
网页采集器的自动识别算法
网页采集器的自动识别算法(网页采集大师这款软件的用途和界面样式的初步介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-01-24 03:07
今天要分享的是一款名为Master of Web Data 采集的软件,名字好听,哈哈。
您可以通过查看名称来判断它的作用。是的,专门用于采集网页中的数据,主要是自动化采集各种列表页和详情页数据。您也可以将其用作爬虫工具。下面简单介绍一下什么是所谓的列表页和详情页。
以某电商网站为例,下图为列表页面,即一个列表中显示了很多相似的数据,一个页面无法完整显示,所以也可以跳转到页面底部的下一页,即分页显示。
列表
如果数据量大,列表页单独显示。
分页
以下为详情页展示:
详情页数据
上面是列表页+详情页,就是这个工具进来的地方。大部分网站都是这样,只要是分页数据,都可以批量采集,< @采集 非常快,非常安全,几乎不用担心被屏蔽。
说完它的功能,我们再来看看它的软件长什么样。
网页采集大师
以上是对软件的用途和界面风格的初步介绍,大师采集。看完界面,是不是觉得很简单呢?是的,这个软件的界面是我设计的。而且所有的代码都是我自己写的。
本软件可以采集PC上几乎所有的网页数据,包括上图所示的列表页和详情页数据,然后生成excel或者文本格式的文件。使用起来非常简单方便。您可以在几分钟内采集 数千条数据,因此您不必再担心没有数据了。
如果你对网页采集、爬虫感兴趣,或者对网页数据有需求,欢迎关注我,以后我会经常分享这个软件的使用方法。如有童鞋毕业设计需要数据,请联系我,帮您快速解决数据问题。
我的头条号: 查看全部
网页采集器的自动识别算法(网页采集大师这款软件的用途和界面样式的初步介绍)
今天要分享的是一款名为Master of Web Data 采集的软件,名字好听,哈哈。
您可以通过查看名称来判断它的作用。是的,专门用于采集网页中的数据,主要是自动化采集各种列表页和详情页数据。您也可以将其用作爬虫工具。下面简单介绍一下什么是所谓的列表页和详情页。
以某电商网站为例,下图为列表页面,即一个列表中显示了很多相似的数据,一个页面无法完整显示,所以也可以跳转到页面底部的下一页,即分页显示。

列表
如果数据量大,列表页单独显示。
分页
以下为详情页展示:
详情页数据
上面是列表页+详情页,就是这个工具进来的地方。大部分网站都是这样,只要是分页数据,都可以批量采集,< @采集 非常快,非常安全,几乎不用担心被屏蔽。
说完它的功能,我们再来看看它的软件长什么样。
网页采集大师
以上是对软件的用途和界面风格的初步介绍,大师采集。看完界面,是不是觉得很简单呢?是的,这个软件的界面是我设计的。而且所有的代码都是我自己写的。
本软件可以采集PC上几乎所有的网页数据,包括上图所示的列表页和详情页数据,然后生成excel或者文本格式的文件。使用起来非常简单方便。您可以在几分钟内采集 数千条数据,因此您不必再担心没有数据了。
如果你对网页采集、爬虫感兴趣,或者对网页数据有需求,欢迎关注我,以后我会经常分享这个软件的使用方法。如有童鞋毕业设计需要数据,请联系我,帮您快速解决数据问题。
我的头条号:
网页采集器的自动识别算法( 2020年03月23日15:55:59python实现识别手写数字)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-01-23 18:18
2020年03月23日15:55:59python实现识别手写数字)
python实现手写数字识别 python图像识别算法
更新时间:2020-03-23 15:55:59 作者:Hanpu_Liang
本文文章主要详细介绍python识别手写数字的实现,python图像识别算法,有一定的参考价值,感兴趣的朋友可以参考一下
写在前面
这一段的内容可以说是最难的部分之一。因为是识别图像,涉及到的算法会比上一个难度更大,所以我尽量说清楚。
并且因为在写的过程中,对之前的一些逻辑也进行了修改和完善,所以一切以本文为准。当然,如果你想直接看代码,代码都放在我的GitHub上,所以这个文章主要负责讲解,如果需要代码,请自行去GitHub。
这个大纲
上次我写了关于建立数据库的文章,我们能够将更新的训练图像实时存储在 CSV 文件中。所以这次继续往下看,就到了识别图片内容的时候了。
首先,我们需要从文件夹中提取出要识别的图片test.png,和训练图片一样的处理,得到一个1x10000的向量。因为两者有细微的差别,我并不想在源码中添加逻辑,所以直接重写了添加待识别图片的函数,命名为GetTestPicture。内容与GetTrainPicture类似,但缺少“添加图片名称”部分。
之后,我们就可以开始正式的图像识别内容了。
主要目的是计算待识别图像与所有训练图像之间的距离。当两张图片更接近时,意味着它们更相似,因此它们很可能会写相同的数字。所以利用这个原理,我们可以找出最接近待识别图像的训练图像,并输出它们的数量。比如我要输出前三个,而前三个分别是3、3、9,则表示要识别的图像很可能是3.
之后,还可以给每个位置加一个权重,细节下次再说。本节内容足够。
(在第一篇文章中,我提到了使用图片孔数来检测,我试过了,觉得有点不合适,具体原因在文末。)
主要代码
所以直接放主代码,逻辑比较清晰
import os
import OperatePicture as OP
import OperateDatabase as OD
import PictureAlgorithm as PA
import csv
##Essential vavriable 基础变量
#Standard size 标准大小
N = 100
#Gray threshold 灰度阈值
color = 200/255
n = 10
#读取原CSV文件
reader = list(csv.reader(open('Database.csv', encoding = 'utf-8')))
#清除读取后的第一个空行
del reader[0]
#读取num目录下的所有文件名
fileNames = os.listdir(r"./num/")
#对比fileNames与reader,得到新增的图片newFileNames
newFileNames = OD.NewFiles(fileNames, reader)
print('New pictures are: ', newFileNames)
#得到newFilesNames对应的矩阵
pic = OP.GetTrainPicture(newFileNames)
#将新增图片矩阵存入CSV中
OD.SaveToCSV(pic, newFileNames)
#将原数据库矩阵与新数据库矩阵合并
pic = OD.Combination(reader, pic)
#得到待识别图片
testFiles = os.listdir(r"./test/")
testPic = OP.GetTestPicture(testFiles)
#计算每一个待识别图片的可能分类
result = PA.CalculateResult(testPic, pic)
for item in result:
for i in range(n):
print('第'+str(i+1)+'个向量为'+str(item[i+n])+',距离为'+str(item[i]))
与上一篇文章的内容相比,本文文章只增加了如下一段代码,即获取待识别图片的名称,获取待识别的图片向量,并计算分类。
下面我们将重点介绍CalculateResult函数的内容,即识别图像的算法。
算法内容
一般算法
我们在大纲里已经简单介绍过了,我就照搬一下,补充一些内容。
假设我们在二维平面上有两个点 A=(1,1) 和 B=(5,5),我现在将另一个点 C=(2,2),那么,哪一个更接近C点?
初中学过数学的都知道,肯定离A点比较近。所以换个说法,我们现在有A和B两个班,A班包括点(1,1) ,B类包括点(5,5),那么对于点(2,2),它可能属于哪个类别?
因为这个点离A类的点有点近,所以很可能属于A类。这就是结论。那么对于3维空间,A类是点(1,1,1),B类是(5,5,5),那么对于点(2,2,2) 必须相同)属于 A 类。
可以看出,我们以两点之间的距离作为判断属于哪个类别的标准。那么对于我们把图片拉进去的1xn维向量,投影到n维空间上其实就是一个点,所以我们把训练向量分成10个类别,分别代表十个数字,那么哪个类别是识别出来的数字close to,然后说明它可能属于这一类。
那么我们这里可以假设对于识别出的向量,列出离他最近的前十个向量属于哪个类别,然后根据排名加上一个权重,计算一个值。这个值代表它可能属于哪个类,所以这就是我们得到的最终结果——识别出的手写数字图片的值。
以上是第一个文章的内容,现在我重点讲数学的内容。
考虑到有些地方不能输入数学公式(或者输入不方便),我还是把这一段贴图。
然后直接挑出最接近识别图片的前几个向量。基本上,这些数字是识别图片的数字。但是这样做有点简单,所以在下一篇文章我会深入,这篇先讲计算距离。
主要代码
在下面的代码中,文件夹test用来存放要识别的图片,通过函数GetTestPicture得到图片向量,然后和训练图片pic一起放入计算距离的函数CalculateResult中计算距离在每个要识别的向量和所有其他图像向量之间。.
#得到待识别图片
testFiles = os.listdir(r"./test/")
testPic = OP.GetTestPicture(testFiles)
#计算每一个待识别图片的可能分类
result = PA.CalculateResult(testPic, pic)
for item in result:
for i in range(n):
print('第'+str(i+1)+'个向量为'+str(item[i+n])+',距离为'+str(item[i]))
函数 CalculateResult 在文件 PictureAlgorithm.py 中。该文件收录两个函数:CalculateDistance 函数和CalculateResult 函数,代表用于识别图片的算法。
函数计算结果
这个函数的逻辑比较简单,没什么好说的。主要连接是计算距离的CalculateDistance 函数。
def CalculateResult(test, train):
'''计算待识别图片test的可能分类'''
#得到每个图片的前n相似图片
testDis = CalculateDistance(test[:,0:N**2], train[:,0:N**2], train[:,N**2], n)
#将testDis变成列表
tt = testDis.tolist()
#输出每一个待识别图片的所有前n个
for i in tt:
for j in i:
print(j)
函数计算距离
在函数中,我导入了四个参数:识别向量test,训练向量train,每个向量对应的训练向量所代表的数字num,以及我要导出的前n个最近的向量。
def CalculateDistance(test, train, num, n):
'''计算每个图片前n相似图片'''
#前n个放距离,后n个放数字
dis = np.zeros(2*n*len(test)).reshape(len(test), 2*n)
for i, item in enumerate(test):
#计算出每个训练图片与该待识别图片的距离
itemDis = np.sqrt(np.sum((item-train)**2, axis=1))
#对距离进行排序,找出前n个
sortDis = np.sort(itemDis)
dis[i, 0:n] = sortDis[0:n]
for j in range(n):
#找到前几个在原矩阵中的位置
maxPoint = list(itemDis).index(sortDis[j])
#找到num对应位置的数字,存入dis中
dis[i, j+n] = num[maxPoint]
return dis
首先,创建一个矩阵,其行数为测试中识别的向量数,列数为 2*n。每行的前 n 是距离,最后 n 是数字。然后循环每个识别的向量。
首先,直接计算每张训练图像与识别图像的距离,可以直接用一行代码表示
itemDis = np.sqrt(np.sum((item-train)**2, axis=1))
这行代码就是上面的算法过程。我个人认为是比较复杂的。你可以仔细看看。我不会在这里详细介绍。下面开始排序,找到最接近的前几个向量。
这里的逻辑是:先排序,找到距离最小的前n个,存入矩阵。求原矩阵的前n个位置,求对应位置的num个数,存入dis的最后n个。
这相当于完成了一切,只需返回dis即可。
实际测试
我手写了一些数字,如图所示。所以实际上我们的数据库还是比较小的。
所以我写了另一个数字作为要识别的图像。运行完程序,我们直接输出前十个最相似的向量:
第一个向量为2.0,距离为33.62347223932534
第二个向量是2.0,距离是35.645
第三个向量为2.0,距离为38.69663119274146
第四个向量为2.0,距离为43.529
第5个向量是2.0,距离是43.694
第6个向量为1.0,距离为43.7314
第7个向量为6.0,距离为44.948
第8个向量为2.0,距离为45.5924
第9个向量为4.0,距离为45.43926712996951
第10个向量为7.0,距离为45.64893989116544
之后,我又从 1 到 9 再试一次,我手写的数字都被正确识别了。可以看出,准确率还是挺高的。所以做了这一步就相当于完成度很高。
于是我试了一下网上找的图片,发现几乎没有正确的。这意味着我们的数据库仍然太小,只能识别我的字体。不过话虽如此,你也可以做一个字体识别程序。
所以如果你想提高准确率,那么扩展图库是必须的。这次就到这里了。
总结
我的 GitHub 里有全部源代码,有兴趣的可以去看看。
这相当于完成了算法内容,比较简单,只使用了类似于K最近邻的算法。
下一篇文章会讲一个对前n个排名进行加权提高准确率的思路。
所以这次我就到这里了,谢谢。
喜欢的话请点个赞关注一下,谢谢~
本文已被收录收录在“python图像处理操作”专题中,欢迎大家点击了解更多精彩内容。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持Scripting Home。 查看全部
网页采集器的自动识别算法(
2020年03月23日15:55:59python实现识别手写数字)
python实现手写数字识别 python图像识别算法
更新时间:2020-03-23 15:55:59 作者:Hanpu_Liang
本文文章主要详细介绍python识别手写数字的实现,python图像识别算法,有一定的参考价值,感兴趣的朋友可以参考一下
写在前面
这一段的内容可以说是最难的部分之一。因为是识别图像,涉及到的算法会比上一个难度更大,所以我尽量说清楚。
并且因为在写的过程中,对之前的一些逻辑也进行了修改和完善,所以一切以本文为准。当然,如果你想直接看代码,代码都放在我的GitHub上,所以这个文章主要负责讲解,如果需要代码,请自行去GitHub。
这个大纲
上次我写了关于建立数据库的文章,我们能够将更新的训练图像实时存储在 CSV 文件中。所以这次继续往下看,就到了识别图片内容的时候了。
首先,我们需要从文件夹中提取出要识别的图片test.png,和训练图片一样的处理,得到一个1x10000的向量。因为两者有细微的差别,我并不想在源码中添加逻辑,所以直接重写了添加待识别图片的函数,命名为GetTestPicture。内容与GetTrainPicture类似,但缺少“添加图片名称”部分。
之后,我们就可以开始正式的图像识别内容了。
主要目的是计算待识别图像与所有训练图像之间的距离。当两张图片更接近时,意味着它们更相似,因此它们很可能会写相同的数字。所以利用这个原理,我们可以找出最接近待识别图像的训练图像,并输出它们的数量。比如我要输出前三个,而前三个分别是3、3、9,则表示要识别的图像很可能是3.
之后,还可以给每个位置加一个权重,细节下次再说。本节内容足够。
(在第一篇文章中,我提到了使用图片孔数来检测,我试过了,觉得有点不合适,具体原因在文末。)
主要代码
所以直接放主代码,逻辑比较清晰
import os
import OperatePicture as OP
import OperateDatabase as OD
import PictureAlgorithm as PA
import csv
##Essential vavriable 基础变量
#Standard size 标准大小
N = 100
#Gray threshold 灰度阈值
color = 200/255
n = 10
#读取原CSV文件
reader = list(csv.reader(open('Database.csv', encoding = 'utf-8')))
#清除读取后的第一个空行
del reader[0]
#读取num目录下的所有文件名
fileNames = os.listdir(r"./num/")
#对比fileNames与reader,得到新增的图片newFileNames
newFileNames = OD.NewFiles(fileNames, reader)
print('New pictures are: ', newFileNames)
#得到newFilesNames对应的矩阵
pic = OP.GetTrainPicture(newFileNames)
#将新增图片矩阵存入CSV中
OD.SaveToCSV(pic, newFileNames)
#将原数据库矩阵与新数据库矩阵合并
pic = OD.Combination(reader, pic)
#得到待识别图片
testFiles = os.listdir(r"./test/")
testPic = OP.GetTestPicture(testFiles)
#计算每一个待识别图片的可能分类
result = PA.CalculateResult(testPic, pic)
for item in result:
for i in range(n):
print('第'+str(i+1)+'个向量为'+str(item[i+n])+',距离为'+str(item[i]))
与上一篇文章的内容相比,本文文章只增加了如下一段代码,即获取待识别图片的名称,获取待识别的图片向量,并计算分类。
下面我们将重点介绍CalculateResult函数的内容,即识别图像的算法。
算法内容
一般算法
我们在大纲里已经简单介绍过了,我就照搬一下,补充一些内容。
假设我们在二维平面上有两个点 A=(1,1) 和 B=(5,5),我现在将另一个点 C=(2,2),那么,哪一个更接近C点?
初中学过数学的都知道,肯定离A点比较近。所以换个说法,我们现在有A和B两个班,A班包括点(1,1) ,B类包括点(5,5),那么对于点(2,2),它可能属于哪个类别?
因为这个点离A类的点有点近,所以很可能属于A类。这就是结论。那么对于3维空间,A类是点(1,1,1),B类是(5,5,5),那么对于点(2,2,2) 必须相同)属于 A 类。
可以看出,我们以两点之间的距离作为判断属于哪个类别的标准。那么对于我们把图片拉进去的1xn维向量,投影到n维空间上其实就是一个点,所以我们把训练向量分成10个类别,分别代表十个数字,那么哪个类别是识别出来的数字close to,然后说明它可能属于这一类。
那么我们这里可以假设对于识别出的向量,列出离他最近的前十个向量属于哪个类别,然后根据排名加上一个权重,计算一个值。这个值代表它可能属于哪个类,所以这就是我们得到的最终结果——识别出的手写数字图片的值。
以上是第一个文章的内容,现在我重点讲数学的内容。
考虑到有些地方不能输入数学公式(或者输入不方便),我还是把这一段贴图。

然后直接挑出最接近识别图片的前几个向量。基本上,这些数字是识别图片的数字。但是这样做有点简单,所以在下一篇文章我会深入,这篇先讲计算距离。
主要代码
在下面的代码中,文件夹test用来存放要识别的图片,通过函数GetTestPicture得到图片向量,然后和训练图片pic一起放入计算距离的函数CalculateResult中计算距离在每个要识别的向量和所有其他图像向量之间。.
#得到待识别图片
testFiles = os.listdir(r"./test/")
testPic = OP.GetTestPicture(testFiles)
#计算每一个待识别图片的可能分类
result = PA.CalculateResult(testPic, pic)
for item in result:
for i in range(n):
print('第'+str(i+1)+'个向量为'+str(item[i+n])+',距离为'+str(item[i]))
函数 CalculateResult 在文件 PictureAlgorithm.py 中。该文件收录两个函数:CalculateDistance 函数和CalculateResult 函数,代表用于识别图片的算法。
函数计算结果
这个函数的逻辑比较简单,没什么好说的。主要连接是计算距离的CalculateDistance 函数。
def CalculateResult(test, train):
'''计算待识别图片test的可能分类'''
#得到每个图片的前n相似图片
testDis = CalculateDistance(test[:,0:N**2], train[:,0:N**2], train[:,N**2], n)
#将testDis变成列表
tt = testDis.tolist()
#输出每一个待识别图片的所有前n个
for i in tt:
for j in i:
print(j)
函数计算距离
在函数中,我导入了四个参数:识别向量test,训练向量train,每个向量对应的训练向量所代表的数字num,以及我要导出的前n个最近的向量。
def CalculateDistance(test, train, num, n):
'''计算每个图片前n相似图片'''
#前n个放距离,后n个放数字
dis = np.zeros(2*n*len(test)).reshape(len(test), 2*n)
for i, item in enumerate(test):
#计算出每个训练图片与该待识别图片的距离
itemDis = np.sqrt(np.sum((item-train)**2, axis=1))
#对距离进行排序,找出前n个
sortDis = np.sort(itemDis)
dis[i, 0:n] = sortDis[0:n]
for j in range(n):
#找到前几个在原矩阵中的位置
maxPoint = list(itemDis).index(sortDis[j])
#找到num对应位置的数字,存入dis中
dis[i, j+n] = num[maxPoint]
return dis
首先,创建一个矩阵,其行数为测试中识别的向量数,列数为 2*n。每行的前 n 是距离,最后 n 是数字。然后循环每个识别的向量。
首先,直接计算每张训练图像与识别图像的距离,可以直接用一行代码表示
itemDis = np.sqrt(np.sum((item-train)**2, axis=1))
这行代码就是上面的算法过程。我个人认为是比较复杂的。你可以仔细看看。我不会在这里详细介绍。下面开始排序,找到最接近的前几个向量。
这里的逻辑是:先排序,找到距离最小的前n个,存入矩阵。求原矩阵的前n个位置,求对应位置的num个数,存入dis的最后n个。
这相当于完成了一切,只需返回dis即可。
实际测试
我手写了一些数字,如图所示。所以实际上我们的数据库还是比较小的。

