6)以IP段为主要关键字,将上述信息保存在样本库中,并将其标记为未标记;(7)标记步骤(I)中未标记的样本,如果确定样本库le是自动采集,会被标记为I;如果用户浏览器正常访问,则标记为0,所有标记的样本都会更新到数据库中; (8)计算机程序会自动从样本库中学习,生成分类模型,用于后期自动采集识别。
自动采集识别模块的实现方法包括以下步骤:(5)identification程序初始化阶段,完成分类器模型的加载,模型可以判断自动采集行为;(6)日志分析程序解析最新的网站访问日志,并将解析出的数据发送给访问统计模块;(7)访问统计模块计算同一IP段的平均页面停留时间,是否为采集web附件信息,网页采集frequency;(8)classifier根据分类模型判断IP段的访问行为,将判断为程序自动采集行为的IP段加入黑名单;表示反@采集在线处理模块实现方法包括以下步骤: (I) 为web服务器转发的访问请求提取访问者的IP信息;(2)比较黑名单库中的IP信息,如果IP已经y在黑名单中,此时通知web服务器拒绝该IP的访问;否则,通知Web服务器正常处理访问请求。与现有技术相比,本发明的有益效果如下: 本发明的系统分析网站网页访问行为的历史,建立一个自动采集分类器,识别自动采集机器人,通过自动机器人采集识别实现网页的反爬行,自动发现搜索引擎网页的采集行为并进行响应采集行为被屏蔽,采集搜索引擎从根本上被淘汰。
图1是现有技术搜索引擎的信息抓取过程示意图;图2是现有技术的第二种分析过程示意图;图3为本发明的anti采集分类器构建框图示意图;图4为本发明自动采集识别模块图;图5为本发明反采集在线处理模块。
具体实施例见附图。一种能够识别网页信息的反抓取系统和方法,包括反采集分类器构建模块、自动采集识别模块和反采集在线处理模块。 采集Classifier 构建模块,该模块主要用于通过计算机程序学习和区分采集自动历史网页信息和正常网页访问行为。该模块提供了自动采集识别的训练模型。自动采集识别模块主要用于加载自动分类器自动识别搜索引擎程序的自动采集行为,并将识别出的采集程序的IP段加入黑名单。该列表用于后续在线拦截自动采集行为。所述anti采集在线处理模块主要用于对来访用户的在线自动判断和处理。如果访问者的IP已经在IP段黑名单中,则该IP被拒绝访问;否则,将访问请求转发给Web服务器进行进一步处理。反采集分类器构建模块实现方法具体包括以下步骤:(9)日志分析子模块通过自动分析站点访问日志,获取用户访问行为信息,包括用户访问网站IP、访问时间,访问URL,源URL;样本选择子模块根据连续时间段内同一IP段内访问频率最高的数据记录,选择步骤I中解析的数据记录作为候选数据样本集合;访问统计子模块对选取的样本数据进行统计,计算出同一IP段的平均页面停留时间、站点总访问页面数、是否为采集网页附件信息、webpage采集
频率; (10)以IP段为主要关键字,将上述信息保存在样本库中,并标记为未标记;(11)对未标记样本执行步骤(I)中的程序如果确定如果样本是机器自动采集,则标记为I;如果用户浏览器正常访问,则标记为0,所有标记的样本都会更新到数据库中;(12)计算机程序会自动检查样本库学习并生成分类模型,用于后续自动采集识别。所述的自动采集识别模块实现方法包括以下步骤:(9)识别程序初始化阶段,完成加载分类器模型,该模型可以自动判断采集行为;(10)日志分析程序解析最新的网站访问日志,并将解析后的数据发送给访问统计模块;(11)访问统计模块计算平均值e 同一IP段的页面停留时间,是否是采集web附件信息,网页采集频率; (12)classifier根据分类模型判断IP段的访问行为,判断为自动程序采集Behavior的IP段加入黑名单;反采集的实现方法在线处理模块包括以下步骤: (i) 为web服务器转发的访问请求提取访问者的IP信息;(2)比较黑名单库中的IP信息,如果IP已经在黑名单中,则通知访问者web server 拒绝访问该IP;否则通知web server 正常处理访问请求 计数器采集classifier 构造 该模块主要用于训练计算机程序,使其能够学习和区分历史web信息自动采集和正常的网页访问行为,该模块可以为后续的自动采集识别提供训练模型,具体包括以下几个步骤。2.2.1.1 日志解析本模块需要解析服务器的历史访问日志(可以选择某一天的日志)提取获取用户的访问行为信息,包括用户访问网站使用的IP、访问发生的时间、访问的URL、和源网址。具体包括以下两个步骤: (I) 为每个要提取的用户访问信息项编写正则表达式。 IP表达式提取正则表达式定义为:
声明
1.一种自动识别网页信息采集的系统及方法,其特征在于它包括反采集分类器构建模块、自动采集识别模块和反采集在线处理模块,反采集分类器构建模块主要用于利用计算机程序学习和区分自动采集历史网页信息和正常网页访问行为。该模块提供了自动采集识别的训练模型。上面提到的自动采集识别模块,该模块通过加载自动分类器自动识别搜索引擎程序的自动采集行为,并将识别出的采集程序的IP段加入黑名单。黑名单用于后续在线拦截自动采集行为。反采集在线处理模块主要用于对访问的用户进行自动在线判断和处理。如果访问者的IP已经在IP段黑名单中,则拒绝访问该IP;否则,将访问请求转发到 Web 服务器进行进一步处理。
2.根据权利要求1所述的一种能够识别网页信息的反爬虫系统及方法,其特征在于:所述反采集分类器构建模块实现方法具体包括以下步骤:(1)日志分析子模块通过对站点访问日志的自动分析,获取用户的访问行为信息,包括用户访问网站所使用的IP、访问时间、访问的URL、来源URL;样本选择子模块用于步骤I 选择中的分析数据记录是根据连续时间段内同一IP段中访问频率最高的数据记录作为候选数据加入样本集;访问统计子-module 对选取的样本数据进行统计,统计同一个IP段的平均页面停留时间,站点总访问页面数,是否采集web附件信息,网页采集频率;(2)以IP段为主要关键字,将上述信息保存在样本库中,并添加 标记为未标记; (3)标记步骤(I)中未标记的样本,如果确定样本是自动采集,则标记为I;如果是用户浏览器正常访问,则标记为O,更新将所有标记的样本存入数据库;(4)计算机程序自动从样本库中学习并生成分类模型供后续采集自动识别。
3.根据权利要求1所述的一种能够识别网页信息的反爬虫系统及方法,其特征在于:自动采集识别模块的实现方法包括以下步骤:(1)识别在程序初始化阶段,加载分类器模型,模型可以自动判断采集行为;(2)日志分析程序解析最新的网站访问日志,并将解析后的数据发送到访问统计Wu块; (3)Access统计模块计算同一IP段的平均页面停留时间,是否是采集网页附件信息,网页采集频率;(4)Classifier基于分类模型访问IP段行为确定,确定为程序自动采集行为的IP段加入黑名单;
4.根据权利要求1所述的一种能够识别网页信息的反爬虫系统和方法,其特征在于:反采集在线处理模块实现方法包括以下步骤:(1)提取网页信息Web服务器转发访问请求的访问者IP信息;(2)比较黑名单库中的IP信息,如果IP已经在黑名单中,通知Web服务器拒绝IP访问;否则通知Web服务器正常处理访问请求。
全文摘要
本发明公开了一种自动识别网页信息采集的系统及方法,包括反采集分类器构建模块、自动采集识别模块、反采集在线处理模块、 anti采集 @classifier 构建模块主要用于利用计算机程序学习和区分自动采集历史网页信息和正常网页访问行为。自动采集识别模块使用上述步骤中的anti采集分类器。 , 自动识别搜索引擎程序的自动采集行为,并将识别出的采集程序所在的IP段加入黑名单。 anti采集在线处理模块主要用于对访问的用户进行自动在线判断和处理。本发明克服了现有技术的不足。系统通过分析网站历史网页访问行为建立自动采集分类器,识别机器人自动采集,并通过机器人自动采集识别实现网页反爬。
文件编号 G06F17/30GK103218431SQ20131012830
出版日期 2013 年 7 月 24 日申请日期 2013 年 4 月 10 日优先权日期 2013 年 4 月 10 日
发明人张伟、金军、吴扬子、姜燕申请人:金军、姜燕
网页采集器的自动识别算法(优采云采集器软件下载,多功能的网页信息数据采集服务工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-09-07 15:05
