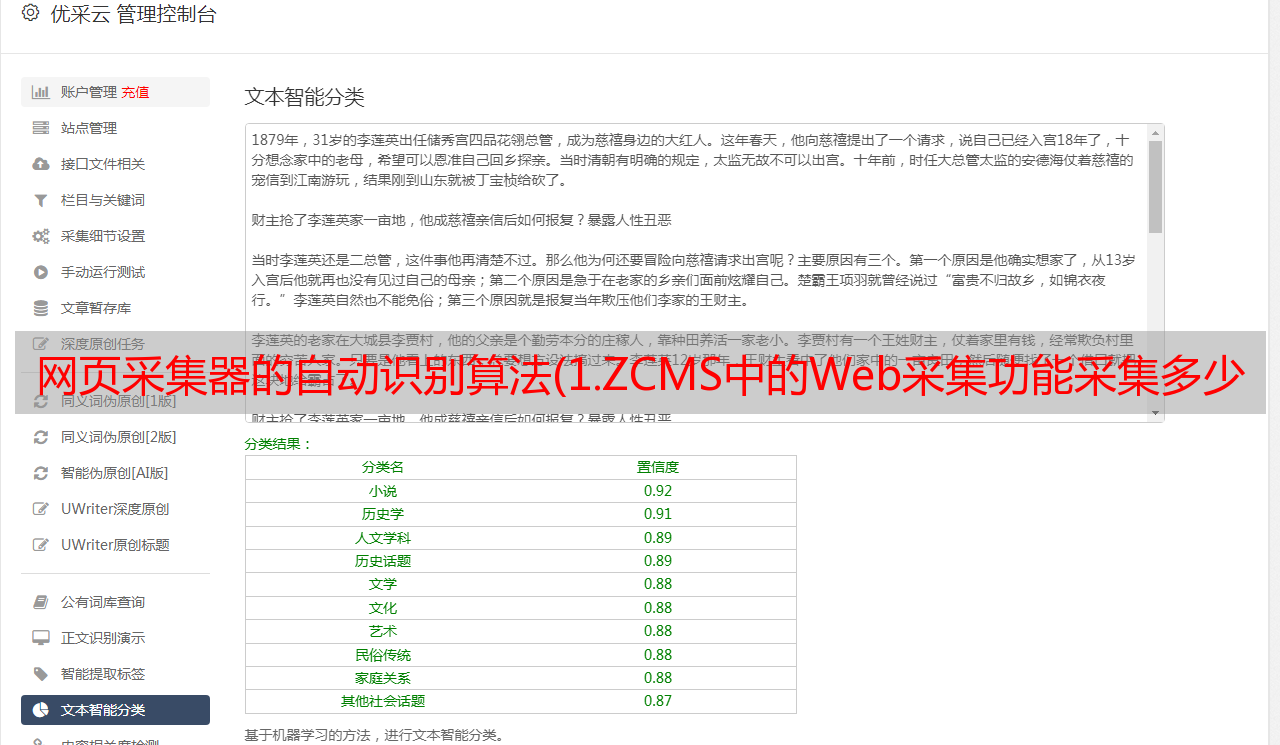
网页采集器的自动识别算法(1.ZCMS中的Web采集功能采集多少个文章页)
优采云 发布时间: 2021-11-11 15:17网页采集器的自动识别算法(1.ZCMS中的Web采集功能采集多少个文章页)
1.Z 中的 Webcms采集
Zcms中的Web采集功能是一款简单易用、功能强大的基于模板的内容采集提取工具,支持自动采集文章列表paging,分页采集,URL重定向后自动采集内容,内容编码自动识别,网页修改日期自动识别,多线程采集,多级URL采集等功能,并支持使用代理服务器和URL过滤、内容过滤。
采集完成后,Zcms会根据匹配块中的规则提取文章的标题、内容等信息,并自动添加到指定的列中以备后续使用由编辑。
2.填写采集基本设置
切换到“数据通道”下的“From Web采集”菜单,点击“新建”按钮,添加一个新的采集任务,如下图:
在:
采集当类别为文章采集时,采集程序直接将网页转换成Zcms中的文档;如果是自定义的采集,那么只有采集数据,无需转换,需要开发程序读取采集返回的文本并进行处理。自定义采集仅用于Zcms的二次开发。
发布日期格式表示网页内容提示的发布日期格式,与JAVA中的日期格式一致,y代表年,M代表月,d代表日,h代表小时,m代表分钟,s 代表秒。
采集 如果勾选了“下载远程图片”,采集程序会自动将内容中的图片下载到Zcms服务器,并替换内容中的图片地址.