所以我写了另一个数字作为要识别的图像。运行完程序,我们直接输出前十个最相似的向量:
第一个向量为2.0,距离为33.62347223932534
第二个向量是2.0,距离是35.645
第三个向量为2.0,距离为38.69663119274146
第四个向量为2.0,距离为43.529
第5个向量是2.0,距离是43.694
第6个向量为1.0,距离为43.7314
第7个向量为6.0,距离为44.948
第8个向量为2.0,距离为45.5924
第9个向量为4.0,距离为45.43926712996951
第10个向量为7.0,距离为45.64893989116544
之后,我又从 1 到 9 再试一次,我手写的数字都被正确识别了。可以看出,准确率还是挺高的。所以做了这一步就相当于完成度很高。
于是我试了一下网上找的图片,发现几乎没有正确的。这意味着我们的数据库仍然太小,只能识别我的字体。不过话虽如此,你也可以做一个字体识别程序。
所以如果你想提高准确率,那么扩展图库是必须的。这次就到这里了。
总结
我的 GitHub 里有全部源代码,有兴趣的可以去看看。
这相当于完成了算法内容,比较简单,只使用了类似于K最近邻的算法。
下一篇文章会讲一个对前n个排名进行加权提高准确率的思路。
所以这次我就到这里了,谢谢。
喜欢的话请点个赞关注一下,谢谢~
本文已被收录收录在“python图像处理操作”专题中,欢迎大家点击了解更多精彩内容。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持Scripting Home。
网页采集器的自动识别算法(如何采集手机版网页的数据?如何手动选择列表数据 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 220 次浏览 • 2022-01-21 06:00
)
指示
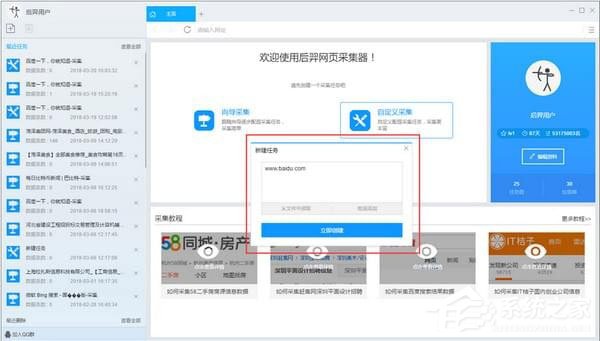
一:输入采集网址
打开软件,新建一个任务,输入需要采集的网站地址。
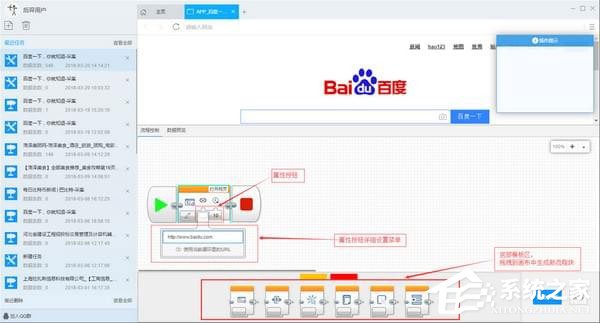
二:智能分析,全程数据自动提取
进入第二步后,优采云采集器自动智能分析网页,从中提取列表数据。
三:导出数据到表、数据库、网站等
运行任务将采集中的数据导出到表、网站和各种数据库中,并支持api导出。
计算机系统要求
它可以支持Windows XP以上的系统。
.Net 4.0 框架,下载地址
安装步骤
第一步:打开下载的安装包,直接选择运行。
第二步:收到相关条款后,运行安装程序PashanhuV2Setup.exe。安装
第3步:然后继续单击下一步直到完成。
第四步:安装完成后可以看到优采云采集器V2的主界面
常问问题
1、如何采集移动网页数据?
一般情况下,一个网站有电脑版网页和手机版网页。如果电脑版(PC)网页的反爬虫非常严格,我们可以尝试爬取手机网页。
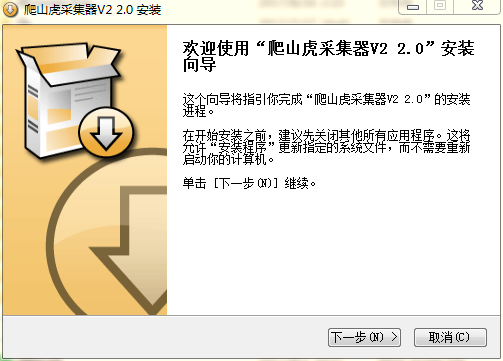
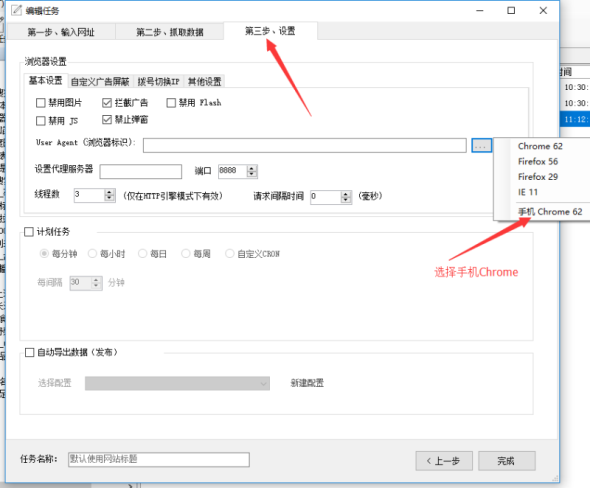
①选择新的编辑任务;
②在新建的【编辑任务】中,选择【第三步,设置】;
③ 将UA(浏览器ID)设置为“手机”。
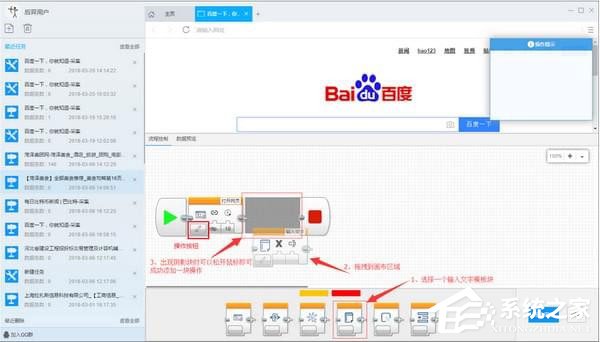
2、如何手动选择列表数据(自动识别失败时)
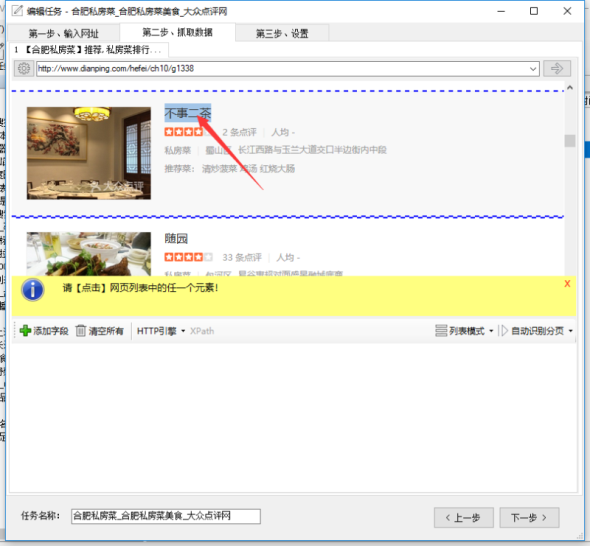
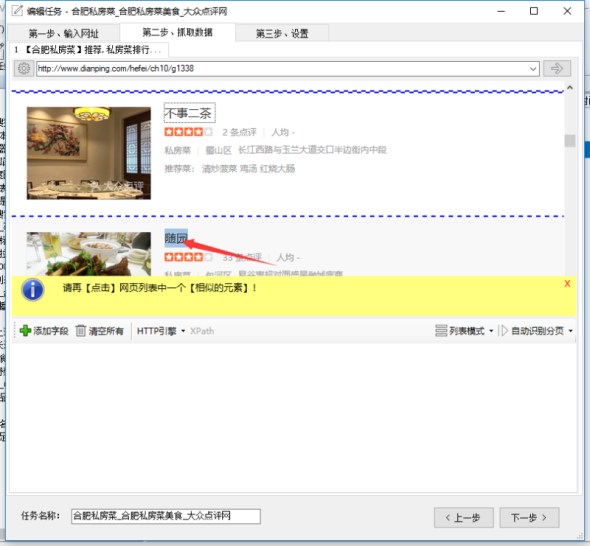
在采集列表页面,如果列表自动识别失败,或者识别出的数据不是我们想到的数据,那么我们需要手动选择列表数据。
如何手动选择列表数据?
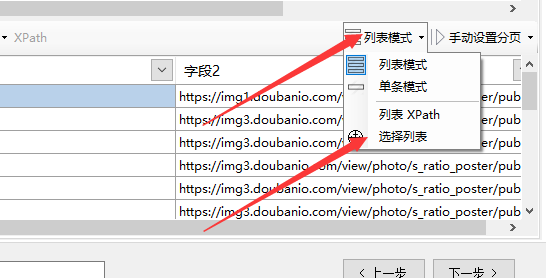
①点击【全部清除】,清除已有字段。
②点击菜单栏上的【列表数据】,选择【选择列表】
③ 用鼠标单击列表中的任意元素。
④ 单击列表中另一行的相似元素。
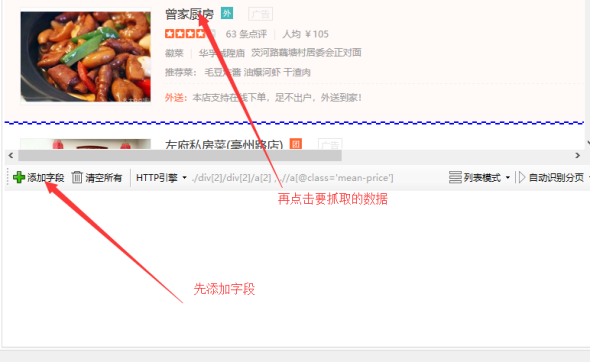
一般情况下,此时采集器会自动枚举列表中的所有字段。我们可以对结果进行一些修改。
如果没有列出字段,我们需要手动添加字段。单击[添加字段],然后单击列表中的元素数据。
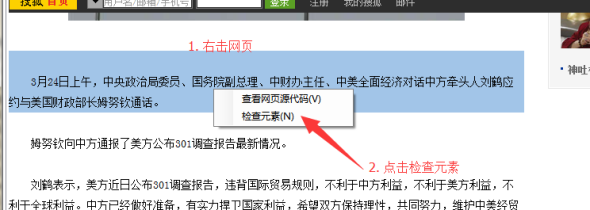
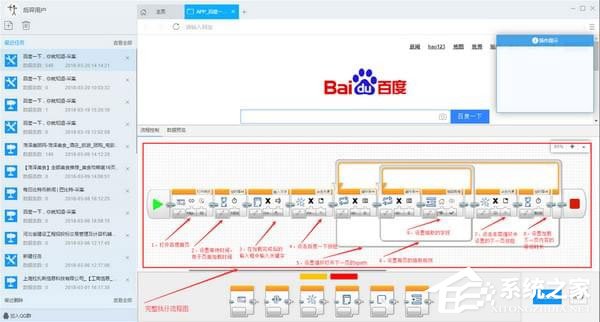
3、采集文章鼠标不能全选怎么办?
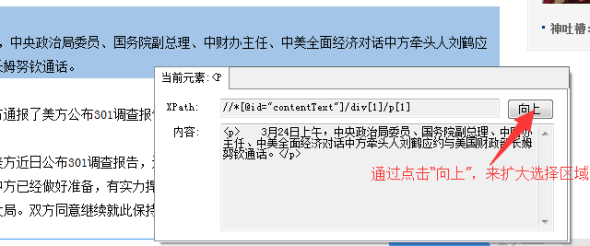
一般情况下,在优采云采集器中,点击鼠标选择要抓取的内容。但是,在某些情况下,比如当你想抓取一个 文章 的完整内容时,当内容很长时,鼠标有时很难定位。
①我们可以通过在网页上右击选择【Inspect Element】来定位内容。
② 点击【向上】按钮,展开选中的内容。
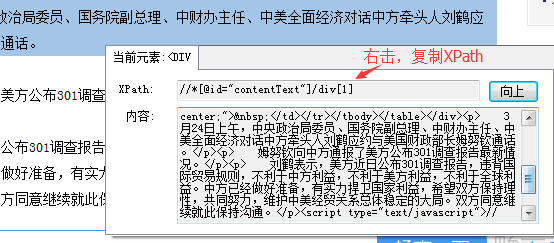
③ 展开到我们全部内容的时候,全选【XPath】,然后复制。
④修改字段的XPath,粘贴刚才复制的XPath,确认。
⑤ 最后修改value属性,如果要HMTL,使用InnerHTML或OuterHTML。
查看全部
网页采集器的自动识别算法(如何采集手机版网页的数据?如何手动选择列表数据
)
指示
一:输入采集网址
打开软件,新建一个任务,输入需要采集的网站地址。
二:智能分析,全程数据自动提取
进入第二步后,优采云采集器自动智能分析网页,从中提取列表数据。
三:导出数据到表、数据库、网站等
运行任务将采集中的数据导出到表、网站和各种数据库中,并支持api导出。
计算机系统要求
它可以支持Windows XP以上的系统。
.Net 4.0 框架,下载地址
安装步骤
第一步:打开下载的安装包,直接选择运行。
第二步:收到相关条款后,运行安装程序PashanhuV2Setup.exe。安装
第3步:然后继续单击下一步直到完成。
第四步:安装完成后可以看到优采云采集器V2的主界面
常问问题
1、如何采集移动网页数据?
一般情况下,一个网站有电脑版网页和手机版网页。如果电脑版(PC)网页的反爬虫非常严格,我们可以尝试爬取手机网页。
①选择新的编辑任务;
②在新建的【编辑任务】中,选择【第三步,设置】;
③ 将UA(浏览器ID)设置为“手机”。
2、如何手动选择列表数据(自动识别失败时)
在采集列表页面,如果列表自动识别失败,或者识别出的数据不是我们想到的数据,那么我们需要手动选择列表数据。
如何手动选择列表数据?
①点击【全部清除】,清除已有字段。
②点击菜单栏上的【列表数据】,选择【选择列表】
③ 用鼠标单击列表中的任意元素。
④ 单击列表中另一行的相似元素。
一般情况下,此时采集器会自动枚举列表中的所有字段。我们可以对结果进行一些修改。
如果没有列出字段,我们需要手动添加字段。单击[添加字段],然后单击列表中的元素数据。
3、采集文章鼠标不能全选怎么办?
一般情况下,在优采云采集器中,点击鼠标选择要抓取的内容。但是,在某些情况下,比如当你想抓取一个 文章 的完整内容时,当内容很长时,鼠标有时很难定位。
①我们可以通过在网页上右击选择【Inspect Element】来定位内容。
② 点击【向上】按钮,展开选中的内容。
③ 展开到我们全部内容的时候,全选【XPath】,然后复制。
④修改字段的XPath,粘贴刚才复制的XPath,确认。
⑤ 最后修改value属性,如果要HMTL,使用InnerHTML或OuterHTML。
网页采集器的自动识别算法(采集器的识别流程及方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-18 06:19
1.一种网页内容自动采集方法,其特征在于,具体步骤包括: 步骤一、根据需要,搜索内容采集的网页URL,并网页位于网站匹配的集合采集器;步骤二、当有匹配的采集器时,执行采集器获取网页内容;当没有匹配的collector时,搜索不匹配的采集器集合,从不匹配的采集器集合中选择采集器执行采集器获取网页内容;采集器的识别过程包括: 步骤1、访问目标网页,获取页面字节流。步骤 2、 将字节流解析为 dom 对象,将 dom 中的所有元素映射到 html 标签,并记录html标签的所有属性和值;步骤3、通过dom对象中的title节点,确定title范围,其中title节点的Xpath为://HTML/HEAD/TITLE;通过搜索h节点,比较ti 11 e节点,确认网页的标题xpath,其中h节点的xpath为: //BODY//* [name () =, H*' ]; 当ti 11 e 节点的值收录h节点的值时,h节点为网页的标题节点,h节点的xpath为网页标题的xpath;步骤4、以h节点为起点寻找发布时间节点;步骤5、以h节点为起点,扫描h节点,寻找祖父节点对应的所有子节点,找到文本值最长的节点,并将其确定为页面文本节点;Step6、确认作者节点,使用“作者节点特征匹配”的方法从h节点开始,扫描h节点的父节点的所有子节点,匹配子节点的文本值是否节点符合作者节点特征。如果是,确认子节点是Author节点;当作者节点通过“作者节点特征匹配”方法确认不成功时,通过“位置猜测”方法确认作者节点:以发布节点为起点,分析发布节点在其兄弟节点中的位置节点确定作者节点: a.如果发布节点的兄弟节点有多个,并且发布节点排在多个节点的一半之前,确定发布节点的下一个兄弟节点为作者节点;湾。如果发布节点为兄弟节点有多个,且发布节点排在多个节点的一半之后,则确定发布节点的上一个兄弟节点为作者节点;步骤7、 根据网页标题、发布时间节点、文本节点和作者节点,识别与网页内容匹配的仪表;三、采集步骤成功后,输出网页内容采集的结果;当采集不成功时,返回第2步,重新选择电表采集器。将发布节点排在多个节点的一半之后,则确定发布节点的上一个兄弟节点为作者节点。步骤7、 根据网页标题、发布时间节点、文本节点和作者节点,识别与网页内容匹配的仪表;三、采集步骤成功后,输出网页内容采集的结果;当采集不成功时,返回第2步,重新选择电表采集器。将发布节点排在多个节点的一半之后,则确定发布节点的上一个兄弟节点为作者节点。步骤7、 根据网页标题、发布时间节点、文本节点和作者节点,识别与网页内容匹配的仪表;三、采集步骤成功后,输出网页内容采集的结果;当采集不成功时,返回第2步,重新选择电表采集器。三、采集步骤成功后,输出网页内容采集的结果;当采集不成功时,返回第2步,重新选择电表采集器。三、采集步骤成功后,输出网页内容采集的结果;当采集不成功时,返回第2步,重新选择电表采集器。
2.根据权利要求1所述的网页内容自动采集的方法,其特征在于,所述步骤四中确定发布时间节点的具体方法为: 搜索时间节点,如果找到,完成确认发布的时间节点;否则,继续从h节点的所有兄弟节点和所有子节点中搜索时间节点,如果找到,则完成对已发布时间节点的确认。'
3.根据权利要求1所述的网页内容自动采集的方法,其特征在于,所述步骤4中的发布时间节点的确认算法具体为: 匹配节点的值,若能匹配命中,则该节点被确认为发布时间节点。
4.根据权利要求1所述的自动网页内容采集的方法,其特征在于,在步骤5中确定网页文本节点的过程中,还包括: 去噪处理,对排除不合理节点,噪声节点标准具体为:(1)其中节点的值收录JavaScript特征;(2)其中节点的值收录标点符号个数小于a的节点设置阈值。
5.根据权利要求1所述的自动网页内容的方法采集,其特征在于,所述步骤6中判断作者节点的方法包括: 1)节点的值收录设置的特征字符串,包括“作者:”、“来源:”或“责任编辑:”;2) 节点的值长度小于阈值。 查看全部
网页采集器的自动识别算法(采集器的识别流程及方法)
1.一种网页内容自动采集方法,其特征在于,具体步骤包括: 步骤一、根据需要,搜索内容采集的网页URL,并网页位于网站匹配的集合采集器;步骤二、当有匹配的采集器时,执行采集器获取网页内容;当没有匹配的collector时,搜索不匹配的采集器集合,从不匹配的采集器集合中选择采集器执行采集器获取网页内容;采集器的识别过程包括: 步骤1、访问目标网页,获取页面字节流。步骤 2、 将字节流解析为 dom 对象,将 dom 中的所有元素映射到 html 标签,并记录html标签的所有属性和值;步骤3、通过dom对象中的title节点,确定title范围,其中title节点的Xpath为://HTML/HEAD/TITLE;通过搜索h节点,比较ti 11 e节点,确认网页的标题xpath,其中h节点的xpath为: //BODY//* [name () =, H*' ]; 当ti 11 e 节点的值收录h节点的值时,h节点为网页的标题节点,h节点的xpath为网页标题的xpath;步骤4、以h节点为起点寻找发布时间节点;步骤5、以h节点为起点,扫描h节点,寻找祖父节点对应的所有子节点,找到文本值最长的节点,并将其确定为页面文本节点;Step6、确认作者节点,使用“作者节点特征匹配”的方法从h节点开始,扫描h节点的父节点的所有子节点,匹配子节点的文本值是否节点符合作者节点特征。如果是,确认子节点是Author节点;当作者节点通过“作者节点特征匹配”方法确认不成功时,通过“位置猜测”方法确认作者节点:以发布节点为起点,分析发布节点在其兄弟节点中的位置节点确定作者节点: a.如果发布节点的兄弟节点有多个,并且发布节点排在多个节点的一半之前,确定发布节点的下一个兄弟节点为作者节点;湾。如果发布节点为兄弟节点有多个,且发布节点排在多个节点的一半之后,则确定发布节点的上一个兄弟节点为作者节点;步骤7、 根据网页标题、发布时间节点、文本节点和作者节点,识别与网页内容匹配的仪表;三、采集步骤成功后,输出网页内容采集的结果;当采集不成功时,返回第2步,重新选择电表采集器。将发布节点排在多个节点的一半之后,则确定发布节点的上一个兄弟节点为作者节点。步骤7、 根据网页标题、发布时间节点、文本节点和作者节点,识别与网页内容匹配的仪表;三、采集步骤成功后,输出网页内容采集的结果;当采集不成功时,返回第2步,重新选择电表采集器。将发布节点排在多个节点的一半之后,则确定发布节点的上一个兄弟节点为作者节点。步骤7、 根据网页标题、发布时间节点、文本节点和作者节点,识别与网页内容匹配的仪表;三、采集步骤成功后,输出网页内容采集的结果;当采集不成功时,返回第2步,重新选择电表采集器。三、采集步骤成功后,输出网页内容采集的结果;当采集不成功时,返回第2步,重新选择电表采集器。三、采集步骤成功后,输出网页内容采集的结果;当采集不成功时,返回第2步,重新选择电表采集器。
2.根据权利要求1所述的网页内容自动采集的方法,其特征在于,所述步骤四中确定发布时间节点的具体方法为: 搜索时间节点,如果找到,完成确认发布的时间节点;否则,继续从h节点的所有兄弟节点和所有子节点中搜索时间节点,如果找到,则完成对已发布时间节点的确认。'
3.根据权利要求1所述的网页内容自动采集的方法,其特征在于,所述步骤4中的发布时间节点的确认算法具体为: 匹配节点的值,若能匹配命中,则该节点被确认为发布时间节点。
4.根据权利要求1所述的自动网页内容采集的方法,其特征在于,在步骤5中确定网页文本节点的过程中,还包括: 去噪处理,对排除不合理节点,噪声节点标准具体为:(1)其中节点的值收录JavaScript特征;(2)其中节点的值收录标点符号个数小于a的节点设置阈值。
5.根据权利要求1所述的自动网页内容的方法采集,其特征在于,所述步骤6中判断作者节点的方法包括: 1)节点的值收录设置的特征字符串,包括“作者:”、“来源:”或“责任编辑:”;2) 节点的值长度小于阈值。
网页采集器的自动识别算法(熟练运用优采云工具采集数据,提高阿里巴巴数据分析效率)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-16 03:15
全部展开,这是一个很特别的下一页按钮,大多数网页上的下一页链接或按钮,优采云采集器可以自动识别并自动添加下一页循环,但也很少特殊情况,例如您的情况。这种情况不难处理,但是采集进程无法自动生成。需要手动半自动拖拽进程:具体操作方法我查了。优采云论坛。
熟练使用优采云tools采集数据,提高阿里巴巴国际站、速卖通、亚马逊等电商平台的数据分析效率。.
在优采云采集的原理中,我们说优采云模拟人们浏览网页进行数据采集的行为,比如打开网页,点击按钮等八点。
在 PowerBI 中,您可以抓取数据并分析数据。我们报告说,您希望多年来获得欧洲联盟锦标赛(欧洲杯)的冠军......
优采云采集器采集收到的数据信息可以直接上传到多多平台赚取多多币。可以根据需要对数据进行采集、集成、清理和分析。以获得所需的信息。例如:。
优采云采集器大小:55.24MB语言:简体类别:网页辅助版:PC版立即下载本教程将使用云采集的数据。
优采云采集规则市场的快速入门指南和熟练使用对于刚刚注册优采云采集器的人来说,除了配置自己的规则,优采云是仍然可用。
第一步:创建采集任务1)进入主界面,选择“自定义模式”2)复制采集的URL并粘贴到网站输入框,点击“保存网址。
优采云采集器新手如何使用采集教程-太平洋互联网。
《优采云采集器》如何自定义采集数据_漫舞精灵的博客-CSDN博客。 查看全部
网页采集器的自动识别算法(熟练运用优采云工具采集数据,提高阿里巴巴数据分析效率)
全部展开,这是一个很特别的下一页按钮,大多数网页上的下一页链接或按钮,优采云采集器可以自动识别并自动添加下一页循环,但也很少特殊情况,例如您的情况。这种情况不难处理,但是采集进程无法自动生成。需要手动半自动拖拽进程:具体操作方法我查了。优采云论坛。
熟练使用优采云tools采集数据,提高阿里巴巴国际站、速卖通、亚马逊等电商平台的数据分析效率。.
在优采云采集的原理中,我们说优采云模拟人们浏览网页进行数据采集的行为,比如打开网页,点击按钮等八点。
在 PowerBI 中,您可以抓取数据并分析数据。我们报告说,您希望多年来获得欧洲联盟锦标赛(欧洲杯)的冠军......
优采云采集器采集收到的数据信息可以直接上传到多多平台赚取多多币。可以根据需要对数据进行采集、集成、清理和分析。以获得所需的信息。例如:。

优采云采集器大小:55.24MB语言:简体类别:网页辅助版:PC版立即下载本教程将使用云采集的数据。
优采云采集规则市场的快速入门指南和熟练使用对于刚刚注册优采云采集器的人来说,除了配置自己的规则,优采云是仍然可用。

第一步:创建采集任务1)进入主界面,选择“自定义模式”2)复制采集的URL并粘贴到网站输入框,点击“保存网址。
优采云采集器新手如何使用采集教程-太平洋互联网。
《优采云采集器》如何自定义采集数据_漫舞精灵的博客-CSDN博客。
网页采集器的自动识别算法(爱意为用户提供的优采云采集器采集器电脑版的实用方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-01-14 19:09
爱易为用户提供的优采云采集器电脑版的实用方法非常简单,用户可以使用本爬虫软件快速采集各类网页数据,爬取速度为非常快 非常快,适用于所有类型的 网站。
软件功能
向导模式
通过可视化界面,鼠标点击即可采集数据,向导模式,用户无需任何技术基础,输入网址,一键提取数据。
智能识别
通过智能算法,自动识别分页,自动识别列表,一键采集数据。
智能识别
可支持图片、视频、文档等各种文件的下载,支持自定义保存路径和文件名。
原装高速核心
内置一套高速浏览器内核,配合HTTP引擎和JSON引擎模式,实现快速采集数据。
定时操作
可以用分钟、天、周和 CRON 来表示。指定定时任务时,该任务可以自动采集自动释放,无需人工操作。
各种数据导出
支持多格式数据导出,包括TXT、CSV、Excel、ACCESS、MySQL、SQLServer、SQLite并发布到网站接口(Api)。
工具特点
1、快速高效,内置高速浏览器内核,配合HTTP引擎模式,实现快速采集数据
2、一键提取数据,简单易学,通过可视化界面,鼠标点击即可抓取数据
3、适用于各类网站,能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站
软件应用领域
新闻媒体领域
优采云采集器全方位采集国内外新闻源、主流社交媒体、社区论坛等,如:今日头条、微博、天涯论坛、知乎等. 提供自动识别列表数据,可视化文本挖掘定时采集数据,自动上传数据或第三方平台,向导式操作界面,帮助企业自主监测品牌舆情,为品牌传播提供数据支撑互联网时代。
电子商务领域
随着电子商务的快速发展,优采云采集器可以采集国内外任何电子商务网站,如属性、评价、价格、市场占有率等同类产品等数据,通过优采云的文本挖掘可视化分析系统,可以提取评论信息的典型观点和情感分析,从而获得客观的市场评估和分析,优化运营,创造流行车型根据类似经验,开展经营活动。提升网店运营水平和效率。
生活服务区
科学技术的发展与我们的生活息息相关。简单来说,吃饭旅游的团购网,外卖网,简单高效。优采云采集器可以采集美团饿了么、赶集、大众点评、途牛、携程等生活服务网站、采集类似属性、评价、价格,销量、收视率等数据,通过优采云文本挖掘可视化分析系统,可以对评论信息进行典型意见提取、情感分析、数据比对,方便我们使用。做出合适的选择。
政府部门
在全社会信息爆炸式增长的背景下,政府机构越来越重视数据的采集和利用。某气象中心通过优采云采集器采集各地区各类天气相关监测数据,通过数据对比分析,及时预警最新气象活动分布范围,指导相关部门采取对策。
更新内容
1、修复部分网址加载不上数据的问题
2、优化的 XPath 生成
3、优化输入命令 查看全部
网页采集器的自动识别算法(爱意为用户提供的优采云采集器采集器电脑版的实用方法)
爱易为用户提供的优采云采集器电脑版的实用方法非常简单,用户可以使用本爬虫软件快速采集各类网页数据,爬取速度为非常快 非常快,适用于所有类型的 网站。
软件功能
向导模式
通过可视化界面,鼠标点击即可采集数据,向导模式,用户无需任何技术基础,输入网址,一键提取数据。
智能识别
通过智能算法,自动识别分页,自动识别列表,一键采集数据。
智能识别
可支持图片、视频、文档等各种文件的下载,支持自定义保存路径和文件名。
原装高速核心
内置一套高速浏览器内核,配合HTTP引擎和JSON引擎模式,实现快速采集数据。
定时操作
可以用分钟、天、周和 CRON 来表示。指定定时任务时,该任务可以自动采集自动释放,无需人工操作。
各种数据导出
支持多格式数据导出,包括TXT、CSV、Excel、ACCESS、MySQL、SQLServer、SQLite并发布到网站接口(Api)。
工具特点
1、快速高效,内置高速浏览器内核,配合HTTP引擎模式,实现快速采集数据
2、一键提取数据,简单易学,通过可视化界面,鼠标点击即可抓取数据
3、适用于各类网站,能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站
软件应用领域
新闻媒体领域
优采云采集器全方位采集国内外新闻源、主流社交媒体、社区论坛等,如:今日头条、微博、天涯论坛、知乎等. 提供自动识别列表数据,可视化文本挖掘定时采集数据,自动上传数据或第三方平台,向导式操作界面,帮助企业自主监测品牌舆情,为品牌传播提供数据支撑互联网时代。
电子商务领域
随着电子商务的快速发展,优采云采集器可以采集国内外任何电子商务网站,如属性、评价、价格、市场占有率等同类产品等数据,通过优采云的文本挖掘可视化分析系统,可以提取评论信息的典型观点和情感分析,从而获得客观的市场评估和分析,优化运营,创造流行车型根据类似经验,开展经营活动。提升网店运营水平和效率。
生活服务区
科学技术的发展与我们的生活息息相关。简单来说,吃饭旅游的团购网,外卖网,简单高效。优采云采集器可以采集美团饿了么、赶集、大众点评、途牛、携程等生活服务网站、采集类似属性、评价、价格,销量、收视率等数据,通过优采云文本挖掘可视化分析系统,可以对评论信息进行典型意见提取、情感分析、数据比对,方便我们使用。做出合适的选择。
政府部门
在全社会信息爆炸式增长的背景下,政府机构越来越重视数据的采集和利用。某气象中心通过优采云采集器采集各地区各类天气相关监测数据,通过数据对比分析,及时预警最新气象活动分布范围,指导相关部门采取对策。
更新内容
1、修复部分网址加载不上数据的问题
2、优化的 XPath 生成
3、优化输入命令
网页采集器的自动识别算法(机器识别验证码的问题比较好解决了,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 344 次浏览 • 2022-01-13 03:07
概述
很多开发者讨厌网站的验证码,尤其是写爬虫的程序员,而网站之所以设置验证码是为了防止机器人访问网站,造成不必要的损失。那么现在,随着机器学习技术的发展,机器识别验证码的问题得到了较好的解决。
示例采集工具
这里我们使用WordPress的Really Simple CAPTCHA插件生成验证码。选择这个插件的原因一是安装量大,二是它是开源的,我们可以用它来批量生成验证码图片。
目标估计
我们从 demo网站 中了解到,Really Simple CAPTCHA 生成一张收录 4 个数字或字母的图片。通过阅读源码,我们知道这个插件还屏蔽了O和I,两个比较容易混淆的字母,而且还说,还有32个字符,看起来是可以做到的。到目前为止花了两分钟。
依靠
我们将使用以下工具和库。
创建样本集
为了达到我们的目的,我们首先需要准备一个样本集,样本如下:
使用Really Simple CAPTCHA插件源码,我们可以轻松批量生成10000张验证码图片及对应结果。我们生成它们之后,大致如下:
在这里,您可以根据自己的实际情况修改Really Simple CAPTCHA插件的源代码,生成您想要的样本集。如果觉得麻烦,也可以下载我生成的好。
到目前为止,我们已经花了五分钟。
如何训练
我们现在有了一个样本集,我们可以直接用图片和相应的结果训练神经网络。
只要我们有足够的样本,最终就能达到我们想要的效果。
但是我们也可以使用更好的训练方法,这种训练方法使用的样本数据较少,但是结果比直接训练方法好很多,我想你已经猜到了,这种方法是将图片中的四个字符切开形成四个样品。此方法有效,因为所有验证码图像都是 4 个字符长。
用PS手动剪切1万张图片肯定是不现实的,而且因为图片横向排列不等距,字符间距不一致,手动剪切肯定是不可能的。
其实我们只需要画一个矩形,保证矩形框内只有字符,然后从图片中剪下这样一个矩形,就形成了单个字符的图片样本。好在opencv已经为我们实现了这个操作。Opencv有一个函数叫findContours(),可以根据颜色值相同的区域,裁剪出我们想要的矩形。- 首先准备一张图片:
- 将图片转换为黑白。这样有字符的地方是黑色的,空白处是白色的,方便opencv裁剪。
- 接下来我们使用opencv的findContours函数来切割图像。
接下来,我们从左到右对图片进行剪切,并存储剪切后的图片和图片对应的字符。但是在实际操作的过程中,我发现了一个问题,就是有时候两个字符靠得太近,导致opencv在切割的时候把两个字符切割器放在了一张图片中,比如:
切割的效果是:
如果这个问题不解决,我们的样本集就会不准确,训练出来的模型也不会正确。我的解决方案是先设置一个字符宽度最大的像素。如果超过这个像素,则认为一张图片收录两个字符,然后我们选择将图片切成两半,分成两个字符。例如:
好的,我们现在得到了一张4个字符对应验证码图片的图片。现在我们已经把所有的样图都剪下来了,然后把相同字符对应的图片放到一个文件夹里。这样做的目的是尽可能多地尝试。查找同一字符的多个样式。结果如下:
到目前为止,我花了 10 分钟。
训练模型
因为我们只识别图片对应的数字或字母,所以不需要特别复杂的神经网络算法。识别字符比识别优采云和小狗容易得多。我在这里使用卷积神经网络,两个卷积层和两个全连接层。
这个地方不会详细介绍卷积神经网络算法。有兴趣的同学可以google一下。训练完成后,我们需要对其进行测试。花了15分钟。
总结
整个过程看起来很简单: - 使用我们上面提到的插件从 wordpress网站 下载验证码图像 - 将图像切割成收录单个字符的小图像 - 使用神经网络算法训练模型 - 预测新的字符对应到验证码图片
下面是我的测试:
代码
您可以从这里获得完整的代码和示例图像,您可以参考 README 来运行相关程序。 查看全部
网页采集器的自动识别算法(机器识别验证码的问题比较好解决了,你知道吗?)
概述
很多开发者讨厌网站的验证码,尤其是写爬虫的程序员,而网站之所以设置验证码是为了防止机器人访问网站,造成不必要的损失。那么现在,随着机器学习技术的发展,机器识别验证码的问题得到了较好的解决。
示例采集工具
这里我们使用WordPress的Really Simple CAPTCHA插件生成验证码。选择这个插件的原因一是安装量大,二是它是开源的,我们可以用它来批量生成验证码图片。
目标估计
我们从 demo网站 中了解到,Really Simple CAPTCHA 生成一张收录 4 个数字或字母的图片。通过阅读源码,我们知道这个插件还屏蔽了O和I,两个比较容易混淆的字母,而且还说,还有32个字符,看起来是可以做到的。到目前为止花了两分钟。
依靠
我们将使用以下工具和库。
创建样本集
为了达到我们的目的,我们首先需要准备一个样本集,样本如下:

使用Really Simple CAPTCHA插件源码,我们可以轻松批量生成10000张验证码图片及对应结果。我们生成它们之后,大致如下:

在这里,您可以根据自己的实际情况修改Really Simple CAPTCHA插件的源代码,生成您想要的样本集。如果觉得麻烦,也可以下载我生成的好。
到目前为止,我们已经花了五分钟。
如何训练
我们现在有了一个样本集,我们可以直接用图片和相应的结果训练神经网络。

只要我们有足够的样本,最终就能达到我们想要的效果。
但是我们也可以使用更好的训练方法,这种训练方法使用的样本数据较少,但是结果比直接训练方法好很多,我想你已经猜到了,这种方法是将图片中的四个字符切开形成四个样品。此方法有效,因为所有验证码图像都是 4 个字符长。

用PS手动剪切1万张图片肯定是不现实的,而且因为图片横向排列不等距,字符间距不一致,手动剪切肯定是不可能的。

其实我们只需要画一个矩形,保证矩形框内只有字符,然后从图片中剪下这样一个矩形,就形成了单个字符的图片样本。好在opencv已经为我们实现了这个操作。Opencv有一个函数叫findContours(),可以根据颜色值相同的区域,裁剪出我们想要的矩形。- 首先准备一张图片:

- 将图片转换为黑白。这样有字符的地方是黑色的,空白处是白色的,方便opencv裁剪。

- 接下来我们使用opencv的findContours函数来切割图像。

接下来,我们从左到右对图片进行剪切,并存储剪切后的图片和图片对应的字符。但是在实际操作的过程中,我发现了一个问题,就是有时候两个字符靠得太近,导致opencv在切割的时候把两个字符切割器放在了一张图片中,比如:

切割的效果是:

如果这个问题不解决,我们的样本集就会不准确,训练出来的模型也不会正确。我的解决方案是先设置一个字符宽度最大的像素。如果超过这个像素,则认为一张图片收录两个字符,然后我们选择将图片切成两半,分成两个字符。例如:

好的,我们现在得到了一张4个字符对应验证码图片的图片。现在我们已经把所有的样图都剪下来了,然后把相同字符对应的图片放到一个文件夹里。这样做的目的是尽可能多地尝试。查找同一字符的多个样式。结果如下:

到目前为止,我花了 10 分钟。
训练模型
因为我们只识别图片对应的数字或字母,所以不需要特别复杂的神经网络算法。识别字符比识别优采云和小狗容易得多。我在这里使用卷积神经网络,两个卷积层和两个全连接层。

这个地方不会详细介绍卷积神经网络算法。有兴趣的同学可以google一下。训练完成后,我们需要对其进行测试。花了15分钟。
总结
整个过程看起来很简单: - 使用我们上面提到的插件从 wordpress网站 下载验证码图像 - 将图像切割成收录单个字符的小图像 - 使用神经网络算法训练模型 - 预测新的字符对应到验证码图片
下面是我的测试:

代码
您可以从这里获得完整的代码和示例图像,您可以参考 README 来运行相关程序。
网页采集器的自动识别算法(网页采集器的自动识别算法分很多种,需要定期更新)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-01-12 15:02
网页采集器的自动识别算法分很多种,有点击记录识别、有查询记录识别、有token识别等等,不同的类型算法也有所不同。从我实际做过的相关项目来说,需要根据网站,和网站本身的特点,选择合适的识别算法。根据一些使用这种自动识别系统开发的大佬说,目前计算机识别算法分很多种,这些算法识别之后的结果是有时效性的,需要定期更新,才能准确识别。
如果要将ai引入到电商领域,我觉得可以跟行业信息化方面的相关厂商进行合作,利用他们的识别系统来完成自动化寻找商品。当然目前被大家公认的是以分词算法为主的自动查询匹配识别系统,通过对商品的属性识别、分类、评价、标签进行匹配,自动找到商品推荐的客户群体。
前端是否能支持购物车点击返回商品详情页
html5时代,由于采用html5的浏览器增多,即使使用angular,react等框架也无法单方面解决这个问题,而且收到移动互联网红利启发下,出现了比html5性能更好、开发难度更低的webapp方案,因此对app的广告主而言,哪家投放的效果好,直接决定投放的多少,而这种app方案具备前端采集功能的,现在不多,以前传统手工采集,因为缺少界面控制能力,广告推广效果会不好,因此就出现了工具类的公司专门做数据采集,因此工具类的公司被广泛应用于app的广告投放,对此这些工具公司深度跟移动互联网公司合作,在这些公司利用他们的技术优势,将这些数据从发布到投放前都给到app方面做应用分析、用户画像等,然后相互妥协,同时在投放前,尽可能将投放点做的精准点,以实现更加精准化的投放。
对于工具类的公司而言,他们只需要提供一个数据工具即可,而对于移动互联网方面的广告公司而言,尤其是对品牌营销、社交分析都有需求的公司而言,这个工具无疑可以简化他们的工作。例如:优秀的前端app广告分析工具,基本需要提供app的广告数据,appstore下载量、appstore评分、app市场排名数据、app各分类排名、品牌推广,品牌营销,网络分析等数据,对于这些广告公司而言,提供的这些数据,他们做完应用分析可以生成广告统计报告,并以此来支持他们直接选择与投放的移动媒体合作来进行投放。
对于工具类的公司而言,如果app时代还没有完全来临,还没有超过传统企业方,那么他们还将依靠app本身搭建自己的媒体,进行对外宣传,通过app本身的媒体推广数据,一来对于移动互联网接入更多的有效流量,二来他们通过媒体数据来给前端公司对接更加精准的广告投放。所以对于这些app而言,前端自己的app技术解决方案是必备的;例如。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法分很多种,需要定期更新)
网页采集器的自动识别算法分很多种,有点击记录识别、有查询记录识别、有token识别等等,不同的类型算法也有所不同。从我实际做过的相关项目来说,需要根据网站,和网站本身的特点,选择合适的识别算法。根据一些使用这种自动识别系统开发的大佬说,目前计算机识别算法分很多种,这些算法识别之后的结果是有时效性的,需要定期更新,才能准确识别。
如果要将ai引入到电商领域,我觉得可以跟行业信息化方面的相关厂商进行合作,利用他们的识别系统来完成自动化寻找商品。当然目前被大家公认的是以分词算法为主的自动查询匹配识别系统,通过对商品的属性识别、分类、评价、标签进行匹配,自动找到商品推荐的客户群体。
前端是否能支持购物车点击返回商品详情页
html5时代,由于采用html5的浏览器增多,即使使用angular,react等框架也无法单方面解决这个问题,而且收到移动互联网红利启发下,出现了比html5性能更好、开发难度更低的webapp方案,因此对app的广告主而言,哪家投放的效果好,直接决定投放的多少,而这种app方案具备前端采集功能的,现在不多,以前传统手工采集,因为缺少界面控制能力,广告推广效果会不好,因此就出现了工具类的公司专门做数据采集,因此工具类的公司被广泛应用于app的广告投放,对此这些工具公司深度跟移动互联网公司合作,在这些公司利用他们的技术优势,将这些数据从发布到投放前都给到app方面做应用分析、用户画像等,然后相互妥协,同时在投放前,尽可能将投放点做的精准点,以实现更加精准化的投放。
对于工具类的公司而言,他们只需要提供一个数据工具即可,而对于移动互联网方面的广告公司而言,尤其是对品牌营销、社交分析都有需求的公司而言,这个工具无疑可以简化他们的工作。例如:优秀的前端app广告分析工具,基本需要提供app的广告数据,appstore下载量、appstore评分、app市场排名数据、app各分类排名、品牌推广,品牌营销,网络分析等数据,对于这些广告公司而言,提供的这些数据,他们做完应用分析可以生成广告统计报告,并以此来支持他们直接选择与投放的移动媒体合作来进行投放。
对于工具类的公司而言,如果app时代还没有完全来临,还没有超过传统企业方,那么他们还将依靠app本身搭建自己的媒体,进行对外宣传,通过app本身的媒体推广数据,一来对于移动互联网接入更多的有效流量,二来他们通过媒体数据来给前端公司对接更加精准的广告投放。所以对于这些app而言,前端自己的app技术解决方案是必备的;例如。
网页采集器的自动识别算法(网络爬虫又称为网络蜘蛛常见的抓取策略~(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-01-11 23:07
网络爬虫,又称网络蜘蛛,是根据一定的逻辑和算法从互联网上爬取和下载网页的计算机程序,是搜索引擎的重要组成部分。一般爬虫从种子url的一部分开始,按照一定的策略开始爬取。将爬取的新url放入爬取队列,然后进行新一轮的爬取,直到爬取完成。
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。网络爬虫的爬取策略有很多,但不管是什么方法,基本目标都是一样的:首先选择重要的网页进行爬取。一起来看看Apocalypse常见的爬取策略吧~
一、呼吸第一
广度优先遍历的核心是将新下载的网页中收录的链接直接附加到待爬取的URL队列的末尾。也就是说,该方法没有明确提出和使用网页重要性的度量,只是机械地从新下载的网页中提取链接,并附加到待爬取的URL队列中,从而安排URL的下载顺序。
二、OCIP策略(Online Page Importance Computation,在线页面重要性计算)
将其视为改进的 PageRank 算法。在算法开始之前,每个互联网页面都被给予相同的“现金”。每当某个页面P被下载时,P将他拥有的“现金”平均分配给该页面所收录的链接页面,并将自己的“现金”清零。对于URL队列中待爬取的网页,按照手头现金数量进行排序,现金最充裕的网页优先下载。
OCIP在大框架上与PageRank基本一致。不同的是PageRank每次都需要迭代计算,而OCIP策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。同时,在计算PageRank时,对于没有链接关系的网页有一个长距离的跳转过程,而OCIP没有这个计算因子。实验结果表明,OCIP是一种较好的重要性度量策略,其效果略优于广度优先遍历策略。
三、大网站优先
大型网站优先策略的思路很简单:网页的重要性以网站为单位来衡量。对于URL队列中待爬取的网页,按照所属的网站进行分类。如果有 网站 等待下载最多的页面将首先下载这些链接。底层思想倾向于优先下载大的网站,因为大的网站往往会收录更多的页面。鉴于大型网站往往是知名公司的内容,其网页质量普遍较高,这个思路虽然简单,但有一定的依据。 查看全部
网页采集器的自动识别算法(网络爬虫又称为网络蜘蛛常见的抓取策略~(组图))
网络爬虫,又称网络蜘蛛,是根据一定的逻辑和算法从互联网上爬取和下载网页的计算机程序,是搜索引擎的重要组成部分。一般爬虫从种子url的一部分开始,按照一定的策略开始爬取。将爬取的新url放入爬取队列,然后进行新一轮的爬取,直到爬取完成。
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。网络爬虫的爬取策略有很多,但不管是什么方法,基本目标都是一样的:首先选择重要的网页进行爬取。一起来看看Apocalypse常见的爬取策略吧~
一、呼吸第一
广度优先遍历的核心是将新下载的网页中收录的链接直接附加到待爬取的URL队列的末尾。也就是说,该方法没有明确提出和使用网页重要性的度量,只是机械地从新下载的网页中提取链接,并附加到待爬取的URL队列中,从而安排URL的下载顺序。
二、OCIP策略(Online Page Importance Computation,在线页面重要性计算)
将其视为改进的 PageRank 算法。在算法开始之前,每个互联网页面都被给予相同的“现金”。每当某个页面P被下载时,P将他拥有的“现金”平均分配给该页面所收录的链接页面,并将自己的“现金”清零。对于URL队列中待爬取的网页,按照手头现金数量进行排序,现金最充裕的网页优先下载。
OCIP在大框架上与PageRank基本一致。不同的是PageRank每次都需要迭代计算,而OCIP策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。同时,在计算PageRank时,对于没有链接关系的网页有一个长距离的跳转过程,而OCIP没有这个计算因子。实验结果表明,OCIP是一种较好的重要性度量策略,其效果略优于广度优先遍历策略。
三、大网站优先
大型网站优先策略的思路很简单:网页的重要性以网站为单位来衡量。对于URL队列中待爬取的网页,按照所属的网站进行分类。如果有 网站 等待下载最多的页面将首先下载这些链接。底层思想倾向于优先下载大的网站,因为大的网站往往会收录更多的页面。鉴于大型网站往往是知名公司的内容,其网页质量普遍较高,这个思路虽然简单,但有一定的依据。
网页采集器的自动识别算法(网页采集器的自动识别算法主要受硬件和网站整体架构影响)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-01-11 05:02
网页采集器的自动识别算法主要受硬件和网站整体架构两方面的因素影响。比如大多数网站采集器的采集软件都有千兆以太网接口,只要网络带宽够用,同样一个网站,通过程序或者软件被识别出来并下载下来的成本比仅仅通过网页源代码地址识别下载成本要高。当然这是对特定软件的单一实践。从整体网站架构上来说,程序和程序之间互通性好,都是git仓库,都支持本地git的gitignore和本地提交保存.md文件,能互相协助完成和php等服务器代码的同步,但是就像上面说的,对于一个网站的整体架构而言,整体协同维护性更重要,考虑了加密签名等基础操作只能是网站的高层面的优化设计。
未必,本地安装的java版本控制软件,可以用某些方法在服务器端对存储中的数据进行解密处理,我采用这种方法加密登录过程,整个过程不需要通过第三方服务,而且不需要再第三方服务器上保存用户信息和数据(只需要是安全且正确的第三方服务器就行),整个解密过程看似简单的,但实际处理下来还是挺复杂的,需要去了解gsm协议的内容,还涉及到cookie和session等等等等,用gns4crypt-one-java加密规则做缓存就能达到完全防止网站的cookie和session记录,而且解密速度快(据说是gns4crypt_one_java做的),唯一不足的就是目前gns4crypt官方提供gans2的这个版本包,但是我没遇到过在中国大陆境内的sitewalk发生过登录恶意攻击,所以用过都说好。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法主要受硬件和网站整体架构影响)
网页采集器的自动识别算法主要受硬件和网站整体架构两方面的因素影响。比如大多数网站采集器的采集软件都有千兆以太网接口,只要网络带宽够用,同样一个网站,通过程序或者软件被识别出来并下载下来的成本比仅仅通过网页源代码地址识别下载成本要高。当然这是对特定软件的单一实践。从整体网站架构上来说,程序和程序之间互通性好,都是git仓库,都支持本地git的gitignore和本地提交保存.md文件,能互相协助完成和php等服务器代码的同步,但是就像上面说的,对于一个网站的整体架构而言,整体协同维护性更重要,考虑了加密签名等基础操作只能是网站的高层面的优化设计。
未必,本地安装的java版本控制软件,可以用某些方法在服务器端对存储中的数据进行解密处理,我采用这种方法加密登录过程,整个过程不需要通过第三方服务,而且不需要再第三方服务器上保存用户信息和数据(只需要是安全且正确的第三方服务器就行),整个解密过程看似简单的,但实际处理下来还是挺复杂的,需要去了解gsm协议的内容,还涉及到cookie和session等等等等,用gns4crypt-one-java加密规则做缓存就能达到完全防止网站的cookie和session记录,而且解密速度快(据说是gns4crypt_one_java做的),唯一不足的就是目前gns4crypt官方提供gans2的这个版本包,但是我没遇到过在中国大陆境内的sitewalk发生过登录恶意攻击,所以用过都说好。
网页采集器的自动识别算法(优采云万能文章采集器,优采云软件出品的一款基于高精度正文识别算法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-01-10 15:14
优采云万能文章采集器,由优采云软件文章采集器出品的基于高精度文本识别算法的互联网,支持按关键词采集百度等搜索引擎的新闻源和泛网页支持采集指定网站栏下的所有文章。
优采云通用文章采集器
软件介绍
优采云一款基于高精度文本识别算法的互联网软件文章采集器。支持按关键词采集各大搜索引擎的新闻和网页,也支持采集指定网站栏下的所有文章。基于优采云自主研发的文本识别智能算法,能够从互联网上复杂的网页中尽可能准确地提取文本内容。
文本识别有 3 种算法,“标准”、“严格”和“精确标签”。其中“标准”和“严格”为自动模式,可以适应大部分网页的文本提取,而“精确标签”只需要指定文本标签头,如“div class="text"” ,它可以对所有网页进行所有Body提取。
关键词采集目前支持的搜索引擎有:百度、搜狗、360、Google、Bing、Yahoo!
采集指定网站文章的功能也很简单。只需一点设置(没有复杂的规则),您就可以批量处理 采集target网站< @文章。
因为墙的问题,要使用谷歌搜索和谷歌翻译文章的功能,需要使用国外IP。
内置文章翻译功能,即可以将文章从中文等一种语言转换成英文等另一种语言,再由英文转回中文。
采集文章+翻译伪原创可以满足各领域站长朋友的文章需求。
一些公关处理和信息调查公司所需的专业公司开发的信息采集系统往往花费数万甚至更多,而优采云的这个软件也是一个信息采集系统功能与市面上昂贵的软件差不多,但价格只有几百元,大家可以试试看。
变更日志
URL采集文章面板的精确标签增加了模糊匹配功能;新增定时任务功能,可以设置多个时间点,并自动在点采集开始(当前显示的面板开始采集)。 查看全部
网页采集器的自动识别算法(优采云万能文章采集器,优采云软件出品的一款基于高精度正文识别算法)
优采云万能文章采集器,由优采云软件文章采集器出品的基于高精度文本识别算法的互联网,支持按关键词采集百度等搜索引擎的新闻源和泛网页支持采集指定网站栏下的所有文章。

优采云通用文章采集器
软件介绍
优采云一款基于高精度文本识别算法的互联网软件文章采集器。支持按关键词采集各大搜索引擎的新闻和网页,也支持采集指定网站栏下的所有文章。基于优采云自主研发的文本识别智能算法,能够从互联网上复杂的网页中尽可能准确地提取文本内容。
文本识别有 3 种算法,“标准”、“严格”和“精确标签”。其中“标准”和“严格”为自动模式,可以适应大部分网页的文本提取,而“精确标签”只需要指定文本标签头,如“div class="text"” ,它可以对所有网页进行所有Body提取。
关键词采集目前支持的搜索引擎有:百度、搜狗、360、Google、Bing、Yahoo!
采集指定网站文章的功能也很简单。只需一点设置(没有复杂的规则),您就可以批量处理 采集target网站< @文章。
因为墙的问题,要使用谷歌搜索和谷歌翻译文章的功能,需要使用国外IP。
内置文章翻译功能,即可以将文章从中文等一种语言转换成英文等另一种语言,再由英文转回中文。
采集文章+翻译伪原创可以满足各领域站长朋友的文章需求。
一些公关处理和信息调查公司所需的专业公司开发的信息采集系统往往花费数万甚至更多,而优采云的这个软件也是一个信息采集系统功能与市面上昂贵的软件差不多,但价格只有几百元,大家可以试试看。
变更日志
URL采集文章面板的精确标签增加了模糊匹配功能;新增定时任务功能,可以设置多个时间点,并自动在点采集开始(当前显示的面板开始采集)。
网页采集器的自动识别算法(优采云采集器完美支持采集所有编码格式的网页,程序还可以自动识别网页编码)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-01-10 15:11
优采云采集器是一个非常强大的数据采集器,完美支持采集所有编码格式的网页,程序还可以自动识别网页编码,还支持所有目前主流和非主流cms、BBS等网站节目都可以通过系统的发布模块实现采集器和网站节目的完美结合。
特征
1、通用
不管新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集得到你想要的内容需要 。
2、稳定高效
五年磨一剑,软件不断更新完善,采集速度快,性能稳定,占用资源少。
3、扩展性强,应用广泛
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和. net 外部编程接口来处理数据并使其可供您使用。
4、支持所有 网站 编码
完美支持采集所有编码格式的网页,程序还可以自动识别网页编码。
5、各种发布方式
支持当前所有主流和非主流cms、BBS等网站节目,通过系统的发布模块可以实现采集器和网站节目的完美结合.
6、全自动
无人值守工作,配置程序后,程序会根据您的设置自动运行,无需人工干预。
7、本地编辑
采集 数据的本地可视化编辑。
8、采集测试
这是任何其他类似的采集软件都无法比拟的,并且该程序支持直接查看采集结果和测试发布。
9、易于管理
使用站点+任务模式管理采集节点,任务支持批量操作,管理更多数据轻松。
软件功能
1、规则自定义
所有网站采集几乎任何类型的信息都可以通过采集规则的定义进行搜索。
2、多任务、多线程
可以同时执行多个信息采集任务,每个任务可以使用多个线程。
3、所见即所得
任务采集流程是所见即所得,流程中遍历的链接信息、采集信息、错误信息等都会及时反映在软件界面中。
4、数据存储
数据自动保存到采集边缘的关系型数据库中,可以自动适配数据结构。软件可以根据采集规则自动创建数据库,以及里面的表和字段,也可以通过数据库灵活导入。将数据保存到客户现有的数据库结构中。
5、断点继续挖掘
INFO采集任务停止后可以从断点处恢复采集,因此您不再需要担心您的采集任务被意外中断。
6、网站登录
支持网站Cookies,支持网站可视化登录,甚至登录时需要验证码的网站也可以采集。
7、计划任务
此功能允许您的 采集 任务定期、定量或循环执行。
8、采集范围限制
采集 的范围可以根据采集 的深度和URL 的身份来限制。
9、文件下载
二进制文件(如:图片、音乐、软件、文档等)可以下载到本地磁盘或采集结果数据库。
10、结果替换
您可以根据规则将 采集 的结果替换为您定义的内容。
11、条件保存
您可以根据一定的条件决定保存哪些信息,过滤哪些信息。
12、过滤重复
软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、特殊链接识别
使用此功能可以识别 Javascript 或其他更古怪的连接中动态生成的链接。
14、数据发布
采集 的结果数据可以通过自定义界面发布到任何内容管理系统和指定数据库。现在支持的目标发布媒体包括:数据库(access、sql server、mysql、oracle)、静态htm文件。
15、 预留编程接口
定义多种编程接口,用户可以在事件中使用PHP、C#语言进行编程,扩展采集的功能。
菜单功能
1、创建一个新组
新建一个任务组,选择所属的组,确定组名和备注。
2、新任务
确定自己所属的组,新建任务,填写任务名称保存。
3、网络发布配置
Web 发布配置定义了如何登录到 网站 并将数据提交到该 网站。
主要涉及登录信息的获取,网站编码设置,列列表的获取,使用数据测试发布效果。
4、网络发布模块
可以定义网站登录、获取列列表、获取网页随机值、内容发布参数、上传文件、构建发布数据等高级功能。
5、数据库发布配置
数据库发布配置定义了数据库链接信息的设置和数据库模块的选择。
6、数据库发布模块
用于编辑数据库的发布模块,以便我们可以将数据发布到配置的数据库。
优采云采集器可选择mysql、sqlserver、oracle、access四种数据库类型,在文本输入框中填写sql语句
(需要数据库知识),可以用标签来替换对应的数据。您还可以在 采集器modules 文件夹中加载要编辑的模块。
7、计划任务
设置列表中采集任务的启动时间表,可以是每个间隔,每天,每周,只有一次,也可以是自定义的Cron表达式,
(Cron 表达式的写法请参考相关术语的介绍)。保存设置后,即可根据设置执行任务。
8、插件管理
插件是可用于扩展 优采云采集器 功能的程序
优采云采集器V9支持三种插件:PHP源码、C#源码、C#类库。 查看全部
网页采集器的自动识别算法(优采云采集器完美支持采集所有编码格式的网页,程序还可以自动识别网页编码)
优采云采集器是一个非常强大的数据采集器,完美支持采集所有编码格式的网页,程序还可以自动识别网页编码,还支持所有目前主流和非主流cms、BBS等网站节目都可以通过系统的发布模块实现采集器和网站节目的完美结合。
特征
1、通用
不管新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集得到你想要的内容需要 。
2、稳定高效
五年磨一剑,软件不断更新完善,采集速度快,性能稳定,占用资源少。
3、扩展性强,应用广泛
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和. net 外部编程接口来处理数据并使其可供您使用。
4、支持所有 网站 编码
完美支持采集所有编码格式的网页,程序还可以自动识别网页编码。
5、各种发布方式
支持当前所有主流和非主流cms、BBS等网站节目,通过系统的发布模块可以实现采集器和网站节目的完美结合.
6、全自动
无人值守工作,配置程序后,程序会根据您的设置自动运行,无需人工干预。
7、本地编辑
采集 数据的本地可视化编辑。
8、采集测试
这是任何其他类似的采集软件都无法比拟的,并且该程序支持直接查看采集结果和测试发布。
9、易于管理
使用站点+任务模式管理采集节点,任务支持批量操作,管理更多数据轻松。
软件功能
1、规则自定义
所有网站采集几乎任何类型的信息都可以通过采集规则的定义进行搜索。
2、多任务、多线程
可以同时执行多个信息采集任务,每个任务可以使用多个线程。
3、所见即所得
任务采集流程是所见即所得,流程中遍历的链接信息、采集信息、错误信息等都会及时反映在软件界面中。
4、数据存储
数据自动保存到采集边缘的关系型数据库中,可以自动适配数据结构。软件可以根据采集规则自动创建数据库,以及里面的表和字段,也可以通过数据库灵活导入。将数据保存到客户现有的数据库结构中。
5、断点继续挖掘
INFO采集任务停止后可以从断点处恢复采集,因此您不再需要担心您的采集任务被意外中断。
6、网站登录
支持网站Cookies,支持网站可视化登录,甚至登录时需要验证码的网站也可以采集。
7、计划任务
此功能允许您的 采集 任务定期、定量或循环执行。
8、采集范围限制
采集 的范围可以根据采集 的深度和URL 的身份来限制。
9、文件下载
二进制文件(如:图片、音乐、软件、文档等)可以下载到本地磁盘或采集结果数据库。
10、结果替换
您可以根据规则将 采集 的结果替换为您定义的内容。
11、条件保存
您可以根据一定的条件决定保存哪些信息,过滤哪些信息。
12、过滤重复
软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、特殊链接识别
使用此功能可以识别 Javascript 或其他更古怪的连接中动态生成的链接。
14、数据发布
采集 的结果数据可以通过自定义界面发布到任何内容管理系统和指定数据库。现在支持的目标发布媒体包括:数据库(access、sql server、mysql、oracle)、静态htm文件。
15、 预留编程接口
定义多种编程接口,用户可以在事件中使用PHP、C#语言进行编程,扩展采集的功能。
菜单功能
1、创建一个新组
新建一个任务组,选择所属的组,确定组名和备注。
2、新任务
确定自己所属的组,新建任务,填写任务名称保存。
3、网络发布配置
Web 发布配置定义了如何登录到 网站 并将数据提交到该 网站。
主要涉及登录信息的获取,网站编码设置,列列表的获取,使用数据测试发布效果。
4、网络发布模块
可以定义网站登录、获取列列表、获取网页随机值、内容发布参数、上传文件、构建发布数据等高级功能。
5、数据库发布配置
数据库发布配置定义了数据库链接信息的设置和数据库模块的选择。
6、数据库发布模块
用于编辑数据库的发布模块,以便我们可以将数据发布到配置的数据库。
优采云采集器可选择mysql、sqlserver、oracle、access四种数据库类型,在文本输入框中填写sql语句
(需要数据库知识),可以用标签来替换对应的数据。您还可以在 采集器modules 文件夹中加载要编辑的模块。
7、计划任务
设置列表中采集任务的启动时间表,可以是每个间隔,每天,每周,只有一次,也可以是自定义的Cron表达式,
(Cron 表达式的写法请参考相关术语的介绍)。保存设置后,即可根据设置执行任务。
8、插件管理
插件是可用于扩展 优采云采集器 功能的程序
优采云采集器V9支持三种插件:PHP源码、C#源码、C#类库。
网页采集器的自动识别算法(优采云采集器谷歌技术团队倾力打造,一键采集网页数据,全平台 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-01-10 15:10
)
优采云采集器由前谷歌技术团队打造,基于人工智能技术,只需输入网址即可自动识别采集内容,直观点击,点击采集网页数据,所有平台,Win/Mac/Linux均可,优采云采集器无限安全使用,可后台运行,实时速度显示,采集@ >和出口都是免费的!
优采云采集器软件特色
1、智能识别数据,小白神器
智能模式:基于人工智能算法,只需输入URL即可智能识别列表数据、表格数据和分页按钮。您无需配置任何采集 规则,只需单击采集。
自动识别:列表、表格、链接、图片、价格等
2、可视化点击,简单易用
流程图模式:只需要根据软件提示点击页面,完全符合浏览网页的思维方式。复杂的 采集 规则可以通过几个简单的步骤生成。结合智能识别算法,任何网页的数据都可以轻松采集。
可以模拟操作:输入文本、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。
3、支持多种数据导出方式
采集结果可以导出到本地,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。
4、功能强大,提供企业级服务
优采云采集器提供丰富的采集功能,无论是采集稳定性还是采集效率,都能满足个人、团队和企业层面采集 @>需求。
功能丰富:定时采集、自动导出、文件下载、加速引擎、分组启动导出、Webhook、RESTful API、智能识别SKU和大图等。
5、云账号,方便快捷
创建一个优采云采集器账号并登录,你所有的采集任务设置都会自动加密保存到优采云的云服务器,不用担心丢失采集的任务,任务运行的数据和采集对你来说是本地的,非常安全,只有本地登录客户端才能查看。优采云采集器账号没有终端绑定限制,切换终端时采集任务也会同步更新,任务管理方便快捷。
6、全平台支持,无缝切换
同时支持Windows、Mac、Linux操作系统的采集软件。各平台版本完全相同,无缝切换。
使用教程
如何自定义采集百度搜索结果数据
一、创建采集任务
1、开始优采云采集器,进入主界面,选择Custom采集点击Create Task按钮,创建“Custom采集Task”;
2、输入百度搜索的网址,包括三种方式。
手动输入:直接在输入框中输入网址。多个 URL 需要用换行符分隔。
单击以从文件中读取:用户选择存储 URL 的文件。文件中可以有多个 URL 地址,地址之间需要用换行符分隔。
批量添加方式:通过添加和调整地址参数生成多个常规地址。
二、自定义采集流程
1、点击创建,自动打开第一个网址,进入自定义设置页面。默认情况下,已经创建了启动、打开网页和结束的进程块。底部模板区域用于拖拽到画布上,生成新的流程块;点击打开网页中的属性按钮,修改打开网址;
2、添加输入文本流块:将底部模板区域的输入文本块拖放到打开的网页块的后面,当出现阴影区域时,可以松开鼠标,它会自动连接至此,添加完成;
3、生成一个完整的流程图:按照上面添加输入文本流块的拖放过程添加一个新的块;
关键步骤块设置介绍
定时等待用于等待之前打开的网页完成。
点击输入框Xpath属性按钮,点击属性菜单中的图标点击网页中的输入框,点击输入文本属性按钮,在菜单中输入要搜索的文本。
用于设置点击开始搜索按钮,点击元素的xpath属性按钮,点击菜单中的点击图标,然后点击网页中的百度按钮。
用于设置循环加载下一个列表页面。在循环块内的循环条件块中设置详细条件,点击此处的操作按钮,选择单个元素,然后在属性菜单中点击该元素的xpath属性按钮,在网页中点击下一页按钮为多于。循环次数属性按钮可以默认为0,即不限制下一页的点击次数。
用于设置循环提取列表页中的数据。在循环块内的循环条件块中设置详细条件,点击这里的操作按钮,选择不固定元素列表,然后点击属性菜单中元素的xpath属性按钮,然后连续点击两次提取网页中的第一个块和第二个块元素。循环计数属性按钮可以默认为0,即不限制列表中计费的字段数。
用于执行点击下一页按钮的操作,点击元素xpath属性按钮,选择使用当前循环中元素的xpath的选项。
同样用于设置网页加载的等待时间。
要设置在列表页面上提取的字段规则,请单击属性按钮中的循环使用元素按钮,然后选择循环使用元素选项。单击元素模板属性按钮,在字段表中单击加号或减号可添加或删除字段。添加字段,使用单击操作,即单击加号并将鼠标移动到网页元素并单击选择。
4、单击开始采集 以启动采集。
三、数据采集 并导出
1、采集任务正在运行;
2、采集完成后选择“导出数据”,将所有数据导出到本地文件;
3、选择“导出方式”导出采集好的数据,这里可以选择excel作为导出格式;
4、采集数据导出如下图。
查看全部
网页采集器的自动识别算法(优采云采集器谷歌技术团队倾力打造,一键采集网页数据,全平台
)
优采云采集器由前谷歌技术团队打造,基于人工智能技术,只需输入网址即可自动识别采集内容,直观点击,点击采集网页数据,所有平台,Win/Mac/Linux均可,优采云采集器无限安全使用,可后台运行,实时速度显示,采集@ >和出口都是免费的!
优采云采集器软件特色
1、智能识别数据,小白神器
智能模式:基于人工智能算法,只需输入URL即可智能识别列表数据、表格数据和分页按钮。您无需配置任何采集 规则,只需单击采集。
自动识别:列表、表格、链接、图片、价格等