优采云采集器软件下载,多功能网页信息数据采集服务工具,优采云采集器(网页多功能信息采集)可以为您带来更便捷优质的网页置信服务工具,采集可以使用多种网站内容,不需要专业的网站爬虫技术,独特的多功能引擎模式可以让数据采集更有效率,用户需要去网站数据采集欢迎到本站下载。
优采云采集器软件功能
1.该软件操作简单,鼠标点击即可轻松选择想要抓取的内容。
2. 支持三种高速引擎:浏览器引擎、HTTP 引擎和 JSON 引擎。
3.加上独创的内存优化,让浏览器采集更方便高速运行。
4.快速多数据内容采集功能全面编辑,更好的管理数据服务。
优采云采集器功能介绍
1.不需要分析网页请求和源码,但支持更多网页采集。
2.高级智能算法,一键生成目标元素XPATH。
3.支持丰富的数据导出方式,可以轻松导出多种不同的文件格式。
4.各种数据库全管理,所有服务更方便快捷。
优采云采集器软件优势
1.定时任务:灵活定义运行时间,全自动运行。
2.多引擎支持:支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎。
3.Smart Recognition:可以自动识别网页列表、采集字段和分页等
4.拦截请求:自定义拦截域名,方便过滤异地广告,提高采集速度。 查看全部
网页采集器的自动识别算法(优采云采集器软件下载,多功能的网页信息数据采集服务工具)
优采云采集器软件下载,多功能网页信息数据采集服务工具,优采云采集器(网页多功能信息采集)可以为您带来更便捷优质的网页置信服务工具,采集可以使用多种网站内容,不需要专业的网站爬虫技术,独特的多功能引擎模式可以让数据采集更有效率,用户需要去网站数据采集欢迎到本站下载。
优采云采集器软件功能
1.该软件操作简单,鼠标点击即可轻松选择想要抓取的内容。
2. 支持三种高速引擎:浏览器引擎、HTTP 引擎和 JSON 引擎。
3.加上独创的内存优化,让浏览器采集更方便高速运行。
4.快速多数据内容采集功能全面编辑,更好的管理数据服务。
优采云采集器功能介绍
1.不需要分析网页请求和源码,但支持更多网页采集。
2.高级智能算法,一键生成目标元素XPATH。
3.支持丰富的数据导出方式,可以轻松导出多种不同的文件格式。
4.各种数据库全管理,所有服务更方便快捷。
优采云采集器软件优势
1.定时任务:灵活定义运行时间,全自动运行。
2.多引擎支持:支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎。
3.Smart Recognition:可以自动识别网页列表、采集字段和分页等
4.拦截请求:自定义拦截域名,方便过滤异地广告,提高采集速度。
网页采集器的自动识别算法(网页采集器的自动识别算法,上古时代产品,不像youtube、优酷、土豆等视频流的主流站点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-07 11:02
网页采集器的自动识别算法,
上古时代产品,不像youtube、优酷、土豆等视频流的主流站点。
网或者做网的公司的个人网站,去花钱买些cdn服务和视频抓取服务。如果连同步账号密码之类的流程都不能自己去搞,
百度全家桶
自动识别算法有局限性这是万物运行的客观规律,好比人性、计算机能识别人、手机能识别图片。
现在阿里自己都采集他家的
最好上阿里云啊,
solidot:真相总是这么不尽人意
现在用谷歌不错,用youtube就没必要了,
自动识别只是为了更好管理数据库,尤其是大数据处理时。这里的意思是什么呢?自动识别有很多代理,网站,图片,文章资源,尤其是高清视频,视频很多,每个网站的画质和解码格式的差异很大,想找到你需要的,耗费时间精力很多。国内视频免费的情况下就用度娘吧,大多数视频并不适合用来做自动识别。
金山快盘
熊猫优酷谷歌
这个问题到时有两个选择,一个是免费的,一个是收费的。免费的找个时间精力多点的团队去做,如果有想法可以发到qq群里,找到愿意投入的人去做。收费的就找一些专业的机构帮你做,不要一个人弄。首先得要有整体框架,以及后续的相关的细节可以让人做好。比如百度。或者像我们这样的公司自己也有关键词大数据团队。找准你们的切入点。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法,上古时代产品,不像youtube、优酷、土豆等视频流的主流站点)