采集 如果勾选了“从内容中删除超链接”,采集 程序会自动将内容中的所有超链接转为纯文本。
采集到这一列表示采集之后的文档存放在哪一列。
采集 内容页数上限表示该任务最多采集 内容页数。
列表页中采集的最大数量表示该任务中采集文章列表页的最大数量。
采集 线程数是指同时采集的线程数。值越大,采集 速度越快,占用的带宽越多。一般1个线程就够了,不超过30个线程。
超时等待时间表示目标网页所在服务器忙时采集程序等待的秒数。默认为 30 秒,一般不应超过 120 秒。
发生错误时的重试次数表示目标服务器没有响应或有错误响应时采集程序重试的次数。
如果Zcms所在的服务器不能直接上网或者目标网页必须通过专门的代理访问,则需要勾选“使用代理服务器”选项并填写代理服务器地址、端口, 用户名和密码。
3.填写网址规则
填写完基本设置后,就可以开始填写URL规则了。以新浪新闻为例,您可以进行如下操作:
1)填写起始网址,填写新浪新闻列表页网址如下图:
2)填写下一级网址
通过观察列表页上的新闻链接,发现大部分新闻链接网址都类似如下:
我们把这个 URL 转换成 URL 通配符,如下图:
${A}/${D}.shtml
其中,${D}表示这里允许数字,${A}表示允许任意字符。
但是,有些新闻链接网址不符合此规则,例如:
我们还将这个 URL 转换为 URL 通配符,如下所示:
${A}/${D}.shtml
然后点击“添加URL级别”按钮,将上面两个URL通配符填入下一级的文本框中,如下图所示:
3)如果列表页不能直接到达文章内容页,可能需要填写多级URL。整个URL处理流程是:先采集起始URL(可以有多个起始URL),然后分析起始URL采集返回的HTML文本中的所有链接URL,一一二级别 URL 通配符比较,如果 URL 和级别 2 URL 通配符之一匹配,则为 采集。当所有符合条件的二级网址采集都完成后,再次从二级网址采集返回的HTML中提取所有链接网址,并一一比较三级网址的通配符...直到最后一级 URL。
4) 有时需要过滤掉一些URL,需要勾选“URL Filtering”选项并填写过滤表达式。这些规则类似于常见的 URL 通配符。采集 程序会将 URL 与过滤后的 URL 通配符进行比较。如果发现它匹配通配符之一,它将忽略 采集。
4.填写内容匹配块
填写完基本信息后,开始填写内容匹配块。内容匹配块有两种匹配方式,简单匹配和复杂匹配。下面介绍一下复杂的匹配模式。
首先打开一个文章内容页面,如下图:
我们看到发布日期的格式是yyyy year MM month dd day HH:mm。如果此格式与我们之前填写的发布日期格式不一致,我们需要将此格式填写到“基本信息”选项卡“中间”的“发布日期格式”中。
然后查看网页源代码,找到收录标题、发布日期和内容的部分,如下图所示:
将收录标题和内容的 HTML 文本复制到复杂匹配块文本框,将标题替换为 ${A:Title},内容替换为 ${A:Content},发布日期替换为 ${A:PublishDate},替换后的字符串如下图所示:
接下来打开另一个文章内容页面,查看页面源代码,将标题、内容、发布日期替换为相关字符串,然后与之前的比较查找所有不一致的地方(有多余的空行)并且行前后空格数不不一致,不需要处理),用${A}代替。替换后的结果如下图所示:
这里${A}和填写URL通配符的意思是一样的,意思是任何字符都可以。
${A:TItle} 中冒号后的部分代表字段名称,采集 程序会将这个名称与数据库中的文章 表字段进行匹配。比如我们可以添加一个${A:Author}匹配符号,匹配的值就会成为文章中author字段的值。
5.填写内容过滤块
有时,内容中可能会插入一些不属于文章正文的广告等文字,需要用字符串替换,所以需要填写内容过滤块。如果不需要过滤任何文本,则无需填写此选项卡。
内容过滤块的填充规则与内容匹配块的填充规则相同。符合内容过滤阻止规则的文本将被替换为空字符串。允许填充多个过滤块,可以通过“添加过滤块”按钮添加一个新的过滤块。
比如我们发现有些页面有iframe广告,所以我们写入过滤块配置,如下图所示:
6.执行采集任务
填写完“基本信息”、“匹配块”、“过滤块”块后,点击“确定”按钮,系统会添加一个新的采集任务并显示在任务列表中,如图在下图中:
选择刚刚添加的任务,点击右侧区域的“执行任务”按钮启动采集,如下图:
如果需要采集任务定时运行,请到“系统管理”菜单下的“定时任务”子菜单配置定时任务,如下图:
7.采集 后处理
采集 完成后,系统会根据匹配块中定义的规则自动提取文章的内容和标题,并自动将提取的URL转换为文章(文章@ >状态为初稿),如下图:
任务执行完毕后,会弹出如下对话框:

表示已经全部转换为列下的文章,没有出现错误。
如果有未提取成功的网址,最后会显示未转换的网址列表,一般是因为我们在填写内容匹配块时没有考虑到某些情况(通常有一些网址不能被提取出来,除非我们特别熟悉目标网站的文章详细页面规则),这时候我们需要回去修改我们的内容匹配块。一般步骤是:
1) 从不匹配的URL中复制一份到浏览器地址栏,打开查看源码,按照填写内容的方法替换内容匹配块中的标题、发布时间、内容匹配块,并将替换的文本与内容匹配块中的差异进行比较;
2) 发现这个页面和我们原来的内容匹配块不一致。这时候我们再次查看网页源代码,修改内容匹配块以适应不一致;
3)然后点击“处理数据”按钮再次运行数据提取程序。注意此时不需要再次执行任务,因为网页已经采集到服务器了。如果您再次执行该任务,它会再次尝试下载网页。
有时可能需要多次重复此步骤以提高匹配块的兼容性。在某些特殊情况下,每个文章内容页面的结构有很大不同,可能需要创建多个采集任务将同一URL下的所有文章转移到指定的列.
同样,在某些情况下可能不考虑过滤块,导致过滤不完整,需要以类似于内容匹配块的方式进行修改。
8.采集效果
经过以上步骤后,目标网站上的文章数据就会出现在指定列下,如图:
如果勾选“下载远程图片”,图片会自动下载;如果目标网页文章中有页面,它们会自动合并为一个文章。