2、可视化点击,简单易用
流程图模式:只需要根据软件提示点击页面,完全符合浏览网页的思维方式。复杂的 采集 规则可以通过几个简单的步骤生成。结合智能识别算法,任何网页的数据都可以轻松采集。
可以模拟操作:输入文本、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。

3、支持多种数据导出方式
采集结果可以导出到本地,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。

4、功能强大,提供企业级服务
优采云采集器提供丰富的采集功能,无论是采集稳定性还是采集效率,都能满足个人、团队和企业层面采集 @>需求。
功能丰富:定时采集、自动导出、文件下载、加速引擎、分组启动导出、Webhook、RESTful API、智能识别SKU和大图等。

5、云账号,方便快捷
创建一个优采云采集器账号并登录,你所有的采集任务设置都会自动加密保存到优采云的云服务器,不用担心丢失采集的任务,任务运行的数据和采集对你来说是本地的,非常安全,只有本地登录客户端才能查看。优采云采集器账号没有终端绑定限制,切换终端时采集任务也会同步更新,任务管理方便快捷。

6、全平台支持,无缝切换
同时支持Windows、Mac、Linux操作系统的采集软件。各平台版本完全相同,无缝切换。
使用教程
如何自定义采集百度搜索结果数据
一、创建采集任务
1、开始优采云采集器,进入主界面,选择Custom采集点击Create Task按钮,创建“Custom采集Task”;
2、输入百度搜索的网址,包括三种方式。
手动输入:直接在输入框中输入网址。多个 URL 需要用换行符分隔。
单击以从文件中读取:用户选择存储 URL 的文件。文件中可以有多个 URL 地址,地址之间需要用换行符分隔。
批量添加方式:通过添加和调整地址参数生成多个常规地址。
二、自定义采集流程
1、点击创建,自动打开第一个网址,进入自定义设置页面。默认情况下,已经创建了启动、打开网页和结束的进程块。底部模板区域用于拖拽到画布上,生成新的流程块;点击打开网页中的属性按钮,修改打开网址;
2、添加输入文本流块:将底部模板区域的输入文本块拖放到打开的网页块的后面,当出现阴影区域时,可以松开鼠标,它会自动连接至此,添加完成;
3、生成一个完整的流程图:按照上面添加输入文本流块的拖放过程添加一个新的块;
关键步骤块设置介绍
定时等待用于等待之前打开的网页完成。
点击输入框Xpath属性按钮,点击属性菜单中的图标点击网页中的输入框,点击输入文本属性按钮,在菜单中输入要搜索的文本。
用于设置点击开始搜索按钮,点击元素的xpath属性按钮,点击菜单中的点击图标,然后点击网页中的百度按钮。
用于设置循环加载下一个列表页面。在循环块内的循环条件块中设置详细条件,点击此处的操作按钮,选择单个元素,然后在属性菜单中点击该元素的xpath属性按钮,在网页中点击下一页按钮为多于。循环次数属性按钮可以默认为0,即不限制下一页的点击次数。
用于设置循环提取列表页中的数据。在循环块内的循环条件块中设置详细条件,点击这里的操作按钮,选择不固定元素列表,然后点击属性菜单中元素的xpath属性按钮,然后连续点击两次提取网页中的第一个块和第二个块元素。循环计数属性按钮可以默认为0,即不限制列表中计费的字段数。
用于执行点击下一页按钮的操作,点击元素xpath属性按钮,选择使用当前循环中元素的xpath的选项。
同样用于设置网页加载的等待时间。
要设置在列表页面上提取的字段规则,请单击属性按钮中的循环使用元素按钮,然后选择循环使用元素选项。单击元素模板属性按钮,在字段表中单击加号或减号可添加或删除字段。添加字段,使用单击操作,即单击加号并将鼠标移动到网页元素并单击选择。
4、单击开始采集 以启动采集。
三、数据采集 并导出
1、采集任务正在运行;
2、采集完成后选择“导出数据”,将所有数据导出到本地文件;
3、选择“导出方式”导出采集好的数据,这里可以选择excel作为导出格式;
4、采集数据导出如下图。
网页采集器的自动识别算法(特色功能1.信息采集添加全自动网站的内容管理方法介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-01-08 17:04
网站Information采集器是一个网站Information采集软件,你可以用这个软件来采集任何网站信息,转换需要的信息内容采集 并自动发布到您的 网站 以进行自动化 网站 内容管理。
特殊功能
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录查看信息内容的网站,网站优采云采集器可以轻松登录采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果需要采集图片等二进制文件,只需设置网站优采云采集器,即可将任意类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别javascript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是常见的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。
变更日志
1.新的分层设置,每一层都可以设置特殊选项,摆脱之前默认的3层限制
2.一次抓取任意多层分类。以前需要先抓取每个分类的url,然后再抓取每个分类
3.图片下载,自定义文件名,以前不能改名
4.新闻内容分页合并设置更简单、更通用、更强大
5.模拟点击更通用更简单。之前的模拟点击需要特殊设置,使用起来很复杂。
6.可以根据内容判断是否重复。以前,它仅基于 URL。
7.采集完成后允许执行自定义vbs脚本endget.vbs,发布后允许执行endpub.vbs。在vbs中,你可以编写自己的数据处理函数
8.导出数据可以包括文本、排除文本、文本截取日期加月份、数字比较、大小、过滤、前后追加字符 查看全部
网页采集器的自动识别算法(特色功能1.信息采集添加全自动网站的内容管理方法介绍)
网站Information采集器是一个网站Information采集软件,你可以用这个软件来采集任何网站信息,转换需要的信息内容采集 并自动发布到您的 网站 以进行自动化 网站 内容管理。
特殊功能
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录查看信息内容的网站,网站优采云采集器可以轻松登录采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果需要采集图片等二进制文件,只需设置网站优采云采集器,即可将任意类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别javascript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是常见的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。
变更日志
1.新的分层设置,每一层都可以设置特殊选项,摆脱之前默认的3层限制
2.一次抓取任意多层分类。以前需要先抓取每个分类的url,然后再抓取每个分类
3.图片下载,自定义文件名,以前不能改名
4.新闻内容分页合并设置更简单、更通用、更强大
5.模拟点击更通用更简单。之前的模拟点击需要特殊设置,使用起来很复杂。
6.可以根据内容判断是否重复。以前,它仅基于 URL。
7.采集完成后允许执行自定义vbs脚本endget.vbs,发布后允许执行endpub.vbs。在vbs中,你可以编写自己的数据处理函数
8.导出数据可以包括文本、排除文本、文本截取日期加月份、数字比较、大小、过滤、前后追加字符
网页采集器的自动识别算法(网页信息采集分类系统的设计思路与应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-01-07 21:05
●概要
互联网已经发展成为一个拥有数亿页的分布式信息空间,而且这个数字还在以每4到6个月翻一番的速度增长。随着网络信息资源的快速增长,人们越来越关注如何开发和利用这些网络信息资源。然而,现有技术不能满足用户对高质量网络信息服务的需求。例如,传统搜索引擎返回的相关网页过多,用户很难快速准确地定位到所需信息。网页信息归类为采集 系统就在这样的环境中应运而生。网络信息分类系统采集是网络信息挖掘的技术实现。它的设计理念是:网页搜索à网页内容提取à内容分类(形成知识库)。系统的研究对象是网页中的信息,如新闻网站的新闻网页、专利的专利介绍网页网站、公司的产品介绍网页网站等。系统的目标是从网络信息资源中找到用户需要的有价值的信息,并及时提供给用户。在整个系统的设计中,我们按照面向功能的原则将系统划分为6个模块,先设计模块之间的接口,再细化为更小的模块。在实现的过程中,从最小的功能单元开始,再组装成更大的功能,最后完成整个系统。在系统的开发过程中,我们研究了与网络信息挖掘相关的技术,包括网页搜索技术、网页内容提取技术、文本分类和聚类等。本文提出了一种网络搜索算法和一种网络内容提取算法,已应用于网络信息分类系统中,取得了良好的效果;文本分类使用现有算法,在系统中使用代码实现。本文积极探索和研究网页信息的采集方面,提供了一套切实可行的技术方案,提高了网络信息的综合利用价值。包括网页搜索技术、网页内容提取技术、文本分类和聚类等。本文提出了一种网络搜索算法和一种网络内容提取算法,已应用于网络信息分类系统中,取得了良好的效果;文本分类使用现有算法,在系统中使用代码实现。本文积极探索和研究网页信息的采集方面,提供了一套切实可行的技术方案,提高了网络信息的综合利用价值。包括网页搜索技术、网页内容提取技术、文本分类和聚类等。本文提出了一种网络搜索算法和一种网络内容提取算法,已应用于网络信息分类系统中,取得了良好的效果;文本分类使用现有算法,在系统中使用代码实现。本文积极探索和研究网页信息的采集方面,提供了一套切实可行的技术方案,提高了网络信息的综合利用价值。已应用于网络信息分类系统,取得了良好的效果;文本分类使用现有算法,在系统中使用代码实现。本文积极探索和研究网页信息的采集方面,提供了一套切实可行的技术方案,提高了网络信息的综合利用价值。已应用于网络信息分类系统,取得了良好的效果;文本分类使用现有算法,在系统中使用代码实现。本文积极探索和研究网页信息的采集方面,提供了一套切实可行的技术方案,提高了网络信息的综合利用价值。 查看全部
网页采集器的自动识别算法(网页信息采集分类系统的设计思路与应用)
●概要
互联网已经发展成为一个拥有数亿页的分布式信息空间,而且这个数字还在以每4到6个月翻一番的速度增长。随着网络信息资源的快速增长,人们越来越关注如何开发和利用这些网络信息资源。然而,现有技术不能满足用户对高质量网络信息服务的需求。例如,传统搜索引擎返回的相关网页过多,用户很难快速准确地定位到所需信息。网页信息归类为采集 系统就在这样的环境中应运而生。网络信息分类系统采集是网络信息挖掘的技术实现。它的设计理念是:网页搜索à网页内容提取à内容分类(形成知识库)。系统的研究对象是网页中的信息,如新闻网站的新闻网页、专利的专利介绍网页网站、公司的产品介绍网页网站等。系统的目标是从网络信息资源中找到用户需要的有价值的信息,并及时提供给用户。在整个系统的设计中,我们按照面向功能的原则将系统划分为6个模块,先设计模块之间的接口,再细化为更小的模块。在实现的过程中,从最小的功能单元开始,再组装成更大的功能,最后完成整个系统。在系统的开发过程中,我们研究了与网络信息挖掘相关的技术,包括网页搜索技术、网页内容提取技术、文本分类和聚类等。本文提出了一种网络搜索算法和一种网络内容提取算法,已应用于网络信息分类系统中,取得了良好的效果;文本分类使用现有算法,在系统中使用代码实现。本文积极探索和研究网页信息的采集方面,提供了一套切实可行的技术方案,提高了网络信息的综合利用价值。包括网页搜索技术、网页内容提取技术、文本分类和聚类等。本文提出了一种网络搜索算法和一种网络内容提取算法,已应用于网络信息分类系统中,取得了良好的效果;文本分类使用现有算法,在系统中使用代码实现。本文积极探索和研究网页信息的采集方面,提供了一套切实可行的技术方案,提高了网络信息的综合利用价值。包括网页搜索技术、网页内容提取技术、文本分类和聚类等。本文提出了一种网络搜索算法和一种网络内容提取算法,已应用于网络信息分类系统中,取得了良好的效果;文本分类使用现有算法,在系统中使用代码实现。本文积极探索和研究网页信息的采集方面,提供了一套切实可行的技术方案,提高了网络信息的综合利用价值。已应用于网络信息分类系统,取得了良好的效果;文本分类使用现有算法,在系统中使用代码实现。本文积极探索和研究网页信息的采集方面,提供了一套切实可行的技术方案,提高了网络信息的综合利用价值。已应用于网络信息分类系统,取得了良好的效果;文本分类使用现有算法,在系统中使用代码实现。本文积极探索和研究网页信息的采集方面,提供了一套切实可行的技术方案,提高了网络信息的综合利用价值。
网页采集器的自动识别算法( 优采云采集器_真免费!导出无限制网络爬虫软件_人工智能数据采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-01-03 23:03
优采云采集器_真免费!导出无限制网络爬虫软件_人工智能数据采集软件)
优采云采集器_免费!导出无限网络爬虫软件_人工智能数据采集软件
优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。该软件功能强大且易于操作。可谓居家旅行神器。 .
优采云采集器_大数据云部署采集爬虫系统,免费无限自动化采集软件
优采云采集器是一款免费无限的爬虫系统,采用php+mysql开发,可部署在云服务器上,让您在电脑端和移动端都可以使用浏览器采集数据可接入任意cms系统,无需登录即可实时发布数据。大数据云时代为网站数据自动化采集发布的最好的云爬虫软件
优采云浏览器官网络-可视化采集软件|网站抓取向导|网站抓取工具|自动验证码识别|自动释放软件
优采云浏览器采集软件,是一款可视化的采集软件,一款网络爬虫工具软件,网站抓取工具,模拟浏览器手动操作采集 发布软件,可以生成EXE。
优采云采集器 – 简单易用的网络数据采集tool_free 网络爬虫软件
优采云采集器是一款简单易用的网络数据采集工具,免费的网络爬虫软件。 优采云采集器简单易学,通过智能算法+可视化界面,随心所欲抓取数据。只需点击鼠标即可采集网页上的数据。
优采云采集器官网-网络爬虫工具_优采云采集器_free网站采集软件
优采云采集器该软件是一个网络爬虫工具,用于网站信息采集、网站信息抓取,包括图片和文字其他信息采集被处理和发布。是目前使用最多的互联网数据采集软件。出品,10年打造网络数据工具采集。
预嗅探大数据 查看全部
网页采集器的自动识别算法(
优采云采集器_真免费!导出无限制网络爬虫软件_人工智能数据采集软件)

优采云采集器_免费!导出无限网络爬虫软件_人工智能数据采集软件
优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。该软件功能强大且易于操作。可谓居家旅行神器。 .
优采云采集器_大数据云部署采集爬虫系统,免费无限自动化采集软件
优采云采集器是一款免费无限的爬虫系统,采用php+mysql开发,可部署在云服务器上,让您在电脑端和移动端都可以使用浏览器采集数据可接入任意cms系统,无需登录即可实时发布数据。大数据云时代为网站数据自动化采集发布的最好的云爬虫软件
优采云浏览器官网络-可视化采集软件|网站抓取向导|网站抓取工具|自动验证码识别|自动释放软件
优采云浏览器采集软件,是一款可视化的采集软件,一款网络爬虫工具软件,网站抓取工具,模拟浏览器手动操作采集 发布软件,可以生成EXE。
优采云采集器 – 简单易用的网络数据采集tool_free 网络爬虫软件
优采云采集器是一款简单易用的网络数据采集工具,免费的网络爬虫软件。 优采云采集器简单易学,通过智能算法+可视化界面,随心所欲抓取数据。只需点击鼠标即可采集网页上的数据。
优采云采集器官网-网络爬虫工具_优采云采集器_free网站采集软件
优采云采集器该软件是一个网络爬虫工具,用于网站信息采集、网站信息抓取,包括图片和文字其他信息采集被处理和发布。是目前使用最多的互联网数据采集软件。出品,10年打造网络数据工具采集。
预嗅探大数据
网页采集器的自动识别算法(VG浏览器软件特色可视化操作操作简单完全兼容JQuery规则)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-03 23:01
Vg浏览器不仅是一个采集浏览器,更是一个营销神器。 vg浏览器也是一个可视化脚本驱动的网页工具,它可以简单的设置脚本,可以创建自动登录、身份验证等许多脚本项目。
VG浏览器基本介绍
VG浏览器是一款由可视化脚本驱动的网页自动运行工具。只需设置一个脚本,即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件。操作数据库、收发邮件等个性化实用的脚本项,还可以使用逻辑运算完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。
VG 浏览器软件功能
视觉操作
操作简单,图形操作完全可视化,无需专业IT人员。
自定义流程
采集就像搭积木一样,功能自由组合。
自动编码
程序注重采集效率,页面解析速度很快。
生成EXE
自动登录,自动识别验证码,是万能浏览器。
如何使用VG浏览器
通过CSS Path定位网页元素的路径是VG浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的这个按钮
点击一个网页元素会自动生成该元素的CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。比如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器,可以通过按F12键或在页面上右键选择评论元素来选择。
右键单击目标部分并选择复制 CSS 路径将 CSS 路径复制到剪贴板,
在 Firefox 中,您还可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Only Selector”复制CSS Path。
CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写JQuery选择器,你也可以自己编写CSS Path
VG 浏览器更新日志
8.5.3.0 (2021-12-16)
新增列表循环“点击标签后等待”时间配置
改进内置浏览器对网页加载的判断,提高网页采集稳定性 查看全部
网页采集器的自动识别算法(VG浏览器软件特色可视化操作操作简单完全兼容JQuery规则)
Vg浏览器不仅是一个采集浏览器,更是一个营销神器。 vg浏览器也是一个可视化脚本驱动的网页工具,它可以简单的设置脚本,可以创建自动登录、身份验证等许多脚本项目。

VG浏览器基本介绍
VG浏览器是一款由可视化脚本驱动的网页自动运行工具。只需设置一个脚本,即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件。操作数据库、收发邮件等个性化实用的脚本项,还可以使用逻辑运算完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。

VG 浏览器软件功能
视觉操作
操作简单,图形操作完全可视化,无需专业IT人员。
自定义流程
采集就像搭积木一样,功能自由组合。
自动编码
程序注重采集效率,页面解析速度很快。
生成EXE
自动登录,自动识别验证码,是万能浏览器。
如何使用VG浏览器
通过CSS Path定位网页元素的路径是VG浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的这个按钮

点击一个网页元素会自动生成该元素的CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。比如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器,可以通过按F12键或在页面上右键选择评论元素来选择。

右键单击目标部分并选择复制 CSS 路径将 CSS 路径复制到剪贴板,

在 Firefox 中,您还可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Only Selector”复制CSS Path。


CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写JQuery选择器,你也可以自己编写CSS Path
VG 浏览器更新日志
8.5.3.0 (2021-12-16)
新增列表循环“点击标签后等待”时间配置
改进内置浏览器对网页加载的判断,提高网页采集稳定性
网页采集器的自动识别算法(网页采集器的自动识别算法代码,可以通过以下接口获取)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-01-02 13:09
网页采集器的自动识别算法代码,可以通过以下接口获取,
国内常用的还是百度的算法ss-api,现在还有第三方的比如说说爱采集的google_ssl_extract_all_content接口,你可以看看。
可以用是自己定制算法生成一个采集器的,把需要的数据有节点采集到;也可以找第三方的,如果是采集大型资源,在上面接spider接口,然后下载采集到。
还是有这样的算法,某宝有卖,自动采集但得花点时间,但是后台设置再下载,
试试把数据流向引入网页采集器,
百度网页采集器,或者通过header爬虫来获取要采集的网站。
百度嘛
存下来
各大搜索引擎都有外链接获取服务,只要把被采集链接都存下来并且发布即可。
全球都有抓取器,有的需要联系官方的,有的是第三方做的。
百度
百度已经公布了,需要安装extract_st后台接口,如果只是获取网页,可以直接spider接口,google/taobao有开发,
推荐使用国外的一个公司,他们可以从googlespider接口获取所有url
你可以参考我的这篇文章:像谷歌等搜索引擎提供了一些能够获取他们中所指定域名数据的api接口!分析方法是你先提取spider被指定域名下的所有网页,就可以了;前提是你注册和登录过它们的网站,而且中国境内正在运行中。用自己的代理也可以;(因为也有别的方法,所以上面说的是常用的方法)按照它们的用法试一下;可以得到相应的结果。-googlespiderapi|milk-博客园。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法代码,可以通过以下接口获取)
网页采集器的自动识别算法代码,可以通过以下接口获取,
国内常用的还是百度的算法ss-api,现在还有第三方的比如说说爱采集的google_ssl_extract_all_content接口,你可以看看。
可以用是自己定制算法生成一个采集器的,把需要的数据有节点采集到;也可以找第三方的,如果是采集大型资源,在上面接spider接口,然后下载采集到。
还是有这样的算法,某宝有卖,自动采集但得花点时间,但是后台设置再下载,
试试把数据流向引入网页采集器,
百度网页采集器,或者通过header爬虫来获取要采集的网站。
百度嘛
存下来
各大搜索引擎都有外链接获取服务,只要把被采集链接都存下来并且发布即可。
全球都有抓取器,有的需要联系官方的,有的是第三方做的。
百度
百度已经公布了,需要安装extract_st后台接口,如果只是获取网页,可以直接spider接口,google/taobao有开发,
推荐使用国外的一个公司,他们可以从googlespider接口获取所有url
你可以参考我的这篇文章:像谷歌等搜索引擎提供了一些能够获取他们中所指定域名数据的api接口!分析方法是你先提取spider被指定域名下的所有网页,就可以了;前提是你注册和登录过它们的网站,而且中国境内正在运行中。用自己的代理也可以;(因为也有别的方法,所以上面说的是常用的方法)按照它们的用法试一下;可以得到相应的结果。-googlespiderapi|milk-博客园。
网页采集器的自动识别算法(优采云收罗器是网页信息收罗东西的软件功效与作用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-01-02 08:10
优采云 采集器是一个非常有用的网页信息采集工具。该工具界面简洁,操作复杂,功能强大。有了它,我们可以采集我们必要网页上的所有信息。无门槛,新手也可以使用。
软件功能
1、零门槛:如果你不会采集爬虫,你会在会议上收到网站数据。
2、多引擎,高速不乱:内置高速浏览器引擎,也可以切换到HTTP引擎模式运行,数据采集更高效。还内置了JSON引擎,无需分析JSON数据布局,直观提取JSON内容。
<p>3、结合各种网站:可以采集99%的互联网网站,包括静态例子网站,比如使用Ajax加载单页。 查看全部