网页采集器的自动识别算法,
上古时代产品,不像youtube、优酷、土豆等视频流的主流站点。
网或者做网的公司的个人网站,去花钱买些cdn服务和视频抓取服务。如果连同步账号密码之类的流程都不能自己去搞,
百度全家桶
自动识别算法有局限性这是万物运行的客观规律,好比人性、计算机能识别人、手机能识别图片。
现在阿里自己都采集他家的
最好上阿里云啊,
solidot:真相总是这么不尽人意
现在用谷歌不错,用youtube就没必要了,
自动识别只是为了更好管理数据库,尤其是大数据处理时。这里的意思是什么呢?自动识别有很多代理,网站,图片,文章资源,尤其是高清视频,视频很多,每个网站的画质和解码格式的差异很大,想找到你需要的,耗费时间精力很多。国内视频免费的情况下就用度娘吧,大多数视频并不适合用来做自动识别。
金山快盘
熊猫优酷谷歌
这个问题到时有两个选择,一个是免费的,一个是收费的。免费的找个时间精力多点的团队去做,如果有想法可以发到qq群里,找到愿意投入的人去做。收费的就找一些专业的机构帮你做,不要一个人弄。首先得要有整体框架,以及后续的相关的细节可以让人做好。比如百度。或者像我们这样的公司自己也有关键词大数据团队。找准你们的切入点。
网页采集器的自动识别算法( 我把微博营销案例全部爬虫到一个了Excel表格里)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-09-07 10:23
我把微博营销案例全部爬虫到一个了Excel表格里)
今天的目标:
读者知道什么?
程序员最难学的不是java或c++,而是社交,俗称“嫂子”。
在社交方面,我被认为是程序员中最好的程序员。
比如之前我做过《海报一代表,把我从叔叔变成小弟弟》,捡到了经营社区的小姐姐。
上个月了,这个月又投入到爬虫的技术研究中了。
技术满足的反面是孤独和空虚。
于是,我决定再次用爬虫来逗妹子。 . .
结果。 . .
我做到了! ! !
我将所有微博营销案例抓取到一张 Excel 表格中。
7-0多份运营分析报告,一键下载
网站中的案例需要一一下载↑
对于表中的案例,喜欢和下载较多的↑
管理社区的女孩们快疯了!
秋叶Excel抖音女主:小梅↑
微博手绘大V博主姜江↑
社区运营老司机:颜敏姐姐↑
让我告诉你,如果我早两年爬行,我现在的室友会是谁? !
1- 什么是爬虫
爬虫,即网络爬虫。就是按照一定的规则自动抓取网络上的数据。
比如自动抓取“社交营销案例库”的案例。
想象一下,如果手动浏览页面下载这些案例,流程是这样的:
1- 打开案例库页面
2- 点击案例进入详情页面
3- 点击下载案例pdf
4- 返回案例库页面,点击下一个案例,重复前三步。
如果要下载所有的pdf案例,需要安排专人反复机械地下载。显然,这个人的价值很低。
爬虫取代了这种机械重复、低价值的数据采集动作,利用程序或代码自动批量完成数据采集。
爬虫的好处
简单总结一下,爬虫的好处主要有两个方面:
1- 自动爬取,解放人力,提高效率
机器,低价值的工作,用机器来完成工作是最好的解决方案。
2- 数据分析,跳线获取优质内容
与手动浏览数据不同,爬虫可以将数据汇总整合成数据表,方便我们以后做数据统计和数据分析。
例如,在“社交营销案例库”中,每个案例都有查看次数和下载次数。如果要按查看次数排序,则会优先查看查看次数最多的案例。将数据抓取到Excel表格中,并使用排序功能,方便浏览。
爬虫案例
可以抓取任何数据。
掌握了爬虫的技巧,可以做的事情很多。
Excelhome 的帖子抓取
我教Excel,Excelhome论坛是个大宝。
一张一张看太难了。抓取1.400 万个帖子,然后选择观看次数最多的帖子。
窗帘选择文章攀取
窗帘是梳理轮廓的好工具。很多大咖用窗帘写读书笔记,不用看全书也能学会要点。
我没时间在屏幕上一一浏览选中的文章,抓取所有选中的文章,整理出自己的知识大纲。
姜操公众号文章crawl
我很喜欢曹将军。拥有同龄人所缺乏的逻辑、归纳、表达能力,文章篇篇精精。
公众号太多,手机看书容易分心?爬入 Excel,然后开始查看最高的行读数。
另外还有抖音播报数据、公众号阅读、评论数据、B站弹幕数据、网易云评论数据。
爬虫+数据分析给网络带来更多乐趣。
2- 简单的爬虫,锋利的工具