网页采集器的自动识别算法(马云的“网购心智”赚钱靠谱,靠谱不等于完美的机器人)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-12-30 04:02
网页采集器的自动识别算法还是非常靠谱的,有些甚至可以识别出isp提供的返利信息。采集数据的时候,有的网站可能只有某一类型的商品才能拿到这个返利,也就是说,小类目可能只返现金,大类目也可能只返商品。他就把这些商品信息自动识别出来。
时刻关注以下两篇文章阿里妈妈助力业务开展,
最靠谱的应该是联盟,
aliexpress。alibaba。com-aliexpress。com!route:feedmarketsite(parallel)-headerstag:1。runon1listing2。excludemoreshopee-aliexpress-feedmarketsitegpsmarketsite&productchannel1。0googlemap搜一下aliexpress的一些信息就可以抓一些aliexpress的返利。
马云的“网购心智”
赚钱靠谱,靠谱不等于完美的机器人。
aliexpress还好,我做海淘,比上的号便宜多了,
网购心智是个好东西,在资金不允许或者说想有更多客源的情况下,不得不用。
一手抓返利机器人,
返利机器人很精准,你使用后然后观察一段时间会有比较不错的效果,操作简单,
能赚多少钱不敢说,
可以吧。有一次还没进5分钱的东西,老板就给返3毛钱。
赚点小钱,赚点动力。他们是给钱才干活的,质量相比来说不知道高了多少倍。返利就是,你花了一块钱,给他返回5毛,你可以在返利上买东西的。 查看全部
网页采集器的自动识别算法(马云的“网购心智”赚钱靠谱,靠谱不等于完美的机器人)
网页采集器的自动识别算法还是非常靠谱的,有些甚至可以识别出isp提供的返利信息。采集数据的时候,有的网站可能只有某一类型的商品才能拿到这个返利,也就是说,小类目可能只返现金,大类目也可能只返商品。他就把这些商品信息自动识别出来。
时刻关注以下两篇文章阿里妈妈助力业务开展,
最靠谱的应该是联盟,
aliexpress。alibaba。com-aliexpress。com!route:feedmarketsite(parallel)-headerstag:1。runon1listing2。excludemoreshopee-aliexpress-feedmarketsitegpsmarketsite&productchannel1。0googlemap搜一下aliexpress的一些信息就可以抓一些aliexpress的返利。
马云的“网购心智”
赚钱靠谱,靠谱不等于完美的机器人。
aliexpress还好,我做海淘,比上的号便宜多了,
网购心智是个好东西,在资金不允许或者说想有更多客源的情况下,不得不用。
一手抓返利机器人,
返利机器人很精准,你使用后然后观察一段时间会有比较不错的效果,操作简单,
能赚多少钱不敢说,
可以吧。有一次还没进5分钱的东西,老板就给返3毛钱。
赚点小钱,赚点动力。他们是给钱才干活的,质量相比来说不知道高了多少倍。返利就是,你花了一块钱,给他返回5毛,你可以在返利上买东西的。
网页采集器的自动识别算法(网页采集大师这款软件的用途和界面样式的初步介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-01-24 03:07
今天要分享的是一款名为Master of Web Data 采集的软件,名字好听,哈哈。
您可以通过查看名称来判断它的作用。是的,专门用于采集网页中的数据,主要是自动化采集各种列表页和详情页数据。您也可以将其用作爬虫工具。下面简单介绍一下什么是所谓的列表页和详情页。
以某电商网站为例,下图为列表页面,即一个列表中显示了很多相似的数据,一个页面无法完整显示,所以也可以跳转到页面底部的下一页,即分页显示。
列表
如果数据量大,列表页单独显示。
分页
以下为详情页展示:
详情页数据
上面是列表页+详情页,就是这个工具进来的地方。大部分网站都是这样,只要是分页数据,都可以批量采集,< @采集 非常快,非常安全,几乎不用担心被屏蔽。
说完它的功能,我们再来看看它的软件长什么样。
网页采集大师
以上是对软件的用途和界面风格的初步介绍,大师采集。看完界面,是不是觉得很简单呢?是的,这个软件的界面是我设计的。而且所有的代码都是我自己写的。
本软件可以采集PC上几乎所有的网页数据,包括上图所示的列表页和详情页数据,然后生成excel或者文本格式的文件。使用起来非常简单方便。您可以在几分钟内采集 数千条数据,因此您不必再担心没有数据了。
如果你对网页采集、爬虫感兴趣,或者对网页数据有需求,欢迎关注我,以后我会经常分享这个软件的使用方法。如有童鞋毕业设计需要数据,请联系我,帮您快速解决数据问题。
我的头条号: 查看全部
网页采集器的自动识别算法(网页采集大师这款软件的用途和界面样式的初步介绍)
今天要分享的是一款名为Master of Web Data 采集的软件,名字好听,哈哈。
您可以通过查看名称来判断它的作用。是的,专门用于采集网页中的数据,主要是自动化采集各种列表页和详情页数据。您也可以将其用作爬虫工具。下面简单介绍一下什么是所谓的列表页和详情页。
以某电商网站为例,下图为列表页面,即一个列表中显示了很多相似的数据,一个页面无法完整显示,所以也可以跳转到页面底部的下一页,即分页显示。
列表
如果数据量大,列表页单独显示。
分页
以下为详情页展示:
详情页数据
上面是列表页+详情页,就是这个工具进来的地方。大部分网站都是这样,只要是分页数据,都可以批量采集,< @采集 非常快,非常安全,几乎不用担心被屏蔽。
说完它的功能,我们再来看看它的软件长什么样。
网页采集大师
以上是对软件的用途和界面风格的初步介绍,大师采集。看完界面,是不是觉得很简单呢?是的,这个软件的界面是我设计的。而且所有的代码都是我自己写的。
本软件可以采集PC上几乎所有的网页数据,包括上图所示的列表页和详情页数据,然后生成excel或者文本格式的文件。使用起来非常简单方便。您可以在几分钟内采集 数千条数据,因此您不必再担心没有数据了。
如果你对网页采集、爬虫感兴趣,或者对网页数据有需求,欢迎关注我,以后我会经常分享这个软件的使用方法。如有童鞋毕业设计需要数据,请联系我,帮您快速解决数据问题。
我的头条号:
网页采集器的自动识别算法( 2020年03月23日15:55:59python实现识别手写数字)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-01-23 18:18
2020年03月23日15:55:59python实现识别手写数字)
python实现手写数字识别 python图像识别算法
更新时间:2020-03-23 15:55:59 作者:Hanpu_Liang
本文文章主要详细介绍python识别手写数字的实现,python图像识别算法,有一定的参考价值,感兴趣的朋友可以参考一下
写在前面
这一段的内容可以说是最难的部分之一。因为是识别图像,涉及到的算法会比上一个难度更大,所以我尽量说清楚。
并且因为在写的过程中,对之前的一些逻辑也进行了修改和完善,所以一切以本文为准。当然,如果你想直接看代码,代码都放在我的GitHub上,所以这个文章主要负责讲解,如果需要代码,请自行去GitHub。
这个大纲
上次我写了关于建立数据库的文章,我们能够将更新的训练图像实时存储在 CSV 文件中。所以这次继续往下看,就到了识别图片内容的时候了。
首先,我们需要从文件夹中提取出要识别的图片test.png,和训练图片一样的处理,得到一个1x10000的向量。因为两者有细微的差别,我并不想在源码中添加逻辑,所以直接重写了添加待识别图片的函数,命名为GetTestPicture。内容与GetTrainPicture类似,但缺少“添加图片名称”部分。
之后,我们就可以开始正式的图像识别内容了。
主要目的是计算待识别图像与所有训练图像之间的距离。当两张图片更接近时,意味着它们更相似,因此它们很可能会写相同的数字。所以利用这个原理,我们可以找出最接近待识别图像的训练图像,并输出它们的数量。比如我要输出前三个,而前三个分别是3、3、9,则表示要识别的图像很可能是3.
之后,还可以给每个位置加一个权重,细节下次再说。本节内容足够。
(在第一篇文章中,我提到了使用图片孔数来检测,我试过了,觉得有点不合适,具体原因在文末。)
主要代码
所以直接放主代码,逻辑比较清晰
import os
import OperatePicture as OP
import OperateDatabase as OD
import PictureAlgorithm as PA
import csv
##Essential vavriable 基础变量
#Standard size 标准大小
N = 100
#Gray threshold 灰度阈值
color = 200/255
n = 10
#读取原CSV文件
reader = list(csv.reader(open('Database.csv', encoding = 'utf-8')))
#清除读取后的第一个空行
del reader[0]
#读取num目录下的所有文件名
fileNames = os.listdir(r"./num/")
#对比fileNames与reader,得到新增的图片newFileNames
newFileNames = OD.NewFiles(fileNames, reader)
print('New pictures are: ', newFileNames)
#得到newFilesNames对应的矩阵
pic = OP.GetTrainPicture(newFileNames)
#将新增图片矩阵存入CSV中
OD.SaveToCSV(pic, newFileNames)
#将原数据库矩阵与新数据库矩阵合并
pic = OD.Combination(reader, pic)
#得到待识别图片
testFiles = os.listdir(r"./test/")
testPic = OP.GetTestPicture(testFiles)
#计算每一个待识别图片的可能分类
result = PA.CalculateResult(testPic, pic)
for item in result:
for i in range(n):
print('第'+str(i+1)+'个向量为'+str(item[i+n])+',距离为'+str(item[i]))
与上一篇文章的内容相比,本文文章只增加了如下一段代码,即获取待识别图片的名称,获取待识别的图片向量,并计算分类。
下面我们将重点介绍CalculateResult函数的内容,即识别图像的算法。
算法内容
一般算法
我们在大纲里已经简单介绍过了,我就照搬一下,补充一些内容。
假设我们在二维平面上有两个点 A=(1,1) 和 B=(5,5),我现在将另一个点 C=(2,2),那么,哪一个更接近C点?
初中学过数学的都知道,肯定离A点比较近。所以换个说法,我们现在有A和B两个班,A班包括点(1,1) ,B类包括点(5,5),那么对于点(2,2),它可能属于哪个类别?
因为这个点离A类的点有点近,所以很可能属于A类。这就是结论。那么对于3维空间,A类是点(1,1,1),B类是(5,5,5),那么对于点(2,2,2) 必须相同)属于 A 类。
可以看出,我们以两点之间的距离作为判断属于哪个类别的标准。那么对于我们把图片拉进去的1xn维向量,投影到n维空间上其实就是一个点,所以我们把训练向量分成10个类别,分别代表十个数字,那么哪个类别是识别出来的数字close to,然后说明它可能属于这一类。
那么我们这里可以假设对于识别出的向量,列出离他最近的前十个向量属于哪个类别,然后根据排名加上一个权重,计算一个值。这个值代表它可能属于哪个类,所以这就是我们得到的最终结果——识别出的手写数字图片的值。
以上是第一个文章的内容,现在我重点讲数学的内容。
考虑到有些地方不能输入数学公式(或者输入不方便),我还是把这一段贴图。
然后直接挑出最接近识别图片的前几个向量。基本上,这些数字是识别图片的数字。但是这样做有点简单,所以在下一篇文章我会深入,这篇先讲计算距离。
主要代码
在下面的代码中,文件夹test用来存放要识别的图片,通过函数GetTestPicture得到图片向量,然后和训练图片pic一起放入计算距离的函数CalculateResult中计算距离在每个要识别的向量和所有其他图像向量之间。.
#得到待识别图片
testFiles = os.listdir(r"./test/")
testPic = OP.GetTestPicture(testFiles)
#计算每一个待识别图片的可能分类
result = PA.CalculateResult(testPic, pic)
for item in result:
for i in range(n):
print('第'+str(i+1)+'个向量为'+str(item[i+n])+',距离为'+str(item[i]))
函数 CalculateResult 在文件 PictureAlgorithm.py 中。该文件收录两个函数:CalculateDistance 函数和CalculateResult 函数,代表用于识别图片的算法。
函数计算结果
这个函数的逻辑比较简单,没什么好说的。主要连接是计算距离的CalculateDistance 函数。
def CalculateResult(test, train):
'''计算待识别图片test的可能分类'''
#得到每个图片的前n相似图片
testDis = CalculateDistance(test[:,0:N**2], train[:,0:N**2], train[:,N**2], n)
#将testDis变成列表
tt = testDis.tolist()
#输出每一个待识别图片的所有前n个
for i in tt:
for j in i:
print(j)
函数计算距离
在函数中,我导入了四个参数:识别向量test,训练向量train,每个向量对应的训练向量所代表的数字num,以及我要导出的前n个最近的向量。
def CalculateDistance(test, train, num, n):
'''计算每个图片前n相似图片'''
#前n个放距离,后n个放数字
dis = np.zeros(2*n*len(test)).reshape(len(test), 2*n)
for i, item in enumerate(test):
#计算出每个训练图片与该待识别图片的距离
itemDis = np.sqrt(np.sum((item-train)**2, axis=1))
#对距离进行排序,找出前n个
sortDis = np.sort(itemDis)
dis[i, 0:n] = sortDis[0:n]
for j in range(n):
#找到前几个在原矩阵中的位置
maxPoint = list(itemDis).index(sortDis[j])
#找到num对应位置的数字,存入dis中
dis[i, j+n] = num[maxPoint]
return dis
首先,创建一个矩阵,其行数为测试中识别的向量数,列数为 2*n。每行的前 n 是距离,最后 n 是数字。然后循环每个识别的向量。
首先,直接计算每张训练图像与识别图像的距离,可以直接用一行代码表示
itemDis = np.sqrt(np.sum((item-train)**2, axis=1))
这行代码就是上面的算法过程。我个人认为是比较复杂的。你可以仔细看看。我不会在这里详细介绍。下面开始排序,找到最接近的前几个向量。
这里的逻辑是:先排序,找到距离最小的前n个,存入矩阵。求原矩阵的前n个位置,求对应位置的num个数,存入dis的最后n个。
这相当于完成了一切,只需返回dis即可。
实际测试
我手写了一些数字,如图所示。所以实际上我们的数据库还是比较小的。
所以我写了另一个数字作为要识别的图像。运行完程序,我们直接输出前十个最相似的向量:
第一个向量为2.0,距离为33.62347223932534
第二个向量是2.0,距离是35.645
第三个向量为2.0,距离为38.69663119274146
第四个向量为2.0,距离为43.529
第5个向量是2.0,距离是43.694
第6个向量为1.0,距离为43.7314
第7个向量为6.0,距离为44.948
第8个向量为2.0,距离为45.5924
第9个向量为4.0,距离为45.43926712996951
第10个向量为7.0,距离为45.64893989116544
之后,我又从 1 到 9 再试一次,我手写的数字都被正确识别了。可以看出,准确率还是挺高的。所以做了这一步就相当于完成度很高。
于是我试了一下网上找的图片,发现几乎没有正确的。这意味着我们的数据库仍然太小,只能识别我的字体。不过话虽如此,你也可以做一个字体识别程序。
所以如果你想提高准确率,那么扩展图库是必须的。这次就到这里了。
总结
我的 GitHub 里有全部源代码,有兴趣的可以去看看。
这相当于完成了算法内容,比较简单,只使用了类似于K最近邻的算法。
下一篇文章会讲一个对前n个排名进行加权提高准确率的思路。
所以这次我就到这里了,谢谢。
喜欢的话请点个赞关注一下,谢谢~
本文已被收录收录在“python图像处理操作”专题中,欢迎大家点击了解更多精彩内容。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持Scripting Home。 查看全部
网页采集器的自动识别算法(
2020年03月23日15:55:59python实现识别手写数字)
python实现手写数字识别 python图像识别算法
更新时间:2020-03-23 15:55:59 作者:Hanpu_Liang
本文文章主要详细介绍python识别手写数字的实现,python图像识别算法,有一定的参考价值,感兴趣的朋友可以参考一下
写在前面
这一段的内容可以说是最难的部分之一。因为是识别图像,涉及到的算法会比上一个难度更大,所以我尽量说清楚。
并且因为在写的过程中,对之前的一些逻辑也进行了修改和完善,所以一切以本文为准。当然,如果你想直接看代码,代码都放在我的GitHub上,所以这个文章主要负责讲解,如果需要代码,请自行去GitHub。
这个大纲
上次我写了关于建立数据库的文章,我们能够将更新的训练图像实时存储在 CSV 文件中。所以这次继续往下看,就到了识别图片内容的时候了。
首先,我们需要从文件夹中提取出要识别的图片test.png,和训练图片一样的处理,得到一个1x10000的向量。因为两者有细微的差别,我并不想在源码中添加逻辑,所以直接重写了添加待识别图片的函数,命名为GetTestPicture。内容与GetTrainPicture类似,但缺少“添加图片名称”部分。
之后,我们就可以开始正式的图像识别内容了。
主要目的是计算待识别图像与所有训练图像之间的距离。当两张图片更接近时,意味着它们更相似,因此它们很可能会写相同的数字。所以利用这个原理,我们可以找出最接近待识别图像的训练图像,并输出它们的数量。比如我要输出前三个,而前三个分别是3、3、9,则表示要识别的图像很可能是3.
之后,还可以给每个位置加一个权重,细节下次再说。本节内容足够。
(在第一篇文章中,我提到了使用图片孔数来检测,我试过了,觉得有点不合适,具体原因在文末。)
主要代码
所以直接放主代码,逻辑比较清晰
import os
import OperatePicture as OP
import OperateDatabase as OD
import PictureAlgorithm as PA
import csv
##Essential vavriable 基础变量
#Standard size 标准大小
N = 100
#Gray threshold 灰度阈值
color = 200/255
n = 10
#读取原CSV文件
reader = list(csv.reader(open('Database.csv', encoding = 'utf-8')))
#清除读取后的第一个空行
del reader[0]
#读取num目录下的所有文件名
fileNames = os.listdir(r"./num/")
#对比fileNames与reader,得到新增的图片newFileNames
newFileNames = OD.NewFiles(fileNames, reader)
print('New pictures are: ', newFileNames)
#得到newFilesNames对应的矩阵
pic = OP.GetTrainPicture(newFileNames)
#将新增图片矩阵存入CSV中
OD.SaveToCSV(pic, newFileNames)
#将原数据库矩阵与新数据库矩阵合并
pic = OD.Combination(reader, pic)
#得到待识别图片
testFiles = os.listdir(r"./test/")
testPic = OP.GetTestPicture(testFiles)
#计算每一个待识别图片的可能分类
result = PA.CalculateResult(testPic, pic)
for item in result:
for i in range(n):
print('第'+str(i+1)+'个向量为'+str(item[i+n])+',距离为'+str(item[i]))
与上一篇文章的内容相比,本文文章只增加了如下一段代码,即获取待识别图片的名称,获取待识别的图片向量,并计算分类。
下面我们将重点介绍CalculateResult函数的内容,即识别图像的算法。
算法内容
一般算法
我们在大纲里已经简单介绍过了,我就照搬一下,补充一些内容。
假设我们在二维平面上有两个点 A=(1,1) 和 B=(5,5),我现在将另一个点 C=(2,2),那么,哪一个更接近C点?
初中学过数学的都知道,肯定离A点比较近。所以换个说法,我们现在有A和B两个班,A班包括点(1,1) ,B类包括点(5,5),那么对于点(2,2),它可能属于哪个类别?
因为这个点离A类的点有点近,所以很可能属于A类。这就是结论。那么对于3维空间,A类是点(1,1,1),B类是(5,5,5),那么对于点(2,2,2) 必须相同)属于 A 类。
可以看出,我们以两点之间的距离作为判断属于哪个类别的标准。那么对于我们把图片拉进去的1xn维向量,投影到n维空间上其实就是一个点,所以我们把训练向量分成10个类别,分别代表十个数字,那么哪个类别是识别出来的数字close to,然后说明它可能属于这一类。
那么我们这里可以假设对于识别出的向量,列出离他最近的前十个向量属于哪个类别,然后根据排名加上一个权重,计算一个值。这个值代表它可能属于哪个类,所以这就是我们得到的最终结果——识别出的手写数字图片的值。
以上是第一个文章的内容,现在我重点讲数学的内容。
考虑到有些地方不能输入数学公式(或者输入不方便),我还是把这一段贴图。
然后直接挑出最接近识别图片的前几个向量。基本上,这些数字是识别图片的数字。但是这样做有点简单,所以在下一篇文章我会深入,这篇先讲计算距离。
主要代码
在下面的代码中,文件夹test用来存放要识别的图片,通过函数GetTestPicture得到图片向量,然后和训练图片pic一起放入计算距离的函数CalculateResult中计算距离在每个要识别的向量和所有其他图像向量之间。.
#得到待识别图片
testFiles = os.listdir(r"./test/")
testPic = OP.GetTestPicture(testFiles)
#计算每一个待识别图片的可能分类
result = PA.CalculateResult(testPic, pic)
for item in result:
for i in range(n):
print('第'+str(i+1)+'个向量为'+str(item[i+n])+',距离为'+str(item[i]))
函数 CalculateResult 在文件 PictureAlgorithm.py 中。该文件收录两个函数:CalculateDistance 函数和CalculateResult 函数,代表用于识别图片的算法。
函数计算结果
这个函数的逻辑比较简单,没什么好说的。主要连接是计算距离的CalculateDistance 函数。
def CalculateResult(test, train):
'''计算待识别图片test的可能分类'''
#得到每个图片的前n相似图片
testDis = CalculateDistance(test[:,0:N**2], train[:,0:N**2], train[:,N**2], n)
#将testDis变成列表
tt = testDis.tolist()
#输出每一个待识别图片的所有前n个
for i in tt:
for j in i:
print(j)
函数计算距离
在函数中,我导入了四个参数:识别向量test,训练向量train,每个向量对应的训练向量所代表的数字num,以及我要导出的前n个最近的向量。
def CalculateDistance(test, train, num, n):
'''计算每个图片前n相似图片'''
#前n个放距离,后n个放数字
dis = np.zeros(2*n*len(test)).reshape(len(test), 2*n)
for i, item in enumerate(test):
#计算出每个训练图片与该待识别图片的距离
itemDis = np.sqrt(np.sum((item-train)**2, axis=1))
#对距离进行排序,找出前n个
sortDis = np.sort(itemDis)
dis[i, 0:n] = sortDis[0:n]
for j in range(n):
#找到前几个在原矩阵中的位置
maxPoint = list(itemDis).index(sortDis[j])
#找到num对应位置的数字,存入dis中
dis[i, j+n] = num[maxPoint]
return dis
首先,创建一个矩阵,其行数为测试中识别的向量数,列数为 2*n。每行的前 n 是距离,最后 n 是数字。然后循环每个识别的向量。
首先,直接计算每张训练图像与识别图像的距离,可以直接用一行代码表示
itemDis = np.sqrt(np.sum((item-train)**2, axis=1))
这行代码就是上面的算法过程。我个人认为是比较复杂的。你可以仔细看看。我不会在这里详细介绍。下面开始排序,找到最接近的前几个向量。
这里的逻辑是:先排序,找到距离最小的前n个,存入矩阵。求原矩阵的前n个位置,求对应位置的num个数,存入dis的最后n个。
这相当于完成了一切,只需返回dis即可。
实际测试
我手写了一些数字,如图所示。所以实际上我们的数据库还是比较小的。
所以我写了另一个数字作为要识别的图像。运行完程序,我们直接输出前十个最相似的向量:
第一个向量为2.0,距离为33.62347223932534
第二个向量是2.0,距离是35.645
第三个向量为2.0,距离为38.69663119274146
第四个向量为2.0,距离为43.529
第5个向量是2.0,距离是43.694
第6个向量为1.0,距离为43.7314
第7个向量为6.0,距离为44.948
第8个向量为2.0,距离为45.5924
第9个向量为4.0,距离为45.43926712996951
第10个向量为7.0,距离为45.64893989116544
之后,我又从 1 到 9 再试一次,我手写的数字都被正确识别了。可以看出,准确率还是挺高的。所以做了这一步就相当于完成度很高。
于是我试了一下网上找的图片,发现几乎没有正确的。这意味着我们的数据库仍然太小,只能识别我的字体。不过话虽如此,你也可以做一个字体识别程序。
所以如果你想提高准确率,那么扩展图库是必须的。这次就到这里了。
总结
我的 GitHub 里有全部源代码,有兴趣的可以去看看。
这相当于完成了算法内容,比较简单,只使用了类似于K最近邻的算法。
下一篇文章会讲一个对前n个排名进行加权提高准确率的思路。
所以这次我就到这里了,谢谢。
喜欢的话请点个赞关注一下,谢谢~
本文已被收录收录在“python图像处理操作”专题中,欢迎大家点击了解更多精彩内容。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持Scripting Home。
网页采集器的自动识别算法(如何采集手机版网页的数据?如何手动选择列表数据 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 220 次浏览 • 2022-01-21 06:00
)
指示
一:输入采集网址
打开软件,新建一个任务,输入需要采集的网站地址。
二:智能分析,全程数据自动提取
进入第二步后,优采云采集器自动智能分析网页,从中提取列表数据。
三:导出数据到表、数据库、网站等
运行任务将采集中的数据导出到表、网站和各种数据库中,并支持api导出。
计算机系统要求
它可以支持Windows XP以上的系统。
.Net 4.0 框架,下载地址
安装步骤
第一步:打开下载的安装包,直接选择运行。
第二步:收到相关条款后,运行安装程序PashanhuV2Setup.exe。安装
第3步:然后继续单击下一步直到完成。
第四步:安装完成后可以看到优采云采集器V2的主界面
常问问题
1、如何采集移动网页数据?
一般情况下,一个网站有电脑版网页和手机版网页。如果电脑版(PC)网页的反爬虫非常严格,我们可以尝试爬取手机网页。
①选择新的编辑任务;
②在新建的【编辑任务】中,选择【第三步,设置】;
③ 将UA(浏览器ID)设置为“手机”。
2、如何手动选择列表数据(自动识别失败时)
在采集列表页面,如果列表自动识别失败,或者识别出的数据不是我们想到的数据,那么我们需要手动选择列表数据。
如何手动选择列表数据?
①点击【全部清除】,清除已有字段。
②点击菜单栏上的【列表数据】,选择【选择列表】
③ 用鼠标单击列表中的任意元素。
④ 单击列表中另一行的相似元素。
一般情况下,此时采集器会自动枚举列表中的所有字段。我们可以对结果进行一些修改。
如果没有列出字段,我们需要手动添加字段。单击[添加字段],然后单击列表中的元素数据。
3、采集文章鼠标不能全选怎么办?
一般情况下,在优采云采集器中,点击鼠标选择要抓取的内容。但是,在某些情况下,比如当你想抓取一个 文章 的完整内容时,当内容很长时,鼠标有时很难定位。
①我们可以通过在网页上右击选择【Inspect Element】来定位内容。
② 点击【向上】按钮,展开选中的内容。
③ 展开到我们全部内容的时候,全选【XPath】,然后复制。
④修改字段的XPath,粘贴刚才复制的XPath,确认。
⑤ 最后修改value属性,如果要HMTL,使用InnerHTML或OuterHTML。
查看全部
网页采集器的自动识别算法(如何采集手机版网页的数据?如何手动选择列表数据
)
指示
一:输入采集网址
打开软件,新建一个任务,输入需要采集的网站地址。
二:智能分析,全程数据自动提取
进入第二步后,优采云采集器自动智能分析网页,从中提取列表数据。
三:导出数据到表、数据库、网站等
运行任务将采集中的数据导出到表、网站和各种数据库中,并支持api导出。
计算机系统要求
它可以支持Windows XP以上的系统。
.Net 4.0 框架,下载地址
安装步骤
第一步:打开下载的安装包,直接选择运行。
第二步:收到相关条款后,运行安装程序PashanhuV2Setup.exe。安装
第3步:然后继续单击下一步直到完成。
第四步:安装完成后可以看到优采云采集器V2的主界面
常问问题
1、如何采集移动网页数据?
一般情况下,一个网站有电脑版网页和手机版网页。如果电脑版(PC)网页的反爬虫非常严格,我们可以尝试爬取手机网页。
①选择新的编辑任务;
②在新建的【编辑任务】中,选择【第三步,设置】;
③ 将UA(浏览器ID)设置为“手机”。
2、如何手动选择列表数据(自动识别失败时)
在采集列表页面,如果列表自动识别失败,或者识别出的数据不是我们想到的数据,那么我们需要手动选择列表数据。
如何手动选择列表数据?
①点击【全部清除】,清除已有字段。
②点击菜单栏上的【列表数据】,选择【选择列表】
③ 用鼠标单击列表中的任意元素。
④ 单击列表中另一行的相似元素。
一般情况下,此时采集器会自动枚举列表中的所有字段。我们可以对结果进行一些修改。
如果没有列出字段,我们需要手动添加字段。单击[添加字段],然后单击列表中的元素数据。
3、采集文章鼠标不能全选怎么办?
一般情况下,在优采云采集器中,点击鼠标选择要抓取的内容。但是,在某些情况下,比如当你想抓取一个 文章 的完整内容时,当内容很长时,鼠标有时很难定位。
①我们可以通过在网页上右击选择【Inspect Element】来定位内容。
② 点击【向上】按钮,展开选中的内容。
③ 展开到我们全部内容的时候,全选【XPath】,然后复制。
④修改字段的XPath,粘贴刚才复制的XPath,确认。
⑤ 最后修改value属性,如果要HMTL,使用InnerHTML或OuterHTML。
网页采集器的自动识别算法(采集器的识别流程及方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-18 06:19
1.一种网页内容自动采集方法,其特征在于,具体步骤包括: 步骤一、根据需要,搜索内容采集的网页URL,并网页位于网站匹配的集合采集器;步骤二、当有匹配的采集器时,执行采集器获取网页内容;当没有匹配的collector时,搜索不匹配的采集器集合,从不匹配的采集器集合中选择采集器执行采集器获取网页内容;采集器的识别过程包括: 步骤1、访问目标网页,获取页面字节流。步骤 2、 将字节流解析为 dom 对象,将 dom 中的所有元素映射到 html 标签,并记录html标签的所有属性和值;步骤3、通过dom对象中的title节点,确定title范围,其中title节点的Xpath为://HTML/HEAD/TITLE;通过搜索h节点,比较ti 11 e节点,确认网页的标题xpath,其中h节点的xpath为: //BODY//* [name () =, H*' ]; 当ti 11 e 节点的值收录h节点的值时,h节点为网页的标题节点,h节点的xpath为网页标题的xpath;步骤4、以h节点为起点寻找发布时间节点;步骤5、以h节点为起点,扫描h节点,寻找祖父节点对应的所有子节点,找到文本值最长的节点,并将其确定为页面文本节点;Step6、确认作者节点,使用“作者节点特征匹配”的方法从h节点开始,扫描h节点的父节点的所有子节点,匹配子节点的文本值是否节点符合作者节点特征。如果是,确认子节点是Author节点;当作者节点通过“作者节点特征匹配”方法确认不成功时,通过“位置猜测”方法确认作者节点:以发布节点为起点,分析发布节点在其兄弟节点中的位置节点确定作者节点: a.如果发布节点的兄弟节点有多个,并且发布节点排在多个节点的一半之前,确定发布节点的下一个兄弟节点为作者节点;湾。如果发布节点为兄弟节点有多个,且发布节点排在多个节点的一半之后,则确定发布节点的上一个兄弟节点为作者节点;步骤7、 根据网页标题、发布时间节点、文本节点和作者节点,识别与网页内容匹配的仪表;三、采集步骤成功后,输出网页内容采集的结果;当采集不成功时,返回第2步,重新选择电表采集器。将发布节点排在多个节点的一半之后,则确定发布节点的上一个兄弟节点为作者节点。步骤7、 根据网页标题、发布时间节点、文本节点和作者节点,识别与网页内容匹配的仪表;三、采集步骤成功后,输出网页内容采集的结果;当采集不成功时,返回第2步,重新选择电表采集器。将发布节点排在多个节点的一半之后,则确定发布节点的上一个兄弟节点为作者节点。步骤7、 根据网页标题、发布时间节点、文本节点和作者节点,识别与网页内容匹配的仪表;三、采集步骤成功后,输出网页内容采集的结果;当采集不成功时,返回第2步,重新选择电表采集器。三、采集步骤成功后,输出网页内容采集的结果;当采集不成功时,返回第2步,重新选择电表采集器。三、采集步骤成功后,输出网页内容采集的结果;当采集不成功时,返回第2步,重新选择电表采集器。
2.根据权利要求1所述的网页内容自动采集的方法,其特征在于,所述步骤四中确定发布时间节点的具体方法为: 搜索时间节点,如果找到,完成确认发布的时间节点;否则,继续从h节点的所有兄弟节点和所有子节点中搜索时间节点,如果找到,则完成对已发布时间节点的确认。'
3.根据权利要求1所述的网页内容自动采集的方法,其特征在于,所述步骤4中的发布时间节点的确认算法具体为: 匹配节点的值,若能匹配命中,则该节点被确认为发布时间节点。
4.根据权利要求1所述的自动网页内容采集的方法,其特征在于,在步骤5中确定网页文本节点的过程中,还包括: 去噪处理,对排除不合理节点,噪声节点标准具体为:(1)其中节点的值收录JavaScript特征;(2)其中节点的值收录标点符号个数小于a的节点设置阈值。
5.根据权利要求1所述的自动网页内容的方法采集,其特征在于,所述步骤6中判断作者节点的方法包括: 1)节点的值收录设置的特征字符串,包括“作者:”、“来源:”或“责任编辑:”;2) 节点的值长度小于阈值。 查看全部
网页采集器的自动识别算法(采集器的识别流程及方法)
1.一种网页内容自动采集方法,其特征在于,具体步骤包括: 步骤一、根据需要,搜索内容采集的网页URL,并网页位于网站匹配的集合采集器;步骤二、当有匹配的采集器时,执行采集器获取网页内容;当没有匹配的collector时,搜索不匹配的采集器集合,从不匹配的采集器集合中选择采集器执行采集器获取网页内容;采集器的识别过程包括: 步骤1、访问目标网页,获取页面字节流。步骤 2、 将字节流解析为 dom 对象,将 dom 中的所有元素映射到 html 标签,并记录html标签的所有属性和值;步骤3、通过dom对象中的title节点,确定title范围,其中title节点的Xpath为://HTML/HEAD/TITLE;通过搜索h节点,比较ti 11 e节点,确认网页的标题xpath,其中h节点的xpath为: //BODY//* [name () =, H*' ]; 当ti 11 e 节点的值收录h节点的值时,h节点为网页的标题节点,h节点的xpath为网页标题的xpath;步骤4、以h节点为起点寻找发布时间节点;步骤5、以h节点为起点,扫描h节点,寻找祖父节点对应的所有子节点,找到文本值最长的节点,并将其确定为页面文本节点;Step6、确认作者节点,使用“作者节点特征匹配”的方法从h节点开始,扫描h节点的父节点的所有子节点,匹配子节点的文本值是否节点符合作者节点特征。如果是,确认子节点是Author节点;当作者节点通过“作者节点特征匹配”方法确认不成功时,通过“位置猜测”方法确认作者节点:以发布节点为起点,分析发布节点在其兄弟节点中的位置节点确定作者节点: a.如果发布节点的兄弟节点有多个,并且发布节点排在多个节点的一半之前,确定发布节点的下一个兄弟节点为作者节点;湾。如果发布节点为兄弟节点有多个,且发布节点排在多个节点的一半之后,则确定发布节点的上一个兄弟节点为作者节点;步骤7、 根据网页标题、发布时间节点、文本节点和作者节点,识别与网页内容匹配的仪表;三、采集步骤成功后,输出网页内容采集的结果;当采集不成功时,返回第2步,重新选择电表采集器。将发布节点排在多个节点的一半之后,则确定发布节点的上一个兄弟节点为作者节点。步骤7、 根据网页标题、发布时间节点、文本节点和作者节点,识别与网页内容匹配的仪表;三、采集步骤成功后,输出网页内容采集的结果;当采集不成功时,返回第2步,重新选择电表采集器。将发布节点排在多个节点的一半之后,则确定发布节点的上一个兄弟节点为作者节点。步骤7、 根据网页标题、发布时间节点、文本节点和作者节点,识别与网页内容匹配的仪表;三、采集步骤成功后,输出网页内容采集的结果;当采集不成功时,返回第2步,重新选择电表采集器。三、采集步骤成功后,输出网页内容采集的结果;当采集不成功时,返回第2步,重新选择电表采集器。三、采集步骤成功后,输出网页内容采集的结果;当采集不成功时,返回第2步,重新选择电表采集器。
2.根据权利要求1所述的网页内容自动采集的方法,其特征在于,所述步骤四中确定发布时间节点的具体方法为: 搜索时间节点,如果找到,完成确认发布的时间节点;否则,继续从h节点的所有兄弟节点和所有子节点中搜索时间节点,如果找到,则完成对已发布时间节点的确认。'
3.根据权利要求1所述的网页内容自动采集的方法,其特征在于,所述步骤4中的发布时间节点的确认算法具体为: 匹配节点的值,若能匹配命中,则该节点被确认为发布时间节点。
4.根据权利要求1所述的自动网页内容采集的方法,其特征在于,在步骤5中确定网页文本节点的过程中,还包括: 去噪处理,对排除不合理节点,噪声节点标准具体为:(1)其中节点的值收录JavaScript特征;(2)其中节点的值收录标点符号个数小于a的节点设置阈值。
5.根据权利要求1所述的自动网页内容的方法采集,其特征在于,所述步骤6中判断作者节点的方法包括: 1)节点的值收录设置的特征字符串,包括“作者:”、“来源:”或“责任编辑:”;2) 节点的值长度小于阈值。
网页采集器的自动识别算法(熟练运用优采云工具采集数据,提高阿里巴巴数据分析效率)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-16 03:15
全部展开,这是一个很特别的下一页按钮,大多数网页上的下一页链接或按钮,优采云采集器可以自动识别并自动添加下一页循环,但也很少特殊情况,例如您的情况。这种情况不难处理,但是采集进程无法自动生成。需要手动半自动拖拽进程:具体操作方法我查了。优采云论坛。
熟练使用优采云tools采集数据,提高阿里巴巴国际站、速卖通、亚马逊等电商平台的数据分析效率。.
在优采云采集的原理中,我们说优采云模拟人们浏览网页进行数据采集的行为,比如打开网页,点击按钮等八点。
在 PowerBI 中,您可以抓取数据并分析数据。我们报告说,您希望多年来获得欧洲联盟锦标赛(欧洲杯)的冠军......
优采云采集器采集收到的数据信息可以直接上传到多多平台赚取多多币。可以根据需要对数据进行采集、集成、清理和分析。以获得所需的信息。例如:。
优采云采集器大小:55.24MB语言:简体类别:网页辅助版:PC版立即下载本教程将使用云采集的数据。
优采云采集规则市场的快速入门指南和熟练使用对于刚刚注册优采云采集器的人来说,除了配置自己的规则,优采云是仍然可用。
第一步:创建采集任务1)进入主界面,选择“自定义模式”2)复制采集的URL并粘贴到网站输入框,点击“保存网址。
优采云采集器新手如何使用采集教程-太平洋互联网。
《优采云采集器》如何自定义采集数据_漫舞精灵的博客-CSDN博客。 查看全部
网页采集器的自动识别算法(熟练运用优采云工具采集数据,提高阿里巴巴数据分析效率)
全部展开,这是一个很特别的下一页按钮,大多数网页上的下一页链接或按钮,优采云采集器可以自动识别并自动添加下一页循环,但也很少特殊情况,例如您的情况。这种情况不难处理,但是采集进程无法自动生成。需要手动半自动拖拽进程:具体操作方法我查了。优采云论坛。
熟练使用优采云tools采集数据,提高阿里巴巴国际站、速卖通、亚马逊等电商平台的数据分析效率。.
在优采云采集的原理中,我们说优采云模拟人们浏览网页进行数据采集的行为,比如打开网页,点击按钮等八点。
在 PowerBI 中,您可以抓取数据并分析数据。我们报告说,您希望多年来获得欧洲联盟锦标赛(欧洲杯)的冠军......
优采云采集器采集收到的数据信息可以直接上传到多多平台赚取多多币。可以根据需要对数据进行采集、集成、清理和分析。以获得所需的信息。例如:。
优采云采集器大小:55.24MB语言:简体类别:网页辅助版:PC版立即下载本教程将使用云采集的数据。
优采云采集规则市场的快速入门指南和熟练使用对于刚刚注册优采云采集器的人来说,除了配置自己的规则,优采云是仍然可用。
第一步:创建采集任务1)进入主界面,选择“自定义模式”2)复制采集的URL并粘贴到网站输入框,点击“保存网址。
优采云采集器新手如何使用采集教程-太平洋互联网。
《优采云采集器》如何自定义采集数据_漫舞精灵的博客-CSDN博客。
网页采集器的自动识别算法(爱意为用户提供的优采云采集器采集器电脑版的实用方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-01-14 19:09
爱易为用户提供的优采云采集器电脑版的实用方法非常简单,用户可以使用本爬虫软件快速采集各类网页数据,爬取速度为非常快 非常快,适用于所有类型的 网站。
软件功能
向导模式
通过可视化界面,鼠标点击即可采集数据,向导模式,用户无需任何技术基础,输入网址,一键提取数据。
智能识别
通过智能算法,自动识别分页,自动识别列表,一键采集数据。
智能识别
可支持图片、视频、文档等各种文件的下载,支持自定义保存路径和文件名。
原装高速核心
内置一套高速浏览器内核,配合HTTP引擎和JSON引擎模式,实现快速采集数据。
定时操作
可以用分钟、天、周和 CRON 来表示。指定定时任务时,该任务可以自动采集自动释放,无需人工操作。
各种数据导出
支持多格式数据导出,包括TXT、CSV、Excel、ACCESS、MySQL、SQLServer、SQLite并发布到网站接口(Api)。
工具特点
1、快速高效,内置高速浏览器内核,配合HTTP引擎模式,实现快速采集数据
2、一键提取数据,简单易学,通过可视化界面,鼠标点击即可抓取数据
3、适用于各类网站,能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站
软件应用领域
新闻媒体领域
优采云采集器全方位采集国内外新闻源、主流社交媒体、社区论坛等,如:今日头条、微博、天涯论坛、知乎等. 提供自动识别列表数据,可视化文本挖掘定时采集数据,自动上传数据或第三方平台,向导式操作界面,帮助企业自主监测品牌舆情,为品牌传播提供数据支撑互联网时代。
电子商务领域
随着电子商务的快速发展,优采云采集器可以采集国内外任何电子商务网站,如属性、评价、价格、市场占有率等同类产品等数据,通过优采云的文本挖掘可视化分析系统,可以提取评论信息的典型观点和情感分析,从而获得客观的市场评估和分析,优化运营,创造流行车型根据类似经验,开展经营活动。提升网店运营水平和效率。
生活服务区
科学技术的发展与我们的生活息息相关。简单来说,吃饭旅游的团购网,外卖网,简单高效。优采云采集器可以采集美团饿了么、赶集、大众点评、途牛、携程等生活服务网站、采集类似属性、评价、价格,销量、收视率等数据,通过优采云文本挖掘可视化分析系统,可以对评论信息进行典型意见提取、情感分析、数据比对,方便我们使用。做出合适的选择。
政府部门
在全社会信息爆炸式增长的背景下,政府机构越来越重视数据的采集和利用。某气象中心通过优采云采集器采集各地区各类天气相关监测数据,通过数据对比分析,及时预警最新气象活动分布范围,指导相关部门采取对策。
更新内容
1、修复部分网址加载不上数据的问题
2、优化的 XPath 生成
3、优化输入命令 查看全部
网页采集器的自动识别算法(爱意为用户提供的优采云采集器采集器电脑版的实用方法)
爱易为用户提供的优采云采集器电脑版的实用方法非常简单,用户可以使用本爬虫软件快速采集各类网页数据,爬取速度为非常快 非常快,适用于所有类型的 网站。
软件功能
向导模式
通过可视化界面,鼠标点击即可采集数据,向导模式,用户无需任何技术基础,输入网址,一键提取数据。
智能识别
通过智能算法,自动识别分页,自动识别列表,一键采集数据。
智能识别
可支持图片、视频、文档等各种文件的下载,支持自定义保存路径和文件名。
原装高速核心
内置一套高速浏览器内核,配合HTTP引擎和JSON引擎模式,实现快速采集数据。
定时操作
可以用分钟、天、周和 CRON 来表示。指定定时任务时,该任务可以自动采集自动释放,无需人工操作。
各种数据导出
支持多格式数据导出,包括TXT、CSV、Excel、ACCESS、MySQL、SQLServer、SQLite并发布到网站接口(Api)。
工具特点
1、快速高效,内置高速浏览器内核,配合HTTP引擎模式,实现快速采集数据
2、一键提取数据,简单易学,通过可视化界面,鼠标点击即可抓取数据
3、适用于各类网站,能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站
软件应用领域
新闻媒体领域
优采云采集器全方位采集国内外新闻源、主流社交媒体、社区论坛等,如:今日头条、微博、天涯论坛、知乎等. 提供自动识别列表数据,可视化文本挖掘定时采集数据,自动上传数据或第三方平台,向导式操作界面,帮助企业自主监测品牌舆情,为品牌传播提供数据支撑互联网时代。
电子商务领域
随着电子商务的快速发展,优采云采集器可以采集国内外任何电子商务网站,如属性、评价、价格、市场占有率等同类产品等数据,通过优采云的文本挖掘可视化分析系统,可以提取评论信息的典型观点和情感分析,从而获得客观的市场评估和分析,优化运营,创造流行车型根据类似经验,开展经营活动。提升网店运营水平和效率。
生活服务区
科学技术的发展与我们的生活息息相关。简单来说,吃饭旅游的团购网,外卖网,简单高效。优采云采集器可以采集美团饿了么、赶集、大众点评、途牛、携程等生活服务网站、采集类似属性、评价、价格,销量、收视率等数据,通过优采云文本挖掘可视化分析系统,可以对评论信息进行典型意见提取、情感分析、数据比对,方便我们使用。做出合适的选择。
政府部门
在全社会信息爆炸式增长的背景下,政府机构越来越重视数据的采集和利用。某气象中心通过优采云采集器采集各地区各类天气相关监测数据,通过数据对比分析,及时预警最新气象活动分布范围,指导相关部门采取对策。
更新内容
1、修复部分网址加载不上数据的问题
2、优化的 XPath 生成
3、优化输入命令
网页采集器的自动识别算法(机器识别验证码的问题比较好解决了,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 344 次浏览 • 2022-01-13 03:07
概述
很多开发者讨厌网站的验证码,尤其是写爬虫的程序员,而网站之所以设置验证码是为了防止机器人访问网站,造成不必要的损失。那么现在,随着机器学习技术的发展,机器识别验证码的问题得到了较好的解决。
示例采集工具
这里我们使用WordPress的Really Simple CAPTCHA插件生成验证码。选择这个插件的原因一是安装量大,二是它是开源的,我们可以用它来批量生成验证码图片。
目标估计
我们从 demo网站 中了解到,Really Simple CAPTCHA 生成一张收录 4 个数字或字母的图片。通过阅读源码,我们知道这个插件还屏蔽了O和I,两个比较容易混淆的字母,而且还说,还有32个字符,看起来是可以做到的。到目前为止花了两分钟。
依靠
我们将使用以下工具和库。
创建样本集
为了达到我们的目的,我们首先需要准备一个样本集,样本如下:
使用Really Simple CAPTCHA插件源码,我们可以轻松批量生成10000张验证码图片及对应结果。我们生成它们之后,大致如下:
在这里,您可以根据自己的实际情况修改Really Simple CAPTCHA插件的源代码,生成您想要的样本集。如果觉得麻烦,也可以下载我生成的好。
到目前为止,我们已经花了五分钟。
如何训练
我们现在有了一个样本集,我们可以直接用图片和相应的结果训练神经网络。
只要我们有足够的样本,最终就能达到我们想要的效果。
但是我们也可以使用更好的训练方法,这种训练方法使用的样本数据较少,但是结果比直接训练方法好很多,我想你已经猜到了,这种方法是将图片中的四个字符切开形成四个样品。此方法有效,因为所有验证码图像都是 4 个字符长。
用PS手动剪切1万张图片肯定是不现实的,而且因为图片横向排列不等距,字符间距不一致,手动剪切肯定是不可能的。
其实我们只需要画一个矩形,保证矩形框内只有字符,然后从图片中剪下这样一个矩形,就形成了单个字符的图片样本。好在opencv已经为我们实现了这个操作。Opencv有一个函数叫findContours(),可以根据颜色值相同的区域,裁剪出我们想要的矩形。- 首先准备一张图片:
- 将图片转换为黑白。这样有字符的地方是黑色的,空白处是白色的,方便opencv裁剪。
- 接下来我们使用opencv的findContours函数来切割图像。
接下来,我们从左到右对图片进行剪切,并存储剪切后的图片和图片对应的字符。但是在实际操作的过程中,我发现了一个问题,就是有时候两个字符靠得太近,导致opencv在切割的时候把两个字符切割器放在了一张图片中,比如:
切割的效果是:
如果这个问题不解决,我们的样本集就会不准确,训练出来的模型也不会正确。我的解决方案是先设置一个字符宽度最大的像素。如果超过这个像素,则认为一张图片收录两个字符,然后我们选择将图片切成两半,分成两个字符。例如:
好的,我们现在得到了一张4个字符对应验证码图片的图片。现在我们已经把所有的样图都剪下来了,然后把相同字符对应的图片放到一个文件夹里。这样做的目的是尽可能多地尝试。查找同一字符的多个样式。结果如下:
到目前为止,我花了 10 分钟。
训练模型
因为我们只识别图片对应的数字或字母,所以不需要特别复杂的神经网络算法。识别字符比识别优采云和小狗容易得多。我在这里使用卷积神经网络,两个卷积层和两个全连接层。
这个地方不会详细介绍卷积神经网络算法。有兴趣的同学可以google一下。训练完成后,我们需要对其进行测试。花了15分钟。
总结
整个过程看起来很简单: - 使用我们上面提到的插件从 wordpress网站 下载验证码图像 - 将图像切割成收录单个字符的小图像 - 使用神经网络算法训练模型 - 预测新的字符对应到验证码图片
下面是我的测试:
代码
您可以从这里获得完整的代码和示例图像,您可以参考 README 来运行相关程序。 查看全部
网页采集器的自动识别算法(机器识别验证码的问题比较好解决了,你知道吗?)
概述
很多开发者讨厌网站的验证码,尤其是写爬虫的程序员,而网站之所以设置验证码是为了防止机器人访问网站,造成不必要的损失。那么现在,随着机器学习技术的发展,机器识别验证码的问题得到了较好的解决。
示例采集工具
这里我们使用WordPress的Really Simple CAPTCHA插件生成验证码。选择这个插件的原因一是安装量大,二是它是开源的,我们可以用它来批量生成验证码图片。
目标估计
我们从 demo网站 中了解到,Really Simple CAPTCHA 生成一张收录 4 个数字或字母的图片。通过阅读源码,我们知道这个插件还屏蔽了O和I,两个比较容易混淆的字母,而且还说,还有32个字符,看起来是可以做到的。到目前为止花了两分钟。
依靠
我们将使用以下工具和库。
创建样本集
为了达到我们的目的,我们首先需要准备一个样本集,样本如下:
使用Really Simple CAPTCHA插件源码,我们可以轻松批量生成10000张验证码图片及对应结果。我们生成它们之后,大致如下:
在这里,您可以根据自己的实际情况修改Really Simple CAPTCHA插件的源代码,生成您想要的样本集。如果觉得麻烦,也可以下载我生成的好。
到目前为止,我们已经花了五分钟。
如何训练
我们现在有了一个样本集,我们可以直接用图片和相应的结果训练神经网络。
只要我们有足够的样本,最终就能达到我们想要的效果。
但是我们也可以使用更好的训练方法,这种训练方法使用的样本数据较少,但是结果比直接训练方法好很多,我想你已经猜到了,这种方法是将图片中的四个字符切开形成四个样品。此方法有效,因为所有验证码图像都是 4 个字符长。
用PS手动剪切1万张图片肯定是不现实的,而且因为图片横向排列不等距,字符间距不一致,手动剪切肯定是不可能的。
其实我们只需要画一个矩形,保证矩形框内只有字符,然后从图片中剪下这样一个矩形,就形成了单个字符的图片样本。好在opencv已经为我们实现了这个操作。Opencv有一个函数叫findContours(),可以根据颜色值相同的区域,裁剪出我们想要的矩形。- 首先准备一张图片:
- 将图片转换为黑白。这样有字符的地方是黑色的,空白处是白色的,方便opencv裁剪。
- 接下来我们使用opencv的findContours函数来切割图像。
接下来,我们从左到右对图片进行剪切,并存储剪切后的图片和图片对应的字符。但是在实际操作的过程中,我发现了一个问题,就是有时候两个字符靠得太近,导致opencv在切割的时候把两个字符切割器放在了一张图片中,比如:
切割的效果是:
如果这个问题不解决,我们的样本集就会不准确,训练出来的模型也不会正确。我的解决方案是先设置一个字符宽度最大的像素。如果超过这个像素,则认为一张图片收录两个字符,然后我们选择将图片切成两半,分成两个字符。例如:
好的,我们现在得到了一张4个字符对应验证码图片的图片。现在我们已经把所有的样图都剪下来了,然后把相同字符对应的图片放到一个文件夹里。这样做的目的是尽可能多地尝试。查找同一字符的多个样式。结果如下:
到目前为止,我花了 10 分钟。
训练模型
因为我们只识别图片对应的数字或字母,所以不需要特别复杂的神经网络算法。识别字符比识别优采云和小狗容易得多。我在这里使用卷积神经网络,两个卷积层和两个全连接层。
这个地方不会详细介绍卷积神经网络算法。有兴趣的同学可以google一下。训练完成后,我们需要对其进行测试。花了15分钟。
总结
整个过程看起来很简单: - 使用我们上面提到的插件从 wordpress网站 下载验证码图像 - 将图像切割成收录单个字符的小图像 - 使用神经网络算法训练模型 - 预测新的字符对应到验证码图片
下面是我的测试:
代码
您可以从这里获得完整的代码和示例图像,您可以参考 README 来运行相关程序。
网页采集器的自动识别算法(网页采集器的自动识别算法分很多种,需要定期更新)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-01-12 15:02
网页采集器的自动识别算法分很多种,有点击记录识别、有查询记录识别、有token识别等等,不同的类型算法也有所不同。从我实际做过的相关项目来说,需要根据网站,和网站本身的特点,选择合适的识别算法。根据一些使用这种自动识别系统开发的大佬说,目前计算机识别算法分很多种,这些算法识别之后的结果是有时效性的,需要定期更新,才能准确识别。
如果要将ai引入到电商领域,我觉得可以跟行业信息化方面的相关厂商进行合作,利用他们的识别系统来完成自动化寻找商品。当然目前被大家公认的是以分词算法为主的自动查询匹配识别系统,通过对商品的属性识别、分类、评价、标签进行匹配,自动找到商品推荐的客户群体。
前端是否能支持购物车点击返回商品详情页