说到爬虫,大部分人都会想到编程计数、python、数据库、beautiful、html结构等,让人望而生畏。
其实基础爬虫很简单,借助一些采集软件,一键即可轻松完成。
常用爬虫软件
我抓取数据时用到了以下软件,推荐给大家:
1-优采云采集器
简单易学,采集data和向导模式可通过可视化界面,鼠标点击,用户无需任何技术基础,输入网址,一键提取数据。
这是我接触的第一个爬虫软件,
优点:
1-使用过程简单,上手特别好。
缺点:
1- 进口数量限制。 采集,非会员只能导出1000条数据。
2- 导出格式限制。非会员只能导出为txt文本格式。
2-优采云
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库
在优采云不能满足我的需求后,我开始尝试更专业的采集软件,找到了优采云。
优点:
1-采集功能更强大,可以自定义采集进程。
2- 导出格式和数据量没有限制。
缺点:
1- 过程有点复杂,新手上手难度较大。
3-优采云采集器(推荐)
智能识别数据,小白神器
基于人工智能算法,只需输入网址即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集。自动识别列表、表格、链接、图片、价格、电子邮件等
这是我现在用的采集软件。可以说抵消了前两个采集器的优缺点,体验更好。
优点:
1-自动识别页面信息,简单上手
2- 导出格式和数据量没有限制
目前没有发现缺点。
3- 爬虫操作流程
注意,注意,接下来是动手部分。
以“屏幕选择文章”为例,用“优采云采集器”体验爬行的乐趣。
采集后的效果如下:
1- 复制采集的链接
打开窗帘官网,点击“精选”进入选中的文章页面。
复制特色页面的网址:
2-优采云采集data
1-登录“优采云采集器”官网,下载安装采集器。
2-打开采集器后,在“智能模式”中点击“开始采集”,新建一个smart采集。
3- 粘贴到屏幕的选定网址中,点击立即创建
在这个过程中采集器会自动识别页面上的列表和数据内容。整个过程由AI算法自动完成,等待识别完成。
页面分析与识别↑
页面识别完成↑
4- 点击“Start采集”->“Enable”开始爬虫之旅。
3-采集数据导出
在数据爬取过程中,您可以点击“停止”结束数据爬取。
或者等待数据爬取完成,在弹出的对话框中点击“导出数据”。
导出格式,选择 Excel,然后导出。
4- 使用 HYPERLINK 函数添加超链接
打开导出的表格,在I列添加HYPERLINK公式,添加超链接,一键打开对应的文章。
公式如下:
=HYPERLINK(B2,"点击查看")
到此,您的第一个爬虫之旅已成功完成!
4- 总结
爬虫就像在 VBA 中记录宏,记录重复动作而不是手动重复操作。
我今天看到的只是简单的数据采集。还有很多关于爬虫的话题和非常深入的内容。例如:
1- 身份验证。需要登录才能抓取页面。
2- 浏览器检查。比如公众号文章只能获取微信阅读数。
3- 参数验证(验证码)。该页面需要验证码。
4- 请求频率。例如页面访问时间不能小于10秒
5- 数据处理。需要抓取的数据需要从数字、英文等内容中提取出来。
了解了爬取过程后,您现在最想爬取什么数据?
我是会设计表格的Excel老师拉小邓
如果你喜欢这个文章,请给我三重品质。今天就到这里,下课结束! 查看全部
网页采集器的自动识别算法(
我把微博营销案例全部爬虫到一个了Excel表格里)
今天的目标:
读者知道什么?
程序员最难学的不是java或c++,而是社交,俗称“嫂子”。
在社交方面,我被认为是程序员中最好的程序员。
比如之前我做过《海报一代表,把我从叔叔变成小弟弟》,捡到了经营社区的小姐姐。
上个月了,这个月又投入到爬虫的技术研究中了。
技术满足的反面是孤独和空虚。
于是,我决定再次用爬虫来逗妹子。 . .
结果。 . .
我做到了! ! !
我将所有微博营销案例抓取到一张 Excel 表格中。
7-0多份运营分析报告,一键下载
网站中的案例需要一一下载↑
对于表中的案例,喜欢和下载较多的↑
管理社区的女孩们快疯了!
秋叶Excel抖音女主:小梅↑
微博手绘大V博主姜江↑
社区运营老司机:颜敏姐姐↑
让我告诉你,如果我早两年爬行,我现在的室友会是谁? !