html5时代,由于采用html5的浏览器增多,即使使用angular,react等框架也无法单方面解决这个问题,而且收到移动互联网红利启发下,出现了比html5性能更好、开发难度更低的webapp方案,因此对app的广告主而言,哪家投放的效果好,直接决定投放的多少,而这种app方案具备前端采集功能的,现在不多,以前传统手工采集,因为缺少界面控制能力,广告推广效果会不好,因此就出现了工具类的公司专门做数据采集,因此工具类的公司被广泛应用于app的广告投放,对此这些工具公司深度跟移动互联网公司合作,在这些公司利用他们的技术优势,将这些数据从发布到投放前都给到app方面做应用分析、用户画像等,然后相互妥协,同时在投放前,尽可能将投放点做的精准点,以实现更加精准化的投放。
对于工具类的公司而言,他们只需要提供一个数据工具即可,而对于移动互联网方面的广告公司而言,尤其是对品牌营销、社交分析都有需求的公司而言,这个工具无疑可以简化他们的工作。例如:优秀的前端app广告分析工具,基本需要提供app的广告数据,appstore下载量、appstore评分、app市场排名数据、app各分类排名、品牌推广,品牌营销,网络分析等数据,对于这些广告公司而言,提供的这些数据,他们做完应用分析可以生成广告统计报告,并以此来支持他们直接选择与投放的移动媒体合作来进行投放。
对于工具类的公司而言,如果app时代还没有完全来临,还没有超过传统企业方,那么他们还将依靠app本身搭建自己的媒体,进行对外宣传,通过app本身的媒体推广数据,一来对于移动互联网接入更多的有效流量,二来他们通过媒体数据来给前端公司对接更加精准的广告投放。所以对于这些app而言,前端自己的app技术解决方案是必备的;例如。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法分很多种,需要定期更新)
网页采集器的自动识别算法分很多种,有点击记录识别、有查询记录识别、有token识别等等,不同的类型算法也有所不同。从我实际做过的相关项目来说,需要根据网站,和网站本身的特点,选择合适的识别算法。根据一些使用这种自动识别系统开发的大佬说,目前计算机识别算法分很多种,这些算法识别之后的结果是有时效性的,需要定期更新,才能准确识别。
如果要将ai引入到电商领域,我觉得可以跟行业信息化方面的相关厂商进行合作,利用他们的识别系统来完成自动化寻找商品。当然目前被大家公认的是以分词算法为主的自动查询匹配识别系统,通过对商品的属性识别、分类、评价、标签进行匹配,自动找到商品推荐的客户群体。
前端是否能支持购物车点击返回商品详情页
html5时代,由于采用html5的浏览器增多,即使使用angular,react等框架也无法单方面解决这个问题,而且收到移动互联网红利启发下,出现了比html5性能更好、开发难度更低的webapp方案,因此对app的广告主而言,哪家投放的效果好,直接决定投放的多少,而这种app方案具备前端采集功能的,现在不多,以前传统手工采集,因为缺少界面控制能力,广告推广效果会不好,因此就出现了工具类的公司专门做数据采集,因此工具类的公司被广泛应用于app的广告投放,对此这些工具公司深度跟移动互联网公司合作,在这些公司利用他们的技术优势,将这些数据从发布到投放前都给到app方面做应用分析、用户画像等,然后相互妥协,同时在投放前,尽可能将投放点做的精准点,以实现更加精准化的投放。
对于工具类的公司而言,他们只需要提供一个数据工具即可,而对于移动互联网方面的广告公司而言,尤其是对品牌营销、社交分析都有需求的公司而言,这个工具无疑可以简化他们的工作。例如:优秀的前端app广告分析工具,基本需要提供app的广告数据,appstore下载量、appstore评分、app市场排名数据、app各分类排名、品牌推广,品牌营销,网络分析等数据,对于这些广告公司而言,提供的这些数据,他们做完应用分析可以生成广告统计报告,并以此来支持他们直接选择与投放的移动媒体合作来进行投放。
对于工具类的公司而言,如果app时代还没有完全来临,还没有超过传统企业方,那么他们还将依靠app本身搭建自己的媒体,进行对外宣传,通过app本身的媒体推广数据,一来对于移动互联网接入更多的有效流量,二来他们通过媒体数据来给前端公司对接更加精准的广告投放。所以对于这些app而言,前端自己的app技术解决方案是必备的;例如。
网页采集器的自动识别算法(网络爬虫又称为网络蜘蛛常见的抓取策略~(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-01-11 23:07
网络爬虫,又称网络蜘蛛,是根据一定的逻辑和算法从互联网上爬取和下载网页的计算机程序,是搜索引擎的重要组成部分。一般爬虫从种子url的一部分开始,按照一定的策略开始爬取。将爬取的新url放入爬取队列,然后进行新一轮的爬取,直到爬取完成。
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。网络爬虫的爬取策略有很多,但不管是什么方法,基本目标都是一样的:首先选择重要的网页进行爬取。一起来看看Apocalypse常见的爬取策略吧~
一、呼吸第一
广度优先遍历的核心是将新下载的网页中收录的链接直接附加到待爬取的URL队列的末尾。也就是说,该方法没有明确提出和使用网页重要性的度量,只是机械地从新下载的网页中提取链接,并附加到待爬取的URL队列中,从而安排URL的下载顺序。
二、OCIP策略(Online Page Importance Computation,在线页面重要性计算)
将其视为改进的 PageRank 算法。在算法开始之前,每个互联网页面都被给予相同的“现金”。每当某个页面P被下载时,P将他拥有的“现金”平均分配给该页面所收录的链接页面,并将自己的“现金”清零。对于URL队列中待爬取的网页,按照手头现金数量进行排序,现金最充裕的网页优先下载。
OCIP在大框架上与PageRank基本一致。不同的是PageRank每次都需要迭代计算,而OCIP策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。同时,在计算PageRank时,对于没有链接关系的网页有一个长距离的跳转过程,而OCIP没有这个计算因子。实验结果表明,OCIP是一种较好的重要性度量策略,其效果略优于广度优先遍历策略。
三、大网站优先
大型网站优先策略的思路很简单:网页的重要性以网站为单位来衡量。对于URL队列中待爬取的网页,按照所属的网站进行分类。如果有 网站 等待下载最多的页面将首先下载这些链接。底层思想倾向于优先下载大的网站,因为大的网站往往会收录更多的页面。鉴于大型网站往往是知名公司的内容,其网页质量普遍较高,这个思路虽然简单,但有一定的依据。 查看全部
网页采集器的自动识别算法(网络爬虫又称为网络蜘蛛常见的抓取策略~(组图))
网络爬虫,又称网络蜘蛛,是根据一定的逻辑和算法从互联网上爬取和下载网页的计算机程序,是搜索引擎的重要组成部分。一般爬虫从种子url的一部分开始,按照一定的策略开始爬取。将爬取的新url放入爬取队列,然后进行新一轮的爬取,直到爬取完成。
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。网络爬虫的爬取策略有很多,但不管是什么方法,基本目标都是一样的:首先选择重要的网页进行爬取。一起来看看Apocalypse常见的爬取策略吧~
一、呼吸第一
广度优先遍历的核心是将新下载的网页中收录的链接直接附加到待爬取的URL队列的末尾。也就是说,该方法没有明确提出和使用网页重要性的度量,只是机械地从新下载的网页中提取链接,并附加到待爬取的URL队列中,从而安排URL的下载顺序。
二、OCIP策略(Online Page Importance Computation,在线页面重要性计算)
将其视为改进的 PageRank 算法。在算法开始之前,每个互联网页面都被给予相同的“现金”。每当某个页面P被下载时,P将他拥有的“现金”平均分配给该页面所收录的链接页面,并将自己的“现金”清零。对于URL队列中待爬取的网页,按照手头现金数量进行排序,现金最充裕的网页优先下载。
OCIP在大框架上与PageRank基本一致。不同的是PageRank每次都需要迭代计算,而OCIP策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。同时,在计算PageRank时,对于没有链接关系的网页有一个长距离的跳转过程,而OCIP没有这个计算因子。实验结果表明,OCIP是一种较好的重要性度量策略,其效果略优于广度优先遍历策略。
三、大网站优先
大型网站优先策略的思路很简单:网页的重要性以网站为单位来衡量。对于URL队列中待爬取的网页,按照所属的网站进行分类。如果有 网站 等待下载最多的页面将首先下载这些链接。底层思想倾向于优先下载大的网站,因为大的网站往往会收录更多的页面。鉴于大型网站往往是知名公司的内容,其网页质量普遍较高,这个思路虽然简单,但有一定的依据。
网页采集器的自动识别算法(网页采集器的自动识别算法主要受硬件和网站整体架构影响)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-01-11 05:02
网页采集器的自动识别算法主要受硬件和网站整体架构两方面的因素影响。比如大多数网站采集器的采集软件都有千兆以太网接口,只要网络带宽够用,同样一个网站,通过程序或者软件被识别出来并下载下来的成本比仅仅通过网页源代码地址识别下载成本要高。当然这是对特定软件的单一实践。从整体网站架构上来说,程序和程序之间互通性好,都是git仓库,都支持本地git的gitignore和本地提交保存.md文件,能互相协助完成和php等服务器代码的同步,但是就像上面说的,对于一个网站的整体架构而言,整体协同维护性更重要,考虑了加密签名等基础操作只能是网站的高层面的优化设计。
未必,本地安装的java版本控制软件,可以用某些方法在服务器端对存储中的数据进行解密处理,我采用这种方法加密登录过程,整个过程不需要通过第三方服务,而且不需要再第三方服务器上保存用户信息和数据(只需要是安全且正确的第三方服务器就行),整个解密过程看似简单的,但实际处理下来还是挺复杂的,需要去了解gsm协议的内容,还涉及到cookie和session等等等等,用gns4crypt-one-java加密规则做缓存就能达到完全防止网站的cookie和session记录,而且解密速度快(据说是gns4crypt_one_java做的),唯一不足的就是目前gns4crypt官方提供gans2的这个版本包,但是我没遇到过在中国大陆境内的sitewalk发生过登录恶意攻击,所以用过都说好。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法主要受硬件和网站整体架构影响)
网页采集器的自动识别算法主要受硬件和网站整体架构两方面的因素影响。比如大多数网站采集器的采集软件都有千兆以太网接口,只要网络带宽够用,同样一个网站,通过程序或者软件被识别出来并下载下来的成本比仅仅通过网页源代码地址识别下载成本要高。当然这是对特定软件的单一实践。从整体网站架构上来说,程序和程序之间互通性好,都是git仓库,都支持本地git的gitignore和本地提交保存.md文件,能互相协助完成和php等服务器代码的同步,但是就像上面说的,对于一个网站的整体架构而言,整体协同维护性更重要,考虑了加密签名等基础操作只能是网站的高层面的优化设计。
未必,本地安装的java版本控制软件,可以用某些方法在服务器端对存储中的数据进行解密处理,我采用这种方法加密登录过程,整个过程不需要通过第三方服务,而且不需要再第三方服务器上保存用户信息和数据(只需要是安全且正确的第三方服务器就行),整个解密过程看似简单的,但实际处理下来还是挺复杂的,需要去了解gsm协议的内容,还涉及到cookie和session等等等等,用gns4crypt-one-java加密规则做缓存就能达到完全防止网站的cookie和session记录,而且解密速度快(据说是gns4crypt_one_java做的),唯一不足的就是目前gns4crypt官方提供gans2的这个版本包,但是我没遇到过在中国大陆境内的sitewalk发生过登录恶意攻击,所以用过都说好。
网页采集器的自动识别算法(优采云万能文章采集器,优采云软件出品的一款基于高精度正文识别算法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-01-10 15:14
优采云万能文章采集器,由优采云软件文章采集器出品的基于高精度文本识别算法的互联网,支持按关键词采集百度等搜索引擎的新闻源和泛网页支持采集指定网站栏下的所有文章。
优采云通用文章采集器
软件介绍
优采云一款基于高精度文本识别算法的互联网软件文章采集器。支持按关键词采集各大搜索引擎的新闻和网页,也支持采集指定网站栏下的所有文章。基于优采云自主研发的文本识别智能算法,能够从互联网上复杂的网页中尽可能准确地提取文本内容。
文本识别有 3 种算法,“标准”、“严格”和“精确标签”。其中“标准”和“严格”为自动模式,可以适应大部分网页的文本提取,而“精确标签”只需要指定文本标签头,如“div class="text"” ,它可以对所有网页进行所有Body提取。
关键词采集目前支持的搜索引擎有:百度、搜狗、360、Google、Bing、Yahoo!
采集指定网站文章的功能也很简单。只需一点设置(没有复杂的规则),您就可以批量处理 采集target网站< @文章。
因为墙的问题,要使用谷歌搜索和谷歌翻译文章的功能,需要使用国外IP。
内置文章翻译功能,即可以将文章从中文等一种语言转换成英文等另一种语言,再由英文转回中文。
采集文章+翻译伪原创可以满足各领域站长朋友的文章需求。
一些公关处理和信息调查公司所需的专业公司开发的信息采集系统往往花费数万甚至更多,而优采云的这个软件也是一个信息采集系统功能与市面上昂贵的软件差不多,但价格只有几百元,大家可以试试看。
变更日志
URL采集文章面板的精确标签增加了模糊匹配功能;新增定时任务功能,可以设置多个时间点,并自动在点采集开始(当前显示的面板开始采集)。 查看全部
网页采集器的自动识别算法(优采云万能文章采集器,优采云软件出品的一款基于高精度正文识别算法)
优采云万能文章采集器,由优采云软件文章采集器出品的基于高精度文本识别算法的互联网,支持按关键词采集百度等搜索引擎的新闻源和泛网页支持采集指定网站栏下的所有文章。
优采云通用文章采集器
软件介绍
优采云一款基于高精度文本识别算法的互联网软件文章采集器。支持按关键词采集各大搜索引擎的新闻和网页,也支持采集指定网站栏下的所有文章。基于优采云自主研发的文本识别智能算法,能够从互联网上复杂的网页中尽可能准确地提取文本内容。
文本识别有 3 种算法,“标准”、“严格”和“精确标签”。其中“标准”和“严格”为自动模式,可以适应大部分网页的文本提取,而“精确标签”只需要指定文本标签头,如“div class="text"” ,它可以对所有网页进行所有Body提取。
关键词采集目前支持的搜索引擎有:百度、搜狗、360、Google、Bing、Yahoo!
采集指定网站文章的功能也很简单。只需一点设置(没有复杂的规则),您就可以批量处理 采集target网站< @文章。
因为墙的问题,要使用谷歌搜索和谷歌翻译文章的功能,需要使用国外IP。
内置文章翻译功能,即可以将文章从中文等一种语言转换成英文等另一种语言,再由英文转回中文。
采集文章+翻译伪原创可以满足各领域站长朋友的文章需求。
一些公关处理和信息调查公司所需的专业公司开发的信息采集系统往往花费数万甚至更多,而优采云的这个软件也是一个信息采集系统功能与市面上昂贵的软件差不多,但价格只有几百元,大家可以试试看。
变更日志
URL采集文章面板的精确标签增加了模糊匹配功能;新增定时任务功能,可以设置多个时间点,并自动在点采集开始(当前显示的面板开始采集)。
网页采集器的自动识别算法(优采云采集器完美支持采集所有编码格式的网页,程序还可以自动识别网页编码)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-01-10 15:11
优采云采集器是一个非常强大的数据采集器,完美支持采集所有编码格式的网页,程序还可以自动识别网页编码,还支持所有目前主流和非主流cms、BBS等网站节目都可以通过系统的发布模块实现采集器和网站节目的完美结合。
特征
1、通用
不管新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集得到你想要的内容需要 。
2、稳定高效
五年磨一剑,软件不断更新完善,采集速度快,性能稳定,占用资源少。
3、扩展性强,应用广泛
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和. net 外部编程接口来处理数据并使其可供您使用。
4、支持所有 网站 编码
完美支持采集所有编码格式的网页,程序还可以自动识别网页编码。
5、各种发布方式
支持当前所有主流和非主流cms、BBS等网站节目,通过系统的发布模块可以实现采集器和网站节目的完美结合.
6、全自动
无人值守工作,配置程序后,程序会根据您的设置自动运行,无需人工干预。
7、本地编辑
采集 数据的本地可视化编辑。
8、采集测试
这是任何其他类似的采集软件都无法比拟的,并且该程序支持直接查看采集结果和测试发布。
9、易于管理
使用站点+任务模式管理采集节点,任务支持批量操作,管理更多数据轻松。
软件功能
1、规则自定义
所有网站采集几乎任何类型的信息都可以通过采集规则的定义进行搜索。
2、多任务、多线程
可以同时执行多个信息采集任务,每个任务可以使用多个线程。
3、所见即所得
任务采集流程是所见即所得,流程中遍历的链接信息、采集信息、错误信息等都会及时反映在软件界面中。
4、数据存储
数据自动保存到采集边缘的关系型数据库中,可以自动适配数据结构。软件可以根据采集规则自动创建数据库,以及里面的表和字段,也可以通过数据库灵活导入。将数据保存到客户现有的数据库结构中。
5、断点继续挖掘
INFO采集任务停止后可以从断点处恢复采集,因此您不再需要担心您的采集任务被意外中断。
6、网站登录
支持网站Cookies,支持网站可视化登录,甚至登录时需要验证码的网站也可以采集。
7、计划任务
此功能允许您的 采集 任务定期、定量或循环执行。
8、采集范围限制
采集 的范围可以根据采集 的深度和URL 的身份来限制。
9、文件下载
二进制文件(如:图片、音乐、软件、文档等)可以下载到本地磁盘或采集结果数据库。
10、结果替换
您可以根据规则将 采集 的结果替换为您定义的内容。
11、条件保存
您可以根据一定的条件决定保存哪些信息,过滤哪些信息。
12、过滤重复
软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、特殊链接识别
使用此功能可以识别 Javascript 或其他更古怪的连接中动态生成的链接。
14、数据发布
采集 的结果数据可以通过自定义界面发布到任何内容管理系统和指定数据库。现在支持的目标发布媒体包括:数据库(access、sql server、mysql、oracle)、静态htm文件。
15、 预留编程接口
定义多种编程接口,用户可以在事件中使用PHP、C#语言进行编程,扩展采集的功能。
菜单功能
1、创建一个新组
新建一个任务组,选择所属的组,确定组名和备注。
2、新任务
确定自己所属的组,新建任务,填写任务名称保存。
3、网络发布配置
Web 发布配置定义了如何登录到 网站 并将数据提交到该 网站。
主要涉及登录信息的获取,网站编码设置,列列表的获取,使用数据测试发布效果。
4、网络发布模块
可以定义网站登录、获取列列表、获取网页随机值、内容发布参数、上传文件、构建发布数据等高级功能。
5、数据库发布配置
数据库发布配置定义了数据库链接信息的设置和数据库模块的选择。
6、数据库发布模块
用于编辑数据库的发布模块,以便我们可以将数据发布到配置的数据库。
优采云采集器可选择mysql、sqlserver、oracle、access四种数据库类型,在文本输入框中填写sql语句
(需要数据库知识),可以用标签来替换对应的数据。您还可以在 采集器modules 文件夹中加载要编辑的模块。
7、计划任务
设置列表中采集任务的启动时间表,可以是每个间隔,每天,每周,只有一次,也可以是自定义的Cron表达式,
(Cron 表达式的写法请参考相关术语的介绍)。保存设置后,即可根据设置执行任务。
8、插件管理
插件是可用于扩展 优采云采集器 功能的程序
优采云采集器V9支持三种插件:PHP源码、C#源码、C#类库。 查看全部
网页采集器的自动识别算法(优采云采集器完美支持采集所有编码格式的网页,程序还可以自动识别网页编码)
优采云采集器是一个非常强大的数据采集器,完美支持采集所有编码格式的网页,程序还可以自动识别网页编码,还支持所有目前主流和非主流cms、BBS等网站节目都可以通过系统的发布模块实现采集器和网站节目的完美结合。
特征
1、通用
不管新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集得到你想要的内容需要 。
2、稳定高效
五年磨一剑,软件不断更新完善,采集速度快,性能稳定,占用资源少。
3、扩展性强,应用广泛
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和. net 外部编程接口来处理数据并使其可供您使用。
4、支持所有 网站 编码
完美支持采集所有编码格式的网页,程序还可以自动识别网页编码。
5、各种发布方式
支持当前所有主流和非主流cms、BBS等网站节目,通过系统的发布模块可以实现采集器和网站节目的完美结合.
6、全自动
无人值守工作,配置程序后,程序会根据您的设置自动运行,无需人工干预。
7、本地编辑
采集 数据的本地可视化编辑。
8、采集测试
这是任何其他类似的采集软件都无法比拟的,并且该程序支持直接查看采集结果和测试发布。
9、易于管理
使用站点+任务模式管理采集节点,任务支持批量操作,管理更多数据轻松。
软件功能
1、规则自定义
所有网站采集几乎任何类型的信息都可以通过采集规则的定义进行搜索。
2、多任务、多线程
可以同时执行多个信息采集任务,每个任务可以使用多个线程。
3、所见即所得
任务采集流程是所见即所得,流程中遍历的链接信息、采集信息、错误信息等都会及时反映在软件界面中。
4、数据存储
数据自动保存到采集边缘的关系型数据库中,可以自动适配数据结构。软件可以根据采集规则自动创建数据库,以及里面的表和字段,也可以通过数据库灵活导入。将数据保存到客户现有的数据库结构中。
5、断点继续挖掘
INFO采集任务停止后可以从断点处恢复采集,因此您不再需要担心您的采集任务被意外中断。
6、网站登录
支持网站Cookies,支持网站可视化登录,甚至登录时需要验证码的网站也可以采集。
7、计划任务
此功能允许您的 采集 任务定期、定量或循环执行。
8、采集范围限制
采集 的范围可以根据采集 的深度和URL 的身份来限制。
9、文件下载
二进制文件(如:图片、音乐、软件、文档等)可以下载到本地磁盘或采集结果数据库。
10、结果替换
您可以根据规则将 采集 的结果替换为您定义的内容。
11、条件保存
您可以根据一定的条件决定保存哪些信息,过滤哪些信息。
12、过滤重复
软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、特殊链接识别
使用此功能可以识别 Javascript 或其他更古怪的连接中动态生成的链接。
14、数据发布
采集 的结果数据可以通过自定义界面发布到任何内容管理系统和指定数据库。现在支持的目标发布媒体包括:数据库(access、sql server、mysql、oracle)、静态htm文件。
15、 预留编程接口
定义多种编程接口,用户可以在事件中使用PHP、C#语言进行编程,扩展采集的功能。
菜单功能
1、创建一个新组
新建一个任务组,选择所属的组,确定组名和备注。
2、新任务
确定自己所属的组,新建任务,填写任务名称保存。
3、网络发布配置
Web 发布配置定义了如何登录到 网站 并将数据提交到该 网站。
主要涉及登录信息的获取,网站编码设置,列列表的获取,使用数据测试发布效果。
4、网络发布模块
可以定义网站登录、获取列列表、获取网页随机值、内容发布参数、上传文件、构建发布数据等高级功能。
5、数据库发布配置
数据库发布配置定义了数据库链接信息的设置和数据库模块的选择。
6、数据库发布模块
用于编辑数据库的发布模块,以便我们可以将数据发布到配置的数据库。
优采云采集器可选择mysql、sqlserver、oracle、access四种数据库类型,在文本输入框中填写sql语句
(需要数据库知识),可以用标签来替换对应的数据。您还可以在 采集器modules 文件夹中加载要编辑的模块。
7、计划任务
设置列表中采集任务的启动时间表,可以是每个间隔,每天,每周,只有一次,也可以是自定义的Cron表达式,
(Cron 表达式的写法请参考相关术语的介绍)。保存设置后,即可根据设置执行任务。
8、插件管理
插件是可用于扩展 优采云采集器 功能的程序
优采云采集器V9支持三种插件:PHP源码、C#源码、C#类库。
网页采集器的自动识别算法(优采云采集器谷歌技术团队倾力打造,一键采集网页数据,全平台 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-01-10 15:10
)
优采云采集器由前谷歌技术团队打造,基于人工智能技术,只需输入网址即可自动识别采集内容,直观点击,点击采集网页数据,所有平台,Win/Mac/Linux均可,优采云采集器无限安全使用,可后台运行,实时速度显示,采集@ >和出口都是免费的!
优采云采集器软件特色
1、智能识别数据,小白神器
智能模式:基于人工智能算法,只需输入URL即可智能识别列表数据、表格数据和分页按钮。您无需配置任何采集 规则,只需单击采集。
自动识别:列表、表格、链接、图片、价格等
2、可视化点击,简单易用
流程图模式:只需要根据软件提示点击页面,完全符合浏览网页的思维方式。复杂的 采集 规则可以通过几个简单的步骤生成。结合智能识别算法,任何网页的数据都可以轻松采集。
可以模拟操作:输入文本、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。
3、支持多种数据导出方式
采集结果可以导出到本地,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。
4、功能强大,提供企业级服务
优采云采集器提供丰富的采集功能,无论是采集稳定性还是采集效率,都能满足个人、团队和企业层面采集 @>需求。
功能丰富:定时采集、自动导出、文件下载、加速引擎、分组启动导出、Webhook、RESTful API、智能识别SKU和大图等。
5、云账号,方便快捷
创建一个优采云采集器账号并登录,你所有的采集任务设置都会自动加密保存到优采云的云服务器,不用担心丢失采集的任务,任务运行的数据和采集对你来说是本地的,非常安全,只有本地登录客户端才能查看。优采云采集器账号没有终端绑定限制,切换终端时采集任务也会同步更新,任务管理方便快捷。
6、全平台支持,无缝切换
同时支持Windows、Mac、Linux操作系统的采集软件。各平台版本完全相同,无缝切换。
使用教程
如何自定义采集百度搜索结果数据
一、创建采集任务
1、开始优采云采集器,进入主界面,选择Custom采集点击Create Task按钮,创建“Custom采集Task”;
2、输入百度搜索的网址,包括三种方式。
手动输入:直接在输入框中输入网址。多个 URL 需要用换行符分隔。
单击以从文件中读取:用户选择存储 URL 的文件。文件中可以有多个 URL 地址,地址之间需要用换行符分隔。
批量添加方式:通过添加和调整地址参数生成多个常规地址。
二、自定义采集流程
1、点击创建,自动打开第一个网址,进入自定义设置页面。默认情况下,已经创建了启动、打开网页和结束的进程块。底部模板区域用于拖拽到画布上,生成新的流程块;点击打开网页中的属性按钮,修改打开网址;
2、添加输入文本流块:将底部模板区域的输入文本块拖放到打开的网页块的后面,当出现阴影区域时,可以松开鼠标,它会自动连接至此,添加完成;
3、生成一个完整的流程图:按照上面添加输入文本流块的拖放过程添加一个新的块;
关键步骤块设置介绍
定时等待用于等待之前打开的网页完成。
点击输入框Xpath属性按钮,点击属性菜单中的图标点击网页中的输入框,点击输入文本属性按钮,在菜单中输入要搜索的文本。
用于设置点击开始搜索按钮,点击元素的xpath属性按钮,点击菜单中的点击图标,然后点击网页中的百度按钮。
用于设置循环加载下一个列表页面。在循环块内的循环条件块中设置详细条件,点击此处的操作按钮,选择单个元素,然后在属性菜单中点击该元素的xpath属性按钮,在网页中点击下一页按钮为多于。循环次数属性按钮可以默认为0,即不限制下一页的点击次数。
用于设置循环提取列表页中的数据。在循环块内的循环条件块中设置详细条件,点击这里的操作按钮,选择不固定元素列表,然后点击属性菜单中元素的xpath属性按钮,然后连续点击两次提取网页中的第一个块和第二个块元素。循环计数属性按钮可以默认为0,即不限制列表中计费的字段数。
用于执行点击下一页按钮的操作,点击元素xpath属性按钮,选择使用当前循环中元素的xpath的选项。
同样用于设置网页加载的等待时间。