1- 什么是爬虫
爬虫,即网络爬虫。就是按照一定的规则自动抓取网络上的数据。
比如自动抓取“社交营销案例库”的案例。
想象一下,如果手动浏览页面下载这些案例,流程是这样的:
1- 打开案例库页面
2- 点击案例进入详情页面
3- 点击下载案例pdf
4- 返回案例库页面,点击下一个案例,重复前三步。
如果要下载所有的pdf案例,需要安排专人反复机械地下载。显然,这个人的价值很低。
爬虫取代了这种机械重复、低价值的数据采集动作,利用程序或代码自动批量完成数据采集。
爬虫的好处
简单总结一下,爬虫的好处主要有两个方面:
1- 自动爬取,解放人力,提高效率
机器,低价值的工作,用机器来完成工作是最好的解决方案。
2- 数据分析,跳线获取优质内容
与手动浏览数据不同,爬虫可以将数据汇总整合成数据表,方便我们以后做数据统计和数据分析。
例如,在“社交营销案例库”中,每个案例都有查看次数和下载次数。如果要按查看次数排序,则会优先查看查看次数最多的案例。将数据抓取到Excel表格中,并使用排序功能,方便浏览。
爬虫案例
可以抓取任何数据。
掌握了爬虫的技巧,可以做的事情很多。
Excelhome 的帖子抓取
我教Excel,Excelhome论坛是个大宝。
一张一张看太难了。抓取1.400 万个帖子,然后选择观看次数最多的帖子。
窗帘选择文章攀取
窗帘是梳理轮廓的好工具。很多大咖用窗帘写读书笔记,不用看全书也能学会要点。
我没时间在屏幕上一一浏览选中的文章,抓取所有选中的文章,整理出自己的知识大纲。
姜操公众号文章crawl
我很喜欢曹将军。拥有同龄人所缺乏的逻辑、归纳、表达能力,文章篇篇精精。
公众号太多,手机看书容易分心?爬入 Excel,然后开始查看最高的行读数。
另外还有抖音播报数据、公众号阅读、评论数据、B站弹幕数据、网易云评论数据。
爬虫+数据分析给网络带来更多乐趣。
2- 简单的爬虫,锋利的工具
说到爬虫,大部分人都会想到编程计数、python、数据库、beautiful、html结构等,让人望而生畏。
其实基础爬虫很简单,借助一些采集软件,一键即可轻松完成。
常用爬虫软件
我抓取数据时用到了以下软件,推荐给大家:
1-优采云采集器
简单易学,采集data和向导模式可通过可视化界面,鼠标点击,用户无需任何技术基础,输入网址,一键提取数据。
这是我接触的第一个爬虫软件,
优点:
1-使用过程简单,上手特别好。
缺点:
1- 进口数量限制。 采集,非会员只能导出1000条数据。
2- 导出格式限制。非会员只能导出为txt文本格式。
2-优采云
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库
在优采云不能满足我的需求后,我开始尝试更专业的采集软件,找到了优采云。
优点:
1-采集功能更强大,可以自定义采集进程。
2- 导出格式和数据量没有限制。
缺点:
1- 过程有点复杂,新手上手难度较大。
3-优采云采集器(推荐)
智能识别数据,小白神器
基于人工智能算法,只需输入网址即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集。自动识别列表、表格、链接、图片、价格、电子邮件等
这是我现在用的采集软件。可以说抵消了前两个采集器的优缺点,体验更好。
优点:
1-自动识别页面信息,简单上手
2- 导出格式和数据量没有限制
目前没有发现缺点。
3- 爬虫操作流程
注意,注意,接下来是动手部分。
以“屏幕选择文章”为例,用“优采云采集器”体验爬行的乐趣。
采集后的效果如下:
1- 复制采集的链接
打开窗帘官网,点击“精选”进入选中的文章页面。
复制特色页面的网址:
2-优采云采集data
1-登录“优采云采集器”官网,下载安装采集器。
2-打开采集器后,在“智能模式”中点击“开始采集”,新建一个smart采集。
3- 粘贴到屏幕的选定网址中,点击立即创建
在这个过程中采集器会自动识别页面上的列表和数据内容。整个过程由AI算法自动完成,等待识别完成。
页面分析与识别↑
页面识别完成↑
4- 点击“Start采集”->“Enable”开始爬虫之旅。
3-采集数据导出
在数据爬取过程中,您可以点击“停止”结束数据爬取。
或者等待数据爬取完成,在弹出的对话框中点击“导出数据”。
导出格式,选择 Excel,然后导出。
4- 使用 HYPERLINK 函数添加超链接
打开导出的表格,在I列添加HYPERLINK公式,添加超链接,一键打开对应的文章。
公式如下:
=HYPERLINK(B2,"点击查看")
到此,您的第一个爬虫之旅已成功完成!
4- 总结
爬虫就像在 VBA 中记录宏,记录重复动作而不是手动重复操作。
我今天看到的只是简单的数据采集。还有很多关于爬虫的话题和非常深入的内容。例如:
1- 身份验证。需要登录才能抓取页面。
2- 浏览器检查。比如公众号文章只能获取微信阅读数。
3- 参数验证(验证码)。该页面需要验证码。
4- 请求频率。例如页面访问时间不能小于10秒
5- 数据处理。需要抓取的数据需要从数字、英文等内容中提取出来。
了解了爬取过程后,您现在最想爬取什么数据?
我是会设计表格的Excel老师拉小邓
如果你喜欢这个文章,请给我三重品质。今天就到这里,下课结束!
网页采集器的自动识别算法(聪明的in-speed技术会动态地将所有设定应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-09-07 06:04
IDM 最多可以将您的下载速度提高 5 倍、安排下载或继续下载一半的软件。互联网下载管理器的恢复功能可以恢复一半因断开连接、网络问题、计算机崩溃甚至意外断电而导致的下载软件。
本程序具有动态文件分割、多下载点技术,无需重新登录即可重用现有连接。巧妙的 in-speed 技术将所有设置动态应用到某种连接类型,以充分利用下载速度。 Internet 下载管理器支持下载队列、防火墙、代理服务器和映射服务器、重定向、cookie、需要验证的目录以及各种服务器平台。该程序与 Internet Explorer 和 Netscape Communicator 紧密集成,可自动处理您的下载需求。本程序还具有优化下载逻辑、查杀病毒、多种偏好设置等功能。
Internet Download Manager 支持所有流行的浏览器,包括:Microsoft Internet Explorer、Netscape、MSN Explorer、AOL、Opera、Mozilla、Mozilla Firefox、Mozilla Firebird、Avant Browser、MyIE2、Google Chrome 等。如果您启用高级集成,您可以从任何程序捕获和接管下载。
Internet 下载管理器支持 HTTP、FTP、HTTPS 和 MMS 协议。 IDM 不是 p2p 下载软件,因此不能用于下载通过 BT 和 eMule 发布的内容。
6.19
改进IDM下载引擎
支持 Firefox 29 和 SeaMonkey 2.24
修复 Chrome 视频嗅探
修复 Chrome 以接管 https 下载
  查看全部
网页采集器的自动识别算法(聪明的in-speed技术会动态地将所有设定应用)
IDM 最多可以将您的下载速度提高 5 倍、安排下载或继续下载一半的软件。互联网下载管理器的恢复功能可以恢复一半因断开连接、网络问题、计算机崩溃甚至意外断电而导致的下载软件。
本程序具有动态文件分割、多下载点技术,无需重新登录即可重用现有连接。巧妙的 in-speed 技术将所有设置动态应用到某种连接类型,以充分利用下载速度。 Internet 下载管理器支持下载队列、防火墙、代理服务器和映射服务器、重定向、cookie、需要验证的目录以及各种服务器平台。该程序与 Internet Explorer 和 Netscape Communicator 紧密集成,可自动处理您的下载需求。本程序还具有优化下载逻辑、查杀病毒、多种偏好设置等功能。
Internet Download Manager 支持所有流行的浏览器,包括:Microsoft Internet Explorer、Netscape、MSN Explorer、AOL、Opera、Mozilla、Mozilla Firefox、Mozilla Firebird、Avant Browser、MyIE2、Google Chrome 等。如果您启用高级集成,您可以从任何程序捕获和接管下载。
Internet 下载管理器支持 HTTP、FTP、HTTPS 和 MMS 协议。 IDM 不是 p2p 下载软件,因此不能用于下载通过 BT 和 eMule 发布的内容。
6.19
改进IDM下载引擎
支持 Firefox 29 和 SeaMonkey 2.24
修复 Chrome 视频嗅探
修复 Chrome 以接管 https 下载
 