要设置在列表页面上提取的字段规则,请单击属性按钮中的循环使用元素按钮,然后选择循环使用元素选项。单击元素模板属性按钮,在字段表中单击加号或减号可添加或删除字段。添加字段,使用单击操作,即单击加号并将鼠标移动到网页元素并单击选择。
4、单击开始采集 以启动采集。
三、数据采集 并导出
1、采集任务正在运行;
2、采集完成后选择“导出数据”,将所有数据导出到本地文件;
3、选择“导出方式”导出采集好的数据,这里可以选择excel作为导出格式;
4、采集数据导出如下图。
查看全部
网页采集器的自动识别算法(优采云采集器谷歌技术团队倾力打造,一键采集网页数据,全平台
)
优采云采集器由前谷歌技术团队打造,基于人工智能技术,只需输入网址即可自动识别采集内容,直观点击,点击采集网页数据,所有平台,Win/Mac/Linux均可,优采云采集器无限安全使用,可后台运行,实时速度显示,采集@ >和出口都是免费的!
优采云采集器软件特色
1、智能识别数据,小白神器
智能模式:基于人工智能算法,只需输入URL即可智能识别列表数据、表格数据和分页按钮。您无需配置任何采集 规则,只需单击采集。
自动识别:列表、表格、链接、图片、价格等
2、可视化点击,简单易用
流程图模式:只需要根据软件提示点击页面,完全符合浏览网页的思维方式。复杂的 采集 规则可以通过几个简单的步骤生成。结合智能识别算法,任何网页的数据都可以轻松采集。
可以模拟操作:输入文本、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。
3、支持多种数据导出方式
采集结果可以导出到本地,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。
4、功能强大,提供企业级服务
优采云采集器提供丰富的采集功能,无论是采集稳定性还是采集效率,都能满足个人、团队和企业层面采集 @>需求。
功能丰富:定时采集、自动导出、文件下载、加速引擎、分组启动导出、Webhook、RESTful API、智能识别SKU和大图等。
5、云账号,方便快捷
创建一个优采云采集器账号并登录,你所有的采集任务设置都会自动加密保存到优采云的云服务器,不用担心丢失采集的任务,任务运行的数据和采集对你来说是本地的,非常安全,只有本地登录客户端才能查看。优采云采集器账号没有终端绑定限制,切换终端时采集任务也会同步更新,任务管理方便快捷。
6、全平台支持,无缝切换
同时支持Windows、Mac、Linux操作系统的采集软件。各平台版本完全相同,无缝切换。
使用教程
如何自定义采集百度搜索结果数据
一、创建采集任务
1、开始优采云采集器,进入主界面,选择Custom采集点击Create Task按钮,创建“Custom采集Task”;
2、输入百度搜索的网址,包括三种方式。
手动输入:直接在输入框中输入网址。多个 URL 需要用换行符分隔。
单击以从文件中读取:用户选择存储 URL 的文件。文件中可以有多个 URL 地址,地址之间需要用换行符分隔。
批量添加方式:通过添加和调整地址参数生成多个常规地址。
二、自定义采集流程
1、点击创建,自动打开第一个网址,进入自定义设置页面。默认情况下,已经创建了启动、打开网页和结束的进程块。底部模板区域用于拖拽到画布上,生成新的流程块;点击打开网页中的属性按钮,修改打开网址;
2、添加输入文本流块:将底部模板区域的输入文本块拖放到打开的网页块的后面,当出现阴影区域时,可以松开鼠标,它会自动连接至此,添加完成;
3、生成一个完整的流程图:按照上面添加输入文本流块的拖放过程添加一个新的块;
关键步骤块设置介绍
定时等待用于等待之前打开的网页完成。
点击输入框Xpath属性按钮,点击属性菜单中的图标点击网页中的输入框,点击输入文本属性按钮,在菜单中输入要搜索的文本。
用于设置点击开始搜索按钮,点击元素的xpath属性按钮,点击菜单中的点击图标,然后点击网页中的百度按钮。
用于设置循环加载下一个列表页面。在循环块内的循环条件块中设置详细条件,点击此处的操作按钮,选择单个元素,然后在属性菜单中点击该元素的xpath属性按钮,在网页中点击下一页按钮为多于。循环次数属性按钮可以默认为0,即不限制下一页的点击次数。
用于设置循环提取列表页中的数据。在循环块内的循环条件块中设置详细条件,点击这里的操作按钮,选择不固定元素列表,然后点击属性菜单中元素的xpath属性按钮,然后连续点击两次提取网页中的第一个块和第二个块元素。循环计数属性按钮可以默认为0,即不限制列表中计费的字段数。
用于执行点击下一页按钮的操作,点击元素xpath属性按钮,选择使用当前循环中元素的xpath的选项。
同样用于设置网页加载的等待时间。
要设置在列表页面上提取的字段规则,请单击属性按钮中的循环使用元素按钮,然后选择循环使用元素选项。单击元素模板属性按钮,在字段表中单击加号或减号可添加或删除字段。添加字段,使用单击操作,即单击加号并将鼠标移动到网页元素并单击选择。
4、单击开始采集 以启动采集。
三、数据采集 并导出
1、采集任务正在运行;
2、采集完成后选择“导出数据”,将所有数据导出到本地文件;
3、选择“导出方式”导出采集好的数据,这里可以选择excel作为导出格式;
4、采集数据导出如下图。
网页采集器的自动识别算法(特色功能1.信息采集添加全自动网站的内容管理方法介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-01-08 17:04
网站Information采集器是一个网站Information采集软件,你可以用这个软件来采集任何网站信息,转换需要的信息内容采集 并自动发布到您的 网站 以进行自动化 网站 内容管理。
特殊功能
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录查看信息内容的网站,网站优采云采集器可以轻松登录采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果需要采集图片等二进制文件,只需设置网站优采云采集器,即可将任意类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别javascript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是常见的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。
变更日志
1.新的分层设置,每一层都可以设置特殊选项,摆脱之前默认的3层限制
2.一次抓取任意多层分类。以前需要先抓取每个分类的url,然后再抓取每个分类
3.图片下载,自定义文件名,以前不能改名
4.新闻内容分页合并设置更简单、更通用、更强大
5.模拟点击更通用更简单。之前的模拟点击需要特殊设置,使用起来很复杂。
6.可以根据内容判断是否重复。以前,它仅基于 URL。
7.采集完成后允许执行自定义vbs脚本endget.vbs,发布后允许执行endpub.vbs。在vbs中,你可以编写自己的数据处理函数
8.导出数据可以包括文本、排除文本、文本截取日期加月份、数字比较、大小、过滤、前后追加字符 查看全部
网页采集器的自动识别算法(特色功能1.信息采集添加全自动网站的内容管理方法介绍)
网站Information采集器是一个网站Information采集软件,你可以用这个软件来采集任何网站信息,转换需要的信息内容采集 并自动发布到您的 网站 以进行自动化 网站 内容管理。
特殊功能
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录查看信息内容的网站,网站优采云采集器可以轻松登录采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果需要采集图片等二进制文件,只需设置网站优采云采集器,即可将任意类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别javascript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是常见的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。
变更日志
1.新的分层设置,每一层都可以设置特殊选项,摆脱之前默认的3层限制
2.一次抓取任意多层分类。以前需要先抓取每个分类的url,然后再抓取每个分类
3.图片下载,自定义文件名,以前不能改名
4.新闻内容分页合并设置更简单、更通用、更强大
5.模拟点击更通用更简单。之前的模拟点击需要特殊设置,使用起来很复杂。
6.可以根据内容判断是否重复。以前,它仅基于 URL。
7.采集完成后允许执行自定义vbs脚本endget.vbs,发布后允许执行endpub.vbs。在vbs中,你可以编写自己的数据处理函数
8.导出数据可以包括文本、排除文本、文本截取日期加月份、数字比较、大小、过滤、前后追加字符
网页采集器的自动识别算法(网页信息采集分类系统的设计思路与应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-01-07 21:05
●概要
互联网已经发展成为一个拥有数亿页的分布式信息空间,而且这个数字还在以每4到6个月翻一番的速度增长。随着网络信息资源的快速增长,人们越来越关注如何开发和利用这些网络信息资源。然而,现有技术不能满足用户对高质量网络信息服务的需求。例如,传统搜索引擎返回的相关网页过多,用户很难快速准确地定位到所需信息。网页信息归类为采集 系统就在这样的环境中应运而生。网络信息分类系统采集是网络信息挖掘的技术实现。它的设计理念是:网页搜索à网页内容提取à内容分类(形成知识库)。系统的研究对象是网页中的信息,如新闻网站的新闻网页、专利的专利介绍网页网站、公司的产品介绍网页网站等。系统的目标是从网络信息资源中找到用户需要的有价值的信息,并及时提供给用户。在整个系统的设计中,我们按照面向功能的原则将系统划分为6个模块,先设计模块之间的接口,再细化为更小的模块。在实现的过程中,从最小的功能单元开始,再组装成更大的功能,最后完成整个系统。在系统的开发过程中,我们研究了与网络信息挖掘相关的技术,包括网页搜索技术、网页内容提取技术、文本分类和聚类等。本文提出了一种网络搜索算法和一种网络内容提取算法,已应用于网络信息分类系统中,取得了良好的效果;文本分类使用现有算法,在系统中使用代码实现。本文积极探索和研究网页信息的采集方面,提供了一套切实可行的技术方案,提高了网络信息的综合利用价值。包括网页搜索技术、网页内容提取技术、文本分类和聚类等。本文提出了一种网络搜索算法和一种网络内容提取算法,已应用于网络信息分类系统中,取得了良好的效果;文本分类使用现有算法,在系统中使用代码实现。本文积极探索和研究网页信息的采集方面,提供了一套切实可行的技术方案,提高了网络信息的综合利用价值。包括网页搜索技术、网页内容提取技术、文本分类和聚类等。本文提出了一种网络搜索算法和一种网络内容提取算法,已应用于网络信息分类系统中,取得了良好的效果;文本分类使用现有算法,在系统中使用代码实现。本文积极探索和研究网页信息的采集方面,提供了一套切实可行的技术方案,提高了网络信息的综合利用价值。已应用于网络信息分类系统,取得了良好的效果;文本分类使用现有算法,在系统中使用代码实现。本文积极探索和研究网页信息的采集方面,提供了一套切实可行的技术方案,提高了网络信息的综合利用价值。已应用于网络信息分类系统,取得了良好的效果;文本分类使用现有算法,在系统中使用代码实现。本文积极探索和研究网页信息的采集方面,提供了一套切实可行的技术方案,提高了网络信息的综合利用价值。 查看全部
网页采集器的自动识别算法(网页信息采集分类系统的设计思路与应用)
●概要
互联网已经发展成为一个拥有数亿页的分布式信息空间,而且这个数字还在以每4到6个月翻一番的速度增长。随着网络信息资源的快速增长,人们越来越关注如何开发和利用这些网络信息资源。然而,现有技术不能满足用户对高质量网络信息服务的需求。例如,传统搜索引擎返回的相关网页过多,用户很难快速准确地定位到所需信息。网页信息归类为采集 系统就在这样的环境中应运而生。网络信息分类系统采集是网络信息挖掘的技术实现。它的设计理念是:网页搜索à网页内容提取à内容分类(形成知识库)。系统的研究对象是网页中的信息,如新闻网站的新闻网页、专利的专利介绍网页网站、公司的产品介绍网页网站等。系统的目标是从网络信息资源中找到用户需要的有价值的信息,并及时提供给用户。在整个系统的设计中,我们按照面向功能的原则将系统划分为6个模块,先设计模块之间的接口,再细化为更小的模块。在实现的过程中,从最小的功能单元开始,再组装成更大的功能,最后完成整个系统。在系统的开发过程中,我们研究了与网络信息挖掘相关的技术,包括网页搜索技术、网页内容提取技术、文本分类和聚类等。本文提出了一种网络搜索算法和一种网络内容提取算法,已应用于网络信息分类系统中,取得了良好的效果;文本分类使用现有算法,在系统中使用代码实现。本文积极探索和研究网页信息的采集方面,提供了一套切实可行的技术方案,提高了网络信息的综合利用价值。包括网页搜索技术、网页内容提取技术、文本分类和聚类等。本文提出了一种网络搜索算法和一种网络内容提取算法,已应用于网络信息分类系统中,取得了良好的效果;文本分类使用现有算法,在系统中使用代码实现。本文积极探索和研究网页信息的采集方面,提供了一套切实可行的技术方案,提高了网络信息的综合利用价值。包括网页搜索技术、网页内容提取技术、文本分类和聚类等。本文提出了一种网络搜索算法和一种网络内容提取算法,已应用于网络信息分类系统中,取得了良好的效果;文本分类使用现有算法,在系统中使用代码实现。本文积极探索和研究网页信息的采集方面,提供了一套切实可行的技术方案,提高了网络信息的综合利用价值。已应用于网络信息分类系统,取得了良好的效果;文本分类使用现有算法,在系统中使用代码实现。本文积极探索和研究网页信息的采集方面,提供了一套切实可行的技术方案,提高了网络信息的综合利用价值。已应用于网络信息分类系统,取得了良好的效果;文本分类使用现有算法,在系统中使用代码实现。本文积极探索和研究网页信息的采集方面,提供了一套切实可行的技术方案,提高了网络信息的综合利用价值。
网页采集器的自动识别算法( 优采云采集器_真免费!导出无限制网络爬虫软件_人工智能数据采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-01-03 23:03
优采云采集器_真免费!导出无限制网络爬虫软件_人工智能数据采集软件)
优采云采集器_免费!导出无限网络爬虫软件_人工智能数据采集软件
优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。该软件功能强大且易于操作。可谓居家旅行神器。 .
优采云采集器_大数据云部署采集爬虫系统,免费无限自动化采集软件
优采云采集器是一款免费无限的爬虫系统,采用php+mysql开发,可部署在云服务器上,让您在电脑端和移动端都可以使用浏览器采集数据可接入任意cms系统,无需登录即可实时发布数据。大数据云时代为网站数据自动化采集发布的最好的云爬虫软件
优采云浏览器官网络-可视化采集软件|网站抓取向导|网站抓取工具|自动验证码识别|自动释放软件
优采云浏览器采集软件,是一款可视化的采集软件,一款网络爬虫工具软件,网站抓取工具,模拟浏览器手动操作采集 发布软件,可以生成EXE。
优采云采集器 – 简单易用的网络数据采集tool_free 网络爬虫软件
优采云采集器是一款简单易用的网络数据采集工具,免费的网络爬虫软件。 优采云采集器简单易学,通过智能算法+可视化界面,随心所欲抓取数据。只需点击鼠标即可采集网页上的数据。
优采云采集器官网-网络爬虫工具_优采云采集器_free网站采集软件
优采云采集器该软件是一个网络爬虫工具,用于网站信息采集、网站信息抓取,包括图片和文字其他信息采集被处理和发布。是目前使用最多的互联网数据采集软件。出品,10年打造网络数据工具采集。
预嗅探大数据 查看全部
网页采集器的自动识别算法(
优采云采集器_真免费!导出无限制网络爬虫软件_人工智能数据采集软件)
优采云采集器_免费!导出无限网络爬虫软件_人工智能数据采集软件
优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。该软件功能强大且易于操作。可谓居家旅行神器。 .
优采云采集器_大数据云部署采集爬虫系统,免费无限自动化采集软件
优采云采集器是一款免费无限的爬虫系统,采用php+mysql开发,可部署在云服务器上,让您在电脑端和移动端都可以使用浏览器采集数据可接入任意cms系统,无需登录即可实时发布数据。大数据云时代为网站数据自动化采集发布的最好的云爬虫软件
优采云浏览器官网络-可视化采集软件|网站抓取向导|网站抓取工具|自动验证码识别|自动释放软件
优采云浏览器采集软件,是一款可视化的采集软件,一款网络爬虫工具软件,网站抓取工具,模拟浏览器手动操作采集 发布软件,可以生成EXE。
优采云采集器 – 简单易用的网络数据采集tool_free 网络爬虫软件
优采云采集器是一款简单易用的网络数据采集工具,免费的网络爬虫软件。 优采云采集器简单易学,通过智能算法+可视化界面,随心所欲抓取数据。只需点击鼠标即可采集网页上的数据。
优采云采集器官网-网络爬虫工具_优采云采集器_free网站采集软件
优采云采集器该软件是一个网络爬虫工具,用于网站信息采集、网站信息抓取,包括图片和文字其他信息采集被处理和发布。是目前使用最多的互联网数据采集软件。出品,10年打造网络数据工具采集。
预嗅探大数据
网页采集器的自动识别算法(VG浏览器软件特色可视化操作操作简单完全兼容JQuery规则)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-03 23:01
Vg浏览器不仅是一个采集浏览器,更是一个营销神器。 vg浏览器也是一个可视化脚本驱动的网页工具,它可以简单的设置脚本,可以创建自动登录、身份验证等许多脚本项目。
VG浏览器基本介绍
VG浏览器是一款由可视化脚本驱动的网页自动运行工具。只需设置一个脚本,即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件。操作数据库、收发邮件等个性化实用的脚本项,还可以使用逻辑运算完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。
VG 浏览器软件功能
视觉操作
操作简单,图形操作完全可视化,无需专业IT人员。
自定义流程
采集就像搭积木一样,功能自由组合。
自动编码
程序注重采集效率,页面解析速度很快。
生成EXE
自动登录,自动识别验证码,是万能浏览器。
如何使用VG浏览器
通过CSS Path定位网页元素的路径是VG浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的这个按钮
点击一个网页元素会自动生成该元素的CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。比如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器,可以通过按F12键或在页面上右键选择评论元素来选择。
右键单击目标部分并选择复制 CSS 路径将 CSS 路径复制到剪贴板,
在 Firefox 中,您还可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Only Selector”复制CSS Path。
CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写JQuery选择器,你也可以自己编写CSS Path
VG 浏览器更新日志
8.5.3.0 (2021-12-16)
新增列表循环“点击标签后等待”时间配置
改进内置浏览器对网页加载的判断,提高网页采集稳定性 查看全部
网页采集器的自动识别算法(VG浏览器软件特色可视化操作操作简单完全兼容JQuery规则)
Vg浏览器不仅是一个采集浏览器,更是一个营销神器。 vg浏览器也是一个可视化脚本驱动的网页工具,它可以简单的设置脚本,可以创建自动登录、身份验证等许多脚本项目。
VG浏览器基本介绍
VG浏览器是一款由可视化脚本驱动的网页自动运行工具。只需设置一个脚本,即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件。操作数据库、收发邮件等个性化实用的脚本项,还可以使用逻辑运算完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。
VG 浏览器软件功能
视觉操作
操作简单,图形操作完全可视化,无需专业IT人员。
自定义流程
采集就像搭积木一样,功能自由组合。
自动编码
程序注重采集效率,页面解析速度很快。
生成EXE
自动登录,自动识别验证码,是万能浏览器。
如何使用VG浏览器
通过CSS Path定位网页元素的路径是VG浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的这个按钮
点击一个网页元素会自动生成该元素的CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。比如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器,可以通过按F12键或在页面上右键选择评论元素来选择。
右键单击目标部分并选择复制 CSS 路径将 CSS 路径复制到剪贴板,
在 Firefox 中,您还可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Only Selector”复制CSS Path。
CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写JQuery选择器,你也可以自己编写CSS Path
VG 浏览器更新日志
8.5.3.0 (2021-12-16)
新增列表循环“点击标签后等待”时间配置
改进内置浏览器对网页加载的判断,提高网页采集稳定性
网页采集器的自动识别算法(网页采集器的自动识别算法代码,可以通过以下接口获取)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-01-02 13:09
网页采集器的自动识别算法代码,可以通过以下接口获取,
国内常用的还是百度的算法ss-api,现在还有第三方的比如说说爱采集的google_ssl_extract_all_content接口,你可以看看。
可以用是自己定制算法生成一个采集器的,把需要的数据有节点采集到;也可以找第三方的,如果是采集大型资源,在上面接spider接口,然后下载采集到。
还是有这样的算法,某宝有卖,自动采集但得花点时间,但是后台设置再下载,
试试把数据流向引入网页采集器,
百度网页采集器,或者通过header爬虫来获取要采集的网站。
百度嘛
存下来
各大搜索引擎都有外链接获取服务,只要把被采集链接都存下来并且发布即可。
全球都有抓取器,有的需要联系官方的,有的是第三方做的。
百度
百度已经公布了,需要安装extract_st后台接口,如果只是获取网页,可以直接spider接口,google/taobao有开发,
推荐使用国外的一个公司,他们可以从googlespider接口获取所有url
你可以参考我的这篇文章:像谷歌等搜索引擎提供了一些能够获取他们中所指定域名数据的api接口!分析方法是你先提取spider被指定域名下的所有网页,就可以了;前提是你注册和登录过它们的网站,而且中国境内正在运行中。用自己的代理也可以;(因为也有别的方法,所以上面说的是常用的方法)按照它们的用法试一下;可以得到相应的结果。-googlespiderapi|milk-博客园。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法代码,可以通过以下接口获取)
网页采集器的自动识别算法代码,可以通过以下接口获取,
国内常用的还是百度的算法ss-api,现在还有第三方的比如说说爱采集的google_ssl_extract_all_content接口,你可以看看。
可以用是自己定制算法生成一个采集器的,把需要的数据有节点采集到;也可以找第三方的,如果是采集大型资源,在上面接spider接口,然后下载采集到。
还是有这样的算法,某宝有卖,自动采集但得花点时间,但是后台设置再下载,
试试把数据流向引入网页采集器,
百度网页采集器,或者通过header爬虫来获取要采集的网站。
百度嘛
存下来
各大搜索引擎都有外链接获取服务,只要把被采集链接都存下来并且发布即可。
全球都有抓取器,有的需要联系官方的,有的是第三方做的。
百度
百度已经公布了,需要安装extract_st后台接口,如果只是获取网页,可以直接spider接口,google/taobao有开发,
推荐使用国外的一个公司,他们可以从googlespider接口获取所有url
你可以参考我的这篇文章:像谷歌等搜索引擎提供了一些能够获取他们中所指定域名数据的api接口!分析方法是你先提取spider被指定域名下的所有网页,就可以了;前提是你注册和登录过它们的网站,而且中国境内正在运行中。用自己的代理也可以;(因为也有别的方法,所以上面说的是常用的方法)按照它们的用法试一下;可以得到相应的结果。-googlespiderapi|milk-博客园。
网页采集器的自动识别算法(优采云收罗器是网页信息收罗东西的软件功效与作用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-01-02 08:10
优采云 采集器是一个非常有用的网页信息采集工具。该工具界面简洁,操作复杂,功能强大。有了它,我们可以采集我们必要网页上的所有信息。无门槛,新手也可以使用。
软件功能
1、零门槛:如果你不会采集爬虫,你会在会议上收到网站数据。
2、多引擎,高速不乱:内置高速浏览器引擎,也可以切换到HTTP引擎模式运行,数据采集更高效。还内置了JSON引擎,无需分析JSON数据布局,直观提取JSON内容。
<p>3、结合各种网站:可以采集99%的互联网网站,包括静态例子网站,比如使用Ajax加载单页。 查看全部
网页采集器的自动识别算法(马云的“网购心智”赚钱靠谱,靠谱不等于完美的机器人)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-12-30 04:02
网页采集器的自动识别算法还是非常靠谱的,有些甚至可以识别出isp提供的返利信息。采集数据的时候,有的网站可能只有某一类型的商品才能拿到这个返利,也就是说,小类目可能只返现金,大类目也可能只返商品。他就把这些商品信息自动识别出来。
时刻关注以下两篇文章阿里妈妈助力业务开展,
最靠谱的应该是联盟,
aliexpress。alibaba。com-aliexpress。com!route:feedmarketsite(parallel)-headerstag:1。runon1listing2。excludemoreshopee-aliexpress-feedmarketsitegpsmarketsite&productchannel1。0googlemap搜一下aliexpress的一些信息就可以抓一些aliexpress的返利。
马云的“网购心智”
赚钱靠谱,靠谱不等于完美的机器人。
aliexpress还好,我做海淘,比上的号便宜多了,
网购心智是个好东西,在资金不允许或者说想有更多客源的情况下,不得不用。
一手抓返利机器人,
返利机器人很精准,你使用后然后观察一段时间会有比较不错的效果,操作简单,
能赚多少钱不敢说,
可以吧。有一次还没进5分钱的东西,老板就给返3毛钱。
赚点小钱,赚点动力。他们是给钱才干活的,质量相比来说不知道高了多少倍。返利就是,你花了一块钱,给他返回5毛,你可以在返利上买东西的。 查看全部
网页采集器的自动识别算法(马云的“网购心智”赚钱靠谱,靠谱不等于完美的机器人)
网页采集器的自动识别算法还是非常靠谱的,有些甚至可以识别出isp提供的返利信息。采集数据的时候,有的网站可能只有某一类型的商品才能拿到这个返利,也就是说,小类目可能只返现金,大类目也可能只返商品。他就把这些商品信息自动识别出来。
时刻关注以下两篇文章阿里妈妈助力业务开展,
最靠谱的应该是联盟,
aliexpress。alibaba。com-aliexpress。com!route:feedmarketsite(parallel)-headerstag:1。runon1listing2。excludemoreshopee-aliexpress-feedmarketsitegpsmarketsite&productchannel1。0googlemap搜一下aliexpress的一些信息就可以抓一些aliexpress的返利。
马云的“网购心智”
赚钱靠谱,靠谱不等于完美的机器人。
aliexpress还好,我做海淘,比上的号便宜多了,
网购心智是个好东西,在资金不允许或者说想有更多客源的情况下,不得不用。
一手抓返利机器人,
返利机器人很精准,你使用后然后观察一段时间会有比较不错的效果,操作简单,
能赚多少钱不敢说,
可以吧。有一次还没进5分钱的东西,老板就给返3毛钱。
赚点小钱,赚点动力。他们是给钱才干活的,质量相比来说不知道高了多少倍。返利就是,你花了一块钱,给他返回5毛,你可以在返利上买东西的。

